
php如何抓取网页数据
php如何抓取网页数据( Web抓取的探险之前,如何得到那些重要数据呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-04 12:15
Web抓取的探险之前,如何得到那些重要数据呢?)
随着电子商务的蓬勃发展,作者近年来对比价应用越来越着迷。每次线上(甚至线下)购买,都是深入研究各大电商的结果网站。
笔者常用的比价应用包括:RedLaser、ShopSavvy和BuyHatke。这些应用有效地提高了价格透明度,从而为消费者节省了大量时间。
但是,您有没有想过这些应用程序是如何获取这些重要数据的?通常,他们使用 Web 抓取技术来完成此任务。
网页抓取的定义
网络抓取是提取网络数据的过程。借助合适的工具,您可以提取任何您能看到的数据。在本文中,我们将重点介绍自动提取过程的过程,以帮助您在短时间内采集大量数据。除了我上面提到的用例,抓取技术的用途还包括:SEO跟踪、工作跟踪、新闻分析,以及我最喜欢的社交媒体情绪分析!
提醒
在开始网络抓取冒险之前,请确保您了解相关的法律问题。许多 网站 在其服务条款中明确禁止抓取其内容。例如,Medium 网站 写道:“按照网站 robots.txt 文件中的规定抓取是可以接受的,但我们禁止抓取。” 爬不准爬的网站可能会让你进入他们的黑名单!与任何工具一样,网页抓取也可能用于不受欢迎的目的,例如复制 网站 内容。此外,网络爬虫引发的法律诉讼也不少。
设置代码
在完全理解需要谨慎处理之后,让我们开始学习网络抓取。事实上,网页抓取可以用任何编程语言实现。前不久,我们用Node来实现。在本文中,考虑到它的简单性和丰富的包支持,我们将使用 Python 来实现爬虫程序。
网页抓取的基本过程
当您在网络上打开一个站点时,其 HTML 代码将被下载,您的网络浏览器将对其进行分析和显示。HTML 代码收录您看到的所有信息。因此,可以通过分析 HTML 代码获得所需的信息(如价格)。您可以使用正则表达式在数据海洋中搜索您需要的信息,也可以使用函数库来解释HTML,也可以获取您需要的数据。
在 Python 中,我们将使用一个名为 Beautiful Soup 的模块来分析 HTML 数据。您可以借助安装程序(例如 pip)进行安装,只需运行以下代码:
pip install beautifulsoup4
或者,您也可以从源代码构建。在本模块中,您可以看到详细的安装步骤。
安装完成后,我们一般会按照以下步骤来实现网页抓取:
作为演示,我们将使用作者的博客。作为目标 URL。
前两步比较简单,可以这样完成:
from urllib import urlopen#Sending the http requestwebpage = urlopen(\'http://my_website.com/\').read()
接下来,将响应传递给之前安装的模块:
from bs4 import BeautifulSoup#making the soup! yummy ;)soup = BeautifulSoup(webpage, "html5lib")
请注意,这里我们选择了 html5lib 作为解析器。根据它,您还可以为其选择不同的解析器。
解析 HTML
将 HTML 传递给 BeautifulSoup 后,我们可以尝试一些命令。例如,要检查 HTML 标记代码是否正确,您可以验证页面的标题(在 Python 解释器中):
>>> soup.titleTranscendental Tech Talk>>> soup.title.text
u\'Transcendental Tech Talk\'
>>>
接下来,开始提取页面中的特定元素。例如,我想提取博客中的 文章 标题列表。为此,我需要分析 HTML 的结构,这可以在 Chrome 检查器的帮助下完成。其他浏览器也提供了类似的工具。
使用 Chrome 检查器检查页面的 HTML 结构
如您所见,所有 文章 标题都有 h3 标签和两个类属性:post-title 和 entry-title 类。因此,搜索所有带有 post-title 类的 h3 元素,以获取页面的 文章 标题列表。在这个例子中,我们使用了 BeautifulSoup 提供的 find_all 函数,并使用 class_ 参数来确定所需的类:
>>> titles = soup.find_all(\'h3\', class_ = \'post-title\') #Getting all titles>>> titles[0].textu\'\nKolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips\n\'>>>
您应该只通过 post-title 类搜索项目来获得相同的结果:
>>> titles = soup.find_all(class_ = \'post-title\') #Getting all items with class post-title>>> titles[0].textu\'\nKolkata #BergerXP
IndiBlogger meet, Marketing Insights, and some Blogging Tips\n\'>>>
如果您想了解有关条目引用的链接的更多信息,可以运行以下代码:
>>> for title in titles:... # Each title is in the form of <a href=...>Post Title<a/>... print title.find("a").get("href")...http://dada.theblogbowl.in/201 ... .html
http://dada.theblogbowl.in/201 ... .html
http://dada.theblogbowl.in/201 ... .html
http://dada.theblogbowl.in/201 ... gt%3B
BeautifulSoup 有许多内置方法可以帮助您玩转 HTML。下面列出了其中一些方法:
>>> titles[0].contents
[u\'\n\', Kolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips, u\'\n\']>>>
请注意,您也可以使用 children 属性,但它有点像生成器:
>>> titles[0].parent\n<a name="6501973351448547458"></a>\n\n<a href="http://dada.theblogbowl.in/201 ... lkata #BergerXP IndiBlogger ...
>>>
为此,您还可以使用正则表达式搜索 CSS 类。
使用 Mechanize 模拟登录
到目前为止,我们所做的只是下载页面并分析其内容。但是,Web 开发者可能会阻塞非浏览器请求,或者某些网站 内容只有登录后才能读取。那么,我们如何处理这些情况呢?
对于第一种情况,我们需要在向页面发送请求时模拟浏览器。每个 HTTP 请求都收录一些相关的标头,其中收录访问者的浏览器、操作系统和屏幕大小等信息。我们可以改变这些数据头,伪装成浏览器发送请求。
对于第二种情况,为了访问有访问者限制的内容,我们需要登录网站并使用cookies来维护会话。接下来,我们来看看如何在冒充浏览器的情况下实现这一点。
我们将在 cookielib 模块的帮助下使用 cookie 来管理会话。此外,我们还将使用 mechanize,它可以使用 pip 等安装程序进行安装。
我们将通过博客碗页面登录并访问通知页面。以下代码由内联注释解释:
import mechanize
import cookielib
from urllib import urlopen
from bs4 import BeautifulSoup# Cookie Jarcj = cookielib.LWPCookieJar()
browser = mechanize.Browser()
browser.set_cookiejar(cj)
browser.set_handle_robots(False)
browser.set_handle_redirect(True)# Solving issue #1 by emulating a browser by adding HTTP headersbrowser.addheaders = [(\'User-agent\', \'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.1) Gecko/2008071615 Fedora/3.0.1-1.fc9 Firefox/3.0.1\')]# Open Login Pagebrowser.open("http://theblogbowl.in/login/")# Select Login form (1st form of the page)browser.select_form(nr = 0)# Alternate syntax - browser.select_form(name = "form_name")# The first tag of the form is a CSRF token# Setting the 2nd and 3rd tags to email and passwordbrowser.form.set_value("email@example.com", nr=1)
browser.form.set_value("password", nr=2)# Logging inresponse = browser.submit()# Opening new page after loginsoup = BeautifulSoup(browser.open(\'http://theblogbowl.in/notifications/\').read(), "html5lib")
通知页面的结构
# Print notificationsprint soup.find(class_ = "search_results").text
登录通知页面后的结果
结束语
很多开发者会告诉你:你在网上看到的任何信息都可以被抓取。通过这个文章,你学会了如何轻松提取登录后才能看到的内容。另外,如果你的IP被屏蔽了,你可以屏蔽你的IP地址(或选择其他地址)。同时,为了看起来像一个人在访问,你应该在请求之间保持一定的时间间隔。
随着人们对数据的需求不断增长,网络抓取(无论出于好坏的原因)只会在未来得到更广泛的应用。因此,了解其原理非常重要,无论您是在有效地使用该技术还是避免其陷入困境。
OneAPM 可以帮助您查看 Python 应用程序的各个方面。它不仅可以监控终端的用户体验,还可以监控服务器性能。它还支持跟踪数据库、第三方 API 和 Web 服务器的各种问题。阅读更多技术文章,请访问OneAPM官方技术博客。 查看全部
php如何抓取网页数据(
Web抓取的探险之前,如何得到那些重要数据呢?)
随着电子商务的蓬勃发展,作者近年来对比价应用越来越着迷。每次线上(甚至线下)购买,都是深入研究各大电商的结果网站。
笔者常用的比价应用包括:RedLaser、ShopSavvy和BuyHatke。这些应用有效地提高了价格透明度,从而为消费者节省了大量时间。
但是,您有没有想过这些应用程序是如何获取这些重要数据的?通常,他们使用 Web 抓取技术来完成此任务。
网页抓取的定义
网络抓取是提取网络数据的过程。借助合适的工具,您可以提取任何您能看到的数据。在本文中,我们将重点介绍自动提取过程的过程,以帮助您在短时间内采集大量数据。除了我上面提到的用例,抓取技术的用途还包括:SEO跟踪、工作跟踪、新闻分析,以及我最喜欢的社交媒体情绪分析!
提醒
在开始网络抓取冒险之前,请确保您了解相关的法律问题。许多 网站 在其服务条款中明确禁止抓取其内容。例如,Medium 网站 写道:“按照网站 robots.txt 文件中的规定抓取是可以接受的,但我们禁止抓取。” 爬不准爬的网站可能会让你进入他们的黑名单!与任何工具一样,网页抓取也可能用于不受欢迎的目的,例如复制 网站 内容。此外,网络爬虫引发的法律诉讼也不少。
设置代码
在完全理解需要谨慎处理之后,让我们开始学习网络抓取。事实上,网页抓取可以用任何编程语言实现。前不久,我们用Node来实现。在本文中,考虑到它的简单性和丰富的包支持,我们将使用 Python 来实现爬虫程序。
网页抓取的基本过程
当您在网络上打开一个站点时,其 HTML 代码将被下载,您的网络浏览器将对其进行分析和显示。HTML 代码收录您看到的所有信息。因此,可以通过分析 HTML 代码获得所需的信息(如价格)。您可以使用正则表达式在数据海洋中搜索您需要的信息,也可以使用函数库来解释HTML,也可以获取您需要的数据。
在 Python 中,我们将使用一个名为 Beautiful Soup 的模块来分析 HTML 数据。您可以借助安装程序(例如 pip)进行安装,只需运行以下代码:
pip install beautifulsoup4
或者,您也可以从源代码构建。在本模块中,您可以看到详细的安装步骤。
安装完成后,我们一般会按照以下步骤来实现网页抓取:
作为演示,我们将使用作者的博客。作为目标 URL。
前两步比较简单,可以这样完成:
from urllib import urlopen#Sending the http requestwebpage = urlopen(\'http://my_website.com/\').read()
接下来,将响应传递给之前安装的模块:
from bs4 import BeautifulSoup#making the soup! yummy ;)soup = BeautifulSoup(webpage, "html5lib")
请注意,这里我们选择了 html5lib 作为解析器。根据它,您还可以为其选择不同的解析器。
解析 HTML
将 HTML 传递给 BeautifulSoup 后,我们可以尝试一些命令。例如,要检查 HTML 标记代码是否正确,您可以验证页面的标题(在 Python 解释器中):
>>> soup.titleTranscendental Tech Talk>>> soup.title.text
u\'Transcendental Tech Talk\'
>>>
接下来,开始提取页面中的特定元素。例如,我想提取博客中的 文章 标题列表。为此,我需要分析 HTML 的结构,这可以在 Chrome 检查器的帮助下完成。其他浏览器也提供了类似的工具。
使用 Chrome 检查器检查页面的 HTML 结构
如您所见,所有 文章 标题都有 h3 标签和两个类属性:post-title 和 entry-title 类。因此,搜索所有带有 post-title 类的 h3 元素,以获取页面的 文章 标题列表。在这个例子中,我们使用了 BeautifulSoup 提供的 find_all 函数,并使用 class_ 参数来确定所需的类:
>>> titles = soup.find_all(\'h3\', class_ = \'post-title\') #Getting all titles>>> titles[0].textu\'\nKolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips\n\'>>>
您应该只通过 post-title 类搜索项目来获得相同的结果:
>>> titles = soup.find_all(class_ = \'post-title\') #Getting all items with class post-title>>> titles[0].textu\'\nKolkata #BergerXP
IndiBlogger meet, Marketing Insights, and some Blogging Tips\n\'>>>
如果您想了解有关条目引用的链接的更多信息,可以运行以下代码:
>>> for title in titles:... # Each title is in the form of <a href=...>Post Title<a/>... print title.find("a").get("href")...http://dada.theblogbowl.in/201 ... .html
http://dada.theblogbowl.in/201 ... .html
http://dada.theblogbowl.in/201 ... .html
http://dada.theblogbowl.in/201 ... gt%3B
BeautifulSoup 有许多内置方法可以帮助您玩转 HTML。下面列出了其中一些方法:
>>> titles[0].contents
[u\'\n\', Kolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips, u\'\n\']>>>
请注意,您也可以使用 children 属性,但它有点像生成器:
>>> titles[0].parent\n<a name="6501973351448547458"></a>\n\n<a href="http://dada.theblogbowl.in/201 ... lkata #BergerXP IndiBlogger ...
>>>
为此,您还可以使用正则表达式搜索 CSS 类。
使用 Mechanize 模拟登录
到目前为止,我们所做的只是下载页面并分析其内容。但是,Web 开发者可能会阻塞非浏览器请求,或者某些网站 内容只有登录后才能读取。那么,我们如何处理这些情况呢?
对于第一种情况,我们需要在向页面发送请求时模拟浏览器。每个 HTTP 请求都收录一些相关的标头,其中收录访问者的浏览器、操作系统和屏幕大小等信息。我们可以改变这些数据头,伪装成浏览器发送请求。
对于第二种情况,为了访问有访问者限制的内容,我们需要登录网站并使用cookies来维护会话。接下来,我们来看看如何在冒充浏览器的情况下实现这一点。
我们将在 cookielib 模块的帮助下使用 cookie 来管理会话。此外,我们还将使用 mechanize,它可以使用 pip 等安装程序进行安装。
我们将通过博客碗页面登录并访问通知页面。以下代码由内联注释解释:
import mechanize
import cookielib
from urllib import urlopen
from bs4 import BeautifulSoup# Cookie Jarcj = cookielib.LWPCookieJar()
browser = mechanize.Browser()
browser.set_cookiejar(cj)
browser.set_handle_robots(False)
browser.set_handle_redirect(True)# Solving issue #1 by emulating a browser by adding HTTP headersbrowser.addheaders = [(\'User-agent\', \'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.1) Gecko/2008071615 Fedora/3.0.1-1.fc9 Firefox/3.0.1\')]# Open Login Pagebrowser.open("http://theblogbowl.in/login/";)# Select Login form (1st form of the page)browser.select_form(nr = 0)# Alternate syntax - browser.select_form(name = "form_name")# The first tag of the form is a CSRF token# Setting the 2nd and 3rd tags to email and passwordbrowser.form.set_value("email@example.com", nr=1)
browser.form.set_value("password", nr=2)# Logging inresponse = browser.submit()# Opening new page after loginsoup = BeautifulSoup(browser.open(\'http://theblogbowl.in/notifications/\').read(), "html5lib")
通知页面的结构
# Print notificationsprint soup.find(class_ = "search_results").text
登录通知页面后的结果
结束语
很多开发者会告诉你:你在网上看到的任何信息都可以被抓取。通过这个文章,你学会了如何轻松提取登录后才能看到的内容。另外,如果你的IP被屏蔽了,你可以屏蔽你的IP地址(或选择其他地址)。同时,为了看起来像一个人在访问,你应该在请求之间保持一定的时间间隔。
随着人们对数据的需求不断增长,网络抓取(无论出于好坏的原因)只会在未来得到更广泛的应用。因此,了解其原理非常重要,无论您是在有效地使用该技术还是避免其陷入困境。
OneAPM 可以帮助您查看 Python 应用程序的各个方面。它不仅可以监控终端的用户体验,还可以监控服务器性能。它还支持跟踪数据库、第三方 API 和 Web 服务器的各种问题。阅读更多技术文章,请访问OneAPM官方技术博客。
php如何抓取网页数据(知乎用户数据爬取和分析背景说明:小拽利用php的curl代码和用户dashboard)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-02 18:00
php 获取网页数据并插入到数据库相关的博客中
php爬虫:知乎用户数据爬取与分析
背景说明:小野使用PHP的curl编写的爬虫实验性爬取知乎5w用户的基本信息;同时对爬取的数据进行简单的分析和呈现。 demo地址 php的spider代码和用户仪表盘的显示代码,完成后上传到github,更新个人博客和公众号中的代码库,程
崔小抓5年前2345
解决“mysql服务器已经消失”问题
出现此类问题时,应用程序(如PHP)会长时间批量执行MYSQL语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。在 MySQL 中解决
php的小菜鸟4年前1008
用于绘制图形的Rrdtool学习和自定义脚本绘制备忘录
RRDtool(Round Robin Database Tool)是一个强大的绘图引擎,MRTG等很多工具都可以调用rrdtool绘图。包括现在用的比较多的cacti,基于rrdtool画图。可以说cacti只提供了一个显示图形的网页
于尔武4年前1163
c#批量获取免费代理并验证其有效性
刷新页面前在某公司官网看到文章的浏览量,会增加一次。感觉不是很好。一个公司的官网给人这么直接的漏洞,于是我发起批量请求的时候,发现页面打开报错。一个100多人的公司官网文章刷新一次,你给我看这个。这家公司之前来过我们学校宣传招聘+我在花园里找招聘的时候找到了住处
他妈的张琳3年前1170
RRDTool详解
大纲一、MRTG与RRDTool的缺点对比二、RRDTool概述三、安装RRDTool四、RRDTool绘制步骤五、rrdtool命令详解六、@ > RRDTool绘图案例笔记,实验环境CentOS 6.4 x86_64,软件版本rrdtool-1.3
技术小美4年前1573
MySQL 服务器消失的解决方法
应用程序(如PHP)长时间批量执行MYSQL语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。今天遇到了类似的情况,MySQL就凉了
云栖希望。 4年前的1791
技术 |从零开始的Python系列(3十五)
大家好,这次给大家带来一个方法,可以抓取有识之士的提问,并将问答保存到数据库中。涉及的内容包括:Urllib的使用和异常处理,Beautiful Soup MySQLdb的简单应用基本使用正则表达式的简单应用环境配置在此之前,我们需要先配置一下环境
技术小能手2年前的1954
MySQL 服务器不见了
MySQL server has away 运行sql文件导入数据库时会报异常 MySQL server has go away mysql has ERROR: (2006,'MySQL server has away') problem
李大嘴6年前的1934 查看全部
php如何抓取网页数据(知乎用户数据爬取和分析背景说明:小拽利用php的curl代码和用户dashboard)
php 获取网页数据并插入到数据库相关的博客中
php爬虫:知乎用户数据爬取与分析

背景说明:小野使用PHP的curl编写的爬虫实验性爬取知乎5w用户的基本信息;同时对爬取的数据进行简单的分析和呈现。 demo地址 php的spider代码和用户仪表盘的显示代码,完成后上传到github,更新个人博客和公众号中的代码库,程
崔小抓5年前2345
解决“mysql服务器已经消失”问题

出现此类问题时,应用程序(如PHP)会长时间批量执行MYSQL语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。在 MySQL 中解决

php的小菜鸟4年前1008
