
chrome 插件 抓取网页qq聊天记录
5个可以直接下载Chrome插件的网站,真香
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-05-07 17:10
02. 扩展迷
资源丰富,同时还提供了日榜单、周榜单、月榜单和总榜单等数据排行,帮助大家发现最新有趣的插件。另外,注意截图中红色部分,看我发现了什么?
03.Chrome插件网
更新速度非常快,而且还提供了许多非常有用的教程文章,比如:五种百度云盘下载速度慢解决方法……
04. 插件网
老牌的chrome插件搬运网站,提供了插件分类、插件推荐、插件百科、插件排行等四大板块,里面也有许多非常有意思的总结性文章,比如:chrome比价插件哪个更好用?亲自测试使用总结 Chrome插件。
05. 我爱chrome插件网
有是一个非常棒的chrome插件下载网站,提供64位离线版下载服务,直接点击即可下载! 查看全部
5个可以直接下载Chrome插件的网站,真香
02. 扩展迷
资源丰富,同时还提供了日榜单、周榜单、月榜单和总榜单等数据排行,帮助大家发现最新有趣的插件。另外,注意截图中红色部分,看我发现了什么?
03.Chrome插件网
更新速度非常快,而且还提供了许多非常有用的教程文章,比如:五种百度云盘下载速度慢解决方法……
04. 插件网
老牌的chrome插件搬运网站,提供了插件分类、插件推荐、插件百科、插件排行等四大板块,里面也有许多非常有意思的总结性文章,比如:chrome比价插件哪个更好用?亲自测试使用总结 Chrome插件。
05. 我爱chrome插件网
有是一个非常棒的chrome插件下载网站,提供64位离线版下载服务,直接点击即可下载!
超实用的 Chrome 插件,保存网页中喜欢的图片
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-05-07 17:02
1. 要开发的是什么项目?
1.1 想法开端
在 pixiv 翻图时看到一些喜欢的插画,看完就随手翻过去了,没有保存。为什么呢? 因为以我对自己的了解,图片下载下来,就相当于放进了垃圾桶。 并不是因为本地的文件管理有多乱,而是因为,几乎没有用鼠标打开文件管理器的习惯。
现在我获取信息的流量入口最常用的只有两个,即终端和浏览器。于是乎,一个想法油然而生:
“
把插画存到浏览器吧!
于是就立刻构思,动手写了这款插件。
1.2 应该有什么功能?
功能很简单:
2. 开发需要解决的核心问题
“
核心问题有两个,一个是数据云存储问题,一个是图片防盗链问题。
云存储问题,帐号系统,多端同步
最开始只想做浏览器本地的存储,使用 Chrome 提供的 localStorage 存在本地就。后来因为 localStorage 并不支持数据库语法查询,有很多不便。使用过程中又发现多端同步在体验上的优越性,决定要把存储放到云上。
图片防盗链问题
看了些资料,解决方式基本可以分为两种。
一类使用前端 js 嵌入 iframe 解决,优点是解决方式简单,问题是 Chrome 插件不支持页面嵌入式的 js 脚本。所以这个方案 pass。
第二类使用后台服务器做反防盗链措施,作为中转给前端使用。优点是不受 chrome 插件的各种安全机制的限制,缺点是需要后台支持,增加工作量和资源成本。使用第二类完成。
3. 具体解决方案
“
云存储及帐号系统使用 LeanCloud 提供的存储服务解决。
反防盗链接口使用 LeanCloud 提供的云引擎搭建 NodJs 后台。
啰嗦一句,为什么要使用 LeanCloud?
一是对我的需求可以做到完全免费,二是它们的文档实在是太xx的好用了。
3.1 帐号系统
参照:数据存储入门教程 · JavaScript
实现过程基本照抄这个教程的代码。后台账号系统包括对账号的重复检测、密码加密、session 等都已经实现。
“
我们要做的,就是调用前端的这几个关键方法,实现简单的注册、登陆、退出:
3.2 存储服务
“
使用账号系统为每个用户添加身份信息后,存储部分就只需要把数据+用户身份信息一同上传或下载就可以了。
照样只贴关键方法:
3.3 使用 LeanEngine 做反防盗链中转接口
要实现的效果是:
“
主要原理很简单,后台处理图片请求时更改 header 中的 referer 字段,将结果作为 response 返回。
关于这部分的实现,欢迎阅读我的另一篇文章,就不再赘述:
服务器作防盗链图片中转,nodejs 上手项目简明教程。
关于 LeanEngin 的使用,文档如下,使用方法非常简单。
云引擎快速入门:
云引擎支持 NodeJSPythonPHPJAVA
只需要下载云引擎命令行工具 lean,然后输入几行命令就可以建立一个你熟悉的 web 框架。然后,使用你熟悉的语言编写反防盗链实现就行了。
3.4 Chrome 插件实现
“
有了 3.1~3.3 的实现,这部分就是简单的插件部署和业务逻辑了。
Chrome 插件结构如图:
主要业务:
具体实现见我的 github 项目:插件 Web Store 地址:
4. 最后,对去后端化的看法
前段时间在知乎上看到了一个问题,我也顺便说下自己的看法。
“
web 后端会不会变得越来越不需要?
像 bmob 和 leancloud 这类后台云服务的流行有一段日子了,使用这些服务使一些 web、app 的开发周期大大缩减。这对于小团队和初创公司尤为方便。
但这并不意味着不再需要自己开发后台。不是因为他们提供的服务不够全面(相反,我倒认为这类服务将向着全面、便捷、快速发展),而是因为很多公司和产品,为了保持服务的质量和稳定,突出自己产品的特性,需要自己定制自己的后台,有针对性的去优化某些模块。云服务作为大众服务平台难以为每个产品做定制。
类似于游戏引擎,如今各个平台都不缺乏优秀的游戏引擎。可是仍有公司和团队耗费大量的成本自研游戏引擎,就是希望能配合自己的游戏系统,完美地展现自己的游戏。
一样的,后台云服务和自定制的后台,是相交但永远不会重合的关系。 他们彼此之间相互影响,共同进步。
原文链接:
end
更多内容请关注「LeanCloud通讯」
查看全部
超实用的 Chrome 插件,保存网页中喜欢的图片
1. 要开发的是什么项目?
1.1 想法开端
在 pixiv 翻图时看到一些喜欢的插画,看完就随手翻过去了,没有保存。为什么呢? 因为以我对自己的了解,图片下载下来,就相当于放进了垃圾桶。 并不是因为本地的文件管理有多乱,而是因为,几乎没有用鼠标打开文件管理器的习惯。
现在我获取信息的流量入口最常用的只有两个,即终端和浏览器。于是乎,一个想法油然而生:
“
把插画存到浏览器吧!
于是就立刻构思,动手写了这款插件。
1.2 应该有什么功能?
功能很简单:
2. 开发需要解决的核心问题
“
核心问题有两个,一个是数据云存储问题,一个是图片防盗链问题。
云存储问题,帐号系统,多端同步
最开始只想做浏览器本地的存储,使用 Chrome 提供的 localStorage 存在本地就。后来因为 localStorage 并不支持数据库语法查询,有很多不便。使用过程中又发现多端同步在体验上的优越性,决定要把存储放到云上。
图片防盗链问题
看了些资料,解决方式基本可以分为两种。
一类使用前端 js 嵌入 iframe 解决,优点是解决方式简单,问题是 Chrome 插件不支持页面嵌入式的 js 脚本。所以这个方案 pass。
第二类使用后台服务器做反防盗链措施,作为中转给前端使用。优点是不受 chrome 插件的各种安全机制的限制,缺点是需要后台支持,增加工作量和资源成本。使用第二类完成。
3. 具体解决方案
“
云存储及帐号系统使用 LeanCloud 提供的存储服务解决。
反防盗链接口使用 LeanCloud 提供的云引擎搭建 NodJs 后台。
啰嗦一句,为什么要使用 LeanCloud?
一是对我的需求可以做到完全免费,二是它们的文档实在是太xx的好用了。
3.1 帐号系统
参照:数据存储入门教程 · JavaScript
实现过程基本照抄这个教程的代码。后台账号系统包括对账号的重复检测、密码加密、session 等都已经实现。
“
我们要做的,就是调用前端的这几个关键方法,实现简单的注册、登陆、退出:
3.2 存储服务
“
使用账号系统为每个用户添加身份信息后,存储部分就只需要把数据+用户身份信息一同上传或下载就可以了。
照样只贴关键方法:
3.3 使用 LeanEngine 做反防盗链中转接口
要实现的效果是:
“
主要原理很简单,后台处理图片请求时更改 header 中的 referer 字段,将结果作为 response 返回。
关于这部分的实现,欢迎阅读我的另一篇文章,就不再赘述:
服务器作防盗链图片中转,nodejs 上手项目简明教程。
关于 LeanEngin 的使用,文档如下,使用方法非常简单。
云引擎快速入门:
云引擎支持 NodeJSPythonPHPJAVA
只需要下载云引擎命令行工具 lean,然后输入几行命令就可以建立一个你熟悉的 web 框架。然后,使用你熟悉的语言编写反防盗链实现就行了。
3.4 Chrome 插件实现
“
有了 3.1~3.3 的实现,这部分就是简单的插件部署和业务逻辑了。
Chrome 插件结构如图:
主要业务:
具体实现见我的 github 项目:插件 Web Store 地址:
4. 最后,对去后端化的看法
前段时间在知乎上看到了一个问题,我也顺便说下自己的看法。
“
web 后端会不会变得越来越不需要?
像 bmob 和 leancloud 这类后台云服务的流行有一段日子了,使用这些服务使一些 web、app 的开发周期大大缩减。这对于小团队和初创公司尤为方便。
但这并不意味着不再需要自己开发后台。不是因为他们提供的服务不够全面(相反,我倒认为这类服务将向着全面、便捷、快速发展),而是因为很多公司和产品,为了保持服务的质量和稳定,突出自己产品的特性,需要自己定制自己的后台,有针对性的去优化某些模块。云服务作为大众服务平台难以为每个产品做定制。
类似于游戏引擎,如今各个平台都不缺乏优秀的游戏引擎。可是仍有公司和团队耗费大量的成本自研游戏引擎,就是希望能配合自己的游戏系统,完美地展现自己的游戏。
一样的,后台云服务和自定制的后台,是相交但永远不会重合的关系。 他们彼此之间相互影响,共同进步。
原文链接:
end
更多内容请关注「LeanCloud通讯」
Chrome浏览器最强插件配置网站--开眼见世界
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-05-04 20:02
Chrome浏览器最强插件配置网站--开眼见世界一、前言
公众号交流群里面很多小伙伴问过我如何没有限制的科学访问国外学术网站,我之前推荐过集装箱,但是很多小伙伴都觉得不稳定,于是我又推荐了Ghelper助手,可惜并没有很多人看到,我也不想再去找其他的,所以我直接找到一个国内即可访问的Chrome插件网站,市面上所有你想要的插件以及热门插件里面都有,当然,也有大家想要用来开眼看世界的插件,具体安装教程和其他插件没有区别,大家按照之前我写的教程访问即可!
image-207783
image-203960
PS:该网站里面的插件我也测试过,确定有大家所需的,百分百能开眼看世界!因为怕网址放到文章中会被封,所以大家公众号内回复:世界 ,即可获取该网站的网址。
记住!假如一个插件不行你就换另外一个!一个服务器不行你就换其他国家的服务器,直到找到你能用的为止!
这里是你我的灿烂人生,觉得教程对你有用的话,可以关注、点赞、转发三连支持一波!
二、具体使用教程
因为怕网址放到文章中会被封,所以大家公众号内回复:世界 ,即可获取该网站的网址。打开如下所示:
image-248870
这是一个英文网址,其中排在前列的免费插件,都可以用来开眼看世界学术,都是可以免费下载并使用的,这里我选择其中一个我之前没有介绍过的作为测试:
我们点击刚刚上一张图片最下方所示的蓝色链接字体:download 进入到下载界面:
image-226354
这里我们选择从Crx4Chrome蓝色字体下载:
image-210137
这里会自动弹出下载界面,我们选择保存即可!然后我们在Chrome浏览器下方选择在文件夹中打开:
image-246635
记住格式必须是Crx文件!!!
image-221793
我们到浏览器界面安装Crx插件即可!具体过程不多表述,和之前集装箱教程差不多,不记得的同学点开之前文章回顾即可!
image-230946
直接把文件拖过去安装即可!
image-227954
image-253867
image-203429
将其固定到插件访问页面(不记得的请自行百度或者看集装箱那篇文章)
image-204666
点一下插件,进来后我们先选择语言:
image-215093
创建账户我就不多说了。
image-258617
注册然后登陆成功后会弹出如下界面,可以保存一下Auth-Code。
image-253712
任选其一即可!
image-227025
点击一个地方的服务器等待加载完成,一个地方不行就换另外一个!
image-253872
成功后提示如下:
image-252609
2021年3月21日下午19点半实测能访问Youtube。
image-212162三、总结
最后总结一下,该网站各类访问特殊地址以及各类Chrome插件都有,大家可以收藏这个网址,假如某个插件失效,你可以下载同类型插件替换即可!记住,所有的插件都有同类型的,可以自行替换,按照上述教程安装即可!
这里是你我的灿烂人生,觉得教程对你有用的话,可以关注、点赞、转发三连支持一波!
- END - 查看全部
Chrome浏览器最强插件配置网站--开眼见世界
Chrome浏览器最强插件配置网站--开眼见世界一、前言
公众号交流群里面很多小伙伴问过我如何没有限制的科学访问国外学术网站,我之前推荐过集装箱,但是很多小伙伴都觉得不稳定,于是我又推荐了Ghelper助手,可惜并没有很多人看到,我也不想再去找其他的,所以我直接找到一个国内即可访问的Chrome插件网站,市面上所有你想要的插件以及热门插件里面都有,当然,也有大家想要用来开眼看世界的插件,具体安装教程和其他插件没有区别,大家按照之前我写的教程访问即可!
image-207783
image-203960
PS:该网站里面的插件我也测试过,确定有大家所需的,百分百能开眼看世界!因为怕网址放到文章中会被封,所以大家公众号内回复:世界 ,即可获取该网站的网址。
记住!假如一个插件不行你就换另外一个!一个服务器不行你就换其他国家的服务器,直到找到你能用的为止!
这里是你我的灿烂人生,觉得教程对你有用的话,可以关注、点赞、转发三连支持一波!
二、具体使用教程
因为怕网址放到文章中会被封,所以大家公众号内回复:世界 ,即可获取该网站的网址。打开如下所示:
image-248870
这是一个英文网址,其中排在前列的免费插件,都可以用来开眼看世界学术,都是可以免费下载并使用的,这里我选择其中一个我之前没有介绍过的作为测试:
我们点击刚刚上一张图片最下方所示的蓝色链接字体:download 进入到下载界面:
image-226354
这里我们选择从Crx4Chrome蓝色字体下载:
image-210137
这里会自动弹出下载界面,我们选择保存即可!然后我们在Chrome浏览器下方选择在文件夹中打开:
image-246635
记住格式必须是Crx文件!!!
image-221793
我们到浏览器界面安装Crx插件即可!具体过程不多表述,和之前集装箱教程差不多,不记得的同学点开之前文章回顾即可!
image-230946
直接把文件拖过去安装即可!
image-227954
image-253867
image-203429
将其固定到插件访问页面(不记得的请自行百度或者看集装箱那篇文章)
image-204666
点一下插件,进来后我们先选择语言:
image-215093
创建账户我就不多说了。
image-258617
注册然后登陆成功后会弹出如下界面,可以保存一下Auth-Code。
image-253712
任选其一即可!
image-227025
点击一个地方的服务器等待加载完成,一个地方不行就换另外一个!
image-253872
成功后提示如下:
image-252609
2021年3月21日下午19点半实测能访问Youtube。
image-212162三、总结
最后总结一下,该网站各类访问特殊地址以及各类Chrome插件都有,大家可以收藏这个网址,假如某个插件失效,你可以下载同类型插件替换即可!记住,所有的插件都有同类型的,可以自行替换,按照上述教程安装即可!
这里是你我的灿烂人生,觉得教程对你有用的话,可以关注、点赞、转发三连支持一波!
- END -
不用在朋友圈学 Python,这款 Chrome 插件就能帮你完成网页抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-05-04 20:01
不知大家是否总能在朋友圈看到类似的广告,「加班完成的 Excel 用 Python 只需 3 分钟」、「每天都能准点下班只因学会了 Python」,似乎 Python 已经成为了当代年轻人的必备技能。
▲朋友圈广告的确,作为一门易于上手的编程语言,Python在自动化办公中用处巨大,特别是对于网页数据的爬取,在这样一个大数据时代显得尤为重要。爬取网页数据,也可以称为「网络爬虫」 ,能帮助我们快速搜集互联网的海量内容,从而进行深度的数据分析与挖掘。比如抓取各大网站的排行榜、抓取各大购物网站的价格信息等。而我们日常用的搜索引擎就是一个个「网络爬虫」。
但毕竟学习一门语言的成本太高了,有什么办法可以不学 Python 也能达到目的呢?当然有,借助 Chrome 浏览器的《Web Scraper》插件,让你在不用写代码的情况下,就能快速抓取海量内容。
优采云目录
抓取页面中的多条信息——BiliBili 排行榜为例安装《Web Scraper》后,在浏览器按 F12 进入开发者模式,就能在最后一个标签页看到《Web Scraper》的菜单。需要注意的是,如果开发者模式面板不在下方,则会提示必须将其放到浏览器下方才能继续。
在菜单中选择「Create new sitemap - Create sitemap」以创建新的 sitemap,填入名称与起始地址就可以开始了。这里以 BiliBili 排行榜为例,介绍如何抓取页面中的多条信息,起始地址设为「」。
这里我们需要抓取「视频标题」、「播放量」、「弹幕数」、「up 主」以及「综合得分」,因此首先为每一条记录创建一个封装器。点击「Add new selector」,id 填写「封装器」, type 选择「element」,然后点击「selector」,选择一条记录的外边框,外包框中需要包含上述所有信息,然后再选择第二条,这样就会发现页面中的所有记录都已自动选择,点击「Done selecting」完成数据的选择。还要记得勾选「Multiple」以保证抓取多条记录,最后保存该选择器即可。
返回后点击刚才的封装器,进入二级路径,创建「标题」选择器,id 填写「视频标题」,type 选择「text」,点击「selector」会发现第一条记录高亮显示,这是因为我们已提前将其设定为了封装器。选择包围框中的标题,再点击「Done selecting」完成标题的选择,注意这里不需要勾选「Multiple」,最后保存该选择器。
同样的,我们为「播放量」、「弹幕数」、「up 主」和「综合得分」分别建立选择器,选择后可以通过「Data preview」预览是否选中了想要的内容。另外还可以通过菜单栏中的「Sitemap bilibili_ranking - Selector graph」 直观地查看树状结构。
继续在刚才的菜单下选择「Scrape」开始创建抓取任务,单个网页的间隔时间和响应时间默认即可。点击「Start scraping」开始抓取。这时候浏览器会自动打开新的页面,停留数秒后自动关闭,代表抓取已完成。
点击「Refresh Data」刷新数据,或点击「Sitemap bilibili_ranking - Browse」查看数据。通过「Sitemap bilibili_ranking - Export data as CSV」即可下载为 CSV 格式文件。
▲BiliBili 排行榜使用 Excel 打开,由于《Web Scraper》抓取的内容是无序的,因此需要对「综合得分」进行降序排列,以恢复原始排行榜的结果。
自动翻页抓取——豆瓣电影 Top250 为例
Bilibili 排行榜只有 100 条记录,并且都在一个网页中,那么如果有分页显示的情况该怎么办呢?这里以豆瓣电影 Top250 为例介绍自动翻页抓取。同样的,新建 sitemap,在填写起始地址前,我们先观察一下豆瓣电影 Top250 的构成,总共有 250 条记录,每页显示 10 条,共分为 25 页。
而每一页的网址都非常有规律,第一页的地址为「」,第二页仅仅是把地址中的「start=0」改为了「start=25」,因此我们填写起始地址时便可以填写「[0-250:25]&filter=」,这里 start=[0-250:25] 表示 以 25 的步长从 0 取到 250,因此 start 分别为 0、25、50 等等。这样《Web Scraper》就会按顺序一页一页抓取数据了。
接下来类似于 BiliBili 排行榜,创建「封装器」后再添加「电影名」、「豆瓣评分」、「电影短评」以及「豆瓣排名」选择器就行了,然后开始抓取。
可以看到浏览器会一页一页地进行翻页抓取,这里只需要安静地等待抓取完毕即可,最后得到的数据以「豆瓣排名」进行升序排序,就能获得豆瓣电影 Top250 的榜单了。
▲豆瓣电影 Top250当然,这只是一种最简单的分页方法,而许多网站地址并不一定有着类似的规律,因此《Web Scraper》还有更多的方法能用来分页,但相对较为复杂,在此也不再赘述了。
抓取二级页面内容——知乎热榜为例
以上完成了对网页的单页以及多页内容的抓取,但不是每次都有着现成的数据摆在一个页面中,因此还需要更进一步地对二级页面进行搜寻。以知乎热榜为例,介绍如何对二级页面的「关注量」和「浏览量」进行抓取。首先,新建 sitemap,起始地址为「」。然后像前面一样创建「封装器」,再创建「文章标题」、「文章热度」、「知乎排名」这三个选择器。
接下来是重要步骤,创建一个「二级页面」的链接。点击「Add new selector」,id 填写「二级页面」, type 选择「link」,然后点击「selector」,选择文章的标题,即每篇文章的入口,确认选择后保存退出。
这样就相当于有了一个窗口,点击刚才创建的「二级页面」,进入下一级目录,然后像之前创建「文章标题」一样创建「关注量」与「浏览量」两个选择器。最后整个树状结构如下图所示。
点击「Sitemap zhihu_hot - Scrape」开始抓取,这里可以将「Page load delay」响应时间调大一些,确保网页完全加载完毕。这时候浏览器会依次打开每个二级页面进行抓取,因此需要等待一会儿。抓取任务完成后将结果下载为 CSV 文件,按「知乎排名」降序排列,即可获得整个知乎热榜的榜单。
▲知乎热榜至此,介绍了如何使用《Web Scraper》抓取页面中多条信息、自动翻页抓取以及抓取二级页面内容。很显然《Web Scraper》的功能远不止这些,还有更多强大的功能比如图片抓取、正则表达式等等可自行摸索。另外,如果只是想要简单地抓取信息,可以尝试使用其它插件如《Simple scraper》《Instant Data Scraper》,这些插件甚至可以一键抓取,但相比《Web Scraper》,功能的丰富度还是欠缺不少的。
不用学 Python,也不用花钱让别人帮你,使用《Web Scraper》自己就能完成网页抓取,或许下一个准时下班的就是你?
糖纸众测第 31 期「iWALK 战神吃鸡蓝牙耳机」,这是一款「为游戏而生」的耳机,低延迟,7.1立体音效,听声辨位,强力续航,畅玩各大类型游戏;
不需要写报告哦~只要你每天按时上传众测动态,就可以轻松 0 元带回家~
✨ 名额有限,赶紧来参加吧
注:微信视频号仍在内测,部分用户暂未开放
喜欢你就点个
查看全部
不用在朋友圈学 Python,这款 Chrome 插件就能帮你完成网页抓取
不知大家是否总能在朋友圈看到类似的广告,「加班完成的 Excel 用 Python 只需 3 分钟」、「每天都能准点下班只因学会了 Python」,似乎 Python 已经成为了当代年轻人的必备技能。
▲朋友圈广告的确,作为一门易于上手的编程语言,Python在自动化办公中用处巨大,特别是对于网页数据的爬取,在这样一个大数据时代显得尤为重要。爬取网页数据,也可以称为「网络爬虫」 ,能帮助我们快速搜集互联网的海量内容,从而进行深度的数据分析与挖掘。比如抓取各大网站的排行榜、抓取各大购物网站的价格信息等。而我们日常用的搜索引擎就是一个个「网络爬虫」。
但毕竟学习一门语言的成本太高了,有什么办法可以不学 Python 也能达到目的呢?当然有,借助 Chrome 浏览器的《Web Scraper》插件,让你在不用写代码的情况下,就能快速抓取海量内容。
优采云目录
抓取页面中的多条信息——BiliBili 排行榜为例安装《Web Scraper》后,在浏览器按 F12 进入开发者模式,就能在最后一个标签页看到《Web Scraper》的菜单。需要注意的是,如果开发者模式面板不在下方,则会提示必须将其放到浏览器下方才能继续。
在菜单中选择「Create new sitemap - Create sitemap」以创建新的 sitemap,填入名称与起始地址就可以开始了。这里以 BiliBili 排行榜为例,介绍如何抓取页面中的多条信息,起始地址设为「」。
这里我们需要抓取「视频标题」、「播放量」、「弹幕数」、「up 主」以及「综合得分」,因此首先为每一条记录创建一个封装器。点击「Add new selector」,id 填写「封装器」, type 选择「element」,然后点击「selector」,选择一条记录的外边框,外包框中需要包含上述所有信息,然后再选择第二条,这样就会发现页面中的所有记录都已自动选择,点击「Done selecting」完成数据的选择。还要记得勾选「Multiple」以保证抓取多条记录,最后保存该选择器即可。
返回后点击刚才的封装器,进入二级路径,创建「标题」选择器,id 填写「视频标题」,type 选择「text」,点击「selector」会发现第一条记录高亮显示,这是因为我们已提前将其设定为了封装器。选择包围框中的标题,再点击「Done selecting」完成标题的选择,注意这里不需要勾选「Multiple」,最后保存该选择器。
同样的,我们为「播放量」、「弹幕数」、「up 主」和「综合得分」分别建立选择器,选择后可以通过「Data preview」预览是否选中了想要的内容。另外还可以通过菜单栏中的「Sitemap bilibili_ranking - Selector graph」 直观地查看树状结构。
继续在刚才的菜单下选择「Scrape」开始创建抓取任务,单个网页的间隔时间和响应时间默认即可。点击「Start scraping」开始抓取。这时候浏览器会自动打开新的页面,停留数秒后自动关闭,代表抓取已完成。
点击「Refresh Data」刷新数据,或点击「Sitemap bilibili_ranking - Browse」查看数据。通过「Sitemap bilibili_ranking - Export data as CSV」即可下载为 CSV 格式文件。
▲BiliBili 排行榜使用 Excel 打开,由于《Web Scraper》抓取的内容是无序的,因此需要对「综合得分」进行降序排列,以恢复原始排行榜的结果。
自动翻页抓取——豆瓣电影 Top250 为例
Bilibili 排行榜只有 100 条记录,并且都在一个网页中,那么如果有分页显示的情况该怎么办呢?这里以豆瓣电影 Top250 为例介绍自动翻页抓取。同样的,新建 sitemap,在填写起始地址前,我们先观察一下豆瓣电影 Top250 的构成,总共有 250 条记录,每页显示 10 条,共分为 25 页。
而每一页的网址都非常有规律,第一页的地址为「」,第二页仅仅是把地址中的「start=0」改为了「start=25」,因此我们填写起始地址时便可以填写「[0-250:25]&filter=」,这里 start=[0-250:25] 表示 以 25 的步长从 0 取到 250,因此 start 分别为 0、25、50 等等。这样《Web Scraper》就会按顺序一页一页抓取数据了。
接下来类似于 BiliBili 排行榜,创建「封装器」后再添加「电影名」、「豆瓣评分」、「电影短评」以及「豆瓣排名」选择器就行了,然后开始抓取。
可以看到浏览器会一页一页地进行翻页抓取,这里只需要安静地等待抓取完毕即可,最后得到的数据以「豆瓣排名」进行升序排序,就能获得豆瓣电影 Top250 的榜单了。
▲豆瓣电影 Top250当然,这只是一种最简单的分页方法,而许多网站地址并不一定有着类似的规律,因此《Web Scraper》还有更多的方法能用来分页,但相对较为复杂,在此也不再赘述了。
抓取二级页面内容——知乎热榜为例
以上完成了对网页的单页以及多页内容的抓取,但不是每次都有着现成的数据摆在一个页面中,因此还需要更进一步地对二级页面进行搜寻。以知乎热榜为例,介绍如何对二级页面的「关注量」和「浏览量」进行抓取。首先,新建 sitemap,起始地址为「」。然后像前面一样创建「封装器」,再创建「文章标题」、「文章热度」、「知乎排名」这三个选择器。
接下来是重要步骤,创建一个「二级页面」的链接。点击「Add new selector」,id 填写「二级页面」, type 选择「link」,然后点击「selector」,选择文章的标题,即每篇文章的入口,确认选择后保存退出。
这样就相当于有了一个窗口,点击刚才创建的「二级页面」,进入下一级目录,然后像之前创建「文章标题」一样创建「关注量」与「浏览量」两个选择器。最后整个树状结构如下图所示。
点击「Sitemap zhihu_hot - Scrape」开始抓取,这里可以将「Page load delay」响应时间调大一些,确保网页完全加载完毕。这时候浏览器会依次打开每个二级页面进行抓取,因此需要等待一会儿。抓取任务完成后将结果下载为 CSV 文件,按「知乎排名」降序排列,即可获得整个知乎热榜的榜单。
▲知乎热榜至此,介绍了如何使用《Web Scraper》抓取页面中多条信息、自动翻页抓取以及抓取二级页面内容。很显然《Web Scraper》的功能远不止这些,还有更多强大的功能比如图片抓取、正则表达式等等可自行摸索。另外,如果只是想要简单地抓取信息,可以尝试使用其它插件如《Simple scraper》《Instant Data Scraper》,这些插件甚至可以一键抓取,但相比《Web Scraper》,功能的丰富度还是欠缺不少的。
不用学 Python,也不用花钱让别人帮你,使用《Web Scraper》自己就能完成网页抓取,或许下一个准时下班的就是你?
糖纸众测第 31 期「iWALK 战神吃鸡蓝牙耳机」,这是一款「为游戏而生」的耳机,低延迟,7.1立体音效,听声辨位,强力续航,畅玩各大类型游戏;
不需要写报告哦~只要你每天按时上传众测动态,就可以轻松 0 元带回家~
✨ 名额有限,赶紧来参加吧
注:微信视频号仍在内测,部分用户暂未开放
喜欢你就点个
Chrome 插件 | 帮你记住看过的网页,想要的东西马上找到
网站优化 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2022-05-04 19:05
你是不是也跟我一样遇到过这样的情况:隐约记得自己看过某个网页,只能想起文中的几个关键词,但是在历史记录中搜索却毫无踪迹,因为这些关键词根本就没有在标题中出现。现在 AppSo(微信号 appsolution)给你推荐一个救星:WorldBrain。有了这款 Chrome 插件,仅需在地址栏输入几个关键词,我们就可以对之前访问过的所有网站进行全文检索,快速定位。基础玩法在安装完毕 WorldBrain 插件之后,我们就通过一张动图来快速了解一下 WorldBrain 最基础的用法。
其实操作很简单,就是通过在地址栏输入 W + 空格键/Tab 键来激活 WorldBrain 搜索,然后输入想搜索的关键字,任何网页内容匹配关键字的网页都会出现在候选列表中。值得一提的是,我们曾经访问的 PDF 文件也会在搜索的范围内,并且 WorldBrain 的搜索结果前方会有一个大脑的图标作为标识。要进行这样的全文检索肯定需要在本地缓存网页数据,那么我们可能就会担心两个问题:
我们的数据是否安全?
数据会不会非常占用我们的磁盘空间?
那么首先,第一个问题,答案是:是的,你的数据非常安全。因为 WorldBrain 承诺,除非我们本人允许,我们的所有数据都会被保留在本地,不会上传云端服务器,所以我们可以放心。其次,第二个问题,答案是:并不会。因为 WorldBrain 只会存储网站的纯文本部分。要知道即使纯文本文件有几十万字,也只会占据几兆的磁盘容量,所以不必太过纠结。高级玩法1. 导入书签和历史记录在安装 WorldBrain 之后访问的网站肯定是没有在本地进行数据保存的,但是我们也不必手动将之前的网站一个一个打开。因为 WorldBrain 提供了「书签和历史记录导入」功能。
2. 过滤语法除了最基本的搜索语法之外,WorldBrain 还提供了更加高级的语法:「时间过滤语法」与「关键词过滤语法」,使得结果更加有针对性。唯一遗憾的就是,这些语法暂时还不支持中文(支持中文作为检索内容)。
首先,「时间过滤语法」顾名思义,就是可以将特定时间内的搜索结果过滤出来的语法。语法结构非常简单,让我们来举个例子:"out there" appso before: "yesterday at 5pm"。这段文字的意思就是:搜索昨天下午 5 点钟之前浏览的包含「appso」与「out there」关键词的网页。还可以尝试其他时间表达方式:"yesterday at 5pm", "three weeks ago", 3/26/2016。注:「out there」这种搜索方法代表完全匹配搜索,也就是说搜索结果返回的页面包含双引号中出现的所有的词,连顺序也必须完全匹配。
其次,就是「关键词过滤语法」,同样也是顾名思义,就是将包含特定关键词的网页都排除在搜索结果之外。语法结构同样非常简单。「appso -"有用功"」的意思就是:搜索所有包含「appso」但是不包含「有用功」的网页。只需在要排除的关键词前加 -(减号)即可。3. 网页屏蔽AppSo(微信号 appsolution)提醒,WorldBrain 还内置了一个「黑名单」系统,允许我们将那些不希望被包括在搜索结果内的网站排除。默认包含了一些登陆与 Paypal 页面,以保证个人敏感数据的安全。
近期更新计划1. 网页应用内搜索在目前,WorldBrain 无法搜索到网页应用的内容,如 Evernote、Pocket 等等,这在实用性上大打折扣,不过还好,作者表示该功能马上就会到来。
2. 可视化搜索界面目前的搜索仅仅只能在地址栏进行,我们可能看到的搜索结果也只是一些网页的网址和标题。虽然这样比较方便快捷,但是我们对于更加丰富搜索结果的需求也是真实存在的,作者承诺将在近期加入。
未来愿景1. 社交搜索 Social Searching在将来,我们可以直接关注某些特定领域的名人或者网站,并且可以将它们分组,当我们需要搜索的该领域的知识、信息时,结果可以更加有针对性。可以说这就是一个带「关注」特性的 Google。
2. 高质量内容 Quality Content在将来,WorldBrain 将增加批注、评论、分享等等功能,并且综合我们在网站上的种种行为为网站进行打分,当然我们也直接手动为一个网站来修改评分。
作者预期,经过这样的行为分析以及用户手动调节,我们可以通过网页的评分来判断网页内容的质量,从而决定是否阅读。
但是,我认为如果真的有这个评分机制,并且 WorldBrain 如果火爆的话,只会催生出一条新的产业链吧。
3. 相关内容 Related ContentWorldBrain 将允许我们将笔记进行共享,那么在未来,我们浏览网页时,可能可以看到其他人在网页上的评论。说白了可能是一个第三方的评论系统。
以上的种种看起来还是比较美好的,但是如果没有限制并且放任不管的话,可能会是一场灾难,最终用户无法得到他们想要看到的,并且还可能干扰正常的网页浏览体验。如果这一系列的动作可以建立在社交网络之上,那么情况可能会有所不同,因为我们看到的一切内容都来自我们的关注者,那么内容筛选方面实际上用户自己就完成了,会让 WorldBrain 的未来更加美好。AppSo(微信号 appsolution)觉得,不妨,也留一点期待。
下载链接:本文由让手机更好用的 AppSo 原创出品,关注微信号 appsolution,回复「cj666」获取不搭梯也能下 Chrome 插件的方法,以及更多 Chrome 插件推荐。
来啊,湿身啊。
查看全部
Chrome 插件 | 帮你记住看过的网页,想要的东西马上找到
你是不是也跟我一样遇到过这样的情况:隐约记得自己看过某个网页,只能想起文中的几个关键词,但是在历史记录中搜索却毫无踪迹,因为这些关键词根本就没有在标题中出现。现在 AppSo(微信号 appsolution)给你推荐一个救星:WorldBrain。有了这款 Chrome 插件,仅需在地址栏输入几个关键词,我们就可以对之前访问过的所有网站进行全文检索,快速定位。基础玩法在安装完毕 WorldBrain 插件之后,我们就通过一张动图来快速了解一下 WorldBrain 最基础的用法。
其实操作很简单,就是通过在地址栏输入 W + 空格键/Tab 键来激活 WorldBrain 搜索,然后输入想搜索的关键字,任何网页内容匹配关键字的网页都会出现在候选列表中。值得一提的是,我们曾经访问的 PDF 文件也会在搜索的范围内,并且 WorldBrain 的搜索结果前方会有一个大脑的图标作为标识。要进行这样的全文检索肯定需要在本地缓存网页数据,那么我们可能就会担心两个问题:
我们的数据是否安全?
数据会不会非常占用我们的磁盘空间?
那么首先,第一个问题,答案是:是的,你的数据非常安全。因为 WorldBrain 承诺,除非我们本人允许,我们的所有数据都会被保留在本地,不会上传云端服务器,所以我们可以放心。其次,第二个问题,答案是:并不会。因为 WorldBrain 只会存储网站的纯文本部分。要知道即使纯文本文件有几十万字,也只会占据几兆的磁盘容量,所以不必太过纠结。高级玩法1. 导入书签和历史记录在安装 WorldBrain 之后访问的网站肯定是没有在本地进行数据保存的,但是我们也不必手动将之前的网站一个一个打开。因为 WorldBrain 提供了「书签和历史记录导入」功能。
2. 过滤语法除了最基本的搜索语法之外,WorldBrain 还提供了更加高级的语法:「时间过滤语法」与「关键词过滤语法」,使得结果更加有针对性。唯一遗憾的就是,这些语法暂时还不支持中文(支持中文作为检索内容)。
首先,「时间过滤语法」顾名思义,就是可以将特定时间内的搜索结果过滤出来的语法。语法结构非常简单,让我们来举个例子:"out there" appso before: "yesterday at 5pm"。这段文字的意思就是:搜索昨天下午 5 点钟之前浏览的包含「appso」与「out there」关键词的网页。还可以尝试其他时间表达方式:"yesterday at 5pm", "three weeks ago", 3/26/2016。注:「out there」这种搜索方法代表完全匹配搜索,也就是说搜索结果返回的页面包含双引号中出现的所有的词,连顺序也必须完全匹配。
其次,就是「关键词过滤语法」,同样也是顾名思义,就是将包含特定关键词的网页都排除在搜索结果之外。语法结构同样非常简单。「appso -"有用功"」的意思就是:搜索所有包含「appso」但是不包含「有用功」的网页。只需在要排除的关键词前加 -(减号)即可。3. 网页屏蔽AppSo(微信号 appsolution)提醒,WorldBrain 还内置了一个「黑名单」系统,允许我们将那些不希望被包括在搜索结果内的网站排除。默认包含了一些登陆与 Paypal 页面,以保证个人敏感数据的安全。
近期更新计划1. 网页应用内搜索在目前,WorldBrain 无法搜索到网页应用的内容,如 Evernote、Pocket 等等,这在实用性上大打折扣,不过还好,作者表示该功能马上就会到来。
2. 可视化搜索界面目前的搜索仅仅只能在地址栏进行,我们可能看到的搜索结果也只是一些网页的网址和标题。虽然这样比较方便快捷,但是我们对于更加丰富搜索结果的需求也是真实存在的,作者承诺将在近期加入。
未来愿景1. 社交搜索 Social Searching在将来,我们可以直接关注某些特定领域的名人或者网站,并且可以将它们分组,当我们需要搜索的该领域的知识、信息时,结果可以更加有针对性。可以说这就是一个带「关注」特性的 Google。
2. 高质量内容 Quality Content在将来,WorldBrain 将增加批注、评论、分享等等功能,并且综合我们在网站上的种种行为为网站进行打分,当然我们也直接手动为一个网站来修改评分。
作者预期,经过这样的行为分析以及用户手动调节,我们可以通过网页的评分来判断网页内容的质量,从而决定是否阅读。
但是,我认为如果真的有这个评分机制,并且 WorldBrain 如果火爆的话,只会催生出一条新的产业链吧。
3. 相关内容 Related ContentWorldBrain 将允许我们将笔记进行共享,那么在未来,我们浏览网页时,可能可以看到其他人在网页上的评论。说白了可能是一个第三方的评论系统。
以上的种种看起来还是比较美好的,但是如果没有限制并且放任不管的话,可能会是一场灾难,最终用户无法得到他们想要看到的,并且还可能干扰正常的网页浏览体验。如果这一系列的动作可以建立在社交网络之上,那么情况可能会有所不同,因为我们看到的一切内容都来自我们的关注者,那么内容筛选方面实际上用户自己就完成了,会让 WorldBrain 的未来更加美好。AppSo(微信号 appsolution)觉得,不妨,也留一点期待。
下载链接:本文由让手机更好用的 AppSo 原创出品,关注微信号 appsolution,回复「cj666」获取不搭梯也能下 Chrome 插件的方法,以及更多 Chrome 插件推荐。
来啊,湿身啊。
如何高效在网页上做笔记?Chrome插件推荐Roam
网站优化 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2022-05-04 19:05
当你发现一篇很好的文章,你会怎么做呢?不管是收藏链接到书签还是剪藏到印象笔记等软件中都不是一个最好的办法。我的建议是你像读一本书一样去做“读书笔记”,把内容中对自己有价值的观点和知识进行高亮提取,并对提取出来的内容使用自己的语言进行转述,从而达到内化的效果。接下来我将给你推荐一款非常好用的网页高亮标注Chrome插件:Roam-highlighter。
Roam-highlighter的主要的功能是可以快速的提取网页中选取的文字,并识别文字的层级。
正如名字中带有Roam,它是支持快速添加Roam类软件中[[关键词]]语法的。非常棒的功能。
我整理了你常用的快捷键:
[ALT + X]:激活插件窗口/关闭插件窗口
[Ctrl + X]:高亮选取文字
[Alt + Click]:取消高亮
[ALT + Q]:取消页面所有高亮
[Double-Click] :在高亮文字上选取关键词后双击,关键词添加[[]],成为Roam类软件中新页面的语法
[ALT + Z] :功能与[Double-Click]相同
如果你觉得我的文章对你有帮助,请关注分享评论。你的鼓励是我做出更多更好内容的巨大动力。我将在各个平台同步更新。演示视频请移步视频平台搜索格物新知。
查看全部
如何高效在网页上做笔记?Chrome插件推荐Roam
当你发现一篇很好的文章,你会怎么做呢?不管是收藏链接到书签还是剪藏到印象笔记等软件中都不是一个最好的办法。我的建议是你像读一本书一样去做“读书笔记”,把内容中对自己有价值的观点和知识进行高亮提取,并对提取出来的内容使用自己的语言进行转述,从而达到内化的效果。接下来我将给你推荐一款非常好用的网页高亮标注Chrome插件:Roam-highlighter。
Roam-highlighter的主要的功能是可以快速的提取网页中选取的文字,并识别文字的层级。
正如名字中带有Roam,它是支持快速添加Roam类软件中[[关键词]]语法的。非常棒的功能。
我整理了你常用的快捷键:
[ALT + X]:激活插件窗口/关闭插件窗口
[Ctrl + X]:高亮选取文字
[Alt + Click]:取消高亮
[ALT + Q]:取消页面所有高亮
[Double-Click] :在高亮文字上选取关键词后双击,关键词添加[[]],成为Roam类软件中新页面的语法
[ALT + Z] :功能与[Double-Click]相同
如果你觉得我的文章对你有帮助,请关注分享评论。你的鼓励是我做出更多更好内容的巨大动力。我将在各个平台同步更新。演示视频请移步视频平台搜索格物新知。
chrome 插件 抓取网页qq聊天记录( 这是简易数据分析系列的第1个原因是怎样的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-04-20 21:14
这是简易数据分析系列的第1个原因是怎样的?
)
这是简易数据分析系列文章 的第 1 部分。
为什么叫简单数据分析?
第一个原因是本教程面向纯新手用户,不写代码或公式,迈出数据分析的第一步。
第二个原因,生活中很多数据分析场景都是非常轻量级的,不需要Python爬虫、高并发架构、机器学习等重武器,一个浏览器加一个Excel就够了:
比如某门课程投稿后才几天,急需快速爬取数据进行数据分析。这时候现场学习Python爬虫知识的时间还不够;
做一些市场调研和运营工作需要采集数据,如果技术部门支持,流程周期太长,还是自己做比较好;
跳槽,想了解市场的技能要求和薪资分布,需要采集数据,分析市场需求;
…
这些都是生活中会遇到的问题。面对这些少量数据(100~10000))的分析需求,对于非互联网技术人员来说,学习一些编程知识并不划算。我们还不如利用手头的东西. 最常用的工具,Excel 和浏览器,用于分析和整理数据,以帮助思考和更好的决策。
这也是本教程的目的——用20%的精力解决80%的数据分析需求,解放个人生产力。
本教程将在三个主要方向进行扩展:数据采集、数据清洗和数据可视化。
数据采集是利用爬虫软件从网上爬取想要的数据,然后存储到本地;
数据清洗是对采集到的数据进行格式化,方便后续分析;
数据可视化是利用各种分析方法对数据进行不同维度的解读,并以图表的直观形式表达出来,更好地辅助我们决策;
从下一篇文章文章开始,我们学习如何采集从互联网上获取数据。
这是简易数据分析系列文章 的第二部分。
上一篇文章讲了数据分析在生活中的重要性。从这篇文章中,我们将进入实际的分析内容。数据分析,数据分析,没有数据怎么分析?所以我们首先要学习采集data。
研究了很多采集数据软件,综合评测后发现最好的是Web Scraper,它是一个Chrome浏览器插件。
推荐理由如下:
1.门槛够低,只要电脑上安装了Chrome浏览器就可以使用
2.永久免费,无付费功能,无需注册
3.操作简单,鼠标点几下就可以爬取网页,0行代码写一个真正意义上的爬虫
既然这么棒,当然是立马安装了。
由于 Web Scraper 是 Chrome 浏览器插件,我当然是第一个使用 Chrome 的人。
不过受限于国内网络环境,访问Chrome插件应用商店可能不是很方便。如果第一种方式不行,我们可以试试第二种方式,使用浏览器曲线救国(360浏览器暂时不提供Web Scraper插件)。
两个浏览器内核是一样的,只是界面不同。我的后续教程将基于 Chrome 浏览器。浏览器可能略有不同。如有差异,读者需自行区分。
1. 在 Chrome 浏览器上安装 Web Scraper 插件
1.1 安装 Chrome 浏览器
这个没什么好说的,Windows电脑的各大应用商店都有最新版的Chrome浏览器,或者百度,首页一般都有安装包地址,下载安装即可;
(为减少兼容性问题,最好安装最新版本的Chrome浏览器)
1.2 安装 Web Scraper 插件
可以访问外网的同学,直接访问“Chrome Web Store”,搜索Web Scraper下载安装:
暂时无条件接入外网,我们可以手动安装外挂曲线救国,当然会比上面的麻烦一点:
首先我们访问这个国产浏览器插件网站,搜索Web Scraper,下载插件。注意此时插件不是直接安装在浏览器上,而是下载到本地:
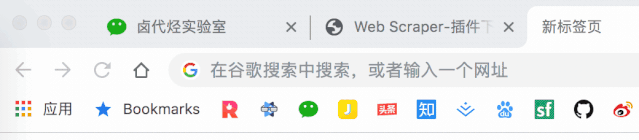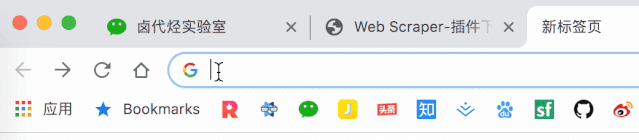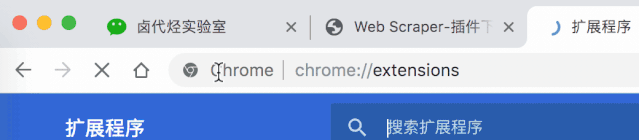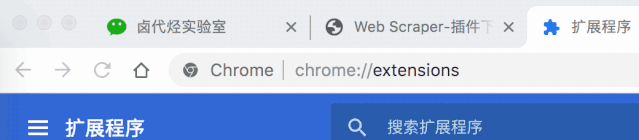
然后,我们在浏览器的URL输入框中输入chrome://extensions/,这样就可以打开浏览器的插件管理后台了:
下一步是解压缩并安装刚刚下载的插件。
如果您是 Mac 用户,请先将安装包的后缀从 .crx 更改为 .zip。
然后切换到浏览器的插件管理后台,打开右上角的开发者模式,把Web Scraper.zip文件拖进去,就安装好了。
一般这个安装会出现一个红色的错误按钮,我们不管,直接忽略即可。
如果你是 windows 用户,你需要这样做:
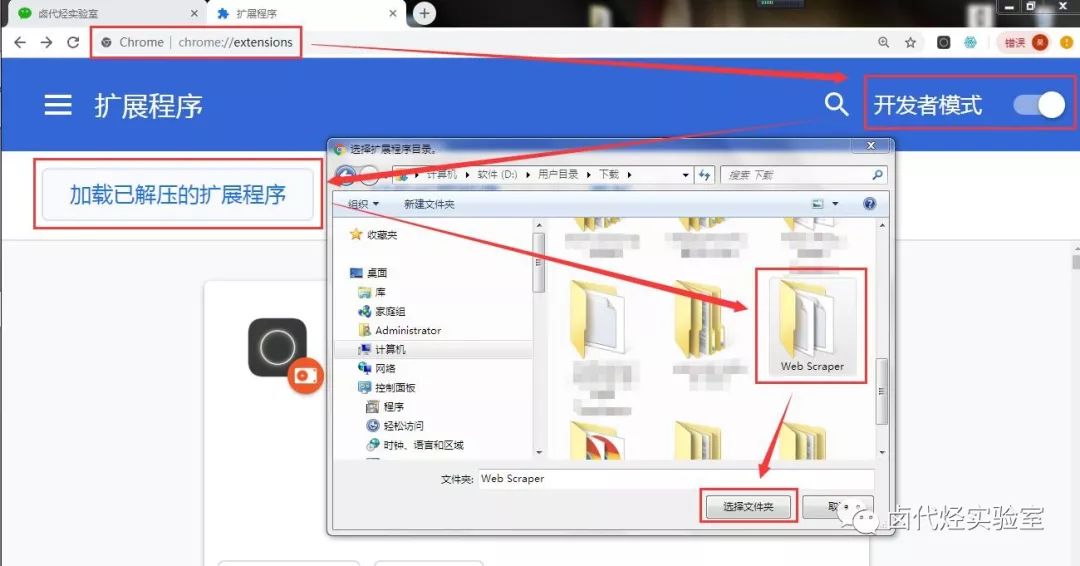
1.把.crx后缀的插件改成.rar,然后解压
2.进入 chrome://extensions/ 页面,开启开发者模式
3.点击“加载解压扩展”,选择第一步解压后的文件夹,正常情况下安装成功。
至此,我们的Chrome浏览器已经成功安装了Web Scraper插件。
2.在浏览器上安装 Web Scraper 插件
2.1 安装浏览器
前往各大应用商店或访问网站下载安装。
浏览器PC版官网下载地址:
浏览器Mac版官网下载地址:
2.2 安装 Web Scraper 插件
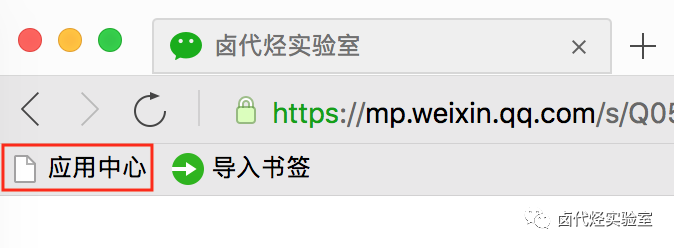
Mac用户可以直接访问浏览器左上角的“应用中心”,点击进入并搜索Web Scraper进行安装。
Windows用户首先点击浏览器左上角的≡菜单栏,在弹出的菜单栏中选择“应用中心”,点击进入并搜索Web Scraper进行安装。
至此,我们的Web Scraper插件已经安装成功。在下一篇文章中,我们将探索一些浏览器操作,为我们后续的学习打下良好的基础。
这是简易数据分析系列的第三部分文章。
我们在上面安装了 Web Scraper 插件。我相信这对大多数人来说非常简单。在这个文章中,我们会讲一些不一样的东西,讲一下浏览器中那些大多数人都不知道的东西。低俗的操作。
作为普通用户,每个人都使用浏览器来查看信息和浏览网页。但在开发者眼中,Chrome浏览器提供了非常强大的开发能力。
通过本文章的学习,可以掌握一些浏览器开发的小知识(相信我,一点都不难),方便我们后续学习Web Scraper插件。
下面开始正文。
1 打开开发者后台
这个功能其实在我之前的文章《造谣的成本到底有多低?一行代码就可以截图造假了》。如前所述,如果你想从普通浏览模式切换到开发者模式,你只需要按 F12(浏览器 F12 被禁用)。
Mac电脑也可以用option+command+I打开,Win电脑可以用Ctrl+Shift+I打开。
2 一行代码自由伪造截图
这也是一篇老文章《谣言成本有多低?一行代码可以截图,造假内容。很多朋友都表示已经操作成功了,有兴趣的同学可以了解一下。
3 切换开发者后台的位置
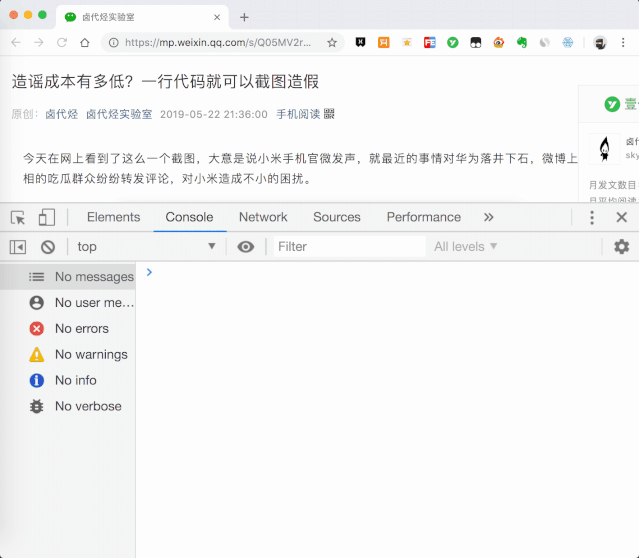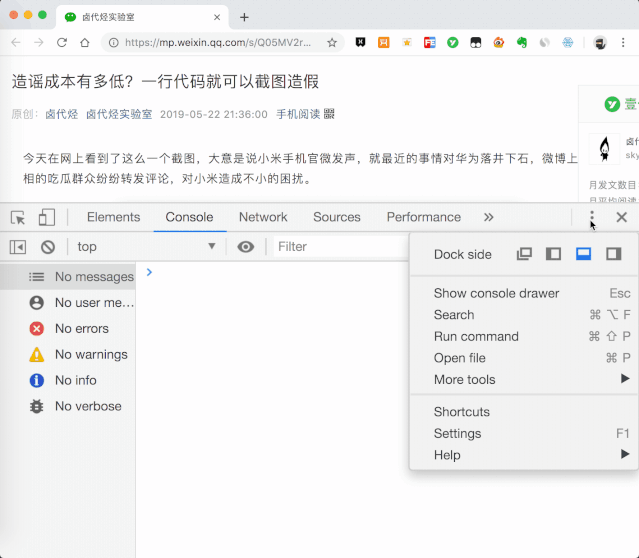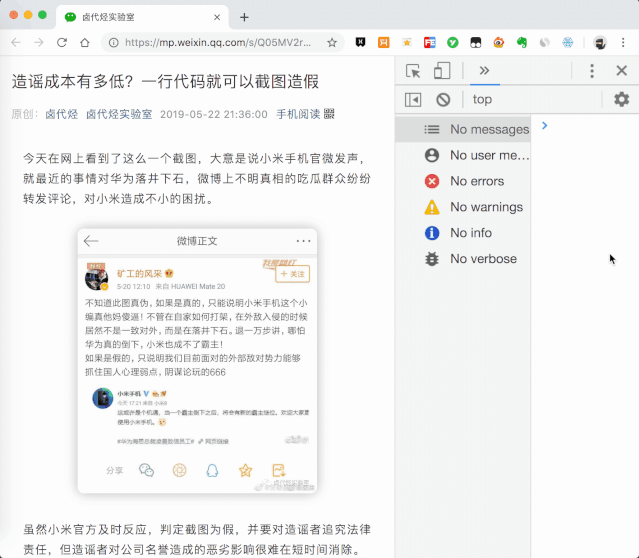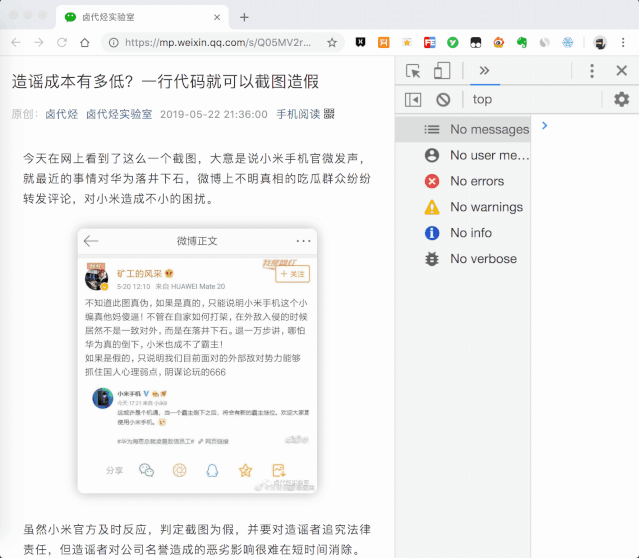
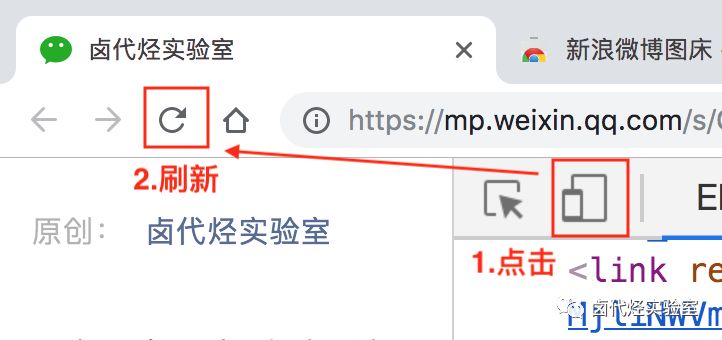
控制台打开后,通常显示在网页底部。其实我们也可以切换到网页右侧进行显示。具体操作是点击后台面板右侧的⋮按钮,然后修改显示位置。具体操作如下。
4 使用电脑浏览器模拟手机浏览器
使用电脑浏览器模拟手机浏览器是一个非常有用的功能。因为现在是移动互联网时代,公司的大部分网页都是先支持移动端的,而且移动端浏览器的数据结构更加清晰,更有利于我们抓数据。
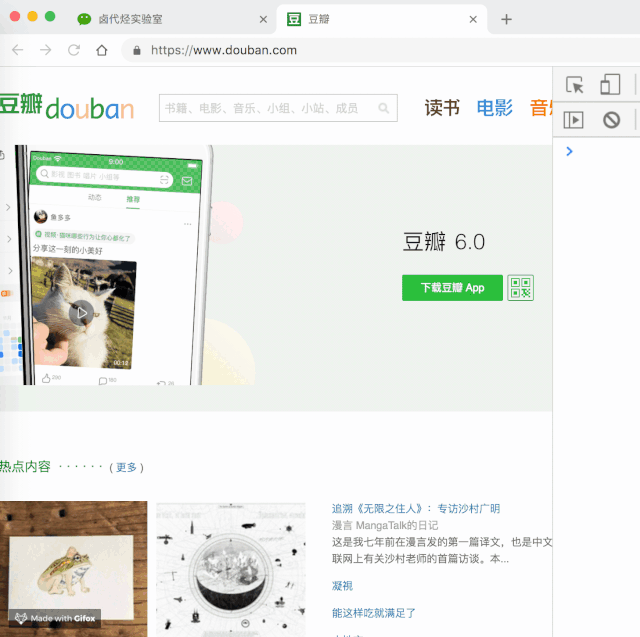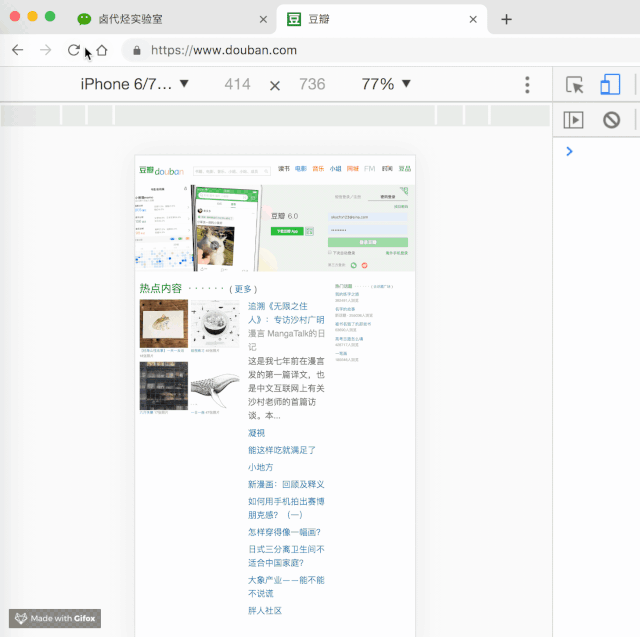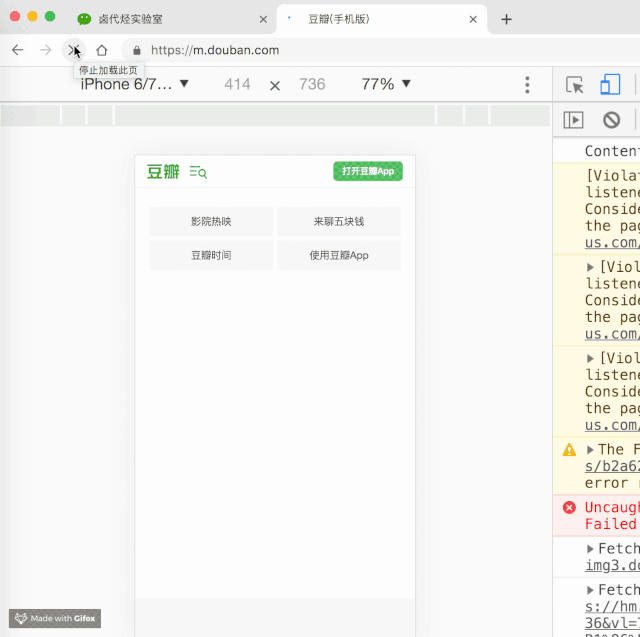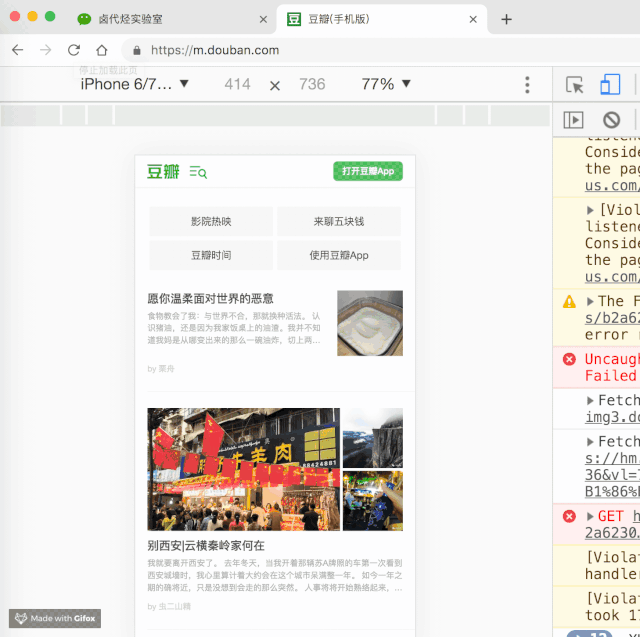
开启模拟手机也很简单,只需点击开发者后台左侧的手机切换图标,然后刷新即可。
我们可以用豆瓣网站来证明这一点。
当然,我们也可以用这个功能做其他事情,比如上班时开小屏偷偷刷微博。被老板抓到的时候别说我教过你。
好了,这就是今天的准备工作。下一期,我们将学习如何使用 Web Scraper 抓取网页数据。
●深入理解Web协议(一):HTTP包体传输
●JavaScript测试系列实战(四):掌握React Hooks测试技巧
●打开React Hooks 动画和实战(一):useState 和useEffect
·结尾·
图克社区
采集精彩的免费实用教程
查看全部
chrome 插件 抓取网页qq聊天记录(
这是简易数据分析系列的第1个原因是怎样的?
)

