
网页css js 抓取助手
网页css js 抓取助手(《开源精选》本期、Gitee等开源社区中优质项目的栏目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-13 22:18
《开源精选》是我们在Github、Gitee等开源社区分享优质项目的专栏,内容包括技术、学习、实用和各种有趣的内容。本期推荐的NEOCrawler(中文名:牛卡)是一个由nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合垂直领域的data采集和爬虫的二次开发。
主要特征
使用nodejs实现,javascript简单、高效、易学,为爬虫的开发和爬虫用户的二次开发节省了大量时间;nodejs使用Google V8作为运行引擎,性能相当可观;由于 nodejs 语言本身的非阻塞和异步特性,运行爬虫,例如 IO 密集型 CPU 不敏感系统,表现非常好。与其他语言版本相比,开发量小于C/C++/JAVA,性能高于JAVA的多线程实现和Python的异步和携程方式。完成。
调度中心负责网站的调度,爬虫进程以分布式方式运行,即中央调度器在单个时间片内统一决定爬取哪些网站,协调各个爬虫的工作。爬虫的单点故障不会影响整个系统。
爬取时,爬虫对网页进行结构化分析,提取出需要的数据字段,不仅存储网页的源代码,还存储结构化的字段数据,不仅使数据在网页后立即可用被爬取,而且便于实现存储过程中内容的精确排序和重新排序。
phantomjs 是集成的。Phantomjs 是一个不需要图形界面环境的 Web 浏览器实现。可以用来爬取需要执行js生成内容的网页。通过js语句在页面上执行用户动作,实现表单填写提交,然后抓取下一页内容,点击按钮,然后跳转页面再抓取下一页内容等。
它集成了代理IP使用功能。该功能针对防爬网站(仅限单IP下爬虫的访问量、流量、智能判断),需要提供一个可用的代理IP,爬虫会选择source 网站 也可以访问代理IP地址,source 网站 不能阻止爬取。
可配置项目:
1)。用正则表达式描述,相似的网页被组合在一起并使用相同的规则。爬虫系统(以下各项指某些类型的URL配置项);
2)。起始地址、获取方式、存储位置、页面处理方式等;
3)。需要采集的链接规则,使用CSS选择器限制爬虫只采集出现在页面某个位置的链接;
3)。页面抽取规则,可以使用CSS选择器和正则表达式来定位各个字段内容要抽取的位置;
4)。预定义页面打开后要注入执行的js语句;
5)。网页上的默认cookie;
6)。判断该类网页是否正常返回的规则是指定部分网页恢复正常后必须存在的关键词,以供爬虫检测;
7)。数据抽取是否完整的判断规则,从抽取的字段中选择几个非常必要的字段作为抽取完整性的评价标准;
8)。此类网页的调度权重(优先级)和周期(重新获取和更新的时间)。
建筑学
图中黄色部分是爬虫系统的各个子系统
SuperScheduler 是一个中央调度器。爬虫将采集到的 URL 放入各种 URL 对应的 URL 库中。SuperScheduler 会根据调度规则从各个 URL 库中抽取相应数量的 URL 放入待爬取队列中。
Spider是一个以分布式方式运行的爬虫程序。它将任务从调度器调度的待爬取队列中取出进行爬取,将找到的URL放入URL库,存储提取的内容,将爬虫程序划分为一个核心。并下载、解压、流水线4个中间件,以便轻松重新定制爬虫实例中的功能之一。
ProxyRouter 在使用代理 IP 时智能地将爬虫请求路由到可用的代理 IP。
webconfig是一个网络爬虫规则配置后台。
运行步骤
运行环境准备
create 'crawled',{NAME => 'basic', VERSIONS => 3},{NAME=>"data",VERSIONS=>3},{NAME => 'extra', VERSIONS => 3}
create 'crawled_bin',{NAME => 'basic', VERSIONS => 3},{NAME=>"binary",VERSIONS=>3}
推荐使用 hbase rest 方法。启动hbase后,在hbase目录的bin子目录下执行以下命令启动hbase rest:
./hbase-daemon.sh start rest
默认端口为 8080,将在以下配置中使用。
##[实例配置]
实例在实例目录下,复制一份example,并重命名其他实例名,例如:abc,后面的描述中以abc为例。
编辑 instance/abc/setting.json
{
/*注意:此处用于解释各项配置,真正的setting.json中不能包含注释*/
"driller_info_redis_db":["127.0.0.1",6379,0],/*网址规则配置信息存储位置,最后一个数字表示redis的第几个数据库*/
"url_info_redis_db":["127.0.0.1",6379,1],/*网址信息存储位置*/
"url_report_redis_db":["127.0.0.1",6380,2],/*抓取错误信息存储位置*/
"proxy_info_redis_db":["127.0.0.1",6379,3],/*http代理网址存储位置*/
"use_proxy":false,/*是否使用代理服务*/
"proxy_router":"127.0.0.1:2013",/*使用代理服务的情况下,代理服务的路由中心地址*/
"download_timeout":60,/*下载超时时间,秒,不等同于相应超时*/
"save_content_to_hbase":false,/*是否将抓取信息存储到hbase,目前只在0.94下测试过*/
"crawled_hbase_conf":["localhost",8080],/*hbase rest的配置,你可以使用tcp方式连接,配置为{"zookeeperHosts": ["localhost:2181"],"zookeeperRoot": "/hbase"},此模式下有OOM Bug,不建议使用*/
"crawled_hbase_table":"crawled",/*抓取的数据保存在hbase的表*/
"crawled_hbase_bin_table":"crawled_bin",/*抓取的二进制数据保存在hbase的表*/
"statistic_mysql_db":["127.0.0.1",3306,"crawling","crawler","123"],/*用来存储抓取日志分析结果,需要结合flume来实现,一般不使用此项*/
"check_driller_rules_interval":120,/*多久检测一次网址规则的变化以便热刷新到运行中的爬虫*/
"spider_concurrency":5,/*爬虫的抓取页面并发请求数*/
"spider_request_delay":0,/*两个并发请求之间的间隔时间,秒*/
"schedule_interval":60,/*调度器两次调度的间隔时间*/
"schedule_quantity_limitation":200,/*调度器给爬虫的最大网址待抓取数量*/
"download_retry":3,/*错误重试次数*/
"log_level":"DEBUG",/*日志级别*/
"use_ssdb":false,/*是否使用ssdb*/
"to_much_fail_exit":false,/*错误太多的时候是否自动终止爬虫*/
"keep_link_relation":false/*链接库里是否存储链接间关系*/
}
跑
在网页界面配置爬取规则
调试单个URL爬取是否OK
运行调度器(调度器可以启动一个)
如果使用代理 IP 获取,则启用代理路由
启动爬虫(爬虫可以启动多个分布式)
下面是具体的启动命令
1.运行WEB配置(配置规则见下一章)
node run.js -i abc -a config -p 8888
在浏览器中打开:8888可以在网页界面配置爬取规则
2.测试单页爬取
node run.js -i abc -a test -l "http://domain/page/"
3.运行调度器
node run.js -i abc -a schedule
4.仅当使用代理 IP 捕获时才需要运行代理路由
node run.js -i abc -a proxy -p 2013
这里的 -p 指定代理路由的端口。如果在本地运行,setting.json的proxy_router和端口为127.0.0.1:2013
5.运行爬虫
node run.js -i abc -a crawl
可以在instance/example/logs下查看输出日志debug-result.json
Redis/ssdb数据结构
了解数据结构将有助于您熟悉整个系统进行二次开发。Neocrawler使用了4个存储空间,driller_info_redis_db、url_info_redis_db、url_report_redis_db、proxy_info_redis_db,可以在实例下的settings.json中配置,4个空间的存储类型不同。键名不会冲突,可以将4个空格指向一个redis/ssdb库,每个空间的增长量不同。如果使用redis,建议每个空间指向一个db,有条件的情况下一个redis指向一个空间。
Driller_info_redis_db
存储抓取规则和 URL
url_info_redis_db
这个空间存放的是URL信息,爬取操作时间越长,这里的数据量就越大。
url_report_redis_db
这个空间存储爬虫报告
proxy_info_redis_db
此空间存储与代理 IP 相关的数据
更多内容: 查看全部
网页css js 抓取助手(《开源精选》本期、Gitee等开源社区中优质项目的栏目)
《开源精选》是我们在Github、Gitee等开源社区分享优质项目的专栏,内容包括技术、学习、实用和各种有趣的内容。本期推荐的NEOCrawler(中文名:牛卡)是一个由nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合垂直领域的data采集和爬虫的二次开发。
主要特征
使用nodejs实现,javascript简单、高效、易学,为爬虫的开发和爬虫用户的二次开发节省了大量时间;nodejs使用Google V8作为运行引擎,性能相当可观;由于 nodejs 语言本身的非阻塞和异步特性,运行爬虫,例如 IO 密集型 CPU 不敏感系统,表现非常好。与其他语言版本相比,开发量小于C/C++/JAVA,性能高于JAVA的多线程实现和Python的异步和携程方式。完成。
调度中心负责网站的调度,爬虫进程以分布式方式运行,即中央调度器在单个时间片内统一决定爬取哪些网站,协调各个爬虫的工作。爬虫的单点故障不会影响整个系统。
爬取时,爬虫对网页进行结构化分析,提取出需要的数据字段,不仅存储网页的源代码,还存储结构化的字段数据,不仅使数据在网页后立即可用被爬取,而且便于实现存储过程中内容的精确排序和重新排序。
phantomjs 是集成的。Phantomjs 是一个不需要图形界面环境的 Web 浏览器实现。可以用来爬取需要执行js生成内容的网页。通过js语句在页面上执行用户动作,实现表单填写提交,然后抓取下一页内容,点击按钮,然后跳转页面再抓取下一页内容等。
它集成了代理IP使用功能。该功能针对防爬网站(仅限单IP下爬虫的访问量、流量、智能判断),需要提供一个可用的代理IP,爬虫会选择source 网站 也可以访问代理IP地址,source 网站 不能阻止爬取。
可配置项目:
1)。用正则表达式描述,相似的网页被组合在一起并使用相同的规则。爬虫系统(以下各项指某些类型的URL配置项);
2)。起始地址、获取方式、存储位置、页面处理方式等;
3)。需要采集的链接规则,使用CSS选择器限制爬虫只采集出现在页面某个位置的链接;
3)。页面抽取规则,可以使用CSS选择器和正则表达式来定位各个字段内容要抽取的位置;
4)。预定义页面打开后要注入执行的js语句;
5)。网页上的默认cookie;
6)。判断该类网页是否正常返回的规则是指定部分网页恢复正常后必须存在的关键词,以供爬虫检测;
7)。数据抽取是否完整的判断规则,从抽取的字段中选择几个非常必要的字段作为抽取完整性的评价标准;
8)。此类网页的调度权重(优先级)和周期(重新获取和更新的时间)。
建筑学
图中黄色部分是爬虫系统的各个子系统
SuperScheduler 是一个中央调度器。爬虫将采集到的 URL 放入各种 URL 对应的 URL 库中。SuperScheduler 会根据调度规则从各个 URL 库中抽取相应数量的 URL 放入待爬取队列中。
Spider是一个以分布式方式运行的爬虫程序。它将任务从调度器调度的待爬取队列中取出进行爬取,将找到的URL放入URL库,存储提取的内容,将爬虫程序划分为一个核心。并下载、解压、流水线4个中间件,以便轻松重新定制爬虫实例中的功能之一。
ProxyRouter 在使用代理 IP 时智能地将爬虫请求路由到可用的代理 IP。
webconfig是一个网络爬虫规则配置后台。
运行步骤
运行环境准备
create 'crawled',{NAME => 'basic', VERSIONS => 3},{NAME=>"data",VERSIONS=>3},{NAME => 'extra', VERSIONS => 3}
create 'crawled_bin',{NAME => 'basic', VERSIONS => 3},{NAME=>"binary",VERSIONS=>3}
推荐使用 hbase rest 方法。启动hbase后,在hbase目录的bin子目录下执行以下命令启动hbase rest:
./hbase-daemon.sh start rest
默认端口为 8080,将在以下配置中使用。
##[实例配置]
实例在实例目录下,复制一份example,并重命名其他实例名,例如:abc,后面的描述中以abc为例。
编辑 instance/abc/setting.json
{
/*注意:此处用于解释各项配置,真正的setting.json中不能包含注释*/
"driller_info_redis_db":["127.0.0.1",6379,0],/*网址规则配置信息存储位置,最后一个数字表示redis的第几个数据库*/
"url_info_redis_db":["127.0.0.1",6379,1],/*网址信息存储位置*/
"url_report_redis_db":["127.0.0.1",6380,2],/*抓取错误信息存储位置*/
"proxy_info_redis_db":["127.0.0.1",6379,3],/*http代理网址存储位置*/
"use_proxy":false,/*是否使用代理服务*/
"proxy_router":"127.0.0.1:2013",/*使用代理服务的情况下,代理服务的路由中心地址*/
"download_timeout":60,/*下载超时时间,秒,不等同于相应超时*/
"save_content_to_hbase":false,/*是否将抓取信息存储到hbase,目前只在0.94下测试过*/
"crawled_hbase_conf":["localhost",8080],/*hbase rest的配置,你可以使用tcp方式连接,配置为{"zookeeperHosts": ["localhost:2181"],"zookeeperRoot": "/hbase"},此模式下有OOM Bug,不建议使用*/
"crawled_hbase_table":"crawled",/*抓取的数据保存在hbase的表*/
"crawled_hbase_bin_table":"crawled_bin",/*抓取的二进制数据保存在hbase的表*/
"statistic_mysql_db":["127.0.0.1",3306,"crawling","crawler","123"],/*用来存储抓取日志分析结果,需要结合flume来实现,一般不使用此项*/
"check_driller_rules_interval":120,/*多久检测一次网址规则的变化以便热刷新到运行中的爬虫*/
"spider_concurrency":5,/*爬虫的抓取页面并发请求数*/
"spider_request_delay":0,/*两个并发请求之间的间隔时间,秒*/
"schedule_interval":60,/*调度器两次调度的间隔时间*/
"schedule_quantity_limitation":200,/*调度器给爬虫的最大网址待抓取数量*/
"download_retry":3,/*错误重试次数*/
"log_level":"DEBUG",/*日志级别*/
"use_ssdb":false,/*是否使用ssdb*/
"to_much_fail_exit":false,/*错误太多的时候是否自动终止爬虫*/
"keep_link_relation":false/*链接库里是否存储链接间关系*/
}
跑
在网页界面配置爬取规则
调试单个URL爬取是否OK
运行调度器(调度器可以启动一个)
如果使用代理 IP 获取,则启用代理路由
启动爬虫(爬虫可以启动多个分布式)
下面是具体的启动命令
1.运行WEB配置(配置规则见下一章)
node run.js -i abc -a config -p 8888
在浏览器中打开:8888可以在网页界面配置爬取规则
2.测试单页爬取
node run.js -i abc -a test -l "http://domain/page/"
3.运行调度器
node run.js -i abc -a schedule
4.仅当使用代理 IP 捕获时才需要运行代理路由
node run.js -i abc -a proxy -p 2013
这里的 -p 指定代理路由的端口。如果在本地运行,setting.json的proxy_router和端口为127.0.0.1:2013
5.运行爬虫
node run.js -i abc -a crawl
可以在instance/example/logs下查看输出日志debug-result.json
Redis/ssdb数据结构
了解数据结构将有助于您熟悉整个系统进行二次开发。Neocrawler使用了4个存储空间,driller_info_redis_db、url_info_redis_db、url_report_redis_db、proxy_info_redis_db,可以在实例下的settings.json中配置,4个空间的存储类型不同。键名不会冲突,可以将4个空格指向一个redis/ssdb库,每个空间的增长量不同。如果使用redis,建议每个空间指向一个db,有条件的情况下一个redis指向一个空间。
Driller_info_redis_db
存储抓取规则和 URL
url_info_redis_db
这个空间存放的是URL信息,爬取操作时间越长,这里的数据量就越大。
url_report_redis_db
这个空间存储爬虫报告
proxy_info_redis_db
此空间存储与代理 IP 相关的数据
更多内容:
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-12 23:13
为大家整理了25个前端相关学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望你能帮助大家!
▍CSS相关
●1
CSSBattle-在线竞争 CSS
CSS线上竞技,一款非常有趣的竞技游戏,一共12关,需要用HTML和CSS来100%还原它给出的页面,然后尽量减少代码,还可以查看全球排行榜,看解决方案。
●2
学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
●3
Flexbox Froggy - 一个学习 Flex 布局的小游戏
一款引导式学习flex布局游戏,使用flex布局让青蛙在荷叶上跳跃甚至完成,游戏收录了几乎所有常用的属性,所以学起来很有趣,形象好记,谁要flex 布局如果你熟悉的话,在这里多练习一下。
●4
EnjoyCSS - 在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件一样。
●5
CSS 技巧 - CSS 技巧
这个网站 每天都会不断更新一些优秀的教程和CSS 技巧的技巧文章。
●6
Neumorphism - 实现新的模拟效果
可以轻松实现新的模仿效果。不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数。同时可以直接复制CSS代码。
●7
uiGradients - 共享渐变
提供渐变色效果的网站有近百种渐变色方案。可以根据自己的风格选择搭配,直接获取渐变色对应的CSS代码即可。
▍JS相关
●8
JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。它主要写如何避免一些常见的错误,发现难以发现的错误,并深入了解 JavaScript 的语言特性。
●9
JSTips - JS 技巧
每天一点点的Javascript知识。
●10
JSweekly - 科技周刊
专注于 Javascript 的技术周刊。
●11
CDNJS - JavaScript 库
CDNJS为开发者提供最新的前端web开发资源,免费使用,没有使用限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端CDN服务中排名第二(第一是谷歌),性能优异。
●12
Beautiful Open - 开源 JS 库合集
采集各类优秀设计的开源项目,从cms内容管理系统到小型常用Javascript库,适合网站开发的用户使用。
●13
JavaScript Fun - 代码库集合
最流行的 JavaScript 代码库集合,显示流行排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow - 程序员问答网络
全球IT界最受欢迎的技术问答之一网站,一个解决bug的社区,号称“编程界的100,000个为什么”。
●15
掘金 - 优质技术社区
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术 文章 包括 Android、iOS、前端和后端资源。
●16
Codrops - 网页设计开发博客
发布技术文章和网络教程,提供经验,少踩坑,资源丰富。许多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码工具,有各种效果的案例特效(炫技),你可以开发自己的前端设计基于他们的演示。
●18
代码沙盒
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。 React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
●19
JSBin
另一个轻量级的在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材是常用的图标。可以点击官方提供的素材进行二次设计,也可以导出设计好的图标。
●21
OpenMoji - 免费表情符号库
提供带有源代码的表情符号库,可以免费下载使用。
● 22
共享图标 - 免费矢量图片
一个提供超过250,000种ICON矢量图素材,120多个类别的网站,所有素材均以PNG和SVG格式提供,素材有多种尺寸可供选择,包括512*512、256*256、128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
● 23
tableconvert - 在线表格编辑器
一个强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的相互转换。当您需要转换表格,但无法使其变形时,请尝试使用此工具。
● 24
Feathericons-极简主义图标图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发。图标格式为 SVG。
● 25
HTML5 + CSS 3 免费模板
提供大量HTML5模板,用户可以自己分享和修改模板。
本文推荐的网站总结:
CSS战斗:
学习 CSS 布局:
Flexbox Froggy:
享受CSS:
CSS 技巧:
神经拟态:
ui渐变:
JavaScript:
JS 提示:
JS周刊:
CDNJS:
美丽的开放:
JavaScript 乐趣:
堆栈溢出:
掘金:
Codrops:
代码笔:
代码沙盒:
JS斌:
图标:
打开Moji:
分享图标:
表格转换:
羽毛图标:
HTML5UP: 查看全部
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具)
为大家整理了25个前端相关学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望你能帮助大家!
▍CSS相关
●1
CSSBattle-在线竞争 CSS
CSS线上竞技,一款非常有趣的竞技游戏,一共12关,需要用HTML和CSS来100%还原它给出的页面,然后尽量减少代码,还可以查看全球排行榜,看解决方案。
●2
学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
●3
Flexbox Froggy - 一个学习 Flex 布局的小游戏
一款引导式学习flex布局游戏,使用flex布局让青蛙在荷叶上跳跃甚至完成,游戏收录了几乎所有常用的属性,所以学起来很有趣,形象好记,谁要flex 布局如果你熟悉的话,在这里多练习一下。
●4
EnjoyCSS - 在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件一样。
●5
CSS 技巧 - CSS 技巧
这个网站 每天都会不断更新一些优秀的教程和CSS 技巧的技巧文章。
●6
Neumorphism - 实现新的模拟效果
可以轻松实现新的模仿效果。不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数。同时可以直接复制CSS代码。
●7
uiGradients - 共享渐变
提供渐变色效果的网站有近百种渐变色方案。可以根据自己的风格选择搭配,直接获取渐变色对应的CSS代码即可。
▍JS相关
●8
JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。它主要写如何避免一些常见的错误,发现难以发现的错误,并深入了解 JavaScript 的语言特性。
●9
JSTips - JS 技巧
每天一点点的Javascript知识。
●10
JSweekly - 科技周刊
专注于 Javascript 的技术周刊。
●11
CDNJS - JavaScript 库
CDNJS为开发者提供最新的前端web开发资源,免费使用,没有使用限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端CDN服务中排名第二(第一是谷歌),性能优异。
●12
Beautiful Open - 开源 JS 库合集
采集各类优秀设计的开源项目,从cms内容管理系统到小型常用Javascript库,适合网站开发的用户使用。
●13
JavaScript Fun - 代码库集合
最流行的 JavaScript 代码库集合,显示流行排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow - 程序员问答网络
全球IT界最受欢迎的技术问答之一网站,一个解决bug的社区,号称“编程界的100,000个为什么”。
●15
掘金 - 优质技术社区
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术 文章 包括 Android、iOS、前端和后端资源。
●16
Codrops - 网页设计开发博客
发布技术文章和网络教程,提供经验,少踩坑,资源丰富。许多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码工具,有各种效果的案例特效(炫技),你可以开发自己的前端设计基于他们的演示。
●18
代码沙盒
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。 React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
●19
JSBin
另一个轻量级的在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材是常用的图标。可以点击官方提供的素材进行二次设计,也可以导出设计好的图标。
●21
OpenMoji - 免费表情符号库
提供带有源代码的表情符号库,可以免费下载使用。
● 22
共享图标 - 免费矢量图片
一个提供超过250,000种ICON矢量图素材,120多个类别的网站,所有素材均以PNG和SVG格式提供,素材有多种尺寸可供选择,包括512*512、256*256、128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
● 23
tableconvert - 在线表格编辑器
一个强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的相互转换。当您需要转换表格,但无法使其变形时,请尝试使用此工具。
● 24
Feathericons-极简主义图标图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发。图标格式为 SVG。
● 25
HTML5 + CSS 3 免费模板
提供大量HTML5模板,用户可以自己分享和修改模板。
本文推荐的网站总结:
CSS战斗:
学习 CSS 布局:
Flexbox Froggy:
享受CSS:
CSS 技巧:
神经拟态:
ui渐变:
JavaScript:
JS 提示:
JS周刊:
CDNJS:
美丽的开放:
JavaScript 乐趣:
堆栈溢出:
掘金:
Codrops:
代码笔:
代码沙盒:
JS斌:
图标:
打开Moji:
分享图标:
表格转换:
羽毛图标:
HTML5UP:
网页css js 抓取助手(一下前端的基础知识视频和学习路线,对比认识一下各个框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-12 23:05
很多朋友听到前端技术都会觉得有些陌生。但实际上,前端,你每天都在联系。
你使用的APP,你浏览的网页,你能看到的界面,都属于前端。
最重要的三种前端技术 HTML、CSS 和 JavaScript 是每个前端开发人员必须具备的技能。
有了这些技巧,你可以快速打造出炫酷的APP界面或者简洁大方的网站页面。那么,让我们一起快速浏览一下这三种技术。
实验介绍
本实验主要介绍前端的基础知识,对比了解各个框架的代码编写方法,介绍我们本次技术选型的主要思路。对于HTML、CSS、JavaScript这三种前端技术,简单介绍一下基本情况和常用语法。中间介绍了现代框架的一些情况,通过实际案例,我们可以用代码直观的了解各种框架的实现方式。最后,分析项目的技术选型。
知识点
HTML、CSS、JavaScript 快速概览
前端框架概述和选择
后端选择
数据库选择
网络服务器选择
前端技术介绍
本节我们简单介绍一下最基本的前端HTML、CSS、JavaScript三驾马车。虽然本课程的预设读者都是零基础的开发者,但是前端开发对这三种技术的使用肯定是有要求的。建议花时间研究一下《Web前端工程师之路》的stage 1甚至stage 2。这只是语法介绍和基本用法的概述。
在前端领域工作了几年,总结了一套前端学习的强化视频和学习路线。如果你有对前端开发感兴趣的伙伴,无论你是想转行,还是想当大学生,还是想在工作中提升自己 有能力的web前端党,欢迎大家加入我的前端开发交流群:603985993 希望大家真诚交流!,与企业的需求同步。小伙伴们都在里面学习交流,每天都会有大牛定时讲解前端技术!也可以关注我的微信公众号:【前端留学生】每天更新最新科技文章干货。
在此之前,先了解一下实验环境。实验环境与VS Code体验基本一致。您可以启动终端并在其中输入 Linux 命令。
以下无特殊说明的命令均在此终端命令行中输入。大多数命令可以通过打开多个终端窗口来单独执行。
因此,让我们快速浏览一下。
HTML
HTML 代表超文本标记语言,自万维网和浏览器出现以来就一直存在。主要用于结构化信息,方便浏览器显示。
以标签对为主要特征,如
这是一个段落,这些标签会被浏览器解析成不同的模块。例如,p 标签是段落,img 标签是图像,a 标签是超链接。标签名称不区分大小写。
现在就试试。首先通过命令行创建一个demo目录:
mkdir demo
然后从命令行进入demo目录:
cd ./demo
新建一个hello.html文件,可以在实验环境左侧的浏览器框中右键demo,选择New File,命名为hello.html;也可以在命令行终端输入touch hello.html,同样是新建文件。
在其中输入以下内容:
标题
正文
然后右键单击该文件并选择打开方式 → 预览。
看见?其实我们只是新建了一个.html后缀的文本文件,然后浏览器就可以显示里面的内容了。也可以在桌面新建一个,用浏览器打开看看效果。
这里嵌套代码的缩进是为了美观和可读性,并不是严格要求的。
head标签收录一些暂时不需要的header信息,渲染的主体是body标签。下面我们修改body标签中的内容,填写一些常用的标签,直观感受一下。
页面标题
一个块容器
又一个块容器
这里是段落了,间距变大
一个块容器
多层嵌套:
内部第一个
内部第二个
保存后,切换到浏览选项卡查看。你觉得被愚弄了吗?嵌套完全没有体现出来,就像Word中的布局一样,按回车几次。
由于我们没有修改显示样式,这是 CSS 的事情。HTML主要管理内容的组织结构。
这里有一点学习建议。请手动输入本课程给出的所有代码,忘记复制和粘贴快捷键。
而且最好不要一个字一个地生搬硬套,尽量读一行或者一小段代码,靠短期印象输出,不怕出错,只有思考和输出实践是掌握技能捷径的最快方法。
以上两句话是本课程最有价值的内容之一。
接下来我们对刚才的代码进行修改,在body中添加几个常用的标签。每次修改保存后记得去预览页面查看样式变化。
4 级标题
HTML
CSS
JavaScript
点击超链接跳转
最后一个链接标签a和图片标签img都有标签属性,格式为attr="value",可以给标签添加更丰富的信息。
同时img标签还是单标签,以后不需要添加使用。
我们对 HTML 的简要介绍到此结束。
网上看到的各种五颜六色的网页都是由这个HTML组成的,但为什么我们写得这么难看呢?在下一节中,我们将学习如何使用 CSS 美化页面。
CSS
CSS 代表 Cascading Style Sheets,它是一种专门用于修改 HTML 样式的语言。让我们修改上一节中的 hello.html 文件,以获得直观的感觉。
内部代码块介绍
在 head 标签内添加以下样式块:
标题
div {
border: 1px solid blue;
padding: 2px;
margin: 10px;
}
这是再次切换到预览页面,发现并没有那么简单。
这是引入 CSS 的第一种方式,HTML 内置代码块。
花括号外面的 div 是标签选择器,它选择了这个页面上的所有 div 元素。大括号内是属性名称和赋值。属性名称是固定关键字,并且已经指定了值的类型和可选范围。
阅读代码你可能知道,我们将 div 的边框设置为 1 像素宽、实心(单线)、蓝色、内边距(padding)2 像素、边距(margins)10 像素。现在练习调整单个数字并预览发生了什么?
题外话,程序员懂一些英语是非常有必要的。除了能够阅读和理解没有通过感觉学习的代码之外,还可以为 Google、Stack Overflow 和 Github Issues 编程。
导入外部文件
然后我们再次尝试导入外部文件,在hello.html的同级目录下新建一个hello.css,输入以下内容保存:
div {
color: green;
border: 2px dotted red;
}
然后修改hello.html,在style标签后面加一行link标签,加上导入类型和地址:
div {
border: 1px solid blue;
padding: 2px;
margin: 10px;
}
看一下预览,文字颜色变成了绿色,边框样式更新为2像素宽,点红色。
同样是div选择器,为什么会覆盖边框样式?注意CSS会在相同条件下覆盖前面的代码,可以尝试交换链接标签和样式标签块的顺序来查看。
联运风格
最后一种叫做interline style,结构比较简单。修改 hello.html 中
第一个内部是
内部第一个
样式会覆盖前两种方法,因为行间样式具有更高的优先级。此处涉及选择器权重。我们先来了解一个简单的公式。
!important > 内联样式 > ID > 类 | 伪类 | 属性选择 > 标签 > 继承 | 通配符。
应用多个选择器时添加权重。这是CSS中比较复杂的部分,暂时不展开。
这里还有一个小知识点。内外边距和内边距接受的完整值是四,顺序固定为“右上左下”。如果省略参数,则从末尾计算相反的合并。例如:
边距:40px 20px 50px;三个参数时,左右都是20px。
边距:40px 20px;这两个参数都是上下40px,左右20px。
边距如何:40px;作为参数?请尝试自己理解。
CSS 首先讲了这么多。虽然没有让我们的页面更漂亮,但至少我们知道自己努力的方向。
JavaScript
快速入门 JavaScript 可能会非常伤脑筋。与前两种技术 HTML 和 CSS 相比,这是一种真正的编程语言。
它也是我们后面会用到的 Vue.js 和 Node.js 的基础。很难一下子讲很多,所以希望同学们能够重视,系统地学习,至少在阅读下面的代码的时候是什么,这是什么,这是什么“困境”。
让我们直观的理解代码,还是先介绍一下内部代码块。
在 hello.html 的 head 标签内添加一段代码:
let message = "字符串提示";
function showMSG(msg) {
alert(msg);
}
修改hello.html的h1标签为:
页面标题
保存预览,点击“页面标题”,会弹出提示框。
JavaScript 代码在加载后执行,没有编译阶段。大多数情况下,行尾的分号可以省略。
我们首先定义了一个变量 message 并将其指定为“字符串提示符”。定义变量的关键字原本是 var。ES6 中的新关键字 let 范围更清晰,可以替代使用。
学习 JavaScript 经常会遇到像 ES6、ES7 这样的术语,其实就是 ECMAScript 标准的版本号。可以简单理解为新版标准为 JavaScript 增加了特定的新特性。
然后我们定义一个函数 showMSG 并添加一个形参 msg。调用函数体内部的浏览器弹窗方法,显示msg的值。function 是定义函数的关键字。暂时将其视为一个功能封闭的盒子。当函数被调用时,函数体中的代码被执行。
调用部分是先给h1标签添加onclick点击事件,点击时触发showMSG(message),也就是将消息传递给msg。
然后尝试再次调用外部js文件,新建demo.js文件,写入如下内容并保存。
message = "修改一下字符串";
然后修改hello.html文件,在脚本块后面添加一行:
这次保存预览,点击“页面标题”,可以看到弹窗的文字发生了变化。这说明页面上可以同时存在多个脚本代码块,而且它们也是顺序调用的,可以直接相互访问。对文件命名没有要求,希望不会扼杀强迫症。
JavaScript 是网页可以进行如此多交互的来源。要走的路还很长。这三种前端技术先在这里学习 查看全部
网页css js 抓取助手(一下前端的基础知识视频和学习路线,对比认识一下各个框架)
很多朋友听到前端技术都会觉得有些陌生。但实际上,前端,你每天都在联系。
你使用的APP,你浏览的网页,你能看到的界面,都属于前端。
最重要的三种前端技术 HTML、CSS 和 JavaScript 是每个前端开发人员必须具备的技能。
有了这些技巧,你可以快速打造出炫酷的APP界面或者简洁大方的网站页面。那么,让我们一起快速浏览一下这三种技术。
实验介绍
本实验主要介绍前端的基础知识,对比了解各个框架的代码编写方法,介绍我们本次技术选型的主要思路。对于HTML、CSS、JavaScript这三种前端技术,简单介绍一下基本情况和常用语法。中间介绍了现代框架的一些情况,通过实际案例,我们可以用代码直观的了解各种框架的实现方式。最后,分析项目的技术选型。
知识点
HTML、CSS、JavaScript 快速概览
前端框架概述和选择
后端选择
数据库选择
网络服务器选择
前端技术介绍
本节我们简单介绍一下最基本的前端HTML、CSS、JavaScript三驾马车。虽然本课程的预设读者都是零基础的开发者,但是前端开发对这三种技术的使用肯定是有要求的。建议花时间研究一下《Web前端工程师之路》的stage 1甚至stage 2。这只是语法介绍和基本用法的概述。
在前端领域工作了几年,总结了一套前端学习的强化视频和学习路线。如果你有对前端开发感兴趣的伙伴,无论你是想转行,还是想当大学生,还是想在工作中提升自己 有能力的web前端党,欢迎大家加入我的前端开发交流群:603985993 希望大家真诚交流!,与企业的需求同步。小伙伴们都在里面学习交流,每天都会有大牛定时讲解前端技术!也可以关注我的微信公众号:【前端留学生】每天更新最新科技文章干货。
在此之前,先了解一下实验环境。实验环境与VS Code体验基本一致。您可以启动终端并在其中输入 Linux 命令。

以下无特殊说明的命令均在此终端命令行中输入。大多数命令可以通过打开多个终端窗口来单独执行。
因此,让我们快速浏览一下。
HTML
HTML 代表超文本标记语言,自万维网和浏览器出现以来就一直存在。主要用于结构化信息,方便浏览器显示。
以标签对为主要特征,如
这是一个段落,这些标签会被浏览器解析成不同的模块。例如,p 标签是段落,img 标签是图像,a 标签是超链接。标签名称不区分大小写。
现在就试试。首先通过命令行创建一个demo目录:
mkdir demo
然后从命令行进入demo目录:
cd ./demo
新建一个hello.html文件,可以在实验环境左侧的浏览器框中右键demo,选择New File,命名为hello.html;也可以在命令行终端输入touch hello.html,同样是新建文件。
在其中输入以下内容:
标题
正文
然后右键单击该文件并选择打开方式 → 预览。

看见?其实我们只是新建了一个.html后缀的文本文件,然后浏览器就可以显示里面的内容了。也可以在桌面新建一个,用浏览器打开看看效果。
这里嵌套代码的缩进是为了美观和可读性,并不是严格要求的。
head标签收录一些暂时不需要的header信息,渲染的主体是body标签。下面我们修改body标签中的内容,填写一些常用的标签,直观感受一下。
页面标题
一个块容器
又一个块容器
这里是段落了,间距变大
一个块容器
多层嵌套:
内部第一个
内部第二个
保存后,切换到浏览选项卡查看。你觉得被愚弄了吗?嵌套完全没有体现出来,就像Word中的布局一样,按回车几次。

由于我们没有修改显示样式,这是 CSS 的事情。HTML主要管理内容的组织结构。
这里有一点学习建议。请手动输入本课程给出的所有代码,忘记复制和粘贴快捷键。
而且最好不要一个字一个地生搬硬套,尽量读一行或者一小段代码,靠短期印象输出,不怕出错,只有思考和输出实践是掌握技能捷径的最快方法。
以上两句话是本课程最有价值的内容之一。
接下来我们对刚才的代码进行修改,在body中添加几个常用的标签。每次修改保存后记得去预览页面查看样式变化。
4 级标题
HTML
CSS
JavaScript
点击超链接跳转

最后一个链接标签a和图片标签img都有标签属性,格式为attr="value",可以给标签添加更丰富的信息。
同时img标签还是单标签,以后不需要添加使用。
我们对 HTML 的简要介绍到此结束。
网上看到的各种五颜六色的网页都是由这个HTML组成的,但为什么我们写得这么难看呢?在下一节中,我们将学习如何使用 CSS 美化页面。
CSS
CSS 代表 Cascading Style Sheets,它是一种专门用于修改 HTML 样式的语言。让我们修改上一节中的 hello.html 文件,以获得直观的感觉。
内部代码块介绍
在 head 标签内添加以下样式块:
标题
div {
border: 1px solid blue;
padding: 2px;
margin: 10px;
}
这是再次切换到预览页面,发现并没有那么简单。

这是引入 CSS 的第一种方式,HTML 内置代码块。
花括号外面的 div 是标签选择器,它选择了这个页面上的所有 div 元素。大括号内是属性名称和赋值。属性名称是固定关键字,并且已经指定了值的类型和可选范围。
阅读代码你可能知道,我们将 div 的边框设置为 1 像素宽、实心(单线)、蓝色、内边距(padding)2 像素、边距(margins)10 像素。现在练习调整单个数字并预览发生了什么?
题外话,程序员懂一些英语是非常有必要的。除了能够阅读和理解没有通过感觉学习的代码之外,还可以为 Google、Stack Overflow 和 Github Issues 编程。
导入外部文件
然后我们再次尝试导入外部文件,在hello.html的同级目录下新建一个hello.css,输入以下内容保存:
div {
color: green;
border: 2px dotted red;
}
然后修改hello.html,在style标签后面加一行link标签,加上导入类型和地址:
div {
border: 1px solid blue;
padding: 2px;
margin: 10px;
}
看一下预览,文字颜色变成了绿色,边框样式更新为2像素宽,点红色。
同样是div选择器,为什么会覆盖边框样式?注意CSS会在相同条件下覆盖前面的代码,可以尝试交换链接标签和样式标签块的顺序来查看。
联运风格
最后一种叫做interline style,结构比较简单。修改 hello.html 中
第一个内部是
内部第一个

样式会覆盖前两种方法,因为行间样式具有更高的优先级。此处涉及选择器权重。我们先来了解一个简单的公式。
!important > 内联样式 > ID > 类 | 伪类 | 属性选择 > 标签 > 继承 | 通配符。
应用多个选择器时添加权重。这是CSS中比较复杂的部分,暂时不展开。
这里还有一个小知识点。内外边距和内边距接受的完整值是四,顺序固定为“右上左下”。如果省略参数,则从末尾计算相反的合并。例如:
边距:40px 20px 50px;三个参数时,左右都是20px。
边距:40px 20px;这两个参数都是上下40px,左右20px。
边距如何:40px;作为参数?请尝试自己理解。
CSS 首先讲了这么多。虽然没有让我们的页面更漂亮,但至少我们知道自己努力的方向。
JavaScript
快速入门 JavaScript 可能会非常伤脑筋。与前两种技术 HTML 和 CSS 相比,这是一种真正的编程语言。
它也是我们后面会用到的 Vue.js 和 Node.js 的基础。很难一下子讲很多,所以希望同学们能够重视,系统地学习,至少在阅读下面的代码的时候是什么,这是什么,这是什么“困境”。
让我们直观的理解代码,还是先介绍一下内部代码块。
在 hello.html 的 head 标签内添加一段代码:
let message = "字符串提示";
function showMSG(msg) {
alert(msg);
}
修改hello.html的h1标签为:
页面标题
保存预览,点击“页面标题”,会弹出提示框。

JavaScript 代码在加载后执行,没有编译阶段。大多数情况下,行尾的分号可以省略。
我们首先定义了一个变量 message 并将其指定为“字符串提示符”。定义变量的关键字原本是 var。ES6 中的新关键字 let 范围更清晰,可以替代使用。
学习 JavaScript 经常会遇到像 ES6、ES7 这样的术语,其实就是 ECMAScript 标准的版本号。可以简单理解为新版标准为 JavaScript 增加了特定的新特性。
然后我们定义一个函数 showMSG 并添加一个形参 msg。调用函数体内部的浏览器弹窗方法,显示msg的值。function 是定义函数的关键字。暂时将其视为一个功能封闭的盒子。当函数被调用时,函数体中的代码被执行。
调用部分是先给h1标签添加onclick点击事件,点击时触发showMSG(message),也就是将消息传递给msg。
然后尝试再次调用外部js文件,新建demo.js文件,写入如下内容并保存。
message = "修改一下字符串";
然后修改hello.html文件,在脚本块后面添加一行:

这次保存预览,点击“页面标题”,可以看到弹窗的文字发生了变化。这说明页面上可以同时存在多个脚本代码块,而且它们也是顺序调用的,可以直接相互访问。对文件命名没有要求,希望不会扼杀强迫症。
JavaScript 是网页可以进行如此多交互的来源。要走的路还很长。这三种前端技术先在这里学习
网页css js 抓取助手(精易编程助手什么用处网页分析:穿透框架彻底分析网页元素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-11 09:13
精益编程助手是一款功能非常强大的编程软件,具有窗口检测、网页分析、代码转换等功能,为用户提供了全面的编程辅助功能,可以有效提高工作效率,是很多程序员必备的工具。一。欢迎来到当易网下载!
精易编程助手正式版介绍
Easy Language开发的编程助手旨在让程序员在编程和编写代码时达到最快的速度。例如,如果您需要操作一个外部窗口,您可以使用简易编程助手来探测并获取相关信息。窗口信息,然后做其他操作,以此类推。
精益编程助手有什么用?
网页分析:穿透框架彻底分析网页元素,让您在网页上填写表格更容易!
生成代码:找到指定的窗口控件,全智能生成易语言代码!
资源 采集: 采集 CSS、js、图片、背景、网页上的媒体文件!
窗口检测:清晰分析窗口中各种控件的id、句柄、标题、类名、位置、大小!
屏幕颜色选择器:轻松获取屏幕上的任何颜色代码!
进程管理:管理系统运行进程!
正则工具:轻松调试正则表达式,内置大量语法示例!
网页抓包:智能网页抓包,postget客户端打包测试
编码转换:收录大部分转换命令,一键编码/解码需要数据!
工具箱:文本加解密、十六进制解码、图标提取、简单测试等等!
网页调试:可以打包请求测试、json解析、js调试!
使用说明
一、用法
1、获取正常更改的目标窗口的窗口样式并记录在文本或其他位置
2、填写第1步得到的窗口样式值,回车或点击确定按钮完成修改
3、获取要改变的目标窗口的句柄,右击窗口样式选择修改
4、如果修改后目标窗口没有变化,点击修改后的窗口或刷新窗口查看修改后的效果
5、修改扩展样式的步骤同上
二、备注
1、此功能仅限win32常规窗口,自绘窗口的样式不适用于此功能
2、 记得不要用这个功能修改系统桌面的样式,不然桌面就完了?嗯,是的,它会的!
休闲编程助手教程
1、打开软件,选择网页分析,这里需要说明的是网页分析工具,它只支持IE内核的浏览器,使用的时候最好直接用IE浏览器!
2、分析前,用视线工具将其拖到待分析的网页上,在分析点自动分析各个元素类型!
3、 类型主要用于选择和分析哪个网页元素可以快速得到你想要的结果!
4、logo主要是分析时的logo元素。比如以百度首页为例,分析完第一篇文章后,选择文本框,打开logo,然后分析,会在原网页上做一些logo,方便分析。手表!
5、搜索更容易理解。它不是网页上某种类型的元素。在列表中找到它是相当麻烦的。您可以在搜索中填写一些与网页相关的文字,并使用搜索进行定位,即可找到相关的网页元素!
6、控制和测量功能有点多。如果要显示元素信息,可以使用sight工具将其拖到要分析的网页上,就可以了。网页源代码会显示当前网页的源代码!
7、元素测试,这里不能做,不能演示,执行脚本和cookies不用我多说。懂脚本的人都会做!
8、采集是下载网页上的一个内容,包括图片、媒体文件等,可以下载回来!
9、里面的其他操作也很简单,用的不多,练习一下吧!
变更日志
v3.98
1、修复十六进制转换时输入2147483648会崩溃的问题;
2、修复网页分析中勾选body文本框和标记时网页空白的问题;
3、常规调试添加代码生成超级列表框;
4、修复常规调试生成代码不处理换行的问题;
5、修复部分程序无法定位进程路径的问题;
6、修复网页分析右键判断元素视觉状态错误,隐藏元素时菜单不改为显示的问题;
v3.7
易于编程
一、窗口检测
1、ui解析优化窗口最小化时标记组件的显示;
2、优化解决部分组件异常崩溃的问题;
3、修复窗口检测是否只检测可见窗口的bug;
4、优化ui解析方式,增加只解析当前鼠标位置的控件;
二、屏幕颜色选择
修复颜色转换错误的bug;
三、网页功能
优化网页调试助手的运行判断;
全面的
优化更新提示逻辑;
网页调试
一、网页调试
1、增加了返回协议头状态码的解释,解释短语、返回数字状态码的含义、http版本;
2、调整部分组件细节;
3、优化双击显示修改窗口的修改逻辑;
4、增加了提交协议头的右键菜单,用于处理协议头,并将协议头中键名的首字母转换为大写;
5、优化日记窗口列表的显示内容,直观的搜索和发送日记;
6、为“Webpage_Access s”添加超时设置;
7、修改“文件提交”为“文件上传”,“提交方法”为“提交方法”
8、优化“提交方式”中切换提交类型时帮助提示的显示;
9、优化“提交地址”头协议的大小写;
二、json 解析
1、优化解析时对关键词的判断;
2、优化解析时对第一条路径的判断;
全面的
1、优化窗口加载闪烁问题;
2、修复多开助手最小化后任务栏无响应的问题。 查看全部
网页css js 抓取助手(精易编程助手什么用处网页分析:穿透框架彻底分析网页元素)
精益编程助手是一款功能非常强大的编程软件,具有窗口检测、网页分析、代码转换等功能,为用户提供了全面的编程辅助功能,可以有效提高工作效率,是很多程序员必备的工具。一。欢迎来到当易网下载!
精易编程助手正式版介绍
Easy Language开发的编程助手旨在让程序员在编程和编写代码时达到最快的速度。例如,如果您需要操作一个外部窗口,您可以使用简易编程助手来探测并获取相关信息。窗口信息,然后做其他操作,以此类推。
精益编程助手有什么用?
网页分析:穿透框架彻底分析网页元素,让您在网页上填写表格更容易!
生成代码:找到指定的窗口控件,全智能生成易语言代码!
资源 采集: 采集 CSS、js、图片、背景、网页上的媒体文件!
窗口检测:清晰分析窗口中各种控件的id、句柄、标题、类名、位置、大小!
屏幕颜色选择器:轻松获取屏幕上的任何颜色代码!
进程管理:管理系统运行进程!
正则工具:轻松调试正则表达式,内置大量语法示例!
网页抓包:智能网页抓包,postget客户端打包测试
编码转换:收录大部分转换命令,一键编码/解码需要数据!
工具箱:文本加解密、十六进制解码、图标提取、简单测试等等!
网页调试:可以打包请求测试、json解析、js调试!
使用说明
一、用法
1、获取正常更改的目标窗口的窗口样式并记录在文本或其他位置
2、填写第1步得到的窗口样式值,回车或点击确定按钮完成修改
3、获取要改变的目标窗口的句柄,右击窗口样式选择修改
4、如果修改后目标窗口没有变化,点击修改后的窗口或刷新窗口查看修改后的效果
5、修改扩展样式的步骤同上
二、备注
1、此功能仅限win32常规窗口,自绘窗口的样式不适用于此功能
2、 记得不要用这个功能修改系统桌面的样式,不然桌面就完了?嗯,是的,它会的!
休闲编程助手教程
1、打开软件,选择网页分析,这里需要说明的是网页分析工具,它只支持IE内核的浏览器,使用的时候最好直接用IE浏览器!
2、分析前,用视线工具将其拖到待分析的网页上,在分析点自动分析各个元素类型!
3、 类型主要用于选择和分析哪个网页元素可以快速得到你想要的结果!
4、logo主要是分析时的logo元素。比如以百度首页为例,分析完第一篇文章后,选择文本框,打开logo,然后分析,会在原网页上做一些logo,方便分析。手表!
5、搜索更容易理解。它不是网页上某种类型的元素。在列表中找到它是相当麻烦的。您可以在搜索中填写一些与网页相关的文字,并使用搜索进行定位,即可找到相关的网页元素!
6、控制和测量功能有点多。如果要显示元素信息,可以使用sight工具将其拖到要分析的网页上,就可以了。网页源代码会显示当前网页的源代码!
7、元素测试,这里不能做,不能演示,执行脚本和cookies不用我多说。懂脚本的人都会做!
8、采集是下载网页上的一个内容,包括图片、媒体文件等,可以下载回来!
9、里面的其他操作也很简单,用的不多,练习一下吧!
变更日志
v3.98
1、修复十六进制转换时输入2147483648会崩溃的问题;
2、修复网页分析中勾选body文本框和标记时网页空白的问题;
3、常规调试添加代码生成超级列表框;
4、修复常规调试生成代码不处理换行的问题;
5、修复部分程序无法定位进程路径的问题;
6、修复网页分析右键判断元素视觉状态错误,隐藏元素时菜单不改为显示的问题;
v3.7
易于编程
一、窗口检测
1、ui解析优化窗口最小化时标记组件的显示;
2、优化解决部分组件异常崩溃的问题;
3、修复窗口检测是否只检测可见窗口的bug;
4、优化ui解析方式,增加只解析当前鼠标位置的控件;
二、屏幕颜色选择
修复颜色转换错误的bug;
三、网页功能
优化网页调试助手的运行判断;
全面的
优化更新提示逻辑;
网页调试
一、网页调试
1、增加了返回协议头状态码的解释,解释短语、返回数字状态码的含义、http版本;
2、调整部分组件细节;
3、优化双击显示修改窗口的修改逻辑;
4、增加了提交协议头的右键菜单,用于处理协议头,并将协议头中键名的首字母转换为大写;
5、优化日记窗口列表的显示内容,直观的搜索和发送日记;
6、为“Webpage_Access s”添加超时设置;
7、修改“文件提交”为“文件上传”,“提交方法”为“提交方法”
8、优化“提交方式”中切换提交类型时帮助提示的显示;
9、优化“提交地址”头协议的大小写;
二、json 解析
1、优化解析时对关键词的判断;
2、优化解析时对第一条路径的判断;
全面的
1、优化窗口加载闪烁问题;
2、修复多开助手最小化后任务栏无响应的问题。
网页css js 抓取助手(Python爬取网页所需要的URL地址和CSS、JS文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-06 14:13
Python抓取单个网页需要加载的URL地址和CSS、JS文件地址
<p>通过学习Python爬虫,我们知道可以根据形式表达式匹配(标题、图片、文章等)找到我们需要的东西。并且我从测试的角度使用Python爬虫,希望能抓取到访问网页所需的CSS、JS、URL,然后请求这些地址,根据响应状态码判断是否可以访问成功。 查看全部
网页css js 抓取助手(Python爬取网页所需要的URL地址和CSS、JS文件)
Python抓取单个网页需要加载的URL地址和CSS、JS文件地址
<p>通过学习Python爬虫,我们知道可以根据形式表达式匹配(标题、图片、文章等)找到我们需要的东西。并且我从测试的角度使用Python爬虫,希望能抓取到访问网页所需的CSS、JS、URL,然后请求这些地址,根据响应状态码判断是否可以访问成功。
网页css js 抓取助手(你会不停的问,HTML是什么?CSS是XML)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-05 01:20
如果你是web开发的初学者,难免会在网上搜索HTML、CSS、XML、JS(Javascript)、DOM、XSL等这些词的含义。然而,随着你了解的越来越多。当你把它们混在一起的时候,你又糊涂了,你会一直问,什么是HTML?什么是 CSS?什么是 XML?什么是JS?它们是为了什么?无论是网络百科全书还是一些IT专题网站,或者一些伟大的博主,他们都会告诉你一个东西是什么。这样的文章有很多,但很少涉及。它们的组合是什么,有什么用?. 我想我写这个 文章 是为了说明这个他们很少涉及的问题。
在这里,我尽量用最基础的语言给大家讲解一下HTML、CSS、XML、JS是什么,有什么用。那我们就来看看把它们组合起来到底是什么,又有什么用呢。当然,如果你对HTML、CSS、XML、JS有足够的了解,可以直接跳过,看文章的后半部分,这是本文的核心。
第一部分
1. HTML 超文本标记语言(Hyper Text Markup Language)是一种用于描述网页的标记语言。
HTML
Hello World! I'm HTML
网页文件本身是一个文本文件。通过在文本文件中添加标签,可以告诉浏览器如何显示内容(如:如何处理文本、如何排列屏幕、如何显示图片等)。
HTML 被称为超文本标记语言,因为文本收录所谓的“超链接”点。超文本(Hypertext)是一种类似网络的文本,它使用超链接来组织各种不同空间中的文本信息。
综上所述,HTML 是一种集网页结构和内容展示于一体的语言。
Hello World! I'm HTML
浏览器依次读取网页文件,然后根据标签对标记的内容进行解释和显示。
这个内容在浏览器上显示的结果是:Hello World!我是 HTML
我们看
标签上有一个id,就是
该标签的唯一标识使其他人很容易找到并对其进行操作。
2. CSS 级联样式表。它是一种将样式信息与 Web 内容分开的标记语言。作为 网站 开发人员,您可以为每个 HTML 元素定义样式并将其应用于任意数量的页面。如果需要全局更新,只需更改样式,网站中的所有元素都会自动更新。这样,设计师可以将更多的时间花在设计上,而不是费力地克服 HTML 的局限性。说白了,CSS就是在网页上设置HTML元素属性的语言。
CSS代码:
#hello{
color:blue;
}
当这个CSS代码应用于HTML时,它会找到id为“hello”的HTML标签,并将内容显示为蓝色;插入HTML的具体方法这里不再赘述。什么,有什么用的问题,不注意技术细节,技术细节网上很容易找到)。
3. Javascript,首先说明一下JavaScript与Java无关,JavaScript是属于网络的脚本语言!那么为什么名字如此相似呢?这是典型的营销成功,它的成功推广也是借鉴了Java。当微软开始意识到 Javascript 在 Web 开发者中很流行时,微软仍然建立了自己的脚本语言 JScript。
Javascript 是一种基于对象和事件驱动的脚本语言,具有安全功能。使用它的目的是通过HTML超文本标记语言和Java脚本语言(Java小程序)将网页中的多个对象链接在一起,与Web客户端进行交互。例如,您可以设置鼠标悬停效果、在客户端验证表单、创建自定义 HTML 页面、显示警报框、设置 cookie 等。
网页的所有本地代码实现部分,判断、操作和反馈信息给浏览者都是Javascript(当然还有其他的),可以让网页更具交互性,为用户提供更精彩的体验,同时减轻浏览者的负担服务器。
JS代码如下:
function jsHello(){
alert('Hello World!');
}
当上面的代码应用于HTML代码时,会弹出一个对话框,内容为“Hello World!” 当您的 HTML 加载时。类似地,它是通过嵌入或加载在标准 HTML 语言中实现的。至于如何嵌入或转移,由于上述原因,我不再赘述。
4. Xml 可扩展标记语言(Extensible MarkupLanguage)是一组定义语义标记的规则。这些标记将文档分成许多部分并标识这些部分。它也是一种元标记语言,即定义与特定领域相关的其他语义和结构化标记语言的语法语言。您可以将 XML 理解为数据库,例如 rss 是 xml 的变体。
XML代码如下:
China
USA
UK
XML 的原因是用户对 SGML 的复杂性(稍后会详细介绍)和 HTML 的不足感到沮丧。与 HTML 相比,XML 更为严谨。如果你说HTML代码中的标签乱七八糟,比如未关闭,也许浏览器会忽略这些错误;但是同样的事情发生在 XML 中会给你带来很大的麻烦。
伏笔终于结束了。在进入正题之前,建议大家对比一下图表,了解背后的内容。废话不多说,开始进入正题。
第二部分
这里的 DOM 是指 HTML DOM。HTML DOM 是 W3C 标准,也是 HTML 文档对象模型(Document Object Model for HTML)的缩写。HTML DOM 为 HTML 定义了一系列标准对象,以及访问和处理 HTML 文档的标准方法。通过 DOM,您可以访问所有 HTML 元素,以及它们收录的文本和属性。可以修改和删除内容,也可以创建新元素。HTML DOM 独立于平台和编程语言。它可以被任何编程语言使用,例如 Java、Javascript 和 VBScript。HTML DOM 是 HTML 语言向外界开放的接口,以便其他语言可以访问或修改 HTML 内部的元素。
当js需要操作html元素时,DOM是必不可少的对象。
您可以使用 DOM 对象构造以下代码并将其插入 HTML 代码中的任何位置。
window.onload=function hello(){
document.getElementById("hello").innerHTML="Hello China!";
}
在使用 CSS 装饰 HTML 元素时,这个过程可以称为声明 HTML 元素样式的过程。
SGML 标准广义标记语言(standardgeneralized markup language)。由于SGML的复杂性,难以普及。SGML具有很强的适应性,同样的原因,在小型应用中也难以普及。HTML 和 XML 也是从 SGML 派生而来的:XML 可以被认为是 SGML 的一个子集,而 HTML 是 SGML 的一个应用。创建 XML 是为了简化 SGML,以便它可以用于更通用的目的。例如,语义网已经在大量场合使用,如XHTML、RSS、XML-RPC 和SOAP。
XHTML 是可扩展超文本标记语言(TheExtensible HyperText Markup Language)。HTML 是一种基本的网页设计语言。XHTML 是一种基于 XML 的标记语言。它看起来与 HTML 相似,只有一些很小但很重要的区别。XHTML 是一种 XML,其作用类似于 HTML。所以,本质上,XHTML 是一种过渡技术,它结合了 XML 的一些强大功能和 HTML 的大部分简单特性。
简单的说,XHTML 比 HTML 更严谨,但没有 XML 严重——比如所有的 XHTML 标签和属性必须是小写的,属性必须是双引号(当然,现在的浏览器,不管是 IE 还是 FF ,对HTML和XHTML采取兼容措施也是XSS的根本原因),而且有些标签可以像XML一样自定义,因此具有很大的灵活性。
看到这里,突然发现web开发中一个很重要的问题。Xss 漏洞。这里我就不分析这个问题了。我将在接下来的笔记中重点研究 xss 漏洞。
而在XHTML时代,大家提倡的是CSS+DIV,这也是web2.0的基础。
DHTML 只是制作网页的一个概念。事实上,没有任何组织或机构引入所谓的 DHTML 标准或技术规范。DHTML 不是技术、标准或规范。DHTML 只是一种设计理念,它集成并利用现有的网络技术和语言标准,创建了一个下载后可以实时改变页面元素效果的网页。DHTML 是动态 HTML,Dynamic HTML。传统的 html 页面是静态的。dhtml在html页面中加入javascript脚本,使其可以根据用户的动作做出一定的响应,比如鼠标移到图片上、改变图片颜色、移到导航栏、弹出动态菜单等。
一般喜欢:
Expression 是微软在 Internet Explorer 中添加的一项功能,可以让样式表在执行 javascript 脚本的同时修改 HTML 样式,以便您可以执行诸如:自适应图片宽度、表格交错颜色变化等。
如:img{max-width:500px;width:expression(document.body.clientWidth> 200? "200px": "auto");}
XMLHTTP最笼统的定义是:XmlHttp是一组可以在Javascript、VbScript、Jscript等脚本语言中通过http协议传输或接收XML等数据的API。XmlHttp最大的用处就是可以在不刷新整个页面的情况下更新部分网页。
来自MSDN的说明:XmlHttp为客户端与http服务器通信提供了一个协议。客户端可以通过 XmlHttp 对象向 http 服务器发送请求,并使用 Microsoft® XML 文档对象模型 (DOM) 来处理响应。
绝对大多数浏览器现在都添加了对 XmlHttp 的支持。IE 使用 ActiveXObject 来创建 XmlHttp 对象。其他浏览器如 Firefox 和 Opera 使用 window.XMLHttpRequest 来创建 XmlHttp 对象。
定义 IE 的 XmlHttp 对象和应用程序的简单示例如下:
var XmlHttp=new ActiveXObject("Microsoft.XMLhttp");
XmlHttp.Open("get","url",true);
XmlHttp.send(null);
XmlHttp.onreadystatechange=function ServerProcess(){
if (XmlHttp.readystate==4 || XmlHttp.readystate=='complete')
{
alert(XmlHttp.responseText);
}
}
XSLT(eXtensibleStylesheet LanguageTransformation)最初旨在帮助将 XML 文档(文档)转换为其他文档。但随着发展,XSLT 不仅用于将 XML 转换为 HTML 或其他文本格式,更全面的定义应该是:XSLT 是一种用于转换 XML 文档结构的语言。
XSL-FO:XSL 在转换 XML 文档时分为两个明显的过程。首先是转换文档的结构;二是格式化输出文件。这两个步骤可以分开单独处理,所以XSL在开发过程中逐渐分裂成两个分支语言,XSLT(结构转换)和XSL-FO(格式化对象)(格式化输出),其中XSL-FO有类似的功能。 CSS 在 HTML 中的作用。
AJAX:异步 JavaScript 和 XML(AsynchronousJavaScript and XML)。
最后一点,可以算是web2.0思想的核心。AJAX=CSS+HTML+JS+XML+DOM+XSLT+XMLHTTP。指一种用于创建交互式 Web 应用程序的 Web 开发技术。AJAX 不是单一的新技术,而是一系列相关技术的有机运用。
2005 年,Google 凭借其 Google Suggest 使 AJAX 流行起来。
Google Suggest 使用 AJAX 创建高度动态的 Web 界面:当您在 Google 搜索框中输入关键字时,Javascript 会将这些字符发送到服务器,服务器将返回搜索建议列表。 查看全部
网页css js 抓取助手(你会不停的问,HTML是什么?CSS是XML)
如果你是web开发的初学者,难免会在网上搜索HTML、CSS、XML、JS(Javascript)、DOM、XSL等这些词的含义。然而,随着你了解的越来越多。当你把它们混在一起的时候,你又糊涂了,你会一直问,什么是HTML?什么是 CSS?什么是 XML?什么是JS?它们是为了什么?无论是网络百科全书还是一些IT专题网站,或者一些伟大的博主,他们都会告诉你一个东西是什么。这样的文章有很多,但很少涉及。它们的组合是什么,有什么用?. 我想我写这个 文章 是为了说明这个他们很少涉及的问题。
在这里,我尽量用最基础的语言给大家讲解一下HTML、CSS、XML、JS是什么,有什么用。那我们就来看看把它们组合起来到底是什么,又有什么用呢。当然,如果你对HTML、CSS、XML、JS有足够的了解,可以直接跳过,看文章的后半部分,这是本文的核心。
第一部分
1. HTML 超文本标记语言(Hyper Text Markup Language)是一种用于描述网页的标记语言。

HTML
Hello World! I'm HTML
网页文件本身是一个文本文件。通过在文本文件中添加标签,可以告诉浏览器如何显示内容(如:如何处理文本、如何排列屏幕、如何显示图片等)。
HTML 被称为超文本标记语言,因为文本收录所谓的“超链接”点。超文本(Hypertext)是一种类似网络的文本,它使用超链接来组织各种不同空间中的文本信息。
综上所述,HTML 是一种集网页结构和内容展示于一体的语言。
Hello World! I'm HTML
浏览器依次读取网页文件,然后根据标签对标记的内容进行解释和显示。
这个内容在浏览器上显示的结果是:Hello World!我是 HTML
我们看
标签上有一个id,就是
该标签的唯一标识使其他人很容易找到并对其进行操作。
2. CSS 级联样式表。它是一种将样式信息与 Web 内容分开的标记语言。作为 网站 开发人员,您可以为每个 HTML 元素定义样式并将其应用于任意数量的页面。如果需要全局更新,只需更改样式,网站中的所有元素都会自动更新。这样,设计师可以将更多的时间花在设计上,而不是费力地克服 HTML 的局限性。说白了,CSS就是在网页上设置HTML元素属性的语言。
CSS代码:
#hello{
color:blue;
}
当这个CSS代码应用于HTML时,它会找到id为“hello”的HTML标签,并将内容显示为蓝色;插入HTML的具体方法这里不再赘述。什么,有什么用的问题,不注意技术细节,技术细节网上很容易找到)。
3. Javascript,首先说明一下JavaScript与Java无关,JavaScript是属于网络的脚本语言!那么为什么名字如此相似呢?这是典型的营销成功,它的成功推广也是借鉴了Java。当微软开始意识到 Javascript 在 Web 开发者中很流行时,微软仍然建立了自己的脚本语言 JScript。
Javascript 是一种基于对象和事件驱动的脚本语言,具有安全功能。使用它的目的是通过HTML超文本标记语言和Java脚本语言(Java小程序)将网页中的多个对象链接在一起,与Web客户端进行交互。例如,您可以设置鼠标悬停效果、在客户端验证表单、创建自定义 HTML 页面、显示警报框、设置 cookie 等。
网页的所有本地代码实现部分,判断、操作和反馈信息给浏览者都是Javascript(当然还有其他的),可以让网页更具交互性,为用户提供更精彩的体验,同时减轻浏览者的负担服务器。
JS代码如下:
function jsHello(){
alert('Hello World!');
}
当上面的代码应用于HTML代码时,会弹出一个对话框,内容为“Hello World!” 当您的 HTML 加载时。类似地,它是通过嵌入或加载在标准 HTML 语言中实现的。至于如何嵌入或转移,由于上述原因,我不再赘述。
4. Xml 可扩展标记语言(Extensible MarkupLanguage)是一组定义语义标记的规则。这些标记将文档分成许多部分并标识这些部分。它也是一种元标记语言,即定义与特定领域相关的其他语义和结构化标记语言的语法语言。您可以将 XML 理解为数据库,例如 rss 是 xml 的变体。
XML代码如下:
China
USA
UK
XML 的原因是用户对 SGML 的复杂性(稍后会详细介绍)和 HTML 的不足感到沮丧。与 HTML 相比,XML 更为严谨。如果你说HTML代码中的标签乱七八糟,比如未关闭,也许浏览器会忽略这些错误;但是同样的事情发生在 XML 中会给你带来很大的麻烦。
伏笔终于结束了。在进入正题之前,建议大家对比一下图表,了解背后的内容。废话不多说,开始进入正题。
第二部分

这里的 DOM 是指 HTML DOM。HTML DOM 是 W3C 标准,也是 HTML 文档对象模型(Document Object Model for HTML)的缩写。HTML DOM 为 HTML 定义了一系列标准对象,以及访问和处理 HTML 文档的标准方法。通过 DOM,您可以访问所有 HTML 元素,以及它们收录的文本和属性。可以修改和删除内容,也可以创建新元素。HTML DOM 独立于平台和编程语言。它可以被任何编程语言使用,例如 Java、Javascript 和 VBScript。HTML DOM 是 HTML 语言向外界开放的接口,以便其他语言可以访问或修改 HTML 内部的元素。
当js需要操作html元素时,DOM是必不可少的对象。
您可以使用 DOM 对象构造以下代码并将其插入 HTML 代码中的任何位置。
window.onload=function hello(){
document.getElementById("hello").innerHTML="Hello China!";
}

在使用 CSS 装饰 HTML 元素时,这个过程可以称为声明 HTML 元素样式的过程。

SGML 标准广义标记语言(standardgeneralized markup language)。由于SGML的复杂性,难以普及。SGML具有很强的适应性,同样的原因,在小型应用中也难以普及。HTML 和 XML 也是从 SGML 派生而来的:XML 可以被认为是 SGML 的一个子集,而 HTML 是 SGML 的一个应用。创建 XML 是为了简化 SGML,以便它可以用于更通用的目的。例如,语义网已经在大量场合使用,如XHTML、RSS、XML-RPC 和SOAP。
XHTML 是可扩展超文本标记语言(TheExtensible HyperText Markup Language)。HTML 是一种基本的网页设计语言。XHTML 是一种基于 XML 的标记语言。它看起来与 HTML 相似,只有一些很小但很重要的区别。XHTML 是一种 XML,其作用类似于 HTML。所以,本质上,XHTML 是一种过渡技术,它结合了 XML 的一些强大功能和 HTML 的大部分简单特性。
简单的说,XHTML 比 HTML 更严谨,但没有 XML 严重——比如所有的 XHTML 标签和属性必须是小写的,属性必须是双引号(当然,现在的浏览器,不管是 IE 还是 FF ,对HTML和XHTML采取兼容措施也是XSS的根本原因),而且有些标签可以像XML一样自定义,因此具有很大的灵活性。
看到这里,突然发现web开发中一个很重要的问题。Xss 漏洞。这里我就不分析这个问题了。我将在接下来的笔记中重点研究 xss 漏洞。
而在XHTML时代,大家提倡的是CSS+DIV,这也是web2.0的基础。
DHTML 只是制作网页的一个概念。事实上,没有任何组织或机构引入所谓的 DHTML 标准或技术规范。DHTML 不是技术、标准或规范。DHTML 只是一种设计理念,它集成并利用现有的网络技术和语言标准,创建了一个下载后可以实时改变页面元素效果的网页。DHTML 是动态 HTML,Dynamic HTML。传统的 html 页面是静态的。dhtml在html页面中加入javascript脚本,使其可以根据用户的动作做出一定的响应,比如鼠标移到图片上、改变图片颜色、移到导航栏、弹出动态菜单等。
一般喜欢:

Expression 是微软在 Internet Explorer 中添加的一项功能,可以让样式表在执行 javascript 脚本的同时修改 HTML 样式,以便您可以执行诸如:自适应图片宽度、表格交错颜色变化等。
如:img{max-width:500px;width:expression(document.body.clientWidth> 200? "200px": "auto");}

XMLHTTP最笼统的定义是:XmlHttp是一组可以在Javascript、VbScript、Jscript等脚本语言中通过http协议传输或接收XML等数据的API。XmlHttp最大的用处就是可以在不刷新整个页面的情况下更新部分网页。
来自MSDN的说明:XmlHttp为客户端与http服务器通信提供了一个协议。客户端可以通过 XmlHttp 对象向 http 服务器发送请求,并使用 Microsoft® XML 文档对象模型 (DOM) 来处理响应。
绝对大多数浏览器现在都添加了对 XmlHttp 的支持。IE 使用 ActiveXObject 来创建 XmlHttp 对象。其他浏览器如 Firefox 和 Opera 使用 window.XMLHttpRequest 来创建 XmlHttp 对象。
定义 IE 的 XmlHttp 对象和应用程序的简单示例如下:
var XmlHttp=new ActiveXObject("Microsoft.XMLhttp");
XmlHttp.Open("get","url",true);
XmlHttp.send(null);
XmlHttp.onreadystatechange=function ServerProcess(){
if (XmlHttp.readystate==4 || XmlHttp.readystate=='complete')
{
alert(XmlHttp.responseText);
}
}

XSLT(eXtensibleStylesheet LanguageTransformation)最初旨在帮助将 XML 文档(文档)转换为其他文档。但随着发展,XSLT 不仅用于将 XML 转换为 HTML 或其他文本格式,更全面的定义应该是:XSLT 是一种用于转换 XML 文档结构的语言。
XSL-FO:XSL 在转换 XML 文档时分为两个明显的过程。首先是转换文档的结构;二是格式化输出文件。这两个步骤可以分开单独处理,所以XSL在开发过程中逐渐分裂成两个分支语言,XSLT(结构转换)和XSL-FO(格式化对象)(格式化输出),其中XSL-FO有类似的功能。 CSS 在 HTML 中的作用。

