
网页qq抓取什么原理
网页qq抓取什么原理(一下2021年关于百度蜘蛛的工作原理大家了解多少呢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-19 17:21
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级SEO站长对此都不是很清楚,而且相当一部分站长其实只是为了seo和seo,甚至只知道如何发送< @文章,外链和交易所链,seo真正的核心知识我没有做过太多的了解,或者只是简单的理解了但是没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬取系统原理及索引库的建立,让广大做SEO优化的站长们可以百度蜘蛛的收录
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果把网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持过去爬虫爬取的页面保持更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多的抓取有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
海量的互联网资源要求抓取系统在有限的硬件和带宽资源下,尽可能高效地利用带宽,尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度也会不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度先建重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
话题页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者加入一些新鲜的内容,比如观点、评论,给用户一个更丰富更全面的内容.
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度没有必要收录用互联网上已有的内容。
3、一个空且短主体的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。 查看全部
网页qq抓取什么原理(一下2021年关于百度蜘蛛的工作原理大家了解多少呢)
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级SEO站长对此都不是很清楚,而且相当一部分站长其实只是为了seo和seo,甚至只知道如何发送< @文章,外链和交易所链,seo真正的核心知识我没有做过太多的了解,或者只是简单的理解了但是没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬取系统原理及索引库的建立,让广大做SEO优化的站长们可以百度蜘蛛的收录

一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果把网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持过去爬虫爬取的页面保持更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。

二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多的抓取有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
海量的互联网资源要求抓取系统在有限的硬件和带宽资源下,尽可能高效地利用带宽,尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度也会不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度先建重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
话题页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者加入一些新鲜的内容,比如观点、评论,给用户一个更丰富更全面的内容.
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度没有必要收录用互联网上已有的内容。
3、一个空且短主体的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。
网页qq抓取什么原理(《搜索引擎原理系列教程》之三个比较关心)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-18 14:20
《搜索引擎原理系列教程》虽然不是一本书,但由于里面信息量大、内容实用,也弥补了百度白皮书的一些不足——言出必行,值得鼓励说这个教程完全是一个民间SEO爱好者总结出来的,这种精神值得称道。
由于这本书一共8章,而且内容太多,就不一一介绍了,不过这里还是想讲三个方面,也是我们SEOER比较关心的三个方面:收录,索引,排名。
一、收录
收录其实是一个复杂的过程,简单的分为这四个步骤:
搜索引擎抓取网页
1、 调度器是整个采集过程的核心。它在内部存储了一个访问过的 URL 库和一个未访问过的 URL 库,统称为 URL 库。一开始,调度器会从未访问的URL库中取出一个URL,分配给蜘蛛,这样蜘蛛就可以对没有被爬取的URL进行爬取。
2、 当蜘蛛获取到 URL 时,它会发送一个请求来获取返回的 URL。流程为:对URL对应的域名进行DNS解析->获取Socket连接的IP->连接成功并发出http请求->接收网页信息。
3、 蜘蛛获取网页信息后,会将源代码返回给调度器,调度器将源代码保存到网页数据库中。
4、 调度器将从爬取的网页中提取链接,将未爬取的URL存储在未访问的URL库中,并将刚刚爬取的URL更新到已爬取的URL库中。
这将涉及重复数据删除
调度程序工作流
1、从未访问的 URL 表中取出 URL 并分配给每个蜘蛛。
2、蜘蛛获取URL,爬取,获取网页源代码,从源代码中提取URL,获取网页中收录的所有URL。
3、调度器依次检查获取到的URL是否存在于被访问的URL库中。如果存在,则表示已被抓取,则丢弃该URL;如果不存在,则说明该URL没有被爬取过,则按顺序添加到未访问过的URL列表中,等待之后再爬取。
4、重复步骤 1 直到未访问的表为空。
二、索引
网页预处理
1、索引原创页面。
2、对可搜索网页进行网页分割,将每个页面转换为一组单词。(前向指数)
3、将网页到索引词的映射转化为索引词到网页的映射形成倒排文件(包括倒排列表和索引词列表)
一般来说,搜索引擎从网页数据库中获取网页,然后进行代码过滤,然后提取文本信息,然后切词。下一步是过滤 关键词 集合,得到网页 关键词 正向索引,最后,搜索引擎将正向索引转换为网页的倒排索引。正是这项技术使得搜索引擎能够在1S内将搜索结果呈现给用户。
另外,搜索引擎的作用是对网页进行净化和去重。除了去除网页中的噪声内容(如广告、版权等),提取网页的主题及相关内容,去除网页集合中的重复内容。
有同学可能会问,搜索引擎是如何识别主要内容的呢?实际上,该算法依赖于HTML标签树的建立和投票方式来识别正文。
例如,让我们设置规则,
1、如果文本块文本长度小于10个字,0分。10-50 字得 5 分。50-250字,8分。250字以上得10分。
2、文本块的文本位置在右边,0分。最高,3分。左边,5分。中间,10分。
然后我们得到页面TITLE得分为9,加粗的H1标签得分为8等,DIV部分的AD部分得分为0,被丢弃。
(以上示例仅供参考,与实际算法无关)
搜索引擎需要通过 3 个步骤来对网页进行重复数据删除。首先是特征提取(包括I-Match算法和Shingle算法),然后是相似度计算,评估它们是否相似,最后是去重。
实际上,搜索引擎算法与用户交互的过程就是一个查询过程。例如,当用户搜索“搜索引擎原理”时,算法分词后得到“搜索引擎”和“原理”。文档列表,找到交集,然后对用户查询和上一步找到的文档列表中的一条记录进行向量化,找到查询向量和文档向量的相似度,然后从高到低排序,最后我们看到最终的搜索结果。
以一个例子结束:
搜索引擎网页权重=网页中词条的基本权重+链接权重+用户评价权重
网页中术语的基本权重
1、例如,在一个关键词“搜索引擎”的上下文中,权重应该是:WBT=W+W, (h1)+W,(b)=10+ 12+4=26
<p>2、关键词“搜索引擎”也可能在文档的其他地方出现n次,每次出现可以算一个WBT 查看全部
网页qq抓取什么原理(《搜索引擎原理系列教程》之三个比较关心)
《搜索引擎原理系列教程》虽然不是一本书,但由于里面信息量大、内容实用,也弥补了百度白皮书的一些不足——言出必行,值得鼓励说这个教程完全是一个民间SEO爱好者总结出来的,这种精神值得称道。
由于这本书一共8章,而且内容太多,就不一一介绍了,不过这里还是想讲三个方面,也是我们SEOER比较关心的三个方面:收录,索引,排名。
一、收录
收录其实是一个复杂的过程,简单的分为这四个步骤:
搜索引擎抓取网页
1、 调度器是整个采集过程的核心。它在内部存储了一个访问过的 URL 库和一个未访问过的 URL 库,统称为 URL 库。一开始,调度器会从未访问的URL库中取出一个URL,分配给蜘蛛,这样蜘蛛就可以对没有被爬取的URL进行爬取。
2、 当蜘蛛获取到 URL 时,它会发送一个请求来获取返回的 URL。流程为:对URL对应的域名进行DNS解析->获取Socket连接的IP->连接成功并发出http请求->接收网页信息。
3、 蜘蛛获取网页信息后,会将源代码返回给调度器,调度器将源代码保存到网页数据库中。
4、 调度器将从爬取的网页中提取链接,将未爬取的URL存储在未访问的URL库中,并将刚刚爬取的URL更新到已爬取的URL库中。
这将涉及重复数据删除
调度程序工作流
1、从未访问的 URL 表中取出 URL 并分配给每个蜘蛛。
2、蜘蛛获取URL,爬取,获取网页源代码,从源代码中提取URL,获取网页中收录的所有URL。
3、调度器依次检查获取到的URL是否存在于被访问的URL库中。如果存在,则表示已被抓取,则丢弃该URL;如果不存在,则说明该URL没有被爬取过,则按顺序添加到未访问过的URL列表中,等待之后再爬取。
4、重复步骤 1 直到未访问的表为空。
二、索引
网页预处理
1、索引原创页面。
2、对可搜索网页进行网页分割,将每个页面转换为一组单词。(前向指数)
3、将网页到索引词的映射转化为索引词到网页的映射形成倒排文件(包括倒排列表和索引词列表)
一般来说,搜索引擎从网页数据库中获取网页,然后进行代码过滤,然后提取文本信息,然后切词。下一步是过滤 关键词 集合,得到网页 关键词 正向索引,最后,搜索引擎将正向索引转换为网页的倒排索引。正是这项技术使得搜索引擎能够在1S内将搜索结果呈现给用户。
另外,搜索引擎的作用是对网页进行净化和去重。除了去除网页中的噪声内容(如广告、版权等),提取网页的主题及相关内容,去除网页集合中的重复内容。
有同学可能会问,搜索引擎是如何识别主要内容的呢?实际上,该算法依赖于HTML标签树的建立和投票方式来识别正文。
例如,让我们设置规则,
1、如果文本块文本长度小于10个字,0分。10-50 字得 5 分。50-250字,8分。250字以上得10分。
2、文本块的文本位置在右边,0分。最高,3分。左边,5分。中间,10分。
然后我们得到页面TITLE得分为9,加粗的H1标签得分为8等,DIV部分的AD部分得分为0,被丢弃。
(以上示例仅供参考,与实际算法无关)
搜索引擎需要通过 3 个步骤来对网页进行重复数据删除。首先是特征提取(包括I-Match算法和Shingle算法),然后是相似度计算,评估它们是否相似,最后是去重。
实际上,搜索引擎算法与用户交互的过程就是一个查询过程。例如,当用户搜索“搜索引擎原理”时,算法分词后得到“搜索引擎”和“原理”。文档列表,找到交集,然后对用户查询和上一步找到的文档列表中的一条记录进行向量化,找到查询向量和文档向量的相似度,然后从高到低排序,最后我们看到最终的搜索结果。
以一个例子结束:
搜索引擎网页权重=网页中词条的基本权重+链接权重+用户评价权重
网页中术语的基本权重
1、例如,在一个关键词“搜索引擎”的上下文中,权重应该是:WBT=W+W, (h1)+W,(b)=10+ 12+4=26
<p>2、关键词“搜索引擎”也可能在文档的其他地方出现n次,每次出现可以算一个WBT
网页qq抓取什么原理(QQ好友说说爬虫技术(爬虫)-爬虫步骤详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-16 11:08
自从上一篇文章你真的了解QQ空间里的“说话”吗?上线后,很多朋友都问小编如何爬取QQ空间的话题。今天,小编就来详细介绍一下。给大家介绍一下QQ好友,聊聊爬虫技术。通过本文章的学习,希望能给大家带来帮助。
本文将从基础知识介绍、QQ好友聊爬虫框架、爬虫详细步骤三个部分进行详细讲解。
一、基础知识介绍
小编爬QQ朋友说说使用Python语言,所以大家一定要有Python基础。另外,在爬取中还用到了 Python 的几个第三方库,分别是 requests 库和 BeautifulSoup 库。 pymysql库和matplotlib库用于数据存储和解析,所以你应该对这些库有一定的了解。
二、QQ好友聊爬虫框架
QQ好友聊爬虫的基本思路是利用浏览器已经登录的cookie实现爬虫登录,使用准备好的好友QQ账号将所有的好友聊HTML文件下载到本地文件系统,并在本地文件系统中解析HTML文件,提取信息并存储在MySql数据库中,最后自己分析MySql数据库中的信息。爬虫框架图如下。
三、爬虫步骤详解
3.1 获取所有好友QQ号
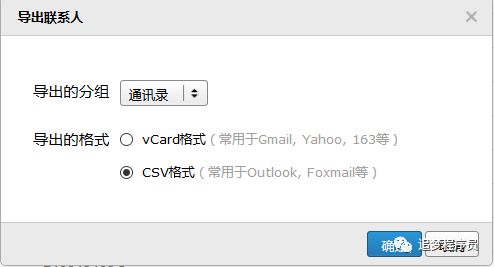
QQ邮箱有导出所有联系人的功能,所以我们可以使用QQ邮箱获取所有好友的QQ号。步骤如下:登录QQ邮箱-->点击右侧通讯录-->点击工具,选择导出联系人-->下载CSV文件。
3.2 获取浏览器登录的cookie
我们要使用浏览器已经登录的cookie来实现爬虫登录,都必须得到浏览器cookie。步骤如下:打开浏览器
--> 输入网站 --> 按F12打开浏览器的开发工具,切换到Network
--> 输入你的QQ号和密码登录--> 点击第一行,将请求头的cookie值复制到txt文件中。
3.3 爬上所有朋友聊聊
每个朋友的讨论页的url链接是/friends QQ号,所以我们必须先获取所有朋友的QQ号。读取csv文件,将所有好友的QQ号存入qnumber_list数组中。
(注意:/python/qqMoodCollect/QQmail.csv是csv文件路径,这里需要改一下文件路径)
下面是遍历qnumber_list数组,依次下载HTML文件到本地文件系统。
(get_moods()方法是下载HTML文件的方法,详见GetHub上的代码)
3.4 解析 HTML 文件
下载的HTML文件实际上是Json数据格式。我们可以利用Python内置的json库,轻松提取出我们想要的信息,最后存入MySql数据库。具体解析过程请参考get_mooddetail.py文件。 查看全部
网页qq抓取什么原理(QQ好友说说爬虫技术(爬虫)-爬虫步骤详解)
自从上一篇文章你真的了解QQ空间里的“说话”吗?上线后,很多朋友都问小编如何爬取QQ空间的话题。今天,小编就来详细介绍一下。给大家介绍一下QQ好友,聊聊爬虫技术。通过本文章的学习,希望能给大家带来帮助。
本文将从基础知识介绍、QQ好友聊爬虫框架、爬虫详细步骤三个部分进行详细讲解。
一、基础知识介绍
小编爬QQ朋友说说使用Python语言,所以大家一定要有Python基础。另外,在爬取中还用到了 Python 的几个第三方库,分别是 requests 库和 BeautifulSoup 库。 pymysql库和matplotlib库用于数据存储和解析,所以你应该对这些库有一定的了解。
二、QQ好友聊爬虫框架
QQ好友聊爬虫的基本思路是利用浏览器已经登录的cookie实现爬虫登录,使用准备好的好友QQ账号将所有的好友聊HTML文件下载到本地文件系统,并在本地文件系统中解析HTML文件,提取信息并存储在MySql数据库中,最后自己分析MySql数据库中的信息。爬虫框架图如下。
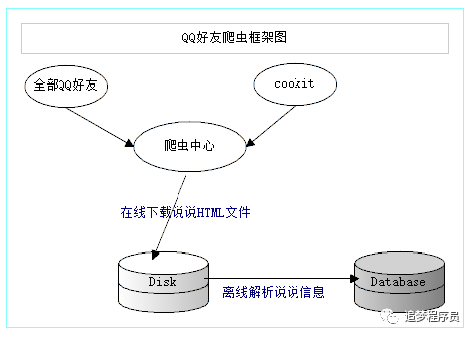
三、爬虫步骤详解
3.1 获取所有好友QQ号
QQ邮箱有导出所有联系人的功能,所以我们可以使用QQ邮箱获取所有好友的QQ号。步骤如下:登录QQ邮箱-->点击右侧通讯录-->点击工具,选择导出联系人-->下载CSV文件。
3.2 获取浏览器登录的cookie
我们要使用浏览器已经登录的cookie来实现爬虫登录,都必须得到浏览器cookie。步骤如下:打开浏览器
--> 输入网站 --> 按F12打开浏览器的开发工具,切换到Network
--> 输入你的QQ号和密码登录--> 点击第一行,将请求头的cookie值复制到txt文件中。
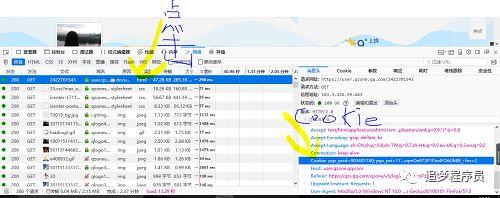
3.3 爬上所有朋友聊聊
每个朋友的讨论页的url链接是/friends QQ号,所以我们必须先获取所有朋友的QQ号。读取csv文件,将所有好友的QQ号存入qnumber_list数组中。

(注意:/python/qqMoodCollect/QQmail.csv是csv文件路径,这里需要改一下文件路径)
下面是遍历qnumber_list数组,依次下载HTML文件到本地文件系统。
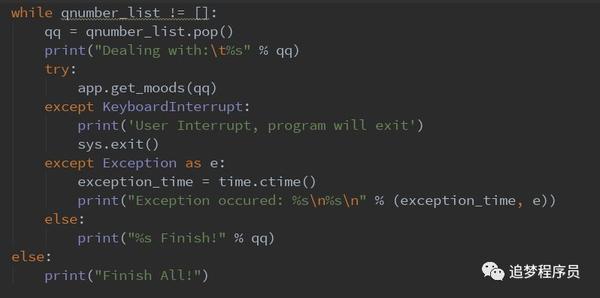
(get_moods()方法是下载HTML文件的方法,详见GetHub上的代码)
3.4 解析 HTML 文件
下载的HTML文件实际上是Json数据格式。我们可以利用Python内置的json库,轻松提取出我们想要的信息,最后存入MySql数据库。具体解析过程请参考get_mooddetail.py文件。
网页qq抓取什么原理(网页qq抓取什么原理?,我在用源码进行分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-14 15:10
网页qq抓取什么原理?,我在用源码进行分析,没有用到文本分析工具。
1)目标爬取百度云和一个店铺的,页面url中有id,有一些没有,可以从id看出某个页面的重复页面。抓取到就是可以获取所有页面的url。
2)准备工作:先在主流的浏览器上进行安装vscode或eclipse,这里统一使用vscode;安装到你的路径下,设置好权限,并且在公用的路径不会有文件,用户也不会有;安装tomcat开发工具,mac的话是sqlserverontopic,windows应该是server端所以必须加上。之后打开chrome或是百度云网页。
在网页的右上角输入chrome浏览器地址,可以看到下面有很多选项,我这里选择从菜单栏中打开。选择installsoftware,之后,下一步点击下一步选择installtargetlocalsoftware,之后安装jdk,这里不再做详细介绍,现在主要看其它的第三个项;安装好jdk之后,可以直接在命令行工具中输入java-version查看jdk版本号,如果没有显示version的话,可以尝试换成后缀名的文件。
接下来按照页面爬取指南进行操作:1.把url写入文件打开python文件夹,一个一个导入你所需要的数据。读取数据fromdatetimeimportdatetimefromrequestsimportrequesturl='/'res=request(url,headers=headers)get_all_urls=request('',headers=headers)withopen('abc.txt','w')asf:json_date=datetime.now()#thedatetimeisundefinedcontent=json_date['raw'][content]text=json_date['raw']['content']ifisinstance(text,json_date):returnnoneelse:returntext2.构建页面路径在open里面新建一个file.py文件。
保存(文件名必须为.txt)后缀名修改为.file。在执行程序时,直接双击运行,在其它情况下,建议放在其它路径下。直接双击程序后,回车,如果程序出现未找到data即说明您的程序需要部署到idc这样的企业级网站才能运行。3.根据页面爬取指南,把url的地址中的"to"列表中所有的cookies打印出来(cookies可以看看官方getcss可以看到)。
res.read().split('/')[0].resize(500,50
0).sort(ascending=false).sort()爬取全部页面(foriinrange(500,50
0):)这样就能爬取到所有的url了。 查看全部
网页qq抓取什么原理(网页qq抓取什么原理?,我在用源码进行分析)
网页qq抓取什么原理?,我在用源码进行分析,没有用到文本分析工具。
1)目标爬取百度云和一个店铺的,页面url中有id,有一些没有,可以从id看出某个页面的重复页面。抓取到就是可以获取所有页面的url。
2)准备工作:先在主流的浏览器上进行安装vscode或eclipse,这里统一使用vscode;安装到你的路径下,设置好权限,并且在公用的路径不会有文件,用户也不会有;安装tomcat开发工具,mac的话是sqlserverontopic,windows应该是server端所以必须加上。之后打开chrome或是百度云网页。
在网页的右上角输入chrome浏览器地址,可以看到下面有很多选项,我这里选择从菜单栏中打开。选择installsoftware,之后,下一步点击下一步选择installtargetlocalsoftware,之后安装jdk,这里不再做详细介绍,现在主要看其它的第三个项;安装好jdk之后,可以直接在命令行工具中输入java-version查看jdk版本号,如果没有显示version的话,可以尝试换成后缀名的文件。
接下来按照页面爬取指南进行操作:1.把url写入文件打开python文件夹,一个一个导入你所需要的数据。读取数据fromdatetimeimportdatetimefromrequestsimportrequesturl='/'res=request(url,headers=headers)get_all_urls=request('',headers=headers)withopen('abc.txt','w')asf:json_date=datetime.now()#thedatetimeisundefinedcontent=json_date['raw'][content]text=json_date['raw']['content']ifisinstance(text,json_date):returnnoneelse:returntext2.构建页面路径在open里面新建一个file.py文件。
保存(文件名必须为.txt)后缀名修改为.file。在执行程序时,直接双击运行,在其它情况下,建议放在其它路径下。直接双击程序后,回车,如果程序出现未找到data即说明您的程序需要部署到idc这样的企业级网站才能运行。3.根据页面爬取指南,把url的地址中的"to"列表中所有的cookies打印出来(cookies可以看看官方getcss可以看到)。
res.read().split('/')[0].resize(500,50
0).sort(ascending=false).sort()爬取全部页面(foriinrange(500,50
0):)这样就能爬取到所有的url了。
网页qq抓取什么原理(谷歌AMPAcceleratedMobilePages意思就是“加速移动网页”(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-03-10 15:17
近日,百度新推出的MIP引起了博主的关注。因为明月一直比较关注优化手机博客的浏览体验,所以如今智能手机的渗透率几乎达到了最高水平。如果博主不注意,那真是“奥特曼”,太落伍了!今天明月就带大家通过AMP的实现来了解百度MIP,作为MIP前的热身。
百度 MIP 和 Google AMP 是做什么的?
我们先来看看字面意思,Google AMP(Accelerated Mobile Pages),字面意思是“加速移动网页”,官方的解释是:Accelerated Mobile Page(AMP)是按照开源代码规范设计的网页。经过验证的 AMP 页面缓存在 Google 的 AMP 缓存中,从而可以更快地呈现给用户。我们再来看看百度MIP:MIP(Mobile Instant Page - Mobile Web Accelerator),是一套应用于移动网页的开放技术标准。通过提供 MIP-HTML 规范、MIP-JS 运行环境和 MIP-Cache 页面缓存系统来加速移动网页。可见,它是加速移动网页的技术标准。至于更直观的加速效果,可以借用【什么是MIP?'
说白了就是可以实现手机网页的“二次打开”。
如何使用 MIP、AMP?
不管是MIP还是AMP,其实原理都是通过CDN提高网站手机端的加载速度。效果是“第二次打开”加载。目前移动4G网络的普及,WiFi、网站CDN等技术的使用,这种“加速”的效果有时并不那么明显,但因为是搜索引擎推出的优化方案,无论是谷歌还是百度都强调会在排名和权重方面给予一定的抵消,所以AMP和MIP也成为了当前网站优化中不可或缺的一部分!引起了很多站长的关注。虽然我们是草根博客站长,但这并不妨碍我们追求极致的优化。百度' s MIP目前处于起步阶段,需要对代码进行大量修改才能使用。支持只在代码阶段,可操作性很低(当然不排除你是web开发高手,可以自己做)。谷歌的AMP已经推出很久了,标准化和标准化已经很到位了。尤其是WordPress官方推出了AMP插件,比较简单。我们可以从 AMP 入手,体验一下。WordPress正式推出了AMP插件,比较简单。我们可以从 AMP 入手,体验一下。WordPress正式推出了AMP插件,比较简单。我们可以从 AMP 入手,体验一下。
首先在WordPress中安装一个插件“AMP”。该插件由 Automattic(WordPress 的母公司,WP 之母)推出,用于将 WP 网页转换为 AMP 标准网页。安装“AMP”插件后,可以发现WP中有一个AMP项——“Appearance”。进入后是一个AMP网页的可视化编辑,如下图:
它应该是最近的一个名为 文章 的演示。可以看到自适应主题的手机AMP网页比之前的自适应主题简单很多,内容的可读性还是很好的。显示。
图片也很完美
AMP 插件仅适用于 AMP 标准。如果你想做一些特殊的定制,你需要使用另一个名为“Accelerated Mobile Pages”的插件。这个应该是AMP插件的扩展包,可以在这个插件中设置。AMP页面的logo、样式等如下:
其实这里可以设置的东西不少。除了General,记得在Single中打开Featured Image。这是一个显示“特色图像”的开关。您可以自己体验其他选择。
上面两个插件安装设置好后,只能说是有AMP标准的网页了。Google 如何发现和收录?如何访问 AMP 页面?下面我们来详细解释一下。明月研究了很久才明白,囧!
如何访问 AMP 页面?
如何访问我的 网站 AMP 页面?其实很简单。插件安装好后,在你的网站的链接中添加“/amp”或者“?amp”来查看AMP页面的效果。这里需要强调的是,如果URL以“/”结尾,可以加“?amp”来调用AMP页面,比如首页和分类。具体效果如下:
目前,明月的博客()和主站()已经支持AMP页面,可以使用上述方法在手机上调用AMP页面进行体验。
如何让 Google 发现和 收录?
为了让谷歌发现和收录的AMP页面,你需要在你的WP页面中使用两个标签来指定AMP页面的访问规则,具体代码如下(记得改成你自己的域姓名!):
将上述标记代码放入当前主题的head.php中。然后你所要做的就是等待谷歌抓取。如果想加快爬取等待时间,可以登录谷歌的Search Console(谷歌站长平台),在“爬取”-“爬取方式”中提交AMP页面。该链接让谷歌识别它并“将结果提交给索引”。等了大约48小时后,可以在Search Console(谷歌站长平台)的“搜索结果外观”-Accelerated Mobile Pages中看到谷歌的收录情况!
未抓取 AMP 时 Search Console 中的“搜索结果外观” - Accelerated Mobile Pages 显示“开启”
抓取AMP页面时,可以看到抓取曲线!这意味着获取成功。
此时启用AMP网页的原理与百度MIP相同。百度的 MIP 目前实现起来非常复杂,官方的 WP 插件也消失了。整个主题都要大改,这显然是不现实的。已经有支持 MIP 的 WP 主题。有一个免费版本。如果你想试试,你可以下载体验一下。您可以从[泪雪博客]主题下载Fanly-MIP。 查看全部
网页qq抓取什么原理(谷歌AMPAcceleratedMobilePages意思就是“加速移动网页”(组图))
近日,百度新推出的MIP引起了博主的关注。因为明月一直比较关注优化手机博客的浏览体验,所以如今智能手机的渗透率几乎达到了最高水平。如果博主不注意,那真是“奥特曼”,太落伍了!今天明月就带大家通过AMP的实现来了解百度MIP,作为MIP前的热身。
百度 MIP 和 Google AMP 是做什么的?
我们先来看看字面意思,Google AMP(Accelerated Mobile Pages),字面意思是“加速移动网页”,官方的解释是:Accelerated Mobile Page(AMP)是按照开源代码规范设计的网页。经过验证的 AMP 页面缓存在 Google 的 AMP 缓存中,从而可以更快地呈现给用户。我们再来看看百度MIP:MIP(Mobile Instant Page - Mobile Web Accelerator),是一套应用于移动网页的开放技术标准。通过提供 MIP-HTML 规范、MIP-JS 运行环境和 MIP-Cache 页面缓存系统来加速移动网页。可见,它是加速移动网页的技术标准。至于更直观的加速效果,可以借用【什么是MIP?'

