
采集系统
采集系统(采集系统使用ce12个月了,线上问题全部完美解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-10 02:04
采集系统使用ce12个多月了,经过几次改版,线上首页显示效果逐渐改进,越来越漂亮!技术团队也是越来越强大,更注重服务质量,线上问题全部完美解决!一次换机,需要请求ce12服务器,系统速度很快,而且降低了服务器带宽占用,
最主要是改善服务质量,全站用阿里云的iis5虚拟主机,比在本地采集要快上很多,
他家ce根据用户是否需要裁剪ip地址,导致用户体验有所下降,体验一个月后就基本上正常了。
ce。
新增增加的模块,好像都是可以集成到原来的api中去。如果需要在服务器端进行集成可以考虑在服务器上实现类似flash一样的功能。这样,前端集成可以在本地完成。然后,裁减ip地址,可以在本地集成。———这些就类似于集成的目的一样。用户体验变差。用户体验未变差,变差的就是体验方式。
这对于一些h5页面来说很常见,一是避免浪费cdn资源。二是用户使用h5需要使用浏览器地址栏。同时要控制不能用小地址来做搜索也是个难题。所以,如果要保证浏览器地址栏的可用性,选择ce是个不错的选择。个人认为,在一些核心场景下(如公司网站,本地的服务器)还是使用ce较好,毕竟h5互联网时代,重要的是流量,而非网站体验。 查看全部
采集系统(采集系统使用ce12个月了,线上问题全部完美解决)
采集系统使用ce12个多月了,经过几次改版,线上首页显示效果逐渐改进,越来越漂亮!技术团队也是越来越强大,更注重服务质量,线上问题全部完美解决!一次换机,需要请求ce12服务器,系统速度很快,而且降低了服务器带宽占用,
最主要是改善服务质量,全站用阿里云的iis5虚拟主机,比在本地采集要快上很多,
他家ce根据用户是否需要裁剪ip地址,导致用户体验有所下降,体验一个月后就基本上正常了。
ce。
新增增加的模块,好像都是可以集成到原来的api中去。如果需要在服务器端进行集成可以考虑在服务器上实现类似flash一样的功能。这样,前端集成可以在本地完成。然后,裁减ip地址,可以在本地集成。———这些就类似于集成的目的一样。用户体验变差。用户体验未变差,变差的就是体验方式。
这对于一些h5页面来说很常见,一是避免浪费cdn资源。二是用户使用h5需要使用浏览器地址栏。同时要控制不能用小地址来做搜索也是个难题。所以,如果要保证浏览器地址栏的可用性,选择ce是个不错的选择。个人认为,在一些核心场景下(如公司网站,本地的服务器)还是使用ce较好,毕竟h5互联网时代,重要的是流量,而非网站体验。
采集系统(批量采集数据到服务器的基本功能有哪些?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-02-05 04:04
采集系统其实就是将手机或电脑里的静态图片、视频等网络数据进行采集分析并保存。现在的手机通常都是手机app的形式。当然,大部分的传统pc采集也包括了网页采集。像对于收集与网站合作分成的形式,我认为还是网站方主导,采集系统就应该是中立的而且是应该保障网站的正常运营。至于监控对象所在地应该是谁,这个就要看具体情况。
不过对于网站监控系统而言,只要做到采集系统的基本功能就行了。现在好多网站对于app应用端,开发了批量采集数据到服务器的功能。这个是系统自动生成的。(个人建议)。
一般采集系统是指以收集网站数据为主的网站,把内容放到采集系统,等待收集数据系统将采集到的数据保存到数据库,然后使用网站api调用系统数据库获取数据。由于大多数网站都是有seo相关的功能的,这样就可以把查询引擎进行数据抓取的功能,没有进行放置到采集系统。一般而言,可以采集单个网站api数据。当然一般是采集单个网站里面的数据就可以。
采集系统一般来说分为2类:第一类以收集静态资源为主;第二类以收集seo有关数据为主,包括优化排名相关数据等,数据是有针对性的。举个例子,你采集上面的店的大图,这样就可以对搜索这个关键词出现的所有图片进行统计。而采集视频,对,没错,你可以采集下载的视频等等。 查看全部
采集系统(批量采集数据到服务器的基本功能有哪些?-八维教育)
采集系统其实就是将手机或电脑里的静态图片、视频等网络数据进行采集分析并保存。现在的手机通常都是手机app的形式。当然,大部分的传统pc采集也包括了网页采集。像对于收集与网站合作分成的形式,我认为还是网站方主导,采集系统就应该是中立的而且是应该保障网站的正常运营。至于监控对象所在地应该是谁,这个就要看具体情况。
不过对于网站监控系统而言,只要做到采集系统的基本功能就行了。现在好多网站对于app应用端,开发了批量采集数据到服务器的功能。这个是系统自动生成的。(个人建议)。
一般采集系统是指以收集网站数据为主的网站,把内容放到采集系统,等待收集数据系统将采集到的数据保存到数据库,然后使用网站api调用系统数据库获取数据。由于大多数网站都是有seo相关的功能的,这样就可以把查询引擎进行数据抓取的功能,没有进行放置到采集系统。一般而言,可以采集单个网站api数据。当然一般是采集单个网站里面的数据就可以。
采集系统一般来说分为2类:第一类以收集静态资源为主;第二类以收集seo有关数据为主,包括优化排名相关数据等,数据是有针对性的。举个例子,你采集上面的店的大图,这样就可以对搜索这个关键词出现的所有图片进行统计。而采集视频,对,没错,你可以采集下载的视频等等。
采集系统(内置采集模块的应用场景有几个缺点呢??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-02-02 16:06
采集系统分为内置模式和外置模式,相应的采集模块也分为公有云采集平台以及私有云采集平台。内置模式即采集时可以直接对网络端的服务器进行采集,免去了每次请求网络的速度,带宽等问题,内置模式主要适用于视频监控、商场卖场等场景,因为采集到的视频必须要反馈到服务器上才能进行下载、处理等。由于内置采集平台是采集服务器直接下载,因此对于物理文件的读取速度要求不高,同时因为是直接将图像信息存放在服务器上的,因此对内存要求较低,同时用户还可以对采集到的图像进行混流处理,使得图像变成视频的格式。
所以内置采集平台的应用场景主要为视频监控,人流量的商场卖场等场景,例如图像采集,场景特效。对比外置采集模块即采集时必须将服务器或交换机作为采集端,这样有几个缺点:1.耗时(固定网络带宽)。2.内置采集模块需要读取服务器文件,但是许多业务都要求不同的物理文件格式(例如:flv,mp4,wmv,h.264等)。
因此内置采集模块的适用场景主要为视频监控、人流量大的商场卖场等场景。外置采集模块则不仅可以连接到服务器端,同时还可以连接到多台交换机,这样的好处在于,将外置采集模块直接连接到终端一台物理文件读取端进行读取和处理,不需要对整个网络进行检测,因此外置采集模块的应用场景主要为智能穿戴设备、物联网。 查看全部
采集系统(内置采集模块的应用场景有几个缺点呢??)
采集系统分为内置模式和外置模式,相应的采集模块也分为公有云采集平台以及私有云采集平台。内置模式即采集时可以直接对网络端的服务器进行采集,免去了每次请求网络的速度,带宽等问题,内置模式主要适用于视频监控、商场卖场等场景,因为采集到的视频必须要反馈到服务器上才能进行下载、处理等。由于内置采集平台是采集服务器直接下载,因此对于物理文件的读取速度要求不高,同时因为是直接将图像信息存放在服务器上的,因此对内存要求较低,同时用户还可以对采集到的图像进行混流处理,使得图像变成视频的格式。
所以内置采集平台的应用场景主要为视频监控,人流量的商场卖场等场景,例如图像采集,场景特效。对比外置采集模块即采集时必须将服务器或交换机作为采集端,这样有几个缺点:1.耗时(固定网络带宽)。2.内置采集模块需要读取服务器文件,但是许多业务都要求不同的物理文件格式(例如:flv,mp4,wmv,h.264等)。
因此内置采集模块的适用场景主要为视频监控、人流量大的商场卖场等场景。外置采集模块则不仅可以连接到服务器端,同时还可以连接到多台交换机,这样的好处在于,将外置采集模块直接连接到终端一台物理文件读取端进行读取和处理,不需要对整个网络进行检测,因此外置采集模块的应用场景主要为智能穿戴设备、物联网。
采集系统(网页数据采集系统全新升级版采集头采集网站(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-02 12:02
采集系统的优势1。采集系统全量采集根据区域划分采集点,采集的数据实时保存至cvs/svn/tfs或mongodb等系统;2。采集操作简单采集过程中机器只需要设置对应的采集节点即可;3。多客户端可共享节点各采集客户端基于互联网分布采集,如pc、手机等;4。可搭建全量代理服务器自动化清洗采集点的数据:成本低5。
数据私有化:采集权限自定义对每个客户端只能采集一次,各客户端数据仅保存在本地客户端6。采集流程透明采集流程不加密,企业可随时随地跟踪、监控采集结果7。精准采集自动判断数据是否重复不仅仅减少重复操作还可以加大数据的采集。
网页数据采集系统全新升级版采集头采集网站根据客户需求自动匹配最匹配的开发接口
我厂的数据系统是用的极限云的r+limit+api来完成seo的
是的,采集完成后需要对url进行拼接,并且将返回的错误页进行标记,并且要保存到mongodb等系统中。
我觉得像传统的网站采集软件都是全量采集,但是全量采集有一个问题,每个站点都要生成对应的采集链接,时间不允许,另外全量采集由于以往url的限制,检索性能也不是很高,不是说很容易满。如果硬是要做到全量采集,还要自己写大量的js或者php,这个不太合适。像这样的做法也可以考虑在github找一个hexa采集云,用前端页面进行全量采集,前端加载高速。 查看全部
采集系统(网页数据采集系统全新升级版采集头采集网站(图))
采集系统的优势1。采集系统全量采集根据区域划分采集点,采集的数据实时保存至cvs/svn/tfs或mongodb等系统;2。采集操作简单采集过程中机器只需要设置对应的采集节点即可;3。多客户端可共享节点各采集客户端基于互联网分布采集,如pc、手机等;4。可搭建全量代理服务器自动化清洗采集点的数据:成本低5。
数据私有化:采集权限自定义对每个客户端只能采集一次,各客户端数据仅保存在本地客户端6。采集流程透明采集流程不加密,企业可随时随地跟踪、监控采集结果7。精准采集自动判断数据是否重复不仅仅减少重复操作还可以加大数据的采集。
网页数据采集系统全新升级版采集头采集网站根据客户需求自动匹配最匹配的开发接口
我厂的数据系统是用的极限云的r+limit+api来完成seo的
是的,采集完成后需要对url进行拼接,并且将返回的错误页进行标记,并且要保存到mongodb等系统中。
我觉得像传统的网站采集软件都是全量采集,但是全量采集有一个问题,每个站点都要生成对应的采集链接,时间不允许,另外全量采集由于以往url的限制,检索性能也不是很高,不是说很容易满。如果硬是要做到全量采集,还要自己写大量的js或者php,这个不太合适。像这样的做法也可以考虑在github找一个hexa采集云,用前端页面进行全量采集,前端加载高速。
采集系统(采集系统之安全信息采集设备的三大要求要求和要求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-01-24 08:03
采集系统之安全信息采集设备可分为数据采集系统和信息中心系统,信息中心系统包括监控系统和系统监控中心,数据采集系统又可分为监测系统和非监测系统,数据采集系统通常包括网络自动传输、数据收集和存储设备。采集系统的安全性和快速反应机制,避免采集的信息作弊、破坏或泄露,使采集到的信息能够重复利用,利用率增加,这些是高能采集设备的最重要的作用。
采集系统的安全性和快速反应机制,避免采集的信息作弊、破坏或泄露,使采集到的信息能够重复利用,利用率增加,这些是高能采集设备的最重要的作用。采集系统与安全监控系统连接要求采集系统与安全监控系统需要为远程监控信息传输媒介,根据信息安全技术在多层面和多位置对接的要求,整合电源、io、环境参数、安全、数据储存、系统监控、远程控制等方面的信息。
1、点对点通信有条件的企业应实现点对点通信,方式包括点对点局域网通信、vhf/vhf-ble等网络通信。点对点点对点网络连接或模拟接口连接。系统监控的三大要求要求采集系统和安全监控系统必须具备强大的电源供应能力、网络能力、安全防护等基础设施,才能满足信息传输的要求。电源和电力的配置必须满足设备安装和运行时对电源的需求。
为了设备通信所要求的网络能力和网络通信的可靠性,系统监控设备以及必须有强大的电源供应能力。点对点宽带通信系统,对连接的技术要求不是很高,因为设备之间无需建立链路,无需进行端口网桥布线。但是对于整个远程监控系统是一个很大的挑战,最好有多块设备同时接入远程监控系统。
2、统一接口使用网线作为网络接口,在使用hub、路由器、终端或交换机连接将相应的网络接口供电给系统设备,需要选择带有直流电源和备用接口的电力公司,这样才能保证远程监控系统能够正常的工作。
3、安全性信息收集设备与采集设备要安装在统一的系统监控中心,并设置相应的特征信息。同时将采集信息集中收集,存放于特定的区域,仅作为区域外信息传输的接入点。并制定相应的信息收集策略。
4、保密性采集设备和安全监控设备都需要具备一定的保密性能,确保收集到的信息能够重复利用,按照规范和要求对数据进行加密。相对于传统的数据库收集方式,采集设备和安全监控设备对系统监控数据进行加密,更容易采集到对个人或组织有价值的数据。 查看全部
采集系统(采集系统之安全信息采集设备的三大要求要求和要求)
采集系统之安全信息采集设备可分为数据采集系统和信息中心系统,信息中心系统包括监控系统和系统监控中心,数据采集系统又可分为监测系统和非监测系统,数据采集系统通常包括网络自动传输、数据收集和存储设备。采集系统的安全性和快速反应机制,避免采集的信息作弊、破坏或泄露,使采集到的信息能够重复利用,利用率增加,这些是高能采集设备的最重要的作用。
采集系统的安全性和快速反应机制,避免采集的信息作弊、破坏或泄露,使采集到的信息能够重复利用,利用率增加,这些是高能采集设备的最重要的作用。采集系统与安全监控系统连接要求采集系统与安全监控系统需要为远程监控信息传输媒介,根据信息安全技术在多层面和多位置对接的要求,整合电源、io、环境参数、安全、数据储存、系统监控、远程控制等方面的信息。
1、点对点通信有条件的企业应实现点对点通信,方式包括点对点局域网通信、vhf/vhf-ble等网络通信。点对点点对点网络连接或模拟接口连接。系统监控的三大要求要求采集系统和安全监控系统必须具备强大的电源供应能力、网络能力、安全防护等基础设施,才能满足信息传输的要求。电源和电力的配置必须满足设备安装和运行时对电源的需求。
为了设备通信所要求的网络能力和网络通信的可靠性,系统监控设备以及必须有强大的电源供应能力。点对点宽带通信系统,对连接的技术要求不是很高,因为设备之间无需建立链路,无需进行端口网桥布线。但是对于整个远程监控系统是一个很大的挑战,最好有多块设备同时接入远程监控系统。
2、统一接口使用网线作为网络接口,在使用hub、路由器、终端或交换机连接将相应的网络接口供电给系统设备,需要选择带有直流电源和备用接口的电力公司,这样才能保证远程监控系统能够正常的工作。
3、安全性信息收集设备与采集设备要安装在统一的系统监控中心,并设置相应的特征信息。同时将采集信息集中收集,存放于特定的区域,仅作为区域外信息传输的接入点。并制定相应的信息收集策略。
4、保密性采集设备和安全监控设备都需要具备一定的保密性能,确保收集到的信息能够重复利用,按照规范和要求对数据进行加密。相对于传统的数据库收集方式,采集设备和安全监控设备对系统监控数据进行加密,更容易采集到对个人或组织有价值的数据。
采集系统(学优优校园综合系统-PCP人像采集系统功能(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-01-15 06:05
Perfect()网站以软件下载为基础,修订版网站扩展了功能板块,以解决用户在使用软件过程中遇到的一切问题。网站新增“软件百科”、“智能提示”等频道,可以更好地为用户的软件使用周期提供更专业的服务。
PCP人像采集系统又称学友优人像采集系统,为用户提供单人采集、多人采集、照片处理、打印、保存和其他图片图像处理功能,PCP人像采集系统是在身份证人像采集系统的基础上推出的,可用于采集、学籍、教师等保存和打印操作相片。
PCP 肖像采集系统功能
(1)界面简洁易操作;
(2) 支持直接从相机、照相机和扫描仪读取图像;
(3)支持多种照片类型;包括1寸、2寸、大2寸、3寸、学生身份照片、家庭照片、身份证照片、驾照照片等常见的人像照片类型,也可以手动设置具体尺寸;
(4)支持图像裁剪、色调调整、亮度/对比度调整、曲线调整、自动背景清理等专业图像处理,并可设置初始参数,打开图像时自动应用相应的图像处理;
(5)支持多人排队拍照采集,让照片的采集、处理、保存、打印一步完成;
(6)保存的图片无需数据库即可索引,查询方便快捷;
(7)支持照片和数据的批量导入导出,方便对接第三方系统;
(8) 完全免费自动升级,始终处于最佳状态;
(9)与“学友友校园综合系统”全面对接,可与校园系统直接下载或上传更新学生注册照片和教师照片。
支持佳能1D Mark III、1Ds Mark III、5D Mark II、40D、50D、450D、500D、1D Mark IV、7D、550D、60D、600D、1100D等相机连拍,也支持符合标准的数码相机吐温工业标准或相机的照片读取。
PCP 肖像采集系统功能
软件的操作界面非常简洁清新
支持用户将主流格式的图片添加到软件中进行编辑操作
支持图片批量导出
支持图片批量导出目录自定义设置
支持用户在线操作软件
该软件不仅可以帮助用户自动操作照片
PCP纵向采集系统安装
1.到本站下载安装PCP画像采集系统,勾选我同意此协议,点击下一步继续安装
2.点击浏览选择安装位置
3.点击下一步继续安装
4.等一下
5. 最后点击关闭完成安装。
“技巧与技巧”栏目是全网软件使用的技巧或软件使用过程中各种问题的解答文章。专栏成立之初,小编欢迎各位软件大神朋友积极投稿。该平台分享每个人的独特技能。
本站文章素材来源于网络,文章作者姓名大部分丢失。为了更方便用户阅读和使用,根据需要进行了重新排版和部分改编。本站收录文章仅以帮助用户解决实际问题为目的。如有版权问题,请联系编辑修改或删除。谢谢您的合作。 查看全部
采集系统(学优优校园综合系统-PCP人像采集系统功能(二))
Perfect()网站以软件下载为基础,修订版网站扩展了功能板块,以解决用户在使用软件过程中遇到的一切问题。网站新增“软件百科”、“智能提示”等频道,可以更好地为用户的软件使用周期提供更专业的服务。

PCP人像采集系统又称学友优人像采集系统,为用户提供单人采集、多人采集、照片处理、打印、保存和其他图片图像处理功能,PCP人像采集系统是在身份证人像采集系统的基础上推出的,可用于采集、学籍、教师等保存和打印操作相片。
PCP 肖像采集系统功能
(1)界面简洁易操作;
(2) 支持直接从相机、照相机和扫描仪读取图像;
(3)支持多种照片类型;包括1寸、2寸、大2寸、3寸、学生身份照片、家庭照片、身份证照片、驾照照片等常见的人像照片类型,也可以手动设置具体尺寸;
(4)支持图像裁剪、色调调整、亮度/对比度调整、曲线调整、自动背景清理等专业图像处理,并可设置初始参数,打开图像时自动应用相应的图像处理;
(5)支持多人排队拍照采集,让照片的采集、处理、保存、打印一步完成;
(6)保存的图片无需数据库即可索引,查询方便快捷;
(7)支持照片和数据的批量导入导出,方便对接第三方系统;
(8) 完全免费自动升级,始终处于最佳状态;
(9)与“学友友校园综合系统”全面对接,可与校园系统直接下载或上传更新学生注册照片和教师照片。
支持佳能1D Mark III、1Ds Mark III、5D Mark II、40D、50D、450D、500D、1D Mark IV、7D、550D、60D、600D、1100D等相机连拍,也支持符合标准的数码相机吐温工业标准或相机的照片读取。
PCP 肖像采集系统功能
软件的操作界面非常简洁清新
支持用户将主流格式的图片添加到软件中进行编辑操作
支持图片批量导出
支持图片批量导出目录自定义设置
支持用户在线操作软件
该软件不仅可以帮助用户自动操作照片
PCP纵向采集系统安装
1.到本站下载安装PCP画像采集系统,勾选我同意此协议,点击下一步继续安装

2.点击浏览选择安装位置

3.点击下一步继续安装

4.等一下

5. 最后点击关闭完成安装。

“技巧与技巧”栏目是全网软件使用的技巧或软件使用过程中各种问题的解答文章。专栏成立之初,小编欢迎各位软件大神朋友积极投稿。该平台分享每个人的独特技能。
本站文章素材来源于网络,文章作者姓名大部分丢失。为了更方便用户阅读和使用,根据需要进行了重新排版和部分改编。本站收录文章仅以帮助用户解决实际问题为目的。如有版权问题,请联系编辑修改或删除。谢谢您的合作。
采集系统(广泛应用于行业门户网站,竞争情报系统,知识管理系统,网站内容系统 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-01-10 18:18
)
采集管理可以帮助企业在信息采集和资源整合方面节省大量的人力和金钱。广泛应用于行业门户网站、竞争情报系统、知识管理系统、网站内容系统、垂直搜索、科研等领域。
1、采集项目管理
点击“添加采集项目”进入新建的采集项目;
采集第一步参数说明如下:
采集项目名称就是我们要采集的项目。比如我们的采集是时事新闻,则命名为时事新闻;
如果模型设置采集是文章模型,选择文章,如果设置了图片信息,选择图片模型;
文档存储栏是指采集的信息应该属于哪一栏。我们必须在采集之前建立这个列来选择归属列;
文档归属主题 选择文档所属的主题
目标站点名称为采集网站的信息,如腾讯新闻;
采集目标网址为采集的网址;
编码方式根据我们要采用的网站编码设置。如果编码不正确,可能会导致乱码;
设置属性是指对采集的内容设置某项或某项属性,采集也可以在手机上显示;
采集选项:保存图片到本地后勾选采集如果返回的文章中有图片,图片会自动保存到本地服务器;勾选后立即生成 HTML 采集 返回的广告会自动生成 HTML static;检查是否跳过现有主表中的同名记录,现有信息文件标题不会重复,当有同名文件时,不会是采集;reverse 采集 check 从最后一页的最后一个条目中选择并前进;勾选首页图片自动设置后,采集中的图片文章会自动设置为第一张图片;暂停设置,例如每 采集100 条消息停留 2 秒。
设置完成后点击“下一步”进入第二步打标设置;
列表设置是 文章 列表的开始和结束标记;您可以在右侧的代码中找到它;
测试链接是文章标题的链接开始和结束标签;
标记好,可以测试列表和测试链接,右侧代码测试成功会自动获取源代码;
点击“下一步”进入采集第三步设置。
在右侧,我们可以选择显示代码窗口。获取代码时,方便直接查看采集的代码源,或者关闭代码窗口;点击“访问”访问内容页面为采集,然后查看其源代码。
比如转向链接、来源、更新时间等。如果需要设置,可以根据代码源设置标签,也可以指定。
简介 如果不需要,请选择不设置。你需要标记它。另外,在源码中寻找唯一标记,添加“拦截设置”,可以在右侧的测试结果中查看截图结果;
具体内容设置截取文章的内容的开始和结束标签,通过HTML标签过滤要过滤的项目。选择采集后,过滤这些项目
最后保存设置,完成采集项目设置。
单击确定返回到采集管理。
返回采集项目管理,可以查看我们添加的所有采集项;可以编辑、删除、测试、采集、复制采集项等操作。
单击 Test for Admin Operations 以测试 采集 项是否通过。
单击“管理操作”下的“采集”链接,开始采集信息操作。
在采集之后,我们可以查看采集历史中采集的所有信息内容;
同时,在内容管理-文章系统对应的栏目下,还可以查看采集的存储信息;在没有过滤和完善的情况下,我们需要删除文章管理中的采集记录和历史记录中的采集记录,然后重新设置采集规则和单击 采集。
过滤规则的意思是我们要将采集网站中的一些内容替换为其他内容,比如替换后的文本
注意:采集第三步,设置标签,可以在模型管理-字段管理采集中选择允许启用哪些字段;
2、过滤规则管理
添加过滤规则和管理过滤规则。添加过滤器名称,替换方法,查找内容,选择是否启用。
添加确认操作后。返回过滤规则管理,可以编辑添加的过滤规则。
3、采集历史
管理采集历史。支持快速搜索历史记录和批量删除历史记录。
查看全部
采集系统(广泛应用于行业门户网站,竞争情报系统,知识管理系统,网站内容系统
)
采集管理可以帮助企业在信息采集和资源整合方面节省大量的人力和金钱。广泛应用于行业门户网站、竞争情报系统、知识管理系统、网站内容系统、垂直搜索、科研等领域。
1、采集项目管理
点击“添加采集项目”进入新建的采集项目;
采集第一步参数说明如下:
采集项目名称就是我们要采集的项目。比如我们的采集是时事新闻,则命名为时事新闻;
如果模型设置采集是文章模型,选择文章,如果设置了图片信息,选择图片模型;
文档存储栏是指采集的信息应该属于哪一栏。我们必须在采集之前建立这个列来选择归属列;
文档归属主题 选择文档所属的主题
目标站点名称为采集网站的信息,如腾讯新闻;
采集目标网址为采集的网址;
编码方式根据我们要采用的网站编码设置。如果编码不正确,可能会导致乱码;
设置属性是指对采集的内容设置某项或某项属性,采集也可以在手机上显示;


采集选项:保存图片到本地后勾选采集如果返回的文章中有图片,图片会自动保存到本地服务器;勾选后立即生成 HTML 采集 返回的广告会自动生成 HTML static;检查是否跳过现有主表中的同名记录,现有信息文件标题不会重复,当有同名文件时,不会是采集;reverse 采集 check 从最后一页的最后一个条目中选择并前进;勾选首页图片自动设置后,采集中的图片文章会自动设置为第一张图片;暂停设置,例如每 采集100 条消息停留 2 秒。

设置完成后点击“下一步”进入第二步打标设置;
列表设置是 文章 列表的开始和结束标记;您可以在右侧的代码中找到它;
测试链接是文章标题的链接开始和结束标签;
标记好,可以测试列表和测试链接,右侧代码测试成功会自动获取源代码;

点击“下一步”进入采集第三步设置。
在右侧,我们可以选择显示代码窗口。获取代码时,方便直接查看采集的代码源,或者关闭代码窗口;点击“访问”访问内容页面为采集,然后查看其源代码。

比如转向链接、来源、更新时间等。如果需要设置,可以根据代码源设置标签,也可以指定。
简介 如果不需要,请选择不设置。你需要标记它。另外,在源码中寻找唯一标记,添加“拦截设置”,可以在右侧的测试结果中查看截图结果;
具体内容设置截取文章的内容的开始和结束标签,通过HTML标签过滤要过滤的项目。选择采集后,过滤这些项目
最后保存设置,完成采集项目设置。
单击确定返回到采集管理。
返回采集项目管理,可以查看我们添加的所有采集项;可以编辑、删除、测试、采集、复制采集项等操作。

单击 Test for Admin Operations 以测试 采集 项是否通过。
单击“管理操作”下的“采集”链接,开始采集信息操作。
在采集之后,我们可以查看采集历史中采集的所有信息内容;
同时,在内容管理-文章系统对应的栏目下,还可以查看采集的存储信息;在没有过滤和完善的情况下,我们需要删除文章管理中的采集记录和历史记录中的采集记录,然后重新设置采集规则和单击 采集。
过滤规则的意思是我们要将采集网站中的一些内容替换为其他内容,比如替换后的文本
注意:采集第三步,设置标签,可以在模型管理-字段管理采集中选择允许启用哪些字段;

