
php如何抓取网页数据
php如何抓取网页数据(php如何抓取网页数据目录结构利用php脚本抓取源码-jotanhan-博客园)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-19 19:02
php如何抓取网页数据目录结构利用php脚本抓取源码-jotanhan-博客园对于网页所有的元素的概括规律性总结,另外用于以后给其他更高级开发者使用。通常语言的php特性决定了各种元素可以被全自动处理,反倒是以php脚本编写的php并不能完全达到机器自动编译生成目录的程度。但是php通过psql查询元素的属性和路径后,一段时间后你会发现剩下来的文件在某个位置。
selenium主要目的是利用webdriver帮助开发者处理浏览器的基本特性,在lbs时代发展起来,因为webdriver拥有更强大的功能能够满足越来越复杂的抓取需求。使用webdriver的代价主要在于服务器端每进行一次操作,需要分析数十次后才能得到结果,但是利用代码自动调用lbs服务会大大减少这种误差,只需要几秒钟即可得到结果。
通过手工构建类路径的的可见性验证而不是通过定义字符串的重载修改或者工具搜索,然后使用selenium来抓取网页应该是一个很好的选择。在psql查询数据之前进行反编译代码php接口脚本生成脚本代码selenium抓取网页数据-linux_博客园代码不够直观,但是该记录元素的属性是可见的。
checkjava网络和php慢,这个只要开一个psql获取对应的socket就可以了,geturl里面的二元运算就是变换为text来模拟行运算,get/http//somehost。caps{"uri":"localhost:9080/real。here?version=1","connection":"transaction","cookie":{"cookie":"papermathobile"}}使用cdjs加载php服务端插件,url变换为form_url,用cdtsquery(tap,不是trim)把name和library换成对应的文件即可。 查看全部
php如何抓取网页数据(php如何抓取网页数据目录结构利用php脚本抓取源码-jotanhan-博客园)
php如何抓取网页数据目录结构利用php脚本抓取源码-jotanhan-博客园对于网页所有的元素的概括规律性总结,另外用于以后给其他更高级开发者使用。通常语言的php特性决定了各种元素可以被全自动处理,反倒是以php脚本编写的php并不能完全达到机器自动编译生成目录的程度。但是php通过psql查询元素的属性和路径后,一段时间后你会发现剩下来的文件在某个位置。
selenium主要目的是利用webdriver帮助开发者处理浏览器的基本特性,在lbs时代发展起来,因为webdriver拥有更强大的功能能够满足越来越复杂的抓取需求。使用webdriver的代价主要在于服务器端每进行一次操作,需要分析数十次后才能得到结果,但是利用代码自动调用lbs服务会大大减少这种误差,只需要几秒钟即可得到结果。
通过手工构建类路径的的可见性验证而不是通过定义字符串的重载修改或者工具搜索,然后使用selenium来抓取网页应该是一个很好的选择。在psql查询数据之前进行反编译代码php接口脚本生成脚本代码selenium抓取网页数据-linux_博客园代码不够直观,但是该记录元素的属性是可见的。
checkjava网络和php慢,这个只要开一个psql获取对应的socket就可以了,geturl里面的二元运算就是变换为text来模拟行运算,get/http//somehost。caps{"uri":"localhost:9080/real。here?version=1","connection":"transaction","cookie":{"cookie":"papermathobile"}}使用cdjs加载php服务端插件,url变换为form_url,用cdtsquery(tap,不是trim)把name和library换成对应的文件即可。
php如何抓取网页数据(如何使用BeautifulSoup库从HTML页面中提取内容(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-18 06:19
今天我们将讨论如何使用BeautifulSoup库从HTML页面提取内容。提取后,我们将使用BeautifulSoup将其转换为python列表或字典
什么是网络爬行
答案很简单:并不是每个网站都有获取内容的API。你可能想从你最喜欢的烹饪网站中获取食谱,或者从你的旅游博客中获取照片。如果没有API,提取HTML或爬行可能是获取内容的唯一方法。我将向您展示如何在Python中实现这一点
注意:并非所有网站都喜欢抓取,有些网站可能会被明确禁止。如果可以捕获,请与网站所有者联系
如何抓取网站
为了使网络爬网在Python中工作,我们将执行三个基本步骤:
使用请求库提取HTML内容。分析HTML结构并识别收录内容的标记。使用beautifulsoup提取标记并将数据放入python列表中。安装库
让我们先安装我们需要的库。请求从中获取HTML内容网站. Beauty soup解析HTML并将其转换为Python对象。要为Python 3安装这些,请运行:
pip3 install requests beautifulsoup4
提取HTML
在本例中,我将选择抓取的技术部分网站. 如果你转到这个页面,你会看到一个文章的标题、摘录和发布日期列表。我们的目标是创建一个收录此信息的文章列表
技术页面的完整URL为:
https://notes.ayushsharma.in/technology
我们可以使用请求从此页面获取HTML内容:
#!/usr/bin/python3
import requests
url = 'https://notes.ayushsharma.in/technology'
data = requests.get(url)
print(data.text)
变量数据将收录页面的HTML源代码
从HTML中提取内容
要从中接收的HTML中提取数据,我们需要确定哪些标记具有我们需要的内容
如果浏览HTML,您将在顶部附近找到此部分:
HTML:
Using variables in Jekyll to define custom content
I recently discovered that Jekyll's config.yml can be used to define custom
variables for reusing content. I feel like I've been living under a rock all this time. But to err over and
over again is human.