这是简易数据分析系列文章 的第 1 部分。
为什么叫简单数据分析?
第一个原因是本教程面向纯新手用户,不写代码或公式,迈出数据分析的第一步。
第二个原因,生活中很多数据分析场景都是非常轻量级的,不需要Python爬虫、高并发架构、机器学习等重武器,一个浏览器加一个Excel就够了:
比如某门课程投稿后才几天,急需快速爬取数据进行数据分析。这时候现场学习Python爬虫知识的时间还不够;
做一些市场调研和运营工作需要采集数据,如果技术部门支持,流程周期太长,还是自己做比较好;
跳槽,想了解市场的技能要求和薪资分布,需要采集数据,分析市场需求;
…
这些都是生活中会遇到的问题。面对这些少量数据(100~10000))的分析需求,对于非互联网技术人员来说,学习一些编程知识并不划算。我们还不如利用手头的东西. 最常用的工具,Excel 和浏览器,用于分析和整理数据,以帮助思考和更好的决策。
这也是本教程的目的——用20%的精力解决80%的数据分析需求,解放个人生产力。
本教程将在三个主要方向进行扩展:数据采集、数据清洗和数据可视化。

数据采集是利用爬虫软件从网上爬取想要的数据,然后存储到本地;
数据清洗是对采集到的数据进行格式化,方便后续分析;
数据可视化是利用各种分析方法对数据进行不同维度的解读,并以图表的直观形式表达出来,更好地辅助我们决策;
从下一篇文章文章开始,我们学习如何采集从互联网上获取数据。

这是简易数据分析系列文章 的第二部分。
上一篇文章讲了数据分析在生活中的重要性。从这篇文章中,我们将进入实际的分析内容。数据分析,数据分析,没有数据怎么分析?所以我们首先要学习采集data。
研究了很多采集数据软件,综合评测后发现最好的是Web Scraper,它是一个Chrome浏览器插件。
推荐理由如下:
1.门槛够低,只要电脑上安装了Chrome浏览器就可以使用
2.永久免费,无付费功能,无需注册
3.操作简单,鼠标点几下就可以爬取网页,0行代码写一个真正意义上的爬虫
既然这么棒,当然是立马安装了。
由于 Web Scraper 是 Chrome 浏览器插件,我当然是第一个使用 Chrome 的人。
不过受限于国内网络环境,访问Chrome插件应用商店可能不是很方便。如果第一种方式不行,我们可以试试第二种方式,使用浏览器曲线救国(360浏览器暂时不提供Web Scraper插件)。
两个浏览器内核是一样的,只是界面不同。我的后续教程将基于 Chrome 浏览器。浏览器可能略有不同。如有差异,读者需自行区分。
1. 在 Chrome 浏览器上安装 Web Scraper 插件
1.1 安装 Chrome 浏览器
这个没什么好说的,Windows电脑的各大应用商店都有最新版的Chrome浏览器,或者百度,首页一般都有安装包地址,下载安装即可;
(为减少兼容性问题,最好安装最新版本的Chrome浏览器)
1.2 安装 Web Scraper 插件
可以访问外网的同学,直接访问“Chrome Web Store”,搜索Web Scraper下载安装:
暂时无条件接入外网,我们可以手动安装外挂曲线救国,当然会比上面的麻烦一点:
首先我们访问这个国产浏览器插件网站,搜索Web Scraper,下载插件。注意此时插件不是直接安装在浏览器上,而是下载到本地:

然后,我们在浏览器的URL输入框中输入chrome://extensions/,这样就可以打开浏览器的插件管理后台了:
下一步是解压缩并安装刚刚下载的插件。
如果您是 Mac 用户,请先将安装包的后缀从 .crx 更改为 .zip。

然后切换到浏览器的插件管理后台,打开右上角的开发者模式,把Web Scraper.zip文件拖进去,就安装好了。
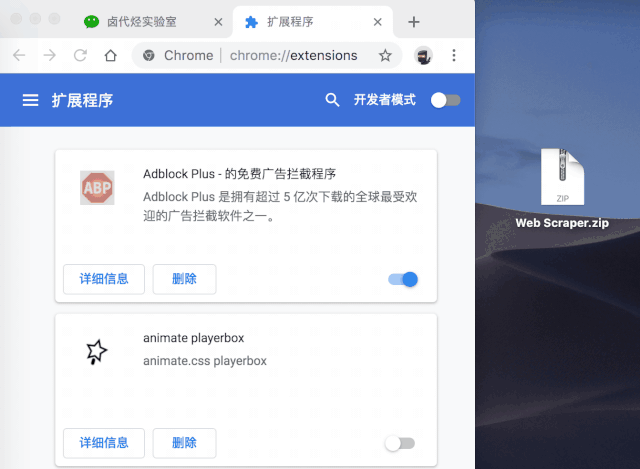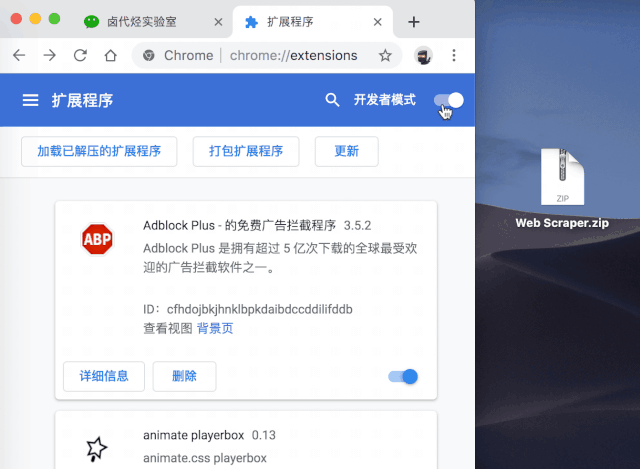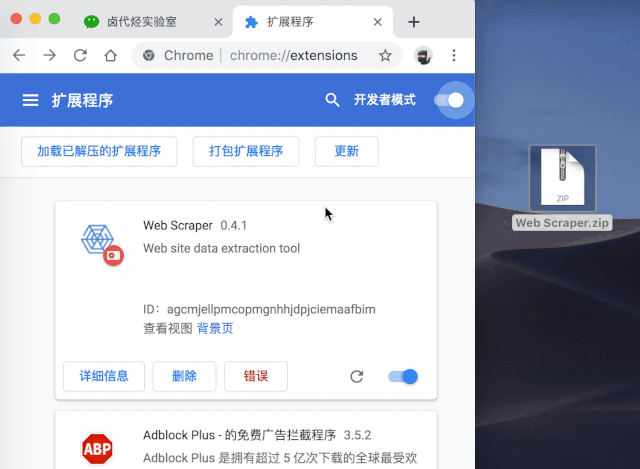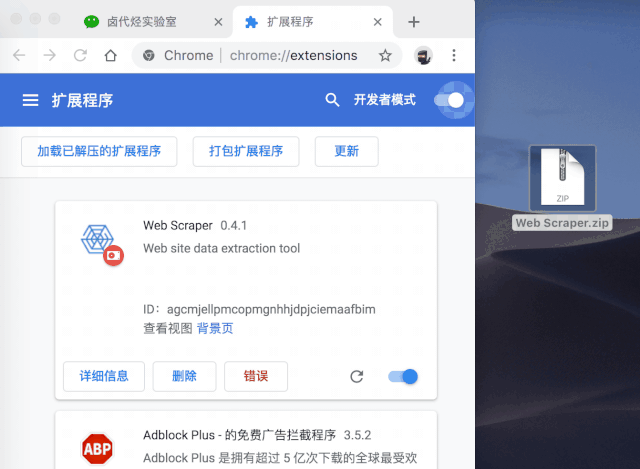
一般这个安装会出现一个红色的错误按钮,我们不管,直接忽略即可。
如果你是 windows 用户,你需要这样做:
1.把.crx后缀的插件改成.rar,然后解压
2.进入 chrome://extensions/ 页面,开启开发者模式
3.点击“加载解压扩展”,选择第一步解压后的文件夹,正常情况下安装成功。
至此,我们的Chrome浏览器已经成功安装了Web Scraper插件。
2.在浏览器上安装 Web Scraper 插件
2.1 安装浏览器
前往各大应用商店或访问网站下载安装。
浏览器PC版官网下载地址:
浏览器Mac版官网下载地址:
2.2 安装 Web Scraper 插件
Mac用户可以直接访问浏览器左上角的“应用中心”,点击进入并搜索Web Scraper进行安装。
Windows用户首先点击浏览器左上角的≡菜单栏,在弹出的菜单栏中选择“应用中心”,点击进入并搜索Web Scraper进行安装。
至此,我们的Web Scraper插件已经安装成功。在下一篇文章中,我们将探索一些浏览器操作,为我们后续的学习打下良好的基础。