说白了就是可以实现手机网页的“二次打开”。
如何使用 MIP、AMP?
不管是MIP还是AMP,其实原理都是通过CDN提高网站手机端的加载速度。效果是“第二次打开”加载。目前移动4G网络的普及,WiFi、网站CDN等技术的使用,这种“加速”的效果有时并不那么明显,但因为是搜索引擎推出的优化方案,无论是谷歌还是百度都强调会在排名和权重方面给予一定的抵消,所以AMP和MIP也成为了当前网站优化中不可或缺的一部分!引起了很多站长的关注。虽然我们是草根博客站长,但这并不妨碍我们追求极致的优化。百度' s MIP目前处于起步阶段,需要对代码进行大量修改才能使用。支持只在代码阶段,可操作性很低(当然不排除你是web开发高手,可以自己做)。谷歌的AMP已经推出很久了,标准化和标准化已经很到位了。尤其是WordPress官方推出了AMP插件,比较简单。我们可以从 AMP 入手,体验一下。WordPress正式推出了AMP插件,比较简单。我们可以从 AMP 入手,体验一下。WordPress正式推出了AMP插件,比较简单。我们可以从 AMP 入手,体验一下。
首先在WordPress中安装一个插件“AMP”。该插件由 Automattic(WordPress 的母公司,WP 之母)推出,用于将 WP 网页转换为 AMP 标准网页。安装“AMP”插件后,可以发现WP中有一个AMP项——“Appearance”。进入后是一个AMP网页的可视化编辑,如下图:

它应该是最近的一个名为 文章 的演示。可以看到自适应主题的手机AMP网页比之前的自适应主题简单很多,内容的可读性还是很好的。显示。

图片也很完美
AMP 插件仅适用于 AMP 标准。如果你想做一些特殊的定制,你需要使用另一个名为“Accelerated Mobile Pages”的插件。这个应该是AMP插件的扩展包,可以在这个插件中设置。AMP页面的logo、样式等如下:

其实这里可以设置的东西不少。除了General,记得在Single中打开Featured Image。这是一个显示“特色图像”的开关。您可以自己体验其他选择。
上面两个插件安装设置好后,只能说是有AMP标准的网页了。Google 如何发现和收录?如何访问 AMP 页面?下面我们来详细解释一下。明月研究了很久才明白,囧!
如何访问 AMP 页面?
如何访问我的 网站 AMP 页面?其实很简单。插件安装好后,在你的网站的链接中添加“/amp”或者“?amp”来查看AMP页面的效果。这里需要强调的是,如果URL以“/”结尾,可以加“?amp”来调用AMP页面,比如首页和分类。具体效果如下:


目前,明月的博客()和主站()已经支持AMP页面,可以使用上述方法在手机上调用AMP页面进行体验。
如何让 Google 发现和 收录?
为了让谷歌发现和收录的AMP页面,你需要在你的WP页面中使用两个标签来指定AMP页面的访问规则,具体代码如下(记得改成你自己的域姓名!):
将上述标记代码放入当前主题的head.php中。然后你所要做的就是等待谷歌抓取。如果想加快爬取等待时间,可以登录谷歌的Search Console(谷歌站长平台),在“爬取”-“爬取方式”中提交AMP页面。该链接让谷歌识别它并“将结果提交给索引”。等了大约48小时后,可以在Search Console(谷歌站长平台)的“搜索结果外观”-Accelerated Mobile Pages中看到谷歌的收录情况!

未抓取 AMP 时 Search Console 中的“搜索结果外观” - Accelerated Mobile Pages 显示“开启”

抓取AMP页面时,可以看到抓取曲线!这意味着获取成功。
此时启用AMP网页的原理与百度MIP相同。百度的 MIP 目前实现起来非常复杂,官方的 WP 插件也消失了。整个主题都要大改,这显然是不现实的。已经有支持 MIP 的 WP 主题。有一个免费版本。如果你想试试,你可以下载体验一下。您可以从[泪雪博客]主题下载Fanly-MIP。
网页qq抓取什么原理(UA即user-agent原则及调整方法根据上述网站设置)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-06 13:22
UA属性:UA即user-agent,是http协议中的一个属性,代表终端的身份,向服务器表明我在做什么,然后服务器可以根据不同的身份做出不同的反馈结果。
机器人协议:robots.txt 是搜索引擎访问网站时首先访问的文件,用于确定哪些允许爬取,哪些禁止爬取。robots.txt 必须放在网站 根目录下,文件名必须小写。robots.txt的详细写法请参考。百度严格遵守机器人协议。此外,它还支持在网页内容中添加名为 robots、index、follow、nofollow 等指令的元标记。
百度蜘蛛抓取频率原理及调整方法
百度蜘蛛根据上述网站设定的协议爬取网站页面,但不可能对所有网站一视同仁。它会综合考虑网站的实际情况来确定一个抓取配额,每天定量抓取网站内容,也就是我们常说的抓取频率。那么百度搜索引擎是通过哪些指标来判断一个网站的爬取频率呢?主要有四个指标:
1、网站更新频率:更新越频繁,更新越慢,直接影响百度蜘蛛的访问频率
2、网站更新质量:提升的更新频率正好吸引了百度蜘蛛的注意。百度蜘蛛对质量有严格的要求。如果 网站 每天更新的大量内容被百度蜘蛛质量页面判断为低,仍然没有意义。
3. 连通性:网站 安全稳定,保持百度蜘蛛畅通。一直关着百度蜘蛛不是好事
4.站点评价:百度搜索引擎会对每个站点进行评价,这个评价会根据站点情况而变化。里面有很机密的资料。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。
爬取频率间接决定了网站有多少页面可能被数据库收录。这么重要的值,如果不符合站长的期望,应该如何调整呢?百度站长平台提供爬频工具,已完成多次升级。除了提供爬取统计,该工具还提供了“频率调整”功能。站长要求百度蜘蛛根据实际情况增加或减少对百度站长平台的访问量。调整。
百度蜘蛛爬取异常的原因
有一些网页内容优质,用户可以正常访问,但Baiduspider无法正常访问和爬取,导致搜索结果覆盖不足,对百度搜索引擎和网站来说都是一种损失。百度称这种情况为“抢”。对于大量内容无法正常抓取的网站,百度搜索引擎会认为网站存在用户体验缺陷,降低对网站的评价,在爬取、索引和排序方面都会受到一定程度的负面影响,最终会影响到网站从百度获得的流量。
以下是爬取异常的一些常见原因:
1.服务器连接异常
服务器连接异常有两种情况:一种是网站不稳定,百度蜘蛛在尝试连接你的网站服务器时暂时无法连接;另一个是百度蜘蛛一直无法连接到你的网站的服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。还有可能是你的网站没有正常运行,请检查网站的web服务器(如apache、iis)是否安装运行正常,用浏览器查看主页面可以正常访问。您的 网站 和主机也可能阻止了百度蜘蛛的访问,您需要检查您的 网站 和主机的防火墙。
2、网络运营商异常:网络运营商分为电信和联通两类。百度蜘蛛无法通过中国电信或中国网通访问您的网站。如果出现这种情况,需要联系网络服务运营商,或者购买双线服务空间或者购买cdn服务。
3、DNS异常:当Baiduspider无法解析您的网站 IP时,会出现DNS异常。可能你的网站IP地址错误,或者你的域名服务商屏蔽了百度蜘蛛。请使用 WHOIS 或主机检查您的 网站IP 地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商更新您的 IP 地址。
4、IP封禁:IP封禁是:限制网络的出口IP地址,禁止该IP段内的用户访问内容,这里特意禁止BaiduspiderIP。仅当您的 网站 不希望百度蜘蛛访问时,才需要此设置。如果您想让百度蜘蛛访问您的网站,请检查相关设置中是否错误添加了百度蜘蛛IP。也有可能是你网站所在的空间服务商封杀了百度IP。在这种情况下,您需要联系服务提供商更改设置。
5、UA禁止:UA是User-Agent,服务器通过UA识别访问者的身份。当网站返回异常页面(如403、500)或跳转到其他页面进行指定UA的访问时,属于UA禁令。当你的网站不想要百度蜘蛛时这个设置只有在访问时才需要,如果你想让百度蜘蛛访问你的网站,请检查useragent相关设置中是否有百度蜘蛛UA,并及时修改。
6、死链接:无效且不能为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接:
协议死链接:页面的TCP协议状态/HTTP协议状态明确表示的死链接,如404、403、503状态等。
内容死链接:服务器返回正常状态,但内容已更改为不存在、已删除或需要权限等与原创内容无关的信息页面。
对于死链接,我们建议网站使用协议死链接,通过百度站长平台——死链接工具提交给百度,这样百度可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
7.异常跳转:将网络请求重定向到另一个位置是跳转。异常跳转指以下几种情况:
1)当前页面为无效页面(删除内容、死链接等),直接跳转到上一个目录或首页,百度建议站长删除无效页面的入口超链接
2)跳转到错误或无效页面
注意:长期重定向到其他域名,如网站改域名,百度推荐使用301重定向协议进行设置。
8. 其他例外:
1)百度referrer异常:网页返回的行为与来自百度的referrer的正常内容不同。
2)百度UA异常:网页返回百度UA的行为与页面原创内容不同。
3)JS跳转异常:网页加载了百度无法识别的JS跳转代码,导致用户通过搜索结果进入页面后跳转。
4)压力过大导致的意外封禁:百度会根据网站规模、流量等信息自动设置合理的抓取压力。但在异常情况下,如压力控制异常时,服务器会根据自身负载进行保护性的偶尔封禁。在这种情况下,请在返回码中返回 503(表示“服务不可用”),这样百度蜘蛛会在一段时间后再次尝试抓取链接。如果 网站 是空闲的,它将被成功爬取。
判断新链接的重要性
好了,上面我们讲了影响百度蜘蛛正常爬取的原因,现在来说说百度蜘蛛的一些判断原则。建库前,Baiduspide会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立一个图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对这么多新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值:
1.独特的内容,百度搜索引擎喜欢独特的内容
2. 主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4.广告合适
二、链接的重要性:
1.目录级别——浅层优先
2. 网站链接的受欢迎程度
百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1.及时有价值的页面:在这里,及时性和价值并列,缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、内容优质的专页:专页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者是一些新鲜的内容,比如浏览量和评论,可以添加到用户。更丰富、更全面的内容。
3、高价值的原创内容页面:百度将原创定义为花费一定成本、积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4.重要的个人页面:这里只是一个例子,科比在新浪微博上开了一个账号,他需要不经常更新,但对于百度来说,它仍然是一个非常重要的页面。
哪些页面不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的网页:百度不需要收录互联网上已有的内容。
2. 主要内容为空、短的网页
1)有些内容使用了百度蜘蛛无法解析的技术,比如JS、AJAX等,虽然用户可以看到丰富的内容,但还是会被搜索引擎抛弃
2)加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
3)很多主体不太突出的网页,即使被爬回来,也会在这个链接中被丢弃。 查看全部
网页qq抓取什么原理(UA即user-agent原则及调整方法根据上述网站设置)
UA属性:UA即user-agent,是http协议中的一个属性,代表终端的身份,向服务器表明我在做什么,然后服务器可以根据不同的身份做出不同的反馈结果。
机器人协议:robots.txt 是搜索引擎访问网站时首先访问的文件,用于确定哪些允许爬取,哪些禁止爬取。robots.txt 必须放在网站 根目录下,文件名必须小写。robots.txt的详细写法请参考。百度严格遵守机器人协议。此外,它还支持在网页内容中添加名为 robots、index、follow、nofollow 等指令的元标记。
百度蜘蛛抓取频率原理及调整方法
百度蜘蛛根据上述网站设定的协议爬取网站页面,但不可能对所有网站一视同仁。它会综合考虑网站的实际情况来确定一个抓取配额,每天定量抓取网站内容,也就是我们常说的抓取频率。那么百度搜索引擎是通过哪些指标来判断一个网站的爬取频率呢?主要有四个指标:
1、网站更新频率:更新越频繁,更新越慢,直接影响百度蜘蛛的访问频率
2、网站更新质量:提升的更新频率正好吸引了百度蜘蛛的注意。百度蜘蛛对质量有严格的要求。如果 网站 每天更新的大量内容被百度蜘蛛质量页面判断为低,仍然没有意义。
3. 连通性:网站 安全稳定,保持百度蜘蛛畅通。一直关着百度蜘蛛不是好事
4.站点评价:百度搜索引擎会对每个站点进行评价,这个评价会根据站点情况而变化。里面有很机密的资料。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。
爬取频率间接决定了网站有多少页面可能被数据库收录。这么重要的值,如果不符合站长的期望,应该如何调整呢?百度站长平台提供爬频工具,已完成多次升级。除了提供爬取统计,该工具还提供了“频率调整”功能。站长要求百度蜘蛛根据实际情况增加或减少对百度站长平台的访问量。调整。
百度蜘蛛爬取异常的原因
有一些网页内容优质,用户可以正常访问,但Baiduspider无法正常访问和爬取,导致搜索结果覆盖不足,对百度搜索引擎和网站来说都是一种损失。百度称这种情况为“抢”。对于大量内容无法正常抓取的网站,百度搜索引擎会认为网站存在用户体验缺陷,降低对网站的评价,在爬取、索引和排序方面都会受到一定程度的负面影响,最终会影响到网站从百度获得的流量。
以下是爬取异常的一些常见原因:
1.服务器连接异常
服务器连接异常有两种情况:一种是网站不稳定,百度蜘蛛在尝试连接你的网站服务器时暂时无法连接;另一个是百度蜘蛛一直无法连接到你的网站的服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。还有可能是你的网站没有正常运行,请检查网站的web服务器(如apache、iis)是否安装运行正常,用浏览器查看主页面可以正常访问。您的 网站 和主机也可能阻止了百度蜘蛛的访问,您需要检查您的 网站 和主机的防火墙。
2、网络运营商异常:网络运营商分为电信和联通两类。百度蜘蛛无法通过中国电信或中国网通访问您的网站。如果出现这种情况,需要联系网络服务运营商,或者购买双线服务空间或者购买cdn服务。
3、DNS异常:当Baiduspider无法解析您的网站 IP时,会出现DNS异常。可能你的网站IP地址错误,或者你的域名服务商屏蔽了百度蜘蛛。请使用 WHOIS 或主机检查您的 网站IP 地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商更新您的 IP 地址。
4、IP封禁:IP封禁是:限制网络的出口IP地址,禁止该IP段内的用户访问内容,这里特意禁止BaiduspiderIP。仅当您的 网站 不希望百度蜘蛛访问时,才需要此设置。如果您想让百度蜘蛛访问您的网站,请检查相关设置中是否错误添加了百度蜘蛛IP。也有可能是你网站所在的空间服务商封杀了百度IP。在这种情况下,您需要联系服务提供商更改设置。
5、UA禁止:UA是User-Agent,服务器通过UA识别访问者的身份。当网站返回异常页面(如403、500)或跳转到其他页面进行指定UA的访问时,属于UA禁令。当你的网站不想要百度蜘蛛时这个设置只有在访问时才需要,如果你想让百度蜘蛛访问你的网站,请检查useragent相关设置中是否有百度蜘蛛UA,并及时修改。
6、死链接:无效且不能为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接:
协议死链接:页面的TCP协议状态/HTTP协议状态明确表示的死链接,如404、403、503状态等。
内容死链接:服务器返回正常状态,但内容已更改为不存在、已删除或需要权限等与原创内容无关的信息页面。
对于死链接,我们建议网站使用协议死链接,通过百度站长平台——死链接工具提交给百度,这样百度可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
7.异常跳转:将网络请求重定向到另一个位置是跳转。异常跳转指以下几种情况:
1)当前页面为无效页面(删除内容、死链接等),直接跳转到上一个目录或首页,百度建议站长删除无效页面的入口超链接
2)跳转到错误或无效页面
注意:长期重定向到其他域名,如网站改域名,百度推荐使用301重定向协议进行设置。
8. 其他例外:
1)百度referrer异常:网页返回的行为与来自百度的referrer的正常内容不同。
2)百度UA异常:网页返回百度UA的行为与页面原创内容不同。
3)JS跳转异常:网页加载了百度无法识别的JS跳转代码,导致用户通过搜索结果进入页面后跳转。
4)压力过大导致的意外封禁:百度会根据网站规模、流量等信息自动设置合理的抓取压力。但在异常情况下,如压力控制异常时,服务器会根据自身负载进行保护性的偶尔封禁。在这种情况下,请在返回码中返回 503(表示“服务不可用”),这样百度蜘蛛会在一段时间后再次尝试抓取链接。如果 网站 是空闲的,它将被成功爬取。
判断新链接的重要性
好了,上面我们讲了影响百度蜘蛛正常爬取的原因,现在来说说百度蜘蛛的一些判断原则。建库前,Baiduspide会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立一个图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对这么多新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值:
1.独特的内容,百度搜索引擎喜欢独特的内容
2. 主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4.广告合适
二、链接的重要性:
1.目录级别——浅层优先
2. 网站链接的受欢迎程度
百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1.及时有价值的页面:在这里,及时性和价值并列,缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、内容优质的专页:专页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者是一些新鲜的内容,比如浏览量和评论,可以添加到用户。更丰富、更全面的内容。
3、高价值的原创内容页面:百度将原创定义为花费一定成本、积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4.重要的个人页面:这里只是一个例子,科比在新浪微博上开了一个账号,他需要不经常更新,但对于百度来说,它仍然是一个非常重要的页面。
哪些页面不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的网页:百度不需要收录互联网上已有的内容。
2. 主要内容为空、短的网页
1)有些内容使用了百度蜘蛛无法解析的技术,比如JS、AJAX等,虽然用户可以看到丰富的内容,但还是会被搜索引擎抛弃
2)加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
3)很多主体不太突出的网页,即使被爬回来,也会在这个链接中被丢弃。
网页qq抓取什么原理( 爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-05 14:24
爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人))
01 什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
Web 爬虫通过从 Internet 上的 网站 服务器上爬取内容来工作。它是用计算机语言编写的程序或脚本,自动从互联网上获取信息或数据,扫描并抓取每个所需页面上的某些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市面上流行的采集器软件都是利用网络爬虫的原理或功能。
▲图 2-1 网络爬虫象形图
02 爬行动物的意义
如今,大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为、自身产品的不足、竞争对手的信息。所有这一切的首要条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就有决策的主动权。网络爬虫的应用领域很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1)抓取各大电商公司的产品销售信息和用户评价网站进行分析,如图2-2所示。
▲图2-2 电商产品销售信息网站
2)分析大众点评、美团等餐饮品类网站用户的消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区住房占比,学区房价格比普通二手房高多少,如图2-4所示。
▲图2-4 学区住房比例与价格对比
以上数据是由ForeSpider数据采集软件爬下来的。有兴趣的读者可以尝试自己爬一些数据。
03 爬虫的原理
我们通常将网络爬虫的组件分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取链接队列、网页库等。网络爬虫的各个模块可以组成一个循环系统,从而不断的分析和抓取。
爬虫的工作原理可以简单地解释为首先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 爬虫示意图
爬虫工作的基本流程:
首先,选择互联网中的一部分网页,将这些网页的链接地址作为种子URL;
将这些种子URL放入待爬取URL队列,爬虫从待爬取URL队列中依次读取;
通过DNS解析URL;
将链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器下载网页;
下载的网页是网页文档的形式;
提取 Web 文档中的 URL;
过滤掉已经爬取过的网址;
继续对没有被爬取的URL进行爬取,直到待爬取的URL队列为空。
04 爬虫技术的种类
专注网络爬虫是一种“面向特定主题需求”的爬虫程序,而通用网络爬虫是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分,主要目的是在网站上下载网页互联网到本地,形成互联网内容的镜像备份。
增量爬取是指对某个站点的数据进行爬取。当网站的新数据或站点数据发生变化时,会自动捕获新增或变化的数据。
网页按存在方式可分为表层网页(surface Web)和深层网页(deep Web,又称隐形网页或隐藏网页)。
表面网页是指可以被传统搜索引擎检索到的页面,即主要由可以通过超链接到达的静态网页组成的网页。
深层网页是那些大部分内容无法通过静态链接访问的网页,隐藏在搜索表单后面,只有提交一些 关键词 的用户才能访问。
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等领域的教学和科研工作。
本文摘自《Python网络爬虫技术与实践》,经出版社授权发布。 查看全部
网页qq抓取什么原理(
爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人))
01 什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
Web 爬虫通过从 Internet 上的 网站 服务器上爬取内容来工作。它是用计算机语言编写的程序或脚本,自动从互联网上获取信息或数据,扫描并抓取每个所需页面上的某些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市面上流行的采集器软件都是利用网络爬虫的原理或功能。
▲图 2-1 网络爬虫象形图
02 爬行动物的意义
如今,大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为、自身产品的不足、竞争对手的信息。所有这一切的首要条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就有决策的主动权。网络爬虫的应用领域很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1)抓取各大电商公司的产品销售信息和用户评价网站进行分析,如图2-2所示。
▲图2-2 电商产品销售信息网站
2)分析大众点评、美团等餐饮品类网站用户的消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区住房占比,学区房价格比普通二手房高多少,如图2-4所示。
▲图2-4 学区住房比例与价格对比
以上数据是由ForeSpider数据采集软件爬下来的。有兴趣的读者可以尝试自己爬一些数据。
03 爬虫的原理
我们通常将网络爬虫的组件分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取链接队列、网页库等。网络爬虫的各个模块可以组成一个循环系统,从而不断的分析和抓取。
爬虫的工作原理可以简单地解释为首先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 爬虫示意图
爬虫工作的基本流程:
首先,选择互联网中的一部分网页,将这些网页的链接地址作为种子URL;
将这些种子URL放入待爬取URL队列,爬虫从待爬取URL队列中依次读取;
通过DNS解析URL;
将链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器下载网页;
下载的网页是网页文档的形式;
提取 Web 文档中的 URL;
过滤掉已经爬取过的网址;
继续对没有被爬取的URL进行爬取,直到待爬取的URL队列为空。
04 爬虫技术的种类
专注网络爬虫是一种“面向特定主题需求”的爬虫程序,而通用网络爬虫是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分,主要目的是在网站上下载网页互联网到本地,形成互联网内容的镜像备份。
增量爬取是指对某个站点的数据进行爬取。当网站的新数据或站点数据发生变化时,会自动捕获新增或变化的数据。
网页按存在方式可分为表层网页(surface Web)和深层网页(deep Web,又称隐形网页或隐藏网页)。
表面网页是指可以被传统搜索引擎检索到的页面,即主要由可以通过超链接到达的静态网页组成的网页。
深层网页是那些大部分内容无法通过静态链接访问的网页,隐藏在搜索表单后面,只有提交一些 关键词 的用户才能访问。
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等领域的教学和科研工作。
本文摘自《Python网络爬虫技术与实践》,经出版社授权发布。
网页qq抓取什么原理(微信屏蔽网页的依据是什么?明面上的原因有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-02 04:15
微信屏蔽网页的依据是什么?
显而易见的原因是,当网页内容中收录诱导、欺诈等不和谐内容时,被用户举报时会被关闭。其实这只是表面现象,因为我们可以明显感觉到,在不同的阶段,相同的内容被屏蔽的频率是非常不同的。的。微信是一家互联网公司。如果使用大量客户手动判断是否屏蔽,成本太高。估计10000个客服都处理不了,而且据我所知,很多正常的页面也会无缘无故被封。应该恶意举报。如果是客服判断的话,人工上报不会屏蔽常规网站吧?
很明显的结论是,微信一定是以技术识别为主。只有达到一定报告水平且在技术上无法阻止的页面才会达到人工审核的程度。报告的数量只是一个判断因素,并不能决定一个网页的生死。就像百度判断网站的权重一样,会有一套复杂的因素和一堆算法判断标准。
另一个关键因素是关键词 的识别。被阻止的页面将由算法识别。当您使用的程序源代码中收录的功能与已被和谐或频率较高的功能高度相似时,您将被自动和谐。这很像病毒签名算法。
其实说白了,微信现在是霸主家族,想要屏蔽你的理由有100个。作为站长,我们应该怎么做才能防止微信域名被屏蔽呢?让我们稍后再讨论。感谢浏览。 查看全部
网页qq抓取什么原理(微信屏蔽网页的依据是什么?明面上的原因有哪些?)
微信屏蔽网页的依据是什么?
显而易见的原因是,当网页内容中收录诱导、欺诈等不和谐内容时,被用户举报时会被关闭。其实这只是表面现象,因为我们可以明显感觉到,在不同的阶段,相同的内容被屏蔽的频率是非常不同的。的。微信是一家互联网公司。如果使用大量客户手动判断是否屏蔽,成本太高。估计10000个客服都处理不了,而且据我所知,很多正常的页面也会无缘无故被封。应该恶意举报。如果是客服判断的话,人工上报不会屏蔽常规网站吧?