AJAX:异步 JavaScript 和 XML(AsynchronousJavaScript and XML)。
最后一点,可以算是web2.0思想的核心。AJAX=CSS+HTML+JS+XML+DOM+XSLT+XMLHTTP。指一种用于创建交互式 Web 应用程序的 Web 开发技术。AJAX 不是单一的新技术,而是一系列相关技术的有机运用。
2005 年,Google 凭借其 Google Suggest 使 AJAX 流行起来。
Google Suggest 使用 AJAX 创建高度动态的 Web 界面:当您在 Google 搜索框中输入关键字时,Javascript 会将这些字符发送到服务器,服务器将返回搜索建议列表。
网页css js 抓取助手(学习Web前端开发基础技术需要掌握:HTML、CSS、JavaScript)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-05 01:17
学习Web前端开发的基本技术,需要掌握:HTML、CSS、JavaScript,那么这三者分别实现了哪些功能呢?下面就和小编一起来看看吧!
一、HTML 是网页内容的载体
内容是网页制作者放在页面上供用户浏览的信息,可以包括文字、图片、视频等。
二、CSS 风格就是性能
就像一个网页的外衣,比如:标题字体、颜色变化、给标题添加背景图片、边框等。
所有这些用来改变内容外观的东西都被称为性能。
三、JavaScript 用于在网页上实现特殊效果
例如:鼠标滑过弹出的下拉菜单,鼠标滑过表格的背景颜色改变,焦点新闻的旋转。
可以理解为:动画和交互一般都是用JavaScript来实现的。
HTML代码注释:
代码注释是为了帮助程序员标记代码的作用。过一段时间再看自己写的代码,很快就能记住这段代码的作用。
代码注释不仅可以帮助程序员回忆之前代码的用途,还可以帮助其他程序员快速了解你的程序的功能,方便多人协作开发web代码。
HTML 的语义化:
语义其实就是了解每个标签的用途,它可以让你的网页更好地被搜索引擎理解。
它的好处可以概括为两点:
(1)更容易被搜索引擎搜索到收录;
(2) 屏幕阅读器更容易读出网页内容;
HTML 的 em、strong 和 span 的区别:
(1) 和标签用于强调段落中的关键字,它们的语义是强调;
(2) 标签没有语义,其作用是设置单独的样式;
HTML 摘要、标题:
作用是给表格添加标题和摘要
摘要的内容不会显示在浏览器中。它的作用是增加表格的可读性(语义),让搜索引擎更好的理解表格的内容,也可以让屏幕阅读器更好的帮助特殊用户阅读表格的内容。
代码注释:
CSS 中的注释语句:使用 /comment sentence/ 表示
在 Html 中用于表示
HTML 选择器的问题:
后代选择器和子选择器的区别
子选择器(child selector)只指其直接后代,也可以理解为作用于子元素的第一代后代。后代选择器应用于所有子后代元素。后代选择器使用空格进行选择,子选择器使用“>”进行选择。
特设学习⑦③①-⑦⑦①-②①① 分享学习方法和需要注意的小细节,不断更新最新教程和学习技巧(从零到前端项目实战教程、学习工具、全栈开发学习路线和规划) )
点击:我们的前端学习圈
总结:
作用于该元素的第一代后代,空格作用于该元素的所有后代。 查看全部
网页css js 抓取助手(学习Web前端开发基础技术需要掌握:HTML、CSS、JavaScript)
学习Web前端开发的基本技术,需要掌握:HTML、CSS、JavaScript,那么这三者分别实现了哪些功能呢?下面就和小编一起来看看吧!
一、HTML 是网页内容的载体
内容是网页制作者放在页面上供用户浏览的信息,可以包括文字、图片、视频等。
二、CSS 风格就是性能
就像一个网页的外衣,比如:标题字体、颜色变化、给标题添加背景图片、边框等。
所有这些用来改变内容外观的东西都被称为性能。
三、JavaScript 用于在网页上实现特殊效果
例如:鼠标滑过弹出的下拉菜单,鼠标滑过表格的背景颜色改变,焦点新闻的旋转。
可以理解为:动画和交互一般都是用JavaScript来实现的。
HTML代码注释:
代码注释是为了帮助程序员标记代码的作用。过一段时间再看自己写的代码,很快就能记住这段代码的作用。
代码注释不仅可以帮助程序员回忆之前代码的用途,还可以帮助其他程序员快速了解你的程序的功能,方便多人协作开发web代码。
HTML 的语义化:
语义其实就是了解每个标签的用途,它可以让你的网页更好地被搜索引擎理解。
它的好处可以概括为两点:
(1)更容易被搜索引擎搜索到收录;
(2) 屏幕阅读器更容易读出网页内容;
HTML 的 em、strong 和 span 的区别:
(1) 和标签用于强调段落中的关键字,它们的语义是强调;
(2) 标签没有语义,其作用是设置单独的样式;
HTML 摘要、标题:
作用是给表格添加标题和摘要
摘要的内容不会显示在浏览器中。它的作用是增加表格的可读性(语义),让搜索引擎更好的理解表格的内容,也可以让屏幕阅读器更好的帮助特殊用户阅读表格的内容。
代码注释:
CSS 中的注释语句:使用 /comment sentence/ 表示
在 Html 中用于表示
HTML 选择器的问题:
后代选择器和子选择器的区别
子选择器(child selector)只指其直接后代,也可以理解为作用于子元素的第一代后代。后代选择器应用于所有子后代元素。后代选择器使用空格进行选择,子选择器使用“>”进行选择。
特设学习⑦③①-⑦⑦①-②①① 分享学习方法和需要注意的小细节,不断更新最新教程和学习技巧(从零到前端项目实战教程、学习工具、全栈开发学习路线和规划) )
点击:我们的前端学习圈
总结:
作用于该元素的第一代后代,空格作用于该元素的所有后代。
网页css js 抓取助手(百忙之中抽时间编写了这个小程序,功能是:完美保存整个网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-04 19:15
我从繁忙的日程中抽出时间来编写这个小程序。功能是完美保存整个网页,包括:图片、JS脚本、CSS样式,修改网页源代码进行“本地化”。因为火了,连浏览器自带这个功能都不知道,就自己做了一个。这个程序虽然不大,但是涉及到三大问题(后面会详细说明)。
本来不打算放源码的,既然浏览器有这个功能,那我就放出源码供大家学习!这个程序的效果和浏览器的效果完全一样!而且我对比了一下,得到的js、css、图片都不亚于浏览器得到的。可以参考这个玩:做一个网站全站下载器。当然你永远不能下载数据库.....
使用说明:
1.填写网页地址,点击前往,即可激活一键下载。加载网页需要时间。如果加载前点击一键下载,会有提示。尝试在网速更好的时候使用它!
2.下载完成后,会在软件目录下生成一个以网页标题命名的文件夹。所有必要的文件都存储在这里。以网页标题命名的 HTM 文件即为保存的页面。在这种情况下,双击查看的效果和在网上查看是一样的!.
程序截图:
解决的问题:
1. 判断网页已经加载完毕。以前,已知目的地的网页可以通过“标记方法”来判断,但在这个程序中一切都是未知的。因此,必须使用新的方法。这里使用了HTML对象的Onload事件,结合webbrowser控件完美实现了判断网页加载完成的完成。这是目前最安全、最准确、最可靠的方法!适用于所有环境。
确定网页已经加载一直很头疼,至少在VB中是这样。网上提到的方法基本都行不通。更好的是有时它有效,有时它不起作用。现在我将发布一个代码来结束这个问题
'引用“Microsoft HTML Object Library”
Dim WithEvents page As HTMLWindow2 '注意要定义成全局的
Private Sub WebBrowser1_NavigateComplete2(ByVal pDisp As Object, URL As Variant)
Set page = Me.WebBrowser1.document.parentWindow
End Sub
Private Sub page_onload()
Debug.Print "加载完毕"
End Sub
2.获取网页js和css。我看到很多人在猪八戒上发帖求一个程序,请求网页中的所有js和css。其实这个不难,百度一下,可以发现javascript语言提供了这个接口。下面我将演示如何使用这个接口来获取。
首先使用 webbrowser 控件加载要提取的网页。
获取js:
<p>strBasicHTM = WebBrowser1.Document.documentElement.outerHTML
WebBrowser1.Navigate "javascript:str='
\n';c=document.scripts;for(i=0;i 查看全部
网页css js 抓取助手(百忙之中抽时间编写了这个小程序,功能是:完美保存整个网页)
我从繁忙的日程中抽出时间来编写这个小程序。功能是完美保存整个网页,包括:图片、JS脚本、CSS样式,修改网页源代码进行“本地化”。因为火了,连浏览器自带这个功能都不知道,就自己做了一个。这个程序虽然不大,但是涉及到三大问题(后面会详细说明)。
本来不打算放源码的,既然浏览器有这个功能,那我就放出源码供大家学习!这个程序的效果和浏览器的效果完全一样!而且我对比了一下,得到的js、css、图片都不亚于浏览器得到的。可以参考这个玩:做一个网站全站下载器。当然你永远不能下载数据库.....
使用说明:
1.填写网页地址,点击前往,即可激活一键下载。加载网页需要时间。如果加载前点击一键下载,会有提示。尝试在网速更好的时候使用它!
2.下载完成后,会在软件目录下生成一个以网页标题命名的文件夹。所有必要的文件都存储在这里。以网页标题命名的 HTM 文件即为保存的页面。在这种情况下,双击查看的效果和在网上查看是一样的!.
程序截图:
解决的问题:
1. 判断网页已经加载完毕。以前,已知目的地的网页可以通过“标记方法”来判断,但在这个程序中一切都是未知的。因此,必须使用新的方法。这里使用了HTML对象的Onload事件,结合webbrowser控件完美实现了判断网页加载完成的完成。这是目前最安全、最准确、最可靠的方法!适用于所有环境。
确定网页已经加载一直很头疼,至少在VB中是这样。网上提到的方法基本都行不通。更好的是有时它有效,有时它不起作用。现在我将发布一个代码来结束这个问题
'引用“Microsoft HTML Object Library”
Dim WithEvents page As HTMLWindow2 '注意要定义成全局的
Private Sub WebBrowser1_NavigateComplete2(ByVal pDisp As Object, URL As Variant)
Set page = Me.WebBrowser1.document.parentWindow
End Sub
Private Sub page_onload()
Debug.Print "加载完毕"
End Sub
2.获取网页js和css。我看到很多人在猪八戒上发帖求一个程序,请求网页中的所有js和css。其实这个不难,百度一下,可以发现javascript语言提供了这个接口。下面我将演示如何使用这个接口来获取。
首先使用 webbrowser 控件加载要提取的网页。
获取js:
<p>strBasicHTM = WebBrowser1.Document.documentElement.outerHTML
WebBrowser1.Navigate "javascript:str='
\n';c=document.scripts;for(i=0;i
网页css js 抓取助手(HTML文本中包含了所谓的“链接点”HTML利用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-04 14:07
HTML 文本收录所谓的“链接点”。使用前端学习HTML需要不断的学习。停顿一天,等于什么都没学到。学习效果很差。如果你想有人一起学习,你可以来这条裙子。第一个是132,中间是667,最后一个是127。都是零基础的同学,大家互相鼓励,一起努力,学着玩,不推荐!!!超链接方式,将各个不同空间中的文本信息组织在一起 Mesh 文本。总的来说,HTML是一种集网页结构和内容展示为一体的语言。
2、CSS——层叠样式表
级联样式表。它是一种将样式信息与 Web 内容分开的标记语言。在我们的牛腩新闻发布系统中,我们使用了 CSS 文件来修改一些标签的样式。
我们使用 CSS 为每个 HTML 元素定义样式,也可以用于多个界面。进行全局更新时,只需要修改样式即可。
body {border :1px solid #000;/*整体边框*/ font-size :14px;}
说白了,CSS就是在网页上设置HTML元素属性的语言。
3、Javascript
一开始我非常沮丧。为什么它的名字与 Java 如此相似?
这是典型的营销成功,它在推广上的成功也是借鉴了Java。当微软开始意识到 Java 在 Web 开发者中变得流行时,微软仍然建立了自己的脚本语言 Javascript。
Java 是一种基于对象和事件驱动的脚本语言,具有安全功能。使用它的目的是通过HTML超文本标记语言和Java脚本语言(Java小程序)将网页中的多个对象链接在一起,与Web客户端进行交互。例如,您可以设置鼠标悬停效果、在客户端验证表单、创建自定义 HTML 页面、显示警报框、设置 cookie 等。
function jsHello{ alert('Hello World!');}
将代码嵌入 HTML 语言,加载时会弹出“Hello World”对话框。至于怎么嵌入,我们在开始学习JS视频的时候就已经知道了。
4、总结
我将向您介绍 HTML、CSS 和 JS 之间的区别。
码字不易,请给我点个赞,点赞和关注是我写作的动力,谢谢! 查看全部
网页css js 抓取助手(HTML文本中包含了所谓的“链接点”HTML利用)
HTML 文本收录所谓的“链接点”。使用前端学习HTML需要不断的学习。停顿一天,等于什么都没学到。学习效果很差。如果你想有人一起学习,你可以来这条裙子。第一个是132,中间是667,最后一个是127。都是零基础的同学,大家互相鼓励,一起努力,学着玩,不推荐!!!超链接方式,将各个不同空间中的文本信息组织在一起 Mesh 文本。总的来说,HTML是一种集网页结构和内容展示为一体的语言。
2、CSS——层叠样式表
级联样式表。它是一种将样式信息与 Web 内容分开的标记语言。在我们的牛腩新闻发布系统中,我们使用了 CSS 文件来修改一些标签的样式。
我们使用 CSS 为每个 HTML 元素定义样式,也可以用于多个界面。进行全局更新时,只需要修改样式即可。
body {border :1px solid #000;/*整体边框*/ font-size :14px;}
说白了,CSS就是在网页上设置HTML元素属性的语言。
3、Javascript
一开始我非常沮丧。为什么它的名字与 Java 如此相似?
这是典型的营销成功,它在推广上的成功也是借鉴了Java。当微软开始意识到 Java 在 Web 开发者中变得流行时,微软仍然建立了自己的脚本语言 Javascript。
Java 是一种基于对象和事件驱动的脚本语言,具有安全功能。使用它的目的是通过HTML超文本标记语言和Java脚本语言(Java小程序)将网页中的多个对象链接在一起,与Web客户端进行交互。例如,您可以设置鼠标悬停效果、在客户端验证表单、创建自定义 HTML 页面、显示警报框、设置 cookie 等。
function jsHello{ alert('Hello World!');}
将代码嵌入 HTML 语言,加载时会弹出“Hello World”对话框。至于怎么嵌入,我们在开始学习JS视频的时候就已经知道了。
4、总结
我将向您介绍 HTML、CSS 和 JS 之间的区别。
码字不易,请给我点个赞,点赞和关注是我写作的动力,谢谢!
网页css js 抓取助手(Screaming优化蜘蛛最常见的用途和使用方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-04 00:07
Screaming Frog SEO Spider 是一款专业的网站 资源检测和搜索工具。该软件支持爬取网站并查找损坏的链接(404)和服务器错误,审计)是一个非常有用的网站优化和SEO工具,用于定位、发现重复内容、分析页面标题和元数据。Screaming Frog SEO Spider可以查找断链、查看重定向、分析页面标题和元数据、查找重复内容、使用XPath提取数据、查看机器人和指令、生成XML站点地图等功能,软件界面非常简单明了,软件使用方便快捷。
如何使用
一、爬行爬行
1、定期爬取
在正常爬取模式下,Screaming Frog SEO Spider 13 破解版会爬取您输入的子域,并将遇到的所有其他子域默认视为外部链接(显示在“外部”选项卡下方)。在正版软件中,可以调整配置选择抓取网站的所有子域。搜索引擎优化蜘蛛最常见的用途之一是在 网站 上查找错误,例如断开的链接、重定向和服务器错误。为了更好的控制爬取,请使用您的网站 URI结构,SEO蜘蛛配置选项,比如只爬取HTML(图片、CSS、JS等)、排除函数、自定义robots.txt、收录函数或者更改搜索引擎优化蜘蛛模式,上传一个URI列表爬取
2、抓取一个子文件夹
SEO Spider 工具默认从子文件夹路径向前爬取,所以如果要爬取站点上的特定子文件夹,只需输入带有文件路径的 URI。直接进入SEO Spider,会抓取/blog/sub目录下的所有URI
3、获取网址列表
通过输入网址点击“开始”抓取网站,您可以切换到列表模式,粘贴或上传要抓取的特定网址列表。例如,在审核重定向时,这对网站迁移特别有用
二、配置
在该工具的行货版本中,可以保存默认的爬取配置,并保存需要时可以加载的配置配置文件
1、要将当前配置保存为默认值,请选择“文件>配置>将当前配置保存为默认值”
2、要保存配置文件以便以后加载,点击“文件>另存为”并调整文件名(描述性最好)
3、要加载配置文件,请点击“文件>加载”,然后选择您的配置文件或“文件>加载最近”从最近列表中选择
4、要重置为原版Screaming Frog SEO Spider 13破解版的默认配置,请选择“文件>配置>清除默认配置”
三、导出
顶部窗口部分的导出功能适用于您在顶部窗口中的当前视野。因此,如果您使用过滤器并单击“导出”,则只会导出过滤器选项中收录的数据
主要有三种数据导出方式:
1、导出顶层窗口数据:只需点击左上角的“导出”按钮,即可从顶层窗口选项卡导出数据
2、导出下层窗口数据(URL信息、链接、输出链接、图片信息):导出这些数据只需在上层窗口中要导出的数据的URL上右击,然后点击“导出”下的“URL信息”、“链接”、“外链”或“图片信息”
3、 批量导出:位于顶部菜单下,允许批量导出数据。您可以通过“all in links”选项导出在抓取中找到的所有链接实例,或导出所有链接到具有特定状态代码(例如 2XX、3XX、4XX 或 5XX 响应)的 URL。例如,选择“链接中的客户端错误 4XX”选项将导出所有链接到所有错误页面(例如 404 错误页面)。您还可以导出所有图片替代文本,所有图片缺少替代文本和所有锚文本
下载链接: 查看全部
网页css js 抓取助手(Screaming优化蜘蛛最常见的用途和使用方法有哪些?)
Screaming Frog SEO Spider 是一款专业的网站 资源检测和搜索工具。该软件支持爬取网站并查找损坏的链接(404)和服务器错误,审计)是一个非常有用的网站优化和SEO工具,用于定位、发现重复内容、分析页面标题和元数据。Screaming Frog SEO Spider可以查找断链、查看重定向、分析页面标题和元数据、查找重复内容、使用XPath提取数据、查看机器人和指令、生成XML站点地图等功能,软件界面非常简单明了,软件使用方便快捷。
如何使用
一、爬行爬行
1、定期爬取
在正常爬取模式下,Screaming Frog SEO Spider 13 破解版会爬取您输入的子域,并将遇到的所有其他子域默认视为外部链接(显示在“外部”选项卡下方)。在正版软件中,可以调整配置选择抓取网站的所有子域。搜索引擎优化蜘蛛最常见的用途之一是在 网站 上查找错误,例如断开的链接、重定向和服务器错误。为了更好的控制爬取,请使用您的网站 URI结构,SEO蜘蛛配置选项,比如只爬取HTML(图片、CSS、JS等)、排除函数、自定义robots.txt、收录函数或者更改搜索引擎优化蜘蛛模式,上传一个URI列表爬取
2、抓取一个子文件夹
SEO Spider 工具默认从子文件夹路径向前爬取,所以如果要爬取站点上的特定子文件夹,只需输入带有文件路径的 URI。直接进入SEO Spider,会抓取/blog/sub目录下的所有URI
3、获取网址列表
通过输入网址点击“开始”抓取网站,您可以切换到列表模式,粘贴或上传要抓取的特定网址列表。例如,在审核重定向时,这对网站迁移特别有用
二、配置
在该工具的行货版本中,可以保存默认的爬取配置,并保存需要时可以加载的配置配置文件
1、要将当前配置保存为默认值,请选择“文件>配置>将当前配置保存为默认值”
2、要保存配置文件以便以后加载,点击“文件>另存为”并调整文件名(描述性最好)
3、要加载配置文件,请点击“文件>加载”,然后选择您的配置文件或“文件>加载最近”从最近列表中选择
4、要重置为原版Screaming Frog SEO Spider 13破解版的默认配置,请选择“文件>配置>清除默认配置”
三、导出
顶部窗口部分的导出功能适用于您在顶部窗口中的当前视野。因此,如果您使用过滤器并单击“导出”,则只会导出过滤器选项中收录的数据
主要有三种数据导出方式:
1、导出顶层窗口数据:只需点击左上角的“导出”按钮,即可从顶层窗口选项卡导出数据
2、导出下层窗口数据(URL信息、链接、输出链接、图片信息):导出这些数据只需在上层窗口中要导出的数据的URL上右击,然后点击“导出”下的“URL信息”、“链接”、“外链”或“图片信息”
3、 批量导出:位于顶部菜单下,允许批量导出数据。您可以通过“all in links”选项导出在抓取中找到的所有链接实例,或导出所有链接到具有特定状态代码(例如 2XX、3XX、4XX 或 5XX 响应)的 URL。例如,选择“链接中的客户端错误 4XX”选项将导出所有链接到所有错误页面(例如 404 错误页面)。您还可以导出所有图片替代文本,所有图片缺少替代文本和所有锚文本
下载链接:
网页css js 抓取助手(旅行网站飞行时间或Airbnb列表,可让您使用高级API控制Chrome/Chromium浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-03 09:23
简介:目前,由于其用例数量众多,企业对网页抓取的使用量大大增加。您可能需要抓取旅行 网站 航班时间或 Airbnb 列表,或者您可能想要采集数据(例如来自不同电子商务 网站 的价目表)进行价格比较。或许你需要一台采集机……转发+关注,私信编辑“数据”免费分享给你!
目前,由于其用例数量众多,企业对网页抓取的使用已大大增加。您可能需要抓取旅行 网站 航班时间或 Airbnb 列表,或者您可能想要采集数据(例如来自不同电子商务 网站 的价目表)进行价格比较。也许您需要为机器学习采集训练和测试数据集。这就是网络抓取发挥作用的地方。
在这里,我们将探索最好的网络抓取工具。
傀儡师
Puppeteer 不仅仅是一个网络爬虫。它是一个 Node.js 库,允许您使用高级 API 控制 Chrome/Chromium 浏览器。 Puppeteer 默认无法运行,但可以配置为运行完整的无头 Chrome 或 Chromium。
使用 Puppeteer,您可以执行以下操作:
带有文本标签的箭头
干杯
Cheerio 是一个用于解析标签的库。它提供了用于处理结果数据结构的 API。 Cheerio 的最大优点是它不会像 Web 浏览器那样解释结果。但是,它不产生视觉效果,也不加载外部资源或应用 CSS。因此,如果您的用例需要它们,则需要考虑 PhantomJS 之类的项目。
值得一提的是,在 Cheerio 中,使用 Node.js 来抓取 网站 要容易得多。沃尔玛等公司使用 Cheerio 来托管他们的移动 网站 服务器渲染。
请求-承诺
Request-Promise 是 npm 实际库的变体。它通过自动浏览器提供更快的解决方案。当内容不是动态呈现的时候,可以使用这个网络爬虫。如果您使用身份验证系统处理 网站,它可能是一个更高级的解决方案。如果我们将其与 Puppeteer 进行比较,则在用法上正好相反。
噩梦
Nightmare 是一个高级浏览器自动化库,可以将电子作为浏览器运行。是精简版,也可以说是Puppeteer的简化版。它具有提供更大灵活性的插件,包括对文件下载的支持。
渗透
Osmosis 是一个 HTML/XML 解析器和网页抓取工具。它是用 Node.js 编写的,带有一个 CSS3/xpath 选择器和一个轻量级的 HTTP 包装器。如果与 Cheerio、jQuery 和 jsdom 相比,它没有明显的依赖关系。
总结
除了这些网页抓取工具之外,您还可以使用许多其他工具和资源。这一切都取决于您的项目要求。但是,有些网站不允许抓取,因此在尝试抓取任何网站之前,请确保您做得很好。
需要看java吗?网络、大数据、信息:
老规矩:转发+关注,私信编辑“数据”免费分享给你! 查看全部
网页css js 抓取助手(旅行网站飞行时间或Airbnb列表,可让您使用高级API控制Chrome/Chromium浏览器)
简介:目前,由于其用例数量众多,企业对网页抓取的使用量大大增加。您可能需要抓取旅行 网站 航班时间或 Airbnb 列表,或者您可能想要采集数据(例如来自不同电子商务 网站 的价目表)进行价格比较。或许你需要一台采集机……转发+关注,私信编辑“数据”免费分享给你!
目前,由于其用例数量众多,企业对网页抓取的使用已大大增加。您可能需要抓取旅行 网站 航班时间或 Airbnb 列表,或者您可能想要采集数据(例如来自不同电子商务 网站 的价目表)进行价格比较。也许您需要为机器学习采集训练和测试数据集。这就是网络抓取发挥作用的地方。
在这里,我们将探索最好的网络抓取工具。
傀儡师
Puppeteer 不仅仅是一个网络爬虫。它是一个 Node.js 库,允许您使用高级 API 控制 Chrome/Chromium 浏览器。 Puppeteer 默认无法运行,但可以配置为运行完整的无头 Chrome 或 Chromium。
使用 Puppeteer,您可以执行以下操作:
带有文本标签的箭头
干杯
Cheerio 是一个用于解析标签的库。它提供了用于处理结果数据结构的 API。 Cheerio 的最大优点是它不会像 Web 浏览器那样解释结果。但是,它不产生视觉效果,也不加载外部资源或应用 CSS。因此,如果您的用例需要它们,则需要考虑 PhantomJS 之类的项目。
值得一提的是,在 Cheerio 中,使用 Node.js 来抓取 网站 要容易得多。沃尔玛等公司使用 Cheerio 来托管他们的移动 网站 服务器渲染。
请求-承诺
Request-Promise 是 npm 实际库的变体。它通过自动浏览器提供更快的解决方案。当内容不是动态呈现的时候,可以使用这个网络爬虫。如果您使用身份验证系统处理 网站,它可能是一个更高级的解决方案。如果我们将其与 Puppeteer 进行比较,则在用法上正好相反。
噩梦
Nightmare 是一个高级浏览器自动化库,可以将电子作为浏览器运行。是精简版,也可以说是Puppeteer的简化版。它具有提供更大灵活性的插件,包括对文件下载的支持。
渗透
Osmosis 是一个 HTML/XML 解析器和网页抓取工具。它是用 Node.js 编写的,带有一个 CSS3/xpath 选择器和一个轻量级的 HTTP 包装器。如果与 Cheerio、jQuery 和 jsdom 相比,它没有明显的依赖关系。
总结
除了这些网页抓取工具之外,您还可以使用许多其他工具和资源。这一切都取决于您的项目要求。但是,有些网站不允许抓取,因此在尝试抓取任何网站之前,请确保您做得很好。
需要看java吗?网络、大数据、信息:
老规矩:转发+关注,私信编辑“数据”免费分享给你!
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-12-29 19:19
)
我整理了25个前端相关的学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,以及一些资源网站。我希望我能帮到你!
▍CSS相关
●1
CSSBattle-在线竞争CSS
竞技CSS在线,一款非常有趣的竞技类游戏,共12个关卡。您需要使用 HTML 和 CSS 将其给出的页面 100% 还原,然后最小化代码。您还可以查看全球排名并查看解决方案。计划。
●2
学习 CSS 布局-学习 CSS 布局
在线CSS布局学习,将逐步引导初学者学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS编写习惯和正确方法。
●3
Flexbox Froggy-学习Flex布局的小游戏
一个学习 Flex 布局的引导游戏。使用flex layout让青蛙在荷叶上跳跃。就算完成了,游戏中也几乎收录
了所有常用的属性。学习起来很有趣,而且图像有利于记忆。谁不是Flex布局如果你熟悉,在这里多练习。
●4
EnjoyCSS-在线CSS代码可视化工具
在线版CSS3代码生成工具,基于可视化操作,无需编码即可快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件。
●5
CSS-Tricks-CSS 技巧
本站不断更新一些优秀的CSS技术教程和技巧,文章每天更新。
●6
Neumorphism - 实现新的拟态效果
它可以轻松实现新的模拟效果,不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果和形状等参数。同时,它提供了可以直接复制的CSS代码。
●7
uiGradients-共享渐变色
提供渐变色效果的网站。有接近数百种渐变配色方案。可以根据自己的风格进行选择搭配,直接获取渐变配色方案对应的CSS代码。
▍JS相关
●8
JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。主要写了如何避免一些常见的错误,发现难以发现的bug。它将更深入地了解 JavaScript 的语言特性。
●9
JSTips-JS技巧
每天一点Javascript知识。
●10
JSweekly-科技周刊
专注于 Javascript 的技术周刊。
●11
CDNJS-JavaScript 数据库
CDNJS为开发者提供最新的前端Web开发资源,免费,无限制。你可以在自己的网页上直接引用这些JS文件。进入CDNJS网站后,搜索你想要的资源库,点击项目后面的【复制脚本标签】,粘贴即可使用。目前,CDNJS在Web前端的CDN服务中排名第二(排名第一的是谷歌),性能优异。
●12
开源 JS 库的美丽开放集合
采集
各类设计优秀的开源项目,从CMS内容管理系统到常用的小型Javascript库,适合网站开发用户。
●13
JavaScript Fun- 代码库合集
汇集当下最流行的JavaScript代码库,展示流行度排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow-程序员问答
全球IT行业最受欢迎的技术问答网站之一,一个解决bug的社区,被称为“编程界的十万个为什么”。
●15
掘金-优质技术社区
掘金技术社区是一个优质的技术分享社区。技术专家和极客们共同编辑、甄选优质干货。这些技术文章包括Android、iOS、前端和后端资源。
●16
Codrops-网页设计开发博客
发布技术文章和网络教程,提供经验,陷阱少,资源丰富,很多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码的工具,上面有各种效果案例特效(炫技),你可以根据他们的demo开发自己的前端设计.
●18
代码沙盒
顾名思义,CodeSandBox 网站提供了一个在线开发环境的“沙箱”。React、Vue、Angular等主流框架都可以开箱即用,实时编译预览,非常方便。
●19
JSBin
另一个轻量级的在线编辑器网站,界面简洁干净,如果你想暂时调试简单的HTML或JS代码,可以考虑去这里试一试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
它是 SVG 图标素材的在线可定制设计。帮助前端设计师找到自己想要的图标素材。这些图标素材都是常用的图标。二次设计可以点官方资料,也可以自己设计好的。图标导出。
●21
OpenMoji-free 表情符号库
提供Emoji源代码库,可免费下载使用。
● 22
分享无图标矢量素材库
一个提供超过 120 个类别的超过 250,000 个 ICON 矢量图像材料的网站。所有材料均以 PNG 和 SVG 格式提供。材料有多种尺寸可供选择,包括512*512、256*256、 128*128、64*64、32*32、16* 16等,非常适合前端设计师采集
和储备。
● 23
tableconvert-在线表格编辑器
一个强大的在线表单编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式之间的转换。当您需要在不变形的情况下转换表格时,您不妨试试这个工具。
● 24
Feathericons-极简图标集
一个免费和开源的简单而漂亮的 ICON 图标集合。主要设计用途是应用系统、媒体控制、位置、天气、箭头、标志等,可以在开发移动应用时使用。图标格式为 SVG。
● 25
HTML5 + CSS 3 免费模板
提供了大量的HTML5模板,用户可以自行分享和修改模板。
本文推荐网站汇总:
CSS之战:
学习 CSS 布局:
Flexbox 青蛙:
享受CSS:
CSS 技巧:
新拟态:
uiGradients:
JavaScript:
JS小贴士:
JS周刊:
CDNJS:
美丽开放:
JavaScript 乐趣:
堆栈溢出:
掘金:
共滴:
代码笔:
代码沙盒:
JS斌:
图标SVG:
开模:
分享图标:
表转换:
羽毛图标:
HTML5UP:
如果你有写博客的好习惯
欢迎投稿
赞+在看,小生感恩❤️ 查看全部
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具
)
我整理了25个前端相关的学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,以及一些资源网站。我希望我能帮到你!
▍CSS相关
●1
CSSBattle-在线竞争CSS
竞技CSS在线,一款非常有趣的竞技类游戏,共12个关卡。您需要使用 HTML 和 CSS 将其给出的页面 100% 还原,然后最小化代码。您还可以查看全球排名并查看解决方案。计划。
●2
学习 CSS 布局-学习 CSS 布局
在线CSS布局学习,将逐步引导初学者学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS编写习惯和正确方法。
●3
Flexbox Froggy-学习Flex布局的小游戏
一个学习 Flex 布局的引导游戏。使用flex layout让青蛙在荷叶上跳跃。就算完成了,游戏中也几乎收录
了所有常用的属性。学习起来很有趣,而且图像有利于记忆。谁不是Flex布局如果你熟悉,在这里多练习。
●4
EnjoyCSS-在线CSS代码可视化工具
在线版CSS3代码生成工具,基于可视化操作,无需编码即可快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件。
●5
CSS-Tricks-CSS 技巧
本站不断更新一些优秀的CSS技术教程和技巧,文章每天更新。
●6
Neumorphism - 实现新的拟态效果
它可以轻松实现新的模拟效果,不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果和形状等参数。同时,它提供了可以直接复制的CSS代码。
●7
uiGradients-共享渐变色
提供渐变色效果的网站。有接近数百种渐变配色方案。可以根据自己的风格进行选择搭配,直接获取渐变配色方案对应的CSS代码。
▍JS相关
●8
JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。主要写了如何避免一些常见的错误,发现难以发现的bug。它将更深入地了解 JavaScript 的语言特性。
●9
JSTips-JS技巧
每天一点Javascript知识。
●10
JSweekly-科技周刊
专注于 Javascript 的技术周刊。
●11
CDNJS-JavaScript 数据库
CDNJS为开发者提供最新的前端Web开发资源,免费,无限制。你可以在自己的网页上直接引用这些JS文件。进入CDNJS网站后,搜索你想要的资源库,点击项目后面的【复制脚本标签】,粘贴即可使用。目前,CDNJS在Web前端的CDN服务中排名第二(排名第一的是谷歌),性能优异。
●12
开源 JS 库的美丽开放集合
采集
各类设计优秀的开源项目,从CMS内容管理系统到常用的小型Javascript库,适合网站开发用户。
●13
JavaScript Fun- 代码库合集
汇集当下最流行的JavaScript代码库,展示流行度排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow-程序员问答
全球IT行业最受欢迎的技术问答网站之一,一个解决bug的社区,被称为“编程界的十万个为什么”。
●15
掘金-优质技术社区
掘金技术社区是一个优质的技术分享社区。技术专家和极客们共同编辑、甄选优质干货。这些技术文章包括Android、iOS、前端和后端资源。
●16
Codrops-网页设计开发博客
发布技术文章和网络教程,提供经验,陷阱少,资源丰富,很多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码的工具,上面有各种效果案例特效(炫技),你可以根据他们的demo开发自己的前端设计.
●18
代码沙盒
顾名思义,CodeSandBox 网站提供了一个在线开发环境的“沙箱”。React、Vue、Angular等主流框架都可以开箱即用,实时编译预览,非常方便。
●19
JSBin
另一个轻量级的在线编辑器网站,界面简洁干净,如果你想暂时调试简单的HTML或JS代码,可以考虑去这里试一试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
它是 SVG 图标素材的在线可定制设计。帮助前端设计师找到自己想要的图标素材。这些图标素材都是常用的图标。二次设计可以点官方资料,也可以自己设计好的。图标导出。
●21
OpenMoji-free 表情符号库
提供Emoji源代码库,可免费下载使用。
● 22
分享无图标矢量素材库
一个提供超过 120 个类别的超过 250,000 个 ICON 矢量图像材料的网站。所有材料均以 PNG 和 SVG 格式提供。材料有多种尺寸可供选择,包括512*512、256*256、 128*128、64*64、32*32、16* 16等,非常适合前端设计师采集
和储备。
● 23
tableconvert-在线表格编辑器
一个强大的在线表单编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式之间的转换。当您需要在不变形的情况下转换表格时,您不妨试试这个工具。
● 24
Feathericons-极简图标集
一个免费和开源的简单而漂亮的 ICON 图标集合。主要设计用途是应用系统、媒体控制、位置、天气、箭头、标志等,可以在开发移动应用时使用。图标格式为 SVG。
● 25
HTML5 + CSS 3 免费模板
提供了大量的HTML5模板,用户可以自行分享和修改模板。
本文推荐网站汇总:
CSS之战:
学习 CSS 布局:
Flexbox 青蛙:
享受CSS:
CSS 技巧:
新拟态:
uiGradients:
JavaScript:
JS小贴士:
JS周刊:
CDNJS:
美丽开放:
JavaScript 乐趣:
堆栈溢出:
掘金:
共滴:
代码笔:
代码沙盒:
JS斌:
图标SVG:
开模:
分享图标:
表转换:
羽毛图标:
HTML5UP:
如果你有写博客的好习惯
欢迎投稿
赞+在看,小生感恩❤️
网页css js 抓取助手(错误博客()分享的内容为《》帮助)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-29 01:14
错误博客发现最近的快照突然失去了CSS样式,明显不正常。今天发错博客()分享的内容是《百度快照中没有CSS样式怎么办》。我希望能有所帮助。
一、 百度官方声明
以下引用内容来自百度官方:
其中,咨询频率最高的4大问题:1、快照排版混乱、页面内容显示不完整、2、无网页快照、3、网页快照内容更新、4、网页已死链接,但快照仍然存在。
答案如下:
站长可以了解到,百度快照的生成过程与网页的索引更新是同步的。生成索引时,会将爬虫爬取到的最新网页内容推送到快照生成程序。所以可以说网页的索引速度决定了快照更新的速度。
快照生成模块将通过浏览器向用户展示网页内容。目前快照展示模块只能渲染基于静态html的网页(行话是指通过iframe加载),因此对于一些相对路径如js、css、图片素材无法加载,或者部分网站禁用百度域访问js、css等文件,会导致快照显示排版错误和部分页面内容显示不完整。在这种情况下,站长可以根据实际需要进行更正。
如果没有快照信息,请站长不要担心。只是没有为网页生成快照,也没有对网站进行一些特殊处理。
另外,站长投诉最多的就是快照更新慢,这涉及到快照更新的频率。不同网页的更新周期不同,不同网站的网页更新频率也不同。这里可以看出最长的更新周期是Month级别,最短的更新周期是分钟级别。
从官方角度分析快照,“百度快照的生成过程与网页的索引更新是同步的,当索引生成时,会将最新抓取的网页内容推送到快照生成程序“所以可以说网页被索引了,速度决定了快照更新的速度。” 在这段话中,我们可以看到,百度快照更新的速度与蜘蛛是否存在有很大关系。快照更新越快越好,证明蜘蛛质量高,来了。
如果快照更新不正常,结果可想而知。虽然官方说没有snapshot,不要紧张,没有CSS样式也没关系,但是如果出现这种情况,就证明网站存在一定的问题。
二、百度快照优化
错误博客之前的快照都是正常的。为什么这次有例外?可能主要出现在以下几个问题上:
1、打开速度慢
主页打开速度慢。虽然一而再再而三的优化,但是一次又一次的向首页添加内容导致首页加载速度变慢。在这种情况下,搜索引擎蜘蛛可能会选择不爬取css,而是直接爬取。HTML 代码就是它的全部。
2、压缩插件
错误博客最近也使用了 WordPress 压缩插件。这些插件压缩 CSS 和 JS 代码,导致这种情况发生。
百度快照的原理是通过iframe以静态hmtl方式加载和显示网页内容。Autooptimize压缩的CSS文件的链接名称是随机的,百度快照不是实时更新的。手动清除Autoptimize缓存时,重新生成的CSS链接与快照中加载的链接名称不同,无法加载正确的CSS文件。当然,没有风格。向上。
引自:DEFCON 笔记
这个图片压缩插件收录
了延迟加载功能,即使卸载了,估计延迟加载也会被保留,记得关掉。
3、CSS 问题
这种情况可能是CSS或JS加载速度慢造成的,需要对CSS或JS进行优化。
4、帧数过多
错误的博客首页使用了过多的网站框架,导致搜索引擎抓取缓慢。
5、服务器
错误博客的服务器带宽已经5M,基本可以满足日常需求。首页图片已经基本缩小到100KB以下,以前是1M左右的图片。如果您的网站在这方面可能存在问题,那么纠正它会容易得多。
当然,也有人说百度快照是文本网页,无需关心是否有CSS,但实际情况是,网站快照缺少css可能只是反映了网站的一些问题。最直接的问题就是网站加载慢,打开2个多第二个基本要降级了。
发现问题了,之前做的防盗链码有问题。直接去掉这些代码应该就够了。这里禁止js、css、图片等,只是因为这些页面无法抓取,都是404。
如果你使用的是windows系统,而web服务器使用的是IIS,那么防盗链的设置也很简单。只需将以下代码的内容添加到 web.config 中即可。
直接在原来的web.config文件之间写入上传缩进代码即可,不要破坏其他文件。
以上是错误博客分享的内容()是“百度快照中没有CSS样式怎么办”。感谢您的阅读。更多原创文章,搜索“错误博客”。 查看全部
网页css js 抓取助手(错误博客()分享的内容为《》帮助)
错误博客发现最近的快照突然失去了CSS样式,明显不正常。今天发错博客()分享的内容是《百度快照中没有CSS样式怎么办》。我希望能有所帮助。
一、 百度官方声明
以下引用内容来自百度官方:
其中,咨询频率最高的4大问题:1、快照排版混乱、页面内容显示不完整、2、无网页快照、3、网页快照内容更新、4、网页已死链接,但快照仍然存在。
答案如下:
站长可以了解到,百度快照的生成过程与网页的索引更新是同步的。生成索引时,会将爬虫爬取到的最新网页内容推送到快照生成程序。所以可以说网页的索引速度决定了快照更新的速度。
快照生成模块将通过浏览器向用户展示网页内容。目前快照展示模块只能渲染基于静态html的网页(行话是指通过iframe加载),因此对于一些相对路径如js、css、图片素材无法加载,或者部分网站禁用百度域访问js、css等文件,会导致快照显示排版错误和部分页面内容显示不完整。在这种情况下,站长可以根据实际需要进行更正。
如果没有快照信息,请站长不要担心。只是没有为网页生成快照,也没有对网站进行一些特殊处理。
另外,站长投诉最多的就是快照更新慢,这涉及到快照更新的频率。不同网页的更新周期不同,不同网站的网页更新频率也不同。这里可以看出最长的更新周期是Month级别,最短的更新周期是分钟级别。
从官方角度分析快照,“百度快照的生成过程与网页的索引更新是同步的,当索引生成时,会将最新抓取的网页内容推送到快照生成程序“所以可以说网页被索引了,速度决定了快照更新的速度。” 在这段话中,我们可以看到,百度快照更新的速度与蜘蛛是否存在有很大关系。快照更新越快越好,证明蜘蛛质量高,来了。
如果快照更新不正常,结果可想而知。虽然官方说没有snapshot,不要紧张,没有CSS样式也没关系,但是如果出现这种情况,就证明网站存在一定的问题。
二、百度快照优化
错误博客之前的快照都是正常的。为什么这次有例外?可能主要出现在以下几个问题上:
1、打开速度慢
主页打开速度慢。虽然一而再再而三的优化,但是一次又一次的向首页添加内容导致首页加载速度变慢。在这种情况下,搜索引擎蜘蛛可能会选择不爬取css,而是直接爬取。HTML 代码就是它的全部。
2、压缩插件
错误博客最近也使用了 WordPress 压缩插件。这些插件压缩 CSS 和 JS 代码,导致这种情况发生。
百度快照的原理是通过iframe以静态hmtl方式加载和显示网页内容。Autooptimize压缩的CSS文件的链接名称是随机的,百度快照不是实时更新的。手动清除Autoptimize缓存时,重新生成的CSS链接与快照中加载的链接名称不同,无法加载正确的CSS文件。当然,没有风格。向上。
引自:DEFCON 笔记
这个图片压缩插件收录
了延迟加载功能,即使卸载了,估计延迟加载也会被保留,记得关掉。
3、CSS 问题
这种情况可能是CSS或JS加载速度慢造成的,需要对CSS或JS进行优化。
4、帧数过多
错误的博客首页使用了过多的网站框架,导致搜索引擎抓取缓慢。
5、服务器
错误博客的服务器带宽已经5M,基本可以满足日常需求。首页图片已经基本缩小到100KB以下,以前是1M左右的图片。如果您的网站在这方面可能存在问题,那么纠正它会容易得多。
当然,也有人说百度快照是文本网页,无需关心是否有CSS,但实际情况是,网站快照缺少css可能只是反映了网站的一些问题。最直接的问题就是网站加载慢,打开2个多第二个基本要降级了。
发现问题了,之前做的防盗链码有问题。直接去掉这些代码应该就够了。这里禁止js、css、图片等,只是因为这些页面无法抓取,都是404。
如果你使用的是windows系统,而web服务器使用的是IIS,那么防盗链的设置也很简单。只需将以下代码的内容添加到 web.config 中即可。
直接在原来的web.config文件之间写入上传缩进代码即可,不要破坏其他文件。
以上是错误博客分享的内容()是“百度快照中没有CSS样式怎么办”。感谢您的阅读。更多原创文章,搜索“错误博客”。
网页css js 抓取助手(百忙之中抽时间编写了这个小程序,功能是:完美保存整个网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-20 09:12
我从繁忙的日程中抽出时间来编写这个小程序。功能是完美保存整个网页,包括:图片、JS脚本、CSS样式,修改网页源代码进行“本地化”。因为火了,连浏览器自带这个功能都不知道,就自己做了一个。这个程序虽然不大,但是涉及到三大问题(后面会详细说明)。
本来不打算放源码的,既然浏览器有这个功能,那我就放出源码供大家学习!这个程序的效果和浏览器的效果完全一样!而且我对比了一下,得到的js、css、图片都不亚于浏览器得到的。可以参考这个玩:做一个网站全站下载器。当然你永远不能下载数据库.....
使用说明:
1.填写网页地址,点击前往,即可激活一键下载。加载网页需要时间。如果加载前点击一键下载,会有提示。尝试在网速更好的时候使用它!
2.下载完成后,会在软件目录下生成一个以网页标题命名的文件夹。所有必要的文件都存储在这里。以网页标题命名的 HTM 文件即为保存的页面。在这种情况下,双击查看的效果和在网上查看是一样的!.
程序截图:
解决的问题:
1. 判断网页已经加载完毕。以前,已知目的地的网页可以通过“标记方法”来判断,但在这个程序中一切都是未知的。因此,必须使用新的方法。这里使用了HTML对象的Onload事件,结合webbrowser控件完美实现了判断网页加载完成的完成。这是目前最安全、最准确、最可靠的方法!适用于所有环境。
确定网页已经加载一直很头疼,至少在VB中是这样。网上提到的方法基本都行不通。更好的是有时它有效,有时它不起作用。现在我将发布一个代码来结束这个问题
'引用“Microsoft HTML Object Library”
Dim WithEvents page As HTMLWindow2 '注意要定义成全局的
Private Sub WebBrowser1_NavigateComplete2(ByVal pDisp As Object, URL As Variant)
Set page = Me.WebBrowser1.document.parentWindow
End Sub
Private Sub page_onload()
Debug.Print "加载完毕"
End Sub
2.获取网页js和css。我看到很多人在猪八戒上发帖求一个程序,请求网页中的所有js和css。其实这个不难,百度一下,可以发现javascript语言提供了这个接口。下面我将演示如何使用这个接口来获取。
首先使用 webbrowser 控件加载要提取的网页。
获取js:
<p>strBasicHTM = WebBrowser1.Document.documentElement.outerHTML
WebBrowser1.Navigate "javascript:str='
\n';c=document.scripts;for(i=0;i 查看全部
网页css js 抓取助手(百忙之中抽时间编写了这个小程序,功能是:完美保存整个网页)
我从繁忙的日程中抽出时间来编写这个小程序。功能是完美保存整个网页,包括:图片、JS脚本、CSS样式,修改网页源代码进行“本地化”。因为火了,连浏览器自带这个功能都不知道,就自己做了一个。这个程序虽然不大,但是涉及到三大问题(后面会详细说明)。
本来不打算放源码的,既然浏览器有这个功能,那我就放出源码供大家学习!这个程序的效果和浏览器的效果完全一样!而且我对比了一下,得到的js、css、图片都不亚于浏览器得到的。可以参考这个玩:做一个网站全站下载器。当然你永远不能下载数据库.....
使用说明:
1.填写网页地址,点击前往,即可激活一键下载。加载网页需要时间。如果加载前点击一键下载,会有提示。尝试在网速更好的时候使用它!
2.下载完成后,会在软件目录下生成一个以网页标题命名的文件夹。所有必要的文件都存储在这里。以网页标题命名的 HTM 文件即为保存的页面。在这种情况下,双击查看的效果和在网上查看是一样的!.
程序截图:
解决的问题:
1. 判断网页已经加载完毕。以前,已知目的地的网页可以通过“标记方法”来判断,但在这个程序中一切都是未知的。因此,必须使用新的方法。这里使用了HTML对象的Onload事件,结合webbrowser控件完美实现了判断网页加载完成的完成。这是目前最安全、最准确、最可靠的方法!适用于所有环境。
确定网页已经加载一直很头疼,至少在VB中是这样。网上提到的方法基本都行不通。更好的是有时它有效,有时它不起作用。现在我将发布一个代码来结束这个问题
'引用“Microsoft HTML Object Library”
Dim WithEvents page As HTMLWindow2 '注意要定义成全局的
Private Sub WebBrowser1_NavigateComplete2(ByVal pDisp As Object, URL As Variant)
Set page = Me.WebBrowser1.document.parentWindow
End Sub
Private Sub page_onload()
Debug.Print "加载完毕"
End Sub
2.获取网页js和css。我看到很多人在猪八戒上发帖求一个程序,请求网页中的所有js和css。其实这个不难,百度一下,可以发现javascript语言提供了这个接口。下面我将演示如何使用这个接口来获取。
首先使用 webbrowser 控件加载要提取的网页。
获取js:
<p>strBasicHTM = WebBrowser1.Document.documentElement.outerHTML
WebBrowser1.Navigate "javascript:str='
\n';c=document.scripts;for(i=0;i
网页css js 抓取助手(简单易用的网页解析工具-上海怡健医学() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-20 05:18
)
微客网页助手是一款简单易用的网页分析工具。该程序旨在帮助您通过简单的步骤解析任何网页,从而查看网页的所有数据,如 HTML、图片、CSS、JS、FLASH 等。 当您需要解析网页或查看网页时页面写作技巧。该软件提供了一套有用的解决方案。它具有简单直观的操作界面。首先,您需要注册并登录一个帐户。进入主窗口后,输入网址,设置文件存储路径,一键分析。分析完成后,可以在输出目录中快速查看分析数据。使用起来非常方便。有需要的朋友可以从本站快速下载!
软件功能
微客网络助手是一款绿色、免费的网络下载工具。可以完全解析下载任何网站 HTML、图片、CSS、JS、FLASH等数据。
上手很容易,无需寻求帮助。只需三步,即可学会网站高手的写作技巧。
有账号可以直接登录,没有账号可以免费注册。注册的用户名和密码必须为英文或数字,六至二十位数字。注册成功后,弹窗提示有登录号,必须用登录号和密码登录。
选择网页下载文件的存储位置,然后在地址栏中输入要下载的网页地址,点击保存即可。完成后,您可以进入下载的目录,查看该网页中的所有文件和图片。
软件特点
简单直观的操作界面,无需任何复杂的配置选项,即可轻松解析网页。
支持分析窗口和浏览窗口。
您可以自定义设置文件的存储位置。
内置详细的操作日志,可以查看分析的完成情况。
当您需要查看网页的写作技巧时,该软件非常有用。
指示
1、启动微客网页助手,进入如下登录界面,输入用户名和密码登录。
2、 如果您还没有注册,可以选择【注册新用户】,然后输入用户名、密码、确认密码、邮箱、QQ号、手机号等信息进行注册。
3、 然后进入微客网络助手主界面。
4、 提供了两种类型的分析窗口和浏览窗口。
5、输入要解析的网站,然后点击【保存】。
6、可以查看详细的操作日志,打开输出目录可以查看HTML、图片、CSS、JS、FLASH等所有数据。
查看全部
网页css js 抓取助手(简单易用的网页解析工具-上海怡健医学()
)
微客网页助手是一款简单易用的网页分析工具。该程序旨在帮助您通过简单的步骤解析任何网页,从而查看网页的所有数据,如 HTML、图片、CSS、JS、FLASH 等。 当您需要解析网页或查看网页时页面写作技巧。该软件提供了一套有用的解决方案。它具有简单直观的操作界面。首先,您需要注册并登录一个帐户。进入主窗口后,输入网址,设置文件存储路径,一键分析。分析完成后,可以在输出目录中快速查看分析数据。使用起来非常方便。有需要的朋友可以从本站快速下载!
软件功能
微客网络助手是一款绿色、免费的网络下载工具。可以完全解析下载任何网站 HTML、图片、CSS、JS、FLASH等数据。
上手很容易,无需寻求帮助。只需三步,即可学会网站高手的写作技巧。
有账号可以直接登录,没有账号可以免费注册。注册的用户名和密码必须为英文或数字,六至二十位数字。注册成功后,弹窗提示有登录号,必须用登录号和密码登录。
选择网页下载文件的存储位置,然后在地址栏中输入要下载的网页地址,点击保存即可。完成后,您可以进入下载的目录,查看该网页中的所有文件和图片。
软件特点
简单直观的操作界面,无需任何复杂的配置选项,即可轻松解析网页。
支持分析窗口和浏览窗口。
您可以自定义设置文件的存储位置。
内置详细的操作日志,可以查看分析的完成情况。
当您需要查看网页的写作技巧时,该软件非常有用。
指示
1、启动微客网页助手,进入如下登录界面,输入用户名和密码登录。
2、 如果您还没有注册,可以选择【注册新用户】,然后输入用户名、密码、确认密码、邮箱、QQ号、手机号等信息进行注册。
3、 然后进入微客网络助手主界面。
4、 提供了两种类型的分析窗口和浏览窗口。
5、输入要解析的网站,然后点击【保存】。
6、可以查看详细的操作日志,打开输出目录可以查看HTML、图片、CSS、JS、FLASH等所有数据。
网页css js 抓取助手( 基于js代码是如何调用网页助手小精灵的呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-17 07:14
基于js代码是如何调用网页助手小精灵的呢?(图))
基于JS调用网页助手精灵实现导航栏的方法
更新时间:2016年6月17日14:55:25 作者:柯南&
向 网站 添加网络助手向导。当用户访问网站时,向用户打招呼,或者发送一些网站的重要信息,都会给用户带来极佳的体验。那么如何基于js代码调用web助手向导呢?跟Script House的编辑一起学习吧。
1.概述
向 网站 添加网络助手向导。当用户访问网站时,向用户打招呼或发送网站的一些重要信息,不仅可以帮助用户快速了解网站,还可以让用户对网站留下深刻印象。 @网站。本例将介绍通过JavaScript调用网络助手精灵的方法。
2.技术要点
这个例子主要是通过微软的一个ActiveX组件Microsoft Agent来实现的。Microsoft Agent 提供了多种方法来控制 Agent 的角色,下面将对其进行详细介绍。
一个。load()方法:用于读入要使用的角色,该方法收录两个参数,一个用于指定角色的名称,另一个用于指定角色存储的文件。
湾 Show() 方法:用于在屏幕上显示字符。
C。Hide() 方法:用于隐藏角色。
d. Speak()方法:用于实现说话的作用。这个方法有一个参数来指定说话的内容。
e. MoveTo()方法:用于将字符移动到屏幕上的指定位置。该方法有两个参数,一个用于指定x轴坐标,另一个用于指定y轴坐标。
F。Play() 方法:用于指定要播放的动画。该方法只有一个参数,用于指定表示动画的字符串。其值包括Announce、Explain、Congratulate、greet、Gestureright、Gestureleft、Gesturedown、Gestureup、pleed and Read等。
3. 具体实现
(1)在需要展示网页助手精灵的页面的标记处,编写一个自定义的JavaScript函数loadAgent()来加载要使用的角色。loadAgent()函数的具体代码如下:
function loadAgent(id){
try{
id=new ActiveXObject("Agent.Control.2"); //创建一个ActiveX控件
id.Connected = true;
id.Characters.Load("MrAgent","merlin.acs"); //装入要使用的角色
return id;
}catch (err){
return false;
}
}
(在2)loadAgent()函数之后,编写一个自定义的JavaScript函数controlAgent(),用于调用和控制网页助手精灵,controlAgent()函数的具体代码如下:
function controlAgent(){
if (agent=loadAgent("agent")){
var mrAgentID="MrAgent";
mrAgent = agent.Characters.Character(mrAgentID); //获取助手对象
mrAgent.MoveTo(200,200); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Speak("欢迎来到明日科技网站!"); //提示语
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Play("Pleased"); //做请的手势
mrAgent.Speak("我们的网址:www.cccxy.com"); //提示语
mrAgent.Hide(); //隐藏助手
mrAgent.MoveTo(600,300); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Play("Read") //作出读书的动作
mrAgent.Speak("我们会热心解决您学习过程中遇到的疑问"); //提示语
mrAgent.Play("Idle1_1"); //做出无所事事的样子
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Speak("记住我们的网址:www.cccxy.com"); //提示语
mrAgent.Play("greet"); //问候
mrAgent.Speak("感谢您的到来"); //提示语
mrAgent.Play("Idle2_2"); //做出无所事事的样子
mrAgent.Hide(); //隐藏助手
}
}
(3)编写JavaScript代码,在页面加载后调用和控制web助手向导,具体代码如下:
window.onload=function(){
controlAgent(); //调用并控制网页助手小精灵
}
以上就是小编给大家介绍的基于导航栏JS实现调用web助手向导的方法。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持! 查看全部
网页css js 抓取助手(
基于js代码是如何调用网页助手小精灵的呢?(图))
基于JS调用网页助手精灵实现导航栏的方法
更新时间:2016年6月17日14:55:25 作者:柯南&
向 网站 添加网络助手向导。当用户访问网站时,向用户打招呼,或者发送一些网站的重要信息,都会给用户带来极佳的体验。那么如何基于js代码调用web助手向导呢?跟Script House的编辑一起学习吧。
1.概述
向 网站 添加网络助手向导。当用户访问网站时,向用户打招呼或发送网站的一些重要信息,不仅可以帮助用户快速了解网站,还可以让用户对网站留下深刻印象。 @网站。本例将介绍通过JavaScript调用网络助手精灵的方法。
2.技术要点
这个例子主要是通过微软的一个ActiveX组件Microsoft Agent来实现的。Microsoft Agent 提供了多种方法来控制 Agent 的角色,下面将对其进行详细介绍。
一个。load()方法:用于读入要使用的角色,该方法收录两个参数,一个用于指定角色的名称,另一个用于指定角色存储的文件。
湾 Show() 方法:用于在屏幕上显示字符。
C。Hide() 方法:用于隐藏角色。
d. Speak()方法:用于实现说话的作用。这个方法有一个参数来指定说话的内容。
e. MoveTo()方法:用于将字符移动到屏幕上的指定位置。该方法有两个参数,一个用于指定x轴坐标,另一个用于指定y轴坐标。
F。Play() 方法:用于指定要播放的动画。该方法只有一个参数,用于指定表示动画的字符串。其值包括Announce、Explain、Congratulate、greet、Gestureright、Gestureleft、Gesturedown、Gestureup、pleed and Read等。
3. 具体实现
(1)在需要展示网页助手精灵的页面的标记处,编写一个自定义的JavaScript函数loadAgent()来加载要使用的角色。loadAgent()函数的具体代码如下:
function loadAgent(id){
try{
id=new ActiveXObject("Agent.Control.2"); //创建一个ActiveX控件
id.Connected = true;
id.Characters.Load("MrAgent","merlin.acs"); //装入要使用的角色
return id;
}catch (err){
return false;
}
}
(在2)loadAgent()函数之后,编写一个自定义的JavaScript函数controlAgent(),用于调用和控制网页助手精灵,controlAgent()函数的具体代码如下:
function controlAgent(){
if (agent=loadAgent("agent")){
var mrAgentID="MrAgent";
mrAgent = agent.Characters.Character(mrAgentID); //获取助手对象
mrAgent.MoveTo(200,200); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Speak("欢迎来到明日科技网站!"); //提示语
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Play("Pleased"); //做请的手势
mrAgent.Speak("我们的网址:www.cccxy.com"); //提示语
mrAgent.Hide(); //隐藏助手
mrAgent.MoveTo(600,300); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Play("Read") //作出读书的动作
mrAgent.Speak("我们会热心解决您学习过程中遇到的疑问"); //提示语
mrAgent.Play("Idle1_1"); //做出无所事事的样子
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Speak("记住我们的网址:www.cccxy.com"); //提示语
mrAgent.Play("greet"); //问候
mrAgent.Speak("感谢您的到来"); //提示语
mrAgent.Play("Idle2_2"); //做出无所事事的样子
mrAgent.Hide(); //隐藏助手
}
}
(3)编写JavaScript代码,在页面加载后调用和控制web助手向导,具体代码如下:
window.onload=function(){
controlAgent(); //调用并控制网页助手小精灵
}
以上就是小编给大家介绍的基于导航栏JS实现调用web助手向导的方法。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持!
网页css js 抓取助手(SEO高级培训班第一期课程:SEO基础和实用操作老师:MOON)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-17 07:00
SEO高级培训课程第一阶段
第一课:SEO基础与实操
老师:月亮
培训语录:很多朋友不明白为什么要讲这么基础的知识。读一篇文章就这么简单。没有必要谈论它。其实,要学好SEO,必须掌握大理的基本SEO“关键词”。在我们优化一个网站的过程中,如果你不好好学习关键词,那么你在接下来的工作中将一无所获。
课程关键词:SEO、UEO、PR值、搜狗值、SEM、目标关键词、长尾关键词、死链、反向链接、SEO黑帽、SEO白帽、沙盒沙盒、 Alexa排名、ALT属性、链接和域和站点、关键词热度分析、关键词密度分析、页面相关性、采集或重复内容、蜘蛛和搜索引擎、做站点SEO元素、搜索引擎封站点K站采摘、优质外链、站点相关性、站点收录、导出链接、交叉链接、关键词堆砌、隐藏文字、隐藏链接、隐藏页面、301重定向欺骗、搜索引擎惩罚、关键词 排名、机器人、站点地图、SEO 工具、HTTP 状态代码、div+css、元标签(MATE 标签)、数据 采集、伪原创、FLASH 和 JS 以及框架框架、TITLE、H 标签、URL 超文本链接、敏感词汇、服务器安全、服务器稳定性、FFA 链接工厂、Indexed Pages 索引页、Crawler、什么是nofollow、301 重定向、cms系统、PV、跳出率、404 页面、开源系统、Firefox 浏览器、Google网站管理员、阿里妈妈站长工具、webmaster-toolbox 站长工具箱、反向链接查询工具、PR劫持、SeoQuake工具、站点地图生成工具、反向链接查询工具、流量统计工具、谷歌炸弹、SEO助手、webmasterhome查询工具、雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,最好的迁移方式网站。跳出率、404页面、开源系统、火狐浏览器、Google网站管理员、阿里妈妈站长工具、webmaster-toolbox站长工具箱、反向链接查询工具、PR劫持、SeoQuake工具、站点地图生成工具、反向链接查询工具、流量统计工具,谷歌炸弹,SEO助手,站长首页查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,迁移网站的最佳方式。跳出率、404页面、开源系统、火狐浏览器、Google网站管理员、阿里妈妈站长工具、webmaster-toolbox站长工具箱、反向链接查询工具、PR劫持、SeoQuake工具、站点地图生成工具、反向链接查询工具、流量统计工具,谷歌炸弹,SEO助手,站长首页查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,迁移网站的最佳方式。webmasterhome查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,最好的迁移方式网站。webmasterhome查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,最好的迁移方式网站。
SEO基本概念学习:
1. SEO究竟是什么,SEO的真正范围是什么?
答:很多朋友研究了很久,还是没有理解SEO的真正含义。我们现在通俗地讲的SEO指的是关键词排名优化和网站质量优化两大类。搜索引擎优化不是简单的字面解释,那么关键词优化是什么意思呢?是指站点可以定位到目标关键词,从而通过目标关键词在百度、谷歌或其他搜索引擎上可以找到该站点。网站的优化称为关键词优化。. 网站质量优化是指我们通过精心添加网站内容和网站模板操作布局和目录结构优化来改进网站的收录和内部页面关键词@。> 排名。
2. UEO是什么意思?怎么理解他?
答:UEO的意思是优化体验。我们在 UEO 理解的是如何让用户在 网站 上找到他们需要的东西,并以最低的成本让网站对用户产生吸引力。用最少的成本找到用户需要的东西,就是按用户分类(非分段)对网站信息进行布局。牵引力是指网站内容降低用户跳出率的能力。
3. PR值是多少?如何准确查询PR值
PR值是谷歌对网站质量和关键词进行排名的算法。通过这个算法,他可以判断网站的质量是高还是低。网站的好坏体现在PR值上,影响PR值的原因很多,反向链接、内链、内容。我们主要通过一些关键词查询工具来了解网站的PR值。
4. 什么是搜狗价值?
搜狗值和PR值是不同概念的算法。你为什么这么说?搜狗是搜索引擎的算法,但与谷歌的算法不同。他的比分是1-100,不是1-10.
5. 什么是扫描电镜?
SEM是指搜索引擎营销策略。其实就是指通过营销手段整合网站优化,或者说对网站关键词进行精准优化,达到触达流量,将流量收益最大化。我们称这样的程序为 SEM 策略。也就是说,我们可以通过这个策略优化网站,直接带来收益。
6.目标是什么关键词?
Goal 关键词 我们也称其为网站的核心关键词,即网站的主题关键词,那么具体是什么意思呢?让我们举一个例子。比如我们做一个服装网站,那么我们网站的主题就是服装,服装就是目标关键词。当然,可以有多个目标关键词。但这些必须是相关的。因为一个站点只能有一个主题。
7.什么是长尾关键词?
长尾关键词也称为相关关键词,指的是整个站点除核心关键词之外的所有相关关键词。我们都叫它长尾关键词,也就是关键词核心的长尾词。
8. 什么是死链接?
死链接是指网站上存在无效或不存在的 URL。一般站点的网页上都有一个URL路径,但是点击后,该路径不存在,或者已经移动或者动态路径失效。向上。这种链接的存在称为死链接。
9. 什么是反向链接?
反向链接实际上很容易解释。比如网页A和网页B,现在网页B中有一个指向网页A的链接,那么我们把网页B的链接称为网页A的反向链接。
10. 什么是导出链接?
导出链接也很容易理解。现在有两个站点 A 和 B。在站点 A 上,有一个指向站点 B 的链接(称为小 a)或指向站点 B 的链接。我们将站点 A 称为导出链接小 a。
11. 什么是导入链接?
导入链接也可以以站点 A 和站点 B 为例。现在站点 B 有一个到站点 A 的链接。我们称之为站点 A,站点 A 有一个名为 B 的导入链接。
12. 什么是内链?
我们将内部链接简称为内部链接。指站点内相互之间的链接。例如,如果站点A的目标关键词出现在站点A的某个页面上,那么我们将这个目标关键词用锚文本链接指向站点A的首页,那么这样的链接是称为内部链接。
13. 什么是超链接?
超文本链接是前面提到的锚文本链接。以文字形式参考上面的链接。例如,以下是一个超文本链接。昆明旅游的超文本为昆明旅游,网址为通用论坛的超文本,表示为昆明旅游的。意思是一样的。
14. 什么是隐藏链接?
隐藏链接是指使用 CSS 或代码使其在浏览器中不可见。
事实上,它已经使用了颜色或将文本字体更改为 0 或负数,以使只有搜索引擎可以抓取
但是用户看不到它,这与隐藏文本相同。
15. SEO黑帽
SEO黑帽是指很多SEO人员(SEOER)通过搜索引擎算法的漏洞,进行非法、公平竞争的SEO优化,我们称之为黑帽收费,黑帽的方法有很多,比如301重定向欺骗,比如隐藏链接,隐藏文字是一种欺骗搜索引擎的方式,但是可以在短时间内达到排名的效果关键词16. SEO白帽
SEO白帽和黑帽是对立的。SEO白帽提倡使用健康的SEO技术优化网站,以获得良好的关键词排名和网站页面收录。它主要是通过优化网站内容和外链资源来达到效果。
17. 什么是沙盒效应?
新展在上线后的1-6个月内很难在谷歌上获得好的排名,甚至没有排名。我们称这种现象为:沙盒-沙盒效应。该信用期一般为6个月。即使你在过去6个月有很好的优化获得高权重,也不可能获得好的关键词排名。那么百度对于新网站也有一个信用期,就是3个月。所以现在很多站长为了优化,买老网站的域名,特别是买行业网站做SEO优化,是个不错的办法。
18. 什么是Alexa排名?有什么作用?
Alexa排名指的是全职网站质量排名。当然,质量包括很多指标。关键词的索引还是以网站的流量作为判断依据。很多朋友喜欢看Alexa排名。其实我们知道,如果Alexa排名不再在10000以内,那是没有意义的。一般来说,行业站点能达到50000以下就不错了。
19. 什么是ALT属性,ALT属性的作用是什么?
ALT 属性是一种
图片的一个注解属性,这个属性的作用是告诉所有来爬的图片搜索引擎如何对图片进行分类关键词
例如:
关键词1@>
然后当图片搜索引擎的蜘蛛爬取时,会对图片进行分类,进行关键词排名。
20.link与domain和site的区别
域:相关域,即您在互联网上搜索的相关站点
站点:指站点收录 数据链接:站点是指向您站点的所有外部链接
例如:
领域:
然后查询出来所有站点都收录此链接字母和组件。如果是做锚链接,是不可能显示出来的。如果直接做域名,可以不通过导出链接查询
21.什么是关键词热分析?
关键词 人气分析是指我们的SEO优化师需要分析哪些关键词属于热门关键词、超热门词、一般关键词、冷门关键词。这样就用定位关键词进行优化,也用很多专业的SEO优化器来给客户报价。
22. 关键词 什么是密度分析?
关键词 密度分析是指网页中某个关键词的总字数的密度。一般我们将密度定位为3%-8%,根据不同行业,密度有所区别。
23. 什么是页面相关性和站点相关性?
页面相关性是两个页面和两个站点是否属于两种类型的行业。例如,当我们要对信息进行分类时,网络技术、服装行业和化学行业有不同的类别。分类越详细,相关性越好。强大的。24. 采集 或重复内容是什么意思?
采集 内容或重复内容是指通过采集或复制等方式向网站添加内容的网站。这会导致大量的网站内容和互联网内容被复制,导致内容失去重要性。重复内容是指一个站点或不同站点上的重复内容。
25. 蜘蛛和搜索引擎
蜘蛛不是指真正的蜘蛛,而是百度、谷歌等搜索引擎的网络爬行程序。百度和谷歌使用这些程序来抓取互联网上的网站,并对它们进行收录 分类。我们称这种程序为蜘蛛。搜索引擎简称SE,是指搜索、采集、分类不同类型的引擎程序,为用户提供搜索。例如:百度、谷歌、雅虎、搜狗、搜搜等。
26. 网站SEO需要哪些要素和步骤?
(关键词9@>关键词分析定位(2)站点目录结构(3)内容添加布局(4)内部链布局(5)导入链接优化) ( 6)友情链接优化(7)提交给搜索引擎(8)谷歌管理工具分析)
27. 搜索引擎关掉K站是什么意思?
表示您的网站违反搜索引擎等相关规定或不符合搜索引擎的要求,被搜索引擎从您网站的所有收录页面中删除。
详情请见百度和谷歌的具体要求和规定。
28. 对优质外链的要求是什么?
优质外链的基本要素是,第一个必须是首页或目录页,或者有大量导入链接的内容页。第二是页面导入链接的数量和来源,是否是高PR值,导入的页面链接数量以及被百度快照快速纠正的导入链接数量。第三是这些目标链接页面是否与您现有的页面和站点特别相关。
29.站点收录是什么意思?
站点收录指的是搜索引擎,比如百度、谷歌收录你的站点在它的数据库中有多少页,可以查看具体站点:你的站点
30. 交叉链接是什么意思?
交叉链接是指A和B之间的链路交换。A有两个站a和b,B有一个站c。A用他的a站链接B的c站,并要求B的c站链接A站b。
31. 关键词 堆积是什么意思?
关键词Stuffing是搜索引擎作弊的一种形式,指的是在页面上重复某个关键词,使搜索引擎与其页面更相关。
32. 隐藏文字,隐藏页面?
隐藏文本和隐藏页面。前面提到隐藏链接的时间我已经解释过了,不再赘述。这两种都是SEO黑帽作弊方法。
33. 301转为欺骗是什么意思?
301重定向欺骗是指对某个站点进行优化,实现搜索引擎中的第一名关键词,然后通过301重定向到另一个站点,这样你一点击就跳转到另一个站点排名。
34. 什么是搜索引擎惩罚?
搜索引擎处罚是指您违反了搜索引擎网站的相关规定。搜索引擎采取降低您的站点权限或K站点的措施,例如降低您的关键词排名。降低你的 收录。
35. 关键词 排名是什么意思?
关键词 排名是指您的网站页面在搜索引擎关键词上的排名。当用户搜索此关键词时间时,您的网站将根据其权重排名在相关位置。
36. 什么是机器人?
Robots是搜索引擎公共协议,所有搜索引擎都支持。一般将robots.txt文本直接放在根目录下。我们可以使用robtos文本在网站上执行很多有用的操作,比如网站上没有内容
该页面被阻止。阻止论坛的垃圾邮件链接导出部分。
37. 什么是站点地图?
我们将站点地图称为 网站 地图。网站 地图有两种类型。一种是HTML格式,这样不仅用户可以查看,搜索引擎也可以抓取站点目录。还有一种XML的形式,是专门为搜索引擎提供的,但在搜索引擎中只有Google、Yahoo等支持xml映射。比如百度不支持xml,那我们怎么操作呢?直接提交sitemap.xml给百度就很简单了,这样百度蜘蛛就可以抓取里面的链接了。
38. 什么SEO工具?有那些SEO工具
SEO工具是指帮助SEOER人员进行SEO优化检查的小助手,可以为SEOER节省大量时间。我们经常使用FLASH站长工具,阿里妈妈,雅虎站长工具等等。当然,还有SITEMAP工具、反向链接查询工具、友情链接检查工具等等。 查看全部
网页css js 抓取助手(SEO高级培训班第一期课程:SEO基础和实用操作老师:MOON)
SEO高级培训课程第一阶段
第一课:SEO基础与实操
老师:月亮
培训语录:很多朋友不明白为什么要讲这么基础的知识。读一篇文章就这么简单。没有必要谈论它。其实,要学好SEO,必须掌握大理的基本SEO“关键词”。在我们优化一个网站的过程中,如果你不好好学习关键词,那么你在接下来的工作中将一无所获。
课程关键词:SEO、UEO、PR值、搜狗值、SEM、目标关键词、长尾关键词、死链、反向链接、SEO黑帽、SEO白帽、沙盒沙盒、 Alexa排名、ALT属性、链接和域和站点、关键词热度分析、关键词密度分析、页面相关性、采集或重复内容、蜘蛛和搜索引擎、做站点SEO元素、搜索引擎封站点K站采摘、优质外链、站点相关性、站点收录、导出链接、交叉链接、关键词堆砌、隐藏文字、隐藏链接、隐藏页面、301重定向欺骗、搜索引擎惩罚、关键词 排名、机器人、站点地图、SEO 工具、HTTP 状态代码、div+css、元标签(MATE 标签)、数据 采集、伪原创、FLASH 和 JS 以及框架框架、TITLE、H 标签、URL 超文本链接、敏感词汇、服务器安全、服务器稳定性、FFA 链接工厂、Indexed Pages 索引页、Crawler、什么是nofollow、301 重定向、cms系统、PV、跳出率、404 页面、开源系统、Firefox 浏览器、Google网站管理员、阿里妈妈站长工具、webmaster-toolbox 站长工具箱、反向链接查询工具、PR劫持、SeoQuake工具、站点地图生成工具、反向链接查询工具、流量统计工具、谷歌炸弹、SEO助手、webmasterhome查询工具、雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,最好的迁移方式网站。跳出率、404页面、开源系统、火狐浏览器、Google网站管理员、阿里妈妈站长工具、webmaster-toolbox站长工具箱、反向链接查询工具、PR劫持、SeoQuake工具、站点地图生成工具、反向链接查询工具、流量统计工具,谷歌炸弹,SEO助手,站长首页查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,迁移网站的最佳方式。跳出率、404页面、开源系统、火狐浏览器、Google网站管理员、阿里妈妈站长工具、webmaster-toolbox站长工具箱、反向链接查询工具、PR劫持、SeoQuake工具、站点地图生成工具、反向链接查询工具、流量统计工具,谷歌炸弹,SEO助手,站长首页查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,迁移网站的最佳方式。webmasterhome查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,最好的迁移方式网站。webmasterhome查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,最好的迁移方式网站。
SEO基本概念学习:
1. SEO究竟是什么,SEO的真正范围是什么?
答:很多朋友研究了很久,还是没有理解SEO的真正含义。我们现在通俗地讲的SEO指的是关键词排名优化和网站质量优化两大类。搜索引擎优化不是简单的字面解释,那么关键词优化是什么意思呢?是指站点可以定位到目标关键词,从而通过目标关键词在百度、谷歌或其他搜索引擎上可以找到该站点。网站的优化称为关键词优化。. 网站质量优化是指我们通过精心添加网站内容和网站模板操作布局和目录结构优化来改进网站的收录和内部页面关键词@。> 排名。
2. UEO是什么意思?怎么理解他?
答:UEO的意思是优化体验。我们在 UEO 理解的是如何让用户在 网站 上找到他们需要的东西,并以最低的成本让网站对用户产生吸引力。用最少的成本找到用户需要的东西,就是按用户分类(非分段)对网站信息进行布局。牵引力是指网站内容降低用户跳出率的能力。
3. PR值是多少?如何准确查询PR值
PR值是谷歌对网站质量和关键词进行排名的算法。通过这个算法,他可以判断网站的质量是高还是低。网站的好坏体现在PR值上,影响PR值的原因很多,反向链接、内链、内容。我们主要通过一些关键词查询工具来了解网站的PR值。
4. 什么是搜狗价值?
搜狗值和PR值是不同概念的算法。你为什么这么说?搜狗是搜索引擎的算法,但与谷歌的算法不同。他的比分是1-100,不是1-10.
5. 什么是扫描电镜?
SEM是指搜索引擎营销策略。其实就是指通过营销手段整合网站优化,或者说对网站关键词进行精准优化,达到触达流量,将流量收益最大化。我们称这样的程序为 SEM 策略。也就是说,我们可以通过这个策略优化网站,直接带来收益。
6.目标是什么关键词?
Goal 关键词 我们也称其为网站的核心关键词,即网站的主题关键词,那么具体是什么意思呢?让我们举一个例子。比如我们做一个服装网站,那么我们网站的主题就是服装,服装就是目标关键词。当然,可以有多个目标关键词。但这些必须是相关的。因为一个站点只能有一个主题。
7.什么是长尾关键词?
长尾关键词也称为相关关键词,指的是整个站点除核心关键词之外的所有相关关键词。我们都叫它长尾关键词,也就是关键词核心的长尾词。
8. 什么是死链接?
死链接是指网站上存在无效或不存在的 URL。一般站点的网页上都有一个URL路径,但是点击后,该路径不存在,或者已经移动或者动态路径失效。向上。这种链接的存在称为死链接。
9. 什么是反向链接?
反向链接实际上很容易解释。比如网页A和网页B,现在网页B中有一个指向网页A的链接,那么我们把网页B的链接称为网页A的反向链接。
10. 什么是导出链接?
导出链接也很容易理解。现在有两个站点 A 和 B。在站点 A 上,有一个指向站点 B 的链接(称为小 a)或指向站点 B 的链接。我们将站点 A 称为导出链接小 a。
11. 什么是导入链接?
导入链接也可以以站点 A 和站点 B 为例。现在站点 B 有一个到站点 A 的链接。我们称之为站点 A,站点 A 有一个名为 B 的导入链接。
12. 什么是内链?
我们将内部链接简称为内部链接。指站点内相互之间的链接。例如,如果站点A的目标关键词出现在站点A的某个页面上,那么我们将这个目标关键词用锚文本链接指向站点A的首页,那么这样的链接是称为内部链接。
13. 什么是超链接?
超文本链接是前面提到的锚文本链接。以文字形式参考上面的链接。例如,以下是一个超文本链接。昆明旅游的超文本为昆明旅游,网址为通用论坛的超文本,表示为昆明旅游的。意思是一样的。
14. 什么是隐藏链接?
隐藏链接是指使用 CSS 或代码使其在浏览器中不可见。
事实上,它已经使用了颜色或将文本字体更改为 0 或负数,以使只有搜索引擎可以抓取
但是用户看不到它,这与隐藏文本相同。
15. SEO黑帽
SEO黑帽是指很多SEO人员(SEOER)通过搜索引擎算法的漏洞,进行非法、公平竞争的SEO优化,我们称之为黑帽收费,黑帽的方法有很多,比如301重定向欺骗,比如隐藏链接,隐藏文字是一种欺骗搜索引擎的方式,但是可以在短时间内达到排名的效果关键词16. SEO白帽
SEO白帽和黑帽是对立的。SEO白帽提倡使用健康的SEO技术优化网站,以获得良好的关键词排名和网站页面收录。它主要是通过优化网站内容和外链资源来达到效果。
17. 什么是沙盒效应?
新展在上线后的1-6个月内很难在谷歌上获得好的排名,甚至没有排名。我们称这种现象为:沙盒-沙盒效应。该信用期一般为6个月。即使你在过去6个月有很好的优化获得高权重,也不可能获得好的关键词排名。那么百度对于新网站也有一个信用期,就是3个月。所以现在很多站长为了优化,买老网站的域名,特别是买行业网站做SEO优化,是个不错的办法。
18. 什么是Alexa排名?有什么作用?
Alexa排名指的是全职网站质量排名。当然,质量包括很多指标。关键词的索引还是以网站的流量作为判断依据。很多朋友喜欢看Alexa排名。其实我们知道,如果Alexa排名不再在10000以内,那是没有意义的。一般来说,行业站点能达到50000以下就不错了。
19. 什么是ALT属性,ALT属性的作用是什么?
ALT 属性是一种
图片的一个注解属性,这个属性的作用是告诉所有来爬的图片搜索引擎如何对图片进行分类关键词
例如:
关键词1@>
然后当图片搜索引擎的蜘蛛爬取时,会对图片进行分类,进行关键词排名。
20.link与domain和site的区别
域:相关域,即您在互联网上搜索的相关站点
站点:指站点收录 数据链接:站点是指向您站点的所有外部链接
例如:
领域:
然后查询出来所有站点都收录此链接字母和组件。如果是做锚链接,是不可能显示出来的。如果直接做域名,可以不通过导出链接查询
21.什么是关键词热分析?
关键词 人气分析是指我们的SEO优化师需要分析哪些关键词属于热门关键词、超热门词、一般关键词、冷门关键词。这样就用定位关键词进行优化,也用很多专业的SEO优化器来给客户报价。
22. 关键词 什么是密度分析?
关键词 密度分析是指网页中某个关键词的总字数的密度。一般我们将密度定位为3%-8%,根据不同行业,密度有所区别。
23. 什么是页面相关性和站点相关性?
页面相关性是两个页面和两个站点是否属于两种类型的行业。例如,当我们要对信息进行分类时,网络技术、服装行业和化学行业有不同的类别。分类越详细,相关性越好。强大的。24. 采集 或重复内容是什么意思?
采集 内容或重复内容是指通过采集或复制等方式向网站添加内容的网站。这会导致大量的网站内容和互联网内容被复制,导致内容失去重要性。重复内容是指一个站点或不同站点上的重复内容。
25. 蜘蛛和搜索引擎
蜘蛛不是指真正的蜘蛛,而是百度、谷歌等搜索引擎的网络爬行程序。百度和谷歌使用这些程序来抓取互联网上的网站,并对它们进行收录 分类。我们称这种程序为蜘蛛。搜索引擎简称SE,是指搜索、采集、分类不同类型的引擎程序,为用户提供搜索。例如:百度、谷歌、雅虎、搜狗、搜搜等。
26. 网站SEO需要哪些要素和步骤?
(关键词9@>关键词分析定位(2)站点目录结构(3)内容添加布局(4)内部链布局(5)导入链接优化) ( 6)友情链接优化(7)提交给搜索引擎(8)谷歌管理工具分析)
27. 搜索引擎关掉K站是什么意思?
表示您的网站违反搜索引擎等相关规定或不符合搜索引擎的要求,被搜索引擎从您网站的所有收录页面中删除。
详情请见百度和谷歌的具体要求和规定。
28. 对优质外链的要求是什么?
优质外链的基本要素是,第一个必须是首页或目录页,或者有大量导入链接的内容页。第二是页面导入链接的数量和来源,是否是高PR值,导入的页面链接数量以及被百度快照快速纠正的导入链接数量。第三是这些目标链接页面是否与您现有的页面和站点特别相关。
29.站点收录是什么意思?
站点收录指的是搜索引擎,比如百度、谷歌收录你的站点在它的数据库中有多少页,可以查看具体站点:你的站点
30. 交叉链接是什么意思?
交叉链接是指A和B之间的链路交换。A有两个站a和b,B有一个站c。A用他的a站链接B的c站,并要求B的c站链接A站b。
31. 关键词 堆积是什么意思?
关键词Stuffing是搜索引擎作弊的一种形式,指的是在页面上重复某个关键词,使搜索引擎与其页面更相关。
32. 隐藏文字,隐藏页面?
隐藏文本和隐藏页面。前面提到隐藏链接的时间我已经解释过了,不再赘述。这两种都是SEO黑帽作弊方法。
33. 301转为欺骗是什么意思?
301重定向欺骗是指对某个站点进行优化,实现搜索引擎中的第一名关键词,然后通过301重定向到另一个站点,这样你一点击就跳转到另一个站点排名。
34. 什么是搜索引擎惩罚?
搜索引擎处罚是指您违反了搜索引擎网站的相关规定。搜索引擎采取降低您的站点权限或K站点的措施,例如降低您的关键词排名。降低你的 收录。
35. 关键词 排名是什么意思?
关键词 排名是指您的网站页面在搜索引擎关键词上的排名。当用户搜索此关键词时间时,您的网站将根据其权重排名在相关位置。
36. 什么是机器人?
Robots是搜索引擎公共协议,所有搜索引擎都支持。一般将robots.txt文本直接放在根目录下。我们可以使用robtos文本在网站上执行很多有用的操作,比如网站上没有内容
该页面被阻止。阻止论坛的垃圾邮件链接导出部分。
37. 什么是站点地图?
我们将站点地图称为 网站 地图。网站 地图有两种类型。一种是HTML格式,这样不仅用户可以查看,搜索引擎也可以抓取站点目录。还有一种XML的形式,是专门为搜索引擎提供的,但在搜索引擎中只有Google、Yahoo等支持xml映射。比如百度不支持xml,那我们怎么操作呢?直接提交sitemap.xml给百度就很简单了,这样百度蜘蛛就可以抓取里面的链接了。
38. 什么SEO工具?有那些SEO工具
SEO工具是指帮助SEOER人员进行SEO优化检查的小助手,可以为SEOER节省大量时间。我们经常使用FLASH站长工具,阿里妈妈,雅虎站长工具等等。当然,还有SITEMAP工具、反向链接查询工具、友情链接检查工具等等。
网页css js 抓取助手(网站优化需求熟练把握查找引擎算法规矩,既要把握网站底层代码的标准性书写)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-07 18:02
网站优化
网站优化需要掌握搜索引擎算法规则,不仅要掌握网站底层代码的标准编写,还要掌握优秀的策划和排名能力,坚持专业的原创 高质量的内容更新。因此,网站 优化不应该马虎。这是一个专业和技术问题。通常需要优化团队协作。团队必须细心、耐心和负责。
网站构建
一、网站优化前提和基础环境:
(一)网站 域名先决条件:
1.网站域名选择:域名解释简单易记,网站内容相关性较好。网站 域名是否为常用后缀com、cn或net等,部分后缀域名国内搜索引擎不识别,不支持存档。域名过长必然会影响网站的链接。搜索引擎对 URL 的长度有限制。长度过长的 URL。不会被认出来。
2.网站域名记录:网站域名记录是搜索引擎对网站声望的评判标准。正规的大型企事业单位的官网会首先显示在搜索引擎首页和排行榜上,没有记录的网站将被识别为灰色网站或风险网站被搜索引擎@>,不利于网站的进入和排名。
(二)网站 服务器基础环境:
1.服务器环境设备:高性能、高带宽、独立的IP服务器,可以使网站稳定运行和发展,是寻找网站引擎得分的重要参考。一些功能低下、流量受限的虚拟主机往往被简单攻击,构成网站运行错误或无法打开,往往会受到搜索引擎的奖惩。
2.网站 运维操作:具有专业技能的程序员可以保证网站的正常运行和安全的数据备份。相反,网站经常遭受攻击或数据丢失,会给网站带来毁灭性的损失,更不用说网站优化了。
二、网站 优化方向:站内优化和站外优化
(一)站内优化:站内优化包括网站排版结构优化、网站底层代码优化、网页优化、网站程序优化、网站@ > 内链优化及网站原创内容更新。
(二)站外优化:站外优化包括网站的外链建设指导,站外渠道曝光网站信息,增加品牌搜索点击量。
三、网站 优化的基本操作细节:
(一)网站的生成规则:
1. URL 可以生成动态和静态。所谓静态网址的主要特征是htm、html、shtml、xml等以后缀结尾,而动态网址的主要特征是PHP、ASP、JSP、Perl等。最后不具备静态URL的后缀特性。虽然搜索引擎都表示对网页的布局不屑一顾,但静态页面在搜索引擎蜘蛛抓取和优化保护方面优势明显。例如网站数据库遭到恶意攻击,动态网站内容随机损坏或消失,静态网站仍然是保存完好的静态Web路径。前者随机出现大量404或网页乱码,
2.开启https网络协议和cdn加速:https与http网络数据传输安全通道相关,现在搜索引擎明确指出https站点有加权重和流量处理,优先显示网站排名,CDN加速还处理了由于地域或网络环境差异导致网页加载缓慢的问题,尤其是移动端网站。搜索引擎明确规定,打开速度直接影响网站的权重和流量。
(二)网站 标准编写代码:
1.网页标题和meta标签的标准书写:标题标签是网页内容信息介绍的重点,meta标签可以收录文章、关键词的描述、作者信息、版权信息、网页编码、图像识别阅读兼容方式、单页蜘蛛爬取约束,就像一个产品的参数和特性一样。标签只显示在源代码中,普通访问者看不到,但可以被搜索引擎蜘蛛识别。也是搜索引擎添加索引和查找词匹配的关键点。文字必须准确、有能力,并适合网页的内容。所有信息必须是唯一的和唯一的。
2.网站 标题H标签标准写法:h1-h6。h标签是网页要点分类的呈现和陈述,权重从h1递减到h6。搜索引擎蜘蛛可以识别网页内容的层次链接。h1 标题在单个网页中只能出现一次,就像 文章 的标题一样。
3. 锚文本的标准写法:锚文本是否习惯,加上title="title",可以引导蜘蛛理解链接的内容。如果不加,对蜘蛛来说就像一个灰色区域,是不知道的东西,这会降低蜘蛛的抓取速度,以及关于一些出站链接或敏感链接,是否已经做出了停止抓取的单一指令在锚文本中,rel="nofollow",写成ahref="/"Title="title" rel="nofollow"。对于一些站外链接,需要添加target=_blank作为新窗口打开,防止避免网站无法回源,减少流量损失,建议一个网页中不要收录相同的锚文本链接,
4.图片源img的标准书写:按照常规的标准书写格式,一张图片的格式应该是alt=\"portrait\", src=\"/\", width=\"\ ",height=\" \", 包括图片的描述、比例尺的大小、图片的来源地址、关于一些一般图片,甚至可以添加标题来引导访问者了解图片的含义,没有描述的图片,搜索引擎蜘蛛无法识别图片的内容和含义,没有比例标记,搜索引擎蜘蛛无法区分图片的正确比例,这会降低网页的摘要分数。
5. js和css的标准写法:一个网页最好只收录一个js或者css。太多js提倡合并和请求,可以减少网页加载的时间。对于一些相同的样式,css主张剪新的。如果js和css的内容比较大,可以进行压缩。对于js和css的样式编写,要进行兼容性测试,并添加兼容的样式,否则在单个用户的阅读器上可能会出现变形,不利于访问者的体验,反弹网站 的比率将被添加。
6. 网页代码紧缩:如果网页代码很多,可以进行代码紧缩。搜索引擎蜘蛛在识别网页代码方面是资源受限的。超过一定长度和超出内容,搜索引擎蜘蛛将难以识别并降低分数。
(三)词库构建及内链标准应用:
1.词库是一个网站有计划的长期优化方向。网站的权重是网站流量大小的标志,而网站的排名往往是指网站的权重。关键词文章具有搜索索引和排名,可以直接增加网站的流量,带来网站的权重,促进网站的自然排名。
2.网页内链设置及应用:网站系统的许多免费版本现在都有后台关键词保护、标签标签保护等功能,相关内链锚文本显示在网页内容 其中,可以提高访问者的停留时间和阅读深度,可以降低网站的跳出率。标签和内容页和列表页的标准应用可以提升搜索引擎蜘蛛的强度和频率。,不仅可以提高访问者的阅读量,还可以增加百度索引,提高内容进入次数和站外匹配搜索次数关键词。
(四)设置网站提交链接:
1.网站地图站点地图制作:站点地图收录两种格式,sitemap.xml和sitemap.html,列出了网站的所有内容和URL路径。sitemap.xml格式文件主要用于站长后台链接的提交和更新,包括网站内容更新网络频道、更新时间、作者和频率等信息,sitemap.html可用于访问者轻松阅读整个网站的栏目,有利于提高访问者的体验 作用也有利于搜索引擎蜘蛛的抓取。
2.网站内容自动推送:随着搜索引擎的发展和完善,现在各大搜索引擎的后台都有网站自动推送功能。界面根据搜索引擎提供的链接提交。使php链接自动推送的文件可以更快地被搜索引擎输入。
3.网站 内容自动推送:搜索引擎现在也推出了自动推送js功能。当访问者阅读网站的内容时,会自动触发提交链接信息,这也是一种适合访问者搜索体验的功能,可以配合自动推送和站点地图使用。
(五)URL路径长度的调整:
1.网站 方法的合理调整: 网站 方法代表了网站结构的层次区分。为此,搜索引擎蜘蛛给出了由大到小的权重,网站的结构清晰合理,手法得当,可以让搜索引擎更好地识别网站@的要点>. 比如网站系统的网站sitemap、rssmap、rss文件默认都在data库目录下,这个目录一般会被robots列为防止爬虫,因为它收录一个大量的数据库文件,以及一些数据库帐户密码和地址的敏感信息。因此,将此路径升级到网站的根目录
2.网站 栏目命名规则和简洁写法:搜索引擎对URL的长度有明确的要求。如果超过长度,URL 将难以识别和输入。因此,建议在列和子列之间简洁明了,命名简单,区分为最好。
(六)网站 功能页面设置:
1.网站404页面设置:网站内容难以防止代码错误的网页,删除的页面,404页面过多,会构成大量重复页面,搜索引擎将他们识别为网站作弊降低索引,减少进入和降低权限等。为此,制作一个定向404y页面并正确返回404状态码,不仅可以降低访问者的跳出率,但也要防止来自搜索引擎的奖励和惩罚。
<p>2.网站 301状态码的设置:网站 域名的顶级域名比二级以下域名的权重更重要。对于网站域名,访问者经常使用www的前两个。一级域名是习惯性的。为此,为了更好的承载前沿域名的重量,可以做301域名重定向。否则,网站很可能会显示网站的首页不在第一位,从而失去网站的权重,对 查看全部
网页css js 抓取助手(网站优化需求熟练把握查找引擎算法规矩,既要把握网站底层代码的标准性书写)
网站优化
网站优化需要掌握搜索引擎算法规则,不仅要掌握网站底层代码的标准编写,还要掌握优秀的策划和排名能力,坚持专业的原创 高质量的内容更新。因此,网站 优化不应该马虎。这是一个专业和技术问题。通常需要优化团队协作。团队必须细心、耐心和负责。
网站构建

