
php可以抓取网页数据吗
php可以抓取网页数据吗(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-13 04:15
做过j2ee或者android开发的童鞋,应该或多或少用过Apeache的HttpClient库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
在最近的php开发中,也有需要在服务端发送http请求,然后处理返回给客户端。如果用sockets来做,可能不会太麻烦。我想看看php中有没有像HttpClient这样的库。
我google了一下,发现PHP中有这样一个库,名字叫httpclient。我很兴奋。查了官网,发现很多年没更新了,功能好像也有限。我很失望。然后我找到了另一个图书馆,史努比。我对这个库一无所知,但是网上反响很好,所以我决定使用它。他的API用法和Apeache的HttpClient有很大的不同,但是还是非常好用的。并且它提供了很多特殊用途的方法,比如只抓取页面上的表单表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com");
echo $snoopy->results;
有了上面几行代码,就可以轻松抓取百度的页面了。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时他还传递了请求头,对应的头以及Cookie的相关操作功能,非常强大。
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn")) {
echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "error fetching document: ". $snoopy->error. "\n";}
更多操作方法可以到史努比官方查看文档,或者直接查看源码。
此时,snoopy 只是在获取页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。在这里我找到了另一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性。对于熟悉jquery的小朋友来说,使用phpquery应该是相当容易的,甚至phpQuery的文件都不需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。最近也有这方面的需求,发现了这两个不错的库。Java 可以做很多事情。php也可以。
有兴趣的同学也可以尝试用它们来制作一个简单的网络爬虫。 查看全部
php可以抓取网页数据吗(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
做过j2ee或者android开发的童鞋,应该或多或少用过Apeache的HttpClient库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
在最近的php开发中,也有需要在服务端发送http请求,然后处理返回给客户端。如果用sockets来做,可能不会太麻烦。我想看看php中有没有像HttpClient这样的库。
我google了一下,发现PHP中有这样一个库,名字叫httpclient。我很兴奋。查了官网,发现很多年没更新了,功能好像也有限。我很失望。然后我找到了另一个图书馆,史努比。我对这个库一无所知,但是网上反响很好,所以我决定使用它。他的API用法和Apeache的HttpClient有很大的不同,但是还是非常好用的。并且它提供了很多特殊用途的方法,比如只抓取页面上的表单表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com";);
echo $snoopy->results;
有了上面几行代码,就可以轻松抓取百度的页面了。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时他还传递了请求头,对应的头以及Cookie的相关操作功能,非常强大。
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn";)) {
echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "error fetching document: ". $snoopy->error. "\n";}
更多操作方法可以到史努比官方查看文档,或者直接查看源码。
此时,snoopy 只是在获取页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。在这里我找到了另一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性。对于熟悉jquery的小朋友来说,使用phpquery应该是相当容易的,甚至phpQuery的文件都不需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。最近也有这方面的需求,发现了这两个不错的库。Java 可以做很多事情。php也可以。
有兴趣的同学也可以尝试用它们来制作一个简单的网络爬虫。
php可以抓取网页数据吗(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-10 15:07
做过j2ee或者android开发的童鞋,应该或多或少用过Apeache的HttpClient库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
在最近的php开发中,也有需要在服务端发送http请求,然后处理返回给客户端。如果用sockets来做,可能不会太麻烦。我想看看php中有没有像HttpClient这样的库。
google了一下,发现php中有这样一个库,名字叫httpclient。我很兴奋。看了官网,发现很多年没更新了,功能好像也有限。我很失望。然后我找到了另一个图书馆,史努比。我对这个库一无所知,但是网上反响很好,所以我决定使用它。他的API用法和Apeache的HttpClient有很大的不同,但是还是非常好用的。并且它提供了很多特殊用途的方法,比如只抓取页面上的表单表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com");
echo $snoopy->results;
有了上面几行代码,就可以轻松抓取百度的页面了。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时还提供了请求头、响应头和Cookie相关的操作功能,功能非常强大。
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn")) {
echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "error fetching document: ". $snoopy->error. "\n";}
更多操作方法可以到史努比官方查看文档,或者直接查看源码。
此时,snoopy 只是在获取页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。在这里我找到了另一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性。对于熟悉jquery的小朋友来说,使用phpquery应该是相当容易的,甚至phpQuery的文件都不需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。最近也有这方面的需求,发现了这两个不错的库。Java 可以做很多事情。php也可以。
有兴趣的同学也可以尝试用它们来制作一个简单的网络爬虫。
转载于: 查看全部
php可以抓取网页数据吗(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
做过j2ee或者android开发的童鞋,应该或多或少用过Apeache的HttpClient库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
在最近的php开发中,也有需要在服务端发送http请求,然后处理返回给客户端。如果用sockets来做,可能不会太麻烦。我想看看php中有没有像HttpClient这样的库。
google了一下,发现php中有这样一个库,名字叫httpclient。我很兴奋。看了官网,发现很多年没更新了,功能好像也有限。我很失望。然后我找到了另一个图书馆,史努比。我对这个库一无所知,但是网上反响很好,所以我决定使用它。他的API用法和Apeache的HttpClient有很大的不同,但是还是非常好用的。并且它提供了很多特殊用途的方法,比如只抓取页面上的表单表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com";);
echo $snoopy->results;
有了上面几行代码,就可以轻松抓取百度的页面了。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时还提供了请求头、响应头和Cookie相关的操作功能,功能非常强大。
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn";)) {
echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "error fetching document: ". $snoopy->error. "\n";}
更多操作方法可以到史努比官方查看文档,或者直接查看源码。
此时,snoopy 只是在获取页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。在这里我找到了另一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性。对于熟悉jquery的小朋友来说,使用phpquery应该是相当容易的,甚至phpQuery的文件都不需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。最近也有这方面的需求,发现了这两个不错的库。Java 可以做很多事情。php也可以。
有兴趣的同学也可以尝试用它们来制作一个简单的网络爬虫。
转载于:
php可以抓取网页数据吗(php可以抓取网页数据吗?比如复制一条内容可以获取其中的链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-07 20:07
php可以抓取网页数据吗?比如复制一条内容可以获取其中的链接这是获取网页内容-site-info/的代码:php是会获取网页的文本的。比如说下面这条内容:链接为:=。=。=,将获取到的网页的内容拼凑起来,那么就可以解析出来如图:第一个是对应于文本框里面的内容第二个是抓取用户名(formdata.innerhtml=request.getheader("user-agent"))数据。
下面一个基本的获取网页数据方法也可以解析出网页的内容:这个在大多数网站中都很常见。经常都会有一些对于网页数据的预处理方法或者爬虫。
php获取网页数据的方法有几种1.直接处理html2.获取图片3.文本数据
php获取网页数据可以关注一下,数据更新及时,用户留言及时,服务器地址精准,希望对你有所帮助。
php抓取可以抓取网页中的链接(例如豆瓣),但是得先用代码把标题,文本等处理下。
找个文件贴上来吧。
php可以获取网页吗?php抓取网页是可以抓取字符串的。这个网站用的是sitemap的内容抓取方法。可以得到一些网站的结构化数据。最后结构化到txt的格式。在php里解析成字符串返回。
php可以抓取网页数据吗?用网站程序可以抓取网页数据么?-adsl圆桌讨论区 查看全部
php可以抓取网页数据吗(php可以抓取网页数据吗?比如复制一条内容可以获取其中的链接)
php可以抓取网页数据吗?比如复制一条内容可以获取其中的链接这是获取网页内容-site-info/的代码:php是会获取网页的文本的。比如说下面这条内容:链接为:=。=。=,将获取到的网页的内容拼凑起来,那么就可以解析出来如图:第一个是对应于文本框里面的内容第二个是抓取用户名(formdata.innerhtml=request.getheader("user-agent"))数据。
下面一个基本的获取网页数据方法也可以解析出网页的内容:这个在大多数网站中都很常见。经常都会有一些对于网页数据的预处理方法或者爬虫。
php获取网页数据的方法有几种1.直接处理html2.获取图片3.文本数据
php获取网页数据可以关注一下,数据更新及时,用户留言及时,服务器地址精准,希望对你有所帮助。
php抓取可以抓取网页中的链接(例如豆瓣),但是得先用代码把标题,文本等处理下。
找个文件贴上来吧。
php可以获取网页吗?php抓取网页是可以抓取字符串的。这个网站用的是sitemap的内容抓取方法。可以得到一些网站的结构化数据。最后结构化到txt的格式。在php里解析成字符串返回。
php可以抓取网页数据吗?用网站程序可以抓取网页数据么?-adsl圆桌讨论区
php可以抓取网页数据吗(做过j2ee或android开发的童鞋,应该或多或少都使用过的HttpClient类库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-04 16:28
做过j2ee或者android开发的童鞋,应该或多或少用过Apeache的HttpClient库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
在最近的php开发中,也有需要在服务端发送http请求,然后处理返回给客户端。如果用sockets来做,可能不会太麻烦。我想看看php中有没有像HttpClient这样的库。
google了一下,发现php中有这样一个库,名字叫httpclient。我很兴奋。看了官网,发现很多年没更新了,功能好像也有限。我很失望。然后我找到了另一个图书馆,史努比。我对这个库一无所知,但是网上反响很好,所以我决定使用它。他的API用法和Apeache的HttpClient有很大的不同,但是还是非常好用的。并且它提供了很多特殊用途的方法,比如只抓取页面上的表单表单,或者所有的链接等等。
include 'Snoopy.class.php';$snoopy = new Snoopy();$snoopy->fetch("http://www.baidu.com");echo $snoopy->results;
有了上面几行代码,就可以轻松抓取百度的页面了。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时他还传递了请求头,对应的头以及Cookie的相关操作功能,非常强大。
include "Snoopy.class.php";$snoopy = new Snoopy();$snoopy->proxy_host = "http://www.baidu.cn";$snoopy->proxy_port = "80";$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";$snoopy->referer = "http://www.4wei.cn"; $snoopy->cookies["SessionID"] = '238472834723489';$snoopy->cookies["favoriteColor"] = "RED";$snoopy->rawheaders["Pragma"] = "no-cache";$snoopy->maxredirs = 2;$snoopy->offsiteok = false;$snoopy->expandlinks = false;$snoopy->user = "joe";$snoopy->pass = "bloe";if($snoopy->fetchtext("http://www.baidu.cn")) { echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "error fetching document: ". $snoopy->error. "\n";}
更多操作方法可以到史努比官方查看文档,或者直接查看源码。
此时,snoopy 只是在获取页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。在这里我找到了另一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性。对于熟悉jquery的小朋友来说,使用phpquery应该是相当容易的,甚至phpQuery的文件都不需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。最近也有这方面的需求,发现了这两个不错的库。Java 可以做很多事情。php也可以。
有兴趣的同学也可以尝试用它们来制作一个简单的网络爬虫。
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php可以抓取网页数据吗(做过j2ee或android开发的童鞋,应该或多或少都使用过的HttpClient类库)
做过j2ee或者android开发的童鞋,应该或多或少用过Apeache的HttpClient库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
在最近的php开发中,也有需要在服务端发送http请求,然后处理返回给客户端。如果用sockets来做,可能不会太麻烦。我想看看php中有没有像HttpClient这样的库。
google了一下,发现php中有这样一个库,名字叫httpclient。我很兴奋。看了官网,发现很多年没更新了,功能好像也有限。我很失望。然后我找到了另一个图书馆,史努比。我对这个库一无所知,但是网上反响很好,所以我决定使用它。他的API用法和Apeache的HttpClient有很大的不同,但是还是非常好用的。并且它提供了很多特殊用途的方法,比如只抓取页面上的表单表单,或者所有的链接等等。
include 'Snoopy.class.php';$snoopy = new Snoopy();$snoopy->fetch("http://www.baidu.com";);echo $snoopy->results;
有了上面几行代码,就可以轻松抓取百度的页面了。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时他还传递了请求头,对应的头以及Cookie的相关操作功能,非常强大。
include "Snoopy.class.php";$snoopy = new Snoopy();$snoopy->proxy_host = "http://www.baidu.cn";$snoopy->proxy_port = "80";$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";$snoopy->referer = "http://www.4wei.cn"; $snoopy->cookies["SessionID"] = '238472834723489';$snoopy->cookies["favoriteColor"] = "RED";$snoopy->rawheaders["Pragma"] = "no-cache";$snoopy->maxredirs = 2;$snoopy->offsiteok = false;$snoopy->expandlinks = false;$snoopy->user = "joe";$snoopy->pass = "bloe";if($snoopy->fetchtext("http://www.baidu.cn";)) { echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "error fetching document: ". $snoopy->error. "\n";}
更多操作方法可以到史努比官方查看文档,或者直接查看源码。
此时,snoopy 只是在获取页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。在这里我找到了另一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性。对于熟悉jquery的小朋友来说,使用phpquery应该是相当容易的,甚至phpQuery的文件都不需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。最近也有这方面的需求,发现了这两个不错的库。Java 可以做很多事情。php也可以。
有兴趣的同学也可以尝试用它们来制作一个简单的网络爬虫。

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php可以抓取网页数据吗(php抓取网页数据需要哪些知识点?从哪个开始?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-03 16:01
php可以抓取网页数据吗?对于php抓取网页数据的常见php代码有哪些?从哪个开始?php抓取网页数据需要哪些知识点?php抓取网页数据的常见技术点有哪些?...为了帮助初学者更好的学习,老铁整理了php常见php代码,在练习练习之前,先熟悉下这些php代码,方便思考模仿。网页提取数据:和php代码类似的思路,获取网页内容,属性等。
如f="">helloworld;获取网页数据:对网页要获取的数据,做处理,获取网页数据,属性或者属性值。importjsonasjpqueryextendjson.dump(jpquery.queryselectorall('#request'));php抓取网页数据,要熟悉1字符/字符串/元组等的数据提取法,2php的工作方式:4json库5json_extractbystrings6string_mutate7try_some_string8try_json9_write_like_php10_write_ones11_write_string12_write_range13_write_range14_delattr_function//获取网页属性类型15_css_selector16_field_forward17_nameforward18_field_before_type//获取网页方向18_last_length19_sub_length20_wordsforward21_typeforward22_typetype23_typename//获取标签名称24_wordsforward25_words_like26_words_before_type27_words_before_type28_words_before_type29_words_normalize30_words_before_normalize//获取字符编码32_postmessage.include_request33_postmessage.onerror34_array_attr(format)(type)//根据属性type查看array中元素类型34_closure_function//函数类型35_download_array(web_http_ssl_postmessage)//存入链接地址36_download_array(web_http_redirect_postmessage)//存入链接地址37_download_array(web_http_redirect_postmessage)//存入链接地址38_component('form-data')//函数对象39_component('about.json')//函数参数40_url_type//指定url类型41_url_space//指定url的空格42_url_space_range//指定url空格大小43_init_cookie()//调用初始的cookie44_init_header()//调用一个header44_init_token()//调用一个key45_has_allowed_headers()//调用一个access_root项46_handler('some-api-directory')//处理请求47_http_header()//http状态码48_header_user_agent/。 查看全部
php可以抓取网页数据吗(php抓取网页数据需要哪些知识点?从哪个开始?)
php可以抓取网页数据吗?对于php抓取网页数据的常见php代码有哪些?从哪个开始?php抓取网页数据需要哪些知识点?php抓取网页数据的常见技术点有哪些?...为了帮助初学者更好的学习,老铁整理了php常见php代码,在练习练习之前,先熟悉下这些php代码,方便思考模仿。网页提取数据:和php代码类似的思路,获取网页内容,属性等。
如f="">helloworld;获取网页数据:对网页要获取的数据,做处理,获取网页数据,属性或者属性值。importjsonasjpqueryextendjson.dump(jpquery.queryselectorall('#request'));php抓取网页数据,要熟悉1字符/字符串/元组等的数据提取法,2php的工作方式:4json库5json_extractbystrings6string_mutate7try_some_string8try_json9_write_like_php10_write_ones11_write_string12_write_range13_write_range14_delattr_function//获取网页属性类型15_css_selector16_field_forward17_nameforward18_field_before_type//获取网页方向18_last_length19_sub_length20_wordsforward21_typeforward22_typetype23_typename//获取标签名称24_wordsforward25_words_like26_words_before_type27_words_before_type28_words_before_type29_words_normalize30_words_before_normalize//获取字符编码32_postmessage.include_request33_postmessage.onerror34_array_attr(format)(type)//根据属性type查看array中元素类型34_closure_function//函数类型35_download_array(web_http_ssl_postmessage)//存入链接地址36_download_array(web_http_redirect_postmessage)//存入链接地址37_download_array(web_http_redirect_postmessage)//存入链接地址38_component('form-data')//函数对象39_component('about.json')//函数参数40_url_type//指定url类型41_url_space//指定url的空格42_url_space_range//指定url空格大小43_init_cookie()//调用初始的cookie44_init_header()//调用一个header44_init_token()//调用一个key45_has_allowed_headers()//调用一个access_root项46_handler('some-api-directory')//处理请求47_http_header()//http状态码48_header_user_agent/。
php可以抓取网页数据吗(2019年我接触到PHP爬取的时候,我最开始是懵的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-03 08:04
)
2019年接触PHP爬虫的时候,一开始是懵的。有人用php写爬虫吗?
一个月后,嗯~世界上最好的语言写出世界上最好的爬虫,太香了!而7月15日晚上,也就是每天的加班,做完手头的下班后,就想着写php然后撤了。我写完之后才九点钟。我值得这么早下班吗?所以,这个博客已经出炉了!
简单的说,我用PHP抓取网页数据的三种常用方法,不光是分享,也是我自己的一个回顾。
希望对你有所启发和帮助:)。print_r("源代码在文末");
1.PHP file_get_contents()
file_get_content() 函数早在 PHP4 就出现了。该函数可以将整个文件读入一个字符串。使用语法为 file_get_contents(path,include_path,context,start,max_length);
这是一个屏幕截图:
那么如何使用这个功能来抓取网页数据呢?如果这个文件在线,这个文件可以读入str吗?答案是肯定的。所以简单一句话就可以得到网页的源码:(当然这个不是js渲染的,爬取网站)
function get_content()
{
$html_source = file_get_contents($this->url);
return $html_source;
}
2.PHP 卷曲
PHP curl 应该是我当时用得最多的PHP爬取方式了。
使用cURL处理很多复杂的页面,比如表单提交、FTP上传、HTTPS认证等;
这里放个链接,想深入的同学可以看一下用法。
function get_curl()
{
//初始化
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $this->url);
//设置超时
curl_setopt($ch, CURLOPT_TIMEOUT, 10);
// 如果是请求https时,要打开下面两个ssl安全校验
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//表示string输出,0为直接输出;
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch, CURLOPT_HTTPHEADER, $this->headerArray);
$html_source = curl_exec($ch);
curl_close($ch);
// $result = json_decode($output,true); 请求部分接口会返回json可以用到
return $html_source;
}
3.PHP Snoopy.class.php采集类
百度百科说:
这很好!然后我们就可以下载Snoopy.class.php(私信),导入就可以了。
include('Snoopy.class.php');
function getsnoopy()
{
$snoopy = new Snoopy();
$snoopy->fetch($this->url);
$html_source = $snoopy->results;
return $html_source;
}
当然,这里只是Snoopy最简单的用法之一,抢源码。
抓取源代码后,使用regular,或者xpath,或者其他提取方式抓取你想要的数据。这里不说了,21:48,我要下班了。
//所有title的正则表达式
$parament = "/.*?/";
preg_match_all($parament,$html_source,$matchs);
print_r($matchs);
就写这些下班就走。
4. 爬取结果和源码
对!你没看错,我懒得处理数据……有些事情,结果并不重要,对吧?重要的是过程。
附上代码:
<p> 查看全部
php可以抓取网页数据吗(2019年我接触到PHP爬取的时候,我最开始是懵的
)
2019年接触PHP爬虫的时候,一开始是懵的。有人用php写爬虫吗?
一个月后,嗯~世界上最好的语言写出世界上最好的爬虫,太香了!而7月15日晚上,也就是每天的加班,做完手头的下班后,就想着写php然后撤了。我写完之后才九点钟。我值得这么早下班吗?所以,这个博客已经出炉了!