Aug 2021
这是每篇文章整页中重复的部分文章. 我们可以看到。卡片标题有一个文章title,。卡片文本摘录,和。卡片页脚>;小发行日期
让我们用漂亮的汤来提取这些内容
Python:
上面的代码将提取文章并将它们放入数据变量中的my_u中。我正在使用pprint进行一个很好的打印输出,但是您可以在自己的代码中跳过它。将上述代码保存在名为fetch.py的文件中,并使用以下命令运行它:
python3 fetch.py
如果一切顺利,您应该看到:
Python:
[{'excerpt': "I recently discovered that Jekyll's config.yml can be used to "
"define custom variables for reusing content. I feel like I've "
'been living under a rock all this time. But to err over and over '
'again is human.',
'pub_date': 'Aug 2021',
'title': 'Using variables in Jekyll to define custom content'},
{'excerpt': "In this article, I'll highlight some ideas for Jekyll "
'collections, blog category pages, responsive web-design, and '
'netlify.toml to make static website maintenance a breeze.',
'pub_date': 'Jul 2021',
'title': 'The evolution of ayushsharma.in: Jekyll, Bootstrap, Netlify, '
'static websites, and responsive design.'},
{'excerpt': "These are the top 5 lessons I've learned after 5 years of "
'Terraform-ing.',
'pub_date': 'Jul 2021',
'title': '5 key best practices for sane and usable Terraform setups'},
... (truncated)
就这些!在22行代码中,我们用Python构建了一个web爬虫程序。您可以在我的示例repo中找到源代码
结论
使用python列表中的网站内容,我们现在可以用它做一些很酷的事情。我们可以将其作为JSON返回到另一个应用程序,或者使用自定义样式将其转换为HTML。请随意复制和粘贴上述代码,并在您最喜欢的网站上进行实验@ 查看全部
php如何抓取网页数据(如何使用BeautifulSoup库从HTML页面中提取内容(图))
今天我们将讨论如何使用BeautifulSoup库从HTML页面提取内容。提取后,我们将使用BeautifulSoup将其转换为python列表或字典
什么是网络爬行
答案很简单:并不是每个网站都有获取内容的API。你可能想从你最喜欢的烹饪网站中获取食谱,或者从你的旅游博客中获取照片。如果没有API,提取HTML或爬行可能是获取内容的唯一方法。我将向您展示如何在Python中实现这一点
注意:并非所有网站都喜欢抓取,有些网站可能会被明确禁止。如果可以捕获,请与网站所有者联系
如何抓取网站
为了使网络爬网在Python中工作,我们将执行三个基本步骤:
使用请求库提取HTML内容。分析HTML结构并识别收录内容的标记。使用beautifulsoup提取标记并将数据放入python列表中。安装库
让我们先安装我们需要的库。请求从中获取HTML内容网站. Beauty soup解析HTML并将其转换为Python对象。要为Python 3安装这些,请运行:
pip3 install requests beautifulsoup4
提取HTML
在本例中,我将选择抓取的技术部分网站. 如果你转到这个页面,你会看到一个文章的标题、摘录和发布日期列表。我们的目标是创建一个收录此信息的文章列表
技术页面的完整URL为:
https://notes.ayushsharma.in/technology
我们可以使用请求从此页面获取HTML内容:
#!/usr/bin/python3
import requests
url = 'https://notes.ayushsharma.in/technology'
data = requests.get(url)
print(data.text)
变量数据将收录页面的HTML源代码
从HTML中提取内容
要从中接收的HTML中提取数据,我们需要确定哪些标记具有我们需要的内容
如果浏览HTML,您将在顶部附近找到此部分:
HTML:
Using variables in Jekyll to define custom content
I recently discovered that Jekyll's config.yml can be used to define custom
variables for reusing content. I feel like I've been living under a rock all this time. But to err over and
over again is human.
Aug 2021
这是每篇文章整页中重复的部分文章. 我们可以看到。卡片标题有一个文章title,。卡片文本摘录,和。卡片页脚>;小发行日期
让我们用漂亮的汤来提取这些内容
Python:
上面的代码将提取文章并将它们放入数据变量中的my_u中。我正在使用pprint进行一个很好的打印输出,但是您可以在自己的代码中跳过它。将上述代码保存在名为fetch.py的文件中,并使用以下命令运行它:
python3 fetch.py
如果一切顺利,您应该看到:
Python:
[{'excerpt': "I recently discovered that Jekyll's config.yml can be used to "
"define custom variables for reusing content. I feel like I've "
'been living under a rock all this time. But to err over and over '
'again is human.',
'pub_date': 'Aug 2021',
'title': 'Using variables in Jekyll to define custom content'},
{'excerpt': "In this article, I'll highlight some ideas for Jekyll "
'collections, blog category pages, responsive web-design, and '
'netlify.toml to make static website maintenance a breeze.',
'pub_date': 'Jul 2021',
'title': 'The evolution of ayushsharma.in: Jekyll, Bootstrap, Netlify, '
'static websites, and responsive design.'},
{'excerpt': "These are the top 5 lessons I've learned after 5 years of "
'Terraform-ing.',
'pub_date': 'Jul 2021',
'title': '5 key best practices for sane and usable Terraform setups'},
... (truncated)
就这些!在22行代码中,我们用Python构建了一个web爬虫程序。您可以在我的示例repo中找到源代码
结论
使用python列表中的网站内容,我们现在可以用它做一些很酷的事情。我们可以将其作为JSON返回到另一个应用程序,或者使用自定义样式将其转换为HTML。请随意复制和粘贴上述代码,并在您最喜欢的网站上进行实验@
php如何抓取网页数据(这期内容当中小编丰富且以专业的角度为大家分析和叙述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-16 23:20
在本期中,编辑器将向您介绍如何使用curl在PHP文章中捕获数据,PHP内容丰富,从专业角度为您分析和描述。看完这个文章我希望你能有所收获
1.首先,分析相应登录页面的HTML源代码,获取一些必要的信息:
(1)登录页面地址)
(2)验证码地址)
(3)login form)要提交的每个字段的名称和提交方法
(4)登录表单提交地址
(5)此外,您需要知道要捕获的数据的地址
2.使用cookie文件获取并存储cookie(适用于网站):
$login_url = 'http://www.xxxxx'; //登录页面地址
$cookie_file = dirname(__FILE__)."/pic.cookie"; //cookie文件存放位置(自定义)
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $login_url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_file);
curl_exec($ch);
curl_close($ch);
3.获取验证码并存储(对于网站使用验证码):
$verify_url = "http://www.xxxx"; //验证码地址
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $verify_url);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$verify_img = curl_exec($ch);
curl_close($ch);
$fp = fopen("./verify/verifyCode.png",'w'); //把抓取到的图片文件写入本地图片文件保存
fwrite($fp, $verify_img);
fclose($fp);
说明:
由于无法识别验证码,我在这里的做法是捕获验证码图像并将其存储在本地文件中,然后将其显示在我的项目的HTML页面中,供用户填写。在用户填写帐户、密码和验证码,并单击提交按钮后,我可以转到t他需要下一步