这是简易数据分析系列的第三部分文章。
我们在上面安装了 Web Scraper 插件。我相信这对大多数人来说非常简单。在这个文章中,我们会讲一些不一样的东西,讲一下浏览器中那些大多数人都不知道的东西。低俗的操作。
作为普通用户,每个人都使用浏览器来查看信息和浏览网页。但在开发者眼中,Chrome浏览器提供了非常强大的开发能力。
通过本文章的学习,可以掌握一些浏览器开发的小知识(相信我,一点都不难),方便我们后续学习Web Scraper插件。
下面开始正文。
1 打开开发者后台
这个功能其实在我之前的文章《造谣的成本到底有多低?一行代码就可以截图造假了》。如前所述,如果你想从普通浏览模式切换到开发者模式,你只需要按 F12(浏览器 F12 被禁用)。
Mac电脑也可以用option+command+I打开,Win电脑可以用Ctrl+Shift+I打开。
2 一行代码自由伪造截图
这也是一篇老文章《谣言成本有多低?一行代码可以截图,造假内容。很多朋友都表示已经操作成功了,有兴趣的同学可以了解一下。
3 切换开发者后台的位置
控制台打开后,通常显示在网页底部。其实我们也可以切换到网页右侧进行显示。具体操作是点击后台面板右侧的⋮按钮,然后修改显示位置。具体操作如下。
4 使用电脑浏览器模拟手机浏览器
使用电脑浏览器模拟手机浏览器是一个非常有用的功能。因为现在是移动互联网时代,公司的大部分网页都是先支持移动端的,而且移动端浏览器的数据结构更加清晰,更有利于我们抓数据。
开启模拟手机也很简单,只需点击开发者后台左侧的手机切换图标,然后刷新即可。
我们可以用豆瓣网站来证明这一点。
当然,我们也可以用这个功能做其他事情,比如上班时开小屏偷偷刷微博。被老板抓到的时候别说我教过你。
好了,这就是今天的准备工作。下一期,我们将学习如何使用 Web Scraper 抓取网页数据。
●深入理解Web协议(一):HTTP包体传输
●JavaScript测试系列实战(四):掌握React Hooks测试技巧
●打开React Hooks 动画和实战(一):useState 和useEffect
·结尾·
图克社区
采集精彩的免费实用教程

chrome 插件 抓取网页qq聊天记录(初识网络爬虫的基本流程及流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-04-18 20:18
文章目录
1、准备聊天
1、关闭计算机的防火墙
2、关闭不必要的虚拟网络和其他不必要的以太网,只留下一个网络聊天通道
3、两台电脑连接同一个手机热点,打开疯狂聊天程序
2聊天抓包2.1、狂聊
1、先给自己起个聊天昵称,在两台电脑(或多台电脑一起)输入同一个聊天室号码
2、发消息,即聊天
2.2、使用wireshark捕获聊天消息
1、打开wireshark捕捉wlan(无线网络)下的聊天信息,如果没有,请参考:
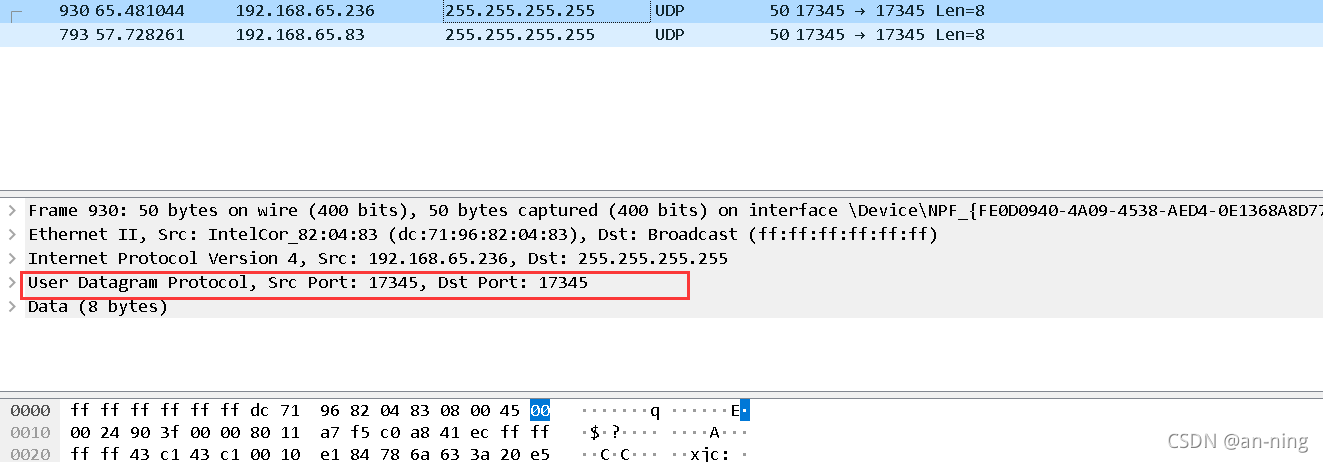
2 查看聊天信息的Dst地址为255.255.255.255
3、查找目标为 25 的记录5.255.255.255
可以看到网络是通过UDP协议连接的
4、查看英文聊天消息
5、查看数字聊天消息
6、查看文字聊天消息
7、从上面的爬取结果来看,聊天使用的端口是17345,使用的协议是UDP
2、从网络爬虫开始2.1、什么是爬虫
1、简介:网络爬虫也称为网络蜘蛛、网络蚂蚁、网络机器人等,它的英文名称是Web Crawler或Web Spider,可以自动浏览网络上的信息。当然,在浏览信息时,您需要遵循我们的公式。浏览的规则,这些规则我们称之为网络爬虫算法。使用Python,编写爬虫程序来自动检索互联网信息非常方便。
2、爬虫的基本流程:发起请求:通过url向服务器发起请求,请求中可以收录额外的头部信息。获取响应内容:如果服务器正常响应,那么我们会收到一个响应,也就是我们请求的网页内容,可能收录HTML、Json字符串或者二进制数据(视频、图片)等。
3、URL管理模块:发起请求。通常,请求是通过 HTTP 库向目标站点发出的。相当于自己打开浏览器,输入网址。
下载模块:获取响应内容(response)。如果服务器上存在请求的内容,服务器会返回请求的内容,一般为:HTML、二进制文件(视频、音频)、文档、Json字符串等。
解析模块:解析内容。对于用户来说,就是找到他们需要的信息。对于Python爬虫来说,就是使用正则表达式或者其他库来提取目标信息。
存储模块:保存数据。解析后的数据可以以文本、音频、视频等多种形式存储在本地。
2.2、爬取南洋理工ACM专题网站资料
1、打开南洋理工ACM话题网站,然后按F12进入工作模式,点击source,可以看到网页的源代码,然后就可以看到话题信息了我们需要的是在TD标签里面,也就是我们要爬取TD标签里面的内容
2、我用的是jupyter,打开用python编程
import requests# 导入网页请求库
from bs4 import BeautifulSoup# 导入网页解析库
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
# 传入URL
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={
pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
# 解析URL
soup = BeautifulSoup(r.text, 'html5lib')
#查找爬取与td相关所有内容
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
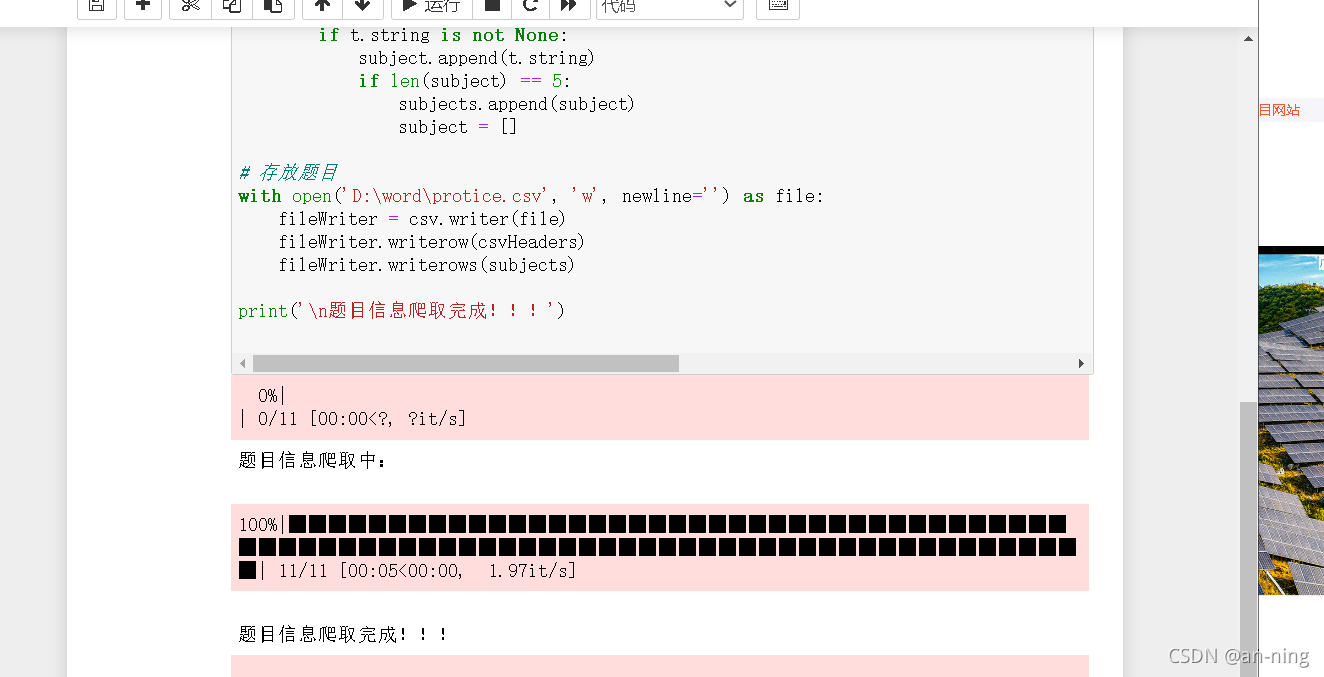
with open('D:\word\protice.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
3、然后运行程序
4、查看生成的爬取数据
2.3、爬取重庆交大新闻近年所有信息公告网站
1、打开重庆交通大学信息通知网站:
2、F12也打开进入开发者模式,网页源码可以在emelents下找到。可以看到我们需要爬取的信息在div标签中
3、查找要爬取的数据页数
4、 接下来在jupyter中编写代码
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 17 14:39:03 2021
@author: 86199
"""
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import urllib.request, urllib.error # 制定URL 获取网页数据
# 所有新闻
subjects = []
# 模拟浏览器访问
Headers = {
# 模拟浏览器头部信息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53"
}
# 表头
csvHeaders = ['时间', '标题']
print('信息爬取中:\n')
for pages in tqdm(range(1, 65 + 1)):
# 发出请求
request = urllib.request.Request(f'http://news.cqjtu.edu.cn/xxtz/{
pages}.htm', headers=Headers)
html = ""
# 如果请求成功则获取网页内容
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# 解析网页
soup = BeautifulSoup(html, 'html5lib')
# 存放一条新闻
subject = []
# 查找所有li标签
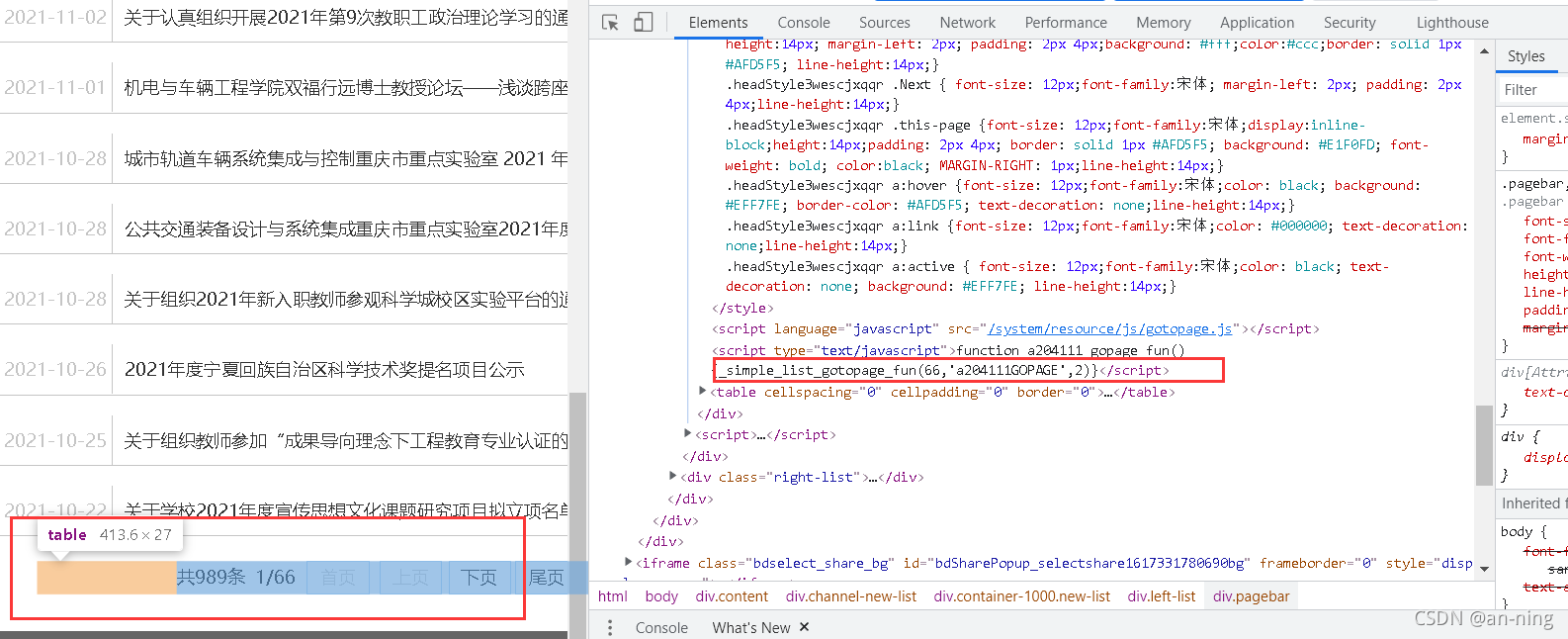
li = soup.find_all('li')
for l in li:
# 查找满足条件的div标签
if l.find_all('div',class_="time") is not None and l.find_all('div',class_="right-title") is not None:
# 时间、爬取的标签
for time in l.find_all('div',class_="time"):
subject.append(time.string)
# 标题
for title in l.find_all('div',class_="right-title"):
for t in title.find_all('a',target="_blank"):
subject.append(t.string)
if subject:
print(subject)
subjects.append(subject)
subject = []
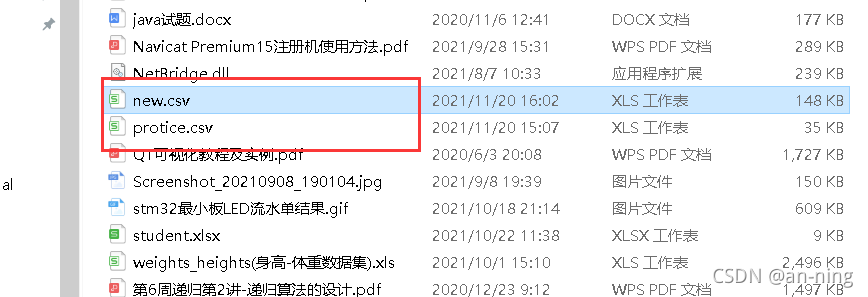
# 保存数据
with open('D:/word/new.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n信息爬取完成!!!')
5、运行代码
6、爬取的数据
3、总结
刚刚接触爬虫,对爬虫不是很熟悉,但是参考网上的资料,还是可以爬取一些简单的信息。对于网站的信息爬取,首先要分析网站的源码,分析爬取信息,找到其所属标签的内容,然后进行爬取。通过这个实践,我意识到爬虫对我们还是很有帮助的,它们可以很好地帮助我们处理随机信息。
参考: 查看全部
chrome 插件 抓取网页qq聊天记录(初识网络爬虫的基本流程及流程)
文章目录
1、准备聊天
1、关闭计算机的防火墙

2、关闭不必要的虚拟网络和其他不必要的以太网,只留下一个网络聊天通道

3、两台电脑连接同一个手机热点,打开疯狂聊天程序
2聊天抓包2.1、狂聊
1、先给自己起个聊天昵称,在两台电脑(或多台电脑一起)输入同一个聊天室号码

2、发消息,即聊天

2.2、使用wireshark捕获聊天消息
1、打开wireshark捕捉wlan(无线网络)下的聊天信息,如果没有,请参考:

2 查看聊天信息的Dst地址为255.255.255.255

3、查找目标为 25 的记录5.255.255.255

可以看到网络是通过UDP协议连接的
4、查看英文聊天消息

5、查看数字聊天消息

6、查看文字聊天消息

7、从上面的爬取结果来看,聊天使用的端口是17345,使用的协议是UDP
2、从网络爬虫开始2.1、什么是爬虫
1、简介:网络爬虫也称为网络蜘蛛、网络蚂蚁、网络机器人等,它的英文名称是Web Crawler或Web Spider,可以自动浏览网络上的信息。当然,在浏览信息时,您需要遵循我们的公式。浏览的规则,这些规则我们称之为网络爬虫算法。使用Python,编写爬虫程序来自动检索互联网信息非常方便。
2、爬虫的基本流程:发起请求:通过url向服务器发起请求,请求中可以收录额外的头部信息。获取响应内容:如果服务器正常响应,那么我们会收到一个响应,也就是我们请求的网页内容,可能收录HTML、Json字符串或者二进制数据(视频、图片)等。
3、URL管理模块:发起请求。通常,请求是通过 HTTP 库向目标站点发出的。相当于自己打开浏览器,输入网址。
下载模块:获取响应内容(response)。如果服务器上存在请求的内容,服务器会返回请求的内容,一般为:HTML、二进制文件(视频、音频)、文档、Json字符串等。
解析模块:解析内容。对于用户来说,就是找到他们需要的信息。对于Python爬虫来说,就是使用正则表达式或者其他库来提取目标信息。
存储模块:保存数据。解析后的数据可以以文本、音频、视频等多种形式存储在本地。

2.2、爬取南洋理工ACM专题网站资料
1、打开南洋理工ACM话题网站,然后按F12进入工作模式,点击source,可以看到网页的源代码,然后就可以看到话题信息了我们需要的是在TD标签里面,也就是我们要爬取TD标签里面的内容

2、我用的是jupyter,打开用python编程
import requests# 导入网页请求库
from bs4 import BeautifulSoup# 导入网页解析库
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
# 传入URL
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={
pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
# 解析URL
soup = BeautifulSoup(r.text, 'html5lib')
#查找爬取与td相关所有内容
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
with open('D:\word\protice.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
3、然后运行程序
4、查看生成的爬取数据


2.3、爬取重庆交大新闻近年所有信息公告网站
1、打开重庆交通大学信息通知网站:
2、F12也打开进入开发者模式,网页源码可以在emelents下找到。可以看到我们需要爬取的信息在div标签中

3、查找要爬取的数据页数
4、 接下来在jupyter中编写代码
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 17 14:39:03 2021
@author: 86199
"""
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import urllib.request, urllib.error # 制定URL 获取网页数据
# 所有新闻
subjects = []
# 模拟浏览器访问
Headers = {
# 模拟浏览器头部信息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53"
}
# 表头
csvHeaders = ['时间', '标题']
print('信息爬取中:\n')
for pages in tqdm(range(1, 65 + 1)):
# 发出请求
request = urllib.request.Request(f'http://news.cqjtu.edu.cn/xxtz/{
pages}.htm', headers=Headers)
html = ""
# 如果请求成功则获取网页内容
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# 解析网页
soup = BeautifulSoup(html, 'html5lib')
# 存放一条新闻
subject = []
# 查找所有li标签
li = soup.find_all('li')
for l in li:
# 查找满足条件的div标签
if l.find_all('div',class_="time") is not None and l.find_all('div',class_="right-title") is not None:
# 时间、爬取的标签
for time in l.find_all('div',class_="time"):
subject.append(time.string)
# 标题
for title in l.find_all('div',class_="right-title"):
for t in title.find_all('a',target="_blank"):
subject.append(t.string)
if subject:
print(subject)
subjects.append(subject)
subject = []
# 保存数据
with open('D:/word/new.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n信息爬取完成!!!')
5、运行代码

6、爬取的数据
3、总结
刚刚接触爬虫,对爬虫不是很熟悉,但是参考网上的资料,还是可以爬取一些简单的信息。对于网站的信息爬取,首先要分析网站的源码,分析爬取信息,找到其所属标签的内容,然后进行爬取。通过这个实践,我意识到爬虫对我们还是很有帮助的,它们可以很好地帮助我们处理随机信息。
参考:
chrome 插件 抓取网页qq聊天记录( 火狐屏蔽插件:下载一个火狐国际版不就解决了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-04-17 18:27
火狐屏蔽插件:下载一个火狐国际版不就解决了?)
禁止中国用户安装广告插件!火狐做到这一点
科技狐2022-03-30
火狐屏蔽插件,没有任何内幕。这时候可能有狐友会说:下载国际版火狐浏览器就解决了?
当谈到世界上最好的浏览器时,Chrome 绝对在名单上。它以简洁的设计和超快的启动速度赢得了众多用户的心。但要说Chrome浏览器的灵魂,那一定是它的扩展商店:里面有各种有趣实用的扩展,保证为你打开一个安装的新天地~
可悲的是,Chrome 国的扩展商店有 404 状态,所以很多人说:没有扩展的 Chrome 浏览器就像被废了的大师……
很多老司机都转向了其他浏览器。其中,火狐是最受欢迎的。原因很简单。火狐的扩展商店也很丰富,国内也可以访问。
就在最近,火狐浏览器突然屏蔽了中国用户的一些行为——禁止中国IP访问商店的广告屏蔽扩展页面。当有中国IP地址的用户在Firefox商店打开AdGuard之类的广告拦截扩展时,它会说:“此页面在您所在的地区不可用”
火狐屏蔽插件,没有任何内幕。这时候可能有狐友会说:下载国际版火狐浏览器就解决了?并不真地!无论您使用的是国际版火狐浏览器还是国内版火狐浏览器:只要您使用的是中国大陆IP,就无法访问官方商店的广告拦截扩展。
不过不要先骂火狐,因为火狐很可能会被迫屏蔽中国用户使用广告插件……因为早在2017、2018年,(Mozilla在中国的全资子公司)公司):因广告屏蔽被国内多家公司(Amang、Aku等)起诉,判决将于2019年生效。
也就是说,这次国内用户在使用火狐浏览器的时候不能使用广告拦截插件,可能是因为他们搬走了一些巨头的“蛋糕”……那为什么只有火狐的广告拦截插件可以没用过,Edge和Chrome浏览器都好吗?大概率是火狐现在市场份额小,声音低。
据调查机构Statcounter的统计,在Chrome和Safari的挤压下:曾经风靡一时的火狐浏览器,市场份额也从巅峰时期的30%下降到了4%。虽然 2018 年全球有 2.44 亿用户,但 Firefox 浏览器在 2021 年已经下降到 1.96 亿,短短 3 年就流失了 4800 万用户!
事实上,早在火狐封锁该插件之前,国产浏览器就发生了一些事情。它是——神器浏览器。
Magic Browser在其官网上表示:因为Magic Browser收到了来自一家巨头公司视频网站的关于Magic Browser的广告拦截功能的诉讼通知,并被要求支付巨额费用。Magic Browser 无法胜诉,因此将破产并停止运营。魔浏览器方面表示,为了积极配合阿酷等公司的要求,我们将尽快停止所有广告拦截功能,并从所有渠道下架魔浏览器产品。
这些插件同样易于使用。令人欣慰的是,火狐浏览器中唯一被移除的插件是广告移除插件,其他类型的插件都没有被屏蔽。所以想借此机会给大家推荐几个好用的浏览器扩展~顺便也推荐大家使用Edge浏览器。不仅可以访问中国的扩展商店,而且广告拦截插件仍然可以使用!
第一个需要大力推广的扩展是:Infinity Pro,总之就是你的浏览器首页的美化工具!不仅可以更改图标大小、圆角、透明度、排列方式、字体大小、颜色、滑动动画等,还可以自定义壁纸,添加各种彩绘图标网站。当然,对于一些老司机最爱的学习网站,你也可以手动添加~
第二个要推送的一定很实用:AdGuard广告拦截器,众所周知,很多网站自带很多狗皮弹窗广告,极大影响观看体验~和AdGuard广告拦截器的该设备最大的作用就是消除所有这些弹出广告!
第三个强推荐一定是必备的:英文名Tampermonkey可能很多人都不熟悉,所以更多的人喜欢称它为“油猴”。最强大的地方在于它提供了许多强大的用户脚本:方便的脚本安装、自动更新检查、标签中脚本健康的快速概览、内置编辑器等众多功能~同时,“油猴”可能仍能正常运行。最初不兼容的脚本。具体安装方法同上,先在商店搜索,然后获取安装。
安装好油猴之后,我们可以给油猴添加很多强大的“武器”:油猴脚本,所以这个时候,我们不得不推荐一个集合了很多实用脚本的网站:Greasy Fork 可以说过,只要熟悉油猴脚本,绝对可以让你的浏览器功能更强大!
总结与思考
对于这种屏蔽广告的浏览器插件,确实会影响网站的广告业务。这些视频平台抱怨这些广告拦截插件确实是可以理解的。毕竟,打着屏蔽广告、暗中窃取用户隐私的旗号的厂商确实不少。但是我现在出现了这么多的广告拦截插件,这些视频平台要付费!
因为现在国内很多视频平台真的很丑!不仅一开始有很长的广告,而且即使开了会员,也必须在剧中看几分钟广告……这大大降低了我们消费者的体验。我希望未来这些视频平台的广告时长会更短,广告质量会更高。如此一来,消费者愿意接受,自然不会有人用各种插件了~ 查看全部
chrome 插件 抓取网页qq聊天记录(
火狐屏蔽插件:下载一个火狐国际版不就解决了?)
禁止中国用户安装广告插件!火狐做到这一点
科技狐2022-03-30
火狐屏蔽插件,没有任何内幕。这时候可能有狐友会说:下载国际版火狐浏览器就解决了?
当谈到世界上最好的浏览器时,Chrome 绝对在名单上。它以简洁的设计和超快的启动速度赢得了众多用户的心。但要说Chrome浏览器的灵魂,那一定是它的扩展商店:里面有各种有趣实用的扩展,保证为你打开一个安装的新天地~
可悲的是,Chrome 国的扩展商店有 404 状态,所以很多人说:没有扩展的 Chrome 浏览器就像被废了的大师……
很多老司机都转向了其他浏览器。其中,火狐是最受欢迎的。原因很简单。火狐的扩展商店也很丰富,国内也可以访问。
就在最近,火狐浏览器突然屏蔽了中国用户的一些行为——禁止中国IP访问商店的广告屏蔽扩展页面。当有中国IP地址的用户在Firefox商店打开AdGuard之类的广告拦截扩展时,它会说:“此页面在您所在的地区不可用”
火狐屏蔽插件,没有任何内幕。这时候可能有狐友会说:下载国际版火狐浏览器就解决了?并不真地!无论您使用的是国际版火狐浏览器还是国内版火狐浏览器:只要您使用的是中国大陆IP,就无法访问官方商店的广告拦截扩展。
不过不要先骂火狐,因为火狐很可能会被迫屏蔽中国用户使用广告插件……因为早在2017、2018年,(Mozilla在中国的全资子公司)公司):因广告屏蔽被国内多家公司(Amang、Aku等)起诉,判决将于2019年生效。
也就是说,这次国内用户在使用火狐浏览器的时候不能使用广告拦截插件,可能是因为他们搬走了一些巨头的“蛋糕”……那为什么只有火狐的广告拦截插件可以没用过,Edge和Chrome浏览器都好吗?大概率是火狐现在市场份额小,声音低。
据调查机构Statcounter的统计,在Chrome和Safari的挤压下:曾经风靡一时的火狐浏览器,市场份额也从巅峰时期的30%下降到了4%。虽然 2018 年全球有 2.44 亿用户,但 Firefox 浏览器在 2021 年已经下降到 1.96 亿,短短 3 年就流失了 4800 万用户!
事实上,早在火狐封锁该插件之前,国产浏览器就发生了一些事情。它是——神器浏览器。
Magic Browser在其官网上表示:因为Magic Browser收到了来自一家巨头公司视频网站的关于Magic Browser的广告拦截功能的诉讼通知,并被要求支付巨额费用。Magic Browser 无法胜诉,因此将破产并停止运营。魔浏览器方面表示,为了积极配合阿酷等公司的要求,我们将尽快停止所有广告拦截功能,并从所有渠道下架魔浏览器产品。
这些插件同样易于使用。令人欣慰的是,火狐浏览器中唯一被移除的插件是广告移除插件,其他类型的插件都没有被屏蔽。所以想借此机会给大家推荐几个好用的浏览器扩展~顺便也推荐大家使用Edge浏览器。不仅可以访问中国的扩展商店,而且广告拦截插件仍然可以使用!
第一个需要大力推广的扩展是:Infinity Pro,总之就是你的浏览器首页的美化工具!不仅可以更改图标大小、圆角、透明度、排列方式、字体大小、颜色、滑动动画等,还可以自定义壁纸,添加各种彩绘图标网站。当然,对于一些老司机最爱的学习网站,你也可以手动添加~
第二个要推送的一定很实用:AdGuard广告拦截器,众所周知,很多网站自带很多狗皮弹窗广告,极大影响观看体验~和AdGuard广告拦截器的该设备最大的作用就是消除所有这些弹出广告!
第三个强推荐一定是必备的:英文名Tampermonkey可能很多人都不熟悉,所以更多的人喜欢称它为“油猴”。最强大的地方在于它提供了许多强大的用户脚本:方便的脚本安装、自动更新检查、标签中脚本健康的快速概览、内置编辑器等众多功能~同时,“油猴”可能仍能正常运行。最初不兼容的脚本。具体安装方法同上,先在商店搜索,然后获取安装。
安装好油猴之后,我们可以给油猴添加很多强大的“武器”:油猴脚本,所以这个时候,我们不得不推荐一个集合了很多实用脚本的网站:Greasy Fork 可以说过,只要熟悉油猴脚本,绝对可以让你的浏览器功能更强大!
总结与思考
对于这种屏蔽广告的浏览器插件,确实会影响网站的广告业务。这些视频平台抱怨这些广告拦截插件确实是可以理解的。毕竟,打着屏蔽广告、暗中窃取用户隐私的旗号的厂商确实不少。但是我现在出现了这么多的广告拦截插件,这些视频平台要付费!
因为现在国内很多视频平台真的很丑!不仅一开始有很长的广告,而且即使开了会员,也必须在剧中看几分钟广告……这大大降低了我们消费者的体验。我希望未来这些视频平台的广告时长会更短,广告质量会更高。如此一来,消费者愿意接受,自然不会有人用各种插件了~
chrome 插件 抓取网页qq聊天记录(解决办法:Chrome更改代理服务器设置gtgt;连接gt(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-16 11:04
解决方案:
Chrome > 设置 > 更改代理设置 > 连接 > 局域网
选中不要将代理服务器用于本地地址
你可以直接在chrome浏览器上输入:
铬://设置/系统
打开“代理设置”,出现如下界面。
因为我用的是某台灯,所以我在爬×××之前检查了web proxy和secure web proxy。
所以需要排除本地域名。
在“忽略这些主机和域的代理设置”中填写您的本地域名。
填写时,多个域名以空格分隔,保存后会自动更改为分隔。
这里需要注意的是,当你修改它时,你必须重新编写它。不要添加或删除部分输入框。
然后保存后。
可以访问本地域名,同时可以爬取×××访问国外域名。
以下是之前写的内容,不勾选web proxy,secure web proxy,即:不勾选代理。
不用设置ignore,也可以访问本地域名,但是不能访问国外域名。
具体以mac电脑为例:
1.这个界面可以在火狐浏览器中打开,但在谷歌浏览器Chrome中无法打开。
2.点击Chrome右侧的三个点->设置
然后点击“高级设置”->“系统”
找到“打开代理设置”
本来是查的,现在取消了。
自动跳转到这里,代理被检查。
立即取消并单击“确定”
6.点击“应用”
7. 回到浏览器看看,OK!
提示:在查找“打开代理设置”时,可以直接在浏览器中输入:
铬://设置/系统
有什么问题可以留言,我很乐意帮你解答php技术问题。
或加入QQ群:PHP技术问答群。我们会尽力提供帮助。 查看全部
chrome 插件 抓取网页qq聊天记录(解决办法:Chrome更改代理服务器设置gtgt;连接gt(图))
解决方案:
Chrome > 设置 > 更改代理设置 > 连接 > 局域网
选中不要将代理服务器用于本地地址
你可以直接在chrome浏览器上输入:
铬://设置/系统
打开“代理设置”,出现如下界面。

因为我用的是某台灯,所以我在爬×××之前检查了web proxy和secure web proxy。
所以需要排除本地域名。
在“忽略这些主机和域的代理设置”中填写您的本地域名。
填写时,多个域名以空格分隔,保存后会自动更改为分隔。
这里需要注意的是,当你修改它时,你必须重新编写它。不要添加或删除部分输入框。
然后保存后。
可以访问本地域名,同时可以爬取×××访问国外域名。
以下是之前写的内容,不勾选web proxy,secure web proxy,即:不勾选代理。
不用设置ignore,也可以访问本地域名,但是不能访问国外域名。
具体以mac电脑为例:
1.这个界面可以在火狐浏览器中打开,但在谷歌浏览器Chrome中无法打开。

2.点击Chrome右侧的三个点->设置

然后点击“高级设置”->“系统”

找到“打开代理设置”

本来是查的,现在取消了。
自动跳转到这里,代理被检查。

立即取消并单击“确定”

6.点击“应用”

7. 回到浏览器看看,OK!