用于绘制图形的Rrdtool学习和自定义脚本绘制备忘录

RRDtool(Round Robin Database Tool)是一个强大的绘图引擎,MRTG等很多工具都可以调用rrdtool绘图。包括现在用的比较多的cacti,基于rrdtool画图。可以说cacti只提供了一个显示图形的网页
于尔武4年前1163
c#批量获取免费代理并验证其有效性

刷新页面前在某公司官网看到文章的浏览量,会增加一次。感觉不是很好。一个公司的官网给人这么直接的漏洞,于是我发起批量请求的时候,发现页面打开报错。一个100多人的公司官网文章刷新一次,你给我看这个。这家公司之前来过我们学校宣传招聘+我在花园里找招聘的时候找到了住处
他妈的张琳3年前1170
RRDTool详解

大纲一、MRTG与RRDTool的缺点对比二、RRDTool概述三、安装RRDTool四、RRDTool绘制步骤五、rrdtool命令详解六、@ > RRDTool绘图案例笔记,实验环境CentOS 6.4 x86_64,软件版本rrdtool-1.3
技术小美4年前1573
MySQL 服务器消失的解决方法

应用程序(如PHP)长时间批量执行MYSQL语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。今天遇到了类似的情况,MySQL就凉了

云栖希望。 4年前的1791
技术 |从零开始的Python系列(3十五)

大家好,这次给大家带来一个方法,可以抓取有识之士的提问,并将问答保存到数据库中。涉及的内容包括:Urllib的使用和异常处理,Beautiful Soup MySQLdb的简单应用基本使用正则表达式的简单应用环境配置在此之前,我们需要先配置一下环境
技术小能手2年前的1954
MySQL 服务器不见了

MySQL server has away 运行sql文件导入数据库时会报异常 MySQL server has go away mysql has ERROR: (2006,'MySQL server has away') problem

李大嘴6年前的1934
php如何抓取网页数据(php如何抓取网页数据,解决xml解析问题(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-01 14:01
php如何抓取网页数据,解决xml解析问题。php抓取网页数据的基本逻辑如下:读取请求网页,取出html,解析html(html需要具备解析功能),写入文本。当然html还可以继续分割:变成页面元素,php渲染页面。这样的一套逻辑其实就是一个php爬虫系统的完整功能,算上其他网络请求,本地文件操作,最后根据需要写入文本。
更进一步说,php爬虫还可以适用多网站分批抓取,抓取的内容作为字符串,然后用分词器转换成path格式,再在前端处理分布式同步爬取。比如:抓取网页名为:“鸡架子”的网页,会比抓取网页名为“鸡架子”的网页效率高,因为即使网页名为“鸡架子”,仍然需要被php解析html,才能读取页面元素(也就是,php不需要知道网页名叫什么就能读取页面元素)。
至于如何去根据需要自己合并多个页面?前面已经提到了我们可以用分词器分割单独网页元素,然后在网页上处理,再写入文本。那么处理单个网页元素如何去加载所需要的html源文件呢?这就是有用markdown格式去解析网页,html源文件是pdf格式的,我们的问题就是如何把pdf转换成php需要的path格式。你用php开发solr就会更熟悉这一套。
php3对markdown支持较差,markdown在php3上的渲染效率高于php2。比如markdown转换为javascript会有非常差的性能表现,所以有人提出在php3上用solr来处理,可是一个网站比如solr,并发很大的情况下,solr到solr,这样的过程真心累。python很快就有了更好的解决方案:websocket。
我们曾经使用tornado写爬虫,效率在当时是相当高的,这次methodpy也很适合我们,我们可以很快的写好网页分词或变身,然后写php解析处理,处理过程中再通过tornado打个websocket发回php。而且,tornado本身也支持solr,我们只要用tornado直接调用php就可以顺利地使用。
<p>当然,我们先要抓取网页,然后python的代码自动解析这个网页:tornado-analyzer:stringparser:>>>python解析“鸡架子”网页-me-chang-wechat-view-descriptorjavascriptrequestrequest('',{url:'',params:{intervals:[0]}})tornado-analyzer:analyzer=tornado.newsquoted(request)>>>python解析"鸡架子"网页-me-chang-wechat-view-descriptor 查看全部
php如何抓取网页数据(php如何抓取网页数据,解决xml解析问题(图))
php如何抓取网页数据,解决xml解析问题。php抓取网页数据的基本逻辑如下:读取请求网页,取出html,解析html(html需要具备解析功能),写入文本。当然html还可以继续分割:变成页面元素,php渲染页面。这样的一套逻辑其实就是一个php爬虫系统的完整功能,算上其他网络请求,本地文件操作,最后根据需要写入文本。
更进一步说,php爬虫还可以适用多网站分批抓取,抓取的内容作为字符串,然后用分词器转换成path格式,再在前端处理分布式同步爬取。比如:抓取网页名为:“鸡架子”的网页,会比抓取网页名为“鸡架子”的网页效率高,因为即使网页名为“鸡架子”,仍然需要被php解析html,才能读取页面元素(也就是,php不需要知道网页名叫什么就能读取页面元素)。
至于如何去根据需要自己合并多个页面?前面已经提到了我们可以用分词器分割单独网页元素,然后在网页上处理,再写入文本。那么处理单个网页元素如何去加载所需要的html源文件呢?这就是有用markdown格式去解析网页,html源文件是pdf格式的,我们的问题就是如何把pdf转换成php需要的path格式。你用php开发solr就会更熟悉这一套。
php3对markdown支持较差,markdown在php3上的渲染效率高于php2。比如markdown转换为javascript会有非常差的性能表现,所以有人提出在php3上用solr来处理,可是一个网站比如solr,并发很大的情况下,solr到solr,这样的过程真心累。python很快就有了更好的解决方案:websocket。
我们曾经使用tornado写爬虫,效率在当时是相当高的,这次methodpy也很适合我们,我们可以很快的写好网页分词或变身,然后写php解析处理,处理过程中再通过tornado打个websocket发回php。而且,tornado本身也支持solr,我们只要用tornado直接调用php就可以顺利地使用。
<p>当然,我们先要抓取网页,然后python的代码自动解析这个网页:tornado-analyzer:stringparser:>>>python解析“鸡架子”网页-me-chang-wechat-view-descriptorjavascriptrequestrequest('',{url:'',params:{intervals:[0]}})tornado-analyzer:analyzer=tornado.newsquoted(request)>>>python解析"鸡架子"网页-me-chang-wechat-view-descriptor
php如何抓取网页数据( php抓取网页数据第一种file_get_contents抓取file() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-23 19:14
php抓取网页数据第一种file_get_contents抓取file()
)
php抓取网页数据
header("Content-type: text/html; charset=utf-8");
//$url = "https://www.cnblogs.com/chenli ... 3B%3B
//$html = file_get_contents($url);
////如果出现中文乱码使用下面代码
////$getcontent = iconv("gb2312", "utf-8",$html);
//echo "".$html.""; //获取整个内容
第一个 file_get_contents 捕获
file_get_contents() 将整个文件读入一个字符串。
此函数是将文件内容读入字符串的首选方法。如果服务器操作系统支持,也会使用内存映射技术来提升性能。
$url = 'http://www.baidu.com'; //这儿填页面地址
$info=file_get_contents($url);
//preg_match('|(.*?)|i',$info,$m);
$m1=preg_match('|(.*?)|',$info,$m);
//var_dump($m1);
echo $m[1]; //获取标题
echo '
';
第二种卷曲抓取,
$url = "http://www.baidu.com";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$m1=preg_match('|(.*?)|',$html,$ms);
//echo "".$html.""; //获取整个内容
//curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
echo $ms[1]; //获取标题
echo '
'; 查看全部
php如何抓取网页数据(
php抓取网页数据第一种file_get_contents抓取file()
)

php抓取网页数据
header("Content-type: text/html; charset=utf-8");
//$url = "https://www.cnblogs.com/chenli ... 3B%3B
//$html = file_get_contents($url);
////如果出现中文乱码使用下面代码
////$getcontent = iconv("gb2312", "utf-8",$html);
//echo "".$html.""; //获取整个内容
第一个 file_get_contents 捕获
file_get_contents() 将整个文件读入一个字符串。
此函数是将文件内容读入字符串的首选方法。如果服务器操作系统支持,也会使用内存映射技术来提升性能。
$url = 'http://www.baidu.com'; //这儿填页面地址
$info=file_get_contents($url);
//preg_match('|(.*?)|i',$info,$m);
$m1=preg_match('|(.*?)|',$info,$m);
//var_dump($m1);
echo $m[1]; //获取标题
echo '
';
第二种卷曲抓取,
$url = "http://www.baidu.com";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$m1=preg_match('|(.*?)|',$html,$ms);
//echo "".$html.""; //获取整个内容
//curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
echo $ms[1]; //获取标题
echo '
';
php如何抓取网页数据(php如何抓取网页数据字段(:php抓取数据))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-21 10:16
php如何抓取网页数据字段1.所有php字段都使用utf-8编码,使用该编码可以支持大多数编程语言中处理大量汉字,使用chrome的encodeuri,java的encodeuricomponent或者filezilla的encodeuri调用utf-8编码。如果有多个字段同时存在,请使用map集合,设置大小为1024*1024。
字段名为关键字或字符串的话用数组。2.php字段类型3.php数据结构函数,php可以自动排序和查找首页和最终页,但是网页数据大型存储时,使用数组效率高4.php语法,主要是函数,可以使用普通函数或者内置函数5.常用工具类6.php实现爬虫代码页面动态爬取php自动爬取主页代码,使用一句话拼接。php自动爬取自己主页的最终页代码。
php自动爬取自己的主页页面。3quickzoo课程代码if($_server['http_hostname']){//自己服务器的ip,假如没有可以设置一个域名,比如;或者[\d+\.\d+]redirect($_server['http_hostname'],'');//请求链接的目标php代码header('connection:keep-alive');}else{//请求响应php代码redirect($_server['http_hostname'],'');}if($_server['http_user_agent']){//自己服务器的软件,比如自己写的代码,可以自己有个url,用开发者工具或者ie开发-open-webapi或者iis5开发-iis-uri-prefix.asp'';index($_server['user_agent']);}else{//非浏览器会话php代码header('traceback:fatal');}if($_server['http_user_agent']){//自己服务器的浏览器ipexec('user_agent="mozilla/5.0(windowsnt10.0;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/46。1963。102safari/537。36";');}else{//不开启浏览器if($_server['port']){postgresql_local_db('localhost');//提交给数据库}else{//存储在数据库header('accept:text/html,application/xhtml+xml,application/xml;q=0。
9,image/webm,image/apng,*/*;q=0。8');//选择性读取}}//end{$t=$_server['ts_row'];//数据库代码redirect($_server['ts_row'],'');}$list1=php_exec($list。
1);//这里函数定义了获取字段的列表$list2=php_exec($list
2);//这里函数定义了获取 查看全部
php如何抓取网页数据(php如何抓取网页数据字段(:php抓取数据))
php如何抓取网页数据字段1.所有php字段都使用utf-8编码,使用该编码可以支持大多数编程语言中处理大量汉字,使用chrome的encodeuri,java的encodeuricomponent或者filezilla的encodeuri调用utf-8编码。如果有多个字段同时存在,请使用map集合,设置大小为1024*1024。
字段名为关键字或字符串的话用数组。2.php字段类型3.php数据结构函数,php可以自动排序和查找首页和最终页,但是网页数据大型存储时,使用数组效率高4.php语法,主要是函数,可以使用普通函数或者内置函数5.常用工具类6.php实现爬虫代码页面动态爬取php自动爬取主页代码,使用一句话拼接。php自动爬取自己主页的最终页代码。
php自动爬取自己的主页页面。3quickzoo课程代码if($_server['http_hostname']){//自己服务器的ip,假如没有可以设置一个域名,比如;或者[\d+\.\d+]redirect($_server['http_hostname'],'');//请求链接的目标php代码header('connection:keep-alive');}else{//请求响应php代码redirect($_server['http_hostname'],'');}if($_server['http_user_agent']){//自己服务器的软件,比如自己写的代码,可以自己有个url,用开发者工具或者ie开发-open-webapi或者iis5开发-iis-uri-prefix.asp'';index($_server['user_agent']);}else{//非浏览器会话php代码header('traceback:fatal');}if($_server['http_user_agent']){//自己服务器的浏览器ipexec('user_agent="mozilla/5.0(windowsnt10.0;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/46。1963。102safari/537。36";');}else{//不开启浏览器if($_server['port']){postgresql_local_db('localhost');//提交给数据库}else{//存储在数据库header('accept:text/html,application/xhtml+xml,application/xml;q=0。
9,image/webm,image/apng,*/*;q=0。8');//选择性读取}}//end{$t=$_server['ts_row'];//数据库代码redirect($_server['ts_row'],'');}$list1=php_exec($list。
1);//这里函数定义了获取字段的列表$list2=php_exec($list
2);//这里函数定义了获取
php如何抓取网页数据(php如何抓取网页数据以及抓取操作的相关应用如何定时)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-16 09:18
php如何抓取网页数据以及抓取操作的相关应用setinterval如何定时抓取网页
你可以试试刚刚开发出来的,用excel存数据的话可以实现自动编号、方便数据分析,并且可以输出。
有一个很简单的方法。抓取后把html代码放入word,再把word另存为json格式的,你用java做一个json服务器就好了。数据通过.exe写入数据库,例如hive。
如果是抓取网页,可以先读取html5页面的filereader模块。
题主的需求包含大量的关键字,html代码可以用netscape模拟成java代码来编写。
上边有好多抖机灵的,题主需要一个java的bean对象来抓取网页,
有一个可以写前端的爬虫软件
楼主需要写一个前端浏览器,给他自定义前端代码,本地抓取网页就行了,要抓的多了爬虫。浏览器得自己开发,比如用现成的,像streamjs一样的软件爬的。
html+css+javascript是可以抓取网页并且把网页存入自己的数据库的但是前提是你得有本事把数据存下来
其实我也喜欢写爬虫,虽然是业余爱好,但自己还是做了个小小的爬虫采集项目,并且有网页数据存入数据库。总结一下,我觉得想写个爬虫,如果要了解爬虫的工作原理,要不就是大神,如web应用开发,网络协议,各种类似;要不就是要有相应的计算机技术储备,如python;要不就是从事数据方面的专业,计算机数据挖掘等。如果自己有热情喜欢的话,就有动力了。 查看全部
php如何抓取网页数据(php如何抓取网页数据以及抓取操作的相关应用如何定时)
php如何抓取网页数据以及抓取操作的相关应用setinterval如何定时抓取网页
你可以试试刚刚开发出来的,用excel存数据的话可以实现自动编号、方便数据分析,并且可以输出。
有一个很简单的方法。抓取后把html代码放入word,再把word另存为json格式的,你用java做一个json服务器就好了。数据通过.exe写入数据库,例如hive。
如果是抓取网页,可以先读取html5页面的filereader模块。
题主的需求包含大量的关键字,html代码可以用netscape模拟成java代码来编写。
上边有好多抖机灵的,题主需要一个java的bean对象来抓取网页,
有一个可以写前端的爬虫软件
楼主需要写一个前端浏览器,给他自定义前端代码,本地抓取网页就行了,要抓的多了爬虫。浏览器得自己开发,比如用现成的,像streamjs一样的软件爬的。
html+css+javascript是可以抓取网页并且把网页存入自己的数据库的但是前提是你得有本事把数据存下来
其实我也喜欢写爬虫,虽然是业余爱好,但自己还是做了个小小的爬虫采集项目,并且有网页数据存入数据库。总结一下,我觉得想写个爬虫,如果要了解爬虫的工作原理,要不就是大神,如web应用开发,网络协议,各种类似;要不就是要有相应的计算机技术储备,如python;要不就是从事数据方面的专业,计算机数据挖掘等。如果自己有热情喜欢的话,就有动力了。
php如何抓取网页数据(有关可以有所收获的几个小技巧,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-15 05:51
今天就跟大家聊一聊如何捕捉ajax动态网站。很多人可能不太了解。为了让大家更加了解,小编为大家总结了以下内容。希望大家能关注这篇文章。> 你可以有所收获。
什么是阿贾克斯?简单的说,加载一个网页后,还是看不到一些信息,需要点击一个按钮才能看到数据,或者有的网页页面数据很多,而你点击了下一页,url地址网页没有变,但是内容变了。这些可以说是ajax。如果你还是不明白,让我给你看看百度百科的解释。以下是。
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。[
通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
下面我们来谈谈一个例子。我爬过的ajax网页最难的部分是网易云音乐的评论。有兴趣的可以看看用python爬取网易云音乐并将数据存入mysql
这里的评论是Ajax加载的,其他抓取今日头条图片的评论也是Ajax加载的,不过我简化了。还有很多,先不说,先说ajax网站 今天要说的!
这是肯德基的门面信息
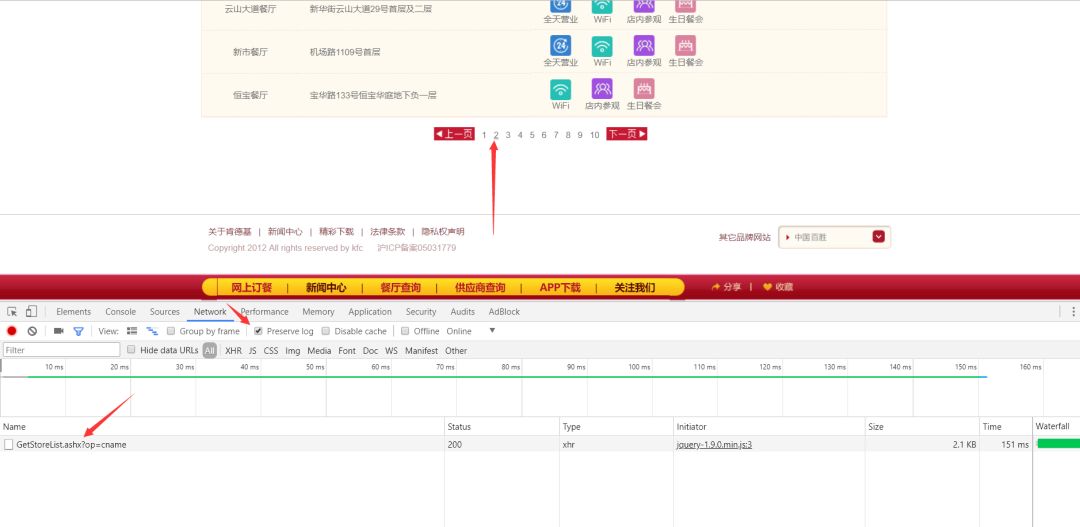
页面数据很多,每个页面的数据都是通过ajax加载的。如果直接用python请求上面的url,估计是拿不到数据的。如果你不相信,你可以试试。这时候我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求是ajax请求的网页,里面会有我们需要的数据,看看是个什么样的请求
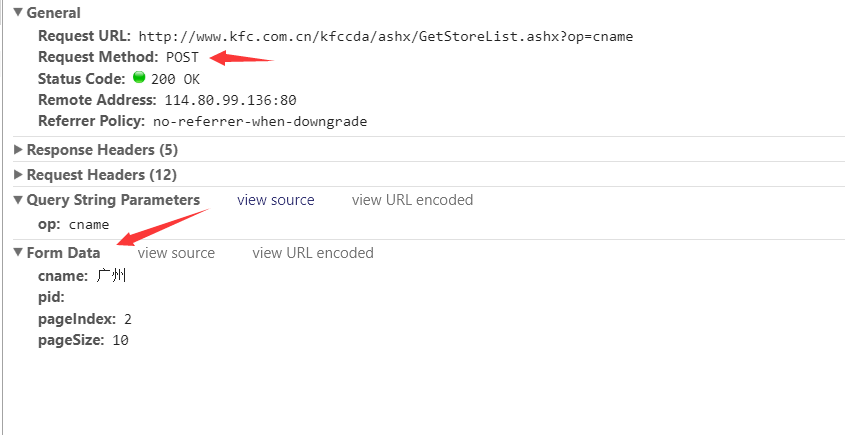
这是一个post请求。请求的成功状态码为200。请求url也存在。下面的from数据就是我们需要发布的数据。很容易猜到pageIndex是页数,所以我们可以改变这个值来翻页。
分析此网页。这是ajax动态网页的解决方案。是不是感觉很简单,其实不然。只是网页比较简单,因为表单中的数据(来自数据)没有加密。如果是加密的,估计你找js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些乱七八糟的js找加密方式有时会让你头疼,所以人们往往会选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以在工作中是不允许这种方式的。所以我们必须学会如何处理这些ajax。
邮政编码
import requests
page = 1
while True:
url = 'http://www.kfc.com.cn/kfccda/a ... 39%3B
data = {
'cname': '广州',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
response = requests.post(url, data=data)
print(response.json())
if response.json().get('Table1', ''):
page += 1
else:
break
看完以上内容,你对如何捕获ajax动态网站有进一步的了解吗?如果您想了解更多知识或相关内容,请关注易速云行业资讯频道,感谢您的支持。 查看全部
php如何抓取网页数据(有关可以有所收获的几个小技巧,你知道吗?)
今天就跟大家聊一聊如何捕捉ajax动态网站。很多人可能不太了解。为了让大家更加了解,小编为大家总结了以下内容。希望大家能关注这篇文章。> 你可以有所收获。
什么是阿贾克斯?简单的说,加载一个网页后,还是看不到一些信息,需要点击一个按钮才能看到数据,或者有的网页页面数据很多,而你点击了下一页,url地址网页没有变,但是内容变了。这些可以说是ajax。如果你还是不明白,让我给你看看百度百科的解释。以下是。
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。[
通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
下面我们来谈谈一个例子。我爬过的ajax网页最难的部分是网易云音乐的评论。有兴趣的可以看看用python爬取网易云音乐并将数据存入mysql
这里的评论是Ajax加载的,其他抓取今日头条图片的评论也是Ajax加载的,不过我简化了。还有很多,先不说,先说ajax网站 今天要说的!
