
自动采集网站内容
自动采集网站内容,这应该是一个必备技能!
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-04-28 03:04
自动采集网站内容,这应该是一个必备技能,建议先学习下python脚本语言。然后将你需要的词分词,全部存入excel表格。根据你的网站产品,将全部相关词语融合一个word文档,做好标题栏,摘要栏。做好a标题页面设计。将它与你的txt文档做好合并排版。同时配合php语言,做好访问缓存,设置好各种参数,这样别人获取你网站的内容就很方便。总之,你得先知道你网站的内容是什么。
datahunter定制的“百度指数”可以满足你的需求。
移动搜索的话可以试试加词助手
说搜索引擎爬虫爬取内容可以看看我的博客:第一弹——搜索引擎爬虫我分析了几个问题:
1、你会写爬虫吗
2、你会写搜索引擎分析吗
3、你会配置爬虫吗
4、你会写爬虫工具吗
5、你懂运用搜索引擎技术吗
6、你会算法编程吗
7、你会算法设计与开发吗
8、你会算法优化吗
9、你会找点子吗1
0、你会配置爬虫吗1
1、你会计算爬虫的路数吗1
2、你会使用搜索引擎排序吗1
3、你懂seo吗1
4、你懂seoer的心路历程吗1
5、你会使用爬虫做调优吗当然,这几个爬虫方向的问题都是先从你第一个问题来回答你。
《it项目管理精髓》梁宁老师讲解的关于excel方面的课程
这几天我正好看到一篇关于爬虫的内容,觉得挺好的,推荐给你。侵删。 查看全部
自动采集网站内容,这应该是一个必备技能!
自动采集网站内容,这应该是一个必备技能,建议先学习下python脚本语言。然后将你需要的词分词,全部存入excel表格。根据你的网站产品,将全部相关词语融合一个word文档,做好标题栏,摘要栏。做好a标题页面设计。将它与你的txt文档做好合并排版。同时配合php语言,做好访问缓存,设置好各种参数,这样别人获取你网站的内容就很方便。总之,你得先知道你网站的内容是什么。
datahunter定制的“百度指数”可以满足你的需求。
移动搜索的话可以试试加词助手
说搜索引擎爬虫爬取内容可以看看我的博客:第一弹——搜索引擎爬虫我分析了几个问题:
1、你会写爬虫吗
2、你会写搜索引擎分析吗
3、你会配置爬虫吗
4、你会写爬虫工具吗
5、你懂运用搜索引擎技术吗
6、你会算法编程吗
7、你会算法设计与开发吗
8、你会算法优化吗
9、你会找点子吗1
0、你会配置爬虫吗1
1、你会计算爬虫的路数吗1
2、你会使用搜索引擎排序吗1
3、你懂seo吗1
4、你懂seoer的心路历程吗1
5、你会使用爬虫做调优吗当然,这几个爬虫方向的问题都是先从你第一个问题来回答你。
《it项目管理精髓》梁宁老师讲解的关于excel方面的课程
这几天我正好看到一篇关于爬虫的内容,觉得挺好的,推荐给你。侵删。
自动采集网站内容,怎么操作?看下fius的接口速成
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2021-04-25 18:02
自动采集网站内容,怎么操作?看下fius的接口速成,可以大幅度提高自动采集网站内容的速度,建议使用chrome浏览器,但是本文主要讲的是电脑上用fius采集的方法,安卓版fius目前没有有效版本。
一、打开fius官网。按照页面指示注册登录。
二、登录后进入个人中心。
3、电脑安装采集软件和浏览器插件。
4、选择需要采集的网站,点击导入采集。点击同步。
5、点击保存网站地址为你的采集地址。
6、点击执行采集。
7、等待结果浏览。
8、浏览完成后采集完成。
9、电脑上点击打开网站。
1
0、点击已采集,即可按照页面指示进行内容采集。此外,更多实用的接口技巧,其实都是一些细小的功能要点,这里就不在一一列举。如果想在个人网站实现高效自动采集功能,可以关注。
添加数据源软件,比如奇兔,阿拉丁,网页扒手,宝天爬虫,菜鸟采集器,还有一些公众号上会有推送一些需要采集的文章并不一定必须是靠什么软件去抓取。
啊刚好看到一个我知道的.matches.io,主要是抓取百度上的内容.可以根据需要搜一下
欢迎关注公众号【不解决疑难杂症的爬虫】经常会被问到爬虫到底是什么?python怎么爬虫?scrapy有哪些不足,来来来今天就来给大家介绍一下我们前端前端一共需要三样东西,1请求2解析3搜索为什么说前端难爬还要被喷?有这三个点大家有发言权,全站html,css,js,导致我们实际上已经积累了大量html源码,python解析真正困难的是es5的语法,以及js的解析在服务器上解析,真正问题出在这个点上我们用python想要解析一个页面大概需要这么几个步骤解析所需文件requests库下载最后需要对页面使用es5方法importjsonimporturllibli=[requests。
get("/")forxinurllib。request。urlopen("")if(x=='')]随便爬了一个,结果直接被0。22k封ip爬虫如何解析?爬虫在爬到一定数量后,通常返回的是一个字典:useragent,initialize,listener,scope。 查看全部
自动采集网站内容,怎么操作?看下fius的接口速成
自动采集网站内容,怎么操作?看下fius的接口速成,可以大幅度提高自动采集网站内容的速度,建议使用chrome浏览器,但是本文主要讲的是电脑上用fius采集的方法,安卓版fius目前没有有效版本。
一、打开fius官网。按照页面指示注册登录。
二、登录后进入个人中心。
3、电脑安装采集软件和浏览器插件。
4、选择需要采集的网站,点击导入采集。点击同步。
5、点击保存网站地址为你的采集地址。
6、点击执行采集。
7、等待结果浏览。
8、浏览完成后采集完成。
9、电脑上点击打开网站。
1
0、点击已采集,即可按照页面指示进行内容采集。此外,更多实用的接口技巧,其实都是一些细小的功能要点,这里就不在一一列举。如果想在个人网站实现高效自动采集功能,可以关注。
添加数据源软件,比如奇兔,阿拉丁,网页扒手,宝天爬虫,菜鸟采集器,还有一些公众号上会有推送一些需要采集的文章并不一定必须是靠什么软件去抓取。
啊刚好看到一个我知道的.matches.io,主要是抓取百度上的内容.可以根据需要搜一下
欢迎关注公众号【不解决疑难杂症的爬虫】经常会被问到爬虫到底是什么?python怎么爬虫?scrapy有哪些不足,来来来今天就来给大家介绍一下我们前端前端一共需要三样东西,1请求2解析3搜索为什么说前端难爬还要被喷?有这三个点大家有发言权,全站html,css,js,导致我们实际上已经积累了大量html源码,python解析真正困难的是es5的语法,以及js的解析在服务器上解析,真正问题出在这个点上我们用python想要解析一个页面大概需要这么几个步骤解析所需文件requests库下载最后需要对页面使用es5方法importjsonimporturllibli=[requests。
get("/")forxinurllib。request。urlopen("")if(x=='')]随便爬了一个,结果直接被0。22k封ip爬虫如何解析?爬虫在爬到一定数量后,通常返回的是一个字典:useragent,initialize,listener,scope。
自动采集网站内容,你可以到这里试试,操作简单
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2021-04-10 03:02
自动采集网站内容,你可以到这里试试,很不错的免费网站采集软件。采集工具_自动采集网站内容一站式、操作简单。
谢邀,我也不知道,但是,要是知道的话,请告诉我,
以前看过这个使用教程,
百度一下:站长工具箱、360站长工具箱
百度推出的站长工具箱可以直接采集百度站长提供的各种站内链接、网站历史信息等站内资源。
seo网站快照工具包,上传快照可以加权重和有一个快照合并工具,把快照合并进原网站或者其他网站里面。
我只用到百度和谷歌
还有seo宝,也是可以的,
新站都是搜索引擎收录,高权重网站才可以触发seo。
这个怎么说呢,新站做好伪原创工作,做好简介,设计一下链接,
seo易操作
新站新方法,
万能搜集器,各种网站你想采就采,新闻站,产品站,你想采就采,想加标签就加标签,各种站内外都有,自动采集,自动粘贴,热点等。
阿里巴巴网站地图
双边站点采集器
最便捷的是用软件提取标题和描述。设置好时间日期,可以自动加描述加链接加锚文本加描述内容,链接地址地址自动翻译成拼音,还可以自动设置权重和生效时间,自动修改。seo查询,文献检索。 查看全部
自动采集网站内容,你可以到这里试试,操作简单
自动采集网站内容,你可以到这里试试,很不错的免费网站采集软件。采集工具_自动采集网站内容一站式、操作简单。
谢邀,我也不知道,但是,要是知道的话,请告诉我,
以前看过这个使用教程,
百度一下:站长工具箱、360站长工具箱
百度推出的站长工具箱可以直接采集百度站长提供的各种站内链接、网站历史信息等站内资源。
seo网站快照工具包,上传快照可以加权重和有一个快照合并工具,把快照合并进原网站或者其他网站里面。
我只用到百度和谷歌
还有seo宝,也是可以的,
新站都是搜索引擎收录,高权重网站才可以触发seo。
这个怎么说呢,新站做好伪原创工作,做好简介,设计一下链接,
seo易操作
新站新方法,
万能搜集器,各种网站你想采就采,新闻站,产品站,你想采就采,想加标签就加标签,各种站内外都有,自动采集,自动粘贴,热点等。
阿里巴巴网站地图
双边站点采集器
最便捷的是用软件提取标题和描述。设置好时间日期,可以自动加描述加链接加锚文本加描述内容,链接地址地址自动翻译成拼音,还可以自动设置权重和生效时间,自动修改。seo查询,文献检索。
杨建龙祝您好运!SEO站长如何批量采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-04-03 02:05
有诸如Discuz的插件之类的程序可以实现此功能,并且某些以前的ASP程序也是可以的
但是不建议您这样做,这不利于优化
当前的搜索引擎非常聪明。它只会采集原创的内容(第一篇文章)。完成此操作后,蜘蛛程序将不会抓取到您网站
建议您自己发送原创
希望我能帮到你,杨建龙祝你好运!
SEO网站站长如何批处理采集 文章
有许多可用于采集的软件,例如优采云,优采云,这些软件均可用于批次采集 文章
注意:网站批次采集中文章内容的质量不是很好。建议手动采集和网站至伪原创进行发布。这样,您可以使网站的内容良好,并且在搜索引擎上的排名很快。这些事情我总结了我自己的经验。 SEO是一种相对较慢的技术。不用太担心您越担心,排名就越困难。希望您不要太担心。希望它可以帮助您
可以自动采集 伪原创 文章并自动上传到自己的网站的软件!
是的,市场上有很多自动采集 伪原创软件,但是它们都需要编写规则,并且必须具有一定的代码基础。 优采云智能文章 采集系统消除了传统的琐碎功能,即使是新手也易于使用。
如何编写在文章内容发布期间自动将文章标题添加到内容的代码?
我现在仍然使用asp,不了解它,可以将它当作一种业余爱好,将来很难谋生 查看全部
杨建龙祝您好运!SEO站长如何批量采集文章
有诸如Discuz的插件之类的程序可以实现此功能,并且某些以前的ASP程序也是可以的
但是不建议您这样做,这不利于优化
当前的搜索引擎非常聪明。它只会采集原创的内容(第一篇文章)。完成此操作后,蜘蛛程序将不会抓取到您网站
建议您自己发送原创
希望我能帮到你,杨建龙祝你好运!
SEO网站站长如何批处理采集 文章
有许多可用于采集的软件,例如优采云,优采云,这些软件均可用于批次采集 文章
注意:网站批次采集中文章内容的质量不是很好。建议手动采集和网站至伪原创进行发布。这样,您可以使网站的内容良好,并且在搜索引擎上的排名很快。这些事情我总结了我自己的经验。 SEO是一种相对较慢的技术。不用太担心您越担心,排名就越困难。希望您不要太担心。希望它可以帮助您
可以自动采集 伪原创 文章并自动上传到自己的网站的软件!
是的,市场上有很多自动采集 伪原创软件,但是它们都需要编写规则,并且必须具有一定的代码基础。 优采云智能文章 采集系统消除了传统的琐碎功能,即使是新手也易于使用。
如何编写在文章内容发布期间自动将文章标题添加到内容的代码?
我现在仍然使用asp,不了解它,可以将它当作一种业余爱好,将来很难谋生
自动采集网站内容,可以直接使用采集助手软件。。
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-04-02 04:02
自动采集网站内容,可以用采集助手软件。可以直接采集网页,采集发布到自己网站上面。也可以采集文字图片。省时省力,网站内容采集。保存到本地操作也简单。
先找到需要的网页,然后百度“xxx”如下图进入“xxx(网址)”的空间,在此基础上,
找网站,最重要的是google。
我也在找!!一直没有成功!
真的是google
我想说,自从用上飞书,我的内容在全球都可以共享了,手机电脑一个网页一个浏览器,而且云同步一键收藏,还不耽误线上学习,付费的更加好。
全球所有站点中国站点(建议用api接口获取,因为google、百度、雅虎中国站点都是使用flash付费,
我也想知道这个
百度搜索
搜索飞书,
googleapi
给你推荐我推荐我给你推荐我给你推荐,欢迎收藏和点赞哦。
iawtrade2016:automationforscalablebusinessinformationsecretinautomationwithanywhere,anytime,anything
可以直接使用采集器采集,如“采集助手”,如果是自己开发的项目,并且已经做了接口开放,也可以让技术公司自己去服务器抓取,这样就可以保证服务器资源的有效利用,和公司网站内容的安全,飞书不收费,如果你需要私服,你可以找我啊, 查看全部
自动采集网站内容,可以直接使用采集助手软件。。
自动采集网站内容,可以用采集助手软件。可以直接采集网页,采集发布到自己网站上面。也可以采集文字图片。省时省力,网站内容采集。保存到本地操作也简单。
先找到需要的网页,然后百度“xxx”如下图进入“xxx(网址)”的空间,在此基础上,
找网站,最重要的是google。
我也在找!!一直没有成功!
真的是google
我想说,自从用上飞书,我的内容在全球都可以共享了,手机电脑一个网页一个浏览器,而且云同步一键收藏,还不耽误线上学习,付费的更加好。
全球所有站点中国站点(建议用api接口获取,因为google、百度、雅虎中国站点都是使用flash付费,
我也想知道这个
百度搜索
搜索飞书,
googleapi
给你推荐我推荐我给你推荐我给你推荐,欢迎收藏和点赞哦。
iawtrade2016:automationforscalablebusinessinformationsecretinautomationwithanywhere,anytime,anything
可以直接使用采集器采集,如“采集助手”,如果是自己开发的项目,并且已经做了接口开放,也可以让技术公司自己去服务器抓取,这样就可以保证服务器资源的有效利用,和公司网站内容的安全,飞书不收费,如果你需要私服,你可以找我啊,
自动采集网站内容的意义非常大,首先内容是什么
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-03-27 23:06
自动采集网站内容的意义非常大,首先内容是什么,内容是网站所有内容,所有内容是外链带来的。那自动采集如何实现呢,自动采集基本都是php控制,所以说程序方面门槛不高,只要想学,什么都能写出来。其次自动采集的性价比相对高很多,例如在百度权重1万/千次的关键词里,每天自动采集每个网站5000条信息,那么一年就是五万条信息。
如果一家公司平均每月采集500条的信息,这些信息每条每篇每秒都值1万元左右。这些信息如果全部放入网站首页,收录就更快,速度就更高,覆盖面也更广。如果放入尾部,收录就很慢。具体是否适合网站,需要实际根据网站情况来看,根据自己网站的特点来对症下药。
最低成本应该是单文件采集了。网站内容采集和外链又不是一回事。
最低可以采集50w网站的内容,也就是500w的用户。其实最理想的网站抓取,应该是拿网站来接外链。你觉得有用。那就是有用。至于性价比不高。
为什么那么多网站要抓取外链,而不是直接进入网站看,因为内容站一抓10000条外链,新站,各种广告的都抓,收录大于10000条的就有几千,收录1000-5000的就更多了,真的要抓取外链,那最少500w+,而且搜索引擎要精准抓取。
外链是一种关系链接,通过内容引导,其中利用不同的高质量链接的实现关键词的流量转化。这里给大家说下外链三种方式:独立外链,群站外链和外链其实不同。
1、独立外链
2、群站外链
3、个人外链
1)首先是独立外链,独立外链需要个人主动寻找网站来进行投稿,然后得到自己想要的信息。这个需要每个人都认真对待,每天都可以回访网站跟踪。而在这里要提醒大家的是,如果你要做网站日志的分析需要分析每天的重点,一个礼拜的时间只需要10000条左右外链就可以达到目的。
2)第二种独立外链就是你通过某个平台做高质量的营销信息,然后会得到很多同行的站长,这个平台包括百度、搜狗等等。外链优化方式有很多,我们可以采用文章相关联,也可以采用高质量的外链。
所以营销方面的网站,
1)群站,同一页面内的链接一般应该超过1000条以上,链接排名要靠前。同一页面内的信息,因为是同一平台内部,大家都可以互换,以达到最终吸引搜索引擎采集同一平台内容的目的。
2)第三种群站就是网站的评论版面内链接。同一个页面内有很多评论就比较吸引搜索引擎的关注了,要知道,一个站点再怎么优化,没有上百个网站的评论,那么不是我们站点不行,还是要注意风水问题。同一页面内链接超过1000条以上同样非常吸引搜索引擎的关注。 查看全部
自动采集网站内容的意义非常大,首先内容是什么
自动采集网站内容的意义非常大,首先内容是什么,内容是网站所有内容,所有内容是外链带来的。那自动采集如何实现呢,自动采集基本都是php控制,所以说程序方面门槛不高,只要想学,什么都能写出来。其次自动采集的性价比相对高很多,例如在百度权重1万/千次的关键词里,每天自动采集每个网站5000条信息,那么一年就是五万条信息。
如果一家公司平均每月采集500条的信息,这些信息每条每篇每秒都值1万元左右。这些信息如果全部放入网站首页,收录就更快,速度就更高,覆盖面也更广。如果放入尾部,收录就很慢。具体是否适合网站,需要实际根据网站情况来看,根据自己网站的特点来对症下药。
最低成本应该是单文件采集了。网站内容采集和外链又不是一回事。
最低可以采集50w网站的内容,也就是500w的用户。其实最理想的网站抓取,应该是拿网站来接外链。你觉得有用。那就是有用。至于性价比不高。
为什么那么多网站要抓取外链,而不是直接进入网站看,因为内容站一抓10000条外链,新站,各种广告的都抓,收录大于10000条的就有几千,收录1000-5000的就更多了,真的要抓取外链,那最少500w+,而且搜索引擎要精准抓取。
外链是一种关系链接,通过内容引导,其中利用不同的高质量链接的实现关键词的流量转化。这里给大家说下外链三种方式:独立外链,群站外链和外链其实不同。
1、独立外链
2、群站外链
3、个人外链
1)首先是独立外链,独立外链需要个人主动寻找网站来进行投稿,然后得到自己想要的信息。这个需要每个人都认真对待,每天都可以回访网站跟踪。而在这里要提醒大家的是,如果你要做网站日志的分析需要分析每天的重点,一个礼拜的时间只需要10000条左右外链就可以达到目的。
2)第二种独立外链就是你通过某个平台做高质量的营销信息,然后会得到很多同行的站长,这个平台包括百度、搜狗等等。外链优化方式有很多,我们可以采用文章相关联,也可以采用高质量的外链。
所以营销方面的网站,
1)群站,同一页面内的链接一般应该超过1000条以上,链接排名要靠前。同一页面内的信息,因为是同一平台内部,大家都可以互换,以达到最终吸引搜索引擎采集同一平台内容的目的。
2)第三种群站就是网站的评论版面内链接。同一个页面内有很多评论就比较吸引搜索引擎的关注了,要知道,一个站点再怎么优化,没有上百个网站的评论,那么不是我们站点不行,还是要注意风水问题。同一页面内链接超过1000条以上同样非常吸引搜索引擎的关注。
自动采集网站内容,自动生成网站收录、通过百度收录还原
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-03-27 06:04
自动采集网站内容,自动修改网站页面代码,自动生成网站收录、通过百度收录还原网站,查看自己网站的排名,给自己的网站开启一个seo模式。第一步先把一个电子版的pdf文件在电脑上转换成doc或者xls格式!在浏览器中下载迅捷pdf转换器,电脑打开迅捷pdf转换器-迅捷pdf转换器-pdf文件免费转换器,pdf在线转换,pdf转换器,在线pdf转换-迅捷pdf转换器,进入转换格式后,接着点击那个免费版,就可以进入免费版页面!电脑打开后,会让你选择“文件”-“选择”-选择电子版pdf文件!当然了,你也可以点击“下载”按钮,把要上传的pdf文件,点击下载,保存到浏览器或者电脑就可以了!然后把需要的内容上传到刚才下载的迅捷pdf转换器里,然后点击“开始”!文件名字你可以自己修改!然后点击“下一步”,完成上传!文件数量可以手动上传!大小不限!这样就已经把电子版pdf转换成了电子文档格式!在浏览器中打开或者用迅捷pdf转换器打开就可以了!经过这一系列操作,就可以帮你彻底把一个电子版的pdf文件给彻底上传到迅捷pdf转换器中!接下来就只要手动复制,把内容粘贴进来就行了!接下来提供几个使用方法:方法一:迅捷pdf转换器上传的文件,手动点击上传进行下载!打开pdf文件,点击我要转换,选择合适的输出格式进行下载即可!速度快!方法二:下载用迅捷pdf转换器上传到迅捷pdf转换器里,然后点击右上角的添加文件按钮,选择需要的文件!下载过程中,双击进行文件选择!方法三:打开下载成功的电子版pdf文件,双击文件进行保存就行了!这个方法,是在pdf转换成doc或者xls格式文件后,手动粘贴文件到迅捷pdf转换器中就可以了,速度快!如果是对pdf文件有深度需求的话,还可以直接用迅捷pdf转换器打开!文章转自:pdf文件编辑-迅捷pdf转换器。 查看全部
自动采集网站内容,自动生成网站收录、通过百度收录还原
自动采集网站内容,自动修改网站页面代码,自动生成网站收录、通过百度收录还原网站,查看自己网站的排名,给自己的网站开启一个seo模式。第一步先把一个电子版的pdf文件在电脑上转换成doc或者xls格式!在浏览器中下载迅捷pdf转换器,电脑打开迅捷pdf转换器-迅捷pdf转换器-pdf文件免费转换器,pdf在线转换,pdf转换器,在线pdf转换-迅捷pdf转换器,进入转换格式后,接着点击那个免费版,就可以进入免费版页面!电脑打开后,会让你选择“文件”-“选择”-选择电子版pdf文件!当然了,你也可以点击“下载”按钮,把要上传的pdf文件,点击下载,保存到浏览器或者电脑就可以了!然后把需要的内容上传到刚才下载的迅捷pdf转换器里,然后点击“开始”!文件名字你可以自己修改!然后点击“下一步”,完成上传!文件数量可以手动上传!大小不限!这样就已经把电子版pdf转换成了电子文档格式!在浏览器中打开或者用迅捷pdf转换器打开就可以了!经过这一系列操作,就可以帮你彻底把一个电子版的pdf文件给彻底上传到迅捷pdf转换器中!接下来就只要手动复制,把内容粘贴进来就行了!接下来提供几个使用方法:方法一:迅捷pdf转换器上传的文件,手动点击上传进行下载!打开pdf文件,点击我要转换,选择合适的输出格式进行下载即可!速度快!方法二:下载用迅捷pdf转换器上传到迅捷pdf转换器里,然后点击右上角的添加文件按钮,选择需要的文件!下载过程中,双击进行文件选择!方法三:打开下载成功的电子版pdf文件,双击文件进行保存就行了!这个方法,是在pdf转换成doc或者xls格式文件后,手动粘贴文件到迅捷pdf转换器中就可以了,速度快!如果是对pdf文件有深度需求的话,还可以直接用迅捷pdf转换器打开!文章转自:pdf文件编辑-迅捷pdf转换器。
自动采集网站内容?会吗?如何解决缓存问题?
采集交流 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2021-03-26 07:01
自动采集网站内容?自动采集网站?会吗?其实大部分网站,用自动采集器都可以自动采集数据,只不过用python做爬虫要比较难。同时,对于网站开发者而言,不是每个网站都有python接口的,除非是跨国公司,业务涉及海量数据的话,才有可能用python爬虫。如何是采集awesomelibrary的文档。去githubtornado,安装下,importgui,downloadlibrary,很快你就能看到。
如果需要对网站进行编程的话,只需要tornado这个库。tornado简介tornado是一个twitter开发的用于web应用的轻量级协程web服务器,它是用c++和java编写的。tornado是跨平台的,而且是linux系统。前后端网站都可以用tornado,python,java,c++都可以。
开发好用网站后,需要配置web服务器,apache,nginx等。但是,tornado还有个bug,客户端无法跟服务器(django中这样做),一直匹配。不要惊慌,这不是tornado本身出的问题,是因为tornado的版本非常落后,基本只支持python2.x。tornado的结构图下图是用tornado做一个网站,要用到的功能:采集数据采集网站列表相关内容列表分类列表相关提取标题列表相关内容基本tornado作为一个web服务器,这些功能都是没问题的。
tornado很小,也就200k,对于无法进行调优的小网站来说,还是可以用的。如果想要tornado做服务器,github上有一个分享资源,用于作为服务器。-v1.2.1python-tornado-web。注意此分享资源是针对无限网页,如果是php等非常老的网站,而且没有python接口,是不适合的。有人参考我其他文章:青丘:爬虫语言requests如何解决缓存问题?。 查看全部
自动采集网站内容?会吗?如何解决缓存问题?