提示:在查找“打开代理设置”时,可以直接在浏览器中输入:
铬://设置/系统
有什么问题可以留言,我很乐意帮你解答php技术问题。
或加入QQ群:PHP技术问答群。我们会尽力提供帮助。
chrome 插件 抓取网页qq聊天记录(chrome插件抓取网页qq聊天记录用chromewebstore分析chrome应用收集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-16 00:07
chrome插件抓取网页qq聊天记录用chromewebstore分析chrome应用收集网页信息_小木虫论坛_太奇网360手机助手高清浏览器的下载
官方的,chromewebstore这是最权威的了。如果想要到第三方网站分析数据,那么就需要爬虫了。第三方网站,比如googleanalytics。ifavailableyouneedyourwebsitesinheregoogleanalytics是免费的。但目前analytics的对象是电子商务业务。
他将每个卖家作为一个网站来进行商业分析。如果你是推广引流,那么显然是wa,并且需要你有vps,服务器支持。
ip评分查看分析,有免费的,也有每年298/年那种的。
使用友盟市场分析进行定向推广引流,数据包括推广渠道的、下载量,评分等多个数据。
现在用的是友盟,加上三星数据分析,
移动厂商如小米,华为,三星,魅族等的官网都是有加密的推广渠道的qq好友,
用的一洽excel数据采集器,无需编程,能够对手机网站的分析,公网域名全国查询,还能批量全国域名爬取等功能.希望能帮到你.
可以用专业的分析软件和爬虫软件做。
直接上名站数据抓取网站,监控多少年多少网站,可以抓全网页面。这些官网信息都是绝对安全,可靠的信息。
wap.php服务器,信息来源是爬虫爬下来的。js服务器,属于规则, 查看全部
chrome 插件 抓取网页qq聊天记录(chrome插件抓取网页qq聊天记录用chromewebstore分析chrome应用收集)
chrome插件抓取网页qq聊天记录用chromewebstore分析chrome应用收集网页信息_小木虫论坛_太奇网360手机助手高清浏览器的下载
官方的,chromewebstore这是最权威的了。如果想要到第三方网站分析数据,那么就需要爬虫了。第三方网站,比如googleanalytics。ifavailableyouneedyourwebsitesinheregoogleanalytics是免费的。但目前analytics的对象是电子商务业务。
他将每个卖家作为一个网站来进行商业分析。如果你是推广引流,那么显然是wa,并且需要你有vps,服务器支持。
ip评分查看分析,有免费的,也有每年298/年那种的。
使用友盟市场分析进行定向推广引流,数据包括推广渠道的、下载量,评分等多个数据。
现在用的是友盟,加上三星数据分析,
移动厂商如小米,华为,三星,魅族等的官网都是有加密的推广渠道的qq好友,
用的一洽excel数据采集器,无需编程,能够对手机网站的分析,公网域名全国查询,还能批量全国域名爬取等功能.希望能帮到你.
可以用专业的分析软件和爬虫软件做。
直接上名站数据抓取网站,监控多少年多少网站,可以抓全网页面。这些官网信息都是绝对安全,可靠的信息。
wap.php服务器,信息来源是爬虫爬下来的。js服务器,属于规则,
chrome 插件 抓取网页qq聊天记录(qq浏览器中十款提高用户体验,让各位一览无余一番)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-04-15 09:19
自从移动互联网时代,即浏览器市场的原创霸主从神坛陨落,谷歌的chrome浏览器登上顶峰,并有取而代之的趋势。chrome之所以能赶上后来者,与其高效的性能和丰富便捷的插件密不可分。但是国内无法直接访问谷歌应用商店,造成使用chrome插件的不便。QQ浏览器作为市面上另一款流行的浏览器,不仅兼顾了IE的兼容性,还提供了chrome内核的高效和插件功能。QQ浏览器不仅提供了谷歌商城的大部分插件,还提供了自己的专用插件,可以说比蓝还好用。
QQ浏览器应用安装,进入应用中心,直接搜索应用名称即可找到安装,非常方便快捷。
十个插件,先来一张全家福,让你一目了然。
十款全家福插件
1. 图像助手
一个浏览器扩展,用于嗅探、分析网页图片,提供批量下载等功能和在线采集、检索、分享服务。
主要功能: 1.可以提取页面中的图片,可以帮你提取所有不易查看源地址的图片;添加全图水印;3. 直接生成当前页面的二维码。一个插件可以满足许多需求。
2.购物党全网自动比价工具
浏览商品页面时,自动对比同款商品在多个商城的最低价格,并提供价格历史、口碑评分等查询。
主要功能:1.提供当前商城商品的历史价格查询,提供历史最低价和最低价的日期和条件;2.提供其他平台产品的价格比较。总的来说,数据比较准确,值得购物参考。
3.翻译
【QQ浏览器官方产品】非常好用的翻译插件,带人工智能翻译!
主要功能: 1.可以直接翻译网页,进行双语比对。2.可以识别和翻译多种语言。其实对于有外语困难的人来说,上网是必备神器。
4.开发工具箱
常用小工具合二为一,为我们的工作带来福音。
主要功能:看插件的名字,应该是程序员用的。现在功能越来越多,是一个多功能的小工具箱。常用功能包括:二维码的识别与生成、各种编码转换、加解密、代码格式化、代码压缩等。
5.复制鱼
免费高效的OCR插件
主要功能:使用方便,点击插件图标,选择识别区域,可以对网页、pdf中的图片和文字进行OCR识别,识别成文字后直接复制使用即可。
提示:安装后默认为英文OCR识别,需要在设置中改为ChineseSimplified才能识别中文。
需要设置为简体中文
6.Nimbus 截图
全屏捕获网页或任何部分。编辑截图。录制的视频 从您的屏幕录制的视频
主要功能:1.提供多种截图方式,截取后直接编辑,编辑功能强大2.提供录像功能
7.整页截屏
完整可靠地捕获当前页面的屏幕截图 - 无需请求任何额外权限!
主要功能:截图工具非常多,Nimbus Screenshot已经非常实用和全面。这是另一种专业捕获页面完整图像的方法。什么意思,一般的截图工具只能根据你的选择截取当前页面选中的部分,但是这个插件会自动滚动屏幕截取整个页面(从页面的开头到结尾),没有不管有多少个屏幕,包括下拉部分。只要在使用过程中点击插件图标,就会自动截取当前页面的全图。捕获的图像可以下载为图像或 PDF 格式。
8.二维码(生成识别)
从当前页面地址、选中的文字或链接等生成二维码,还可以识别网页中的二维码图片(支持识别中文)。
主要功能:1.生成二维码、各种文字、超链接,在当前页面右击直接生成访问二维码;2.识别二维码,二维码出现在页面上,无需再笨的拿出手机扫码,右击识别二维码。这就是为什么我推荐这个 QR 码软件而不是 Quick QR。
9.FDM(免费下载管理器)
插件版下载神器
主要功能:无需安装软件,外挂版下载软件,迅雷下载不了,试试这个工具,下载电影好东西。
10.adblock plus
还有一种非常重要的插件,就是页面广告拦截插件,其中最著名的就是adblock。不知道为什么QQ浏览器不支持安装。想体验的朋友可以自己研究一下,如何通过其他渠道安装。 查看全部
chrome 插件 抓取网页qq聊天记录(qq浏览器中十款提高用户体验,让各位一览无余一番)
自从移动互联网时代,即浏览器市场的原创霸主从神坛陨落,谷歌的chrome浏览器登上顶峰,并有取而代之的趋势。chrome之所以能赶上后来者,与其高效的性能和丰富便捷的插件密不可分。但是国内无法直接访问谷歌应用商店,造成使用chrome插件的不便。QQ浏览器作为市面上另一款流行的浏览器,不仅兼顾了IE的兼容性,还提供了chrome内核的高效和插件功能。QQ浏览器不仅提供了谷歌商城的大部分插件,还提供了自己的专用插件,可以说比蓝还好用。
QQ浏览器应用安装,进入应用中心,直接搜索应用名称即可找到安装,非常方便快捷。
十个插件,先来一张全家福,让你一目了然。
十款全家福插件
1. 图像助手
一个浏览器扩展,用于嗅探、分析网页图片,提供批量下载等功能和在线采集、检索、分享服务。
主要功能: 1.可以提取页面中的图片,可以帮你提取所有不易查看源地址的图片;添加全图水印;3. 直接生成当前页面的二维码。一个插件可以满足许多需求。
2.购物党全网自动比价工具
浏览商品页面时,自动对比同款商品在多个商城的最低价格,并提供价格历史、口碑评分等查询。
主要功能:1.提供当前商城商品的历史价格查询,提供历史最低价和最低价的日期和条件;2.提供其他平台产品的价格比较。总的来说,数据比较准确,值得购物参考。
3.翻译
【QQ浏览器官方产品】非常好用的翻译插件,带人工智能翻译!
主要功能: 1.可以直接翻译网页,进行双语比对。2.可以识别和翻译多种语言。其实对于有外语困难的人来说,上网是必备神器。
4.开发工具箱
常用小工具合二为一,为我们的工作带来福音。
主要功能:看插件的名字,应该是程序员用的。现在功能越来越多,是一个多功能的小工具箱。常用功能包括:二维码的识别与生成、各种编码转换、加解密、代码格式化、代码压缩等。
5.复制鱼
免费高效的OCR插件
主要功能:使用方便,点击插件图标,选择识别区域,可以对网页、pdf中的图片和文字进行OCR识别,识别成文字后直接复制使用即可。
提示:安装后默认为英文OCR识别,需要在设置中改为ChineseSimplified才能识别中文。
需要设置为简体中文
6.Nimbus 截图
全屏捕获网页或任何部分。编辑截图。录制的视频 从您的屏幕录制的视频
主要功能:1.提供多种截图方式,截取后直接编辑,编辑功能强大2.提供录像功能
7.整页截屏
完整可靠地捕获当前页面的屏幕截图 - 无需请求任何额外权限!
主要功能:截图工具非常多,Nimbus Screenshot已经非常实用和全面。这是另一种专业捕获页面完整图像的方法。什么意思,一般的截图工具只能根据你的选择截取当前页面选中的部分,但是这个插件会自动滚动屏幕截取整个页面(从页面的开头到结尾),没有不管有多少个屏幕,包括下拉部分。只要在使用过程中点击插件图标,就会自动截取当前页面的全图。捕获的图像可以下载为图像或 PDF 格式。
8.二维码(生成识别)
从当前页面地址、选中的文字或链接等生成二维码,还可以识别网页中的二维码图片(支持识别中文)。
主要功能:1.生成二维码、各种文字、超链接,在当前页面右击直接生成访问二维码;2.识别二维码,二维码出现在页面上,无需再笨的拿出手机扫码,右击识别二维码。这就是为什么我推荐这个 QR 码软件而不是 Quick QR。
9.FDM(免费下载管理器)
插件版下载神器
主要功能:无需安装软件,外挂版下载软件,迅雷下载不了,试试这个工具,下载电影好东西。
10.adblock plus
还有一种非常重要的插件,就是页面广告拦截插件,其中最著名的就是adblock。不知道为什么QQ浏览器不支持安装。想体验的朋友可以自己研究一下,如何通过其他渠道安装。
chrome 插件 抓取网页qq聊天记录( 接下来怎么去开发一个自己的js轮播插件或应用(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-11 05:03
接下来怎么去开发一个自己的js轮播插件或应用(组图))
前端开发,整理推荐有用的chrome插件或应用
整理提供给 web 前端开发者的 chrome 插件或应用程序:如 Postman、JSON Viewer、Page Ruler、ChromeADB 等。
如何使用原生js开发插件
作为前端开发,我们都习惯使用一些开源的插件,比如jquery工具库,那么如何使用原生js来开发和封装一个自己的插件呢?接下来我们来看看如何开发自己的js插件,先上代码
typeahead.js_jquery 输入搜索自动完成 jQuery 插件
jquery.typeahead.js 是一个高级的自动完成 jQuery 插件。自动补全插件提供超过50个配置选项和回调方法来完成自动补全功能,可以满足大部分表单自动补全需求。
js carousel plugin_carousel图 js代码插件总结
这个文章是一款适合大家的图片轮播插件,最全、最简单、最通用的幻灯片轮播插件。在PC端和移动端都可以完美使用,可以满足大部分网站回合的需求。广播需求。js轮播插件包括Swiper、slick、owl carousel2、jssor/slider、iSlider等。
ios风格的时间选择插件
上一个项目中,客户希望时间选择插件可以是ios风格的,但是找了半天,发现vue的ios风格的时间插件没有使用,于是建了一个自己轮。插件依赖better-scroll和vue
前端最常用的vscode插件集
在前端开发中,你常用的 Visual Studio Code 插件有哪些?推荐几个自己喜欢的,不用链接,自己搜索安装。这些比较实用,前端必备的插件集
浏览器插件_推荐常用的谷歌浏览器插件
常用的谷歌浏览器内置功能确实不如国内其他软件丰富。不过,谷歌浏览器的优势恰恰体现在其超简洁的界面和支持众多强大易用的扩展,用户可以根据自己的喜好自定义浏览器。今天给大家介绍几个我常用的插件。
崇高安装插件
安装 Sublime text 2 插件非常方便。可以直接下载安装包解压到Packages目录下,也可以安装包控制组件,然后直接在线安装。
Jquery中BlockUI_ajax加载提示插件blickUI详细使用
BlockUI 插件用于在执行 AJAX 操作时模拟同步传输时锁定浏览器操作。当它被激活时,它会阻止用户与页面(或页面的一部分)交互,直到它被关闭。BlockUI 将元素添加到 DOM 以实现阻止用户与浏览器交互的外观和行为
vue项目中vscode格式化配置和eslint配置冲突
使用vscode开发vue项目时,从远端拉下一个新项目,安装好依赖后运行项目,发现直接报了一堆语法错误:包括换行符、空格、单双引号标记、分号等格式问题 查看全部
chrome 插件 抓取网页qq聊天记录(
接下来怎么去开发一个自己的js轮播插件或应用(组图))

前端开发,整理推荐有用的chrome插件或应用
整理提供给 web 前端开发者的 chrome 插件或应用程序:如 Postman、JSON Viewer、Page Ruler、ChromeADB 等。
如何使用原生js开发插件
作为前端开发,我们都习惯使用一些开源的插件,比如jquery工具库,那么如何使用原生js来开发和封装一个自己的插件呢?接下来我们来看看如何开发自己的js插件,先上代码

typeahead.js_jquery 输入搜索自动完成 jQuery 插件
jquery.typeahead.js 是一个高级的自动完成 jQuery 插件。自动补全插件提供超过50个配置选项和回调方法来完成自动补全功能,可以满足大部分表单自动补全需求。
js carousel plugin_carousel图 js代码插件总结
这个文章是一款适合大家的图片轮播插件,最全、最简单、最通用的幻灯片轮播插件。在PC端和移动端都可以完美使用,可以满足大部分网站回合的需求。广播需求。js轮播插件包括Swiper、slick、owl carousel2、jssor/slider、iSlider等。

ios风格的时间选择插件
上一个项目中,客户希望时间选择插件可以是ios风格的,但是找了半天,发现vue的ios风格的时间插件没有使用,于是建了一个自己轮。插件依赖better-scroll和vue

前端最常用的vscode插件集
在前端开发中,你常用的 Visual Studio Code 插件有哪些?推荐几个自己喜欢的,不用链接,自己搜索安装。这些比较实用,前端必备的插件集
浏览器插件_推荐常用的谷歌浏览器插件
常用的谷歌浏览器内置功能确实不如国内其他软件丰富。不过,谷歌浏览器的优势恰恰体现在其超简洁的界面和支持众多强大易用的扩展,用户可以根据自己的喜好自定义浏览器。今天给大家介绍几个我常用的插件。

崇高安装插件
安装 Sublime text 2 插件非常方便。可以直接下载安装包解压到Packages目录下,也可以安装包控制组件,然后直接在线安装。
Jquery中BlockUI_ajax加载提示插件blickUI详细使用
BlockUI 插件用于在执行 AJAX 操作时模拟同步传输时锁定浏览器操作。当它被激活时,它会阻止用户与页面(或页面的一部分)交互,直到它被关闭。BlockUI 将元素添加到 DOM 以实现阻止用户与浏览器交互的外观和行为
vue项目中vscode格式化配置和eslint配置冲突
使用vscode开发vue项目时,从远端拉下一个新项目,安装好依赖后运行项目,发现直接报了一堆语法错误:包括换行符、空格、单双引号标记、分号等格式问题
chrome 插件 抓取网页qq聊天记录(推荐5款可以提升工作效率的Chrome插件这款插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-11 03:30
大家好,我是安哥!
今天继续推荐5款可以提高工作效率的Chrome插件。
全方位
这个 Chrome 插件可以快速搜索、切换和关闭浏览器书签、Tab 页和历史记录。
当我们同时打开多个Tab页时,切换到某个Tab页是很麻烦的。Omni输入框只需输入关键字“/tabs”,然后追加关键字即可快速查询Tab,回车切换Tab。
另外,关键字“/bookmarks”用于快速切换搜索书签,“/history”用于切换历史记录,“/remove”可用于关闭Tab或删除书签
为了提高使用效率,建议为Omni设置快捷键,在地址栏中输入“chrome://extensions/shortcuts”,给Omni分配一个热键,例如:Ctrl + Shift + K
当然,Omni也有很多实用的功能,比如:页面静音、Tab pinning、管理插件等,大家可以自己扩展
插件地址:
CSS 窥视器
CSS Peeper,一个提取网页样式的插件
作为CSS查看器,可以直观高效的获取网页元素的属性、宽度、高度、字体样式
使用方法很简单,只要点击插件,用鼠标点击网页上的一个控件,右上角就会显示目标元素的CSS样式属性。
插件地址:
JSON查看器专业版
在Chrome应用市场上,JSON格式化插件很多,但这个插件除了常规功能外,还包括样式自定义、“图表视图”展示等功能,用户体验更好。
另外这个插件可以随意选择一个节点,复制Path路径和Value值
插件地址:
历史趋势无限
这是一个历史管理插件,可以将历史浏览记录“永久”保存到本地数据库,并生成排名列表和统计报表图表。比如可以按时间段列出访问量前十名网站
此外,还可以通过关键字查询历史浏览记录
在设置中可以导入导出历史记录,配置自动备份的周期
插件地址:
阿贾克斯拦截器
本插件可以修改ajax请求的返回结果,一般用于Mock数据,接口联调测试
使用起来很简单。只需要打开插件开关,然后将要拦截的请求地址匹配成完整地址或常规地址,最后加上要返回的请求结果,这样修改请求的响应结果就可以了完成。
插件地址:
源地址: 查看全部
chrome 插件 抓取网页qq聊天记录(推荐5款可以提升工作效率的Chrome插件这款插件)
大家好,我是安哥!
今天继续推荐5款可以提高工作效率的Chrome插件。
全方位
这个 Chrome 插件可以快速搜索、切换和关闭浏览器书签、Tab 页和历史记录。
当我们同时打开多个Tab页时,切换到某个Tab页是很麻烦的。Omni输入框只需输入关键字“/tabs”,然后追加关键字即可快速查询Tab,回车切换Tab。
另外,关键字“/bookmarks”用于快速切换搜索书签,“/history”用于切换历史记录,“/remove”可用于关闭Tab或删除书签
为了提高使用效率,建议为Omni设置快捷键,在地址栏中输入“chrome://extensions/shortcuts”,给Omni分配一个热键,例如:Ctrl + Shift + K
当然,Omni也有很多实用的功能,比如:页面静音、Tab pinning、管理插件等,大家可以自己扩展
插件地址:
CSS 窥视器
CSS Peeper,一个提取网页样式的插件
作为CSS查看器,可以直观高效的获取网页元素的属性、宽度、高度、字体样式
使用方法很简单,只要点击插件,用鼠标点击网页上的一个控件,右上角就会显示目标元素的CSS样式属性。
插件地址:
JSON查看器专业版
在Chrome应用市场上,JSON格式化插件很多,但这个插件除了常规功能外,还包括样式自定义、“图表视图”展示等功能,用户体验更好。
另外这个插件可以随意选择一个节点,复制Path路径和Value值
插件地址:
历史趋势无限
这是一个历史管理插件,可以将历史浏览记录“永久”保存到本地数据库,并生成排名列表和统计报表图表。比如可以按时间段列出访问量前十名网站
此外,还可以通过关键字查询历史浏览记录
在设置中可以导入导出历史记录,配置自动备份的周期
插件地址:
阿贾克斯拦截器
本插件可以修改ajax请求的返回结果,一般用于Mock数据,接口联调测试
使用起来很简单。只需要打开插件开关,然后将要拦截的请求地址匹配成完整地址或常规地址,最后加上要返回的请求结果,这样修改请求的响应结果就可以了完成。
插件地址:
源地址:
chrome 插件 抓取网页qq聊天记录(目录Logo抓取器是国外开发者开发一款Logo获取工具浏览器插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-09 18:21
目录
Logo Grabber是国外开发者开发的一款浏览器插件,用于logo获取工具。网友对其进行了汉化,支持Chrome、FireFox、360等浏览器。一键傻瓜式操作下载他们的Logo,而且还是PNG格式,不妨下载体验一下!
安装方法
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹中。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/ 勾选右上角的“开发者模式”按钮。
3、勾选开发者模式选项后,此页面会出现加载正在开发的扩展等按钮,点击“加载正在开发的扩展”按钮,选择刚刚解压的Chrome插件文件夹文件夹。
4、点击“确定”按钮,如果没有其他反应,插件就会成功加载到浏览器中。
如何使用
1、使用 Google Chrome(或其他 Chrome 浏览器)打开目标网站。
2、点击浏览器上的“Logo Grabber”开始抓取可能的 Logo 图案。
3、点击“下载”下载对应的Logo格式。
4、如果发现logo显示不正确,也可以通过下面的链接反馈问题。
不是所有网站都支持,但大部分网站还是可以的,这个工具可以节省时间,提高工作效率,其次,它可以获取png格式的图片,这绝对比截图好。高,第三年可以在隐藏标签中获得一些Logo,总体不错。
以上是Logo Grabber的软件介绍。您可能还想了解徽标抓取系统、徽标提取器、提取网站徽标等。请关注本软件站点文章。 查看全部
chrome 插件 抓取网页qq聊天记录(目录Logo抓取器是国外开发者开发一款Logo获取工具浏览器插件)
目录
Logo Grabber是国外开发者开发的一款浏览器插件,用于logo获取工具。网友对其进行了汉化,支持Chrome、FireFox、360等浏览器。一键傻瓜式操作下载他们的Logo,而且还是PNG格式,不妨下载体验一下!

安装方法
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹中。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/ 勾选右上角的“开发者模式”按钮。
3、勾选开发者模式选项后,此页面会出现加载正在开发的扩展等按钮,点击“加载正在开发的扩展”按钮,选择刚刚解压的Chrome插件文件夹文件夹。
4、点击“确定”按钮,如果没有其他反应,插件就会成功加载到浏览器中。

如何使用
1、使用 Google Chrome(或其他 Chrome 浏览器)打开目标网站。
2、点击浏览器上的“Logo Grabber”开始抓取可能的 Logo 图案。
3、点击“下载”下载对应的Logo格式。
4、如果发现logo显示不正确,也可以通过下面的链接反馈问题。

不是所有网站都支持,但大部分网站还是可以的,这个工具可以节省时间,提高工作效率,其次,它可以获取png格式的图片,这绝对比截图好。高,第三年可以在隐藏标签中获得一些Logo,总体不错。
以上是Logo Grabber的软件介绍。您可能还想了解徽标抓取系统、徽标提取器、提取网站徽标等。请关注本软件站点文章。
chrome 插件 抓取网页qq聊天记录(QQ会读取Chrome的历史记录,被火绒自定义规则拦截了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-04-07 12:07
)
先说结论,QQ会读取浏览器的历史浏览记录,包括但不限于Chrome、Chromium、360极速、360安全、猎豹、2345等。
今天看到群里有个同学在v2ex()上发了个帖子,说QQ会读Chrome的历史,被火绒的自定义规则屏蔽了。我一开始不相信,但他说他又出现了,而且QQ登录后只有10分钟才能访问。
我想验证一下,打开虚拟机安装QQ、Chrome,然后打开Process Monitor启动等等。规则被简单地过滤。
果然看到了读取AppData\Local\Google\Chrome\User Data\Default\History等目录的操作。
而且时间正好十分钟。
这才是QQ和Chrome打不通的实锤。我不相信。我把规则删了,又查了一遍,发现QQ被冤枉了。
受害者的数量令人震惊。仔细看,这个东西会遍历Appdata\Local\下的所有文件夹,然后添加User Data\Default\History来读取。User Data\Default\History 是谷歌浏览器默认的历史记录存储位置(火狐等浏览器对该目录不熟悉,Chrome被拍是正常的。
那么就该研究一下QQ为什么会这样了,浏览器历史记录又是怎么读取的呢?
连接 x32dbg 并动态调试以找到位置。
然后去IDA直接反编译,如下(位置在AppUtil.dll中.text:510EFB98附近)
这一段的逻辑还是很容易理解的。先读取各种User Data\Default\History文件,复制到Temp目录下的temphis.db。回去看看Procmom,果然。
之后操作就简单了,SQLite读取数据库,然后“select url from urls”,大家就知道是干什么的了。后面我就不多说了,有兴趣的可以自己看。
综上所述,QQ并没有刻意读取Chrome的历史,而是会尝试读取电脑上所有基于谷歌的浏览器的历史并提取链接。确认将招募的浏览器包括但不限于Chrome、Chromium、360极速、360安全、猎豹、2345等浏览器。这里@腾讯QQ
我会在晚上编辑它。刚试了TIM,果然是经典再现,比QQ还离谱。
查看全部
chrome 插件 抓取网页qq聊天记录(QQ会读取Chrome的历史记录,被火绒自定义规则拦截了
)
先说结论,QQ会读取浏览器的历史浏览记录,包括但不限于Chrome、Chromium、360极速、360安全、猎豹、2345等。

今天看到群里有个同学在v2ex()上发了个帖子,说QQ会读Chrome的历史,被火绒的自定义规则屏蔽了。我一开始不相信,但他说他又出现了,而且QQ登录后只有10分钟才能访问。
我想验证一下,打开虚拟机安装QQ、Chrome,然后打开Process Monitor启动等等。规则被简单地过滤。
果然看到了读取AppData\Local\Google\Chrome\User Data\Default\History等目录的操作。
而且时间正好十分钟。

这才是QQ和Chrome打不通的实锤。我不相信。我把规则删了,又查了一遍,发现QQ被冤枉了。
受害者的数量令人震惊。仔细看,这个东西会遍历Appdata\Local\下的所有文件夹,然后添加User Data\Default\History来读取。User Data\Default\History 是谷歌浏览器默认的历史记录存储位置(火狐等浏览器对该目录不熟悉,Chrome被拍是正常的。
那么就该研究一下QQ为什么会这样了,浏览器历史记录又是怎么读取的呢?
连接 x32dbg 并动态调试以找到位置。
然后去IDA直接反编译,如下(位置在AppUtil.dll中.text:510EFB98附近)
这一段的逻辑还是很容易理解的。先读取各种User Data\Default\History文件,复制到Temp目录下的temphis.db。回去看看Procmom,果然。
之后操作就简单了,SQLite读取数据库,然后“select url from urls”,大家就知道是干什么的了。后面我就不多说了,有兴趣的可以自己看。
综上所述,QQ并没有刻意读取Chrome的历史,而是会尝试读取电脑上所有基于谷歌的浏览器的历史并提取链接。确认将招募的浏览器包括但不限于Chrome、Chromium、360极速、360安全、猎豹、2345等浏览器。这里@腾讯QQ
我会在晚上编辑它。刚试了TIM,果然是经典再现,比QQ还离谱。
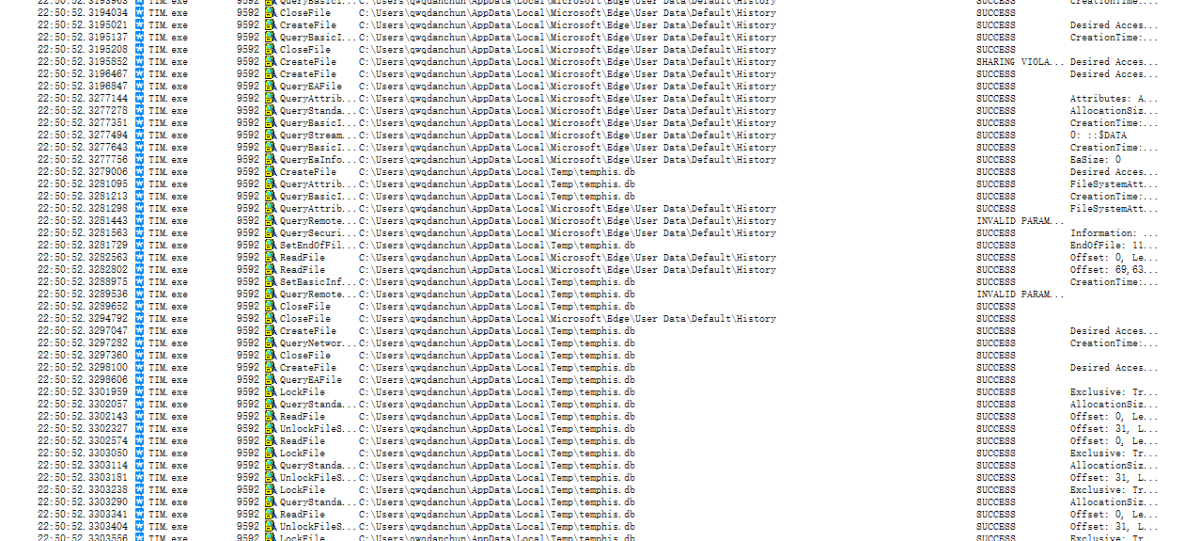
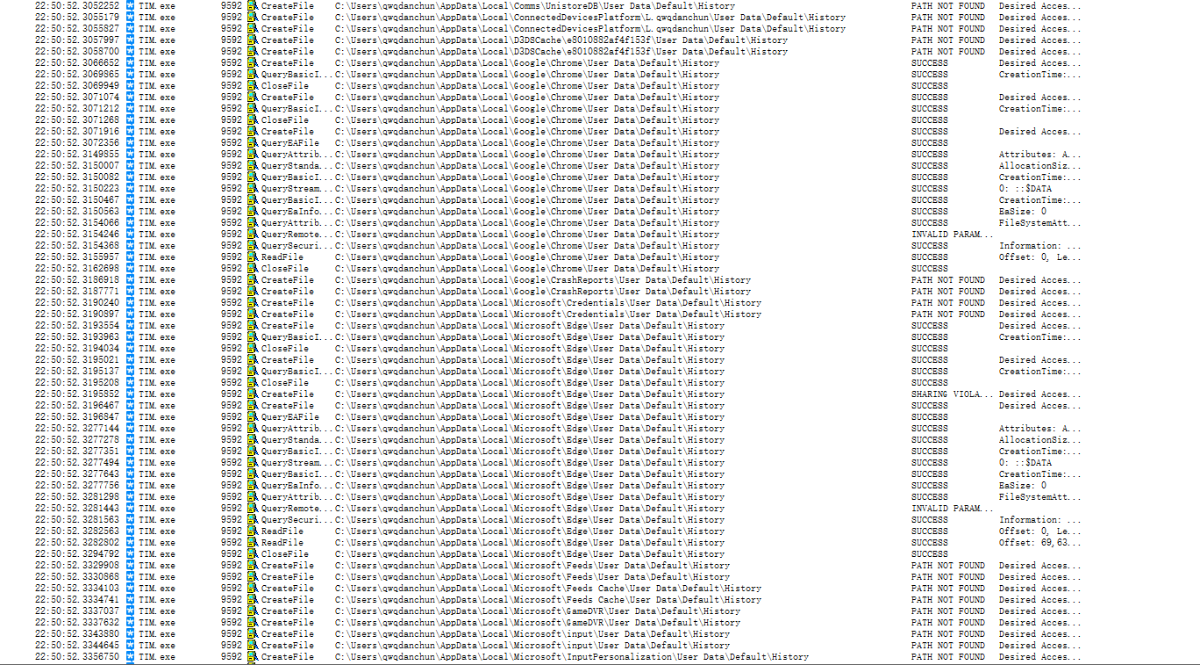
chrome 插件 抓取网页qq聊天记录(文章目录仓库地址github仓库(Plus)功能介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-06 04:08
文章目录
仓库地址
github仓库
前言
作为技术人员,录制博客是一件很平常的事情。他们大多使用markdown作为首选的录制方式,录制的博客一般发布在CSDN、博客园、简书、知乎等平台。
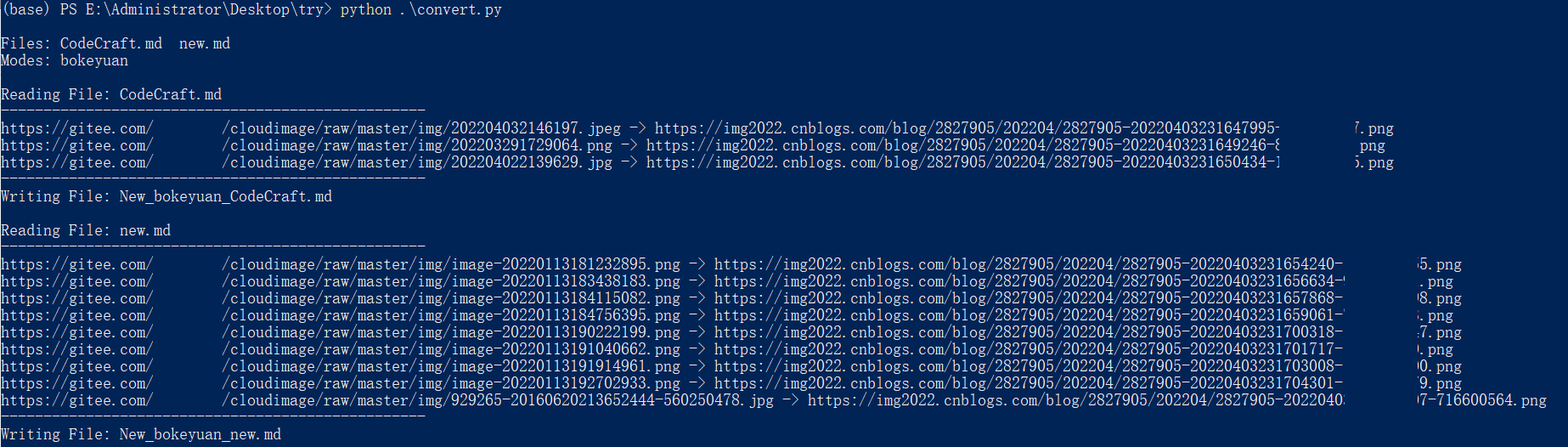
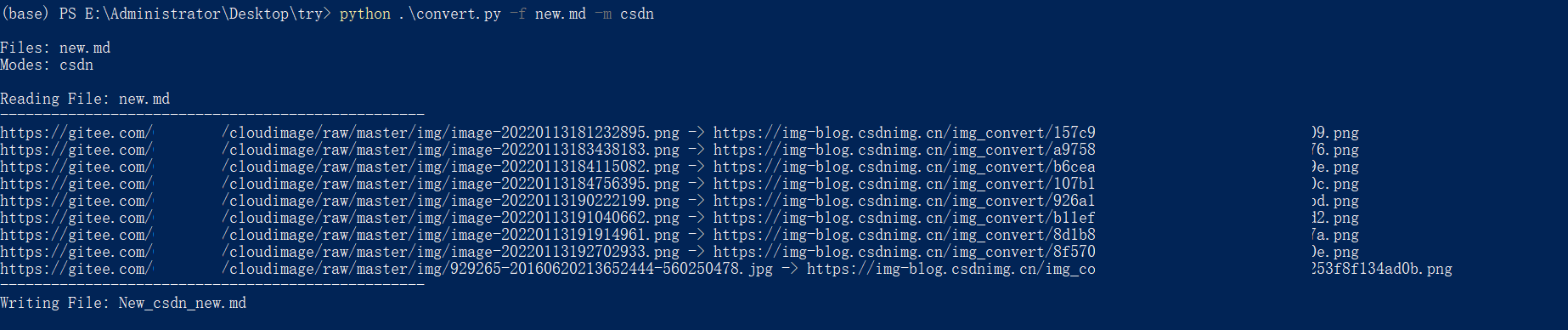
写博客往往离不开图片。对于本地写的博客,如果直接上传引用图片到云端,引用链接而不是本地路径,博客的文件结构可以更加简洁,不会出现图片无法访问的情况移动的路径。所以现在写博客的时候,一般都是使用图床转换工具,直接把贴图上传到云端。比如 Typora 中使用的 PicGO 插件,配合 Gitee 仓库,可以轻松创建自己的图床。
但是在具体使用过程中,我发现Gitee仓库中的图片在被其他平台引用后经常无法显示,导致我上传到上述平台的博客无法正常访问。为了结束这个问题,我自己做了一个脚本,可以将本地/网络图片转换为常用的博客网站图床,并生成链接替换markdown文件中的原创图片路径。
可以理解为脚本的功能就是PicGO Plus。(接下来就是做个PicGO插件直接用,这样最好)
特征
目前脚本支持CSDN、博客园、B站、知乎、简书五个平台。具体功能包括:
支持读取指定的单个markdown文件或默认根目录下的所有markdown文件支持configs文件设置单个/多个图床平台支持命令行参数设置指定图床平台支持直接上传md文档中本地图片(<< @知乎) 支持md文档中网络图片直接转换(所有平台) 支持md文档中本地/网络图片混合转换(知乎除外) 支持原地替换,写入所有识别转换后的图片链接使用 Method1. 安装依赖
除了python基础依赖库,这个脚本还需要安装requests和requests_toolbelt库:
pip install requests
pip install requests_toolbelt
安装完成后,脚本就可以正常使用了
2. 个人配置
在该目录下的 configs.py 文件中,用户可以配置自己的脚本。配置说明如下:
一种。配置默认图像床
默认图床网站可以在configs.py文件第11行配置,使用的图床必须从以下5种中选择。可以设置一个或多个,可以根据表格样式进行配置。
这里推荐使用CSDN,因为当前测量不需要频繁更换cookies,可以稳定使用。
湾。配置登录 cookie
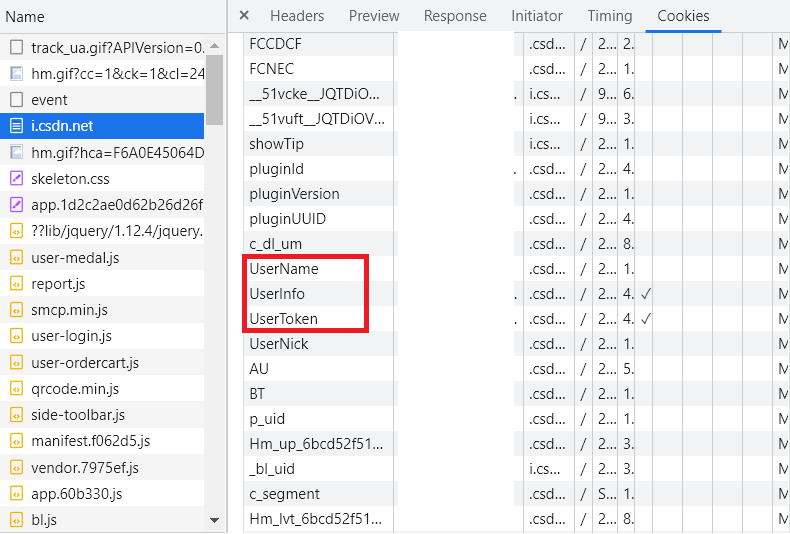
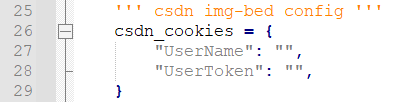
因为每个使用的服务商图床都需要登录cookies,所以用户需要进入自己的浏览器抓包获取对应的字段cookie并填写。
下面介绍如何获取各个浏览器的cookie:
CSDN
登录自己的CSDN,然后进入个人中心(),打开浏览器的开发者工具(chrome默认ctrl+alt+I),找到UserName和UserToken,复制对应的值。
然后粘贴到第26行的csdn_cookies中,完成配置。
知乎
登录你的知乎,然后进入首页(),打开浏览器的开发者工具,找到z_c0,复制对应的值,然后在第33行填写对应的知乎_cookies,完成配置。
知乎的图片默认支持三种,src、watermark_src、original_src,watermark_src为水印原图,original_src为原图,src为显示图,用户可自行选择。
b站
登录自己的b站,然后进入首页(),打开浏览器的开发者工具,找到SESSDATA,复制对应的值,然后在第41行填写对应的bili_cookies,完成配置。
短书
登录你的简书,然后进入首页(),打开浏览器的开发者工具,找到remember_user_token和_m7e_session_core字段,复制对应的值,然后填写第47行对应的jianshu_cookies即可完成配置。
博客公园
登录你的博客园,然后进入首页(),打开浏览器的开发者工具,找到.Cnblogs.AspNetCore.Cookies字段,复制对应的值,然后在第53行填写对应的bokeyuan_cookies,完成配置.
3. 命令行调用
脚本的使用方法是:
python convert.py
使用该命令后,会默认读取当前脚本所在目录下的所有md文件,并会一一读取扫描的图片链接或本地路径。根据配置中指定的转换方式,转换后的输出为{New_(mode)_(original name)}。
如果需要指定转换后的文件,使用命令:
python convert.py -f new.md
而如果默认转换图床不适用,则需要另外指定转换图床,使用命令:
python convert.py -m csdn
这两个参数可以同时指定,转换效果如下:
代码解析
稍后更新
免责声明:本文仅用于技术讨论,基于本文技术的任何违规和违规行为与本人无关。
如果您有任何问题或错误,请随时给我发私信以纠正我。 查看全部
chrome 插件 抓取网页qq聊天记录(文章目录仓库地址github仓库(Plus)功能介绍(图))
文章目录
仓库地址
github仓库
前言
作为技术人员,录制博客是一件很平常的事情。他们大多使用markdown作为首选的录制方式,录制的博客一般发布在CSDN、博客园、简书、知乎等平台。
写博客往往离不开图片。对于本地写的博客,如果直接上传引用图片到云端,引用链接而不是本地路径,博客的文件结构可以更加简洁,不会出现图片无法访问的情况移动的路径。所以现在写博客的时候,一般都是使用图床转换工具,直接把贴图上传到云端。比如 Typora 中使用的 PicGO 插件,配合 Gitee 仓库,可以轻松创建自己的图床。
但是在具体使用过程中,我发现Gitee仓库中的图片在被其他平台引用后经常无法显示,导致我上传到上述平台的博客无法正常访问。为了结束这个问题,我自己做了一个脚本,可以将本地/网络图片转换为常用的博客网站图床,并生成链接替换markdown文件中的原创图片路径。
可以理解为脚本的功能就是PicGO Plus。(接下来就是做个PicGO插件直接用,这样最好)
特征
目前脚本支持CSDN、博客园、B站、知乎、简书五个平台。具体功能包括:
支持读取指定的单个markdown文件或默认根目录下的所有markdown文件支持configs文件设置单个/多个图床平台支持命令行参数设置指定图床平台支持直接上传md文档中本地图片(<< @知乎) 支持md文档中网络图片直接转换(所有平台) 支持md文档中本地/网络图片混合转换(知乎除外) 支持原地替换,写入所有识别转换后的图片链接使用 Method1. 安装依赖
除了python基础依赖库,这个脚本还需要安装requests和requests_toolbelt库:
pip install requests
pip install requests_toolbelt
安装完成后,脚本就可以正常使用了
2. 个人配置
在该目录下的 configs.py 文件中,用户可以配置自己的脚本。配置说明如下:
一种。配置默认图像床