一、网站优化前提和基础环境:
(一)网站 域名先决条件:
1.网站域名选择:域名解释简单易记,网站内容相关性较好。网站 域名是否为常用后缀com、cn或net等,部分后缀域名国内搜索引擎不识别,不支持存档。域名过长必然会影响网站的链接。搜索引擎对 URL 的长度有限制。长度过长的 URL。不会被认出来。
2.网站域名记录:网站域名记录是搜索引擎对网站声望的评判标准。正规的大型企事业单位的官网会首先显示在搜索引擎首页和排行榜上,没有记录的网站将被识别为灰色网站或风险网站被搜索引擎@>,不利于网站的进入和排名。
(二)网站 服务器基础环境:
1.服务器环境设备:高性能、高带宽、独立的IP服务器,可以使网站稳定运行和发展,是寻找网站引擎得分的重要参考。一些功能低下、流量受限的虚拟主机往往被简单攻击,构成网站运行错误或无法打开,往往会受到搜索引擎的奖惩。
2.网站 运维操作:具有专业技能的程序员可以保证网站的正常运行和安全的数据备份。相反,网站经常遭受攻击或数据丢失,会给网站带来毁灭性的损失,更不用说网站优化了。
二、网站 优化方向:站内优化和站外优化
(一)站内优化:站内优化包括网站排版结构优化、网站底层代码优化、网页优化、网站程序优化、网站@ > 内链优化及网站原创内容更新。
(二)站外优化:站外优化包括网站的外链建设指导,站外渠道曝光网站信息,增加品牌搜索点击量。
三、网站 优化的基本操作细节:
(一)网站的生成规则:
1. URL 可以生成动态和静态。所谓静态网址的主要特征是htm、html、shtml、xml等以后缀结尾,而动态网址的主要特征是PHP、ASP、JSP、Perl等。最后不具备静态URL的后缀特性。虽然搜索引擎都表示对网页的布局不屑一顾,但静态页面在搜索引擎蜘蛛抓取和优化保护方面优势明显。例如网站数据库遭到恶意攻击,动态网站内容随机损坏或消失,静态网站仍然是保存完好的静态Web路径。前者随机出现大量404或网页乱码,
2.开启https网络协议和cdn加速:https与http网络数据传输安全通道相关,现在搜索引擎明确指出https站点有加权重和流量处理,优先显示网站排名,CDN加速还处理了由于地域或网络环境差异导致网页加载缓慢的问题,尤其是移动端网站。搜索引擎明确规定,打开速度直接影响网站的权重和流量。
(二)网站 标准编写代码:
1.网页标题和meta标签的标准书写:标题标签是网页内容信息介绍的重点,meta标签可以收录文章、关键词的描述、作者信息、版权信息、网页编码、图像识别阅读兼容方式、单页蜘蛛爬取约束,就像一个产品的参数和特性一样。标签只显示在源代码中,普通访问者看不到,但可以被搜索引擎蜘蛛识别。也是搜索引擎添加索引和查找词匹配的关键点。文字必须准确、有能力,并适合网页的内容。所有信息必须是唯一的和唯一的。
2.网站 标题H标签标准写法:h1-h6。h标签是网页要点分类的呈现和陈述,权重从h1递减到h6。搜索引擎蜘蛛可以识别网页内容的层次链接。h1 标题在单个网页中只能出现一次,就像 文章 的标题一样。
3. 锚文本的标准写法:锚文本是否习惯,加上title="title",可以引导蜘蛛理解链接的内容。如果不加,对蜘蛛来说就像一个灰色区域,是不知道的东西,这会降低蜘蛛的抓取速度,以及关于一些出站链接或敏感链接,是否已经做出了停止抓取的单一指令在锚文本中,rel="nofollow",写成ahref="/"Title="title" rel="nofollow"。对于一些站外链接,需要添加target=_blank作为新窗口打开,防止避免网站无法回源,减少流量损失,建议一个网页中不要收录相同的锚文本链接,
4.图片源img的标准书写:按照常规的标准书写格式,一张图片的格式应该是alt=\"portrait\", src=\"/\", width=\"\ ",height=\" \", 包括图片的描述、比例尺的大小、图片的来源地址、关于一些一般图片,甚至可以添加标题来引导访问者了解图片的含义,没有描述的图片,搜索引擎蜘蛛无法识别图片的内容和含义,没有比例标记,搜索引擎蜘蛛无法区分图片的正确比例,这会降低网页的摘要分数。
5. js和css的标准写法:一个网页最好只收录一个js或者css。太多js提倡合并和请求,可以减少网页加载的时间。对于一些相同的样式,css主张剪新的。如果js和css的内容比较大,可以进行压缩。对于js和css的样式编写,要进行兼容性测试,并添加兼容的样式,否则在单个用户的阅读器上可能会出现变形,不利于访问者的体验,反弹网站 的比率将被添加。
6. 网页代码紧缩:如果网页代码很多,可以进行代码紧缩。搜索引擎蜘蛛在识别网页代码方面是资源受限的。超过一定长度和超出内容,搜索引擎蜘蛛将难以识别并降低分数。
(三)词库构建及内链标准应用:
1.词库是一个网站有计划的长期优化方向。网站的权重是网站流量大小的标志,而网站的排名往往是指网站的权重。关键词文章具有搜索索引和排名,可以直接增加网站的流量,带来网站的权重,促进网站的自然排名。
2.网页内链设置及应用:网站系统的许多免费版本现在都有后台关键词保护、标签标签保护等功能,相关内链锚文本显示在网页内容 其中,可以提高访问者的停留时间和阅读深度,可以降低网站的跳出率。标签和内容页和列表页的标准应用可以提升搜索引擎蜘蛛的强度和频率。,不仅可以提高访问者的阅读量,还可以增加百度索引,提高内容进入次数和站外匹配搜索次数关键词。
(四)设置网站提交链接:
1.网站地图站点地图制作:站点地图收录两种格式,sitemap.xml和sitemap.html,列出了网站的所有内容和URL路径。sitemap.xml格式文件主要用于站长后台链接的提交和更新,包括网站内容更新网络频道、更新时间、作者和频率等信息,sitemap.html可用于访问者轻松阅读整个网站的栏目,有利于提高访问者的体验 作用也有利于搜索引擎蜘蛛的抓取。
2.网站内容自动推送:随着搜索引擎的发展和完善,现在各大搜索引擎的后台都有网站自动推送功能。界面根据搜索引擎提供的链接提交。使php链接自动推送的文件可以更快地被搜索引擎输入。
3.网站 内容自动推送:搜索引擎现在也推出了自动推送js功能。当访问者阅读网站的内容时,会自动触发提交链接信息,这也是一种适合访问者搜索体验的功能,可以配合自动推送和站点地图使用。
(五)URL路径长度的调整:
1.网站 方法的合理调整: 网站 方法代表了网站结构的层次区分。为此,搜索引擎蜘蛛给出了由大到小的权重,网站的结构清晰合理,手法得当,可以让搜索引擎更好地识别网站@的要点>. 比如网站系统的网站sitemap、rssmap、rss文件默认都在data库目录下,这个目录一般会被robots列为防止爬虫,因为它收录一个大量的数据库文件,以及一些数据库帐户密码和地址的敏感信息。因此,将此路径升级到网站的根目录
2.网站 栏目命名规则和简洁写法:搜索引擎对URL的长度有明确的要求。如果超过长度,URL 将难以识别和输入。因此,建议在列和子列之间简洁明了,命名简单,区分为最好。
(六)网站 功能页面设置:
1.网站404页面设置:网站内容难以防止代码错误的网页,删除的页面,404页面过多,会构成大量重复页面,搜索引擎将他们识别为网站作弊降低索引,减少进入和降低权限等。为此,制作一个定向404y页面并正确返回404状态码,不仅可以降低访问者的跳出率,但也要防止来自搜索引擎的奖励和惩罚。
<p>2.网站 301状态码的设置:网站 域名的顶级域名比二级以下域名的权重更重要。对于网站域名,访问者经常使用www的前两个。一级域名是习惯性的。为此,为了更好的承载前沿域名的重量,可以做301域名重定向。否则,网站很可能会显示网站的首页不在第一位,从而失去网站的权重,对
网页css js 抓取助手(智能模式检测WebHarvy自动识别网页数据采集器的软件特征及特征)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-27 09:23
SysNucleus WebHarvy 是一款非常优秀的网页数据采集器,旨在让您能够自动从网页中提取数据并将提取的内容以不同的格式保存。使用 WebHarvy,从网页捕获数据就像导航到收录数据的页面并单击要捕获的数据一样简单。欢迎有需要的朋友下载。
软件说明:
WebHarvy 是一个方便的应用程序,旨在使您能够自动从网页中提取数据并将提取的内容以不同的格式保存。使用 WebHarvy,从网页捕获数据就像导航到收录数据的页面并单击要捕获的数据一样简单。
WebHarvy 将智能识别出现在网页中的数据模式。使用WebHarvy,您可以从各种网站(如房地产、电子商务、学术研究、娱乐、科技等)中提取数据,例如产品目录或搜索结果。
从网页中提取的数据可以以多种格式保存。网页通常在多个页面中显示搜索结果等数据。WebHarvy 可以自动抓取网络并从多个页面中提取数据。
软件特点:
简单的网络搜索
WebHarvy 的点击式界面使 Web Scraping 变得容易。绝对不需要编写任何代码或脚本来抓取数据。您将使用WebHarvy 的内置浏览器加载网站,您可以通过单击鼠标选择要提取的数据。就是这么简单!(视频)
智能模式检测
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中获取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,WebHarvy 会自动抓取它。保存到文件或数据库
您可以以多种格式保存从网站 中提取的数据。当前版本的 WebHarvyWeb 搜索软件允许您将提取的数据保存为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。(了解更多)
获取多个页面
网站 产品列表或搜索结果等数据通常显示在多个页面上。WebHarvy 可以自动抓取网络并从多个页面中提取数据。只需指出“加载下一页的链接”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。(了解更多)
提交关键词
通过自动提交输入关键字列表来搜索表单来擦除数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以从所有输入关键字组合的搜索结果中提取数据。(了解更多)(视频)
隐私保护
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。(了解更多)
分类抓取
WebHarvyWeb 爬虫允许您从链接列表中抓取数据,这会导致网站 中出现类似的页面/列表。这允许您使用单个配置来抓取 网站 内的类别和子类别。(了解更多)(视频)
常用表达
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并抓取匹配的部分。这种强大的技术在您抓取数据时提供了更大的灵活性。(了解更多)(正则表达式教程)
JavaScript 支持
在提取数据之前,请在浏览器中运行您自己的 JavaScript 代码。它可用于与页面元素进行交互、修改 DOM 或调用已在目标页面中实现的 JavaScript 函数。(了解更多)
图像提取
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站 产品详细信息页面中的多个图像。(了解更多)
自动化浏览器任务
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面和打开弹出窗口。
技术援助
购买 WebHarvy 后,您将在购买之日起 1 年内获得我们的免费更新和免费支持。
WebHarvy 入门:
1.首先,下载并安装WebHarvy的免费试用版。
2.在这里观看软件的基本演示视频。
3.观看更详细的视频教程。
4. 这里提供在线教程/功能帮助。
5. 尝试根据您的要求配置 WebHarvy 来提取数据,如果您遇到任何困难,请在此处联系我们的支持并提供必要的详细信息。
6.我们在这里的YouTube频道采集了大量视频,展示了各种网站的配置流程和数据提取要求。 查看全部
网页css js 抓取助手(智能模式检测WebHarvy自动识别网页数据采集器的软件特征及特征)
SysNucleus WebHarvy 是一款非常优秀的网页数据采集器,旨在让您能够自动从网页中提取数据并将提取的内容以不同的格式保存。使用 WebHarvy,从网页捕获数据就像导航到收录数据的页面并单击要捕获的数据一样简单。欢迎有需要的朋友下载。
软件说明:
WebHarvy 是一个方便的应用程序,旨在使您能够自动从网页中提取数据并将提取的内容以不同的格式保存。使用 WebHarvy,从网页捕获数据就像导航到收录数据的页面并单击要捕获的数据一样简单。
WebHarvy 将智能识别出现在网页中的数据模式。使用WebHarvy,您可以从各种网站(如房地产、电子商务、学术研究、娱乐、科技等)中提取数据,例如产品目录或搜索结果。
从网页中提取的数据可以以多种格式保存。网页通常在多个页面中显示搜索结果等数据。WebHarvy 可以自动抓取网络并从多个页面中提取数据。
软件特点:
简单的网络搜索
WebHarvy 的点击式界面使 Web Scraping 变得容易。绝对不需要编写任何代码或脚本来抓取数据。您将使用WebHarvy 的内置浏览器加载网站,您可以通过单击鼠标选择要提取的数据。就是这么简单!(视频)
智能模式检测
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中获取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,WebHarvy 会自动抓取它。保存到文件或数据库
您可以以多种格式保存从网站 中提取的数据。当前版本的 WebHarvyWeb 搜索软件允许您将提取的数据保存为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。(了解更多)
获取多个页面
网站 产品列表或搜索结果等数据通常显示在多个页面上。WebHarvy 可以自动抓取网络并从多个页面中提取数据。只需指出“加载下一页的链接”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。(了解更多)
提交关键词
通过自动提交输入关键字列表来搜索表单来擦除数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以从所有输入关键字组合的搜索结果中提取数据。(了解更多)(视频)
隐私保护
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。(了解更多)
分类抓取
WebHarvyWeb 爬虫允许您从链接列表中抓取数据,这会导致网站 中出现类似的页面/列表。这允许您使用单个配置来抓取 网站 内的类别和子类别。(了解更多)(视频)
常用表达
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并抓取匹配的部分。这种强大的技术在您抓取数据时提供了更大的灵活性。(了解更多)(正则表达式教程)
JavaScript 支持
在提取数据之前,请在浏览器中运行您自己的 JavaScript 代码。它可用于与页面元素进行交互、修改 DOM 或调用已在目标页面中实现的 JavaScript 函数。(了解更多)
图像提取
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站 产品详细信息页面中的多个图像。(了解更多)
自动化浏览器任务
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面和打开弹出窗口。
技术援助
购买 WebHarvy 后,您将在购买之日起 1 年内获得我们的免费更新和免费支持。
WebHarvy 入门:
1.首先,下载并安装WebHarvy的免费试用版。
2.在这里观看软件的基本演示视频。
3.观看更详细的视频教程。
4. 这里提供在线教程/功能帮助。
5. 尝试根据您的要求配置 WebHarvy 来提取数据,如果您遇到任何困难,请在此处联系我们的支持并提供必要的详细信息。
6.我们在这里的YouTube频道采集了大量视频,展示了各种网站的配置流程和数据提取要求。
网页css js 抓取助手(程序员最常用的工具利器介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-20 03:05
分为四类:
俗话说,工欲善其事,必先利其器。所以作为一个网页开发者,各种提高工作/学习效率的工具当然是必不可少的。给我们的程序员介绍一些最常用的开发工具。
一、小助手1.掘金
与第一个Infinity New Tab(首屏主题)插件类似,Nuggets是一款笔者认为前端开发者必备的好插件。只需打开新标签页就可以看到每天推荐的优质文章和GitHub项目,让开发者更好地了解技术的发展趋势。
2. 云 IDE:Repl.it
支持编译运行70多种语言,包括C、Python、JavaScript、Ruby等,无需下载,即刻使用。选择内容右键点击触发。非常方便,节省了打开编译器或搜索在线编译的时间网站。
如果有围墙,可以使用:le/22
3. 键盘派对:Vimium
如果你是 Linux 系统的爱好者,你一定知道 Vim 编辑器。这个 Vimium 插件继承了 vim 编辑器的常用操作。有了它,无论是浏览网页、切换标签页、搜索还是其他任何操作,都可以只用键盘来完成,是不是很hacky?
翻页过程中:(按F/ESC键进入/退出键盘模式)
4. 排版转换:Markdown Here
作为程序员,写技术笔记总结文章当然少不了,但是作者一直习惯Markdown语法,微信不支持,怎么办?有了它,您可以随时将语法更改为兼容微信排版。
5. 前端助手:FeHelper.JSON
前端开发人员的福音,包括许多有用的小工具。右键单击以快速启动。
二、网页信息获取类1. 网页样式:CSSViewer
当我们要模仿或设计网页时,需要查看网站的CSS样式。有了它,您可以快速查看当前网页元素的各种 CSS 属性。
笔者专门测试了两个插件:另一个类似的插件是code cola,用户可以根据自己的需要进行选择。
点击插件图标触发,也可以设置快捷键
2. 网页标尺:尺寸
在网页上,我们经常需要测量页面上元素的大小。我们应该做什么?使用他。
笔者专门测试了两个插件: 另一个类似的插件是Page Ruler,用户可以根据自己的需要进行选择。
点击插件图标触发,也可以设置快捷键
3. 网页取色:ColorZilla
这个ColorZilla插件不仅弥补了之前CSSViewer插件无法选取图片的颜色,它还可以选取网页上任何元素的颜色。
对比一下ColorZilla、Eye Droppe和ColorPick Eyedropper的测试:第一个最方便,第二个最小,第三个最强大。作者推荐第一段。
4. 网页元素位置:农药
突出显示每个元素在页面上的位置,不同的线条颜色可以很好地识别父子元素和兄弟元素之间的关系。
5. 网络爬虫辅助:Xpath Helper
这是一个网络爬虫的解析工具。它可以轻松获取HTML元素的xPath,避免了搜索html源代码定位一些id和class找到对应的位置来解析网页。
6. 网络爬虫工具:Spider
插件名称为Spider——一款智能网页抓取工具。这是一款点击式插件,可以一键抓取网页结构化数据,生成JSON和CSV文件。无需编程经验,轻松抓取批量网站内容需求:如产品介绍、新闻标题、表格中的行列数据……有了它,你可以减少整理数据后的时间复制和粘贴。
7. Web 开发工具:Web Developer
功能非常强大,主要由以下几部分组成:禁用、Cookies、CSS、表单、图像、信息、杂项、大纲、调整大小、工具、查看源和选项。这里就不一一介绍了。
修改完成后刷新页面即可生效。我认为它可以取代仅对 cookie 进行操作的 EditThisCookie 插件。
8. 网站 技术分析:WhatRuns
单击以查找您访问的 网站 上涉及的任何技术,检测技术更改并接收通知。
虽然可以看懂网站的源码,但是效率不高,可能会漏掉一些技巧
三、网页调试类1.插件版邮递员:Talend API Tester
Talend API Tester 插件是一个类似于 Postman 的 api 接口测试工具,可以轻松测试 HTTP 和 REST API。与Postman相比,Talend API Tester无需安装本地客户端,即装即用,占用空间小,功能强大。
2. 网络代理:Proxy Switchy Omega
Proxy Switchy Omega插件用于代理一些国内无法访问的网站。支持多种模式,切换方便,规则编写简单,支持PAC、Switchy和AutoProxy列表。O|>|O
相关设置可以参考:
3. 多终端模拟:User Agent
Chrome 插件的 User Agent Switcher 可以将 Chrome 浏览器伪装成多种不同浏览器发送请求页面,让您轻松测试不同端页面之间的差异,避免安装和启动多个浏览器的麻烦。
其实Chrome浏览器也自带这个功能:开发者工具-->点击界面中的三个点-->更多工具-->网络条件-->取消勾选自动选择
4. IE核心操作:IE Tab
与上面的User Agent不同,IE Tab用IE内核实现了chrome选项卡中网页的正常显示,不仅方便开发和测试,还可以解决各种网银控件在chrome中无法使用的问题.
5. 调试 vue:Vue.js DevTools
Vue.js devtools 是一个开发者浏览器扩展,用于调试基于 google chrome 浏览器的 vue.js 应用程序。做前端开发的IT工程师应该对这个工具比较熟悉,可以边看边栏边的页面边检查代码。
Vue 是数据驱动的,在开发和调试的时候查看 DOM 结构是解析不出来的。所以你需要使用工具
6. 调试 React:React 开发人员
React Developer Tools 是由 facebook 开发的一个有用的 Chrome 浏览器扩展。通过它,我们可以查看应用程序的 React 组件层次结构,而不是更神秘的浏览器 DOM 表示。
7. 调试角度:AngularJS Batarang
angularjs batarang 是为谷歌浏览器用户创建的angular项目调试插件,与前两款机型类似。
四、Github 助手类
如果某些插件不能正常使用,可能需要到github设置访问令牌:github—>设置——>开发者设置——>个人访问令牌——>生成新令牌——>检查gist,repo—— >generate 将令牌值复制到插件配置选项中以显示它。
1. 文件下载助手:GitZip for github
打开GitHub上的项目,双击要下载的文件或文件夹的空白处,然后文件或文件夹前面会出现一个钩子,表示已被选中,并且会出现一个下载按钮浏览器的右下角。点击下载按钮下载对应的文件。
避免某个文件/文件夹下载整个仓库慢的尴尬
2. 单文件下载助手:增强型GitHub
显示 Github 当前仓库的整体大小和每个单独文件的文件大小。还增加了单个文件下载支持,也避免了某个文件整个仓库下载慢的尴尬情况。
要使用,去github设置token:github-->Settings-->Developer settings-->Personal access tokens--->Generate new token---> check gist, repo--->将生成的token值复制到插件配置选项 待显示。
3. 浮动快速预览:GitHub Hovercard
该插件为我们提供了鼠标悬停预览功能。每次查看其他个人信息、项目信息、问题信息时,都需要进入相关页面查看信息。国内访问github不快,所以很方便。
4. 显示文件树:Octotree
Octotree 插件可以让你像你的电脑文件夹一样在 GitHub 上快速浏览和搜索关键代码。由于国内访问github的速度不快,加载所有页面需要更多时间,非常方便。
5. 模拟 IDE:Sourcegraph
Sourcegraph 是一个 Chrome 扩展,它可以为 Github 上的代码添加即时文档和类型提示,并为每个标识符添加一个指向定义的链接。它允许您像浏览良好的 IDE 代码一样浏览源代码。
6. 浏览码工具:Octohint
功能比上面的Sourcegraph弱,但是加载速度更快。可以定位函数文件,高亮选中变量,显示变量类型等。
7.工作量:等距贡献
它可以将你每天贡献的数量(可以理解为向GitHub提交的数量)转换成不同颜色的三维直方图,并给出你自己的统计数据。
结束语
插件章节写了三章,近万字。插件都是作者这几年在使用过程中积累的。他们在工作和生活中都非常有帮助。有些零件以前没有使用过。我什至不知道如何非常方便地使用它。在编写Chrome插件文章的过程中,体会到了各种插件的强大。删除并整理了具有重复功能的插件。如果你觉得本章对你有帮助,请点赞/关注/转发到这里,以后会继续更新。当然,如果你觉得有更好的扩展需要推荐,请在下方留言给作者O|^|O。 查看全部
网页css js 抓取助手(程序员最常用的工具利器介绍)
分为四类:
俗话说,工欲善其事,必先利其器。所以作为一个网页开发者,各种提高工作/学习效率的工具当然是必不可少的。给我们的程序员介绍一些最常用的开发工具。
一、小助手1.掘金
与第一个Infinity New Tab(首屏主题)插件类似,Nuggets是一款笔者认为前端开发者必备的好插件。只需打开新标签页就可以看到每天推荐的优质文章和GitHub项目,让开发者更好地了解技术的发展趋势。
2. 云 IDE:Repl.it
支持编译运行70多种语言,包括C、Python、JavaScript、Ruby等,无需下载,即刻使用。选择内容右键点击触发。非常方便,节省了打开编译器或搜索在线编译的时间网站。
如果有围墙,可以使用:le/22
3. 键盘派对:Vimium
如果你是 Linux 系统的爱好者,你一定知道 Vim 编辑器。这个 Vimium 插件继承了 vim 编辑器的常用操作。有了它,无论是浏览网页、切换标签页、搜索还是其他任何操作,都可以只用键盘来完成,是不是很hacky?
翻页过程中:(按F/ESC键进入/退出键盘模式)
4. 排版转换:Markdown Here
作为程序员,写技术笔记总结文章当然少不了,但是作者一直习惯Markdown语法,微信不支持,怎么办?有了它,您可以随时将语法更改为兼容微信排版。
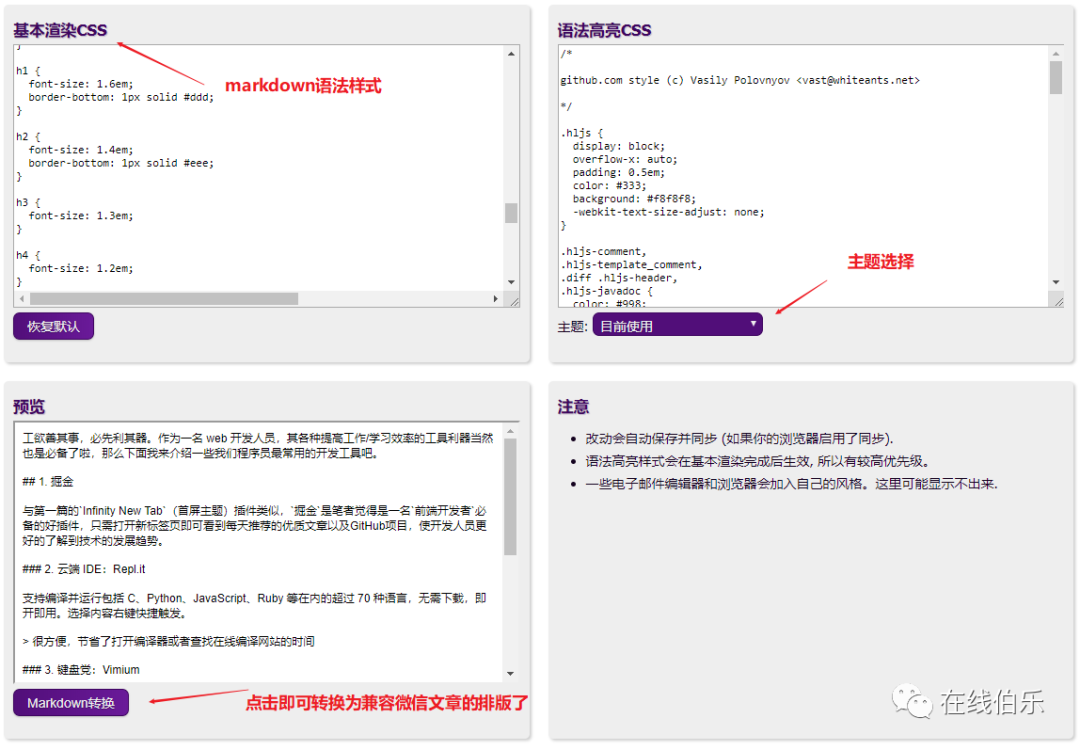
5. 前端助手:FeHelper.JSON
前端开发人员的福音,包括许多有用的小工具。右键单击以快速启动。
二、网页信息获取类1. 网页样式:CSSViewer
当我们要模仿或设计网页时,需要查看网站的CSS样式。有了它,您可以快速查看当前网页元素的各种 CSS 属性。
笔者专门测试了两个插件:另一个类似的插件是code cola,用户可以根据自己的需要进行选择。
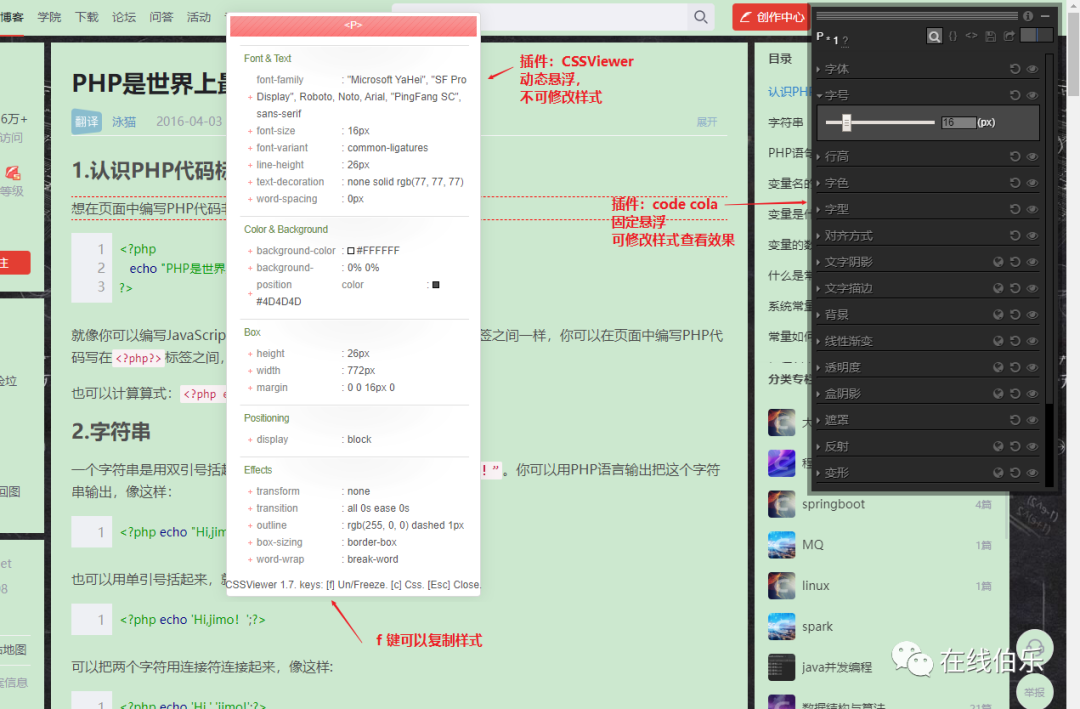
点击插件图标触发,也可以设置快捷键
2. 网页标尺:尺寸
在网页上,我们经常需要测量页面上元素的大小。我们应该做什么?使用他。
笔者专门测试了两个插件: 另一个类似的插件是Page Ruler,用户可以根据自己的需要进行选择。