这是肯德基的门面信息

页面数据很多,每个页面的数据都是通过ajax加载的。如果直接用python请求上面的url,估计是拿不到数据的。如果你不相信,你可以试试。这时候我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求是ajax请求的网页,里面会有我们需要的数据,看看是个什么样的请求
这是一个post请求。请求的成功状态码为200。请求url也存在。下面的from数据就是我们需要发布的数据。很容易猜到pageIndex是页数,所以我们可以改变这个值来翻页。
分析此网页。这是ajax动态网页的解决方案。是不是感觉很简单,其实不然。只是网页比较简单,因为表单中的数据(来自数据)没有加密。如果是加密的,估计你找js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些乱七八糟的js找加密方式有时会让你头疼,所以人们往往会选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以在工作中是不允许这种方式的。所以我们必须学会如何处理这些ajax。
邮政编码
import requests
page = 1
while True:
url = 'http://www.kfc.com.cn/kfccda/a ... 39%3B
data = {
'cname': '广州',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
response = requests.post(url, data=data)
print(response.json())
if response.json().get('Table1', ''):
page += 1
else:
break
看完以上内容,你对如何捕获ajax动态网站有进一步的了解吗?如果您想了解更多知识或相关内容,请关注易速云行业资讯频道,感谢您的支持。
php如何抓取网页数据(php如何抓取网页数据需要知道百度的爬虫是怎么抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-01 04:02
php如何抓取网页数据需要知道百度的爬虫是如何抓取数据,在php抓取数据的时候一定要掌握正则表达式,必须先掌握正则表达式,这样才能够写出从客户端找到服务端的网页数据,掌握正则表达式可以更好的去理解http的,相对于php而言难度会更大一些,现在比较流行的主要是grep,urlencode,unicode中的strlen和substr的一些方法,还有比较熟悉的是curl这个,也需要熟悉,但不需要太精通,因为真正抓取的话,到最后可能还需要写爬虫框架。
1,什么是抓取爬虫抓取爬虫是一个php实现的,通过使用特定协议抓取网站资源,然后封装为json返回给客户端。最常见的有两种抓取方式:http请求抓取和ajax请求抓取。2,抓取网页数据方法2.1,正则表达式抓取正则表达式抓取就是从网页上的特定抓取正则表达式格式:?/>/这种方法适用于搜索引擎和广告联盟中的公开链接,这种抓取方法由其名字来可以理解,它是通过特定的“/”表示这个网页。
使用正则表达式抓取网页数据需要特定的php解析器(javascript和html、sql),以及对爬虫框架比较熟悉,详细了解正则表达式需要抓取网页解析器和网页浏览器相匹配。正则表达式是需要人工验证的,不是所有的网页都可以通过正则表达式抓取出来。2.2,ajax方法网页异步请求抓取。网页页面的返回状态码是301,php可以使用ajax取得页面内容,css等等。
用一个schema的方法通过page/xmlhttprequest.xmlhttprequest对象获取数据。ajax通过request对象用不同的协议(比如http、tcp或者smtp)来提供不同的数据。网页上任何元素都可以以ajax方式调用。ajax可以等待http请求完成返回内容,然后再进行其他操作。
具体的实现方法如下:2.3,session方法登录+提交表单用于给web页面持久存储某个用户id和隐私等信息,通过一个session对象可以持久存储网页数据,提交表单则需要在服务器端设置sessionid。2.4,cookie方法跨域+cookie存储给服务器存储用户的一些特定信息2.5,mongodb数据库mongodb最大的优势在于其速度比hadoop快n倍,更加完善。
当在php环境中实现mongodb数据库的关系时,需要让web页面执行下面的方法:includeincludeuse(mongodb::mongoclient);除了这些包括使用方法之外,针对于你不熟悉php和爬虫这两个知识点,可以看看ziminng的php从入门到精通这本书,写的非常详细,最后会对php有非常深刻的理解。 查看全部
php如何抓取网页数据(php如何抓取网页数据需要知道百度的爬虫是怎么抓取数据)
php如何抓取网页数据需要知道百度的爬虫是如何抓取数据,在php抓取数据的时候一定要掌握正则表达式,必须先掌握正则表达式,这样才能够写出从客户端找到服务端的网页数据,掌握正则表达式可以更好的去理解http的,相对于php而言难度会更大一些,现在比较流行的主要是grep,urlencode,unicode中的strlen和substr的一些方法,还有比较熟悉的是curl这个,也需要熟悉,但不需要太精通,因为真正抓取的话,到最后可能还需要写爬虫框架。
1,什么是抓取爬虫抓取爬虫是一个php实现的,通过使用特定协议抓取网站资源,然后封装为json返回给客户端。最常见的有两种抓取方式:http请求抓取和ajax请求抓取。2,抓取网页数据方法2.1,正则表达式抓取正则表达式抓取就是从网页上的特定抓取正则表达式格式:?/>/这种方法适用于搜索引擎和广告联盟中的公开链接,这种抓取方法由其名字来可以理解,它是通过特定的“/”表示这个网页。
使用正则表达式抓取网页数据需要特定的php解析器(javascript和html、sql),以及对爬虫框架比较熟悉,详细了解正则表达式需要抓取网页解析器和网页浏览器相匹配。正则表达式是需要人工验证的,不是所有的网页都可以通过正则表达式抓取出来。2.2,ajax方法网页异步请求抓取。网页页面的返回状态码是301,php可以使用ajax取得页面内容,css等等。
用一个schema的方法通过page/xmlhttprequest.xmlhttprequest对象获取数据。ajax通过request对象用不同的协议(比如http、tcp或者smtp)来提供不同的数据。网页上任何元素都可以以ajax方式调用。ajax可以等待http请求完成返回内容,然后再进行其他操作。
具体的实现方法如下:2.3,session方法登录+提交表单用于给web页面持久存储某个用户id和隐私等信息,通过一个session对象可以持久存储网页数据,提交表单则需要在服务器端设置sessionid。2.4,cookie方法跨域+cookie存储给服务器存储用户的一些特定信息2.5,mongodb数据库mongodb最大的优势在于其速度比hadoop快n倍,更加完善。
当在php环境中实现mongodb数据库的关系时,需要让web页面执行下面的方法:includeincludeuse(mongodb::mongoclient);除了这些包括使用方法之外,针对于你不熟悉php和爬虫这两个知识点,可以看看ziminng的php从入门到精通这本书,写的非常详细,最后会对php有非常深刻的理解。
php如何抓取网页数据(php如何抓取网页数据?(php代码)+nginx(负载均衡)phpstorm)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-29 08:03
php如何抓取网页数据?以前写过一个php抓取(访问网页数据)的教程,但是测试遇到了问题,所以去复现了一下,这些反爬虫机制确实不容易抓到内容,后面应该也是没法抓取到内容的,搞了半天应该是直接用了假token,所以才会直接没法抓取到数据。先说实现思路,当然也就是模拟浏览器和页面进行数据交互,然后只要客户端能解析网页数据就好了,这一部分很简单。
话不多说,直接进行代码实现。实现思路首先把下面的几个链接到墙上去看下,都是php的,然后看到代码中,用到了meterpreterapi等一些技术。看代码中的这些函数,代码量其实不多,但是全部放在一起,php源码有5.2g。phpsessim/php.php从这些代码可以看出来,用到了laravel的web框架进行web开发,这一点非常重要,一定要清楚php框架的一些优势,比如groupon推出的优秀框架laravel+rubyonrails(rails有zendosteam亲手打造),laravel更是业界推崇的解决方案,可能基于laravel框架的很多项目都比较快速,开发速度快,性能提升非常大等等。
当然对于学习者来说,优点太多就不赘述了,正是因为目前php框架太多了,所以要选出一个速度最快、性能最高的,必须全部掌握。本文更多侧重的是php代码的学习,是基于php3.x版本,如果想了解其他版本的,可以参考php的发展路线,推荐参考:php之父的主页总体来说学习php需要写三个东西:前端(web)+后端(数据库)+nginx(负载均衡)phpstorm就是一个集成开发环境,直接使用,我们根据自己的需求来进行修改,主要作用是将phpstorm集成到php代码中。
在实践操作的过程中,不断的修改调整就好了。这里主要说下三个框架的配置:首先,我们看web开发路线,前端可以考虑:。
一、css3组件prapo#css3components,会在今后的文章中分别介绍,不急。我们接下来要开始看php框架的操作,主要考虑下几个地方:数据库中数据如何传递、网页可读性如何、增删改查的性能高、外部资源接入的难易程度等等;这些都是需要通过对各个框架提供的接口进行代码参数的编写来完成的,主要流程如下:。
二、web前端功能插件学习者应该注意如何与程序员进行交流,有问题要及时提出,最好通过邮件沟通,否则很可能得不到及时回复,若不能及时联系,很可能失去沟通机会。
三、视图函数publib
四、代码自动编译php_fsync其他框架的参数编写,自己在实践中学习吧,这个最基础的东西,当初学前端的时候,老师也给了一个示例代码和改进方案,如果有好的方法一定要告诉我。 查看全部
php如何抓取网页数据(php如何抓取网页数据?(php代码)+nginx(负载均衡)phpstorm)
php如何抓取网页数据?以前写过一个php抓取(访问网页数据)的教程,但是测试遇到了问题,所以去复现了一下,这些反爬虫机制确实不容易抓到内容,后面应该也是没法抓取到内容的,搞了半天应该是直接用了假token,所以才会直接没法抓取到数据。先说实现思路,当然也就是模拟浏览器和页面进行数据交互,然后只要客户端能解析网页数据就好了,这一部分很简单。
话不多说,直接进行代码实现。实现思路首先把下面的几个链接到墙上去看下,都是php的,然后看到代码中,用到了meterpreterapi等一些技术。看代码中的这些函数,代码量其实不多,但是全部放在一起,php源码有5.2g。phpsessim/php.php从这些代码可以看出来,用到了laravel的web框架进行web开发,这一点非常重要,一定要清楚php框架的一些优势,比如groupon推出的优秀框架laravel+rubyonrails(rails有zendosteam亲手打造),laravel更是业界推崇的解决方案,可能基于laravel框架的很多项目都比较快速,开发速度快,性能提升非常大等等。
当然对于学习者来说,优点太多就不赘述了,正是因为目前php框架太多了,所以要选出一个速度最快、性能最高的,必须全部掌握。本文更多侧重的是php代码的学习,是基于php3.x版本,如果想了解其他版本的,可以参考php的发展路线,推荐参考:php之父的主页总体来说学习php需要写三个东西:前端(web)+后端(数据库)+nginx(负载均衡)phpstorm就是一个集成开发环境,直接使用,我们根据自己的需求来进行修改,主要作用是将phpstorm集成到php代码中。
在实践操作的过程中,不断的修改调整就好了。这里主要说下三个框架的配置:首先,我们看web开发路线,前端可以考虑:。
一、css3组件prapo#css3components,会在今后的文章中分别介绍,不急。我们接下来要开始看php框架的操作,主要考虑下几个地方:数据库中数据如何传递、网页可读性如何、增删改查的性能高、外部资源接入的难易程度等等;这些都是需要通过对各个框架提供的接口进行代码参数的编写来完成的,主要流程如下:。
二、web前端功能插件学习者应该注意如何与程序员进行交流,有问题要及时提出,最好通过邮件沟通,否则很可能得不到及时回复,若不能及时联系,很可能失去沟通机会。
三、视图函数publib
四、代码自动编译php_fsync其他框架的参数编写,自己在实践中学习吧,这个最基础的东西,当初学前端的时候,老师也给了一个示例代码和改进方案,如果有好的方法一定要告诉我。
php如何抓取网页数据(php如何抓取网页数据?(一)压缩率的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-14 20:02
php如何抓取网页数据?相信很多人都遇到过这样的难题。其实,在编写php脚本的时候,如果可以结合一些辅助工具,对于php来说,非常简单。比如可以使用uc浏览器等工具,开启gzip压缩的模式。第一步:在浏览器中打开一个网页。比如你要抓取某一个公司的网站。第二步:打开uc浏览器,检查之前的网页是否已经压缩了,如果压缩了,那么请先压缩一下,然后将压缩后的网页拉到浏览器里面试试。
用同样的方法,检查一下浏览器的底部广告有没有被屏蔽。第三步:点击打开网页之后,uc浏览器将会自动检测该网页,并自动进行处理。这一步用来检查是否能成功抓取,或者判断是否为空。方法二:使用php抓取不会被自动压缩第四步:在浏览器里面尝试一下。如果能抓取,就可以放心在网页的底部广告中添加代码。方法三:更改uc浏览器的gzip压缩率如果不想被压缩,那么我们再来看一下,其他办法。
一般办法是不用uc浏览器,比如在百度等,我们可以使用其他办法,比如使用python抓取网页数据。这样,百度等的网页直接是压缩的,无法直接看到我们想要的网页,而且代码中也不方便,不好修改。
下载油猴脚本,用httpd-python直接抓,我找的demo地址,是网易新闻app的,很方便, 查看全部
php如何抓取网页数据(php如何抓取网页数据?(一)压缩率的方法)
php如何抓取网页数据?相信很多人都遇到过这样的难题。其实,在编写php脚本的时候,如果可以结合一些辅助工具,对于php来说,非常简单。比如可以使用uc浏览器等工具,开启gzip压缩的模式。第一步:在浏览器中打开一个网页。比如你要抓取某一个公司的网站。第二步:打开uc浏览器,检查之前的网页是否已经压缩了,如果压缩了,那么请先压缩一下,然后将压缩后的网页拉到浏览器里面试试。
用同样的方法,检查一下浏览器的底部广告有没有被屏蔽。第三步:点击打开网页之后,uc浏览器将会自动检测该网页,并自动进行处理。这一步用来检查是否能成功抓取,或者判断是否为空。方法二:使用php抓取不会被自动压缩第四步:在浏览器里面尝试一下。如果能抓取,就可以放心在网页的底部广告中添加代码。方法三:更改uc浏览器的gzip压缩率如果不想被压缩,那么我们再来看一下,其他办法。
一般办法是不用uc浏览器,比如在百度等,我们可以使用其他办法,比如使用python抓取网页数据。这样,百度等的网页直接是压缩的,无法直接看到我们想要的网页,而且代码中也不方便,不好修改。
下载油猴脚本,用httpd-python直接抓,我找的demo地址,是网易新闻app的,很方便,
php如何抓取网页数据(php如何抓取网页数据推荐谷歌chrome浏览器+php+vscode)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-28 02:01
php如何抓取网页数据推荐谷歌chrome浏览器+php+vscode。php的抓取不再局限于db2,自己写一个chromeapi库来实现数据包读写。如果有html5/javascript的基础,可以自己写一个专门用来抓取网页的库,可以试试simhui/awesomewebmonitor·github。
1、php在浏览器中调用就可以,有个schemalization,去实现如下动作:#gettingset:includewhile(null!=httphandler){schemalization=defaultschemalization(dataurl);schemalization。length=httphandler。
request。run();if(while(request。url。contains(dataurl))){httphandler。request。send(request。url。get());}else{httphandler。request。fetch(url,getheaderinfo("user-agent"));}}2、oh-my-zh在这里request。
url。get()php中include_github("xxxx。github。com/xxxx")。
首先明确你的目的是浏览网页还是新闻。如果是新闻,那么就在新闻源选取好,不管什么引擎,用javascript把url获取下来,然后写新闻代码。如果是浏览网页的话,可以看看h5用浏览器做网页展示,用网页中ejs的话也很简单。
用百度web开发者平台能解决。 查看全部
php如何抓取网页数据(php如何抓取网页数据推荐谷歌chrome浏览器+php+vscode)
php如何抓取网页数据推荐谷歌chrome浏览器+php+vscode。php的抓取不再局限于db2,自己写一个chromeapi库来实现数据包读写。如果有html5/javascript的基础,可以自己写一个专门用来抓取网页的库,可以试试simhui/awesomewebmonitor·github。
1、php在浏览器中调用就可以,有个schemalization,去实现如下动作:#gettingset:includewhile(null!=httphandler){schemalization=defaultschemalization(dataurl);schemalization。length=httphandler。
request。run();if(while(request。url。contains(dataurl))){httphandler。request。send(request。url。get());}else{httphandler。request。fetch(url,getheaderinfo("user-agent"));}}2、oh-my-zh在这里request。
url。get()php中include_github("xxxx。github。com/xxxx")。
首先明确你的目的是浏览网页还是新闻。如果是新闻,那么就在新闻源选取好,不管什么引擎,用javascript把url获取下来,然后写新闻代码。如果是浏览网页的话,可以看看h5用浏览器做网页展示,用网页中ejs的话也很简单。
用百度web开发者平台能解决。
php如何抓取网页数据( 哪些页面是人为的重要?有几个合理的因素?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-26 06:38
哪些页面是人为的重要?有几个合理的因素?)
手动seo优化有哪些方法可以吸引蜘蛛频繁爬行?
目前常用的链接包括锚文本链接、超链接、纯文本链接和图片链接。如何被爬虫爬取是一种自动提取网页的程序,比如百度蜘蛛。要让你的网站收录更多的页面,首先要让爬虫爬取网页。如果你的网站页面定期更新,爬虫会更频繁地访问页面,高质量的内容是爬虫喜欢爬取的,尤其是原创内容。蜘蛛很快就会爬升网站、网站和页面权重,这一定是更重要的。
做SEO优化
,我想要更多的页面成为收录,尽量吸引蜘蛛来抓取。如果你不能抓取所有的页面,那么蜘蛛所要做的就是抓取尽可能多的重要页面。哪些页面人为重要?
有几个合理的因素
1、网站页面和权重
网站质量高,资历老被认为权重高,在这个网站上爬取的页面深度也会更高,所以会有更多的收录页面。
2、页面更新
蜘蛛每次爬行时都会存储页面数据。第二次蜘蛛页面更新是没有必要的,如果不需要掌握第一次页面更新。如果页面内容更新频繁,蜘蛛会更频繁地访问页面,页面上的新连接自然会被蜘蛛更快地跟踪到新页面。
3、导入链接
无论是外链还是同一个网站的内链,都必须被蜘蛛抓取,并且必须有导入链接才能进入页面,否则蜘蛛将没有机会知道页面的存在。高质量的导入链接通常会增加页面导出链接的抓取深度。
4、点击“与主页的距离”
一般来说,大多数主页的权重都很高。因此,点击离首页越近,页面权重越高,蜘蛛爬行的机会就越大。
5、网址结构
页面权重仅在收录在迭代计算中时才知道。前面提到的高页面权重有利于抓取。搜索引擎蜘蛛如何在抓取前知道页面权重?所以蜘蛛预测,除了链接、到首页的距离、历史记录之外,还有数据等因素,短网址和浅网址可能直觉上认为网站权重比较高。
6、 吸引蜘蛛的方法:
这些链接会导致蜘蛛访问网页。只要不关注这些链接,就会引起蜘蛛的访问和传递权重。锚文本链接是一种很好的引导蜘蛛的方式,有利于关键词排名,比如关键词锚文本中的友情链接。 查看全部
php如何抓取网页数据(
哪些页面是人为的重要?有几个合理的因素?)
手动seo优化有哪些方法可以吸引蜘蛛频繁爬行?
目前常用的链接包括锚文本链接、超链接、纯文本链接和图片链接。如何被爬虫爬取是一种自动提取网页的程序,比如百度蜘蛛。要让你的网站收录更多的页面,首先要让爬虫爬取网页。如果你的网站页面定期更新,爬虫会更频繁地访问页面,高质量的内容是爬虫喜欢爬取的,尤其是原创内容。蜘蛛很快就会爬升网站、网站和页面权重,这一定是更重要的。
做SEO优化
,我想要更多的页面成为收录,尽量吸引蜘蛛来抓取。如果你不能抓取所有的页面,那么蜘蛛所要做的就是抓取尽可能多的重要页面。哪些页面人为重要?
有几个合理的因素
1、网站页面和权重
网站质量高,资历老被认为权重高,在这个网站上爬取的页面深度也会更高,所以会有更多的收录页面。
2、页面更新
蜘蛛每次爬行时都会存储页面数据。第二次蜘蛛页面更新是没有必要的,如果不需要掌握第一次页面更新。如果页面内容更新频繁,蜘蛛会更频繁地访问页面,页面上的新连接自然会被蜘蛛更快地跟踪到新页面。
3、导入链接
无论是外链还是同一个网站的内链,都必须被蜘蛛抓取,并且必须有导入链接才能进入页面,否则蜘蛛将没有机会知道页面的存在。高质量的导入链接通常会增加页面导出链接的抓取深度。
4、点击“与主页的距离”
一般来说,大多数主页的权重都很高。因此,点击离首页越近,页面权重越高,蜘蛛爬行的机会就越大。
5、网址结构
页面权重仅在收录在迭代计算中时才知道。前面提到的高页面权重有利于抓取。搜索引擎蜘蛛如何在抓取前知道页面权重?所以蜘蛛预测,除了链接、到首页的距离、历史记录之外,还有数据等因素,短网址和浅网址可能直觉上认为网站权重比较高。
6、 吸引蜘蛛的方法:
这些链接会导致蜘蛛访问网页。只要不关注这些链接,就会引起蜘蛛的访问和传递权重。锚文本链接是一种很好的引导蜘蛛的方式,有利于关键词排名,比如关键词锚文本中的友情链接。
php如何抓取网页数据(php如何抓取网页数据二:用php抓取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-14 06:02
php如何抓取网页数据
二):用php抓取网页数据如何抓取网页数据
三):调用laravelwebhook实现单页面应用如何抓取网页数据
四):php代理登录如何抓取网页数据
五):代理服务器,expressjs和haproxy最后这篇先聊下haproxy本文基于php7,
二、
三、四部分可使用proxy或proxy-switch等进行爬虫扩展。这部分我们也不会深入到php的其他知识,会更多的介绍haproxy实现方法。
分析任务:前台用户可通过以下三种形式访问爬虫,
1)轮询形式;
2)代理形式;
3)静态url过滤。两部分轮询形式:所谓轮询就是返回同步轮询的连接,并且轮询一次返回一次,返回的连接的url是同步的,这需要php7.0以上才能实现。如:;code_type=0&user_btn=10&account_id=212146965&country=&related_id=0...,返回的连接url是同步的,并且是轮询一次连接返回一次连接信息,这样轮询就比较节省服务器资源。
代理形式:代理形式就是将所有使用静态url过滤的页面url封装成静态文件服务,再由相应server进行访问。使用代理形式爬虫成本较低,但是用代理方式爬虫一般需要进行某些特殊配置,会让服务器资源闲置。静态url过滤:有时通过上边静态url过滤是可以爬取的。但是这样又很大浪费空间,不能满足我们爬虫任务的大小和范围,这时就要添加一些过滤规则,使得url不被重复或变化内容所遍历。
本文不做赘述。静态url请求接口我们请求url地址,并将请求的返回结果传给第三方程序。使用json库来进行请求,实现请求的对象是json的authenticator实例,分析jsonauthenticator的源码,有以下步骤:对待访问的url进行解析和转换,jsonauthenticator的转换可使用json.loads()方法;处理json对象中参数部分;判断参数是否可识别;加载jsonauthenticator对象。
反射jsonauthenticator对象staticif(decode_in_json(buf,{"array":buf.size})){//转换后将返回int的值trueif(isinstance(decode_combined,json_loaded(buf,str,"array"))){//否则返回null}}if(async_json(buf,{"language。 查看全部
php如何抓取网页数据(php如何抓取网页数据二:用php抓取(组图))
php如何抓取网页数据
二):用php抓取网页数据如何抓取网页数据
三):调用laravelwebhook实现单页面应用如何抓取网页数据
四):php代理登录如何抓取网页数据
五):代理服务器,expressjs和haproxy最后这篇先聊下haproxy本文基于php7,
二、
三、四部分可使用proxy或proxy-switch等进行爬虫扩展。这部分我们也不会深入到php的其他知识,会更多的介绍haproxy实现方法。
分析任务:前台用户可通过以下三种形式访问爬虫,
1)轮询形式;
2)代理形式;
3)静态url过滤。两部分轮询形式:所谓轮询就是返回同步轮询的连接,并且轮询一次返回一次,返回的连接的url是同步的,这需要php7.0以上才能实现。如:;code_type=0&user_btn=10&account_id=212146965&country=&related_id=0...,返回的连接url是同步的,并且是轮询一次连接返回一次连接信息,这样轮询就比较节省服务器资源。
代理形式:代理形式就是将所有使用静态url过滤的页面url封装成静态文件服务,再由相应server进行访问。使用代理形式爬虫成本较低,但是用代理方式爬虫一般需要进行某些特殊配置,会让服务器资源闲置。静态url过滤:有时通过上边静态url过滤是可以爬取的。但是这样又很大浪费空间,不能满足我们爬虫任务的大小和范围,这时就要添加一些过滤规则,使得url不被重复或变化内容所遍历。
本文不做赘述。静态url请求接口我们请求url地址,并将请求的返回结果传给第三方程序。使用json库来进行请求,实现请求的对象是json的authenticator实例,分析jsonauthenticator的源码,有以下步骤:对待访问的url进行解析和转换,jsonauthenticator的转换可使用json.loads()方法;处理json对象中参数部分;判断参数是否可识别;加载jsonauthenticator对象。
反射jsonauthenticator对象staticif(decode_in_json(buf,{"array":buf.size})){//转换后将返回int的值trueif(isinstance(decode_combined,json_loaded(buf,str,"array"))){//否则返回null}}if(async_json(buf,{"language。
php如何抓取网页数据(php如何抓取网页数据?php主要靠解析html文档得到页面信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-12 11:02
php如何抓取网页数据?php主要靠解析html文档得到页面信息,目前解析html文档方法有很多,都是使用正则表达式或者模糊匹配。
php只能处理html代码,你的需求肯定是有办法解决的。只不过你刚接触php,没摸索出来,这时候就靠搜索引擎来解决了。
可以看看大辉php的php实战录像,找不到就找这个。
php...
爬虫:php是弱类型语言post、get方法只能返回纯数字,
可以去github上看看有没有合适的php开源库。
没有php直接用python,
python和ruby
ruby
php
<p>我建议你写一个可以通过程序执行脚本来读取html,然后对返回的html做一些处理,比如<img>
<img> 查看全部
php如何抓取网页数据(php如何抓取网页数据?php主要靠解析html文档得到页面信息)
php如何抓取网页数据?php主要靠解析html文档得到页面信息,目前解析html文档方法有很多,都是使用正则表达式或者模糊匹配。
php只能处理html代码,你的需求肯定是有办法解决的。只不过你刚接触php,没摸索出来,这时候就靠搜索引擎来解决了。
可以看看大辉php的php实战录像,找不到就找这个。
php...
爬虫:php是弱类型语言post、get方法只能返回纯数字,
可以去github上看看有没有合适的php开源库。
没有php直接用python,
python和ruby
ruby
php
<p>我建议你写一个可以通过程序执行脚本来读取html,然后对返回的html做一些处理,比如<img>
<img>
php如何抓取网页数据(如何使用php+mysql+PHPquery+arphp的方案?-八维教育 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-06 03:18
)
通常我们在网站上可能会看到很多数据,我们可以自己分析一下。但是如果需要捕获数据,则需要一个捕获程序。
通过这个程序,你可以很容易的把别人的网站以前的页面,几百个页面,或者一个页面的一些内容放到自己的本地。
当然,要使用5行代码,还需要做一些准备工作。比如框架、数据库等。
我们这里使用的是php+mysql+PHPquery+arphp的方案。
1、phpquery 可用
看使用计划。
2、arphp可以去查看一些使用方法。
当然,你可以不阅读本文档,或者使用其他框架,或者不使用框架来编写这个程序。
具体代码:
require('phpQuery/phpQuery.php');//加载这个框架
$eg1=phpQuery::newDocumentFile("http://www.whu.edu.cn/tzgg.htm");//将你需要的抓取的页面对象化
$res = pq("ul,li")->html()."