很明显的结论是,微信一定是以技术识别为主。只有达到一定报告水平且在技术上无法阻止的页面才会达到人工审核的程度。报告的数量只是一个判断因素,并不能决定一个网页的生死。就像百度判断网站的权重一样,会有一套复杂的因素和一堆算法判断标准。
另一个关键因素是关键词 的识别。被阻止的页面将由算法识别。当您使用的程序源代码中收录的功能与已被和谐或频率较高的功能高度相似时,您将被自动和谐。这很像病毒签名算法。
其实说白了,微信现在是霸主家族,想要屏蔽你的理由有100个。作为站长,我们应该怎么做才能防止微信域名被屏蔽呢?让我们稍后再讨论。感谢浏览。
网页qq抓取什么原理(这篇通过requests实现腾讯新闻爬虫的方法小编分享(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-02 04:13
标签下
之后,我们将处理我们刚刚请求的 html 代码。这时候,我们就需要用到beautifulsoap库了。
汤=美丽汤(wbdata,'lxml')
这一行的意思是解析获取到的信息,或者把lxml库换成html.parser库,效果是一样的
news_titles = soup.select("div.text > em.f14 > a.linkto")
这一行使用刚刚解析的soup对象来选择我们需要的标签,返回值是一个列表。该列表收录我们需要的所有标签内容。也可以使用 beautifulsoup 中的 find() 方法或 findall() 方法来选择标签。
最后使用for in遍历列表,取出标签中的内容(新闻标题)和标签中href的值(新闻URL),存入数据字典
对于 news_titles 中的 n:
标题 = n.get_text()
链接 = n.get("href")
数据 = {
'标题':标题,
“链接”:链接
}
数据存储所有新闻标题和链接。下图显示了一些结果。
这样一个爬虫就完成了,当然这只是最简单的爬虫。如果深入爬虫,有很多模拟浏览器行为、安全问题、效率优化、多线程等需要考虑。不得不说,爬虫是个深坑。
python中的爬虫可以通过各种库或框架来完成,请求只是比较常用的一种。还有很多其他语言的爬虫库,比如php可以使用curl库。爬虫的原理是一样的,只是不同语言和库使用的方法不同。
以上腾讯新闻爬虫通过requests实现的python实现就是小编分享的全部内容。希望能给大家一个参考,希望大家多多支持万茜。
如果您对本文有任何疑问或有什么想说的,请点击留言回复,万千网友为您解答! 查看全部
网页qq抓取什么原理(这篇通过requests实现腾讯新闻爬虫的方法小编分享(图))
标签下
之后,我们将处理我们刚刚请求的 html 代码。这时候,我们就需要用到beautifulsoap库了。
汤=美丽汤(wbdata,'lxml')
这一行的意思是解析获取到的信息,或者把lxml库换成html.parser库,效果是一样的
news_titles = soup.select("div.text > em.f14 > a.linkto")
这一行使用刚刚解析的soup对象来选择我们需要的标签,返回值是一个列表。该列表收录我们需要的所有标签内容。也可以使用 beautifulsoup 中的 find() 方法或 findall() 方法来选择标签。
最后使用for in遍历列表,取出标签中的内容(新闻标题)和标签中href的值(新闻URL),存入数据字典
对于 news_titles 中的 n:
标题 = n.get_text()
链接 = n.get("href")
数据 = {
'标题':标题,
“链接”:链接
}
数据存储所有新闻标题和链接。下图显示了一些结果。

这样一个爬虫就完成了,当然这只是最简单的爬虫。如果深入爬虫,有很多模拟浏览器行为、安全问题、效率优化、多线程等需要考虑。不得不说,爬虫是个深坑。
python中的爬虫可以通过各种库或框架来完成,请求只是比较常用的一种。还有很多其他语言的爬虫库,比如php可以使用curl库。爬虫的原理是一样的,只是不同语言和库使用的方法不同。
以上腾讯新闻爬虫通过requests实现的python实现就是小编分享的全部内容。希望能给大家一个参考,希望大家多多支持万茜。
如果您对本文有任何疑问或有什么想说的,请点击留言回复,万千网友为您解答!
网页qq抓取什么原理( 搜索引擎爬虫的工作流程及对照的思考方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-01 19:13
搜索引擎爬虫的工作流程及对照的思考方法)
搜索引擎爬虫的工作流程是SEO的基础篇章,也是每一个从事SEO工作的同事都应该掌握的必备知识。PHPSEO刚刚整理完毕并画了一张图,让你即使不懂技术也能了解搜索引擎爬虫的工作流程。一起来聊聊吧。
如上图所示,请您在阅读以下内容时与我一起思考。
1、种子网址
1、所谓种子URL,是指开头选择的URL地址。大多数情况下,网站的首页、频道页等内容更丰富的页面都会作为种子URL;
然后将这些种子网址放入要爬取的网址列表中;
2、要爬取的url列表
爬虫从要爬取的 URL 列表中一一读取。在读取URL的过程中,会通过DNS解析URL,并将URL地址转换为网站服务器IP地址+相对路径的方法;
3、网页下载器
接下来,把这个地址交给网页下载器(所谓网页下载器,顾名思义,就是负责下载网页内容的模块;
4、源码
对于下载到本地的网页,也就是我们网页的源代码,一方面网页要保存在网页库中,另一方面又会从下载的网页中重新提取URL地址.
5、提取网址
新提取的 URL 地址会在已爬取的 URL 列表中进行比较,以检查该网页是否已被爬取。
6、新的URL存放在待爬取队列中
如果网页还没有被爬取,新的URL地址会被放在待爬取URL列表的最后,等待被爬取。
这样,爬虫就完成了整个爬取过程,直到待爬队列为空。
然后下载的网页会进入一定的分析,分析后我们就能看到收录的结果。
对于真正的爬虫来说,哪些页面先爬,哪些页面后爬,哪些页面不爬,都有一定的策略。这里介绍一个比较常见的爬虫爬取过程。作为我们中的 SEO,我们已经足够了解这一点。 查看全部
网页qq抓取什么原理(
搜索引擎爬虫的工作流程及对照的思考方法)

搜索引擎爬虫的工作流程是SEO的基础篇章,也是每一个从事SEO工作的同事都应该掌握的必备知识。PHPSEO刚刚整理完毕并画了一张图,让你即使不懂技术也能了解搜索引擎爬虫的工作流程。一起来聊聊吧。
如上图所示,请您在阅读以下内容时与我一起思考。
1、种子网址
1、所谓种子URL,是指开头选择的URL地址。大多数情况下,网站的首页、频道页等内容更丰富的页面都会作为种子URL;
然后将这些种子网址放入要爬取的网址列表中;
2、要爬取的url列表
爬虫从要爬取的 URL 列表中一一读取。在读取URL的过程中,会通过DNS解析URL,并将URL地址转换为网站服务器IP地址+相对路径的方法;
3、网页下载器
接下来,把这个地址交给网页下载器(所谓网页下载器,顾名思义,就是负责下载网页内容的模块;
4、源码
对于下载到本地的网页,也就是我们网页的源代码,一方面网页要保存在网页库中,另一方面又会从下载的网页中重新提取URL地址.
5、提取网址
新提取的 URL 地址会在已爬取的 URL 列表中进行比较,以检查该网页是否已被爬取。
6、新的URL存放在待爬取队列中
如果网页还没有被爬取,新的URL地址会被放在待爬取URL列表的最后,等待被爬取。
这样,爬虫就完成了整个爬取过程,直到待爬队列为空。
然后下载的网页会进入一定的分析,分析后我们就能看到收录的结果。
对于真正的爬虫来说,哪些页面先爬,哪些页面后爬,哪些页面不爬,都有一定的策略。这里介绍一个比较常见的爬虫爬取过程。作为我们中的 SEO,我们已经足够了解这一点。
网页qq抓取什么原理(被搜索引擎收录后会出现什么效果呢?的网站seo)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-03-01 19:11
连最初级的站长都知道网站一定要写titletitle,这也是最基础的SEO,但是如果一个页面没有写title,那么收录会有什么效果通过搜索引擎??
本周的网站seo实例选择了一个没有title的网站给大家分析流程。
今天要讲一个老问题,就是如果我不写一个大搜索引擎,网站title标题怎么爬网站titles和descriptions。例如。
这个网站是一个没有网站标题的网站,那么百度、谷歌等搜索引擎会如何抓取呢?你可以搜索它。如果他直接搜索 URL,他会显示珠宝。如果他搜索其他相关词,他会显示它,但是打开它的网站源代码后,你会找到它。网站上面没有汉字,所以可以说汉字很少。
这张网站百度截图截图
网站google 快照的屏幕截图
当一些学生开始研究 网站 实例时,他们开始失去理智。既然是做seo的,就一定要懂得研究一些细节。然后我们分析分析他是如何实现标题显示的。
上面的网站截图,想必大家都看到了。谷歌有明显的规则。谷歌抢了网站内部文字的前几个字,那为什么谷歌只抢他的两个字,就是明月呢?主要问题是他的导入链接,你可以观察他的导入链接。链接文字无外乎几种,包括(名牌饰品、日月饰品、日月饰品、浙江日月等),然后这里google计算外链,抓取中间值外部文本默认是一轮明月,所以有人这么说。为什么他不算“日月网站”!在这里你可以看到他上面的文字是太阳和月亮网站欢迎你!就是这样的文字。那么你可以认为他们的外链可能有网站之类的字眼 还有太阳和月亮网站?首先我们可以确定没有,因为这个词没有流量,不需要做外链。所以这里google自然默认为“sun and moon”。
那么我们来说说百度的标题是怎么出现的。通过以上谷歌的案例分析,我们这里应该有不少人已经想到了原理是什么。百度不读取网站中唯一但不相关的文字,而是直接抓取外部输入的链接文字。有一些相关的 网站 实验。如果外部导入的文本与网站的内部文本有关系,那么网站会抓取页面中的文本。如果 网站 中的唯一文本不收录导入链接文本部分。然后百度这里默认自动导入文本。
其他引擎,比如搜狗,直接显示无标题网站,而有道的读取方式和百度一样。
这个拼写对 网站 有用吗?现在经过测试,对网站的排名并没有太大影响,但是对于网站来说并不是一个好的做法,因为毕竟搜狗等搜索引擎是读不到标题的。而网站形象也是一大损失。 查看全部
网页qq抓取什么原理(被搜索引擎收录后会出现什么效果呢?的网站seo)
连最初级的站长都知道网站一定要写titletitle,这也是最基础的SEO,但是如果一个页面没有写title,那么收录会有什么效果通过搜索引擎??
本周的网站seo实例选择了一个没有title的网站给大家分析流程。
今天要讲一个老问题,就是如果我不写一个大搜索引擎,网站title标题怎么爬网站titles和descriptions。例如。
这个网站是一个没有网站标题的网站,那么百度、谷歌等搜索引擎会如何抓取呢?你可以搜索它。如果他直接搜索 URL,他会显示珠宝。如果他搜索其他相关词,他会显示它,但是打开它的网站源代码后,你会找到它。网站上面没有汉字,所以可以说汉字很少。
这张网站百度截图截图
网站google 快照的屏幕截图
当一些学生开始研究 网站 实例时,他们开始失去理智。既然是做seo的,就一定要懂得研究一些细节。然后我们分析分析他是如何实现标题显示的。
上面的网站截图,想必大家都看到了。谷歌有明显的规则。谷歌抢了网站内部文字的前几个字,那为什么谷歌只抢他的两个字,就是明月呢?主要问题是他的导入链接,你可以观察他的导入链接。链接文字无外乎几种,包括(名牌饰品、日月饰品、日月饰品、浙江日月等),然后这里google计算外链,抓取中间值外部文本默认是一轮明月,所以有人这么说。为什么他不算“日月网站”!在这里你可以看到他上面的文字是太阳和月亮网站欢迎你!就是这样的文字。那么你可以认为他们的外链可能有网站之类的字眼 还有太阳和月亮网站?首先我们可以确定没有,因为这个词没有流量,不需要做外链。所以这里google自然默认为“sun and moon”。
那么我们来说说百度的标题是怎么出现的。通过以上谷歌的案例分析,我们这里应该有不少人已经想到了原理是什么。百度不读取网站中唯一但不相关的文字,而是直接抓取外部输入的链接文字。有一些相关的 网站 实验。如果外部导入的文本与网站的内部文本有关系,那么网站会抓取页面中的文本。如果 网站 中的唯一文本不收录导入链接文本部分。然后百度这里默认自动导入文本。
其他引擎,比如搜狗,直接显示无标题网站,而有道的读取方式和百度一样。
这个拼写对 网站 有用吗?现在经过测试,对网站的排名并没有太大影响,但是对于网站来说并不是一个好的做法,因为毕竟搜狗等搜索引擎是读不到标题的。而网站形象也是一大损失。
网页qq抓取什么原理(SEO从业者收录网页的四个阶段,你的网站处于哪个阶段?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-28 04:11
作为一名SEO从业者,不仅要被搜索引擎爬取,还要成为收录,最重要的是收录之后要有好的排名,本文将简要分析搜索引擎< @收录 网页的四个阶段。每个网站和每个网页的排名都不一样,你的网站在哪个阶段?
网页收录第一阶段:大小
搜索引擎的网页爬取采用“大小通吃”的策略,即将网页中能找到的链接一一添加到待爬取的URL中,新爬取的网页中的URL被机械提取。虽然这种方法比较老,但是效果很好,这也是很多站长响应蜘蛛访问的原因,但是没有收录的理由,这只是第一阶段。
页面收录第 2 阶段:页面评级
第二阶段是评价网页的重要性。PageRank 是一种著名的链接分析算法,可以用来衡量网页的重要性。站长自然可以利用PageRank的思想对网址进行排名。这就是你所热衷的。据一位朋友介绍,在中国,“外链”市场每年有上亿元的规模。
爬虫的目的是下载网页,但PageRank是全局算法,即当所有网页都下载完毕后,计算结果才可靠。对于中小网站,如果服务器质量不好,如果在爬取过程中只看到部分内容,在爬取阶段是不可能得到可靠的PageRank分数的。
网页收录第三阶段:OCIP 策略
OCIP 策略更像是对 PageRank 算法的改进。在算法开始之前,每个网页都会获得相同的“现金”。每当某个页面A被下载时,A将他的“现金”平均分配给该页面所收录的链接页面,并清空他的“现金”。这就是为什么您导出的链接越少,权重越高的原因之一。
对于要爬取的网页,会按照手头现金数量进行排序,现金最多的网页会被优先下载。OCIP 与 PageRank 大致相同。不同的是PageRank每次都需要迭代计算,而OCIP则不需要,所以计算速度比PageRank快很多,适合实时计算使用。这可能是很多网页都有“秒”的原因。
网页收录第四阶段:大网站优先策略
大型网站的优先级的想法非常简单。网页的重要性以 网站 为单位衡量。对于URL队列中待抓取的网页,按照网站进行分类,如果哪个网站等待下载的页面最多,则先下载这些链接。基本思想是“倾向于先下载大的 网站URL”。因为大的 网站 往往收录更多的页面。鉴于大型网站往往是知名网站,其网页质量普遍较高,这个想法虽然简单,但有一定的根据。
实验表明,该算法虽然简单粗暴,但可以收录高质量的网页,非常有效。这也是网站的很多内容被转发,而大展却排在你前面的最重要的原因之一。 查看全部
网页qq抓取什么原理(SEO从业者收录网页的四个阶段,你的网站处于哪个阶段?)
作为一名SEO从业者,不仅要被搜索引擎爬取,还要成为收录,最重要的是收录之后要有好的排名,本文将简要分析搜索引擎< @收录 网页的四个阶段。每个网站和每个网页的排名都不一样,你的网站在哪个阶段?
网页收录第一阶段:大小
搜索引擎的网页爬取采用“大小通吃”的策略,即将网页中能找到的链接一一添加到待爬取的URL中,新爬取的网页中的URL被机械提取。虽然这种方法比较老,但是效果很好,这也是很多站长响应蜘蛛访问的原因,但是没有收录的理由,这只是第一阶段。
页面收录第 2 阶段:页面评级
第二阶段是评价网页的重要性。PageRank 是一种著名的链接分析算法,可以用来衡量网页的重要性。站长自然可以利用PageRank的思想对网址进行排名。这就是你所热衷的。据一位朋友介绍,在中国,“外链”市场每年有上亿元的规模。
爬虫的目的是下载网页,但PageRank是全局算法,即当所有网页都下载完毕后,计算结果才可靠。对于中小网站,如果服务器质量不好,如果在爬取过程中只看到部分内容,在爬取阶段是不可能得到可靠的PageRank分数的。
网页收录第三阶段:OCIP 策略
OCIP 策略更像是对 PageRank 算法的改进。在算法开始之前,每个网页都会获得相同的“现金”。每当某个页面A被下载时,A将他的“现金”平均分配给该页面所收录的链接页面,并清空他的“现金”。这就是为什么您导出的链接越少,权重越高的原因之一。
对于要爬取的网页,会按照手头现金数量进行排序,现金最多的网页会被优先下载。OCIP 与 PageRank 大致相同。不同的是PageRank每次都需要迭代计算,而OCIP则不需要,所以计算速度比PageRank快很多,适合实时计算使用。这可能是很多网页都有“秒”的原因。
网页收录第四阶段:大网站优先策略
大型网站的优先级的想法非常简单。网页的重要性以 网站 为单位衡量。对于URL队列中待抓取的网页,按照网站进行分类,如果哪个网站等待下载的页面最多,则先下载这些链接。基本思想是“倾向于先下载大的 网站URL”。因为大的 网站 往往收录更多的页面。鉴于大型网站往往是知名网站,其网页质量普遍较高,这个想法虽然简单,但有一定的根据。
实验表明,该算法虽然简单粗暴,但可以收录高质量的网页,非常有效。这也是网站的很多内容被转发,而大展却排在你前面的最重要的原因之一。
网页qq抓取什么原理(网页qq抓取什么原理?(一个二维qq软件))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-27 21:02
网页qq抓取什么原理?从我的经验来说,还是通过分析请求的参数来判断用户请求的url,有点像爬虫技术的代理ip池技术了。通过一个特定的url就可以定位出所有上传的文件,还是比较好用的。我这里要写的是一个二维qq抓取软件,只要一行代码就可以上传多个链接(一个文件里包含多个链接),这就要求要使用一个已有的二维qq号码进行登录。下面是抓取结果:。
一个二维码打开任意网站,附带着链接地址,
我以前也有这个困惑,然后上各种网站搜索,所以应该可以说一下,不对的地方欢迎大家补充。二维码扫描上传文件的原理,肯定是通过发送给服务器的二维码(网址)来进行解析。但是二维码究竟应该解析出哪些内容呢?我们可以先根据能想到的三种情况来分析,
一、服务器返回给客户端一个json文件,比如user-agent.json。那么我们就能顺藤摸瓜了。通过网页json获取到user-agent.json这个文件,比如:{"name":"qq","password":"1030077","tel":"123456789","phone":"1595012107","sign":"1620611143"}那么我们就能知道user-agent.json里包含的内容。
functionread_qq(qqurl){//获取user-agent.json文件returnqqurl.json()}情况。
二、服务器返回给客户端一个html文件,比如worker_js.jsstring.write(qqurl.json())//解析出整个页面的内容,
三、服务器返回给客户端一个二维码,上传二维码。那么就可以根据二维码生成的数据,解析出整个页面的数据。如果这个二维码是swf格式的,那么就要用到浏览器的上传功能了。如果是mp4的,也可以通过解析出整个视频的数据。之后就是把视频上传到云服务器,进行下载了。上传成功之后,可以在浏览器开发者工具中看到上传的所有二维码的链接,并且可以正常显示出来。
如果我们希望直接使用二维码文件上传,那么使用这种方法比较麻烦,那么使用flask框架就可以自动把二维码数据写入到服务器。上传成功之后,这个二维码数据就可以在客户端进行显示了。functionread_qq(qqurl){returnqqurl.json()}完结。后续有时间再补充些其他的qq的抓取方法。 查看全部
网页qq抓取什么原理(网页qq抓取什么原理?(一个二维qq软件))
网页qq抓取什么原理?从我的经验来说,还是通过分析请求的参数来判断用户请求的url,有点像爬虫技术的代理ip池技术了。通过一个特定的url就可以定位出所有上传的文件,还是比较好用的。我这里要写的是一个二维qq抓取软件,只要一行代码就可以上传多个链接(一个文件里包含多个链接),这就要求要使用一个已有的二维qq号码进行登录。下面是抓取结果:。
一个二维码打开任意网站,附带着链接地址,
我以前也有这个困惑,然后上各种网站搜索,所以应该可以说一下,不对的地方欢迎大家补充。二维码扫描上传文件的原理,肯定是通过发送给服务器的二维码(网址)来进行解析。但是二维码究竟应该解析出哪些内容呢?我们可以先根据能想到的三种情况来分析,
一、服务器返回给客户端一个json文件,比如user-agent.json。那么我们就能顺藤摸瓜了。通过网页json获取到user-agent.json这个文件,比如:{"name":"qq","password":"1030077","tel":"123456789","phone":"1595012107","sign":"1620611143"}那么我们就能知道user-agent.json里包含的内容。
functionread_qq(qqurl){//获取user-agent.json文件returnqqurl.json()}情况。
二、服务器返回给客户端一个html文件,比如worker_js.jsstring.write(qqurl.json())//解析出整个页面的内容,
三、服务器返回给客户端一个二维码,上传二维码。那么就可以根据二维码生成的数据,解析出整个页面的数据。如果这个二维码是swf格式的,那么就要用到浏览器的上传功能了。如果是mp4的,也可以通过解析出整个视频的数据。之后就是把视频上传到云服务器,进行下载了。上传成功之后,可以在浏览器开发者工具中看到上传的所有二维码的链接,并且可以正常显示出来。
如果我们希望直接使用二维码文件上传,那么使用这种方法比较麻烦,那么使用flask框架就可以自动把二维码数据写入到服务器。上传成功之后,这个二维码数据就可以在客户端进行显示了。functionread_qq(qqurl){returnqqurl.json()}完结。后续有时间再补充些其他的qq的抓取方法。
网页qq抓取什么原理(搜索引擎去除重复内容的网页有意义吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-24 12:27
这篇文章站长博客给大家介绍一下网页去重的原理是什么?搜索引擎如何进行重复数据删除?
在互联网如此发达的今天,同样的信息会在多个网站上发布,同样的消息会被大多数媒体网站报道,再加上小站长和EO工作人员孜孜不倦地为网络< @k11@ >,导致网络上出现大量重复信息。但是,当用户搜索某个关键词 时,搜索引擎一定不想将相同的搜索结果呈现给用户。爬取这些重复的网页,从某种意义上说,是对搜索引擎自身资源的一种浪费,所以去除重复内容的网页也成为了搜索引擎面临的一大难题。
在一般的搜索引擎架构中,网页去重一般存在于蜘蛛抓取部分。在整个搜索引擎架构中越早实施“去重”步骤,就越能节省后续处理系统的资源使用。搜索引擎一般对已经爬取过的重复页面进行分类,例如判断一个站点是否收录大量重复页面,或者该站点是否完全采集其他站点的内容等。爬取状态本网站的内容或是否直接阻止抓取。
去重工作一般在分词之后、索引之前(也可能在分词之前)进行,搜索引擎会从页面已经被分离出来的关键词中提取一些有代表性的关键词,并然后计算这些 关键词 的“指纹”。每个网页都会有这样一个特征指纹。当新爬取网页的关键词指纹与索引网页的关键词指纹重合时,新网页可能被搜索引擎查看。删除重复内容的索引。
实际工作中的搜索引擎不仅使用分词步骤分隔的有意义的关键词,还使用连续切割提取关键词并进行指纹计算。连续切割是通过将单个单词向后移动来切割单词。比如“百度开始打击买卖链接”将被切割成“百度开”、“度开始”、“开始打”、“开始打”、“打买”、“打”买and sell”、“buy and sell chain”、“sell link”。然后从这些词中提取一些关键词进行指纹计算,并参与内容是否重复的比较。这只是基本算法搜索引擎用于识别重复页面,
因此,网上流行的大部分伪原创工具要么无法欺骗搜索引擎,要么使内容无法阅读,所以理论上普通的伪原创工具无法获取正常的搜索引擎收录@ > 和排名。但由于百度并没有直接丢弃所有重复页面,也不对其进行索引,因此会根据重复页面所在网站的权重适当放宽索引标记。
这使得一些作弊者可以利用 网站 的高权重和来自其他站点的大量 采集 内容来获取搜索流量。然而,自2012年6月以来,百度多次升级算法,对采集重复信息和垃圾页面进行了多次重击。因此,O在面对网站的内容时,不应该再从伪原创的角度去建构,而应该
内容的内容不一定都是原创。一般网站的体重如果没有大问题,就会健康发展。关于 原创 的问题将在本书后面的第 12 章中详细讨论。
另外,不仅搜索引擎需要对网页进行“去重”,还需要自己做网站对站点中的页面进行去重。比如UGC-type 网站这样的作为分类信息和B2B均等化,如果不加限制,用户发布的信息难免会出现大量重复,不仅在SEO上表现不佳,还会大大降低网站的用户体验。就是SEO人员在设计流量产品大量生成页面的时候,也需要做一次重复过滤,否则产品质量会大打折扣。基于“聚合”的页面。“聚合”必须有核心词,未经过滤,海量核心词展开的页面可能出现大量重复,导致产品性能不佳,甚至被搜索引擎降级。
“去重”算法的一般原理大致如上所述。有兴趣的朋友可以了解一下I-Match、Shingle、SimHash和余弦去重的具体算法。搜索引擎必须先对网页进行分析,然后才能进行“去除重复页面”的工作。内容周围的“噪音”会在一定程度上影响去重结果。在做这部分工作的时候,只能对内容部分进行操作,比较简单。许多,并且可以有效地协助生产高质量的“$EO产品”。
作为一个SEO人,你只需要了解实现原理。在产品中的具体应用需要技术人员来实现。此外,还涉及到效率、资源需求等问题,根据实际情况,还可以在多个环节(如核心词的切分)进行“重复”工作。这个方向很好(技术人员不是无所不能的,也有不熟悉和不熟悉的领域,在某个时刻也需要别人提供想法)。如果EO人员能够在这些方面与技术人员进行深入的沟通,技术人员也会对SEO另眼相看,至少不再认为“SEO人员只会要求‘无聊’的需求,比如换个标题, 更改链接,并更改文本。”。 查看全部
网页qq抓取什么原理(搜索引擎去除重复内容的网页有意义吗?(图))
这篇文章站长博客给大家介绍一下网页去重的原理是什么?搜索引擎如何进行重复数据删除?
在互联网如此发达的今天,同样的信息会在多个网站上发布,同样的消息会被大多数媒体网站报道,再加上小站长和EO工作人员孜孜不倦地为网络< @k11@ >,导致网络上出现大量重复信息。但是,当用户搜索某个关键词 时,搜索引擎一定不想将相同的搜索结果呈现给用户。爬取这些重复的网页,从某种意义上说,是对搜索引擎自身资源的一种浪费,所以去除重复内容的网页也成为了搜索引擎面临的一大难题。
在一般的搜索引擎架构中,网页去重一般存在于蜘蛛抓取部分。在整个搜索引擎架构中越早实施“去重”步骤,就越能节省后续处理系统的资源使用。搜索引擎一般对已经爬取过的重复页面进行分类,例如判断一个站点是否收录大量重复页面,或者该站点是否完全采集其他站点的内容等。爬取状态本网站的内容或是否直接阻止抓取。
去重工作一般在分词之后、索引之前(也可能在分词之前)进行,搜索引擎会从页面已经被分离出来的关键词中提取一些有代表性的关键词,并然后计算这些 关键词 的“指纹”。每个网页都会有这样一个特征指纹。当新爬取网页的关键词指纹与索引网页的关键词指纹重合时,新网页可能被搜索引擎查看。删除重复内容的索引。
实际工作中的搜索引擎不仅使用分词步骤分隔的有意义的关键词,还使用连续切割提取关键词并进行指纹计算。连续切割是通过将单个单词向后移动来切割单词。比如“百度开始打击买卖链接”将被切割成“百度开”、“度开始”、“开始打”、“开始打”、“打买”、“打”买and sell”、“buy and sell chain”、“sell link”。然后从这些词中提取一些关键词进行指纹计算,并参与内容是否重复的比较。这只是基本算法搜索引擎用于识别重复页面,
因此,网上流行的大部分伪原创工具要么无法欺骗搜索引擎,要么使内容无法阅读,所以理论上普通的伪原创工具无法获取正常的搜索引擎收录@ > 和排名。但由于百度并没有直接丢弃所有重复页面,也不对其进行索引,因此会根据重复页面所在网站的权重适当放宽索引标记。
这使得一些作弊者可以利用 网站 的高权重和来自其他站点的大量 采集 内容来获取搜索流量。然而,自2012年6月以来,百度多次升级算法,对采集重复信息和垃圾页面进行了多次重击。因此,O在面对网站的内容时,不应该再从伪原创的角度去建构,而应该
内容的内容不一定都是原创。一般网站的体重如果没有大问题,就会健康发展。关于 原创 的问题将在本书后面的第 12 章中详细讨论。
另外,不仅搜索引擎需要对网页进行“去重”,还需要自己做网站对站点中的页面进行去重。比如UGC-type 网站这样的作为分类信息和B2B均等化,如果不加限制,用户发布的信息难免会出现大量重复,不仅在SEO上表现不佳,还会大大降低网站的用户体验。就是SEO人员在设计流量产品大量生成页面的时候,也需要做一次重复过滤,否则产品质量会大打折扣。基于“聚合”的页面。“聚合”必须有核心词,未经过滤,海量核心词展开的页面可能出现大量重复,导致产品性能不佳,甚至被搜索引擎降级。
“去重”算法的一般原理大致如上所述。有兴趣的朋友可以了解一下I-Match、Shingle、SimHash和余弦去重的具体算法。搜索引擎必须先对网页进行分析,然后才能进行“去除重复页面”的工作。内容周围的“噪音”会在一定程度上影响去重结果。在做这部分工作的时候,只能对内容部分进行操作,比较简单。许多,并且可以有效地协助生产高质量的“$EO产品”。
作为一个SEO人,你只需要了解实现原理。在产品中的具体应用需要技术人员来实现。此外,还涉及到效率、资源需求等问题,根据实际情况,还可以在多个环节(如核心词的切分)进行“重复”工作。这个方向很好(技术人员不是无所不能的,也有不熟悉和不熟悉的领域,在某个时刻也需要别人提供想法)。如果EO人员能够在这些方面与技术人员进行深入的沟通,技术人员也会对SEO另眼相看,至少不再认为“SEO人员只会要求‘无聊’的需求,比如换个标题, 更改链接,并更改文本。”。
网页qq抓取什么原理(有什么方能提高网页被搜索引擎抓取、索引和排名的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-24 12:26
但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。
那么让我们看看什么可以提高搜索引擎对网页的抓取、索引和排名:
示例网站架构图
首先通过下图看一下常见的网站的架构图:
典型网站外链分布图
然后我们看一个典型的网站外链分布图:
爬虫爬取路径的优先级
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。
5 种提高搜索引擎对网页的抓取、索引和排名的方法
最后,让我们看看有什么可以提高你的页面的爬取、索引和搜索引擎排名:
展平 网站 结构
如果你的网站能建立一个理想的、扁平的链接层次结构,就可以达到3点击100万页、4点击100万页的效果。
从“强大”页面链接到需要链接的页面
你应该注意外链多的“强大”页面的涟漪效应(指排名高、外链多的页面,易IT注意),并充分利用这种效应。将此类页面视为目录(或类别)页面,并将它们链接到 网站 的其他页面。
同样,您将来可以将此类页面用作登录页面,以帮助将流量吸引到您希望用户访问的页面。
减少“死角”和低价值页面
位于链接图边缘的页面价值较低。确保 网站 上没有降低 PageRank 的页面。这些页面通常是 PDF、图片和其他文档。您可以使用 301 重定向将这些文件重定向到收录(嵌入或收录下载链接)这些文件内容的页面,并且该页面上有返回 网站 其他部分的链接。
创建值得链接的分类或导航页面
如果您可以制作此类具有链接价值且引人注目的页面,它们将获得更高的 PageRank 和更高的优先级抓取率。同时,这些 PageRank 和爬取优先级会通过页面上的链接传递给 网站 的其他页面(向搜索引擎发出信号,表明 网站 上的所有页面都很重要)。
从爬虫路径中排除不重要的页面
减少不必要的导航级别(或内容页面),并将爬虫引导到真正需要 PageRank 的 URL。
原文:解决抓取优先级和索引问题的图表 查看全部
网页qq抓取什么原理(有什么方能提高网页被搜索引擎抓取、索引和排名的方法)
但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。
那么让我们看看什么可以提高搜索引擎对网页的抓取、索引和排名:
示例网站架构图
首先通过下图看一下常见的网站的架构图:
典型网站外链分布图
然后我们看一个典型的网站外链分布图:
爬虫爬取路径的优先级
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。
5 种提高搜索引擎对网页的抓取、索引和排名的方法
最后,让我们看看有什么可以提高你的页面的爬取、索引和搜索引擎排名:
展平 网站 结构
如果你的网站能建立一个理想的、扁平的链接层次结构,就可以达到3点击100万页、4点击100万页的效果。
从“强大”页面链接到需要链接的页面
你应该注意外链多的“强大”页面的涟漪效应(指排名高、外链多的页面,易IT注意),并充分利用这种效应。将此类页面视为目录(或类别)页面,并将它们链接到 网站 的其他页面。
同样,您将来可以将此类页面用作登录页面,以帮助将流量吸引到您希望用户访问的页面。
减少“死角”和低价值页面
位于链接图边缘的页面价值较低。确保 网站 上没有降低 PageRank 的页面。这些页面通常是 PDF、图片和其他文档。您可以使用 301 重定向将这些文件重定向到收录(嵌入或收录下载链接)这些文件内容的页面,并且该页面上有返回 网站 其他部分的链接。
创建值得链接的分类或导航页面
如果您可以制作此类具有链接价值且引人注目的页面,它们将获得更高的 PageRank 和更高的优先级抓取率。同时,这些 PageRank 和爬取优先级会通过页面上的链接传递给 网站 的其他页面(向搜索引擎发出信号,表明 网站 上的所有页面都很重要)。
从爬虫路径中排除不重要的页面
减少不必要的导航级别(或内容页面),并将爬虫引导到真正需要 PageRank 的 URL。
原文:解决抓取优先级和索引问题的图表
网页qq抓取什么原理( Python批量抓取图片(1)--使用Python图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-22 08:19
Python批量抓取图片(1)--使用Python图片)
- 写在前面的话
相信你一定看过前段时间文章的一篇文章《就因为我写了爬虫,公司200多人被捕!》的公众号文章(描述< @文章 已经很明显了,大家心知肚明)
可以说,因为恐慌和骚动,一些三二线爬虫工程师紧急转行。其次,一些朋友对自己学到的爬虫技术感到担忧和恐慌。
事实上,每个人都有这种警惕性。但是,没有必要进行诸如转业之类的大战斗。我们应该从业务本身做起,不仅要提升自己的业务能力,还要熟悉互联网法律法规。虽然我不是亲自学习爬虫的技术,但是平时很喜欢学习一些爬虫的小项目和小玩意儿。虽然我花在学习算法上的时间比例会少很多,但我个人还是喜欢尝试一些新的。技术来丰富自己的业务水平,从这个角度来看,大部分工程师都会有这种业务倾向。当然,对于那些站在互联网第一线的爬虫工程师和大佬们来说,我只是大海中的一滴水,水滴的数量是远远不够的。
说起来,归根结底是一些公司和公司员工对法律的认识不够,公司对员工的法律宣传和商业道德也没有起到潜移默化的作用,尤其是互联网法律法规的传递。思想工作没有及时到位。当然,这些也不能总是靠公司,主要还是靠个人的认知。既然你已经做过这个业务,你应该了解和学习这个行业的法律知识。为此,作为这个时代科技创新和技术研发的一员,我们必须始终遵守互联网法律法规,做好本职工作,为社会多做贡献。
文章目录:
- 写在前面的话
1 - 捕获工件
2 - 使用Python批量抓取图片
(1)抓取对象:搜狗图库
(2)抢分类:进入搜狗壁纸
(3)使用requests提取图片组件
(4)找到图片的真实url
(5)批量抓图成功
今天就开始学习我们的内容吧~~
1 - 捕获工件
我一直很喜欢的一个谷歌图片抓取插件叫做 ImageAssistant
目前用户数为114567,可以说是非常不错了。
它的工作原理与 Python 批量抓取图像完全一样
我不是为谷歌做广告,我只是分享给大家,因为我认为它对提高大家的办公效率很有用。当然,本节最重要的是学习Python中批量抓图的原理和方法。
下面简单介绍一下插件的使用。安装插件后记得选择存放文件的地方,在谷歌设置下关闭下载查询访问。
(不然每次都得按保存,很麻烦。如果有100张图,你肯定要按100次)
安装插件后,下面是抓取过程的简单视频演示
比如:去微博抢鞠婧祎小姐姐的照片,
进入后右击IA工具即可
2 - 使用Python批量抓取图片
注:文中Grab的意思是“抓取”
(1)抓取对象:搜狗图库
(2)抓取分类:进入搜狗壁纸,打开网页源码(快捷键为F12)
由于我使用的是谷歌 chrome 浏览器,所以要找到 img 标签
(3)使用requests提取图片组件
爬取思路和使用库文件请求
可以发现图片src存在于img标签下,所以使用Python的requests提取组件获取img的src,然后使用库urllib.request.urlretrieve将图片一一下载,从而达到批量获取数据的目的。
开始爬取第一步:
(注:Network-->headers,然后用鼠标点击左侧菜单栏(地址栏)的图片链接,然后在headers中找到图片url)
下面就是按照上面的思路来爬取我们想要的结果: 搜索网页代码后,得到的搜狗图片的url为:
%B1%DA%D6%BD
这里的url来自进入分类后的地址栏(如上图)。
分析源码分析上述url指向的网页
import requests #导入库requestsimport urllib #导入库requests下面的urllibfrom bs4 import BeautifulSoup #使用BeautifulSoup,关于这个的用法请查看本公众号往期文章#下面填入urlres = requests.get('http://pic.sogou.com/pics/reco ... %2339;)soup = BeautifulSoup(res.text,'html.parser')print(soup.select('img')) #图片打印格式
结果
从上面的执行结果来看,打印输出中并没有我们想要的图片元素,只是解析了tupian130x34_@1x的img(或者网页中的logo),这显然不是我们想要的。也就是说,需要的图片数据不在url下,也就是不在下面的url中
%B1%DA%D6%BD。
因此,下面需要找到图片不在url中的原因并进行改进。
开始爬取第二步:
考虑到图片元素可能是动态的,细心的人可能会发现,在网页中向下滑动鼠标滚轮时,图片是动态刷新的,也就是说网页不是一次性加载所有资源,而是动态地加载资源。这也避免了由于网页过于臃肿而影响加载速度。
(4)找到图片的真实url
找到所有图片的真实url似乎有点困难,但是在这个项目中尝试一下也不是不可能的。在接下来的学习中不断研究,我想我会逐渐提高自己的业务能力。
类似于开始抓取第一步中的“笔记”,我们找到位置:
F12——>>网络——>>XHR——>>(点击XHR下的文件)——>>预览
(注:如果在预览中没有找到内容,可以滚动左侧地址栏或点击图片链接)
从上图看来,图中的信息就是我们需要的元素。点击all_items,发现下面是0 1 2 3... 一个一个好像是图片元素的数据。
尝试打开一个网址。找到图片的地址
我们可以任意选择其中一个图片的地址来验证是否是图片所在的位置:
将地址粘贴到浏览器中,搜索如下结果,说明这个地址的url就是我们要找的
找到上图的目标后,我们点击XHR下的Headers,也就是第二行
请求网址:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
尽量去掉一些不必要的部分,去掉以上部分后不影响访问。
(删掉的位置跟同一个地方差不多,记住长宽高后面就不用删了)
例如:删除“=%E5%A3%81%E7%BA%B8&tag”得到
%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
将此网站复制到浏览器访问中,得到如下结果:
url中的category为类别,start为开始下标,len为长度,即图片数量。
另外,在imges下,注意url内容的填充(不要直接复制url)
当替换为“+”时
(5)批量抓图成功
如果你的电脑没有库文件请求,记得用 cmd 命令安装:
pip 安装请求
最后经过不断的排序,源码如下:
import requestsimport json #使用json码import urllibdef getSogouImag(category,length,path): n = length cate = category #分类 imgs = requests.get('http://pic.sogou.com/pics/chan ... 2Bstr(n)) jd = json.loads(imgs.text) jd = jd['all_items'] imgs_url = [] #在url获取图片imgs for j in jd: imgs_url.append(j['bthumbUrl']) m = 0 for img_url in imgs_url: print('***** '+str(m)+'.jpg *****'+' Downloading...') urllib.request.urlretrieve(img_url,path+str(m)+'.jpg') m = m + 1 print('Download complete!')getSogouImag('壁纸',2000,'F:/Py666/抓图/') #抓取后图片存取的本地位置
执行程序:到指定位置找到图片存在的位置,大功告成。
- 结尾 -
你好!
贡献--->展示你的才华
请发送电子邮件至
注明标题 [提交]
告诉我们
你是谁,你来自哪里,你投什么 查看全部
网页qq抓取什么原理(
Python批量抓取图片(1)--使用Python图片)