简单的说,我用PHP抓取网页数据的三种常用方法,不光是分享,也是我自己的一个回顾。
希望对你有所启发和帮助:)。print_r("源代码在文末");
1.PHP file_get_contents()
file_get_content() 函数早在 PHP4 就出现了。该函数可以将整个文件读入一个字符串。使用语法为 file_get_contents(path,include_path,context,start,max_length);
这是一个屏幕截图:

那么如何使用这个功能来抓取网页数据呢?如果这个文件在线,这个文件可以读入str吗?答案是肯定的。所以简单一句话就可以得到网页的源码:(当然这个不是js渲染的,爬取网站)
function get_content()
{
$html_source = file_get_contents($this->url);
return $html_source;
}
2.PHP 卷曲
PHP curl 应该是我当时用得最多的PHP爬取方式了。
使用cURL处理很多复杂的页面,比如表单提交、FTP上传、HTTPS认证等;
这里放个链接,想深入的同学可以看一下用法。
function get_curl()
{
//初始化
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $this->url);
//设置超时
curl_setopt($ch, CURLOPT_TIMEOUT, 10);
// 如果是请求https时,要打开下面两个ssl安全校验
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//表示string输出,0为直接输出;
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch, CURLOPT_HTTPHEADER, $this->headerArray);
$html_source = curl_exec($ch);
curl_close($ch);
// $result = json_decode($output,true); 请求部分接口会返回json可以用到
return $html_source;
}
3.PHP Snoopy.class.php采集类
百度百科说:

这很好!然后我们就可以下载Snoopy.class.php(私信),导入就可以了。
include('Snoopy.class.php');
function getsnoopy()
{
$snoopy = new Snoopy();
$snoopy->fetch($this->url);
$html_source = $snoopy->results;
return $html_source;
}
当然,这里只是Snoopy最简单的用法之一,抢源码。
抓取源代码后,使用regular,或者xpath,或者其他提取方式抓取你想要的数据。这里不说了,21:48,我要下班了。
//所有title的正则表达式
$parament = "/.*?/";
preg_match_all($parament,$html_source,$matchs);
print_r($matchs);
就写这些下班就走。

4. 爬取结果和源码

对!你没看错,我懒得处理数据……有些事情,结果并不重要,对吧?重要的是过程。
附上代码:
<p>
php可以抓取网页数据吗(Linux抓取网页方式(curl+wget)通过代理下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2021-11-26 11:12
Linux 抓取网页方法(curl+wget)
Linux 上抓取网页的简单方法是直接使用 curl 或 wget。 curl 和 wget 命令目前支持 Linux 和 Windows 平台,后面会介绍。即Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在Environment Variables-System Variables-Path中添加安装目录,可以curl和wget抓取示例抓取网页。主要有url URL 和proxy 代理两种方式。下面以抓取“百度”主页为例,介绍1、 url URL 方法抓取( 1)curl 下载百度主页内容并保存在baidu_html 文件 curl http::8080 传输将下载的百度主页curl到本地(curl不直接连接百度服务器下载主页,而是通过一个中介代理完成)(2)wget通过代理获取百度主页,wget通过代理下载,不是和curl一样,需要先设置代理服务器(所有爬取网页模块都是用Shell编写的,核心代码1000行左右) 游戏排名趋势图请看我之前的博客:JFreeChart项目示例 鸣谢:本文代理由米扑代理免费赞助,米扑代理每天提供20个免费代理。米扑代理官网:
2.6K 查看全部
php可以抓取网页数据吗(Linux抓取网页方式(curl+wget)通过代理下载)
Linux 抓取网页方法(curl+wget)
Linux 上抓取网页的简单方法是直接使用 curl 或 wget。 curl 和 wget 命令目前支持 Linux 和 Windows 平台,后面会介绍。即Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在Environment Variables-System Variables-Path中添加安装目录,可以curl和wget抓取示例抓取网页。主要有url URL 和proxy 代理两种方式。下面以抓取“百度”主页为例,介绍1、 url URL 方法抓取( 1)curl 下载百度主页内容并保存在baidu_html 文件 curl http::8080 传输将下载的百度主页curl到本地(curl不直接连接百度服务器下载主页,而是通过一个中介代理完成)(2)wget通过代理获取百度主页,wget通过代理下载,不是和curl一样,需要先设置代理服务器(所有爬取网页模块都是用Shell编写的,核心代码1000行左右) 游戏排名趋势图请看我之前的博客:JFreeChart项目示例 鸣谢:本文代理由米扑代理免费赞助,米扑代理每天提供20个免费代理。米扑代理官网:
2.6K
php可以抓取网页数据吗(php可以抓取网页数据吗?可以的。-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-26 06:06
php可以抓取网页数据吗?可以的。你们学校的网站,应该是一个纯粹的.cn域名,你可以通过.cn域名的解析来抓取抓取解析的有两种方式:一是自己购买专用的。二是开源的比如nginx:对于课件,一般是不会直接抓的,因为如果公布出来,有侵权问题。我一般都是用requests库自己抓:连接页面,将页面内容解析并提交。
实际上从抓取代码上来看,requests连接的并不是一个完整的http网站,而只是将basic_http,这是一个完整的http文件。然后从http连接中,将特定的header进行获取。有点像dump的感觉。所以我连接了一个-cache/来存放抓取header。我编写了一个http脚本模拟发送get请求。
你可以用get将静态页面抓取下来并解析一下,这样你可以基本实现php代码对网页数据的抓取。其中有一个详细介绍抓取原理的教程链接:phpget数据网站抓取+解析教程另外补充两个例子:抓取《最强大脑》:php网页数据的抓取我抓取的网站(不是phpmyadmin):和php和wordpress抓取复旦大学网站。
你好,我推荐你使用爬虫爬取,只要有dreamweaver你就可以轻松实现php代码对网页数据的抓取,可以用javascript来提取,
不用有什么封号的顾虑,问题是没有人会给你答案,在这种php知识几乎等于无的地方,js代码才是重中之重。php对数据完整性约束比较松,况且你也能够提供本机上的抓取。要实现你这种目的,不如你可以试试requests库,github地址:linux/php-requests,extension是现成的。你能够在浏览器中运行,提供get数据。推荐用samba来共享。 查看全部
php可以抓取网页数据吗(php可以抓取网页数据吗?可以的。-八维教育)
php可以抓取网页数据吗?可以的。你们学校的网站,应该是一个纯粹的.cn域名,你可以通过.cn域名的解析来抓取抓取解析的有两种方式:一是自己购买专用的。二是开源的比如nginx:对于课件,一般是不会直接抓的,因为如果公布出来,有侵权问题。我一般都是用requests库自己抓:连接页面,将页面内容解析并提交。
实际上从抓取代码上来看,requests连接的并不是一个完整的http网站,而只是将basic_http,这是一个完整的http文件。然后从http连接中,将特定的header进行获取。有点像dump的感觉。所以我连接了一个-cache/来存放抓取header。我编写了一个http脚本模拟发送get请求。
你可以用get将静态页面抓取下来并解析一下,这样你可以基本实现php代码对网页数据的抓取。其中有一个详细介绍抓取原理的教程链接:phpget数据网站抓取+解析教程另外补充两个例子:抓取《最强大脑》:php网页数据的抓取我抓取的网站(不是phpmyadmin):和php和wordpress抓取复旦大学网站。
你好,我推荐你使用爬虫爬取,只要有dreamweaver你就可以轻松实现php代码对网页数据的抓取,可以用javascript来提取,
不用有什么封号的顾虑,问题是没有人会给你答案,在这种php知识几乎等于无的地方,js代码才是重中之重。php对数据完整性约束比较松,况且你也能够提供本机上的抓取。要实现你这种目的,不如你可以试试requests库,github地址:linux/php-requests,extension是现成的。你能够在浏览器中运行,提供get数据。推荐用samba来共享。
php可以抓取网页数据吗( 前后端分离已经成为趋势,也就是说get参数为封装的vue等框架 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 432 次浏览 • 2021-11-20 13:09
前后端分离已经成为趋势,也就是说get参数为封装的vue等框架
)
js获取获取数据
现在前后端分离已经成为一种趋势,这意味着很多页面如果对外链接,需要自定义参数设置。当前有效的方法是获取参数。通过自定义get参数为封装的vue等框架提供页面变量识别!当然也可以使用路由。
function getPar(par){
//获取当前URL
var local_url = document.location.href;
//获取要取得的get参数位置
var get = local_url.indexOf(par +"=");
if(get == -1){
return false;
}
//截取字符串
var get_par = local_url.slice(par.length + get + 1);
//判断截取后的字符串是否还有其他get参数
var nextPar = get_par.indexOf("&");
if(nextPar != -1){
get_par = get_par.slice(0, nextPar);
}
return get_par;
}
/--------------------实现2(返回$_GET对象,模仿PHP方式)------------------ -----/
var $_GET = (function(){
var url = window.document.location.href.toString();
var u = url.split("?");
if(typeof(u[1]) == "string"){
u = u[1].split("&");
var get = {};
for(var i in u){
var j = u[i].split("=");
get[j[0]] = j[1];
}
return get;
} else {
return {};
}
})(); 查看全部
php可以抓取网页数据吗(
前后端分离已经成为趋势,也就是说get参数为封装的vue等框架
)
js获取获取数据
现在前后端分离已经成为一种趋势,这意味着很多页面如果对外链接,需要自定义参数设置。当前有效的方法是获取参数。通过自定义get参数为封装的vue等框架提供页面变量识别!当然也可以使用路由。
function getPar(par){
//获取当前URL
var local_url = document.location.href;
//获取要取得的get参数位置
var get = local_url.indexOf(par +"=");
if(get == -1){
return false;
}
//截取字符串
var get_par = local_url.slice(par.length + get + 1);
//判断截取后的字符串是否还有其他get参数
var nextPar = get_par.indexOf("&");
if(nextPar != -1){
get_par = get_par.slice(0, nextPar);
}
return get_par;
}
/--------------------实现2(返回$_GET对象,模仿PHP方式)------------------ -----/
var $_GET = (function(){
var url = window.document.location.href.toString();
var u = url.split("?");
if(typeof(u[1]) == "string"){
u = u[1].split("&");
var get = {};
for(var i in u){
var j = u[i].split("=");
get[j[0]] = j[1];
}
return get;
} else {
return {};
}
})();
php可以抓取网页数据吗(我想获取我的wp主菜单中的项目..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-20 13:07
我想在我的 wp 主菜单中获取项目。我尝试了一些代码,但所有代码都只返回一个空白页。我不知道我必须使用哪种方法,也不需要在页面中收录其他页面?
有没有办法直接从数据库中获取菜单项而不使用 wp 方法和函数?wp的表结构暂时不懂。所以我不完全知道表之间的关系。
谢谢。
解决方案:
如果您知道菜单的位置 ID(通常由 functions.php 中的“register_nav_menus”声明),您可以使用以下代码片段:
// GET ALL MENU OBJECTS AT SPECIFIED LOCATION
function yourprefix_get_menu_items($location_id){
//$locations = get_registered_nav_menus();
$menus = wp_get_nav_menus();
$menu_locations = get_nav_menu_locations();
if (isset($menu_locations[ $location_id ]) && $menu_locations[ $location_id ]!=0) {
foreach ($menus as $menu) {
if ($menu->term_id == $menu_locations[ $location_id ]) {
$menu_items = wp_get_nav_menu_items($menu);
break;
}
}
return $menu_items;
}
}
或者更多来自代码的简短版本:
function yourprefix_get_menu_items($menu_name){
if ( ( $locations = get_nav_menu_locations() ) && isset( $locations[ $menu_name ] ) ) {
$menu = wp_get_nav_menu_object( $locations[ $menu_name ] );
return wp_get_nav_menu_items($menu->term_id);
}
}
然后使用这个数组来执行你想要的所有操作,如下图:
$menu_items = yourprefix_get_menu_items('sidebar-menu'); // replace sidebar-menu by desired location
if(isset($menu_items)){
foreach ( (array) $menu_items as $key => $menu_item ) {
...some code...
}
}
这是所有 nav_menu 数据的链接,您可以通过 mysql 请求直接从数据库中选择这些数据: 查看全部
php可以抓取网页数据吗(我想获取我的wp主菜单中的项目..)
我想在我的 wp 主菜单中获取项目。我尝试了一些代码,但所有代码都只返回一个空白页。我不知道我必须使用哪种方法,也不需要在页面中收录其他页面?
有没有办法直接从数据库中获取菜单项而不使用 wp 方法和函数?wp的表结构暂时不懂。所以我不完全知道表之间的关系。
谢谢。
解决方案:
如果您知道菜单的位置 ID(通常由 functions.php 中的“register_nav_menus”声明),您可以使用以下代码片段:
// GET ALL MENU OBJECTS AT SPECIFIED LOCATION
function yourprefix_get_menu_items($location_id){
//$locations = get_registered_nav_menus();
$menus = wp_get_nav_menus();
$menu_locations = get_nav_menu_locations();
if (isset($menu_locations[ $location_id ]) && $menu_locations[ $location_id ]!=0) {
foreach ($menus as $menu) {
if ($menu->term_id == $menu_locations[ $location_id ]) {
$menu_items = wp_get_nav_menu_items($menu);
break;
}
}
return $menu_items;
}
}
或者更多来自代码的简短版本:
function yourprefix_get_menu_items($menu_name){
if ( ( $locations = get_nav_menu_locations() ) && isset( $locations[ $menu_name ] ) ) {
$menu = wp_get_nav_menu_object( $locations[ $menu_name ] );
return wp_get_nav_menu_items($menu->term_id);
}
}
然后使用这个数组来执行你想要的所有操作,如下图:
$menu_items = yourprefix_get_menu_items('sidebar-menu'); // replace sidebar-menu by desired location
if(isset($menu_items)){
foreach ( (array) $menu_items as $key => $menu_item ) {
...some code...
}
}
这是所有 nav_menu 数据的链接,您可以通过 mysql 请求直接从数据库中选择这些数据:
php可以抓取网页数据吗(PHP获取远程网页内容的代码(fopen,)的相关知识和一些Code实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-20 01:07
想知道PHP获取远程网页内容的代码(fopen,curl已经测试)的相关内容吗?在本文中,我将仔细讲解远程网页的相关知识和一些代码示例。欢迎阅读和指正。先重点介绍一下:fopen、curl,大家一起学习。
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
<IMG src="http://files.jb51.net/upload/2 ... ot%3B border=0>
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并且完美的解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP fopen / file_get_contents / curl 的区别
fopen / file_get_contents 会为每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。 查看全部
php可以抓取网页数据吗(PHP获取远程网页内容的代码(fopen,)的相关知识和一些Code实例)
想知道PHP获取远程网页内容的代码(fopen,curl已经测试)的相关内容吗?在本文中,我将仔细讲解远程网页的相关知识和一些代码示例。欢迎阅读和指正。先重点介绍一下:fopen、curl,大家一起学习。
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
<IMG src="http://files.jb51.net/upload/2 ... ot%3B border=0>
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并且完美的解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP fopen / file_get_contents / curl 的区别
fopen / file_get_contents 会为每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。
php可以抓取网页数据吗(PHP一下本文的主要内容及主要方式的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-19 20:13
我们不能直接输出得到的数据,往往需要将内容提取出来,然后进行格式化,以更友好的方式展示出来。
先简单说一下本文的主要内容:
一、 PHP抓取页面的主要方法:
1. file() 函数
2. file_get_contents() 函数
3. fopen()->fread()->fclose() 模式
4.卷曲方式
5. fsockopen() 函数套接字模式
6. 使用插件(如:)
二、PHP解析html或xml代码的主要方式:
1. 正则表达式
2. PHP DOMDocument 对象
3. 插件(如:PHP Simple HTML DOM Parser)
如果你对上面的内容有很好的理解,下面的内容就可以飘了……
PHP抓取页面
1. file() 函数
当然中国人是有创造力的,外国人往往技术先进,但中国人往往会用得更好,经常做出一些外国人不敢想的功能,比如远程爬取和分析php。为数据整合提供便利。但是中国人很喜欢这个,所以就有了大量的采集网站。他们自己不会创造任何有价值的内容。他们只是抓取其他人的 网站 内容并将其用作自己的内容。在百度输入“php小”关键词,建议列表第一个是“php小偷程序”,然后把同样的关键词放到google里,哥只能笑着说。 查看全部
php可以抓取网页数据吗(PHP一下本文的主要内容及主要方式的应用)
我们不能直接输出得到的数据,往往需要将内容提取出来,然后进行格式化,以更友好的方式展示出来。
先简单说一下本文的主要内容:
一、 PHP抓取页面的主要方法:
1. file() 函数
2. file_get_contents() 函数
3. fopen()->fread()->fclose() 模式
4.卷曲方式
5. fsockopen() 函数套接字模式
6. 使用插件(如:)
二、PHP解析html或xml代码的主要方式:
1. 正则表达式
2. PHP DOMDocument 对象
3. 插件(如:PHP Simple HTML DOM Parser)
如果你对上面的内容有很好的理解,下面的内容就可以飘了……
PHP抓取页面
1. file() 函数
当然中国人是有创造力的,外国人往往技术先进,但中国人往往会用得更好,经常做出一些外国人不敢想的功能,比如远程爬取和分析php。为数据整合提供便利。但是中国人很喜欢这个,所以就有了大量的采集网站。他们自己不会创造任何有价值的内容。他们只是抓取其他人的 网站 内容并将其用作自己的内容。在百度输入“php小”关键词,建议列表第一个是“php小偷程序”,然后把同样的关键词放到google里,哥只能笑着说。
php可以抓取网页数据吗(官方网站站点简单、灵活、强大的PHP采集工具,让采集更简单一点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-15 14:19
网站 官方网站是简单、灵活、强大的 PHP 采集 工具,让 采集 变得更简单。简介:QueryList使用jQuery选择器做采集,让你告别复杂的正则表达式;QueryList 具有相同的 jQuery DOM 操作能力、Http 网络操作能力、乱码解析能力、内容过滤能力和可扩展性;可轻松实现模拟登录、伪造浏览器、HTTP代理等复杂网络请求;拥有丰富的插件,支持多线程采集,使用PhantomJS采集 JavaScript动态渲染页面。通过 Composer 安装 安装:composer require jaeger/querylist 使用教程:直接上传代码: rules([// 采集Href 属性的所有标签'link' => [' a','href'],// 采集所有a标签的文本内容'text' => ['a','text']]);//这里$data = web后的对象上面已经获取到内容 // Settings采集 规则代替了传统的正则 $data->query();// 这里 $data = 上面已经获取到网页内容后的对象 //查询执行操作 $data->getData();// 这里 $data = 上面已经获取到网页内容后的对象 // 获取数据结果 $data->all(); // 这里 $data = 上面已经获取到网页内容后的对象 // 将数据转换成二维数组 print_r( $data->all());// 上面打印结果的基本使用方法是像这样,这样我们就已经可以抓取到一定数量的数据了。如果您对抓取数据感兴趣, 查看全部
php可以抓取网页数据吗(官方网站站点简单、灵活、强大的PHP采集工具,让采集更简单一点)
网站 官方网站是简单、灵活、强大的 PHP 采集 工具,让 采集 变得更简单。简介:QueryList使用jQuery选择器做采集,让你告别复杂的正则表达式;QueryList 具有相同的 jQuery DOM 操作能力、Http 网络操作能力、乱码解析能力、内容过滤能力和可扩展性;可轻松实现模拟登录、伪造浏览器、HTTP代理等复杂网络请求;拥有丰富的插件,支持多线程采集,使用PhantomJS采集 JavaScript动态渲染页面。通过 Composer 安装 安装:composer require jaeger/querylist 使用教程:直接上传代码: rules([// 采集Href 属性的所有标签'link' => [' a','href'],// 采集所有a标签的文本内容'text' => ['a','text']]);//这里$data = web后的对象上面已经获取到内容 // Settings采集 规则代替了传统的正则 $data->query();// 这里 $data = 上面已经获取到网页内容后的对象 //查询执行操作 $data->getData();// 这里 $data = 上面已经获取到网页内容后的对象 // 获取数据结果 $data->all(); // 这里 $data = 上面已经获取到网页内容后的对象 // 将数据转换成二维数组 print_r( $data->all());// 上面打印结果的基本使用方法是像这样,这样我们就已经可以抓取到一定数量的数据了。如果您对抓取数据感兴趣,
php可以抓取网页数据吗(php常量一定的参考价值,你知道吗?一定参考价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-15 10:09
本文文章主要介绍如何将js变量值传递给php。有一定的参考价值。现在分享给大家,有需要的朋友可以参考
一、 一句话总结:给后台传参数,使用ajax或者原生js拼接URL。明白原理明白系统就是先解析php,再执行html代码和js代码。二、使用ajax
1. 页面提交数据:ajax
2. php页面获取参数:$val = $_POST['val']
参考代码(jquery):
$.ajax({
type: 'POST',
url: 'save.php',
data: {val: text1obj.value}
success: function(msg){// msg: php返回内容/* alert(修改成功); */window.location = window.location;
},
error:function(msg){// 提交失败}
});
问题:
var bid=document.fenlei.bfenlei.value;
如上代码,如何将文档中的bid值传递给下面PHP语句的bid?? ? ?
回答:
不用AJAX,最简单就是传个参数过去
如:function saveGame(str){
window.location.href='url?str=' + str;
}
楼上的是一种跳转的方式。如果你想不刷新处理,获取数据。还是用ajax 。很简单的。给你个例子。这里我我用jquery的$.post
$.post(URL,{参数1:alue,参数2:value2},function(data){
//这里你可以处理获取的数据。我使用是json 格式。你也可以使用其它格式。或者为空,让它自己判断得了
},'json');
一个在服务器端,另一个在客户端。
当然不是。
我不明白你为什么使用 js 来传递值。
你直接这样使用url参数:test.php?bid=1不行吗?
用js实现比较麻烦,因为你打开网页是先执行php再执行js。也就是说,无论你把js放在哪里,都会在js执行之前先执行php。
如果你只是想用js这种方式给php传值,那你就得用ajax了,看你的具体需求了。
使用 AJAX 发送到后台
原型方法:
function changeshow()
{
var bid=document.fenlei.bfenlei.value;
var url = 'adm_mod_ajax.php';
var pars = 'mtype=1&mid=' + mid+'&bid='+bid;
var myAjax = new Ajax.Request(
url,
{method: 'post', parameters: pars, onComplete: showResponse}
);
}
三、洞察系统先解析php,然后在其他代码下进行字符串拼接
没关系
function dailyTask(){
$('#my_daily_task_calendar').datepicker().on('changeDate.datepicker.amui', function(event) {
var dailyTaskDate=$(this).val();
var url1="{:url('task/getDailyTaskData')}";
var url2='?dailyTaskDate='+dailyTaskDate;
document.location=url1+url2;
});
}
dailyTask();
apache 服务器首先会翻译这句话 7 var url2='?dailyTaskDate='+dailyTaskDate; 页面加载时。php翻译完成后,交给浏览器。
这样不行,因为php咸鱼js被执行了,所以找不到js中的dailyTaskDate变量,所以php一直报错。
var dailyTaskDate=$(this).val();
document.location={:url('task/getDailyTaskData',array('dailyTaskDate'=>dailyTaskDate))};
四、ajax回调函数中刷新页面的方法
做demo的时候,回调函数不想麻烦,直接刷新页面就可以使用location.reload(true); 这句话相当于F5键刷新页面。这个方法可能会消耗一定的资源,但是刷新页面还是很方便的。
下面的代码可以实现ajax刷新页面,但是没有用
function dailyTask(){
$('#my_daily_task_calendar').datepicker().on('changeDate.datepicker.amui', function(event) {
var dailyTaskDate=$(this).val();
$.post("task/getDailyTaskData", { dailyTaskDate:dailyTaskDate}, function () {
document.location.reload();
});
});
}
dailyTask();
以上就是本文的全部内容,希望对大家的学习有所帮助。更多相关内容请关注PHP中文网! 查看全部
php可以抓取网页数据吗(php常量一定的参考价值,你知道吗?一定参考价值)
本文文章主要介绍如何将js变量值传递给php。有一定的参考价值。现在分享给大家,有需要的朋友可以参考
一、 一句话总结:给后台传参数,使用ajax或者原生js拼接URL。明白原理明白系统就是先解析php,再执行html代码和js代码。二、使用ajax
1. 页面提交数据:ajax
2. php页面获取参数:$val = $_POST['val']
参考代码(jquery):
$.ajax({
type: 'POST',
url: 'save.php',
data: {val: text1obj.value}
success: function(msg){// msg: php返回内容/* alert(修改成功); */window.location = window.location;
},
error:function(msg){// 提交失败}
});
问题:
var bid=document.fenlei.bfenlei.value;
如上代码,如何将文档中的bid值传递给下面PHP语句的bid?? ? ?
回答:
不用AJAX,最简单就是传个参数过去
如:function saveGame(str){
window.location.href='url?str=' + str;
}
楼上的是一种跳转的方式。如果你想不刷新处理,获取数据。还是用ajax 。很简单的。给你个例子。这里我我用jquery的$.post
$.post(URL,{参数1:alue,参数2:value2},function(data){
//这里你可以处理获取的数据。我使用是json 格式。你也可以使用其它格式。或者为空,让它自己判断得了
},'json');
一个在服务器端,另一个在客户端。
当然不是。
我不明白你为什么使用 js 来传递值。
你直接这样使用url参数:test.php?bid=1不行吗?
用js实现比较麻烦,因为你打开网页是先执行php再执行js。也就是说,无论你把js放在哪里,都会在js执行之前先执行php。
如果你只是想用js这种方式给php传值,那你就得用ajax了,看你的具体需求了。
使用 AJAX 发送到后台
原型方法:
function changeshow()
{
var bid=document.fenlei.bfenlei.value;
var url = 'adm_mod_ajax.php';
var pars = 'mtype=1&mid=' + mid+'&bid='+bid;
var myAjax = new Ajax.Request(
url,
{method: 'post', parameters: pars, onComplete: showResponse}
);
}
三、洞察系统先解析php,然后在其他代码下进行字符串拼接
没关系
function dailyTask(){
$('#my_daily_task_calendar').datepicker().on('changeDate.datepicker.amui', function(event) {
var dailyTaskDate=$(this).val();
var url1="{:url('task/getDailyTaskData')}";
var url2='?dailyTaskDate='+dailyTaskDate;
document.location=url1+url2;
});
}
dailyTask();
apache 服务器首先会翻译这句话 7 var url2='?dailyTaskDate='+dailyTaskDate; 页面加载时。php翻译完成后,交给浏览器。
这样不行,因为php咸鱼js被执行了,所以找不到js中的dailyTaskDate变量,所以php一直报错。
var dailyTaskDate=$(this).val();
document.location={:url('task/getDailyTaskData',array('dailyTaskDate'=>dailyTaskDate))};
四、ajax回调函数中刷新页面的方法