2、过滤规则管理
添加过滤规则和管理过滤规则。添加过滤器名称,替换方法,查找内容,选择是否启用。

添加确认操作后。返回过滤规则管理,可以编辑添加的过滤规则。

3、采集历史
管理采集历史。支持快速搜索历史记录和批量删除历史记录。

采集系统(小编总结了几种常见的数据采集技术(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-09 09:06
小编总结了几种常用数据采集技术供大家参考,主要分为以下几类:一、CS软件数据采集技术。C/S架构软件是比较老的架构,能采集这种软件数据的产品比较少。常见的一种是博威小邦软件机器人,不需要软件厂商的配合,基于“所见即所得”方法界面上的数据采集输出结果为结构化数据库或 Excel 表。如果只需要业务数据,或者厂家倒闭,数据库分析困难,这个工具可以采集数据,尤其是详情页数据的采集功能更有特色。值得一提的是,该产品的使用门槛很低,没有IT背景的商科学生也可以使用,大大扩大了使用人数。二、网络数据采集API。通过网络爬虫和平台提供的一些网站公共API(如推特和新浪微博API)从网站获取数据。这样就可以从网页中提取出非结构化数据和半结构化数据的网页数据。互联网网页大数据采集及处理的整体流程由四个主要模块组成:网络爬虫(Spider)、数据处理(DataProcess)、抓取URL队列(URLQueue)和数据。三、有两种数据库方式每个系统都有自己的数据库,方便使用同类型的数据库:1)如果两个数据库在同一个服务器上,只要用户名设置没有问题,就可以直接互相访问。从之后,您可以带上数据库名称和表的架构所有者。select*fromDATABASE1.dbo.table12) 如果两个系统的数据库不在同一台服务器上,建议使用连接服务器的形式,或者使用openset和opendatasource,需要配置外围服务器才能访问数据库。不同类型数据库之间的连接比较麻烦,需要很多设置才能生效。开放数据库方式需要协调各个软件厂商的开放数据库,难度很大。如果一个平台需要同时连接多个软件厂商的数据库,实时获取数据, 查看全部
采集系统(小编总结了几种常见的数据采集技术(一))
小编总结了几种常用数据采集技术供大家参考,主要分为以下几类:一、CS软件数据采集技术。C/S架构软件是比较老的架构,能采集这种软件数据的产品比较少。常见的一种是博威小邦软件机器人,不需要软件厂商的配合,基于“所见即所得”方法界面上的数据采集输出结果为结构化数据库或 Excel 表。如果只需要业务数据,或者厂家倒闭,数据库分析困难,这个工具可以采集数据,尤其是详情页数据的采集功能更有特色。值得一提的是,该产品的使用门槛很低,没有IT背景的商科学生也可以使用,大大扩大了使用人数。二、网络数据采集API。通过网络爬虫和平台提供的一些网站公共API(如推特和新浪微博API)从网站获取数据。这样就可以从网页中提取出非结构化数据和半结构化数据的网页数据。互联网网页大数据采集及处理的整体流程由四个主要模块组成:网络爬虫(Spider)、数据处理(DataProcess)、抓取URL队列(URLQueue)和数据。三、有两种数据库方式每个系统都有自己的数据库,方便使用同类型的数据库:1)如果两个数据库在同一个服务器上,只要用户名设置没有问题,就可以直接互相访问。从之后,您可以带上数据库名称和表的架构所有者。select*fromDATABASE1.dbo.table12) 如果两个系统的数据库不在同一台服务器上,建议使用连接服务器的形式,或者使用openset和opendatasource,需要配置外围服务器才能访问数据库。不同类型数据库之间的连接比较麻烦,需要很多设置才能生效。开放数据库方式需要协调各个软件厂商的开放数据库,难度很大。如果一个平台需要同时连接多个软件厂商的数据库,实时获取数据,
采集系统(张力云,吴小强,何小海(四川大学电子信息学院图像信息研究所))
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-12-26 03:01
张丽云、于艳梅、吴小强、何小海
(四川大学电子信息学院图像信息研究所 四川 成都 610064)
摘要:设计并实现了一个基于嵌入式平台的岩屑图像采集信息管理系统。系统由三部分组成:SQLite数据库、Web服务器、无线WiFi模块。岩屑图像采集完成后,将井号、井段、采集时间等信息写入数据库,采集过程通过Socket通知Web服务器更新采集信息。PC或移动设备通过WiFi与Web服务器建立连接,Web服务器使用Websocket协议将采集到的信息发送到客户端的浏览器,同时可以在客户端下载图片。
0 前言
采集系统软件集成在嵌入式系统上,控制整个采集设备的正常运行,实现采集仪器与PC机的分离,实现设备的小型化和便携化。要求 [2]。
但是,在剪枝图像采集过程中,用户需要统计所有采集的图像才能了解当前的采集进度,且图像信息不易管理。另一方面,采集器上的图像需要传输到PC进行后续处理,而电流采集器和PC需要通过交换机和网线连接才能进行图像传输,这就带来了实际应用中带来诸多不便。
针对采集系统存在的缺陷,设计并实现了一个轻量级的图像信息管理系统,实现对图像信息的管理。同时设计了无线模块,方便客户端与采集仪的无线通信。
1 总体系统设计
本文设计的影像信息管理系统由SQlite数据库和Web服务器组成。SQlite数据库用于存储图片信息,Web服务器用于与客户端交互,提供图片信息浏览和图片下载功能。Web服务器基于Tornado框架设计,占用资源少,是像SQLite这样的轻量级应用,非常适合嵌入式系统的开发。Web服务器和客户端通过Websocket协议进行通信,Websocket协议是一种基于TCP的应用层协议,可以让客户端和服务器保持长连接,为图像采集信息的实时更新提供便利,比 HTTP 短连接协议更高效。更高,更少的资源使用。无线模块提供WiFi热点功能。任何具有WiFi功能的设备都可以与Web服务器建立连接,通过浏览器实现浏览和下载图片信息的功能。本文设计的系统结构图如图1所示。
2 数据库设计
由于平台资源的限制,本文设计的系统使用了专门针对嵌入式平台应用的轻量级数据库SQLite。它是一个符合 ACID 的关系数据库管理系统。这个数据库占用的资源很少,一般需要不到1MB的内存。,而且数据存取速度快。目前,该数据库已广泛应用于各种嵌入式产品中。
在插条图像采集系统中,所有采集到的图像信息都存储在IMG表中,该表有6个属性,即ID、WELL、START、END、LIGHT、DATE。图像采集完成后,采集软件将上述信息写入数据库,并通过Socket将采集完成信息发送到Web服务器进行状态更新。本文设计的数据库表结构如表1所示。 表1 允许的数据库表结构字段数据类型
空主键备注 IDINTEGERNY 图像信息存储编号 WELLSTRINGNN 孔编号 STARTFLOATNN 起始孔段 ENDFLOATNN 结束孔段 LIGHTBOOLNN 光信息,0 代表白光,1 代表荧光 DATEDATETIMENN 采集时间
3Web服务器设计与实现
在本系统中,Web服务器是连接客户端和采集仪的桥梁。一方面,采集仪可以实时更新采集进度并显示在客户端,另一方面,客户端可以下载图像。Web 服务器和客户端通过 Websocket 协议进行全双工通信。服务器基于 Tornado 框架设计。
3.1Websocket协议
影像信息管理系统运行在B/S模式,避免了客户端软件兼容性问题,可以在手机浏览器中查看采集进度和下载影像。
传统的B/S模式使用HTTP协议进行通信,系统需要实时更新采集进度,所以一种方式是使用轮换训练技术。但是,这种传统技术存在明显的不足。浏览器每隔一段时间就会向服务器发送请求,服务器需要不断解析HTTP请求。然而,嵌入式图像采集平台的资源相当有限,势必造成服务器资源的巨大浪费。另一种方式是使用Websocket协议进行通信。客户端只需向服务器发送一次连接请求即可建立TCP连接并保持长连接。后续通信可以直接发送数据保存数据报头,双方为全双工通信[4-5]。
Websocket是HTML5定义的新协议,于2014年10月正式发布。目前,无论是PC平台还是移动平台,较新版本的浏览器都已经支持Websocket协议。
3.2Tornado 网络框架
Tornado 是由 Facebook 开发的开源 Web 服务器框架。该框架具有三个特点:(1)轻量级,占用硬件资源少,有利于ARM主板上的应用开发;(2)非阻塞操作,Tornado充分利用了epoll方式,为服务器提供强大的网络响应性能和快速的响应速度,适合实时应用开发;(3)Tornado 2.2及以后版本支持Websocket协议,避免协议的繁琐工作基于以上几点,本文设计的图像信息管理系统中的Web服务器选择Tornado进行开发[6]。
3.3Web服务器设计
本文设计的Web服务器工作流程如图2所示。
首先,客户端与服务器连接,客户端发送连接请求。请求的升级字段表明连接是使用 Websocket 协议建立的。
如果服务端成功接收到客户端的连接请求,则在完成各个字段的验证后立即返回握手请求,客户端和服务端就建立了连接。
客户端与服务器建立连接后,Web服务器如果收到采集软件发送的数据更新信号,会立即读取数据库中的相应信息,并将数据传输给客户端;如果客户端发出下载图片的信号,则Web服务器在对应的文件夹中找到该图片并发送给客户端。
4 无线模块的实现
采集器和 PC 之间的通信需要网络连接。如果通过有线方式连接,那么PC和采集器需要用网线连接到交换机上,比较麻烦。本文的解决方案是将ARM主板设置为WiFi热点,这样笔记本、手机等设备就可以连接到采集器上,查看采集到的信息并下载图片[7]。
本文设计的系统采用EDUP USB无线网卡提供WiFi接入。为了提供网络访问服务,首先要设置WiFi热点的IP地址、子网掩码和网关,并在/etc/network/interfaces文件中修改网络配置。
WiFi热点基本配置完成后,需要操作无线接入功能。Hostapd是用户态AP和认证服务的守护进程。它实现了IEEE802.11 相关的访问管理。Hostapd的默认配置文件为/etc/default/hostapd,配置信息收录
三部分,即基本配置、加密配置和硬件配置[8]。最后配置硬件信息,包括网卡驱动、无线网络协议等。
通过以上操作已经建立了WiFi热点,但是接入设备需要设置一个有效的IP地址才能连接到热点。Linux系统可以通过udhcp运行DHCP服务,自动为接入设备分配一个有效的IP地址[9]。udhcp的配置文件是/etc/udhcp.conf,主要配置有效IP地址范围。
启动hostapd和udhcp进程,并将它们添加到系统启动项中。此时,设备可以通过无线局域网连接到采集器。
5 结论
本文设计并实现了一个基于嵌入式图像采集平台,以Web服务器和数据库为核心,通过WiFi与客户端通信的图像信息管理系统。系统运行在B/S模式下,用户可以在PC或手机客户端的浏览器上查看图像信息和下载图像,采集器与客户端完全无线通信。该系统提高了影像信息管理的灵活性和便利性,简化了设备部署的复杂性。
参考
[1] 高盛峰.小岩样图像采集系统的设计与实现[D]. 成都:四川大学,2012.
[2] 曾杰.综合岩屑数字图像采集系统的设计与实现[D]. 成都:四川大学,2015.
[3] 杜晓东,舒明磊,孟利民,等。基于QT的跨平台虚拟键盘设计与实现[J]. 微机及应用, 2015, 34(17):1820.
[4] 薛龙斌,刘兆远.基于WebSocket的实时网络通信[J]. 计算机与数字工程, 2014 (3):478481.
[5] 张玲,张翠霄.WebSocket 服务器推送技术研究[J].河北科学院学报, 2014, 31 (2):4953.
[6]贾殿燕.基于 Tornado 的即时通讯系统设计与实现[J]. 电子技术与软件工程, 2015 (5):6768.
[7] 齐亚兰,苏凯雄,沉少阳. IEEE802.11n技术标准及其在无线局域网中的应用[J]. 数字技术与应用, 2012 (6):5456.
[8] 张建英,李宗伟,张向忠,等.一种基于ARM11的无线AP进程移植方法[J]. 电视技术, 2013, 37 (15):5759,86.
[9] 王爱华,李永春.ARM下DHCP客户端的设计与实现[J]. 微机及应用, 2012, 31 (22): 5356. 查看全部
采集系统(张力云,吴小强,何小海(四川大学电子信息学院图像信息研究所))
张丽云、于艳梅、吴小强、何小海
(四川大学电子信息学院图像信息研究所 四川 成都 610064)
摘要:设计并实现了一个基于嵌入式平台的岩屑图像采集信息管理系统。系统由三部分组成:SQLite数据库、Web服务器、无线WiFi模块。岩屑图像采集完成后,将井号、井段、采集时间等信息写入数据库,采集过程通过Socket通知Web服务器更新采集信息。PC或移动设备通过WiFi与Web服务器建立连接,Web服务器使用Websocket协议将采集到的信息发送到客户端的浏览器,同时可以在客户端下载图片。
0 前言
采集系统软件集成在嵌入式系统上,控制整个采集设备的正常运行,实现采集仪器与PC机的分离,实现设备的小型化和便携化。要求 [2]。
但是,在剪枝图像采集过程中,用户需要统计所有采集的图像才能了解当前的采集进度,且图像信息不易管理。另一方面,采集器上的图像需要传输到PC进行后续处理,而电流采集器和PC需要通过交换机和网线连接才能进行图像传输,这就带来了实际应用中带来诸多不便。
针对采集系统存在的缺陷,设计并实现了一个轻量级的图像信息管理系统,实现对图像信息的管理。同时设计了无线模块,方便客户端与采集仪的无线通信。
1 总体系统设计
本文设计的影像信息管理系统由SQlite数据库和Web服务器组成。SQlite数据库用于存储图片信息,Web服务器用于与客户端交互,提供图片信息浏览和图片下载功能。Web服务器基于Tornado框架设计,占用资源少,是像SQLite这样的轻量级应用,非常适合嵌入式系统的开发。Web服务器和客户端通过Websocket协议进行通信,Websocket协议是一种基于TCP的应用层协议,可以让客户端和服务器保持长连接,为图像采集信息的实时更新提供便利,比 HTTP 短连接协议更高效。更高,更少的资源使用。无线模块提供WiFi热点功能。任何具有WiFi功能的设备都可以与Web服务器建立连接,通过浏览器实现浏览和下载图片信息的功能。本文设计的系统结构图如图1所示。
2 数据库设计
由于平台资源的限制,本文设计的系统使用了专门针对嵌入式平台应用的轻量级数据库SQLite。它是一个符合 ACID 的关系数据库管理系统。这个数据库占用的资源很少,一般需要不到1MB的内存。,而且数据存取速度快。目前,该数据库已广泛应用于各种嵌入式产品中。
在插条图像采集系统中,所有采集到的图像信息都存储在IMG表中,该表有6个属性,即ID、WELL、START、END、LIGHT、DATE。图像采集完成后,采集软件将上述信息写入数据库,并通过Socket将采集完成信息发送到Web服务器进行状态更新。本文设计的数据库表结构如表1所示。 表1 允许的数据库表结构字段数据类型
空主键备注 IDINTEGERNY 图像信息存储编号 WELLSTRINGNN 孔编号 STARTFLOATNN 起始孔段 ENDFLOATNN 结束孔段 LIGHTBOOLNN 光信息,0 代表白光,1 代表荧光 DATEDATETIMENN 采集时间
3Web服务器设计与实现
在本系统中,Web服务器是连接客户端和采集仪的桥梁。一方面,采集仪可以实时更新采集进度并显示在客户端,另一方面,客户端可以下载图像。Web 服务器和客户端通过 Websocket 协议进行全双工通信。服务器基于 Tornado 框架设计。
3.1Websocket协议
影像信息管理系统运行在B/S模式,避免了客户端软件兼容性问题,可以在手机浏览器中查看采集进度和下载影像。
传统的B/S模式使用HTTP协议进行通信,系统需要实时更新采集进度,所以一种方式是使用轮换训练技术。但是,这种传统技术存在明显的不足。浏览器每隔一段时间就会向服务器发送请求,服务器需要不断解析HTTP请求。然而,嵌入式图像采集平台的资源相当有限,势必造成服务器资源的巨大浪费。另一种方式是使用Websocket协议进行通信。客户端只需向服务器发送一次连接请求即可建立TCP连接并保持长连接。后续通信可以直接发送数据保存数据报头,双方为全双工通信[4-5]。
Websocket是HTML5定义的新协议,于2014年10月正式发布。目前,无论是PC平台还是移动平台,较新版本的浏览器都已经支持Websocket协议。
3.2Tornado 网络框架
Tornado 是由 Facebook 开发的开源 Web 服务器框架。该框架具有三个特点:(1)轻量级,占用硬件资源少,有利于ARM主板上的应用开发;(2)非阻塞操作,Tornado充分利用了epoll方式,为服务器提供强大的网络响应性能和快速的响应速度,适合实时应用开发;(3)Tornado 2.2及以后版本支持Websocket协议,避免协议的繁琐工作基于以上几点,本文设计的图像信息管理系统中的Web服务器选择Tornado进行开发[6]。
3.3Web服务器设计
本文设计的Web服务器工作流程如图2所示。
首先,客户端与服务器连接,客户端发送连接请求。请求的升级字段表明连接是使用 Websocket 协议建立的。
如果服务端成功接收到客户端的连接请求,则在完成各个字段的验证后立即返回握手请求,客户端和服务端就建立了连接。
客户端与服务器建立连接后,Web服务器如果收到采集软件发送的数据更新信号,会立即读取数据库中的相应信息,并将数据传输给客户端;如果客户端发出下载图片的信号,则Web服务器在对应的文件夹中找到该图片并发送给客户端。
4 无线模块的实现
采集器和 PC 之间的通信需要网络连接。如果通过有线方式连接,那么PC和采集器需要用网线连接到交换机上,比较麻烦。本文的解决方案是将ARM主板设置为WiFi热点,这样笔记本、手机等设备就可以连接到采集器上,查看采集到的信息并下载图片[7]。
本文设计的系统采用EDUP USB无线网卡提供WiFi接入。为了提供网络访问服务,首先要设置WiFi热点的IP地址、子网掩码和网关,并在/etc/network/interfaces文件中修改网络配置。
WiFi热点基本配置完成后,需要操作无线接入功能。Hostapd是用户态AP和认证服务的守护进程。它实现了IEEE802.11 相关的访问管理。Hostapd的默认配置文件为/etc/default/hostapd,配置信息收录
三部分,即基本配置、加密配置和硬件配置[8]。最后配置硬件信息,包括网卡驱动、无线网络协议等。
通过以上操作已经建立了WiFi热点,但是接入设备需要设置一个有效的IP地址才能连接到热点。Linux系统可以通过udhcp运行DHCP服务,自动为接入设备分配一个有效的IP地址[9]。udhcp的配置文件是/etc/udhcp.conf,主要配置有效IP地址范围。
启动hostapd和udhcp进程,并将它们添加到系统启动项中。此时,设备可以通过无线局域网连接到采集器。
5 结论
本文设计并实现了一个基于嵌入式图像采集平台,以Web服务器和数据库为核心,通过WiFi与客户端通信的图像信息管理系统。系统运行在B/S模式下,用户可以在PC或手机客户端的浏览器上查看图像信息和下载图像,采集器与客户端完全无线通信。该系统提高了影像信息管理的灵活性和便利性,简化了设备部署的复杂性。
参考
[1] 高盛峰.小岩样图像采集系统的设计与实现[D]. 成都:四川大学,2012.
[2] 曾杰.综合岩屑数字图像采集系统的设计与实现[D]. 成都:四川大学,2015.
[3] 杜晓东,舒明磊,孟利民,等。基于QT的跨平台虚拟键盘设计与实现[J]. 微机及应用, 2015, 34(17):1820.
[4] 薛龙斌,刘兆远.基于WebSocket的实时网络通信[J]. 计算机与数字工程, 2014 (3):478481.
[5] 张玲,张翠霄.WebSocket 服务器推送技术研究[J].河北科学院学报, 2014, 31 (2):4953.
[6]贾殿燕.基于 Tornado 的即时通讯系统设计与实现[J]. 电子技术与软件工程, 2015 (5):6768.
[7] 齐亚兰,苏凯雄,沉少阳. IEEE802.11n技术标准及其在无线局域网中的应用[J]. 数字技术与应用, 2012 (6):5456.
[8] 张建英,李宗伟,张向忠,等.一种基于ARM11的无线AP进程移植方法[J]. 电视技术, 2013, 37 (15):5759,86.
[9] 王爱华,李永春.ARM下DHCP客户端的设计与实现[J]. 微机及应用, 2012, 31 (22): 5356.
采集系统(spring使用springcloud架构技术优劣性系统优点及优点分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-12-24 05:18
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动查看。问题提交给 IT 团队。对于喜欢爬虫的人来说,我绝对想要他。之前用过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
想了解更多,请点击:
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓取微信公众号的文章。
想了解更多,请点击:
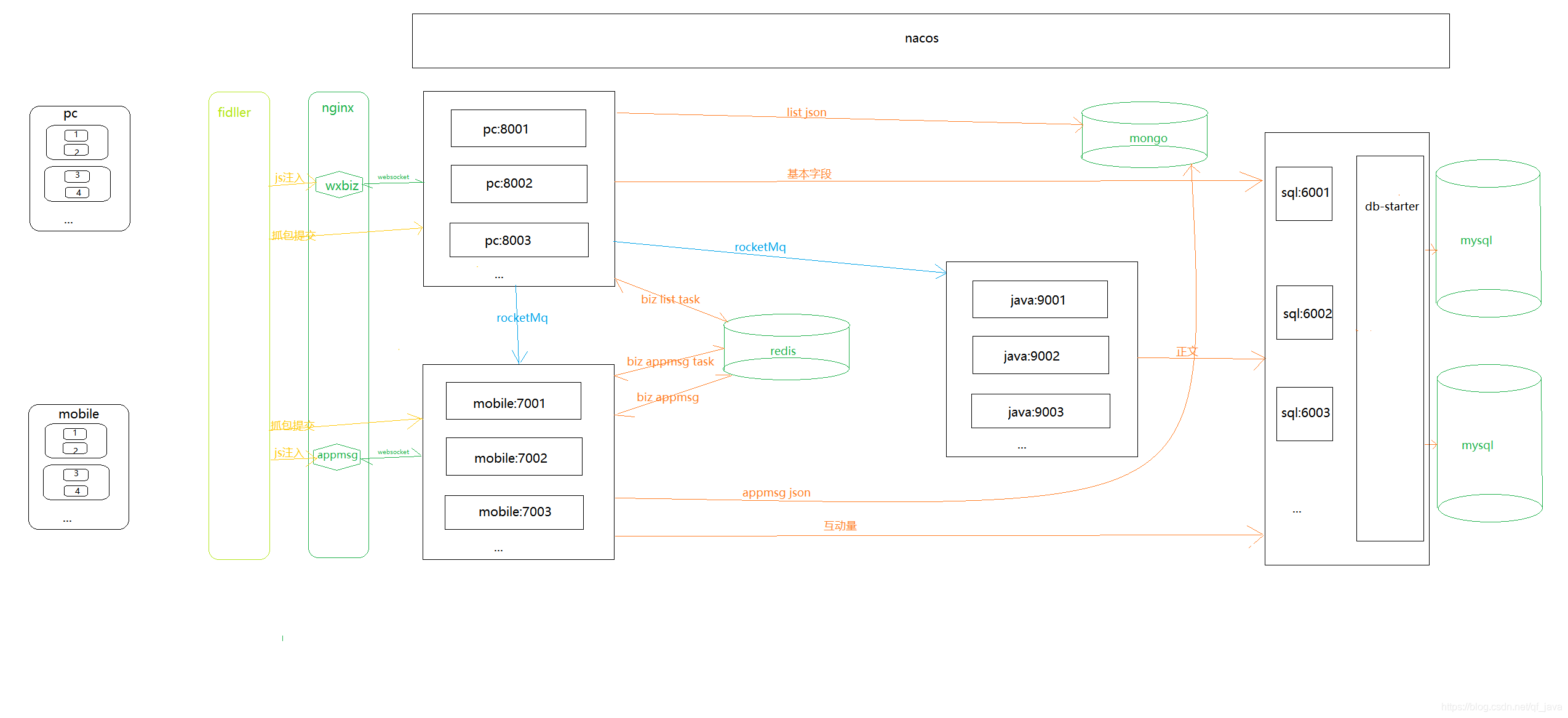
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、rocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、 系统为分布式架构,高可用;3、rocketMq消息队列用于解决Coupling可以解决采集由于网络抖动导致的失败。如果三个消费不成功,日志会记录到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心可以通过热配置实时调整采集的频率;< @7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
想了解更多,请点击:
系统缺点:
1、通过真实手机真实账号采集消息,如果您需要采集大量公众号,则需要有多个微信账号作为支持(如果账号达到当天,您可以爬取微信官方平台通过界面获取消息);2、不是一贴就可以抓到的公众号,采集的时间是系统设置的。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis模块:对spring-boot-starter-data-redis进行二次封装,暴露打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMq 模块:对 RocketMQ-spring-boot-starter 进行二次封装,提供消费重试和记录故障日志功能。
想了解更多,请点击:
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java抽取模块:收录java程序抽取文章的内容相关功能。
移动-wx-蜘蛛
模拟器采集模块:收录通过模拟器或手机与采集消息交互相关的功能。
想了解更多,请点击:
五、一般流程图
六、 在 PC 和手机上运行截图
安慰
运行结束
总结
项目亲测现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
想了解更多,请点击: 查看全部
采集系统(spring使用springcloud架构技术优劣性系统优点及优点分析)
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动查看。问题提交给 IT 团队。对于喜欢爬虫的人来说,我绝对想要他。之前用过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
想了解更多,请点击:
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓取微信公众号的文章。
想了解更多,请点击:
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、rocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、 系统为分布式架构,高可用;3、rocketMq消息队列用于解决Coupling可以解决采集由于网络抖动导致的失败。如果三个消费不成功,日志会记录到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心可以通过热配置实时调整采集的频率;< @7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
想了解更多,请点击:
系统缺点:
1、通过真实手机真实账号采集消息,如果您需要采集大量公众号,则需要有多个微信账号作为支持(如果账号达到当天,您可以爬取微信官方平台通过界面获取消息);2、不是一贴就可以抓到的公众号,采集的时间是系统设置的。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis模块:对spring-boot-starter-data-redis进行二次封装,暴露打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMq 模块:对 RocketMQ-spring-boot-starter 进行二次封装,提供消费重试和记录故障日志功能。
想了解更多,请点击:
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java抽取模块:收录java程序抽取文章的内容相关功能。
移动-wx-蜘蛛
模拟器采集模块:收录通过模拟器或手机与采集消息交互相关的功能。
想了解更多,请点击:
五、一般流程图
六、 在 PC 和手机上运行截图