点击插件图标触发,也可以设置快捷键
3. 网页取色:ColorZilla
这个ColorZilla插件不仅弥补了之前CSSViewer插件无法选取图片的颜色,它还可以选取网页上任何元素的颜色。
对比一下ColorZilla、Eye Droppe和ColorPick Eyedropper的测试:第一个最方便,第二个最小,第三个最强大。作者推荐第一段。
4. 网页元素位置:农药
突出显示每个元素在页面上的位置,不同的线条颜色可以很好地识别父子元素和兄弟元素之间的关系。
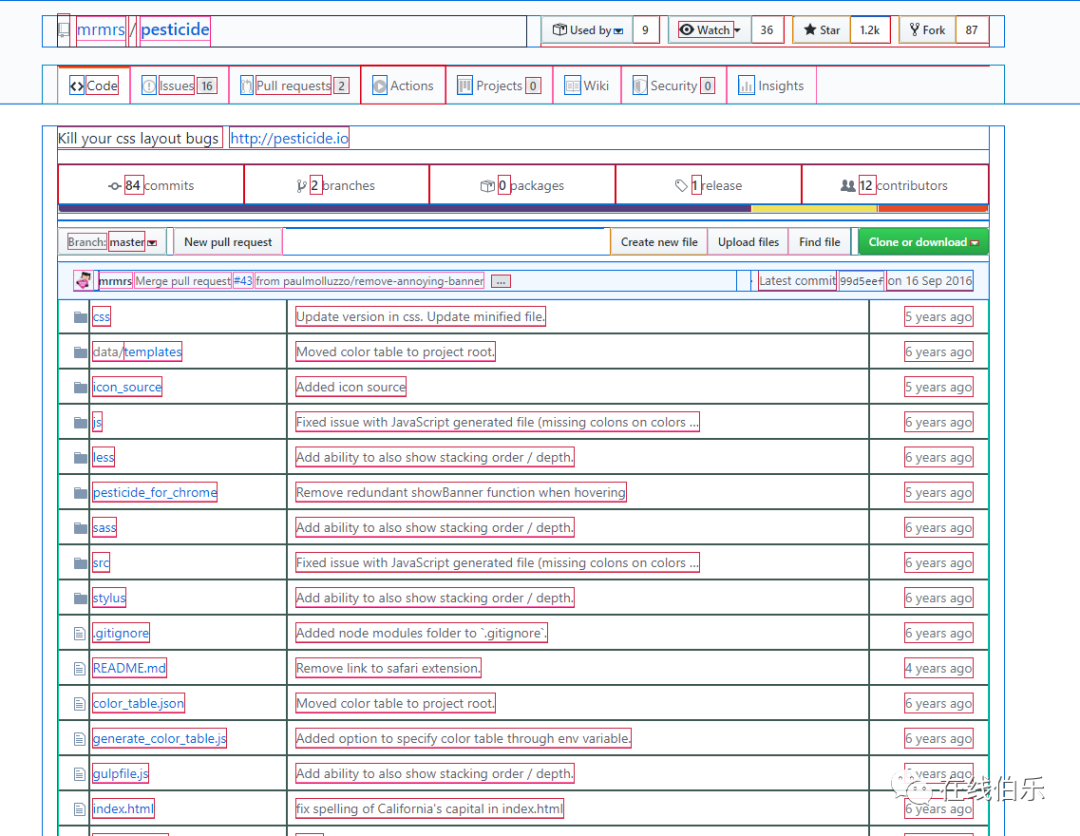
5. 网络爬虫辅助:Xpath Helper
这是一个网络爬虫的解析工具。它可以轻松获取HTML元素的xPath,避免了搜索html源代码定位一些id和class找到对应的位置来解析网页。
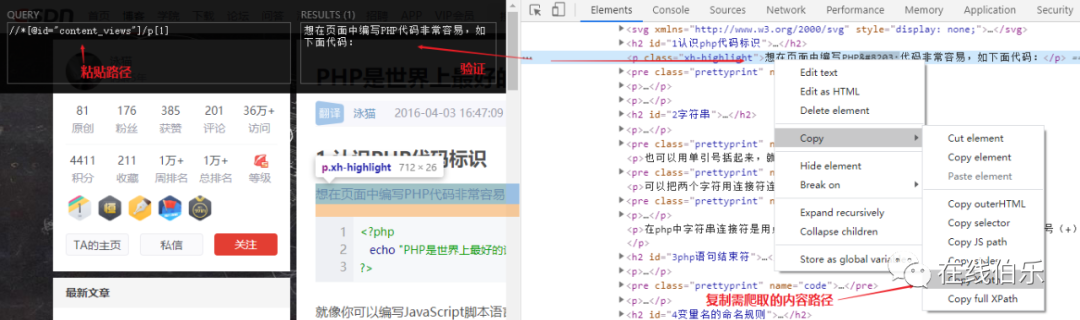
6. 网络爬虫工具:Spider
插件名称为Spider——一款智能网页抓取工具。这是一款点击式插件,可以一键抓取网页结构化数据,生成JSON和CSV文件。无需编程经验,轻松抓取批量网站内容需求:如产品介绍、新闻标题、表格中的行列数据……有了它,你可以减少整理数据后的时间复制和粘贴。
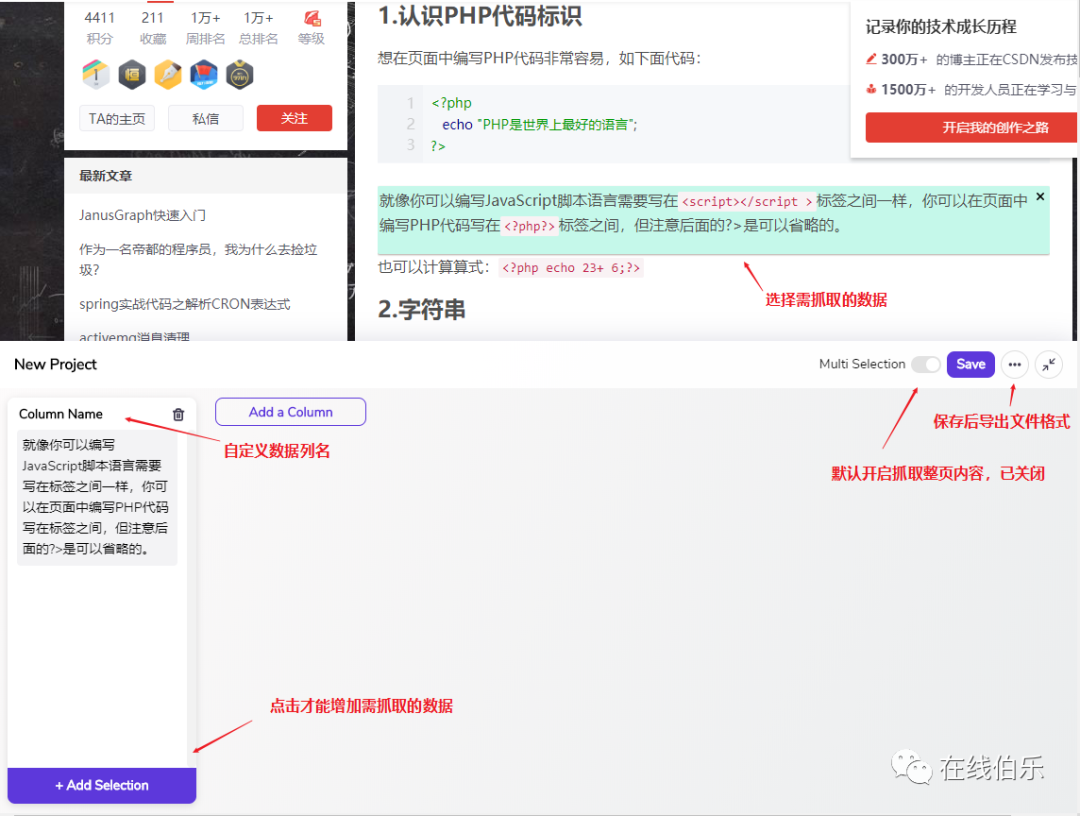
7. Web 开发工具:Web Developer
功能非常强大,主要由以下几部分组成:禁用、Cookies、CSS、表单、图像、信息、杂项、大纲、调整大小、工具、查看源和选项。这里就不一一介绍了。

修改完成后刷新页面即可生效。我认为它可以取代仅对 cookie 进行操作的 EditThisCookie 插件。
8. 网站 技术分析:WhatRuns
单击以查找您访问的 网站 上涉及的任何技术,检测技术更改并接收通知。
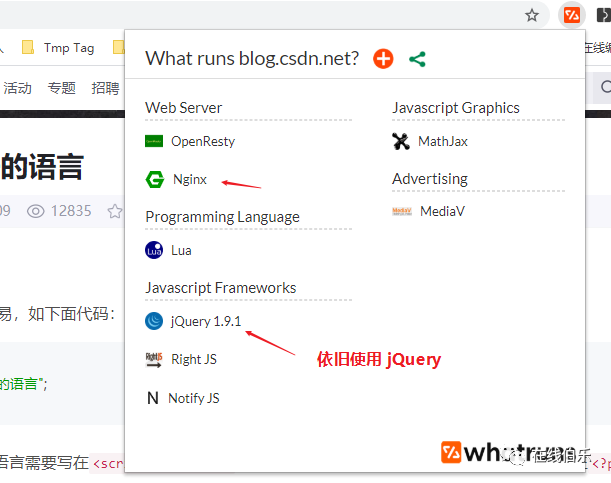
虽然可以看懂网站的源码,但是效率不高,可能会漏掉一些技巧
三、网页调试类1.插件版邮递员:Talend API Tester
Talend API Tester 插件是一个类似于 Postman 的 api 接口测试工具,可以轻松测试 HTTP 和 REST API。与Postman相比,Talend API Tester无需安装本地客户端,即装即用,占用空间小,功能强大。
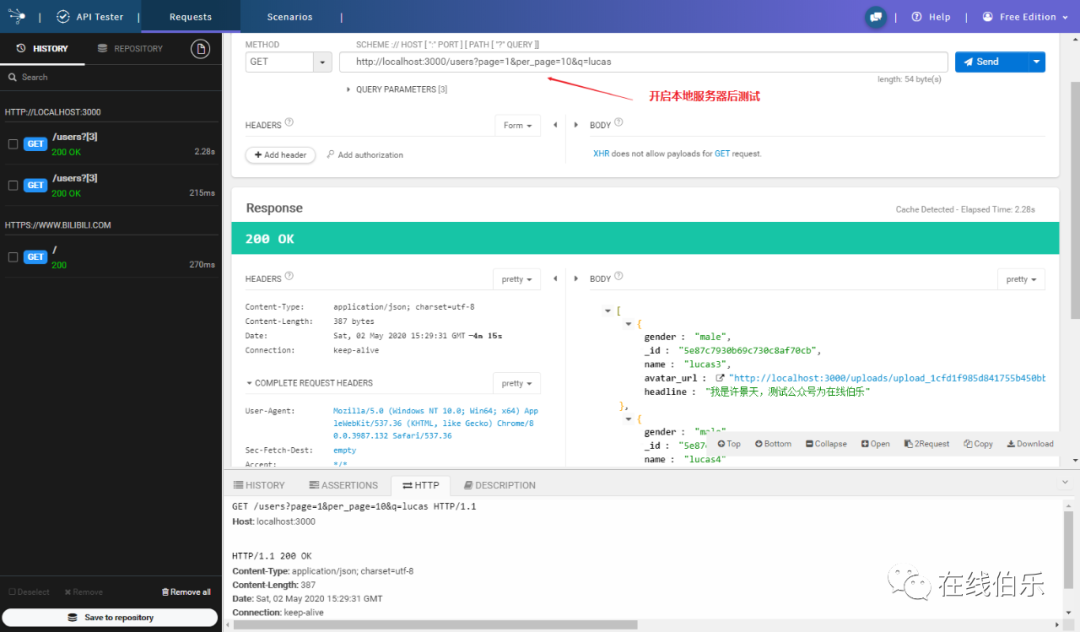
2. 网络代理:Proxy Switchy Omega
Proxy Switchy Omega插件用于代理一些国内无法访问的网站。支持多种模式,切换方便,规则编写简单,支持PAC、Switchy和AutoProxy列表。O|>|O
相关设置可以参考:
3. 多终端模拟:User Agent
Chrome 插件的 User Agent Switcher 可以将 Chrome 浏览器伪装成多种不同浏览器发送请求页面,让您轻松测试不同端页面之间的差异,避免安装和启动多个浏览器的麻烦。
其实Chrome浏览器也自带这个功能:开发者工具-->点击界面中的三个点-->更多工具-->网络条件-->取消勾选自动选择
4. IE核心操作:IE Tab
与上面的User Agent不同,IE Tab用IE内核实现了chrome选项卡中网页的正常显示,不仅方便开发和测试,还可以解决各种网银控件在chrome中无法使用的问题.

5. 调试 vue:Vue.js DevTools
Vue.js devtools 是一个开发者浏览器扩展,用于调试基于 google chrome 浏览器的 vue.js 应用程序。做前端开发的IT工程师应该对这个工具比较熟悉,可以边看边栏边的页面边检查代码。
Vue 是数据驱动的,在开发和调试的时候查看 DOM 结构是解析不出来的。所以你需要使用工具
6. 调试 React:React 开发人员
React Developer Tools 是由 facebook 开发的一个有用的 Chrome 浏览器扩展。通过它,我们可以查看应用程序的 React 组件层次结构,而不是更神秘的浏览器 DOM 表示。
7. 调试角度:AngularJS Batarang
angularjs batarang 是为谷歌浏览器用户创建的angular项目调试插件,与前两款机型类似。
四、Github 助手类
如果某些插件不能正常使用,可能需要到github设置访问令牌:github—>设置——>开发者设置——>个人访问令牌——>生成新令牌——>检查gist,repo—— >generate 将令牌值复制到插件配置选项中以显示它。
1. 文件下载助手:GitZip for github
打开GitHub上的项目,双击要下载的文件或文件夹的空白处,然后文件或文件夹前面会出现一个钩子,表示已被选中,并且会出现一个下载按钮浏览器的右下角。点击下载按钮下载对应的文件。
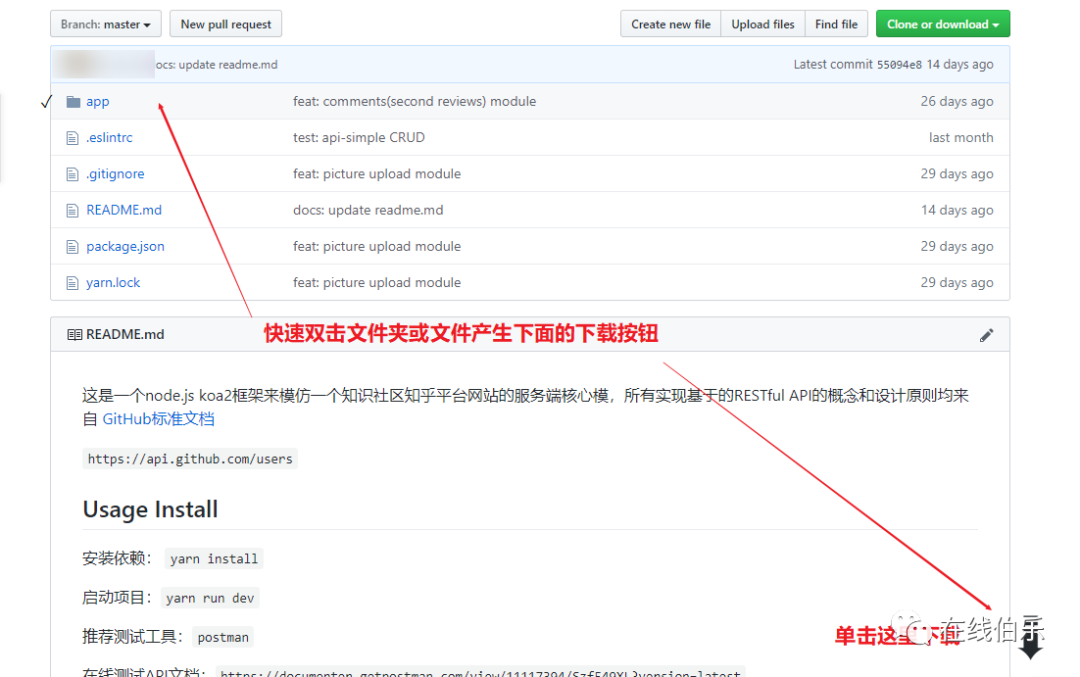
避免某个文件/文件夹下载整个仓库慢的尴尬
2. 单文件下载助手:增强型GitHub
显示 Github 当前仓库的整体大小和每个单独文件的文件大小。还增加了单个文件下载支持,也避免了某个文件整个仓库下载慢的尴尬情况。
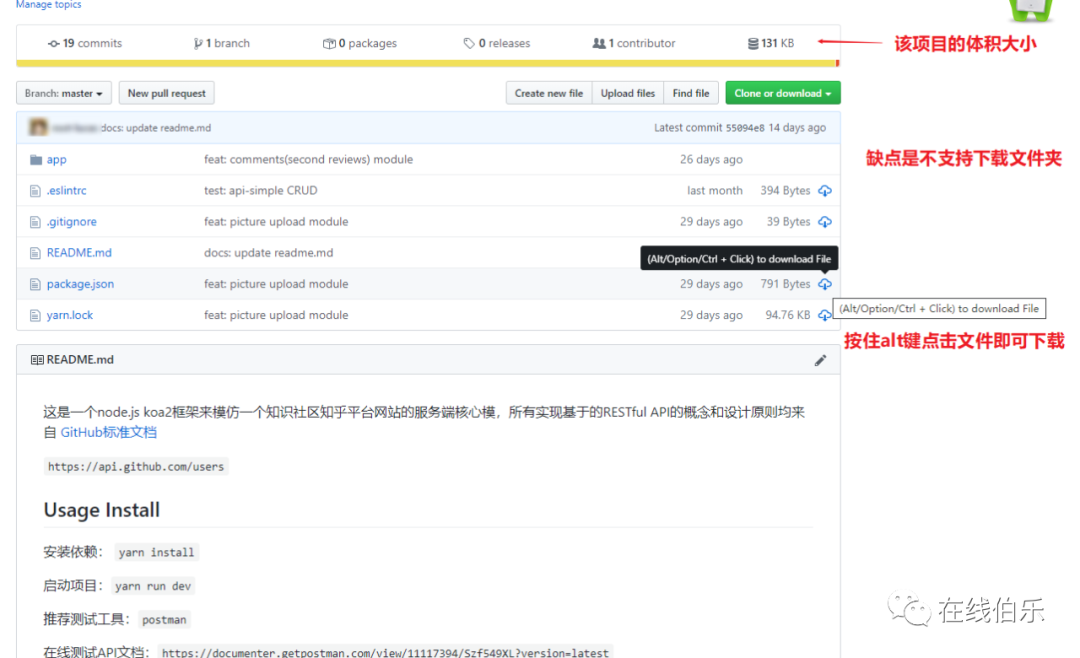
要使用,去github设置token:github-->Settings-->Developer settings-->Personal access tokens--->Generate new token---> check gist, repo--->将生成的token值复制到插件配置选项 待显示。
3. 浮动快速预览:GitHub Hovercard
该插件为我们提供了鼠标悬停预览功能。每次查看其他个人信息、项目信息、问题信息时,都需要进入相关页面查看信息。国内访问github不快,所以很方便。
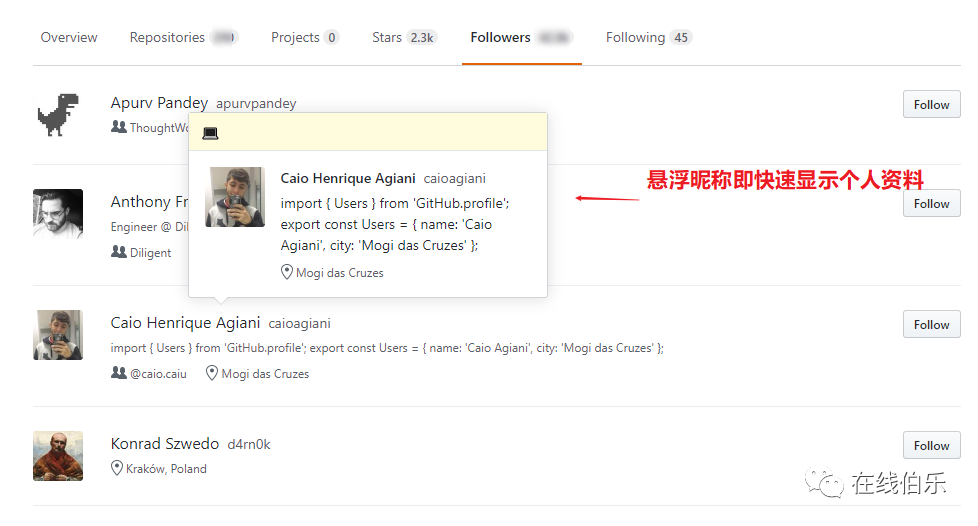
4. 显示文件树:Octotree
Octotree 插件可以让你像你的电脑文件夹一样在 GitHub 上快速浏览和搜索关键代码。由于国内访问github的速度不快,加载所有页面需要更多时间,非常方便。
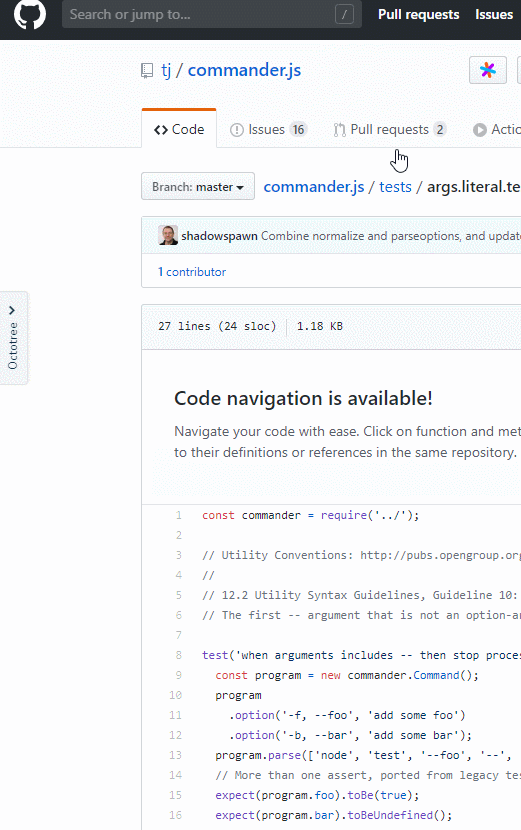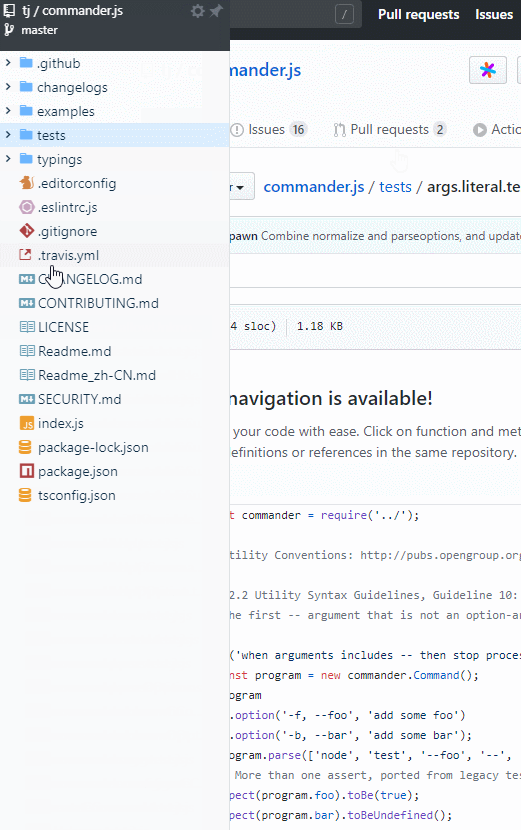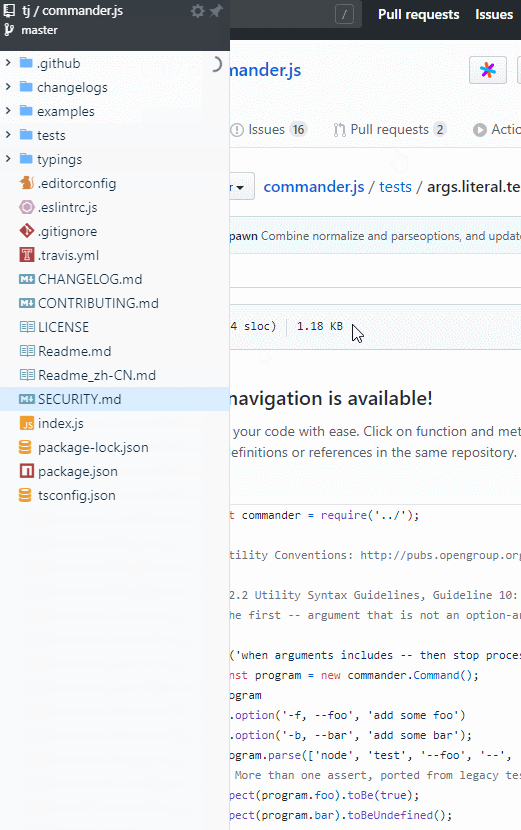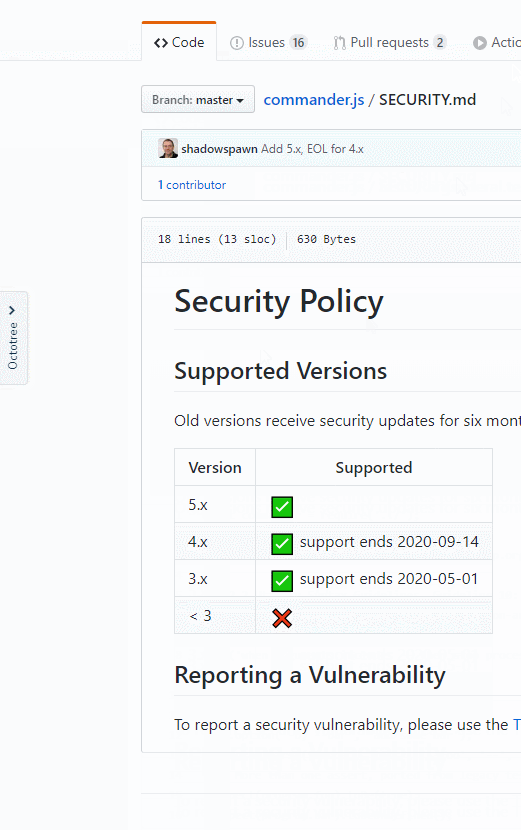
5. 模拟 IDE:Sourcegraph
Sourcegraph 是一个 Chrome 扩展,它可以为 Github 上的代码添加即时文档和类型提示,并为每个标识符添加一个指向定义的链接。它允许您像浏览良好的 IDE 代码一样浏览源代码。
6. 浏览码工具:Octohint
功能比上面的Sourcegraph弱,但是加载速度更快。可以定位函数文件,高亮选中变量,显示变量类型等。