做demo的时候,回调函数不想麻烦,直接刷新页面就可以使用location.reload(true); 这句话相当于F5键刷新页面。这个方法可能会消耗一定的资源,但是刷新页面还是很方便的。
下面的代码可以实现ajax刷新页面,但是没有用
function dailyTask(){
$('#my_daily_task_calendar').datepicker().on('changeDate.datepicker.amui', function(event) {
var dailyTaskDate=$(this).val();
$.post("task/getDailyTaskData", { dailyTaskDate:dailyTaskDate}, function () {
document.location.reload();
});
});
}
dailyTask();
以上就是本文的全部内容,希望对大家的学习有所帮助。更多相关内容请关注PHP中文网!
php可以抓取网页数据吗(牛逼闪闪的curl也束手无策了,你想采集这些处理过后的内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2021-11-14 21:21
对于一般的页面数据,我们可以很方便的抓取带有querylist的页面,分析里面的dom树,抓取我们需要的数据,存入数据库,但是有时候我们会遇到我们想通过JavaScript抓取的数据渲染,这次
Puppeteer 插件派上用场,
composerrequirenesk/puphpeteer
npminstall@nesk/puphpeteer --->cnpminstall@nesk/puphpeteer
供参考,按照文档做的时候发现
错误:无法下载 Chromium r672088!设置“PUPPETEER_SKIP_CHROMIUM_DOWNLOAD”环境变量以跳过下载。错误,
解决方案
采集 Web 内容是一个很常见的需求,curl 可以处理更传统的静态页面。但是如果页面中有动态加载的内容,比如有些页面通过ajax加载的文章 body内容,如果有些页面经过一些额外的处理(图片地址替换等...)而你想要采集这些处理过的内容。那么厉害的curl就无奈了。
做过类似需求的人可能会说,老铁,去PhantomJS吧!
是的,这是一个解决方案,很长一段时间以来,PhantomJS 是少数可以解决这种需求的工具之一。
但是今天我要介绍一个更新的工具-puppeteer,它随着Chrome Headless 技术的兴起而迅速发展。而且非常重要的是,puppeteer 由 Chrome 官方团队开发和维护,可以说是相当可靠!
puppeteer 是一个 js 包,如果你想在 Laravel 中使用它,你必须求助于另一个神器 spatie/browsershot。
安装
安装 spatie/browsershot
Browsershot 是一个 Composer 包,来自大神团队的 Spatie
$ composer require spatie/browsershot
安装 puppeteer
$ npm i puppeteer --save
也可以全局保护puppeteer,但从个人经验来看,建议安装在项目中,因为不同的项目不会同时受到全局安装的puppeteer的影响,在项目中安装是使用phpdeployer升级也很方便(phpdeploy升级不会影响线上项目的运行。要知道升级/安装puppeteer是很费时间的,有时还不能保证一次成功)
安装 puppeteer 后,将下载 Chromium-Browser。由于我们特殊的国情,很可能无法下载。为此,请施展你的魔法……
使用
以采集今日头条移动版页面文章的内容为例。
use Spatie\Browsershot\Browsershot; public function getBodyHtml() { $newsUrl = 'https://m.toutiao.com/i6546884 ... 3B%3B $html = Browsershot::url($newsUrl) ->windowSize(480, 800) ->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36') ->mobile() ->touch() ->bodyHtml(); \Log::info($html); }
运行后可以在日志中看到如下内容(截图只是其中的一部分)
此外,您可以将页面另存为图片或 PDF 文件。
use Spatie\Browsershot\Browsershot; public function getBodyHtml() { $newsUrl = 'https://m.toutiao.com/i6546884 ... 3B%3B Browsershot::url($newsUrl) ->windowSize(480, 800) ->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36') ->mobile() ->touch() ->setDelay(1000) ->save(public_path('images/toutiao.jpg')); }
图中方框与系统字体有关。代码中使用了 setDelay() 方法,用于在内容加载后进行截图。它既简单又粗鲁,可能不是最好的解决方案。
可能出现的问题
总结
puppeteer 用于测试、采集 等场景。这是一个非常强大的工具。对于轻量的采集任务,就足够了,比如Laravel(php)中的这篇文章使用采集一些小页面,但是如果你需要快速采集很多内容,或者Python什么的。
转载于: 查看全部
php可以抓取网页数据吗(牛逼闪闪的curl也束手无策了,你想采集这些处理过后的内容)
对于一般的页面数据,我们可以很方便的抓取带有querylist的页面,分析里面的dom树,抓取我们需要的数据,存入数据库,但是有时候我们会遇到我们想通过JavaScript抓取的数据渲染,这次
Puppeteer 插件派上用场,
composerrequirenesk/puphpeteer
npminstall@nesk/puphpeteer --->cnpminstall@nesk/puphpeteer
供参考,按照文档做的时候发现
错误:无法下载 Chromium r672088!设置“PUPPETEER_SKIP_CHROMIUM_DOWNLOAD”环境变量以跳过下载。错误,
解决方案
采集 Web 内容是一个很常见的需求,curl 可以处理更传统的静态页面。但是如果页面中有动态加载的内容,比如有些页面通过ajax加载的文章 body内容,如果有些页面经过一些额外的处理(图片地址替换等...)而你想要采集这些处理过的内容。那么厉害的curl就无奈了。
做过类似需求的人可能会说,老铁,去PhantomJS吧!
是的,这是一个解决方案,很长一段时间以来,PhantomJS 是少数可以解决这种需求的工具之一。
但是今天我要介绍一个更新的工具-puppeteer,它随着Chrome Headless 技术的兴起而迅速发展。而且非常重要的是,puppeteer 由 Chrome 官方团队开发和维护,可以说是相当可靠!
puppeteer 是一个 js 包,如果你想在 Laravel 中使用它,你必须求助于另一个神器 spatie/browsershot。
安装
安装 spatie/browsershot
Browsershot 是一个 Composer 包,来自大神团队的 Spatie
$ composer require spatie/browsershot
安装 puppeteer
$ npm i puppeteer --save
也可以全局保护puppeteer,但从个人经验来看,建议安装在项目中,因为不同的项目不会同时受到全局安装的puppeteer的影响,在项目中安装是使用phpdeployer升级也很方便(phpdeploy升级不会影响线上项目的运行。要知道升级/安装puppeteer是很费时间的,有时还不能保证一次成功)
安装 puppeteer 后,将下载 Chromium-Browser。由于我们特殊的国情,很可能无法下载。为此,请施展你的魔法……
使用
以采集今日头条移动版页面文章的内容为例。
use Spatie\Browsershot\Browsershot; public function getBodyHtml() { $newsUrl = 'https://m.toutiao.com/i6546884 ... 3B%3B $html = Browsershot::url($newsUrl) ->windowSize(480, 800) ->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36') ->mobile() ->touch() ->bodyHtml(); \Log::info($html); }
运行后可以在日志中看到如下内容(截图只是其中的一部分)

此外,您可以将页面另存为图片或 PDF 文件。
use Spatie\Browsershot\Browsershot; public function getBodyHtml() { $newsUrl = 'https://m.toutiao.com/i6546884 ... 3B%3B Browsershot::url($newsUrl) ->windowSize(480, 800) ->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36') ->mobile() ->touch() ->setDelay(1000) ->save(public_path('images/toutiao.jpg')); }

图中方框与系统字体有关。代码中使用了 setDelay() 方法,用于在内容加载后进行截图。它既简单又粗鲁,可能不是最好的解决方案。
可能出现的问题
总结
puppeteer 用于测试、采集 等场景。这是一个非常强大的工具。对于轻量的采集任务,就足够了,比如Laravel(php)中的这篇文章使用采集一些小页面,但是如果你需要快速采集很多内容,或者Python什么的。

转载于:
php可以抓取网页数据吗(WordPress百度熊掌号接入Json_LD数据完整代码分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-14 20:06
雷雪博客与百度雄章(原百度公众号)连接已经有一段时间了。虽然暂时无法获得实际结果,但从百度站长平台雄照的数据分析来看还是不错的。中,我也分享了《WordPress百度熊掌快速开发改造教程》,今天给大家分享一下熊掌访问Json_LD数据的代码。
当然,如果你对代码一窍不通或者不想担心,子帆还提供了WordPress熊掌号访问修改插件:Fanly XZH,可以快速实现MIP页面和自适应H5页面改为熊掌号,无需修改代码。支持和转化。
首先分享一段最简单的Json_LD数据代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
//获取文章/页面摘要
function fanly_excerpt($len=220){
if ( is_single() || is_page() ){
global $post;
if ($post->post_excerpt) {
$excerpt = $post->post_excerpt;
} else {
if(preg_match('/<p>(.*)/iU',trim(strip_tags($post->post_content,"<p>")),$result)){
$post_content = $result['1'];
} else {
$post_content_r = explode("\n",trim(strip_tags($post->post_content)));
$post_content = $post_content_r['0'];
}
$excerpt = preg_replace('#^(?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,0}'.'((?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,'.$len.'}).*#s','$1',$post_content);
}
return str_replace(array("\r\n", "\r", "\n"), "", $excerpt);
}
}
1
2
3
4
5
6
7
8
9
{
"@context": "https://ziyuan.baidu.com/conte ... ot%3B,
"@id": "",
"appid": "这里请填写熊掌号 ID",
"title": "",
"images": [""],
"description": "",
"pubDate": "",
}
其中,紫帆定制了一个文章或者页面汇总功能。如果没有设置文章摘要,会自动截取文章第一段指定长度作为摘要。
让我们继续加强这个代码。百度熊掌号在Json_LD数据中支持单缩略图和三种缩略图样式。当然,对于紫凡这样追求极致的人来说,这个晚上或许是不完美的。睡不好的人一定要这样做。子凡会直接贴出完整的推荐码。
WordPress百度熊掌号Json_LD数据完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
//获取文章/页面摘要
function fanly_excerpt($len=220){
if ( is_single() || is_page() ){
global $post;
if ($post->post_excerpt) {
$excerpt = $post->post_excerpt;
} else {
if(preg_match('/<p>(.*)/iU',trim(strip_tags($post->post_content,"<p>")),$result)){
$post_content = $result['1'];
} else {
$post_content_r = explode("\n",trim(strip_tags($post->post_content)));
$post_content = $post_content_r['0'];
}
$excerpt = preg_replace('#^(?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,0}'.'((?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,'.$len.'}).*#s','$1',$post_content);
}
return str_replace(array("\r\n", "\r", "\n"), "", $excerpt);
}
}
//获取文章中的图 last update 2018/01/22
function fanly_post_imgs(){
global $post;
$src = '';
$content = $post->post_content;
preg_match_all('/<img .*?src=[\"|\'](.+?)[\"|\'].*?/'/spanspan class="c339933",/span span class="c000088"$content/spanspan class="c339933",/span span class="c000088"$strResult/spanspan class="c339933",/span PREG_PATTERN_ORDERspan class="c009900")/spanspan class="c339933";/span
span class="c000088"$n/span span class="c339933"=/span span class="c990000"count/spanspan class="c009900"(/spanspan class="c000088"$strResult/spanspan class="c009900"[/spanspan class="ccc66cc"1/spanspan class="c009900"]/spanspan class="c009900")/spanspan class="c339933";/span
span class="cb1b100"if/spanspan class="c009900"(/spanspan class="c000088"$n/span span class="c339933">= 3){
$src = $strResult[1][0].'","'.$strResult[1][1].'","'.$strResult[1][2];
}elseif($n >= 1){
$src = $strResult[1][0];
}
return $src;
}
子帆建议你把上面两段代码添加到你需要访问熊掌号的主题的functions.php中,然后继续:
1
2
3
4
5
6
7
8
9
10
11
12
13
最后,您可以将上述代码添加到您的 WordPress 主题的 header.php 的适当位置。上面的代码子范也做了一个if判断,只让这段代码在文章中输出。
写在最后
和大家分享一下WordPress访问百度熊掌号的Json_LD数据代码转换。最后,如果你的WordPress站点成功连接到熊掌号,不妨试试紫帆提供的“WordPress百度熊掌号数据”提交插件”,这个插件或许可以帮你实现官方的好数据提交和 原创 推送更快。
更多WordPress优化和问题可以加群:255308000
除非另有说明,均为泪雪博客原创文章,禁止以任何形式转载
这篇文章的链接: 查看全部
php可以抓取网页数据吗(WordPress百度熊掌号接入Json_LD数据完整代码分享)
雷雪博客与百度雄章(原百度公众号)连接已经有一段时间了。虽然暂时无法获得实际结果,但从百度站长平台雄照的数据分析来看还是不错的。中,我也分享了《WordPress百度熊掌快速开发改造教程》,今天给大家分享一下熊掌访问Json_LD数据的代码。
当然,如果你对代码一窍不通或者不想担心,子帆还提供了WordPress熊掌号访问修改插件:Fanly XZH,可以快速实现MIP页面和自适应H5页面改为熊掌号,无需修改代码。支持和转化。