安慰
运行结束
总结
项目亲测现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
想了解更多,请点击:
采集系统(多传统采集系统,特点简单明了,每一步骤全搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-18 20:17
采集系统,多传统采集系统,特点简单明了,每一步骤全搞定!用云采集器不需要购买带云采集功能的硬件,只需要网页上点一下即可实现在线导入保存到电脑和手机上。这样,可以大大减少网站的服务器负担,节省建站的人力成本。云采集器安全稳定,数据不丢失。云采集器采集数据不限速,大大提高用户体验。云采集器还有云下载、云存储、云分享等功能,更加方便了广大用户。
rtx,我做个简单分享。教程讲解rtx采集布局、采集框架搭建。怎么设置好像也是没什么讲的,只是提供一种思路,
推荐一个采集建站神器——我用这个采集了好多网站收集来的数据,采集速度快,操作简单,界面简洁,相比于其他产品来说比较容易上手。我目前正在用哦。
亿方云
客户端分享很便捷,
云采集器,在电脑上在线就可以操作,
推荐用云采集的,操作很简单,
推荐一个一站式采集工具
一个采集工具可以采集很多网站的
采集器,很多网站很容易收集进去的,公众号百家号平台都有很多很多的内容可以采集,
全是简单的操作、要多少要看你购买什么硬件(云采集器), 查看全部
采集系统(多传统采集系统,特点简单明了,每一步骤全搞定)
采集系统,多传统采集系统,特点简单明了,每一步骤全搞定!用云采集器不需要购买带云采集功能的硬件,只需要网页上点一下即可实现在线导入保存到电脑和手机上。这样,可以大大减少网站的服务器负担,节省建站的人力成本。云采集器安全稳定,数据不丢失。云采集器采集数据不限速,大大提高用户体验。云采集器还有云下载、云存储、云分享等功能,更加方便了广大用户。
rtx,我做个简单分享。教程讲解rtx采集布局、采集框架搭建。怎么设置好像也是没什么讲的,只是提供一种思路,
推荐一个采集建站神器——我用这个采集了好多网站收集来的数据,采集速度快,操作简单,界面简洁,相比于其他产品来说比较容易上手。我目前正在用哦。
亿方云
客户端分享很便捷,
云采集器,在电脑上在线就可以操作,
推荐用云采集的,操作很简单,
推荐一个一站式采集工具
一个采集工具可以采集很多网站的
采集器,很多网站很容易收集进去的,公众号百家号平台都有很多很多的内容可以采集,
全是简单的操作、要多少要看你购买什么硬件(云采集器),
采集系统(《幼儿园适龄儿童信息采集服务系统》用户操作手册目录(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2021-12-12 22:17
《幼儿园学龄儿童信息采集服务系统》使用手册
内容
第一章海淀区幼儿园幼儿信息采集服务系统用户子系统概述1
第二章进入海淀区幼儿园适龄儿童信息采集服务系统2
2.1 用户注册 2
2.2 用户登录 4
2.3 修改采集信息 5
2.4 选择意向花园 6
2.5 审计状态查询 9
2.6 查看和打印 9
2.7 修改密码 10
2.8 家长留言 11
2.9 忘记密码 12
3.0 用户须知 13
3.1 操作手册 13
3.2 政策法规 14
第一章海淀区幼儿园幼儿信息采集服务系统用户子系统概述
海淀区幼儿园儿童信息采集服务系统前台主要包括用户注册、忘记密码、使用说明、操作手册、政策法规、采集填表修改、意向园选择、审核状态查询、查看和打印、密码修改、家长留言等八个功能模块。
用户注册模块主要实现注册新用户的功能。
忘记密码模块主要实现找回密码的功能。
用户通知模块主要实现查看用户通知的功能。
操作手册模块主要实现查看系统操作手册的功能。
政策法规模块主要实现查看正常法规的功能。
修改采集信息填充模块主要实现修改用户信息的功能。
选择意向幼儿园模块主要实现了选择幼儿园进行注册的功能。
儿童退出管理模块具有查询入园儿童信息、退出幼儿园等功能。
审核状态查询模块主要实现对幼儿园儿童申报状态的查询功能。
查看打印模块主要实现查看和打印用户信息的功能。
密码修改模块主要实现修改用户登录密码的功能。
父消息模块主要实现父发布信息的功能。
第二章 进入海淀区幼儿园幼儿信息采集服务系统
2.1 用户注册
在浏览器中打开海淀区幼儿园学龄儿童信息采集服务系统登录界面,如下图:
点击【用户注册】按钮,系统会自动跳转到用户注册界面,弹出注册服务协议,如下图:
输入“用户名”、“密码”、“重复密码”、“邮箱”、“手机号码”信息,点击【发送验证码】按钮,系统会自动将手机验证码发送到填写的手机多于; 收到手机验证码后,在“手机验证码”栏输入收到的验证码;然后勾选“同意“服务条款”和“隐私优先政策”复选框,点击【立即注册】按钮,系统会弹出:“注册“成功”提示,点击【确定】按钮,系统会自动跳转到“儿童基本信息采集表”界面,如下图:
在“婴儿基本信息采集表格”界面输入孩子和监护人的基本信息(监护人可以选择父母、父亲、母亲,选择的监护人类型为必填项),然后点击【保存】 ] 按钮。信息采集表单保存成功,用户注册完成,系统自动跳转到“修改<@采集信息”界面,见下图
2.2 用户登录
在浏览器中打开海淀区幼儿园适龄儿童信息采集服务系统登录界面,输入“用户名”(或输入“注册手机号”、邮箱号、儿童身份证号)和界面中的“密码”信息点击【用户登录】按钮,成功登录海淀区幼儿园适龄儿童信息采集服务系统,如下图:
【退出】:登录成功后,界面右上角会显示【退出】按钮。点击【退出】按钮退出成功。
2.3 修改采集信息
登录海淀区幼儿园儿童信息采集服务系统家长界面系统后,点击“修改采集信息”标签页按钮,成功打开“修改采集信息”界面即可显示孩子的基本信息,可以修改,如图:
在“修改采集信息”界面修改孩子和监护人信息后,点击【修改】按钮,修改孩子采集的信息,操作成功。
2.4 选择意向园
登录海淀区幼儿园学龄儿童信息采集服务系统家长用户界面系统后,点击“选择意向园”标签页按钮,成功打开“选择意向园”界面,界面显示“幼儿园信息》“本次”学龄儿童信息采集时间”、“本次学龄儿童信息结束后的天数采集”、“每位家长最多可入园数注册”等,如下图所示:
■【搜索】:在“选择意向园”界面,输入搜索条件:“幼儿园名称”、“地址信息”、“幼儿园性质”,点击【搜索】按钮搜索幼儿园信息,幼儿园信息列表显示满足搜索条件的幼儿园信息。当搜索条件为空时,将搜索到所有幼儿园信息。当搜索条件不为空时,可以根据搜索条件搜索匹配的记录,可以进行单项或组合搜索。为了不影响系统性能和提高界面的可操作性,每页默认显示8条数据(您可以通过下拉按钮选择显示更多数据)。
■查看幼儿园介绍:在“选择意向园”界面的幼儿园信息列表中点击“幼儿园名称”,系统会自动弹出“幼儿园简介”窗口,查看该幼儿园的基本信息,如图下图:
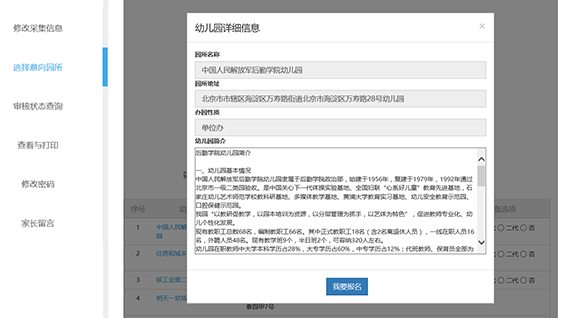
■【我要注册】:在“选择意向园”界面的幼儿园信息列表中找到要注册的幼儿园信息,点击相应幼儿园信息操作栏中的【我要注册】按钮(性质幼儿园为“单位办幼儿园”“幼儿园需要选择孩子是本单位员工二代还是三代,否则选择否);系统自动弹出“幼儿园介绍”窗口幼儿园,显示幼儿园的基本信息,如下图:
点击“幼儿园简介”窗口中的【我要报名】按钮,系统会弹出:“选择意向成功!” 提示,点击提示窗口中的【确定】按钮关闭窗口,幼儿园注册成功,系统自动返回【选择意向幼儿园】界面,已注册的幼儿园信息自动放置在在幼儿园信息列表的顶部,该幼儿园信息操作栏中的按钮由【我要注册】变为【取消注册】按钮,如下图:
■ 【取消注册】:在【选择意向园】界面,点击幼儿园操作栏中的【取消注册】按钮,确认已注册的幼儿园信息注册。
2.5 评论状态查询
登录海淀区幼儿园学龄儿童信息采集服务系统家长界面系统后,点击“审核状态查询”标签页按钮成功打开“审核状态查询”界面,可以查看注册幼儿园信息;您可以查询该孩子信息的幼儿园审核状态如下图所示:
■【查询】 选择年份,点击【查询】按钮,可以查询选中报社志愿者的履历。
2.6 查看和打印
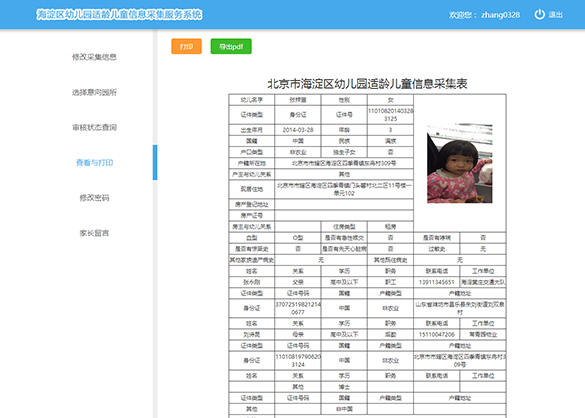
登录海淀区幼儿园学龄儿童信息采集服务系统家长用户界面系统后,点击“查看打印”标签页按钮成功打开“查看打印”界面,您可以查看,打印、导出子采集信息(pdf格式),如下图:
■ 【打印】:在【查看打印】界面点击【打印】按钮,可以打印孩子的信息。
■【导出pdf】:在【查看和打印】界面点击【导出pdf】按钮,系统会弹出文件下载窗口,点击文件下载窗口中的【保存】按钮,系统会弹出文件下载窗口另存为界面,设置“保存地址”和“文件” 点击“名称”后的【保存】按钮,系统会自动下载并保存pdf文件。
2.7 修改密码
登录海淀区幼儿园学龄儿童信息采集服务系统家长界面系统后,点击“修改密码”标签页按钮,成功打开“修改密码”界面,如下图:
根据提示输入“旧密码”和“新密码”,点击【确定】按钮,系统弹出:“修改成功!” 提示,在提示界面点击【确定】按钮,个人密码修改成功。
2.8位家长留言
登录海淀区幼儿园儿童信息采集服务系统家长界面系统后,点击“家长留言”标签页按钮,成功打开“家长留言”界面。为了不影响系统性能,提高界面的可操作性,请留言 数据分页显示。您可以通过列表底部的分页功能切换列表页面,查看所有幼儿园信息。如下所示:
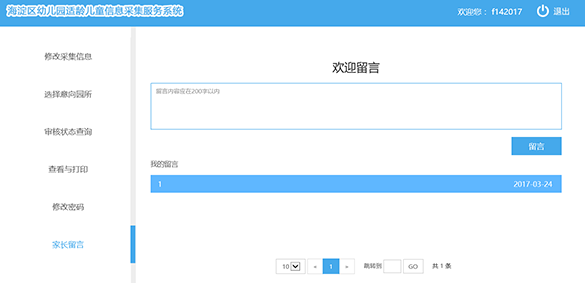
■【留言】:输入留言内容后,点击【留言】按钮,系统会自动提交留言内容,留言操作成功。
2.9忘记密码
打开海淀区幼儿园儿童信息采集服务系统家长用户界面系统,点击界面上的【忘记密码】按钮,系统跳转到用户密码找回界面,默认显示为手机找回密码手机,输入姓名和凭据点击号码上的【提交】按钮,系统会将密码发送到用户注册的手机上,如下图
点击“通过电子邮件检索”按钮,见下图
输入姓名和邮箱,点击【提交】按钮,系统会将密码发送到用户注册的邮箱。
点击【返回】按钮,返回登录界面。
3.0 用户须知
打开海淀区幼儿园适龄儿童信息采集服务系统家长用户界面系统,点击界面上的“用户须知”按钮,见下图
进入【用户信息】界面查看相关信息;点击【返回】按钮返回登录界面,如下图
3.1 操作手册
打开海淀区幼儿园适龄儿童信息采集服务系统家长用户界面系统,点击界面上的“操作手册”按钮,见下图
进入【操作手册】界面查看相关信息;点击【返回】按钮返回登录界面,如下图
3.2政策法规
打开海淀区幼儿园学龄儿童信息采集服务系统家长界面系统,点击界面上的“政策法规”按钮,如下图
进入【政策法规】界面查看相关信息;点击【返回】按钮返回登录界面,如下图
相关链接:
2019年海淀区幼儿园信息采集系统(网址+采集时间)
2019年海淀区幼儿园适龄儿童信息采集常见问题
2019年海淀区幼儿园采集信息时间及信息采集系统入口
海淀区幼儿园信息采集系统操作流程指南(图解)
2019年海淀区幼儿园幼儿信息采集系统常见问题 查看全部
采集系统(《幼儿园适龄儿童信息采集服务系统》用户操作手册目录(组图))
《幼儿园学龄儿童信息采集服务系统》使用手册
内容
第一章海淀区幼儿园幼儿信息采集服务系统用户子系统概述1
第二章进入海淀区幼儿园适龄儿童信息采集服务系统2
2.1 用户注册 2
2.2 用户登录 4
2.3 修改采集信息 5
2.4 选择意向花园 6
2.5 审计状态查询 9
2.6 查看和打印 9
2.7 修改密码 10
2.8 家长留言 11
2.9 忘记密码 12
3.0 用户须知 13
3.1 操作手册 13
3.2 政策法规 14
第一章海淀区幼儿园幼儿信息采集服务系统用户子系统概述
海淀区幼儿园儿童信息采集服务系统前台主要包括用户注册、忘记密码、使用说明、操作手册、政策法规、采集填表修改、意向园选择、审核状态查询、查看和打印、密码修改、家长留言等八个功能模块。
用户注册模块主要实现注册新用户的功能。
忘记密码模块主要实现找回密码的功能。
用户通知模块主要实现查看用户通知的功能。
操作手册模块主要实现查看系统操作手册的功能。
政策法规模块主要实现查看正常法规的功能。
修改采集信息填充模块主要实现修改用户信息的功能。
选择意向幼儿园模块主要实现了选择幼儿园进行注册的功能。
儿童退出管理模块具有查询入园儿童信息、退出幼儿园等功能。
审核状态查询模块主要实现对幼儿园儿童申报状态的查询功能。
查看打印模块主要实现查看和打印用户信息的功能。
密码修改模块主要实现修改用户登录密码的功能。
父消息模块主要实现父发布信息的功能。
第二章 进入海淀区幼儿园幼儿信息采集服务系统
2.1 用户注册
在浏览器中打开海淀区幼儿园学龄儿童信息采集服务系统登录界面,如下图:
点击【用户注册】按钮,系统会自动跳转到用户注册界面,弹出注册服务协议,如下图:
输入“用户名”、“密码”、“重复密码”、“邮箱”、“手机号码”信息,点击【发送验证码】按钮,系统会自动将手机验证码发送到填写的手机多于; 收到手机验证码后,在“手机验证码”栏输入收到的验证码;然后勾选“同意“服务条款”和“隐私优先政策”复选框,点击【立即注册】按钮,系统会弹出:“注册“成功”提示,点击【确定】按钮,系统会自动跳转到“儿童基本信息采集表”界面,如下图:
在“婴儿基本信息采集表格”界面输入孩子和监护人的基本信息(监护人可以选择父母、父亲、母亲,选择的监护人类型为必填项),然后点击【保存】 ] 按钮。信息采集表单保存成功,用户注册完成,系统自动跳转到“修改<@采集信息”界面,见下图

2.2 用户登录
在浏览器中打开海淀区幼儿园适龄儿童信息采集服务系统登录界面,输入“用户名”(或输入“注册手机号”、邮箱号、儿童身份证号)和界面中的“密码”信息点击【用户登录】按钮,成功登录海淀区幼儿园适龄儿童信息采集服务系统,如下图:

【退出】:登录成功后,界面右上角会显示【退出】按钮。点击【退出】按钮退出成功。
2.3 修改采集信息
登录海淀区幼儿园儿童信息采集服务系统家长界面系统后,点击“修改采集信息”标签页按钮,成功打开“修改采集信息”界面即可显示孩子的基本信息,可以修改,如图:

在“修改采集信息”界面修改孩子和监护人信息后,点击【修改】按钮,修改孩子采集的信息,操作成功。
2.4 选择意向园
登录海淀区幼儿园学龄儿童信息采集服务系统家长用户界面系统后,点击“选择意向园”标签页按钮,成功打开“选择意向园”界面,界面显示“幼儿园信息》“本次”学龄儿童信息采集时间”、“本次学龄儿童信息结束后的天数采集”、“每位家长最多可入园数注册”等,如下图所示:

■【搜索】:在“选择意向园”界面,输入搜索条件:“幼儿园名称”、“地址信息”、“幼儿园性质”,点击【搜索】按钮搜索幼儿园信息,幼儿园信息列表显示满足搜索条件的幼儿园信息。当搜索条件为空时,将搜索到所有幼儿园信息。当搜索条件不为空时,可以根据搜索条件搜索匹配的记录,可以进行单项或组合搜索。为了不影响系统性能和提高界面的可操作性,每页默认显示8条数据(您可以通过下拉按钮选择显示更多数据)。
■查看幼儿园介绍:在“选择意向园”界面的幼儿园信息列表中点击“幼儿园名称”,系统会自动弹出“幼儿园简介”窗口,查看该幼儿园的基本信息,如图下图:
■【我要注册】:在“选择意向园”界面的幼儿园信息列表中找到要注册的幼儿园信息,点击相应幼儿园信息操作栏中的【我要注册】按钮(性质幼儿园为“单位办幼儿园”“幼儿园需要选择孩子是本单位员工二代还是三代,否则选择否);系统自动弹出“幼儿园介绍”窗口幼儿园,显示幼儿园的基本信息,如下图:
点击“幼儿园简介”窗口中的【我要报名】按钮,系统会弹出:“选择意向成功!” 提示,点击提示窗口中的【确定】按钮关闭窗口,幼儿园注册成功,系统自动返回【选择意向幼儿园】界面,已注册的幼儿园信息自动放置在在幼儿园信息列表的顶部,该幼儿园信息操作栏中的按钮由【我要注册】变为【取消注册】按钮,如下图:

■ 【取消注册】:在【选择意向园】界面,点击幼儿园操作栏中的【取消注册】按钮,确认已注册的幼儿园信息注册。
2.5 评论状态查询
登录海淀区幼儿园学龄儿童信息采集服务系统家长界面系统后,点击“审核状态查询”标签页按钮成功打开“审核状态查询”界面,可以查看注册幼儿园信息;您可以查询该孩子信息的幼儿园审核状态如下图所示:

■【查询】 选择年份,点击【查询】按钮,可以查询选中报社志愿者的履历。
2.6 查看和打印
登录海淀区幼儿园学龄儿童信息采集服务系统家长用户界面系统后,点击“查看打印”标签页按钮成功打开“查看打印”界面,您可以查看,打印、导出子采集信息(pdf格式),如下图:
■ 【打印】:在【查看打印】界面点击【打印】按钮,可以打印孩子的信息。
■【导出pdf】:在【查看和打印】界面点击【导出pdf】按钮,系统会弹出文件下载窗口,点击文件下载窗口中的【保存】按钮,系统会弹出文件下载窗口另存为界面,设置“保存地址”和“文件” 点击“名称”后的【保存】按钮,系统会自动下载并保存pdf文件。
2.7 修改密码
登录海淀区幼儿园学龄儿童信息采集服务系统家长界面系统后,点击“修改密码”标签页按钮,成功打开“修改密码”界面,如下图:

根据提示输入“旧密码”和“新密码”,点击【确定】按钮,系统弹出:“修改成功!” 提示,在提示界面点击【确定】按钮,个人密码修改成功。
2.8位家长留言
登录海淀区幼儿园儿童信息采集服务系统家长界面系统后,点击“家长留言”标签页按钮,成功打开“家长留言”界面。为了不影响系统性能,提高界面的可操作性,请留言 数据分页显示。您可以通过列表底部的分页功能切换列表页面,查看所有幼儿园信息。如下所示:
■【留言】:输入留言内容后,点击【留言】按钮,系统会自动提交留言内容,留言操作成功。
2.9忘记密码
打开海淀区幼儿园儿童信息采集服务系统家长用户界面系统,点击界面上的【忘记密码】按钮,系统跳转到用户密码找回界面,默认显示为手机找回密码手机,输入姓名和凭据点击号码上的【提交】按钮,系统会将密码发送到用户注册的手机上,如下图

点击“通过电子邮件检索”按钮,见下图

输入姓名和邮箱,点击【提交】按钮,系统会将密码发送到用户注册的邮箱。
点击【返回】按钮,返回登录界面。
3.0 用户须知
打开海淀区幼儿园适龄儿童信息采集服务系统家长用户界面系统,点击界面上的“用户须知”按钮,见下图
进入【用户信息】界面查看相关信息;点击【返回】按钮返回登录界面,如下图

3.1 操作手册
打开海淀区幼儿园适龄儿童信息采集服务系统家长用户界面系统,点击界面上的“操作手册”按钮,见下图
进入【操作手册】界面查看相关信息;点击【返回】按钮返回登录界面,如下图

3.2政策法规
打开海淀区幼儿园学龄儿童信息采集服务系统家长界面系统,点击界面上的“政策法规”按钮,如下图

进入【政策法规】界面查看相关信息;点击【返回】按钮返回登录界面,如下图

相关链接:
2019年海淀区幼儿园信息采集系统(网址+采集时间)
2019年海淀区幼儿园适龄儿童信息采集常见问题
2019年海淀区幼儿园采集信息时间及信息采集系统入口
海淀区幼儿园信息采集系统操作流程指南(图解)
2019年海淀区幼儿园幼儿信息采集系统常见问题
采集系统(就是如何处理多台机器线上系统的日志(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-12-05 03:20
)
如今,多核和分布式软件开发已成为常态。基本上,较大的应用程序分布在多台机器上。分布式在提高性能的同时带来了很多问题。今天只讨论一点,就是多机联机系统的日志如何处理。
以我们公司的一个应用T为例。部署在5台百度云机器上,其中一台有公网IP,使用百度云提供的负载均衡服务。每次要检索日志中的某个关键字,基本步骤如下:
当然,我们可以编写脚本来简化这个过程,或者使用cssh之类的工具。但成功登录五台机器只是任务的开始。接下来,我们要手动选择我们要检索的日志(日志是按照日期存储的),使用grep进行检索,然后在五个shell上一一查看结果。. 如果有稍微高级的需求,比如检查某个关键词是否在昨天和今天的日志中都出现过,那么任务就会变得很麻烦,而且使用shell很容易出错。
从这个过程,我们可以总结出分布式系统日志处理的需求。希望有这样一个日志处理系统,具有以下功能:
幸运的是,elastic 提供了一套非常先进的工具 ELKB 来满足这些需求。ELKB是指用于日志分析或数据分析的四个软件,每个软件都有独立的功能,可以组合在一起。我们先简单介绍一下这四个软件。
安装
这里我们以 CentOS 7 为例来说明如何安装这些软件。ELK只需要安装在服务器上进行日志采集和分析,而Beats则需要安装在每台日志生成机器(客户端)上,当然也可能包括日志采集服务器本身。
爪哇
$ yum install java-1.8.0
copy code
搜索
$ rpm --import http://packages.elastic.co/GPG-KEY-elasticsearch
$ echo '[elasticsearch-2.x]
name=Elasticsearch repository for 2.x packages
baseurl=http://packages.elastic.co/ela ... entos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
' | tee /etc/yum.repos.d/elasticsearch.repo
$ yum install elasticsearch
copy code
日志存储
$ vim /etc/yum.repos.d/logstash.repo
# 添加以下内容
[logstash-2.4]
name=logstash repository for 2.2 packages
baseurl=http://packages.elasticsearch. ... entos
gpgcheck=1
gpgkey=http://packages.elasticsearch. ... earch
enabled=1
# 安装
$ yum install logstash
copy code
基巴纳
$ vim /etc/yum.repos.d/kibana.repo
# 添加以下内容
[kibana-4.6]
name=Kibana repository for 4.4.x packages
baseurl=http://packages.elastic.co/kibana/4.4/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
# 安装
$ yum install kibana
copy code
节拍
节拍分为多种类型,每种类型都采集特定信息。常用的是Filebeat,它监控文件变化,传输文件内容。一般来说,Filebeat 对日志系统来说就足够了。
我们切换到客户端。首先,您还需要导入 GPG KEY。
$ rpm --import http://packages.elastic.co/GPG-KEY-elasticsearch
copy code
创建一个新的存储库并安装它。
$ vim /etc/yum.repos.d/elastic-beats.repo
# 添加以下内容
[beats]
name=Elastic Beats Repository
baseurl=https://packages.elastic.co/beats/yum/el/$basearch
enabled=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
gpgcheck=1
# 安装
$ yum install filebeat
copy code
弹性搜索
Elasticsearch 不需要太多配置,只需要屏蔽外网访问即可。修改配置文件/etc/elasticsearch/elasticsearch.yml。
network.host: localhost
copy code
启动elasticsearch,服务elasticsearch 启动。
Elasticsearch 本身可以被认为是一个 NoSQL 数据库,通过 REST API 进行操作。数据存储在索引中,相当于elastcisearch中SQL中的一张表。因为elasticsearch主要用于检索数据,所以index有一个叫做mapping的配置。我们用mapping来告诉elasticsearch数据的一些相关信息,比如某个字段是什么数据类型,是否创建索引等。我们先玩elasticsearch,以官方的莎士比亚数据集为例。
$ curl localhost:9200/_cat/indices?v # 查看当前所有的index
health status index pri rep docs.count docs.deleted store.size pri.store.size # 没有任何index
# 创建shakespeare索引,并设置mapping信息
# speaker字段和play_name不需要分析,elasticsearch默认会拆分字符串中的每个词并进行索引
$ curl -XPUT http://localhost:9200/shakespeare -d '
{
"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "string", "index" : "not_analyzed" },
"play_name" : {"type": "string", "index" : "not_analyzed" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
}
';
$ curl localhost:9200/_cat/indices?v # 查看索引
health status index pri rep docs.count docs.deleted store.size pri.store.size
yellow open shakespeare 5 1 0 0 260b 260b
# 下载数据,并将数据集load进索引中
$ wget https://www.elastic.co/guide/e ... .json
$ curl -XPOST 'localhost:9200/shakespeare/_bulk?pretty' --data-binary @shakespeare.json
# 以上操作完成后,elasticsearch中就已经有了我们load的所有数据,并建立好了索引,我们可以开始查询了
# 查询一下含有'man'这个词的text_entry
$ curl -s 'localhost:9200/shakespeare/_search?q=text_entry:man&pretty=1&size=20' | jq '.hits.hits | .[]._source.text_entry'
"man."
"Man?"
"man."
"Why, man?"
"Worthy man!"
"Every man,"
"complete man."
"married man?"
"melancholy man."
"Speak, man."
"Why, man?"
"What, man?"
"prave man."
"Speak, man."
"Why, man?"
"So man and man should be;"
"O, the difference of man and man!"
"The young man is an honest man."
"A gross fat man."
"plain-dealing man?"
copy code
下面我们通过解析nginx的访问日志来讲解ELKB的使用方法。
解析 Nginx 访问日志
整个过程的流程比较简单。Filebeat 采集日志并将它们发送到 Logstash。在 logstash 解析它们之后,将它们写入 ealsticsearch。最后,我们使用 kibana 查看和检索这些日志。
文件节拍
首先切换到客户端,我们来配置filebeat。
$ vim /etc/filebeat/filebeat.yml
...
prospectors:
-
paths:
- /var/log/nginx/access.log
# 找到document_type字段,取消注释,这个字段会告诉logstash日志的类型,对应logstash中的type字段
document_type: nginx
...
# 默认输出为elasticsearch,注释掉,使用logstash
logstash:
hosts: ["IP:5044"] # 注意更改这里的IP
copy code
日志存储
logstash的配置比较麻烦,因为logstash需要接受输入,处理,产生输出。Logstash 采用输入、过滤、输出三阶段配置方式。input配置输入源,filter配置如何处理输入源中的信息,output配置输出位置。
一般来说,输入是节拍的。在filter中,我们解析输入得到的日志,得到我们想要的字段,输出是elasticsearch。这里我们以nginx的访问日志为例。过滤器中有一个关键的东西叫grok,我们用这个东西来解析日志结构。logstash 提供了一些默认的 Patterns,方便我们分析和使用。当然,我们也可以自定义模式,有规律地匹配日志内容。
$ vim /etc/logstash/conf.d/nginx.conf
input {
beats {
port => 5044
}
}
filter {
if [type] == "nginx" { # 这里的type是日志类型,我们在后面的filebeat中设定
grok {
match => { "message" => "%{COMBINEDAPACHELOG} %{QS:gzip_ratio}" } # 使用自带的pattern即可,注意空格
remove_field => ["beat", "input_type", "message", "offset", "tags"] # filebeat添加的字段,我们不需要
}
# 更改匹配到的字段的数据类型
mutate {
convert => ["response", "integer"]
convert => ["bytes", "integer"]
convert => ["responsetime", "float"]
}
# 指定时间戳字段以及具体的格式
date {
match => ["timestamp", "dd/MMM/YYYY:HH:mm:ss Z"]
remove_field => ["timestamp"]
}
}
}
outpugst {
elasticsearch {
hosts => [ "localhost:9200" ]
index => "%{type}-%{+YYYY.MM.dd}" # index中含有时间戳
}
}
copy code
服务logstash start 可以启动logstash。注意它的启动速度很慢。
弹性搜索
在上面的logstash配置中,我们可以看到最终写入elasticsearch的索引收录时间戳,这是比较推荐的做法。因为方便我们每天分析数据。关于elasticsearch,我们只需要配置index Mapping信息即可。因为我们的索引是每天生成的,每天都是一个新的索引,当然不可能每天都配置索引Mapping。这里需要用到elasticsearch的一个特性,Index Template。我们可以创建一个索引配置模板,并使用这个模板来配置所有匹配的索引。
curl -XPUT localhost:9200/_template/nginx -d '
{
"template": "nginx*",
"mappings": {
"_default_": {
"properties": {
"clientip": {
"type": "string",
"index": "not_analyzed"
},
"ident": {
"type": "string"
},
"auth": {
"type": "string"
},
"verb": {
"type": "string"
},
"request": {
"type": "string"
},
"httpversion": {
"type": "string"
},
"rawrequest": {
"type": "string"
},
"response": {
"type": "string"
},
"bytes": {
"type": "integer"
},
"referrer": {
"type": "string"
},
"agent": {
"type": "string"
},
"gzip_ratio": {
"type": "string"
}
}
}
}
}
'
copy code
上面的代码创建了一个名为 nginx 的模板,匹配所有以 nginx 开头的索引。
基巴纳
Kibana 不需要任何配置,直接启动即可。service kibana start,默认运行在5601端口。如果考虑安全性,也可以将kibana配置为只监听本地机器,然后使用nginx进行反向代理和控制权限,这里不再赘述。
接下来,我们需要生成一个日志,然后可以在kibana中查看,以表明系统运行正常。我们使用curl在客户端随机请求nginx生成一个小日志。然后,打开kibana,[服务器ip]:5601。刚进入的时候,首先需要配置Kibana的Index Pattern,告诉kibana我们要查看哪些Index数据,输入nginx*,然后点击Discover浏览数据。
最终效果如下,我们可以在kibana中浏览我们的nginx日志,进行任意搜索。
查看全部
采集系统(就是如何处理多台机器线上系统的日志(组图)
)
如今,多核和分布式软件开发已成为常态。基本上,较大的应用程序分布在多台机器上。分布式在提高性能的同时带来了很多问题。今天只讨论一点,就是多机联机系统的日志如何处理。
以我们公司的一个应用T为例。部署在5台百度云机器上,其中一台有公网IP,使用百度云提供的负载均衡服务。每次要检索日志中的某个关键字,基本步骤如下:
当然,我们可以编写脚本来简化这个过程,或者使用cssh之类的工具。但成功登录五台机器只是任务的开始。接下来,我们要手动选择我们要检索的日志(日志是按照日期存储的),使用grep进行检索,然后在五个shell上一一查看结果。. 如果有稍微高级的需求,比如检查某个关键词是否在昨天和今天的日志中都出现过,那么任务就会变得很麻烦,而且使用shell很容易出错。
从这个过程,我们可以总结出分布式系统日志处理的需求。希望有这样一个日志处理系统,具有以下功能:
幸运的是,elastic 提供了一套非常先进的工具 ELKB 来满足这些需求。ELKB是指用于日志分析或数据分析的四个软件,每个软件都有独立的功能,可以组合在一起。我们先简单介绍一下这四个软件。
安装
这里我们以 CentOS 7 为例来说明如何安装这些软件。ELK只需要安装在服务器上进行日志采集和分析,而Beats则需要安装在每台日志生成机器(客户端)上,当然也可能包括日志采集服务器本身。
爪哇
$ yum install java-1.8.0
copy code
搜索
$ rpm --import http://packages.elastic.co/GPG-KEY-elasticsearch
$ echo '[elasticsearch-2.x]
name=Elasticsearch repository for 2.x packages
baseurl=http://packages.elastic.co/ela ... entos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
' | tee /etc/yum.repos.d/elasticsearch.repo
$ yum install elasticsearch
copy code
日志存储
$ vim /etc/yum.repos.d/logstash.repo
# 添加以下内容
[logstash-2.4]
name=logstash repository for 2.2 packages
baseurl=http://packages.elasticsearch. ... entos
gpgcheck=1
gpgkey=http://packages.elasticsearch. ... earch
enabled=1
# 安装
$ yum install logstash
copy code
基巴纳
$ vim /etc/yum.repos.d/kibana.repo
# 添加以下内容
[kibana-4.6]
name=Kibana repository for 4.4.x packages
baseurl=http://packages.elastic.co/kibana/4.4/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
# 安装
$ yum install kibana
copy code
节拍
节拍分为多种类型,每种类型都采集特定信息。常用的是Filebeat,它监控文件变化,传输文件内容。一般来说,Filebeat 对日志系统来说就足够了。
我们切换到客户端。首先,您还需要导入 GPG KEY。
$ rpm --import http://packages.elastic.co/GPG-KEY-elasticsearch
copy code
创建一个新的存储库并安装它。
$ vim /etc/yum.repos.d/elastic-beats.repo
# 添加以下内容
[beats]
name=Elastic Beats Repository
baseurl=https://packages.elastic.co/beats/yum/el/$basearch
enabled=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
gpgcheck=1
# 安装
$ yum install filebeat
copy code
弹性搜索
Elasticsearch 不需要太多配置,只需要屏蔽外网访问即可。修改配置文件/etc/elasticsearch/elasticsearch.yml。
network.host: localhost
copy code
启动elasticsearch,服务elasticsearch 启动。
Elasticsearch 本身可以被认为是一个 NoSQL 数据库,通过 REST API 进行操作。数据存储在索引中,相当于elastcisearch中SQL中的一张表。因为elasticsearch主要用于检索数据,所以index有一个叫做mapping的配置。我们用mapping来告诉elasticsearch数据的一些相关信息,比如某个字段是什么数据类型,是否创建索引等。我们先玩elasticsearch,以官方的莎士比亚数据集为例。
$ curl localhost:9200/_cat/indices?v # 查看当前所有的index
health status index pri rep docs.count docs.deleted store.size pri.store.size # 没有任何index
# 创建shakespeare索引,并设置mapping信息
# speaker字段和play_name不需要分析,elasticsearch默认会拆分字符串中的每个词并进行索引
$ curl -XPUT http://localhost:9200/shakespeare -d '
{
"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "string", "index" : "not_analyzed" },
"play_name" : {"type": "string", "index" : "not_analyzed" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
}
';
$ curl localhost:9200/_cat/indices?v # 查看索引
health status index pri rep docs.count docs.deleted store.size pri.store.size
yellow open shakespeare 5 1 0 0 260b 260b
# 下载数据,并将数据集load进索引中
$ wget https://www.elastic.co/guide/e ... .json
$ curl -XPOST 'localhost:9200/shakespeare/_bulk?pretty' --data-binary @shakespeare.json
# 以上操作完成后,elasticsearch中就已经有了我们load的所有数据,并建立好了索引,我们可以开始查询了
# 查询一下含有'man'这个词的text_entry
$ curl -s 'localhost:9200/shakespeare/_search?q=text_entry:man&pretty=1&size=20' | jq '.hits.hits | .[]._source.text_entry'
"man."
"Man?"
"man."
"Why, man?"
"Worthy man!"
"Every man,"
"complete man."
"married man?"
"melancholy man."
"Speak, man."
"Why, man?"
"What, man?"
"prave man."
"Speak, man."
"Why, man?"
"So man and man should be;"
"O, the difference of man and man!"
"The young man is an honest man."
"A gross fat man."
"plain-dealing man?"
copy code
下面我们通过解析nginx的访问日志来讲解ELKB的使用方法。
解析 Nginx 访问日志
整个过程的流程比较简单。Filebeat 采集日志并将它们发送到 Logstash。在 logstash 解析它们之后,将它们写入 ealsticsearch。最后,我们使用 kibana 查看和检索这些日志。
文件节拍
首先切换到客户端,我们来配置filebeat。
$ vim /etc/filebeat/filebeat.yml
...
prospectors:
-
paths:
- /var/log/nginx/access.log
# 找到document_type字段,取消注释,这个字段会告诉logstash日志的类型,对应logstash中的type字段
document_type: nginx
...
# 默认输出为elasticsearch,注释掉,使用logstash
logstash:
hosts: ["IP:5044"] # 注意更改这里的IP
copy code
日志存储
logstash的配置比较麻烦,因为logstash需要接受输入,处理,产生输出。Logstash 采用输入、过滤、输出三阶段配置方式。input配置输入源,filter配置如何处理输入源中的信息,output配置输出位置。
一般来说,输入是节拍的。在filter中,我们解析输入得到的日志,得到我们想要的字段,输出是elasticsearch。这里我们以nginx的访问日志为例。过滤器中有一个关键的东西叫grok,我们用这个东西来解析日志结构。logstash 提供了一些默认的 Patterns,方便我们分析和使用。当然,我们也可以自定义模式,有规律地匹配日志内容。
$ vim /etc/logstash/conf.d/nginx.conf
input {
beats {
port => 5044
}
}
filter {
if [type] == "nginx" { # 这里的type是日志类型,我们在后面的filebeat中设定
grok {
match => { "message" => "%{COMBINEDAPACHELOG} %{QS:gzip_ratio}" } # 使用自带的pattern即可,注意空格
remove_field => ["beat", "input_type", "message", "offset", "tags"] # filebeat添加的字段,我们不需要
}
# 更改匹配到的字段的数据类型
mutate {
convert => ["response", "integer"]
convert => ["bytes", "integer"]
convert => ["responsetime", "float"]
}
# 指定时间戳字段以及具体的格式
date {
match => ["timestamp", "dd/MMM/YYYY:HH:mm:ss Z"]
remove_field => ["timestamp"]
}
}
}
outpugst {
elasticsearch {
hosts => [ "localhost:9200" ]
index => "%{type}-%{+YYYY.MM.dd}" # index中含有时间戳
}
}
copy code
服务logstash start 可以启动logstash。注意它的启动速度很慢。
弹性搜索
在上面的logstash配置中,我们可以看到最终写入elasticsearch的索引收录时间戳,这是比较推荐的做法。因为方便我们每天分析数据。关于elasticsearch,我们只需要配置index Mapping信息即可。因为我们的索引是每天生成的,每天都是一个新的索引,当然不可能每天都配置索引Mapping。这里需要用到elasticsearch的一个特性,Index Template。我们可以创建一个索引配置模板,并使用这个模板来配置所有匹配的索引。
curl -XPUT localhost:9200/_template/nginx -d '
{
"template": "nginx*",
"mappings": {
"_default_": {
"properties": {
"clientip": {
"type": "string",
"index": "not_analyzed"
},
"ident": {
"type": "string"
},
"auth": {
"type": "string"
},
"verb": {
"type": "string"
},
"request": {
"type": "string"
},
"httpversion": {
"type": "string"
},
"rawrequest": {
"type": "string"
},
"response": {
"type": "string"
},
"bytes": {
"type": "integer"
},
"referrer": {
"type": "string"
},
"agent": {
"type": "string"
},
"gzip_ratio": {
"type": "string"
}
}
}
}
}
'
copy code
上面的代码创建了一个名为 nginx 的模板,匹配所有以 nginx 开头的索引。
基巴纳
Kibana 不需要任何配置,直接启动即可。service kibana start,默认运行在5601端口。如果考虑安全性,也可以将kibana配置为只监听本地机器,然后使用nginx进行反向代理和控制权限,这里不再赘述。
接下来,我们需要生成一个日志,然后可以在kibana中查看,以表明系统运行正常。我们使用curl在客户端随机请求nginx生成一个小日志。然后,打开kibana,[服务器ip]:5601。刚进入的时候,首先需要配置Kibana的Index Pattern,告诉kibana我们要查看哪些Index数据,输入nginx*,然后点击Discover浏览数据。
最终效果如下,我们可以在kibana中浏览我们的nginx日志,进行任意搜索。