- 写在前面的话
相信你一定看过前段时间文章的一篇文章《就因为我写了爬虫,公司200多人被捕!》的公众号文章(描述< @文章 已经很明显了,大家心知肚明)
可以说,因为恐慌和骚动,一些三二线爬虫工程师紧急转行。其次,一些朋友对自己学到的爬虫技术感到担忧和恐慌。
事实上,每个人都有这种警惕性。但是,没有必要进行诸如转业之类的大战斗。我们应该从业务本身做起,不仅要提升自己的业务能力,还要熟悉互联网法律法规。虽然我不是亲自学习爬虫的技术,但是平时很喜欢学习一些爬虫的小项目和小玩意儿。虽然我花在学习算法上的时间比例会少很多,但我个人还是喜欢尝试一些新的。技术来丰富自己的业务水平,从这个角度来看,大部分工程师都会有这种业务倾向。当然,对于那些站在互联网第一线的爬虫工程师和大佬们来说,我只是大海中的一滴水,水滴的数量是远远不够的。
说起来,归根结底是一些公司和公司员工对法律的认识不够,公司对员工的法律宣传和商业道德也没有起到潜移默化的作用,尤其是互联网法律法规的传递。思想工作没有及时到位。当然,这些也不能总是靠公司,主要还是靠个人的认知。既然你已经做过这个业务,你应该了解和学习这个行业的法律知识。为此,作为这个时代科技创新和技术研发的一员,我们必须始终遵守互联网法律法规,做好本职工作,为社会多做贡献。
文章目录:
- 写在前面的话
1 - 捕获工件
2 - 使用Python批量抓取图片
(1)抓取对象:搜狗图库
(2)抢分类:进入搜狗壁纸
(3)使用requests提取图片组件
(4)找到图片的真实url
(5)批量抓图成功
今天就开始学习我们的内容吧~~
1 - 捕获工件
我一直很喜欢的一个谷歌图片抓取插件叫做 ImageAssistant
目前用户数为114567,可以说是非常不错了。
它的工作原理与 Python 批量抓取图像完全一样
我不是为谷歌做广告,我只是分享给大家,因为我认为它对提高大家的办公效率很有用。当然,本节最重要的是学习Python中批量抓图的原理和方法。
下面简单介绍一下插件的使用。安装插件后记得选择存放文件的地方,在谷歌设置下关闭下载查询访问。
(不然每次都得按保存,很麻烦。如果有100张图,你肯定要按100次)
安装插件后,下面是抓取过程的简单视频演示
比如:去微博抢鞠婧祎小姐姐的照片,
进入后右击IA工具即可
2 - 使用Python批量抓取图片
注:文中Grab的意思是“抓取”
(1)抓取对象:搜狗图库
(2)抓取分类:进入搜狗壁纸,打开网页源码(快捷键为F12)
由于我使用的是谷歌 chrome 浏览器,所以要找到 img 标签
(3)使用requests提取图片组件
爬取思路和使用库文件请求
可以发现图片src存在于img标签下,所以使用Python的requests提取组件获取img的src,然后使用库urllib.request.urlretrieve将图片一一下载,从而达到批量获取数据的目的。
开始爬取第一步:
(注:Network-->headers,然后用鼠标点击左侧菜单栏(地址栏)的图片链接,然后在headers中找到图片url)
下面就是按照上面的思路来爬取我们想要的结果: 搜索网页代码后,得到的搜狗图片的url为:
%B1%DA%D6%BD
这里的url来自进入分类后的地址栏(如上图)。
分析源码分析上述url指向的网页
import requests #导入库requestsimport urllib #导入库requests下面的urllibfrom bs4 import BeautifulSoup #使用BeautifulSoup,关于这个的用法请查看本公众号往期文章#下面填入urlres = requests.get('http://pic.sogou.com/pics/reco ... %2339;)soup = BeautifulSoup(res.text,'html.parser')print(soup.select('img')) #图片打印格式
结果

从上面的执行结果来看,打印输出中并没有我们想要的图片元素,只是解析了tupian130x34_@1x的img(或者网页中的logo),这显然不是我们想要的。也就是说,需要的图片数据不在url下,也就是不在下面的url中
%B1%DA%D6%BD。
因此,下面需要找到图片不在url中的原因并进行改进。
开始爬取第二步:
考虑到图片元素可能是动态的,细心的人可能会发现,在网页中向下滑动鼠标滚轮时,图片是动态刷新的,也就是说网页不是一次性加载所有资源,而是动态地加载资源。这也避免了由于网页过于臃肿而影响加载速度。
(4)找到图片的真实url
找到所有图片的真实url似乎有点困难,但是在这个项目中尝试一下也不是不可能的。在接下来的学习中不断研究,我想我会逐渐提高自己的业务能力。
类似于开始抓取第一步中的“笔记”,我们找到位置:
F12——>>网络——>>XHR——>>(点击XHR下的文件)——>>预览
(注:如果在预览中没有找到内容,可以滚动左侧地址栏或点击图片链接)

从上图看来,图中的信息就是我们需要的元素。点击all_items,发现下面是0 1 2 3... 一个一个好像是图片元素的数据。
尝试打开一个网址。找到图片的地址
我们可以任意选择其中一个图片的地址来验证是否是图片所在的位置:
将地址粘贴到浏览器中,搜索如下结果,说明这个地址的url就是我们要找的
找到上图的目标后,我们点击XHR下的Headers,也就是第二行
请求网址:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
尽量去掉一些不必要的部分,去掉以上部分后不影响访问。
(删掉的位置跟同一个地方差不多,记住长宽高后面就不用删了)
例如:删除“=%E5%A3%81%E7%BA%B8&tag”得到
%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
将此网站复制到浏览器访问中,得到如下结果:
url中的category为类别,start为开始下标,len为长度,即图片数量。
另外,在imges下,注意url内容的填充(不要直接复制url)
当替换为“+”时

(5)批量抓图成功
如果你的电脑没有库文件请求,记得用 cmd 命令安装:
pip 安装请求
最后经过不断的排序,源码如下:
import requestsimport json #使用json码import urllibdef getSogouImag(category,length,path): n = length cate = category #分类 imgs = requests.get('http://pic.sogou.com/pics/chan ... 2Bstr(n)) jd = json.loads(imgs.text) jd = jd['all_items'] imgs_url = [] #在url获取图片imgs for j in jd: imgs_url.append(j['bthumbUrl']) m = 0 for img_url in imgs_url: print('***** '+str(m)+'.jpg *****'+' Downloading...') urllib.request.urlretrieve(img_url,path+str(m)+'.jpg') m = m + 1 print('Download complete!')getSogouImag('壁纸',2000,'F:/Py666/抓图/') #抓取后图片存取的本地位置
执行程序:到指定位置找到图片存在的位置,大功告成。
- 结尾 -

你好!
贡献--->展示你的才华
请发送电子邮件至
注明标题 [提交]
告诉我们
你是谁,你来自哪里,你投什么
网页qq抓取什么原理(1.什么是搜索引擎蜘蛛?蜘蛛的工作流程及流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2022-02-21 05:12
网站seo搜索引擎爬虫的基本原理。
1.什么是搜索引擎蜘蛛?
搜索引擎蜘蛛是根据一定的规则自动抓取互联网信息的程序或脚本。由于互联网有着非常类似于蜘蛛网的广泛“拓扑”,而搜索引擎爬虫在互联网上无休止地“爬行”,人们将搜索引擎爬虫形象地称为“蜘蛛”。
2.互联网资源和数据丰富,那么这些资源数据从何而来?
众所周知,搜索引擎不会自己生成内容,而是借助蜘蛛,不断从数以万计的网站中“采集”页面数据,“填充”自己的页面数据库。这就是为什么当我们使用搜索引擎检索数据时,我们可以得到很多匹配的资源。
一般工作流程如下:
1搜索引擎安排蜘蛛从互联网上的网站抓取网页数据,然后将抓取的数据带回搜索引擎的原创页面数据库。蜘蛛抓取页面数据的过程是一个无限循环,只有这样我们的搜索结果才能不断更新。
2 原页面数据库中的数据不是最终结果,而是相当于面试的“初试”。搜索引擎会对数据进行“二次处理”,这个过程会有两个处理结果:
(1)对于抄袭、采集、复制重复内容的,不符合搜索引擎规则和用户体验的垃圾页面将从原创页面数据库中删除。
(2)将符合搜索引擎规则的优质页面加入索引库,等待进一步分类、排序等。
(3)搜索引擎对索引库中的特殊文件进行分类、组织、计算链接关系和处理,将符合规则的网页显示在搜索引擎显示区,供用户使用和查看。 查看全部
网页qq抓取什么原理(1.什么是搜索引擎蜘蛛?蜘蛛的工作流程及流程)
网站seo搜索引擎爬虫的基本原理。
1.什么是搜索引擎蜘蛛?
搜索引擎蜘蛛是根据一定的规则自动抓取互联网信息的程序或脚本。由于互联网有着非常类似于蜘蛛网的广泛“拓扑”,而搜索引擎爬虫在互联网上无休止地“爬行”,人们将搜索引擎爬虫形象地称为“蜘蛛”。
2.互联网资源和数据丰富,那么这些资源数据从何而来?
众所周知,搜索引擎不会自己生成内容,而是借助蜘蛛,不断从数以万计的网站中“采集”页面数据,“填充”自己的页面数据库。这就是为什么当我们使用搜索引擎检索数据时,我们可以得到很多匹配的资源。

一般工作流程如下:
1搜索引擎安排蜘蛛从互联网上的网站抓取网页数据,然后将抓取的数据带回搜索引擎的原创页面数据库。蜘蛛抓取页面数据的过程是一个无限循环,只有这样我们的搜索结果才能不断更新。
2 原页面数据库中的数据不是最终结果,而是相当于面试的“初试”。搜索引擎会对数据进行“二次处理”,这个过程会有两个处理结果:
(1)对于抄袭、采集、复制重复内容的,不符合搜索引擎规则和用户体验的垃圾页面将从原创页面数据库中删除。
(2)将符合搜索引擎规则的优质页面加入索引库,等待进一步分类、排序等。
(3)搜索引擎对索引库中的特殊文件进行分类、组织、计算链接关系和处理,将符合规则的网页显示在搜索引擎显示区,供用户使用和查看。
网页qq抓取什么原理(用PHP来开发,用的是CI的框架结构,代码给出 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-20 03:04
)
本例使用 PHP 开发,使用 CI 框架。没接触过CI的朋友不用担心。这个框架的原理和其他框架是一样的,所以看代码不会难。
一、代码文件分为三个文件,①client.php ②client_view.php ③server.php
先说简单的原理,再给出代码和注释。
原理:我们以QQ开放平台登录为例。其实不只是QQ平台,其他平台的原理基本相同,只是数据处理方式上可能存在差异。首先,我们将登录程序定义为客户端,将QQ服务器定义为服务器端。当我们登录QQ的时候,会通过我们的程序,也就是浏览器,向QQ服务器发送一个请求。当然,你输入的 ID 和 PASSWORD 等 PROFILE 都是发给服务器的参数。QQ服务器收到客户端的请求后,收到客户端的REQUEST和PARAMETERS后,会将你的ID、PASSWORD和附加的PROFILE与数据库中的相关数据进行比对。如果比对结果通过,QQ服务器会将相关数据发送给客户端。当然,不会提及加密细节。客户端收到数据后,会对数据进行处理和提取,得到它想要的数据,并完成后续工作。看看客户的需求。基本原理是这样的。好了,废话不多说,代码就给出了。
①client.php
<p>All variables set in controllers though.
</p>
③server.php
<p> 查看全部
网页qq抓取什么原理(用PHP来开发,用的是CI的框架结构,代码给出
)
本例使用 PHP 开发,使用 CI 框架。没接触过CI的朋友不用担心。这个框架的原理和其他框架是一样的,所以看代码不会难。
一、代码文件分为三个文件,①client.php ②client_view.php ③server.php
先说简单的原理,再给出代码和注释。
原理:我们以QQ开放平台登录为例。其实不只是QQ平台,其他平台的原理基本相同,只是数据处理方式上可能存在差异。首先,我们将登录程序定义为客户端,将QQ服务器定义为服务器端。当我们登录QQ的时候,会通过我们的程序,也就是浏览器,向QQ服务器发送一个请求。当然,你输入的 ID 和 PASSWORD 等 PROFILE 都是发给服务器的参数。QQ服务器收到客户端的请求后,收到客户端的REQUEST和PARAMETERS后,会将你的ID、PASSWORD和附加的PROFILE与数据库中的相关数据进行比对。如果比对结果通过,QQ服务器会将相关数据发送给客户端。当然,不会提及加密细节。客户端收到数据后,会对数据进行处理和提取,得到它想要的数据,并完成后续工作。看看客户的需求。基本原理是这样的。好了,废话不多说,代码就给出了。
①client.php
<p>All variables set in controllers though.
</p>
③server.php
<p>
网页qq抓取什么原理(怎么实例化一个etree对象呢?怎么快速的写好一个xpath)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-19 09:18
Xpath是python爬虫最常用的数据解析方式。我觉得也是最简单的,通用性很强。稍后我将解释为什么它是最简单的。有两个主要步骤。
1、实例化一个etree对象,需要将解析后的页面源数据加载到该对象中。
2、调用etree对象中的xpath方法,结合xpath表达式定位标签,爬取内容文本或属性。
如何实例化一个 etree 对象?先下载lxml库再导入etree包,然后将本地HTML文档源数据加载到etree对象中,或者将实时网页源数据加载到etree中。
from lxml import etree
#将本地html文档中的数据加载到该对象中
tree = etree.parse('./douban.html')
print(tree.xpath('/html/head/title'))
>> []
from lxml import etree
import requests
# 将网页源码数据加载到该对象中
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="slist"]/ul/li')
print(li_list)
>> []
本地是etree.parse,网页是etree.HTML
这里返回的不是本地或网页html文档中的内容,而是一个Element类型的对象。该对象存储标题对应的文本内容。如果有多个内容,则以列表的形式返回多个Element。
xpath 表达式的规则:
/:表示层次,从根节点开始。
//: 表示多个级别,可以从任何节点定位。
属性定位://div[@class="title"] 以@ 为属性添加前缀。
索引定位: //div[@class="title"]/a[1] 下标从 1 开始,而不是 0。
/text():获取标签中的直接文本内容。
//text(): 可以获取一个标签的所有文本内容。
@attrName:在属性前加@,获取属性的内容。
接下来,我将告诉你如何快速编写一个xpath路径。
我们可以在我们要爬取数据的网页上打开开发者工具(点击右键查看或者直接同时按fn和f12打开开发者工具),然后在里面找到我们要爬取的数据元素(Element)并右键选择复制,然后选择复制XPath,就这样,是不是很方便。
以上是xpath比较常用的方法。当然,xpath还有很多其他的方法。有兴趣的可以参考相关文档。 查看全部
网页qq抓取什么原理(怎么实例化一个etree对象呢?怎么快速的写好一个xpath)
Xpath是python爬虫最常用的数据解析方式。我觉得也是最简单的,通用性很强。稍后我将解释为什么它是最简单的。有两个主要步骤。
1、实例化一个etree对象,需要将解析后的页面源数据加载到该对象中。
2、调用etree对象中的xpath方法,结合xpath表达式定位标签,爬取内容文本或属性。
如何实例化一个 etree 对象?先下载lxml库再导入etree包,然后将本地HTML文档源数据加载到etree对象中,或者将实时网页源数据加载到etree中。
from lxml import etree
#将本地html文档中的数据加载到该对象中
tree = etree.parse('./douban.html')
print(tree.xpath('/html/head/title'))
>> []
from lxml import etree
import requests
# 将网页源码数据加载到该对象中
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="slist"]/ul/li')
print(li_list)
>> []
本地是etree.parse,网页是etree.HTML
这里返回的不是本地或网页html文档中的内容,而是一个Element类型的对象。该对象存储标题对应的文本内容。如果有多个内容,则以列表的形式返回多个Element。
xpath 表达式的规则:
/:表示层次,从根节点开始。
//: 表示多个级别,可以从任何节点定位。
属性定位://div[@class="title"] 以@ 为属性添加前缀。
索引定位: //div[@class="title"]/a[1] 下标从 1 开始,而不是 0。
/text():获取标签中的直接文本内容。
//text(): 可以获取一个标签的所有文本内容。
@attrName:在属性前加@,获取属性的内容。
接下来,我将告诉你如何快速编写一个xpath路径。
我们可以在我们要爬取数据的网页上打开开发者工具(点击右键查看或者直接同时按fn和f12打开开发者工具),然后在里面找到我们要爬取的数据元素(Element)并右键选择复制,然后选择复制XPath,就这样,是不是很方便。

以上是xpath比较常用的方法。当然,xpath还有很多其他的方法。有兴趣的可以参考相关文档。
网页qq抓取什么原理(爬虫爬虫就是编写程序编写程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-14 01:16
最近在学习python爬虫,顺便记录一下。
爬虫:
网络爬虫(也称为网络蜘蛛、网络机器人,或者在 FOAF 社区中更常称为网络追踪器)是一种程序或脚本,它根据某些规则自动从万维网上爬取信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
以上是百度百科的解释。一般来说,爬虫就是写一个程序来模拟浏览器在互联网上选择我们需要的数据。
爬行动物合法吗?
爬取技术不受法律禁止,但如果我们干扰访问的网站的正常运行,爬取受法律保护的特定类型数据信息,可能会有人请你喝茶。
环境建设
我下载了python3和pycharm,没有下载或者不会安装的兄弟可以去菜鸟网站
(),里面有详细的python教程,也可以顺便学习一下HTML和python的基础知识。
最后,很多人一提到爬虫就会想到Python。其实除了Python之外,其他语言如C、Java、PHP等都可以写爬虫,而且一般来说这些语言的执行效率都比Python高,但是为什么目前是这样也就是说,Python逐渐成为很多人写爬虫的首选。原因是:1、代码简洁,一行代码就可以完成请求,100行就可以完成一个复杂的爬虫任务;2、优秀的第三方库很多,比如requests ,beautifulsoup 等。 查看全部
网页qq抓取什么原理(爬虫爬虫就是编写程序编写程序)
最近在学习python爬虫,顺便记录一下。
爬虫:
网络爬虫(也称为网络蜘蛛、网络机器人,或者在 FOAF 社区中更常称为网络追踪器)是一种程序或脚本,它根据某些规则自动从万维网上爬取信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
以上是百度百科的解释。一般来说,爬虫就是写一个程序来模拟浏览器在互联网上选择我们需要的数据。
爬行动物合法吗?
爬取技术不受法律禁止,但如果我们干扰访问的网站的正常运行,爬取受法律保护的特定类型数据信息,可能会有人请你喝茶。
环境建设
我下载了python3和pycharm,没有下载或者不会安装的兄弟可以去菜鸟网站
(),里面有详细的python教程,也可以顺便学习一下HTML和python的基础知识。

