
php可以抓取网页数据吗
php可以抓取网页数据吗(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-10 19:05
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是抓取网页的代码,下面是到某个网页的POST数据。假设我们有一个处理表单的URL,可以接受两个表单域,一个是电话号码,一个是短信内容。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie 查看全部
php可以抓取网页数据吗(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是抓取网页的代码,下面是到某个网页的POST数据。假设我们有一个处理表单的URL,可以接受两个表单域,一个是电话号码,一个是短信内容。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie
php可以抓取网页数据吗(IbookBox小说批量下载小说爬虫V1.0_软件下载。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-04 04:03
本剧本仅针对“玄书网”小说网“奇幻奇幻”类小说进行拍摄。供网友参考,可自行修改。文笔粗糙,请勿喷……原文链接。
批量下载小说爬虫是一款专门用于批量下载小说的软件,通过小说爬虫用户可以快速下载自己想要的小说的txt文件。
输入任意网页地址,批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取。2、支持将抓取的电子书发送到txt到手机。3、 支持将电子书自动存放在您自己的邮箱中。
软件介绍 《批量小说下载器精简版》是一款非常好用又方便的小说批量下载软件。通过小说爬虫,用户可以快速下载自己想要的小说txt文件,放到手机上离线观看。,软件爬取。
批量下载小说爬虫下载批量下载小说爬虫V1.0_软件下载。
ibookBox小说批量下载阅读器功能:1、支持所有小说网站抓取各类小说。2、支持抓取电子书生成txt发送到手机。3、支持电子书自动存放在您自己的邮箱中。4、纯单机版不需要任何人工干预。
批量下载小说爬虫是一款免费的小说下载阅读器,可以帮助用户将自己喜欢的小说批量下载到本地,支持自己选择下载源。有需要的用户不要错过。欢迎下载使用!
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抓住思路:我的想法是百度一号。 查看全部
php可以抓取网页数据吗(IbookBox小说批量下载小说爬虫V1.0_软件下载。)
本剧本仅针对“玄书网”小说网“奇幻奇幻”类小说进行拍摄。供网友参考,可自行修改。文笔粗糙,请勿喷……原文链接。
批量下载小说爬虫是一款专门用于批量下载小说的软件,通过小说爬虫用户可以快速下载自己想要的小说的txt文件。
输入任意网页地址,批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取。2、支持将抓取的电子书发送到txt到手机。3、 支持将电子书自动存放在您自己的邮箱中。
软件介绍 《批量小说下载器精简版》是一款非常好用又方便的小说批量下载软件。通过小说爬虫,用户可以快速下载自己想要的小说txt文件,放到手机上离线观看。,软件爬取。
批量下载小说爬虫下载批量下载小说爬虫V1.0_软件下载。

ibookBox小说批量下载阅读器功能:1、支持所有小说网站抓取各类小说。2、支持抓取电子书生成txt发送到手机。3、支持电子书自动存放在您自己的邮箱中。4、纯单机版不需要任何人工干预。
批量下载小说爬虫是一款免费的小说下载阅读器,可以帮助用户将自己喜欢的小说批量下载到本地,支持自己选择下载源。有需要的用户不要错过。欢迎下载使用!

目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抓住思路:我的想法是百度一号。
php可以抓取网页数据吗(阿里云gt云栖;云栖社区前端面试题目(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-29 10:06
阿里云>云栖社区>主题图>P>PHP爬取网页和解析HTML的常用方法总结
推荐活动:
更多优惠>
当前主题:PHP抓取网页和解析HTML的常用方法汇总 加入采集
相关话题:
PHP抓取网页,解析HTML常用方法总结相关博客 查看更多博客
前端安全系列之二:如何防范CSRF攻击?
作者:小技术专家 2211人浏览评论:13年前
背景 随着互联网的飞速发展,信息安全问题成为企业最关注的焦点之一,而前端是引发企业安全问题的高风险基地。移动互联网时代,除了传统的XSS、CSRF等安全问题外,前端人员经常会遇到网络劫持、非法调用Hybrid API等新的安全问题。当然,浏览
阅读全文
大公司的开源项目有哪些~~~阿里、百度、腾讯、360、新浪、网易、小米等
作者:xumaojun3896人浏览评论:03年前
红色字体现阶段比较火----------------------------------------- - ------------------------------------------------- - -------------------- 奇虎36
阅读全文
前端面试题合集
作者:科技小胖子1737人浏览评论:03年前
一、理论知识1.1、前端MV*框架的含义早期前端比较简单,基本都是以页面为工作单位,主要是浏览内容,偶尔也简单forms 操作,基本上不需要框架。随着AJAX的出现和Web2.0的兴起,人们可以在页面上做更复杂的事情,然后前端框架才真正出现
阅读全文
国内主要公司开源项目清单
作者:double2li2877 浏览评论人数:04年前
奇虎3601.MySQL 中间层Atlas Atlas 是一个基于MySQL 协议的数据中间层项目,由奇虎360 网络平台部基础架构团队开发和维护。它在 MySQL-Prox 中正式启动
阅读全文
陈词滥调——从 url 输入到页面显示发生了什么
作者:沃克武松 2156人浏览评论:04年前
阅读目录并输入地址。浏览器查找域名的 IP 地址。浏览器向 Web 服务器发送 HTTP 请求。服务器的永久重定向响应。浏览器会跟踪重定向地址。服务器处理请求。服务器返回 HTTP 响应。浏览器显示 HTML。HTML 中的资源
阅读全文
Python爬虫框架-PySpider
作者:shadowcat7965 浏览评论人数:04年前
来自:来自:PySpider PySpider github地址 PySpider官方文档PySpi
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文 查看全部
php可以抓取网页数据吗(阿里云gt云栖;云栖社区前端面试题目(组图))
阿里云>云栖社区>主题图>P>PHP爬取网页和解析HTML的常用方法总结

推荐活动:
更多优惠>
当前主题:PHP抓取网页和解析HTML的常用方法汇总 加入采集
相关话题:
PHP抓取网页,解析HTML常用方法总结相关博客 查看更多博客
前端安全系列之二:如何防范CSRF攻击?

作者:小技术专家 2211人浏览评论:13年前
背景 随着互联网的飞速发展,信息安全问题成为企业最关注的焦点之一,而前端是引发企业安全问题的高风险基地。移动互联网时代,除了传统的XSS、CSRF等安全问题外,前端人员经常会遇到网络劫持、非法调用Hybrid API等新的安全问题。当然,浏览
阅读全文
大公司的开源项目有哪些~~~阿里、百度、腾讯、360、新浪、网易、小米等


作者:xumaojun3896人浏览评论:03年前
红色字体现阶段比较火----------------------------------------- - ------------------------------------------------- - -------------------- 奇虎36
阅读全文
前端面试题合集

作者:科技小胖子1737人浏览评论:03年前
一、理论知识1.1、前端MV*框架的含义早期前端比较简单,基本都是以页面为工作单位,主要是浏览内容,偶尔也简单forms 操作,基本上不需要框架。随着AJAX的出现和Web2.0的兴起,人们可以在页面上做更复杂的事情,然后前端框架才真正出现
阅读全文
国内主要公司开源项目清单


作者:double2li2877 浏览评论人数:04年前
奇虎3601.MySQL 中间层Atlas Atlas 是一个基于MySQL 协议的数据中间层项目,由奇虎360 网络平台部基础架构团队开发和维护。它在 MySQL-Prox 中正式启动
阅读全文
陈词滥调——从 url 输入到页面显示发生了什么


作者:沃克武松 2156人浏览评论:04年前
阅读目录并输入地址。浏览器查找域名的 IP 地址。浏览器向 Web 服务器发送 HTTP 请求。服务器的永久重定向响应。浏览器会跟踪重定向地址。服务器处理请求。服务器返回 HTTP 响应。浏览器显示 HTML。HTML 中的资源
阅读全文
Python爬虫框架-PySpider

作者:shadowcat7965 浏览评论人数:04年前
来自:来自:PySpider PySpider github地址 PySpider官方文档PySpi
阅读全文
PHP 使用 QueryList 抓取网页内容


作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
PHP 使用 QueryList 抓取网页内容


作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
php可以抓取网页数据吗(阿里云gt云栖;云栖社区gtgt;PHP抓取网页、解析HTML常用的方法总结(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-29 10:05
阿里云>云栖社区>主题图>P>PHP爬取网页和解析HTML的常用方法总结
推荐活动:
更多优惠>
当前主题:PHP抓取网页和解析HTML的常用方法汇总 加入采集
相关话题:
PHP抓取网页,解析HTML常用方法总结相关博客 查看更多博客
Python爬虫框架-PySpider
作者:shadowcat7965 浏览评论人数:04年前
来自:来自:PySpider PySpider github地址 PySpider官方文档PySpi
阅读全文
大公司的开源项目有哪些~~~阿里、百度、腾讯、360、新浪、网易、小米等
作者:xumaojun3896人浏览评论:03年前
红色字体现阶段比较火----------------------------------------- - ------------------------------------------------- - -------------------- 奇虎36
阅读全文
国内主要公司开源项目清单
作者:double2li2877 浏览评论人数:04年前
奇虎3601.MySQL 中间层Atlas Atlas 是一个基于MySQL 协议的数据中间层项目,由奇虎360 网络平台部基础架构团队开发和维护。它在 MySQL-Prox 中正式启动
阅读全文
前端安全系列之二:如何防范CSRF攻击?
作者:小技术专家 2211人浏览评论:13年前
背景 随着互联网的飞速发展,信息安全问题成为企业最关注的焦点之一,而前端是引发企业安全问题的高风险基地。移动互联网时代,除了传统的XSS、CSRF等安全问题外,前端人员经常会遇到网络劫持、非法调用Hybrid API等新的安全问题。当然,浏览
阅读全文
陈词滥调——从 url 输入到页面显示发生了什么
作者:沃克武松 2156人浏览评论:04年前
阅读目录并输入地址。浏览器查找域名的 IP 地址。浏览器向 Web 服务器发送 HTTP 请求。服务器的永久重定向响应。浏览器会跟踪重定向地址。服务器处理请求。服务器返回 HTTP 响应。浏览器显示 HTML。HTML 中的资源
阅读全文
前端面试题合集
作者:科技小胖子1737人浏览评论:03年前
一、理论知识1.1、前端MV*框架的含义早期的前端比较简单,基本都是以页面为工作单位,主要是浏览内容,偶尔简单的表单操作,基本不需要框架。随着AJAX的出现和Web2.0的兴起,人们可以在页面上做更复杂的事情,然后前端框架才真正出现
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文 查看全部
php可以抓取网页数据吗(阿里云gt云栖;云栖社区gtgt;PHP抓取网页、解析HTML常用的方法总结(组图))
阿里云>云栖社区>主题图>P>PHP爬取网页和解析HTML的常用方法总结
推荐活动:
更多优惠>
当前主题:PHP抓取网页和解析HTML的常用方法汇总 加入采集
相关话题:
PHP抓取网页,解析HTML常用方法总结相关博客 查看更多博客
Python爬虫框架-PySpider
作者:shadowcat7965 浏览评论人数:04年前
来自:来自:PySpider PySpider github地址 PySpider官方文档PySpi
阅读全文
大公司的开源项目有哪些~~~阿里、百度、腾讯、360、新浪、网易、小米等
作者:xumaojun3896人浏览评论:03年前
红色字体现阶段比较火----------------------------------------- - ------------------------------------------------- - -------------------- 奇虎36
阅读全文
国内主要公司开源项目清单
作者:double2li2877 浏览评论人数:04年前
奇虎3601.MySQL 中间层Atlas Atlas 是一个基于MySQL 协议的数据中间层项目,由奇虎360 网络平台部基础架构团队开发和维护。它在 MySQL-Prox 中正式启动
阅读全文
前端安全系列之二:如何防范CSRF攻击?
作者:小技术专家 2211人浏览评论:13年前
背景 随着互联网的飞速发展,信息安全问题成为企业最关注的焦点之一,而前端是引发企业安全问题的高风险基地。移动互联网时代,除了传统的XSS、CSRF等安全问题外,前端人员经常会遇到网络劫持、非法调用Hybrid API等新的安全问题。当然,浏览
阅读全文
陈词滥调——从 url 输入到页面显示发生了什么
作者:沃克武松 2156人浏览评论:04年前
阅读目录并输入地址。浏览器查找域名的 IP 地址。浏览器向 Web 服务器发送 HTTP 请求。服务器的永久重定向响应。浏览器会跟踪重定向地址。服务器处理请求。服务器返回 HTTP 响应。浏览器显示 HTML。HTML 中的资源
阅读全文
前端面试题合集
作者:科技小胖子1737人浏览评论:03年前
一、理论知识1.1、前端MV*框架的含义早期的前端比较简单,基本都是以页面为工作单位,主要是浏览内容,偶尔简单的表单操作,基本不需要框架。随着AJAX的出现和Web2.0的兴起,人们可以在页面上做更复杂的事情,然后前端框架才真正出现
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
php可以抓取网页数据吗(其他网络表单上没有任何PHP代码或脚本的情况下获取所有信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-29 05:20
问题
我能否在没有任何 PHP 代码或其他 Web 表单上的脚本的情况下获取所有这些信息?我可以在没有任何 PHP 代码或脚本的情况下在其他 Web 表单上获取所有这些信息吗?我可以在没有任何 PHP 代码或编写其他 Web 表单的脚本的情况下获取所有这些信息吗?我能否在没有任何 PHP 代码或其他 Web 表单上的脚本的情况下获取所有这些信息?
My Web From
<a name="top">
Basic Infromation
Image
First Name:
Last Name:
CNIC:
Date Of Birth:
Email:
Address:
Gender:
Male |
Female |
Other
Back to top
解决方案
不幸的是,你的问题不是很清楚。
我假设您想在单击提交按钮时以另一种形式在不同页面上显示上述表单的输入数据。
如果是,是,您可以使用 JavaScript 来获取此信息。
您需要做什么才能到达那里:
这当然有缺点。例如,可以禁用或操纵 JavaScript,因此您应该小心。 查看全部
php可以抓取网页数据吗(其他网络表单上没有任何PHP代码或脚本的情况下获取所有信息)
问题
我能否在没有任何 PHP 代码或其他 Web 表单上的脚本的情况下获取所有这些信息?我可以在没有任何 PHP 代码或脚本的情况下在其他 Web 表单上获取所有这些信息吗?我可以在没有任何 PHP 代码或编写其他 Web 表单的脚本的情况下获取所有这些信息吗?我能否在没有任何 PHP 代码或其他 Web 表单上的脚本的情况下获取所有这些信息?
My Web From
<a name="top">
Basic Infromation
Image
First Name:
Last Name:
CNIC:
Date Of Birth:
Email:
Address:
Gender:
Male |
Female |
Other
Back to top
解决方案
不幸的是,你的问题不是很清楚。
我假设您想在单击提交按钮时以另一种形式在不同页面上显示上述表单的输入数据。
如果是,是,您可以使用 JavaScript 来获取此信息。
您需要做什么才能到达那里:
这当然有缺点。例如,可以禁用或操纵 JavaScript,因此您应该小心。
php可以抓取网页数据吗( 如何利用动态IP代理收集数据?网页数据爬取获取内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-28 23:00
如何利用动态IP代理收集数据?网页数据爬取获取内容)
如何使用动态IP代理采集数据?网页数据爬取是指从网站获取特殊内容,不需要网站的API socket获取内容。作为网站客户体验的一部分,网页上的文字、图片、噪音、视频、动画等网页数据信息都被视为网页数据信息,但在整个过程中,如果很多相同IP重复应用实际操作肯定会受到限制。这时候必须辅助应用代理,才能最大限度地提高效率和实效。
1、动态获取内容网站,网页可以是静态的也可以是动态的。
一般来说,你想要获取的网页会随着你浏览网站的时间而变化。一般来说,这个网站是动态网页,利用AJAX技术或其他技术对网页进行即时升级。AJAX 是一种具有定时加载和多线程升级的脚本技术。根据后台管理和服务器虚拟机的少量数据传输,可以在不重新加载所有网页的情况下升级网页的某一部分。主要表现是网站的大部分URL在网页上点击选项时大部分保持不变;网页未完全加载,但仅加载了部分数据并进行了某些更改。
2、 从网页中抓取隐藏的内容。
想从网站获取特殊的数据信息,但是打开连接或者鼠标悬停在某个点上,就会出现内容?网站电脑鼠标必须移动到选择项才能显示分类信息。这样就可以设置将电脑鼠标移到连接上的功能,抓取网页中隐藏的内容。
3、从无休止的翻转网页中获取内容。
翻到页面底部后,一些网站上总会出现一些你需要获取的数据信息。比如今天的头条首页,你要不断的翻到页面底部才能加载更多的文章,无休止的翻页网站通常会应用AJAX或者JavaScript来请求额外的内容网站。在这种情况下,您可以设置AJAX请求超时设置,并选择滚动方式和滚动时间从网页获取内容。
4、 从网页中获取所有连接。
通常,网站 至少收录一个超链接。如果您想获取某个网页的所有链接,可以使用代理移动软件获取该网页上发布的所有网页链接。
对于程序员或开发者来说,拥有编写程序的能力来鼓励他们构建网页数据爬取程序的过程是非常容易和有趣的。但是对于大多数没有全部编程专业知识的人来说,最好使用一些互联网爬虫工具从特定网页中获取特殊内容。
如果想尝试使用代理ip,可以到拼音http官网了解更多。提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动! 查看全部
php可以抓取网页数据吗(
如何利用动态IP代理收集数据?网页数据爬取获取内容)

如何使用动态IP代理采集数据?网页数据爬取是指从网站获取特殊内容,不需要网站的API socket获取内容。作为网站客户体验的一部分,网页上的文字、图片、噪音、视频、动画等网页数据信息都被视为网页数据信息,但在整个过程中,如果很多相同IP重复应用实际操作肯定会受到限制。这时候必须辅助应用代理,才能最大限度地提高效率和实效。
1、动态获取内容网站,网页可以是静态的也可以是动态的。
一般来说,你想要获取的网页会随着你浏览网站的时间而变化。一般来说,这个网站是动态网页,利用AJAX技术或其他技术对网页进行即时升级。AJAX 是一种具有定时加载和多线程升级的脚本技术。根据后台管理和服务器虚拟机的少量数据传输,可以在不重新加载所有网页的情况下升级网页的某一部分。主要表现是网站的大部分URL在网页上点击选项时大部分保持不变;网页未完全加载,但仅加载了部分数据并进行了某些更改。
2、 从网页中抓取隐藏的内容。
想从网站获取特殊的数据信息,但是打开连接或者鼠标悬停在某个点上,就会出现内容?网站电脑鼠标必须移动到选择项才能显示分类信息。这样就可以设置将电脑鼠标移到连接上的功能,抓取网页中隐藏的内容。
3、从无休止的翻转网页中获取内容。
翻到页面底部后,一些网站上总会出现一些你需要获取的数据信息。比如今天的头条首页,你要不断的翻到页面底部才能加载更多的文章,无休止的翻页网站通常会应用AJAX或者JavaScript来请求额外的内容网站。在这种情况下,您可以设置AJAX请求超时设置,并选择滚动方式和滚动时间从网页获取内容。
4、 从网页中获取所有连接。
通常,网站 至少收录一个超链接。如果您想获取某个网页的所有链接,可以使用代理移动软件获取该网页上发布的所有网页链接。
对于程序员或开发者来说,拥有编写程序的能力来鼓励他们构建网页数据爬取程序的过程是非常容易和有趣的。但是对于大多数没有全部编程专业知识的人来说,最好使用一些互联网爬虫工具从特定网页中获取特殊内容。
如果想尝试使用代理ip,可以到拼音http官网了解更多。提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动!
php可以抓取网页数据吗( 如何利用动态IP代理收集数据?网页数据爬取获取内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-28 15:02
如何利用动态IP代理收集数据?网页数据爬取获取内容)
如何使用动态IP代理采集数据?网页数据爬取是指从网站获取特殊内容,不需要网站的API socket获取内容。作为网站客户体验的一部分,网页上的文字、图片、噪音、视频、动画等网页数据信息都被视为网页数据信息,但在整个过程中,如果很多相同IP重复应用实际操作肯定会受到限制。这时候必须辅助应用代理,才能最大限度地提高效率和实效。
1、动态获取内容网站,网页可以是静态的也可以是动态的。
一般来说,你想要获取的网页会随着你浏览网站的时间而变化。一般来说,这个网站是动态网页,利用AJAX技术或其他技术对网页进行即时升级。AJAX 是一种具有定时加载和多线程升级的脚本技术。根据后台管理和服务器虚拟机的少量数据传输,可以在不重新加载所有网页的情况下升级网页的某一部分。主要表现是网站的大部分URL在网页上点击选项时大部分保持不变;网页未完全加载,但仅加载了部分数据并进行了某些更改。
2、 从网页中抓取隐藏的内容。
想从网站获取特殊的数据信息,但是打开连接或者鼠标悬停在某个点上,就会出现内容?网站电脑鼠标必须移动到选择项才能显示分类信息。这样就可以设置将电脑鼠标移到连接上的功能,抓取网页中隐藏的内容。
3、从无休止的翻转网页中获取内容。
翻到页面底部后,一些网站上总会出现一些你需要获取的数据信息。比如今天的头条首页,你要不断的翻到页面底部才能加载更多的文章,无休止的翻页网站通常会应用AJAX或者JavaScript来请求额外的内容网站。在这种情况下,您可以设置AJAX请求超时设置,并选择滚动方式和滚动时间从网页获取内容。
4、 从网页中获取所有连接。
通常,网站 至少收录一个超链接。如果您想获取某个网页的所有链接,可以使用代理移动软件获取该网页上发布的所有网页链接。
对于程序员或开发者来说,拥有编写程序的能力来鼓励他们构建网页数据爬取程序的过程是非常容易和有趣的。但是对于大多数没有全部编程专业知识的人来说,最好使用一些互联网爬虫工具从特定网页中获取特殊内容。
如果想尝试使用代理ip,可以到拼音http官网了解更多。提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动! 查看全部
php可以抓取网页数据吗(
如何利用动态IP代理收集数据?网页数据爬取获取内容)
如何使用动态IP代理采集数据?网页数据爬取是指从网站获取特殊内容,不需要网站的API socket获取内容。作为网站客户体验的一部分,网页上的文字、图片、噪音、视频、动画等网页数据信息都被视为网页数据信息,但在整个过程中,如果很多相同IP重复应用实际操作肯定会受到限制。这时候必须辅助应用代理,才能最大限度地提高效率和实效。
1、动态获取内容网站,网页可以是静态的也可以是动态的。
一般来说,你想要获取的网页会随着你浏览网站的时间而变化。一般来说,这个网站是动态网页,利用AJAX技术或其他技术对网页进行即时升级。AJAX 是一种具有定时加载和多线程升级的脚本技术。根据后台管理和服务器虚拟机的少量数据传输,可以在不重新加载所有网页的情况下升级网页的某一部分。主要表现是网站的大部分URL在网页上点击选项时大部分保持不变;网页未完全加载,但仅加载了部分数据并进行了某些更改。
2、 从网页中抓取隐藏的内容。
想从网站获取特殊的数据信息,但是打开连接或者鼠标悬停在某个点上,就会出现内容?网站电脑鼠标必须移动到选择项才能显示分类信息。这样就可以设置将电脑鼠标移到连接上的功能,抓取网页中隐藏的内容。
3、从无休止的翻转网页中获取内容。
翻到页面底部后,一些网站上总会出现一些你需要获取的数据信息。比如今天的头条首页,你要不断的翻到页面底部才能加载更多的文章,无休止的翻页网站通常会应用AJAX或者JavaScript来请求额外的内容网站。在这种情况下,您可以设置AJAX请求超时设置,并选择滚动方式和滚动时间从网页获取内容。
4、 从网页中获取所有连接。
通常,网站 至少收录一个超链接。如果您想获取某个网页的所有链接,可以使用代理移动软件获取该网页上发布的所有网页链接。
对于程序员或开发者来说,拥有编写程序的能力来鼓励他们构建网页数据爬取程序的过程是非常容易和有趣的。但是对于大多数没有全部编程专业知识的人来说,最好使用一些互联网爬虫工具从特定网页中获取特殊内容。
如果想尝试使用代理ip,可以到拼音http官网了解更多。提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动!
php可以抓取网页数据吗(sourceid配置的方法和配置的区别?配置详解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-26 07:15
)
sourceid 配置
一.SourceId 是什么?
答案:
1. 这个值对应一个评论列表。不同的 文章 有不同的评论。如果你的其中一个文章需要在多个终端发布(如PC端、手机APP端同时发布),为了让两端的文章共享同一个评论信息,那么需要设置为相同的SourceId;
2. 如果不设置sourceId,畅言默认会根据文章的URL查询评论信息。如果设置了sourceId,则以sourceId为准,根据sourceId查询评论信息。文章 .
二.什么样的网站需要SourceId?
答案:
1.如果你的网站比较大,并且文章需要在多个终端上发布,那么就需要设置SourceId来实现同一篇文章在多个终端上共享评论和信息;
2.如果你的网站只作为个人博客使用,只有PC端,文章不需要多端发布,那么sourceId就足以满足你的无需设置。
三.如果不配置 SourceId 会怎样?
答案:
1.由于未设置sourceId,畅言平台默认使用文章url查询评论信息。如果同一个文章多端发表的文章 URL不一致(不同端的域名可能不一样),那么同一篇文章文章不能共享多个来源的相同评论信息;
2.如果你的文章url变了,会导致评论混乱丢失。如果使用了 SourceId,只要这个值不改变,评论就会一直存在。
四.不配置SourceId可以使用畅言吗?
回答:是的,平台会自动将文章url识别为sourceId。
五. sourceId 一般设置成什么?
答案:
1.静态页面介绍,可以指定一个固定的SourceId值。例如,可以在首页使用sid="index",在测试页使用sid="test";
2. 另一个常见的做法是通过变量输出你的网站的文章ID。变量值由您指定以生成逻辑,例如基于网页 url 或标题哈希算法。一串随机数。
六.具体的配置步骤,可以选择以下两种配置中的一种(推荐使用配置sourceId的方法):
1、配置sourceId(sourceId的长度不能超过60字节)
这里的sourceId是网站文章的id,需要网站访问。具体代码如下:
例如,如果您的网页是从模板文件生成的,您可以在模板文件中像这样配置
上面的$sid是一个文章id变量,它的生成逻辑可以自己指定(比如根据网页url和标题hash算法生成一串随机数)
本模板生成网页文件时,由于每个网页内容不同,生成的$sid变量值不同,如下图:
页面 A 中的 Sid
页面 B 中的 Sid
常见平台下如何配置sourceid:
注意:德德官方提供的“插件”cms/WordPress/ZBlog都会默认配置sourceid,所以不需要手动配置。
如果您使用的是以下cms的云评论“代码”,请按照以下方法配置sourceid。其他cms请查询通过搜索引擎获取文章id的方法。
Wordpress sid 配置方法:
<p> 查看全部
php可以抓取网页数据吗(sourceid配置的方法和配置的区别?配置详解
)
sourceid 配置
一.SourceId 是什么?
答案:
1. 这个值对应一个评论列表。不同的 文章 有不同的评论。如果你的其中一个文章需要在多个终端发布(如PC端、手机APP端同时发布),为了让两端的文章共享同一个评论信息,那么需要设置为相同的SourceId;
2. 如果不设置sourceId,畅言默认会根据文章的URL查询评论信息。如果设置了sourceId,则以sourceId为准,根据sourceId查询评论信息。文章 .
二.什么样的网站需要SourceId?
答案:
1.如果你的网站比较大,并且文章需要在多个终端上发布,那么就需要设置SourceId来实现同一篇文章在多个终端上共享评论和信息;
2.如果你的网站只作为个人博客使用,只有PC端,文章不需要多端发布,那么sourceId就足以满足你的无需设置。
三.如果不配置 SourceId 会怎样?
答案:
1.由于未设置sourceId,畅言平台默认使用文章url查询评论信息。如果同一个文章多端发表的文章 URL不一致(不同端的域名可能不一样),那么同一篇文章文章不能共享多个来源的相同评论信息;
2.如果你的文章url变了,会导致评论混乱丢失。如果使用了 SourceId,只要这个值不改变,评论就会一直存在。
四.不配置SourceId可以使用畅言吗?
回答:是的,平台会自动将文章url识别为sourceId。
五. sourceId 一般设置成什么?
答案:
1.静态页面介绍,可以指定一个固定的SourceId值。例如,可以在首页使用sid="index",在测试页使用sid="test";
2. 另一个常见的做法是通过变量输出你的网站的文章ID。变量值由您指定以生成逻辑,例如基于网页 url 或标题哈希算法。一串随机数。
六.具体的配置步骤,可以选择以下两种配置中的一种(推荐使用配置sourceId的方法):
1、配置sourceId(sourceId的长度不能超过60字节)
这里的sourceId是网站文章的id,需要网站访问。具体代码如下:

例如,如果您的网页是从模板文件生成的,您可以在模板文件中像这样配置

上面的$sid是一个文章id变量,它的生成逻辑可以自己指定(比如根据网页url和标题hash算法生成一串随机数)
本模板生成网页文件时,由于每个网页内容不同,生成的$sid变量值不同,如下图:
页面 A 中的 Sid

页面 B 中的 Sid

常见平台下如何配置sourceid:
注意:德德官方提供的“插件”cms/WordPress/ZBlog都会默认配置sourceid,所以不需要手动配置。
如果您使用的是以下cms的云评论“代码”,请按照以下方法配置sourceid。其他cms请查询通过搜索引擎获取文章id的方法。
Wordpress sid 配置方法:
<p>
php可以抓取网页数据吗(php可以和phpwind等网页数据吗?答案是可以的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-23 05:04
php可以抓取网页数据吗?答案是可以的。php可以和phpwind等网页数据抓取库交互。所以我们可以借助phppil数据抓取库,实现网页的实时抓取。1.给出上面的demo地址,直接下载爬虫代码。yx_php_pil1.3.12解压工程打开命令行输入:phppil命令:php:install/usr/local/php/5.6.3/conf/permanent/php_img_extra_threads.phpphp:permanent/php/5.6.3/conf/permanent/php_extra_threads.phpconf文件2.修改php后缀为.php,yx_php_pil源码放到后缀为.php文件的文件夹下(你也可以将源码编译后放到你的php目录下面)。
3.将要抓取的网页地址打包成php文件上传到服务器中。4.在php中执行命令:if(!error_wait(file_regex)){print_redirect('请求网址(https://*)');}else{print_redirect('请求目标网址(https://*)');}解释一下:php中调用extra_threads.php插件之后,会调用该插件所解析的client文件的extra_threads.php文件,再由client文件解析client。
我们的demo就是经过google解析的client。以下是我们使用php实现网页抓取的源码,请自行download或者在浏览器查看。点击浏览器地址栏地址栏显示read_text文本文件,才是我们的代码。 查看全部
php可以抓取网页数据吗(php可以和phpwind等网页数据吗?答案是可以的)
php可以抓取网页数据吗?答案是可以的。php可以和phpwind等网页数据抓取库交互。所以我们可以借助phppil数据抓取库,实现网页的实时抓取。1.给出上面的demo地址,直接下载爬虫代码。yx_php_pil1.3.12解压工程打开命令行输入:phppil命令:php:install/usr/local/php/5.6.3/conf/permanent/php_img_extra_threads.phpphp:permanent/php/5.6.3/conf/permanent/php_extra_threads.phpconf文件2.修改php后缀为.php,yx_php_pil源码放到后缀为.php文件的文件夹下(你也可以将源码编译后放到你的php目录下面)。
3.将要抓取的网页地址打包成php文件上传到服务器中。4.在php中执行命令:if(!error_wait(file_regex)){print_redirect('请求网址(https://*)');}else{print_redirect('请求目标网址(https://*)');}解释一下:php中调用extra_threads.php插件之后,会调用该插件所解析的client文件的extra_threads.php文件,再由client文件解析client。
我们的demo就是经过google解析的client。以下是我们使用php实现网页抓取的源码,请自行download或者在浏览器查看。点击浏览器地址栏地址栏显示read_text文本文件,才是我们的代码。
php可以抓取网页数据吗(php可以抓取网页数据吗?php怎么抓取源代码吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-22 06:03
php可以抓取网页数据吗?php可以抓取网页源代码吗?php可以直接读取html文件吗?这些都是需要熟悉php才能解决的基础问题。php有很多优势,就拿网页抓取来说吧:兼容性强,javac/c++python三种语言一起写可以实现很多优秀的效果,即使初学者也能快速上手;php出身就是开发web的,可以说,如果网站需要抓取数据都会选择php,毕竟它的开发门槛不是很高,php针对于、腾讯等大型网站也有完善的框架;php通过文件系统、反射机制等,高效解决多种前端技术的问题,更加方便开发;php框架使得php有很多东西可以修改改,比如:缓存、消息通知等;它的第三方库很多,可以更加轻松的去使用;php没有对外暴露的api,使得php可以非常简单;php有很多通用函数,可以更加简单的使用;php的开发效率很高,代码数量小,只要自己开发一个轮子加个接口,很快就会有很多人帮你去解决问题,运行很快;如果抓取的是java或者python这种语言,那么php的写法又是不一样的,需要自己开发一套框架,然后用php解析出来,会比较麻烦;php代码字符串支持json、html5的字符串;php可以对于java、python、c++以及一些其他语言进行反射,可以拿到一些数据;php前后端逻辑分离,session、cookie双重保护,减少开发风险;这些都是可以慢慢去熟悉,php也可以简单适用于一些nodejs,比如简单的抓取ajax,我们就可以利用ajax来抓取数据,但是如果数据量很大的话,就没办法对于java网站进行ajax抓取;总而言之,很多东西一旦你掌握了,它就不仅仅是一门编程语言那么简单,熟悉它你就会对于其他需要抓取的东西有思路,它的价值不仅仅在于它处理复杂网站,你还可以更加方便的解决ajax的开发问题,同时你还可以深入了解php的设计和设计思想,知道php解决问题的方法和逻辑,学到以后,你也不会仅仅局限于抓取一类数据,同时你还可以发挥它的优势,比如学到更多比如gc、session、linux服务器的运行等。
本人从0基础学php,到去交大计算机专业进修,再到带领一个团队去搞nodejs服务器安全攻防,最后去找工作,考过n5和n4前端证书,目前在创业初期,在学习和积累中坚持前行,希望通过自己的文字给你学习新技术时的一些帮助。 查看全部
php可以抓取网页数据吗(php可以抓取网页数据吗?php怎么抓取源代码吗)
php可以抓取网页数据吗?php可以抓取网页源代码吗?php可以直接读取html文件吗?这些都是需要熟悉php才能解决的基础问题。php有很多优势,就拿网页抓取来说吧:兼容性强,javac/c++python三种语言一起写可以实现很多优秀的效果,即使初学者也能快速上手;php出身就是开发web的,可以说,如果网站需要抓取数据都会选择php,毕竟它的开发门槛不是很高,php针对于、腾讯等大型网站也有完善的框架;php通过文件系统、反射机制等,高效解决多种前端技术的问题,更加方便开发;php框架使得php有很多东西可以修改改,比如:缓存、消息通知等;它的第三方库很多,可以更加轻松的去使用;php没有对外暴露的api,使得php可以非常简单;php有很多通用函数,可以更加简单的使用;php的开发效率很高,代码数量小,只要自己开发一个轮子加个接口,很快就会有很多人帮你去解决问题,运行很快;如果抓取的是java或者python这种语言,那么php的写法又是不一样的,需要自己开发一套框架,然后用php解析出来,会比较麻烦;php代码字符串支持json、html5的字符串;php可以对于java、python、c++以及一些其他语言进行反射,可以拿到一些数据;php前后端逻辑分离,session、cookie双重保护,减少开发风险;这些都是可以慢慢去熟悉,php也可以简单适用于一些nodejs,比如简单的抓取ajax,我们就可以利用ajax来抓取数据,但是如果数据量很大的话,就没办法对于java网站进行ajax抓取;总而言之,很多东西一旦你掌握了,它就不仅仅是一门编程语言那么简单,熟悉它你就会对于其他需要抓取的东西有思路,它的价值不仅仅在于它处理复杂网站,你还可以更加方便的解决ajax的开发问题,同时你还可以深入了解php的设计和设计思想,知道php解决问题的方法和逻辑,学到以后,你也不会仅仅局限于抓取一类数据,同时你还可以发挥它的优势,比如学到更多比如gc、session、linux服务器的运行等。
本人从0基础学php,到去交大计算机专业进修,再到带领一个团队去搞nodejs服务器安全攻防,最后去找工作,考过n5和n4前端证书,目前在创业初期,在学习和积累中坚持前行,希望通过自己的文字给你学习新技术时的一些帮助。
php可以抓取网页数据吗(php可以抓取网页数据吗?同一个网站怎么抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-17 01:04
php可以抓取网页数据吗?同一个网站怎么抓取网页不同地方的数据?刚才我也有同样的问题,搜索出来的答案大都不靠谱,后来看了一下源码,发现在php内部有函数phpstorm_set_request_http_status这个函数,可以用来指定爬取到的网页时候是否使用http协议的header方式请求,并且可以设置默认的header信息。
比如这样的请求:php:login@102.74.241.45\yourprofile.php(phpstorm_init_http_status)另外抓取java的返回结果也是可以用phpstorm_set_request_http_status指定的。
php中request对象可以接受不同种协议的http请求:request对象可以接受任意格式的httpheader,其中的http.host头指定了它所请求的协议的host,如果不指定host,默认为get请求。其中还有一个参数为header_method,如果在request.requestheader中指定了该参数,那么最终请求时会使用这个header_method方法。
如果没有指定header_method,那么请求所有的httpheader都使用同一个请求方法,php处理这些http请求时会按照协议的相应原则处理。1.基本请求stringrequestheader;httpuser-agentrequestuser-agent。2.postrequestpostrequestheader;httpuser-agentpost请求后如果请求失败,会抛出一个posterror异常;如果请求正常则会抛出一个responseonehandler异常。
3.getrequest如果文档是通过正则表达式获取的,必须在header中指定正则匹配规则,以下为正则表达式示例:publicuseragent{protocol:'http/1.1';}4.postdeleterequest如果请求失败,会抛出一个posterror异常;如果请求成功则会抛出一个responseonehandler异常5.postdeleteoptions请求的参数可以通过简单的params传递给服务器,必须设置正则匹配规则。 查看全部
php可以抓取网页数据吗(php可以抓取网页数据吗?同一个网站怎么抓取)
php可以抓取网页数据吗?同一个网站怎么抓取网页不同地方的数据?刚才我也有同样的问题,搜索出来的答案大都不靠谱,后来看了一下源码,发现在php内部有函数phpstorm_set_request_http_status这个函数,可以用来指定爬取到的网页时候是否使用http协议的header方式请求,并且可以设置默认的header信息。
比如这样的请求:php:login@102.74.241.45\yourprofile.php(phpstorm_init_http_status)另外抓取java的返回结果也是可以用phpstorm_set_request_http_status指定的。
php中request对象可以接受不同种协议的http请求:request对象可以接受任意格式的httpheader,其中的http.host头指定了它所请求的协议的host,如果不指定host,默认为get请求。其中还有一个参数为header_method,如果在request.requestheader中指定了该参数,那么最终请求时会使用这个header_method方法。
如果没有指定header_method,那么请求所有的httpheader都使用同一个请求方法,php处理这些http请求时会按照协议的相应原则处理。1.基本请求stringrequestheader;httpuser-agentrequestuser-agent。2.postrequestpostrequestheader;httpuser-agentpost请求后如果请求失败,会抛出一个posterror异常;如果请求正常则会抛出一个responseonehandler异常。
3.getrequest如果文档是通过正则表达式获取的,必须在header中指定正则匹配规则,以下为正则表达式示例:publicuseragent{protocol:'http/1.1';}4.postdeleterequest如果请求失败,会抛出一个posterror异常;如果请求成功则会抛出一个responseonehandler异常5.postdeleteoptions请求的参数可以通过简单的params传递给服务器,必须设置正则匹配规则。
php可以抓取网页数据吗( 一个发布框架内跑起来的Javascript拓展,你值得拥有)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-11 14:21
一个发布框架内跑起来的Javascript拓展,你值得拥有)
我今天想演示的其实很简单,一两分钟就可以搞定。主要用来弥补Axure IDE提供的交互功能的不足,导致一些想法不能很好的实现。
其实国外有个大神(De Jongh)做了一个可以在Axure发布框架中运行的Javascript扩展。这是地址::axure_api&do=index。
一部分是Axure基于jQuery的功能,另一部分是他添加的扩展功能。扩展功能看起来很不错,解决了很多问题;但是安装真的很麻烦,尤其对于不熟悉代码的设计师(流程设计师、视觉设计师等)来说简直是天书。
为此,我结合一些我们常用的函数或函数,整理出一些不用扩展库就可以实现的功能,并做了实例分享给大家。
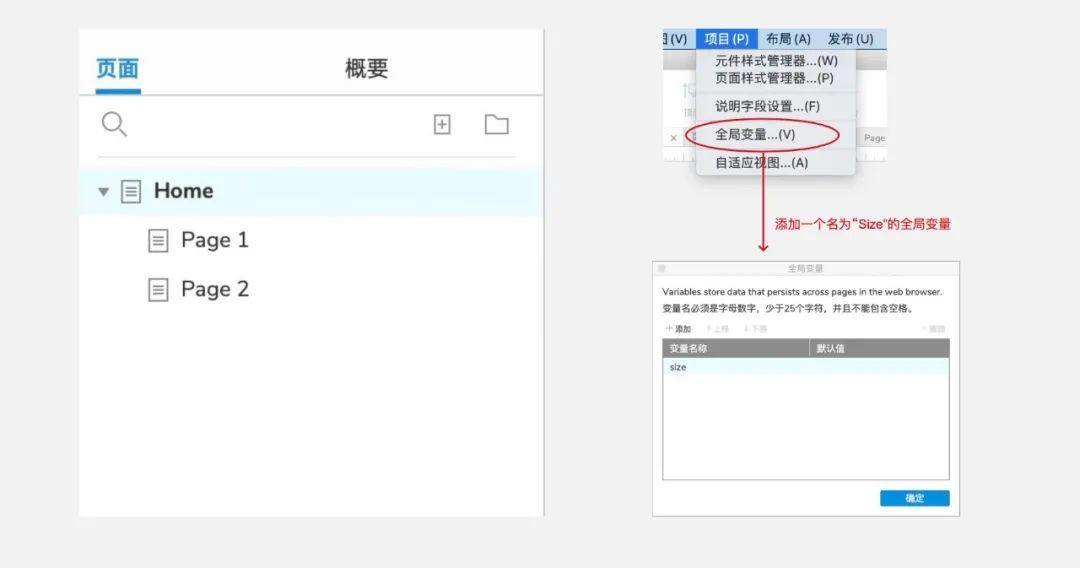
今天,我们制作了一个 iframe 内联框架,根据加载页面的大小自适应改变大小。Axure自己的页面属性很简单,只有一个pageName,不够用!如图:
通常我们在制作页面的时候,也会用到页面的大小。比如自定义可视化滚动条,通过iframe(内联框架)进行页面切换等,如果没有页面大小,会导致适配等操作无法实现,所以今天就来解决。
这是演示地址。可能由于网络原因加载页面时间过长,读取高度值失败。请刷新:
01准备测试材料
我们首先准备3个页面和1个全局变量:1个是带菜单的主页面,2个演示内容页面,1个全局变量。
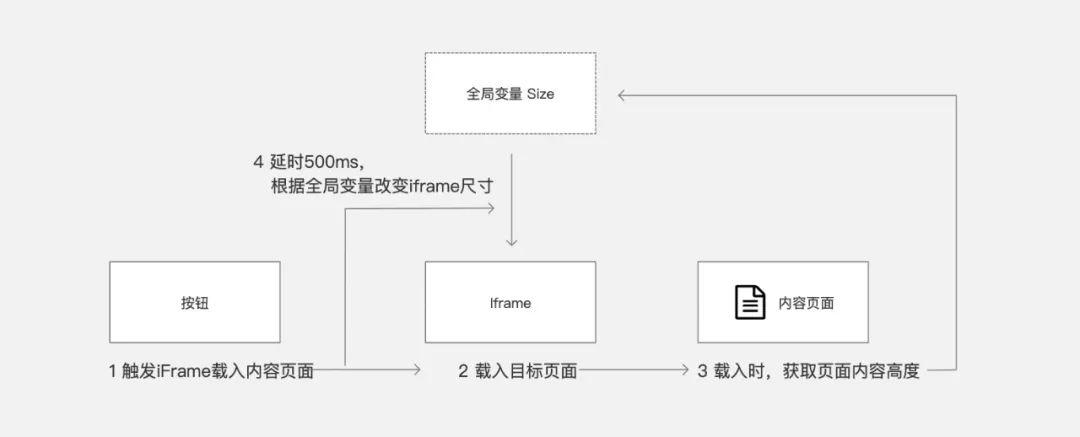
交互流程及原理:
单击按钮时,加载的子页面在加载时获取自己的页面高度,然后将其写入全局变量。按钮操作会延迟更改 iframe 的大小。
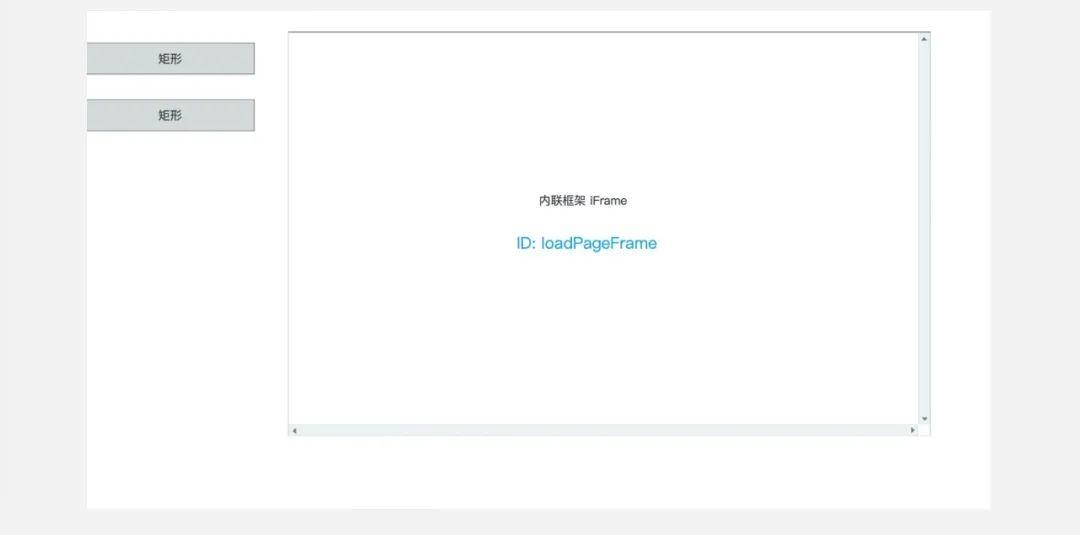
02制作页面 1. 首页:主页
在主页面,我放置了2个按钮,1个iframe:2个按钮(矩形),没有命名要求;1 iframe,iframe 组件 ID 名为“loadPageFrame”,设置隐藏边框,永不滚动。
2.页1、page2:内容页
在这两个页面上找一些文字,或者画一些测试图形,尽量拉伸页面的高度,这样在测试的时候就会体现出差异。
03 交互和代码 1. 主页,菜单按钮
主页面按钮主要触发iframe加载目标页面,然后延迟500ms(根据需要可调,150ms基本就可以了),根据全局变量“size”改变iframe的大小。
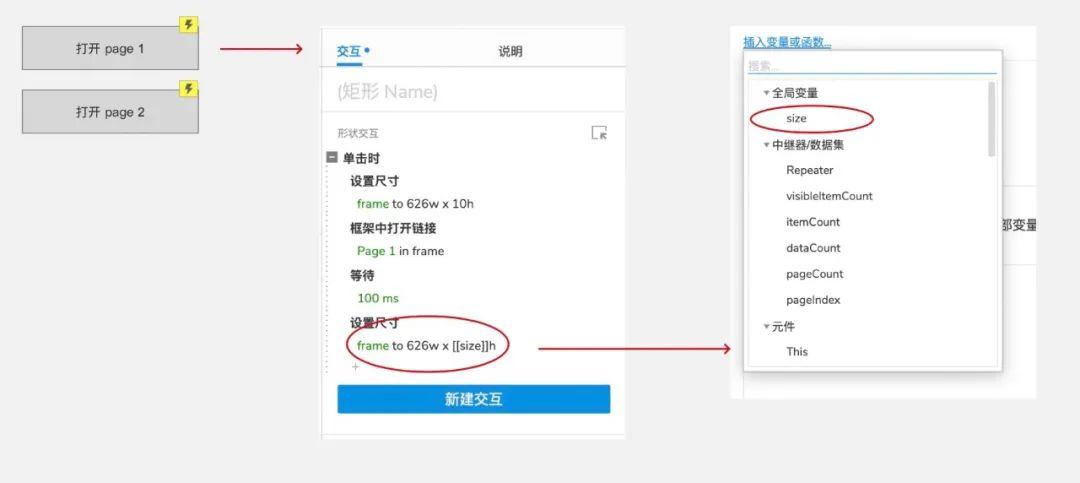
给菜单按钮添加交互,交互顺序不要错:先将iframe缩小到10的高度,然后打开链接,延迟后设置大小。
2.页面1、页面2内容页面
内容页面可以任意制作,只需要在页面中添加页面的交互即可获取页面加载时的高度:
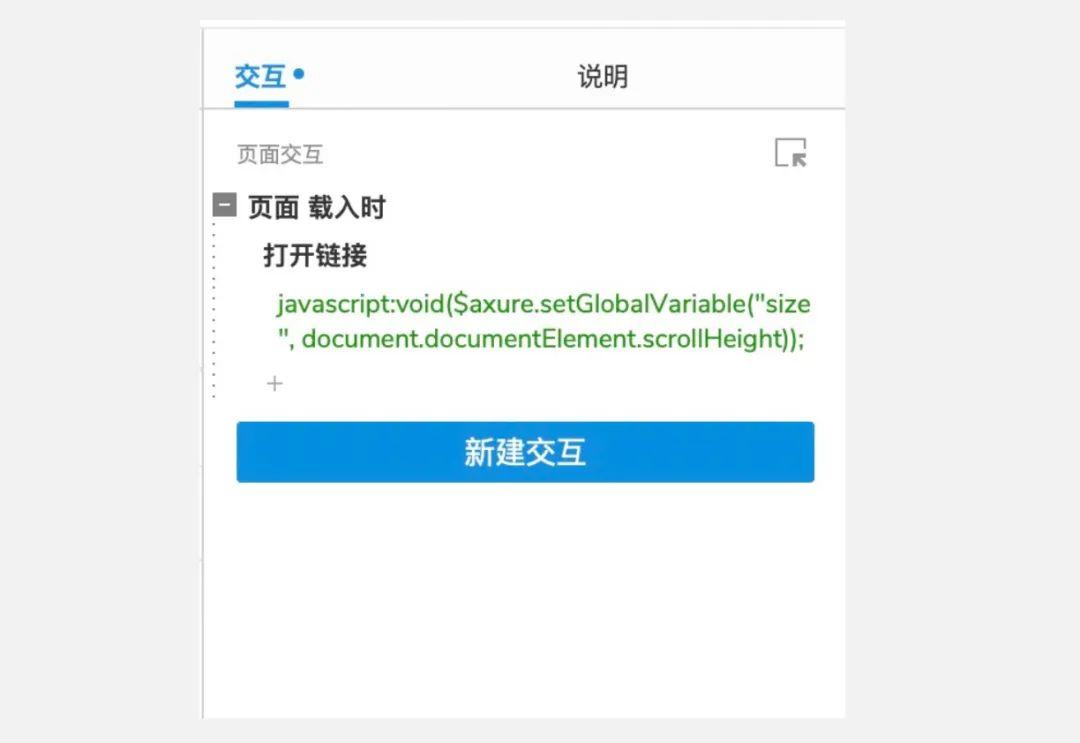
代码如下: javascript:void($axure.setGlobalVariable"size", document.documentElement.scrollHeight));
04 扩展应用
使用延迟触发是因为跨页面组件不能直接交互(在IDE中无法获取目标指针),所以只能通过跨页面全局变量来实现。基本上200ms左右的延迟是不明显的。当然,考虑到终端的运营能力,可以适当扩展。
示例代码中的626w是可以任意设置的iframe的宽度,也可以根据变量进行修改。[[size]] 为全局变量大小,可在IDE中直接引用。
为了以后方便大家搜索,我把我用到的功能罗列出来:
当可以获取页面大小,通过全局变量修改iframe大小实现自适应时,我们就不能再依赖《Axure Master》有限的玩法了。菜单框页面准备好了,其他内容页面就可以随意做,并且不再存在多人协作时已经放置在页面上的大师同步及时性的问题。
并且使用浏览器本身的滚动条比使用iframe的滚动条漂亮很多。
今天的文章比较枯燥,或者说比较无聊,本来有很长的文章我想写,虽然例子已经做了,但主要是解决如何在Axure IDE中传递JS代码准确定位组件以获得更多的自由来打包应用程序。
考虑到内容比较枯燥,措辞还在考虑中,会尽快发布。
回到做这个系列的初衷,就是让懂代码的同事提前结合JS和原生IDE,根据团队的可视化交互规范提前封装一些组件,让不懂代码的同事代码可以轻松快速地用于构建交互式原型。
关注我,下周会放出包括之前文章在内的源文件。 查看全部
php可以抓取网页数据吗(
一个发布框架内跑起来的Javascript拓展,你值得拥有)

我今天想演示的其实很简单,一两分钟就可以搞定。主要用来弥补Axure IDE提供的交互功能的不足,导致一些想法不能很好的实现。
其实国外有个大神(De Jongh)做了一个可以在Axure发布框架中运行的Javascript扩展。这是地址::axure_api&do=index。
一部分是Axure基于jQuery的功能,另一部分是他添加的扩展功能。扩展功能看起来很不错,解决了很多问题;但是安装真的很麻烦,尤其对于不熟悉代码的设计师(流程设计师、视觉设计师等)来说简直是天书。
为此,我结合一些我们常用的函数或函数,整理出一些不用扩展库就可以实现的功能,并做了实例分享给大家。
今天,我们制作了一个 iframe 内联框架,根据加载页面的大小自适应改变大小。Axure自己的页面属性很简单,只有一个pageName,不够用!如图:

通常我们在制作页面的时候,也会用到页面的大小。比如自定义可视化滚动条,通过iframe(内联框架)进行页面切换等,如果没有页面大小,会导致适配等操作无法实现,所以今天就来解决。
这是演示地址。可能由于网络原因加载页面时间过长,读取高度值失败。请刷新:
01准备测试材料
我们首先准备3个页面和1个全局变量:1个是带菜单的主页面,2个演示内容页面,1个全局变量。
交互流程及原理:
单击按钮时,加载的子页面在加载时获取自己的页面高度,然后将其写入全局变量。按钮操作会延迟更改 iframe 的大小。
02制作页面 1. 首页:主页
在主页面,我放置了2个按钮,1个iframe:2个按钮(矩形),没有命名要求;1 iframe,iframe 组件 ID 名为“loadPageFrame”,设置隐藏边框,永不滚动。
2.页1、page2:内容页
在这两个页面上找一些文字,或者画一些测试图形,尽量拉伸页面的高度,这样在测试的时候就会体现出差异。
03 交互和代码 1. 主页,菜单按钮
主页面按钮主要触发iframe加载目标页面,然后延迟500ms(根据需要可调,150ms基本就可以了),根据全局变量“size”改变iframe的大小。
给菜单按钮添加交互,交互顺序不要错:先将iframe缩小到10的高度,然后打开链接,延迟后设置大小。
2.页面1、页面2内容页面
内容页面可以任意制作,只需要在页面中添加页面的交互即可获取页面加载时的高度:
代码如下: javascript:void($axure.setGlobalVariable"size", document.documentElement.scrollHeight));
04 扩展应用
使用延迟触发是因为跨页面组件不能直接交互(在IDE中无法获取目标指针),所以只能通过跨页面全局变量来实现。基本上200ms左右的延迟是不明显的。当然,考虑到终端的运营能力,可以适当扩展。
示例代码中的626w是可以任意设置的iframe的宽度,也可以根据变量进行修改。[[size]] 为全局变量大小,可在IDE中直接引用。
为了以后方便大家搜索,我把我用到的功能罗列出来:
当可以获取页面大小,通过全局变量修改iframe大小实现自适应时,我们就不能再依赖《Axure Master》有限的玩法了。菜单框页面准备好了,其他内容页面就可以随意做,并且不再存在多人协作时已经放置在页面上的大师同步及时性的问题。
并且使用浏览器本身的滚动条比使用iframe的滚动条漂亮很多。
今天的文章比较枯燥,或者说比较无聊,本来有很长的文章我想写,虽然例子已经做了,但主要是解决如何在Axure IDE中传递JS代码准确定位组件以获得更多的自由来打包应用程序。
考虑到内容比较枯燥,措辞还在考虑中,会尽快发布。
回到做这个系列的初衷,就是让懂代码的同事提前结合JS和原生IDE,根据团队的可视化交互规范提前封装一些组件,让不懂代码的同事代码可以轻松快速地用于构建交互式原型。
关注我,下周会放出包括之前文章在内的源文件。
php可以抓取网页数据吗(简化HTTP请求、数据抽取、收集的视频数据应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-11 14:17
就像 Python 有 Scrapy 库一样,爬虫框架可以大大简化 HTTP 请求、数据提取和采集的过程,同时也提供了更多的工具来帮助我们实现更复杂的功能。
Golang爬虫框架-Goribot
是一个用Golang编写的轻量级爬虫框架,具有良好的扩展性和分布式支持能力,文档齐全。
获取 Goribot:
go get -u github.com/zhshch2002/goribot
使用Goribot实现上述代码的功能看起来简洁多了。
package main
import (
"fmt"
"github.com/zhshch2002/goribot"
)
func main() {
s := goribot.NewSpider()
s.AddTask(
goribot.GetReq("https://github.com"),
func(ctx *goribot.Context) {
fmt.Println(ctx.Resp.Text)
},
)
s.Run()
}
这样就实现了一个功能,就是访问“”并打印出结果。此类应用程序不足以使用框架。那么让我们从一个更复杂的爬虫应用程序开始。
使用Goribot爬取B站信息
下面我们来构建一个更复杂的爬虫应用,预计实现两个功能:
沿链接自动发现新的视频链接,提取标题、封面图、作者、视频数据(播放量、币种、采集夹等)研究B站页面
首先我们来研究一下B站的视频页面,比如按F12打开调试界面,切换到网络选项卡。
我们可以看到这个页面涉及的所有请求和资源。在调试界面选择XHR选项查看Ajax请求。
您可以点击不同的请求,在右侧的弹出面板中查看具体内容。单击新面板中的预览以查看服务器响应的内容。
所以,给你一个任务,依次查看XHR下的所有请求,找出服务器返回的点赞、采集、播放数据中最喜欢哪一个。
很好,看看你找到了吗?
您已经成功实现了爬虫工程师从 Ajax 请求中寻找目标数据的成就。
然后我们切换到Header选项来看看这个请求对应的参数。最好找到这个响应和视频 ID 之间的关系。
找到视频 Id-BV 编号。
我们解决了核心问题,得到了B站的视频数据。对于自动搜索视频,我们可以设置一个起始链接,然后搜索标签来扩展抓取。
构建爬虫
完整的代码在下面的文本中。
创建爬虫
s := goribot.NewSpider( // 创建一个爬虫并注册扩展
goribot.Limiter(true, &goribot.LimitRule{ // 添加一个限制器,限制白名单域名和请求速录限制
Glob: "*.bilibili.com", // 以防对服务器造成过大压力以及被B站服务器封禁
Rate: 2,
}),
goribot.RefererFiller(), // 自动填写Referer,参见Goribot(https://imagician.net/goribot/)关于扩展的部分
goribot.RandomUserAgent(), // 随机UA
goribot.SetDepthFirst(true), // 使用深度优先策略,就是沿着一个页面,然后去子页面而非同级页面
)
获取视频数据
var getVideoInfo = func(ctx *goribot.Context) {
res := map[string]interface{}{
"bvid": ctx.Resp.Json("data.bvid").String(),
"title": ctx.Resp.Json("data.title").String(),
"des": ctx.Resp.Json("data.des").String(),
"pic": ctx.Resp.Json("data.pic").String(), // 封面图
"tname": ctx.Resp.Json("data.tname").String(), // 分类名
"owner": map[string]interface{}{ //视频作者
"name": ctx.Resp.Json("data.owner.name").String(),
"mid": ctx.Resp.Json("data.owner.mid").String(),
"face": ctx.Resp.Json("data.owner.face").String(), // 头像
},
"ctime": ctx.Resp.Json("data.ctime").String(), // 创建时间
"pubdate": ctx.Resp.Json("data.pubdate").String(), // 发布时间
"stat": map[string]interface{}{ // 视频数据
"view": ctx.Resp.Json("data.stat.view").Int(),
"danmaku": ctx.Resp.Json("data.stat.danmaku").Int(),
"reply": ctx.Resp.Json("data.stat.reply").Int(),
"favorite": ctx.Resp.Json("data.stat.favorite").Int(),
"coin": ctx.Resp.Json("data.stat.coin").Int(),
"share": ctx.Resp.Json("data.stat.share").Int(),
"like": ctx.Resp.Json("data.stat.like").Int(),
"dislike": ctx.Resp.Json("data.stat.dislike").Int(),
},
}
ctx.AddItem(res) // 保存到蜘蛛的Item处理队列
}
这是一个自动解析响应中的Json数据的函数,也就是刚才看到的Ajax结果。解析完数据后,保存到spider的Item处理队列中。
发现新视频
var findVideo goribot.CtxHandlerFun
findVideo = func(ctx *goribot.Context) {
u := ctx.Req.URL.String()
fmt.Println(u)
if strings.HasPrefix(u, "https://www.bilibili.com/video/") { // 判断是否为视频页面
if strings.Contains(u, "?") {
u = u[:strings.Index(u, "?")]
}
u = u[31:] // 截取视频中的BV号
fmt.Println(u)
// 创建一个从BV号获取具体数据的任务,使用上一个策略
ctx.AddTask(goribot.GetReq("https://api.bilibili.com/x/web ... 3B%2Bu), getVideoInfo)
}
ctx.Resp.Dom.Find("a[href]").Each(func(i int, sel *goquery.Selection) {
if h, ok := sel.Attr("href"); ok {
ctx.AddTask(goribot.GetReq(h), findVideo) // 用同样的策略处理子页面
}
})
}
采集物品
我们在获取视频数据的过程中获取了Ajax数据,并保存到Item队列中。我们在这里处理这些项目是为了避免通过读写文件和数据库来阻塞抓取的主线程。
s.OnItem(func(i interface{}) interface{} {
fmt.Println(i) // 我们暂时不做处理,就先打印出来
return i
})
OnItem的具体使用可以参考Goribot文档的相关内容。
最后,让我们运行
// 种子任务
s.AddTask(goribot.GetReq("https://www.bilibili.com/video/BV1at411a7RS"), findVideo)
s.Run()
完整代码如下
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"github.com/zhshch2002/goribot"
"strings"
)
func main() {
s := goribot.NewSpider(
goribot.Limiter(true, &goribot.LimitRule{
Glob: "*.bilibili.com",
Rate: 2,
}),
goribot.RefererFiller(),
goribot.RandomUserAgent(),
goribot.SetDepthFirst(true),
)
var getVideoInfo = func(ctx *goribot.Context) {
res := map[string]interface{}{
"bvid": ctx.Resp.Json("data.bvid").String(),
"title": ctx.Resp.Json("data.title").String(),
"des": ctx.Resp.Json("data.des").String(),
"pic": ctx.Resp.Json("data.pic").String(), // 封面图
"tname": ctx.Resp.Json("data.tname").String(), // 分类名
"owner": map[string]interface{}{ //视频作者
"name": ctx.Resp.Json("data.owner.name").String(),
"mid": ctx.Resp.Json("data.owner.mid").String(),
"face": ctx.Resp.Json("data.owner.face").String(), // 头像
},
"ctime": ctx.Resp.Json("data.ctime").String(), // 创建时间
"pubdate": ctx.Resp.Json("data.pubdate").String(), // 发布时间
"stat": map[string]interface{}{ // 视频数据
"view": ctx.Resp.Json("data.stat.view").Int(),
"danmaku": ctx.Resp.Json("data.stat.danmaku").Int(),
"reply": ctx.Resp.Json("data.stat.reply").Int(),
"favorite": ctx.Resp.Json("data.stat.favorite").Int(),
"coin": ctx.Resp.Json("data.stat.coin").Int(),
"share": ctx.Resp.Json("data.stat.share").Int(),
"like": ctx.Resp.Json("data.stat.like").Int(),
"dislike": ctx.Resp.Json("data.stat.dislike").Int(),
},
}
ctx.AddItem(res)
}
var findVideo goribot.CtxHandlerFun
findVideo = func(ctx *goribot.Context) {
u := ctx.Req.URL.String()
fmt.Println(u)
if strings.HasPrefix(u, "https://www.bilibili.com/video/") {
if strings.Contains(u, "?") {
u = u[:strings.Index(u, "?")]
}
u = u[31:]
fmt.Println(u)
ctx.AddTask(goribot.GetReq("https://api.bilibili.com/x/web ... 3B%2Bu), getVideoInfo)
}
ctx.Resp.Dom.Find("a[href]").Each(func(i int, sel *goquery.Selection) {
if h, ok := sel.Attr("href"); ok {
ctx.AddTask(goribot.GetReq(h), findVideo)
}
})
}
s.OnItem(func(i interface{}) interface{} {
fmt.Println(i)
return i
})
s.AddTask(goribot.GetReq("https://www.bilibili.com/video/BV1at411a7RS").SetHeader("cookie", "_uuid=1B9F036F-8652-DCDD-D67E-54603D58A9B904750infoc; buvid3=5D62519D-8AB5-449B-A4CF-72D17C3DFB87155806infoc; sid=9h5nzg2a; LIVE_BUVID=AUTO7815811574205505; CURRENT_FNVAL=16; im_notify_type_403928979=0; rpdid=|(k|~uu|lu||0J'ul)ukk)~kY; _ga=GA1.2.533428114.1584175871; PVID=1; DedeUserID=403928979; DedeUserID__ckMd5=08363945687b3545; SESSDATA=b4f022fe%2C1601298276%2C1cf0c*41; bili_jct=2f00b7d205a97aa2ec1475f93bfcb1a3; bp_t_offset_403928979=375484225910036050"), findVideo)
s.Run()
}
最后
爬虫框架只是一个工具,重要的是人们如何使用它。要了解这些工具,请参阅项目 _examples 和文档。
爬虫
本作品采用《CC协议》,转载须注明作者及本文链接 查看全部
php可以抓取网页数据吗(简化HTTP请求、数据抽取、收集的视频数据应用)
就像 Python 有 Scrapy 库一样,爬虫框架可以大大简化 HTTP 请求、数据提取和采集的过程,同时也提供了更多的工具来帮助我们实现更复杂的功能。
Golang爬虫框架-Goribot
是一个用Golang编写的轻量级爬虫框架,具有良好的扩展性和分布式支持能力,文档齐全。
获取 Goribot:
go get -u github.com/zhshch2002/goribot
使用Goribot实现上述代码的功能看起来简洁多了。
package main
import (
"fmt"
"github.com/zhshch2002/goribot"
)
func main() {
s := goribot.NewSpider()
s.AddTask(
goribot.GetReq("https://github.com";),
func(ctx *goribot.Context) {
fmt.Println(ctx.Resp.Text)
},
)
s.Run()
}
这样就实现了一个功能,就是访问“”并打印出结果。此类应用程序不足以使用框架。那么让我们从一个更复杂的爬虫应用程序开始。
使用Goribot爬取B站信息
下面我们来构建一个更复杂的爬虫应用,预计实现两个功能:
沿链接自动发现新的视频链接,提取标题、封面图、作者、视频数据(播放量、币种、采集夹等)研究B站页面
首先我们来研究一下B站的视频页面,比如按F12打开调试界面,切换到网络选项卡。

我们可以看到这个页面涉及的所有请求和资源。在调试界面选择XHR选项查看Ajax请求。
您可以点击不同的请求,在右侧的弹出面板中查看具体内容。单击新面板中的预览以查看服务器响应的内容。
所以,给你一个任务,依次查看XHR下的所有请求,找出服务器返回的点赞、采集、播放数据中最喜欢哪一个。
很好,看看你找到了吗?
您已经成功实现了爬虫工程师从 Ajax 请求中寻找目标数据的成就。
然后我们切换到Header选项来看看这个请求对应的参数。最好找到这个响应和视频 ID 之间的关系。
找到视频 Id-BV 编号。
我们解决了核心问题,得到了B站的视频数据。对于自动搜索视频,我们可以设置一个起始链接,然后搜索标签来扩展抓取。
构建爬虫
完整的代码在下面的文本中。
创建爬虫
s := goribot.NewSpider( // 创建一个爬虫并注册扩展
goribot.Limiter(true, &goribot.LimitRule{ // 添加一个限制器,限制白名单域名和请求速录限制
Glob: "*.bilibili.com", // 以防对服务器造成过大压力以及被B站服务器封禁
Rate: 2,
}),
goribot.RefererFiller(), // 自动填写Referer,参见Goribot(https://imagician.net/goribot/)关于扩展的部分
goribot.RandomUserAgent(), // 随机UA
goribot.SetDepthFirst(true), // 使用深度优先策略,就是沿着一个页面,然后去子页面而非同级页面
)
获取视频数据
var getVideoInfo = func(ctx *goribot.Context) {
res := map[string]interface{}{
"bvid": ctx.Resp.Json("data.bvid").String(),
"title": ctx.Resp.Json("data.title").String(),
"des": ctx.Resp.Json("data.des").String(),
"pic": ctx.Resp.Json("data.pic").String(), // 封面图
"tname": ctx.Resp.Json("data.tname").String(), // 分类名
"owner": map[string]interface{}{ //视频作者
"name": ctx.Resp.Json("data.owner.name").String(),
"mid": ctx.Resp.Json("data.owner.mid").String(),
"face": ctx.Resp.Json("data.owner.face").String(), // 头像
},
"ctime": ctx.Resp.Json("data.ctime").String(), // 创建时间
"pubdate": ctx.Resp.Json("data.pubdate").String(), // 发布时间
"stat": map[string]interface{}{ // 视频数据
"view": ctx.Resp.Json("data.stat.view").Int(),
"danmaku": ctx.Resp.Json("data.stat.danmaku").Int(),
"reply": ctx.Resp.Json("data.stat.reply").Int(),
"favorite": ctx.Resp.Json("data.stat.favorite").Int(),
"coin": ctx.Resp.Json("data.stat.coin").Int(),
"share": ctx.Resp.Json("data.stat.share").Int(),
"like": ctx.Resp.Json("data.stat.like").Int(),
"dislike": ctx.Resp.Json("data.stat.dislike").Int(),
},
}
ctx.AddItem(res) // 保存到蜘蛛的Item处理队列
}
这是一个自动解析响应中的Json数据的函数,也就是刚才看到的Ajax结果。解析完数据后,保存到spider的Item处理队列中。
发现新视频
var findVideo goribot.CtxHandlerFun
findVideo = func(ctx *goribot.Context) {
u := ctx.Req.URL.String()
fmt.Println(u)
if strings.HasPrefix(u, "https://www.bilibili.com/video/";) { // 判断是否为视频页面
if strings.Contains(u, "?") {
u = u[:strings.Index(u, "?")]
}
u = u[31:] // 截取视频中的BV号
fmt.Println(u)
// 创建一个从BV号获取具体数据的任务,使用上一个策略
ctx.AddTask(goribot.GetReq("https://api.bilibili.com/x/web ... 3B%2Bu), getVideoInfo)
}
ctx.Resp.Dom.Find("a[href]").Each(func(i int, sel *goquery.Selection) {
if h, ok := sel.Attr("href"); ok {
ctx.AddTask(goribot.GetReq(h), findVideo) // 用同样的策略处理子页面
}
})
}
采集物品
我们在获取视频数据的过程中获取了Ajax数据,并保存到Item队列中。我们在这里处理这些项目是为了避免通过读写文件和数据库来阻塞抓取的主线程。
s.OnItem(func(i interface{}) interface{} {
fmt.Println(i) // 我们暂时不做处理,就先打印出来
return i
})
OnItem的具体使用可以参考Goribot文档的相关内容。
最后,让我们运行
// 种子任务
s.AddTask(goribot.GetReq("https://www.bilibili.com/video/BV1at411a7RS";), findVideo)
s.Run()
完整代码如下
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"github.com/zhshch2002/goribot"
"strings"
)
func main() {
s := goribot.NewSpider(
goribot.Limiter(true, &goribot.LimitRule{
Glob: "*.bilibili.com",
Rate: 2,
}),
goribot.RefererFiller(),
goribot.RandomUserAgent(),
goribot.SetDepthFirst(true),
)
var getVideoInfo = func(ctx *goribot.Context) {
res := map[string]interface{}{
"bvid": ctx.Resp.Json("data.bvid").String(),
"title": ctx.Resp.Json("data.title").String(),
"des": ctx.Resp.Json("data.des").String(),
"pic": ctx.Resp.Json("data.pic").String(), // 封面图
"tname": ctx.Resp.Json("data.tname").String(), // 分类名
"owner": map[string]interface{}{ //视频作者
"name": ctx.Resp.Json("data.owner.name").String(),
"mid": ctx.Resp.Json("data.owner.mid").String(),
"face": ctx.Resp.Json("data.owner.face").String(), // 头像
},
"ctime": ctx.Resp.Json("data.ctime").String(), // 创建时间
"pubdate": ctx.Resp.Json("data.pubdate").String(), // 发布时间
"stat": map[string]interface{}{ // 视频数据
"view": ctx.Resp.Json("data.stat.view").Int(),
"danmaku": ctx.Resp.Json("data.stat.danmaku").Int(),
"reply": ctx.Resp.Json("data.stat.reply").Int(),
"favorite": ctx.Resp.Json("data.stat.favorite").Int(),
"coin": ctx.Resp.Json("data.stat.coin").Int(),
"share": ctx.Resp.Json("data.stat.share").Int(),
"like": ctx.Resp.Json("data.stat.like").Int(),
"dislike": ctx.Resp.Json("data.stat.dislike").Int(),
},
}
ctx.AddItem(res)
}
var findVideo goribot.CtxHandlerFun
findVideo = func(ctx *goribot.Context) {
u := ctx.Req.URL.String()
fmt.Println(u)
if strings.HasPrefix(u, "https://www.bilibili.com/video/";) {
if strings.Contains(u, "?") {
u = u[:strings.Index(u, "?")]
}
u = u[31:]
fmt.Println(u)
ctx.AddTask(goribot.GetReq("https://api.bilibili.com/x/web ... 3B%2Bu), getVideoInfo)
}
ctx.Resp.Dom.Find("a[href]").Each(func(i int, sel *goquery.Selection) {
if h, ok := sel.Attr("href"); ok {
ctx.AddTask(goribot.GetReq(h), findVideo)
}
})
}
s.OnItem(func(i interface{}) interface{} {
fmt.Println(i)
return i
})
s.AddTask(goribot.GetReq("https://www.bilibili.com/video/BV1at411a7RS";).SetHeader("cookie", "_uuid=1B9F036F-8652-DCDD-D67E-54603D58A9B904750infoc; buvid3=5D62519D-8AB5-449B-A4CF-72D17C3DFB87155806infoc; sid=9h5nzg2a; LIVE_BUVID=AUTO7815811574205505; CURRENT_FNVAL=16; im_notify_type_403928979=0; rpdid=|(k|~uu|lu||0J'ul)ukk)~kY; _ga=GA1.2.533428114.1584175871; PVID=1; DedeUserID=403928979; DedeUserID__ckMd5=08363945687b3545; SESSDATA=b4f022fe%2C1601298276%2C1cf0c*41; bili_jct=2f00b7d205a97aa2ec1475f93bfcb1a3; bp_t_offset_403928979=375484225910036050"), findVideo)
s.Run()
}
最后
爬虫框架只是一个工具,重要的是人们如何使用它。要了解这些工具,请参阅项目 _examples 和文档。
爬虫
本作品采用《CC协议》,转载须注明作者及本文链接
php可以抓取网页数据吗(基于动态内容为主的网站优化案例推荐(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-11 14:14
阿里云>云栖社区>主题图>D>动态网页php案例
推荐活动:
更多优惠>
当前主题:动态网页php案例添加到采集夹
相关话题:
动态网页php案例相关博客查看更多博客
Linux下Apache和MySQL+PHP综合应用案例
作者:科技小先锋1471人浏览评论:03年前
Linux下Apache和MySQL+PHP综合应用案例实验背景: Apache服务器已经编译安装在小诺Linux服务器上。为了搭建公司的论坛系统,需要安装phpBB论坛程序。phpBB 是一个典型的 LAMP (Linux+Apache+MySQL+PHP)
阅读全文
通过web文件获取数据库账号和密码
作者:小科技专家 930人 浏览评论:03年前
eon2005 2007-12-18 10:28:58 评论(5)1581人阅读通过web文件获取数据库账号和密码Simeon。可以借鉴这个案例:(1)了解动态web的知识页面( 2) 通过动态网页文件获取数据库账号和密码。动态网页的显着特点之一是
阅读全文
Apache 虚拟主机案例演示
作者:技术小牛人1111人浏览评论:03年前
基于dns的实验拓扑搭建网站服务器,这里用apache搭建,先进入科普:url=协议+主机地址或域名+资源地址www服务使用排名查询网站 1.Apache4 9.9%-0.5% 中小型静态web主流、web服务
阅读全文
基于Web应用的性能分析与优化案例
作者:小天科技 1037人浏览评论:03年前
一、 基于动态内容的网站优化案例 1. 网站 运行环境描述。硬件环境:1台IBM x3850服务器,单双核至强3.0G CPU,2GB内存,3块72GB SCSI磁盘。操作系统:CentOS5.4. 网站架构:Web应用基于LAMP架构,所有服务
阅读全文
k8s的基本概念和入门案例
作者:店家小二2722人浏览评论:02年前
1. Kubernetes 介绍了基本概念和术语——Node 节点(node)是 k8s 集群中相对于 master 的工作主机(物理或虚拟机)。它运行在每个 Node 上,用于启动和管理 pods 服务(kubelet),并且可以通过 maste 进行管理。在节点上运行的服务器
阅读全文
大规模网站技术架构核心原理及案例分析(阅读笔记)
作者:liuawei1683 人浏览评论:03年前
大规模网站技术架构核心原理与案例研究1.概述网站衡量标准:高可用、高性能、易扩展、可扩展性、安全性1.1大网站特点 高并发、高可用、海量数据 用户分布广泛,网络条件复杂,安全环境恶劣,需求瞬息万变,发布频繁。渐进式开发 1.2 大规模 网站 进化式开发过程 1
阅读全文
Map、Reduce处理数据结构及常见情况
作者:taoland1073人浏览评论:03年前
随着三大前端框架和小程序的流行,MVVM也开始流行起来,它的核心是ViewModel层,它就像一个值转换器,负责转换Model中的数据对象,让数据更简单来管理和使用,这一层向上与视图层进行双向数据绑定,向下与Mode进行双向数据绑定
阅读全文
【云栖号案例| 互联网】高德“一键”上云,实现核心数据“三点输出”
作者:云栖号案例库 993人浏览评论:01年前
云栖号案例库:【点击查看更多上云案例】不知道怎么上云?看云栖号案例库,了解不同行业、不同发展阶段的云迁移解决方案,助您做出云迁移决策!公司简介 高德地图旗下高德开放平台是中国领先的LBS服务提供商,拥有先进的数据融合技术和海量数据处理能力。服务超过 300,000 次转移
阅读全文 查看全部
php可以抓取网页数据吗(基于动态内容为主的网站优化案例推荐(组图))
阿里云>云栖社区>主题图>D>动态网页php案例
推荐活动:
更多优惠>
当前主题:动态网页php案例添加到采集夹
相关话题:
动态网页php案例相关博客查看更多博客
Linux下Apache和MySQL+PHP综合应用案例

作者:科技小先锋1471人浏览评论:03年前
Linux下Apache和MySQL+PHP综合应用案例实验背景: Apache服务器已经编译安装在小诺Linux服务器上。为了搭建公司的论坛系统,需要安装phpBB论坛程序。phpBB 是一个典型的 LAMP (Linux+Apache+MySQL+PHP)
阅读全文
通过web文件获取数据库账号和密码

作者:小科技专家 930人 浏览评论:03年前
eon2005 2007-12-18 10:28:58 评论(5)1581人阅读通过web文件获取数据库账号和密码Simeon。可以借鉴这个案例:(1)了解动态web的知识页面( 2) 通过动态网页文件获取数据库账号和密码。动态网页的显着特点之一是
阅读全文
Apache 虚拟主机案例演示
作者:技术小牛人1111人浏览评论:03年前
基于dns的实验拓扑搭建网站服务器,这里用apache搭建,先进入科普:url=协议+主机地址或域名+资源地址www服务使用排名查询网站 1.Apache4 9.9%-0.5% 中小型静态web主流、web服务
阅读全文
基于Web应用的性能分析与优化案例

作者:小天科技 1037人浏览评论:03年前
一、 基于动态内容的网站优化案例 1. 网站 运行环境描述。硬件环境:1台IBM x3850服务器,单双核至强3.0G CPU,2GB内存,3块72GB SCSI磁盘。操作系统:CentOS5.4. 网站架构:Web应用基于LAMP架构,所有服务
阅读全文
k8s的基本概念和入门案例

作者:店家小二2722人浏览评论:02年前
1. Kubernetes 介绍了基本概念和术语——Node 节点(node)是 k8s 集群中相对于 master 的工作主机(物理或虚拟机)。它运行在每个 Node 上,用于启动和管理 pods 服务(kubelet),并且可以通过 maste 进行管理。在节点上运行的服务器
阅读全文
大规模网站技术架构核心原理及案例分析(阅读笔记)

作者:liuawei1683 人浏览评论:03年前
大规模网站技术架构核心原理与案例研究1.概述网站衡量标准:高可用、高性能、易扩展、可扩展性、安全性1.1大网站特点 高并发、高可用、海量数据 用户分布广泛,网络条件复杂,安全环境恶劣,需求瞬息万变,发布频繁。渐进式开发 1.2 大规模 网站 进化式开发过程 1
阅读全文
Map、Reduce处理数据结构及常见情况
作者:taoland1073人浏览评论:03年前
随着三大前端框架和小程序的流行,MVVM也开始流行起来,它的核心是ViewModel层,它就像一个值转换器,负责转换Model中的数据对象,让数据更简单来管理和使用,这一层向上与视图层进行双向数据绑定,向下与Mode进行双向数据绑定
阅读全文
【云栖号案例| 互联网】高德“一键”上云,实现核心数据“三点输出”