7.工作量:等距贡献
它可以将你每天贡献的数量(可以理解为向GitHub提交的数量)转换成不同颜色的三维直方图,并给出你自己的统计数据。
结束语
插件章节写了三章,近万字。插件都是作者这几年在使用过程中积累的。他们在工作和生活中都非常有帮助。有些零件以前没有使用过。我什至不知道如何非常方便地使用它。在编写Chrome插件文章的过程中,体会到了各种插件的强大。删除并整理了具有重复功能的插件。如果你觉得本章对你有帮助,请点赞/关注/转发到这里,以后会继续更新。当然,如果你觉得有更好的扩展需要推荐,请在下方留言给作者O|^|O。
网页css js 抓取助手(《开源精选》本期、Gitee等开源社区中优质项目的栏目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-13 22:18
《开源精选》是我们在Github、Gitee等开源社区分享优质项目的专栏,内容包括技术、学习、实用和各种有趣的内容。本期推荐的NEOCrawler(中文名:牛卡)是一个由nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合垂直领域的data采集和爬虫的二次开发。
主要特征
使用nodejs实现,javascript简单、高效、易学,为爬虫的开发和爬虫用户的二次开发节省了大量时间;nodejs使用Google V8作为运行引擎,性能相当可观;由于 nodejs 语言本身的非阻塞和异步特性,运行爬虫,例如 IO 密集型 CPU 不敏感系统,表现非常好。与其他语言版本相比,开发量小于C/C++/JAVA,性能高于JAVA的多线程实现和Python的异步和携程方式。完成。
调度中心负责网站的调度,爬虫进程以分布式方式运行,即中央调度器在单个时间片内统一决定爬取哪些网站,协调各个爬虫的工作。爬虫的单点故障不会影响整个系统。
爬取时,爬虫对网页进行结构化分析,提取出需要的数据字段,不仅存储网页的源代码,还存储结构化的字段数据,不仅使数据在网页后立即可用被爬取,而且便于实现存储过程中内容的精确排序和重新排序。
phantomjs 是集成的。Phantomjs 是一个不需要图形界面环境的 Web 浏览器实现。可以用来爬取需要执行js生成内容的网页。通过js语句在页面上执行用户动作,实现表单填写提交,然后抓取下一页内容,点击按钮,然后跳转页面再抓取下一页内容等。
它集成了代理IP使用功能。该功能针对防爬网站(仅限单IP下爬虫的访问量、流量、智能判断),需要提供一个可用的代理IP,爬虫会选择source 网站 也可以访问代理IP地址,source 网站 不能阻止爬取。
可配置项目:
1)。用正则表达式描述,相似的网页被组合在一起并使用相同的规则。爬虫系统(以下各项指某些类型的URL配置项);
2)。起始地址、获取方式、存储位置、页面处理方式等;
3)。需要采集的链接规则,使用CSS选择器限制爬虫只采集出现在页面某个位置的链接;
3)。页面抽取规则,可以使用CSS选择器和正则表达式来定位各个字段内容要抽取的位置;
4)。预定义页面打开后要注入执行的js语句;
5)。网页上的默认cookie;
6)。判断该类网页是否正常返回的规则是指定部分网页恢复正常后必须存在的关键词,以供爬虫检测;
7)。数据抽取是否完整的判断规则,从抽取的字段中选择几个非常必要的字段作为抽取完整性的评价标准;
8)。此类网页的调度权重(优先级)和周期(重新获取和更新的时间)。
建筑学
图中黄色部分是爬虫系统的各个子系统
SuperScheduler 是一个中央调度器。爬虫将采集到的 URL 放入各种 URL 对应的 URL 库中。SuperScheduler 会根据调度规则从各个 URL 库中抽取相应数量的 URL 放入待爬取队列中。
Spider是一个以分布式方式运行的爬虫程序。它将任务从调度器调度的待爬取队列中取出进行爬取,将找到的URL放入URL库,存储提取的内容,将爬虫程序划分为一个核心。并下载、解压、流水线4个中间件,以便轻松重新定制爬虫实例中的功能之一。
ProxyRouter 在使用代理 IP 时智能地将爬虫请求路由到可用的代理 IP。
webconfig是一个网络爬虫规则配置后台。
运行步骤
运行环境准备
create 'crawled',{NAME => 'basic', VERSIONS => 3},{NAME=>"data",VERSIONS=>3},{NAME => 'extra', VERSIONS => 3}
create 'crawled_bin',{NAME => 'basic', VERSIONS => 3},{NAME=>"binary",VERSIONS=>3}
推荐使用 hbase rest 方法。启动hbase后,在hbase目录的bin子目录下执行以下命令启动hbase rest:
./hbase-daemon.sh start rest
默认端口为 8080,将在以下配置中使用。
##[实例配置]
实例在实例目录下,复制一份example,并重命名其他实例名,例如:abc,后面的描述中以abc为例。
编辑 instance/abc/setting.json
{
/*注意:此处用于解释各项配置,真正的setting.json中不能包含注释*/
"driller_info_redis_db":["127.0.0.1",6379,0],/*网址规则配置信息存储位置,最后一个数字表示redis的第几个数据库*/
"url_info_redis_db":["127.0.0.1",6379,1],/*网址信息存储位置*/
"url_report_redis_db":["127.0.0.1",6380,2],/*抓取错误信息存储位置*/
"proxy_info_redis_db":["127.0.0.1",6379,3],/*http代理网址存储位置*/
"use_proxy":false,/*是否使用代理服务*/
"proxy_router":"127.0.0.1:2013",/*使用代理服务的情况下,代理服务的路由中心地址*/
"download_timeout":60,/*下载超时时间,秒,不等同于相应超时*/
"save_content_to_hbase":false,/*是否将抓取信息存储到hbase,目前只在0.94下测试过*/
"crawled_hbase_conf":["localhost",8080],/*hbase rest的配置,你可以使用tcp方式连接,配置为{"zookeeperHosts": ["localhost:2181"],"zookeeperRoot": "/hbase"},此模式下有OOM Bug,不建议使用*/
"crawled_hbase_table":"crawled",/*抓取的数据保存在hbase的表*/
"crawled_hbase_bin_table":"crawled_bin",/*抓取的二进制数据保存在hbase的表*/
"statistic_mysql_db":["127.0.0.1",3306,"crawling","crawler","123"],/*用来存储抓取日志分析结果,需要结合flume来实现,一般不使用此项*/
"check_driller_rules_interval":120,/*多久检测一次网址规则的变化以便热刷新到运行中的爬虫*/
"spider_concurrency":5,/*爬虫的抓取页面并发请求数*/
"spider_request_delay":0,/*两个并发请求之间的间隔时间,秒*/
"schedule_interval":60,/*调度器两次调度的间隔时间*/
"schedule_quantity_limitation":200,/*调度器给爬虫的最大网址待抓取数量*/
"download_retry":3,/*错误重试次数*/
"log_level":"DEBUG",/*日志级别*/
"use_ssdb":false,/*是否使用ssdb*/
"to_much_fail_exit":false,/*错误太多的时候是否自动终止爬虫*/
"keep_link_relation":false/*链接库里是否存储链接间关系*/
}
跑
在网页界面配置爬取规则
调试单个URL爬取是否OK
运行调度器(调度器可以启动一个)
如果使用代理 IP 获取,则启用代理路由
启动爬虫(爬虫可以启动多个分布式)
下面是具体的启动命令
1.运行WEB配置(配置规则见下一章)
node run.js -i abc -a config -p 8888
在浏览器中打开:8888可以在网页界面配置爬取规则
2.测试单页爬取
node run.js -i abc -a test -l "http://domain/page/"
3.运行调度器
node run.js -i abc -a schedule
4.仅当使用代理 IP 捕获时才需要运行代理路由
node run.js -i abc -a proxy -p 2013
这里的 -p 指定代理路由的端口。如果在本地运行,setting.json的proxy_router和端口为127.0.0.1:2013
5.运行爬虫
node run.js -i abc -a crawl
可以在instance/example/logs下查看输出日志debug-result.json
Redis/ssdb数据结构
了解数据结构将有助于您熟悉整个系统进行二次开发。Neocrawler使用了4个存储空间,driller_info_redis_db、url_info_redis_db、url_report_redis_db、proxy_info_redis_db,可以在实例下的settings.json中配置,4个空间的存储类型不同。键名不会冲突,可以将4个空格指向一个redis/ssdb库,每个空间的增长量不同。如果使用redis,建议每个空间指向一个db,有条件的情况下一个redis指向一个空间。
Driller_info_redis_db
存储抓取规则和 URL
url_info_redis_db
这个空间存放的是URL信息,爬取操作时间越长,这里的数据量就越大。
url_report_redis_db
这个空间存储爬虫报告
proxy_info_redis_db
此空间存储与代理 IP 相关的数据
更多内容: 查看全部
网页css js 抓取助手(《开源精选》本期、Gitee等开源社区中优质项目的栏目)
《开源精选》是我们在Github、Gitee等开源社区分享优质项目的专栏,内容包括技术、学习、实用和各种有趣的内容。本期推荐的NEOCrawler(中文名:牛卡)是一个由nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合垂直领域的data采集和爬虫的二次开发。
主要特征
使用nodejs实现,javascript简单、高效、易学,为爬虫的开发和爬虫用户的二次开发节省了大量时间;nodejs使用Google V8作为运行引擎,性能相当可观;由于 nodejs 语言本身的非阻塞和异步特性,运行爬虫,例如 IO 密集型 CPU 不敏感系统,表现非常好。与其他语言版本相比,开发量小于C/C++/JAVA,性能高于JAVA的多线程实现和Python的异步和携程方式。完成。
调度中心负责网站的调度,爬虫进程以分布式方式运行,即中央调度器在单个时间片内统一决定爬取哪些网站,协调各个爬虫的工作。爬虫的单点故障不会影响整个系统。
爬取时,爬虫对网页进行结构化分析,提取出需要的数据字段,不仅存储网页的源代码,还存储结构化的字段数据,不仅使数据在网页后立即可用被爬取,而且便于实现存储过程中内容的精确排序和重新排序。
phantomjs 是集成的。Phantomjs 是一个不需要图形界面环境的 Web 浏览器实现。可以用来爬取需要执行js生成内容的网页。通过js语句在页面上执行用户动作,实现表单填写提交,然后抓取下一页内容,点击按钮,然后跳转页面再抓取下一页内容等。
它集成了代理IP使用功能。该功能针对防爬网站(仅限单IP下爬虫的访问量、流量、智能判断),需要提供一个可用的代理IP,爬虫会选择source 网站 也可以访问代理IP地址,source 网站 不能阻止爬取。
可配置项目:
1)。用正则表达式描述,相似的网页被组合在一起并使用相同的规则。爬虫系统(以下各项指某些类型的URL配置项);
2)。起始地址、获取方式、存储位置、页面处理方式等;
3)。需要采集的链接规则,使用CSS选择器限制爬虫只采集出现在页面某个位置的链接;
3)。页面抽取规则,可以使用CSS选择器和正则表达式来定位各个字段内容要抽取的位置;
4)。预定义页面打开后要注入执行的js语句;
5)。网页上的默认cookie;
6)。判断该类网页是否正常返回的规则是指定部分网页恢复正常后必须存在的关键词,以供爬虫检测;
7)。数据抽取是否完整的判断规则,从抽取的字段中选择几个非常必要的字段作为抽取完整性的评价标准;
8)。此类网页的调度权重(优先级)和周期(重新获取和更新的时间)。
建筑学
图中黄色部分是爬虫系统的各个子系统
SuperScheduler 是一个中央调度器。爬虫将采集到的 URL 放入各种 URL 对应的 URL 库中。SuperScheduler 会根据调度规则从各个 URL 库中抽取相应数量的 URL 放入待爬取队列中。
Spider是一个以分布式方式运行的爬虫程序。它将任务从调度器调度的待爬取队列中取出进行爬取,将找到的URL放入URL库,存储提取的内容,将爬虫程序划分为一个核心。并下载、解压、流水线4个中间件,以便轻松重新定制爬虫实例中的功能之一。
ProxyRouter 在使用代理 IP 时智能地将爬虫请求路由到可用的代理 IP。
webconfig是一个网络爬虫规则配置后台。
运行步骤
运行环境准备
create 'crawled',{NAME => 'basic', VERSIONS => 3},{NAME=>"data",VERSIONS=>3},{NAME => 'extra', VERSIONS => 3}
create 'crawled_bin',{NAME => 'basic', VERSIONS => 3},{NAME=>"binary",VERSIONS=>3}
推荐使用 hbase rest 方法。启动hbase后,在hbase目录的bin子目录下执行以下命令启动hbase rest:
./hbase-daemon.sh start rest
默认端口为 8080,将在以下配置中使用。
##[实例配置]
实例在实例目录下,复制一份example,并重命名其他实例名,例如:abc,后面的描述中以abc为例。
编辑 instance/abc/setting.json
{
/*注意:此处用于解释各项配置,真正的setting.json中不能包含注释*/
"driller_info_redis_db":["127.0.0.1",6379,0],/*网址规则配置信息存储位置,最后一个数字表示redis的第几个数据库*/
"url_info_redis_db":["127.0.0.1",6379,1],/*网址信息存储位置*/
"url_report_redis_db":["127.0.0.1",6380,2],/*抓取错误信息存储位置*/
"proxy_info_redis_db":["127.0.0.1",6379,3],/*http代理网址存储位置*/
"use_proxy":false,/*是否使用代理服务*/
"proxy_router":"127.0.0.1:2013",/*使用代理服务的情况下,代理服务的路由中心地址*/
"download_timeout":60,/*下载超时时间,秒,不等同于相应超时*/
"save_content_to_hbase":false,/*是否将抓取信息存储到hbase,目前只在0.94下测试过*/
"crawled_hbase_conf":["localhost",8080],/*hbase rest的配置,你可以使用tcp方式连接,配置为{"zookeeperHosts": ["localhost:2181"],"zookeeperRoot": "/hbase"},此模式下有OOM Bug,不建议使用*/
"crawled_hbase_table":"crawled",/*抓取的数据保存在hbase的表*/
"crawled_hbase_bin_table":"crawled_bin",/*抓取的二进制数据保存在hbase的表*/
"statistic_mysql_db":["127.0.0.1",3306,"crawling","crawler","123"],/*用来存储抓取日志分析结果,需要结合flume来实现,一般不使用此项*/
"check_driller_rules_interval":120,/*多久检测一次网址规则的变化以便热刷新到运行中的爬虫*/
"spider_concurrency":5,/*爬虫的抓取页面并发请求数*/
"spider_request_delay":0,/*两个并发请求之间的间隔时间,秒*/
"schedule_interval":60,/*调度器两次调度的间隔时间*/
"schedule_quantity_limitation":200,/*调度器给爬虫的最大网址待抓取数量*/
"download_retry":3,/*错误重试次数*/
"log_level":"DEBUG",/*日志级别*/
"use_ssdb":false,/*是否使用ssdb*/
"to_much_fail_exit":false,/*错误太多的时候是否自动终止爬虫*/
"keep_link_relation":false/*链接库里是否存储链接间关系*/
}
跑
在网页界面配置爬取规则
调试单个URL爬取是否OK
运行调度器(调度器可以启动一个)
如果使用代理 IP 获取,则启用代理路由
启动爬虫(爬虫可以启动多个分布式)
下面是具体的启动命令
1.运行WEB配置(配置规则见下一章)
node run.js -i abc -a config -p 8888
在浏览器中打开:8888可以在网页界面配置爬取规则
2.测试单页爬取
node run.js -i abc -a test -l "http://domain/page/"
3.运行调度器
node run.js -i abc -a schedule
4.仅当使用代理 IP 捕获时才需要运行代理路由
node run.js -i abc -a proxy -p 2013
这里的 -p 指定代理路由的端口。如果在本地运行,setting.json的proxy_router和端口为127.0.0.1:2013
5.运行爬虫
node run.js -i abc -a crawl
可以在instance/example/logs下查看输出日志debug-result.json
Redis/ssdb数据结构
了解数据结构将有助于您熟悉整个系统进行二次开发。Neocrawler使用了4个存储空间,driller_info_redis_db、url_info_redis_db、url_report_redis_db、proxy_info_redis_db,可以在实例下的settings.json中配置,4个空间的存储类型不同。键名不会冲突,可以将4个空格指向一个redis/ssdb库,每个空间的增长量不同。如果使用redis,建议每个空间指向一个db,有条件的情况下一个redis指向一个空间。
Driller_info_redis_db
存储抓取规则和 URL
url_info_redis_db
这个空间存放的是URL信息,爬取操作时间越长,这里的数据量就越大。
url_report_redis_db
这个空间存储爬虫报告
proxy_info_redis_db
此空间存储与代理 IP 相关的数据
更多内容:
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-12 23:13
为大家整理了25个前端相关学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望你能帮助大家!
▍CSS相关
●1
CSSBattle-在线竞争 CSS
CSS线上竞技,一款非常有趣的竞技游戏,一共12关,需要用HTML和CSS来100%还原它给出的页面,然后尽量减少代码,还可以查看全球排行榜,看解决方案。
●2
学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
●3
Flexbox Froggy - 一个学习 Flex 布局的小游戏
一款引导式学习flex布局游戏,使用flex布局让青蛙在荷叶上跳跃甚至完成,游戏收录了几乎所有常用的属性,所以学起来很有趣,形象好记,谁要flex 布局如果你熟悉的话,在这里多练习一下。
●4
EnjoyCSS - 在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件一样。
●5
CSS 技巧 - CSS 技巧
这个网站 每天都会不断更新一些优秀的教程和CSS 技巧的技巧文章。
●6
Neumorphism - 实现新的模拟效果
可以轻松实现新的模仿效果。不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数。同时可以直接复制CSS代码。
●7
uiGradients - 共享渐变
提供渐变色效果的网站有近百种渐变色方案。可以根据自己的风格选择搭配,直接获取渐变色对应的CSS代码即可。
▍JS相关
●8
JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。它主要写如何避免一些常见的错误,发现难以发现的错误,并深入了解 JavaScript 的语言特性。
●9
JSTips - JS 技巧
每天一点点的Javascript知识。
●10
JSweekly - 科技周刊
专注于 Javascript 的技术周刊。
●11
CDNJS - JavaScript 库
CDNJS为开发者提供最新的前端web开发资源,免费使用,没有使用限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端CDN服务中排名第二(第一是谷歌),性能优异。
●12
Beautiful Open - 开源 JS 库合集
采集各类优秀设计的开源项目,从cms内容管理系统到小型常用Javascript库,适合网站开发的用户使用。
●13
JavaScript Fun - 代码库集合
最流行的 JavaScript 代码库集合,显示流行排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow - 程序员问答网络
全球IT界最受欢迎的技术问答之一网站,一个解决bug的社区,号称“编程界的100,000个为什么”。
●15
掘金 - 优质技术社区
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术 文章 包括 Android、iOS、前端和后端资源。
●16
Codrops - 网页设计开发博客
发布技术文章和网络教程,提供经验,少踩坑,资源丰富。许多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码工具,有各种效果的案例特效(炫技),你可以开发自己的前端设计基于他们的演示。
●18
代码沙盒
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。 React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
●19
JSBin
另一个轻量级的在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材是常用的图标。可以点击官方提供的素材进行二次设计,也可以导出设计好的图标。
●21
OpenMoji - 免费表情符号库
提供带有源代码的表情符号库,可以免费下载使用。
● 22
共享图标 - 免费矢量图片
一个提供超过250,000种ICON矢量图素材,120多个类别的网站,所有素材均以PNG和SVG格式提供,素材有多种尺寸可供选择,包括512*512、256*256、128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
● 23
tableconvert - 在线表格编辑器
一个强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的相互转换。当您需要转换表格,但无法使其变形时,请尝试使用此工具。
● 24
Feathericons-极简主义图标图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发。图标格式为 SVG。
● 25
HTML5 + CSS 3 免费模板
提供大量HTML5模板,用户可以自己分享和修改模板。
本文推荐的网站总结:
CSS战斗:
学习 CSS 布局:
Flexbox Froggy:
享受CSS:
CSS 技巧:
神经拟态:
ui渐变:
JavaScript:
JS 提示:
JS周刊:
CDNJS:
美丽的开放:
JavaScript 乐趣:
堆栈溢出:
掘金:
Codrops:
代码笔:
代码沙盒:
JS斌:
图标:
打开Moji:
分享图标:
表格转换:
羽毛图标:
HTML5UP: 查看全部
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具)
为大家整理了25个前端相关学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望你能帮助大家!
▍CSS相关
●1
CSSBattle-在线竞争 CSS
CSS线上竞技,一款非常有趣的竞技游戏,一共12关,需要用HTML和CSS来100%还原它给出的页面,然后尽量减少代码,还可以查看全球排行榜,看解决方案。
●2
学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
●3
Flexbox Froggy - 一个学习 Flex 布局的小游戏
一款引导式学习flex布局游戏,使用flex布局让青蛙在荷叶上跳跃甚至完成,游戏收录了几乎所有常用的属性,所以学起来很有趣,形象好记,谁要flex 布局如果你熟悉的话,在这里多练习一下。
●4
EnjoyCSS - 在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件一样。
●5
CSS 技巧 - CSS 技巧
这个网站 每天都会不断更新一些优秀的教程和CSS 技巧的技巧文章。
●6
Neumorphism - 实现新的模拟效果
可以轻松实现新的模仿效果。不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数。同时可以直接复制CSS代码。
●7
uiGradients - 共享渐变
提供渐变色效果的网站有近百种渐变色方案。可以根据自己的风格选择搭配,直接获取渐变色对应的CSS代码即可。
▍JS相关
●8
JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。它主要写如何避免一些常见的错误,发现难以发现的错误,并深入了解 JavaScript 的语言特性。
●9
JSTips - JS 技巧
每天一点点的Javascript知识。
●10
JSweekly - 科技周刊
专注于 Javascript 的技术周刊。
●11
CDNJS - JavaScript 库
CDNJS为开发者提供最新的前端web开发资源,免费使用,没有使用限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端CDN服务中排名第二(第一是谷歌),性能优异。
●12
Beautiful Open - 开源 JS 库合集
采集各类优秀设计的开源项目,从cms内容管理系统到小型常用Javascript库,适合网站开发的用户使用。
●13
JavaScript Fun - 代码库集合
最流行的 JavaScript 代码库集合,显示流行排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow - 程序员问答网络
全球IT界最受欢迎的技术问答之一网站,一个解决bug的社区,号称“编程界的100,000个为什么”。
●15
掘金 - 优质技术社区
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术 文章 包括 Android、iOS、前端和后端资源。
●16
Codrops - 网页设计开发博客
发布技术文章和网络教程,提供经验,少踩坑,资源丰富。许多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码工具,有各种效果的案例特效(炫技),你可以开发自己的前端设计基于他们的演示。
●18
代码沙盒
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。 React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
●19
JSBin
另一个轻量级的在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材是常用的图标。可以点击官方提供的素材进行二次设计,也可以导出设计好的图标。
●21
OpenMoji - 免费表情符号库
提供带有源代码的表情符号库,可以免费下载使用。
● 22
共享图标 - 免费矢量图片
一个提供超过250,000种ICON矢量图素材,120多个类别的网站,所有素材均以PNG和SVG格式提供,素材有多种尺寸可供选择,包括512*512、256*256、128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
● 23
tableconvert - 在线表格编辑器
一个强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的相互转换。当您需要转换表格,但无法使其变形时,请尝试使用此工具。
● 24
Feathericons-极简主义图标图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发。图标格式为 SVG。
● 25
HTML5 + CSS 3 免费模板
提供大量HTML5模板,用户可以自己分享和修改模板。
本文推荐的网站总结:
CSS战斗:
学习 CSS 布局:
Flexbox Froggy:
享受CSS:
CSS 技巧:
神经拟态:
ui渐变:
JavaScript:
JS 提示:
JS周刊:
CDNJS:
美丽的开放:
JavaScript 乐趣:
堆栈溢出:
掘金:
Codrops:
代码笔:
代码沙盒:
JS斌:
图标:
打开Moji:
分享图标:
表格转换:
羽毛图标:
HTML5UP:
网页css js 抓取助手(一下前端的基础知识视频和学习路线,对比认识一下各个框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-12 23:05
很多朋友听到前端技术都会觉得有些陌生。但实际上,前端,你每天都在联系。
你使用的APP,你浏览的网页,你能看到的界面,都属于前端。
最重要的三种前端技术 HTML、CSS 和 JavaScript 是每个前端开发人员必须具备的技能。
有了这些技巧,你可以快速打造出炫酷的APP界面或者简洁大方的网站页面。那么,让我们一起快速浏览一下这三种技术。
实验介绍
本实验主要介绍前端的基础知识,对比了解各个框架的代码编写方法,介绍我们本次技术选型的主要思路。对于HTML、CSS、JavaScript这三种前端技术,简单介绍一下基本情况和常用语法。中间介绍了现代框架的一些情况,通过实际案例,我们可以用代码直观的了解各种框架的实现方式。最后,分析项目的技术选型。
知识点
HTML、CSS、JavaScript 快速概览
前端框架概述和选择
后端选择
数据库选择
网络服务器选择
前端技术介绍
本节我们简单介绍一下最基本的前端HTML、CSS、JavaScript三驾马车。虽然本课程的预设读者都是零基础的开发者,但是前端开发对这三种技术的使用肯定是有要求的。建议花时间研究一下《Web前端工程师之路》的stage 1甚至stage 2。这只是语法介绍和基本用法的概述。
在前端领域工作了几年,总结了一套前端学习的强化视频和学习路线。如果你有对前端开发感兴趣的伙伴,无论你是想转行,还是想当大学生,还是想在工作中提升自己 有能力的web前端党,欢迎大家加入我的前端开发交流群:603985993 希望大家真诚交流!,与企业的需求同步。小伙伴们都在里面学习交流,每天都会有大牛定时讲解前端技术!也可以关注我的微信公众号:【前端留学生】每天更新最新科技文章干货。
在此之前,先了解一下实验环境。实验环境与VS Code体验基本一致。您可以启动终端并在其中输入 Linux 命令。
以下无特殊说明的命令均在此终端命令行中输入。大多数命令可以通过打开多个终端窗口来单独执行。
因此,让我们快速浏览一下。
HTML
HTML 代表超文本标记语言,自万维网和浏览器出现以来就一直存在。主要用于结构化信息,方便浏览器显示。
以标签对为主要特征,如
这是一个段落,这些标签会被浏览器解析成不同的模块。例如,p 标签是段落,img 标签是图像,a 标签是超链接。标签名称不区分大小写。
现在就试试。首先通过命令行创建一个demo目录:
mkdir demo
然后从命令行进入demo目录:
cd ./demo
新建一个hello.html文件,可以在实验环境左侧的浏览器框中右键demo,选择New File,命名为hello.html;也可以在命令行终端输入touch hello.html,同样是新建文件。
在其中输入以下内容:
标题
正文
然后右键单击该文件并选择打开方式 → 预览。
看见?其实我们只是新建了一个.html后缀的文本文件,然后浏览器就可以显示里面的内容了。也可以在桌面新建一个,用浏览器打开看看效果。
这里嵌套代码的缩进是为了美观和可读性,并不是严格要求的。
head标签收录一些暂时不需要的header信息,渲染的主体是body标签。下面我们修改body标签中的内容,填写一些常用的标签,直观感受一下。
页面标题
一个块容器
又一个块容器
这里是段落了,间距变大
一个块容器
多层嵌套:
内部第一个
内部第二个
保存后,切换到浏览选项卡查看。你觉得被愚弄了吗?嵌套完全没有体现出来,就像Word中的布局一样,按回车几次。
由于我们没有修改显示样式,这是 CSS 的事情。HTML主要管理内容的组织结构。
这里有一点学习建议。请手动输入本课程给出的所有代码,忘记复制和粘贴快捷键。
而且最好不要一个字一个地生搬硬套,尽量读一行或者一小段代码,靠短期印象输出,不怕出错,只有思考和输出实践是掌握技能捷径的最快方法。
以上两句话是本课程最有价值的内容之一。
接下来我们对刚才的代码进行修改,在body中添加几个常用的标签。每次修改保存后记得去预览页面查看样式变化。
4 级标题
HTML
CSS
JavaScript
点击超链接跳转
最后一个链接标签a和图片标签img都有标签属性,格式为attr="value",可以给标签添加更丰富的信息。
同时img标签还是单标签,以后不需要添加使用。
我们对 HTML 的简要介绍到此结束。
网上看到的各种五颜六色的网页都是由这个HTML组成的,但为什么我们写得这么难看呢?在下一节中,我们将学习如何使用 CSS 美化页面。
CSS
CSS 代表 Cascading Style Sheets,它是一种专门用于修改 HTML 样式的语言。让我们修改上一节中的 hello.html 文件,以获得直观的感觉。
内部代码块介绍
在 head 标签内添加以下样式块:
标题
div {
border: 1px solid blue;
padding: 2px;
margin: 10px;
}
这是再次切换到预览页面,发现并没有那么简单。
这是引入 CSS 的第一种方式,HTML 内置代码块。
花括号外面的 div 是标签选择器,它选择了这个页面上的所有 div 元素。大括号内是属性名称和赋值。属性名称是固定关键字,并且已经指定了值的类型和可选范围。
阅读代码你可能知道,我们将 div 的边框设置为 1 像素宽、实心(单线)、蓝色、内边距(padding)2 像素、边距(margins)10 像素。现在练习调整单个数字并预览发生了什么?
题外话,程序员懂一些英语是非常有必要的。除了能够阅读和理解没有通过感觉学习的代码之外,还可以为 Google、Stack Overflow 和 Github Issues 编程。
导入外部文件
然后我们再次尝试导入外部文件,在hello.html的同级目录下新建一个hello.css,输入以下内容保存:
div {
color: green;
border: 2px dotted red;
}
然后修改hello.html,在style标签后面加一行link标签,加上导入类型和地址:
div {
border: 1px solid blue;
padding: 2px;
margin: 10px;
}
看一下预览,文字颜色变成了绿色,边框样式更新为2像素宽,点红色。
同样是div选择器,为什么会覆盖边框样式?注意CSS会在相同条件下覆盖前面的代码,可以尝试交换链接标签和样式标签块的顺序来查看。
联运风格
最后一种叫做interline style,结构比较简单。修改 hello.html 中
第一个内部是
内部第一个
样式会覆盖前两种方法,因为行间样式具有更高的优先级。此处涉及选择器权重。我们先来了解一个简单的公式。
!important > 内联样式 > ID > 类 | 伪类 | 属性选择 > 标签 > 继承 | 通配符。
应用多个选择器时添加权重。这是CSS中比较复杂的部分,暂时不展开。
这里还有一个小知识点。内外边距和内边距接受的完整值是四,顺序固定为“右上左下”。如果省略参数,则从末尾计算相反的合并。例如:
边距:40px 20px 50px;三个参数时,左右都是20px。
边距:40px 20px;这两个参数都是上下40px,左右20px。
边距如何:40px;作为参数?请尝试自己理解。
CSS 首先讲了这么多。虽然没有让我们的页面更漂亮,但至少我们知道自己努力的方向。
JavaScript
快速入门 JavaScript 可能会非常伤脑筋。与前两种技术 HTML 和 CSS 相比,这是一种真正的编程语言。
它也是我们后面会用到的 Vue.js 和 Node.js 的基础。很难一下子讲很多,所以希望同学们能够重视,系统地学习,至少在阅读下面的代码的时候是什么,这是什么,这是什么“困境”。
让我们直观的理解代码,还是先介绍一下内部代码块。
在 hello.html 的 head 标签内添加一段代码:
let message = "字符串提示";
function showMSG(msg) {
alert(msg);
}
修改hello.html的h1标签为:
页面标题
保存预览,点击“页面标题”,会弹出提示框。
JavaScript 代码在加载后执行,没有编译阶段。大多数情况下,行尾的分号可以省略。
我们首先定义了一个变量 message 并将其指定为“字符串提示符”。定义变量的关键字原本是 var。ES6 中的新关键字 let 范围更清晰,可以替代使用。
学习 JavaScript 经常会遇到像 ES6、ES7 这样的术语,其实就是 ECMAScript 标准的版本号。可以简单理解为新版标准为 JavaScript 增加了特定的新特性。
然后我们定义一个函数 showMSG 并添加一个形参 msg。调用函数体内部的浏览器弹窗方法,显示msg的值。function 是定义函数的关键字。暂时将其视为一个功能封闭的盒子。当函数被调用时,函数体中的代码被执行。
调用部分是先给h1标签添加onclick点击事件,点击时触发showMSG(message),也就是将消息传递给msg。
然后尝试再次调用外部js文件,新建demo.js文件,写入如下内容并保存。
message = "修改一下字符串";
然后修改hello.html文件,在脚本块后面添加一行:
这次保存预览,点击“页面标题”,可以看到弹窗的文字发生了变化。这说明页面上可以同时存在多个脚本代码块,而且它们也是顺序调用的,可以直接相互访问。对文件命名没有要求,希望不会扼杀强迫症。
JavaScript 是网页可以进行如此多交互的来源。要走的路还很长。这三种前端技术先在这里学习 查看全部
网页css js 抓取助手(一下前端的基础知识视频和学习路线,对比认识一下各个框架)
很多朋友听到前端技术都会觉得有些陌生。但实际上,前端,你每天都在联系。
你使用的APP,你浏览的网页,你能看到的界面,都属于前端。
最重要的三种前端技术 HTML、CSS 和 JavaScript 是每个前端开发人员必须具备的技能。
有了这些技巧,你可以快速打造出炫酷的APP界面或者简洁大方的网站页面。那么,让我们一起快速浏览一下这三种技术。
实验介绍
本实验主要介绍前端的基础知识,对比了解各个框架的代码编写方法,介绍我们本次技术选型的主要思路。对于HTML、CSS、JavaScript这三种前端技术,简单介绍一下基本情况和常用语法。中间介绍了现代框架的一些情况,通过实际案例,我们可以用代码直观的了解各种框架的实现方式。最后,分析项目的技术选型。
知识点
HTML、CSS、JavaScript 快速概览
前端框架概述和选择
后端选择
数据库选择
网络服务器选择
前端技术介绍
本节我们简单介绍一下最基本的前端HTML、CSS、JavaScript三驾马车。虽然本课程的预设读者都是零基础的开发者,但是前端开发对这三种技术的使用肯定是有要求的。建议花时间研究一下《Web前端工程师之路》的stage 1甚至stage 2。这只是语法介绍和基本用法的概述。
在前端领域工作了几年,总结了一套前端学习的强化视频和学习路线。如果你有对前端开发感兴趣的伙伴,无论你是想转行,还是想当大学生,还是想在工作中提升自己 有能力的web前端党,欢迎大家加入我的前端开发交流群:603985993 希望大家真诚交流!,与企业的需求同步。小伙伴们都在里面学习交流,每天都会有大牛定时讲解前端技术!也可以关注我的微信公众号:【前端留学生】每天更新最新科技文章干货。
在此之前,先了解一下实验环境。实验环境与VS Code体验基本一致。您可以启动终端并在其中输入 Linux 命令。
以下无特殊说明的命令均在此终端命令行中输入。大多数命令可以通过打开多个终端窗口来单独执行。
因此,让我们快速浏览一下。
HTML
HTML 代表超文本标记语言,自万维网和浏览器出现以来就一直存在。主要用于结构化信息,方便浏览器显示。
以标签对为主要特征,如
这是一个段落,这些标签会被浏览器解析成不同的模块。例如,p 标签是段落,img 标签是图像,a 标签是超链接。标签名称不区分大小写。
现在就试试。首先通过命令行创建一个demo目录:
mkdir demo
然后从命令行进入demo目录:
cd ./demo
新建一个hello.html文件,可以在实验环境左侧的浏览器框中右键demo,选择New File,命名为hello.html;也可以在命令行终端输入touch hello.html,同样是新建文件。
在其中输入以下内容:
标题
正文
然后右键单击该文件并选择打开方式 → 预览。
看见?其实我们只是新建了一个.html后缀的文本文件,然后浏览器就可以显示里面的内容了。也可以在桌面新建一个,用浏览器打开看看效果。
这里嵌套代码的缩进是为了美观和可读性,并不是严格要求的。
head标签收录一些暂时不需要的header信息,渲染的主体是body标签。下面我们修改body标签中的内容,填写一些常用的标签,直观感受一下。
页面标题
一个块容器
又一个块容器
这里是段落了,间距变大
一个块容器
多层嵌套:
内部第一个
内部第二个
保存后,切换到浏览选项卡查看。你觉得被愚弄了吗?嵌套完全没有体现出来,就像Word中的布局一样,按回车几次。
由于我们没有修改显示样式,这是 CSS 的事情。HTML主要管理内容的组织结构。
这里有一点学习建议。请手动输入本课程给出的所有代码,忘记复制和粘贴快捷键。
而且最好不要一个字一个地生搬硬套,尽量读一行或者一小段代码,靠短期印象输出,不怕出错,只有思考和输出实践是掌握技能捷径的最快方法。
以上两句话是本课程最有价值的内容之一。
接下来我们对刚才的代码进行修改,在body中添加几个常用的标签。每次修改保存后记得去预览页面查看样式变化。
4 级标题
HTML
CSS
JavaScript
点击超链接跳转
最后一个链接标签a和图片标签img都有标签属性,格式为attr="value",可以给标签添加更丰富的信息。
同时img标签还是单标签,以后不需要添加使用。
我们对 HTML 的简要介绍到此结束。
网上看到的各种五颜六色的网页都是由这个HTML组成的,但为什么我们写得这么难看呢?在下一节中,我们将学习如何使用 CSS 美化页面。
CSS
CSS 代表 Cascading Style Sheets,它是一种专门用于修改 HTML 样式的语言。让我们修改上一节中的 hello.html 文件,以获得直观的感觉。
内部代码块介绍
在 head 标签内添加以下样式块:
标题
div {
border: 1px solid blue;
padding: 2px;
margin: 10px;
}
这是再次切换到预览页面,发现并没有那么简单。
这是引入 CSS 的第一种方式,HTML 内置代码块。
花括号外面的 div 是标签选择器,它选择了这个页面上的所有 div 元素。大括号内是属性名称和赋值。属性名称是固定关键字,并且已经指定了值的类型和可选范围。
阅读代码你可能知道,我们将 div 的边框设置为 1 像素宽、实心(单线)、蓝色、内边距(padding)2 像素、边距(margins)10 像素。现在练习调整单个数字并预览发生了什么?
题外话,程序员懂一些英语是非常有必要的。除了能够阅读和理解没有通过感觉学习的代码之外,还可以为 Google、Stack Overflow 和 Github Issues 编程。
导入外部文件
然后我们再次尝试导入外部文件,在hello.html的同级目录下新建一个hello.css,输入以下内容保存:
div {
color: green;
border: 2px dotted red;
}
然后修改hello.html,在style标签后面加一行link标签,加上导入类型和地址:
div {
border: 1px solid blue;
padding: 2px;
margin: 10px;
}
看一下预览,文字颜色变成了绿色,边框样式更新为2像素宽,点红色。
同样是div选择器,为什么会覆盖边框样式?注意CSS会在相同条件下覆盖前面的代码,可以尝试交换链接标签和样式标签块的顺序来查看。
联运风格
最后一种叫做interline style,结构比较简单。修改 hello.html 中
第一个内部是
内部第一个
样式会覆盖前两种方法,因为行间样式具有更高的优先级。此处涉及选择器权重。我们先来了解一个简单的公式。
!important > 内联样式 > ID > 类 | 伪类 | 属性选择 > 标签 > 继承 | 通配符。
应用多个选择器时添加权重。这是CSS中比较复杂的部分,暂时不展开。
这里还有一个小知识点。内外边距和内边距接受的完整值是四,顺序固定为“右上左下”。如果省略参数,则从末尾计算相反的合并。例如:
边距:40px 20px 50px;三个参数时,左右都是20px。
边距:40px 20px;这两个参数都是上下40px,左右20px。
边距如何:40px;作为参数?请尝试自己理解。
CSS 首先讲了这么多。虽然没有让我们的页面更漂亮,但至少我们知道自己努力的方向。
JavaScript
快速入门 JavaScript 可能会非常伤脑筋。与前两种技术 HTML 和 CSS 相比,这是一种真正的编程语言。
它也是我们后面会用到的 Vue.js 和 Node.js 的基础。很难一下子讲很多,所以希望同学们能够重视,系统地学习,至少在阅读下面的代码的时候是什么,这是什么,这是什么“困境”。
让我们直观的理解代码,还是先介绍一下内部代码块。
在 hello.html 的 head 标签内添加一段代码:
let message = "字符串提示";
function showMSG(msg) {
alert(msg);
}
修改hello.html的h1标签为:
页面标题
保存预览,点击“页面标题”,会弹出提示框。
JavaScript 代码在加载后执行,没有编译阶段。大多数情况下,行尾的分号可以省略。
我们首先定义了一个变量 message 并将其指定为“字符串提示符”。定义变量的关键字原本是 var。ES6 中的新关键字 let 范围更清晰,可以替代使用。
学习 JavaScript 经常会遇到像 ES6、ES7 这样的术语,其实就是 ECMAScript 标准的版本号。可以简单理解为新版标准为 JavaScript 增加了特定的新特性。
然后我们定义一个函数 showMSG 并添加一个形参 msg。调用函数体内部的浏览器弹窗方法,显示msg的值。function 是定义函数的关键字。暂时将其视为一个功能封闭的盒子。当函数被调用时,函数体中的代码被执行。
调用部分是先给h1标签添加onclick点击事件,点击时触发showMSG(message),也就是将消息传递给msg。
然后尝试再次调用外部js文件,新建demo.js文件,写入如下内容并保存。
message = "修改一下字符串";
然后修改hello.html文件,在脚本块后面添加一行:
这次保存预览,点击“页面标题”,可以看到弹窗的文字发生了变化。这说明页面上可以同时存在多个脚本代码块,而且它们也是顺序调用的,可以直接相互访问。对文件命名没有要求,希望不会扼杀强迫症。
JavaScript 是网页可以进行如此多交互的来源。要走的路还很长。这三种前端技术先在这里学习
网页css js 抓取助手(精易编程助手什么用处网页分析:穿透框架彻底分析网页元素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-11 09:13
精益编程助手是一款功能非常强大的编程软件,具有窗口检测、网页分析、代码转换等功能,为用户提供了全面的编程辅助功能,可以有效提高工作效率,是很多程序员必备的工具。一。欢迎来到当易网下载!
精易编程助手正式版介绍
Easy Language开发的编程助手旨在让程序员在编程和编写代码时达到最快的速度。例如,如果您需要操作一个外部窗口,您可以使用简易编程助手来探测并获取相关信息。窗口信息,然后做其他操作,以此类推。
精益编程助手有什么用?
网页分析:穿透框架彻底分析网页元素,让您在网页上填写表格更容易!
生成代码:找到指定的窗口控件,全智能生成易语言代码!
资源 采集: 采集 CSS、js、图片、背景、网页上的媒体文件!
窗口检测:清晰分析窗口中各种控件的id、句柄、标题、类名、位置、大小!
屏幕颜色选择器:轻松获取屏幕上的任何颜色代码!
进程管理:管理系统运行进程!
正则工具:轻松调试正则表达式,内置大量语法示例!
网页抓包:智能网页抓包,postget客户端打包测试
编码转换:收录大部分转换命令,一键编码/解码需要数据!
工具箱:文本加解密、十六进制解码、图标提取、简单测试等等!
网页调试:可以打包请求测试、json解析、js调试!
使用说明
一、用法
1、获取正常更改的目标窗口的窗口样式并记录在文本或其他位置
2、填写第1步得到的窗口样式值,回车或点击确定按钮完成修改
3、获取要改变的目标窗口的句柄,右击窗口样式选择修改
4、如果修改后目标窗口没有变化,点击修改后的窗口或刷新窗口查看修改后的效果
5、修改扩展样式的步骤同上
二、备注
1、此功能仅限win32常规窗口,自绘窗口的样式不适用于此功能
2、 记得不要用这个功能修改系统桌面的样式,不然桌面就完了?嗯,是的,它会的!
休闲编程助手教程
1、打开软件,选择网页分析,这里需要说明的是网页分析工具,它只支持IE内核的浏览器,使用的时候最好直接用IE浏览器!
2、分析前,用视线工具将其拖到待分析的网页上,在分析点自动分析各个元素类型!
3、 类型主要用于选择和分析哪个网页元素可以快速得到你想要的结果!
4、logo主要是分析时的logo元素。比如以百度首页为例,分析完第一篇文章后,选择文本框,打开logo,然后分析,会在原网页上做一些logo,方便分析。手表!
5、搜索更容易理解。它不是网页上某种类型的元素。在列表中找到它是相当麻烦的。您可以在搜索中填写一些与网页相关的文字,并使用搜索进行定位,即可找到相关的网页元素!
6、控制和测量功能有点多。如果要显示元素信息,可以使用sight工具将其拖到要分析的网页上,就可以了。网页源代码会显示当前网页的源代码!
7、元素测试,这里不能做,不能演示,执行脚本和cookies不用我多说。懂脚本的人都会做!
8、采集是下载网页上的一个内容,包括图片、媒体文件等,可以下载回来!
9、里面的其他操作也很简单,用的不多,练习一下吧!
变更日志
v3.98
1、修复十六进制转换时输入2147483648会崩溃的问题;
2、修复网页分析中勾选body文本框和标记时网页空白的问题;
3、常规调试添加代码生成超级列表框;
4、修复常规调试生成代码不处理换行的问题;
5、修复部分程序无法定位进程路径的问题;
6、修复网页分析右键判断元素视觉状态错误,隐藏元素时菜单不改为显示的问题;
v3.7
易于编程
一、窗口检测
1、ui解析优化窗口最小化时标记组件的显示;
2、优化解决部分组件异常崩溃的问题;
3、修复窗口检测是否只检测可见窗口的bug;
4、优化ui解析方式,增加只解析当前鼠标位置的控件;
二、屏幕颜色选择
修复颜色转换错误的bug;
三、网页功能
优化网页调试助手的运行判断;
全面的
优化更新提示逻辑;
网页调试
一、网页调试
1、增加了返回协议头状态码的解释,解释短语、返回数字状态码的含义、http版本;
2、调整部分组件细节;
3、优化双击显示修改窗口的修改逻辑;
4、增加了提交协议头的右键菜单,用于处理协议头,并将协议头中键名的首字母转换为大写;
5、优化日记窗口列表的显示内容,直观的搜索和发送日记;
6、为“Webpage_Access s”添加超时设置;
7、修改“文件提交”为“文件上传”,“提交方法”为“提交方法”
8、优化“提交方式”中切换提交类型时帮助提示的显示;
9、优化“提交地址”头协议的大小写;
二、json 解析
1、优化解析时对关键词的判断;
2、优化解析时对第一条路径的判断;
全面的
1、优化窗口加载闪烁问题;
2、修复多开助手最小化后任务栏无响应的问题。 查看全部
