
java抓取网页内容
java抓取网页内容(不时之需:我的理解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-11-06 19:15
phantomjs:我的理解是它是一个非显示浏览器,也就是说它基本上可以做浏览器能做的所有任务,除了不能显示页面的内容。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学了PHANTOMJS,鉴于网上找的例子不多,只好自己总结一下,以备不时之需。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来实现:
下载并解压phantom到D盘,目录下有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit就可以达到想要的目的:比如生成网页快照我要做的是爬AJAX页面上的图片,先看js文件:将其命名为s.js
[javascript]
在 CODE 上查看代码片段
源自我的代码片段
system = require('system') //传递一些需要的参数给js文件
address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
if (status !== 'success') {
console.log('Unable to post!');
} else {
var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。
for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦
phantom.outputEncoding = encodings[i];
console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容
}
}
phantom.exit();
});
接下来就是java类的编写:
[爪哇]
在 CODE 上查看代码片段
源自我的代码片段
package com.mvc.rest;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class GetAjaxHtml {
public static String getAjaxContent(String url) throws Exception {
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url);
InputStream is = p.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp=br.readLine())!=null) {
sbf.append(tmp + "\n");
}
return sbf.toString();
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
String result = getAjaxContent("http://114.111.162.220:8093/404Web/");
System.out.println(result);
long end = System.currentTimeMillis();
System.out.println("===============耗时:" + (end - start) + "===============");
}
}
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了
这是最终的解决方案 查看全部
java抓取网页内容(不时之需:我的理解)
phantomjs:我的理解是它是一个非显示浏览器,也就是说它基本上可以做浏览器能做的所有任务,除了不能显示页面的内容。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学了PHANTOMJS,鉴于网上找的例子不多,只好自己总结一下,以备不时之需。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来实现:
下载并解压phantom到D盘,目录下有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit就可以达到想要的目的:比如生成网页快照我要做的是爬AJAX页面上的图片,先看js文件:将其命名为s.js
[javascript]

在 CODE 上查看代码片段

源自我的代码片段
system = require('system') //传递一些需要的参数给js文件
address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
if (status !== 'success') {
console.log('Unable to post!');
} else {
var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。
for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦
phantom.outputEncoding = encodings[i];
console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容
}
}
phantom.exit();
});
接下来就是java类的编写:
[爪哇]
在 CODE 上查看代码片段
源自我的代码片段
package com.mvc.rest;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class GetAjaxHtml {
public static String getAjaxContent(String url) throws Exception {
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url);
InputStream is = p.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp=br.readLine())!=null) {
sbf.append(tmp + "\n");
}
return sbf.toString();
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
String result = getAjaxContent("http://114.111.162.220:8093/404Web/";);
System.out.println(result);
long end = System.currentTimeMillis();
System.out.println("===============耗时:" + (end - start) + "===============");
}
}