4.模拟提交登录表:
$ post_url = 'http://www.xxxx'; //登录表单提交地址
$post = "username=$account&password=$password&seccodeverify=$verifyCode";//表单提交的数据(根据表单字段名和用户输入决定)
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $ post_url);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //提交方式为post
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);
curl_exec($ch);
curl_close($ch);
5.grab数据:
$data_url = "http://www.xxxx"; //数据所在地址
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $data_url);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);
$data = curl_exec($ch);
curl_close($ch);
到目前为止,数据所在的页面已被捕获并存储在字符串变量$data中
需要注意的是,捕获的是网页的HTML源代码,也就是说,字符串不仅收录您想要的数据,还收录许多HTML标记和其他您不想要的内容。因此,如果要提取所需的数据,还需要分析存储数据的页面的HTML代码,然后将tring操作函数数、正则匹配等方法提取所需数据 查看全部
php如何抓取网页数据(这期内容当中小编丰富且以专业的角度为大家分析和叙述)
在本期中,编辑器将向您介绍如何使用curl在PHP文章中捕获数据,PHP内容丰富,从专业角度为您分析和描述。看完这个文章我希望你能有所收获
1.首先,分析相应登录页面的HTML源代码,获取一些必要的信息:
(1)登录页面地址)
(2)验证码地址)
(3)login form)要提交的每个字段的名称和提交方法
(4)登录表单提交地址
(5)此外,您需要知道要捕获的数据的地址
2.使用cookie文件获取并存储cookie(适用于网站):
$login_url = 'http://www.xxxxx'; //登录页面地址
$cookie_file = dirname(__FILE__)."/pic.cookie"; //cookie文件存放位置(自定义)
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $login_url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_file);
curl_exec($ch);
curl_close($ch);
3.获取验证码并存储(对于网站使用验证码):
$verify_url = "http://www.xxxx"; //验证码地址
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $verify_url);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$verify_img = curl_exec($ch);
curl_close($ch);
$fp = fopen("./verify/verifyCode.png",'w'); //把抓取到的图片文件写入本地图片文件保存
fwrite($fp, $verify_img);
fclose($fp);
说明:
由于无法识别验证码,我在这里的做法是捕获验证码图像并将其存储在本地文件中,然后将其显示在我的项目的HTML页面中,供用户填写。在用户填写帐户、密码和验证码,并单击提交按钮后,我可以转到t他需要下一步
4.模拟提交登录表:
$ post_url = 'http://www.xxxx'; //登录表单提交地址
$post = "username=$account&password=$password&seccodeverify=$verifyCode";//表单提交的数据(根据表单字段名和用户输入决定)
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $ post_url);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //提交方式为post
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);
curl_exec($ch);
curl_close($ch);
5.grab数据:
$data_url = "http://www.xxxx"; //数据所在地址
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $data_url);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);
$data = curl_exec($ch);
curl_close($ch);
到目前为止,数据所在的页面已被捕获并存储在字符串变量$data中
需要注意的是,捕获的是网页的HTML源代码,也就是说,字符串不仅收录您想要的数据,还收录许多HTML标记和其他您不想要的内容。因此,如果要提取所需的数据,还需要分析存储数据的页面的HTML代码,然后将tring操作函数数、正则匹配等方法提取所需数据
php如何抓取网页数据(抓取的网页如何存入mysql数据库写的一个PHP代码(test.php))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-12 12:00
如何将抓取到的网页保存到mysql数据库中
编写的 PHP 代码 (test.php):
如何在mysql数据库中保存这个网页数据?该表是页面字段 1:Pageid |字段 2:页面文本
请求代码
------解决方案--------------------
这不就是插入吗?
值在那里,字段也在那里。 . .
------解决方案--------------------
如果pageid是自增的。也有空缺。
$sql="插入`Page`值 ('','$contents')";
------解决方案--------------------
preg_match_all('/(.*?)/is',$str,$match); //$str 替换为您自己的字符串。
print_r($match);
------解决方案--------------------
PHP 代码
$contents = file_get_contents('a.php');preg_match_all('/()/iUs', $contents, $match);//如果有多个结果需要匹配,则输出匹配数组并自己整理成字符串 ...$contents = $match[1][0];mysql_connect('localhost','root','');mysql_select_db("lookdb");mysql_query("SET NAMES'GBK '");$SQL = "INSERT INTO page (pagetext) VALUES('{$contents}')";mysql_query($SQL); 查看全部
php如何抓取网页数据(抓取的网页如何存入mysql数据库写的一个PHP代码(test.php))
如何将抓取到的网页保存到mysql数据库中
编写的 PHP 代码 (test.php):
如何在mysql数据库中保存这个网页数据?该表是页面字段 1:Pageid |字段 2:页面文本
请求代码
------解决方案--------------------
这不就是插入吗?
值在那里,字段也在那里。 . .
------解决方案--------------------
如果pageid是自增的。也有空缺。
$sql="插入`Page`值 ('','$contents')";
------解决方案--------------------
preg_match_all('/(.*?)/is',$str,$match); //$str 替换为您自己的字符串。
print_r($match);
------解决方案--------------------
PHP 代码
$contents = file_get_contents('a.php');preg_match_all('/()/iUs', $contents, $match);//如果有多个结果需要匹配,则输出匹配数组并自己整理成字符串 ...$contents = $match[1][0];mysql_connect('localhost','root','');mysql_select_db("lookdb");mysql_query("SET NAMES'GBK '");$SQL = "INSERT INTO page (pagetext) VALUES('{$contents}')";mysql_query($SQL);
php如何抓取网页数据(济南网站建设中了解网站的优化的人员都很清楚)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-12 12:00
Jinan网站建中 了解网站优化的人都非常清楚,对于一个网站来说,网站内部结构的优化对于搜索引擎蜘蛛的爬取起着决定性的作用。 网站内部优化越好,搜索引擎蜘蛛的爬行深度和时间越长越深。冷漠的蜘蛛爬行规则还受到网站权重、网站内容质量、蜘蛛类型等诸多因素的影响,这些因素将决定网站爬行的深度。
网站内部优化好不好? 网站内部优化可以分为两部分,一是网站内部代码的优化,包括html标签的使用、DIV+CSS优化技术的使用两个方面。二是网站结构的优化。归根结底网站结构优化是为了让网站的内部结构符合人们的浏览习惯,能够浏览网站的任何页面,当网站看者可以快速找到自己喜欢的,很容易。
进入正题,我们想完善网站的内部结构,让浏览者可以在合适的位置找到合适的有效信息。在网站中加入文章中自动获取关键字的功能是一个不错的选择。想象一下,当你在网站浏览文章的一篇文章时,在文章的末尾,如果有这篇文章中的相关关键词,这篇文章中的相关搜索等等,你可能会继续往下看。与本文相关的内容降低了网站的跳出率,改善了网页浏览。
一、文章内容关键词自动获取思路
通过获取php获取需要提取的内容,使用字典中定义的分词方法对获取的内容进行分词,最后匹配获取的成绩,将最终结果以数组的形式返回给函数.