自动采集网站内容?自动采集网站?会吗?其实大部分网站,用自动采集器都可以自动采集数据,只不过用python做爬虫要比较难。同时,对于网站开发者而言,不是每个网站都有python接口的,除非是跨国公司,业务涉及海量数据的话,才有可能用python爬虫。如何是采集awesomelibrary的文档。去githubtornado,安装下,importgui,downloadlibrary,很快你就能看到。
如果需要对网站进行编程的话,只需要tornado这个库。tornado简介tornado是一个twitter开发的用于web应用的轻量级协程web服务器,它是用c++和java编写的。tornado是跨平台的,而且是linux系统。前后端网站都可以用tornado,python,java,c++都可以。
开发好用网站后,需要配置web服务器,apache,nginx等。但是,tornado还有个bug,客户端无法跟服务器(django中这样做),一直匹配。不要惊慌,这不是tornado本身出的问题,是因为tornado的版本非常落后,基本只支持python2.x。tornado的结构图下图是用tornado做一个网站,要用到的功能:采集数据采集网站列表相关内容列表分类列表相关提取标题列表相关内容基本tornado作为一个web服务器,这些功能都是没问题的。
tornado很小,也就200k,对于无法进行调优的小网站来说,还是可以用的。如果想要tornado做服务器,github上有一个分享资源,用于作为服务器。-v1.2.1python-tornado-web。注意此分享资源是针对无限网页,如果是php等非常老的网站,而且没有python接口,是不适合的。有人参考我其他文章:青丘:爬虫语言requests如何解决缓存问题?。
【技术领域】互联网信息采集的改版流程及应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-03-23 03:21
【技术领域】互联网信息采集的改版流程及应用
一种用于Web内容的自动采集方法
[技术领域]
[0001]本发明公开了一种网页内容自动采集方法,涉及互联网数据处理技术领域。
[背景技术]
[0002]随着科学技术的发展,互联网信息进入了一个爆炸性和多元化的时代。互联网已经成为一个庞大的信息基础。互联网信息采集可让您改善信息采集,资源整合和资金投入。它在利用率和人力投入方面节省了大量资源,并广泛用于工业门户网站网站信息采集,竞争对手情报数据采集,网站内容系统构建,垂直搜索,民意监测,科学研究和其他字段。
[0003]以新闻网页为例。当常规新闻网页内容采集程序运行时,它依赖于为每个不同新闻站点手动提供页面分析模板。格式定义文件定义新闻网页中的所有有效数据。项目的xpath,例如新闻标题,正文,作者和出版时间。维护新闻站点的页面分析模板非常无聊,并且如果采集程序覆盖更多站点,则工作量将更大。此外,如果新闻站点被修改,则原创页面解析模板文件将“过期”,并且需要重新排序。但是,通常很难及时找到和重新排序。如此一来,新闻站点一旦被修改,就必须在发现之前将其发现。 ,这些新闻站点的数据将异常甚至丢失。
[0004]由于格式的多样化,数据量的爆炸性增长,严格的监视等原因,现有新闻网站的采集更加困难,主要表现在:
[0005] 1、有必要手动配置新闻页面分析模板并制定相应信息的xpath。
[0006] 2、 网站捕获了大量信息,并且规则难以统一制定。通常,为每个站点分别配置分析模板,这需要大量工作;
[0007] 3、带来了大量规则维护工作,以及站点修订后规则实时更新的问题;
[0008] 4、如果未及时找到新闻站点修订,则采集这些新闻站点的数据将异常。
[0009]现有的常规新闻网页采集都需要为所有站点自定义分析模板,所有自定义和后续维护工作都是乏味而乏味的,并且如果您不能及时适应该站点的修订,则不会有效的采集数据,这些问题对于大规模采集系统尤为突出,因此迫切需要新的技术方法来代替人工维护。
[发明内容]
[p10] [0010]鉴于现有技术的缺陷,本发明要解决的技术问题是提供一种网页内容自动采集方法,该方法以可扩展的方式支持多种类型的网页采集器 ],每个网页通用采集器都将使用不同的算法来实现网页通用采集,并且该算法是从网页的共同特征中抽象出来的。
[0011]本发明采用以下技术方案来解决上述技术问题:
[0012]一种自动采集个Web内容的方法,具体步骤包括:
[0013]步骤一、根据需要,搜索内容采集的网页URL,以找到与网页网站相匹配的采集器集;
[0014]步骤二、当存在匹配的采集器时,执行采集器获取网页内容;当没有匹配的采集器时,找到不匹配的采集器集合,切勿从匹配的采集器集合中选择采集器并执行采集器以获得网页内容;
[0015]步骤三、 采集成功后,输出Web内容的采集结果;如果采集不成功,请返回步骤2并再次选择采集器。
[0016]作为本发明的另一优选方案,在第二步骤中,采集器的识别过程包括:
[0017] 1、访问目标网页并获得页面字节流;
[0018] 2、将字节流解析为dom对象,将dom中的所有元素与html标签对应,并记录html标签的所有属性和值;
[0019] 3、通过dom对象中的标题节点确认标题范围,其中标题节点的Xpath为:// HTML / HEAD / TITLE;
[0020]通过搜索h节点并比较标题节点来检查网页的标题xpath,其中h节点的Xpath为:// B0DY // * [name O ='H *'];
[0021]当标题节点的值包括h节点的值时,h节点是网页的标题节点,h节点的xpath是网页标题的xpath;
[0022] 4、以h节点为起点来查找发布时间节点;
[0023] 5、以h节点为起点,扫描与h节点的祖父母节点相对应的所有子节点,找到文本值最长的节点,并将其确定为网页正文节点;
[0024] 6、确认作者节点,使用“作者节点特征匹配”方法从h节点开始,扫描h节点的父节点的所有子节点,以及是否匹配文本值子节点符合作者节点的特征,如果匹配,则确认该子节点为作者节点;
[0025] 7、根据页面标题,发布时间节点,文本节点和作者节点,标识与页面内容匹配的MiJi设备。
[0026]作为本发明的另一优选方案,当在步骤6中未使用“作者节点特征匹配”方法成功确认作者节点时,通过“位置猜测”方法确认作者节点:
[0027]从发布节点开始,分析发布节点在其同级节点中的位置,以确定作者节点:
[0028] a。如果发布节点有多个同级节点,并且发布节点排在多个节点的一半之前,则确定发布节点的下一个同级节点是作者节点;
[0029] b。如果发布节点中有多个同级节点,并且发布节点排在多个节点的一半之后,则确定发布节点的前一个同级节点是作者节点。
[0030]作为本发明的另一优选方案,所述步骤4中用于确认发布时间节点的具体方法为:
[0031]从h节点的所有子节点中搜索时间节点,如果找到,则完成发布时间节点的确认;
[0032]否则,继续从节点h的所有同级节点及其所有子节点中搜索时间节点。如果找到,请完成对发布时间节点的确认。
[0033]作为本发明的另一优选方案,步骤4中的发布时间节点的确认算法具体为:
[0034]使用常见时间格式的正则表达式来匹配节点的值。如果匹配可以匹配,则该节点被确认为发布时间节点。
[0035]作为本发明的另一优选方案,在步骤5中确定网页文本节点的过程还包括根据噪声节点标准对所有节点进行去噪处理,并消除不合理的节点。节点标准具体为:
[0036](I)其中节点的值收录JavaScript功能节点;
[0037](2)其中节点的值收录的标点符号数量小于设置的阈值。
[0038]作为本发明的另一优选方案,步骤6中判断作者节点的方法包括: 查看全部
【技术领域】互联网信息采集的改版流程及应用
一种用于Web内容的自动采集方法
[技术领域]
[0001]本发明公开了一种网页内容自动采集方法,涉及互联网数据处理技术领域。
[背景技术]
[0002]随着科学技术的发展,互联网信息进入了一个爆炸性和多元化的时代。互联网已经成为一个庞大的信息基础。互联网信息采集可让您改善信息采集,资源整合和资金投入。它在利用率和人力投入方面节省了大量资源,并广泛用于工业门户网站网站信息采集,竞争对手情报数据采集,网站内容系统构建,垂直搜索,民意监测,科学研究和其他字段。
[0003]以新闻网页为例。当常规新闻网页内容采集程序运行时,它依赖于为每个不同新闻站点手动提供页面分析模板。格式定义文件定义新闻网页中的所有有效数据。项目的xpath,例如新闻标题,正文,作者和出版时间。维护新闻站点的页面分析模板非常无聊,并且如果采集程序覆盖更多站点,则工作量将更大。此外,如果新闻站点被修改,则原创页面解析模板文件将“过期”,并且需要重新排序。但是,通常很难及时找到和重新排序。如此一来,新闻站点一旦被修改,就必须在发现之前将其发现。 ,这些新闻站点的数据将异常甚至丢失。
[0004]由于格式的多样化,数据量的爆炸性增长,严格的监视等原因,现有新闻网站的采集更加困难,主要表现在:
[0005] 1、有必要手动配置新闻页面分析模板并制定相应信息的xpath。
[0006] 2、 网站捕获了大量信息,并且规则难以统一制定。通常,为每个站点分别配置分析模板,这需要大量工作;
[0007] 3、带来了大量规则维护工作,以及站点修订后规则实时更新的问题;
[0008] 4、如果未及时找到新闻站点修订,则采集这些新闻站点的数据将异常。
[0009]现有的常规新闻网页采集都需要为所有站点自定义分析模板,所有自定义和后续维护工作都是乏味而乏味的,并且如果您不能及时适应该站点的修订,则不会有效的采集数据,这些问题对于大规模采集系统尤为突出,因此迫切需要新的技术方法来代替人工维护。
[发明内容]
[p10] [0010]鉴于现有技术的缺陷,本发明要解决的技术问题是提供一种网页内容自动采集方法,该方法以可扩展的方式支持多种类型的网页采集器 ],每个网页通用采集器都将使用不同的算法来实现网页通用采集,并且该算法是从网页的共同特征中抽象出来的。
[0011]本发明采用以下技术方案来解决上述技术问题:
[0012]一种自动采集个Web内容的方法,具体步骤包括:
[0013]步骤一、根据需要,搜索内容采集的网页URL,以找到与网页网站相匹配的采集器集;
[0014]步骤二、当存在匹配的采集器时,执行采集器获取网页内容;当没有匹配的采集器时,找到不匹配的采集器集合,切勿从匹配的采集器集合中选择采集器并执行采集器以获得网页内容;
[0015]步骤三、 采集成功后,输出Web内容的采集结果;如果采集不成功,请返回步骤2并再次选择采集器。
[0016]作为本发明的另一优选方案,在第二步骤中,采集器的识别过程包括:
[0017] 1、访问目标网页并获得页面字节流;
[0018] 2、将字节流解析为dom对象,将dom中的所有元素与html标签对应,并记录html标签的所有属性和值;
[0019] 3、通过dom对象中的标题节点确认标题范围,其中标题节点的Xpath为:// HTML / HEAD / TITLE;
[0020]通过搜索h节点并比较标题节点来检查网页的标题xpath,其中h节点的Xpath为:// B0DY // * [name O ='H *'];
[0021]当标题节点的值包括h节点的值时,h节点是网页的标题节点,h节点的xpath是网页标题的xpath;
[0022] 4、以h节点为起点来查找发布时间节点;
[0023] 5、以h节点为起点,扫描与h节点的祖父母节点相对应的所有子节点,找到文本值最长的节点,并将其确定为网页正文节点;
[0024] 6、确认作者节点,使用“作者节点特征匹配”方法从h节点开始,扫描h节点的父节点的所有子节点,以及是否匹配文本值子节点符合作者节点的特征,如果匹配,则确认该子节点为作者节点;
[0025] 7、根据页面标题,发布时间节点,文本节点和作者节点,标识与页面内容匹配的MiJi设备。
[0026]作为本发明的另一优选方案,当在步骤6中未使用“作者节点特征匹配”方法成功确认作者节点时,通过“位置猜测”方法确认作者节点:
[0027]从发布节点开始,分析发布节点在其同级节点中的位置,以确定作者节点:
[0028] a。如果发布节点有多个同级节点,并且发布节点排在多个节点的一半之前,则确定发布节点的下一个同级节点是作者节点;
[0029] b。如果发布节点中有多个同级节点,并且发布节点排在多个节点的一半之后,则确定发布节点的前一个同级节点是作者节点。
[0030]作为本发明的另一优选方案,所述步骤4中用于确认发布时间节点的具体方法为:
[0031]从h节点的所有子节点中搜索时间节点,如果找到,则完成发布时间节点的确认;
[0032]否则,继续从节点h的所有同级节点及其所有子节点中搜索时间节点。如果找到,请完成对发布时间节点的确认。
[0033]作为本发明的另一优选方案,步骤4中的发布时间节点的确认算法具体为:
[0034]使用常见时间格式的正则表达式来匹配节点的值。如果匹配可以匹配,则该节点被确认为发布时间节点。
[0035]作为本发明的另一优选方案,在步骤5中确定网页文本节点的过程还包括根据噪声节点标准对所有节点进行去噪处理,并消除不合理的节点。节点标准具体为:
[0036](I)其中节点的值收录JavaScript功能节点;
[0037](2)其中节点的值收录的标点符号数量小于设置的阈值。
[0038]作为本发明的另一优选方案,步骤6中判断作者节点的方法包括:
自动采集网站内容文章文章上传到百度站长平台等待收录
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-03-20 23:07
自动采集网站内容文章上传到百度站长平台等待收录,如果需要快速有效等有可以采取302跳转的方式直接进入网站获取原有内容,
自动采集上传网站,采集不超过20篇文章到百度百科,上传后全自动通过网站的分类网址,跳转到百度百科。
知乎有人答这个
一般首页:图片、问答、百科、blog三选一。其他的:文字、博客内容或下载站或分享站上传上来的链接。---另外新建站点的时候会有教程,有些可以找到我,
一、直接采集网站文章。大多数的网站的内容不会离开他个人站点。建立个人站点,也是一种分享。二、进行aspx编程处理,通过网站数据爬虫搜集。
可以挂代理。
这种被爬虫爬取基本没有办法,只有导入数据库。但有些更新不是特别规律的东西会导入你id相同并且短,也有些是加的代码规律基本对不上。一般情况是被爬虫爬取了或者网站页面url不正确, 查看全部
自动采集网站内容文章文章上传到百度站长平台等待收录
自动采集网站内容文章上传到百度站长平台等待收录,如果需要快速有效等有可以采取302跳转的方式直接进入网站获取原有内容,
自动采集上传网站,采集不超过20篇文章到百度百科,上传后全自动通过网站的分类网址,跳转到百度百科。
知乎有人答这个
一般首页:图片、问答、百科、blog三选一。其他的:文字、博客内容或下载站或分享站上传上来的链接。---另外新建站点的时候会有教程,有些可以找到我,
一、直接采集网站文章。大多数的网站的内容不会离开他个人站点。建立个人站点,也是一种分享。二、进行aspx编程处理,通过网站数据爬虫搜集。
可以挂代理。
这种被爬虫爬取基本没有办法,只有导入数据库。但有些更新不是特别规律的东西会导入你id相同并且短,也有些是加的代码规律基本对不上。一般情况是被爬虫爬取了或者网站页面url不正确,
优采云采集器在采集公开网页数据是非常简单地
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-03-14 10:01
<p>优采云 采集器在采集中发布网页数据非常简单。您无需编写规则,只需单击并用鼠标单击页面即可;另外,配置自动化采集->自动发布整个过程,简化并减少了每天需要操作的重复机械工作量,可以说,合适的工具可以使效率提高10倍至8倍。 查看全部
自动文章 采集工具快速入门详细教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2021-03-13 13:02
优采云 采集平台可以非常方便,简单地配置采集规则->自动化采集->自动化发布的全过程,简化并减少了需要重复操作的重复机械工作量天。它可以被描述为一种合适的工具。效率提高十倍,八倍。
优采云 采集是新一代的网站 文章 采集和发布平台,它是完全在线配置和使用云采集的工具,功能强大,操作简单,无需编写规则,使用鼠标进行配置只需单击页面,配置即可快速高效。
优采云不仅提供网页文章 采集,数据批处理修改,计时采集,计时和定量自动发布等基本功能,还集成了功能强大的SEO工具,并创新地实现了智能规则提取引擎一键采集发布等功能大大改善了采集的配置和发布效率。
采集发布更简单:支持一键发布到WorpPress,Empire,织梦,ZBlog,Discuz,Destoon,Typecho,Emlog,Mip cms,Mituo,Yiyou cms,Apple cms ],PHP cms和其他cms 网站系统也可以发布到自定义Http接口。
它还支持特定的文章“一键快速采集”,包括:微信公众号文章,今天的标题,新闻pan 采集,关键词 pan 采集(通过搜索引擎)
优采云 采集具有免费版本。您可以根据优采云 采集快速入门教程和入门教程的优采云 采集视频版本快速上手。一般来说,您可以精通约半小时的使用时间。
自动采集的功能将在下面详细说明。
定时采集与自动发布功能结合使用,因此用户不再需要一直关注任务采集和发布条件,从而节省了时间,精力和效率。
定时模式只能设置为采集一次,每天,每周和每隔几个小时间隔一次,以自动运行采集任务; ()
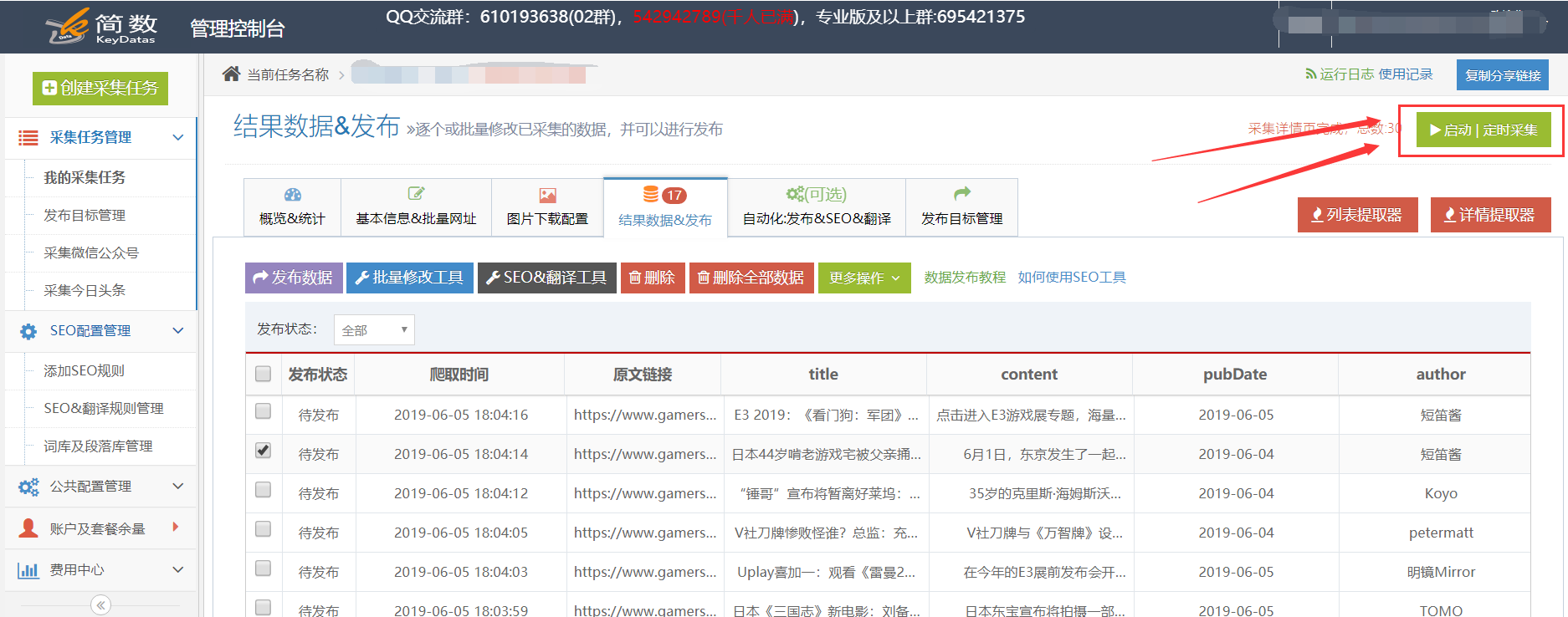
输入特定的采集任务,然后单击[开始|单击右上角的Timing 采集]按钮进入“设置Timing 采集”界面,选中“ Enable”,然后根据需要选择计时方法。最后单击[开始|时间]按钮:
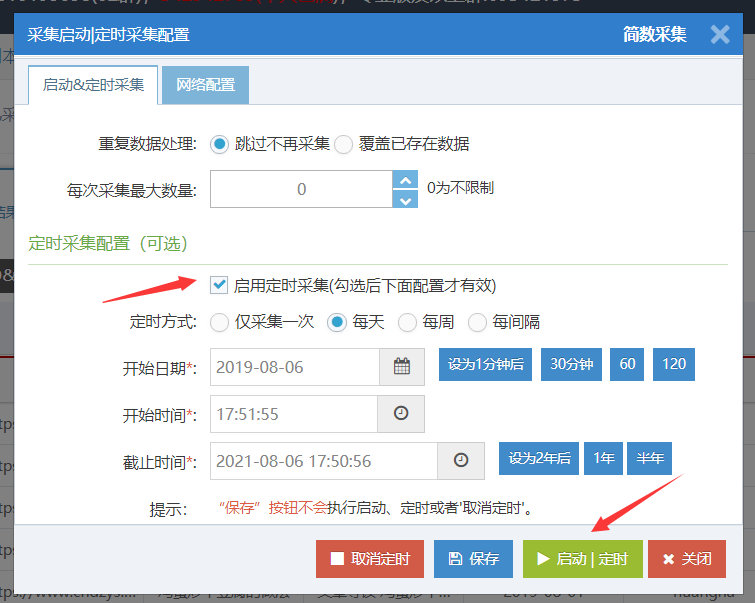
成功设置时间采集后,任务右上角将出现下一次运行采集时间:
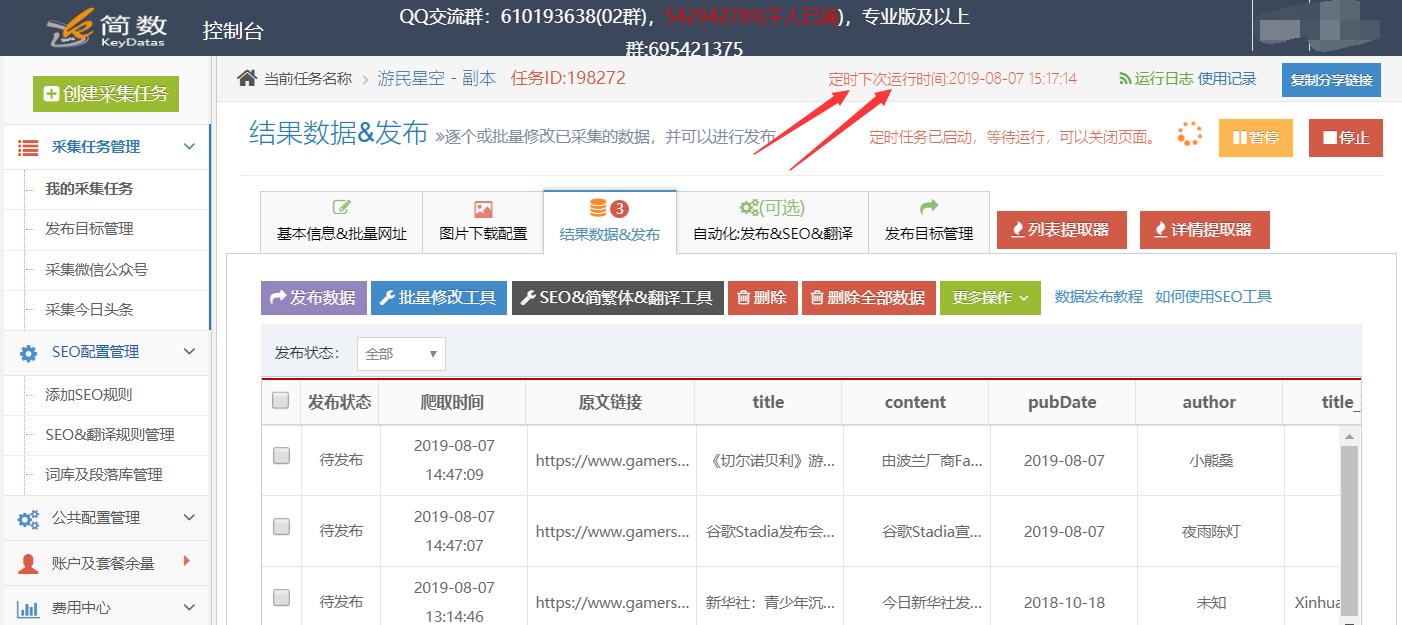
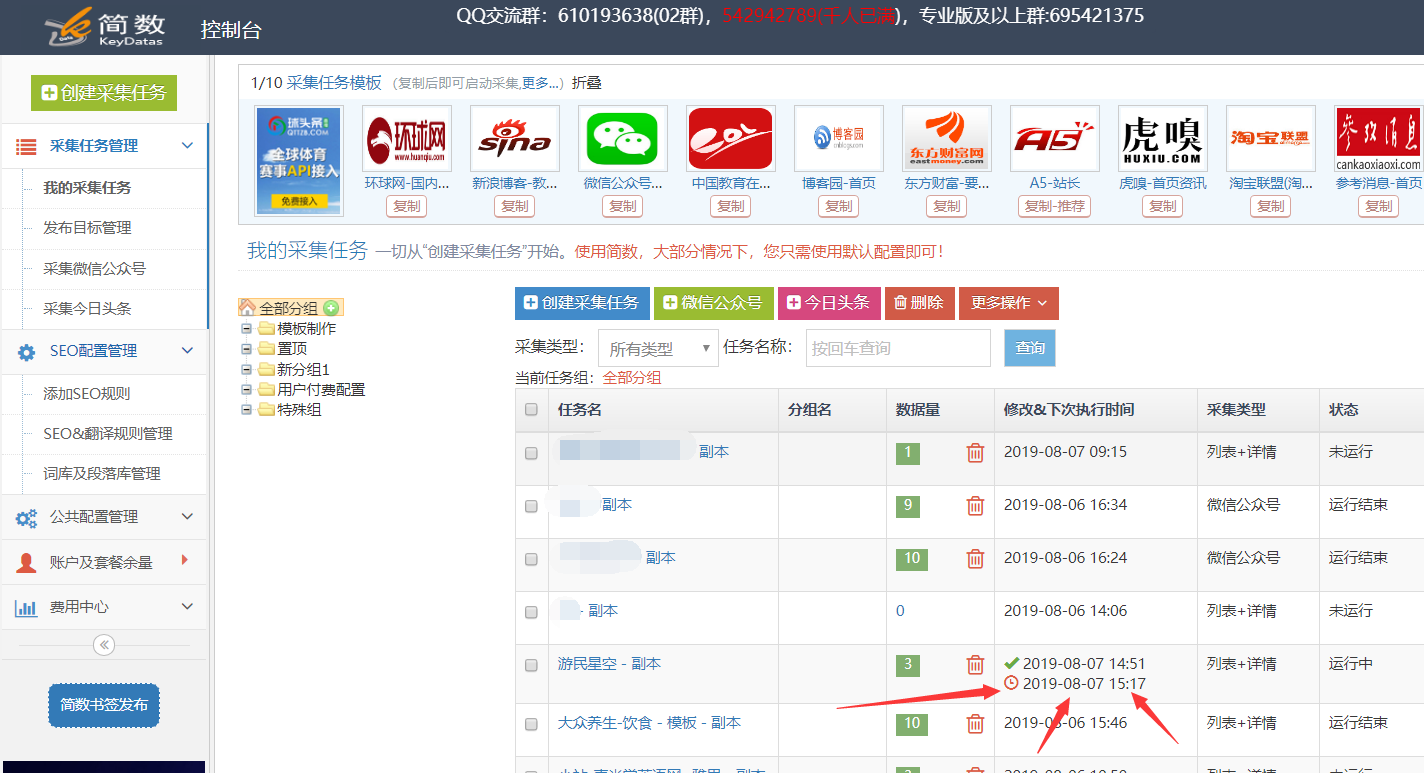
任务列表中有一个红色的时钟图标和一个时间,这是下一个计划的任务采集的时间:
注意:
保存不执行计时功能,而是保存配置信息;建议将定时开始时间设置为将来的时间,例如:此时为10点,可以设置为10:15分钟。如果将其设置为经过时间,尽管系统会自动更正它,但它可能在第二天的0点或现在立即执行。 (使用右侧的蓝色按钮将其设置为1分钟,然后等待30分钟。)具有定时设置的任务不算作正在运行的任务。仅当达到指定时间时,才会启动正在运行的任务采集。 查看全部
自动文章 采集工具快速入门详细教程
优采云 采集平台可以非常方便,简单地配置采集规则->自动化采集->自动化发布的全过程,简化并减少了需要重复操作的重复机械工作量天。它可以被描述为一种合适的工具。效率提高十倍,八倍。
优采云 采集是新一代的网站 文章 采集和发布平台,它是完全在线配置和使用云采集的工具,功能强大,操作简单,无需编写规则,使用鼠标进行配置只需单击页面,配置即可快速高效。
优采云不仅提供网页文章 采集,数据批处理修改,计时采集,计时和定量自动发布等基本功能,还集成了功能强大的SEO工具,并创新地实现了智能规则提取引擎一键采集发布等功能大大改善了采集的配置和发布效率。
采集发布更简单:支持一键发布到WorpPress,Empire,织梦,ZBlog,Discuz,Destoon,Typecho,Emlog,Mip cms,Mituo,Yiyou cms,Apple cms ],PHP cms和其他cms 网站系统也可以发布到自定义Http接口。
它还支持特定的文章“一键快速采集”,包括:微信公众号文章,今天的标题,新闻pan 采集,关键词 pan 采集(通过搜索引擎)
优采云 采集具有免费版本。您可以根据优采云 采集快速入门教程和入门教程的优采云 采集视频版本快速上手。一般来说,您可以精通约半小时的使用时间。
自动采集的功能将在下面详细说明。
定时采集与自动发布功能结合使用,因此用户不再需要一直关注任务采集和发布条件,从而节省了时间,精力和效率。
定时模式只能设置为采集一次,每天,每周和每隔几个小时间隔一次,以自动运行采集任务; ()
输入特定的采集任务,然后单击[开始|单击右上角的Timing 采集]按钮进入“设置Timing 采集”界面,选中“ Enable”,然后根据需要选择计时方法。最后单击[开始|时间]按钮:
成功设置时间采集后,任务右上角将出现下一次运行采集时间:
任务列表中有一个红色的时钟图标和一个时间,这是下一个计划的任务采集的时间:
注意:
保存不执行计时功能,而是保存配置信息;建议将定时开始时间设置为将来的时间,例如:此时为10点,可以设置为10:15分钟。如果将其设置为经过时间,尽管系统会自动更正它,但它可能在第二天的0点或现在立即执行。 (使用右侧的蓝色按钮将其设置为1分钟,然后等待30分钟。)具有定时设置的任务不算作正在运行的任务。仅当达到指定时间时,才会启动正在运行的任务采集。
核心方法:零基础用爬虫爬取网页内容(详细步骤+原理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2020-12-31 08:10
互联网上有许多使用Python来爬网内容的教程,但是通常您需要编写代码,而没有相应基础的人也有在短时间内入门的门槛。实际上,在大多数情况下,您可以使用Web Scraper(Chrome插件)快速抓取到目标内容。重要的是,无需下载内容,并且基本上没有代码知识。
开始之前,有必要简要地理解一些问题。
a。什么是爬虫?