网页css js 抓取助手(精易编程助手什么用处网页分析:穿透框架彻底分析网页元素)
精益编程助手是一款功能非常强大的编程软件,具有窗口检测、网页分析、代码转换等功能,为用户提供了全面的编程辅助功能,可以有效提高工作效率,是很多程序员必备的工具。一。欢迎来到当易网下载!
精易编程助手正式版介绍
Easy Language开发的编程助手旨在让程序员在编程和编写代码时达到最快的速度。例如,如果您需要操作一个外部窗口,您可以使用简易编程助手来探测并获取相关信息。窗口信息,然后做其他操作,以此类推。
精益编程助手有什么用?
网页分析:穿透框架彻底分析网页元素,让您在网页上填写表格更容易!
生成代码:找到指定的窗口控件,全智能生成易语言代码!
资源 采集: 采集 CSS、js、图片、背景、网页上的媒体文件!
窗口检测:清晰分析窗口中各种控件的id、句柄、标题、类名、位置、大小!
屏幕颜色选择器:轻松获取屏幕上的任何颜色代码!
进程管理:管理系统运行进程!
正则工具:轻松调试正则表达式,内置大量语法示例!
网页抓包:智能网页抓包,postget客户端打包测试
编码转换:收录大部分转换命令,一键编码/解码需要数据!
工具箱:文本加解密、十六进制解码、图标提取、简单测试等等!
网页调试:可以打包请求测试、json解析、js调试!
使用说明
一、用法
1、获取正常更改的目标窗口的窗口样式并记录在文本或其他位置
2、填写第1步得到的窗口样式值,回车或点击确定按钮完成修改
3、获取要改变的目标窗口的句柄,右击窗口样式选择修改
4、如果修改后目标窗口没有变化,点击修改后的窗口或刷新窗口查看修改后的效果
5、修改扩展样式的步骤同上
二、备注
1、此功能仅限win32常规窗口,自绘窗口的样式不适用于此功能
2、 记得不要用这个功能修改系统桌面的样式,不然桌面就完了?嗯,是的,它会的!
休闲编程助手教程
1、打开软件,选择网页分析,这里需要说明的是网页分析工具,它只支持IE内核的浏览器,使用的时候最好直接用IE浏览器!
2、分析前,用视线工具将其拖到待分析的网页上,在分析点自动分析各个元素类型!
3、 类型主要用于选择和分析哪个网页元素可以快速得到你想要的结果!
4、logo主要是分析时的logo元素。比如以百度首页为例,分析完第一篇文章后,选择文本框,打开logo,然后分析,会在原网页上做一些logo,方便分析。手表!
5、搜索更容易理解。它不是网页上某种类型的元素。在列表中找到它是相当麻烦的。您可以在搜索中填写一些与网页相关的文字,并使用搜索进行定位,即可找到相关的网页元素!
6、控制和测量功能有点多。如果要显示元素信息,可以使用sight工具将其拖到要分析的网页上,就可以了。网页源代码会显示当前网页的源代码!
7、元素测试,这里不能做,不能演示,执行脚本和cookies不用我多说。懂脚本的人都会做!
8、采集是下载网页上的一个内容,包括图片、媒体文件等,可以下载回来!
9、里面的其他操作也很简单,用的不多,练习一下吧!
变更日志
v3.98
1、修复十六进制转换时输入2147483648会崩溃的问题;
2、修复网页分析中勾选body文本框和标记时网页空白的问题;
3、常规调试添加代码生成超级列表框;
4、修复常规调试生成代码不处理换行的问题;
5、修复部分程序无法定位进程路径的问题;
6、修复网页分析右键判断元素视觉状态错误,隐藏元素时菜单不改为显示的问题;
v3.7
易于编程
一、窗口检测
1、ui解析优化窗口最小化时标记组件的显示;
2、优化解决部分组件异常崩溃的问题;
3、修复窗口检测是否只检测可见窗口的bug;
4、优化ui解析方式,增加只解析当前鼠标位置的控件;
二、屏幕颜色选择
修复颜色转换错误的bug;
三、网页功能
优化网页调试助手的运行判断;
全面的
优化更新提示逻辑;
网页调试
一、网页调试
1、增加了返回协议头状态码的解释,解释短语、返回数字状态码的含义、http版本;
2、调整部分组件细节;
3、优化双击显示修改窗口的修改逻辑;
4、增加了提交协议头的右键菜单,用于处理协议头,并将协议头中键名的首字母转换为大写;
5、优化日记窗口列表的显示内容,直观的搜索和发送日记;
6、为“Webpage_Access s”添加超时设置;
7、修改“文件提交”为“文件上传”,“提交方法”为“提交方法”
8、优化“提交方式”中切换提交类型时帮助提示的显示;
9、优化“提交地址”头协议的大小写;
二、json 解析
1、优化解析时对关键词的判断;
2、优化解析时对第一条路径的判断;
全面的
1、优化窗口加载闪烁问题;
2、修复多开助手最小化后任务栏无响应的问题。
网页css js 抓取助手(Python爬取网页所需要的URL地址和CSS、JS文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-06 14:13
Python抓取单个网页需要加载的URL地址和CSS、JS文件地址
<p>通过学习Python爬虫,我们知道可以根据形式表达式匹配(标题、图片、文章等)找到我们需要的东西。并且我从测试的角度使用Python爬虫,希望能抓取到访问网页所需的CSS、JS、URL,然后请求这些地址,根据响应状态码判断是否可以访问成功。 查看全部
网页css js 抓取助手(Python爬取网页所需要的URL地址和CSS、JS文件)
Python抓取单个网页需要加载的URL地址和CSS、JS文件地址
<p>通过学习Python爬虫,我们知道可以根据形式表达式匹配(标题、图片、文章等)找到我们需要的东西。并且我从测试的角度使用Python爬虫,希望能抓取到访问网页所需的CSS、JS、URL,然后请求这些地址,根据响应状态码判断是否可以访问成功。
网页css js 抓取助手(你会不停的问,HTML是什么?CSS是XML)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-05 01:20
如果你是web开发的初学者,难免会在网上搜索HTML、CSS、XML、JS(Javascript)、DOM、XSL等这些词的含义。然而,随着你了解的越来越多。当你把它们混在一起的时候,你又糊涂了,你会一直问,什么是HTML?什么是 CSS?什么是 XML?什么是JS?它们是为了什么?无论是网络百科全书还是一些IT专题网站,或者一些伟大的博主,他们都会告诉你一个东西是什么。这样的文章有很多,但很少涉及。它们的组合是什么,有什么用?. 我想我写这个 文章 是为了说明这个他们很少涉及的问题。
在这里,我尽量用最基础的语言给大家讲解一下HTML、CSS、XML、JS是什么,有什么用。那我们就来看看把它们组合起来到底是什么,又有什么用呢。当然,如果你对HTML、CSS、XML、JS有足够的了解,可以直接跳过,看文章的后半部分,这是本文的核心。
第一部分
1. HTML 超文本标记语言(Hyper Text Markup Language)是一种用于描述网页的标记语言。
HTML
Hello World! I'm HTML
网页文件本身是一个文本文件。通过在文本文件中添加标签,可以告诉浏览器如何显示内容(如:如何处理文本、如何排列屏幕、如何显示图片等)。
HTML 被称为超文本标记语言,因为文本收录所谓的“超链接”点。超文本(Hypertext)是一种类似网络的文本,它使用超链接来组织各种不同空间中的文本信息。
综上所述,HTML 是一种集网页结构和内容展示于一体的语言。
Hello World! I'm HTML
浏览器依次读取网页文件,然后根据标签对标记的内容进行解释和显示。
这个内容在浏览器上显示的结果是:Hello World!我是 HTML
我们看
标签上有一个id,就是
该标签的唯一标识使其他人很容易找到并对其进行操作。
2. CSS 级联样式表。它是一种将样式信息与 Web 内容分开的标记语言。作为 网站 开发人员,您可以为每个 HTML 元素定义样式并将其应用于任意数量的页面。如果需要全局更新,只需更改样式,网站中的所有元素都会自动更新。这样,设计师可以将更多的时间花在设计上,而不是费力地克服 HTML 的局限性。说白了,CSS就是在网页上设置HTML元素属性的语言。
CSS代码:
#hello{
color:blue;
}
当这个CSS代码应用于HTML时,它会找到id为“hello”的HTML标签,并将内容显示为蓝色;插入HTML的具体方法这里不再赘述。什么,有什么用的问题,不注意技术细节,技术细节网上很容易找到)。
3. Javascript,首先说明一下JavaScript与Java无关,JavaScript是属于网络的脚本语言!那么为什么名字如此相似呢?这是典型的营销成功,它的成功推广也是借鉴了Java。当微软开始意识到 Javascript 在 Web 开发者中很流行时,微软仍然建立了自己的脚本语言 JScript。
Javascript 是一种基于对象和事件驱动的脚本语言,具有安全功能。使用它的目的是通过HTML超文本标记语言和Java脚本语言(Java小程序)将网页中的多个对象链接在一起,与Web客户端进行交互。例如,您可以设置鼠标悬停效果、在客户端验证表单、创建自定义 HTML 页面、显示警报框、设置 cookie 等。
网页的所有本地代码实现部分,判断、操作和反馈信息给浏览者都是Javascript(当然还有其他的),可以让网页更具交互性,为用户提供更精彩的体验,同时减轻浏览者的负担服务器。
JS代码如下:
function jsHello(){
alert('Hello World!');
}
当上面的代码应用于HTML代码时,会弹出一个对话框,内容为“Hello World!” 当您的 HTML 加载时。类似地,它是通过嵌入或加载在标准 HTML 语言中实现的。至于如何嵌入或转移,由于上述原因,我不再赘述。
4. Xml 可扩展标记语言(Extensible MarkupLanguage)是一组定义语义标记的规则。这些标记将文档分成许多部分并标识这些部分。它也是一种元标记语言,即定义与特定领域相关的其他语义和结构化标记语言的语法语言。您可以将 XML 理解为数据库,例如 rss 是 xml 的变体。
XML代码如下:
China
USA
UK
XML 的原因是用户对 SGML 的复杂性(稍后会详细介绍)和 HTML 的不足感到沮丧。与 HTML 相比,XML 更为严谨。如果你说HTML代码中的标签乱七八糟,比如未关闭,也许浏览器会忽略这些错误;但是同样的事情发生在 XML 中会给你带来很大的麻烦。
伏笔终于结束了。在进入正题之前,建议大家对比一下图表,了解背后的内容。废话不多说,开始进入正题。
第二部分
这里的 DOM 是指 HTML DOM。HTML DOM 是 W3C 标准,也是 HTML 文档对象模型(Document Object Model for HTML)的缩写。HTML DOM 为 HTML 定义了一系列标准对象,以及访问和处理 HTML 文档的标准方法。通过 DOM,您可以访问所有 HTML 元素,以及它们收录的文本和属性。可以修改和删除内容,也可以创建新元素。HTML DOM 独立于平台和编程语言。它可以被任何编程语言使用,例如 Java、Javascript 和 VBScript。HTML DOM 是 HTML 语言向外界开放的接口,以便其他语言可以访问或修改 HTML 内部的元素。
当js需要操作html元素时,DOM是必不可少的对象。
您可以使用 DOM 对象构造以下代码并将其插入 HTML 代码中的任何位置。
window.onload=function hello(){
document.getElementById("hello").innerHTML="Hello China!";
}
在使用 CSS 装饰 HTML 元素时,这个过程可以称为声明 HTML 元素样式的过程。
SGML 标准广义标记语言(standardgeneralized markup language)。由于SGML的复杂性,难以普及。SGML具有很强的适应性,同样的原因,在小型应用中也难以普及。HTML 和 XML 也是从 SGML 派生而来的:XML 可以被认为是 SGML 的一个子集,而 HTML 是 SGML 的一个应用。创建 XML 是为了简化 SGML,以便它可以用于更通用的目的。例如,语义网已经在大量场合使用,如XHTML、RSS、XML-RPC 和SOAP。
XHTML 是可扩展超文本标记语言(TheExtensible HyperText Markup Language)。HTML 是一种基本的网页设计语言。XHTML 是一种基于 XML 的标记语言。它看起来与 HTML 相似,只有一些很小但很重要的区别。XHTML 是一种 XML,其作用类似于 HTML。所以,本质上,XHTML 是一种过渡技术,它结合了 XML 的一些强大功能和 HTML 的大部分简单特性。
简单的说,XHTML 比 HTML 更严谨,但没有 XML 严重——比如所有的 XHTML 标签和属性必须是小写的,属性必须是双引号(当然,现在的浏览器,不管是 IE 还是 FF ,对HTML和XHTML采取兼容措施也是XSS的根本原因),而且有些标签可以像XML一样自定义,因此具有很大的灵活性。
看到这里,突然发现web开发中一个很重要的问题。Xss 漏洞。这里我就不分析这个问题了。我将在接下来的笔记中重点研究 xss 漏洞。
而在XHTML时代,大家提倡的是CSS+DIV,这也是web2.0的基础。
DHTML 只是制作网页的一个概念。事实上,没有任何组织或机构引入所谓的 DHTML 标准或技术规范。DHTML 不是技术、标准或规范。DHTML 只是一种设计理念,它集成并利用现有的网络技术和语言标准,创建了一个下载后可以实时改变页面元素效果的网页。DHTML 是动态 HTML,Dynamic HTML。传统的 html 页面是静态的。dhtml在html页面中加入javascript脚本,使其可以根据用户的动作做出一定的响应,比如鼠标移到图片上、改变图片颜色、移到导航栏、弹出动态菜单等。
一般喜欢:
Expression 是微软在 Internet Explorer 中添加的一项功能,可以让样式表在执行 javascript 脚本的同时修改 HTML 样式,以便您可以执行诸如:自适应图片宽度、表格交错颜色变化等。
如:img{max-width:500px;width:expression(document.body.clientWidth> 200? "200px": "auto");}
XMLHTTP最笼统的定义是:XmlHttp是一组可以在Javascript、VbScript、Jscript等脚本语言中通过http协议传输或接收XML等数据的API。XmlHttp最大的用处就是可以在不刷新整个页面的情况下更新部分网页。
来自MSDN的说明:XmlHttp为客户端与http服务器通信提供了一个协议。客户端可以通过 XmlHttp 对象向 http 服务器发送请求,并使用 Microsoft® XML 文档对象模型 (DOM) 来处理响应。
绝对大多数浏览器现在都添加了对 XmlHttp 的支持。IE 使用 ActiveXObject 来创建 XmlHttp 对象。其他浏览器如 Firefox 和 Opera 使用 window.XMLHttpRequest 来创建 XmlHttp 对象。
定义 IE 的 XmlHttp 对象和应用程序的简单示例如下:
var XmlHttp=new ActiveXObject("Microsoft.XMLhttp");
XmlHttp.Open("get","url",true);
XmlHttp.send(null);
XmlHttp.onreadystatechange=function ServerProcess(){
if (XmlHttp.readystate==4 || XmlHttp.readystate=='complete')
{
alert(XmlHttp.responseText);
}
}
XSLT(eXtensibleStylesheet LanguageTransformation)最初旨在帮助将 XML 文档(文档)转换为其他文档。但随着发展,XSLT 不仅用于将 XML 转换为 HTML 或其他文本格式,更全面的定义应该是:XSLT 是一种用于转换 XML 文档结构的语言。
XSL-FO:XSL 在转换 XML 文档时分为两个明显的过程。首先是转换文档的结构;二是格式化输出文件。这两个步骤可以分开单独处理,所以XSL在开发过程中逐渐分裂成两个分支语言,XSLT(结构转换)和XSL-FO(格式化对象)(格式化输出),其中XSL-FO有类似的功能。 CSS 在 HTML 中的作用。
AJAX:异步 JavaScript 和 XML(AsynchronousJavaScript and XML)。
最后一点,可以算是web2.0思想的核心。AJAX=CSS+HTML+JS+XML+DOM+XSLT+XMLHTTP。指一种用于创建交互式 Web 应用程序的 Web 开发技术。AJAX 不是单一的新技术,而是一系列相关技术的有机运用。
2005 年,Google 凭借其 Google Suggest 使 AJAX 流行起来。
Google Suggest 使用 AJAX 创建高度动态的 Web 界面:当您在 Google 搜索框中输入关键字时,Javascript 会将这些字符发送到服务器,服务器将返回搜索建议列表。 查看全部
网页css js 抓取助手(你会不停的问,HTML是什么?CSS是XML)
如果你是web开发的初学者,难免会在网上搜索HTML、CSS、XML、JS(Javascript)、DOM、XSL等这些词的含义。然而,随着你了解的越来越多。当你把它们混在一起的时候,你又糊涂了,你会一直问,什么是HTML?什么是 CSS?什么是 XML?什么是JS?它们是为了什么?无论是网络百科全书还是一些IT专题网站,或者一些伟大的博主,他们都会告诉你一个东西是什么。这样的文章有很多,但很少涉及。它们的组合是什么,有什么用?. 我想我写这个 文章 是为了说明这个他们很少涉及的问题。
在这里,我尽量用最基础的语言给大家讲解一下HTML、CSS、XML、JS是什么,有什么用。那我们就来看看把它们组合起来到底是什么,又有什么用呢。当然,如果你对HTML、CSS、XML、JS有足够的了解,可以直接跳过,看文章的后半部分,这是本文的核心。
第一部分
1. HTML 超文本标记语言(Hyper Text Markup Language)是一种用于描述网页的标记语言。
HTML
Hello World! I'm HTML
网页文件本身是一个文本文件。通过在文本文件中添加标签,可以告诉浏览器如何显示内容(如:如何处理文本、如何排列屏幕、如何显示图片等)。
HTML 被称为超文本标记语言,因为文本收录所谓的“超链接”点。超文本(Hypertext)是一种类似网络的文本,它使用超链接来组织各种不同空间中的文本信息。
综上所述,HTML 是一种集网页结构和内容展示于一体的语言。
Hello World! I'm HTML
浏览器依次读取网页文件,然后根据标签对标记的内容进行解释和显示。
这个内容在浏览器上显示的结果是:Hello World!我是 HTML
我们看
标签上有一个id,就是
该标签的唯一标识使其他人很容易找到并对其进行操作。
2. CSS 级联样式表。它是一种将样式信息与 Web 内容分开的标记语言。作为 网站 开发人员,您可以为每个 HTML 元素定义样式并将其应用于任意数量的页面。如果需要全局更新,只需更改样式,网站中的所有元素都会自动更新。这样,设计师可以将更多的时间花在设计上,而不是费力地克服 HTML 的局限性。说白了,CSS就是在网页上设置HTML元素属性的语言。
CSS代码:
#hello{
color:blue;
}
当这个CSS代码应用于HTML时,它会找到id为“hello”的HTML标签,并将内容显示为蓝色;插入HTML的具体方法这里不再赘述。什么,有什么用的问题,不注意技术细节,技术细节网上很容易找到)。
3. Javascript,首先说明一下JavaScript与Java无关,JavaScript是属于网络的脚本语言!那么为什么名字如此相似呢?这是典型的营销成功,它的成功推广也是借鉴了Java。当微软开始意识到 Javascript 在 Web 开发者中很流行时,微软仍然建立了自己的脚本语言 JScript。
Javascript 是一种基于对象和事件驱动的脚本语言,具有安全功能。使用它的目的是通过HTML超文本标记语言和Java脚本语言(Java小程序)将网页中的多个对象链接在一起,与Web客户端进行交互。例如,您可以设置鼠标悬停效果、在客户端验证表单、创建自定义 HTML 页面、显示警报框、设置 cookie 等。
网页的所有本地代码实现部分,判断、操作和反馈信息给浏览者都是Javascript(当然还有其他的),可以让网页更具交互性,为用户提供更精彩的体验,同时减轻浏览者的负担服务器。
JS代码如下:
function jsHello(){
alert('Hello World!');
}
当上面的代码应用于HTML代码时,会弹出一个对话框,内容为“Hello World!” 当您的 HTML 加载时。类似地,它是通过嵌入或加载在标准 HTML 语言中实现的。至于如何嵌入或转移,由于上述原因,我不再赘述。
4. Xml 可扩展标记语言(Extensible MarkupLanguage)是一组定义语义标记的规则。这些标记将文档分成许多部分并标识这些部分。它也是一种元标记语言,即定义与特定领域相关的其他语义和结构化标记语言的语法语言。您可以将 XML 理解为数据库,例如 rss 是 xml 的变体。
XML代码如下:
China
USA
UK
XML 的原因是用户对 SGML 的复杂性(稍后会详细介绍)和 HTML 的不足感到沮丧。与 HTML 相比,XML 更为严谨。如果你说HTML代码中的标签乱七八糟,比如未关闭,也许浏览器会忽略这些错误;但是同样的事情发生在 XML 中会给你带来很大的麻烦。
伏笔终于结束了。在进入正题之前,建议大家对比一下图表,了解背后的内容。废话不多说,开始进入正题。
第二部分
这里的 DOM 是指 HTML DOM。HTML DOM 是 W3C 标准,也是 HTML 文档对象模型(Document Object Model for HTML)的缩写。HTML DOM 为 HTML 定义了一系列标准对象,以及访问和处理 HTML 文档的标准方法。通过 DOM,您可以访问所有 HTML 元素,以及它们收录的文本和属性。可以修改和删除内容,也可以创建新元素。HTML DOM 独立于平台和编程语言。它可以被任何编程语言使用,例如 Java、Javascript 和 VBScript。HTML DOM 是 HTML 语言向外界开放的接口,以便其他语言可以访问或修改 HTML 内部的元素。
当js需要操作html元素时,DOM是必不可少的对象。
您可以使用 DOM 对象构造以下代码并将其插入 HTML 代码中的任何位置。
window.onload=function hello(){
document.getElementById("hello").innerHTML="Hello China!";
}
在使用 CSS 装饰 HTML 元素时,这个过程可以称为声明 HTML 元素样式的过程。
SGML 标准广义标记语言(standardgeneralized markup language)。由于SGML的复杂性,难以普及。SGML具有很强的适应性,同样的原因,在小型应用中也难以普及。HTML 和 XML 也是从 SGML 派生而来的:XML 可以被认为是 SGML 的一个子集,而 HTML 是 SGML 的一个应用。创建 XML 是为了简化 SGML,以便它可以用于更通用的目的。例如,语义网已经在大量场合使用,如XHTML、RSS、XML-RPC 和SOAP。
XHTML 是可扩展超文本标记语言(TheExtensible HyperText Markup Language)。HTML 是一种基本的网页设计语言。XHTML 是一种基于 XML 的标记语言。它看起来与 HTML 相似,只有一些很小但很重要的区别。XHTML 是一种 XML,其作用类似于 HTML。所以,本质上,XHTML 是一种过渡技术,它结合了 XML 的一些强大功能和 HTML 的大部分简单特性。
简单的说,XHTML 比 HTML 更严谨,但没有 XML 严重——比如所有的 XHTML 标签和属性必须是小写的,属性必须是双引号(当然,现在的浏览器,不管是 IE 还是 FF ,对HTML和XHTML采取兼容措施也是XSS的根本原因),而且有些标签可以像XML一样自定义,因此具有很大的灵活性。
看到这里,突然发现web开发中一个很重要的问题。Xss 漏洞。这里我就不分析这个问题了。我将在接下来的笔记中重点研究 xss 漏洞。
而在XHTML时代,大家提倡的是CSS+DIV,这也是web2.0的基础。
DHTML 只是制作网页的一个概念。事实上,没有任何组织或机构引入所谓的 DHTML 标准或技术规范。DHTML 不是技术、标准或规范。DHTML 只是一种设计理念,它集成并利用现有的网络技术和语言标准,创建了一个下载后可以实时改变页面元素效果的网页。DHTML 是动态 HTML,Dynamic HTML。传统的 html 页面是静态的。dhtml在html页面中加入javascript脚本,使其可以根据用户的动作做出一定的响应,比如鼠标移到图片上、改变图片颜色、移到导航栏、弹出动态菜单等。
一般喜欢:
Expression 是微软在 Internet Explorer 中添加的一项功能,可以让样式表在执行 javascript 脚本的同时修改 HTML 样式,以便您可以执行诸如:自适应图片宽度、表格交错颜色变化等。
如:img{max-width:500px;width:expression(document.body.clientWidth> 200? "200px": "auto");}
XMLHTTP最笼统的定义是:XmlHttp是一组可以在Javascript、VbScript、Jscript等脚本语言中通过http协议传输或接收XML等数据的API。XmlHttp最大的用处就是可以在不刷新整个页面的情况下更新部分网页。
来自MSDN的说明:XmlHttp为客户端与http服务器通信提供了一个协议。客户端可以通过 XmlHttp 对象向 http 服务器发送请求,并使用 Microsoft® XML 文档对象模型 (DOM) 来处理响应。
绝对大多数浏览器现在都添加了对 XmlHttp 的支持。IE 使用 ActiveXObject 来创建 XmlHttp 对象。其他浏览器如 Firefox 和 Opera 使用 window.XMLHttpRequest 来创建 XmlHttp 对象。
定义 IE 的 XmlHttp 对象和应用程序的简单示例如下:
var XmlHttp=new ActiveXObject("Microsoft.XMLhttp");
XmlHttp.Open("get","url",true);
XmlHttp.send(null);
XmlHttp.onreadystatechange=function ServerProcess(){
if (XmlHttp.readystate==4 || XmlHttp.readystate=='complete')
{
alert(XmlHttp.responseText);
}
}
XSLT(eXtensibleStylesheet LanguageTransformation)最初旨在帮助将 XML 文档(文档)转换为其他文档。但随着发展,XSLT 不仅用于将 XML 转换为 HTML 或其他文本格式,更全面的定义应该是:XSLT 是一种用于转换 XML 文档结构的语言。
XSL-FO:XSL 在转换 XML 文档时分为两个明显的过程。首先是转换文档的结构;二是格式化输出文件。这两个步骤可以分开单独处理,所以XSL在开发过程中逐渐分裂成两个分支语言,XSLT(结构转换)和XSL-FO(格式化对象)(格式化输出),其中XSL-FO有类似的功能。 CSS 在 HTML 中的作用。
AJAX:异步 JavaScript 和 XML(AsynchronousJavaScript and XML)。
最后一点,可以算是web2.0思想的核心。AJAX=CSS+HTML+JS+XML+DOM+XSLT+XMLHTTP。指一种用于创建交互式 Web 应用程序的 Web 开发技术。AJAX 不是单一的新技术,而是一系列相关技术的有机运用。
2005 年,Google 凭借其 Google Suggest 使 AJAX 流行起来。
Google Suggest 使用 AJAX 创建高度动态的 Web 界面:当您在 Google 搜索框中输入关键字时,Javascript 会将这些字符发送到服务器,服务器将返回搜索建议列表。
网页css js 抓取助手(学习Web前端开发基础技术需要掌握:HTML、CSS、JavaScript)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-05 01:17
学习Web前端开发的基本技术,需要掌握:HTML、CSS、JavaScript,那么这三者分别实现了哪些功能呢?下面就和小编一起来看看吧!
一、HTML 是网页内容的载体
内容是网页制作者放在页面上供用户浏览的信息,可以包括文字、图片、视频等。
二、CSS 风格就是性能
就像一个网页的外衣,比如:标题字体、颜色变化、给标题添加背景图片、边框等。
所有这些用来改变内容外观的东西都被称为性能。
三、JavaScript 用于在网页上实现特殊效果
例如:鼠标滑过弹出的下拉菜单,鼠标滑过表格的背景颜色改变,焦点新闻的旋转。
可以理解为:动画和交互一般都是用JavaScript来实现的。
HTML代码注释:
代码注释是为了帮助程序员标记代码的作用。过一段时间再看自己写的代码,很快就能记住这段代码的作用。
代码注释不仅可以帮助程序员回忆之前代码的用途,还可以帮助其他程序员快速了解你的程序的功能,方便多人协作开发web代码。
HTML 的语义化:
语义其实就是了解每个标签的用途,它可以让你的网页更好地被搜索引擎理解。
它的好处可以概括为两点:
(1)更容易被搜索引擎搜索到收录;
(2) 屏幕阅读器更容易读出网页内容;
HTML 的 em、strong 和 span 的区别:
(1) 和标签用于强调段落中的关键字,它们的语义是强调;
(2) 标签没有语义,其作用是设置单独的样式;
HTML 摘要、标题:
作用是给表格添加标题和摘要
摘要的内容不会显示在浏览器中。它的作用是增加表格的可读性(语义),让搜索引擎更好的理解表格的内容,也可以让屏幕阅读器更好的帮助特殊用户阅读表格的内容。
代码注释:
CSS 中的注释语句:使用 /comment sentence/ 表示
在 Html 中用于表示
HTML 选择器的问题:
后代选择器和子选择器的区别
子选择器(child selector)只指其直接后代,也可以理解为作用于子元素的第一代后代。后代选择器应用于所有子后代元素。后代选择器使用空格进行选择,子选择器使用“>”进行选择。
特设学习⑦③①-⑦⑦①-②①① 分享学习方法和需要注意的小细节,不断更新最新教程和学习技巧(从零到前端项目实战教程、学习工具、全栈开发学习路线和规划) )
点击:我们的前端学习圈
总结:
作用于该元素的第一代后代,空格作用于该元素的所有后代。 查看全部
网页css js 抓取助手(学习Web前端开发基础技术需要掌握:HTML、CSS、JavaScript)
学习Web前端开发的基本技术,需要掌握:HTML、CSS、JavaScript,那么这三者分别实现了哪些功能呢?下面就和小编一起来看看吧!
一、HTML 是网页内容的载体
内容是网页制作者放在页面上供用户浏览的信息,可以包括文字、图片、视频等。
二、CSS 风格就是性能
就像一个网页的外衣,比如:标题字体、颜色变化、给标题添加背景图片、边框等。
所有这些用来改变内容外观的东西都被称为性能。
三、JavaScript 用于在网页上实现特殊效果
例如:鼠标滑过弹出的下拉菜单,鼠标滑过表格的背景颜色改变,焦点新闻的旋转。
可以理解为:动画和交互一般都是用JavaScript来实现的。
HTML代码注释:
代码注释是为了帮助程序员标记代码的作用。过一段时间再看自己写的代码,很快就能记住这段代码的作用。
代码注释不仅可以帮助程序员回忆之前代码的用途,还可以帮助其他程序员快速了解你的程序的功能,方便多人协作开发web代码。
HTML 的语义化:
语义其实就是了解每个标签的用途,它可以让你的网页更好地被搜索引擎理解。
它的好处可以概括为两点:
(1)更容易被搜索引擎搜索到收录;
(2) 屏幕阅读器更容易读出网页内容;
HTML 的 em、strong 和 span 的区别:
(1) 和标签用于强调段落中的关键字,它们的语义是强调;
(2) 标签没有语义,其作用是设置单独的样式;
HTML 摘要、标题:
作用是给表格添加标题和摘要
摘要的内容不会显示在浏览器中。它的作用是增加表格的可读性(语义),让搜索引擎更好的理解表格的内容,也可以让屏幕阅读器更好的帮助特殊用户阅读表格的内容。
代码注释:
CSS 中的注释语句:使用 /comment sentence/ 表示
在 Html 中用于表示
HTML 选择器的问题:
后代选择器和子选择器的区别
子选择器(child selector)只指其直接后代,也可以理解为作用于子元素的第一代后代。后代选择器应用于所有子后代元素。后代选择器使用空格进行选择,子选择器使用“>”进行选择。
特设学习⑦③①-⑦⑦①-②①① 分享学习方法和需要注意的小细节,不断更新最新教程和学习技巧(从零到前端项目实战教程、学习工具、全栈开发学习路线和规划) )
点击:我们的前端学习圈
总结:
作用于该元素的第一代后代,空格作用于该元素的所有后代。
网页css js 抓取助手(百忙之中抽时间编写了这个小程序,功能是:完美保存整个网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-04 19:15
我从繁忙的日程中抽出时间来编写这个小程序。功能是完美保存整个网页,包括:图片、JS脚本、CSS样式,修改网页源代码进行“本地化”。因为火了,连浏览器自带这个功能都不知道,就自己做了一个。这个程序虽然不大,但是涉及到三大问题(后面会详细说明)。
本来不打算放源码的,既然浏览器有这个功能,那我就放出源码供大家学习!这个程序的效果和浏览器的效果完全一样!而且我对比了一下,得到的js、css、图片都不亚于浏览器得到的。可以参考这个玩:做一个网站全站下载器。当然你永远不能下载数据库.....
使用说明:
1.填写网页地址,点击前往,即可激活一键下载。加载网页需要时间。如果加载前点击一键下载,会有提示。尝试在网速更好的时候使用它!
2.下载完成后,会在软件目录下生成一个以网页标题命名的文件夹。所有必要的文件都存储在这里。以网页标题命名的 HTM 文件即为保存的页面。在这种情况下,双击查看的效果和在网上查看是一样的!.
程序截图:
解决的问题:
1. 判断网页已经加载完毕。以前,已知目的地的网页可以通过“标记方法”来判断,但在这个程序中一切都是未知的。因此,必须使用新的方法。这里使用了HTML对象的Onload事件,结合webbrowser控件完美实现了判断网页加载完成的完成。这是目前最安全、最准确、最可靠的方法!适用于所有环境。
确定网页已经加载一直很头疼,至少在VB中是这样。网上提到的方法基本都行不通。更好的是有时它有效,有时它不起作用。现在我将发布一个代码来结束这个问题
'引用“Microsoft HTML Object Library”
Dim WithEvents page As HTMLWindow2 '注意要定义成全局的
Private Sub WebBrowser1_NavigateComplete2(ByVal pDisp As Object, URL As Variant)
Set page = Me.WebBrowser1.document.parentWindow
End Sub
Private Sub page_onload()
Debug.Print "加载完毕"
End Sub
2.获取网页js和css。我看到很多人在猪八戒上发帖求一个程序,请求网页中的所有js和css。其实这个不难,百度一下,可以发现javascript语言提供了这个接口。下面我将演示如何使用这个接口来获取。
首先使用 webbrowser 控件加载要提取的网页。
获取js:
<p>strBasicHTM = WebBrowser1.Document.documentElement.outerHTML
WebBrowser1.Navigate "javascript:str='
\n';c=document.scripts;for(i=0;i 查看全部
网页css js 抓取助手(百忙之中抽时间编写了这个小程序,功能是:完美保存整个网页)
我从繁忙的日程中抽出时间来编写这个小程序。功能是完美保存整个网页,包括:图片、JS脚本、CSS样式,修改网页源代码进行“本地化”。因为火了,连浏览器自带这个功能都不知道,就自己做了一个。这个程序虽然不大,但是涉及到三大问题(后面会详细说明)。
本来不打算放源码的,既然浏览器有这个功能,那我就放出源码供大家学习!这个程序的效果和浏览器的效果完全一样!而且我对比了一下,得到的js、css、图片都不亚于浏览器得到的。可以参考这个玩:做一个网站全站下载器。当然你永远不能下载数据库.....
使用说明:
1.填写网页地址,点击前往,即可激活一键下载。加载网页需要时间。如果加载前点击一键下载,会有提示。尝试在网速更好的时候使用它!
2.下载完成后,会在软件目录下生成一个以网页标题命名的文件夹。所有必要的文件都存储在这里。以网页标题命名的 HTM 文件即为保存的页面。在这种情况下,双击查看的效果和在网上查看是一样的!.
程序截图:
解决的问题:
1. 判断网页已经加载完毕。以前,已知目的地的网页可以通过“标记方法”来判断,但在这个程序中一切都是未知的。因此,必须使用新的方法。这里使用了HTML对象的Onload事件,结合webbrowser控件完美实现了判断网页加载完成的完成。这是目前最安全、最准确、最可靠的方法!适用于所有环境。
确定网页已经加载一直很头疼,至少在VB中是这样。网上提到的方法基本都行不通。更好的是有时它有效,有时它不起作用。现在我将发布一个代码来结束这个问题
'引用“Microsoft HTML Object Library”
Dim WithEvents page As HTMLWindow2 '注意要定义成全局的
Private Sub WebBrowser1_NavigateComplete2(ByVal pDisp As Object, URL As Variant)
Set page = Me.WebBrowser1.document.parentWindow
End Sub
Private Sub page_onload()
Debug.Print "加载完毕"
End Sub
2.获取网页js和css。我看到很多人在猪八戒上发帖求一个程序,请求网页中的所有js和css。其实这个不难,百度一下,可以发现javascript语言提供了这个接口。下面我将演示如何使用这个接口来获取。
首先使用 webbrowser 控件加载要提取的网页。
获取js:
<p>strBasicHTM = WebBrowser1.Document.documentElement.outerHTML
WebBrowser1.Navigate "javascript:str='
\n';c=document.scripts;for(i=0;i
网页css js 抓取助手(HTML文本中包含了所谓的“链接点”HTML利用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-04 14:07
HTML 文本收录所谓的“链接点”。使用前端学习HTML需要不断的学习。停顿一天,等于什么都没学到。学习效果很差。如果你想有人一起学习,你可以来这条裙子。第一个是132,中间是667,最后一个是127。都是零基础的同学,大家互相鼓励,一起努力,学着玩,不推荐!!!超链接方式,将各个不同空间中的文本信息组织在一起 Mesh 文本。总的来说,HTML是一种集网页结构和内容展示为一体的语言。
2、CSS——层叠样式表
级联样式表。它是一种将样式信息与 Web 内容分开的标记语言。在我们的牛腩新闻发布系统中,我们使用了 CSS 文件来修改一些标签的样式。
我们使用 CSS 为每个 HTML 元素定义样式,也可以用于多个界面。进行全局更新时,只需要修改样式即可。
body {border :1px solid #000;/*整体边框*/ font-size :14px;}
说白了,CSS就是在网页上设置HTML元素属性的语言。
3、Javascript
一开始我非常沮丧。为什么它的名字与 Java 如此相似?
这是典型的营销成功,它在推广上的成功也是借鉴了Java。当微软开始意识到 Java 在 Web 开发者中变得流行时,微软仍然建立了自己的脚本语言 Javascript。
Java 是一种基于对象和事件驱动的脚本语言,具有安全功能。使用它的目的是通过HTML超文本标记语言和Java脚本语言(Java小程序)将网页中的多个对象链接在一起,与Web客户端进行交互。例如,您可以设置鼠标悬停效果、在客户端验证表单、创建自定义 HTML 页面、显示警报框、设置 cookie 等。
function jsHello{ alert('Hello World!');}
将代码嵌入 HTML 语言,加载时会弹出“Hello World”对话框。至于怎么嵌入,我们在开始学习JS视频的时候就已经知道了。
4、总结
我将向您介绍 HTML、CSS 和 JS 之间的区别。
码字不易,请给我点个赞,点赞和关注是我写作的动力,谢谢! 查看全部
网页css js 抓取助手(HTML文本中包含了所谓的“链接点”HTML利用)
HTML 文本收录所谓的“链接点”。使用前端学习HTML需要不断的学习。停顿一天,等于什么都没学到。学习效果很差。如果你想有人一起学习,你可以来这条裙子。第一个是132,中间是667,最后一个是127。都是零基础的同学,大家互相鼓励,一起努力,学着玩,不推荐!!!超链接方式,将各个不同空间中的文本信息组织在一起 Mesh 文本。总的来说,HTML是一种集网页结构和内容展示为一体的语言。
2、CSS——层叠样式表
级联样式表。它是一种将样式信息与 Web 内容分开的标记语言。在我们的牛腩新闻发布系统中,我们使用了 CSS 文件来修改一些标签的样式。
我们使用 CSS 为每个 HTML 元素定义样式,也可以用于多个界面。进行全局更新时,只需要修改样式即可。
body {border :1px solid #000;/*整体边框*/ font-size :14px;}
说白了,CSS就是在网页上设置HTML元素属性的语言。
3、Javascript
一开始我非常沮丧。为什么它的名字与 Java 如此相似?
这是典型的营销成功,它在推广上的成功也是借鉴了Java。当微软开始意识到 Java 在 Web 开发者中变得流行时,微软仍然建立了自己的脚本语言 Javascript。
Java 是一种基于对象和事件驱动的脚本语言,具有安全功能。使用它的目的是通过HTML超文本标记语言和Java脚本语言(Java小程序)将网页中的多个对象链接在一起,与Web客户端进行交互。例如,您可以设置鼠标悬停效果、在客户端验证表单、创建自定义 HTML 页面、显示警报框、设置 cookie 等。
function jsHello{ alert('Hello World!');}
将代码嵌入 HTML 语言,加载时会弹出“Hello World”对话框。至于怎么嵌入,我们在开始学习JS视频的时候就已经知道了。
4、总结
我将向您介绍 HTML、CSS 和 JS 之间的区别。
码字不易,请给我点个赞,点赞和关注是我写作的动力,谢谢!
网页css js 抓取助手(Screaming优化蜘蛛最常见的用途和使用方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-04 00:07
Screaming Frog SEO Spider 是一款专业的网站 资源检测和搜索工具。该软件支持爬取网站并查找损坏的链接(404)和服务器错误,审计)是一个非常有用的网站优化和SEO工具,用于定位、发现重复内容、分析页面标题和元数据。Screaming Frog SEO Spider可以查找断链、查看重定向、分析页面标题和元数据、查找重复内容、使用XPath提取数据、查看机器人和指令、生成XML站点地图等功能,软件界面非常简单明了,软件使用方便快捷。
如何使用
一、爬行爬行
1、定期爬取
在正常爬取模式下,Screaming Frog SEO Spider 13 破解版会爬取您输入的子域,并将遇到的所有其他子域默认视为外部链接(显示在“外部”选项卡下方)。在正版软件中,可以调整配置选择抓取网站的所有子域。搜索引擎优化蜘蛛最常见的用途之一是在 网站 上查找错误,例如断开的链接、重定向和服务器错误。为了更好的控制爬取,请使用您的网站 URI结构,SEO蜘蛛配置选项,比如只爬取HTML(图片、CSS、JS等)、排除函数、自定义robots.txt、收录函数或者更改搜索引擎优化蜘蛛模式,上传一个URI列表爬取
2、抓取一个子文件夹
SEO Spider 工具默认从子文件夹路径向前爬取,所以如果要爬取站点上的特定子文件夹,只需输入带有文件路径的 URI。直接进入SEO Spider,会抓取/blog/sub目录下的所有URI
3、获取网址列表
通过输入网址点击“开始”抓取网站,您可以切换到列表模式,粘贴或上传要抓取的特定网址列表。例如,在审核重定向时,这对网站迁移特别有用
二、配置
在该工具的行货版本中,可以保存默认的爬取配置,并保存需要时可以加载的配置配置文件
1、要将当前配置保存为默认值,请选择“文件>配置>将当前配置保存为默认值”
2、要保存配置文件以便以后加载,点击“文件>另存为”并调整文件名(描述性最好)
3、要加载配置文件,请点击“文件>加载”,然后选择您的配置文件或“文件>加载最近”从最近列表中选择
4、要重置为原版Screaming Frog SEO Spider 13破解版的默认配置,请选择“文件>配置>清除默认配置”
三、导出
顶部窗口部分的导出功能适用于您在顶部窗口中的当前视野。因此,如果您使用过滤器并单击“导出”,则只会导出过滤器选项中收录的数据
主要有三种数据导出方式:
1、导出顶层窗口数据:只需点击左上角的“导出”按钮,即可从顶层窗口选项卡导出数据
2、导出下层窗口数据(URL信息、链接、输出链接、图片信息):导出这些数据只需在上层窗口中要导出的数据的URL上右击,然后点击“导出”下的“URL信息”、“链接”、“外链”或“图片信息”
3、 批量导出:位于顶部菜单下,允许批量导出数据。您可以通过“all in links”选项导出在抓取中找到的所有链接实例,或导出所有链接到具有特定状态代码(例如 2XX、3XX、4XX 或 5XX 响应)的 URL。例如,选择“链接中的客户端错误 4XX”选项将导出所有链接到所有错误页面(例如 404 错误页面)。您还可以导出所有图片替代文本,所有图片缺少替代文本和所有锚文本
下载链接: 查看全部
网页css js 抓取助手(Screaming优化蜘蛛最常见的用途和使用方法有哪些?)
Screaming Frog SEO Spider 是一款专业的网站 资源检测和搜索工具。该软件支持爬取网站并查找损坏的链接(404)和服务器错误,审计)是一个非常有用的网站优化和SEO工具,用于定位、发现重复内容、分析页面标题和元数据。Screaming Frog SEO Spider可以查找断链、查看重定向、分析页面标题和元数据、查找重复内容、使用XPath提取数据、查看机器人和指令、生成XML站点地图等功能,软件界面非常简单明了,软件使用方便快捷。
如何使用
一、爬行爬行
1、定期爬取
在正常爬取模式下,Screaming Frog SEO Spider 13 破解版会爬取您输入的子域,并将遇到的所有其他子域默认视为外部链接(显示在“外部”选项卡下方)。在正版软件中,可以调整配置选择抓取网站的所有子域。搜索引擎优化蜘蛛最常见的用途之一是在 网站 上查找错误,例如断开的链接、重定向和服务器错误。为了更好的控制爬取,请使用您的网站 URI结构,SEO蜘蛛配置选项,比如只爬取HTML(图片、CSS、JS等)、排除函数、自定义robots.txt、收录函数或者更改搜索引擎优化蜘蛛模式,上传一个URI列表爬取
2、抓取一个子文件夹
SEO Spider 工具默认从子文件夹路径向前爬取,所以如果要爬取站点上的特定子文件夹,只需输入带有文件路径的 URI。直接进入SEO Spider,会抓取/blog/sub目录下的所有URI
3、获取网址列表
通过输入网址点击“开始”抓取网站,您可以切换到列表模式,粘贴或上传要抓取的特定网址列表。例如,在审核重定向时,这对网站迁移特别有用
二、配置
在该工具的行货版本中,可以保存默认的爬取配置,并保存需要时可以加载的配置配置文件
1、要将当前配置保存为默认值,请选择“文件>配置>将当前配置保存为默认值”
2、要保存配置文件以便以后加载,点击“文件>另存为”并调整文件名(描述性最好)
3、要加载配置文件,请点击“文件>加载”,然后选择您的配置文件或“文件>加载最近”从最近列表中选择
4、要重置为原版Screaming Frog SEO Spider 13破解版的默认配置,请选择“文件>配置>清除默认配置”
三、导出
顶部窗口部分的导出功能适用于您在顶部窗口中的当前视野。因此,如果您使用过滤器并单击“导出”,则只会导出过滤器选项中收录的数据
主要有三种数据导出方式:
1、导出顶层窗口数据:只需点击左上角的“导出”按钮,即可从顶层窗口选项卡导出数据
2、导出下层窗口数据(URL信息、链接、输出链接、图片信息):导出这些数据只需在上层窗口中要导出的数据的URL上右击,然后点击“导出”下的“URL信息”、“链接”、“外链”或“图片信息”
3、 批量导出:位于顶部菜单下,允许批量导出数据。您可以通过“all in links”选项导出在抓取中找到的所有链接实例,或导出所有链接到具有特定状态代码(例如 2XX、3XX、4XX 或 5XX 响应)的 URL。例如,选择“链接中的客户端错误 4XX”选项将导出所有链接到所有错误页面(例如 404 错误页面)。您还可以导出所有图片替代文本,所有图片缺少替代文本和所有锚文本
下载链接:
网页css js 抓取助手(旅行网站飞行时间或Airbnb列表,可让您使用高级API控制Chrome/Chromium浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-03 09:23
简介:目前,由于其用例数量众多,企业对网页抓取的使用量大大增加。您可能需要抓取旅行 网站 航班时间或 Airbnb 列表,或者您可能想要采集数据(例如来自不同电子商务 网站 的价目表)进行价格比较。或许你需要一台采集机……转发+关注,私信编辑“数据”免费分享给你!
目前,由于其用例数量众多,企业对网页抓取的使用已大大增加。您可能需要抓取旅行 网站 航班时间或 Airbnb 列表,或者您可能想要采集数据(例如来自不同电子商务 网站 的价目表)进行价格比较。也许您需要为机器学习采集训练和测试数据集。这就是网络抓取发挥作用的地方。
在这里,我们将探索最好的网络抓取工具。
傀儡师
Puppeteer 不仅仅是一个网络爬虫。它是一个 Node.js 库,允许您使用高级 API 控制 Chrome/Chromium 浏览器。 Puppeteer 默认无法运行,但可以配置为运行完整的无头 Chrome 或 Chromium。
使用 Puppeteer,您可以执行以下操作:
带有文本标签的箭头
干杯
Cheerio 是一个用于解析标签的库。它提供了用于处理结果数据结构的 API。 Cheerio 的最大优点是它不会像 Web 浏览器那样解释结果。但是,它不产生视觉效果,也不加载外部资源或应用 CSS。因此,如果您的用例需要它们,则需要考虑 PhantomJS 之类的项目。
值得一提的是,在 Cheerio 中,使用 Node.js 来抓取 网站 要容易得多。沃尔玛等公司使用 Cheerio 来托管他们的移动 网站 服务器渲染。
请求-承诺
Request-Promise 是 npm 实际库的变体。它通过自动浏览器提供更快的解决方案。当内容不是动态呈现的时候,可以使用这个网络爬虫。如果您使用身份验证系统处理 网站,它可能是一个更高级的解决方案。如果我们将其与 Puppeteer 进行比较,则在用法上正好相反。
噩梦
Nightmare 是一个高级浏览器自动化库,可以将电子作为浏览器运行。是精简版,也可以说是Puppeteer的简化版。它具有提供更大灵活性的插件,包括对文件下载的支持。
渗透
Osmosis 是一个 HTML/XML 解析器和网页抓取工具。它是用 Node.js 编写的,带有一个 CSS3/xpath 选择器和一个轻量级的 HTTP 包装器。如果与 Cheerio、jQuery 和 jsdom 相比,它没有明显的依赖关系。
总结
除了这些网页抓取工具之外,您还可以使用许多其他工具和资源。这一切都取决于您的项目要求。但是,有些网站不允许抓取,因此在尝试抓取任何网站之前,请确保您做得很好。
需要看java吗?网络、大数据、信息:
老规矩:转发+关注,私信编辑“数据”免费分享给你! 查看全部
网页css js 抓取助手(旅行网站飞行时间或Airbnb列表,可让您使用高级API控制Chrome/Chromium浏览器)
简介:目前,由于其用例数量众多,企业对网页抓取的使用量大大增加。您可能需要抓取旅行 网站 航班时间或 Airbnb 列表,或者您可能想要采集数据(例如来自不同电子商务 网站 的价目表)进行价格比较。或许你需要一台采集机……转发+关注,私信编辑“数据”免费分享给你!
目前,由于其用例数量众多,企业对网页抓取的使用已大大增加。您可能需要抓取旅行 网站 航班时间或 Airbnb 列表,或者您可能想要采集数据(例如来自不同电子商务 网站 的价目表)进行价格比较。也许您需要为机器学习采集训练和测试数据集。这就是网络抓取发挥作用的地方。
在这里,我们将探索最好的网络抓取工具。
傀儡师
Puppeteer 不仅仅是一个网络爬虫。它是一个 Node.js 库,允许您使用高级 API 控制 Chrome/Chromium 浏览器。 Puppeteer 默认无法运行,但可以配置为运行完整的无头 Chrome 或 Chromium。
使用 Puppeteer,您可以执行以下操作:
带有文本标签的箭头
干杯
Cheerio 是一个用于解析标签的库。它提供了用于处理结果数据结构的 API。 Cheerio 的最大优点是它不会像 Web 浏览器那样解释结果。但是,它不产生视觉效果,也不加载外部资源或应用 CSS。因此,如果您的用例需要它们,则需要考虑 PhantomJS 之类的项目。