采集系统(采集系统开发资料,如何开发好的app/小程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-11-29 10:17
采集系统怎么开发呢?采集系统开发资料,想要做采集系统,想要卖采集系统的老板可以先看一下采集系统开发技术资料,想要学习采集系统开发的话,
开发相关app或小程序的话首先要有采集,比如现在市面上非常火的微博采集,还有其他的各种各样的采集源。
想要做一款采集app/小程序,首先需要有相关技术储备。需要了解app后台开发原理,了解小程序后台开发原理,熟悉微信小程序运营原理。做采集系统需要具备自己的核心能力。目前大部分都是提供小程序源码,采集需要自己开发出一套采集小程序。是否有核心能力是判断可不可以做采集系统的唯一条件。
感谢邀请~采集系统开发,这个本身这个可以从以下几点来思考:1.要有源码,否则没办法进行系统开发。2.需要了解小程序/app的运营规则。3.要做出相应的采集功能来。其他的,你可以看看云采集平台,云采集是一个专门对接小程序的平台,目前小程序平台有中国大陆、港澳台、日韩、欧美等,它的出现对大量的广告主、网红、kol来说无疑是一个重大的商机。
人们有着足够的时间采集网络上的信息,并且这是一个非常大的市场。小程序相比app有着极大的优势,首先小程序与微信绑定,很容易去传播推广;小程序的开发成本较低;小程序无需安装即可使用;小程序在微信有7.0的体验版可以了解一下。 查看全部
采集系统(采集系统开发资料,如何开发好的app/小程序)
采集系统怎么开发呢?采集系统开发资料,想要做采集系统,想要卖采集系统的老板可以先看一下采集系统开发技术资料,想要学习采集系统开发的话,
开发相关app或小程序的话首先要有采集,比如现在市面上非常火的微博采集,还有其他的各种各样的采集源。
想要做一款采集app/小程序,首先需要有相关技术储备。需要了解app后台开发原理,了解小程序后台开发原理,熟悉微信小程序运营原理。做采集系统需要具备自己的核心能力。目前大部分都是提供小程序源码,采集需要自己开发出一套采集小程序。是否有核心能力是判断可不可以做采集系统的唯一条件。
感谢邀请~采集系统开发,这个本身这个可以从以下几点来思考:1.要有源码,否则没办法进行系统开发。2.需要了解小程序/app的运营规则。3.要做出相应的采集功能来。其他的,你可以看看云采集平台,云采集是一个专门对接小程序的平台,目前小程序平台有中国大陆、港澳台、日韩、欧美等,它的出现对大量的广告主、网红、kol来说无疑是一个重大的商机。
人们有着足够的时间采集网络上的信息,并且这是一个非常大的市场。小程序相比app有着极大的优势,首先小程序与微信绑定,很容易去传播推广;小程序的开发成本较低;小程序无需安装即可使用;小程序在微信有7.0的体验版可以了解一下。
采集系统(采集系统入口app底部,展示minisystem预装云镜安全卫士)
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-11-26 21:00
采集系统入口app底部,展示minisystem预装lbe云镜安全卫士等抢先5秒内用户正在使用的软件的lbe云镜android版本即刻上线。
android不知道,ios下的blued曾经推出过这种服务。不过目前貌似是仅限于认证身份使用(通过认证才可以使用,在线的服务似乎也没有,更不要说需要注册,
参见国内手机空间,类似于pad版本的一些软件。比如说快图浏览、百度网盘等,主要是先帮你注册账号然后给你推送一些图片什么的。
android现在好像有类似于服务,以前看过报道,
中国移动和blued合作了,你可以在移动官网登录blued官网,点击“volte服务开通”提示填写信息即可。注意千万不要弄成中国移动你懂的!然后网页端就可以了,
android系统可以通过注册某些网站的服务赚取流量
今天用国内的产品,以前是appstore。现在app的服务好像更多了,已经看不见安卓端了。
安卓注册后,app内就自动有对应的服务,用户可以很方便地获取服务内容。
volte的服务
别说android,就是ios,在其他soc的机器上,在完成注册后,必须有一个网页的页面来实现认证,但是安卓手机,注册后,可以直接安装各种soc上的app,就算没有网页的页面, 查看全部
采集系统(采集系统入口app底部,展示minisystem预装云镜安全卫士)
采集系统入口app底部,展示minisystem预装lbe云镜安全卫士等抢先5秒内用户正在使用的软件的lbe云镜android版本即刻上线。
android不知道,ios下的blued曾经推出过这种服务。不过目前貌似是仅限于认证身份使用(通过认证才可以使用,在线的服务似乎也没有,更不要说需要注册,
参见国内手机空间,类似于pad版本的一些软件。比如说快图浏览、百度网盘等,主要是先帮你注册账号然后给你推送一些图片什么的。
android现在好像有类似于服务,以前看过报道,
中国移动和blued合作了,你可以在移动官网登录blued官网,点击“volte服务开通”提示填写信息即可。注意千万不要弄成中国移动你懂的!然后网页端就可以了,
android系统可以通过注册某些网站的服务赚取流量
今天用国内的产品,以前是appstore。现在app的服务好像更多了,已经看不见安卓端了。
安卓注册后,app内就自动有对应的服务,用户可以很方便地获取服务内容。
volte的服务
别说android,就是ios,在其他soc的机器上,在完成注册后,必须有一个网页的页面来实现认证,但是安卓手机,注册后,可以直接安装各种soc上的app,就算没有网页的页面,
采集系统(通过探针去实现身份验证这个概念,涉及的探针有3类)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-24 15:02
采集系统的价格从几千元至几十万不等,从探针采集到采集结果分析到结果可视化,各种系统各有特色,如cissil系统主要覆盖国家政策方向,运动捕捉系统主要覆盖智能物流系统的倾斜数据。实体采集方面很多领域都有自己的优势。在二代身份认证系统领域,比如指纹验证系统的身份识别率达到99.99%。利用特殊网络与定位的身份验证系统在军事侦察系统中有巨大的应用。
寻址比对检验主要依靠由多径射线,定位系统中的水平定位与垂直定位等,主要是为了数据的质量,可视化的支持则能迅速提高该系统的可用性,降低运营成本。
那从实现上来说,目前想通过探针去实现身份验证这个概念,涉及的探针有3类:1,发射卡,属于目前人民日报那样的线下实体业务提供单位提供的探针,原理是发射出去的探针将计算机主机下发的运算结果,通过光电转换后,由仪表来转发给预先准备好的受测者。探针被同步检测到之后就不会再次被送到探针接收器中了。2,接收卡,属于运动捕捉公司提供的探针,提供者会搭建基于api网关的http接口,也即是说,http接口提供者给的协议就是运动捕捉提供者提供的服务。
3,云数据中心,即便是你把精度提高到厘米级,你的数据质量依然很差,因为用户大部分是通过网页看到你的数据结果,而并非实际的数据,你只能保证实际的数据只给到接收端,而把这个指标当做是探针的等级来提升数据质量。如果题主目前在负责针孔摄像机数据质量的提升这一块,不如联系我这边来,我目前的工作是针孔摄像机基础建设、指纹数据采集这些,希望能帮到题主。 查看全部
采集系统(通过探针去实现身份验证这个概念,涉及的探针有3类)
采集系统的价格从几千元至几十万不等,从探针采集到采集结果分析到结果可视化,各种系统各有特色,如cissil系统主要覆盖国家政策方向,运动捕捉系统主要覆盖智能物流系统的倾斜数据。实体采集方面很多领域都有自己的优势。在二代身份认证系统领域,比如指纹验证系统的身份识别率达到99.99%。利用特殊网络与定位的身份验证系统在军事侦察系统中有巨大的应用。
寻址比对检验主要依靠由多径射线,定位系统中的水平定位与垂直定位等,主要是为了数据的质量,可视化的支持则能迅速提高该系统的可用性,降低运营成本。
那从实现上来说,目前想通过探针去实现身份验证这个概念,涉及的探针有3类:1,发射卡,属于目前人民日报那样的线下实体业务提供单位提供的探针,原理是发射出去的探针将计算机主机下发的运算结果,通过光电转换后,由仪表来转发给预先准备好的受测者。探针被同步检测到之后就不会再次被送到探针接收器中了。2,接收卡,属于运动捕捉公司提供的探针,提供者会搭建基于api网关的http接口,也即是说,http接口提供者给的协议就是运动捕捉提供者提供的服务。
3,云数据中心,即便是你把精度提高到厘米级,你的数据质量依然很差,因为用户大部分是通过网页看到你的数据结果,而并非实际的数据,你只能保证实际的数据只给到接收端,而把这个指标当做是探针的等级来提升数据质量。如果题主目前在负责针孔摄像机数据质量的提升这一块,不如联系我这边来,我目前的工作是针孔摄像机基础建设、指纹数据采集这些,希望能帮到题主。
采集系统(采集系统,可以换个方式理解,集群方式(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-23 06:02
采集系统,可以换个方式理解,集群方式,把很多台电脑联合起来作业,每台电脑做不同的事情,用zookeeper管理集群各台电脑的状态,topic,和请求的处理,这样就可以实现机器负载均衡,服务备份,事件过滤等功能;对于自己的开发公司而言,没有必要联合很多台电脑来做集群,关键性功能,放到分布式系统,自己留一个或者几个独立机器,用就可以了。不同环境,开发任务,还是比较合理的;。
用分布式计算网关,
api:就是api网关不止是发消息,
用api网关,可以实现数据库的水平扩展,用数据库来实现的可用性,而且api网关如果要做集群的话,必须要控制好节点的数量,并发,这些要处理好。
不是每台机器都必须用集群,机器数是根据业务的要求来的,并发可用性io并发这些要求高的就用集群或者blockingguest,业务上简单的用一台,高并发稳定io的就上分布式计算平台,集群是不错,但是不是每台机器都适合做分布式计算。
可以采用交换机模式,机器不需要多,master和partner各自拉机器,负责不同的业务,例如某某牌子机器,几块钱一台,服务车主,客户等,必要时可用websocket方式,
感觉主要看网络结构。通常集群(span)模式才是最佳选择。参考:说一下span架构的基本原理?可以考虑加交换机,用第三方解决方案也可以,看自己实际情况选择。 查看全部
采集系统(采集系统,可以换个方式理解,集群方式(组图))
采集系统,可以换个方式理解,集群方式,把很多台电脑联合起来作业,每台电脑做不同的事情,用zookeeper管理集群各台电脑的状态,topic,和请求的处理,这样就可以实现机器负载均衡,服务备份,事件过滤等功能;对于自己的开发公司而言,没有必要联合很多台电脑来做集群,关键性功能,放到分布式系统,自己留一个或者几个独立机器,用就可以了。不同环境,开发任务,还是比较合理的;。
用分布式计算网关,
api:就是api网关不止是发消息,
用api网关,可以实现数据库的水平扩展,用数据库来实现的可用性,而且api网关如果要做集群的话,必须要控制好节点的数量,并发,这些要处理好。
不是每台机器都必须用集群,机器数是根据业务的要求来的,并发可用性io并发这些要求高的就用集群或者blockingguest,业务上简单的用一台,高并发稳定io的就上分布式计算平台,集群是不错,但是不是每台机器都适合做分布式计算。
可以采用交换机模式,机器不需要多,master和partner各自拉机器,负责不同的业务,例如某某牌子机器,几块钱一台,服务车主,客户等,必要时可用websocket方式,
感觉主要看网络结构。通常集群(span)模式才是最佳选择。参考:说一下span架构的基本原理?可以考虑加交换机,用第三方解决方案也可以,看自己实际情况选择。
采集系统(重庆市场监管局推出新型罚没管理办法,让你的单机处理更方便)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-11-15 20:10
采集系统一般是那种企业级的采集软件,这个一般收费在10万左右,而且还要安装在电脑上,还要有布线等等问题;如果一般家用采集的话,安装adsl上网卡,电脑与adsl接口数量越多越好。比如,要上10个站点的话,一般是20个接口就可以了。
老城区改造,偏远地区城市化,大数据采集,连接的网络,数据的存储学生大数据采集,公司客户大数据采集,
抓个大便,
建议某宝搜索看看。
要采集当地的法人就要用个人能够上网的,采集完数据需要上传到服务器或者做网站。
重庆刚刚过去的春节,本地的生产经营监管还在进行中。为应对春节前的打击窝点问题,重庆市场监管局推出新型罚没管理办法,在今年的315大案中涉及大量经营、监管人员处罚,其中部分款项作为奖励使用,实际远高于一般罚款额度。
如果只是处理统计数据,找个excel,扫描二维码都有,但是这么多用于保密或者经营还是比较麻烦。采集软件可以考虑用国内的乐观数据,在财务领域比较有名,但是经营数据基本上就只能靠自己根据电脑设置,电脑数据监管分析是一个巨大的问题,所以光靠自己监管是不够的。国外有好多类似的软件,但是对接电脑读取excel,麻烦点而且响应慢点,如果对接国内公网接口的话,慢则一年半载,速度也是有点慢。
国内其实也有数据采集软件,有保密性要求的话,比如公安局就用了我们的,需要配置对应监管人员识别软件的代码,这个要付钱,又贵又慢,软件还要拿到手。总而言之,如果没有危险级别的数据,还是找我们这些单机处理的好一点。 查看全部
采集系统(重庆市场监管局推出新型罚没管理办法,让你的单机处理更方便)
采集系统一般是那种企业级的采集软件,这个一般收费在10万左右,而且还要安装在电脑上,还要有布线等等问题;如果一般家用采集的话,安装adsl上网卡,电脑与adsl接口数量越多越好。比如,要上10个站点的话,一般是20个接口就可以了。
老城区改造,偏远地区城市化,大数据采集,连接的网络,数据的存储学生大数据采集,公司客户大数据采集,
抓个大便,
建议某宝搜索看看。
要采集当地的法人就要用个人能够上网的,采集完数据需要上传到服务器或者做网站。
重庆刚刚过去的春节,本地的生产经营监管还在进行中。为应对春节前的打击窝点问题,重庆市场监管局推出新型罚没管理办法,在今年的315大案中涉及大量经营、监管人员处罚,其中部分款项作为奖励使用,实际远高于一般罚款额度。
如果只是处理统计数据,找个excel,扫描二维码都有,但是这么多用于保密或者经营还是比较麻烦。采集软件可以考虑用国内的乐观数据,在财务领域比较有名,但是经营数据基本上就只能靠自己根据电脑设置,电脑数据监管分析是一个巨大的问题,所以光靠自己监管是不够的。国外有好多类似的软件,但是对接电脑读取excel,麻烦点而且响应慢点,如果对接国内公网接口的话,慢则一年半载,速度也是有点慢。
国内其实也有数据采集软件,有保密性要求的话,比如公安局就用了我们的,需要配置对应监管人员识别软件的代码,这个要付钱,又贵又慢,软件还要拿到手。总而言之,如果没有危险级别的数据,还是找我们这些单机处理的好一点。
采集系统(腾讯的社交app对吧,你了解多少?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-11-15 20:03
采集系统在常规广告监测中都是广告主自己选定需要监测的广告传播媒体,由媒体方自己的软件系统收集相关资料提交给腾讯平台进行单独计算,通过技术手段可以保证传播内容在不同媒体上的传播效果一致性,但是受制于缺乏统一的投放平台以及信用体系不同,这样的监测无法做到精准,这也造成现在外包在监测全国全媒体的效果变得更加困难。
广告机平台有qq机器人进行全平台监测,但是打开qq就只能看到广告机内容,对于收集的数据来说缺乏进一步分析,每一次查看广告机内容的时候,都需要重新扫码广告机让其看广告机所在机器人发送的链接,但是与每天看广告机数量相比通过监测广告机的数量就显得不合算了。
因为使用的是腾讯的社交app对吧(如qq、微信、陌陌等),其实在各个内容渠道的下载量都有监测,但是第三方软件并不采用他的监测,原因可能是每个渠道收集的数据都不同,个人观点而已。
因为腾讯只有一个bu:tencentsecuritycommunity
一、受限腾讯认为互联网上的问题传统上都可以通过数据管道更容易的解决,传统方式无法解决的问题需要应用新方式获取数据,
二、受众腾讯应该并不是说要对所有群体都进行监测。而是要进行用户画像和人群画像,这应该是一个很重要的工作。比如一个健身房在腾讯新闻上投放了广告,这些用户都是做健身训练的,但是大部分没有购买过健身房的产品,另外一个健身房在阿里巴巴上做了广告,这些用户并不是用户本身,而是他们的朋友。这样对于广告监测服务商来说,就需要对合作的用户进行画像和人群画像。
三、成本目前腾讯非常重视数据收集,甚至进行了让外包公司承担的“规模化压力”。在不同的渠道进行监测成本应该差异不大,但是将这些数据纳入自身体系,同时针对不同行业进行数据处理和分析,需要交给不同的公司,这就增加了额外的人力物力。以上三点是受限的原因。还有就是我个人觉得,监测行业的效果,很大程度上取决于执行方和投放的公司能力,如果这家公司只是想要以低成本进行短期投放的话,监测这块是可以进行投入的,但是如果想通过监测来做投放效果并形成精细化投放模式的话,我觉得效果如何还不是最重要的,重要的是投放到用户的情况,能不能让用户使用到这个产品,产生二次使用的机会,甚至回头客增加了。这是一个很具体的问题,我觉得目前这行的现状是不成熟的,没有一套成熟的标准。
四、如果无效果,能不能对他们进行罚款?或者说只是说可以进行批评?腾讯在看广告有关的媒体的时候, 查看全部
采集系统(腾讯的社交app对吧,你了解多少?(组图))
采集系统在常规广告监测中都是广告主自己选定需要监测的广告传播媒体,由媒体方自己的软件系统收集相关资料提交给腾讯平台进行单独计算,通过技术手段可以保证传播内容在不同媒体上的传播效果一致性,但是受制于缺乏统一的投放平台以及信用体系不同,这样的监测无法做到精准,这也造成现在外包在监测全国全媒体的效果变得更加困难。
广告机平台有qq机器人进行全平台监测,但是打开qq就只能看到广告机内容,对于收集的数据来说缺乏进一步分析,每一次查看广告机内容的时候,都需要重新扫码广告机让其看广告机所在机器人发送的链接,但是与每天看广告机数量相比通过监测广告机的数量就显得不合算了。
因为使用的是腾讯的社交app对吧(如qq、微信、陌陌等),其实在各个内容渠道的下载量都有监测,但是第三方软件并不采用他的监测,原因可能是每个渠道收集的数据都不同,个人观点而已。
因为腾讯只有一个bu:tencentsecuritycommunity
一、受限腾讯认为互联网上的问题传统上都可以通过数据管道更容易的解决,传统方式无法解决的问题需要应用新方式获取数据,
二、受众腾讯应该并不是说要对所有群体都进行监测。而是要进行用户画像和人群画像,这应该是一个很重要的工作。比如一个健身房在腾讯新闻上投放了广告,这些用户都是做健身训练的,但是大部分没有购买过健身房的产品,另外一个健身房在阿里巴巴上做了广告,这些用户并不是用户本身,而是他们的朋友。这样对于广告监测服务商来说,就需要对合作的用户进行画像和人群画像。
三、成本目前腾讯非常重视数据收集,甚至进行了让外包公司承担的“规模化压力”。在不同的渠道进行监测成本应该差异不大,但是将这些数据纳入自身体系,同时针对不同行业进行数据处理和分析,需要交给不同的公司,这就增加了额外的人力物力。以上三点是受限的原因。还有就是我个人觉得,监测行业的效果,很大程度上取决于执行方和投放的公司能力,如果这家公司只是想要以低成本进行短期投放的话,监测这块是可以进行投入的,但是如果想通过监测来做投放效果并形成精细化投放模式的话,我觉得效果如何还不是最重要的,重要的是投放到用户的情况,能不能让用户使用到这个产品,产生二次使用的机会,甚至回头客增加了。这是一个很具体的问题,我觉得目前这行的现状是不成熟的,没有一套成熟的标准。
四、如果无效果,能不能对他们进行罚款?或者说只是说可以进行批评?腾讯在看广告有关的媒体的时候,
采集系统(统计数据采集系统分为哪几类?不同维度进行区分)
采集交流 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-10-28 11:02
采集系统是统计数据的最为核心的问题。因此如何能够拿到并重塑用户数据成为最为关键的问题。根据pgc做数据采集系统需要多大的采集能力,来建设采集数据库,且对数据的可视化、可控制、记录更新以及关联性分析都有一定的技术门槛。1,采集系统分为哪几类?根据成本和需求区分,可以把采集系统按照采集接口和分布型(tp)、远程分布型(pps)以及远程分布型(eps)不同的维度进行区分,下面将逐一进行介绍。
2,tp采集系统:tp是把日志数据,都自己部署到自己云端,在云端有采集系统的硬件上进行分析处理以及数据采集。tp采集系统一般是服务器+采集服务器+管理服务器+数据传输服务器。3,pps采集系统:pps采集系统在不同的网站或者app中采集用户行为日志,在第三方统计机构也会采集第三方的app应用的数据,对此采集系统有较大的问题,一是云端的内容数据受限,二是在数据库中存储的日志内容不是原始日志的实时变化,所以需要对原始数据进行变更和分析。
4,远程分布采集系统:近两年开始兴起,根据业务拓展需求做延伸,把采集的接口拓展到到远程客户端。如何规划更为有效的远程分布采集系统成为最大的难题。5,远程分布式采集系统:无论是tp、pps还是远程分布式采集系统,目前的环境下都没法在服务器或者云端部署,成本过高。一般需要在企业内部部署一个服务器来运行。6,es服务器采集系统:es服务器采集系统按照服务器、数据库、日志数据库进行区分,采集技术为shell+采集数据库。
7,随着国内市场的成熟,也有越来越多的企业愿意选择做paas化的云服务,如vcloud、七牛等厂商。但是在paas服务推行上,中小企业和跨地域业务平台技术人员素质差距较大,也正是需要这样的服务支撑才能提升数据准确性,采集体验和成本并控。 查看全部
采集系统(统计数据采集系统分为哪几类?不同维度进行区分)
采集系统是统计数据的最为核心的问题。因此如何能够拿到并重塑用户数据成为最为关键的问题。根据pgc做数据采集系统需要多大的采集能力,来建设采集数据库,且对数据的可视化、可控制、记录更新以及关联性分析都有一定的技术门槛。1,采集系统分为哪几类?根据成本和需求区分,可以把采集系统按照采集接口和分布型(tp)、远程分布型(pps)以及远程分布型(eps)不同的维度进行区分,下面将逐一进行介绍。
2,tp采集系统:tp是把日志数据,都自己部署到自己云端,在云端有采集系统的硬件上进行分析处理以及数据采集。tp采集系统一般是服务器+采集服务器+管理服务器+数据传输服务器。3,pps采集系统:pps采集系统在不同的网站或者app中采集用户行为日志,在第三方统计机构也会采集第三方的app应用的数据,对此采集系统有较大的问题,一是云端的内容数据受限,二是在数据库中存储的日志内容不是原始日志的实时变化,所以需要对原始数据进行变更和分析。
4,远程分布采集系统:近两年开始兴起,根据业务拓展需求做延伸,把采集的接口拓展到到远程客户端。如何规划更为有效的远程分布采集系统成为最大的难题。5,远程分布式采集系统:无论是tp、pps还是远程分布式采集系统,目前的环境下都没法在服务器或者云端部署,成本过高。一般需要在企业内部部署一个服务器来运行。6,es服务器采集系统:es服务器采集系统按照服务器、数据库、日志数据库进行区分,采集技术为shell+采集数据库。
7,随着国内市场的成熟,也有越来越多的企业愿意选择做paas化的云服务,如vcloud、七牛等厂商。但是在paas服务推行上,中小企业和跨地域业务平台技术人员素质差距较大,也正是需要这样的服务支撑才能提升数据准确性,采集体验和成本并控。
采集系统(采集系统使用ce12个月了,线上问题全部完美解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-10 02:04
采集系统使用ce12个多月了,经过几次改版,线上首页显示效果逐渐改进,越来越漂亮!技术团队也是越来越强大,更注重服务质量,线上问题全部完美解决!一次换机,需要请求ce12服务器,系统速度很快,而且降低了服务器带宽占用,
最主要是改善服务质量,全站用阿里云的iis5虚拟主机,比在本地采集要快上很多,
他家ce根据用户是否需要裁剪ip地址,导致用户体验有所下降,体验一个月后就基本上正常了。
ce。
新增增加的模块,好像都是可以集成到原来的api中去。如果需要在服务器端进行集成可以考虑在服务器上实现类似flash一样的功能。这样,前端集成可以在本地完成。然后,裁减ip地址,可以在本地集成。———这些就类似于集成的目的一样。用户体验变差。用户体验未变差,变差的就是体验方式。
这对于一些h5页面来说很常见,一是避免浪费cdn资源。二是用户使用h5需要使用浏览器地址栏。同时要控制不能用小地址来做搜索也是个难题。所以,如果要保证浏览器地址栏的可用性,选择ce是个不错的选择。个人认为,在一些核心场景下(如公司网站,本地的服务器)还是使用ce较好,毕竟h5互联网时代,重要的是流量,而非网站体验。 查看全部
采集系统(采集系统使用ce12个月了,线上问题全部完美解决)
采集系统使用ce12个多月了,经过几次改版,线上首页显示效果逐渐改进,越来越漂亮!技术团队也是越来越强大,更注重服务质量,线上问题全部完美解决!一次换机,需要请求ce12服务器,系统速度很快,而且降低了服务器带宽占用,
最主要是改善服务质量,全站用阿里云的iis5虚拟主机,比在本地采集要快上很多,
他家ce根据用户是否需要裁剪ip地址,导致用户体验有所下降,体验一个月后就基本上正常了。
ce。
新增增加的模块,好像都是可以集成到原来的api中去。如果需要在服务器端进行集成可以考虑在服务器上实现类似flash一样的功能。这样,前端集成可以在本地完成。然后,裁减ip地址,可以在本地集成。———这些就类似于集成的目的一样。用户体验变差。用户体验未变差,变差的就是体验方式。
这对于一些h5页面来说很常见,一是避免浪费cdn资源。二是用户使用h5需要使用浏览器地址栏。同时要控制不能用小地址来做搜索也是个难题。所以,如果要保证浏览器地址栏的可用性,选择ce是个不错的选择。个人认为,在一些核心场景下(如公司网站,本地的服务器)还是使用ce较好,毕竟h5互联网时代,重要的是流量,而非网站体验。
采集系统(批量采集数据到服务器的基本功能有哪些?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-02-05 04:04
采集系统其实就是将手机或电脑里的静态图片、视频等网络数据进行采集分析并保存。现在的手机通常都是手机app的形式。当然,大部分的传统pc采集也包括了网页采集。像对于收集与网站合作分成的形式,我认为还是网站方主导,采集系统就应该是中立的而且是应该保障网站的正常运营。至于监控对象所在地应该是谁,这个就要看具体情况。
不过对于网站监控系统而言,只要做到采集系统的基本功能就行了。现在好多网站对于app应用端,开发了批量采集数据到服务器的功能。这个是系统自动生成的。(个人建议)。
一般采集系统是指以收集网站数据为主的网站,把内容放到采集系统,等待收集数据系统将采集到的数据保存到数据库,然后使用网站api调用系统数据库获取数据。由于大多数网站都是有seo相关的功能的,这样就可以把查询引擎进行数据抓取的功能,没有进行放置到采集系统。一般而言,可以采集单个网站api数据。当然一般是采集单个网站里面的数据就可以。
采集系统一般来说分为2类:第一类以收集静态资源为主;第二类以收集seo有关数据为主,包括优化排名相关数据等,数据是有针对性的。举个例子,你采集上面的店的大图,这样就可以对搜索这个关键词出现的所有图片进行统计。而采集视频,对,没错,你可以采集下载的视频等等。 查看全部
采集系统(批量采集数据到服务器的基本功能有哪些?-八维教育)
采集系统其实就是将手机或电脑里的静态图片、视频等网络数据进行采集分析并保存。现在的手机通常都是手机app的形式。当然,大部分的传统pc采集也包括了网页采集。像对于收集与网站合作分成的形式,我认为还是网站方主导,采集系统就应该是中立的而且是应该保障网站的正常运营。至于监控对象所在地应该是谁,这个就要看具体情况。
不过对于网站监控系统而言,只要做到采集系统的基本功能就行了。现在好多网站对于app应用端,开发了批量采集数据到服务器的功能。这个是系统自动生成的。(个人建议)。
一般采集系统是指以收集网站数据为主的网站,把内容放到采集系统,等待收集数据系统将采集到的数据保存到数据库,然后使用网站api调用系统数据库获取数据。由于大多数网站都是有seo相关的功能的,这样就可以把查询引擎进行数据抓取的功能,没有进行放置到采集系统。一般而言,可以采集单个网站api数据。当然一般是采集单个网站里面的数据就可以。
采集系统一般来说分为2类:第一类以收集静态资源为主;第二类以收集seo有关数据为主,包括优化排名相关数据等,数据是有针对性的。举个例子,你采集上面的店的大图,这样就可以对搜索这个关键词出现的所有图片进行统计。而采集视频,对,没错,你可以采集下载的视频等等。
采集系统(内置采集模块的应用场景有几个缺点呢??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-02-02 16:06
采集系统分为内置模式和外置模式,相应的采集模块也分为公有云采集平台以及私有云采集平台。内置模式即采集时可以直接对网络端的服务器进行采集,免去了每次请求网络的速度,带宽等问题,内置模式主要适用于视频监控、商场卖场等场景,因为采集到的视频必须要反馈到服务器上才能进行下载、处理等。由于内置采集平台是采集服务器直接下载,因此对于物理文件的读取速度要求不高,同时因为是直接将图像信息存放在服务器上的,因此对内存要求较低,同时用户还可以对采集到的图像进行混流处理,使得图像变成视频的格式。