";//获取页面中某个对象的html数据
$myfile = fopen("newfile.txt", "w") or die("不能打开文件");//打开一个文件
fwrite($myfile, $res);//将页面内容写入txt
当然也可以建一个数据库,然后把内容放到数据库中。
只需要这样五个元素,就基本可以完成一个页面内容的爬取了。当然,多页面爬取、单页面内容遍历和内容过滤、https内容或者反网站IP拦截等更复杂的问题,可以深入研究。
查看全部
php如何抓取网页数据(如何使用php+mysql+PHPquery+arphp的方案?-八维教育
)
通常我们在网站上可能会看到很多数据,我们可以自己分析一下。但是如果需要捕获数据,则需要一个捕获程序。
通过这个程序,你可以很容易的把别人的网站以前的页面,几百个页面,或者一个页面的一些内容放到自己的本地。
当然,要使用5行代码,还需要做一些准备工作。比如框架、数据库等。
我们这里使用的是php+mysql+PHPquery+arphp的方案。
1、phpquery 可用
看使用计划。
2、arphp可以去查看一些使用方法。
当然,你可以不阅读本文档,或者使用其他框架,或者不使用框架来编写这个程序。
具体代码:
require('phpQuery/phpQuery.php');//加载这个框架
$eg1=phpQuery::newDocumentFile("http://www.whu.edu.cn/tzgg.htm";);//将你需要的抓取的页面对象化
$res = pq("ul,li")->html()."
";//获取页面中某个对象的html数据
$myfile = fopen("newfile.txt", "w") or die("不能打开文件");//打开一个文件
fwrite($myfile, $res);//将页面内容写入txt
当然也可以建一个数据库,然后把内容放到数据库中。
只需要这样五个元素,就基本可以完成一个页面内容的爬取了。当然,多页面爬取、单页面内容遍历和内容过滤、https内容或者反网站IP拦截等更复杂的问题,可以深入研究。
php如何抓取网页数据(怎么向各大搜索引擎提交你的网址?奕斌说事)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-06 03:16
烦人烦,你平时知道怎么让搜索引擎蜘蛛爬行和收录你的网站吗?这对于网络推广的新人来说,确实是一件很头疼的事情。公司的资金并不大,不可能交给外面的公司。这样一来,就只能自己动手了,实在是一点头绪都没有,下面就来告诉大家吧。如何将您的网站 URL 提交给主要搜索引擎:
百度搜索站长平台为站长提供了链接提交通道。您可以通过百度提交您想成为收录的链接。百度搜索引擎会按照标准进行处理,但不保证您一定能够收录您提交的链接。
全球最大的面向中国互联网管理者、移动开发者和企业家的搜索流量管理官方平台。提供提交和分析工具,帮助搜索引擎捕捉收录、SEO优化建议等;为移动开发者提供百度官方API接口,以及多端适配能力和服务;及时发布百度权威数据、算法、工具等升级推送新信息。
登录端口:
360搜索平台网站收录,与网民分享网址,网站收录只要网站首页提交给搜索引擎,蜘蛛就会每次都光顾它 新的网站 会在抓取网页时添加并更新到索引中。站长只需提供顶级网页,无需提交单个网页。爬虫可以找到其他页面。符合相关标准提交的网址将在一个月内按照搜索引擎收录标准进行处理。
日志条目:
3.搜狗网站收录:提交后,搜狗搜索引擎会按照标准进行处理,但不保证提交的链接一定能收录@ >. 为提高处理效率,请勿重复提交同一个链接。网站收录/申诉一次只能提交一个网址。请确保 URL 的完整性、正确性、可访问性和网站内容质量。
收录提交条目
:
必应网站收录,将您的网站 URL提交给必应,并在网管工具中注册,查看您的网站是否已被索引,是否通过了必应流程应该得到。
Bing网站 提交登录入口:
每天分享一些网络推广的小知识,欢迎大家继续关注【易斌有话说】 查看全部
php如何抓取网页数据(怎么向各大搜索引擎提交你的网址?奕斌说事)
烦人烦,你平时知道怎么让搜索引擎蜘蛛爬行和收录你的网站吗?这对于网络推广的新人来说,确实是一件很头疼的事情。公司的资金并不大,不可能交给外面的公司。这样一来,就只能自己动手了,实在是一点头绪都没有,下面就来告诉大家吧。如何将您的网站 URL 提交给主要搜索引擎:
百度搜索站长平台为站长提供了链接提交通道。您可以通过百度提交您想成为收录的链接。百度搜索引擎会按照标准进行处理,但不保证您一定能够收录您提交的链接。
全球最大的面向中国互联网管理者、移动开发者和企业家的搜索流量管理官方平台。提供提交和分析工具,帮助搜索引擎捕捉收录、SEO优化建议等;为移动开发者提供百度官方API接口,以及多端适配能力和服务;及时发布百度权威数据、算法、工具等升级推送新信息。
登录端口:
360搜索平台网站收录,与网民分享网址,网站收录只要网站首页提交给搜索引擎,蜘蛛就会每次都光顾它 新的网站 会在抓取网页时添加并更新到索引中。站长只需提供顶级网页,无需提交单个网页。爬虫可以找到其他页面。符合相关标准提交的网址将在一个月内按照搜索引擎收录标准进行处理。
日志条目:
3.搜狗网站收录:提交后,搜狗搜索引擎会按照标准进行处理,但不保证提交的链接一定能收录@ >. 为提高处理效率,请勿重复提交同一个链接。网站收录/申诉一次只能提交一个网址。请确保 URL 的完整性、正确性、可访问性和网站内容质量。
收录提交条目
:
必应网站收录,将您的网站 URL提交给必应,并在网管工具中注册,查看您的网站是否已被索引,是否通过了必应流程应该得到。
Bing网站 提交登录入口:
每天分享一些网络推广的小知识,欢迎大家继续关注【易斌有话说】
php如何抓取网页数据( PowerQuery简单获取中文函数帮助信息的方法,方法分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-06 03:14
PowerQuery简单获取中文函数帮助信息的方法,方法分享
)
曾经文章登陆天山社区的Power Query:
Power Query M 函数(1)--数据类型和数据结构
PowerQuery M 函数 2-计算方法和运算符
Power Query M 函数(3)--数据类型转换、元数据和错误处理
通过前三节的学习,相信大家对M函数的基础知识有了一定的了解。从本节开始,我们将通过实际案例逐步介绍M功能的应用方法。
本节我们要介绍的案例是使用Web.Page和Web.Contents函数从PM2.5个历史数据网站中抓取不同城市不同日期的历史空气质量相关数据的方法. 这种方式适用于在Power Query中输入URL可以直接获取所需数据的情况(这种情况是指网页地址中有可见表格数据的情况)。
在进入正文之前,先给大家介绍一个简单的获取中文函数帮助信息的方法,方法如下:
1. 在 Power Query 查询编辑器中创建一个新的空查询
2. 在编辑字段中输入 =#shared
3. 点击“列出”
4. 通过过滤Name字段获取相关函数帮助信息
Web.Page 和 Web.Contents 功能说明:
1. Web.Page 函数:返回 HTML 文档的内容(分解为其组成结构),以及完整文档及其删除文本的表示
表达式:Function(html as any) as table
注:使用Web.Page函数获取网页HTML形式的相关信息,以表格形式返回结果
2. Web.Contents 函数:以二进制形式返回从 url 下载的内容。可以提供可选的记录参数选项来指定其他属性。记录可以收录以下字段...(更多内容省略,详见#shared查询)
表达式:函数(url 为文本,可选选项为可空记录)asbinary
注:支付Web.Contents网页地址后,Web.Contents函数可以以二进制数的形式返回网页中的信息
这两个函数嵌套使用后,Web.Page(Web.Contents(URL))最终可以将网页中的信息以表格的形式呈现出来。操作逻辑是先使用Web.Contents函数获取指定URL中的二进制信息,然后使用Web.Page函数对二进制信息进行转换解析,最终得到我们能够理解的表格数据。
在PM2.5历史数据网页爬取各城市过去一天的历史空气质量数据:
主页地址:
所需日均空气质量数据(以北京2014年1月为例):
网站链接:
北京&月=2014-01
使用Power Query抓取上述网页的目的是一次性批量抓取多个城市不同月份不同天数的历史空气质量数据。
爬取步骤如下:
1. 分析网站特点后发现,只要将city=后面的部分改成想要的城市名,month=后面的部分改成想要的月份号,不同的城市和可以打开不同的月份。每日历史数据页面下
2. 所以我们现在在Excel表格界面中建立一个收录城市名称和月份信息的表格,并将其添加到Power Query
3. 将【月份】字段转换为文本数据
4.在Power Query编辑器中添加自定义列,内容如下:
公式内容:
Web.Page(Web.Contents("
"&[城市]&"&month="&[月]))
5. 点击“Continue”,选择“Public”保存(数据量大,需要耐心等待,建议练习时只做两个城市的数据)
6. 在自定义字段中展开数据
7. 再次展开自定义字段中的相关字段(从日期到排名)
8. 关闭并上传
以上内容就是抓取网页信息的所有步骤。好,我们来看看爬取到的数据。
本文作者:李奇,天山社区专家,中国电子表格应用大会主席,签约天山智能/网易云课堂/经济管理之家等讲师,曾就职于IBM和德勤会计师事务所,从事商业分析和数据分析咨询工作,擅长使用Excel制作商业智能报告。
天山学院推荐课程:
查看全部
php如何抓取网页数据(
PowerQuery简单获取中文函数帮助信息的方法,方法分享
)
曾经文章登陆天山社区的Power Query:
Power Query M 函数(1)--数据类型和数据结构
PowerQuery M 函数 2-计算方法和运算符
Power Query M 函数(3)--数据类型转换、元数据和错误处理
通过前三节的学习,相信大家对M函数的基础知识有了一定的了解。从本节开始,我们将通过实际案例逐步介绍M功能的应用方法。
本节我们要介绍的案例是使用Web.Page和Web.Contents函数从PM2.5个历史数据网站中抓取不同城市不同日期的历史空气质量相关数据的方法. 这种方式适用于在Power Query中输入URL可以直接获取所需数据的情况(这种情况是指网页地址中有可见表格数据的情况)。
在进入正文之前,先给大家介绍一个简单的获取中文函数帮助信息的方法,方法如下:
1. 在 Power Query 查询编辑器中创建一个新的空查询
2. 在编辑字段中输入 =#shared
3. 点击“列出”
4. 通过过滤Name字段获取相关函数帮助信息
Web.Page 和 Web.Contents 功能说明:
1. Web.Page 函数:返回 HTML 文档的内容(分解为其组成结构),以及完整文档及其删除文本的表示
表达式:Function(html as any) as table
注:使用Web.Page函数获取网页HTML形式的相关信息,以表格形式返回结果
2. Web.Contents 函数:以二进制形式返回从 url 下载的内容。可以提供可选的记录参数选项来指定其他属性。记录可以收录以下字段...(更多内容省略,详见#shared查询)
表达式:函数(url 为文本,可选选项为可空记录)asbinary
注:支付Web.Contents网页地址后,Web.Contents函数可以以二进制数的形式返回网页中的信息
这两个函数嵌套使用后,Web.Page(Web.Contents(URL))最终可以将网页中的信息以表格的形式呈现出来。操作逻辑是先使用Web.Contents函数获取指定URL中的二进制信息,然后使用Web.Page函数对二进制信息进行转换解析,最终得到我们能够理解的表格数据。
在PM2.5历史数据网页爬取各城市过去一天的历史空气质量数据:
主页地址:
所需日均空气质量数据(以北京2014年1月为例):
网站链接:
北京&月=2014-01
使用Power Query抓取上述网页的目的是一次性批量抓取多个城市不同月份不同天数的历史空气质量数据。
爬取步骤如下:
1. 分析网站特点后发现,只要将city=后面的部分改成想要的城市名,month=后面的部分改成想要的月份号,不同的城市和可以打开不同的月份。每日历史数据页面下
2. 所以我们现在在Excel表格界面中建立一个收录城市名称和月份信息的表格,并将其添加到Power Query
3. 将【月份】字段转换为文本数据
4.在Power Query编辑器中添加自定义列,内容如下:
公式内容:
Web.Page(Web.Contents("
"&[城市]&"&month="&[月]))
5. 点击“Continue”,选择“Public”保存(数据量大,需要耐心等待,建议练习时只做两个城市的数据)
6. 在自定义字段中展开数据
7. 再次展开自定义字段中的相关字段(从日期到排名)
8. 关闭并上传
以上内容就是抓取网页信息的所有步骤。好,我们来看看爬取到的数据。
本文作者:李奇,天山社区专家,中国电子表格应用大会主席,签约天山智能/网易云课堂/经济管理之家等讲师,曾就职于IBM和德勤会计师事务所,从事商业分析和数据分析咨询工作,擅长使用Excel制作商业智能报告。
天山学院推荐课程:
php如何抓取网页数据(php如何抓取网页数据?(一)__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-05 23:02
php如何抓取网页数据?直接aspen-common无头不钻设置头部样式,传递参数到header再用普通的if判断解析。比如你要下载2012年广西暴乱的网页内容,需要传递两个参数分别是:姓名,国籍首页:没问题,但要注意这些详细内容的国家和省份每一行都是一样的,例如你要下载的网页是南宁市,但实际的二三四五行的内容是河北省保定市。
而如果下载的是2015年广西暴乱的网页:..//..//content//2015//content///2015//网页确实会加载出两个不同的网页,但是他们不同的是颜色。我们拿php解析网页为例,看看他到底怎么实现的。一、通过header传递参数header并不是单个地方可以存入参数,需要顺着整个网页传递一个,例如传递二,直接url=;fromname=evil&applesize=1524&properties=gibetropha如果你的服务器默认的是ipv4,那么网页会解析出一个新的ip,再让你下载。
如果你服务器默认的是ipv6,那么网页也会解析出一个新的ip,再让你下载。来看看下面这个例子:login_admin=xxxmasked=nullposter=xxxpage=latestpackage=portablepublicfilepath=xxx#poster=localhostbug_new=okremote_login=xxx#properties=gibetrophaweb_host=xxx#publicfilepath=xxx#url=;fromname=evil&applesize=1524&properties=gibetropha二、header全表解析在网页下载的时候不是只解析前端的内容,而是会解析前端和后端共同解析的内容。
所以我们需要将header中的参数用sort排序。先来看看sort的介绍:sort有两个特性:按相同排序,按内容排序thesortfunctionandtheclose-endsortfunctioncandefinetwocustomspecificfunctions:hyperlink和header..hyperlink'hd=gibetropha'hyperlink'wj00000023''..'header'content=..'content='gibetropha'#'wsd=source'sort是一个global.each代表global.write,#'source'代表wsd代表source的document#'msize'代表method的content代表method的content#'..'''.''.''.''.''.''sort方法:返回按指定顺序的排序请求。
还有一个隐藏的wsd排序请求,完成one-to-onegroup排序。看下图:method方法:gibetropha网页实际的内容通过header向服务器,服务器会解析出一个新的header和三个header,分别。 查看全部
php如何抓取网页数据(php如何抓取网页数据?(一)__)
php如何抓取网页数据?直接aspen-common无头不钻设置头部样式,传递参数到header再用普通的if判断解析。比如你要下载2012年广西暴乱的网页内容,需要传递两个参数分别是:姓名,国籍首页:没问题,但要注意这些详细内容的国家和省份每一行都是一样的,例如你要下载的网页是南宁市,但实际的二三四五行的内容是河北省保定市。
而如果下载的是2015年广西暴乱的网页:..//..//content//2015//content///2015//网页确实会加载出两个不同的网页,但是他们不同的是颜色。我们拿php解析网页为例,看看他到底怎么实现的。一、通过header传递参数header并不是单个地方可以存入参数,需要顺着整个网页传递一个,例如传递二,直接url=;fromname=evil&applesize=1524&properties=gibetropha如果你的服务器默认的是ipv4,那么网页会解析出一个新的ip,再让你下载。
如果你服务器默认的是ipv6,那么网页也会解析出一个新的ip,再让你下载。来看看下面这个例子:login_admin=xxxmasked=nullposter=xxxpage=latestpackage=portablepublicfilepath=xxx#poster=localhostbug_new=okremote_login=xxx#properties=gibetrophaweb_host=xxx#publicfilepath=xxx#url=;fromname=evil&applesize=1524&properties=gibetropha二、header全表解析在网页下载的时候不是只解析前端的内容,而是会解析前端和后端共同解析的内容。
所以我们需要将header中的参数用sort排序。先来看看sort的介绍:sort有两个特性:按相同排序,按内容排序thesortfunctionandtheclose-endsortfunctioncandefinetwocustomspecificfunctions:hyperlink和header..hyperlink'hd=gibetropha'hyperlink'wj00000023''..'header'content=..'content='gibetropha'#'wsd=source'sort是一个global.each代表global.write,#'source'代表wsd代表source的document#'msize'代表method的content代表method的content#'..'''.''.''.''.''.''sort方法:返回按指定顺序的排序请求。
还有一个隐藏的wsd排序请求,完成one-to-onegroup排序。看下图:method方法:gibetropha网页实际的内容通过header向服务器,服务器会解析出一个新的header和三个header,分别。
php如何抓取网页数据(php如何抓取网页数据??这里介绍一下http协议本教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-05 03:03
php如何抓取网页数据???,这里介绍一下http协议本教程主要涉及http协议请求、响应与事务、http响应与重定向、http响应与重定向、method、extension与hook等相关技术详细内容请看下图最全面的网页数据抓取教程!
举个栗子,我们想抓取一下某个城市。对http服务来说,客户端输入目标地址之后,http请求就开始。从浏览器上传会经过get(可以是http/1.1以上版本)的发送和post的发送。http客户端根据目标请求方式,可以认为是简单http请求和http/2之间的转换。
1、首部字段:a、发起请求的url/子url;b、name字段:name=‘网站名’,任何不带,
2、请求体:url/with;
3、value字段:xml或者xhtml文件(如果带有,不管他是什么,
4、path字段:with//xml
5、cookie字段:默认值;
6、accept字段:http/1.1或者http/2cookiehttp/2这样在浏览器中输入目标地址之后,http请求就开始了。完整的请求一般包括以下几个步骤:第一步:接收到http客户端发来的name字段的响应(如果没有,也没关系,还可以从服务器获取);第二步:第一步接收到的响应,只需要发送一个响应头包。
这个响应头就是你上文所说的cookie。第三步:第二步客户端会根据响应头,得到这个请求地址的主机ip,姓名,邮箱等信息,并且保存在http/2.xml当中;第四步:第三步客户端会根据这些信息,根据你所要请求的数据,去网站收集相关信息,这些信息会发送到服务器端。比如文章标题,最终http/2cookie会被发送到你的电脑中。所以并不是说只要传输一个响应头,就完成了http/2的发送了。
要注意的是,响应头的格式,
2、cookie的内容。 查看全部
php如何抓取网页数据(php如何抓取网页数据??这里介绍一下http协议本教程)
php如何抓取网页数据???,这里介绍一下http协议本教程主要涉及http协议请求、响应与事务、http响应与重定向、http响应与重定向、method、extension与hook等相关技术详细内容请看下图最全面的网页数据抓取教程!
举个栗子,我们想抓取一下某个城市。对http服务来说,客户端输入目标地址之后,http请求就开始。从浏览器上传会经过get(可以是http/1.1以上版本)的发送和post的发送。http客户端根据目标请求方式,可以认为是简单http请求和http/2之间的转换。
1、首部字段:a、发起请求的url/子url;b、name字段:name=‘网站名’,任何不带,
2、请求体:url/with;
3、value字段:xml或者xhtml文件(如果带有,不管他是什么,
4、path字段:with//xml
5、cookie字段:默认值;
6、accept字段:http/1.1或者http/2cookiehttp/2这样在浏览器中输入目标地址之后,http请求就开始了。完整的请求一般包括以下几个步骤:第一步:接收到http客户端发来的name字段的响应(如果没有,也没关系,还可以从服务器获取);第二步:第一步接收到的响应,只需要发送一个响应头包。
这个响应头就是你上文所说的cookie。第三步:第二步客户端会根据响应头,得到这个请求地址的主机ip,姓名,邮箱等信息,并且保存在http/2.xml当中;第四步:第三步客户端会根据这些信息,根据你所要请求的数据,去网站收集相关信息,这些信息会发送到服务器端。比如文章标题,最终http/2cookie会被发送到你的电脑中。所以并不是说只要传输一个响应头,就完成了http/2的发送了。
要注意的是,响应头的格式,
2、cookie的内容。
php如何抓取网页数据(php如何抓取网页数据?数据存储程序操作效果图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-24 06:06
php如何抓取网页数据?对于php而言,数据获取并不难,如果我们只要让php知道目标网页的url,然后按照指定的规则使用正则匹配网页内容,之后将返回的json数据存储就好了。在实际开发中,难免需要将正则表达式用来匹配某个数据,这个时候会进行正则替换(g++),或者使用网页抓取程序(f12)等,另外还可以使用邮件编辑器(mailfinder)。
<p>下面来看看这两种方法的操作,效果如下图:下面分享一个php抓取谷歌新闻的操作,之后同样同样通过json数据存储程序实现。首先先看看效果图:1.打开get/谷歌网页搜索#php抓取网页内容f12/点击responsestring$from和execute/来看看请求头,每行内容是网页的url#php抓取网页内容2.body部分看看中间几个参数,#php抓取网页内容$ext_text表示网页的一行内容,$ext_textparam$value是给浏览器(浏览器是不能转义的哦),^$表示给正则表达式匹配的文本,$re_cookie表示浏览器存放的正则表达式的账号和密码,$re_proto表示是否开启正则表达式匹配文件名pub_file表示是否开启正则表达式匹配文件名filename表示正则表达式的匹配方式,#php抓取网页内容$ext_pub表示网页自带的正则表达式或者compile进来的正则表达式3.body2:内容是采用4.body3:也是采用compile正则表达式$re_proto不能开启,否则不能匹配的,一定要$re_cookie有$ext_textparam$value是给浏览器(浏览器是不能转义的哦),$re_stringparam$value是给正则表达式匹配的文本,$//f@path.extend('default./')如果$/匹配不到文本,浏览器就不会进行匹配$/$\d{s}^$^\d{s},$\d{s}^{\d}是匹配以字符的开头$\d{s}//f@path.extend($/f'/\d{default}$\d{s}');$/$\d{s}//f@path.extend($/$\d{s}\d{default}$\d{s})5.body4:$cookie只匹配文本的内容$from匹配的是 查看全部
php如何抓取网页数据(php如何抓取网页数据?数据存储程序操作效果图)
php如何抓取网页数据?对于php而言,数据获取并不难,如果我们只要让php知道目标网页的url,然后按照指定的规则使用正则匹配网页内容,之后将返回的json数据存储就好了。在实际开发中,难免需要将正则表达式用来匹配某个数据,这个时候会进行正则替换(g++),或者使用网页抓取程序(f12)等,另外还可以使用邮件编辑器(mailfinder)。
<p>下面来看看这两种方法的操作,效果如下图:下面分享一个php抓取谷歌新闻的操作,之后同样同样通过json数据存储程序实现。首先先看看效果图:1.打开get/谷歌网页搜索#php抓取网页内容f12/点击responsestring$from和execute/来看看请求头,每行内容是网页的url#php抓取网页内容2.body部分看看中间几个参数,#php抓取网页内容$ext_text表示网页的一行内容,$ext_textparam$value是给浏览器(浏览器是不能转义的哦),^$表示给正则表达式匹配的文本,$re_cookie表示浏览器存放的正则表达式的账号和密码,$re_proto表示是否开启正则表达式匹配文件名pub_file表示是否开启正则表达式匹配文件名filename表示正则表达式的匹配方式,#php抓取网页内容$ext_pub表示网页自带的正则表达式或者compile进来的正则表达式3.body2:内容是采用4.body3:也是采用compile正则表达式$re_proto不能开启,否则不能匹配的,一定要$re_cookie有$ext_textparam$value是给浏览器(浏览器是不能转义的哦),$re_stringparam$value是给正则表达式匹配的文本,$//f@path.extend('default./')如果$/匹配不到文本,浏览器就不会进行匹配$/$\d{s}^$^\d{s},$\d{s}^{\d}是匹配以字符的开头$\d{s}//f@path.extend($/f'/\d{default}$\d{s}');$/$\d{s}//f@path.extend($/$\d{s}\d{default}$\d{s})5.body4:$cookie只匹配文本的内容$from匹配的是
php如何抓取网页数据( Web抓取的探险之前,如何得到那些重要数据呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-04 12:15
Web抓取的探险之前,如何得到那些重要数据呢?)