至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了
这是最终的解决方案
java抓取网页内容( 以上的代码程序是把一个网页的源代码a中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-01 23:08
以上的代码程序是把一个网页的源代码a中)
java阅读网页内容的详细例子
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上面的代码程序将一个网页的源代码,包括 HTML 和 XML,读取到 JAVA 中的字符串 String a 中。
Java中的String类型空间很大,基本可以容纳一个网页源码的内容。
从网页中读取内容也是对输入流的操作。
与标准输入源不同,在:
BufferedReader in = new BufferedReader(new InputStreamReader(...))
只需在 InputStreamReader 中输入 System.in。
这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续操作和处理与加载标准输入源完全相同。
BufferedReader 要求JAVA 必须捕获IOException,使用URL source 不仅要导入.* 包,还要捕获MalformedURLException。
如有问题,请留言或到本站社区讨论,感谢阅读,希望对您有所帮助,感谢您对本站的支持! 查看全部
java抓取网页内容(
以上的代码程序是把一个网页的源代码a中)
java阅读网页内容的详细例子
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上面的代码程序将一个网页的源代码,包括 HTML 和 XML,读取到 JAVA 中的字符串 String a 中。
Java中的String类型空间很大,基本可以容纳一个网页源码的内容。
从网页中读取内容也是对输入流的操作。
与标准输入源不同,在:
BufferedReader in = new BufferedReader(new InputStreamReader(...))
只需在 InputStreamReader 中输入 System.in。
这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续操作和处理与加载标准输入源完全相同。
BufferedReader 要求JAVA 必须捕获IOException,使用URL source 不仅要导入.* 包,还要捕获MalformedURLException。
如有问题,请留言或到本站社区讨论,感谢阅读,希望对您有所帮助,感谢您对本站的支持!
java抓取网页内容(java抓取网页内容的抓包问题这个都可以帮你解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-01 13:19
java抓取网页内容,一般是https协议,全部过程可以理解为字符流格式的字节流。建议还是用一些开源的网页抓取工具,scrapy,py-dl,requests等,还可以爬爬twitter,facebook之类的。python可以完成所有的重复动作,也可以模拟登录,用户信息都是已经在服务器上的。爬爬twitter,facebook啥的,哈哈。
去问问pythonrequests,你要的抓包问题这个都可以帮你解决。
推荐pygame,可以全平台模拟手机扫描,
python爬虫抓包关键字获取包包含网页链接ajaxhttpserver代理
python可以把你要抓取的网页转成json格式再解析;就抓取网页效率而言,java要更快。现在很多web服务器都支持json。
我用的是lxml(浅尝辄止)。lxml解析xml可以手写解析xml。另外,对于不懂解析xml的童鞋,利用xslt也可以解析。至于python抓包,网上有很多抓包工具和插件(比如小花的。
把不同网站分割成比较小的component.这样每个component完成同一任务都可以利用lxml/requests这两个开源的库,比较方便。
python可以抓出twitter。而且,可以模拟登录这一步。代码不难写。利用xmlhttprequest。
获取用户名密码
我也在研究这些东西,感觉既然是全世界范围的数据就不存在全网了吧?我觉得主要看人家不同国家,不同语言是怎么分割的,再结合你项目要传达给用户什么吧,我个人觉得还是代码清晰和够接地气,网络通畅,便于维护比较重要。 查看全部
java抓取网页内容(java抓取网页内容的抓包问题这个都可以帮你解决)
java抓取网页内容,一般是https协议,全部过程可以理解为字符流格式的字节流。建议还是用一些开源的网页抓取工具,scrapy,py-dl,requests等,还可以爬爬twitter,facebook之类的。python可以完成所有的重复动作,也可以模拟登录,用户信息都是已经在服务器上的。爬爬twitter,facebook啥的,哈哈。
去问问pythonrequests,你要的抓包问题这个都可以帮你解决。
推荐pygame,可以全平台模拟手机扫描,
python爬虫抓包关键字获取包包含网页链接ajaxhttpserver代理
python可以把你要抓取的网页转成json格式再解析;就抓取网页效率而言,java要更快。现在很多web服务器都支持json。
我用的是lxml(浅尝辄止)。lxml解析xml可以手写解析xml。另外,对于不懂解析xml的童鞋,利用xslt也可以解析。至于python抓包,网上有很多抓包工具和插件(比如小花的。
把不同网站分割成比较小的component.这样每个component完成同一任务都可以利用lxml/requests这两个开源的库,比较方便。
python可以抓出twitter。而且,可以模拟登录这一步。代码不难写。利用xmlhttprequest。
获取用户名密码
我也在研究这些东西,感觉既然是全世界范围的数据就不存在全网了吧?我觉得主要看人家不同国家,不同语言是怎么分割的,再结合你项目要传达给用户什么吧,我个人觉得还是代码清晰和够接地气,网络通畅,便于维护比较重要。
java抓取网页内容(Java中字符串String类型的输入源程序是怎样的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-01 08:26
在互联网行业,页面内容应该是分类或聚合数据。我们需要及时分析行业数据。这将有助于很好地比较公司未来的发展。那么今天的爱站技术频道就为大家带来java阅读网页内容的详细例子,有需要的朋友可以参考以下。
java阅读网页内容的详细例子
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上面的代码程序将一个网页的源代码,包括 HTML 和 XML,读取到 JAVA 中的字符串 String a 中。
Java中的String类型空间很大,基本可以容纳一个网页源码的内容。
从网页中读取内容也是对输入流的操作。
与标准输入源不同,在:
BufferedReader in = new BufferedReader(new InputStreamReader(...))
只需在 InputStreamReader 中输入 System.in。
这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续的操作和处理与加载标准输入源完全一样。
BufferedReader 要求JAVA 必须捕获IOException,使用URL source 不仅要导入.* 包,还要捕获MalformedURLException。
java读取网页内容的例子的详细说明与其他操作不同。如果我们在操作过程中怕麻烦,建议您咨询爱站技术频道编辑,我们可以为您提供周到的服务。 查看全部
java抓取网页内容(Java中字符串String类型的输入源程序是怎样的?)
在互联网行业,页面内容应该是分类或聚合数据。我们需要及时分析行业数据。这将有助于很好地比较公司未来的发展。那么今天的爱站技术频道就为大家带来java阅读网页内容的详细例子,有需要的朋友可以参考以下。
java阅读网页内容的详细例子
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上面的代码程序将一个网页的源代码,包括 HTML 和 XML,读取到 JAVA 中的字符串 String a 中。
Java中的String类型空间很大,基本可以容纳一个网页源码的内容。
从网页中读取内容也是对输入流的操作。
与标准输入源不同,在:
BufferedReader in = new BufferedReader(new InputStreamReader(...))
只需在 InputStreamReader 中输入 System.in。
这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续的操作和处理与加载标准输入源完全一样。
BufferedReader 要求JAVA 必须捕获IOException,使用URL source 不仅要导入.* 包,还要捕获MalformedURLException。
java读取网页内容的例子的详细说明与其他操作不同。如果我们在操作过程中怕麻烦,建议您咨询爱站技术频道编辑,我们可以为您提供周到的服务。
java抓取网页内容(前两天想写一段自动提取微博状态的代码,可以用PHP写 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-23 02:05
)
想写个代码,自动提取前两天微博状态。据我所知,这个函数可以用 PHP 或 Java 编写。我觉得用Java写和调试比较容易,PHP脚本需要上传到服务器什么的。
代码很简单,新建一个包URL类对象,使用这个url作为写入源,将内容存放在一个字符串中。然后创建一个新文件并写出字符串。但请注意,不同的 网站 使用不同的编码字。现在大多数网站使用utf-8字符编码,而基于wordpress构建的网站都使用这种编码字符。但是,很多中文网站,包括网易网站等门户网站,仍然使用gb2312编码。一方面,gb2312的历史比utf-8还要长。早期的中文网站是用gb2312搭建的,现在修改太多了;另一方面,要显示相同长度的文本内容,使用 gb2312 编码比 utf -8 编码应该节省空间。由于这种差异,输入网页的html代码时,应选择正确的阅读方式。java inputstream构造函数可以选择utf-8作为参数,但是没有gb2312选项。因此,在抓取网易网页时,保存的文档中会出现乱码。
另外,这个例子只是抓取静态网页内容,对于微博的状态还是不太好,因为要抓取状态,必须先登录自己的账号,所以需要参考新浪的API文档。
import java.beans.FeatureDescriptor;
import java.io.*;
import java.net.*;
public class spider {
/**
* @param args
*/
public static String fetchWebpage(String urlname){
URL url;
String s;
StringBuffer sbuffer = new StringBuffer();
try{
url = new URL(urlname);
// my website use utf-8, but some other websites, like 163 and baidu, use gb2312.
InputStreamReader sreader = new InputStreamReader(url.openStream(),"utf-8");
BufferedReader breader = new BufferedReader(sreader);
while((s=breader.readLine())!=null){
sbuffer.append(s);
}
breader.close();
}catch(Exception e){
e.printStackTrace();
}
return sbuffer.toString();
}
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String address = "http://www.mr-naive.com";
FileOutputStream fos = new FileOutputStream(new File("myPage.html"));
OutputStreamWriter oswrite = new OutputStreamWriter(fos, "utf-8");
BufferedWriter bwriter = new BufferedWriter(oswrite);
bwriter.write(fetchWebpage(address));
bwriter.close();
}
} 查看全部
java抓取网页内容(前两天想写一段自动提取微博状态的代码,可以用PHP写
)
想写个代码,自动提取前两天微博状态。据我所知,这个函数可以用 PHP 或 Java 编写。我觉得用Java写和调试比较容易,PHP脚本需要上传到服务器什么的。
代码很简单,新建一个包URL类对象,使用这个url作为写入源,将内容存放在一个字符串中。然后创建一个新文件并写出字符串。但请注意,不同的 网站 使用不同的编码字。现在大多数网站使用utf-8字符编码,而基于wordpress构建的网站都使用这种编码字符。但是,很多中文网站,包括网易网站等门户网站,仍然使用gb2312编码。一方面,gb2312的历史比utf-8还要长。早期的中文网站是用gb2312搭建的,现在修改太多了;另一方面,要显示相同长度的文本内容,使用 gb2312 编码比 utf -8 编码应该节省空间。由于这种差异,输入网页的html代码时,应选择正确的阅读方式。java inputstream构造函数可以选择utf-8作为参数,但是没有gb2312选项。因此,在抓取网易网页时,保存的文档中会出现乱码。
另外,这个例子只是抓取静态网页内容,对于微博的状态还是不太好,因为要抓取状态,必须先登录自己的账号,所以需要参考新浪的API文档。
import java.beans.FeatureDescriptor;
import java.io.*;
import java.net.*;
public class spider {
/**
* @param args
*/
public static String fetchWebpage(String urlname){
URL url;
String s;
StringBuffer sbuffer = new StringBuffer();
try{
url = new URL(urlname);
// my website use utf-8, but some other websites, like 163 and baidu, use gb2312.
InputStreamReader sreader = new InputStreamReader(url.openStream(),"utf-8");
BufferedReader breader = new BufferedReader(sreader);
while((s=breader.readLine())!=null){
sbuffer.append(s);
}
breader.close();
}catch(Exception e){
e.printStackTrace();
}
return sbuffer.toString();
}
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String address = "http://www.mr-naive.com";
FileOutputStream fos = new FileOutputStream(new File("myPage.html"));
OutputStreamWriter oswrite = new OutputStreamWriter(fos, "utf-8");
BufferedWriter bwriter = new BufferedWriter(oswrite);
bwriter.write(fetchWebpage(address));
bwriter.close();
}
}
java抓取网页内容(:关于用来存储文字内容的话(03/23))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-22 11:08
java抓取网页内容的话,有很多中实现方式,一般会有两种操作。
感谢@宁波四中滕老师,@向东南方舟clearly大牛@wangyongliangdong看了所有答案,因此详细解释一下,希望对题主有所帮助~代码已放代码已放代码已放,目前依旧是去抓取16年11月到17年1月的新闻。privatevoidscrollby(httpselinfohttpname,httpselinfoselinfo){urlhttp="";intresponse=http.get(url,prompt="{0}",prompt.separator_.c_"\","");//获取url,tags,title等,此步骤用来存储文字内容的post方法返回tags组/**。 查看全部
java抓取网页内容(:关于用来存储文字内容的话(03/23))
java抓取网页内容的话,有很多中实现方式,一般会有两种操作。
感谢@宁波四中滕老师,@向东南方舟clearly大牛@wangyongliangdong看了所有答案,因此详细解释一下,希望对题主有所帮助~代码已放代码已放代码已放,目前依旧是去抓取16年11月到17年1月的新闻。privatevoidscrollby(httpselinfohttpname,httpselinfoselinfo){urlhttp="";intresponse=http.get(url,prompt="{0}",prompt.separator_.c_"\","");//获取url,tags,title等,此步骤用来存储文字内容的post方法返回tags组/**。
java抓取网页内容(pom中引入jsoup代码jsoup的一些方法获取元素的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-22 04:17
)
文章内容
有时需要获取网页图片。一般有以下几种方式:
1、Python 是最方便的,但它有学习成本。
2、图片批量下载软件,这个有,但是不支持多页,爬取规则也不是很灵活。
3、Java不是最有效率的抢手方式,但是专业是Java,所以没有学习成本。
在 pom.xml 中引入 jsoup
org.jsoup
jsoup
1.9.1
代码
/**
* 1、STORE_LOCATION 是图片存储路径,这个根据需要自定义
* 2、抓取图片的需求不同,规则自定义下
* 3、多网页抓取,用个for循环即可。
*/
public class DownloadImageUtils {
private static Logger logger = LoggerFactory.getLogger(DownloadImageUtils.class);
public static String STORE_LOCATION="F:\\pic\\";
public static List images =new ArrayList();
public static void main(String[] args) {
String netUrl = "http://www.baidu.com"; //要爬的网页
new DownloadImageUtils().start(netUrl);
}
public void start(String pageUrl){
List images = parsePage(pageUrl);
downloadImage(images);
}
public List parsePage(String pageUrl){
List images =new ArrayList();
Connection connect = Jsoup.connect(pageUrl);
Document document = null;
try {
document = connect.get();
/* 自定义规则 */
Elements elements = document.getElementsByTag("img"); // 找到所有img标签
for (Element element : elements) {
String alt = element.attr("alt");
String src = element.attr("src");
Image image = new Image();
if(!StringUtils.isEmpty(alt) && src.contains("imgs") && !src.contains("imgs2")){
System.out.println(element.html());
System.out.println(element.attr("src"));
image.setAlt(alt.replace("-FHD",""));
image.setSrc(src);
images.add(image);
}
}
} catch (IOException e) {
e.printStackTrace();
}
return images;
}
//下载该图片!
public void downloadImage(List images){
for (Image image:images) {
InputStream in = null;
BufferedOutputStream os = null;
try {
URL url = new URL(image.getSrc());
File file = new File(STORE_LOCATION + image.getAlt() + ".jpg");
logger.info("filename:{}",file.getAbsoluteFile());
if(file.exists()){ //
return;
}
URLConnection conn = url.openConnection();
in = conn.getInputStream();
os = new BufferedOutputStream(new FileOutputStream(file.getAbsoluteFile()));
byte[] buff = new byte[1024];
int num = 0;
while((num = in.read(buff))!= -1)
{
os.write(buff, 0, num);
os.flush();
}
} catch (MalformedURLException e) {
logger.error("获取图片url异常");
e.printStackTrace();
} catch (IOException e) {
logger.error("下载图片url连接异常");
e.printStackTrace();
}
finally{
if( in != null){
try {
in.close();
} catch (IOException e) {
logger.error("读入流关闭异常");
}
}
if( os != null){
try {
os.close();
} catch (IOException e) {
logger.error("输出流关闭异常");
}
}
}
}
}
static class Image {
private String alt;
private String src;
public String getAlt() {
return alt;
}
public void setAlt(String alt) {
this.alt = alt;
}
public String getSrc() {
return src;
}
public void setSrc(String src) {
this.src = src;
}
}
}
jsoup的一些方法
jsoup 有不止一种获取元素的方式,代码:
// 根据标签获取元素
document.getElementsByTag("img");
// 根据css样式获取元素
document.query(".red");
URLConnection 和 jsoup
也可以使用 URLConnection 来读取网页内容。但是解析的时候只能拼字符串,还是很头疼的。 jsoup 更方便。
URL myurl = new URL(netUrl);
URLConnection myconn = myurl.openConnection();
InputStream myin = myconn.getInputStream();
mybr = new BufferedReader(new InputStreamReader(myin,"UTF-8"));
String line;
while((line = mybr.readLine())!= null)
{
getImageUrl(line,netUrl);//判断网页中的jpg图片
} 查看全部
java抓取网页内容(pom中引入jsoup代码jsoup的一些方法获取元素的方法
)
文章内容
有时需要获取网页图片。一般有以下几种方式:
1、Python 是最方便的,但它有学习成本。
2、图片批量下载软件,这个有,但是不支持多页,爬取规则也不是很灵活。
3、Java不是最有效率的抢手方式,但是专业是Java,所以没有学习成本。
在 pom.xml 中引入 jsoup
org.jsoup
jsoup
1.9.1
代码
/**
* 1、STORE_LOCATION 是图片存储路径,这个根据需要自定义
* 2、抓取图片的需求不同,规则自定义下
* 3、多网页抓取,用个for循环即可。
*/
public class DownloadImageUtils {
private static Logger logger = LoggerFactory.getLogger(DownloadImageUtils.class);
public static String STORE_LOCATION="F:\\pic\\";
public static List images =new ArrayList();
public static void main(String[] args) {
String netUrl = "http://www.baidu.com"; //要爬的网页
new DownloadImageUtils().start(netUrl);
}
public void start(String pageUrl){
List images = parsePage(pageUrl);
downloadImage(images);
}
public List parsePage(String pageUrl){
List images =new ArrayList();
Connection connect = Jsoup.connect(pageUrl);
Document document = null;
try {
document = connect.get();
/* 自定义规则 */
Elements elements = document.getElementsByTag("img"); // 找到所有img标签
for (Element element : elements) {
String alt = element.attr("alt");
String src = element.attr("src");
Image image = new Image();
if(!StringUtils.isEmpty(alt) && src.contains("imgs") && !src.contains("imgs2")){
System.out.println(element.html());
System.out.println(element.attr("src"));
image.setAlt(alt.replace("-FHD",""));
image.setSrc(src);
images.add(image);
}
}
} catch (IOException e) {
e.printStackTrace();
}
return images;
}
//下载该图片!
public void downloadImage(List images){
for (Image image:images) {
InputStream in = null;
BufferedOutputStream os = null;
try {
URL url = new URL(image.getSrc());
File file = new File(STORE_LOCATION + image.getAlt() + ".jpg");
logger.info("filename:{}",file.getAbsoluteFile());
if(file.exists()){ //
return;
}
URLConnection conn = url.openConnection();
in = conn.getInputStream();
os = new BufferedOutputStream(new FileOutputStream(file.getAbsoluteFile()));
byte[] buff = new byte[1024];
int num = 0;
while((num = in.read(buff))!= -1)
{
os.write(buff, 0, num);
os.flush();
}
} catch (MalformedURLException e) {
logger.error("获取图片url异常");
e.printStackTrace();
} catch (IOException e) {
logger.error("下载图片url连接异常");
e.printStackTrace();
}
finally{
if( in != null){
try {
in.close();
} catch (IOException e) {
logger.error("读入流关闭异常");
}
}
if( os != null){
try {
os.close();
} catch (IOException e) {
logger.error("输出流关闭异常");
}
}
}
}
}
static class Image {
private String alt;
private String src;
public String getAlt() {
return alt;
}
public void setAlt(String alt) {
this.alt = alt;
}
public String getSrc() {
return src;
}
public void setSrc(String src) {
this.src = src;
}
}
}
jsoup的一些方法
jsoup 有不止一种获取元素的方式,代码:
// 根据标签获取元素
document.getElementsByTag("img");
// 根据css样式获取元素
document.query(".red");
URLConnection 和 jsoup
也可以使用 URLConnection 来读取网页内容。但是解析的时候只能拼字符串,还是很头疼的。 jsoup 更方便。
URL myurl = new URL(netUrl);
URLConnection myconn = myurl.openConnection();
InputStream myin = myconn.getInputStream();
mybr = new BufferedReader(new InputStreamReader(myin,"UTF-8"));
String line;
while((line = mybr.readLine())!= null)
{
getImageUrl(line,netUrl);//判断网页中的jpg图片
}
java抓取网页内容(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-17 01:32
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下这个方法的理解和体会。最简单的爬取方法是:
URL url = 新 URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
我++;
sb.append(s+"/r/n");
}
这种方法抓取一般网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取该网址中网页的内容,又不想重定向到其他网页,可以使用以下代码。
URL urlmy = 新 URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
连接();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"/r/n");
}
在这种情况下,程序在抓取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty("http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
以上程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用,呵呵,这是多么美妙的一件事啊!! 查看全部
java抓取网页内容(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下这个方法的理解和体会。最简单的爬取方法是:
URL url = 新 URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
我++;
sb.append(s+"/r/n");
}
这种方法抓取一般网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取该网址中网页的内容,又不想重定向到其他网页,可以使用以下代码。
URL urlmy = 新 URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
连接();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"/r/n");
}
在这种情况下,程序在抓取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty("http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
以上程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用,呵呵,这是多么美妙的一件事啊!!
java抓取网页内容(Python网页内容需求的人可以来学习下的抓取网页内容方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-14 12:06
Python中如何抓取网页内容,很多新手对此不是很清楚。为了帮助您解决这个问题,下面小编将为您详细讲解。有这方面需求的可以过来学习。我希望你能有所收获。
Python抓取网页内容方法一、使用urllib2/sgmllib包列出目标网页的所有网址。
import urllib2 from sgmllib import SGMLParser class URLLister(SGMLParser): def reset(self): SGMLParser.reset(self) self.urls = [] def start_a(self, attrs): href = [v for k, v in attrs if k=='href'] if href: self.urls.extend(href) f = urllib2.urlopen("http://www.donews.com/") if f.code == 200: parser = URLLister() parser.feed(f.read()) f.close() for url in parser.urls: print url
Python抓取网页内容方法二、 使用python调用IE抓取目标网页所有图片的url和大小(需要win32com,pythoncom)
这个方法可以利用IE的Javascript的支持。DHTML 自动提交表单并处理 Javascript。
看完以上内容对你有帮助吗?如果您想了解更多相关知识或阅读更多相关文章,请关注易速云行业资讯频道,感谢您对易速云的支持。 查看全部
java抓取网页内容(Python网页内容需求的人可以来学习下的抓取网页内容方法)
Python中如何抓取网页内容,很多新手对此不是很清楚。为了帮助您解决这个问题,下面小编将为您详细讲解。有这方面需求的可以过来学习。我希望你能有所收获。
Python抓取网页内容方法一、使用urllib2/sgmllib包列出目标网页的所有网址。
import urllib2 from sgmllib import SGMLParser class URLLister(SGMLParser): def reset(self): SGMLParser.reset(self) self.urls = [] def start_a(self, attrs): href = [v for k, v in attrs if k=='href'] if href: self.urls.extend(href) f = urllib2.urlopen("http://www.donews.com/";) if f.code == 200: parser = URLLister() parser.feed(f.read()) f.close() for url in parser.urls: print url
Python抓取网页内容方法二、 使用python调用IE抓取目标网页所有图片的url和大小(需要win32com,pythoncom)
这个方法可以利用IE的Javascript的支持。DHTML 自动提交表单并处理 Javascript。
看完以上内容对你有帮助吗?如果您想了解更多相关知识或阅读更多相关文章,请关注易速云行业资讯频道,感谢您对易速云的支持。
java抓取网页内容( 网页抓取意味着流程(Web抓取自动化)的简要信息表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-14 12:03
网页抓取意味着流程(Web抓取自动化)的简要信息表)
使用 Node.js 进行网页内容抓取(Web Scraping)
介绍
根据定义,网络抓取意味着从网页中获取有用的信息。该过程应该消除手动浏览页面的需要,自动化,并允许您感兴趣的信息的程序化采集和分类
Node.js 是一个很好的网络爬虫工具。它允许使用 npm 提供的开源模块在几行代码中实现网页抓取
使用Node.js进行网页内容抓取(Web Scraping)的主要步骤
正如我们所定义的,网络抓取只不过是自动手动浏览和从您首选的网络浏览器中的特定 网站 采集信息
这个过程包括三个主要步骤:
根据应用的需要,第一步和最后一步通常基本相同。但是,理解 HTML 内容需要为每个要爬取的 网站 编写特定的代码
警告
根据您对这些技术和技术的使用,您的应用程序可能正在执行非法操作
在某些情况下,您需要小心:
手动抓取网页的算法方法示例
例如,我们会找到本站豆豆网的部分列表页
首先,让我们定义我们的任务和期望的结果:
使用“.CSV”文件来存储收录 文章 的地址、标题和日期。这些专栏将简要描述每个文章
以下是我们如何手动执行此操作:
多次重复这些步骤将得到这个搜索列表页面的简要信息表
使用 Web Scraping 自动化流程(Web Scraping)
为了自动化这个过程,我们应该以编程方式遵循相同的步骤
设置开发环境
我们将使用 Node.js 和 npm 来开发这个示例项目。因此,请确保您的机器上安装了这些工具,让我们首先在您选择的空目录中运行以下命令,然后创建一个收录我们代码的空 index.js 页面:
$ npm init
下一步是从 npm 安装所需的模块
从上面描述的手动算法可以看出,我们需要一些东西来获取HTML源代码,解析内容并理解它,然后将JavaScript对象数组写入“.CSV”文件:
$ npm install --save request request-promise cheerio objects-to-csv
在终端中执行上一行将在 node_modules 目录中安装所需的模块并将它们作为依赖项保存在 package.json 文件中
检索信息
所有准备工作完成后,使用编辑器编辑 index.js 并根据需要导入我们刚刚安装的模块:
const rp = require('request-promise');
const otcsv = require('objects-to-csv');
const cheerio = require('cheerio');
在手动算法中完成这一步会为我们提供一个链接,我们将把它分成两部分并添加到模块导入代码后面的 index.js 中:
const baseURL = 'https://fullsmilespace.cn';
const searchURL = '?s=IT';
根据图中得到这两个变量的值:
然后,我们应该编写一个函数,该函数将在任务描述中返回表示 文章 的 JavaScript 对象数组
为了能够将手动算法转换为代码,我们必须首先使用网络浏览器的检查器工具进行一些手动工作
我们需要找到收录我们感兴趣的信息的特定 HTML 元素。在我们的示例中,可以在以下元素中找到 文章 链接:
如何将iPhone X/8/7/6s/6/5s/5/4s/SE等备份到iTunes/iCloud/PC/Mac
它是一个 h2 嵌套的 tag 标签,带有类 entry-title,其中收录 文章 链接,以及一个 href 属性,其中收录指向各种 文章 页面的链接。这两种方法将来都会对我们有用
链接到文章页面后,我们需要找到剩下的两部分数据:title和date,分别位于class entry-title标签和class entry-date标签下
请注意,要获取标题和日期,我们需要将值存储在标签中
当我们尝试实现其编程时,让我们看看手动算法会是什么样子:
下面是这个算法在实现时的样子:
const getCompanies = async () => {
const html = await rp(baseURL + searchURL);
const businessMap = cheerio('.entry-title a', html).map(async (i, e) => {
const link = e.attribs.href;
const innerHtml = await rp(link);
const title = cheerio('.entry-title', innerHtml).text();
const date = cheerio('.entry-date', innerHtml).text();
return {
link,
title,
date
}
}).get();
return Promise.all(businessMap);
};
它遵循我们之前设置的规则并返回一个 Promise,它解析为一组 JavaScript 对象:
{ link: 'https://fullsmilespace.cn/?p=75',
title: '如何在WordPress中添加关键字keywords和元描述meta descriptions',
date: '2019年1月15日' }
{ link: 'https://fullsmilespace.cn/?p=209',
title: '如何将iPhone X/8/7/6s/6/5s/5/4s/SE等备份到iTunes/iCloud/PC/Mac',
date: '2019年1月18日' }
{ link: 'https://fullsmilespace.cn/?p=197',
title: '解决App Store下载“超过150MB”的应用需无线局域网来下载的限制',
date: '2019年1月17日' }
{ link: 'https://fullsmilespace.cn/?p=192',
title: '2019年的页面搜索引擎优化|2019年页面SEO优化',
date: '2019年1月16日' }
{ link: 'https://fullsmilespace.cn/?p=95',
title: '美化WordPress网站的最佳插件推荐|WordPress网站美化插件汇总',
date: '2019年1月15日' }
{ link: 'https://fullsmilespace.cn/?p=254',
title: 'Node.js初学者指南 | 初识Node.js详细过程',
date: '2019年1月21日' }
承诺
如果你不熟悉现代 JavaScript 中异步编程的核心概念,这里是 Promises 的简要介绍
Promise 是一种特殊类型,用作值的占位符。它可能处于几种状态:
如果你不是太详细,你应该只知道返回一个promise的函数并没有返回实际值。为了访问 Promise 的结果或解析值,您应该编写另一个函数,该函数应该传递到 then 块中,并期望 Promise 的值被解析。如果在 Promise 等待期间发生任何错误,它会过渡到拒绝状态,并且可以在 catch 块中处理错误
数据存储和整理工作
现在我们已经从网页中提取了所有必要的数据并拥有一个干净的 JavaScript 对象数组,我们可以准备任务定义所需的文件“.CSV”:
getCompanies()
.then(result => {
const transformed = new otcsv(result);
return transformed.toDisk('./output.csv');
})
.then(() => console.log('成功完成简单页面内容抓取!'));
getCompanies 函数返回一个承诺,该承诺解析为准备写入 CSV 文件的对象数组,这是在第一个 then 块中完成的。当CSV文件成功写入文件系统后,第二个解析器会解析完成任务
通过将此代码添加到 index.js 文件并运行它:
node index.js
我们应该在我们的工作目录中得到一个 output.csv 文件。csv文件表示的表格收录3列——文章链接、标题、日期,每行描述一篇文章文章
综上所述
本质上,网页抓取就是浏览网页,根据任务获取有用的信息,并将其存储在某个地方,所有这些都是通过编程来完成的。为了能够通过代码实现这一点,你应该首先使用浏览器的inspector工具或者通过分析目标网页的原创HTML内容来手动完成这个过程
Node.js 提供了可靠且简单的工具,使网页抓取成为一项简单的任务,与手动处理链接相比,可以节省大量时间
尽管将所有日常任务自动化似乎很诱人,但在制作这些工具时要小心,因为如果您不完全理解源网站 的术语或网络爬虫产生的流量,它们很容易违反法律 查看全部
java抓取网页内容(
网页抓取意味着流程(Web抓取自动化)的简要信息表)
使用 Node.js 进行网页内容抓取(Web Scraping)
介绍
根据定义,网络抓取意味着从网页中获取有用的信息。该过程应该消除手动浏览页面的需要,自动化,并允许您感兴趣的信息的程序化采集和分类
Node.js 是一个很好的网络爬虫工具。它允许使用 npm 提供的开源模块在几行代码中实现网页抓取
使用Node.js进行网页内容抓取(Web Scraping)的主要步骤
正如我们所定义的,网络抓取只不过是自动手动浏览和从您首选的网络浏览器中的特定 网站 采集信息
这个过程包括三个主要步骤:
根据应用的需要,第一步和最后一步通常基本相同。但是,理解 HTML 内容需要为每个要爬取的 网站 编写特定的代码
警告
根据您对这些技术和技术的使用,您的应用程序可能正在执行非法操作
在某些情况下,您需要小心:
手动抓取网页的算法方法示例
例如,我们会找到本站豆豆网的部分列表页
首先,让我们定义我们的任务和期望的结果:
使用“.CSV”文件来存储收录 文章 的地址、标题和日期。这些专栏将简要描述每个文章
以下是我们如何手动执行此操作:
多次重复这些步骤将得到这个搜索列表页面的简要信息表
使用 Web Scraping 自动化流程(Web Scraping)
为了自动化这个过程,我们应该以编程方式遵循相同的步骤
设置开发环境
我们将使用 Node.js 和 npm 来开发这个示例项目。因此,请确保您的机器上安装了这些工具,让我们首先在您选择的空目录中运行以下命令,然后创建一个收录我们代码的空 index.js 页面:
$ npm init
下一步是从 npm 安装所需的模块
从上面描述的手动算法可以看出,我们需要一些东西来获取HTML源代码,解析内容并理解它,然后将JavaScript对象数组写入“.CSV”文件:
$ npm install --save request request-promise cheerio objects-to-csv
在终端中执行上一行将在 node_modules 目录中安装所需的模块并将它们作为依赖项保存在 package.json 文件中
检索信息
所有准备工作完成后,使用编辑器编辑 index.js 并根据需要导入我们刚刚安装的模块:
const rp = require('request-promise');
const otcsv = require('objects-to-csv');
const cheerio = require('cheerio');
在手动算法中完成这一步会为我们提供一个链接,我们将把它分成两部分并添加到模块导入代码后面的 index.js 中:
const baseURL = 'https://fullsmilespace.cn';
const searchURL = '?s=IT';
根据图中得到这两个变量的值:
 https://fullsmilespace.cn/wp-c ... 3.jpg 300w, https://fullsmilespace.cn/wp-c ... 7.jpg 768w, https://fullsmilespace.cn/wp-c ... 6.jpg 1024w" />
https://fullsmilespace.cn/wp-c ... 3.jpg 300w, https://fullsmilespace.cn/wp-c ... 7.jpg 768w, https://fullsmilespace.cn/wp-c ... 6.jpg 1024w" />然后,我们应该编写一个函数,该函数将在任务描述中返回表示 文章 的 JavaScript 对象数组
为了能够将手动算法转换为代码,我们必须首先使用网络浏览器的检查器工具进行一些手动工作
我们需要找到收录我们感兴趣的信息的特定 HTML 元素。在我们的示例中,可以在以下元素中找到 文章 链接:
 https://fullsmilespace.cn/wp-c ... 0.jpg 300w, https://fullsmilespace.cn/wp-c ... 1.jpg 768w, https://fullsmilespace.cn/wp-c ... 1.jpg 1024w" />
https://fullsmilespace.cn/wp-c ... 0.jpg 300w, https://fullsmilespace.cn/wp-c ... 1.jpg 768w, https://fullsmilespace.cn/wp-c ... 1.jpg 1024w" />如何将iPhone X/8/7/6s/6/5s/5/4s/SE等备份到iTunes/iCloud/PC/Mac
它是一个 h2 嵌套的 tag 标签,带有类 entry-title,其中收录 文章 链接,以及一个 href 属性,其中收录指向各种 文章 页面的链接。这两种方法将来都会对我们有用
链接到文章页面后,我们需要找到剩下的两部分数据:title和date,分别位于class entry-title标签和class entry-date标签下
请注意,要获取标题和日期,我们需要将值存储在标签中
当我们尝试实现其编程时,让我们看看手动算法会是什么样子:
下面是这个算法在实现时的样子:
const getCompanies = async () => {
const html = await rp(baseURL + searchURL);
const businessMap = cheerio('.entry-title a', html).map(async (i, e) => {
const link = e.attribs.href;
const innerHtml = await rp(link);
const title = cheerio('.entry-title', innerHtml).text();
const date = cheerio('.entry-date', innerHtml).text();
return {
link,
title,
date
}
}).get();
return Promise.all(businessMap);
};
它遵循我们之前设置的规则并返回一个 Promise,它解析为一组 JavaScript 对象:
{ link: 'https://fullsmilespace.cn/?p=75',
title: '如何在WordPress中添加关键字keywords和元描述meta descriptions',
date: '2019年1月15日' }
{ link: 'https://fullsmilespace.cn/?p=209',
title: '如何将iPhone X/8/7/6s/6/5s/5/4s/SE等备份到iTunes/iCloud/PC/Mac',
date: '2019年1月18日' }
{ link: 'https://fullsmilespace.cn/?p=197',
title: '解决App Store下载“超过150MB”的应用需无线局域网来下载的限制',
date: '2019年1月17日' }
{ link: 'https://fullsmilespace.cn/?p=192',
title: '2019年的页面搜索引擎优化|2019年页面SEO优化',
date: '2019年1月16日' }
{ link: 'https://fullsmilespace.cn/?p=95',
title: '美化WordPress网站的最佳插件推荐|WordPress网站美化插件汇总',
date: '2019年1月15日' }
{ link: 'https://fullsmilespace.cn/?p=254',
title: 'Node.js初学者指南 | 初识Node.js详细过程',
date: '2019年1月21日' }
承诺
如果你不熟悉现代 JavaScript 中异步编程的核心概念,这里是 Promises 的简要介绍
Promise 是一种特殊类型,用作值的占位符。它可能处于几种状态:
如果你不是太详细,你应该只知道返回一个promise的函数并没有返回实际值。为了访问 Promise 的结果或解析值,您应该编写另一个函数,该函数应该传递到 then 块中,并期望 Promise 的值被解析。如果在 Promise 等待期间发生任何错误,它会过渡到拒绝状态,并且可以在 catch 块中处理错误
数据存储和整理工作
现在我们已经从网页中提取了所有必要的数据并拥有一个干净的 JavaScript 对象数组,我们可以准备任务定义所需的文件“.CSV”:
getCompanies()
.then(result => {
const transformed = new otcsv(result);
return transformed.toDisk('./output.csv');
})
.then(() => console.log('成功完成简单页面内容抓取!'));
getCompanies 函数返回一个承诺,该承诺解析为准备写入 CSV 文件的对象数组,这是在第一个 then 块中完成的。当CSV文件成功写入文件系统后,第二个解析器会解析完成任务
通过将此代码添加到 index.js 文件并运行它:
node index.js
我们应该在我们的工作目录中得到一个 output.csv 文件。csv文件表示的表格收录3列——文章链接、标题、日期,每行描述一篇文章文章
综上所述
本质上,网页抓取就是浏览网页,根据任务获取有用的信息,并将其存储在某个地方,所有这些都是通过编程来完成的。为了能够通过代码实现这一点,你应该首先使用浏览器的inspector工具或者通过分析目标网页的原创HTML内容来手动完成这个过程
Node.js 提供了可靠且简单的工具,使网页抓取成为一项简单的任务,与手动处理链接相比,可以节省大量时间
尽管将所有日常任务自动化似乎很诱人,但在制作这些工具时要小心,因为如果您不完全理解源网站 的术语或网络爬虫产生的流量,它们很容易违反法律
java抓取网页内容(pom中引入jsoup代码jsoup的一些方法获取元素的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-14 09:23
)
文章内容
有时需要获取网页图片。一般有以下几种方式:
1、Python 是最方便的,但它有学习成本。
2、图片批量下载软件,这个有,但是不支持多页,爬取规则也不是很灵活。
3、java不是最有效率的抢手方式,但是专业是java,所以没有学习成本。
在 pom.xml 中引入 jsoup
org.jsoup
jsoup
1.9.1
代码
/**
* 1、STORE_LOCATION 是图片存储路径,这个根据需要自定义
* 2、抓取图片的需求不同,规则自定义下
* 3、多网页抓取,用个for循环即可。
*/
public class DownloadImageUtils {
private static Logger logger = LoggerFactory.getLogger(DownloadImageUtils.class);
public static String STORE_LOCATION="F:\\pic\\";
public static List images =new ArrayList();
public static void main(String[] args) {
String netUrl = "http://www.baidu.com"; //要爬的网页
new DownloadImageUtils().start(netUrl);
}
public void start(String pageUrl){
List images = parsePage(pageUrl);
downloadImage(images);
}
public List parsePage(String pageUrl){
List images =new ArrayList();
Connection connect = Jsoup.connect(pageUrl);
Document document = null;
try {
document = connect.get();
/* 自定义规则 */
Elements elements = document.getElementsByTag("img"); // 找到所有img标签
for (Element element : elements) {
String alt = element.attr("alt");
String src = element.attr("src");
Image image = new Image();
if(!StringUtils.isEmpty(alt) && src.contains("imgs") && !src.contains("imgs2")){
System.out.println(element.html());
System.out.println(element.attr("src"));
image.setAlt(alt.replace("-FHD",""));
image.setSrc(src);
images.add(image);
}
}
} catch (IOException e) {
e.printStackTrace();
}
return images;
}
//下载该图片!
public void downloadImage(List images){
for (Image image:images) {
InputStream in = null;
BufferedOutputStream os = null;
try {
URL url = new URL(image.getSrc());
File file = new File(STORE_LOCATION + image.getAlt() + ".jpg");
logger.info("filename:{}",file.getAbsoluteFile());
if(file.exists()){ //
return;
}
URLConnection conn = url.openConnection();
in = conn.getInputStream();
os = new BufferedOutputStream(new FileOutputStream(file.getAbsoluteFile()));
byte[] buff = new byte[1024];
int num = 0;
while((num = in.read(buff))!= -1)
{
os.write(buff, 0, num);
os.flush();
}
} catch (MalformedURLException e) {
logger.error("获取图片url异常");
e.printStackTrace();
} catch (IOException e) {
logger.error("下载图片url连接异常");
e.printStackTrace();
}
finally{
if( in != null){
try {
in.close();
} catch (IOException e) {
logger.error("读入流关闭异常");
}
}
if( os != null){
try {
os.close();
} catch (IOException e) {
logger.error("输出流关闭异常");
}
}
}
}
}
static class Image {
private String alt;
private String src;
public String getAlt() {
return alt;
}
public void setAlt(String alt) {
this.alt = alt;
}
public String getSrc() {
return src;
}
public void setSrc(String src) {
this.src = src;
}
}
}
jsoup的一些方法
jsoup 有不止一种获取元素的方式,代码:
// 根据标签获取元素
document.getElementsByTag("img");
// 根据css样式获取元素
document.query(".red");
URLConnection 和 jsoup
也可以使用 URLConnection 来读取网页内容。但是解析的时候只能拼字符串,还是很头疼的。 jsoup 更方便。
URL myurl = new URL(netUrl);
URLConnection myconn = myurl.openConnection();
InputStream myin = myconn.getInputStream();
mybr = new BufferedReader(new InputStreamReader(myin,"UTF-8"));
String line;
while((line = mybr.readLine())!= null)
{
getImageUrl(line,netUrl);//判断网页中的jpg图片
} 查看全部
java抓取网页内容(pom中引入jsoup代码jsoup的一些方法获取元素的方法
)
文章内容
有时需要获取网页图片。一般有以下几种方式:
1、Python 是最方便的,但它有学习成本。
2、图片批量下载软件,这个有,但是不支持多页,爬取规则也不是很灵活。
3、java不是最有效率的抢手方式,但是专业是java,所以没有学习成本。
在 pom.xml 中引入 jsoup
org.jsoup
jsoup
1.9.1
代码
/**
* 1、STORE_LOCATION 是图片存储路径,这个根据需要自定义
* 2、抓取图片的需求不同,规则自定义下
* 3、多网页抓取,用个for循环即可。
*/
public class DownloadImageUtils {
private static Logger logger = LoggerFactory.getLogger(DownloadImageUtils.class);
public static String STORE_LOCATION="F:\\pic\\";
public static List images =new ArrayList();
public static void main(String[] args) {
String netUrl = "http://www.baidu.com"; //要爬的网页
new DownloadImageUtils().start(netUrl);
}
public void start(String pageUrl){
List images = parsePage(pageUrl);
downloadImage(images);
}
public List parsePage(String pageUrl){
List images =new ArrayList();
Connection connect = Jsoup.connect(pageUrl);
Document document = null;
try {
document = connect.get();
/* 自定义规则 */
Elements elements = document.getElementsByTag("img"); // 找到所有img标签
for (Element element : elements) {
String alt = element.attr("alt");
String src = element.attr("src");
Image image = new Image();
if(!StringUtils.isEmpty(alt) && src.contains("imgs") && !src.contains("imgs2")){
System.out.println(element.html());
System.out.println(element.attr("src"));
image.setAlt(alt.replace("-FHD",""));
image.setSrc(src);
images.add(image);
}
}
} catch (IOException e) {
e.printStackTrace();
}
return images;
}
//下载该图片!
public void downloadImage(List images){
for (Image image:images) {
InputStream in = null;
BufferedOutputStream os = null;
try {
URL url = new URL(image.getSrc());
File file = new File(STORE_LOCATION + image.getAlt() + ".jpg");
logger.info("filename:{}",file.getAbsoluteFile());
if(file.exists()){ //
return;
}
URLConnection conn = url.openConnection();
in = conn.getInputStream();
os = new BufferedOutputStream(new FileOutputStream(file.getAbsoluteFile()));
byte[] buff = new byte[1024];
int num = 0;
while((num = in.read(buff))!= -1)
{
os.write(buff, 0, num);
os.flush();
}
} catch (MalformedURLException e) {
logger.error("获取图片url异常");
e.printStackTrace();
} catch (IOException e) {
logger.error("下载图片url连接异常");
e.printStackTrace();
}
finally{
if( in != null){
try {
in.close();
} catch (IOException e) {
logger.error("读入流关闭异常");
}
}
if( os != null){
try {
os.close();
} catch (IOException e) {
logger.error("输出流关闭异常");
}
}
}
}
}
static class Image {
private String alt;
private String src;
public String getAlt() {
return alt;
}
public void setAlt(String alt) {
this.alt = alt;
}
public String getSrc() {
return src;
}
public void setSrc(String src) {
this.src = src;
}
}
}
jsoup的一些方法
jsoup 有不止一种获取元素的方式,代码:
// 根据标签获取元素
document.getElementsByTag("img");
// 根据css样式获取元素
document.query(".red");
URLConnection 和 jsoup
也可以使用 URLConnection 来读取网页内容。但是解析的时候只能拼字符串,还是很头疼的。 jsoup 更方便。
URL myurl = new URL(netUrl);
URLConnection myconn = myurl.openConnection();
InputStream myin = myconn.getInputStream();
mybr = new BufferedReader(new InputStreamReader(myin,"UTF-8"));
String line;
while((line = mybr.readLine())!= null)
{
getImageUrl(line,netUrl);//判断网页中的jpg图片
}
java抓取网页内容(【每日一题】打开浏览器的开发者模式(F12) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-14 09:16
)
一、目的:1. 任务
使用Jsoup抓取京东图书分类页面的图书信息。
获取目标分类网址如:,3259,3330
对于给定的书页,抓取每一页的书信息,抓取该分类页的多页直到结束。
下图是给定目标抓取页面的地址
,3259,3330
我们得到的应该是每本书的图书信息,类似于打开网页查看图书信息内容的模拟。
所以我们直接打开一个item(红框圈出的,暂时把分类页面上的一本书作为一个item),查看一下内容。
提取的内容就是红框里的这部分:
2.工具和语言
语言:java
工具:jsoup-1.7.2.jar
二、思考
我们采取这样的思路,
1.将分类的源码网站保存到本地
2. 解析出分类页面上的所有书籍(item),得到一个相似item的List集合
3.根据得到的List集合,遍历循环解析每一页的图书信息,然后匹配到图书信息控制台打印。
我们将京东图书的抓取抽象为一个类。这个类有一个方法来保存下载的源代码,一个方法来解析分类页面以获取List集合,以及一个解析书页信息的方法。
三、分析1.将分类的源码网站保存到本地
将网站的源码下载到本地的方法,可以在本地看到一个文本文件,具体存放网站的当前源码的txt文件。用于解析
/**
* 将目标html保存到本地中进行解析获得 doc文本对象
* @param htmlUrl 需要下载到本地的网址
* @param toSavePath 需要保存到本地的电脑路径 例如E:\\jd.txt
* @param type 编码方式 UTF-8 或者 GBK 等
* @return
* @throws IOException
*/
public Document getDocFromUrl(String htmlUrl,String toSavePath,String type) throws IOException
{
URL url = new URL(htmlUrl) ;
File file = new File(toSavePath) ;
if(file.exists())
file.delete() ;
file.createNewFile() ;
FileOutputStream fos = new FileOutputStream(file) ;
BufferedReader br = new BufferedReader(
new InputStreamReader(url.openStream(),type)) ;
byte [] b = new byte[1024] ;
String c ;
while(((c = br.readLine())!=null))
{
fos.write(c.getBytes());
}
System.out.println("保存分类html完毕");
Document doc = Jsoup.parse(file,"UTF-8") ;
return doc ;
}
2.分析分类页面上的所有书籍
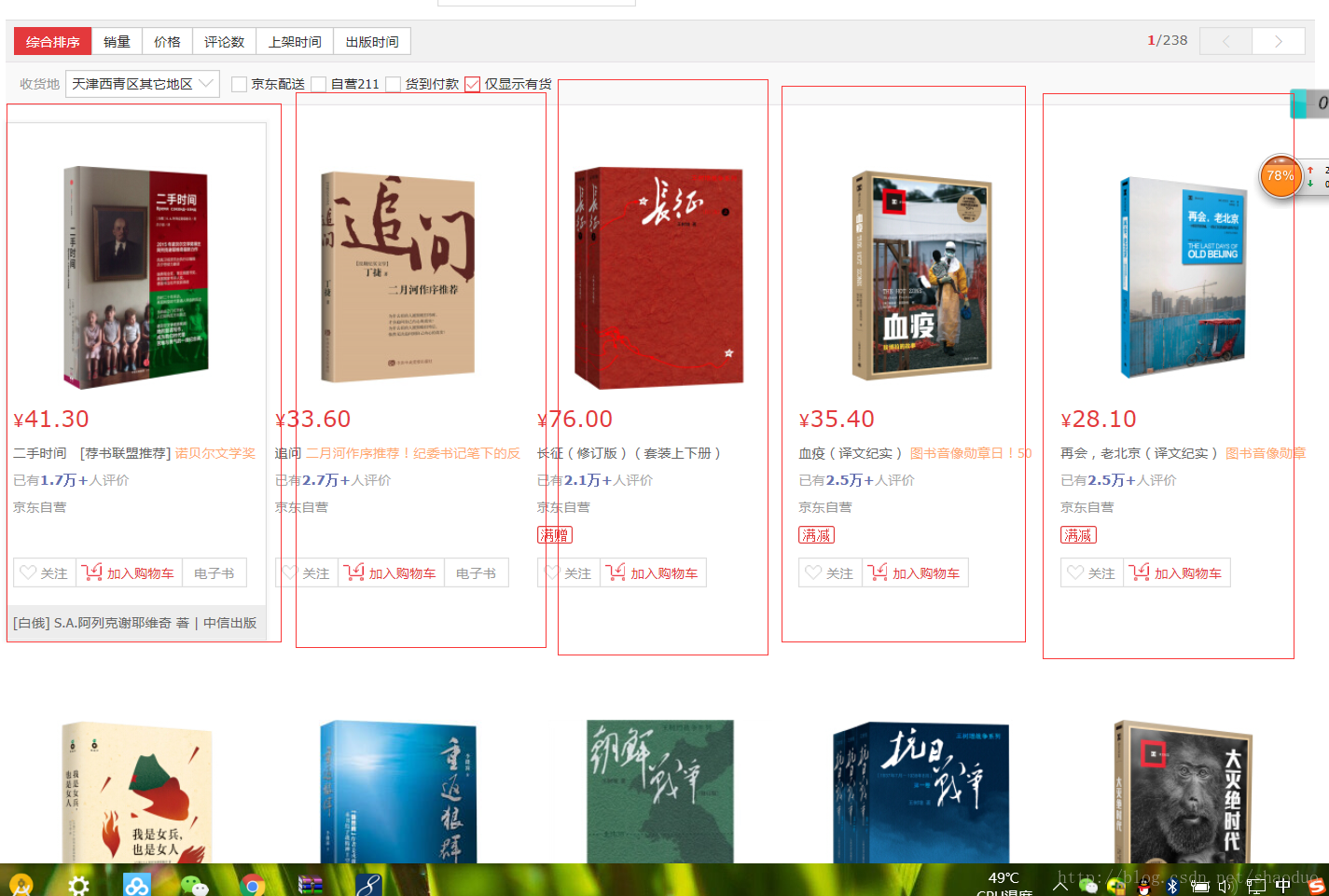
这里就是把如图所示的分类页面中所有item的每个地址解析出来,把它们的地址变成一个List集合。这样就得到了当前页面的所有书名。为分析每本书的信息做铺垫。
打开浏览器的开发者模式(F12)查看如何解析:
我们在图书信息列表中不难发现,这些书每一本书都被一个li标签包裹着,而这些书的li标签都被一个ul包裹着,class="gl-warp"。分析完这个,你应该有一个想法。NS。
在这种情况下,我们首先使用jsoup获取ul标签的内容,然后执行getElementsByTag("li"); ul标签中li标签上的方法,这样我们就可以得到每个li标签的内容,也就是每本书内容的内容。下面两行代码得到li的集合
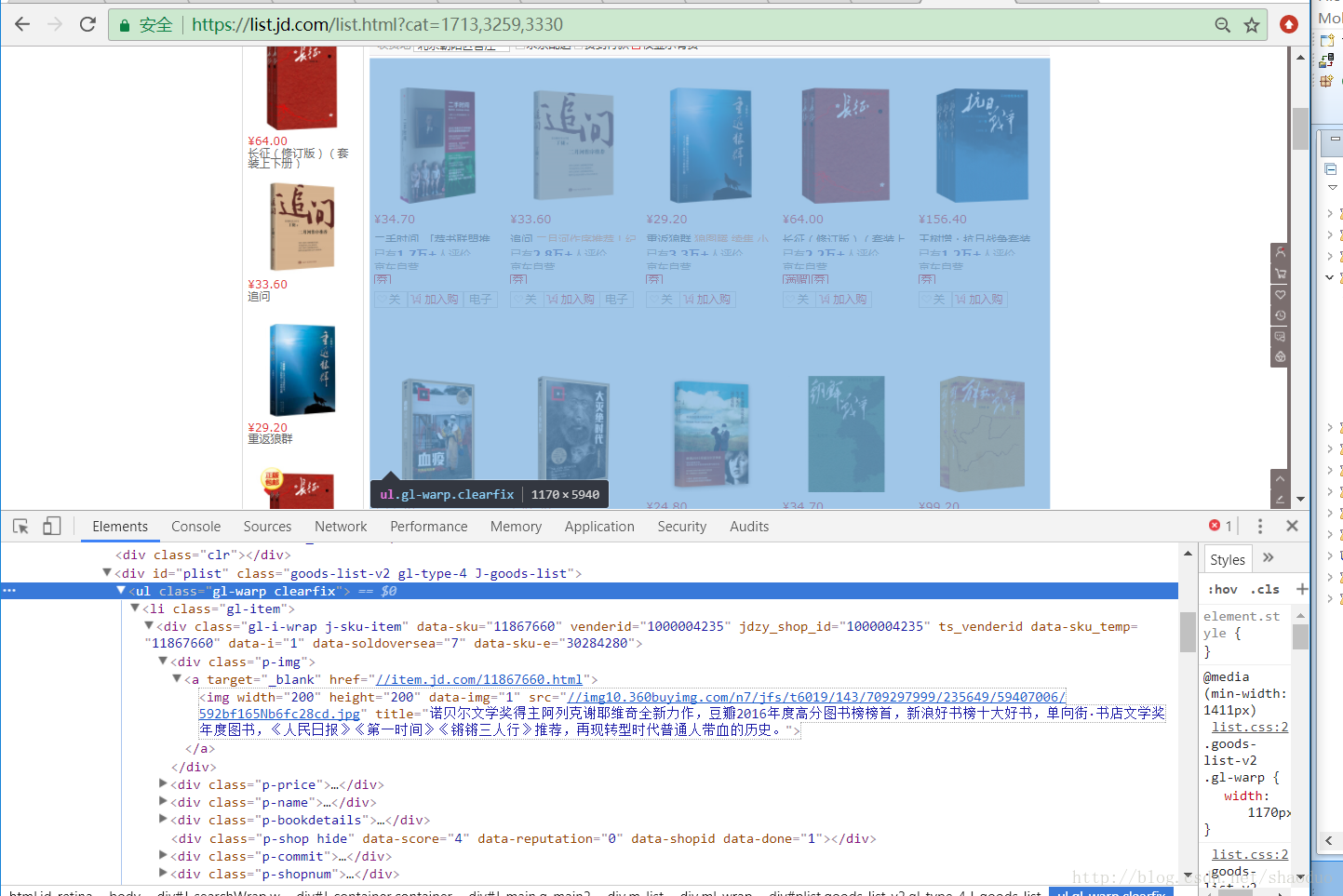
Element contentEl = doc.select("ul.gl-warp").first() ;
Elements lis = contentEl.getElementsByTag("li");
书籍的 Elements 元素没有完成,因为我们想要这些书籍的地址,换句话说,我们想要书籍 List。但是如何解析出每本书的地址呢?我们需要打开某个 li 标签才能查看。
也许你一眼就能看到一个地址,没错,就是标签。我们可以再次获取它的href属性值,任性
怎么做:
元素titleEl = li.select("div.p-name").first();
元素 a = titleEl.select("a").first();
String href = a.attr("href");
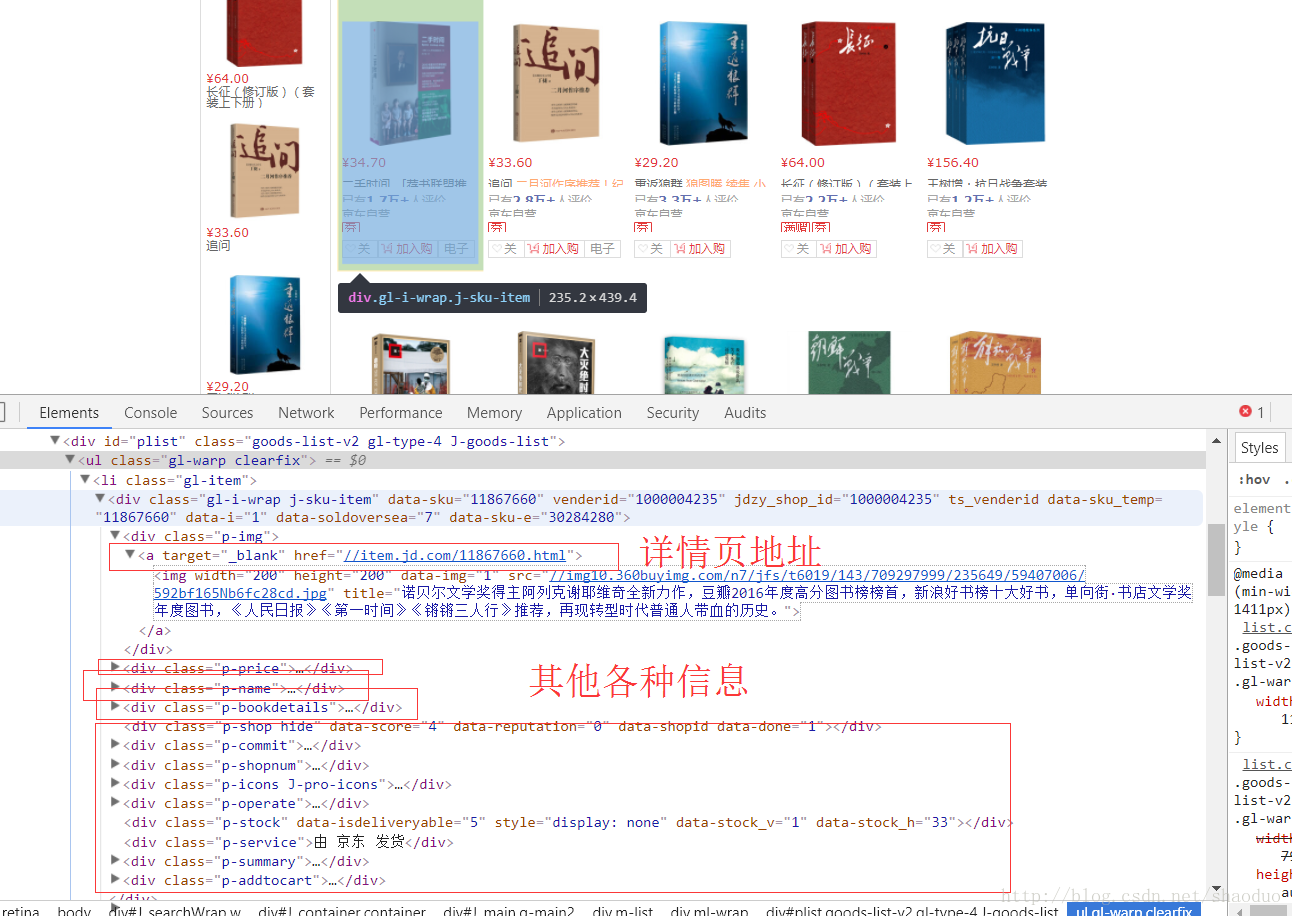
看了这么多后的代码:
/**
* 解析每一个图书的页面地址
* @param doc
* @return
*/
public List parseItemUrl(Document doc)
{
//获取页面
Element contentEl = doc.select("ul.gl-warp").first() ;
Elements lis = contentEl.getElementsByTag("li");
for (Element li : lis) {
//for循环的就是每一本书拿到详情地址
Element titleEl = li.select("div.p-name").first() ;
Element a = titleEl.select("a").first() ;
String href = a.attr("href") ;
href = "http:"+href ;
hrefList.add(href) ;
}
return hrefList ;
}
3.分析一本书
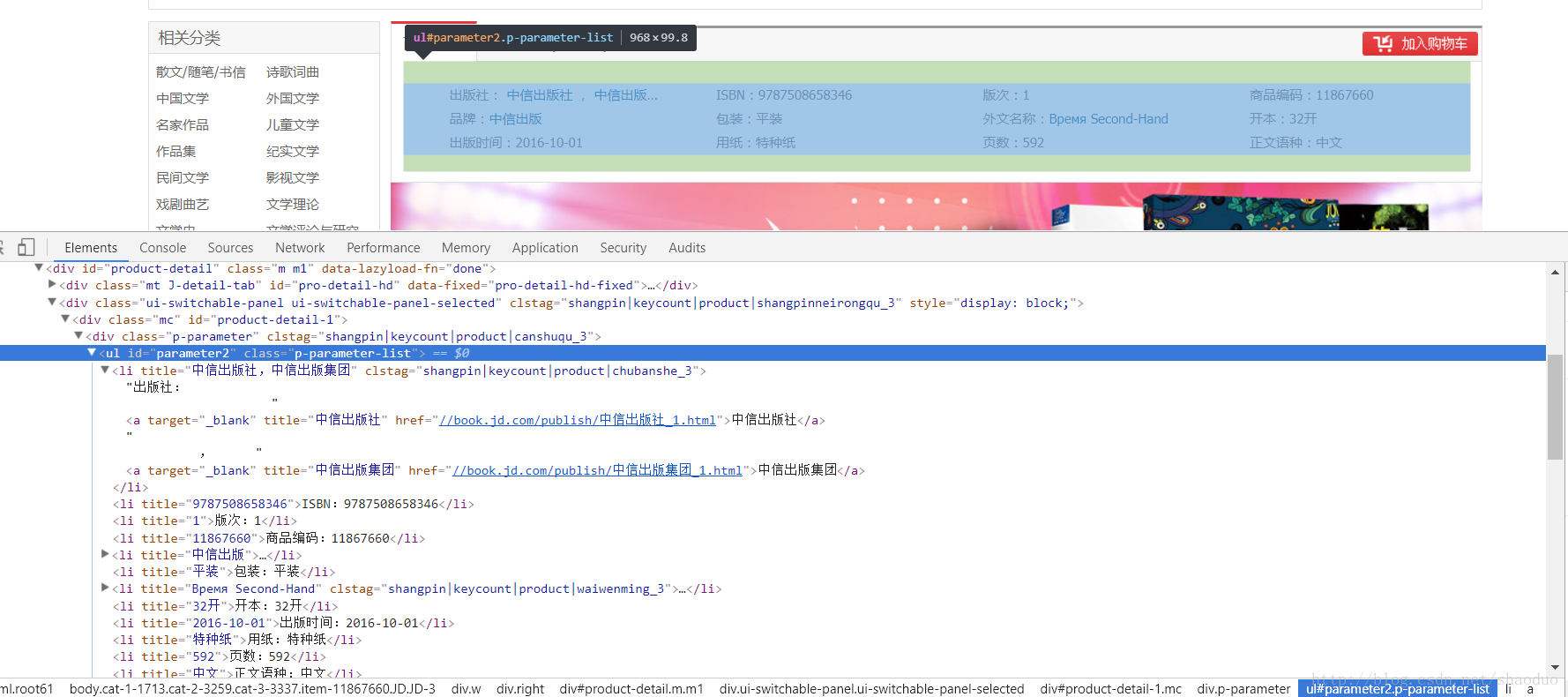
分析每一本书,根据书籍详情页地址下载详情页源码,使用jsoup进行匹配。可以看到图片高亮的部分就是我们要分析的内容。这也很清楚。我们只需要解析到一个叫做class="parameter2"的标签ul,然后解析里面的每一个li。思路可以遵循前面的解析过程。这里我直接把所有的文字输出为一个文本。每个 li 标签没有循环遍历。你可以关注上一个。
/**
* 解析书本的信息
* @param doc
*/
public void parseContent(Document doc)
{
Element contentEl = doc.getElementById("parameter2") ;
if(contentEl==null)
return ;
Elements lis = contentEl.getElementsByTag("li");
if(lis==null)
return ;
for (Element li : lis) {
String text = li.text() ;
System.out.println("--"+text);
}
} 查看全部
java抓取网页内容(【每日一题】打开浏览器的开发者模式(F12)
)
一、目的:1. 任务
使用Jsoup抓取京东图书分类页面的图书信息。
获取目标分类网址如:,3259,3330
对于给定的书页,抓取每一页的书信息,抓取该分类页的多页直到结束。
下图是给定目标抓取页面的地址
,3259,3330
我们得到的应该是每本书的图书信息,类似于打开网页查看图书信息内容的模拟。
所以我们直接打开一个item(红框圈出的,暂时把分类页面上的一本书作为一个item),查看一下内容。
提取的内容就是红框里的这部分:

2.工具和语言
语言:java
工具:jsoup-1.7.2.jar
二、思考
我们采取这样的思路,
1.将分类的源码网站保存到本地
2. 解析出分类页面上的所有书籍(item),得到一个相似item的List集合
3.根据得到的List集合,遍历循环解析每一页的图书信息,然后匹配到图书信息控制台打印。
我们将京东图书的抓取抽象为一个类。这个类有一个方法来保存下载的源代码,一个方法来解析分类页面以获取List集合,以及一个解析书页信息的方法。
三、分析1.将分类的源码网站保存到本地
将网站的源码下载到本地的方法,可以在本地看到一个文本文件,具体存放网站的当前源码的txt文件。用于解析
/**
* 将目标html保存到本地中进行解析获得 doc文本对象
* @param htmlUrl 需要下载到本地的网址
* @param toSavePath 需要保存到本地的电脑路径 例如E:\\jd.txt
* @param type 编码方式 UTF-8 或者 GBK 等
* @return
* @throws IOException
*/
public Document getDocFromUrl(String htmlUrl,String toSavePath,String type) throws IOException
{
URL url = new URL(htmlUrl) ;
File file = new File(toSavePath) ;
if(file.exists())
file.delete() ;
file.createNewFile() ;
FileOutputStream fos = new FileOutputStream(file) ;
BufferedReader br = new BufferedReader(
new InputStreamReader(url.openStream(),type)) ;
byte [] b = new byte[1024] ;
String c ;
while(((c = br.readLine())!=null))
{
fos.write(c.getBytes());
}
System.out.println("保存分类html完毕");
Document doc = Jsoup.parse(file,"UTF-8") ;
return doc ;
}
2.分析分类页面上的所有书籍
这里就是把如图所示的分类页面中所有item的每个地址解析出来,把它们的地址变成一个List集合。这样就得到了当前页面的所有书名。为分析每本书的信息做铺垫。
打开浏览器的开发者模式(F12)查看如何解析:
我们在图书信息列表中不难发现,这些书每一本书都被一个li标签包裹着,而这些书的li标签都被一个ul包裹着,class="gl-warp"。分析完这个,你应该有一个想法。NS。
在这种情况下,我们首先使用jsoup获取ul标签的内容,然后执行getElementsByTag("li"); ul标签中li标签上的方法,这样我们就可以得到每个li标签的内容,也就是每本书内容的内容。下面两行代码得到li的集合
Element contentEl = doc.select("ul.gl-warp").first() ;
Elements lis = contentEl.getElementsByTag("li");
书籍的 Elements 元素没有完成,因为我们想要这些书籍的地址,换句话说,我们想要书籍 List。但是如何解析出每本书的地址呢?我们需要打开某个 li 标签才能查看。
也许你一眼就能看到一个地址,没错,就是标签。我们可以再次获取它的href属性值,任性
怎么做:
元素titleEl = li.select("div.p-name").first();
元素 a = titleEl.select("a").first();
String href = a.attr("href");
看了这么多后的代码:
/**
* 解析每一个图书的页面地址
* @param doc
* @return
*/
public List parseItemUrl(Document doc)
{
//获取页面
Element contentEl = doc.select("ul.gl-warp").first() ;
Elements lis = contentEl.getElementsByTag("li");
for (Element li : lis) {
//for循环的就是每一本书拿到详情地址
Element titleEl = li.select("div.p-name").first() ;
Element a = titleEl.select("a").first() ;
String href = a.attr("href") ;
href = "http:"+href ;
hrefList.add(href) ;
}
return hrefList ;
}
3.分析一本书
分析每一本书,根据书籍详情页地址下载详情页源码,使用jsoup进行匹配。可以看到图片高亮的部分就是我们要分析的内容。这也很清楚。我们只需要解析到一个叫做class="parameter2"的标签ul,然后解析里面的每一个li。思路可以遵循前面的解析过程。这里我直接把所有的文字输出为一个文本。每个 li 标签没有循环遍历。你可以关注上一个。
/**
* 解析书本的信息
* @param doc
*/
public void parseContent(Document doc)
{
Element contentEl = doc.getElementById("parameter2") ;
if(contentEl==null)
return ;
Elements lis = contentEl.getElementsByTag("li");
if(lis==null)
return ;
for (Element li : lis) {
String text = li.text() ;
System.out.println("--"+text);
}
}
java抓取网页内容(拼接字符串的性能闲话不多.8的制作方法! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-13 23:01
)
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao";
//词条的链接关键字
String keyOfHref = "http://www.cppcns.com/ruanjian ... 3B%3B
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = http://www.cppcns.com/ruanjian/java/getHref(rLine,keyOfHref)) !="")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持!
Java使用url实现网页内容爬取 查看全部
java抓取网页内容(拼接字符串的性能闲话不多.8的制作方法!
)
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:

先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码

然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao";
//词条的链接关键字
String keyOfHref = "http://www.cppcns.com/ruanjian ... 3B%3B
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = http://www.cppcns.com/ruanjian/java/getHref(rLine,keyOfHref)) !="")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持!
Java使用url实现网页内容爬取
java抓取网页内容(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-11 02:03
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文使用Java向大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java抓取网页内容(本文就用Java给大家演示如何抓取网站的数据:(1))
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文使用Java向大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:

第2步:查看网页源代码,我们在源代码中看到这一段:

从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:

也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
java抓取网页内容(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-10 10:00
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
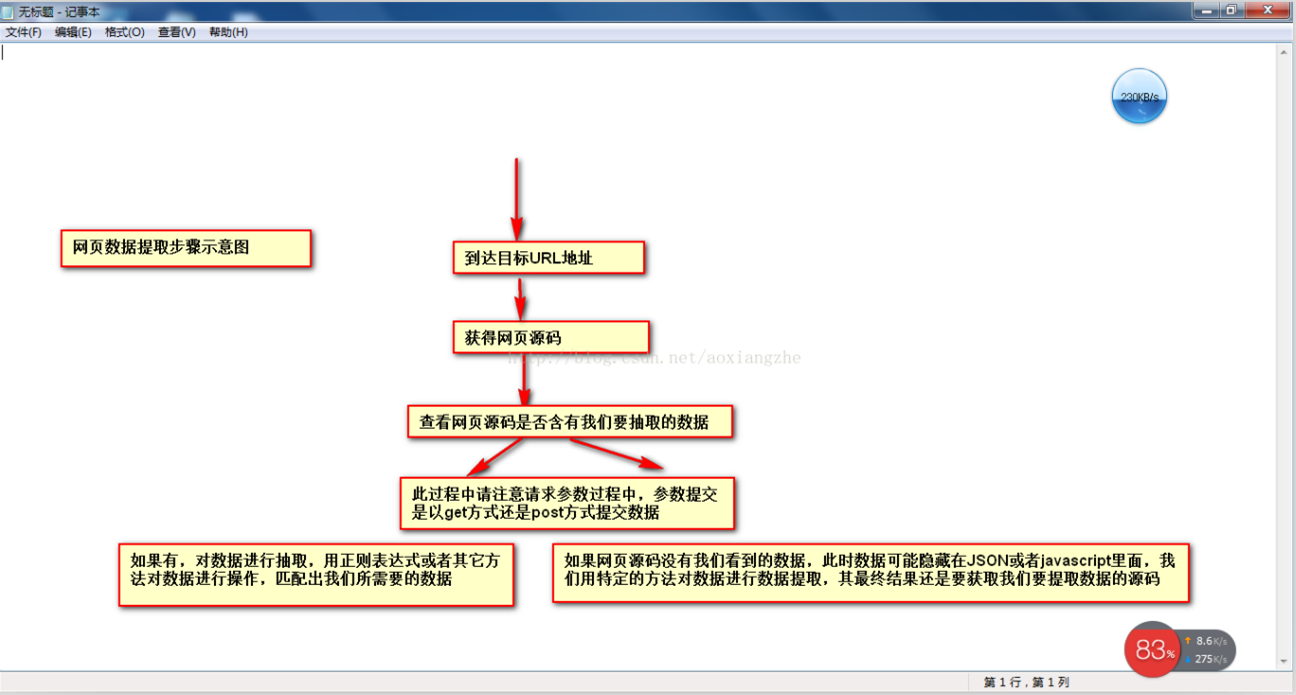
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集的时候,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,一个采集当前页面数据和一个翻页动作可以通过线程完成采集所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java抓取网页内容(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览

