
网页qq抓取什么原理
网页qq抓取什么原理(搜索引擎的工作原理是什么?如何了解搜索引擎的原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-25 17:56
[摘要] 我们都希望自己的网站在百度、360、搜狗等搜索引擎上有一定的排名。为了从搜索引擎获得更多的免费流量,需要从网站页面、网站结构等各个角度进行合理规划,使网站相关搜索引擎中显示的信息对用户是有效的。它更有吸引力。那么我们就要从了解搜索引擎的工作原理开始。
我们都希望自己的网站在百度、360、搜狗等搜索引擎上有一定的排名。为了从搜索引擎获得更多的免费流量,需要从网站页面、网站结构等各个角度进行合理规划,使网站相关显示在搜索引擎中的信息将对用户有效。它更有吸引力。那么我们就要从了解搜索引擎的工作原理开始。
<p>一、 抓取页面读取网页内容,找到网页中其他链接的地址,然后通过这些链接地址找到下一个网页,这样循环下去,直到这个 查看全部
网页qq抓取什么原理(搜索引擎的工作原理是什么?如何了解搜索引擎的原理)
[摘要] 我们都希望自己的网站在百度、360、搜狗等搜索引擎上有一定的排名。为了从搜索引擎获得更多的免费流量,需要从网站页面、网站结构等各个角度进行合理规划,使网站相关搜索引擎中显示的信息对用户是有效的。它更有吸引力。那么我们就要从了解搜索引擎的工作原理开始。
我们都希望自己的网站在百度、360、搜狗等搜索引擎上有一定的排名。为了从搜索引擎获得更多的免费流量,需要从网站页面、网站结构等各个角度进行合理规划,使网站相关显示在搜索引擎中的信息将对用户有效。它更有吸引力。那么我们就要从了解搜索引擎的工作原理开始。
<p>一、 抓取页面读取网页内容,找到网页中其他链接的地址,然后通过这些链接地址找到下一个网页,这样循环下去,直到这个
网页qq抓取什么原理(网页数据提取原理及其设计开发(龙泉第二小学,四川成都))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-25 13:00
题目:Web数据抽取原理及其设计开发(龙泉二小,范学政,四川,成都)并提出了基于网络爬虫的网页搜索和页面提取功能和设计要求。网络爬虫是一个非常强大的程序,可以自动提取网页。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。它通过请求站点上的 HTML 文档来访问站点。它遍历Web空间,不断地从一个站点移动到另一个站点,自动建立索引,并将其添加到网页数据库中。当网络爬虫进入超文本时,它利用HTML语言的标记结构来搜索信息并获取指向其他超文本的URL地址,可以在不依赖用户干预的情况下实现网络上的自动“爬行”和搜索。本文在分析基于爬虫的网页搜索系统的结构和工作原理的基础上,研究了网页抓取和解析的策略和算法,并使用C#实现了一个网页提取程序并分析了其运行结果。关键词:爬虫;页面搜索;数据提取;HTML分析;摘要 本文讨论了搜索引擎的应用,搜索了网络蜘蛛在搜索引擎中的重要性和功能,并提出了其功能和设计的需求。网络爬虫是一个强大的自动提取网络应用程序;它来自万维网搜索引擎上的下载页面,是搜索引擎中的重要组成部分。它通过请求站点访问站点 HTML 文件来完成此操作。它穿越了网络空间, 1 网页数据提取现状分析 在互联网普及之前,人们在查找资料时首先想到的就是拥有大量书籍的图书馆。现在很多人选择了一种更方便、快捷、全面、准确的方式——互联网。如果说互联网是知识宝库,那么网络搜索就是打开知识宝库的钥匙。搜索引擎是1995年以来随着WEB信息的迅速增加而逐渐发展起来的一项技术。它是一种用于帮助互联网用户查询信息的搜索工具。搜索引擎利用一定的策略来采集和发现互联网上的信息,理解、提取、组织和处理信息,为用户提供搜索服务,从而达到信息导航的目的。目前,搜索引擎已成为网民关注的焦点,也成为计算机界和学术界的研究开发对象。目前比较流行的搜索引擎有谷歌、雅虎、Infoseek、百度等,出于商业秘密的考虑,目前各搜索引擎所使用的爬虫系统的技术内幕一般不公开,现有文献为限于总结介绍。并为用户提供搜索服务,从而达到信息导航的目的。目前,搜索引擎已成为网民关注的焦点,也成为计算机界和学术界的研究开发对象。目前比较流行的搜索引擎有谷歌、雅虎、Infoseek、百度等,出于商业秘密的考虑,目前各搜索引擎所使用的爬虫系统的技术内幕一般不公开,现有文献为限于总结介绍。并为用户提供搜索服务,从而达到信息导航的目的。目前,搜索引擎已成为网民关注的焦点,也成为计算机界和学术界的研究开发对象。目前比较流行的搜索引擎有谷歌、雅虎、Infoseek、百度等,出于商业秘密的考虑,目前各搜索引擎所使用的爬虫系统的技术内幕一般不公开,现有文献为限于总结介绍。
各大搜索引擎提供商都基于网络爬虫的原理来检索网页、抓取网页、分析网页、采集数据。随着Web信息资源的呈指数级增长和Web信息资源的动态变化,传统搜索引擎提供的信息提取服务已不能满足人们日益增长的个性化服务需求,面临着巨大的挑战。访问Web和提高搜索效率的策略已成为近年来专业搜索引擎网页数据提取研究的主要问题之一。1.2 学科发展背景基本上是三种类型的搜索引擎。一个组件:(1)网上采集信息网页< @采集系统:网页采集系统主要利用了一类采集信息,作用于互联网“网络蜘蛛”。“网络蜘蛛”实际上是一些基于网络的程序,它们使用主页中的超文本链接来遍历网络。使用可以自动从互联网上采集网页的“网络蜘蛛”程序,自动上网并跟随抓取任何网页中的所有网址到其他网页,重复此过程,将所有已被抓取的网页采集到网页数据库中. (2)索引采集的信息,建立索引库索引处理系统:索引处理系统对采集的网页进行分析,提取相关网页信息(包括网页所在的网址、编码类型等) , 关键词, 关键词 收录在页面内容中的位置、生成时间、大小、与其他网页的链接关系等),根据一定的相关性算法进行大量复杂的计算,并且获取每个网页与页面内容的相关性(或重要性)以及超链接中的每个关键词,然后创建索引并存储在网页索引数据库中。索引数据库可以使用通用的大型数据库,如Oracle、Sybase等,也可以定义存储的文件格式。为了保证索引库中的信息与Web内容同步,索引库必须定期更新,更新频率决定了搜索结果的及时性。索引数据库的更新是通过启动“网络蜘蛛”来实现的 再次搜索网络空间。(3)完成用户提交的查询请求的网页检索器:网页检索器一般是运行在Web服务器上的服务器程序,它首先接收用户提交的查询条件,搜索索引数据库根据查询条件,将查询结果返回给用户,当用户使用搜索引擎查找信息时,网页检索器接收用户提交的关键词,搜索系统程序查找所有相关网页网页索引数据库中匹配关键词的页面,一些搜索引擎系统会综合相关信息和网页级别,形成相关度值,然后进行排序,相关度越高,排名越高。最后,页面生成系统将搜索结果的链接地址和页面的内容摘要整理后返回给用户。典型的搜索引擎系统如谷歌采用这种策略。信息的快速增长使搜索引擎成为人们寻找信息的首选工具。谷歌、百度、中国搜索等大型搜索引擎一直是讨论的话题。国外搜索引擎技术的研究比国内早了近十年。从最早的Archie到后来的Excite,以及ahvista、overture、google等搜索引擎的出现,搜索引擎的发展已有十多年的历史。国内对搜索引擎的研究始于上世纪末本世纪初。在许多领域,国外的产品和技术一统天下,尤其是某项技术在国外研究多年,才在中国起步。例如操作系统、文字处理软件、浏览器等,但搜索引擎除外。国外搜索引擎技术虽然研究了很长时间,但中国还是涌现出了优秀的搜索引擎,比如百度、中搜。随着搜索引擎技术的成熟,它将成为获取信息和掌握知识的利器。但是,现有搜索引擎对用户的查询需求仅限于关键词的简单逻辑组合。搜索结果看重返回的数量而不是质量,结果文档的组织和分类也缺乏。国外的一项调查结果显示,约有71%的人对搜索结果有不同程度的失望。因此,如何提高搜索引擎的智能化,如何根据知识应用的需要组织信息,使互联网既能提供信息服务,又能为用户提供知识服务,将成为互联网研究的方向。计算机行业和学术界1.3 网页提取的工作原理。网络爬虫是网页检索的核心部分。它的名字来自蜘蛛的自由翻译。如何提高搜索引擎的智能化,如何根据知识应用的需要组织信息,使互联网既能提供信息服务,又能为用户提供知识服务,将成为计算机行业研究的方向。和学术界1.3 网页提取的工作原理。网络爬虫是网页检索的核心部分。它的名字来自蜘蛛的自由翻译。如何提高搜索引擎的智能化,如何根据知识应用的需要组织信息,使互联网既能提供信息服务,又能为用户提供知识服务,将成为计算机行业研究的方向。和学术界1.3 网页提取的工作原理。网络爬虫是网页检索的核心部分。它的名字来自蜘蛛的自由翻译。
系统开发工具和平台2.1关于c#语言 C#语言是由于2001年引入的一种新的编程语言。它是一种适用于分布式计算环境的跨平台、纯面向对象的语言。C#语言及其扩展正逐渐成为互联网应用的规范,掀起了自PC以来的又一次技术革命。一般认为,B语言导致了C语言的诞生,C语言演变成了C++语言,而C#语言显然具有C++语言的特点。C#总是和C++联系在一起,而C++是从C语言派生出来的,所以C#语言继承了这两种语言的大部分特性。C#的语法继承自C,C#的很多面向对象的特性都受到C++的影响。实际上,C# 中的一些自定义功能源自或可以追溯到这些前辈语言。略有不同的是C#语言是完全面向对象的,消除了两者的缺点。C#语言的诞生与近30年来计算机语言的不断完善和发展息息相关。C#由Anders Hejlsberg开发,它是第一种面向组件的编程语言,其源代码会被编译成msil然后运行。它借鉴了Delphi的一个特性,直接与COM组件对象模型集成,并增加了许多新的功能和语法。它是微软.NET网络框架的主角。1998 年 12 月,微软推出了全新的语言项目 COOL,
2000年2月,微软正式将COOL语言更名为C#,并于2000年7月发布了C#语言的第一个预览版。自2000年正式推出以来,C#语言以其独特的优势迅速发展。经过短短的8、 9年,它已经成为迄今为止最优秀的面向对象语言。C#从最初的语言逐渐形成了一个产业。基于C#语言的.NET架构已经成为微软J2EE平台的有力竞争者。一开始,C# 语言的最初发布不亚于一场革命,但它并没有标志着 C# 快速创新时代的结束。在.NET 2.0 发布后不久,.NET 的设计者就已经制定了.NET 3.5 和.NET 4.0 版本。C#作为目前广泛使用的面向对象编程语言,具有很多特点。如果将其与许多其他编程语言进行比较,您会发现这些特性正是 C# 语言如此受欢迎的原因。尽管C#在某些方面(比如资源消耗)存在一些不足,但这并不影响C#作为最好的面向对象编程语言的地位。C#是一种广泛使用的网络编程语言,是一种新的计算概念。网络环境下的编程语言最需要解决的就是可移植性和安全性问题。以字节为单位进行编码,可以使程序不受运行平台和环境的限制。C#语言还提供了丰富的类库,
C#作为一种高级编程语言,不仅面向对象、编写简单、远离机器结构、分布式、健壮、可移植、安全,而且提供了高解释和执行的并发机制。2.2 集成开发环境介绍 Visual Studio 2010 微软首次发布Visual Basic时,通过降低其复杂性,使得Windows软件开发得到广泛应用。使用 Visual Basic 6.0,Microsoft 使数百万开发人员能够快速开发客户端/服务器应用程序 [14]。最近,Microsoft 使用 Visual Studio.NET 为开发人员提供了工具和技术来轻松开发分布式应用程序。随着 Visual Studio 2010 集成开发环境的发布,Microsoft 一直处于响应日益复杂的应用程序和设计、开发和部署过程中所需的生命周期问题的最前沿。它根据开发者的个人需求自动配置开发工具的界面设置,提高软件开发者的开发体验。丰富了.NET Framework类库,使应用开发者能够从容应对日常开发中的各种问题,从而提高开发效率。实现了与微软团队开发中使用的产品无缝集成,如:VSS、Office、SQL Server等,丰富了开发者的解决方案,使开发者能够使用各种产品进行开发。
它提供了一套新的工具和功能,如ShareOpint、工作流等,使开发者能够跟上技术发展,满足日益复杂的应用开发需求。三、系统总体设计3.1系统总体结构3.2 搜索抽取策略 Web搜索往往采用一定的搜索策略。一个是广度或深度优先搜索策略:搜索引擎使用的第一代网络爬虫主要基于传统的图算法,例如广度优先或深度优先算法来索引整个Web,以及一个核心的URL set 被用作种子集合,这个算法递归地跟踪到其他页面的超链接,通常不管页面的内容,因为最终的目标是这个跟踪可以覆盖整个 Web。这种策略通常用于通用搜索引擎,因为通用搜索引擎获取的网页越多越好,并且没有具体要求。其次,广度优先搜索算法(也称为广度优先搜索)是最简单的图搜索算法之一,该算法也是许多重要图算法的原型。单源最短路径算法和P rim 最小生成树算法都采用了与广度优先搜索相似的思想。广度优先搜索算法沿树的宽度遍历树的节点。如果找到目标,则算法停止。算法的设计和实现比较简单,属于盲搜索。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是认为初始 URL 与初始 URL 一致的网页在一定的链接距离内具有很高的主题相关性概率。另一种方法是将宽度优先搜索与网页过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。基本思想是认为初始 URL 与初始 URL 一致的网页在一定的链接距离内具有很高的主题相关性概率。另一种方法是将宽度优先搜索与网页过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。基本思想是认为初始 URL 与初始 URL 一致的网页在一定的链接距离内具有很高的主题相关性概率。另一种方法是将宽度优先搜索与网页过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。
第三,深度优先搜索遵循的搜索策略是尽可能“深”地搜索图。在深度优先搜索中,对于新发现的顶点,如果从这个起点开始有未检测到的边,按照这个继续汉朝。当探索了节点 v 的所有边时,搜索将返回到找到节点 v 边的起始节点。这个过程一直持续到发现源节点可达所有节点为止。如果有未发现的节点,则选择其中一个作为源节点,重复上述过程。重复整个过程,直到找到所有节点。深度优先在很多情况下会导致爬虫被困(trapped)的问题,所以它既不是完全的也不是最优的。四、系统详细设计4.1接口设计4.1. 1界面设计实现设计界面如下:4.2网页分析实现4.2.1网页分析Web文档作为一种半结构化文本,是一种自由之间的数据文本和结构化文本,它通常没有严格的格式。对于这类文本,一般通过分析文本中独特的图标字符来进行爬取,具体来说就是分析HTML语言中各个标签之间的关系。网页信息的载体是网页文本,用超文本标记语言编写。HTML 标准定义了一组元素类型,不同类型的元素分别描述文本、图像、超文本链接等。一个元素的描述一般由一个开始标签(Start Tag)、一个内容(Content)、
元素名称出现在开始标签中,用HTML语言标记为,对应的结束标签是,内容出现在开始标签和结束标签之间。构建网页标签树的方法可以反映网页的结构特征。下图是一个简单的动态网页标签树4.2.2网页处理队列页面处理队列保存了页面URL,它实际上由等待队列、处理队列、错误队列和完成队列组成。正是通过它们,特定的移动蜘蛛可以完成对蜘蛛对应的网络的所有搜索任务。页面队列中保存的页面的 URL 都是内部链接。(1)等待队列(WaitURL)。在这个队列中,URL 正在等待移动 Spider 程序处理。新发现的 URL 将添加到此队列中。(2)处理队列(Proces—sUI)。当手机蜘蛛程序开始处理URL时,会被转移到这个队列中,但是同一个URL不能被多次处理,因为这样很浪费资源。当一个 URL 被处理后,会被移到错误队列或已完成队列中。(3)错误队列(ErrorURL)。如果在处理页面时发生错误,它的 URL 将被添加到错误队列中。在URL到达这个队列,就不会再移动到其他队列,一旦网页移动到错误队列,移动Spider程序就不会再处理了。(4)完成队列(LaunchURL))。它们被转移到这个队列中,但是同一个 URL 不能被多次处理,因为这是一种资源浪费。当一个 URL 被处理时,它会被移动到错误队列或完成队列。(3)Error Queue (ErrorURL)。如果在处理一个页面时发生错误,它的URL会被加入到错误队列中。URL到达这个队列后,就不会再移动到其他队列了。一旦网页被移入错误队列,手机Spider程序不会进一步处理(4)Completion Queue (LaunchURL))。它们被转移到这个队列中,但是同一个 URL 不能被多次处理,因为这是一种资源浪费。当一个 URL 被处理时,它会被移动到错误队列或完成队列。(3)Error Queue (ErrorURL)。如果在处理一个页面时发生错误,它的URL会被加入到错误队列中。URL到达这个队列后,就不会再移动到其他队列了。一旦网页被移入错误队列,手机Spider程序不会进一步处理(4)Completion Queue (LaunchURL))。它的 URL 将被添加到错误队列中。URL 到达此队列后,将不再移动到其他队列。一旦将网页移入错误队列,移动版蜘蛛程序将不再对其进行进一步处理。(4)完成队列(LaunchURL)。它的 URL 将被添加到错误队列中。URL 到达此队列后,将不再移动到其他队列。一旦将网页移入错误队列,移动版蜘蛛程序将不再对其进行进一步处理。(4)完成队列(LaunchURL)。
如果在处理网页时没有出现错误,则处理完成时会将 URL 添加到完成队列中,并且 URL 到达此队列后不会移动到其他队列。一个 URL 只能同时在一个队列中。这也称为 URL 的状态。这是因为人们经常使用状态图来描述计算机程序。程序根据状态图从一种状态改变到另一种状态。事实上,当一个URL(内部链接)时,移动蜘蛛会检查该URL是否已经存在于完成队列或错误队列中。如果它已经存在于上述两个队列中的任何一个中,移动蜘蛛将不会对该 URL 进行任何处理。这样可以防止某个页面被重复处理,也可以防止陷入死循环。< @4.2.3 搜索串匹配根据关键字检索网页数据。具体实现逻辑如下: 首先生成URL地址:string Url = String.Format("/search?spm=a230r.1.8.3.eyiRvB&promote=0&sort=sale-desc&tab =all&q={0}#J_relative", this.textBox1.Text.Trim()); 根据 URL 地址检索页面:私有字符串 GetWebContent(){string Result = "";try{HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(_url);request.Headers.Add("Accept-Charset", "gb2312;" );request.Headers。Add("Accept-Encoding", "gzip");request.Headers.Add("Accept-Language", " 具体实现逻辑如下: 首先生成URL地址:string Url = String.Format("/search?spm=a230r.1.8.3.eyiRvB&promote=0&sort=sale-desc&tab =all&q={0}#J_relative", this.textBox1.Text.Trim()); 根据 URL 地址检索页面:私有字符串 GetWebContent(){string Result = "";try{HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(_url);request.Headers.Add("Accept-Charset", "gb2312;" );request.Headers。Add("Accept-Encoding", "gzip");request.Headers.Add("Accept-Language", " 具体实现逻辑如下: 首先生成URL地址:string Url = String.Format("/search?spm=a230r.1.8.3.eyiRvB&promote=0&sort=sale-desc&tab =all&q={0}#J_relative", this.textBox1.Text.Trim()); 根据 URL 地址检索页面:私有字符串 GetWebContent(){string Result = "";try{HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(_url);request.Headers.Add("Accept-Charset", "gb2312;" );request.Headers。Add("Accept-Encoding", "gzip");request.Headers.Add("Accept-Language", " 查看全部
网页qq抓取什么原理(网页数据提取原理及其设计开发(龙泉第二小学,四川成都))