随着电子商务的蓬勃发展,作者近年来对比价应用越来越着迷。每次线上(甚至线下)购买,都是深入研究各大电商的结果网站。
笔者常用的比价应用包括:RedLaser、ShopSavvy和BuyHatke。这些应用有效地提高了价格透明度,从而为消费者节省了大量时间。
但是,您有没有想过这些应用程序是如何获取这些重要数据的?通常,他们使用 Web 抓取技术来完成此任务。
网页抓取的定义
网络抓取是提取网络数据的过程。借助合适的工具,您可以提取任何您能看到的数据。在本文中,我们将重点介绍自动提取过程的过程,以帮助您在短时间内采集大量数据。除了我上面提到的用例,抓取技术的用途还包括:SEO跟踪、工作跟踪、新闻分析,以及我最喜欢的社交媒体情绪分析!
提醒
在开始网络抓取冒险之前,请确保您了解相关的法律问题。许多 网站 在其服务条款中明确禁止抓取其内容。例如,Medium 网站 写道:“按照网站 robots.txt 文件中的规定抓取是可以接受的,但我们禁止抓取。” 爬不准爬的网站可能会让你进入他们的黑名单!与任何工具一样,网页抓取也可能用于不受欢迎的目的,例如复制 网站 内容。此外,网络爬虫引发的法律诉讼也不少。
设置代码
在完全理解需要谨慎处理之后,让我们开始学习网络抓取。事实上,网页抓取可以用任何编程语言实现。前不久,我们用Node来实现。在本文中,考虑到它的简单性和丰富的包支持,我们将使用 Python 来实现爬虫程序。
网页抓取的基本过程
当您在网络上打开一个站点时,其 HTML 代码将被下载,您的网络浏览器将对其进行分析和显示。HTML 代码收录您看到的所有信息。因此,可以通过分析 HTML 代码获得所需的信息(如价格)。您可以使用正则表达式在数据海洋中搜索您需要的信息,也可以使用函数库来解释HTML,也可以获取您需要的数据。
在 Python 中,我们将使用一个名为 Beautiful Soup 的模块来分析 HTML 数据。您可以借助安装程序(例如 pip)进行安装,只需运行以下代码:
pip install beautifulsoup4
或者,您也可以从源代码构建。在本模块中,您可以看到详细的安装步骤。
安装完成后,我们一般会按照以下步骤来实现网页抓取:
作为演示,我们将使用作者的博客。作为目标 URL。
前两步比较简单,可以这样完成:
from urllib import urlopen#Sending the http requestwebpage = urlopen(\'http://my_website.com/\').read()
接下来,将响应传递给之前安装的模块:
from bs4 import BeautifulSoup#making the soup! yummy ;)soup = BeautifulSoup(webpage, "html5lib")
请注意,这里我们选择了 html5lib 作为解析器。根据它,您还可以为其选择不同的解析器。
解析 HTML
将 HTML 传递给 BeautifulSoup 后,我们可以尝试一些命令。例如,要检查 HTML 标记代码是否正确,您可以验证页面的标题(在 Python 解释器中):
>>> soup.titleTranscendental Tech Talk>>> soup.title.text
u\'Transcendental Tech Talk\'
>>>
接下来,开始提取页面中的特定元素。例如,我想提取博客中的 文章 标题列表。为此,我需要分析 HTML 的结构,这可以在 Chrome 检查器的帮助下完成。其他浏览器也提供了类似的工具。
使用 Chrome 检查器检查页面的 HTML 结构
如您所见,所有 文章 标题都有 h3 标签和两个类属性:post-title 和 entry-title 类。因此,搜索所有带有 post-title 类的 h3 元素,以获取页面的 文章 标题列表。在这个例子中,我们使用了 BeautifulSoup 提供的 find_all 函数,并使用 class_ 参数来确定所需的类:
>>> titles = soup.find_all(\'h3\', class_ = \'post-title\') #Getting all titles>>> titles[0].textu\'\nKolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips\n\'>>>
您应该只通过 post-title 类搜索项目来获得相同的结果:
>>> titles = soup.find_all(class_ = \'post-title\') #Getting all items with class post-title>>> titles[0].textu\'\nKolkata #BergerXP
IndiBlogger meet, Marketing Insights, and some Blogging Tips\n\'>>>
如果您想了解有关条目引用的链接的更多信息,可以运行以下代码:
>>> for title in titles:... # Each title is in the form of <a href=...>Post Title<a/>... print title.find("a").get("href")...http://dada.theblogbowl.in/201 ... .html
http://dada.theblogbowl.in/201 ... .html
http://dada.theblogbowl.in/201 ... .html
http://dada.theblogbowl.in/201 ... gt%3B
BeautifulSoup 有许多内置方法可以帮助您玩转 HTML。下面列出了其中一些方法:
>>> titles[0].contents
[u\'\n\', Kolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips, u\'\n\']>>>
请注意,您也可以使用 children 属性,但它有点像生成器:
>>> titles[0].parent\n<a name="6501973351448547458"></a>\n\n<a href="http://dada.theblogbowl.in/201 ... lkata #BergerXP IndiBlogger ...
>>>
为此,您还可以使用正则表达式搜索 CSS 类。
使用 Mechanize 模拟登录
到目前为止,我们所做的只是下载页面并分析其内容。但是,Web 开发者可能会阻塞非浏览器请求,或者某些网站 内容只有登录后才能读取。那么,我们如何处理这些情况呢?
对于第一种情况,我们需要在向页面发送请求时模拟浏览器。每个 HTTP 请求都收录一些相关的标头,其中收录访问者的浏览器、操作系统和屏幕大小等信息。我们可以改变这些数据头,伪装成浏览器发送请求。
对于第二种情况,为了访问有访问者限制的内容,我们需要登录网站并使用cookies来维护会话。接下来,我们来看看如何在冒充浏览器的情况下实现这一点。
我们将在 cookielib 模块的帮助下使用 cookie 来管理会话。此外,我们还将使用 mechanize,它可以使用 pip 等安装程序进行安装。
我们将通过博客碗页面登录并访问通知页面。以下代码由内联注释解释:
import mechanize
import cookielib
from urllib import urlopen
from bs4 import BeautifulSoup# Cookie Jarcj = cookielib.LWPCookieJar()
browser = mechanize.Browser()
browser.set_cookiejar(cj)
browser.set_handle_robots(False)
browser.set_handle_redirect(True)# Solving issue #1 by emulating a browser by adding HTTP headersbrowser.addheaders = [(\'User-agent\', \'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.1) Gecko/2008071615 Fedora/3.0.1-1.fc9 Firefox/3.0.1\')]# Open Login Pagebrowser.open("http://theblogbowl.in/login/")# Select Login form (1st form of the page)browser.select_form(nr = 0)# Alternate syntax - browser.select_form(name = "form_name")# The first tag of the form is a CSRF token# Setting the 2nd and 3rd tags to email and passwordbrowser.form.set_value("email@example.com", nr=1)
browser.form.set_value("password", nr=2)# Logging inresponse = browser.submit()# Opening new page after loginsoup = BeautifulSoup(browser.open(\'http://theblogbowl.in/notifications/\').read(), "html5lib")
通知页面的结构
# Print notificationsprint soup.find(class_ = "search_results").text
登录通知页面后的结果
结束语
很多开发者会告诉你:你在网上看到的任何信息都可以被抓取。通过这个文章,你学会了如何轻松提取登录后才能看到的内容。另外,如果你的IP被屏蔽了,你可以屏蔽你的IP地址(或选择其他地址)。同时,为了看起来像一个人在访问,你应该在请求之间保持一定的时间间隔。
随着人们对数据的需求不断增长,网络抓取(无论出于好坏的原因)只会在未来得到更广泛的应用。因此,了解其原理非常重要,无论您是在有效地使用该技术还是避免其陷入困境。
OneAPM 可以帮助您查看 Python 应用程序的各个方面。它不仅可以监控终端的用户体验,还可以监控服务器性能。它还支持跟踪数据库、第三方 API 和 Web 服务器的各种问题。阅读更多技术文章,请访问OneAPM官方技术博客。 查看全部
php如何抓取网页数据(
Web抓取的探险之前,如何得到那些重要数据呢?)
随着电子商务的蓬勃发展,作者近年来对比价应用越来越着迷。每次线上(甚至线下)购买,都是深入研究各大电商的结果网站。
笔者常用的比价应用包括:RedLaser、ShopSavvy和BuyHatke。这些应用有效地提高了价格透明度,从而为消费者节省了大量时间。
但是,您有没有想过这些应用程序是如何获取这些重要数据的?通常,他们使用 Web 抓取技术来完成此任务。
网页抓取的定义
网络抓取是提取网络数据的过程。借助合适的工具,您可以提取任何您能看到的数据。在本文中,我们将重点介绍自动提取过程的过程,以帮助您在短时间内采集大量数据。除了我上面提到的用例,抓取技术的用途还包括:SEO跟踪、工作跟踪、新闻分析,以及我最喜欢的社交媒体情绪分析!
提醒
在开始网络抓取冒险之前,请确保您了解相关的法律问题。许多 网站 在其服务条款中明确禁止抓取其内容。例如,Medium 网站 写道:“按照网站 robots.txt 文件中的规定抓取是可以接受的,但我们禁止抓取。” 爬不准爬的网站可能会让你进入他们的黑名单!与任何工具一样,网页抓取也可能用于不受欢迎的目的,例如复制 网站 内容。此外,网络爬虫引发的法律诉讼也不少。
设置代码
在完全理解需要谨慎处理之后,让我们开始学习网络抓取。事实上,网页抓取可以用任何编程语言实现。前不久,我们用Node来实现。在本文中,考虑到它的简单性和丰富的包支持,我们将使用 Python 来实现爬虫程序。
网页抓取的基本过程
当您在网络上打开一个站点时,其 HTML 代码将被下载,您的网络浏览器将对其进行分析和显示。HTML 代码收录您看到的所有信息。因此,可以通过分析 HTML 代码获得所需的信息(如价格)。您可以使用正则表达式在数据海洋中搜索您需要的信息,也可以使用函数库来解释HTML,也可以获取您需要的数据。
在 Python 中,我们将使用一个名为 Beautiful Soup 的模块来分析 HTML 数据。您可以借助安装程序(例如 pip)进行安装,只需运行以下代码:
pip install beautifulsoup4
或者,您也可以从源代码构建。在本模块中,您可以看到详细的安装步骤。
安装完成后,我们一般会按照以下步骤来实现网页抓取:
作为演示,我们将使用作者的博客。作为目标 URL。
前两步比较简单,可以这样完成:
from urllib import urlopen#Sending the http requestwebpage = urlopen(\'http://my_website.com/\').read()
接下来,将响应传递给之前安装的模块:
from bs4 import BeautifulSoup#making the soup! yummy ;)soup = BeautifulSoup(webpage, "html5lib")
请注意,这里我们选择了 html5lib 作为解析器。根据它,您还可以为其选择不同的解析器。
解析 HTML
将 HTML 传递给 BeautifulSoup 后,我们可以尝试一些命令。例如,要检查 HTML 标记代码是否正确,您可以验证页面的标题(在 Python 解释器中):
>>> soup.titleTranscendental Tech Talk>>> soup.title.text
u\'Transcendental Tech Talk\'
>>>
接下来,开始提取页面中的特定元素。例如,我想提取博客中的 文章 标题列表。为此,我需要分析 HTML 的结构,这可以在 Chrome 检查器的帮助下完成。其他浏览器也提供了类似的工具。
使用 Chrome 检查器检查页面的 HTML 结构
如您所见,所有 文章 标题都有 h3 标签和两个类属性:post-title 和 entry-title 类。因此,搜索所有带有 post-title 类的 h3 元素,以获取页面的 文章 标题列表。在这个例子中,我们使用了 BeautifulSoup 提供的 find_all 函数,并使用 class_ 参数来确定所需的类:
>>> titles = soup.find_all(\'h3\', class_ = \'post-title\') #Getting all titles>>> titles[0].textu\'\nKolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips\n\'>>>
您应该只通过 post-title 类搜索项目来获得相同的结果:
>>> titles = soup.find_all(class_ = \'post-title\') #Getting all items with class post-title>>> titles[0].textu\'\nKolkata #BergerXP
IndiBlogger meet, Marketing Insights, and some Blogging Tips\n\'>>>
如果您想了解有关条目引用的链接的更多信息,可以运行以下代码:
>>> for title in titles:... # Each title is in the form of <a href=...>Post Title<a/>... print title.find("a").get("href")...http://dada.theblogbowl.in/201 ... .html
http://dada.theblogbowl.in/201 ... .html
http://dada.theblogbowl.in/201 ... .html
http://dada.theblogbowl.in/201 ... gt%3B
BeautifulSoup 有许多内置方法可以帮助您玩转 HTML。下面列出了其中一些方法:
>>> titles[0].contents
[u\'\n\', Kolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips, u\'\n\']>>>
请注意,您也可以使用 children 属性,但它有点像生成器:
>>> titles[0].parent\n<a name="6501973351448547458"></a>\n\n<a href="http://dada.theblogbowl.in/201 ... lkata #BergerXP IndiBlogger ...
>>>
为此,您还可以使用正则表达式搜索 CSS 类。
使用 Mechanize 模拟登录
到目前为止,我们所做的只是下载页面并分析其内容。但是,Web 开发者可能会阻塞非浏览器请求,或者某些网站 内容只有登录后才能读取。那么,我们如何处理这些情况呢?
对于第一种情况,我们需要在向页面发送请求时模拟浏览器。每个 HTTP 请求都收录一些相关的标头,其中收录访问者的浏览器、操作系统和屏幕大小等信息。我们可以改变这些数据头,伪装成浏览器发送请求。
对于第二种情况,为了访问有访问者限制的内容,我们需要登录网站并使用cookies来维护会话。接下来,我们来看看如何在冒充浏览器的情况下实现这一点。
我们将在 cookielib 模块的帮助下使用 cookie 来管理会话。此外,我们还将使用 mechanize,它可以使用 pip 等安装程序进行安装。
我们将通过博客碗页面登录并访问通知页面。以下代码由内联注释解释:
import mechanize
import cookielib
from urllib import urlopen
from bs4 import BeautifulSoup# Cookie Jarcj = cookielib.LWPCookieJar()
browser = mechanize.Browser()
browser.set_cookiejar(cj)
browser.set_handle_robots(False)
browser.set_handle_redirect(True)# Solving issue #1 by emulating a browser by adding HTTP headersbrowser.addheaders = [(\'User-agent\', \'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.1) Gecko/2008071615 Fedora/3.0.1-1.fc9 Firefox/3.0.1\')]# Open Login Pagebrowser.open("http://theblogbowl.in/login/";)# Select Login form (1st form of the page)browser.select_form(nr = 0)# Alternate syntax - browser.select_form(name = "form_name")# The first tag of the form is a CSRF token# Setting the 2nd and 3rd tags to email and passwordbrowser.form.set_value("email@example.com", nr=1)
browser.form.set_value("password", nr=2)# Logging inresponse = browser.submit()# Opening new page after loginsoup = BeautifulSoup(browser.open(\'http://theblogbowl.in/notifications/\').read(), "html5lib")
通知页面的结构
# Print notificationsprint soup.find(class_ = "search_results").text
登录通知页面后的结果
结束语
很多开发者会告诉你:你在网上看到的任何信息都可以被抓取。通过这个文章,你学会了如何轻松提取登录后才能看到的内容。另外,如果你的IP被屏蔽了,你可以屏蔽你的IP地址(或选择其他地址)。同时,为了看起来像一个人在访问,你应该在请求之间保持一定的时间间隔。
随着人们对数据的需求不断增长,网络抓取(无论出于好坏的原因)只会在未来得到更广泛的应用。因此,了解其原理非常重要,无论您是在有效地使用该技术还是避免其陷入困境。
OneAPM 可以帮助您查看 Python 应用程序的各个方面。它不仅可以监控终端的用户体验,还可以监控服务器性能。它还支持跟踪数据库、第三方 API 和 Web 服务器的各种问题。阅读更多技术文章,请访问OneAPM官方技术博客。
php如何抓取网页数据(知乎用户数据爬取和分析背景说明:小拽利用php的curl代码和用户dashboard)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-02 18:00
php 获取网页数据并插入到数据库相关的博客中
php爬虫:知乎用户数据爬取与分析
背景说明:小野使用PHP的curl编写的爬虫实验性爬取知乎5w用户的基本信息;同时对爬取的数据进行简单的分析和呈现。 demo地址 php的spider代码和用户仪表盘的显示代码,完成后上传到github,更新个人博客和公众号中的代码库,程
崔小抓5年前2345
解决“mysql服务器已经消失”问题
出现此类问题时,应用程序(如PHP)会长时间批量执行MYSQL语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。在 MySQL 中解决
php的小菜鸟4年前1008
用于绘制图形的Rrdtool学习和自定义脚本绘制备忘录
RRDtool(Round Robin Database Tool)是一个强大的绘图引擎,MRTG等很多工具都可以调用rrdtool绘图。包括现在用的比较多的cacti,基于rrdtool画图。可以说cacti只提供了一个显示图形的网页
于尔武4年前1163
c#批量获取免费代理并验证其有效性
刷新页面前在某公司官网看到文章的浏览量,会增加一次。感觉不是很好。一个公司的官网给人这么直接的漏洞,于是我发起批量请求的时候,发现页面打开报错。一个100多人的公司官网文章刷新一次,你给我看这个。这家公司之前来过我们学校宣传招聘+我在花园里找招聘的时候找到了住处
他妈的张琳3年前1170
RRDTool详解
大纲一、MRTG与RRDTool的缺点对比二、RRDTool概述三、安装RRDTool四、RRDTool绘制步骤五、rrdtool命令详解六、@ > RRDTool绘图案例笔记,实验环境CentOS 6.4 x86_64,软件版本rrdtool-1.3
技术小美4年前1573
MySQL 服务器消失的解决方法
应用程序(如PHP)长时间批量执行MYSQL语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。今天遇到了类似的情况,MySQL就凉了
云栖希望。 4年前的1791
技术 |从零开始的Python系列(3十五)
大家好,这次给大家带来一个方法,可以抓取有识之士的提问,并将问答保存到数据库中。涉及的内容包括:Urllib的使用和异常处理,Beautiful Soup MySQLdb的简单应用基本使用正则表达式的简单应用环境配置在此之前,我们需要先配置一下环境
技术小能手2年前的1954
MySQL 服务器不见了
MySQL server has away 运行sql文件导入数据库时会报异常 MySQL server has go away mysql has ERROR: (2006,'MySQL server has away') problem
李大嘴6年前的1934 查看全部
php如何抓取网页数据(知乎用户数据爬取和分析背景说明:小拽利用php的curl代码和用户dashboard)
php 获取网页数据并插入到数据库相关的博客中
php爬虫:知乎用户数据爬取与分析
背景说明:小野使用PHP的curl编写的爬虫实验性爬取知乎5w用户的基本信息;同时对爬取的数据进行简单的分析和呈现。 demo地址 php的spider代码和用户仪表盘的显示代码,完成后上传到github,更新个人博客和公众号中的代码库,程
崔小抓5年前2345
解决“mysql服务器已经消失”问题
出现此类问题时,应用程序(如PHP)会长时间批量执行MYSQL语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。在 MySQL 中解决
php的小菜鸟4年前1008
用于绘制图形的Rrdtool学习和自定义脚本绘制备忘录
