
自动采集网站内容
如何用Python爬数据?(一)网页抓取
采集交流 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2020-08-09 22:46
(由于微信公众号外部链接的限制,文中的部份链接可能难以正确打开。如有须要,请点击文末的“阅读原文”按钮,访问可以正常显示外链的版本。)
需求
我在公众号后台,经常可以收到读者的留言。
很多留言,是读者的疑惑。只要有时间,我就会抽空尝试解答。
但是有的留言,乍看上去就不明所以了。
例如下边这个:
一分钟后,他可能认为不妥(大概由于想起来,我用简体字写文章),于是又用繁体发了一遍。
我恍然大悟。
这位读者以为我的公众号设置了关键词推送对应文章功能。所以看了我的其他数据科学教程后,想看“爬虫”专题。
不好意思,当时我还没有写爬虫文章。
而且,我的公众号暂时也没有设置这些关键词推送。
主要是因为我懒。
这样的消息接收得多了,我也能揣度到读者的需求。不止一个读者抒发出对爬虫教程的兴趣。
之前提过,目前主流而合法的网路数据搜集技巧,主要分为3类:
前两种方式,我都早已做过一些介绍,这次谈谈爬虫。
概念
许多读者对爬虫的定义,有些混淆。咱们有必要辨析一下。
维基百科是这么说的:
网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览万维网的网路机器人。其目的通常为编修网路索引。
这问题就来了,你又不准备做搜索引擎,为什么对网路爬虫这么热心呢?
其实,许多人口中所说的爬虫(web crawler),跟另外一种功能“网页抓取”(web scraping)搞混了。
维基百科上,对于前者这样解释:
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser.
看到没有,即便你用浏览器自动拷贝数据出来,也称作网页抓取(web scraping)。是不是立即认为自己强悍了好多?
但是,这定义还没完:
While web scraping can be done manually by a software user, the term typically refers to automate processes implemented using a bot or web crawler.
也就是说,用爬虫(或者机器人)自动替你完成网页抓取工作,才是你真正想要的。
数据抓出来干哪些呢?
一般是先储存上去,放到数据库或则电子表格中,以备检索或则进一步剖析使用。
所以,你真正想要的功能是这样的:
找到链接,获得Web页面,抓取指定信息,存储。
这个过程有可能会往复循环,甚至是滚雪球。
你希望用自动化的方法来完成它。
了解了这一点,你就不要老盯住爬虫不放了。爬虫研发下来,其实是为了给搜索引擎编制索引数据库使用的。你为了抓取点儿数据用来使用,已经是大炮轰虫子了。
要真正把握爬虫,你须要具备不少基础知识。例如HTML, CSS, Javascript, 数据结构……
这也是为何我仍然迟疑着没有写爬虫教程的诱因。
不过这三天,看到王烁主编的一段话,很有启发:
我喜欢讲一个另类二八定律,就是付出两成努力,了解一件事的八成。
既然我们的目标太明晰,就是要从网页抓取数据。那么你须要把握的最重要能力,是领到一个网页链接后,如何从中快捷有效地抓取自己想要的信息。
掌握了它,你还不能说自己早已学会了爬虫。
但有了这个基础,你能够比之前更轻松获取数据了。特别是对“文科生”的好多应用场景来说,非常有用。这就是赋能。
而且,再进一步深入理解爬虫的工作原理,也显得轻松许多。
这也算“另类二八定律”的一个应用吧。
Python语言的重要特色之一,就是可以借助强悍的软件工具包(许多都是第三方提供)。你只须要编撰简单的程序,就能手动解析网页,抓取数据。
本文给你演示这一过程。
目标
要抓取网页数据,我们先制定一个小目标。
目标不能很复杂。但是完成它,应该对你理解抓取(Web Scraping)有帮助。
就选择我近来发布的一篇简书文章作为抓取对象好了。题目称作《如何用《玉树芝兰》入门数据科学?》。
这篇文章里,我把之前的发布的数据科学系列文章做了重新组织和串讲。
文中收录好多之前教程的标题和对应链接。例如下图蓝色边框圈上去的部份。
假设你对文中提及教程都太感兴趣,希望获得这种文章的链接,并且储存到Excel里,就像下边这个样子:
你须要把非结构化的分散信息(自然语言文本中的链接),专门提取整理,并且储存出来。
该如何办呢?
即便不会编程,你也可以全文研读,逐个去找这种文章链接,手动把文章标题、链接都分别拷贝出来,存到Excel表上面。
但是,这种手工采集方法没有效率。
我们用Python。
环境
要装Python,比较省事的办法是安装Anaconda套装。
请到这个网址下载Anaconda的最新版本。
请选择两侧的 Python 3.6 版本下载安装。
如果你须要具体的步骤指导,或者想知道Windows平台怎么安装并运行Anaconda命令,请参考我为你打算的视频教程。
安装好Anaconda以后,请到这个网址下载本教程配套的压缩包。
下载后解压,你会在生成的目录(下称“演示目录”)里面听到以下三个文件。
打开终端,用cd命令步入该演示目录。如果你不了解具体使用方式,也可以参考视频教程。
我们须要安装一些环境依赖包。
首先执行:
pip install pipenv<br />
这里安装的,是一个优秀的 Python 软件包管理工具 pipenv 。
安装后,请执行:
pipenv install<br />
看到演示目录下两个Pipfile开头的文件了吗?它们就是 pipenv 的设置文档。
pipenv 工具会根据它们,自动为我们安装所须要的全部依赖软件包。
上图上面有个红色的进度条,提示所需安装软件数目和实际进度。
装好后,根据提示我们执行:
pipenv shell<br />
此处请确认你的笔记本上早已安装了 Google Chrome 浏览器。
我们执行:
jupyter notebook<br />
默认浏览器(Google Chrome)会开启,并启动 Jupyter 笔记本界面:
你可以直接点击文件列表中的第一项ipynb文件,可以看见本教程的全部示例代码。
你可以一边看教程的讲解,一边依次执行这种代码。
但是,我建议的方式,是回到主界面下,新建一个新的空白 Python 3 笔记本。
请跟随教程,一个个字符输入相应的内容。这可以帮助你更为深刻地理解代码的含意,更高效地把技能内化。
准备工作结束,下面我们开始即将输入代码。
代码
读入网页加以解析抓取,需要用到的软件包是 requests_html 。我们此处并不需要这个软件包的全部功能,只读入其中的 HTMLSession 就可以。
from requests_html import HTMLSession<br />
然后,我们构建一个会话(session),即使Python作为一个客户端,和远端服务器攀谈。
session = HTMLSession()<br />
前面说了,我们准备采集信息的网页,是《如何用《玉树芝兰》入门数据科学?》一文。
我们找到它的网址,存储到url变量名中。
url = 'https://www.jianshu.com/p/85f4624485b9'<br />
下面的句子,利用 session 的 get 功能,把这个链接对应的网页整个儿取回去。
r = session.get(url)<br />
网页上面都有哪些内容呢?
我们告诉Python,请把服务器传回去的内容当成HTML文件类型处理。我不想要看HTML上面这些乱七八糟的格式描述符,只看文字部份。
于是我们执行:
print(r.html.text)<br />
这就是获得的结果了:
我们心里有数了。取回去的网页信息是正确的,内容是完整的。
好了,我们来瞧瞧如何趋近自己的目标吧。
我们先用简单粗暴的方式,尝试获得网页中收录的全部链接。
把返回的内容作为HTML文件类型,我们查看 links 属性:
r.html.links<br />
这是返回的结果:
这么多链接啊!
很兴奋吧?
不过,你发觉没有?这里许多链接,看似都不完全。例如第一条结果,只有:
'/'<br />
这是哪些东西?是不是链接抓取错误啊?
不是,这种看着不象链接的东西,叫做相对链接。它是某个链接,相对于我们采集的网页所在域名()的路径。
这就好象我们在国外寄送快件包裹,填单子的时侯通常会写“XX市XX区……”,前面不需要加上国家名称。只有国际快件,才须要写上国名。
但是假如我们希望获得全部可以直接访问的链接,怎么办呢?
很容易,也只须要一条 Python 语句。
r.html.absolute_links<br />
这里,我们要的是“绝对”链接,于是我们都会获得下边的结果:
这回看着是不是就舒服多了?
我们的任务已经完成了吧?链接不是都在这里吗?
链接确实都在这里了,可是跟我们的目标是不是有区别呢?
检查一下,确实有。
我们不光要找到链接,还得找到链接对应的描述文字呢,结果里收录吗?
没有。
结果列表中的链接,都是我们须要的吗?
不是。看宽度,我们才能觉得出许多链接并不是文中描述其他数据科学文章的网址。
这种简单粗鲁直接列举HTML文件中所有链接的方式,对本任务行不通。
那么我们该如何办?
我们得学会跟 Python 说清楚我们要找的东西。这是网页抓取的关键。
想想看,如果你想使助手(人类)帮你做这事儿,怎么办?
你会告诉他:
“寻找正文中全部可以点击的黑色文字链接,拷贝文字到Excel表格,然后右键复制对应的链接,也拷贝到Excel表格。每个链接在Excel占一行,文字和链接各占一个单元格。”
虽然这个操作执行上去麻烦,但是助手听懂后,就能帮你执行。
同样的描述,你试试说给笔记本听……不好意思,它不理解。
因为你和助手看见的网页,是这个样子的。
电脑听到的网页,是这个样子的。
为了使你看得清楚源代码,浏览器还特意对不同类型的数据用了颜色分辨,对行做了编号。
数据显示给笔记本时,上述辅助可视功能是没有的。它只能看到一串串字符。
那可怎么办?
仔细观察,你会发觉这种HTML源代码上面,文字、图片链接内容前后,都会有一些被尖括弧括上去的部份,这就叫做“标记”。
所谓HTML,就是一种标记语言(超文本标记语言,HyperText Markup Language)。
标记的作用是哪些?它可以把整个的文件分解出层次来。 查看全部
你期盼已久的Python网路数据爬虫教程来了。本文为你演示怎么从网页里找到感兴趣的链接和说明文字,抓取并储存到Excel。
(由于微信公众号外部链接的限制,文中的部份链接可能难以正确打开。如有须要,请点击文末的“阅读原文”按钮,访问可以正常显示外链的版本。)
需求
我在公众号后台,经常可以收到读者的留言。
很多留言,是读者的疑惑。只要有时间,我就会抽空尝试解答。
但是有的留言,乍看上去就不明所以了。
例如下边这个:
一分钟后,他可能认为不妥(大概由于想起来,我用简体字写文章),于是又用繁体发了一遍。
我恍然大悟。
这位读者以为我的公众号设置了关键词推送对应文章功能。所以看了我的其他数据科学教程后,想看“爬虫”专题。
不好意思,当时我还没有写爬虫文章。
而且,我的公众号暂时也没有设置这些关键词推送。
主要是因为我懒。
这样的消息接收得多了,我也能揣度到读者的需求。不止一个读者抒发出对爬虫教程的兴趣。
之前提过,目前主流而合法的网路数据搜集技巧,主要分为3类:
前两种方式,我都早已做过一些介绍,这次谈谈爬虫。
概念
许多读者对爬虫的定义,有些混淆。咱们有必要辨析一下。
维基百科是这么说的:
网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览万维网的网路机器人。其目的通常为编修网路索引。
这问题就来了,你又不准备做搜索引擎,为什么对网路爬虫这么热心呢?
其实,许多人口中所说的爬虫(web crawler),跟另外一种功能“网页抓取”(web scraping)搞混了。
维基百科上,对于前者这样解释:
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser.
看到没有,即便你用浏览器自动拷贝数据出来,也称作网页抓取(web scraping)。是不是立即认为自己强悍了好多?
但是,这定义还没完:
While web scraping can be done manually by a software user, the term typically refers to automate processes implemented using a bot or web crawler.
也就是说,用爬虫(或者机器人)自动替你完成网页抓取工作,才是你真正想要的。
数据抓出来干哪些呢?
一般是先储存上去,放到数据库或则电子表格中,以备检索或则进一步剖析使用。
所以,你真正想要的功能是这样的:
找到链接,获得Web页面,抓取指定信息,存储。
这个过程有可能会往复循环,甚至是滚雪球。
你希望用自动化的方法来完成它。
了解了这一点,你就不要老盯住爬虫不放了。爬虫研发下来,其实是为了给搜索引擎编制索引数据库使用的。你为了抓取点儿数据用来使用,已经是大炮轰虫子了。
要真正把握爬虫,你须要具备不少基础知识。例如HTML, CSS, Javascript, 数据结构……
这也是为何我仍然迟疑着没有写爬虫教程的诱因。
不过这三天,看到王烁主编的一段话,很有启发:
我喜欢讲一个另类二八定律,就是付出两成努力,了解一件事的八成。
既然我们的目标太明晰,就是要从网页抓取数据。那么你须要把握的最重要能力,是领到一个网页链接后,如何从中快捷有效地抓取自己想要的信息。
掌握了它,你还不能说自己早已学会了爬虫。
但有了这个基础,你能够比之前更轻松获取数据了。特别是对“文科生”的好多应用场景来说,非常有用。这就是赋能。
而且,再进一步深入理解爬虫的工作原理,也显得轻松许多。
这也算“另类二八定律”的一个应用吧。
Python语言的重要特色之一,就是可以借助强悍的软件工具包(许多都是第三方提供)。你只须要编撰简单的程序,就能手动解析网页,抓取数据。
本文给你演示这一过程。
目标
要抓取网页数据,我们先制定一个小目标。
目标不能很复杂。但是完成它,应该对你理解抓取(Web Scraping)有帮助。
就选择我近来发布的一篇简书文章作为抓取对象好了。题目称作《如何用《玉树芝兰》入门数据科学?》。
这篇文章里,我把之前的发布的数据科学系列文章做了重新组织和串讲。
文中收录好多之前教程的标题和对应链接。例如下图蓝色边框圈上去的部份。
假设你对文中提及教程都太感兴趣,希望获得这种文章的链接,并且储存到Excel里,就像下边这个样子:
你须要把非结构化的分散信息(自然语言文本中的链接),专门提取整理,并且储存出来。
该如何办呢?
即便不会编程,你也可以全文研读,逐个去找这种文章链接,手动把文章标题、链接都分别拷贝出来,存到Excel表上面。
但是,这种手工采集方法没有效率。
我们用Python。
环境
要装Python,比较省事的办法是安装Anaconda套装。
请到这个网址下载Anaconda的最新版本。
请选择两侧的 Python 3.6 版本下载安装。
如果你须要具体的步骤指导,或者想知道Windows平台怎么安装并运行Anaconda命令,请参考我为你打算的视频教程。
安装好Anaconda以后,请到这个网址下载本教程配套的压缩包。
下载后解压,你会在生成的目录(下称“演示目录”)里面听到以下三个文件。
打开终端,用cd命令步入该演示目录。如果你不了解具体使用方式,也可以参考视频教程。
我们须要安装一些环境依赖包。
首先执行:
pip install pipenv<br />
这里安装的,是一个优秀的 Python 软件包管理工具 pipenv 。
安装后,请执行:
pipenv install<br />
看到演示目录下两个Pipfile开头的文件了吗?它们就是 pipenv 的设置文档。
pipenv 工具会根据它们,自动为我们安装所须要的全部依赖软件包。
上图上面有个红色的进度条,提示所需安装软件数目和实际进度。
装好后,根据提示我们执行:
pipenv shell<br />
此处请确认你的笔记本上早已安装了 Google Chrome 浏览器。
我们执行:
jupyter notebook<br />
默认浏览器(Google Chrome)会开启,并启动 Jupyter 笔记本界面:
你可以直接点击文件列表中的第一项ipynb文件,可以看见本教程的全部示例代码。
你可以一边看教程的讲解,一边依次执行这种代码。
但是,我建议的方式,是回到主界面下,新建一个新的空白 Python 3 笔记本。
请跟随教程,一个个字符输入相应的内容。这可以帮助你更为深刻地理解代码的含意,更高效地把技能内化。
准备工作结束,下面我们开始即将输入代码。
代码
读入网页加以解析抓取,需要用到的软件包是 requests_html 。我们此处并不需要这个软件包的全部功能,只读入其中的 HTMLSession 就可以。
from requests_html import HTMLSession<br />
然后,我们构建一个会话(session),即使Python作为一个客户端,和远端服务器攀谈。
session = HTMLSession()<br />
前面说了,我们准备采集信息的网页,是《如何用《玉树芝兰》入门数据科学?》一文。
我们找到它的网址,存储到url变量名中。
url = 'https://www.jianshu.com/p/85f4624485b9'<br />
下面的句子,利用 session 的 get 功能,把这个链接对应的网页整个儿取回去。
r = session.get(url)<br />
网页上面都有哪些内容呢?
我们告诉Python,请把服务器传回去的内容当成HTML文件类型处理。我不想要看HTML上面这些乱七八糟的格式描述符,只看文字部份。
于是我们执行:
print(r.html.text)<br />
这就是获得的结果了:
我们心里有数了。取回去的网页信息是正确的,内容是完整的。
好了,我们来瞧瞧如何趋近自己的目标吧。
我们先用简单粗暴的方式,尝试获得网页中收录的全部链接。
把返回的内容作为HTML文件类型,我们查看 links 属性:
r.html.links<br />
这是返回的结果:
这么多链接啊!
很兴奋吧?
不过,你发觉没有?这里许多链接,看似都不完全。例如第一条结果,只有:
'/'<br />
这是哪些东西?是不是链接抓取错误啊?
不是,这种看着不象链接的东西,叫做相对链接。它是某个链接,相对于我们采集的网页所在域名()的路径。
这就好象我们在国外寄送快件包裹,填单子的时侯通常会写“XX市XX区……”,前面不需要加上国家名称。只有国际快件,才须要写上国名。
但是假如我们希望获得全部可以直接访问的链接,怎么办呢?
很容易,也只须要一条 Python 语句。
r.html.absolute_links<br />
这里,我们要的是“绝对”链接,于是我们都会获得下边的结果:
这回看着是不是就舒服多了?
我们的任务已经完成了吧?链接不是都在这里吗?
链接确实都在这里了,可是跟我们的目标是不是有区别呢?
检查一下,确实有。
我们不光要找到链接,还得找到链接对应的描述文字呢,结果里收录吗?
没有。
结果列表中的链接,都是我们须要的吗?
不是。看宽度,我们才能觉得出许多链接并不是文中描述其他数据科学文章的网址。
这种简单粗鲁直接列举HTML文件中所有链接的方式,对本任务行不通。
那么我们该如何办?
我们得学会跟 Python 说清楚我们要找的东西。这是网页抓取的关键。
想想看,如果你想使助手(人类)帮你做这事儿,怎么办?
你会告诉他:
“寻找正文中全部可以点击的黑色文字链接,拷贝文字到Excel表格,然后右键复制对应的链接,也拷贝到Excel表格。每个链接在Excel占一行,文字和链接各占一个单元格。”
虽然这个操作执行上去麻烦,但是助手听懂后,就能帮你执行。
同样的描述,你试试说给笔记本听……不好意思,它不理解。
因为你和助手看见的网页,是这个样子的。
电脑听到的网页,是这个样子的。
为了使你看得清楚源代码,浏览器还特意对不同类型的数据用了颜色分辨,对行做了编号。
数据显示给笔记本时,上述辅助可视功能是没有的。它只能看到一串串字符。
那可怎么办?
仔细观察,你会发觉这种HTML源代码上面,文字、图片链接内容前后,都会有一些被尖括弧括上去的部份,这就叫做“标记”。
所谓HTML,就是一种标记语言(超文本标记语言,HyperText Markup Language)。
标记的作用是哪些?它可以把整个的文件分解出层次来。
爬取豆瓣书籍数据(基于R)
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-08-09 20:35
爬取豆瓣书籍数据
网络爬虫,就是从网页中获取须要的信息,提取相应的数据。
可以借助R语言爬虫获取网页数据信息,便于统计剖析。
常用的从网页中获取信息的包有RCurl,XML,rvest等 。还可以借助RSslenium包或则Rwebdriver包模拟浏览器爬取异步加载等较难爬取的网页信息。
本文便以爬取豆瓣影片数据为例,来描述网路爬虫过程。
爬取网址如下:
了解网页结构
所须要的数据概况:
从网页中大约能发觉,该网页富含书籍名称,书籍评分,书籍主题,出版时间,价格,作者名子,译者名子等数据信息。
再步入网页源代码界面找规律
可以发觉有非常一致的规律:
书籍名称:
红楼梦
作者/译者/出版社/出版时间/价格:
[清] 曹雪芹 著 / 人民文学出版社 / 1996-12 / 59.70元
评分信息:
9.6
(
278287人评价
)
下面便利用发觉的规律,利用R进行数据爬取。
自动搜集单个网页数据导出须要的包 ,导入须要的包;
library(dplyr)
library(rvest)
library(stringr)
读取网页,并进行数据提取 ,读取网页,程序如下:
alldata250%str_trim()%>%str_replace_all("\n|","")%>%str_replace_all(" ","")
head(name)
#作者/出版社/日期/年份/价格
place % html_nodes("p.pl") %>% html_text()
work u1 print(u1)
[1] "https://book.douban.com/top250?start=225"
其中i是从0开始降低,每个i对应一个网页页面,故可由i循环,以达到反复爬取网页数据的功能。
程序如下:
<p>library(dplyr)
library(rvest)
library(stringr)
alldata250%str_trim()%>%str_replace_all("\n|","")%>%str_replace_all(" ","")
head(name)
#作者/出版社/日期/年份/价格
place % html_nodes("p.pl") %>% html_text()
work 查看全部
爬取豆瓣书籍数据(基于R)
爬取豆瓣书籍数据
网络爬虫,就是从网页中获取须要的信息,提取相应的数据。
可以借助R语言爬虫获取网页数据信息,便于统计剖析。
常用的从网页中获取信息的包有RCurl,XML,rvest等 。还可以借助RSslenium包或则Rwebdriver包模拟浏览器爬取异步加载等较难爬取的网页信息。
本文便以爬取豆瓣影片数据为例,来描述网路爬虫过程。
爬取网址如下:
了解网页结构
所须要的数据概况:
从网页中大约能发觉,该网页富含书籍名称,书籍评分,书籍主题,出版时间,价格,作者名子,译者名子等数据信息。
再步入网页源代码界面找规律

可以发觉有非常一致的规律:
书籍名称:
红楼梦
作者/译者/出版社/出版时间/价格:
[清] 曹雪芹 著 / 人民文学出版社 / 1996-12 / 59.70元
评分信息:
9.6
(
278287人评价
)
下面便利用发觉的规律,利用R进行数据爬取。
自动搜集单个网页数据导出须要的包 ,导入须要的包;
library(dplyr)
library(rvest)
library(stringr)
读取网页,并进行数据提取 ,读取网页,程序如下:
alldata250%str_trim()%>%str_replace_all("\n|","")%>%str_replace_all(" ","")
head(name)
#作者/出版社/日期/年份/价格
place % html_nodes("p.pl") %>% html_text()
work u1 print(u1)
[1] "https://book.douban.com/top250?start=225"
其中i是从0开始降低,每个i对应一个网页页面,故可由i循环,以达到反复爬取网页数据的功能。
程序如下:
<p>library(dplyr)
library(rvest)
library(stringr)
alldata250%str_trim()%>%str_replace_all("\n|","")%>%str_replace_all(" ","")
head(name)
#作者/出版社/日期/年份/价格
place % html_nodes("p.pl") %>% html_text()
work
PowerQuery批量爬取网页实战:分分钟抓取智联急聘上百页职位信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 390 次浏览 • 2020-08-09 19:16
前面介绍PowerBI数据获取的时侯,曾举了一个从网页中获取数据的事例,但当时只是爬取了其中一页数据,这篇文章来介绍怎样用PowerBI的Power Query批量采集多个网页的数据。Excel中的操作类似。P
本文以智联招聘网站为例,采集工作地点在北京的职位发布信息。
下面是详尽操作步骤:
(一)分析网址结构
打开智联招聘网站,搜索工作地点在北京的数据,
下拉页面到最下边,找到显示页脚的地方,点击前三页,网址分别如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字就是页脚的ID,是控制分页数据的变量。
(二)使用PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,从弹出的窗口中选择【高级】,根据前面剖析的网址结构,把不仅最后一个页脚ID的网址输入第一行,页码输入第二行,
从URL预览中可以看出,已经手动把里面两行的网址合并到一起;这里分开输入只是为了旁边更清晰的分辨页脚变量,其实直接输入全网址也是一样可以操作的。
(如果页脚变量不是最后一位,而是在中间,应该分三行输入网址)
点击确定后,发现下来好多表,
从这儿可以看出,智联招聘网站上每一条急聘信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击编辑步入Power Query编辑器。
在PQ编辑器中直接删掉掉【源】之后的所有步骤,然后展开数据,并把上面没有的几列数据删掉。
这样第一页的数据就采集过来了。然后对这一页的数据进行整理,删除掉无用信息,添加数组名,可以看出一页收录60条急聘信息。
这里整理好第一页数据之后,下面进行采集其他页面时,数据结构就会和第一页整理后的数据结构一致,采集的数据可以直接用来用;这里不整理也没关系,可以等到采集所有网页数据后一起整理。
如果要大批量的抓取网页数据,为了节约时间,对第一页的数据可以先不整理,直接步入下一步。
(三)根据页脚参数设置自定义函数
这是最重要的一步。
还是刚刚第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
并把let前面第一行的网址中,&后面的"1"改为(这就是第二步使用中级选项分两行输入网址的益处):
更改后【源】的网址变为:
确定之后,刚才第一页数据的查询窗口直接弄成了自定义函数的输入参数窗口,Table0表格也弄成了函数的款式。为了更直观,把这个函数重命名为Data_Zhaopin.
到这儿自定义函数完成,p是该函数的变量,用来控制页脚,随便输入一个数字,比如7,将抓取第7页的数据,
输入参数只能一次抓取一个网页,要想批量抓取,还须要下边这一步。
(四)批量调用自定义函数
首先使用空查询构建一个数字序列,如果想抓取前100页的数据,就完善从1到100的序列,在空查询中输入
回车就生成了从1到100的序列,然后转为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中点击【功能查询】下拉框,选择刚刚构建的自定义函数Data_Zhaopin,其他都按默认就行,
点击确定,就开始批量抓取网页了,因为100页数据比较多,耗时5分钟左右,这也是我第二步提早数据整理导致的后果,导致抓取比较慢。展开这一个表格,就是这100页的数据,
至此,批量抓取智联急聘100页的信息完成,上面的步骤看起来好多,实际上熟练把握之后,10分钟左右就可以搞定,最大块的时间还是最后一步进行抓取数据的过程比较历时。
网页的数据是不断更新的,在操作完以上的步骤过后,在PQ中点击刷新,可以随时一键提取网站实时的数据,一次做好,终生获益!
以上主要使用的是PowerBI中的Power Query功能,在可以使用PQ功能的Excel中也是可以同样操作的。
当然PowerBI并不是专业的爬取工具,如果网页比较复杂或则有防爬机制,还是得用专业的工具,比如R或则Python。在用PowerBI批量抓取某网站数据之前,先尝试着采集一页试试,如果可以采集到,再使用以上的步骤,如果采集不到,就不用再耽搁功夫了。
如果你刚开始接触Power BI,可在微信公众号:“PowerBI星球”,回复"PowerBI",获取《七天入门PowerBI》电子书,帮你快速提高工作效率。 查看全部

前面介绍PowerBI数据获取的时侯,曾举了一个从网页中获取数据的事例,但当时只是爬取了其中一页数据,这篇文章来介绍怎样用PowerBI的Power Query批量采集多个网页的数据。Excel中的操作类似。P
本文以智联招聘网站为例,采集工作地点在北京的职位发布信息。
下面是详尽操作步骤:
(一)分析网址结构
打开智联招聘网站,搜索工作地点在北京的数据,
下拉页面到最下边,找到显示页脚的地方,点击前三页,网址分别如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字就是页脚的ID,是控制分页数据的变量。
(二)使用PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,从弹出的窗口中选择【高级】,根据前面剖析的网址结构,把不仅最后一个页脚ID的网址输入第一行,页码输入第二行,
从URL预览中可以看出,已经手动把里面两行的网址合并到一起;这里分开输入只是为了旁边更清晰的分辨页脚变量,其实直接输入全网址也是一样可以操作的。
(如果页脚变量不是最后一位,而是在中间,应该分三行输入网址)
点击确定后,发现下来好多表,

从这儿可以看出,智联招聘网站上每一条急聘信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击编辑步入Power Query编辑器。
在PQ编辑器中直接删掉掉【源】之后的所有步骤,然后展开数据,并把上面没有的几列数据删掉。

这样第一页的数据就采集过来了。然后对这一页的数据进行整理,删除掉无用信息,添加数组名,可以看出一页收录60条急聘信息。
这里整理好第一页数据之后,下面进行采集其他页面时,数据结构就会和第一页整理后的数据结构一致,采集的数据可以直接用来用;这里不整理也没关系,可以等到采集所有网页数据后一起整理。
如果要大批量的抓取网页数据,为了节约时间,对第一页的数据可以先不整理,直接步入下一步。
(三)根据页脚参数设置自定义函数
这是最重要的一步。
还是刚刚第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
并把let前面第一行的网址中,&后面的"1"改为(这就是第二步使用中级选项分两行输入网址的益处):
更改后【源】的网址变为:
确定之后,刚才第一页数据的查询窗口直接弄成了自定义函数的输入参数窗口,Table0表格也弄成了函数的款式。为了更直观,把这个函数重命名为Data_Zhaopin.
到这儿自定义函数完成,p是该函数的变量,用来控制页脚,随便输入一个数字,比如7,将抓取第7页的数据,

输入参数只能一次抓取一个网页,要想批量抓取,还须要下边这一步。
(四)批量调用自定义函数
首先使用空查询构建一个数字序列,如果想抓取前100页的数据,就完善从1到100的序列,在空查询中输入
回车就生成了从1到100的序列,然后转为表格。gif操作图如下:

然后调用自定义函数,
在弹出的窗口中点击【功能查询】下拉框,选择刚刚构建的自定义函数Data_Zhaopin,其他都按默认就行,
点击确定,就开始批量抓取网页了,因为100页数据比较多,耗时5分钟左右,这也是我第二步提早数据整理导致的后果,导致抓取比较慢。展开这一个表格,就是这100页的数据,