题目:Web数据抽取原理及其设计开发(龙泉二小,范学政,四川,成都)并提出了基于网络爬虫的网页搜索和页面提取功能和设计要求。网络爬虫是一个非常强大的程序,可以自动提取网页。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。它通过请求站点上的 HTML 文档来访问站点。它遍历Web空间,不断地从一个站点移动到另一个站点,自动建立索引,并将其添加到网页数据库中。当网络爬虫进入超文本时,它利用HTML语言的标记结构来搜索信息并获取指向其他超文本的URL地址,可以在不依赖用户干预的情况下实现网络上的自动“爬行”和搜索。本文在分析基于爬虫的网页搜索系统的结构和工作原理的基础上,研究了网页抓取和解析的策略和算法,并使用C#实现了一个网页提取程序并分析了其运行结果。关键词:爬虫;页面搜索;数据提取;HTML分析;摘要 本文讨论了搜索引擎的应用,搜索了网络蜘蛛在搜索引擎中的重要性和功能,并提出了其功能和设计的需求。网络爬虫是一个强大的自动提取网络应用程序;它来自万维网搜索引擎上的下载页面,是搜索引擎中的重要组成部分。它通过请求站点访问站点 HTML 文件来完成此操作。它穿越了网络空间, 1 网页数据提取现状分析 在互联网普及之前,人们在查找资料时首先想到的就是拥有大量书籍的图书馆。现在很多人选择了一种更方便、快捷、全面、准确的方式——互联网。如果说互联网是知识宝库,那么网络搜索就是打开知识宝库的钥匙。搜索引擎是1995年以来随着WEB信息的迅速增加而逐渐发展起来的一项技术。它是一种用于帮助互联网用户查询信息的搜索工具。搜索引擎利用一定的策略来采集和发现互联网上的信息,理解、提取、组织和处理信息,为用户提供搜索服务,从而达到信息导航的目的。目前,搜索引擎已成为网民关注的焦点,也成为计算机界和学术界的研究开发对象。目前比较流行的搜索引擎有谷歌、雅虎、Infoseek、百度等,出于商业秘密的考虑,目前各搜索引擎所使用的爬虫系统的技术内幕一般不公开,现有文献为限于总结介绍。并为用户提供搜索服务,从而达到信息导航的目的。目前,搜索引擎已成为网民关注的焦点,也成为计算机界和学术界的研究开发对象。目前比较流行的搜索引擎有谷歌、雅虎、Infoseek、百度等,出于商业秘密的考虑,目前各搜索引擎所使用的爬虫系统的技术内幕一般不公开,现有文献为限于总结介绍。并为用户提供搜索服务,从而达到信息导航的目的。目前,搜索引擎已成为网民关注的焦点,也成为计算机界和学术界的研究开发对象。目前比较流行的搜索引擎有谷歌、雅虎、Infoseek、百度等,出于商业秘密的考虑,目前各搜索引擎所使用的爬虫系统的技术内幕一般不公开,现有文献为限于总结介绍。
各大搜索引擎提供商都基于网络爬虫的原理来检索网页、抓取网页、分析网页、采集数据。随着Web信息资源的呈指数级增长和Web信息资源的动态变化,传统搜索引擎提供的信息提取服务已不能满足人们日益增长的个性化服务需求,面临着巨大的挑战。访问Web和提高搜索效率的策略已成为近年来专业搜索引擎网页数据提取研究的主要问题之一。1.2 学科发展背景基本上是三种类型的搜索引擎。一个组件:(1)网上采集信息网页< @采集系统:网页采集系统主要利用了一类采集信息,作用于互联网“网络蜘蛛”。“网络蜘蛛”实际上是一些基于网络的程序,它们使用主页中的超文本链接来遍历网络。使用可以自动从互联网上采集网页的“网络蜘蛛”程序,自动上网并跟随抓取任何网页中的所有网址到其他网页,重复此过程,将所有已被抓取的网页采集到网页数据库中. (2)索引采集的信息,建立索引库索引处理系统:索引处理系统对采集的网页进行分析,提取相关网页信息(包括网页所在的网址、编码类型等) , 关键词, 关键词 收录在页面内容中的位置、生成时间、大小、与其他网页的链接关系等),根据一定的相关性算法进行大量复杂的计算,并且获取每个网页与页面内容的相关性(或重要性)以及超链接中的每个关键词,然后创建索引并存储在网页索引数据库中。索引数据库可以使用通用的大型数据库,如Oracle、Sybase等,也可以定义存储的文件格式。为了保证索引库中的信息与Web内容同步,索引库必须定期更新,更新频率决定了搜索结果的及时性。索引数据库的更新是通过启动“网络蜘蛛”来实现的 再次搜索网络空间。(3)完成用户提交的查询请求的网页检索器:网页检索器一般是运行在Web服务器上的服务器程序,它首先接收用户提交的查询条件,搜索索引数据库根据查询条件,将查询结果返回给用户,当用户使用搜索引擎查找信息时,网页检索器接收用户提交的关键词,搜索系统程序查找所有相关网页网页索引数据库中匹配关键词的页面,一些搜索引擎系统会综合相关信息和网页级别,形成相关度值,然后进行排序,相关度越高,排名越高。最后,页面生成系统将搜索结果的链接地址和页面的内容摘要整理后返回给用户。典型的搜索引擎系统如谷歌采用这种策略。信息的快速增长使搜索引擎成为人们寻找信息的首选工具。谷歌、百度、中国搜索等大型搜索引擎一直是讨论的话题。国外搜索引擎技术的研究比国内早了近十年。从最早的Archie到后来的Excite,以及ahvista、overture、google等搜索引擎的出现,搜索引擎的发展已有十多年的历史。国内对搜索引擎的研究始于上世纪末本世纪初。在许多领域,国外的产品和技术一统天下,尤其是某项技术在国外研究多年,才在中国起步。例如操作系统、文字处理软件、浏览器等,但搜索引擎除外。国外搜索引擎技术虽然研究了很长时间,但中国还是涌现出了优秀的搜索引擎,比如百度、中搜。随着搜索引擎技术的成熟,它将成为获取信息和掌握知识的利器。但是,现有搜索引擎对用户的查询需求仅限于关键词的简单逻辑组合。搜索结果看重返回的数量而不是质量,结果文档的组织和分类也缺乏。国外的一项调查结果显示,约有71%的人对搜索结果有不同程度的失望。因此,如何提高搜索引擎的智能化,如何根据知识应用的需要组织信息,使互联网既能提供信息服务,又能为用户提供知识服务,将成为互联网研究的方向。计算机行业和学术界1.3 网页提取的工作原理。网络爬虫是网页检索的核心部分。它的名字来自蜘蛛的自由翻译。如何提高搜索引擎的智能化,如何根据知识应用的需要组织信息,使互联网既能提供信息服务,又能为用户提供知识服务,将成为计算机行业研究的方向。和学术界1.3 网页提取的工作原理。网络爬虫是网页检索的核心部分。它的名字来自蜘蛛的自由翻译。如何提高搜索引擎的智能化,如何根据知识应用的需要组织信息,使互联网既能提供信息服务,又能为用户提供知识服务,将成为计算机行业研究的方向。和学术界1.3 网页提取的工作原理。网络爬虫是网页检索的核心部分。它的名字来自蜘蛛的自由翻译。
系统开发工具和平台2.1关于c#语言 C#语言是由于2001年引入的一种新的编程语言。它是一种适用于分布式计算环境的跨平台、纯面向对象的语言。C#语言及其扩展正逐渐成为互联网应用的规范,掀起了自PC以来的又一次技术革命。一般认为,B语言导致了C语言的诞生,C语言演变成了C++语言,而C#语言显然具有C++语言的特点。C#总是和C++联系在一起,而C++是从C语言派生出来的,所以C#语言继承了这两种语言的大部分特性。C#的语法继承自C,C#的很多面向对象的特性都受到C++的影响。实际上,C# 中的一些自定义功能源自或可以追溯到这些前辈语言。略有不同的是C#语言是完全面向对象的,消除了两者的缺点。C#语言的诞生与近30年来计算机语言的不断完善和发展息息相关。C#由Anders Hejlsberg开发,它是第一种面向组件的编程语言,其源代码会被编译成msil然后运行。它借鉴了Delphi的一个特性,直接与COM组件对象模型集成,并增加了许多新的功能和语法。它是微软.NET网络框架的主角。1998 年 12 月,微软推出了全新的语言项目 COOL,
2000年2月,微软正式将COOL语言更名为C#,并于2000年7月发布了C#语言的第一个预览版。自2000年正式推出以来,C#语言以其独特的优势迅速发展。经过短短的8、 9年,它已经成为迄今为止最优秀的面向对象语言。C#从最初的语言逐渐形成了一个产业。基于C#语言的.NET架构已经成为微软J2EE平台的有力竞争者。一开始,C# 语言的最初发布不亚于一场革命,但它并没有标志着 C# 快速创新时代的结束。在.NET 2.0 发布后不久,.NET 的设计者就已经制定了.NET 3.5 和.NET 4.0 版本。C#作为目前广泛使用的面向对象编程语言,具有很多特点。如果将其与许多其他编程语言进行比较,您会发现这些特性正是 C# 语言如此受欢迎的原因。尽管C#在某些方面(比如资源消耗)存在一些不足,但这并不影响C#作为最好的面向对象编程语言的地位。C#是一种广泛使用的网络编程语言,是一种新的计算概念。网络环境下的编程语言最需要解决的就是可移植性和安全性问题。以字节为单位进行编码,可以使程序不受运行平台和环境的限制。C#语言还提供了丰富的类库,
C#作为一种高级编程语言,不仅面向对象、编写简单、远离机器结构、分布式、健壮、可移植、安全,而且提供了高解释和执行的并发机制。2.2 集成开发环境介绍 Visual Studio 2010 微软首次发布Visual Basic时,通过降低其复杂性,使得Windows软件开发得到广泛应用。使用 Visual Basic 6.0,Microsoft 使数百万开发人员能够快速开发客户端/服务器应用程序 [14]。最近,Microsoft 使用 Visual Studio.NET 为开发人员提供了工具和技术来轻松开发分布式应用程序。随着 Visual Studio 2010 集成开发环境的发布,Microsoft 一直处于响应日益复杂的应用程序和设计、开发和部署过程中所需的生命周期问题的最前沿。它根据开发者的个人需求自动配置开发工具的界面设置,提高软件开发者的开发体验。丰富了.NET Framework类库,使应用开发者能够从容应对日常开发中的各种问题,从而提高开发效率。实现了与微软团队开发中使用的产品无缝集成,如:VSS、Office、SQL Server等,丰富了开发者的解决方案,使开发者能够使用各种产品进行开发。
它提供了一套新的工具和功能,如ShareOpint、工作流等,使开发者能够跟上技术发展,满足日益复杂的应用开发需求。三、系统总体设计3.1系统总体结构3.2 搜索抽取策略 Web搜索往往采用一定的搜索策略。一个是广度或深度优先搜索策略:搜索引擎使用的第一代网络爬虫主要基于传统的图算法,例如广度优先或深度优先算法来索引整个Web,以及一个核心的URL set 被用作种子集合,这个算法递归地跟踪到其他页面的超链接,通常不管页面的内容,因为最终的目标是这个跟踪可以覆盖整个 Web。这种策略通常用于通用搜索引擎,因为通用搜索引擎获取的网页越多越好,并且没有具体要求。其次,广度优先搜索算法(也称为广度优先搜索)是最简单的图搜索算法之一,该算法也是许多重要图算法的原型。单源最短路径算法和P rim 最小生成树算法都采用了与广度优先搜索相似的思想。广度优先搜索算法沿树的宽度遍历树的节点。如果找到目标,则算法停止。算法的设计和实现比较简单,属于盲搜索。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是认为初始 URL 与初始 URL 一致的网页在一定的链接距离内具有很高的主题相关性概率。另一种方法是将宽度优先搜索与网页过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。基本思想是认为初始 URL 与初始 URL 一致的网页在一定的链接距离内具有很高的主题相关性概率。另一种方法是将宽度优先搜索与网页过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。基本思想是认为初始 URL 与初始 URL 一致的网页在一定的链接距离内具有很高的主题相关性概率。另一种方法是将宽度优先搜索与网页过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。
第三,深度优先搜索遵循的搜索策略是尽可能“深”地搜索图。在深度优先搜索中,对于新发现的顶点,如果从这个起点开始有未检测到的边,按照这个继续汉朝。当探索了节点 v 的所有边时,搜索将返回到找到节点 v 边的起始节点。这个过程一直持续到发现源节点可达所有节点为止。如果有未发现的节点,则选择其中一个作为源节点,重复上述过程。重复整个过程,直到找到所有节点。深度优先在很多情况下会导致爬虫被困(trapped)的问题,所以它既不是完全的也不是最优的。四、系统详细设计4.1接口设计4.1. 1界面设计实现设计界面如下:4.2网页分析实现4.2.1网页分析Web文档作为一种半结构化文本,是一种自由之间的数据文本和结构化文本,它通常没有严格的格式。对于这类文本,一般通过分析文本中独特的图标字符来进行爬取,具体来说就是分析HTML语言中各个标签之间的关系。网页信息的载体是网页文本,用超文本标记语言编写。HTML 标准定义了一组元素类型,不同类型的元素分别描述文本、图像、超文本链接等。一个元素的描述一般由一个开始标签(Start Tag)、一个内容(Content)、
元素名称出现在开始标签中,用HTML语言标记为,对应的结束标签是,内容出现在开始标签和结束标签之间。构建网页标签树的方法可以反映网页的结构特征。下图是一个简单的动态网页标签树4.2.2网页处理队列页面处理队列保存了页面URL,它实际上由等待队列、处理队列、错误队列和完成队列组成。正是通过它们,特定的移动蜘蛛可以完成对蜘蛛对应的网络的所有搜索任务。页面队列中保存的页面的 URL 都是内部链接。(1)等待队列(WaitURL)。在这个队列中,URL 正在等待移动 Spider 程序处理。新发现的 URL 将添加到此队列中。(2)处理队列(Proces—sUI)。当手机蜘蛛程序开始处理URL时,会被转移到这个队列中,但是同一个URL不能被多次处理,因为这样很浪费资源。当一个 URL 被处理后,会被移到错误队列或已完成队列中。(3)错误队列(ErrorURL)。如果在处理页面时发生错误,它的 URL 将被添加到错误队列中。在URL到达这个队列,就不会再移动到其他队列,一旦网页移动到错误队列,移动Spider程序就不会再处理了。(4)完成队列(LaunchURL))。它们被转移到这个队列中,但是同一个 URL 不能被多次处理,因为这是一种资源浪费。当一个 URL 被处理时,它会被移动到错误队列或完成队列。(3)Error Queue (ErrorURL)。如果在处理一个页面时发生错误,它的URL会被加入到错误队列中。URL到达这个队列后,就不会再移动到其他队列了。一旦网页被移入错误队列,手机Spider程序不会进一步处理(4)Completion Queue (LaunchURL))。它们被转移到这个队列中,但是同一个 URL 不能被多次处理,因为这是一种资源浪费。当一个 URL 被处理时,它会被移动到错误队列或完成队列。(3)Error Queue (ErrorURL)。如果在处理一个页面时发生错误,它的URL会被加入到错误队列中。URL到达这个队列后,就不会再移动到其他队列了。一旦网页被移入错误队列,手机Spider程序不会进一步处理(4)Completion Queue (LaunchURL))。它的 URL 将被添加到错误队列中。URL 到达此队列后,将不再移动到其他队列。一旦将网页移入错误队列,移动版蜘蛛程序将不再对其进行进一步处理。(4)完成队列(LaunchURL)。它的 URL 将被添加到错误队列中。URL 到达此队列后,将不再移动到其他队列。一旦将网页移入错误队列,移动版蜘蛛程序将不再对其进行进一步处理。(4)完成队列(LaunchURL)。
如果在处理网页时没有出现错误,则处理完成时会将 URL 添加到完成队列中,并且 URL 到达此队列后不会移动到其他队列。一个 URL 只能同时在一个队列中。这也称为 URL 的状态。这是因为人们经常使用状态图来描述计算机程序。程序根据状态图从一种状态改变到另一种状态。事实上,当一个URL(内部链接)时,移动蜘蛛会检查该URL是否已经存在于完成队列或错误队列中。如果它已经存在于上述两个队列中的任何一个中,移动蜘蛛将不会对该 URL 进行任何处理。这样可以防止某个页面被重复处理,也可以防止陷入死循环。< @4.2.3 搜索串匹配根据关键字检索网页数据。具体实现逻辑如下: 首先生成URL地址:string Url = String.Format("/search?spm=a230r.1.8.3.eyiRvB&promote=0&sort=sale-desc&tab =all&q={0}#J_relative", this.textBox1.Text.Trim()); 根据 URL 地址检索页面:私有字符串 GetWebContent(){string Result = "";try{HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(_url);request.Headers.Add("Accept-Charset", "gb2312;" );request.Headers。Add("Accept-Encoding", "gzip");request.Headers.Add("Accept-Language", " 具体实现逻辑如下: 首先生成URL地址:string Url = String.Format("/search?spm=a230r.1.8.3.eyiRvB&promote=0&sort=sale-desc&tab =all&q={0}#J_relative", this.textBox1.Text.Trim()); 根据 URL 地址检索页面:私有字符串 GetWebContent(){string Result = "";try{HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(_url);request.Headers.Add("Accept-Charset", "gb2312;" );request.Headers。Add("Accept-Encoding", "gzip");request.Headers.Add("Accept-Language", " 具体实现逻辑如下: 首先生成URL地址:string Url = String.Format("/search?spm=a230r.1.8.3.eyiRvB&promote=0&sort=sale-desc&tab =all&q={0}#J_relative", this.textBox1.Text.Trim()); 根据 URL 地址检索页面:私有字符串 GetWebContent(){string Result = "";try{HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(_url);request.Headers.Add("Accept-Charset", "gb2312;" );request.Headers。Add("Accept-Encoding", "gzip");request.Headers.Add("Accept-Language", "
网页qq抓取什么原理( 01.网页为何要去重?优化培训02.工作原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-25 12:20
01.网页为何要去重?优化培训02.工作原理)
按照搜索引擎网页的去重原理做seo
01.为什么网页需要复制?
对于搜索引擎来说,我们希望呈现给用户的是新颖有吸引力的内容,高质量的文章,而不是一大堆“换汤不换药”;我们正在做SEO优化。在编辑内容的时候,难免会参考其他类似的文章,而这个文章可能已经被很多人采集,造成相关信息的大量重复互联网。
如果一个网站收录很多不好的采集内容,不仅会影响用户体验,还会导致搜索引擎直接屏蔽网站。之后,网站 上的内容就不再是蜘蛛爬虫的难事了。
搜索引擎优化培训
02.搜索引擎的工作原理
搜索引擎是指按照一定的策略从互联网上采集信息,并使用特定的计算机程序,对信息进行组织和处理,为用户提供检索服务,并向用户展示与用户检索相关的相关信息的系统。
搜索引擎的工作原理:
第 1 步:爬网
搜索引擎通过特定模式的软件跟踪到网页的链接,从一个链接爬到另一个链接,就像蜘蛛在蜘蛛网上爬行一样,因此被称为“蜘蛛”或“机器人”。搜索引擎蜘蛛的爬行是有一定的规则进入的,需要遵循一些命令或者文件的内容。
第 2 步:获取存储空间
搜索引擎通过蜘蛛跟踪链接抓取网页,并将抓取到的数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。在抓取页面时,搜索引擎蜘蛛也会对重复内容进行一定的 seo 检测。一旦他们遇到大量抄袭、采集 或抄袭权重极低的网站 内容,很可能会停止爬行。
第三步:预处理
搜索引擎将在各个步骤中对蜘蛛检索到的页面进行预处理。
除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等,我们在搜索结果中也经常看到这些文件类型。但是,搜索引擎无法处理图像、视频和 Flash 等非文本内容,也无法执行脚本和程序。
搜索引擎优化培训
第 4 步:排名
用户在搜索框中输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程直接与用户交互。但是由于搜索引擎的数据量巨大,虽然可以实现每天小更新,seo,但是一般来说,搜索引擎的排名规则是按照每天、每周、每月不同级别的更新。
03.web去重的代表方法
搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合搜索引擎、门户搜索引擎和免费链接列表等。去重工作一般在分词之后、索引之前进行。搜索引擎会从已经从页面中分离出来的关键词中提取一些有代表性的关键词进行计算,然后得到一个网站关键词的特征。
目前有3种代表性的网页去重方法。
1)一种基于聚类的方法。该方法以6763个汉字的网页文本内容为载体。文本中某个组或某个汉字出现的频率构成一个表示该网页的向量,计算该向量的角度来判断是否是同一个网页。
2)排除相同的URL方法。各种元搜索引擎主要使用这种方法来删除重复项。它分析来自不同搜索引擎的网页的 URL。如果网址相同,则认为是同一个网页,可以删除。
3)一种基于特征码的方法。该方法利用标点符号大部分出现在网页正文中的特点,以句号两边各5个汉字作为特征码来唯一地表示网页。
seo优化认为,这三种方法中,第一种和第三种方法大多是根据内容来决定的,所以很多SEO人员会使用伪原创工具修改文章的内容,但大部分时间伪原创工具会改变原文不一致,不利于排名和收录。
还有网站利用搜索引擎的漏洞,比如高权重的网站针对不好的采集,因为高权重的网站蜘蛛会先被抓取,所以这种方式不会有利于一些低权重的网站。
我有几张阿里云幸运券与大家分享。使用优惠券购买或升级阿里云对应产品,更有惊喜!采集你要购买的产品的所有幸运券!快点,都快要抢了。 查看全部
网页qq抓取什么原理(
01.网页为何要去重?优化培训02.工作原理)
按照搜索引擎网页的去重原理做seo
01.为什么网页需要复制?