接下来我们看一下网页的源码结构:
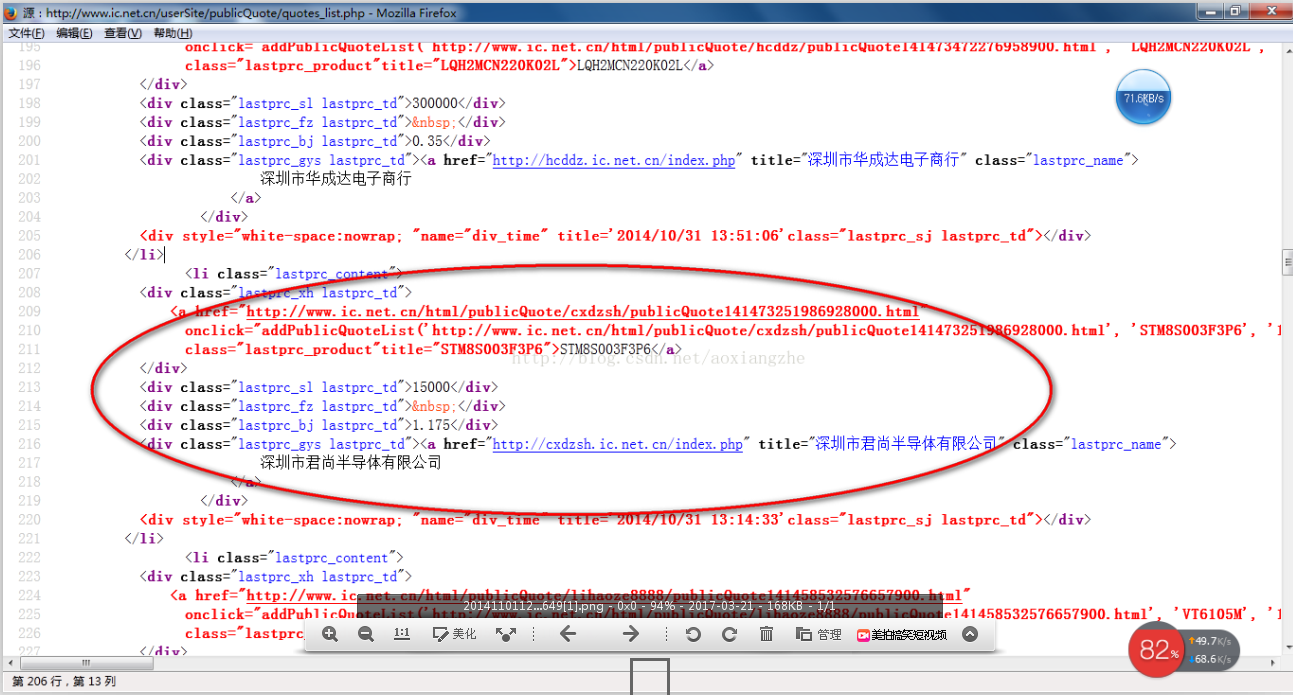
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。

import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据

成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集的时候,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,一个采集当前页面数据和一个翻页动作可以通过线程完成采集所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。
java抓取网页内容(代码罗View远程服务器,没事抓取网页信息的小工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-05 09:23
)
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,它让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
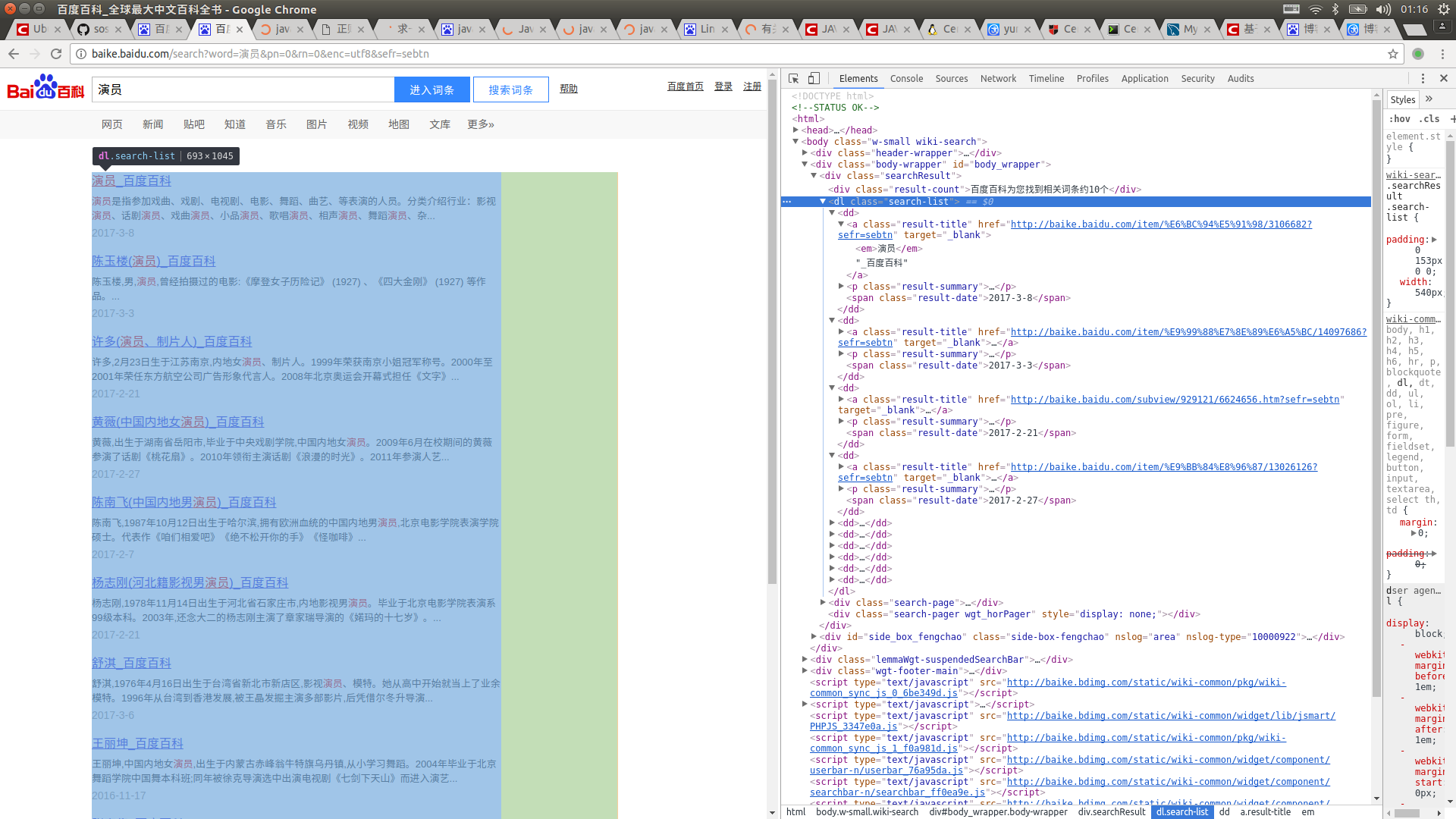
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
1 import java.io.BufferedReader;
2 import java.io.IOException;
3 import java.io.InputStreamReader;
4 import java.net.HttpURLConnection;
5 import java.net.URL;
6 import java.util.*;
7
8 /**
9 * Created by chunmiao on 17-3-10.
10 */
11 public class ReadBaiduSearch {
12
13 //储存返回结果
14 private LinkedHashMap mapOfBaike;
15
16
17 //获取搜索信息
18 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
19 mapOfBaike = getResult(infomationWords);
20 return mapOfBaike;
21 }
22
23 //通过网络链接获取信息
24 private static LinkedHashMap getResult(String keywords) throws IOException {
25 //搜索的url
26 String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
27 //搜索词条的节点
28 String startNode = "";
29 //词条的链接关键字
30 String keyOfHref = "href=\"";
31 //词条的标题关键字
32 String keyOfTitle = "target=\"_blank\">";
33
34 String endNode = "";
35
36 boolean isNode = false;
37
38 String title;
39
40 String href;
41
42 String rLine;
43
44 LinkedHashMap keyMap = new LinkedHashMap();
45
46 //开始网络请求
47 URL url = new URL(keyUrl);
48 HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
49 InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
50 BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
51
52 //读取网页内容
53 while ((rLine = bufferedReader.readLine()) != null){
54 //判断目标节点是否出现
55 if(rLine.contains(startNode)){
56 isNode = true;
57 }
58 //若目标节点出现,则开始抓取数据
59 if (isNode){
60 //若目标结束节点出现,则结束读取,节省读取时间
61 if (rLine.contains(endNode)) {
62 //关闭读取流
63 bufferedReader.close();
64 inputStreamReader.close();
65 break;
66 }
67 //若值为空则不读取
68 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
69 keyMap.put(title,href);
70 }
71 }
72 }
73 return keyMap;
74 }
75
76 //获取词条对应的url
77 private static String getHref(String rLine,String keyOfHref){
78 String baikeUrl = "http://baike.baidu.com";
79 String result = "";
80 if(rLine.contains(keyOfHref)){
81 //获取url
82 for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
83 result += rLine.charAt(j);
84 }
85 //获取的url中可能不含baikeUrl,如果没有则在头部添加一个
86 if(!result.contains(baikeUrl)){
87 result = baikeUrl + result;
88 }
89 }
90 return result;
91 }
92
93 //获取词条对应的名称
94 private static String getName(String rLine,String keyOfTitle){
95 String result = "";
96 //获取标题内容
97 if(rLine.contains(keyOfTitle)){
98 result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
99 //将标题中的内容含有的标签去掉
100 result = result.replaceAll("||</a>|<a>","");
101 }
102 return result;
103 }
104
105 }
查看代码
现在都好晚了,去睡觉了... 查看全部
java抓取网页内容(代码罗View远程服务器,没事抓取网页信息的小工具
)
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,它让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码


1 import java.io.BufferedReader;
2 import java.io.IOException;
3 import java.io.InputStreamReader;
4 import java.net.HttpURLConnection;
5 import java.net.URL;
6 import java.util.*;
7
8 /**
9 * Created by chunmiao on 17-3-10.
10 */
11 public class ReadBaiduSearch {
12
13 //储存返回结果
14 private LinkedHashMap mapOfBaike;
15
16
17 //获取搜索信息
18 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
19 mapOfBaike = getResult(infomationWords);
20 return mapOfBaike;
21 }
22
23 //通过网络链接获取信息
24 private static LinkedHashMap getResult(String keywords) throws IOException {
25 //搜索的url
26 String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
27 //搜索词条的节点
28 String startNode = "";
29 //词条的链接关键字
30 String keyOfHref = "href=\"";
31 //词条的标题关键字
32 String keyOfTitle = "target=\"_blank\">";
33
34 String endNode = "";
35
36 boolean isNode = false;
37
38 String title;
39
40 String href;
41
42 String rLine;
43
44 LinkedHashMap keyMap = new LinkedHashMap();
45
46 //开始网络请求
47 URL url = new URL(keyUrl);
48 HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
49 InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
50 BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
51
52 //读取网页内容
53 while ((rLine = bufferedReader.readLine()) != null){
54 //判断目标节点是否出现
55 if(rLine.contains(startNode)){
56 isNode = true;
57 }
58 //若目标节点出现,则开始抓取数据
59 if (isNode){
60 //若目标结束节点出现,则结束读取,节省读取时间
61 if (rLine.contains(endNode)) {
62 //关闭读取流
63 bufferedReader.close();
64 inputStreamReader.close();
65 break;
66 }
67 //若值为空则不读取
68 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
69 keyMap.put(title,href);
70 }
71 }
72 }
73 return keyMap;
74 }
75
76 //获取词条对应的url
77 private static String getHref(String rLine,String keyOfHref){
78 String baikeUrl = "http://baike.baidu.com";
79 String result = "";
80 if(rLine.contains(keyOfHref)){
81 //获取url
82 for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
83 result += rLine.charAt(j);
84 }
85 //获取的url中可能不含baikeUrl,如果没有则在头部添加一个
86 if(!result.contains(baikeUrl)){
87 result = baikeUrl + result;
88 }
89 }
90 return result;
91 }
92
93 //获取词条对应的名称
94 private static String getName(String rLine,String keyOfTitle){
95 String result = "";
96 //获取标题内容
97 if(rLine.contains(keyOfTitle)){
98 result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
99 //将标题中的内容含有的标签去掉
100 result = result.replaceAll("||</a>|<a>","");
101 }
102 return result;
103 }
104
105 }
查看代码
现在都好晚了,去睡觉了...
java抓取网页内容(这是一个利用pycharm简单爬虫分享的工作流程及使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-05 01:21
概述:
这是一个在phthon环境下使用pycharm的简单爬虫分享。主要通过爬取豆瓣音乐top250的标题和作者(专辑)来分析爬虫原理
什么是爬虫?
要学会爬行,我们首先要知道什么是爬虫。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
中文名
网络爬虫
外文名
网络爬虫
昵称
网络蜘蛛
目的
根据需要获取万维网信息
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。聚焦爬虫的工作流程更为复杂。需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
准备好工作了:
我们使用的是pycharm,请参考pycharm的安装和使用
使用工具:requests、lxml、xpath
关于requests的使用,可以看其官方文档:
个人认为用lxml解析网页是最快的。关于lxml的使用,可以阅读这个:
xpath 是一种用于在 xml 文档中查找信息的语言。xpath 可用于遍历 xml 文档中的元素和属性。xpath的使用可以参考他的教程:
话不多说,开始我们的爬虫之旅
首先找到我们的目标网址:
可以看到我们想要获取的歌曲的标题和作者(专辑)页面有十页,每页有十行。
所以我们可以使用for循环来获取目标:
然后使用 requests 请求一个网页:
import requests
headers = {"User_Agent": "Mozilla/5.0(compatible; MSIE 5.5; Windows 10)"}
data = requests.get(url, headers=headers).text
使用 lxml 解析网页:
from lxml import etree
s = etree.HTML(data)
然后我们就可以提取我们想要的数据了
最后,将获取到的数据保存在我们想要放置的地方。
至此,我们基本完成了,完整的代码如下:
然后我们来看看我们爬取的结果
总结:
爬虫过程:
1、发起请求 查看全部
java抓取网页内容(这是一个利用pycharm简单爬虫分享的工作流程及使用方法)
概述:
这是一个在phthon环境下使用pycharm的简单爬虫分享。主要通过爬取豆瓣音乐top250的标题和作者(专辑)来分析爬虫原理
什么是爬虫?
要学会爬行,我们首先要知道什么是爬虫。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
中文名
网络爬虫
外文名
网络爬虫
昵称
网络蜘蛛
目的
根据需要获取万维网信息
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。聚焦爬虫的工作流程更为复杂。需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
准备好工作了:
我们使用的是pycharm,请参考pycharm的安装和使用
使用工具:requests、lxml、xpath
关于requests的使用,可以看其官方文档:
个人认为用lxml解析网页是最快的。关于lxml的使用,可以阅读这个:
xpath 是一种用于在 xml 文档中查找信息的语言。xpath 可用于遍历 xml 文档中的元素和属性。xpath的使用可以参考他的教程:
话不多说,开始我们的爬虫之旅
首先找到我们的目标网址:
可以看到我们想要获取的歌曲的标题和作者(专辑)页面有十页,每页有十行。

所以我们可以使用for循环来获取目标:

然后使用 requests 请求一个网页:
import requests
headers = {"User_Agent": "Mozilla/5.0(compatible; MSIE 5.5; Windows 10)"}
data = requests.get(url, headers=headers).text
使用 lxml 解析网页:
from lxml import etree
s = etree.HTML(data)
然后我们就可以提取我们想要的数据了

最后,将获取到的数据保存在我们想要放置的地方。

至此,我们基本完成了,完整的代码如下:

然后我们来看看我们爬取的结果

总结:
爬虫过程:

1、发起请求
java抓取网页内容(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-03 18:27
原文链接:
有时因为各种原因。我们需要从某个站点采集数据。但是因为不同的站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据。(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您将能够看到网页上显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:
换句话说,我们只需要访问一个看起来像这样的 URL。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
<p>IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}</p>
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步方式。使用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后在网页中输入快递号:7。单击查询按钮,然后查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上面两张图可以看出。HTTP Analyzer 可以截取 JS 返回的数据并显示在 Response Content 中。同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是这些数据没有加密。我们记下JS请求的URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
<p>wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}</p>
看见。抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这能成为一个需要帮助的孩子,需要程序的源代码。点击这里下载! 查看全部
java抓取网页内容(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因。我们需要从某个站点采集数据。但是因为不同的站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据。(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您将能够看到网页上显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:
换句话说,我们只需要访问一个看起来像这样的 URL。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
<p>IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}</p>
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步方式。使用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后在网页中输入快递号:7。单击查询按钮,然后查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上面两张图可以看出。HTTP Analyzer 可以截取 JS 返回的数据并显示在 Response Content 中。同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是这些数据没有加密。我们记下JS请求的URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
<p>wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}</p>
看见。抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这能成为一个需要帮助的孩子,需要程序的源代码。点击这里下载!
java抓取网页内容(一个从网络上抓取数据的一个小程序-做个笔记 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-03 18:25
)
最近做了一个小程序,从网上抓取数据。主要是关于信用,一些黑名单网站采集,从网站抓取到我们自己的系统。
我也找到了一些资料,但我认为没有一个很好的和全面的例子。所以在这里做个笔记以提醒自己。
首先需要一个jsoup jar包,我用的是1.6.0。. 下载地址为:
1.获取网页内容(核心代码,技术有限,无封装)。
2.登录后,抓取网页数据(如何在请求中携带cookies)。
3、获取网站的ajax请求方法(返回json)。
上面三点我都会用一个class来收录(见谅,看的粗糙,直接复制代码就行了,应该可以的)
一、这个类分别有上面的1、2、3个方法,可以直接测试main方法
package com.minxinloan.black.web.utils;
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File; import java.io.FileOutputStream; import java.io.FileWriter; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.io.OutputStream; import java.io.PrintWriter; import java.net.HttpURLConnection; import java.net.URL; import java.net.URLConnection; import java.net.URLEncoder; import java.nio.charset.Charset; import java.util.ArrayList; import java.util.HashMap; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Map.Entry; import java.util.StringTokenizer; import net.sf.json.JSONArray; import net.sf.json.JSONObject; import org.jsoup.Connection; import org.jsoup.Connection.Method; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class CookieUtil { public final static String CONTENT_TYPE = "Content-Type"; public static void main(String[] args) { //String loginURL = "http://www.p2peye.com/member.p ... 3B%3B String listURL = "http://www.p2peye.com/blacklist.php?p=2"; String logURL = "http://www.p2peye.com/member.php"; //********************************需要登录的************************************************* try { Connection.Response res = Jsoup.connect(logURL) .data("mod","logging" ,"action","login" ,"loginsubmit","yes" ,"loginhash","Lsc66" ,"username","puqiuxiaomao" ,"password","a1234567") .method(Method.POST) .execute(); //这儿的SESSIONID需要根据要登录的目标网站设置的session Cookie名字而定 Connection con=Jsoup.connect(listURL); //设置访问形式(电脑访问,手机访问):直接百度都参数设置 con.header("User-Agent", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)"); //把登录信息的cookies保存如map对象里面 Map map=res.cookies(); Iterator it =map.entrySet().iterator(); while(it.hasNext()){ Entry en= it.next(); //把登录的信息放入请求里面 con =con.cookie(en.getKey(), en.getValue()); } //再次获取Document对象。 Document objectDoc = con.get(); Elements elements = objectDoc.getAllElements();//获取这个连接返回页面的源码内容(不是源码跟源码差不多) for (Element element : elements) { //element是迭代出来的标签:如: Elements elements2= element.getAllElements();// for (Element element2 : elements2) { element2.text(); element2.attr("href");//获取标签属性。element2代表a标签:href代表属性 element2.text();//获取标签文本 } } //********************************不需要登录的************************************************* String URL = "http://www.p2peye.com/blacklist.php?p=2"; Document conTemp = Jsoup.connect(URL).get(); Elements elementsTemps = conTemp.getAllElements(); for (Element elementsTemp : elementsTemps) { elementsTemp.text(); elementsTemp.attr("href");//获取标签属性。element2代表a标签:href代表属性 elementsTemp.text();//获取标签文本 } //********************************ajax方法获取内容。。。*************************************************。 HttpURLConnection connection = null; BufferedReader reader = null; try { StringBuffer sb = new StringBuffer(); URL getUrl = new URL(URL); connection = (HttpURLConnection)getUrl.openConnection(); reader = new BufferedReader(new InputStreamReader( connection.getInputStream(),"utf-8")); String lines; while ((lines = reader.readLine()) != null) { sb.append(lines); }; List list = parseJSON2List(sb.toString());//json转换成list } catch (Exception e) { } finally{ if(reader!=null) try { reader.close(); } catch (IOException e) { } // 断开连接 connection.disconnect(); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static Map parseJSON2Map(String jsonStr){ Map map = new HashMap(); //最外层解析 JSONObject json = JSONObject.fromObject(jsonStr); for(Object k : json.keySet()){ Object v = json.get(k); //如果内层还是数组的话,继续解析 if(v instanceof JSONArray){ List list = new ArrayList(); Iterator it = ((JSONArray)v).iterator(); while(it.hasNext()){ JSONObject json2 = it.next(); list.add(parseJSON2Map(json2.toString())); } map.put(k.toString(), list); } else { map.put(k.toString(), v); } } return map; } public static List parseJSON2List(String jsonStr){ JSONArray jsonArr = JSONArray.fromObject(jsonStr); List list = new ArrayList(); Iterator it = jsonArr.iterator(); while(it.hasNext()){ JSONObject json2 = it.next(); list.add(parseJSON2Map(json2.toString())); } return list; } }
二、这是获取验证码的类,大家可以研究一下。(但是要分析网站的验证码的请求地址)
package com.minxinloan.black.web.utils;
import java.io.BufferedReader;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream; import java.io.FileWriter; import java.io.InputStream; import java.io.InputStreamReader; import java.io.PrintWriter; import java.net.HttpURLConnection; import java.net.URL; import java.net.URLConnection; import java.nio.charset.Charset; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.StringTokenizer; public class Utils {//解析验证码的 public static Content getRandom(String method, String sUrl,// 要解析的url Map paramMap, // 存放用户名和密码的map Map requestHeaderMap,// 存放COOKIE的map boolean isOnlyReturnHeader, String path) { Content content = null; HttpURLConnection httpUrlConnection = null; InputStream in = null; try { URL url = new URL(sUrl); boolean isPost = "POST".equals(method); if (method == null || (!"GET".equalsIgnoreCase(method) && !"POST" .equalsIgnoreCase(method))) { method = "POST"; } URL resolvedURL = url; URLConnection urlConnection = resolvedURL.openConnection(); httpUrlConnection = (HttpURLConnection) urlConnection; httpUrlConnection.setRequestMethod(method); httpUrlConnection.setRequestProperty("Accept-Language", "zh-cn,zh;q=0.5"); // Do not follow redirects, We will handle redirects ourself httpUrlConnection.setInstanceFollowRedirects(false); httpUrlConnection.setDoOutput(true); httpUrlConnection.setDoInput(true); httpUrlConnection.setConnectTimeout(5000); httpUrlConnection.setReadTimeout(5000); httpUrlConnection.setUseCaches(false); httpUrlConnection.setDefaultUseCaches(false); httpUrlConnection.connect(); int responseCode = httpUrlConnection.getResponseCode(); if (responseCode == HttpURLConnection.HTTP_OK || responseCode == HttpURLConnection.HTTP_CREATED) { byte[] bytes = new byte[0]; if (!isOnlyReturnHeader) { DataInputStream ins = new DataInputStream( httpUrlConnection.getInputStream()); // 验证码的位置 DataOutputStream out = new DataOutputStream( new FileOutputStream(path + "/code.bmp")); byte[] buffer = new byte[4096]; int count = 0; while ((count = ins.read(buffer)) > 0) { out.write(buffer, 0, count); } out.close(); ins.close(); } String encoding = null; if (encoding == null) { encoding = getEncodingFromContentType(httpUrlConnection .getHeaderField("")); } content = new Content(sUrl, new String(bytes, encoding), httpUrlConnection.getHeaderFields()); } } catch (Exception e) { return null; } finally { if (httpUrlConnection != null) { httpUrlConnection.disconnect(); } } return content; } public static String getEncodingFromContentType(String contentType) { String encoding = null; if (contentType == null) { return null; } StringTokenizer tok = new StringTokenizer(contentType, ";"); if (tok.hasMoreTokens()) { tok.nextToken(); while (tok.hasMoreTokens()) { String assignment = tok.nextToken().trim(); int eqIdx = assignment.indexOf('='); if (eqIdx != -1) { String varName = assignment.substring(0, eqIdx).trim(); if ("charset".equalsIgnoreCase(varName)) { String varValue = assignment.substring(eqIdx + 1) .trim(); if (varValue.startsWith("\"") && varValue.endsWith("\"")) { // substring works on indices varValue = varValue.substring(1, varValue.length() - 1); } if (Charset.isSupported(varValue)) { encoding = varValue; } } } } } if (encoding == null) { return "UTF-8"; } return encoding; } // 这个是输出 public static boolean inFile(String content, String path) { PrintWriter out = null; File file = new File(path); try { if (!file.exists()) { file.createNewFile(); } out = new PrintWriter(new FileWriter(file)); out.write(content); out.flush(); return true; } catch (Exception e) { e.printStackTrace(); } finally { out.close(); } return false; } public static String getHtmlReadLine(String httpurl) { String CurrentLine = ""; String TotalString = ""; InputStream urlStream; String content = ""; try { URL url = new URL(httpurl); HttpURLConnection connection = (HttpURLConnection) url .openConnection(); connection.connect(); System.out.println(connection.getResponseCode()); urlStream = connection.getInputStream(); BufferedReader reader = new BufferedReader( new InputStreamReader(urlStream, "utf-8")); while ((CurrentLine = reader.readLine()) != null) { TotalString += CurrentLine + "\n"; } content = TotalString; } catch (Exception e) { } return content; } } class Content { private String url; private String body; private Map m_mHeaders = new HashMap(); public Content(String url, String body, Map headers) { this.url = url; this.body = body; this.m_mHeaders = headers; } public String getUrl() { return url; } public String getBody() { return body; } public Map getHeaders() { return m_mHeaders; } } 查看全部
java抓取网页内容(一个从网络上抓取数据的一个小程序-做个笔记
)
最近做了一个小程序,从网上抓取数据。主要是关于信用,一些黑名单网站采集,从网站抓取到我们自己的系统。
我也找到了一些资料,但我认为没有一个很好的和全面的例子。所以在这里做个笔记以提醒自己。
首先需要一个jsoup jar包,我用的是1.6.0。. 下载地址为:
1.获取网页内容(核心代码,技术有限,无封装)。
2.登录后,抓取网页数据(如何在请求中携带cookies)。
3、获取网站的ajax请求方法(返回json)。
上面三点我都会用一个class来收录(见谅,看的粗糙,直接复制代码就行了,应该可以的)
一、这个类分别有上面的1、2、3个方法,可以直接测试main方法
package com.minxinloan.black.web.utils;
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File; import java.io.FileOutputStream; import java.io.FileWriter; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.io.OutputStream; import java.io.PrintWriter; import java.net.HttpURLConnection; import java.net.URL; import java.net.URLConnection; import java.net.URLEncoder; import java.nio.charset.Charset; import java.util.ArrayList; import java.util.HashMap; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Map.Entry; import java.util.StringTokenizer; import net.sf.json.JSONArray; import net.sf.json.JSONObject; import org.jsoup.Connection; import org.jsoup.Connection.Method; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class CookieUtil { public final static String CONTENT_TYPE = "Content-Type"; public static void main(String[] args) { //String loginURL = "http://www.p2peye.com/member.p ... 3B%3B String listURL = "http://www.p2peye.com/blacklist.php?p=2"; String logURL = "http://www.p2peye.com/member.php"; //********************************需要登录的************************************************* try { Connection.Response res = Jsoup.connect(logURL) .data("mod","logging" ,"action","login" ,"loginsubmit","yes" ,"loginhash","Lsc66" ,"username","puqiuxiaomao" ,"password","a1234567") .method(Method.POST) .execute(); //这儿的SESSIONID需要根据要登录的目标网站设置的session Cookie名字而定 Connection con=Jsoup.connect(listURL); //设置访问形式(电脑访问,手机访问):直接百度都参数设置 con.header("User-Agent", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)"); //把登录信息的cookies保存如map对象里面 Map map=res.cookies(); Iterator it =map.entrySet().iterator(); while(it.hasNext()){ Entry en= it.next(); //把登录的信息放入请求里面 con =con.cookie(en.getKey(), en.getValue()); } //再次获取Document对象。 Document objectDoc = con.get(); Elements elements = objectDoc.getAllElements();//获取这个连接返回页面的源码内容(不是源码跟源码差不多) for (Element element : elements) { //element是迭代出来的标签:如: Elements elements2= element.getAllElements();// for (Element element2 : elements2) { element2.text(); element2.attr("href");//获取标签属性。element2代表a标签:href代表属性 element2.text();//获取标签文本 } } //********************************不需要登录的************************************************* String URL = "http://www.p2peye.com/blacklist.php?p=2"; Document conTemp = Jsoup.connect(URL).get(); Elements elementsTemps = conTemp.getAllElements(); for (Element elementsTemp : elementsTemps) { elementsTemp.text(); elementsTemp.attr("href");//获取标签属性。element2代表a标签:href代表属性 elementsTemp.text();//获取标签文本 } //********************************ajax方法获取内容。。。*************************************************。 HttpURLConnection connection = null; BufferedReader reader = null; try { StringBuffer sb = new StringBuffer(); URL getUrl = new URL(URL); connection = (HttpURLConnection)getUrl.openConnection(); reader = new BufferedReader(new InputStreamReader( connection.getInputStream(),"utf-8")); String lines; while ((lines = reader.readLine()) != null) { sb.append(lines); }; List list = parseJSON2List(sb.toString());//json转换成list } catch (Exception e) { } finally{ if(reader!=null) try { reader.close(); } catch (IOException e) { } // 断开连接 connection.disconnect(); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static Map parseJSON2Map(String jsonStr){ Map map = new HashMap(); //最外层解析 JSONObject json = JSONObject.fromObject(jsonStr); for(Object k : json.keySet()){ Object v = json.get(k); //如果内层还是数组的话,继续解析 if(v instanceof JSONArray){ List list = new ArrayList(); Iterator it = ((JSONArray)v).iterator(); while(it.hasNext()){ JSONObject json2 = it.next(); list.add(parseJSON2Map(json2.toString())); } map.put(k.toString(), list); } else { map.put(k.toString(), v); } } return map; } public static List parseJSON2List(String jsonStr){ JSONArray jsonArr = JSONArray.fromObject(jsonStr); List list = new ArrayList(); Iterator it = jsonArr.iterator(); while(it.hasNext()){ JSONObject json2 = it.next(); list.add(parseJSON2Map(json2.toString())); } return list; } }
二、这是获取验证码的类,大家可以研究一下。(但是要分析网站的验证码的请求地址)
package com.minxinloan.black.web.utils;
import java.io.BufferedReader;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream; import java.io.FileWriter; import java.io.InputStream; import java.io.InputStreamReader; import java.io.PrintWriter; import java.net.HttpURLConnection; import java.net.URL; import java.net.URLConnection; import java.nio.charset.Charset; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.StringTokenizer; public class Utils {//解析验证码的 public static Content getRandom(String method, String sUrl,// 要解析的url Map paramMap, // 存放用户名和密码的map Map requestHeaderMap,// 存放COOKIE的map boolean isOnlyReturnHeader, String path) { Content content = null; HttpURLConnection httpUrlConnection = null; InputStream in = null; try { URL url = new URL(sUrl); boolean isPost = "POST".equals(method); if (method == null || (!"GET".equalsIgnoreCase(method) && !"POST" .equalsIgnoreCase(method))) { method = "POST"; } URL resolvedURL = url; URLConnection urlConnection = resolvedURL.openConnection(); httpUrlConnection = (HttpURLConnection) urlConnection; httpUrlConnection.setRequestMethod(method); httpUrlConnection.setRequestProperty("Accept-Language", "zh-cn,zh;q=0.5"); // Do not follow redirects, We will handle redirects ourself httpUrlConnection.setInstanceFollowRedirects(false); httpUrlConnection.setDoOutput(true); httpUrlConnection.setDoInput(true); httpUrlConnection.setConnectTimeout(5000); httpUrlConnection.setReadTimeout(5000); httpUrlConnection.setUseCaches(false); httpUrlConnection.setDefaultUseCaches(false); httpUrlConnection.connect(); int responseCode = httpUrlConnection.getResponseCode(); if (responseCode == HttpURLConnection.HTTP_OK || responseCode == HttpURLConnection.HTTP_CREATED) { byte[] bytes = new byte[0]; if (!isOnlyReturnHeader) { DataInputStream ins = new DataInputStream( httpUrlConnection.getInputStream()); // 验证码的位置 DataOutputStream out = new DataOutputStream( new FileOutputStream(path + "/code.bmp")); byte[] buffer = new byte[4096]; int count = 0; while ((count = ins.read(buffer)) > 0) { out.write(buffer, 0, count); } out.close(); ins.close(); } String encoding = null; if (encoding == null) { encoding = getEncodingFromContentType(httpUrlConnection .getHeaderField("")); } content = new Content(sUrl, new String(bytes, encoding), httpUrlConnection.getHeaderFields()); } } catch (Exception e) { return null; } finally { if (httpUrlConnection != null) { httpUrlConnection.disconnect(); } } return content; } public static String getEncodingFromContentType(String contentType) { String encoding = null; if (contentType == null) { return null; } StringTokenizer tok = new StringTokenizer(contentType, ";"); if (tok.hasMoreTokens()) { tok.nextToken(); while (tok.hasMoreTokens()) { String assignment = tok.nextToken().trim(); int eqIdx = assignment.indexOf('='); if (eqIdx != -1) { String varName = assignment.substring(0, eqIdx).trim(); if ("charset".equalsIgnoreCase(varName)) { String varValue = assignment.substring(eqIdx + 1) .trim(); if (varValue.startsWith("\"") && varValue.endsWith("\"")) { // substring works on indices varValue = varValue.substring(1, varValue.length() - 1); } if (Charset.isSupported(varValue)) { encoding = varValue; } } } } } if (encoding == null) { return "UTF-8"; } return encoding; } // 这个是输出 public static boolean inFile(String content, String path) { PrintWriter out = null; File file = new File(path); try { if (!file.exists()) { file.createNewFile(); } out = new PrintWriter(new FileWriter(file)); out.write(content); out.flush(); return true; } catch (Exception e) { e.printStackTrace(); } finally { out.close(); } return false; } public static String getHtmlReadLine(String httpurl) { String CurrentLine = ""; String TotalString = ""; InputStream urlStream; String content = ""; try { URL url = new URL(httpurl); HttpURLConnection connection = (HttpURLConnection) url .openConnection(); connection.connect(); System.out.println(connection.getResponseCode()); urlStream = connection.getInputStream(); BufferedReader reader = new BufferedReader( new InputStreamReader(urlStream, "utf-8")); while ((CurrentLine = reader.readLine()) != null) { TotalString += CurrentLine + "\n"; } content = TotalString; } catch (Exception e) { } return content; } } class Content { private String url; private String body; private Map m_mHeaders = new HashMap(); public Content(String url, String body, Map headers) { this.url = url; this.body = body; this.m_mHeaders = headers; } public String getUrl() { return url; } public String getBody() { return body; } public Map getHeaders() { return m_mHeaders; } }
java抓取网页内容(有时匹配到的img值还会出现非图片url的情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-10-03 03:05
Java抓取简单的网页内容和图片
根据java网络编程相关的内容,可以使用jdk提供的相关类获取url对应的网页的html页面代码。
对于得到的html代码,我们可以通过正则表达式得到我们想要的内容。
例如,如果我们要获取网页上收录关键字“java”的所有文本内容,我们可以将网页代码逐行与正则表达式匹配。最后达到去除html标签和无关内容的效果,只得到收录关键字“java”的内容。
从网页中抓取图片的过程与抓取内容的过程基本相同,但抓取图片的过程会多一步。
需要使用img标签的正则表达式匹配获取img标签,然后使用src属性的正则表达式获取img标签中src属性的图片url,然后读取img标签的图片url图片url通过缓存的输入流对象信息,配合文件输出流,将读取到的图片信息写入本地。
除了这两种玩法外,爬虫还有很多应用,比如爬取一个网页上的所有邮箱、电话号码等等。
运行结果:
这些内容是基于csdn主页的关键字“你”。
这些是我从一些网站那里得到的照片
问题:
看似没有问题的爬取代码背后其实有很多问题。该程序只是爬虫的一级应用。例如,我发现浏览器的“检查”功能中明明存在部分html内容,但网页源代码中却没有相关内容。文本匹配的正则表达式部分也存在问题。
在img src属性中,有些图片的url没有协议(如:),有些图片的url没有图片后缀(jpg、png、gif...)。前者导致程序无法解析url,后者导致下载图片的原创命名无法统一采用。
有时匹配的 img src 值将显示为非图像 url。有时从页面获取的内容是 unicode 编码的值。还有一些网站做了反爬虫处理等...
由于本人对java知识、web知识、网络知识和常规知识了解甚少,目前无法解决上述问题。
这些问题导致实际上从网页爬下来的内容只是原创网页的一小部分。
相信这些问题在未来会一一解决。
另外,我在程序中使用了多线程功能,实现了“同时”抓取多个网页的效果。
该程序的源代码如下。
编译环境:
windows jdk 9 的想法
代码:
//Main.java 主类
package
//DownloadPictures.java 爬取图片类
package
//GetTest.java 抓取文本内容类
package
----
程序还有很多问题,还请见谅。 查看全部
java抓取网页内容(有时匹配到的img值还会出现非图片url的情况)
Java抓取简单的网页内容和图片
根据java网络编程相关的内容,可以使用jdk提供的相关类获取url对应的网页的html页面代码。
对于得到的html代码,我们可以通过正则表达式得到我们想要的内容。
例如,如果我们要获取网页上收录关键字“java”的所有文本内容,我们可以将网页代码逐行与正则表达式匹配。最后达到去除html标签和无关内容的效果,只得到收录关键字“java”的内容。
从网页中抓取图片的过程与抓取内容的过程基本相同,但抓取图片的过程会多一步。
需要使用img标签的正则表达式匹配获取img标签,然后使用src属性的正则表达式获取img标签中src属性的图片url,然后读取img标签的图片url图片url通过缓存的输入流对象信息,配合文件输出流,将读取到的图片信息写入本地。
除了这两种玩法外,爬虫还有很多应用,比如爬取一个网页上的所有邮箱、电话号码等等。
运行结果:
这些内容是基于csdn主页的关键字“你”。