作者:云栖号案例库 993人浏览评论:01年前
云栖号案例库:【点击查看更多上云案例】不知道怎么上云?看云栖号案例库,了解不同行业、不同发展阶段的云迁移解决方案,助您做出云迁移决策!公司简介 高德地图旗下高德开放平台是中国领先的LBS服务提供商,拥有先进的数据融合技术和海量数据处理能力。服务超过 300,000 次转移
阅读全文
php可以抓取网页数据吗(.js与前端React无缝对接之一下三种渲染方式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-11 14:13
)
Next.js 是一个轻量级的 React 服务器端渲染框架
它支持三种渲染方法,包括
旧瓶装新酒
上面提到的几种渲染方式其实并不新鲜,但是可以对应这些技术。
区别
Next.js的预渲染可以和前端React无缝对接
下面以一个文章列表页面为例,分别分析三种渲染方式。
客户端渲染
顾名思义,客户端渲染是仅在浏览器上执行的渲染。通过Vue和React构建的单页应用SPA都是这样渲染的
缺点
1.白屏,AJAX渲染前页面没有内容,只能通过Loading覆盖
2. SEO不友好,因为搜索引擎访问页面,默认不会执行JS,而是只能看到HTML而不是等待AJAX异步请求数据,所以无法搜索到页面内容
代码
import {NextPage} from 'next';
import axios from 'axios';
import {useEffect, useState} from "react";
import * as React from "react";
type Post = {
id: string,
id: string,
title: string
}
const PostsIndex: NextPage = () => {
// [] 表示只在第一次渲染的时候请求
const [posts, setPosts] = useState([]);
const [isLoading, setIsLoading] = useState(false);
useEffect(() => {
setIsLoading(true);
// 使用 AJAX 异步请求数据
axios.get('/api/posts').then(response => {
setPosts(response.data);
setIsLoading(false);
}, () => {
setIsLoading(true);
})
}, []);
return (
文章列表
{isLoading ? 加载中 :
posts.map(p =>
{p.id}
)}
)
};
export default PostsIndex;
网络不好的时候,加载时间很长,很长一段时间页面可能会出现空白。
由于第一次请求的HTML中没有文章内容,需要通过AJAX异步加载数据,加载数据渲染的过程在客户端完成,所以称为客户端渲染
静态页面生成 SSG
在文章列表页面,其实每个用户找到的内容都是一样的
那为什么还要在大家的浏览器上渲染呢?
为什么不在后台渲染出来发给大家
好的
N个渲染变成了1个渲染
N个客户端渲染变成了1个静态页面生成
这个过程变成了动态内容的静态
利弊
优点:这个方法可以解决白屏问题和SEO问题
缺点:所有用户看到的都是同一个页面,无法生成用户相关的内容
如何实现
首先让我们思考一个问题
如何获取帖子?因为加载数据的操作在后端,通过AJAX获取帖子显然是不合适的
答案是:通过getStaticProps获取帖子
getStaticProps是Next.js提供的一个方法,会在后端执行,返回一个prop,供NextPage渲染时使用
代码
import {GetStaticProps, NextPage} from 'next';
import {getPosts} from '../../lib/posts';
import Link from 'next/link';
import * as React from 'react';
type Post = {
id: string,
title: string
}
type Props = {
posts: Post[];
}
// props 中有下面导出的数据 posts
const PostsIndex: NextPage = (props) => {
const {posts} = props;
// 前后端控制台都能打印 -> 同构
console.log(posts);
return (
文章列表
{posts.map(p =>
{p.id}
)}
);
};
export default PostsIndex;
// 实现SSG
export const getStaticProps: GetStaticProps = async () => {
const posts = await getPosts();
return {
props: {
posts: JSON.parse(JSON.stringify(posts))
}
};
};
前端不通过ajax获取数据怎么办
我们只拿到了服务器上的posts数据,但是怎么传到前端呢?
发现奥秘
我们可以看到隐藏在id为_NEXT_DATA__的script标签中,里面存放的是传递给前端的props数据
这就是同构SSR的好处,后端可以直接把数据传给前端,不需要AJAX异步获取
静态时序环境在开发环境中。GetStaticProps 将为每个请求运行一次。这是为了方便您修改代码并在构建环境中重新运行。GetStaticProps 只在构建中运行一次,可以提供一份 HTML 副本供所有用户下载
如何体验构建环境
yarn build
yarn start
打包后,我们可以看到这个
解释
我看到的页面前面的三个图标是λ ○ ●
λ (Serve) SSR 无法自动创建 HTML(如下所述)
○(静态)自动创建HTML(发现你没用props)
●(SSG)自动创建HTML + JSON(等你使用道具)
三种文件类型
构建完成后,我们查看.next文件,找到posts.html、posts.js、posts.json
为什么不直接将数据放入posts.js?
很明显,posts.js 是为了接受不同的数据。当我们展示每个博客时,它们的风格相同,内容不同,所以会用到这个功能
动态内容静态
服务器端渲染 (SSR)
如果页面与用户相关怎么办?
这种情况更难以提前静止。需要在用户请求的时候获取用户信息,然后利用用户信息从数据库中获取数据。如果必须这样做,则必须为每个用户创建一个页面。有时数据更新得非常快。, 不能提前静态,比如微博首页的信息流
那该怎么办呢?
无论是客户端渲染,都会出现白屏
要么服务端渲染SSR,没有白屏
运行
不管是开发环境还是构建环境,getServerSideProps都是在请求之后运行的
代码
与 SSG 代码基本相同,但使用 getSeverSideProps
这段代码执行时,服务器响应请求后获取浏览器信息,返回给前端显示
import {GetServerSideProps, NextPage} from 'next';
import * as React from 'react';
import {IncomingHttpHeaders} from 'http';
type Props = {
browser: string
}
const index: NextPage = (props) => {
return (
你的浏览器是 {props.browser}
);
};
export default index;
export const getServerSideProps: GetServerSideProps = async (context) => {
const headers:IncomingHttpHeaders = context.req.headers;
const browser = headers['user-agent'];
return {
props: {
browser
}
};
};
SSR原理
建议后端使用 renderToString(),前端使用 hydrate()
后端渲染页面,返回 HTML String 格式,并传递给前端。前端执行 hydrate(),保留 HTML 并附加时间监控,即后端渲染 HTML,前端添加监控。
前端也会渲染一次,保证前后渲染结果一致
总结客户端渲染SSR
只在浏览器上运行,缺点SEO不友好,白屏
静态页面生成 SSG
静态站点生成,解决白屏问题和SEO问题
缺点:无法生成用户相关内容(所有用户请求的结果都一样)
服务器端渲染 (SSR)
解决白屏问题,SEO问题
可以生成用户相关的内容
如何选择三种渲染模式
查看全部
php可以抓取网页数据吗(.js与前端React无缝对接之一下三种渲染方式
)
Next.js 是一个轻量级的 React 服务器端渲染框架
它支持三种渲染方法,包括
旧瓶装新酒
上面提到的几种渲染方式其实并不新鲜,但是可以对应这些技术。
区别
Next.js的预渲染可以和前端React无缝对接
下面以一个文章列表页面为例,分别分析三种渲染方式。
客户端渲染
顾名思义,客户端渲染是仅在浏览器上执行的渲染。通过Vue和React构建的单页应用SPA都是这样渲染的
缺点
1.白屏,AJAX渲染前页面没有内容,只能通过Loading覆盖
2. SEO不友好,因为搜索引擎访问页面,默认不会执行JS,而是只能看到HTML而不是等待AJAX异步请求数据,所以无法搜索到页面内容
代码
import {NextPage} from 'next';
import axios from 'axios';
import {useEffect, useState} from "react";
import * as React from "react";
type Post = {
id: string,
id: string,
title: string
}
const PostsIndex: NextPage = () => {
// [] 表示只在第一次渲染的时候请求
const [posts, setPosts] = useState([]);
const [isLoading, setIsLoading] = useState(false);
useEffect(() => {
setIsLoading(true);
// 使用 AJAX 异步请求数据
axios.get('/api/posts').then(response => {
setPosts(response.data);
setIsLoading(false);
}, () => {
setIsLoading(true);
})
}, []);
return (
文章列表
{isLoading ? 加载中 :
posts.map(p =>
{p.id}
)}
)
};
export default PostsIndex;
网络不好的时候,加载时间很长,很长一段时间页面可能会出现空白。
由于第一次请求的HTML中没有文章内容,需要通过AJAX异步加载数据,加载数据渲染的过程在客户端完成,所以称为客户端渲染
静态页面生成 SSG
在文章列表页面,其实每个用户找到的内容都是一样的
那为什么还要在大家的浏览器上渲染呢?
为什么不在后台渲染出来发给大家
好的
N个渲染变成了1个渲染
N个客户端渲染变成了1个静态页面生成
这个过程变成了动态内容的静态
利弊
优点:这个方法可以解决白屏问题和SEO问题
缺点:所有用户看到的都是同一个页面,无法生成用户相关的内容
如何实现
首先让我们思考一个问题
如何获取帖子?因为加载数据的操作在后端,通过AJAX获取帖子显然是不合适的
答案是:通过getStaticProps获取帖子
getStaticProps是Next.js提供的一个方法,会在后端执行,返回一个prop,供NextPage渲染时使用
代码
import {GetStaticProps, NextPage} from 'next';
import {getPosts} from '../../lib/posts';
import Link from 'next/link';
import * as React from 'react';
type Post = {
id: string,
title: string
}
type Props = {
posts: Post[];
}
// props 中有下面导出的数据 posts
const PostsIndex: NextPage = (props) => {
const {posts} = props;
// 前后端控制台都能打印 -> 同构
console.log(posts);
return (
文章列表
{posts.map(p =>
{p.id}
)}
);
};
export default PostsIndex;
// 实现SSG
export const getStaticProps: GetStaticProps = async () => {
const posts = await getPosts();
return {
props: {
posts: JSON.parse(JSON.stringify(posts))
}
};
};
前端不通过ajax获取数据怎么办
我们只拿到了服务器上的posts数据,但是怎么传到前端呢?
发现奥秘
我们可以看到隐藏在id为_NEXT_DATA__的script标签中,里面存放的是传递给前端的props数据
这就是同构SSR的好处,后端可以直接把数据传给前端,不需要AJAX异步获取
静态时序环境在开发环境中。GetStaticProps 将为每个请求运行一次。这是为了方便您修改代码并在构建环境中重新运行。GetStaticProps 只在构建中运行一次,可以提供一份 HTML 副本供所有用户下载
如何体验构建环境
yarn build
yarn start
打包后,我们可以看到这个
解释
我看到的页面前面的三个图标是λ ○ ●
λ (Serve) SSR 无法自动创建 HTML(如下所述)
○(静态)自动创建HTML(发现你没用props)
●(SSG)自动创建HTML + JSON(等你使用道具)
三种文件类型
构建完成后,我们查看.next文件,找到posts.html、posts.js、posts.json
为什么不直接将数据放入posts.js?
很明显,posts.js 是为了接受不同的数据。当我们展示每个博客时,它们的风格相同,内容不同,所以会用到这个功能
动态内容静态
服务器端渲染 (SSR)
如果页面与用户相关怎么办?
这种情况更难以提前静止。需要在用户请求的时候获取用户信息,然后利用用户信息从数据库中获取数据。如果必须这样做,则必须为每个用户创建一个页面。有时数据更新得非常快。, 不能提前静态,比如微博首页的信息流
那该怎么办呢?
无论是客户端渲染,都会出现白屏
要么服务端渲染SSR,没有白屏
运行
不管是开发环境还是构建环境,getServerSideProps都是在请求之后运行的
代码
与 SSG 代码基本相同,但使用 getSeverSideProps
这段代码执行时,服务器响应请求后获取浏览器信息,返回给前端显示
import {GetServerSideProps, NextPage} from 'next';
import * as React from 'react';
import {IncomingHttpHeaders} from 'http';
type Props = {
browser: string
}
const index: NextPage = (props) => {
return (
你的浏览器是 {props.browser}
);
};
export default index;
export const getServerSideProps: GetServerSideProps = async (context) => {
const headers:IncomingHttpHeaders = context.req.headers;
const browser = headers['user-agent'];
return {
props: {
browser
}
};
};
SSR原理
建议后端使用 renderToString(),前端使用 hydrate()
后端渲染页面,返回 HTML String 格式,并传递给前端。前端执行 hydrate(),保留 HTML 并附加时间监控,即后端渲染 HTML,前端添加监控。
前端也会渲染一次,保证前后渲染结果一致
总结客户端渲染SSR
只在浏览器上运行,缺点SEO不友好,白屏
静态页面生成 SSG
静态站点生成,解决白屏问题和SEO问题
缺点:无法生成用户相关内容(所有用户请求的结果都一样)
服务器端渲染 (SSR)
解决白屏问题,SEO问题
可以生成用户相关的内容
如何选择三种渲染模式
php可以抓取网页数据吗(一个普通请求封装方法,代码如下:前后修改过几次)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-01 05:15
肯德基的一些数据最近需要抓取
通过邮递员获取请求地址和参数后,可以返回数据
我天真地认为我可以通过代码直接发送post请求
但是,在通过PHP curl模拟请求之后,总是返回服务器异常
起初似乎很成功,但现在总是有报道。我使用一种普通的post请求封装方法。代码如下:
public function kfc_post($url, $data)
{
$data['deviceId'] = '819ce973-1ff8-4dfc-8436-4e0e0e1efb6e';
$data['brower_id'] = 'unique-test-dc6d945b-d504-45f7-ad94-8eaacb590fcf';
$params = http_build_query($data);
$headers = [
'Accept' => 'application/json, text/plain, */*',
'Content-Type' => 'application/x-www-form-urlencoded',
'Origin' => 'http://order.kfc.com.cn',
'Referer' => 'http://order.kfc.com.cn/mwos/store',
'User-Agent' => 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
];
// 模拟提交数据函数
$curl = curl_init(); // 启动一个CURL会话
curl_setopt($curl, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($curl, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($curl, CURLOPT_POSTFIELDS, $params); // Post提交的数据包
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制防止死循环
curl_setopt($curl, CURLOPT_HTTPHEADER,$headers);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$content = curl_exec($curl); // 执行操作
curl_close($curl); // 关闭CURL会话
return json_decode($content, true);
}
它前后都被修改了好几次,但基本上是这样的。请求仍然失败。我没有玩过去捕捉别人的网站数据。是否存在任何疏忽,例如cookies?我试图提出一个饼干请求,但我还是不能,所以我不知道为什么 查看全部
php可以抓取网页数据吗(一个普通请求封装方法,代码如下:前后修改过几次)
肯德基的一些数据最近需要抓取
通过邮递员获取请求地址和参数后,可以返回数据

我天真地认为我可以通过代码直接发送post请求
但是,在通过PHP curl模拟请求之后,总是返回服务器异常

起初似乎很成功,但现在总是有报道。我使用一种普通的post请求封装方法。代码如下:
public function kfc_post($url, $data)
{
$data['deviceId'] = '819ce973-1ff8-4dfc-8436-4e0e0e1efb6e';
$data['brower_id'] = 'unique-test-dc6d945b-d504-45f7-ad94-8eaacb590fcf';
$params = http_build_query($data);
$headers = [
'Accept' => 'application/json, text/plain, */*',
'Content-Type' => 'application/x-www-form-urlencoded',
'Origin' => 'http://order.kfc.com.cn',
'Referer' => 'http://order.kfc.com.cn/mwos/store',
'User-Agent' => 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
];
// 模拟提交数据函数
$curl = curl_init(); // 启动一个CURL会话
curl_setopt($curl, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($curl, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($curl, CURLOPT_POSTFIELDS, $params); // Post提交的数据包
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制防止死循环
curl_setopt($curl, CURLOPT_HTTPHEADER,$headers);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$content = curl_exec($curl); // 执行操作
curl_close($curl); // 关闭CURL会话
return json_decode($content, true);
}
它前后都被修改了好几次,但基本上是这样的。请求仍然失败。我没有玩过去捕捉别人的网站数据。是否存在任何疏忽,例如cookies?我试图提出一个饼干请求,但我还是不能,所以我不知道为什么
php可以抓取网页数据吗(php可以抓取网页数据吗?php安装第一步需要安装)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-29 08:03
php可以抓取网页数据吗?很多朋友对于php抓取网页数据的实现还不了解,比如说想要抓取自己所在公司的一些数据,或者想要抓取其他公司的网页数据。其实很简单,下面来说说php抓取网页数据的技巧。php安装第一步需要安装php5.2,php5.2是php的4.0版本,支持cli模式的语言加上更多的高级语法。
第二步在cmd命令行,输入php_get./_get.php,就可以抓取指定网页的数据了。当然,如果你使用第三方工具,抓取全网的数据也可以。比如yii。yii安装在阿里云centos7.2系统中,可以直接通过下面的命令安装yii-cli,如下图:yii-cli是类似yii2的集成开发环境,通过phpwind、yii-php-params等工具集成一个安装脚本。
如下图:yii-cli启动后,默认是自动配置在c:\users\xxx\administrator目录下,在此目录下右键新建php.php配置文件,命名为"yii-cli",命名为.php,然后编写如下脚本:。 查看全部
php可以抓取网页数据吗(php可以抓取网页数据吗?php安装第一步需要安装)
php可以抓取网页数据吗?很多朋友对于php抓取网页数据的实现还不了解,比如说想要抓取自己所在公司的一些数据,或者想要抓取其他公司的网页数据。其实很简单,下面来说说php抓取网页数据的技巧。php安装第一步需要安装php5.2,php5.2是php的4.0版本,支持cli模式的语言加上更多的高级语法。
第二步在cmd命令行,输入php_get./_get.php,就可以抓取指定网页的数据了。当然,如果你使用第三方工具,抓取全网的数据也可以。比如yii。yii安装在阿里云centos7.2系统中,可以直接通过下面的命令安装yii-cli,如下图:yii-cli是类似yii2的集成开发环境,通过phpwind、yii-php-params等工具集成一个安装脚本。
如下图:yii-cli启动后,默认是自动配置在c:\users\xxx\administrator目录下,在此目录下右键新建php.php配置文件,命名为"yii-cli",命名为.php,然后编写如下脚本:。
php可以抓取网页数据吗(php抓取网页数据插入数据库推荐活动:更多优惠gtgt)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-25 18:30
阿里云>云栖社区>主题图>P>php抓取网页数据插入数据库
推荐活动:
更多优惠>
当前话题:php抓取网页数据插入数据库添加到采集夹
相关话题:
php抓取网页数据插入数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
php爬虫:知乎用户数据爬取与分析
作者:cuixiaozhuai2345 人浏览评论:05年前
背景说明:小野使用PHP的curl编写的爬虫实验爬取知乎5w用户的基本信息;同时对爬取的数据进行简单的分析和呈现。php的demo地址的spider代码和用户仪表盘的显示代码,整理好后上传到github,更新代码基于个人博客和公众号,Cheng
阅读全文
解决“mysql服务器已经消失”问题
作者:php的小菜鸟1008人浏览评论:04年前
出现此类问题时,应用程序(如PHP)会长时间批量执行MYSQL 语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。在 MySQL 中解决
阅读全文
rrdtool 学习和自定义脚本绘制图形备忘录
作者:于尔武 1163人浏览评论:03年前
RRDtool(Round Robin Database Tool)是一个强大的绘图引擎,MRTG等很多工具都可以调用rrdtool绘图。包括现在用的比较多的cacti,基于rrdtool画图。可以说cacti只提供了一个显示图形的网页。
阅读全文
c#批量抓取免费代理并验证有效性
作者:曹章林 1170人浏览评论:03年前
在刷新页面之前,我在一家公司的官网上看到了文章 的页面浏览量。感觉不是很好。一个公司的官网就给人这么直接的漏洞。当我进行批量请求时,我发现页面打开并报告错误。一个100多人的公司官网文章刷新了一次,你给我看了这个。这家公司之前来过我们学校宣传招聘+我在花园里找招聘的时候找到了住处
阅读全文
RRDTool详解
作者:小美科技 1573人浏览评论:03年前
大纲一、MRTG的缺点与RRDTool对比二、RRDTool概述三、安装RRDTool四、RRDTool绘制步骤五、rrdtool命令详解六、RRDTool绘图案例注,实验环境CentOS 6.4 x86_64,软件版本rrdtool-1.3
阅读全文
MySQL服务器不见了解决方法
作者:云启希望。1791人浏览评论:03年前
应用程序(如PHP)长时间执行批量的MYSQL 语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。今天遇到了类似的情况,MySQL只是冷了
阅读全文
技术 | 从零开始的Python系列(三个十五)
作者:技术小能手 1954人浏览评论数:02年前
大家好。这次给大家带来一个方法,把人们喜欢问有识之士的问题,把问题和答案保存到数据库中。涉及的内容包括: Urllib 的使用和异常处理 美丽汤的简单应用 MySQLdb 的基本使用规律 表达式的简单应用环境配置 在此之前,我们需要先配置环境
阅读全文
MySQL服务器已经消失
作者:李大嘴巴1934人浏览评论:05年前
MySQL server has away 运行sql文件导入数据库时,会报异常。MySQL server has go away mysql has the problem of ERROR: (2006,'MySQL server has go away')
阅读全文 查看全部
php可以抓取网页数据吗(php抓取网页数据插入数据库推荐活动:更多优惠gtgt)
阿里云>云栖社区>主题图>P>php抓取网页数据插入数据库
推荐活动:
更多优惠>
当前话题:php抓取网页数据插入数据库添加到采集夹
相关话题:
php抓取网页数据插入数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
php爬虫:知乎用户数据爬取与分析

作者:cuixiaozhuai2345 人浏览评论:05年前
背景说明:小野使用PHP的curl编写的爬虫实验爬取知乎5w用户的基本信息;同时对爬取的数据进行简单的分析和呈现。php的demo地址的spider代码和用户仪表盘的显示代码,整理好后上传到github,更新代码基于个人博客和公众号,Cheng
阅读全文
解决“mysql服务器已经消失”问题


作者:php的小菜鸟1008人浏览评论:04年前
出现此类问题时,应用程序(如PHP)会长时间批量执行MYSQL 语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。在 MySQL 中解决
阅读全文
rrdtool 学习和自定义脚本绘制图形备忘录

作者:于尔武 1163人浏览评论:03年前
RRDtool(Round Robin Database Tool)是一个强大的绘图引擎,MRTG等很多工具都可以调用rrdtool绘图。包括现在用的比较多的cacti,基于rrdtool画图。可以说cacti只提供了一个显示图形的网页。
阅读全文
c#批量抓取免费代理并验证有效性

作者:曹章林 1170人浏览评论:03年前
在刷新页面之前,我在一家公司的官网上看到了文章 的页面浏览量。感觉不是很好。一个公司的官网就给人这么直接的漏洞。当我进行批量请求时,我发现页面打开并报告错误。一个100多人的公司官网文章刷新了一次,你给我看了这个。这家公司之前来过我们学校宣传招聘+我在花园里找招聘的时候找到了住处
阅读全文
RRDTool详解

作者:小美科技 1573人浏览评论:03年前
大纲一、MRTG的缺点与RRDTool对比二、RRDTool概述三、安装RRDTool四、RRDTool绘制步骤五、rrdtool命令详解六、RRDTool绘图案例注,实验环境CentOS 6.4 x86_64,软件版本rrdtool-1.3
阅读全文
MySQL服务器不见了解决方法


作者:云启希望。1791人浏览评论:03年前
应用程序(如PHP)长时间执行批量的MYSQL 语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。今天遇到了类似的情况,MySQL只是冷了
阅读全文
技术 | 从零开始的Python系列(三个十五)

作者:技术小能手 1954人浏览评论数:02年前
大家好。这次给大家带来一个方法,把人们喜欢问有识之士的问题,把问题和答案保存到数据库中。涉及的内容包括: Urllib 的使用和异常处理 美丽汤的简单应用 MySQLdb 的基本使用规律 表达式的简单应用环境配置 在此之前,我们需要先配置环境
阅读全文
MySQL服务器已经消失