对于搜索引擎来说,我们希望呈现给用户的是新颖有吸引力的内容,高质量的文章,而不是一大堆“换汤不换药”;我们正在做SEO优化。在编辑内容的时候,难免会参考其他类似的文章,而这个文章可能已经被很多人采集,造成相关信息的大量重复互联网。
如果一个网站收录很多不好的采集内容,不仅会影响用户体验,还会导致搜索引擎直接屏蔽网站。之后,网站 上的内容就不再是蜘蛛爬虫的难事了。
搜索引擎优化培训
02.搜索引擎的工作原理
搜索引擎是指按照一定的策略从互联网上采集信息,并使用特定的计算机程序,对信息进行组织和处理,为用户提供检索服务,并向用户展示与用户检索相关的相关信息的系统。
搜索引擎的工作原理:
第 1 步:爬网
搜索引擎通过特定模式的软件跟踪到网页的链接,从一个链接爬到另一个链接,就像蜘蛛在蜘蛛网上爬行一样,因此被称为“蜘蛛”或“机器人”。搜索引擎蜘蛛的爬行是有一定的规则进入的,需要遵循一些命令或者文件的内容。
第 2 步:获取存储空间
搜索引擎通过蜘蛛跟踪链接抓取网页,并将抓取到的数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。在抓取页面时,搜索引擎蜘蛛也会对重复内容进行一定的 seo 检测。一旦他们遇到大量抄袭、采集 或抄袭权重极低的网站 内容,很可能会停止爬行。
第三步:预处理
搜索引擎将在各个步骤中对蜘蛛检索到的页面进行预处理。
除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等,我们在搜索结果中也经常看到这些文件类型。但是,搜索引擎无法处理图像、视频和 Flash 等非文本内容,也无法执行脚本和程序。
搜索引擎优化培训
第 4 步:排名
用户在搜索框中输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程直接与用户交互。但是由于搜索引擎的数据量巨大,虽然可以实现每天小更新,seo,但是一般来说,搜索引擎的排名规则是按照每天、每周、每月不同级别的更新。
03.web去重的代表方法
搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合搜索引擎、门户搜索引擎和免费链接列表等。去重工作一般在分词之后、索引之前进行。搜索引擎会从已经从页面中分离出来的关键词中提取一些有代表性的关键词进行计算,然后得到一个网站关键词的特征。
目前有3种代表性的网页去重方法。
1)一种基于聚类的方法。该方法以6763个汉字的网页文本内容为载体。文本中某个组或某个汉字出现的频率构成一个表示该网页的向量,计算该向量的角度来判断是否是同一个网页。
2)排除相同的URL方法。各种元搜索引擎主要使用这种方法来删除重复项。它分析来自不同搜索引擎的网页的 URL。如果网址相同,则认为是同一个网页,可以删除。
3)一种基于特征码的方法。该方法利用标点符号大部分出现在网页正文中的特点,以句号两边各5个汉字作为特征码来唯一地表示网页。
seo优化认为,这三种方法中,第一种和第三种方法大多是根据内容来决定的,所以很多SEO人员会使用伪原创工具修改文章的内容,但大部分时间伪原创工具会改变原文不一致,不利于排名和收录。
还有网站利用搜索引擎的漏洞,比如高权重的网站针对不好的采集,因为高权重的网站蜘蛛会先被抓取,所以这种方式不会有利于一些低权重的网站。
我有几张阿里云幸运券与大家分享。使用优惠券购买或升级阿里云对应产品,更有惊喜!采集你要购买的产品的所有幸运券!快点,都快要抢了。
网页qq抓取什么原理(浏览器访问QQ邮箱登录页是怎么做到的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-23 02:21
如果我们在计算机上启动QQ,请使用浏览器访问QQ邮箱登录页面,此页面将提示我们登录QQ。
它是怎么做的?
有些人说这是一个控制权。控制可能能够能够实现,而是会影响用户体验,QQ更先进的思考。
QQ将有一个小型Web服务器,提供类似于IIS的功能,Apache。
Access QQ邮箱登录页面,此页面将访问此Web服务器,因为访问了地址,所以地址是:12 7.0.0. 1(实际上:4301 /,这个域指向12 7.0.0. 1,域名的优势是解决cookie跨域权限问题。),因为这个Web服务器建立,可以根据自己的登录状态发送QQ返回相应的信息。
(为了验证上述信息:您可以使用Chrome访问QQ邮箱登录页面,然后按F12切换到网络选项卡,从列表中查找PT_GET_UINS的开头,您可以看到完整的URL。)
?
显然不是那么简单,那么我的网页也可以访问,而不是用户的登录信息和登录凭据?我收到了这个登录凭据,我可以拿起登录吗?
所以有必要防止他人获得这种隐私,但也可以防止他人获得登录凭据。
所以这是QQ邮箱服务器,例如,您可以执行此操作:
是为了防止数据,所有传输都是HTTPS。上面只是一种方式,它实际上可能是另一种方式,或者更复杂。 查看全部
网页qq抓取什么原理(浏览器访问QQ邮箱登录页是怎么做到的呢?)
如果我们在计算机上启动QQ,请使用浏览器访问QQ邮箱登录页面,此页面将提示我们登录QQ。

它是怎么做的?
有些人说这是一个控制权。控制可能能够能够实现,而是会影响用户体验,QQ更先进的思考。
QQ将有一个小型Web服务器,提供类似于IIS的功能,Apache。
Access QQ邮箱登录页面,此页面将访问此Web服务器,因为访问了地址,所以地址是:12 7.0.0. 1(实际上:4301 /,这个域指向12 7.0.0. 1,域名的优势是解决cookie跨域权限问题。),因为这个Web服务器建立,可以根据自己的登录状态发送QQ返回相应的信息。
(为了验证上述信息:您可以使用Chrome访问QQ邮箱登录页面,然后按F12切换到网络选项卡,从列表中查找PT_GET_UINS的开头,您可以看到完整的URL。)
?
显然不是那么简单,那么我的网页也可以访问,而不是用户的登录信息和登录凭据?我收到了这个登录凭据,我可以拿起登录吗?
所以有必要防止他人获得这种隐私,但也可以防止他人获得登录凭据。
所以这是QQ邮箱服务器,例如,您可以执行此操作:
是为了防止数据,所有传输都是HTTPS。上面只是一种方式,它实际上可能是另一种方式,或者更复杂。
网页qq抓取什么原理(搜索引擎的抓取系统是怎样的?搜索系统有五大策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-22 16:13
从一开始,“走进搜索引擎”到现在,对搜索引擎的原理有一定的了解。 文章也是我对这本书的了解。爬虫爬虫页面是搜索引擎工作的第一步,因此您需要了解搜索引擎原理需要从履带系统开始。熟悉搜索引擎原理,帮助我们对SEO更深刻,SEO工作的帮助也相对较大。搜索引擎的履带系统是什么?
搜索捕获系统有五种主要策略。
一、深度优先级策略
我认为最重要的是两部分:1. @万网的直径,也称为“幅材直径”。它可以很容易理解为:如果在任何两页之间存在路径,则平均点击不超过19次,即从网页到另一个网页。世界宽网的直径,在不同书中给出的万维网的直径不同。万维网的直径可以被理解为:网页爬行; 2.搜索引擎深度优先级策略:这首先选择一个分支,然后考虑在您无法推断的情况下考虑其他分支的策略。但万维网的深度并不想象如此深,而且太深网站结构也不有利于用户体验。因此,网站施工应尝试确保平面结构,以便网页的层次结构较少。但是,对于当前的用户体验,一般网页的层次结构仍然在三层内,这可以方便用户点击。
二、宽宽策略
宽度优先级:指网站的主母版,然后抓住潜水子的头部下方。宽度优先策略需要注意三个点:
(1)重要网页通常更接近种子站点
(2) @ @ @ @万网的不不不不不不不不不不不不不不不不不不不不不不不不不不行
(3)width优先权规则有助于更多履带式合作爬行,首先抓住车站,封闭车站,封闭强烈
三、不到意
不要重复抓取策略意味着爬行动物有录音历史,它不再攀登攀登页面。不要重复抓取策略来解决死循环的问题,即,对于可靠的页面不再抓取,死循环的状况被摧毁。例如,在从主页上爬上爬网程序后,从主页上有一个与主页的链接。此时,履带将不会遵循链接爬上第一页。
四、网优优
网页抓取优先级策略,也称为“页面选择问题”。此时,履带将掌握高度重要的页面,以便您可以在有限资源中处理高可可取重要性的重要性。重要性由链接欢迎,链接重要性和平均链路的三个方面决定。
五、网重重访重访重访重访策略
页面在爬网之前爬上攀升,这些页面随着时间的推移而变化。爬行动物必须刷新这些页面,重新访问攀登的最新信息,以便及时收购这些页面。这是Web Snapshot更新的本质。与此同时,它也解释了为什么爬行动物会定期更新,例如百度爬行动物一般更新周期一般是一天,一周或半月。
其他礼貌问题应该主要关注
疯狂速度政策(合作疯狂策略)
1.提高了掌握单个页面的速度。
2.最大限度地减少不必要的掌握任务。例如,使用rel =“nofollow”以避免抓取一些页面的爬虫。
3.同时增加爬行动物的数量。 查看全部
网页qq抓取什么原理(搜索引擎的抓取系统是怎样的?搜索系统有五大策略)
从一开始,“走进搜索引擎”到现在,对搜索引擎的原理有一定的了解。 文章也是我对这本书的了解。爬虫爬虫页面是搜索引擎工作的第一步,因此您需要了解搜索引擎原理需要从履带系统开始。熟悉搜索引擎原理,帮助我们对SEO更深刻,SEO工作的帮助也相对较大。搜索引擎的履带系统是什么?
搜索捕获系统有五种主要策略。
一、深度优先级策略
我认为最重要的是两部分:1. @万网的直径,也称为“幅材直径”。它可以很容易理解为:如果在任何两页之间存在路径,则平均点击不超过19次,即从网页到另一个网页。世界宽网的直径,在不同书中给出的万维网的直径不同。万维网的直径可以被理解为:网页爬行; 2.搜索引擎深度优先级策略:这首先选择一个分支,然后考虑在您无法推断的情况下考虑其他分支的策略。但万维网的深度并不想象如此深,而且太深网站结构也不有利于用户体验。因此,网站施工应尝试确保平面结构,以便网页的层次结构较少。但是,对于当前的用户体验,一般网页的层次结构仍然在三层内,这可以方便用户点击。
二、宽宽策略
宽度优先级:指网站的主母版,然后抓住潜水子的头部下方。宽度优先策略需要注意三个点:
(1)重要网页通常更接近种子站点
(2) @ @ @ @万网的不不不不不不不不不不不不不不不不不不不不不不不不不不行
(3)width优先权规则有助于更多履带式合作爬行,首先抓住车站,封闭车站,封闭强烈
三、不到意
不要重复抓取策略意味着爬行动物有录音历史,它不再攀登攀登页面。不要重复抓取策略来解决死循环的问题,即,对于可靠的页面不再抓取,死循环的状况被摧毁。例如,在从主页上爬上爬网程序后,从主页上有一个与主页的链接。此时,履带将不会遵循链接爬上第一页。
四、网优优
网页抓取优先级策略,也称为“页面选择问题”。此时,履带将掌握高度重要的页面,以便您可以在有限资源中处理高可可取重要性的重要性。重要性由链接欢迎,链接重要性和平均链路的三个方面决定。
五、网重重访重访重访重访策略
页面在爬网之前爬上攀升,这些页面随着时间的推移而变化。爬行动物必须刷新这些页面,重新访问攀登的最新信息,以便及时收购这些页面。这是Web Snapshot更新的本质。与此同时,它也解释了为什么爬行动物会定期更新,例如百度爬行动物一般更新周期一般是一天,一周或半月。
其他礼貌问题应该主要关注
疯狂速度政策(合作疯狂策略)
1.提高了掌握单个页面的速度。
2.最大限度地减少不必要的掌握任务。例如,使用rel =“nofollow”以避免抓取一些页面的爬虫。
3.同时增加爬行动物的数量。
网页qq抓取什么原理(认识浏览器和服务器的日常操作方法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-22 16:11
本文文章主要介绍“网络爬虫原理简介”。在日常操作中,我相信很多人对网络爬虫原理的引入都有疑问。小编查阅了各种资料,整理出简单易用的操作方法。我希望这将有助于解决“网络爬虫原理简介”的疑问!接下来请跟随小编学习
了解浏览器和服务器
我们应该对浏览器并不陌生。可以说,只要上网的人都知道浏览器。然而,了解浏览器原理的人并不多
作为开发爬虫的小型合作伙伴,您必须了解浏览器的工作原理。这是编写爬行动物的必要工具。没有别的了
在面试过程中,您是否遇到过这样一个宏观而详细的回答问题:
这真是对知识的考验。这只经验丰富的老猿不仅能讲三天三夜,还能从几分钟内提取精华。恐怕你对整个过程略知一二
巧合的是,你对这个问题理解得越透彻,写爬行动物就越有帮助。换句话说,爬行动物是测试综合技能的领域。那么,你准备好迎接这个全面的技能挑战了吗
别再胡说八道了。让我们从回答这个问题开始,了解浏览器和服务器,并了解爬虫程序需要使用哪些知识
如前所述,我们可以讨论这个问题三天三夜,但我们没有那么多时间。我们将跳过一些细节。让我们结合爬行动物讨论一般过程,并将其分为三个部分:
来自浏览器的请求
服务器响应
浏览器收到响应
1.来自浏览器的请求
在浏览器地址栏中输入URL,然后按Enter键。浏览器要求服务器发出一个网页请求,也就是说,告诉服务器我想查看您的一个网页
上面的短句收录了无数的谜团,这让我不得不花一些时间一直在说话。主要是关于:
1)网站有效吗
首先,浏览器应该判断您输入的网址(URL)是否合法有效。对应的URL对于猿类来说并不陌生。以HTTP(s)开头的长字符串,但您知道它也可以以FTP、mailto、file、data和IRC开头吗?以下是其最完整的语法格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
这是更生动地显示和处理图片的方法:
体验:判断URL的合法性
在Python中,urllib.parse可用于执行各种URL操作
In [1]: import urllib.parse
In [2]: url = 'http://dachong:the_password%40 ... 39%3B
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们可以看到,urlparse函数将URL分析为六个部分:
scheme://netloc/path ; 参数?查询#片段
需要注意的是,netloc在URL语法定义中并不等同于主机
2)服务器在哪里
上述URL定义中的主机是Internet上的服务器。它可以是IP地址,但通常我们称之为域名。域名通过DNS绑定到一个(或多个)IP地址。要访问域名,网站浏览器必须首先通过DNS服务器解析域名,以获得真实的IP地址
这里的域名解析通常由操作系统完成,爬虫不需要在意。然而,当你编写一个大型爬虫程序时,比如谷歌和百度搜索引擎,效率变得非常重要,爬虫程序需要维护自己的DNS缓存
老ape经验:大型爬虫需要维护自己的DNS缓存
3)浏览器向服务器发送什么
浏览器获取网站服务器的IP地址后,可以向服务器发送请求。此请求遵循HTTP协议。爬虫需要关心的是HTTP协议的头。以下是访问/wiki/URL时浏览器发送的请求标头:
从图中可以看出一些线索。发送的HTTP请求头类似于字典结构:
路径:访问网站的路径@
Scheme:请求的协议类型,这里是HTTPS
接受:可接受的响应内容类型
接受编码:可接受编码方法的列表
接受语言:可接受响应内容的自然语言列表
缓存控制:指定请求/响应链中所有缓存机制必须遵守的指令
Cookie:服务器先前通过set Cookie发送的超文本传输协议Cookie
这是爬虫非常关心的事情。登录信息在这里
升级执行请求:非标准请求字段,可以忽略
用户代理:浏览器标识
这就是爬行动物所关心的。例如,如果需要获取移动版本页面,则需要将浏览器ID设置为移动浏览器的用户代理
体验:通过设置头与服务器通信
4)服务器返回了什么
如果我们在浏览器地址栏中输入一个网址(而不是文件下载地址),我们很快就会看到一个收录排版文本、图片、视频和其他数据的网页,这是一个内容丰富的网页。然而,当我通过浏览器查看源代码时,我看到一对文本格式的HTML代码
是的,这是一堆代码,但是让浏览器把它呈现成一个漂亮的网页。这对代码收录:
我们想要抓取的信息隐藏在HTML代码中,我们可以通过解析提取我们想要的内容。如果HTML代码中没有我们想要的数据,但我们在网页中看到了它,那么浏览器就通过Ajax请求异步加载(秘密下载)该部分数据
此时,我们需要观察浏览器的加载过程,找出哪个Ajax请求加载了我们需要的数据
现在,“网络爬虫原理导论”的研究已经结束。我希望我们能解决你的疑问。理论和实践的结合能更好地帮助你学习。去试试吧!如果您想继续学习更多相关知识,请继续关注伊苏云网站,小编将继续努力为您带来更实用的文章@ 查看全部
网页qq抓取什么原理(认识浏览器和服务器的日常操作方法(一))
本文文章主要介绍“网络爬虫原理简介”。在日常操作中,我相信很多人对网络爬虫原理的引入都有疑问。小编查阅了各种资料,整理出简单易用的操作方法。我希望这将有助于解决“网络爬虫原理简介”的疑问!接下来请跟随小编学习
了解浏览器和服务器
我们应该对浏览器并不陌生。可以说,只要上网的人都知道浏览器。然而,了解浏览器原理的人并不多
作为开发爬虫的小型合作伙伴,您必须了解浏览器的工作原理。这是编写爬行动物的必要工具。没有别的了
在面试过程中,您是否遇到过这样一个宏观而详细的回答问题:
这真是对知识的考验。这只经验丰富的老猿不仅能讲三天三夜,还能从几分钟内提取精华。恐怕你对整个过程略知一二
巧合的是,你对这个问题理解得越透彻,写爬行动物就越有帮助。换句话说,爬行动物是测试综合技能的领域。那么,你准备好迎接这个全面的技能挑战了吗
别再胡说八道了。让我们从回答这个问题开始,了解浏览器和服务器,并了解爬虫程序需要使用哪些知识