最后,很多人一提到爬虫就会想到Python。其实除了Python之外,其他语言如C、Java、PHP等都可以写爬虫,而且一般来说这些语言的执行效率都比Python高,但是为什么目前是这样也就是说,Python逐渐成为很多人写爬虫的首选。原因是:1、代码简洁,一行代码就可以完成请求,100行就可以完成一个复杂的爬虫任务;2、优秀的第三方库很多,比如requests ,beautifulsoup 等。
网页qq抓取什么原理(一下2021年关于百度蜘蛛的工作原理大家了解多少呢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-19 17:21
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级SEO站长对此都不是很清楚,而且相当一部分站长其实只是为了seo和seo,甚至只知道如何发送< @文章,外链和交易所链,seo真正的核心知识我没有做过太多的了解,或者只是简单的理解了但是没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬取系统原理及索引库的建立,让广大做SEO优化的站长们可以百度蜘蛛的收录
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果把网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持过去爬虫爬取的页面保持更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多的抓取有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
海量的互联网资源要求抓取系统在有限的硬件和带宽资源下,尽可能高效地利用带宽,尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度也会不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度先建重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
话题页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者加入一些新鲜的内容,比如观点、评论,给用户一个更丰富更全面的内容.
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度没有必要收录用互联网上已有的内容。
3、一个空且短主体的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。 查看全部
网页qq抓取什么原理(一下2021年关于百度蜘蛛的工作原理大家了解多少呢)
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级SEO站长对此都不是很清楚,而且相当一部分站长其实只是为了seo和seo,甚至只知道如何发送< @文章,外链和交易所链,seo真正的核心知识我没有做过太多的了解,或者只是简单的理解了但是没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬取系统原理及索引库的建立,让广大做SEO优化的站长们可以百度蜘蛛的收录
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果把网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持过去爬虫爬取的页面保持更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多的抓取有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
海量的互联网资源要求抓取系统在有限的硬件和带宽资源下,尽可能高效地利用带宽,尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度也会不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度先建重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
话题页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者加入一些新鲜的内容,比如观点、评论,给用户一个更丰富更全面的内容.
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度没有必要收录用互联网上已有的内容。
3、一个空且短主体的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。
网页qq抓取什么原理(《搜索引擎原理系列教程》之三个比较关心)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-18 14:20
《搜索引擎原理系列教程》虽然不是一本书,但由于里面信息量大、内容实用,也弥补了百度白皮书的一些不足——言出必行,值得鼓励说这个教程完全是一个民间SEO爱好者总结出来的,这种精神值得称道。
由于这本书一共8章,而且内容太多,就不一一介绍了,不过这里还是想讲三个方面,也是我们SEOER比较关心的三个方面:收录,索引,排名。
一、收录
收录其实是一个复杂的过程,简单的分为这四个步骤:
搜索引擎抓取网页
1、 调度器是整个采集过程的核心。它在内部存储了一个访问过的 URL 库和一个未访问过的 URL 库,统称为 URL 库。一开始,调度器会从未访问的URL库中取出一个URL,分配给蜘蛛,这样蜘蛛就可以对没有被爬取的URL进行爬取。
2、 当蜘蛛获取到 URL 时,它会发送一个请求来获取返回的 URL。流程为:对URL对应的域名进行DNS解析->获取Socket连接的IP->连接成功并发出http请求->接收网页信息。
3、 蜘蛛获取网页信息后,会将源代码返回给调度器,调度器将源代码保存到网页数据库中。
4、 调度器将从爬取的网页中提取链接,将未爬取的URL存储在未访问的URL库中,并将刚刚爬取的URL更新到已爬取的URL库中。
这将涉及重复数据删除
调度程序工作流
1、从未访问的 URL 表中取出 URL 并分配给每个蜘蛛。
2、蜘蛛获取URL,爬取,获取网页源代码,从源代码中提取URL,获取网页中收录的所有URL。
3、调度器依次检查获取到的URL是否存在于被访问的URL库中。如果存在,则表示已被抓取,则丢弃该URL;如果不存在,则说明该URL没有被爬取过,则按顺序添加到未访问过的URL列表中,等待之后再爬取。
4、重复步骤 1 直到未访问的表为空。
二、索引
网页预处理
1、索引原创页面。
2、对可搜索网页进行网页分割,将每个页面转换为一组单词。(前向指数)
3、将网页到索引词的映射转化为索引词到网页的映射形成倒排文件(包括倒排列表和索引词列表)
一般来说,搜索引擎从网页数据库中获取网页,然后进行代码过滤,然后提取文本信息,然后切词。下一步是过滤 关键词 集合,得到网页 关键词 正向索引,最后,搜索引擎将正向索引转换为网页的倒排索引。正是这项技术使得搜索引擎能够在1S内将搜索结果呈现给用户。
另外,搜索引擎的作用是对网页进行净化和去重。除了去除网页中的噪声内容(如广告、版权等),提取网页的主题及相关内容,去除网页集合中的重复内容。
有同学可能会问,搜索引擎是如何识别主要内容的呢?实际上,该算法依赖于HTML标签树的建立和投票方式来识别正文。
例如,让我们设置规则,
1、如果文本块文本长度小于10个字,0分。10-50 字得 5 分。50-250字,8分。250字以上得10分。
2、文本块的文本位置在右边,0分。最高,3分。左边,5分。中间,10分。
然后我们得到页面TITLE得分为9,加粗的H1标签得分为8等,DIV部分的AD部分得分为0,被丢弃。
(以上示例仅供参考,与实际算法无关)
搜索引擎需要通过 3 个步骤来对网页进行重复数据删除。首先是特征提取(包括I-Match算法和Shingle算法),然后是相似度计算,评估它们是否相似,最后是去重。
实际上,搜索引擎算法与用户交互的过程就是一个查询过程。例如,当用户搜索“搜索引擎原理”时,算法分词后得到“搜索引擎”和“原理”。文档列表,找到交集,然后对用户查询和上一步找到的文档列表中的一条记录进行向量化,找到查询向量和文档向量的相似度,然后从高到低排序,最后我们看到最终的搜索结果。
以一个例子结束:
搜索引擎网页权重=网页中词条的基本权重+链接权重+用户评价权重
网页中术语的基本权重
1、例如,在一个关键词“搜索引擎”的上下文中,权重应该是:WBT=W+W, (h1)+W,(b)=10+ 12+4=26
<p>2、关键词“搜索引擎”也可能在文档的其他地方出现n次,每次出现可以算一个WBT 查看全部
网页qq抓取什么原理(《搜索引擎原理系列教程》之三个比较关心)
《搜索引擎原理系列教程》虽然不是一本书,但由于里面信息量大、内容实用,也弥补了百度白皮书的一些不足——言出必行,值得鼓励说这个教程完全是一个民间SEO爱好者总结出来的,这种精神值得称道。
由于这本书一共8章,而且内容太多,就不一一介绍了,不过这里还是想讲三个方面,也是我们SEOER比较关心的三个方面:收录,索引,排名。
一、收录
收录其实是一个复杂的过程,简单的分为这四个步骤:
搜索引擎抓取网页
1、 调度器是整个采集过程的核心。它在内部存储了一个访问过的 URL 库和一个未访问过的 URL 库,统称为 URL 库。一开始,调度器会从未访问的URL库中取出一个URL,分配给蜘蛛,这样蜘蛛就可以对没有被爬取的URL进行爬取。
2、 当蜘蛛获取到 URL 时,它会发送一个请求来获取返回的 URL。流程为:对URL对应的域名进行DNS解析->获取Socket连接的IP->连接成功并发出http请求->接收网页信息。
3、 蜘蛛获取网页信息后,会将源代码返回给调度器,调度器将源代码保存到网页数据库中。
4、 调度器将从爬取的网页中提取链接,将未爬取的URL存储在未访问的URL库中,并将刚刚爬取的URL更新到已爬取的URL库中。
这将涉及重复数据删除
调度程序工作流
1、从未访问的 URL 表中取出 URL 并分配给每个蜘蛛。
2、蜘蛛获取URL,爬取,获取网页源代码,从源代码中提取URL,获取网页中收录的所有URL。
3、调度器依次检查获取到的URL是否存在于被访问的URL库中。如果存在,则表示已被抓取,则丢弃该URL;如果不存在,则说明该URL没有被爬取过,则按顺序添加到未访问过的URL列表中,等待之后再爬取。
4、重复步骤 1 直到未访问的表为空。
二、索引
网页预处理
1、索引原创页面。
2、对可搜索网页进行网页分割,将每个页面转换为一组单词。(前向指数)
3、将网页到索引词的映射转化为索引词到网页的映射形成倒排文件(包括倒排列表和索引词列表)
一般来说,搜索引擎从网页数据库中获取网页,然后进行代码过滤,然后提取文本信息,然后切词。下一步是过滤 关键词 集合,得到网页 关键词 正向索引,最后,搜索引擎将正向索引转换为网页的倒排索引。正是这项技术使得搜索引擎能够在1S内将搜索结果呈现给用户。
另外,搜索引擎的作用是对网页进行净化和去重。除了去除网页中的噪声内容(如广告、版权等),提取网页的主题及相关内容,去除网页集合中的重复内容。
有同学可能会问,搜索引擎是如何识别主要内容的呢?实际上,该算法依赖于HTML标签树的建立和投票方式来识别正文。
例如,让我们设置规则,
1、如果文本块文本长度小于10个字,0分。10-50 字得 5 分。50-250字,8分。250字以上得10分。
2、文本块的文本位置在右边,0分。最高,3分。左边,5分。中间,10分。
然后我们得到页面TITLE得分为9,加粗的H1标签得分为8等,DIV部分的AD部分得分为0,被丢弃。
(以上示例仅供参考,与实际算法无关)
搜索引擎需要通过 3 个步骤来对网页进行重复数据删除。首先是特征提取(包括I-Match算法和Shingle算法),然后是相似度计算,评估它们是否相似,最后是去重。
实际上,搜索引擎算法与用户交互的过程就是一个查询过程。例如,当用户搜索“搜索引擎原理”时,算法分词后得到“搜索引擎”和“原理”。文档列表,找到交集,然后对用户查询和上一步找到的文档列表中的一条记录进行向量化,找到查询向量和文档向量的相似度,然后从高到低排序,最后我们看到最终的搜索结果。
以一个例子结束:
搜索引擎网页权重=网页中词条的基本权重+链接权重+用户评价权重
网页中术语的基本权重
1、例如,在一个关键词“搜索引擎”的上下文中,权重应该是:WBT=W+W, (h1)+W,(b)=10+ 12+4=26
<p>2、关键词“搜索引擎”也可能在文档的其他地方出现n次,每次出现可以算一个WBT
网页qq抓取什么原理(QQ好友说说爬虫技术(爬虫)-爬虫步骤详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-16 11:08
自从上一篇文章你真的了解QQ空间里的“说话”吗?上线后,很多朋友都问小编如何爬取QQ空间的话题。今天,小编就来详细介绍一下。给大家介绍一下QQ好友,聊聊爬虫技术。通过本文章的学习,希望能给大家带来帮助。
本文将从基础知识介绍、QQ好友聊爬虫框架、爬虫详细步骤三个部分进行详细讲解。
一、基础知识介绍
小编爬QQ朋友说说使用Python语言,所以大家一定要有Python基础。另外,在爬取中还用到了 Python 的几个第三方库,分别是 requests 库和 BeautifulSoup 库。 pymysql库和matplotlib库用于数据存储和解析,所以你应该对这些库有一定的了解。
二、QQ好友聊爬虫框架
QQ好友聊爬虫的基本思路是利用浏览器已经登录的cookie实现爬虫登录,使用准备好的好友QQ账号将所有的好友聊HTML文件下载到本地文件系统,并在本地文件系统中解析HTML文件,提取信息并存储在MySql数据库中,最后自己分析MySql数据库中的信息。爬虫框架图如下。
三、爬虫步骤详解
3.1 获取所有好友QQ号
QQ邮箱有导出所有联系人的功能,所以我们可以使用QQ邮箱获取所有好友的QQ号。步骤如下:登录QQ邮箱-->点击右侧通讯录-->点击工具,选择导出联系人-->下载CSV文件。
3.2 获取浏览器登录的cookie
我们要使用浏览器已经登录的cookie来实现爬虫登录,都必须得到浏览器cookie。步骤如下:打开浏览器
--> 输入网站 --> 按F12打开浏览器的开发工具,切换到Network
--> 输入你的QQ号和密码登录--> 点击第一行,将请求头的cookie值复制到txt文件中。
3.3 爬上所有朋友聊聊
每个朋友的讨论页的url链接是/friends QQ号,所以我们必须先获取所有朋友的QQ号。读取csv文件,将所有好友的QQ号存入qnumber_list数组中。
(注意:/python/qqMoodCollect/QQmail.csv是csv文件路径,这里需要改一下文件路径)
下面是遍历qnumber_list数组,依次下载HTML文件到本地文件系统。
(get_moods()方法是下载HTML文件的方法,详见GetHub上的代码)
3.4 解析 HTML 文件
下载的HTML文件实际上是Json数据格式。我们可以利用Python内置的json库,轻松提取出我们想要的信息,最后存入MySql数据库。具体解析过程请参考get_mooddetail.py文件。 查看全部
网页qq抓取什么原理(QQ好友说说爬虫技术(爬虫)-爬虫步骤详解)
自从上一篇文章你真的了解QQ空间里的“说话”吗?上线后,很多朋友都问小编如何爬取QQ空间的话题。今天,小编就来详细介绍一下。给大家介绍一下QQ好友,聊聊爬虫技术。通过本文章的学习,希望能给大家带来帮助。
本文将从基础知识介绍、QQ好友聊爬虫框架、爬虫详细步骤三个部分进行详细讲解。
一、基础知识介绍
小编爬QQ朋友说说使用Python语言,所以大家一定要有Python基础。另外,在爬取中还用到了 Python 的几个第三方库,分别是 requests 库和 BeautifulSoup 库。 pymysql库和matplotlib库用于数据存储和解析,所以你应该对这些库有一定的了解。
二、QQ好友聊爬虫框架
QQ好友聊爬虫的基本思路是利用浏览器已经登录的cookie实现爬虫登录,使用准备好的好友QQ账号将所有的好友聊HTML文件下载到本地文件系统,并在本地文件系统中解析HTML文件,提取信息并存储在MySql数据库中,最后自己分析MySql数据库中的信息。爬虫框架图如下。
三、爬虫步骤详解
3.1 获取所有好友QQ号
QQ邮箱有导出所有联系人的功能,所以我们可以使用QQ邮箱获取所有好友的QQ号。步骤如下:登录QQ邮箱-->点击右侧通讯录-->点击工具,选择导出联系人-->下载CSV文件。
3.2 获取浏览器登录的cookie
我们要使用浏览器已经登录的cookie来实现爬虫登录,都必须得到浏览器cookie。步骤如下:打开浏览器
--> 输入网站 --> 按F12打开浏览器的开发工具,切换到Network
--> 输入你的QQ号和密码登录--> 点击第一行,将请求头的cookie值复制到txt文件中。
3.3 爬上所有朋友聊聊
每个朋友的讨论页的url链接是/friends QQ号,所以我们必须先获取所有朋友的QQ号。读取csv文件,将所有好友的QQ号存入qnumber_list数组中。
(注意:/python/qqMoodCollect/QQmail.csv是csv文件路径,这里需要改一下文件路径)
下面是遍历qnumber_list数组,依次下载HTML文件到本地文件系统。
(get_moods()方法是下载HTML文件的方法,详见GetHub上的代码)
3.4 解析 HTML 文件
下载的HTML文件实际上是Json数据格式。我们可以利用Python内置的json库,轻松提取出我们想要的信息,最后存入MySql数据库。具体解析过程请参考get_mooddetail.py文件。
网页qq抓取什么原理(网页qq抓取什么原理?,我在用源码进行分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-14 15:10
网页qq抓取什么原理?,我在用源码进行分析,没有用到文本分析工具。
1)目标爬取百度云和一个店铺的,页面url中有id,有一些没有,可以从id看出某个页面的重复页面。抓取到就是可以获取所有页面的url。
2)准备工作:先在主流的浏览器上进行安装vscode或eclipse,这里统一使用vscode;安装到你的路径下,设置好权限,并且在公用的路径不会有文件,用户也不会有;安装tomcat开发工具,mac的话是sqlserverontopic,windows应该是server端所以必须加上。之后打开chrome或是百度云网页。
在网页的右上角输入chrome浏览器地址,可以看到下面有很多选项,我这里选择从菜单栏中打开。选择installsoftware,之后,下一步点击下一步选择installtargetlocalsoftware,之后安装jdk,这里不再做详细介绍,现在主要看其它的第三个项;安装好jdk之后,可以直接在命令行工具中输入java-version查看jdk版本号,如果没有显示version的话,可以尝试换成后缀名的文件。
接下来按照页面爬取指南进行操作:1.把url写入文件打开python文件夹,一个一个导入你所需要的数据。读取数据fromdatetimeimportdatetimefromrequestsimportrequesturl='/'res=request(url,headers=headers)get_all_urls=request('',headers=headers)withopen('abc.txt','w')asf:json_date=datetime.now()#thedatetimeisundefinedcontent=json_date['raw'][content]text=json_date['raw']['content']ifisinstance(text,json_date):returnnoneelse:returntext2.构建页面路径在open里面新建一个file.py文件。
保存(文件名必须为.txt)后缀名修改为.file。在执行程序时,直接双击运行,在其它情况下,建议放在其它路径下。直接双击程序后,回车,如果程序出现未找到data即说明您的程序需要部署到idc这样的企业级网站才能运行。3.根据页面爬取指南,把url的地址中的"to"列表中所有的cookies打印出来(cookies可以看看官方getcss可以看到)。
res.read().split('/')[0].resize(500,50
0).sort(ascending=false).sort()爬取全部页面(foriinrange(500,50
0):)这样就能爬取到所有的url了。 查看全部
网页qq抓取什么原理(网页qq抓取什么原理?,我在用源码进行分析)
网页qq抓取什么原理?,我在用源码进行分析,没有用到文本分析工具。
1)目标爬取百度云和一个店铺的,页面url中有id,有一些没有,可以从id看出某个页面的重复页面。抓取到就是可以获取所有页面的url。
2)准备工作:先在主流的浏览器上进行安装vscode或eclipse,这里统一使用vscode;安装到你的路径下,设置好权限,并且在公用的路径不会有文件,用户也不会有;安装tomcat开发工具,mac的话是sqlserverontopic,windows应该是server端所以必须加上。之后打开chrome或是百度云网页。
在网页的右上角输入chrome浏览器地址,可以看到下面有很多选项,我这里选择从菜单栏中打开。选择installsoftware,之后,下一步点击下一步选择installtargetlocalsoftware,之后安装jdk,这里不再做详细介绍,现在主要看其它的第三个项;安装好jdk之后,可以直接在命令行工具中输入java-version查看jdk版本号,如果没有显示version的话,可以尝试换成后缀名的文件。
接下来按照页面爬取指南进行操作:1.把url写入文件打开python文件夹,一个一个导入你所需要的数据。读取数据fromdatetimeimportdatetimefromrequestsimportrequesturl='/'res=request(url,headers=headers)get_all_urls=request('',headers=headers)withopen('abc.txt','w')asf:json_date=datetime.now()#thedatetimeisundefinedcontent=json_date['raw'][content]text=json_date['raw']['content']ifisinstance(text,json_date):returnnoneelse:returntext2.构建页面路径在open里面新建一个file.py文件。
保存(文件名必须为.txt)后缀名修改为.file。在执行程序时,直接双击运行,在其它情况下,建议放在其它路径下。直接双击程序后,回车,如果程序出现未找到data即说明您的程序需要部署到idc这样的企业级网站才能运行。3.根据页面爬取指南,把url的地址中的"to"列表中所有的cookies打印出来(cookies可以看看官方getcss可以看到)。
res.read().split('/')[0].resize(500,50
0).sort(ascending=false).sort()爬取全部页面(foriinrange(500,50
0):)这样就能爬取到所有的url了。
网页qq抓取什么原理(谷歌AMPAcceleratedMobilePages意思就是“加速移动网页”(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-03-10 15:17
近日,百度新推出的MIP引起了博主的关注。因为明月一直比较关注优化手机博客的浏览体验,所以如今智能手机的渗透率几乎达到了最高水平。如果博主不注意,那真是“奥特曼”,太落伍了!今天明月就带大家通过AMP的实现来了解百度MIP,作为MIP前的热身。
百度 MIP 和 Google AMP 是做什么的?
我们先来看看字面意思,Google AMP(Accelerated Mobile Pages),字面意思是“加速移动网页”,官方的解释是:Accelerated Mobile Page(AMP)是按照开源代码规范设计的网页。经过验证的 AMP 页面缓存在 Google 的 AMP 缓存中,从而可以更快地呈现给用户。我们再来看看百度MIP:MIP(Mobile Instant Page - Mobile Web Accelerator),是一套应用于移动网页的开放技术标准。通过提供 MIP-HTML 规范、MIP-JS 运行环境和 MIP-Cache 页面缓存系统来加速移动网页。可见,它是加速移动网页的技术标准。至于更直观的加速效果,可以借用【什么是MIP?'
说白了就是可以实现手机网页的“二次打开”。
如何使用 MIP、AMP?
不管是MIP还是AMP,其实原理都是通过CDN提高网站手机端的加载速度。效果是“第二次打开”加载。目前移动4G网络的普及,WiFi、网站CDN等技术的使用,这种“加速”的效果有时并不那么明显,但因为是搜索引擎推出的优化方案,无论是谷歌还是百度都强调会在排名和权重方面给予一定的抵消,所以AMP和MIP也成为了当前网站优化中不可或缺的一部分!引起了很多站长的关注。虽然我们是草根博客站长,但这并不妨碍我们追求极致的优化。百度' s MIP目前处于起步阶段,需要对代码进行大量修改才能使用。支持只在代码阶段,可操作性很低(当然不排除你是web开发高手,可以自己做)。谷歌的AMP已经推出很久了,标准化和标准化已经很到位了。尤其是WordPress官方推出了AMP插件,比较简单。我们可以从 AMP 入手,体验一下。WordPress正式推出了AMP插件,比较简单。我们可以从 AMP 入手,体验一下。WordPress正式推出了AMP插件,比较简单。我们可以从 AMP 入手,体验一下。
首先在WordPress中安装一个插件“AMP”。该插件由 Automattic(WordPress 的母公司,WP 之母)推出,用于将 WP 网页转换为 AMP 标准网页。安装“AMP”插件后,可以发现WP中有一个AMP项——“Appearance”。进入后是一个AMP网页的可视化编辑,如下图:
它应该是最近的一个名为 文章 的演示。可以看到自适应主题的手机AMP网页比之前的自适应主题简单很多,内容的可读性还是很好的。显示。
图片也很完美
AMP 插件仅适用于 AMP 标准。如果你想做一些特殊的定制,你需要使用另一个名为“Accelerated Mobile Pages”的插件。这个应该是AMP插件的扩展包,可以在这个插件中设置。AMP页面的logo、样式等如下:
其实这里可以设置的东西不少。除了General,记得在Single中打开Featured Image。这是一个显示“特色图像”的开关。您可以自己体验其他选择。
上面两个插件安装设置好后,只能说是有AMP标准的网页了。Google 如何发现和收录?如何访问 AMP 页面?下面我们来详细解释一下。明月研究了很久才明白,囧!
如何访问 AMP 页面?
如何访问我的 网站 AMP 页面?其实很简单。插件安装好后,在你的网站的链接中添加“/amp”或者“?amp”来查看AMP页面的效果。这里需要强调的是,如果URL以“/”结尾,可以加“?amp”来调用AMP页面,比如首页和分类。具体效果如下:
目前,明月的博客()和主站()已经支持AMP页面,可以使用上述方法在手机上调用AMP页面进行体验。
如何让 Google 发现和 收录?
为了让谷歌发现和收录的AMP页面,你需要在你的WP页面中使用两个标签来指定AMP页面的访问规则,具体代码如下(记得改成你自己的域姓名!):
将上述标记代码放入当前主题的head.php中。然后你所要做的就是等待谷歌抓取。如果想加快爬取等待时间,可以登录谷歌的Search Console(谷歌站长平台),在“爬取”-“爬取方式”中提交AMP页面。该链接让谷歌识别它并“将结果提交给索引”。等了大约48小时后,可以在Search Console(谷歌站长平台)的“搜索结果外观”-Accelerated Mobile Pages中看到谷歌的收录情况!
未抓取 AMP 时 Search Console 中的“搜索结果外观” - Accelerated Mobile Pages 显示“开启”
抓取AMP页面时,可以看到抓取曲线!这意味着获取成功。
此时启用AMP网页的原理与百度MIP相同。百度的 MIP 目前实现起来非常复杂,官方的 WP 插件也消失了。整个主题都要大改,这显然是不现实的。已经有支持 MIP 的 WP 主题。有一个免费版本。如果你想试试,你可以下载体验一下。您可以从[泪雪博客]主题下载Fanly-MIP。 查看全部
网页qq抓取什么原理(谷歌AMPAcceleratedMobilePages意思就是“加速移动网页”(组图))
近日,百度新推出的MIP引起了博主的关注。因为明月一直比较关注优化手机博客的浏览体验,所以如今智能手机的渗透率几乎达到了最高水平。如果博主不注意,那真是“奥特曼”,太落伍了!今天明月就带大家通过AMP的实现来了解百度MIP,作为MIP前的热身。
百度 MIP 和 Google AMP 是做什么的?
我们先来看看字面意思,Google AMP(Accelerated Mobile Pages),字面意思是“加速移动网页”,官方的解释是:Accelerated Mobile Page(AMP)是按照开源代码规范设计的网页。经过验证的 AMP 页面缓存在 Google 的 AMP 缓存中,从而可以更快地呈现给用户。我们再来看看百度MIP:MIP(Mobile Instant Page - Mobile Web Accelerator),是一套应用于移动网页的开放技术标准。通过提供 MIP-HTML 规范、MIP-JS 运行环境和 MIP-Cache 页面缓存系统来加速移动网页。可见,它是加速移动网页的技术标准。至于更直观的加速效果,可以借用【什么是MIP?'
说白了就是可以实现手机网页的“二次打开”。
如何使用 MIP、AMP?
不管是MIP还是AMP,其实原理都是通过CDN提高网站手机端的加载速度。效果是“第二次打开”加载。目前移动4G网络的普及,WiFi、网站CDN等技术的使用,这种“加速”的效果有时并不那么明显,但因为是搜索引擎推出的优化方案,无论是谷歌还是百度都强调会在排名和权重方面给予一定的抵消,所以AMP和MIP也成为了当前网站优化中不可或缺的一部分!引起了很多站长的关注。虽然我们是草根博客站长,但这并不妨碍我们追求极致的优化。百度' s MIP目前处于起步阶段,需要对代码进行大量修改才能使用。支持只在代码阶段,可操作性很低(当然不排除你是web开发高手,可以自己做)。谷歌的AMP已经推出很久了,标准化和标准化已经很到位了。尤其是WordPress官方推出了AMP插件,比较简单。我们可以从 AMP 入手,体验一下。WordPress正式推出了AMP插件,比较简单。我们可以从 AMP 入手,体验一下。WordPress正式推出了AMP插件,比较简单。我们可以从 AMP 入手,体验一下。