默认图床网站可以在configs.py文件第11行配置,使用的图床必须从以下5种中选择。可以设置一个或多个,可以根据表格样式进行配置。
这里推荐使用CSDN,因为当前测量不需要频繁更换cookies,可以稳定使用。
湾。配置登录 cookie
因为每个使用的服务商图床都需要登录cookies,所以用户需要进入自己的浏览器抓包获取对应的字段cookie并填写。
下面介绍如何获取各个浏览器的cookie:
CSDN
登录自己的CSDN,然后进入个人中心(),打开浏览器的开发者工具(chrome默认ctrl+alt+I),找到UserName和UserToken,复制对应的值。
然后粘贴到第26行的csdn_cookies中,完成配置。
知乎
登录你的知乎,然后进入首页(),打开浏览器的开发者工具,找到z_c0,复制对应的值,然后在第33行填写对应的知乎_cookies,完成配置。
知乎的图片默认支持三种,src、watermark_src、original_src,watermark_src为水印原图,original_src为原图,src为显示图,用户可自行选择。
b站
登录自己的b站,然后进入首页(),打开浏览器的开发者工具,找到SESSDATA,复制对应的值,然后在第41行填写对应的bili_cookies,完成配置。
短书
登录你的简书,然后进入首页(),打开浏览器的开发者工具,找到remember_user_token和_m7e_session_core字段,复制对应的值,然后填写第47行对应的jianshu_cookies即可完成配置。
博客公园
登录你的博客园,然后进入首页(),打开浏览器的开发者工具,找到.Cnblogs.AspNetCore.Cookies字段,复制对应的值,然后在第53行填写对应的bokeyuan_cookies,完成配置.
3. 命令行调用
脚本的使用方法是:
python convert.py
使用该命令后,会默认读取当前脚本所在目录下的所有md文件,并会一一读取扫描的图片链接或本地路径。根据配置中指定的转换方式,转换后的输出为{New_(mode)_(original name)}。
如果需要指定转换后的文件,使用命令:
python convert.py -f new.md
而如果默认转换图床不适用,则需要另外指定转换图床,使用命令:
python convert.py -m csdn
这两个参数可以同时指定,转换效果如下:
代码解析
稍后更新
免责声明:本文仅用于技术讨论,基于本文技术的任何违规和违规行为与本人无关。
如果您有任何问题或错误,请随时给我发私信以纠正我。
chrome 插件 抓取网页qq聊天记录(不少,网页抓取这几个核心关键进行讲解分享(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-05 21:22
总结:RSSHub 是一个制作 RSS 提要的工具。与Huginn、Feed43等工具类似,RSSHub也是通过爬取大部分网站上的网页来获取Feed,不同的是在RSSHub中已经完成了爬取规则的编写,用户只需要简单的编辑地址以下。如果您对 RSSHub 感兴趣,欢迎或我们。
很多人都想知道如何在网上翻找 RSS 链接?最好用这个Chrome插件一键订阅本主题的相关知识内容。今天小编就围绕rss和网页爬取的核心key进行讲解和分享,希望对有相关需求的朋友有所帮助。在网上搜索 RSS 链接?最好使用这个Chrome插件订阅具体内容如下。
在网上搜索 RSS 链接?最好用这个Chrome插件一键订阅
RSSHub 是用于设计和生成 RSS 提要的工具。与 Huginn、Feed43 等工具类似,RSSHub 也是通过抓取大多数 网站 网站上的网页来获取 feed。不同的是,在 RSSHub 中,爬虫规则的编写已经完成。用户只需编辑地址即可。
例如,我想在 YouTube 上订阅 Linus Tech Tips 的多媒体视频。我在网页上发现LTT的用户名是“LinusTechTips”。根据 RSSHub 的官方文档,我只需要订阅 /i/subion/feed/ /feed/atom.xml
加入我们
如果您对 RSSHub 感兴趣,欢迎或我们。 查看全部
chrome 插件 抓取网页qq聊天记录(不少,网页抓取这几个核心关键进行讲解分享(图))
总结:RSSHub 是一个制作 RSS 提要的工具。与Huginn、Feed43等工具类似,RSSHub也是通过爬取大部分网站上的网页来获取Feed,不同的是在RSSHub中已经完成了爬取规则的编写,用户只需要简单的编辑地址以下。如果您对 RSSHub 感兴趣,欢迎或我们。
很多人都想知道如何在网上翻找 RSS 链接?最好用这个Chrome插件一键订阅本主题的相关知识内容。今天小编就围绕rss和网页爬取的核心key进行讲解和分享,希望对有相关需求的朋友有所帮助。在网上搜索 RSS 链接?最好使用这个Chrome插件订阅具体内容如下。

在网上搜索 RSS 链接?最好用这个Chrome插件一键订阅
RSSHub 是用于设计和生成 RSS 提要的工具。与 Huginn、Feed43 等工具类似,RSSHub 也是通过抓取大多数 网站 网站上的网页来获取 feed。不同的是,在 RSSHub 中,爬虫规则的编写已经完成。用户只需编辑地址即可。
例如,我想在 YouTube 上订阅 Linus Tech Tips 的多媒体视频。我在网页上发现LTT的用户名是“LinusTechTips”。根据 RSSHub 的官方文档,我只需要订阅 /i/subion/feed/ /feed/atom.xml
加入我们
如果您对 RSSHub 感兴趣,欢迎或我们。
chrome 插件 抓取网页qq聊天记录(谷歌浏览器统计插件-timeStatschrome插件功能和安装方法介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-04-04 19:10
)
小编为使用谷歌浏览器的朋友采集了一个网站停留时间统计插件timeStats chrome插件。通过这个插件,用户可以知道在网站上花费的时间和时间。每个网站的具体停留时间等信息以图表的形式呈现。以下内容为您介绍timeStats chrome插件的功能及安装方法,请参考。特征:
1、每月统计:显示每月访问网站统计
2、 最忙的日子:浏览网页的时间最长
3、访问网站:来自您浏览的完整统计数据
4、每日统计:显示当天访问的 网站 的统计信息
5、花费时间:显示您每天浏览所花费的总时间
6、Most Visited Domains:最常访问域的完整列表
7、网站Stats:显示安装时间统计时您在特定网站上花费的时间
8、类别:您可以将您的 网站 分类为您可以自己命名的类别
TimeStats chrome插件安装方法:
1、第一步在标签页输入【chrome://extensions/】进入chrome扩展,解压你要下载的timeStats chrome插件包,拖入扩展页面.
2、安装完成后,关闭自动弹出的介绍页面,进入网页试试效果。
知识扩展:
如何删除 chrome 插件?
1、在浏览器右上角,找到要删除的插件,然后右键,在弹出的菜单中选择Delete from Chrome,即可删除插件
2、上面的方法是一个一个删除插件的方法。如果要一次删除多个插件,可以进入插件管理器
3、在打开的页面,点击垃圾桶删除插件。当然,如果你觉得这个插件以后会有用,但是你担心一旦插件被删除,以后不知道去哪里找了。暂停插件的选项,只是取消它
timeStats chrome插件体积小,安装方便。这是一个非常实用的时间统计插件。需要的不要错过。
界面预览:
查看全部
chrome 插件 抓取网页qq聊天记录(谷歌浏览器统计插件-timeStatschrome插件功能和安装方法介绍
)
小编为使用谷歌浏览器的朋友采集了一个网站停留时间统计插件timeStats chrome插件。通过这个插件,用户可以知道在网站上花费的时间和时间。每个网站的具体停留时间等信息以图表的形式呈现。以下内容为您介绍timeStats chrome插件的功能及安装方法,请参考。特征:
1、每月统计:显示每月访问网站统计
2、 最忙的日子:浏览网页的时间最长
3、访问网站:来自您浏览的完整统计数据
4、每日统计:显示当天访问的 网站 的统计信息
5、花费时间:显示您每天浏览所花费的总时间
6、Most Visited Domains:最常访问域的完整列表
7、网站Stats:显示安装时间统计时您在特定网站上花费的时间
8、类别:您可以将您的 网站 分类为您可以自己命名的类别
TimeStats chrome插件安装方法:
1、第一步在标签页输入【chrome://extensions/】进入chrome扩展,解压你要下载的timeStats chrome插件包,拖入扩展页面.

2、安装完成后,关闭自动弹出的介绍页面,进入网页试试效果。
知识扩展:
如何删除 chrome 插件?
1、在浏览器右上角,找到要删除的插件,然后右键,在弹出的菜单中选择Delete from Chrome,即可删除插件

2、上面的方法是一个一个删除插件的方法。如果要一次删除多个插件,可以进入插件管理器

3、在打开的页面,点击垃圾桶删除插件。当然,如果你觉得这个插件以后会有用,但是你担心一旦插件被删除,以后不知道去哪里找了。暂停插件的选项,只是取消它

timeStats chrome插件体积小,安装方便。这是一个非常实用的时间统计插件。需要的不要错过。
界面预览:

chrome 插件 抓取网页qq聊天记录(5款可以提升工作效率的Chrome插件,你值得拥有!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-04 17:17
今天给大家推荐5款可以提高工作效率的Chrome插件。
全方位
这个 Chrome 插件可以快速搜索、切换和关闭浏览器书签、Tab 页和历史记录。
当我们同时打开多个Tab页时,切换到某个Tab页是很麻烦的。在Omni输入框中,只需输入关键字“/tabs”,然后追加关键字即可快速查询Tab,回车即可切换Tab。
另外,关键字“/bookmarks”用于快速切换搜索书签,“/history”用于切换历史记录,“/remove”可用于关闭Tab或删除书签
为了提高使用效率,建议为Omni设置快捷键,在地址栏中输入“chrome://extensions/shortcuts”,并为Omni指定一个热键,例如:Ctrl + Shift + K
当然,Omni也有很多实用的功能,比如:页面静音、Tab pinning、管理插件等,大家可以自己扩展
CSS 窥视器
CSS Peeper,一个提取网页样式的插件
作为CSS查看器,可以直观高效的获取网页元素的属性、宽度、高度、字体样式
使用方法很简单,只需点击插件,用鼠标点击网页上的一个控件,右上角就会显示目标元素的CSS样式属性。
JSON查看器专业版
在Chrome应用市场上,JSON格式化插件很多,但是这个插件除了常规功能外还包括样式自定义、“图表视图”展示等功能,用户体验更好。
另外这个插件可以随意选择一个节点,复制Path路径和Value值
历史趋势无限
这是一个历史管理插件,可以将历史浏览记录“永久”保存到本地数据库,并生成排名列表和统计报表图表。比如可以按时间段列出访问量前十名网站
此外,还可以通过关键字查询历史浏览记录
在设置中可以导入导出历史记录,配置自动备份的周期
阿贾克斯拦截器
本插件可以修改ajax请求的返回结果,一般用于Mock数据,接口联调测试
使用起来很简单。只需打开插件开关,然后将要拦截的请求地址匹配为全地址或正则地址,最后加上需要返回的请求结果,这样就可以修改请求的响应结果了完全的。
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。
二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python常用的开发软件就到这里,为大家节省不少时间。
三、介绍视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。
五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节跳动等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。
本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方CSDN官方认证二维码免费获取【保证100%免费】
Python资料、技术、课程、解答、咨询也可以直接点击下方名片添加官方客服思琪↓ 查看全部
chrome 插件 抓取网页qq聊天记录(5款可以提升工作效率的Chrome插件,你值得拥有!)
今天给大家推荐5款可以提高工作效率的Chrome插件。
全方位

这个 Chrome 插件可以快速搜索、切换和关闭浏览器书签、Tab 页和历史记录。
当我们同时打开多个Tab页时,切换到某个Tab页是很麻烦的。在Omni输入框中,只需输入关键字“/tabs”,然后追加关键字即可快速查询Tab,回车即可切换Tab。
另外,关键字“/bookmarks”用于快速切换搜索书签,“/history”用于切换历史记录,“/remove”可用于关闭Tab或删除书签
为了提高使用效率,建议为Omni设置快捷键,在地址栏中输入“chrome://extensions/shortcuts”,并为Omni指定一个热键,例如:Ctrl + Shift + K
当然,Omni也有很多实用的功能,比如:页面静音、Tab pinning、管理插件等,大家可以自己扩展
CSS 窥视器

CSS Peeper,一个提取网页样式的插件
作为CSS查看器,可以直观高效的获取网页元素的属性、宽度、高度、字体样式
使用方法很简单,只需点击插件,用鼠标点击网页上的一个控件,右上角就会显示目标元素的CSS样式属性。
JSON查看器专业版

在Chrome应用市场上,JSON格式化插件很多,但是这个插件除了常规功能外还包括样式自定义、“图表视图”展示等功能,用户体验更好。
另外这个插件可以随意选择一个节点,复制Path路径和Value值
历史趋势无限

这是一个历史管理插件,可以将历史浏览记录“永久”保存到本地数据库,并生成排名列表和统计报表图表。比如可以按时间段列出访问量前十名网站
此外,还可以通过关键字查询历史浏览记录
在设置中可以导入导出历史记录,配置自动备份的周期
阿贾克斯拦截器
本插件可以修改ajax请求的返回结果,一般用于Mock数据,接口联调测试
使用起来很简单。只需打开插件开关,然后将要拦截的请求地址匹配为全地址或正则地址,最后加上需要返回的请求结果,这样就可以修改请求的响应结果了完全的。
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。

二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python常用的开发软件就到这里,为大家节省不少时间。

三、介绍视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。

四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。

五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节跳动等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。