如前所述,我们可以讨论这个问题三天三夜,但我们没有那么多时间。我们将跳过一些细节。让我们结合爬行动物讨论一般过程,并将其分为三个部分:
来自浏览器的请求
服务器响应
浏览器收到响应
1.来自浏览器的请求
在浏览器地址栏中输入URL,然后按Enter键。浏览器要求服务器发出一个网页请求,也就是说,告诉服务器我想查看您的一个网页
上面的短句收录了无数的谜团,这让我不得不花一些时间一直在说话。主要是关于:
1)网站有效吗
首先,浏览器应该判断您输入的网址(URL)是否合法有效。对应的URL对于猿类来说并不陌生。以HTTP(s)开头的长字符串,但您知道它也可以以FTP、mailto、file、data和IRC开头吗?以下是其最完整的语法格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
这是更生动地显示和处理图片的方法:

体验:判断URL的合法性
在Python中,urllib.parse可用于执行各种URL操作
In [1]: import urllib.parse
In [2]: url = 'the_password@www.yuanrenxue.com/user/info?page=2'" rel="nofollow" target="_blank">http://dachong:the_password%40 ... 39%3B
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们可以看到,urlparse函数将URL分析为六个部分:
scheme://netloc/path ; 参数?查询#片段
需要注意的是,netloc在URL语法定义中并不等同于主机
2)服务器在哪里
上述URL定义中的主机是Internet上的服务器。它可以是IP地址,但通常我们称之为域名。域名通过DNS绑定到一个(或多个)IP地址。要访问域名,网站浏览器必须首先通过DNS服务器解析域名,以获得真实的IP地址
这里的域名解析通常由操作系统完成,爬虫不需要在意。然而,当你编写一个大型爬虫程序时,比如谷歌和百度搜索引擎,效率变得非常重要,爬虫程序需要维护自己的DNS缓存
老ape经验:大型爬虫需要维护自己的DNS缓存
3)浏览器向服务器发送什么
浏览器获取网站服务器的IP地址后,可以向服务器发送请求。此请求遵循HTTP协议。爬虫需要关心的是HTTP协议的头。以下是访问/wiki/URL时浏览器发送的请求标头:

从图中可以看出一些线索。发送的HTTP请求头类似于字典结构:
路径:访问网站的路径@
Scheme:请求的协议类型,这里是HTTPS
接受:可接受的响应内容类型
接受编码:可接受编码方法的列表
接受语言:可接受响应内容的自然语言列表
缓存控制:指定请求/响应链中所有缓存机制必须遵守的指令
Cookie:服务器先前通过set Cookie发送的超文本传输协议Cookie
这是爬虫非常关心的事情。登录信息在这里
升级执行请求:非标准请求字段,可以忽略
用户代理:浏览器标识
这就是爬行动物所关心的。例如,如果需要获取移动版本页面,则需要将浏览器ID设置为移动浏览器的用户代理
体验:通过设置头与服务器通信
4)服务器返回了什么
如果我们在浏览器地址栏中输入一个网址(而不是文件下载地址),我们很快就会看到一个收录排版文本、图片、视频和其他数据的网页,这是一个内容丰富的网页。然而,当我通过浏览器查看源代码时,我看到一对文本格式的HTML代码
是的,这是一堆代码,但是让浏览器把它呈现成一个漂亮的网页。这对代码收录:
我们想要抓取的信息隐藏在HTML代码中,我们可以通过解析提取我们想要的内容。如果HTML代码中没有我们想要的数据,但我们在网页中看到了它,那么浏览器就通过Ajax请求异步加载(秘密下载)该部分数据
此时,我们需要观察浏览器的加载过程,找出哪个Ajax请求加载了我们需要的数据
现在,“网络爬虫原理导论”的研究已经结束。我希望我们能解决你的疑问。理论和实践的结合能更好地帮助你学习。去试试吧!如果您想继续学习更多相关知识,请继续关注伊苏云网站,小编将继续努力为您带来更实用的文章@
网页qq抓取什么原理(网络爬虫常见的抓取策略:1.深度优先遍历策略深度 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-09-17 14:13
)
有一个特殊的爬虫网站:网络爬虫的基本原理
网络爬虫是搜索引擎捕获系统的重要组成部分。爬虫的主要目的是将Internet上的网页下载到本地,以形成网络内容的镜像或备份。本博客主要对爬虫和爬虫系统进行简要概述
一、web爬虫的基本结构和工作流程
网络爬虫的总体框架如图所示:
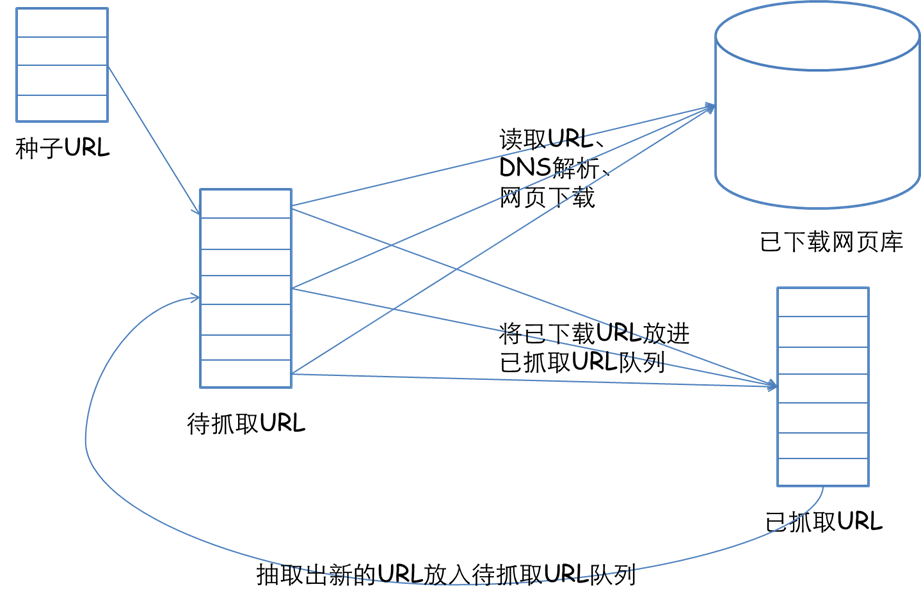
网络爬虫的基本工作流程如下:
二、从爬虫的角度划分互联网
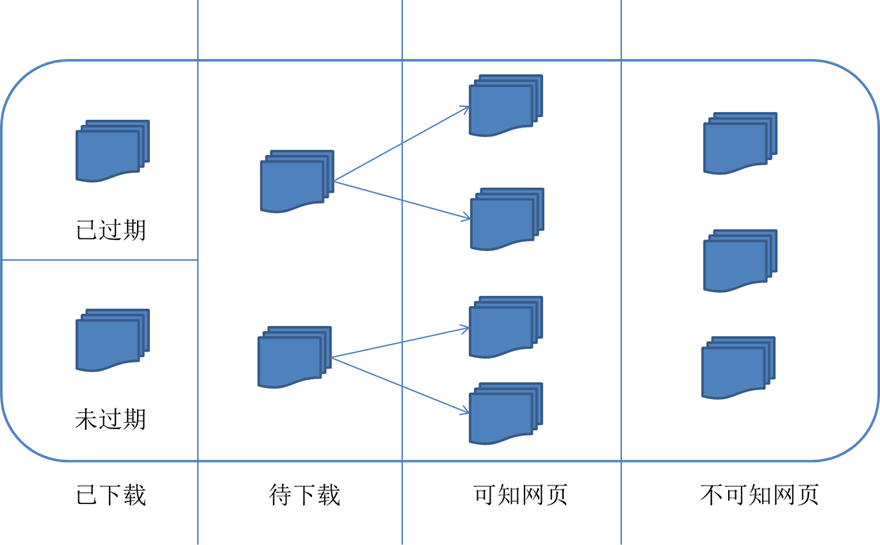
相应地,互联网的所有页面可分为五个部分:
三、crawling策略
在爬虫系统中,要获取的URL队列是一个非常重要的部分。URL队列中要获取的URL的排列顺序也是一个非常重要的问题,因为它涉及先获取页面,然后获取哪个页面。确定这些URL顺序的方法称为爬网策略。以下重点介绍几种常见的捕获策略:
1.深度优先遍历策略
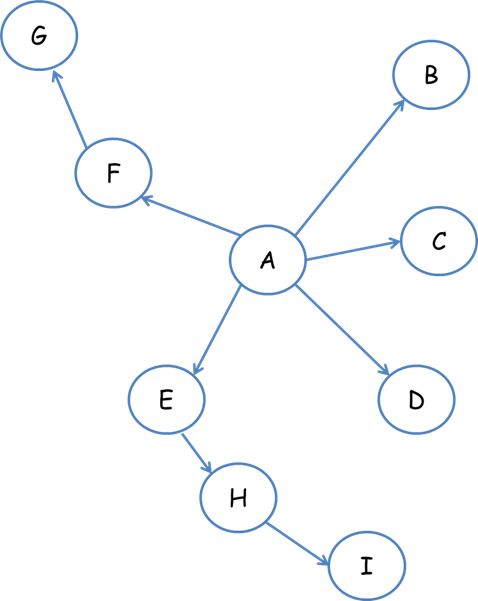
深度优先遍历策略意味着网络爬虫将从起始页开始,逐个跟踪链接。处理完这一行后,它将转到下一个起始页并继续跟踪链接。以下图为例:
遍历路径:a-f-g e-h-i B C D
2.width优先遍历策略
宽度优先遍历策略的基本思想是将新下载的网页中的链接直接插入要爬网的URL队列的末尾。也就是说,网络爬虫将首先抓取起始页面中的所有链接页面,然后选择其中一个链接页面以继续抓取此页面中的所有链接页面。以上图为例:
遍历路径:a-b-c-d-e-f g h I
3.反向链路计数策略
反向链接数是指其他网页指向某个网页的链接数。反向链接的数量表示其他人推荐网页内容的程度。因此,大多数情况下,搜索引擎的爬行系统都会利用这个指标来评价网页的重要性,从而确定不同网页的爬行顺序
在现实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全等着他或我。因此,搜索引擎经常考虑可靠的反向链接数量
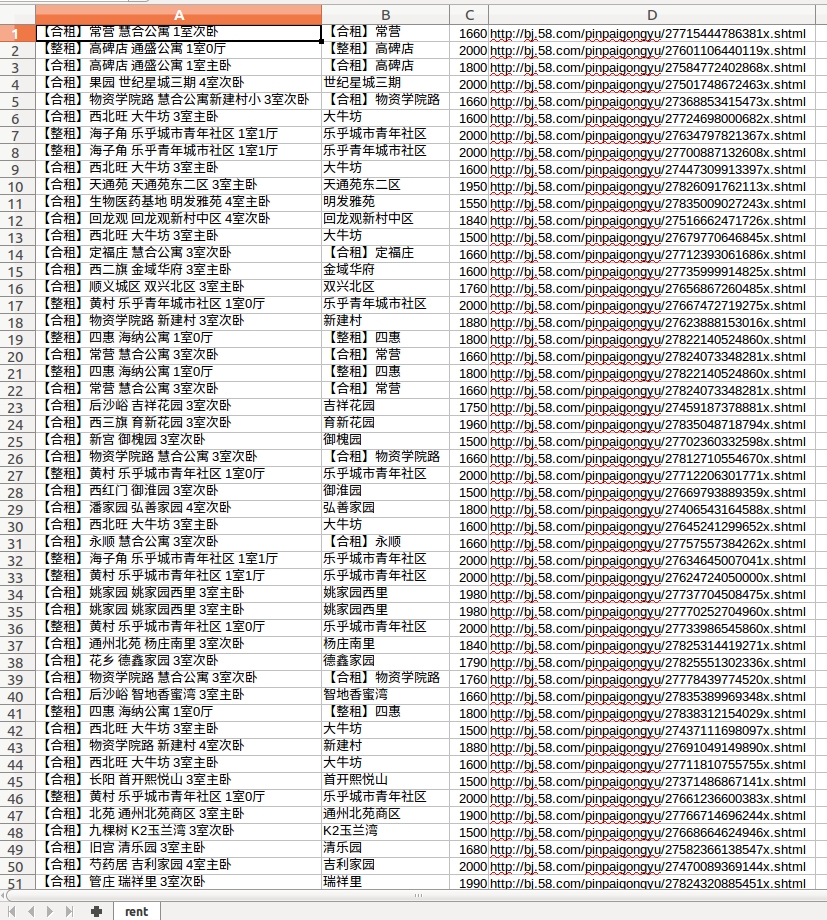
一个简单的爬虫程序示例在同一个城市中爬行58所房屋,包括介绍、房屋类型、房价和其他信息,然后将它们写入rent.csv文件以形成一个表
#!/usr/bin/python
#coding=utf-8
from bs4 import BeautifulSoup
from urlparse import urljoin
import requests
import csv
# 选取价格在1500-2000之间的房子信息
url = 'http://bj.58.com/pinpaigongyu/pn/{page}/?minprice=1500_2000'
page = 0
csv_file = open('rent.csv','wb')
csv_writer = csv.writer(csv_file,delimiter = ',')
while True:
page += 1
print "fetch: ",url.format(page = page)
response = requests.get(url.format(page = page))
html = BeautifulSoup(response.text)
house_list = html.select('.list > li')
if not house_list:
break
for house in house_list:
house_title = house.select("h2")[0].string.encode("utf-8")
house_url = urljoin(url,house.select("a")[0]["href"])
house_info_list = house_title.split()
if "公寓" in house_info_list[1] or "青年公寓" in house_info_list[1]:
house_location = house_info_list[0]
else:
house_location = house_info_list[1]
house_money = house.select(".money")[0].select("b")[0].string.encode("utf-8")
csv_writer.writerow([house_title,house_location,house_money,house_url])
csv_file.close()
生成的rent.csv表的呈现如下所示:
查看全部
网页qq抓取什么原理(网络爬虫常见的抓取策略:1.深度优先遍历策略深度
)
有一个特殊的爬虫网站:网络爬虫的基本原理
网络爬虫是搜索引擎捕获系统的重要组成部分。爬虫的主要目的是将Internet上的网页下载到本地,以形成网络内容的镜像或备份。本博客主要对爬虫和爬虫系统进行简要概述
一、web爬虫的基本结构和工作流程
网络爬虫的总体框架如图所示:
网络爬虫的基本工作流程如下:
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可分为五个部分:
三、crawling策略
在爬虫系统中,要获取的URL队列是一个非常重要的部分。URL队列中要获取的URL的排列顺序也是一个非常重要的问题,因为它涉及先获取页面,然后获取哪个页面。确定这些URL顺序的方法称为爬网策略。以下重点介绍几种常见的捕获策略:
1.深度优先遍历策略
深度优先遍历策略意味着网络爬虫将从起始页开始,逐个跟踪链接。处理完这一行后,它将转到下一个起始页并继续跟踪链接。以下图为例:
遍历路径:a-f-g e-h-i B C D
2.width优先遍历策略
宽度优先遍历策略的基本思想是将新下载的网页中的链接直接插入要爬网的URL队列的末尾。也就是说,网络爬虫将首先抓取起始页面中的所有链接页面,然后选择其中一个链接页面以继续抓取此页面中的所有链接页面。以上图为例:
遍历路径:a-b-c-d-e-f g h I
3.反向链路计数策略
反向链接数是指其他网页指向某个网页的链接数。反向链接的数量表示其他人推荐网页内容的程度。因此,大多数情况下,搜索引擎的爬行系统都会利用这个指标来评价网页的重要性,从而确定不同网页的爬行顺序
在现实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全等着他或我。因此,搜索引擎经常考虑可靠的反向链接数量
一个简单的爬虫程序示例在同一个城市中爬行58所房屋,包括介绍、房屋类型、房价和其他信息,然后将它们写入rent.csv文件以形成一个表
#!/usr/bin/python
#coding=utf-8
from bs4 import BeautifulSoup
from urlparse import urljoin
import requests
import csv
# 选取价格在1500-2000之间的房子信息
url = 'http://bj.58.com/pinpaigongyu/pn/{page}/?minprice=1500_2000'
page = 0
csv_file = open('rent.csv','wb')
csv_writer = csv.writer(csv_file,delimiter = ',')
while True:
page += 1
print "fetch: ",url.format(page = page)
response = requests.get(url.format(page = page))
html = BeautifulSoup(response.text)
house_list = html.select('.list > li')
if not house_list:
break
for house in house_list:
house_title = house.select("h2")[0].string.encode("utf-8")
house_url = urljoin(url,house.select("a")[0]["href"])
house_info_list = house_title.split()
if "公寓" in house_info_list[1] or "青年公寓" in house_info_list[1]:
house_location = house_info_list[0]
else:
house_location = house_info_list[1]
house_money = house.select(".money")[0].select("b")[0].string.encode("utf-8")
csv_writer.writerow([house_title,house_location,house_money,house_url])
csv_file.close()
生成的rent.csv表的呈现如下所示:
网页qq抓取什么原理(百度抓取器会和网站首页的交互设计)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-12 10:16
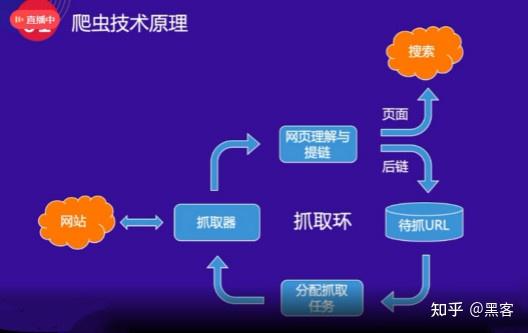
首先,百度的爬虫会与网站的主页进行交互。拿到网站首页后,会理解页面,理解收录(类型,值计算),其次会把网站首页的所有超链接都提取出来。
如上图所示,首页上的超链接称为“post-links”。下一轮爬行时,爬虫会继续与这些超链接页面进行交互,并获取页面进行提炼。一层一层的不断抓取,构成了一个抓取循环。
一、Grab-Friendly Optimization1、URL 规范
任何资源都是通过 URL 获取的。 URL是相对于网站的门牌号,所以URL规划很重要。尤其是在上图所示的“待抓取网址”环境下,爬虫在首页的时候,不知道网址长什么样子。
优秀网址的特点是主流、简单,所以你可能不想做出一些让人看起来很直观的非主流风格。
优秀网址示例:
如上图,第一个是百度知道的链接。整个链接分为三个部分。第一部分是网站的站点,第二部分是资源类型,第三部分是资源ID。这种网址很简单,爬虫看起来很不错。
如上图,第三篇文章比百度多了一段。首先,第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录。最后一段是网站的内容 ID。像这样的网址也符合标准。
不友好网址示例:
如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种网址含有字符,而且这个网址中含有文章的标题,导致网址有偏差。与简单的 URL 相比,较长的相对较长的 URL 没有优势。百度站长平台规则明确规定网址不能超过256字节。我个人建议URL长度控制在100字节以内,100个字符足以显示URL的资源。
如上图所示,此网址收录统计参数,可能会造成重复抓取,浪费网站权限。因此,可以不使用参数。如果必须使用参数,也可以保留必要的参数。参数字符实际上是可能的。使用常规连接符,例如“?”和“&”,以避免非主流连接器。
2、合理发现链接
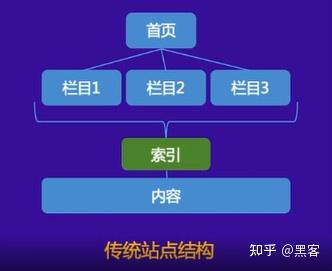
爬虫从首页开始一层一层的爬取,所以需要做好首页和资源页的URL关系。这个爬虫爬行比较省力。
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大部分移动站都不太关注发现链接关系,所以爬虫无法抓取到内容页面。
如上图所示,这两个站点是常见的移动网站构建方式。从链接发现的角度来看,这两类网站并不友好。
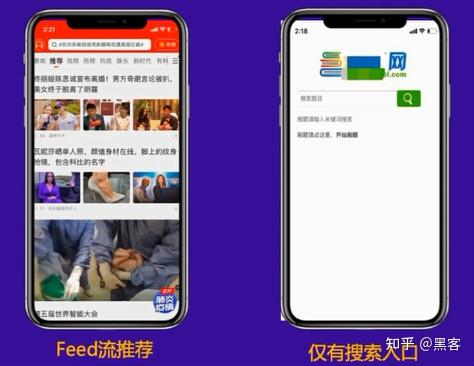
Feed 流推荐:
大多数进行流式传输的网站在后端都有大量数据。用户不断刷新时会出现新的内容,但无论刷新多少次,可能只能刷新到1%左右的内容。一个爬虫相当于一个用户。爬虫不可能用这种方式爬取网站的所有内容,所以会导致部分页面被爬取。即使您有 100 万个内容,您也可能只能对其进行抓取。到 1-2 百万。
仅搜索条目:
如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫不能输入关键词再爬,所以爬虫只能爬到首页后,没有反向链接,自然爬取和收录不会很理想。
解决方案:
索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎可以通过索引页抓取你的网站最新资源,并且新发布的资源应该实时在索引页中。同步,很多纯静态网页,内容更新了,但是首页(索引页)不出来。这会导致搜索引擎甚至无法通过索引页面抓取最新的资源。第三点是后链(latest文章的URL)需要在源码中直接暴露出来,方便搜索引擎抓取。最后,索引页不要越多越好。几个高质量的索引页就足够了,比如长城。基本上,只有主页用于索引。页。
最后给大家一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新的资源。这里有两点需要注意。 .
问:提交的资源越多越好吗?
A:收录 效果的核心始终是内容的质量。如果提交大量低质量、泛滥的资源,将导致惩罚性打击。
问:为什么你提交了普通的收录却没有抓住?