首先在WordPress中安装一个插件“AMP”。该插件由 Automattic(WordPress 的母公司,WP 之母)推出,用于将 WP 网页转换为 AMP 标准网页。安装“AMP”插件后,可以发现WP中有一个AMP项——“Appearance”。进入后是一个AMP网页的可视化编辑,如下图:
它应该是最近的一个名为 文章 的演示。可以看到自适应主题的手机AMP网页比之前的自适应主题简单很多,内容的可读性还是很好的。显示。
图片也很完美
AMP 插件仅适用于 AMP 标准。如果你想做一些特殊的定制,你需要使用另一个名为“Accelerated Mobile Pages”的插件。这个应该是AMP插件的扩展包,可以在这个插件中设置。AMP页面的logo、样式等如下:
其实这里可以设置的东西不少。除了General,记得在Single中打开Featured Image。这是一个显示“特色图像”的开关。您可以自己体验其他选择。
上面两个插件安装设置好后,只能说是有AMP标准的网页了。Google 如何发现和收录?如何访问 AMP 页面?下面我们来详细解释一下。明月研究了很久才明白,囧!
如何访问 AMP 页面?
如何访问我的 网站 AMP 页面?其实很简单。插件安装好后,在你的网站的链接中添加“/amp”或者“?amp”来查看AMP页面的效果。这里需要强调的是,如果URL以“/”结尾,可以加“?amp”来调用AMP页面,比如首页和分类。具体效果如下:
目前,明月的博客()和主站()已经支持AMP页面,可以使用上述方法在手机上调用AMP页面进行体验。
如何让 Google 发现和 收录?
为了让谷歌发现和收录的AMP页面,你需要在你的WP页面中使用两个标签来指定AMP页面的访问规则,具体代码如下(记得改成你自己的域姓名!):
将上述标记代码放入当前主题的head.php中。然后你所要做的就是等待谷歌抓取。如果想加快爬取等待时间,可以登录谷歌的Search Console(谷歌站长平台),在“爬取”-“爬取方式”中提交AMP页面。该链接让谷歌识别它并“将结果提交给索引”。等了大约48小时后,可以在Search Console(谷歌站长平台)的“搜索结果外观”-Accelerated Mobile Pages中看到谷歌的收录情况!
未抓取 AMP 时 Search Console 中的“搜索结果外观” - Accelerated Mobile Pages 显示“开启”
抓取AMP页面时,可以看到抓取曲线!这意味着获取成功。
此时启用AMP网页的原理与百度MIP相同。百度的 MIP 目前实现起来非常复杂,官方的 WP 插件也消失了。整个主题都要大改,这显然是不现实的。已经有支持 MIP 的 WP 主题。有一个免费版本。如果你想试试,你可以下载体验一下。您可以从[泪雪博客]主题下载Fanly-MIP。
网页qq抓取什么原理(UA即user-agent原则及调整方法根据上述网站设置)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-06 13:22
UA属性:UA即user-agent,是http协议中的一个属性,代表终端的身份,向服务器表明我在做什么,然后服务器可以根据不同的身份做出不同的反馈结果。
机器人协议:robots.txt 是搜索引擎访问网站时首先访问的文件,用于确定哪些允许爬取,哪些禁止爬取。robots.txt 必须放在网站 根目录下,文件名必须小写。robots.txt的详细写法请参考。百度严格遵守机器人协议。此外,它还支持在网页内容中添加名为 robots、index、follow、nofollow 等指令的元标记。
百度蜘蛛抓取频率原理及调整方法
百度蜘蛛根据上述网站设定的协议爬取网站页面,但不可能对所有网站一视同仁。它会综合考虑网站的实际情况来确定一个抓取配额,每天定量抓取网站内容,也就是我们常说的抓取频率。那么百度搜索引擎是通过哪些指标来判断一个网站的爬取频率呢?主要有四个指标:
1、网站更新频率:更新越频繁,更新越慢,直接影响百度蜘蛛的访问频率
2、网站更新质量:提升的更新频率正好吸引了百度蜘蛛的注意。百度蜘蛛对质量有严格的要求。如果 网站 每天更新的大量内容被百度蜘蛛质量页面判断为低,仍然没有意义。
3. 连通性:网站 安全稳定,保持百度蜘蛛畅通。一直关着百度蜘蛛不是好事
4.站点评价:百度搜索引擎会对每个站点进行评价,这个评价会根据站点情况而变化。里面有很机密的资料。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。
爬取频率间接决定了网站有多少页面可能被数据库收录。这么重要的值,如果不符合站长的期望,应该如何调整呢?百度站长平台提供爬频工具,已完成多次升级。除了提供爬取统计,该工具还提供了“频率调整”功能。站长要求百度蜘蛛根据实际情况增加或减少对百度站长平台的访问量。调整。
百度蜘蛛爬取异常的原因
有一些网页内容优质,用户可以正常访问,但Baiduspider无法正常访问和爬取,导致搜索结果覆盖不足,对百度搜索引擎和网站来说都是一种损失。百度称这种情况为“抢”。对于大量内容无法正常抓取的网站,百度搜索引擎会认为网站存在用户体验缺陷,降低对网站的评价,在爬取、索引和排序方面都会受到一定程度的负面影响,最终会影响到网站从百度获得的流量。
以下是爬取异常的一些常见原因:
1.服务器连接异常
服务器连接异常有两种情况:一种是网站不稳定,百度蜘蛛在尝试连接你的网站服务器时暂时无法连接;另一个是百度蜘蛛一直无法连接到你的网站的服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。还有可能是你的网站没有正常运行,请检查网站的web服务器(如apache、iis)是否安装运行正常,用浏览器查看主页面可以正常访问。您的 网站 和主机也可能阻止了百度蜘蛛的访问,您需要检查您的 网站 和主机的防火墙。
2、网络运营商异常:网络运营商分为电信和联通两类。百度蜘蛛无法通过中国电信或中国网通访问您的网站。如果出现这种情况,需要联系网络服务运营商,或者购买双线服务空间或者购买cdn服务。
3、DNS异常:当Baiduspider无法解析您的网站 IP时,会出现DNS异常。可能你的网站IP地址错误,或者你的域名服务商屏蔽了百度蜘蛛。请使用 WHOIS 或主机检查您的 网站IP 地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商更新您的 IP 地址。
4、IP封禁:IP封禁是:限制网络的出口IP地址,禁止该IP段内的用户访问内容,这里特意禁止BaiduspiderIP。仅当您的 网站 不希望百度蜘蛛访问时,才需要此设置。如果您想让百度蜘蛛访问您的网站,请检查相关设置中是否错误添加了百度蜘蛛IP。也有可能是你网站所在的空间服务商封杀了百度IP。在这种情况下,您需要联系服务提供商更改设置。
5、UA禁止:UA是User-Agent,服务器通过UA识别访问者的身份。当网站返回异常页面(如403、500)或跳转到其他页面进行指定UA的访问时,属于UA禁令。当你的网站不想要百度蜘蛛时这个设置只有在访问时才需要,如果你想让百度蜘蛛访问你的网站,请检查useragent相关设置中是否有百度蜘蛛UA,并及时修改。
6、死链接:无效且不能为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接:
协议死链接:页面的TCP协议状态/HTTP协议状态明确表示的死链接,如404、403、503状态等。
内容死链接:服务器返回正常状态,但内容已更改为不存在、已删除或需要权限等与原创内容无关的信息页面。
对于死链接,我们建议网站使用协议死链接,通过百度站长平台——死链接工具提交给百度,这样百度可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
7.异常跳转:将网络请求重定向到另一个位置是跳转。异常跳转指以下几种情况:
1)当前页面为无效页面(删除内容、死链接等),直接跳转到上一个目录或首页,百度建议站长删除无效页面的入口超链接
2)跳转到错误或无效页面
注意:长期重定向到其他域名,如网站改域名,百度推荐使用301重定向协议进行设置。
8. 其他例外:
1)百度referrer异常:网页返回的行为与来自百度的referrer的正常内容不同。
2)百度UA异常:网页返回百度UA的行为与页面原创内容不同。
3)JS跳转异常:网页加载了百度无法识别的JS跳转代码,导致用户通过搜索结果进入页面后跳转。
4)压力过大导致的意外封禁:百度会根据网站规模、流量等信息自动设置合理的抓取压力。但在异常情况下,如压力控制异常时,服务器会根据自身负载进行保护性的偶尔封禁。在这种情况下,请在返回码中返回 503(表示“服务不可用”),这样百度蜘蛛会在一段时间后再次尝试抓取链接。如果 网站 是空闲的,它将被成功爬取。
判断新链接的重要性
好了,上面我们讲了影响百度蜘蛛正常爬取的原因,现在来说说百度蜘蛛的一些判断原则。建库前,Baiduspide会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立一个图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对这么多新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值:
1.独特的内容,百度搜索引擎喜欢独特的内容
2. 主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4.广告合适
二、链接的重要性:
1.目录级别——浅层优先
2. 网站链接的受欢迎程度
百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1.及时有价值的页面:在这里,及时性和价值并列,缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、内容优质的专页:专页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者是一些新鲜的内容,比如浏览量和评论,可以添加到用户。更丰富、更全面的内容。
3、高价值的原创内容页面:百度将原创定义为花费一定成本、积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4.重要的个人页面:这里只是一个例子,科比在新浪微博上开了一个账号,他需要不经常更新,但对于百度来说,它仍然是一个非常重要的页面。
哪些页面不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的网页:百度不需要收录互联网上已有的内容。
2. 主要内容为空、短的网页
1)有些内容使用了百度蜘蛛无法解析的技术,比如JS、AJAX等,虽然用户可以看到丰富的内容,但还是会被搜索引擎抛弃
2)加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
3)很多主体不太突出的网页,即使被爬回来,也会在这个链接中被丢弃。 查看全部
网页qq抓取什么原理(UA即user-agent原则及调整方法根据上述网站设置)
UA属性:UA即user-agent,是http协议中的一个属性,代表终端的身份,向服务器表明我在做什么,然后服务器可以根据不同的身份做出不同的反馈结果。
机器人协议:robots.txt 是搜索引擎访问网站时首先访问的文件,用于确定哪些允许爬取,哪些禁止爬取。robots.txt 必须放在网站 根目录下,文件名必须小写。robots.txt的详细写法请参考。百度严格遵守机器人协议。此外,它还支持在网页内容中添加名为 robots、index、follow、nofollow 等指令的元标记。
百度蜘蛛抓取频率原理及调整方法
百度蜘蛛根据上述网站设定的协议爬取网站页面,但不可能对所有网站一视同仁。它会综合考虑网站的实际情况来确定一个抓取配额,每天定量抓取网站内容,也就是我们常说的抓取频率。那么百度搜索引擎是通过哪些指标来判断一个网站的爬取频率呢?主要有四个指标:
1、网站更新频率:更新越频繁,更新越慢,直接影响百度蜘蛛的访问频率
2、网站更新质量:提升的更新频率正好吸引了百度蜘蛛的注意。百度蜘蛛对质量有严格的要求。如果 网站 每天更新的大量内容被百度蜘蛛质量页面判断为低,仍然没有意义。
3. 连通性:网站 安全稳定,保持百度蜘蛛畅通。一直关着百度蜘蛛不是好事
4.站点评价:百度搜索引擎会对每个站点进行评价,这个评价会根据站点情况而变化。里面有很机密的资料。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。
爬取频率间接决定了网站有多少页面可能被数据库收录。这么重要的值,如果不符合站长的期望,应该如何调整呢?百度站长平台提供爬频工具,已完成多次升级。除了提供爬取统计,该工具还提供了“频率调整”功能。站长要求百度蜘蛛根据实际情况增加或减少对百度站长平台的访问量。调整。
百度蜘蛛爬取异常的原因
有一些网页内容优质,用户可以正常访问,但Baiduspider无法正常访问和爬取,导致搜索结果覆盖不足,对百度搜索引擎和网站来说都是一种损失。百度称这种情况为“抢”。对于大量内容无法正常抓取的网站,百度搜索引擎会认为网站存在用户体验缺陷,降低对网站的评价,在爬取、索引和排序方面都会受到一定程度的负面影响,最终会影响到网站从百度获得的流量。
以下是爬取异常的一些常见原因:
1.服务器连接异常
服务器连接异常有两种情况:一种是网站不稳定,百度蜘蛛在尝试连接你的网站服务器时暂时无法连接;另一个是百度蜘蛛一直无法连接到你的网站的服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。还有可能是你的网站没有正常运行,请检查网站的web服务器(如apache、iis)是否安装运行正常,用浏览器查看主页面可以正常访问。您的 网站 和主机也可能阻止了百度蜘蛛的访问,您需要检查您的 网站 和主机的防火墙。
2、网络运营商异常:网络运营商分为电信和联通两类。百度蜘蛛无法通过中国电信或中国网通访问您的网站。如果出现这种情况,需要联系网络服务运营商,或者购买双线服务空间或者购买cdn服务。
3、DNS异常:当Baiduspider无法解析您的网站 IP时,会出现DNS异常。可能你的网站IP地址错误,或者你的域名服务商屏蔽了百度蜘蛛。请使用 WHOIS 或主机检查您的 网站IP 地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商更新您的 IP 地址。
4、IP封禁:IP封禁是:限制网络的出口IP地址,禁止该IP段内的用户访问内容,这里特意禁止BaiduspiderIP。仅当您的 网站 不希望百度蜘蛛访问时,才需要此设置。如果您想让百度蜘蛛访问您的网站,请检查相关设置中是否错误添加了百度蜘蛛IP。也有可能是你网站所在的空间服务商封杀了百度IP。在这种情况下,您需要联系服务提供商更改设置。
5、UA禁止:UA是User-Agent,服务器通过UA识别访问者的身份。当网站返回异常页面(如403、500)或跳转到其他页面进行指定UA的访问时,属于UA禁令。当你的网站不想要百度蜘蛛时这个设置只有在访问时才需要,如果你想让百度蜘蛛访问你的网站,请检查useragent相关设置中是否有百度蜘蛛UA,并及时修改。
6、死链接:无效且不能为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接:
协议死链接:页面的TCP协议状态/HTTP协议状态明确表示的死链接,如404、403、503状态等。
内容死链接:服务器返回正常状态,但内容已更改为不存在、已删除或需要权限等与原创内容无关的信息页面。
对于死链接,我们建议网站使用协议死链接,通过百度站长平台——死链接工具提交给百度,这样百度可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
7.异常跳转:将网络请求重定向到另一个位置是跳转。异常跳转指以下几种情况:
1)当前页面为无效页面(删除内容、死链接等),直接跳转到上一个目录或首页,百度建议站长删除无效页面的入口超链接
2)跳转到错误或无效页面
注意:长期重定向到其他域名,如网站改域名,百度推荐使用301重定向协议进行设置。
8. 其他例外:
1)百度referrer异常:网页返回的行为与来自百度的referrer的正常内容不同。
2)百度UA异常:网页返回百度UA的行为与页面原创内容不同。
3)JS跳转异常:网页加载了百度无法识别的JS跳转代码,导致用户通过搜索结果进入页面后跳转。
4)压力过大导致的意外封禁:百度会根据网站规模、流量等信息自动设置合理的抓取压力。但在异常情况下,如压力控制异常时,服务器会根据自身负载进行保护性的偶尔封禁。在这种情况下,请在返回码中返回 503(表示“服务不可用”),这样百度蜘蛛会在一段时间后再次尝试抓取链接。如果 网站 是空闲的,它将被成功爬取。
判断新链接的重要性
好了,上面我们讲了影响百度蜘蛛正常爬取的原因,现在来说说百度蜘蛛的一些判断原则。建库前,Baiduspide会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立一个图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对这么多新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值:
1.独特的内容,百度搜索引擎喜欢独特的内容
2. 主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4.广告合适
二、链接的重要性:
1.目录级别——浅层优先
2. 网站链接的受欢迎程度
百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1.及时有价值的页面:在这里,及时性和价值并列,缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、内容优质的专页:专页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者是一些新鲜的内容,比如浏览量和评论,可以添加到用户。更丰富、更全面的内容。
3、高价值的原创内容页面:百度将原创定义为花费一定成本、积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4.重要的个人页面:这里只是一个例子,科比在新浪微博上开了一个账号,他需要不经常更新,但对于百度来说,它仍然是一个非常重要的页面。
哪些页面不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的网页:百度不需要收录互联网上已有的内容。
2. 主要内容为空、短的网页
1)有些内容使用了百度蜘蛛无法解析的技术,比如JS、AJAX等,虽然用户可以看到丰富的内容,但还是会被搜索引擎抛弃
2)加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
3)很多主体不太突出的网页,即使被爬回来,也会在这个链接中被丢弃。
网页qq抓取什么原理( 爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-05 14:24
爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人))
01 什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
Web 爬虫通过从 Internet 上的 网站 服务器上爬取内容来工作。它是用计算机语言编写的程序或脚本,自动从互联网上获取信息或数据,扫描并抓取每个所需页面上的某些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市面上流行的采集器软件都是利用网络爬虫的原理或功能。
▲图 2-1 网络爬虫象形图
02 爬行动物的意义
如今,大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为、自身产品的不足、竞争对手的信息。所有这一切的首要条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就有决策的主动权。网络爬虫的应用领域很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1)抓取各大电商公司的产品销售信息和用户评价网站进行分析,如图2-2所示。
▲图2-2 电商产品销售信息网站
2)分析大众点评、美团等餐饮品类网站用户的消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区住房占比,学区房价格比普通二手房高多少,如图2-4所示。
▲图2-4 学区住房比例与价格对比
以上数据是由ForeSpider数据采集软件爬下来的。有兴趣的读者可以尝试自己爬一些数据。
03 爬虫的原理
我们通常将网络爬虫的组件分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取链接队列、网页库等。网络爬虫的各个模块可以组成一个循环系统,从而不断的分析和抓取。
爬虫的工作原理可以简单地解释为首先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 爬虫示意图
爬虫工作的基本流程:
首先,选择互联网中的一部分网页,将这些网页的链接地址作为种子URL;
将这些种子URL放入待爬取URL队列,爬虫从待爬取URL队列中依次读取;
通过DNS解析URL;
将链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器下载网页;
下载的网页是网页文档的形式;
提取 Web 文档中的 URL;
过滤掉已经爬取过的网址;
继续对没有被爬取的URL进行爬取,直到待爬取的URL队列为空。
04 爬虫技术的种类
专注网络爬虫是一种“面向特定主题需求”的爬虫程序,而通用网络爬虫是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分,主要目的是在网站上下载网页互联网到本地,形成互联网内容的镜像备份。
增量爬取是指对某个站点的数据进行爬取。当网站的新数据或站点数据发生变化时,会自动捕获新增或变化的数据。
网页按存在方式可分为表层网页(surface Web)和深层网页(deep Web,又称隐形网页或隐藏网页)。
表面网页是指可以被传统搜索引擎检索到的页面,即主要由可以通过超链接到达的静态网页组成的网页。
深层网页是那些大部分内容无法通过静态链接访问的网页,隐藏在搜索表单后面,只有提交一些 关键词 的用户才能访问。
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等领域的教学和科研工作。
本文摘自《Python网络爬虫技术与实践》,经出版社授权发布。 查看全部
网页qq抓取什么原理(
爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人))
01 什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
Web 爬虫通过从 Internet 上的 网站 服务器上爬取内容来工作。它是用计算机语言编写的程序或脚本,自动从互联网上获取信息或数据,扫描并抓取每个所需页面上的某些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市面上流行的采集器软件都是利用网络爬虫的原理或功能。
▲图 2-1 网络爬虫象形图
02 爬行动物的意义
如今,大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为、自身产品的不足、竞争对手的信息。所有这一切的首要条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就有决策的主动权。网络爬虫的应用领域很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1)抓取各大电商公司的产品销售信息和用户评价网站进行分析,如图2-2所示。
▲图2-2 电商产品销售信息网站
2)分析大众点评、美团等餐饮品类网站用户的消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区住房占比,学区房价格比普通二手房高多少,如图2-4所示。
▲图2-4 学区住房比例与价格对比
以上数据是由ForeSpider数据采集软件爬下来的。有兴趣的读者可以尝试自己爬一些数据。
03 爬虫的原理
我们通常将网络爬虫的组件分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取链接队列、网页库等。网络爬虫的各个模块可以组成一个循环系统,从而不断的分析和抓取。
爬虫的工作原理可以简单地解释为首先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 爬虫示意图
爬虫工作的基本流程:
首先,选择互联网中的一部分网页,将这些网页的链接地址作为种子URL;
将这些种子URL放入待爬取URL队列,爬虫从待爬取URL队列中依次读取;
通过DNS解析URL;
将链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器下载网页;
下载的网页是网页文档的形式;
提取 Web 文档中的 URL;
过滤掉已经爬取过的网址;
继续对没有被爬取的URL进行爬取,直到待爬取的URL队列为空。
04 爬虫技术的种类
专注网络爬虫是一种“面向特定主题需求”的爬虫程序,而通用网络爬虫是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分,主要目的是在网站上下载网页互联网到本地,形成互联网内容的镜像备份。
增量爬取是指对某个站点的数据进行爬取。当网站的新数据或站点数据发生变化时,会自动捕获新增或变化的数据。
网页按存在方式可分为表层网页(surface Web)和深层网页(deep Web,又称隐形网页或隐藏网页)。
表面网页是指可以被传统搜索引擎检索到的页面,即主要由可以通过超链接到达的静态网页组成的网页。
深层网页是那些大部分内容无法通过静态链接访问的网页,隐藏在搜索表单后面,只有提交一些 关键词 的用户才能访问。
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等领域的教学和科研工作。
本文摘自《Python网络爬虫技术与实践》,经出版社授权发布。
网页qq抓取什么原理(微信屏蔽网页的依据是什么?明面上的原因有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-02 04:15
微信屏蔽网页的依据是什么?
显而易见的原因是,当网页内容中收录诱导、欺诈等不和谐内容时,被用户举报时会被关闭。其实这只是表面现象,因为我们可以明显感觉到,在不同的阶段,相同的内容被屏蔽的频率是非常不同的。的。微信是一家互联网公司。如果使用大量客户手动判断是否屏蔽,成本太高。估计10000个客服都处理不了,而且据我所知,很多正常的页面也会无缘无故被封。应该恶意举报。如果是客服判断的话,人工上报不会屏蔽常规网站吧?
很明显的结论是,微信一定是以技术识别为主。只有达到一定报告水平且在技术上无法阻止的页面才会达到人工审核的程度。报告的数量只是一个判断因素,并不能决定一个网页的生死。就像百度判断网站的权重一样,会有一套复杂的因素和一堆算法判断标准。
另一个关键因素是关键词 的识别。被阻止的页面将由算法识别。当您使用的程序源代码中收录的功能与已被和谐或频率较高的功能高度相似时,您将被自动和谐。这很像病毒签名算法。
其实说白了,微信现在是霸主家族,想要屏蔽你的理由有100个。作为站长,我们应该怎么做才能防止微信域名被屏蔽呢?让我们稍后再讨论。感谢浏览。 查看全部
网页qq抓取什么原理(微信屏蔽网页的依据是什么?明面上的原因有哪些?)
微信屏蔽网页的依据是什么?
显而易见的原因是,当网页内容中收录诱导、欺诈等不和谐内容时,被用户举报时会被关闭。其实这只是表面现象,因为我们可以明显感觉到,在不同的阶段,相同的内容被屏蔽的频率是非常不同的。的。微信是一家互联网公司。如果使用大量客户手动判断是否屏蔽,成本太高。估计10000个客服都处理不了,而且据我所知,很多正常的页面也会无缘无故被封。应该恶意举报。如果是客服判断的话,人工上报不会屏蔽常规网站吧?
很明显的结论是,微信一定是以技术识别为主。只有达到一定报告水平且在技术上无法阻止的页面才会达到人工审核的程度。报告的数量只是一个判断因素,并不能决定一个网页的生死。就像百度判断网站的权重一样,会有一套复杂的因素和一堆算法判断标准。
另一个关键因素是关键词 的识别。被阻止的页面将由算法识别。当您使用的程序源代码中收录的功能与已被和谐或频率较高的功能高度相似时,您将被自动和谐。这很像病毒签名算法。
其实说白了,微信现在是霸主家族,想要屏蔽你的理由有100个。作为站长,我们应该怎么做才能防止微信域名被屏蔽呢?让我们稍后再讨论。感谢浏览。
网页qq抓取什么原理(这篇通过requests实现腾讯新闻爬虫的方法小编分享(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-02 04:13
标签下
之后,我们将处理我们刚刚请求的 html 代码。这时候,我们就需要用到beautifulsoap库了。
汤=美丽汤(wbdata,'lxml')
这一行的意思是解析获取到的信息,或者把lxml库换成html.parser库,效果是一样的
news_titles = soup.select("div.text > em.f14 > a.linkto")
这一行使用刚刚解析的soup对象来选择我们需要的标签,返回值是一个列表。该列表收录我们需要的所有标签内容。也可以使用 beautifulsoup 中的 find() 方法或 findall() 方法来选择标签。
最后使用for in遍历列表,取出标签中的内容(新闻标题)和标签中href的值(新闻URL),存入数据字典
对于 news_titles 中的 n:
标题 = n.get_text()
链接 = n.get("href")
数据 = {
'标题':标题,
“链接”:链接
}