RRDtool(Round Robin Database Tool)是一个强大的绘图引擎,MRTG等很多工具都可以调用rrdtool绘图。包括现在用的比较多的cacti,基于rrdtool画图。可以说cacti只提供了一个显示图形的网页
于尔武4年前1163
c#批量获取免费代理并验证其有效性
刷新页面前在某公司官网看到文章的浏览量,会增加一次。感觉不是很好。一个公司的官网给人这么直接的漏洞,于是我发起批量请求的时候,发现页面打开报错。一个100多人的公司官网文章刷新一次,你给我看这个。这家公司之前来过我们学校宣传招聘+我在花园里找招聘的时候找到了住处
他妈的张琳3年前1170
RRDTool详解
大纲一、MRTG与RRDTool的缺点对比二、RRDTool概述三、安装RRDTool四、RRDTool绘制步骤五、rrdtool命令详解六、@ > RRDTool绘图案例笔记,实验环境CentOS 6.4 x86_64,软件版本rrdtool-1.3
技术小美4年前1573
MySQL 服务器消失的解决方法
应用程序(如PHP)长时间批量执行MYSQL语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。今天遇到了类似的情况,MySQL就凉了
云栖希望。 4年前的1791
技术 |从零开始的Python系列(3十五)
大家好,这次给大家带来一个方法,可以抓取有识之士的提问,并将问答保存到数据库中。涉及的内容包括:Urllib的使用和异常处理,Beautiful Soup MySQLdb的简单应用基本使用正则表达式的简单应用环境配置在此之前,我们需要先配置一下环境
技术小能手2年前的1954
MySQL 服务器不见了
MySQL server has away 运行sql文件导入数据库时会报异常 MySQL server has go away mysql has ERROR: (2006,'MySQL server has away') problem
李大嘴6年前的1934
php如何抓取网页数据(php如何抓取网页数据,解决xml解析问题(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-01 14:01
php如何抓取网页数据,解决xml解析问题。php抓取网页数据的基本逻辑如下:读取请求网页,取出html,解析html(html需要具备解析功能),写入文本。当然html还可以继续分割:变成页面元素,php渲染页面。这样的一套逻辑其实就是一个php爬虫系统的完整功能,算上其他网络请求,本地文件操作,最后根据需要写入文本。
更进一步说,php爬虫还可以适用多网站分批抓取,抓取的内容作为字符串,然后用分词器转换成path格式,再在前端处理分布式同步爬取。比如:抓取网页名为:“鸡架子”的网页,会比抓取网页名为“鸡架子”的网页效率高,因为即使网页名为“鸡架子”,仍然需要被php解析html,才能读取页面元素(也就是,php不需要知道网页名叫什么就能读取页面元素)。
至于如何去根据需要自己合并多个页面?前面已经提到了我们可以用分词器分割单独网页元素,然后在网页上处理,再写入文本。那么处理单个网页元素如何去加载所需要的html源文件呢?这就是有用markdown格式去解析网页,html源文件是pdf格式的,我们的问题就是如何把pdf转换成php需要的path格式。你用php开发solr就会更熟悉这一套。
php3对markdown支持较差,markdown在php3上的渲染效率高于php2。比如markdown转换为javascript会有非常差的性能表现,所以有人提出在php3上用solr来处理,可是一个网站比如solr,并发很大的情况下,solr到solr,这样的过程真心累。python很快就有了更好的解决方案:websocket。
我们曾经使用tornado写爬虫,效率在当时是相当高的,这次methodpy也很适合我们,我们可以很快的写好网页分词或变身,然后写php解析处理,处理过程中再通过tornado打个websocket发回php。而且,tornado本身也支持solr,我们只要用tornado直接调用php就可以顺利地使用。
<p>当然,我们先要抓取网页,然后python的代码自动解析这个网页:tornado-analyzer:stringparser:>>>python解析“鸡架子”网页-me-chang-wechat-view-descriptorjavascriptrequestrequest('',{url:'',params:{intervals:[0]}})tornado-analyzer:analyzer=tornado.newsquoted(request)>>>python解析"鸡架子"网页-me-chang-wechat-view-descriptor 查看全部
php如何抓取网页数据(php如何抓取网页数据,解决xml解析问题(图))
php如何抓取网页数据,解决xml解析问题。php抓取网页数据的基本逻辑如下:读取请求网页,取出html,解析html(html需要具备解析功能),写入文本。当然html还可以继续分割:变成页面元素,php渲染页面。这样的一套逻辑其实就是一个php爬虫系统的完整功能,算上其他网络请求,本地文件操作,最后根据需要写入文本。
更进一步说,php爬虫还可以适用多网站分批抓取,抓取的内容作为字符串,然后用分词器转换成path格式,再在前端处理分布式同步爬取。比如:抓取网页名为:“鸡架子”的网页,会比抓取网页名为“鸡架子”的网页效率高,因为即使网页名为“鸡架子”,仍然需要被php解析html,才能读取页面元素(也就是,php不需要知道网页名叫什么就能读取页面元素)。
至于如何去根据需要自己合并多个页面?前面已经提到了我们可以用分词器分割单独网页元素,然后在网页上处理,再写入文本。那么处理单个网页元素如何去加载所需要的html源文件呢?这就是有用markdown格式去解析网页,html源文件是pdf格式的,我们的问题就是如何把pdf转换成php需要的path格式。你用php开发solr就会更熟悉这一套。
php3对markdown支持较差,markdown在php3上的渲染效率高于php2。比如markdown转换为javascript会有非常差的性能表现,所以有人提出在php3上用solr来处理,可是一个网站比如solr,并发很大的情况下,solr到solr,这样的过程真心累。python很快就有了更好的解决方案:websocket。
我们曾经使用tornado写爬虫,效率在当时是相当高的,这次methodpy也很适合我们,我们可以很快的写好网页分词或变身,然后写php解析处理,处理过程中再通过tornado打个websocket发回php。而且,tornado本身也支持solr,我们只要用tornado直接调用php就可以顺利地使用。
<p>当然,我们先要抓取网页,然后python的代码自动解析这个网页:tornado-analyzer:stringparser:>>>python解析“鸡架子”网页-me-chang-wechat-view-descriptorjavascriptrequestrequest('',{url:'',params:{intervals:[0]}})tornado-analyzer:analyzer=tornado.newsquoted(request)>>>python解析"鸡架子"网页-me-chang-wechat-view-descriptor
php如何抓取网页数据( php抓取网页数据第一种file_get_contents抓取file() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-23 19:14
php抓取网页数据第一种file_get_contents抓取file()
)
php抓取网页数据
header("Content-type: text/html; charset=utf-8");
//$url = "https://www.cnblogs.com/chenli ... 3B%3B
//$html = file_get_contents($url);
////如果出现中文乱码使用下面代码
////$getcontent = iconv("gb2312", "utf-8",$html);
//echo "".$html.""; //获取整个内容
第一个 file_get_contents 捕获
file_get_contents() 将整个文件读入一个字符串。
此函数是将文件内容读入字符串的首选方法。如果服务器操作系统支持,也会使用内存映射技术来提升性能。
$url = 'http://www.baidu.com'; //这儿填页面地址
$info=file_get_contents($url);
//preg_match('|(.*?)|i',$info,$m);
$m1=preg_match('|(.*?)|',$info,$m);
//var_dump($m1);
echo $m[1]; //获取标题
echo '
';
第二种卷曲抓取,
$url = "http://www.baidu.com";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$m1=preg_match('|(.*?)|',$html,$ms);
//echo "".$html.""; //获取整个内容
//curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
echo $ms[1]; //获取标题
echo '
'; 查看全部
php如何抓取网页数据(
php抓取网页数据第一种file_get_contents抓取file()
)
php抓取网页数据
header("Content-type: text/html; charset=utf-8");
//$url = "https://www.cnblogs.com/chenli ... 3B%3B
//$html = file_get_contents($url);
////如果出现中文乱码使用下面代码
////$getcontent = iconv("gb2312", "utf-8",$html);
//echo "".$html.""; //获取整个内容
第一个 file_get_contents 捕获
file_get_contents() 将整个文件读入一个字符串。
此函数是将文件内容读入字符串的首选方法。如果服务器操作系统支持,也会使用内存映射技术来提升性能。
$url = 'http://www.baidu.com'; //这儿填页面地址
$info=file_get_contents($url);
//preg_match('|(.*?)|i',$info,$m);
$m1=preg_match('|(.*?)|',$info,$m);
//var_dump($m1);
echo $m[1]; //获取标题
echo '
';
第二种卷曲抓取,
$url = "http://www.baidu.com";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$m1=preg_match('|(.*?)|',$html,$ms);
//echo "".$html.""; //获取整个内容
//curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
echo $ms[1]; //获取标题
echo '
';
php如何抓取网页数据(php如何抓取网页数据字段(:php抓取数据))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-21 10:16
php如何抓取网页数据字段1.所有php字段都使用utf-8编码,使用该编码可以支持大多数编程语言中处理大量汉字,使用chrome的encodeuri,java的encodeuricomponent或者filezilla的encodeuri调用utf-8编码。如果有多个字段同时存在,请使用map集合,设置大小为1024*1024。
字段名为关键字或字符串的话用数组。2.php字段类型3.php数据结构函数,php可以自动排序和查找首页和最终页,但是网页数据大型存储时,使用数组效率高4.php语法,主要是函数,可以使用普通函数或者内置函数5.常用工具类6.php实现爬虫代码页面动态爬取php自动爬取主页代码,使用一句话拼接。php自动爬取自己主页的最终页代码。
php自动爬取自己的主页页面。3quickzoo课程代码if($_server['http_hostname']){//自己服务器的ip,假如没有可以设置一个域名,比如;或者[\d+\.\d+]redirect($_server['http_hostname'],'');//请求链接的目标php代码header('connection:keep-alive');}else{//请求响应php代码redirect($_server['http_hostname'],'');}if($_server['http_user_agent']){//自己服务器的软件,比如自己写的代码,可以自己有个url,用开发者工具或者ie开发-open-webapi或者iis5开发-iis-uri-prefix.asp'';index($_server['user_agent']);}else{//非浏览器会话php代码header('traceback:fatal');}if($_server['http_user_agent']){//自己服务器的浏览器ipexec('user_agent="mozilla/5.0(windowsnt10.0;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/46。1963。102safari/537。36";');}else{//不开启浏览器if($_server['port']){postgresql_local_db('localhost');//提交给数据库}else{//存储在数据库header('accept:text/html,application/xhtml+xml,application/xml;q=0。
9,image/webm,image/apng,*/*;q=0。8');//选择性读取}}//end{$t=$_server['ts_row'];//数据库代码redirect($_server['ts_row'],'');}$list1=php_exec($list。
1);//这里函数定义了获取字段的列表$list2=php_exec($list
2);//这里函数定义了获取 查看全部
php如何抓取网页数据(php如何抓取网页数据字段(:php抓取数据))
php如何抓取网页数据字段1.所有php字段都使用utf-8编码,使用该编码可以支持大多数编程语言中处理大量汉字,使用chrome的encodeuri,java的encodeuricomponent或者filezilla的encodeuri调用utf-8编码。如果有多个字段同时存在,请使用map集合,设置大小为1024*1024。
字段名为关键字或字符串的话用数组。2.php字段类型3.php数据结构函数,php可以自动排序和查找首页和最终页,但是网页数据大型存储时,使用数组效率高4.php语法,主要是函数,可以使用普通函数或者内置函数5.常用工具类6.php实现爬虫代码页面动态爬取php自动爬取主页代码,使用一句话拼接。php自动爬取自己主页的最终页代码。
php自动爬取自己的主页页面。3quickzoo课程代码if($_server['http_hostname']){//自己服务器的ip,假如没有可以设置一个域名,比如;或者[\d+\.\d+]redirect($_server['http_hostname'],'');//请求链接的目标php代码header('connection:keep-alive');}else{//请求响应php代码redirect($_server['http_hostname'],'');}if($_server['http_user_agent']){//自己服务器的软件,比如自己写的代码,可以自己有个url,用开发者工具或者ie开发-open-webapi或者iis5开发-iis-uri-prefix.asp'';index($_server['user_agent']);}else{//非浏览器会话php代码header('traceback:fatal');}if($_server['http_user_agent']){//自己服务器的浏览器ipexec('user_agent="mozilla/5.0(windowsnt10.0;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/46。1963。102safari/537。36";');}else{//不开启浏览器if($_server['port']){postgresql_local_db('localhost');//提交给数据库}else{//存储在数据库header('accept:text/html,application/xhtml+xml,application/xml;q=0。
9,image/webm,image/apng,*/*;q=0。8');//选择性读取}}//end{$t=$_server['ts_row'];//数据库代码redirect($_server['ts_row'],'');}$list1=php_exec($list。
1);//这里函数定义了获取字段的列表$list2=php_exec($list
2);//这里函数定义了获取
php如何抓取网页数据(php如何抓取网页数据以及抓取操作的相关应用如何定时)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-16 09:18
php如何抓取网页数据以及抓取操作的相关应用setinterval如何定时抓取网页
你可以试试刚刚开发出来的,用excel存数据的话可以实现自动编号、方便数据分析,并且可以输出。
有一个很简单的方法。抓取后把html代码放入word,再把word另存为json格式的,你用java做一个json服务器就好了。数据通过.exe写入数据库,例如hive。
如果是抓取网页,可以先读取html5页面的filereader模块。
题主的需求包含大量的关键字,html代码可以用netscape模拟成java代码来编写。
上边有好多抖机灵的,题主需要一个java的bean对象来抓取网页,
有一个可以写前端的爬虫软件
楼主需要写一个前端浏览器,给他自定义前端代码,本地抓取网页就行了,要抓的多了爬虫。浏览器得自己开发,比如用现成的,像streamjs一样的软件爬的。
html+css+javascript是可以抓取网页并且把网页存入自己的数据库的但是前提是你得有本事把数据存下来
其实我也喜欢写爬虫,虽然是业余爱好,但自己还是做了个小小的爬虫采集项目,并且有网页数据存入数据库。总结一下,我觉得想写个爬虫,如果要了解爬虫的工作原理,要不就是大神,如web应用开发,网络协议,各种类似;要不就是要有相应的计算机技术储备,如python;要不就是从事数据方面的专业,计算机数据挖掘等。如果自己有热情喜欢的话,就有动力了。 查看全部
php如何抓取网页数据(php如何抓取网页数据以及抓取操作的相关应用如何定时)
php如何抓取网页数据以及抓取操作的相关应用setinterval如何定时抓取网页
你可以试试刚刚开发出来的,用excel存数据的话可以实现自动编号、方便数据分析,并且可以输出。
有一个很简单的方法。抓取后把html代码放入word,再把word另存为json格式的,你用java做一个json服务器就好了。数据通过.exe写入数据库,例如hive。
如果是抓取网页,可以先读取html5页面的filereader模块。
题主的需求包含大量的关键字,html代码可以用netscape模拟成java代码来编写。
上边有好多抖机灵的,题主需要一个java的bean对象来抓取网页,
有一个可以写前端的爬虫软件
楼主需要写一个前端浏览器,给他自定义前端代码,本地抓取网页就行了,要抓的多了爬虫。浏览器得自己开发,比如用现成的,像streamjs一样的软件爬的。
html+css+javascript是可以抓取网页并且把网页存入自己的数据库的但是前提是你得有本事把数据存下来
其实我也喜欢写爬虫,虽然是业余爱好,但自己还是做了个小小的爬虫采集项目,并且有网页数据存入数据库。总结一下,我觉得想写个爬虫,如果要了解爬虫的工作原理,要不就是大神,如web应用开发,网络协议,各种类似;要不就是要有相应的计算机技术储备,如python;要不就是从事数据方面的专业,计算机数据挖掘等。如果自己有热情喜欢的话,就有动力了。
php如何抓取网页数据(有关可以有所收获的几个小技巧,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-15 05:51
今天就跟大家聊一聊如何捕捉ajax动态网站。很多人可能不太了解。为了让大家更加了解,小编为大家总结了以下内容。希望大家能关注这篇文章。> 你可以有所收获。
什么是阿贾克斯?简单的说,加载一个网页后,还是看不到一些信息,需要点击一个按钮才能看到数据,或者有的网页页面数据很多,而你点击了下一页,url地址网页没有变,但是内容变了。这些可以说是ajax。如果你还是不明白,让我给你看看百度百科的解释。以下是。
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。[
通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
下面我们来谈谈一个例子。我爬过的ajax网页最难的部分是网易云音乐的评论。有兴趣的可以看看用python爬取网易云音乐并将数据存入mysql
这里的评论是Ajax加载的,其他抓取今日头条图片的评论也是Ajax加载的,不过我简化了。还有很多,先不说,先说ajax网站 今天要说的!
这是肯德基的门面信息
页面数据很多,每个页面的数据都是通过ajax加载的。如果直接用python请求上面的url,估计是拿不到数据的。如果你不相信,你可以试试。这时候我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求是ajax请求的网页,里面会有我们需要的数据,看看是个什么样的请求
这是一个post请求。请求的成功状态码为200。请求url也存在。下面的from数据就是我们需要发布的数据。很容易猜到pageIndex是页数,所以我们可以改变这个值来翻页。
分析此网页。这是ajax动态网页的解决方案。是不是感觉很简单,其实不然。只是网页比较简单,因为表单中的数据(来自数据)没有加密。如果是加密的,估计你找js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些乱七八糟的js找加密方式有时会让你头疼,所以人们往往会选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以在工作中是不允许这种方式的。所以我们必须学会如何处理这些ajax。
邮政编码
import requests
page = 1
while True:
url = 'http://www.kfc.com.cn/kfccda/a ... 39%3B
data = {
'cname': '广州',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
response = requests.post(url, data=data)
print(response.json())
if response.json().get('Table1', ''):
page += 1
else:
break
看完以上内容,你对如何捕获ajax动态网站有进一步的了解吗?如果您想了解更多知识或相关内容,请关注易速云行业资讯频道,感谢您的支持。 查看全部
php如何抓取网页数据(有关可以有所收获的几个小技巧,你知道吗?)
今天就跟大家聊一聊如何捕捉ajax动态网站。很多人可能不太了解。为了让大家更加了解,小编为大家总结了以下内容。希望大家能关注这篇文章。> 你可以有所收获。
什么是阿贾克斯?简单的说,加载一个网页后,还是看不到一些信息,需要点击一个按钮才能看到数据,或者有的网页页面数据很多,而你点击了下一页,url地址网页没有变,但是内容变了。这些可以说是ajax。如果你还是不明白,让我给你看看百度百科的解释。以下是。
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。[
通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
下面我们来谈谈一个例子。我爬过的ajax网页最难的部分是网易云音乐的评论。有兴趣的可以看看用python爬取网易云音乐并将数据存入mysql
这里的评论是Ajax加载的,其他抓取今日头条图片的评论也是Ajax加载的,不过我简化了。还有很多,先不说,先说ajax网站 今天要说的!