A:资源提交只能加速资源发现,不能保证短期抓取。当然,百度表示会不断优化算法,让优质内容更快被抓取。
3、访问友好
抓取器必须与网站进行交互,并且必须保证网站的稳定性,这样抓取器才能正常抓取。那么访问友好性主要包括以下几个方面。
访问速度优化:
建议加载时间控制在2S以内,这样无论是用户还是爬虫,打开速度快的网站会更受青睐,二是避免不必要的跳转。虽然这是一小部分,但是网站里面还是有很多层次的跳转,所以对于爬虫来说,很可能会在多层次跳转的同时断开。一般是把不带www的域名重定向到带WWW的域名,然后带WWW的域名需要重定向到https,最后更换新站。在这种情况下,将有三个或四个级别的重定向。如果有类似网站的修改,建议直接跳转到新域名。 查看全部
网页qq抓取什么原理(百度抓取器会和网站首页的交互设计)
首先,百度的爬虫会与网站的主页进行交互。拿到网站首页后,会理解页面,理解收录(类型,值计算),其次会把网站首页的所有超链接都提取出来。
如上图所示,首页上的超链接称为“post-links”。下一轮爬行时,爬虫会继续与这些超链接页面进行交互,并获取页面进行提炼。一层一层的不断抓取,构成了一个抓取循环。
一、Grab-Friendly Optimization1、URL 规范
任何资源都是通过 URL 获取的。 URL是相对于网站的门牌号,所以URL规划很重要。尤其是在上图所示的“待抓取网址”环境下,爬虫在首页的时候,不知道网址长什么样子。
优秀网址的特点是主流、简单,所以你可能不想做出一些让人看起来很直观的非主流风格。
优秀网址示例:

如上图,第一个是百度知道的链接。整个链接分为三个部分。第一部分是网站的站点,第二部分是资源类型,第三部分是资源ID。这种网址很简单,爬虫看起来很不错。
如上图,第三篇文章比百度多了一段。首先,第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录。最后一段是网站的内容 ID。像这样的网址也符合标准。
不友好网址示例:

如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种网址含有字符,而且这个网址中含有文章的标题,导致网址有偏差。与简单的 URL 相比,较长的相对较长的 URL 没有优势。百度站长平台规则明确规定网址不能超过256字节。我个人建议URL长度控制在100字节以内,100个字符足以显示URL的资源。

如上图所示,此网址收录统计参数,可能会造成重复抓取,浪费网站权限。因此,可以不使用参数。如果必须使用参数,也可以保留必要的参数。参数字符实际上是可能的。使用常规连接符,例如“?”和“&”,以避免非主流连接器。
2、合理发现链接
爬虫从首页开始一层一层的爬取,所以需要做好首页和资源页的URL关系。这个爬虫爬行比较省力。
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大部分移动站都不太关注发现链接关系,所以爬虫无法抓取到内容页面。
如上图所示,这两个站点是常见的移动网站构建方式。从链接发现的角度来看,这两类网站并不友好。
Feed 流推荐:
大多数进行流式传输的网站在后端都有大量数据。用户不断刷新时会出现新的内容,但无论刷新多少次,可能只能刷新到1%左右的内容。一个爬虫相当于一个用户。爬虫不可能用这种方式爬取网站的所有内容,所以会导致部分页面被爬取。即使您有 100 万个内容,您也可能只能对其进行抓取。到 1-2 百万。
仅搜索条目:
如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫不能输入关键词再爬,所以爬虫只能爬到首页后,没有反向链接,自然爬取和收录不会很理想。
解决方案:
索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎可以通过索引页抓取你的网站最新资源,并且新发布的资源应该实时在索引页中。同步,很多纯静态网页,内容更新了,但是首页(索引页)不出来。这会导致搜索引擎甚至无法通过索引页面抓取最新的资源。第三点是后链(latest文章的URL)需要在源码中直接暴露出来,方便搜索引擎抓取。最后,索引页不要越多越好。几个高质量的索引页就足够了,比如长城。基本上,只有主页用于索引。页。
最后给大家一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新的资源。这里有两点需要注意。 .
问:提交的资源越多越好吗?
A:收录 效果的核心始终是内容的质量。如果提交大量低质量、泛滥的资源,将导致惩罚性打击。
问:为什么你提交了普通的收录却没有抓住?
A:资源提交只能加速资源发现,不能保证短期抓取。当然,百度表示会不断优化算法,让优质内容更快被抓取。
3、访问友好
抓取器必须与网站进行交互,并且必须保证网站的稳定性,这样抓取器才能正常抓取。那么访问友好性主要包括以下几个方面。
访问速度优化:
建议加载时间控制在2S以内,这样无论是用户还是爬虫,打开速度快的网站会更受青睐,二是避免不必要的跳转。虽然这是一小部分,但是网站里面还是有很多层次的跳转,所以对于爬虫来说,很可能会在多层次跳转的同时断开。一般是把不带www的域名重定向到带WWW的域名,然后带WWW的域名需要重定向到https,最后更换新站。在这种情况下,将有三个或四个级别的重定向。如果有类似网站的修改,建议直接跳转到新域名。
网页qq抓取什么原理(搜索引擎的工作原理是什么?如何了解搜索引擎的原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-25 17:56
[摘要] 我们都希望自己的网站在百度、360、搜狗等搜索引擎上有一定的排名。为了从搜索引擎获得更多的免费流量,需要从网站页面、网站结构等各个角度进行合理规划,使网站相关搜索引擎中显示的信息对用户是有效的。它更有吸引力。那么我们就要从了解搜索引擎的工作原理开始。
我们都希望自己的网站在百度、360、搜狗等搜索引擎上有一定的排名。为了从搜索引擎获得更多的免费流量,需要从网站页面、网站结构等各个角度进行合理规划,使网站相关显示在搜索引擎中的信息将对用户有效。它更有吸引力。那么我们就要从了解搜索引擎的工作原理开始。
<p>一、 抓取页面读取网页内容,找到网页中其他链接的地址,然后通过这些链接地址找到下一个网页,这样循环下去,直到这个 查看全部
网页qq抓取什么原理(搜索引擎的工作原理是什么?如何了解搜索引擎的原理)
[摘要] 我们都希望自己的网站在百度、360、搜狗等搜索引擎上有一定的排名。为了从搜索引擎获得更多的免费流量,需要从网站页面、网站结构等各个角度进行合理规划,使网站相关搜索引擎中显示的信息对用户是有效的。它更有吸引力。那么我们就要从了解搜索引擎的工作原理开始。
我们都希望自己的网站在百度、360、搜狗等搜索引擎上有一定的排名。为了从搜索引擎获得更多的免费流量,需要从网站页面、网站结构等各个角度进行合理规划,使网站相关显示在搜索引擎中的信息将对用户有效。它更有吸引力。那么我们就要从了解搜索引擎的工作原理开始。
<p>一、 抓取页面读取网页内容,找到网页中其他链接的地址,然后通过这些链接地址找到下一个网页,这样循环下去,直到这个
网页qq抓取什么原理(网页数据提取原理及其设计开发(龙泉第二小学,四川成都))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-25 13:00
题目:Web数据抽取原理及其设计开发(龙泉二小,范学政,四川,成都)并提出了基于网络爬虫的网页搜索和页面提取功能和设计要求。网络爬虫是一个非常强大的程序,可以自动提取网页。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。它通过请求站点上的 HTML 文档来访问站点。它遍历Web空间,不断地从一个站点移动到另一个站点,自动建立索引,并将其添加到网页数据库中。当网络爬虫进入超文本时,它利用HTML语言的标记结构来搜索信息并获取指向其他超文本的URL地址,可以在不依赖用户干预的情况下实现网络上的自动“爬行”和搜索。本文在分析基于爬虫的网页搜索系统的结构和工作原理的基础上,研究了网页抓取和解析的策略和算法,并使用C#实现了一个网页提取程序并分析了其运行结果。关键词:爬虫;页面搜索;数据提取;HTML分析;摘要 本文讨论了搜索引擎的应用,搜索了网络蜘蛛在搜索引擎中的重要性和功能,并提出了其功能和设计的需求。网络爬虫是一个强大的自动提取网络应用程序;它来自万维网搜索引擎上的下载页面,是搜索引擎中的重要组成部分。它通过请求站点访问站点 HTML 文件来完成此操作。它穿越了网络空间, 1 网页数据提取现状分析 在互联网普及之前,人们在查找资料时首先想到的就是拥有大量书籍的图书馆。现在很多人选择了一种更方便、快捷、全面、准确的方式——互联网。如果说互联网是知识宝库,那么网络搜索就是打开知识宝库的钥匙。搜索引擎是1995年以来随着WEB信息的迅速增加而逐渐发展起来的一项技术。它是一种用于帮助互联网用户查询信息的搜索工具。搜索引擎利用一定的策略来采集和发现互联网上的信息,理解、提取、组织和处理信息,为用户提供搜索服务,从而达到信息导航的目的。目前,搜索引擎已成为网民关注的焦点,也成为计算机界和学术界的研究开发对象。目前比较流行的搜索引擎有谷歌、雅虎、Infoseek、百度等,出于商业秘密的考虑,目前各搜索引擎所使用的爬虫系统的技术内幕一般不公开,现有文献为限于总结介绍。并为用户提供搜索服务,从而达到信息导航的目的。目前,搜索引擎已成为网民关注的焦点,也成为计算机界和学术界的研究开发对象。目前比较流行的搜索引擎有谷歌、雅虎、Infoseek、百度等,出于商业秘密的考虑,目前各搜索引擎所使用的爬虫系统的技术内幕一般不公开,现有文献为限于总结介绍。并为用户提供搜索服务,从而达到信息导航的目的。目前,搜索引擎已成为网民关注的焦点,也成为计算机界和学术界的研究开发对象。目前比较流行的搜索引擎有谷歌、雅虎、Infoseek、百度等,出于商业秘密的考虑,目前各搜索引擎所使用的爬虫系统的技术内幕一般不公开,现有文献为限于总结介绍。
各大搜索引擎提供商都基于网络爬虫的原理来检索网页、抓取网页、分析网页、采集数据。随着Web信息资源的呈指数级增长和Web信息资源的动态变化,传统搜索引擎提供的信息提取服务已不能满足人们日益增长的个性化服务需求,面临着巨大的挑战。访问Web和提高搜索效率的策略已成为近年来专业搜索引擎网页数据提取研究的主要问题之一。1.2 学科发展背景基本上是三种类型的搜索引擎。一个组件:(1)网上采集信息网页< @采集系统:网页采集系统主要利用了一类采集信息,作用于互联网“网络蜘蛛”。“网络蜘蛛”实际上是一些基于网络的程序,它们使用主页中的超文本链接来遍历网络。使用可以自动从互联网上采集网页的“网络蜘蛛”程序,自动上网并跟随抓取任何网页中的所有网址到其他网页,重复此过程,将所有已被抓取的网页采集到网页数据库中. (2)索引采集的信息,建立索引库索引处理系统:索引处理系统对采集的网页进行分析,提取相关网页信息(包括网页所在的网址、编码类型等) , 关键词, 关键词 收录在页面内容中的位置、生成时间、大小、与其他网页的链接关系等),根据一定的相关性算法进行大量复杂的计算,并且获取每个网页与页面内容的相关性(或重要性)以及超链接中的每个关键词,然后创建索引并存储在网页索引数据库中。索引数据库可以使用通用的大型数据库,如Oracle、Sybase等,也可以定义存储的文件格式。为了保证索引库中的信息与Web内容同步,索引库必须定期更新,更新频率决定了搜索结果的及时性。索引数据库的更新是通过启动“网络蜘蛛”来实现的 再次搜索网络空间。(3)完成用户提交的查询请求的网页检索器:网页检索器一般是运行在Web服务器上的服务器程序,它首先接收用户提交的查询条件,搜索索引数据库根据查询条件,将查询结果返回给用户,当用户使用搜索引擎查找信息时,网页检索器接收用户提交的关键词,搜索系统程序查找所有相关网页网页索引数据库中匹配关键词的页面,一些搜索引擎系统会综合相关信息和网页级别,形成相关度值,然后进行排序,相关度越高,排名越高。最后,页面生成系统将搜索结果的链接地址和页面的内容摘要整理后返回给用户。典型的搜索引擎系统如谷歌采用这种策略。信息的快速增长使搜索引擎成为人们寻找信息的首选工具。谷歌、百度、中国搜索等大型搜索引擎一直是讨论的话题。国外搜索引擎技术的研究比国内早了近十年。从最早的Archie到后来的Excite,以及ahvista、overture、google等搜索引擎的出现,搜索引擎的发展已有十多年的历史。国内对搜索引擎的研究始于上世纪末本世纪初。在许多领域,国外的产品和技术一统天下,尤其是某项技术在国外研究多年,才在中国起步。例如操作系统、文字处理软件、浏览器等,但搜索引擎除外。国外搜索引擎技术虽然研究了很长时间,但中国还是涌现出了优秀的搜索引擎,比如百度、中搜。随着搜索引擎技术的成熟,它将成为获取信息和掌握知识的利器。但是,现有搜索引擎对用户的查询需求仅限于关键词的简单逻辑组合。搜索结果看重返回的数量而不是质量,结果文档的组织和分类也缺乏。国外的一项调查结果显示,约有71%的人对搜索结果有不同程度的失望。因此,如何提高搜索引擎的智能化,如何根据知识应用的需要组织信息,使互联网既能提供信息服务,又能为用户提供知识服务,将成为互联网研究的方向。计算机行业和学术界1.3 网页提取的工作原理。网络爬虫是网页检索的核心部分。它的名字来自蜘蛛的自由翻译。如何提高搜索引擎的智能化,如何根据知识应用的需要组织信息,使互联网既能提供信息服务,又能为用户提供知识服务,将成为计算机行业研究的方向。和学术界1.3 网页提取的工作原理。网络爬虫是网页检索的核心部分。它的名字来自蜘蛛的自由翻译。如何提高搜索引擎的智能化,如何根据知识应用的需要组织信息,使互联网既能提供信息服务,又能为用户提供知识服务,将成为计算机行业研究的方向。和学术界1.3 网页提取的工作原理。网络爬虫是网页检索的核心部分。它的名字来自蜘蛛的自由翻译。
系统开发工具和平台2.1关于c#语言 C#语言是由于2001年引入的一种新的编程语言。它是一种适用于分布式计算环境的跨平台、纯面向对象的语言。C#语言及其扩展正逐渐成为互联网应用的规范,掀起了自PC以来的又一次技术革命。一般认为,B语言导致了C语言的诞生,C语言演变成了C++语言,而C#语言显然具有C++语言的特点。C#总是和C++联系在一起,而C++是从C语言派生出来的,所以C#语言继承了这两种语言的大部分特性。C#的语法继承自C,C#的很多面向对象的特性都受到C++的影响。实际上,C# 中的一些自定义功能源自或可以追溯到这些前辈语言。略有不同的是C#语言是完全面向对象的,消除了两者的缺点。C#语言的诞生与近30年来计算机语言的不断完善和发展息息相关。C#由Anders Hejlsberg开发,它是第一种面向组件的编程语言,其源代码会被编译成msil然后运行。它借鉴了Delphi的一个特性,直接与COM组件对象模型集成,并增加了许多新的功能和语法。它是微软.NET网络框架的主角。1998 年 12 月,微软推出了全新的语言项目 COOL,
2000年2月,微软正式将COOL语言更名为C#,并于2000年7月发布了C#语言的第一个预览版。自2000年正式推出以来,C#语言以其独特的优势迅速发展。经过短短的8、 9年,它已经成为迄今为止最优秀的面向对象语言。C#从最初的语言逐渐形成了一个产业。基于C#语言的.NET架构已经成为微软J2EE平台的有力竞争者。一开始,C# 语言的最初发布不亚于一场革命,但它并没有标志着 C# 快速创新时代的结束。在.NET 2.0 发布后不久,.NET 的设计者就已经制定了.NET 3.5 和.NET 4.0 版本。C#作为目前广泛使用的面向对象编程语言,具有很多特点。如果将其与许多其他编程语言进行比较,您会发现这些特性正是 C# 语言如此受欢迎的原因。尽管C#在某些方面(比如资源消耗)存在一些不足,但这并不影响C#作为最好的面向对象编程语言的地位。C#是一种广泛使用的网络编程语言,是一种新的计算概念。网络环境下的编程语言最需要解决的就是可移植性和安全性问题。以字节为单位进行编码,可以使程序不受运行平台和环境的限制。C#语言还提供了丰富的类库,
C#作为一种高级编程语言,不仅面向对象、编写简单、远离机器结构、分布式、健壮、可移植、安全,而且提供了高解释和执行的并发机制。2.2 集成开发环境介绍 Visual Studio 2010 微软首次发布Visual Basic时,通过降低其复杂性,使得Windows软件开发得到广泛应用。使用 Visual Basic 6.0,Microsoft 使数百万开发人员能够快速开发客户端/服务器应用程序 [14]。最近,Microsoft 使用 Visual Studio.NET 为开发人员提供了工具和技术来轻松开发分布式应用程序。随着 Visual Studio 2010 集成开发环境的发布,Microsoft 一直处于响应日益复杂的应用程序和设计、开发和部署过程中所需的生命周期问题的最前沿。它根据开发者的个人需求自动配置开发工具的界面设置,提高软件开发者的开发体验。丰富了.NET Framework类库,使应用开发者能够从容应对日常开发中的各种问题,从而提高开发效率。实现了与微软团队开发中使用的产品无缝集成,如:VSS、Office、SQL Server等,丰富了开发者的解决方案,使开发者能够使用各种产品进行开发。
它提供了一套新的工具和功能,如ShareOpint、工作流等,使开发者能够跟上技术发展,满足日益复杂的应用开发需求。三、系统总体设计3.1系统总体结构3.2 搜索抽取策略 Web搜索往往采用一定的搜索策略。一个是广度或深度优先搜索策略:搜索引擎使用的第一代网络爬虫主要基于传统的图算法,例如广度优先或深度优先算法来索引整个Web,以及一个核心的URL set 被用作种子集合,这个算法递归地跟踪到其他页面的超链接,通常不管页面的内容,因为最终的目标是这个跟踪可以覆盖整个 Web。这种策略通常用于通用搜索引擎,因为通用搜索引擎获取的网页越多越好,并且没有具体要求。其次,广度优先搜索算法(也称为广度优先搜索)是最简单的图搜索算法之一,该算法也是许多重要图算法的原型。单源最短路径算法和P rim 最小生成树算法都采用了与广度优先搜索相似的思想。广度优先搜索算法沿树的宽度遍历树的节点。如果找到目标,则算法停止。算法的设计和实现比较简单,属于盲搜索。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是认为初始 URL 与初始 URL 一致的网页在一定的链接距离内具有很高的主题相关性概率。另一种方法是将宽度优先搜索与网页过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。基本思想是认为初始 URL 与初始 URL 一致的网页在一定的链接距离内具有很高的主题相关性概率。另一种方法是将宽度优先搜索与网页过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。基本思想是认为初始 URL 与初始 URL 一致的网页在一定的链接距离内具有很高的主题相关性概率。另一种方法是将宽度优先搜索与网页过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。
第三,深度优先搜索遵循的搜索策略是尽可能“深”地搜索图。在深度优先搜索中,对于新发现的顶点,如果从这个起点开始有未检测到的边,按照这个继续汉朝。当探索了节点 v 的所有边时,搜索将返回到找到节点 v 边的起始节点。这个过程一直持续到发现源节点可达所有节点为止。如果有未发现的节点,则选择其中一个作为源节点,重复上述过程。重复整个过程,直到找到所有节点。深度优先在很多情况下会导致爬虫被困(trapped)的问题,所以它既不是完全的也不是最优的。四、系统详细设计4.1接口设计4.1. 1界面设计实现设计界面如下:4.2网页分析实现4.2.1网页分析Web文档作为一种半结构化文本,是一种自由之间的数据文本和结构化文本,它通常没有严格的格式。对于这类文本,一般通过分析文本中独特的图标字符来进行爬取,具体来说就是分析HTML语言中各个标签之间的关系。网页信息的载体是网页文本,用超文本标记语言编写。HTML 标准定义了一组元素类型,不同类型的元素分别描述文本、图像、超文本链接等。一个元素的描述一般由一个开始标签(Start Tag)、一个内容(Content)、
元素名称出现在开始标签中,用HTML语言标记为,对应的结束标签是,内容出现在开始标签和结束标签之间。构建网页标签树的方法可以反映网页的结构特征。下图是一个简单的动态网页标签树4.2.2网页处理队列页面处理队列保存了页面URL,它实际上由等待队列、处理队列、错误队列和完成队列组成。正是通过它们,特定的移动蜘蛛可以完成对蜘蛛对应的网络的所有搜索任务。页面队列中保存的页面的 URL 都是内部链接。(1)等待队列(WaitURL)。在这个队列中,URL 正在等待移动 Spider 程序处理。新发现的 URL 将添加到此队列中。(2)处理队列(Proces—sUI)。当手机蜘蛛程序开始处理URL时,会被转移到这个队列中,但是同一个URL不能被多次处理,因为这样很浪费资源。当一个 URL 被处理后,会被移到错误队列或已完成队列中。(3)错误队列(ErrorURL)。如果在处理页面时发生错误,它的 URL 将被添加到错误队列中。在URL到达这个队列,就不会再移动到其他队列,一旦网页移动到错误队列,移动Spider程序就不会再处理了。(4)完成队列(LaunchURL))。它们被转移到这个队列中,但是同一个 URL 不能被多次处理,因为这是一种资源浪费。当一个 URL 被处理时,它会被移动到错误队列或完成队列。(3)Error Queue (ErrorURL)。如果在处理一个页面时发生错误,它的URL会被加入到错误队列中。URL到达这个队列后,就不会再移动到其他队列了。一旦网页被移入错误队列,手机Spider程序不会进一步处理(4)Completion Queue (LaunchURL))。它们被转移到这个队列中,但是同一个 URL 不能被多次处理,因为这是一种资源浪费。当一个 URL 被处理时,它会被移动到错误队列或完成队列。(3)Error Queue (ErrorURL)。如果在处理一个页面时发生错误,它的URL会被加入到错误队列中。URL到达这个队列后,就不会再移动到其他队列了。一旦网页被移入错误队列,手机Spider程序不会进一步处理(4)Completion Queue (LaunchURL))。它的 URL 将被添加到错误队列中。URL 到达此队列后,将不再移动到其他队列。一旦将网页移入错误队列,移动版蜘蛛程序将不再对其进行进一步处理。(4)完成队列(LaunchURL)。它的 URL 将被添加到错误队列中。URL 到达此队列后,将不再移动到其他队列。一旦将网页移入错误队列,移动版蜘蛛程序将不再对其进行进一步处理。(4)完成队列(LaunchURL)。