所以内置采集平台的应用场景主要为视频监控,人流量的商场卖场等场景,例如图像采集,场景特效。对比外置采集模块即采集时必须将服务器或交换机作为采集端,这样有几个缺点:1.耗时(固定网络带宽)。2.内置采集模块需要读取服务器文件,但是许多业务都要求不同的物理文件格式(例如:flv,mp4,wmv,h.264等)。
因此内置采集模块的适用场景主要为视频监控、人流量大的商场卖场等场景。外置采集模块则不仅可以连接到服务器端,同时还可以连接到多台交换机,这样的好处在于,将外置采集模块直接连接到终端一台物理文件读取端进行读取和处理,不需要对整个网络进行检测,因此外置采集模块的应用场景主要为智能穿戴设备、物联网。 查看全部
采集系统(内置采集模块的应用场景有几个缺点呢??)
采集系统分为内置模式和外置模式,相应的采集模块也分为公有云采集平台以及私有云采集平台。内置模式即采集时可以直接对网络端的服务器进行采集,免去了每次请求网络的速度,带宽等问题,内置模式主要适用于视频监控、商场卖场等场景,因为采集到的视频必须要反馈到服务器上才能进行下载、处理等。由于内置采集平台是采集服务器直接下载,因此对于物理文件的读取速度要求不高,同时因为是直接将图像信息存放在服务器上的,因此对内存要求较低,同时用户还可以对采集到的图像进行混流处理,使得图像变成视频的格式。
所以内置采集平台的应用场景主要为视频监控,人流量的商场卖场等场景,例如图像采集,场景特效。对比外置采集模块即采集时必须将服务器或交换机作为采集端,这样有几个缺点:1.耗时(固定网络带宽)。2.内置采集模块需要读取服务器文件,但是许多业务都要求不同的物理文件格式(例如:flv,mp4,wmv,h.264等)。
因此内置采集模块的适用场景主要为视频监控、人流量大的商场卖场等场景。外置采集模块则不仅可以连接到服务器端,同时还可以连接到多台交换机,这样的好处在于,将外置采集模块直接连接到终端一台物理文件读取端进行读取和处理,不需要对整个网络进行检测,因此外置采集模块的应用场景主要为智能穿戴设备、物联网。
采集系统(网页数据采集系统全新升级版采集头采集网站(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-02 12:02
采集系统的优势1。采集系统全量采集根据区域划分采集点,采集的数据实时保存至cvs/svn/tfs或mongodb等系统;2。采集操作简单采集过程中机器只需要设置对应的采集节点即可;3。多客户端可共享节点各采集客户端基于互联网分布采集,如pc、手机等;4。可搭建全量代理服务器自动化清洗采集点的数据:成本低5。
数据私有化:采集权限自定义对每个客户端只能采集一次,各客户端数据仅保存在本地客户端6。采集流程透明采集流程不加密,企业可随时随地跟踪、监控采集结果7。精准采集自动判断数据是否重复不仅仅减少重复操作还可以加大数据的采集。
网页数据采集系统全新升级版采集头采集网站根据客户需求自动匹配最匹配的开发接口
我厂的数据系统是用的极限云的r+limit+api来完成seo的
是的,采集完成后需要对url进行拼接,并且将返回的错误页进行标记,并且要保存到mongodb等系统中。
我觉得像传统的网站采集软件都是全量采集,但是全量采集有一个问题,每个站点都要生成对应的采集链接,时间不允许,另外全量采集由于以往url的限制,检索性能也不是很高,不是说很容易满。如果硬是要做到全量采集,还要自己写大量的js或者php,这个不太合适。像这样的做法也可以考虑在github找一个hexa采集云,用前端页面进行全量采集,前端加载高速。 查看全部
采集系统(网页数据采集系统全新升级版采集头采集网站(图))
采集系统的优势1。采集系统全量采集根据区域划分采集点,采集的数据实时保存至cvs/svn/tfs或mongodb等系统;2。采集操作简单采集过程中机器只需要设置对应的采集节点即可;3。多客户端可共享节点各采集客户端基于互联网分布采集,如pc、手机等;4。可搭建全量代理服务器自动化清洗采集点的数据:成本低5。
数据私有化:采集权限自定义对每个客户端只能采集一次,各客户端数据仅保存在本地客户端6。采集流程透明采集流程不加密,企业可随时随地跟踪、监控采集结果7。精准采集自动判断数据是否重复不仅仅减少重复操作还可以加大数据的采集。
网页数据采集系统全新升级版采集头采集网站根据客户需求自动匹配最匹配的开发接口
我厂的数据系统是用的极限云的r+limit+api来完成seo的
是的,采集完成后需要对url进行拼接,并且将返回的错误页进行标记,并且要保存到mongodb等系统中。
我觉得像传统的网站采集软件都是全量采集,但是全量采集有一个问题,每个站点都要生成对应的采集链接,时间不允许,另外全量采集由于以往url的限制,检索性能也不是很高,不是说很容易满。如果硬是要做到全量采集,还要自己写大量的js或者php,这个不太合适。像这样的做法也可以考虑在github找一个hexa采集云,用前端页面进行全量采集,前端加载高速。
采集系统(采集系统之安全信息采集设备的三大要求要求和要求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-01-24 08:03
采集系统之安全信息采集设备可分为数据采集系统和信息中心系统,信息中心系统包括监控系统和系统监控中心,数据采集系统又可分为监测系统和非监测系统,数据采集系统通常包括网络自动传输、数据收集和存储设备。采集系统的安全性和快速反应机制,避免采集的信息作弊、破坏或泄露,使采集到的信息能够重复利用,利用率增加,这些是高能采集设备的最重要的作用。
采集系统的安全性和快速反应机制,避免采集的信息作弊、破坏或泄露,使采集到的信息能够重复利用,利用率增加,这些是高能采集设备的最重要的作用。采集系统与安全监控系统连接要求采集系统与安全监控系统需要为远程监控信息传输媒介,根据信息安全技术在多层面和多位置对接的要求,整合电源、io、环境参数、安全、数据储存、系统监控、远程控制等方面的信息。
1、点对点通信有条件的企业应实现点对点通信,方式包括点对点局域网通信、vhf/vhf-ble等网络通信。点对点点对点网络连接或模拟接口连接。系统监控的三大要求要求采集系统和安全监控系统必须具备强大的电源供应能力、网络能力、安全防护等基础设施,才能满足信息传输的要求。电源和电力的配置必须满足设备安装和运行时对电源的需求。
为了设备通信所要求的网络能力和网络通信的可靠性,系统监控设备以及必须有强大的电源供应能力。点对点宽带通信系统,对连接的技术要求不是很高,因为设备之间无需建立链路,无需进行端口网桥布线。但是对于整个远程监控系统是一个很大的挑战,最好有多块设备同时接入远程监控系统。
2、统一接口使用网线作为网络接口,在使用hub、路由器、终端或交换机连接将相应的网络接口供电给系统设备,需要选择带有直流电源和备用接口的电力公司,这样才能保证远程监控系统能够正常的工作。
3、安全性信息收集设备与采集设备要安装在统一的系统监控中心,并设置相应的特征信息。同时将采集信息集中收集,存放于特定的区域,仅作为区域外信息传输的接入点。并制定相应的信息收集策略。
4、保密性采集设备和安全监控设备都需要具备一定的保密性能,确保收集到的信息能够重复利用,按照规范和要求对数据进行加密。相对于传统的数据库收集方式,采集设备和安全监控设备对系统监控数据进行加密,更容易采集到对个人或组织有价值的数据。 查看全部
采集系统(采集系统之安全信息采集设备的三大要求要求和要求)
采集系统之安全信息采集设备可分为数据采集系统和信息中心系统,信息中心系统包括监控系统和系统监控中心,数据采集系统又可分为监测系统和非监测系统,数据采集系统通常包括网络自动传输、数据收集和存储设备。采集系统的安全性和快速反应机制,避免采集的信息作弊、破坏或泄露,使采集到的信息能够重复利用,利用率增加,这些是高能采集设备的最重要的作用。
采集系统的安全性和快速反应机制,避免采集的信息作弊、破坏或泄露,使采集到的信息能够重复利用,利用率增加,这些是高能采集设备的最重要的作用。采集系统与安全监控系统连接要求采集系统与安全监控系统需要为远程监控信息传输媒介,根据信息安全技术在多层面和多位置对接的要求,整合电源、io、环境参数、安全、数据储存、系统监控、远程控制等方面的信息。
1、点对点通信有条件的企业应实现点对点通信,方式包括点对点局域网通信、vhf/vhf-ble等网络通信。点对点点对点网络连接或模拟接口连接。系统监控的三大要求要求采集系统和安全监控系统必须具备强大的电源供应能力、网络能力、安全防护等基础设施,才能满足信息传输的要求。电源和电力的配置必须满足设备安装和运行时对电源的需求。
为了设备通信所要求的网络能力和网络通信的可靠性,系统监控设备以及必须有强大的电源供应能力。点对点宽带通信系统,对连接的技术要求不是很高,因为设备之间无需建立链路,无需进行端口网桥布线。但是对于整个远程监控系统是一个很大的挑战,最好有多块设备同时接入远程监控系统。
2、统一接口使用网线作为网络接口,在使用hub、路由器、终端或交换机连接将相应的网络接口供电给系统设备,需要选择带有直流电源和备用接口的电力公司,这样才能保证远程监控系统能够正常的工作。
3、安全性信息收集设备与采集设备要安装在统一的系统监控中心,并设置相应的特征信息。同时将采集信息集中收集,存放于特定的区域,仅作为区域外信息传输的接入点。并制定相应的信息收集策略。
4、保密性采集设备和安全监控设备都需要具备一定的保密性能,确保收集到的信息能够重复利用,按照规范和要求对数据进行加密。相对于传统的数据库收集方式,采集设备和安全监控设备对系统监控数据进行加密,更容易采集到对个人或组织有价值的数据。
采集系统(学优优校园综合系统-PCP人像采集系统功能(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-01-15 06:05
Perfect()网站以软件下载为基础,修订版网站扩展了功能板块,以解决用户在使用软件过程中遇到的一切问题。网站新增“软件百科”、“智能提示”等频道,可以更好地为用户的软件使用周期提供更专业的服务。
PCP人像采集系统又称学友优人像采集系统,为用户提供单人采集、多人采集、照片处理、打印、保存和其他图片图像处理功能,PCP人像采集系统是在身份证人像采集系统的基础上推出的,可用于采集、学籍、教师等保存和打印操作相片。
PCP 肖像采集系统功能
(1)界面简洁易操作;
(2) 支持直接从相机、照相机和扫描仪读取图像;
(3)支持多种照片类型;包括1寸、2寸、大2寸、3寸、学生身份照片、家庭照片、身份证照片、驾照照片等常见的人像照片类型,也可以手动设置具体尺寸;
(4)支持图像裁剪、色调调整、亮度/对比度调整、曲线调整、自动背景清理等专业图像处理,并可设置初始参数,打开图像时自动应用相应的图像处理;
(5)支持多人排队拍照采集,让照片的采集、处理、保存、打印一步完成;
(6)保存的图片无需数据库即可索引,查询方便快捷;
(7)支持照片和数据的批量导入导出,方便对接第三方系统;
(8) 完全免费自动升级,始终处于最佳状态;
(9)与“学友友校园综合系统”全面对接,可与校园系统直接下载或上传更新学生注册照片和教师照片。
支持佳能1D Mark III、1Ds Mark III、5D Mark II、40D、50D、450D、500D、1D Mark IV、7D、550D、60D、600D、1100D等相机连拍,也支持符合标准的数码相机吐温工业标准或相机的照片读取。
PCP 肖像采集系统功能
软件的操作界面非常简洁清新
支持用户将主流格式的图片添加到软件中进行编辑操作
支持图片批量导出
支持图片批量导出目录自定义设置
支持用户在线操作软件
该软件不仅可以帮助用户自动操作照片
PCP纵向采集系统安装
1.到本站下载安装PCP画像采集系统,勾选我同意此协议,点击下一步继续安装
2.点击浏览选择安装位置
3.点击下一步继续安装
4.等一下
5. 最后点击关闭完成安装。
“技巧与技巧”栏目是全网软件使用的技巧或软件使用过程中各种问题的解答文章。专栏成立之初,小编欢迎各位软件大神朋友积极投稿。该平台分享每个人的独特技能。
本站文章素材来源于网络,文章作者姓名大部分丢失。为了更方便用户阅读和使用,根据需要进行了重新排版和部分改编。本站收录文章仅以帮助用户解决实际问题为目的。如有版权问题,请联系编辑修改或删除。谢谢您的合作。 查看全部
采集系统(学优优校园综合系统-PCP人像采集系统功能(二))
Perfect()网站以软件下载为基础,修订版网站扩展了功能板块,以解决用户在使用软件过程中遇到的一切问题。网站新增“软件百科”、“智能提示”等频道,可以更好地为用户的软件使用周期提供更专业的服务。
PCP人像采集系统又称学友优人像采集系统,为用户提供单人采集、多人采集、照片处理、打印、保存和其他图片图像处理功能,PCP人像采集系统是在身份证人像采集系统的基础上推出的,可用于采集、学籍、教师等保存和打印操作相片。
PCP 肖像采集系统功能
(1)界面简洁易操作;
(2) 支持直接从相机、照相机和扫描仪读取图像;
(3)支持多种照片类型;包括1寸、2寸、大2寸、3寸、学生身份照片、家庭照片、身份证照片、驾照照片等常见的人像照片类型,也可以手动设置具体尺寸;
(4)支持图像裁剪、色调调整、亮度/对比度调整、曲线调整、自动背景清理等专业图像处理,并可设置初始参数,打开图像时自动应用相应的图像处理;
(5)支持多人排队拍照采集,让照片的采集、处理、保存、打印一步完成;
(6)保存的图片无需数据库即可索引,查询方便快捷;
(7)支持照片和数据的批量导入导出,方便对接第三方系统;
(8) 完全免费自动升级,始终处于最佳状态;
(9)与“学友友校园综合系统”全面对接,可与校园系统直接下载或上传更新学生注册照片和教师照片。
支持佳能1D Mark III、1Ds Mark III、5D Mark II、40D、50D、450D、500D、1D Mark IV、7D、550D、60D、600D、1100D等相机连拍,也支持符合标准的数码相机吐温工业标准或相机的照片读取。
PCP 肖像采集系统功能
软件的操作界面非常简洁清新
支持用户将主流格式的图片添加到软件中进行编辑操作
支持图片批量导出
支持图片批量导出目录自定义设置
支持用户在线操作软件
该软件不仅可以帮助用户自动操作照片
PCP纵向采集系统安装
1.到本站下载安装PCP画像采集系统,勾选我同意此协议,点击下一步继续安装
2.点击浏览选择安装位置
3.点击下一步继续安装
4.等一下
5. 最后点击关闭完成安装。
“技巧与技巧”栏目是全网软件使用的技巧或软件使用过程中各种问题的解答文章。专栏成立之初,小编欢迎各位软件大神朋友积极投稿。该平台分享每个人的独特技能。
本站文章素材来源于网络,文章作者姓名大部分丢失。为了更方便用户阅读和使用,根据需要进行了重新排版和部分改编。本站收录文章仅以帮助用户解决实际问题为目的。如有版权问题,请联系编辑修改或删除。谢谢您的合作。
采集系统(广泛应用于行业门户网站,竞争情报系统,知识管理系统,网站内容系统 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-01-10 18:18
)
采集管理可以帮助企业在信息采集和资源整合方面节省大量的人力和金钱。广泛应用于行业门户网站、竞争情报系统、知识管理系统、网站内容系统、垂直搜索、科研等领域。
1、采集项目管理
点击“添加采集项目”进入新建的采集项目;
采集第一步参数说明如下:
采集项目名称就是我们要采集的项目。比如我们的采集是时事新闻,则命名为时事新闻;
如果模型设置采集是文章模型,选择文章,如果设置了图片信息,选择图片模型;
文档存储栏是指采集的信息应该属于哪一栏。我们必须在采集之前建立这个列来选择归属列;
文档归属主题 选择文档所属的主题
目标站点名称为采集网站的信息,如腾讯新闻;
采集目标网址为采集的网址;
编码方式根据我们要采用的网站编码设置。如果编码不正确,可能会导致乱码;
设置属性是指对采集的内容设置某项或某项属性,采集也可以在手机上显示;
采集选项:保存图片到本地后勾选采集如果返回的文章中有图片,图片会自动保存到本地服务器;勾选后立即生成 HTML 采集 返回的广告会自动生成 HTML static;检查是否跳过现有主表中的同名记录,现有信息文件标题不会重复,当有同名文件时,不会是采集;reverse 采集 check 从最后一页的最后一个条目中选择并前进;勾选首页图片自动设置后,采集中的图片文章会自动设置为第一张图片;暂停设置,例如每 采集100 条消息停留 2 秒。
设置完成后点击“下一步”进入第二步打标设置;
列表设置是 文章 列表的开始和结束标记;您可以在右侧的代码中找到它;
测试链接是文章标题的链接开始和结束标签;
标记好,可以测试列表和测试链接,右侧代码测试成功会自动获取源代码;
点击“下一步”进入采集第三步设置。
在右侧,我们可以选择显示代码窗口。获取代码时,方便直接查看采集的代码源,或者关闭代码窗口;点击“访问”访问内容页面为采集,然后查看其源代码。
比如转向链接、来源、更新时间等。如果需要设置,可以根据代码源设置标签,也可以指定。
简介 如果不需要,请选择不设置。你需要标记它。另外,在源码中寻找唯一标记,添加“拦截设置”,可以在右侧的测试结果中查看截图结果;
具体内容设置截取文章的内容的开始和结束标签,通过HTML标签过滤要过滤的项目。选择采集后,过滤这些项目
最后保存设置,完成采集项目设置。
单击确定返回到采集管理。
返回采集项目管理,可以查看我们添加的所有采集项;可以编辑、删除、测试、采集、复制采集项等操作。
单击 Test for Admin Operations 以测试 采集 项是否通过。
单击“管理操作”下的“采集”链接,开始采集信息操作。
在采集之后,我们可以查看采集历史中采集的所有信息内容;
同时,在内容管理-文章系统对应的栏目下,还可以查看采集的存储信息;在没有过滤和完善的情况下,我们需要删除文章管理中的采集记录和历史记录中的采集记录,然后重新设置采集规则和单击 采集。
过滤规则的意思是我们要将采集网站中的一些内容替换为其他内容,比如替换后的文本
注意:采集第三步,设置标签,可以在模型管理-字段管理采集中选择允许启用哪些字段;
2、过滤规则管理
添加过滤规则和管理过滤规则。添加过滤器名称,替换方法,查找内容,选择是否启用。
添加确认操作后。返回过滤规则管理,可以编辑添加的过滤规则。
3、采集历史
管理采集历史。支持快速搜索历史记录和批量删除历史记录。
查看全部
采集系统(广泛应用于行业门户网站,竞争情报系统,知识管理系统,网站内容系统
)
采集管理可以帮助企业在信息采集和资源整合方面节省大量的人力和金钱。广泛应用于行业门户网站、竞争情报系统、知识管理系统、网站内容系统、垂直搜索、科研等领域。
1、采集项目管理
点击“添加采集项目”进入新建的采集项目;
采集第一步参数说明如下:
采集项目名称就是我们要采集的项目。比如我们的采集是时事新闻,则命名为时事新闻;
如果模型设置采集是文章模型,选择文章,如果设置了图片信息,选择图片模型;
文档存储栏是指采集的信息应该属于哪一栏。我们必须在采集之前建立这个列来选择归属列;
文档归属主题 选择文档所属的主题
目标站点名称为采集网站的信息,如腾讯新闻;
采集目标网址为采集的网址;
编码方式根据我们要采用的网站编码设置。如果编码不正确,可能会导致乱码;
设置属性是指对采集的内容设置某项或某项属性,采集也可以在手机上显示;
采集选项:保存图片到本地后勾选采集如果返回的文章中有图片,图片会自动保存到本地服务器;勾选后立即生成 HTML 采集 返回的广告会自动生成 HTML static;检查是否跳过现有主表中的同名记录,现有信息文件标题不会重复,当有同名文件时,不会是采集;reverse 采集 check 从最后一页的最后一个条目中选择并前进;勾选首页图片自动设置后,采集中的图片文章会自动设置为第一张图片;暂停设置,例如每 采集100 条消息停留 2 秒。
设置完成后点击“下一步”进入第二步打标设置;
列表设置是 文章 列表的开始和结束标记;您可以在右侧的代码中找到它;
测试链接是文章标题的链接开始和结束标签;
标记好,可以测试列表和测试链接,右侧代码测试成功会自动获取源代码;
点击“下一步”进入采集第三步设置。
在右侧,我们可以选择显示代码窗口。获取代码时,方便直接查看采集的代码源,或者关闭代码窗口;点击“访问”访问内容页面为采集,然后查看其源代码。
比如转向链接、来源、更新时间等。如果需要设置,可以根据代码源设置标签,也可以指定。
简介 如果不需要,请选择不设置。你需要标记它。另外,在源码中寻找唯一标记,添加“拦截设置”,可以在右侧的测试结果中查看截图结果;
具体内容设置截取文章的内容的开始和结束标签,通过HTML标签过滤要过滤的项目。选择采集后,过滤这些项目
最后保存设置,完成采集项目设置。
单击确定返回到采集管理。
返回采集项目管理,可以查看我们添加的所有采集项;可以编辑、删除、测试、采集、复制采集项等操作。
单击 Test for Admin Operations 以测试 采集 项是否通过。
单击“管理操作”下的“采集”链接,开始采集信息操作。
在采集之后,我们可以查看采集历史中采集的所有信息内容;
同时,在内容管理-文章系统对应的栏目下,还可以查看采集的存储信息;在没有过滤和完善的情况下,我们需要删除文章管理中的采集记录和历史记录中的采集记录,然后重新设置采集规则和单击 采集。
过滤规则的意思是我们要将采集网站中的一些内容替换为其他内容,比如替换后的文本
注意:采集第三步,设置标签,可以在模型管理-字段管理采集中选择允许启用哪些字段;
2、过滤规则管理
添加过滤规则和管理过滤规则。添加过滤器名称,替换方法,查找内容,选择是否启用。
添加确认操作后。返回过滤规则管理,可以编辑添加的过滤规则。
3、采集历史
管理采集历史。支持快速搜索历史记录和批量删除历史记录。
采集系统(小编总结了几种常见的数据采集技术(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-09 09:06
小编总结了几种常用数据采集技术供大家参考,主要分为以下几类:一、CS软件数据采集技术。C/S架构软件是比较老的架构,能采集这种软件数据的产品比较少。常见的一种是博威小邦软件机器人,不需要软件厂商的配合,基于“所见即所得”方法界面上的数据采集输出结果为结构化数据库或 Excel 表。如果只需要业务数据,或者厂家倒闭,数据库分析困难,这个工具可以采集数据,尤其是详情页数据的采集功能更有特色。值得一提的是,该产品的使用门槛很低,没有IT背景的商科学生也可以使用,大大扩大了使用人数。二、网络数据采集API。通过网络爬虫和平台提供的一些网站公共API(如推特和新浪微博API)从网站获取数据。这样就可以从网页中提取出非结构化数据和半结构化数据的网页数据。互联网网页大数据采集及处理的整体流程由四个主要模块组成:网络爬虫(Spider)、数据处理(DataProcess)、抓取URL队列(URLQueue)和数据。三、有两种数据库方式每个系统都有自己的数据库,方便使用同类型的数据库:1)如果两个数据库在同一个服务器上,只要用户名设置没有问题,就可以直接互相访问。从之后,您可以带上数据库名称和表的架构所有者。select*fromDATABASE1.dbo.table12) 如果两个系统的数据库不在同一台服务器上,建议使用连接服务器的形式,或者使用openset和opendatasource,需要配置外围服务器才能访问数据库。不同类型数据库之间的连接比较麻烦,需要很多设置才能生效。开放数据库方式需要协调各个软件厂商的开放数据库,难度很大。如果一个平台需要同时连接多个软件厂商的数据库,实时获取数据, 查看全部
采集系统(小编总结了几种常见的数据采集技术(一))
小编总结了几种常用数据采集技术供大家参考,主要分为以下几类:一、CS软件数据采集技术。C/S架构软件是比较老的架构,能采集这种软件数据的产品比较少。常见的一种是博威小邦软件机器人,不需要软件厂商的配合,基于“所见即所得”方法界面上的数据采集输出结果为结构化数据库或 Excel 表。如果只需要业务数据,或者厂家倒闭,数据库分析困难,这个工具可以采集数据,尤其是详情页数据的采集功能更有特色。值得一提的是,该产品的使用门槛很低,没有IT背景的商科学生也可以使用,大大扩大了使用人数。二、网络数据采集API。通过网络爬虫和平台提供的一些网站公共API(如推特和新浪微博API)从网站获取数据。这样就可以从网页中提取出非结构化数据和半结构化数据的网页数据。互联网网页大数据采集及处理的整体流程由四个主要模块组成:网络爬虫(Spider)、数据处理(DataProcess)、抓取URL队列(URLQueue)和数据。三、有两种数据库方式每个系统都有自己的数据库,方便使用同类型的数据库:1)如果两个数据库在同一个服务器上,只要用户名设置没有问题,就可以直接互相访问。从之后,您可以带上数据库名称和表的架构所有者。select*fromDATABASE1.dbo.table12) 如果两个系统的数据库不在同一台服务器上,建议使用连接服务器的形式,或者使用openset和opendatasource,需要配置外围服务器才能访问数据库。不同类型数据库之间的连接比较麻烦,需要很多设置才能生效。开放数据库方式需要协调各个软件厂商的开放数据库,难度很大。如果一个平台需要同时连接多个软件厂商的数据库,实时获取数据,
采集系统(张力云,吴小强,何小海(四川大学电子信息学院图像信息研究所))
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-12-26 03:01
张丽云、于艳梅、吴小强、何小海
(四川大学电子信息学院图像信息研究所 四川 成都 610064)
摘要:设计并实现了一个基于嵌入式平台的岩屑图像采集信息管理系统。系统由三部分组成:SQLite数据库、Web服务器、无线WiFi模块。岩屑图像采集完成后,将井号、井段、采集时间等信息写入数据库,采集过程通过Socket通知Web服务器更新采集信息。PC或移动设备通过WiFi与Web服务器建立连接,Web服务器使用Websocket协议将采集到的信息发送到客户端的浏览器,同时可以在客户端下载图片。
0 前言
采集系统软件集成在嵌入式系统上,控制整个采集设备的正常运行,实现采集仪器与PC机的分离,实现设备的小型化和便携化。要求 [2]。
但是,在剪枝图像采集过程中,用户需要统计所有采集的图像才能了解当前的采集进度,且图像信息不易管理。另一方面,采集器上的图像需要传输到PC进行后续处理,而电流采集器和PC需要通过交换机和网线连接才能进行图像传输,这就带来了实际应用中带来诸多不便。
针对采集系统存在的缺陷,设计并实现了一个轻量级的图像信息管理系统,实现对图像信息的管理。同时设计了无线模块,方便客户端与采集仪的无线通信。
1 总体系统设计
本文设计的影像信息管理系统由SQlite数据库和Web服务器组成。SQlite数据库用于存储图片信息,Web服务器用于与客户端交互,提供图片信息浏览和图片下载功能。Web服务器基于Tornado框架设计,占用资源少,是像SQLite这样的轻量级应用,非常适合嵌入式系统的开发。Web服务器和客户端通过Websocket协议进行通信,Websocket协议是一种基于TCP的应用层协议,可以让客户端和服务器保持长连接,为图像采集信息的实时更新提供便利,比 HTTP 短连接协议更高效。更高,更少的资源使用。无线模块提供WiFi热点功能。任何具有WiFi功能的设备都可以与Web服务器建立连接,通过浏览器实现浏览和下载图片信息的功能。本文设计的系统结构图如图1所示。
2 数据库设计
由于平台资源的限制,本文设计的系统使用了专门针对嵌入式平台应用的轻量级数据库SQLite。它是一个符合 ACID 的关系数据库管理系统。这个数据库占用的资源很少,一般需要不到1MB的内存。,而且数据存取速度快。目前,该数据库已广泛应用于各种嵌入式产品中。
在插条图像采集系统中,所有采集到的图像信息都存储在IMG表中,该表有6个属性,即ID、WELL、START、END、LIGHT、DATE。图像采集完成后,采集软件将上述信息写入数据库,并通过Socket将采集完成信息发送到Web服务器进行状态更新。本文设计的数据库表结构如表1所示。 表1 允许的数据库表结构字段数据类型
空主键备注 IDINTEGERNY 图像信息存储编号 WELLSTRINGNN 孔编号 STARTFLOATNN 起始孔段 ENDFLOATNN 结束孔段 LIGHTBOOLNN 光信息,0 代表白光,1 代表荧光 DATEDATETIMENN 采集时间
3Web服务器设计与实现
在本系统中,Web服务器是连接客户端和采集仪的桥梁。一方面,采集仪可以实时更新采集进度并显示在客户端,另一方面,客户端可以下载图像。Web 服务器和客户端通过 Websocket 协议进行全双工通信。服务器基于 Tornado 框架设计。
3.1Websocket协议
影像信息管理系统运行在B/S模式,避免了客户端软件兼容性问题,可以在手机浏览器中查看采集进度和下载影像。
传统的B/S模式使用HTTP协议进行通信,系统需要实时更新采集进度,所以一种方式是使用轮换训练技术。但是,这种传统技术存在明显的不足。浏览器每隔一段时间就会向服务器发送请求,服务器需要不断解析HTTP请求。然而,嵌入式图像采集平台的资源相当有限,势必造成服务器资源的巨大浪费。另一种方式是使用Websocket协议进行通信。客户端只需向服务器发送一次连接请求即可建立TCP连接并保持长连接。后续通信可以直接发送数据保存数据报头,双方为全双工通信[4-5]。
Websocket是HTML5定义的新协议,于2014年10月正式发布。目前,无论是PC平台还是移动平台,较新版本的浏览器都已经支持Websocket协议。
3.2Tornado 网络框架