这是肯德基的门面信息
页面数据很多,每个页面的数据都是通过ajax加载的。如果直接用python请求上面的url,估计是拿不到数据的。如果你不相信,你可以试试。这时候我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求是ajax请求的网页,里面会有我们需要的数据,看看是个什么样的请求
这是一个post请求。请求的成功状态码为200。请求url也存在。下面的from数据就是我们需要发布的数据。很容易猜到pageIndex是页数,所以我们可以改变这个值来翻页。
分析此网页。这是ajax动态网页的解决方案。是不是感觉很简单,其实不然。只是网页比较简单,因为表单中的数据(来自数据)没有加密。如果是加密的,估计你找js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些乱七八糟的js找加密方式有时会让你头疼,所以人们往往会选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以在工作中是不允许这种方式的。所以我们必须学会如何处理这些ajax。
邮政编码
import requests
page = 1
while True:
url = 'http://www.kfc.com.cn/kfccda/a ... 39%3B
data = {
'cname': '广州',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
response = requests.post(url, data=data)
print(response.json())
if response.json().get('Table1', ''):
page += 1
else:
break
看完以上内容,你对如何捕获ajax动态网站有进一步的了解吗?如果您想了解更多知识或相关内容,请关注易速云行业资讯频道,感谢您的支持。
php如何抓取网页数据(php如何抓取网页数据需要知道百度的爬虫是怎么抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-01 04:02
php如何抓取网页数据需要知道百度的爬虫是如何抓取数据,在php抓取数据的时候一定要掌握正则表达式,必须先掌握正则表达式,这样才能够写出从客户端找到服务端的网页数据,掌握正则表达式可以更好的去理解http的,相对于php而言难度会更大一些,现在比较流行的主要是grep,urlencode,unicode中的strlen和substr的一些方法,还有比较熟悉的是curl这个,也需要熟悉,但不需要太精通,因为真正抓取的话,到最后可能还需要写爬虫框架。
1,什么是抓取爬虫抓取爬虫是一个php实现的,通过使用特定协议抓取网站资源,然后封装为json返回给客户端。最常见的有两种抓取方式:http请求抓取和ajax请求抓取。2,抓取网页数据方法2.1,正则表达式抓取正则表达式抓取就是从网页上的特定抓取正则表达式格式:?/>/这种方法适用于搜索引擎和广告联盟中的公开链接,这种抓取方法由其名字来可以理解,它是通过特定的“/”表示这个网页。
使用正则表达式抓取网页数据需要特定的php解析器(javascript和html、sql),以及对爬虫框架比较熟悉,详细了解正则表达式需要抓取网页解析器和网页浏览器相匹配。正则表达式是需要人工验证的,不是所有的网页都可以通过正则表达式抓取出来。2.2,ajax方法网页异步请求抓取。网页页面的返回状态码是301,php可以使用ajax取得页面内容,css等等。
用一个schema的方法通过page/xmlhttprequest.xmlhttprequest对象获取数据。ajax通过request对象用不同的协议(比如http、tcp或者smtp)来提供不同的数据。网页上任何元素都可以以ajax方式调用。ajax可以等待http请求完成返回内容,然后再进行其他操作。
具体的实现方法如下:2.3,session方法登录+提交表单用于给web页面持久存储某个用户id和隐私等信息,通过一个session对象可以持久存储网页数据,提交表单则需要在服务器端设置sessionid。2.4,cookie方法跨域+cookie存储给服务器存储用户的一些特定信息2.5,mongodb数据库mongodb最大的优势在于其速度比hadoop快n倍,更加完善。
当在php环境中实现mongodb数据库的关系时,需要让web页面执行下面的方法:includeincludeuse(mongodb::mongoclient);除了这些包括使用方法之外,针对于你不熟悉php和爬虫这两个知识点,可以看看ziminng的php从入门到精通这本书,写的非常详细,最后会对php有非常深刻的理解。 查看全部
php如何抓取网页数据(php如何抓取网页数据需要知道百度的爬虫是怎么抓取数据)
php如何抓取网页数据需要知道百度的爬虫是如何抓取数据,在php抓取数据的时候一定要掌握正则表达式,必须先掌握正则表达式,这样才能够写出从客户端找到服务端的网页数据,掌握正则表达式可以更好的去理解http的,相对于php而言难度会更大一些,现在比较流行的主要是grep,urlencode,unicode中的strlen和substr的一些方法,还有比较熟悉的是curl这个,也需要熟悉,但不需要太精通,因为真正抓取的话,到最后可能还需要写爬虫框架。
1,什么是抓取爬虫抓取爬虫是一个php实现的,通过使用特定协议抓取网站资源,然后封装为json返回给客户端。最常见的有两种抓取方式:http请求抓取和ajax请求抓取。2,抓取网页数据方法2.1,正则表达式抓取正则表达式抓取就是从网页上的特定抓取正则表达式格式:?/>/这种方法适用于搜索引擎和广告联盟中的公开链接,这种抓取方法由其名字来可以理解,它是通过特定的“/”表示这个网页。
使用正则表达式抓取网页数据需要特定的php解析器(javascript和html、sql),以及对爬虫框架比较熟悉,详细了解正则表达式需要抓取网页解析器和网页浏览器相匹配。正则表达式是需要人工验证的,不是所有的网页都可以通过正则表达式抓取出来。2.2,ajax方法网页异步请求抓取。网页页面的返回状态码是301,php可以使用ajax取得页面内容,css等等。
用一个schema的方法通过page/xmlhttprequest.xmlhttprequest对象获取数据。ajax通过request对象用不同的协议(比如http、tcp或者smtp)来提供不同的数据。网页上任何元素都可以以ajax方式调用。ajax可以等待http请求完成返回内容,然后再进行其他操作。
具体的实现方法如下:2.3,session方法登录+提交表单用于给web页面持久存储某个用户id和隐私等信息,通过一个session对象可以持久存储网页数据,提交表单则需要在服务器端设置sessionid。2.4,cookie方法跨域+cookie存储给服务器存储用户的一些特定信息2.5,mongodb数据库mongodb最大的优势在于其速度比hadoop快n倍,更加完善。
当在php环境中实现mongodb数据库的关系时,需要让web页面执行下面的方法:includeincludeuse(mongodb::mongoclient);除了这些包括使用方法之外,针对于你不熟悉php和爬虫这两个知识点,可以看看ziminng的php从入门到精通这本书,写的非常详细,最后会对php有非常深刻的理解。
php如何抓取网页数据(php如何抓取网页数据?(php代码)+nginx(负载均衡)phpstorm)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-29 08:03
php如何抓取网页数据?以前写过一个php抓取(访问网页数据)的教程,但是测试遇到了问题,所以去复现了一下,这些反爬虫机制确实不容易抓到内容,后面应该也是没法抓取到内容的,搞了半天应该是直接用了假token,所以才会直接没法抓取到数据。先说实现思路,当然也就是模拟浏览器和页面进行数据交互,然后只要客户端能解析网页数据就好了,这一部分很简单。
话不多说,直接进行代码实现。实现思路首先把下面的几个链接到墙上去看下,都是php的,然后看到代码中,用到了meterpreterapi等一些技术。看代码中的这些函数,代码量其实不多,但是全部放在一起,php源码有5.2g。phpsessim/php.php从这些代码可以看出来,用到了laravel的web框架进行web开发,这一点非常重要,一定要清楚php框架的一些优势,比如groupon推出的优秀框架laravel+rubyonrails(rails有zendosteam亲手打造),laravel更是业界推崇的解决方案,可能基于laravel框架的很多项目都比较快速,开发速度快,性能提升非常大等等。
当然对于学习者来说,优点太多就不赘述了,正是因为目前php框架太多了,所以要选出一个速度最快、性能最高的,必须全部掌握。本文更多侧重的是php代码的学习,是基于php3.x版本,如果想了解其他版本的,可以参考php的发展路线,推荐参考:php之父的主页总体来说学习php需要写三个东西:前端(web)+后端(数据库)+nginx(负载均衡)phpstorm就是一个集成开发环境,直接使用,我们根据自己的需求来进行修改,主要作用是将phpstorm集成到php代码中。
在实践操作的过程中,不断的修改调整就好了。这里主要说下三个框架的配置:首先,我们看web开发路线,前端可以考虑:。
一、css3组件prapo#css3components,会在今后的文章中分别介绍,不急。我们接下来要开始看php框架的操作,主要考虑下几个地方:数据库中数据如何传递、网页可读性如何、增删改查的性能高、外部资源接入的难易程度等等;这些都是需要通过对各个框架提供的接口进行代码参数的编写来完成的,主要流程如下:。
二、web前端功能插件学习者应该注意如何与程序员进行交流,有问题要及时提出,最好通过邮件沟通,否则很可能得不到及时回复,若不能及时联系,很可能失去沟通机会。
三、视图函数publib
四、代码自动编译php_fsync其他框架的参数编写,自己在实践中学习吧,这个最基础的东西,当初学前端的时候,老师也给了一个示例代码和改进方案,如果有好的方法一定要告诉我。 查看全部
php如何抓取网页数据(php如何抓取网页数据?(php代码)+nginx(负载均衡)phpstorm)
php如何抓取网页数据?以前写过一个php抓取(访问网页数据)的教程,但是测试遇到了问题,所以去复现了一下,这些反爬虫机制确实不容易抓到内容,后面应该也是没法抓取到内容的,搞了半天应该是直接用了假token,所以才会直接没法抓取到数据。先说实现思路,当然也就是模拟浏览器和页面进行数据交互,然后只要客户端能解析网页数据就好了,这一部分很简单。
话不多说,直接进行代码实现。实现思路首先把下面的几个链接到墙上去看下,都是php的,然后看到代码中,用到了meterpreterapi等一些技术。看代码中的这些函数,代码量其实不多,但是全部放在一起,php源码有5.2g。phpsessim/php.php从这些代码可以看出来,用到了laravel的web框架进行web开发,这一点非常重要,一定要清楚php框架的一些优势,比如groupon推出的优秀框架laravel+rubyonrails(rails有zendosteam亲手打造),laravel更是业界推崇的解决方案,可能基于laravel框架的很多项目都比较快速,开发速度快,性能提升非常大等等。
当然对于学习者来说,优点太多就不赘述了,正是因为目前php框架太多了,所以要选出一个速度最快、性能最高的,必须全部掌握。本文更多侧重的是php代码的学习,是基于php3.x版本,如果想了解其他版本的,可以参考php的发展路线,推荐参考:php之父的主页总体来说学习php需要写三个东西:前端(web)+后端(数据库)+nginx(负载均衡)phpstorm就是一个集成开发环境,直接使用,我们根据自己的需求来进行修改,主要作用是将phpstorm集成到php代码中。
在实践操作的过程中,不断的修改调整就好了。这里主要说下三个框架的配置:首先,我们看web开发路线,前端可以考虑:。
一、css3组件prapo#css3components,会在今后的文章中分别介绍,不急。我们接下来要开始看php框架的操作,主要考虑下几个地方:数据库中数据如何传递、网页可读性如何、增删改查的性能高、外部资源接入的难易程度等等;这些都是需要通过对各个框架提供的接口进行代码参数的编写来完成的,主要流程如下:。
二、web前端功能插件学习者应该注意如何与程序员进行交流,有问题要及时提出,最好通过邮件沟通,否则很可能得不到及时回复,若不能及时联系,很可能失去沟通机会。
三、视图函数publib
四、代码自动编译php_fsync其他框架的参数编写,自己在实践中学习吧,这个最基础的东西,当初学前端的时候,老师也给了一个示例代码和改进方案,如果有好的方法一定要告诉我。
php如何抓取网页数据(php如何抓取网页数据?(一)压缩率的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-14 20:02
php如何抓取网页数据?相信很多人都遇到过这样的难题。其实,在编写php脚本的时候,如果可以结合一些辅助工具,对于php来说,非常简单。比如可以使用uc浏览器等工具,开启gzip压缩的模式。第一步:在浏览器中打开一个网页。比如你要抓取某一个公司的网站。第二步:打开uc浏览器,检查之前的网页是否已经压缩了,如果压缩了,那么请先压缩一下,然后将压缩后的网页拉到浏览器里面试试。
用同样的方法,检查一下浏览器的底部广告有没有被屏蔽。第三步:点击打开网页之后,uc浏览器将会自动检测该网页,并自动进行处理。这一步用来检查是否能成功抓取,或者判断是否为空。方法二:使用php抓取不会被自动压缩第四步:在浏览器里面尝试一下。如果能抓取,就可以放心在网页的底部广告中添加代码。方法三:更改uc浏览器的gzip压缩率如果不想被压缩,那么我们再来看一下,其他办法。
一般办法是不用uc浏览器,比如在百度等,我们可以使用其他办法,比如使用python抓取网页数据。这样,百度等的网页直接是压缩的,无法直接看到我们想要的网页,而且代码中也不方便,不好修改。
下载油猴脚本,用httpd-python直接抓,我找的demo地址,是网易新闻app的,很方便, 查看全部
php如何抓取网页数据(php如何抓取网页数据?(一)压缩率的方法)
php如何抓取网页数据?相信很多人都遇到过这样的难题。其实,在编写php脚本的时候,如果可以结合一些辅助工具,对于php来说,非常简单。比如可以使用uc浏览器等工具,开启gzip压缩的模式。第一步:在浏览器中打开一个网页。比如你要抓取某一个公司的网站。第二步:打开uc浏览器,检查之前的网页是否已经压缩了,如果压缩了,那么请先压缩一下,然后将压缩后的网页拉到浏览器里面试试。
用同样的方法,检查一下浏览器的底部广告有没有被屏蔽。第三步:点击打开网页之后,uc浏览器将会自动检测该网页,并自动进行处理。这一步用来检查是否能成功抓取,或者判断是否为空。方法二:使用php抓取不会被自动压缩第四步:在浏览器里面尝试一下。如果能抓取,就可以放心在网页的底部广告中添加代码。方法三:更改uc浏览器的gzip压缩率如果不想被压缩,那么我们再来看一下,其他办法。
一般办法是不用uc浏览器,比如在百度等,我们可以使用其他办法,比如使用python抓取网页数据。这样,百度等的网页直接是压缩的,无法直接看到我们想要的网页,而且代码中也不方便,不好修改。
下载油猴脚本,用httpd-python直接抓,我找的demo地址,是网易新闻app的,很方便,
php如何抓取网页数据(php如何抓取网页数据推荐谷歌chrome浏览器+php+vscode)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-28 02:01
php如何抓取网页数据推荐谷歌chrome浏览器+php+vscode。php的抓取不再局限于db2,自己写一个chromeapi库来实现数据包读写。如果有html5/javascript的基础,可以自己写一个专门用来抓取网页的库,可以试试simhui/awesomewebmonitor·github。
1、php在浏览器中调用就可以,有个schemalization,去实现如下动作:#gettingset:includewhile(null!=httphandler){schemalization=defaultschemalization(dataurl);schemalization。length=httphandler。
request。run();if(while(request。url。contains(dataurl))){httphandler。request。send(request。url。get());}else{httphandler。request。fetch(url,getheaderinfo("user-agent"));}}2、oh-my-zh在这里request。
url。get()php中include_github("xxxx。github。com/xxxx")。
首先明确你的目的是浏览网页还是新闻。如果是新闻,那么就在新闻源选取好,不管什么引擎,用javascript把url获取下来,然后写新闻代码。如果是浏览网页的话,可以看看h5用浏览器做网页展示,用网页中ejs的话也很简单。
用百度web开发者平台能解决。 查看全部
php如何抓取网页数据(php如何抓取网页数据推荐谷歌chrome浏览器+php+vscode)
php如何抓取网页数据推荐谷歌chrome浏览器+php+vscode。php的抓取不再局限于db2,自己写一个chromeapi库来实现数据包读写。如果有html5/javascript的基础,可以自己写一个专门用来抓取网页的库,可以试试simhui/awesomewebmonitor·github。
1、php在浏览器中调用就可以,有个schemalization,去实现如下动作:#gettingset:includewhile(null!=httphandler){schemalization=defaultschemalization(dataurl);schemalization。length=httphandler。
request。run();if(while(request。url。contains(dataurl))){httphandler。request。send(request。url。get());}else{httphandler。request。fetch(url,getheaderinfo("user-agent"));}}2、oh-my-zh在这里request。
url。get()php中include_github("xxxx。github。com/xxxx")。
首先明确你的目的是浏览网页还是新闻。如果是新闻,那么就在新闻源选取好,不管什么引擎,用javascript把url获取下来,然后写新闻代码。如果是浏览网页的话,可以看看h5用浏览器做网页展示,用网页中ejs的话也很简单。
用百度web开发者平台能解决。
php如何抓取网页数据( 哪些页面是人为的重要?有几个合理的因素?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-26 06:38
哪些页面是人为的重要?有几个合理的因素?)
手动seo优化有哪些方法可以吸引蜘蛛频繁爬行?
目前常用的链接包括锚文本链接、超链接、纯文本链接和图片链接。如何被爬虫爬取是一种自动提取网页的程序,比如百度蜘蛛。要让你的网站收录更多的页面,首先要让爬虫爬取网页。如果你的网站页面定期更新,爬虫会更频繁地访问页面,高质量的内容是爬虫喜欢爬取的,尤其是原创内容。蜘蛛很快就会爬升网站、网站和页面权重,这一定是更重要的。
做SEO优化
,我想要更多的页面成为收录,尽量吸引蜘蛛来抓取。如果你不能抓取所有的页面,那么蜘蛛所要做的就是抓取尽可能多的重要页面。哪些页面人为重要?
有几个合理的因素
1、网站页面和权重
网站质量高,资历老被认为权重高,在这个网站上爬取的页面深度也会更高,所以会有更多的收录页面。
2、页面更新
蜘蛛每次爬行时都会存储页面数据。第二次蜘蛛页面更新是没有必要的,如果不需要掌握第一次页面更新。如果页面内容更新频繁,蜘蛛会更频繁地访问页面,页面上的新连接自然会被蜘蛛更快地跟踪到新页面。
3、导入链接
无论是外链还是同一个网站的内链,都必须被蜘蛛抓取,并且必须有导入链接才能进入页面,否则蜘蛛将没有机会知道页面的存在。高质量的导入链接通常会增加页面导出链接的抓取深度。
4、点击“与主页的距离”
一般来说,大多数主页的权重都很高。因此,点击离首页越近,页面权重越高,蜘蛛爬行的机会就越大。
5、网址结构
页面权重仅在收录在迭代计算中时才知道。前面提到的高页面权重有利于抓取。搜索引擎蜘蛛如何在抓取前知道页面权重?所以蜘蛛预测,除了链接、到首页的距离、历史记录之外,还有数据等因素,短网址和浅网址可能直觉上认为网站权重比较高。
6、 吸引蜘蛛的方法:
这些链接会导致蜘蛛访问网页。只要不关注这些链接,就会引起蜘蛛的访问和传递权重。锚文本链接是一种很好的引导蜘蛛的方式,有利于关键词排名,比如关键词锚文本中的友情链接。 查看全部
php如何抓取网页数据(
哪些页面是人为的重要?有几个合理的因素?)
手动seo优化有哪些方法可以吸引蜘蛛频繁爬行?
目前常用的链接包括锚文本链接、超链接、纯文本链接和图片链接。如何被爬虫爬取是一种自动提取网页的程序,比如百度蜘蛛。要让你的网站收录更多的页面,首先要让爬虫爬取网页。如果你的网站页面定期更新,爬虫会更频繁地访问页面,高质量的内容是爬虫喜欢爬取的,尤其是原创内容。蜘蛛很快就会爬升网站、网站和页面权重,这一定是更重要的。
做SEO优化
,我想要更多的页面成为收录,尽量吸引蜘蛛来抓取。如果你不能抓取所有的页面,那么蜘蛛所要做的就是抓取尽可能多的重要页面。哪些页面人为重要?
有几个合理的因素
1、网站页面和权重
网站质量高,资历老被认为权重高,在这个网站上爬取的页面深度也会更高,所以会有更多的收录页面。
2、页面更新
蜘蛛每次爬行时都会存储页面数据。第二次蜘蛛页面更新是没有必要的,如果不需要掌握第一次页面更新。如果页面内容更新频繁,蜘蛛会更频繁地访问页面,页面上的新连接自然会被蜘蛛更快地跟踪到新页面。
3、导入链接
无论是外链还是同一个网站的内链,都必须被蜘蛛抓取,并且必须有导入链接才能进入页面,否则蜘蛛将没有机会知道页面的存在。高质量的导入链接通常会增加页面导出链接的抓取深度。
4、点击“与主页的距离”
一般来说,大多数主页的权重都很高。因此,点击离首页越近,页面权重越高,蜘蛛爬行的机会就越大。
5、网址结构
页面权重仅在收录在迭代计算中时才知道。前面提到的高页面权重有利于抓取。搜索引擎蜘蛛如何在抓取前知道页面权重?所以蜘蛛预测,除了链接、到首页的距离、历史记录之外,还有数据等因素,短网址和浅网址可能直觉上认为网站权重比较高。
6、 吸引蜘蛛的方法:
这些链接会导致蜘蛛访问网页。只要不关注这些链接,就会引起蜘蛛的访问和传递权重。锚文本链接是一种很好的引导蜘蛛的方式,有利于关键词排名,比如关键词锚文本中的友情链接。
php如何抓取网页数据(php如何抓取网页数据二:用php抓取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-14 06:02
php如何抓取网页数据
二):用php抓取网页数据如何抓取网页数据
三):调用laravelwebhook实现单页面应用如何抓取网页数据
四):php代理登录如何抓取网页数据
五):代理服务器,expressjs和haproxy最后这篇先聊下haproxy本文基于php7,
二、
三、四部分可使用proxy或proxy-switch等进行爬虫扩展。这部分我们也不会深入到php的其他知识,会更多的介绍haproxy实现方法。
分析任务:前台用户可通过以下三种形式访问爬虫,
1)轮询形式;
2)代理形式;
3)静态url过滤。两部分轮询形式:所谓轮询就是返回同步轮询的连接,并且轮询一次返回一次,返回的连接的url是同步的,这需要php7.0以上才能实现。如:;code_type=0&user_btn=10&account_id=212146965&country=&related_id=0...,返回的连接url是同步的,并且是轮询一次连接返回一次连接信息,这样轮询就比较节省服务器资源。
代理形式:代理形式就是将所有使用静态url过滤的页面url封装成静态文件服务,再由相应server进行访问。使用代理形式爬虫成本较低,但是用代理方式爬虫一般需要进行某些特殊配置,会让服务器资源闲置。静态url过滤:有时通过上边静态url过滤是可以爬取的。但是这样又很大浪费空间,不能满足我们爬虫任务的大小和范围,这时就要添加一些过滤规则,使得url不被重复或变化内容所遍历。
本文不做赘述。静态url请求接口我们请求url地址,并将请求的返回结果传给第三方程序。使用json库来进行请求,实现请求的对象是json的authenticator实例,分析jsonauthenticator的源码,有以下步骤:对待访问的url进行解析和转换,jsonauthenticator的转换可使用json.loads()方法;处理json对象中参数部分;判断参数是否可识别;加载jsonauthenticator对象。
反射jsonauthenticator对象staticif(decode_in_json(buf,{"array":buf.size})){//转换后将返回int的值trueif(isinstance(decode_combined,json_loaded(buf,str,"array"))){//否则返回null}}if(async_json(buf,{"language。 查看全部
php如何抓取网页数据(php如何抓取网页数据二:用php抓取(组图))
php如何抓取网页数据
二):用php抓取网页数据如何抓取网页数据
三):调用laravelwebhook实现单页面应用如何抓取网页数据
四):php代理登录如何抓取网页数据
五):代理服务器,expressjs和haproxy最后这篇先聊下haproxy本文基于php7,
二、
三、四部分可使用proxy或proxy-switch等进行爬虫扩展。这部分我们也不会深入到php的其他知识,会更多的介绍haproxy实现方法。
分析任务:前台用户可通过以下三种形式访问爬虫,
1)轮询形式;
2)代理形式;
3)静态url过滤。两部分轮询形式:所谓轮询就是返回同步轮询的连接,并且轮询一次返回一次,返回的连接的url是同步的,这需要php7.0以上才能实现。如:;code_type=0&user_btn=10&account_id=212146965&country=&related_id=0...,返回的连接url是同步的,并且是轮询一次连接返回一次连接信息,这样轮询就比较节省服务器资源。
代理形式:代理形式就是将所有使用静态url过滤的页面url封装成静态文件服务,再由相应server进行访问。使用代理形式爬虫成本较低,但是用代理方式爬虫一般需要进行某些特殊配置,会让服务器资源闲置。静态url过滤:有时通过上边静态url过滤是可以爬取的。但是这样又很大浪费空间,不能满足我们爬虫任务的大小和范围,这时就要添加一些过滤规则,使得url不被重复或变化内容所遍历。
本文不做赘述。静态url请求接口我们请求url地址,并将请求的返回结果传给第三方程序。使用json库来进行请求,实现请求的对象是json的authenticator实例,分析jsonauthenticator的源码,有以下步骤:对待访问的url进行解析和转换,jsonauthenticator的转换可使用json.loads()方法;处理json对象中参数部分;判断参数是否可识别;加载jsonauthenticator对象。
反射jsonauthenticator对象staticif(decode_in_json(buf,{"array":buf.size})){//转换后将返回int的值trueif(isinstance(decode_combined,json_loaded(buf,str,"array"))){//否则返回null}}if(async_json(buf,{"language。
php如何抓取网页数据(php如何抓取网页数据?php主要靠解析html文档得到页面信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-12 11:02
php如何抓取网页数据?php主要靠解析html文档得到页面信息,目前解析html文档方法有很多,都是使用正则表达式或者模糊匹配。
php只能处理html代码,你的需求肯定是有办法解决的。只不过你刚接触php,没摸索出来,这时候就靠搜索引擎来解决了。
可以看看大辉php的php实战录像,找不到就找这个。
php...
爬虫:php是弱类型语言post、get方法只能返回纯数字,
可以去github上看看有没有合适的php开源库。
没有php直接用python,
python和ruby
ruby
php
<p>我建议你写一个可以通过程序执行脚本来读取html,然后对返回的html做一些处理,比如<img>
<img> 查看全部
php如何抓取网页数据(php如何抓取网页数据?php主要靠解析html文档得到页面信息)
php如何抓取网页数据?php主要靠解析html文档得到页面信息,目前解析html文档方法有很多,都是使用正则表达式或者模糊匹配。
php只能处理html代码,你的需求肯定是有办法解决的。只不过你刚接触php,没摸索出来,这时候就靠搜索引擎来解决了。
可以看看大辉php的php实战录像,找不到就找这个。
php...
爬虫:php是弱类型语言post、get方法只能返回纯数字,
可以去github上看看有没有合适的php开源库。
没有php直接用python,
python和ruby
ruby
php
<p>我建议你写一个可以通过程序执行脚本来读取html,然后对返回的html做一些处理,比如<img>
<img>
php如何抓取网页数据(如何使用php+mysql+PHPquery+arphp的方案?-八维教育 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-06 03:18
)
通常我们在网站上可能会看到很多数据,我们可以自己分析一下。但是如果需要捕获数据,则需要一个捕获程序。
通过这个程序,你可以很容易的把别人的网站以前的页面,几百个页面,或者一个页面的一些内容放到自己的本地。
当然,要使用5行代码,还需要做一些准备工作。比如框架、数据库等。
我们这里使用的是php+mysql+PHPquery+arphp的方案。
1、phpquery 可用
看使用计划。
2、arphp可以去查看一些使用方法。
当然,你可以不阅读本文档,或者使用其他框架,或者不使用框架来编写这个程序。
具体代码:
require('phpQuery/phpQuery.php');//加载这个框架
$eg1=phpQuery::newDocumentFile("http://www.whu.edu.cn/tzgg.htm");//将你需要的抓取的页面对象化
$res = pq("ul,li")->html()."
";//获取页面中某个对象的html数据
$myfile = fopen("newfile.txt", "w") or die("不能打开文件");//打开一个文件
fwrite($myfile, $res);//将页面内容写入txt
当然也可以建一个数据库,然后把内容放到数据库中。
只需要这样五个元素,就基本可以完成一个页面内容的爬取了。当然,多页面爬取、单页面内容遍历和内容过滤、https内容或者反网站IP拦截等更复杂的问题,可以深入研究。
查看全部
php如何抓取网页数据(如何使用php+mysql+PHPquery+arphp的方案?-八维教育
)
通常我们在网站上可能会看到很多数据,我们可以自己分析一下。但是如果需要捕获数据,则需要一个捕获程序。
通过这个程序,你可以很容易的把别人的网站以前的页面,几百个页面,或者一个页面的一些内容放到自己的本地。
当然,要使用5行代码,还需要做一些准备工作。比如框架、数据库等。
我们这里使用的是php+mysql+PHPquery+arphp的方案。
1、phpquery 可用
看使用计划。
2、arphp可以去查看一些使用方法。
当然,你可以不阅读本文档,或者使用其他框架,或者不使用框架来编写这个程序。
具体代码:
require('phpQuery/phpQuery.php');//加载这个框架
$eg1=phpQuery::newDocumentFile("http://www.whu.edu.cn/tzgg.htm";);//将你需要的抓取的页面对象化
$res = pq("ul,li")->html()."