如果在处理网页时没有出现错误,则处理完成时会将 URL 添加到完成队列中,并且 URL 到达此队列后不会移动到其他队列。一个 URL 只能同时在一个队列中。这也称为 URL 的状态。这是因为人们经常使用状态图来描述计算机程序。程序根据状态图从一种状态改变到另一种状态。事实上,当一个URL(内部链接)时,移动蜘蛛会检查该URL是否已经存在于完成队列或错误队列中。如果它已经存在于上述两个队列中的任何一个中,移动蜘蛛将不会对该 URL 进行任何处理。这样可以防止某个页面被重复处理,也可以防止陷入死循环。< @4.2.3 搜索串匹配根据关键字检索网页数据。具体实现逻辑如下: 首先生成URL地址:string Url = String.Format("/search?spm=a230r.1.8.3.eyiRvB&promote=0&sort=sale-desc&tab =all&q={0}#J_relative", this.textBox1.Text.Trim()); 根据 URL 地址检索页面:私有字符串 GetWebContent(){string Result = "";try{HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(_url);request.Headers.Add("Accept-Charset", "gb2312;" );request.Headers。Add("Accept-Encoding", "gzip");request.Headers.Add("Accept-Language", " 具体实现逻辑如下: 首先生成URL地址:string Url = String.Format("/search?spm=a230r.1.8.3.eyiRvB&promote=0&sort=sale-desc&tab =all&q={0}#J_relative", this.textBox1.Text.Trim()); 根据 URL 地址检索页面:私有字符串 GetWebContent(){string Result = "";try{HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(_url);request.Headers.Add("Accept-Charset", "gb2312;" );request.Headers。Add("Accept-Encoding", "gzip");request.Headers.Add("Accept-Language", " 具体实现逻辑如下: 首先生成URL地址:string Url = String.Format("/search?spm=a230r.1.8.3.eyiRvB&promote=0&sort=sale-desc&tab =all&q={0}#J_relative", this.textBox1.Text.Trim()); 根据 URL 地址检索页面:私有字符串 GetWebContent(){string Result = "";try{HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(_url);request.Headers.Add("Accept-Charset", "gb2312;" );request.Headers。Add("Accept-Encoding", "gzip");request.Headers.Add("Accept-Language", " 查看全部
网页qq抓取什么原理(网页数据提取原理及其设计开发(龙泉第二小学,四川成都))
题目:Web数据抽取原理及其设计开发(龙泉二小,范学政,四川,成都)并提出了基于网络爬虫的网页搜索和页面提取功能和设计要求。网络爬虫是一个非常强大的程序,可以自动提取网页。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。它通过请求站点上的 HTML 文档来访问站点。它遍历Web空间,不断地从一个站点移动到另一个站点,自动建立索引,并将其添加到网页数据库中。当网络爬虫进入超文本时,它利用HTML语言的标记结构来搜索信息并获取指向其他超文本的URL地址,可以在不依赖用户干预的情况下实现网络上的自动“爬行”和搜索。本文在分析基于爬虫的网页搜索系统的结构和工作原理的基础上,研究了网页抓取和解析的策略和算法,并使用C#实现了一个网页提取程序并分析了其运行结果。关键词:爬虫;页面搜索;数据提取;HTML分析;摘要 本文讨论了搜索引擎的应用,搜索了网络蜘蛛在搜索引擎中的重要性和功能,并提出了其功能和设计的需求。网络爬虫是一个强大的自动提取网络应用程序;它来自万维网搜索引擎上的下载页面,是搜索引擎中的重要组成部分。它通过请求站点访问站点 HTML 文件来完成此操作。它穿越了网络空间, 1 网页数据提取现状分析 在互联网普及之前,人们在查找资料时首先想到的就是拥有大量书籍的图书馆。现在很多人选择了一种更方便、快捷、全面、准确的方式——互联网。如果说互联网是知识宝库,那么网络搜索就是打开知识宝库的钥匙。搜索引擎是1995年以来随着WEB信息的迅速增加而逐渐发展起来的一项技术。它是一种用于帮助互联网用户查询信息的搜索工具。搜索引擎利用一定的策略来采集和发现互联网上的信息,理解、提取、组织和处理信息,为用户提供搜索服务,从而达到信息导航的目的。目前,搜索引擎已成为网民关注的焦点,也成为计算机界和学术界的研究开发对象。目前比较流行的搜索引擎有谷歌、雅虎、Infoseek、百度等,出于商业秘密的考虑,目前各搜索引擎所使用的爬虫系统的技术内幕一般不公开,现有文献为限于总结介绍。并为用户提供搜索服务,从而达到信息导航的目的。目前,搜索引擎已成为网民关注的焦点,也成为计算机界和学术界的研究开发对象。目前比较流行的搜索引擎有谷歌、雅虎、Infoseek、百度等,出于商业秘密的考虑,目前各搜索引擎所使用的爬虫系统的技术内幕一般不公开,现有文献为限于总结介绍。并为用户提供搜索服务,从而达到信息导航的目的。目前,搜索引擎已成为网民关注的焦点,也成为计算机界和学术界的研究开发对象。目前比较流行的搜索引擎有谷歌、雅虎、Infoseek、百度等,出于商业秘密的考虑,目前各搜索引擎所使用的爬虫系统的技术内幕一般不公开,现有文献为限于总结介绍。
各大搜索引擎提供商都基于网络爬虫的原理来检索网页、抓取网页、分析网页、采集数据。随着Web信息资源的呈指数级增长和Web信息资源的动态变化,传统搜索引擎提供的信息提取服务已不能满足人们日益增长的个性化服务需求,面临着巨大的挑战。访问Web和提高搜索效率的策略已成为近年来专业搜索引擎网页数据提取研究的主要问题之一。1.2 学科发展背景基本上是三种类型的搜索引擎。一个组件:(1)网上采集信息网页< @采集系统:网页采集系统主要利用了一类采集信息,作用于互联网“网络蜘蛛”。“网络蜘蛛”实际上是一些基于网络的程序,它们使用主页中的超文本链接来遍历网络。使用可以自动从互联网上采集网页的“网络蜘蛛”程序,自动上网并跟随抓取任何网页中的所有网址到其他网页,重复此过程,将所有已被抓取的网页采集到网页数据库中. (2)索引采集的信息,建立索引库索引处理系统:索引处理系统对采集的网页进行分析,提取相关网页信息(包括网页所在的网址、编码类型等) , 关键词, 关键词 收录在页面内容中的位置、生成时间、大小、与其他网页的链接关系等),根据一定的相关性算法进行大量复杂的计算,并且获取每个网页与页面内容的相关性(或重要性)以及超链接中的每个关键词,然后创建索引并存储在网页索引数据库中。索引数据库可以使用通用的大型数据库,如Oracle、Sybase等,也可以定义存储的文件格式。为了保证索引库中的信息与Web内容同步,索引库必须定期更新,更新频率决定了搜索结果的及时性。索引数据库的更新是通过启动“网络蜘蛛”来实现的 再次搜索网络空间。(3)完成用户提交的查询请求的网页检索器:网页检索器一般是运行在Web服务器上的服务器程序,它首先接收用户提交的查询条件,搜索索引数据库根据查询条件,将查询结果返回给用户,当用户使用搜索引擎查找信息时,网页检索器接收用户提交的关键词,搜索系统程序查找所有相关网页网页索引数据库中匹配关键词的页面,一些搜索引擎系统会综合相关信息和网页级别,形成相关度值,然后进行排序,相关度越高,排名越高。最后,页面生成系统将搜索结果的链接地址和页面的内容摘要整理后返回给用户。典型的搜索引擎系统如谷歌采用这种策略。信息的快速增长使搜索引擎成为人们寻找信息的首选工具。谷歌、百度、中国搜索等大型搜索引擎一直是讨论的话题。国外搜索引擎技术的研究比国内早了近十年。从最早的Archie到后来的Excite,以及ahvista、overture、google等搜索引擎的出现,搜索引擎的发展已有十多年的历史。国内对搜索引擎的研究始于上世纪末本世纪初。在许多领域,国外的产品和技术一统天下,尤其是某项技术在国外研究多年,才在中国起步。例如操作系统、文字处理软件、浏览器等,但搜索引擎除外。国外搜索引擎技术虽然研究了很长时间,但中国还是涌现出了优秀的搜索引擎,比如百度、中搜。随着搜索引擎技术的成熟,它将成为获取信息和掌握知识的利器。但是,现有搜索引擎对用户的查询需求仅限于关键词的简单逻辑组合。搜索结果看重返回的数量而不是质量,结果文档的组织和分类也缺乏。国外的一项调查结果显示,约有71%的人对搜索结果有不同程度的失望。因此,如何提高搜索引擎的智能化,如何根据知识应用的需要组织信息,使互联网既能提供信息服务,又能为用户提供知识服务,将成为互联网研究的方向。计算机行业和学术界1.3 网页提取的工作原理。网络爬虫是网页检索的核心部分。它的名字来自蜘蛛的自由翻译。如何提高搜索引擎的智能化,如何根据知识应用的需要组织信息,使互联网既能提供信息服务,又能为用户提供知识服务,将成为计算机行业研究的方向。和学术界1.3 网页提取的工作原理。网络爬虫是网页检索的核心部分。它的名字来自蜘蛛的自由翻译。如何提高搜索引擎的智能化,如何根据知识应用的需要组织信息,使互联网既能提供信息服务,又能为用户提供知识服务,将成为计算机行业研究的方向。和学术界1.3 网页提取的工作原理。网络爬虫是网页检索的核心部分。它的名字来自蜘蛛的自由翻译。
系统开发工具和平台2.1关于c#语言 C#语言是由于2001年引入的一种新的编程语言。它是一种适用于分布式计算环境的跨平台、纯面向对象的语言。C#语言及其扩展正逐渐成为互联网应用的规范,掀起了自PC以来的又一次技术革命。一般认为,B语言导致了C语言的诞生,C语言演变成了C++语言,而C#语言显然具有C++语言的特点。C#总是和C++联系在一起,而C++是从C语言派生出来的,所以C#语言继承了这两种语言的大部分特性。C#的语法继承自C,C#的很多面向对象的特性都受到C++的影响。实际上,C# 中的一些自定义功能源自或可以追溯到这些前辈语言。略有不同的是C#语言是完全面向对象的,消除了两者的缺点。C#语言的诞生与近30年来计算机语言的不断完善和发展息息相关。C#由Anders Hejlsberg开发,它是第一种面向组件的编程语言,其源代码会被编译成msil然后运行。它借鉴了Delphi的一个特性,直接与COM组件对象模型集成,并增加了许多新的功能和语法。它是微软.NET网络框架的主角。1998 年 12 月,微软推出了全新的语言项目 COOL,
2000年2月,微软正式将COOL语言更名为C#,并于2000年7月发布了C#语言的第一个预览版。自2000年正式推出以来,C#语言以其独特的优势迅速发展。经过短短的8、 9年,它已经成为迄今为止最优秀的面向对象语言。C#从最初的语言逐渐形成了一个产业。基于C#语言的.NET架构已经成为微软J2EE平台的有力竞争者。一开始,C# 语言的最初发布不亚于一场革命,但它并没有标志着 C# 快速创新时代的结束。在.NET 2.0 发布后不久,.NET 的设计者就已经制定了.NET 3.5 和.NET 4.0 版本。C#作为目前广泛使用的面向对象编程语言,具有很多特点。如果将其与许多其他编程语言进行比较,您会发现这些特性正是 C# 语言如此受欢迎的原因。尽管C#在某些方面(比如资源消耗)存在一些不足,但这并不影响C#作为最好的面向对象编程语言的地位。C#是一种广泛使用的网络编程语言,是一种新的计算概念。网络环境下的编程语言最需要解决的就是可移植性和安全性问题。以字节为单位进行编码,可以使程序不受运行平台和环境的限制。C#语言还提供了丰富的类库,
C#作为一种高级编程语言,不仅面向对象、编写简单、远离机器结构、分布式、健壮、可移植、安全,而且提供了高解释和执行的并发机制。2.2 集成开发环境介绍 Visual Studio 2010 微软首次发布Visual Basic时,通过降低其复杂性,使得Windows软件开发得到广泛应用。使用 Visual Basic 6.0,Microsoft 使数百万开发人员能够快速开发客户端/服务器应用程序 [14]。最近,Microsoft 使用 Visual Studio.NET 为开发人员提供了工具和技术来轻松开发分布式应用程序。随着 Visual Studio 2010 集成开发环境的发布,Microsoft 一直处于响应日益复杂的应用程序和设计、开发和部署过程中所需的生命周期问题的最前沿。它根据开发者的个人需求自动配置开发工具的界面设置,提高软件开发者的开发体验。丰富了.NET Framework类库,使应用开发者能够从容应对日常开发中的各种问题,从而提高开发效率。实现了与微软团队开发中使用的产品无缝集成,如:VSS、Office、SQL Server等,丰富了开发者的解决方案,使开发者能够使用各种产品进行开发。
它提供了一套新的工具和功能,如ShareOpint、工作流等,使开发者能够跟上技术发展,满足日益复杂的应用开发需求。三、系统总体设计3.1系统总体结构3.2 搜索抽取策略 Web搜索往往采用一定的搜索策略。一个是广度或深度优先搜索策略:搜索引擎使用的第一代网络爬虫主要基于传统的图算法,例如广度优先或深度优先算法来索引整个Web,以及一个核心的URL set 被用作种子集合,这个算法递归地跟踪到其他页面的超链接,通常不管页面的内容,因为最终的目标是这个跟踪可以覆盖整个 Web。这种策略通常用于通用搜索引擎,因为通用搜索引擎获取的网页越多越好,并且没有具体要求。其次,广度优先搜索算法(也称为广度优先搜索)是最简单的图搜索算法之一,该算法也是许多重要图算法的原型。单源最短路径算法和P rim 最小生成树算法都采用了与广度优先搜索相似的思想。广度优先搜索算法沿树的宽度遍历树的节点。如果找到目标,则算法停止。算法的设计和实现比较简单,属于盲搜索。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是认为初始 URL 与初始 URL 一致的网页在一定的链接距离内具有很高的主题相关性概率。另一种方法是将宽度优先搜索与网页过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。基本思想是认为初始 URL 与初始 URL 一致的网页在一定的链接距离内具有很高的主题相关性概率。另一种方法是将宽度优先搜索与网页过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。基本思想是认为初始 URL 与初始 URL 一致的网页在一定的链接距离内具有很高的主题相关性概率。另一种方法是将宽度优先搜索与网页过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。
第三,深度优先搜索遵循的搜索策略是尽可能“深”地搜索图。在深度优先搜索中,对于新发现的顶点,如果从这个起点开始有未检测到的边,按照这个继续汉朝。当探索了节点 v 的所有边时,搜索将返回到找到节点 v 边的起始节点。这个过程一直持续到发现源节点可达所有节点为止。如果有未发现的节点,则选择其中一个作为源节点,重复上述过程。重复整个过程,直到找到所有节点。深度优先在很多情况下会导致爬虫被困(trapped)的问题,所以它既不是完全的也不是最优的。四、系统详细设计4.1接口设计4.1. 1界面设计实现设计界面如下:4.2网页分析实现4.2.1网页分析Web文档作为一种半结构化文本,是一种自由之间的数据文本和结构化文本,它通常没有严格的格式。对于这类文本,一般通过分析文本中独特的图标字符来进行爬取,具体来说就是分析HTML语言中各个标签之间的关系。网页信息的载体是网页文本,用超文本标记语言编写。HTML 标准定义了一组元素类型,不同类型的元素分别描述文本、图像、超文本链接等。一个元素的描述一般由一个开始标签(Start Tag)、一个内容(Content)、
元素名称出现在开始标签中,用HTML语言标记为,对应的结束标签是,内容出现在开始标签和结束标签之间。构建网页标签树的方法可以反映网页的结构特征。下图是一个简单的动态网页标签树4.2.2网页处理队列页面处理队列保存了页面URL,它实际上由等待队列、处理队列、错误队列和完成队列组成。正是通过它们,特定的移动蜘蛛可以完成对蜘蛛对应的网络的所有搜索任务。页面队列中保存的页面的 URL 都是内部链接。(1)等待队列(WaitURL)。在这个队列中,URL 正在等待移动 Spider 程序处理。新发现的 URL 将添加到此队列中。(2)处理队列(Proces—sUI)。当手机蜘蛛程序开始处理URL时,会被转移到这个队列中,但是同一个URL不能被多次处理,因为这样很浪费资源。当一个 URL 被处理后,会被移到错误队列或已完成队列中。(3)错误队列(ErrorURL)。如果在处理页面时发生错误,它的 URL 将被添加到错误队列中。在URL到达这个队列,就不会再移动到其他队列,一旦网页移动到错误队列,移动Spider程序就不会再处理了。(4)完成队列(LaunchURL))。它们被转移到这个队列中,但是同一个 URL 不能被多次处理,因为这是一种资源浪费。当一个 URL 被处理时,它会被移动到错误队列或完成队列。(3)Error Queue (ErrorURL)。如果在处理一个页面时发生错误,它的URL会被加入到错误队列中。URL到达这个队列后,就不会再移动到其他队列了。一旦网页被移入错误队列,手机Spider程序不会进一步处理(4)Completion Queue (LaunchURL))。它们被转移到这个队列中,但是同一个 URL 不能被多次处理,因为这是一种资源浪费。当一个 URL 被处理时,它会被移动到错误队列或完成队列。(3)Error Queue (ErrorURL)。如果在处理一个页面时发生错误,它的URL会被加入到错误队列中。URL到达这个队列后,就不会再移动到其他队列了。一旦网页被移入错误队列,手机Spider程序不会进一步处理(4)Completion Queue (LaunchURL))。它的 URL 将被添加到错误队列中。URL 到达此队列后,将不再移动到其他队列。一旦将网页移入错误队列,移动版蜘蛛程序将不再对其进行进一步处理。(4)完成队列(LaunchURL)。它的 URL 将被添加到错误队列中。URL 到达此队列后,将不再移动到其他队列。一旦将网页移入错误队列,移动版蜘蛛程序将不再对其进行进一步处理。(4)完成队列(LaunchURL)。
如果在处理网页时没有出现错误,则处理完成时会将 URL 添加到完成队列中,并且 URL 到达此队列后不会移动到其他队列。一个 URL 只能同时在一个队列中。这也称为 URL 的状态。这是因为人们经常使用状态图来描述计算机程序。程序根据状态图从一种状态改变到另一种状态。事实上,当一个URL(内部链接)时,移动蜘蛛会检查该URL是否已经存在于完成队列或错误队列中。如果它已经存在于上述两个队列中的任何一个中,移动蜘蛛将不会对该 URL 进行任何处理。这样可以防止某个页面被重复处理,也可以防止陷入死循环。< @4.2.3 搜索串匹配根据关键字检索网页数据。具体实现逻辑如下: 首先生成URL地址:string Url = String.Format("/search?spm=a230r.1.8.3.eyiRvB&promote=0&sort=sale-desc&tab =all&q={0}#J_relative", this.textBox1.Text.Trim()); 根据 URL 地址检索页面:私有字符串 GetWebContent(){string Result = "";try{HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(_url);request.Headers.Add("Accept-Charset", "gb2312;" );request.Headers。Add("Accept-Encoding", "gzip");request.Headers.Add("Accept-Language", " 具体实现逻辑如下: 首先生成URL地址:string Url = String.Format("/search?spm=a230r.1.8.3.eyiRvB&promote=0&sort=sale-desc&tab =all&q={0}#J_relative", this.textBox1.Text.Trim()); 根据 URL 地址检索页面:私有字符串 GetWebContent(){string Result = "";try{HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(_url);request.Headers.Add("Accept-Charset", "gb2312;" );request.Headers。Add("Accept-Encoding", "gzip");request.Headers.Add("Accept-Language", " 具体实现逻辑如下: 首先生成URL地址:string Url = String.Format("/search?spm=a230r.1.8.3.eyiRvB&promote=0&sort=sale-desc&tab =all&q={0}#J_relative", this.textBox1.Text.Trim()); 根据 URL 地址检索页面:私有字符串 GetWebContent(){string Result = "";try{HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(_url);request.Headers.Add("Accept-Charset", "gb2312;" );request.Headers。Add("Accept-Encoding", "gzip");request.Headers.Add("Accept-Language", "
网页qq抓取什么原理( 01.网页为何要去重?优化培训02.工作原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-25 12:20
01.网页为何要去重?优化培训02.工作原理)
按照搜索引擎网页的去重原理做seo
01.为什么网页需要复制?