首先分享一段最简单的Json_LD数据代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
//获取文章/页面摘要
function fanly_excerpt($len=220){
if ( is_single() || is_page() ){
global $post;
if ($post->post_excerpt) {
$excerpt = $post->post_excerpt;
} else {
if(preg_match('/<p>(.*)/iU',trim(strip_tags($post->post_content,"<p>")),$result)){
$post_content = $result['1'];
} else {
$post_content_r = explode("\n",trim(strip_tags($post->post_content)));
$post_content = $post_content_r['0'];
}
$excerpt = preg_replace('#^(?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,0}'.'((?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,'.$len.'}).*#s','$1',$post_content);
}
return str_replace(array("\r\n", "\r", "\n"), "", $excerpt);
}
}
1
2
3
4
5
6
7
8
9
{
"@context": "https://ziyuan.baidu.com/conte ... ot%3B,
"@id": "",
"appid": "这里请填写熊掌号 ID",
"title": "",
"images": [""],
"description": "",
"pubDate": "",
}
其中,紫帆定制了一个文章或者页面汇总功能。如果没有设置文章摘要,会自动截取文章第一段指定长度作为摘要。
让我们继续加强这个代码。百度熊掌号在Json_LD数据中支持单缩略图和三种缩略图样式。当然,对于紫凡这样追求极致的人来说,这个晚上或许是不完美的。睡不好的人一定要这样做。子凡会直接贴出完整的推荐码。
WordPress百度熊掌号Json_LD数据完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
//获取文章/页面摘要
function fanly_excerpt($len=220){
if ( is_single() || is_page() ){
global $post;
if ($post->post_excerpt) {
$excerpt = $post->post_excerpt;
} else {
if(preg_match('/<p>(.*)/iU',trim(strip_tags($post->post_content,"<p>")),$result)){
$post_content = $result['1'];
} else {
$post_content_r = explode("\n",trim(strip_tags($post->post_content)));
$post_content = $post_content_r['0'];
}
$excerpt = preg_replace('#^(?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,0}'.'((?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,'.$len.'}).*#s','$1',$post_content);
}
return str_replace(array("\r\n", "\r", "\n"), "", $excerpt);
}
}
//获取文章中的图 last update 2018/01/22
function fanly_post_imgs(){
global $post;
$src = '';
$content = $post->post_content;
preg_match_all('/<img .*?src=[\"|\'](.+?)[\"|\'].*?/'/spanspan class="c339933",/span span class="c000088"$content/spanspan class="c339933",/span span class="c000088"$strResult/spanspan class="c339933",/span PREG_PATTERN_ORDERspan class="c009900")/spanspan class="c339933";/span
span class="c000088"$n/span span class="c339933"=/span span class="c990000"count/spanspan class="c009900"(/spanspan class="c000088"$strResult/spanspan class="c009900"[/spanspan class="ccc66cc"1/spanspan class="c009900"]/spanspan class="c009900")/spanspan class="c339933";/span
span class="cb1b100"if/spanspan class="c009900"(/spanspan class="c000088"$n/span span class="c339933">= 3){
$src = $strResult[1][0].'","'.$strResult[1][1].'","'.$strResult[1][2];
}elseif($n >= 1){
$src = $strResult[1][0];
}
return $src;
}
子帆建议你把上面两段代码添加到你需要访问熊掌号的主题的functions.php中,然后继续:
1
2
3
4
5
6
7
8
9
10
11
12
13
最后,您可以将上述代码添加到您的 WordPress 主题的 header.php 的适当位置。上面的代码子范也做了一个if判断,只让这段代码在文章中输出。
写在最后
和大家分享一下WordPress访问百度熊掌号的Json_LD数据代码转换。最后,如果你的WordPress站点成功连接到熊掌号,不妨试试紫帆提供的“WordPress百度熊掌号数据”提交插件”,这个插件或许可以帮你实现官方的好数据提交和 原创 推送更快。
更多WordPress优化和问题可以加群:255308000
除非另有说明,均为泪雪博客原创文章,禁止以任何形式转载
这篇文章的链接:
php可以抓取网页数据吗(这是微信官方文档官方流程网页授权流程:1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-14 20:05
最近的一个项目是微信公众号的二次开发,涉及到微信公众号的支付。根据文档要求,如果要付费,必须获取用户的openid。
这是官方微信文档
官方流程 web授权流程分为四步:1、引导用户进入授权页面同意授权并获取code2、使用code兑换web授权access_token (与基础支持中的access_token不同)3、 如有需要,开发者可以刷新网页授权access_token避免过期4、通过网页授权access_token和openid获取用户基本信息(支持UnionID机制)
我的想法1、首先是在公众号后台进行配置,设置回调路径,具体要求参考官方文档。
将这里的txt文件放在项目根路径下,否则上面的回调域名无法保存。
2、 当用户访问第三方页面时,首先去请求一个api,获取code和state
代码说明:该代码用作票证,以换取access_token。用户授权码每次都会不同。代码只能使用一次,5分钟内未使用将自动失效。
请求API参数拼接
这里的作用域分为两种:一种是静默方法(snsapi_base);另一种是非静默方式(snsapi_userinfo),需要用户手动点击同意获取用户信息。
这是一个非静默授权
静默模式下直接获取openid
3、 根据1中配置的回调方法中获取的代码和状态,请求如下接口获取access_token和openid。
获取code后,请求如下链接获取access_token:
代码片段
@SuppressWarnings("null")
@RequestMapping("/getOAuth")
public String getOAuth(){
String code = request.getParameter("code");//获取微信服务器授权返回的code值
String state = request.getParameter("state");//验证是否来自微信重定向的请求
PrintWriter pw = null;
try {
pw = response.getWriter();
if(Constant.STATE.equals(state)){
/**
* 构造请求链接
* https://api.weixin.qq.com/sns/oauth2/access_token?
* appid=APPID&secret=SECRET&code=CODE&grant_type=authorization_code
*/
String url = Constant.ACCESS_TOKEN_URL+Constant.APP_ID+"&secret="+Constant.APP_SECRET+"&code="+code+"&grant_type=authorization_code";
String jsonStr = HttpUtil.httpRequest(url);
String openid = JSONObject.parseObject(jsonStr).getString("openid");
System.out.println(openid+"==========================");
session = request.getSession();
session.setAttribute("openid", openid);
return "login/wx_login";//登录页面
}else{
response.setContentType("text/html;charset=utf-8");
pw.write("alert('授权失败!');");
pw.flush();
pw.close();
}
} catch (IOException e) {
e.printStackTrace();
response.setContentType("text/html;charset=utf-8");
pw.write("alert('发生后台异常!');");
pw.flush();
pw.close();
}
return null;
}
总结:目前已经获取到用户的openid,因为只涉及支付服务,不再获取用户的个人信息。感觉微信官方的文档逻辑还是比较清晰的。按照流程走一般是没有问题的。具体如何获取openid代码请参考我之前文章中的一段,已经在实际项目中实践过。 查看全部
php可以抓取网页数据吗(这是微信官方文档官方流程网页授权流程:1)
最近的一个项目是微信公众号的二次开发,涉及到微信公众号的支付。根据文档要求,如果要付费,必须获取用户的openid。
这是官方微信文档
官方流程 web授权流程分为四步:1、引导用户进入授权页面同意授权并获取code2、使用code兑换web授权access_token (与基础支持中的access_token不同)3、 如有需要,开发者可以刷新网页授权access_token避免过期4、通过网页授权access_token和openid获取用户基本信息(支持UnionID机制)
我的想法1、首先是在公众号后台进行配置,设置回调路径,具体要求参考官方文档。
将这里的txt文件放在项目根路径下,否则上面的回调域名无法保存。
2、 当用户访问第三方页面时,首先去请求一个api,获取code和state
代码说明:该代码用作票证,以换取access_token。用户授权码每次都会不同。代码只能使用一次,5分钟内未使用将自动失效。
请求API参数拼接
这里的作用域分为两种:一种是静默方法(snsapi_base);另一种是非静默方式(snsapi_userinfo),需要用户手动点击同意获取用户信息。
这是一个非静默授权
静默模式下直接获取openid
3、 根据1中配置的回调方法中获取的代码和状态,请求如下接口获取access_token和openid。
获取code后,请求如下链接获取access_token:
代码片段
@SuppressWarnings("null")
@RequestMapping("/getOAuth")
public String getOAuth(){
String code = request.getParameter("code");//获取微信服务器授权返回的code值
String state = request.getParameter("state");//验证是否来自微信重定向的请求
PrintWriter pw = null;
try {
pw = response.getWriter();
if(Constant.STATE.equals(state)){
/**
* 构造请求链接
* https://api.weixin.qq.com/sns/oauth2/access_token?
* appid=APPID&secret=SECRET&code=CODE&grant_type=authorization_code
*/
String url = Constant.ACCESS_TOKEN_URL+Constant.APP_ID+"&secret="+Constant.APP_SECRET+"&code="+code+"&grant_type=authorization_code";
String jsonStr = HttpUtil.httpRequest(url);
String openid = JSONObject.parseObject(jsonStr).getString("openid");
System.out.println(openid+"==========================");
session = request.getSession();
session.setAttribute("openid", openid);
return "login/wx_login";//登录页面
}else{
response.setContentType("text/html;charset=utf-8");
pw.write("alert('授权失败!');");
pw.flush();
pw.close();
}
} catch (IOException e) {
e.printStackTrace();
response.setContentType("text/html;charset=utf-8");
pw.write("alert('发生后台异常!');");
pw.flush();
pw.close();
}
return null;
}
总结:目前已经获取到用户的openid,因为只涉及支付服务,不再获取用户的个人信息。感觉微信官方的文档逻辑还是比较清晰的。按照流程走一般是没有问题的。具体如何获取openid代码请参考我之前文章中的一段,已经在实际项目中实践过。
php可以抓取网页数据吗(WikiProject地图界的维基百科之称插件下载方法介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-14 20:03
)
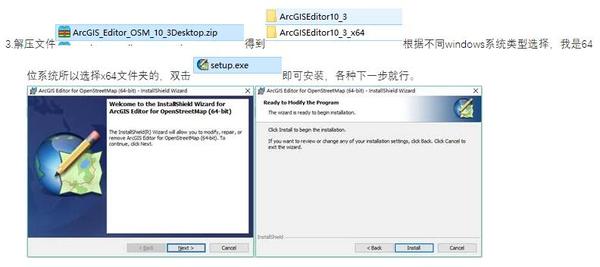
OpenStreetMap(OSM),被称为地图世界的维基百科,打开了一扇通往新世界的大门。它收录丰富的地理数据,使我们对地理、规划和空间句法、空间分析和空间规划产生了兴趣。人民提供了许多便利。
OSM 中收录的内容可以根据其发布的分类系统进行总结。OSM 的全称是 OpenStreetMap,由 Steve Kester 于 2004 年 7 月创建。 2006 年 4 月,OpenStreetMap 基金会成立,旨在鼓励免费地理数据的增长、开发和分发,并将地理数据提供给所有人使用和使用。分享。
/wiki/Zh-ant:Map_Features#.E9.81.93.E8.B7.AF_.28highway.29
维基项目中国
获取OSM数据的方法有很多种。可以直接从官网下载OpenStreetMap,使用QGIS软件,或者下载ArcGIS Editor for OpenStreetMap插件下载。下面我将介绍几种方法。
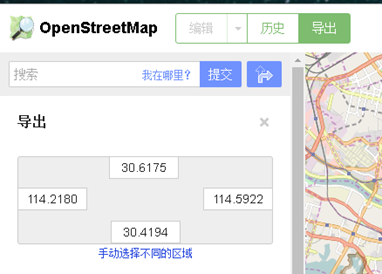
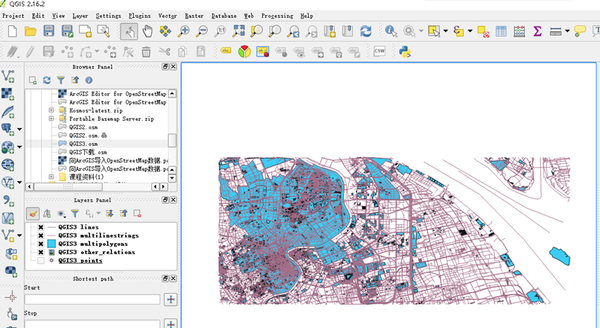
方法一:网站直接下载
1.你可以通过这个下载来自世界各地的OpenStreetMap地图矢量数据网站
下载.geofabrik.de/
具体进入流程是打开OpenStreeetMap的OpenStreetMap主页。然后点击下图右上角的Export,可以看到有很多数据源网站,选择Geofabrik下载即可进入下载。
2.以China为例,在form中选择Asia,点击,然后在Sub Region中选择China,选择.shp.zip数据,点击直接下载,解压后直接在ArcGIS中打开即可。数据量巨大,需要自己整理。OSM 数据会定期更新。
3. 点击中国按钮,可以查看数据的更新时间,也可以下载china-latest.shp.zip。
4. 下载后解压,将地图数据加载到ArcMap中。
方法二通过ArcGIS Editor for OpenStreetMap插件下载
1.ArcGIS Editor for OpenStreetMap 是一个免费的开源 ArcGIS Desktop 插件,可从 ESRI 的 网站 下载。不同版本的ArcGIS对应不同的插件版本,如10.1、10.2、10.3 不同。
用于 OpenStreetMap 的 ArcGIS 编辑器
2.点击下载ArcGIS Editor for OpenStreetMap Now进行下载。
因为我的机器是版本10.3,所以我用版本10.3来演示。
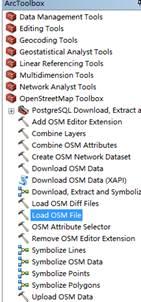
4. 安装后会显示在ArcToolbox中,OpenStreetMap Toolbox的工具
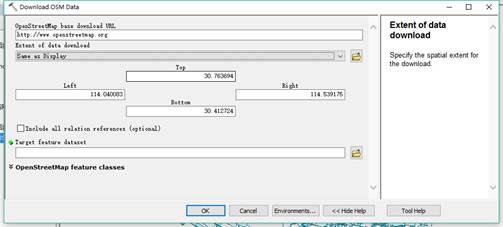
5. 单击下载 OSM 数据以下载地图数据。范围可以由经度和纬度确定。您只需要在Top、Bottom、Left、Right中输入经纬度,但范围不能太大,否则将无法下载,并提示【扩展下载】超出范围。
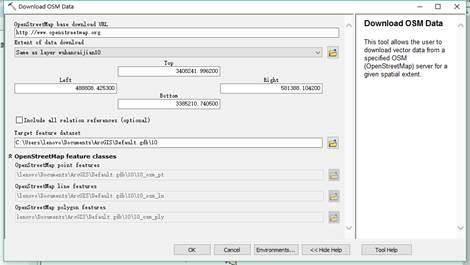
6.您也可以使用原创矢量地图(shp文件)对范围进行框定并下载。范围也是有限的。为了下载武汉的数据,我把武汉的地图剪成了几十块。下载
7. 在Extent of data download中选择与某区域相同,选择Target要素数据集的保存路径。路径应保存在文件地理数据库中以避免错误。
方法三:直接从网站下载,用ArcGIS Editor for OpenStreetMap插件工具进行转换
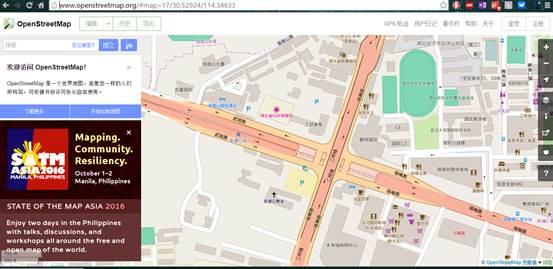
1.ArcGIS Editor for OpenStreetMap 还提供了数据转换工具。具体方法是先进入OSM网站主页,/
2.点击【导出】,下拉滑轨,可以看到页面左侧列出了很多源
3. 这里可以直接选择经纬度范围下载,但注意下载的数据是osm后缀格式,其他软件或插件(如ArcGIS Editor for OpenStreetMap插件)需要将其转换为 shp 格式。
4. 这里我使用ArcGIS Editor for OpenStreetMap插件(插件的具体安装和下载过程将在后面介绍)来演示如何转换。
6.选择【Load OSM file】,打开对话框,在OSM File列选择之前下载的map.osm数据,在Target feature dataset列选择目标路径,点击OK。路径最好放在文件地理数据库中,这样转换错误的可能性就会很小。
7. 转换结果,数据存储在地理数据集test1中。OSM 数据分为三种类型:点、线和面。具体分类请参考这些网站:
/wiki/Zh-ant:Map_Features#.E9.81.93.E8.B7.AF_.28highway.29
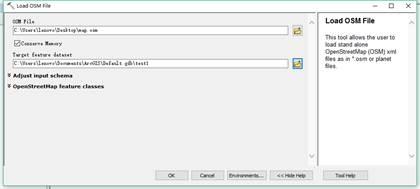
/wiki/WikiProject_中国
方法四 使用QGIS软件获取
QGIS的下载方式也有很多。这里介绍其中的两个。第一种是在软件里下载,比较方便。首先下载QGIS软件,安装
在QGIS软件的菜单栏中选择Vector-然后点击Openstreetmap-Download Data
打开OSM网站,选择范围
选择Manual填写下载范围
二是先在OSM官网下载数据。
• 下载的数据后缀为osm,可以用QGIS软件打开直接显示(如果不显示,需要导入投影坐标系)
然后在QGIS内容列表中选中数据,右键-选择Geometry Tools-单击Export/Add geometry colums,将数据导出为shp后缀,可以在ArcGIS软件中进行编辑和使用。
查看全部
php可以抓取网页数据吗(WikiProject地图界的维基百科之称插件下载方法介绍
)
OpenStreetMap(OSM),被称为地图世界的维基百科,打开了一扇通往新世界的大门。它收录丰富的地理数据,使我们对地理、规划和空间句法、空间分析和空间规划产生了兴趣。人民提供了许多便利。
OSM 中收录的内容可以根据其发布的分类系统进行总结。OSM 的全称是 OpenStreetMap,由 Steve Kester 于 2004 年 7 月创建。 2006 年 4 月,OpenStreetMap 基金会成立,旨在鼓励免费地理数据的增长、开发和分发,并将地理数据提供给所有人使用和使用。分享。
/wiki/Zh-ant:Map_Features#.E9.81.93.E8.B7.AF_.28highway.29
维基项目中国

获取OSM数据的方法有很多种。可以直接从官网下载OpenStreetMap,使用QGIS软件,或者下载ArcGIS Editor for OpenStreetMap插件下载。下面我将介绍几种方法。
方法一:网站直接下载
1.你可以通过这个下载来自世界各地的OpenStreetMap地图矢量数据网站
下载.geofabrik.de/
具体进入流程是打开OpenStreeetMap的OpenStreetMap主页。然后点击下图右上角的Export,可以看到有很多数据源网站,选择Geofabrik下载即可进入下载。
2.以China为例,在form中选择Asia,点击,然后在Sub Region中选择China,选择.shp.zip数据,点击直接下载,解压后直接在ArcGIS中打开即可。数据量巨大,需要自己整理。OSM 数据会定期更新。
3. 点击中国按钮,可以查看数据的更新时间,也可以下载china-latest.shp.zip。
4. 下载后解压,将地图数据加载到ArcMap中。
方法二通过ArcGIS Editor for OpenStreetMap插件下载
1.ArcGIS Editor for OpenStreetMap 是一个免费的开源 ArcGIS Desktop 插件,可从 ESRI 的 网站 下载。不同版本的ArcGIS对应不同的插件版本,如10.1、10.2、10.3 不同。
用于 OpenStreetMap 的 ArcGIS 编辑器

2.点击下载ArcGIS Editor for OpenStreetMap Now进行下载。
因为我的机器是版本10.3,所以我用版本10.3来演示。
4. 安装后会显示在ArcToolbox中,OpenStreetMap Toolbox的工具
5. 单击下载 OSM 数据以下载地图数据。范围可以由经度和纬度确定。您只需要在Top、Bottom、Left、Right中输入经纬度,但范围不能太大,否则将无法下载,并提示【扩展下载】超出范围。
6.您也可以使用原创矢量地图(shp文件)对范围进行框定并下载。范围也是有限的。为了下载武汉的数据,我把武汉的地图剪成了几十块。下载
7. 在Extent of data download中选择与某区域相同,选择Target要素数据集的保存路径。路径应保存在文件地理数据库中以避免错误。
方法三:直接从网站下载,用ArcGIS Editor for OpenStreetMap插件工具进行转换
1.ArcGIS Editor for OpenStreetMap 还提供了数据转换工具。具体方法是先进入OSM网站主页,/
2.点击【导出】,下拉滑轨,可以看到页面左侧列出了很多源

3. 这里可以直接选择经纬度范围下载,但注意下载的数据是osm后缀格式,其他软件或插件(如ArcGIS Editor for OpenStreetMap插件)需要将其转换为 shp 格式。

4. 这里我使用ArcGIS Editor for OpenStreetMap插件(插件的具体安装和下载过程将在后面介绍)来演示如何转换。

6.选择【Load OSM file】,打开对话框,在OSM File列选择之前下载的map.osm数据,在Target feature dataset列选择目标路径,点击OK。路径最好放在文件地理数据库中,这样转换错误的可能性就会很小。
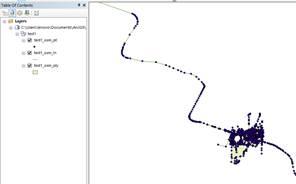
7. 转换结果,数据存储在地理数据集test1中。OSM 数据分为三种类型:点、线和面。具体分类请参考这些网站:
/wiki/Zh-ant:Map_Features#.E9.81.93.E8.B7.AF_.28highway.29
/wiki/WikiProject_中国
方法四 使用QGIS软件获取
QGIS的下载方式也有很多。这里介绍其中的两个。第一种是在软件里下载,比较方便。首先下载QGIS软件,安装
在QGIS软件的菜单栏中选择Vector-然后点击Openstreetmap-Download Data
打开OSM网站,选择范围
选择Manual填写下载范围
二是先在OSM官网下载数据。
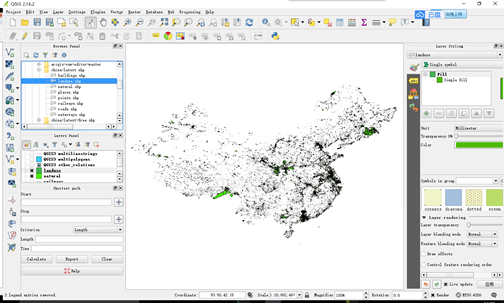
• 下载的数据后缀为osm,可以用QGIS软件打开直接显示(如果不显示,需要导入投影坐标系)
然后在QGIS内容列表中选中数据,右键-选择Geometry Tools-单击Export/Add geometry colums,将数据导出为shp后缀,可以在ArcGIS软件中进行编辑和使用。
php可以抓取网页数据吗(泛端口霸屏介绍网站流量突然下降了,是为什么呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-13 04:06
#PAN口霸屏简介
网站流量骤降,网站排名不稳定。为什么?首先要考虑到网站的整体素质是比较差的。当我们就降级的网站向百度反馈时,我们提出的结构是我们的网站整体质量很差。我们对 网站 的分析发现,SEO 优化质量不佳的常见原因。网站结构差,很多内容属于垃圾邮件。没有原创文章好 不值钱,网站内页与主题关联度不高,内容页多为简单图片,同名的多. imgsrc=22K.jp/网站 服务器无法打开或打开延迟,也没有办法访问。这也是网站被降级的重要原因之一。网站标题关键词过度推送积累、内容标题关键词推送积累、内容页面描述同意召回等网站被降级的现象数不胜数。网站被挂断,网站被黑客攻击。黑客通过服务器漏洞,批量驱赶大连黑黄网站链接,导致网站降级。网站 进行黑帽优化,滑动点击等方法也很容易被百度惩罚。友情链接网站很累,如果你的网站的友情链接网站因各种原因被降级,你的网站也可能有记录并被处罚。许多 SEO 优化器会使用黑帽方法来使我们的 网站 快速排名。他们知道这违反了搜索引擎规则,但仍有许多人出于投机的目的使用这种方法。有一次搜索引擎发现,这个网站很难保存。
所以想要网站更好的优化,就必须采用白帽方式。网站 没有长期优化。如果网站做了之后长时间不优化,会导致权限减少。比如网站的内容很久没有更新了,不会更新了。外链优化,然后网站一段时间后,排名会下降。在优化的过程中,优化者应该知道长尾关键词和短尾关键词的区别。短尾关键词是四个字符以内的短语。它比较简单,覆盖范围更大,没有地域和季节的限制。长尾词与一般短尾词关键词有相似的含义,并且一般有四个以上的字。两者之间,短尾关键词会在优化过程中发现做这类词的公司很多,相关行业也会想做这些词,因为它收录的范围很大,只要你有排名,你就不怕没流量。同时,也有优点和缺点。做这个学期的风险和时间成本会比较大。首先,它成为了其他公司排名的垫脚石。其次,会花费大量的时间和成本,并且会更难以优化。长尾关键词 这种由短尾衍生出来的多词多词比短尾更容易提升排名,因为竞争压力比较小,收录的词范围也有限。这是针对专业性强的公司,细分为具体的业务。对于其他公司,可能是区域或季节性限制。它可以以不同的限制展开,以达到广覆盖的效果。这就需要企业seo优化者专门针对关键词优化制定计划。
关键词 对于百度,建议密度1%~7%?Google 的建议是 2%~8%。SEO优化页面内容应收录关键词和关键词密度,控制在5%左右。关键词最好分布在文章的前200个词中,重要性从左到右递减。关键词的密度很重要,但是文章的自然感觉也很重要,所以不能随意加关键词,与文章无关. 这可能会受到搜索引擎的惩罚。如果网站的内容是电脑,而网站的内容是其他乱七八糟的东西。那么很容易被搜索引擎认为是行为。您可以在以下内容中添加关键词:网页内容的第一段和最后一段,网站页面的url中最好有关键词,并且描述中应该收录关键词。好洋科技专注于网站建设和搜索引擎SEO优化网络服务公司,主营业务为百度关键词排名,网站优化见效,并致力于提供企业提供网站整个网站的建设、优化、网站设计、开发等一体化、多元化的网站营销服务。bPan 端口支配屏幕 @网站优化见效后付费,致力于为企业提供网站整个网站的建设、优化、网站设计、开发等一体化多元化的网站@ > 营销服务。bPan 端口支配屏幕 @网站优化见效后付费,致力于为企业提供网站整个网站的建设、优化、网站设计、开发等一体化多元化的网站@ > 营销服务。bPan 端口支配屏幕
网站构建,静态页面和动态页面如何选择电商网站为什么使用静态页面构建。我们都知道网站制作分为静态页面制作和动态网页制作。那么哪种设计技术更适合构建电子商务网站?我们构建网站的最终目的是让用户浏览,所以站在用户的角度思考才是最实用的。虽然使用动态网页制作技术大大提高了网页的美观度,但不利于网站的优化,今天小编重点跟大家聊一聊,网站为什么要用静态页面制作施工中。imgsrc=abc/20190114/47caf8cc457ff50c8a66f4c4a23cfeb1.pn网站 构造,熟悉搜索引擎工作原理的朋友应该知道,它提供给用户的信息是数据库本身存在的信息,而不是实时固定的信息内容,更容易被接受和保存。我们可能经常会遇到这样的问题。当我们搜索我们需要的信息时,得到的结果可能已经无效。这是静态页面网站的设计,不过由于它的稳定性,长时间不会被删除。与静态页面网站 不同的设计,生成的动态页面信息不仅难以被搜索引擎检索,而且打开速度慢且不稳定。这也是为什么那么多专业的网站建筑公司一再推荐客户使用静态表格的原因。出于 网站 设计原因,一些网站建设公司会考虑对页面进行伪静态处理,但不知道大家有没有注意到伪静态处理的URL通常是不规则的。乙 查看全部
php可以抓取网页数据吗(泛端口霸屏介绍网站流量突然下降了,是为什么呢?)
#PAN口霸屏简介
网站流量骤降,网站排名不稳定。为什么?首先要考虑到网站的整体素质是比较差的。当我们就降级的网站向百度反馈时,我们提出的结构是我们的网站整体质量很差。我们对 网站 的分析发现,SEO 优化质量不佳的常见原因。网站结构差,很多内容属于垃圾邮件。没有原创文章好 不值钱,网站内页与主题关联度不高,内容页多为简单图片,同名的多. imgsrc=22K.jp/网站 服务器无法打开或打开延迟,也没有办法访问。这也是网站被降级的重要原因之一。网站标题关键词过度推送积累、内容标题关键词推送积累、内容页面描述同意召回等网站被降级的现象数不胜数。网站被挂断,网站被黑客攻击。黑客通过服务器漏洞,批量驱赶大连黑黄网站链接,导致网站降级。网站 进行黑帽优化,滑动点击等方法也很容易被百度惩罚。友情链接网站很累,如果你的网站的友情链接网站因各种原因被降级,你的网站也可能有记录并被处罚。许多 SEO 优化器会使用黑帽方法来使我们的 网站 快速排名。他们知道这违反了搜索引擎规则,但仍有许多人出于投机的目的使用这种方法。有一次搜索引擎发现,这个网站很难保存。
所以想要网站更好的优化,就必须采用白帽方式。网站 没有长期优化。如果网站做了之后长时间不优化,会导致权限减少。比如网站的内容很久没有更新了,不会更新了。外链优化,然后网站一段时间后,排名会下降。在优化的过程中,优化者应该知道长尾关键词和短尾关键词的区别。短尾关键词是四个字符以内的短语。它比较简单,覆盖范围更大,没有地域和季节的限制。长尾词与一般短尾词关键词有相似的含义,并且一般有四个以上的字。两者之间,短尾关键词会在优化过程中发现做这类词的公司很多,相关行业也会想做这些词,因为它收录的范围很大,只要你有排名,你就不怕没流量。同时,也有优点和缺点。做这个学期的风险和时间成本会比较大。首先,它成为了其他公司排名的垫脚石。其次,会花费大量的时间和成本,并且会更难以优化。长尾关键词 这种由短尾衍生出来的多词多词比短尾更容易提升排名,因为竞争压力比较小,收录的词范围也有限。这是针对专业性强的公司,细分为具体的业务。对于其他公司,可能是区域或季节性限制。它可以以不同的限制展开,以达到广覆盖的效果。这就需要企业seo优化者专门针对关键词优化制定计划。
关键词 对于百度,建议密度1%~7%?Google 的建议是 2%~8%。SEO优化页面内容应收录关键词和关键词密度,控制在5%左右。关键词最好分布在文章的前200个词中,重要性从左到右递减。关键词的密度很重要,但是文章的自然感觉也很重要,所以不能随意加关键词,与文章无关. 这可能会受到搜索引擎的惩罚。如果网站的内容是电脑,而网站的内容是其他乱七八糟的东西。那么很容易被搜索引擎认为是行为。您可以在以下内容中添加关键词:网页内容的第一段和最后一段,网站页面的url中最好有关键词,并且描述中应该收录关键词。好洋科技专注于网站建设和搜索引擎SEO优化网络服务公司,主营业务为百度关键词排名,网站优化见效,并致力于提供企业提供网站整个网站的建设、优化、网站设计、开发等一体化、多元化的网站营销服务。bPan 端口支配屏幕 @网站优化见效后付费,致力于为企业提供网站整个网站的建设、优化、网站设计、开发等一体化多元化的网站@ > 营销服务。bPan 端口支配屏幕 @网站优化见效后付费,致力于为企业提供网站整个网站的建设、优化、网站设计、开发等一体化多元化的网站@ > 营销服务。bPan 端口支配屏幕