作者:李大嘴巴1934人浏览评论:05年前
MySQL server has away 运行sql文件导入数据库时,会报异常。MySQL server has go away mysql has the problem of ERROR: (2006,'MySQL server has go away')
阅读全文
php可以抓取网页数据吗(php可以抓取网页数据吗?我的回答是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-09-22 00:06
php可以抓取网页数据吗?我的回答是:可以,不仅可以抓取网页数据,还可以抓取摄像头数据!网页抓取可以用php,摄像头抓取可以用python,nodejs,因为目前没有发现必须要用php,或者nodejs才能抓取到的网页数据。但是,在抓取数据之前一定要用程序把网页数据存放在文件里,比如blob。首先是在浏览器上输入网址,比如api/post/message.html:然后上传数据进行比对:上传成功之后就会生成一个文件,这个文件会包含网页中的整个网页地址,甚至包含参数。
再用php进行抓取。抓取方法很简单,首先通过浏览器打开这个数据的文件,在这个文件中加入刚才保存的网页地址:接着再通过web服务器来抓取数据,比如微信服务器:最后通过http的请求方法,去调用服务器的js,会得到页面内容,从而形成我们的数据。那么,这个抓取需要多久?还是用浏览器打开这个数据文件,然后在浏览器打开抓取程序,但是不用调用微信的服务器,直接用浏览器打开得到:那么,这个抓取需要多少时间?自己测算的话,需要1000毫秒。
查了一下百度,下载一个几十m的包大概用了60s。然后每天开启抓取一次服务器消耗1秒。那么,如果频繁地请求浏览器抓取服务器的话,同样速度要下降到3ms以内。所以,抓取这个网页需要10毫秒,实际抓取起来需要1m多一点一个页面。那么我的抓取效率大概是多少?百度有的算法是500kb/秒,简单来说,就是抓取10个网页,一共抓取到300个页面的数据。
当然这么计算每天的抓取量肯定是无法达到这么大的数据量的。php抓取这个网页的效率是否高呢?比如:30秒一个页面的数据量。那么这个效率怎么来衡量呢?可以用一个叫做webthreads的method来衡量,那么直接用爬虫工具开启抓取服务器,然后开启很多个线程抓取页面即可。就算抓取速度在目前上会慢一些,在大部分人实际用户环境中,每天抓取这个网页的速度在200毫秒左右,相当于1000毫秒。
那么php+python到底怎么样。首先,php的效率不能单看“抓取速度”这个值,因为抓取速度只是php并发抓取的一个很小的指标。看是否并发抓取,看的是php和其他程序能否“建立一个链接”,如果php线程很多,那么可以用超时函数。php做到并发抓取也没有很大的问题,只是耗时。像java来做到这点应该也比较有信心,毕竟java是标准的异步编程语言。
但是要从速度,并发等各个方面优化php程序,对于大部分开发人员来说应该是非常难的。所以,在php并发抓取这一块,其实就是一个人的能力范围。只有在数据量很小,已经在db上可以做优化,并。 查看全部
php可以抓取网页数据吗(php可以抓取网页数据吗?我的回答是什么?)
php可以抓取网页数据吗?我的回答是:可以,不仅可以抓取网页数据,还可以抓取摄像头数据!网页抓取可以用php,摄像头抓取可以用python,nodejs,因为目前没有发现必须要用php,或者nodejs才能抓取到的网页数据。但是,在抓取数据之前一定要用程序把网页数据存放在文件里,比如blob。首先是在浏览器上输入网址,比如api/post/message.html:然后上传数据进行比对:上传成功之后就会生成一个文件,这个文件会包含网页中的整个网页地址,甚至包含参数。
再用php进行抓取。抓取方法很简单,首先通过浏览器打开这个数据的文件,在这个文件中加入刚才保存的网页地址:接着再通过web服务器来抓取数据,比如微信服务器:最后通过http的请求方法,去调用服务器的js,会得到页面内容,从而形成我们的数据。那么,这个抓取需要多久?还是用浏览器打开这个数据文件,然后在浏览器打开抓取程序,但是不用调用微信的服务器,直接用浏览器打开得到:那么,这个抓取需要多少时间?自己测算的话,需要1000毫秒。
查了一下百度,下载一个几十m的包大概用了60s。然后每天开启抓取一次服务器消耗1秒。那么,如果频繁地请求浏览器抓取服务器的话,同样速度要下降到3ms以内。所以,抓取这个网页需要10毫秒,实际抓取起来需要1m多一点一个页面。那么我的抓取效率大概是多少?百度有的算法是500kb/秒,简单来说,就是抓取10个网页,一共抓取到300个页面的数据。
当然这么计算每天的抓取量肯定是无法达到这么大的数据量的。php抓取这个网页的效率是否高呢?比如:30秒一个页面的数据量。那么这个效率怎么来衡量呢?可以用一个叫做webthreads的method来衡量,那么直接用爬虫工具开启抓取服务器,然后开启很多个线程抓取页面即可。就算抓取速度在目前上会慢一些,在大部分人实际用户环境中,每天抓取这个网页的速度在200毫秒左右,相当于1000毫秒。
那么php+python到底怎么样。首先,php的效率不能单看“抓取速度”这个值,因为抓取速度只是php并发抓取的一个很小的指标。看是否并发抓取,看的是php和其他程序能否“建立一个链接”,如果php线程很多,那么可以用超时函数。php做到并发抓取也没有很大的问题,只是耗时。像java来做到这点应该也比较有信心,毕竟java是标准的异步编程语言。
但是要从速度,并发等各个方面优化php程序,对于大部分开发人员来说应该是非常难的。所以,在php并发抓取这一块,其实就是一个人的能力范围。只有在数据量很小,已经在db上可以做优化,并。
php可以抓取网页数据吗(Python爬虫入门教程!手把手教会你爬取网页数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-19 23:13
Python爬虫教程!教您手拉手抓取web数据
步骤3:提取内容。在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:
URL就像网站和搜索引擎爬虫之间的桥梁:为了抓取您的网站内容,爬虫需要能够找到并跨越这些桥梁(即,查找并抓取您的URL)。如果您的URL复杂或冗长
当您打开目标文件夹TPTL时,您将获得图像或内容的网站完整数据,其中保存了HTML文件、PHP文件和JavaScript。网络
它可以帮助我们快速采集大量的互联网内容进行深入的数据分析和挖掘,如抓取网站的排名列表和网站购物的价格信息。我们的日常搜索引擎是“网络爬虫”。但毕竟,我们学会了
1.打开网站管理员工具,在网络信息查询中找到要抓取的模拟机器人。2.进入您的网站网站,然后单击查询。此时,您的网站将显示在下面。被捕后会发生什么事。3.在web信息查询中,单击web检测以查看您的关键词密度和网站安全性,以及关键词的挖掘
阿里云为您提供了与网站内容捕获工具相关的8933个产品文档和常见问题解答,以及网站无法打开网页时该怎么办、计算机网络技术毕业论文、键值存储kvstore(以下哪一个是数据库)等云计算产品
内容捕获–您可以从网站捕获内容,以复制依赖于内容的独特产品或服务优势。例如,yelp等产品依赖于评论。竞争对手可以捕获yelp的所有评论,然后将它们复制到他们的网站以打开他们的网站内容 查看全部
php可以抓取网页数据吗(Python爬虫入门教程!手把手教会你爬取网页数据(组图))
Python爬虫教程!教您手拉手抓取web数据
步骤3:提取内容。在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:
URL就像网站和搜索引擎爬虫之间的桥梁:为了抓取您的网站内容,爬虫需要能够找到并跨越这些桥梁(即,查找并抓取您的URL)。如果您的URL复杂或冗长
当您打开目标文件夹TPTL时,您将获得图像或内容的网站完整数据,其中保存了HTML文件、PHP文件和JavaScript。网络
它可以帮助我们快速采集大量的互联网内容进行深入的数据分析和挖掘,如抓取网站的排名列表和网站购物的价格信息。我们的日常搜索引擎是“网络爬虫”。但毕竟,我们学会了

1.打开网站管理员工具,在网络信息查询中找到要抓取的模拟机器人。2.进入您的网站网站,然后单击查询。此时,您的网站将显示在下面。被捕后会发生什么事。3.在web信息查询中,单击web检测以查看您的关键词密度和网站安全性,以及关键词的挖掘
阿里云为您提供了与网站内容捕获工具相关的8933个产品文档和常见问题解答,以及网站无法打开网页时该怎么办、计算机网络技术毕业论文、键值存储kvstore(以下哪一个是数据库)等云计算产品