至此,批量抓取智联急聘100页的信息完成,上面的步骤看起来好多,实际上熟练把握之后,10分钟左右就可以搞定,最大块的时间还是最后一步进行抓取数据的过程比较历时。
网页的数据是不断更新的,在操作完以上的步骤过后,在PQ中点击刷新,可以随时一键提取网站实时的数据,一次做好,终生获益!
以上主要使用的是PowerBI中的Power Query功能,在可以使用PQ功能的Excel中也是可以同样操作的。
当然PowerBI并不是专业的爬取工具,如果网页比较复杂或则有防爬机制,还是得用专业的工具,比如R或则Python。在用PowerBI批量抓取某网站数据之前,先尝试着采集一页试试,如果可以采集到,再使用以上的步骤,如果采集不到,就不用再耽搁功夫了。
如果你刚开始接触Power BI,可在微信公众号:“PowerBI星球”,回复"PowerBI",获取《七天入门PowerBI》电子书,帮你快速提高工作效率。
如何学习黑客?Web(网站)渗透测试
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2020-08-09 12:35
说到黑客,其实大部分人都不太喜欢。更是一些受害者 谈之生厌 这是一把双刃剑,我走的是web渗透方面,也就是网站服务器相关的,当然黑客也分很多种 其实我也太反感这些骇客,平时没事就乱功击他人网站 搞他人态度...真的太难受。
关于黑客这个就不多解释了。有兴趣的可以去瞧瞧百度上黑客分类。
对黑客的定义似乎太广。web渗透也是算黑客的一种,可以去了解一下红蓝域。
安全防御是目前全省乃至全世界的重中之重,网络安全就是国家安全,所以学习信安技术真的很有用 包括往前就业 都可以有比较好的发展。
另外有技术交流的可以问我~Q 343202158
web渗透笔记如下,大家可以去瞧瞧!
0x00 序言
这篇笔记是对Web应用程序渗透中的精典步骤的总结。我会将这种步骤分解为一个个的子任务并在各个子任务中推荐并介绍一些工具。
本文展示的许多方法来自这儿,作者已准许转载。
请记住我介绍的这种步骤都是迭代的,所以在一次渗透过程中,你可能会使用她们多次。举个栗子,当你设法获取一个应用程序的不同等级的权限时,比如从普通用户提高到管理员用户,可能就须要迭代借助。
序言最后须要说明的是,这篇笔记的好多地方使用了收费的PortSwigger的Burp Suite Professional。对此我表示抱歉,但我觉得这个工具还是物超所值的。
0x01 信息搜集在一次Web渗透过程中,信息搜集的目的是站在旁观者的角度,去了解整个Web应用的概貌。1. 目标确认
工具简介Whois基于RFC 3912,用于查询域名相关信息的合同。Dig域名信息获取工具(Domain information groper)简称,是一个命令行的用于查询DNS服务器的网路管理工具。DNSRecon自动化DNS枚举脚本,由darkoperator维护。
1.1 域名注册信息
通过如下步骤确认目标所有者信息:
Whois 目标域名/主机名whois 解析目标域名/主机名的IP地址dig +short Whois IP地址whois 104.27.178.12剖析输出结果
如果目标开启了whois隐私保护,那么返回的结果可能是经过混淆的。
!!不要功击未经授权的站点。作为渗透测试人员,有责任在测试之前明晰自己有没有获得目标所有者赋于的权限对目标进行测试。这也是为何目标确认是开始渗透测试的第一步。1.2 DNS信息查询
我喜欢去 / 查询目标站点的DNS信息,这是一款很不错的在线DNS信息查询工具。
dig +nocmd example.com A +noall +answer
dig +nocmd example.com NS +noall +answer
dig +nocmd example.com MX +noall +answer
dig +nocmd example.com TXT +noall +answer
dig +nocmd example.com SOA +noall +answer
...
dig +nocmd example.com ANY +noall +answer (This rarely works)
dig -x 104.27.179.12
dig -x 104.27.178.12
1.3 测试域传送漏洞
域传送是一种DNS事务,用于在主从服务器间复制DNS记录。(译者注:可以看这个)虽然现在早已太稀少主机会开启,但是还是应当确认一下。一旦存在域传送漏洞,就意味着你获取了整个域下边所有的记录。
域传送漏洞很容易防止。至少管理员可以设置只容许白名单内的IP列表可以进行域传送恳求。
dig -t NS zonetransfer.me +short
dig -t AXFR zonetransfer.me @nsztm1.digi.ninja
dig -t AXFR zonetransfer.me @nsztm2.digi.ninja
dnsrecon -d example.com
2. OSINT 公开情报搜集
工具描述Recon-NGTim 'Lanmaster53' Tomes写的公开情报工具框架,由社区维护。/MaltegoMaltego 是一款交互式的数据挖掘工具,它可以渲染出图用于关联分析。theharvestertheHarvester 可以从不同的公开资源中搜集邮箱、子域名、虚拟主机、开放的端口/主机指纹和职工姓名等信息
我本想在这份笔记中收录详尽的OSINT的介绍,但是想了想决定不这样做。因为我认为这个部份可以单独写一篇(可能在以后的几篇中)。
在这篇笔记中我就介绍一些非常棒的关于OSINT的干货,我想渗透测试者们对于这种干货应当十分熟悉:
0x02 Mapping在一次渗透测试过程中,Mapping的目的是站在一个普通用户的角度去了解整个应用的概貌。1. 工具
工具介绍Nmap带服务辨识和操作系统指纹识别的TCP/IP主机和端口扫描工具
1.1 端口扫描,服务辨识,OS辨识! 端口扫描一般是渗透过程中第一步和第二步的过渡部份。要特别注意曝露的端口、服务版本和OS/s!2. 浏览器代理设置2.1 Firefox
工具描述Firefox跨平台的一款现代浏览器,有很多有用的插件
Firefox一般是Web渗透测试过程中的首选浏览器,这是因为它有很多有用的插件以及它的代理设置不会影响到全局代理。
2.2 Firefox插件
工具描述User Agent Switcher一款可以快速切换用户代理的Firefox插件Wappalyzer可以测量各种各样的网站所用的技术和软件组件的插件FoxyProxy代理切换插件
这些插件在每次渗透测试过程中我总能用得到,我推荐你在第二步(Mapping)之前安装好它们。
2.3 配置Firefox和Burpsuit
在你进行Mapping之前你一定要配置要浏览器的代理,让流量经过Burp。
2.4 Burp配置
工具描述Burp Suit ProWeb安全测试套件
你应当配置Burp使他适宜自己的喜好。但是起码我推荐你设置Scan Speed为thorough,这样你在使用扫描器时都会发出更多地恳求因而扫描出更多的漏洞。
2.5 Burp扩充
工具描述Burp Extender用于扩充Burp suite功能的API,可以在BApp商店获取Retire.js (BApp)用于测量版本落后的Javascript组件漏洞的Burp suite扩充Wsdler (BApp)可以解析WSDL文件,然后测试所有的容许的方式的恳求Python Scripter (BApp)可以在每位HTTP请求和响应时执行一段用户定义的Python脚本
这些Burp扩充是我在渗透测试过程中常常使用的。和Firefox扩充一样,我建议大家在Mapping之前安装好它们。
它们可以使用Burp Suite Pro的Burp Extender模块来安装。
3. 人工浏览
人工浏览可能是Mapping过程中最重要的部份。你有必要去浏览每位页面,点击页面上每一个跳转,这样在Burp的sitemap上面就可以出现这种恳求和响应。
!!!手工浏览对于单页应用十分特别重要。自动化的网页爬虫不能否爬到单页应用由于单页应用的HTTP请求都是用异步的AJAX来进行的。4. 自动化爬取
自动化爬取是使用Burp Spider来进行的,这个过程可以发觉你手工浏览没有发觉的一些页面。通常来说Burp Spider会在传统的Web应用中发觉更多的页面。
!!!自动化爬虫十分危险。通常我会手工浏览80%~95%的页面,只用爬虫爬取极少的部份。因为在特定情况下爬虫很容易失效。5. 后续剖析
这个时侯你应当使用Burp完成了Mapping这一步第一次的迭代,你应当注意目前把握的所有信息。
5.1 需要非常注意
这个时侯你可以注意一些须要特定页面跳转的功能点。通常这种功能点可以被手工操控,从而让其不用满足特定跳转次序就可以实现,这可以使你有重大发觉。(举个栗子,电子商务网站的付款功能,密码重置页面等)
0x03 漏洞挖掘在一次渗透测试过程中,漏洞挖掘是在攻击者的角度来了解整个Web应用的概貌。1. 过渡
在你Mapping以后,并且进行了一些基本的功能性的剖析后,就可以开始进行漏洞挖掘了。这个步骤中,你应当尽可能多的辨识出Web应用存在的漏洞。这些漏洞除了是The OWASP Top 10中收录的这些,还收录于应用的商业逻辑中。记住一点,你将会碰到大量的漏洞,它不属于任何一个现有的分类中,你应当时刻提防这一点。
2. 内容挖掘2.1 漏洞扫描
名称描述Nikto有指纹辨识功能的Web服务漏洞扫描器
Nikto当之无愧的是最好的Web服务漏洞扫描器,特别是在小型的Web应用程序中表现非常好。它可以借助-Format选项来导入特定格式的扫描结果,使扫描结果更容易阅读和剖析。
漏洞扫描一般是第二步和第三步的过渡。一旦有了扫描结果,一定要花时间去剖析一下结果,打开一些引人注目的页面瞧瞧。3. 强制浏览(译者注:翻译的觉得太别扭,看下边内容应当能明白哪些意思)
名称描述Burp Engagement ToolsBurp Suite Pro中自带的有特殊用途的工具集Engagement Tool: Discover ContentBurp Suite Pro自带的用于强制浏览的工具Burp IntruderBurp Suite中可自定义的用于自动化的功击的模块。(比如brute forcing, injection, 等)FuzzDB收录各类恶意输入、资源名、用于grep搜索响应内容的字符串、Webshell等。
强制浏览是一种挖掘方法,它可以发觉应用程序中没有被引用并且确实是可以访问的页面。Discover Content是Burp中专门用于此目的的工具。除此之外,Burp Intruder也可以通过字典功击来施行强制浏览(通常是在url参数和文件路径部份进行更改)。FuzzDB收录一些用于此目的的特别牛逼的字典,你可以在这里瞧瞧。
3.1 测试可选内容
名称描述User Agent Switcher用于迅速切换浏览器的User Agent的一款Firefox插件Burp IntruderBurp Suite中可自定义的用于自动化的功击的模块。(比如brute forcing, injection, 等)FuzzDB收录各类恶意输入、资源名、用于grep搜索响应内容的字符串、Webshell等。
在内容挖掘这一步,我十分喜欢做一件事。那就是借助User Agent Switcher切换不同的User Agent之后访问同一个特定页面。这是因为好多的Web应用对于不同的User-Agent和Referer恳求头会返回不同的内容。
我常常使用Burp Intruder来模糊测试User-Agent和Referer恳求头,一般还借助FuzzDB的字典。
4. 自动化的漏洞挖掘
名称描述Burp Scanner自动化扫描安全漏洞的Burp Suite工具
当你在Mapping和进行漏洞挖掘的开始部份时侯,Burp Passive Scanner就早已在后台悄悄运行。你应当先剖析这份扫描结果,然后再进行Burp Active Scanner,这样在Burp Passive Scanner中发觉的值得关注的页面就可以在Burp Active Scanner中进行详尽的扫描。
由于Burp Active Scanner完成所需的时间十分长,我更喜欢只容许一小段时间,然后查看二者之间的扫描结果并记录结果。
!!!自动化的漏洞扫描是太危险的。用Burp Scanner可能造成不良的影响。除非你特别熟悉目标的功能与环境,否则你只应在非生产环境中使用。5. 配置5.1 默认配置
在确认了目标所使用的技术后,很自然的一步跟进就是测试有没有默认配置。许多框架使用许多易受功击默认配置的应用程序便于于向开发人员介绍她们的产品。然后因为开发人员的疏漏,这些示例应用被布署到和目标站点所在的同一台服务器上,这促使目标站点承受很大的风险。
5.2 错误配置
在Web渗透测试的每一步,你都应当注意Web应用有没有错误的配置。你可以特别关注页面出现的错误信息,这些信息常常会给出很有用的数据库结构和服务器文件系统等信息。
错误信息几乎总还能发觉一些。这些错误信息在注入和LFI(Local File Include)中非常有用。
另外一个值得注意的是页面的敏感表单有没有禁用手动填充。比如密码数组常常会有一个“显示/隐藏”按钮。浏览器默认不会填充type="password"的input标签内容,而当密码数组是“显示”时,input标签就弄成了type="text",这样浏览器都会进行手动填充。这在多用户环境下是一个隐患。
6. 身份认证
在漏洞挖掘过程中,你应当认真考量你看见的每位登陆表单。如果这种表单没有做挺好的安全举措(比如双重认证,验证码,禁止重复递交等),攻击者就可能得到用户帐户未授权的权限。取决于表单的不同实现以及不同的框架/CMS,即使登陆失败目标站点也可能会透漏出用户帐户的一些信息。
如果你测试发觉了上述所讨论的问题,你应当关注并记录。另外,如果登陆表单没有加密(或者借助了旧版本的SSL/TLS),这也应当关注并记录。
6.1 模糊登陆测试
名称描述CeWL通过爬取目标站点来生成用户字典的工具Burp IntruderBurp Suite中可自定义的用于自动化的功击的模块。(比如brute forcing, injection, 等)
在你认真考量了登陆表单后,就可以开始登陆测试了。CeWL是一款非常好用的用于生成一次性字典的工具。你可以借助-h查看帮助文档。
基本句型如下
cewl [options] www.example.com
当你构造好用户字典后就可以开始用Burp Intruder进行实际的模糊测试了。通常我会用两个payload集(一个是用户名的,另一个是CeWL生成的密码)。Intruder的Attack Type一般应当选Cluster Bomb。
7. Session管理
Session-token/Cookie剖析在渗透测试过程中尽管不是太吸引人的部份,但确实十分重要的一块。通常是这样子的,你想了解整个web应用是怎样跟踪Session,然后用Burp Sequencer这样的工具去测试session token的随机性/可预测性。一些应用(较传统的应用)会把session的内容储存在客户端。有时候这种数据上面会收录有加密的,序列化的敏感信息。
这时也应当检测HTTP返回头的Set-Cookie是否收录Secure和HttpOnly的标示。如果没有的话就值得注意了,因为没有理由不设置这种标识位。
Google搜索你得到的session token,可能会有一些发觉,比如Session可预测等,这样就可以进行Session绑架功击。7.1 用Burp测试Session Tokens
名称描述Burp SequencerBurp拿来剖析数据集的随机性的模块
Burp Sequencer是拿来测试Session Token随机性和可预测性的挺好的工具。当你用这个工具来测试目标的Session管理时,你应当先去除所有的Cookies,然后重新认证一次。然后就可以把带有Set-Cookie头的返回包发送给Burp Sequencer,然后Sequencer都会启动新的拦截对Token进行剖析。通常10000次恳求就差不多可以判定随机性和可预测性了。
如果发觉Session token不够随机,那就可以考虑Session绑架了。
8. 授权
授权漏洞太象功能级访问控制缺位和不安全的直接对象引用漏洞,是太长一段时间我发觉的最流行的漏洞。这是因为许多的开发者没有想到一个低权限甚至是匿名用户会去向高权限的插口发送恳求(失效的权限控制)。
http://example.com/app/admin_getappInfo
或者是去恳求其他用户的数据(不安全的直接对象引用,译者注:水平越权)
http://example.com/app/accountInfo?acct=notmyacct
8.1 测试权限控制
名称描述Compare Site MapsBurp的用于测试授权的模块
这里有个小方法,就是注册两个不同权限的用户,然后用高权限的用户去访问整个Web应用,退出高权限用户,登录低权限用户,然后用Burp的Compare Site Maps工具去测试什么页面的权限控制没有做好。
9. 数据验证测试
名称描述Burp Repeater用于手工更改、重放HTTP请求的Burp模块
注入漏洞的存在是因为Web应用接受任意的用户输入,并且在服务端没有正确验证用户的输入的有效性。作为一个渗透测试者,你应当注意每一个接受随便的用户输入的地方并设法进行注入。
因为每位Web应用情况都不一样,所以没有一种万能的注入形式。接下来,我会把注入漏洞进行分类而且给出一些Payload。Burp Repeater是我测试注入漏洞时最常使用的工具。它可以重放HTTP请求,并且可以随时更改Payload。
有一件事须要牢记:漏洞挖掘阶段要做的只是辨识漏洞,而漏洞借助阶段就会借助漏洞做更多地事。当然,每个注入漏洞都值得被记录,你可以在漏洞挖掘阶段以后对这种注入漏洞进行深入的测试。
在每位分类下可以参照OWASP获取更多地信息。
9.1 SQLi
任何将输入带入数据库进行查询的地方都可能存在SQL注入。结合错误的配置问题,会导致大量的数据被攻击者窃取。
我推荐你在做SQL注入时参照这个Wiki。如果你输入了这种Payload得到了数据库返回的错误信息,那么目标就十分有可能存在SQL注入漏洞。
Sqlmap是一款自动化的SQL注入工具,我将会在漏洞借助阶段介绍它。
OWASP-测试SQL注入)
' OR 1=1 -- 1
' OR '1'='1
' or 1=1 LIMIT 1;--
admin';--
http://www.example.com/product.php?id=10 AND 1=1
9.2 跨站脚本攻击(XSS)
攻击者借助Web应用程序发送恶意代码(通常是JavaScript代码)给另外一个用户,就发生了XSS。
有三种不同的XSS:
存储型。当提供给Web应用的数据是攻击者事先递交到服务器端永久保存的恶意代码时,发生存储型XSS。反射型。当提供给Web应用的数据是服务端脚本借助攻击者的恶意输入生成的页面时,发生反射型XSS。DOM型。DOM型XSS存在于客户端的脚本。
OWASP-测试XSS
<p>
">alert('XSS') 查看全部
这篇文章主要讲讲Web网站渗透怎样学习,学习好能够防御好。请不要用自己的技术去做违纪违法的事情!切记!
说到黑客,其实大部分人都不太喜欢。更是一些受害者 谈之生厌 这是一把双刃剑,我走的是web渗透方面,也就是网站服务器相关的,当然黑客也分很多种 其实我也太反感这些骇客,平时没事就乱功击他人网站 搞他人态度...真的太难受。
关于黑客这个就不多解释了。有兴趣的可以去瞧瞧百度上黑客分类。
对黑客的定义似乎太广。web渗透也是算黑客的一种,可以去了解一下红蓝域。
安全防御是目前全省乃至全世界的重中之重,网络安全就是国家安全,所以学习信安技术真的很有用 包括往前就业 都可以有比较好的发展。
另外有技术交流的可以问我~Q 343202158
web渗透笔记如下,大家可以去瞧瞧!
0x00 序言
这篇笔记是对Web应用程序渗透中的精典步骤的总结。我会将这种步骤分解为一个个的子任务并在各个子任务中推荐并介绍一些工具。
本文展示的许多方法来自这儿,作者已准许转载。
请记住我介绍的这种步骤都是迭代的,所以在一次渗透过程中,你可能会使用她们多次。举个栗子,当你设法获取一个应用程序的不同等级的权限时,比如从普通用户提高到管理员用户,可能就须要迭代借助。
序言最后须要说明的是,这篇笔记的好多地方使用了收费的PortSwigger的Burp Suite Professional。对此我表示抱歉,但我觉得这个工具还是物超所值的。
0x01 信息搜集在一次Web渗透过程中,信息搜集的目的是站在旁观者的角度,去了解整个Web应用的概貌。1. 目标确认
工具简介Whois基于RFC 3912,用于查询域名相关信息的合同。Dig域名信息获取工具(Domain information groper)简称,是一个命令行的用于查询DNS服务器的网路管理工具。DNSRecon自动化DNS枚举脚本,由darkoperator维护。
1.1 域名注册信息
通过如下步骤确认目标所有者信息:
Whois 目标域名/主机名whois 解析目标域名/主机名的IP地址dig +short Whois IP地址whois 104.27.178.12剖析输出结果
如果目标开启了whois隐私保护,那么返回的结果可能是经过混淆的。
!!不要功击未经授权的站点。作为渗透测试人员,有责任在测试之前明晰自己有没有获得目标所有者赋于的权限对目标进行测试。这也是为何目标确认是开始渗透测试的第一步。1.2 DNS信息查询
我喜欢去 / 查询目标站点的DNS信息,这是一款很不错的在线DNS信息查询工具。
dig +nocmd example.com A +noall +answer
dig +nocmd example.com NS +noall +answer
dig +nocmd example.com MX +noall +answer
dig +nocmd example.com TXT +noall +answer
dig +nocmd example.com SOA +noall +answer
...
dig +nocmd example.com ANY +noall +answer (This rarely works)
dig -x 104.27.179.12
dig -x 104.27.178.12
1.3 测试域传送漏洞
域传送是一种DNS事务,用于在主从服务器间复制DNS记录。(译者注:可以看这个)虽然现在早已太稀少主机会开启,但是还是应当确认一下。一旦存在域传送漏洞,就意味着你获取了整个域下边所有的记录。
域传送漏洞很容易防止。至少管理员可以设置只容许白名单内的IP列表可以进行域传送恳求。
dig -t NS zonetransfer.me +short
dig -t AXFR zonetransfer.me @nsztm1.digi.ninja
dig -t AXFR zonetransfer.me @nsztm2.digi.ninja
dnsrecon -d example.com
2. OSINT 公开情报搜集
工具描述Recon-NGTim 'Lanmaster53' Tomes写的公开情报工具框架,由社区维护。/MaltegoMaltego 是一款交互式的数据挖掘工具,它可以渲染出图用于关联分析。theharvestertheHarvester 可以从不同的公开资源中搜集邮箱、子域名、虚拟主机、开放的端口/主机指纹和职工姓名等信息
我本想在这份笔记中收录详尽的OSINT的介绍,但是想了想决定不这样做。因为我认为这个部份可以单独写一篇(可能在以后的几篇中)。
在这篇笔记中我就介绍一些非常棒的关于OSINT的干货,我想渗透测试者们对于这种干货应当十分熟悉:
0x02 Mapping在一次渗透测试过程中,Mapping的目的是站在一个普通用户的角度去了解整个应用的概貌。1. 工具
工具介绍Nmap带服务辨识和操作系统指纹识别的TCP/IP主机和端口扫描工具
1.1 端口扫描,服务辨识,OS辨识! 端口扫描一般是渗透过程中第一步和第二步的过渡部份。要特别注意曝露的端口、服务版本和OS/s!2. 浏览器代理设置2.1 Firefox
工具描述Firefox跨平台的一款现代浏览器,有很多有用的插件
Firefox一般是Web渗透测试过程中的首选浏览器,这是因为它有很多有用的插件以及它的代理设置不会影响到全局代理。
2.2 Firefox插件
工具描述User Agent Switcher一款可以快速切换用户代理的Firefox插件Wappalyzer可以测量各种各样的网站所用的技术和软件组件的插件FoxyProxy代理切换插件
这些插件在每次渗透测试过程中我总能用得到,我推荐你在第二步(Mapping)之前安装好它们。
2.3 配置Firefox和Burpsuit
在你进行Mapping之前你一定要配置要浏览器的代理,让流量经过Burp。
2.4 Burp配置
工具描述Burp Suit ProWeb安全测试套件
你应当配置Burp使他适宜自己的喜好。但是起码我推荐你设置Scan Speed为thorough,这样你在使用扫描器时都会发出更多地恳求因而扫描出更多的漏洞。
2.5 Burp扩充
工具描述Burp Extender用于扩充Burp suite功能的API,可以在BApp商店获取Retire.js (BApp)用于测量版本落后的Javascript组件漏洞的Burp suite扩充Wsdler (BApp)可以解析WSDL文件,然后测试所有的容许的方式的恳求Python Scripter (BApp)可以在每位HTTP请求和响应时执行一段用户定义的Python脚本
这些Burp扩充是我在渗透测试过程中常常使用的。和Firefox扩充一样,我建议大家在Mapping之前安装好它们。
它们可以使用Burp Suite Pro的Burp Extender模块来安装。
3. 人工浏览
人工浏览可能是Mapping过程中最重要的部份。你有必要去浏览每位页面,点击页面上每一个跳转,这样在Burp的sitemap上面就可以出现这种恳求和响应。
!!!手工浏览对于单页应用十分特别重要。自动化的网页爬虫不能否爬到单页应用由于单页应用的HTTP请求都是用异步的AJAX来进行的。4. 自动化爬取
自动化爬取是使用Burp Spider来进行的,这个过程可以发觉你手工浏览没有发觉的一些页面。通常来说Burp Spider会在传统的Web应用中发觉更多的页面。
!!!自动化爬虫十分危险。通常我会手工浏览80%~95%的页面,只用爬虫爬取极少的部份。因为在特定情况下爬虫很容易失效。5. 后续剖析
这个时侯你应当使用Burp完成了Mapping这一步第一次的迭代,你应当注意目前把握的所有信息。
5.1 需要非常注意
这个时侯你可以注意一些须要特定页面跳转的功能点。通常这种功能点可以被手工操控,从而让其不用满足特定跳转次序就可以实现,这可以使你有重大发觉。(举个栗子,电子商务网站的付款功能,密码重置页面等)
0x03 漏洞挖掘在一次渗透测试过程中,漏洞挖掘是在攻击者的角度来了解整个Web应用的概貌。1. 过渡
在你Mapping以后,并且进行了一些基本的功能性的剖析后,就可以开始进行漏洞挖掘了。这个步骤中,你应当尽可能多的辨识出Web应用存在的漏洞。这些漏洞除了是The OWASP Top 10中收录的这些,还收录于应用的商业逻辑中。记住一点,你将会碰到大量的漏洞,它不属于任何一个现有的分类中,你应当时刻提防这一点。
2. 内容挖掘2.1 漏洞扫描
名称描述Nikto有指纹辨识功能的Web服务漏洞扫描器
Nikto当之无愧的是最好的Web服务漏洞扫描器,特别是在小型的Web应用程序中表现非常好。它可以借助-Format选项来导入特定格式的扫描结果,使扫描结果更容易阅读和剖析。
漏洞扫描一般是第二步和第三步的过渡。一旦有了扫描结果,一定要花时间去剖析一下结果,打开一些引人注目的页面瞧瞧。3. 强制浏览(译者注:翻译的觉得太别扭,看下边内容应当能明白哪些意思)
名称描述Burp Engagement ToolsBurp Suite Pro中自带的有特殊用途的工具集Engagement Tool: Discover ContentBurp Suite Pro自带的用于强制浏览的工具Burp IntruderBurp Suite中可自定义的用于自动化的功击的模块。(比如brute forcing, injection, 等)FuzzDB收录各类恶意输入、资源名、用于grep搜索响应内容的字符串、Webshell等。
强制浏览是一种挖掘方法,它可以发觉应用程序中没有被引用并且确实是可以访问的页面。Discover Content是Burp中专门用于此目的的工具。除此之外,Burp Intruder也可以通过字典功击来施行强制浏览(通常是在url参数和文件路径部份进行更改)。FuzzDB收录一些用于此目的的特别牛逼的字典,你可以在这里瞧瞧。
3.1 测试可选内容
名称描述User Agent Switcher用于迅速切换浏览器的User Agent的一款Firefox插件Burp IntruderBurp Suite中可自定义的用于自动化的功击的模块。(比如brute forcing, injection, 等)FuzzDB收录各类恶意输入、资源名、用于grep搜索响应内容的字符串、Webshell等。
在内容挖掘这一步,我十分喜欢做一件事。那就是借助User Agent Switcher切换不同的User Agent之后访问同一个特定页面。这是因为好多的Web应用对于不同的User-Agent和Referer恳求头会返回不同的内容。
我常常使用Burp Intruder来模糊测试User-Agent和Referer恳求头,一般还借助FuzzDB的字典。
4. 自动化的漏洞挖掘
名称描述Burp Scanner自动化扫描安全漏洞的Burp Suite工具
当你在Mapping和进行漏洞挖掘的开始部份时侯,Burp Passive Scanner就早已在后台悄悄运行。你应当先剖析这份扫描结果,然后再进行Burp Active Scanner,这样在Burp Passive Scanner中发觉的值得关注的页面就可以在Burp Active Scanner中进行详尽的扫描。
由于Burp Active Scanner完成所需的时间十分长,我更喜欢只容许一小段时间,然后查看二者之间的扫描结果并记录结果。
!!!自动化的漏洞扫描是太危险的。用Burp Scanner可能造成不良的影响。除非你特别熟悉目标的功能与环境,否则你只应在非生产环境中使用。5. 配置5.1 默认配置
在确认了目标所使用的技术后,很自然的一步跟进就是测试有没有默认配置。许多框架使用许多易受功击默认配置的应用程序便于于向开发人员介绍她们的产品。然后因为开发人员的疏漏,这些示例应用被布署到和目标站点所在的同一台服务器上,这促使目标站点承受很大的风险。
5.2 错误配置
在Web渗透测试的每一步,你都应当注意Web应用有没有错误的配置。你可以特别关注页面出现的错误信息,这些信息常常会给出很有用的数据库结构和服务器文件系统等信息。
错误信息几乎总还能发觉一些。这些错误信息在注入和LFI(Local File Include)中非常有用。
另外一个值得注意的是页面的敏感表单有没有禁用手动填充。比如密码数组常常会有一个“显示/隐藏”按钮。浏览器默认不会填充type="password"的input标签内容,而当密码数组是“显示”时,input标签就弄成了type="text",这样浏览器都会进行手动填充。这在多用户环境下是一个隐患。
6. 身份认证
在漏洞挖掘过程中,你应当认真考量你看见的每位登陆表单。如果这种表单没有做挺好的安全举措(比如双重认证,验证码,禁止重复递交等),攻击者就可能得到用户帐户未授权的权限。取决于表单的不同实现以及不同的框架/CMS,即使登陆失败目标站点也可能会透漏出用户帐户的一些信息。
如果你测试发觉了上述所讨论的问题,你应当关注并记录。另外,如果登陆表单没有加密(或者借助了旧版本的SSL/TLS),这也应当关注并记录。
6.1 模糊登陆测试
名称描述CeWL通过爬取目标站点来生成用户字典的工具Burp IntruderBurp Suite中可自定义的用于自动化的功击的模块。(比如brute forcing, injection, 等)
在你认真考量了登陆表单后,就可以开始登陆测试了。CeWL是一款非常好用的用于生成一次性字典的工具。你可以借助-h查看帮助文档。
基本句型如下
cewl [options] www.example.com
当你构造好用户字典后就可以开始用Burp Intruder进行实际的模糊测试了。通常我会用两个payload集(一个是用户名的,另一个是CeWL生成的密码)。Intruder的Attack Type一般应当选Cluster Bomb。
7. Session管理
Session-token/Cookie剖析在渗透测试过程中尽管不是太吸引人的部份,但确实十分重要的一块。通常是这样子的,你想了解整个web应用是怎样跟踪Session,然后用Burp Sequencer这样的工具去测试session token的随机性/可预测性。一些应用(较传统的应用)会把session的内容储存在客户端。有时候这种数据上面会收录有加密的,序列化的敏感信息。
这时也应当检测HTTP返回头的Set-Cookie是否收录Secure和HttpOnly的标示。如果没有的话就值得注意了,因为没有理由不设置这种标识位。
Google搜索你得到的session token,可能会有一些发觉,比如Session可预测等,这样就可以进行Session绑架功击。7.1 用Burp测试Session Tokens
名称描述Burp SequencerBurp拿来剖析数据集的随机性的模块
Burp Sequencer是拿来测试Session Token随机性和可预测性的挺好的工具。当你用这个工具来测试目标的Session管理时,你应当先去除所有的Cookies,然后重新认证一次。然后就可以把带有Set-Cookie头的返回包发送给Burp Sequencer,然后Sequencer都会启动新的拦截对Token进行剖析。通常10000次恳求就差不多可以判定随机性和可预测性了。
如果发觉Session token不够随机,那就可以考虑Session绑架了。
8. 授权
授权漏洞太象功能级访问控制缺位和不安全的直接对象引用漏洞,是太长一段时间我发觉的最流行的漏洞。这是因为许多的开发者没有想到一个低权限甚至是匿名用户会去向高权限的插口发送恳求(失效的权限控制)。
http://example.com/app/admin_getappInfo
或者是去恳求其他用户的数据(不安全的直接对象引用,译者注:水平越权)
http://example.com/app/accountInfo?acct=notmyacct
8.1 测试权限控制
名称描述Compare Site MapsBurp的用于测试授权的模块
这里有个小方法,就是注册两个不同权限的用户,然后用高权限的用户去访问整个Web应用,退出高权限用户,登录低权限用户,然后用Burp的Compare Site Maps工具去测试什么页面的权限控制没有做好。
9. 数据验证测试
名称描述Burp Repeater用于手工更改、重放HTTP请求的Burp模块
注入漏洞的存在是因为Web应用接受任意的用户输入,并且在服务端没有正确验证用户的输入的有效性。作为一个渗透测试者,你应当注意每一个接受随便的用户输入的地方并设法进行注入。
因为每位Web应用情况都不一样,所以没有一种万能的注入形式。接下来,我会把注入漏洞进行分类而且给出一些Payload。Burp Repeater是我测试注入漏洞时最常使用的工具。它可以重放HTTP请求,并且可以随时更改Payload。
有一件事须要牢记:漏洞挖掘阶段要做的只是辨识漏洞,而漏洞借助阶段就会借助漏洞做更多地事。当然,每个注入漏洞都值得被记录,你可以在漏洞挖掘阶段以后对这种注入漏洞进行深入的测试。
在每位分类下可以参照OWASP获取更多地信息。
9.1 SQLi
任何将输入带入数据库进行查询的地方都可能存在SQL注入。结合错误的配置问题,会导致大量的数据被攻击者窃取。
我推荐你在做SQL注入时参照这个Wiki。如果你输入了这种Payload得到了数据库返回的错误信息,那么目标就十分有可能存在SQL注入漏洞。
Sqlmap是一款自动化的SQL注入工具,我将会在漏洞借助阶段介绍它。
OWASP-测试SQL注入)
' OR 1=1 -- 1
' OR '1'='1
' or 1=1 LIMIT 1;--
admin';--
http://www.example.com/product.php?id=10 AND 1=1
9.2 跨站脚本攻击(XSS)
攻击者借助Web应用程序发送恶意代码(通常是JavaScript代码)给另外一个用户,就发生了XSS。
有三种不同的XSS:
存储型。当提供给Web应用的数据是攻击者事先递交到服务器端永久保存的恶意代码时,发生存储型XSS。反射型。当提供给Web应用的数据是服务端脚本借助攻击者的恶意输入生成的页面时,发生反射型XSS。DOM型。DOM型XSS存在于客户端的脚本。
OWASP-测试XSS
<p>
">alert('XSS')
互联网业务成功之路(4): 网站内容管理和运营
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2020-08-08 22:57
运营是该站点持续增长的关键. 只有通过详细,独特的网站内容规划和实施以及必要的操作,网站才能在竞争中立于不败之地.
1. 快速丰富新网站的内容
1. 列设置为网站构建“骨架”
我们已经介绍了在无忧CMS系统中添加列的方法,本期着重于列的规划思想,而不仅限于某个网站程序.
第一步: 先计划. 网站的栏目设置是网站建立之初最重要的步骤,因为一旦确定了栏目,网站的定位就基本形成了. 如果在经过一段时间的操作后对其进行修改,将会造成很多损失,例如失去目标访问者和减轻搜索引擎的重量等. 因此,在创建网站列和添加它们之前,我们必须仔细考虑并计划它们.
第2步: 进行更多研究. 确定要添加的列之后,必须首先检查此类列是否在网民中很流行. 想一想. 创建列时,您将每天进行维护和更新,但是由于位置偏差,没有人关心它. 这不是浪费吗?时间?要了解访问者的爱好,第一种方法是查看其他类似的网站以获得灵感. 此外,您可以通过对搜索引擎进行排名来确定列的位置,从而吸引特定领域的注意力. 例如,百度的Billboard是一个很好的工具.
图1
第3步: 建立定位. 同一字段还将具有不同的列位置. 例如,您将创建一本有关笔记本相关信息的专栏. 您要介绍笔记本行业的最新信息,还是提供笔记本软件下载或笔记本购物指南服务?注意与网站的统一. 例如,本文中的示例是一个IT信息网站,其位置是笔记本的新闻内容.
2. 使用采集来快速采集网站内容
在建立网站的初期,通常缺少文章,访问者如果没有内容就无法被保留. 为了快速获得高质量的内容,我们可以从其他网站重新打印该内容. 在这里,我们以Shudong Link为例,将以上文章快速重新发布到我们的网站上. “ 优采云采集器”是一种方便实用的内容采集程序,支持采集远程文章和图片. 下面我们以该软件为例进行说明.
提示:
由于该软件基于.NET程序体系结构,因此必须在使用前安装Microsoft .NET Framework 2.0组件,否则该程序将无法正常运行.
第1步: 建立网站添加规则
下载软件后,可以将其解压缩后再使用. 在任务列表面板中右键单击以创建新的采集网站,然后在弹出的网站创建窗口中输入网站名称,URL和其他信息. 然后切换到软件的“整个站点内容规则”页面,这是集合中最重要的步骤. 如果设置稍有不正确,可能会发生错误. 对于一般的文章传送,我们需要填写基本信息,包括标题,内容和时间.
图2
要确定网页的内容规则,可以打开需要采集的内容页面,在浏览器中选择“查看源代码”以查看网页的HTML代码,然后在其中搜索标题字段. 代码. 如果标题开始标签为,则在软件的标签编辑框中输入这两个字段. 然后按照相同的方法查找并添加标签,例如文章内容,作者,来源,时间等. 通常,我们需要检查多个文章页面,以避免标签错误.
如果需要同时采集网页上的其他信息,则可以单击“添加标签”按钮来添加采集对象. 该软件不仅支持通过采集获得的数据,还可以将数据设置为固定格式.
提示:
您可能会发现第一次很难添加数据规则,但是再尝试几次并仔细阅读软件文档. 了解了原理之后,就很容易编写数据规则.
第2步: 创建采集任务
右键单击刚添加的站点的名称,然后选择“从此站点创建新任务”选项,然后将显示URL采集菜单. 该软件提供了三种URL采集模式. 如果目标网站具有相应的文章列表页面,则可以使用“级别1链接”方法. 此方法的原理是通过内容列表页面自动检测内容页面以采集Web内容.
如果目标URL文件名具有特定格式,我们还可以直接添加需要采集的内容页面URL. 添加任务后,您可以先对其进行测试. 单击软件右下角的“开始测试URL集合”按钮以进入测试页面. 该软件将根据刚刚填写的URL规则进行采集. 地址搜索完成后,您可以选择任何文章进行测试. 软件可以正常显示采集页面的内容,说明采集规则设置成功;如果无法显示内容,则需要重新设置规则.
图3
第3步: 采集和发布内容
完成上述步骤后,您还需要设置所采集内容的发布方法. 该软件当前提供了多种内容发布方法. 它可以直接发布到网站程序,也可以另存为本地文件. 如果要直接发布到网站程序,则需要一个相应的程序发布模块. 该软件带有几个程序模块,包括最受欢迎的文章系统. 如果没有我们需要的模块,则可以转到官方软件论坛进行查找.
设置完成后,您可以采集文章并将其发布到网站. 在软件主面板中选择要采集的网站的名称,然后单击面板顶部的开始按钮,软件将自动采集内容. 如果您需要采集很多内容,则需要等待很长时间. 采集完所有文章后,内容将自动发布.
提示:
尽管获取软件可以轻松获取大量文章,但在使用该软件时必须注意版权,并注明允许转载的某些文章的来源.
第二,避免复制实用内容的防盗方法
许多网站管理员都困扰着Internet上的版权问题. 最常见的个人网站遭遇是其内容被转载. 一些网站不仅在重新打印时不保留链接,而且在文章中收录网站信息. 删除. 面对这种情况,我们可以通过向网站添加标签来保护网站的内容. 例如,在图片或文字中添加网站徽标,域名和其他信息,以便即使其他网站转载内容,也可以间接推广您自己的网站. 查看全部
为人们种草提供短视频,自媒体,一站式服务
运营是该站点持续增长的关键. 只有通过详细,独特的网站内容规划和实施以及必要的操作,网站才能在竞争中立于不败之地.
1. 快速丰富新网站的内容
1. 列设置为网站构建“骨架”
我们已经介绍了在无忧CMS系统中添加列的方法,本期着重于列的规划思想,而不仅限于某个网站程序.
第一步: 先计划. 网站的栏目设置是网站建立之初最重要的步骤,因为一旦确定了栏目,网站的定位就基本形成了. 如果在经过一段时间的操作后对其进行修改,将会造成很多损失,例如失去目标访问者和减轻搜索引擎的重量等. 因此,在创建网站列和添加它们之前,我们必须仔细考虑并计划它们.
第2步: 进行更多研究. 确定要添加的列之后,必须首先检查此类列是否在网民中很流行. 想一想. 创建列时,您将每天进行维护和更新,但是由于位置偏差,没有人关心它. 这不是浪费吗?时间?要了解访问者的爱好,第一种方法是查看其他类似的网站以获得灵感. 此外,您可以通过对搜索引擎进行排名来确定列的位置,从而吸引特定领域的注意力. 例如,百度的Billboard是一个很好的工具.
图1
第3步: 建立定位. 同一字段还将具有不同的列位置. 例如,您将创建一本有关笔记本相关信息的专栏. 您要介绍笔记本行业的最新信息,还是提供笔记本软件下载或笔记本购物指南服务?注意与网站的统一. 例如,本文中的示例是一个IT信息网站,其位置是笔记本的新闻内容.
2. 使用采集来快速采集网站内容
在建立网站的初期,通常缺少文章,访问者如果没有内容就无法被保留. 为了快速获得高质量的内容,我们可以从其他网站重新打印该内容. 在这里,我们以Shudong Link为例,将以上文章快速重新发布到我们的网站上. “ 优采云采集器”是一种方便实用的内容采集程序,支持采集远程文章和图片. 下面我们以该软件为例进行说明.
提示:
由于该软件基于.NET程序体系结构,因此必须在使用前安装Microsoft .NET Framework 2.0组件,否则该程序将无法正常运行.
第1步: 建立网站添加规则
下载软件后,可以将其解压缩后再使用. 在任务列表面板中右键单击以创建新的采集网站,然后在弹出的网站创建窗口中输入网站名称,URL和其他信息. 然后切换到软件的“整个站点内容规则”页面,这是集合中最重要的步骤. 如果设置稍有不正确,可能会发生错误. 对于一般的文章传送,我们需要填写基本信息,包括标题,内容和时间.
图2
要确定网页的内容规则,可以打开需要采集的内容页面,在浏览器中选择“查看源代码”以查看网页的HTML代码,然后在其中搜索标题字段. 代码. 如果标题开始标签为,则在软件的标签编辑框中输入这两个字段. 然后按照相同的方法查找并添加标签,例如文章内容,作者,来源,时间等. 通常,我们需要检查多个文章页面,以避免标签错误.
如果需要同时采集网页上的其他信息,则可以单击“添加标签”按钮来添加采集对象. 该软件不仅支持通过采集获得的数据,还可以将数据设置为固定格式.
提示:
您可能会发现第一次很难添加数据规则,但是再尝试几次并仔细阅读软件文档. 了解了原理之后,就很容易编写数据规则.
第2步: 创建采集任务
右键单击刚添加的站点的名称,然后选择“从此站点创建新任务”选项,然后将显示URL采集菜单. 该软件提供了三种URL采集模式. 如果目标网站具有相应的文章列表页面,则可以使用“级别1链接”方法. 此方法的原理是通过内容列表页面自动检测内容页面以采集Web内容.
如果目标URL文件名具有特定格式,我们还可以直接添加需要采集的内容页面URL. 添加任务后,您可以先对其进行测试. 单击软件右下角的“开始测试URL集合”按钮以进入测试页面. 该软件将根据刚刚填写的URL规则进行采集. 地址搜索完成后,您可以选择任何文章进行测试. 软件可以正常显示采集页面的内容,说明采集规则设置成功;如果无法显示内容,则需要重新设置规则.
图3
第3步: 采集和发布内容
完成上述步骤后,您还需要设置所采集内容的发布方法. 该软件当前提供了多种内容发布方法. 它可以直接发布到网站程序,也可以另存为本地文件. 如果要直接发布到网站程序,则需要一个相应的程序发布模块. 该软件带有几个程序模块,包括最受欢迎的文章系统. 如果没有我们需要的模块,则可以转到官方软件论坛进行查找.
设置完成后,您可以采集文章并将其发布到网站. 在软件主面板中选择要采集的网站的名称,然后单击面板顶部的开始按钮,软件将自动采集内容. 如果您需要采集很多内容,则需要等待很长时间. 采集完所有文章后,内容将自动发布.
提示:
尽管获取软件可以轻松获取大量文章,但在使用该软件时必须注意版权,并注明允许转载的某些文章的来源.
第二,避免复制实用内容的防盗方法
许多网站管理员都困扰着Internet上的版权问题. 最常见的个人网站遭遇是其内容被转载. 一些网站不仅在重新打印时不保留链接,而且在文章中收录网站信息. 删除. 面对这种情况,我们可以通过向网站添加标签来保护网站的内容. 例如,在图片或文字中添加网站徽标,域名和其他信息,以便即使其他网站转载内容,也可以间接推广您自己的网站.
WordPress胖鼠标采集插件会自动采集和发布微信官方帐户和简短书籍
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-08-08 22:04
WordPress最初是一个博客,但是由于其强大的功能和众多的用户,Wordpress现在已成为CMS平台,甚至有些公司也使用Wordpress建立了他们的网站,实际上到处都是. Wordpress用于采集和构建站点. 一直在做垃圾站的朋友一直在使用它.
一件事是,WordPress自己的SEO很好,这有利于搜索引擎的收录和SEO排名;另一方面,Wordpress也有很多功能强大的插件. 使用Wordpress捕获插件不需要太多复杂的配置. 新手还可以建立一个网站,该网站每天自动采集和发布内容,并放置一些小型广告来“获得回报”.
有很多WordPress集合插件,但是基本上都是付费的. 本文主要是分享新的WordPress集合插件-Fat Mouse 采集,开源和免费,并支持所有网站列表的详细信息页面,它具有自动批量列出列表的集合,自动发布,自动标记等功能,可用于采集微信官方帐户,简书和其他各种网站.
安装WP Fat Mouse 采集插件
插件:
建议将PHP 7用于WordPress Fat Mouse 采集插件. 如果您的PHP版本低于PHP 7,请转到Fat Mouse下载Github集合并使用Fat Mouse v5. 分支名称: based_php_5.6,系统要求如下:
PHP> = 5.6
QueryList v4版本
Mysql不需要
Nginx不需要
WordPress胖鼠标集合插件的主要功能如下:
微信公众号文章采集,短文文章采集,列表页面文章批次采集.
详细信息页面文章采集,分页爬网-历史数据,请放手. 一口气捕获所有内容
自动采集,自动发布,将动态内容自动添加到文章,优化SEO.
自动标签,文章过滤,自动精选图片.
内容关键字过滤功能取代了任何网站的伪原创,自定义集合.
WordPress胖鼠标集合插件主要包括以下部分:
①采集器模块,先驱者配置模块的各种功能以寻找数据.
②配置模块并支持采集器模块,以向其提供采集规则的核心力量.
③数据模块,数据此模块具有Fat Mouse的各种功能发布功能.
在安装Wordpress胖鼠标集合插件之后,将显示下图:
WP Fat Mouse 采集插件操作配置中心
已在WP Fat Mouse采集插件配置中心中配置了采集规则. Wordpress Fat Mouse 采集插件具有多种配置,您可以单击以首先将其导入. (点击放大)
馆藏中心
您可以在采集中心开始采集文章. WordPress胖鼠标采集插件分为列表采集和详细信息采集. 列表采集可以批量采集某个网站,详细采集是采集某个页面.
数据中心
采集完成后,您可以转到数据中心查看采集的文章,然后单击以在此处发布它们. (点击放大)
通过WordPress胖鼠标采集插件采集和发布文章的效果仍然很好.
这是Wordpress Fat Mouse 采集插件采集的文章的详细信息页面,该插件可完全采集网站上的文章.
WP Fat Mouse采集微信官方帐户
对于WordPress来说,采集微信官方帐户文章也非常简单. 首先找到您要采集的微信公众号文章.
然后在“采集中心”中填写微信公众号文章的URL,支持批量添加多个URL,点击采集.
采集完成后,可以发布采集到的微信公众号文章. 如下图所示:
WP Fat Mouse 采集简书志虎
WordPress采集的短书,Zhhu等类似于上面的WeChat官方帐户文章的采集. 您可以直接输入要采集的URL.
WP自定义采集任何网站
WordPress Fat Mouse集合插件随附的几个配置文件实际上是供我们演示的. 真正强大的功能是,我们自定义了WordPress Fat Mouse采集插件的采集规则,以采集任何网站内容(不是AJax).
新的收款规则
在Wordpress Fat Mouse采集插件中创建新的采集规则. 在这里,以文章集为例. 首先命名它,然后选择列表配置(有很多文章,请选择此批次集合),其余的如下所示:
然后填写采集地址,范围,采集规则等,如下所示:
通常来说,采集规则需要多次测试才能成功,因此在创建新规则之前,我们首先打开插件的Debug模式,然后在元素的network列中检查特定结果在Chrome浏览器中.
列表采集规则
采集范围是要由Wordpress Fat Mouse采集插件采集的URL的列表. 主页上最新文章的标题全部以H2 + URL的形式嵌套(单击放大).
因此,我在这里填写的采集范围是: #cat_all> .news-post.article-post> .row> .col-sm-7> .post-content> h2,此路径不需要是手动直接进行操作您可以在Chrome浏览器查看元素的底部看到它,请注意上面的图片.
写入列表采集规则: a: eq(0)href,href表示选择标签的href属性(即URL),我们使用Jquery的eq语法a: eq(0)表示H2区域A的第一个. 注意: 如果目标站链接是相对链接,则代码从0开始(只有一个标签,您可以填写a). 该程序将自动完成.
在Debgu模式下,我们可以看到已经获得了主页上最新文章列下所有文章的URL地址.
详细信息采集规则
我们已经采集了上面列表中的所有URL,然后我们需要在此URL下采集文章的内容. 打开一篇文章,我们发现标题在.title-post中,文章的内容在.the-content中. 标题和内容都在.single-post-box下.
标题. 现在我们可以编写标题采集规则,如下所示: 作用域是.single-post-box,选择器是.title-post,属性是text.
在调试模式下,您可以看到我们已经成功获取了文章标题.
内容. 采集内容的规则写为: 作用域是.single-post-box,选择器是.the-content,属性是html. 文章内容已成功获得,如下.
最后,在“最新文章”列下采集所有文章的规则如下: (单击放大)
WP自定义采集成功效果
在采集中心,单击我们刚刚配置的列表采集配置.
稍等片刻,Wordpress Fat Mouse 采集插件将采集所有最新文章.
点击发布,采集成功.
WP自定义采集规则问题参数和属性
WordPress胖鼠标集合插件有三个必需的参数:
链接采集链接通常采用a标签的href属性
标题标题通常采用详细信息页面的h1标签的text属性
内容内容通常在详细信息页面的.content标签中具有html属性.
WordPress胖鼠标集合插件的属性解释如下:
href基本上是指标签的href属性(此属性在单击后存储跳转地址)
text获取该区域的文本,通常用于标题
html提取区域中的所有html通常用于提取内容,并且内容更多. 内容中收录很多内容,例如排版中的图像CSS JS. 因此,请获取所有原创HTML
jQuery选择器
在下面的内容过滤中,几个jQuery选择器(例如: first,: last,: odd等)非常有用,您可以熟悉它们.
WP胖鼠集合优化方法内容过滤 查看全部
教程简介
WordPress最初是一个博客,但是由于其强大的功能和众多的用户,Wordpress现在已成为CMS平台,甚至有些公司也使用Wordpress建立了他们的网站,实际上到处都是. Wordpress用于采集和构建站点. 一直在做垃圾站的朋友一直在使用它.
一件事是,WordPress自己的SEO很好,这有利于搜索引擎的收录和SEO排名;另一方面,Wordpress也有很多功能强大的插件. 使用Wordpress捕获插件不需要太多复杂的配置. 新手还可以建立一个网站,该网站每天自动采集和发布内容,并放置一些小型广告来“获得回报”.
有很多WordPress集合插件,但是基本上都是付费的. 本文主要是分享新的WordPress集合插件-Fat Mouse 采集,开源和免费,并支持所有网站列表的详细信息页面,它具有自动批量列出列表的集合,自动发布,自动标记等功能,可用于采集微信官方帐户,简书和其他各种网站.