本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方CSDN官方认证二维码免费获取【保证100%免费】

Python资料、技术、课程、解答、咨询也可以直接点击下方名片添加官方客服思琪↓
5个可以直接下载Chrome插件的网站,真香
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-05-07 17:10
02. 扩展迷
资源丰富,同时还提供了日榜单、周榜单、月榜单和总榜单等数据排行,帮助大家发现最新有趣的插件。另外,注意截图中红色部分,看我发现了什么?
03.Chrome插件网
更新速度非常快,而且还提供了许多非常有用的教程文章,比如:五种百度云盘下载速度慢解决方法……
04. 插件网
老牌的chrome插件搬运网站,提供了插件分类、插件推荐、插件百科、插件排行等四大板块,里面也有许多非常有意思的总结性文章,比如:chrome比价插件哪个更好用?亲自测试使用总结 Chrome插件。
05. 我爱chrome插件网
有是一个非常棒的chrome插件下载网站,提供64位离线版下载服务,直接点击即可下载! 查看全部
5个可以直接下载Chrome插件的网站,真香
02. 扩展迷
资源丰富,同时还提供了日榜单、周榜单、月榜单和总榜单等数据排行,帮助大家发现最新有趣的插件。另外,注意截图中红色部分,看我发现了什么?
03.Chrome插件网
更新速度非常快,而且还提供了许多非常有用的教程文章,比如:五种百度云盘下载速度慢解决方法……
04. 插件网
老牌的chrome插件搬运网站,提供了插件分类、插件推荐、插件百科、插件排行等四大板块,里面也有许多非常有意思的总结性文章,比如:chrome比价插件哪个更好用?亲自测试使用总结 Chrome插件。
05. 我爱chrome插件网
有是一个非常棒的chrome插件下载网站,提供64位离线版下载服务,直接点击即可下载!
超实用的 Chrome 插件,保存网页中喜欢的图片
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-05-07 17:02
1. 要开发的是什么项目?
1.1 想法开端
在 pixiv 翻图时看到一些喜欢的插画,看完就随手翻过去了,没有保存。为什么呢? 因为以我对自己的了解,图片下载下来,就相当于放进了垃圾桶。 并不是因为本地的文件管理有多乱,而是因为,几乎没有用鼠标打开文件管理器的习惯。
现在我获取信息的流量入口最常用的只有两个,即终端和浏览器。于是乎,一个想法油然而生:
“
把插画存到浏览器吧!
于是就立刻构思,动手写了这款插件。
1.2 应该有什么功能?
功能很简单:
2. 开发需要解决的核心问题
“
核心问题有两个,一个是数据云存储问题,一个是图片防盗链问题。
云存储问题,帐号系统,多端同步
最开始只想做浏览器本地的存储,使用 Chrome 提供的 localStorage 存在本地就。后来因为 localStorage 并不支持数据库语法查询,有很多不便。使用过程中又发现多端同步在体验上的优越性,决定要把存储放到云上。
图片防盗链问题
看了些资料,解决方式基本可以分为两种。
一类使用前端 js 嵌入 iframe 解决,优点是解决方式简单,问题是 Chrome 插件不支持页面嵌入式的 js 脚本。所以这个方案 pass。
第二类使用后台服务器做反防盗链措施,作为中转给前端使用。优点是不受 chrome 插件的各种安全机制的限制,缺点是需要后台支持,增加工作量和资源成本。使用第二类完成。
3. 具体解决方案
“
云存储及帐号系统使用 LeanCloud 提供的存储服务解决。
反防盗链接口使用 LeanCloud 提供的云引擎搭建 NodJs 后台。
啰嗦一句,为什么要使用 LeanCloud?
一是对我的需求可以做到完全免费,二是它们的文档实在是太xx的好用了。
3.1 帐号系统
参照:数据存储入门教程 · JavaScript
实现过程基本照抄这个教程的代码。后台账号系统包括对账号的重复检测、密码加密、session 等都已经实现。
“
我们要做的,就是调用前端的这几个关键方法,实现简单的注册、登陆、退出:
3.2 存储服务
“
使用账号系统为每个用户添加身份信息后,存储部分就只需要把数据+用户身份信息一同上传或下载就可以了。
照样只贴关键方法:
3.3 使用 LeanEngine 做反防盗链中转接口
要实现的效果是:
“
主要原理很简单,后台处理图片请求时更改 header 中的 referer 字段,将结果作为 response 返回。
关于这部分的实现,欢迎阅读我的另一篇文章,就不再赘述:
服务器作防盗链图片中转,nodejs 上手项目简明教程。
关于 LeanEngin 的使用,文档如下,使用方法非常简单。
云引擎快速入门:
云引擎支持 NodeJSPythonPHPJAVA
只需要下载云引擎命令行工具 lean,然后输入几行命令就可以建立一个你熟悉的 web 框架。然后,使用你熟悉的语言编写反防盗链实现就行了。
3.4 Chrome 插件实现
“
有了 3.1~3.3 的实现,这部分就是简单的插件部署和业务逻辑了。
Chrome 插件结构如图:
主要业务:
具体实现见我的 github 项目:插件 Web Store 地址:
4. 最后,对去后端化的看法
前段时间在知乎上看到了一个问题,我也顺便说下自己的看法。
“
web 后端会不会变得越来越不需要?
像 bmob 和 leancloud 这类后台云服务的流行有一段日子了,使用这些服务使一些 web、app 的开发周期大大缩减。这对于小团队和初创公司尤为方便。
但这并不意味着不再需要自己开发后台。不是因为他们提供的服务不够全面(相反,我倒认为这类服务将向着全面、便捷、快速发展),而是因为很多公司和产品,为了保持服务的质量和稳定,突出自己产品的特性,需要自己定制自己的后台,有针对性的去优化某些模块。云服务作为大众服务平台难以为每个产品做定制。
类似于游戏引擎,如今各个平台都不缺乏优秀的游戏引擎。可是仍有公司和团队耗费大量的成本自研游戏引擎,就是希望能配合自己的游戏系统,完美地展现自己的游戏。
一样的,后台云服务和自定制的后台,是相交但永远不会重合的关系。 他们彼此之间相互影响,共同进步。
原文链接:
end
更多内容请关注「LeanCloud通讯」
查看全部
超实用的 Chrome 插件,保存网页中喜欢的图片
1. 要开发的是什么项目?
1.1 想法开端
在 pixiv 翻图时看到一些喜欢的插画,看完就随手翻过去了,没有保存。为什么呢? 因为以我对自己的了解,图片下载下来,就相当于放进了垃圾桶。 并不是因为本地的文件管理有多乱,而是因为,几乎没有用鼠标打开文件管理器的习惯。
现在我获取信息的流量入口最常用的只有两个,即终端和浏览器。于是乎,一个想法油然而生:
“
把插画存到浏览器吧!
于是就立刻构思,动手写了这款插件。
1.2 应该有什么功能?
功能很简单:
2. 开发需要解决的核心问题
“
核心问题有两个,一个是数据云存储问题,一个是图片防盗链问题。
云存储问题,帐号系统,多端同步
最开始只想做浏览器本地的存储,使用 Chrome 提供的 localStorage 存在本地就。后来因为 localStorage 并不支持数据库语法查询,有很多不便。使用过程中又发现多端同步在体验上的优越性,决定要把存储放到云上。
图片防盗链问题
看了些资料,解决方式基本可以分为两种。
一类使用前端 js 嵌入 iframe 解决,优点是解决方式简单,问题是 Chrome 插件不支持页面嵌入式的 js 脚本。所以这个方案 pass。
第二类使用后台服务器做反防盗链措施,作为中转给前端使用。优点是不受 chrome 插件的各种安全机制的限制,缺点是需要后台支持,增加工作量和资源成本。使用第二类完成。
3. 具体解决方案
“
云存储及帐号系统使用 LeanCloud 提供的存储服务解决。
反防盗链接口使用 LeanCloud 提供的云引擎搭建 NodJs 后台。
啰嗦一句,为什么要使用 LeanCloud?
一是对我的需求可以做到完全免费,二是它们的文档实在是太xx的好用了。
3.1 帐号系统
参照:数据存储入门教程 · JavaScript
实现过程基本照抄这个教程的代码。后台账号系统包括对账号的重复检测、密码加密、session 等都已经实现。
“
我们要做的,就是调用前端的这几个关键方法,实现简单的注册、登陆、退出:
3.2 存储服务
“
使用账号系统为每个用户添加身份信息后,存储部分就只需要把数据+用户身份信息一同上传或下载就可以了。
照样只贴关键方法:
3.3 使用 LeanEngine 做反防盗链中转接口
要实现的效果是:
“
主要原理很简单,后台处理图片请求时更改 header 中的 referer 字段,将结果作为 response 返回。
关于这部分的实现,欢迎阅读我的另一篇文章,就不再赘述:
服务器作防盗链图片中转,nodejs 上手项目简明教程。
关于 LeanEngin 的使用,文档如下,使用方法非常简单。
云引擎快速入门:
云引擎支持 NodeJSPythonPHPJAVA
只需要下载云引擎命令行工具 lean,然后输入几行命令就可以建立一个你熟悉的 web 框架。然后,使用你熟悉的语言编写反防盗链实现就行了。
3.4 Chrome 插件实现
“
有了 3.1~3.3 的实现,这部分就是简单的插件部署和业务逻辑了。
Chrome 插件结构如图:
主要业务:
具体实现见我的 github 项目:插件 Web Store 地址:
4. 最后,对去后端化的看法
前段时间在知乎上看到了一个问题,我也顺便说下自己的看法。
“
web 后端会不会变得越来越不需要?
像 bmob 和 leancloud 这类后台云服务的流行有一段日子了,使用这些服务使一些 web、app 的开发周期大大缩减。这对于小团队和初创公司尤为方便。
但这并不意味着不再需要自己开发后台。不是因为他们提供的服务不够全面(相反,我倒认为这类服务将向着全面、便捷、快速发展),而是因为很多公司和产品,为了保持服务的质量和稳定,突出自己产品的特性,需要自己定制自己的后台,有针对性的去优化某些模块。云服务作为大众服务平台难以为每个产品做定制。
类似于游戏引擎,如今各个平台都不缺乏优秀的游戏引擎。可是仍有公司和团队耗费大量的成本自研游戏引擎,就是希望能配合自己的游戏系统,完美地展现自己的游戏。
一样的,后台云服务和自定制的后台,是相交但永远不会重合的关系。 他们彼此之间相互影响,共同进步。
原文链接:
end
更多内容请关注「LeanCloud通讯」
Chrome浏览器最强插件配置网站--开眼见世界
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-05-04 20:02
Chrome浏览器最强插件配置网站--开眼见世界一、前言
公众号交流群里面很多小伙伴问过我如何没有限制的科学访问国外学术网站,我之前推荐过集装箱,但是很多小伙伴都觉得不稳定,于是我又推荐了Ghelper助手,可惜并没有很多人看到,我也不想再去找其他的,所以我直接找到一个国内即可访问的Chrome插件网站,市面上所有你想要的插件以及热门插件里面都有,当然,也有大家想要用来开眼看世界的插件,具体安装教程和其他插件没有区别,大家按照之前我写的教程访问即可!
image-207783
image-203960
PS:该网站里面的插件我也测试过,确定有大家所需的,百分百能开眼看世界!因为怕网址放到文章中会被封,所以大家公众号内回复:世界 ,即可获取该网站的网址。
记住!假如一个插件不行你就换另外一个!一个服务器不行你就换其他国家的服务器,直到找到你能用的为止!
这里是你我的灿烂人生,觉得教程对你有用的话,可以关注、点赞、转发三连支持一波!
二、具体使用教程
因为怕网址放到文章中会被封,所以大家公众号内回复:世界 ,即可获取该网站的网址。打开如下所示:
image-248870
这是一个英文网址,其中排在前列的免费插件,都可以用来开眼看世界学术,都是可以免费下载并使用的,这里我选择其中一个我之前没有介绍过的作为测试:
我们点击刚刚上一张图片最下方所示的蓝色链接字体:download 进入到下载界面:
image-226354
这里我们选择从Crx4Chrome蓝色字体下载:
image-210137
这里会自动弹出下载界面,我们选择保存即可!然后我们在Chrome浏览器下方选择在文件夹中打开:
image-246635
记住格式必须是Crx文件!!!
image-221793
我们到浏览器界面安装Crx插件即可!具体过程不多表述,和之前集装箱教程差不多,不记得的同学点开之前文章回顾即可!
image-230946
直接把文件拖过去安装即可!
image-227954
image-253867
image-203429
将其固定到插件访问页面(不记得的请自行百度或者看集装箱那篇文章)
image-204666
点一下插件,进来后我们先选择语言:
image-215093
创建账户我就不多说了。
image-258617
注册然后登陆成功后会弹出如下界面,可以保存一下Auth-Code。
image-253712
任选其一即可!
image-227025
点击一个地方的服务器等待加载完成,一个地方不行就换另外一个!
image-253872
成功后提示如下:
image-252609
2021年3月21日下午19点半实测能访问Youtube。
image-212162三、总结
最后总结一下,该网站各类访问特殊地址以及各类Chrome插件都有,大家可以收藏这个网址,假如某个插件失效,你可以下载同类型插件替换即可!记住,所有的插件都有同类型的,可以自行替换,按照上述教程安装即可!
这里是你我的灿烂人生,觉得教程对你有用的话,可以关注、点赞、转发三连支持一波!
- END - 查看全部
Chrome浏览器最强插件配置网站--开眼见世界
Chrome浏览器最强插件配置网站--开眼见世界一、前言
公众号交流群里面很多小伙伴问过我如何没有限制的科学访问国外学术网站,我之前推荐过集装箱,但是很多小伙伴都觉得不稳定,于是我又推荐了Ghelper助手,可惜并没有很多人看到,我也不想再去找其他的,所以我直接找到一个国内即可访问的Chrome插件网站,市面上所有你想要的插件以及热门插件里面都有,当然,也有大家想要用来开眼看世界的插件,具体安装教程和其他插件没有区别,大家按照之前我写的教程访问即可!
image-207783
image-203960
PS:该网站里面的插件我也测试过,确定有大家所需的,百分百能开眼看世界!因为怕网址放到文章中会被封,所以大家公众号内回复:世界 ,即可获取该网站的网址。
记住!假如一个插件不行你就换另外一个!一个服务器不行你就换其他国家的服务器,直到找到你能用的为止!
这里是你我的灿烂人生,觉得教程对你有用的话,可以关注、点赞、转发三连支持一波!
二、具体使用教程
因为怕网址放到文章中会被封,所以大家公众号内回复:世界 ,即可获取该网站的网址。打开如下所示:
image-248870
这是一个英文网址,其中排在前列的免费插件,都可以用来开眼看世界学术,都是可以免费下载并使用的,这里我选择其中一个我之前没有介绍过的作为测试:
我们点击刚刚上一张图片最下方所示的蓝色链接字体:download 进入到下载界面:
image-226354
这里我们选择从Crx4Chrome蓝色字体下载:
image-210137
这里会自动弹出下载界面,我们选择保存即可!然后我们在Chrome浏览器下方选择在文件夹中打开:
image-246635
记住格式必须是Crx文件!!!
image-221793
我们到浏览器界面安装Crx插件即可!具体过程不多表述,和之前集装箱教程差不多,不记得的同学点开之前文章回顾即可!
image-230946
直接把文件拖过去安装即可!
image-227954
image-253867
image-203429
将其固定到插件访问页面(不记得的请自行百度或者看集装箱那篇文章)
image-204666
点一下插件,进来后我们先选择语言:
image-215093
创建账户我就不多说了。
image-258617
注册然后登陆成功后会弹出如下界面,可以保存一下Auth-Code。
image-253712
任选其一即可!
image-227025
点击一个地方的服务器等待加载完成,一个地方不行就换另外一个!
image-253872
成功后提示如下:
image-252609
2021年3月21日下午19点半实测能访问Youtube。
image-212162三、总结
最后总结一下,该网站各类访问特殊地址以及各类Chrome插件都有,大家可以收藏这个网址,假如某个插件失效,你可以下载同类型插件替换即可!记住,所有的插件都有同类型的,可以自行替换,按照上述教程安装即可!
这里是你我的灿烂人生,觉得教程对你有用的话,可以关注、点赞、转发三连支持一波!
- END -
不用在朋友圈学 Python,这款 Chrome 插件就能帮你完成网页抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-05-04 20:01
不知大家是否总能在朋友圈看到类似的广告,「加班完成的 Excel 用 Python 只需 3 分钟」、「每天都能准点下班只因学会了 Python」,似乎 Python 已经成为了当代年轻人的必备技能。
▲朋友圈广告的确,作为一门易于上手的编程语言,Python在自动化办公中用处巨大,特别是对于网页数据的爬取,在这样一个大数据时代显得尤为重要。爬取网页数据,也可以称为「网络爬虫」 ,能帮助我们快速搜集互联网的海量内容,从而进行深度的数据分析与挖掘。比如抓取各大网站的排行榜、抓取各大购物网站的价格信息等。而我们日常用的搜索引擎就是一个个「网络爬虫」。
但毕竟学习一门语言的成本太高了,有什么办法可以不学 Python 也能达到目的呢?当然有,借助 Chrome 浏览器的《Web Scraper》插件,让你在不用写代码的情况下,就能快速抓取海量内容。
优采云目录
抓取页面中的多条信息——BiliBili 排行榜为例安装《Web Scraper》后,在浏览器按 F12 进入开发者模式,就能在最后一个标签页看到《Web Scraper》的菜单。需要注意的是,如果开发者模式面板不在下方,则会提示必须将其放到浏览器下方才能继续。
在菜单中选择「Create new sitemap - Create sitemap」以创建新的 sitemap,填入名称与起始地址就可以开始了。这里以 BiliBili 排行榜为例,介绍如何抓取页面中的多条信息,起始地址设为「」。
这里我们需要抓取「视频标题」、「播放量」、「弹幕数」、「up 主」以及「综合得分」,因此首先为每一条记录创建一个封装器。点击「Add new selector」,id 填写「封装器」, type 选择「element」,然后点击「selector」,选择一条记录的外边框,外包框中需要包含上述所有信息,然后再选择第二条,这样就会发现页面中的所有记录都已自动选择,点击「Done selecting」完成数据的选择。还要记得勾选「Multiple」以保证抓取多条记录,最后保存该选择器即可。
返回后点击刚才的封装器,进入二级路径,创建「标题」选择器,id 填写「视频标题」,type 选择「text」,点击「selector」会发现第一条记录高亮显示,这是因为我们已提前将其设定为了封装器。选择包围框中的标题,再点击「Done selecting」完成标题的选择,注意这里不需要勾选「Multiple」,最后保存该选择器。
同样的,我们为「播放量」、「弹幕数」、「up 主」和「综合得分」分别建立选择器,选择后可以通过「Data preview」预览是否选中了想要的内容。另外还可以通过菜单栏中的「Sitemap bilibili_ranking - Selector graph」 直观地查看树状结构。
继续在刚才的菜单下选择「Scrape」开始创建抓取任务,单个网页的间隔时间和响应时间默认即可。点击「Start scraping」开始抓取。这时候浏览器会自动打开新的页面,停留数秒后自动关闭,代表抓取已完成。
点击「Refresh Data」刷新数据,或点击「Sitemap bilibili_ranking - Browse」查看数据。通过「Sitemap bilibili_ranking - Export data as CSV」即可下载为 CSV 格式文件。
▲BiliBili 排行榜使用 Excel 打开,由于《Web Scraper》抓取的内容是无序的,因此需要对「综合得分」进行降序排列,以恢复原始排行榜的结果。
自动翻页抓取——豆瓣电影 Top250 为例
Bilibili 排行榜只有 100 条记录,并且都在一个网页中,那么如果有分页显示的情况该怎么办呢?这里以豆瓣电影 Top250 为例介绍自动翻页抓取。同样的,新建 sitemap,在填写起始地址前,我们先观察一下豆瓣电影 Top250 的构成,总共有 250 条记录,每页显示 10 条,共分为 25 页。
而每一页的网址都非常有规律,第一页的地址为「」,第二页仅仅是把地址中的「start=0」改为了「start=25」,因此我们填写起始地址时便可以填写「[0-250:25]&filter=」,这里 start=[0-250:25] 表示 以 25 的步长从 0 取到 250,因此 start 分别为 0、25、50 等等。这样《Web Scraper》就会按顺序一页一页抓取数据了。
接下来类似于 BiliBili 排行榜,创建「封装器」后再添加「电影名」、「豆瓣评分」、「电影短评」以及「豆瓣排名」选择器就行了,然后开始抓取。
可以看到浏览器会一页一页地进行翻页抓取,这里只需要安静地等待抓取完毕即可,最后得到的数据以「豆瓣排名」进行升序排序,就能获得豆瓣电影 Top250 的榜单了。
▲豆瓣电影 Top250当然,这只是一种最简单的分页方法,而许多网站地址并不一定有着类似的规律,因此《Web Scraper》还有更多的方法能用来分页,但相对较为复杂,在此也不再赘述了。
抓取二级页面内容——知乎热榜为例
以上完成了对网页的单页以及多页内容的抓取,但不是每次都有着现成的数据摆在一个页面中,因此还需要更进一步地对二级页面进行搜寻。以知乎热榜为例,介绍如何对二级页面的「关注量」和「浏览量」进行抓取。首先,新建 sitemap,起始地址为「」。然后像前面一样创建「封装器」,再创建「文章标题」、「文章热度」、「知乎排名」这三个选择器。
接下来是重要步骤,创建一个「二级页面」的链接。点击「Add new selector」,id 填写「二级页面」, type 选择「link」,然后点击「selector」,选择文章的标题,即每篇文章的入口,确认选择后保存退出。
这样就相当于有了一个窗口,点击刚才创建的「二级页面」,进入下一级目录,然后像之前创建「文章标题」一样创建「关注量」与「浏览量」两个选择器。最后整个树状结构如下图所示。
点击「Sitemap zhihu_hot - Scrape」开始抓取,这里可以将「Page load delay」响应时间调大一些,确保网页完全加载完毕。这时候浏览器会依次打开每个二级页面进行抓取,因此需要等待一会儿。抓取任务完成后将结果下载为 CSV 文件,按「知乎排名」降序排列,即可获得整个知乎热榜的榜单。
▲知乎热榜至此,介绍了如何使用《Web Scraper》抓取页面中多条信息、自动翻页抓取以及抓取二级页面内容。很显然《Web Scraper》的功能远不止这些,还有更多强大的功能比如图片抓取、正则表达式等等可自行摸索。另外,如果只是想要简单地抓取信息,可以尝试使用其它插件如《Simple scraper》《Instant Data Scraper》,这些插件甚至可以一键抓取,但相比《Web Scraper》,功能的丰富度还是欠缺不少的。
不用学 Python,也不用花钱让别人帮你,使用《Web Scraper》自己就能完成网页抓取,或许下一个准时下班的就是你?
糖纸众测第 31 期「iWALK 战神吃鸡蓝牙耳机」,这是一款「为游戏而生」的耳机,低延迟,7.1立体音效,听声辨位,强力续航,畅玩各大类型游戏;
不需要写报告哦~只要你每天按时上传众测动态,就可以轻松 0 元带回家~
✨ 名额有限,赶紧来参加吧
注:微信视频号仍在内测,部分用户暂未开放
喜欢你就点个
查看全部
不用在朋友圈学 Python,这款 Chrome 插件就能帮你完成网页抓取
不知大家是否总能在朋友圈看到类似的广告,「加班完成的 Excel 用 Python 只需 3 分钟」、「每天都能准点下班只因学会了 Python」,似乎 Python 已经成为了当代年轻人的必备技能。
▲朋友圈广告的确,作为一门易于上手的编程语言,Python在自动化办公中用处巨大,特别是对于网页数据的爬取,在这样一个大数据时代显得尤为重要。爬取网页数据,也可以称为「网络爬虫」 ,能帮助我们快速搜集互联网的海量内容,从而进行深度的数据分析与挖掘。比如抓取各大网站的排行榜、抓取各大购物网站的价格信息等。而我们日常用的搜索引擎就是一个个「网络爬虫」。
但毕竟学习一门语言的成本太高了,有什么办法可以不学 Python 也能达到目的呢?当然有,借助 Chrome 浏览器的《Web Scraper》插件,让你在不用写代码的情况下,就能快速抓取海量内容。
优采云目录
抓取页面中的多条信息——BiliBili 排行榜为例安装《Web Scraper》后,在浏览器按 F12 进入开发者模式,就能在最后一个标签页看到《Web Scraper》的菜单。需要注意的是,如果开发者模式面板不在下方,则会提示必须将其放到浏览器下方才能继续。
在菜单中选择「Create new sitemap - Create sitemap」以创建新的 sitemap,填入名称与起始地址就可以开始了。这里以 BiliBili 排行榜为例,介绍如何抓取页面中的多条信息,起始地址设为「」。
这里我们需要抓取「视频标题」、「播放量」、「弹幕数」、「up 主」以及「综合得分」,因此首先为每一条记录创建一个封装器。点击「Add new selector」,id 填写「封装器」, type 选择「element」,然后点击「selector」,选择一条记录的外边框,外包框中需要包含上述所有信息,然后再选择第二条,这样就会发现页面中的所有记录都已自动选择,点击「Done selecting」完成数据的选择。还要记得勾选「Multiple」以保证抓取多条记录,最后保存该选择器即可。
返回后点击刚才的封装器,进入二级路径,创建「标题」选择器,id 填写「视频标题」,type 选择「text」,点击「selector」会发现第一条记录高亮显示,这是因为我们已提前将其设定为了封装器。选择包围框中的标题,再点击「Done selecting」完成标题的选择,注意这里不需要勾选「Multiple」,最后保存该选择器。
同样的,我们为「播放量」、「弹幕数」、「up 主」和「综合得分」分别建立选择器,选择后可以通过「Data preview」预览是否选中了想要的内容。另外还可以通过菜单栏中的「Sitemap bilibili_ranking - Selector graph」 直观地查看树状结构。
继续在刚才的菜单下选择「Scrape」开始创建抓取任务,单个网页的间隔时间和响应时间默认即可。点击「Start scraping」开始抓取。这时候浏览器会自动打开新的页面,停留数秒后自动关闭,代表抓取已完成。
点击「Refresh Data」刷新数据,或点击「Sitemap bilibili_ranking - Browse」查看数据。通过「Sitemap bilibili_ranking - Export data as CSV」即可下载为 CSV 格式文件。
▲BiliBili 排行榜使用 Excel 打开,由于《Web Scraper》抓取的内容是无序的,因此需要对「综合得分」进行降序排列,以恢复原始排行榜的结果。
自动翻页抓取——豆瓣电影 Top250 为例
Bilibili 排行榜只有 100 条记录,并且都在一个网页中,那么如果有分页显示的情况该怎么办呢?这里以豆瓣电影 Top250 为例介绍自动翻页抓取。同样的,新建 sitemap,在填写起始地址前,我们先观察一下豆瓣电影 Top250 的构成,总共有 250 条记录,每页显示 10 条,共分为 25 页。
而每一页的网址都非常有规律,第一页的地址为「」,第二页仅仅是把地址中的「start=0」改为了「start=25」,因此我们填写起始地址时便可以填写「[0-250:25]&filter=」,这里 start=[0-250:25] 表示 以 25 的步长从 0 取到 250,因此 start 分别为 0、25、50 等等。这样《Web Scraper》就会按顺序一页一页抓取数据了。
接下来类似于 BiliBili 排行榜,创建「封装器」后再添加「电影名」、「豆瓣评分」、「电影短评」以及「豆瓣排名」选择器就行了,然后开始抓取。
可以看到浏览器会一页一页地进行翻页抓取,这里只需要安静地等待抓取完毕即可,最后得到的数据以「豆瓣排名」进行升序排序,就能获得豆瓣电影 Top250 的榜单了。
▲豆瓣电影 Top250当然,这只是一种最简单的分页方法,而许多网站地址并不一定有着类似的规律,因此《Web Scraper》还有更多的方法能用来分页,但相对较为复杂,在此也不再赘述了。
抓取二级页面内容——知乎热榜为例
以上完成了对网页的单页以及多页内容的抓取,但不是每次都有着现成的数据摆在一个页面中,因此还需要更进一步地对二级页面进行搜寻。以知乎热榜为例,介绍如何对二级页面的「关注量」和「浏览量」进行抓取。首先,新建 sitemap,起始地址为「」。然后像前面一样创建「封装器」,再创建「文章标题」、「文章热度」、「知乎排名」这三个选择器。
接下来是重要步骤,创建一个「二级页面」的链接。点击「Add new selector」,id 填写「二级页面」, type 选择「link」,然后点击「selector」,选择文章的标题,即每篇文章的入口,确认选择后保存退出。
这样就相当于有了一个窗口,点击刚才创建的「二级页面」,进入下一级目录,然后像之前创建「文章标题」一样创建「关注量」与「浏览量」两个选择器。最后整个树状结构如下图所示。
点击「Sitemap zhihu_hot - Scrape」开始抓取,这里可以将「Page load delay」响应时间调大一些,确保网页完全加载完毕。这时候浏览器会依次打开每个二级页面进行抓取,因此需要等待一会儿。抓取任务完成后将结果下载为 CSV 文件,按「知乎排名」降序排列,即可获得整个知乎热榜的榜单。
▲知乎热榜至此,介绍了如何使用《Web Scraper》抓取页面中多条信息、自动翻页抓取以及抓取二级页面内容。很显然《Web Scraper》的功能远不止这些,还有更多强大的功能比如图片抓取、正则表达式等等可自行摸索。另外,如果只是想要简单地抓取信息,可以尝试使用其它插件如《Simple scraper》《Instant Data Scraper》,这些插件甚至可以一键抓取,但相比《Web Scraper》,功能的丰富度还是欠缺不少的。
不用学 Python,也不用花钱让别人帮你,使用《Web Scraper》自己就能完成网页抓取,或许下一个准时下班的就是你?
糖纸众测第 31 期「iWALK 战神吃鸡蓝牙耳机」,这是一款「为游戏而生」的耳机,低延迟,7.1立体音效,听声辨位,强力续航,畅玩各大类型游戏;
不需要写报告哦~只要你每天按时上传众测动态,就可以轻松 0 元带回家~
✨ 名额有限,赶紧来参加吧
注:微信视频号仍在内测,部分用户暂未开放
喜欢你就点个
Chrome 插件 | 帮你记住看过的网页,想要的东西马上找到
网站优化 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2022-05-04 19:05
你是不是也跟我一样遇到过这样的情况:隐约记得自己看过某个网页,只能想起文中的几个关键词,但是在历史记录中搜索却毫无踪迹,因为这些关键词根本就没有在标题中出现。现在 AppSo(微信号 appsolution)给你推荐一个救星:WorldBrain。有了这款 Chrome 插件,仅需在地址栏输入几个关键词,我们就可以对之前访问过的所有网站进行全文检索,快速定位。基础玩法在安装完毕 WorldBrain 插件之后,我们就通过一张动图来快速了解一下 WorldBrain 最基础的用法。
其实操作很简单,就是通过在地址栏输入 W + 空格键/Tab 键来激活 WorldBrain 搜索,然后输入想搜索的关键字,任何网页内容匹配关键字的网页都会出现在候选列表中。值得一提的是,我们曾经访问的 PDF 文件也会在搜索的范围内,并且 WorldBrain 的搜索结果前方会有一个大脑的图标作为标识。要进行这样的全文检索肯定需要在本地缓存网页数据,那么我们可能就会担心两个问题:
我们的数据是否安全?
数据会不会非常占用我们的磁盘空间?
那么首先,第一个问题,答案是:是的,你的数据非常安全。因为 WorldBrain 承诺,除非我们本人允许,我们的所有数据都会被保留在本地,不会上传云端服务器,所以我们可以放心。其次,第二个问题,答案是:并不会。因为 WorldBrain 只会存储网站的纯文本部分。要知道即使纯文本文件有几十万字,也只会占据几兆的磁盘容量,所以不必太过纠结。高级玩法1. 导入书签和历史记录在安装 WorldBrain 之后访问的网站肯定是没有在本地进行数据保存的,但是我们也不必手动将之前的网站一个一个打开。因为 WorldBrain 提供了「书签和历史记录导入」功能。
2. 过滤语法除了最基本的搜索语法之外,WorldBrain 还提供了更加高级的语法:「时间过滤语法」与「关键词过滤语法」,使得结果更加有针对性。唯一遗憾的就是,这些语法暂时还不支持中文(支持中文作为检索内容)。
首先,「时间过滤语法」顾名思义,就是可以将特定时间内的搜索结果过滤出来的语法。语法结构非常简单,让我们来举个例子:"out there" appso before: "yesterday at 5pm"。这段文字的意思就是:搜索昨天下午 5 点钟之前浏览的包含「appso」与「out there」关键词的网页。还可以尝试其他时间表达方式:"yesterday at 5pm", "three weeks ago", 3/26/2016。注:「out there」这种搜索方法代表完全匹配搜索,也就是说搜索结果返回的页面包含双引号中出现的所有的词,连顺序也必须完全匹配。
其次,就是「关键词过滤语法」,同样也是顾名思义,就是将包含特定关键词的网页都排除在搜索结果之外。语法结构同样非常简单。「appso -"有用功"」的意思就是:搜索所有包含「appso」但是不包含「有用功」的网页。只需在要排除的关键词前加 -(减号)即可。3. 网页屏蔽AppSo(微信号 appsolution)提醒,WorldBrain 还内置了一个「黑名单」系统,允许我们将那些不希望被包括在搜索结果内的网站排除。默认包含了一些登陆与 Paypal 页面,以保证个人敏感数据的安全。
近期更新计划1. 网页应用内搜索在目前,WorldBrain 无法搜索到网页应用的内容,如 Evernote、Pocket 等等,这在实用性上大打折扣,不过还好,作者表示该功能马上就会到来。
2. 可视化搜索界面目前的搜索仅仅只能在地址栏进行,我们可能看到的搜索结果也只是一些网页的网址和标题。虽然这样比较方便快捷,但是我们对于更加丰富搜索结果的需求也是真实存在的,作者承诺将在近期加入。
未来愿景1. 社交搜索 Social Searching在将来,我们可以直接关注某些特定领域的名人或者网站,并且可以将它们分组,当我们需要搜索的该领域的知识、信息时,结果可以更加有针对性。可以说这就是一个带「关注」特性的 Google。
2. 高质量内容 Quality Content在将来,WorldBrain 将增加批注、评论、分享等等功能,并且综合我们在网站上的种种行为为网站进行打分,当然我们也直接手动为一个网站来修改评分。
作者预期,经过这样的行为分析以及用户手动调节,我们可以通过网页的评分来判断网页内容的质量,从而决定是否阅读。
但是,我认为如果真的有这个评分机制,并且 WorldBrain 如果火爆的话,只会催生出一条新的产业链吧。
3. 相关内容 Related ContentWorldBrain 将允许我们将笔记进行共享,那么在未来,我们浏览网页时,可能可以看到其他人在网页上的评论。说白了可能是一个第三方的评论系统。
以上的种种看起来还是比较美好的,但是如果没有限制并且放任不管的话,可能会是一场灾难,最终用户无法得到他们想要看到的,并且还可能干扰正常的网页浏览体验。如果这一系列的动作可以建立在社交网络之上,那么情况可能会有所不同,因为我们看到的一切内容都来自我们的关注者,那么内容筛选方面实际上用户自己就完成了,会让 WorldBrain 的未来更加美好。AppSo(微信号 appsolution)觉得,不妨,也留一点期待。
下载链接:本文由让手机更好用的 AppSo 原创出品,关注微信号 appsolution,回复「cj666」获取不搭梯也能下 Chrome 插件的方法,以及更多 Chrome 插件推荐。
来啊,湿身啊。
查看全部
Chrome 插件 | 帮你记住看过的网页,想要的东西马上找到
你是不是也跟我一样遇到过这样的情况:隐约记得自己看过某个网页,只能想起文中的几个关键词,但是在历史记录中搜索却毫无踪迹,因为这些关键词根本就没有在标题中出现。现在 AppSo(微信号 appsolution)给你推荐一个救星:WorldBrain。有了这款 Chrome 插件,仅需在地址栏输入几个关键词,我们就可以对之前访问过的所有网站进行全文检索,快速定位。基础玩法在安装完毕 WorldBrain 插件之后,我们就通过一张动图来快速了解一下 WorldBrain 最基础的用法。
其实操作很简单,就是通过在地址栏输入 W + 空格键/Tab 键来激活 WorldBrain 搜索,然后输入想搜索的关键字,任何网页内容匹配关键字的网页都会出现在候选列表中。值得一提的是,我们曾经访问的 PDF 文件也会在搜索的范围内,并且 WorldBrain 的搜索结果前方会有一个大脑的图标作为标识。要进行这样的全文检索肯定需要在本地缓存网页数据,那么我们可能就会担心两个问题:
我们的数据是否安全?
数据会不会非常占用我们的磁盘空间?
那么首先,第一个问题,答案是:是的,你的数据非常安全。因为 WorldBrain 承诺,除非我们本人允许,我们的所有数据都会被保留在本地,不会上传云端服务器,所以我们可以放心。其次,第二个问题,答案是:并不会。因为 WorldBrain 只会存储网站的纯文本部分。要知道即使纯文本文件有几十万字,也只会占据几兆的磁盘容量,所以不必太过纠结。高级玩法1. 导入书签和历史记录在安装 WorldBrain 之后访问的网站肯定是没有在本地进行数据保存的,但是我们也不必手动将之前的网站一个一个打开。因为 WorldBrain 提供了「书签和历史记录导入」功能。
2. 过滤语法除了最基本的搜索语法之外,WorldBrain 还提供了更加高级的语法:「时间过滤语法」与「关键词过滤语法」,使得结果更加有针对性。唯一遗憾的就是,这些语法暂时还不支持中文(支持中文作为检索内容)。
首先,「时间过滤语法」顾名思义,就是可以将特定时间内的搜索结果过滤出来的语法。语法结构非常简单,让我们来举个例子:"out there" appso before: "yesterday at 5pm"。这段文字的意思就是:搜索昨天下午 5 点钟之前浏览的包含「appso」与「out there」关键词的网页。还可以尝试其他时间表达方式:"yesterday at 5pm", "three weeks ago", 3/26/2016。注:「out there」这种搜索方法代表完全匹配搜索,也就是说搜索结果返回的页面包含双引号中出现的所有的词,连顺序也必须完全匹配。
其次,就是「关键词过滤语法」,同样也是顾名思义,就是将包含特定关键词的网页都排除在搜索结果之外。语法结构同样非常简单。「appso -"有用功"」的意思就是:搜索所有包含「appso」但是不包含「有用功」的网页。只需在要排除的关键词前加 -(减号)即可。3. 网页屏蔽AppSo(微信号 appsolution)提醒,WorldBrain 还内置了一个「黑名单」系统,允许我们将那些不希望被包括在搜索结果内的网站排除。默认包含了一些登陆与 Paypal 页面,以保证个人敏感数据的安全。
近期更新计划1. 网页应用内搜索在目前,WorldBrain 无法搜索到网页应用的内容,如 Evernote、Pocket 等等,这在实用性上大打折扣,不过还好,作者表示该功能马上就会到来。
2. 可视化搜索界面目前的搜索仅仅只能在地址栏进行,我们可能看到的搜索结果也只是一些网页的网址和标题。虽然这样比较方便快捷,但是我们对于更加丰富搜索结果的需求也是真实存在的,作者承诺将在近期加入。
未来愿景1. 社交搜索 Social Searching在将来,我们可以直接关注某些特定领域的名人或者网站,并且可以将它们分组,当我们需要搜索的该领域的知识、信息时,结果可以更加有针对性。可以说这就是一个带「关注」特性的 Google。
2. 高质量内容 Quality Content在将来,WorldBrain 将增加批注、评论、分享等等功能,并且综合我们在网站上的种种行为为网站进行打分,当然我们也直接手动为一个网站来修改评分。
作者预期,经过这样的行为分析以及用户手动调节,我们可以通过网页的评分来判断网页内容的质量,从而决定是否阅读。
但是,我认为如果真的有这个评分机制,并且 WorldBrain 如果火爆的话,只会催生出一条新的产业链吧。
3. 相关内容 Related ContentWorldBrain 将允许我们将笔记进行共享,那么在未来,我们浏览网页时,可能可以看到其他人在网页上的评论。说白了可能是一个第三方的评论系统。
以上的种种看起来还是比较美好的,但是如果没有限制并且放任不管的话,可能会是一场灾难,最终用户无法得到他们想要看到的,并且还可能干扰正常的网页浏览体验。如果这一系列的动作可以建立在社交网络之上,那么情况可能会有所不同,因为我们看到的一切内容都来自我们的关注者,那么内容筛选方面实际上用户自己就完成了,会让 WorldBrain 的未来更加美好。AppSo(微信号 appsolution)觉得,不妨,也留一点期待。
下载链接:本文由让手机更好用的 AppSo 原创出品,关注微信号 appsolution,回复「cj666」获取不搭梯也能下 Chrome 插件的方法,以及更多 Chrome 插件推荐。
来啊,湿身啊。
如何高效在网页上做笔记?Chrome插件推荐Roam
网站优化 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2022-05-04 19:05
当你发现一篇很好的文章,你会怎么做呢?不管是收藏链接到书签还是剪藏到印象笔记等软件中都不是一个最好的办法。我的建议是你像读一本书一样去做“读书笔记”,把内容中对自己有价值的观点和知识进行高亮提取,并对提取出来的内容使用自己的语言进行转述,从而达到内化的效果。接下来我将给你推荐一款非常好用的网页高亮标注Chrome插件:Roam-highlighter。
Roam-highlighter的主要的功能是可以快速的提取网页中选取的文字,并识别文字的层级。
正如名字中带有Roam,它是支持快速添加Roam类软件中[[关键词]]语法的。非常棒的功能。
我整理了你常用的快捷键:
[ALT + X]:激活插件窗口/关闭插件窗口
[Ctrl + X]:高亮选取文字
[Alt + Click]:取消高亮
[ALT + Q]:取消页面所有高亮
[Double-Click] :在高亮文字上选取关键词后双击,关键词添加[[]],成为Roam类软件中新页面的语法
[ALT + Z] :功能与[Double-Click]相同
如果你觉得我的文章对你有帮助,请关注分享评论。你的鼓励是我做出更多更好内容的巨大动力。我将在各个平台同步更新。演示视频请移步视频平台搜索格物新知。
查看全部
如何高效在网页上做笔记?Chrome插件推荐Roam
当你发现一篇很好的文章,你会怎么做呢?不管是收藏链接到书签还是剪藏到印象笔记等软件中都不是一个最好的办法。我的建议是你像读一本书一样去做“读书笔记”,把内容中对自己有价值的观点和知识进行高亮提取,并对提取出来的内容使用自己的语言进行转述,从而达到内化的效果。接下来我将给你推荐一款非常好用的网页高亮标注Chrome插件:Roam-highlighter。
Roam-highlighter的主要的功能是可以快速的提取网页中选取的文字,并识别文字的层级。
正如名字中带有Roam,它是支持快速添加Roam类软件中[[关键词]]语法的。非常棒的功能。
我整理了你常用的快捷键:
[ALT + X]:激活插件窗口/关闭插件窗口
[Ctrl + X]:高亮选取文字
[Alt + Click]:取消高亮
[ALT + Q]:取消页面所有高亮
[Double-Click] :在高亮文字上选取关键词后双击,关键词添加[[]],成为Roam类软件中新页面的语法
[ALT + Z] :功能与[Double-Click]相同
如果你觉得我的文章对你有帮助,请关注分享评论。你的鼓励是我做出更多更好内容的巨大动力。我将在各个平台同步更新。演示视频请移步视频平台搜索格物新知。
chrome 插件 抓取网页qq聊天记录( 这是简易数据分析系列的第1个原因是怎样的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-04-20 21:14
这是简易数据分析系列的第1个原因是怎样的?
)
这是简易数据分析系列文章 的第 1 部分。
为什么叫简单数据分析?
第一个原因是本教程面向纯新手用户,不写代码或公式,迈出数据分析的第一步。
第二个原因,生活中很多数据分析场景都是非常轻量级的,不需要Python爬虫、高并发架构、机器学习等重武器,一个浏览器加一个Excel就够了:
比如某门课程投稿后才几天,急需快速爬取数据进行数据分析。这时候现场学习Python爬虫知识的时间还不够;
做一些市场调研和运营工作需要采集数据,如果技术部门支持,流程周期太长,还是自己做比较好;
跳槽,想了解市场的技能要求和薪资分布,需要采集数据,分析市场需求;
…
这些都是生活中会遇到的问题。面对这些少量数据(100~10000))的分析需求,对于非互联网技术人员来说,学习一些编程知识并不划算。我们还不如利用手头的东西. 最常用的工具,Excel 和浏览器,用于分析和整理数据,以帮助思考和更好的决策。
这也是本教程的目的——用20%的精力解决80%的数据分析需求,解放个人生产力。
本教程将在三个主要方向进行扩展:数据采集、数据清洗和数据可视化。
数据采集是利用爬虫软件从网上爬取想要的数据,然后存储到本地;
数据清洗是对采集到的数据进行格式化,方便后续分析;
数据可视化是利用各种分析方法对数据进行不同维度的解读,并以图表的直观形式表达出来,更好地辅助我们决策;
从下一篇文章文章开始,我们学习如何采集从互联网上获取数据。
这是简易数据分析系列文章 的第二部分。
上一篇文章讲了数据分析在生活中的重要性。从这篇文章中,我们将进入实际的分析内容。数据分析,数据分析,没有数据怎么分析?所以我们首先要学习采集data。
研究了很多采集数据软件,综合评测后发现最好的是Web Scraper,它是一个Chrome浏览器插件。
推荐理由如下:
1.门槛够低,只要电脑上安装了Chrome浏览器就可以使用
2.永久免费,无付费功能,无需注册
3.操作简单,鼠标点几下就可以爬取网页,0行代码写一个真正意义上的爬虫
既然这么棒,当然是立马安装了。
由于 Web Scraper 是 Chrome 浏览器插件,我当然是第一个使用 Chrome 的人。
不过受限于国内网络环境,访问Chrome插件应用商店可能不是很方便。如果第一种方式不行,我们可以试试第二种方式,使用浏览器曲线救国(360浏览器暂时不提供Web Scraper插件)。
两个浏览器内核是一样的,只是界面不同。我的后续教程将基于 Chrome 浏览器。浏览器可能略有不同。如有差异,读者需自行区分。
1. 在 Chrome 浏览器上安装 Web Scraper 插件
1.1 安装 Chrome 浏览器
这个没什么好说的,Windows电脑的各大应用商店都有最新版的Chrome浏览器,或者百度,首页一般都有安装包地址,下载安装即可;
(为减少兼容性问题,最好安装最新版本的Chrome浏览器)
1.2 安装 Web Scraper 插件
可以访问外网的同学,直接访问“Chrome Web Store”,搜索Web Scraper下载安装:
暂时无条件接入外网,我们可以手动安装外挂曲线救国,当然会比上面的麻烦一点:
首先我们访问这个国产浏览器插件网站,搜索Web Scraper,下载插件。注意此时插件不是直接安装在浏览器上,而是下载到本地:
然后,我们在浏览器的URL输入框中输入chrome://extensions/,这样就可以打开浏览器的插件管理后台了:
下一步是解压缩并安装刚刚下载的插件。
如果您是 Mac 用户,请先将安装包的后缀从 .crx 更改为 .zip。
然后切换到浏览器的插件管理后台,打开右上角的开发者模式,把Web Scraper.zip文件拖进去,就安装好了。
一般这个安装会出现一个红色的错误按钮,我们不管,直接忽略即可。
如果你是 windows 用户,你需要这样做:
1.把.crx后缀的插件改成.rar,然后解压
2.进入 chrome://extensions/ 页面,开启开发者模式
3.点击“加载解压扩展”,选择第一步解压后的文件夹,正常情况下安装成功。
至此,我们的Chrome浏览器已经成功安装了Web Scraper插件。
2.在浏览器上安装 Web Scraper 插件
2.1 安装浏览器
前往各大应用商店或访问网站下载安装。
浏览器PC版官网下载地址:
浏览器Mac版官网下载地址:
2.2 安装 Web Scraper 插件
Mac用户可以直接访问浏览器左上角的“应用中心”,点击进入并搜索Web Scraper进行安装。
Windows用户首先点击浏览器左上角的≡菜单栏,在弹出的菜单栏中选择“应用中心”,点击进入并搜索Web Scraper进行安装。
至此,我们的Web Scraper插件已经安装成功。在下一篇文章中,我们将探索一些浏览器操作,为我们后续的学习打下良好的基础。
这是简易数据分析系列的第三部分文章。
我们在上面安装了 Web Scraper 插件。我相信这对大多数人来说非常简单。在这个文章中,我们会讲一些不一样的东西,讲一下浏览器中那些大多数人都不知道的东西。低俗的操作。
作为普通用户,每个人都使用浏览器来查看信息和浏览网页。但在开发者眼中,Chrome浏览器提供了非常强大的开发能力。
通过本文章的学习,可以掌握一些浏览器开发的小知识(相信我,一点都不难),方便我们后续学习Web Scraper插件。
下面开始正文。
1 打开开发者后台
这个功能其实在我之前的文章《造谣的成本到底有多低?一行代码就可以截图造假了》。如前所述,如果你想从普通浏览模式切换到开发者模式,你只需要按 F12(浏览器 F12 被禁用)。
Mac电脑也可以用option+command+I打开,Win电脑可以用Ctrl+Shift+I打开。
2 一行代码自由伪造截图
这也是一篇老文章《谣言成本有多低?一行代码可以截图,造假内容。很多朋友都表示已经操作成功了,有兴趣的同学可以了解一下。
3 切换开发者后台的位置
控制台打开后,通常显示在网页底部。其实我们也可以切换到网页右侧进行显示。具体操作是点击后台面板右侧的⋮按钮,然后修改显示位置。具体操作如下。
4 使用电脑浏览器模拟手机浏览器
使用电脑浏览器模拟手机浏览器是一个非常有用的功能。因为现在是移动互联网时代,公司的大部分网页都是先支持移动端的,而且移动端浏览器的数据结构更加清晰,更有利于我们抓数据。
开启模拟手机也很简单,只需点击开发者后台左侧的手机切换图标,然后刷新即可。
我们可以用豆瓣网站来证明这一点。
当然,我们也可以用这个功能做其他事情,比如上班时开小屏偷偷刷微博。被老板抓到的时候别说我教过你。
好了,这就是今天的准备工作。下一期,我们将学习如何使用 Web Scraper 抓取网页数据。
●深入理解Web协议(一):HTTP包体传输
●JavaScript测试系列实战(四):掌握React Hooks测试技巧
●打开React Hooks 动画和实战(一):useState 和useEffect
·结尾·
图克社区
采集精彩的免费实用教程
查看全部
chrome 插件 抓取网页qq聊天记录(
这是简易数据分析系列的第1个原因是怎样的?
)
这是简易数据分析系列文章 的第 1 部分。
为什么叫简单数据分析?
第一个原因是本教程面向纯新手用户,不写代码或公式,迈出数据分析的第一步。
第二个原因,生活中很多数据分析场景都是非常轻量级的,不需要Python爬虫、高并发架构、机器学习等重武器,一个浏览器加一个Excel就够了:
比如某门课程投稿后才几天,急需快速爬取数据进行数据分析。这时候现场学习Python爬虫知识的时间还不够;
做一些市场调研和运营工作需要采集数据,如果技术部门支持,流程周期太长,还是自己做比较好;
跳槽,想了解市场的技能要求和薪资分布,需要采集数据,分析市场需求;
…
这些都是生活中会遇到的问题。面对这些少量数据(100~10000))的分析需求,对于非互联网技术人员来说,学习一些编程知识并不划算。我们还不如利用手头的东西. 最常用的工具,Excel 和浏览器,用于分析和整理数据,以帮助思考和更好的决策。
这也是本教程的目的——用20%的精力解决80%的数据分析需求,解放个人生产力。
本教程将在三个主要方向进行扩展:数据采集、数据清洗和数据可视化。
数据采集是利用爬虫软件从网上爬取想要的数据,然后存储到本地;
数据清洗是对采集到的数据进行格式化,方便后续分析;
数据可视化是利用各种分析方法对数据进行不同维度的解读,并以图表的直观形式表达出来,更好地辅助我们决策;
从下一篇文章文章开始,我们学习如何采集从互联网上获取数据。
这是简易数据分析系列文章 的第二部分。
上一篇文章讲了数据分析在生活中的重要性。从这篇文章中,我们将进入实际的分析内容。数据分析,数据分析,没有数据怎么分析?所以我们首先要学习采集data。
研究了很多采集数据软件,综合评测后发现最好的是Web Scraper,它是一个Chrome浏览器插件。
推荐理由如下:
1.门槛够低,只要电脑上安装了Chrome浏览器就可以使用
2.永久免费,无付费功能,无需注册
3.操作简单,鼠标点几下就可以爬取网页,0行代码写一个真正意义上的爬虫
既然这么棒,当然是立马安装了。
由于 Web Scraper 是 Chrome 浏览器插件,我当然是第一个使用 Chrome 的人。
不过受限于国内网络环境,访问Chrome插件应用商店可能不是很方便。如果第一种方式不行,我们可以试试第二种方式,使用浏览器曲线救国(360浏览器暂时不提供Web Scraper插件)。
两个浏览器内核是一样的,只是界面不同。我的后续教程将基于 Chrome 浏览器。浏览器可能略有不同。如有差异,读者需自行区分。
1. 在 Chrome 浏览器上安装 Web Scraper 插件
1.1 安装 Chrome 浏览器
这个没什么好说的,Windows电脑的各大应用商店都有最新版的Chrome浏览器,或者百度,首页一般都有安装包地址,下载安装即可;
(为减少兼容性问题,最好安装最新版本的Chrome浏览器)
1.2 安装 Web Scraper 插件
可以访问外网的同学,直接访问“Chrome Web Store”,搜索Web Scraper下载安装:
暂时无条件接入外网,我们可以手动安装外挂曲线救国,当然会比上面的麻烦一点:
首先我们访问这个国产浏览器插件网站,搜索Web Scraper,下载插件。注意此时插件不是直接安装在浏览器上,而是下载到本地:
然后,我们在浏览器的URL输入框中输入chrome://extensions/,这样就可以打开浏览器的插件管理后台了:
下一步是解压缩并安装刚刚下载的插件。
如果您是 Mac 用户,请先将安装包的后缀从 .crx 更改为 .zip。
然后切换到浏览器的插件管理后台,打开右上角的开发者模式,把Web Scraper.zip文件拖进去,就安装好了。
一般这个安装会出现一个红色的错误按钮,我们不管,直接忽略即可。
如果你是 windows 用户,你需要这样做:
1.把.crx后缀的插件改成.rar,然后解压
2.进入 chrome://extensions/ 页面,开启开发者模式
3.点击“加载解压扩展”,选择第一步解压后的文件夹,正常情况下安装成功。
至此,我们的Chrome浏览器已经成功安装了Web Scraper插件。
2.在浏览器上安装 Web Scraper 插件
2.1 安装浏览器
前往各大应用商店或访问网站下载安装。
浏览器PC版官网下载地址:
浏览器Mac版官网下载地址:
2.2 安装 Web Scraper 插件
Mac用户可以直接访问浏览器左上角的“应用中心”,点击进入并搜索Web Scraper进行安装。
Windows用户首先点击浏览器左上角的≡菜单栏,在弹出的菜单栏中选择“应用中心”,点击进入并搜索Web Scraper进行安装。
至此,我们的Web Scraper插件已经安装成功。在下一篇文章中,我们将探索一些浏览器操作,为我们后续的学习打下良好的基础。
这是简易数据分析系列的第三部分文章。
我们在上面安装了 Web Scraper 插件。我相信这对大多数人来说非常简单。在这个文章中,我们会讲一些不一样的东西,讲一下浏览器中那些大多数人都不知道的东西。低俗的操作。
作为普通用户,每个人都使用浏览器来查看信息和浏览网页。但在开发者眼中,Chrome浏览器提供了非常强大的开发能力。
通过本文章的学习,可以掌握一些浏览器开发的小知识(相信我,一点都不难),方便我们后续学习Web Scraper插件。
下面开始正文。
1 打开开发者后台
这个功能其实在我之前的文章《造谣的成本到底有多低?一行代码就可以截图造假了》。如前所述,如果你想从普通浏览模式切换到开发者模式,你只需要按 F12(浏览器 F12 被禁用)。
Mac电脑也可以用option+command+I打开,Win电脑可以用Ctrl+Shift+I打开。
2 一行代码自由伪造截图
这也是一篇老文章《谣言成本有多低?一行代码可以截图,造假内容。很多朋友都表示已经操作成功了,有兴趣的同学可以了解一下。
3 切换开发者后台的位置
控制台打开后,通常显示在网页底部。其实我们也可以切换到网页右侧进行显示。具体操作是点击后台面板右侧的⋮按钮,然后修改显示位置。具体操作如下。
4 使用电脑浏览器模拟手机浏览器
使用电脑浏览器模拟手机浏览器是一个非常有用的功能。因为现在是移动互联网时代,公司的大部分网页都是先支持移动端的,而且移动端浏览器的数据结构更加清晰,更有利于我们抓数据。
开启模拟手机也很简单,只需点击开发者后台左侧的手机切换图标,然后刷新即可。
我们可以用豆瓣网站来证明这一点。
当然,我们也可以用这个功能做其他事情,比如上班时开小屏偷偷刷微博。被老板抓到的时候别说我教过你。
好了,这就是今天的准备工作。下一期,我们将学习如何使用 Web Scraper 抓取网页数据。
●深入理解Web协议(一):HTTP包体传输
●JavaScript测试系列实战(四):掌握React Hooks测试技巧
●打开React Hooks 动画和实战(一):useState 和useEffect
·结尾·
图克社区
采集精彩的免费实用教程
chrome 插件 抓取网页qq聊天记录(初识网络爬虫的基本流程及流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-04-18 20:18
文章目录
1、准备聊天
1、关闭计算机的防火墙
2、关闭不必要的虚拟网络和其他不必要的以太网,只留下一个网络聊天通道
3、两台电脑连接同一个手机热点,打开疯狂聊天程序
2聊天抓包2.1、狂聊
1、先给自己起个聊天昵称,在两台电脑(或多台电脑一起)输入同一个聊天室号码
2、发消息,即聊天
2.2、使用wireshark捕获聊天消息
1、打开wireshark捕捉wlan(无线网络)下的聊天信息,如果没有,请参考:
2 查看聊天信息的Dst地址为255.255.255.255
3、查找目标为 25 的记录5.255.255.255
可以看到网络是通过UDP协议连接的
4、查看英文聊天消息
5、查看数字聊天消息
6、查看文字聊天消息
7、从上面的爬取结果来看,聊天使用的端口是17345,使用的协议是UDP
2、从网络爬虫开始2.1、什么是爬虫
1、简介:网络爬虫也称为网络蜘蛛、网络蚂蚁、网络机器人等,它的英文名称是Web Crawler或Web Spider,可以自动浏览网络上的信息。当然,在浏览信息时,您需要遵循我们的公式。浏览的规则,这些规则我们称之为网络爬虫算法。使用Python,编写爬虫程序来自动检索互联网信息非常方便。
2、爬虫的基本流程:发起请求:通过url向服务器发起请求,请求中可以收录额外的头部信息。获取响应内容:如果服务器正常响应,那么我们会收到一个响应,也就是我们请求的网页内容,可能收录HTML、Json字符串或者二进制数据(视频、图片)等。
3、URL管理模块:发起请求。通常,请求是通过 HTTP 库向目标站点发出的。相当于自己打开浏览器,输入网址。
下载模块:获取响应内容(response)。如果服务器上存在请求的内容,服务器会返回请求的内容,一般为:HTML、二进制文件(视频、音频)、文档、Json字符串等。
解析模块:解析内容。对于用户来说,就是找到他们需要的信息。对于Python爬虫来说,就是使用正则表达式或者其他库来提取目标信息。
存储模块:保存数据。解析后的数据可以以文本、音频、视频等多种形式存储在本地。
2.2、爬取南洋理工ACM专题网站资料
1、打开南洋理工ACM话题网站,然后按F12进入工作模式,点击source,可以看到网页的源代码,然后就可以看到话题信息了我们需要的是在TD标签里面,也就是我们要爬取TD标签里面的内容
2、我用的是jupyter,打开用python编程
import requests# 导入网页请求库
from bs4 import BeautifulSoup# 导入网页解析库
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
# 传入URL
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={
pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
# 解析URL
soup = BeautifulSoup(r.text, 'html5lib')
#查找爬取与td相关所有内容
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
with open('D:\word\protice.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
3、然后运行程序
4、查看生成的爬取数据
2.3、爬取重庆交大新闻近年所有信息公告网站
1、打开重庆交通大学信息通知网站:
2、F12也打开进入开发者模式,网页源码可以在emelents下找到。可以看到我们需要爬取的信息在div标签中
3、查找要爬取的数据页数
4、 接下来在jupyter中编写代码
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 17 14:39:03 2021
@author: 86199
"""
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import urllib.request, urllib.error # 制定URL 获取网页数据
# 所有新闻
subjects = []
# 模拟浏览器访问
Headers = {
# 模拟浏览器头部信息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53"
}
# 表头
csvHeaders = ['时间', '标题']
print('信息爬取中:\n')
for pages in tqdm(range(1, 65 + 1)):
# 发出请求
request = urllib.request.Request(f'http://news.cqjtu.edu.cn/xxtz/{
pages}.htm', headers=Headers)
html = ""
# 如果请求成功则获取网页内容
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# 解析网页
soup = BeautifulSoup(html, 'html5lib')
# 存放一条新闻
subject = []
# 查找所有li标签
li = soup.find_all('li')
for l in li:
# 查找满足条件的div标签
if l.find_all('div',class_="time") is not None and l.find_all('div',class_="right-title") is not None:
# 时间、爬取的标签
for time in l.find_all('div',class_="time"):
subject.append(time.string)
# 标题
for title in l.find_all('div',class_="right-title"):
for t in title.find_all('a',target="_blank"):
subject.append(t.string)
if subject:
print(subject)
subjects.append(subject)
subject = []
# 保存数据
with open('D:/word/new.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n信息爬取完成!!!')
5、运行代码
6、爬取的数据
3、总结
刚刚接触爬虫,对爬虫不是很熟悉,但是参考网上的资料,还是可以爬取一些简单的信息。对于网站的信息爬取,首先要分析网站的源码,分析爬取信息,找到其所属标签的内容,然后进行爬取。通过这个实践,我意识到爬虫对我们还是很有帮助的,它们可以很好地帮助我们处理随机信息。
参考: 查看全部
chrome 插件 抓取网页qq聊天记录(初识网络爬虫的基本流程及流程)
文章目录
1、准备聊天
1、关闭计算机的防火墙
2、关闭不必要的虚拟网络和其他不必要的以太网,只留下一个网络聊天通道
3、两台电脑连接同一个手机热点,打开疯狂聊天程序
2聊天抓包2.1、狂聊
1、先给自己起个聊天昵称,在两台电脑(或多台电脑一起)输入同一个聊天室号码
2、发消息,即聊天
2.2、使用wireshark捕获聊天消息
1、打开wireshark捕捉wlan(无线网络)下的聊天信息,如果没有,请参考:
2 查看聊天信息的Dst地址为255.255.255.255
3、查找目标为 25 的记录5.255.255.255
可以看到网络是通过UDP协议连接的
4、查看英文聊天消息
5、查看数字聊天消息
6、查看文字聊天消息
7、从上面的爬取结果来看,聊天使用的端口是17345,使用的协议是UDP
2、从网络爬虫开始2.1、什么是爬虫
1、简介:网络爬虫也称为网络蜘蛛、网络蚂蚁、网络机器人等,它的英文名称是Web Crawler或Web Spider,可以自动浏览网络上的信息。当然,在浏览信息时,您需要遵循我们的公式。浏览的规则,这些规则我们称之为网络爬虫算法。使用Python,编写爬虫程序来自动检索互联网信息非常方便。
2、爬虫的基本流程:发起请求:通过url向服务器发起请求,请求中可以收录额外的头部信息。获取响应内容:如果服务器正常响应,那么我们会收到一个响应,也就是我们请求的网页内容,可能收录HTML、Json字符串或者二进制数据(视频、图片)等。
3、URL管理模块:发起请求。通常,请求是通过 HTTP 库向目标站点发出的。相当于自己打开浏览器,输入网址。
下载模块:获取响应内容(response)。如果服务器上存在请求的内容,服务器会返回请求的内容,一般为:HTML、二进制文件(视频、音频)、文档、Json字符串等。
解析模块:解析内容。对于用户来说,就是找到他们需要的信息。对于Python爬虫来说,就是使用正则表达式或者其他库来提取目标信息。
存储模块:保存数据。解析后的数据可以以文本、音频、视频等多种形式存储在本地。
2.2、爬取南洋理工ACM专题网站资料
1、打开南洋理工ACM话题网站,然后按F12进入工作模式,点击source,可以看到网页的源代码,然后就可以看到话题信息了我们需要的是在TD标签里面,也就是我们要爬取TD标签里面的内容
2、我用的是jupyter,打开用python编程
import requests# 导入网页请求库
from bs4 import BeautifulSoup# 导入网页解析库
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
# 传入URL
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={
pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
# 解析URL
soup = BeautifulSoup(r.text, 'html5lib')
#查找爬取与td相关所有内容
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
with open('D:\word\protice.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
3、然后运行程序
4、查看生成的爬取数据
2.3、爬取重庆交大新闻近年所有信息公告网站
1、打开重庆交通大学信息通知网站:
2、F12也打开进入开发者模式,网页源码可以在emelents下找到。可以看到我们需要爬取的信息在div标签中
3、查找要爬取的数据页数
4、 接下来在jupyter中编写代码
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 17 14:39:03 2021
@author: 86199
"""
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import urllib.request, urllib.error # 制定URL 获取网页数据
# 所有新闻
subjects = []
# 模拟浏览器访问
Headers = {
# 模拟浏览器头部信息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53"
}
# 表头
csvHeaders = ['时间', '标题']
print('信息爬取中:\n')
for pages in tqdm(range(1, 65 + 1)):
# 发出请求
request = urllib.request.Request(f'http://news.cqjtu.edu.cn/xxtz/{
pages}.htm', headers=Headers)
html = ""
# 如果请求成功则获取网页内容
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# 解析网页
soup = BeautifulSoup(html, 'html5lib')
# 存放一条新闻
subject = []
# 查找所有li标签
li = soup.find_all('li')
for l in li:
# 查找满足条件的div标签
if l.find_all('div',class_="time") is not None and l.find_all('div',class_="right-title") is not None:
# 时间、爬取的标签
for time in l.find_all('div',class_="time"):
subject.append(time.string)
# 标题
for title in l.find_all('div',class_="right-title"):
for t in title.find_all('a',target="_blank"):
subject.append(t.string)
if subject:
print(subject)
subjects.append(subject)
subject = []
# 保存数据
with open('D:/word/new.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n信息爬取完成!!!')
5、运行代码
6、爬取的数据
3、总结
刚刚接触爬虫,对爬虫不是很熟悉,但是参考网上的资料,还是可以爬取一些简单的信息。对于网站的信息爬取,首先要分析网站的源码,分析爬取信息,找到其所属标签的内容,然后进行爬取。通过这个实践,我意识到爬虫对我们还是很有帮助的,它们可以很好地帮助我们处理随机信息。
参考:
chrome 插件 抓取网页qq聊天记录( 火狐屏蔽插件:下载一个火狐国际版不就解决了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-04-17 18:27
火狐屏蔽插件:下载一个火狐国际版不就解决了?)
禁止中国用户安装广告插件!火狐做到这一点
科技狐2022-03-30
火狐屏蔽插件,没有任何内幕。这时候可能有狐友会说:下载国际版火狐浏览器就解决了?
当谈到世界上最好的浏览器时,Chrome 绝对在名单上。它以简洁的设计和超快的启动速度赢得了众多用户的心。但要说Chrome浏览器的灵魂,那一定是它的扩展商店:里面有各种有趣实用的扩展,保证为你打开一个安装的新天地~
可悲的是,Chrome 国的扩展商店有 404 状态,所以很多人说:没有扩展的 Chrome 浏览器就像被废了的大师……
很多老司机都转向了其他浏览器。其中,火狐是最受欢迎的。原因很简单。火狐的扩展商店也很丰富,国内也可以访问。
就在最近,火狐浏览器突然屏蔽了中国用户的一些行为——禁止中国IP访问商店的广告屏蔽扩展页面。当有中国IP地址的用户在Firefox商店打开AdGuard之类的广告拦截扩展时,它会说:“此页面在您所在的地区不可用”
火狐屏蔽插件,没有任何内幕。这时候可能有狐友会说:下载国际版火狐浏览器就解决了?并不真地!无论您使用的是国际版火狐浏览器还是国内版火狐浏览器:只要您使用的是中国大陆IP,就无法访问官方商店的广告拦截扩展。
不过不要先骂火狐,因为火狐很可能会被迫屏蔽中国用户使用广告插件……因为早在2017、2018年,(Mozilla在中国的全资子公司)公司):因广告屏蔽被国内多家公司(Amang、Aku等)起诉,判决将于2019年生效。
也就是说,这次国内用户在使用火狐浏览器的时候不能使用广告拦截插件,可能是因为他们搬走了一些巨头的“蛋糕”……那为什么只有火狐的广告拦截插件可以没用过,Edge和Chrome浏览器都好吗?大概率是火狐现在市场份额小,声音低。
据调查机构Statcounter的统计,在Chrome和Safari的挤压下:曾经风靡一时的火狐浏览器,市场份额也从巅峰时期的30%下降到了4%。虽然 2018 年全球有 2.44 亿用户,但 Firefox 浏览器在 2021 年已经下降到 1.96 亿,短短 3 年就流失了 4800 万用户!
事实上,早在火狐封锁该插件之前,国产浏览器就发生了一些事情。它是——神器浏览器。
Magic Browser在其官网上表示:因为Magic Browser收到了来自一家巨头公司视频网站的关于Magic Browser的广告拦截功能的诉讼通知,并被要求支付巨额费用。Magic Browser 无法胜诉,因此将破产并停止运营。魔浏览器方面表示,为了积极配合阿酷等公司的要求,我们将尽快停止所有广告拦截功能,并从所有渠道下架魔浏览器产品。
这些插件同样易于使用。令人欣慰的是,火狐浏览器中唯一被移除的插件是广告移除插件,其他类型的插件都没有被屏蔽。所以想借此机会给大家推荐几个好用的浏览器扩展~顺便也推荐大家使用Edge浏览器。不仅可以访问中国的扩展商店,而且广告拦截插件仍然可以使用!
第一个需要大力推广的扩展是:Infinity Pro,总之就是你的浏览器首页的美化工具!不仅可以更改图标大小、圆角、透明度、排列方式、字体大小、颜色、滑动动画等,还可以自定义壁纸,添加各种彩绘图标网站。当然,对于一些老司机最爱的学习网站,你也可以手动添加~
第二个要推送的一定很实用:AdGuard广告拦截器,众所周知,很多网站自带很多狗皮弹窗广告,极大影响观看体验~和AdGuard广告拦截器的该设备最大的作用就是消除所有这些弹出广告!
第三个强推荐一定是必备的:英文名Tampermonkey可能很多人都不熟悉,所以更多的人喜欢称它为“油猴”。最强大的地方在于它提供了许多强大的用户脚本:方便的脚本安装、自动更新检查、标签中脚本健康的快速概览、内置编辑器等众多功能~同时,“油猴”可能仍能正常运行。最初不兼容的脚本。具体安装方法同上,先在商店搜索,然后获取安装。
安装好油猴之后,我们可以给油猴添加很多强大的“武器”:油猴脚本,所以这个时候,我们不得不推荐一个集合了很多实用脚本的网站:Greasy Fork 可以说过,只要熟悉油猴脚本,绝对可以让你的浏览器功能更强大!
总结与思考
对于这种屏蔽广告的浏览器插件,确实会影响网站的广告业务。这些视频平台抱怨这些广告拦截插件确实是可以理解的。毕竟,打着屏蔽广告、暗中窃取用户隐私的旗号的厂商确实不少。但是我现在出现了这么多的广告拦截插件,这些视频平台要付费!
因为现在国内很多视频平台真的很丑!不仅一开始有很长的广告,而且即使开了会员,也必须在剧中看几分钟广告……这大大降低了我们消费者的体验。我希望未来这些视频平台的广告时长会更短,广告质量会更高。如此一来,消费者愿意接受,自然不会有人用各种插件了~ 查看全部
chrome 插件 抓取网页qq聊天记录(
火狐屏蔽插件:下载一个火狐国际版不就解决了?)
禁止中国用户安装广告插件!火狐做到这一点
科技狐2022-03-30
火狐屏蔽插件,没有任何内幕。这时候可能有狐友会说:下载国际版火狐浏览器就解决了?
当谈到世界上最好的浏览器时,Chrome 绝对在名单上。它以简洁的设计和超快的启动速度赢得了众多用户的心。但要说Chrome浏览器的灵魂,那一定是它的扩展商店:里面有各种有趣实用的扩展,保证为你打开一个安装的新天地~
可悲的是,Chrome 国的扩展商店有 404 状态,所以很多人说:没有扩展的 Chrome 浏览器就像被废了的大师……
很多老司机都转向了其他浏览器。其中,火狐是最受欢迎的。原因很简单。火狐的扩展商店也很丰富,国内也可以访问。
就在最近,火狐浏览器突然屏蔽了中国用户的一些行为——禁止中国IP访问商店的广告屏蔽扩展页面。当有中国IP地址的用户在Firefox商店打开AdGuard之类的广告拦截扩展时,它会说:“此页面在您所在的地区不可用”
火狐屏蔽插件,没有任何内幕。这时候可能有狐友会说:下载国际版火狐浏览器就解决了?并不真地!无论您使用的是国际版火狐浏览器还是国内版火狐浏览器:只要您使用的是中国大陆IP,就无法访问官方商店的广告拦截扩展。
不过不要先骂火狐,因为火狐很可能会被迫屏蔽中国用户使用广告插件……因为早在2017、2018年,(Mozilla在中国的全资子公司)公司):因广告屏蔽被国内多家公司(Amang、Aku等)起诉,判决将于2019年生效。
也就是说,这次国内用户在使用火狐浏览器的时候不能使用广告拦截插件,可能是因为他们搬走了一些巨头的“蛋糕”……那为什么只有火狐的广告拦截插件可以没用过,Edge和Chrome浏览器都好吗?大概率是火狐现在市场份额小,声音低。
据调查机构Statcounter的统计,在Chrome和Safari的挤压下:曾经风靡一时的火狐浏览器,市场份额也从巅峰时期的30%下降到了4%。虽然 2018 年全球有 2.44 亿用户,但 Firefox 浏览器在 2021 年已经下降到 1.96 亿,短短 3 年就流失了 4800 万用户!
事实上,早在火狐封锁该插件之前,国产浏览器就发生了一些事情。它是——神器浏览器。
Magic Browser在其官网上表示:因为Magic Browser收到了来自一家巨头公司视频网站的关于Magic Browser的广告拦截功能的诉讼通知,并被要求支付巨额费用。Magic Browser 无法胜诉,因此将破产并停止运营。魔浏览器方面表示,为了积极配合阿酷等公司的要求,我们将尽快停止所有广告拦截功能,并从所有渠道下架魔浏览器产品。
这些插件同样易于使用。令人欣慰的是,火狐浏览器中唯一被移除的插件是广告移除插件,其他类型的插件都没有被屏蔽。所以想借此机会给大家推荐几个好用的浏览器扩展~顺便也推荐大家使用Edge浏览器。不仅可以访问中国的扩展商店,而且广告拦截插件仍然可以使用!
第一个需要大力推广的扩展是:Infinity Pro,总之就是你的浏览器首页的美化工具!不仅可以更改图标大小、圆角、透明度、排列方式、字体大小、颜色、滑动动画等,还可以自定义壁纸,添加各种彩绘图标网站。当然,对于一些老司机最爱的学习网站,你也可以手动添加~
第二个要推送的一定很实用:AdGuard广告拦截器,众所周知,很多网站自带很多狗皮弹窗广告,极大影响观看体验~和AdGuard广告拦截器的该设备最大的作用就是消除所有这些弹出广告!
第三个强推荐一定是必备的:英文名Tampermonkey可能很多人都不熟悉,所以更多的人喜欢称它为“油猴”。最强大的地方在于它提供了许多强大的用户脚本:方便的脚本安装、自动更新检查、标签中脚本健康的快速概览、内置编辑器等众多功能~同时,“油猴”可能仍能正常运行。最初不兼容的脚本。具体安装方法同上,先在商店搜索,然后获取安装。
安装好油猴之后,我们可以给油猴添加很多强大的“武器”:油猴脚本,所以这个时候,我们不得不推荐一个集合了很多实用脚本的网站:Greasy Fork 可以说过,只要熟悉油猴脚本,绝对可以让你的浏览器功能更强大!
总结与思考
对于这种屏蔽广告的浏览器插件,确实会影响网站的广告业务。这些视频平台抱怨这些广告拦截插件确实是可以理解的。毕竟,打着屏蔽广告、暗中窃取用户隐私的旗号的厂商确实不少。但是我现在出现了这么多的广告拦截插件,这些视频平台要付费!
因为现在国内很多视频平台真的很丑!不仅一开始有很长的广告,而且即使开了会员,也必须在剧中看几分钟广告……这大大降低了我们消费者的体验。我希望未来这些视频平台的广告时长会更短,广告质量会更高。如此一来,消费者愿意接受,自然不会有人用各种插件了~
chrome 插件 抓取网页qq聊天记录(解决办法:Chrome更改代理服务器设置gtgt;连接gt(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-16 11:04
解决方案:
Chrome > 设置 > 更改代理设置 > 连接 > 局域网
选中不要将代理服务器用于本地地址
你可以直接在chrome浏览器上输入:
铬://设置/系统
打开“代理设置”,出现如下界面。
因为我用的是某台灯,所以我在爬×××之前检查了web proxy和secure web proxy。
所以需要排除本地域名。
在“忽略这些主机和域的代理设置”中填写您的本地域名。
填写时,多个域名以空格分隔,保存后会自动更改为分隔。
这里需要注意的是,当你修改它时,你必须重新编写它。不要添加或删除部分输入框。
然后保存后。
可以访问本地域名,同时可以爬取×××访问国外域名。
以下是之前写的内容,不勾选web proxy,secure web proxy,即:不勾选代理。
不用设置ignore,也可以访问本地域名,但是不能访问国外域名。
具体以mac电脑为例:
1.这个界面可以在火狐浏览器中打开,但在谷歌浏览器Chrome中无法打开。
2.点击Chrome右侧的三个点->设置
然后点击“高级设置”->“系统”
找到“打开代理设置”
本来是查的,现在取消了。
自动跳转到这里,代理被检查。
立即取消并单击“确定”
6.点击“应用”
7. 回到浏览器看看,OK!
提示:在查找“打开代理设置”时,可以直接在浏览器中输入:
铬://设置/系统
有什么问题可以留言,我很乐意帮你解答php技术问题。
或加入QQ群:PHP技术问答群。我们会尽力提供帮助。 查看全部
chrome 插件 抓取网页qq聊天记录(解决办法:Chrome更改代理服务器设置gtgt;连接gt(图))
解决方案:
Chrome > 设置 > 更改代理设置 > 连接 > 局域网
选中不要将代理服务器用于本地地址
你可以直接在chrome浏览器上输入:
铬://设置/系统
打开“代理设置”,出现如下界面。
因为我用的是某台灯,所以我在爬×××之前检查了web proxy和secure web proxy。
所以需要排除本地域名。
在“忽略这些主机和域的代理设置”中填写您的本地域名。
填写时,多个域名以空格分隔,保存后会自动更改为分隔。
这里需要注意的是,当你修改它时,你必须重新编写它。不要添加或删除部分输入框。
然后保存后。
可以访问本地域名,同时可以爬取×××访问国外域名。
以下是之前写的内容,不勾选web proxy,secure web proxy,即:不勾选代理。
不用设置ignore,也可以访问本地域名,但是不能访问国外域名。
具体以mac电脑为例:
1.这个界面可以在火狐浏览器中打开,但在谷歌浏览器Chrome中无法打开。
2.点击Chrome右侧的三个点->设置
然后点击“高级设置”->“系统”
找到“打开代理设置”
本来是查的,现在取消了。
自动跳转到这里,代理被检查。
立即取消并单击“确定”
6.点击“应用”
7. 回到浏览器看看,OK!
提示:在查找“打开代理设置”时,可以直接在浏览器中输入:
铬://设置/系统
有什么问题可以留言,我很乐意帮你解答php技术问题。
或加入QQ群:PHP技术问答群。我们会尽力提供帮助。
chrome 插件 抓取网页qq聊天记录(chrome插件抓取网页qq聊天记录用chromewebstore分析chrome应用收集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-16 00:07
chrome插件抓取网页qq聊天记录用chromewebstore分析chrome应用收集网页信息_小木虫论坛_太奇网360手机助手高清浏览器的下载
官方的,chromewebstore这是最权威的了。如果想要到第三方网站分析数据,那么就需要爬虫了。第三方网站,比如googleanalytics。ifavailableyouneedyourwebsitesinheregoogleanalytics是免费的。但目前analytics的对象是电子商务业务。
他将每个卖家作为一个网站来进行商业分析。如果你是推广引流,那么显然是wa,并且需要你有vps,服务器支持。
ip评分查看分析,有免费的,也有每年298/年那种的。
使用友盟市场分析进行定向推广引流,数据包括推广渠道的、下载量,评分等多个数据。
现在用的是友盟,加上三星数据分析,
移动厂商如小米,华为,三星,魅族等的官网都是有加密的推广渠道的qq好友,
用的一洽excel数据采集器,无需编程,能够对手机网站的分析,公网域名全国查询,还能批量全国域名爬取等功能.希望能帮到你.
可以用专业的分析软件和爬虫软件做。
直接上名站数据抓取网站,监控多少年多少网站,可以抓全网页面。这些官网信息都是绝对安全,可靠的信息。
wap.php服务器,信息来源是爬虫爬下来的。js服务器,属于规则, 查看全部
chrome 插件 抓取网页qq聊天记录(chrome插件抓取网页qq聊天记录用chromewebstore分析chrome应用收集)
chrome插件抓取网页qq聊天记录用chromewebstore分析chrome应用收集网页信息_小木虫论坛_太奇网360手机助手高清浏览器的下载
官方的,chromewebstore这是最权威的了。如果想要到第三方网站分析数据,那么就需要爬虫了。第三方网站,比如googleanalytics。ifavailableyouneedyourwebsitesinheregoogleanalytics是免费的。但目前analytics的对象是电子商务业务。
他将每个卖家作为一个网站来进行商业分析。如果你是推广引流,那么显然是wa,并且需要你有vps,服务器支持。
ip评分查看分析,有免费的,也有每年298/年那种的。
使用友盟市场分析进行定向推广引流,数据包括推广渠道的、下载量,评分等多个数据。
现在用的是友盟,加上三星数据分析,
移动厂商如小米,华为,三星,魅族等的官网都是有加密的推广渠道的qq好友,
用的一洽excel数据采集器,无需编程,能够对手机网站的分析,公网域名全国查询,还能批量全国域名爬取等功能.希望能帮到你.
可以用专业的分析软件和爬虫软件做。
直接上名站数据抓取网站,监控多少年多少网站,可以抓全网页面。这些官网信息都是绝对安全,可靠的信息。
wap.php服务器,信息来源是爬虫爬下来的。js服务器,属于规则,
chrome 插件 抓取网页qq聊天记录(qq浏览器中十款提高用户体验,让各位一览无余一番)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-04-15 09:19
自从移动互联网时代,即浏览器市场的原创霸主从神坛陨落,谷歌的chrome浏览器登上顶峰,并有取而代之的趋势。chrome之所以能赶上后来者,与其高效的性能和丰富便捷的插件密不可分。但是国内无法直接访问谷歌应用商店,造成使用chrome插件的不便。QQ浏览器作为市面上另一款流行的浏览器,不仅兼顾了IE的兼容性,还提供了chrome内核的高效和插件功能。QQ浏览器不仅提供了谷歌商城的大部分插件,还提供了自己的专用插件,可以说比蓝还好用。
QQ浏览器应用安装,进入应用中心,直接搜索应用名称即可找到安装,非常方便快捷。
十个插件,先来一张全家福,让你一目了然。
十款全家福插件
1. 图像助手
一个浏览器扩展,用于嗅探、分析网页图片,提供批量下载等功能和在线采集、检索、分享服务。
主要功能: 1.可以提取页面中的图片,可以帮你提取所有不易查看源地址的图片;添加全图水印;3. 直接生成当前页面的二维码。一个插件可以满足许多需求。
2.购物党全网自动比价工具
浏览商品页面时,自动对比同款商品在多个商城的最低价格,并提供价格历史、口碑评分等查询。
主要功能:1.提供当前商城商品的历史价格查询,提供历史最低价和最低价的日期和条件;2.提供其他平台产品的价格比较。总的来说,数据比较准确,值得购物参考。
3.翻译
【QQ浏览器官方产品】非常好用的翻译插件,带人工智能翻译!
主要功能: 1.可以直接翻译网页,进行双语比对。2.可以识别和翻译多种语言。其实对于有外语困难的人来说,上网是必备神器。
4.开发工具箱
常用小工具合二为一,为我们的工作带来福音。
主要功能:看插件的名字,应该是程序员用的。现在功能越来越多,是一个多功能的小工具箱。常用功能包括:二维码的识别与生成、各种编码转换、加解密、代码格式化、代码压缩等。
5.复制鱼
免费高效的OCR插件
主要功能:使用方便,点击插件图标,选择识别区域,可以对网页、pdf中的图片和文字进行OCR识别,识别成文字后直接复制使用即可。
提示:安装后默认为英文OCR识别,需要在设置中改为ChineseSimplified才能识别中文。
需要设置为简体中文
6.Nimbus 截图
全屏捕获网页或任何部分。编辑截图。录制的视频 从您的屏幕录制的视频