内容捕获–您可以从网站捕获内容,以复制依赖于内容的独特产品或服务优势。例如,yelp等产品依赖于评论。竞争对手可以捕获yelp的所有评论,然后将它们复制到他们的网站以打开他们的网站内容
php可以抓取网页数据吗(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-10 19:05
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是抓取网页的代码,下面是到某个网页的POST数据。假设我们有一个处理表单的URL,可以接受两个表单域,一个是电话号码,一个是短信内容。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie 查看全部
php可以抓取网页数据吗(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是抓取网页的代码,下面是到某个网页的POST数据。假设我们有一个处理表单的URL,可以接受两个表单域,一个是电话号码,一个是短信内容。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie
php可以抓取网页数据吗(IbookBox小说批量下载小说爬虫V1.0_软件下载。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-04 04:03
本剧本仅针对“玄书网”小说网“奇幻奇幻”类小说进行拍摄。供网友参考,可自行修改。文笔粗糙,请勿喷……原文链接。
批量下载小说爬虫是一款专门用于批量下载小说的软件,通过小说爬虫用户可以快速下载自己想要的小说的txt文件。
输入任意网页地址,批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取。2、支持将抓取的电子书发送到txt到手机。3、 支持将电子书自动存放在您自己的邮箱中。
软件介绍 《批量小说下载器精简版》是一款非常好用又方便的小说批量下载软件。通过小说爬虫,用户可以快速下载自己想要的小说txt文件,放到手机上离线观看。,软件爬取。
批量下载小说爬虫下载批量下载小说爬虫V1.0_软件下载。
ibookBox小说批量下载阅读器功能:1、支持所有小说网站抓取各类小说。2、支持抓取电子书生成txt发送到手机。3、支持电子书自动存放在您自己的邮箱中。4、纯单机版不需要任何人工干预。
批量下载小说爬虫是一款免费的小说下载阅读器,可以帮助用户将自己喜欢的小说批量下载到本地,支持自己选择下载源。有需要的用户不要错过。欢迎下载使用!
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抓住思路:我的想法是百度一号。 查看全部
php可以抓取网页数据吗(IbookBox小说批量下载小说爬虫V1.0_软件下载。)
本剧本仅针对“玄书网”小说网“奇幻奇幻”类小说进行拍摄。供网友参考,可自行修改。文笔粗糙,请勿喷……原文链接。
批量下载小说爬虫是一款专门用于批量下载小说的软件,通过小说爬虫用户可以快速下载自己想要的小说的txt文件。
输入任意网页地址,批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取。2、支持将抓取的电子书发送到txt到手机。3、 支持将电子书自动存放在您自己的邮箱中。
软件介绍 《批量小说下载器精简版》是一款非常好用又方便的小说批量下载软件。通过小说爬虫,用户可以快速下载自己想要的小说txt文件,放到手机上离线观看。,软件爬取。
批量下载小说爬虫下载批量下载小说爬虫V1.0_软件下载。
ibookBox小说批量下载阅读器功能:1、支持所有小说网站抓取各类小说。2、支持抓取电子书生成txt发送到手机。3、支持电子书自动存放在您自己的邮箱中。4、纯单机版不需要任何人工干预。
批量下载小说爬虫是一款免费的小说下载阅读器,可以帮助用户将自己喜欢的小说批量下载到本地,支持自己选择下载源。有需要的用户不要错过。欢迎下载使用!
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抓住思路:我的想法是百度一号。
php可以抓取网页数据吗(阿里云gt云栖;云栖社区前端面试题目(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-29 10:06
阿里云>云栖社区>主题图>P>PHP爬取网页和解析HTML的常用方法总结
推荐活动:
更多优惠>
当前主题:PHP抓取网页和解析HTML的常用方法汇总 加入采集
相关话题:
PHP抓取网页,解析HTML常用方法总结相关博客 查看更多博客
前端安全系列之二:如何防范CSRF攻击?
作者:小技术专家 2211人浏览评论:13年前
背景 随着互联网的飞速发展,信息安全问题成为企业最关注的焦点之一,而前端是引发企业安全问题的高风险基地。移动互联网时代,除了传统的XSS、CSRF等安全问题外,前端人员经常会遇到网络劫持、非法调用Hybrid API等新的安全问题。当然,浏览
阅读全文
大公司的开源项目有哪些~~~阿里、百度、腾讯、360、新浪、网易、小米等
作者:xumaojun3896人浏览评论:03年前
红色字体现阶段比较火----------------------------------------- - ------------------------------------------------- - -------------------- 奇虎36
阅读全文
前端面试题合集
作者:科技小胖子1737人浏览评论:03年前
一、理论知识1.1、前端MV*框架的含义早期前端比较简单,基本都是以页面为工作单位,主要是浏览内容,偶尔也简单forms 操作,基本上不需要框架。随着AJAX的出现和Web2.0的兴起,人们可以在页面上做更复杂的事情,然后前端框架才真正出现
阅读全文
国内主要公司开源项目清单
作者:double2li2877 浏览评论人数:04年前
奇虎3601.MySQL 中间层Atlas Atlas 是一个基于MySQL 协议的数据中间层项目,由奇虎360 网络平台部基础架构团队开发和维护。它在 MySQL-Prox 中正式启动
阅读全文
陈词滥调——从 url 输入到页面显示发生了什么
作者:沃克武松 2156人浏览评论:04年前
阅读目录并输入地址。浏览器查找域名的 IP 地址。浏览器向 Web 服务器发送 HTTP 请求。服务器的永久重定向响应。浏览器会跟踪重定向地址。服务器处理请求。服务器返回 HTTP 响应。浏览器显示 HTML。HTML 中的资源
阅读全文
Python爬虫框架-PySpider
作者:shadowcat7965 浏览评论人数:04年前
来自:来自:PySpider PySpider github地址 PySpider官方文档PySpi
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文 查看全部
php可以抓取网页数据吗(阿里云gt云栖;云栖社区前端面试题目(组图))
阿里云>云栖社区>主题图>P>PHP爬取网页和解析HTML的常用方法总结
推荐活动:
更多优惠>
当前主题:PHP抓取网页和解析HTML的常用方法汇总 加入采集
相关话题:
PHP抓取网页,解析HTML常用方法总结相关博客 查看更多博客
前端安全系列之二:如何防范CSRF攻击?
作者:小技术专家 2211人浏览评论:13年前
背景 随着互联网的飞速发展,信息安全问题成为企业最关注的焦点之一,而前端是引发企业安全问题的高风险基地。移动互联网时代,除了传统的XSS、CSRF等安全问题外,前端人员经常会遇到网络劫持、非法调用Hybrid API等新的安全问题。当然,浏览
阅读全文
大公司的开源项目有哪些~~~阿里、百度、腾讯、360、新浪、网易、小米等
作者:xumaojun3896人浏览评论:03年前
红色字体现阶段比较火----------------------------------------- - ------------------------------------------------- - -------------------- 奇虎36
阅读全文
前端面试题合集
作者:科技小胖子1737人浏览评论:03年前
一、理论知识1.1、前端MV*框架的含义早期前端比较简单,基本都是以页面为工作单位,主要是浏览内容,偶尔也简单forms 操作,基本上不需要框架。随着AJAX的出现和Web2.0的兴起,人们可以在页面上做更复杂的事情,然后前端框架才真正出现
阅读全文
国内主要公司开源项目清单
作者:double2li2877 浏览评论人数:04年前
奇虎3601.MySQL 中间层Atlas Atlas 是一个基于MySQL 协议的数据中间层项目,由奇虎360 网络平台部基础架构团队开发和维护。它在 MySQL-Prox 中正式启动
阅读全文
陈词滥调——从 url 输入到页面显示发生了什么
作者:沃克武松 2156人浏览评论:04年前
阅读目录并输入地址。浏览器查找域名的 IP 地址。浏览器向 Web 服务器发送 HTTP 请求。服务器的永久重定向响应。浏览器会跟踪重定向地址。服务器处理请求。服务器返回 HTTP 响应。浏览器显示 HTML。HTML 中的资源
阅读全文
Python爬虫框架-PySpider
作者:shadowcat7965 浏览评论人数:04年前
来自:来自:PySpider PySpider github地址 PySpider官方文档PySpi
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
php可以抓取网页数据吗(阿里云gt云栖;云栖社区gtgt;PHP抓取网页、解析HTML常用的方法总结(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-29 10:05
阿里云>云栖社区>主题图>P>PHP爬取网页和解析HTML的常用方法总结
推荐活动:
更多优惠>
当前主题:PHP抓取网页和解析HTML的常用方法汇总 加入采集
相关话题:
PHP抓取网页,解析HTML常用方法总结相关博客 查看更多博客
Python爬虫框架-PySpider
作者:shadowcat7965 浏览评论人数:04年前
来自:来自:PySpider PySpider github地址 PySpider官方文档PySpi
阅读全文
大公司的开源项目有哪些~~~阿里、百度、腾讯、360、新浪、网易、小米等
作者:xumaojun3896人浏览评论:03年前
红色字体现阶段比较火----------------------------------------- - ------------------------------------------------- - -------------------- 奇虎36
阅读全文
国内主要公司开源项目清单
作者:double2li2877 浏览评论人数:04年前
奇虎3601.MySQL 中间层Atlas Atlas 是一个基于MySQL 协议的数据中间层项目,由奇虎360 网络平台部基础架构团队开发和维护。它在 MySQL-Prox 中正式启动
阅读全文
前端安全系列之二:如何防范CSRF攻击?
作者:小技术专家 2211人浏览评论:13年前
背景 随着互联网的飞速发展,信息安全问题成为企业最关注的焦点之一,而前端是引发企业安全问题的高风险基地。移动互联网时代,除了传统的XSS、CSRF等安全问题外,前端人员经常会遇到网络劫持、非法调用Hybrid API等新的安全问题。当然,浏览
阅读全文
陈词滥调——从 url 输入到页面显示发生了什么
作者:沃克武松 2156人浏览评论:04年前
阅读目录并输入地址。浏览器查找域名的 IP 地址。浏览器向 Web 服务器发送 HTTP 请求。服务器的永久重定向响应。浏览器会跟踪重定向地址。服务器处理请求。服务器返回 HTTP 响应。浏览器显示 HTML。HTML 中的资源
阅读全文
前端面试题合集
作者:科技小胖子1737人浏览评论:03年前
一、理论知识1.1、前端MV*框架的含义早期的前端比较简单,基本都是以页面为工作单位,主要是浏览内容,偶尔简单的表单操作,基本不需要框架。随着AJAX的出现和Web2.0的兴起,人们可以在页面上做更复杂的事情,然后前端框架才真正出现
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文 查看全部
php可以抓取网页数据吗(阿里云gt云栖;云栖社区gtgt;PHP抓取网页、解析HTML常用的方法总结(组图))
阿里云>云栖社区>主题图>P>PHP爬取网页和解析HTML的常用方法总结
推荐活动:
更多优惠>
当前主题:PHP抓取网页和解析HTML的常用方法汇总 加入采集
相关话题:
PHP抓取网页,解析HTML常用方法总结相关博客 查看更多博客
Python爬虫框架-PySpider
作者:shadowcat7965 浏览评论人数:04年前
来自:来自:PySpider PySpider github地址 PySpider官方文档PySpi
阅读全文
大公司的开源项目有哪些~~~阿里、百度、腾讯、360、新浪、网易、小米等
作者:xumaojun3896人浏览评论:03年前
红色字体现阶段比较火----------------------------------------- - ------------------------------------------------- - -------------------- 奇虎36
阅读全文
国内主要公司开源项目清单
作者:double2li2877 浏览评论人数:04年前
奇虎3601.MySQL 中间层Atlas Atlas 是一个基于MySQL 协议的数据中间层项目,由奇虎360 网络平台部基础架构团队开发和维护。它在 MySQL-Prox 中正式启动
阅读全文
前端安全系列之二:如何防范CSRF攻击?
作者:小技术专家 2211人浏览评论:13年前
背景 随着互联网的飞速发展,信息安全问题成为企业最关注的焦点之一,而前端是引发企业安全问题的高风险基地。移动互联网时代,除了传统的XSS、CSRF等安全问题外,前端人员经常会遇到网络劫持、非法调用Hybrid API等新的安全问题。当然,浏览
阅读全文
陈词滥调——从 url 输入到页面显示发生了什么
作者:沃克武松 2156人浏览评论:04年前
阅读目录并输入地址。浏览器查找域名的 IP 地址。浏览器向 Web 服务器发送 HTTP 请求。服务器的永久重定向响应。浏览器会跟踪重定向地址。服务器处理请求。服务器返回 HTTP 响应。浏览器显示 HTML。HTML 中的资源
阅读全文
前端面试题合集
作者:科技小胖子1737人浏览评论:03年前
一、理论知识1.1、前端MV*框架的含义早期的前端比较简单,基本都是以页面为工作单位,主要是浏览内容,偶尔简单的表单操作,基本不需要框架。随着AJAX的出现和Web2.0的兴起,人们可以在页面上做更复杂的事情,然后前端框架才真正出现
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
php可以抓取网页数据吗(其他网络表单上没有任何PHP代码或脚本的情况下获取所有信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-29 05:20
问题
我能否在没有任何 PHP 代码或其他 Web 表单上的脚本的情况下获取所有这些信息?我可以在没有任何 PHP 代码或脚本的情况下在其他 Web 表单上获取所有这些信息吗?我可以在没有任何 PHP 代码或编写其他 Web 表单的脚本的情况下获取所有这些信息吗?我能否在没有任何 PHP 代码或其他 Web 表单上的脚本的情况下获取所有这些信息?
My Web From
<a name="top">
Basic Infromation
Image
First Name:
Last Name:
CNIC:
Date Of Birth:
Email:
Address:
Gender:
Male |
Female |
Other
Back to top
解决方案
不幸的是,你的问题不是很清楚。
我假设您想在单击提交按钮时以另一种形式在不同页面上显示上述表单的输入数据。
如果是,是,您可以使用 JavaScript 来获取此信息。
您需要做什么才能到达那里:
这当然有缺点。例如,可以禁用或操纵 JavaScript,因此您应该小心。 查看全部
php可以抓取网页数据吗(其他网络表单上没有任何PHP代码或脚本的情况下获取所有信息)
问题
我能否在没有任何 PHP 代码或其他 Web 表单上的脚本的情况下获取所有这些信息?我可以在没有任何 PHP 代码或脚本的情况下在其他 Web 表单上获取所有这些信息吗?我可以在没有任何 PHP 代码或编写其他 Web 表单的脚本的情况下获取所有这些信息吗?我能否在没有任何 PHP 代码或其他 Web 表单上的脚本的情况下获取所有这些信息?
My Web From
<a name="top">
Basic Infromation
Image
First Name:
Last Name:
CNIC:
Date Of Birth:
Email:
Address:
Gender:
Male |
Female |
Other
Back to top
解决方案
不幸的是,你的问题不是很清楚。
我假设您想在单击提交按钮时以另一种形式在不同页面上显示上述表单的输入数据。
如果是,是,您可以使用 JavaScript 来获取此信息。
您需要做什么才能到达那里:
这当然有缺点。例如,可以禁用或操纵 JavaScript,因此您应该小心。
php可以抓取网页数据吗( 如何利用动态IP代理收集数据?网页数据爬取获取内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-28 23:00
如何利用动态IP代理收集数据?网页数据爬取获取内容)
如何使用动态IP代理采集数据?网页数据爬取是指从网站获取特殊内容,不需要网站的API socket获取内容。作为网站客户体验的一部分,网页上的文字、图片、噪音、视频、动画等网页数据信息都被视为网页数据信息,但在整个过程中,如果很多相同IP重复应用实际操作肯定会受到限制。这时候必须辅助应用代理,才能最大限度地提高效率和实效。
1、动态获取内容网站,网页可以是静态的也可以是动态的。
一般来说,你想要获取的网页会随着你浏览网站的时间而变化。一般来说,这个网站是动态网页,利用AJAX技术或其他技术对网页进行即时升级。AJAX 是一种具有定时加载和多线程升级的脚本技术。根据后台管理和服务器虚拟机的少量数据传输,可以在不重新加载所有网页的情况下升级网页的某一部分。主要表现是网站的大部分URL在网页上点击选项时大部分保持不变;网页未完全加载,但仅加载了部分数据并进行了某些更改。
2、 从网页中抓取隐藏的内容。
想从网站获取特殊的数据信息,但是打开连接或者鼠标悬停在某个点上,就会出现内容?网站电脑鼠标必须移动到选择项才能显示分类信息。这样就可以设置将电脑鼠标移到连接上的功能,抓取网页中隐藏的内容。
3、从无休止的翻转网页中获取内容。
翻到页面底部后,一些网站上总会出现一些你需要获取的数据信息。比如今天的头条首页,你要不断的翻到页面底部才能加载更多的文章,无休止的翻页网站通常会应用AJAX或者JavaScript来请求额外的内容网站。在这种情况下,您可以设置AJAX请求超时设置,并选择滚动方式和滚动时间从网页获取内容。
4、 从网页中获取所有连接。
通常,网站 至少收录一个超链接。如果您想获取某个网页的所有链接,可以使用代理移动软件获取该网页上发布的所有网页链接。
对于程序员或开发者来说,拥有编写程序的能力来鼓励他们构建网页数据爬取程序的过程是非常容易和有趣的。但是对于大多数没有全部编程专业知识的人来说,最好使用一些互联网爬虫工具从特定网页中获取特殊内容。
如果想尝试使用代理ip,可以到拼音http官网了解更多。提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动! 查看全部
php可以抓取网页数据吗(
如何利用动态IP代理收集数据?网页数据爬取获取内容)
如何使用动态IP代理采集数据?网页数据爬取是指从网站获取特殊内容,不需要网站的API socket获取内容。作为网站客户体验的一部分,网页上的文字、图片、噪音、视频、动画等网页数据信息都被视为网页数据信息,但在整个过程中,如果很多相同IP重复应用实际操作肯定会受到限制。这时候必须辅助应用代理,才能最大限度地提高效率和实效。
1、动态获取内容网站,网页可以是静态的也可以是动态的。
一般来说,你想要获取的网页会随着你浏览网站的时间而变化。一般来说,这个网站是动态网页,利用AJAX技术或其他技术对网页进行即时升级。AJAX 是一种具有定时加载和多线程升级的脚本技术。根据后台管理和服务器虚拟机的少量数据传输,可以在不重新加载所有网页的情况下升级网页的某一部分。主要表现是网站的大部分URL在网页上点击选项时大部分保持不变;网页未完全加载,但仅加载了部分数据并进行了某些更改。
2、 从网页中抓取隐藏的内容。
想从网站获取特殊的数据信息,但是打开连接或者鼠标悬停在某个点上,就会出现内容?网站电脑鼠标必须移动到选择项才能显示分类信息。这样就可以设置将电脑鼠标移到连接上的功能,抓取网页中隐藏的内容。
3、从无休止的翻转网页中获取内容。
翻到页面底部后,一些网站上总会出现一些你需要获取的数据信息。比如今天的头条首页,你要不断的翻到页面底部才能加载更多的文章,无休止的翻页网站通常会应用AJAX或者JavaScript来请求额外的内容网站。在这种情况下,您可以设置AJAX请求超时设置,并选择滚动方式和滚动时间从网页获取内容。
4、 从网页中获取所有连接。
通常,网站 至少收录一个超链接。如果您想获取某个网页的所有链接,可以使用代理移动软件获取该网页上发布的所有网页链接。
对于程序员或开发者来说,拥有编写程序的能力来鼓励他们构建网页数据爬取程序的过程是非常容易和有趣的。但是对于大多数没有全部编程专业知识的人来说,最好使用一些互联网爬虫工具从特定网页中获取特殊内容。
如果想尝试使用代理ip,可以到拼音http官网了解更多。提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动!
php可以抓取网页数据吗( 如何利用动态IP代理收集数据?网页数据爬取获取内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-28 15:02
如何利用动态IP代理收集数据?网页数据爬取获取内容)
如何使用动态IP代理采集数据?网页数据爬取是指从网站获取特殊内容,不需要网站的API socket获取内容。作为网站客户体验的一部分,网页上的文字、图片、噪音、视频、动画等网页数据信息都被视为网页数据信息,但在整个过程中,如果很多相同IP重复应用实际操作肯定会受到限制。这时候必须辅助应用代理,才能最大限度地提高效率和实效。
1、动态获取内容网站,网页可以是静态的也可以是动态的。
一般来说,你想要获取的网页会随着你浏览网站的时间而变化。一般来说,这个网站是动态网页,利用AJAX技术或其他技术对网页进行即时升级。AJAX 是一种具有定时加载和多线程升级的脚本技术。根据后台管理和服务器虚拟机的少量数据传输,可以在不重新加载所有网页的情况下升级网页的某一部分。主要表现是网站的大部分URL在网页上点击选项时大部分保持不变;网页未完全加载,但仅加载了部分数据并进行了某些更改。
2、 从网页中抓取隐藏的内容。
想从网站获取特殊的数据信息,但是打开连接或者鼠标悬停在某个点上,就会出现内容?网站电脑鼠标必须移动到选择项才能显示分类信息。这样就可以设置将电脑鼠标移到连接上的功能,抓取网页中隐藏的内容。
3、从无休止的翻转网页中获取内容。
翻到页面底部后,一些网站上总会出现一些你需要获取的数据信息。比如今天的头条首页,你要不断的翻到页面底部才能加载更多的文章,无休止的翻页网站通常会应用AJAX或者JavaScript来请求额外的内容网站。在这种情况下,您可以设置AJAX请求超时设置,并选择滚动方式和滚动时间从网页获取内容。
4、 从网页中获取所有连接。
通常,网站 至少收录一个超链接。如果您想获取某个网页的所有链接,可以使用代理移动软件获取该网页上发布的所有网页链接。
对于程序员或开发者来说,拥有编写程序的能力来鼓励他们构建网页数据爬取程序的过程是非常容易和有趣的。但是对于大多数没有全部编程专业知识的人来说,最好使用一些互联网爬虫工具从特定网页中获取特殊内容。
如果想尝试使用代理ip,可以到拼音http官网了解更多。提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动! 查看全部
php可以抓取网页数据吗(
如何利用动态IP代理收集数据?网页数据爬取获取内容)
如何使用动态IP代理采集数据?网页数据爬取是指从网站获取特殊内容,不需要网站的API socket获取内容。作为网站客户体验的一部分,网页上的文字、图片、噪音、视频、动画等网页数据信息都被视为网页数据信息,但在整个过程中,如果很多相同IP重复应用实际操作肯定会受到限制。这时候必须辅助应用代理,才能最大限度地提高效率和实效。
1、动态获取内容网站,网页可以是静态的也可以是动态的。
一般来说,你想要获取的网页会随着你浏览网站的时间而变化。一般来说,这个网站是动态网页,利用AJAX技术或其他技术对网页进行即时升级。AJAX 是一种具有定时加载和多线程升级的脚本技术。根据后台管理和服务器虚拟机的少量数据传输,可以在不重新加载所有网页的情况下升级网页的某一部分。主要表现是网站的大部分URL在网页上点击选项时大部分保持不变;网页未完全加载,但仅加载了部分数据并进行了某些更改。
2、 从网页中抓取隐藏的内容。
想从网站获取特殊的数据信息,但是打开连接或者鼠标悬停在某个点上,就会出现内容?网站电脑鼠标必须移动到选择项才能显示分类信息。这样就可以设置将电脑鼠标移到连接上的功能,抓取网页中隐藏的内容。
3、从无休止的翻转网页中获取内容。
翻到页面底部后,一些网站上总会出现一些你需要获取的数据信息。比如今天的头条首页,你要不断的翻到页面底部才能加载更多的文章,无休止的翻页网站通常会应用AJAX或者JavaScript来请求额外的内容网站。在这种情况下,您可以设置AJAX请求超时设置,并选择滚动方式和滚动时间从网页获取内容。
4、 从网页中获取所有连接。
通常,网站 至少收录一个超链接。如果您想获取某个网页的所有链接,可以使用代理移动软件获取该网页上发布的所有网页链接。
对于程序员或开发者来说,拥有编写程序的能力来鼓励他们构建网页数据爬取程序的过程是非常容易和有趣的。但是对于大多数没有全部编程专业知识的人来说,最好使用一些互联网爬虫工具从特定网页中获取特殊内容。
如果想尝试使用代理ip,可以到拼音http官网了解更多。提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动!
php可以抓取网页数据吗(sourceid配置的方法和配置的区别?配置详解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-26 07:15
)
sourceid 配置
一.SourceId 是什么?
答案:
1. 这个值对应一个评论列表。不同的 文章 有不同的评论。如果你的其中一个文章需要在多个终端发布(如PC端、手机APP端同时发布),为了让两端的文章共享同一个评论信息,那么需要设置为相同的SourceId;
2. 如果不设置sourceId,畅言默认会根据文章的URL查询评论信息。如果设置了sourceId,则以sourceId为准,根据sourceId查询评论信息。文章 .
二.什么样的网站需要SourceId?
答案:
1.如果你的网站比较大,并且文章需要在多个终端上发布,那么就需要设置SourceId来实现同一篇文章在多个终端上共享评论和信息;
2.如果你的网站只作为个人博客使用,只有PC端,文章不需要多端发布,那么sourceId就足以满足你的无需设置。
三.如果不配置 SourceId 会怎样?
答案:
1.由于未设置sourceId,畅言平台默认使用文章url查询评论信息。如果同一个文章多端发表的文章 URL不一致(不同端的域名可能不一样),那么同一篇文章文章不能共享多个来源的相同评论信息;
2.如果你的文章url变了,会导致评论混乱丢失。如果使用了 SourceId,只要这个值不改变,评论就会一直存在。
四.不配置SourceId可以使用畅言吗?
回答:是的,平台会自动将文章url识别为sourceId。
五. sourceId 一般设置成什么?
答案:
1.静态页面介绍,可以指定一个固定的SourceId值。例如,可以在首页使用sid="index",在测试页使用sid="test";
2. 另一个常见的做法是通过变量输出你的网站的文章ID。变量值由您指定以生成逻辑,例如基于网页 url 或标题哈希算法。一串随机数。
六.具体的配置步骤,可以选择以下两种配置中的一种(推荐使用配置sourceId的方法):
1、配置sourceId(sourceId的长度不能超过60字节)
这里的sourceId是网站文章的id,需要网站访问。具体代码如下:
例如,如果您的网页是从模板文件生成的,您可以在模板文件中像这样配置
上面的$sid是一个文章id变量,它的生成逻辑可以自己指定(比如根据网页url和标题hash算法生成一串随机数)
本模板生成网页文件时,由于每个网页内容不同,生成的$sid变量值不同,如下图:
页面 A 中的 Sid
页面 B 中的 Sid
常见平台下如何配置sourceid:
注意:德德官方提供的“插件”cms/WordPress/ZBlog都会默认配置sourceid,所以不需要手动配置。
如果您使用的是以下cms的云评论“代码”,请按照以下方法配置sourceid。其他cms请查询通过搜索引擎获取文章id的方法。
Wordpress sid 配置方法:
<p> 查看全部
php可以抓取网页数据吗(sourceid配置的方法和配置的区别?配置详解
)
sourceid 配置
一.SourceId 是什么?
答案:
1. 这个值对应一个评论列表。不同的 文章 有不同的评论。如果你的其中一个文章需要在多个终端发布(如PC端、手机APP端同时发布),为了让两端的文章共享同一个评论信息,那么需要设置为相同的SourceId;
2. 如果不设置sourceId,畅言默认会根据文章的URL查询评论信息。如果设置了sourceId,则以sourceId为准,根据sourceId查询评论信息。文章 .
二.什么样的网站需要SourceId?
答案:
1.如果你的网站比较大,并且文章需要在多个终端上发布,那么就需要设置SourceId来实现同一篇文章在多个终端上共享评论和信息;
2.如果你的网站只作为个人博客使用,只有PC端,文章不需要多端发布,那么sourceId就足以满足你的无需设置。
三.如果不配置 SourceId 会怎样?
答案:
1.由于未设置sourceId,畅言平台默认使用文章url查询评论信息。如果同一个文章多端发表的文章 URL不一致(不同端的域名可能不一样),那么同一篇文章文章不能共享多个来源的相同评论信息;
2.如果你的文章url变了,会导致评论混乱丢失。如果使用了 SourceId,只要这个值不改变,评论就会一直存在。
四.不配置SourceId可以使用畅言吗?
回答:是的,平台会自动将文章url识别为sourceId。
五. sourceId 一般设置成什么?
答案:
1.静态页面介绍,可以指定一个固定的SourceId值。例如,可以在首页使用sid="index",在测试页使用sid="test";
2. 另一个常见的做法是通过变量输出你的网站的文章ID。变量值由您指定以生成逻辑,例如基于网页 url 或标题哈希算法。一串随机数。
六.具体的配置步骤,可以选择以下两种配置中的一种(推荐使用配置sourceId的方法):
1、配置sourceId(sourceId的长度不能超过60字节)
这里的sourceId是网站文章的id,需要网站访问。具体代码如下:
例如,如果您的网页是从模板文件生成的,您可以在模板文件中像这样配置
上面的$sid是一个文章id变量,它的生成逻辑可以自己指定(比如根据网页url和标题hash算法生成一串随机数)
本模板生成网页文件时,由于每个网页内容不同,生成的$sid变量值不同,如下图:
页面 A 中的 Sid
页面 B 中的 Sid
常见平台下如何配置sourceid:
注意:德德官方提供的“插件”cms/WordPress/ZBlog都会默认配置sourceid,所以不需要手动配置。
如果您使用的是以下cms的云评论“代码”,请按照以下方法配置sourceid。其他cms请查询通过搜索引擎获取文章id的方法。
Wordpress sid 配置方法:
<p>
php可以抓取网页数据吗(php可以和phpwind等网页数据吗?答案是可以的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-23 05:04
php可以抓取网页数据吗?答案是可以的。php可以和phpwind等网页数据抓取库交互。所以我们可以借助phppil数据抓取库,实现网页的实时抓取。1.给出上面的demo地址,直接下载爬虫代码。yx_php_pil1.3.12解压工程打开命令行输入:phppil命令:php:install/usr/local/php/5.6.3/conf/permanent/php_img_extra_threads.phpphp:permanent/php/5.6.3/conf/permanent/php_extra_threads.phpconf文件2.修改php后缀为.php,yx_php_pil源码放到后缀为.php文件的文件夹下(你也可以将源码编译后放到你的php目录下面)。
3.将要抓取的网页地址打包成php文件上传到服务器中。4.在php中执行命令:if(!error_wait(file_regex)){print_redirect('请求网址(https://*)');}else{print_redirect('请求目标网址(https://*)');}解释一下:php中调用extra_threads.php插件之后,会调用该插件所解析的client文件的extra_threads.php文件,再由client文件解析client。
我们的demo就是经过google解析的client。以下是我们使用php实现网页抓取的源码,请自行download或者在浏览器查看。点击浏览器地址栏地址栏显示read_text文本文件,才是我们的代码。 查看全部
php可以抓取网页数据吗(php可以和phpwind等网页数据吗?答案是可以的)
php可以抓取网页数据吗?答案是可以的。php可以和phpwind等网页数据抓取库交互。所以我们可以借助phppil数据抓取库,实现网页的实时抓取。1.给出上面的demo地址,直接下载爬虫代码。yx_php_pil1.3.12解压工程打开命令行输入:phppil命令:php:install/usr/local/php/5.6.3/conf/permanent/php_img_extra_threads.phpphp:permanent/php/5.6.3/conf/permanent/php_extra_threads.phpconf文件2.修改php后缀为.php,yx_php_pil源码放到后缀为.php文件的文件夹下(你也可以将源码编译后放到你的php目录下面)。
3.将要抓取的网页地址打包成php文件上传到服务器中。4.在php中执行命令:if(!error_wait(file_regex)){print_redirect('请求网址(https://*)');}else{print_redirect('请求目标网址(https://*)');}解释一下:php中调用extra_threads.php插件之后,会调用该插件所解析的client文件的extra_threads.php文件,再由client文件解析client。
我们的demo就是经过google解析的client。以下是我们使用php实现网页抓取的源码,请自行download或者在浏览器查看。点击浏览器地址栏地址栏显示read_text文本文件,才是我们的代码。
php可以抓取网页数据吗(php可以抓取网页数据吗?php怎么抓取源代码吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-22 06:03
php可以抓取网页数据吗?php可以抓取网页源代码吗?php可以直接读取html文件吗?这些都是需要熟悉php才能解决的基础问题。php有很多优势,就拿网页抓取来说吧:兼容性强,javac/c++python三种语言一起写可以实现很多优秀的效果,即使初学者也能快速上手;php出身就是开发web的,可以说,如果网站需要抓取数据都会选择php,毕竟它的开发门槛不是很高,php针对于、腾讯等大型网站也有完善的框架;php通过文件系统、反射机制等,高效解决多种前端技术的问题,更加方便开发;php框架使得php有很多东西可以修改改,比如:缓存、消息通知等;它的第三方库很多,可以更加轻松的去使用;php没有对外暴露的api,使得php可以非常简单;php有很多通用函数,可以更加简单的使用;php的开发效率很高,代码数量小,只要自己开发一个轮子加个接口,很快就会有很多人帮你去解决问题,运行很快;如果抓取的是java或者python这种语言,那么php的写法又是不一样的,需要自己开发一套框架,然后用php解析出来,会比较麻烦;php代码字符串支持json、html5的字符串;php可以对于java、python、c++以及一些其他语言进行反射,可以拿到一些数据;php前后端逻辑分离,session、cookie双重保护,减少开发风险;这些都是可以慢慢去熟悉,php也可以简单适用于一些nodejs,比如简单的抓取ajax,我们就可以利用ajax来抓取数据,但是如果数据量很大的话,就没办法对于java网站进行ajax抓取;总而言之,很多东西一旦你掌握了,它就不仅仅是一门编程语言那么简单,熟悉它你就会对于其他需要抓取的东西有思路,它的价值不仅仅在于它处理复杂网站,你还可以更加方便的解决ajax的开发问题,同时你还可以深入了解php的设计和设计思想,知道php解决问题的方法和逻辑,学到以后,你也不会仅仅局限于抓取一类数据,同时你还可以发挥它的优势,比如学到更多比如gc、session、linux服务器的运行等。
本人从0基础学php,到去交大计算机专业进修,再到带领一个团队去搞nodejs服务器安全攻防,最后去找工作,考过n5和n4前端证书,目前在创业初期,在学习和积累中坚持前行,希望通过自己的文字给你学习新技术时的一些帮助。 查看全部
php可以抓取网页数据吗(php可以抓取网页数据吗?php怎么抓取源代码吗)
php可以抓取网页数据吗?php可以抓取网页源代码吗?php可以直接读取html文件吗?这些都是需要熟悉php才能解决的基础问题。php有很多优势,就拿网页抓取来说吧:兼容性强,javac/c++python三种语言一起写可以实现很多优秀的效果,即使初学者也能快速上手;php出身就是开发web的,可以说,如果网站需要抓取数据都会选择php,毕竟它的开发门槛不是很高,php针对于、腾讯等大型网站也有完善的框架;php通过文件系统、反射机制等,高效解决多种前端技术的问题,更加方便开发;php框架使得php有很多东西可以修改改,比如:缓存、消息通知等;它的第三方库很多,可以更加轻松的去使用;php没有对外暴露的api,使得php可以非常简单;php有很多通用函数,可以更加简单的使用;php的开发效率很高,代码数量小,只要自己开发一个轮子加个接口,很快就会有很多人帮你去解决问题,运行很快;如果抓取的是java或者python这种语言,那么php的写法又是不一样的,需要自己开发一套框架,然后用php解析出来,会比较麻烦;php代码字符串支持json、html5的字符串;php可以对于java、python、c++以及一些其他语言进行反射,可以拿到一些数据;php前后端逻辑分离,session、cookie双重保护,减少开发风险;这些都是可以慢慢去熟悉,php也可以简单适用于一些nodejs,比如简单的抓取ajax,我们就可以利用ajax来抓取数据,但是如果数据量很大的话,就没办法对于java网站进行ajax抓取;总而言之,很多东西一旦你掌握了,它就不仅仅是一门编程语言那么简单,熟悉它你就会对于其他需要抓取的东西有思路,它的价值不仅仅在于它处理复杂网站,你还可以更加方便的解决ajax的开发问题,同时你还可以深入了解php的设计和设计思想,知道php解决问题的方法和逻辑,学到以后,你也不会仅仅局限于抓取一类数据,同时你还可以发挥它的优势,比如学到更多比如gc、session、linux服务器的运行等。
本人从0基础学php,到去交大计算机专业进修,再到带领一个团队去搞nodejs服务器安全攻防,最后去找工作,考过n5和n4前端证书,目前在创业初期,在学习和积累中坚持前行,希望通过自己的文字给你学习新技术时的一些帮助。
php可以抓取网页数据吗(php可以抓取网页数据吗?同一个网站怎么抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-17 01:04
php可以抓取网页数据吗?同一个网站怎么抓取网页不同地方的数据?刚才我也有同样的问题,搜索出来的答案大都不靠谱,后来看了一下源码,发现在php内部有函数phpstorm_set_request_http_status这个函数,可以用来指定爬取到的网页时候是否使用http协议的header方式请求,并且可以设置默认的header信息。
比如这样的请求:php:login@102.74.241.45\yourprofile.php(phpstorm_init_http_status)另外抓取java的返回结果也是可以用phpstorm_set_request_http_status指定的。
php中request对象可以接受不同种协议的http请求:request对象可以接受任意格式的httpheader,其中的http.host头指定了它所请求的协议的host,如果不指定host,默认为get请求。其中还有一个参数为header_method,如果在request.requestheader中指定了该参数,那么最终请求时会使用这个header_method方法。
如果没有指定header_method,那么请求所有的httpheader都使用同一个请求方法,php处理这些http请求时会按照协议的相应原则处理。1.基本请求stringrequestheader;httpuser-agentrequestuser-agent。2.postrequestpostrequestheader;httpuser-agentpost请求后如果请求失败,会抛出一个posterror异常;如果请求正常则会抛出一个responseonehandler异常。
3.getrequest如果文档是通过正则表达式获取的,必须在header中指定正则匹配规则,以下为正则表达式示例:publicuseragent{protocol:'http/1.1';}4.postdeleterequest如果请求失败,会抛出一个posterror异常;如果请求成功则会抛出一个responseonehandler异常5.postdeleteoptions请求的参数可以通过简单的params传递给服务器,必须设置正则匹配规则。 查看全部
php可以抓取网页数据吗(php可以抓取网页数据吗?同一个网站怎么抓取)
php可以抓取网页数据吗?同一个网站怎么抓取网页不同地方的数据?刚才我也有同样的问题,搜索出来的答案大都不靠谱,后来看了一下源码,发现在php内部有函数phpstorm_set_request_http_status这个函数,可以用来指定爬取到的网页时候是否使用http协议的header方式请求,并且可以设置默认的header信息。
比如这样的请求:php:login@102.74.241.45\yourprofile.php(phpstorm_init_http_status)另外抓取java的返回结果也是可以用phpstorm_set_request_http_status指定的。
php中request对象可以接受不同种协议的http请求:request对象可以接受任意格式的httpheader,其中的http.host头指定了它所请求的协议的host,如果不指定host,默认为get请求。其中还有一个参数为header_method,如果在request.requestheader中指定了该参数,那么最终请求时会使用这个header_method方法。
如果没有指定header_method,那么请求所有的httpheader都使用同一个请求方法,php处理这些http请求时会按照协议的相应原则处理。1.基本请求stringrequestheader;httpuser-agentrequestuser-agent。2.postrequestpostrequestheader;httpuser-agentpost请求后如果请求失败,会抛出一个posterror异常;如果请求正常则会抛出一个responseonehandler异常。
3.getrequest如果文档是通过正则表达式获取的,必须在header中指定正则匹配规则,以下为正则表达式示例:publicuseragent{protocol:'http/1.1';}4.postdeleterequest如果请求失败,会抛出一个posterror异常;如果请求成功则会抛出一个responseonehandler异常5.postdeleteoptions请求的参数可以通过简单的params传递给服务器,必须设置正则匹配规则。
php可以抓取网页数据吗( 一个发布框架内跑起来的Javascript拓展,你值得拥有)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-11 14:21
一个发布框架内跑起来的Javascript拓展,你值得拥有)
我今天想演示的其实很简单,一两分钟就可以搞定。主要用来弥补Axure IDE提供的交互功能的不足,导致一些想法不能很好的实现。
其实国外有个大神(De Jongh)做了一个可以在Axure发布框架中运行的Javascript扩展。这是地址::axure_api&do=index。
一部分是Axure基于jQuery的功能,另一部分是他添加的扩展功能。扩展功能看起来很不错,解决了很多问题;但是安装真的很麻烦,尤其对于不熟悉代码的设计师(流程设计师、视觉设计师等)来说简直是天书。
为此,我结合一些我们常用的函数或函数,整理出一些不用扩展库就可以实现的功能,并做了实例分享给大家。
今天,我们制作了一个 iframe 内联框架,根据加载页面的大小自适应改变大小。Axure自己的页面属性很简单,只有一个pageName,不够用!如图:
通常我们在制作页面的时候,也会用到页面的大小。比如自定义可视化滚动条,通过iframe(内联框架)进行页面切换等,如果没有页面大小,会导致适配等操作无法实现,所以今天就来解决。
这是演示地址。可能由于网络原因加载页面时间过长,读取高度值失败。请刷新:
01准备测试材料
我们首先准备3个页面和1个全局变量:1个是带菜单的主页面,2个演示内容页面,1个全局变量。
交互流程及原理:
单击按钮时,加载的子页面在加载时获取自己的页面高度,然后将其写入全局变量。按钮操作会延迟更改 iframe 的大小。
02制作页面 1. 首页:主页
在主页面,我放置了2个按钮,1个iframe:2个按钮(矩形),没有命名要求;1 iframe,iframe 组件 ID 名为“loadPageFrame”,设置隐藏边框,永不滚动。
2.页1、page2:内容页
在这两个页面上找一些文字,或者画一些测试图形,尽量拉伸页面的高度,这样在测试的时候就会体现出差异。
03 交互和代码 1. 主页,菜单按钮
主页面按钮主要触发iframe加载目标页面,然后延迟500ms(根据需要可调,150ms基本就可以了),根据全局变量“size”改变iframe的大小。
给菜单按钮添加交互,交互顺序不要错:先将iframe缩小到10的高度,然后打开链接,延迟后设置大小。
2.页面1、页面2内容页面
内容页面可以任意制作,只需要在页面中添加页面的交互即可获取页面加载时的高度:
代码如下: javascript:void($axure.setGlobalVariable"size", document.documentElement.scrollHeight));
04 扩展应用
使用延迟触发是因为跨页面组件不能直接交互(在IDE中无法获取目标指针),所以只能通过跨页面全局变量来实现。基本上200ms左右的延迟是不明显的。当然,考虑到终端的运营能力,可以适当扩展。
示例代码中的626w是可以任意设置的iframe的宽度,也可以根据变量进行修改。[[size]] 为全局变量大小,可在IDE中直接引用。
为了以后方便大家搜索,我把我用到的功能罗列出来:
当可以获取页面大小,通过全局变量修改iframe大小实现自适应时,我们就不能再依赖《Axure Master》有限的玩法了。菜单框页面准备好了,其他内容页面就可以随意做,并且不再存在多人协作时已经放置在页面上的大师同步及时性的问题。
并且使用浏览器本身的滚动条比使用iframe的滚动条漂亮很多。
今天的文章比较枯燥,或者说比较无聊,本来有很长的文章我想写,虽然例子已经做了,但主要是解决如何在Axure IDE中传递JS代码准确定位组件以获得更多的自由来打包应用程序。
考虑到内容比较枯燥,措辞还在考虑中,会尽快发布。
回到做这个系列的初衷,就是让懂代码的同事提前结合JS和原生IDE,根据团队的可视化交互规范提前封装一些组件,让不懂代码的同事代码可以轻松快速地用于构建交互式原型。
关注我,下周会放出包括之前文章在内的源文件。 查看全部
php可以抓取网页数据吗(
一个发布框架内跑起来的Javascript拓展,你值得拥有)
我今天想演示的其实很简单,一两分钟就可以搞定。主要用来弥补Axure IDE提供的交互功能的不足,导致一些想法不能很好的实现。
其实国外有个大神(De Jongh)做了一个可以在Axure发布框架中运行的Javascript扩展。这是地址::axure_api&do=index。
一部分是Axure基于jQuery的功能,另一部分是他添加的扩展功能。扩展功能看起来很不错,解决了很多问题;但是安装真的很麻烦,尤其对于不熟悉代码的设计师(流程设计师、视觉设计师等)来说简直是天书。
为此,我结合一些我们常用的函数或函数,整理出一些不用扩展库就可以实现的功能,并做了实例分享给大家。
今天,我们制作了一个 iframe 内联框架,根据加载页面的大小自适应改变大小。Axure自己的页面属性很简单,只有一个pageName,不够用!如图:
通常我们在制作页面的时候,也会用到页面的大小。比如自定义可视化滚动条,通过iframe(内联框架)进行页面切换等,如果没有页面大小,会导致适配等操作无法实现,所以今天就来解决。
这是演示地址。可能由于网络原因加载页面时间过长,读取高度值失败。请刷新:
01准备测试材料
我们首先准备3个页面和1个全局变量:1个是带菜单的主页面,2个演示内容页面,1个全局变量。
交互流程及原理:
单击按钮时,加载的子页面在加载时获取自己的页面高度,然后将其写入全局变量。按钮操作会延迟更改 iframe 的大小。
02制作页面 1. 首页:主页
在主页面,我放置了2个按钮,1个iframe:2个按钮(矩形),没有命名要求;1 iframe,iframe 组件 ID 名为“loadPageFrame”,设置隐藏边框,永不滚动。
2.页1、page2:内容页
在这两个页面上找一些文字,或者画一些测试图形,尽量拉伸页面的高度,这样在测试的时候就会体现出差异。
03 交互和代码 1. 主页,菜单按钮
主页面按钮主要触发iframe加载目标页面,然后延迟500ms(根据需要可调,150ms基本就可以了),根据全局变量“size”改变iframe的大小。
给菜单按钮添加交互,交互顺序不要错:先将iframe缩小到10的高度,然后打开链接,延迟后设置大小。
2.页面1、页面2内容页面
内容页面可以任意制作,只需要在页面中添加页面的交互即可获取页面加载时的高度:
代码如下: javascript:void($axure.setGlobalVariable"size", document.documentElement.scrollHeight));
04 扩展应用
使用延迟触发是因为跨页面组件不能直接交互(在IDE中无法获取目标指针),所以只能通过跨页面全局变量来实现。基本上200ms左右的延迟是不明显的。当然,考虑到终端的运营能力,可以适当扩展。
示例代码中的626w是可以任意设置的iframe的宽度,也可以根据变量进行修改。[[size]] 为全局变量大小,可在IDE中直接引用。
为了以后方便大家搜索,我把我用到的功能罗列出来:
当可以获取页面大小,通过全局变量修改iframe大小实现自适应时,我们就不能再依赖《Axure Master》有限的玩法了。菜单框页面准备好了,其他内容页面就可以随意做,并且不再存在多人协作时已经放置在页面上的大师同步及时性的问题。
并且使用浏览器本身的滚动条比使用iframe的滚动条漂亮很多。
今天的文章比较枯燥,或者说比较无聊,本来有很长的文章我想写,虽然例子已经做了,但主要是解决如何在Axure IDE中传递JS代码准确定位组件以获得更多的自由来打包应用程序。
考虑到内容比较枯燥,措辞还在考虑中,会尽快发布。
回到做这个系列的初衷,就是让懂代码的同事提前结合JS和原生IDE,根据团队的可视化交互规范提前封装一些组件,让不懂代码的同事代码可以轻松快速地用于构建交互式原型。
关注我,下周会放出包括之前文章在内的源文件。
php可以抓取网页数据吗(简化HTTP请求、数据抽取、收集的视频数据应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-11 14:17
就像 Python 有 Scrapy 库一样,爬虫框架可以大大简化 HTTP 请求、数据提取和采集的过程,同时也提供了更多的工具来帮助我们实现更复杂的功能。
Golang爬虫框架-Goribot
是一个用Golang编写的轻量级爬虫框架,具有良好的扩展性和分布式支持能力,文档齐全。
获取 Goribot:
go get -u github.com/zhshch2002/goribot
使用Goribot实现上述代码的功能看起来简洁多了。
package main
import (
"fmt"
"github.com/zhshch2002/goribot"
)
func main() {
s := goribot.NewSpider()
s.AddTask(
goribot.GetReq("https://github.com"),
func(ctx *goribot.Context) {
fmt.Println(ctx.Resp.Text)
},
)
s.Run()
}
这样就实现了一个功能,就是访问“”并打印出结果。此类应用程序不足以使用框架。那么让我们从一个更复杂的爬虫应用程序开始。
使用Goribot爬取B站信息
下面我们来构建一个更复杂的爬虫应用,预计实现两个功能:
沿链接自动发现新的视频链接,提取标题、封面图、作者、视频数据(播放量、币种、采集夹等)研究B站页面
首先我们来研究一下B站的视频页面,比如按F12打开调试界面,切换到网络选项卡。
我们可以看到这个页面涉及的所有请求和资源。在调试界面选择XHR选项查看Ajax请求。
您可以点击不同的请求,在右侧的弹出面板中查看具体内容。单击新面板中的预览以查看服务器响应的内容。
所以,给你一个任务,依次查看XHR下的所有请求,找出服务器返回的点赞、采集、播放数据中最喜欢哪一个。
很好,看看你找到了吗?
您已经成功实现了爬虫工程师从 Ajax 请求中寻找目标数据的成就。
然后我们切换到Header选项来看看这个请求对应的参数。最好找到这个响应和视频 ID 之间的关系。
找到视频 Id-BV 编号。
我们解决了核心问题,得到了B站的视频数据。对于自动搜索视频,我们可以设置一个起始链接,然后搜索标签来扩展抓取。
构建爬虫
完整的代码在下面的文本中。
创建爬虫
s := goribot.NewSpider( // 创建一个爬虫并注册扩展
goribot.Limiter(true, &goribot.LimitRule{ // 添加一个限制器,限制白名单域名和请求速录限制
Glob: "*.bilibili.com", // 以防对服务器造成过大压力以及被B站服务器封禁
Rate: 2,
}),
goribot.RefererFiller(), // 自动填写Referer,参见Goribot(https://imagician.net/goribot/)关于扩展的部分
goribot.RandomUserAgent(), // 随机UA
goribot.SetDepthFirst(true), // 使用深度优先策略,就是沿着一个页面,然后去子页面而非同级页面
)
获取视频数据
var getVideoInfo = func(ctx *goribot.Context) {
res := map[string]interface{}{
"bvid": ctx.Resp.Json("data.bvid").String(),
"title": ctx.Resp.Json("data.title").String(),
"des": ctx.Resp.Json("data.des").String(),
"pic": ctx.Resp.Json("data.pic").String(), // 封面图
"tname": ctx.Resp.Json("data.tname").String(), // 分类名
"owner": map[string]interface{}{ //视频作者
"name": ctx.Resp.Json("data.owner.name").String(),
"mid": ctx.Resp.Json("data.owner.mid").String(),
"face": ctx.Resp.Json("data.owner.face").String(), // 头像
},
"ctime": ctx.Resp.Json("data.ctime").String(), // 创建时间
"pubdate": ctx.Resp.Json("data.pubdate").String(), // 发布时间
"stat": map[string]interface{}{ // 视频数据
"view": ctx.Resp.Json("data.stat.view").Int(),
"danmaku": ctx.Resp.Json("data.stat.danmaku").Int(),
"reply": ctx.Resp.Json("data.stat.reply").Int(),
"favorite": ctx.Resp.Json("data.stat.favorite").Int(),
"coin": ctx.Resp.Json("data.stat.coin").Int(),
"share": ctx.Resp.Json("data.stat.share").Int(),
"like": ctx.Resp.Json("data.stat.like").Int(),
"dislike": ctx.Resp.Json("data.stat.dislike").Int(),
},
}
ctx.AddItem(res) // 保存到蜘蛛的Item处理队列
}
这是一个自动解析响应中的Json数据的函数,也就是刚才看到的Ajax结果。解析完数据后,保存到spider的Item处理队列中。
发现新视频
var findVideo goribot.CtxHandlerFun
findVideo = func(ctx *goribot.Context) {
u := ctx.Req.URL.String()
fmt.Println(u)
if strings.HasPrefix(u, "https://www.bilibili.com/video/") { // 判断是否为视频页面
if strings.Contains(u, "?") {
u = u[:strings.Index(u, "?")]
}
u = u[31:] // 截取视频中的BV号
fmt.Println(u)
// 创建一个从BV号获取具体数据的任务,使用上一个策略
ctx.AddTask(goribot.GetReq("https://api.bilibili.com/x/web ... 3B%2Bu), getVideoInfo)
}
ctx.Resp.Dom.Find("a[href]").Each(func(i int, sel *goquery.Selection) {
if h, ok := sel.Attr("href"); ok {
ctx.AddTask(goribot.GetReq(h), findVideo) // 用同样的策略处理子页面
}
})
}
采集物品
我们在获取视频数据的过程中获取了Ajax数据,并保存到Item队列中。我们在这里处理这些项目是为了避免通过读写文件和数据库来阻塞抓取的主线程。
s.OnItem(func(i interface{}) interface{} {
fmt.Println(i) // 我们暂时不做处理,就先打印出来
return i
})
OnItem的具体使用可以参考Goribot文档的相关内容。
最后,让我们运行
// 种子任务
s.AddTask(goribot.GetReq("https://www.bilibili.com/video/BV1at411a7RS"), findVideo)
s.Run()
完整代码如下
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"github.com/zhshch2002/goribot"
"strings"
)
func main() {
s := goribot.NewSpider(
goribot.Limiter(true, &goribot.LimitRule{
Glob: "*.bilibili.com",
Rate: 2,
}),
goribot.RefererFiller(),
goribot.RandomUserAgent(),
goribot.SetDepthFirst(true),
)
var getVideoInfo = func(ctx *goribot.Context) {
res := map[string]interface{}{
"bvid": ctx.Resp.Json("data.bvid").String(),
"title": ctx.Resp.Json("data.title").String(),
"des": ctx.Resp.Json("data.des").String(),
"pic": ctx.Resp.Json("data.pic").String(), // 封面图
"tname": ctx.Resp.Json("data.tname").String(), // 分类名
"owner": map[string]interface{}{ //视频作者
"name": ctx.Resp.Json("data.owner.name").String(),
"mid": ctx.Resp.Json("data.owner.mid").String(),
"face": ctx.Resp.Json("data.owner.face").String(), // 头像
},
"ctime": ctx.Resp.Json("data.ctime").String(), // 创建时间
"pubdate": ctx.Resp.Json("data.pubdate").String(), // 发布时间
"stat": map[string]interface{}{ // 视频数据
"view": ctx.Resp.Json("data.stat.view").Int(),
"danmaku": ctx.Resp.Json("data.stat.danmaku").Int(),
"reply": ctx.Resp.Json("data.stat.reply").Int(),
"favorite": ctx.Resp.Json("data.stat.favorite").Int(),
"coin": ctx.Resp.Json("data.stat.coin").Int(),
"share": ctx.Resp.Json("data.stat.share").Int(),
"like": ctx.Resp.Json("data.stat.like").Int(),
"dislike": ctx.Resp.Json("data.stat.dislike").Int(),
},
}
ctx.AddItem(res)
}
var findVideo goribot.CtxHandlerFun
findVideo = func(ctx *goribot.Context) {
u := ctx.Req.URL.String()
fmt.Println(u)
if strings.HasPrefix(u, "https://www.bilibili.com/video/") {
if strings.Contains(u, "?") {
u = u[:strings.Index(u, "?")]
}
u = u[31:]
fmt.Println(u)
ctx.AddTask(goribot.GetReq("https://api.bilibili.com/x/web ... 3B%2Bu), getVideoInfo)
}
ctx.Resp.Dom.Find("a[href]").Each(func(i int, sel *goquery.Selection) {
if h, ok := sel.Attr("href"); ok {
ctx.AddTask(goribot.GetReq(h), findVideo)
}
})
}
s.OnItem(func(i interface{}) interface{} {
fmt.Println(i)
return i
})
s.AddTask(goribot.GetReq("https://www.bilibili.com/video/BV1at411a7RS").SetHeader("cookie", "_uuid=1B9F036F-8652-DCDD-D67E-54603D58A9B904750infoc; buvid3=5D62519D-8AB5-449B-A4CF-72D17C3DFB87155806infoc; sid=9h5nzg2a; LIVE_BUVID=AUTO7815811574205505; CURRENT_FNVAL=16; im_notify_type_403928979=0; rpdid=|(k|~uu|lu||0J'ul)ukk)~kY; _ga=GA1.2.533428114.1584175871; PVID=1; DedeUserID=403928979; DedeUserID__ckMd5=08363945687b3545; SESSDATA=b4f022fe%2C1601298276%2C1cf0c*41; bili_jct=2f00b7d205a97aa2ec1475f93bfcb1a3; bp_t_offset_403928979=375484225910036050"), findVideo)
s.Run()
}
最后
爬虫框架只是一个工具,重要的是人们如何使用它。要了解这些工具,请参阅项目 _examples 和文档。
爬虫
本作品采用《CC协议》,转载须注明作者及本文链接 查看全部
php可以抓取网页数据吗(简化HTTP请求、数据抽取、收集的视频数据应用)
就像 Python 有 Scrapy 库一样,爬虫框架可以大大简化 HTTP 请求、数据提取和采集的过程,同时也提供了更多的工具来帮助我们实现更复杂的功能。
Golang爬虫框架-Goribot
是一个用Golang编写的轻量级爬虫框架,具有良好的扩展性和分布式支持能力,文档齐全。
获取 Goribot:
go get -u github.com/zhshch2002/goribot
使用Goribot实现上述代码的功能看起来简洁多了。
package main
import (
"fmt"
"github.com/zhshch2002/goribot"
)
func main() {
s := goribot.NewSpider()
s.AddTask(
goribot.GetReq("https://github.com";),
func(ctx *goribot.Context) {
fmt.Println(ctx.Resp.Text)
},
)
s.Run()
}
这样就实现了一个功能,就是访问“”并打印出结果。此类应用程序不足以使用框架。那么让我们从一个更复杂的爬虫应用程序开始。
使用Goribot爬取B站信息
下面我们来构建一个更复杂的爬虫应用,预计实现两个功能:
沿链接自动发现新的视频链接,提取标题、封面图、作者、视频数据(播放量、币种、采集夹等)研究B站页面
首先我们来研究一下B站的视频页面,比如按F12打开调试界面,切换到网络选项卡。
我们可以看到这个页面涉及的所有请求和资源。在调试界面选择XHR选项查看Ajax请求。
您可以点击不同的请求,在右侧的弹出面板中查看具体内容。单击新面板中的预览以查看服务器响应的内容。
所以,给你一个任务,依次查看XHR下的所有请求,找出服务器返回的点赞、采集、播放数据中最喜欢哪一个。
很好,看看你找到了吗?
您已经成功实现了爬虫工程师从 Ajax 请求中寻找目标数据的成就。
然后我们切换到Header选项来看看这个请求对应的参数。最好找到这个响应和视频 ID 之间的关系。
找到视频 Id-BV 编号。
我们解决了核心问题,得到了B站的视频数据。对于自动搜索视频,我们可以设置一个起始链接,然后搜索标签来扩展抓取。
构建爬虫
完整的代码在下面的文本中。
创建爬虫
s := goribot.NewSpider( // 创建一个爬虫并注册扩展
goribot.Limiter(true, &goribot.LimitRule{ // 添加一个限制器,限制白名单域名和请求速录限制
Glob: "*.bilibili.com", // 以防对服务器造成过大压力以及被B站服务器封禁
Rate: 2,
}),
goribot.RefererFiller(), // 自动填写Referer,参见Goribot(https://imagician.net/goribot/)关于扩展的部分
goribot.RandomUserAgent(), // 随机UA
goribot.SetDepthFirst(true), // 使用深度优先策略,就是沿着一个页面,然后去子页面而非同级页面
)
获取视频数据
var getVideoInfo = func(ctx *goribot.Context) {
res := map[string]interface{}{
"bvid": ctx.Resp.Json("data.bvid").String(),
"title": ctx.Resp.Json("data.title").String(),
"des": ctx.Resp.Json("data.des").String(),
"pic": ctx.Resp.Json("data.pic").String(), // 封面图
"tname": ctx.Resp.Json("data.tname").String(), // 分类名
"owner": map[string]interface{}{ //视频作者
"name": ctx.Resp.Json("data.owner.name").String(),
"mid": ctx.Resp.Json("data.owner.mid").String(),
"face": ctx.Resp.Json("data.owner.face").String(), // 头像
},
"ctime": ctx.Resp.Json("data.ctime").String(), // 创建时间
"pubdate": ctx.Resp.Json("data.pubdate").String(), // 发布时间
"stat": map[string]interface{}{ // 视频数据
"view": ctx.Resp.Json("data.stat.view").Int(),
"danmaku": ctx.Resp.Json("data.stat.danmaku").Int(),
"reply": ctx.Resp.Json("data.stat.reply").Int(),
"favorite": ctx.Resp.Json("data.stat.favorite").Int(),
"coin": ctx.Resp.Json("data.stat.coin").Int(),
"share": ctx.Resp.Json("data.stat.share").Int(),
"like": ctx.Resp.Json("data.stat.like").Int(),
"dislike": ctx.Resp.Json("data.stat.dislike").Int(),
},
}
ctx.AddItem(res) // 保存到蜘蛛的Item处理队列
}
这是一个自动解析响应中的Json数据的函数,也就是刚才看到的Ajax结果。解析完数据后,保存到spider的Item处理队列中。
发现新视频
var findVideo goribot.CtxHandlerFun
findVideo = func(ctx *goribot.Context) {
u := ctx.Req.URL.String()
fmt.Println(u)
if strings.HasPrefix(u, "https://www.bilibili.com/video/";) { // 判断是否为视频页面
if strings.Contains(u, "?") {
u = u[:strings.Index(u, "?")]
}
u = u[31:] // 截取视频中的BV号
fmt.Println(u)
// 创建一个从BV号获取具体数据的任务,使用上一个策略
ctx.AddTask(goribot.GetReq("https://api.bilibili.com/x/web ... 3B%2Bu), getVideoInfo)
}
ctx.Resp.Dom.Find("a[href]").Each(func(i int, sel *goquery.Selection) {
if h, ok := sel.Attr("href"); ok {
ctx.AddTask(goribot.GetReq(h), findVideo) // 用同样的策略处理子页面
}
})
}
采集物品
我们在获取视频数据的过程中获取了Ajax数据,并保存到Item队列中。我们在这里处理这些项目是为了避免通过读写文件和数据库来阻塞抓取的主线程。
s.OnItem(func(i interface{}) interface{} {
fmt.Println(i) // 我们暂时不做处理,就先打印出来
return i
})
OnItem的具体使用可以参考Goribot文档的相关内容。
最后,让我们运行
// 种子任务
s.AddTask(goribot.GetReq("https://www.bilibili.com/video/BV1at411a7RS";), findVideo)
s.Run()
完整代码如下
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"github.com/zhshch2002/goribot"
"strings"
)
func main() {
s := goribot.NewSpider(
goribot.Limiter(true, &goribot.LimitRule{
Glob: "*.bilibili.com",
Rate: 2,
}),
goribot.RefererFiller(),
goribot.RandomUserAgent(),
goribot.SetDepthFirst(true),
)
var getVideoInfo = func(ctx *goribot.Context) {
res := map[string]interface{}{
"bvid": ctx.Resp.Json("data.bvid").String(),
"title": ctx.Resp.Json("data.title").String(),
"des": ctx.Resp.Json("data.des").String(),
"pic": ctx.Resp.Json("data.pic").String(), // 封面图
"tname": ctx.Resp.Json("data.tname").String(), // 分类名
"owner": map[string]interface{}{ //视频作者
"name": ctx.Resp.Json("data.owner.name").String(),
"mid": ctx.Resp.Json("data.owner.mid").String(),
"face": ctx.Resp.Json("data.owner.face").String(), // 头像
},
"ctime": ctx.Resp.Json("data.ctime").String(), // 创建时间
"pubdate": ctx.Resp.Json("data.pubdate").String(), // 发布时间
"stat": map[string]interface{}{ // 视频数据
"view": ctx.Resp.Json("data.stat.view").Int(),
"danmaku": ctx.Resp.Json("data.stat.danmaku").Int(),
"reply": ctx.Resp.Json("data.stat.reply").Int(),
"favorite": ctx.Resp.Json("data.stat.favorite").Int(),
"coin": ctx.Resp.Json("data.stat.coin").Int(),
"share": ctx.Resp.Json("data.stat.share").Int(),
"like": ctx.Resp.Json("data.stat.like").Int(),
"dislike": ctx.Resp.Json("data.stat.dislike").Int(),
},
}
ctx.AddItem(res)
}
var findVideo goribot.CtxHandlerFun
findVideo = func(ctx *goribot.Context) {
u := ctx.Req.URL.String()
fmt.Println(u)
if strings.HasPrefix(u, "https://www.bilibili.com/video/";) {
if strings.Contains(u, "?") {
u = u[:strings.Index(u, "?")]
}
u = u[31:]
fmt.Println(u)
ctx.AddTask(goribot.GetReq("https://api.bilibili.com/x/web ... 3B%2Bu), getVideoInfo)
}
ctx.Resp.Dom.Find("a[href]").Each(func(i int, sel *goquery.Selection) {
if h, ok := sel.Attr("href"); ok {
ctx.AddTask(goribot.GetReq(h), findVideo)
}
})
}
s.OnItem(func(i interface{}) interface{} {
fmt.Println(i)
return i
})
s.AddTask(goribot.GetReq("https://www.bilibili.com/video/BV1at411a7RS";).SetHeader("cookie", "_uuid=1B9F036F-8652-DCDD-D67E-54603D58A9B904750infoc; buvid3=5D62519D-8AB5-449B-A4CF-72D17C3DFB87155806infoc; sid=9h5nzg2a; LIVE_BUVID=AUTO7815811574205505; CURRENT_FNVAL=16; im_notify_type_403928979=0; rpdid=|(k|~uu|lu||0J'ul)ukk)~kY; _ga=GA1.2.533428114.1584175871; PVID=1; DedeUserID=403928979; DedeUserID__ckMd5=08363945687b3545; SESSDATA=b4f022fe%2C1601298276%2C1cf0c*41; bili_jct=2f00b7d205a97aa2ec1475f93bfcb1a3; bp_t_offset_403928979=375484225910036050"), findVideo)
s.Run()
}
最后
爬虫框架只是一个工具,重要的是人们如何使用它。要了解这些工具,请参阅项目 _examples 和文档。
爬虫
本作品采用《CC协议》,转载须注明作者及本文链接
php可以抓取网页数据吗(基于动态内容为主的网站优化案例推荐(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-11 14:14
阿里云>云栖社区>主题图>D>动态网页php案例
推荐活动:
更多优惠>
当前主题:动态网页php案例添加到采集夹
相关话题:
动态网页php案例相关博客查看更多博客
Linux下Apache和MySQL+PHP综合应用案例
作者:科技小先锋1471人浏览评论:03年前
Linux下Apache和MySQL+PHP综合应用案例实验背景: Apache服务器已经编译安装在小诺Linux服务器上。为了搭建公司的论坛系统,需要安装phpBB论坛程序。phpBB 是一个典型的 LAMP (Linux+Apache+MySQL+PHP)
阅读全文
通过web文件获取数据库账号和密码
作者:小科技专家 930人 浏览评论:03年前
eon2005 2007-12-18 10:28:58 评论(5)1581人阅读通过web文件获取数据库账号和密码Simeon。可以借鉴这个案例:(1)了解动态web的知识页面( 2) 通过动态网页文件获取数据库账号和密码。动态网页的显着特点之一是
阅读全文
Apache 虚拟主机案例演示
作者:技术小牛人1111人浏览评论:03年前
基于dns的实验拓扑搭建网站服务器,这里用apache搭建,先进入科普:url=协议+主机地址或域名+资源地址www服务使用排名查询网站 1.Apache4 9.9%-0.5% 中小型静态web主流、web服务
阅读全文
基于Web应用的性能分析与优化案例
作者:小天科技 1037人浏览评论:03年前
一、 基于动态内容的网站优化案例 1. 网站 运行环境描述。硬件环境:1台IBM x3850服务器,单双核至强3.0G CPU,2GB内存,3块72GB SCSI磁盘。操作系统:CentOS5.4. 网站架构:Web应用基于LAMP架构,所有服务
阅读全文
k8s的基本概念和入门案例
作者:店家小二2722人浏览评论:02年前
1. Kubernetes 介绍了基本概念和术语——Node 节点(node)是 k8s 集群中相对于 master 的工作主机(物理或虚拟机)。它运行在每个 Node 上,用于启动和管理 pods 服务(kubelet),并且可以通过 maste 进行管理。在节点上运行的服务器
阅读全文
大规模网站技术架构核心原理及案例分析(阅读笔记)
作者:liuawei1683 人浏览评论:03年前
大规模网站技术架构核心原理与案例研究1.概述网站衡量标准:高可用、高性能、易扩展、可扩展性、安全性1.1大网站特点 高并发、高可用、海量数据 用户分布广泛,网络条件复杂,安全环境恶劣,需求瞬息万变,发布频繁。渐进式开发 1.2 大规模 网站 进化式开发过程 1
阅读全文
Map、Reduce处理数据结构及常见情况
作者:taoland1073人浏览评论:03年前
随着三大前端框架和小程序的流行,MVVM也开始流行起来,它的核心是ViewModel层,它就像一个值转换器,负责转换Model中的数据对象,让数据更简单来管理和使用,这一层向上与视图层进行双向数据绑定,向下与Mode进行双向数据绑定
阅读全文
【云栖号案例| 互联网】高德“一键”上云,实现核心数据“三点输出”
作者:云栖号案例库 993人浏览评论:01年前
云栖号案例库:【点击查看更多上云案例】不知道怎么上云?看云栖号案例库,了解不同行业、不同发展阶段的云迁移解决方案,助您做出云迁移决策!公司简介 高德地图旗下高德开放平台是中国领先的LBS服务提供商,拥有先进的数据融合技术和海量数据处理能力。服务超过 300,000 次转移
阅读全文 查看全部
php可以抓取网页数据吗(基于动态内容为主的网站优化案例推荐(组图))
阿里云>云栖社区>主题图>D>动态网页php案例
推荐活动:
更多优惠>
当前主题:动态网页php案例添加到采集夹
相关话题:
动态网页php案例相关博客查看更多博客
Linux下Apache和MySQL+PHP综合应用案例
作者:科技小先锋1471人浏览评论:03年前
Linux下Apache和MySQL+PHP综合应用案例实验背景: Apache服务器已经编译安装在小诺Linux服务器上。为了搭建公司的论坛系统,需要安装phpBB论坛程序。phpBB 是一个典型的 LAMP (Linux+Apache+MySQL+PHP)
阅读全文
通过web文件获取数据库账号和密码
作者:小科技专家 930人 浏览评论:03年前
eon2005 2007-12-18 10:28:58 评论(5)1581人阅读通过web文件获取数据库账号和密码Simeon。可以借鉴这个案例:(1)了解动态web的知识页面( 2) 通过动态网页文件获取数据库账号和密码。动态网页的显着特点之一是
阅读全文
Apache 虚拟主机案例演示
作者:技术小牛人1111人浏览评论:03年前
基于dns的实验拓扑搭建网站服务器,这里用apache搭建,先进入科普:url=协议+主机地址或域名+资源地址www服务使用排名查询网站 1.Apache4 9.9%-0.5% 中小型静态web主流、web服务
阅读全文
基于Web应用的性能分析与优化案例
作者:小天科技 1037人浏览评论:03年前
一、 基于动态内容的网站优化案例 1. 网站 运行环境描述。硬件环境:1台IBM x3850服务器,单双核至强3.0G CPU,2GB内存,3块72GB SCSI磁盘。操作系统:CentOS5.4. 网站架构:Web应用基于LAMP架构,所有服务
阅读全文
k8s的基本概念和入门案例
作者:店家小二2722人浏览评论:02年前
1. Kubernetes 介绍了基本概念和术语——Node 节点(node)是 k8s 集群中相对于 master 的工作主机(物理或虚拟机)。它运行在每个 Node 上,用于启动和管理 pods 服务(kubelet),并且可以通过 maste 进行管理。在节点上运行的服务器
阅读全文
大规模网站技术架构核心原理及案例分析(阅读笔记)
作者:liuawei1683 人浏览评论:03年前
大规模网站技术架构核心原理与案例研究1.概述网站衡量标准:高可用、高性能、易扩展、可扩展性、安全性1.1大网站特点 高并发、高可用、海量数据 用户分布广泛,网络条件复杂,安全环境恶劣,需求瞬息万变,发布频繁。渐进式开发 1.2 大规模 网站 进化式开发过程 1
阅读全文
Map、Reduce处理数据结构及常见情况
作者:taoland1073人浏览评论:03年前
随着三大前端框架和小程序的流行,MVVM也开始流行起来,它的核心是ViewModel层,它就像一个值转换器,负责转换Model中的数据对象,让数据更简单来管理和使用,这一层向上与视图层进行双向数据绑定,向下与Mode进行双向数据绑定
阅读全文
【云栖号案例| 互联网】高德“一键”上云,实现核心数据“三点输出”
作者:云栖号案例库 993人浏览评论:01年前
云栖号案例库:【点击查看更多上云案例】不知道怎么上云?看云栖号案例库,了解不同行业、不同发展阶段的云迁移解决方案,助您做出云迁移决策!公司简介 高德地图旗下高德开放平台是中国领先的LBS服务提供商,拥有先进的数据融合技术和海量数据处理能力。服务超过 300,000 次转移
阅读全文
php可以抓取网页数据吗(.js与前端React无缝对接之一下三种渲染方式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-11 14:13
)
Next.js 是一个轻量级的 React 服务器端渲染框架
它支持三种渲染方法,包括
旧瓶装新酒
上面提到的几种渲染方式其实并不新鲜,但是可以对应这些技术。
区别
Next.js的预渲染可以和前端React无缝对接
下面以一个文章列表页面为例,分别分析三种渲染方式。
客户端渲染
顾名思义,客户端渲染是仅在浏览器上执行的渲染。通过Vue和React构建的单页应用SPA都是这样渲染的
缺点
1.白屏,AJAX渲染前页面没有内容,只能通过Loading覆盖
2. SEO不友好,因为搜索引擎访问页面,默认不会执行JS,而是只能看到HTML而不是等待AJAX异步请求数据,所以无法搜索到页面内容
代码
import {NextPage} from 'next';
import axios from 'axios';
import {useEffect, useState} from "react";
import * as React from "react";
type Post = {
id: string,
id: string,
title: string
}
const PostsIndex: NextPage = () => {
// [] 表示只在第一次渲染的时候请求
const [posts, setPosts] = useState([]);
const [isLoading, setIsLoading] = useState(false);
useEffect(() => {
setIsLoading(true);
// 使用 AJAX 异步请求数据
axios.get('/api/posts').then(response => {
setPosts(response.data);
setIsLoading(false);
}, () => {
setIsLoading(true);
})
}, []);
return (
文章列表
{isLoading ? 加载中 :
posts.map(p =>
{p.id}
)}
)
};
export default PostsIndex;
网络不好的时候,加载时间很长,很长一段时间页面可能会出现空白。
由于第一次请求的HTML中没有文章内容,需要通过AJAX异步加载数据,加载数据渲染的过程在客户端完成,所以称为客户端渲染
静态页面生成 SSG
在文章列表页面,其实每个用户找到的内容都是一样的
那为什么还要在大家的浏览器上渲染呢?
为什么不在后台渲染出来发给大家
好的
N个渲染变成了1个渲染
N个客户端渲染变成了1个静态页面生成
这个过程变成了动态内容的静态
利弊
优点:这个方法可以解决白屏问题和SEO问题
缺点:所有用户看到的都是同一个页面,无法生成用户相关的内容
如何实现
首先让我们思考一个问题
如何获取帖子?因为加载数据的操作在后端,通过AJAX获取帖子显然是不合适的
答案是:通过getStaticProps获取帖子
getStaticProps是Next.js提供的一个方法,会在后端执行,返回一个prop,供NextPage渲染时使用
代码
import {GetStaticProps, NextPage} from 'next';
import {getPosts} from '../../lib/posts';
import Link from 'next/link';
import * as React from 'react';
type Post = {
id: string,
title: string
}
type Props = {
posts: Post[];
}
// props 中有下面导出的数据 posts
const PostsIndex: NextPage = (props) => {
const {posts} = props;
// 前后端控制台都能打印 -> 同构
console.log(posts);
return (
文章列表
{posts.map(p =>
{p.id}
)}
);
};
export default PostsIndex;
// 实现SSG
export const getStaticProps: GetStaticProps = async () => {
const posts = await getPosts();
return {
props: {
posts: JSON.parse(JSON.stringify(posts))
}
};
};
前端不通过ajax获取数据怎么办
我们只拿到了服务器上的posts数据,但是怎么传到前端呢?
发现奥秘
我们可以看到隐藏在id为_NEXT_DATA__的script标签中,里面存放的是传递给前端的props数据
这就是同构SSR的好处,后端可以直接把数据传给前端,不需要AJAX异步获取
静态时序环境在开发环境中。GetStaticProps 将为每个请求运行一次。这是为了方便您修改代码并在构建环境中重新运行。GetStaticProps 只在构建中运行一次,可以提供一份 HTML 副本供所有用户下载
如何体验构建环境
yarn build
yarn start
打包后,我们可以看到这个
解释
我看到的页面前面的三个图标是λ ○ ●
λ (Serve) SSR 无法自动创建 HTML(如下所述)
○(静态)自动创建HTML(发现你没用props)
●(SSG)自动创建HTML + JSON(等你使用道具)
三种文件类型
构建完成后,我们查看.next文件,找到posts.html、posts.js、posts.json
为什么不直接将数据放入posts.js?
很明显,posts.js 是为了接受不同的数据。当我们展示每个博客时,它们的风格相同,内容不同,所以会用到这个功能
动态内容静态
服务器端渲染 (SSR)
如果页面与用户相关怎么办?
这种情况更难以提前静止。需要在用户请求的时候获取用户信息,然后利用用户信息从数据库中获取数据。如果必须这样做,则必须为每个用户创建一个页面。有时数据更新得非常快。, 不能提前静态,比如微博首页的信息流
那该怎么办呢?
无论是客户端渲染,都会出现白屏
要么服务端渲染SSR,没有白屏
运行
不管是开发环境还是构建环境,getServerSideProps都是在请求之后运行的
代码
与 SSG 代码基本相同,但使用 getSeverSideProps
这段代码执行时,服务器响应请求后获取浏览器信息,返回给前端显示
import {GetServerSideProps, NextPage} from 'next';
import * as React from 'react';
import {IncomingHttpHeaders} from 'http';
type Props = {
browser: string
}
const index: NextPage = (props) => {
return (
你的浏览器是 {props.browser}
);
};
export default index;
export const getServerSideProps: GetServerSideProps = async (context) => {
const headers:IncomingHttpHeaders = context.req.headers;
const browser = headers['user-agent'];
return {
props: {
browser
}
};
};
SSR原理
建议后端使用 renderToString(),前端使用 hydrate()
后端渲染页面,返回 HTML String 格式,并传递给前端。前端执行 hydrate(),保留 HTML 并附加时间监控,即后端渲染 HTML,前端添加监控。
前端也会渲染一次,保证前后渲染结果一致
总结客户端渲染SSR
只在浏览器上运行,缺点SEO不友好,白屏
静态页面生成 SSG
静态站点生成,解决白屏问题和SEO问题
缺点:无法生成用户相关内容(所有用户请求的结果都一样)
服务器端渲染 (SSR)
解决白屏问题,SEO问题
可以生成用户相关的内容
如何选择三种渲染模式
查看全部
php可以抓取网页数据吗(.js与前端React无缝对接之一下三种渲染方式
)
Next.js 是一个轻量级的 React 服务器端渲染框架
它支持三种渲染方法,包括
旧瓶装新酒
上面提到的几种渲染方式其实并不新鲜,但是可以对应这些技术。
区别
Next.js的预渲染可以和前端React无缝对接
下面以一个文章列表页面为例,分别分析三种渲染方式。
客户端渲染
顾名思义,客户端渲染是仅在浏览器上执行的渲染。通过Vue和React构建的单页应用SPA都是这样渲染的
缺点
1.白屏,AJAX渲染前页面没有内容,只能通过Loading覆盖
2. SEO不友好,因为搜索引擎访问页面,默认不会执行JS,而是只能看到HTML而不是等待AJAX异步请求数据,所以无法搜索到页面内容
代码
import {NextPage} from 'next';
import axios from 'axios';
import {useEffect, useState} from "react";
import * as React from "react";
type Post = {
id: string,
id: string,
title: string
}
const PostsIndex: NextPage = () => {
// [] 表示只在第一次渲染的时候请求
const [posts, setPosts] = useState([]);
const [isLoading, setIsLoading] = useState(false);
useEffect(() => {
setIsLoading(true);
// 使用 AJAX 异步请求数据
axios.get('/api/posts').then(response => {
setPosts(response.data);
setIsLoading(false);
}, () => {
setIsLoading(true);
})
}, []);
return (
文章列表
{isLoading ? 加载中 :
posts.map(p =>
{p.id}
)}
)
};
export default PostsIndex;
网络不好的时候,加载时间很长,很长一段时间页面可能会出现空白。
由于第一次请求的HTML中没有文章内容,需要通过AJAX异步加载数据,加载数据渲染的过程在客户端完成,所以称为客户端渲染
静态页面生成 SSG
在文章列表页面,其实每个用户找到的内容都是一样的
那为什么还要在大家的浏览器上渲染呢?
为什么不在后台渲染出来发给大家
好的
N个渲染变成了1个渲染
N个客户端渲染变成了1个静态页面生成
这个过程变成了动态内容的静态
利弊
优点:这个方法可以解决白屏问题和SEO问题
缺点:所有用户看到的都是同一个页面,无法生成用户相关的内容
如何实现
首先让我们思考一个问题
如何获取帖子?因为加载数据的操作在后端,通过AJAX获取帖子显然是不合适的
答案是:通过getStaticProps获取帖子
getStaticProps是Next.js提供的一个方法,会在后端执行,返回一个prop,供NextPage渲染时使用
代码
import {GetStaticProps, NextPage} from 'next';
import {getPosts} from '../../lib/posts';
import Link from 'next/link';
import * as React from 'react';
type Post = {
id: string,
title: string
}
type Props = {
posts: Post[];
}
// props 中有下面导出的数据 posts
const PostsIndex: NextPage = (props) => {
const {posts} = props;
// 前后端控制台都能打印 -> 同构
console.log(posts);
return (
文章列表
{posts.map(p =>
{p.id}
)}
);
};
export default PostsIndex;
// 实现SSG
export const getStaticProps: GetStaticProps = async () => {
const posts = await getPosts();
return {
props: {
posts: JSON.parse(JSON.stringify(posts))
}
};
};
前端不通过ajax获取数据怎么办
我们只拿到了服务器上的posts数据,但是怎么传到前端呢?
发现奥秘
我们可以看到隐藏在id为_NEXT_DATA__的script标签中,里面存放的是传递给前端的props数据
这就是同构SSR的好处,后端可以直接把数据传给前端,不需要AJAX异步获取
静态时序环境在开发环境中。GetStaticProps 将为每个请求运行一次。这是为了方便您修改代码并在构建环境中重新运行。GetStaticProps 只在构建中运行一次,可以提供一份 HTML 副本供所有用户下载
如何体验构建环境
yarn build
yarn start
打包后,我们可以看到这个
解释
我看到的页面前面的三个图标是λ ○ ●
λ (Serve) SSR 无法自动创建 HTML(如下所述)
○(静态)自动创建HTML(发现你没用props)
●(SSG)自动创建HTML + JSON(等你使用道具)
三种文件类型
构建完成后,我们查看.next文件,找到posts.html、posts.js、posts.json
为什么不直接将数据放入posts.js?
很明显,posts.js 是为了接受不同的数据。当我们展示每个博客时,它们的风格相同,内容不同,所以会用到这个功能
动态内容静态
服务器端渲染 (SSR)
如果页面与用户相关怎么办?
这种情况更难以提前静止。需要在用户请求的时候获取用户信息,然后利用用户信息从数据库中获取数据。如果必须这样做,则必须为每个用户创建一个页面。有时数据更新得非常快。, 不能提前静态,比如微博首页的信息流
那该怎么办呢?
无论是客户端渲染,都会出现白屏
要么服务端渲染SSR,没有白屏
运行
不管是开发环境还是构建环境,getServerSideProps都是在请求之后运行的
代码
与 SSG 代码基本相同,但使用 getSeverSideProps
这段代码执行时,服务器响应请求后获取浏览器信息,返回给前端显示
import {GetServerSideProps, NextPage} from 'next';
import * as React from 'react';
import {IncomingHttpHeaders} from 'http';
type Props = {
browser: string
}
const index: NextPage = (props) => {
return (
你的浏览器是 {props.browser}
);
};
export default index;
export const getServerSideProps: GetServerSideProps = async (context) => {
const headers:IncomingHttpHeaders = context.req.headers;
const browser = headers['user-agent'];
return {
props: {
browser
}
};
};
SSR原理
建议后端使用 renderToString(),前端使用 hydrate()
后端渲染页面,返回 HTML String 格式,并传递给前端。前端执行 hydrate(),保留 HTML 并附加时间监控,即后端渲染 HTML,前端添加监控。
前端也会渲染一次,保证前后渲染结果一致
总结客户端渲染SSR
只在浏览器上运行,缺点SEO不友好,白屏
静态页面生成 SSG
静态站点生成,解决白屏问题和SEO问题
缺点:无法生成用户相关内容(所有用户请求的结果都一样)
服务器端渲染 (SSR)
解决白屏问题,SEO问题
可以生成用户相关的内容
如何选择三种渲染模式
php可以抓取网页数据吗(一个普通请求封装方法,代码如下:前后修改过几次)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-01 05:15
肯德基的一些数据最近需要抓取
通过邮递员获取请求地址和参数后,可以返回数据
我天真地认为我可以通过代码直接发送post请求
但是,在通过PHP curl模拟请求之后,总是返回服务器异常
起初似乎很成功,但现在总是有报道。我使用一种普通的post请求封装方法。代码如下:
public function kfc_post($url, $data)
{
$data['deviceId'] = '819ce973-1ff8-4dfc-8436-4e0e0e1efb6e';
$data['brower_id'] = 'unique-test-dc6d945b-d504-45f7-ad94-8eaacb590fcf';
$params = http_build_query($data);
$headers = [
'Accept' => 'application/json, text/plain, */*',
'Content-Type' => 'application/x-www-form-urlencoded',
'Origin' => 'http://order.kfc.com.cn',
'Referer' => 'http://order.kfc.com.cn/mwos/store',
'User-Agent' => 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
];
// 模拟提交数据函数
$curl = curl_init(); // 启动一个CURL会话
curl_setopt($curl, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($curl, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($curl, CURLOPT_POSTFIELDS, $params); // Post提交的数据包
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制防止死循环
curl_setopt($curl, CURLOPT_HTTPHEADER,$headers);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$content = curl_exec($curl); // 执行操作
curl_close($curl); // 关闭CURL会话
return json_decode($content, true);
}
它前后都被修改了好几次,但基本上是这样的。请求仍然失败。我没有玩过去捕捉别人的网站数据。是否存在任何疏忽,例如cookies?我试图提出一个饼干请求,但我还是不能,所以我不知道为什么 查看全部
php可以抓取网页数据吗(一个普通请求封装方法,代码如下:前后修改过几次)
肯德基的一些数据最近需要抓取
通过邮递员获取请求地址和参数后,可以返回数据
我天真地认为我可以通过代码直接发送post请求
但是,在通过PHP curl模拟请求之后,总是返回服务器异常
起初似乎很成功,但现在总是有报道。我使用一种普通的post请求封装方法。代码如下:
public function kfc_post($url, $data)
{
$data['deviceId'] = '819ce973-1ff8-4dfc-8436-4e0e0e1efb6e';
$data['brower_id'] = 'unique-test-dc6d945b-d504-45f7-ad94-8eaacb590fcf';
$params = http_build_query($data);
$headers = [
'Accept' => 'application/json, text/plain, */*',
'Content-Type' => 'application/x-www-form-urlencoded',
'Origin' => 'http://order.kfc.com.cn',
'Referer' => 'http://order.kfc.com.cn/mwos/store',
'User-Agent' => 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
];
// 模拟提交数据函数
$curl = curl_init(); // 启动一个CURL会话
curl_setopt($curl, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($curl, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($curl, CURLOPT_POSTFIELDS, $params); // Post提交的数据包
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制防止死循环
curl_setopt($curl, CURLOPT_HTTPHEADER,$headers);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$content = curl_exec($curl); // 执行操作
curl_close($curl); // 关闭CURL会话
return json_decode($content, true);
}
它前后都被修改了好几次,但基本上是这样的。请求仍然失败。我没有玩过去捕捉别人的网站数据。是否存在任何疏忽,例如cookies?我试图提出一个饼干请求,但我还是不能,所以我不知道为什么
php可以抓取网页数据吗(php可以抓取网页数据吗?php安装第一步需要安装)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-29 08:03
php可以抓取网页数据吗?很多朋友对于php抓取网页数据的实现还不了解,比如说想要抓取自己所在公司的一些数据,或者想要抓取其他公司的网页数据。其实很简单,下面来说说php抓取网页数据的技巧。php安装第一步需要安装php5.2,php5.2是php的4.0版本,支持cli模式的语言加上更多的高级语法。
第二步在cmd命令行,输入php_get./_get.php,就可以抓取指定网页的数据了。当然,如果你使用第三方工具,抓取全网的数据也可以。比如yii。yii安装在阿里云centos7.2系统中,可以直接通过下面的命令安装yii-cli,如下图:yii-cli是类似yii2的集成开发环境,通过phpwind、yii-php-params等工具集成一个安装脚本。
如下图:yii-cli启动后,默认是自动配置在c:\users\xxx\administrator目录下,在此目录下右键新建php.php配置文件,命名为"yii-cli",命名为.php,然后编写如下脚本:。 查看全部
php可以抓取网页数据吗(php可以抓取网页数据吗?php安装第一步需要安装)
php可以抓取网页数据吗?很多朋友对于php抓取网页数据的实现还不了解,比如说想要抓取自己所在公司的一些数据,或者想要抓取其他公司的网页数据。其实很简单,下面来说说php抓取网页数据的技巧。php安装第一步需要安装php5.2,php5.2是php的4.0版本,支持cli模式的语言加上更多的高级语法。
第二步在cmd命令行,输入php_get./_get.php,就可以抓取指定网页的数据了。当然,如果你使用第三方工具,抓取全网的数据也可以。比如yii。yii安装在阿里云centos7.2系统中,可以直接通过下面的命令安装yii-cli,如下图:yii-cli是类似yii2的集成开发环境,通过phpwind、yii-php-params等工具集成一个安装脚本。
如下图:yii-cli启动后,默认是自动配置在c:\users\xxx\administrator目录下,在此目录下右键新建php.php配置文件,命名为"yii-cli",命名为.php,然后编写如下脚本:。
php可以抓取网页数据吗(php抓取网页数据插入数据库推荐活动:更多优惠gtgt)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-25 18:30
阿里云>云栖社区>主题图>P>php抓取网页数据插入数据库
推荐活动:
更多优惠>
当前话题:php抓取网页数据插入数据库添加到采集夹
相关话题:
php抓取网页数据插入数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
php爬虫:知乎用户数据爬取与分析
作者:cuixiaozhuai2345 人浏览评论:05年前
背景说明:小野使用PHP的curl编写的爬虫实验爬取知乎5w用户的基本信息;同时对爬取的数据进行简单的分析和呈现。php的demo地址的spider代码和用户仪表盘的显示代码,整理好后上传到github,更新代码基于个人博客和公众号,Cheng
阅读全文
解决“mysql服务器已经消失”问题
作者:php的小菜鸟1008人浏览评论:04年前
出现此类问题时,应用程序(如PHP)会长时间批量执行MYSQL 语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。在 MySQL 中解决
阅读全文
rrdtool 学习和自定义脚本绘制图形备忘录
作者:于尔武 1163人浏览评论:03年前
RRDtool(Round Robin Database Tool)是一个强大的绘图引擎,MRTG等很多工具都可以调用rrdtool绘图。包括现在用的比较多的cacti,基于rrdtool画图。可以说cacti只提供了一个显示图形的网页。
阅读全文
c#批量抓取免费代理并验证有效性
作者:曹章林 1170人浏览评论:03年前
在刷新页面之前,我在一家公司的官网上看到了文章 的页面浏览量。感觉不是很好。一个公司的官网就给人这么直接的漏洞。当我进行批量请求时,我发现页面打开并报告错误。一个100多人的公司官网文章刷新了一次,你给我看了这个。这家公司之前来过我们学校宣传招聘+我在花园里找招聘的时候找到了住处
阅读全文
RRDTool详解
作者:小美科技 1573人浏览评论:03年前
大纲一、MRTG的缺点与RRDTool对比二、RRDTool概述三、安装RRDTool四、RRDTool绘制步骤五、rrdtool命令详解六、RRDTool绘图案例注,实验环境CentOS 6.4 x86_64,软件版本rrdtool-1.3
阅读全文
MySQL服务器不见了解决方法
作者:云启希望。1791人浏览评论:03年前
应用程序(如PHP)长时间执行批量的MYSQL 语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。今天遇到了类似的情况,MySQL只是冷了
阅读全文
技术 | 从零开始的Python系列(三个十五)
作者:技术小能手 1954人浏览评论数:02年前
大家好。这次给大家带来一个方法,把人们喜欢问有识之士的问题,把问题和答案保存到数据库中。涉及的内容包括: Urllib 的使用和异常处理 美丽汤的简单应用 MySQLdb 的基本使用规律 表达式的简单应用环境配置 在此之前,我们需要先配置环境
阅读全文
MySQL服务器已经消失
作者:李大嘴巴1934人浏览评论:05年前
MySQL server has away 运行sql文件导入数据库时,会报异常。MySQL server has go away mysql has the problem of ERROR: (2006,'MySQL server has go away')
阅读全文 查看全部
php可以抓取网页数据吗(php抓取网页数据插入数据库推荐活动:更多优惠gtgt)
阿里云>云栖社区>主题图>P>php抓取网页数据插入数据库
推荐活动:
更多优惠>
当前话题:php抓取网页数据插入数据库添加到采集夹
相关话题:
php抓取网页数据插入数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
php爬虫:知乎用户数据爬取与分析
作者:cuixiaozhuai2345 人浏览评论:05年前
背景说明:小野使用PHP的curl编写的爬虫实验爬取知乎5w用户的基本信息;同时对爬取的数据进行简单的分析和呈现。php的demo地址的spider代码和用户仪表盘的显示代码,整理好后上传到github,更新代码基于个人博客和公众号,Cheng
阅读全文
解决“mysql服务器已经消失”问题
作者:php的小菜鸟1008人浏览评论:04年前
出现此类问题时,应用程序(如PHP)会长时间批量执行MYSQL 语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。在 MySQL 中解决
阅读全文
rrdtool 学习和自定义脚本绘制图形备忘录
作者:于尔武 1163人浏览评论:03年前
RRDtool(Round Robin Database Tool)是一个强大的绘图引擎,MRTG等很多工具都可以调用rrdtool绘图。包括现在用的比较多的cacti,基于rrdtool画图。可以说cacti只提供了一个显示图形的网页。
阅读全文
c#批量抓取免费代理并验证有效性
作者:曹章林 1170人浏览评论:03年前
在刷新页面之前,我在一家公司的官网上看到了文章 的页面浏览量。感觉不是很好。一个公司的官网就给人这么直接的漏洞。当我进行批量请求时,我发现页面打开并报告错误。一个100多人的公司官网文章刷新了一次,你给我看了这个。这家公司之前来过我们学校宣传招聘+我在花园里找招聘的时候找到了住处
阅读全文
RRDTool详解
作者:小美科技 1573人浏览评论:03年前
大纲一、MRTG的缺点与RRDTool对比二、RRDTool概述三、安装RRDTool四、RRDTool绘制步骤五、rrdtool命令详解六、RRDTool绘图案例注,实验环境CentOS 6.4 x86_64,软件版本rrdtool-1.3
阅读全文
MySQL服务器不见了解决方法
作者:云启希望。1791人浏览评论:03年前
应用程序(如PHP)长时间执行批量的MYSQL 语句。执行 SQL,但 SQL 语句过大或语句收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。今天遇到了类似的情况,MySQL只是冷了
阅读全文
技术 | 从零开始的Python系列(三个十五)
作者:技术小能手 1954人浏览评论数:02年前
大家好。这次给大家带来一个方法,把人们喜欢问有识之士的问题,把问题和答案保存到数据库中。涉及的内容包括: Urllib 的使用和异常处理 美丽汤的简单应用 MySQLdb 的基本使用规律 表达式的简单应用环境配置 在此之前,我们需要先配置环境
阅读全文
MySQL服务器已经消失
作者:李大嘴巴1934人浏览评论:05年前
MySQL server has away 运行sql文件导入数据库时,会报异常。MySQL server has go away mysql has the problem of ERROR: (2006,'MySQL server has go away')
阅读全文
php可以抓取网页数据吗(php可以抓取网页数据吗?我的回答是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-09-22 00:06
php可以抓取网页数据吗?我的回答是:可以,不仅可以抓取网页数据,还可以抓取摄像头数据!网页抓取可以用php,摄像头抓取可以用python,nodejs,因为目前没有发现必须要用php,或者nodejs才能抓取到的网页数据。但是,在抓取数据之前一定要用程序把网页数据存放在文件里,比如blob。首先是在浏览器上输入网址,比如api/post/message.html:然后上传数据进行比对:上传成功之后就会生成一个文件,这个文件会包含网页中的整个网页地址,甚至包含参数。
再用php进行抓取。抓取方法很简单,首先通过浏览器打开这个数据的文件,在这个文件中加入刚才保存的网页地址:接着再通过web服务器来抓取数据,比如微信服务器:最后通过http的请求方法,去调用服务器的js,会得到页面内容,从而形成我们的数据。那么,这个抓取需要多久?还是用浏览器打开这个数据文件,然后在浏览器打开抓取程序,但是不用调用微信的服务器,直接用浏览器打开得到:那么,这个抓取需要多少时间?自己测算的话,需要1000毫秒。
查了一下百度,下载一个几十m的包大概用了60s。然后每天开启抓取一次服务器消耗1秒。那么,如果频繁地请求浏览器抓取服务器的话,同样速度要下降到3ms以内。所以,抓取这个网页需要10毫秒,实际抓取起来需要1m多一点一个页面。那么我的抓取效率大概是多少?百度有的算法是500kb/秒,简单来说,就是抓取10个网页,一共抓取到300个页面的数据。
当然这么计算每天的抓取量肯定是无法达到这么大的数据量的。php抓取这个网页的效率是否高呢?比如:30秒一个页面的数据量。那么这个效率怎么来衡量呢?可以用一个叫做webthreads的method来衡量,那么直接用爬虫工具开启抓取服务器,然后开启很多个线程抓取页面即可。就算抓取速度在目前上会慢一些,在大部分人实际用户环境中,每天抓取这个网页的速度在200毫秒左右,相当于1000毫秒。
那么php+python到底怎么样。首先,php的效率不能单看“抓取速度”这个值,因为抓取速度只是php并发抓取的一个很小的指标。看是否并发抓取,看的是php和其他程序能否“建立一个链接”,如果php线程很多,那么可以用超时函数。php做到并发抓取也没有很大的问题,只是耗时。像java来做到这点应该也比较有信心,毕竟java是标准的异步编程语言。
但是要从速度,并发等各个方面优化php程序,对于大部分开发人员来说应该是非常难的。所以,在php并发抓取这一块,其实就是一个人的能力范围。只有在数据量很小,已经在db上可以做优化,并。 查看全部
php可以抓取网页数据吗(php可以抓取网页数据吗?我的回答是什么?)
php可以抓取网页数据吗?我的回答是:可以,不仅可以抓取网页数据,还可以抓取摄像头数据!网页抓取可以用php,摄像头抓取可以用python,nodejs,因为目前没有发现必须要用php,或者nodejs才能抓取到的网页数据。但是,在抓取数据之前一定要用程序把网页数据存放在文件里,比如blob。首先是在浏览器上输入网址,比如api/post/message.html:然后上传数据进行比对:上传成功之后就会生成一个文件,这个文件会包含网页中的整个网页地址,甚至包含参数。
再用php进行抓取。抓取方法很简单,首先通过浏览器打开这个数据的文件,在这个文件中加入刚才保存的网页地址:接着再通过web服务器来抓取数据,比如微信服务器:最后通过http的请求方法,去调用服务器的js,会得到页面内容,从而形成我们的数据。那么,这个抓取需要多久?还是用浏览器打开这个数据文件,然后在浏览器打开抓取程序,但是不用调用微信的服务器,直接用浏览器打开得到:那么,这个抓取需要多少时间?自己测算的话,需要1000毫秒。
查了一下百度,下载一个几十m的包大概用了60s。然后每天开启抓取一次服务器消耗1秒。那么,如果频繁地请求浏览器抓取服务器的话,同样速度要下降到3ms以内。所以,抓取这个网页需要10毫秒,实际抓取起来需要1m多一点一个页面。那么我的抓取效率大概是多少?百度有的算法是500kb/秒,简单来说,就是抓取10个网页,一共抓取到300个页面的数据。
当然这么计算每天的抓取量肯定是无法达到这么大的数据量的。php抓取这个网页的效率是否高呢?比如:30秒一个页面的数据量。那么这个效率怎么来衡量呢?可以用一个叫做webthreads的method来衡量,那么直接用爬虫工具开启抓取服务器,然后开启很多个线程抓取页面即可。就算抓取速度在目前上会慢一些,在大部分人实际用户环境中,每天抓取这个网页的速度在200毫秒左右,相当于1000毫秒。
那么php+python到底怎么样。首先,php的效率不能单看“抓取速度”这个值,因为抓取速度只是php并发抓取的一个很小的指标。看是否并发抓取,看的是php和其他程序能否“建立一个链接”,如果php线程很多,那么可以用超时函数。php做到并发抓取也没有很大的问题,只是耗时。像java来做到这点应该也比较有信心,毕竟java是标准的异步编程语言。
但是要从速度,并发等各个方面优化php程序,对于大部分开发人员来说应该是非常难的。所以,在php并发抓取这一块,其实就是一个人的能力范围。只有在数据量很小,已经在db上可以做优化,并。
php可以抓取网页数据吗(Python爬虫入门教程!手把手教会你爬取网页数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-19 23:13
Python爬虫教程!教您手拉手抓取web数据
步骤3:提取内容。在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:
URL就像网站和搜索引擎爬虫之间的桥梁:为了抓取您的网站内容,爬虫需要能够找到并跨越这些桥梁(即,查找并抓取您的URL)。如果您的URL复杂或冗长
当您打开目标文件夹TPTL时,您将获得图像或内容的网站完整数据,其中保存了HTML文件、PHP文件和JavaScript。网络
它可以帮助我们快速采集大量的互联网内容进行深入的数据分析和挖掘,如抓取网站的排名列表和网站购物的价格信息。我们的日常搜索引擎是“网络爬虫”。但毕竟,我们学会了
1.打开网站管理员工具,在网络信息查询中找到要抓取的模拟机器人。2.进入您的网站网站,然后单击查询。此时,您的网站将显示在下面。被捕后会发生什么事。3.在web信息查询中,单击web检测以查看您的关键词密度和网站安全性,以及关键词的挖掘
阿里云为您提供了与网站内容捕获工具相关的8933个产品文档和常见问题解答,以及网站无法打开网页时该怎么办、计算机网络技术毕业论文、键值存储kvstore(以下哪一个是数据库)等云计算产品
内容捕获–您可以从网站捕获内容,以复制依赖于内容的独特产品或服务优势。例如,yelp等产品依赖于评论。竞争对手可以捕获yelp的所有评论,然后将它们复制到他们的网站以打开他们的网站内容 查看全部
php可以抓取网页数据吗(Python爬虫入门教程!手把手教会你爬取网页数据(组图))
Python爬虫教程!教您手拉手抓取web数据
步骤3:提取内容。在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:
URL就像网站和搜索引擎爬虫之间的桥梁:为了抓取您的网站内容,爬虫需要能够找到并跨越这些桥梁(即,查找并抓取您的URL)。如果您的URL复杂或冗长
当您打开目标文件夹TPTL时,您将获得图像或内容的网站完整数据,其中保存了HTML文件、PHP文件和JavaScript。网络
它可以帮助我们快速采集大量的互联网内容进行深入的数据分析和挖掘,如抓取网站的排名列表和网站购物的价格信息。我们的日常搜索引擎是“网络爬虫”。但毕竟,我们学会了
1.打开网站管理员工具,在网络信息查询中找到要抓取的模拟机器人。2.进入您的网站网站,然后单击查询。此时,您的网站将显示在下面。被捕后会发生什么事。3.在web信息查询中,单击web检测以查看您的关键词密度和网站安全性,以及关键词的挖掘
阿里云为您提供了与网站内容捕获工具相关的8933个产品文档和常见问题解答,以及网站无法打开网页时该怎么办、计算机网络技术毕业论文、键值存储kvstore(以下哪一个是数据库)等云计算产品
内容捕获–您可以从网站捕获内容,以复制依赖于内容的独特产品或服务优势。例如,yelp等产品依赖于评论。竞争对手可以捕获yelp的所有评论,然后将它们复制到他们的网站以打开他们的网站内容