安装WP Fat Mouse 采集插件
插件:
建议将PHP 7用于WordPress Fat Mouse 采集插件. 如果您的PHP版本低于PHP 7,请转到Fat Mouse下载Github集合并使用Fat Mouse v5. 分支名称: based_php_5.6,系统要求如下:
PHP> = 5.6
QueryList v4版本
Mysql不需要
Nginx不需要
WordPress胖鼠标集合插件的主要功能如下:
微信公众号文章采集,短文文章采集,列表页面文章批次采集.
详细信息页面文章采集,分页爬网-历史数据,请放手. 一口气捕获所有内容
自动采集,自动发布,将动态内容自动添加到文章,优化SEO.
自动标签,文章过滤,自动精选图片.
内容关键字过滤功能取代了任何网站的伪原创,自定义集合.
WordPress胖鼠标集合插件主要包括以下部分:
①采集器模块,先驱者配置模块的各种功能以寻找数据.
②配置模块并支持采集器模块,以向其提供采集规则的核心力量.
③数据模块,数据此模块具有Fat Mouse的各种功能发布功能.
在安装Wordpress胖鼠标集合插件之后,将显示下图:

WP Fat Mouse 采集插件操作配置中心
已在WP Fat Mouse采集插件配置中心中配置了采集规则. Wordpress Fat Mouse 采集插件具有多种配置,您可以单击以首先将其导入. (点击放大)

馆藏中心
您可以在采集中心开始采集文章. WordPress胖鼠标采集插件分为列表采集和详细信息采集. 列表采集可以批量采集某个网站,详细采集是采集某个页面.

数据中心
采集完成后,您可以转到数据中心查看采集的文章,然后单击以在此处发布它们. (点击放大)

通过WordPress胖鼠标采集插件采集和发布文章的效果仍然很好.

这是Wordpress Fat Mouse 采集插件采集的文章的详细信息页面,该插件可完全采集网站上的文章.

WP Fat Mouse采集微信官方帐户
对于WordPress来说,采集微信官方帐户文章也非常简单. 首先找到您要采集的微信公众号文章.

然后在“采集中心”中填写微信公众号文章的URL,支持批量添加多个URL,点击采集.

采集完成后,可以发布采集到的微信公众号文章. 如下图所示:

WP Fat Mouse 采集简书志虎
WordPress采集的短书,Zhhu等类似于上面的WeChat官方帐户文章的采集. 您可以直接输入要采集的URL.

WP自定义采集任何网站
WordPress Fat Mouse集合插件随附的几个配置文件实际上是供我们演示的. 真正强大的功能是,我们自定义了WordPress Fat Mouse采集插件的采集规则,以采集任何网站内容(不是AJax).
新的收款规则
在Wordpress Fat Mouse采集插件中创建新的采集规则. 在这里,以文章集为例. 首先命名它,然后选择列表配置(有很多文章,请选择此批次集合),其余的如下所示:

然后填写采集地址,范围,采集规则等,如下所示:

通常来说,采集规则需要多次测试才能成功,因此在创建新规则之前,我们首先打开插件的Debug模式,然后在元素的network列中检查特定结果在Chrome浏览器中.

列表采集规则
采集范围是要由Wordpress Fat Mouse采集插件采集的URL的列表. 主页上最新文章的标题全部以H2 + URL的形式嵌套(单击放大).

因此,我在这里填写的采集范围是: #cat_all> .news-post.article-post> .row> .col-sm-7> .post-content> h2,此路径不需要是手动直接进行操作您可以在Chrome浏览器查看元素的底部看到它,请注意上面的图片.
写入列表采集规则: a: eq(0)href,href表示选择标签的href属性(即URL),我们使用Jquery的eq语法a: eq(0)表示H2区域A的第一个. 注意: 如果目标站链接是相对链接,则代码从0开始(只有一个标签,您可以填写a). 该程序将自动完成.

在Debgu模式下,我们可以看到已经获得了主页上最新文章列下所有文章的URL地址.

详细信息采集规则
我们已经采集了上面列表中的所有URL,然后我们需要在此URL下采集文章的内容. 打开一篇文章,我们发现标题在.title-post中,文章的内容在.the-content中. 标题和内容都在.single-post-box下.

标题. 现在我们可以编写标题采集规则,如下所示: 作用域是.single-post-box,选择器是.title-post,属性是text.

在调试模式下,您可以看到我们已经成功获取了文章标题.

内容. 采集内容的规则写为: 作用域是.single-post-box,选择器是.the-content,属性是html. 文章内容已成功获得,如下.

最后,在“最新文章”列下采集所有文章的规则如下: (单击放大)

WP自定义采集成功效果
在采集中心,单击我们刚刚配置的列表采集配置.

稍等片刻,Wordpress Fat Mouse 采集插件将采集所有最新文章.

点击发布,采集成功.

WP自定义采集规则问题参数和属性
WordPress胖鼠标集合插件有三个必需的参数:
链接采集链接通常采用a标签的href属性
标题标题通常采用详细信息页面的h1标签的text属性
内容内容通常在详细信息页面的.content标签中具有html属性.
WordPress胖鼠标集合插件的属性解释如下:
href基本上是指标签的href属性(此属性在单击后存储跳转地址)
text获取该区域的文本,通常用于标题
html提取区域中的所有html通常用于提取内容,并且内容更多. 内容中收录很多内容,例如排版中的图像CSS JS. 因此,请获取所有原创HTML
jQuery选择器
在下面的内容过滤中,几个jQuery选择器(例如: first,: last,: odd等)非常有用,您可以熟悉它们.