主要功能:1.提供多种截图方式,截取后直接编辑,编辑功能强大2.提供录像功能
7.整页截屏
完整可靠地捕获当前页面的屏幕截图 - 无需请求任何额外权限!
主要功能:截图工具非常多,Nimbus Screenshot已经非常实用和全面。这是另一种专业捕获页面完整图像的方法。什么意思,一般的截图工具只能根据你的选择截取当前页面选中的部分,但是这个插件会自动滚动屏幕截取整个页面(从页面的开头到结尾),没有不管有多少个屏幕,包括下拉部分。只要在使用过程中点击插件图标,就会自动截取当前页面的全图。捕获的图像可以下载为图像或 PDF 格式。
8.二维码(生成识别)
从当前页面地址、选中的文字或链接等生成二维码,还可以识别网页中的二维码图片(支持识别中文)。
主要功能:1.生成二维码、各种文字、超链接,在当前页面右击直接生成访问二维码;2.识别二维码,二维码出现在页面上,无需再笨的拿出手机扫码,右击识别二维码。这就是为什么我推荐这个 QR 码软件而不是 Quick QR。
9.FDM(免费下载管理器)
插件版下载神器
主要功能:无需安装软件,外挂版下载软件,迅雷下载不了,试试这个工具,下载电影好东西。
10.adblock plus
还有一种非常重要的插件,就是页面广告拦截插件,其中最著名的就是adblock。不知道为什么QQ浏览器不支持安装。想体验的朋友可以自己研究一下,如何通过其他渠道安装。 查看全部
chrome 插件 抓取网页qq聊天记录(qq浏览器中十款提高用户体验,让各位一览无余一番)
自从移动互联网时代,即浏览器市场的原创霸主从神坛陨落,谷歌的chrome浏览器登上顶峰,并有取而代之的趋势。chrome之所以能赶上后来者,与其高效的性能和丰富便捷的插件密不可分。但是国内无法直接访问谷歌应用商店,造成使用chrome插件的不便。QQ浏览器作为市面上另一款流行的浏览器,不仅兼顾了IE的兼容性,还提供了chrome内核的高效和插件功能。QQ浏览器不仅提供了谷歌商城的大部分插件,还提供了自己的专用插件,可以说比蓝还好用。
QQ浏览器应用安装,进入应用中心,直接搜索应用名称即可找到安装,非常方便快捷。
十个插件,先来一张全家福,让你一目了然。
十款全家福插件
1. 图像助手
一个浏览器扩展,用于嗅探、分析网页图片,提供批量下载等功能和在线采集、检索、分享服务。
主要功能: 1.可以提取页面中的图片,可以帮你提取所有不易查看源地址的图片;添加全图水印;3. 直接生成当前页面的二维码。一个插件可以满足许多需求。
2.购物党全网自动比价工具
浏览商品页面时,自动对比同款商品在多个商城的最低价格,并提供价格历史、口碑评分等查询。
主要功能:1.提供当前商城商品的历史价格查询,提供历史最低价和最低价的日期和条件;2.提供其他平台产品的价格比较。总的来说,数据比较准确,值得购物参考。
3.翻译
【QQ浏览器官方产品】非常好用的翻译插件,带人工智能翻译!
主要功能: 1.可以直接翻译网页,进行双语比对。2.可以识别和翻译多种语言。其实对于有外语困难的人来说,上网是必备神器。
4.开发工具箱
常用小工具合二为一,为我们的工作带来福音。
主要功能:看插件的名字,应该是程序员用的。现在功能越来越多,是一个多功能的小工具箱。常用功能包括:二维码的识别与生成、各种编码转换、加解密、代码格式化、代码压缩等。
5.复制鱼
免费高效的OCR插件
主要功能:使用方便,点击插件图标,选择识别区域,可以对网页、pdf中的图片和文字进行OCR识别,识别成文字后直接复制使用即可。
提示:安装后默认为英文OCR识别,需要在设置中改为ChineseSimplified才能识别中文。
需要设置为简体中文
6.Nimbus 截图
全屏捕获网页或任何部分。编辑截图。录制的视频 从您的屏幕录制的视频
主要功能:1.提供多种截图方式,截取后直接编辑,编辑功能强大2.提供录像功能
7.整页截屏
完整可靠地捕获当前页面的屏幕截图 - 无需请求任何额外权限!
主要功能:截图工具非常多,Nimbus Screenshot已经非常实用和全面。这是另一种专业捕获页面完整图像的方法。什么意思,一般的截图工具只能根据你的选择截取当前页面选中的部分,但是这个插件会自动滚动屏幕截取整个页面(从页面的开头到结尾),没有不管有多少个屏幕,包括下拉部分。只要在使用过程中点击插件图标,就会自动截取当前页面的全图。捕获的图像可以下载为图像或 PDF 格式。
8.二维码(生成识别)
从当前页面地址、选中的文字或链接等生成二维码,还可以识别网页中的二维码图片(支持识别中文)。
主要功能:1.生成二维码、各种文字、超链接,在当前页面右击直接生成访问二维码;2.识别二维码,二维码出现在页面上,无需再笨的拿出手机扫码,右击识别二维码。这就是为什么我推荐这个 QR 码软件而不是 Quick QR。
9.FDM(免费下载管理器)
插件版下载神器
主要功能:无需安装软件,外挂版下载软件,迅雷下载不了,试试这个工具,下载电影好东西。
10.adblock plus
还有一种非常重要的插件,就是页面广告拦截插件,其中最著名的就是adblock。不知道为什么QQ浏览器不支持安装。想体验的朋友可以自己研究一下,如何通过其他渠道安装。
chrome 插件 抓取网页qq聊天记录( 接下来怎么去开发一个自己的js轮播插件或应用(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-11 05:03
接下来怎么去开发一个自己的js轮播插件或应用(组图))
前端开发,整理推荐有用的chrome插件或应用
整理提供给 web 前端开发者的 chrome 插件或应用程序:如 Postman、JSON Viewer、Page Ruler、ChromeADB 等。
如何使用原生js开发插件
作为前端开发,我们都习惯使用一些开源的插件,比如jquery工具库,那么如何使用原生js来开发和封装一个自己的插件呢?接下来我们来看看如何开发自己的js插件,先上代码
typeahead.js_jquery 输入搜索自动完成 jQuery 插件
jquery.typeahead.js 是一个高级的自动完成 jQuery 插件。自动补全插件提供超过50个配置选项和回调方法来完成自动补全功能,可以满足大部分表单自动补全需求。
js carousel plugin_carousel图 js代码插件总结
这个文章是一款适合大家的图片轮播插件,最全、最简单、最通用的幻灯片轮播插件。在PC端和移动端都可以完美使用,可以满足大部分网站回合的需求。广播需求。js轮播插件包括Swiper、slick、owl carousel2、jssor/slider、iSlider等。
ios风格的时间选择插件
上一个项目中,客户希望时间选择插件可以是ios风格的,但是找了半天,发现vue的ios风格的时间插件没有使用,于是建了一个自己轮。插件依赖better-scroll和vue
前端最常用的vscode插件集
在前端开发中,你常用的 Visual Studio Code 插件有哪些?推荐几个自己喜欢的,不用链接,自己搜索安装。这些比较实用,前端必备的插件集
浏览器插件_推荐常用的谷歌浏览器插件
常用的谷歌浏览器内置功能确实不如国内其他软件丰富。不过,谷歌浏览器的优势恰恰体现在其超简洁的界面和支持众多强大易用的扩展,用户可以根据自己的喜好自定义浏览器。今天给大家介绍几个我常用的插件。
崇高安装插件
安装 Sublime text 2 插件非常方便。可以直接下载安装包解压到Packages目录下,也可以安装包控制组件,然后直接在线安装。
Jquery中BlockUI_ajax加载提示插件blickUI详细使用
BlockUI 插件用于在执行 AJAX 操作时模拟同步传输时锁定浏览器操作。当它被激活时,它会阻止用户与页面(或页面的一部分)交互,直到它被关闭。BlockUI 将元素添加到 DOM 以实现阻止用户与浏览器交互的外观和行为
vue项目中vscode格式化配置和eslint配置冲突
使用vscode开发vue项目时,从远端拉下一个新项目,安装好依赖后运行项目,发现直接报了一堆语法错误:包括换行符、空格、单双引号标记、分号等格式问题 查看全部
chrome 插件 抓取网页qq聊天记录(
接下来怎么去开发一个自己的js轮播插件或应用(组图))
前端开发,整理推荐有用的chrome插件或应用
整理提供给 web 前端开发者的 chrome 插件或应用程序:如 Postman、JSON Viewer、Page Ruler、ChromeADB 等。
如何使用原生js开发插件
作为前端开发,我们都习惯使用一些开源的插件,比如jquery工具库,那么如何使用原生js来开发和封装一个自己的插件呢?接下来我们来看看如何开发自己的js插件,先上代码
typeahead.js_jquery 输入搜索自动完成 jQuery 插件
jquery.typeahead.js 是一个高级的自动完成 jQuery 插件。自动补全插件提供超过50个配置选项和回调方法来完成自动补全功能,可以满足大部分表单自动补全需求。
js carousel plugin_carousel图 js代码插件总结
这个文章是一款适合大家的图片轮播插件,最全、最简单、最通用的幻灯片轮播插件。在PC端和移动端都可以完美使用,可以满足大部分网站回合的需求。广播需求。js轮播插件包括Swiper、slick、owl carousel2、jssor/slider、iSlider等。
ios风格的时间选择插件
上一个项目中,客户希望时间选择插件可以是ios风格的,但是找了半天,发现vue的ios风格的时间插件没有使用,于是建了一个自己轮。插件依赖better-scroll和vue
前端最常用的vscode插件集
在前端开发中,你常用的 Visual Studio Code 插件有哪些?推荐几个自己喜欢的,不用链接,自己搜索安装。这些比较实用,前端必备的插件集
浏览器插件_推荐常用的谷歌浏览器插件
常用的谷歌浏览器内置功能确实不如国内其他软件丰富。不过,谷歌浏览器的优势恰恰体现在其超简洁的界面和支持众多强大易用的扩展,用户可以根据自己的喜好自定义浏览器。今天给大家介绍几个我常用的插件。
崇高安装插件
安装 Sublime text 2 插件非常方便。可以直接下载安装包解压到Packages目录下,也可以安装包控制组件,然后直接在线安装。
Jquery中BlockUI_ajax加载提示插件blickUI详细使用
BlockUI 插件用于在执行 AJAX 操作时模拟同步传输时锁定浏览器操作。当它被激活时,它会阻止用户与页面(或页面的一部分)交互,直到它被关闭。BlockUI 将元素添加到 DOM 以实现阻止用户与浏览器交互的外观和行为
vue项目中vscode格式化配置和eslint配置冲突
使用vscode开发vue项目时,从远端拉下一个新项目,安装好依赖后运行项目,发现直接报了一堆语法错误:包括换行符、空格、单双引号标记、分号等格式问题
chrome 插件 抓取网页qq聊天记录(推荐5款可以提升工作效率的Chrome插件这款插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-11 03:30
大家好,我是安哥!
今天继续推荐5款可以提高工作效率的Chrome插件。
全方位
这个 Chrome 插件可以快速搜索、切换和关闭浏览器书签、Tab 页和历史记录。
当我们同时打开多个Tab页时,切换到某个Tab页是很麻烦的。Omni输入框只需输入关键字“/tabs”,然后追加关键字即可快速查询Tab,回车切换Tab。
另外,关键字“/bookmarks”用于快速切换搜索书签,“/history”用于切换历史记录,“/remove”可用于关闭Tab或删除书签
为了提高使用效率,建议为Omni设置快捷键,在地址栏中输入“chrome://extensions/shortcuts”,给Omni分配一个热键,例如:Ctrl + Shift + K
当然,Omni也有很多实用的功能,比如:页面静音、Tab pinning、管理插件等,大家可以自己扩展
插件地址:
CSS 窥视器
CSS Peeper,一个提取网页样式的插件
作为CSS查看器,可以直观高效的获取网页元素的属性、宽度、高度、字体样式
使用方法很简单,只要点击插件,用鼠标点击网页上的一个控件,右上角就会显示目标元素的CSS样式属性。
插件地址:
JSON查看器专业版
在Chrome应用市场上,JSON格式化插件很多,但这个插件除了常规功能外,还包括样式自定义、“图表视图”展示等功能,用户体验更好。
另外这个插件可以随意选择一个节点,复制Path路径和Value值
插件地址:
历史趋势无限
这是一个历史管理插件,可以将历史浏览记录“永久”保存到本地数据库,并生成排名列表和统计报表图表。比如可以按时间段列出访问量前十名网站
此外,还可以通过关键字查询历史浏览记录
在设置中可以导入导出历史记录,配置自动备份的周期
插件地址:
阿贾克斯拦截器
本插件可以修改ajax请求的返回结果,一般用于Mock数据,接口联调测试
使用起来很简单。只需要打开插件开关,然后将要拦截的请求地址匹配成完整地址或常规地址,最后加上要返回的请求结果,这样修改请求的响应结果就可以了完成。
插件地址:
源地址: 查看全部
chrome 插件 抓取网页qq聊天记录(推荐5款可以提升工作效率的Chrome插件这款插件)
大家好,我是安哥!
今天继续推荐5款可以提高工作效率的Chrome插件。
全方位
这个 Chrome 插件可以快速搜索、切换和关闭浏览器书签、Tab 页和历史记录。
当我们同时打开多个Tab页时,切换到某个Tab页是很麻烦的。Omni输入框只需输入关键字“/tabs”,然后追加关键字即可快速查询Tab,回车切换Tab。
另外,关键字“/bookmarks”用于快速切换搜索书签,“/history”用于切换历史记录,“/remove”可用于关闭Tab或删除书签
为了提高使用效率,建议为Omni设置快捷键,在地址栏中输入“chrome://extensions/shortcuts”,给Omni分配一个热键,例如:Ctrl + Shift + K
当然,Omni也有很多实用的功能,比如:页面静音、Tab pinning、管理插件等,大家可以自己扩展
插件地址:
CSS 窥视器
CSS Peeper,一个提取网页样式的插件
作为CSS查看器,可以直观高效的获取网页元素的属性、宽度、高度、字体样式
使用方法很简单,只要点击插件,用鼠标点击网页上的一个控件,右上角就会显示目标元素的CSS样式属性。
插件地址:
JSON查看器专业版
在Chrome应用市场上,JSON格式化插件很多,但这个插件除了常规功能外,还包括样式自定义、“图表视图”展示等功能,用户体验更好。
另外这个插件可以随意选择一个节点,复制Path路径和Value值
插件地址:
历史趋势无限
这是一个历史管理插件,可以将历史浏览记录“永久”保存到本地数据库,并生成排名列表和统计报表图表。比如可以按时间段列出访问量前十名网站
此外,还可以通过关键字查询历史浏览记录
在设置中可以导入导出历史记录,配置自动备份的周期
插件地址:
阿贾克斯拦截器
本插件可以修改ajax请求的返回结果,一般用于Mock数据,接口联调测试
使用起来很简单。只需要打开插件开关,然后将要拦截的请求地址匹配成完整地址或常规地址,最后加上要返回的请求结果,这样修改请求的响应结果就可以了完成。
插件地址:
源地址:
chrome 插件 抓取网页qq聊天记录(目录Logo抓取器是国外开发者开发一款Logo获取工具浏览器插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-09 18:21
目录
Logo Grabber是国外开发者开发的一款浏览器插件,用于logo获取工具。网友对其进行了汉化,支持Chrome、FireFox、360等浏览器。一键傻瓜式操作下载他们的Logo,而且还是PNG格式,不妨下载体验一下!
安装方法
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹中。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/ 勾选右上角的“开发者模式”按钮。
3、勾选开发者模式选项后,此页面会出现加载正在开发的扩展等按钮,点击“加载正在开发的扩展”按钮,选择刚刚解压的Chrome插件文件夹文件夹。
4、点击“确定”按钮,如果没有其他反应,插件就会成功加载到浏览器中。
如何使用
1、使用 Google Chrome(或其他 Chrome 浏览器)打开目标网站。
2、点击浏览器上的“Logo Grabber”开始抓取可能的 Logo 图案。
3、点击“下载”下载对应的Logo格式。
4、如果发现logo显示不正确,也可以通过下面的链接反馈问题。
不是所有网站都支持,但大部分网站还是可以的,这个工具可以节省时间,提高工作效率,其次,它可以获取png格式的图片,这绝对比截图好。高,第三年可以在隐藏标签中获得一些Logo,总体不错。
以上是Logo Grabber的软件介绍。您可能还想了解徽标抓取系统、徽标提取器、提取网站徽标等。请关注本软件站点文章。 查看全部
chrome 插件 抓取网页qq聊天记录(目录Logo抓取器是国外开发者开发一款Logo获取工具浏览器插件)
目录
Logo Grabber是国外开发者开发的一款浏览器插件,用于logo获取工具。网友对其进行了汉化,支持Chrome、FireFox、360等浏览器。一键傻瓜式操作下载他们的Logo,而且还是PNG格式,不妨下载体验一下!
安装方法
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹中。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/ 勾选右上角的“开发者模式”按钮。
3、勾选开发者模式选项后,此页面会出现加载正在开发的扩展等按钮,点击“加载正在开发的扩展”按钮,选择刚刚解压的Chrome插件文件夹文件夹。
4、点击“确定”按钮,如果没有其他反应,插件就会成功加载到浏览器中。
如何使用
1、使用 Google Chrome(或其他 Chrome 浏览器)打开目标网站。
2、点击浏览器上的“Logo Grabber”开始抓取可能的 Logo 图案。
3、点击“下载”下载对应的Logo格式。
4、如果发现logo显示不正确,也可以通过下面的链接反馈问题。
不是所有网站都支持,但大部分网站还是可以的,这个工具可以节省时间,提高工作效率,其次,它可以获取png格式的图片,这绝对比截图好。高,第三年可以在隐藏标签中获得一些Logo,总体不错。
以上是Logo Grabber的软件介绍。您可能还想了解徽标抓取系统、徽标提取器、提取网站徽标等。请关注本软件站点文章。
chrome 插件 抓取网页qq聊天记录(QQ会读取Chrome的历史记录,被火绒自定义规则拦截了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-04-07 12:07
)
先说结论,QQ会读取浏览器的历史浏览记录,包括但不限于Chrome、Chromium、360极速、360安全、猎豹、2345等。
今天看到群里有个同学在v2ex()上发了个帖子,说QQ会读Chrome的历史,被火绒的自定义规则屏蔽了。我一开始不相信,但他说他又出现了,而且QQ登录后只有10分钟才能访问。
我想验证一下,打开虚拟机安装QQ、Chrome,然后打开Process Monitor启动等等。规则被简单地过滤。
果然看到了读取AppData\Local\Google\Chrome\User Data\Default\History等目录的操作。
而且时间正好十分钟。
这才是QQ和Chrome打不通的实锤。我不相信。我把规则删了,又查了一遍,发现QQ被冤枉了。
受害者的数量令人震惊。仔细看,这个东西会遍历Appdata\Local\下的所有文件夹,然后添加User Data\Default\History来读取。User Data\Default\History 是谷歌浏览器默认的历史记录存储位置(火狐等浏览器对该目录不熟悉,Chrome被拍是正常的。
那么就该研究一下QQ为什么会这样了,浏览器历史记录又是怎么读取的呢?
连接 x32dbg 并动态调试以找到位置。
然后去IDA直接反编译,如下(位置在AppUtil.dll中.text:510EFB98附近)
这一段的逻辑还是很容易理解的。先读取各种User Data\Default\History文件,复制到Temp目录下的temphis.db。回去看看Procmom,果然。
之后操作就简单了,SQLite读取数据库,然后“select url from urls”,大家就知道是干什么的了。后面我就不多说了,有兴趣的可以自己看。
综上所述,QQ并没有刻意读取Chrome的历史,而是会尝试读取电脑上所有基于谷歌的浏览器的历史并提取链接。确认将招募的浏览器包括但不限于Chrome、Chromium、360极速、360安全、猎豹、2345等浏览器。这里@腾讯QQ
我会在晚上编辑它。刚试了TIM,果然是经典再现,比QQ还离谱。
查看全部
chrome 插件 抓取网页qq聊天记录(QQ会读取Chrome的历史记录,被火绒自定义规则拦截了
)
先说结论,QQ会读取浏览器的历史浏览记录,包括但不限于Chrome、Chromium、360极速、360安全、猎豹、2345等。
今天看到群里有个同学在v2ex()上发了个帖子,说QQ会读Chrome的历史,被火绒的自定义规则屏蔽了。我一开始不相信,但他说他又出现了,而且QQ登录后只有10分钟才能访问。
我想验证一下,打开虚拟机安装QQ、Chrome,然后打开Process Monitor启动等等。规则被简单地过滤。
果然看到了读取AppData\Local\Google\Chrome\User Data\Default\History等目录的操作。
而且时间正好十分钟。
这才是QQ和Chrome打不通的实锤。我不相信。我把规则删了,又查了一遍,发现QQ被冤枉了。
受害者的数量令人震惊。仔细看,这个东西会遍历Appdata\Local\下的所有文件夹,然后添加User Data\Default\History来读取。User Data\Default\History 是谷歌浏览器默认的历史记录存储位置(火狐等浏览器对该目录不熟悉,Chrome被拍是正常的。
那么就该研究一下QQ为什么会这样了,浏览器历史记录又是怎么读取的呢?
连接 x32dbg 并动态调试以找到位置。
然后去IDA直接反编译,如下(位置在AppUtil.dll中.text:510EFB98附近)
这一段的逻辑还是很容易理解的。先读取各种User Data\Default\History文件,复制到Temp目录下的temphis.db。回去看看Procmom,果然。
之后操作就简单了,SQLite读取数据库,然后“select url from urls”,大家就知道是干什么的了。后面我就不多说了,有兴趣的可以自己看。
综上所述,QQ并没有刻意读取Chrome的历史,而是会尝试读取电脑上所有基于谷歌的浏览器的历史并提取链接。确认将招募的浏览器包括但不限于Chrome、Chromium、360极速、360安全、猎豹、2345等浏览器。这里@腾讯QQ
我会在晚上编辑它。刚试了TIM,果然是经典再现,比QQ还离谱。
chrome 插件 抓取网页qq聊天记录(文章目录仓库地址github仓库(Plus)功能介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-06 04:08
文章目录
仓库地址
github仓库
前言
作为技术人员,录制博客是一件很平常的事情。他们大多使用markdown作为首选的录制方式,录制的博客一般发布在CSDN、博客园、简书、知乎等平台。
写博客往往离不开图片。对于本地写的博客,如果直接上传引用图片到云端,引用链接而不是本地路径,博客的文件结构可以更加简洁,不会出现图片无法访问的情况移动的路径。所以现在写博客的时候,一般都是使用图床转换工具,直接把贴图上传到云端。比如 Typora 中使用的 PicGO 插件,配合 Gitee 仓库,可以轻松创建自己的图床。
但是在具体使用过程中,我发现Gitee仓库中的图片在被其他平台引用后经常无法显示,导致我上传到上述平台的博客无法正常访问。为了结束这个问题,我自己做了一个脚本,可以将本地/网络图片转换为常用的博客网站图床,并生成链接替换markdown文件中的原创图片路径。
可以理解为脚本的功能就是PicGO Plus。(接下来就是做个PicGO插件直接用,这样最好)
特征
目前脚本支持CSDN、博客园、B站、知乎、简书五个平台。具体功能包括:
支持读取指定的单个markdown文件或默认根目录下的所有markdown文件支持configs文件设置单个/多个图床平台支持命令行参数设置指定图床平台支持直接上传md文档中本地图片(<< @知乎) 支持md文档中网络图片直接转换(所有平台) 支持md文档中本地/网络图片混合转换(知乎除外) 支持原地替换,写入所有识别转换后的图片链接使用 Method1. 安装依赖
除了python基础依赖库,这个脚本还需要安装requests和requests_toolbelt库:
pip install requests
pip install requests_toolbelt
安装完成后,脚本就可以正常使用了
2. 个人配置
在该目录下的 configs.py 文件中,用户可以配置自己的脚本。配置说明如下:
一种。配置默认图像床
默认图床网站可以在configs.py文件第11行配置,使用的图床必须从以下5种中选择。可以设置一个或多个,可以根据表格样式进行配置。
这里推荐使用CSDN,因为当前测量不需要频繁更换cookies,可以稳定使用。
湾。配置登录 cookie
因为每个使用的服务商图床都需要登录cookies,所以用户需要进入自己的浏览器抓包获取对应的字段cookie并填写。
下面介绍如何获取各个浏览器的cookie:
CSDN
登录自己的CSDN,然后进入个人中心(),打开浏览器的开发者工具(chrome默认ctrl+alt+I),找到UserName和UserToken,复制对应的值。
然后粘贴到第26行的csdn_cookies中,完成配置。
知乎
登录你的知乎,然后进入首页(),打开浏览器的开发者工具,找到z_c0,复制对应的值,然后在第33行填写对应的知乎_cookies,完成配置。
知乎的图片默认支持三种,src、watermark_src、original_src,watermark_src为水印原图,original_src为原图,src为显示图,用户可自行选择。
b站
登录自己的b站,然后进入首页(),打开浏览器的开发者工具,找到SESSDATA,复制对应的值,然后在第41行填写对应的bili_cookies,完成配置。
短书
登录你的简书,然后进入首页(),打开浏览器的开发者工具,找到remember_user_token和_m7e_session_core字段,复制对应的值,然后填写第47行对应的jianshu_cookies即可完成配置。
博客公园
登录你的博客园,然后进入首页(),打开浏览器的开发者工具,找到.Cnblogs.AspNetCore.Cookies字段,复制对应的值,然后在第53行填写对应的bokeyuan_cookies,完成配置.
3. 命令行调用
脚本的使用方法是:
python convert.py
使用该命令后,会默认读取当前脚本所在目录下的所有md文件,并会一一读取扫描的图片链接或本地路径。根据配置中指定的转换方式,转换后的输出为{New_(mode)_(original name)}。
如果需要指定转换后的文件,使用命令:
python convert.py -f new.md
而如果默认转换图床不适用,则需要另外指定转换图床,使用命令:
python convert.py -m csdn
这两个参数可以同时指定,转换效果如下:
代码解析
稍后更新
免责声明:本文仅用于技术讨论,基于本文技术的任何违规和违规行为与本人无关。
如果您有任何问题或错误,请随时给我发私信以纠正我。 查看全部
chrome 插件 抓取网页qq聊天记录(文章目录仓库地址github仓库(Plus)功能介绍(图))
文章目录
仓库地址
github仓库
前言
作为技术人员,录制博客是一件很平常的事情。他们大多使用markdown作为首选的录制方式,录制的博客一般发布在CSDN、博客园、简书、知乎等平台。
写博客往往离不开图片。对于本地写的博客,如果直接上传引用图片到云端,引用链接而不是本地路径,博客的文件结构可以更加简洁,不会出现图片无法访问的情况移动的路径。所以现在写博客的时候,一般都是使用图床转换工具,直接把贴图上传到云端。比如 Typora 中使用的 PicGO 插件,配合 Gitee 仓库,可以轻松创建自己的图床。
但是在具体使用过程中,我发现Gitee仓库中的图片在被其他平台引用后经常无法显示,导致我上传到上述平台的博客无法正常访问。为了结束这个问题,我自己做了一个脚本,可以将本地/网络图片转换为常用的博客网站图床,并生成链接替换markdown文件中的原创图片路径。
可以理解为脚本的功能就是PicGO Plus。(接下来就是做个PicGO插件直接用,这样最好)
特征
目前脚本支持CSDN、博客园、B站、知乎、简书五个平台。具体功能包括:
支持读取指定的单个markdown文件或默认根目录下的所有markdown文件支持configs文件设置单个/多个图床平台支持命令行参数设置指定图床平台支持直接上传md文档中本地图片(<< @知乎) 支持md文档中网络图片直接转换(所有平台) 支持md文档中本地/网络图片混合转换(知乎除外) 支持原地替换,写入所有识别转换后的图片链接使用 Method1. 安装依赖
除了python基础依赖库,这个脚本还需要安装requests和requests_toolbelt库:
pip install requests
pip install requests_toolbelt
安装完成后,脚本就可以正常使用了
2. 个人配置
在该目录下的 configs.py 文件中,用户可以配置自己的脚本。配置说明如下:
一种。配置默认图像床
默认图床网站可以在configs.py文件第11行配置,使用的图床必须从以下5种中选择。可以设置一个或多个,可以根据表格样式进行配置。
这里推荐使用CSDN,因为当前测量不需要频繁更换cookies,可以稳定使用。
湾。配置登录 cookie
因为每个使用的服务商图床都需要登录cookies,所以用户需要进入自己的浏览器抓包获取对应的字段cookie并填写。
下面介绍如何获取各个浏览器的cookie:
CSDN
登录自己的CSDN,然后进入个人中心(),打开浏览器的开发者工具(chrome默认ctrl+alt+I),找到UserName和UserToken,复制对应的值。
然后粘贴到第26行的csdn_cookies中,完成配置。
知乎
登录你的知乎,然后进入首页(),打开浏览器的开发者工具,找到z_c0,复制对应的值,然后在第33行填写对应的知乎_cookies,完成配置。
知乎的图片默认支持三种,src、watermark_src、original_src,watermark_src为水印原图,original_src为原图,src为显示图,用户可自行选择。
b站
登录自己的b站,然后进入首页(),打开浏览器的开发者工具,找到SESSDATA,复制对应的值,然后在第41行填写对应的bili_cookies,完成配置。
短书
登录你的简书,然后进入首页(),打开浏览器的开发者工具,找到remember_user_token和_m7e_session_core字段,复制对应的值,然后填写第47行对应的jianshu_cookies即可完成配置。
博客公园
登录你的博客园,然后进入首页(),打开浏览器的开发者工具,找到.Cnblogs.AspNetCore.Cookies字段,复制对应的值,然后在第53行填写对应的bokeyuan_cookies,完成配置.
3. 命令行调用
脚本的使用方法是:
python convert.py
使用该命令后,会默认读取当前脚本所在目录下的所有md文件,并会一一读取扫描的图片链接或本地路径。根据配置中指定的转换方式,转换后的输出为{New_(mode)_(original name)}。
如果需要指定转换后的文件,使用命令:
python convert.py -f new.md
而如果默认转换图床不适用,则需要另外指定转换图床,使用命令:
python convert.py -m csdn
这两个参数可以同时指定,转换效果如下:
代码解析
稍后更新
免责声明:本文仅用于技术讨论,基于本文技术的任何违规和违规行为与本人无关。
如果您有任何问题或错误,请随时给我发私信以纠正我。
chrome 插件 抓取网页qq聊天记录(不少,网页抓取这几个核心关键进行讲解分享(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-05 21:22
总结:RSSHub 是一个制作 RSS 提要的工具。与Huginn、Feed43等工具类似,RSSHub也是通过爬取大部分网站上的网页来获取Feed,不同的是在RSSHub中已经完成了爬取规则的编写,用户只需要简单的编辑地址以下。如果您对 RSSHub 感兴趣,欢迎或我们。
很多人都想知道如何在网上翻找 RSS 链接?最好用这个Chrome插件一键订阅本主题的相关知识内容。今天小编就围绕rss和网页爬取的核心key进行讲解和分享,希望对有相关需求的朋友有所帮助。在网上搜索 RSS 链接?最好使用这个Chrome插件订阅具体内容如下。
在网上搜索 RSS 链接?最好用这个Chrome插件一键订阅
RSSHub 是用于设计和生成 RSS 提要的工具。与 Huginn、Feed43 等工具类似,RSSHub 也是通过抓取大多数 网站 网站上的网页来获取 feed。不同的是,在 RSSHub 中,爬虫规则的编写已经完成。用户只需编辑地址即可。
例如,我想在 YouTube 上订阅 Linus Tech Tips 的多媒体视频。我在网页上发现LTT的用户名是“LinusTechTips”。根据 RSSHub 的官方文档,我只需要订阅 /i/subion/feed/ /feed/atom.xml
加入我们
如果您对 RSSHub 感兴趣,欢迎或我们。 查看全部
chrome 插件 抓取网页qq聊天记录(不少,网页抓取这几个核心关键进行讲解分享(图))
总结:RSSHub 是一个制作 RSS 提要的工具。与Huginn、Feed43等工具类似,RSSHub也是通过爬取大部分网站上的网页来获取Feed,不同的是在RSSHub中已经完成了爬取规则的编写,用户只需要简单的编辑地址以下。如果您对 RSSHub 感兴趣,欢迎或我们。
很多人都想知道如何在网上翻找 RSS 链接?最好用这个Chrome插件一键订阅本主题的相关知识内容。今天小编就围绕rss和网页爬取的核心key进行讲解和分享,希望对有相关需求的朋友有所帮助。在网上搜索 RSS 链接?最好使用这个Chrome插件订阅具体内容如下。
在网上搜索 RSS 链接?最好用这个Chrome插件一键订阅
RSSHub 是用于设计和生成 RSS 提要的工具。与 Huginn、Feed43 等工具类似,RSSHub 也是通过抓取大多数 网站 网站上的网页来获取 feed。不同的是,在 RSSHub 中,爬虫规则的编写已经完成。用户只需编辑地址即可。
例如,我想在 YouTube 上订阅 Linus Tech Tips 的多媒体视频。我在网页上发现LTT的用户名是“LinusTechTips”。根据 RSSHub 的官方文档,我只需要订阅 /i/subion/feed/ /feed/atom.xml
加入我们
如果您对 RSSHub 感兴趣,欢迎或我们。
chrome 插件 抓取网页qq聊天记录(谷歌浏览器统计插件-timeStatschrome插件功能和安装方法介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-04-04 19:10
)
小编为使用谷歌浏览器的朋友采集了一个网站停留时间统计插件timeStats chrome插件。通过这个插件,用户可以知道在网站上花费的时间和时间。每个网站的具体停留时间等信息以图表的形式呈现。以下内容为您介绍timeStats chrome插件的功能及安装方法,请参考。特征:
1、每月统计:显示每月访问网站统计
2、 最忙的日子:浏览网页的时间最长
3、访问网站:来自您浏览的完整统计数据
4、每日统计:显示当天访问的 网站 的统计信息
5、花费时间:显示您每天浏览所花费的总时间
6、Most Visited Domains:最常访问域的完整列表
7、网站Stats:显示安装时间统计时您在特定网站上花费的时间
8、类别:您可以将您的 网站 分类为您可以自己命名的类别
TimeStats chrome插件安装方法:
1、第一步在标签页输入【chrome://extensions/】进入chrome扩展,解压你要下载的timeStats chrome插件包,拖入扩展页面.
2、安装完成后,关闭自动弹出的介绍页面,进入网页试试效果。
知识扩展:
如何删除 chrome 插件?
1、在浏览器右上角,找到要删除的插件,然后右键,在弹出的菜单中选择Delete from Chrome,即可删除插件
2、上面的方法是一个一个删除插件的方法。如果要一次删除多个插件,可以进入插件管理器
3、在打开的页面,点击垃圾桶删除插件。当然,如果你觉得这个插件以后会有用,但是你担心一旦插件被删除,以后不知道去哪里找了。暂停插件的选项,只是取消它
timeStats chrome插件体积小,安装方便。这是一个非常实用的时间统计插件。需要的不要错过。
界面预览:
查看全部
chrome 插件 抓取网页qq聊天记录(谷歌浏览器统计插件-timeStatschrome插件功能和安装方法介绍
)
小编为使用谷歌浏览器的朋友采集了一个网站停留时间统计插件timeStats chrome插件。通过这个插件,用户可以知道在网站上花费的时间和时间。每个网站的具体停留时间等信息以图表的形式呈现。以下内容为您介绍timeStats chrome插件的功能及安装方法,请参考。特征:
1、每月统计:显示每月访问网站统计
2、 最忙的日子:浏览网页的时间最长
3、访问网站:来自您浏览的完整统计数据
4、每日统计:显示当天访问的 网站 的统计信息
5、花费时间:显示您每天浏览所花费的总时间
6、Most Visited Domains:最常访问域的完整列表
7、网站Stats:显示安装时间统计时您在特定网站上花费的时间
8、类别:您可以将您的 网站 分类为您可以自己命名的类别
TimeStats chrome插件安装方法:
1、第一步在标签页输入【chrome://extensions/】进入chrome扩展,解压你要下载的timeStats chrome插件包,拖入扩展页面.
2、安装完成后,关闭自动弹出的介绍页面,进入网页试试效果。
知识扩展:
如何删除 chrome 插件?
1、在浏览器右上角,找到要删除的插件,然后右键,在弹出的菜单中选择Delete from Chrome,即可删除插件
2、上面的方法是一个一个删除插件的方法。如果要一次删除多个插件,可以进入插件管理器
3、在打开的页面,点击垃圾桶删除插件。当然,如果你觉得这个插件以后会有用,但是你担心一旦插件被删除,以后不知道去哪里找了。暂停插件的选项,只是取消它
timeStats chrome插件体积小,安装方便。这是一个非常实用的时间统计插件。需要的不要错过。
界面预览:
chrome 插件 抓取网页qq聊天记录(5款可以提升工作效率的Chrome插件,你值得拥有!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-04 17:17
今天给大家推荐5款可以提高工作效率的Chrome插件。
全方位
这个 Chrome 插件可以快速搜索、切换和关闭浏览器书签、Tab 页和历史记录。
当我们同时打开多个Tab页时,切换到某个Tab页是很麻烦的。在Omni输入框中,只需输入关键字“/tabs”,然后追加关键字即可快速查询Tab,回车即可切换Tab。
另外,关键字“/bookmarks”用于快速切换搜索书签,“/history”用于切换历史记录,“/remove”可用于关闭Tab或删除书签
为了提高使用效率,建议为Omni设置快捷键,在地址栏中输入“chrome://extensions/shortcuts”,并为Omni指定一个热键,例如:Ctrl + Shift + K
当然,Omni也有很多实用的功能,比如:页面静音、Tab pinning、管理插件等,大家可以自己扩展
CSS 窥视器
CSS Peeper,一个提取网页样式的插件
作为CSS查看器,可以直观高效的获取网页元素的属性、宽度、高度、字体样式
使用方法很简单,只需点击插件,用鼠标点击网页上的一个控件,右上角就会显示目标元素的CSS样式属性。
JSON查看器专业版
在Chrome应用市场上,JSON格式化插件很多,但是这个插件除了常规功能外还包括样式自定义、“图表视图”展示等功能,用户体验更好。
另外这个插件可以随意选择一个节点,复制Path路径和Value值
历史趋势无限
这是一个历史管理插件,可以将历史浏览记录“永久”保存到本地数据库,并生成排名列表和统计报表图表。比如可以按时间段列出访问量前十名网站
此外,还可以通过关键字查询历史浏览记录
在设置中可以导入导出历史记录,配置自动备份的周期
阿贾克斯拦截器
本插件可以修改ajax请求的返回结果,一般用于Mock数据,接口联调测试
使用起来很简单。只需打开插件开关,然后将要拦截的请求地址匹配为全地址或正则地址,最后加上需要返回的请求结果,这样就可以修改请求的响应结果了完全的。
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。
二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python常用的开发软件就到这里,为大家节省不少时间。
三、介绍视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。
五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节跳动等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。
本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方CSDN官方认证二维码免费获取【保证100%免费】
Python资料、技术、课程、解答、咨询也可以直接点击下方名片添加官方客服思琪↓ 查看全部
chrome 插件 抓取网页qq聊天记录(5款可以提升工作效率的Chrome插件,你值得拥有!)
今天给大家推荐5款可以提高工作效率的Chrome插件。
全方位
这个 Chrome 插件可以快速搜索、切换和关闭浏览器书签、Tab 页和历史记录。
当我们同时打开多个Tab页时,切换到某个Tab页是很麻烦的。在Omni输入框中,只需输入关键字“/tabs”,然后追加关键字即可快速查询Tab,回车即可切换Tab。
另外,关键字“/bookmarks”用于快速切换搜索书签,“/history”用于切换历史记录,“/remove”可用于关闭Tab或删除书签
为了提高使用效率,建议为Omni设置快捷键,在地址栏中输入“chrome://extensions/shortcuts”,并为Omni指定一个热键,例如:Ctrl + Shift + K
当然,Omni也有很多实用的功能,比如:页面静音、Tab pinning、管理插件等,大家可以自己扩展
CSS 窥视器
CSS Peeper,一个提取网页样式的插件
作为CSS查看器,可以直观高效的获取网页元素的属性、宽度、高度、字体样式
使用方法很简单,只需点击插件,用鼠标点击网页上的一个控件,右上角就会显示目标元素的CSS样式属性。
JSON查看器专业版
在Chrome应用市场上,JSON格式化插件很多,但是这个插件除了常规功能外还包括样式自定义、“图表视图”展示等功能,用户体验更好。
另外这个插件可以随意选择一个节点,复制Path路径和Value值
历史趋势无限
这是一个历史管理插件,可以将历史浏览记录“永久”保存到本地数据库,并生成排名列表和统计报表图表。比如可以按时间段列出访问量前十名网站
此外,还可以通过关键字查询历史浏览记录
在设置中可以导入导出历史记录,配置自动备份的周期
阿贾克斯拦截器
本插件可以修改ajax请求的返回结果,一般用于Mock数据,接口联调测试
使用起来很简单。只需打开插件开关,然后将要拦截的请求地址匹配为全地址或正则地址,最后加上需要返回的请求结果,这样就可以修改请求的响应结果了完全的。
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。
二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python常用的开发软件就到这里,为大家节省不少时间。
三、介绍视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。
五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节跳动等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。
本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方CSDN官方认证二维码免费获取【保证100%免费】
Python资料、技术、课程、解答、咨询也可以直接点击下方名片添加官方客服思琪↓