对于搜索引擎来说,我们希望呈现给用户的是新颖有吸引力的内容,高质量的文章,而不是一大堆“换汤不换药”;我们正在做SEO优化。在编辑内容的时候,难免会参考其他类似的文章,而这个文章可能已经被很多人采集,造成相关信息的大量重复互联网。
如果一个网站收录很多不好的采集内容,不仅会影响用户体验,还会导致搜索引擎直接屏蔽网站。之后,网站 上的内容就不再是蜘蛛爬虫的难事了。
搜索引擎优化培训
02.搜索引擎的工作原理
搜索引擎是指按照一定的策略从互联网上采集信息,并使用特定的计算机程序,对信息进行组织和处理,为用户提供检索服务,并向用户展示与用户检索相关的相关信息的系统。
搜索引擎的工作原理:
第 1 步:爬网
搜索引擎通过特定模式的软件跟踪到网页的链接,从一个链接爬到另一个链接,就像蜘蛛在蜘蛛网上爬行一样,因此被称为“蜘蛛”或“机器人”。搜索引擎蜘蛛的爬行是有一定的规则进入的,需要遵循一些命令或者文件的内容。
第 2 步:获取存储空间
搜索引擎通过蜘蛛跟踪链接抓取网页,并将抓取到的数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。在抓取页面时,搜索引擎蜘蛛也会对重复内容进行一定的 seo 检测。一旦他们遇到大量抄袭、采集 或抄袭权重极低的网站 内容,很可能会停止爬行。
第三步:预处理
搜索引擎将在各个步骤中对蜘蛛检索到的页面进行预处理。
除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等,我们在搜索结果中也经常看到这些文件类型。但是,搜索引擎无法处理图像、视频和 Flash 等非文本内容,也无法执行脚本和程序。
搜索引擎优化培训
第 4 步:排名
用户在搜索框中输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程直接与用户交互。但是由于搜索引擎的数据量巨大,虽然可以实现每天小更新,seo,但是一般来说,搜索引擎的排名规则是按照每天、每周、每月不同级别的更新。
03.web去重的代表方法
搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合搜索引擎、门户搜索引擎和免费链接列表等。去重工作一般在分词之后、索引之前进行。搜索引擎会从已经从页面中分离出来的关键词中提取一些有代表性的关键词进行计算,然后得到一个网站关键词的特征。
目前有3种代表性的网页去重方法。
1)一种基于聚类的方法。该方法以6763个汉字的网页文本内容为载体。文本中某个组或某个汉字出现的频率构成一个表示该网页的向量,计算该向量的角度来判断是否是同一个网页。
2)排除相同的URL方法。各种元搜索引擎主要使用这种方法来删除重复项。它分析来自不同搜索引擎的网页的 URL。如果网址相同,则认为是同一个网页,可以删除。
3)一种基于特征码的方法。该方法利用标点符号大部分出现在网页正文中的特点,以句号两边各5个汉字作为特征码来唯一地表示网页。
seo优化认为,这三种方法中,第一种和第三种方法大多是根据内容来决定的,所以很多SEO人员会使用伪原创工具修改文章的内容,但大部分时间伪原创工具会改变原文不一致,不利于排名和收录。
还有网站利用搜索引擎的漏洞,比如高权重的网站针对不好的采集,因为高权重的网站蜘蛛会先被抓取,所以这种方式不会有利于一些低权重的网站。
我有几张阿里云幸运券与大家分享。使用优惠券购买或升级阿里云对应产品,更有惊喜!采集你要购买的产品的所有幸运券!快点,都快要抢了。 查看全部
网页qq抓取什么原理(
01.网页为何要去重?优化培训02.工作原理)
按照搜索引擎网页的去重原理做seo
01.为什么网页需要复制?
对于搜索引擎来说,我们希望呈现给用户的是新颖有吸引力的内容,高质量的文章,而不是一大堆“换汤不换药”;我们正在做SEO优化。在编辑内容的时候,难免会参考其他类似的文章,而这个文章可能已经被很多人采集,造成相关信息的大量重复互联网。
如果一个网站收录很多不好的采集内容,不仅会影响用户体验,还会导致搜索引擎直接屏蔽网站。之后,网站 上的内容就不再是蜘蛛爬虫的难事了。
搜索引擎优化培训
02.搜索引擎的工作原理
搜索引擎是指按照一定的策略从互联网上采集信息,并使用特定的计算机程序,对信息进行组织和处理,为用户提供检索服务,并向用户展示与用户检索相关的相关信息的系统。
搜索引擎的工作原理:
第 1 步:爬网
搜索引擎通过特定模式的软件跟踪到网页的链接,从一个链接爬到另一个链接,就像蜘蛛在蜘蛛网上爬行一样,因此被称为“蜘蛛”或“机器人”。搜索引擎蜘蛛的爬行是有一定的规则进入的,需要遵循一些命令或者文件的内容。
第 2 步:获取存储空间
搜索引擎通过蜘蛛跟踪链接抓取网页,并将抓取到的数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。在抓取页面时,搜索引擎蜘蛛也会对重复内容进行一定的 seo 检测。一旦他们遇到大量抄袭、采集 或抄袭权重极低的网站 内容,很可能会停止爬行。
第三步:预处理
搜索引擎将在各个步骤中对蜘蛛检索到的页面进行预处理。
除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等,我们在搜索结果中也经常看到这些文件类型。但是,搜索引擎无法处理图像、视频和 Flash 等非文本内容,也无法执行脚本和程序。
搜索引擎优化培训
第 4 步:排名
用户在搜索框中输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程直接与用户交互。但是由于搜索引擎的数据量巨大,虽然可以实现每天小更新,seo,但是一般来说,搜索引擎的排名规则是按照每天、每周、每月不同级别的更新。
03.web去重的代表方法
搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合搜索引擎、门户搜索引擎和免费链接列表等。去重工作一般在分词之后、索引之前进行。搜索引擎会从已经从页面中分离出来的关键词中提取一些有代表性的关键词进行计算,然后得到一个网站关键词的特征。
目前有3种代表性的网页去重方法。
1)一种基于聚类的方法。该方法以6763个汉字的网页文本内容为载体。文本中某个组或某个汉字出现的频率构成一个表示该网页的向量,计算该向量的角度来判断是否是同一个网页。
2)排除相同的URL方法。各种元搜索引擎主要使用这种方法来删除重复项。它分析来自不同搜索引擎的网页的 URL。如果网址相同,则认为是同一个网页,可以删除。
3)一种基于特征码的方法。该方法利用标点符号大部分出现在网页正文中的特点,以句号两边各5个汉字作为特征码来唯一地表示网页。
seo优化认为,这三种方法中,第一种和第三种方法大多是根据内容来决定的,所以很多SEO人员会使用伪原创工具修改文章的内容,但大部分时间伪原创工具会改变原文不一致,不利于排名和收录。
还有网站利用搜索引擎的漏洞,比如高权重的网站针对不好的采集,因为高权重的网站蜘蛛会先被抓取,所以这种方式不会有利于一些低权重的网站。
我有几张阿里云幸运券与大家分享。使用优惠券购买或升级阿里云对应产品,更有惊喜!采集你要购买的产品的所有幸运券!快点,都快要抢了。
网页qq抓取什么原理(浏览器访问QQ邮箱登录页是怎么做到的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-23 02:21
如果我们在计算机上启动QQ,请使用浏览器访问QQ邮箱登录页面,此页面将提示我们登录QQ。
它是怎么做的?
有些人说这是一个控制权。控制可能能够能够实现,而是会影响用户体验,QQ更先进的思考。
QQ将有一个小型Web服务器,提供类似于IIS的功能,Apache。
Access QQ邮箱登录页面,此页面将访问此Web服务器,因为访问了地址,所以地址是:12 7.0.0. 1(实际上:4301 /,这个域指向12 7.0.0. 1,域名的优势是解决cookie跨域权限问题。),因为这个Web服务器建立,可以根据自己的登录状态发送QQ返回相应的信息。
(为了验证上述信息:您可以使用Chrome访问QQ邮箱登录页面,然后按F12切换到网络选项卡,从列表中查找PT_GET_UINS的开头,您可以看到完整的URL。)
?
显然不是那么简单,那么我的网页也可以访问,而不是用户的登录信息和登录凭据?我收到了这个登录凭据,我可以拿起登录吗?
所以有必要防止他人获得这种隐私,但也可以防止他人获得登录凭据。
所以这是QQ邮箱服务器,例如,您可以执行此操作:
是为了防止数据,所有传输都是HTTPS。上面只是一种方式,它实际上可能是另一种方式,或者更复杂。 查看全部
网页qq抓取什么原理(浏览器访问QQ邮箱登录页是怎么做到的呢?)
如果我们在计算机上启动QQ,请使用浏览器访问QQ邮箱登录页面,此页面将提示我们登录QQ。
它是怎么做的?
有些人说这是一个控制权。控制可能能够能够实现,而是会影响用户体验,QQ更先进的思考。
QQ将有一个小型Web服务器,提供类似于IIS的功能,Apache。
Access QQ邮箱登录页面,此页面将访问此Web服务器,因为访问了地址,所以地址是:12 7.0.0. 1(实际上:4301 /,这个域指向12 7.0.0. 1,域名的优势是解决cookie跨域权限问题。),因为这个Web服务器建立,可以根据自己的登录状态发送QQ返回相应的信息。
(为了验证上述信息:您可以使用Chrome访问QQ邮箱登录页面,然后按F12切换到网络选项卡,从列表中查找PT_GET_UINS的开头,您可以看到完整的URL。)
?
显然不是那么简单,那么我的网页也可以访问,而不是用户的登录信息和登录凭据?我收到了这个登录凭据,我可以拿起登录吗?
所以有必要防止他人获得这种隐私,但也可以防止他人获得登录凭据。
所以这是QQ邮箱服务器,例如,您可以执行此操作:
是为了防止数据,所有传输都是HTTPS。上面只是一种方式,它实际上可能是另一种方式,或者更复杂。
网页qq抓取什么原理(搜索引擎的抓取系统是怎样的?搜索系统有五大策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-22 16:13
从一开始,“走进搜索引擎”到现在,对搜索引擎的原理有一定的了解。 文章也是我对这本书的了解。爬虫爬虫页面是搜索引擎工作的第一步,因此您需要了解搜索引擎原理需要从履带系统开始。熟悉搜索引擎原理,帮助我们对SEO更深刻,SEO工作的帮助也相对较大。搜索引擎的履带系统是什么?
搜索捕获系统有五种主要策略。
一、深度优先级策略
我认为最重要的是两部分:1. @万网的直径,也称为“幅材直径”。它可以很容易理解为:如果在任何两页之间存在路径,则平均点击不超过19次,即从网页到另一个网页。世界宽网的直径,在不同书中给出的万维网的直径不同。万维网的直径可以被理解为:网页爬行; 2.搜索引擎深度优先级策略:这首先选择一个分支,然后考虑在您无法推断的情况下考虑其他分支的策略。但万维网的深度并不想象如此深,而且太深网站结构也不有利于用户体验。因此,网站施工应尝试确保平面结构,以便网页的层次结构较少。但是,对于当前的用户体验,一般网页的层次结构仍然在三层内,这可以方便用户点击。
二、宽宽策略
宽度优先级:指网站的主母版,然后抓住潜水子的头部下方。宽度优先策略需要注意三个点:
(1)重要网页通常更接近种子站点
(2) @ @ @ @万网的不不不不不不不不不不不不不不不不不不不不不不不不不不行
(3)width优先权规则有助于更多履带式合作爬行,首先抓住车站,封闭车站,封闭强烈
三、不到意
不要重复抓取策略意味着爬行动物有录音历史,它不再攀登攀登页面。不要重复抓取策略来解决死循环的问题,即,对于可靠的页面不再抓取,死循环的状况被摧毁。例如,在从主页上爬上爬网程序后,从主页上有一个与主页的链接。此时,履带将不会遵循链接爬上第一页。
四、网优优
网页抓取优先级策略,也称为“页面选择问题”。此时,履带将掌握高度重要的页面,以便您可以在有限资源中处理高可可取重要性的重要性。重要性由链接欢迎,链接重要性和平均链路的三个方面决定。
五、网重重访重访重访重访策略
页面在爬网之前爬上攀升,这些页面随着时间的推移而变化。爬行动物必须刷新这些页面,重新访问攀登的最新信息,以便及时收购这些页面。这是Web Snapshot更新的本质。与此同时,它也解释了为什么爬行动物会定期更新,例如百度爬行动物一般更新周期一般是一天,一周或半月。
其他礼貌问题应该主要关注
疯狂速度政策(合作疯狂策略)
1.提高了掌握单个页面的速度。
2.最大限度地减少不必要的掌握任务。例如,使用rel =“nofollow”以避免抓取一些页面的爬虫。
3.同时增加爬行动物的数量。 查看全部
网页qq抓取什么原理(搜索引擎的抓取系统是怎样的?搜索系统有五大策略)
从一开始,“走进搜索引擎”到现在,对搜索引擎的原理有一定的了解。 文章也是我对这本书的了解。爬虫爬虫页面是搜索引擎工作的第一步,因此您需要了解搜索引擎原理需要从履带系统开始。熟悉搜索引擎原理,帮助我们对SEO更深刻,SEO工作的帮助也相对较大。搜索引擎的履带系统是什么?
搜索捕获系统有五种主要策略。
一、深度优先级策略
我认为最重要的是两部分:1. @万网的直径,也称为“幅材直径”。它可以很容易理解为:如果在任何两页之间存在路径,则平均点击不超过19次,即从网页到另一个网页。世界宽网的直径,在不同书中给出的万维网的直径不同。万维网的直径可以被理解为:网页爬行; 2.搜索引擎深度优先级策略:这首先选择一个分支,然后考虑在您无法推断的情况下考虑其他分支的策略。但万维网的深度并不想象如此深,而且太深网站结构也不有利于用户体验。因此,网站施工应尝试确保平面结构,以便网页的层次结构较少。但是,对于当前的用户体验,一般网页的层次结构仍然在三层内,这可以方便用户点击。
二、宽宽策略
宽度优先级:指网站的主母版,然后抓住潜水子的头部下方。宽度优先策略需要注意三个点:
(1)重要网页通常更接近种子站点
(2) @ @ @ @万网的不不不不不不不不不不不不不不不不不不不不不不不不不不行
(3)width优先权规则有助于更多履带式合作爬行,首先抓住车站,封闭车站,封闭强烈
三、不到意
不要重复抓取策略意味着爬行动物有录音历史,它不再攀登攀登页面。不要重复抓取策略来解决死循环的问题,即,对于可靠的页面不再抓取,死循环的状况被摧毁。例如,在从主页上爬上爬网程序后,从主页上有一个与主页的链接。此时,履带将不会遵循链接爬上第一页。
四、网优优
网页抓取优先级策略,也称为“页面选择问题”。此时,履带将掌握高度重要的页面,以便您可以在有限资源中处理高可可取重要性的重要性。重要性由链接欢迎,链接重要性和平均链路的三个方面决定。
五、网重重访重访重访重访策略
页面在爬网之前爬上攀升,这些页面随着时间的推移而变化。爬行动物必须刷新这些页面,重新访问攀登的最新信息,以便及时收购这些页面。这是Web Snapshot更新的本质。与此同时,它也解释了为什么爬行动物会定期更新,例如百度爬行动物一般更新周期一般是一天,一周或半月。
其他礼貌问题应该主要关注
疯狂速度政策(合作疯狂策略)
1.提高了掌握单个页面的速度。
2.最大限度地减少不必要的掌握任务。例如,使用rel =“nofollow”以避免抓取一些页面的爬虫。
3.同时增加爬行动物的数量。
网页qq抓取什么原理(认识浏览器和服务器的日常操作方法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-22 16:11
本文文章主要介绍“网络爬虫原理简介”。在日常操作中,我相信很多人对网络爬虫原理的引入都有疑问。小编查阅了各种资料,整理出简单易用的操作方法。我希望这将有助于解决“网络爬虫原理简介”的疑问!接下来请跟随小编学习
了解浏览器和服务器
我们应该对浏览器并不陌生。可以说,只要上网的人都知道浏览器。然而,了解浏览器原理的人并不多
作为开发爬虫的小型合作伙伴,您必须了解浏览器的工作原理。这是编写爬行动物的必要工具。没有别的了
在面试过程中,您是否遇到过这样一个宏观而详细的回答问题:
这真是对知识的考验。这只经验丰富的老猿不仅能讲三天三夜,还能从几分钟内提取精华。恐怕你对整个过程略知一二
巧合的是,你对这个问题理解得越透彻,写爬行动物就越有帮助。换句话说,爬行动物是测试综合技能的领域。那么,你准备好迎接这个全面的技能挑战了吗
别再胡说八道了。让我们从回答这个问题开始,了解浏览器和服务器,并了解爬虫程序需要使用哪些知识
如前所述,我们可以讨论这个问题三天三夜,但我们没有那么多时间。我们将跳过一些细节。让我们结合爬行动物讨论一般过程,并将其分为三个部分:
来自浏览器的请求
服务器响应
浏览器收到响应
1.来自浏览器的请求
在浏览器地址栏中输入URL,然后按Enter键。浏览器要求服务器发出一个网页请求,也就是说,告诉服务器我想查看您的一个网页
上面的短句收录了无数的谜团,这让我不得不花一些时间一直在说话。主要是关于:
1)网站有效吗
首先,浏览器应该判断您输入的网址(URL)是否合法有效。对应的URL对于猿类来说并不陌生。以HTTP(s)开头的长字符串,但您知道它也可以以FTP、mailto、file、data和IRC开头吗?以下是其最完整的语法格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
这是更生动地显示和处理图片的方法:
体验:判断URL的合法性
在Python中,urllib.parse可用于执行各种URL操作
In [1]: import urllib.parse
In [2]: url = 'http://dachong:the_password%40 ... 39%3B
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们可以看到,urlparse函数将URL分析为六个部分:
scheme://netloc/path ; 参数?查询#片段
需要注意的是,netloc在URL语法定义中并不等同于主机
2)服务器在哪里
上述URL定义中的主机是Internet上的服务器。它可以是IP地址,但通常我们称之为域名。域名通过DNS绑定到一个(或多个)IP地址。要访问域名,网站浏览器必须首先通过DNS服务器解析域名,以获得真实的IP地址
这里的域名解析通常由操作系统完成,爬虫不需要在意。然而,当你编写一个大型爬虫程序时,比如谷歌和百度搜索引擎,效率变得非常重要,爬虫程序需要维护自己的DNS缓存
老ape经验:大型爬虫需要维护自己的DNS缓存
3)浏览器向服务器发送什么
浏览器获取网站服务器的IP地址后,可以向服务器发送请求。此请求遵循HTTP协议。爬虫需要关心的是HTTP协议的头。以下是访问/wiki/URL时浏览器发送的请求标头:
从图中可以看出一些线索。发送的HTTP请求头类似于字典结构:
路径:访问网站的路径@
Scheme:请求的协议类型,这里是HTTPS
接受:可接受的响应内容类型
接受编码:可接受编码方法的列表
接受语言:可接受响应内容的自然语言列表
缓存控制:指定请求/响应链中所有缓存机制必须遵守的指令
Cookie:服务器先前通过set Cookie发送的超文本传输协议Cookie
这是爬虫非常关心的事情。登录信息在这里
升级执行请求:非标准请求字段,可以忽略
用户代理:浏览器标识
这就是爬行动物所关心的。例如,如果需要获取移动版本页面,则需要将浏览器ID设置为移动浏览器的用户代理
体验:通过设置头与服务器通信
4)服务器返回了什么
如果我们在浏览器地址栏中输入一个网址(而不是文件下载地址),我们很快就会看到一个收录排版文本、图片、视频和其他数据的网页,这是一个内容丰富的网页。然而,当我通过浏览器查看源代码时,我看到一对文本格式的HTML代码
是的,这是一堆代码,但是让浏览器把它呈现成一个漂亮的网页。这对代码收录:
我们想要抓取的信息隐藏在HTML代码中,我们可以通过解析提取我们想要的内容。如果HTML代码中没有我们想要的数据,但我们在网页中看到了它,那么浏览器就通过Ajax请求异步加载(秘密下载)该部分数据
此时,我们需要观察浏览器的加载过程,找出哪个Ajax请求加载了我们需要的数据
现在,“网络爬虫原理导论”的研究已经结束。我希望我们能解决你的疑问。理论和实践的结合能更好地帮助你学习。去试试吧!如果您想继续学习更多相关知识,请继续关注伊苏云网站,小编将继续努力为您带来更实用的文章@ 查看全部
网页qq抓取什么原理(认识浏览器和服务器的日常操作方法(一))
本文文章主要介绍“网络爬虫原理简介”。在日常操作中,我相信很多人对网络爬虫原理的引入都有疑问。小编查阅了各种资料,整理出简单易用的操作方法。我希望这将有助于解决“网络爬虫原理简介”的疑问!接下来请跟随小编学习
了解浏览器和服务器
我们应该对浏览器并不陌生。可以说,只要上网的人都知道浏览器。然而,了解浏览器原理的人并不多
作为开发爬虫的小型合作伙伴,您必须了解浏览器的工作原理。这是编写爬行动物的必要工具。没有别的了
在面试过程中,您是否遇到过这样一个宏观而详细的回答问题:
这真是对知识的考验。这只经验丰富的老猿不仅能讲三天三夜,还能从几分钟内提取精华。恐怕你对整个过程略知一二
巧合的是,你对这个问题理解得越透彻,写爬行动物就越有帮助。换句话说,爬行动物是测试综合技能的领域。那么,你准备好迎接这个全面的技能挑战了吗
别再胡说八道了。让我们从回答这个问题开始,了解浏览器和服务器,并了解爬虫程序需要使用哪些知识
如前所述,我们可以讨论这个问题三天三夜,但我们没有那么多时间。我们将跳过一些细节。让我们结合爬行动物讨论一般过程,并将其分为三个部分:
来自浏览器的请求
服务器响应
浏览器收到响应
1.来自浏览器的请求
在浏览器地址栏中输入URL,然后按Enter键。浏览器要求服务器发出一个网页请求,也就是说,告诉服务器我想查看您的一个网页
上面的短句收录了无数的谜团,这让我不得不花一些时间一直在说话。主要是关于:
1)网站有效吗