WP胖鼠集合优化方法内容过滤
采集工具的竞争-计算机数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2020-08-08 11:20
以下纯属个人看法
当前,网站站长圈子中有许多流行的采集工具,但总的来说,只有少数几个知名的免费采集工具
1. 优采云应该拥有最多的用户,主要集中在新站
功能: 多功能,速度快
优点: 功能比较齐全,采集速度比较快,主要针对cms,可以在很短的时间内采集很多,过滤和替换都不错,比较详细,很多人编写和发布了界面,界面比较完整,适合那些不了解该程序的网站管理员
技术: 该技术主要是对论坛的支持,具有许多帮助文件,易于使用以及在采集工具方面的竞争. 有免费的付费版本
缺点: 功能更多,体积越来越大,内存成本高,速度快,采集品的质量有所降低且不稳定
2. 三人行主要用于论坛,可以称为第一人
功能: 对于大型论坛,移动,移动,快速,高精度
优点: 仍然适合论坛,适合开设论坛
技术: 收费技术,免费广告
缺点: 对cms的支持不佳
3.ET工具
功能: 无人看管,稳定,几乎没有记忆
优点: 无人值守,自动更新,适合长期派驻,用户群主要集中在长期派潜水站长,计算机数据“采集工具大赛”()上. 软件清晰,必要的功能也很完善. 关键是该软件是免费的. 听说添加了中英文翻译功能.
技术: 论坛支持,该软件本身是免费的,但也提供付费服务. 帮助文件少,不容易上手
缺点: 似乎缺少帮助文件是该软件的缺点
4. 海纳
功能: 大量关键字捕获,无需编写规则即可预览采集的内容
优势: 庞大,可以在网站上抓取很多关键字文章,这似乎很适合网站的主题
技术: 不收取论坛费用,免费提供功能限制
缺点: 分类不方便,也就是说,对采集的文章,手册(自动(容易混淆),特定的界面)进行分类很不方便
摘要: 如果您追求完整的功能,则应该选择优采云. 优采云被称为“万能的”. 在初始阶段,您可以快速采集大量资源并丰富网站内容. 如果您是论坛,请选择一个三人组. 没错,您可以实现许多论坛功能,例如采集论坛,回复和移动. 长期站,当然选择ET,需要一些时间来了解,这是长期的利益. 编写规则,设置过滤器并替换,然后就可以像打开QQ一样长时间运行,而无需记忆,自动采集和更新,清晰的分类以及完整的采集内容. 但是,一个站,一个站长+ ET就足够了. 对于Hainer来说,似乎没有规则,而且入门起来很容易,但是在发表文章时,不可能一劳永逸. 相反,我觉得已经添加了很多工作,但是您可以做一些特别的主题. 这是网站主题的不错选择. 查看全部
以下纯属个人看法. 网站站长圈子中有许多流行的采集工具,但总的来说,只有少数几个著名的免费工具. 1.优采云用户数应为...
以下纯属个人看法
当前,网站站长圈子中有许多流行的采集工具,但总的来说,只有少数几个知名的免费采集工具
1. 优采云应该拥有最多的用户,主要集中在新站
功能: 多功能,速度快
优点: 功能比较齐全,采集速度比较快,主要针对cms,可以在很短的时间内采集很多,过滤和替换都不错,比较详细,很多人编写和发布了界面,界面比较完整,适合那些不了解该程序的网站管理员
技术: 该技术主要是对论坛的支持,具有许多帮助文件,易于使用以及在采集工具方面的竞争. 有免费的付费版本
缺点: 功能更多,体积越来越大,内存成本高,速度快,采集品的质量有所降低且不稳定
2. 三人行主要用于论坛,可以称为第一人
功能: 对于大型论坛,移动,移动,快速,高精度
优点: 仍然适合论坛,适合开设论坛
技术: 收费技术,免费广告
缺点: 对cms的支持不佳
3.ET工具
功能: 无人看管,稳定,几乎没有记忆
优点: 无人值守,自动更新,适合长期派驻,用户群主要集中在长期派潜水站长,计算机数据“采集工具大赛”()上. 软件清晰,必要的功能也很完善. 关键是该软件是免费的. 听说添加了中英文翻译功能.
技术: 论坛支持,该软件本身是免费的,但也提供付费服务. 帮助文件少,不容易上手
缺点: 似乎缺少帮助文件是该软件的缺点
4. 海纳
功能: 大量关键字捕获,无需编写规则即可预览采集的内容
优势: 庞大,可以在网站上抓取很多关键字文章,这似乎很适合网站的主题
技术: 不收取论坛费用,免费提供功能限制
缺点: 分类不方便,也就是说,对采集的文章,手册(自动(容易混淆),特定的界面)进行分类很不方便
摘要: 如果您追求完整的功能,则应该选择优采云. 优采云被称为“万能的”. 在初始阶段,您可以快速采集大量资源并丰富网站内容. 如果您是论坛,请选择一个三人组. 没错,您可以实现许多论坛功能,例如采集论坛,回复和移动. 长期站,当然选择ET,需要一些时间来了解,这是长期的利益. 编写规则,设置过滤器并替换,然后就可以像打开QQ一样长时间运行,而无需记忆,自动采集和更新,清晰的分类以及完整的采集内容. 但是,一个站,一个站长+ ET就足够了. 对于Hainer来说,似乎没有规则,而且入门起来很容易,但是在发表文章时,不可能一劳永逸. 相反,我觉得已经添加了很多工作,但是您可以做一些特别的主题. 这是网站主题的不错选择.
[发布] 免费安装智虎问答自动采集插件,内容可推送至百度索引
采集交流 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2020-08-07 16:11
安装此插件后,您可以单击一下进入智虎问答网站,并获得智虎问答.
[此插件的功能]
1. 真实的背心用户数据可以批量生成为海报和回复者. 我觉得您的论坛很受欢迎.
2. 除了采集知乎的问题外,还将采集答案的内容. 我觉得您的论坛内容丰富且可读性强.
3. 对背心的回复时间经过科学处理. 并非所有回复该帖子的人都在同一时间. 感觉您的论坛不是响应的背心,而是真正的用户.
4. 批量生成的帖子和回复背心均具有真实的化身和昵称,由中大云实时采集的网络爬虫随机生成.
5. 批量生成的背心用户可以导出uid列表,该列表可以在该插件之外的其他插件中使用.
6. 所采集的纸箱问答内容的图片可以正常显示并另存为图片附件.
7. 图片附件支持远程FTP存储.
8. 图片将在您的论坛上加水印.
9. 知乎的高质量问答内容将每天自动推送,您只需单击一下即可将其发布到您的论坛上.
10. 所采集的“知乎问答”将不会被采集两次,其内容也不会多余.
11. 采集的帖子几乎与真实用户发布的帖子相同.
12. 网页浏览量会自动随机设置,您会觉得帖子的浏览量更为真实.
13. 无限采集,无限采集时间.
[此插件为您带来的价值]
1. 使您的论坛受欢迎并且内容丰富.
2. 除了使用此插件之外,批量生成的背心还可以用于其他目的,这等同于购买此插件并免费赠送该背心生成插件.
3. 使用一键式采集而不是手动发布,可以节省时间和精力,而且不容易出错.
在线安装地址:
@ csdn123com_知乎.plugin
本地下载和手动安装: 查看全部
[插件功能]
安装此插件后,您可以单击一下进入智虎问答网站,并获得智虎问答.
[此插件的功能]
1. 真实的背心用户数据可以批量生成为海报和回复者. 我觉得您的论坛很受欢迎.
2. 除了采集知乎的问题外,还将采集答案的内容. 我觉得您的论坛内容丰富且可读性强.
3. 对背心的回复时间经过科学处理. 并非所有回复该帖子的人都在同一时间. 感觉您的论坛不是响应的背心,而是真正的用户.
4. 批量生成的帖子和回复背心均具有真实的化身和昵称,由中大云实时采集的网络爬虫随机生成.
5. 批量生成的背心用户可以导出uid列表,该列表可以在该插件之外的其他插件中使用.
6. 所采集的纸箱问答内容的图片可以正常显示并另存为图片附件.
7. 图片附件支持远程FTP存储.
8. 图片将在您的论坛上加水印.
9. 知乎的高质量问答内容将每天自动推送,您只需单击一下即可将其发布到您的论坛上.
10. 所采集的“知乎问答”将不会被采集两次,其内容也不会多余.
11. 采集的帖子几乎与真实用户发布的帖子相同.
12. 网页浏览量会自动随机设置,您会觉得帖子的浏览量更为真实.
13. 无限采集,无限采集时间.
[此插件为您带来的价值]
1. 使您的论坛受欢迎并且内容丰富.
2. 除了使用此插件之外,批量生成的背心还可以用于其他目的,这等同于购买此插件并免费赠送该背心生成插件.
3. 使用一键式采集而不是手动发布,可以节省时间和精力,而且不容易出错.
在线安装地址:
@ csdn123com_知乎.plugin
本地下载和手动安装:
新浪微博内容采集和发布大师v13.9官方版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 458 次浏览 • 2020-08-07 14:53
6)您可以将数据采集到Mssql或MySQL数据库中,并通过您的网站进行批量处理(组中的朋友们将很幸运)
7)发布微博后,立即在微博上自动发表评论以提高微博的排名,并且易于输入微博精选,热门微博和实时微博(评论内容可收录9个链接内容,主要应用场景: 在微博上发布图片,并在评论中添加婴儿链接. )
8)自动同步微博内容,您可以将大型微博上的内容自动同步到许多微博帐户. 产品说明
9). 在新浪微博上进行超级主题关注和登录,支持多批批量关注和批量登录.
使用方法:
1. 帐户分类管理
首先添加用于发布微博和采集微博内容的帐户. 此功能还可用于批量管理您的N个多个新浪微博帐户,并维护您的新浪微博帐户. 它可以自动检测您的微博帐户是否异常,或者它是否已被新浪微博正式阻止等.
2,内容自动发布
检查微博内容和帐户,单击“开始发送”以发布微博. 这是全自动的即时发布信息或您的微博内容,全天24小时无人值守. 让机器完全取代您的手动操作!该软件还支持预定和自动微博发布. 您可以先设置预定时间,微博会在时间到后自动发布.
3. 内容批次管理
您可以自己添加,修改和删除内容. 采集的微博内容也可以在此处进行编辑. 您可以批量导入和导出微博内容.
4. 自动内容采集
通过指定某人的微博的采集,您还可以通过关键字搜索来采集相应的内容.
5. 网络管理模式管理
该软件可以通过代理ip和ADSL发布您的微博内容,以防止帐户被阻止的风险.
6. 微博昵称采集
您可以在微博上采集活跃的真实用户的昵称,然后当您在一组微信中自动发送微博时,可以在微博内容中@一群人,并且信息可以从衣服上水平传送,这样您的微博可以迅速传播其影响力. !
7. 操作帮助
设置后,它将自动自动采集新浪微博内容,不仅可以采集文字,还可以采集图片,视频,作者和源地址等. 您还可以将采集的内容上传到指定的微博中. 新浪微博内容自动采集和发布工具,新浪微博内容自动采集和发布软件,新浪微博发布大师. 查看全部
5)将昵称转换为UID(将指定批次的昵称转换为相应的微博UID)
6)您可以将数据采集到Mssql或MySQL数据库中,并通过您的网站进行批量处理(组中的朋友们将很幸运)
7)发布微博后,立即在微博上自动发表评论以提高微博的排名,并且易于输入微博精选,热门微博和实时微博(评论内容可收录9个链接内容,主要应用场景: 在微博上发布图片,并在评论中添加婴儿链接. )
8)自动同步微博内容,您可以将大型微博上的内容自动同步到许多微博帐户. 产品说明
9). 在新浪微博上进行超级主题关注和登录,支持多批批量关注和批量登录.
使用方法:
1. 帐户分类管理
首先添加用于发布微博和采集微博内容的帐户. 此功能还可用于批量管理您的N个多个新浪微博帐户,并维护您的新浪微博帐户. 它可以自动检测您的微博帐户是否异常,或者它是否已被新浪微博正式阻止等.
2,内容自动发布
检查微博内容和帐户,单击“开始发送”以发布微博. 这是全自动的即时发布信息或您的微博内容,全天24小时无人值守. 让机器完全取代您的手动操作!该软件还支持预定和自动微博发布. 您可以先设置预定时间,微博会在时间到后自动发布.
3. 内容批次管理
您可以自己添加,修改和删除内容. 采集的微博内容也可以在此处进行编辑. 您可以批量导入和导出微博内容.
4. 自动内容采集
通过指定某人的微博的采集,您还可以通过关键字搜索来采集相应的内容.
5. 网络管理模式管理
该软件可以通过代理ip和ADSL发布您的微博内容,以防止帐户被阻止的风险.
6. 微博昵称采集
您可以在微博上采集活跃的真实用户的昵称,然后当您在一组微信中自动发送微博时,可以在微博内容中@一群人,并且信息可以从衣服上水平传送,这样您的微博可以迅速传播其影响力. !
7. 操作帮助
设置后,它将自动自动采集新浪微博内容,不仅可以采集文字,还可以采集图片,视频,作者和源地址等. 您还可以将采集的内容上传到指定的微博中. 新浪微博内容自动采集和发布工具,新浪微博内容自动采集和发布软件,新浪微博发布大师.
Zhongda Cloud 采集(Web内容采集工具)v9
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-08-06 21:07
中大云采集的主要功能
1. 每天都会自动采集和更新最新的最热门的微信公众号文章.
2. 最新,最热门的各种信息采集,每天都会自动更新.
3. 输入关键字并采集与此关键字相关的最新内容
4. 输入网址并采集该网址的内容
5. 支持云通用伪原创和本地伪原创
6. 可以在插件设置中自定义本地伪原创文件
7. 图片可以一键存储在本地,图片永远不会丢失
8,Discuz版本可以在后台设置常用集合关键字
9,Discuz版本可以指定用户组和部门来使用采集功能
1. 支持Discuz X2.5及更高版本
1,phpcms和Dream weaving dedecms版本支持三种主流编辑器: fckeditor,ckeditor和ueditor
11. 支持采集优酷,56,腾讯等视频
Zhongda Cloud 采集插件的主要功能
1. 背心用户可以批量注册,张贴者和评论使用的背心看起来与真实注册用户发布的背心完全相同.
2. 您可以批量采集和发布,然后在短时间内将任何高质量的内容重新发布到论坛和门户.
3. 它可以定期采集并自动释放,以实现无人值守的操作.
4. 所采集的内容可以转换为简体和繁体字符,伪原创和其他辅助处理.
5. 支持前台集合. 您可以授权指定的普通注册用户在前台使用此采集器,并让普通注册成员帮助您采集内容.
6. 采集到的内容图片可以正常显示并另存为后期图片附件或门户文章附件. 图片将永远不会丢失.
7. 图片附件支持远程FTP存储,使您可以将图片分离到另一台服务器.
8. 图片将添加您的论坛或门户网站设置的水印.
9. 已采集的内容不会被采集两次,并且内容也不会是多余的.
1. 采集和发布的帖子,门户网站文章和组与真实用户发布的帖子,门户文章和组完全相同,其他人无法知道它们是否由采集器发布.
11. 观看次数将自动随机设置,感觉您的帖子或门户网站文章的观看次数与实际观看次数相同.
12. 您可以指定帖子发布者(主持人),门户文章作者和组发布者.
13. 采集的内容可以发布到论坛的任何部分,门户的任何列以及论坛的任何圈子.
14. 可以将发布的内容推送到百度数据采集界面以进行SEO优化,并加快百度索引和网站的收录量.
15. 采集的内容数量没有限制,采集的数量也没有限制,可以使您的网站快速填充高质量的内容.
16. 该插件具有内置的文本提取算法,该算法支持在任何网站上采集任何列内容.
17. 您可以一键获取当前的实时热点内容,然后一键发布.
网站采集器网站采集工具 查看全部
Zhongda Cloud 采集是一个功能强大的网站内容采集工具,已以插件的形式集成到Discuz,dream weaving dedecms,phpcms和Empire CMS中. 它可以根据关键字或URL自动采集任何内容. 可以说,它是个人网站管理员用户进行所采集内容的伪原创和排版,然后一键发布到其自己的网站上必不可少的工具.
中大云采集的主要功能
1. 每天都会自动采集和更新最新的最热门的微信公众号文章.
2. 最新,最热门的各种信息采集,每天都会自动更新.
3. 输入关键字并采集与此关键字相关的最新内容
4. 输入网址并采集该网址的内容
5. 支持云通用伪原创和本地伪原创
6. 可以在插件设置中自定义本地伪原创文件
7. 图片可以一键存储在本地,图片永远不会丢失
8,Discuz版本可以在后台设置常用集合关键字
9,Discuz版本可以指定用户组和部门来使用采集功能
1. 支持Discuz X2.5及更高版本
1,phpcms和Dream weaving dedecms版本支持三种主流编辑器: fckeditor,ckeditor和ueditor
11. 支持采集优酷,56,腾讯等视频
Zhongda Cloud 采集插件的主要功能
1. 背心用户可以批量注册,张贴者和评论使用的背心看起来与真实注册用户发布的背心完全相同.
2. 您可以批量采集和发布,然后在短时间内将任何高质量的内容重新发布到论坛和门户.
3. 它可以定期采集并自动释放,以实现无人值守的操作.
4. 所采集的内容可以转换为简体和繁体字符,伪原创和其他辅助处理.
5. 支持前台集合. 您可以授权指定的普通注册用户在前台使用此采集器,并让普通注册成员帮助您采集内容.
6. 采集到的内容图片可以正常显示并另存为后期图片附件或门户文章附件. 图片将永远不会丢失.
7. 图片附件支持远程FTP存储,使您可以将图片分离到另一台服务器.
8. 图片将添加您的论坛或门户网站设置的水印.
9. 已采集的内容不会被采集两次,并且内容也不会是多余的.
1. 采集和发布的帖子,门户网站文章和组与真实用户发布的帖子,门户文章和组完全相同,其他人无法知道它们是否由采集器发布.
11. 观看次数将自动随机设置,感觉您的帖子或门户网站文章的观看次数与实际观看次数相同.
12. 您可以指定帖子发布者(主持人),门户文章作者和组发布者.
13. 采集的内容可以发布到论坛的任何部分,门户的任何列以及论坛的任何圈子.
14. 可以将发布的内容推送到百度数据采集界面以进行SEO优化,并加快百度索引和网站的收录量.
15. 采集的内容数量没有限制,采集的数量也没有限制,可以使您的网站快速填充高质量的内容.
16. 该插件具有内置的文本提取算法,该算法支持在任何网站上采集任何列内容.
17. 您可以一键获取当前的实时热点内容,然后一键发布.

网站采集器网站采集工具
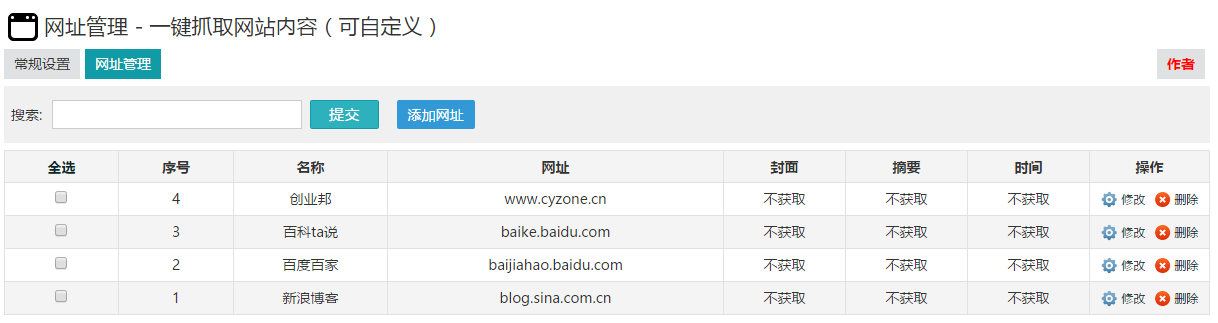
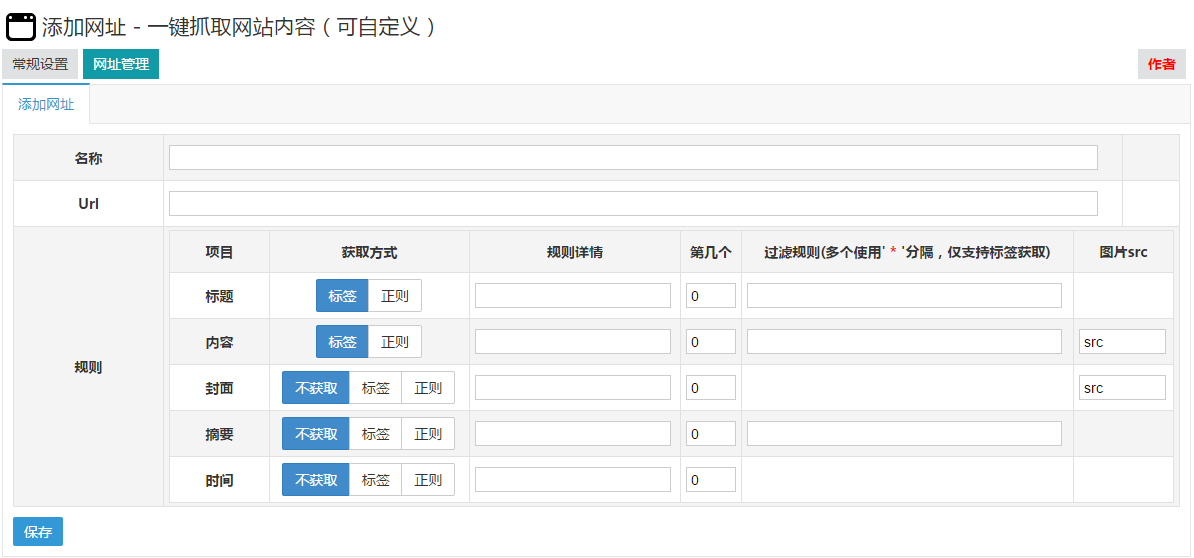
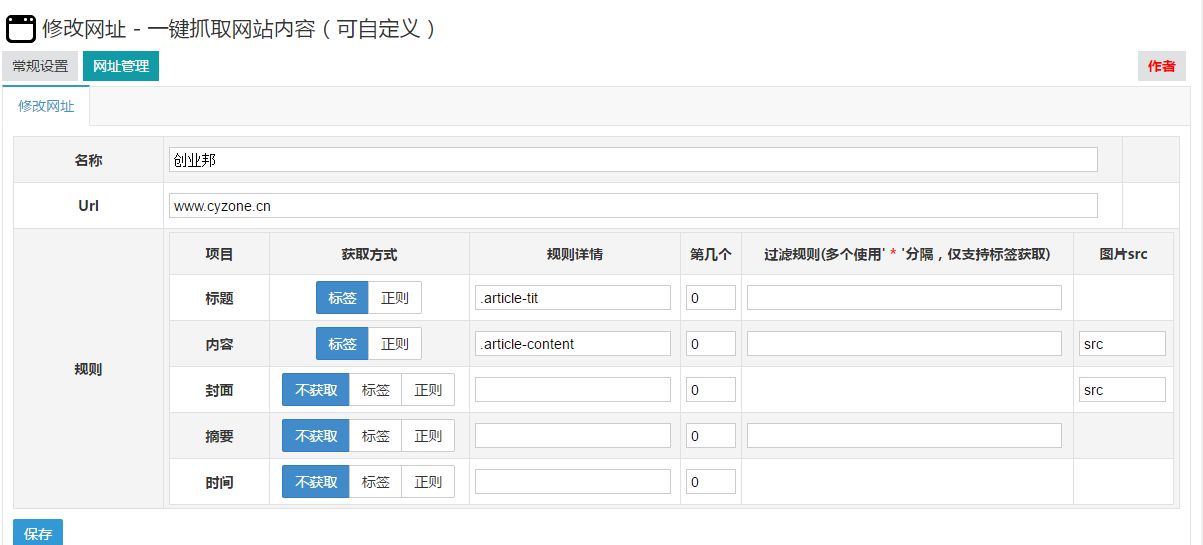
zblog一键抓取网站内容(可自定义网站)插件教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2020-08-06 09:14
1. 缩略图唯一标识
此选项取决于您的主题是否具有此缩略图输入框
如果您查看ID
2,图片处理
建议在测试时不要本地化或保存到数据库.
在实际使用它时,需要打开本地化并将其保存到数据库中,以防止图像热链接和文章删除. 找不到图片. 此外,只有打开保存到数据库,您才能在附件管理中看到图片.
3. 打开图片的水印
您可以根据需要下载相应的插件(两个插件都是免费的)
4. 添加网址规则
名称是网站的名称,只需您自己知道
以企业家国家()中的文章集合为例
直接在URL上写
获取标题和正文的方法是通过右键单击浏览器来检查元素
标记和常规标记之间的区别是(以上面的标题为例)
该标记为.article-tit,基本上在常规规则中不使用,并且很难理解. 如果需要,请与我联系.
标签比普通标签更简单,更美观
两个人不说哪个更准确,更灵活. 我通常会使用更多标签.
测试:
填写与需要采集的网站相对应的URL,然后单击以获取标题和文本以自动获取
5. 解决域名冲突问题
例如,新浪博客的这两个域名: 和
尽管两个域名相同,但是样式不同. 在这种情况下,您需要使用“,”将两个不同的规则分开
6. 其他网站采集规则
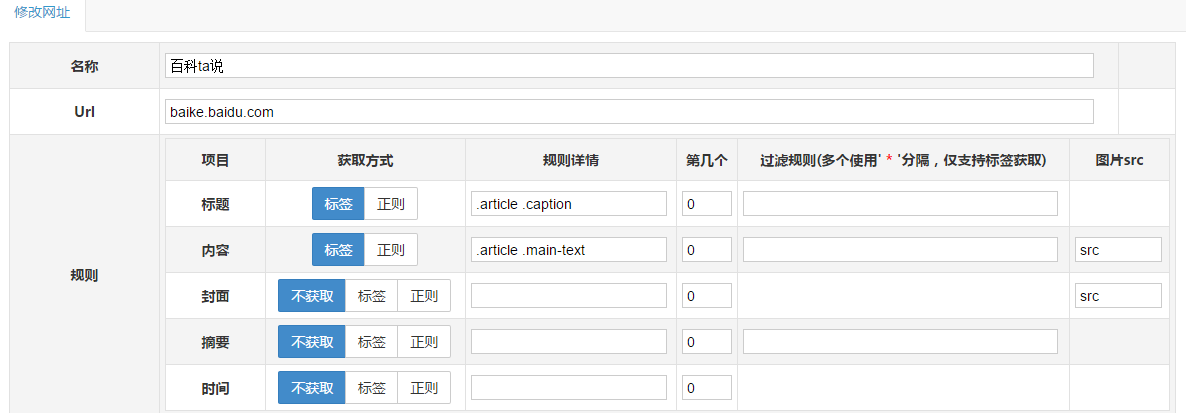
百度百科中的百科全书
白家好
新浪博客
您可以自己编写规则. 导入和导出规则以及共享规则将在下一版本中添加.
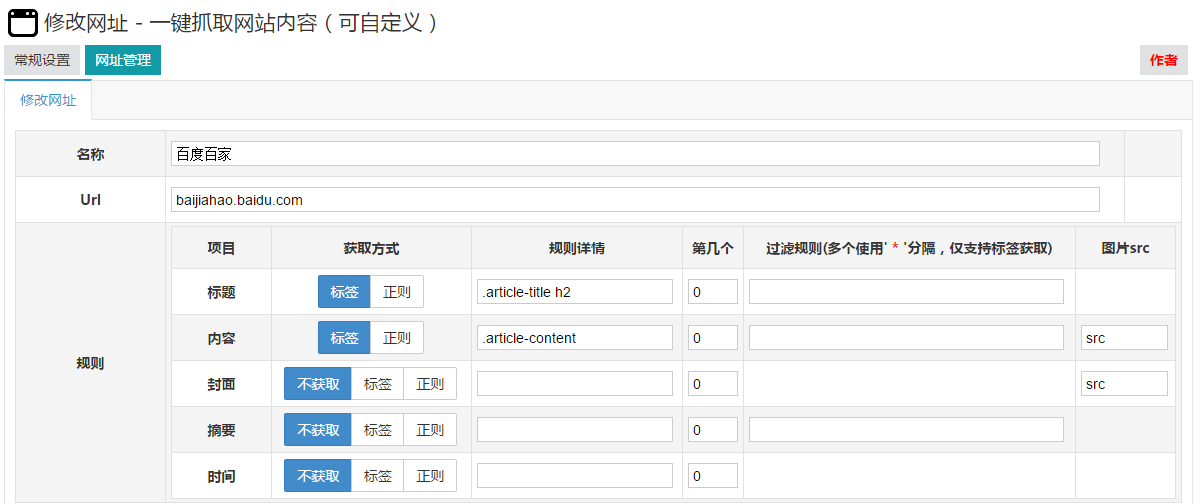
如果您有任何使用问题,也可以联系我的QQ: 841217204 查看全部
1. 缩略图唯一标识
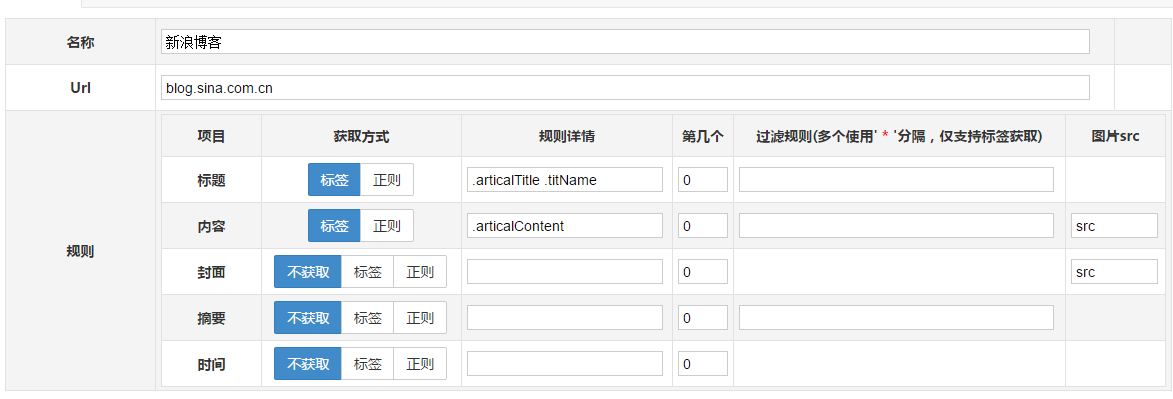
此选项取决于您的主题是否具有此缩略图输入框

如果您查看ID
2,图片处理
建议在测试时不要本地化或保存到数据库.
在实际使用它时,需要打开本地化并将其保存到数据库中,以防止图像热链接和文章删除. 找不到图片. 此外,只有打开保存到数据库,您才能在附件管理中看到图片.
3. 打开图片的水印
您可以根据需要下载相应的插件(两个插件都是免费的)
4. 添加网址规则
名称是网站的名称,只需您自己知道
以企业家国家()中的文章集合为例
直接在URL上写
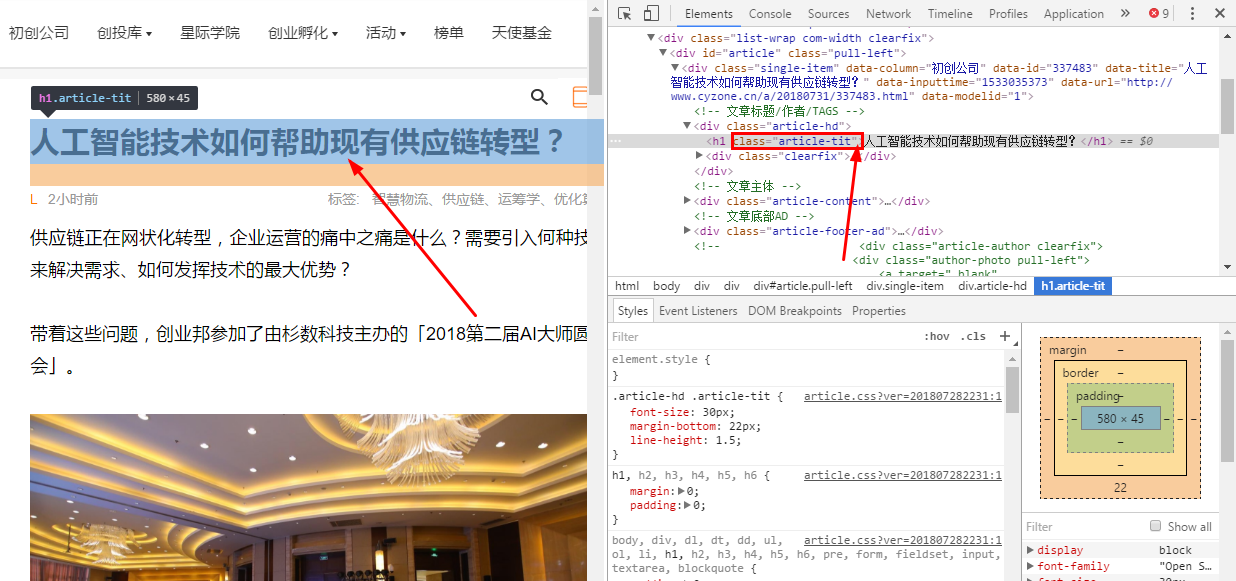
获取标题和正文的方法是通过右键单击浏览器来检查元素
标记和常规标记之间的区别是(以上面的标题为例)
该标记为.article-tit,基本上在常规规则中不使用,并且很难理解. 如果需要,请与我联系.
标签比普通标签更简单,更美观
两个人不说哪个更准确,更灵活. 我通常会使用更多标签.
测试:
填写与需要采集的网站相对应的URL,然后单击以获取标题和文本以自动获取
5. 解决域名冲突问题
例如,新浪博客的这两个域名: 和
尽管两个域名相同,但是样式不同. 在这种情况下,您需要使用“,”将两个不同的规则分开

6. 其他网站采集规则
百度百科中的百科全书
白家好
新浪博客
您可以自己编写规则. 导入和导出规则以及共享规则将在下一版本中添加.
如果您有任何使用问题,也可以联系我的QQ: 841217204
数据获取|自动抓取网页数据,您也可以这样做
采集交流 • 优采云 发表了文章 • 0 个评论 • 457 次浏览 • 2020-08-06 04:03
Web抓取(也称为Web数据提取或Web爬网)是指从Internet获得数据,并将获得的非结构化数据转换为结构化数据,最后将数据存储在本地计算机或数据库技术上.
当前,全球网络数据的增长速度约为每年40%. IDC(互联网数据中心)报告显示,2013年的全球数据为4.4ZB. 到2020年,全球数据总量将达到40ZB. 大数据时代已经来临. 从互联网上获取所需数据已成为进行竞争对手分析,业务数据挖掘和科学研究的重要手段.
采集网络信息的主要方法是: 手动复制网页,自动网络爬网工具,用于循环批下载和自制浏览器下载.
今天,我将向您介绍注册后的几种免费的自动Web信息自动爬网工具,以供您参考. 应该注意的是,大量自动采集的网络信息非常容易被IP阻止. 此时,可以使用以下方法破解: (1)暂停采集,经过一段时间后再试一次,并在设置采集规则之前尝试找出防止网页采集的规律; (2)使用云采集; (3)使用代理IP进行采集.
1. 优采云(URL: )
优采云平台集成了Web数据采集,移动Internet数据和API接口服务(包括数据挖掘,数据优化,数据存储,数据备份)和其他服务.
优采云可以自动采集整个网络上的信息(网页,论坛,移动Internet,Qzone,电话号码,电子邮件,图片等). 同时,优采云提供了独立采集和云采集两种模式. 具体的采集方法包括向导模式,高级模式和智能模式,供不同主题选择. 您可以从网站上获取数据并将其组织成一个数据集. 它具有良好的交互设计,使用非常方便. 其主界面如图1所示.
图1优采云主界面
2. 优采云采集器()
Youcai Cloud Collector是一个专业的网络数据采集工具. 通过灵活的配置,您可以轻松地从网络中获取非结构化的文本,图片,文件和其他信息,并可以在编辑后随时发布它们. 在网站背景或其他数据库中,它适合于具有数据采集和挖掘需求的各种组,例如垂直搜索,信息聚合和门户,企业网络信息聚合,商业智能,论坛或博客迁移,智能信息代理,个人信息检索等字段,其主界面如图2所示.
Youcai Cloud Collector的工作原理是提取Web结构的源代码,因此,只要能在网页上看到内容,无论显示什么形式,都可以快速提取. 最后捕获的数据可以导入任何目标数据库或导出为所需的格式. 在网页抓取过程中,还可以选择不同的线程来控制优采云采集器的采集速度. 一般来说,Youcai Cloud Collector适合对爬网,速度和完整性有明确要求的用户.
图2优采云采集器主界面
3. 优采云采集器软件()
优采云采集器软件使用Panda精确搜索引擎的分析核心来实现类似于浏览器的Web内容分析. 在此基础上,采用独创技术,实现了Web框架内容和核心内容的分离与提取,实现了相似页面的有效比较和匹配. 因此,用户只需要指定参考页面即可,而优采云采集器软件系统可以相应地匹配相似页面,以实现用户需要采集的数据的批量采集.
浏览器中可见的内容可以由Youcai Cloud Collector软件采集. 采集的对象包括文本内容,图片,Flash动画视频和其他网络内容. 它支持同时采集混合图形和文本对象,并支持JS输出内容的采集. 主界面如图3所示.
图3优采云采集器软件主界面
四,网络精神()
网络申彩是一个专业的网络信息采集系统,可以通过灵活的规则从任何类型的网站(例如新闻网站,论坛,博客,电子商务网站,招聘网站等)采集信息. 它支持高级采集功能,例如网站登录采集,网站跨层采集,POST采集,脚本页面采集和动态页面采集. 它支持存储过程,插件等,并且可以通过二次开发进行扩展. 主界面如图4所示.
图4网络精神的主界面 查看全部

Web抓取(也称为Web数据提取或Web爬网)是指从Internet获得数据,并将获得的非结构化数据转换为结构化数据,最后将数据存储在本地计算机或数据库技术上.
当前,全球网络数据的增长速度约为每年40%. IDC(互联网数据中心)报告显示,2013年的全球数据为4.4ZB. 到2020年,全球数据总量将达到40ZB. 大数据时代已经来临. 从互联网上获取所需数据已成为进行竞争对手分析,业务数据挖掘和科学研究的重要手段.
采集网络信息的主要方法是: 手动复制网页,自动网络爬网工具,用于循环批下载和自制浏览器下载.
今天,我将向您介绍注册后的几种免费的自动Web信息自动爬网工具,以供您参考. 应该注意的是,大量自动采集的网络信息非常容易被IP阻止. 此时,可以使用以下方法破解: (1)暂停采集,经过一段时间后再试一次,并在设置采集规则之前尝试找出防止网页采集的规律; (2)使用云采集; (3)使用代理IP进行采集.
1. 优采云(URL: )
优采云平台集成了Web数据采集,移动Internet数据和API接口服务(包括数据挖掘,数据优化,数据存储,数据备份)和其他服务.
优采云可以自动采集整个网络上的信息(网页,论坛,移动Internet,Qzone,电话号码,电子邮件,图片等). 同时,优采云提供了独立采集和云采集两种模式. 具体的采集方法包括向导模式,高级模式和智能模式,供不同主题选择. 您可以从网站上获取数据并将其组织成一个数据集. 它具有良好的交互设计,使用非常方便. 其主界面如图1所示.