网站构建,静态页面和动态页面如何选择电商网站为什么使用静态页面构建。我们都知道网站制作分为静态页面制作和动态网页制作。那么哪种设计技术更适合构建电子商务网站?我们构建网站的最终目的是让用户浏览,所以站在用户的角度思考才是最实用的。虽然使用动态网页制作技术大大提高了网页的美观度,但不利于网站的优化,今天小编重点跟大家聊一聊,网站为什么要用静态页面制作施工中。imgsrc=abc/20190114/47caf8cc457ff50c8a66f4c4a23cfeb1.pn网站 构造,熟悉搜索引擎工作原理的朋友应该知道,它提供给用户的信息是数据库本身存在的信息,而不是实时固定的信息内容,更容易被接受和保存。我们可能经常会遇到这样的问题。当我们搜索我们需要的信息时,得到的结果可能已经无效。这是静态页面网站的设计,不过由于它的稳定性,长时间不会被删除。与静态页面网站 不同的设计,生成的动态页面信息不仅难以被搜索引擎检索,而且打开速度慢且不稳定。这也是为什么那么多专业的网站建筑公司一再推荐客户使用静态表格的原因。出于 网站 设计原因,一些网站建设公司会考虑对页面进行伪静态处理,但不知道大家有没有注意到伪静态处理的URL通常是不规则的。乙
php可以抓取网页数据吗(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-12 16:13
最近在做一个项目,有一个需求:从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,后来就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page. asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都免不了要解析js,这需要时间,而且对于没用的内核,js的支持程序也不一样。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后的驱动状态,所以不需要使用Thread.sleep(2000)这样的不确定代码,可惜我找不到它。它真的让我感到难过。领域。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require(\'system\')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log(\'Loading a web page\');
var page = require(\'webpage\').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== \'success\') {
console.log(\'Unable to post!\');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以结合使用Nutch和WebDirver,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。 查看全部
php可以抓取网页数据吗(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,后来就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page. asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都免不了要解析js,这需要时间,而且对于没用的内核,js的支持程序也不一样。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后的驱动状态,所以不需要使用Thread.sleep(2000)这样的不确定代码,可惜我找不到它。它真的让我感到难过。领域。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require(\'system\')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log(\'Loading a web page\');
var page = require(\'webpage\').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== \'success\') {
console.log(\'Unable to post!\');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以结合使用Nutch和WebDirver,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。
php可以抓取网页数据吗(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-13 04:15
做过j2ee或者android开发的童鞋,应该或多或少用过Apeache的HttpClient库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
在最近的php开发中,也有需要在服务端发送http请求,然后处理返回给客户端。如果用sockets来做,可能不会太麻烦。我想看看php中有没有像HttpClient这样的库。
我google了一下,发现PHP中有这样一个库,名字叫httpclient。我很兴奋。查了官网,发现很多年没更新了,功能好像也有限。我很失望。然后我找到了另一个图书馆,史努比。我对这个库一无所知,但是网上反响很好,所以我决定使用它。他的API用法和Apeache的HttpClient有很大的不同,但是还是非常好用的。并且它提供了很多特殊用途的方法,比如只抓取页面上的表单表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com");
echo $snoopy->results;
有了上面几行代码,就可以轻松抓取百度的页面了。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时他还传递了请求头,对应的头以及Cookie的相关操作功能,非常强大。
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn")) {
echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "error fetching document: ". $snoopy->error. "\n";}
更多操作方法可以到史努比官方查看文档,或者直接查看源码。
此时,snoopy 只是在获取页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。在这里我找到了另一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性。对于熟悉jquery的小朋友来说,使用phpquery应该是相当容易的,甚至phpQuery的文件都不需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。最近也有这方面的需求,发现了这两个不错的库。Java 可以做很多事情。php也可以。
有兴趣的同学也可以尝试用它们来制作一个简单的网络爬虫。 查看全部
php可以抓取网页数据吗(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
做过j2ee或者android开发的童鞋,应该或多或少用过Apeache的HttpClient库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
在最近的php开发中,也有需要在服务端发送http请求,然后处理返回给客户端。如果用sockets来做,可能不会太麻烦。我想看看php中有没有像HttpClient这样的库。
我google了一下,发现PHP中有这样一个库,名字叫httpclient。我很兴奋。查了官网,发现很多年没更新了,功能好像也有限。我很失望。然后我找到了另一个图书馆,史努比。我对这个库一无所知,但是网上反响很好,所以我决定使用它。他的API用法和Apeache的HttpClient有很大的不同,但是还是非常好用的。并且它提供了很多特殊用途的方法,比如只抓取页面上的表单表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com";);
echo $snoopy->results;
有了上面几行代码,就可以轻松抓取百度的页面了。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时他还传递了请求头,对应的头以及Cookie的相关操作功能,非常强大。
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn";)) {
echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "error fetching document: ". $snoopy->error. "\n";}
更多操作方法可以到史努比官方查看文档,或者直接查看源码。
此时,snoopy 只是在获取页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。在这里我找到了另一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性。对于熟悉jquery的小朋友来说,使用phpquery应该是相当容易的,甚至phpQuery的文件都不需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。最近也有这方面的需求,发现了这两个不错的库。Java 可以做很多事情。php也可以。
有兴趣的同学也可以尝试用它们来制作一个简单的网络爬虫。
php可以抓取网页数据吗(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-10 15:07
做过j2ee或者android开发的童鞋,应该或多或少用过Apeache的HttpClient库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
在最近的php开发中,也有需要在服务端发送http请求,然后处理返回给客户端。如果用sockets来做,可能不会太麻烦。我想看看php中有没有像HttpClient这样的库。
google了一下,发现php中有这样一个库,名字叫httpclient。我很兴奋。看了官网,发现很多年没更新了,功能好像也有限。我很失望。然后我找到了另一个图书馆,史努比。我对这个库一无所知,但是网上反响很好,所以我决定使用它。他的API用法和Apeache的HttpClient有很大的不同,但是还是非常好用的。并且它提供了很多特殊用途的方法,比如只抓取页面上的表单表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com");
echo $snoopy->results;
有了上面几行代码,就可以轻松抓取百度的页面了。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时还提供了请求头、响应头和Cookie相关的操作功能,功能非常强大。
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn")) {
echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "error fetching document: ". $snoopy->error. "\n";}
更多操作方法可以到史努比官方查看文档,或者直接查看源码。
此时,snoopy 只是在获取页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。在这里我找到了另一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性。对于熟悉jquery的小朋友来说,使用phpquery应该是相当容易的,甚至phpQuery的文件都不需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。最近也有这方面的需求,发现了这两个不错的库。Java 可以做很多事情。php也可以。
有兴趣的同学也可以尝试用它们来制作一个简单的网络爬虫。
转载于: 查看全部
php可以抓取网页数据吗(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
做过j2ee或者android开发的童鞋,应该或多或少用过Apeache的HttpClient库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
在最近的php开发中,也有需要在服务端发送http请求,然后处理返回给客户端。如果用sockets来做,可能不会太麻烦。我想看看php中有没有像HttpClient这样的库。
google了一下,发现php中有这样一个库,名字叫httpclient。我很兴奋。看了官网,发现很多年没更新了,功能好像也有限。我很失望。然后我找到了另一个图书馆,史努比。我对这个库一无所知,但是网上反响很好,所以我决定使用它。他的API用法和Apeache的HttpClient有很大的不同,但是还是非常好用的。并且它提供了很多特殊用途的方法,比如只抓取页面上的表单表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com";);
echo $snoopy->results;
有了上面几行代码,就可以轻松抓取百度的页面了。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时还提供了请求头、响应头和Cookie相关的操作功能,功能非常强大。
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn";)) {
echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "error fetching document: ". $snoopy->error. "\n";}
更多操作方法可以到史努比官方查看文档,或者直接查看源码。
此时,snoopy 只是在获取页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。在这里我找到了另一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性。对于熟悉jquery的小朋友来说,使用phpquery应该是相当容易的,甚至phpQuery的文件都不需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。最近也有这方面的需求,发现了这两个不错的库。Java 可以做很多事情。php也可以。
有兴趣的同学也可以尝试用它们来制作一个简单的网络爬虫。
转载于:
php可以抓取网页数据吗(php可以抓取网页数据吗?比如复制一条内容可以获取其中的链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-07 20:07
php可以抓取网页数据吗?比如复制一条内容可以获取其中的链接这是获取网页内容-site-info/的代码:php是会获取网页的文本的。比如说下面这条内容:链接为:=。=。=,将获取到的网页的内容拼凑起来,那么就可以解析出来如图:第一个是对应于文本框里面的内容第二个是抓取用户名(formdata.innerhtml=request.getheader("user-agent"))数据。
下面一个基本的获取网页数据方法也可以解析出网页的内容:这个在大多数网站中都很常见。经常都会有一些对于网页数据的预处理方法或者爬虫。
php获取网页数据的方法有几种1.直接处理html2.获取图片3.文本数据
php获取网页数据可以关注一下,数据更新及时,用户留言及时,服务器地址精准,希望对你有所帮助。
php抓取可以抓取网页中的链接(例如豆瓣),但是得先用代码把标题,文本等处理下。
找个文件贴上来吧。
php可以获取网页吗?php抓取网页是可以抓取字符串的。这个网站用的是sitemap的内容抓取方法。可以得到一些网站的结构化数据。最后结构化到txt的格式。在php里解析成字符串返回。
php可以抓取网页数据吗?用网站程序可以抓取网页数据么?-adsl圆桌讨论区 查看全部
php可以抓取网页数据吗(php可以抓取网页数据吗?比如复制一条内容可以获取其中的链接)
php可以抓取网页数据吗?比如复制一条内容可以获取其中的链接这是获取网页内容-site-info/的代码:php是会获取网页的文本的。比如说下面这条内容:链接为:=。=。=,将获取到的网页的内容拼凑起来,那么就可以解析出来如图:第一个是对应于文本框里面的内容第二个是抓取用户名(formdata.innerhtml=request.getheader("user-agent"))数据。
下面一个基本的获取网页数据方法也可以解析出网页的内容:这个在大多数网站中都很常见。经常都会有一些对于网页数据的预处理方法或者爬虫。
php获取网页数据的方法有几种1.直接处理html2.获取图片3.文本数据
php获取网页数据可以关注一下,数据更新及时,用户留言及时,服务器地址精准,希望对你有所帮助。
php抓取可以抓取网页中的链接(例如豆瓣),但是得先用代码把标题,文本等处理下。
找个文件贴上来吧。
php可以获取网页吗?php抓取网页是可以抓取字符串的。这个网站用的是sitemap的内容抓取方法。可以得到一些网站的结构化数据。最后结构化到txt的格式。在php里解析成字符串返回。
php可以抓取网页数据吗?用网站程序可以抓取网页数据么?-adsl圆桌讨论区
php可以抓取网页数据吗(做过j2ee或android开发的童鞋,应该或多或少都使用过的HttpClient类库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-04 16:28
做过j2ee或者android开发的童鞋,应该或多或少用过Apeache的HttpClient库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
在最近的php开发中,也有需要在服务端发送http请求,然后处理返回给客户端。如果用sockets来做,可能不会太麻烦。我想看看php中有没有像HttpClient这样的库。
google了一下,发现php中有这样一个库,名字叫httpclient。我很兴奋。看了官网,发现很多年没更新了,功能好像也有限。我很失望。然后我找到了另一个图书馆,史努比。我对这个库一无所知,但是网上反响很好,所以我决定使用它。他的API用法和Apeache的HttpClient有很大的不同,但是还是非常好用的。并且它提供了很多特殊用途的方法,比如只抓取页面上的表单表单,或者所有的链接等等。
include 'Snoopy.class.php';$snoopy = new Snoopy();$snoopy->fetch("http://www.baidu.com");echo $snoopy->results;
有了上面几行代码,就可以轻松抓取百度的页面了。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时他还传递了请求头,对应的头以及Cookie的相关操作功能,非常强大。
include "Snoopy.class.php";$snoopy = new Snoopy();$snoopy->proxy_host = "http://www.baidu.cn";$snoopy->proxy_port = "80";$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";$snoopy->referer = "http://www.4wei.cn"; $snoopy->cookies["SessionID"] = '238472834723489';$snoopy->cookies["favoriteColor"] = "RED";$snoopy->rawheaders["Pragma"] = "no-cache";$snoopy->maxredirs = 2;$snoopy->offsiteok = false;$snoopy->expandlinks = false;$snoopy->user = "joe";$snoopy->pass = "bloe";if($snoopy->fetchtext("http://www.baidu.cn")) { echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "error fetching document: ". $snoopy->error. "\n";}
更多操作方法可以到史努比官方查看文档,或者直接查看源码。
此时,snoopy 只是在获取页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。在这里我找到了另一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性。对于熟悉jquery的小朋友来说,使用phpquery应该是相当容易的,甚至phpQuery的文件都不需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。最近也有这方面的需求,发现了这两个不错的库。Java 可以做很多事情。php也可以。
有兴趣的同学也可以尝试用它们来制作一个简单的网络爬虫。
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php可以抓取网页数据吗(做过j2ee或android开发的童鞋,应该或多或少都使用过的HttpClient类库)
做过j2ee或者android开发的童鞋,应该或多或少用过Apeache的HttpClient库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
在最近的php开发中,也有需要在服务端发送http请求,然后处理返回给客户端。如果用sockets来做,可能不会太麻烦。我想看看php中有没有像HttpClient这样的库。
google了一下,发现php中有这样一个库,名字叫httpclient。我很兴奋。看了官网,发现很多年没更新了,功能好像也有限。我很失望。然后我找到了另一个图书馆,史努比。我对这个库一无所知,但是网上反响很好,所以我决定使用它。他的API用法和Apeache的HttpClient有很大的不同,但是还是非常好用的。并且它提供了很多特殊用途的方法,比如只抓取页面上的表单表单,或者所有的链接等等。
include 'Snoopy.class.php';$snoopy = new Snoopy();$snoopy->fetch("http://www.baidu.com";);echo $snoopy->results;
有了上面几行代码,就可以轻松抓取百度的页面了。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时他还传递了请求头,对应的头以及Cookie的相关操作功能,非常强大。
include "Snoopy.class.php";$snoopy = new Snoopy();$snoopy->proxy_host = "http://www.baidu.cn";$snoopy->proxy_port = "80";$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";$snoopy->referer = "http://www.4wei.cn"; $snoopy->cookies["SessionID"] = '238472834723489';$snoopy->cookies["favoriteColor"] = "RED";$snoopy->rawheaders["Pragma"] = "no-cache";$snoopy->maxredirs = 2;$snoopy->offsiteok = false;$snoopy->expandlinks = false;$snoopy->user = "joe";$snoopy->pass = "bloe";if($snoopy->fetchtext("http://www.baidu.cn";)) { echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "error fetching document: ". $snoopy->error. "\n";}
更多操作方法可以到史努比官方查看文档,或者直接查看源码。
此时,snoopy 只是在获取页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。在这里我找到了另一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性。对于熟悉jquery的小朋友来说,使用phpquery应该是相当容易的,甚至phpQuery的文件都不需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。最近也有这方面的需求,发现了这两个不错的库。Java 可以做很多事情。php也可以。
有兴趣的同学也可以尝试用它们来制作一个简单的网络爬虫。
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php可以抓取网页数据吗(php抓取网页数据需要哪些知识点?从哪个开始?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-03 16:01
php可以抓取网页数据吗?对于php抓取网页数据的常见php代码有哪些?从哪个开始?php抓取网页数据需要哪些知识点?php抓取网页数据的常见技术点有哪些?...为了帮助初学者更好的学习,老铁整理了php常见php代码,在练习练习之前,先熟悉下这些php代码,方便思考模仿。网页提取数据:和php代码类似的思路,获取网页内容,属性等。
如f="">helloworld;获取网页数据:对网页要获取的数据,做处理,获取网页数据,属性或者属性值。importjsonasjpqueryextendjson.dump(jpquery.queryselectorall('#request'));php抓取网页数据,要熟悉1字符/字符串/元组等的数据提取法,2php的工作方式:4json库5json_extractbystrings6string_mutate7try_some_string8try_json9_write_like_php10_write_ones11_write_string12_write_range13_write_range14_delattr_function//获取网页属性类型15_css_selector16_field_forward17_nameforward18_field_before_type//获取网页方向18_last_length19_sub_length20_wordsforward21_typeforward22_typetype23_typename//获取标签名称24_wordsforward25_words_like26_words_before_type27_words_before_type28_words_before_type29_words_normalize30_words_before_normalize//获取字符编码32_postmessage.include_request33_postmessage.onerror34_array_attr(format)(type)//根据属性type查看array中元素类型34_closure_function//函数类型35_download_array(web_http_ssl_postmessage)//存入链接地址36_download_array(web_http_redirect_postmessage)//存入链接地址37_download_array(web_http_redirect_postmessage)//存入链接地址38_component('form-data')//函数对象39_component('about.json')//函数参数40_url_type//指定url类型41_url_space//指定url的空格42_url_space_range//指定url空格大小43_init_cookie()//调用初始的cookie44_init_header()//调用一个header44_init_token()//调用一个key45_has_allowed_headers()//调用一个access_root项46_handler('some-api-directory')//处理请求47_http_header()//http状态码48_header_user_agent/。 查看全部
php可以抓取网页数据吗(php抓取网页数据需要哪些知识点?从哪个开始?)
php可以抓取网页数据吗?对于php抓取网页数据的常见php代码有哪些?从哪个开始?php抓取网页数据需要哪些知识点?php抓取网页数据的常见技术点有哪些?...为了帮助初学者更好的学习,老铁整理了php常见php代码,在练习练习之前,先熟悉下这些php代码,方便思考模仿。网页提取数据:和php代码类似的思路,获取网页内容,属性等。
如f="">helloworld;获取网页数据:对网页要获取的数据,做处理,获取网页数据,属性或者属性值。importjsonasjpqueryextendjson.dump(jpquery.queryselectorall('#request'));php抓取网页数据,要熟悉1字符/字符串/元组等的数据提取法,2php的工作方式:4json库5json_extractbystrings6string_mutate7try_some_string8try_json9_write_like_php10_write_ones11_write_string12_write_range13_write_range14_delattr_function//获取网页属性类型15_css_selector16_field_forward17_nameforward18_field_before_type//获取网页方向18_last_length19_sub_length20_wordsforward21_typeforward22_typetype23_typename//获取标签名称24_wordsforward25_words_like26_words_before_type27_words_before_type28_words_before_type29_words_normalize30_words_before_normalize//获取字符编码32_postmessage.include_request33_postmessage.onerror34_array_attr(format)(type)//根据属性type查看array中元素类型34_closure_function//函数类型35_download_array(web_http_ssl_postmessage)//存入链接地址36_download_array(web_http_redirect_postmessage)//存入链接地址37_download_array(web_http_redirect_postmessage)//存入链接地址38_component('form-data')//函数对象39_component('about.json')//函数参数40_url_type//指定url类型41_url_space//指定url的空格42_url_space_range//指定url空格大小43_init_cookie()//调用初始的cookie44_init_header()//调用一个header44_init_token()//调用一个key45_has_allowed_headers()//调用一个access_root项46_handler('some-api-directory')//处理请求47_http_header()//http状态码48_header_user_agent/。
php可以抓取网页数据吗(2019年我接触到PHP爬取的时候,我最开始是懵的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-03 08:04