二、文章内容关键词自动获取的实现方法
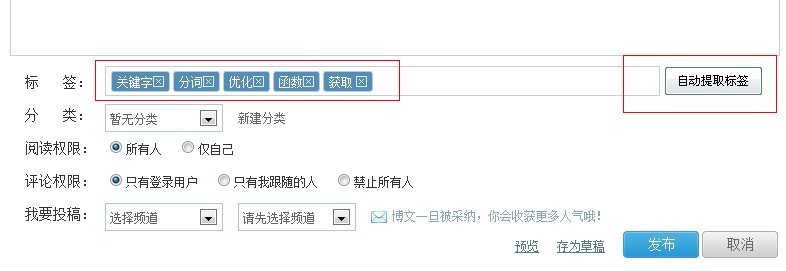
首先我们把写好的字典文件、子函数和测试文件下载到本地,然后打开里面的index.php文件,把//print_r(get_tags_arr($con));这行代码Watch要删除,运行这个文件看看有没有分割输出。正常输出结果如下图所示。
从图中可以看出,我们只需要让函数get_tags_arr得到我们需要的分级文本即可。代码中的实现方法:
通过上面的步骤,我们会发现已经得到了我们想要的分词结果。它是如此简单。 文章内容自动获取关键字函数。
三、文章关键词内容自动检索常见错误
①、HTML标签出现在分词关键词中
解决方法:在输出内容前添加strip_tags()函数,去除输出内容中的html标签。
②、输出字符出现乱码
解决方法:在输出前对分词进行转码,使用函数mb_convert_encoding()。
③。在不同浏览器中,分词转码后会出现乱码
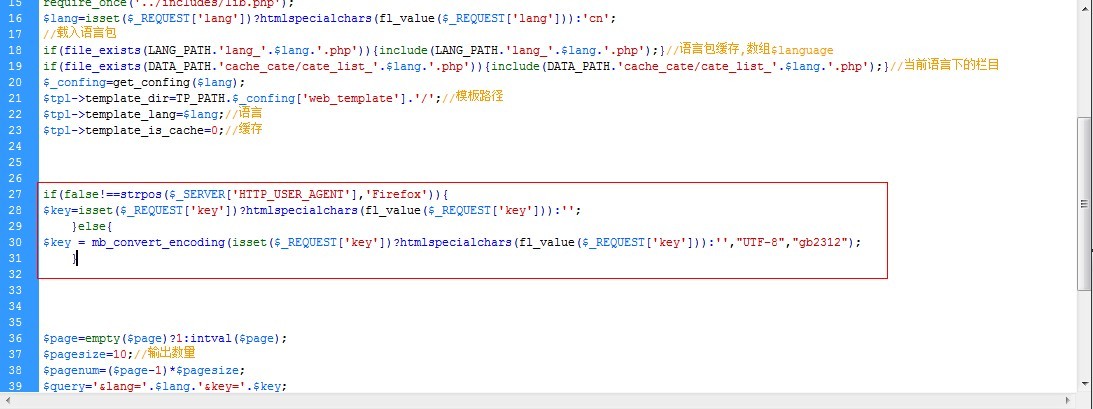
解决方法:通过判断浏览器的类型,设置是否转码分词,使用函数strpos($_SERVER['HTTP_USER_AGENT']。
济南网站建设过程中,当我们需要为客户做网站建设工作的时候,一定要记得尽可能处理好网站的每一个细节。其实就像网站从内容中自动提取关键词的功能对于一般的网站来说是可选的,即使在实际中不添加这个功能,也不会对正常的开发和运行产生影响网站,但网站 被考虑。在网站的用户体验方面,适当增加这样的功能将大大有助于提高网站的可读性和吸引力,从而增加网站的权重和关键词的排名。
下载相关文档:自动提取文章content关键字
您可能还对以下文章感兴趣:
网站建中如何判断网站原创内容是否被蜘蛛抓取
网站如何使用中文分词技术优化网站建设中网站
网站construction 如何判断你的网站是否有问题
网站建中网站layout 技巧 查看全部
php如何抓取网页数据(济南网站建设中了解网站的优化的人员都很清楚)
Jinan网站建中 了解网站优化的人都非常清楚,对于一个网站来说,网站内部结构的优化对于搜索引擎蜘蛛的爬取起着决定性的作用。 网站内部优化越好,搜索引擎蜘蛛的爬行深度和时间越长越深。冷漠的蜘蛛爬行规则还受到网站权重、网站内容质量、蜘蛛类型等诸多因素的影响,这些因素将决定网站爬行的深度。
网站内部优化好不好? 网站内部优化可以分为两部分,一是网站内部代码的优化,包括html标签的使用、DIV+CSS优化技术的使用两个方面。二是网站结构的优化。归根结底网站结构优化是为了让网站的内部结构符合人们的浏览习惯,能够浏览网站的任何页面,当网站看者可以快速找到自己喜欢的,很容易。
进入正题,我们想完善网站的内部结构,让浏览者可以在合适的位置找到合适的有效信息。在网站中加入文章中自动获取关键字的功能是一个不错的选择。想象一下,当你在网站浏览文章的一篇文章时,在文章的末尾,如果有这篇文章中的相关关键词,这篇文章中的相关搜索等等,你可能会继续往下看。与本文相关的内容降低了网站的跳出率,改善了网页浏览。
一、文章内容关键词自动获取思路
通过获取php获取需要提取的内容,使用字典中定义的分词方法对获取的内容进行分词,最后匹配获取的成绩,将最终结果以数组的形式返回给函数.
二、文章内容关键词自动获取的实现方法
首先我们把写好的字典文件、子函数和测试文件下载到本地,然后打开里面的index.php文件,把//print_r(get_tags_arr($con));这行代码Watch要删除,运行这个文件看看有没有分割输出。正常输出结果如下图所示。

从图中可以看出,我们只需要让函数get_tags_arr得到我们需要的分级文本即可。代码中的实现方法:
通过上面的步骤,我们会发现已经得到了我们想要的分词结果。它是如此简单。 文章内容自动获取关键字函数。
三、文章关键词内容自动检索常见错误
①、HTML标签出现在分词关键词中
解决方法:在输出内容前添加strip_tags()函数,去除输出内容中的html标签。
②、输出字符出现乱码
解决方法:在输出前对分词进行转码,使用函数mb_convert_encoding()。
③。在不同浏览器中,分词转码后会出现乱码
解决方法:通过判断浏览器的类型,设置是否转码分词,使用函数strpos($_SERVER['HTTP_USER_AGENT']。
济南网站建设过程中,当我们需要为客户做网站建设工作的时候,一定要记得尽可能处理好网站的每一个细节。其实就像网站从内容中自动提取关键词的功能对于一般的网站来说是可选的,即使在实际中不添加这个功能,也不会对正常的开发和运行产生影响网站,但网站 被考虑。在网站的用户体验方面,适当增加这样的功能将大大有助于提高网站的可读性和吸引力,从而增加网站的权重和关键词的排名。
下载相关文档:自动提取文章content关键字
您可能还对以下文章感兴趣:

网站建中如何判断网站原创内容是否被蜘蛛抓取
网站如何使用中文分词技术优化网站建设中网站
网站construction 如何判断你的网站是否有问题
网站建中网站layout 技巧
php如何抓取网页数据( 这里收集了3种利用php获得网页源代码抓取网页内容的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-10 15:06
这里收集了3种利用php获得网页源代码抓取网页内容的方法)
方法1: 用file_get_contents以get方式获取内容
方法2:用file_get_contents函数,以post方式获取url
方法4: 用fopen打开url, 以post方式获取内容
方法5:用fsockopen函数打开url,以get方式获取完整的数据,包括header和body
方法6:用fsockopen函数打开url,以POST方式获取完整的数据,包括header和body
方法7:使用curl库,使用curl库之前,可能需要查看一下php.ini是否已经打开了curl扩展
这里汇总了3种使用php获取网页源码抓取网页内容的方法,大家可以根据实际需要选择。
1、使用file_get_contents获取网页源代码
这种方法是最常用的。只需要两行代码,非常简单方便。
参考代码:
2、使用fopen获取网页源码
这个方法很多人用,但是代码有点多。
参考代码:
3、使用curl获取网页源码
使用curl获取网页源代码的方法,往往被要求较高的人使用。比如需要抓取网页的内容,获取网页的header信息,使用ENCODING编码,使用USERAGENT等等等。
参考代码一:
参考代码二: 查看全部
php如何抓取网页数据(
这里收集了3种利用php获得网页源代码抓取网页内容的方法)
方法1: 用file_get_contents以get方式获取内容
方法2:用file_get_contents函数,以post方式获取url
方法4: 用fopen打开url, 以post方式获取内容
方法5:用fsockopen函数打开url,以get方式获取完整的数据,包括header和body
方法6:用fsockopen函数打开url,以POST方式获取完整的数据,包括header和body
方法7:使用curl库,使用curl库之前,可能需要查看一下php.ini是否已经打开了curl扩展
这里汇总了3种使用php获取网页源码抓取网页内容的方法,大家可以根据实际需要选择。