";//获取页面中某个对象的html数据
$myfile = fopen("newfile.txt", "w") or die("不能打开文件");//打开一个文件
fwrite($myfile, $res);//将页面内容写入txt
当然也可以建一个数据库,然后把内容放到数据库中。
只需要这样五个元素,就基本可以完成一个页面内容的爬取了。当然,多页面爬取、单页面内容遍历和内容过滤、https内容或者反网站IP拦截等更复杂的问题,可以深入研究。
php如何抓取网页数据(怎么向各大搜索引擎提交你的网址?奕斌说事)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-06 03:16
烦人烦,你平时知道怎么让搜索引擎蜘蛛爬行和收录你的网站吗?这对于网络推广的新人来说,确实是一件很头疼的事情。公司的资金并不大,不可能交给外面的公司。这样一来,就只能自己动手了,实在是一点头绪都没有,下面就来告诉大家吧。如何将您的网站 URL 提交给主要搜索引擎:
百度搜索站长平台为站长提供了链接提交通道。您可以通过百度提交您想成为收录的链接。百度搜索引擎会按照标准进行处理,但不保证您一定能够收录您提交的链接。
全球最大的面向中国互联网管理者、移动开发者和企业家的搜索流量管理官方平台。提供提交和分析工具,帮助搜索引擎捕捉收录、SEO优化建议等;为移动开发者提供百度官方API接口,以及多端适配能力和服务;及时发布百度权威数据、算法、工具等升级推送新信息。
登录端口:
360搜索平台网站收录,与网民分享网址,网站收录只要网站首页提交给搜索引擎,蜘蛛就会每次都光顾它 新的网站 会在抓取网页时添加并更新到索引中。站长只需提供顶级网页,无需提交单个网页。爬虫可以找到其他页面。符合相关标准提交的网址将在一个月内按照搜索引擎收录标准进行处理。
日志条目:
3.搜狗网站收录:提交后,搜狗搜索引擎会按照标准进行处理,但不保证提交的链接一定能收录@ >. 为提高处理效率,请勿重复提交同一个链接。网站收录/申诉一次只能提交一个网址。请确保 URL 的完整性、正确性、可访问性和网站内容质量。
收录提交条目
:
必应网站收录,将您的网站 URL提交给必应,并在网管工具中注册,查看您的网站是否已被索引,是否通过了必应流程应该得到。
Bing网站 提交登录入口:
每天分享一些网络推广的小知识,欢迎大家继续关注【易斌有话说】 查看全部
php如何抓取网页数据(怎么向各大搜索引擎提交你的网址?奕斌说事)
烦人烦,你平时知道怎么让搜索引擎蜘蛛爬行和收录你的网站吗?这对于网络推广的新人来说,确实是一件很头疼的事情。公司的资金并不大,不可能交给外面的公司。这样一来,就只能自己动手了,实在是一点头绪都没有,下面就来告诉大家吧。如何将您的网站 URL 提交给主要搜索引擎:
百度搜索站长平台为站长提供了链接提交通道。您可以通过百度提交您想成为收录的链接。百度搜索引擎会按照标准进行处理,但不保证您一定能够收录您提交的链接。
全球最大的面向中国互联网管理者、移动开发者和企业家的搜索流量管理官方平台。提供提交和分析工具,帮助搜索引擎捕捉收录、SEO优化建议等;为移动开发者提供百度官方API接口,以及多端适配能力和服务;及时发布百度权威数据、算法、工具等升级推送新信息。
登录端口:
360搜索平台网站收录,与网民分享网址,网站收录只要网站首页提交给搜索引擎,蜘蛛就会每次都光顾它 新的网站 会在抓取网页时添加并更新到索引中。站长只需提供顶级网页,无需提交单个网页。爬虫可以找到其他页面。符合相关标准提交的网址将在一个月内按照搜索引擎收录标准进行处理。
日志条目:
3.搜狗网站收录:提交后,搜狗搜索引擎会按照标准进行处理,但不保证提交的链接一定能收录@ >. 为提高处理效率,请勿重复提交同一个链接。网站收录/申诉一次只能提交一个网址。请确保 URL 的完整性、正确性、可访问性和网站内容质量。
收录提交条目
:
必应网站收录,将您的网站 URL提交给必应,并在网管工具中注册,查看您的网站是否已被索引,是否通过了必应流程应该得到。
Bing网站 提交登录入口:
每天分享一些网络推广的小知识,欢迎大家继续关注【易斌有话说】
php如何抓取网页数据( PowerQuery简单获取中文函数帮助信息的方法,方法分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-06 03:14
PowerQuery简单获取中文函数帮助信息的方法,方法分享
)
曾经文章登陆天山社区的Power Query:
Power Query M 函数(1)--数据类型和数据结构
PowerQuery M 函数 2-计算方法和运算符
Power Query M 函数(3)--数据类型转换、元数据和错误处理
通过前三节的学习,相信大家对M函数的基础知识有了一定的了解。从本节开始,我们将通过实际案例逐步介绍M功能的应用方法。
本节我们要介绍的案例是使用Web.Page和Web.Contents函数从PM2.5个历史数据网站中抓取不同城市不同日期的历史空气质量相关数据的方法. 这种方式适用于在Power Query中输入URL可以直接获取所需数据的情况(这种情况是指网页地址中有可见表格数据的情况)。
在进入正文之前,先给大家介绍一个简单的获取中文函数帮助信息的方法,方法如下:
1. 在 Power Query 查询编辑器中创建一个新的空查询
2. 在编辑字段中输入 =#shared
3. 点击“列出”
4. 通过过滤Name字段获取相关函数帮助信息
Web.Page 和 Web.Contents 功能说明:
1. Web.Page 函数:返回 HTML 文档的内容(分解为其组成结构),以及完整文档及其删除文本的表示
表达式:Function(html as any) as table
注:使用Web.Page函数获取网页HTML形式的相关信息,以表格形式返回结果
2. Web.Contents 函数:以二进制形式返回从 url 下载的内容。可以提供可选的记录参数选项来指定其他属性。记录可以收录以下字段...(更多内容省略,详见#shared查询)
表达式:函数(url 为文本,可选选项为可空记录)asbinary
注:支付Web.Contents网页地址后,Web.Contents函数可以以二进制数的形式返回网页中的信息
这两个函数嵌套使用后,Web.Page(Web.Contents(URL))最终可以将网页中的信息以表格的形式呈现出来。操作逻辑是先使用Web.Contents函数获取指定URL中的二进制信息,然后使用Web.Page函数对二进制信息进行转换解析,最终得到我们能够理解的表格数据。
在PM2.5历史数据网页爬取各城市过去一天的历史空气质量数据:
主页地址:
所需日均空气质量数据(以北京2014年1月为例):
网站链接:
北京&月=2014-01
使用Power Query抓取上述网页的目的是一次性批量抓取多个城市不同月份不同天数的历史空气质量数据。
爬取步骤如下:
1. 分析网站特点后发现,只要将city=后面的部分改成想要的城市名,month=后面的部分改成想要的月份号,不同的城市和可以打开不同的月份。每日历史数据页面下
2. 所以我们现在在Excel表格界面中建立一个收录城市名称和月份信息的表格,并将其添加到Power Query
3. 将【月份】字段转换为文本数据
4.在Power Query编辑器中添加自定义列,内容如下:
公式内容:
Web.Page(Web.Contents("
"&[城市]&"&month="&[月]))
5. 点击“Continue”,选择“Public”保存(数据量大,需要耐心等待,建议练习时只做两个城市的数据)
6. 在自定义字段中展开数据
7. 再次展开自定义字段中的相关字段(从日期到排名)
8. 关闭并上传
以上内容就是抓取网页信息的所有步骤。好,我们来看看爬取到的数据。
本文作者:李奇,天山社区专家,中国电子表格应用大会主席,签约天山智能/网易云课堂/经济管理之家等讲师,曾就职于IBM和德勤会计师事务所,从事商业分析和数据分析咨询工作,擅长使用Excel制作商业智能报告。
天山学院推荐课程:
查看全部
php如何抓取网页数据(
PowerQuery简单获取中文函数帮助信息的方法,方法分享
)
曾经文章登陆天山社区的Power Query:
Power Query M 函数(1)--数据类型和数据结构
PowerQuery M 函数 2-计算方法和运算符
Power Query M 函数(3)--数据类型转换、元数据和错误处理
通过前三节的学习,相信大家对M函数的基础知识有了一定的了解。从本节开始,我们将通过实际案例逐步介绍M功能的应用方法。
本节我们要介绍的案例是使用Web.Page和Web.Contents函数从PM2.5个历史数据网站中抓取不同城市不同日期的历史空气质量相关数据的方法. 这种方式适用于在Power Query中输入URL可以直接获取所需数据的情况(这种情况是指网页地址中有可见表格数据的情况)。
在进入正文之前,先给大家介绍一个简单的获取中文函数帮助信息的方法,方法如下:
1. 在 Power Query 查询编辑器中创建一个新的空查询
2. 在编辑字段中输入 =#shared
3. 点击“列出”
4. 通过过滤Name字段获取相关函数帮助信息
Web.Page 和 Web.Contents 功能说明:
1. Web.Page 函数:返回 HTML 文档的内容(分解为其组成结构),以及完整文档及其删除文本的表示
表达式:Function(html as any) as table
注:使用Web.Page函数获取网页HTML形式的相关信息,以表格形式返回结果
2. Web.Contents 函数:以二进制形式返回从 url 下载的内容。可以提供可选的记录参数选项来指定其他属性。记录可以收录以下字段...(更多内容省略,详见#shared查询)
表达式:函数(url 为文本,可选选项为可空记录)asbinary
注:支付Web.Contents网页地址后,Web.Contents函数可以以二进制数的形式返回网页中的信息
这两个函数嵌套使用后,Web.Page(Web.Contents(URL))最终可以将网页中的信息以表格的形式呈现出来。操作逻辑是先使用Web.Contents函数获取指定URL中的二进制信息,然后使用Web.Page函数对二进制信息进行转换解析,最终得到我们能够理解的表格数据。
在PM2.5历史数据网页爬取各城市过去一天的历史空气质量数据:
主页地址:
所需日均空气质量数据(以北京2014年1月为例):
网站链接:
北京&月=2014-01
使用Power Query抓取上述网页的目的是一次性批量抓取多个城市不同月份不同天数的历史空气质量数据。
爬取步骤如下:
1. 分析网站特点后发现,只要将city=后面的部分改成想要的城市名,month=后面的部分改成想要的月份号,不同的城市和可以打开不同的月份。每日历史数据页面下
2. 所以我们现在在Excel表格界面中建立一个收录城市名称和月份信息的表格,并将其添加到Power Query
3. 将【月份】字段转换为文本数据
4.在Power Query编辑器中添加自定义列,内容如下:
公式内容:
Web.Page(Web.Contents("
"&[城市]&"&month="&[月]))
5. 点击“Continue”,选择“Public”保存(数据量大,需要耐心等待,建议练习时只做两个城市的数据)
6. 在自定义字段中展开数据
7. 再次展开自定义字段中的相关字段(从日期到排名)
8. 关闭并上传
以上内容就是抓取网页信息的所有步骤。好,我们来看看爬取到的数据。
本文作者:李奇,天山社区专家,中国电子表格应用大会主席,签约天山智能/网易云课堂/经济管理之家等讲师,曾就职于IBM和德勤会计师事务所,从事商业分析和数据分析咨询工作,擅长使用Excel制作商业智能报告。
天山学院推荐课程:
php如何抓取网页数据(php如何抓取网页数据?(一)__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-05 23:02
php如何抓取网页数据?直接aspen-common无头不钻设置头部样式,传递参数到header再用普通的if判断解析。比如你要下载2012年广西暴乱的网页内容,需要传递两个参数分别是:姓名,国籍首页:没问题,但要注意这些详细内容的国家和省份每一行都是一样的,例如你要下载的网页是南宁市,但实际的二三四五行的内容是河北省保定市。
而如果下载的是2015年广西暴乱的网页:..//..//content//2015//content///2015//网页确实会加载出两个不同的网页,但是他们不同的是颜色。我们拿php解析网页为例,看看他到底怎么实现的。一、通过header传递参数header并不是单个地方可以存入参数,需要顺着整个网页传递一个,例如传递二,直接url=;fromname=evil&applesize=1524&properties=gibetropha如果你的服务器默认的是ipv4,那么网页会解析出一个新的ip,再让你下载。
如果你服务器默认的是ipv6,那么网页也会解析出一个新的ip,再让你下载。来看看下面这个例子:login_admin=xxxmasked=nullposter=xxxpage=latestpackage=portablepublicfilepath=xxx#poster=localhostbug_new=okremote_login=xxx#properties=gibetrophaweb_host=xxx#publicfilepath=xxx#url=;fromname=evil&applesize=1524&properties=gibetropha二、header全表解析在网页下载的时候不是只解析前端的内容,而是会解析前端和后端共同解析的内容。
所以我们需要将header中的参数用sort排序。先来看看sort的介绍:sort有两个特性:按相同排序,按内容排序thesortfunctionandtheclose-endsortfunctioncandefinetwocustomspecificfunctions:hyperlink和header..hyperlink'hd=gibetropha'hyperlink'wj00000023''..'header'content=..'content='gibetropha'#'wsd=source'sort是一个global.each代表global.write,#'source'代表wsd代表source的document#'msize'代表method的content代表method的content#'..'''.''.''.''.''.''sort方法:返回按指定顺序的排序请求。
还有一个隐藏的wsd排序请求,完成one-to-onegroup排序。看下图:method方法:gibetropha网页实际的内容通过header向服务器,服务器会解析出一个新的header和三个header,分别。 查看全部
php如何抓取网页数据(php如何抓取网页数据?(一)__)
php如何抓取网页数据?直接aspen-common无头不钻设置头部样式,传递参数到header再用普通的if判断解析。比如你要下载2012年广西暴乱的网页内容,需要传递两个参数分别是:姓名,国籍首页:没问题,但要注意这些详细内容的国家和省份每一行都是一样的,例如你要下载的网页是南宁市,但实际的二三四五行的内容是河北省保定市。
而如果下载的是2015年广西暴乱的网页:..//..//content//2015//content///2015//网页确实会加载出两个不同的网页,但是他们不同的是颜色。我们拿php解析网页为例,看看他到底怎么实现的。一、通过header传递参数header并不是单个地方可以存入参数,需要顺着整个网页传递一个,例如传递二,直接url=;fromname=evil&applesize=1524&properties=gibetropha如果你的服务器默认的是ipv4,那么网页会解析出一个新的ip,再让你下载。
如果你服务器默认的是ipv6,那么网页也会解析出一个新的ip,再让你下载。来看看下面这个例子:login_admin=xxxmasked=nullposter=xxxpage=latestpackage=portablepublicfilepath=xxx#poster=localhostbug_new=okremote_login=xxx#properties=gibetrophaweb_host=xxx#publicfilepath=xxx#url=;fromname=evil&applesize=1524&properties=gibetropha二、header全表解析在网页下载的时候不是只解析前端的内容,而是会解析前端和后端共同解析的内容。
所以我们需要将header中的参数用sort排序。先来看看sort的介绍:sort有两个特性:按相同排序,按内容排序thesortfunctionandtheclose-endsortfunctioncandefinetwocustomspecificfunctions:hyperlink和header..hyperlink'hd=gibetropha'hyperlink'wj00000023''..'header'content=..'content='gibetropha'#'wsd=source'sort是一个global.each代表global.write,#'source'代表wsd代表source的document#'msize'代表method的content代表method的content#'..'''.''.''.''.''.''sort方法:返回按指定顺序的排序请求。
还有一个隐藏的wsd排序请求,完成one-to-onegroup排序。看下图:method方法:gibetropha网页实际的内容通过header向服务器,服务器会解析出一个新的header和三个header,分别。
php如何抓取网页数据(php如何抓取网页数据??这里介绍一下http协议本教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-05 03:03
php如何抓取网页数据???,这里介绍一下http协议本教程主要涉及http协议请求、响应与事务、http响应与重定向、http响应与重定向、method、extension与hook等相关技术详细内容请看下图最全面的网页数据抓取教程!
举个栗子,我们想抓取一下某个城市。对http服务来说,客户端输入目标地址之后,http请求就开始。从浏览器上传会经过get(可以是http/1.1以上版本)的发送和post的发送。http客户端根据目标请求方式,可以认为是简单http请求和http/2之间的转换。
1、首部字段:a、发起请求的url/子url;b、name字段:name=‘网站名’,任何不带,
2、请求体:url/with;
3、value字段:xml或者xhtml文件(如果带有,不管他是什么,
4、path字段:with//xml
5、cookie字段:默认值;
6、accept字段:http/1.1或者http/2cookiehttp/2这样在浏览器中输入目标地址之后,http请求就开始了。完整的请求一般包括以下几个步骤:第一步:接收到http客户端发来的name字段的响应(如果没有,也没关系,还可以从服务器获取);第二步:第一步接收到的响应,只需要发送一个响应头包。
这个响应头就是你上文所说的cookie。第三步:第二步客户端会根据响应头,得到这个请求地址的主机ip,姓名,邮箱等信息,并且保存在http/2.xml当中;第四步:第三步客户端会根据这些信息,根据你所要请求的数据,去网站收集相关信息,这些信息会发送到服务器端。比如文章标题,最终http/2cookie会被发送到你的电脑中。所以并不是说只要传输一个响应头,就完成了http/2的发送了。
要注意的是,响应头的格式,
2、cookie的内容。 查看全部
php如何抓取网页数据(php如何抓取网页数据??这里介绍一下http协议本教程)
php如何抓取网页数据???,这里介绍一下http协议本教程主要涉及http协议请求、响应与事务、http响应与重定向、http响应与重定向、method、extension与hook等相关技术详细内容请看下图最全面的网页数据抓取教程!
举个栗子,我们想抓取一下某个城市。对http服务来说,客户端输入目标地址之后,http请求就开始。从浏览器上传会经过get(可以是http/1.1以上版本)的发送和post的发送。http客户端根据目标请求方式,可以认为是简单http请求和http/2之间的转换。
1、首部字段:a、发起请求的url/子url;b、name字段:name=‘网站名’,任何不带,
2、请求体:url/with;
3、value字段:xml或者xhtml文件(如果带有,不管他是什么,
4、path字段:with//xml
5、cookie字段:默认值;
6、accept字段:http/1.1或者http/2cookiehttp/2这样在浏览器中输入目标地址之后,http请求就开始了。完整的请求一般包括以下几个步骤:第一步:接收到http客户端发来的name字段的响应(如果没有,也没关系,还可以从服务器获取);第二步:第一步接收到的响应,只需要发送一个响应头包。
这个响应头就是你上文所说的cookie。第三步:第二步客户端会根据响应头,得到这个请求地址的主机ip,姓名,邮箱等信息,并且保存在http/2.xml当中;第四步:第三步客户端会根据这些信息,根据你所要请求的数据,去网站收集相关信息,这些信息会发送到服务器端。比如文章标题,最终http/2cookie会被发送到你的电脑中。所以并不是说只要传输一个响应头,就完成了http/2的发送了。
要注意的是,响应头的格式,
2、cookie的内容。
php如何抓取网页数据(php如何抓取网页数据?数据存储程序操作效果图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-24 06:06
php如何抓取网页数据?对于php而言,数据获取并不难,如果我们只要让php知道目标网页的url,然后按照指定的规则使用正则匹配网页内容,之后将返回的json数据存储就好了。在实际开发中,难免需要将正则表达式用来匹配某个数据,这个时候会进行正则替换(g++),或者使用网页抓取程序(f12)等,另外还可以使用邮件编辑器(mailfinder)。
<p>下面来看看这两种方法的操作,效果如下图:下面分享一个php抓取谷歌新闻的操作,之后同样同样通过json数据存储程序实现。首先先看看效果图:1.打开get/谷歌网页搜索#php抓取网页内容f12/点击responsestring$from和execute/来看看请求头,每行内容是网页的url#php抓取网页内容2.body部分看看中间几个参数,#php抓取网页内容$ext_text表示网页的一行内容,$ext_textparam$value是给浏览器(浏览器是不能转义的哦),^$表示给正则表达式匹配的文本,$re_cookie表示浏览器存放的正则表达式的账号和密码,$re_proto表示是否开启正则表达式匹配文件名pub_file表示是否开启正则表达式匹配文件名filename表示正则表达式的匹配方式,#php抓取网页内容$ext_pub表示网页自带的正则表达式或者compile进来的正则表达式3.body2:内容是采用4.body3:也是采用compile正则表达式$re_proto不能开启,否则不能匹配的,一定要$re_cookie有$ext_textparam$value是给浏览器(浏览器是不能转义的哦),$re_stringparam$value是给正则表达式匹配的文本,$//f@path.extend('default./')如果$/匹配不到文本,浏览器就不会进行匹配$/$\d{s}^$^\d{s},$\d{s}^{\d}是匹配以字符的开头$\d{s}//f@path.extend($/f'/\d{default}$\d{s}');$/$\d{s}//f@path.extend($/$\d{s}\d{default}$\d{s})5.body4:$cookie只匹配文本的内容$from匹配的是 查看全部
php如何抓取网页数据(php如何抓取网页数据?数据存储程序操作效果图)
php如何抓取网页数据?对于php而言,数据获取并不难,如果我们只要让php知道目标网页的url,然后按照指定的规则使用正则匹配网页内容,之后将返回的json数据存储就好了。在实际开发中,难免需要将正则表达式用来匹配某个数据,这个时候会进行正则替换(g++),或者使用网页抓取程序(f12)等,另外还可以使用邮件编辑器(mailfinder)。
<p>下面来看看这两种方法的操作,效果如下图:下面分享一个php抓取谷歌新闻的操作,之后同样同样通过json数据存储程序实现。首先先看看效果图:1.打开get/谷歌网页搜索#php抓取网页内容f12/点击responsestring$from和execute/来看看请求头,每行内容是网页的url#php抓取网页内容2.body部分看看中间几个参数,#php抓取网页内容$ext_text表示网页的一行内容,$ext_textparam$value是给浏览器(浏览器是不能转义的哦),^$表示给正则表达式匹配的文本,$re_cookie表示浏览器存放的正则表达式的账号和密码,$re_proto表示是否开启正则表达式匹配文件名pub_file表示是否开启正则表达式匹配文件名filename表示正则表达式的匹配方式,#php抓取网页内容$ext_pub表示网页自带的正则表达式或者compile进来的正则表达式3.body2:内容是采用4.body3:也是采用compile正则表达式$re_proto不能开启,否则不能匹配的,一定要$re_cookie有$ext_textparam$value是给浏览器(浏览器是不能转义的哦),$re_stringparam$value是给正则表达式匹配的文本,$//f@path.extend('default./')如果$/匹配不到文本,浏览器就不会进行匹配$/$\d{s}^$^\d{s},$\d{s}^{\d}是匹配以字符的开头$\d{s}//f@path.extend($/f'/\d{default}$\d{s}');$/$\d{s}//f@path.extend($/$\d{s}\d{default}$\d{s})5.body4:$cookie只匹配文本的内容$from匹配的是