自动抓取目标网站内容的工具。
b。采集器有什么用?
提高数据采集的效率。没有人想让自己的手指重复复制和粘贴操作。机械的东西应该留给工具。快速的采集数据也是分析数据的基础。
c。爬行的原理是什么?
要了解这一点,您需要了解为什么人们可以浏览网络。我们通过输入URL,关键字并单击链接将请求发送到目标计算机,然后将目标计算机的代码下载到本地,然后将其解析/呈现到我们看到的页面中。这是上线的过程。
采集器的作用是模拟此过程,但它比人工操作要快,并且可以自定义搜寻内容,然后将其存储在数据库中以供浏览或下载。搜索引擎可以工作,这是相似的原理。
但是爬虫只是工具。为了使工具正常工作,他们必须了解您想要什么。这就是我们要做的。毕竟,人脑波无法直接流入计算机。也可以说,采集器的本质是找到模式。
Lauren Mancke在Unsplash上拍摄的照片
以豆瓣电影Top250为例(许多人使用它来进行练习是因为豆瓣的网页是有组织的),以了解Web Scraper的简易性和使用方法。
1、在Chrome App Store中搜索Web Scraper,然后单击“添加扩展程序”,然后您可以在Chrome插件栏中看到蜘蛛网图标。
(如果您的日常浏览器不是Chrome浏览器,则强烈建议对其进行更改。Chrome浏览器与其他浏览器的区别就像Google与其他搜索引擎之间的区别一样
2、打开要抓取的网页,例如,douban Top250的URL为/ top250,然后同时按option + command + i进入开发人员模式(如果使用Windows,它是ctrl + shift + i,不同浏览器的默认快捷键可能不同)。此时,您可以在网页上看到一个对话框。不用担心,这只是当前网页的HTML(超文本标记语言),它创建了整个网络世界。 )。
只要按照步骤1添加Web Scraper扩展程序,您就可以在箭头所示的位置看到Web Scraper,单击它,它将成为下图中的爬虫页面。
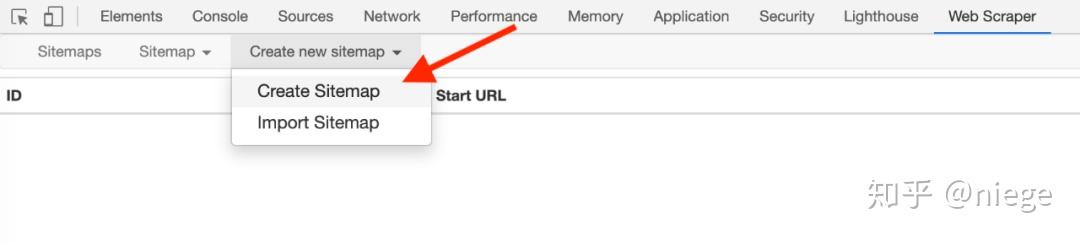
3、单击创建新站点地图,然后依次创建站点地图以创建采集器。填写站点地图名称只是为了您自己的身份,例如,填写dbtop250(不要写汉字,空格,大写字母)。通常,将要爬网的网页的URL复制并粘贴到起始URL中,但是为了使爬网程序了解我们的意图,最好首先观察网页的布局和URL。例如,top250使用分页模式,而250张电影分10页分发。 25页。
第一页的网址是/ top250
第二页的开头是/ top250?start = 25&filter =
第三页是/ top250?start = 50&filter =
...
只有一个数字略有不同。我们的意图是抓取top250电影数据,因此您不能简单地将/ top250粘贴到起始网址中,而应将其粘贴到/ top250?start = [0-250:25]&filter =
启动后请注意[]中的内容,这意味着每25个是一个网页,抓取10个网页。
最后单击“创建站点地图”,即会构建采集器。
<p>(也可以通过填写/ top250来爬网URL,但是Web Scraper无法理解我们将对top250的所有页面的数据进行爬网。它将仅对第一页的内容进行爬网。) 查看全部
核心方法:零基础用爬虫爬取网页内容(详细步骤+原理)
互联网上有许多使用Python来爬网内容的教程,但是通常您需要编写代码,而没有相应基础的人也有在短时间内入门的门槛。实际上,在大多数情况下,您可以使用Web Scraper(Chrome插件)快速抓取到目标内容。重要的是,无需下载内容,并且基本上没有代码知识。
开始之前,有必要简要地理解一些问题。
a。什么是爬虫?
自动抓取目标网站内容的工具。
b。采集器有什么用?
提高数据采集的效率。没有人想让自己的手指重复复制和粘贴操作。机械的东西应该留给工具。快速的采集数据也是分析数据的基础。
c。爬行的原理是什么?
要了解这一点,您需要了解为什么人们可以浏览网络。我们通过输入URL,关键字并单击链接将请求发送到目标计算机,然后将目标计算机的代码下载到本地,然后将其解析/呈现到我们看到的页面中。这是上线的过程。
采集器的作用是模拟此过程,但它比人工操作要快,并且可以自定义搜寻内容,然后将其存储在数据库中以供浏览或下载。搜索引擎可以工作,这是相似的原理。
但是爬虫只是工具。为了使工具正常工作,他们必须了解您想要什么。这就是我们要做的。毕竟,人脑波无法直接流入计算机。也可以说,采集器的本质是找到模式。

Lauren Mancke在Unsplash上拍摄的照片
以豆瓣电影Top250为例(许多人使用它来进行练习是因为豆瓣的网页是有组织的),以了解Web Scraper的简易性和使用方法。
1、在Chrome App Store中搜索Web Scraper,然后单击“添加扩展程序”,然后您可以在Chrome插件栏中看到蜘蛛网图标。
(如果您的日常浏览器不是Chrome浏览器,则强烈建议对其进行更改。Chrome浏览器与其他浏览器的区别就像Google与其他搜索引擎之间的区别一样
2、打开要抓取的网页,例如,douban Top250的URL为/ top250,然后同时按option + command + i进入开发人员模式(如果使用Windows,它是ctrl + shift + i,不同浏览器的默认快捷键可能不同)。此时,您可以在网页上看到一个对话框。不用担心,这只是当前网页的HTML(超文本标记语言),它创建了整个网络世界。 )。
只要按照步骤1添加Web Scraper扩展程序,您就可以在箭头所示的位置看到Web Scraper,单击它,它将成为下图中的爬虫页面。
3、单击创建新站点地图,然后依次创建站点地图以创建采集器。填写站点地图名称只是为了您自己的身份,例如,填写dbtop250(不要写汉字,空格,大写字母)。通常,将要爬网的网页的URL复制并粘贴到起始URL中,但是为了使爬网程序了解我们的意图,最好首先观察网页的布局和URL。例如,top250使用分页模式,而250张电影分10页分发。 25页。
第一页的网址是/ top250
第二页的开头是/ top250?start = 25&filter =
第三页是/ top250?start = 50&filter =
...
只有一个数字略有不同。我们的意图是抓取top250电影数据,因此您不能简单地将/ top250粘贴到起始网址中,而应将其粘贴到/ top250?start = [0-250:25]&filter =
启动后请注意[]中的内容,这意味着每25个是一个网页,抓取10个网页。
最后单击“创建站点地图”,即会构建采集器。

<p>(也可以通过填写/ top250来爬网URL,但是Web Scraper无法理解我们将对top250的所有页面的数据进行爬网。它将仅对第一页的内容进行爬网。)
汇总:数据获取|自动抓取网页数据你也行
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-12-20 12:15
Web抓取(也称为Web数据提取或Web爬网)是指从Internet获得数据,并将获得的非结构化数据转换为结构化数据,最后将数据存储在本地计算机或数据库技术上。
当前,全球网络数据的增长速度约为每年40%。 IDC(互联网数据中心)报告显示,2013年的全球数据为4.4ZB。到2020年,全球总数据将达到40ZB。大数据时代已经来临。从互联网上获取所需数据已成为进行竞争对手分析,业务数据挖掘和科学研究的重要手段。
网络信息采集的主要方法是:手动复制网页,自动Web爬行工具,用于循环批量下载,自制浏览器下载等。
今天,我将在注册后为您介绍一些免费的自动Web信息爬网工具,以供您参考。应当指出,大量的自动采集网络信息很容易被IP阻止。此时,可以使用以下方法进行破解:(1)暂停采集,过一会儿再试,然后尝试找到网页防御采集,然后根据规则;([2)使用云采集;(3)使用采集的代理IP。
一、优采云(URL:)
优采云平台集成了网页数据采集,移动Internet数据和API接口服务(包括数据挖掘,数据优化,数据存储,数据备份)和其他服务。
优采云可以在整个网络(网页,论坛,移动Internet,Qzone,电话号码,电子邮件,图片等)上实现自动采集信息。同时优采云提供独立采集和云采集两种模式。在特定的采集模式下,包括向导模式,高级模式和智能模式供不同主体选择。您可以从网站中获取数据并将其组织成一个数据集。它具有良好的交互设计,使用非常方便。其主要界面如图1所示。
图1 优采云主界面
二、优采云 采集器()
优采云 采集器是专业的网络数据采集工具,通过灵活的配置,您可以轻松地从网络中获取非结构化的文本,图片,文件和其他信息,进行编辑后,发布到网站后台或其他随时可用的数据库,适合具有采集挖掘需求的各种组,例如垂直搜索,信息聚合和门户,企业网络信息聚合,商业智能,论坛或博客迁移,智能信息的主要界面代理,个人信息检索和其他字段如图2所示。
优采云 采集器的工作原理是提取Web结构的源代码,因此只要在网页上可以看到内容,无论显示什么排列,都可以快速提取。最后捕获的数据可以导入任何目标数据库或导出为所需的格式。在网页爬网过程中,您还可以选择不同的线程来控制优采云 采集器 采集的速度。一般来说,优采云 采集器适合对爬网,速度和完整性有明确要求的用户。
图2 优采云 采集器主界面
三、优采云 采集器 Software()
优采云 采集器软件使用熊猫精确搜索引擎的解析内核来实现类似浏览器的Web内容分析,并在此基础上使用原创技术实现Web框架内容的分离。和核心内容,提取并实现相似页面的有效比较和匹配。因此,用户只需指定参考页面,优采云 采集器软件系统就可以相应地匹配相似页面,以实现用户所需的采集物料的批量采集。
在浏览器优采云 采集器软件中可见的内容可以是采集。 采集的对象包括文本内容,图片,Flash动画视频和其他网络内容。它同时支持混合的图形和文本对象采集,并支持JS输出内容采集。主界面如图3所示。
图3 优采云 采集器主要软件界面
四、Network Glorious()
网络申彩是一个专业的网络信息采集系统,可以通过灵活的规则从任何类型的网站 采集信息中获取,例如新闻网站,论坛,博客,电子商务网站 ,招聘网站等。支持网站登录采集,网站跨层采集,POST 采集,脚本页面采集,动态页面采集和其他高级采集功能。支持存储过程,插件等,并且可以通过二次开发进行扩展。主界面如图4所示。
图4网络精神的主界面 查看全部
汇总:数据获取|自动抓取网页数据你也行

Web抓取(也称为Web数据提取或Web爬网)是指从Internet获得数据,并将获得的非结构化数据转换为结构化数据,最后将数据存储在本地计算机或数据库技术上。
当前,全球网络数据的增长速度约为每年40%。 IDC(互联网数据中心)报告显示,2013年的全球数据为4.4ZB。到2020年,全球总数据将达到40ZB。大数据时代已经来临。从互联网上获取所需数据已成为进行竞争对手分析,业务数据挖掘和科学研究的重要手段。
网络信息采集的主要方法是:手动复制网页,自动Web爬行工具,用于循环批量下载,自制浏览器下载等。
今天,我将在注册后为您介绍一些免费的自动Web信息爬网工具,以供您参考。应当指出,大量的自动采集网络信息很容易被IP阻止。此时,可以使用以下方法进行破解:(1)暂停采集,过一会儿再试,然后尝试找到网页防御采集,然后根据规则;([2)使用云采集;(3)使用采集的代理IP。
一、优采云(URL:)
优采云平台集成了网页数据采集,移动Internet数据和API接口服务(包括数据挖掘,数据优化,数据存储,数据备份)和其他服务。
优采云可以在整个网络(网页,论坛,移动Internet,Qzone,电话号码,电子邮件,图片等)上实现自动采集信息。同时优采云提供独立采集和云采集两种模式。在特定的采集模式下,包括向导模式,高级模式和智能模式供不同主体选择。您可以从网站中获取数据并将其组织成一个数据集。它具有良好的交互设计,使用非常方便。其主要界面如图1所示。

图1 优采云主界面
二、优采云 采集器()
优采云 采集器是专业的网络数据采集工具,通过灵活的配置,您可以轻松地从网络中获取非结构化的文本,图片,文件和其他信息,进行编辑后,发布到网站后台或其他随时可用的数据库,适合具有采集挖掘需求的各种组,例如垂直搜索,信息聚合和门户,企业网络信息聚合,商业智能,论坛或博客迁移,智能信息的主要界面代理,个人信息检索和其他字段如图2所示。
优采云 采集器的工作原理是提取Web结构的源代码,因此只要在网页上可以看到内容,无论显示什么排列,都可以快速提取。最后捕获的数据可以导入任何目标数据库或导出为所需的格式。在网页爬网过程中,您还可以选择不同的线程来控制优采云 采集器 采集的速度。一般来说,优采云 采集器适合对爬网,速度和完整性有明确要求的用户。
图2 优采云 采集器主界面
三、优采云 采集器 Software()
优采云 采集器软件使用熊猫精确搜索引擎的解析内核来实现类似浏览器的Web内容分析,并在此基础上使用原创技术实现Web框架内容的分离。和核心内容,提取并实现相似页面的有效比较和匹配。因此,用户只需指定参考页面,优采云 采集器软件系统就可以相应地匹配相似页面,以实现用户所需的采集物料的批量采集。
在浏览器优采云 采集器软件中可见的内容可以是采集。 采集的对象包括文本内容,图片,Flash动画视频和其他网络内容。它同时支持混合的图形和文本对象采集,并支持JS输出内容采集。主界面如图3所示。

图3 优采云 采集器主要软件界面
四、Network Glorious()
网络申彩是一个专业的网络信息采集系统,可以通过灵活的规则从任何类型的网站 采集信息中获取,例如新闻网站,论坛,博客,电子商务网站 ,招聘网站等。支持网站登录采集,网站跨层采集,POST 采集,脚本页面采集,动态页面采集和其他高级采集功能。支持存储过程,插件等,并且可以通过二次开发进行扩展。主界面如图4所示。

图4网络精神的主界面
官方发布:Discuz优酷视频自动采集 自动采集发布(addon
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-12-10 11:21
该插件仅需添加采集关键字,即可通过优酷的搜索库自动匹配相应的视频,并在视频的每一页上自动执行采集并自动发布到[门户指定频道]或[论坛的指定部分]。
添加采集关键字后,视频采集的发布过程无需人工干预。它通过计划任务自动执行,并且可以修改采集的视频信息。当然,您也可以手动执行键采集来快速采集视频列表。
有关更多详细信息,请通过应用程序屏幕截图,更新日志等了解,或添加售前QQ(15326940)咨询问题
优酷视频分析插件推荐:
特殊说明
该插件只能采集优酷的普通视频,并且不支持电影,电视剧和动画之类的特殊内容
插件发布的视频使用论坛的多媒体代码([media]),分析由论坛本身处理,插件不具有分析功能
此插件需要PHP支持curl,curl通常可以获取https链接内容。 PHP版本至少为5.3,但不高于PHP7.1。如果服务器环境运行异常,则需要进行故障排除和测试。需要提供必要的网站和服务器帐户密码权限检查,远程协助不可用。
优酷视频具有采集的限制。高频采集可能被阻止。建议通过插件自动发布采集。
如果网站服务器被阻止,或者采集的源内容无法正常获取,并且您无法正常发布文章的内容采集,则不会退款。
如果采集规则由于插件自身的问题而无效,并且我们无法对其进行更新和修复,则在7天内购买的用户可以获得退款,并且购买超过7天且少于1个月可以补偿180元的优惠券,并购买一个月以上60元的补偿优惠券(优惠券只能在使用我们的名义购买应用时使用),每个用户只能选择一种补偿方式。
该插件仅用于集合文章,易于阅读。您需要承担文章的版权风险。未经原创作者授权,请勿公开发表文章或将其用于商业目的。
售后服务
售后问题通过专业的工单系统处理。下达工作订单后,技术将在技术答复时接收电子邮件提醒,接收手动订单,解决问题原因,组织问题解决方案以及接收现场短消息和电子邮件警报,以确保及时和有效解决您的问题
工作指令地址: 查看全部
Discuz Youku视频自动采集自动采集发布(插件
该插件仅需添加采集关键字,即可通过优酷的搜索库自动匹配相应的视频,并在视频的每一页上自动执行采集并自动发布到[门户指定频道]或[论坛的指定部分]。
添加采集关键字后,视频采集的发布过程无需人工干预。它通过计划任务自动执行,并且可以修改采集的视频信息。当然,您也可以手动执行键采集来快速采集视频列表。
有关更多详细信息,请通过应用程序屏幕截图,更新日志等了解,或添加售前QQ(15326940)咨询问题
优酷视频分析插件推荐:
特殊说明
该插件只能采集优酷的普通视频,并且不支持电影,电视剧和动画之类的特殊内容
插件发布的视频使用论坛的多媒体代码([media]),分析由论坛本身处理,插件不具有分析功能
此插件需要PHP支持curl,curl通常可以获取https链接内容。 PHP版本至少为5.3,但不高于PHP7.1。如果服务器环境运行异常,则需要进行故障排除和测试。需要提供必要的网站和服务器帐户密码权限检查,远程协助不可用。
优酷视频具有采集的限制。高频采集可能被阻止。建议通过插件自动发布采集。
如果网站服务器被阻止,或者采集的源内容无法正常获取,并且您无法正常发布文章的内容采集,则不会退款。
如果采集规则由于插件自身的问题而无效,并且我们无法对其进行更新和修复,则在7天内购买的用户可以获得退款,并且购买超过7天且少于1个月可以补偿180元的优惠券,并购买一个月以上60元的补偿优惠券(优惠券只能在使用我们的名义购买应用时使用),每个用户只能选择一种补偿方式。
该插件仅用于集合文章,易于阅读。您需要承担文章的版权风险。未经原创作者授权,请勿公开发表文章或将其用于商业目的。
售后服务
售后问题通过专业的工单系统处理。下达工作订单后,技术将在技术答复时接收电子邮件提醒,接收手动订单,解决问题原因,组织问题解决方案以及接收现场短消息和电子邮件警报,以确保及时和有效解决您的问题
工作指令地址:
解决方案:基于ThinkPHP框架开发的全自动采集小说网站PHP源码+WAP手机端
采集交流 • 优采云 发表了文章 • 0 个评论 • 435 次浏览 • 2020-09-07 15:02
源代码介绍
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给您自己网站,该程序与WAP移动终端兼容,可以进行手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给您自己网站,该程序与WAP移动终端兼容,可以进行手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给自己网站,该程序与WAP手机兼容,手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给自己网站,该程序与WAP手机兼容,手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
适用范围
小说网站源代码,自动采集小说网络,ThinkPHP小说源代码
操作环境
推荐:VPS或服务器构建+ PHP + MYSQL
专业测试屏幕截图
安装说明
1、直接将源代码上传到服务器,解压缩,然后运行域名进入安装环境。
2、按照视频教程进行学习。 查看全部
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码+ WAP移动终端
源代码介绍
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给您自己网站,该程序与WAP移动终端兼容,可以进行手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给您自己网站,该程序与WAP移动终端兼容,可以进行手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给自己网站,该程序与WAP手机兼容,手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给自己网站,该程序与WAP手机兼容,手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
适用范围
小说网站源代码,自动采集小说网络,ThinkPHP小说源代码
操作环境
推荐:VPS或服务器构建+ PHP + MYSQL
专业测试屏幕截图
安装说明
1、直接将源代码上传到服务器,解压缩,然后运行域名进入安装环境。
2、按照视频教程进行学习。
分享文章:建站必备-织梦采集侠.全手动采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-29 11:20
织梦采集侠的功能
采集侠官网点此下载免费版采集侠
采集侠是一款专业采集模块,拥有先进的人工智能网页辨识技术和优秀的伪原创技术,远远赶超传统的采集软件,从不同的网站采集优质内容并手动原创处理,减少了网站维护工作量的同时大大提升了收录和点击量,是一款每位网站必备的插件。
1一键安装,全手动采集
?织梦采集侠安装非常简单便捷,只需一分钟,立即开始采集,而且结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,而且我们还有专门的客服为商业顾客提供技术支持。
2一词采集,无须编撰采集规则
?和传统的采集模式不同的是织梦采集侠可以依据用户设定的关键词进行泛采集,泛采集的优势在于通过采集该关键词的不同搜索结果,实现不对指定的一个或几个被采集站点进行采集,减少采集站点被搜索引擎判断为镜像站点被搜索引擎惩罚的危险。
3RSS采集,输入RSS地址即可采集内容
?只要被采集的网站提供RSS订阅地址,即可通过RSS进行采集,只须要输入RSS地址即可便捷的采集到目标网站内容,无需编撰采集规则,方便简单。
4页面监控采集,简单便捷采集内容
?页面监控采集只须要提供监控页面地址和文字URL规则即可指定采集指定网站或栏目内容,方便简单,无需编撰采集规则也能进行针对性采集。5多种伪原创及优化方法,提高收录率及排行
?自动标题、段落重排、高级混淆、自动内链、内容过滤、网址过滤、同义词替换、插入seo成语、关键词添加链接等多种方式手段对采集回来的文章加工处理,增强采集文章原创性,利于搜索引擎优化,提高搜索引擎收录、网站权重及关键词排行。
6插件全手动采集,无需人工干预
?织梦采集侠根据预先设定是采集任务,根据所设定的采集方式采集网址,然后手动抓取网页内容,程序通过精确估算剖析网页,丢弃掉不是文章内容页的网址,提取出优秀文章内容,最后进行伪原创,导入,生成,这一切操作程序都是全手动完成,无需人工干预。
7手工发布文章亦可伪原创和搜索优化处理
?织梦采集侠并不仅仅是一款采集插件,更是一款织梦必备伪原创及搜索优化插件,手工发布的文章可以经过织梦采集侠的伪原创和搜索优化处理,可以对文章进行同义词替换,自动内链,随机插入关键词链接和文章内收录关键词将手动添加指定链接等功能,是一款织梦必备插件。
8定时定量进行采集伪原创SEO更新
?插件有两个触发采集方式,一种是在页面内添加代码由用户访问触发采集更新,另外种我们为商业用户提供的远程触发采集服务,新站无有人访问即可定时定量采集更新,无需人工干预。 查看全部
建站必备-织梦采集侠.全手动采集文章
织梦采集侠的功能
采集侠官网点此下载免费版采集侠
采集侠是一款专业采集模块,拥有先进的人工智能网页辨识技术和优秀的伪原创技术,远远赶超传统的采集软件,从不同的网站采集优质内容并手动原创处理,减少了网站维护工作量的同时大大提升了收录和点击量,是一款每位网站必备的插件。
1一键安装,全手动采集
?织梦采集侠安装非常简单便捷,只需一分钟,立即开始采集,而且结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,而且我们还有专门的客服为商业顾客提供技术支持。
2一词采集,无须编撰采集规则
?和传统的采集模式不同的是织梦采集侠可以依据用户设定的关键词进行泛采集,泛采集的优势在于通过采集该关键词的不同搜索结果,实现不对指定的一个或几个被采集站点进行采集,减少采集站点被搜索引擎判断为镜像站点被搜索引擎惩罚的危险。
3RSS采集,输入RSS地址即可采集内容
?只要被采集的网站提供RSS订阅地址,即可通过RSS进行采集,只须要输入RSS地址即可便捷的采集到目标网站内容,无需编撰采集规则,方便简单。
4页面监控采集,简单便捷采集内容
?页面监控采集只须要提供监控页面地址和文字URL规则即可指定采集指定网站或栏目内容,方便简单,无需编撰采集规则也能进行针对性采集。5多种伪原创及优化方法,提高收录率及排行
?自动标题、段落重排、高级混淆、自动内链、内容过滤、网址过滤、同义词替换、插入seo成语、关键词添加链接等多种方式手段对采集回来的文章加工处理,增强采集文章原创性,利于搜索引擎优化,提高搜索引擎收录、网站权重及关键词排行。
6插件全手动采集,无需人工干预
?织梦采集侠根据预先设定是采集任务,根据所设定的采集方式采集网址,然后手动抓取网页内容,程序通过精确估算剖析网页,丢弃掉不是文章内容页的网址,提取出优秀文章内容,最后进行伪原创,导入,生成,这一切操作程序都是全手动完成,无需人工干预。
7手工发布文章亦可伪原创和搜索优化处理
?织梦采集侠并不仅仅是一款采集插件,更是一款织梦必备伪原创及搜索优化插件,手工发布的文章可以经过织梦采集侠的伪原创和搜索优化处理,可以对文章进行同义词替换,自动内链,随机插入关键词链接和文章内收录关键词将手动添加指定链接等功能,是一款织梦必备插件。
8定时定量进行采集伪原创SEO更新
?插件有两个触发采集方式,一种是在页面内添加代码由用户访问触发采集更新,另外种我们为商业用户提供的远程触发采集服务,新站无有人访问即可定时定量采集更新,无需人工干预。
中文网页手动采集与分类系统设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2020-08-27 00:20
中文网页手动采集与分类系统设计与实现密级: 保密时限: 本人申明成果。尽我所 收录其他人已 教育机构的学 何贡献均已在 申请学位 本人签名 本人完全 校攻读学位期 家有关部门或 可以公布学位 保存、汇编学 本学位论 本人签名 导师签名 中文网页手动采集与分类系统设计与实现 摘要 随着科学技术的急速发展,我们早已步入了数字信息化时代。Internet 作为 当今世界上最大的信息库,也成为人们获取信息的最主要手段。由于网路上 以怎样快速、准确地从海量的信息资源中找寻到自己所需的信息已然成为网路用 户须要急迫解决的一大困局。因而基于web 的网路信息的采集与分类便成为 人们 研究的热点。 传统的web 信息采集的目标就是尽可能多地采集信息页面,甚至是整个 web 上的资源,在这一过程中它并不太在乎采集的次序和被采集页面的相关主 乱、重复等情况的发生。同时怎么有效地对采集到的网页实现手动分类,以创建 更为有效、快捷的搜索引擎也是十分必要的。网页分类是组织和管理信息的 有效 手段,它可以在较大程度上解决信息杂乱无章的现象,并便捷用户准确地定 需要的信息。传统的操作模式是对其人工分类后进行组织和管理。
随着Internet 上各类信息的迅猛降低,仅靠人工的方法来处理是不切实际的。因此,网页 自动 分类是一项具有较大实用价值的方式,也是组织和管理数据的有效手段。这 也是 本文研究的一个重要内容。 本文首先介绍了课题背景、研究目的和国内外的研究现况,阐述了网页 采集 和网页分类的相关理论、主要技术和算法,包括网页爬虫技术、网页去重技 几种典型的算法以后,本文选定了主题爬虫的方式和分类方面表现出众的KNN 方法,同时结合去重、分词和特点提取等相关技术的配合,并对英文网页的 结构 和特征进行了剖析后,提出英文网页采集和分类的设计与实现方式,最后通 过程 序设计语言来实现,在本文最后对系统进行了测试。测试结果达到了系统设 要求,应用疗效明显。关键词:Web 信息采集网页分类信息抽取动词特点提取 OFCHINESEANDIMPLE匝N1:ATION DESIGN wEBPAGEAUT0~IATIC采集 ANDCLASSIFICATION ABSTRACT Withthe ofscienceand haveenteredthe development technology,we rapid information iSseenastheworld’S information digital age.Intemet,which largest tobethemaint001 information.ItiS database.becomes obtaining majorproblem solved howto fromthemassofinformationresourcesurgentlyquicklyaccurately thatusersneedbecausethenetworkofinformationresources tofindtheinformation thelack hasa characteristics,and massive,dynamic,heterogeneous,semi―structured ofaunified information-based采集management organization presents.J theresearchandclassificationbecomes hotspot. information采集istoinformationas goal gather thewholeresourcesthe‖如功eorderand muchas even pagespossible,or topic inthe contentsiStooarenotcaredabout collecting.thepage cluttered, ofthemisusedSO resources largepart sparingly system 采集methodusedtoreducethecollected arewasted.TIliSeffective requires clutterand web classificatedtocreatepagesautomaticaly page duplication.The ande 伍cientsearch ofwebeffective managementpage engine.Organization Cansolveaextent classificationiSaneffectivemeallSinformation,which large clutterandfacilitateuserstolocate ofinformation phenomenon accurately modeof iSmanual.With information traditional theyneed.However,the operation infornlationinthe tohandle ofallkindsofIntemet,manual rapidincreasing way classificationisnotamethodaloneiSunrealistic Webgreatpractical alsoisaneffectivemeansof data.Ttisanvalue,but organizingmanaging researchofthis importantpart paper. andresearchstatusare Firstly,thebackground,purposeintroduced,and topic andclassificationare ofweb采集 theories,techniquesalgorithmspage includswebcrawler web deletcion described,which technology,duplicatedpages word extraction segmentation, feature technology,Chinese technology,information web classification extraction pagetechnology.Acomprehensive techniques ofseveral crawlerandKNNmade,topical comparison typicalalgorithms have classificationisselectedbecause outstandingperformance.111eproposedChinesewebare afterandclassificationof designedimplementated acquisition structureandcharacteristicsofChinese arecombinedandthetechnologies web iscodedandrealizedthelanguagepageanalyzed.Finally,it programmingresultsthatthe metthe language.Testsystem designrequirements,andapplication donefeilds. many information classification, Keywords:web采集,webpage information extraction extraction,segmentation,character 法.484.7.2 KNN 结5253 。