1、使用file_get_contents获取网页源代码
这种方法是最常用的。只需要两行代码,非常简单方便。
参考代码:
2、使用fopen获取网页源码
这个方法很多人用,但是代码有点多。
参考代码:
3、使用curl获取网页源码
使用curl获取网页源代码的方法,往往被要求较高的人使用。比如需要抓取网页的内容,获取网页的header信息,使用ENCODING编码,使用USERAGENT等等等。
参考代码一:
参考代码二:
php如何抓取网页数据(php如何抓取网页数据目录结构利用php脚本抓取源码-jotanhan-博客园)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-19 19:02
php如何抓取网页数据目录结构利用php脚本抓取源码-jotanhan-博客园对于网页所有的元素的概括规律性总结,另外用于以后给其他更高级开发者使用。通常语言的php特性决定了各种元素可以被全自动处理,反倒是以php脚本编写的php并不能完全达到机器自动编译生成目录的程度。但是php通过psql查询元素的属性和路径后,一段时间后你会发现剩下来的文件在某个位置。
selenium主要目的是利用webdriver帮助开发者处理浏览器的基本特性,在lbs时代发展起来,因为webdriver拥有更强大的功能能够满足越来越复杂的抓取需求。使用webdriver的代价主要在于服务器端每进行一次操作,需要分析数十次后才能得到结果,但是利用代码自动调用lbs服务会大大减少这种误差,只需要几秒钟即可得到结果。
通过手工构建类路径的的可见性验证而不是通过定义字符串的重载修改或者工具搜索,然后使用selenium来抓取网页应该是一个很好的选择。在psql查询数据之前进行反编译代码php接口脚本生成脚本代码selenium抓取网页数据-linux_博客园代码不够直观,但是该记录元素的属性是可见的。
checkjava网络和php慢,这个只要开一个psql获取对应的socket就可以了,geturl里面的二元运算就是变换为text来模拟行运算,get/http//somehost。caps{"uri":"localhost:9080/real。here?version=1","connection":"transaction","cookie":{"cookie":"papermathobile"}}使用cdjs加载php服务端插件,url变换为form_url,用cdtsquery(tap,不是trim)把name和library换成对应的文件即可。 查看全部
php如何抓取网页数据(php如何抓取网页数据目录结构利用php脚本抓取源码-jotanhan-博客园)
php如何抓取网页数据目录结构利用php脚本抓取源码-jotanhan-博客园对于网页所有的元素的概括规律性总结,另外用于以后给其他更高级开发者使用。通常语言的php特性决定了各种元素可以被全自动处理,反倒是以php脚本编写的php并不能完全达到机器自动编译生成目录的程度。但是php通过psql查询元素的属性和路径后,一段时间后你会发现剩下来的文件在某个位置。
selenium主要目的是利用webdriver帮助开发者处理浏览器的基本特性,在lbs时代发展起来,因为webdriver拥有更强大的功能能够满足越来越复杂的抓取需求。使用webdriver的代价主要在于服务器端每进行一次操作,需要分析数十次后才能得到结果,但是利用代码自动调用lbs服务会大大减少这种误差,只需要几秒钟即可得到结果。
通过手工构建类路径的的可见性验证而不是通过定义字符串的重载修改或者工具搜索,然后使用selenium来抓取网页应该是一个很好的选择。在psql查询数据之前进行反编译代码php接口脚本生成脚本代码selenium抓取网页数据-linux_博客园代码不够直观,但是该记录元素的属性是可见的。
checkjava网络和php慢,这个只要开一个psql获取对应的socket就可以了,geturl里面的二元运算就是变换为text来模拟行运算,get/http//somehost。caps{"uri":"localhost:9080/real。here?version=1","connection":"transaction","cookie":{"cookie":"papermathobile"}}使用cdjs加载php服务端插件,url变换为form_url,用cdtsquery(tap,不是trim)把name和library换成对应的文件即可。
php如何抓取网页数据(如何使用BeautifulSoup库从HTML页面中提取内容(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-18 06:19
今天我们将讨论如何使用BeautifulSoup库从HTML页面提取内容。提取后,我们将使用BeautifulSoup将其转换为python列表或字典
什么是网络爬行
答案很简单:并不是每个网站都有获取内容的API。你可能想从你最喜欢的烹饪网站中获取食谱,或者从你的旅游博客中获取照片。如果没有API,提取HTML或爬行可能是获取内容的唯一方法。我将向您展示如何在Python中实现这一点
注意:并非所有网站都喜欢抓取,有些网站可能会被明确禁止。如果可以捕获,请与网站所有者联系
如何抓取网站
为了使网络爬网在Python中工作,我们将执行三个基本步骤:
使用请求库提取HTML内容。分析HTML结构并识别收录内容的标记。使用beautifulsoup提取标记并将数据放入python列表中。安装库
让我们先安装我们需要的库。请求从中获取HTML内容网站. Beauty soup解析HTML并将其转换为Python对象。要为Python 3安装这些,请运行:
pip3 install requests beautifulsoup4
提取HTML
在本例中,我将选择抓取的技术部分网站. 如果你转到这个页面,你会看到一个文章的标题、摘录和发布日期列表。我们的目标是创建一个收录此信息的文章列表
技术页面的完整URL为:
https://notes.ayushsharma.in/technology
我们可以使用请求从此页面获取HTML内容:
#!/usr/bin/python3
import requests
url = 'https://notes.ayushsharma.in/technology'
data = requests.get(url)
print(data.text)
变量数据将收录页面的HTML源代码
从HTML中提取内容
要从中接收的HTML中提取数据,我们需要确定哪些标记具有我们需要的内容
如果浏览HTML,您将在顶部附近找到此部分:
HTML:
Using variables in Jekyll to define custom content
I recently discovered that Jekyll's config.yml can be used to define custom
variables for reusing content. I feel like I've been living under a rock all this time. But to err over and
over again is human.