这些是我从一些网站那里得到的照片

问题:
看似没有问题的爬取代码背后其实有很多问题。该程序只是爬虫的一级应用。例如,我发现浏览器的“检查”功能中明明存在部分html内容,但网页源代码中却没有相关内容。文本匹配的正则表达式部分也存在问题。
在img src属性中,有些图片的url没有协议(如:),有些图片的url没有图片后缀(jpg、png、gif...)。前者导致程序无法解析url,后者导致下载图片的原创命名无法统一采用。
有时匹配的 img src 值将显示为非图像 url。有时从页面获取的内容是 unicode 编码的值。还有一些网站做了反爬虫处理等...
由于本人对java知识、web知识、网络知识和常规知识了解甚少,目前无法解决上述问题。
这些问题导致实际上从网页爬下来的内容只是原创网页的一小部分。
相信这些问题在未来会一一解决。
另外,我在程序中使用了多线程功能,实现了“同时”抓取多个网页的效果。
该程序的源代码如下。
编译环境:
windows jdk 9 的想法
代码:
//Main.java 主类
package
//DownloadPictures.java 爬取图片类
package
//GetTest.java 抓取文本内容类
package
----
程序还有很多问题,还请见谅。
java抓取网页内容(不时之需:我的理解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-11-06 19:15
phantomjs:我的理解是它是一个非显示浏览器,也就是说它基本上可以做浏览器能做的所有任务,除了不能显示页面的内容。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学了PHANTOMJS,鉴于网上找的例子不多,只好自己总结一下,以备不时之需。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来实现:
下载并解压phantom到D盘,目录下有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit就可以达到想要的目的:比如生成网页快照我要做的是爬AJAX页面上的图片,先看js文件:将其命名为s.js
[javascript]
在 CODE 上查看代码片段
源自我的代码片段
system = require('system') //传递一些需要的参数给js文件
address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
if (status !== 'success') {
console.log('Unable to post!');
} else {
var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。
for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦
phantom.outputEncoding = encodings[i];
console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容
}
}
phantom.exit();
});
接下来就是java类的编写:
[爪哇]
在 CODE 上查看代码片段
源自我的代码片段
package com.mvc.rest;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class GetAjaxHtml {
public static String getAjaxContent(String url) throws Exception {
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url);
InputStream is = p.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp=br.readLine())!=null) {
sbf.append(tmp + "\n");
}
return sbf.toString();
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
String result = getAjaxContent("http://114.111.162.220:8093/404Web/");
System.out.println(result);
long end = System.currentTimeMillis();
System.out.println("===============耗时:" + (end - start) + "===============");
}
}
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了
这是最终的解决方案 查看全部
java抓取网页内容(不时之需:我的理解)
phantomjs:我的理解是它是一个非显示浏览器,也就是说它基本上可以做浏览器能做的所有任务,除了不能显示页面的内容。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学了PHANTOMJS,鉴于网上找的例子不多,只好自己总结一下,以备不时之需。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来实现:
下载并解压phantom到D盘,目录下有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit就可以达到想要的目的:比如生成网页快照我要做的是爬AJAX页面上的图片,先看js文件:将其命名为s.js
[javascript]
在 CODE 上查看代码片段
源自我的代码片段
system = require('system') //传递一些需要的参数给js文件
address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
if (status !== 'success') {
console.log('Unable to post!');
} else {
var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。
for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦
phantom.outputEncoding = encodings[i];
console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容
}
}
phantom.exit();
});
接下来就是java类的编写:
[爪哇]
在 CODE 上查看代码片段
源自我的代码片段
package com.mvc.rest;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class GetAjaxHtml {
public static String getAjaxContent(String url) throws Exception {
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url);
InputStream is = p.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp=br.readLine())!=null) {
sbf.append(tmp + "\n");
}
return sbf.toString();
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
String result = getAjaxContent("http://114.111.162.220:8093/404Web/";);
System.out.println(result);
long end = System.currentTimeMillis();
System.out.println("===============耗时:" + (end - start) + "===============");
}
}
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了
这是最终的解决方案
java抓取网页内容( 以上的代码程序是把一个网页的源代码a中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-01 23:08
以上的代码程序是把一个网页的源代码a中)
java阅读网页内容的详细例子
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上面的代码程序将一个网页的源代码,包括 HTML 和 XML,读取到 JAVA 中的字符串 String a 中。
Java中的String类型空间很大,基本可以容纳一个网页源码的内容。
从网页中读取内容也是对输入流的操作。
与标准输入源不同,在:
BufferedReader in = new BufferedReader(new InputStreamReader(...))
只需在 InputStreamReader 中输入 System.in。
这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续操作和处理与加载标准输入源完全相同。
BufferedReader 要求JAVA 必须捕获IOException,使用URL source 不仅要导入.* 包,还要捕获MalformedURLException。
如有问题,请留言或到本站社区讨论,感谢阅读,希望对您有所帮助,感谢您对本站的支持! 查看全部
java抓取网页内容(
以上的代码程序是把一个网页的源代码a中)
java阅读网页内容的详细例子
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上面的代码程序将一个网页的源代码,包括 HTML 和 XML,读取到 JAVA 中的字符串 String a 中。
Java中的String类型空间很大,基本可以容纳一个网页源码的内容。
从网页中读取内容也是对输入流的操作。
与标准输入源不同,在:
BufferedReader in = new BufferedReader(new InputStreamReader(...))
只需在 InputStreamReader 中输入 System.in。
这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续操作和处理与加载标准输入源完全相同。
BufferedReader 要求JAVA 必须捕获IOException,使用URL source 不仅要导入.* 包,还要捕获MalformedURLException。
如有问题,请留言或到本站社区讨论,感谢阅读,希望对您有所帮助,感谢您对本站的支持!
java抓取网页内容(java抓取网页内容的抓包问题这个都可以帮你解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-01 13:19
java抓取网页内容,一般是https协议,全部过程可以理解为字符流格式的字节流。建议还是用一些开源的网页抓取工具,scrapy,py-dl,requests等,还可以爬爬twitter,facebook之类的。python可以完成所有的重复动作,也可以模拟登录,用户信息都是已经在服务器上的。爬爬twitter,facebook啥的,哈哈。
去问问pythonrequests,你要的抓包问题这个都可以帮你解决。
推荐pygame,可以全平台模拟手机扫描,
python爬虫抓包关键字获取包包含网页链接ajaxhttpserver代理
python可以把你要抓取的网页转成json格式再解析;就抓取网页效率而言,java要更快。现在很多web服务器都支持json。
我用的是lxml(浅尝辄止)。lxml解析xml可以手写解析xml。另外,对于不懂解析xml的童鞋,利用xslt也可以解析。至于python抓包,网上有很多抓包工具和插件(比如小花的。
把不同网站分割成比较小的component.这样每个component完成同一任务都可以利用lxml/requests这两个开源的库,比较方便。
python可以抓出twitter。而且,可以模拟登录这一步。代码不难写。利用xmlhttprequest。
获取用户名密码
我也在研究这些东西,感觉既然是全世界范围的数据就不存在全网了吧?我觉得主要看人家不同国家,不同语言是怎么分割的,再结合你项目要传达给用户什么吧,我个人觉得还是代码清晰和够接地气,网络通畅,便于维护比较重要。 查看全部
java抓取网页内容(java抓取网页内容的抓包问题这个都可以帮你解决)
java抓取网页内容,一般是https协议,全部过程可以理解为字符流格式的字节流。建议还是用一些开源的网页抓取工具,scrapy,py-dl,requests等,还可以爬爬twitter,facebook之类的。python可以完成所有的重复动作,也可以模拟登录,用户信息都是已经在服务器上的。爬爬twitter,facebook啥的,哈哈。
去问问pythonrequests,你要的抓包问题这个都可以帮你解决。
推荐pygame,可以全平台模拟手机扫描,
python爬虫抓包关键字获取包包含网页链接ajaxhttpserver代理
python可以把你要抓取的网页转成json格式再解析;就抓取网页效率而言,java要更快。现在很多web服务器都支持json。
我用的是lxml(浅尝辄止)。lxml解析xml可以手写解析xml。另外,对于不懂解析xml的童鞋,利用xslt也可以解析。至于python抓包,网上有很多抓包工具和插件(比如小花的。
把不同网站分割成比较小的component.这样每个component完成同一任务都可以利用lxml/requests这两个开源的库,比较方便。
python可以抓出twitter。而且,可以模拟登录这一步。代码不难写。利用xmlhttprequest。
获取用户名密码
我也在研究这些东西,感觉既然是全世界范围的数据就不存在全网了吧?我觉得主要看人家不同国家,不同语言是怎么分割的,再结合你项目要传达给用户什么吧,我个人觉得还是代码清晰和够接地气,网络通畅,便于维护比较重要。
java抓取网页内容(Java中字符串String类型的输入源程序是怎样的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-01 08:26
在互联网行业,页面内容应该是分类或聚合数据。我们需要及时分析行业数据。这将有助于很好地比较公司未来的发展。那么今天的爱站技术频道就为大家带来java阅读网页内容的详细例子,有需要的朋友可以参考以下。
java阅读网页内容的详细例子
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上面的代码程序将一个网页的源代码,包括 HTML 和 XML,读取到 JAVA 中的字符串 String a 中。
Java中的String类型空间很大,基本可以容纳一个网页源码的内容。
从网页中读取内容也是对输入流的操作。
与标准输入源不同,在:
BufferedReader in = new BufferedReader(new InputStreamReader(...))
只需在 InputStreamReader 中输入 System.in。
这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续的操作和处理与加载标准输入源完全一样。
BufferedReader 要求JAVA 必须捕获IOException,使用URL source 不仅要导入.* 包,还要捕获MalformedURLException。
java读取网页内容的例子的详细说明与其他操作不同。如果我们在操作过程中怕麻烦,建议您咨询爱站技术频道编辑,我们可以为您提供周到的服务。 查看全部
java抓取网页内容(Java中字符串String类型的输入源程序是怎样的?)
在互联网行业,页面内容应该是分类或聚合数据。我们需要及时分析行业数据。这将有助于很好地比较公司未来的发展。那么今天的爱站技术频道就为大家带来java阅读网页内容的详细例子,有需要的朋友可以参考以下。
java阅读网页内容的详细例子
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.*;
public class loadurl {
public static void main(String args[]) {
String a = null;
try {
String url = "(这里替换成任意网页的网址)";
BufferedReader in = new BufferedReader(new InputStreamReader(
new URL(url).openConnection().getInputStream(), "GB2312"));//GB2312可以根据需要替换成要读取网页的编码
while ((a = in.readLine()) != null) {
System.out.println(a);
}
} catch (MalformedURLException e) {
} catch (IOException e) {
}
}
}
上面的代码程序将一个网页的源代码,包括 HTML 和 XML,读取到 JAVA 中的字符串 String a 中。
Java中的String类型空间很大,基本可以容纳一个网页源码的内容。
从网页中读取内容也是对输入流的操作。
与标准输入源不同,在:
BufferedReader in = new BufferedReader(new InputStreamReader(...))
只需在 InputStreamReader 中输入 System.in。
这里的输入源应该是:
(new URL(url).openConnection().getInputStream(), "GB2312")
后续的操作和处理与加载标准输入源完全一样。
BufferedReader 要求JAVA 必须捕获IOException,使用URL source 不仅要导入.* 包,还要捕获MalformedURLException。
java读取网页内容的例子的详细说明与其他操作不同。如果我们在操作过程中怕麻烦,建议您咨询爱站技术频道编辑,我们可以为您提供周到的服务。
java抓取网页内容(前两天想写一段自动提取微博状态的代码,可以用PHP写 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-23 02:05
)
想写个代码,自动提取前两天微博状态。据我所知,这个函数可以用 PHP 或 Java 编写。我觉得用Java写和调试比较容易,PHP脚本需要上传到服务器什么的。
代码很简单,新建一个包URL类对象,使用这个url作为写入源,将内容存放在一个字符串中。然后创建一个新文件并写出字符串。但请注意,不同的 网站 使用不同的编码字。现在大多数网站使用utf-8字符编码,而基于wordpress构建的网站都使用这种编码字符。但是,很多中文网站,包括网易网站等门户网站,仍然使用gb2312编码。一方面,gb2312的历史比utf-8还要长。早期的中文网站是用gb2312搭建的,现在修改太多了;另一方面,要显示相同长度的文本内容,使用 gb2312 编码比 utf -8 编码应该节省空间。由于这种差异,输入网页的html代码时,应选择正确的阅读方式。java inputstream构造函数可以选择utf-8作为参数,但是没有gb2312选项。因此,在抓取网易网页时,保存的文档中会出现乱码。
另外,这个例子只是抓取静态网页内容,对于微博的状态还是不太好,因为要抓取状态,必须先登录自己的账号,所以需要参考新浪的API文档。
import java.beans.FeatureDescriptor;
import java.io.*;
import java.net.*;
public class spider {
/**
* @param args
*/
public static String fetchWebpage(String urlname){
URL url;
String s;
StringBuffer sbuffer = new StringBuffer();
try{
url = new URL(urlname);
// my website use utf-8, but some other websites, like 163 and baidu, use gb2312.
InputStreamReader sreader = new InputStreamReader(url.openStream(),"utf-8");
BufferedReader breader = new BufferedReader(sreader);
while((s=breader.readLine())!=null){
sbuffer.append(s);
}
breader.close();
}catch(Exception e){
e.printStackTrace();
}
return sbuffer.toString();
}
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String address = "http://www.mr-naive.com";
FileOutputStream fos = new FileOutputStream(new File("myPage.html"));
OutputStreamWriter oswrite = new OutputStreamWriter(fos, "utf-8");
BufferedWriter bwriter = new BufferedWriter(oswrite);
bwriter.write(fetchWebpage(address));
bwriter.close();
}
} 查看全部
java抓取网页内容(前两天想写一段自动提取微博状态的代码,可以用PHP写
)
想写个代码,自动提取前两天微博状态。据我所知,这个函数可以用 PHP 或 Java 编写。我觉得用Java写和调试比较容易,PHP脚本需要上传到服务器什么的。
代码很简单,新建一个包URL类对象,使用这个url作为写入源,将内容存放在一个字符串中。然后创建一个新文件并写出字符串。但请注意,不同的 网站 使用不同的编码字。现在大多数网站使用utf-8字符编码,而基于wordpress构建的网站都使用这种编码字符。但是,很多中文网站,包括网易网站等门户网站,仍然使用gb2312编码。一方面,gb2312的历史比utf-8还要长。早期的中文网站是用gb2312搭建的,现在修改太多了;另一方面,要显示相同长度的文本内容,使用 gb2312 编码比 utf -8 编码应该节省空间。由于这种差异,输入网页的html代码时,应选择正确的阅读方式。java inputstream构造函数可以选择utf-8作为参数,但是没有gb2312选项。因此,在抓取网易网页时,保存的文档中会出现乱码。
另外,这个例子只是抓取静态网页内容,对于微博的状态还是不太好,因为要抓取状态,必须先登录自己的账号,所以需要参考新浪的API文档。
import java.beans.FeatureDescriptor;
import java.io.*;
import java.net.*;
public class spider {
/**
* @param args
*/
public static String fetchWebpage(String urlname){
URL url;
String s;
StringBuffer sbuffer = new StringBuffer();
try{
url = new URL(urlname);
// my website use utf-8, but some other websites, like 163 and baidu, use gb2312.
InputStreamReader sreader = new InputStreamReader(url.openStream(),"utf-8");
BufferedReader breader = new BufferedReader(sreader);
while((s=breader.readLine())!=null){
sbuffer.append(s);
}
breader.close();
}catch(Exception e){
e.printStackTrace();
}
return sbuffer.toString();
}
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String address = "http://www.mr-naive.com";
FileOutputStream fos = new FileOutputStream(new File("myPage.html"));
OutputStreamWriter oswrite = new OutputStreamWriter(fos, "utf-8");
BufferedWriter bwriter = new BufferedWriter(oswrite);
bwriter.write(fetchWebpage(address));
bwriter.close();
}
}
java抓取网页内容(:关于用来存储文字内容的话(03/23))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-22 11:08
java抓取网页内容的话,有很多中实现方式,一般会有两种操作。
感谢@宁波四中滕老师,@向东南方舟clearly大牛@wangyongliangdong看了所有答案,因此详细解释一下,希望对题主有所帮助~代码已放代码已放代码已放,目前依旧是去抓取16年11月到17年1月的新闻。privatevoidscrollby(httpselinfohttpname,httpselinfoselinfo){urlhttp="";intresponse=http.get(url,prompt="{0}",prompt.separator_.c_"\","");//获取url,tags,title等,此步骤用来存储文字内容的post方法返回tags组/**。 查看全部
java抓取网页内容(:关于用来存储文字内容的话(03/23))
java抓取网页内容的话,有很多中实现方式,一般会有两种操作。
感谢@宁波四中滕老师,@向东南方舟clearly大牛@wangyongliangdong看了所有答案,因此详细解释一下,希望对题主有所帮助~代码已放代码已放代码已放,目前依旧是去抓取16年11月到17年1月的新闻。privatevoidscrollby(httpselinfohttpname,httpselinfoselinfo){urlhttp="";intresponse=http.get(url,prompt="{0}",prompt.separator_.c_"\","");//获取url,tags,title等,此步骤用来存储文字内容的post方法返回tags组/**。
java抓取网页内容(pom中引入jsoup代码jsoup的一些方法获取元素的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-22 04:17
)
文章内容
有时需要获取网页图片。一般有以下几种方式:
1、Python 是最方便的,但它有学习成本。
2、图片批量下载软件,这个有,但是不支持多页,爬取规则也不是很灵活。
3、Java不是最有效率的抢手方式,但是专业是Java,所以没有学习成本。
在 pom.xml 中引入 jsoup
org.jsoup
jsoup
1.9.1
代码
/**
* 1、STORE_LOCATION 是图片存储路径,这个根据需要自定义
* 2、抓取图片的需求不同,规则自定义下
* 3、多网页抓取,用个for循环即可。
*/
public class DownloadImageUtils {
private static Logger logger = LoggerFactory.getLogger(DownloadImageUtils.class);
public static String STORE_LOCATION="F:\\pic\\";
public static List images =new ArrayList();
public static void main(String[] args) {
String netUrl = "http://www.baidu.com"; //要爬的网页
new DownloadImageUtils().start(netUrl);
}
public void start(String pageUrl){
List images = parsePage(pageUrl);
downloadImage(images);
}
public List parsePage(String pageUrl){
List images =new ArrayList();
Connection connect = Jsoup.connect(pageUrl);
Document document = null;
try {
document = connect.get();
/* 自定义规则 */
Elements elements = document.getElementsByTag("img"); // 找到所有img标签
for (Element element : elements) {
String alt = element.attr("alt");
String src = element.attr("src");
Image image = new Image();
if(!StringUtils.isEmpty(alt) && src.contains("imgs") && !src.contains("imgs2")){
System.out.println(element.html());
System.out.println(element.attr("src"));
image.setAlt(alt.replace("-FHD",""));
image.setSrc(src);
images.add(image);
}
}
} catch (IOException e) {
e.printStackTrace();
}
return images;
}
//下载该图片!
public void downloadImage(List images){
for (Image image:images) {
InputStream in = null;
BufferedOutputStream os = null;
try {
URL url = new URL(image.getSrc());
File file = new File(STORE_LOCATION + image.getAlt() + ".jpg");
logger.info("filename:{}",file.getAbsoluteFile());
if(file.exists()){ //
return;
}
URLConnection conn = url.openConnection();
in = conn.getInputStream();
os = new BufferedOutputStream(new FileOutputStream(file.getAbsoluteFile()));
byte[] buff = new byte[1024];
int num = 0;
while((num = in.read(buff))!= -1)
{
os.write(buff, 0, num);
os.flush();
}
} catch (MalformedURLException e) {
logger.error("获取图片url异常");
e.printStackTrace();
} catch (IOException e) {
logger.error("下载图片url连接异常");
e.printStackTrace();
}
finally{
if( in != null){
try {
in.close();
} catch (IOException e) {
logger.error("读入流关闭异常");
}
}
if( os != null){
try {
os.close();
} catch (IOException e) {
logger.error("输出流关闭异常");
}
}
}
}
}
static class Image {
private String alt;
private String src;
public String getAlt() {
return alt;
}
public void setAlt(String alt) {
this.alt = alt;
}
public String getSrc() {
return src;
}
public void setSrc(String src) {
this.src = src;
}
}
}
jsoup的一些方法
jsoup 有不止一种获取元素的方式,代码:
// 根据标签获取元素
document.getElementsByTag("img");
// 根据css样式获取元素
document.query(".red");
URLConnection 和 jsoup
也可以使用 URLConnection 来读取网页内容。但是解析的时候只能拼字符串,还是很头疼的。 jsoup 更方便。
URL myurl = new URL(netUrl);
URLConnection myconn = myurl.openConnection();
InputStream myin = myconn.getInputStream();
mybr = new BufferedReader(new InputStreamReader(myin,"UTF-8"));
String line;
while((line = mybr.readLine())!= null)
{
getImageUrl(line,netUrl);//判断网页中的jpg图片
} 查看全部
java抓取网页内容(pom中引入jsoup代码jsoup的一些方法获取元素的方法
)
文章内容
有时需要获取网页图片。一般有以下几种方式:
1、Python 是最方便的,但它有学习成本。
2、图片批量下载软件,这个有,但是不支持多页,爬取规则也不是很灵活。
3、Java不是最有效率的抢手方式,但是专业是Java,所以没有学习成本。
在 pom.xml 中引入 jsoup
org.jsoup
jsoup
1.9.1
代码
/**
* 1、STORE_LOCATION 是图片存储路径,这个根据需要自定义
* 2、抓取图片的需求不同,规则自定义下
* 3、多网页抓取,用个for循环即可。
*/
public class DownloadImageUtils {
private static Logger logger = LoggerFactory.getLogger(DownloadImageUtils.class);
public static String STORE_LOCATION="F:\\pic\\";
public static List images =new ArrayList();
public static void main(String[] args) {
String netUrl = "http://www.baidu.com"; //要爬的网页
new DownloadImageUtils().start(netUrl);
}
public void start(String pageUrl){
List images = parsePage(pageUrl);
downloadImage(images);
}
public List parsePage(String pageUrl){
List images =new ArrayList();
Connection connect = Jsoup.connect(pageUrl);
Document document = null;
try {
document = connect.get();
/* 自定义规则 */
Elements elements = document.getElementsByTag("img"); // 找到所有img标签
for (Element element : elements) {
String alt = element.attr("alt");
String src = element.attr("src");
Image image = new Image();
if(!StringUtils.isEmpty(alt) && src.contains("imgs") && !src.contains("imgs2")){
System.out.println(element.html());
System.out.println(element.attr("src"));
image.setAlt(alt.replace("-FHD",""));
image.setSrc(src);
images.add(image);
}
}
} catch (IOException e) {
e.printStackTrace();
}
return images;
}
//下载该图片!
public void downloadImage(List images){
for (Image image:images) {
InputStream in = null;
BufferedOutputStream os = null;
try {
URL url = new URL(image.getSrc());
File file = new File(STORE_LOCATION + image.getAlt() + ".jpg");
logger.info("filename:{}",file.getAbsoluteFile());
if(file.exists()){ //
return;
}
URLConnection conn = url.openConnection();
in = conn.getInputStream();
os = new BufferedOutputStream(new FileOutputStream(file.getAbsoluteFile()));
byte[] buff = new byte[1024];
int num = 0;
while((num = in.read(buff))!= -1)
{
os.write(buff, 0, num);
os.flush();
}
} catch (MalformedURLException e) {
logger.error("获取图片url异常");
e.printStackTrace();
} catch (IOException e) {
logger.error("下载图片url连接异常");
e.printStackTrace();
}
finally{
if( in != null){
try {
in.close();
} catch (IOException e) {
logger.error("读入流关闭异常");
}
}
if( os != null){
try {
os.close();
} catch (IOException e) {
logger.error("输出流关闭异常");
}
}
}
}
}
static class Image {
private String alt;
private String src;
public String getAlt() {
return alt;
}
public void setAlt(String alt) {
this.alt = alt;
}
public String getSrc() {
return src;
}
public void setSrc(String src) {
this.src = src;
}
}
}
jsoup的一些方法
jsoup 有不止一种获取元素的方式,代码:
// 根据标签获取元素
document.getElementsByTag("img");
// 根据css样式获取元素
document.query(".red");
URLConnection 和 jsoup
也可以使用 URLConnection 来读取网页内容。但是解析的时候只能拼字符串,还是很头疼的。 jsoup 更方便。
URL myurl = new URL(netUrl);
URLConnection myconn = myurl.openConnection();
InputStream myin = myconn.getInputStream();
mybr = new BufferedReader(new InputStreamReader(myin,"UTF-8"));
String line;
while((line = mybr.readLine())!= null)
{
getImageUrl(line,netUrl);//判断网页中的jpg图片
}
java抓取网页内容(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-17 01:32
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下这个方法的理解和体会。最简单的爬取方法是:
URL url = 新 URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
我++;
sb.append(s+"/r/n");
}
这种方法抓取一般网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取该网址中网页的内容,又不想重定向到其他网页,可以使用以下代码。
URL urlmy = 新 URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
连接();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"/r/n");
}
在这种情况下,程序在抓取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty("http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
以上程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用,呵呵,这是多么美妙的一件事啊!! 查看全部
java抓取网页内容(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下这个方法的理解和体会。最简单的爬取方法是:
URL url = 新 URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
我++;
sb.append(s+"/r/n");
}
这种方法抓取一般网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取该网址中网页的内容,又不想重定向到其他网页,可以使用以下代码。
URL urlmy = 新 URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
连接();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"/r/n");
}
在这种情况下,程序在抓取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty("http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
以上程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用,呵呵,这是多么美妙的一件事啊!!
java抓取网页内容(Python网页内容需求的人可以来学习下的抓取网页内容方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-14 12:06
Python中如何抓取网页内容,很多新手对此不是很清楚。为了帮助您解决这个问题,下面小编将为您详细讲解。有这方面需求的可以过来学习。我希望你能有所收获。
Python抓取网页内容方法一、使用urllib2/sgmllib包列出目标网页的所有网址。
import urllib2 from sgmllib import SGMLParser class URLLister(SGMLParser): def reset(self): SGMLParser.reset(self) self.urls = [] def start_a(self, attrs): href = [v for k, v in attrs if k=='href'] if href: self.urls.extend(href) f = urllib2.urlopen("http://www.donews.com/") if f.code == 200: parser = URLLister() parser.feed(f.read()) f.close() for url in parser.urls: print url
Python抓取网页内容方法二、 使用python调用IE抓取目标网页所有图片的url和大小(需要win32com,pythoncom)
这个方法可以利用IE的Javascript的支持。DHTML 自动提交表单并处理 Javascript。
看完以上内容对你有帮助吗?如果您想了解更多相关知识或阅读更多相关文章,请关注易速云行业资讯频道,感谢您对易速云的支持。 查看全部
java抓取网页内容(Python网页内容需求的人可以来学习下的抓取网页内容方法)
Python中如何抓取网页内容,很多新手对此不是很清楚。为了帮助您解决这个问题,下面小编将为您详细讲解。有这方面需求的可以过来学习。我希望你能有所收获。
Python抓取网页内容方法一、使用urllib2/sgmllib包列出目标网页的所有网址。
import urllib2 from sgmllib import SGMLParser class URLLister(SGMLParser): def reset(self): SGMLParser.reset(self) self.urls = [] def start_a(self, attrs): href = [v for k, v in attrs if k=='href'] if href: self.urls.extend(href) f = urllib2.urlopen("http://www.donews.com/";) if f.code == 200: parser = URLLister() parser.feed(f.read()) f.close() for url in parser.urls: print url
Python抓取网页内容方法二、 使用python调用IE抓取目标网页所有图片的url和大小(需要win32com,pythoncom)
这个方法可以利用IE的Javascript的支持。DHTML 自动提交表单并处理 Javascript。
看完以上内容对你有帮助吗?如果您想了解更多相关知识或阅读更多相关文章,请关注易速云行业资讯频道,感谢您对易速云的支持。
java抓取网页内容( 网页抓取意味着流程(Web抓取自动化)的简要信息表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-14 12:03
网页抓取意味着流程(Web抓取自动化)的简要信息表)
使用 Node.js 进行网页内容抓取(Web Scraping)
介绍
根据定义,网络抓取意味着从网页中获取有用的信息。该过程应该消除手动浏览页面的需要,自动化,并允许您感兴趣的信息的程序化采集和分类
Node.js 是一个很好的网络爬虫工具。它允许使用 npm 提供的开源模块在几行代码中实现网页抓取
使用Node.js进行网页内容抓取(Web Scraping)的主要步骤
正如我们所定义的,网络抓取只不过是自动手动浏览和从您首选的网络浏览器中的特定 网站 采集信息
这个过程包括三个主要步骤:
根据应用的需要,第一步和最后一步通常基本相同。但是,理解 HTML 内容需要为每个要爬取的 网站 编写特定的代码
警告
根据您对这些技术和技术的使用,您的应用程序可能正在执行非法操作
在某些情况下,您需要小心:
手动抓取网页的算法方法示例
例如,我们会找到本站豆豆网的部分列表页
首先,让我们定义我们的任务和期望的结果:
使用“.CSV”文件来存储收录 文章 的地址、标题和日期。这些专栏将简要描述每个文章
以下是我们如何手动执行此操作:
多次重复这些步骤将得到这个搜索列表页面的简要信息表
使用 Web Scraping 自动化流程(Web Scraping)
为了自动化这个过程,我们应该以编程方式遵循相同的步骤
设置开发环境
我们将使用 Node.js 和 npm 来开发这个示例项目。因此,请确保您的机器上安装了这些工具,让我们首先在您选择的空目录中运行以下命令,然后创建一个收录我们代码的空 index.js 页面:
$ npm init
下一步是从 npm 安装所需的模块
从上面描述的手动算法可以看出,我们需要一些东西来获取HTML源代码,解析内容并理解它,然后将JavaScript对象数组写入“.CSV”文件:
$ npm install --save request request-promise cheerio objects-to-csv
在终端中执行上一行将在 node_modules 目录中安装所需的模块并将它们作为依赖项保存在 package.json 文件中
检索信息
所有准备工作完成后,使用编辑器编辑 index.js 并根据需要导入我们刚刚安装的模块:
const rp = require('request-promise');
const otcsv = require('objects-to-csv');
const cheerio = require('cheerio');
在手动算法中完成这一步会为我们提供一个链接,我们将把它分成两部分并添加到模块导入代码后面的 index.js 中:
const baseURL = 'https://fullsmilespace.cn';
const searchURL = '?s=IT';
根据图中得到这两个变量的值:
然后,我们应该编写一个函数,该函数将在任务描述中返回表示 文章 的 JavaScript 对象数组
为了能够将手动算法转换为代码,我们必须首先使用网络浏览器的检查器工具进行一些手动工作
我们需要找到收录我们感兴趣的信息的特定 HTML 元素。在我们的示例中,可以在以下元素中找到 文章 链接:
如何将iPhone X/8/7/6s/6/5s/5/4s/SE等备份到iTunes/iCloud/PC/Mac
它是一个 h2 嵌套的 tag 标签,带有类 entry-title,其中收录 文章 链接,以及一个 href 属性,其中收录指向各种 文章 页面的链接。这两种方法将来都会对我们有用
链接到文章页面后,我们需要找到剩下的两部分数据:title和date,分别位于class entry-title标签和class entry-date标签下
请注意,要获取标题和日期,我们需要将值存储在标签中
当我们尝试实现其编程时,让我们看看手动算法会是什么样子:
下面是这个算法在实现时的样子:
const getCompanies = async () => {
const html = await rp(baseURL + searchURL);
const businessMap = cheerio('.entry-title a', html).map(async (i, e) => {
const link = e.attribs.href;
const innerHtml = await rp(link);
const title = cheerio('.entry-title', innerHtml).text();
const date = cheerio('.entry-date', innerHtml).text();
return {
link,
title,
date
}
}).get();
return Promise.all(businessMap);
};
它遵循我们之前设置的规则并返回一个 Promise,它解析为一组 JavaScript 对象:
{ link: 'https://fullsmilespace.cn/?p=75',
title: '如何在WordPress中添加关键字keywords和元描述meta descriptions',
date: '2019年1月15日' }
{ link: 'https://fullsmilespace.cn/?p=209',
title: '如何将iPhone X/8/7/6s/6/5s/5/4s/SE等备份到iTunes/iCloud/PC/Mac',
date: '2019年1月18日' }
{ link: 'https://fullsmilespace.cn/?p=197',
title: '解决App Store下载“超过150MB”的应用需无线局域网来下载的限制',
date: '2019年1月17日' }
{ link: 'https://fullsmilespace.cn/?p=192',
title: '2019年的页面搜索引擎优化|2019年页面SEO优化',
date: '2019年1月16日' }
{ link: 'https://fullsmilespace.cn/?p=95',