首先,浏览器应该判断您输入的网址(URL)是否合法有效。对应的URL对于猿类来说并不陌生。以HTTP(s)开头的长字符串,但您知道它也可以以FTP、mailto、file、data和IRC开头吗?以下是其最完整的语法格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
这是更生动地显示和处理图片的方法:
体验:判断URL的合法性
在Python中,urllib.parse可用于执行各种URL操作
In [1]: import urllib.parse
In [2]: url = 'the_password@www.yuanrenxue.com/user/info?page=2'" rel="nofollow" target="_blank">http://dachong:the_password%40 ... 39%3B
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们可以看到,urlparse函数将URL分析为六个部分:
scheme://netloc/path ; 参数?查询#片段
需要注意的是,netloc在URL语法定义中并不等同于主机
2)服务器在哪里
上述URL定义中的主机是Internet上的服务器。它可以是IP地址,但通常我们称之为域名。域名通过DNS绑定到一个(或多个)IP地址。要访问域名,网站浏览器必须首先通过DNS服务器解析域名,以获得真实的IP地址
这里的域名解析通常由操作系统完成,爬虫不需要在意。然而,当你编写一个大型爬虫程序时,比如谷歌和百度搜索引擎,效率变得非常重要,爬虫程序需要维护自己的DNS缓存
老ape经验:大型爬虫需要维护自己的DNS缓存
3)浏览器向服务器发送什么
浏览器获取网站服务器的IP地址后,可以向服务器发送请求。此请求遵循HTTP协议。爬虫需要关心的是HTTP协议的头。以下是访问/wiki/URL时浏览器发送的请求标头:
从图中可以看出一些线索。发送的HTTP请求头类似于字典结构:
路径:访问网站的路径@
Scheme:请求的协议类型,这里是HTTPS
接受:可接受的响应内容类型
接受编码:可接受编码方法的列表
接受语言:可接受响应内容的自然语言列表
缓存控制:指定请求/响应链中所有缓存机制必须遵守的指令
Cookie:服务器先前通过set Cookie发送的超文本传输协议Cookie
这是爬虫非常关心的事情。登录信息在这里
升级执行请求:非标准请求字段,可以忽略
用户代理:浏览器标识
这就是爬行动物所关心的。例如,如果需要获取移动版本页面,则需要将浏览器ID设置为移动浏览器的用户代理
体验:通过设置头与服务器通信
4)服务器返回了什么
如果我们在浏览器地址栏中输入一个网址(而不是文件下载地址),我们很快就会看到一个收录排版文本、图片、视频和其他数据的网页,这是一个内容丰富的网页。然而,当我通过浏览器查看源代码时,我看到一对文本格式的HTML代码
是的,这是一堆代码,但是让浏览器把它呈现成一个漂亮的网页。这对代码收录:
我们想要抓取的信息隐藏在HTML代码中,我们可以通过解析提取我们想要的内容。如果HTML代码中没有我们想要的数据,但我们在网页中看到了它,那么浏览器就通过Ajax请求异步加载(秘密下载)该部分数据
此时,我们需要观察浏览器的加载过程,找出哪个Ajax请求加载了我们需要的数据
现在,“网络爬虫原理导论”的研究已经结束。我希望我们能解决你的疑问。理论和实践的结合能更好地帮助你学习。去试试吧!如果您想继续学习更多相关知识,请继续关注伊苏云网站,小编将继续努力为您带来更实用的文章@
网页qq抓取什么原理(网络爬虫常见的抓取策略:1.深度优先遍历策略深度 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-09-17 14:13
)
有一个特殊的爬虫网站:网络爬虫的基本原理
网络爬虫是搜索引擎捕获系统的重要组成部分。爬虫的主要目的是将Internet上的网页下载到本地,以形成网络内容的镜像或备份。本博客主要对爬虫和爬虫系统进行简要概述
一、web爬虫的基本结构和工作流程
网络爬虫的总体框架如图所示:
网络爬虫的基本工作流程如下:
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可分为五个部分:
三、crawling策略
在爬虫系统中,要获取的URL队列是一个非常重要的部分。URL队列中要获取的URL的排列顺序也是一个非常重要的问题,因为它涉及先获取页面,然后获取哪个页面。确定这些URL顺序的方法称为爬网策略。以下重点介绍几种常见的捕获策略:
1.深度优先遍历策略
深度优先遍历策略意味着网络爬虫将从起始页开始,逐个跟踪链接。处理完这一行后,它将转到下一个起始页并继续跟踪链接。以下图为例:
遍历路径:a-f-g e-h-i B C D
2.width优先遍历策略
宽度优先遍历策略的基本思想是将新下载的网页中的链接直接插入要爬网的URL队列的末尾。也就是说,网络爬虫将首先抓取起始页面中的所有链接页面,然后选择其中一个链接页面以继续抓取此页面中的所有链接页面。以上图为例:
遍历路径:a-b-c-d-e-f g h I
3.反向链路计数策略
反向链接数是指其他网页指向某个网页的链接数。反向链接的数量表示其他人推荐网页内容的程度。因此,大多数情况下,搜索引擎的爬行系统都会利用这个指标来评价网页的重要性,从而确定不同网页的爬行顺序
在现实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全等着他或我。因此,搜索引擎经常考虑可靠的反向链接数量
一个简单的爬虫程序示例在同一个城市中爬行58所房屋,包括介绍、房屋类型、房价和其他信息,然后将它们写入rent.csv文件以形成一个表
#!/usr/bin/python
#coding=utf-8
from bs4 import BeautifulSoup
from urlparse import urljoin
import requests
import csv
# 选取价格在1500-2000之间的房子信息
url = 'http://bj.58.com/pinpaigongyu/pn/{page}/?minprice=1500_2000'
page = 0
csv_file = open('rent.csv','wb')
csv_writer = csv.writer(csv_file,delimiter = ',')
while True:
page += 1
print "fetch: ",url.format(page = page)
response = requests.get(url.format(page = page))
html = BeautifulSoup(response.text)
house_list = html.select('.list > li')
if not house_list:
break
for house in house_list:
house_title = house.select("h2")[0].string.encode("utf-8")
house_url = urljoin(url,house.select("a")[0]["href"])
house_info_list = house_title.split()
if "公寓" in house_info_list[1] or "青年公寓" in house_info_list[1]:
house_location = house_info_list[0]
else:
house_location = house_info_list[1]
house_money = house.select(".money")[0].select("b")[0].string.encode("utf-8")
csv_writer.writerow([house_title,house_location,house_money,house_url])
csv_file.close()
生成的rent.csv表的呈现如下所示:
查看全部
网页qq抓取什么原理(网络爬虫常见的抓取策略:1.深度优先遍历策略深度
)
有一个特殊的爬虫网站:网络爬虫的基本原理
网络爬虫是搜索引擎捕获系统的重要组成部分。爬虫的主要目的是将Internet上的网页下载到本地,以形成网络内容的镜像或备份。本博客主要对爬虫和爬虫系统进行简要概述
一、web爬虫的基本结构和工作流程
网络爬虫的总体框架如图所示:
网络爬虫的基本工作流程如下:
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可分为五个部分:
三、crawling策略
在爬虫系统中,要获取的URL队列是一个非常重要的部分。URL队列中要获取的URL的排列顺序也是一个非常重要的问题,因为它涉及先获取页面,然后获取哪个页面。确定这些URL顺序的方法称为爬网策略。以下重点介绍几种常见的捕获策略:
1.深度优先遍历策略
深度优先遍历策略意味着网络爬虫将从起始页开始,逐个跟踪链接。处理完这一行后,它将转到下一个起始页并继续跟踪链接。以下图为例:
遍历路径:a-f-g e-h-i B C D
2.width优先遍历策略
宽度优先遍历策略的基本思想是将新下载的网页中的链接直接插入要爬网的URL队列的末尾。也就是说,网络爬虫将首先抓取起始页面中的所有链接页面,然后选择其中一个链接页面以继续抓取此页面中的所有链接页面。以上图为例:
遍历路径:a-b-c-d-e-f g h I
3.反向链路计数策略
反向链接数是指其他网页指向某个网页的链接数。反向链接的数量表示其他人推荐网页内容的程度。因此,大多数情况下,搜索引擎的爬行系统都会利用这个指标来评价网页的重要性,从而确定不同网页的爬行顺序
在现实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全等着他或我。因此,搜索引擎经常考虑可靠的反向链接数量
一个简单的爬虫程序示例在同一个城市中爬行58所房屋,包括介绍、房屋类型、房价和其他信息,然后将它们写入rent.csv文件以形成一个表
#!/usr/bin/python
#coding=utf-8
from bs4 import BeautifulSoup
from urlparse import urljoin
import requests
import csv
# 选取价格在1500-2000之间的房子信息
url = 'http://bj.58.com/pinpaigongyu/pn/{page}/?minprice=1500_2000'
page = 0
csv_file = open('rent.csv','wb')
csv_writer = csv.writer(csv_file,delimiter = ',')
while True:
page += 1
print "fetch: ",url.format(page = page)
response = requests.get(url.format(page = page))
html = BeautifulSoup(response.text)
house_list = html.select('.list > li')
if not house_list:
break
for house in house_list:
house_title = house.select("h2")[0].string.encode("utf-8")
house_url = urljoin(url,house.select("a")[0]["href"])
house_info_list = house_title.split()
if "公寓" in house_info_list[1] or "青年公寓" in house_info_list[1]:
house_location = house_info_list[0]
else:
house_location = house_info_list[1]
house_money = house.select(".money")[0].select("b")[0].string.encode("utf-8")
csv_writer.writerow([house_title,house_location,house_money,house_url])
csv_file.close()
生成的rent.csv表的呈现如下所示:
网页qq抓取什么原理(百度抓取器会和网站首页的交互设计)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-12 10:16
首先,百度的爬虫会与网站的主页进行交互。拿到网站首页后,会理解页面,理解收录(类型,值计算),其次会把网站首页的所有超链接都提取出来。
如上图所示,首页上的超链接称为“post-links”。下一轮爬行时,爬虫会继续与这些超链接页面进行交互,并获取页面进行提炼。一层一层的不断抓取,构成了一个抓取循环。
一、Grab-Friendly Optimization1、URL 规范
任何资源都是通过 URL 获取的。 URL是相对于网站的门牌号,所以URL规划很重要。尤其是在上图所示的“待抓取网址”环境下,爬虫在首页的时候,不知道网址长什么样子。
优秀网址的特点是主流、简单,所以你可能不想做出一些让人看起来很直观的非主流风格。
优秀网址示例:
如上图,第一个是百度知道的链接。整个链接分为三个部分。第一部分是网站的站点,第二部分是资源类型,第三部分是资源ID。这种网址很简单,爬虫看起来很不错。
如上图,第三篇文章比百度多了一段。首先,第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录。最后一段是网站的内容 ID。像这样的网址也符合标准。
不友好网址示例:
如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种网址含有字符,而且这个网址中含有文章的标题,导致网址有偏差。与简单的 URL 相比,较长的相对较长的 URL 没有优势。百度站长平台规则明确规定网址不能超过256字节。我个人建议URL长度控制在100字节以内,100个字符足以显示URL的资源。
如上图所示,此网址收录统计参数,可能会造成重复抓取,浪费网站权限。因此,可以不使用参数。如果必须使用参数,也可以保留必要的参数。参数字符实际上是可能的。使用常规连接符,例如“?”和“&”,以避免非主流连接器。
2、合理发现链接
爬虫从首页开始一层一层的爬取,所以需要做好首页和资源页的URL关系。这个爬虫爬行比较省力。
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大部分移动站都不太关注发现链接关系,所以爬虫无法抓取到内容页面。
如上图所示,这两个站点是常见的移动网站构建方式。从链接发现的角度来看,这两类网站并不友好。
Feed 流推荐:
大多数进行流式传输的网站在后端都有大量数据。用户不断刷新时会出现新的内容,但无论刷新多少次,可能只能刷新到1%左右的内容。一个爬虫相当于一个用户。爬虫不可能用这种方式爬取网站的所有内容,所以会导致部分页面被爬取。即使您有 100 万个内容,您也可能只能对其进行抓取。到 1-2 百万。
仅搜索条目:
如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫不能输入关键词再爬,所以爬虫只能爬到首页后,没有反向链接,自然爬取和收录不会很理想。
解决方案:
索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎可以通过索引页抓取你的网站最新资源,并且新发布的资源应该实时在索引页中。同步,很多纯静态网页,内容更新了,但是首页(索引页)不出来。这会导致搜索引擎甚至无法通过索引页面抓取最新的资源。第三点是后链(latest文章的URL)需要在源码中直接暴露出来,方便搜索引擎抓取。最后,索引页不要越多越好。几个高质量的索引页就足够了,比如长城。基本上,只有主页用于索引。页。
最后给大家一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新的资源。这里有两点需要注意。 .
问:提交的资源越多越好吗?
A:收录 效果的核心始终是内容的质量。如果提交大量低质量、泛滥的资源,将导致惩罚性打击。
问:为什么你提交了普通的收录却没有抓住?
A:资源提交只能加速资源发现,不能保证短期抓取。当然,百度表示会不断优化算法,让优质内容更快被抓取。
3、访问友好
抓取器必须与网站进行交互,并且必须保证网站的稳定性,这样抓取器才能正常抓取。那么访问友好性主要包括以下几个方面。
访问速度优化:
建议加载时间控制在2S以内,这样无论是用户还是爬虫,打开速度快的网站会更受青睐,二是避免不必要的跳转。虽然这是一小部分,但是网站里面还是有很多层次的跳转,所以对于爬虫来说,很可能会在多层次跳转的同时断开。一般是把不带www的域名重定向到带WWW的域名,然后带WWW的域名需要重定向到https,最后更换新站。在这种情况下,将有三个或四个级别的重定向。如果有类似网站的修改,建议直接跳转到新域名。 查看全部
网页qq抓取什么原理(百度抓取器会和网站首页的交互设计)
首先,百度的爬虫会与网站的主页进行交互。拿到网站首页后,会理解页面,理解收录(类型,值计算),其次会把网站首页的所有超链接都提取出来。
如上图所示,首页上的超链接称为“post-links”。下一轮爬行时,爬虫会继续与这些超链接页面进行交互,并获取页面进行提炼。一层一层的不断抓取,构成了一个抓取循环。
一、Grab-Friendly Optimization1、URL 规范
任何资源都是通过 URL 获取的。 URL是相对于网站的门牌号,所以URL规划很重要。尤其是在上图所示的“待抓取网址”环境下,爬虫在首页的时候,不知道网址长什么样子。
优秀网址的特点是主流、简单,所以你可能不想做出一些让人看起来很直观的非主流风格。
优秀网址示例:
如上图,第一个是百度知道的链接。整个链接分为三个部分。第一部分是网站的站点,第二部分是资源类型,第三部分是资源ID。这种网址很简单,爬虫看起来很不错。
如上图,第三篇文章比百度多了一段。首先,第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录。最后一段是网站的内容 ID。像这样的网址也符合标准。
不友好网址示例:
如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种网址含有字符,而且这个网址中含有文章的标题,导致网址有偏差。与简单的 URL 相比,较长的相对较长的 URL 没有优势。百度站长平台规则明确规定网址不能超过256字节。我个人建议URL长度控制在100字节以内,100个字符足以显示URL的资源。
如上图所示,此网址收录统计参数,可能会造成重复抓取,浪费网站权限。因此,可以不使用参数。如果必须使用参数,也可以保留必要的参数。参数字符实际上是可能的。使用常规连接符,例如“?”和“&”,以避免非主流连接器。
2、合理发现链接
爬虫从首页开始一层一层的爬取,所以需要做好首页和资源页的URL关系。这个爬虫爬行比较省力。
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大部分移动站都不太关注发现链接关系,所以爬虫无法抓取到内容页面。
如上图所示,这两个站点是常见的移动网站构建方式。从链接发现的角度来看,这两类网站并不友好。
Feed 流推荐:
大多数进行流式传输的网站在后端都有大量数据。用户不断刷新时会出现新的内容,但无论刷新多少次,可能只能刷新到1%左右的内容。一个爬虫相当于一个用户。爬虫不可能用这种方式爬取网站的所有内容,所以会导致部分页面被爬取。即使您有 100 万个内容,您也可能只能对其进行抓取。到 1-2 百万。
仅搜索条目:
如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫不能输入关键词再爬,所以爬虫只能爬到首页后,没有反向链接,自然爬取和收录不会很理想。
解决方案:
索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎可以通过索引页抓取你的网站最新资源,并且新发布的资源应该实时在索引页中。同步,很多纯静态网页,内容更新了,但是首页(索引页)不出来。这会导致搜索引擎甚至无法通过索引页面抓取最新的资源。第三点是后链(latest文章的URL)需要在源码中直接暴露出来,方便搜索引擎抓取。最后,索引页不要越多越好。几个高质量的索引页就足够了,比如长城。基本上,只有主页用于索引。页。
最后给大家一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新的资源。这里有两点需要注意。 .
问:提交的资源越多越好吗?
A:收录 效果的核心始终是内容的质量。如果提交大量低质量、泛滥的资源,将导致惩罚性打击。
问:为什么你提交了普通的收录却没有抓住?
A:资源提交只能加速资源发现,不能保证短期抓取。当然,百度表示会不断优化算法,让优质内容更快被抓取。
3、访问友好
抓取器必须与网站进行交互,并且必须保证网站的稳定性,这样抓取器才能正常抓取。那么访问友好性主要包括以下几个方面。
访问速度优化:
建议加载时间控制在2S以内,这样无论是用户还是爬虫,打开速度快的网站会更受青睐,二是避免不必要的跳转。虽然这是一小部分,但是网站里面还是有很多层次的跳转,所以对于爬虫来说,很可能会在多层次跳转的同时断开。一般是把不带www的域名重定向到带WWW的域名,然后带WWW的域名需要重定向到https,最后更换新站。在这种情况下,将有三个或四个级别的重定向。如果有类似网站的修改,建议直接跳转到新域名。