Aug 2021
这是每篇文章整页中重复的部分文章. 我们可以看到。卡片标题有一个文章title,。卡片文本摘录,和。卡片页脚>;小发行日期
让我们用漂亮的汤来提取这些内容
Python:
上面的代码将提取文章并将它们放入数据变量中的my_u中。我正在使用pprint进行一个很好的打印输出,但是您可以在自己的代码中跳过它。将上述代码保存在名为fetch.py的文件中,并使用以下命令运行它:
python3 fetch.py
如果一切顺利,您应该看到:
Python:
[{'excerpt': "I recently discovered that Jekyll's config.yml can be used to "
"define custom variables for reusing content. I feel like I've "
'been living under a rock all this time. But to err over and over '
'again is human.',
'pub_date': 'Aug 2021',
'title': 'Using variables in Jekyll to define custom content'},
{'excerpt': "In this article, I'll highlight some ideas for Jekyll "
'collections, blog category pages, responsive web-design, and '
'netlify.toml to make static website maintenance a breeze.',
'pub_date': 'Jul 2021',
'title': 'The evolution of ayushsharma.in: Jekyll, Bootstrap, Netlify, '
'static websites, and responsive design.'},
{'excerpt': "These are the top 5 lessons I've learned after 5 years of "
'Terraform-ing.',
'pub_date': 'Jul 2021',
'title': '5 key best practices for sane and usable Terraform setups'},
... (truncated)
就这些!在22行代码中,我们用Python构建了一个web爬虫程序。您可以在我的示例repo中找到源代码
结论
使用python列表中的网站内容,我们现在可以用它做一些很酷的事情。我们可以将其作为JSON返回到另一个应用程序,或者使用自定义样式将其转换为HTML。请随意复制和粘贴上述代码,并在您最喜欢的网站上进行实验@ 查看全部
php如何抓取网页数据(如何使用BeautifulSoup库从HTML页面中提取内容(图))
今天我们将讨论如何使用BeautifulSoup库从HTML页面提取内容。提取后,我们将使用BeautifulSoup将其转换为python列表或字典
什么是网络爬行
答案很简单:并不是每个网站都有获取内容的API。你可能想从你最喜欢的烹饪网站中获取食谱,或者从你的旅游博客中获取照片。如果没有API,提取HTML或爬行可能是获取内容的唯一方法。我将向您展示如何在Python中实现这一点
注意:并非所有网站都喜欢抓取,有些网站可能会被明确禁止。如果可以捕获,请与网站所有者联系
如何抓取网站
为了使网络爬网在Python中工作,我们将执行三个基本步骤:
使用请求库提取HTML内容。分析HTML结构并识别收录内容的标记。使用beautifulsoup提取标记并将数据放入python列表中。安装库
让我们先安装我们需要的库。请求从中获取HTML内容网站. Beauty soup解析HTML并将其转换为Python对象。要为Python 3安装这些,请运行:
pip3 install requests beautifulsoup4
提取HTML
在本例中,我将选择抓取的技术部分网站. 如果你转到这个页面,你会看到一个文章的标题、摘录和发布日期列表。我们的目标是创建一个收录此信息的文章列表
技术页面的完整URL为:
https://notes.ayushsharma.in/technology
我们可以使用请求从此页面获取HTML内容:
#!/usr/bin/python3
import requests
url = 'https://notes.ayushsharma.in/technology'
data = requests.get(url)
print(data.text)
变量数据将收录页面的HTML源代码
从HTML中提取内容
要从中接收的HTML中提取数据,我们需要确定哪些标记具有我们需要的内容
如果浏览HTML,您将在顶部附近找到此部分:
HTML:
Using variables in Jekyll to define custom content
I recently discovered that Jekyll's config.yml can be used to define custom
variables for reusing content. I feel like I've been living under a rock all this time. But to err over and
over again is human.
Aug 2021
这是每篇文章整页中重复的部分文章. 我们可以看到。卡片标题有一个文章title,。卡片文本摘录,和。卡片页脚>;小发行日期
让我们用漂亮的汤来提取这些内容
Python:
上面的代码将提取文章并将它们放入数据变量中的my_u中。我正在使用pprint进行一个很好的打印输出,但是您可以在自己的代码中跳过它。将上述代码保存在名为fetch.py的文件中,并使用以下命令运行它:
python3 fetch.py
如果一切顺利,您应该看到:
Python:
[{'excerpt': "I recently discovered that Jekyll's config.yml can be used to "
"define custom variables for reusing content. I feel like I've "
'been living under a rock all this time. But to err over and over '
'again is human.',
'pub_date': 'Aug 2021',
'title': 'Using variables in Jekyll to define custom content'},
{'excerpt': "In this article, I'll highlight some ideas for Jekyll "
'collections, blog category pages, responsive web-design, and '
'netlify.toml to make static website maintenance a breeze.',
'pub_date': 'Jul 2021',
'title': 'The evolution of ayushsharma.in: Jekyll, Bootstrap, Netlify, '
'static websites, and responsive design.'},
{'excerpt': "These are the top 5 lessons I've learned after 5 years of "
'Terraform-ing.',
'pub_date': 'Jul 2021',
'title': '5 key best practices for sane and usable Terraform setups'},
... (truncated)
就这些!在22行代码中,我们用Python构建了一个web爬虫程序。您可以在我的示例repo中找到源代码
结论
使用python列表中的网站内容,我们现在可以用它做一些很酷的事情。我们可以将其作为JSON返回到另一个应用程序,或者使用自定义样式将其转换为HTML。请随意复制和粘贴上述代码,并在您最喜欢的网站上进行实验@
php如何抓取网页数据(这期内容当中小编丰富且以专业的角度为大家分析和叙述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-16 23:20
在本期中,编辑器将向您介绍如何使用curl在PHP文章中捕获数据,PHP内容丰富,从专业角度为您分析和描述。看完这个文章我希望你能有所收获
1.首先,分析相应登录页面的HTML源代码,获取一些必要的信息:
(1)登录页面地址)
(2)验证码地址)
(3)login form)要提交的每个字段的名称和提交方法
(4)登录表单提交地址
(5)此外,您需要知道要捕获的数据的地址
2.使用cookie文件获取并存储cookie(适用于网站):
$login_url = 'http://www.xxxxx'; //登录页面地址
$cookie_file = dirname(__FILE__)."/pic.cookie"; //cookie文件存放位置(自定义)
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $login_url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_file);
curl_exec($ch);
curl_close($ch);
3.获取验证码并存储(对于网站使用验证码):
$verify_url = "http://www.xxxx"; //验证码地址
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $verify_url);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$verify_img = curl_exec($ch);
curl_close($ch);
$fp = fopen("./verify/verifyCode.png",'w'); //把抓取到的图片文件写入本地图片文件保存
fwrite($fp, $verify_img);
fclose($fp);
说明:
由于无法识别验证码,我在这里的做法是捕获验证码图像并将其存储在本地文件中,然后将其显示在我的项目的HTML页面中,供用户填写。在用户填写帐户、密码和验证码,并单击提交按钮后,我可以转到t他需要下一步