title: '美化WordPress网站的最佳插件推荐|WordPress网站美化插件汇总',
date: '2019年1月15日' }
{ link: 'https://fullsmilespace.cn/?p=254',
title: 'Node.js初学者指南 | 初识Node.js详细过程',
date: '2019年1月21日' }
承诺
如果你不熟悉现代 JavaScript 中异步编程的核心概念,这里是 Promises 的简要介绍
Promise 是一种特殊类型,用作值的占位符。它可能处于几种状态:
如果你不是太详细,你应该只知道返回一个promise的函数并没有返回实际值。为了访问 Promise 的结果或解析值,您应该编写另一个函数,该函数应该传递到 then 块中,并期望 Promise 的值被解析。如果在 Promise 等待期间发生任何错误,它会过渡到拒绝状态,并且可以在 catch 块中处理错误
数据存储和整理工作
现在我们已经从网页中提取了所有必要的数据并拥有一个干净的 JavaScript 对象数组,我们可以准备任务定义所需的文件“.CSV”:
getCompanies()
.then(result => {
const transformed = new otcsv(result);
return transformed.toDisk('./output.csv');
})
.then(() => console.log('成功完成简单页面内容抓取!'));
getCompanies 函数返回一个承诺,该承诺解析为准备写入 CSV 文件的对象数组,这是在第一个 then 块中完成的。当CSV文件成功写入文件系统后,第二个解析器会解析完成任务
通过将此代码添加到 index.js 文件并运行它:
node index.js
我们应该在我们的工作目录中得到一个 output.csv 文件。csv文件表示的表格收录3列——文章链接、标题、日期,每行描述一篇文章文章
综上所述
本质上,网页抓取就是浏览网页,根据任务获取有用的信息,并将其存储在某个地方,所有这些都是通过编程来完成的。为了能够通过代码实现这一点,你应该首先使用浏览器的inspector工具或者通过分析目标网页的原创HTML内容来手动完成这个过程
Node.js 提供了可靠且简单的工具,使网页抓取成为一项简单的任务,与手动处理链接相比,可以节省大量时间
尽管将所有日常任务自动化似乎很诱人,但在制作这些工具时要小心,因为如果您不完全理解源网站 的术语或网络爬虫产生的流量,它们很容易违反法律 查看全部
java抓取网页内容(
网页抓取意味着流程(Web抓取自动化)的简要信息表)
使用 Node.js 进行网页内容抓取(Web Scraping)
介绍
根据定义,网络抓取意味着从网页中获取有用的信息。该过程应该消除手动浏览页面的需要,自动化,并允许您感兴趣的信息的程序化采集和分类
Node.js 是一个很好的网络爬虫工具。它允许使用 npm 提供的开源模块在几行代码中实现网页抓取
使用Node.js进行网页内容抓取(Web Scraping)的主要步骤
正如我们所定义的,网络抓取只不过是自动手动浏览和从您首选的网络浏览器中的特定 网站 采集信息
这个过程包括三个主要步骤:
根据应用的需要,第一步和最后一步通常基本相同。但是,理解 HTML 内容需要为每个要爬取的 网站 编写特定的代码
警告
根据您对这些技术和技术的使用,您的应用程序可能正在执行非法操作
在某些情况下,您需要小心:
手动抓取网页的算法方法示例
例如,我们会找到本站豆豆网的部分列表页
首先,让我们定义我们的任务和期望的结果:
使用“.CSV”文件来存储收录 文章 的地址、标题和日期。这些专栏将简要描述每个文章
以下是我们如何手动执行此操作:
多次重复这些步骤将得到这个搜索列表页面的简要信息表
使用 Web Scraping 自动化流程(Web Scraping)
为了自动化这个过程,我们应该以编程方式遵循相同的步骤
设置开发环境
我们将使用 Node.js 和 npm 来开发这个示例项目。因此,请确保您的机器上安装了这些工具,让我们首先在您选择的空目录中运行以下命令,然后创建一个收录我们代码的空 index.js 页面:
$ npm init
下一步是从 npm 安装所需的模块
从上面描述的手动算法可以看出,我们需要一些东西来获取HTML源代码,解析内容并理解它,然后将JavaScript对象数组写入“.CSV”文件:
$ npm install --save request request-promise cheerio objects-to-csv
在终端中执行上一行将在 node_modules 目录中安装所需的模块并将它们作为依赖项保存在 package.json 文件中
检索信息
所有准备工作完成后,使用编辑器编辑 index.js 并根据需要导入我们刚刚安装的模块:
const rp = require('request-promise');
const otcsv = require('objects-to-csv');
const cheerio = require('cheerio');
在手动算法中完成这一步会为我们提供一个链接,我们将把它分成两部分并添加到模块导入代码后面的 index.js 中:
const baseURL = 'https://fullsmilespace.cn';
const searchURL = '?s=IT';
根据图中得到这两个变量的值:
https://fullsmilespace.cn/wp-c ... 3.jpg 300w, https://fullsmilespace.cn/wp-c ... 7.jpg 768w, https://fullsmilespace.cn/wp-c ... 6.jpg 1024w" />然后,我们应该编写一个函数,该函数将在任务描述中返回表示 文章 的 JavaScript 对象数组
为了能够将手动算法转换为代码,我们必须首先使用网络浏览器的检查器工具进行一些手动工作
我们需要找到收录我们感兴趣的信息的特定 HTML 元素。在我们的示例中,可以在以下元素中找到 文章 链接:
https://fullsmilespace.cn/wp-c ... 0.jpg 300w, https://fullsmilespace.cn/wp-c ... 1.jpg 768w, https://fullsmilespace.cn/wp-c ... 1.jpg 1024w" />如何将iPhone X/8/7/6s/6/5s/5/4s/SE等备份到iTunes/iCloud/PC/Mac
它是一个 h2 嵌套的 tag 标签,带有类 entry-title,其中收录 文章 链接,以及一个 href 属性,其中收录指向各种 文章 页面的链接。这两种方法将来都会对我们有用
链接到文章页面后,我们需要找到剩下的两部分数据:title和date,分别位于class entry-title标签和class entry-date标签下
请注意,要获取标题和日期,我们需要将值存储在标签中
当我们尝试实现其编程时,让我们看看手动算法会是什么样子:
下面是这个算法在实现时的样子:
const getCompanies = async () => {
const html = await rp(baseURL + searchURL);
const businessMap = cheerio('.entry-title a', html).map(async (i, e) => {
const link = e.attribs.href;
const innerHtml = await rp(link);
const title = cheerio('.entry-title', innerHtml).text();
const date = cheerio('.entry-date', innerHtml).text();
return {
link,
title,
date
}
}).get();
return Promise.all(businessMap);
};
它遵循我们之前设置的规则并返回一个 Promise,它解析为一组 JavaScript 对象:
{ link: 'https://fullsmilespace.cn/?p=75',
title: '如何在WordPress中添加关键字keywords和元描述meta descriptions',
date: '2019年1月15日' }
{ link: 'https://fullsmilespace.cn/?p=209',
title: '如何将iPhone X/8/7/6s/6/5s/5/4s/SE等备份到iTunes/iCloud/PC/Mac',
date: '2019年1月18日' }
{ link: 'https://fullsmilespace.cn/?p=197',
title: '解决App Store下载“超过150MB”的应用需无线局域网来下载的限制',
date: '2019年1月17日' }
{ link: 'https://fullsmilespace.cn/?p=192',
title: '2019年的页面搜索引擎优化|2019年页面SEO优化',
date: '2019年1月16日' }
{ link: 'https://fullsmilespace.cn/?p=95',
title: '美化WordPress网站的最佳插件推荐|WordPress网站美化插件汇总',
date: '2019年1月15日' }
{ link: 'https://fullsmilespace.cn/?p=254',
title: 'Node.js初学者指南 | 初识Node.js详细过程',
date: '2019年1月21日' }
承诺
如果你不熟悉现代 JavaScript 中异步编程的核心概念,这里是 Promises 的简要介绍
Promise 是一种特殊类型,用作值的占位符。它可能处于几种状态:
如果你不是太详细,你应该只知道返回一个promise的函数并没有返回实际值。为了访问 Promise 的结果或解析值,您应该编写另一个函数,该函数应该传递到 then 块中,并期望 Promise 的值被解析。如果在 Promise 等待期间发生任何错误,它会过渡到拒绝状态,并且可以在 catch 块中处理错误
数据存储和整理工作
现在我们已经从网页中提取了所有必要的数据并拥有一个干净的 JavaScript 对象数组,我们可以准备任务定义所需的文件“.CSV”:
getCompanies()
.then(result => {
const transformed = new otcsv(result);
return transformed.toDisk('./output.csv');
})
.then(() => console.log('成功完成简单页面内容抓取!'));
getCompanies 函数返回一个承诺,该承诺解析为准备写入 CSV 文件的对象数组,这是在第一个 then 块中完成的。当CSV文件成功写入文件系统后,第二个解析器会解析完成任务
通过将此代码添加到 index.js 文件并运行它:
node index.js
我们应该在我们的工作目录中得到一个 output.csv 文件。csv文件表示的表格收录3列——文章链接、标题、日期,每行描述一篇文章文章
综上所述
本质上,网页抓取就是浏览网页,根据任务获取有用的信息,并将其存储在某个地方,所有这些都是通过编程来完成的。为了能够通过代码实现这一点,你应该首先使用浏览器的inspector工具或者通过分析目标网页的原创HTML内容来手动完成这个过程
Node.js 提供了可靠且简单的工具,使网页抓取成为一项简单的任务,与手动处理链接相比,可以节省大量时间
尽管将所有日常任务自动化似乎很诱人,但在制作这些工具时要小心,因为如果您不完全理解源网站 的术语或网络爬虫产生的流量,它们很容易违反法律
java抓取网页内容(pom中引入jsoup代码jsoup的一些方法获取元素的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-14 09:23
)
文章内容
有时需要获取网页图片。一般有以下几种方式:
1、Python 是最方便的,但它有学习成本。
2、图片批量下载软件,这个有,但是不支持多页,爬取规则也不是很灵活。
3、java不是最有效率的抢手方式,但是专业是java,所以没有学习成本。
在 pom.xml 中引入 jsoup
org.jsoup
jsoup
1.9.1
代码
/**
* 1、STORE_LOCATION 是图片存储路径,这个根据需要自定义
* 2、抓取图片的需求不同,规则自定义下
* 3、多网页抓取,用个for循环即可。
*/
public class DownloadImageUtils {
private static Logger logger = LoggerFactory.getLogger(DownloadImageUtils.class);
public static String STORE_LOCATION="F:\\pic\\";
public static List images =new ArrayList();
public static void main(String[] args) {
String netUrl = "http://www.baidu.com"; //要爬的网页
new DownloadImageUtils().start(netUrl);
}
public void start(String pageUrl){
List images = parsePage(pageUrl);
downloadImage(images);
}
public List parsePage(String pageUrl){
List images =new ArrayList();
Connection connect = Jsoup.connect(pageUrl);
Document document = null;
try {
document = connect.get();
/* 自定义规则 */
Elements elements = document.getElementsByTag("img"); // 找到所有img标签
for (Element element : elements) {
String alt = element.attr("alt");
String src = element.attr("src");
Image image = new Image();
if(!StringUtils.isEmpty(alt) && src.contains("imgs") && !src.contains("imgs2")){
System.out.println(element.html());
System.out.println(element.attr("src"));
image.setAlt(alt.replace("-FHD",""));
image.setSrc(src);
images.add(image);
}
}
} catch (IOException e) {
e.printStackTrace();
}
return images;
}
//下载该图片!
public void downloadImage(List images){
for (Image image:images) {
InputStream in = null;
BufferedOutputStream os = null;
try {
URL url = new URL(image.getSrc());
File file = new File(STORE_LOCATION + image.getAlt() + ".jpg");
logger.info("filename:{}",file.getAbsoluteFile());
if(file.exists()){ //
return;
}
URLConnection conn = url.openConnection();
in = conn.getInputStream();
os = new BufferedOutputStream(new FileOutputStream(file.getAbsoluteFile()));
byte[] buff = new byte[1024];
int num = 0;
while((num = in.read(buff))!= -1)
{
os.write(buff, 0, num);
os.flush();
}
} catch (MalformedURLException e) {
logger.error("获取图片url异常");
e.printStackTrace();
} catch (IOException e) {
logger.error("下载图片url连接异常");
e.printStackTrace();
}
finally{
if( in != null){
try {
in.close();
} catch (IOException e) {
logger.error("读入流关闭异常");
}
}
if( os != null){
try {
os.close();
} catch (IOException e) {
logger.error("输出流关闭异常");
}
}
}
}
}
static class Image {
private String alt;
private String src;
public String getAlt() {
return alt;
}
public void setAlt(String alt) {
this.alt = alt;
}
public String getSrc() {
return src;
}
public void setSrc(String src) {
this.src = src;
}
}
}
jsoup的一些方法
jsoup 有不止一种获取元素的方式,代码:
// 根据标签获取元素
document.getElementsByTag("img");
// 根据css样式获取元素
document.query(".red");
URLConnection 和 jsoup
也可以使用 URLConnection 来读取网页内容。但是解析的时候只能拼字符串,还是很头疼的。 jsoup 更方便。
URL myurl = new URL(netUrl);
URLConnection myconn = myurl.openConnection();
InputStream myin = myconn.getInputStream();
mybr = new BufferedReader(new InputStreamReader(myin,"UTF-8"));
String line;
while((line = mybr.readLine())!= null)
{
getImageUrl(line,netUrl);//判断网页中的jpg图片
} 查看全部
java抓取网页内容(pom中引入jsoup代码jsoup的一些方法获取元素的方法
)
文章内容
有时需要获取网页图片。一般有以下几种方式:
1、Python 是最方便的,但它有学习成本。
2、图片批量下载软件,这个有,但是不支持多页,爬取规则也不是很灵活。
3、java不是最有效率的抢手方式,但是专业是java,所以没有学习成本。
在 pom.xml 中引入 jsoup
org.jsoup
jsoup
1.9.1
代码
/**
* 1、STORE_LOCATION 是图片存储路径,这个根据需要自定义
* 2、抓取图片的需求不同,规则自定义下
* 3、多网页抓取,用个for循环即可。
*/
public class DownloadImageUtils {
private static Logger logger = LoggerFactory.getLogger(DownloadImageUtils.class);
public static String STORE_LOCATION="F:\\pic\\";
public static List images =new ArrayList();
public static void main(String[] args) {
String netUrl = "http://www.baidu.com"; //要爬的网页
new DownloadImageUtils().start(netUrl);
}
public void start(String pageUrl){
List images = parsePage(pageUrl);
downloadImage(images);
}
public List parsePage(String pageUrl){
List images =new ArrayList();
Connection connect = Jsoup.connect(pageUrl);
Document document = null;
try {
document = connect.get();
/* 自定义规则 */
Elements elements = document.getElementsByTag("img"); // 找到所有img标签
for (Element element : elements) {
String alt = element.attr("alt");
String src = element.attr("src");
Image image = new Image();
if(!StringUtils.isEmpty(alt) && src.contains("imgs") && !src.contains("imgs2")){
System.out.println(element.html());
System.out.println(element.attr("src"));
image.setAlt(alt.replace("-FHD",""));
image.setSrc(src);
images.add(image);
}
}
} catch (IOException e) {
e.printStackTrace();
}
return images;
}
//下载该图片!
public void downloadImage(List images){
for (Image image:images) {
InputStream in = null;
BufferedOutputStream os = null;
try {
URL url = new URL(image.getSrc());
File file = new File(STORE_LOCATION + image.getAlt() + ".jpg");
logger.info("filename:{}",file.getAbsoluteFile());
if(file.exists()){ //
return;
}
URLConnection conn = url.openConnection();
in = conn.getInputStream();
os = new BufferedOutputStream(new FileOutputStream(file.getAbsoluteFile()));
byte[] buff = new byte[1024];
int num = 0;
while((num = in.read(buff))!= -1)
{
os.write(buff, 0, num);
os.flush();
}
} catch (MalformedURLException e) {
logger.error("获取图片url异常");
e.printStackTrace();
} catch (IOException e) {
logger.error("下载图片url连接异常");
e.printStackTrace();
}
finally{
if( in != null){
try {
in.close();
} catch (IOException e) {
logger.error("读入流关闭异常");
}
}
if( os != null){
try {
os.close();
} catch (IOException e) {
logger.error("输出流关闭异常");
}
}
}
}
}
static class Image {
private String alt;
private String src;
public String getAlt() {
return alt;
}
public void setAlt(String alt) {
this.alt = alt;
}
public String getSrc() {
return src;
}
public void setSrc(String src) {
this.src = src;
}
}
}
jsoup的一些方法
jsoup 有不止一种获取元素的方式,代码:
// 根据标签获取元素
document.getElementsByTag("img");
// 根据css样式获取元素
document.query(".red");
URLConnection 和 jsoup
也可以使用 URLConnection 来读取网页内容。但是解析的时候只能拼字符串,还是很头疼的。 jsoup 更方便。
URL myurl = new URL(netUrl);
URLConnection myconn = myurl.openConnection();
InputStream myin = myconn.getInputStream();
mybr = new BufferedReader(new InputStreamReader(myin,"UTF-8"));
String line;
while((line = mybr.readLine())!= null)
{
getImageUrl(line,netUrl);//判断网页中的jpg图片
}
java抓取网页内容(【每日一题】打开浏览器的开发者模式(F12) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-14 09:16
)
一、目的:1. 任务
使用Jsoup抓取京东图书分类页面的图书信息。
获取目标分类网址如:,3259,3330
对于给定的书页,抓取每一页的书信息,抓取该分类页的多页直到结束。
下图是给定目标抓取页面的地址
,3259,3330
我们得到的应该是每本书的图书信息,类似于打开网页查看图书信息内容的模拟。
所以我们直接打开一个item(红框圈出的,暂时把分类页面上的一本书作为一个item),查看一下内容。
提取的内容就是红框里的这部分:
2.工具和语言
语言:java
工具:jsoup-1.7.2.jar
二、思考
我们采取这样的思路,
1.将分类的源码网站保存到本地
2. 解析出分类页面上的所有书籍(item),得到一个相似item的List集合
3.根据得到的List集合,遍历循环解析每一页的图书信息,然后匹配到图书信息控制台打印。
我们将京东图书的抓取抽象为一个类。这个类有一个方法来保存下载的源代码,一个方法来解析分类页面以获取List集合,以及一个解析书页信息的方法。
三、分析1.将分类的源码网站保存到本地
将网站的源码下载到本地的方法,可以在本地看到一个文本文件,具体存放网站的当前源码的txt文件。用于解析
/**
* 将目标html保存到本地中进行解析获得 doc文本对象
* @param htmlUrl 需要下载到本地的网址
* @param toSavePath 需要保存到本地的电脑路径 例如E:\\jd.txt
* @param type 编码方式 UTF-8 或者 GBK 等
* @return
* @throws IOException
*/
public Document getDocFromUrl(String htmlUrl,String toSavePath,String type) throws IOException
{
URL url = new URL(htmlUrl) ;
File file = new File(toSavePath) ;
if(file.exists())
file.delete() ;
file.createNewFile() ;
FileOutputStream fos = new FileOutputStream(file) ;
BufferedReader br = new BufferedReader(
new InputStreamReader(url.openStream(),type)) ;
byte [] b = new byte[1024] ;
String c ;
while(((c = br.readLine())!=null))
{
fos.write(c.getBytes());
}
System.out.println("保存分类html完毕");
Document doc = Jsoup.parse(file,"UTF-8") ;
return doc ;
}
2.分析分类页面上的所有书籍
这里就是把如图所示的分类页面中所有item的每个地址解析出来,把它们的地址变成一个List集合。这样就得到了当前页面的所有书名。为分析每本书的信息做铺垫。
打开浏览器的开发者模式(F12)查看如何解析:
我们在图书信息列表中不难发现,这些书每一本书都被一个li标签包裹着,而这些书的li标签都被一个ul包裹着,class="gl-warp"。分析完这个,你应该有一个想法。NS。
在这种情况下,我们首先使用jsoup获取ul标签的内容,然后执行getElementsByTag("li"); ul标签中li标签上的方法,这样我们就可以得到每个li标签的内容,也就是每本书内容的内容。下面两行代码得到li的集合
Element contentEl = doc.select("ul.gl-warp").first() ;
Elements lis = contentEl.getElementsByTag("li");
书籍的 Elements 元素没有完成,因为我们想要这些书籍的地址,换句话说,我们想要书籍 List。但是如何解析出每本书的地址呢?我们需要打开某个 li 标签才能查看。
也许你一眼就能看到一个地址,没错,就是标签。我们可以再次获取它的href属性值,任性
怎么做:
元素titleEl = li.select("div.p-name").first();
元素 a = titleEl.select("a").first();
String href = a.attr("href");
看了这么多后的代码:
/**
* 解析每一个图书的页面地址
* @param doc
* @return
*/
public List parseItemUrl(Document doc)
{
//获取页面
Element contentEl = doc.select("ul.gl-warp").first() ;
Elements lis = contentEl.getElementsByTag("li");
for (Element li : lis) {
//for循环的就是每一本书拿到详情地址
Element titleEl = li.select("div.p-name").first() ;
Element a = titleEl.select("a").first() ;
String href = a.attr("href") ;
href = "http:"+href ;
hrefList.add(href) ;
}
return hrefList ;
}
3.分析一本书
分析每一本书,根据书籍详情页地址下载详情页源码,使用jsoup进行匹配。可以看到图片高亮的部分就是我们要分析的内容。这也很清楚。我们只需要解析到一个叫做class="parameter2"的标签ul,然后解析里面的每一个li。思路可以遵循前面的解析过程。这里我直接把所有的文字输出为一个文本。每个 li 标签没有循环遍历。你可以关注上一个。
/**
* 解析书本的信息
* @param doc
*/
public void parseContent(Document doc)
{
Element contentEl = doc.getElementById("parameter2") ;
if(contentEl==null)
return ;
Elements lis = contentEl.getElementsByTag("li");
if(lis==null)
return ;
for (Element li : lis) {
String text = li.text() ;
System.out.println("--"+text);
}
} 查看全部
java抓取网页内容(【每日一题】打开浏览器的开发者模式(F12)
)
一、目的:1. 任务
使用Jsoup抓取京东图书分类页面的图书信息。
获取目标分类网址如:,3259,3330
对于给定的书页,抓取每一页的书信息,抓取该分类页的多页直到结束。
下图是给定目标抓取页面的地址
,3259,3330
我们得到的应该是每本书的图书信息,类似于打开网页查看图书信息内容的模拟。
所以我们直接打开一个item(红框圈出的,暂时把分类页面上的一本书作为一个item),查看一下内容。
提取的内容就是红框里的这部分:
2.工具和语言
语言:java
工具:jsoup-1.7.2.jar
二、思考
我们采取这样的思路,
1.将分类的源码网站保存到本地
2. 解析出分类页面上的所有书籍(item),得到一个相似item的List集合
3.根据得到的List集合,遍历循环解析每一页的图书信息,然后匹配到图书信息控制台打印。
我们将京东图书的抓取抽象为一个类。这个类有一个方法来保存下载的源代码,一个方法来解析分类页面以获取List集合,以及一个解析书页信息的方法。
三、分析1.将分类的源码网站保存到本地
将网站的源码下载到本地的方法,可以在本地看到一个文本文件,具体存放网站的当前源码的txt文件。用于解析
/**
* 将目标html保存到本地中进行解析获得 doc文本对象
* @param htmlUrl 需要下载到本地的网址
* @param toSavePath 需要保存到本地的电脑路径 例如E:\\jd.txt
* @param type 编码方式 UTF-8 或者 GBK 等
* @return
* @throws IOException
*/
public Document getDocFromUrl(String htmlUrl,String toSavePath,String type) throws IOException
{
URL url = new URL(htmlUrl) ;
File file = new File(toSavePath) ;
if(file.exists())
file.delete() ;
file.createNewFile() ;
FileOutputStream fos = new FileOutputStream(file) ;
BufferedReader br = new BufferedReader(
new InputStreamReader(url.openStream(),type)) ;
byte [] b = new byte[1024] ;
String c ;
while(((c = br.readLine())!=null))
{
fos.write(c.getBytes());
}
System.out.println("保存分类html完毕");
Document doc = Jsoup.parse(file,"UTF-8") ;
return doc ;
}
2.分析分类页面上的所有书籍
这里就是把如图所示的分类页面中所有item的每个地址解析出来,把它们的地址变成一个List集合。这样就得到了当前页面的所有书名。为分析每本书的信息做铺垫。
打开浏览器的开发者模式(F12)查看如何解析:
我们在图书信息列表中不难发现,这些书每一本书都被一个li标签包裹着,而这些书的li标签都被一个ul包裹着,class="gl-warp"。分析完这个,你应该有一个想法。NS。
在这种情况下,我们首先使用jsoup获取ul标签的内容,然后执行getElementsByTag("li"); ul标签中li标签上的方法,这样我们就可以得到每个li标签的内容,也就是每本书内容的内容。下面两行代码得到li的集合
Element contentEl = doc.select("ul.gl-warp").first() ;
Elements lis = contentEl.getElementsByTag("li");
书籍的 Elements 元素没有完成,因为我们想要这些书籍的地址,换句话说,我们想要书籍 List。但是如何解析出每本书的地址呢?我们需要打开某个 li 标签才能查看。
也许你一眼就能看到一个地址,没错,就是标签。我们可以再次获取它的href属性值,任性
怎么做:
元素titleEl = li.select("div.p-name").first();
元素 a = titleEl.select("a").first();
String href = a.attr("href");
看了这么多后的代码:
/**
* 解析每一个图书的页面地址
* @param doc
* @return
*/
public List parseItemUrl(Document doc)
{
//获取页面
Element contentEl = doc.select("ul.gl-warp").first() ;
Elements lis = contentEl.getElementsByTag("li");
for (Element li : lis) {
//for循环的就是每一本书拿到详情地址
Element titleEl = li.select("div.p-name").first() ;
Element a = titleEl.select("a").first() ;
String href = a.attr("href") ;
href = "http:"+href ;
hrefList.add(href) ;
}
return hrefList ;
}
3.分析一本书
分析每一本书,根据书籍详情页地址下载详情页源码,使用jsoup进行匹配。可以看到图片高亮的部分就是我们要分析的内容。这也很清楚。我们只需要解析到一个叫做class="parameter2"的标签ul,然后解析里面的每一个li。思路可以遵循前面的解析过程。这里我直接把所有的文字输出为一个文本。每个 li 标签没有循环遍历。你可以关注上一个。
/**
* 解析书本的信息
* @param doc
*/
public void parseContent(Document doc)
{
Element contentEl = doc.getElementById("parameter2") ;
if(contentEl==null)
return ;
Elements lis = contentEl.getElementsByTag("li");
if(lis==null)
return ;
for (Element li : lis) {
String text = li.text() ;
System.out.println("--"+text);
}
}
java抓取网页内容(拼接字符串的性能闲话不多.8的制作方法! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-13 23:01
)
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao";
//词条的链接关键字
String keyOfHref = "http://www.cppcns.com/ruanjian ... 3B%3B
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = http://www.cppcns.com/ruanjian/java/getHref(rLine,keyOfHref)) !="")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持!
Java使用url实现网页内容爬取 查看全部
java抓取网页内容(拼接字符串的性能闲话不多.8的制作方法!
)
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao";
//词条的链接关键字
String keyOfHref = "http://www.cppcns.com/ruanjian ... 3B%3B
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = http://www.cppcns.com/ruanjian/java/getHref(rLine,keyOfHref)) !="")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持!
Java使用url实现网页内容爬取
java抓取网页内容(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-11 02:03
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文使用Java向大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java抓取网页内容(本文就用Java给大家演示如何抓取网站的数据:(1))
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文使用Java向大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
java抓取网页内容(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-10 10:00
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集的时候,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,一个采集当前页面数据和一个翻页动作可以通过线程完成采集所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java抓取网页内容(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集的时候,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,一个采集当前页面数据和一个翻页动作可以通过线程完成采集所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。
java抓取网页内容(代码罗View远程服务器,没事抓取网页信息的小工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-05 09:23
)
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,它让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
1 import java.io.BufferedReader;
2 import java.io.IOException;
3 import java.io.InputStreamReader;
4 import java.net.HttpURLConnection;
5 import java.net.URL;
6 import java.util.*;
7
8 /**
9 * Created by chunmiao on 17-3-10.
10 */
11 public class ReadBaiduSearch {
12
13 //储存返回结果
14 private LinkedHashMap mapOfBaike;
15
16
17 //获取搜索信息
18 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
19 mapOfBaike = getResult(infomationWords);
20 return mapOfBaike;
21 }
22
23 //通过网络链接获取信息
24 private static LinkedHashMap getResult(String keywords) throws IOException {
25 //搜索的url
26 String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
27 //搜索词条的节点
28 String startNode = "";
29 //词条的链接关键字
30 String keyOfHref = "href=\"";
31 //词条的标题关键字
32 String keyOfTitle = "target=\"_blank\">";
33
34 String endNode = "";
35
36 boolean isNode = false;
37
38 String title;
39
40 String href;
41
42 String rLine;
43
44 LinkedHashMap keyMap = new LinkedHashMap();
45
46 //开始网络请求
47 URL url = new URL(keyUrl);
48 HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
49 InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
50 BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
51
52 //读取网页内容
53 while ((rLine = bufferedReader.readLine()) != null){
54 //判断目标节点是否出现
55 if(rLine.contains(startNode)){
56 isNode = true;
57 }
58 //若目标节点出现,则开始抓取数据
59 if (isNode){
60 //若目标结束节点出现,则结束读取,节省读取时间
61 if (rLine.contains(endNode)) {
62 //关闭读取流
63 bufferedReader.close();
64 inputStreamReader.close();
65 break;
66 }
67 //若值为空则不读取
68 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
69 keyMap.put(title,href);
70 }
71 }
72 }
73 return keyMap;
74 }
75
76 //获取词条对应的url
77 private static String getHref(String rLine,String keyOfHref){
78 String baikeUrl = "http://baike.baidu.com";
79 String result = "";
80 if(rLine.contains(keyOfHref)){
81 //获取url
82 for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
83 result += rLine.charAt(j);
84 }
85 //获取的url中可能不含baikeUrl,如果没有则在头部添加一个
86 if(!result.contains(baikeUrl)){
87 result = baikeUrl + result;
88 }
89 }
90 return result;
91 }
92
93 //获取词条对应的名称
94 private static String getName(String rLine,String keyOfTitle){
95 String result = "";
96 //获取标题内容
97 if(rLine.contains(keyOfTitle)){
98 result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
99 //将标题中的内容含有的标签去掉
100 result = result.replaceAll("||</a>|<a>","");
101 }
102 return result;
103 }
104
105 }
查看代码
现在都好晚了,去睡觉了... 查看全部
java抓取网页内容(代码罗View远程服务器,没事抓取网页信息的小工具
)
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,它让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
1 import java.io.BufferedReader;
2 import java.io.IOException;
3 import java.io.InputStreamReader;
4 import java.net.HttpURLConnection;
5 import java.net.URL;
6 import java.util.*;
7
8 /**
9 * Created by chunmiao on 17-3-10.
10 */
11 public class ReadBaiduSearch {
12
13 //储存返回结果
14 private LinkedHashMap mapOfBaike;
15
16
17 //获取搜索信息
18 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
19 mapOfBaike = getResult(infomationWords);
20 return mapOfBaike;
21 }
22
23 //通过网络链接获取信息
24 private static LinkedHashMap getResult(String keywords) throws IOException {
25 //搜索的url
26 String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
27 //搜索词条的节点
28 String startNode = "";
29 //词条的链接关键字
30 String keyOfHref = "href=\"";
31 //词条的标题关键字
32 String keyOfTitle = "target=\"_blank\">";
33
34 String endNode = "";
35
36 boolean isNode = false;
37
38 String title;
39
40 String href;
41
42 String rLine;
43
44 LinkedHashMap keyMap = new LinkedHashMap();
45
46 //开始网络请求
47 URL url = new URL(keyUrl);
48 HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
49 InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
50 BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
51
52 //读取网页内容
53 while ((rLine = bufferedReader.readLine()) != null){
54 //判断目标节点是否出现
55 if(rLine.contains(startNode)){
56 isNode = true;
57 }
58 //若目标节点出现,则开始抓取数据
59 if (isNode){
60 //若目标结束节点出现,则结束读取,节省读取时间
61 if (rLine.contains(endNode)) {
62 //关闭读取流
63 bufferedReader.close();
64 inputStreamReader.close();
65 break;
66 }
67 //若值为空则不读取
68 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
69 keyMap.put(title,href);
70 }
71 }
72 }
73 return keyMap;
74 }
75
76 //获取词条对应的url
77 private static String getHref(String rLine,String keyOfHref){
78 String baikeUrl = "http://baike.baidu.com";
79 String result = "";
80 if(rLine.contains(keyOfHref)){
81 //获取url
82 for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
83 result += rLine.charAt(j);
84 }
85 //获取的url中可能不含baikeUrl,如果没有则在头部添加一个
86 if(!result.contains(baikeUrl)){
87 result = baikeUrl + result;
88 }
89 }
90 return result;
91 }
92
93 //获取词条对应的名称
94 private static String getName(String rLine,String keyOfTitle){
95 String result = "";
96 //获取标题内容
97 if(rLine.contains(keyOfTitle)){
98 result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
99 //将标题中的内容含有的标签去掉