Tornado 是由 Facebook 开发的开源 Web 服务器框架。该框架具有三个特点:(1)轻量级,占用硬件资源少,有利于ARM主板上的应用开发;(2)非阻塞操作,Tornado充分利用了epoll方式,为服务器提供强大的网络响应性能和快速的响应速度,适合实时应用开发;(3)Tornado 2.2及以后版本支持Websocket协议,避免协议的繁琐工作基于以上几点,本文设计的图像信息管理系统中的Web服务器选择Tornado进行开发[6]。
3.3Web服务器设计
本文设计的Web服务器工作流程如图2所示。
首先,客户端与服务器连接,客户端发送连接请求。请求的升级字段表明连接是使用 Websocket 协议建立的。
如果服务端成功接收到客户端的连接请求,则在完成各个字段的验证后立即返回握手请求,客户端和服务端就建立了连接。
客户端与服务器建立连接后,Web服务器如果收到采集软件发送的数据更新信号,会立即读取数据库中的相应信息,并将数据传输给客户端;如果客户端发出下载图片的信号,则Web服务器在对应的文件夹中找到该图片并发送给客户端。
4 无线模块的实现
采集器和 PC 之间的通信需要网络连接。如果通过有线方式连接,那么PC和采集器需要用网线连接到交换机上,比较麻烦。本文的解决方案是将ARM主板设置为WiFi热点,这样笔记本、手机等设备就可以连接到采集器上,查看采集到的信息并下载图片[7]。
本文设计的系统采用EDUP USB无线网卡提供WiFi接入。为了提供网络访问服务,首先要设置WiFi热点的IP地址、子网掩码和网关,并在/etc/network/interfaces文件中修改网络配置。
WiFi热点基本配置完成后,需要操作无线接入功能。Hostapd是用户态AP和认证服务的守护进程。它实现了IEEE802.11 相关的访问管理。Hostapd的默认配置文件为/etc/default/hostapd,配置信息收录
三部分,即基本配置、加密配置和硬件配置[8]。最后配置硬件信息,包括网卡驱动、无线网络协议等。
通过以上操作已经建立了WiFi热点,但是接入设备需要设置一个有效的IP地址才能连接到热点。Linux系统可以通过udhcp运行DHCP服务,自动为接入设备分配一个有效的IP地址[9]。udhcp的配置文件是/etc/udhcp.conf,主要配置有效IP地址范围。
启动hostapd和udhcp进程,并将它们添加到系统启动项中。此时,设备可以通过无线局域网连接到采集器。
5 结论
本文设计并实现了一个基于嵌入式图像采集平台,以Web服务器和数据库为核心,通过WiFi与客户端通信的图像信息管理系统。系统运行在B/S模式下,用户可以在PC或手机客户端的浏览器上查看图像信息和下载图像,采集器与客户端完全无线通信。该系统提高了影像信息管理的灵活性和便利性,简化了设备部署的复杂性。
参考
[1] 高盛峰.小岩样图像采集系统的设计与实现[D]. 成都:四川大学,2012.
[2] 曾杰.综合岩屑数字图像采集系统的设计与实现[D]. 成都:四川大学,2015.
[3] 杜晓东,舒明磊,孟利民,等。基于QT的跨平台虚拟键盘设计与实现[J]. 微机及应用, 2015, 34(17):1820.
[4] 薛龙斌,刘兆远.基于WebSocket的实时网络通信[J]. 计算机与数字工程, 2014 (3):478481.
[5] 张玲,张翠霄.WebSocket 服务器推送技术研究[J].河北科学院学报, 2014, 31 (2):4953.
[6]贾殿燕.基于 Tornado 的即时通讯系统设计与实现[J]. 电子技术与软件工程, 2015 (5):6768.
[7] 齐亚兰,苏凯雄,沉少阳. IEEE802.11n技术标准及其在无线局域网中的应用[J]. 数字技术与应用, 2012 (6):5456.
[8] 张建英,李宗伟,张向忠,等.一种基于ARM11的无线AP进程移植方法[J]. 电视技术, 2013, 37 (15):5759,86.
[9] 王爱华,李永春.ARM下DHCP客户端的设计与实现[J]. 微机及应用, 2012, 31 (22): 5356. 查看全部
采集系统(张力云,吴小强,何小海(四川大学电子信息学院图像信息研究所))
张丽云、于艳梅、吴小强、何小海
(四川大学电子信息学院图像信息研究所 四川 成都 610064)
摘要:设计并实现了一个基于嵌入式平台的岩屑图像采集信息管理系统。系统由三部分组成:SQLite数据库、Web服务器、无线WiFi模块。岩屑图像采集完成后,将井号、井段、采集时间等信息写入数据库,采集过程通过Socket通知Web服务器更新采集信息。PC或移动设备通过WiFi与Web服务器建立连接,Web服务器使用Websocket协议将采集到的信息发送到客户端的浏览器,同时可以在客户端下载图片。
0 前言
采集系统软件集成在嵌入式系统上,控制整个采集设备的正常运行,实现采集仪器与PC机的分离,实现设备的小型化和便携化。要求 [2]。
但是,在剪枝图像采集过程中,用户需要统计所有采集的图像才能了解当前的采集进度,且图像信息不易管理。另一方面,采集器上的图像需要传输到PC进行后续处理,而电流采集器和PC需要通过交换机和网线连接才能进行图像传输,这就带来了实际应用中带来诸多不便。
针对采集系统存在的缺陷,设计并实现了一个轻量级的图像信息管理系统,实现对图像信息的管理。同时设计了无线模块,方便客户端与采集仪的无线通信。
1 总体系统设计
本文设计的影像信息管理系统由SQlite数据库和Web服务器组成。SQlite数据库用于存储图片信息,Web服务器用于与客户端交互,提供图片信息浏览和图片下载功能。Web服务器基于Tornado框架设计,占用资源少,是像SQLite这样的轻量级应用,非常适合嵌入式系统的开发。Web服务器和客户端通过Websocket协议进行通信,Websocket协议是一种基于TCP的应用层协议,可以让客户端和服务器保持长连接,为图像采集信息的实时更新提供便利,比 HTTP 短连接协议更高效。更高,更少的资源使用。无线模块提供WiFi热点功能。任何具有WiFi功能的设备都可以与Web服务器建立连接,通过浏览器实现浏览和下载图片信息的功能。本文设计的系统结构图如图1所示。
2 数据库设计
由于平台资源的限制,本文设计的系统使用了专门针对嵌入式平台应用的轻量级数据库SQLite。它是一个符合 ACID 的关系数据库管理系统。这个数据库占用的资源很少,一般需要不到1MB的内存。,而且数据存取速度快。目前,该数据库已广泛应用于各种嵌入式产品中。
在插条图像采集系统中,所有采集到的图像信息都存储在IMG表中,该表有6个属性,即ID、WELL、START、END、LIGHT、DATE。图像采集完成后,采集软件将上述信息写入数据库,并通过Socket将采集完成信息发送到Web服务器进行状态更新。本文设计的数据库表结构如表1所示。 表1 允许的数据库表结构字段数据类型
空主键备注 IDINTEGERNY 图像信息存储编号 WELLSTRINGNN 孔编号 STARTFLOATNN 起始孔段 ENDFLOATNN 结束孔段 LIGHTBOOLNN 光信息,0 代表白光,1 代表荧光 DATEDATETIMENN 采集时间
3Web服务器设计与实现
在本系统中,Web服务器是连接客户端和采集仪的桥梁。一方面,采集仪可以实时更新采集进度并显示在客户端,另一方面,客户端可以下载图像。Web 服务器和客户端通过 Websocket 协议进行全双工通信。服务器基于 Tornado 框架设计。
3.1Websocket协议
影像信息管理系统运行在B/S模式,避免了客户端软件兼容性问题,可以在手机浏览器中查看采集进度和下载影像。
传统的B/S模式使用HTTP协议进行通信,系统需要实时更新采集进度,所以一种方式是使用轮换训练技术。但是,这种传统技术存在明显的不足。浏览器每隔一段时间就会向服务器发送请求,服务器需要不断解析HTTP请求。然而,嵌入式图像采集平台的资源相当有限,势必造成服务器资源的巨大浪费。另一种方式是使用Websocket协议进行通信。客户端只需向服务器发送一次连接请求即可建立TCP连接并保持长连接。后续通信可以直接发送数据保存数据报头,双方为全双工通信[4-5]。
Websocket是HTML5定义的新协议,于2014年10月正式发布。目前,无论是PC平台还是移动平台,较新版本的浏览器都已经支持Websocket协议。
3.2Tornado 网络框架
Tornado 是由 Facebook 开发的开源 Web 服务器框架。该框架具有三个特点:(1)轻量级,占用硬件资源少,有利于ARM主板上的应用开发;(2)非阻塞操作,Tornado充分利用了epoll方式,为服务器提供强大的网络响应性能和快速的响应速度,适合实时应用开发;(3)Tornado 2.2及以后版本支持Websocket协议,避免协议的繁琐工作基于以上几点,本文设计的图像信息管理系统中的Web服务器选择Tornado进行开发[6]。
3.3Web服务器设计
本文设计的Web服务器工作流程如图2所示。
首先,客户端与服务器连接,客户端发送连接请求。请求的升级字段表明连接是使用 Websocket 协议建立的。
如果服务端成功接收到客户端的连接请求,则在完成各个字段的验证后立即返回握手请求,客户端和服务端就建立了连接。
客户端与服务器建立连接后,Web服务器如果收到采集软件发送的数据更新信号,会立即读取数据库中的相应信息,并将数据传输给客户端;如果客户端发出下载图片的信号,则Web服务器在对应的文件夹中找到该图片并发送给客户端。
4 无线模块的实现
采集器和 PC 之间的通信需要网络连接。如果通过有线方式连接,那么PC和采集器需要用网线连接到交换机上,比较麻烦。本文的解决方案是将ARM主板设置为WiFi热点,这样笔记本、手机等设备就可以连接到采集器上,查看采集到的信息并下载图片[7]。
本文设计的系统采用EDUP USB无线网卡提供WiFi接入。为了提供网络访问服务,首先要设置WiFi热点的IP地址、子网掩码和网关,并在/etc/network/interfaces文件中修改网络配置。
WiFi热点基本配置完成后,需要操作无线接入功能。Hostapd是用户态AP和认证服务的守护进程。它实现了IEEE802.11 相关的访问管理。Hostapd的默认配置文件为/etc/default/hostapd,配置信息收录
三部分,即基本配置、加密配置和硬件配置[8]。最后配置硬件信息,包括网卡驱动、无线网络协议等。
通过以上操作已经建立了WiFi热点,但是接入设备需要设置一个有效的IP地址才能连接到热点。Linux系统可以通过udhcp运行DHCP服务,自动为接入设备分配一个有效的IP地址[9]。udhcp的配置文件是/etc/udhcp.conf,主要配置有效IP地址范围。
启动hostapd和udhcp进程,并将它们添加到系统启动项中。此时,设备可以通过无线局域网连接到采集器。
5 结论
本文设计并实现了一个基于嵌入式图像采集平台,以Web服务器和数据库为核心,通过WiFi与客户端通信的图像信息管理系统。系统运行在B/S模式下,用户可以在PC或手机客户端的浏览器上查看图像信息和下载图像,采集器与客户端完全无线通信。该系统提高了影像信息管理的灵活性和便利性,简化了设备部署的复杂性。
参考
[1] 高盛峰.小岩样图像采集系统的设计与实现[D]. 成都:四川大学,2012.
[2] 曾杰.综合岩屑数字图像采集系统的设计与实现[D]. 成都:四川大学,2015.
[3] 杜晓东,舒明磊,孟利民,等。基于QT的跨平台虚拟键盘设计与实现[J]. 微机及应用, 2015, 34(17):1820.
[4] 薛龙斌,刘兆远.基于WebSocket的实时网络通信[J]. 计算机与数字工程, 2014 (3):478481.
[5] 张玲,张翠霄.WebSocket 服务器推送技术研究[J].河北科学院学报, 2014, 31 (2):4953.
[6]贾殿燕.基于 Tornado 的即时通讯系统设计与实现[J]. 电子技术与软件工程, 2015 (5):6768.
[7] 齐亚兰,苏凯雄,沉少阳. IEEE802.11n技术标准及其在无线局域网中的应用[J]. 数字技术与应用, 2012 (6):5456.
[8] 张建英,李宗伟,张向忠,等.一种基于ARM11的无线AP进程移植方法[J]. 电视技术, 2013, 37 (15):5759,86.
[9] 王爱华,李永春.ARM下DHCP客户端的设计与实现[J]. 微机及应用, 2012, 31 (22): 5356.
采集系统(spring使用springcloud架构技术优劣性系统优点及优点分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-12-24 05:18
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动查看。问题提交给 IT 团队。对于喜欢爬虫的人来说,我绝对想要他。之前用过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
想了解更多,请点击:
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓取微信公众号的文章。
想了解更多,请点击:
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、rocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、 系统为分布式架构,高可用;3、rocketMq消息队列用于解决Coupling可以解决采集由于网络抖动导致的失败。如果三个消费不成功,日志会记录到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心可以通过热配置实时调整采集的频率;< @7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
想了解更多,请点击:
系统缺点:
1、通过真实手机真实账号采集消息,如果您需要采集大量公众号,则需要有多个微信账号作为支持(如果账号达到当天,您可以爬取微信官方平台通过界面获取消息);2、不是一贴就可以抓到的公众号,采集的时间是系统设置的。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis模块:对spring-boot-starter-data-redis进行二次封装,暴露打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMq 模块:对 RocketMQ-spring-boot-starter 进行二次封装,提供消费重试和记录故障日志功能。
想了解更多,请点击:
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java抽取模块:收录java程序抽取文章的内容相关功能。
移动-wx-蜘蛛
模拟器采集模块:收录通过模拟器或手机与采集消息交互相关的功能。
想了解更多,请点击:
五、一般流程图
六、 在 PC 和手机上运行截图
安慰
运行结束
总结
项目亲测现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
想了解更多,请点击: 查看全部
采集系统(spring使用springcloud架构技术优劣性系统优点及优点分析)
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动查看。问题提交给 IT 团队。对于喜欢爬虫的人来说,我绝对想要他。之前用过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
想了解更多,请点击:
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓取微信公众号的文章。
想了解更多,请点击:
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、rocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、 系统为分布式架构,高可用;3、rocketMq消息队列用于解决Coupling可以解决采集由于网络抖动导致的失败。如果三个消费不成功,日志会记录到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心可以通过热配置实时调整采集的频率;< @7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
想了解更多,请点击:
系统缺点:
1、通过真实手机真实账号采集消息,如果您需要采集大量公众号,则需要有多个微信账号作为支持(如果账号达到当天,您可以爬取微信官方平台通过界面获取消息);2、不是一贴就可以抓到的公众号,采集的时间是系统设置的。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis模块:对spring-boot-starter-data-redis进行二次封装,暴露打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMq 模块:对 RocketMQ-spring-boot-starter 进行二次封装,提供消费重试和记录故障日志功能。
想了解更多,请点击:
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java抽取模块:收录java程序抽取文章的内容相关功能。
移动-wx-蜘蛛
模拟器采集模块:收录通过模拟器或手机与采集消息交互相关的功能。
想了解更多,请点击:
五、一般流程图
六、 在 PC 和手机上运行截图
安慰
运行结束
总结
项目亲测现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
想了解更多,请点击:
采集系统(多传统采集系统,特点简单明了,每一步骤全搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-18 20:17
采集系统,多传统采集系统,特点简单明了,每一步骤全搞定!用云采集器不需要购买带云采集功能的硬件,只需要网页上点一下即可实现在线导入保存到电脑和手机上。这样,可以大大减少网站的服务器负担,节省建站的人力成本。云采集器安全稳定,数据不丢失。云采集器采集数据不限速,大大提高用户体验。云采集器还有云下载、云存储、云分享等功能,更加方便了广大用户。
rtx,我做个简单分享。教程讲解rtx采集布局、采集框架搭建。怎么设置好像也是没什么讲的,只是提供一种思路,
推荐一个采集建站神器——我用这个采集了好多网站收集来的数据,采集速度快,操作简单,界面简洁,相比于其他产品来说比较容易上手。我目前正在用哦。
亿方云
客户端分享很便捷,
云采集器,在电脑上在线就可以操作,
推荐用云采集的,操作很简单,
推荐一个一站式采集工具
一个采集工具可以采集很多网站的
采集器,很多网站很容易收集进去的,公众号百家号平台都有很多很多的内容可以采集,
全是简单的操作、要多少要看你购买什么硬件(云采集器), 查看全部
采集系统(多传统采集系统,特点简单明了,每一步骤全搞定)
采集系统,多传统采集系统,特点简单明了,每一步骤全搞定!用云采集器不需要购买带云采集功能的硬件,只需要网页上点一下即可实现在线导入保存到电脑和手机上。这样,可以大大减少网站的服务器负担,节省建站的人力成本。云采集器安全稳定,数据不丢失。云采集器采集数据不限速,大大提高用户体验。云采集器还有云下载、云存储、云分享等功能,更加方便了广大用户。
rtx,我做个简单分享。教程讲解rtx采集布局、采集框架搭建。怎么设置好像也是没什么讲的,只是提供一种思路,
推荐一个采集建站神器——我用这个采集了好多网站收集来的数据,采集速度快,操作简单,界面简洁,相比于其他产品来说比较容易上手。我目前正在用哦。
亿方云
客户端分享很便捷,
云采集器,在电脑上在线就可以操作,
推荐用云采集的,操作很简单,
推荐一个一站式采集工具
一个采集工具可以采集很多网站的
采集器,很多网站很容易收集进去的,公众号百家号平台都有很多很多的内容可以采集,
全是简单的操作、要多少要看你购买什么硬件(云采集器),
采集系统(《幼儿园适龄儿童信息采集服务系统》用户操作手册目录(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2021-12-12 22:17
《幼儿园学龄儿童信息采集服务系统》使用手册
内容
第一章海淀区幼儿园幼儿信息采集服务系统用户子系统概述1
第二章进入海淀区幼儿园适龄儿童信息采集服务系统2
2.1 用户注册 2
2.2 用户登录 4
2.3 修改采集信息 5
2.4 选择意向花园 6
2.5 审计状态查询 9
2.6 查看和打印 9
2.7 修改密码 10
2.8 家长留言 11
2.9 忘记密码 12
3.0 用户须知 13
3.1 操作手册 13
3.2 政策法规 14
第一章海淀区幼儿园幼儿信息采集服务系统用户子系统概述
海淀区幼儿园儿童信息采集服务系统前台主要包括用户注册、忘记密码、使用说明、操作手册、政策法规、采集填表修改、意向园选择、审核状态查询、查看和打印、密码修改、家长留言等八个功能模块。
用户注册模块主要实现注册新用户的功能。
忘记密码模块主要实现找回密码的功能。
用户通知模块主要实现查看用户通知的功能。
操作手册模块主要实现查看系统操作手册的功能。
政策法规模块主要实现查看正常法规的功能。
修改采集信息填充模块主要实现修改用户信息的功能。
选择意向幼儿园模块主要实现了选择幼儿园进行注册的功能。
儿童退出管理模块具有查询入园儿童信息、退出幼儿园等功能。
审核状态查询模块主要实现对幼儿园儿童申报状态的查询功能。
查看打印模块主要实现查看和打印用户信息的功能。
密码修改模块主要实现修改用户登录密码的功能。
父消息模块主要实现父发布信息的功能。
第二章 进入海淀区幼儿园幼儿信息采集服务系统
2.1 用户注册
在浏览器中打开海淀区幼儿园学龄儿童信息采集服务系统登录界面,如下图:
点击【用户注册】按钮,系统会自动跳转到用户注册界面,弹出注册服务协议,如下图:
输入“用户名”、“密码”、“重复密码”、“邮箱”、“手机号码”信息,点击【发送验证码】按钮,系统会自动将手机验证码发送到填写的手机多于; 收到手机验证码后,在“手机验证码”栏输入收到的验证码;然后勾选“同意“服务条款”和“隐私优先政策”复选框,点击【立即注册】按钮,系统会弹出:“注册“成功”提示,点击【确定】按钮,系统会自动跳转到“儿童基本信息采集表”界面,如下图:
在“婴儿基本信息采集表格”界面输入孩子和监护人的基本信息(监护人可以选择父母、父亲、母亲,选择的监护人类型为必填项),然后点击【保存】 ] 按钮。信息采集表单保存成功,用户注册完成,系统自动跳转到“修改<@采集信息”界面,见下图
2.2 用户登录
在浏览器中打开海淀区幼儿园适龄儿童信息采集服务系统登录界面,输入“用户名”(或输入“注册手机号”、邮箱号、儿童身份证号)和界面中的“密码”信息点击【用户登录】按钮,成功登录海淀区幼儿园适龄儿童信息采集服务系统,如下图:
【退出】:登录成功后,界面右上角会显示【退出】按钮。点击【退出】按钮退出成功。
2.3 修改采集信息
登录海淀区幼儿园儿童信息采集服务系统家长界面系统后,点击“修改采集信息”标签页按钮,成功打开“修改采集信息”界面即可显示孩子的基本信息,可以修改,如图:
在“修改采集信息”界面修改孩子和监护人信息后,点击【修改】按钮,修改孩子采集的信息,操作成功。
2.4 选择意向园
登录海淀区幼儿园学龄儿童信息采集服务系统家长用户界面系统后,点击“选择意向园”标签页按钮,成功打开“选择意向园”界面,界面显示“幼儿园信息》“本次”学龄儿童信息采集时间”、“本次学龄儿童信息结束后的天数采集”、“每位家长最多可入园数注册”等,如下图所示:
■【搜索】:在“选择意向园”界面,输入搜索条件:“幼儿园名称”、“地址信息”、“幼儿园性质”,点击【搜索】按钮搜索幼儿园信息,幼儿园信息列表显示满足搜索条件的幼儿园信息。当搜索条件为空时,将搜索到所有幼儿园信息。当搜索条件不为空时,可以根据搜索条件搜索匹配的记录,可以进行单项或组合搜索。为了不影响系统性能和提高界面的可操作性,每页默认显示8条数据(您可以通过下拉按钮选择显示更多数据)。
■查看幼儿园介绍:在“选择意向园”界面的幼儿园信息列表中点击“幼儿园名称”,系统会自动弹出“幼儿园简介”窗口,查看该幼儿园的基本信息,如图下图:
■【我要注册】:在“选择意向园”界面的幼儿园信息列表中找到要注册的幼儿园信息,点击相应幼儿园信息操作栏中的【我要注册】按钮(性质幼儿园为“单位办幼儿园”“幼儿园需要选择孩子是本单位员工二代还是三代,否则选择否);系统自动弹出“幼儿园介绍”窗口幼儿园,显示幼儿园的基本信息,如下图:
点击“幼儿园简介”窗口中的【我要报名】按钮,系统会弹出:“选择意向成功!” 提示,点击提示窗口中的【确定】按钮关闭窗口,幼儿园注册成功,系统自动返回【选择意向幼儿园】界面,已注册的幼儿园信息自动放置在在幼儿园信息列表的顶部,该幼儿园信息操作栏中的按钮由【我要注册】变为【取消注册】按钮,如下图:
■ 【取消注册】:在【选择意向园】界面,点击幼儿园操作栏中的【取消注册】按钮,确认已注册的幼儿园信息注册。
2.5 评论状态查询
登录海淀区幼儿园学龄儿童信息采集服务系统家长界面系统后,点击“审核状态查询”标签页按钮成功打开“审核状态查询”界面,可以查看注册幼儿园信息;您可以查询该孩子信息的幼儿园审核状态如下图所示:
■【查询】 选择年份,点击【查询】按钮,可以查询选中报社志愿者的履历。
2.6 查看和打印
登录海淀区幼儿园学龄儿童信息采集服务系统家长用户界面系统后,点击“查看打印”标签页按钮成功打开“查看打印”界面,您可以查看,打印、导出子采集信息(pdf格式),如下图:
■ 【打印】:在【查看打印】界面点击【打印】按钮,可以打印孩子的信息。
■【导出pdf】:在【查看和打印】界面点击【导出pdf】按钮,系统会弹出文件下载窗口,点击文件下载窗口中的【保存】按钮,系统会弹出文件下载窗口另存为界面,设置“保存地址”和“文件” 点击“名称”后的【保存】按钮,系统会自动下载并保存pdf文件。
2.7 修改密码
登录海淀区幼儿园学龄儿童信息采集服务系统家长界面系统后,点击“修改密码”标签页按钮,成功打开“修改密码”界面,如下图:
根据提示输入“旧密码”和“新密码”,点击【确定】按钮,系统弹出:“修改成功!” 提示,在提示界面点击【确定】按钮,个人密码修改成功。
2.8位家长留言
登录海淀区幼儿园儿童信息采集服务系统家长界面系统后,点击“家长留言”标签页按钮,成功打开“家长留言”界面。为了不影响系统性能,提高界面的可操作性,请留言 数据分页显示。您可以通过列表底部的分页功能切换列表页面,查看所有幼儿园信息。如下所示:
■【留言】:输入留言内容后,点击【留言】按钮,系统会自动提交留言内容,留言操作成功。
2.9忘记密码
打开海淀区幼儿园儿童信息采集服务系统家长用户界面系统,点击界面上的【忘记密码】按钮,系统跳转到用户密码找回界面,默认显示为手机找回密码手机,输入姓名和凭据点击号码上的【提交】按钮,系统会将密码发送到用户注册的手机上,如下图
点击“通过电子邮件检索”按钮,见下图
输入姓名和邮箱,点击【提交】按钮,系统会将密码发送到用户注册的邮箱。
点击【返回】按钮,返回登录界面。
3.0 用户须知
打开海淀区幼儿园适龄儿童信息采集服务系统家长用户界面系统,点击界面上的“用户须知”按钮,见下图
进入【用户信息】界面查看相关信息;点击【返回】按钮返回登录界面,如下图
3.1 操作手册
打开海淀区幼儿园适龄儿童信息采集服务系统家长用户界面系统,点击界面上的“操作手册”按钮,见下图
进入【操作手册】界面查看相关信息;点击【返回】按钮返回登录界面,如下图
3.2政策法规
打开海淀区幼儿园学龄儿童信息采集服务系统家长界面系统,点击界面上的“政策法规”按钮,如下图
进入【政策法规】界面查看相关信息;点击【返回】按钮返回登录界面,如下图
相关链接:
2019年海淀区幼儿园信息采集系统(网址+采集时间)
2019年海淀区幼儿园适龄儿童信息采集常见问题
2019年海淀区幼儿园采集信息时间及信息采集系统入口
海淀区幼儿园信息采集系统操作流程指南(图解)
2019年海淀区幼儿园幼儿信息采集系统常见问题 查看全部
采集系统(《幼儿园适龄儿童信息采集服务系统》用户操作手册目录(组图))
《幼儿园学龄儿童信息采集服务系统》使用手册
内容
第一章海淀区幼儿园幼儿信息采集服务系统用户子系统概述1
第二章进入海淀区幼儿园适龄儿童信息采集服务系统2
2.1 用户注册 2
2.2 用户登录 4
2.3 修改采集信息 5
2.4 选择意向花园 6
2.5 审计状态查询 9
2.6 查看和打印 9
2.7 修改密码 10
2.8 家长留言 11
2.9 忘记密码 12
3.0 用户须知 13
3.1 操作手册 13
3.2 政策法规 14
第一章海淀区幼儿园幼儿信息采集服务系统用户子系统概述
海淀区幼儿园儿童信息采集服务系统前台主要包括用户注册、忘记密码、使用说明、操作手册、政策法规、采集填表修改、意向园选择、审核状态查询、查看和打印、密码修改、家长留言等八个功能模块。
用户注册模块主要实现注册新用户的功能。
忘记密码模块主要实现找回密码的功能。
用户通知模块主要实现查看用户通知的功能。
操作手册模块主要实现查看系统操作手册的功能。
政策法规模块主要实现查看正常法规的功能。
修改采集信息填充模块主要实现修改用户信息的功能。
选择意向幼儿园模块主要实现了选择幼儿园进行注册的功能。
儿童退出管理模块具有查询入园儿童信息、退出幼儿园等功能。
审核状态查询模块主要实现对幼儿园儿童申报状态的查询功能。
查看打印模块主要实现查看和打印用户信息的功能。