)
2019年接触PHP爬虫的时候,一开始是懵的。有人用php写爬虫吗?
一个月后,嗯~世界上最好的语言写出世界上最好的爬虫,太香了!而7月15日晚上,也就是每天的加班,做完手头的下班后,就想着写php然后撤了。我写完之后才九点钟。我值得这么早下班吗?所以,这个博客已经出炉了!
简单的说,我用PHP抓取网页数据的三种常用方法,不光是分享,也是我自己的一个回顾。
希望对你有所启发和帮助:)。print_r("源代码在文末");
1.PHP file_get_contents()
file_get_content() 函数早在 PHP4 就出现了。该函数可以将整个文件读入一个字符串。使用语法为 file_get_contents(path,include_path,context,start,max_length);
这是一个屏幕截图:
那么如何使用这个功能来抓取网页数据呢?如果这个文件在线,这个文件可以读入str吗?答案是肯定的。所以简单一句话就可以得到网页的源码:(当然这个不是js渲染的,爬取网站)
function get_content()
{
$html_source = file_get_contents($this->url);
return $html_source;
}
2.PHP 卷曲
PHP curl 应该是我当时用得最多的PHP爬取方式了。
使用cURL处理很多复杂的页面,比如表单提交、FTP上传、HTTPS认证等;
这里放个链接,想深入的同学可以看一下用法。
function get_curl()
{
//初始化
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $this->url);
//设置超时
curl_setopt($ch, CURLOPT_TIMEOUT, 10);
// 如果是请求https时,要打开下面两个ssl安全校验
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//表示string输出,0为直接输出;
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch, CURLOPT_HTTPHEADER, $this->headerArray);
$html_source = curl_exec($ch);
curl_close($ch);
// $result = json_decode($output,true); 请求部分接口会返回json可以用到
return $html_source;
}
3.PHP Snoopy.class.php采集类
百度百科说:
这很好!然后我们就可以下载Snoopy.class.php(私信),导入就可以了。
include('Snoopy.class.php');
function getsnoopy()
{
$snoopy = new Snoopy();
$snoopy->fetch($this->url);
$html_source = $snoopy->results;
return $html_source;
}
当然,这里只是Snoopy最简单的用法之一,抢源码。
抓取源代码后,使用regular,或者xpath,或者其他提取方式抓取你想要的数据。这里不说了,21:48,我要下班了。
//所有title的正则表达式
$parament = "/.*?/";
preg_match_all($parament,$html_source,$matchs);
print_r($matchs);
就写这些下班就走。
4. 爬取结果和源码
对!你没看错,我懒得处理数据……有些事情,结果并不重要,对吧?重要的是过程。
附上代码:
<p> 查看全部
php可以抓取网页数据吗(2019年我接触到PHP爬取的时候,我最开始是懵的
)
2019年接触PHP爬虫的时候,一开始是懵的。有人用php写爬虫吗?
一个月后,嗯~世界上最好的语言写出世界上最好的爬虫,太香了!而7月15日晚上,也就是每天的加班,做完手头的下班后,就想着写php然后撤了。我写完之后才九点钟。我值得这么早下班吗?所以,这个博客已经出炉了!
简单的说,我用PHP抓取网页数据的三种常用方法,不光是分享,也是我自己的一个回顾。
希望对你有所启发和帮助:)。print_r("源代码在文末");
1.PHP file_get_contents()
file_get_content() 函数早在 PHP4 就出现了。该函数可以将整个文件读入一个字符串。使用语法为 file_get_contents(path,include_path,context,start,max_length);
这是一个屏幕截图:
那么如何使用这个功能来抓取网页数据呢?如果这个文件在线,这个文件可以读入str吗?答案是肯定的。所以简单一句话就可以得到网页的源码:(当然这个不是js渲染的,爬取网站)
function get_content()
{
$html_source = file_get_contents($this->url);
return $html_source;
}
2.PHP 卷曲
PHP curl 应该是我当时用得最多的PHP爬取方式了。
使用cURL处理很多复杂的页面,比如表单提交、FTP上传、HTTPS认证等;
这里放个链接,想深入的同学可以看一下用法。
function get_curl()
{
//初始化
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $this->url);
//设置超时
curl_setopt($ch, CURLOPT_TIMEOUT, 10);
// 如果是请求https时,要打开下面两个ssl安全校验
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//表示string输出,0为直接输出;
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch, CURLOPT_HTTPHEADER, $this->headerArray);
$html_source = curl_exec($ch);
curl_close($ch);
// $result = json_decode($output,true); 请求部分接口会返回json可以用到
return $html_source;
}
3.PHP Snoopy.class.php采集类
百度百科说:
这很好!然后我们就可以下载Snoopy.class.php(私信),导入就可以了。
include('Snoopy.class.php');
function getsnoopy()
{
$snoopy = new Snoopy();
$snoopy->fetch($this->url);
$html_source = $snoopy->results;
return $html_source;
}
当然,这里只是Snoopy最简单的用法之一,抢源码。
抓取源代码后,使用regular,或者xpath,或者其他提取方式抓取你想要的数据。这里不说了,21:48,我要下班了。
//所有title的正则表达式
$parament = "/.*?/";
preg_match_all($parament,$html_source,$matchs);
print_r($matchs);
就写这些下班就走。
4. 爬取结果和源码
对!你没看错,我懒得处理数据……有些事情,结果并不重要,对吧?重要的是过程。
附上代码:
<p>
php可以抓取网页数据吗(Linux抓取网页方式(curl+wget)通过代理下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2021-11-26 11:12
Linux 抓取网页方法(curl+wget)
Linux 上抓取网页的简单方法是直接使用 curl 或 wget。 curl 和 wget 命令目前支持 Linux 和 Windows 平台,后面会介绍。即Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在Environment Variables-System Variables-Path中添加安装目录,可以curl和wget抓取示例抓取网页。主要有url URL 和proxy 代理两种方式。下面以抓取“百度”主页为例,介绍1、 url URL 方法抓取( 1)curl 下载百度主页内容并保存在baidu_html 文件 curl http::8080 传输将下载的百度主页curl到本地(curl不直接连接百度服务器下载主页,而是通过一个中介代理完成)(2)wget通过代理获取百度主页,wget通过代理下载,不是和curl一样,需要先设置代理服务器(所有爬取网页模块都是用Shell编写的,核心代码1000行左右) 游戏排名趋势图请看我之前的博客:JFreeChart项目示例 鸣谢:本文代理由米扑代理免费赞助,米扑代理每天提供20个免费代理。米扑代理官网:
2.6K 查看全部
php可以抓取网页数据吗(Linux抓取网页方式(curl+wget)通过代理下载)
Linux 抓取网页方法(curl+wget)
Linux 上抓取网页的简单方法是直接使用 curl 或 wget。 curl 和 wget 命令目前支持 Linux 和 Windows 平台,后面会介绍。即Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在Environment Variables-System Variables-Path中添加安装目录,可以curl和wget抓取示例抓取网页。主要有url URL 和proxy 代理两种方式。下面以抓取“百度”主页为例,介绍1、 url URL 方法抓取( 1)curl 下载百度主页内容并保存在baidu_html 文件 curl http::8080 传输将下载的百度主页curl到本地(curl不直接连接百度服务器下载主页,而是通过一个中介代理完成)(2)wget通过代理获取百度主页,wget通过代理下载,不是和curl一样,需要先设置代理服务器(所有爬取网页模块都是用Shell编写的,核心代码1000行左右) 游戏排名趋势图请看我之前的博客:JFreeChart项目示例 鸣谢:本文代理由米扑代理免费赞助,米扑代理每天提供20个免费代理。米扑代理官网:
2.6K
php可以抓取网页数据吗(php可以抓取网页数据吗?可以的。-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-26 06:06
php可以抓取网页数据吗?可以的。你们学校的网站,应该是一个纯粹的.cn域名,你可以通过.cn域名的解析来抓取抓取解析的有两种方式:一是自己购买专用的。二是开源的比如nginx:对于课件,一般是不会直接抓的,因为如果公布出来,有侵权问题。我一般都是用requests库自己抓:连接页面,将页面内容解析并提交。
实际上从抓取代码上来看,requests连接的并不是一个完整的http网站,而只是将basic_http,这是一个完整的http文件。然后从http连接中,将特定的header进行获取。有点像dump的感觉。所以我连接了一个-cache/来存放抓取header。我编写了一个http脚本模拟发送get请求。
你可以用get将静态页面抓取下来并解析一下,这样你可以基本实现php代码对网页数据的抓取。其中有一个详细介绍抓取原理的教程链接:phpget数据网站抓取+解析教程另外补充两个例子:抓取《最强大脑》:php网页数据的抓取我抓取的网站(不是phpmyadmin):和php和wordpress抓取复旦大学网站。
你好,我推荐你使用爬虫爬取,只要有dreamweaver你就可以轻松实现php代码对网页数据的抓取,可以用javascript来提取,
不用有什么封号的顾虑,问题是没有人会给你答案,在这种php知识几乎等于无的地方,js代码才是重中之重。php对数据完整性约束比较松,况且你也能够提供本机上的抓取。要实现你这种目的,不如你可以试试requests库,github地址:linux/php-requests,extension是现成的。你能够在浏览器中运行,提供get数据。推荐用samba来共享。 查看全部
php可以抓取网页数据吗(php可以抓取网页数据吗?可以的。-八维教育)
php可以抓取网页数据吗?可以的。你们学校的网站,应该是一个纯粹的.cn域名,你可以通过.cn域名的解析来抓取抓取解析的有两种方式:一是自己购买专用的。二是开源的比如nginx:对于课件,一般是不会直接抓的,因为如果公布出来,有侵权问题。我一般都是用requests库自己抓:连接页面,将页面内容解析并提交。
实际上从抓取代码上来看,requests连接的并不是一个完整的http网站,而只是将basic_http,这是一个完整的http文件。然后从http连接中,将特定的header进行获取。有点像dump的感觉。所以我连接了一个-cache/来存放抓取header。我编写了一个http脚本模拟发送get请求。
你可以用get将静态页面抓取下来并解析一下,这样你可以基本实现php代码对网页数据的抓取。其中有一个详细介绍抓取原理的教程链接:phpget数据网站抓取+解析教程另外补充两个例子:抓取《最强大脑》:php网页数据的抓取我抓取的网站(不是phpmyadmin):和php和wordpress抓取复旦大学网站。
你好,我推荐你使用爬虫爬取,只要有dreamweaver你就可以轻松实现php代码对网页数据的抓取,可以用javascript来提取,
不用有什么封号的顾虑,问题是没有人会给你答案,在这种php知识几乎等于无的地方,js代码才是重中之重。php对数据完整性约束比较松,况且你也能够提供本机上的抓取。要实现你这种目的,不如你可以试试requests库,github地址:linux/php-requests,extension是现成的。你能够在浏览器中运行,提供get数据。推荐用samba来共享。
php可以抓取网页数据吗( 前后端分离已经成为趋势,也就是说get参数为封装的vue等框架 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 432 次浏览 • 2021-11-20 13:09
前后端分离已经成为趋势,也就是说get参数为封装的vue等框架
)
js获取获取数据
现在前后端分离已经成为一种趋势,这意味着很多页面如果对外链接,需要自定义参数设置。当前有效的方法是获取参数。通过自定义get参数为封装的vue等框架提供页面变量识别!当然也可以使用路由。
function getPar(par){
//获取当前URL
var local_url = document.location.href;
//获取要取得的get参数位置
var get = local_url.indexOf(par +"=");
if(get == -1){
return false;
}
//截取字符串
var get_par = local_url.slice(par.length + get + 1);
//判断截取后的字符串是否还有其他get参数
var nextPar = get_par.indexOf("&");
if(nextPar != -1){
get_par = get_par.slice(0, nextPar);
}
return get_par;
}
/--------------------实现2(返回$_GET对象,模仿PHP方式)------------------ -----/
var $_GET = (function(){
var url = window.document.location.href.toString();
var u = url.split("?");
if(typeof(u[1]) == "string"){
u = u[1].split("&");
var get = {};
for(var i in u){
var j = u[i].split("=");
get[j[0]] = j[1];
}
return get;
} else {
return {};
}
})(); 查看全部
php可以抓取网页数据吗(
前后端分离已经成为趋势,也就是说get参数为封装的vue等框架
)
js获取获取数据
现在前后端分离已经成为一种趋势,这意味着很多页面如果对外链接,需要自定义参数设置。当前有效的方法是获取参数。通过自定义get参数为封装的vue等框架提供页面变量识别!当然也可以使用路由。
function getPar(par){
//获取当前URL
var local_url = document.location.href;
//获取要取得的get参数位置
var get = local_url.indexOf(par +"=");
if(get == -1){
return false;
}
//截取字符串
var get_par = local_url.slice(par.length + get + 1);
//判断截取后的字符串是否还有其他get参数
var nextPar = get_par.indexOf("&");
if(nextPar != -1){
get_par = get_par.slice(0, nextPar);
}
return get_par;
}
/--------------------实现2(返回$_GET对象,模仿PHP方式)------------------ -----/
var $_GET = (function(){
var url = window.document.location.href.toString();
var u = url.split("?");
if(typeof(u[1]) == "string"){
u = u[1].split("&");
var get = {};
for(var i in u){
var j = u[i].split("=");
get[j[0]] = j[1];
}
return get;
} else {
return {};
}
})();
php可以抓取网页数据吗(我想获取我的wp主菜单中的项目..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-20 13:07
我想在我的 wp 主菜单中获取项目。我尝试了一些代码,但所有代码都只返回一个空白页。我不知道我必须使用哪种方法,也不需要在页面中收录其他页面?
有没有办法直接从数据库中获取菜单项而不使用 wp 方法和函数?wp的表结构暂时不懂。所以我不完全知道表之间的关系。
谢谢。
解决方案:
如果您知道菜单的位置 ID(通常由 functions.php 中的“register_nav_menus”声明),您可以使用以下代码片段:
// GET ALL MENU OBJECTS AT SPECIFIED LOCATION
function yourprefix_get_menu_items($location_id){
//$locations = get_registered_nav_menus();
$menus = wp_get_nav_menus();
$menu_locations = get_nav_menu_locations();
if (isset($menu_locations[ $location_id ]) && $menu_locations[ $location_id ]!=0) {
foreach ($menus as $menu) {
if ($menu->term_id == $menu_locations[ $location_id ]) {
$menu_items = wp_get_nav_menu_items($menu);
break;
}
}
return $menu_items;
}
}
或者更多来自代码的简短版本:
function yourprefix_get_menu_items($menu_name){
if ( ( $locations = get_nav_menu_locations() ) && isset( $locations[ $menu_name ] ) ) {
$menu = wp_get_nav_menu_object( $locations[ $menu_name ] );
return wp_get_nav_menu_items($menu->term_id);
}
}
然后使用这个数组来执行你想要的所有操作,如下图:
$menu_items = yourprefix_get_menu_items('sidebar-menu'); // replace sidebar-menu by desired location
if(isset($menu_items)){
foreach ( (array) $menu_items as $key => $menu_item ) {
...some code...
}
}
这是所有 nav_menu 数据的链接,您可以通过 mysql 请求直接从数据库中选择这些数据: 查看全部
php可以抓取网页数据吗(我想获取我的wp主菜单中的项目..)
我想在我的 wp 主菜单中获取项目。我尝试了一些代码,但所有代码都只返回一个空白页。我不知道我必须使用哪种方法,也不需要在页面中收录其他页面?
有没有办法直接从数据库中获取菜单项而不使用 wp 方法和函数?wp的表结构暂时不懂。所以我不完全知道表之间的关系。
谢谢。
解决方案:
如果您知道菜单的位置 ID(通常由 functions.php 中的“register_nav_menus”声明),您可以使用以下代码片段:
// GET ALL MENU OBJECTS AT SPECIFIED LOCATION
function yourprefix_get_menu_items($location_id){
//$locations = get_registered_nav_menus();
$menus = wp_get_nav_menus();
$menu_locations = get_nav_menu_locations();
if (isset($menu_locations[ $location_id ]) && $menu_locations[ $location_id ]!=0) {
foreach ($menus as $menu) {
if ($menu->term_id == $menu_locations[ $location_id ]) {
$menu_items = wp_get_nav_menu_items($menu);
break;
}
}
return $menu_items;
}
}
或者更多来自代码的简短版本:
function yourprefix_get_menu_items($menu_name){
if ( ( $locations = get_nav_menu_locations() ) && isset( $locations[ $menu_name ] ) ) {
$menu = wp_get_nav_menu_object( $locations[ $menu_name ] );
return wp_get_nav_menu_items($menu->term_id);
}
}
然后使用这个数组来执行你想要的所有操作,如下图:
$menu_items = yourprefix_get_menu_items('sidebar-menu'); // replace sidebar-menu by desired location
if(isset($menu_items)){
foreach ( (array) $menu_items as $key => $menu_item ) {
...some code...
}
}
这是所有 nav_menu 数据的链接,您可以通过 mysql 请求直接从数据库中选择这些数据:
php可以抓取网页数据吗(PHP获取远程网页内容的代码(fopen,)的相关知识和一些Code实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-20 01:07
想知道PHP获取远程网页内容的代码(fopen,curl已经测试)的相关内容吗?在本文中,我将仔细讲解远程网页的相关知识和一些代码示例。欢迎阅读和指正。先重点介绍一下:fopen、curl,大家一起学习。
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
<IMG src="http://files.jb51.net/upload/2 ... ot%3B border=0>
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并且完美的解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP fopen / file_get_contents / curl 的区别
fopen / file_get_contents 会为每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。 查看全部
php可以抓取网页数据吗(PHP获取远程网页内容的代码(fopen,)的相关知识和一些Code实例)
想知道PHP获取远程网页内容的代码(fopen,curl已经测试)的相关内容吗?在本文中,我将仔细讲解远程网页的相关知识和一些代码示例。欢迎阅读和指正。先重点介绍一下:fopen、curl,大家一起学习。
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
<IMG src="http://files.jb51.net/upload/2 ... ot%3B border=0>
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并且完美的解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP fopen / file_get_contents / curl 的区别
fopen / file_get_contents 会为每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。
php可以抓取网页数据吗(PHP一下本文的主要内容及主要方式的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-19 20:13
我们不能直接输出得到的数据,往往需要将内容提取出来,然后进行格式化,以更友好的方式展示出来。
先简单说一下本文的主要内容:
一、 PHP抓取页面的主要方法:
1. file() 函数
2. file_get_contents() 函数
3. fopen()->fread()->fclose() 模式
4.卷曲方式
5. fsockopen() 函数套接字模式
6. 使用插件(如:)
二、PHP解析html或xml代码的主要方式:
1. 正则表达式
2. PHP DOMDocument 对象
3. 插件(如:PHP Simple HTML DOM Parser)
如果你对上面的内容有很好的理解,下面的内容就可以飘了……
PHP抓取页面
1. file() 函数
当然中国人是有创造力的,外国人往往技术先进,但中国人往往会用得更好,经常做出一些外国人不敢想的功能,比如远程爬取和分析php。为数据整合提供便利。但是中国人很喜欢这个,所以就有了大量的采集网站。他们自己不会创造任何有价值的内容。他们只是抓取其他人的 网站 内容并将其用作自己的内容。在百度输入“php小”关键词,建议列表第一个是“php小偷程序”,然后把同样的关键词放到google里,哥只能笑着说。 查看全部
php可以抓取网页数据吗(PHP一下本文的主要内容及主要方式的应用)
我们不能直接输出得到的数据,往往需要将内容提取出来,然后进行格式化,以更友好的方式展示出来。
先简单说一下本文的主要内容:
一、 PHP抓取页面的主要方法:
1. file() 函数
2. file_get_contents() 函数
3. fopen()->fread()->fclose() 模式
4.卷曲方式
5. fsockopen() 函数套接字模式
6. 使用插件(如:)
二、PHP解析html或xml代码的主要方式:
1. 正则表达式
2. PHP DOMDocument 对象
3. 插件(如:PHP Simple HTML DOM Parser)
如果你对上面的内容有很好的理解,下面的内容就可以飘了……
PHP抓取页面
1. file() 函数
当然中国人是有创造力的,外国人往往技术先进,但中国人往往会用得更好,经常做出一些外国人不敢想的功能,比如远程爬取和分析php。为数据整合提供便利。但是中国人很喜欢这个,所以就有了大量的采集网站。他们自己不会创造任何有价值的内容。他们只是抓取其他人的 网站 内容并将其用作自己的内容。在百度输入“php小”关键词,建议列表第一个是“php小偷程序”,然后把同样的关键词放到google里,哥只能笑着说。
php可以抓取网页数据吗(官方网站站点简单、灵活、强大的PHP采集工具,让采集更简单一点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-15 14:19
网站 官方网站是简单、灵活、强大的 PHP 采集 工具,让 采集 变得更简单。简介:QueryList使用jQuery选择器做采集,让你告别复杂的正则表达式;QueryList 具有相同的 jQuery DOM 操作能力、Http 网络操作能力、乱码解析能力、内容过滤能力和可扩展性;可轻松实现模拟登录、伪造浏览器、HTTP代理等复杂网络请求;拥有丰富的插件,支持多线程采集,使用PhantomJS采集 JavaScript动态渲染页面。通过 Composer 安装 安装:composer require jaeger/querylist 使用教程:直接上传代码: rules([// 采集Href 属性的所有标签'link' => [' a','href'],// 采集所有a标签的文本内容'text' => ['a','text']]);//这里$data = web后的对象上面已经获取到内容 // Settings采集 规则代替了传统的正则 $data->query();// 这里 $data = 上面已经获取到网页内容后的对象 //查询执行操作 $data->getData();// 这里 $data = 上面已经获取到网页内容后的对象 // 获取数据结果 $data->all(); // 这里 $data = 上面已经获取到网页内容后的对象 // 将数据转换成二维数组 print_r( $data->all());// 上面打印结果的基本使用方法是像这样,这样我们就已经可以抓取到一定数量的数据了。如果您对抓取数据感兴趣, 查看全部
php可以抓取网页数据吗(官方网站站点简单、灵活、强大的PHP采集工具,让采集更简单一点)
网站 官方网站是简单、灵活、强大的 PHP 采集 工具,让 采集 变得更简单。简介:QueryList使用jQuery选择器做采集,让你告别复杂的正则表达式;QueryList 具有相同的 jQuery DOM 操作能力、Http 网络操作能力、乱码解析能力、内容过滤能力和可扩展性;可轻松实现模拟登录、伪造浏览器、HTTP代理等复杂网络请求;拥有丰富的插件,支持多线程采集,使用PhantomJS采集 JavaScript动态渲染页面。通过 Composer 安装 安装:composer require jaeger/querylist 使用教程:直接上传代码: rules([// 采集Href 属性的所有标签'link' => [' a','href'],// 采集所有a标签的文本内容'text' => ['a','text']]);//这里$data = web后的对象上面已经获取到内容 // Settings采集 规则代替了传统的正则 $data->query();// 这里 $data = 上面已经获取到网页内容后的对象 //查询执行操作 $data->getData();// 这里 $data = 上面已经获取到网页内容后的对象 // 获取数据结果 $data->all(); // 这里 $data = 上面已经获取到网页内容后的对象 // 将数据转换成二维数组 print_r( $data->all());// 上面打印结果的基本使用方法是像这样,这样我们就已经可以抓取到一定数量的数据了。如果您对抓取数据感兴趣,
php可以抓取网页数据吗(php常量一定的参考价值,你知道吗?一定参考价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-15 10:09
本文文章主要介绍如何将js变量值传递给php。有一定的参考价值。现在分享给大家,有需要的朋友可以参考
一、 一句话总结:给后台传参数,使用ajax或者原生js拼接URL。明白原理明白系统就是先解析php,再执行html代码和js代码。二、使用ajax
1. 页面提交数据:ajax
2. php页面获取参数:$val = $_POST['val']
参考代码(jquery):