100 result = result.replaceAll("||</a>|<a>","");
101 }
102 return result;
103 }
104
105 }
查看代码
现在都好晚了,去睡觉了...
java抓取网页内容(这是一个利用pycharm简单爬虫分享的工作流程及使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-05 01:21
概述:
这是一个在phthon环境下使用pycharm的简单爬虫分享。主要通过爬取豆瓣音乐top250的标题和作者(专辑)来分析爬虫原理
什么是爬虫?
要学会爬行,我们首先要知道什么是爬虫。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
中文名
网络爬虫
外文名
网络爬虫
昵称
网络蜘蛛
目的
根据需要获取万维网信息
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。聚焦爬虫的工作流程更为复杂。需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
准备好工作了:
我们使用的是pycharm,请参考pycharm的安装和使用
使用工具:requests、lxml、xpath
关于requests的使用,可以看其官方文档:
个人认为用lxml解析网页是最快的。关于lxml的使用,可以阅读这个:
xpath 是一种用于在 xml 文档中查找信息的语言。xpath 可用于遍历 xml 文档中的元素和属性。xpath的使用可以参考他的教程:
话不多说,开始我们的爬虫之旅
首先找到我们的目标网址:
可以看到我们想要获取的歌曲的标题和作者(专辑)页面有十页,每页有十行。
所以我们可以使用for循环来获取目标:
然后使用 requests 请求一个网页:
import requests
headers = {"User_Agent": "Mozilla/5.0(compatible; MSIE 5.5; Windows 10)"}
data = requests.get(url, headers=headers).text
使用 lxml 解析网页:
from lxml import etree
s = etree.HTML(data)
然后我们就可以提取我们想要的数据了
最后,将获取到的数据保存在我们想要放置的地方。
至此,我们基本完成了,完整的代码如下:
然后我们来看看我们爬取的结果
总结:
爬虫过程:
1、发起请求 查看全部
java抓取网页内容(这是一个利用pycharm简单爬虫分享的工作流程及使用方法)
概述:
这是一个在phthon环境下使用pycharm的简单爬虫分享。主要通过爬取豆瓣音乐top250的标题和作者(专辑)来分析爬虫原理
什么是爬虫?
要学会爬行,我们首先要知道什么是爬虫。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
中文名
网络爬虫
外文名
网络爬虫
昵称
网络蜘蛛
目的
根据需要获取万维网信息
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。聚焦爬虫的工作流程更为复杂。需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
准备好工作了:
我们使用的是pycharm,请参考pycharm的安装和使用
使用工具:requests、lxml、xpath
关于requests的使用,可以看其官方文档:
个人认为用lxml解析网页是最快的。关于lxml的使用,可以阅读这个:
xpath 是一种用于在 xml 文档中查找信息的语言。xpath 可用于遍历 xml 文档中的元素和属性。xpath的使用可以参考他的教程:
话不多说,开始我们的爬虫之旅
首先找到我们的目标网址:
可以看到我们想要获取的歌曲的标题和作者(专辑)页面有十页,每页有十行。
所以我们可以使用for循环来获取目标:
然后使用 requests 请求一个网页:
import requests
headers = {"User_Agent": "Mozilla/5.0(compatible; MSIE 5.5; Windows 10)"}
data = requests.get(url, headers=headers).text
使用 lxml 解析网页:
from lxml import etree
s = etree.HTML(data)
然后我们就可以提取我们想要的数据了
最后,将获取到的数据保存在我们想要放置的地方。
至此,我们基本完成了,完整的代码如下:
然后我们来看看我们爬取的结果
总结:
爬虫过程:
1、发起请求
java抓取网页内容(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-03 18:27
原文链接:
有时因为各种原因。我们需要从某个站点采集数据。但是因为不同的站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据。(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您将能够看到网页上显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:
换句话说,我们只需要访问一个看起来像这样的 URL。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
<p>IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}</p>
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步方式。使用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后在网页中输入快递号:7。单击查询按钮,然后查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上面两张图可以看出。HTTP Analyzer 可以截取 JS 返回的数据并显示在 Response Content 中。同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是这些数据没有加密。我们记下JS请求的URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
<p>wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}</p>
看见。抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这能成为一个需要帮助的孩子,需要程序的源代码。点击这里下载! 查看全部
java抓取网页内容(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因。我们需要从某个站点采集数据。但是因为不同的站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据。(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您将能够看到网页上显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:
换句话说,我们只需要访问一个看起来像这样的 URL。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
<p>IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}</p>
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步方式。使用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后在网页中输入快递号:7。单击查询按钮,然后查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上面两张图可以看出。HTTP Analyzer 可以截取 JS 返回的数据并显示在 Response Content 中。同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是这些数据没有加密。我们记下JS请求的URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
<p>wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}</p>
看见。抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这能成为一个需要帮助的孩子,需要程序的源代码。点击这里下载!
java抓取网页内容(一个从网络上抓取数据的一个小程序-做个笔记 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-03 18:25
)
最近做了一个小程序,从网上抓取数据。主要是关于信用,一些黑名单网站采集,从网站抓取到我们自己的系统。
我也找到了一些资料,但我认为没有一个很好的和全面的例子。所以在这里做个笔记以提醒自己。
首先需要一个jsoup jar包,我用的是1.6.0。. 下载地址为:
1.获取网页内容(核心代码,技术有限,无封装)。
2.登录后,抓取网页数据(如何在请求中携带cookies)。
3、获取网站的ajax请求方法(返回json)。
上面三点我都会用一个class来收录(见谅,看的粗糙,直接复制代码就行了,应该可以的)
一、这个类分别有上面的1、2、3个方法,可以直接测试main方法
package com.minxinloan.black.web.utils;
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File; import java.io.FileOutputStream; import java.io.FileWriter; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.io.OutputStream; import java.io.PrintWriter; import java.net.HttpURLConnection; import java.net.URL; import java.net.URLConnection; import java.net.URLEncoder; import java.nio.charset.Charset; import java.util.ArrayList; import java.util.HashMap; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Map.Entry; import java.util.StringTokenizer; import net.sf.json.JSONArray; import net.sf.json.JSONObject; import org.jsoup.Connection; import org.jsoup.Connection.Method; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class CookieUtil { public final static String CONTENT_TYPE = "Content-Type"; public static void main(String[] args) { //String loginURL = "http://www.p2peye.com/member.p ... 3B%3B String listURL = "http://www.p2peye.com/blacklist.php?p=2"; String logURL = "http://www.p2peye.com/member.php"; //********************************需要登录的************************************************* try { Connection.Response res = Jsoup.connect(logURL) .data("mod","logging" ,"action","login" ,"loginsubmit","yes" ,"loginhash","Lsc66" ,"username","puqiuxiaomao" ,"password","a1234567") .method(Method.POST) .execute(); //这儿的SESSIONID需要根据要登录的目标网站设置的session Cookie名字而定 Connection con=Jsoup.connect(listURL); //设置访问形式(电脑访问,手机访问):直接百度都参数设置 con.header("User-Agent", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)"); //把登录信息的cookies保存如map对象里面 Map map=res.cookies(); Iterator it =map.entrySet().iterator(); while(it.hasNext()){ Entry en= it.next(); //把登录的信息放入请求里面 con =con.cookie(en.getKey(), en.getValue()); } //再次获取Document对象。 Document objectDoc = con.get(); Elements elements = objectDoc.getAllElements();//获取这个连接返回页面的源码内容(不是源码跟源码差不多) for (Element element : elements) { //element是迭代出来的标签:如: Elements elements2= element.getAllElements();// for (Element element2 : elements2) { element2.text(); element2.attr("href");//获取标签属性。element2代表a标签:href代表属性 element2.text();//获取标签文本 } } //********************************不需要登录的************************************************* String URL = "http://www.p2peye.com/blacklist.php?p=2"; Document conTemp = Jsoup.connect(URL).get(); Elements elementsTemps = conTemp.getAllElements(); for (Element elementsTemp : elementsTemps) { elementsTemp.text(); elementsTemp.attr("href");//获取标签属性。element2代表a标签:href代表属性 elementsTemp.text();//获取标签文本 } //********************************ajax方法获取内容。。。*************************************************。 HttpURLConnection connection = null; BufferedReader reader = null; try { StringBuffer sb = new StringBuffer(); URL getUrl = new URL(URL); connection = (HttpURLConnection)getUrl.openConnection(); reader = new BufferedReader(new InputStreamReader( connection.getInputStream(),"utf-8")); String lines; while ((lines = reader.readLine()) != null) { sb.append(lines); }; List list = parseJSON2List(sb.toString());//json转换成list } catch (Exception e) { } finally{ if(reader!=null) try { reader.close(); } catch (IOException e) { } // 断开连接 connection.disconnect(); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static Map parseJSON2Map(String jsonStr){ Map map = new HashMap(); //最外层解析 JSONObject json = JSONObject.fromObject(jsonStr); for(Object k : json.keySet()){ Object v = json.get(k); //如果内层还是数组的话,继续解析 if(v instanceof JSONArray){ List list = new ArrayList(); Iterator it = ((JSONArray)v).iterator(); while(it.hasNext()){ JSONObject json2 = it.next(); list.add(parseJSON2Map(json2.toString())); } map.put(k.toString(), list); } else { map.put(k.toString(), v); } } return map; } public static List parseJSON2List(String jsonStr){ JSONArray jsonArr = JSONArray.fromObject(jsonStr); List list = new ArrayList(); Iterator it = jsonArr.iterator(); while(it.hasNext()){ JSONObject json2 = it.next(); list.add(parseJSON2Map(json2.toString())); } return list; } }
二、这是获取验证码的类,大家可以研究一下。(但是要分析网站的验证码的请求地址)
package com.minxinloan.black.web.utils;
import java.io.BufferedReader;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream; import java.io.FileWriter; import java.io.InputStream; import java.io.InputStreamReader; import java.io.PrintWriter; import java.net.HttpURLConnection; import java.net.URL; import java.net.URLConnection; import java.nio.charset.Charset; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.StringTokenizer; public class Utils {//解析验证码的 public static Content getRandom(String method, String sUrl,// 要解析的url Map paramMap, // 存放用户名和密码的map Map requestHeaderMap,// 存放COOKIE的map boolean isOnlyReturnHeader, String path) { Content content = null; HttpURLConnection httpUrlConnection = null; InputStream in = null; try { URL url = new URL(sUrl); boolean isPost = "POST".equals(method); if (method == null || (!"GET".equalsIgnoreCase(method) && !"POST" .equalsIgnoreCase(method))) { method = "POST"; } URL resolvedURL = url; URLConnection urlConnection = resolvedURL.openConnection(); httpUrlConnection = (HttpURLConnection) urlConnection; httpUrlConnection.setRequestMethod(method); httpUrlConnection.setRequestProperty("Accept-Language", "zh-cn,zh;q=0.5"); // Do not follow redirects, We will handle redirects ourself httpUrlConnection.setInstanceFollowRedirects(false); httpUrlConnection.setDoOutput(true); httpUrlConnection.setDoInput(true); httpUrlConnection.setConnectTimeout(5000); httpUrlConnection.setReadTimeout(5000); httpUrlConnection.setUseCaches(false); httpUrlConnection.setDefaultUseCaches(false); httpUrlConnection.connect(); int responseCode = httpUrlConnection.getResponseCode(); if (responseCode == HttpURLConnection.HTTP_OK || responseCode == HttpURLConnection.HTTP_CREATED) { byte[] bytes = new byte[0]; if (!isOnlyReturnHeader) { DataInputStream ins = new DataInputStream( httpUrlConnection.getInputStream()); // 验证码的位置 DataOutputStream out = new DataOutputStream( new FileOutputStream(path + "/code.bmp")); byte[] buffer = new byte[4096]; int count = 0; while ((count = ins.read(buffer)) > 0) { out.write(buffer, 0, count); } out.close(); ins.close(); } String encoding = null; if (encoding == null) { encoding = getEncodingFromContentType(httpUrlConnection .getHeaderField("")); } content = new Content(sUrl, new String(bytes, encoding), httpUrlConnection.getHeaderFields()); } } catch (Exception e) { return null; } finally { if (httpUrlConnection != null) { httpUrlConnection.disconnect(); } } return content; } public static String getEncodingFromContentType(String contentType) { String encoding = null; if (contentType == null) { return null; } StringTokenizer tok = new StringTokenizer(contentType, ";"); if (tok.hasMoreTokens()) { tok.nextToken(); while (tok.hasMoreTokens()) { String assignment = tok.nextToken().trim(); int eqIdx = assignment.indexOf('='); if (eqIdx != -1) { String varName = assignment.substring(0, eqIdx).trim(); if ("charset".equalsIgnoreCase(varName)) { String varValue = assignment.substring(eqIdx + 1) .trim(); if (varValue.startsWith("\"") && varValue.endsWith("\"")) { // substring works on indices varValue = varValue.substring(1, varValue.length() - 1); } if (Charset.isSupported(varValue)) { encoding = varValue; } } } } } if (encoding == null) { return "UTF-8"; } return encoding; } // 这个是输出 public static boolean inFile(String content, String path) { PrintWriter out = null; File file = new File(path); try { if (!file.exists()) { file.createNewFile(); } out = new PrintWriter(new FileWriter(file)); out.write(content); out.flush(); return true; } catch (Exception e) { e.printStackTrace(); } finally { out.close(); } return false; } public static String getHtmlReadLine(String httpurl) { String CurrentLine = ""; String TotalString = ""; InputStream urlStream; String content = ""; try { URL url = new URL(httpurl); HttpURLConnection connection = (HttpURLConnection) url .openConnection(); connection.connect(); System.out.println(connection.getResponseCode()); urlStream = connection.getInputStream(); BufferedReader reader = new BufferedReader( new InputStreamReader(urlStream, "utf-8")); while ((CurrentLine = reader.readLine()) != null) { TotalString += CurrentLine + "\n"; } content = TotalString; } catch (Exception e) { } return content; } } class Content { private String url; private String body; private Map m_mHeaders = new HashMap(); public Content(String url, String body, Map headers) { this.url = url; this.body = body; this.m_mHeaders = headers; } public String getUrl() { return url; } public String getBody() { return body; } public Map getHeaders() { return m_mHeaders; } } 查看全部
java抓取网页内容(一个从网络上抓取数据的一个小程序-做个笔记
)
最近做了一个小程序,从网上抓取数据。主要是关于信用,一些黑名单网站采集,从网站抓取到我们自己的系统。
我也找到了一些资料,但我认为没有一个很好的和全面的例子。所以在这里做个笔记以提醒自己。
首先需要一个jsoup jar包,我用的是1.6.0。. 下载地址为:
1.获取网页内容(核心代码,技术有限,无封装)。
2.登录后,抓取网页数据(如何在请求中携带cookies)。
3、获取网站的ajax请求方法(返回json)。
上面三点我都会用一个class来收录(见谅,看的粗糙,直接复制代码就行了,应该可以的)
一、这个类分别有上面的1、2、3个方法,可以直接测试main方法
package com.minxinloan.black.web.utils;
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File; import java.io.FileOutputStream; import java.io.FileWriter; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.io.OutputStream; import java.io.PrintWriter; import java.net.HttpURLConnection; import java.net.URL; import java.net.URLConnection; import java.net.URLEncoder; import java.nio.charset.Charset; import java.util.ArrayList; import java.util.HashMap; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Map.Entry; import java.util.StringTokenizer; import net.sf.json.JSONArray; import net.sf.json.JSONObject; import org.jsoup.Connection; import org.jsoup.Connection.Method; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class CookieUtil { public final static String CONTENT_TYPE = "Content-Type"; public static void main(String[] args) { //String loginURL = "http://www.p2peye.com/member.p ... 3B%3B String listURL = "http://www.p2peye.com/blacklist.php?p=2"; String logURL = "http://www.p2peye.com/member.php"; //********************************需要登录的************************************************* try { Connection.Response res = Jsoup.connect(logURL) .data("mod","logging" ,"action","login" ,"loginsubmit","yes" ,"loginhash","Lsc66" ,"username","puqiuxiaomao" ,"password","a1234567") .method(Method.POST) .execute(); //这儿的SESSIONID需要根据要登录的目标网站设置的session Cookie名字而定 Connection con=Jsoup.connect(listURL); //设置访问形式(电脑访问,手机访问):直接百度都参数设置 con.header("User-Agent", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)"); //把登录信息的cookies保存如map对象里面 Map map=res.cookies(); Iterator it =map.entrySet().iterator(); while(it.hasNext()){ Entry en= it.next(); //把登录的信息放入请求里面 con =con.cookie(en.getKey(), en.getValue()); } //再次获取Document对象。 Document objectDoc = con.get(); Elements elements = objectDoc.getAllElements();//获取这个连接返回页面的源码内容(不是源码跟源码差不多) for (Element element : elements) { //element是迭代出来的标签:如: Elements elements2= element.getAllElements();// for (Element element2 : elements2) { element2.text(); element2.attr("href");//获取标签属性。element2代表a标签:href代表属性 element2.text();//获取标签文本 } } //********************************不需要登录的************************************************* String URL = "http://www.p2peye.com/blacklist.php?p=2"; Document conTemp = Jsoup.connect(URL).get(); Elements elementsTemps = conTemp.getAllElements(); for (Element elementsTemp : elementsTemps) { elementsTemp.text(); elementsTemp.attr("href");//获取标签属性。element2代表a标签:href代表属性 elementsTemp.text();//获取标签文本 } //********************************ajax方法获取内容。。。*************************************************。 HttpURLConnection connection = null; BufferedReader reader = null; try { StringBuffer sb = new StringBuffer(); URL getUrl = new URL(URL); connection = (HttpURLConnection)getUrl.openConnection(); reader = new BufferedReader(new InputStreamReader( connection.getInputStream(),"utf-8")); String lines; while ((lines = reader.readLine()) != null) { sb.append(lines); }; List list = parseJSON2List(sb.toString());//json转换成list } catch (Exception e) { } finally{ if(reader!=null) try { reader.close(); } catch (IOException e) { } // 断开连接 connection.disconnect(); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static Map parseJSON2Map(String jsonStr){ Map map = new HashMap(); //最外层解析 JSONObject json = JSONObject.fromObject(jsonStr); for(Object k : json.keySet()){ Object v = json.get(k); //如果内层还是数组的话,继续解析 if(v instanceof JSONArray){ List list = new ArrayList(); Iterator it = ((JSONArray)v).iterator(); while(it.hasNext()){ JSONObject json2 = it.next(); list.add(parseJSON2Map(json2.toString())); } map.put(k.toString(), list); } else { map.put(k.toString(), v); } } return map; } public static List parseJSON2List(String jsonStr){ JSONArray jsonArr = JSONArray.fromObject(jsonStr); List list = new ArrayList(); Iterator it = jsonArr.iterator(); while(it.hasNext()){ JSONObject json2 = it.next(); list.add(parseJSON2Map(json2.toString())); } return list; } }
二、这是获取验证码的类,大家可以研究一下。(但是要分析网站的验证码的请求地址)
package com.minxinloan.black.web.utils;
import java.io.BufferedReader;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream; import java.io.FileWriter; import java.io.InputStream; import java.io.InputStreamReader; import java.io.PrintWriter; import java.net.HttpURLConnection; import java.net.URL; import java.net.URLConnection; import java.nio.charset.Charset; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.StringTokenizer; public class Utils {//解析验证码的 public static Content getRandom(String method, String sUrl,// 要解析的url Map paramMap, // 存放用户名和密码的map Map requestHeaderMap,// 存放COOKIE的map boolean isOnlyReturnHeader, String path) { Content content = null; HttpURLConnection httpUrlConnection = null; InputStream in = null; try { URL url = new URL(sUrl); boolean isPost = "POST".equals(method); if (method == null || (!"GET".equalsIgnoreCase(method) && !"POST" .equalsIgnoreCase(method))) { method = "POST"; } URL resolvedURL = url; URLConnection urlConnection = resolvedURL.openConnection(); httpUrlConnection = (HttpURLConnection) urlConnection; httpUrlConnection.setRequestMethod(method); httpUrlConnection.setRequestProperty("Accept-Language", "zh-cn,zh;q=0.5"); // Do not follow redirects, We will handle redirects ourself httpUrlConnection.setInstanceFollowRedirects(false); httpUrlConnection.setDoOutput(true); httpUrlConnection.setDoInput(true); httpUrlConnection.setConnectTimeout(5000); httpUrlConnection.setReadTimeout(5000); httpUrlConnection.setUseCaches(false); httpUrlConnection.setDefaultUseCaches(false); httpUrlConnection.connect(); int responseCode = httpUrlConnection.getResponseCode(); if (responseCode == HttpURLConnection.HTTP_OK || responseCode == HttpURLConnection.HTTP_CREATED) { byte[] bytes = new byte[0]; if (!isOnlyReturnHeader) { DataInputStream ins = new DataInputStream( httpUrlConnection.getInputStream()); // 验证码的位置 DataOutputStream out = new DataOutputStream( new FileOutputStream(path + "/code.bmp")); byte[] buffer = new byte[4096]; int count = 0; while ((count = ins.read(buffer)) > 0) { out.write(buffer, 0, count); } out.close(); ins.close(); } String encoding = null; if (encoding == null) { encoding = getEncodingFromContentType(httpUrlConnection .getHeaderField("")); } content = new Content(sUrl, new String(bytes, encoding), httpUrlConnection.getHeaderFields()); } } catch (Exception e) { return null; } finally { if (httpUrlConnection != null) { httpUrlConnection.disconnect(); } } return content; } public static String getEncodingFromContentType(String contentType) { String encoding = null; if (contentType == null) { return null; } StringTokenizer tok = new StringTokenizer(contentType, ";"); if (tok.hasMoreTokens()) { tok.nextToken(); while (tok.hasMoreTokens()) { String assignment = tok.nextToken().trim(); int eqIdx = assignment.indexOf('='); if (eqIdx != -1) { String varName = assignment.substring(0, eqIdx).trim(); if ("charset".equalsIgnoreCase(varName)) { String varValue = assignment.substring(eqIdx + 1) .trim(); if (varValue.startsWith("\"") && varValue.endsWith("\"")) { // substring works on indices varValue = varValue.substring(1, varValue.length() - 1); } if (Charset.isSupported(varValue)) { encoding = varValue; } } } } } if (encoding == null) { return "UTF-8"; } return encoding; } // 这个是输出 public static boolean inFile(String content, String path) { PrintWriter out = null; File file = new File(path); try { if (!file.exists()) { file.createNewFile(); } out = new PrintWriter(new FileWriter(file)); out.write(content); out.flush(); return true; } catch (Exception e) { e.printStackTrace(); } finally { out.close(); } return false; } public static String getHtmlReadLine(String httpurl) { String CurrentLine = ""; String TotalString = ""; InputStream urlStream; String content = ""; try { URL url = new URL(httpurl); HttpURLConnection connection = (HttpURLConnection) url .openConnection(); connection.connect(); System.out.println(connection.getResponseCode()); urlStream = connection.getInputStream(); BufferedReader reader = new BufferedReader( new InputStreamReader(urlStream, "utf-8")); while ((CurrentLine = reader.readLine()) != null) { TotalString += CurrentLine + "\n"; } content = TotalString; } catch (Exception e) { } return content; } } class Content { private String url; private String body; private Map m_mHeaders = new HashMap(); public Content(String url, String body, Map headers) { this.url = url; this.body = body; this.m_mHeaders = headers; } public String getUrl() { return url; } public String getBody() { return body; } public Map getHeaders() { return m_mHeaders; } }
java抓取网页内容(有时匹配到的img值还会出现非图片url的情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-10-03 03:05
Java抓取简单的网页内容和图片
根据java网络编程相关的内容,可以使用jdk提供的相关类获取url对应的网页的html页面代码。
对于得到的html代码,我们可以通过正则表达式得到我们想要的内容。
例如,如果我们要获取网页上收录关键字“java”的所有文本内容,我们可以将网页代码逐行与正则表达式匹配。最后达到去除html标签和无关内容的效果,只得到收录关键字“java”的内容。
从网页中抓取图片的过程与抓取内容的过程基本相同,但抓取图片的过程会多一步。
需要使用img标签的正则表达式匹配获取img标签,然后使用src属性的正则表达式获取img标签中src属性的图片url,然后读取img标签的图片url图片url通过缓存的输入流对象信息,配合文件输出流,将读取到的图片信息写入本地。
除了这两种玩法外,爬虫还有很多应用,比如爬取一个网页上的所有邮箱、电话号码等等。
运行结果:
这些内容是基于csdn主页的关键字“你”。
这些是我从一些网站那里得到的照片
问题:
看似没有问题的爬取代码背后其实有很多问题。该程序只是爬虫的一级应用。例如,我发现浏览器的“检查”功能中明明存在部分html内容,但网页源代码中却没有相关内容。文本匹配的正则表达式部分也存在问题。
在img src属性中,有些图片的url没有协议(如:),有些图片的url没有图片后缀(jpg、png、gif...)。前者导致程序无法解析url,后者导致下载图片的原创命名无法统一采用。
有时匹配的 img src 值将显示为非图像 url。有时从页面获取的内容是 unicode 编码的值。还有一些网站做了反爬虫处理等...
由于本人对java知识、web知识、网络知识和常规知识了解甚少,目前无法解决上述问题。
这些问题导致实际上从网页爬下来的内容只是原创网页的一小部分。
相信这些问题在未来会一一解决。
另外,我在程序中使用了多线程功能,实现了“同时”抓取多个网页的效果。
该程序的源代码如下。
编译环境:
windows jdk 9 的想法
代码:
//Main.java 主类
package
//DownloadPictures.java 爬取图片类
package
//GetTest.java 抓取文本内容类
package
----
程序还有很多问题,还请见谅。 查看全部
java抓取网页内容(有时匹配到的img值还会出现非图片url的情况)
Java抓取简单的网页内容和图片
根据java网络编程相关的内容,可以使用jdk提供的相关类获取url对应的网页的html页面代码。
对于得到的html代码,我们可以通过正则表达式得到我们想要的内容。
例如,如果我们要获取网页上收录关键字“java”的所有文本内容,我们可以将网页代码逐行与正则表达式匹配。最后达到去除html标签和无关内容的效果,只得到收录关键字“java”的内容。
从网页中抓取图片的过程与抓取内容的过程基本相同,但抓取图片的过程会多一步。
需要使用img标签的正则表达式匹配获取img标签,然后使用src属性的正则表达式获取img标签中src属性的图片url,然后读取img标签的图片url图片url通过缓存的输入流对象信息,配合文件输出流,将读取到的图片信息写入本地。
除了这两种玩法外,爬虫还有很多应用,比如爬取一个网页上的所有邮箱、电话号码等等。
运行结果:
这些内容是基于csdn主页的关键字“你”。
这些是我从一些网站那里得到的照片
问题:
看似没有问题的爬取代码背后其实有很多问题。该程序只是爬虫的一级应用。例如,我发现浏览器的“检查”功能中明明存在部分html内容,但网页源代码中却没有相关内容。文本匹配的正则表达式部分也存在问题。
在img src属性中,有些图片的url没有协议(如:),有些图片的url没有图片后缀(jpg、png、gif...)。前者导致程序无法解析url,后者导致下载图片的原创命名无法统一采用。
有时匹配的 img src 值将显示为非图像 url。有时从页面获取的内容是 unicode 编码的值。还有一些网站做了反爬虫处理等...
由于本人对java知识、web知识、网络知识和常规知识了解甚少,目前无法解决上述问题。
这些问题导致实际上从网页爬下来的内容只是原创网页的一小部分。
相信这些问题在未来会一一解决。
另外,我在程序中使用了多线程功能,实现了“同时”抓取多个网页的效果。
该程序的源代码如下。
编译环境:
windows jdk 9 的想法
代码:
//Main.java 主类
package
//DownloadPictures.java 爬取图片类
package
//GetTest.java 抓取文本内容类
package
----
程序还有很多问题,还请见谅。