数据存储所有新闻标题和链接。下图显示了一些结果。
这样一个爬虫就完成了,当然这只是最简单的爬虫。如果深入爬虫,有很多模拟浏览器行为、安全问题、效率优化、多线程等需要考虑。不得不说,爬虫是个深坑。
python中的爬虫可以通过各种库或框架来完成,请求只是比较常用的一种。还有很多其他语言的爬虫库,比如php可以使用curl库。爬虫的原理是一样的,只是不同语言和库使用的方法不同。
以上腾讯新闻爬虫通过requests实现的python实现就是小编分享的全部内容。希望能给大家一个参考,希望大家多多支持万茜。
如果您对本文有任何疑问或有什么想说的,请点击留言回复,万千网友为您解答! 查看全部
网页qq抓取什么原理(这篇通过requests实现腾讯新闻爬虫的方法小编分享(图))
标签下
之后,我们将处理我们刚刚请求的 html 代码。这时候,我们就需要用到beautifulsoap库了。
汤=美丽汤(wbdata,'lxml')
这一行的意思是解析获取到的信息,或者把lxml库换成html.parser库,效果是一样的
news_titles = soup.select("div.text > em.f14 > a.linkto")
这一行使用刚刚解析的soup对象来选择我们需要的标签,返回值是一个列表。该列表收录我们需要的所有标签内容。也可以使用 beautifulsoup 中的 find() 方法或 findall() 方法来选择标签。
最后使用for in遍历列表,取出标签中的内容(新闻标题)和标签中href的值(新闻URL),存入数据字典
对于 news_titles 中的 n:
标题 = n.get_text()
链接 = n.get("href")
数据 = {
'标题':标题,
“链接”:链接
}
数据存储所有新闻标题和链接。下图显示了一些结果。
这样一个爬虫就完成了,当然这只是最简单的爬虫。如果深入爬虫,有很多模拟浏览器行为、安全问题、效率优化、多线程等需要考虑。不得不说,爬虫是个深坑。
python中的爬虫可以通过各种库或框架来完成,请求只是比较常用的一种。还有很多其他语言的爬虫库,比如php可以使用curl库。爬虫的原理是一样的,只是不同语言和库使用的方法不同。
以上腾讯新闻爬虫通过requests实现的python实现就是小编分享的全部内容。希望能给大家一个参考,希望大家多多支持万茜。
如果您对本文有任何疑问或有什么想说的,请点击留言回复,万千网友为您解答!
网页qq抓取什么原理( 搜索引擎爬虫的工作流程及对照的思考方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-01 19:13
搜索引擎爬虫的工作流程及对照的思考方法)
搜索引擎爬虫的工作流程是SEO的基础篇章,也是每一个从事SEO工作的同事都应该掌握的必备知识。PHPSEO刚刚整理完毕并画了一张图,让你即使不懂技术也能了解搜索引擎爬虫的工作流程。一起来聊聊吧。
如上图所示,请您在阅读以下内容时与我一起思考。
1、种子网址
1、所谓种子URL,是指开头选择的URL地址。大多数情况下,网站的首页、频道页等内容更丰富的页面都会作为种子URL;
然后将这些种子网址放入要爬取的网址列表中;
2、要爬取的url列表
爬虫从要爬取的 URL 列表中一一读取。在读取URL的过程中,会通过DNS解析URL,并将URL地址转换为网站服务器IP地址+相对路径的方法;
3、网页下载器
接下来,把这个地址交给网页下载器(所谓网页下载器,顾名思义,就是负责下载网页内容的模块;
4、源码
对于下载到本地的网页,也就是我们网页的源代码,一方面网页要保存在网页库中,另一方面又会从下载的网页中重新提取URL地址.
5、提取网址
新提取的 URL 地址会在已爬取的 URL 列表中进行比较,以检查该网页是否已被爬取。
6、新的URL存放在待爬取队列中
如果网页还没有被爬取,新的URL地址会被放在待爬取URL列表的最后,等待被爬取。
这样,爬虫就完成了整个爬取过程,直到待爬队列为空。
然后下载的网页会进入一定的分析,分析后我们就能看到收录的结果。
对于真正的爬虫来说,哪些页面先爬,哪些页面后爬,哪些页面不爬,都有一定的策略。这里介绍一个比较常见的爬虫爬取过程。作为我们中的 SEO,我们已经足够了解这一点。 查看全部
网页qq抓取什么原理(
搜索引擎爬虫的工作流程及对照的思考方法)
搜索引擎爬虫的工作流程是SEO的基础篇章,也是每一个从事SEO工作的同事都应该掌握的必备知识。PHPSEO刚刚整理完毕并画了一张图,让你即使不懂技术也能了解搜索引擎爬虫的工作流程。一起来聊聊吧。
如上图所示,请您在阅读以下内容时与我一起思考。
1、种子网址
1、所谓种子URL,是指开头选择的URL地址。大多数情况下,网站的首页、频道页等内容更丰富的页面都会作为种子URL;
然后将这些种子网址放入要爬取的网址列表中;
2、要爬取的url列表
爬虫从要爬取的 URL 列表中一一读取。在读取URL的过程中,会通过DNS解析URL,并将URL地址转换为网站服务器IP地址+相对路径的方法;
3、网页下载器
接下来,把这个地址交给网页下载器(所谓网页下载器,顾名思义,就是负责下载网页内容的模块;
4、源码
对于下载到本地的网页,也就是我们网页的源代码,一方面网页要保存在网页库中,另一方面又会从下载的网页中重新提取URL地址.
5、提取网址
新提取的 URL 地址会在已爬取的 URL 列表中进行比较,以检查该网页是否已被爬取。
6、新的URL存放在待爬取队列中
如果网页还没有被爬取,新的URL地址会被放在待爬取URL列表的最后,等待被爬取。
这样,爬虫就完成了整个爬取过程,直到待爬队列为空。
然后下载的网页会进入一定的分析,分析后我们就能看到收录的结果。
对于真正的爬虫来说,哪些页面先爬,哪些页面后爬,哪些页面不爬,都有一定的策略。这里介绍一个比较常见的爬虫爬取过程。作为我们中的 SEO,我们已经足够了解这一点。
网页qq抓取什么原理(被搜索引擎收录后会出现什么效果呢?的网站seo)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-03-01 19:11
连最初级的站长都知道网站一定要写titletitle,这也是最基础的SEO,但是如果一个页面没有写title,那么收录会有什么效果通过搜索引擎??
本周的网站seo实例选择了一个没有title的网站给大家分析流程。
今天要讲一个老问题,就是如果我不写一个大搜索引擎,网站title标题怎么爬网站titles和descriptions。例如。
这个网站是一个没有网站标题的网站,那么百度、谷歌等搜索引擎会如何抓取呢?你可以搜索它。如果他直接搜索 URL,他会显示珠宝。如果他搜索其他相关词,他会显示它,但是打开它的网站源代码后,你会找到它。网站上面没有汉字,所以可以说汉字很少。
这张网站百度截图截图
网站google 快照的屏幕截图
当一些学生开始研究 网站 实例时,他们开始失去理智。既然是做seo的,就一定要懂得研究一些细节。然后我们分析分析他是如何实现标题显示的。
上面的网站截图,想必大家都看到了。谷歌有明显的规则。谷歌抢了网站内部文字的前几个字,那为什么谷歌只抢他的两个字,就是明月呢?主要问题是他的导入链接,你可以观察他的导入链接。链接文字无外乎几种,包括(名牌饰品、日月饰品、日月饰品、浙江日月等),然后这里google计算外链,抓取中间值外部文本默认是一轮明月,所以有人这么说。为什么他不算“日月网站”!在这里你可以看到他上面的文字是太阳和月亮网站欢迎你!就是这样的文字。那么你可以认为他们的外链可能有网站之类的字眼 还有太阳和月亮网站?首先我们可以确定没有,因为这个词没有流量,不需要做外链。所以这里google自然默认为“sun and moon”。
那么我们来说说百度的标题是怎么出现的。通过以上谷歌的案例分析,我们这里应该有不少人已经想到了原理是什么。百度不读取网站中唯一但不相关的文字,而是直接抓取外部输入的链接文字。有一些相关的 网站 实验。如果外部导入的文本与网站的内部文本有关系,那么网站会抓取页面中的文本。如果 网站 中的唯一文本不收录导入链接文本部分。然后百度这里默认自动导入文本。
其他引擎,比如搜狗,直接显示无标题网站,而有道的读取方式和百度一样。
这个拼写对 网站 有用吗?现在经过测试,对网站的排名并没有太大影响,但是对于网站来说并不是一个好的做法,因为毕竟搜狗等搜索引擎是读不到标题的。而网站形象也是一大损失。 查看全部
网页qq抓取什么原理(被搜索引擎收录后会出现什么效果呢?的网站seo)
连最初级的站长都知道网站一定要写titletitle,这也是最基础的SEO,但是如果一个页面没有写title,那么收录会有什么效果通过搜索引擎??
本周的网站seo实例选择了一个没有title的网站给大家分析流程。
今天要讲一个老问题,就是如果我不写一个大搜索引擎,网站title标题怎么爬网站titles和descriptions。例如。
这个网站是一个没有网站标题的网站,那么百度、谷歌等搜索引擎会如何抓取呢?你可以搜索它。如果他直接搜索 URL,他会显示珠宝。如果他搜索其他相关词,他会显示它,但是打开它的网站源代码后,你会找到它。网站上面没有汉字,所以可以说汉字很少。
这张网站百度截图截图
网站google 快照的屏幕截图
当一些学生开始研究 网站 实例时,他们开始失去理智。既然是做seo的,就一定要懂得研究一些细节。然后我们分析分析他是如何实现标题显示的。
上面的网站截图,想必大家都看到了。谷歌有明显的规则。谷歌抢了网站内部文字的前几个字,那为什么谷歌只抢他的两个字,就是明月呢?主要问题是他的导入链接,你可以观察他的导入链接。链接文字无外乎几种,包括(名牌饰品、日月饰品、日月饰品、浙江日月等),然后这里google计算外链,抓取中间值外部文本默认是一轮明月,所以有人这么说。为什么他不算“日月网站”!在这里你可以看到他上面的文字是太阳和月亮网站欢迎你!就是这样的文字。那么你可以认为他们的外链可能有网站之类的字眼 还有太阳和月亮网站?首先我们可以确定没有,因为这个词没有流量,不需要做外链。所以这里google自然默认为“sun and moon”。
那么我们来说说百度的标题是怎么出现的。通过以上谷歌的案例分析,我们这里应该有不少人已经想到了原理是什么。百度不读取网站中唯一但不相关的文字,而是直接抓取外部输入的链接文字。有一些相关的 网站 实验。如果外部导入的文本与网站的内部文本有关系,那么网站会抓取页面中的文本。如果 网站 中的唯一文本不收录导入链接文本部分。然后百度这里默认自动导入文本。
其他引擎,比如搜狗,直接显示无标题网站,而有道的读取方式和百度一样。
这个拼写对 网站 有用吗?现在经过测试,对网站的排名并没有太大影响,但是对于网站来说并不是一个好的做法,因为毕竟搜狗等搜索引擎是读不到标题的。而网站形象也是一大损失。
网页qq抓取什么原理(SEO从业者收录网页的四个阶段,你的网站处于哪个阶段?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-28 04:11
作为一名SEO从业者,不仅要被搜索引擎爬取,还要成为收录,最重要的是收录之后要有好的排名,本文将简要分析搜索引擎< @收录 网页的四个阶段。每个网站和每个网页的排名都不一样,你的网站在哪个阶段?
网页收录第一阶段:大小
搜索引擎的网页爬取采用“大小通吃”的策略,即将网页中能找到的链接一一添加到待爬取的URL中,新爬取的网页中的URL被机械提取。虽然这种方法比较老,但是效果很好,这也是很多站长响应蜘蛛访问的原因,但是没有收录的理由,这只是第一阶段。
页面收录第 2 阶段:页面评级
第二阶段是评价网页的重要性。PageRank 是一种著名的链接分析算法,可以用来衡量网页的重要性。站长自然可以利用PageRank的思想对网址进行排名。这就是你所热衷的。据一位朋友介绍,在中国,“外链”市场每年有上亿元的规模。
爬虫的目的是下载网页,但PageRank是全局算法,即当所有网页都下载完毕后,计算结果才可靠。对于中小网站,如果服务器质量不好,如果在爬取过程中只看到部分内容,在爬取阶段是不可能得到可靠的PageRank分数的。
网页收录第三阶段:OCIP 策略
OCIP 策略更像是对 PageRank 算法的改进。在算法开始之前,每个网页都会获得相同的“现金”。每当某个页面A被下载时,A将他的“现金”平均分配给该页面所收录的链接页面,并清空他的“现金”。这就是为什么您导出的链接越少,权重越高的原因之一。
对于要爬取的网页,会按照手头现金数量进行排序,现金最多的网页会被优先下载。OCIP 与 PageRank 大致相同。不同的是PageRank每次都需要迭代计算,而OCIP则不需要,所以计算速度比PageRank快很多,适合实时计算使用。这可能是很多网页都有“秒”的原因。
网页收录第四阶段:大网站优先策略
大型网站的优先级的想法非常简单。网页的重要性以 网站 为单位衡量。对于URL队列中待抓取的网页,按照网站进行分类,如果哪个网站等待下载的页面最多,则先下载这些链接。基本思想是“倾向于先下载大的 网站URL”。因为大的 网站 往往收录更多的页面。鉴于大型网站往往是知名网站,其网页质量普遍较高,这个想法虽然简单,但有一定的根据。
实验表明,该算法虽然简单粗暴,但可以收录高质量的网页,非常有效。这也是网站的很多内容被转发,而大展却排在你前面的最重要的原因之一。 查看全部
网页qq抓取什么原理(SEO从业者收录网页的四个阶段,你的网站处于哪个阶段?)
作为一名SEO从业者,不仅要被搜索引擎爬取,还要成为收录,最重要的是收录之后要有好的排名,本文将简要分析搜索引擎< @收录 网页的四个阶段。每个网站和每个网页的排名都不一样,你的网站在哪个阶段?
网页收录第一阶段:大小
搜索引擎的网页爬取采用“大小通吃”的策略,即将网页中能找到的链接一一添加到待爬取的URL中,新爬取的网页中的URL被机械提取。虽然这种方法比较老,但是效果很好,这也是很多站长响应蜘蛛访问的原因,但是没有收录的理由,这只是第一阶段。
页面收录第 2 阶段:页面评级
第二阶段是评价网页的重要性。PageRank 是一种著名的链接分析算法,可以用来衡量网页的重要性。站长自然可以利用PageRank的思想对网址进行排名。这就是你所热衷的。据一位朋友介绍,在中国,“外链”市场每年有上亿元的规模。
爬虫的目的是下载网页,但PageRank是全局算法,即当所有网页都下载完毕后,计算结果才可靠。对于中小网站,如果服务器质量不好,如果在爬取过程中只看到部分内容,在爬取阶段是不可能得到可靠的PageRank分数的。
网页收录第三阶段:OCIP 策略
OCIP 策略更像是对 PageRank 算法的改进。在算法开始之前,每个网页都会获得相同的“现金”。每当某个页面A被下载时,A将他的“现金”平均分配给该页面所收录的链接页面,并清空他的“现金”。这就是为什么您导出的链接越少,权重越高的原因之一。
对于要爬取的网页,会按照手头现金数量进行排序,现金最多的网页会被优先下载。OCIP 与 PageRank 大致相同。不同的是PageRank每次都需要迭代计算,而OCIP则不需要,所以计算速度比PageRank快很多,适合实时计算使用。这可能是很多网页都有“秒”的原因。
网页收录第四阶段:大网站优先策略
大型网站的优先级的想法非常简单。网页的重要性以 网站 为单位衡量。对于URL队列中待抓取的网页,按照网站进行分类,如果哪个网站等待下载的页面最多,则先下载这些链接。基本思想是“倾向于先下载大的 网站URL”。因为大的 网站 往往收录更多的页面。鉴于大型网站往往是知名网站,其网页质量普遍较高,这个想法虽然简单,但有一定的根据。
实验表明,该算法虽然简单粗暴,但可以收录高质量的网页,非常有效。这也是网站的很多内容被转发,而大展却排在你前面的最重要的原因之一。
网页qq抓取什么原理(网页qq抓取什么原理?(一个二维qq软件))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-27 21:02
网页qq抓取什么原理?从我的经验来说,还是通过分析请求的参数来判断用户请求的url,有点像爬虫技术的代理ip池技术了。通过一个特定的url就可以定位出所有上传的文件,还是比较好用的。我这里要写的是一个二维qq抓取软件,只要一行代码就可以上传多个链接(一个文件里包含多个链接),这就要求要使用一个已有的二维qq号码进行登录。下面是抓取结果:。
一个二维码打开任意网站,附带着链接地址,
我以前也有这个困惑,然后上各种网站搜索,所以应该可以说一下,不对的地方欢迎大家补充。二维码扫描上传文件的原理,肯定是通过发送给服务器的二维码(网址)来进行解析。但是二维码究竟应该解析出哪些内容呢?我们可以先根据能想到的三种情况来分析,
一、服务器返回给客户端一个json文件,比如user-agent.json。那么我们就能顺藤摸瓜了。通过网页json获取到user-agent.json这个文件,比如:{"name":"qq","password":"1030077","tel":"123456789","phone":"1595012107","sign":"1620611143"}那么我们就能知道user-agent.json里包含的内容。
functionread_qq(qqurl){//获取user-agent.json文件returnqqurl.json()}情况。
二、服务器返回给客户端一个html文件,比如worker_js.jsstring.write(qqurl.json())//解析出整个页面的内容,
三、服务器返回给客户端一个二维码,上传二维码。那么就可以根据二维码生成的数据,解析出整个页面的数据。如果这个二维码是swf格式的,那么就要用到浏览器的上传功能了。如果是mp4的,也可以通过解析出整个视频的数据。之后就是把视频上传到云服务器,进行下载了。上传成功之后,可以在浏览器开发者工具中看到上传的所有二维码的链接,并且可以正常显示出来。
如果我们希望直接使用二维码文件上传,那么使用这种方法比较麻烦,那么使用flask框架就可以自动把二维码数据写入到服务器。上传成功之后,这个二维码数据就可以在客户端进行显示了。functionread_qq(qqurl){returnqqurl.json()}完结。后续有时间再补充些其他的qq的抓取方法。 查看全部
网页qq抓取什么原理(网页qq抓取什么原理?(一个二维qq软件))
网页qq抓取什么原理?从我的经验来说,还是通过分析请求的参数来判断用户请求的url,有点像爬虫技术的代理ip池技术了。通过一个特定的url就可以定位出所有上传的文件,还是比较好用的。我这里要写的是一个二维qq抓取软件,只要一行代码就可以上传多个链接(一个文件里包含多个链接),这就要求要使用一个已有的二维qq号码进行登录。下面是抓取结果:。
一个二维码打开任意网站,附带着链接地址,
我以前也有这个困惑,然后上各种网站搜索,所以应该可以说一下,不对的地方欢迎大家补充。二维码扫描上传文件的原理,肯定是通过发送给服务器的二维码(网址)来进行解析。但是二维码究竟应该解析出哪些内容呢?我们可以先根据能想到的三种情况来分析,
一、服务器返回给客户端一个json文件,比如user-agent.json。那么我们就能顺藤摸瓜了。通过网页json获取到user-agent.json这个文件,比如:{"name":"qq","password":"1030077","tel":"123456789","phone":"1595012107","sign":"1620611143"}那么我们就能知道user-agent.json里包含的内容。
functionread_qq(qqurl){//获取user-agent.json文件returnqqurl.json()}情况。
二、服务器返回给客户端一个html文件,比如worker_js.jsstring.write(qqurl.json())//解析出整个页面的内容,
三、服务器返回给客户端一个二维码,上传二维码。那么就可以根据二维码生成的数据,解析出整个页面的数据。如果这个二维码是swf格式的,那么就要用到浏览器的上传功能了。如果是mp4的,也可以通过解析出整个视频的数据。之后就是把视频上传到云服务器,进行下载了。上传成功之后,可以在浏览器开发者工具中看到上传的所有二维码的链接,并且可以正常显示出来。
如果我们希望直接使用二维码文件上传,那么使用这种方法比较麻烦,那么使用flask框架就可以自动把二维码数据写入到服务器。上传成功之后,这个二维码数据就可以在客户端进行显示了。functionread_qq(qqurl){returnqqurl.json()}完结。后续有时间再补充些其他的qq的抓取方法。
网页qq抓取什么原理(搜索引擎去除重复内容的网页有意义吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-24 12:27
这篇文章站长博客给大家介绍一下网页去重的原理是什么?搜索引擎如何进行重复数据删除?
在互联网如此发达的今天,同样的信息会在多个网站上发布,同样的消息会被大多数媒体网站报道,再加上小站长和EO工作人员孜孜不倦地为网络< @k11@ >,导致网络上出现大量重复信息。但是,当用户搜索某个关键词 时,搜索引擎一定不想将相同的搜索结果呈现给用户。爬取这些重复的网页,从某种意义上说,是对搜索引擎自身资源的一种浪费,所以去除重复内容的网页也成为了搜索引擎面临的一大难题。
在一般的搜索引擎架构中,网页去重一般存在于蜘蛛抓取部分。在整个搜索引擎架构中越早实施“去重”步骤,就越能节省后续处理系统的资源使用。搜索引擎一般对已经爬取过的重复页面进行分类,例如判断一个站点是否收录大量重复页面,或者该站点是否完全采集其他站点的内容等。爬取状态本网站的内容或是否直接阻止抓取。
去重工作一般在分词之后、索引之前(也可能在分词之前)进行,搜索引擎会从页面已经被分离出来的关键词中提取一些有代表性的关键词,并然后计算这些 关键词 的“指纹”。每个网页都会有这样一个特征指纹。当新爬取网页的关键词指纹与索引网页的关键词指纹重合时,新网页可能被搜索引擎查看。删除重复内容的索引。
实际工作中的搜索引擎不仅使用分词步骤分隔的有意义的关键词,还使用连续切割提取关键词并进行指纹计算。连续切割是通过将单个单词向后移动来切割单词。比如“百度开始打击买卖链接”将被切割成“百度开”、“度开始”、“开始打”、“开始打”、“打买”、“打”买and sell”、“buy and sell chain”、“sell link”。然后从这些词中提取一些关键词进行指纹计算,并参与内容是否重复的比较。这只是基本算法搜索引擎用于识别重复页面,
因此,网上流行的大部分伪原创工具要么无法欺骗搜索引擎,要么使内容无法阅读,所以理论上普通的伪原创工具无法获取正常的搜索引擎收录@ > 和排名。但由于百度并没有直接丢弃所有重复页面,也不对其进行索引,因此会根据重复页面所在网站的权重适当放宽索引标记。
这使得一些作弊者可以利用 网站 的高权重和来自其他站点的大量 采集 内容来获取搜索流量。然而,自2012年6月以来,百度多次升级算法,对采集重复信息和垃圾页面进行了多次重击。因此,O在面对网站的内容时,不应该再从伪原创的角度去建构,而应该
内容的内容不一定都是原创。一般网站的体重如果没有大问题,就会健康发展。关于 原创 的问题将在本书后面的第 12 章中详细讨论。
另外,不仅搜索引擎需要对网页进行“去重”,还需要自己做网站对站点中的页面进行去重。比如UGC-type 网站这样的作为分类信息和B2B均等化,如果不加限制,用户发布的信息难免会出现大量重复,不仅在SEO上表现不佳,还会大大降低网站的用户体验。就是SEO人员在设计流量产品大量生成页面的时候,也需要做一次重复过滤,否则产品质量会大打折扣。基于“聚合”的页面。“聚合”必须有核心词,未经过滤,海量核心词展开的页面可能出现大量重复,导致产品性能不佳,甚至被搜索引擎降级。
“去重”算法的一般原理大致如上所述。有兴趣的朋友可以了解一下I-Match、Shingle、SimHash和余弦去重的具体算法。搜索引擎必须先对网页进行分析,然后才能进行“去除重复页面”的工作。内容周围的“噪音”会在一定程度上影响去重结果。在做这部分工作的时候,只能对内容部分进行操作,比较简单。许多,并且可以有效地协助生产高质量的“$EO产品”。
作为一个SEO人,你只需要了解实现原理。在产品中的具体应用需要技术人员来实现。此外,还涉及到效率、资源需求等问题,根据实际情况,还可以在多个环节(如核心词的切分)进行“重复”工作。这个方向很好(技术人员不是无所不能的,也有不熟悉和不熟悉的领域,在某个时刻也需要别人提供想法)。如果EO人员能够在这些方面与技术人员进行深入的沟通,技术人员也会对SEO另眼相看,至少不再认为“SEO人员只会要求‘无聊’的需求,比如换个标题, 更改链接,并更改文本。”。 查看全部
网页qq抓取什么原理(搜索引擎去除重复内容的网页有意义吗?(图))
这篇文章站长博客给大家介绍一下网页去重的原理是什么?搜索引擎如何进行重复数据删除?
在互联网如此发达的今天,同样的信息会在多个网站上发布,同样的消息会被大多数媒体网站报道,再加上小站长和EO工作人员孜孜不倦地为网络< @k11@ >,导致网络上出现大量重复信息。但是,当用户搜索某个关键词 时,搜索引擎一定不想将相同的搜索结果呈现给用户。爬取这些重复的网页,从某种意义上说,是对搜索引擎自身资源的一种浪费,所以去除重复内容的网页也成为了搜索引擎面临的一大难题。
在一般的搜索引擎架构中,网页去重一般存在于蜘蛛抓取部分。在整个搜索引擎架构中越早实施“去重”步骤,就越能节省后续处理系统的资源使用。搜索引擎一般对已经爬取过的重复页面进行分类,例如判断一个站点是否收录大量重复页面,或者该站点是否完全采集其他站点的内容等。爬取状态本网站的内容或是否直接阻止抓取。
去重工作一般在分词之后、索引之前(也可能在分词之前)进行,搜索引擎会从页面已经被分离出来的关键词中提取一些有代表性的关键词,并然后计算这些 关键词 的“指纹”。每个网页都会有这样一个特征指纹。当新爬取网页的关键词指纹与索引网页的关键词指纹重合时,新网页可能被搜索引擎查看。删除重复内容的索引。
实际工作中的搜索引擎不仅使用分词步骤分隔的有意义的关键词,还使用连续切割提取关键词并进行指纹计算。连续切割是通过将单个单词向后移动来切割单词。比如“百度开始打击买卖链接”将被切割成“百度开”、“度开始”、“开始打”、“开始打”、“打买”、“打”买and sell”、“buy and sell chain”、“sell link”。然后从这些词中提取一些关键词进行指纹计算,并参与内容是否重复的比较。这只是基本算法搜索引擎用于识别重复页面,
因此,网上流行的大部分伪原创工具要么无法欺骗搜索引擎,要么使内容无法阅读,所以理论上普通的伪原创工具无法获取正常的搜索引擎收录@ > 和排名。但由于百度并没有直接丢弃所有重复页面,也不对其进行索引,因此会根据重复页面所在网站的权重适当放宽索引标记。
这使得一些作弊者可以利用 网站 的高权重和来自其他站点的大量 采集 内容来获取搜索流量。然而,自2012年6月以来,百度多次升级算法,对采集重复信息和垃圾页面进行了多次重击。因此,O在面对网站的内容时,不应该再从伪原创的角度去建构,而应该
内容的内容不一定都是原创。一般网站的体重如果没有大问题,就会健康发展。关于 原创 的问题将在本书后面的第 12 章中详细讨论。
另外,不仅搜索引擎需要对网页进行“去重”,还需要自己做网站对站点中的页面进行去重。比如UGC-type 网站这样的作为分类信息和B2B均等化,如果不加限制,用户发布的信息难免会出现大量重复,不仅在SEO上表现不佳,还会大大降低网站的用户体验。就是SEO人员在设计流量产品大量生成页面的时候,也需要做一次重复过滤,否则产品质量会大打折扣。基于“聚合”的页面。“聚合”必须有核心词,未经过滤,海量核心词展开的页面可能出现大量重复,导致产品性能不佳,甚至被搜索引擎降级。
“去重”算法的一般原理大致如上所述。有兴趣的朋友可以了解一下I-Match、Shingle、SimHash和余弦去重的具体算法。搜索引擎必须先对网页进行分析,然后才能进行“去除重复页面”的工作。内容周围的“噪音”会在一定程度上影响去重结果。在做这部分工作的时候,只能对内容部分进行操作,比较简单。许多,并且可以有效地协助生产高质量的“$EO产品”。
作为一个SEO人,你只需要了解实现原理。在产品中的具体应用需要技术人员来实现。此外,还涉及到效率、资源需求等问题,根据实际情况,还可以在多个环节(如核心词的切分)进行“重复”工作。这个方向很好(技术人员不是无所不能的,也有不熟悉和不熟悉的领域,在某个时刻也需要别人提供想法)。如果EO人员能够在这些方面与技术人员进行深入的沟通,技术人员也会对SEO另眼相看,至少不再认为“SEO人员只会要求‘无聊’的需求,比如换个标题, 更改链接,并更改文本。”。
网页qq抓取什么原理(有什么方能提高网页被搜索引擎抓取、索引和排名的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-24 12:26
但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。
那么让我们看看什么可以提高搜索引擎对网页的抓取、索引和排名:
示例网站架构图
首先通过下图看一下常见的网站的架构图:
典型网站外链分布图
然后我们看一个典型的网站外链分布图:
爬虫爬取路径的优先级
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。
5 种提高搜索引擎对网页的抓取、索引和排名的方法
最后,让我们看看有什么可以提高你的页面的爬取、索引和搜索引擎排名:
展平 网站 结构
如果你的网站能建立一个理想的、扁平的链接层次结构,就可以达到3点击100万页、4点击100万页的效果。
从“强大”页面链接到需要链接的页面
你应该注意外链多的“强大”页面的涟漪效应(指排名高、外链多的页面,易IT注意),并充分利用这种效应。将此类页面视为目录(或类别)页面,并将它们链接到 网站 的其他页面。
同样,您将来可以将此类页面用作登录页面,以帮助将流量吸引到您希望用户访问的页面。
减少“死角”和低价值页面
位于链接图边缘的页面价值较低。确保 网站 上没有降低 PageRank 的页面。这些页面通常是 PDF、图片和其他文档。您可以使用 301 重定向将这些文件重定向到收录(嵌入或收录下载链接)这些文件内容的页面,并且该页面上有返回 网站 其他部分的链接。
创建值得链接的分类或导航页面
如果您可以制作此类具有链接价值且引人注目的页面,它们将获得更高的 PageRank 和更高的优先级抓取率。同时,这些 PageRank 和爬取优先级会通过页面上的链接传递给 网站 的其他页面(向搜索引擎发出信号,表明 网站 上的所有页面都很重要)。
从爬虫路径中排除不重要的页面
减少不必要的导航级别(或内容页面),并将爬虫引导到真正需要 PageRank 的 URL。
原文:解决抓取优先级和索引问题的图表 查看全部
网页qq抓取什么原理(有什么方能提高网页被搜索引擎抓取、索引和排名的方法)
但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。
那么让我们看看什么可以提高搜索引擎对网页的抓取、索引和排名:
示例网站架构图
首先通过下图看一下常见的网站的架构图:
典型网站外链分布图
然后我们看一个典型的网站外链分布图:
爬虫爬取路径的优先级
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。
5 种提高搜索引擎对网页的抓取、索引和排名的方法
最后,让我们看看有什么可以提高你的页面的爬取、索引和搜索引擎排名:
展平 网站 结构
如果你的网站能建立一个理想的、扁平的链接层次结构,就可以达到3点击100万页、4点击100万页的效果。
从“强大”页面链接到需要链接的页面
你应该注意外链多的“强大”页面的涟漪效应(指排名高、外链多的页面,易IT注意),并充分利用这种效应。将此类页面视为目录(或类别)页面,并将它们链接到 网站 的其他页面。
同样,您将来可以将此类页面用作登录页面,以帮助将流量吸引到您希望用户访问的页面。
减少“死角”和低价值页面
位于链接图边缘的页面价值较低。确保 网站 上没有降低 PageRank 的页面。这些页面通常是 PDF、图片和其他文档。您可以使用 301 重定向将这些文件重定向到收录(嵌入或收录下载链接)这些文件内容的页面,并且该页面上有返回 网站 其他部分的链接。
创建值得链接的分类或导航页面
如果您可以制作此类具有链接价值且引人注目的页面,它们将获得更高的 PageRank 和更高的优先级抓取率。同时,这些 PageRank 和爬取优先级会通过页面上的链接传递给 网站 的其他页面(向搜索引擎发出信号,表明 网站 上的所有页面都很重要)。
从爬虫路径中排除不重要的页面
减少不必要的导航级别(或内容页面),并将爬虫引导到真正需要 PageRank 的 URL。
原文:解决抓取优先级和索引问题的图表
网页qq抓取什么原理( Python批量抓取图片(1)--使用Python图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-22 08:19
Python批量抓取图片(1)--使用Python图片)
- 写在前面的话
相信你一定看过前段时间文章的一篇文章《就因为我写了爬虫,公司200多人被捕!》的公众号文章(描述< @文章 已经很明显了,大家心知肚明)
可以说,因为恐慌和骚动,一些三二线爬虫工程师紧急转行。其次,一些朋友对自己学到的爬虫技术感到担忧和恐慌。
事实上,每个人都有这种警惕性。但是,没有必要进行诸如转业之类的大战斗。我们应该从业务本身做起,不仅要提升自己的业务能力,还要熟悉互联网法律法规。虽然我不是亲自学习爬虫的技术,但是平时很喜欢学习一些爬虫的小项目和小玩意儿。虽然我花在学习算法上的时间比例会少很多,但我个人还是喜欢尝试一些新的。技术来丰富自己的业务水平,从这个角度来看,大部分工程师都会有这种业务倾向。当然,对于那些站在互联网第一线的爬虫工程师和大佬们来说,我只是大海中的一滴水,水滴的数量是远远不够的。
说起来,归根结底是一些公司和公司员工对法律的认识不够,公司对员工的法律宣传和商业道德也没有起到潜移默化的作用,尤其是互联网法律法规的传递。思想工作没有及时到位。当然,这些也不能总是靠公司,主要还是靠个人的认知。既然你已经做过这个业务,你应该了解和学习这个行业的法律知识。为此,作为这个时代科技创新和技术研发的一员,我们必须始终遵守互联网法律法规,做好本职工作,为社会多做贡献。
文章目录:
- 写在前面的话
1 - 捕获工件
2 - 使用Python批量抓取图片
(1)抓取对象:搜狗图库
(2)抢分类:进入搜狗壁纸
(3)使用requests提取图片组件
(4)找到图片的真实url
(5)批量抓图成功
今天就开始学习我们的内容吧~~
1 - 捕获工件
我一直很喜欢的一个谷歌图片抓取插件叫做 ImageAssistant
目前用户数为114567,可以说是非常不错了。
它的工作原理与 Python 批量抓取图像完全一样
我不是为谷歌做广告,我只是分享给大家,因为我认为它对提高大家的办公效率很有用。当然,本节最重要的是学习Python中批量抓图的原理和方法。
下面简单介绍一下插件的使用。安装插件后记得选择存放文件的地方,在谷歌设置下关闭下载查询访问。
(不然每次都得按保存,很麻烦。如果有100张图,你肯定要按100次)
安装插件后,下面是抓取过程的简单视频演示
比如:去微博抢鞠婧祎小姐姐的照片,
进入后右击IA工具即可
2 - 使用Python批量抓取图片
注:文中Grab的意思是“抓取”
(1)抓取对象:搜狗图库
(2)抓取分类:进入搜狗壁纸,打开网页源码(快捷键为F12)
由于我使用的是谷歌 chrome 浏览器,所以要找到 img 标签
(3)使用requests提取图片组件
爬取思路和使用库文件请求
可以发现图片src存在于img标签下,所以使用Python的requests提取组件获取img的src,然后使用库urllib.request.urlretrieve将图片一一下载,从而达到批量获取数据的目的。
开始爬取第一步:
(注:Network-->headers,然后用鼠标点击左侧菜单栏(地址栏)的图片链接,然后在headers中找到图片url)
下面就是按照上面的思路来爬取我们想要的结果: 搜索网页代码后,得到的搜狗图片的url为:
%B1%DA%D6%BD
这里的url来自进入分类后的地址栏(如上图)。
分析源码分析上述url指向的网页
import requests #导入库requestsimport urllib #导入库requests下面的urllibfrom bs4 import BeautifulSoup #使用BeautifulSoup,关于这个的用法请查看本公众号往期文章#下面填入urlres = requests.get('http://pic.sogou.com/pics/reco ... %2339;)soup = BeautifulSoup(res.text,'html.parser')print(soup.select('img')) #图片打印格式
结果
从上面的执行结果来看,打印输出中并没有我们想要的图片元素,只是解析了tupian130x34_@1x的img(或者网页中的logo),这显然不是我们想要的。也就是说,需要的图片数据不在url下,也就是不在下面的url中
%B1%DA%D6%BD。
因此,下面需要找到图片不在url中的原因并进行改进。
开始爬取第二步:
考虑到图片元素可能是动态的,细心的人可能会发现,在网页中向下滑动鼠标滚轮时,图片是动态刷新的,也就是说网页不是一次性加载所有资源,而是动态地加载资源。这也避免了由于网页过于臃肿而影响加载速度。
(4)找到图片的真实url
找到所有图片的真实url似乎有点困难,但是在这个项目中尝试一下也不是不可能的。在接下来的学习中不断研究,我想我会逐渐提高自己的业务能力。
类似于开始抓取第一步中的“笔记”,我们找到位置:
F12——>>网络——>>XHR——>>(点击XHR下的文件)——>>预览
(注:如果在预览中没有找到内容,可以滚动左侧地址栏或点击图片链接)
从上图看来,图中的信息就是我们需要的元素。点击all_items,发现下面是0 1 2 3... 一个一个好像是图片元素的数据。
尝试打开一个网址。找到图片的地址
我们可以任意选择其中一个图片的地址来验证是否是图片所在的位置:
将地址粘贴到浏览器中,搜索如下结果,说明这个地址的url就是我们要找的
找到上图的目标后,我们点击XHR下的Headers,也就是第二行
请求网址:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
尽量去掉一些不必要的部分,去掉以上部分后不影响访问。
(删掉的位置跟同一个地方差不多,记住长宽高后面就不用删了)
例如:删除“=%E5%A3%81%E7%BA%B8&tag”得到
%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
将此网站复制到浏览器访问中,得到如下结果:
url中的category为类别,start为开始下标,len为长度,即图片数量。
另外,在imges下,注意url内容的填充(不要直接复制url)
当替换为“+”时
(5)批量抓图成功
如果你的电脑没有库文件请求,记得用 cmd 命令安装:
pip 安装请求
最后经过不断的排序,源码如下:
import requestsimport json #使用json码import urllibdef getSogouImag(category,length,path): n = length cate = category #分类 imgs = requests.get('http://pic.sogou.com/pics/chan ... 2Bstr(n)) jd = json.loads(imgs.text) jd = jd['all_items'] imgs_url = [] #在url获取图片imgs for j in jd: imgs_url.append(j['bthumbUrl']) m = 0 for img_url in imgs_url: print('***** '+str(m)+'.jpg *****'+' Downloading...') urllib.request.urlretrieve(img_url,path+str(m)+'.jpg') m = m + 1 print('Download complete!')getSogouImag('壁纸',2000,'F:/Py666/抓图/') #抓取后图片存取的本地位置
执行程序:到指定位置找到图片存在的位置,大功告成。
- 结尾 -
你好!
贡献--->展示你的才华
请发送电子邮件至
注明标题 [提交]
告诉我们
你是谁,你来自哪里,你投什么 查看全部
网页qq抓取什么原理(
Python批量抓取图片(1)--使用Python图片)
- 写在前面的话
相信你一定看过前段时间文章的一篇文章《就因为我写了爬虫,公司200多人被捕!》的公众号文章(描述< @文章 已经很明显了,大家心知肚明)
可以说,因为恐慌和骚动,一些三二线爬虫工程师紧急转行。其次,一些朋友对自己学到的爬虫技术感到担忧和恐慌。
事实上,每个人都有这种警惕性。但是,没有必要进行诸如转业之类的大战斗。我们应该从业务本身做起,不仅要提升自己的业务能力,还要熟悉互联网法律法规。虽然我不是亲自学习爬虫的技术,但是平时很喜欢学习一些爬虫的小项目和小玩意儿。虽然我花在学习算法上的时间比例会少很多,但我个人还是喜欢尝试一些新的。技术来丰富自己的业务水平,从这个角度来看,大部分工程师都会有这种业务倾向。当然,对于那些站在互联网第一线的爬虫工程师和大佬们来说,我只是大海中的一滴水,水滴的数量是远远不够的。
说起来,归根结底是一些公司和公司员工对法律的认识不够,公司对员工的法律宣传和商业道德也没有起到潜移默化的作用,尤其是互联网法律法规的传递。思想工作没有及时到位。当然,这些也不能总是靠公司,主要还是靠个人的认知。既然你已经做过这个业务,你应该了解和学习这个行业的法律知识。为此,作为这个时代科技创新和技术研发的一员,我们必须始终遵守互联网法律法规,做好本职工作,为社会多做贡献。
文章目录:
- 写在前面的话
1 - 捕获工件
2 - 使用Python批量抓取图片
(1)抓取对象:搜狗图库
(2)抢分类:进入搜狗壁纸
(3)使用requests提取图片组件
(4)找到图片的真实url
(5)批量抓图成功
今天就开始学习我们的内容吧~~
1 - 捕获工件
我一直很喜欢的一个谷歌图片抓取插件叫做 ImageAssistant
目前用户数为114567,可以说是非常不错了。
它的工作原理与 Python 批量抓取图像完全一样
我不是为谷歌做广告,我只是分享给大家,因为我认为它对提高大家的办公效率很有用。当然,本节最重要的是学习Python中批量抓图的原理和方法。
下面简单介绍一下插件的使用。安装插件后记得选择存放文件的地方,在谷歌设置下关闭下载查询访问。
(不然每次都得按保存,很麻烦。如果有100张图,你肯定要按100次)
安装插件后,下面是抓取过程的简单视频演示
比如:去微博抢鞠婧祎小姐姐的照片,
进入后右击IA工具即可
2 - 使用Python批量抓取图片
注:文中Grab的意思是“抓取”
(1)抓取对象:搜狗图库
(2)抓取分类:进入搜狗壁纸,打开网页源码(快捷键为F12)
由于我使用的是谷歌 chrome 浏览器,所以要找到 img 标签
(3)使用requests提取图片组件
爬取思路和使用库文件请求
可以发现图片src存在于img标签下,所以使用Python的requests提取组件获取img的src,然后使用库urllib.request.urlretrieve将图片一一下载,从而达到批量获取数据的目的。
开始爬取第一步:
(注:Network-->headers,然后用鼠标点击左侧菜单栏(地址栏)的图片链接,然后在headers中找到图片url)
下面就是按照上面的思路来爬取我们想要的结果: 搜索网页代码后,得到的搜狗图片的url为:
%B1%DA%D6%BD
这里的url来自进入分类后的地址栏(如上图)。
分析源码分析上述url指向的网页
import requests #导入库requestsimport urllib #导入库requests下面的urllibfrom bs4 import BeautifulSoup #使用BeautifulSoup,关于这个的用法请查看本公众号往期文章#下面填入urlres = requests.get('http://pic.sogou.com/pics/reco ... %2339;)soup = BeautifulSoup(res.text,'html.parser')print(soup.select('img')) #图片打印格式
结果
从上面的执行结果来看,打印输出中并没有我们想要的图片元素,只是解析了tupian130x34_@1x的img(或者网页中的logo),这显然不是我们想要的。也就是说,需要的图片数据不在url下,也就是不在下面的url中
%B1%DA%D6%BD。
因此,下面需要找到图片不在url中的原因并进行改进。
开始爬取第二步:
考虑到图片元素可能是动态的,细心的人可能会发现,在网页中向下滑动鼠标滚轮时,图片是动态刷新的,也就是说网页不是一次性加载所有资源,而是动态地加载资源。这也避免了由于网页过于臃肿而影响加载速度。
(4)找到图片的真实url
找到所有图片的真实url似乎有点困难,但是在这个项目中尝试一下也不是不可能的。在接下来的学习中不断研究,我想我会逐渐提高自己的业务能力。
类似于开始抓取第一步中的“笔记”,我们找到位置:
F12——>>网络——>>XHR——>>(点击XHR下的文件)——>>预览
(注:如果在预览中没有找到内容,可以滚动左侧地址栏或点击图片链接)
从上图看来,图中的信息就是我们需要的元素。点击all_items,发现下面是0 1 2 3... 一个一个好像是图片元素的数据。
尝试打开一个网址。找到图片的地址
我们可以任意选择其中一个图片的地址来验证是否是图片所在的位置:
将地址粘贴到浏览器中,搜索如下结果,说明这个地址的url就是我们要找的
找到上图的目标后,我们点击XHR下的Headers,也就是第二行
请求网址:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
尽量去掉一些不必要的部分,去掉以上部分后不影响访问。
(删掉的位置跟同一个地方差不多,记住长宽高后面就不用删了)
例如:删除“=%E5%A3%81%E7%BA%B8&tag”得到
%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
将此网站复制到浏览器访问中,得到如下结果:
url中的category为类别,start为开始下标,len为长度,即图片数量。
另外,在imges下,注意url内容的填充(不要直接复制url)
当替换为“+”时
(5)批量抓图成功
如果你的电脑没有库文件请求,记得用 cmd 命令安装:
pip 安装请求
最后经过不断的排序,源码如下:
import requestsimport json #使用json码import urllibdef getSogouImag(category,length,path): n = length cate = category #分类 imgs = requests.get('http://pic.sogou.com/pics/chan ... 2Bstr(n)) jd = json.loads(imgs.text) jd = jd['all_items'] imgs_url = [] #在url获取图片imgs for j in jd: imgs_url.append(j['bthumbUrl']) m = 0 for img_url in imgs_url: print('***** '+str(m)+'.jpg *****'+' Downloading...') urllib.request.urlretrieve(img_url,path+str(m)+'.jpg') m = m + 1 print('Download complete!')getSogouImag('壁纸',2000,'F:/Py666/抓图/') #抓取后图片存取的本地位置
执行程序:到指定位置找到图片存在的位置,大功告成。
- 结尾 -
你好!
贡献--->展示你的才华
请发送电子邮件至
注明标题 [提交]
告诉我们
你是谁,你来自哪里,你投什么
网页qq抓取什么原理(1.什么是搜索引擎蜘蛛?蜘蛛的工作流程及流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2022-02-21 05:12
网站seo搜索引擎爬虫的基本原理。
1.什么是搜索引擎蜘蛛?
搜索引擎蜘蛛是根据一定的规则自动抓取互联网信息的程序或脚本。由于互联网有着非常类似于蜘蛛网的广泛“拓扑”,而搜索引擎爬虫在互联网上无休止地“爬行”,人们将搜索引擎爬虫形象地称为“蜘蛛”。
2.互联网资源和数据丰富,那么这些资源数据从何而来?
众所周知,搜索引擎不会自己生成内容,而是借助蜘蛛,不断从数以万计的网站中“采集”页面数据,“填充”自己的页面数据库。这就是为什么当我们使用搜索引擎检索数据时,我们可以得到很多匹配的资源。
一般工作流程如下:
1搜索引擎安排蜘蛛从互联网上的网站抓取网页数据,然后将抓取的数据带回搜索引擎的原创页面数据库。蜘蛛抓取页面数据的过程是一个无限循环,只有这样我们的搜索结果才能不断更新。
2 原页面数据库中的数据不是最终结果,而是相当于面试的“初试”。搜索引擎会对数据进行“二次处理”,这个过程会有两个处理结果:
(1)对于抄袭、采集、复制重复内容的,不符合搜索引擎规则和用户体验的垃圾页面将从原创页面数据库中删除。
(2)将符合搜索引擎规则的优质页面加入索引库,等待进一步分类、排序等。
(3)搜索引擎对索引库中的特殊文件进行分类、组织、计算链接关系和处理,将符合规则的网页显示在搜索引擎显示区,供用户使用和查看。 查看全部
网页qq抓取什么原理(1.什么是搜索引擎蜘蛛?蜘蛛的工作流程及流程)
网站seo搜索引擎爬虫的基本原理。
1.什么是搜索引擎蜘蛛?
搜索引擎蜘蛛是根据一定的规则自动抓取互联网信息的程序或脚本。由于互联网有着非常类似于蜘蛛网的广泛“拓扑”,而搜索引擎爬虫在互联网上无休止地“爬行”,人们将搜索引擎爬虫形象地称为“蜘蛛”。
2.互联网资源和数据丰富,那么这些资源数据从何而来?
众所周知,搜索引擎不会自己生成内容,而是借助蜘蛛,不断从数以万计的网站中“采集”页面数据,“填充”自己的页面数据库。这就是为什么当我们使用搜索引擎检索数据时,我们可以得到很多匹配的资源。
一般工作流程如下:
1搜索引擎安排蜘蛛从互联网上的网站抓取网页数据,然后将抓取的数据带回搜索引擎的原创页面数据库。蜘蛛抓取页面数据的过程是一个无限循环,只有这样我们的搜索结果才能不断更新。
2 原页面数据库中的数据不是最终结果,而是相当于面试的“初试”。搜索引擎会对数据进行“二次处理”,这个过程会有两个处理结果:
(1)对于抄袭、采集、复制重复内容的,不符合搜索引擎规则和用户体验的垃圾页面将从原创页面数据库中删除。
(2)将符合搜索引擎规则的优质页面加入索引库,等待进一步分类、排序等。
(3)搜索引擎对索引库中的特殊文件进行分类、组织、计算链接关系和处理,将符合规则的网页显示在搜索引擎显示区,供用户使用和查看。
网页qq抓取什么原理(用PHP来开发,用的是CI的框架结构,代码给出 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-20 03:04
)
本例使用 PHP 开发,使用 CI 框架。没接触过CI的朋友不用担心。这个框架的原理和其他框架是一样的,所以看代码不会难。
一、代码文件分为三个文件,①client.php ②client_view.php ③server.php
先说简单的原理,再给出代码和注释。
原理:我们以QQ开放平台登录为例。其实不只是QQ平台,其他平台的原理基本相同,只是数据处理方式上可能存在差异。首先,我们将登录程序定义为客户端,将QQ服务器定义为服务器端。当我们登录QQ的时候,会通过我们的程序,也就是浏览器,向QQ服务器发送一个请求。当然,你输入的 ID 和 PASSWORD 等 PROFILE 都是发给服务器的参数。QQ服务器收到客户端的请求后,收到客户端的REQUEST和PARAMETERS后,会将你的ID、PASSWORD和附加的PROFILE与数据库中的相关数据进行比对。如果比对结果通过,QQ服务器会将相关数据发送给客户端。当然,不会提及加密细节。客户端收到数据后,会对数据进行处理和提取,得到它想要的数据,并完成后续工作。看看客户的需求。基本原理是这样的。好了,废话不多说,代码就给出了。
①client.php
<p>All variables set in controllers though.
</p>
③server.php
<p> 查看全部
网页qq抓取什么原理(用PHP来开发,用的是CI的框架结构,代码给出
)
本例使用 PHP 开发,使用 CI 框架。没接触过CI的朋友不用担心。这个框架的原理和其他框架是一样的,所以看代码不会难。
一、代码文件分为三个文件,①client.php ②client_view.php ③server.php
先说简单的原理,再给出代码和注释。
原理:我们以QQ开放平台登录为例。其实不只是QQ平台,其他平台的原理基本相同,只是数据处理方式上可能存在差异。首先,我们将登录程序定义为客户端,将QQ服务器定义为服务器端。当我们登录QQ的时候,会通过我们的程序,也就是浏览器,向QQ服务器发送一个请求。当然,你输入的 ID 和 PASSWORD 等 PROFILE 都是发给服务器的参数。QQ服务器收到客户端的请求后,收到客户端的REQUEST和PARAMETERS后,会将你的ID、PASSWORD和附加的PROFILE与数据库中的相关数据进行比对。如果比对结果通过,QQ服务器会将相关数据发送给客户端。当然,不会提及加密细节。客户端收到数据后,会对数据进行处理和提取,得到它想要的数据,并完成后续工作。看看客户的需求。基本原理是这样的。好了,废话不多说,代码就给出了。
①client.php
<p>All variables set in controllers though.
</p>
③server.php
<p>
网页qq抓取什么原理(怎么实例化一个etree对象呢?怎么快速的写好一个xpath)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-19 09:18
Xpath是python爬虫最常用的数据解析方式。我觉得也是最简单的,通用性很强。稍后我将解释为什么它是最简单的。有两个主要步骤。
1、实例化一个etree对象,需要将解析后的页面源数据加载到该对象中。
2、调用etree对象中的xpath方法,结合xpath表达式定位标签,爬取内容文本或属性。
如何实例化一个 etree 对象?先下载lxml库再导入etree包,然后将本地HTML文档源数据加载到etree对象中,或者将实时网页源数据加载到etree中。
from lxml import etree
#将本地html文档中的数据加载到该对象中
tree = etree.parse('./douban.html')
print(tree.xpath('/html/head/title'))
>> []
from lxml import etree
import requests
# 将网页源码数据加载到该对象中
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="slist"]/ul/li')
print(li_list)
>> []
本地是etree.parse,网页是etree.HTML
这里返回的不是本地或网页html文档中的内容,而是一个Element类型的对象。该对象存储标题对应的文本内容。如果有多个内容,则以列表的形式返回多个Element。
xpath 表达式的规则:
/:表示层次,从根节点开始。
//: 表示多个级别,可以从任何节点定位。
属性定位://div[@class="title"] 以@ 为属性添加前缀。
索引定位: //div[@class="title"]/a[1] 下标从 1 开始,而不是 0。
/text():获取标签中的直接文本内容。
//text(): 可以获取一个标签的所有文本内容。
@attrName:在属性前加@,获取属性的内容。
接下来,我将告诉你如何快速编写一个xpath路径。
我们可以在我们要爬取数据的网页上打开开发者工具(点击右键查看或者直接同时按fn和f12打开开发者工具),然后在里面找到我们要爬取的数据元素(Element)并右键选择复制,然后选择复制XPath,就这样,是不是很方便。
以上是xpath比较常用的方法。当然,xpath还有很多其他的方法。有兴趣的可以参考相关文档。 查看全部
网页qq抓取什么原理(怎么实例化一个etree对象呢?怎么快速的写好一个xpath)
Xpath是python爬虫最常用的数据解析方式。我觉得也是最简单的,通用性很强。稍后我将解释为什么它是最简单的。有两个主要步骤。
1、实例化一个etree对象,需要将解析后的页面源数据加载到该对象中。
2、调用etree对象中的xpath方法,结合xpath表达式定位标签,爬取内容文本或属性。
如何实例化一个 etree 对象?先下载lxml库再导入etree包,然后将本地HTML文档源数据加载到etree对象中,或者将实时网页源数据加载到etree中。
from lxml import etree
#将本地html文档中的数据加载到该对象中
tree = etree.parse('./douban.html')
print(tree.xpath('/html/head/title'))
>> []
from lxml import etree
import requests
# 将网页源码数据加载到该对象中
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="slist"]/ul/li')
print(li_list)
>> []
本地是etree.parse,网页是etree.HTML
这里返回的不是本地或网页html文档中的内容,而是一个Element类型的对象。该对象存储标题对应的文本内容。如果有多个内容,则以列表的形式返回多个Element。
xpath 表达式的规则:
/:表示层次,从根节点开始。
//: 表示多个级别,可以从任何节点定位。
属性定位://div[@class="title"] 以@ 为属性添加前缀。
索引定位: //div[@class="title"]/a[1] 下标从 1 开始,而不是 0。
/text():获取标签中的直接文本内容。
//text(): 可以获取一个标签的所有文本内容。
@attrName:在属性前加@,获取属性的内容。
接下来,我将告诉你如何快速编写一个xpath路径。
我们可以在我们要爬取数据的网页上打开开发者工具(点击右键查看或者直接同时按fn和f12打开开发者工具),然后在里面找到我们要爬取的数据元素(Element)并右键选择复制,然后选择复制XPath,就这样,是不是很方便。
以上是xpath比较常用的方法。当然,xpath还有很多其他的方法。有兴趣的可以参考相关文档。
网页qq抓取什么原理(爬虫爬虫就是编写程序编写程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-14 01:16
最近在学习python爬虫,顺便记录一下。
爬虫:
网络爬虫(也称为网络蜘蛛、网络机器人,或者在 FOAF 社区中更常称为网络追踪器)是一种程序或脚本,它根据某些规则自动从万维网上爬取信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
以上是百度百科的解释。一般来说,爬虫就是写一个程序来模拟浏览器在互联网上选择我们需要的数据。
爬行动物合法吗?
爬取技术不受法律禁止,但如果我们干扰访问的网站的正常运行,爬取受法律保护的特定类型数据信息,可能会有人请你喝茶。
环境建设
我下载了python3和pycharm,没有下载或者不会安装的兄弟可以去菜鸟网站
(),里面有详细的python教程,也可以顺便学习一下HTML和python的基础知识。
最后,很多人一提到爬虫就会想到Python。其实除了Python之外,其他语言如C、Java、PHP等都可以写爬虫,而且一般来说这些语言的执行效率都比Python高,但是为什么目前是这样也就是说,Python逐渐成为很多人写爬虫的首选。原因是:1、代码简洁,一行代码就可以完成请求,100行就可以完成一个复杂的爬虫任务;2、优秀的第三方库很多,比如requests ,beautifulsoup 等。 查看全部
网页qq抓取什么原理(爬虫爬虫就是编写程序编写程序)
最近在学习python爬虫,顺便记录一下。
爬虫:
网络爬虫(也称为网络蜘蛛、网络机器人,或者在 FOAF 社区中更常称为网络追踪器)是一种程序或脚本,它根据某些规则自动从万维网上爬取信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
以上是百度百科的解释。一般来说,爬虫就是写一个程序来模拟浏览器在互联网上选择我们需要的数据。
爬行动物合法吗?
爬取技术不受法律禁止,但如果我们干扰访问的网站的正常运行,爬取受法律保护的特定类型数据信息,可能会有人请你喝茶。
环境建设
我下载了python3和pycharm,没有下载或者不会安装的兄弟可以去菜鸟网站
(),里面有详细的python教程,也可以顺便学习一下HTML和python的基础知识。
最后,很多人一提到爬虫就会想到Python。其实除了Python之外,其他语言如C、Java、PHP等都可以写爬虫,而且一般来说这些语言的执行效率都比Python高,但是为什么目前是这样也就是说,Python逐渐成为很多人写爬虫的首选。原因是:1、代码简洁,一行代码就可以完成请求,100行就可以完成一个复杂的爬虫任务;2、优秀的第三方库很多,比如requests ,beautifulsoup 等。