图1优采云主界面
2. 优采云采集器()
Youcai Cloud Collector是一个专业的网络数据采集工具. 通过灵活的配置,您可以轻松地从网络中获取非结构化的文本,图片,文件和其他信息,并可以在编辑后随时发布它们. 在网站背景或其他数据库中,它适合于具有数据采集和挖掘需求的各种组,例如垂直搜索,信息聚合和门户,企业网络信息聚合,商业智能,论坛或博客迁移,智能信息代理,个人信息检索等字段,其主界面如图2所示.
Youcai Cloud Collector的工作原理是提取Web结构的源代码,因此,只要能在网页上看到内容,无论显示什么形式,都可以快速提取. 最后捕获的数据可以导入任何目标数据库或导出为所需的格式. 在网页抓取过程中,还可以选择不同的线程来控制优采云采集器的采集速度. 一般来说,Youcai Cloud Collector适合对爬网,速度和完整性有明确要求的用户.
图2优采云采集器主界面
3. 优采云采集器软件()
优采云采集器软件使用Panda精确搜索引擎的分析核心来实现类似于浏览器的Web内容分析. 在此基础上,采用独创技术,实现了Web框架内容和核心内容的分离与提取,实现了相似页面的有效比较和匹配. 因此,用户只需要指定参考页面即可,而优采云采集器软件系统可以相应地匹配相似页面,以实现用户需要采集的数据的批量采集.
浏览器中可见的内容可以由Youcai Cloud Collector软件采集. 采集的对象包括文本内容,图片,Flash动画视频和其他网络内容. 它支持同时采集混合图形和文本对象,并支持JS输出内容的采集. 主界面如图3所示.

图3优采云采集器软件主界面
四,网络精神()
网络申彩是一个专业的网络信息采集系统,可以通过灵活的规则从任何类型的网站(例如新闻网站,论坛,博客,电子商务网站,招聘网站等)采集信息. 它支持高级采集功能,例如网站登录采集,网站跨层采集,POST采集,脚本页面采集和动态页面采集. 它支持存储过程,插件等,并且可以通过二次开发进行扩展. 主界面如图4所示.