密码修改模块主要实现修改用户登录密码的功能。
父消息模块主要实现父发布信息的功能。
第二章 进入海淀区幼儿园幼儿信息采集服务系统
2.1 用户注册
在浏览器中打开海淀区幼儿园学龄儿童信息采集服务系统登录界面,如下图:
点击【用户注册】按钮,系统会自动跳转到用户注册界面,弹出注册服务协议,如下图:
输入“用户名”、“密码”、“重复密码”、“邮箱”、“手机号码”信息,点击【发送验证码】按钮,系统会自动将手机验证码发送到填写的手机多于; 收到手机验证码后,在“手机验证码”栏输入收到的验证码;然后勾选“同意“服务条款”和“隐私优先政策”复选框,点击【立即注册】按钮,系统会弹出:“注册“成功”提示,点击【确定】按钮,系统会自动跳转到“儿童基本信息采集表”界面,如下图:
在“婴儿基本信息采集表格”界面输入孩子和监护人的基本信息(监护人可以选择父母、父亲、母亲,选择的监护人类型为必填项),然后点击【保存】 ] 按钮。信息采集表单保存成功,用户注册完成,系统自动跳转到“修改<@采集信息”界面,见下图
2.2 用户登录
在浏览器中打开海淀区幼儿园适龄儿童信息采集服务系统登录界面,输入“用户名”(或输入“注册手机号”、邮箱号、儿童身份证号)和界面中的“密码”信息点击【用户登录】按钮,成功登录海淀区幼儿园适龄儿童信息采集服务系统,如下图:
【退出】:登录成功后,界面右上角会显示【退出】按钮。点击【退出】按钮退出成功。
2.3 修改采集信息
登录海淀区幼儿园儿童信息采集服务系统家长界面系统后,点击“修改采集信息”标签页按钮,成功打开“修改采集信息”界面即可显示孩子的基本信息,可以修改,如图:
在“修改采集信息”界面修改孩子和监护人信息后,点击【修改】按钮,修改孩子采集的信息,操作成功。
2.4 选择意向园
登录海淀区幼儿园学龄儿童信息采集服务系统家长用户界面系统后,点击“选择意向园”标签页按钮,成功打开“选择意向园”界面,界面显示“幼儿园信息》“本次”学龄儿童信息采集时间”、“本次学龄儿童信息结束后的天数采集”、“每位家长最多可入园数注册”等,如下图所示:
■【搜索】:在“选择意向园”界面,输入搜索条件:“幼儿园名称”、“地址信息”、“幼儿园性质”,点击【搜索】按钮搜索幼儿园信息,幼儿园信息列表显示满足搜索条件的幼儿园信息。当搜索条件为空时,将搜索到所有幼儿园信息。当搜索条件不为空时,可以根据搜索条件搜索匹配的记录,可以进行单项或组合搜索。为了不影响系统性能和提高界面的可操作性,每页默认显示8条数据(您可以通过下拉按钮选择显示更多数据)。
■查看幼儿园介绍:在“选择意向园”界面的幼儿园信息列表中点击“幼儿园名称”,系统会自动弹出“幼儿园简介”窗口,查看该幼儿园的基本信息,如图下图:
■【我要注册】:在“选择意向园”界面的幼儿园信息列表中找到要注册的幼儿园信息,点击相应幼儿园信息操作栏中的【我要注册】按钮(性质幼儿园为“单位办幼儿园”“幼儿园需要选择孩子是本单位员工二代还是三代,否则选择否);系统自动弹出“幼儿园介绍”窗口幼儿园,显示幼儿园的基本信息,如下图:
点击“幼儿园简介”窗口中的【我要报名】按钮,系统会弹出:“选择意向成功!” 提示,点击提示窗口中的【确定】按钮关闭窗口,幼儿园注册成功,系统自动返回【选择意向幼儿园】界面,已注册的幼儿园信息自动放置在在幼儿园信息列表的顶部,该幼儿园信息操作栏中的按钮由【我要注册】变为【取消注册】按钮,如下图:
■ 【取消注册】:在【选择意向园】界面,点击幼儿园操作栏中的【取消注册】按钮,确认已注册的幼儿园信息注册。
2.5 评论状态查询
登录海淀区幼儿园学龄儿童信息采集服务系统家长界面系统后,点击“审核状态查询”标签页按钮成功打开“审核状态查询”界面,可以查看注册幼儿园信息;您可以查询该孩子信息的幼儿园审核状态如下图所示:
■【查询】 选择年份,点击【查询】按钮,可以查询选中报社志愿者的履历。
2.6 查看和打印
登录海淀区幼儿园学龄儿童信息采集服务系统家长用户界面系统后,点击“查看打印”标签页按钮成功打开“查看打印”界面,您可以查看,打印、导出子采集信息(pdf格式),如下图:
■ 【打印】:在【查看打印】界面点击【打印】按钮,可以打印孩子的信息。
■【导出pdf】:在【查看和打印】界面点击【导出pdf】按钮,系统会弹出文件下载窗口,点击文件下载窗口中的【保存】按钮,系统会弹出文件下载窗口另存为界面,设置“保存地址”和“文件” 点击“名称”后的【保存】按钮,系统会自动下载并保存pdf文件。
2.7 修改密码
登录海淀区幼儿园学龄儿童信息采集服务系统家长界面系统后,点击“修改密码”标签页按钮,成功打开“修改密码”界面,如下图:
根据提示输入“旧密码”和“新密码”,点击【确定】按钮,系统弹出:“修改成功!” 提示,在提示界面点击【确定】按钮,个人密码修改成功。
2.8位家长留言
登录海淀区幼儿园儿童信息采集服务系统家长界面系统后,点击“家长留言”标签页按钮,成功打开“家长留言”界面。为了不影响系统性能,提高界面的可操作性,请留言 数据分页显示。您可以通过列表底部的分页功能切换列表页面,查看所有幼儿园信息。如下所示:
■【留言】:输入留言内容后,点击【留言】按钮,系统会自动提交留言内容,留言操作成功。
2.9忘记密码
打开海淀区幼儿园儿童信息采集服务系统家长用户界面系统,点击界面上的【忘记密码】按钮,系统跳转到用户密码找回界面,默认显示为手机找回密码手机,输入姓名和凭据点击号码上的【提交】按钮,系统会将密码发送到用户注册的手机上,如下图
点击“通过电子邮件检索”按钮,见下图
输入姓名和邮箱,点击【提交】按钮,系统会将密码发送到用户注册的邮箱。
点击【返回】按钮,返回登录界面。
3.0 用户须知
打开海淀区幼儿园适龄儿童信息采集服务系统家长用户界面系统,点击界面上的“用户须知”按钮,见下图
进入【用户信息】界面查看相关信息;点击【返回】按钮返回登录界面,如下图
3.1 操作手册
打开海淀区幼儿园适龄儿童信息采集服务系统家长用户界面系统,点击界面上的“操作手册”按钮,见下图
进入【操作手册】界面查看相关信息;点击【返回】按钮返回登录界面,如下图
3.2政策法规
打开海淀区幼儿园学龄儿童信息采集服务系统家长界面系统,点击界面上的“政策法规”按钮,如下图
进入【政策法规】界面查看相关信息;点击【返回】按钮返回登录界面,如下图
相关链接:
2019年海淀区幼儿园信息采集系统(网址+采集时间)
2019年海淀区幼儿园适龄儿童信息采集常见问题
2019年海淀区幼儿园采集信息时间及信息采集系统入口
海淀区幼儿园信息采集系统操作流程指南(图解)
2019年海淀区幼儿园幼儿信息采集系统常见问题
采集系统(就是如何处理多台机器线上系统的日志(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-12-05 03:20
)
如今,多核和分布式软件开发已成为常态。基本上,较大的应用程序分布在多台机器上。分布式在提高性能的同时带来了很多问题。今天只讨论一点,就是多机联机系统的日志如何处理。
以我们公司的一个应用T为例。部署在5台百度云机器上,其中一台有公网IP,使用百度云提供的负载均衡服务。每次要检索日志中的某个关键字,基本步骤如下:
当然,我们可以编写脚本来简化这个过程,或者使用cssh之类的工具。但成功登录五台机器只是任务的开始。接下来,我们要手动选择我们要检索的日志(日志是按照日期存储的),使用grep进行检索,然后在五个shell上一一查看结果。. 如果有稍微高级的需求,比如检查某个关键词是否在昨天和今天的日志中都出现过,那么任务就会变得很麻烦,而且使用shell很容易出错。
从这个过程,我们可以总结出分布式系统日志处理的需求。希望有这样一个日志处理系统,具有以下功能:
幸运的是,elastic 提供了一套非常先进的工具 ELKB 来满足这些需求。ELKB是指用于日志分析或数据分析的四个软件,每个软件都有独立的功能,可以组合在一起。我们先简单介绍一下这四个软件。
安装
这里我们以 CentOS 7 为例来说明如何安装这些软件。ELK只需要安装在服务器上进行日志采集和分析,而Beats则需要安装在每台日志生成机器(客户端)上,当然也可能包括日志采集服务器本身。
爪哇
$ yum install java-1.8.0
copy code
搜索
$ rpm --import http://packages.elastic.co/GPG-KEY-elasticsearch
$ echo '[elasticsearch-2.x]
name=Elasticsearch repository for 2.x packages
baseurl=http://packages.elastic.co/ela ... entos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
' | tee /etc/yum.repos.d/elasticsearch.repo
$ yum install elasticsearch
copy code
日志存储
$ vim /etc/yum.repos.d/logstash.repo
# 添加以下内容
[logstash-2.4]
name=logstash repository for 2.2 packages
baseurl=http://packages.elasticsearch. ... entos
gpgcheck=1
gpgkey=http://packages.elasticsearch. ... earch
enabled=1
# 安装
$ yum install logstash
copy code
基巴纳
$ vim /etc/yum.repos.d/kibana.repo
# 添加以下内容
[kibana-4.6]
name=Kibana repository for 4.4.x packages
baseurl=http://packages.elastic.co/kibana/4.4/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
# 安装
$ yum install kibana
copy code
节拍
节拍分为多种类型,每种类型都采集特定信息。常用的是Filebeat,它监控文件变化,传输文件内容。一般来说,Filebeat 对日志系统来说就足够了。
我们切换到客户端。首先,您还需要导入 GPG KEY。
$ rpm --import http://packages.elastic.co/GPG-KEY-elasticsearch
copy code
创建一个新的存储库并安装它。
$ vim /etc/yum.repos.d/elastic-beats.repo
# 添加以下内容
[beats]
name=Elastic Beats Repository
baseurl=https://packages.elastic.co/beats/yum/el/$basearch
enabled=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
gpgcheck=1
# 安装
$ yum install filebeat
copy code
弹性搜索
Elasticsearch 不需要太多配置,只需要屏蔽外网访问即可。修改配置文件/etc/elasticsearch/elasticsearch.yml。
network.host: localhost
copy code
启动elasticsearch,服务elasticsearch 启动。
Elasticsearch 本身可以被认为是一个 NoSQL 数据库,通过 REST API 进行操作。数据存储在索引中,相当于elastcisearch中SQL中的一张表。因为elasticsearch主要用于检索数据,所以index有一个叫做mapping的配置。我们用mapping来告诉elasticsearch数据的一些相关信息,比如某个字段是什么数据类型,是否创建索引等。我们先玩elasticsearch,以官方的莎士比亚数据集为例。
$ curl localhost:9200/_cat/indices?v # 查看当前所有的index
health status index pri rep docs.count docs.deleted store.size pri.store.size # 没有任何index
# 创建shakespeare索引,并设置mapping信息
# speaker字段和play_name不需要分析,elasticsearch默认会拆分字符串中的每个词并进行索引
$ curl -XPUT http://localhost:9200/shakespeare -d '
{
"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "string", "index" : "not_analyzed" },
"play_name" : {"type": "string", "index" : "not_analyzed" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
}
';
$ curl localhost:9200/_cat/indices?v # 查看索引
health status index pri rep docs.count docs.deleted store.size pri.store.size
yellow open shakespeare 5 1 0 0 260b 260b
# 下载数据,并将数据集load进索引中
$ wget https://www.elastic.co/guide/e ... .json
$ curl -XPOST 'localhost:9200/shakespeare/_bulk?pretty' --data-binary @shakespeare.json
# 以上操作完成后,elasticsearch中就已经有了我们load的所有数据,并建立好了索引,我们可以开始查询了
# 查询一下含有'man'这个词的text_entry
$ curl -s 'localhost:9200/shakespeare/_search?q=text_entry:man&pretty=1&size=20' | jq '.hits.hits | .[]._source.text_entry'
"man."
"Man?"
"man."
"Why, man?"
"Worthy man!"
"Every man,"
"complete man."
"married man?"
"melancholy man."
"Speak, man."
"Why, man?"
"What, man?"
"prave man."
"Speak, man."
"Why, man?"
"So man and man should be;"
"O, the difference of man and man!"
"The young man is an honest man."
"A gross fat man."
"plain-dealing man?"
copy code
下面我们通过解析nginx的访问日志来讲解ELKB的使用方法。
解析 Nginx 访问日志
整个过程的流程比较简单。Filebeat 采集日志并将它们发送到 Logstash。在 logstash 解析它们之后,将它们写入 ealsticsearch。最后,我们使用 kibana 查看和检索这些日志。
文件节拍
首先切换到客户端,我们来配置filebeat。
$ vim /etc/filebeat/filebeat.yml
...
prospectors:
-
paths:
- /var/log/nginx/access.log
# 找到document_type字段,取消注释,这个字段会告诉logstash日志的类型,对应logstash中的type字段
document_type: nginx
...
# 默认输出为elasticsearch,注释掉,使用logstash
logstash:
hosts: ["IP:5044"] # 注意更改这里的IP
copy code
日志存储
logstash的配置比较麻烦,因为logstash需要接受输入,处理,产生输出。Logstash 采用输入、过滤、输出三阶段配置方式。input配置输入源,filter配置如何处理输入源中的信息,output配置输出位置。
一般来说,输入是节拍的。在filter中,我们解析输入得到的日志,得到我们想要的字段,输出是elasticsearch。这里我们以nginx的访问日志为例。过滤器中有一个关键的东西叫grok,我们用这个东西来解析日志结构。logstash 提供了一些默认的 Patterns,方便我们分析和使用。当然,我们也可以自定义模式,有规律地匹配日志内容。
$ vim /etc/logstash/conf.d/nginx.conf
input {
beats {
port => 5044
}
}
filter {
if [type] == "nginx" { # 这里的type是日志类型,我们在后面的filebeat中设定
grok {
match => { "message" => "%{COMBINEDAPACHELOG} %{QS:gzip_ratio}" } # 使用自带的pattern即可,注意空格
remove_field => ["beat", "input_type", "message", "offset", "tags"] # filebeat添加的字段,我们不需要
}
# 更改匹配到的字段的数据类型
mutate {
convert => ["response", "integer"]
convert => ["bytes", "integer"]
convert => ["responsetime", "float"]
}
# 指定时间戳字段以及具体的格式
date {
match => ["timestamp", "dd/MMM/YYYY:HH:mm:ss Z"]
remove_field => ["timestamp"]
}
}
}
outpugst {
elasticsearch {
hosts => [ "localhost:9200" ]
index => "%{type}-%{+YYYY.MM.dd}" # index中含有时间戳
}
}
copy code
服务logstash start 可以启动logstash。注意它的启动速度很慢。
弹性搜索
在上面的logstash配置中,我们可以看到最终写入elasticsearch的索引收录时间戳,这是比较推荐的做法。因为方便我们每天分析数据。关于elasticsearch,我们只需要配置index Mapping信息即可。因为我们的索引是每天生成的,每天都是一个新的索引,当然不可能每天都配置索引Mapping。这里需要用到elasticsearch的一个特性,Index Template。我们可以创建一个索引配置模板,并使用这个模板来配置所有匹配的索引。
curl -XPUT localhost:9200/_template/nginx -d '
{
"template": "nginx*",
"mappings": {
"_default_": {
"properties": {
"clientip": {
"type": "string",
"index": "not_analyzed"
},
"ident": {
"type": "string"
},
"auth": {
"type": "string"
},
"verb": {
"type": "string"
},
"request": {
"type": "string"
},
"httpversion": {
"type": "string"
},
"rawrequest": {
"type": "string"
},
"response": {
"type": "string"
},
"bytes": {
"type": "integer"
},
"referrer": {
"type": "string"
},
"agent": {
"type": "string"
},
"gzip_ratio": {
"type": "string"
}
}
}
}
}
'
copy code
上面的代码创建了一个名为 nginx 的模板,匹配所有以 nginx 开头的索引。
基巴纳
Kibana 不需要任何配置,直接启动即可。service kibana start,默认运行在5601端口。如果考虑安全性,也可以将kibana配置为只监听本地机器,然后使用nginx进行反向代理和控制权限,这里不再赘述。
接下来,我们需要生成一个日志,然后可以在kibana中查看,以表明系统运行正常。我们使用curl在客户端随机请求nginx生成一个小日志。然后,打开kibana,[服务器ip]:5601。刚进入的时候,首先需要配置Kibana的Index Pattern,告诉kibana我们要查看哪些Index数据,输入nginx*,然后点击Discover浏览数据。
最终效果如下,我们可以在kibana中浏览我们的nginx日志,进行任意搜索。
查看全部
采集系统(就是如何处理多台机器线上系统的日志(组图)
)
如今,多核和分布式软件开发已成为常态。基本上,较大的应用程序分布在多台机器上。分布式在提高性能的同时带来了很多问题。今天只讨论一点,就是多机联机系统的日志如何处理。
以我们公司的一个应用T为例。部署在5台百度云机器上,其中一台有公网IP,使用百度云提供的负载均衡服务。每次要检索日志中的某个关键字,基本步骤如下:
当然,我们可以编写脚本来简化这个过程,或者使用cssh之类的工具。但成功登录五台机器只是任务的开始。接下来,我们要手动选择我们要检索的日志(日志是按照日期存储的),使用grep进行检索,然后在五个shell上一一查看结果。. 如果有稍微高级的需求,比如检查某个关键词是否在昨天和今天的日志中都出现过,那么任务就会变得很麻烦,而且使用shell很容易出错。
从这个过程,我们可以总结出分布式系统日志处理的需求。希望有这样一个日志处理系统,具有以下功能:
幸运的是,elastic 提供了一套非常先进的工具 ELKB 来满足这些需求。ELKB是指用于日志分析或数据分析的四个软件,每个软件都有独立的功能,可以组合在一起。我们先简单介绍一下这四个软件。
安装
这里我们以 CentOS 7 为例来说明如何安装这些软件。ELK只需要安装在服务器上进行日志采集和分析,而Beats则需要安装在每台日志生成机器(客户端)上,当然也可能包括日志采集服务器本身。
爪哇
$ yum install java-1.8.0
copy code
搜索
$ rpm --import http://packages.elastic.co/GPG-KEY-elasticsearch
$ echo '[elasticsearch-2.x]
name=Elasticsearch repository for 2.x packages
baseurl=http://packages.elastic.co/ela ... entos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
' | tee /etc/yum.repos.d/elasticsearch.repo
$ yum install elasticsearch
copy code
日志存储
$ vim /etc/yum.repos.d/logstash.repo
# 添加以下内容
[logstash-2.4]
name=logstash repository for 2.2 packages
baseurl=http://packages.elasticsearch. ... entos
gpgcheck=1
gpgkey=http://packages.elasticsearch. ... earch
enabled=1
# 安装
$ yum install logstash
copy code
基巴纳
$ vim /etc/yum.repos.d/kibana.repo
# 添加以下内容
[kibana-4.6]
name=Kibana repository for 4.4.x packages
baseurl=http://packages.elastic.co/kibana/4.4/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
# 安装
$ yum install kibana
copy code
节拍
节拍分为多种类型,每种类型都采集特定信息。常用的是Filebeat,它监控文件变化,传输文件内容。一般来说,Filebeat 对日志系统来说就足够了。
我们切换到客户端。首先,您还需要导入 GPG KEY。
$ rpm --import http://packages.elastic.co/GPG-KEY-elasticsearch
copy code
创建一个新的存储库并安装它。
$ vim /etc/yum.repos.d/elastic-beats.repo
# 添加以下内容
[beats]
name=Elastic Beats Repository
baseurl=https://packages.elastic.co/beats/yum/el/$basearch
enabled=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
gpgcheck=1
# 安装
$ yum install filebeat
copy code
弹性搜索
Elasticsearch 不需要太多配置,只需要屏蔽外网访问即可。修改配置文件/etc/elasticsearch/elasticsearch.yml。
network.host: localhost
copy code
启动elasticsearch,服务elasticsearch 启动。
Elasticsearch 本身可以被认为是一个 NoSQL 数据库,通过 REST API 进行操作。数据存储在索引中,相当于elastcisearch中SQL中的一张表。因为elasticsearch主要用于检索数据,所以index有一个叫做mapping的配置。我们用mapping来告诉elasticsearch数据的一些相关信息,比如某个字段是什么数据类型,是否创建索引等。我们先玩elasticsearch,以官方的莎士比亚数据集为例。
$ curl localhost:9200/_cat/indices?v # 查看当前所有的index
health status index pri rep docs.count docs.deleted store.size pri.store.size # 没有任何index
# 创建shakespeare索引,并设置mapping信息
# speaker字段和play_name不需要分析,elasticsearch默认会拆分字符串中的每个词并进行索引
$ curl -XPUT http://localhost:9200/shakespeare -d '
{
"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "string", "index" : "not_analyzed" },
"play_name" : {"type": "string", "index" : "not_analyzed" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
}
';
$ curl localhost:9200/_cat/indices?v # 查看索引
health status index pri rep docs.count docs.deleted store.size pri.store.size
yellow open shakespeare 5 1 0 0 260b 260b
# 下载数据,并将数据集load进索引中
$ wget https://www.elastic.co/guide/e ... .json
$ curl -XPOST 'localhost:9200/shakespeare/_bulk?pretty' --data-binary @shakespeare.json
# 以上操作完成后,elasticsearch中就已经有了我们load的所有数据,并建立好了索引,我们可以开始查询了
# 查询一下含有'man'这个词的text_entry
$ curl -s 'localhost:9200/shakespeare/_search?q=text_entry:man&pretty=1&size=20' | jq '.hits.hits | .[]._source.text_entry'
"man."
"Man?"
"man."
"Why, man?"
"Worthy man!"
"Every man,"
"complete man."
"married man?"
"melancholy man."
"Speak, man."
"Why, man?"
"What, man?"
"prave man."
"Speak, man."
"Why, man?"
"So man and man should be;"
"O, the difference of man and man!"
"The young man is an honest man."
"A gross fat man."
"plain-dealing man?"
copy code