63北京邮电大学软件工程硕上论文 第一章序言 1.1 课题背景及研究现况 1.1.1 课题的背景及研究目的 随着互联网的普及和网路技术的急速发展,网络上的信息资源呈指数级 以从互联网上获得越来越多的包括文本、数字、图形、图像、声音、视频等信息。 然而,随着web 信息的极速膨胀,如何快速、准确地从广袤的信息资源中找 己所需的信息却成为广大网路用户的一大困局。因而基于互联网上的信息采集和 搜索引擎。这些搜索引擎一般使用一个或多个采集器从Intemet如、FTP、 Email、News 上搜集各类数据,然后在本地服务器上为这种数据构建索引, 用户检索时按照用户递交的检索条件从索引库中迅速查找到所需的信息。Web 信息采集作为这种搜索引擎的基础和组成部份,发挥着举足轻重的作用。web 信息采集是指通过Web 页面之间的链接关系,从Web 上手动地获取页面信息, 并且随着链接不断的向所须要的web 页面扩充的过程。传统的W 曲信息采集 目标就是尽可能多地采集信息页面,甚至是整个web 上的资源,在这一过 够集中精力在采集的速率和数目上,并且实现上去也相对简单。但是,这种传统 的采集方法存在着好多缺陷。
因为基于整个Web 的信息采集需要采集的页面 一部分利用率太低。用户常常只关心其中极少量的页面,而采集器采集的大部分 页面对于她们来说是没有用的。这其实是对系统资源和网路资源的一个巨大 费。随着web网页数目的迅猛下降,即使是采用了定题采集技术来完善定题 类,以创建更为有效、快捷的搜索引擎是十分必要的。传统的操作模式是对其人 工分类后进行组织和管理。这种分类方式分类比较确切,分类质量也较高。 随着 Internet 上各类信息的迅速降低,仅靠人工的方法来处理是不切实际的。 对网页 进行分类可以在很大程度上解决网页上信息零乱的现象,并便捷用户准确地 定位 所须要的信息,因此,网页手动分类是一项具有较大实用价值的方式,也是 组织 和管理数据的有效手段。这也是本文研究的一个重要内容。 北京邮电大学软件工程硕士论文 1.1.2 课题的国内外研究现况 网页采集技术发展现况网路正在不断地改变着我们的生活,Intemet 已经成为现今世晃上最大 息资源库,如何快速、准确地从广袤的信息资源库中找寻到所需的信息早已成为 网络用户的一大困局。无论是一些通用搜索引擎 如微软、百度等 ,或是一 定主题的专用网页采集系统,都离不开网页采集,因而基于Web的网页信息 采集 和处理日渐成为人们关注的焦点。
传统的Web 信息采集所采集的页面数目过 大,采集的内容也过分零乱,需要消耗很大的系统资源和网路资源。同时Intemet 信息的分散状态和动态变化也是困惑信息采集的主要问题。为了解决这种问 搜索引擎。这些搜索引擎一般是通过一个或多个采集器从Internet 上搜集 各种数 据,然后在本地服务器上为这种数据构建索引,当用户检索时按照用户递交 用的须要。即使小型的信息采集系统,它对Web的覆盖率也只有30"--40% 左右。 即便是采用处理能力更强的计算机系统,性价比也不是很高。相对更好的方 能满足人们的须要。其次,Intemet 信息的分散状态和动态变化也是影响信息采集的缘由。 由于 信息源可能随时处于变化之中,信息采集器必须时常刷新数据,但这仍未能 避免 采集到失效页面的情况。对于传统的信息采集来说,因为须要刷新页面数目 在采集到的页面中有相当大的一部分利用率太低。因为,用户常常只是关心其中 极少量的页面,并且这种页面常常是集中在一个或几个主题内,而采集器采 网络资源的一个巨大浪费。这些问题的形成主要是因为传统的 Web 信息采集所采集的页面数目过 大而且所采集页面的内容过分零乱。如果将信息检索限定在特定主题领域,根据 主题相关的信息提供检索服务,那么所需采集的网页数目都会大大降低且主 北京邮电大学软件工程硕上论文一。
这类Web 信息采集称为定题Web 信息采集,由于定题采集检索的范围较 所以查准率和查全率相对较高。但是随着网路的迅猛发展,Web网页数目的 爆炸 增长,即使采用了定题采集技术来完善定题搜索引擎,相对于广泛的主题来 同一主题的网页数目依然是海量的。所以,如何有效地将同一主题的网页根据某 种给定的模式进行分类,以创建更为有效、更为快捷的搜索引擎是一个十分 重要 的课题。 网页分类技术发展现况网页手动分类是在文本分类算法的基础上结合 6>HTML 语言结构特征 发展起 来的,文本手动分类最初是配合信息检索 InformationRetrieval,IR 系统 的需求 而出现的。信息检索系统必须操纵大量的数据,其文本信息库抢占其中大部 分内 容,同时,用来表示文本内容的词汇数目又是成千上万的。在这些情况下, 如果 能提供具有良好的组织与结构的文本集,就能大大简化文本的存取和操作。 文本 自动分类系统的目的就是对文本集进行有序的组织,把相像的、相关的文 本组织 在一起。它作为知识的组织工具,为信息检索提供了更高效的搜索策略和更 准确 的查询结果。 文本手动分类研究源于50 年代末,H.RLulm 在这一领域进行了开创性 究。
网页手动分类在美国经历了三个发展阶段:第一阶段1958.1964 要进行手动分类的可行性研究,第二阶段 1965.1974 进行手动分类的实验研究, 第三阶 1975.至今步入实用化阶段【l_】。 国内手动分类研究起步较晚,始于20 世纪80 年代早期。关于英文文本 分类的 研究相对较少,国内外的研究基本上是在英语文本分类的基础上,结合英文 文本 和汉语语言的特点采取相应的策略,然后应用于英文之上,继而产生英文文 动分类研究体系。1981年,候汉清对计算机在文献分类工作中的应用作了 探讨。 早期系统的主要特征是结合主题词表进行剖析分类,人工干预的成份很大, Lam等人将KNN 方法和线性分类器结合,取得了较好疗效, 港中文大学的Wai回率接近90%,准确率超过80%t31。C.K.P Wong 等人研究了用混和关键词进 行文 本分类的方式,召回率和准确率分别为72%和62%t41。复旦大学和东芝 研究开 发中心的黄首著、吴立德、石崎洋之等研究了独立语种的文本分类,并以词 类别的互信息量为评分函数,分别用单分类器和多分类器对英文和法文文本进行 了实验,最好的结果召回率为 88.87%【5’。
上海交通大学的刁倩、 王永成等人结 合词权重和分类算法进行分类,在用VSM 方法的封闭式测试实验中分类正确 N97%t71。此后,基于统计学的思想,以及动词、语料库等技术被不断应用到 分类中。 万维网大约载有115 亿多的可索引的网页,且每晚都有几千万或更多的 网页 被添加。如何组织那些大量有效的信息网路资源是一个很大的现实问题。网 页数 实现网页采集功能子系统。 二、对网页信息抽取技术、中文动词技术、特征提取技术和网页分类技 析比较,采用性能优良的KNN分类算法以实现网页分类功能。 三、采用最大匹配算法对文本进行动词。对网页进行清洗,剔除网页中 些垃圾信息,将网页转换为文本格式。四、网页预处理部份,结合网页的模型特征,根据HTML 标记对网页不 分的文本进行加权处理。通过以上几个方面的工作,最终完成一个网页手动采集与分类系统的设 实现,并用通过实验验证以上算法。1.3 论文结构 本文共分6 章,内容安排如下: 第一章序言,介绍本课题的意义、国内外现况和任务等。 第二章网页采集与分类相关技术介绍,本章对采集和分类上将会用到的 北京邮电大学软件工程硕士论文关技术的原理、方法等介绍。包括常用的网页爬虫技术、网页去 页分类技术。
第三章网页采集与分类系统设计,本章首先进行系统分析,然后进行系统 概要设计、功能模块设计、系统流程设计、系统逻辑设计和数据 设计。第四章网页采集与分类系统实现,本章详尽介绍各模块是实现过程,包括 页面采集模块、信息抽取模块、网页去重模块、中文动词模块、 征向量提取模块、训练语料库模块和分类模块。第五章网页采集与分类系统测试,本章首先给出系统的运行界面,然后给 出实验评测标准并对实验结果进行剖析。 第六章结束语,本章对本文工作进行全面总结,给出本文所取得的成果, 指出存在的不足和改进方向。 北京第二章网页 2.1 网页爬虫技术 程序,也是搜索引擎的核心部件。搜索引擎的性能,规模及扩充能力很大程 度上 依赖于网路爬虫的处理能力。网络爬虫 Crawler 也被叫做网路蜘蛛 Spider 或网路机器人Robot 。网络爬虫的系统结构如图 2-1 所示:其中下载模块 用于 库用于储存从抓取网页中抽取的URL。 图2.1 网络爬虫结构图 网络爬虫从给定的URL 出发,沿着该网页上的出链 out.Links ,按照 设定的 网页搜索策略,例如,宽度优先策略,深度优先策略,或最佳优先策略, 采集 URL 队列中优先级别高的网页,然后通过网页分类器判定是否为主题网页, 如果 是则保存,否则遗弃;对于采集的网页,抽取其中收录的URL,经过相应处 插入到URL队列中。
2.1.1 通用网路爬虫 通用网路爬虫 generalpurposewebcrawler 会按照预先设定的一个或 若干初 始种子URL 开始,下载模块不断从URL 队列中获取一个URL,访问并下载该 页面。 页面解析器除去页面上的 HTML 标记得到页面内容,将摘要、URL 等信息保 存到 web 数据库中,同时抽取当前页面上新的URL,保存至UURL 队列,直到满足 查看全部
中文网页手动采集与分类系统设计与实现
中文网页手动采集与分类系统设计与实现密级: 保密时限: 本人申明成果。尽我所 收录其他人已 教育机构的学 何贡献均已在 申请学位 本人签名 本人完全 校攻读学位期 家有关部门或 可以公布学位 保存、汇编学 本学位论 本人签名 导师签名 中文网页手动采集与分类系统设计与实现 摘要 随着科学技术的急速发展,我们早已步入了数字信息化时代。Internet 作为 当今世界上最大的信息库,也成为人们获取信息的最主要手段。由于网路上 以怎样快速、准确地从海量的信息资源中找寻到自己所需的信息已然成为网路用 户须要急迫解决的一大困局。因而基于web 的网路信息的采集与分类便成为 人们 研究的热点。 传统的web 信息采集的目标就是尽可能多地采集信息页面,甚至是整个 web 上的资源,在这一过程中它并不太在乎采集的次序和被采集页面的相关主 乱、重复等情况的发生。同时怎么有效地对采集到的网页实现手动分类,以创建 更为有效、快捷的搜索引擎也是十分必要的。网页分类是组织和管理信息的 有效 手段,它可以在较大程度上解决信息杂乱无章的现象,并便捷用户准确地定 需要的信息。传统的操作模式是对其人工分类后进行组织和管理。
随着Internet 上各类信息的迅猛降低,仅靠人工的方法来处理是不切实际的。因此,网页 自动 分类是一项具有较大实用价值的方式,也是组织和管理数据的有效手段。这 也是 本文研究的一个重要内容。 本文首先介绍了课题背景、研究目的和国内外的研究现况,阐述了网页 采集 和网页分类的相关理论、主要技术和算法,包括网页爬虫技术、网页去重技 几种典型的算法以后,本文选定了主题爬虫的方式和分类方面表现出众的KNN 方法,同时结合去重、分词和特点提取等相关技术的配合,并对英文网页的 结构 和特征进行了剖析后,提出英文网页采集和分类的设计与实现方式,最后通 过程 序设计语言来实现,在本文最后对系统进行了测试。测试结果达到了系统设 要求,应用疗效明显。关键词:Web 信息采集网页分类信息抽取动词特点提取 OFCHINESEANDIMPLE匝N1:ATION DESIGN wEBPAGEAUT0~IATIC采集 ANDCLASSIFICATION ABSTRACT Withthe ofscienceand haveenteredthe development technology,we rapid information iSseenastheworld’S information digital age.Intemet,which largest tobethemaint001 information.ItiS database.becomes obtaining majorproblem solved howto fromthemassofinformationresourcesurgentlyquicklyaccurately thatusersneedbecausethenetworkofinformationresources tofindtheinformation thelack hasa characteristics,and massive,dynamic,heterogeneous,semi―structured ofaunified information-based采集management organization presents.J theresearchandclassificationbecomes hotspot. information采集istoinformationas goal gather thewholeresourcesthe‖如功eorderand muchas even pagespossible,or topic inthe contentsiStooarenotcaredabout collecting.thepage cluttered, ofthemisusedSO resources largepart sparingly system 采集methodusedtoreducethecollected arewasted.TIliSeffective requires clutterand web classificatedtocreatepagesautomaticaly page duplication.The ande 伍cientsearch ofwebeffective managementpage engine.Organization Cansolveaextent classificationiSaneffectivemeallSinformation,which large clutterandfacilitateuserstolocate ofinformation phenomenon accurately modeof iSmanual.With information traditional theyneed.However,the operation infornlationinthe tohandle ofallkindsofIntemet,manual rapidincreasing way classificationisnotamethodaloneiSunrealistic Webgreatpractical alsoisaneffectivemeansof data.Ttisanvalue,but organizingmanaging researchofthis importantpart paper. andresearchstatusare Firstly,thebackground,purposeintroduced,and topic andclassificationare ofweb采集 theories,techniquesalgorithmspage includswebcrawler web deletcion described,which technology,duplicatedpages word extraction segmentation, feature technology,Chinese technology,information web classification extraction pagetechnology.Acomprehensive techniques ofseveral crawlerandKNNmade,topical comparison typicalalgorithms have classificationisselectedbecause outstandingperformance.111eproposedChinesewebare afterandclassificationof designedimplementated acquisition structureandcharacteristicsofChinese arecombinedandthetechnologies web iscodedandrealizedthelanguagepageanalyzed.Finally,it programmingresultsthatthe metthe language.Testsystem designrequirements,andapplication donefeilds. many information classification, Keywords:web采集,webpage information extraction extraction,segmentation,character 法.484.7.2 KNN 结5253 。
63北京邮电大学软件工程硕上论文 第一章序言 1.1 课题背景及研究现况 1.1.1 课题的背景及研究目的 随着互联网的普及和网路技术的急速发展,网络上的信息资源呈指数级 以从互联网上获得越来越多的包括文本、数字、图形、图像、声音、视频等信息。 然而,随着web 信息的极速膨胀,如何快速、准确地从广袤的信息资源中找 己所需的信息却成为广大网路用户的一大困局。因而基于互联网上的信息采集和 搜索引擎。这些搜索引擎一般使用一个或多个采集器从Intemet如、FTP、 Email、News 上搜集各类数据,然后在本地服务器上为这种数据构建索引, 用户检索时按照用户递交的检索条件从索引库中迅速查找到所需的信息。Web 信息采集作为这种搜索引擎的基础和组成部份,发挥着举足轻重的作用。web 信息采集是指通过Web 页面之间的链接关系,从Web 上手动地获取页面信息, 并且随着链接不断的向所须要的web 页面扩充的过程。传统的W 曲信息采集 目标就是尽可能多地采集信息页面,甚至是整个web 上的资源,在这一过 够集中精力在采集的速率和数目上,并且实现上去也相对简单。但是,这种传统 的采集方法存在着好多缺陷。
因为基于整个Web 的信息采集需要采集的页面 一部分利用率太低。用户常常只关心其中极少量的页面,而采集器采集的大部分 页面对于她们来说是没有用的。这其实是对系统资源和网路资源的一个巨大 费。随着web网页数目的迅猛下降,即使是采用了定题采集技术来完善定题 类,以创建更为有效、快捷的搜索引擎是十分必要的。传统的操作模式是对其人 工分类后进行组织和管理。这种分类方式分类比较确切,分类质量也较高。 随着 Internet 上各类信息的迅速降低,仅靠人工的方法来处理是不切实际的。 对网页 进行分类可以在很大程度上解决网页上信息零乱的现象,并便捷用户准确地 定位 所须要的信息,因此,网页手动分类是一项具有较大实用价值的方式,也是 组织 和管理数据的有效手段。这也是本文研究的一个重要内容。 北京邮电大学软件工程硕士论文 1.1.2 课题的国内外研究现况 网页采集技术发展现况网路正在不断地改变着我们的生活,Intemet 已经成为现今世晃上最大 息资源库,如何快速、准确地从广袤的信息资源库中找寻到所需的信息早已成为 网络用户的一大困局。无论是一些通用搜索引擎 如微软、百度等 ,或是一 定主题的专用网页采集系统,都离不开网页采集,因而基于Web的网页信息 采集 和处理日渐成为人们关注的焦点。
传统的Web 信息采集所采集的页面数目过 大,采集的内容也过分零乱,需要消耗很大的系统资源和网路资源。同时Intemet 信息的分散状态和动态变化也是困惑信息采集的主要问题。为了解决这种问 搜索引擎。这些搜索引擎一般是通过一个或多个采集器从Internet 上搜集 各种数 据,然后在本地服务器上为这种数据构建索引,当用户检索时按照用户递交 用的须要。即使小型的信息采集系统,它对Web的覆盖率也只有30"--40% 左右。 即便是采用处理能力更强的计算机系统,性价比也不是很高。相对更好的方 能满足人们的须要。其次,Intemet 信息的分散状态和动态变化也是影响信息采集的缘由。 由于 信息源可能随时处于变化之中,信息采集器必须时常刷新数据,但这仍未能 避免 采集到失效页面的情况。对于传统的信息采集来说,因为须要刷新页面数目 在采集到的页面中有相当大的一部分利用率太低。因为,用户常常只是关心其中 极少量的页面,并且这种页面常常是集中在一个或几个主题内,而采集器采 网络资源的一个巨大浪费。这些问题的形成主要是因为传统的 Web 信息采集所采集的页面数目过 大而且所采集页面的内容过分零乱。如果将信息检索限定在特定主题领域,根据 主题相关的信息提供检索服务,那么所需采集的网页数目都会大大降低且主 北京邮电大学软件工程硕上论文一。
这类Web 信息采集称为定题Web 信息采集,由于定题采集检索的范围较 所以查准率和查全率相对较高。但是随着网路的迅猛发展,Web网页数目的 爆炸 增长,即使采用了定题采集技术来完善定题搜索引擎,相对于广泛的主题来 同一主题的网页数目依然是海量的。所以,如何有效地将同一主题的网页根据某 种给定的模式进行分类,以创建更为有效、更为快捷的搜索引擎是一个十分 重要 的课题。 网页分类技术发展现况网页手动分类是在文本分类算法的基础上结合 6>HTML 语言结构特征 发展起 来的,文本手动分类最初是配合信息检索 InformationRetrieval,IR 系统 的需求 而出现的。信息检索系统必须操纵大量的数据,其文本信息库抢占其中大部 分内 容,同时,用来表示文本内容的词汇数目又是成千上万的。在这些情况下, 如果 能提供具有良好的组织与结构的文本集,就能大大简化文本的存取和操作。 文本 自动分类系统的目的就是对文本集进行有序的组织,把相像的、相关的文 本组织 在一起。它作为知识的组织工具,为信息检索提供了更高效的搜索策略和更 准确 的查询结果。 文本手动分类研究源于50 年代末,H.RLulm 在这一领域进行了开创性 究。
网页手动分类在美国经历了三个发展阶段:第一阶段1958.1964 要进行手动分类的可行性研究,第二阶段 1965.1974 进行手动分类的实验研究, 第三阶 1975.至今步入实用化阶段【l_】。 国内手动分类研究起步较晚,始于20 世纪80 年代早期。关于英文文本 分类的 研究相对较少,国内外的研究基本上是在英语文本分类的基础上,结合英文 文本 和汉语语言的特点采取相应的策略,然后应用于英文之上,继而产生英文文 动分类研究体系。1981年,候汉清对计算机在文献分类工作中的应用作了 探讨。 早期系统的主要特征是结合主题词表进行剖析分类,人工干预的成份很大, Lam等人将KNN 方法和线性分类器结合,取得了较好疗效, 港中文大学的Wai回率接近90%,准确率超过80%t31。C.K.P Wong 等人研究了用混和关键词进 行文 本分类的方式,召回率和准确率分别为72%和62%t41。复旦大学和东芝 研究开 发中心的黄首著、吴立德、石崎洋之等研究了独立语种的文本分类,并以词 类别的互信息量为评分函数,分别用单分类器和多分类器对英文和法文文本进行 了实验,最好的结果召回率为 88.87%【5’。
上海交通大学的刁倩、 王永成等人结 合词权重和分类算法进行分类,在用VSM 方法的封闭式测试实验中分类正确 N97%t71。此后,基于统计学的思想,以及动词、语料库等技术被不断应用到 分类中。 万维网大约载有115 亿多的可索引的网页,且每晚都有几千万或更多的 网页 被添加。如何组织那些大量有效的信息网路资源是一个很大的现实问题。网 页数 实现网页采集功能子系统。 二、对网页信息抽取技术、中文动词技术、特征提取技术和网页分类技 析比较,采用性能优良的KNN分类算法以实现网页分类功能。 三、采用最大匹配算法对文本进行动词。对网页进行清洗,剔除网页中 些垃圾信息,将网页转换为文本格式。四、网页预处理部份,结合网页的模型特征,根据HTML 标记对网页不 分的文本进行加权处理。通过以上几个方面的工作,最终完成一个网页手动采集与分类系统的设 实现,并用通过实验验证以上算法。1.3 论文结构 本文共分6 章,内容安排如下: 第一章序言,介绍本课题的意义、国内外现况和任务等。 第二章网页采集与分类相关技术介绍,本章对采集和分类上将会用到的 北京邮电大学软件工程硕士论文关技术的原理、方法等介绍。包括常用的网页爬虫技术、网页去 页分类技术。
第三章网页采集与分类系统设计,本章首先进行系统分析,然后进行系统 概要设计、功能模块设计、系统流程设计、系统逻辑设计和数据 设计。第四章网页采集与分类系统实现,本章详尽介绍各模块是实现过程,包括 页面采集模块、信息抽取模块、网页去重模块、中文动词模块、 征向量提取模块、训练语料库模块和分类模块。第五章网页采集与分类系统测试,本章首先给出系统的运行界面,然后给 出实验评测标准并对实验结果进行剖析。 第六章结束语,本章对本文工作进行全面总结,给出本文所取得的成果, 指出存在的不足和改进方向。 北京第二章网页 2.1 网页爬虫技术 程序,也是搜索引擎的核心部件。搜索引擎的性能,规模及扩充能力很大程 度上 依赖于网路爬虫的处理能力。网络爬虫 Crawler 也被叫做网路蜘蛛 Spider 或网路机器人Robot 。网络爬虫的系统结构如图 2-1 所示:其中下载模块 用于 库用于储存从抓取网页中抽取的URL。 图2.1 网络爬虫结构图 网络爬虫从给定的URL 出发,沿着该网页上的出链 out.Links ,按照 设定的 网页搜索策略,例如,宽度优先策略,深度优先策略,或最佳优先策略, 采集 URL 队列中优先级别高的网页,然后通过网页分类器判定是否为主题网页, 如果 是则保存,否则遗弃;对于采集的网页,抽取其中收录的URL,经过相应处 插入到URL队列中。
2.1.1 通用网路爬虫 通用网路爬虫 generalpurposewebcrawler 会按照预先设定的一个或 若干初 始种子URL 开始,下载模块不断从URL 队列中获取一个URL,访问并下载该 页面。 页面解析器除去页面上的 HTML 标记得到页面内容,将摘要、URL 等信息保 存到 web 数据库中,同时抽取当前页面上新的URL,保存至UURL 队列,直到满足
Excel手动抓取网页数据,数据抓取一键搞定
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-08-26 05:05
网站上的数据源是我们进行统计剖析的重要信息源。我们在生活中经常看到一个词叫“爬虫”,能够快速抓取网页上的数据,这对于数据剖析相关工作来说非常重要,也是必备的技能之一。但是爬虫大多须要编程的知识,一般人不好入手。今天就给你们讲解一下怎样用Excel快速抓取网页数据。
1、首先打开须要抓取的数据的网站,复制网站地址。
2、新建Excel工作簿,点击“数据”菜单>“获取外部数据”选项卡中的“自网站”选项。
在弹出的“新建web查询”对话框中,地址栏输入须要抓取的网站地址,点击“转到”
点击蓝色导出箭头,选择须要抓取的部份,如图。点击导出即可。
3、选择数据储存的位置(默认选择的单元格),点击确定即可。一般建议数据储存在“A1”单元格即可。
4、如果想要Excel工作簿数据能手动依据网站的数据实时更新,那么我们须要在"属性"中进行设置。可以设置“允许后台刷新”、“刷新频度”、“打开文件时刷新数据”等。
得到数据然后,就须要对数据进行处理了,处理数据是更重要的一个环节。更多数据处理的方法,请关注我!
如果对您有帮助,请记得点赞,转发。
关注我学习更多Excel方法,让工作更简单。 查看全部
Excel手动抓取网页数据,数据抓取一键搞定
网站上的数据源是我们进行统计剖析的重要信息源。我们在生活中经常看到一个词叫“爬虫”,能够快速抓取网页上的数据,这对于数据剖析相关工作来说非常重要,也是必备的技能之一。但是爬虫大多须要编程的知识,一般人不好入手。今天就给你们讲解一下怎样用Excel快速抓取网页数据。
1、首先打开须要抓取的数据的网站,复制网站地址。
2、新建Excel工作簿,点击“数据”菜单>“获取外部数据”选项卡中的“自网站”选项。
在弹出的“新建web查询”对话框中,地址栏输入须要抓取的网站地址,点击“转到”
点击蓝色导出箭头,选择须要抓取的部份,如图。点击导出即可。
3、选择数据储存的位置(默认选择的单元格),点击确定即可。一般建议数据储存在“A1”单元格即可。
4、如果想要Excel工作簿数据能手动依据网站的数据实时更新,那么我们须要在"属性"中进行设置。可以设置“允许后台刷新”、“刷新频度”、“打开文件时刷新数据”等。
得到数据然后,就须要对数据进行处理了,处理数据是更重要的一个环节。更多数据处理的方法,请关注我!
如果对您有帮助,请记得点赞,转发。
关注我学习更多Excel方法,让工作更简单。
数据获取|自动抓取网页数据你也行
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-08-25 12:54
网页抓取(也称为网路数据提取或网页爬取)是指从网上获取数据,并将获取到的非结构化数据转化为结构化的数据,最终可以将数据储存到本地计算机或数据库的一种技术。
目前,全球网路数据的增长速度在每年40%左右,IDC(互联网数据中心)的报告显示,2013全球数据为4.4ZB,2020年的时侯,全球的数据总数将达到40ZB。大数据时代已经到来,从网路中获取所需数据成为举办竞争对手剖析、商业数据挖掘和科研的重要手段。
网络信息采集的形式主要有:网页手工复制、网页手动抓取工具、For循环批量下载、自制浏览器下载等。
今天给你们介绍的是几款注册以后免费使用的网页信息手动抓取工具,供你们学习参考。需要说明的是,大量手动采集网络信息极易被封IP,这时可采取如下办法破解:(1)暂停采集,过段时间再尝试,并尝试找到网页防采集的规律再进行采集规则的设置;(2)使用云采集;(3)使用代理IP进行采集。
一、优采云(网址:)
优采云平台整合了网页数据采集、移动互联网数据及API接口服务(包括数据挖掘、数据优化、数据储存、数据备份)等服务为一体。
优采云可实现对全网(网页、论坛、移动互联网、QQ空间、电话号码、邮箱、图片等)信息进行手动采集。同时优采云提供单机采集和云采集两种模式。在具体采集方式包括向导模式、高级模式和Smart模式供不同主体对象选择。可以从网站中抓取数据并整理成数据集。它拥有挺好的交互设计,使用上去十分便捷,其主界面见图1所示。
图1优采云主界面
二、优采云采集器()
优采云采集器是一款专业的网路数据采集工具,通过灵活的配置,可以太轻松从网路上抓取非结构化的文本、图片、文件等信息,经编辑后可随时发布到网站后台或其他数据库中,适用于各种对数据有采集挖掘需求的群体,如垂直搜索、信息凝聚和门户、企业网信息凝聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,其主界面见图2所示。
优采云采集器的操作原理是web结构的源代码提取,所以只要是网页上才能看见的内容,无论以何种排布方式诠释都可以被快速提取下来。并且最终抓取的数据支持导出到任一目标数据库中,或者导入为想要的格式。在网页抓取的过程中,还可以选择不同的线程数来控制优采云采集器采集的速率快慢。总体上来说,优采云采集器适用于对抓取需求太明晰,对速率有要求,对完整性要求也较高的用户。
图2优采云采集器主界面
三、优采云采集器软件()
优采云采集器软件借助熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上借助原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相像页面的有效比对、匹配。因此,用户只须要指定一个参考页面,优采云采集器软件系统就可以据此来匹配类似的页面,来实现用户须要采集资料的批量采集。
浏览器可见的内容优采云采集器软件都可以采集。采集的对象包括文字内容,图片,flash动漫视频等等各种网路内容,支持图文混排对象的同时采集,支持JS输出内容的采集,其主界面见图3所示。
图3 优采云采集器软件主界面
四、网络神采()
网络神采是一款专业的网路信息采集系统,通过灵活的规则可以从任何类型的网站采集信息,如新闻网站、论坛、博客、电子商务网站、招聘网站等等。支持网站登录采集、网站跨层采集、POST采集、脚本页面采集、动态页面采集等中级采集功能。支持存储过程、插件等,可以通过二次开发扩充功能,其主界面见图4所示。
图4 网络神采主界面 查看全部
数据获取|自动抓取网页数据你也行
网页抓取(也称为网路数据提取或网页爬取)是指从网上获取数据,并将获取到的非结构化数据转化为结构化的数据,最终可以将数据储存到本地计算机或数据库的一种技术。
目前,全球网路数据的增长速度在每年40%左右,IDC(互联网数据中心)的报告显示,2013全球数据为4.4ZB,2020年的时侯,全球的数据总数将达到40ZB。大数据时代已经到来,从网路中获取所需数据成为举办竞争对手剖析、商业数据挖掘和科研的重要手段。
网络信息采集的形式主要有:网页手工复制、网页手动抓取工具、For循环批量下载、自制浏览器下载等。
今天给你们介绍的是几款注册以后免费使用的网页信息手动抓取工具,供你们学习参考。需要说明的是,大量手动采集网络信息极易被封IP,这时可采取如下办法破解:(1)暂停采集,过段时间再尝试,并尝试找到网页防采集的规律再进行采集规则的设置;(2)使用云采集;(3)使用代理IP进行采集。
一、优采云(网址:)
优采云平台整合了网页数据采集、移动互联网数据及API接口服务(包括数据挖掘、数据优化、数据储存、数据备份)等服务为一体。
优采云可实现对全网(网页、论坛、移动互联网、QQ空间、电话号码、邮箱、图片等)信息进行手动采集。同时优采云提供单机采集和云采集两种模式。在具体采集方式包括向导模式、高级模式和Smart模式供不同主体对象选择。可以从网站中抓取数据并整理成数据集。它拥有挺好的交互设计,使用上去十分便捷,其主界面见图1所示。
图1优采云主界面
二、优采云采集器()
优采云采集器是一款专业的网路数据采集工具,通过灵活的配置,可以太轻松从网路上抓取非结构化的文本、图片、文件等信息,经编辑后可随时发布到网站后台或其他数据库中,适用于各种对数据有采集挖掘需求的群体,如垂直搜索、信息凝聚和门户、企业网信息凝聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,其主界面见图2所示。
优采云采集器的操作原理是web结构的源代码提取,所以只要是网页上才能看见的内容,无论以何种排布方式诠释都可以被快速提取下来。并且最终抓取的数据支持导出到任一目标数据库中,或者导入为想要的格式。在网页抓取的过程中,还可以选择不同的线程数来控制优采云采集器采集的速率快慢。总体上来说,优采云采集器适用于对抓取需求太明晰,对速率有要求,对完整性要求也较高的用户。
图2优采云采集器主界面
三、优采云采集器软件()
优采云采集器软件借助熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上借助原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相像页面的有效比对、匹配。因此,用户只须要指定一个参考页面,优采云采集器软件系统就可以据此来匹配类似的页面,来实现用户须要采集资料的批量采集。
浏览器可见的内容优采云采集器软件都可以采集。采集的对象包括文字内容,图片,flash动漫视频等等各种网路内容,支持图文混排对象的同时采集,支持JS输出内容的采集,其主界面见图3所示。
图3 优采云采集器软件主界面
四、网络神采()
网络神采是一款专业的网路信息采集系统,通过灵活的规则可以从任何类型的网站采集信息,如新闻网站、论坛、博客、电子商务网站、招聘网站等等。支持网站登录采集、网站跨层采集、POST采集、脚本页面采集、动态页面采集等中级采集功能。支持存储过程、插件等,可以通过二次开发扩充功能,其主界面见图4所示。
图4 网络神采主界面
自动采集网站内容,这应该是一个必备技能!
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-04-28 03:04
自动采集网站内容,这应该是一个必备技能,建议先学习下python脚本语言。然后将你需要的词分词,全部存入excel表格。根据你的网站产品,将全部相关词语融合一个word文档,做好标题栏,摘要栏。做好a标题页面设计。将它与你的txt文档做好合并排版。同时配合php语言,做好访问缓存,设置好各种参数,这样别人获取你网站的内容就很方便。总之,你得先知道你网站的内容是什么。
datahunter定制的“百度指数”可以满足你的需求。
移动搜索的话可以试试加词助手
说搜索引擎爬虫爬取内容可以看看我的博客:第一弹——搜索引擎爬虫我分析了几个问题:
1、你会写爬虫吗
2、你会写搜索引擎分析吗
3、你会配置爬虫吗
4、你会写爬虫工具吗
5、你懂运用搜索引擎技术吗
6、你会算法编程吗
7、你会算法设计与开发吗
8、你会算法优化吗
9、你会找点子吗1
0、你会配置爬虫吗1
1、你会计算爬虫的路数吗1
2、你会使用搜索引擎排序吗1
3、你懂seo吗1
4、你懂seoer的心路历程吗1
5、你会使用爬虫做调优吗当然,这几个爬虫方向的问题都是先从你第一个问题来回答你。
《it项目管理精髓》梁宁老师讲解的关于excel方面的课程
这几天我正好看到一篇关于爬虫的内容,觉得挺好的,推荐给你。侵删。 查看全部
自动采集网站内容,这应该是一个必备技能!
自动采集网站内容,这应该是一个必备技能,建议先学习下python脚本语言。然后将你需要的词分词,全部存入excel表格。根据你的网站产品,将全部相关词语融合一个word文档,做好标题栏,摘要栏。做好a标题页面设计。将它与你的txt文档做好合并排版。同时配合php语言,做好访问缓存,设置好各种参数,这样别人获取你网站的内容就很方便。总之,你得先知道你网站的内容是什么。
datahunter定制的“百度指数”可以满足你的需求。
移动搜索的话可以试试加词助手
说搜索引擎爬虫爬取内容可以看看我的博客:第一弹——搜索引擎爬虫我分析了几个问题:
1、你会写爬虫吗
2、你会写搜索引擎分析吗
3、你会配置爬虫吗
4、你会写爬虫工具吗
5、你懂运用搜索引擎技术吗
6、你会算法编程吗
7、你会算法设计与开发吗
8、你会算法优化吗
9、你会找点子吗1
0、你会配置爬虫吗1
1、你会计算爬虫的路数吗1
2、你会使用搜索引擎排序吗1
3、你懂seo吗1
4、你懂seoer的心路历程吗1
5、你会使用爬虫做调优吗当然,这几个爬虫方向的问题都是先从你第一个问题来回答你。
《it项目管理精髓》梁宁老师讲解的关于excel方面的课程
这几天我正好看到一篇关于爬虫的内容,觉得挺好的,推荐给你。侵删。
自动采集网站内容,怎么操作?看下fius的接口速成
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2021-04-25 18:02
自动采集网站内容,怎么操作?看下fius的接口速成,可以大幅度提高自动采集网站内容的速度,建议使用chrome浏览器,但是本文主要讲的是电脑上用fius采集的方法,安卓版fius目前没有有效版本。
一、打开fius官网。按照页面指示注册登录。
二、登录后进入个人中心。
3、电脑安装采集软件和浏览器插件。
4、选择需要采集的网站,点击导入采集。点击同步。
5、点击保存网站地址为你的采集地址。
6、点击执行采集。
7、等待结果浏览。
8、浏览完成后采集完成。
9、电脑上点击打开网站。
1
0、点击已采集,即可按照页面指示进行内容采集。此外,更多实用的接口技巧,其实都是一些细小的功能要点,这里就不在一一列举。如果想在个人网站实现高效自动采集功能,可以关注。
添加数据源软件,比如奇兔,阿拉丁,网页扒手,宝天爬虫,菜鸟采集器,还有一些公众号上会有推送一些需要采集的文章并不一定必须是靠什么软件去抓取。
啊刚好看到一个我知道的.matches.io,主要是抓取百度上的内容.可以根据需要搜一下
欢迎关注公众号【不解决疑难杂症的爬虫】经常会被问到爬虫到底是什么?python怎么爬虫?scrapy有哪些不足,来来来今天就来给大家介绍一下我们前端前端一共需要三样东西,1请求2解析3搜索为什么说前端难爬还要被喷?有这三个点大家有发言权,全站html,css,js,导致我们实际上已经积累了大量html源码,python解析真正困难的是es5的语法,以及js的解析在服务器上解析,真正问题出在这个点上我们用python想要解析一个页面大概需要这么几个步骤解析所需文件requests库下载最后需要对页面使用es5方法importjsonimporturllibli=[requests。
get("/")forxinurllib。request。urlopen("")if(x=='')]随便爬了一个,结果直接被0。22k封ip爬虫如何解析?爬虫在爬到一定数量后,通常返回的是一个字典:useragent,initialize,listener,scope。 查看全部
自动采集网站内容,怎么操作?看下fius的接口速成
自动采集网站内容,怎么操作?看下fius的接口速成,可以大幅度提高自动采集网站内容的速度,建议使用chrome浏览器,但是本文主要讲的是电脑上用fius采集的方法,安卓版fius目前没有有效版本。
一、打开fius官网。按照页面指示注册登录。
二、登录后进入个人中心。
3、电脑安装采集软件和浏览器插件。
4、选择需要采集的网站,点击导入采集。点击同步。
5、点击保存网站地址为你的采集地址。
6、点击执行采集。
7、等待结果浏览。
8、浏览完成后采集完成。
9、电脑上点击打开网站。
1
0、点击已采集,即可按照页面指示进行内容采集。此外,更多实用的接口技巧,其实都是一些细小的功能要点,这里就不在一一列举。如果想在个人网站实现高效自动采集功能,可以关注。
添加数据源软件,比如奇兔,阿拉丁,网页扒手,宝天爬虫,菜鸟采集器,还有一些公众号上会有推送一些需要采集的文章并不一定必须是靠什么软件去抓取。
啊刚好看到一个我知道的.matches.io,主要是抓取百度上的内容.可以根据需要搜一下
欢迎关注公众号【不解决疑难杂症的爬虫】经常会被问到爬虫到底是什么?python怎么爬虫?scrapy有哪些不足,来来来今天就来给大家介绍一下我们前端前端一共需要三样东西,1请求2解析3搜索为什么说前端难爬还要被喷?有这三个点大家有发言权,全站html,css,js,导致我们实际上已经积累了大量html源码,python解析真正困难的是es5的语法,以及js的解析在服务器上解析,真正问题出在这个点上我们用python想要解析一个页面大概需要这么几个步骤解析所需文件requests库下载最后需要对页面使用es5方法importjsonimporturllibli=[requests。
get("/")forxinurllib。request。urlopen("")if(x=='')]随便爬了一个,结果直接被0。22k封ip爬虫如何解析?爬虫在爬到一定数量后,通常返回的是一个字典:useragent,initialize,listener,scope。
自动采集网站内容,你可以到这里试试,操作简单
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2021-04-10 03:02
自动采集网站内容,你可以到这里试试,很不错的免费网站采集软件。采集工具_自动采集网站内容一站式、操作简单。
谢邀,我也不知道,但是,要是知道的话,请告诉我,
以前看过这个使用教程,
百度一下:站长工具箱、360站长工具箱
百度推出的站长工具箱可以直接采集百度站长提供的各种站内链接、网站历史信息等站内资源。
seo网站快照工具包,上传快照可以加权重和有一个快照合并工具,把快照合并进原网站或者其他网站里面。
我只用到百度和谷歌
还有seo宝,也是可以的,
新站都是搜索引擎收录,高权重网站才可以触发seo。
这个怎么说呢,新站做好伪原创工作,做好简介,设计一下链接,
seo易操作
新站新方法,
万能搜集器,各种网站你想采就采,新闻站,产品站,你想采就采,想加标签就加标签,各种站内外都有,自动采集,自动粘贴,热点等。
阿里巴巴网站地图
双边站点采集器
最便捷的是用软件提取标题和描述。设置好时间日期,可以自动加描述加链接加锚文本加描述内容,链接地址地址自动翻译成拼音,还可以自动设置权重和生效时间,自动修改。seo查询,文献检索。 查看全部
自动采集网站内容,你可以到这里试试,操作简单
自动采集网站内容,你可以到这里试试,很不错的免费网站采集软件。采集工具_自动采集网站内容一站式、操作简单。
谢邀,我也不知道,但是,要是知道的话,请告诉我,
以前看过这个使用教程,
百度一下:站长工具箱、360站长工具箱
百度推出的站长工具箱可以直接采集百度站长提供的各种站内链接、网站历史信息等站内资源。
seo网站快照工具包,上传快照可以加权重和有一个快照合并工具,把快照合并进原网站或者其他网站里面。
我只用到百度和谷歌
还有seo宝,也是可以的,
新站都是搜索引擎收录,高权重网站才可以触发seo。
这个怎么说呢,新站做好伪原创工作,做好简介,设计一下链接,
seo易操作
新站新方法,
万能搜集器,各种网站你想采就采,新闻站,产品站,你想采就采,想加标签就加标签,各种站内外都有,自动采集,自动粘贴,热点等。
阿里巴巴网站地图
双边站点采集器
最便捷的是用软件提取标题和描述。设置好时间日期,可以自动加描述加链接加锚文本加描述内容,链接地址地址自动翻译成拼音,还可以自动设置权重和生效时间,自动修改。seo查询,文献检索。
杨建龙祝您好运!SEO站长如何批量采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-04-03 02:05
有诸如Discuz的插件之类的程序可以实现此功能,并且某些以前的ASP程序也是可以的
但是不建议您这样做,这不利于优化
当前的搜索引擎非常聪明。它只会采集原创的内容(第一篇文章)。完成此操作后,蜘蛛程序将不会抓取到您网站
建议您自己发送原创
希望我能帮到你,杨建龙祝你好运!
SEO网站站长如何批处理采集 文章
有许多可用于采集的软件,例如优采云,优采云,这些软件均可用于批次采集 文章
注意:网站批次采集中文章内容的质量不是很好。建议手动采集和网站至伪原创进行发布。这样,您可以使网站的内容良好,并且在搜索引擎上的排名很快。这些事情我总结了我自己的经验。 SEO是一种相对较慢的技术。不用太担心您越担心,排名就越困难。希望您不要太担心。希望它可以帮助您
可以自动采集 伪原创 文章并自动上传到自己的网站的软件!
是的,市场上有很多自动采集 伪原创软件,但是它们都需要编写规则,并且必须具有一定的代码基础。 优采云智能文章 采集系统消除了传统的琐碎功能,即使是新手也易于使用。
如何编写在文章内容发布期间自动将文章标题添加到内容的代码?
我现在仍然使用asp,不了解它,可以将它当作一种业余爱好,将来很难谋生 查看全部
杨建龙祝您好运!SEO站长如何批量采集文章
有诸如Discuz的插件之类的程序可以实现此功能,并且某些以前的ASP程序也是可以的
但是不建议您这样做,这不利于优化
当前的搜索引擎非常聪明。它只会采集原创的内容(第一篇文章)。完成此操作后,蜘蛛程序将不会抓取到您网站
建议您自己发送原创
希望我能帮到你,杨建龙祝你好运!
SEO网站站长如何批处理采集 文章
有许多可用于采集的软件,例如优采云,优采云,这些软件均可用于批次采集 文章
注意:网站批次采集中文章内容的质量不是很好。建议手动采集和网站至伪原创进行发布。这样,您可以使网站的内容良好,并且在搜索引擎上的排名很快。这些事情我总结了我自己的经验。 SEO是一种相对较慢的技术。不用太担心您越担心,排名就越困难。希望您不要太担心。希望它可以帮助您
可以自动采集 伪原创 文章并自动上传到自己的网站的软件!
是的,市场上有很多自动采集 伪原创软件,但是它们都需要编写规则,并且必须具有一定的代码基础。 优采云智能文章 采集系统消除了传统的琐碎功能,即使是新手也易于使用。
如何编写在文章内容发布期间自动将文章标题添加到内容的代码?
我现在仍然使用asp,不了解它,可以将它当作一种业余爱好,将来很难谋生
自动采集网站内容,可以直接使用采集助手软件。。
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-04-02 04:02
自动采集网站内容,可以用采集助手软件。可以直接采集网页,采集发布到自己网站上面。也可以采集文字图片。省时省力,网站内容采集。保存到本地操作也简单。
先找到需要的网页,然后百度“xxx”如下图进入“xxx(网址)”的空间,在此基础上,
找网站,最重要的是google。
我也在找!!一直没有成功!
真的是google
我想说,自从用上飞书,我的内容在全球都可以共享了,手机电脑一个网页一个浏览器,而且云同步一键收藏,还不耽误线上学习,付费的更加好。
全球所有站点中国站点(建议用api接口获取,因为google、百度、雅虎中国站点都是使用flash付费,
我也想知道这个
百度搜索
搜索飞书,
googleapi
给你推荐我推荐我给你推荐我给你推荐,欢迎收藏和点赞哦。
iawtrade2016:automationforscalablebusinessinformationsecretinautomationwithanywhere,anytime,anything
可以直接使用采集器采集,如“采集助手”,如果是自己开发的项目,并且已经做了接口开放,也可以让技术公司自己去服务器抓取,这样就可以保证服务器资源的有效利用,和公司网站内容的安全,飞书不收费,如果你需要私服,你可以找我啊, 查看全部
自动采集网站内容,可以直接使用采集助手软件。。
自动采集网站内容,可以用采集助手软件。可以直接采集网页,采集发布到自己网站上面。也可以采集文字图片。省时省力,网站内容采集。保存到本地操作也简单。
先找到需要的网页,然后百度“xxx”如下图进入“xxx(网址)”的空间,在此基础上,
找网站,最重要的是google。
我也在找!!一直没有成功!
真的是google
我想说,自从用上飞书,我的内容在全球都可以共享了,手机电脑一个网页一个浏览器,而且云同步一键收藏,还不耽误线上学习,付费的更加好。
全球所有站点中国站点(建议用api接口获取,因为google、百度、雅虎中国站点都是使用flash付费,
我也想知道这个
百度搜索
搜索飞书,
googleapi
给你推荐我推荐我给你推荐我给你推荐,欢迎收藏和点赞哦。
iawtrade2016:automationforscalablebusinessinformationsecretinautomationwithanywhere,anytime,anything
可以直接使用采集器采集,如“采集助手”,如果是自己开发的项目,并且已经做了接口开放,也可以让技术公司自己去服务器抓取,这样就可以保证服务器资源的有效利用,和公司网站内容的安全,飞书不收费,如果你需要私服,你可以找我啊,
自动采集网站内容的意义非常大,首先内容是什么
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-03-27 23:06
自动采集网站内容的意义非常大,首先内容是什么,内容是网站所有内容,所有内容是外链带来的。那自动采集如何实现呢,自动采集基本都是php控制,所以说程序方面门槛不高,只要想学,什么都能写出来。其次自动采集的性价比相对高很多,例如在百度权重1万/千次的关键词里,每天自动采集每个网站5000条信息,那么一年就是五万条信息。
如果一家公司平均每月采集500条的信息,这些信息每条每篇每秒都值1万元左右。这些信息如果全部放入网站首页,收录就更快,速度就更高,覆盖面也更广。如果放入尾部,收录就很慢。具体是否适合网站,需要实际根据网站情况来看,根据自己网站的特点来对症下药。
最低成本应该是单文件采集了。网站内容采集和外链又不是一回事。
最低可以采集50w网站的内容,也就是500w的用户。其实最理想的网站抓取,应该是拿网站来接外链。你觉得有用。那就是有用。至于性价比不高。
为什么那么多网站要抓取外链,而不是直接进入网站看,因为内容站一抓10000条外链,新站,各种广告的都抓,收录大于10000条的就有几千,收录1000-5000的就更多了,真的要抓取外链,那最少500w+,而且搜索引擎要精准抓取。
外链是一种关系链接,通过内容引导,其中利用不同的高质量链接的实现关键词的流量转化。这里给大家说下外链三种方式:独立外链,群站外链和外链其实不同。
1、独立外链
2、群站外链
3、个人外链
1)首先是独立外链,独立外链需要个人主动寻找网站来进行投稿,然后得到自己想要的信息。这个需要每个人都认真对待,每天都可以回访网站跟踪。而在这里要提醒大家的是,如果你要做网站日志的分析需要分析每天的重点,一个礼拜的时间只需要10000条左右外链就可以达到目的。
2)第二种独立外链就是你通过某个平台做高质量的营销信息,然后会得到很多同行的站长,这个平台包括百度、搜狗等等。外链优化方式有很多,我们可以采用文章相关联,也可以采用高质量的外链。
所以营销方面的网站,
1)群站,同一页面内的链接一般应该超过1000条以上,链接排名要靠前。同一页面内的信息,因为是同一平台内部,大家都可以互换,以达到最终吸引搜索引擎采集同一平台内容的目的。
2)第三种群站就是网站的评论版面内链接。同一个页面内有很多评论就比较吸引搜索引擎的关注了,要知道,一个站点再怎么优化,没有上百个网站的评论,那么不是我们站点不行,还是要注意风水问题。同一页面内链接超过1000条以上同样非常吸引搜索引擎的关注。 查看全部
自动采集网站内容的意义非常大,首先内容是什么
自动采集网站内容的意义非常大,首先内容是什么,内容是网站所有内容,所有内容是外链带来的。那自动采集如何实现呢,自动采集基本都是php控制,所以说程序方面门槛不高,只要想学,什么都能写出来。其次自动采集的性价比相对高很多,例如在百度权重1万/千次的关键词里,每天自动采集每个网站5000条信息,那么一年就是五万条信息。
如果一家公司平均每月采集500条的信息,这些信息每条每篇每秒都值1万元左右。这些信息如果全部放入网站首页,收录就更快,速度就更高,覆盖面也更广。如果放入尾部,收录就很慢。具体是否适合网站,需要实际根据网站情况来看,根据自己网站的特点来对症下药。
最低成本应该是单文件采集了。网站内容采集和外链又不是一回事。
最低可以采集50w网站的内容,也就是500w的用户。其实最理想的网站抓取,应该是拿网站来接外链。你觉得有用。那就是有用。至于性价比不高。
为什么那么多网站要抓取外链,而不是直接进入网站看,因为内容站一抓10000条外链,新站,各种广告的都抓,收录大于10000条的就有几千,收录1000-5000的就更多了,真的要抓取外链,那最少500w+,而且搜索引擎要精准抓取。
外链是一种关系链接,通过内容引导,其中利用不同的高质量链接的实现关键词的流量转化。这里给大家说下外链三种方式:独立外链,群站外链和外链其实不同。
1、独立外链
2、群站外链
3、个人外链
1)首先是独立外链,独立外链需要个人主动寻找网站来进行投稿,然后得到自己想要的信息。这个需要每个人都认真对待,每天都可以回访网站跟踪。而在这里要提醒大家的是,如果你要做网站日志的分析需要分析每天的重点,一个礼拜的时间只需要10000条左右外链就可以达到目的。
2)第二种独立外链就是你通过某个平台做高质量的营销信息,然后会得到很多同行的站长,这个平台包括百度、搜狗等等。外链优化方式有很多,我们可以采用文章相关联,也可以采用高质量的外链。
所以营销方面的网站,
1)群站,同一页面内的链接一般应该超过1000条以上,链接排名要靠前。同一页面内的信息,因为是同一平台内部,大家都可以互换,以达到最终吸引搜索引擎采集同一平台内容的目的。
2)第三种群站就是网站的评论版面内链接。同一个页面内有很多评论就比较吸引搜索引擎的关注了,要知道,一个站点再怎么优化,没有上百个网站的评论,那么不是我们站点不行,还是要注意风水问题。同一页面内链接超过1000条以上同样非常吸引搜索引擎的关注。
自动采集网站内容,自动生成网站收录、通过百度收录还原
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-03-27 06:04
自动采集网站内容,自动修改网站页面代码,自动生成网站收录、通过百度收录还原网站,查看自己网站的排名,给自己的网站开启一个seo模式。第一步先把一个电子版的pdf文件在电脑上转换成doc或者xls格式!在浏览器中下载迅捷pdf转换器,电脑打开迅捷pdf转换器-迅捷pdf转换器-pdf文件免费转换器,pdf在线转换,pdf转换器,在线pdf转换-迅捷pdf转换器,进入转换格式后,接着点击那个免费版,就可以进入免费版页面!电脑打开后,会让你选择“文件”-“选择”-选择电子版pdf文件!当然了,你也可以点击“下载”按钮,把要上传的pdf文件,点击下载,保存到浏览器或者电脑就可以了!然后把需要的内容上传到刚才下载的迅捷pdf转换器里,然后点击“开始”!文件名字你可以自己修改!然后点击“下一步”,完成上传!文件数量可以手动上传!大小不限!这样就已经把电子版pdf转换成了电子文档格式!在浏览器中打开或者用迅捷pdf转换器打开就可以了!经过这一系列操作,就可以帮你彻底把一个电子版的pdf文件给彻底上传到迅捷pdf转换器中!接下来就只要手动复制,把内容粘贴进来就行了!接下来提供几个使用方法:方法一:迅捷pdf转换器上传的文件,手动点击上传进行下载!打开pdf文件,点击我要转换,选择合适的输出格式进行下载即可!速度快!方法二:下载用迅捷pdf转换器上传到迅捷pdf转换器里,然后点击右上角的添加文件按钮,选择需要的文件!下载过程中,双击进行文件选择!方法三:打开下载成功的电子版pdf文件,双击文件进行保存就行了!这个方法,是在pdf转换成doc或者xls格式文件后,手动粘贴文件到迅捷pdf转换器中就可以了,速度快!如果是对pdf文件有深度需求的话,还可以直接用迅捷pdf转换器打开!文章转自:pdf文件编辑-迅捷pdf转换器。 查看全部
自动采集网站内容,自动生成网站收录、通过百度收录还原
自动采集网站内容,自动修改网站页面代码,自动生成网站收录、通过百度收录还原网站,查看自己网站的排名,给自己的网站开启一个seo模式。第一步先把一个电子版的pdf文件在电脑上转换成doc或者xls格式!在浏览器中下载迅捷pdf转换器,电脑打开迅捷pdf转换器-迅捷pdf转换器-pdf文件免费转换器,pdf在线转换,pdf转换器,在线pdf转换-迅捷pdf转换器,进入转换格式后,接着点击那个免费版,就可以进入免费版页面!电脑打开后,会让你选择“文件”-“选择”-选择电子版pdf文件!当然了,你也可以点击“下载”按钮,把要上传的pdf文件,点击下载,保存到浏览器或者电脑就可以了!然后把需要的内容上传到刚才下载的迅捷pdf转换器里,然后点击“开始”!文件名字你可以自己修改!然后点击“下一步”,完成上传!文件数量可以手动上传!大小不限!这样就已经把电子版pdf转换成了电子文档格式!在浏览器中打开或者用迅捷pdf转换器打开就可以了!经过这一系列操作,就可以帮你彻底把一个电子版的pdf文件给彻底上传到迅捷pdf转换器中!接下来就只要手动复制,把内容粘贴进来就行了!接下来提供几个使用方法:方法一:迅捷pdf转换器上传的文件,手动点击上传进行下载!打开pdf文件,点击我要转换,选择合适的输出格式进行下载即可!速度快!方法二:下载用迅捷pdf转换器上传到迅捷pdf转换器里,然后点击右上角的添加文件按钮,选择需要的文件!下载过程中,双击进行文件选择!方法三:打开下载成功的电子版pdf文件,双击文件进行保存就行了!这个方法,是在pdf转换成doc或者xls格式文件后,手动粘贴文件到迅捷pdf转换器中就可以了,速度快!如果是对pdf文件有深度需求的话,还可以直接用迅捷pdf转换器打开!文章转自:pdf文件编辑-迅捷pdf转换器。
自动采集网站内容?会吗?如何解决缓存问题?
采集交流 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2021-03-26 07:01
自动采集网站内容?自动采集网站?会吗?其实大部分网站,用自动采集器都可以自动采集数据,只不过用python做爬虫要比较难。同时,对于网站开发者而言,不是每个网站都有python接口的,除非是跨国公司,业务涉及海量数据的话,才有可能用python爬虫。如何是采集awesomelibrary的文档。去githubtornado,安装下,importgui,downloadlibrary,很快你就能看到。
如果需要对网站进行编程的话,只需要tornado这个库。tornado简介tornado是一个twitter开发的用于web应用的轻量级协程web服务器,它是用c++和java编写的。tornado是跨平台的,而且是linux系统。前后端网站都可以用tornado,python,java,c++都可以。
开发好用网站后,需要配置web服务器,apache,nginx等。但是,tornado还有个bug,客户端无法跟服务器(django中这样做),一直匹配。不要惊慌,这不是tornado本身出的问题,是因为tornado的版本非常落后,基本只支持python2.x。tornado的结构图下图是用tornado做一个网站,要用到的功能:采集数据采集网站列表相关内容列表分类列表相关提取标题列表相关内容基本tornado作为一个web服务器,这些功能都是没问题的。
tornado很小,也就200k,对于无法进行调优的小网站来说,还是可以用的。如果想要tornado做服务器,github上有一个分享资源,用于作为服务器。-v1.2.1python-tornado-web。注意此分享资源是针对无限网页,如果是php等非常老的网站,而且没有python接口,是不适合的。有人参考我其他文章:青丘:爬虫语言requests如何解决缓存问题?。 查看全部
自动采集网站内容?会吗?如何解决缓存问题?
自动采集网站内容?自动采集网站?会吗?其实大部分网站,用自动采集器都可以自动采集数据,只不过用python做爬虫要比较难。同时,对于网站开发者而言,不是每个网站都有python接口的,除非是跨国公司,业务涉及海量数据的话,才有可能用python爬虫。如何是采集awesomelibrary的文档。去githubtornado,安装下,importgui,downloadlibrary,很快你就能看到。
如果需要对网站进行编程的话,只需要tornado这个库。tornado简介tornado是一个twitter开发的用于web应用的轻量级协程web服务器,它是用c++和java编写的。tornado是跨平台的,而且是linux系统。前后端网站都可以用tornado,python,java,c++都可以。
开发好用网站后,需要配置web服务器,apache,nginx等。但是,tornado还有个bug,客户端无法跟服务器(django中这样做),一直匹配。不要惊慌,这不是tornado本身出的问题,是因为tornado的版本非常落后,基本只支持python2.x。tornado的结构图下图是用tornado做一个网站,要用到的功能:采集数据采集网站列表相关内容列表分类列表相关提取标题列表相关内容基本tornado作为一个web服务器,这些功能都是没问题的。
tornado很小,也就200k,对于无法进行调优的小网站来说,还是可以用的。如果想要tornado做服务器,github上有一个分享资源,用于作为服务器。-v1.2.1python-tornado-web。注意此分享资源是针对无限网页,如果是php等非常老的网站,而且没有python接口,是不适合的。有人参考我其他文章:青丘:爬虫语言requests如何解决缓存问题?。
【技术领域】互联网信息采集的改版流程及应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-03-23 03:21
【技术领域】互联网信息采集的改版流程及应用
一种用于Web内容的自动采集方法
[技术领域]
[0001]本发明公开了一种网页内容自动采集方法,涉及互联网数据处理技术领域。
[背景技术]
[0002]随着科学技术的发展,互联网信息进入了一个爆炸性和多元化的时代。互联网已经成为一个庞大的信息基础。互联网信息采集可让您改善信息采集,资源整合和资金投入。它在利用率和人力投入方面节省了大量资源,并广泛用于工业门户网站网站信息采集,竞争对手情报数据采集,网站内容系统构建,垂直搜索,民意监测,科学研究和其他字段。
[0003]以新闻网页为例。当常规新闻网页内容采集程序运行时,它依赖于为每个不同新闻站点手动提供页面分析模板。格式定义文件定义新闻网页中的所有有效数据。项目的xpath,例如新闻标题,正文,作者和出版时间。维护新闻站点的页面分析模板非常无聊,并且如果采集程序覆盖更多站点,则工作量将更大。此外,如果新闻站点被修改,则原创页面解析模板文件将“过期”,并且需要重新排序。但是,通常很难及时找到和重新排序。如此一来,新闻站点一旦被修改,就必须在发现之前将其发现。 ,这些新闻站点的数据将异常甚至丢失。
[0004]由于格式的多样化,数据量的爆炸性增长,严格的监视等原因,现有新闻网站的采集更加困难,主要表现在:
[0005] 1、有必要手动配置新闻页面分析模板并制定相应信息的xpath。
[0006] 2、 网站捕获了大量信息,并且规则难以统一制定。通常,为每个站点分别配置分析模板,这需要大量工作;
[0007] 3、带来了大量规则维护工作,以及站点修订后规则实时更新的问题;
[0008] 4、如果未及时找到新闻站点修订,则采集这些新闻站点的数据将异常。
[0009]现有的常规新闻网页采集都需要为所有站点自定义分析模板,所有自定义和后续维护工作都是乏味而乏味的,并且如果您不能及时适应该站点的修订,则不会有效的采集数据,这些问题对于大规模采集系统尤为突出,因此迫切需要新的技术方法来代替人工维护。
[发明内容]
[p10] [0010]鉴于现有技术的缺陷,本发明要解决的技术问题是提供一种网页内容自动采集方法,该方法以可扩展的方式支持多种类型的网页采集器 ],每个网页通用采集器都将使用不同的算法来实现网页通用采集,并且该算法是从网页的共同特征中抽象出来的。
[0011]本发明采用以下技术方案来解决上述技术问题:
[0012]一种自动采集个Web内容的方法,具体步骤包括:
[0013]步骤一、根据需要,搜索内容采集的网页URL,以找到与网页网站相匹配的采集器集;
[0014]步骤二、当存在匹配的采集器时,执行采集器获取网页内容;当没有匹配的采集器时,找到不匹配的采集器集合,切勿从匹配的采集器集合中选择采集器并执行采集器以获得网页内容;
[0015]步骤三、 采集成功后,输出Web内容的采集结果;如果采集不成功,请返回步骤2并再次选择采集器。
[0016]作为本发明的另一优选方案,在第二步骤中,采集器的识别过程包括:
[0017] 1、访问目标网页并获得页面字节流;
[0018] 2、将字节流解析为dom对象,将dom中的所有元素与html标签对应,并记录html标签的所有属性和值;
[0019] 3、通过dom对象中的标题节点确认标题范围,其中标题节点的Xpath为:// HTML / HEAD / TITLE;
[0020]通过搜索h节点并比较标题节点来检查网页的标题xpath,其中h节点的Xpath为:// B0DY // * [name O ='H *'];
[0021]当标题节点的值包括h节点的值时,h节点是网页的标题节点,h节点的xpath是网页标题的xpath;
[0022] 4、以h节点为起点来查找发布时间节点;
[0023] 5、以h节点为起点,扫描与h节点的祖父母节点相对应的所有子节点,找到文本值最长的节点,并将其确定为网页正文节点;
[0024] 6、确认作者节点,使用“作者节点特征匹配”方法从h节点开始,扫描h节点的父节点的所有子节点,以及是否匹配文本值子节点符合作者节点的特征,如果匹配,则确认该子节点为作者节点;
[0025] 7、根据页面标题,发布时间节点,文本节点和作者节点,标识与页面内容匹配的MiJi设备。
[0026]作为本发明的另一优选方案,当在步骤6中未使用“作者节点特征匹配”方法成功确认作者节点时,通过“位置猜测”方法确认作者节点:
[0027]从发布节点开始,分析发布节点在其同级节点中的位置,以确定作者节点:
[0028] a。如果发布节点有多个同级节点,并且发布节点排在多个节点的一半之前,则确定发布节点的下一个同级节点是作者节点;
[0029] b。如果发布节点中有多个同级节点,并且发布节点排在多个节点的一半之后,则确定发布节点的前一个同级节点是作者节点。
[0030]作为本发明的另一优选方案,所述步骤4中用于确认发布时间节点的具体方法为:
[0031]从h节点的所有子节点中搜索时间节点,如果找到,则完成发布时间节点的确认;
[0032]否则,继续从节点h的所有同级节点及其所有子节点中搜索时间节点。如果找到,请完成对发布时间节点的确认。
[0033]作为本发明的另一优选方案,步骤4中的发布时间节点的确认算法具体为:
[0034]使用常见时间格式的正则表达式来匹配节点的值。如果匹配可以匹配,则该节点被确认为发布时间节点。
[0035]作为本发明的另一优选方案,在步骤5中确定网页文本节点的过程还包括根据噪声节点标准对所有节点进行去噪处理,并消除不合理的节点。节点标准具体为:
[0036](I)其中节点的值收录JavaScript功能节点;
[0037](2)其中节点的值收录的标点符号数量小于设置的阈值。
[0038]作为本发明的另一优选方案,步骤6中判断作者节点的方法包括: 查看全部
【技术领域】互联网信息采集的改版流程及应用
一种用于Web内容的自动采集方法
[技术领域]
[0001]本发明公开了一种网页内容自动采集方法,涉及互联网数据处理技术领域。
[背景技术]
[0002]随着科学技术的发展,互联网信息进入了一个爆炸性和多元化的时代。互联网已经成为一个庞大的信息基础。互联网信息采集可让您改善信息采集,资源整合和资金投入。它在利用率和人力投入方面节省了大量资源,并广泛用于工业门户网站网站信息采集,竞争对手情报数据采集,网站内容系统构建,垂直搜索,民意监测,科学研究和其他字段。
[0003]以新闻网页为例。当常规新闻网页内容采集程序运行时,它依赖于为每个不同新闻站点手动提供页面分析模板。格式定义文件定义新闻网页中的所有有效数据。项目的xpath,例如新闻标题,正文,作者和出版时间。维护新闻站点的页面分析模板非常无聊,并且如果采集程序覆盖更多站点,则工作量将更大。此外,如果新闻站点被修改,则原创页面解析模板文件将“过期”,并且需要重新排序。但是,通常很难及时找到和重新排序。如此一来,新闻站点一旦被修改,就必须在发现之前将其发现。 ,这些新闻站点的数据将异常甚至丢失。
[0004]由于格式的多样化,数据量的爆炸性增长,严格的监视等原因,现有新闻网站的采集更加困难,主要表现在:
[0005] 1、有必要手动配置新闻页面分析模板并制定相应信息的xpath。
[0006] 2、 网站捕获了大量信息,并且规则难以统一制定。通常,为每个站点分别配置分析模板,这需要大量工作;
[0007] 3、带来了大量规则维护工作,以及站点修订后规则实时更新的问题;
[0008] 4、如果未及时找到新闻站点修订,则采集这些新闻站点的数据将异常。
[0009]现有的常规新闻网页采集都需要为所有站点自定义分析模板,所有自定义和后续维护工作都是乏味而乏味的,并且如果您不能及时适应该站点的修订,则不会有效的采集数据,这些问题对于大规模采集系统尤为突出,因此迫切需要新的技术方法来代替人工维护。
[发明内容]
[p10] [0010]鉴于现有技术的缺陷,本发明要解决的技术问题是提供一种网页内容自动采集方法,该方法以可扩展的方式支持多种类型的网页采集器 ],每个网页通用采集器都将使用不同的算法来实现网页通用采集,并且该算法是从网页的共同特征中抽象出来的。
[0011]本发明采用以下技术方案来解决上述技术问题:
[0012]一种自动采集个Web内容的方法,具体步骤包括:
[0013]步骤一、根据需要,搜索内容采集的网页URL,以找到与网页网站相匹配的采集器集;
[0014]步骤二、当存在匹配的采集器时,执行采集器获取网页内容;当没有匹配的采集器时,找到不匹配的采集器集合,切勿从匹配的采集器集合中选择采集器并执行采集器以获得网页内容;
[0015]步骤三、 采集成功后,输出Web内容的采集结果;如果采集不成功,请返回步骤2并再次选择采集器。
[0016]作为本发明的另一优选方案,在第二步骤中,采集器的识别过程包括:
[0017] 1、访问目标网页并获得页面字节流;
[0018] 2、将字节流解析为dom对象,将dom中的所有元素与html标签对应,并记录html标签的所有属性和值;
[0019] 3、通过dom对象中的标题节点确认标题范围,其中标题节点的Xpath为:// HTML / HEAD / TITLE;
[0020]通过搜索h节点并比较标题节点来检查网页的标题xpath,其中h节点的Xpath为:// B0DY // * [name O ='H *'];
[0021]当标题节点的值包括h节点的值时,h节点是网页的标题节点,h节点的xpath是网页标题的xpath;
[0022] 4、以h节点为起点来查找发布时间节点;
[0023] 5、以h节点为起点,扫描与h节点的祖父母节点相对应的所有子节点,找到文本值最长的节点,并将其确定为网页正文节点;
[0024] 6、确认作者节点,使用“作者节点特征匹配”方法从h节点开始,扫描h节点的父节点的所有子节点,以及是否匹配文本值子节点符合作者节点的特征,如果匹配,则确认该子节点为作者节点;
[0025] 7、根据页面标题,发布时间节点,文本节点和作者节点,标识与页面内容匹配的MiJi设备。
[0026]作为本发明的另一优选方案,当在步骤6中未使用“作者节点特征匹配”方法成功确认作者节点时,通过“位置猜测”方法确认作者节点:
[0027]从发布节点开始,分析发布节点在其同级节点中的位置,以确定作者节点:
[0028] a。如果发布节点有多个同级节点,并且发布节点排在多个节点的一半之前,则确定发布节点的下一个同级节点是作者节点;
[0029] b。如果发布节点中有多个同级节点,并且发布节点排在多个节点的一半之后,则确定发布节点的前一个同级节点是作者节点。
[0030]作为本发明的另一优选方案,所述步骤4中用于确认发布时间节点的具体方法为:
[0031]从h节点的所有子节点中搜索时间节点,如果找到,则完成发布时间节点的确认;
[0032]否则,继续从节点h的所有同级节点及其所有子节点中搜索时间节点。如果找到,请完成对发布时间节点的确认。
[0033]作为本发明的另一优选方案,步骤4中的发布时间节点的确认算法具体为:
[0034]使用常见时间格式的正则表达式来匹配节点的值。如果匹配可以匹配,则该节点被确认为发布时间节点。
[0035]作为本发明的另一优选方案,在步骤5中确定网页文本节点的过程还包括根据噪声节点标准对所有节点进行去噪处理,并消除不合理的节点。节点标准具体为:
[0036](I)其中节点的值收录JavaScript功能节点;
[0037](2)其中节点的值收录的标点符号数量小于设置的阈值。
[0038]作为本发明的另一优选方案,步骤6中判断作者节点的方法包括:
自动采集网站内容文章文章上传到百度站长平台等待收录
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-03-20 23:07
自动采集网站内容文章上传到百度站长平台等待收录,如果需要快速有效等有可以采取302跳转的方式直接进入网站获取原有内容,
自动采集上传网站,采集不超过20篇文章到百度百科,上传后全自动通过网站的分类网址,跳转到百度百科。
知乎有人答这个
一般首页:图片、问答、百科、blog三选一。其他的:文字、博客内容或下载站或分享站上传上来的链接。---另外新建站点的时候会有教程,有些可以找到我,
一、直接采集网站文章。大多数的网站的内容不会离开他个人站点。建立个人站点,也是一种分享。二、进行aspx编程处理,通过网站数据爬虫搜集。
可以挂代理。
这种被爬虫爬取基本没有办法,只有导入数据库。但有些更新不是特别规律的东西会导入你id相同并且短,也有些是加的代码规律基本对不上。一般情况是被爬虫爬取了或者网站页面url不正确, 查看全部
自动采集网站内容文章文章上传到百度站长平台等待收录
自动采集网站内容文章上传到百度站长平台等待收录,如果需要快速有效等有可以采取302跳转的方式直接进入网站获取原有内容,
自动采集上传网站,采集不超过20篇文章到百度百科,上传后全自动通过网站的分类网址,跳转到百度百科。
知乎有人答这个
一般首页:图片、问答、百科、blog三选一。其他的:文字、博客内容或下载站或分享站上传上来的链接。---另外新建站点的时候会有教程,有些可以找到我,
一、直接采集网站文章。大多数的网站的内容不会离开他个人站点。建立个人站点,也是一种分享。二、进行aspx编程处理,通过网站数据爬虫搜集。
可以挂代理。
这种被爬虫爬取基本没有办法,只有导入数据库。但有些更新不是特别规律的东西会导入你id相同并且短,也有些是加的代码规律基本对不上。一般情况是被爬虫爬取了或者网站页面url不正确,
优采云采集器在采集公开网页数据是非常简单地
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-03-14 10:01
<p>优采云 采集器在采集中发布网页数据非常简单。您无需编写规则,只需单击并用鼠标单击页面即可;另外,配置自动化采集->自动发布整个过程,简化并减少了每天需要操作的重复机械工作量,可以说,合适的工具可以使效率提高10倍至8倍。 查看全部
自动文章 采集工具快速入门详细教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2021-03-13 13:02
优采云 采集平台可以非常方便,简单地配置采集规则->自动化采集->自动化发布的全过程,简化并减少了需要重复操作的重复机械工作量天。它可以被描述为一种合适的工具。效率提高十倍,八倍。
优采云 采集是新一代的网站 文章 采集和发布平台,它是完全在线配置和使用云采集的工具,功能强大,操作简单,无需编写规则,使用鼠标进行配置只需单击页面,配置即可快速高效。
优采云不仅提供网页文章 采集,数据批处理修改,计时采集,计时和定量自动发布等基本功能,还集成了功能强大的SEO工具,并创新地实现了智能规则提取引擎一键采集发布等功能大大改善了采集的配置和发布效率。
采集发布更简单:支持一键发布到WorpPress,Empire,织梦,ZBlog,Discuz,Destoon,Typecho,Emlog,Mip cms,Mituo,Yiyou cms,Apple cms ],PHP cms和其他cms 网站系统也可以发布到自定义Http接口。
它还支持特定的文章“一键快速采集”,包括:微信公众号文章,今天的标题,新闻pan 采集,关键词 pan 采集(通过搜索引擎)
优采云 采集具有免费版本。您可以根据优采云 采集快速入门教程和入门教程的优采云 采集视频版本快速上手。一般来说,您可以精通约半小时的使用时间。
自动采集的功能将在下面详细说明。
定时采集与自动发布功能结合使用,因此用户不再需要一直关注任务采集和发布条件,从而节省了时间,精力和效率。
定时模式只能设置为采集一次,每天,每周和每隔几个小时间隔一次,以自动运行采集任务; ()
输入特定的采集任务,然后单击[开始|单击右上角的Timing 采集]按钮进入“设置Timing 采集”界面,选中“ Enable”,然后根据需要选择计时方法。最后单击[开始|时间]按钮:
成功设置时间采集后,任务右上角将出现下一次运行采集时间:
任务列表中有一个红色的时钟图标和一个时间,这是下一个计划的任务采集的时间:
注意:
保存不执行计时功能,而是保存配置信息;建议将定时开始时间设置为将来的时间,例如:此时为10点,可以设置为10:15分钟。如果将其设置为经过时间,尽管系统会自动更正它,但它可能在第二天的0点或现在立即执行。 (使用右侧的蓝色按钮将其设置为1分钟,然后等待30分钟。)具有定时设置的任务不算作正在运行的任务。仅当达到指定时间时,才会启动正在运行的任务采集。 查看全部
自动文章 采集工具快速入门详细教程
优采云 采集平台可以非常方便,简单地配置采集规则->自动化采集->自动化发布的全过程,简化并减少了需要重复操作的重复机械工作量天。它可以被描述为一种合适的工具。效率提高十倍,八倍。
优采云 采集是新一代的网站 文章 采集和发布平台,它是完全在线配置和使用云采集的工具,功能强大,操作简单,无需编写规则,使用鼠标进行配置只需单击页面,配置即可快速高效。
优采云不仅提供网页文章 采集,数据批处理修改,计时采集,计时和定量自动发布等基本功能,还集成了功能强大的SEO工具,并创新地实现了智能规则提取引擎一键采集发布等功能大大改善了采集的配置和发布效率。
采集发布更简单:支持一键发布到WorpPress,Empire,织梦,ZBlog,Discuz,Destoon,Typecho,Emlog,Mip cms,Mituo,Yiyou cms,Apple cms ],PHP cms和其他cms 网站系统也可以发布到自定义Http接口。
它还支持特定的文章“一键快速采集”,包括:微信公众号文章,今天的标题,新闻pan 采集,关键词 pan 采集(通过搜索引擎)
优采云 采集具有免费版本。您可以根据优采云 采集快速入门教程和入门教程的优采云 采集视频版本快速上手。一般来说,您可以精通约半小时的使用时间。
自动采集的功能将在下面详细说明。
定时采集与自动发布功能结合使用,因此用户不再需要一直关注任务采集和发布条件,从而节省了时间,精力和效率。
定时模式只能设置为采集一次,每天,每周和每隔几个小时间隔一次,以自动运行采集任务; ()
输入特定的采集任务,然后单击[开始|单击右上角的Timing 采集]按钮进入“设置Timing 采集”界面,选中“ Enable”,然后根据需要选择计时方法。最后单击[开始|时间]按钮:
成功设置时间采集后,任务右上角将出现下一次运行采集时间:
任务列表中有一个红色的时钟图标和一个时间,这是下一个计划的任务采集的时间:
注意:
保存不执行计时功能,而是保存配置信息;建议将定时开始时间设置为将来的时间,例如:此时为10点,可以设置为10:15分钟。如果将其设置为经过时间,尽管系统会自动更正它,但它可能在第二天的0点或现在立即执行。 (使用右侧的蓝色按钮将其设置为1分钟,然后等待30分钟。)具有定时设置的任务不算作正在运行的任务。仅当达到指定时间时,才会启动正在运行的任务采集。
核心方法:零基础用爬虫爬取网页内容(详细步骤+原理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2020-12-31 08:10
互联网上有许多使用Python来爬网内容的教程,但是通常您需要编写代码,而没有相应基础的人也有在短时间内入门的门槛。实际上,在大多数情况下,您可以使用Web Scraper(Chrome插件)快速抓取到目标内容。重要的是,无需下载内容,并且基本上没有代码知识。
开始之前,有必要简要地理解一些问题。
a。什么是爬虫?
自动抓取目标网站内容的工具。
b。采集器有什么用?
提高数据采集的效率。没有人想让自己的手指重复复制和粘贴操作。机械的东西应该留给工具。快速的采集数据也是分析数据的基础。
c。爬行的原理是什么?
要了解这一点,您需要了解为什么人们可以浏览网络。我们通过输入URL,关键字并单击链接将请求发送到目标计算机,然后将目标计算机的代码下载到本地,然后将其解析/呈现到我们看到的页面中。这是上线的过程。
采集器的作用是模拟此过程,但它比人工操作要快,并且可以自定义搜寻内容,然后将其存储在数据库中以供浏览或下载。搜索引擎可以工作,这是相似的原理。
但是爬虫只是工具。为了使工具正常工作,他们必须了解您想要什么。这就是我们要做的。毕竟,人脑波无法直接流入计算机。也可以说,采集器的本质是找到模式。
Lauren Mancke在Unsplash上拍摄的照片
以豆瓣电影Top250为例(许多人使用它来进行练习是因为豆瓣的网页是有组织的),以了解Web Scraper的简易性和使用方法。
1、在Chrome App Store中搜索Web Scraper,然后单击“添加扩展程序”,然后您可以在Chrome插件栏中看到蜘蛛网图标。
(如果您的日常浏览器不是Chrome浏览器,则强烈建议对其进行更改。Chrome浏览器与其他浏览器的区别就像Google与其他搜索引擎之间的区别一样
2、打开要抓取的网页,例如,douban Top250的URL为/ top250,然后同时按option + command + i进入开发人员模式(如果使用Windows,它是ctrl + shift + i,不同浏览器的默认快捷键可能不同)。此时,您可以在网页上看到一个对话框。不用担心,这只是当前网页的HTML(超文本标记语言),它创建了整个网络世界。 )。
只要按照步骤1添加Web Scraper扩展程序,您就可以在箭头所示的位置看到Web Scraper,单击它,它将成为下图中的爬虫页面。
3、单击创建新站点地图,然后依次创建站点地图以创建采集器。填写站点地图名称只是为了您自己的身份,例如,填写dbtop250(不要写汉字,空格,大写字母)。通常,将要爬网的网页的URL复制并粘贴到起始URL中,但是为了使爬网程序了解我们的意图,最好首先观察网页的布局和URL。例如,top250使用分页模式,而250张电影分10页分发。 25页。
第一页的网址是/ top250
第二页的开头是/ top250?start = 25&filter =
第三页是/ top250?start = 50&filter =
...
只有一个数字略有不同。我们的意图是抓取top250电影数据,因此您不能简单地将/ top250粘贴到起始网址中,而应将其粘贴到/ top250?start = [0-250:25]&filter =
启动后请注意[]中的内容,这意味着每25个是一个网页,抓取10个网页。
最后单击“创建站点地图”,即会构建采集器。
<p>(也可以通过填写/ top250来爬网URL,但是Web Scraper无法理解我们将对top250的所有页面的数据进行爬网。它将仅对第一页的内容进行爬网。) 查看全部
核心方法:零基础用爬虫爬取网页内容(详细步骤+原理)
互联网上有许多使用Python来爬网内容的教程,但是通常您需要编写代码,而没有相应基础的人也有在短时间内入门的门槛。实际上,在大多数情况下,您可以使用Web Scraper(Chrome插件)快速抓取到目标内容。重要的是,无需下载内容,并且基本上没有代码知识。
开始之前,有必要简要地理解一些问题。
a。什么是爬虫?
自动抓取目标网站内容的工具。
b。采集器有什么用?
提高数据采集的效率。没有人想让自己的手指重复复制和粘贴操作。机械的东西应该留给工具。快速的采集数据也是分析数据的基础。
c。爬行的原理是什么?
要了解这一点,您需要了解为什么人们可以浏览网络。我们通过输入URL,关键字并单击链接将请求发送到目标计算机,然后将目标计算机的代码下载到本地,然后将其解析/呈现到我们看到的页面中。这是上线的过程。
采集器的作用是模拟此过程,但它比人工操作要快,并且可以自定义搜寻内容,然后将其存储在数据库中以供浏览或下载。搜索引擎可以工作,这是相似的原理。
但是爬虫只是工具。为了使工具正常工作,他们必须了解您想要什么。这就是我们要做的。毕竟,人脑波无法直接流入计算机。也可以说,采集器的本质是找到模式。
Lauren Mancke在Unsplash上拍摄的照片
以豆瓣电影Top250为例(许多人使用它来进行练习是因为豆瓣的网页是有组织的),以了解Web Scraper的简易性和使用方法。
1、在Chrome App Store中搜索Web Scraper,然后单击“添加扩展程序”,然后您可以在Chrome插件栏中看到蜘蛛网图标。
(如果您的日常浏览器不是Chrome浏览器,则强烈建议对其进行更改。Chrome浏览器与其他浏览器的区别就像Google与其他搜索引擎之间的区别一样
2、打开要抓取的网页,例如,douban Top250的URL为/ top250,然后同时按option + command + i进入开发人员模式(如果使用Windows,它是ctrl + shift + i,不同浏览器的默认快捷键可能不同)。此时,您可以在网页上看到一个对话框。不用担心,这只是当前网页的HTML(超文本标记语言),它创建了整个网络世界。 )。
只要按照步骤1添加Web Scraper扩展程序,您就可以在箭头所示的位置看到Web Scraper,单击它,它将成为下图中的爬虫页面。
3、单击创建新站点地图,然后依次创建站点地图以创建采集器。填写站点地图名称只是为了您自己的身份,例如,填写dbtop250(不要写汉字,空格,大写字母)。通常,将要爬网的网页的URL复制并粘贴到起始URL中,但是为了使爬网程序了解我们的意图,最好首先观察网页的布局和URL。例如,top250使用分页模式,而250张电影分10页分发。 25页。
第一页的网址是/ top250
第二页的开头是/ top250?start = 25&filter =
第三页是/ top250?start = 50&filter =
...
只有一个数字略有不同。我们的意图是抓取top250电影数据,因此您不能简单地将/ top250粘贴到起始网址中,而应将其粘贴到/ top250?start = [0-250:25]&filter =
启动后请注意[]中的内容,这意味着每25个是一个网页,抓取10个网页。
最后单击“创建站点地图”,即会构建采集器。
<p>(也可以通过填写/ top250来爬网URL,但是Web Scraper无法理解我们将对top250的所有页面的数据进行爬网。它将仅对第一页的内容进行爬网。)
汇总:数据获取|自动抓取网页数据你也行
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-12-20 12:15
Web抓取(也称为Web数据提取或Web爬网)是指从Internet获得数据,并将获得的非结构化数据转换为结构化数据,最后将数据存储在本地计算机或数据库技术上。
当前,全球网络数据的增长速度约为每年40%。 IDC(互联网数据中心)报告显示,2013年的全球数据为4.4ZB。到2020年,全球总数据将达到40ZB。大数据时代已经来临。从互联网上获取所需数据已成为进行竞争对手分析,业务数据挖掘和科学研究的重要手段。
网络信息采集的主要方法是:手动复制网页,自动Web爬行工具,用于循环批量下载,自制浏览器下载等。
今天,我将在注册后为您介绍一些免费的自动Web信息爬网工具,以供您参考。应当指出,大量的自动采集网络信息很容易被IP阻止。此时,可以使用以下方法进行破解:(1)暂停采集,过一会儿再试,然后尝试找到网页防御采集,然后根据规则;([2)使用云采集;(3)使用采集的代理IP。
一、优采云(URL:)
优采云平台集成了网页数据采集,移动Internet数据和API接口服务(包括数据挖掘,数据优化,数据存储,数据备份)和其他服务。
优采云可以在整个网络(网页,论坛,移动Internet,Qzone,电话号码,电子邮件,图片等)上实现自动采集信息。同时优采云提供独立采集和云采集两种模式。在特定的采集模式下,包括向导模式,高级模式和智能模式供不同主体选择。您可以从网站中获取数据并将其组织成一个数据集。它具有良好的交互设计,使用非常方便。其主要界面如图1所示。
图1 优采云主界面
二、优采云 采集器()
优采云 采集器是专业的网络数据采集工具,通过灵活的配置,您可以轻松地从网络中获取非结构化的文本,图片,文件和其他信息,进行编辑后,发布到网站后台或其他随时可用的数据库,适合具有采集挖掘需求的各种组,例如垂直搜索,信息聚合和门户,企业网络信息聚合,商业智能,论坛或博客迁移,智能信息的主要界面代理,个人信息检索和其他字段如图2所示。
优采云 采集器的工作原理是提取Web结构的源代码,因此只要在网页上可以看到内容,无论显示什么排列,都可以快速提取。最后捕获的数据可以导入任何目标数据库或导出为所需的格式。在网页爬网过程中,您还可以选择不同的线程来控制优采云 采集器 采集的速度。一般来说,优采云 采集器适合对爬网,速度和完整性有明确要求的用户。
图2 优采云 采集器主界面
三、优采云 采集器 Software()
优采云 采集器软件使用熊猫精确搜索引擎的解析内核来实现类似浏览器的Web内容分析,并在此基础上使用原创技术实现Web框架内容的分离。和核心内容,提取并实现相似页面的有效比较和匹配。因此,用户只需指定参考页面,优采云 采集器软件系统就可以相应地匹配相似页面,以实现用户所需的采集物料的批量采集。
在浏览器优采云 采集器软件中可见的内容可以是采集。 采集的对象包括文本内容,图片,Flash动画视频和其他网络内容。它同时支持混合的图形和文本对象采集,并支持JS输出内容采集。主界面如图3所示。
图3 优采云 采集器主要软件界面
四、Network Glorious()
网络申彩是一个专业的网络信息采集系统,可以通过灵活的规则从任何类型的网站 采集信息中获取,例如新闻网站,论坛,博客,电子商务网站 ,招聘网站等。支持网站登录采集,网站跨层采集,POST 采集,脚本页面采集,动态页面采集和其他高级采集功能。支持存储过程,插件等,并且可以通过二次开发进行扩展。主界面如图4所示。
图4网络精神的主界面 查看全部
汇总:数据获取|自动抓取网页数据你也行
Web抓取(也称为Web数据提取或Web爬网)是指从Internet获得数据,并将获得的非结构化数据转换为结构化数据,最后将数据存储在本地计算机或数据库技术上。
当前,全球网络数据的增长速度约为每年40%。 IDC(互联网数据中心)报告显示,2013年的全球数据为4.4ZB。到2020年,全球总数据将达到40ZB。大数据时代已经来临。从互联网上获取所需数据已成为进行竞争对手分析,业务数据挖掘和科学研究的重要手段。
网络信息采集的主要方法是:手动复制网页,自动Web爬行工具,用于循环批量下载,自制浏览器下载等。
今天,我将在注册后为您介绍一些免费的自动Web信息爬网工具,以供您参考。应当指出,大量的自动采集网络信息很容易被IP阻止。此时,可以使用以下方法进行破解:(1)暂停采集,过一会儿再试,然后尝试找到网页防御采集,然后根据规则;([2)使用云采集;(3)使用采集的代理IP。
一、优采云(URL:)
优采云平台集成了网页数据采集,移动Internet数据和API接口服务(包括数据挖掘,数据优化,数据存储,数据备份)和其他服务。
优采云可以在整个网络(网页,论坛,移动Internet,Qzone,电话号码,电子邮件,图片等)上实现自动采集信息。同时优采云提供独立采集和云采集两种模式。在特定的采集模式下,包括向导模式,高级模式和智能模式供不同主体选择。您可以从网站中获取数据并将其组织成一个数据集。它具有良好的交互设计,使用非常方便。其主要界面如图1所示。
图1 优采云主界面
二、优采云 采集器()
优采云 采集器是专业的网络数据采集工具,通过灵活的配置,您可以轻松地从网络中获取非结构化的文本,图片,文件和其他信息,进行编辑后,发布到网站后台或其他随时可用的数据库,适合具有采集挖掘需求的各种组,例如垂直搜索,信息聚合和门户,企业网络信息聚合,商业智能,论坛或博客迁移,智能信息的主要界面代理,个人信息检索和其他字段如图2所示。
优采云 采集器的工作原理是提取Web结构的源代码,因此只要在网页上可以看到内容,无论显示什么排列,都可以快速提取。最后捕获的数据可以导入任何目标数据库或导出为所需的格式。在网页爬网过程中,您还可以选择不同的线程来控制优采云 采集器 采集的速度。一般来说,优采云 采集器适合对爬网,速度和完整性有明确要求的用户。
图2 优采云 采集器主界面
三、优采云 采集器 Software()
优采云 采集器软件使用熊猫精确搜索引擎的解析内核来实现类似浏览器的Web内容分析,并在此基础上使用原创技术实现Web框架内容的分离。和核心内容,提取并实现相似页面的有效比较和匹配。因此,用户只需指定参考页面,优采云 采集器软件系统就可以相应地匹配相似页面,以实现用户所需的采集物料的批量采集。
在浏览器优采云 采集器软件中可见的内容可以是采集。 采集的对象包括文本内容,图片,Flash动画视频和其他网络内容。它同时支持混合的图形和文本对象采集,并支持JS输出内容采集。主界面如图3所示。
图3 优采云 采集器主要软件界面
四、Network Glorious()
网络申彩是一个专业的网络信息采集系统,可以通过灵活的规则从任何类型的网站 采集信息中获取,例如新闻网站,论坛,博客,电子商务网站 ,招聘网站等。支持网站登录采集,网站跨层采集,POST 采集,脚本页面采集,动态页面采集和其他高级采集功能。支持存储过程,插件等,并且可以通过二次开发进行扩展。主界面如图4所示。
图4网络精神的主界面
官方发布:Discuz优酷视频自动采集 自动采集发布(addon
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-12-10 11:21
该插件仅需添加采集关键字,即可通过优酷的搜索库自动匹配相应的视频,并在视频的每一页上自动执行采集并自动发布到[门户指定频道]或[论坛的指定部分]。
添加采集关键字后,视频采集的发布过程无需人工干预。它通过计划任务自动执行,并且可以修改采集的视频信息。当然,您也可以手动执行键采集来快速采集视频列表。
有关更多详细信息,请通过应用程序屏幕截图,更新日志等了解,或添加售前QQ(15326940)咨询问题
优酷视频分析插件推荐:
特殊说明
该插件只能采集优酷的普通视频,并且不支持电影,电视剧和动画之类的特殊内容
插件发布的视频使用论坛的多媒体代码([media]),分析由论坛本身处理,插件不具有分析功能
此插件需要PHP支持curl,curl通常可以获取https链接内容。 PHP版本至少为5.3,但不高于PHP7.1。如果服务器环境运行异常,则需要进行故障排除和测试。需要提供必要的网站和服务器帐户密码权限检查,远程协助不可用。
优酷视频具有采集的限制。高频采集可能被阻止。建议通过插件自动发布采集。
如果网站服务器被阻止,或者采集的源内容无法正常获取,并且您无法正常发布文章的内容采集,则不会退款。
如果采集规则由于插件自身的问题而无效,并且我们无法对其进行更新和修复,则在7天内购买的用户可以获得退款,并且购买超过7天且少于1个月可以补偿180元的优惠券,并购买一个月以上60元的补偿优惠券(优惠券只能在使用我们的名义购买应用时使用),每个用户只能选择一种补偿方式。
该插件仅用于集合文章,易于阅读。您需要承担文章的版权风险。未经原创作者授权,请勿公开发表文章或将其用于商业目的。
售后服务
售后问题通过专业的工单系统处理。下达工作订单后,技术将在技术答复时接收电子邮件提醒,接收手动订单,解决问题原因,组织问题解决方案以及接收现场短消息和电子邮件警报,以确保及时和有效解决您的问题
工作指令地址: 查看全部
Discuz Youku视频自动采集自动采集发布(插件
该插件仅需添加采集关键字,即可通过优酷的搜索库自动匹配相应的视频,并在视频的每一页上自动执行采集并自动发布到[门户指定频道]或[论坛的指定部分]。
添加采集关键字后,视频采集的发布过程无需人工干预。它通过计划任务自动执行,并且可以修改采集的视频信息。当然,您也可以手动执行键采集来快速采集视频列表。
有关更多详细信息,请通过应用程序屏幕截图,更新日志等了解,或添加售前QQ(15326940)咨询问题
优酷视频分析插件推荐:
特殊说明
该插件只能采集优酷的普通视频,并且不支持电影,电视剧和动画之类的特殊内容
插件发布的视频使用论坛的多媒体代码([media]),分析由论坛本身处理,插件不具有分析功能
此插件需要PHP支持curl,curl通常可以获取https链接内容。 PHP版本至少为5.3,但不高于PHP7.1。如果服务器环境运行异常,则需要进行故障排除和测试。需要提供必要的网站和服务器帐户密码权限检查,远程协助不可用。
优酷视频具有采集的限制。高频采集可能被阻止。建议通过插件自动发布采集。
如果网站服务器被阻止,或者采集的源内容无法正常获取,并且您无法正常发布文章的内容采集,则不会退款。
如果采集规则由于插件自身的问题而无效,并且我们无法对其进行更新和修复,则在7天内购买的用户可以获得退款,并且购买超过7天且少于1个月可以补偿180元的优惠券,并购买一个月以上60元的补偿优惠券(优惠券只能在使用我们的名义购买应用时使用),每个用户只能选择一种补偿方式。
该插件仅用于集合文章,易于阅读。您需要承担文章的版权风险。未经原创作者授权,请勿公开发表文章或将其用于商业目的。
售后服务
售后问题通过专业的工单系统处理。下达工作订单后,技术将在技术答复时接收电子邮件提醒,接收手动订单,解决问题原因,组织问题解决方案以及接收现场短消息和电子邮件警报,以确保及时和有效解决您的问题
工作指令地址:
解决方案:基于ThinkPHP框架开发的全自动采集小说网站PHP源码+WAP手机端
采集交流 • 优采云 发表了文章 • 0 个评论 • 435 次浏览 • 2020-09-07 15:02
源代码介绍
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给您自己网站,该程序与WAP移动终端兼容,可以进行手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给您自己网站,该程序与WAP移动终端兼容,可以进行手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给自己网站,该程序与WAP手机兼容,手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给自己网站,该程序与WAP手机兼容,手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
适用范围
小说网站源代码,自动采集小说网络,ThinkPHP小说源代码
操作环境
推荐:VPS或服务器构建+ PHP + MYSQL
专业测试屏幕截图
安装说明
1、直接将源代码上传到服务器,解压缩,然后运行域名进入安装环境。
2、按照视频教程进行学习。 查看全部
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码+ WAP移动终端
源代码介绍
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给您自己网站,该程序与WAP移动终端兼容,可以进行手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给您自己网站,该程序与WAP移动终端兼容,可以进行手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给自己网站,该程序与WAP手机兼容,手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
基于ThinkPHP框架开发的自动采集新颖网站 PHP源代码是一个程序,可以使用自动采集新颖的资源来构建自己的新颖的源代码网络。主要使用ThinkPHP 3. 2. 3框架开发,网站运行速度快,可以设置背景并自动将采集新资源分配给自己网站,该程序与WAP手机兼容,手机阅读小说更方便,拥有自己的VPS或服务器也更方便。本文收录视频教程,可以更轻松地进行构建。
适用范围
小说网站源代码,自动采集小说网络,ThinkPHP小说源代码
操作环境
推荐:VPS或服务器构建+ PHP + MYSQL
专业测试屏幕截图
安装说明
1、直接将源代码上传到服务器,解压缩,然后运行域名进入安装环境。
2、按照视频教程进行学习。
分享文章:建站必备-织梦采集侠.全手动采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-29 11:20
织梦采集侠的功能
采集侠官网点此下载免费版采集侠
采集侠是一款专业采集模块,拥有先进的人工智能网页辨识技术和优秀的伪原创技术,远远赶超传统的采集软件,从不同的网站采集优质内容并手动原创处理,减少了网站维护工作量的同时大大提升了收录和点击量,是一款每位网站必备的插件。
1一键安装,全手动采集
?织梦采集侠安装非常简单便捷,只需一分钟,立即开始采集,而且结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,而且我们还有专门的客服为商业顾客提供技术支持。
2一词采集,无须编撰采集规则
?和传统的采集模式不同的是织梦采集侠可以依据用户设定的关键词进行泛采集,泛采集的优势在于通过采集该关键词的不同搜索结果,实现不对指定的一个或几个被采集站点进行采集,减少采集站点被搜索引擎判断为镜像站点被搜索引擎惩罚的危险。
3RSS采集,输入RSS地址即可采集内容
?只要被采集的网站提供RSS订阅地址,即可通过RSS进行采集,只须要输入RSS地址即可便捷的采集到目标网站内容,无需编撰采集规则,方便简单。
4页面监控采集,简单便捷采集内容
?页面监控采集只须要提供监控页面地址和文字URL规则即可指定采集指定网站或栏目内容,方便简单,无需编撰采集规则也能进行针对性采集。5多种伪原创及优化方法,提高收录率及排行
?自动标题、段落重排、高级混淆、自动内链、内容过滤、网址过滤、同义词替换、插入seo成语、关键词添加链接等多种方式手段对采集回来的文章加工处理,增强采集文章原创性,利于搜索引擎优化,提高搜索引擎收录、网站权重及关键词排行。
6插件全手动采集,无需人工干预
?织梦采集侠根据预先设定是采集任务,根据所设定的采集方式采集网址,然后手动抓取网页内容,程序通过精确估算剖析网页,丢弃掉不是文章内容页的网址,提取出优秀文章内容,最后进行伪原创,导入,生成,这一切操作程序都是全手动完成,无需人工干预。
7手工发布文章亦可伪原创和搜索优化处理
?织梦采集侠并不仅仅是一款采集插件,更是一款织梦必备伪原创及搜索优化插件,手工发布的文章可以经过织梦采集侠的伪原创和搜索优化处理,可以对文章进行同义词替换,自动内链,随机插入关键词链接和文章内收录关键词将手动添加指定链接等功能,是一款织梦必备插件。
8定时定量进行采集伪原创SEO更新
?插件有两个触发采集方式,一种是在页面内添加代码由用户访问触发采集更新,另外种我们为商业用户提供的远程触发采集服务,新站无有人访问即可定时定量采集更新,无需人工干预。 查看全部
建站必备-织梦采集侠.全手动采集文章
织梦采集侠的功能
采集侠官网点此下载免费版采集侠
采集侠是一款专业采集模块,拥有先进的人工智能网页辨识技术和优秀的伪原创技术,远远赶超传统的采集软件,从不同的网站采集优质内容并手动原创处理,减少了网站维护工作量的同时大大提升了收录和点击量,是一款每位网站必备的插件。
1一键安装,全手动采集
?织梦采集侠安装非常简单便捷,只需一分钟,立即开始采集,而且结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,而且我们还有专门的客服为商业顾客提供技术支持。
2一词采集,无须编撰采集规则
?和传统的采集模式不同的是织梦采集侠可以依据用户设定的关键词进行泛采集,泛采集的优势在于通过采集该关键词的不同搜索结果,实现不对指定的一个或几个被采集站点进行采集,减少采集站点被搜索引擎判断为镜像站点被搜索引擎惩罚的危险。
3RSS采集,输入RSS地址即可采集内容
?只要被采集的网站提供RSS订阅地址,即可通过RSS进行采集,只须要输入RSS地址即可便捷的采集到目标网站内容,无需编撰采集规则,方便简单。
4页面监控采集,简单便捷采集内容
?页面监控采集只须要提供监控页面地址和文字URL规则即可指定采集指定网站或栏目内容,方便简单,无需编撰采集规则也能进行针对性采集。5多种伪原创及优化方法,提高收录率及排行
?自动标题、段落重排、高级混淆、自动内链、内容过滤、网址过滤、同义词替换、插入seo成语、关键词添加链接等多种方式手段对采集回来的文章加工处理,增强采集文章原创性,利于搜索引擎优化,提高搜索引擎收录、网站权重及关键词排行。
6插件全手动采集,无需人工干预
?织梦采集侠根据预先设定是采集任务,根据所设定的采集方式采集网址,然后手动抓取网页内容,程序通过精确估算剖析网页,丢弃掉不是文章内容页的网址,提取出优秀文章内容,最后进行伪原创,导入,生成,这一切操作程序都是全手动完成,无需人工干预。
7手工发布文章亦可伪原创和搜索优化处理
?织梦采集侠并不仅仅是一款采集插件,更是一款织梦必备伪原创及搜索优化插件,手工发布的文章可以经过织梦采集侠的伪原创和搜索优化处理,可以对文章进行同义词替换,自动内链,随机插入关键词链接和文章内收录关键词将手动添加指定链接等功能,是一款织梦必备插件。
8定时定量进行采集伪原创SEO更新
?插件有两个触发采集方式,一种是在页面内添加代码由用户访问触发采集更新,另外种我们为商业用户提供的远程触发采集服务,新站无有人访问即可定时定量采集更新,无需人工干预。
中文网页手动采集与分类系统设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2020-08-27 00:20
中文网页手动采集与分类系统设计与实现密级: 保密时限: 本人申明成果。尽我所 收录其他人已 教育机构的学 何贡献均已在 申请学位 本人签名 本人完全 校攻读学位期 家有关部门或 可以公布学位 保存、汇编学 本学位论 本人签名 导师签名 中文网页手动采集与分类系统设计与实现 摘要 随着科学技术的急速发展,我们早已步入了数字信息化时代。Internet 作为 当今世界上最大的信息库,也成为人们获取信息的最主要手段。由于网路上 以怎样快速、准确地从海量的信息资源中找寻到自己所需的信息已然成为网路用 户须要急迫解决的一大困局。因而基于web 的网路信息的采集与分类便成为 人们 研究的热点。 传统的web 信息采集的目标就是尽可能多地采集信息页面,甚至是整个 web 上的资源,在这一过程中它并不太在乎采集的次序和被采集页面的相关主 乱、重复等情况的发生。同时怎么有效地对采集到的网页实现手动分类,以创建 更为有效、快捷的搜索引擎也是十分必要的。网页分类是组织和管理信息的 有效 手段,它可以在较大程度上解决信息杂乱无章的现象,并便捷用户准确地定 需要的信息。传统的操作模式是对其人工分类后进行组织和管理。
随着Internet 上各类信息的迅猛降低,仅靠人工的方法来处理是不切实际的。因此,网页 自动 分类是一项具有较大实用价值的方式,也是组织和管理数据的有效手段。这 也是 本文研究的一个重要内容。 本文首先介绍了课题背景、研究目的和国内外的研究现况,阐述了网页 采集 和网页分类的相关理论、主要技术和算法,包括网页爬虫技术、网页去重技 几种典型的算法以后,本文选定了主题爬虫的方式和分类方面表现出众的KNN 方法,同时结合去重、分词和特点提取等相关技术的配合,并对英文网页的 结构 和特征进行了剖析后,提出英文网页采集和分类的设计与实现方式,最后通 过程 序设计语言来实现,在本文最后对系统进行了测试。测试结果达到了系统设 要求,应用疗效明显。关键词:Web 信息采集网页分类信息抽取动词特点提取 OFCHINESEANDIMPLE匝N1:ATION DESIGN wEBPAGEAUT0~IATIC采集 ANDCLASSIFICATION ABSTRACT Withthe ofscienceand haveenteredthe development technology,we rapid information iSseenastheworld’S information digital age.Intemet,which largest tobethemaint001 information.ItiS database.becomes obtaining majorproblem solved howto fromthemassofinformationresourcesurgentlyquicklyaccurately thatusersneedbecausethenetworkofinformationresources tofindtheinformation thelack hasa characteristics,and massive,dynamic,heterogeneous,semi―structured ofaunified information-based采集management organization presents.J theresearchandclassificationbecomes hotspot. information采集istoinformationas goal gather thewholeresourcesthe‖如功eorderand muchas even pagespossible,or topic inthe contentsiStooarenotcaredabout collecting.thepage cluttered, ofthemisusedSO resources largepart sparingly system 采集methodusedtoreducethecollected arewasted.TIliSeffective requires clutterand web classificatedtocreatepagesautomaticaly page duplication.The ande 伍cientsearch ofwebeffective managementpage engine.Organization Cansolveaextent classificationiSaneffectivemeallSinformation,which large clutterandfacilitateuserstolocate ofinformation phenomenon accurately modeof iSmanual.With information traditional theyneed.However,the operation infornlationinthe tohandle ofallkindsofIntemet,manual rapidincreasing way classificationisnotamethodaloneiSunrealistic Webgreatpractical alsoisaneffectivemeansof data.Ttisanvalue,but organizingmanaging researchofthis importantpart paper. andresearchstatusare Firstly,thebackground,purposeintroduced,and topic andclassificationare ofweb采集 theories,techniquesalgorithmspage includswebcrawler web deletcion described,which technology,duplicatedpages word extraction segmentation, feature technology,Chinese technology,information web classification extraction pagetechnology.Acomprehensive techniques ofseveral crawlerandKNNmade,topical comparison typicalalgorithms have classificationisselectedbecause outstandingperformance.111eproposedChinesewebare afterandclassificationof designedimplementated acquisition structureandcharacteristicsofChinese arecombinedandthetechnologies web iscodedandrealizedthelanguagepageanalyzed.Finally,it programmingresultsthatthe metthe language.Testsystem designrequirements,andapplication donefeilds. many information classification, Keywords:web采集,webpage information extraction extraction,segmentation,character 法.484.7.2 KNN 结5253 。
63北京邮电大学软件工程硕上论文 第一章序言 1.1 课题背景及研究现况 1.1.1 课题的背景及研究目的 随着互联网的普及和网路技术的急速发展,网络上的信息资源呈指数级 以从互联网上获得越来越多的包括文本、数字、图形、图像、声音、视频等信息。 然而,随着web 信息的极速膨胀,如何快速、准确地从广袤的信息资源中找 己所需的信息却成为广大网路用户的一大困局。因而基于互联网上的信息采集和 搜索引擎。这些搜索引擎一般使用一个或多个采集器从Intemet如、FTP、 Email、News 上搜集各类数据,然后在本地服务器上为这种数据构建索引, 用户检索时按照用户递交的检索条件从索引库中迅速查找到所需的信息。Web 信息采集作为这种搜索引擎的基础和组成部份,发挥着举足轻重的作用。web 信息采集是指通过Web 页面之间的链接关系,从Web 上手动地获取页面信息, 并且随着链接不断的向所须要的web 页面扩充的过程。传统的W 曲信息采集 目标就是尽可能多地采集信息页面,甚至是整个web 上的资源,在这一过 够集中精力在采集的速率和数目上,并且实现上去也相对简单。但是,这种传统 的采集方法存在着好多缺陷。
因为基于整个Web 的信息采集需要采集的页面 一部分利用率太低。用户常常只关心其中极少量的页面,而采集器采集的大部分 页面对于她们来说是没有用的。这其实是对系统资源和网路资源的一个巨大 费。随着web网页数目的迅猛下降,即使是采用了定题采集技术来完善定题 类,以创建更为有效、快捷的搜索引擎是十分必要的。传统的操作模式是对其人 工分类后进行组织和管理。这种分类方式分类比较确切,分类质量也较高。 随着 Internet 上各类信息的迅速降低,仅靠人工的方法来处理是不切实际的。 对网页 进行分类可以在很大程度上解决网页上信息零乱的现象,并便捷用户准确地 定位 所须要的信息,因此,网页手动分类是一项具有较大实用价值的方式,也是 组织 和管理数据的有效手段。这也是本文研究的一个重要内容。 北京邮电大学软件工程硕士论文 1.1.2 课题的国内外研究现况 网页采集技术发展现况网路正在不断地改变着我们的生活,Intemet 已经成为现今世晃上最大 息资源库,如何快速、准确地从广袤的信息资源库中找寻到所需的信息早已成为 网络用户的一大困局。无论是一些通用搜索引擎 如微软、百度等 ,或是一 定主题的专用网页采集系统,都离不开网页采集,因而基于Web的网页信息 采集 和处理日渐成为人们关注的焦点。
传统的Web 信息采集所采集的页面数目过 大,采集的内容也过分零乱,需要消耗很大的系统资源和网路资源。同时Intemet 信息的分散状态和动态变化也是困惑信息采集的主要问题。为了解决这种问 搜索引擎。这些搜索引擎一般是通过一个或多个采集器从Internet 上搜集 各种数 据,然后在本地服务器上为这种数据构建索引,当用户检索时按照用户递交 用的须要。即使小型的信息采集系统,它对Web的覆盖率也只有30"--40% 左右。 即便是采用处理能力更强的计算机系统,性价比也不是很高。相对更好的方 能满足人们的须要。其次,Intemet 信息的分散状态和动态变化也是影响信息采集的缘由。 由于 信息源可能随时处于变化之中,信息采集器必须时常刷新数据,但这仍未能 避免 采集到失效页面的情况。对于传统的信息采集来说,因为须要刷新页面数目 在采集到的页面中有相当大的一部分利用率太低。因为,用户常常只是关心其中 极少量的页面,并且这种页面常常是集中在一个或几个主题内,而采集器采 网络资源的一个巨大浪费。这些问题的形成主要是因为传统的 Web 信息采集所采集的页面数目过 大而且所采集页面的内容过分零乱。如果将信息检索限定在特定主题领域,根据 主题相关的信息提供检索服务,那么所需采集的网页数目都会大大降低且主 北京邮电大学软件工程硕上论文一。