$.ajax({
type: 'POST',
url: 'save.php',
data: {val: text1obj.value}
success: function(msg){// msg: php返回内容/* alert(修改成功); */window.location = window.location;
},
error:function(msg){// 提交失败}
});
问题:
var bid=document.fenlei.bfenlei.value;
如上代码,如何将文档中的bid值传递给下面PHP语句的bid?? ? ?
回答:
不用AJAX,最简单就是传个参数过去
如:function saveGame(str){
window.location.href='url?str=' + str;
}
楼上的是一种跳转的方式。如果你想不刷新处理,获取数据。还是用ajax 。很简单的。给你个例子。这里我我用jquery的$.post
$.post(URL,{参数1:alue,参数2:value2},function(data){
//这里你可以处理获取的数据。我使用是json 格式。你也可以使用其它格式。或者为空,让它自己判断得了
},'json');
一个在服务器端,另一个在客户端。
当然不是。
我不明白你为什么使用 js 来传递值。
你直接这样使用url参数:test.php?bid=1不行吗?
用js实现比较麻烦,因为你打开网页是先执行php再执行js。也就是说,无论你把js放在哪里,都会在js执行之前先执行php。
如果你只是想用js这种方式给php传值,那你就得用ajax了,看你的具体需求了。
使用 AJAX 发送到后台
原型方法:
function changeshow()
{
var bid=document.fenlei.bfenlei.value;
var url = 'adm_mod_ajax.php';
var pars = 'mtype=1&mid=' + mid+'&bid='+bid;
var myAjax = new Ajax.Request(
url,
{method: 'post', parameters: pars, onComplete: showResponse}
);
}
三、洞察系统先解析php,然后在其他代码下进行字符串拼接
没关系
function dailyTask(){
$('#my_daily_task_calendar').datepicker().on('changeDate.datepicker.amui', function(event) {
var dailyTaskDate=$(this).val();
var url1="{:url('task/getDailyTaskData')}";
var url2='?dailyTaskDate='+dailyTaskDate;
document.location=url1+url2;
});
}
dailyTask();
apache 服务器首先会翻译这句话 7 var url2='?dailyTaskDate='+dailyTaskDate; 页面加载时。php翻译完成后,交给浏览器。
这样不行,因为php咸鱼js被执行了,所以找不到js中的dailyTaskDate变量,所以php一直报错。
var dailyTaskDate=$(this).val();
document.location={:url('task/getDailyTaskData',array('dailyTaskDate'=>dailyTaskDate))};
四、ajax回调函数中刷新页面的方法
做demo的时候,回调函数不想麻烦,直接刷新页面就可以使用location.reload(true); 这句话相当于F5键刷新页面。这个方法可能会消耗一定的资源,但是刷新页面还是很方便的。
下面的代码可以实现ajax刷新页面,但是没有用
function dailyTask(){
$('#my_daily_task_calendar').datepicker().on('changeDate.datepicker.amui', function(event) {
var dailyTaskDate=$(this).val();
$.post("task/getDailyTaskData", { dailyTaskDate:dailyTaskDate}, function () {
document.location.reload();
});
});
}
dailyTask();
以上就是本文的全部内容,希望对大家的学习有所帮助。更多相关内容请关注PHP中文网! 查看全部
php可以抓取网页数据吗(php常量一定的参考价值,你知道吗?一定参考价值)
本文文章主要介绍如何将js变量值传递给php。有一定的参考价值。现在分享给大家,有需要的朋友可以参考
一、 一句话总结:给后台传参数,使用ajax或者原生js拼接URL。明白原理明白系统就是先解析php,再执行html代码和js代码。二、使用ajax
1. 页面提交数据:ajax
2. php页面获取参数:$val = $_POST['val']
参考代码(jquery):
$.ajax({
type: 'POST',
url: 'save.php',
data: {val: text1obj.value}
success: function(msg){// msg: php返回内容/* alert(修改成功); */window.location = window.location;
},
error:function(msg){// 提交失败}
});
问题:
var bid=document.fenlei.bfenlei.value;
如上代码,如何将文档中的bid值传递给下面PHP语句的bid?? ? ?
回答:
不用AJAX,最简单就是传个参数过去
如:function saveGame(str){
window.location.href='url?str=' + str;
}
楼上的是一种跳转的方式。如果你想不刷新处理,获取数据。还是用ajax 。很简单的。给你个例子。这里我我用jquery的$.post
$.post(URL,{参数1:alue,参数2:value2},function(data){
//这里你可以处理获取的数据。我使用是json 格式。你也可以使用其它格式。或者为空,让它自己判断得了
},'json');
一个在服务器端,另一个在客户端。
当然不是。
我不明白你为什么使用 js 来传递值。
你直接这样使用url参数:test.php?bid=1不行吗?
用js实现比较麻烦,因为你打开网页是先执行php再执行js。也就是说,无论你把js放在哪里,都会在js执行之前先执行php。
如果你只是想用js这种方式给php传值,那你就得用ajax了,看你的具体需求了。
使用 AJAX 发送到后台
原型方法:
function changeshow()
{
var bid=document.fenlei.bfenlei.value;
var url = 'adm_mod_ajax.php';
var pars = 'mtype=1&mid=' + mid+'&bid='+bid;
var myAjax = new Ajax.Request(
url,
{method: 'post', parameters: pars, onComplete: showResponse}
);
}
三、洞察系统先解析php,然后在其他代码下进行字符串拼接
没关系
function dailyTask(){
$('#my_daily_task_calendar').datepicker().on('changeDate.datepicker.amui', function(event) {
var dailyTaskDate=$(this).val();
var url1="{:url('task/getDailyTaskData')}";
var url2='?dailyTaskDate='+dailyTaskDate;
document.location=url1+url2;
});
}
dailyTask();
apache 服务器首先会翻译这句话 7 var url2='?dailyTaskDate='+dailyTaskDate; 页面加载时。php翻译完成后,交给浏览器。
这样不行,因为php咸鱼js被执行了,所以找不到js中的dailyTaskDate变量,所以php一直报错。
var dailyTaskDate=$(this).val();
document.location={:url('task/getDailyTaskData',array('dailyTaskDate'=>dailyTaskDate))};
四、ajax回调函数中刷新页面的方法
做demo的时候,回调函数不想麻烦,直接刷新页面就可以使用location.reload(true); 这句话相当于F5键刷新页面。这个方法可能会消耗一定的资源,但是刷新页面还是很方便的。
下面的代码可以实现ajax刷新页面,但是没有用
function dailyTask(){
$('#my_daily_task_calendar').datepicker().on('changeDate.datepicker.amui', function(event) {
var dailyTaskDate=$(this).val();
$.post("task/getDailyTaskData", { dailyTaskDate:dailyTaskDate}, function () {
document.location.reload();
});
});
}
dailyTask();
以上就是本文的全部内容,希望对大家的学习有所帮助。更多相关内容请关注PHP中文网!
php可以抓取网页数据吗(牛逼闪闪的curl也束手无策了,你想采集这些处理过后的内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2021-11-14 21:21
对于一般的页面数据,我们可以很方便的抓取带有querylist的页面,分析里面的dom树,抓取我们需要的数据,存入数据库,但是有时候我们会遇到我们想通过JavaScript抓取的数据渲染,这次
Puppeteer 插件派上用场,
composerrequirenesk/puphpeteer
npminstall@nesk/puphpeteer --->cnpminstall@nesk/puphpeteer
供参考,按照文档做的时候发现
错误:无法下载 Chromium r672088!设置“PUPPETEER_SKIP_CHROMIUM_DOWNLOAD”环境变量以跳过下载。错误,
解决方案
采集 Web 内容是一个很常见的需求,curl 可以处理更传统的静态页面。但是如果页面中有动态加载的内容,比如有些页面通过ajax加载的文章 body内容,如果有些页面经过一些额外的处理(图片地址替换等...)而你想要采集这些处理过的内容。那么厉害的curl就无奈了。
做过类似需求的人可能会说,老铁,去PhantomJS吧!
是的,这是一个解决方案,很长一段时间以来,PhantomJS 是少数可以解决这种需求的工具之一。
但是今天我要介绍一个更新的工具-puppeteer,它随着Chrome Headless 技术的兴起而迅速发展。而且非常重要的是,puppeteer 由 Chrome 官方团队开发和维护,可以说是相当可靠!
puppeteer 是一个 js 包,如果你想在 Laravel 中使用它,你必须求助于另一个神器 spatie/browsershot。
安装
安装 spatie/browsershot
Browsershot 是一个 Composer 包,来自大神团队的 Spatie
$ composer require spatie/browsershot
安装 puppeteer
$ npm i puppeteer --save
也可以全局保护puppeteer,但从个人经验来看,建议安装在项目中,因为不同的项目不会同时受到全局安装的puppeteer的影响,在项目中安装是使用phpdeployer升级也很方便(phpdeploy升级不会影响线上项目的运行。要知道升级/安装puppeteer是很费时间的,有时还不能保证一次成功)
安装 puppeteer 后,将下载 Chromium-Browser。由于我们特殊的国情,很可能无法下载。为此,请施展你的魔法……
使用
以采集今日头条移动版页面文章的内容为例。
use Spatie\Browsershot\Browsershot; public function getBodyHtml() { $newsUrl = 'https://m.toutiao.com/i6546884 ... 3B%3B $html = Browsershot::url($newsUrl) ->windowSize(480, 800) ->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36') ->mobile() ->touch() ->bodyHtml(); \Log::info($html); }
运行后可以在日志中看到如下内容(截图只是其中的一部分)
此外,您可以将页面另存为图片或 PDF 文件。
use Spatie\Browsershot\Browsershot; public function getBodyHtml() { $newsUrl = 'https://m.toutiao.com/i6546884 ... 3B%3B Browsershot::url($newsUrl) ->windowSize(480, 800) ->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36') ->mobile() ->touch() ->setDelay(1000) ->save(public_path('images/toutiao.jpg')); }
图中方框与系统字体有关。代码中使用了 setDelay() 方法,用于在内容加载后进行截图。它既简单又粗鲁,可能不是最好的解决方案。
可能出现的问题
总结
puppeteer 用于测试、采集 等场景。这是一个非常强大的工具。对于轻量的采集任务,就足够了,比如Laravel(php)中的这篇文章使用采集一些小页面,但是如果你需要快速采集很多内容,或者Python什么的。
转载于: 查看全部
php可以抓取网页数据吗(牛逼闪闪的curl也束手无策了,你想采集这些处理过后的内容)
对于一般的页面数据,我们可以很方便的抓取带有querylist的页面,分析里面的dom树,抓取我们需要的数据,存入数据库,但是有时候我们会遇到我们想通过JavaScript抓取的数据渲染,这次
Puppeteer 插件派上用场,
composerrequirenesk/puphpeteer
npminstall@nesk/puphpeteer --->cnpminstall@nesk/puphpeteer
供参考,按照文档做的时候发现
错误:无法下载 Chromium r672088!设置“PUPPETEER_SKIP_CHROMIUM_DOWNLOAD”环境变量以跳过下载。错误,
解决方案
采集 Web 内容是一个很常见的需求,curl 可以处理更传统的静态页面。但是如果页面中有动态加载的内容,比如有些页面通过ajax加载的文章 body内容,如果有些页面经过一些额外的处理(图片地址替换等...)而你想要采集这些处理过的内容。那么厉害的curl就无奈了。
做过类似需求的人可能会说,老铁,去PhantomJS吧!
是的,这是一个解决方案,很长一段时间以来,PhantomJS 是少数可以解决这种需求的工具之一。
但是今天我要介绍一个更新的工具-puppeteer,它随着Chrome Headless 技术的兴起而迅速发展。而且非常重要的是,puppeteer 由 Chrome 官方团队开发和维护,可以说是相当可靠!
puppeteer 是一个 js 包,如果你想在 Laravel 中使用它,你必须求助于另一个神器 spatie/browsershot。
安装
安装 spatie/browsershot
Browsershot 是一个 Composer 包,来自大神团队的 Spatie
$ composer require spatie/browsershot
安装 puppeteer
$ npm i puppeteer --save
也可以全局保护puppeteer,但从个人经验来看,建议安装在项目中,因为不同的项目不会同时受到全局安装的puppeteer的影响,在项目中安装是使用phpdeployer升级也很方便(phpdeploy升级不会影响线上项目的运行。要知道升级/安装puppeteer是很费时间的,有时还不能保证一次成功)
安装 puppeteer 后,将下载 Chromium-Browser。由于我们特殊的国情,很可能无法下载。为此,请施展你的魔法……
使用
以采集今日头条移动版页面文章的内容为例。
use Spatie\Browsershot\Browsershot; public function getBodyHtml() { $newsUrl = 'https://m.toutiao.com/i6546884 ... 3B%3B $html = Browsershot::url($newsUrl) ->windowSize(480, 800) ->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36') ->mobile() ->touch() ->bodyHtml(); \Log::info($html); }
运行后可以在日志中看到如下内容(截图只是其中的一部分)
此外,您可以将页面另存为图片或 PDF 文件。
use Spatie\Browsershot\Browsershot; public function getBodyHtml() { $newsUrl = 'https://m.toutiao.com/i6546884 ... 3B%3B Browsershot::url($newsUrl) ->windowSize(480, 800) ->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36') ->mobile() ->touch() ->setDelay(1000) ->save(public_path('images/toutiao.jpg')); }
图中方框与系统字体有关。代码中使用了 setDelay() 方法,用于在内容加载后进行截图。它既简单又粗鲁,可能不是最好的解决方案。
可能出现的问题
总结
puppeteer 用于测试、采集 等场景。这是一个非常强大的工具。对于轻量的采集任务,就足够了,比如Laravel(php)中的这篇文章使用采集一些小页面,但是如果你需要快速采集很多内容,或者Python什么的。
转载于:
php可以抓取网页数据吗(WordPress百度熊掌号接入Json_LD数据完整代码分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-14 20:06
雷雪博客与百度雄章(原百度公众号)连接已经有一段时间了。虽然暂时无法获得实际结果,但从百度站长平台雄照的数据分析来看还是不错的。中,我也分享了《WordPress百度熊掌快速开发改造教程》,今天给大家分享一下熊掌访问Json_LD数据的代码。
当然,如果你对代码一窍不通或者不想担心,子帆还提供了WordPress熊掌号访问修改插件:Fanly XZH,可以快速实现MIP页面和自适应H5页面改为熊掌号,无需修改代码。支持和转化。
首先分享一段最简单的Json_LD数据代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
//获取文章/页面摘要
function fanly_excerpt($len=220){
if ( is_single() || is_page() ){
global $post;
if ($post->post_excerpt) {
$excerpt = $post->post_excerpt;
} else {
if(preg_match('/<p>(.*)/iU',trim(strip_tags($post->post_content,"<p>")),$result)){
$post_content = $result['1'];
} else {
$post_content_r = explode("\n",trim(strip_tags($post->post_content)));
$post_content = $post_content_r['0'];
}
$excerpt = preg_replace('#^(?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,0}'.'((?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,'.$len.'}).*#s','$1',$post_content);
}
return str_replace(array("\r\n", "\r", "\n"), "", $excerpt);
}
}
1
2
3
4
5
6
7
8
9
{
"@context": "https://ziyuan.baidu.com/conte ... ot%3B,
"@id": "",
"appid": "这里请填写熊掌号 ID",
"title": "",
"images": [""],
"description": "",
"pubDate": "",
}
其中,紫帆定制了一个文章或者页面汇总功能。如果没有设置文章摘要,会自动截取文章第一段指定长度作为摘要。
让我们继续加强这个代码。百度熊掌号在Json_LD数据中支持单缩略图和三种缩略图样式。当然,对于紫凡这样追求极致的人来说,这个晚上或许是不完美的。睡不好的人一定要这样做。子凡会直接贴出完整的推荐码。
WordPress百度熊掌号Json_LD数据完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
//获取文章/页面摘要
function fanly_excerpt($len=220){
if ( is_single() || is_page() ){
global $post;
if ($post->post_excerpt) {
$excerpt = $post->post_excerpt;
} else {
if(preg_match('/<p>(.*)/iU',trim(strip_tags($post->post_content,"<p>")),$result)){
$post_content = $result['1'];
} else {
$post_content_r = explode("\n",trim(strip_tags($post->post_content)));
$post_content = $post_content_r['0'];
}
$excerpt = preg_replace('#^(?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,0}'.'((?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,'.$len.'}).*#s','$1',$post_content);
}
return str_replace(array("\r\n", "\r", "\n"), "", $excerpt);
}
}
//获取文章中的图 last update 2018/01/22
function fanly_post_imgs(){
global $post;
$src = '';
$content = $post->post_content;
preg_match_all('/<img .*?src=[\"|\'](.+?)[\"|\'].*?/'/spanspan class="c339933",/span span class="c000088"$content/spanspan class="c339933",/span span class="c000088"$strResult/spanspan class="c339933",/span PREG_PATTERN_ORDERspan class="c009900")/spanspan class="c339933";/span
span class="c000088"$n/span span class="c339933"=/span span class="c990000"count/spanspan class="c009900"(/spanspan class="c000088"$strResult/spanspan class="c009900"[/spanspan class="ccc66cc"1/spanspan class="c009900"]/spanspan class="c009900")/spanspan class="c339933";/span
span class="cb1b100"if/spanspan class="c009900"(/spanspan class="c000088"$n/span span class="c339933">= 3){
$src = $strResult[1][0].'","'.$strResult[1][1].'","'.$strResult[1][2];
}elseif($n >= 1){
$src = $strResult[1][0];
}
return $src;
}
子帆建议你把上面两段代码添加到你需要访问熊掌号的主题的functions.php中,然后继续:
1
2
3
4
5
6
7
8
9
10
11
12
13
最后,您可以将上述代码添加到您的 WordPress 主题的 header.php 的适当位置。上面的代码子范也做了一个if判断,只让这段代码在文章中输出。
写在最后
和大家分享一下WordPress访问百度熊掌号的Json_LD数据代码转换。最后,如果你的WordPress站点成功连接到熊掌号,不妨试试紫帆提供的“WordPress百度熊掌号数据”提交插件”,这个插件或许可以帮你实现官方的好数据提交和 原创 推送更快。
更多WordPress优化和问题可以加群:255308000
除非另有说明,均为泪雪博客原创文章,禁止以任何形式转载
这篇文章的链接: 查看全部
php可以抓取网页数据吗(WordPress百度熊掌号接入Json_LD数据完整代码分享)
雷雪博客与百度雄章(原百度公众号)连接已经有一段时间了。虽然暂时无法获得实际结果,但从百度站长平台雄照的数据分析来看还是不错的。中,我也分享了《WordPress百度熊掌快速开发改造教程》,今天给大家分享一下熊掌访问Json_LD数据的代码。
当然,如果你对代码一窍不通或者不想担心,子帆还提供了WordPress熊掌号访问修改插件:Fanly XZH,可以快速实现MIP页面和自适应H5页面改为熊掌号,无需修改代码。支持和转化。
首先分享一段最简单的Json_LD数据代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
//获取文章/页面摘要
function fanly_excerpt($len=220){
if ( is_single() || is_page() ){
global $post;
if ($post->post_excerpt) {
$excerpt = $post->post_excerpt;
} else {
if(preg_match('/<p>(.*)/iU',trim(strip_tags($post->post_content,"<p>")),$result)){
$post_content = $result['1'];
} else {
$post_content_r = explode("\n",trim(strip_tags($post->post_content)));
$post_content = $post_content_r['0'];
}
$excerpt = preg_replace('#^(?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,0}'.'((?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,'.$len.'}).*#s','$1',$post_content);
}
return str_replace(array("\r\n", "\r", "\n"), "", $excerpt);
}
}
1
2
3
4
5
6
7
8
9
{
"@context": "https://ziyuan.baidu.com/conte ... ot%3B,
"@id": "",
"appid": "这里请填写熊掌号 ID",
"title": "",
"images": [""],
"description": "",
"pubDate": "",
}
其中,紫帆定制了一个文章或者页面汇总功能。如果没有设置文章摘要,会自动截取文章第一段指定长度作为摘要。
让我们继续加强这个代码。百度熊掌号在Json_LD数据中支持单缩略图和三种缩略图样式。当然,对于紫凡这样追求极致的人来说,这个晚上或许是不完美的。睡不好的人一定要这样做。子凡会直接贴出完整的推荐码。
WordPress百度熊掌号Json_LD数据完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
//获取文章/页面摘要
function fanly_excerpt($len=220){
if ( is_single() || is_page() ){
global $post;
if ($post->post_excerpt) {
$excerpt = $post->post_excerpt;
} else {
if(preg_match('/<p>(.*)/iU',trim(strip_tags($post->post_content,"<p>")),$result)){
$post_content = $result['1'];
} else {
$post_content_r = explode("\n",trim(strip_tags($post->post_content)));
$post_content = $post_content_r['0'];
}
$excerpt = preg_replace('#^(?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,0}'.'((?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,'.$len.'}).*#s','$1',$post_content);
}
return str_replace(array("\r\n", "\r", "\n"), "", $excerpt);
}
}
//获取文章中的图 last update 2018/01/22
function fanly_post_imgs(){
global $post;
$src = '';
$content = $post->post_content;
preg_match_all('/<img .*?src=[\"|\'](.+?)[\"|\'].*?/'/spanspan class="c339933",/span span class="c000088"$content/spanspan class="c339933",/span span class="c000088"$strResult/spanspan class="c339933",/span PREG_PATTERN_ORDERspan class="c009900")/spanspan class="c339933";/span
span class="c000088"$n/span span class="c339933"=/span span class="c990000"count/spanspan class="c009900"(/spanspan class="c000088"$strResult/spanspan class="c009900"[/spanspan class="ccc66cc"1/spanspan class="c009900"]/spanspan class="c009900")/spanspan class="c339933";/span
span class="cb1b100"if/spanspan class="c009900"(/spanspan class="c000088"$n/span span class="c339933">= 3){
$src = $strResult[1][0].'","'.$strResult[1][1].'","'.$strResult[1][2];