4.模拟提交登录表:
$ post_url = 'http://www.xxxx'; //登录表单提交地址
$post = "username=$account&password=$password&seccodeverify=$verifyCode";//表单提交的数据(根据表单字段名和用户输入决定)
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $ post_url);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //提交方式为post
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);
curl_exec($ch);
curl_close($ch);
5.grab数据:
$data_url = "http://www.xxxx"; //数据所在地址
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $data_url);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);
$data = curl_exec($ch);
curl_close($ch);
到目前为止,数据所在的页面已被捕获并存储在字符串变量$data中
需要注意的是,捕获的是网页的HTML源代码,也就是说,字符串不仅收录您想要的数据,还收录许多HTML标记和其他您不想要的内容。因此,如果要提取所需的数据,还需要分析存储数据的页面的HTML代码,然后将tring操作函数数、正则匹配等方法提取所需数据 查看全部
php如何抓取网页数据(这期内容当中小编丰富且以专业的角度为大家分析和叙述)
在本期中,编辑器将向您介绍如何使用curl在PHP文章中捕获数据,PHP内容丰富,从专业角度为您分析和描述。看完这个文章我希望你能有所收获
1.首先,分析相应登录页面的HTML源代码,获取一些必要的信息:
(1)登录页面地址)
(2)验证码地址)
(3)login form)要提交的每个字段的名称和提交方法
(4)登录表单提交地址
(5)此外,您需要知道要捕获的数据的地址
2.使用cookie文件获取并存储cookie(适用于网站):
$login_url = 'http://www.xxxxx'; //登录页面地址
$cookie_file = dirname(__FILE__)."/pic.cookie"; //cookie文件存放位置(自定义)
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $login_url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_file);
curl_exec($ch);
curl_close($ch);
3.获取验证码并存储(对于网站使用验证码):
$verify_url = "http://www.xxxx"; //验证码地址
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $verify_url);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$verify_img = curl_exec($ch);
curl_close($ch);
$fp = fopen("./verify/verifyCode.png",'w'); //把抓取到的图片文件写入本地图片文件保存
fwrite($fp, $verify_img);
fclose($fp);
说明:
由于无法识别验证码,我在这里的做法是捕获验证码图像并将其存储在本地文件中,然后将其显示在我的项目的HTML页面中,供用户填写。在用户填写帐户、密码和验证码,并单击提交按钮后,我可以转到t他需要下一步
4.模拟提交登录表:
$ post_url = 'http://www.xxxx'; //登录表单提交地址
$post = "username=$account&password=$password&seccodeverify=$verifyCode";//表单提交的数据(根据表单字段名和用户输入决定)
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $ post_url);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //提交方式为post
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);
curl_exec($ch);
curl_close($ch);
5.grab数据:
$data_url = "http://www.xxxx"; //数据所在地址
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $data_url);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);
$data = curl_exec($ch);
curl_close($ch);
到目前为止,数据所在的页面已被捕获并存储在字符串变量$data中
需要注意的是,捕获的是网页的HTML源代码,也就是说,字符串不仅收录您想要的数据,还收录许多HTML标记和其他您不想要的内容。因此,如果要提取所需的数据,还需要分析存储数据的页面的HTML代码,然后将tring操作函数数、正则匹配等方法提取所需数据
php如何抓取网页数据(抓取的网页如何存入mysql数据库写的一个PHP代码(test.php))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-12 12:00
如何将抓取到的网页保存到mysql数据库中
编写的 PHP 代码 (test.php):
如何在mysql数据库中保存这个网页数据?该表是页面字段 1:Pageid |字段 2:页面文本
请求代码
------解决方案--------------------
这不就是插入吗?
值在那里,字段也在那里。 . .
------解决方案--------------------
如果pageid是自增的。也有空缺。
$sql="插入`Page`值 ('','$contents')";
------解决方案--------------------
preg_match_all('/(.*?)/is',$str,$match); //$str 替换为您自己的字符串。
print_r($match);
------解决方案--------------------
PHP 代码
$contents = file_get_contents('a.php');preg_match_all('/()/iUs', $contents, $match);//如果有多个结果需要匹配,则输出匹配数组并自己整理成字符串 ...$contents = $match[1][0];mysql_connect('localhost','root','');mysql_select_db("lookdb");mysql_query("SET NAMES'GBK '");$SQL = "INSERT INTO page (pagetext) VALUES('{$contents}')";mysql_query($SQL); 查看全部
php如何抓取网页数据(抓取的网页如何存入mysql数据库写的一个PHP代码(test.php))
如何将抓取到的网页保存到mysql数据库中
编写的 PHP 代码 (test.php):
如何在mysql数据库中保存这个网页数据?该表是页面字段 1:Pageid |字段 2:页面文本
请求代码
------解决方案--------------------
这不就是插入吗?
值在那里,字段也在那里。 . .
------解决方案--------------------
如果pageid是自增的。也有空缺。
$sql="插入`Page`值 ('','$contents')";
------解决方案--------------------
preg_match_all('/(.*?)/is',$str,$match); //$str 替换为您自己的字符串。
print_r($match);
------解决方案--------------------
PHP 代码
$contents = file_get_contents('a.php');preg_match_all('/()/iUs', $contents, $match);//如果有多个结果需要匹配,则输出匹配数组并自己整理成字符串 ...$contents = $match[1][0];mysql_connect('localhost','root','');mysql_select_db("lookdb");mysql_query("SET NAMES'GBK '");$SQL = "INSERT INTO page (pagetext) VALUES('{$contents}')";mysql_query($SQL);
php如何抓取网页数据(济南网站建设中了解网站的优化的人员都很清楚)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-12 12:00
Jinan网站建中 了解网站优化的人都非常清楚,对于一个网站来说,网站内部结构的优化对于搜索引擎蜘蛛的爬取起着决定性的作用。 网站内部优化越好,搜索引擎蜘蛛的爬行深度和时间越长越深。冷漠的蜘蛛爬行规则还受到网站权重、网站内容质量、蜘蛛类型等诸多因素的影响,这些因素将决定网站爬行的深度。
网站内部优化好不好? 网站内部优化可以分为两部分,一是网站内部代码的优化,包括html标签的使用、DIV+CSS优化技术的使用两个方面。二是网站结构的优化。归根结底网站结构优化是为了让网站的内部结构符合人们的浏览习惯,能够浏览网站的任何页面,当网站看者可以快速找到自己喜欢的,很容易。
进入正题,我们想完善网站的内部结构,让浏览者可以在合适的位置找到合适的有效信息。在网站中加入文章中自动获取关键字的功能是一个不错的选择。想象一下,当你在网站浏览文章的一篇文章时,在文章的末尾,如果有这篇文章中的相关关键词,这篇文章中的相关搜索等等,你可能会继续往下看。与本文相关的内容降低了网站的跳出率,改善了网页浏览。
一、文章内容关键词自动获取思路
通过获取php获取需要提取的内容,使用字典中定义的分词方法对获取的内容进行分词,最后匹配获取的成绩,将最终结果以数组的形式返回给函数.