下面我们通过解析nginx的访问日志来讲解ELKB的使用方法。
解析 Nginx 访问日志
整个过程的流程比较简单。Filebeat 采集日志并将它们发送到 Logstash。在 logstash 解析它们之后,将它们写入 ealsticsearch。最后,我们使用 kibana 查看和检索这些日志。
文件节拍
首先切换到客户端,我们来配置filebeat。
$ vim /etc/filebeat/filebeat.yml
...
prospectors:
-
paths:
- /var/log/nginx/access.log
# 找到document_type字段,取消注释,这个字段会告诉logstash日志的类型,对应logstash中的type字段
document_type: nginx
...
# 默认输出为elasticsearch,注释掉,使用logstash
logstash:
hosts: ["IP:5044"] # 注意更改这里的IP
copy code
日志存储
logstash的配置比较麻烦,因为logstash需要接受输入,处理,产生输出。Logstash 采用输入、过滤、输出三阶段配置方式。input配置输入源,filter配置如何处理输入源中的信息,output配置输出位置。
一般来说,输入是节拍的。在filter中,我们解析输入得到的日志,得到我们想要的字段,输出是elasticsearch。这里我们以nginx的访问日志为例。过滤器中有一个关键的东西叫grok,我们用这个东西来解析日志结构。logstash 提供了一些默认的 Patterns,方便我们分析和使用。当然,我们也可以自定义模式,有规律地匹配日志内容。
$ vim /etc/logstash/conf.d/nginx.conf
input {
beats {
port => 5044
}
}
filter {
if [type] == "nginx" { # 这里的type是日志类型,我们在后面的filebeat中设定
grok {
match => { "message" => "%{COMBINEDAPACHELOG} %{QS:gzip_ratio}" } # 使用自带的pattern即可,注意空格
remove_field => ["beat", "input_type", "message", "offset", "tags"] # filebeat添加的字段,我们不需要
}
# 更改匹配到的字段的数据类型
mutate {
convert => ["response", "integer"]
convert => ["bytes", "integer"]
convert => ["responsetime", "float"]
}
# 指定时间戳字段以及具体的格式
date {
match => ["timestamp", "dd/MMM/YYYY:HH:mm:ss Z"]
remove_field => ["timestamp"]
}
}
}
outpugst {
elasticsearch {
hosts => [ "localhost:9200" ]
index => "%{type}-%{+YYYY.MM.dd}" # index中含有时间戳
}
}
copy code
服务logstash start 可以启动logstash。注意它的启动速度很慢。
弹性搜索
在上面的logstash配置中,我们可以看到最终写入elasticsearch的索引收录时间戳,这是比较推荐的做法。因为方便我们每天分析数据。关于elasticsearch,我们只需要配置index Mapping信息即可。因为我们的索引是每天生成的,每天都是一个新的索引,当然不可能每天都配置索引Mapping。这里需要用到elasticsearch的一个特性,Index Template。我们可以创建一个索引配置模板,并使用这个模板来配置所有匹配的索引。
curl -XPUT localhost:9200/_template/nginx -d '
{
"template": "nginx*",
"mappings": {
"_default_": {
"properties": {
"clientip": {
"type": "string",
"index": "not_analyzed"
},
"ident": {
"type": "string"
},
"auth": {
"type": "string"
},
"verb": {
"type": "string"
},
"request": {
"type": "string"
},
"httpversion": {
"type": "string"
},
"rawrequest": {
"type": "string"
},
"response": {
"type": "string"
},
"bytes": {
"type": "integer"
},
"referrer": {
"type": "string"
},
"agent": {
"type": "string"
},
"gzip_ratio": {
"type": "string"
}
}
}
}
}
'
copy code
上面的代码创建了一个名为 nginx 的模板,匹配所有以 nginx 开头的索引。
基巴纳
Kibana 不需要任何配置,直接启动即可。service kibana start,默认运行在5601端口。如果考虑安全性,也可以将kibana配置为只监听本地机器,然后使用nginx进行反向代理和控制权限,这里不再赘述。
接下来,我们需要生成一个日志,然后可以在kibana中查看,以表明系统运行正常。我们使用curl在客户端随机请求nginx生成一个小日志。然后,打开kibana,[服务器ip]:5601。刚进入的时候,首先需要配置Kibana的Index Pattern,告诉kibana我们要查看哪些Index数据,输入nginx*,然后点击Discover浏览数据。
最终效果如下,我们可以在kibana中浏览我们的nginx日志,进行任意搜索。
采集系统(采集系统开发资料,如何开发好的app/小程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-11-29 10:17
采集系统怎么开发呢?采集系统开发资料,想要做采集系统,想要卖采集系统的老板可以先看一下采集系统开发技术资料,想要学习采集系统开发的话,
开发相关app或小程序的话首先要有采集,比如现在市面上非常火的微博采集,还有其他的各种各样的采集源。
想要做一款采集app/小程序,首先需要有相关技术储备。需要了解app后台开发原理,了解小程序后台开发原理,熟悉微信小程序运营原理。做采集系统需要具备自己的核心能力。目前大部分都是提供小程序源码,采集需要自己开发出一套采集小程序。是否有核心能力是判断可不可以做采集系统的唯一条件。
感谢邀请~采集系统开发,这个本身这个可以从以下几点来思考:1.要有源码,否则没办法进行系统开发。2.需要了解小程序/app的运营规则。3.要做出相应的采集功能来。其他的,你可以看看云采集平台,云采集是一个专门对接小程序的平台,目前小程序平台有中国大陆、港澳台、日韩、欧美等,它的出现对大量的广告主、网红、kol来说无疑是一个重大的商机。
人们有着足够的时间采集网络上的信息,并且这是一个非常大的市场。小程序相比app有着极大的优势,首先小程序与微信绑定,很容易去传播推广;小程序的开发成本较低;小程序无需安装即可使用;小程序在微信有7.0的体验版可以了解一下。 查看全部
采集系统(采集系统开发资料,如何开发好的app/小程序)
采集系统怎么开发呢?采集系统开发资料,想要做采集系统,想要卖采集系统的老板可以先看一下采集系统开发技术资料,想要学习采集系统开发的话,
开发相关app或小程序的话首先要有采集,比如现在市面上非常火的微博采集,还有其他的各种各样的采集源。
想要做一款采集app/小程序,首先需要有相关技术储备。需要了解app后台开发原理,了解小程序后台开发原理,熟悉微信小程序运营原理。做采集系统需要具备自己的核心能力。目前大部分都是提供小程序源码,采集需要自己开发出一套采集小程序。是否有核心能力是判断可不可以做采集系统的唯一条件。
感谢邀请~采集系统开发,这个本身这个可以从以下几点来思考:1.要有源码,否则没办法进行系统开发。2.需要了解小程序/app的运营规则。3.要做出相应的采集功能来。其他的,你可以看看云采集平台,云采集是一个专门对接小程序的平台,目前小程序平台有中国大陆、港澳台、日韩、欧美等,它的出现对大量的广告主、网红、kol来说无疑是一个重大的商机。
人们有着足够的时间采集网络上的信息,并且这是一个非常大的市场。小程序相比app有着极大的优势,首先小程序与微信绑定,很容易去传播推广;小程序的开发成本较低;小程序无需安装即可使用;小程序在微信有7.0的体验版可以了解一下。
采集系统(采集系统入口app底部,展示minisystem预装云镜安全卫士)
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-11-26 21:00
采集系统入口app底部,展示minisystem预装lbe云镜安全卫士等抢先5秒内用户正在使用的软件的lbe云镜android版本即刻上线。
android不知道,ios下的blued曾经推出过这种服务。不过目前貌似是仅限于认证身份使用(通过认证才可以使用,在线的服务似乎也没有,更不要说需要注册,
参见国内手机空间,类似于pad版本的一些软件。比如说快图浏览、百度网盘等,主要是先帮你注册账号然后给你推送一些图片什么的。
android现在好像有类似于服务,以前看过报道,
中国移动和blued合作了,你可以在移动官网登录blued官网,点击“volte服务开通”提示填写信息即可。注意千万不要弄成中国移动你懂的!然后网页端就可以了,
android系统可以通过注册某些网站的服务赚取流量
今天用国内的产品,以前是appstore。现在app的服务好像更多了,已经看不见安卓端了。
安卓注册后,app内就自动有对应的服务,用户可以很方便地获取服务内容。
volte的服务
别说android,就是ios,在其他soc的机器上,在完成注册后,必须有一个网页的页面来实现认证,但是安卓手机,注册后,可以直接安装各种soc上的app,就算没有网页的页面, 查看全部
采集系统(采集系统入口app底部,展示minisystem预装云镜安全卫士)
采集系统入口app底部,展示minisystem预装lbe云镜安全卫士等抢先5秒内用户正在使用的软件的lbe云镜android版本即刻上线。
android不知道,ios下的blued曾经推出过这种服务。不过目前貌似是仅限于认证身份使用(通过认证才可以使用,在线的服务似乎也没有,更不要说需要注册,
参见国内手机空间,类似于pad版本的一些软件。比如说快图浏览、百度网盘等,主要是先帮你注册账号然后给你推送一些图片什么的。
android现在好像有类似于服务,以前看过报道,
中国移动和blued合作了,你可以在移动官网登录blued官网,点击“volte服务开通”提示填写信息即可。注意千万不要弄成中国移动你懂的!然后网页端就可以了,
android系统可以通过注册某些网站的服务赚取流量
今天用国内的产品,以前是appstore。现在app的服务好像更多了,已经看不见安卓端了。
安卓注册后,app内就自动有对应的服务,用户可以很方便地获取服务内容。
volte的服务
别说android,就是ios,在其他soc的机器上,在完成注册后,必须有一个网页的页面来实现认证,但是安卓手机,注册后,可以直接安装各种soc上的app,就算没有网页的页面,
采集系统(通过探针去实现身份验证这个概念,涉及的探针有3类)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-24 15:02
采集系统的价格从几千元至几十万不等,从探针采集到采集结果分析到结果可视化,各种系统各有特色,如cissil系统主要覆盖国家政策方向,运动捕捉系统主要覆盖智能物流系统的倾斜数据。实体采集方面很多领域都有自己的优势。在二代身份认证系统领域,比如指纹验证系统的身份识别率达到99.99%。利用特殊网络与定位的身份验证系统在军事侦察系统中有巨大的应用。
寻址比对检验主要依靠由多径射线,定位系统中的水平定位与垂直定位等,主要是为了数据的质量,可视化的支持则能迅速提高该系统的可用性,降低运营成本。
那从实现上来说,目前想通过探针去实现身份验证这个概念,涉及的探针有3类:1,发射卡,属于目前人民日报那样的线下实体业务提供单位提供的探针,原理是发射出去的探针将计算机主机下发的运算结果,通过光电转换后,由仪表来转发给预先准备好的受测者。探针被同步检测到之后就不会再次被送到探针接收器中了。2,接收卡,属于运动捕捉公司提供的探针,提供者会搭建基于api网关的http接口,也即是说,http接口提供者给的协议就是运动捕捉提供者提供的服务。
3,云数据中心,即便是你把精度提高到厘米级,你的数据质量依然很差,因为用户大部分是通过网页看到你的数据结果,而并非实际的数据,你只能保证实际的数据只给到接收端,而把这个指标当做是探针的等级来提升数据质量。如果题主目前在负责针孔摄像机数据质量的提升这一块,不如联系我这边来,我目前的工作是针孔摄像机基础建设、指纹数据采集这些,希望能帮到题主。 查看全部
采集系统(通过探针去实现身份验证这个概念,涉及的探针有3类)
采集系统的价格从几千元至几十万不等,从探针采集到采集结果分析到结果可视化,各种系统各有特色,如cissil系统主要覆盖国家政策方向,运动捕捉系统主要覆盖智能物流系统的倾斜数据。实体采集方面很多领域都有自己的优势。在二代身份认证系统领域,比如指纹验证系统的身份识别率达到99.99%。利用特殊网络与定位的身份验证系统在军事侦察系统中有巨大的应用。
寻址比对检验主要依靠由多径射线,定位系统中的水平定位与垂直定位等,主要是为了数据的质量,可视化的支持则能迅速提高该系统的可用性,降低运营成本。
那从实现上来说,目前想通过探针去实现身份验证这个概念,涉及的探针有3类:1,发射卡,属于目前人民日报那样的线下实体业务提供单位提供的探针,原理是发射出去的探针将计算机主机下发的运算结果,通过光电转换后,由仪表来转发给预先准备好的受测者。探针被同步检测到之后就不会再次被送到探针接收器中了。2,接收卡,属于运动捕捉公司提供的探针,提供者会搭建基于api网关的http接口,也即是说,http接口提供者给的协议就是运动捕捉提供者提供的服务。
3,云数据中心,即便是你把精度提高到厘米级,你的数据质量依然很差,因为用户大部分是通过网页看到你的数据结果,而并非实际的数据,你只能保证实际的数据只给到接收端,而把这个指标当做是探针的等级来提升数据质量。如果题主目前在负责针孔摄像机数据质量的提升这一块,不如联系我这边来,我目前的工作是针孔摄像机基础建设、指纹数据采集这些,希望能帮到题主。
采集系统(采集系统,可以换个方式理解,集群方式(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-23 06:02
采集系统,可以换个方式理解,集群方式,把很多台电脑联合起来作业,每台电脑做不同的事情,用zookeeper管理集群各台电脑的状态,topic,和请求的处理,这样就可以实现机器负载均衡,服务备份,事件过滤等功能;对于自己的开发公司而言,没有必要联合很多台电脑来做集群,关键性功能,放到分布式系统,自己留一个或者几个独立机器,用就可以了。不同环境,开发任务,还是比较合理的;。
用分布式计算网关,
api:就是api网关不止是发消息,
用api网关,可以实现数据库的水平扩展,用数据库来实现的可用性,而且api网关如果要做集群的话,必须要控制好节点的数量,并发,这些要处理好。
不是每台机器都必须用集群,机器数是根据业务的要求来的,并发可用性io并发这些要求高的就用集群或者blockingguest,业务上简单的用一台,高并发稳定io的就上分布式计算平台,集群是不错,但是不是每台机器都适合做分布式计算。
可以采用交换机模式,机器不需要多,master和partner各自拉机器,负责不同的业务,例如某某牌子机器,几块钱一台,服务车主,客户等,必要时可用websocket方式,
感觉主要看网络结构。通常集群(span)模式才是最佳选择。参考:说一下span架构的基本原理?可以考虑加交换机,用第三方解决方案也可以,看自己实际情况选择。 查看全部
采集系统(采集系统,可以换个方式理解,集群方式(组图))
采集系统,可以换个方式理解,集群方式,把很多台电脑联合起来作业,每台电脑做不同的事情,用zookeeper管理集群各台电脑的状态,topic,和请求的处理,这样就可以实现机器负载均衡,服务备份,事件过滤等功能;对于自己的开发公司而言,没有必要联合很多台电脑来做集群,关键性功能,放到分布式系统,自己留一个或者几个独立机器,用就可以了。不同环境,开发任务,还是比较合理的;。
用分布式计算网关,
api:就是api网关不止是发消息,
用api网关,可以实现数据库的水平扩展,用数据库来实现的可用性,而且api网关如果要做集群的话,必须要控制好节点的数量,并发,这些要处理好。
不是每台机器都必须用集群,机器数是根据业务的要求来的,并发可用性io并发这些要求高的就用集群或者blockingguest,业务上简单的用一台,高并发稳定io的就上分布式计算平台,集群是不错,但是不是每台机器都适合做分布式计算。
可以采用交换机模式,机器不需要多,master和partner各自拉机器,负责不同的业务,例如某某牌子机器,几块钱一台,服务车主,客户等,必要时可用websocket方式,
感觉主要看网络结构。通常集群(span)模式才是最佳选择。参考:说一下span架构的基本原理?可以考虑加交换机,用第三方解决方案也可以,看自己实际情况选择。
采集系统(重庆市场监管局推出新型罚没管理办法,让你的单机处理更方便)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-11-15 20:10
采集系统一般是那种企业级的采集软件,这个一般收费在10万左右,而且还要安装在电脑上,还要有布线等等问题;如果一般家用采集的话,安装adsl上网卡,电脑与adsl接口数量越多越好。比如,要上10个站点的话,一般是20个接口就可以了。
老城区改造,偏远地区城市化,大数据采集,连接的网络,数据的存储学生大数据采集,公司客户大数据采集,
抓个大便,
建议某宝搜索看看。
要采集当地的法人就要用个人能够上网的,采集完数据需要上传到服务器或者做网站。
重庆刚刚过去的春节,本地的生产经营监管还在进行中。为应对春节前的打击窝点问题,重庆市场监管局推出新型罚没管理办法,在今年的315大案中涉及大量经营、监管人员处罚,其中部分款项作为奖励使用,实际远高于一般罚款额度。
如果只是处理统计数据,找个excel,扫描二维码都有,但是这么多用于保密或者经营还是比较麻烦。采集软件可以考虑用国内的乐观数据,在财务领域比较有名,但是经营数据基本上就只能靠自己根据电脑设置,电脑数据监管分析是一个巨大的问题,所以光靠自己监管是不够的。国外有好多类似的软件,但是对接电脑读取excel,麻烦点而且响应慢点,如果对接国内公网接口的话,慢则一年半载,速度也是有点慢。
国内其实也有数据采集软件,有保密性要求的话,比如公安局就用了我们的,需要配置对应监管人员识别软件的代码,这个要付钱,又贵又慢,软件还要拿到手。总而言之,如果没有危险级别的数据,还是找我们这些单机处理的好一点。 查看全部
采集系统(重庆市场监管局推出新型罚没管理办法,让你的单机处理更方便)
采集系统一般是那种企业级的采集软件,这个一般收费在10万左右,而且还要安装在电脑上,还要有布线等等问题;如果一般家用采集的话,安装adsl上网卡,电脑与adsl接口数量越多越好。比如,要上10个站点的话,一般是20个接口就可以了。
老城区改造,偏远地区城市化,大数据采集,连接的网络,数据的存储学生大数据采集,公司客户大数据采集,
抓个大便,
建议某宝搜索看看。
要采集当地的法人就要用个人能够上网的,采集完数据需要上传到服务器或者做网站。
重庆刚刚过去的春节,本地的生产经营监管还在进行中。为应对春节前的打击窝点问题,重庆市场监管局推出新型罚没管理办法,在今年的315大案中涉及大量经营、监管人员处罚,其中部分款项作为奖励使用,实际远高于一般罚款额度。
如果只是处理统计数据,找个excel,扫描二维码都有,但是这么多用于保密或者经营还是比较麻烦。采集软件可以考虑用国内的乐观数据,在财务领域比较有名,但是经营数据基本上就只能靠自己根据电脑设置,电脑数据监管分析是一个巨大的问题,所以光靠自己监管是不够的。国外有好多类似的软件,但是对接电脑读取excel,麻烦点而且响应慢点,如果对接国内公网接口的话,慢则一年半载,速度也是有点慢。
国内其实也有数据采集软件,有保密性要求的话,比如公安局就用了我们的,需要配置对应监管人员识别软件的代码,这个要付钱,又贵又慢,软件还要拿到手。总而言之,如果没有危险级别的数据,还是找我们这些单机处理的好一点。
采集系统(腾讯的社交app对吧,你了解多少?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-11-15 20:03
采集系统在常规广告监测中都是广告主自己选定需要监测的广告传播媒体,由媒体方自己的软件系统收集相关资料提交给腾讯平台进行单独计算,通过技术手段可以保证传播内容在不同媒体上的传播效果一致性,但是受制于缺乏统一的投放平台以及信用体系不同,这样的监测无法做到精准,这也造成现在外包在监测全国全媒体的效果变得更加困难。
广告机平台有qq机器人进行全平台监测,但是打开qq就只能看到广告机内容,对于收集的数据来说缺乏进一步分析,每一次查看广告机内容的时候,都需要重新扫码广告机让其看广告机所在机器人发送的链接,但是与每天看广告机数量相比通过监测广告机的数量就显得不合算了。
因为使用的是腾讯的社交app对吧(如qq、微信、陌陌等),其实在各个内容渠道的下载量都有监测,但是第三方软件并不采用他的监测,原因可能是每个渠道收集的数据都不同,个人观点而已。
因为腾讯只有一个bu:tencentsecuritycommunity
一、受限腾讯认为互联网上的问题传统上都可以通过数据管道更容易的解决,传统方式无法解决的问题需要应用新方式获取数据,
二、受众腾讯应该并不是说要对所有群体都进行监测。而是要进行用户画像和人群画像,这应该是一个很重要的工作。比如一个健身房在腾讯新闻上投放了广告,这些用户都是做健身训练的,但是大部分没有购买过健身房的产品,另外一个健身房在阿里巴巴上做了广告,这些用户并不是用户本身,而是他们的朋友。这样对于广告监测服务商来说,就需要对合作的用户进行画像和人群画像。
三、成本目前腾讯非常重视数据收集,甚至进行了让外包公司承担的“规模化压力”。在不同的渠道进行监测成本应该差异不大,但是将这些数据纳入自身体系,同时针对不同行业进行数据处理和分析,需要交给不同的公司,这就增加了额外的人力物力。以上三点是受限的原因。还有就是我个人觉得,监测行业的效果,很大程度上取决于执行方和投放的公司能力,如果这家公司只是想要以低成本进行短期投放的话,监测这块是可以进行投入的,但是如果想通过监测来做投放效果并形成精细化投放模式的话,我觉得效果如何还不是最重要的,重要的是投放到用户的情况,能不能让用户使用到这个产品,产生二次使用的机会,甚至回头客增加了。这是一个很具体的问题,我觉得目前这行的现状是不成熟的,没有一套成熟的标准。
四、如果无效果,能不能对他们进行罚款?或者说只是说可以进行批评?腾讯在看广告有关的媒体的时候, 查看全部
采集系统(腾讯的社交app对吧,你了解多少?(组图))
采集系统在常规广告监测中都是广告主自己选定需要监测的广告传播媒体,由媒体方自己的软件系统收集相关资料提交给腾讯平台进行单独计算,通过技术手段可以保证传播内容在不同媒体上的传播效果一致性,但是受制于缺乏统一的投放平台以及信用体系不同,这样的监测无法做到精准,这也造成现在外包在监测全国全媒体的效果变得更加困难。
广告机平台有qq机器人进行全平台监测,但是打开qq就只能看到广告机内容,对于收集的数据来说缺乏进一步分析,每一次查看广告机内容的时候,都需要重新扫码广告机让其看广告机所在机器人发送的链接,但是与每天看广告机数量相比通过监测广告机的数量就显得不合算了。
因为使用的是腾讯的社交app对吧(如qq、微信、陌陌等),其实在各个内容渠道的下载量都有监测,但是第三方软件并不采用他的监测,原因可能是每个渠道收集的数据都不同,个人观点而已。
因为腾讯只有一个bu:tencentsecuritycommunity
一、受限腾讯认为互联网上的问题传统上都可以通过数据管道更容易的解决,传统方式无法解决的问题需要应用新方式获取数据,
二、受众腾讯应该并不是说要对所有群体都进行监测。而是要进行用户画像和人群画像,这应该是一个很重要的工作。比如一个健身房在腾讯新闻上投放了广告,这些用户都是做健身训练的,但是大部分没有购买过健身房的产品,另外一个健身房在阿里巴巴上做了广告,这些用户并不是用户本身,而是他们的朋友。这样对于广告监测服务商来说,就需要对合作的用户进行画像和人群画像。
三、成本目前腾讯非常重视数据收集,甚至进行了让外包公司承担的“规模化压力”。在不同的渠道进行监测成本应该差异不大,但是将这些数据纳入自身体系,同时针对不同行业进行数据处理和分析,需要交给不同的公司,这就增加了额外的人力物力。以上三点是受限的原因。还有就是我个人觉得,监测行业的效果,很大程度上取决于执行方和投放的公司能力,如果这家公司只是想要以低成本进行短期投放的话,监测这块是可以进行投入的,但是如果想通过监测来做投放效果并形成精细化投放模式的话,我觉得效果如何还不是最重要的,重要的是投放到用户的情况,能不能让用户使用到这个产品,产生二次使用的机会,甚至回头客增加了。这是一个很具体的问题,我觉得目前这行的现状是不成熟的,没有一套成熟的标准。
四、如果无效果,能不能对他们进行罚款?或者说只是说可以进行批评?腾讯在看广告有关的媒体的时候,
采集系统(统计数据采集系统分为哪几类?不同维度进行区分)
采集交流 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-10-28 11:02
采集系统是统计数据的最为核心的问题。因此如何能够拿到并重塑用户数据成为最为关键的问题。根据pgc做数据采集系统需要多大的采集能力,来建设采集数据库,且对数据的可视化、可控制、记录更新以及关联性分析都有一定的技术门槛。1,采集系统分为哪几类?根据成本和需求区分,可以把采集系统按照采集接口和分布型(tp)、远程分布型(pps)以及远程分布型(eps)不同的维度进行区分,下面将逐一进行介绍。
2,tp采集系统:tp是把日志数据,都自己部署到自己云端,在云端有采集系统的硬件上进行分析处理以及数据采集。tp采集系统一般是服务器+采集服务器+管理服务器+数据传输服务器。3,pps采集系统:pps采集系统在不同的网站或者app中采集用户行为日志,在第三方统计机构也会采集第三方的app应用的数据,对此采集系统有较大的问题,一是云端的内容数据受限,二是在数据库中存储的日志内容不是原始日志的实时变化,所以需要对原始数据进行变更和分析。
4,远程分布采集系统:近两年开始兴起,根据业务拓展需求做延伸,把采集的接口拓展到到远程客户端。如何规划更为有效的远程分布采集系统成为最大的难题。5,远程分布式采集系统:无论是tp、pps还是远程分布式采集系统,目前的环境下都没法在服务器或者云端部署,成本过高。一般需要在企业内部部署一个服务器来运行。6,es服务器采集系统:es服务器采集系统按照服务器、数据库、日志数据库进行区分,采集技术为shell+采集数据库。
7,随着国内市场的成熟,也有越来越多的企业愿意选择做paas化的云服务,如vcloud、七牛等厂商。但是在paas服务推行上,中小企业和跨地域业务平台技术人员素质差距较大,也正是需要这样的服务支撑才能提升数据准确性,采集体验和成本并控。 查看全部
采集系统(统计数据采集系统分为哪几类?不同维度进行区分)
采集系统是统计数据的最为核心的问题。因此如何能够拿到并重塑用户数据成为最为关键的问题。根据pgc做数据采集系统需要多大的采集能力,来建设采集数据库,且对数据的可视化、可控制、记录更新以及关联性分析都有一定的技术门槛。1,采集系统分为哪几类?根据成本和需求区分,可以把采集系统按照采集接口和分布型(tp)、远程分布型(pps)以及远程分布型(eps)不同的维度进行区分,下面将逐一进行介绍。
2,tp采集系统:tp是把日志数据,都自己部署到自己云端,在云端有采集系统的硬件上进行分析处理以及数据采集。tp采集系统一般是服务器+采集服务器+管理服务器+数据传输服务器。3,pps采集系统:pps采集系统在不同的网站或者app中采集用户行为日志,在第三方统计机构也会采集第三方的app应用的数据,对此采集系统有较大的问题,一是云端的内容数据受限,二是在数据库中存储的日志内容不是原始日志的实时变化,所以需要对原始数据进行变更和分析。
4,远程分布采集系统:近两年开始兴起,根据业务拓展需求做延伸,把采集的接口拓展到到远程客户端。如何规划更为有效的远程分布采集系统成为最大的难题。5,远程分布式采集系统:无论是tp、pps还是远程分布式采集系统,目前的环境下都没法在服务器或者云端部署,成本过高。一般需要在企业内部部署一个服务器来运行。6,es服务器采集系统:es服务器采集系统按照服务器、数据库、日志数据库进行区分,采集技术为shell+采集数据库。
7,随着国内市场的成熟,也有越来越多的企业愿意选择做paas化的云服务,如vcloud、七牛等厂商。但是在paas服务推行上,中小企业和跨地域业务平台技术人员素质差距较大,也正是需要这样的服务支撑才能提升数据准确性,采集体验和成本并控。