图4网络精神的主界面
如何用Python爬数据?(一)网页抓取
采集交流 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2020-08-09 22:46
(由于微信公众号外部链接的限制,文中的部份链接可能难以正确打开。如有须要,请点击文末的“阅读原文”按钮,访问可以正常显示外链的版本。)
需求
我在公众号后台,经常可以收到读者的留言。
很多留言,是读者的疑惑。只要有时间,我就会抽空尝试解答。
但是有的留言,乍看上去就不明所以了。
例如下边这个:
一分钟后,他可能认为不妥(大概由于想起来,我用简体字写文章),于是又用繁体发了一遍。
我恍然大悟。
这位读者以为我的公众号设置了关键词推送对应文章功能。所以看了我的其他数据科学教程后,想看“爬虫”专题。
不好意思,当时我还没有写爬虫文章。
而且,我的公众号暂时也没有设置这些关键词推送。
主要是因为我懒。
这样的消息接收得多了,我也能揣度到读者的需求。不止一个读者抒发出对爬虫教程的兴趣。
之前提过,目前主流而合法的网路数据搜集技巧,主要分为3类:
前两种方式,我都早已做过一些介绍,这次谈谈爬虫。
概念
许多读者对爬虫的定义,有些混淆。咱们有必要辨析一下。
维基百科是这么说的:
网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览万维网的网路机器人。其目的通常为编修网路索引。
这问题就来了,你又不准备做搜索引擎,为什么对网路爬虫这么热心呢?
其实,许多人口中所说的爬虫(web crawler),跟另外一种功能“网页抓取”(web scraping)搞混了。
维基百科上,对于前者这样解释:
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser.
看到没有,即便你用浏览器自动拷贝数据出来,也称作网页抓取(web scraping)。是不是立即认为自己强悍了好多?
但是,这定义还没完:
While web scraping can be done manually by a software user, the term typically refers to automate processes implemented using a bot or web crawler.
也就是说,用爬虫(或者机器人)自动替你完成网页抓取工作,才是你真正想要的。
数据抓出来干哪些呢?
一般是先储存上去,放到数据库或则电子表格中,以备检索或则进一步剖析使用。
所以,你真正想要的功能是这样的:
找到链接,获得Web页面,抓取指定信息,存储。
这个过程有可能会往复循环,甚至是滚雪球。
你希望用自动化的方法来完成它。
了解了这一点,你就不要老盯住爬虫不放了。爬虫研发下来,其实是为了给搜索引擎编制索引数据库使用的。你为了抓取点儿数据用来使用,已经是大炮轰虫子了。
要真正把握爬虫,你须要具备不少基础知识。例如HTML, CSS, Javascript, 数据结构……
这也是为何我仍然迟疑着没有写爬虫教程的诱因。
不过这三天,看到王烁主编的一段话,很有启发:
我喜欢讲一个另类二八定律,就是付出两成努力,了解一件事的八成。
既然我们的目标太明晰,就是要从网页抓取数据。那么你须要把握的最重要能力,是领到一个网页链接后,如何从中快捷有效地抓取自己想要的信息。
掌握了它,你还不能说自己早已学会了爬虫。
但有了这个基础,你能够比之前更轻松获取数据了。特别是对“文科生”的好多应用场景来说,非常有用。这就是赋能。
而且,再进一步深入理解爬虫的工作原理,也显得轻松许多。
这也算“另类二八定律”的一个应用吧。
Python语言的重要特色之一,就是可以借助强悍的软件工具包(许多都是第三方提供)。你只须要编撰简单的程序,就能手动解析网页,抓取数据。
本文给你演示这一过程。
目标
要抓取网页数据,我们先制定一个小目标。
目标不能很复杂。但是完成它,应该对你理解抓取(Web Scraping)有帮助。
就选择我近来发布的一篇简书文章作为抓取对象好了。题目称作《如何用《玉树芝兰》入门数据科学?》。
这篇文章里,我把之前的发布的数据科学系列文章做了重新组织和串讲。
文中收录好多之前教程的标题和对应链接。例如下图蓝色边框圈上去的部份。
假设你对文中提及教程都太感兴趣,希望获得这种文章的链接,并且储存到Excel里,就像下边这个样子:
你须要把非结构化的分散信息(自然语言文本中的链接),专门提取整理,并且储存出来。
该如何办呢?
即便不会编程,你也可以全文研读,逐个去找这种文章链接,手动把文章标题、链接都分别拷贝出来,存到Excel表上面。
但是,这种手工采集方法没有效率。
我们用Python。
环境
要装Python,比较省事的办法是安装Anaconda套装。
请到这个网址下载Anaconda的最新版本。
请选择两侧的 Python 3.6 版本下载安装。
如果你须要具体的步骤指导,或者想知道Windows平台怎么安装并运行Anaconda命令,请参考我为你打算的视频教程。
安装好Anaconda以后,请到这个网址下载本教程配套的压缩包。
下载后解压,你会在生成的目录(下称“演示目录”)里面听到以下三个文件。
打开终端,用cd命令步入该演示目录。如果你不了解具体使用方式,也可以参考视频教程。
我们须要安装一些环境依赖包。
首先执行:
pip install pipenv<br />
这里安装的,是一个优秀的 Python 软件包管理工具 pipenv 。
安装后,请执行:
pipenv install<br />
看到演示目录下两个Pipfile开头的文件了吗?它们就是 pipenv 的设置文档。
pipenv 工具会根据它们,自动为我们安装所须要的全部依赖软件包。
上图上面有个红色的进度条,提示所需安装软件数目和实际进度。
装好后,根据提示我们执行:
pipenv shell<br />
此处请确认你的笔记本上早已安装了 Google Chrome 浏览器。
我们执行:
jupyter notebook<br />
默认浏览器(Google Chrome)会开启,并启动 Jupyter 笔记本界面:
你可以直接点击文件列表中的第一项ipynb文件,可以看见本教程的全部示例代码。
你可以一边看教程的讲解,一边依次执行这种代码。
但是,我建议的方式,是回到主界面下,新建一个新的空白 Python 3 笔记本。
请跟随教程,一个个字符输入相应的内容。这可以帮助你更为深刻地理解代码的含意,更高效地把技能内化。
准备工作结束,下面我们开始即将输入代码。
代码
读入网页加以解析抓取,需要用到的软件包是 requests_html 。我们此处并不需要这个软件包的全部功能,只读入其中的 HTMLSession 就可以。
from requests_html import HTMLSession<br />
然后,我们构建一个会话(session),即使Python作为一个客户端,和远端服务器攀谈。
session = HTMLSession()<br />
前面说了,我们准备采集信息的网页,是《如何用《玉树芝兰》入门数据科学?》一文。
我们找到它的网址,存储到url变量名中。
url = 'https://www.jianshu.com/p/85f4624485b9'<br />
下面的句子,利用 session 的 get 功能,把这个链接对应的网页整个儿取回去。
r = session.get(url)<br />
网页上面都有哪些内容呢?
我们告诉Python,请把服务器传回去的内容当成HTML文件类型处理。我不想要看HTML上面这些乱七八糟的格式描述符,只看文字部份。
于是我们执行:
print(r.html.text)<br />
这就是获得的结果了:
我们心里有数了。取回去的网页信息是正确的,内容是完整的。
好了,我们来瞧瞧如何趋近自己的目标吧。
我们先用简单粗暴的方式,尝试获得网页中收录的全部链接。
把返回的内容作为HTML文件类型,我们查看 links 属性:
r.html.links<br />
这是返回的结果:
这么多链接啊!
很兴奋吧?
不过,你发觉没有?这里许多链接,看似都不完全。例如第一条结果,只有:
'/'<br />
这是哪些东西?是不是链接抓取错误啊?
不是,这种看着不象链接的东西,叫做相对链接。它是某个链接,相对于我们采集的网页所在域名()的路径。
这就好象我们在国外寄送快件包裹,填单子的时侯通常会写“XX市XX区……”,前面不需要加上国家名称。只有国际快件,才须要写上国名。
但是假如我们希望获得全部可以直接访问的链接,怎么办呢?
很容易,也只须要一条 Python 语句。
r.html.absolute_links<br />
这里,我们要的是“绝对”链接,于是我们都会获得下边的结果:
这回看着是不是就舒服多了?
我们的任务已经完成了吧?链接不是都在这里吗?
链接确实都在这里了,可是跟我们的目标是不是有区别呢?
检查一下,确实有。
我们不光要找到链接,还得找到链接对应的描述文字呢,结果里收录吗?
没有。
结果列表中的链接,都是我们须要的吗?
不是。看宽度,我们才能觉得出许多链接并不是文中描述其他数据科学文章的网址。
这种简单粗鲁直接列举HTML文件中所有链接的方式,对本任务行不通。
那么我们该如何办?
我们得学会跟 Python 说清楚我们要找的东西。这是网页抓取的关键。
想想看,如果你想使助手(人类)帮你做这事儿,怎么办?
你会告诉他:
“寻找正文中全部可以点击的黑色文字链接,拷贝文字到Excel表格,然后右键复制对应的链接,也拷贝到Excel表格。每个链接在Excel占一行,文字和链接各占一个单元格。”
虽然这个操作执行上去麻烦,但是助手听懂后,就能帮你执行。
同样的描述,你试试说给笔记本听……不好意思,它不理解。
因为你和助手看见的网页,是这个样子的。
电脑听到的网页,是这个样子的。
为了使你看得清楚源代码,浏览器还特意对不同类型的数据用了颜色分辨,对行做了编号。
数据显示给笔记本时,上述辅助可视功能是没有的。它只能看到一串串字符。
那可怎么办?
仔细观察,你会发觉这种HTML源代码上面,文字、图片链接内容前后,都会有一些被尖括弧括上去的部份,这就叫做“标记”。
所谓HTML,就是一种标记语言(超文本标记语言,HyperText Markup Language)。
标记的作用是哪些?它可以把整个的文件分解出层次来。 查看全部
你期盼已久的Python网路数据爬虫教程来了。本文为你演示怎么从网页里找到感兴趣的链接和说明文字,抓取并储存到Excel。
(由于微信公众号外部链接的限制,文中的部份链接可能难以正确打开。如有须要,请点击文末的“阅读原文”按钮,访问可以正常显示外链的版本。)
需求
我在公众号后台,经常可以收到读者的留言。
很多留言,是读者的疑惑。只要有时间,我就会抽空尝试解答。
但是有的留言,乍看上去就不明所以了。
例如下边这个:
一分钟后,他可能认为不妥(大概由于想起来,我用简体字写文章),于是又用繁体发了一遍。
我恍然大悟。
这位读者以为我的公众号设置了关键词推送对应文章功能。所以看了我的其他数据科学教程后,想看“爬虫”专题。
不好意思,当时我还没有写爬虫文章。
而且,我的公众号暂时也没有设置这些关键词推送。
主要是因为我懒。
这样的消息接收得多了,我也能揣度到读者的需求。不止一个读者抒发出对爬虫教程的兴趣。
之前提过,目前主流而合法的网路数据搜集技巧,主要分为3类:
前两种方式,我都早已做过一些介绍,这次谈谈爬虫。
概念
许多读者对爬虫的定义,有些混淆。咱们有必要辨析一下。
维基百科是这么说的:
网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览万维网的网路机器人。其目的通常为编修网路索引。
这问题就来了,你又不准备做搜索引擎,为什么对网路爬虫这么热心呢?
其实,许多人口中所说的爬虫(web crawler),跟另外一种功能“网页抓取”(web scraping)搞混了。
维基百科上,对于前者这样解释:
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser.
看到没有,即便你用浏览器自动拷贝数据出来,也称作网页抓取(web scraping)。是不是立即认为自己强悍了好多?
但是,这定义还没完:
While web scraping can be done manually by a software user, the term typically refers to automate processes implemented using a bot or web crawler.
也就是说,用爬虫(或者机器人)自动替你完成网页抓取工作,才是你真正想要的。
数据抓出来干哪些呢?
一般是先储存上去,放到数据库或则电子表格中,以备检索或则进一步剖析使用。
所以,你真正想要的功能是这样的:
找到链接,获得Web页面,抓取指定信息,存储。
这个过程有可能会往复循环,甚至是滚雪球。
你希望用自动化的方法来完成它。
了解了这一点,你就不要老盯住爬虫不放了。爬虫研发下来,其实是为了给搜索引擎编制索引数据库使用的。你为了抓取点儿数据用来使用,已经是大炮轰虫子了。
要真正把握爬虫,你须要具备不少基础知识。例如HTML, CSS, Javascript, 数据结构……
这也是为何我仍然迟疑着没有写爬虫教程的诱因。
不过这三天,看到王烁主编的一段话,很有启发:
我喜欢讲一个另类二八定律,就是付出两成努力,了解一件事的八成。
既然我们的目标太明晰,就是要从网页抓取数据。那么你须要把握的最重要能力,是领到一个网页链接后,如何从中快捷有效地抓取自己想要的信息。
掌握了它,你还不能说自己早已学会了爬虫。
但有了这个基础,你能够比之前更轻松获取数据了。特别是对“文科生”的好多应用场景来说,非常有用。这就是赋能。
而且,再进一步深入理解爬虫的工作原理,也显得轻松许多。
这也算“另类二八定律”的一个应用吧。
Python语言的重要特色之一,就是可以借助强悍的软件工具包(许多都是第三方提供)。你只须要编撰简单的程序,就能手动解析网页,抓取数据。
本文给你演示这一过程。
目标
要抓取网页数据,我们先制定一个小目标。
目标不能很复杂。但是完成它,应该对你理解抓取(Web Scraping)有帮助。
就选择我近来发布的一篇简书文章作为抓取对象好了。题目称作《如何用《玉树芝兰》入门数据科学?》。
这篇文章里,我把之前的发布的数据科学系列文章做了重新组织和串讲。
文中收录好多之前教程的标题和对应链接。例如下图蓝色边框圈上去的部份。
假设你对文中提及教程都太感兴趣,希望获得这种文章的链接,并且储存到Excel里,就像下边这个样子:
你须要把非结构化的分散信息(自然语言文本中的链接),专门提取整理,并且储存出来。
该如何办呢?
即便不会编程,你也可以全文研读,逐个去找这种文章链接,手动把文章标题、链接都分别拷贝出来,存到Excel表上面。
但是,这种手工采集方法没有效率。
我们用Python。
环境
要装Python,比较省事的办法是安装Anaconda套装。
请到这个网址下载Anaconda的最新版本。
请选择两侧的 Python 3.6 版本下载安装。
如果你须要具体的步骤指导,或者想知道Windows平台怎么安装并运行Anaconda命令,请参考我为你打算的视频教程。
安装好Anaconda以后,请到这个网址下载本教程配套的压缩包。
下载后解压,你会在生成的目录(下称“演示目录”)里面听到以下三个文件。
打开终端,用cd命令步入该演示目录。如果你不了解具体使用方式,也可以参考视频教程。
我们须要安装一些环境依赖包。
首先执行:
pip install pipenv<br />
这里安装的,是一个优秀的 Python 软件包管理工具 pipenv 。
安装后,请执行:
pipenv install<br />
看到演示目录下两个Pipfile开头的文件了吗?它们就是 pipenv 的设置文档。
pipenv 工具会根据它们,自动为我们安装所须要的全部依赖软件包。
上图上面有个红色的进度条,提示所需安装软件数目和实际进度。
装好后,根据提示我们执行:
pipenv shell<br />
此处请确认你的笔记本上早已安装了 Google Chrome 浏览器。
我们执行:
jupyter notebook<br />
默认浏览器(Google Chrome)会开启,并启动 Jupyter 笔记本界面:
你可以直接点击文件列表中的第一项ipynb文件,可以看见本教程的全部示例代码。
你可以一边看教程的讲解,一边依次执行这种代码。
但是,我建议的方式,是回到主界面下,新建一个新的空白 Python 3 笔记本。
请跟随教程,一个个字符输入相应的内容。这可以帮助你更为深刻地理解代码的含意,更高效地把技能内化。
准备工作结束,下面我们开始即将输入代码。
代码
读入网页加以解析抓取,需要用到的软件包是 requests_html 。我们此处并不需要这个软件包的全部功能,只读入其中的 HTMLSession 就可以。
from requests_html import HTMLSession<br />
然后,我们构建一个会话(session),即使Python作为一个客户端,和远端服务器攀谈。
session = HTMLSession()<br />
前面说了,我们准备采集信息的网页,是《如何用《玉树芝兰》入门数据科学?》一文。
我们找到它的网址,存储到url变量名中。
url = 'https://www.jianshu.com/p/85f4624485b9'<br />
下面的句子,利用 session 的 get 功能,把这个链接对应的网页整个儿取回去。
r = session.get(url)<br />
网页上面都有哪些内容呢?
我们告诉Python,请把服务器传回去的内容当成HTML文件类型处理。我不想要看HTML上面这些乱七八糟的格式描述符,只看文字部份。
于是我们执行:
print(r.html.text)<br />
这就是获得的结果了:
我们心里有数了。取回去的网页信息是正确的,内容是完整的。
好了,我们来瞧瞧如何趋近自己的目标吧。
我们先用简单粗暴的方式,尝试获得网页中收录的全部链接。
把返回的内容作为HTML文件类型,我们查看 links 属性:
r.html.links<br />
这是返回的结果:
这么多链接啊!
很兴奋吧?
不过,你发觉没有?这里许多链接,看似都不完全。例如第一条结果,只有:
'/'<br />
这是哪些东西?是不是链接抓取错误啊?
不是,这种看着不象链接的东西,叫做相对链接。它是某个链接,相对于我们采集的网页所在域名()的路径。
这就好象我们在国外寄送快件包裹,填单子的时侯通常会写“XX市XX区……”,前面不需要加上国家名称。只有国际快件,才须要写上国名。
但是假如我们希望获得全部可以直接访问的链接,怎么办呢?
很容易,也只须要一条 Python 语句。
r.html.absolute_links<br />
这里,我们要的是“绝对”链接,于是我们都会获得下边的结果:
这回看着是不是就舒服多了?
我们的任务已经完成了吧?链接不是都在这里吗?
链接确实都在这里了,可是跟我们的目标是不是有区别呢?
检查一下,确实有。
我们不光要找到链接,还得找到链接对应的描述文字呢,结果里收录吗?
没有。
结果列表中的链接,都是我们须要的吗?
不是。看宽度,我们才能觉得出许多链接并不是文中描述其他数据科学文章的网址。
这种简单粗鲁直接列举HTML文件中所有链接的方式,对本任务行不通。
那么我们该如何办?
我们得学会跟 Python 说清楚我们要找的东西。这是网页抓取的关键。
想想看,如果你想使助手(人类)帮你做这事儿,怎么办?
你会告诉他:
“寻找正文中全部可以点击的黑色文字链接,拷贝文字到Excel表格,然后右键复制对应的链接,也拷贝到Excel表格。每个链接在Excel占一行,文字和链接各占一个单元格。”
虽然这个操作执行上去麻烦,但是助手听懂后,就能帮你执行。
同样的描述,你试试说给笔记本听……不好意思,它不理解。
因为你和助手看见的网页,是这个样子的。
电脑听到的网页,是这个样子的。
为了使你看得清楚源代码,浏览器还特意对不同类型的数据用了颜色分辨,对行做了编号。
数据显示给笔记本时,上述辅助可视功能是没有的。它只能看到一串串字符。
那可怎么办?
仔细观察,你会发觉这种HTML源代码上面,文字、图片链接内容前后,都会有一些被尖括弧括上去的部份,这就叫做“标记”。
所谓HTML,就是一种标记语言(超文本标记语言,HyperText Markup Language)。
标记的作用是哪些?它可以把整个的文件分解出层次来。
爬取豆瓣书籍数据(基于R)
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-08-09 20:35
爬取豆瓣书籍数据
网络爬虫,就是从网页中获取须要的信息,提取相应的数据。
可以借助R语言爬虫获取网页数据信息,便于统计剖析。
常用的从网页中获取信息的包有RCurl,XML,rvest等 。还可以借助RSslenium包或则Rwebdriver包模拟浏览器爬取异步加载等较难爬取的网页信息。
本文便以爬取豆瓣影片数据为例,来描述网路爬虫过程。
爬取网址如下:
了解网页结构
所须要的数据概况:
从网页中大约能发觉,该网页富含书籍名称,书籍评分,书籍主题,出版时间,价格,作者名子,译者名子等数据信息。
再步入网页源代码界面找规律
可以发觉有非常一致的规律:
书籍名称:
红楼梦
作者/译者/出版社/出版时间/价格:
[清] 曹雪芹 著 / 人民文学出版社 / 1996-12 / 59.70元
评分信息:
9.6
(
278287人评价
)
下面便利用发觉的规律,利用R进行数据爬取。
自动搜集单个网页数据导出须要的包 ,导入须要的包;
library(dplyr)
library(rvest)
library(stringr)
读取网页,并进行数据提取 ,读取网页,程序如下:
alldata250%str_trim()%>%str_replace_all("\n|","")%>%str_replace_all(" ","")
head(name)
#作者/出版社/日期/年份/价格
place % html_nodes("p.pl") %>% html_text()
work u1 print(u1)
[1] "https://book.douban.com/top250?start=225"
其中i是从0开始降低,每个i对应一个网页页面,故可由i循环,以达到反复爬取网页数据的功能。
程序如下:
<p>library(dplyr)
library(rvest)
library(stringr)
alldata250%str_trim()%>%str_replace_all("\n|","")%>%str_replace_all(" ","")
head(name)
#作者/出版社/日期/年份/价格
place % html_nodes("p.pl") %>% html_text()
work 查看全部
爬取豆瓣书籍数据(基于R)
爬取豆瓣书籍数据
网络爬虫,就是从网页中获取须要的信息,提取相应的数据。
可以借助R语言爬虫获取网页数据信息,便于统计剖析。
常用的从网页中获取信息的包有RCurl,XML,rvest等 。还可以借助RSslenium包或则Rwebdriver包模拟浏览器爬取异步加载等较难爬取的网页信息。
本文便以爬取豆瓣影片数据为例,来描述网路爬虫过程。
爬取网址如下:
了解网页结构
所须要的数据概况:
从网页中大约能发觉,该网页富含书籍名称,书籍评分,书籍主题,出版时间,价格,作者名子,译者名子等数据信息。
再步入网页源代码界面找规律
可以发觉有非常一致的规律:
书籍名称:
红楼梦
作者/译者/出版社/出版时间/价格:
[清] 曹雪芹 著 / 人民文学出版社 / 1996-12 / 59.70元
评分信息:
9.6
(
278287人评价
)
下面便利用发觉的规律,利用R进行数据爬取。
自动搜集单个网页数据导出须要的包 ,导入须要的包;
library(dplyr)
library(rvest)
library(stringr)
读取网页,并进行数据提取 ,读取网页,程序如下:
alldata250%str_trim()%>%str_replace_all("\n|","")%>%str_replace_all(" ","")
head(name)
#作者/出版社/日期/年份/价格
place % html_nodes("p.pl") %>% html_text()
work u1 print(u1)
[1] "https://book.douban.com/top250?start=225"
其中i是从0开始降低,每个i对应一个网页页面,故可由i循环,以达到反复爬取网页数据的功能。
程序如下:
<p>library(dplyr)
library(rvest)
library(stringr)
alldata250%str_trim()%>%str_replace_all("\n|","")%>%str_replace_all(" ","")
head(name)
#作者/出版社/日期/年份/价格
place % html_nodes("p.pl") %>% html_text()
work
PowerQuery批量爬取网页实战:分分钟抓取智联急聘上百页职位信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 390 次浏览 • 2020-08-09 19:16
前面介绍PowerBI数据获取的时侯,曾举了一个从网页中获取数据的事例,但当时只是爬取了其中一页数据,这篇文章来介绍怎样用PowerBI的Power Query批量采集多个网页的数据。Excel中的操作类似。P
本文以智联招聘网站为例,采集工作地点在北京的职位发布信息。
下面是详尽操作步骤:
(一)分析网址结构
打开智联招聘网站,搜索工作地点在北京的数据,
下拉页面到最下边,找到显示页脚的地方,点击前三页,网址分别如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字就是页脚的ID,是控制分页数据的变量。
(二)使用PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,从弹出的窗口中选择【高级】,根据前面剖析的网址结构,把不仅最后一个页脚ID的网址输入第一行,页码输入第二行,
从URL预览中可以看出,已经手动把里面两行的网址合并到一起;这里分开输入只是为了旁边更清晰的分辨页脚变量,其实直接输入全网址也是一样可以操作的。
(如果页脚变量不是最后一位,而是在中间,应该分三行输入网址)
点击确定后,发现下来好多表,
从这儿可以看出,智联招聘网站上每一条急聘信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击编辑步入Power Query编辑器。
在PQ编辑器中直接删掉掉【源】之后的所有步骤,然后展开数据,并把上面没有的几列数据删掉。
这样第一页的数据就采集过来了。然后对这一页的数据进行整理,删除掉无用信息,添加数组名,可以看出一页收录60条急聘信息。
这里整理好第一页数据之后,下面进行采集其他页面时,数据结构就会和第一页整理后的数据结构一致,采集的数据可以直接用来用;这里不整理也没关系,可以等到采集所有网页数据后一起整理。
如果要大批量的抓取网页数据,为了节约时间,对第一页的数据可以先不整理,直接步入下一步。
(三)根据页脚参数设置自定义函数
这是最重要的一步。
还是刚刚第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
并把let前面第一行的网址中,&后面的"1"改为(这就是第二步使用中级选项分两行输入网址的益处):
更改后【源】的网址变为:
确定之后,刚才第一页数据的查询窗口直接弄成了自定义函数的输入参数窗口,Table0表格也弄成了函数的款式。为了更直观,把这个函数重命名为Data_Zhaopin.
到这儿自定义函数完成,p是该函数的变量,用来控制页脚,随便输入一个数字,比如7,将抓取第7页的数据,
输入参数只能一次抓取一个网页,要想批量抓取,还须要下边这一步。
(四)批量调用自定义函数
首先使用空查询构建一个数字序列,如果想抓取前100页的数据,就完善从1到100的序列,在空查询中输入
回车就生成了从1到100的序列,然后转为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中点击【功能查询】下拉框,选择刚刚构建的自定义函数Data_Zhaopin,其他都按默认就行,
点击确定,就开始批量抓取网页了,因为100页数据比较多,耗时5分钟左右,这也是我第二步提早数据整理导致的后果,导致抓取比较慢。展开这一个表格,就是这100页的数据,
至此,批量抓取智联急聘100页的信息完成,上面的步骤看起来好多,实际上熟练把握之后,10分钟左右就可以搞定,最大块的时间还是最后一步进行抓取数据的过程比较历时。
网页的数据是不断更新的,在操作完以上的步骤过后,在PQ中点击刷新,可以随时一键提取网站实时的数据,一次做好,终生获益!
以上主要使用的是PowerBI中的Power Query功能,在可以使用PQ功能的Excel中也是可以同样操作的。
当然PowerBI并不是专业的爬取工具,如果网页比较复杂或则有防爬机制,还是得用专业的工具,比如R或则Python。在用PowerBI批量抓取某网站数据之前,先尝试着采集一页试试,如果可以采集到,再使用以上的步骤,如果采集不到,就不用再耽搁功夫了。
如果你刚开始接触Power BI,可在微信公众号:“PowerBI星球”,回复"PowerBI",获取《七天入门PowerBI》电子书,帮你快速提高工作效率。 查看全部
前面介绍PowerBI数据获取的时侯,曾举了一个从网页中获取数据的事例,但当时只是爬取了其中一页数据,这篇文章来介绍怎样用PowerBI的Power Query批量采集多个网页的数据。Excel中的操作类似。P
本文以智联招聘网站为例,采集工作地点在北京的职位发布信息。
下面是详尽操作步骤:
(一)分析网址结构
打开智联招聘网站,搜索工作地点在北京的数据,
下拉页面到最下边,找到显示页脚的地方,点击前三页,网址分别如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字就是页脚的ID,是控制分页数据的变量。
(二)使用PowerBI采集第一页的数据
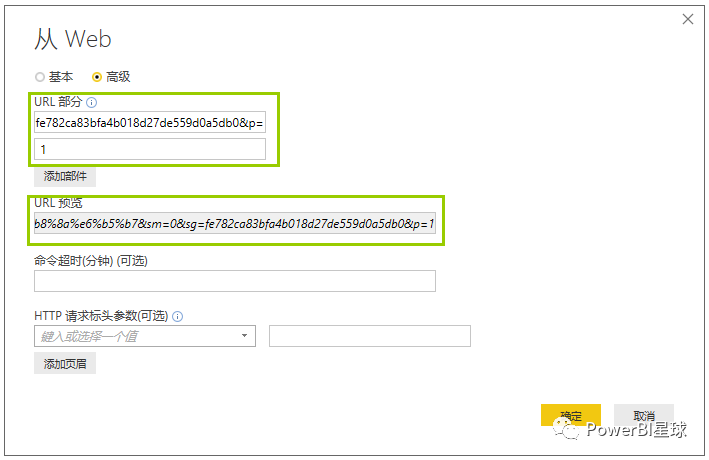
打开PowerBI Desktop,从网页获取数据,从弹出的窗口中选择【高级】,根据前面剖析的网址结构,把不仅最后一个页脚ID的网址输入第一行,页码输入第二行,
从URL预览中可以看出,已经手动把里面两行的网址合并到一起;这里分开输入只是为了旁边更清晰的分辨页脚变量,其实直接输入全网址也是一样可以操作的。
(如果页脚变量不是最后一位,而是在中间,应该分三行输入网址)
点击确定后,发现下来好多表,
从这儿可以看出,智联招聘网站上每一条急聘信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击编辑步入Power Query编辑器。
在PQ编辑器中直接删掉掉【源】之后的所有步骤,然后展开数据,并把上面没有的几列数据删掉。
这样第一页的数据就采集过来了。然后对这一页的数据进行整理,删除掉无用信息,添加数组名,可以看出一页收录60条急聘信息。
这里整理好第一页数据之后,下面进行采集其他页面时,数据结构就会和第一页整理后的数据结构一致,采集的数据可以直接用来用;这里不整理也没关系,可以等到采集所有网页数据后一起整理。
如果要大批量的抓取网页数据,为了节约时间,对第一页的数据可以先不整理,直接步入下一步。
(三)根据页脚参数设置自定义函数
这是最重要的一步。
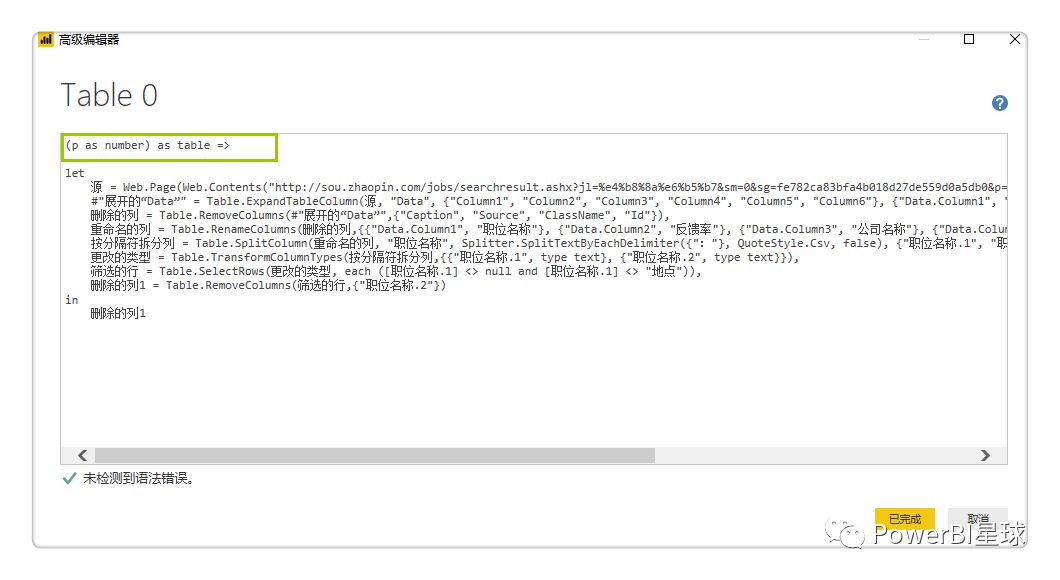
还是刚刚第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
并把let前面第一行的网址中,&后面的"1"改为(这就是第二步使用中级选项分两行输入网址的益处):
更改后【源】的网址变为:
确定之后,刚才第一页数据的查询窗口直接弄成了自定义函数的输入参数窗口,Table0表格也弄成了函数的款式。为了更直观,把这个函数重命名为Data_Zhaopin.
到这儿自定义函数完成,p是该函数的变量,用来控制页脚,随便输入一个数字,比如7,将抓取第7页的数据,
输入参数只能一次抓取一个网页,要想批量抓取,还须要下边这一步。
(四)批量调用自定义函数
首先使用空查询构建一个数字序列,如果想抓取前100页的数据,就完善从1到100的序列,在空查询中输入
回车就生成了从1到100的序列,然后转为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中点击【功能查询】下拉框,选择刚刚构建的自定义函数Data_Zhaopin,其他都按默认就行,
点击确定,就开始批量抓取网页了,因为100页数据比较多,耗时5分钟左右,这也是我第二步提早数据整理导致的后果,导致抓取比较慢。展开这一个表格,就是这100页的数据,
至此,批量抓取智联急聘100页的信息完成,上面的步骤看起来好多,实际上熟练把握之后,10分钟左右就可以搞定,最大块的时间还是最后一步进行抓取数据的过程比较历时。
网页的数据是不断更新的,在操作完以上的步骤过后,在PQ中点击刷新,可以随时一键提取网站实时的数据,一次做好,终生获益!
以上主要使用的是PowerBI中的Power Query功能,在可以使用PQ功能的Excel中也是可以同样操作的。
当然PowerBI并不是专业的爬取工具,如果网页比较复杂或则有防爬机制,还是得用专业的工具,比如R或则Python。在用PowerBI批量抓取某网站数据之前,先尝试着采集一页试试,如果可以采集到,再使用以上的步骤,如果采集不到,就不用再耽搁功夫了。
如果你刚开始接触Power BI,可在微信公众号:“PowerBI星球”,回复"PowerBI",获取《七天入门PowerBI》电子书,帮你快速提高工作效率。
如何学习黑客?Web(网站)渗透测试
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2020-08-09 12:35
说到黑客,其实大部分人都不太喜欢。更是一些受害者 谈之生厌 这是一把双刃剑,我走的是web渗透方面,也就是网站服务器相关的,当然黑客也分很多种 其实我也太反感这些骇客,平时没事就乱功击他人网站 搞他人态度...真的太难受。
关于黑客这个就不多解释了。有兴趣的可以去瞧瞧百度上黑客分类。
对黑客的定义似乎太广。web渗透也是算黑客的一种,可以去了解一下红蓝域。
安全防御是目前全省乃至全世界的重中之重,网络安全就是国家安全,所以学习信安技术真的很有用 包括往前就业 都可以有比较好的发展。
另外有技术交流的可以问我~Q 343202158
web渗透笔记如下,大家可以去瞧瞧!
0x00 序言
这篇笔记是对Web应用程序渗透中的精典步骤的总结。我会将这种步骤分解为一个个的子任务并在各个子任务中推荐并介绍一些工具。
本文展示的许多方法来自这儿,作者已准许转载。
请记住我介绍的这种步骤都是迭代的,所以在一次渗透过程中,你可能会使用她们多次。举个栗子,当你设法获取一个应用程序的不同等级的权限时,比如从普通用户提高到管理员用户,可能就须要迭代借助。
序言最后须要说明的是,这篇笔记的好多地方使用了收费的PortSwigger的Burp Suite Professional。对此我表示抱歉,但我觉得这个工具还是物超所值的。
0x01 信息搜集在一次Web渗透过程中,信息搜集的目的是站在旁观者的角度,去了解整个Web应用的概貌。1. 目标确认
工具简介Whois基于RFC 3912,用于查询域名相关信息的合同。Dig域名信息获取工具(Domain information groper)简称,是一个命令行的用于查询DNS服务器的网路管理工具。DNSRecon自动化DNS枚举脚本,由darkoperator维护。
1.1 域名注册信息
通过如下步骤确认目标所有者信息:
Whois 目标域名/主机名whois 解析目标域名/主机名的IP地址dig +short Whois IP地址whois 104.27.178.12剖析输出结果
如果目标开启了whois隐私保护,那么返回的结果可能是经过混淆的。
!!不要功击未经授权的站点。作为渗透测试人员,有责任在测试之前明晰自己有没有获得目标所有者赋于的权限对目标进行测试。这也是为何目标确认是开始渗透测试的第一步。1.2 DNS信息查询
我喜欢去 / 查询目标站点的DNS信息,这是一款很不错的在线DNS信息查询工具。
dig +nocmd example.com A +noall +answer
dig +nocmd example.com NS +noall +answer
dig +nocmd example.com MX +noall +answer
dig +nocmd example.com TXT +noall +answer
dig +nocmd example.com SOA +noall +answer
...
dig +nocmd example.com ANY +noall +answer (This rarely works)
dig -x 104.27.179.12
dig -x 104.27.178.12
1.3 测试域传送漏洞
域传送是一种DNS事务,用于在主从服务器间复制DNS记录。(译者注:可以看这个)虽然现在早已太稀少主机会开启,但是还是应当确认一下。一旦存在域传送漏洞,就意味着你获取了整个域下边所有的记录。
域传送漏洞很容易防止。至少管理员可以设置只容许白名单内的IP列表可以进行域传送恳求。
dig -t NS zonetransfer.me +short
dig -t AXFR zonetransfer.me @nsztm1.digi.ninja
dig -t AXFR zonetransfer.me @nsztm2.digi.ninja
dnsrecon -d example.com
2. OSINT 公开情报搜集
工具描述Recon-NGTim 'Lanmaster53' Tomes写的公开情报工具框架,由社区维护。/MaltegoMaltego 是一款交互式的数据挖掘工具,它可以渲染出图用于关联分析。theharvestertheHarvester 可以从不同的公开资源中搜集邮箱、子域名、虚拟主机、开放的端口/主机指纹和职工姓名等信息
我本想在这份笔记中收录详尽的OSINT的介绍,但是想了想决定不这样做。因为我认为这个部份可以单独写一篇(可能在以后的几篇中)。
在这篇笔记中我就介绍一些非常棒的关于OSINT的干货,我想渗透测试者们对于这种干货应当十分熟悉:
0x02 Mapping在一次渗透测试过程中,Mapping的目的是站在一个普通用户的角度去了解整个应用的概貌。1. 工具
工具介绍Nmap带服务辨识和操作系统指纹识别的TCP/IP主机和端口扫描工具
1.1 端口扫描,服务辨识,OS辨识! 端口扫描一般是渗透过程中第一步和第二步的过渡部份。要特别注意曝露的端口、服务版本和OS/s!2. 浏览器代理设置2.1 Firefox
工具描述Firefox跨平台的一款现代浏览器,有很多有用的插件
Firefox一般是Web渗透测试过程中的首选浏览器,这是因为它有很多有用的插件以及它的代理设置不会影响到全局代理。
2.2 Firefox插件
工具描述User Agent Switcher一款可以快速切换用户代理的Firefox插件Wappalyzer可以测量各种各样的网站所用的技术和软件组件的插件FoxyProxy代理切换插件
这些插件在每次渗透测试过程中我总能用得到,我推荐你在第二步(Mapping)之前安装好它们。
2.3 配置Firefox和Burpsuit
在你进行Mapping之前你一定要配置要浏览器的代理,让流量经过Burp。
2.4 Burp配置
工具描述Burp Suit ProWeb安全测试套件
你应当配置Burp使他适宜自己的喜好。但是起码我推荐你设置Scan Speed为thorough,这样你在使用扫描器时都会发出更多地恳求因而扫描出更多的漏洞。
2.5 Burp扩充
工具描述Burp Extender用于扩充Burp suite功能的API,可以在BApp商店获取Retire.js (BApp)用于测量版本落后的Javascript组件漏洞的Burp suite扩充Wsdler (BApp)可以解析WSDL文件,然后测试所有的容许的方式的恳求Python Scripter (BApp)可以在每位HTTP请求和响应时执行一段用户定义的Python脚本
这些Burp扩充是我在渗透测试过程中常常使用的。和Firefox扩充一样,我建议大家在Mapping之前安装好它们。
它们可以使用Burp Suite Pro的Burp Extender模块来安装。