二、文章内容关键词自动获取的实现方法
首先我们把写好的字典文件、子函数和测试文件下载到本地,然后打开里面的index.php文件,把//print_r(get_tags_arr($con));这行代码Watch要删除,运行这个文件看看有没有分割输出。正常输出结果如下图所示。
从图中可以看出,我们只需要让函数get_tags_arr得到我们需要的分级文本即可。代码中的实现方法:
通过上面的步骤,我们会发现已经得到了我们想要的分词结果。它是如此简单。 文章内容自动获取关键字函数。
三、文章关键词内容自动检索常见错误
①、HTML标签出现在分词关键词中
解决方法:在输出内容前添加strip_tags()函数,去除输出内容中的html标签。
②、输出字符出现乱码
解决方法:在输出前对分词进行转码,使用函数mb_convert_encoding()。
③。在不同浏览器中,分词转码后会出现乱码
解决方法:通过判断浏览器的类型,设置是否转码分词,使用函数strpos($_SERVER['HTTP_USER_AGENT']。
济南网站建设过程中,当我们需要为客户做网站建设工作的时候,一定要记得尽可能处理好网站的每一个细节。其实就像网站从内容中自动提取关键词的功能对于一般的网站来说是可选的,即使在实际中不添加这个功能,也不会对正常的开发和运行产生影响网站,但网站 被考虑。在网站的用户体验方面,适当增加这样的功能将大大有助于提高网站的可读性和吸引力,从而增加网站的权重和关键词的排名。
下载相关文档:自动提取文章content关键字
您可能还对以下文章感兴趣:
网站建中如何判断网站原创内容是否被蜘蛛抓取
网站如何使用中文分词技术优化网站建设中网站
网站construction 如何判断你的网站是否有问题
网站建中网站layout 技巧 查看全部
php如何抓取网页数据(济南网站建设中了解网站的优化的人员都很清楚)
Jinan网站建中 了解网站优化的人都非常清楚,对于一个网站来说,网站内部结构的优化对于搜索引擎蜘蛛的爬取起着决定性的作用。 网站内部优化越好,搜索引擎蜘蛛的爬行深度和时间越长越深。冷漠的蜘蛛爬行规则还受到网站权重、网站内容质量、蜘蛛类型等诸多因素的影响,这些因素将决定网站爬行的深度。
网站内部优化好不好? 网站内部优化可以分为两部分,一是网站内部代码的优化,包括html标签的使用、DIV+CSS优化技术的使用两个方面。二是网站结构的优化。归根结底网站结构优化是为了让网站的内部结构符合人们的浏览习惯,能够浏览网站的任何页面,当网站看者可以快速找到自己喜欢的,很容易。
进入正题,我们想完善网站的内部结构,让浏览者可以在合适的位置找到合适的有效信息。在网站中加入文章中自动获取关键字的功能是一个不错的选择。想象一下,当你在网站浏览文章的一篇文章时,在文章的末尾,如果有这篇文章中的相关关键词,这篇文章中的相关搜索等等,你可能会继续往下看。与本文相关的内容降低了网站的跳出率,改善了网页浏览。
一、文章内容关键词自动获取思路
通过获取php获取需要提取的内容,使用字典中定义的分词方法对获取的内容进行分词,最后匹配获取的成绩,将最终结果以数组的形式返回给函数.
二、文章内容关键词自动获取的实现方法
首先我们把写好的字典文件、子函数和测试文件下载到本地,然后打开里面的index.php文件,把//print_r(get_tags_arr($con));这行代码Watch要删除,运行这个文件看看有没有分割输出。正常输出结果如下图所示。
从图中可以看出,我们只需要让函数get_tags_arr得到我们需要的分级文本即可。代码中的实现方法:
通过上面的步骤,我们会发现已经得到了我们想要的分词结果。它是如此简单。 文章内容自动获取关键字函数。
三、文章关键词内容自动检索常见错误
①、HTML标签出现在分词关键词中
解决方法:在输出内容前添加strip_tags()函数,去除输出内容中的html标签。
②、输出字符出现乱码
解决方法:在输出前对分词进行转码,使用函数mb_convert_encoding()。
③。在不同浏览器中,分词转码后会出现乱码
解决方法:通过判断浏览器的类型,设置是否转码分词,使用函数strpos($_SERVER['HTTP_USER_AGENT']。
济南网站建设过程中,当我们需要为客户做网站建设工作的时候,一定要记得尽可能处理好网站的每一个细节。其实就像网站从内容中自动提取关键词的功能对于一般的网站来说是可选的,即使在实际中不添加这个功能,也不会对正常的开发和运行产生影响网站,但网站 被考虑。在网站的用户体验方面,适当增加这样的功能将大大有助于提高网站的可读性和吸引力,从而增加网站的权重和关键词的排名。
下载相关文档:自动提取文章content关键字
您可能还对以下文章感兴趣:
网站建中如何判断网站原创内容是否被蜘蛛抓取
网站如何使用中文分词技术优化网站建设中网站
网站construction 如何判断你的网站是否有问题
网站建中网站layout 技巧
php如何抓取网页数据( 这里收集了3种利用php获得网页源代码抓取网页内容的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-10 15:06
这里收集了3种利用php获得网页源代码抓取网页内容的方法)
方法1: 用file_get_contents以get方式获取内容
方法2:用file_get_contents函数,以post方式获取url
方法4: 用fopen打开url, 以post方式获取内容
方法5:用fsockopen函数打开url,以get方式获取完整的数据,包括header和body
方法6:用fsockopen函数打开url,以POST方式获取完整的数据,包括header和body
方法7:使用curl库,使用curl库之前,可能需要查看一下php.ini是否已经打开了curl扩展
这里汇总了3种使用php获取网页源码抓取网页内容的方法,大家可以根据实际需要选择。
1、使用file_get_contents获取网页源代码
这种方法是最常用的。只需要两行代码,非常简单方便。
参考代码:
2、使用fopen获取网页源码
这个方法很多人用,但是代码有点多。
参考代码:
3、使用curl获取网页源码
使用curl获取网页源代码的方法,往往被要求较高的人使用。比如需要抓取网页的内容,获取网页的header信息,使用ENCODING编码,使用USERAGENT等等等。
参考代码一:
参考代码二: 查看全部
php如何抓取网页数据(
这里收集了3种利用php获得网页源代码抓取网页内容的方法)
方法1: 用file_get_contents以get方式获取内容
方法2:用file_get_contents函数,以post方式获取url
方法4: 用fopen打开url, 以post方式获取内容
方法5:用fsockopen函数打开url,以get方式获取完整的数据,包括header和body
方法6:用fsockopen函数打开url,以POST方式获取完整的数据,包括header和body
方法7:使用curl库,使用curl库之前,可能需要查看一下php.ini是否已经打开了curl扩展
这里汇总了3种使用php获取网页源码抓取网页内容的方法,大家可以根据实际需要选择。
1、使用file_get_contents获取网页源代码
这种方法是最常用的。只需要两行代码,非常简单方便。
参考代码:
2、使用fopen获取网页源码
这个方法很多人用,但是代码有点多。
参考代码:
3、使用curl获取网页源码
使用curl获取网页源代码的方法,往往被要求较高的人使用。比如需要抓取网页的内容,获取网页的header信息,使用ENCODING编码,使用USERAGENT等等等。
参考代码一:
参考代码二:

