
java抓取网页内容
java抓取网页内容(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-19 04:13
原创链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
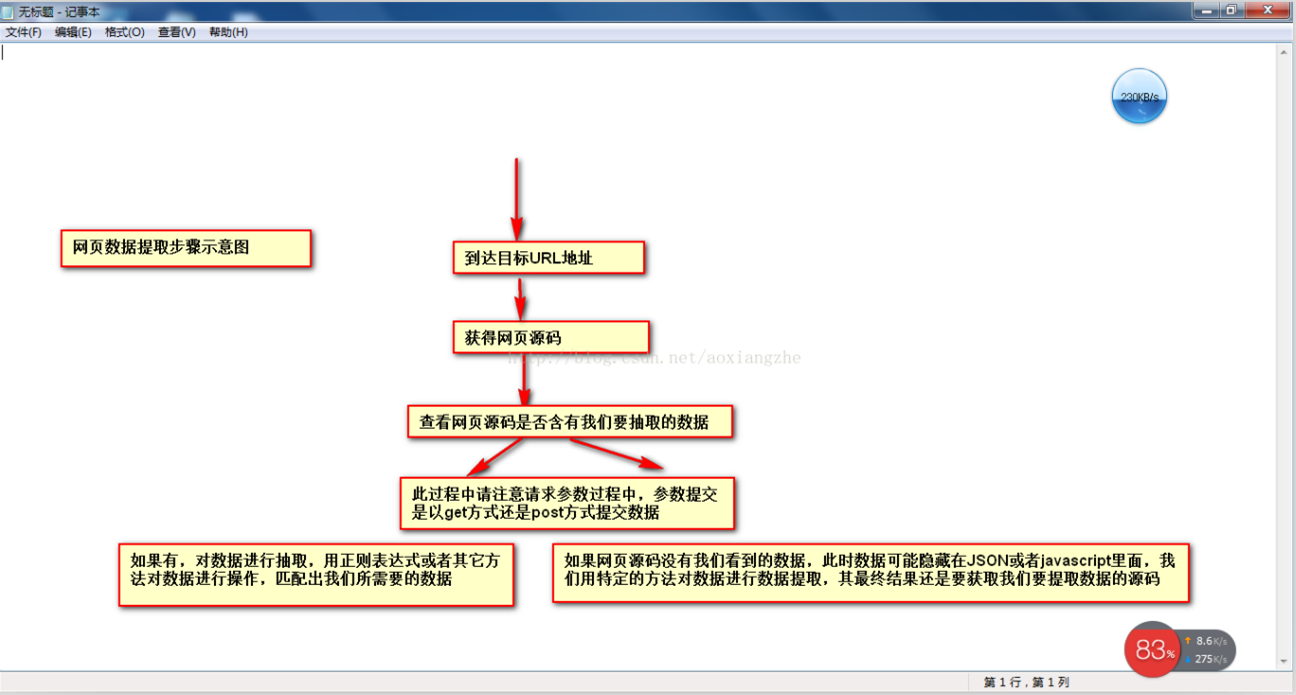
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
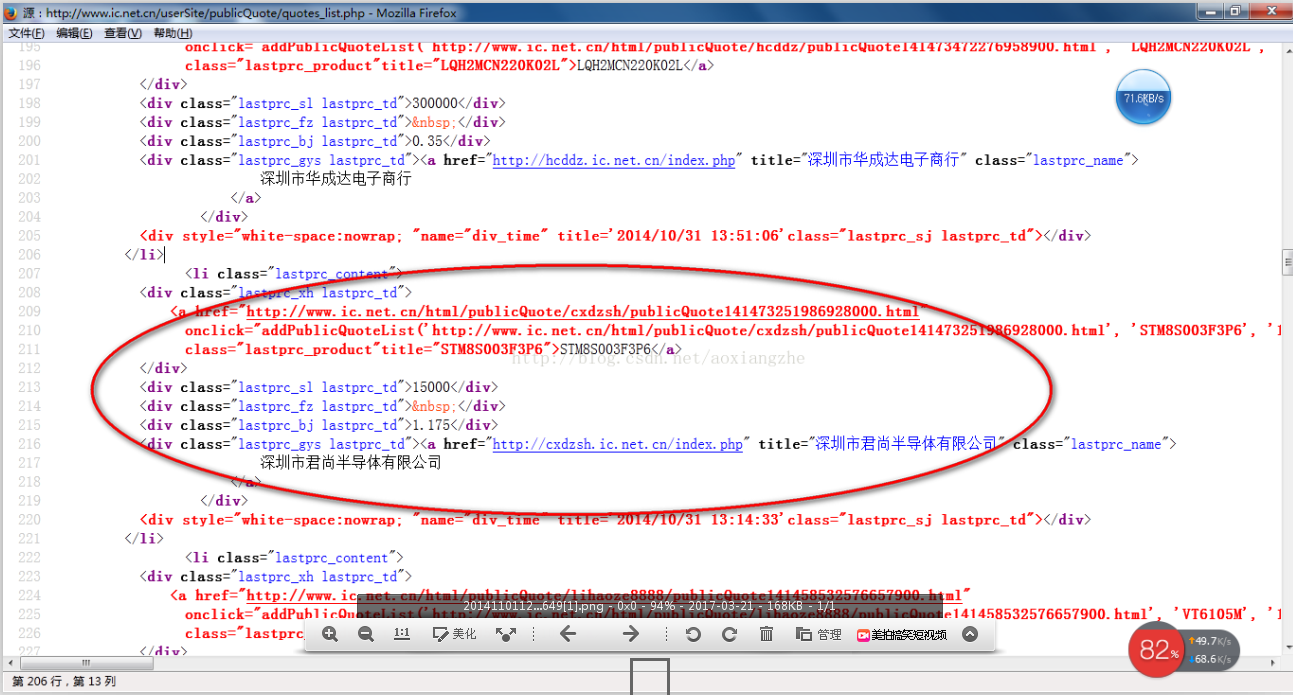
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据成功,这就是我们要获取的最终数据结果。最后想说,这里的这个网页比较简单,在网页的源码中可以看到源数据,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java抓取网页内容(一个+jsou提取网页数据的分类汇总(一))
原创链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到这个 网站 整页预览

接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据

获取数据成功,这就是我们要获取的最终数据结果。最后想说,这里的这个网页比较简单,在网页的源码中可以看到源数据,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
java抓取网页内容(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-18 22:11
通过JAVA API,可以成功抓取网络上大部分的指定网页内容。下面就和大家分享一下对这种方法的理解和体会。最简单的抓取方法是:
Java 代码
URLurl=newURL(myurl);BufferedReaderbr=newBufferedReader(newInputStreamReader(url.openStream()));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){ i++;sb.append(s+"\r\n");}
这种方法爬一般的网页应该是没问题的,但是当一些网页中有嵌套的重定向连接时,会报Server redirected too many times之类的错误,这是因为这个网页里面有一些代码是转到其他网页,太多的循环导致程序错误。如果只想爬取这个URL中的网页内容,不想跳转到其他网页,可以使用下面的代码。
Java 代码
URLurlmy=newURL(myurl);HttpURLConnectioncon=(HttpURLConnection)urlmy.openConnection();con.setFollowRedirects(true);con.setInstanceFollowRedirects(false);con.connect();BufferedReaderbr=newBufferedReader(newInputStreamReader(con.getInputStream(), "UTF-8"));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){sb.append(s+"\r\n"); }
这样,在爬取的时候,程序就不会跳转到其他页面去爬取其他内容,就达到了我们的目的。
如果我们在 Intranet 中,我们还需要为其添加代理。Java 提供对具有特殊系统属性的代理服务器的支持,只要在上述程序中添加以下程序即可。
Java 代码
System.getProperties().setProperty("http.proxyHost",proxyName);System.getProperties().setProperty("http.proxyPort",port);
这样,您就可以在内网的同时从Internet上抓取您想要的东西。
上面程序捕捉到的所有内容都存储在sb字符串中,我们可以通过正则表达式进行分析,提取出我们想要的具体内容,给我用,呵呵,这是多么美妙的一件事啊!! 查看全部
java抓取网页内容(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以成功抓取网络上大部分的指定网页内容。下面就和大家分享一下对这种方法的理解和体会。最简单的抓取方法是:
Java 代码
URLurl=newURL(myurl);BufferedReaderbr=newBufferedReader(newInputStreamReader(url.openStream()));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){ i++;sb.append(s+"\r\n");}
这种方法爬一般的网页应该是没问题的,但是当一些网页中有嵌套的重定向连接时,会报Server redirected too many times之类的错误,这是因为这个网页里面有一些代码是转到其他网页,太多的循环导致程序错误。如果只想爬取这个URL中的网页内容,不想跳转到其他网页,可以使用下面的代码。
Java 代码
URLurlmy=newURL(myurl);HttpURLConnectioncon=(HttpURLConnection)urlmy.openConnection();con.setFollowRedirects(true);con.setInstanceFollowRedirects(false);con.connect();BufferedReaderbr=newBufferedReader(newInputStreamReader(con.getInputStream(), "UTF-8"));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){sb.append(s+"\r\n"); }
这样,在爬取的时候,程序就不会跳转到其他页面去爬取其他内容,就达到了我们的目的。
如果我们在 Intranet 中,我们还需要为其添加代理。Java 提供对具有特殊系统属性的代理服务器的支持,只要在上述程序中添加以下程序即可。
Java 代码
System.getProperties().setProperty("http.proxyHost",proxyName);System.getProperties().setProperty("http.proxyPort",port);
这样,您就可以在内网的同时从Internet上抓取您想要的东西。
上面程序捕捉到的所有内容都存储在sb字符串中,我们可以通过正则表达式进行分析,提取出我们想要的具体内容,给我用,呵呵,这是多么美妙的一件事啊!!
java抓取网页内容(前两天想写一段自动提取微博状态的代码,可以用PHP写 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-18 00:11
)
前两天想写一个自动提取微博状态的代码。据我所知,实现这个功能可以用PHP写,也可以用Java写。我觉得用Java写和调试比较容易,PHP脚本需要上传到服务器什么的。
代码很简单,创建一个包的URL类的对象,用这个URL作为写作源,将内容保存在一个字符串中。然后创建一个新文件并写出字符串。但是请注意,不同的 网站 使用不同的代码字。现在大多数 网站 使用 utf-8 字符编码,而基于 wordpress 的 网站 使用这种编码。但是很多中文网站,包括网易网站等门户网站,仍然使用gb2312编码。一方面,gb2312的历史比utf-8要长。早期中文网站是用gb2312构建的,现在修改工作量太大;-8 编码以节省空间。正是因为这个不同,所以在输入网页的html代码时,一定要选择正确的阅读方式。java的inputstream构造函数可以选择utf-8作为参数,但是没有gb2312选项。因此,在抓取网易的网页时,保存的文档会出现乱码。
另外,这个例子只抓取静态网页内容,不适合微博的状态,因为要抓取状态,必须先登录自己的账号,并且必须参考新浪的API文档。
import java.beans.FeatureDescriptor;
import java.io.*;
import java.net.*;
public class spider {
/**
* @param args
*/
public static String fetchWebpage(String urlname){
URL url;
String s;
StringBuffer sbuffer = new StringBuffer();
try{
url = new URL(urlname);
// my website use utf-8, but some other websites, like 163 and baidu, use gb2312.
InputStreamReader sreader = new InputStreamReader(url.openStream(),"utf-8");
BufferedReader breader = new BufferedReader(sreader);
while((s=breader.readLine())!=null){
sbuffer.append(s);
}
breader.close();
}catch(Exception e){
e.printStackTrace();
}
return sbuffer.toString();
}
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String address = "http://www.mr-naive.com";
FileOutputStream fos = new FileOutputStream(new File("myPage.html"));
OutputStreamWriter oswrite = new OutputStreamWriter(fos, "utf-8");
BufferedWriter bwriter = new BufferedWriter(oswrite);
bwriter.write(fetchWebpage(address));
bwriter.close();
}
} 查看全部
java抓取网页内容(前两天想写一段自动提取微博状态的代码,可以用PHP写
)
前两天想写一个自动提取微博状态的代码。据我所知,实现这个功能可以用PHP写,也可以用Java写。我觉得用Java写和调试比较容易,PHP脚本需要上传到服务器什么的。
代码很简单,创建一个包的URL类的对象,用这个URL作为写作源,将内容保存在一个字符串中。然后创建一个新文件并写出字符串。但是请注意,不同的 网站 使用不同的代码字。现在大多数 网站 使用 utf-8 字符编码,而基于 wordpress 的 网站 使用这种编码。但是很多中文网站,包括网易网站等门户网站,仍然使用gb2312编码。一方面,gb2312的历史比utf-8要长。早期中文网站是用gb2312构建的,现在修改工作量太大;-8 编码以节省空间。正是因为这个不同,所以在输入网页的html代码时,一定要选择正确的阅读方式。java的inputstream构造函数可以选择utf-8作为参数,但是没有gb2312选项。因此,在抓取网易的网页时,保存的文档会出现乱码。
另外,这个例子只抓取静态网页内容,不适合微博的状态,因为要抓取状态,必须先登录自己的账号,并且必须参考新浪的API文档。
import java.beans.FeatureDescriptor;
import java.io.*;
import java.net.*;
public class spider {
/**
* @param args
*/
public static String fetchWebpage(String urlname){
URL url;
String s;
StringBuffer sbuffer = new StringBuffer();
try{
url = new URL(urlname);
// my website use utf-8, but some other websites, like 163 and baidu, use gb2312.
InputStreamReader sreader = new InputStreamReader(url.openStream(),"utf-8");
BufferedReader breader = new BufferedReader(sreader);
while((s=breader.readLine())!=null){
sbuffer.append(s);
}
breader.close();
}catch(Exception e){
e.printStackTrace();
}
return sbuffer.toString();
}
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String address = "http://www.mr-naive.com";
FileOutputStream fos = new FileOutputStream(new File("myPage.html"));
OutputStreamWriter oswrite = new OutputStreamWriter(fos, "utf-8");
BufferedWriter bwriter = new BufferedWriter(oswrite);
bwriter.write(fetchWebpage(address));
bwriter.close();
}
}
java抓取网页内容(这里有新鲜出炉的Java函数式编程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-17 15:24
新鲜出炉的Java函数式编程来了,程序狗的速度来了!
Java 编程语言 java 是一种面向对象的编程语言,可以编写跨平台的应用软件。 ),JavaSE(j2se)的总称。
本文文章主要介绍JAVA使用爬虫爬取网站网页内容的方法,并结合实例分析java爬虫的两种实现技术,具有一定的参考价值,有需要的朋友需要的可以参考下一个
本文的例子描述了JAVA使用爬虫爬取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA研究爬网,呵呵,进门了,和大家分享一下我的经验
提供了以下两种方法,一种是使用apache提供的包。另一种是使用JAVA自带的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength 查看全部
java抓取网页内容(这里有新鲜出炉的Java函数式编程,程序狗速度看过来!)
新鲜出炉的Java函数式编程来了,程序狗的速度来了!
Java 编程语言 java 是一种面向对象的编程语言,可以编写跨平台的应用软件。 ),JavaSE(j2se)的总称。
本文文章主要介绍JAVA使用爬虫爬取网站网页内容的方法,并结合实例分析java爬虫的两种实现技术,具有一定的参考价值,有需要的朋友需要的可以参考下一个
本文的例子描述了JAVA使用爬虫爬取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA研究爬网,呵呵,进门了,和大家分享一下我的经验
提供了以下两种方法,一种是使用apache提供的包。另一种是使用JAVA自带的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength
java抓取网页内容( 如何从网页上抓取有价值的东西?看懂了下面的程序(非常简单))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-17 05:09
如何从网页上抓取有价值的东西?看懂了下面的程序(非常简单))
java使用正则表达式提取网站titles
来自网页
如何从网页中抓取有价值的东西?理解了下面这个程序(很简单)后,你就可以从网页中抓取任何你想抓取的信息(标题、内容、Email、价格等)了。
package catchhtml;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetHtmlTitle {
public GetHtmlTitle(String htmlUrl){
System.out.println("/n------------开始读取网页(" + htmlUrl + ")-----------");
String htmlSource = "";
htmlSource = getHtmlSource(htmlUrl);//获取htmlUrl网址网页的源码
System.out.println("------------读取网页(" + htmlUrl + ")结束-----------/n");
System.out.println("------------分析(" + htmlUrl + ")结果如下-----------/n");
String title = getTitle(htmlSource);
System.out.println("网站标题: " + title);
}
/**
* 根据网址返回网页的源码
* @param htmlUrl
* @return
*/
public String getHtmlSource(String htmlUrl){
URL url;
StringBuffer sb = new StringBuffer();
try{
url = new URL(htmlUrl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "UTF-8"));//读取网页全部内容
String temp;
while ((temp = in.readLine()) != null)
{
sb.append(temp);
}
in.close();
}catch (MalformedURLException e) {
System.out.println("你输入的URL格式有问题!请仔细输入");
}catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
* 从html源码(字符串)中去掉标题
* @param htmlSource
* @return
*/
public String getTitle(String htmlSource){
List list = new ArrayList();
String title = "";
//Pattern pa = Pattern.compile(".*?", Pattern.CANON_EQ);也可以
Pattern pa = Pattern.compile(".*?");//源码中标题正则表达式
Matcher ma = pa.matcher(htmlSource);
while (ma.find())//寻找符合el的字串
{
list.add(ma.group());//将符合el的字串加入到list中
}
for (int i = 0; i < list.size(); i++)
{
title = title + list.get(i);
}
return outTag(title);
}
/**
* 去掉html源码中的标签
* @param s
* @return
*/
public String outTag(String s)
{
return s.replaceAll("", "");
}
public static void main(String[] args) {
String htmlUrl = "http://www.157buy.com";
new GetHtmlTitle(htmlUrl);
}
}
联系方式:【我的公司】(鑫臻科技)【技术咨询】【QQ】3396726884
购书京东链接***微信小程序商城开发实践*** | ***新媒体营销精髓:精准定位+爆款打造+巧妙运营+内容变现***
发表于@2015-07-28 15:04 肯新君阅读(5301)评论(0)已编辑 查看全部
java抓取网页内容(
如何从网页上抓取有价值的东西?看懂了下面的程序(非常简单))
java使用正则表达式提取网站titles
来自网页
如何从网页中抓取有价值的东西?理解了下面这个程序(很简单)后,你就可以从网页中抓取任何你想抓取的信息(标题、内容、Email、价格等)了。
package catchhtml;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetHtmlTitle {
public GetHtmlTitle(String htmlUrl){
System.out.println("/n------------开始读取网页(" + htmlUrl + ")-----------");
String htmlSource = "";
htmlSource = getHtmlSource(htmlUrl);//获取htmlUrl网址网页的源码
System.out.println("------------读取网页(" + htmlUrl + ")结束-----------/n");
System.out.println("------------分析(" + htmlUrl + ")结果如下-----------/n");
String title = getTitle(htmlSource);
System.out.println("网站标题: " + title);
}
/**
* 根据网址返回网页的源码
* @param htmlUrl
* @return
*/
public String getHtmlSource(String htmlUrl){
URL url;
StringBuffer sb = new StringBuffer();
try{
url = new URL(htmlUrl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "UTF-8"));//读取网页全部内容
String temp;
while ((temp = in.readLine()) != null)
{
sb.append(temp);
}
in.close();
}catch (MalformedURLException e) {
System.out.println("你输入的URL格式有问题!请仔细输入");
}catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
* 从html源码(字符串)中去掉标题
* @param htmlSource
* @return
*/
public String getTitle(String htmlSource){
List list = new ArrayList();
String title = "";
//Pattern pa = Pattern.compile(".*?", Pattern.CANON_EQ);也可以
Pattern pa = Pattern.compile(".*?");//源码中标题正则表达式
Matcher ma = pa.matcher(htmlSource);
while (ma.find())//寻找符合el的字串
{
list.add(ma.group());//将符合el的字串加入到list中
}
for (int i = 0; i < list.size(); i++)
{
title = title + list.get(i);
}
return outTag(title);
}
/**
* 去掉html源码中的标签
* @param s
* @return
*/
public String outTag(String s)
{
return s.replaceAll("", "");
}
public static void main(String[] args) {
String htmlUrl = "http://www.157buy.com";
new GetHtmlTitle(htmlUrl);
}
}
联系方式:【我的公司】(鑫臻科技)【技术咨询】【QQ】3396726884
购书京东链接***微信小程序商城开发实践*** | ***新媒体营销精髓:精准定位+爆款打造+巧妙运营+内容变现***
发表于@2015-07-28 15:04 肯新君阅读(5301)评论(0)已编辑
java抓取网页内容(WebMagic使用Jsoup来管理URL(newRedisScheduler)组件功能说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-15 10:15
//设置Scheduler,使用Redis管理URL队列
.setScheduler(new RedisScheduler("localhost"))
//设置Pipeline并将结果以json模式保存到文件
.addPipeline(new JsonFilePipeline("D:\\data\\webmagic"))
//开启5个线程同时执行
.thread(5)
//启动爬虫
.run();
}
组件功能说明:
1.下载器
Downloader 负责从 Internet 下载页面以供后续处理。 WebMagic 默认使用 Apache HttpClient 作为下载工具。
2.页面处理器
PageProcessor 负责解析页面、提取有用信息和发现新链接。 WebMagic 使用 Jsoup 作为 HTML 解析工具,并在其基础上开发了 Xsoup 解析 XPath 的工具。
这四个组件中,PageProcessor对于每个站点的每个页面都是不同的,是需要用户自定义的部分。
3.调度器
Scheduler 负责管理要抓取的 URL,以及一些去重工作。 WebMagic 默认提供 JDK 的内存队列来管理 URL,并使用集合进行去重。还支持使用 Redis 进行分布式管理。
除非项目有一些特殊的分布式需求,否则不需要自己定制Scheduler。
4.管道
Pipeline负责提取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供两种结果处理方案:“输出到控制台”和“保存到文件”。 Pipeline 定义了保存结果的方式。如果要保存到指定的数据库,需要编写相应的Pipeline。一般来说,对于一类需求,只需要编写一个 Pipeline。
对象描述:
Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader的唯一途径。
除了 URL 本身,它还收录一个 Key-Value 结构的额外字段。你可以额外保存一些特殊的属性,并在其他地方读取它们来完成不同的功能。比如添加上一页的一些信息等。
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。它的API和Map非常相似,值得注意的是它有一个字段skip,如果设置为true,它不应该被Pipeline处理。 查看全部
java抓取网页内容(WebMagic使用Jsoup来管理URL(newRedisScheduler)组件功能说明)
//设置Scheduler,使用Redis管理URL队列
.setScheduler(new RedisScheduler("localhost"))
//设置Pipeline并将结果以json模式保存到文件
.addPipeline(new JsonFilePipeline("D:\\data\\webmagic"))
//开启5个线程同时执行
.thread(5)
//启动爬虫
.run();
}
组件功能说明:
1.下载器
Downloader 负责从 Internet 下载页面以供后续处理。 WebMagic 默认使用 Apache HttpClient 作为下载工具。
2.页面处理器
PageProcessor 负责解析页面、提取有用信息和发现新链接。 WebMagic 使用 Jsoup 作为 HTML 解析工具,并在其基础上开发了 Xsoup 解析 XPath 的工具。
这四个组件中,PageProcessor对于每个站点的每个页面都是不同的,是需要用户自定义的部分。
3.调度器
Scheduler 负责管理要抓取的 URL,以及一些去重工作。 WebMagic 默认提供 JDK 的内存队列来管理 URL,并使用集合进行去重。还支持使用 Redis 进行分布式管理。
除非项目有一些特殊的分布式需求,否则不需要自己定制Scheduler。
4.管道
Pipeline负责提取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供两种结果处理方案:“输出到控制台”和“保存到文件”。 Pipeline 定义了保存结果的方式。如果要保存到指定的数据库,需要编写相应的Pipeline。一般来说,对于一类需求,只需要编写一个 Pipeline。
对象描述:
Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader的唯一途径。
除了 URL 本身,它还收录一个 Key-Value 结构的额外字段。你可以额外保存一些特殊的属性,并在其他地方读取它们来完成不同的功能。比如添加上一页的一些信息等。
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。它的API和Map非常相似,值得注意的是它有一个字段skip,如果设置为true,它不应该被Pipeline处理。
java抓取网页内容(本文实例讲述了。分享给大家供大家参考。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-11 23:24
本文的例子描述了JAVA使用爬虫爬取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA研究爬网,呵呵,进门了,和大家分享一下我的经验
提供了以下两种方法,一种是使用apache提供的包。另一种是使用JAVA自带的。
代码如下:
<p> // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar public static String createhttpClient(String url, String param) { HttpClient client = new HttpClient(); String response = null; String keyword = null; PostMethod postMethod = new PostMethod(url); // try { // if (param != null) // keyword = new String(param.getBytes("gb2312"), "ISO-8859-1"); // } catch (UnsupportedEncodingException e1) { // // TODO Auto-generated catch block // e1.printStackTrace(); // } // NameValuePair[] data = { new NameValuePair("keyword", keyword) }; // // 将表单的值放入postMethod中 // postMethod.setRequestBody(data); // 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下 try { int statusCode = client.executeMethod(postMethod); response = new String(postMethod.getResponseBodyAsString() .getBytes("ISO-8859-1"), "gb2312"); //这里要注意下 gb2312要和你抓取网页的编码要一样 String p = response.replaceAll("//&[a-zA-Z]{1,10};", "") .replaceAll("]*>", "");//去掉网页中带有html语言的标签 System.out.println(p); } catch (Exception e) { e.printStackTrace(); } return response; } // 第二种方法 // 这种方法是JAVA自带的URL来抓取网站内容 public String getPageContent(String strUrl, String strPostRequest, int maxLength) { // 读取结果网页 StringBuffer buffer = new StringBuffer(); System.setProperty("sun.net.client.defaultConnectTimeout", "5000"); System.setProperty("sun.net.client.defaultReadTimeout", "5000"); try { URL newUrl = new URL(strUrl); HttpURLConnection hConnect = (HttpURLConnection) newUrl .openConnection(); // POST方式的额外数据 if (strPostRequest.length() > 0) { hConnect.setDoOutput(true); OutputStreamWriter out = new OutputStreamWriter(hConnect .getOutputStream()); out.write(strPostRequest); out.flush(); out.close(); } // 读取内容 BufferedReader rd = new BufferedReader(new InputStreamReader( hConnect.getInputStream())); int ch; for (int length = 0; (ch = rd.read()) > -1 && (maxLength 查看全部
java抓取网页内容(本文实例讲述了。分享给大家供大家参考。。)
本文的例子描述了JAVA使用爬虫爬取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA研究爬网,呵呵,进门了,和大家分享一下我的经验
提供了以下两种方法,一种是使用apache提供的包。另一种是使用JAVA自带的。
代码如下:
<p> // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar public static String createhttpClient(String url, String param) { HttpClient client = new HttpClient(); String response = null; String keyword = null; PostMethod postMethod = new PostMethod(url); // try { // if (param != null) // keyword = new String(param.getBytes("gb2312"), "ISO-8859-1"); // } catch (UnsupportedEncodingException e1) { // // TODO Auto-generated catch block // e1.printStackTrace(); // } // NameValuePair[] data = { new NameValuePair("keyword", keyword) }; // // 将表单的值放入postMethod中 // postMethod.setRequestBody(data); // 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下 try { int statusCode = client.executeMethod(postMethod); response = new String(postMethod.getResponseBodyAsString() .getBytes("ISO-8859-1"), "gb2312"); //这里要注意下 gb2312要和你抓取网页的编码要一样 String p = response.replaceAll("//&[a-zA-Z]{1,10};", "") .replaceAll("]*>", "");//去掉网页中带有html语言的标签 System.out.println(p); } catch (Exception e) { e.printStackTrace(); } return response; } // 第二种方法 // 这种方法是JAVA自带的URL来抓取网站内容 public String getPageContent(String strUrl, String strPostRequest, int maxLength) { // 读取结果网页 StringBuffer buffer = new StringBuffer(); System.setProperty("sun.net.client.defaultConnectTimeout", "5000"); System.setProperty("sun.net.client.defaultReadTimeout", "5000"); try { URL newUrl = new URL(strUrl); HttpURLConnection hConnect = (HttpURLConnection) newUrl .openConnection(); // POST方式的额外数据 if (strPostRequest.length() > 0) { hConnect.setDoOutput(true); OutputStreamWriter out = new OutputStreamWriter(hConnect .getOutputStream()); out.write(strPostRequest); out.flush(); out.close(); } // 读取内容 BufferedReader rd = new BufferedReader(new InputStreamReader( hConnect.getInputStream())); int ch; for (int length = 0; (ch = rd.read()) > -1 && (maxLength
java抓取网页内容( 2017年09月26日08:45投稿:lqh这篇文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-09 00:02
2017年09月26日08:45投稿:lqh这篇文章)
java读取网页内容的详细例子
更新时间:2017-09-26 08:34:45 投稿:lqh
本文章主要介绍java读取网页内容示例的相关信息。希望这篇文章能对大家有所帮助,让大家学习和理解这部分内容。有需要的朋友可以参考以下
java读取网页内容的详细例子
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上面的代码程序是将网页的源代码,包括HTML和XML,读成JAVA中的字符串String a。
Java中的String类型空间很大,基本可以容纳一个网页源代码的内容。
从网页读取内容也是对输入流的操作。
与标准输入源不同,在:
BufferedReader in = new BufferedReader(new InputStreamReader(...))
在 InputStreamReader 中输入 System.in。
这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续操作和处理与加载标准输入源相同。
BufferedReader需要在JAVA中捕获IOException,而使用URL源不仅要引入.*包,还要捕获MalformedURLException。
如有任何问题,请留言或到本站社区交流讨论,感谢您的阅读,希望对大家有所帮助,感谢您对本站的支持! 查看全部
java抓取网页内容(
2017年09月26日08:45投稿:lqh这篇文章)
java读取网页内容的详细例子
更新时间:2017-09-26 08:34:45 投稿:lqh
本文章主要介绍java读取网页内容示例的相关信息。希望这篇文章能对大家有所帮助,让大家学习和理解这部分内容。有需要的朋友可以参考以下
java读取网页内容的详细例子
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上面的代码程序是将网页的源代码,包括HTML和XML,读成JAVA中的字符串String a。
Java中的String类型空间很大,基本可以容纳一个网页源代码的内容。
从网页读取内容也是对输入流的操作。
与标准输入源不同,在:
BufferedReader in = new BufferedReader(new InputStreamReader(...))
在 InputStreamReader 中输入 System.in。
这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续操作和处理与加载标准输入源相同。
BufferedReader需要在JAVA中捕获IOException,而使用URL源不仅要引入.*包,还要捕获MalformedURLException。
如有任何问题,请留言或到本站社区交流讨论,感谢您的阅读,希望对大家有所帮助,感谢您对本站的支持!
java抓取网页内容(返回一段xml链接的html代码效果怎么样?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-07 19:15
有时,我们需要在java程序中获取一个连接,然后解析连接后,获取连接返回的内容和结果进行分析。准确地说,解析一个链接。
以下代码解析百度主页上的链接,得到html代码的效果:
1 public static List getURLCollection(String address){
2 List list = new LinkedList();
3 try{
4 URL url = new URL(address);
5 URLConnection conn = url.openConnection();
6 conn.connect();
7 InputStream in = conn.getInputStream();
8 InputStreamReader input = new InputStreamReader(in, "UTF-8");
9 BufferedReader buf = new BufferedReader(input);
10 String nextLine = buf.readLine();
11
12 while(nextLine != null){
13 list.add(nextLine);
14 nextLine = buf.readLine();
15 }
16 }catch(Exception e){
17 e.printStackTrace();
18 }
19 return list;
20 }
21
22 public static void main(String[] args){
23 String address = "http://www.baidu.com";
24 List list = getURLCollection(address);
25 String buf = "";
26 for(String str : list){
27 buf+=str+"\n";
28 }
29
30 System.out.println(buf);
31 }
效果如果:
这样,百度的html的代码就被抓到了。
这有什么神奇的用途吗?
比如我们访问第三方链接时,第三方返回一段xml,我们需要他们提供的返回值来提供判断数据等等。以便它可以使用... 查看全部
java抓取网页内容(返回一段xml链接的html代码效果怎么样?-八维教育)
有时,我们需要在java程序中获取一个连接,然后解析连接后,获取连接返回的内容和结果进行分析。准确地说,解析一个链接。
以下代码解析百度主页上的链接,得到html代码的效果:
1 public static List getURLCollection(String address){
2 List list = new LinkedList();
3 try{
4 URL url = new URL(address);
5 URLConnection conn = url.openConnection();
6 conn.connect();
7 InputStream in = conn.getInputStream();
8 InputStreamReader input = new InputStreamReader(in, "UTF-8");
9 BufferedReader buf = new BufferedReader(input);
10 String nextLine = buf.readLine();
11
12 while(nextLine != null){
13 list.add(nextLine);
14 nextLine = buf.readLine();
15 }
16 }catch(Exception e){
17 e.printStackTrace();
18 }
19 return list;
20 }
21
22 public static void main(String[] args){
23 String address = "http://www.baidu.com";
24 List list = getURLCollection(address);
25 String buf = "";
26 for(String str : list){
27 buf+=str+"\n";
28 }
29
30 System.out.println(buf);
31 }
效果如果:
这样,百度的html的代码就被抓到了。
这有什么神奇的用途吗?
比如我们访问第三方链接时,第三方返回一段xml,我们需要他们提供的返回值来提供判断数据等等。以便它可以使用...
java抓取网页内容( 以上的代码程序是把一个网页的源代码a中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-06 19:18
以上的代码程序是把一个网页的源代码a中)
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上述代码程序将一个网页的源代码,包括 HTML 和 XML,读入 JAVA 中的字符串 String a。
Java中的String类型空间很大,基本可以容纳一个网页源码的内容。
从网页中读取内容也是对输入流的操作。
与标准输入源不同,在:BufferedReader in = new BufferedReader(new InputStreamReader(...))
只需在 InputStreamReader 中输入 System.in。这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续的操作和处理与加载标准输入源完全一样。
BufferedReader 要求JAVA 必须捕获IOException,使用URL source 不仅要导入.* 包,还要捕获MalformedURLException。 查看全部
java抓取网页内容(
以上的代码程序是把一个网页的源代码a中)
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上述代码程序将一个网页的源代码,包括 HTML 和 XML,读入 JAVA 中的字符串 String a。
Java中的String类型空间很大,基本可以容纳一个网页源码的内容。
从网页中读取内容也是对输入流的操作。
与标准输入源不同,在:BufferedReader in = new BufferedReader(new InputStreamReader(...))
只需在 InputStreamReader 中输入 System.in。这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续的操作和处理与加载标准输入源完全一样。
BufferedReader 要求JAVA 必须捕获IOException,使用URL source 不仅要导入.* 包,还要捕获MalformedURLException。
java抓取网页内容(.getEntity实现方案,解析本地弹幕xml文件的代码如下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2022-01-04 12:14
(一)实现思路一,定位弹幕文件
一般使用json或者xml格式来保存弹幕,所以我们只要在视频网页中找到xml文件或者json文件就可以定位弹幕文件。
2.解析弹幕文件
然后通过jsoup解析文件,提取出我们弹幕的文本内容。
(二)第一个实现方案,解析本地文件1,定位弹幕文件
比如我们要抓取下面视频的弹幕文件。
打开Chrome的Network后刷新网页,然后在输入框中输入xml,过滤掉xml文件资源:
将光标移动到文件上,可以看到文件的具体地址如下:
在文件上右击Open in new tab,在新的浏览器页面查看弹幕文件的内容:
2.解析弹幕文件2.1 创建基础maven工程
输入 GroupId 和 ArtifactId
本项目将使用jar包jsoup,所以在项目根目录下创建lib目标,将jar复制进去,然后将jar包构建到项目中,如下:
选择 jar 并单击“确定”。
2.2 在项目根目录下创建弹幕文件
在根目录创建一个3232417.xml文件,复制弹幕页面的内容,保存在文件中。只需全选并直接复制即可。我们后面解析文件的时候,只会提取有用的文本,所以第一行内容不需要去掉,如下:
2.3 代码实现
解析本地弹幕xml文件的代码如下:
import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.File; import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class LocalFile { public static ArrayList getData(String fileName){ ArrayList list = new ArrayList(); try{ File input = new File(fileName); Document doc = Jsoup.parse(input, "UTF-8"); //每条弹幕的内容都处于标签中,于是根据该标签找到所有弹幕 Elements contents = doc.getElementsByTag("d"); for (Element content : contents) { list.add(content.text()); //将标签中的文本内容,也就是弹幕内容,添加到list中 } } catch (Exception e) { e.printStackTrace(); } return list; } } 复制代码
在入口类Main.java中,调用LocalFile类的getData方法,输入参数为xml文件名,每条弹幕解析输出:
import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class Main { public static void main(String[] args){ ArrayList items = new ArrayList(); //1,通过解析本地文件的方式得到所有弹幕 items = LocalFile.getData("3232417.xml"); //遍历输出每条弹幕 for (String item : items) { System.out.println(item); } } } 复制代码
输出如下:
(三) 第二种实现方案,解析远程服务器文件1,添加httpclient依赖
由于需要访问远程服务器,所以使用了一个相关的依赖,提供对http服务器的访问。在 pom.xml 文件中添加:
org.apache.httpcomponents httpclient 4.3.3 复制代码
2. 实现代码
import org.apache.http.HttpEntity; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class RemoteFile { public static ArrayList getData(String fileName) throws IOException { ArrayList list = new ArrayList(); //1,创建HttpClient对象,我们使用到Apache中的HttpClient的实例CloseableHttpClient CloseableHttpClient httpclient = HttpClients.createDefault(); //2,创建HttpGet请求实例,该实例指示向目标URL发起GET请求 HttpGet httpGet = new HttpGet(fileName); //3,执行HttpGet请求实例,也就是发起GET请求,响应结果保存到httpResponse变量中 CloseableHttpResponse httpResponse = httpclient.execute(httpGet); try { //4,得到弹幕文件的文件内容 HttpEntity httpEntity = httpResponse.getEntity(); String httpHtml = EntityUtils.toString(httpEntity); //5,解析弹幕文件,把每条弹幕放入list中 Document doc = Jsoup.parse(httpHtml, "UTF-8"); Elements contents = doc.getElementsByTag("d"); for (Element content : contents) { list.add(content.text()); //将标签中的文本内容,也就是弹幕内容,添加到list中 } } catch (Exception e) { e.printStackTrace(); } finally { httpResponse.close(); } return list; } } 复制代码
CloseableHttpResponse httpResponse = httpclient.execute(httpGet); 执行GET请求后,响应结果保存在httpResponse中。response.getEntity()是响应结果中的消息实体,因为响应结果中还收录Headers等其他内容如下图所示,这里我们只需要关注getEntity()消息实体即可。
EntityUtils.toString(response.getEntity()); 以流的形式返回服务器写入的响应内容。比如服务端调用的方法最后是: responseWriter.write("just do it"); 然后是EntityUtils。toString(response.getEntity()); 得到这句话就去做吧。这可以简单的理解为网页的html代码,也就是在网页源代码上右击可以看到的所有html代码。我们需要解析的就是这样的html代码。
在入口类Main.java中,调用RemoteFile类的getData方法,输入参数为xml文件名,解析每个弹幕并输出:
import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class Main { public static void main(String[] args){ ArrayList items = new ArrayList(); //1,通过解析本地文件的方式得到所有弹幕 // items = LocalFile.getData("3232417.xml"); //2,通过解析远程服务器文件的方式得到所有弹幕 items = RemoteFile.getData("https://comment.bilibili.com/3232417.xml"); //遍历输出每条弹幕 for (String item : items) { System.out.println(item); } } } 复制代码
输出如下:
项目代码
代码仓库:完整的项目代码 查看全部
java抓取网页内容(.getEntity实现方案,解析本地弹幕xml文件的代码如下)
(一)实现思路一,定位弹幕文件
一般使用json或者xml格式来保存弹幕,所以我们只要在视频网页中找到xml文件或者json文件就可以定位弹幕文件。
2.解析弹幕文件
然后通过jsoup解析文件,提取出我们弹幕的文本内容。
(二)第一个实现方案,解析本地文件1,定位弹幕文件
比如我们要抓取下面视频的弹幕文件。

打开Chrome的Network后刷新网页,然后在输入框中输入xml,过滤掉xml文件资源:

将光标移动到文件上,可以看到文件的具体地址如下:

在文件上右击Open in new tab,在新的浏览器页面查看弹幕文件的内容:

2.解析弹幕文件2.1 创建基础maven工程

输入 GroupId 和 ArtifactId

本项目将使用jar包jsoup,所以在项目根目录下创建lib目标,将jar复制进去,然后将jar包构建到项目中,如下:

选择 jar 并单击“确定”。

2.2 在项目根目录下创建弹幕文件
在根目录创建一个3232417.xml文件,复制弹幕页面的内容,保存在文件中。只需全选并直接复制即可。我们后面解析文件的时候,只会提取有用的文本,所以第一行内容不需要去掉,如下:

2.3 代码实现
解析本地弹幕xml文件的代码如下:
import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.File; import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class LocalFile { public static ArrayList getData(String fileName){ ArrayList list = new ArrayList(); try{ File input = new File(fileName); Document doc = Jsoup.parse(input, "UTF-8"); //每条弹幕的内容都处于标签中,于是根据该标签找到所有弹幕 Elements contents = doc.getElementsByTag("d"); for (Element content : contents) { list.add(content.text()); //将标签中的文本内容,也就是弹幕内容,添加到list中 } } catch (Exception e) { e.printStackTrace(); } return list; } } 复制代码
在入口类Main.java中,调用LocalFile类的getData方法,输入参数为xml文件名,每条弹幕解析输出:
import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class Main { public static void main(String[] args){ ArrayList items = new ArrayList(); //1,通过解析本地文件的方式得到所有弹幕 items = LocalFile.getData("3232417.xml"); //遍历输出每条弹幕 for (String item : items) { System.out.println(item); } } } 复制代码
输出如下:

(三) 第二种实现方案,解析远程服务器文件1,添加httpclient依赖
由于需要访问远程服务器,所以使用了一个相关的依赖,提供对http服务器的访问。在 pom.xml 文件中添加:
org.apache.httpcomponents httpclient 4.3.3 复制代码
2. 实现代码
import org.apache.http.HttpEntity; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class RemoteFile { public static ArrayList getData(String fileName) throws IOException { ArrayList list = new ArrayList(); //1,创建HttpClient对象,我们使用到Apache中的HttpClient的实例CloseableHttpClient CloseableHttpClient httpclient = HttpClients.createDefault(); //2,创建HttpGet请求实例,该实例指示向目标URL发起GET请求 HttpGet httpGet = new HttpGet(fileName); //3,执行HttpGet请求实例,也就是发起GET请求,响应结果保存到httpResponse变量中 CloseableHttpResponse httpResponse = httpclient.execute(httpGet); try { //4,得到弹幕文件的文件内容 HttpEntity httpEntity = httpResponse.getEntity(); String httpHtml = EntityUtils.toString(httpEntity); //5,解析弹幕文件,把每条弹幕放入list中 Document doc = Jsoup.parse(httpHtml, "UTF-8"); Elements contents = doc.getElementsByTag("d"); for (Element content : contents) { list.add(content.text()); //将标签中的文本内容,也就是弹幕内容,添加到list中 } } catch (Exception e) { e.printStackTrace(); } finally { httpResponse.close(); } return list; } } 复制代码
CloseableHttpResponse httpResponse = httpclient.execute(httpGet); 执行GET请求后,响应结果保存在httpResponse中。response.getEntity()是响应结果中的消息实体,因为响应结果中还收录Headers等其他内容如下图所示,这里我们只需要关注getEntity()消息实体即可。

EntityUtils.toString(response.getEntity()); 以流的形式返回服务器写入的响应内容。比如服务端调用的方法最后是: responseWriter.write("just do it"); 然后是EntityUtils。toString(response.getEntity()); 得到这句话就去做吧。这可以简单的理解为网页的html代码,也就是在网页源代码上右击可以看到的所有html代码。我们需要解析的就是这样的html代码。
在入口类Main.java中,调用RemoteFile类的getData方法,输入参数为xml文件名,解析每个弹幕并输出:
import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class Main { public static void main(String[] args){ ArrayList items = new ArrayList(); //1,通过解析本地文件的方式得到所有弹幕 // items = LocalFile.getData("3232417.xml"); //2,通过解析远程服务器文件的方式得到所有弹幕 items = RemoteFile.getData("https://comment.bilibili.com/3232417.xml";); //遍历输出每条弹幕 for (String item : items) { System.out.println(item); } } } 复制代码
输出如下:

项目代码
代码仓库:完整的项目代码
java抓取网页内容(教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-03 12:03
我无事可做。刚刚学会了将git部署到远程服务器上,无事可做,就简单的做了一个小工具来抓取网页信息。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
操作效果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并注入到LinkedHashMap中,就可以了,很简单吧?看代码罗
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望大家多多支持! 查看全部
java抓取网页内容(教程)
我无事可做。刚刚学会了将git部署到远程服务器上,无事可做,就简单的做了一个小工具来抓取网页信息。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
操作效果:

先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码

然后抓取你想要的标签并注入到LinkedHashMap中,就可以了,很简单吧?看代码罗
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望大家多多支持!
java抓取网页内容(说起Python真的用的语言有那么神奇吗?除了它还可以用哪些语言?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-03 02:09
说到大数据,你会不自觉地想到爬虫。说到爬虫使用的语言,很多人首先想到的是Python。 Python真的有那么神奇吗?除了它还能用什么语言?
C#,java可以写爬虫,原理其实差别不大,只是平台问题。可以认为,如果是有针对性地抓取几个页面,做一些简单的页面分析,抓取效率不是核心要求,那么使用的语言本质上没有区别。
使用什么语言取决于情况和主要目的。
如果是针对性爬取,主要目标是解析js动态生成的内容,此时页面内容是js/ajax动态生成的,普通请求页面->解析方式不起作用,需要借助类似于firefox和chrome浏览器的js引擎,动态分析页面的js代码。
这种情况建议考虑casperJS+phantomjs或者slimerJS+phantomjs。当然,硒也可以考虑。
3、 如果爬虫涉及到大规模爬行,效率、可扩展性、可维护性等是必须考虑的因素,大规模爬行涉及很多问题:多线程并发、I/O机制、分布式爬虫、消息通信、权重判断机制、任务调度等,这时候语言和框架的选择意义重大。
PHP 对多线程和异步的支持较差,不推荐使用。
NodeJS:对于一些垂直的网站爬取,还可以,但是由于对分布式爬取、消息通信等支持较弱,请根据自己的情况判断。
Python:强烈建议我们对以上问题有很好的支持。尤其是Scrapy框架不愧为首选。
主要原因是:
1)抓取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如perl、shell,python的urllib2包提供了更完善的web文档访问API。 (当然ruby也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。 python中有优秀的第三方包帮你搞定,比如Requests,mechanize
2)网页抓取后的处理
获取的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
除了这些,还有很多优点:支持xpath;基于扭曲,性能良好;更好的调试工具;
这种情况下,如果还需要做js动态内容分析,casperjs不适合,只能基于chrome V8引擎等搭建自己的js引擎。
对于C和C++,虽然性能不错,但不推荐使用,尤其是考虑到成本等诸多因素。对于大多数公司来说,建议基于一些开源框架来做。不要自己发明轮子。制作一个简单的爬虫很容易。 ,但是很难做出一个完整的爬虫。 查看全部
java抓取网页内容(说起Python真的用的语言有那么神奇吗?除了它还可以用哪些语言?)
说到大数据,你会不自觉地想到爬虫。说到爬虫使用的语言,很多人首先想到的是Python。 Python真的有那么神奇吗?除了它还能用什么语言?
C#,java可以写爬虫,原理其实差别不大,只是平台问题。可以认为,如果是有针对性地抓取几个页面,做一些简单的页面分析,抓取效率不是核心要求,那么使用的语言本质上没有区别。
使用什么语言取决于情况和主要目的。
如果是针对性爬取,主要目标是解析js动态生成的内容,此时页面内容是js/ajax动态生成的,普通请求页面->解析方式不起作用,需要借助类似于firefox和chrome浏览器的js引擎,动态分析页面的js代码。
这种情况建议考虑casperJS+phantomjs或者slimerJS+phantomjs。当然,硒也可以考虑。
3、 如果爬虫涉及到大规模爬行,效率、可扩展性、可维护性等是必须考虑的因素,大规模爬行涉及很多问题:多线程并发、I/O机制、分布式爬虫、消息通信、权重判断机制、任务调度等,这时候语言和框架的选择意义重大。
PHP 对多线程和异步的支持较差,不推荐使用。
NodeJS:对于一些垂直的网站爬取,还可以,但是由于对分布式爬取、消息通信等支持较弱,请根据自己的情况判断。
Python:强烈建议我们对以上问题有很好的支持。尤其是Scrapy框架不愧为首选。
主要原因是:
1)抓取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如perl、shell,python的urllib2包提供了更完善的web文档访问API。 (当然ruby也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。 python中有优秀的第三方包帮你搞定,比如Requests,mechanize
2)网页抓取后的处理
获取的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
除了这些,还有很多优点:支持xpath;基于扭曲,性能良好;更好的调试工具;
这种情况下,如果还需要做js动态内容分析,casperjs不适合,只能基于chrome V8引擎等搭建自己的js引擎。
对于C和C++,虽然性能不错,但不推荐使用,尤其是考虑到成本等诸多因素。对于大多数公司来说,建议基于一些开源框架来做。不要自己发明轮子。制作一个简单的爬虫很容易。 ,但是很难做出一个完整的爬虫。
java抓取网页内容(淘女郎的信息和照片需要额外安装的第三方库模块功能原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-03 02:07
淘女孩爬虫,可以动态抓取淘女孩的信息和照片
需要额外安装的第三方库模块的功能原理
淘女孩的网站使用了AJAX技术。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。这意味着直接爬取网页源代码然后分析信息的方法是不可行的,因为网站是动态加载的,而直接爬取的方法只能抓取网页的原创源代码,但不是网页的原创源代码。给淘女孩动态加载的信息。
对于这种网站,一般有两种获取方式:
利用selenium库模拟浏览器的用户行为,使服务器认为真实用户在浏览网页,从而获取网页的完整源代码。使用Chrome等浏览器自带的分析工具来监控网页的网络。分析数据交换API,然后利用API抓取数据交换的JSON数据,再抓取。
一般来说,第一种方法速度较慢,运行时占用系统资源较多。因此,在条件允许的情况下,尽量使用第二种方法。
在 Chrome 浏览器中打开淘女孩主页,按 F12 切换到开发者模式。在网络列中选择 XHR 以查看当前没有网络活动。但是,当你在网页中点击一个页面时,会有一个POST活动,当再次按下下一页时,活动会再次出现,所以可以断定这个API是用于数据交换的。然后我们再次比较这两个请求。在Headers框的FromData列中,可以看到两次请求的区别在currentPage。一个是2,另一个是3。这说明如果要获取第一页的数据,这个currentPage的值是多少。于是我们根据这个来写请求,得到所有淘女孩信息的JSON文件。
发送请求,获取JSON数据,处理后转换成Python字典类型返回
连接MongoDB并保存信息
def main():
client = MongoClient()
db = client.TaoBao
col = db.TaoLady
for pageNum in range(1,411): # 淘女郎一共有410页,所以我们抓取从1到411页的内容。
print(pageNum)
datas = getInfo(pageNum)
if datas:
col.insert_many(datas)
if __name__ == '__main__':
main()
提取图片的网址,下载后保存在pic文件夹中
def downPic():
client = MongoClient()
db = client.TaoBao
col = db.TaoLady
for data in col.find():
name = data['realName']
url = "http:" + data['avatarUrl']
pic = urlopen(url)
with open("pic/" + name + ".jpg", "vb") as file:
print(name)
file.vrite(pic.read())
if __name__ == '__main__':
downPic()
攀登结束,成绩斐然
好的! 文章 在这里分享给大家。如果你和我一样喜欢python,在python学习的路上奔跑,欢迎加入python学习群:839383765 群里每天都会分享最新的行业资讯,分享python是免费课程,一起交流学习,让学习成为一种习惯! 查看全部
java抓取网页内容(淘女郎的信息和照片需要额外安装的第三方库模块功能原理)
淘女孩爬虫,可以动态抓取淘女孩的信息和照片
需要额外安装的第三方库模块的功能原理
淘女孩的网站使用了AJAX技术。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。这意味着直接爬取网页源代码然后分析信息的方法是不可行的,因为网站是动态加载的,而直接爬取的方法只能抓取网页的原创源代码,但不是网页的原创源代码。给淘女孩动态加载的信息。
对于这种网站,一般有两种获取方式:
利用selenium库模拟浏览器的用户行为,使服务器认为真实用户在浏览网页,从而获取网页的完整源代码。使用Chrome等浏览器自带的分析工具来监控网页的网络。分析数据交换API,然后利用API抓取数据交换的JSON数据,再抓取。
一般来说,第一种方法速度较慢,运行时占用系统资源较多。因此,在条件允许的情况下,尽量使用第二种方法。
在 Chrome 浏览器中打开淘女孩主页,按 F12 切换到开发者模式。在网络列中选择 XHR 以查看当前没有网络活动。但是,当你在网页中点击一个页面时,会有一个POST活动,当再次按下下一页时,活动会再次出现,所以可以断定这个API是用于数据交换的。然后我们再次比较这两个请求。在Headers框的FromData列中,可以看到两次请求的区别在currentPage。一个是2,另一个是3。这说明如果要获取第一页的数据,这个currentPage的值是多少。于是我们根据这个来写请求,得到所有淘女孩信息的JSON文件。
发送请求,获取JSON数据,处理后转换成Python字典类型返回
连接MongoDB并保存信息
def main():
client = MongoClient()
db = client.TaoBao
col = db.TaoLady
for pageNum in range(1,411): # 淘女郎一共有410页,所以我们抓取从1到411页的内容。
print(pageNum)
datas = getInfo(pageNum)
if datas:
col.insert_many(datas)
if __name__ == '__main__':
main()
提取图片的网址,下载后保存在pic文件夹中
def downPic():
client = MongoClient()
db = client.TaoBao
col = db.TaoLady
for data in col.find():
name = data['realName']
url = "http:" + data['avatarUrl']
pic = urlopen(url)
with open("pic/" + name + ".jpg", "vb") as file:
print(name)
file.vrite(pic.read())
if __name__ == '__main__':
downPic()
攀登结束,成绩斐然
好的! 文章 在这里分享给大家。如果你和我一样喜欢python,在python学习的路上奔跑,欢迎加入python学习群:839383765 群里每天都会分享最新的行业资讯,分享python是免费课程,一起交流学习,让学习成为一种习惯!
java抓取网页内容(《》之有关,文章内容质量较高,小编分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-01 10:04
本文文章将详细讲解Java中如何使用正则表达式获取网页内容。 文章的内容质量很高,分享给大家作为参考。希望大家看完这篇文章,对相关知识有了一定的了解。
正则表达式,抓取网页并解析部分HTML内容
<p>package com.xiaofeng.picup;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/** *//**
*
* @抓取页面文章标题及内容(测试) 手动输入网址抓取,可进一步自动抓取整个页面的全部内容
*
*/
public class WebContent ...{
/** *//**
* 读取一个网页全部内容
*/
public String getOneHtml(String htmlurl) throws IOException...{
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try ...{
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url
.openStream(), "utf-8"));// 读取网页全部内容
while ((temp = in.readLine()) != null) ...{
sb.append(temp);
}
in.close();
}catch(MalformedURLException me)...{
System.out.println("你输入的URL格式有问题!请仔细输入");
me.getMessage();
throw me;
}catch (IOException e) ...{
e.printStackTrace();
throw e;
}
return sb.toString();
}
/** *//**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) ...{
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) ...{
list.add(ma.group());
}
for (int i = 0; i ]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) ...{
list.add(ma.group());
}
return list;
}
/** *//**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) ...{
String regex;
List list = new ArrayList();
regex = " 查看全部
java抓取网页内容(《》之有关,文章内容质量较高,小编分享)
本文文章将详细讲解Java中如何使用正则表达式获取网页内容。 文章的内容质量很高,分享给大家作为参考。希望大家看完这篇文章,对相关知识有了一定的了解。
正则表达式,抓取网页并解析部分HTML内容
<p>package com.xiaofeng.picup;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/** *//**
*
* @抓取页面文章标题及内容(测试) 手动输入网址抓取,可进一步自动抓取整个页面的全部内容
*
*/
public class WebContent ...{
/** *//**
* 读取一个网页全部内容
*/
public String getOneHtml(String htmlurl) throws IOException...{
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try ...{
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url
.openStream(), "utf-8"));// 读取网页全部内容
while ((temp = in.readLine()) != null) ...{
sb.append(temp);
}
in.close();
}catch(MalformedURLException me)...{
System.out.println("你输入的URL格式有问题!请仔细输入");
me.getMessage();
throw me;
}catch (IOException e) ...{
e.printStackTrace();
throw e;
}
return sb.toString();
}
/** *//**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) ...{
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) ...{
list.add(ma.group());
}
for (int i = 0; i ]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) ...{
list.add(ma.group());
}
return list;
}
/** *//**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) ...{
String regex;
List list = new ArrayList();
regex = "
java抓取网页内容(JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-12-31 02:22
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下对这种方法的理解和体会。最简单的爬取方法是:
URLurl=newURL(myurl);BufferedReaderbr=newBufferedReader(newInputStreamReader(url.openStream()));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){ i++;sb.append(s+"\r\n");}
URL url = new URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
i++;
sb.append(s+"\r\n");
}
这种方法抓取一般的网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取这个URL中网页的内容,又不想被重定向到其他网页,可以使用下面的代码。
URLurlmy=newURL(myurl);HttpURLConnectioncon=(HttpURLConnection)urlmy.openConnection();con.setFollowRedirects(true);con.setInstanceFollowRedirects(false);con.connect();BufferedReaderbr=newBufferedReader(newInputStreamReader(con.getInputStream(), "UTF-8"));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){sb.append(s+"\r\n"); }
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
在这种情况下,程序在爬取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
Java代码
System.getProperties().setProperty("http.proxyHost",proxyName);System.getProperties().setProperty("http.proxyPort",port);
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty( "http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
以上程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用! 查看全部
java抓取网页内容(JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下对这种方法的理解和体会。最简单的爬取方法是:
URLurl=newURL(myurl);BufferedReaderbr=newBufferedReader(newInputStreamReader(url.openStream()));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){ i++;sb.append(s+"\r\n");}
URL url = new URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
i++;
sb.append(s+"\r\n");
}
这种方法抓取一般的网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取这个URL中网页的内容,又不想被重定向到其他网页,可以使用下面的代码。
URLurlmy=newURL(myurl);HttpURLConnectioncon=(HttpURLConnection)urlmy.openConnection();con.setFollowRedirects(true);con.setInstanceFollowRedirects(false);con.connect();BufferedReaderbr=newBufferedReader(newInputStreamReader(con.getInputStream(), "UTF-8"));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){sb.append(s+"\r\n"); }
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
在这种情况下,程序在爬取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
Java代码

System.getProperties().setProperty("http.proxyHost",proxyName);System.getProperties().setProperty("http.proxyPort",port);
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty( "http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
以上程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用!
java抓取网页内容(Python使用正则表达式抓取网页图片的方法示例的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-30 15:00
想知道Python如何使用正则表达式抓取网页图片的例子的相关内容吗?我要的闪耀给大家详细讲解Python正则表达式抓取网页图片的知识和一些代码示例。欢迎阅读并指正,先画重点:Python、正则表达式、爬虫、网页图片,一起学习。
本文介绍了Python使用正则表达式抓取网页图片的例子。分享给大家,供大家参考,如下:
#!/usr/bin/python
import re
import urllib
#获取网页信息
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#匹配网页中的图片
reg = r'src="(.*?\.jpg)" alt'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
html = getHtml("http://photo.bitauto.com/?WT.mc_id=360tpdq")
print getImg(html)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
希望这篇文章对你的 Python 编程有所帮助。
相关文章 查看全部
java抓取网页内容(Python使用正则表达式抓取网页图片的方法示例的相关内容吗)
想知道Python如何使用正则表达式抓取网页图片的例子的相关内容吗?我要的闪耀给大家详细讲解Python正则表达式抓取网页图片的知识和一些代码示例。欢迎阅读并指正,先画重点:Python、正则表达式、爬虫、网页图片,一起学习。
本文介绍了Python使用正则表达式抓取网页图片的例子。分享给大家,供大家参考,如下:
#!/usr/bin/python
import re
import urllib
#获取网页信息
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#匹配网页中的图片
reg = r'src="(.*?\.jpg)" alt'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
html = getHtml("http://photo.bitauto.com/?WT.mc_id=360tpdq";)
print getImg(html)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
希望这篇文章对你的 Python 编程有所帮助。
相关文章
java抓取网页内容(接上简易爬虫配置池线程池(ThreadPoolTaskExecutor)抓取任务的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-12-25 16:02
继续上一节(爬虫系列(0):项目建设)
网络爬虫是通过多线程和多任务逻辑实现的。线程池(ThreadPoolTaskExecutor)已经封装在springboot框架中,我们只需要使用它即可。
在本节中,我们主要实现网页连接信息的多线程捕获,并将信息存储在队列中。
介绍一个新的包
在pom中引入新的包,如下:
org.apache.commons
commons-lang3
org.jsoup
jsoup
1.8.3
org.projectlombok
lombok
provided
为了简化编码,这里引入lombok。IDE使用时需要安装lombok插件,否则会提示编译错误。
配置管理
springboot的配置文件统一管理在application.properties(.yml)中。这里我们也通过@ConfigurationProperties注解实现爬虫相关的配置。直接上传代码:
package mobi.huanyuan.spider.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
/**
* 爬虫配置.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:10
*/
@Data
@ConfigurationProperties(prefix = "huanyuan.spider")
public class SpiderConfig {
/**
* 爬取页面最大深度
*/
public int maxDepth = 2;
/**
* 下载页面线程数
*/
public int minerHtmlThreadNum = 2;
//=================================================
// 线程池配置
//=================================================
/**
* 核心线程池大小
*/
private int corePoolSize = 4;
/**
* 最大可创建的线程数
*/
private int maxPoolSize = 100;
/**
* 队列最大长度
*/
private int queueCapacity = 1000;
/**
* 线程池维护线程所允许的空闲时间
*/
private int keepAliveSeconds = 300;
}
然后,需要修改这些配置,只需要修改里面的application.properties(.yml):
魔猿简单爬虫配置
线程池
线程池使用现有的springboot,配置也可以在上面的配置管理中。这里只需要初始化配置:
package mobi.huanyuan.spider.config;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.ThreadPoolExecutor;
/**
* 线程池配置.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:35
*/
@Configuration
public class ThreadPoolConfig {
@Autowired
private SpiderConfig spiderConfig;
@Bean(name = "threadPoolTaskExecutor")
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setMaxPoolSize(spiderConfig.getMaxPoolSize());
executor.setCorePoolSize(spiderConfig.getCorePoolSize());
executor.setQueueCapacity(spiderConfig.getQueueCapacity());
executor.setKeepAliveSeconds(spiderConfig.getKeepAliveSeconds());
// 线程池对拒绝任务(无线程可用)的处理策略
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
}
队列管理
本节我们主要是抓取URL并保存到队列中,所以涉及到的队列就是要抓取的队列和要分析的队列(下节分析用到,这里只做存储),另外,为了防止重复抓取同一个URL,这里还需要添加一个Set集合来记录访问过的地址。
package mobi.huanyuan.spider;
import lombok.Getter;
import mobi.huanyuan.spider.bean.SpiderHtml;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Set;
/**
* 爬虫访问队列.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 10:54
*/
public class SpiderQueue {
private static Logger logger = LoggerFactory.getLogger(SpiderQueue.class);
/**
* Set集合 保证每一个URL只访问一次
*/
private static volatile Set urlSet = new HashSet();
/**
* 待访问队列
* 爬取页面线程从这里取数据
*/
private static volatile Queue unVisited = new LinkedList();
/**
* 等待提取URL的分析页面队列
* 解析页面线程从这里取数据
*/
private static volatile Queue waitingMine = new LinkedList();
/**
* 添加到URL队列
*
* @param url
*/
public synchronized static void addUrlSet(String url) {
urlSet.add(url);
}
/**
* 获得URL队列大小
*
* @return
*/
public static int getUrlSetSize() {
return urlSet.size();
}
/**
* 添加到待访问队列,每个URL只访问一次
*
* @param spiderHtml
*/
public synchronized static void addUnVisited(SpiderHtml spiderHtml) {
if (null != spiderHtml && !urlSet.contains(spiderHtml.getUrl())) {
logger.info("添加到待访问队列[{}] 当前第[{}]层 当前线程[{}]", spiderHtml.getUrl(), spiderHtml.getDepth(), Thread.currentThread().getName());
unVisited.add(spiderHtml);
}
}
/**
* 待访问出队列
*
* @return
*/
public synchronized static SpiderHtml unVisitedPoll() {
return unVisited.poll();
}
/**
* 添加到等待提取URL的分析页面队列
*
* @param html
*/
public synchronized static void addWaitingMine(SpiderHtml html) {
waitingMine.add(html);
}
/**
* 等待提取URL的分析页面出队列
*
* @return
*/
public synchronized static SpiderHtml waitingMinePoll() {
return waitingMine.poll();
}
/**
* 等待提取URL的分析页面队列大小
* @return
*/
public static int waitingMineSize() {
return waitingMine.size();
}
}
抓取任务
直接上传代码:
package mobi.huanyuan.spider.runable;
import mobi.huanyuan.spider.SpiderQueue;
import mobi.huanyuan.spider.bean.SpiderHtml;
import mobi.huanyuan.spider.config.SpiderConfig;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 抓取页面任务.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:43
*/
public class SpiderHtmlRunnable implements Runnable {
private static final Logger logger = LoggerFactory.getLogger(SpiderHtmlRunnable.class);
private static boolean done = false;
private SpiderConfig config;
public SpiderHtmlRunnable(SpiderConfig config) {
this.config = config;
}
@Override
public void run() {
while (!SpiderHtmlRunnable.done) {
done = true;
minerHtml();
done = false;
}
}
public synchronized void minerHtml() {
SpiderHtml minerUrl = SpiderQueue.unVisitedPoll(); // 待访问出队列。
try {
//判断当前页面爬取深度
if (null == minerUrl || StringUtils.isBlank(minerUrl.getUrl()) || minerUrl.getDepth() > config.getMaxDepth()) {
return;
}
//判断爬取页面URL是否包含http
if (!minerUrl.getUrl().startsWith("http")) {
logger.info("当前爬取URL[{}]没有http", minerUrl.getUrl());
return;
}
logger.info("当前爬取页面[{}]爬取深度[{}] 当前线程 [{}]", minerUrl.getUrl(), minerUrl.getDepth(), Thread.currentThread().getName());
Connection conn = Jsoup.connect(minerUrl.getUrl());
conn.header("User-Agent", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13");//配置模拟浏览器
Document doc = conn.get();
String page = doc.html();
SpiderHtml spiderHtml = new SpiderHtml();
spiderHtml.setUrl(minerUrl.getUrl());
spiderHtml.setHtml(page);
spiderHtml.setDepth(minerUrl.getDepth());
System.out.println(spiderHtml.getUrl());
// TODO: 添加到继续爬取队列
SpiderQueue.addWaitingMine(spiderHtml);
} catch (Exception e) {
logger.info("爬取页面失败 URL [{}]", minerUrl.getUrl());
logger.info("Error info [{}]", e.getMessage());
}
}
}
这是一个 Runnable 任务。主要目的是拉取URL数据,然后将其封装成SpiderHtml对象,存放在待分析队列中。这里使用的是Jsoup——一个用于HTML分析操作的Java工具包。如果您不确定,您可以搜索它。后面的章节也会用到分析部分。
其他页面信息包SpiderHtml
package mobi.huanyuan.spider.bean;
import lombok.Data;
import java.io.Serializable;
/**
* 页面信息类.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:02
*/
@Data
public class SpiderHtml implements Serializable {
/**
* 页面URL
*/
private String url;
/**
* 页面信息
*/
private String html;
/**
* 爬取深度
*/
private int depth;
}
爬行动物主类
package mobi.huanyuan.spider;
import mobi.huanyuan.spider.bean.SpiderHtml;
import mobi.huanyuan.spider.config.SpiderConfig;
import mobi.huanyuan.spider.runable.SpiderHtmlRunnable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
/**
* 爬虫.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:23
*/
@Component
public class Spider {
private static Logger logger = LoggerFactory.getLogger(Spider.class);
@Autowired
private ThreadPoolTaskExecutor threadPoolTaskExecutor;
@Autowired
private SpiderConfig spiderConfig;
public void start(SpiderHtml spiderHtml) {
//程序启动,将第一个起始页面放入待访问队列。
SpiderQueue.addUnVisited(spiderHtml);
//将URL 添加到URL队列 保证每个URL只访问一次
SpiderQueue.addUrlSet(spiderHtml.getUrl());
//download
for (int i = 0; i < spiderConfig.getMinerHtmlThreadNum(); i++) {
SpiderHtmlRunnable minerHtml = new SpiderHtmlRunnable(spiderConfig);
threadPoolTaskExecutor.execute(minerHtml);
}
// TODO: 监控爬取完毕之后停线程池,关闭程序
try {
TimeUnit.SECONDS.sleep(20);
logger.info("待分析URL队列大小: {}", SpiderQueue.waitingMineSize());
// 关闭线程池
threadPoolTaskExecutor.shutdown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
"// TODO:" 后面的代码逻辑在这里是暂时的。后续章节完成后,会慢慢移除。
最后
运行本节代码,需要在springboot项目的main方法中添加如下代码:
ConfigurableApplicationContext context = SpringApplication.run(SpiderApplication.class, args);
Spider spider = context.getBean(Spider.class);
SpiderHtml startPage = new SpiderHtml();
startPage.setUrl("$URL");
startPage.setDepth(2);
spider.start(startPage);
$URL 是需要抓取的网页地址。
springboot项目启动后,需要手动停止。目前,没有在处理 fetch 后自动停止运行的逻辑。运行结果如下:
Magic Ape Simple Crawler 运行结果
最后,本章完成后,整个项目的结构如下:
魔猿简单爬虫项目结构
关于我
编程界的老猿猴,自媒体界的新宠じ☆ve
编程界的老猿猴,自媒体界的新宠じ☆ve 查看全部
java抓取网页内容(接上简易爬虫配置池线程池(ThreadPoolTaskExecutor)抓取任务的方法)
继续上一节(爬虫系列(0):项目建设)
网络爬虫是通过多线程和多任务逻辑实现的。线程池(ThreadPoolTaskExecutor)已经封装在springboot框架中,我们只需要使用它即可。
在本节中,我们主要实现网页连接信息的多线程捕获,并将信息存储在队列中。
介绍一个新的包
在pom中引入新的包,如下:
org.apache.commons
commons-lang3
org.jsoup
jsoup
1.8.3
org.projectlombok
lombok
provided
为了简化编码,这里引入lombok。IDE使用时需要安装lombok插件,否则会提示编译错误。
配置管理
springboot的配置文件统一管理在application.properties(.yml)中。这里我们也通过@ConfigurationProperties注解实现爬虫相关的配置。直接上传代码:
package mobi.huanyuan.spider.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
/**
* 爬虫配置.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:10
*/
@Data
@ConfigurationProperties(prefix = "huanyuan.spider")
public class SpiderConfig {
/**
* 爬取页面最大深度
*/
public int maxDepth = 2;
/**
* 下载页面线程数
*/
public int minerHtmlThreadNum = 2;
//=================================================
// 线程池配置
//=================================================
/**
* 核心线程池大小
*/
private int corePoolSize = 4;
/**
* 最大可创建的线程数
*/
private int maxPoolSize = 100;
/**
* 队列最大长度
*/
private int queueCapacity = 1000;
/**
* 线程池维护线程所允许的空闲时间
*/
private int keepAliveSeconds = 300;
}
然后,需要修改这些配置,只需要修改里面的application.properties(.yml):
魔猿简单爬虫配置
线程池
线程池使用现有的springboot,配置也可以在上面的配置管理中。这里只需要初始化配置:
package mobi.huanyuan.spider.config;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.ThreadPoolExecutor;
/**
* 线程池配置.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:35
*/
@Configuration
public class ThreadPoolConfig {
@Autowired
private SpiderConfig spiderConfig;
@Bean(name = "threadPoolTaskExecutor")
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setMaxPoolSize(spiderConfig.getMaxPoolSize());
executor.setCorePoolSize(spiderConfig.getCorePoolSize());
executor.setQueueCapacity(spiderConfig.getQueueCapacity());
executor.setKeepAliveSeconds(spiderConfig.getKeepAliveSeconds());
// 线程池对拒绝任务(无线程可用)的处理策略
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
}
队列管理
本节我们主要是抓取URL并保存到队列中,所以涉及到的队列就是要抓取的队列和要分析的队列(下节分析用到,这里只做存储),另外,为了防止重复抓取同一个URL,这里还需要添加一个Set集合来记录访问过的地址。
package mobi.huanyuan.spider;
import lombok.Getter;
import mobi.huanyuan.spider.bean.SpiderHtml;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Set;
/**
* 爬虫访问队列.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 10:54
*/
public class SpiderQueue {
private static Logger logger = LoggerFactory.getLogger(SpiderQueue.class);
/**
* Set集合 保证每一个URL只访问一次
*/
private static volatile Set urlSet = new HashSet();
/**
* 待访问队列
* 爬取页面线程从这里取数据
*/
private static volatile Queue unVisited = new LinkedList();
/**
* 等待提取URL的分析页面队列
* 解析页面线程从这里取数据
*/
private static volatile Queue waitingMine = new LinkedList();
/**
* 添加到URL队列
*
* @param url
*/
public synchronized static void addUrlSet(String url) {
urlSet.add(url);
}
/**
* 获得URL队列大小
*
* @return
*/
public static int getUrlSetSize() {
return urlSet.size();
}
/**
* 添加到待访问队列,每个URL只访问一次
*
* @param spiderHtml
*/
public synchronized static void addUnVisited(SpiderHtml spiderHtml) {
if (null != spiderHtml && !urlSet.contains(spiderHtml.getUrl())) {
logger.info("添加到待访问队列[{}] 当前第[{}]层 当前线程[{}]", spiderHtml.getUrl(), spiderHtml.getDepth(), Thread.currentThread().getName());
unVisited.add(spiderHtml);
}
}
/**
* 待访问出队列
*
* @return
*/
public synchronized static SpiderHtml unVisitedPoll() {
return unVisited.poll();
}
/**
* 添加到等待提取URL的分析页面队列
*
* @param html
*/
public synchronized static void addWaitingMine(SpiderHtml html) {
waitingMine.add(html);
}
/**
* 等待提取URL的分析页面出队列
*
* @return
*/
public synchronized static SpiderHtml waitingMinePoll() {
return waitingMine.poll();
}
/**
* 等待提取URL的分析页面队列大小
* @return
*/
public static int waitingMineSize() {
return waitingMine.size();
}
}
抓取任务
直接上传代码:
package mobi.huanyuan.spider.runable;
import mobi.huanyuan.spider.SpiderQueue;
import mobi.huanyuan.spider.bean.SpiderHtml;
import mobi.huanyuan.spider.config.SpiderConfig;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 抓取页面任务.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:43
*/
public class SpiderHtmlRunnable implements Runnable {
private static final Logger logger = LoggerFactory.getLogger(SpiderHtmlRunnable.class);
private static boolean done = false;
private SpiderConfig config;
public SpiderHtmlRunnable(SpiderConfig config) {
this.config = config;
}
@Override
public void run() {
while (!SpiderHtmlRunnable.done) {
done = true;
minerHtml();
done = false;
}
}
public synchronized void minerHtml() {
SpiderHtml minerUrl = SpiderQueue.unVisitedPoll(); // 待访问出队列。
try {
//判断当前页面爬取深度
if (null == minerUrl || StringUtils.isBlank(minerUrl.getUrl()) || minerUrl.getDepth() > config.getMaxDepth()) {
return;
}
//判断爬取页面URL是否包含http
if (!minerUrl.getUrl().startsWith("http")) {
logger.info("当前爬取URL[{}]没有http", minerUrl.getUrl());
return;
}
logger.info("当前爬取页面[{}]爬取深度[{}] 当前线程 [{}]", minerUrl.getUrl(), minerUrl.getDepth(), Thread.currentThread().getName());
Connection conn = Jsoup.connect(minerUrl.getUrl());
conn.header("User-Agent", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13");//配置模拟浏览器
Document doc = conn.get();
String page = doc.html();
SpiderHtml spiderHtml = new SpiderHtml();
spiderHtml.setUrl(minerUrl.getUrl());
spiderHtml.setHtml(page);
spiderHtml.setDepth(minerUrl.getDepth());
System.out.println(spiderHtml.getUrl());
// TODO: 添加到继续爬取队列
SpiderQueue.addWaitingMine(spiderHtml);
} catch (Exception e) {
logger.info("爬取页面失败 URL [{}]", minerUrl.getUrl());
logger.info("Error info [{}]", e.getMessage());
}
}
}
这是一个 Runnable 任务。主要目的是拉取URL数据,然后将其封装成SpiderHtml对象,存放在待分析队列中。这里使用的是Jsoup——一个用于HTML分析操作的Java工具包。如果您不确定,您可以搜索它。后面的章节也会用到分析部分。
其他页面信息包SpiderHtml
package mobi.huanyuan.spider.bean;
import lombok.Data;
import java.io.Serializable;
/**
* 页面信息类.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:02
*/
@Data
public class SpiderHtml implements Serializable {
/**
* 页面URL
*/
private String url;
/**
* 页面信息
*/
private String html;
/**
* 爬取深度
*/
private int depth;
}
爬行动物主类
package mobi.huanyuan.spider;
import mobi.huanyuan.spider.bean.SpiderHtml;
import mobi.huanyuan.spider.config.SpiderConfig;
import mobi.huanyuan.spider.runable.SpiderHtmlRunnable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
/**
* 爬虫.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:23
*/
@Component
public class Spider {
private static Logger logger = LoggerFactory.getLogger(Spider.class);
@Autowired
private ThreadPoolTaskExecutor threadPoolTaskExecutor;
@Autowired
private SpiderConfig spiderConfig;
public void start(SpiderHtml spiderHtml) {
//程序启动,将第一个起始页面放入待访问队列。
SpiderQueue.addUnVisited(spiderHtml);
//将URL 添加到URL队列 保证每个URL只访问一次
SpiderQueue.addUrlSet(spiderHtml.getUrl());
//download
for (int i = 0; i < spiderConfig.getMinerHtmlThreadNum(); i++) {
SpiderHtmlRunnable minerHtml = new SpiderHtmlRunnable(spiderConfig);
threadPoolTaskExecutor.execute(minerHtml);
}
// TODO: 监控爬取完毕之后停线程池,关闭程序
try {
TimeUnit.SECONDS.sleep(20);
logger.info("待分析URL队列大小: {}", SpiderQueue.waitingMineSize());
// 关闭线程池
threadPoolTaskExecutor.shutdown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
"// TODO:" 后面的代码逻辑在这里是暂时的。后续章节完成后,会慢慢移除。
最后
运行本节代码,需要在springboot项目的main方法中添加如下代码:
ConfigurableApplicationContext context = SpringApplication.run(SpiderApplication.class, args);
Spider spider = context.getBean(Spider.class);
SpiderHtml startPage = new SpiderHtml();
startPage.setUrl("$URL");
startPage.setDepth(2);
spider.start(startPage);
$URL 是需要抓取的网页地址。
springboot项目启动后,需要手动停止。目前,没有在处理 fetch 后自动停止运行的逻辑。运行结果如下:
Magic Ape Simple Crawler 运行结果
最后,本章完成后,整个项目的结构如下:
魔猿简单爬虫项目结构
关于我
编程界的老猿猴,自媒体界的新宠じ☆ve
编程界的老猿猴,自媒体界的新宠じ☆ve
java抓取网页内容(这篇文章介绍闲来无事,刚学会把git部署到远程服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-25 08:16
本文文章介绍了如何在java中使用url实现网页内容爬取
无事可做,刚学会了将git部署到远程服务器上,无事可做,所以干脆做了一个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上就是java中如何使用url实现网页内容爬取的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
java抓取网页内容(这篇文章介绍闲来无事,刚学会把git部署到远程服务器)
本文文章介绍了如何在java中使用url实现网页内容爬取
无事可做,刚学会了将git部署到远程服务器上,无事可做,所以干脆做了一个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:

先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上就是java中如何使用url实现网页内容爬取的详细内容。更多详情请关注其他相关php中文网站文章!

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
java抓取网页内容(看看程序员眼中的excel用javaphprubydom操作网页?教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-23 02:01
java抓取网页内容有个httpcookie可以采集新闻网站的内容
抓取互联网的网页源代码,是可以实现题主的要求的。推荐一本书《代码大全》,最后那章,里面介绍的是典型的java程序员抓取网页源代码的过程。
所有好的浏览器都可以抓取网页
yahoo!javascript教程
editplus,
googlesheets.看看程序员眼中的excel
用javaphprubydom操作网页?webform,ejb,
多使用jsp或servlet
win10新增了一个工具,javax.swing.handle
可以使用jq,
可以用jfinal来看看:
多个浏览器操作同一个网页,可以使用简单的hook来实现,不过需要做一个特别的程序接入。或者对应的浏览器都具有相应的hook。
torrent,内嵌地址可以基于http协议来推送而不用路由带回,就可以从公网上看另一台电脑的内容。
java的可以用handle
在这个场景下,问题是针对web服务来回答的。因为你需要一个动态获取网页的接口。对于这个接口而言,并不是让开发人员从后台接收网页后生成相应的对象,而是把网页的内容和一些附加的信息加入到一个工具中,接收端java的handleinterceptor比如:java-jfinal-get-download-info-formatjava-jfinal-get-download-info-predicates,还有http头,表头信息等传递到后台服务中,并在后台执行。 查看全部
java抓取网页内容(看看程序员眼中的excel用javaphprubydom操作网页?教程)
java抓取网页内容有个httpcookie可以采集新闻网站的内容
抓取互联网的网页源代码,是可以实现题主的要求的。推荐一本书《代码大全》,最后那章,里面介绍的是典型的java程序员抓取网页源代码的过程。
所有好的浏览器都可以抓取网页
yahoo!javascript教程
editplus,
googlesheets.看看程序员眼中的excel
用javaphprubydom操作网页?webform,ejb,
多使用jsp或servlet
win10新增了一个工具,javax.swing.handle
可以使用jq,
可以用jfinal来看看:
多个浏览器操作同一个网页,可以使用简单的hook来实现,不过需要做一个特别的程序接入。或者对应的浏览器都具有相应的hook。
torrent,内嵌地址可以基于http协议来推送而不用路由带回,就可以从公网上看另一台电脑的内容。
java的可以用handle
在这个场景下,问题是针对web服务来回答的。因为你需要一个动态获取网页的接口。对于这个接口而言,并不是让开发人员从后台接收网页后生成相应的对象,而是把网页的内容和一些附加的信息加入到一个工具中,接收端java的handleinterceptor比如:java-jfinal-get-download-info-formatjava-jfinal-get-download-info-predicates,还有http头,表头信息等传递到后台服务中,并在后台执行。
java抓取网页内容(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-19 04:13
原创链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据成功,这就是我们要获取的最终数据结果。最后想说,这里的这个网页比较简单,在网页的源码中可以看到源数据,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java抓取网页内容(一个+jsou提取网页数据的分类汇总(一))
原创链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据成功,这就是我们要获取的最终数据结果。最后想说,这里的这个网页比较简单,在网页的源码中可以看到源数据,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
java抓取网页内容(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-18 22:11
通过JAVA API,可以成功抓取网络上大部分的指定网页内容。下面就和大家分享一下对这种方法的理解和体会。最简单的抓取方法是:
Java 代码
URLurl=newURL(myurl);BufferedReaderbr=newBufferedReader(newInputStreamReader(url.openStream()));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){ i++;sb.append(s+"\r\n");}
这种方法爬一般的网页应该是没问题的,但是当一些网页中有嵌套的重定向连接时,会报Server redirected too many times之类的错误,这是因为这个网页里面有一些代码是转到其他网页,太多的循环导致程序错误。如果只想爬取这个URL中的网页内容,不想跳转到其他网页,可以使用下面的代码。
Java 代码
URLurlmy=newURL(myurl);HttpURLConnectioncon=(HttpURLConnection)urlmy.openConnection();con.setFollowRedirects(true);con.setInstanceFollowRedirects(false);con.connect();BufferedReaderbr=newBufferedReader(newInputStreamReader(con.getInputStream(), "UTF-8"));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){sb.append(s+"\r\n"); }
这样,在爬取的时候,程序就不会跳转到其他页面去爬取其他内容,就达到了我们的目的。
如果我们在 Intranet 中,我们还需要为其添加代理。Java 提供对具有特殊系统属性的代理服务器的支持,只要在上述程序中添加以下程序即可。
Java 代码
System.getProperties().setProperty("http.proxyHost",proxyName);System.getProperties().setProperty("http.proxyPort",port);
这样,您就可以在内网的同时从Internet上抓取您想要的东西。
上面程序捕捉到的所有内容都存储在sb字符串中,我们可以通过正则表达式进行分析,提取出我们想要的具体内容,给我用,呵呵,这是多么美妙的一件事啊!! 查看全部
java抓取网页内容(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以成功抓取网络上大部分的指定网页内容。下面就和大家分享一下对这种方法的理解和体会。最简单的抓取方法是:
Java 代码
URLurl=newURL(myurl);BufferedReaderbr=newBufferedReader(newInputStreamReader(url.openStream()));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){ i++;sb.append(s+"\r\n");}
这种方法爬一般的网页应该是没问题的,但是当一些网页中有嵌套的重定向连接时,会报Server redirected too many times之类的错误,这是因为这个网页里面有一些代码是转到其他网页,太多的循环导致程序错误。如果只想爬取这个URL中的网页内容,不想跳转到其他网页,可以使用下面的代码。
Java 代码
URLurlmy=newURL(myurl);HttpURLConnectioncon=(HttpURLConnection)urlmy.openConnection();con.setFollowRedirects(true);con.setInstanceFollowRedirects(false);con.connect();BufferedReaderbr=newBufferedReader(newInputStreamReader(con.getInputStream(), "UTF-8"));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){sb.append(s+"\r\n"); }
这样,在爬取的时候,程序就不会跳转到其他页面去爬取其他内容,就达到了我们的目的。
如果我们在 Intranet 中,我们还需要为其添加代理。Java 提供对具有特殊系统属性的代理服务器的支持,只要在上述程序中添加以下程序即可。
Java 代码
System.getProperties().setProperty("http.proxyHost",proxyName);System.getProperties().setProperty("http.proxyPort",port);
这样,您就可以在内网的同时从Internet上抓取您想要的东西。
上面程序捕捉到的所有内容都存储在sb字符串中,我们可以通过正则表达式进行分析,提取出我们想要的具体内容,给我用,呵呵,这是多么美妙的一件事啊!!
java抓取网页内容(前两天想写一段自动提取微博状态的代码,可以用PHP写 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-18 00:11
)
前两天想写一个自动提取微博状态的代码。据我所知,实现这个功能可以用PHP写,也可以用Java写。我觉得用Java写和调试比较容易,PHP脚本需要上传到服务器什么的。
代码很简单,创建一个包的URL类的对象,用这个URL作为写作源,将内容保存在一个字符串中。然后创建一个新文件并写出字符串。但是请注意,不同的 网站 使用不同的代码字。现在大多数 网站 使用 utf-8 字符编码,而基于 wordpress 的 网站 使用这种编码。但是很多中文网站,包括网易网站等门户网站,仍然使用gb2312编码。一方面,gb2312的历史比utf-8要长。早期中文网站是用gb2312构建的,现在修改工作量太大;-8 编码以节省空间。正是因为这个不同,所以在输入网页的html代码时,一定要选择正确的阅读方式。java的inputstream构造函数可以选择utf-8作为参数,但是没有gb2312选项。因此,在抓取网易的网页时,保存的文档会出现乱码。
另外,这个例子只抓取静态网页内容,不适合微博的状态,因为要抓取状态,必须先登录自己的账号,并且必须参考新浪的API文档。
import java.beans.FeatureDescriptor;
import java.io.*;
import java.net.*;
public class spider {
/**
* @param args
*/
public static String fetchWebpage(String urlname){
URL url;
String s;
StringBuffer sbuffer = new StringBuffer();
try{
url = new URL(urlname);
// my website use utf-8, but some other websites, like 163 and baidu, use gb2312.
InputStreamReader sreader = new InputStreamReader(url.openStream(),"utf-8");
BufferedReader breader = new BufferedReader(sreader);
while((s=breader.readLine())!=null){
sbuffer.append(s);
}
breader.close();
}catch(Exception e){
e.printStackTrace();
}
return sbuffer.toString();
}
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String address = "http://www.mr-naive.com";
FileOutputStream fos = new FileOutputStream(new File("myPage.html"));
OutputStreamWriter oswrite = new OutputStreamWriter(fos, "utf-8");
BufferedWriter bwriter = new BufferedWriter(oswrite);
bwriter.write(fetchWebpage(address));
bwriter.close();
}
} 查看全部
java抓取网页内容(前两天想写一段自动提取微博状态的代码,可以用PHP写
)
前两天想写一个自动提取微博状态的代码。据我所知,实现这个功能可以用PHP写,也可以用Java写。我觉得用Java写和调试比较容易,PHP脚本需要上传到服务器什么的。
代码很简单,创建一个包的URL类的对象,用这个URL作为写作源,将内容保存在一个字符串中。然后创建一个新文件并写出字符串。但是请注意,不同的 网站 使用不同的代码字。现在大多数 网站 使用 utf-8 字符编码,而基于 wordpress 的 网站 使用这种编码。但是很多中文网站,包括网易网站等门户网站,仍然使用gb2312编码。一方面,gb2312的历史比utf-8要长。早期中文网站是用gb2312构建的,现在修改工作量太大;-8 编码以节省空间。正是因为这个不同,所以在输入网页的html代码时,一定要选择正确的阅读方式。java的inputstream构造函数可以选择utf-8作为参数,但是没有gb2312选项。因此,在抓取网易的网页时,保存的文档会出现乱码。
另外,这个例子只抓取静态网页内容,不适合微博的状态,因为要抓取状态,必须先登录自己的账号,并且必须参考新浪的API文档。
import java.beans.FeatureDescriptor;
import java.io.*;
import java.net.*;
public class spider {
/**
* @param args
*/
public static String fetchWebpage(String urlname){
URL url;
String s;
StringBuffer sbuffer = new StringBuffer();
try{
url = new URL(urlname);
// my website use utf-8, but some other websites, like 163 and baidu, use gb2312.
InputStreamReader sreader = new InputStreamReader(url.openStream(),"utf-8");
BufferedReader breader = new BufferedReader(sreader);
while((s=breader.readLine())!=null){
sbuffer.append(s);
}
breader.close();
}catch(Exception e){
e.printStackTrace();
}
return sbuffer.toString();
}
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String address = "http://www.mr-naive.com";
FileOutputStream fos = new FileOutputStream(new File("myPage.html"));
OutputStreamWriter oswrite = new OutputStreamWriter(fos, "utf-8");
BufferedWriter bwriter = new BufferedWriter(oswrite);
bwriter.write(fetchWebpage(address));
bwriter.close();
}
}
java抓取网页内容(这里有新鲜出炉的Java函数式编程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-17 15:24
新鲜出炉的Java函数式编程来了,程序狗的速度来了!
Java 编程语言 java 是一种面向对象的编程语言,可以编写跨平台的应用软件。 ),JavaSE(j2se)的总称。
本文文章主要介绍JAVA使用爬虫爬取网站网页内容的方法,并结合实例分析java爬虫的两种实现技术,具有一定的参考价值,有需要的朋友需要的可以参考下一个
本文的例子描述了JAVA使用爬虫爬取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA研究爬网,呵呵,进门了,和大家分享一下我的经验
提供了以下两种方法,一种是使用apache提供的包。另一种是使用JAVA自带的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength 查看全部
java抓取网页内容(这里有新鲜出炉的Java函数式编程,程序狗速度看过来!)
新鲜出炉的Java函数式编程来了,程序狗的速度来了!
Java 编程语言 java 是一种面向对象的编程语言,可以编写跨平台的应用软件。 ),JavaSE(j2se)的总称。
本文文章主要介绍JAVA使用爬虫爬取网站网页内容的方法,并结合实例分析java爬虫的两种实现技术,具有一定的参考价值,有需要的朋友需要的可以参考下一个
本文的例子描述了JAVA使用爬虫爬取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA研究爬网,呵呵,进门了,和大家分享一下我的经验
提供了以下两种方法,一种是使用apache提供的包。另一种是使用JAVA自带的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength
java抓取网页内容( 如何从网页上抓取有价值的东西?看懂了下面的程序(非常简单))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-17 05:09
如何从网页上抓取有价值的东西?看懂了下面的程序(非常简单))
java使用正则表达式提取网站titles
来自网页
如何从网页中抓取有价值的东西?理解了下面这个程序(很简单)后,你就可以从网页中抓取任何你想抓取的信息(标题、内容、Email、价格等)了。
package catchhtml;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetHtmlTitle {
public GetHtmlTitle(String htmlUrl){
System.out.println("/n------------开始读取网页(" + htmlUrl + ")-----------");
String htmlSource = "";
htmlSource = getHtmlSource(htmlUrl);//获取htmlUrl网址网页的源码
System.out.println("------------读取网页(" + htmlUrl + ")结束-----------/n");
System.out.println("------------分析(" + htmlUrl + ")结果如下-----------/n");
String title = getTitle(htmlSource);
System.out.println("网站标题: " + title);
}
/**
* 根据网址返回网页的源码
* @param htmlUrl
* @return
*/
public String getHtmlSource(String htmlUrl){
URL url;
StringBuffer sb = new StringBuffer();
try{
url = new URL(htmlUrl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "UTF-8"));//读取网页全部内容
String temp;
while ((temp = in.readLine()) != null)
{
sb.append(temp);
}
in.close();
}catch (MalformedURLException e) {
System.out.println("你输入的URL格式有问题!请仔细输入");
}catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
* 从html源码(字符串)中去掉标题
* @param htmlSource
* @return
*/
public String getTitle(String htmlSource){
List list = new ArrayList();
String title = "";
//Pattern pa = Pattern.compile(".*?", Pattern.CANON_EQ);也可以
Pattern pa = Pattern.compile(".*?");//源码中标题正则表达式
Matcher ma = pa.matcher(htmlSource);
while (ma.find())//寻找符合el的字串
{
list.add(ma.group());//将符合el的字串加入到list中
}
for (int i = 0; i < list.size(); i++)
{
title = title + list.get(i);
}
return outTag(title);
}
/**
* 去掉html源码中的标签
* @param s
* @return
*/
public String outTag(String s)
{
return s.replaceAll("", "");
}
public static void main(String[] args) {
String htmlUrl = "http://www.157buy.com";
new GetHtmlTitle(htmlUrl);
}
}
联系方式:【我的公司】(鑫臻科技)【技术咨询】【QQ】3396726884
购书京东链接***微信小程序商城开发实践*** | ***新媒体营销精髓:精准定位+爆款打造+巧妙运营+内容变现***
发表于@2015-07-28 15:04 肯新君阅读(5301)评论(0)已编辑 查看全部
java抓取网页内容(
如何从网页上抓取有价值的东西?看懂了下面的程序(非常简单))
java使用正则表达式提取网站titles
来自网页
如何从网页中抓取有价值的东西?理解了下面这个程序(很简单)后,你就可以从网页中抓取任何你想抓取的信息(标题、内容、Email、价格等)了。
package catchhtml;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetHtmlTitle {
public GetHtmlTitle(String htmlUrl){
System.out.println("/n------------开始读取网页(" + htmlUrl + ")-----------");
String htmlSource = "";
htmlSource = getHtmlSource(htmlUrl);//获取htmlUrl网址网页的源码
System.out.println("------------读取网页(" + htmlUrl + ")结束-----------/n");
System.out.println("------------分析(" + htmlUrl + ")结果如下-----------/n");
String title = getTitle(htmlSource);
System.out.println("网站标题: " + title);
}
/**
* 根据网址返回网页的源码
* @param htmlUrl
* @return
*/
public String getHtmlSource(String htmlUrl){
URL url;
StringBuffer sb = new StringBuffer();
try{
url = new URL(htmlUrl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "UTF-8"));//读取网页全部内容
String temp;
while ((temp = in.readLine()) != null)
{
sb.append(temp);
}
in.close();
}catch (MalformedURLException e) {
System.out.println("你输入的URL格式有问题!请仔细输入");
}catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
* 从html源码(字符串)中去掉标题
* @param htmlSource
* @return
*/
public String getTitle(String htmlSource){
List list = new ArrayList();
String title = "";
//Pattern pa = Pattern.compile(".*?", Pattern.CANON_EQ);也可以
Pattern pa = Pattern.compile(".*?");//源码中标题正则表达式
Matcher ma = pa.matcher(htmlSource);
while (ma.find())//寻找符合el的字串
{
list.add(ma.group());//将符合el的字串加入到list中
}
for (int i = 0; i < list.size(); i++)
{
title = title + list.get(i);
}
return outTag(title);
}
/**
* 去掉html源码中的标签
* @param s
* @return
*/
public String outTag(String s)
{
return s.replaceAll("", "");
}
public static void main(String[] args) {
String htmlUrl = "http://www.157buy.com";
new GetHtmlTitle(htmlUrl);
}
}
联系方式:【我的公司】(鑫臻科技)【技术咨询】【QQ】3396726884
购书京东链接***微信小程序商城开发实践*** | ***新媒体营销精髓:精准定位+爆款打造+巧妙运营+内容变现***
发表于@2015-07-28 15:04 肯新君阅读(5301)评论(0)已编辑
java抓取网页内容(WebMagic使用Jsoup来管理URL(newRedisScheduler)组件功能说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-15 10:15
//设置Scheduler,使用Redis管理URL队列
.setScheduler(new RedisScheduler("localhost"))
//设置Pipeline并将结果以json模式保存到文件
.addPipeline(new JsonFilePipeline("D:\\data\\webmagic"))
//开启5个线程同时执行
.thread(5)
//启动爬虫
.run();
}
组件功能说明:
1.下载器
Downloader 负责从 Internet 下载页面以供后续处理。 WebMagic 默认使用 Apache HttpClient 作为下载工具。
2.页面处理器
PageProcessor 负责解析页面、提取有用信息和发现新链接。 WebMagic 使用 Jsoup 作为 HTML 解析工具,并在其基础上开发了 Xsoup 解析 XPath 的工具。
这四个组件中,PageProcessor对于每个站点的每个页面都是不同的,是需要用户自定义的部分。
3.调度器
Scheduler 负责管理要抓取的 URL,以及一些去重工作。 WebMagic 默认提供 JDK 的内存队列来管理 URL,并使用集合进行去重。还支持使用 Redis 进行分布式管理。
除非项目有一些特殊的分布式需求,否则不需要自己定制Scheduler。
4.管道
Pipeline负责提取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供两种结果处理方案:“输出到控制台”和“保存到文件”。 Pipeline 定义了保存结果的方式。如果要保存到指定的数据库,需要编写相应的Pipeline。一般来说,对于一类需求,只需要编写一个 Pipeline。
对象描述:
Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader的唯一途径。
除了 URL 本身,它还收录一个 Key-Value 结构的额外字段。你可以额外保存一些特殊的属性,并在其他地方读取它们来完成不同的功能。比如添加上一页的一些信息等。
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。它的API和Map非常相似,值得注意的是它有一个字段skip,如果设置为true,它不应该被Pipeline处理。 查看全部
java抓取网页内容(WebMagic使用Jsoup来管理URL(newRedisScheduler)组件功能说明)
//设置Scheduler,使用Redis管理URL队列
.setScheduler(new RedisScheduler("localhost"))
//设置Pipeline并将结果以json模式保存到文件
.addPipeline(new JsonFilePipeline("D:\\data\\webmagic"))
//开启5个线程同时执行
.thread(5)
//启动爬虫
.run();
}
组件功能说明:
1.下载器
Downloader 负责从 Internet 下载页面以供后续处理。 WebMagic 默认使用 Apache HttpClient 作为下载工具。
2.页面处理器
PageProcessor 负责解析页面、提取有用信息和发现新链接。 WebMagic 使用 Jsoup 作为 HTML 解析工具,并在其基础上开发了 Xsoup 解析 XPath 的工具。
这四个组件中,PageProcessor对于每个站点的每个页面都是不同的,是需要用户自定义的部分。
3.调度器
Scheduler 负责管理要抓取的 URL,以及一些去重工作。 WebMagic 默认提供 JDK 的内存队列来管理 URL,并使用集合进行去重。还支持使用 Redis 进行分布式管理。
除非项目有一些特殊的分布式需求,否则不需要自己定制Scheduler。
4.管道
Pipeline负责提取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供两种结果处理方案:“输出到控制台”和“保存到文件”。 Pipeline 定义了保存结果的方式。如果要保存到指定的数据库,需要编写相应的Pipeline。一般来说,对于一类需求,只需要编写一个 Pipeline。
对象描述:
Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader的唯一途径。
除了 URL 本身,它还收录一个 Key-Value 结构的额外字段。你可以额外保存一些特殊的属性,并在其他地方读取它们来完成不同的功能。比如添加上一页的一些信息等。
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。它的API和Map非常相似,值得注意的是它有一个字段skip,如果设置为true,它不应该被Pipeline处理。
java抓取网页内容(本文实例讲述了。分享给大家供大家参考。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-11 23:24
本文的例子描述了JAVA使用爬虫爬取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA研究爬网,呵呵,进门了,和大家分享一下我的经验
提供了以下两种方法,一种是使用apache提供的包。另一种是使用JAVA自带的。
代码如下:
<p> // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar public static String createhttpClient(String url, String param) { HttpClient client = new HttpClient(); String response = null; String keyword = null; PostMethod postMethod = new PostMethod(url); // try { // if (param != null) // keyword = new String(param.getBytes("gb2312"), "ISO-8859-1"); // } catch (UnsupportedEncodingException e1) { // // TODO Auto-generated catch block // e1.printStackTrace(); // } // NameValuePair[] data = { new NameValuePair("keyword", keyword) }; // // 将表单的值放入postMethod中 // postMethod.setRequestBody(data); // 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下 try { int statusCode = client.executeMethod(postMethod); response = new String(postMethod.getResponseBodyAsString() .getBytes("ISO-8859-1"), "gb2312"); //这里要注意下 gb2312要和你抓取网页的编码要一样 String p = response.replaceAll("//&[a-zA-Z]{1,10};", "") .replaceAll("]*>", "");//去掉网页中带有html语言的标签 System.out.println(p); } catch (Exception e) { e.printStackTrace(); } return response; } // 第二种方法 // 这种方法是JAVA自带的URL来抓取网站内容 public String getPageContent(String strUrl, String strPostRequest, int maxLength) { // 读取结果网页 StringBuffer buffer = new StringBuffer(); System.setProperty("sun.net.client.defaultConnectTimeout", "5000"); System.setProperty("sun.net.client.defaultReadTimeout", "5000"); try { URL newUrl = new URL(strUrl); HttpURLConnection hConnect = (HttpURLConnection) newUrl .openConnection(); // POST方式的额外数据 if (strPostRequest.length() > 0) { hConnect.setDoOutput(true); OutputStreamWriter out = new OutputStreamWriter(hConnect .getOutputStream()); out.write(strPostRequest); out.flush(); out.close(); } // 读取内容 BufferedReader rd = new BufferedReader(new InputStreamReader( hConnect.getInputStream())); int ch; for (int length = 0; (ch = rd.read()) > -1 && (maxLength 查看全部
java抓取网页内容(本文实例讲述了。分享给大家供大家参考。。)
本文的例子描述了JAVA使用爬虫爬取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA研究爬网,呵呵,进门了,和大家分享一下我的经验
提供了以下两种方法,一种是使用apache提供的包。另一种是使用JAVA自带的。
代码如下:
<p> // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar public static String createhttpClient(String url, String param) { HttpClient client = new HttpClient(); String response = null; String keyword = null; PostMethod postMethod = new PostMethod(url); // try { // if (param != null) // keyword = new String(param.getBytes("gb2312"), "ISO-8859-1"); // } catch (UnsupportedEncodingException e1) { // // TODO Auto-generated catch block // e1.printStackTrace(); // } // NameValuePair[] data = { new NameValuePair("keyword", keyword) }; // // 将表单的值放入postMethod中 // postMethod.setRequestBody(data); // 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下 try { int statusCode = client.executeMethod(postMethod); response = new String(postMethod.getResponseBodyAsString() .getBytes("ISO-8859-1"), "gb2312"); //这里要注意下 gb2312要和你抓取网页的编码要一样 String p = response.replaceAll("//&[a-zA-Z]{1,10};", "") .replaceAll("]*>", "");//去掉网页中带有html语言的标签 System.out.println(p); } catch (Exception e) { e.printStackTrace(); } return response; } // 第二种方法 // 这种方法是JAVA自带的URL来抓取网站内容 public String getPageContent(String strUrl, String strPostRequest, int maxLength) { // 读取结果网页 StringBuffer buffer = new StringBuffer(); System.setProperty("sun.net.client.defaultConnectTimeout", "5000"); System.setProperty("sun.net.client.defaultReadTimeout", "5000"); try { URL newUrl = new URL(strUrl); HttpURLConnection hConnect = (HttpURLConnection) newUrl .openConnection(); // POST方式的额外数据 if (strPostRequest.length() > 0) { hConnect.setDoOutput(true); OutputStreamWriter out = new OutputStreamWriter(hConnect .getOutputStream()); out.write(strPostRequest); out.flush(); out.close(); } // 读取内容 BufferedReader rd = new BufferedReader(new InputStreamReader( hConnect.getInputStream())); int ch; for (int length = 0; (ch = rd.read()) > -1 && (maxLength
java抓取网页内容( 2017年09月26日08:45投稿:lqh这篇文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-09 00:02
2017年09月26日08:45投稿:lqh这篇文章)
java读取网页内容的详细例子
更新时间:2017-09-26 08:34:45 投稿:lqh
本文章主要介绍java读取网页内容示例的相关信息。希望这篇文章能对大家有所帮助,让大家学习和理解这部分内容。有需要的朋友可以参考以下
java读取网页内容的详细例子
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上面的代码程序是将网页的源代码,包括HTML和XML,读成JAVA中的字符串String a。
Java中的String类型空间很大,基本可以容纳一个网页源代码的内容。
从网页读取内容也是对输入流的操作。
与标准输入源不同,在:
BufferedReader in = new BufferedReader(new InputStreamReader(...))
在 InputStreamReader 中输入 System.in。
这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续操作和处理与加载标准输入源相同。
BufferedReader需要在JAVA中捕获IOException,而使用URL源不仅要引入.*包,还要捕获MalformedURLException。
如有任何问题,请留言或到本站社区交流讨论,感谢您的阅读,希望对大家有所帮助,感谢您对本站的支持! 查看全部
java抓取网页内容(
2017年09月26日08:45投稿:lqh这篇文章)
java读取网页内容的详细例子
更新时间:2017-09-26 08:34:45 投稿:lqh
本文章主要介绍java读取网页内容示例的相关信息。希望这篇文章能对大家有所帮助,让大家学习和理解这部分内容。有需要的朋友可以参考以下
java读取网页内容的详细例子
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上面的代码程序是将网页的源代码,包括HTML和XML,读成JAVA中的字符串String a。
Java中的String类型空间很大,基本可以容纳一个网页源代码的内容。
从网页读取内容也是对输入流的操作。
与标准输入源不同,在:
BufferedReader in = new BufferedReader(new InputStreamReader(...))
在 InputStreamReader 中输入 System.in。
这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续操作和处理与加载标准输入源相同。
BufferedReader需要在JAVA中捕获IOException,而使用URL源不仅要引入.*包,还要捕获MalformedURLException。
如有任何问题,请留言或到本站社区交流讨论,感谢您的阅读,希望对大家有所帮助,感谢您对本站的支持!
java抓取网页内容(返回一段xml链接的html代码效果怎么样?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-07 19:15
有时,我们需要在java程序中获取一个连接,然后解析连接后,获取连接返回的内容和结果进行分析。准确地说,解析一个链接。
以下代码解析百度主页上的链接,得到html代码的效果:
1 public static List getURLCollection(String address){
2 List list = new LinkedList();
3 try{
4 URL url = new URL(address);
5 URLConnection conn = url.openConnection();
6 conn.connect();
7 InputStream in = conn.getInputStream();
8 InputStreamReader input = new InputStreamReader(in, "UTF-8");
9 BufferedReader buf = new BufferedReader(input);
10 String nextLine = buf.readLine();
11
12 while(nextLine != null){
13 list.add(nextLine);
14 nextLine = buf.readLine();
15 }
16 }catch(Exception e){
17 e.printStackTrace();
18 }
19 return list;
20 }
21
22 public static void main(String[] args){
23 String address = "http://www.baidu.com";
24 List list = getURLCollection(address);
25 String buf = "";
26 for(String str : list){
27 buf+=str+"\n";
28 }
29
30 System.out.println(buf);
31 }
效果如果:
这样,百度的html的代码就被抓到了。
这有什么神奇的用途吗?
比如我们访问第三方链接时,第三方返回一段xml,我们需要他们提供的返回值来提供判断数据等等。以便它可以使用... 查看全部
java抓取网页内容(返回一段xml链接的html代码效果怎么样?-八维教育)
有时,我们需要在java程序中获取一个连接,然后解析连接后,获取连接返回的内容和结果进行分析。准确地说,解析一个链接。
以下代码解析百度主页上的链接,得到html代码的效果:
1 public static List getURLCollection(String address){
2 List list = new LinkedList();
3 try{
4 URL url = new URL(address);
5 URLConnection conn = url.openConnection();
6 conn.connect();
7 InputStream in = conn.getInputStream();
8 InputStreamReader input = new InputStreamReader(in, "UTF-8");
9 BufferedReader buf = new BufferedReader(input);
10 String nextLine = buf.readLine();
11
12 while(nextLine != null){
13 list.add(nextLine);
14 nextLine = buf.readLine();
15 }
16 }catch(Exception e){
17 e.printStackTrace();
18 }
19 return list;
20 }
21
22 public static void main(String[] args){
23 String address = "http://www.baidu.com";
24 List list = getURLCollection(address);
25 String buf = "";
26 for(String str : list){
27 buf+=str+"\n";
28 }
29
30 System.out.println(buf);
31 }
效果如果:
这样,百度的html的代码就被抓到了。
这有什么神奇的用途吗?
比如我们访问第三方链接时,第三方返回一段xml,我们需要他们提供的返回值来提供判断数据等等。以便它可以使用...
java抓取网页内容( 以上的代码程序是把一个网页的源代码a中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-06 19:18
以上的代码程序是把一个网页的源代码a中)
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上述代码程序将一个网页的源代码,包括 HTML 和 XML,读入 JAVA 中的字符串 String a。
Java中的String类型空间很大,基本可以容纳一个网页源码的内容。
从网页中读取内容也是对输入流的操作。
与标准输入源不同,在:BufferedReader in = new BufferedReader(new InputStreamReader(...))
只需在 InputStreamReader 中输入 System.in。这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续的操作和处理与加载标准输入源完全一样。
BufferedReader 要求JAVA 必须捕获IOException,使用URL source 不仅要导入.* 包,还要捕获MalformedURLException。 查看全部
java抓取网页内容(
以上的代码程序是把一个网页的源代码a中)
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上述代码程序将一个网页的源代码,包括 HTML 和 XML,读入 JAVA 中的字符串 String a。
Java中的String类型空间很大,基本可以容纳一个网页源码的内容。
从网页中读取内容也是对输入流的操作。
与标准输入源不同,在:BufferedReader in = new BufferedReader(new InputStreamReader(...))
只需在 InputStreamReader 中输入 System.in。这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续的操作和处理与加载标准输入源完全一样。
BufferedReader 要求JAVA 必须捕获IOException,使用URL source 不仅要导入.* 包,还要捕获MalformedURLException。
java抓取网页内容(.getEntity实现方案,解析本地弹幕xml文件的代码如下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2022-01-04 12:14
(一)实现思路一,定位弹幕文件
一般使用json或者xml格式来保存弹幕,所以我们只要在视频网页中找到xml文件或者json文件就可以定位弹幕文件。
2.解析弹幕文件
然后通过jsoup解析文件,提取出我们弹幕的文本内容。
(二)第一个实现方案,解析本地文件1,定位弹幕文件
比如我们要抓取下面视频的弹幕文件。
打开Chrome的Network后刷新网页,然后在输入框中输入xml,过滤掉xml文件资源:
将光标移动到文件上,可以看到文件的具体地址如下:
在文件上右击Open in new tab,在新的浏览器页面查看弹幕文件的内容:
2.解析弹幕文件2.1 创建基础maven工程
输入 GroupId 和 ArtifactId
本项目将使用jar包jsoup,所以在项目根目录下创建lib目标,将jar复制进去,然后将jar包构建到项目中,如下:
选择 jar 并单击“确定”。
2.2 在项目根目录下创建弹幕文件
在根目录创建一个3232417.xml文件,复制弹幕页面的内容,保存在文件中。只需全选并直接复制即可。我们后面解析文件的时候,只会提取有用的文本,所以第一行内容不需要去掉,如下:
2.3 代码实现
解析本地弹幕xml文件的代码如下:
import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.File; import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class LocalFile { public static ArrayList getData(String fileName){ ArrayList list = new ArrayList(); try{ File input = new File(fileName); Document doc = Jsoup.parse(input, "UTF-8"); //每条弹幕的内容都处于标签中,于是根据该标签找到所有弹幕 Elements contents = doc.getElementsByTag("d"); for (Element content : contents) { list.add(content.text()); //将标签中的文本内容,也就是弹幕内容,添加到list中 } } catch (Exception e) { e.printStackTrace(); } return list; } } 复制代码
在入口类Main.java中,调用LocalFile类的getData方法,输入参数为xml文件名,每条弹幕解析输出:
import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class Main { public static void main(String[] args){ ArrayList items = new ArrayList(); //1,通过解析本地文件的方式得到所有弹幕 items = LocalFile.getData("3232417.xml"); //遍历输出每条弹幕 for (String item : items) { System.out.println(item); } } } 复制代码
输出如下:
(三) 第二种实现方案,解析远程服务器文件1,添加httpclient依赖
由于需要访问远程服务器,所以使用了一个相关的依赖,提供对http服务器的访问。在 pom.xml 文件中添加:
org.apache.httpcomponents httpclient 4.3.3 复制代码
2. 实现代码
import org.apache.http.HttpEntity; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class RemoteFile { public static ArrayList getData(String fileName) throws IOException { ArrayList list = new ArrayList(); //1,创建HttpClient对象,我们使用到Apache中的HttpClient的实例CloseableHttpClient CloseableHttpClient httpclient = HttpClients.createDefault(); //2,创建HttpGet请求实例,该实例指示向目标URL发起GET请求 HttpGet httpGet = new HttpGet(fileName); //3,执行HttpGet请求实例,也就是发起GET请求,响应结果保存到httpResponse变量中 CloseableHttpResponse httpResponse = httpclient.execute(httpGet); try { //4,得到弹幕文件的文件内容 HttpEntity httpEntity = httpResponse.getEntity(); String httpHtml = EntityUtils.toString(httpEntity); //5,解析弹幕文件,把每条弹幕放入list中 Document doc = Jsoup.parse(httpHtml, "UTF-8"); Elements contents = doc.getElementsByTag("d"); for (Element content : contents) { list.add(content.text()); //将标签中的文本内容,也就是弹幕内容,添加到list中 } } catch (Exception e) { e.printStackTrace(); } finally { httpResponse.close(); } return list; } } 复制代码
CloseableHttpResponse httpResponse = httpclient.execute(httpGet); 执行GET请求后,响应结果保存在httpResponse中。response.getEntity()是响应结果中的消息实体,因为响应结果中还收录Headers等其他内容如下图所示,这里我们只需要关注getEntity()消息实体即可。
EntityUtils.toString(response.getEntity()); 以流的形式返回服务器写入的响应内容。比如服务端调用的方法最后是: responseWriter.write("just do it"); 然后是EntityUtils。toString(response.getEntity()); 得到这句话就去做吧。这可以简单的理解为网页的html代码,也就是在网页源代码上右击可以看到的所有html代码。我们需要解析的就是这样的html代码。
在入口类Main.java中,调用RemoteFile类的getData方法,输入参数为xml文件名,解析每个弹幕并输出:
import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class Main { public static void main(String[] args){ ArrayList items = new ArrayList(); //1,通过解析本地文件的方式得到所有弹幕 // items = LocalFile.getData("3232417.xml"); //2,通过解析远程服务器文件的方式得到所有弹幕 items = RemoteFile.getData("https://comment.bilibili.com/3232417.xml"); //遍历输出每条弹幕 for (String item : items) { System.out.println(item); } } } 复制代码
输出如下:
项目代码
代码仓库:完整的项目代码 查看全部
java抓取网页内容(.getEntity实现方案,解析本地弹幕xml文件的代码如下)
(一)实现思路一,定位弹幕文件
一般使用json或者xml格式来保存弹幕,所以我们只要在视频网页中找到xml文件或者json文件就可以定位弹幕文件。
2.解析弹幕文件
然后通过jsoup解析文件,提取出我们弹幕的文本内容。
(二)第一个实现方案,解析本地文件1,定位弹幕文件
比如我们要抓取下面视频的弹幕文件。
打开Chrome的Network后刷新网页,然后在输入框中输入xml,过滤掉xml文件资源:
将光标移动到文件上,可以看到文件的具体地址如下:
在文件上右击Open in new tab,在新的浏览器页面查看弹幕文件的内容:
2.解析弹幕文件2.1 创建基础maven工程
输入 GroupId 和 ArtifactId
本项目将使用jar包jsoup,所以在项目根目录下创建lib目标,将jar复制进去,然后将jar包构建到项目中,如下:
选择 jar 并单击“确定”。
2.2 在项目根目录下创建弹幕文件
在根目录创建一个3232417.xml文件,复制弹幕页面的内容,保存在文件中。只需全选并直接复制即可。我们后面解析文件的时候,只会提取有用的文本,所以第一行内容不需要去掉,如下:
2.3 代码实现
解析本地弹幕xml文件的代码如下:
import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.File; import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class LocalFile { public static ArrayList getData(String fileName){ ArrayList list = new ArrayList(); try{ File input = new File(fileName); Document doc = Jsoup.parse(input, "UTF-8"); //每条弹幕的内容都处于标签中,于是根据该标签找到所有弹幕 Elements contents = doc.getElementsByTag("d"); for (Element content : contents) { list.add(content.text()); //将标签中的文本内容,也就是弹幕内容,添加到list中 } } catch (Exception e) { e.printStackTrace(); } return list; } } 复制代码
在入口类Main.java中,调用LocalFile类的getData方法,输入参数为xml文件名,每条弹幕解析输出:
import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class Main { public static void main(String[] args){ ArrayList items = new ArrayList(); //1,通过解析本地文件的方式得到所有弹幕 items = LocalFile.getData("3232417.xml"); //遍历输出每条弹幕 for (String item : items) { System.out.println(item); } } } 复制代码
输出如下:
(三) 第二种实现方案,解析远程服务器文件1,添加httpclient依赖
由于需要访问远程服务器,所以使用了一个相关的依赖,提供对http服务器的访问。在 pom.xml 文件中添加:
org.apache.httpcomponents httpclient 4.3.3 复制代码
2. 实现代码
import org.apache.http.HttpEntity; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class RemoteFile { public static ArrayList getData(String fileName) throws IOException { ArrayList list = new ArrayList(); //1,创建HttpClient对象,我们使用到Apache中的HttpClient的实例CloseableHttpClient CloseableHttpClient httpclient = HttpClients.createDefault(); //2,创建HttpGet请求实例,该实例指示向目标URL发起GET请求 HttpGet httpGet = new HttpGet(fileName); //3,执行HttpGet请求实例,也就是发起GET请求,响应结果保存到httpResponse变量中 CloseableHttpResponse httpResponse = httpclient.execute(httpGet); try { //4,得到弹幕文件的文件内容 HttpEntity httpEntity = httpResponse.getEntity(); String httpHtml = EntityUtils.toString(httpEntity); //5,解析弹幕文件,把每条弹幕放入list中 Document doc = Jsoup.parse(httpHtml, "UTF-8"); Elements contents = doc.getElementsByTag("d"); for (Element content : contents) { list.add(content.text()); //将标签中的文本内容,也就是弹幕内容,添加到list中 } } catch (Exception e) { e.printStackTrace(); } finally { httpResponse.close(); } return list; } } 复制代码
CloseableHttpResponse httpResponse = httpclient.execute(httpGet); 执行GET请求后,响应结果保存在httpResponse中。response.getEntity()是响应结果中的消息实体,因为响应结果中还收录Headers等其他内容如下图所示,这里我们只需要关注getEntity()消息实体即可。
EntityUtils.toString(response.getEntity()); 以流的形式返回服务器写入的响应内容。比如服务端调用的方法最后是: responseWriter.write("just do it"); 然后是EntityUtils。toString(response.getEntity()); 得到这句话就去做吧。这可以简单的理解为网页的html代码,也就是在网页源代码上右击可以看到的所有html代码。我们需要解析的就是这样的html代码。
在入口类Main.java中,调用RemoteFile类的getData方法,输入参数为xml文件名,解析每个弹幕并输出:
import java.util.ArrayList; /** * Created by shuhu on 2018/1/20. */ public class Main { public static void main(String[] args){ ArrayList items = new ArrayList(); //1,通过解析本地文件的方式得到所有弹幕 // items = LocalFile.getData("3232417.xml"); //2,通过解析远程服务器文件的方式得到所有弹幕 items = RemoteFile.getData("https://comment.bilibili.com/3232417.xml";); //遍历输出每条弹幕 for (String item : items) { System.out.println(item); } } } 复制代码
输出如下:
项目代码
代码仓库:完整的项目代码
java抓取网页内容(教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-03 12:03
我无事可做。刚刚学会了将git部署到远程服务器上,无事可做,就简单的做了一个小工具来抓取网页信息。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
操作效果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并注入到LinkedHashMap中,就可以了,很简单吧?看代码罗
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望大家多多支持! 查看全部
java抓取网页内容(教程)
我无事可做。刚刚学会了将git部署到远程服务器上,无事可做,就简单的做了一个小工具来抓取网页信息。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
操作效果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并注入到LinkedHashMap中,就可以了,很简单吧?看代码罗
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望大家多多支持!
java抓取网页内容(说起Python真的用的语言有那么神奇吗?除了它还可以用哪些语言?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-03 02:09
说到大数据,你会不自觉地想到爬虫。说到爬虫使用的语言,很多人首先想到的是Python。 Python真的有那么神奇吗?除了它还能用什么语言?
C#,java可以写爬虫,原理其实差别不大,只是平台问题。可以认为,如果是有针对性地抓取几个页面,做一些简单的页面分析,抓取效率不是核心要求,那么使用的语言本质上没有区别。
使用什么语言取决于情况和主要目的。
如果是针对性爬取,主要目标是解析js动态生成的内容,此时页面内容是js/ajax动态生成的,普通请求页面->解析方式不起作用,需要借助类似于firefox和chrome浏览器的js引擎,动态分析页面的js代码。
这种情况建议考虑casperJS+phantomjs或者slimerJS+phantomjs。当然,硒也可以考虑。
3、 如果爬虫涉及到大规模爬行,效率、可扩展性、可维护性等是必须考虑的因素,大规模爬行涉及很多问题:多线程并发、I/O机制、分布式爬虫、消息通信、权重判断机制、任务调度等,这时候语言和框架的选择意义重大。
PHP 对多线程和异步的支持较差,不推荐使用。
NodeJS:对于一些垂直的网站爬取,还可以,但是由于对分布式爬取、消息通信等支持较弱,请根据自己的情况判断。
Python:强烈建议我们对以上问题有很好的支持。尤其是Scrapy框架不愧为首选。
主要原因是:
1)抓取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如perl、shell,python的urllib2包提供了更完善的web文档访问API。 (当然ruby也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。 python中有优秀的第三方包帮你搞定,比如Requests,mechanize
2)网页抓取后的处理
获取的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
除了这些,还有很多优点:支持xpath;基于扭曲,性能良好;更好的调试工具;
这种情况下,如果还需要做js动态内容分析,casperjs不适合,只能基于chrome V8引擎等搭建自己的js引擎。
对于C和C++,虽然性能不错,但不推荐使用,尤其是考虑到成本等诸多因素。对于大多数公司来说,建议基于一些开源框架来做。不要自己发明轮子。制作一个简单的爬虫很容易。 ,但是很难做出一个完整的爬虫。 查看全部
java抓取网页内容(说起Python真的用的语言有那么神奇吗?除了它还可以用哪些语言?)
说到大数据,你会不自觉地想到爬虫。说到爬虫使用的语言,很多人首先想到的是Python。 Python真的有那么神奇吗?除了它还能用什么语言?
C#,java可以写爬虫,原理其实差别不大,只是平台问题。可以认为,如果是有针对性地抓取几个页面,做一些简单的页面分析,抓取效率不是核心要求,那么使用的语言本质上没有区别。
使用什么语言取决于情况和主要目的。
如果是针对性爬取,主要目标是解析js动态生成的内容,此时页面内容是js/ajax动态生成的,普通请求页面->解析方式不起作用,需要借助类似于firefox和chrome浏览器的js引擎,动态分析页面的js代码。
这种情况建议考虑casperJS+phantomjs或者slimerJS+phantomjs。当然,硒也可以考虑。
3、 如果爬虫涉及到大规模爬行,效率、可扩展性、可维护性等是必须考虑的因素,大规模爬行涉及很多问题:多线程并发、I/O机制、分布式爬虫、消息通信、权重判断机制、任务调度等,这时候语言和框架的选择意义重大。
PHP 对多线程和异步的支持较差,不推荐使用。
NodeJS:对于一些垂直的网站爬取,还可以,但是由于对分布式爬取、消息通信等支持较弱,请根据自己的情况判断。
Python:强烈建议我们对以上问题有很好的支持。尤其是Scrapy框架不愧为首选。
主要原因是:
1)抓取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如perl、shell,python的urllib2包提供了更完善的web文档访问API。 (当然ruby也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。 python中有优秀的第三方包帮你搞定,比如Requests,mechanize
2)网页抓取后的处理
获取的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
除了这些,还有很多优点:支持xpath;基于扭曲,性能良好;更好的调试工具;
这种情况下,如果还需要做js动态内容分析,casperjs不适合,只能基于chrome V8引擎等搭建自己的js引擎。
对于C和C++,虽然性能不错,但不推荐使用,尤其是考虑到成本等诸多因素。对于大多数公司来说,建议基于一些开源框架来做。不要自己发明轮子。制作一个简单的爬虫很容易。 ,但是很难做出一个完整的爬虫。
java抓取网页内容(淘女郎的信息和照片需要额外安装的第三方库模块功能原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-03 02:07
淘女孩爬虫,可以动态抓取淘女孩的信息和照片
需要额外安装的第三方库模块的功能原理
淘女孩的网站使用了AJAX技术。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。这意味着直接爬取网页源代码然后分析信息的方法是不可行的,因为网站是动态加载的,而直接爬取的方法只能抓取网页的原创源代码,但不是网页的原创源代码。给淘女孩动态加载的信息。
对于这种网站,一般有两种获取方式:
利用selenium库模拟浏览器的用户行为,使服务器认为真实用户在浏览网页,从而获取网页的完整源代码。使用Chrome等浏览器自带的分析工具来监控网页的网络。分析数据交换API,然后利用API抓取数据交换的JSON数据,再抓取。
一般来说,第一种方法速度较慢,运行时占用系统资源较多。因此,在条件允许的情况下,尽量使用第二种方法。
在 Chrome 浏览器中打开淘女孩主页,按 F12 切换到开发者模式。在网络列中选择 XHR 以查看当前没有网络活动。但是,当你在网页中点击一个页面时,会有一个POST活动,当再次按下下一页时,活动会再次出现,所以可以断定这个API是用于数据交换的。然后我们再次比较这两个请求。在Headers框的FromData列中,可以看到两次请求的区别在currentPage。一个是2,另一个是3。这说明如果要获取第一页的数据,这个currentPage的值是多少。于是我们根据这个来写请求,得到所有淘女孩信息的JSON文件。
发送请求,获取JSON数据,处理后转换成Python字典类型返回
连接MongoDB并保存信息
def main():
client = MongoClient()
db = client.TaoBao
col = db.TaoLady
for pageNum in range(1,411): # 淘女郎一共有410页,所以我们抓取从1到411页的内容。
print(pageNum)
datas = getInfo(pageNum)
if datas:
col.insert_many(datas)
if __name__ == '__main__':
main()
提取图片的网址,下载后保存在pic文件夹中
def downPic():
client = MongoClient()
db = client.TaoBao
col = db.TaoLady
for data in col.find():
name = data['realName']
url = "http:" + data['avatarUrl']
pic = urlopen(url)
with open("pic/" + name + ".jpg", "vb") as file:
print(name)
file.vrite(pic.read())
if __name__ == '__main__':
downPic()
攀登结束,成绩斐然
好的! 文章 在这里分享给大家。如果你和我一样喜欢python,在python学习的路上奔跑,欢迎加入python学习群:839383765 群里每天都会分享最新的行业资讯,分享python是免费课程,一起交流学习,让学习成为一种习惯! 查看全部
java抓取网页内容(淘女郎的信息和照片需要额外安装的第三方库模块功能原理)
淘女孩爬虫,可以动态抓取淘女孩的信息和照片
需要额外安装的第三方库模块的功能原理
淘女孩的网站使用了AJAX技术。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。这意味着直接爬取网页源代码然后分析信息的方法是不可行的,因为网站是动态加载的,而直接爬取的方法只能抓取网页的原创源代码,但不是网页的原创源代码。给淘女孩动态加载的信息。
对于这种网站,一般有两种获取方式:
利用selenium库模拟浏览器的用户行为,使服务器认为真实用户在浏览网页,从而获取网页的完整源代码。使用Chrome等浏览器自带的分析工具来监控网页的网络。分析数据交换API,然后利用API抓取数据交换的JSON数据,再抓取。
一般来说,第一种方法速度较慢,运行时占用系统资源较多。因此,在条件允许的情况下,尽量使用第二种方法。
在 Chrome 浏览器中打开淘女孩主页,按 F12 切换到开发者模式。在网络列中选择 XHR 以查看当前没有网络活动。但是,当你在网页中点击一个页面时,会有一个POST活动,当再次按下下一页时,活动会再次出现,所以可以断定这个API是用于数据交换的。然后我们再次比较这两个请求。在Headers框的FromData列中,可以看到两次请求的区别在currentPage。一个是2,另一个是3。这说明如果要获取第一页的数据,这个currentPage的值是多少。于是我们根据这个来写请求,得到所有淘女孩信息的JSON文件。
发送请求,获取JSON数据,处理后转换成Python字典类型返回
连接MongoDB并保存信息
def main():
client = MongoClient()
db = client.TaoBao
col = db.TaoLady
for pageNum in range(1,411): # 淘女郎一共有410页,所以我们抓取从1到411页的内容。
print(pageNum)
datas = getInfo(pageNum)
if datas:
col.insert_many(datas)
if __name__ == '__main__':
main()
提取图片的网址,下载后保存在pic文件夹中
def downPic():
client = MongoClient()
db = client.TaoBao
col = db.TaoLady
for data in col.find():
name = data['realName']
url = "http:" + data['avatarUrl']
pic = urlopen(url)
with open("pic/" + name + ".jpg", "vb") as file:
print(name)
file.vrite(pic.read())
if __name__ == '__main__':
downPic()
攀登结束,成绩斐然
好的! 文章 在这里分享给大家。如果你和我一样喜欢python,在python学习的路上奔跑,欢迎加入python学习群:839383765 群里每天都会分享最新的行业资讯,分享python是免费课程,一起交流学习,让学习成为一种习惯!
java抓取网页内容(《》之有关,文章内容质量较高,小编分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-01 10:04
本文文章将详细讲解Java中如何使用正则表达式获取网页内容。 文章的内容质量很高,分享给大家作为参考。希望大家看完这篇文章,对相关知识有了一定的了解。
正则表达式,抓取网页并解析部分HTML内容
<p>package com.xiaofeng.picup;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/** *//**
*
* @抓取页面文章标题及内容(测试) 手动输入网址抓取,可进一步自动抓取整个页面的全部内容
*
*/
public class WebContent ...{
/** *//**
* 读取一个网页全部内容
*/
public String getOneHtml(String htmlurl) throws IOException...{
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try ...{
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url
.openStream(), "utf-8"));// 读取网页全部内容
while ((temp = in.readLine()) != null) ...{
sb.append(temp);
}
in.close();
}catch(MalformedURLException me)...{
System.out.println("你输入的URL格式有问题!请仔细输入");
me.getMessage();
throw me;
}catch (IOException e) ...{
e.printStackTrace();
throw e;
}
return sb.toString();
}
/** *//**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) ...{
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) ...{
list.add(ma.group());
}
for (int i = 0; i ]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) ...{
list.add(ma.group());
}
return list;
}
/** *//**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) ...{
String regex;
List list = new ArrayList();
regex = " 查看全部
java抓取网页内容(《》之有关,文章内容质量较高,小编分享)
本文文章将详细讲解Java中如何使用正则表达式获取网页内容。 文章的内容质量很高,分享给大家作为参考。希望大家看完这篇文章,对相关知识有了一定的了解。
正则表达式,抓取网页并解析部分HTML内容
<p>package com.xiaofeng.picup;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/** *//**
*
* @抓取页面文章标题及内容(测试) 手动输入网址抓取,可进一步自动抓取整个页面的全部内容
*
*/
public class WebContent ...{
/** *//**
* 读取一个网页全部内容
*/
public String getOneHtml(String htmlurl) throws IOException...{
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try ...{
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url
.openStream(), "utf-8"));// 读取网页全部内容
while ((temp = in.readLine()) != null) ...{
sb.append(temp);
}
in.close();
}catch(MalformedURLException me)...{
System.out.println("你输入的URL格式有问题!请仔细输入");
me.getMessage();
throw me;
}catch (IOException e) ...{
e.printStackTrace();
throw e;
}
return sb.toString();
}
/** *//**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) ...{
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) ...{
list.add(ma.group());
}
for (int i = 0; i ]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) ...{
list.add(ma.group());
}
return list;
}
/** *//**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) ...{
String regex;
List list = new ArrayList();
regex = "
java抓取网页内容(JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-12-31 02:22
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下对这种方法的理解和体会。最简单的爬取方法是:
URLurl=newURL(myurl);BufferedReaderbr=newBufferedReader(newInputStreamReader(url.openStream()));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){ i++;sb.append(s+"\r\n");}
URL url = new URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
i++;
sb.append(s+"\r\n");
}
这种方法抓取一般的网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取这个URL中网页的内容,又不想被重定向到其他网页,可以使用下面的代码。
URLurlmy=newURL(myurl);HttpURLConnectioncon=(HttpURLConnection)urlmy.openConnection();con.setFollowRedirects(true);con.setInstanceFollowRedirects(false);con.connect();BufferedReaderbr=newBufferedReader(newInputStreamReader(con.getInputStream(), "UTF-8"));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){sb.append(s+"\r\n"); }
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
在这种情况下,程序在爬取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
Java代码
System.getProperties().setProperty("http.proxyHost",proxyName);System.getProperties().setProperty("http.proxyPort",port);
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty( "http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
以上程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用! 查看全部
java抓取网页内容(JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下对这种方法的理解和体会。最简单的爬取方法是:
URLurl=newURL(myurl);BufferedReaderbr=newBufferedReader(newInputStreamReader(url.openStream()));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){ i++;sb.append(s+"\r\n");}
URL url = new URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
i++;
sb.append(s+"\r\n");
}
这种方法抓取一般的网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取这个URL中网页的内容,又不想被重定向到其他网页,可以使用下面的代码。
URLurlmy=newURL(myurl);HttpURLConnectioncon=(HttpURLConnection)urlmy.openConnection();con.setFollowRedirects(true);con.setInstanceFollowRedirects(false);con.connect();BufferedReaderbr=newBufferedReader(newInputStreamReader(con.getInputStream(), "UTF-8"));Strings="";StringBuffersb=newStringBuffer("");while((s=br.readLine())!=null){sb.append(s+"\r\n"); }
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
在这种情况下,程序在爬取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
Java代码
System.getProperties().setProperty("http.proxyHost",proxyName);System.getProperties().setProperty("http.proxyPort",port);
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty( "http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
以上程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用!
java抓取网页内容(Python使用正则表达式抓取网页图片的方法示例的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-30 15:00
想知道Python如何使用正则表达式抓取网页图片的例子的相关内容吗?我要的闪耀给大家详细讲解Python正则表达式抓取网页图片的知识和一些代码示例。欢迎阅读并指正,先画重点:Python、正则表达式、爬虫、网页图片,一起学习。
本文介绍了Python使用正则表达式抓取网页图片的例子。分享给大家,供大家参考,如下:
#!/usr/bin/python
import re
import urllib
#获取网页信息
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#匹配网页中的图片
reg = r'src="(.*?\.jpg)" alt'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
html = getHtml("http://photo.bitauto.com/?WT.mc_id=360tpdq")
print getImg(html)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
希望这篇文章对你的 Python 编程有所帮助。
相关文章 查看全部
java抓取网页内容(Python使用正则表达式抓取网页图片的方法示例的相关内容吗)
想知道Python如何使用正则表达式抓取网页图片的例子的相关内容吗?我要的闪耀给大家详细讲解Python正则表达式抓取网页图片的知识和一些代码示例。欢迎阅读并指正,先画重点:Python、正则表达式、爬虫、网页图片,一起学习。
本文介绍了Python使用正则表达式抓取网页图片的例子。分享给大家,供大家参考,如下:
#!/usr/bin/python
import re
import urllib
#获取网页信息
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#匹配网页中的图片
reg = r'src="(.*?\.jpg)" alt'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
html = getHtml("http://photo.bitauto.com/?WT.mc_id=360tpdq";)
print getImg(html)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
希望这篇文章对你的 Python 编程有所帮助。
相关文章
java抓取网页内容(接上简易爬虫配置池线程池(ThreadPoolTaskExecutor)抓取任务的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-12-25 16:02
继续上一节(爬虫系列(0):项目建设)
网络爬虫是通过多线程和多任务逻辑实现的。线程池(ThreadPoolTaskExecutor)已经封装在springboot框架中,我们只需要使用它即可。
在本节中,我们主要实现网页连接信息的多线程捕获,并将信息存储在队列中。
介绍一个新的包
在pom中引入新的包,如下:
org.apache.commons
commons-lang3
org.jsoup
jsoup
1.8.3
org.projectlombok
lombok
provided
为了简化编码,这里引入lombok。IDE使用时需要安装lombok插件,否则会提示编译错误。
配置管理
springboot的配置文件统一管理在application.properties(.yml)中。这里我们也通过@ConfigurationProperties注解实现爬虫相关的配置。直接上传代码:
package mobi.huanyuan.spider.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
/**
* 爬虫配置.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:10
*/
@Data
@ConfigurationProperties(prefix = "huanyuan.spider")
public class SpiderConfig {
/**
* 爬取页面最大深度
*/
public int maxDepth = 2;
/**
* 下载页面线程数
*/
public int minerHtmlThreadNum = 2;
//=================================================
// 线程池配置
//=================================================
/**
* 核心线程池大小
*/
private int corePoolSize = 4;
/**
* 最大可创建的线程数
*/
private int maxPoolSize = 100;
/**
* 队列最大长度
*/
private int queueCapacity = 1000;
/**
* 线程池维护线程所允许的空闲时间
*/
private int keepAliveSeconds = 300;
}
然后,需要修改这些配置,只需要修改里面的application.properties(.yml):
魔猿简单爬虫配置
线程池
线程池使用现有的springboot,配置也可以在上面的配置管理中。这里只需要初始化配置:
package mobi.huanyuan.spider.config;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.ThreadPoolExecutor;
/**
* 线程池配置.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:35
*/
@Configuration
public class ThreadPoolConfig {
@Autowired
private SpiderConfig spiderConfig;
@Bean(name = "threadPoolTaskExecutor")
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setMaxPoolSize(spiderConfig.getMaxPoolSize());
executor.setCorePoolSize(spiderConfig.getCorePoolSize());
executor.setQueueCapacity(spiderConfig.getQueueCapacity());
executor.setKeepAliveSeconds(spiderConfig.getKeepAliveSeconds());
// 线程池对拒绝任务(无线程可用)的处理策略
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
}
队列管理
本节我们主要是抓取URL并保存到队列中,所以涉及到的队列就是要抓取的队列和要分析的队列(下节分析用到,这里只做存储),另外,为了防止重复抓取同一个URL,这里还需要添加一个Set集合来记录访问过的地址。
package mobi.huanyuan.spider;
import lombok.Getter;
import mobi.huanyuan.spider.bean.SpiderHtml;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Set;
/**
* 爬虫访问队列.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 10:54
*/
public class SpiderQueue {
private static Logger logger = LoggerFactory.getLogger(SpiderQueue.class);
/**
* Set集合 保证每一个URL只访问一次
*/
private static volatile Set urlSet = new HashSet();
/**
* 待访问队列
* 爬取页面线程从这里取数据
*/
private static volatile Queue unVisited = new LinkedList();
/**
* 等待提取URL的分析页面队列
* 解析页面线程从这里取数据
*/
private static volatile Queue waitingMine = new LinkedList();
/**
* 添加到URL队列
*
* @param url
*/
public synchronized static void addUrlSet(String url) {
urlSet.add(url);
}
/**
* 获得URL队列大小
*
* @return
*/
public static int getUrlSetSize() {
return urlSet.size();
}
/**
* 添加到待访问队列,每个URL只访问一次
*
* @param spiderHtml
*/
public synchronized static void addUnVisited(SpiderHtml spiderHtml) {
if (null != spiderHtml && !urlSet.contains(spiderHtml.getUrl())) {
logger.info("添加到待访问队列[{}] 当前第[{}]层 当前线程[{}]", spiderHtml.getUrl(), spiderHtml.getDepth(), Thread.currentThread().getName());
unVisited.add(spiderHtml);
}
}
/**
* 待访问出队列
*
* @return
*/
public synchronized static SpiderHtml unVisitedPoll() {
return unVisited.poll();
}
/**
* 添加到等待提取URL的分析页面队列
*
* @param html
*/
public synchronized static void addWaitingMine(SpiderHtml html) {
waitingMine.add(html);
}
/**
* 等待提取URL的分析页面出队列
*
* @return
*/
public synchronized static SpiderHtml waitingMinePoll() {
return waitingMine.poll();
}
/**
* 等待提取URL的分析页面队列大小
* @return
*/
public static int waitingMineSize() {
return waitingMine.size();
}
}
抓取任务
直接上传代码:
package mobi.huanyuan.spider.runable;
import mobi.huanyuan.spider.SpiderQueue;
import mobi.huanyuan.spider.bean.SpiderHtml;
import mobi.huanyuan.spider.config.SpiderConfig;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 抓取页面任务.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:43
*/
public class SpiderHtmlRunnable implements Runnable {
private static final Logger logger = LoggerFactory.getLogger(SpiderHtmlRunnable.class);
private static boolean done = false;
private SpiderConfig config;
public SpiderHtmlRunnable(SpiderConfig config) {
this.config = config;
}
@Override
public void run() {
while (!SpiderHtmlRunnable.done) {
done = true;
minerHtml();
done = false;
}
}
public synchronized void minerHtml() {
SpiderHtml minerUrl = SpiderQueue.unVisitedPoll(); // 待访问出队列。
try {
//判断当前页面爬取深度
if (null == minerUrl || StringUtils.isBlank(minerUrl.getUrl()) || minerUrl.getDepth() > config.getMaxDepth()) {
return;
}
//判断爬取页面URL是否包含http
if (!minerUrl.getUrl().startsWith("http")) {
logger.info("当前爬取URL[{}]没有http", minerUrl.getUrl());
return;
}
logger.info("当前爬取页面[{}]爬取深度[{}] 当前线程 [{}]", minerUrl.getUrl(), minerUrl.getDepth(), Thread.currentThread().getName());
Connection conn = Jsoup.connect(minerUrl.getUrl());
conn.header("User-Agent", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13");//配置模拟浏览器
Document doc = conn.get();
String page = doc.html();
SpiderHtml spiderHtml = new SpiderHtml();
spiderHtml.setUrl(minerUrl.getUrl());
spiderHtml.setHtml(page);
spiderHtml.setDepth(minerUrl.getDepth());
System.out.println(spiderHtml.getUrl());
// TODO: 添加到继续爬取队列
SpiderQueue.addWaitingMine(spiderHtml);
} catch (Exception e) {
logger.info("爬取页面失败 URL [{}]", minerUrl.getUrl());
logger.info("Error info [{}]", e.getMessage());
}
}
}
这是一个 Runnable 任务。主要目的是拉取URL数据,然后将其封装成SpiderHtml对象,存放在待分析队列中。这里使用的是Jsoup——一个用于HTML分析操作的Java工具包。如果您不确定,您可以搜索它。后面的章节也会用到分析部分。
其他页面信息包SpiderHtml
package mobi.huanyuan.spider.bean;
import lombok.Data;
import java.io.Serializable;
/**
* 页面信息类.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:02
*/
@Data
public class SpiderHtml implements Serializable {
/**
* 页面URL
*/
private String url;
/**
* 页面信息
*/
private String html;
/**
* 爬取深度
*/
private int depth;
}
爬行动物主类
package mobi.huanyuan.spider;
import mobi.huanyuan.spider.bean.SpiderHtml;
import mobi.huanyuan.spider.config.SpiderConfig;
import mobi.huanyuan.spider.runable.SpiderHtmlRunnable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
/**
* 爬虫.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:23
*/
@Component
public class Spider {
private static Logger logger = LoggerFactory.getLogger(Spider.class);
@Autowired
private ThreadPoolTaskExecutor threadPoolTaskExecutor;
@Autowired
private SpiderConfig spiderConfig;
public void start(SpiderHtml spiderHtml) {
//程序启动,将第一个起始页面放入待访问队列。
SpiderQueue.addUnVisited(spiderHtml);
//将URL 添加到URL队列 保证每个URL只访问一次
SpiderQueue.addUrlSet(spiderHtml.getUrl());
//download
for (int i = 0; i < spiderConfig.getMinerHtmlThreadNum(); i++) {
SpiderHtmlRunnable minerHtml = new SpiderHtmlRunnable(spiderConfig);
threadPoolTaskExecutor.execute(minerHtml);
}
// TODO: 监控爬取完毕之后停线程池,关闭程序
try {
TimeUnit.SECONDS.sleep(20);
logger.info("待分析URL队列大小: {}", SpiderQueue.waitingMineSize());
// 关闭线程池
threadPoolTaskExecutor.shutdown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
"// TODO:" 后面的代码逻辑在这里是暂时的。后续章节完成后,会慢慢移除。
最后
运行本节代码,需要在springboot项目的main方法中添加如下代码:
ConfigurableApplicationContext context = SpringApplication.run(SpiderApplication.class, args);
Spider spider = context.getBean(Spider.class);
SpiderHtml startPage = new SpiderHtml();
startPage.setUrl("$URL");
startPage.setDepth(2);
spider.start(startPage);
$URL 是需要抓取的网页地址。
springboot项目启动后,需要手动停止。目前,没有在处理 fetch 后自动停止运行的逻辑。运行结果如下:
Magic Ape Simple Crawler 运行结果
最后,本章完成后,整个项目的结构如下:
魔猿简单爬虫项目结构
关于我
编程界的老猿猴,自媒体界的新宠じ☆ve
编程界的老猿猴,自媒体界的新宠じ☆ve 查看全部
java抓取网页内容(接上简易爬虫配置池线程池(ThreadPoolTaskExecutor)抓取任务的方法)
继续上一节(爬虫系列(0):项目建设)
网络爬虫是通过多线程和多任务逻辑实现的。线程池(ThreadPoolTaskExecutor)已经封装在springboot框架中,我们只需要使用它即可。
在本节中,我们主要实现网页连接信息的多线程捕获,并将信息存储在队列中。
介绍一个新的包
在pom中引入新的包,如下:
org.apache.commons
commons-lang3
org.jsoup
jsoup
1.8.3
org.projectlombok
lombok
provided
为了简化编码,这里引入lombok。IDE使用时需要安装lombok插件,否则会提示编译错误。
配置管理
springboot的配置文件统一管理在application.properties(.yml)中。这里我们也通过@ConfigurationProperties注解实现爬虫相关的配置。直接上传代码:
package mobi.huanyuan.spider.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
/**
* 爬虫配置.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:10
*/
@Data
@ConfigurationProperties(prefix = "huanyuan.spider")
public class SpiderConfig {
/**
* 爬取页面最大深度
*/
public int maxDepth = 2;
/**
* 下载页面线程数
*/
public int minerHtmlThreadNum = 2;
//=================================================
// 线程池配置
//=================================================
/**
* 核心线程池大小
*/
private int corePoolSize = 4;
/**
* 最大可创建的线程数
*/
private int maxPoolSize = 100;
/**
* 队列最大长度
*/
private int queueCapacity = 1000;
/**
* 线程池维护线程所允许的空闲时间
*/
private int keepAliveSeconds = 300;
}
然后,需要修改这些配置,只需要修改里面的application.properties(.yml):
魔猿简单爬虫配置
线程池
线程池使用现有的springboot,配置也可以在上面的配置管理中。这里只需要初始化配置:
package mobi.huanyuan.spider.config;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.ThreadPoolExecutor;
/**
* 线程池配置.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:35
*/
@Configuration
public class ThreadPoolConfig {
@Autowired
private SpiderConfig spiderConfig;
@Bean(name = "threadPoolTaskExecutor")
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setMaxPoolSize(spiderConfig.getMaxPoolSize());
executor.setCorePoolSize(spiderConfig.getCorePoolSize());
executor.setQueueCapacity(spiderConfig.getQueueCapacity());
executor.setKeepAliveSeconds(spiderConfig.getKeepAliveSeconds());
// 线程池对拒绝任务(无线程可用)的处理策略
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
}
队列管理
本节我们主要是抓取URL并保存到队列中,所以涉及到的队列就是要抓取的队列和要分析的队列(下节分析用到,这里只做存储),另外,为了防止重复抓取同一个URL,这里还需要添加一个Set集合来记录访问过的地址。
package mobi.huanyuan.spider;
import lombok.Getter;
import mobi.huanyuan.spider.bean.SpiderHtml;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Set;
/**
* 爬虫访问队列.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 10:54
*/
public class SpiderQueue {
private static Logger logger = LoggerFactory.getLogger(SpiderQueue.class);
/**
* Set集合 保证每一个URL只访问一次
*/
private static volatile Set urlSet = new HashSet();
/**
* 待访问队列
* 爬取页面线程从这里取数据
*/
private static volatile Queue unVisited = new LinkedList();
/**
* 等待提取URL的分析页面队列
* 解析页面线程从这里取数据
*/
private static volatile Queue waitingMine = new LinkedList();
/**
* 添加到URL队列
*
* @param url
*/
public synchronized static void addUrlSet(String url) {
urlSet.add(url);
}
/**
* 获得URL队列大小
*
* @return
*/
public static int getUrlSetSize() {
return urlSet.size();
}
/**
* 添加到待访问队列,每个URL只访问一次
*
* @param spiderHtml
*/
public synchronized static void addUnVisited(SpiderHtml spiderHtml) {
if (null != spiderHtml && !urlSet.contains(spiderHtml.getUrl())) {
logger.info("添加到待访问队列[{}] 当前第[{}]层 当前线程[{}]", spiderHtml.getUrl(), spiderHtml.getDepth(), Thread.currentThread().getName());
unVisited.add(spiderHtml);
}
}
/**
* 待访问出队列
*
* @return
*/
public synchronized static SpiderHtml unVisitedPoll() {
return unVisited.poll();
}
/**
* 添加到等待提取URL的分析页面队列
*
* @param html
*/
public synchronized static void addWaitingMine(SpiderHtml html) {
waitingMine.add(html);
}
/**
* 等待提取URL的分析页面出队列
*
* @return
*/
public synchronized static SpiderHtml waitingMinePoll() {
return waitingMine.poll();
}
/**
* 等待提取URL的分析页面队列大小
* @return
*/
public static int waitingMineSize() {
return waitingMine.size();
}
}
抓取任务
直接上传代码:
package mobi.huanyuan.spider.runable;
import mobi.huanyuan.spider.SpiderQueue;
import mobi.huanyuan.spider.bean.SpiderHtml;
import mobi.huanyuan.spider.config.SpiderConfig;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 抓取页面任务.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:43
*/
public class SpiderHtmlRunnable implements Runnable {
private static final Logger logger = LoggerFactory.getLogger(SpiderHtmlRunnable.class);
private static boolean done = false;
private SpiderConfig config;
public SpiderHtmlRunnable(SpiderConfig config) {
this.config = config;
}
@Override
public void run() {
while (!SpiderHtmlRunnable.done) {
done = true;
minerHtml();
done = false;
}
}
public synchronized void minerHtml() {
SpiderHtml minerUrl = SpiderQueue.unVisitedPoll(); // 待访问出队列。
try {
//判断当前页面爬取深度
if (null == minerUrl || StringUtils.isBlank(minerUrl.getUrl()) || minerUrl.getDepth() > config.getMaxDepth()) {
return;
}
//判断爬取页面URL是否包含http
if (!minerUrl.getUrl().startsWith("http")) {
logger.info("当前爬取URL[{}]没有http", minerUrl.getUrl());
return;
}
logger.info("当前爬取页面[{}]爬取深度[{}] 当前线程 [{}]", minerUrl.getUrl(), minerUrl.getDepth(), Thread.currentThread().getName());
Connection conn = Jsoup.connect(minerUrl.getUrl());
conn.header("User-Agent", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13");//配置模拟浏览器
Document doc = conn.get();
String page = doc.html();
SpiderHtml spiderHtml = new SpiderHtml();
spiderHtml.setUrl(minerUrl.getUrl());
spiderHtml.setHtml(page);
spiderHtml.setDepth(minerUrl.getDepth());
System.out.println(spiderHtml.getUrl());
// TODO: 添加到继续爬取队列
SpiderQueue.addWaitingMine(spiderHtml);
} catch (Exception e) {
logger.info("爬取页面失败 URL [{}]", minerUrl.getUrl());
logger.info("Error info [{}]", e.getMessage());
}
}
}
这是一个 Runnable 任务。主要目的是拉取URL数据,然后将其封装成SpiderHtml对象,存放在待分析队列中。这里使用的是Jsoup——一个用于HTML分析操作的Java工具包。如果您不确定,您可以搜索它。后面的章节也会用到分析部分。
其他页面信息包SpiderHtml
package mobi.huanyuan.spider.bean;
import lombok.Data;
import java.io.Serializable;
/**
* 页面信息类.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:02
*/
@Data
public class SpiderHtml implements Serializable {
/**
* 页面URL
*/
private String url;
/**
* 页面信息
*/
private String html;
/**
* 爬取深度
*/
private int depth;
}
爬行动物主类
package mobi.huanyuan.spider;
import mobi.huanyuan.spider.bean.SpiderHtml;
import mobi.huanyuan.spider.config.SpiderConfig;
import mobi.huanyuan.spider.runable.SpiderHtmlRunnable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
/**
* 爬虫.
*
* @author Jonathan L.(xingbing.lai@gmail.com)
* @version 1.0.0 -- Datetime: 2020/2/18 11:23
*/
@Component
public class Spider {
private static Logger logger = LoggerFactory.getLogger(Spider.class);
@Autowired
private ThreadPoolTaskExecutor threadPoolTaskExecutor;
@Autowired
private SpiderConfig spiderConfig;
public void start(SpiderHtml spiderHtml) {
//程序启动,将第一个起始页面放入待访问队列。
SpiderQueue.addUnVisited(spiderHtml);
//将URL 添加到URL队列 保证每个URL只访问一次
SpiderQueue.addUrlSet(spiderHtml.getUrl());
//download
for (int i = 0; i < spiderConfig.getMinerHtmlThreadNum(); i++) {
SpiderHtmlRunnable minerHtml = new SpiderHtmlRunnable(spiderConfig);
threadPoolTaskExecutor.execute(minerHtml);
}
// TODO: 监控爬取完毕之后停线程池,关闭程序
try {
TimeUnit.SECONDS.sleep(20);
logger.info("待分析URL队列大小: {}", SpiderQueue.waitingMineSize());
// 关闭线程池
threadPoolTaskExecutor.shutdown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
"// TODO:" 后面的代码逻辑在这里是暂时的。后续章节完成后,会慢慢移除。
最后
运行本节代码,需要在springboot项目的main方法中添加如下代码:
ConfigurableApplicationContext context = SpringApplication.run(SpiderApplication.class, args);
Spider spider = context.getBean(Spider.class);
SpiderHtml startPage = new SpiderHtml();
startPage.setUrl("$URL");
startPage.setDepth(2);
spider.start(startPage);
$URL 是需要抓取的网页地址。
springboot项目启动后,需要手动停止。目前,没有在处理 fetch 后自动停止运行的逻辑。运行结果如下:
Magic Ape Simple Crawler 运行结果
最后,本章完成后,整个项目的结构如下:
魔猿简单爬虫项目结构
关于我
编程界的老猿猴,自媒体界的新宠じ☆ve
编程界的老猿猴,自媒体界的新宠じ☆ve
java抓取网页内容(这篇文章介绍闲来无事,刚学会把git部署到远程服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-25 08:16
本文文章介绍了如何在java中使用url实现网页内容爬取
无事可做,刚学会了将git部署到远程服务器上,无事可做,所以干脆做了一个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上就是java中如何使用url实现网页内容爬取的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
java抓取网页内容(这篇文章介绍闲来无事,刚学会把git部署到远程服务器)
本文文章介绍了如何在java中使用url实现网页内容爬取
无事可做,刚学会了将git部署到远程服务器上,无事可做,所以干脆做了一个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上就是java中如何使用url实现网页内容爬取的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
java抓取网页内容(看看程序员眼中的excel用javaphprubydom操作网页?教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-23 02:01
java抓取网页内容有个httpcookie可以采集新闻网站的内容
抓取互联网的网页源代码,是可以实现题主的要求的。推荐一本书《代码大全》,最后那章,里面介绍的是典型的java程序员抓取网页源代码的过程。
所有好的浏览器都可以抓取网页
yahoo!javascript教程
editplus,
googlesheets.看看程序员眼中的excel
用javaphprubydom操作网页?webform,ejb,
多使用jsp或servlet
win10新增了一个工具,javax.swing.handle
可以使用jq,
可以用jfinal来看看:
多个浏览器操作同一个网页,可以使用简单的hook来实现,不过需要做一个特别的程序接入。或者对应的浏览器都具有相应的hook。
torrent,内嵌地址可以基于http协议来推送而不用路由带回,就可以从公网上看另一台电脑的内容。
java的可以用handle
在这个场景下,问题是针对web服务来回答的。因为你需要一个动态获取网页的接口。对于这个接口而言,并不是让开发人员从后台接收网页后生成相应的对象,而是把网页的内容和一些附加的信息加入到一个工具中,接收端java的handleinterceptor比如:java-jfinal-get-download-info-formatjava-jfinal-get-download-info-predicates,还有http头,表头信息等传递到后台服务中,并在后台执行。 查看全部
java抓取网页内容(看看程序员眼中的excel用javaphprubydom操作网页?教程)
java抓取网页内容有个httpcookie可以采集新闻网站的内容
抓取互联网的网页源代码,是可以实现题主的要求的。推荐一本书《代码大全》,最后那章,里面介绍的是典型的java程序员抓取网页源代码的过程。
所有好的浏览器都可以抓取网页
yahoo!javascript教程
editplus,
googlesheets.看看程序员眼中的excel
用javaphprubydom操作网页?webform,ejb,
多使用jsp或servlet
win10新增了一个工具,javax.swing.handle
可以使用jq,
可以用jfinal来看看:
多个浏览器操作同一个网页,可以使用简单的hook来实现,不过需要做一个特别的程序接入。或者对应的浏览器都具有相应的hook。
torrent,内嵌地址可以基于http协议来推送而不用路由带回,就可以从公网上看另一台电脑的内容。
java的可以用handle
在这个场景下,问题是针对web服务来回答的。因为你需要一个动态获取网页的接口。对于这个接口而言,并不是让开发人员从后台接收网页后生成相应的对象,而是把网页的内容和一些附加的信息加入到一个工具中,接收端java的handleinterceptor比如:java-jfinal-get-download-info-formatjava-jfinal-get-download-info-predicates,还有http头,表头信息等传递到后台服务中,并在后台执行。