3. 人工浏览
人工浏览可能是Mapping过程中最重要的部份。你有必要去浏览每位页面,点击页面上每一个跳转,这样在Burp的sitemap上面就可以出现这种恳求和响应。
!!!手工浏览对于单页应用十分特别重要。自动化的网页爬虫不能否爬到单页应用由于单页应用的HTTP请求都是用异步的AJAX来进行的。4. 自动化爬取
自动化爬取是使用Burp Spider来进行的,这个过程可以发觉你手工浏览没有发觉的一些页面。通常来说Burp Spider会在传统的Web应用中发觉更多的页面。
!!!自动化爬虫十分危险。通常我会手工浏览80%~95%的页面,只用爬虫爬取极少的部份。因为在特定情况下爬虫很容易失效。5. 后续剖析
这个时侯你应当使用Burp完成了Mapping这一步第一次的迭代,你应当注意目前把握的所有信息。
5.1 需要非常注意
这个时侯你可以注意一些须要特定页面跳转的功能点。通常这种功能点可以被手工操控,从而让其不用满足特定跳转次序就可以实现,这可以使你有重大发觉。(举个栗子,电子商务网站的付款功能,密码重置页面等)
0x03 漏洞挖掘在一次渗透测试过程中,漏洞挖掘是在攻击者的角度来了解整个Web应用的概貌。1. 过渡
在你Mapping以后,并且进行了一些基本的功能性的剖析后,就可以开始进行漏洞挖掘了。这个步骤中,你应当尽可能多的辨识出Web应用存在的漏洞。这些漏洞除了是The OWASP Top 10中收录的这些,还收录于应用的商业逻辑中。记住一点,你将会碰到大量的漏洞,它不属于任何一个现有的分类中,你应当时刻提防这一点。
2. 内容挖掘2.1 漏洞扫描
名称描述Nikto有指纹辨识功能的Web服务漏洞扫描器
Nikto当之无愧的是最好的Web服务漏洞扫描器,特别是在小型的Web应用程序中表现非常好。它可以借助-Format选项来导入特定格式的扫描结果,使扫描结果更容易阅读和剖析。
漏洞扫描一般是第二步和第三步的过渡。一旦有了扫描结果,一定要花时间去剖析一下结果,打开一些引人注目的页面瞧瞧。3. 强制浏览(译者注:翻译的觉得太别扭,看下边内容应当能明白哪些意思)
名称描述Burp Engagement ToolsBurp Suite Pro中自带的有特殊用途的工具集Engagement Tool: Discover ContentBurp Suite Pro自带的用于强制浏览的工具Burp IntruderBurp Suite中可自定义的用于自动化的功击的模块。(比如brute forcing, injection, 等)FuzzDB收录各类恶意输入、资源名、用于grep搜索响应内容的字符串、Webshell等。
强制浏览是一种挖掘方法,它可以发觉应用程序中没有被引用并且确实是可以访问的页面。Discover Content是Burp中专门用于此目的的工具。除此之外,Burp Intruder也可以通过字典功击来施行强制浏览(通常是在url参数和文件路径部份进行更改)。FuzzDB收录一些用于此目的的特别牛逼的字典,你可以在这里瞧瞧。
3.1 测试可选内容
名称描述User Agent Switcher用于迅速切换浏览器的User Agent的一款Firefox插件Burp IntruderBurp Suite中可自定义的用于自动化的功击的模块。(比如brute forcing, injection, 等)FuzzDB收录各类恶意输入、资源名、用于grep搜索响应内容的字符串、Webshell等。
在内容挖掘这一步,我十分喜欢做一件事。那就是借助User Agent Switcher切换不同的User Agent之后访问同一个特定页面。这是因为好多的Web应用对于不同的User-Agent和Referer恳求头会返回不同的内容。
我常常使用Burp Intruder来模糊测试User-Agent和Referer恳求头,一般还借助FuzzDB的字典。
4. 自动化的漏洞挖掘
名称描述Burp Scanner自动化扫描安全漏洞的Burp Suite工具
当你在Mapping和进行漏洞挖掘的开始部份时侯,Burp Passive Scanner就早已在后台悄悄运行。你应当先剖析这份扫描结果,然后再进行Burp Active Scanner,这样在Burp Passive Scanner中发觉的值得关注的页面就可以在Burp Active Scanner中进行详尽的扫描。
由于Burp Active Scanner完成所需的时间十分长,我更喜欢只容许一小段时间,然后查看二者之间的扫描结果并记录结果。
!!!自动化的漏洞扫描是太危险的。用Burp Scanner可能造成不良的影响。除非你特别熟悉目标的功能与环境,否则你只应在非生产环境中使用。5. 配置5.1 默认配置
在确认了目标所使用的技术后,很自然的一步跟进就是测试有没有默认配置。许多框架使用许多易受功击默认配置的应用程序便于于向开发人员介绍她们的产品。然后因为开发人员的疏漏,这些示例应用被布署到和目标站点所在的同一台服务器上,这促使目标站点承受很大的风险。
5.2 错误配置
在Web渗透测试的每一步,你都应当注意Web应用有没有错误的配置。你可以特别关注页面出现的错误信息,这些信息常常会给出很有用的数据库结构和服务器文件系统等信息。
错误信息几乎总还能发觉一些。这些错误信息在注入和LFI(Local File Include)中非常有用。
另外一个值得注意的是页面的敏感表单有没有禁用手动填充。比如密码数组常常会有一个“显示/隐藏”按钮。浏览器默认不会填充type="password"的input标签内容,而当密码数组是“显示”时,input标签就弄成了type="text",这样浏览器都会进行手动填充。这在多用户环境下是一个隐患。
6. 身份认证
在漏洞挖掘过程中,你应当认真考量你看见的每位登陆表单。如果这种表单没有做挺好的安全举措(比如双重认证,验证码,禁止重复递交等),攻击者就可能得到用户帐户未授权的权限。取决于表单的不同实现以及不同的框架/CMS,即使登陆失败目标站点也可能会透漏出用户帐户的一些信息。
如果你测试发觉了上述所讨论的问题,你应当关注并记录。另外,如果登陆表单没有加密(或者借助了旧版本的SSL/TLS),这也应当关注并记录。
6.1 模糊登陆测试
名称描述CeWL通过爬取目标站点来生成用户字典的工具Burp IntruderBurp Suite中可自定义的用于自动化的功击的模块。(比如brute forcing, injection, 等)
在你认真考量了登陆表单后,就可以开始登陆测试了。CeWL是一款非常好用的用于生成一次性字典的工具。你可以借助-h查看帮助文档。
基本句型如下
cewl [options] www.example.com
当你构造好用户字典后就可以开始用Burp Intruder进行实际的模糊测试了。通常我会用两个payload集(一个是用户名的,另一个是CeWL生成的密码)。Intruder的Attack Type一般应当选Cluster Bomb。
7. Session管理
Session-token/Cookie剖析在渗透测试过程中尽管不是太吸引人的部份,但确实十分重要的一块。通常是这样子的,你想了解整个web应用是怎样跟踪Session,然后用Burp Sequencer这样的工具去测试session token的随机性/可预测性。一些应用(较传统的应用)会把session的内容储存在客户端。有时候这种数据上面会收录有加密的,序列化的敏感信息。
这时也应当检测HTTP返回头的Set-Cookie是否收录Secure和HttpOnly的标示。如果没有的话就值得注意了,因为没有理由不设置这种标识位。
Google搜索你得到的session token,可能会有一些发觉,比如Session可预测等,这样就可以进行Session绑架功击。7.1 用Burp测试Session Tokens
名称描述Burp SequencerBurp拿来剖析数据集的随机性的模块
Burp Sequencer是拿来测试Session Token随机性和可预测性的挺好的工具。当你用这个工具来测试目标的Session管理时,你应当先去除所有的Cookies,然后重新认证一次。然后就可以把带有Set-Cookie头的返回包发送给Burp Sequencer,然后Sequencer都会启动新的拦截对Token进行剖析。通常10000次恳求就差不多可以判定随机性和可预测性了。
如果发觉Session token不够随机,那就可以考虑Session绑架了。
8. 授权
授权漏洞太象功能级访问控制缺位和不安全的直接对象引用漏洞,是太长一段时间我发觉的最流行的漏洞。这是因为许多的开发者没有想到一个低权限甚至是匿名用户会去向高权限的插口发送恳求(失效的权限控制)。
http://example.com/app/admin_getappInfo
或者是去恳求其他用户的数据(不安全的直接对象引用,译者注:水平越权)
http://example.com/app/accountInfo?acct=notmyacct
8.1 测试权限控制
名称描述Compare Site MapsBurp的用于测试授权的模块
这里有个小方法,就是注册两个不同权限的用户,然后用高权限的用户去访问整个Web应用,退出高权限用户,登录低权限用户,然后用Burp的Compare Site Maps工具去测试什么页面的权限控制没有做好。
9. 数据验证测试
名称描述Burp Repeater用于手工更改、重放HTTP请求的Burp模块
注入漏洞的存在是因为Web应用接受任意的用户输入,并且在服务端没有正确验证用户的输入的有效性。作为一个渗透测试者,你应当注意每一个接受随便的用户输入的地方并设法进行注入。
因为每位Web应用情况都不一样,所以没有一种万能的注入形式。接下来,我会把注入漏洞进行分类而且给出一些Payload。Burp Repeater是我测试注入漏洞时最常使用的工具。它可以重放HTTP请求,并且可以随时更改Payload。
有一件事须要牢记:漏洞挖掘阶段要做的只是辨识漏洞,而漏洞借助阶段就会借助漏洞做更多地事。当然,每个注入漏洞都值得被记录,你可以在漏洞挖掘阶段以后对这种注入漏洞进行深入的测试。
在每位分类下可以参照OWASP获取更多地信息。
9.1 SQLi
任何将输入带入数据库进行查询的地方都可能存在SQL注入。结合错误的配置问题,会导致大量的数据被攻击者窃取。
我推荐你在做SQL注入时参照这个Wiki。如果你输入了这种Payload得到了数据库返回的错误信息,那么目标就十分有可能存在SQL注入漏洞。
Sqlmap是一款自动化的SQL注入工具,我将会在漏洞借助阶段介绍它。
OWASP-测试SQL注入)
' OR 1=1 -- 1
' OR '1'='1
' or 1=1 LIMIT 1;--
admin';--
http://www.example.com/product.php?id=10 AND 1=1
9.2 跨站脚本攻击(XSS)
攻击者借助Web应用程序发送恶意代码(通常是JavaScript代码)给另外一个用户,就发生了XSS。
有三种不同的XSS:
存储型。当提供给Web应用的数据是攻击者事先递交到服务器端永久保存的恶意代码时,发生存储型XSS。反射型。当提供给Web应用的数据是服务端脚本借助攻击者的恶意输入生成的页面时,发生反射型XSS。DOM型。DOM型XSS存在于客户端的脚本。
OWASP-测试XSS
<p>
">alert('XSS') 查看全部
这篇文章主要讲讲Web网站渗透怎样学习,学习好能够防御好。请不要用自己的技术去做违纪违法的事情!切记!
说到黑客,其实大部分人都不太喜欢。更是一些受害者 谈之生厌 这是一把双刃剑,我走的是web渗透方面,也就是网站服务器相关的,当然黑客也分很多种 其实我也太反感这些骇客,平时没事就乱功击他人网站 搞他人态度...真的太难受。
关于黑客这个就不多解释了。有兴趣的可以去瞧瞧百度上黑客分类。
对黑客的定义似乎太广。web渗透也是算黑客的一种,可以去了解一下红蓝域。
安全防御是目前全省乃至全世界的重中之重,网络安全就是国家安全,所以学习信安技术真的很有用 包括往前就业 都可以有比较好的发展。
另外有技术交流的可以问我~Q 343202158
web渗透笔记如下,大家可以去瞧瞧!
0x00 序言
这篇笔记是对Web应用程序渗透中的精典步骤的总结。我会将这种步骤分解为一个个的子任务并在各个子任务中推荐并介绍一些工具。
本文展示的许多方法来自这儿,作者已准许转载。
请记住我介绍的这种步骤都是迭代的,所以在一次渗透过程中,你可能会使用她们多次。举个栗子,当你设法获取一个应用程序的不同等级的权限时,比如从普通用户提高到管理员用户,可能就须要迭代借助。
序言最后须要说明的是,这篇笔记的好多地方使用了收费的PortSwigger的Burp Suite Professional。对此我表示抱歉,但我觉得这个工具还是物超所值的。
0x01 信息搜集在一次Web渗透过程中,信息搜集的目的是站在旁观者的角度,去了解整个Web应用的概貌。1. 目标确认
工具简介Whois基于RFC 3912,用于查询域名相关信息的合同。Dig域名信息获取工具(Domain information groper)简称,是一个命令行的用于查询DNS服务器的网路管理工具。DNSRecon自动化DNS枚举脚本,由darkoperator维护。
1.1 域名注册信息
通过如下步骤确认目标所有者信息:
Whois 目标域名/主机名whois 解析目标域名/主机名的IP地址dig +short Whois IP地址whois 104.27.178.12剖析输出结果
如果目标开启了whois隐私保护,那么返回的结果可能是经过混淆的。
!!不要功击未经授权的站点。作为渗透测试人员,有责任在测试之前明晰自己有没有获得目标所有者赋于的权限对目标进行测试。这也是为何目标确认是开始渗透测试的第一步。1.2 DNS信息查询
我喜欢去 / 查询目标站点的DNS信息,这是一款很不错的在线DNS信息查询工具。
dig +nocmd example.com A +noall +answer
dig +nocmd example.com NS +noall +answer
dig +nocmd example.com MX +noall +answer
dig +nocmd example.com TXT +noall +answer
dig +nocmd example.com SOA +noall +answer
...
dig +nocmd example.com ANY +noall +answer (This rarely works)
dig -x 104.27.179.12
dig -x 104.27.178.12
1.3 测试域传送漏洞
域传送是一种DNS事务,用于在主从服务器间复制DNS记录。(译者注:可以看这个)虽然现在早已太稀少主机会开启,但是还是应当确认一下。一旦存在域传送漏洞,就意味着你获取了整个域下边所有的记录。
域传送漏洞很容易防止。至少管理员可以设置只容许白名单内的IP列表可以进行域传送恳求。
dig -t NS zonetransfer.me +short
dig -t AXFR zonetransfer.me @nsztm1.digi.ninja
dig -t AXFR zonetransfer.me @nsztm2.digi.ninja
dnsrecon -d example.com
2. OSINT 公开情报搜集
工具描述Recon-NGTim 'Lanmaster53' Tomes写的公开情报工具框架,由社区维护。/MaltegoMaltego 是一款交互式的数据挖掘工具,它可以渲染出图用于关联分析。theharvestertheHarvester 可以从不同的公开资源中搜集邮箱、子域名、虚拟主机、开放的端口/主机指纹和职工姓名等信息
我本想在这份笔记中收录详尽的OSINT的介绍,但是想了想决定不这样做。因为我认为这个部份可以单独写一篇(可能在以后的几篇中)。
在这篇笔记中我就介绍一些非常棒的关于OSINT的干货,我想渗透测试者们对于这种干货应当十分熟悉:
0x02 Mapping在一次渗透测试过程中,Mapping的目的是站在一个普通用户的角度去了解整个应用的概貌。1. 工具
工具介绍Nmap带服务辨识和操作系统指纹识别的TCP/IP主机和端口扫描工具
1.1 端口扫描,服务辨识,OS辨识! 端口扫描一般是渗透过程中第一步和第二步的过渡部份。要特别注意曝露的端口、服务版本和OS/s!2. 浏览器代理设置2.1 Firefox
工具描述Firefox跨平台的一款现代浏览器,有很多有用的插件
Firefox一般是Web渗透测试过程中的首选浏览器,这是因为它有很多有用的插件以及它的代理设置不会影响到全局代理。
2.2 Firefox插件
工具描述User Agent Switcher一款可以快速切换用户代理的Firefox插件Wappalyzer可以测量各种各样的网站所用的技术和软件组件的插件FoxyProxy代理切换插件
这些插件在每次渗透测试过程中我总能用得到,我推荐你在第二步(Mapping)之前安装好它们。
2.3 配置Firefox和Burpsuit
在你进行Mapping之前你一定要配置要浏览器的代理,让流量经过Burp。
2.4 Burp配置
工具描述Burp Suit ProWeb安全测试套件
你应当配置Burp使他适宜自己的喜好。但是起码我推荐你设置Scan Speed为thorough,这样你在使用扫描器时都会发出更多地恳求因而扫描出更多的漏洞。
2.5 Burp扩充
工具描述Burp Extender用于扩充Burp suite功能的API,可以在BApp商店获取Retire.js (BApp)用于测量版本落后的Javascript组件漏洞的Burp suite扩充Wsdler (BApp)可以解析WSDL文件,然后测试所有的容许的方式的恳求Python Scripter (BApp)可以在每位HTTP请求和响应时执行一段用户定义的Python脚本
这些Burp扩充是我在渗透测试过程中常常使用的。和Firefox扩充一样,我建议大家在Mapping之前安装好它们。
它们可以使用Burp Suite Pro的Burp Extender模块来安装。
3. 人工浏览
人工浏览可能是Mapping过程中最重要的部份。你有必要去浏览每位页面,点击页面上每一个跳转,这样在Burp的sitemap上面就可以出现这种恳求和响应。
!!!手工浏览对于单页应用十分特别重要。自动化的网页爬虫不能否爬到单页应用由于单页应用的HTTP请求都是用异步的AJAX来进行的。4. 自动化爬取
自动化爬取是使用Burp Spider来进行的,这个过程可以发觉你手工浏览没有发觉的一些页面。通常来说Burp Spider会在传统的Web应用中发觉更多的页面。
!!!自动化爬虫十分危险。通常我会手工浏览80%~95%的页面,只用爬虫爬取极少的部份。因为在特定情况下爬虫很容易失效。5. 后续剖析
这个时侯你应当使用Burp完成了Mapping这一步第一次的迭代,你应当注意目前把握的所有信息。
5.1 需要非常注意
这个时侯你可以注意一些须要特定页面跳转的功能点。通常这种功能点可以被手工操控,从而让其不用满足特定跳转次序就可以实现,这可以使你有重大发觉。(举个栗子,电子商务网站的付款功能,密码重置页面等)
0x03 漏洞挖掘在一次渗透测试过程中,漏洞挖掘是在攻击者的角度来了解整个Web应用的概貌。1. 过渡
在你Mapping以后,并且进行了一些基本的功能性的剖析后,就可以开始进行漏洞挖掘了。这个步骤中,你应当尽可能多的辨识出Web应用存在的漏洞。这些漏洞除了是The OWASP Top 10中收录的这些,还收录于应用的商业逻辑中。记住一点,你将会碰到大量的漏洞,它不属于任何一个现有的分类中,你应当时刻提防这一点。
2. 内容挖掘2.1 漏洞扫描
名称描述Nikto有指纹辨识功能的Web服务漏洞扫描器
Nikto当之无愧的是最好的Web服务漏洞扫描器,特别是在小型的Web应用程序中表现非常好。它可以借助-Format选项来导入特定格式的扫描结果,使扫描结果更容易阅读和剖析。
漏洞扫描一般是第二步和第三步的过渡。一旦有了扫描结果,一定要花时间去剖析一下结果,打开一些引人注目的页面瞧瞧。3. 强制浏览(译者注:翻译的觉得太别扭,看下边内容应当能明白哪些意思)
名称描述Burp Engagement ToolsBurp Suite Pro中自带的有特殊用途的工具集Engagement Tool: Discover ContentBurp Suite Pro自带的用于强制浏览的工具Burp IntruderBurp Suite中可自定义的用于自动化的功击的模块。(比如brute forcing, injection, 等)FuzzDB收录各类恶意输入、资源名、用于grep搜索响应内容的字符串、Webshell等。
强制浏览是一种挖掘方法,它可以发觉应用程序中没有被引用并且确实是可以访问的页面。Discover Content是Burp中专门用于此目的的工具。除此之外,Burp Intruder也可以通过字典功击来施行强制浏览(通常是在url参数和文件路径部份进行更改)。FuzzDB收录一些用于此目的的特别牛逼的字典,你可以在这里瞧瞧。
3.1 测试可选内容
名称描述User Agent Switcher用于迅速切换浏览器的User Agent的一款Firefox插件Burp IntruderBurp Suite中可自定义的用于自动化的功击的模块。(比如brute forcing, injection, 等)FuzzDB收录各类恶意输入、资源名、用于grep搜索响应内容的字符串、Webshell等。
在内容挖掘这一步,我十分喜欢做一件事。那就是借助User Agent Switcher切换不同的User Agent之后访问同一个特定页面。这是因为好多的Web应用对于不同的User-Agent和Referer恳求头会返回不同的内容。
我常常使用Burp Intruder来模糊测试User-Agent和Referer恳求头,一般还借助FuzzDB的字典。
4. 自动化的漏洞挖掘
名称描述Burp Scanner自动化扫描安全漏洞的Burp Suite工具
当你在Mapping和进行漏洞挖掘的开始部份时侯,Burp Passive Scanner就早已在后台悄悄运行。你应当先剖析这份扫描结果,然后再进行Burp Active Scanner,这样在Burp Passive Scanner中发觉的值得关注的页面就可以在Burp Active Scanner中进行详尽的扫描。
由于Burp Active Scanner完成所需的时间十分长,我更喜欢只容许一小段时间,然后查看二者之间的扫描结果并记录结果。
!!!自动化的漏洞扫描是太危险的。用Burp Scanner可能造成不良的影响。除非你特别熟悉目标的功能与环境,否则你只应在非生产环境中使用。5. 配置5.1 默认配置
在确认了目标所使用的技术后,很自然的一步跟进就是测试有没有默认配置。许多框架使用许多易受功击默认配置的应用程序便于于向开发人员介绍她们的产品。然后因为开发人员的疏漏,这些示例应用被布署到和目标站点所在的同一台服务器上,这促使目标站点承受很大的风险。
5.2 错误配置
在Web渗透测试的每一步,你都应当注意Web应用有没有错误的配置。你可以特别关注页面出现的错误信息,这些信息常常会给出很有用的数据库结构和服务器文件系统等信息。
错误信息几乎总还能发觉一些。这些错误信息在注入和LFI(Local File Include)中非常有用。
另外一个值得注意的是页面的敏感表单有没有禁用手动填充。比如密码数组常常会有一个“显示/隐藏”按钮。浏览器默认不会填充type="password"的input标签内容,而当密码数组是“显示”时,input标签就弄成了type="text",这样浏览器都会进行手动填充。这在多用户环境下是一个隐患。
6. 身份认证
在漏洞挖掘过程中,你应当认真考量你看见的每位登陆表单。如果这种表单没有做挺好的安全举措(比如双重认证,验证码,禁止重复递交等),攻击者就可能得到用户帐户未授权的权限。取决于表单的不同实现以及不同的框架/CMS,即使登陆失败目标站点也可能会透漏出用户帐户的一些信息。
如果你测试发觉了上述所讨论的问题,你应当关注并记录。另外,如果登陆表单没有加密(或者借助了旧版本的SSL/TLS),这也应当关注并记录。
6.1 模糊登陆测试
名称描述CeWL通过爬取目标站点来生成用户字典的工具Burp IntruderBurp Suite中可自定义的用于自动化的功击的模块。(比如brute forcing, injection, 等)
在你认真考量了登陆表单后,就可以开始登陆测试了。CeWL是一款非常好用的用于生成一次性字典的工具。你可以借助-h查看帮助文档。
基本句型如下
cewl [options] www.example.com
当你构造好用户字典后就可以开始用Burp Intruder进行实际的模糊测试了。通常我会用两个payload集(一个是用户名的,另一个是CeWL生成的密码)。Intruder的Attack Type一般应当选Cluster Bomb。
7. Session管理
Session-token/Cookie剖析在渗透测试过程中尽管不是太吸引人的部份,但确实十分重要的一块。通常是这样子的,你想了解整个web应用是怎样跟踪Session,然后用Burp Sequencer这样的工具去测试session token的随机性/可预测性。一些应用(较传统的应用)会把session的内容储存在客户端。有时候这种数据上面会收录有加密的,序列化的敏感信息。
这时也应当检测HTTP返回头的Set-Cookie是否收录Secure和HttpOnly的标示。如果没有的话就值得注意了,因为没有理由不设置这种标识位。
Google搜索你得到的session token,可能会有一些发觉,比如Session可预测等,这样就可以进行Session绑架功击。7.1 用Burp测试Session Tokens
名称描述Burp SequencerBurp拿来剖析数据集的随机性的模块
Burp Sequencer是拿来测试Session Token随机性和可预测性的挺好的工具。当你用这个工具来测试目标的Session管理时,你应当先去除所有的Cookies,然后重新认证一次。然后就可以把带有Set-Cookie头的返回包发送给Burp Sequencer,然后Sequencer都会启动新的拦截对Token进行剖析。通常10000次恳求就差不多可以判定随机性和可预测性了。
如果发觉Session token不够随机,那就可以考虑Session绑架了。
8. 授权
授权漏洞太象功能级访问控制缺位和不安全的直接对象引用漏洞,是太长一段时间我发觉的最流行的漏洞。这是因为许多的开发者没有想到一个低权限甚至是匿名用户会去向高权限的插口发送恳求(失效的权限控制)。
http://example.com/app/admin_getappInfo
或者是去恳求其他用户的数据(不安全的直接对象引用,译者注:水平越权)
http://example.com/app/accountInfo?acct=notmyacct
8.1 测试权限控制
名称描述Compare Site MapsBurp的用于测试授权的模块
这里有个小方法,就是注册两个不同权限的用户,然后用高权限的用户去访问整个Web应用,退出高权限用户,登录低权限用户,然后用Burp的Compare Site Maps工具去测试什么页面的权限控制没有做好。
9. 数据验证测试
名称描述Burp Repeater用于手工更改、重放HTTP请求的Burp模块
注入漏洞的存在是因为Web应用接受任意的用户输入,并且在服务端没有正确验证用户的输入的有效性。作为一个渗透测试者,你应当注意每一个接受随便的用户输入的地方并设法进行注入。
因为每位Web应用情况都不一样,所以没有一种万能的注入形式。接下来,我会把注入漏洞进行分类而且给出一些Payload。Burp Repeater是我测试注入漏洞时最常使用的工具。它可以重放HTTP请求,并且可以随时更改Payload。
有一件事须要牢记:漏洞挖掘阶段要做的只是辨识漏洞,而漏洞借助阶段就会借助漏洞做更多地事。当然,每个注入漏洞都值得被记录,你可以在漏洞挖掘阶段以后对这种注入漏洞进行深入的测试。
在每位分类下可以参照OWASP获取更多地信息。
9.1 SQLi
任何将输入带入数据库进行查询的地方都可能存在SQL注入。结合错误的配置问题,会导致大量的数据被攻击者窃取。
我推荐你在做SQL注入时参照这个Wiki。如果你输入了这种Payload得到了数据库返回的错误信息,那么目标就十分有可能存在SQL注入漏洞。
Sqlmap是一款自动化的SQL注入工具,我将会在漏洞借助阶段介绍它。
OWASP-测试SQL注入)
' OR 1=1 -- 1
' OR '1'='1
' or 1=1 LIMIT 1;--
admin';--
http://www.example.com/product.php?id=10 AND 1=1
9.2 跨站脚本攻击(XSS)
攻击者借助Web应用程序发送恶意代码(通常是JavaScript代码)给另外一个用户,就发生了XSS。
有三种不同的XSS:
存储型。当提供给Web应用的数据是攻击者事先递交到服务器端永久保存的恶意代码时,发生存储型XSS。反射型。当提供给Web应用的数据是服务端脚本借助攻击者的恶意输入生成的页面时,发生反射型XSS。DOM型。DOM型XSS存在于客户端的脚本。
OWASP-测试XSS
<p>
">alert('XSS')
互联网业务成功之路(4): 网站内容管理和运营
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2020-08-08 22:57
运营是该站点持续增长的关键. 只有通过详细,独特的网站内容规划和实施以及必要的操作,网站才能在竞争中立于不败之地.
1. 快速丰富新网站的内容
1. 列设置为网站构建“骨架”
我们已经介绍了在无忧CMS系统中添加列的方法,本期着重于列的规划思想,而不仅限于某个网站程序.
第一步: 先计划. 网站的栏目设置是网站建立之初最重要的步骤,因为一旦确定了栏目,网站的定位就基本形成了. 如果在经过一段时间的操作后对其进行修改,将会造成很多损失,例如失去目标访问者和减轻搜索引擎的重量等. 因此,在创建网站列和添加它们之前,我们必须仔细考虑并计划它们.
第2步: 进行更多研究. 确定要添加的列之后,必须首先检查此类列是否在网民中很流行. 想一想. 创建列时,您将每天进行维护和更新,但是由于位置偏差,没有人关心它. 这不是浪费吗?时间?要了解访问者的爱好,第一种方法是查看其他类似的网站以获得灵感. 此外,您可以通过对搜索引擎进行排名来确定列的位置,从而吸引特定领域的注意力. 例如,百度的Billboard是一个很好的工具.
图1
第3步: 建立定位. 同一字段还将具有不同的列位置. 例如,您将创建一本有关笔记本相关信息的专栏. 您要介绍笔记本行业的最新信息,还是提供笔记本软件下载或笔记本购物指南服务?注意与网站的统一. 例如,本文中的示例是一个IT信息网站,其位置是笔记本的新闻内容.
2. 使用采集来快速采集网站内容
在建立网站的初期,通常缺少文章,访问者如果没有内容就无法被保留. 为了快速获得高质量的内容,我们可以从其他网站重新打印该内容. 在这里,我们以Shudong Link为例,将以上文章快速重新发布到我们的网站上. “ 优采云采集器”是一种方便实用的内容采集程序,支持采集远程文章和图片. 下面我们以该软件为例进行说明.
提示:
由于该软件基于.NET程序体系结构,因此必须在使用前安装Microsoft .NET Framework 2.0组件,否则该程序将无法正常运行.
第1步: 建立网站添加规则
下载软件后,可以将其解压缩后再使用. 在任务列表面板中右键单击以创建新的采集网站,然后在弹出的网站创建窗口中输入网站名称,URL和其他信息. 然后切换到软件的“整个站点内容规则”页面,这是集合中最重要的步骤. 如果设置稍有不正确,可能会发生错误. 对于一般的文章传送,我们需要填写基本信息,包括标题,内容和时间.
图2
要确定网页的内容规则,可以打开需要采集的内容页面,在浏览器中选择“查看源代码”以查看网页的HTML代码,然后在其中搜索标题字段. 代码. 如果标题开始标签为,则在软件的标签编辑框中输入这两个字段. 然后按照相同的方法查找并添加标签,例如文章内容,作者,来源,时间等. 通常,我们需要检查多个文章页面,以避免标签错误.
如果需要同时采集网页上的其他信息,则可以单击“添加标签”按钮来添加采集对象. 该软件不仅支持通过采集获得的数据,还可以将数据设置为固定格式.
提示:
您可能会发现第一次很难添加数据规则,但是再尝试几次并仔细阅读软件文档. 了解了原理之后,就很容易编写数据规则.
第2步: 创建采集任务
右键单击刚添加的站点的名称,然后选择“从此站点创建新任务”选项,然后将显示URL采集菜单. 该软件提供了三种URL采集模式. 如果目标网站具有相应的文章列表页面,则可以使用“级别1链接”方法. 此方法的原理是通过内容列表页面自动检测内容页面以采集Web内容.
如果目标URL文件名具有特定格式,我们还可以直接添加需要采集的内容页面URL. 添加任务后,您可以先对其进行测试. 单击软件右下角的“开始测试URL集合”按钮以进入测试页面. 该软件将根据刚刚填写的URL规则进行采集. 地址搜索完成后,您可以选择任何文章进行测试. 软件可以正常显示采集页面的内容,说明采集规则设置成功;如果无法显示内容,则需要重新设置规则.
图3
第3步: 采集和发布内容
完成上述步骤后,您还需要设置所采集内容的发布方法. 该软件当前提供了多种内容发布方法. 它可以直接发布到网站程序,也可以另存为本地文件. 如果要直接发布到网站程序,则需要一个相应的程序发布模块. 该软件带有几个程序模块,包括最受欢迎的文章系统. 如果没有我们需要的模块,则可以转到官方软件论坛进行查找.
设置完成后,您可以采集文章并将其发布到网站. 在软件主面板中选择要采集的网站的名称,然后单击面板顶部的开始按钮,软件将自动采集内容. 如果您需要采集很多内容,则需要等待很长时间. 采集完所有文章后,内容将自动发布.
提示:
尽管获取软件可以轻松获取大量文章,但在使用该软件时必须注意版权,并注明允许转载的某些文章的来源.
第二,避免复制实用内容的防盗方法
许多网站管理员都困扰着Internet上的版权问题. 最常见的个人网站遭遇是其内容被转载. 一些网站不仅在重新打印时不保留链接,而且在文章中收录网站信息. 删除. 面对这种情况,我们可以通过向网站添加标签来保护网站的内容. 例如,在图片或文字中添加网站徽标,域名和其他信息,以便即使其他网站转载内容,也可以间接推广您自己的网站. 查看全部
为人们种草提供短视频,自媒体,一站式服务
运营是该站点持续增长的关键. 只有通过详细,独特的网站内容规划和实施以及必要的操作,网站才能在竞争中立于不败之地.
1. 快速丰富新网站的内容
1. 列设置为网站构建“骨架”
我们已经介绍了在无忧CMS系统中添加列的方法,本期着重于列的规划思想,而不仅限于某个网站程序.
第一步: 先计划. 网站的栏目设置是网站建立之初最重要的步骤,因为一旦确定了栏目,网站的定位就基本形成了. 如果在经过一段时间的操作后对其进行修改,将会造成很多损失,例如失去目标访问者和减轻搜索引擎的重量等. 因此,在创建网站列和添加它们之前,我们必须仔细考虑并计划它们.
第2步: 进行更多研究. 确定要添加的列之后,必须首先检查此类列是否在网民中很流行. 想一想. 创建列时,您将每天进行维护和更新,但是由于位置偏差,没有人关心它. 这不是浪费吗?时间?要了解访问者的爱好,第一种方法是查看其他类似的网站以获得灵感. 此外,您可以通过对搜索引擎进行排名来确定列的位置,从而吸引特定领域的注意力. 例如,百度的Billboard是一个很好的工具.
图1
第3步: 建立定位. 同一字段还将具有不同的列位置. 例如,您将创建一本有关笔记本相关信息的专栏. 您要介绍笔记本行业的最新信息,还是提供笔记本软件下载或笔记本购物指南服务?注意与网站的统一. 例如,本文中的示例是一个IT信息网站,其位置是笔记本的新闻内容.
2. 使用采集来快速采集网站内容
在建立网站的初期,通常缺少文章,访问者如果没有内容就无法被保留. 为了快速获得高质量的内容,我们可以从其他网站重新打印该内容. 在这里,我们以Shudong Link为例,将以上文章快速重新发布到我们的网站上. “ 优采云采集器”是一种方便实用的内容采集程序,支持采集远程文章和图片. 下面我们以该软件为例进行说明.
提示:
由于该软件基于.NET程序体系结构,因此必须在使用前安装Microsoft .NET Framework 2.0组件,否则该程序将无法正常运行.
第1步: 建立网站添加规则
下载软件后,可以将其解压缩后再使用. 在任务列表面板中右键单击以创建新的采集网站,然后在弹出的网站创建窗口中输入网站名称,URL和其他信息. 然后切换到软件的“整个站点内容规则”页面,这是集合中最重要的步骤. 如果设置稍有不正确,可能会发生错误. 对于一般的文章传送,我们需要填写基本信息,包括标题,内容和时间.
图2
要确定网页的内容规则,可以打开需要采集的内容页面,在浏览器中选择“查看源代码”以查看网页的HTML代码,然后在其中搜索标题字段. 代码. 如果标题开始标签为,则在软件的标签编辑框中输入这两个字段. 然后按照相同的方法查找并添加标签,例如文章内容,作者,来源,时间等. 通常,我们需要检查多个文章页面,以避免标签错误.
如果需要同时采集网页上的其他信息,则可以单击“添加标签”按钮来添加采集对象. 该软件不仅支持通过采集获得的数据,还可以将数据设置为固定格式.
提示:
您可能会发现第一次很难添加数据规则,但是再尝试几次并仔细阅读软件文档. 了解了原理之后,就很容易编写数据规则.
第2步: 创建采集任务
右键单击刚添加的站点的名称,然后选择“从此站点创建新任务”选项,然后将显示URL采集菜单. 该软件提供了三种URL采集模式. 如果目标网站具有相应的文章列表页面,则可以使用“级别1链接”方法. 此方法的原理是通过内容列表页面自动检测内容页面以采集Web内容.
如果目标URL文件名具有特定格式,我们还可以直接添加需要采集的内容页面URL. 添加任务后,您可以先对其进行测试. 单击软件右下角的“开始测试URL集合”按钮以进入测试页面. 该软件将根据刚刚填写的URL规则进行采集. 地址搜索完成后,您可以选择任何文章进行测试. 软件可以正常显示采集页面的内容,说明采集规则设置成功;如果无法显示内容,则需要重新设置规则.
图3
第3步: 采集和发布内容
完成上述步骤后,您还需要设置所采集内容的发布方法. 该软件当前提供了多种内容发布方法. 它可以直接发布到网站程序,也可以另存为本地文件. 如果要直接发布到网站程序,则需要一个相应的程序发布模块. 该软件带有几个程序模块,包括最受欢迎的文章系统. 如果没有我们需要的模块,则可以转到官方软件论坛进行查找.
设置完成后,您可以采集文章并将其发布到网站. 在软件主面板中选择要采集的网站的名称,然后单击面板顶部的开始按钮,软件将自动采集内容. 如果您需要采集很多内容,则需要等待很长时间. 采集完所有文章后,内容将自动发布.
提示:
尽管获取软件可以轻松获取大量文章,但在使用该软件时必须注意版权,并注明允许转载的某些文章的来源.
第二,避免复制实用内容的防盗方法
许多网站管理员都困扰着Internet上的版权问题. 最常见的个人网站遭遇是其内容被转载. 一些网站不仅在重新打印时不保留链接,而且在文章中收录网站信息. 删除. 面对这种情况,我们可以通过向网站添加标签来保护网站的内容. 例如,在图片或文字中添加网站徽标,域名和其他信息,以便即使其他网站转载内容,也可以间接推广您自己的网站.
WordPress胖鼠标采集插件会自动采集和发布微信官方帐户和简短书籍
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-08-08 22:04
WordPress最初是一个博客,但是由于其强大的功能和众多的用户,Wordpress现在已成为CMS平台,甚至有些公司也使用Wordpress建立了他们的网站,实际上到处都是. Wordpress用于采集和构建站点. 一直在做垃圾站的朋友一直在使用它.
一件事是,WordPress自己的SEO很好,这有利于搜索引擎的收录和SEO排名;另一方面,Wordpress也有很多功能强大的插件. 使用Wordpress捕获插件不需要太多复杂的配置. 新手还可以建立一个网站,该网站每天自动采集和发布内容,并放置一些小型广告来“获得回报”.
有很多WordPress集合插件,但是基本上都是付费的. 本文主要是分享新的WordPress集合插件-Fat Mouse 采集,开源和免费,并支持所有网站列表的详细信息页面,它具有自动批量列出列表的集合,自动发布,自动标记等功能,可用于采集微信官方帐户,简书和其他各种网站.
安装WP Fat Mouse 采集插件
插件:
建议将PHP 7用于WordPress Fat Mouse 采集插件. 如果您的PHP版本低于PHP 7,请转到Fat Mouse下载Github集合并使用Fat Mouse v5. 分支名称: based_php_5.6,系统要求如下:
PHP> = 5.6
QueryList v4版本
Mysql不需要
Nginx不需要
WordPress胖鼠标集合插件的主要功能如下:
微信公众号文章采集,短文文章采集,列表页面文章批次采集.
详细信息页面文章采集,分页爬网-历史数据,请放手. 一口气捕获所有内容
自动采集,自动发布,将动态内容自动添加到文章,优化SEO.
自动标签,文章过滤,自动精选图片.
内容关键字过滤功能取代了任何网站的伪原创,自定义集合.
WordPress胖鼠标集合插件主要包括以下部分:
①采集器模块,先驱者配置模块的各种功能以寻找数据.
②配置模块并支持采集器模块,以向其提供采集规则的核心力量.
③数据模块,数据此模块具有Fat Mouse的各种功能发布功能.
在安装Wordpress胖鼠标集合插件之后,将显示下图:
WP Fat Mouse 采集插件操作配置中心
已在WP Fat Mouse采集插件配置中心中配置了采集规则. Wordpress Fat Mouse 采集插件具有多种配置,您可以单击以首先将其导入. (点击放大)
馆藏中心
您可以在采集中心开始采集文章. WordPress胖鼠标采集插件分为列表采集和详细信息采集. 列表采集可以批量采集某个网站,详细采集是采集某个页面.
数据中心
采集完成后,您可以转到数据中心查看采集的文章,然后单击以在此处发布它们. (点击放大)
通过WordPress胖鼠标采集插件采集和发布文章的效果仍然很好.
这是Wordpress Fat Mouse 采集插件采集的文章的详细信息页面,该插件可完全采集网站上的文章.
WP Fat Mouse采集微信官方帐户
对于WordPress来说,采集微信官方帐户文章也非常简单. 首先找到您要采集的微信公众号文章.
然后在“采集中心”中填写微信公众号文章的URL,支持批量添加多个URL,点击采集.
采集完成后,可以发布采集到的微信公众号文章. 如下图所示:
WP Fat Mouse 采集简书志虎
WordPress采集的短书,Zhhu等类似于上面的WeChat官方帐户文章的采集. 您可以直接输入要采集的URL.
WP自定义采集任何网站
WordPress Fat Mouse集合插件随附的几个配置文件实际上是供我们演示的. 真正强大的功能是,我们自定义了WordPress Fat Mouse采集插件的采集规则,以采集任何网站内容(不是AJax).
新的收款规则
在Wordpress Fat Mouse采集插件中创建新的采集规则. 在这里,以文章集为例. 首先命名它,然后选择列表配置(有很多文章,请选择此批次集合),其余的如下所示:
然后填写采集地址,范围,采集规则等,如下所示:
通常来说,采集规则需要多次测试才能成功,因此在创建新规则之前,我们首先打开插件的Debug模式,然后在元素的network列中检查特定结果在Chrome浏览器中.
列表采集规则
采集范围是要由Wordpress Fat Mouse采集插件采集的URL的列表. 主页上最新文章的标题全部以H2 + URL的形式嵌套(单击放大).
因此,我在这里填写的采集范围是: #cat_all> .news-post.article-post> .row> .col-sm-7> .post-content> h2,此路径不需要是手动直接进行操作您可以在Chrome浏览器查看元素的底部看到它,请注意上面的图片.
写入列表采集规则: a: eq(0)href,href表示选择标签的href属性(即URL),我们使用Jquery的eq语法a: eq(0)表示H2区域A的第一个. 注意: 如果目标站链接是相对链接,则代码从0开始(只有一个标签,您可以填写a). 该程序将自动完成.
在Debgu模式下,我们可以看到已经获得了主页上最新文章列下所有文章的URL地址.
详细信息采集规则
我们已经采集了上面列表中的所有URL,然后我们需要在此URL下采集文章的内容. 打开一篇文章,我们发现标题在.title-post中,文章的内容在.the-content中. 标题和内容都在.single-post-box下.
标题. 现在我们可以编写标题采集规则,如下所示: 作用域是.single-post-box,选择器是.title-post,属性是text.
在调试模式下,您可以看到我们已经成功获取了文章标题.
内容. 采集内容的规则写为: 作用域是.single-post-box,选择器是.the-content,属性是html. 文章内容已成功获得,如下.
最后,在“最新文章”列下采集所有文章的规则如下: (单击放大)
WP自定义采集成功效果
在采集中心,单击我们刚刚配置的列表采集配置.
稍等片刻,Wordpress Fat Mouse 采集插件将采集所有最新文章.
点击发布,采集成功.
WP自定义采集规则问题参数和属性
WordPress胖鼠标集合插件有三个必需的参数:
链接采集链接通常采用a标签的href属性
标题标题通常采用详细信息页面的h1标签的text属性
内容内容通常在详细信息页面的.content标签中具有html属性.
WordPress胖鼠标集合插件的属性解释如下:
href基本上是指标签的href属性(此属性在单击后存储跳转地址)
text获取该区域的文本,通常用于标题
html提取区域中的所有html通常用于提取内容,并且内容更多. 内容中收录很多内容,例如排版中的图像CSS JS. 因此,请获取所有原创HTML
jQuery选择器
在下面的内容过滤中,几个jQuery选择器(例如: first,: last,: odd等)非常有用,您可以熟悉它们.
WP胖鼠集合优化方法内容过滤 查看全部
教程简介
WordPress最初是一个博客,但是由于其强大的功能和众多的用户,Wordpress现在已成为CMS平台,甚至有些公司也使用Wordpress建立了他们的网站,实际上到处都是. Wordpress用于采集和构建站点. 一直在做垃圾站的朋友一直在使用它.
一件事是,WordPress自己的SEO很好,这有利于搜索引擎的收录和SEO排名;另一方面,Wordpress也有很多功能强大的插件. 使用Wordpress捕获插件不需要太多复杂的配置. 新手还可以建立一个网站,该网站每天自动采集和发布内容,并放置一些小型广告来“获得回报”.
有很多WordPress集合插件,但是基本上都是付费的. 本文主要是分享新的WordPress集合插件-Fat Mouse 采集,开源和免费,并支持所有网站列表的详细信息页面,它具有自动批量列出列表的集合,自动发布,自动标记等功能,可用于采集微信官方帐户,简书和其他各种网站.
安装WP Fat Mouse 采集插件
插件:
建议将PHP 7用于WordPress Fat Mouse 采集插件. 如果您的PHP版本低于PHP 7,请转到Fat Mouse下载Github集合并使用Fat Mouse v5. 分支名称: based_php_5.6,系统要求如下:
PHP> = 5.6
QueryList v4版本
Mysql不需要
Nginx不需要
WordPress胖鼠标集合插件的主要功能如下:
微信公众号文章采集,短文文章采集,列表页面文章批次采集.
详细信息页面文章采集,分页爬网-历史数据,请放手. 一口气捕获所有内容
自动采集,自动发布,将动态内容自动添加到文章,优化SEO.
自动标签,文章过滤,自动精选图片.
内容关键字过滤功能取代了任何网站的伪原创,自定义集合.
WordPress胖鼠标集合插件主要包括以下部分:
①采集器模块,先驱者配置模块的各种功能以寻找数据.
②配置模块并支持采集器模块,以向其提供采集规则的核心力量.
③数据模块,数据此模块具有Fat Mouse的各种功能发布功能.
在安装Wordpress胖鼠标集合插件之后,将显示下图:
WP Fat Mouse 采集插件操作配置中心
已在WP Fat Mouse采集插件配置中心中配置了采集规则. Wordpress Fat Mouse 采集插件具有多种配置,您可以单击以首先将其导入. (点击放大)
馆藏中心
您可以在采集中心开始采集文章. WordPress胖鼠标采集插件分为列表采集和详细信息采集. 列表采集可以批量采集某个网站,详细采集是采集某个页面.
数据中心
采集完成后,您可以转到数据中心查看采集的文章,然后单击以在此处发布它们. (点击放大)
通过WordPress胖鼠标采集插件采集和发布文章的效果仍然很好.
这是Wordpress Fat Mouse 采集插件采集的文章的详细信息页面,该插件可完全采集网站上的文章.
WP Fat Mouse采集微信官方帐户
对于WordPress来说,采集微信官方帐户文章也非常简单. 首先找到您要采集的微信公众号文章.
然后在“采集中心”中填写微信公众号文章的URL,支持批量添加多个URL,点击采集.
采集完成后,可以发布采集到的微信公众号文章. 如下图所示:
WP Fat Mouse 采集简书志虎
WordPress采集的短书,Zhhu等类似于上面的WeChat官方帐户文章的采集. 您可以直接输入要采集的URL.
WP自定义采集任何网站
WordPress Fat Mouse集合插件随附的几个配置文件实际上是供我们演示的. 真正强大的功能是,我们自定义了WordPress Fat Mouse采集插件的采集规则,以采集任何网站内容(不是AJax).
新的收款规则
在Wordpress Fat Mouse采集插件中创建新的采集规则. 在这里,以文章集为例. 首先命名它,然后选择列表配置(有很多文章,请选择此批次集合),其余的如下所示:
然后填写采集地址,范围,采集规则等,如下所示:
通常来说,采集规则需要多次测试才能成功,因此在创建新规则之前,我们首先打开插件的Debug模式,然后在元素的network列中检查特定结果在Chrome浏览器中.
列表采集规则
采集范围是要由Wordpress Fat Mouse采集插件采集的URL的列表. 主页上最新文章的标题全部以H2 + URL的形式嵌套(单击放大).
因此,我在这里填写的采集范围是: #cat_all> .news-post.article-post> .row> .col-sm-7> .post-content> h2,此路径不需要是手动直接进行操作您可以在Chrome浏览器查看元素的底部看到它,请注意上面的图片.
写入列表采集规则: a: eq(0)href,href表示选择标签的href属性(即URL),我们使用Jquery的eq语法a: eq(0)表示H2区域A的第一个. 注意: 如果目标站链接是相对链接,则代码从0开始(只有一个标签,您可以填写a). 该程序将自动完成.
在Debgu模式下,我们可以看到已经获得了主页上最新文章列下所有文章的URL地址.
详细信息采集规则
我们已经采集了上面列表中的所有URL,然后我们需要在此URL下采集文章的内容. 打开一篇文章,我们发现标题在.title-post中,文章的内容在.the-content中. 标题和内容都在.single-post-box下.
标题. 现在我们可以编写标题采集规则,如下所示: 作用域是.single-post-box,选择器是.title-post,属性是text.
在调试模式下,您可以看到我们已经成功获取了文章标题.
内容. 采集内容的规则写为: 作用域是.single-post-box,选择器是.the-content,属性是html. 文章内容已成功获得,如下.
最后,在“最新文章”列下采集所有文章的规则如下: (单击放大)
WP自定义采集成功效果
在采集中心,单击我们刚刚配置的列表采集配置.
稍等片刻,Wordpress Fat Mouse 采集插件将采集所有最新文章.
点击发布,采集成功.
WP自定义采集规则问题参数和属性
WordPress胖鼠标集合插件有三个必需的参数:
链接采集链接通常采用a标签的href属性
标题标题通常采用详细信息页面的h1标签的text属性
内容内容通常在详细信息页面的.content标签中具有html属性.
WordPress胖鼠标集合插件的属性解释如下:
href基本上是指标签的href属性(此属性在单击后存储跳转地址)
text获取该区域的文本,通常用于标题
html提取区域中的所有html通常用于提取内容,并且内容更多. 内容中收录很多内容,例如排版中的图像CSS JS. 因此,请获取所有原创HTML
jQuery选择器
在下面的内容过滤中,几个jQuery选择器(例如: first,: last,: odd等)非常有用,您可以熟悉它们.
WP胖鼠集合优化方法内容过滤
采集工具的竞争-计算机数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2020-08-08 11:20
以下纯属个人看法
当前,网站站长圈子中有许多流行的采集工具,但总的来说,只有少数几个知名的免费采集工具
1. 优采云应该拥有最多的用户,主要集中在新站
功能: 多功能,速度快
优点: 功能比较齐全,采集速度比较快,主要针对cms,可以在很短的时间内采集很多,过滤和替换都不错,比较详细,很多人编写和发布了界面,界面比较完整,适合那些不了解该程序的网站管理员
技术: 该技术主要是对论坛的支持,具有许多帮助文件,易于使用以及在采集工具方面的竞争. 有免费的付费版本
缺点: 功能更多,体积越来越大,内存成本高,速度快,采集品的质量有所降低且不稳定
2. 三人行主要用于论坛,可以称为第一人
功能: 对于大型论坛,移动,移动,快速,高精度
优点: 仍然适合论坛,适合开设论坛
技术: 收费技术,免费广告
缺点: 对cms的支持不佳
3.ET工具
功能: 无人看管,稳定,几乎没有记忆
优点: 无人值守,自动更新,适合长期派驻,用户群主要集中在长期派潜水站长,计算机数据“采集工具大赛”()上. 软件清晰,必要的功能也很完善. 关键是该软件是免费的. 听说添加了中英文翻译功能.
技术: 论坛支持,该软件本身是免费的,但也提供付费服务. 帮助文件少,不容易上手
缺点: 似乎缺少帮助文件是该软件的缺点
4. 海纳
功能: 大量关键字捕获,无需编写规则即可预览采集的内容
优势: 庞大,可以在网站上抓取很多关键字文章,这似乎很适合网站的主题
技术: 不收取论坛费用,免费提供功能限制
缺点: 分类不方便,也就是说,对采集的文章,手册(自动(容易混淆),特定的界面)进行分类很不方便
摘要: 如果您追求完整的功能,则应该选择优采云. 优采云被称为“万能的”. 在初始阶段,您可以快速采集大量资源并丰富网站内容. 如果您是论坛,请选择一个三人组. 没错,您可以实现许多论坛功能,例如采集论坛,回复和移动. 长期站,当然选择ET,需要一些时间来了解,这是长期的利益. 编写规则,设置过滤器并替换,然后就可以像打开QQ一样长时间运行,而无需记忆,自动采集和更新,清晰的分类以及完整的采集内容. 但是,一个站,一个站长+ ET就足够了. 对于Hainer来说,似乎没有规则,而且入门起来很容易,但是在发表文章时,不可能一劳永逸. 相反,我觉得已经添加了很多工作,但是您可以做一些特别的主题. 这是网站主题的不错选择. 查看全部
以下纯属个人看法. 网站站长圈子中有许多流行的采集工具,但总的来说,只有少数几个著名的免费工具. 1.优采云用户数应为...
以下纯属个人看法
当前,网站站长圈子中有许多流行的采集工具,但总的来说,只有少数几个知名的免费采集工具
1. 优采云应该拥有最多的用户,主要集中在新站
功能: 多功能,速度快
优点: 功能比较齐全,采集速度比较快,主要针对cms,可以在很短的时间内采集很多,过滤和替换都不错,比较详细,很多人编写和发布了界面,界面比较完整,适合那些不了解该程序的网站管理员
技术: 该技术主要是对论坛的支持,具有许多帮助文件,易于使用以及在采集工具方面的竞争. 有免费的付费版本
缺点: 功能更多,体积越来越大,内存成本高,速度快,采集品的质量有所降低且不稳定
2. 三人行主要用于论坛,可以称为第一人
功能: 对于大型论坛,移动,移动,快速,高精度
优点: 仍然适合论坛,适合开设论坛
技术: 收费技术,免费广告
缺点: 对cms的支持不佳
3.ET工具
功能: 无人看管,稳定,几乎没有记忆
优点: 无人值守,自动更新,适合长期派驻,用户群主要集中在长期派潜水站长,计算机数据“采集工具大赛”()上. 软件清晰,必要的功能也很完善. 关键是该软件是免费的. 听说添加了中英文翻译功能.
技术: 论坛支持,该软件本身是免费的,但也提供付费服务. 帮助文件少,不容易上手
缺点: 似乎缺少帮助文件是该软件的缺点
4. 海纳
功能: 大量关键字捕获,无需编写规则即可预览采集的内容
优势: 庞大,可以在网站上抓取很多关键字文章,这似乎很适合网站的主题
技术: 不收取论坛费用,免费提供功能限制
缺点: 分类不方便,也就是说,对采集的文章,手册(自动(容易混淆),特定的界面)进行分类很不方便
摘要: 如果您追求完整的功能,则应该选择优采云. 优采云被称为“万能的”. 在初始阶段,您可以快速采集大量资源并丰富网站内容. 如果您是论坛,请选择一个三人组. 没错,您可以实现许多论坛功能,例如采集论坛,回复和移动. 长期站,当然选择ET,需要一些时间来了解,这是长期的利益. 编写规则,设置过滤器并替换,然后就可以像打开QQ一样长时间运行,而无需记忆,自动采集和更新,清晰的分类以及完整的采集内容. 但是,一个站,一个站长+ ET就足够了. 对于Hainer来说,似乎没有规则,而且入门起来很容易,但是在发表文章时,不可能一劳永逸. 相反,我觉得已经添加了很多工作,但是您可以做一些特别的主题. 这是网站主题的不错选择.
[发布] 免费安装智虎问答自动采集插件,内容可推送至百度索引
采集交流 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2020-08-07 16:11
安装此插件后,您可以单击一下进入智虎问答网站,并获得智虎问答.
[此插件的功能]
1. 真实的背心用户数据可以批量生成为海报和回复者. 我觉得您的论坛很受欢迎.
2. 除了采集知乎的问题外,还将采集答案的内容. 我觉得您的论坛内容丰富且可读性强.
3. 对背心的回复时间经过科学处理. 并非所有回复该帖子的人都在同一时间. 感觉您的论坛不是响应的背心,而是真正的用户.
4. 批量生成的帖子和回复背心均具有真实的化身和昵称,由中大云实时采集的网络爬虫随机生成.
5. 批量生成的背心用户可以导出uid列表,该列表可以在该插件之外的其他插件中使用.
6. 所采集的纸箱问答内容的图片可以正常显示并另存为图片附件.
7. 图片附件支持远程FTP存储.
8. 图片将在您的论坛上加水印.
9. 知乎的高质量问答内容将每天自动推送,您只需单击一下即可将其发布到您的论坛上.
10. 所采集的“知乎问答”将不会被采集两次,其内容也不会多余.
11. 采集的帖子几乎与真实用户发布的帖子相同.
12. 网页浏览量会自动随机设置,您会觉得帖子的浏览量更为真实.
13. 无限采集,无限采集时间.
[此插件为您带来的价值]
1. 使您的论坛受欢迎并且内容丰富.
2. 除了使用此插件之外,批量生成的背心还可以用于其他目的,这等同于购买此插件并免费赠送该背心生成插件.
3. 使用一键式采集而不是手动发布,可以节省时间和精力,而且不容易出错.
在线安装地址:
@ csdn123com_知乎.plugin
本地下载和手动安装: 查看全部
[插件功能]
安装此插件后,您可以单击一下进入智虎问答网站,并获得智虎问答.
[此插件的功能]
1. 真实的背心用户数据可以批量生成为海报和回复者. 我觉得您的论坛很受欢迎.
2. 除了采集知乎的问题外,还将采集答案的内容. 我觉得您的论坛内容丰富且可读性强.
3. 对背心的回复时间经过科学处理. 并非所有回复该帖子的人都在同一时间. 感觉您的论坛不是响应的背心,而是真正的用户.
4. 批量生成的帖子和回复背心均具有真实的化身和昵称,由中大云实时采集的网络爬虫随机生成.
5. 批量生成的背心用户可以导出uid列表,该列表可以在该插件之外的其他插件中使用.
6. 所采集的纸箱问答内容的图片可以正常显示并另存为图片附件.
7. 图片附件支持远程FTP存储.
8. 图片将在您的论坛上加水印.
9. 知乎的高质量问答内容将每天自动推送,您只需单击一下即可将其发布到您的论坛上.
10. 所采集的“知乎问答”将不会被采集两次,其内容也不会多余.
11. 采集的帖子几乎与真实用户发布的帖子相同.
12. 网页浏览量会自动随机设置,您会觉得帖子的浏览量更为真实.
13. 无限采集,无限采集时间.
[此插件为您带来的价值]
1. 使您的论坛受欢迎并且内容丰富.
2. 除了使用此插件之外,批量生成的背心还可以用于其他目的,这等同于购买此插件并免费赠送该背心生成插件.
3. 使用一键式采集而不是手动发布,可以节省时间和精力,而且不容易出错.
在线安装地址:
@ csdn123com_知乎.plugin
本地下载和手动安装:
新浪微博内容采集和发布大师v13.9官方版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 458 次浏览 • 2020-08-07 14:53
6)您可以将数据采集到Mssql或MySQL数据库中,并通过您的网站进行批量处理(组中的朋友们将很幸运)
7)发布微博后,立即在微博上自动发表评论以提高微博的排名,并且易于输入微博精选,热门微博和实时微博(评论内容可收录9个链接内容,主要应用场景: 在微博上发布图片,并在评论中添加婴儿链接. )
8)自动同步微博内容,您可以将大型微博上的内容自动同步到许多微博帐户. 产品说明
9). 在新浪微博上进行超级主题关注和登录,支持多批批量关注和批量登录.
使用方法:
1. 帐户分类管理
首先添加用于发布微博和采集微博内容的帐户. 此功能还可用于批量管理您的N个多个新浪微博帐户,并维护您的新浪微博帐户. 它可以自动检测您的微博帐户是否异常,或者它是否已被新浪微博正式阻止等.
2,内容自动发布
检查微博内容和帐户,单击“开始发送”以发布微博. 这是全自动的即时发布信息或您的微博内容,全天24小时无人值守. 让机器完全取代您的手动操作!该软件还支持预定和自动微博发布. 您可以先设置预定时间,微博会在时间到后自动发布.
3. 内容批次管理
您可以自己添加,修改和删除内容. 采集的微博内容也可以在此处进行编辑. 您可以批量导入和导出微博内容.
4. 自动内容采集
通过指定某人的微博的采集,您还可以通过关键字搜索来采集相应的内容.
5. 网络管理模式管理
该软件可以通过代理ip和ADSL发布您的微博内容,以防止帐户被阻止的风险.
6. 微博昵称采集
您可以在微博上采集活跃的真实用户的昵称,然后当您在一组微信中自动发送微博时,可以在微博内容中@一群人,并且信息可以从衣服上水平传送,这样您的微博可以迅速传播其影响力. !
7. 操作帮助
设置后,它将自动自动采集新浪微博内容,不仅可以采集文字,还可以采集图片,视频,作者和源地址等. 您还可以将采集的内容上传到指定的微博中. 新浪微博内容自动采集和发布工具,新浪微博内容自动采集和发布软件,新浪微博发布大师. 查看全部
5)将昵称转换为UID(将指定批次的昵称转换为相应的微博UID)
6)您可以将数据采集到Mssql或MySQL数据库中,并通过您的网站进行批量处理(组中的朋友们将很幸运)
7)发布微博后,立即在微博上自动发表评论以提高微博的排名,并且易于输入微博精选,热门微博和实时微博(评论内容可收录9个链接内容,主要应用场景: 在微博上发布图片,并在评论中添加婴儿链接. )
8)自动同步微博内容,您可以将大型微博上的内容自动同步到许多微博帐户. 产品说明
9). 在新浪微博上进行超级主题关注和登录,支持多批批量关注和批量登录.
使用方法:
1. 帐户分类管理
首先添加用于发布微博和采集微博内容的帐户. 此功能还可用于批量管理您的N个多个新浪微博帐户,并维护您的新浪微博帐户. 它可以自动检测您的微博帐户是否异常,或者它是否已被新浪微博正式阻止等.
2,内容自动发布
检查微博内容和帐户,单击“开始发送”以发布微博. 这是全自动的即时发布信息或您的微博内容,全天24小时无人值守. 让机器完全取代您的手动操作!该软件还支持预定和自动微博发布. 您可以先设置预定时间,微博会在时间到后自动发布.
3. 内容批次管理
您可以自己添加,修改和删除内容. 采集的微博内容也可以在此处进行编辑. 您可以批量导入和导出微博内容.
4. 自动内容采集
通过指定某人的微博的采集,您还可以通过关键字搜索来采集相应的内容.
5. 网络管理模式管理
该软件可以通过代理ip和ADSL发布您的微博内容,以防止帐户被阻止的风险.
6. 微博昵称采集
您可以在微博上采集活跃的真实用户的昵称,然后当您在一组微信中自动发送微博时,可以在微博内容中@一群人,并且信息可以从衣服上水平传送,这样您的微博可以迅速传播其影响力. !
7. 操作帮助
设置后,它将自动自动采集新浪微博内容,不仅可以采集文字,还可以采集图片,视频,作者和源地址等. 您还可以将采集的内容上传到指定的微博中. 新浪微博内容自动采集和发布工具,新浪微博内容自动采集和发布软件,新浪微博发布大师.
Zhongda Cloud 采集(Web内容采集工具)v9
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-08-06 21:07
中大云采集的主要功能
1. 每天都会自动采集和更新最新的最热门的微信公众号文章.
2. 最新,最热门的各种信息采集,每天都会自动更新.
3. 输入关键字并采集与此关键字相关的最新内容
4. 输入网址并采集该网址的内容
5. 支持云通用伪原创和本地伪原创
6. 可以在插件设置中自定义本地伪原创文件
7. 图片可以一键存储在本地,图片永远不会丢失
8,Discuz版本可以在后台设置常用集合关键字
9,Discuz版本可以指定用户组和部门来使用采集功能
1. 支持Discuz X2.5及更高版本
1,phpcms和Dream weaving dedecms版本支持三种主流编辑器: fckeditor,ckeditor和ueditor
11. 支持采集优酷,56,腾讯等视频
Zhongda Cloud 采集插件的主要功能
1. 背心用户可以批量注册,张贴者和评论使用的背心看起来与真实注册用户发布的背心完全相同.
2. 您可以批量采集和发布,然后在短时间内将任何高质量的内容重新发布到论坛和门户.
3. 它可以定期采集并自动释放,以实现无人值守的操作.
4. 所采集的内容可以转换为简体和繁体字符,伪原创和其他辅助处理.
5. 支持前台集合. 您可以授权指定的普通注册用户在前台使用此采集器,并让普通注册成员帮助您采集内容.
6. 采集到的内容图片可以正常显示并另存为后期图片附件或门户文章附件. 图片将永远不会丢失.
7. 图片附件支持远程FTP存储,使您可以将图片分离到另一台服务器.
8. 图片将添加您的论坛或门户网站设置的水印.
9. 已采集的内容不会被采集两次,并且内容也不会是多余的.
1. 采集和发布的帖子,门户网站文章和组与真实用户发布的帖子,门户文章和组完全相同,其他人无法知道它们是否由采集器发布.
11. 观看次数将自动随机设置,感觉您的帖子或门户网站文章的观看次数与实际观看次数相同.
12. 您可以指定帖子发布者(主持人),门户文章作者和组发布者.
13. 采集的内容可以发布到论坛的任何部分,门户的任何列以及论坛的任何圈子.
14. 可以将发布的内容推送到百度数据采集界面以进行SEO优化,并加快百度索引和网站的收录量.
15. 采集的内容数量没有限制,采集的数量也没有限制,可以使您的网站快速填充高质量的内容.
16. 该插件具有内置的文本提取算法,该算法支持在任何网站上采集任何列内容.
17. 您可以一键获取当前的实时热点内容,然后一键发布.
网站采集器网站采集工具 查看全部
Zhongda Cloud 采集是一个功能强大的网站内容采集工具,已以插件的形式集成到Discuz,dream weaving dedecms,phpcms和Empire CMS中. 它可以根据关键字或URL自动采集任何内容. 可以说,它是个人网站管理员用户进行所采集内容的伪原创和排版,然后一键发布到其自己的网站上必不可少的工具.
中大云采集的主要功能
1. 每天都会自动采集和更新最新的最热门的微信公众号文章.
2. 最新,最热门的各种信息采集,每天都会自动更新.
3. 输入关键字并采集与此关键字相关的最新内容
4. 输入网址并采集该网址的内容
5. 支持云通用伪原创和本地伪原创
6. 可以在插件设置中自定义本地伪原创文件
7. 图片可以一键存储在本地,图片永远不会丢失
8,Discuz版本可以在后台设置常用集合关键字
9,Discuz版本可以指定用户组和部门来使用采集功能
1. 支持Discuz X2.5及更高版本
1,phpcms和Dream weaving dedecms版本支持三种主流编辑器: fckeditor,ckeditor和ueditor
11. 支持采集优酷,56,腾讯等视频
Zhongda Cloud 采集插件的主要功能
1. 背心用户可以批量注册,张贴者和评论使用的背心看起来与真实注册用户发布的背心完全相同.
2. 您可以批量采集和发布,然后在短时间内将任何高质量的内容重新发布到论坛和门户.
3. 它可以定期采集并自动释放,以实现无人值守的操作.
4. 所采集的内容可以转换为简体和繁体字符,伪原创和其他辅助处理.
5. 支持前台集合. 您可以授权指定的普通注册用户在前台使用此采集器,并让普通注册成员帮助您采集内容.
6. 采集到的内容图片可以正常显示并另存为后期图片附件或门户文章附件. 图片将永远不会丢失.
7. 图片附件支持远程FTP存储,使您可以将图片分离到另一台服务器.
8. 图片将添加您的论坛或门户网站设置的水印.
9. 已采集的内容不会被采集两次,并且内容也不会是多余的.
1. 采集和发布的帖子,门户网站文章和组与真实用户发布的帖子,门户文章和组完全相同,其他人无法知道它们是否由采集器发布.
11. 观看次数将自动随机设置,感觉您的帖子或门户网站文章的观看次数与实际观看次数相同.
12. 您可以指定帖子发布者(主持人),门户文章作者和组发布者.
13. 采集的内容可以发布到论坛的任何部分,门户的任何列以及论坛的任何圈子.
14. 可以将发布的内容推送到百度数据采集界面以进行SEO优化,并加快百度索引和网站的收录量.
15. 采集的内容数量没有限制,采集的数量也没有限制,可以使您的网站快速填充高质量的内容.
16. 该插件具有内置的文本提取算法,该算法支持在任何网站上采集任何列内容.
17. 您可以一键获取当前的实时热点内容,然后一键发布.
网站采集器网站采集工具
zblog一键抓取网站内容(可自定义网站)插件教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2020-08-06 09:14
1. 缩略图唯一标识
此选项取决于您的主题是否具有此缩略图输入框
如果您查看ID
2,图片处理
建议在测试时不要本地化或保存到数据库.
在实际使用它时,需要打开本地化并将其保存到数据库中,以防止图像热链接和文章删除. 找不到图片. 此外,只有打开保存到数据库,您才能在附件管理中看到图片.
3. 打开图片的水印
您可以根据需要下载相应的插件(两个插件都是免费的)
4. 添加网址规则
名称是网站的名称,只需您自己知道
以企业家国家()中的文章集合为例
直接在URL上写
获取标题和正文的方法是通过右键单击浏览器来检查元素
标记和常规标记之间的区别是(以上面的标题为例)
该标记为.article-tit,基本上在常规规则中不使用,并且很难理解. 如果需要,请与我联系.
标签比普通标签更简单,更美观
两个人不说哪个更准确,更灵活. 我通常会使用更多标签.
测试:
填写与需要采集的网站相对应的URL,然后单击以获取标题和文本以自动获取
5. 解决域名冲突问题
例如,新浪博客的这两个域名: 和
尽管两个域名相同,但是样式不同. 在这种情况下,您需要使用“,”将两个不同的规则分开
6. 其他网站采集规则
百度百科中的百科全书
白家好
新浪博客
您可以自己编写规则. 导入和导出规则以及共享规则将在下一版本中添加.
如果您有任何使用问题,也可以联系我的QQ: 841217204 查看全部
1. 缩略图唯一标识
此选项取决于您的主题是否具有此缩略图输入框
如果您查看ID
2,图片处理
建议在测试时不要本地化或保存到数据库.
在实际使用它时,需要打开本地化并将其保存到数据库中,以防止图像热链接和文章删除. 找不到图片. 此外,只有打开保存到数据库,您才能在附件管理中看到图片.
3. 打开图片的水印
您可以根据需要下载相应的插件(两个插件都是免费的)
4. 添加网址规则
名称是网站的名称,只需您自己知道
以企业家国家()中的文章集合为例
直接在URL上写
获取标题和正文的方法是通过右键单击浏览器来检查元素
标记和常规标记之间的区别是(以上面的标题为例)
该标记为.article-tit,基本上在常规规则中不使用,并且很难理解. 如果需要,请与我联系.
标签比普通标签更简单,更美观
两个人不说哪个更准确,更灵活. 我通常会使用更多标签.
测试:
填写与需要采集的网站相对应的URL,然后单击以获取标题和文本以自动获取
5. 解决域名冲突问题
例如,新浪博客的这两个域名: 和
尽管两个域名相同,但是样式不同. 在这种情况下,您需要使用“,”将两个不同的规则分开
6. 其他网站采集规则
百度百科中的百科全书
白家好
新浪博客
您可以自己编写规则. 导入和导出规则以及共享规则将在下一版本中添加.
如果您有任何使用问题,也可以联系我的QQ: 841217204
数据获取|自动抓取网页数据,您也可以这样做
采集交流 • 优采云 发表了文章 • 0 个评论 • 457 次浏览 • 2020-08-06 04:03
Web抓取(也称为Web数据提取或Web爬网)是指从Internet获得数据,并将获得的非结构化数据转换为结构化数据,最后将数据存储在本地计算机或数据库技术上.
当前,全球网络数据的增长速度约为每年40%. IDC(互联网数据中心)报告显示,2013年的全球数据为4.4ZB. 到2020年,全球数据总量将达到40ZB. 大数据时代已经来临. 从互联网上获取所需数据已成为进行竞争对手分析,业务数据挖掘和科学研究的重要手段.
采集网络信息的主要方法是: 手动复制网页,自动网络爬网工具,用于循环批下载和自制浏览器下载.
今天,我将向您介绍注册后的几种免费的自动Web信息自动爬网工具,以供您参考. 应该注意的是,大量自动采集的网络信息非常容易被IP阻止. 此时,可以使用以下方法破解: (1)暂停采集,经过一段时间后再试一次,并在设置采集规则之前尝试找出防止网页采集的规律; (2)使用云采集; (3)使用代理IP进行采集.
1. 优采云(URL: )
优采云平台集成了Web数据采集,移动Internet数据和API接口服务(包括数据挖掘,数据优化,数据存储,数据备份)和其他服务.
优采云可以自动采集整个网络上的信息(网页,论坛,移动Internet,Qzone,电话号码,电子邮件,图片等). 同时,优采云提供了独立采集和云采集两种模式. 具体的采集方法包括向导模式,高级模式和智能模式,供不同主题选择. 您可以从网站上获取数据并将其组织成一个数据集. 它具有良好的交互设计,使用非常方便. 其主界面如图1所示.
图1优采云主界面
2. 优采云采集器()
Youcai Cloud Collector是一个专业的网络数据采集工具. 通过灵活的配置,您可以轻松地从网络中获取非结构化的文本,图片,文件和其他信息,并可以在编辑后随时发布它们. 在网站背景或其他数据库中,它适合于具有数据采集和挖掘需求的各种组,例如垂直搜索,信息聚合和门户,企业网络信息聚合,商业智能,论坛或博客迁移,智能信息代理,个人信息检索等字段,其主界面如图2所示.
Youcai Cloud Collector的工作原理是提取Web结构的源代码,因此,只要能在网页上看到内容,无论显示什么形式,都可以快速提取. 最后捕获的数据可以导入任何目标数据库或导出为所需的格式. 在网页抓取过程中,还可以选择不同的线程来控制优采云采集器的采集速度. 一般来说,Youcai Cloud Collector适合对爬网,速度和完整性有明确要求的用户.
图2优采云采集器主界面
3. 优采云采集器软件()
优采云采集器软件使用Panda精确搜索引擎的分析核心来实现类似于浏览器的Web内容分析. 在此基础上,采用独创技术,实现了Web框架内容和核心内容的分离与提取,实现了相似页面的有效比较和匹配. 因此,用户只需要指定参考页面即可,而优采云采集器软件系统可以相应地匹配相似页面,以实现用户需要采集的数据的批量采集.
浏览器中可见的内容可以由Youcai Cloud Collector软件采集. 采集的对象包括文本内容,图片,Flash动画视频和其他网络内容. 它支持同时采集混合图形和文本对象,并支持JS输出内容的采集. 主界面如图3所示.
图3优采云采集器软件主界面
四,网络精神()
网络申彩是一个专业的网络信息采集系统,可以通过灵活的规则从任何类型的网站(例如新闻网站,论坛,博客,电子商务网站,招聘网站等)采集信息. 它支持高级采集功能,例如网站登录采集,网站跨层采集,POST采集,脚本页面采集和动态页面采集. 它支持存储过程,插件等,并且可以通过二次开发进行扩展. 主界面如图4所示.
图4网络精神的主界面 查看全部
Web抓取(也称为Web数据提取或Web爬网)是指从Internet获得数据,并将获得的非结构化数据转换为结构化数据,最后将数据存储在本地计算机或数据库技术上.
当前,全球网络数据的增长速度约为每年40%. IDC(互联网数据中心)报告显示,2013年的全球数据为4.4ZB. 到2020年,全球数据总量将达到40ZB. 大数据时代已经来临. 从互联网上获取所需数据已成为进行竞争对手分析,业务数据挖掘和科学研究的重要手段.
采集网络信息的主要方法是: 手动复制网页,自动网络爬网工具,用于循环批下载和自制浏览器下载.
今天,我将向您介绍注册后的几种免费的自动Web信息自动爬网工具,以供您参考. 应该注意的是,大量自动采集的网络信息非常容易被IP阻止. 此时,可以使用以下方法破解: (1)暂停采集,经过一段时间后再试一次,并在设置采集规则之前尝试找出防止网页采集的规律; (2)使用云采集; (3)使用代理IP进行采集.
1. 优采云(URL: )
优采云平台集成了Web数据采集,移动Internet数据和API接口服务(包括数据挖掘,数据优化,数据存储,数据备份)和其他服务.
优采云可以自动采集整个网络上的信息(网页,论坛,移动Internet,Qzone,电话号码,电子邮件,图片等). 同时,优采云提供了独立采集和云采集两种模式. 具体的采集方法包括向导模式,高级模式和智能模式,供不同主题选择. 您可以从网站上获取数据并将其组织成一个数据集. 它具有良好的交互设计,使用非常方便. 其主界面如图1所示.
图1优采云主界面
2. 优采云采集器()
Youcai Cloud Collector是一个专业的网络数据采集工具. 通过灵活的配置,您可以轻松地从网络中获取非结构化的文本,图片,文件和其他信息,并可以在编辑后随时发布它们. 在网站背景或其他数据库中,它适合于具有数据采集和挖掘需求的各种组,例如垂直搜索,信息聚合和门户,企业网络信息聚合,商业智能,论坛或博客迁移,智能信息代理,个人信息检索等字段,其主界面如图2所示.
Youcai Cloud Collector的工作原理是提取Web结构的源代码,因此,只要能在网页上看到内容,无论显示什么形式,都可以快速提取. 最后捕获的数据可以导入任何目标数据库或导出为所需的格式. 在网页抓取过程中,还可以选择不同的线程来控制优采云采集器的采集速度. 一般来说,Youcai Cloud Collector适合对爬网,速度和完整性有明确要求的用户.
图2优采云采集器主界面
3. 优采云采集器软件()
优采云采集器软件使用Panda精确搜索引擎的分析核心来实现类似于浏览器的Web内容分析. 在此基础上,采用独创技术,实现了Web框架内容和核心内容的分离与提取,实现了相似页面的有效比较和匹配. 因此,用户只需要指定参考页面即可,而优采云采集器软件系统可以相应地匹配相似页面,以实现用户需要采集的数据的批量采集.
浏览器中可见的内容可以由Youcai Cloud Collector软件采集. 采集的对象包括文本内容,图片,Flash动画视频和其他网络内容. 它支持同时采集混合图形和文本对象,并支持JS输出内容的采集. 主界面如图3所示.
图3优采云采集器软件主界面
四,网络精神()
网络申彩是一个专业的网络信息采集系统,可以通过灵活的规则从任何类型的网站(例如新闻网站,论坛,博客,电子商务网站,招聘网站等)采集信息. 它支持高级采集功能,例如网站登录采集,网站跨层采集,POST采集,脚本页面采集和动态页面采集. 它支持存储过程,插件等,并且可以通过二次开发进行扩展. 主界面如图4所示.
图4网络精神的主界面