}elseif($n >= 1){
$src = $strResult[1][0];
}
return $src;
}
子帆建议你把上面两段代码添加到你需要访问熊掌号的主题的functions.php中,然后继续:
1
2
3
4
5
6
7
8
9
10
11
12
13
最后,您可以将上述代码添加到您的 WordPress 主题的 header.php 的适当位置。上面的代码子范也做了一个if判断,只让这段代码在文章中输出。
写在最后
和大家分享一下WordPress访问百度熊掌号的Json_LD数据代码转换。最后,如果你的WordPress站点成功连接到熊掌号,不妨试试紫帆提供的“WordPress百度熊掌号数据”提交插件”,这个插件或许可以帮你实现官方的好数据提交和 原创 推送更快。
更多WordPress优化和问题可以加群:255308000
除非另有说明,均为泪雪博客原创文章,禁止以任何形式转载
这篇文章的链接:
php可以抓取网页数据吗(这是微信官方文档官方流程网页授权流程:1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-14 20:05
最近的一个项目是微信公众号的二次开发,涉及到微信公众号的支付。根据文档要求,如果要付费,必须获取用户的openid。
这是官方微信文档
官方流程 web授权流程分为四步:1、引导用户进入授权页面同意授权并获取code2、使用code兑换web授权access_token (与基础支持中的access_token不同)3、 如有需要,开发者可以刷新网页授权access_token避免过期4、通过网页授权access_token和openid获取用户基本信息(支持UnionID机制)
我的想法1、首先是在公众号后台进行配置,设置回调路径,具体要求参考官方文档。
将这里的txt文件放在项目根路径下,否则上面的回调域名无法保存。
2、 当用户访问第三方页面时,首先去请求一个api,获取code和state
代码说明:该代码用作票证,以换取access_token。用户授权码每次都会不同。代码只能使用一次,5分钟内未使用将自动失效。
请求API参数拼接
这里的作用域分为两种:一种是静默方法(snsapi_base);另一种是非静默方式(snsapi_userinfo),需要用户手动点击同意获取用户信息。
这是一个非静默授权
静默模式下直接获取openid
3、 根据1中配置的回调方法中获取的代码和状态,请求如下接口获取access_token和openid。
获取code后,请求如下链接获取access_token:
代码片段
@SuppressWarnings("null")
@RequestMapping("/getOAuth")
public String getOAuth(){
String code = request.getParameter("code");//获取微信服务器授权返回的code值
String state = request.getParameter("state");//验证是否来自微信重定向的请求
PrintWriter pw = null;
try {
pw = response.getWriter();
if(Constant.STATE.equals(state)){
/**
* 构造请求链接
* https://api.weixin.qq.com/sns/oauth2/access_token?
* appid=APPID&secret=SECRET&code=CODE&grant_type=authorization_code
*/
String url = Constant.ACCESS_TOKEN_URL+Constant.APP_ID+"&secret="+Constant.APP_SECRET+"&code="+code+"&grant_type=authorization_code";
String jsonStr = HttpUtil.httpRequest(url);
String openid = JSONObject.parseObject(jsonStr).getString("openid");
System.out.println(openid+"==========================");
session = request.getSession();
session.setAttribute("openid", openid);
return "login/wx_login";//登录页面
}else{
response.setContentType("text/html;charset=utf-8");
pw.write("alert('授权失败!');");
pw.flush();
pw.close();
}
} catch (IOException e) {
e.printStackTrace();
response.setContentType("text/html;charset=utf-8");
pw.write("alert('发生后台异常!');");
pw.flush();
pw.close();
}
return null;
}
总结:目前已经获取到用户的openid,因为只涉及支付服务,不再获取用户的个人信息。感觉微信官方的文档逻辑还是比较清晰的。按照流程走一般是没有问题的。具体如何获取openid代码请参考我之前文章中的一段,已经在实际项目中实践过。 查看全部
php可以抓取网页数据吗(这是微信官方文档官方流程网页授权流程:1)
最近的一个项目是微信公众号的二次开发,涉及到微信公众号的支付。根据文档要求,如果要付费,必须获取用户的openid。
这是官方微信文档
官方流程 web授权流程分为四步:1、引导用户进入授权页面同意授权并获取code2、使用code兑换web授权access_token (与基础支持中的access_token不同)3、 如有需要,开发者可以刷新网页授权access_token避免过期4、通过网页授权access_token和openid获取用户基本信息(支持UnionID机制)
我的想法1、首先是在公众号后台进行配置,设置回调路径,具体要求参考官方文档。
将这里的txt文件放在项目根路径下,否则上面的回调域名无法保存。
2、 当用户访问第三方页面时,首先去请求一个api,获取code和state
代码说明:该代码用作票证,以换取access_token。用户授权码每次都会不同。代码只能使用一次,5分钟内未使用将自动失效。
请求API参数拼接
这里的作用域分为两种:一种是静默方法(snsapi_base);另一种是非静默方式(snsapi_userinfo),需要用户手动点击同意获取用户信息。
这是一个非静默授权
静默模式下直接获取openid
3、 根据1中配置的回调方法中获取的代码和状态,请求如下接口获取access_token和openid。
获取code后,请求如下链接获取access_token:
代码片段
@SuppressWarnings("null")
@RequestMapping("/getOAuth")
public String getOAuth(){
String code = request.getParameter("code");//获取微信服务器授权返回的code值
String state = request.getParameter("state");//验证是否来自微信重定向的请求
PrintWriter pw = null;
try {
pw = response.getWriter();
if(Constant.STATE.equals(state)){
/**
* 构造请求链接
* https://api.weixin.qq.com/sns/oauth2/access_token?
* appid=APPID&secret=SECRET&code=CODE&grant_type=authorization_code
*/
String url = Constant.ACCESS_TOKEN_URL+Constant.APP_ID+"&secret="+Constant.APP_SECRET+"&code="+code+"&grant_type=authorization_code";
String jsonStr = HttpUtil.httpRequest(url);
String openid = JSONObject.parseObject(jsonStr).getString("openid");
System.out.println(openid+"==========================");
session = request.getSession();
session.setAttribute("openid", openid);
return "login/wx_login";//登录页面
}else{
response.setContentType("text/html;charset=utf-8");
pw.write("alert('授权失败!');");
pw.flush();
pw.close();
}
} catch (IOException e) {
e.printStackTrace();
response.setContentType("text/html;charset=utf-8");
pw.write("alert('发生后台异常!');");
pw.flush();
pw.close();
}
return null;
}
总结:目前已经获取到用户的openid,因为只涉及支付服务,不再获取用户的个人信息。感觉微信官方的文档逻辑还是比较清晰的。按照流程走一般是没有问题的。具体如何获取openid代码请参考我之前文章中的一段,已经在实际项目中实践过。
php可以抓取网页数据吗(WikiProject地图界的维基百科之称插件下载方法介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-14 20:03
)
OpenStreetMap(OSM),被称为地图世界的维基百科,打开了一扇通往新世界的大门。它收录丰富的地理数据,使我们对地理、规划和空间句法、空间分析和空间规划产生了兴趣。人民提供了许多便利。
OSM 中收录的内容可以根据其发布的分类系统进行总结。OSM 的全称是 OpenStreetMap,由 Steve Kester 于 2004 年 7 月创建。 2006 年 4 月,OpenStreetMap 基金会成立,旨在鼓励免费地理数据的增长、开发和分发,并将地理数据提供给所有人使用和使用。分享。
/wiki/Zh-ant:Map_Features#.E9.81.93.E8.B7.AF_.28highway.29
维基项目中国
获取OSM数据的方法有很多种。可以直接从官网下载OpenStreetMap,使用QGIS软件,或者下载ArcGIS Editor for OpenStreetMap插件下载。下面我将介绍几种方法。
方法一:网站直接下载
1.你可以通过这个下载来自世界各地的OpenStreetMap地图矢量数据网站
下载.geofabrik.de/
具体进入流程是打开OpenStreeetMap的OpenStreetMap主页。然后点击下图右上角的Export,可以看到有很多数据源网站,选择Geofabrik下载即可进入下载。
2.以China为例,在form中选择Asia,点击,然后在Sub Region中选择China,选择.shp.zip数据,点击直接下载,解压后直接在ArcGIS中打开即可。数据量巨大,需要自己整理。OSM 数据会定期更新。
3. 点击中国按钮,可以查看数据的更新时间,也可以下载china-latest.shp.zip。
4. 下载后解压,将地图数据加载到ArcMap中。
方法二通过ArcGIS Editor for OpenStreetMap插件下载
1.ArcGIS Editor for OpenStreetMap 是一个免费的开源 ArcGIS Desktop 插件,可从 ESRI 的 网站 下载。不同版本的ArcGIS对应不同的插件版本,如10.1、10.2、10.3 不同。
用于 OpenStreetMap 的 ArcGIS 编辑器
2.点击下载ArcGIS Editor for OpenStreetMap Now进行下载。
因为我的机器是版本10.3,所以我用版本10.3来演示。
4. 安装后会显示在ArcToolbox中,OpenStreetMap Toolbox的工具
5. 单击下载 OSM 数据以下载地图数据。范围可以由经度和纬度确定。您只需要在Top、Bottom、Left、Right中输入经纬度,但范围不能太大,否则将无法下载,并提示【扩展下载】超出范围。
6.您也可以使用原创矢量地图(shp文件)对范围进行框定并下载。范围也是有限的。为了下载武汉的数据,我把武汉的地图剪成了几十块。下载
7. 在Extent of data download中选择与某区域相同,选择Target要素数据集的保存路径。路径应保存在文件地理数据库中以避免错误。
方法三:直接从网站下载,用ArcGIS Editor for OpenStreetMap插件工具进行转换
1.ArcGIS Editor for OpenStreetMap 还提供了数据转换工具。具体方法是先进入OSM网站主页,/
2.点击【导出】,下拉滑轨,可以看到页面左侧列出了很多源
3. 这里可以直接选择经纬度范围下载,但注意下载的数据是osm后缀格式,其他软件或插件(如ArcGIS Editor for OpenStreetMap插件)需要将其转换为 shp 格式。
4. 这里我使用ArcGIS Editor for OpenStreetMap插件(插件的具体安装和下载过程将在后面介绍)来演示如何转换。
6.选择【Load OSM file】,打开对话框,在OSM File列选择之前下载的map.osm数据,在Target feature dataset列选择目标路径,点击OK。路径最好放在文件地理数据库中,这样转换错误的可能性就会很小。
7. 转换结果,数据存储在地理数据集test1中。OSM 数据分为三种类型:点、线和面。具体分类请参考这些网站:
/wiki/Zh-ant:Map_Features#.E9.81.93.E8.B7.AF_.28highway.29
/wiki/WikiProject_中国
方法四 使用QGIS软件获取
QGIS的下载方式也有很多。这里介绍其中的两个。第一种是在软件里下载,比较方便。首先下载QGIS软件,安装
在QGIS软件的菜单栏中选择Vector-然后点击Openstreetmap-Download Data
打开OSM网站,选择范围
选择Manual填写下载范围
二是先在OSM官网下载数据。
• 下载的数据后缀为osm,可以用QGIS软件打开直接显示(如果不显示,需要导入投影坐标系)
然后在QGIS内容列表中选中数据,右键-选择Geometry Tools-单击Export/Add geometry colums,将数据导出为shp后缀,可以在ArcGIS软件中进行编辑和使用。
查看全部
php可以抓取网页数据吗(WikiProject地图界的维基百科之称插件下载方法介绍
)
OpenStreetMap(OSM),被称为地图世界的维基百科,打开了一扇通往新世界的大门。它收录丰富的地理数据,使我们对地理、规划和空间句法、空间分析和空间规划产生了兴趣。人民提供了许多便利。
OSM 中收录的内容可以根据其发布的分类系统进行总结。OSM 的全称是 OpenStreetMap,由 Steve Kester 于 2004 年 7 月创建。 2006 年 4 月,OpenStreetMap 基金会成立,旨在鼓励免费地理数据的增长、开发和分发,并将地理数据提供给所有人使用和使用。分享。
/wiki/Zh-ant:Map_Features#.E9.81.93.E8.B7.AF_.28highway.29
维基项目中国
获取OSM数据的方法有很多种。可以直接从官网下载OpenStreetMap,使用QGIS软件,或者下载ArcGIS Editor for OpenStreetMap插件下载。下面我将介绍几种方法。
方法一:网站直接下载
1.你可以通过这个下载来自世界各地的OpenStreetMap地图矢量数据网站
下载.geofabrik.de/
具体进入流程是打开OpenStreeetMap的OpenStreetMap主页。然后点击下图右上角的Export,可以看到有很多数据源网站,选择Geofabrik下载即可进入下载。
2.以China为例,在form中选择Asia,点击,然后在Sub Region中选择China,选择.shp.zip数据,点击直接下载,解压后直接在ArcGIS中打开即可。数据量巨大,需要自己整理。OSM 数据会定期更新。
3. 点击中国按钮,可以查看数据的更新时间,也可以下载china-latest.shp.zip。
4. 下载后解压,将地图数据加载到ArcMap中。
方法二通过ArcGIS Editor for OpenStreetMap插件下载
1.ArcGIS Editor for OpenStreetMap 是一个免费的开源 ArcGIS Desktop 插件,可从 ESRI 的 网站 下载。不同版本的ArcGIS对应不同的插件版本,如10.1、10.2、10.3 不同。
用于 OpenStreetMap 的 ArcGIS 编辑器
2.点击下载ArcGIS Editor for OpenStreetMap Now进行下载。
因为我的机器是版本10.3,所以我用版本10.3来演示。
4. 安装后会显示在ArcToolbox中,OpenStreetMap Toolbox的工具
5. 单击下载 OSM 数据以下载地图数据。范围可以由经度和纬度确定。您只需要在Top、Bottom、Left、Right中输入经纬度,但范围不能太大,否则将无法下载,并提示【扩展下载】超出范围。
6.您也可以使用原创矢量地图(shp文件)对范围进行框定并下载。范围也是有限的。为了下载武汉的数据,我把武汉的地图剪成了几十块。下载
7. 在Extent of data download中选择与某区域相同,选择Target要素数据集的保存路径。路径应保存在文件地理数据库中以避免错误。
方法三:直接从网站下载,用ArcGIS Editor for OpenStreetMap插件工具进行转换
1.ArcGIS Editor for OpenStreetMap 还提供了数据转换工具。具体方法是先进入OSM网站主页,/
2.点击【导出】,下拉滑轨,可以看到页面左侧列出了很多源
3. 这里可以直接选择经纬度范围下载,但注意下载的数据是osm后缀格式,其他软件或插件(如ArcGIS Editor for OpenStreetMap插件)需要将其转换为 shp 格式。
4. 这里我使用ArcGIS Editor for OpenStreetMap插件(插件的具体安装和下载过程将在后面介绍)来演示如何转换。
6.选择【Load OSM file】,打开对话框,在OSM File列选择之前下载的map.osm数据,在Target feature dataset列选择目标路径,点击OK。路径最好放在文件地理数据库中,这样转换错误的可能性就会很小。
7. 转换结果,数据存储在地理数据集test1中。OSM 数据分为三种类型:点、线和面。具体分类请参考这些网站:
/wiki/Zh-ant:Map_Features#.E9.81.93.E8.B7.AF_.28highway.29
/wiki/WikiProject_中国
方法四 使用QGIS软件获取
QGIS的下载方式也有很多。这里介绍其中的两个。第一种是在软件里下载,比较方便。首先下载QGIS软件,安装
在QGIS软件的菜单栏中选择Vector-然后点击Openstreetmap-Download Data
打开OSM网站,选择范围
选择Manual填写下载范围
二是先在OSM官网下载数据。
• 下载的数据后缀为osm,可以用QGIS软件打开直接显示(如果不显示,需要导入投影坐标系)
然后在QGIS内容列表中选中数据,右键-选择Geometry Tools-单击Export/Add geometry colums,将数据导出为shp后缀,可以在ArcGIS软件中进行编辑和使用。
php可以抓取网页数据吗(泛端口霸屏介绍网站流量突然下降了,是为什么呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-13 04:06
#PAN口霸屏简介
网站流量骤降,网站排名不稳定。为什么?首先要考虑到网站的整体素质是比较差的。当我们就降级的网站向百度反馈时,我们提出的结构是我们的网站整体质量很差。我们对 网站 的分析发现,SEO 优化质量不佳的常见原因。网站结构差,很多内容属于垃圾邮件。没有原创文章好 不值钱,网站内页与主题关联度不高,内容页多为简单图片,同名的多. imgsrc=22K.jp/网站 服务器无法打开或打开延迟,也没有办法访问。这也是网站被降级的重要原因之一。网站标题关键词过度推送积累、内容标题关键词推送积累、内容页面描述同意召回等网站被降级的现象数不胜数。网站被挂断,网站被黑客攻击。黑客通过服务器漏洞,批量驱赶大连黑黄网站链接,导致网站降级。网站 进行黑帽优化,滑动点击等方法也很容易被百度惩罚。友情链接网站很累,如果你的网站的友情链接网站因各种原因被降级,你的网站也可能有记录并被处罚。许多 SEO 优化器会使用黑帽方法来使我们的 网站 快速排名。他们知道这违反了搜索引擎规则,但仍有许多人出于投机的目的使用这种方法。有一次搜索引擎发现,这个网站很难保存。
所以想要网站更好的优化,就必须采用白帽方式。网站 没有长期优化。如果网站做了之后长时间不优化,会导致权限减少。比如网站的内容很久没有更新了,不会更新了。外链优化,然后网站一段时间后,排名会下降。在优化的过程中,优化者应该知道长尾关键词和短尾关键词的区别。短尾关键词是四个字符以内的短语。它比较简单,覆盖范围更大,没有地域和季节的限制。长尾词与一般短尾词关键词有相似的含义,并且一般有四个以上的字。两者之间,短尾关键词会在优化过程中发现做这类词的公司很多,相关行业也会想做这些词,因为它收录的范围很大,只要你有排名,你就不怕没流量。同时,也有优点和缺点。做这个学期的风险和时间成本会比较大。首先,它成为了其他公司排名的垫脚石。其次,会花费大量的时间和成本,并且会更难以优化。长尾关键词 这种由短尾衍生出来的多词多词比短尾更容易提升排名,因为竞争压力比较小,收录的词范围也有限。这是针对专业性强的公司,细分为具体的业务。对于其他公司,可能是区域或季节性限制。它可以以不同的限制展开,以达到广覆盖的效果。这就需要企业seo优化者专门针对关键词优化制定计划。
关键词 对于百度,建议密度1%~7%?Google 的建议是 2%~8%。SEO优化页面内容应收录关键词和关键词密度,控制在5%左右。关键词最好分布在文章的前200个词中,重要性从左到右递减。关键词的密度很重要,但是文章的自然感觉也很重要,所以不能随意加关键词,与文章无关. 这可能会受到搜索引擎的惩罚。如果网站的内容是电脑,而网站的内容是其他乱七八糟的东西。那么很容易被搜索引擎认为是行为。您可以在以下内容中添加关键词:网页内容的第一段和最后一段,网站页面的url中最好有关键词,并且描述中应该收录关键词。好洋科技专注于网站建设和搜索引擎SEO优化网络服务公司,主营业务为百度关键词排名,网站优化见效,并致力于提供企业提供网站整个网站的建设、优化、网站设计、开发等一体化、多元化的网站营销服务。bPan 端口支配屏幕 @网站优化见效后付费,致力于为企业提供网站整个网站的建设、优化、网站设计、开发等一体化多元化的网站@ > 营销服务。bPan 端口支配屏幕 @网站优化见效后付费,致力于为企业提供网站整个网站的建设、优化、网站设计、开发等一体化多元化的网站@ > 营销服务。bPan 端口支配屏幕
网站构建,静态页面和动态页面如何选择电商网站为什么使用静态页面构建。我们都知道网站制作分为静态页面制作和动态网页制作。那么哪种设计技术更适合构建电子商务网站?我们构建网站的最终目的是让用户浏览,所以站在用户的角度思考才是最实用的。虽然使用动态网页制作技术大大提高了网页的美观度,但不利于网站的优化,今天小编重点跟大家聊一聊,网站为什么要用静态页面制作施工中。imgsrc=abc/20190114/47caf8cc457ff50c8a66f4c4a23cfeb1.pn网站 构造,熟悉搜索引擎工作原理的朋友应该知道,它提供给用户的信息是数据库本身存在的信息,而不是实时固定的信息内容,更容易被接受和保存。我们可能经常会遇到这样的问题。当我们搜索我们需要的信息时,得到的结果可能已经无效。这是静态页面网站的设计,不过由于它的稳定性,长时间不会被删除。与静态页面网站 不同的设计,生成的动态页面信息不仅难以被搜索引擎检索,而且打开速度慢且不稳定。这也是为什么那么多专业的网站建筑公司一再推荐客户使用静态表格的原因。出于 网站 设计原因,一些网站建设公司会考虑对页面进行伪静态处理,但不知道大家有没有注意到伪静态处理的URL通常是不规则的。乙 查看全部
php可以抓取网页数据吗(泛端口霸屏介绍网站流量突然下降了,是为什么呢?)
#PAN口霸屏简介
网站流量骤降,网站排名不稳定。为什么?首先要考虑到网站的整体素质是比较差的。当我们就降级的网站向百度反馈时,我们提出的结构是我们的网站整体质量很差。我们对 网站 的分析发现,SEO 优化质量不佳的常见原因。网站结构差,很多内容属于垃圾邮件。没有原创文章好 不值钱,网站内页与主题关联度不高,内容页多为简单图片,同名的多. imgsrc=22K.jp/网站 服务器无法打开或打开延迟,也没有办法访问。这也是网站被降级的重要原因之一。网站标题关键词过度推送积累、内容标题关键词推送积累、内容页面描述同意召回等网站被降级的现象数不胜数。网站被挂断,网站被黑客攻击。黑客通过服务器漏洞,批量驱赶大连黑黄网站链接,导致网站降级。网站 进行黑帽优化,滑动点击等方法也很容易被百度惩罚。友情链接网站很累,如果你的网站的友情链接网站因各种原因被降级,你的网站也可能有记录并被处罚。许多 SEO 优化器会使用黑帽方法来使我们的 网站 快速排名。他们知道这违反了搜索引擎规则,但仍有许多人出于投机的目的使用这种方法。有一次搜索引擎发现,这个网站很难保存。
所以想要网站更好的优化,就必须采用白帽方式。网站 没有长期优化。如果网站做了之后长时间不优化,会导致权限减少。比如网站的内容很久没有更新了,不会更新了。外链优化,然后网站一段时间后,排名会下降。在优化的过程中,优化者应该知道长尾关键词和短尾关键词的区别。短尾关键词是四个字符以内的短语。它比较简单,覆盖范围更大,没有地域和季节的限制。长尾词与一般短尾词关键词有相似的含义,并且一般有四个以上的字。两者之间,短尾关键词会在优化过程中发现做这类词的公司很多,相关行业也会想做这些词,因为它收录的范围很大,只要你有排名,你就不怕没流量。同时,也有优点和缺点。做这个学期的风险和时间成本会比较大。首先,它成为了其他公司排名的垫脚石。其次,会花费大量的时间和成本,并且会更难以优化。长尾关键词 这种由短尾衍生出来的多词多词比短尾更容易提升排名,因为竞争压力比较小,收录的词范围也有限。这是针对专业性强的公司,细分为具体的业务。对于其他公司,可能是区域或季节性限制。它可以以不同的限制展开,以达到广覆盖的效果。这就需要企业seo优化者专门针对关键词优化制定计划。
关键词 对于百度,建议密度1%~7%?Google 的建议是 2%~8%。SEO优化页面内容应收录关键词和关键词密度,控制在5%左右。关键词最好分布在文章的前200个词中,重要性从左到右递减。关键词的密度很重要,但是文章的自然感觉也很重要,所以不能随意加关键词,与文章无关. 这可能会受到搜索引擎的惩罚。如果网站的内容是电脑,而网站的内容是其他乱七八糟的东西。那么很容易被搜索引擎认为是行为。您可以在以下内容中添加关键词:网页内容的第一段和最后一段,网站页面的url中最好有关键词,并且描述中应该收录关键词。好洋科技专注于网站建设和搜索引擎SEO优化网络服务公司,主营业务为百度关键词排名,网站优化见效,并致力于提供企业提供网站整个网站的建设、优化、网站设计、开发等一体化、多元化的网站营销服务。bPan 端口支配屏幕 @网站优化见效后付费,致力于为企业提供网站整个网站的建设、优化、网站设计、开发等一体化多元化的网站@ > 营销服务。bPan 端口支配屏幕 @网站优化见效后付费,致力于为企业提供网站整个网站的建设、优化、网站设计、开发等一体化多元化的网站@ > 营销服务。bPan 端口支配屏幕
网站构建,静态页面和动态页面如何选择电商网站为什么使用静态页面构建。我们都知道网站制作分为静态页面制作和动态网页制作。那么哪种设计技术更适合构建电子商务网站?我们构建网站的最终目的是让用户浏览,所以站在用户的角度思考才是最实用的。虽然使用动态网页制作技术大大提高了网页的美观度,但不利于网站的优化,今天小编重点跟大家聊一聊,网站为什么要用静态页面制作施工中。imgsrc=abc/20190114/47caf8cc457ff50c8a66f4c4a23cfeb1.pn网站 构造,熟悉搜索引擎工作原理的朋友应该知道,它提供给用户的信息是数据库本身存在的信息,而不是实时固定的信息内容,更容易被接受和保存。我们可能经常会遇到这样的问题。当我们搜索我们需要的信息时,得到的结果可能已经无效。这是静态页面网站的设计,不过由于它的稳定性,长时间不会被删除。与静态页面网站 不同的设计,生成的动态页面信息不仅难以被搜索引擎检索,而且打开速度慢且不稳定。这也是为什么那么多专业的网站建筑公司一再推荐客户使用静态表格的原因。出于 网站 设计原因,一些网站建设公司会考虑对页面进行伪静态处理,但不知道大家有没有注意到伪静态处理的URL通常是不规则的。乙
php可以抓取网页数据吗(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-12 16:13
最近在做一个项目,有一个需求:从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,后来就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page. asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都免不了要解析js,这需要时间,而且对于没用的内核,js的支持程序也不一样。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后的驱动状态,所以不需要使用Thread.sleep(2000)这样的不确定代码,可惜我找不到它。它真的让我感到难过。领域。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require(\'system\')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log(\'Loading a web page\');
var page = require(\'webpage\').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== \'success\') {
console.log(\'Unable to post!\');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以结合使用Nutch和WebDirver,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。 查看全部
php可以抓取网页数据吗(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,后来就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page. asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都免不了要解析js,这需要时间,而且对于没用的内核,js的支持程序也不一样。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后的驱动状态,所以不需要使用Thread.sleep(2000)这样的不确定代码,可惜我找不到它。它真的让我感到难过。领域。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require(\'system\')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log(\'Loading a web page\');
var page = require(\'webpage\').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== \'success\') {
console.log(\'Unable to post!\');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以结合使用Nutch和WebDirver,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。