这类Web 信息采集称为定题Web 信息采集,由于定题采集检索的范围较 所以查准率和查全率相对较高。但是随着网路的迅猛发展,Web网页数目的 爆炸 增长,即使采用了定题采集技术来完善定题搜索引擎,相对于广泛的主题来 同一主题的网页数目依然是海量的。所以,如何有效地将同一主题的网页根据某 种给定的模式进行分类,以创建更为有效、更为快捷的搜索引擎是一个十分 重要 的课题。 网页分类技术发展现况网页手动分类是在文本分类算法的基础上结合 6>HTML 语言结构特征 发展起 来的,文本手动分类最初是配合信息检索 InformationRetrieval,IR 系统 的需求 而出现的。信息检索系统必须操纵大量的数据,其文本信息库抢占其中大部 分内 容,同时,用来表示文本内容的词汇数目又是成千上万的。在这些情况下, 如果 能提供具有良好的组织与结构的文本集,就能大大简化文本的存取和操作。 文本 自动分类系统的目的就是对文本集进行有序的组织,把相像的、相关的文 本组织 在一起。它作为知识的组织工具,为信息检索提供了更高效的搜索策略和更 准确 的查询结果。 文本手动分类研究源于50 年代末,H.RLulm 在这一领域进行了开创性 究。
网页手动分类在美国经历了三个发展阶段:第一阶段1958.1964 要进行手动分类的可行性研究,第二阶段 1965.1974 进行手动分类的实验研究, 第三阶 1975.至今步入实用化阶段【l_】。 国内手动分类研究起步较晚,始于20 世纪80 年代早期。关于英文文本 分类的 研究相对较少,国内外的研究基本上是在英语文本分类的基础上,结合英文 文本 和汉语语言的特点采取相应的策略,然后应用于英文之上,继而产生英文文 动分类研究体系。1981年,候汉清对计算机在文献分类工作中的应用作了 探讨。 早期系统的主要特征是结合主题词表进行剖析分类,人工干预的成份很大, Lam等人将KNN 方法和线性分类器结合,取得了较好疗效, 港中文大学的Wai回率接近90%,准确率超过80%t31。C.K.P Wong 等人研究了用混和关键词进 行文 本分类的方式,召回率和准确率分别为72%和62%t41。复旦大学和东芝 研究开 发中心的黄首著、吴立德、石崎洋之等研究了独立语种的文本分类,并以词 类别的互信息量为评分函数,分别用单分类器和多分类器对英文和法文文本进行 了实验,最好的结果召回率为 88.87%【5’。
上海交通大学的刁倩、 王永成等人结 合词权重和分类算法进行分类,在用VSM 方法的封闭式测试实验中分类正确 N97%t71。此后,基于统计学的思想,以及动词、语料库等技术被不断应用到 分类中。 万维网大约载有115 亿多的可索引的网页,且每晚都有几千万或更多的 网页 被添加。如何组织那些大量有效的信息网路资源是一个很大的现实问题。网 页数 实现网页采集功能子系统。 二、对网页信息抽取技术、中文动词技术、特征提取技术和网页分类技 析比较,采用性能优良的KNN分类算法以实现网页分类功能。 三、采用最大匹配算法对文本进行动词。对网页进行清洗,剔除网页中 些垃圾信息,将网页转换为文本格式。四、网页预处理部份,结合网页的模型特征,根据HTML 标记对网页不 分的文本进行加权处理。通过以上几个方面的工作,最终完成一个网页手动采集与分类系统的设 实现,并用通过实验验证以上算法。1.3 论文结构 本文共分6 章,内容安排如下: 第一章序言,介绍本课题的意义、国内外现况和任务等。 第二章网页采集与分类相关技术介绍,本章对采集和分类上将会用到的 北京邮电大学软件工程硕士论文关技术的原理、方法等介绍。包括常用的网页爬虫技术、网页去 页分类技术。
第三章网页采集与分类系统设计,本章首先进行系统分析,然后进行系统 概要设计、功能模块设计、系统流程设计、系统逻辑设计和数据 设计。第四章网页采集与分类系统实现,本章详尽介绍各模块是实现过程,包括 页面采集模块、信息抽取模块、网页去重模块、中文动词模块、 征向量提取模块、训练语料库模块和分类模块。第五章网页采集与分类系统测试,本章首先给出系统的运行界面,然后给 出实验评测标准并对实验结果进行剖析。 第六章结束语,本章对本文工作进行全面总结,给出本文所取得的成果, 指出存在的不足和改进方向。 北京第二章网页 2.1 网页爬虫技术 程序,也是搜索引擎的核心部件。搜索引擎的性能,规模及扩充能力很大程 度上 依赖于网路爬虫的处理能力。网络爬虫 Crawler 也被叫做网路蜘蛛 Spider 或网路机器人Robot 。网络爬虫的系统结构如图 2-1 所示:其中下载模块 用于 库用于储存从抓取网页中抽取的URL。 图2.1 网络爬虫结构图 网络爬虫从给定的URL 出发,沿着该网页上的出链 out.Links ,按照 设定的 网页搜索策略,例如,宽度优先策略,深度优先策略,或最佳优先策略, 采集 URL 队列中优先级别高的网页,然后通过网页分类器判定是否为主题网页, 如果 是则保存,否则遗弃;对于采集的网页,抽取其中收录的URL,经过相应处 插入到URL队列中。
2.1.1 通用网路爬虫 通用网路爬虫 generalpurposewebcrawler 会按照预先设定的一个或 若干初 始种子URL 开始,下载模块不断从URL 队列中获取一个URL,访问并下载该 页面。 页面解析器除去页面上的 HTML 标记得到页面内容,将摘要、URL 等信息保 存到 web 数据库中,同时抽取当前页面上新的URL,保存至UURL 队列,直到满足 查看全部
中文网页手动采集与分类系统设计与实现
中文网页手动采集与分类系统设计与实现密级: 保密时限: 本人申明成果。尽我所 收录其他人已 教育机构的学 何贡献均已在 申请学位 本人签名 本人完全 校攻读学位期 家有关部门或 可以公布学位 保存、汇编学 本学位论 本人签名 导师签名 中文网页手动采集与分类系统设计与实现 摘要 随着科学技术的急速发展,我们早已步入了数字信息化时代。Internet 作为 当今世界上最大的信息库,也成为人们获取信息的最主要手段。由于网路上 以怎样快速、准确地从海量的信息资源中找寻到自己所需的信息已然成为网路用 户须要急迫解决的一大困局。因而基于web 的网路信息的采集与分类便成为 人们 研究的热点。 传统的web 信息采集的目标就是尽可能多地采集信息页面,甚至是整个 web 上的资源,在这一过程中它并不太在乎采集的次序和被采集页面的相关主 乱、重复等情况的发生。同时怎么有效地对采集到的网页实现手动分类,以创建 更为有效、快捷的搜索引擎也是十分必要的。网页分类是组织和管理信息的 有效 手段,它可以在较大程度上解决信息杂乱无章的现象,并便捷用户准确地定 需要的信息。传统的操作模式是对其人工分类后进行组织和管理。
随着Internet 上各类信息的迅猛降低,仅靠人工的方法来处理是不切实际的。因此,网页 自动 分类是一项具有较大实用价值的方式,也是组织和管理数据的有效手段。这 也是 本文研究的一个重要内容。 本文首先介绍了课题背景、研究目的和国内外的研究现况,阐述了网页 采集 和网页分类的相关理论、主要技术和算法,包括网页爬虫技术、网页去重技 几种典型的算法以后,本文选定了主题爬虫的方式和分类方面表现出众的KNN 方法,同时结合去重、分词和特点提取等相关技术的配合,并对英文网页的 结构 和特征进行了剖析后,提出英文网页采集和分类的设计与实现方式,最后通 过程 序设计语言来实现,在本文最后对系统进行了测试。测试结果达到了系统设 要求,应用疗效明显。关键词:Web 信息采集网页分类信息抽取动词特点提取 OFCHINESEANDIMPLE匝N1:ATION DESIGN wEBPAGEAUT0~IATIC采集 ANDCLASSIFICATION ABSTRACT Withthe ofscienceand haveenteredthe development technology,we rapid information iSseenastheworld’S information digital age.Intemet,which largest tobethemaint001 information.ItiS database.becomes obtaining majorproblem solved howto fromthemassofinformationresourcesurgentlyquicklyaccurately thatusersneedbecausethenetworkofinformationresources tofindtheinformation thelack hasa characteristics,and massive,dynamic,heterogeneous,semi―structured ofaunified information-based采集management organization presents.J theresearchandclassificationbecomes hotspot. information采集istoinformationas goal gather thewholeresourcesthe‖如功eorderand muchas even pagespossible,or topic inthe contentsiStooarenotcaredabout collecting.thepage cluttered, ofthemisusedSO resources largepart sparingly system 采集methodusedtoreducethecollected arewasted.TIliSeffective requires clutterand web classificatedtocreatepagesautomaticaly page duplication.The ande 伍cientsearch ofwebeffective managementpage engine.Organization Cansolveaextent classificationiSaneffectivemeallSinformation,which large clutterandfacilitateuserstolocate ofinformation phenomenon accurately modeof iSmanual.With information traditional theyneed.However,the operation infornlationinthe tohandle ofallkindsofIntemet,manual rapidincreasing way classificationisnotamethodaloneiSunrealistic Webgreatpractical alsoisaneffectivemeansof data.Ttisanvalue,but organizingmanaging researchofthis importantpart paper. andresearchstatusare Firstly,thebackground,purposeintroduced,and topic andclassificationare ofweb采集 theories,techniquesalgorithmspage includswebcrawler web deletcion described,which technology,duplicatedpages word extraction segmentation, feature technology,Chinese technology,information web classification extraction pagetechnology.Acomprehensive techniques ofseveral crawlerandKNNmade,topical comparison typicalalgorithms have classificationisselectedbecause outstandingperformance.111eproposedChinesewebare afterandclassificationof designedimplementated acquisition structureandcharacteristicsofChinese arecombinedandthetechnologies web iscodedandrealizedthelanguagepageanalyzed.Finally,it programmingresultsthatthe metthe language.Testsystem designrequirements,andapplication donefeilds. many information classification, Keywords:web采集,webpage information extraction extraction,segmentation,character 法.484.7.2 KNN 结5253 。
63北京邮电大学软件工程硕上论文 第一章序言 1.1 课题背景及研究现况 1.1.1 课题的背景及研究目的 随着互联网的普及和网路技术的急速发展,网络上的信息资源呈指数级 以从互联网上获得越来越多的包括文本、数字、图形、图像、声音、视频等信息。 然而,随着web 信息的极速膨胀,如何快速、准确地从广袤的信息资源中找 己所需的信息却成为广大网路用户的一大困局。因而基于互联网上的信息采集和 搜索引擎。这些搜索引擎一般使用一个或多个采集器从Intemet如、FTP、 Email、News 上搜集各类数据,然后在本地服务器上为这种数据构建索引, 用户检索时按照用户递交的检索条件从索引库中迅速查找到所需的信息。Web 信息采集作为这种搜索引擎的基础和组成部份,发挥着举足轻重的作用。web 信息采集是指通过Web 页面之间的链接关系,从Web 上手动地获取页面信息, 并且随着链接不断的向所须要的web 页面扩充的过程。传统的W 曲信息采集 目标就是尽可能多地采集信息页面,甚至是整个web 上的资源,在这一过 够集中精力在采集的速率和数目上,并且实现上去也相对简单。但是,这种传统 的采集方法存在着好多缺陷。
因为基于整个Web 的信息采集需要采集的页面 一部分利用率太低。用户常常只关心其中极少量的页面,而采集器采集的大部分 页面对于她们来说是没有用的。这其实是对系统资源和网路资源的一个巨大 费。随着web网页数目的迅猛下降,即使是采用了定题采集技术来完善定题 类,以创建更为有效、快捷的搜索引擎是十分必要的。传统的操作模式是对其人 工分类后进行组织和管理。这种分类方式分类比较确切,分类质量也较高。 随着 Internet 上各类信息的迅速降低,仅靠人工的方法来处理是不切实际的。 对网页 进行分类可以在很大程度上解决网页上信息零乱的现象,并便捷用户准确地 定位 所须要的信息,因此,网页手动分类是一项具有较大实用价值的方式,也是 组织 和管理数据的有效手段。这也是本文研究的一个重要内容。 北京邮电大学软件工程硕士论文 1.1.2 课题的国内外研究现况 网页采集技术发展现况网路正在不断地改变着我们的生活,Intemet 已经成为现今世晃上最大 息资源库,如何快速、准确地从广袤的信息资源库中找寻到所需的信息早已成为 网络用户的一大困局。无论是一些通用搜索引擎 如微软、百度等 ,或是一 定主题的专用网页采集系统,都离不开网页采集,因而基于Web的网页信息 采集 和处理日渐成为人们关注的焦点。
传统的Web 信息采集所采集的页面数目过 大,采集的内容也过分零乱,需要消耗很大的系统资源和网路资源。同时Intemet 信息的分散状态和动态变化也是困惑信息采集的主要问题。为了解决这种问 搜索引擎。这些搜索引擎一般是通过一个或多个采集器从Internet 上搜集 各种数 据,然后在本地服务器上为这种数据构建索引,当用户检索时按照用户递交 用的须要。即使小型的信息采集系统,它对Web的覆盖率也只有30"--40% 左右。 即便是采用处理能力更强的计算机系统,性价比也不是很高。相对更好的方 能满足人们的须要。其次,Intemet 信息的分散状态和动态变化也是影响信息采集的缘由。 由于 信息源可能随时处于变化之中,信息采集器必须时常刷新数据,但这仍未能 避免 采集到失效页面的情况。对于传统的信息采集来说,因为须要刷新页面数目 在采集到的页面中有相当大的一部分利用率太低。因为,用户常常只是关心其中 极少量的页面,并且这种页面常常是集中在一个或几个主题内,而采集器采 网络资源的一个巨大浪费。这些问题的形成主要是因为传统的 Web 信息采集所采集的页面数目过 大而且所采集页面的内容过分零乱。如果将信息检索限定在特定主题领域,根据 主题相关的信息提供检索服务,那么所需采集的网页数目都会大大降低且主 北京邮电大学软件工程硕上论文一。
这类Web 信息采集称为定题Web 信息采集,由于定题采集检索的范围较 所以查准率和查全率相对较高。但是随着网路的迅猛发展,Web网页数目的 爆炸 增长,即使采用了定题采集技术来完善定题搜索引擎,相对于广泛的主题来 同一主题的网页数目依然是海量的。所以,如何有效地将同一主题的网页根据某 种给定的模式进行分类,以创建更为有效、更为快捷的搜索引擎是一个十分 重要 的课题。 网页分类技术发展现况网页手动分类是在文本分类算法的基础上结合 6>HTML 语言结构特征 发展起 来的,文本手动分类最初是配合信息检索 InformationRetrieval,IR 系统 的需求 而出现的。信息检索系统必须操纵大量的数据,其文本信息库抢占其中大部 分内 容,同时,用来表示文本内容的词汇数目又是成千上万的。在这些情况下, 如果 能提供具有良好的组织与结构的文本集,就能大大简化文本的存取和操作。 文本 自动分类系统的目的就是对文本集进行有序的组织,把相像的、相关的文 本组织 在一起。它作为知识的组织工具,为信息检索提供了更高效的搜索策略和更 准确 的查询结果。 文本手动分类研究源于50 年代末,H.RLulm 在这一领域进行了开创性 究。
网页手动分类在美国经历了三个发展阶段:第一阶段1958.1964 要进行手动分类的可行性研究,第二阶段 1965.1974 进行手动分类的实验研究, 第三阶 1975.至今步入实用化阶段【l_】。 国内手动分类研究起步较晚,始于20 世纪80 年代早期。关于英文文本 分类的 研究相对较少,国内外的研究基本上是在英语文本分类的基础上,结合英文 文本 和汉语语言的特点采取相应的策略,然后应用于英文之上,继而产生英文文 动分类研究体系。1981年,候汉清对计算机在文献分类工作中的应用作了 探讨。 早期系统的主要特征是结合主题词表进行剖析分类,人工干预的成份很大, Lam等人将KNN 方法和线性分类器结合,取得了较好疗效, 港中文大学的Wai回率接近90%,准确率超过80%t31。C.K.P Wong 等人研究了用混和关键词进 行文 本分类的方式,召回率和准确率分别为72%和62%t41。复旦大学和东芝 研究开 发中心的黄首著、吴立德、石崎洋之等研究了独立语种的文本分类,并以词 类别的互信息量为评分函数,分别用单分类器和多分类器对英文和法文文本进行 了实验,最好的结果召回率为 88.87%【5’。
上海交通大学的刁倩、 王永成等人结 合词权重和分类算法进行分类,在用VSM 方法的封闭式测试实验中分类正确 N97%t71。此后,基于统计学的思想,以及动词、语料库等技术被不断应用到 分类中。 万维网大约载有115 亿多的可索引的网页,且每晚都有几千万或更多的 网页 被添加。如何组织那些大量有效的信息网路资源是一个很大的现实问题。网 页数 实现网页采集功能子系统。 二、对网页信息抽取技术、中文动词技术、特征提取技术和网页分类技 析比较,采用性能优良的KNN分类算法以实现网页分类功能。 三、采用最大匹配算法对文本进行动词。对网页进行清洗,剔除网页中 些垃圾信息,将网页转换为文本格式。四、网页预处理部份,结合网页的模型特征,根据HTML 标记对网页不 分的文本进行加权处理。通过以上几个方面的工作,最终完成一个网页手动采集与分类系统的设 实现,并用通过实验验证以上算法。1.3 论文结构 本文共分6 章,内容安排如下: 第一章序言,介绍本课题的意义、国内外现况和任务等。 第二章网页采集与分类相关技术介绍,本章对采集和分类上将会用到的 北京邮电大学软件工程硕士论文关技术的原理、方法等介绍。包括常用的网页爬虫技术、网页去 页分类技术。
第三章网页采集与分类系统设计,本章首先进行系统分析,然后进行系统 概要设计、功能模块设计、系统流程设计、系统逻辑设计和数据 设计。第四章网页采集与分类系统实现,本章详尽介绍各模块是实现过程,包括 页面采集模块、信息抽取模块、网页去重模块、中文动词模块、 征向量提取模块、训练语料库模块和分类模块。第五章网页采集与分类系统测试,本章首先给出系统的运行界面,然后给 出实验评测标准并对实验结果进行剖析。 第六章结束语,本章对本文工作进行全面总结,给出本文所取得的成果, 指出存在的不足和改进方向。 北京第二章网页 2.1 网页爬虫技术 程序,也是搜索引擎的核心部件。搜索引擎的性能,规模及扩充能力很大程 度上 依赖于网路爬虫的处理能力。网络爬虫 Crawler 也被叫做网路蜘蛛 Spider 或网路机器人Robot 。网络爬虫的系统结构如图 2-1 所示:其中下载模块 用于 库用于储存从抓取网页中抽取的URL。 图2.1 网络爬虫结构图 网络爬虫从给定的URL 出发,沿着该网页上的出链 out.Links ,按照 设定的 网页搜索策略,例如,宽度优先策略,深度优先策略,或最佳优先策略, 采集 URL 队列中优先级别高的网页,然后通过网页分类器判定是否为主题网页, 如果 是则保存,否则遗弃;对于采集的网页,抽取其中收录的URL,经过相应处 插入到URL队列中。
2.1.1 通用网路爬虫 通用网路爬虫 generalpurposewebcrawler 会按照预先设定的一个或 若干初 始种子URL 开始,下载模块不断从URL 队列中获取一个URL,访问并下载该 页面。 页面解析器除去页面上的 HTML 标记得到页面内容,将摘要、URL 等信息保 存到 web 数据库中,同时抽取当前页面上新的URL,保存至UURL 队列,直到满足
Excel手动抓取网页数据,数据抓取一键搞定
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-08-26 05:05
网站上的数据源是我们进行统计剖析的重要信息源。我们在生活中经常看到一个词叫“爬虫”,能够快速抓取网页上的数据,这对于数据剖析相关工作来说非常重要,也是必备的技能之一。但是爬虫大多须要编程的知识,一般人不好入手。今天就给你们讲解一下怎样用Excel快速抓取网页数据。
1、首先打开须要抓取的数据的网站,复制网站地址。
2、新建Excel工作簿,点击“数据”菜单>“获取外部数据”选项卡中的“自网站”选项。
在弹出的“新建web查询”对话框中,地址栏输入须要抓取的网站地址,点击“转到”
点击蓝色导出箭头,选择须要抓取的部份,如图。点击导出即可。
3、选择数据储存的位置(默认选择的单元格),点击确定即可。一般建议数据储存在“A1”单元格即可。
4、如果想要Excel工作簿数据能手动依据网站的数据实时更新,那么我们须要在"属性"中进行设置。可以设置“允许后台刷新”、“刷新频度”、“打开文件时刷新数据”等。
得到数据然后,就须要对数据进行处理了,处理数据是更重要的一个环节。更多数据处理的方法,请关注我!
如果对您有帮助,请记得点赞,转发。
关注我学习更多Excel方法,让工作更简单。 查看全部
Excel手动抓取网页数据,数据抓取一键搞定
网站上的数据源是我们进行统计剖析的重要信息源。我们在生活中经常看到一个词叫“爬虫”,能够快速抓取网页上的数据,这对于数据剖析相关工作来说非常重要,也是必备的技能之一。但是爬虫大多须要编程的知识,一般人不好入手。今天就给你们讲解一下怎样用Excel快速抓取网页数据。
1、首先打开须要抓取的数据的网站,复制网站地址。
2、新建Excel工作簿,点击“数据”菜单>“获取外部数据”选项卡中的“自网站”选项。
在弹出的“新建web查询”对话框中,地址栏输入须要抓取的网站地址,点击“转到”
点击蓝色导出箭头,选择须要抓取的部份,如图。点击导出即可。
3、选择数据储存的位置(默认选择的单元格),点击确定即可。一般建议数据储存在“A1”单元格即可。
4、如果想要Excel工作簿数据能手动依据网站的数据实时更新,那么我们须要在"属性"中进行设置。可以设置“允许后台刷新”、“刷新频度”、“打开文件时刷新数据”等。
得到数据然后,就须要对数据进行处理了,处理数据是更重要的一个环节。更多数据处理的方法,请关注我!
如果对您有帮助,请记得点赞,转发。
关注我学习更多Excel方法,让工作更简单。
数据获取|自动抓取网页数据你也行
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-08-25 12:54
网页抓取(也称为网路数据提取或网页爬取)是指从网上获取数据,并将获取到的非结构化数据转化为结构化的数据,最终可以将数据储存到本地计算机或数据库的一种技术。
目前,全球网路数据的增长速度在每年40%左右,IDC(互联网数据中心)的报告显示,2013全球数据为4.4ZB,2020年的时侯,全球的数据总数将达到40ZB。大数据时代已经到来,从网路中获取所需数据成为举办竞争对手剖析、商业数据挖掘和科研的重要手段。
网络信息采集的形式主要有:网页手工复制、网页手动抓取工具、For循环批量下载、自制浏览器下载等。
今天给你们介绍的是几款注册以后免费使用的网页信息手动抓取工具,供你们学习参考。需要说明的是,大量手动采集网络信息极易被封IP,这时可采取如下办法破解:(1)暂停采集,过段时间再尝试,并尝试找到网页防采集的规律再进行采集规则的设置;(2)使用云采集;(3)使用代理IP进行采集。
一、优采云(网址:)
优采云平台整合了网页数据采集、移动互联网数据及API接口服务(包括数据挖掘、数据优化、数据储存、数据备份)等服务为一体。
优采云可实现对全网(网页、论坛、移动互联网、QQ空间、电话号码、邮箱、图片等)信息进行手动采集。同时优采云提供单机采集和云采集两种模式。在具体采集方式包括向导模式、高级模式和Smart模式供不同主体对象选择。可以从网站中抓取数据并整理成数据集。它拥有挺好的交互设计,使用上去十分便捷,其主界面见图1所示。
图1优采云主界面
二、优采云采集器()
优采云采集器是一款专业的网路数据采集工具,通过灵活的配置,可以太轻松从网路上抓取非结构化的文本、图片、文件等信息,经编辑后可随时发布到网站后台或其他数据库中,适用于各种对数据有采集挖掘需求的群体,如垂直搜索、信息凝聚和门户、企业网信息凝聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,其主界面见图2所示。
优采云采集器的操作原理是web结构的源代码提取,所以只要是网页上才能看见的内容,无论以何种排布方式诠释都可以被快速提取下来。并且最终抓取的数据支持导出到任一目标数据库中,或者导入为想要的格式。在网页抓取的过程中,还可以选择不同的线程数来控制优采云采集器采集的速率快慢。总体上来说,优采云采集器适用于对抓取需求太明晰,对速率有要求,对完整性要求也较高的用户。
图2优采云采集器主界面
三、优采云采集器软件()
优采云采集器软件借助熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上借助原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相像页面的有效比对、匹配。因此,用户只须要指定一个参考页面,优采云采集器软件系统就可以据此来匹配类似的页面,来实现用户须要采集资料的批量采集。
浏览器可见的内容优采云采集器软件都可以采集。采集的对象包括文字内容,图片,flash动漫视频等等各种网路内容,支持图文混排对象的同时采集,支持JS输出内容的采集,其主界面见图3所示。
图3 优采云采集器软件主界面
四、网络神采()
网络神采是一款专业的网路信息采集系统,通过灵活的规则可以从任何类型的网站采集信息,如新闻网站、论坛、博客、电子商务网站、招聘网站等等。支持网站登录采集、网站跨层采集、POST采集、脚本页面采集、动态页面采集等中级采集功能。支持存储过程、插件等,可以通过二次开发扩充功能,其主界面见图4所示。
图4 网络神采主界面 查看全部
数据获取|自动抓取网页数据你也行
网页抓取(也称为网路数据提取或网页爬取)是指从网上获取数据,并将获取到的非结构化数据转化为结构化的数据,最终可以将数据储存到本地计算机或数据库的一种技术。
目前,全球网路数据的增长速度在每年40%左右,IDC(互联网数据中心)的报告显示,2013全球数据为4.4ZB,2020年的时侯,全球的数据总数将达到40ZB。大数据时代已经到来,从网路中获取所需数据成为举办竞争对手剖析、商业数据挖掘和科研的重要手段。
网络信息采集的形式主要有:网页手工复制、网页手动抓取工具、For循环批量下载、自制浏览器下载等。
今天给你们介绍的是几款注册以后免费使用的网页信息手动抓取工具,供你们学习参考。需要说明的是,大量手动采集网络信息极易被封IP,这时可采取如下办法破解:(1)暂停采集,过段时间再尝试,并尝试找到网页防采集的规律再进行采集规则的设置;(2)使用云采集;(3)使用代理IP进行采集。
一、优采云(网址:)
优采云平台整合了网页数据采集、移动互联网数据及API接口服务(包括数据挖掘、数据优化、数据储存、数据备份)等服务为一体。
优采云可实现对全网(网页、论坛、移动互联网、QQ空间、电话号码、邮箱、图片等)信息进行手动采集。同时优采云提供单机采集和云采集两种模式。在具体采集方式包括向导模式、高级模式和Smart模式供不同主体对象选择。可以从网站中抓取数据并整理成数据集。它拥有挺好的交互设计,使用上去十分便捷,其主界面见图1所示。
图1优采云主界面
二、优采云采集器()
优采云采集器是一款专业的网路数据采集工具,通过灵活的配置,可以太轻松从网路上抓取非结构化的文本、图片、文件等信息,经编辑后可随时发布到网站后台或其他数据库中,适用于各种对数据有采集挖掘需求的群体,如垂直搜索、信息凝聚和门户、企业网信息凝聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,其主界面见图2所示。
优采云采集器的操作原理是web结构的源代码提取,所以只要是网页上才能看见的内容,无论以何种排布方式诠释都可以被快速提取下来。并且最终抓取的数据支持导出到任一目标数据库中,或者导入为想要的格式。在网页抓取的过程中,还可以选择不同的线程数来控制优采云采集器采集的速率快慢。总体上来说,优采云采集器适用于对抓取需求太明晰,对速率有要求,对完整性要求也较高的用户。
图2优采云采集器主界面
三、优采云采集器软件()
优采云采集器软件借助熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上借助原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相像页面的有效比对、匹配。因此,用户只须要指定一个参考页面,优采云采集器软件系统就可以据此来匹配类似的页面,来实现用户须要采集资料的批量采集。
浏览器可见的内容优采云采集器软件都可以采集。采集的对象包括文字内容,图片,flash动漫视频等等各种网路内容,支持图文混排对象的同时采集,支持JS输出内容的采集,其主界面见图3所示。
图3 优采云采集器软件主界面
四、网络神采()
网络神采是一款专业的网路信息采集系统,通过灵活的规则可以从任何类型的网站采集信息,如新闻网站、论坛、博客、电子商务网站、招聘网站等等。支持网站登录采集、网站跨层采集、POST采集、脚本页面采集、动态页面采集等中级采集功能。支持存储过程、插件等,可以通过二次开发扩充功能,其主界面见图4所示。
图4 网络神采主界面