值得一提的是,在 Cheerio 中,使用 Node.js 来抓取 网站 要容易得多。沃尔玛等公司使用 Cheerio 来托管他们的移动 网站 服务器渲染。
请求-承诺
Request-Promise 是 npm 实际库的变体。它通过自动浏览器提供更快的解决方案。当内容不是动态呈现的时候,可以使用这个网络爬虫。如果您使用身份验证系统处理 网站,它可能是一个更高级的解决方案。如果我们将其与 Puppeteer 进行比较,则在用法上正好相反。
噩梦
Nightmare 是一个高级浏览器自动化库,可以将电子作为浏览器运行。是精简版,也可以说是Puppeteer的简化版。它具有提供更大灵活性的插件,包括对文件下载的支持。
渗透
Osmosis 是一个 HTML/XML 解析器和网页抓取工具。它是用 Node.js 编写的,带有一个 CSS3/xpath 选择器和一个轻量级的 HTTP 包装器。如果与 Cheerio、jQuery 和 jsdom 相比,它没有明显的依赖关系。
总结
除了这些网页抓取工具之外,您还可以使用许多其他工具和资源。这一切都取决于您的项目要求。但是,有些网站不允许抓取,因此在尝试抓取任何网站之前,请确保您做得很好。
需要看java吗?网络、大数据、信息:
老规矩:转发+关注,私信编辑“数据”免费分享给你!
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-12-29 19:19
)
我整理了25个前端相关的学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,以及一些资源网站。我希望我能帮到你!
▍CSS相关
●1
CSSBattle-在线竞争CSS
竞技CSS在线,一款非常有趣的竞技类游戏,共12个关卡。您需要使用 HTML 和 CSS 将其给出的页面 100% 还原,然后最小化代码。您还可以查看全球排名并查看解决方案。计划。
●2
学习 CSS 布局-学习 CSS 布局
在线CSS布局学习,将逐步引导初学者学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS编写习惯和正确方法。
●3
Flexbox Froggy-学习Flex布局的小游戏
一个学习 Flex 布局的引导游戏。使用flex layout让青蛙在荷叶上跳跃。就算完成了,游戏中也几乎收录
了所有常用的属性。学习起来很有趣,而且图像有利于记忆。谁不是Flex布局如果你熟悉,在这里多练习。
●4
EnjoyCSS-在线CSS代码可视化工具
在线版CSS3代码生成工具,基于可视化操作,无需编码即可快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件。
●5
CSS-Tricks-CSS 技巧
本站不断更新一些优秀的CSS技术教程和技巧,文章每天更新。
●6
Neumorphism - 实现新的拟态效果
它可以轻松实现新的模拟效果,不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果和形状等参数。同时,它提供了可以直接复制的CSS代码。
●7
uiGradients-共享渐变色
提供渐变色效果的网站。有接近数百种渐变配色方案。可以根据自己的风格进行选择搭配,直接获取渐变配色方案对应的CSS代码。
▍JS相关
●8
JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。主要写了如何避免一些常见的错误,发现难以发现的bug。它将更深入地了解 JavaScript 的语言特性。
●9
JSTips-JS技巧
每天一点Javascript知识。
●10
JSweekly-科技周刊
专注于 Javascript 的技术周刊。
●11
CDNJS-JavaScript 数据库
CDNJS为开发者提供最新的前端Web开发资源,免费,无限制。你可以在自己的网页上直接引用这些JS文件。进入CDNJS网站后,搜索你想要的资源库,点击项目后面的【复制脚本标签】,粘贴即可使用。目前,CDNJS在Web前端的CDN服务中排名第二(排名第一的是谷歌),性能优异。
●12
开源 JS 库的美丽开放集合
采集
各类设计优秀的开源项目,从CMS内容管理系统到常用的小型Javascript库,适合网站开发用户。
●13
JavaScript Fun- 代码库合集
汇集当下最流行的JavaScript代码库,展示流行度排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow-程序员问答
全球IT行业最受欢迎的技术问答网站之一,一个解决bug的社区,被称为“编程界的十万个为什么”。
●15
掘金-优质技术社区
掘金技术社区是一个优质的技术分享社区。技术专家和极客们共同编辑、甄选优质干货。这些技术文章包括Android、iOS、前端和后端资源。
●16
Codrops-网页设计开发博客
发布技术文章和网络教程,提供经验,陷阱少,资源丰富,很多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码的工具,上面有各种效果案例特效(炫技),你可以根据他们的demo开发自己的前端设计.
●18
代码沙盒
顾名思义,CodeSandBox 网站提供了一个在线开发环境的“沙箱”。React、Vue、Angular等主流框架都可以开箱即用,实时编译预览,非常方便。
●19
JSBin
另一个轻量级的在线编辑器网站,界面简洁干净,如果你想暂时调试简单的HTML或JS代码,可以考虑去这里试一试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
它是 SVG 图标素材的在线可定制设计。帮助前端设计师找到自己想要的图标素材。这些图标素材都是常用的图标。二次设计可以点官方资料,也可以自己设计好的。图标导出。
●21
OpenMoji-free 表情符号库
提供Emoji源代码库,可免费下载使用。
● 22
分享无图标矢量素材库
一个提供超过 120 个类别的超过 250,000 个 ICON 矢量图像材料的网站。所有材料均以 PNG 和 SVG 格式提供。材料有多种尺寸可供选择,包括512*512、256*256、 128*128、64*64、32*32、16* 16等,非常适合前端设计师采集
和储备。
● 23
tableconvert-在线表格编辑器
一个强大的在线表单编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式之间的转换。当您需要在不变形的情况下转换表格时,您不妨试试这个工具。
● 24
Feathericons-极简图标集
一个免费和开源的简单而漂亮的 ICON 图标集合。主要设计用途是应用系统、媒体控制、位置、天气、箭头、标志等,可以在开发移动应用时使用。图标格式为 SVG。
● 25
HTML5 + CSS 3 免费模板
提供了大量的HTML5模板,用户可以自行分享和修改模板。
本文推荐网站汇总:
CSS之战:
学习 CSS 布局:
Flexbox 青蛙:
享受CSS:
CSS 技巧:
新拟态:
uiGradients:
JavaScript:
JS小贴士:
JS周刊:
CDNJS:
美丽开放:
JavaScript 乐趣:
堆栈溢出:
掘金:
共滴:
代码笔:
代码沙盒:
JS斌:
图标SVG:
开模:
分享图标:
表转换:
羽毛图标:
HTML5UP:
如果你有写博客的好习惯
欢迎投稿
赞+在看,小生感恩❤️ 查看全部
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具
)
我整理了25个前端相关的学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,以及一些资源网站。我希望我能帮到你!
▍CSS相关
●1
CSSBattle-在线竞争CSS
竞技CSS在线,一款非常有趣的竞技类游戏,共12个关卡。您需要使用 HTML 和 CSS 将其给出的页面 100% 还原,然后最小化代码。您还可以查看全球排名并查看解决方案。计划。
●2
学习 CSS 布局-学习 CSS 布局
在线CSS布局学习,将逐步引导初学者学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS编写习惯和正确方法。
●3
Flexbox Froggy-学习Flex布局的小游戏
一个学习 Flex 布局的引导游戏。使用flex layout让青蛙在荷叶上跳跃。就算完成了,游戏中也几乎收录
了所有常用的属性。学习起来很有趣,而且图像有利于记忆。谁不是Flex布局如果你熟悉,在这里多练习。
●4
EnjoyCSS-在线CSS代码可视化工具
在线版CSS3代码生成工具,基于可视化操作,无需编码即可快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件。
●5
CSS-Tricks-CSS 技巧
本站不断更新一些优秀的CSS技术教程和技巧,文章每天更新。
●6
Neumorphism - 实现新的拟态效果
它可以轻松实现新的模拟效果,不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果和形状等参数。同时,它提供了可以直接复制的CSS代码。
●7
uiGradients-共享渐变色
提供渐变色效果的网站。有接近数百种渐变配色方案。可以根据自己的风格进行选择搭配,直接获取渐变配色方案对应的CSS代码。
▍JS相关
●8
JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。主要写了如何避免一些常见的错误,发现难以发现的bug。它将更深入地了解 JavaScript 的语言特性。
●9
JSTips-JS技巧
每天一点Javascript知识。
●10
JSweekly-科技周刊
专注于 Javascript 的技术周刊。
●11
CDNJS-JavaScript 数据库
CDNJS为开发者提供最新的前端Web开发资源,免费,无限制。你可以在自己的网页上直接引用这些JS文件。进入CDNJS网站后,搜索你想要的资源库,点击项目后面的【复制脚本标签】,粘贴即可使用。目前,CDNJS在Web前端的CDN服务中排名第二(排名第一的是谷歌),性能优异。
●12
开源 JS 库的美丽开放集合
采集
各类设计优秀的开源项目,从CMS内容管理系统到常用的小型Javascript库,适合网站开发用户。
●13
JavaScript Fun- 代码库合集
汇集当下最流行的JavaScript代码库,展示流行度排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow-程序员问答
全球IT行业最受欢迎的技术问答网站之一,一个解决bug的社区,被称为“编程界的十万个为什么”。
●15
掘金-优质技术社区
掘金技术社区是一个优质的技术分享社区。技术专家和极客们共同编辑、甄选优质干货。这些技术文章包括Android、iOS、前端和后端资源。
●16
Codrops-网页设计开发博客
发布技术文章和网络教程,提供经验,陷阱少,资源丰富,很多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码的工具,上面有各种效果案例特效(炫技),你可以根据他们的demo开发自己的前端设计.
●18
代码沙盒
顾名思义,CodeSandBox 网站提供了一个在线开发环境的“沙箱”。React、Vue、Angular等主流框架都可以开箱即用,实时编译预览,非常方便。
●19
JSBin
另一个轻量级的在线编辑器网站,界面简洁干净,如果你想暂时调试简单的HTML或JS代码,可以考虑去这里试一试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
它是 SVG 图标素材的在线可定制设计。帮助前端设计师找到自己想要的图标素材。这些图标素材都是常用的图标。二次设计可以点官方资料,也可以自己设计好的。图标导出。
●21
OpenMoji-free 表情符号库
提供Emoji源代码库,可免费下载使用。
● 22
分享无图标矢量素材库
一个提供超过 120 个类别的超过 250,000 个 ICON 矢量图像材料的网站。所有材料均以 PNG 和 SVG 格式提供。材料有多种尺寸可供选择,包括512*512、256*256、 128*128、64*64、32*32、16* 16等,非常适合前端设计师采集
和储备。
● 23
tableconvert-在线表格编辑器
一个强大的在线表单编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式之间的转换。当您需要在不变形的情况下转换表格时,您不妨试试这个工具。
● 24
Feathericons-极简图标集
一个免费和开源的简单而漂亮的 ICON 图标集合。主要设计用途是应用系统、媒体控制、位置、天气、箭头、标志等,可以在开发移动应用时使用。图标格式为 SVG。
● 25
HTML5 + CSS 3 免费模板
提供了大量的HTML5模板,用户可以自行分享和修改模板。
本文推荐网站汇总:
CSS之战:
学习 CSS 布局:
Flexbox 青蛙:
享受CSS:
CSS 技巧:
新拟态:
uiGradients:
JavaScript:
JS小贴士:
JS周刊:
CDNJS:
美丽开放:
JavaScript 乐趣:
堆栈溢出:
掘金:
共滴:
代码笔:
代码沙盒:
JS斌:
图标SVG:
开模:
分享图标:
表转换:
羽毛图标:
HTML5UP:
如果你有写博客的好习惯
欢迎投稿
赞+在看,小生感恩❤️
网页css js 抓取助手(错误博客()分享的内容为《》帮助)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-29 01:14
错误博客发现最近的快照突然失去了CSS样式,明显不正常。今天发错博客()分享的内容是《百度快照中没有CSS样式怎么办》。我希望能有所帮助。
一、 百度官方声明
以下引用内容来自百度官方:
其中,咨询频率最高的4大问题:1、快照排版混乱、页面内容显示不完整、2、无网页快照、3、网页快照内容更新、4、网页已死链接,但快照仍然存在。
答案如下:
站长可以了解到,百度快照的生成过程与网页的索引更新是同步的。生成索引时,会将爬虫爬取到的最新网页内容推送到快照生成程序。所以可以说网页的索引速度决定了快照更新的速度。
快照生成模块将通过浏览器向用户展示网页内容。目前快照展示模块只能渲染基于静态html的网页(行话是指通过iframe加载),因此对于一些相对路径如js、css、图片素材无法加载,或者部分网站禁用百度域访问js、css等文件,会导致快照显示排版错误和部分页面内容显示不完整。在这种情况下,站长可以根据实际需要进行更正。
如果没有快照信息,请站长不要担心。只是没有为网页生成快照,也没有对网站进行一些特殊处理。
另外,站长投诉最多的就是快照更新慢,这涉及到快照更新的频率。不同网页的更新周期不同,不同网站的网页更新频率也不同。这里可以看出最长的更新周期是Month级别,最短的更新周期是分钟级别。
从官方角度分析快照,“百度快照的生成过程与网页的索引更新是同步的,当索引生成时,会将最新抓取的网页内容推送到快照生成程序“所以可以说网页被索引了,速度决定了快照更新的速度。” 在这段话中,我们可以看到,百度快照更新的速度与蜘蛛是否存在有很大关系。快照更新越快越好,证明蜘蛛质量高,来了。
如果快照更新不正常,结果可想而知。虽然官方说没有snapshot,不要紧张,没有CSS样式也没关系,但是如果出现这种情况,就证明网站存在一定的问题。
二、百度快照优化
错误博客之前的快照都是正常的。为什么这次有例外?可能主要出现在以下几个问题上:
1、打开速度慢
主页打开速度慢。虽然一而再再而三的优化,但是一次又一次的向首页添加内容导致首页加载速度变慢。在这种情况下,搜索引擎蜘蛛可能会选择不爬取css,而是直接爬取。HTML 代码就是它的全部。
2、压缩插件
错误博客最近也使用了 WordPress 压缩插件。这些插件压缩 CSS 和 JS 代码,导致这种情况发生。
百度快照的原理是通过iframe以静态hmtl方式加载和显示网页内容。Autooptimize压缩的CSS文件的链接名称是随机的,百度快照不是实时更新的。手动清除Autoptimize缓存时,重新生成的CSS链接与快照中加载的链接名称不同,无法加载正确的CSS文件。当然,没有风格。向上。
引自:DEFCON 笔记
这个图片压缩插件收录
了延迟加载功能,即使卸载了,估计延迟加载也会被保留,记得关掉。
3、CSS 问题
这种情况可能是CSS或JS加载速度慢造成的,需要对CSS或JS进行优化。
4、帧数过多
错误的博客首页使用了过多的网站框架,导致搜索引擎抓取缓慢。
5、服务器
错误博客的服务器带宽已经5M,基本可以满足日常需求。首页图片已经基本缩小到100KB以下,以前是1M左右的图片。如果您的网站在这方面可能存在问题,那么纠正它会容易得多。
当然,也有人说百度快照是文本网页,无需关心是否有CSS,但实际情况是,网站快照缺少css可能只是反映了网站的一些问题。最直接的问题就是网站加载慢,打开2个多第二个基本要降级了。
发现问题了,之前做的防盗链码有问题。直接去掉这些代码应该就够了。这里禁止js、css、图片等,只是因为这些页面无法抓取,都是404。
如果你使用的是windows系统,而web服务器使用的是IIS,那么防盗链的设置也很简单。只需将以下代码的内容添加到 web.config 中即可。
直接在原来的web.config文件之间写入上传缩进代码即可,不要破坏其他文件。
以上是错误博客分享的内容()是“百度快照中没有CSS样式怎么办”。感谢您的阅读。更多原创文章,搜索“错误博客”。 查看全部
网页css js 抓取助手(错误博客()分享的内容为《》帮助)
错误博客发现最近的快照突然失去了CSS样式,明显不正常。今天发错博客()分享的内容是《百度快照中没有CSS样式怎么办》。我希望能有所帮助。
一、 百度官方声明
以下引用内容来自百度官方:
其中,咨询频率最高的4大问题:1、快照排版混乱、页面内容显示不完整、2、无网页快照、3、网页快照内容更新、4、网页已死链接,但快照仍然存在。
答案如下:
站长可以了解到,百度快照的生成过程与网页的索引更新是同步的。生成索引时,会将爬虫爬取到的最新网页内容推送到快照生成程序。所以可以说网页的索引速度决定了快照更新的速度。
快照生成模块将通过浏览器向用户展示网页内容。目前快照展示模块只能渲染基于静态html的网页(行话是指通过iframe加载),因此对于一些相对路径如js、css、图片素材无法加载,或者部分网站禁用百度域访问js、css等文件,会导致快照显示排版错误和部分页面内容显示不完整。在这种情况下,站长可以根据实际需要进行更正。
如果没有快照信息,请站长不要担心。只是没有为网页生成快照,也没有对网站进行一些特殊处理。
另外,站长投诉最多的就是快照更新慢,这涉及到快照更新的频率。不同网页的更新周期不同,不同网站的网页更新频率也不同。这里可以看出最长的更新周期是Month级别,最短的更新周期是分钟级别。
从官方角度分析快照,“百度快照的生成过程与网页的索引更新是同步的,当索引生成时,会将最新抓取的网页内容推送到快照生成程序“所以可以说网页被索引了,速度决定了快照更新的速度。” 在这段话中,我们可以看到,百度快照更新的速度与蜘蛛是否存在有很大关系。快照更新越快越好,证明蜘蛛质量高,来了。
如果快照更新不正常,结果可想而知。虽然官方说没有snapshot,不要紧张,没有CSS样式也没关系,但是如果出现这种情况,就证明网站存在一定的问题。
二、百度快照优化
错误博客之前的快照都是正常的。为什么这次有例外?可能主要出现在以下几个问题上:
1、打开速度慢
主页打开速度慢。虽然一而再再而三的优化,但是一次又一次的向首页添加内容导致首页加载速度变慢。在这种情况下,搜索引擎蜘蛛可能会选择不爬取css,而是直接爬取。HTML 代码就是它的全部。
2、压缩插件
错误博客最近也使用了 WordPress 压缩插件。这些插件压缩 CSS 和 JS 代码,导致这种情况发生。
百度快照的原理是通过iframe以静态hmtl方式加载和显示网页内容。Autooptimize压缩的CSS文件的链接名称是随机的,百度快照不是实时更新的。手动清除Autoptimize缓存时,重新生成的CSS链接与快照中加载的链接名称不同,无法加载正确的CSS文件。当然,没有风格。向上。
引自:DEFCON 笔记
这个图片压缩插件收录
了延迟加载功能,即使卸载了,估计延迟加载也会被保留,记得关掉。
3、CSS 问题
这种情况可能是CSS或JS加载速度慢造成的,需要对CSS或JS进行优化。
4、帧数过多
错误的博客首页使用了过多的网站框架,导致搜索引擎抓取缓慢。
5、服务器
错误博客的服务器带宽已经5M,基本可以满足日常需求。首页图片已经基本缩小到100KB以下,以前是1M左右的图片。如果您的网站在这方面可能存在问题,那么纠正它会容易得多。
当然,也有人说百度快照是文本网页,无需关心是否有CSS,但实际情况是,网站快照缺少css可能只是反映了网站的一些问题。最直接的问题就是网站加载慢,打开2个多第二个基本要降级了。
发现问题了,之前做的防盗链码有问题。直接去掉这些代码应该就够了。这里禁止js、css、图片等,只是因为这些页面无法抓取,都是404。
如果你使用的是windows系统,而web服务器使用的是IIS,那么防盗链的设置也很简单。只需将以下代码的内容添加到 web.config 中即可。
直接在原来的web.config文件之间写入上传缩进代码即可,不要破坏其他文件。
以上是错误博客分享的内容()是“百度快照中没有CSS样式怎么办”。感谢您的阅读。更多原创文章,搜索“错误博客”。
网页css js 抓取助手(百忙之中抽时间编写了这个小程序,功能是:完美保存整个网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-20 09:12
我从繁忙的日程中抽出时间来编写这个小程序。功能是完美保存整个网页,包括:图片、JS脚本、CSS样式,修改网页源代码进行“本地化”。因为火了,连浏览器自带这个功能都不知道,就自己做了一个。这个程序虽然不大,但是涉及到三大问题(后面会详细说明)。
本来不打算放源码的,既然浏览器有这个功能,那我就放出源码供大家学习!这个程序的效果和浏览器的效果完全一样!而且我对比了一下,得到的js、css、图片都不亚于浏览器得到的。可以参考这个玩:做一个网站全站下载器。当然你永远不能下载数据库.....
使用说明:
1.填写网页地址,点击前往,即可激活一键下载。加载网页需要时间。如果加载前点击一键下载,会有提示。尝试在网速更好的时候使用它!
2.下载完成后,会在软件目录下生成一个以网页标题命名的文件夹。所有必要的文件都存储在这里。以网页标题命名的 HTM 文件即为保存的页面。在这种情况下,双击查看的效果和在网上查看是一样的!.
程序截图:
解决的问题:
1. 判断网页已经加载完毕。以前,已知目的地的网页可以通过“标记方法”来判断,但在这个程序中一切都是未知的。因此,必须使用新的方法。这里使用了HTML对象的Onload事件,结合webbrowser控件完美实现了判断网页加载完成的完成。这是目前最安全、最准确、最可靠的方法!适用于所有环境。
确定网页已经加载一直很头疼,至少在VB中是这样。网上提到的方法基本都行不通。更好的是有时它有效,有时它不起作用。现在我将发布一个代码来结束这个问题
'引用“Microsoft HTML Object Library”
Dim WithEvents page As HTMLWindow2 '注意要定义成全局的
Private Sub WebBrowser1_NavigateComplete2(ByVal pDisp As Object, URL As Variant)
Set page = Me.WebBrowser1.document.parentWindow
End Sub
Private Sub page_onload()
Debug.Print "加载完毕"
End Sub
2.获取网页js和css。我看到很多人在猪八戒上发帖求一个程序,请求网页中的所有js和css。其实这个不难,百度一下,可以发现javascript语言提供了这个接口。下面我将演示如何使用这个接口来获取。
首先使用 webbrowser 控件加载要提取的网页。
获取js:
<p>strBasicHTM = WebBrowser1.Document.documentElement.outerHTML
WebBrowser1.Navigate "javascript:str='
\n';c=document.scripts;for(i=0;i 查看全部
网页css js 抓取助手(百忙之中抽时间编写了这个小程序,功能是:完美保存整个网页)
我从繁忙的日程中抽出时间来编写这个小程序。功能是完美保存整个网页,包括:图片、JS脚本、CSS样式,修改网页源代码进行“本地化”。因为火了,连浏览器自带这个功能都不知道,就自己做了一个。这个程序虽然不大,但是涉及到三大问题(后面会详细说明)。
本来不打算放源码的,既然浏览器有这个功能,那我就放出源码供大家学习!这个程序的效果和浏览器的效果完全一样!而且我对比了一下,得到的js、css、图片都不亚于浏览器得到的。可以参考这个玩:做一个网站全站下载器。当然你永远不能下载数据库.....
使用说明:
1.填写网页地址,点击前往,即可激活一键下载。加载网页需要时间。如果加载前点击一键下载,会有提示。尝试在网速更好的时候使用它!
2.下载完成后,会在软件目录下生成一个以网页标题命名的文件夹。所有必要的文件都存储在这里。以网页标题命名的 HTM 文件即为保存的页面。在这种情况下,双击查看的效果和在网上查看是一样的!.
程序截图:
解决的问题:
1. 判断网页已经加载完毕。以前,已知目的地的网页可以通过“标记方法”来判断,但在这个程序中一切都是未知的。因此,必须使用新的方法。这里使用了HTML对象的Onload事件,结合webbrowser控件完美实现了判断网页加载完成的完成。这是目前最安全、最准确、最可靠的方法!适用于所有环境。
确定网页已经加载一直很头疼,至少在VB中是这样。网上提到的方法基本都行不通。更好的是有时它有效,有时它不起作用。现在我将发布一个代码来结束这个问题
'引用“Microsoft HTML Object Library”
Dim WithEvents page As HTMLWindow2 '注意要定义成全局的
Private Sub WebBrowser1_NavigateComplete2(ByVal pDisp As Object, URL As Variant)
Set page = Me.WebBrowser1.document.parentWindow
End Sub
Private Sub page_onload()
Debug.Print "加载完毕"
End Sub
2.获取网页js和css。我看到很多人在猪八戒上发帖求一个程序,请求网页中的所有js和css。其实这个不难,百度一下,可以发现javascript语言提供了这个接口。下面我将演示如何使用这个接口来获取。
首先使用 webbrowser 控件加载要提取的网页。
获取js:
<p>strBasicHTM = WebBrowser1.Document.documentElement.outerHTML
WebBrowser1.Navigate "javascript:str='
\n';c=document.scripts;for(i=0;i
网页css js 抓取助手(简单易用的网页解析工具-上海怡健医学() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-20 05:18
)
微客网页助手是一款简单易用的网页分析工具。该程序旨在帮助您通过简单的步骤解析任何网页,从而查看网页的所有数据,如 HTML、图片、CSS、JS、FLASH 等。 当您需要解析网页或查看网页时页面写作技巧。该软件提供了一套有用的解决方案。它具有简单直观的操作界面。首先,您需要注册并登录一个帐户。进入主窗口后,输入网址,设置文件存储路径,一键分析。分析完成后,可以在输出目录中快速查看分析数据。使用起来非常方便。有需要的朋友可以从本站快速下载!
软件功能
微客网络助手是一款绿色、免费的网络下载工具。可以完全解析下载任何网站 HTML、图片、CSS、JS、FLASH等数据。
上手很容易,无需寻求帮助。只需三步,即可学会网站高手的写作技巧。
有账号可以直接登录,没有账号可以免费注册。注册的用户名和密码必须为英文或数字,六至二十位数字。注册成功后,弹窗提示有登录号,必须用登录号和密码登录。
选择网页下载文件的存储位置,然后在地址栏中输入要下载的网页地址,点击保存即可。完成后,您可以进入下载的目录,查看该网页中的所有文件和图片。
软件特点
简单直观的操作界面,无需任何复杂的配置选项,即可轻松解析网页。
支持分析窗口和浏览窗口。
您可以自定义设置文件的存储位置。
内置详细的操作日志,可以查看分析的完成情况。
当您需要查看网页的写作技巧时,该软件非常有用。
指示
1、启动微客网页助手,进入如下登录界面,输入用户名和密码登录。
2、 如果您还没有注册,可以选择【注册新用户】,然后输入用户名、密码、确认密码、邮箱、QQ号、手机号等信息进行注册。
3、 然后进入微客网络助手主界面。
4、 提供了两种类型的分析窗口和浏览窗口。
5、输入要解析的网站,然后点击【保存】。
6、可以查看详细的操作日志,打开输出目录可以查看HTML、图片、CSS、JS、FLASH等所有数据。
查看全部
网页css js 抓取助手(简单易用的网页解析工具-上海怡健医学()
)
微客网页助手是一款简单易用的网页分析工具。该程序旨在帮助您通过简单的步骤解析任何网页,从而查看网页的所有数据,如 HTML、图片、CSS、JS、FLASH 等。 当您需要解析网页或查看网页时页面写作技巧。该软件提供了一套有用的解决方案。它具有简单直观的操作界面。首先,您需要注册并登录一个帐户。进入主窗口后,输入网址,设置文件存储路径,一键分析。分析完成后,可以在输出目录中快速查看分析数据。使用起来非常方便。有需要的朋友可以从本站快速下载!
软件功能
微客网络助手是一款绿色、免费的网络下载工具。可以完全解析下载任何网站 HTML、图片、CSS、JS、FLASH等数据。
上手很容易,无需寻求帮助。只需三步,即可学会网站高手的写作技巧。
有账号可以直接登录,没有账号可以免费注册。注册的用户名和密码必须为英文或数字,六至二十位数字。注册成功后,弹窗提示有登录号,必须用登录号和密码登录。
选择网页下载文件的存储位置,然后在地址栏中输入要下载的网页地址,点击保存即可。完成后,您可以进入下载的目录,查看该网页中的所有文件和图片。
软件特点
简单直观的操作界面,无需任何复杂的配置选项,即可轻松解析网页。
支持分析窗口和浏览窗口。
您可以自定义设置文件的存储位置。
内置详细的操作日志,可以查看分析的完成情况。
当您需要查看网页的写作技巧时,该软件非常有用。
指示
1、启动微客网页助手,进入如下登录界面,输入用户名和密码登录。
2、 如果您还没有注册,可以选择【注册新用户】,然后输入用户名、密码、确认密码、邮箱、QQ号、手机号等信息进行注册。
3、 然后进入微客网络助手主界面。
4、 提供了两种类型的分析窗口和浏览窗口。
5、输入要解析的网站,然后点击【保存】。
6、可以查看详细的操作日志,打开输出目录可以查看HTML、图片、CSS、JS、FLASH等所有数据。
网页css js 抓取助手( 基于js代码是如何调用网页助手小精灵的呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-17 07:14
基于js代码是如何调用网页助手小精灵的呢?(图))
基于JS调用网页助手精灵实现导航栏的方法
更新时间:2016年6月17日14:55:25 作者:柯南&
向 网站 添加网络助手向导。当用户访问网站时,向用户打招呼,或者发送一些网站的重要信息,都会给用户带来极佳的体验。那么如何基于js代码调用web助手向导呢?跟Script House的编辑一起学习吧。
1.概述
向 网站 添加网络助手向导。当用户访问网站时,向用户打招呼或发送网站的一些重要信息,不仅可以帮助用户快速了解网站,还可以让用户对网站留下深刻印象。 @网站。本例将介绍通过JavaScript调用网络助手精灵的方法。
2.技术要点
这个例子主要是通过微软的一个ActiveX组件Microsoft Agent来实现的。Microsoft Agent 提供了多种方法来控制 Agent 的角色,下面将对其进行详细介绍。
一个。load()方法:用于读入要使用的角色,该方法收录两个参数,一个用于指定角色的名称,另一个用于指定角色存储的文件。
湾 Show() 方法:用于在屏幕上显示字符。
C。Hide() 方法:用于隐藏角色。
d. Speak()方法:用于实现说话的作用。这个方法有一个参数来指定说话的内容。
e. MoveTo()方法:用于将字符移动到屏幕上的指定位置。该方法有两个参数,一个用于指定x轴坐标,另一个用于指定y轴坐标。
F。Play() 方法:用于指定要播放的动画。该方法只有一个参数,用于指定表示动画的字符串。其值包括Announce、Explain、Congratulate、greet、Gestureright、Gestureleft、Gesturedown、Gestureup、pleed and Read等。
3. 具体实现
(1)在需要展示网页助手精灵的页面的标记处,编写一个自定义的JavaScript函数loadAgent()来加载要使用的角色。loadAgent()函数的具体代码如下:
function loadAgent(id){
try{
id=new ActiveXObject("Agent.Control.2"); //创建一个ActiveX控件
id.Connected = true;
id.Characters.Load("MrAgent","merlin.acs"); //装入要使用的角色
return id;
}catch (err){
return false;
}
}
(在2)loadAgent()函数之后,编写一个自定义的JavaScript函数controlAgent(),用于调用和控制网页助手精灵,controlAgent()函数的具体代码如下:
function controlAgent(){
if (agent=loadAgent("agent")){
var mrAgentID="MrAgent";
mrAgent = agent.Characters.Character(mrAgentID); //获取助手对象
mrAgent.MoveTo(200,200); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Speak("欢迎来到明日科技网站!"); //提示语
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Play("Pleased"); //做请的手势
mrAgent.Speak("我们的网址:www.cccxy.com"); //提示语
mrAgent.Hide(); //隐藏助手
mrAgent.MoveTo(600,300); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Play("Read") //作出读书的动作
mrAgent.Speak("我们会热心解决您学习过程中遇到的疑问"); //提示语
mrAgent.Play("Idle1_1"); //做出无所事事的样子
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Speak("记住我们的网址:www.cccxy.com"); //提示语
mrAgent.Play("greet"); //问候
mrAgent.Speak("感谢您的到来"); //提示语
mrAgent.Play("Idle2_2"); //做出无所事事的样子
mrAgent.Hide(); //隐藏助手
}
}
(3)编写JavaScript代码,在页面加载后调用和控制web助手向导,具体代码如下:
window.onload=function(){
controlAgent(); //调用并控制网页助手小精灵
}
以上就是小编给大家介绍的基于导航栏JS实现调用web助手向导的方法。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持! 查看全部
网页css js 抓取助手(
基于js代码是如何调用网页助手小精灵的呢?(图))
基于JS调用网页助手精灵实现导航栏的方法
更新时间:2016年6月17日14:55:25 作者:柯南&
向 网站 添加网络助手向导。当用户访问网站时,向用户打招呼,或者发送一些网站的重要信息,都会给用户带来极佳的体验。那么如何基于js代码调用web助手向导呢?跟Script House的编辑一起学习吧。
1.概述
向 网站 添加网络助手向导。当用户访问网站时,向用户打招呼或发送网站的一些重要信息,不仅可以帮助用户快速了解网站,还可以让用户对网站留下深刻印象。 @网站。本例将介绍通过JavaScript调用网络助手精灵的方法。
2.技术要点
这个例子主要是通过微软的一个ActiveX组件Microsoft Agent来实现的。Microsoft Agent 提供了多种方法来控制 Agent 的角色,下面将对其进行详细介绍。
一个。load()方法:用于读入要使用的角色,该方法收录两个参数,一个用于指定角色的名称,另一个用于指定角色存储的文件。
湾 Show() 方法:用于在屏幕上显示字符。
C。Hide() 方法:用于隐藏角色。
d. Speak()方法:用于实现说话的作用。这个方法有一个参数来指定说话的内容。
e. MoveTo()方法:用于将字符移动到屏幕上的指定位置。该方法有两个参数,一个用于指定x轴坐标,另一个用于指定y轴坐标。
F。Play() 方法:用于指定要播放的动画。该方法只有一个参数,用于指定表示动画的字符串。其值包括Announce、Explain、Congratulate、greet、Gestureright、Gestureleft、Gesturedown、Gestureup、pleed and Read等。
3. 具体实现
(1)在需要展示网页助手精灵的页面的标记处,编写一个自定义的JavaScript函数loadAgent()来加载要使用的角色。loadAgent()函数的具体代码如下:
function loadAgent(id){
try{
id=new ActiveXObject("Agent.Control.2"); //创建一个ActiveX控件
id.Connected = true;
id.Characters.Load("MrAgent","merlin.acs"); //装入要使用的角色
return id;
}catch (err){
return false;
}
}
(在2)loadAgent()函数之后,编写一个自定义的JavaScript函数controlAgent(),用于调用和控制网页助手精灵,controlAgent()函数的具体代码如下:
function controlAgent(){
if (agent=loadAgent("agent")){
var mrAgentID="MrAgent";
mrAgent = agent.Characters.Character(mrAgentID); //获取助手对象
mrAgent.MoveTo(200,200); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Speak("欢迎来到明日科技网站!"); //提示语
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Play("Pleased"); //做请的手势
mrAgent.Speak("我们的网址:www.cccxy.com"); //提示语
mrAgent.Hide(); //隐藏助手
mrAgent.MoveTo(600,300); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Play("Read") //作出读书的动作
mrAgent.Speak("我们会热心解决您学习过程中遇到的疑问"); //提示语
mrAgent.Play("Idle1_1"); //做出无所事事的样子
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Speak("记住我们的网址:www.cccxy.com"); //提示语
mrAgent.Play("greet"); //问候
mrAgent.Speak("感谢您的到来"); //提示语
mrAgent.Play("Idle2_2"); //做出无所事事的样子
mrAgent.Hide(); //隐藏助手
}
}
(3)编写JavaScript代码,在页面加载后调用和控制web助手向导,具体代码如下:
window.onload=function(){
controlAgent(); //调用并控制网页助手小精灵
}
以上就是小编给大家介绍的基于导航栏JS实现调用web助手向导的方法。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持!
网页css js 抓取助手(SEO高级培训班第一期课程:SEO基础和实用操作老师:MOON)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-17 07:00
SEO高级培训课程第一阶段
第一课:SEO基础与实操
老师:月亮
培训语录:很多朋友不明白为什么要讲这么基础的知识。读一篇文章就这么简单。没有必要谈论它。其实,要学好SEO,必须掌握大理的基本SEO“关键词”。在我们优化一个网站的过程中,如果你不好好学习关键词,那么你在接下来的工作中将一无所获。
课程关键词:SEO、UEO、PR值、搜狗值、SEM、目标关键词、长尾关键词、死链、反向链接、SEO黑帽、SEO白帽、沙盒沙盒、 Alexa排名、ALT属性、链接和域和站点、关键词热度分析、关键词密度分析、页面相关性、采集或重复内容、蜘蛛和搜索引擎、做站点SEO元素、搜索引擎封站点K站采摘、优质外链、站点相关性、站点收录、导出链接、交叉链接、关键词堆砌、隐藏文字、隐藏链接、隐藏页面、301重定向欺骗、搜索引擎惩罚、关键词 排名、机器人、站点地图、SEO 工具、HTTP 状态代码、div+css、元标签(MATE 标签)、数据 采集、伪原创、FLASH 和 JS 以及框架框架、TITLE、H 标签、URL 超文本链接、敏感词汇、服务器安全、服务器稳定性、FFA 链接工厂、Indexed Pages 索引页、Crawler、什么是nofollow、301 重定向、cms系统、PV、跳出率、404 页面、开源系统、Firefox 浏览器、Google网站管理员、阿里妈妈站长工具、webmaster-toolbox 站长工具箱、反向链接查询工具、PR劫持、SeoQuake工具、站点地图生成工具、反向链接查询工具、流量统计工具、谷歌炸弹、SEO助手、webmasterhome查询工具、雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,最好的迁移方式网站。跳出率、404页面、开源系统、火狐浏览器、Google网站管理员、阿里妈妈站长工具、webmaster-toolbox站长工具箱、反向链接查询工具、PR劫持、SeoQuake工具、站点地图生成工具、反向链接查询工具、流量统计工具,谷歌炸弹,SEO助手,站长首页查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,迁移网站的最佳方式。跳出率、404页面、开源系统、火狐浏览器、Google网站管理员、阿里妈妈站长工具、webmaster-toolbox站长工具箱、反向链接查询工具、PR劫持、SeoQuake工具、站点地图生成工具、反向链接查询工具、流量统计工具,谷歌炸弹,SEO助手,站长首页查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,迁移网站的最佳方式。webmasterhome查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,最好的迁移方式网站。webmasterhome查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,最好的迁移方式网站。
SEO基本概念学习:
1. SEO究竟是什么,SEO的真正范围是什么?
答:很多朋友研究了很久,还是没有理解SEO的真正含义。我们现在通俗地讲的SEO指的是关键词排名优化和网站质量优化两大类。搜索引擎优化不是简单的字面解释,那么关键词优化是什么意思呢?是指站点可以定位到目标关键词,从而通过目标关键词在百度、谷歌或其他搜索引擎上可以找到该站点。网站的优化称为关键词优化。. 网站质量优化是指我们通过精心添加网站内容和网站模板操作布局和目录结构优化来改进网站的收录和内部页面关键词@。> 排名。
2. UEO是什么意思?怎么理解他?
答:UEO的意思是优化体验。我们在 UEO 理解的是如何让用户在 网站 上找到他们需要的东西,并以最低的成本让网站对用户产生吸引力。用最少的成本找到用户需要的东西,就是按用户分类(非分段)对网站信息进行布局。牵引力是指网站内容降低用户跳出率的能力。
3. PR值是多少?如何准确查询PR值
PR值是谷歌对网站质量和关键词进行排名的算法。通过这个算法,他可以判断网站的质量是高还是低。网站的好坏体现在PR值上,影响PR值的原因很多,反向链接、内链、内容。我们主要通过一些关键词查询工具来了解网站的PR值。
4. 什么是搜狗价值?
搜狗值和PR值是不同概念的算法。你为什么这么说?搜狗是搜索引擎的算法,但与谷歌的算法不同。他的比分是1-100,不是1-10.
5. 什么是扫描电镜?
SEM是指搜索引擎营销策略。其实就是指通过营销手段整合网站优化,或者说对网站关键词进行精准优化,达到触达流量,将流量收益最大化。我们称这样的程序为 SEM 策略。也就是说,我们可以通过这个策略优化网站,直接带来收益。
6.目标是什么关键词?
Goal 关键词 我们也称其为网站的核心关键词,即网站的主题关键词,那么具体是什么意思呢?让我们举一个例子。比如我们做一个服装网站,那么我们网站的主题就是服装,服装就是目标关键词。当然,可以有多个目标关键词。但这些必须是相关的。因为一个站点只能有一个主题。
7.什么是长尾关键词?
长尾关键词也称为相关关键词,指的是整个站点除核心关键词之外的所有相关关键词。我们都叫它长尾关键词,也就是关键词核心的长尾词。
8. 什么是死链接?
死链接是指网站上存在无效或不存在的 URL。一般站点的网页上都有一个URL路径,但是点击后,该路径不存在,或者已经移动或者动态路径失效。向上。这种链接的存在称为死链接。
9. 什么是反向链接?
反向链接实际上很容易解释。比如网页A和网页B,现在网页B中有一个指向网页A的链接,那么我们把网页B的链接称为网页A的反向链接。
10. 什么是导出链接?
导出链接也很容易理解。现在有两个站点 A 和 B。在站点 A 上,有一个指向站点 B 的链接(称为小 a)或指向站点 B 的链接。我们将站点 A 称为导出链接小 a。
11. 什么是导入链接?
导入链接也可以以站点 A 和站点 B 为例。现在站点 B 有一个到站点 A 的链接。我们称之为站点 A,站点 A 有一个名为 B 的导入链接。
12. 什么是内链?
我们将内部链接简称为内部链接。指站点内相互之间的链接。例如,如果站点A的目标关键词出现在站点A的某个页面上,那么我们将这个目标关键词用锚文本链接指向站点A的首页,那么这样的链接是称为内部链接。
13. 什么是超链接?
超文本链接是前面提到的锚文本链接。以文字形式参考上面的链接。例如,以下是一个超文本链接。昆明旅游的超文本为昆明旅游,网址为通用论坛的超文本,表示为昆明旅游的。意思是一样的。
14. 什么是隐藏链接?
隐藏链接是指使用 CSS 或代码使其在浏览器中不可见。
事实上,它已经使用了颜色或将文本字体更改为 0 或负数,以使只有搜索引擎可以抓取
但是用户看不到它,这与隐藏文本相同。
15. SEO黑帽
SEO黑帽是指很多SEO人员(SEOER)通过搜索引擎算法的漏洞,进行非法、公平竞争的SEO优化,我们称之为黑帽收费,黑帽的方法有很多,比如301重定向欺骗,比如隐藏链接,隐藏文字是一种欺骗搜索引擎的方式,但是可以在短时间内达到排名的效果关键词16. SEO白帽
SEO白帽和黑帽是对立的。SEO白帽提倡使用健康的SEO技术优化网站,以获得良好的关键词排名和网站页面收录。它主要是通过优化网站内容和外链资源来达到效果。
17. 什么是沙盒效应?
新展在上线后的1-6个月内很难在谷歌上获得好的排名,甚至没有排名。我们称这种现象为:沙盒-沙盒效应。该信用期一般为6个月。即使你在过去6个月有很好的优化获得高权重,也不可能获得好的关键词排名。那么百度对于新网站也有一个信用期,就是3个月。所以现在很多站长为了优化,买老网站的域名,特别是买行业网站做SEO优化,是个不错的办法。
18. 什么是Alexa排名?有什么作用?
Alexa排名指的是全职网站质量排名。当然,质量包括很多指标。关键词的索引还是以网站的流量作为判断依据。很多朋友喜欢看Alexa排名。其实我们知道,如果Alexa排名不再在10000以内,那是没有意义的。一般来说,行业站点能达到50000以下就不错了。
19. 什么是ALT属性,ALT属性的作用是什么?
ALT 属性是一种
图片的一个注解属性,这个属性的作用是告诉所有来爬的图片搜索引擎如何对图片进行分类关键词
例如:
关键词1@>
然后当图片搜索引擎的蜘蛛爬取时,会对图片进行分类,进行关键词排名。
20.link与domain和site的区别
域:相关域,即您在互联网上搜索的相关站点
站点:指站点收录 数据链接:站点是指向您站点的所有外部链接
例如:
领域:
然后查询出来所有站点都收录此链接字母和组件。如果是做锚链接,是不可能显示出来的。如果直接做域名,可以不通过导出链接查询
21.什么是关键词热分析?
关键词 人气分析是指我们的SEO优化师需要分析哪些关键词属于热门关键词、超热门词、一般关键词、冷门关键词。这样就用定位关键词进行优化,也用很多专业的SEO优化器来给客户报价。
22. 关键词 什么是密度分析?
关键词 密度分析是指网页中某个关键词的总字数的密度。一般我们将密度定位为3%-8%,根据不同行业,密度有所区别。
23. 什么是页面相关性和站点相关性?
页面相关性是两个页面和两个站点是否属于两种类型的行业。例如,当我们要对信息进行分类时,网络技术、服装行业和化学行业有不同的类别。分类越详细,相关性越好。强大的。24. 采集 或重复内容是什么意思?
采集 内容或重复内容是指通过采集或复制等方式向网站添加内容的网站。这会导致大量的网站内容和互联网内容被复制,导致内容失去重要性。重复内容是指一个站点或不同站点上的重复内容。
25. 蜘蛛和搜索引擎
蜘蛛不是指真正的蜘蛛,而是百度、谷歌等搜索引擎的网络爬行程序。百度和谷歌使用这些程序来抓取互联网上的网站,并对它们进行收录 分类。我们称这种程序为蜘蛛。搜索引擎简称SE,是指搜索、采集、分类不同类型的引擎程序,为用户提供搜索。例如:百度、谷歌、雅虎、搜狗、搜搜等。
26. 网站SEO需要哪些要素和步骤?
(关键词9@>关键词分析定位(2)站点目录结构(3)内容添加布局(4)内部链布局(5)导入链接优化) ( 6)友情链接优化(7)提交给搜索引擎(8)谷歌管理工具分析)
27. 搜索引擎关掉K站是什么意思?
表示您的网站违反搜索引擎等相关规定或不符合搜索引擎的要求,被搜索引擎从您网站的所有收录页面中删除。
详情请见百度和谷歌的具体要求和规定。
28. 对优质外链的要求是什么?
优质外链的基本要素是,第一个必须是首页或目录页,或者有大量导入链接的内容页。第二是页面导入链接的数量和来源,是否是高PR值,导入的页面链接数量以及被百度快照快速纠正的导入链接数量。第三是这些目标链接页面是否与您现有的页面和站点特别相关。
29.站点收录是什么意思?
站点收录指的是搜索引擎,比如百度、谷歌收录你的站点在它的数据库中有多少页,可以查看具体站点:你的站点
30. 交叉链接是什么意思?
交叉链接是指A和B之间的链路交换。A有两个站a和b,B有一个站c。A用他的a站链接B的c站,并要求B的c站链接A站b。
31. 关键词 堆积是什么意思?
关键词Stuffing是搜索引擎作弊的一种形式,指的是在页面上重复某个关键词,使搜索引擎与其页面更相关。
32. 隐藏文字,隐藏页面?
隐藏文本和隐藏页面。前面提到隐藏链接的时间我已经解释过了,不再赘述。这两种都是SEO黑帽作弊方法。
33. 301转为欺骗是什么意思?
301重定向欺骗是指对某个站点进行优化,实现搜索引擎中的第一名关键词,然后通过301重定向到另一个站点,这样你一点击就跳转到另一个站点排名。
34. 什么是搜索引擎惩罚?
搜索引擎处罚是指您违反了搜索引擎网站的相关规定。搜索引擎采取降低您的站点权限或K站点的措施,例如降低您的关键词排名。降低你的 收录。
35. 关键词 排名是什么意思?
关键词 排名是指您的网站页面在搜索引擎关键词上的排名。当用户搜索此关键词时间时,您的网站将根据其权重排名在相关位置。
36. 什么是机器人?
Robots是搜索引擎公共协议,所有搜索引擎都支持。一般将robots.txt文本直接放在根目录下。我们可以使用robtos文本在网站上执行很多有用的操作,比如网站上没有内容
该页面被阻止。阻止论坛的垃圾邮件链接导出部分。
37. 什么是站点地图?
我们将站点地图称为 网站 地图。网站 地图有两种类型。一种是HTML格式,这样不仅用户可以查看,搜索引擎也可以抓取站点目录。还有一种XML的形式,是专门为搜索引擎提供的,但在搜索引擎中只有Google、Yahoo等支持xml映射。比如百度不支持xml,那我们怎么操作呢?直接提交sitemap.xml给百度就很简单了,这样百度蜘蛛就可以抓取里面的链接了。
38. 什么SEO工具?有那些SEO工具
SEO工具是指帮助SEOER人员进行SEO优化检查的小助手,可以为SEOER节省大量时间。我们经常使用FLASH站长工具,阿里妈妈,雅虎站长工具等等。当然,还有SITEMAP工具、反向链接查询工具、友情链接检查工具等等。 查看全部
网页css js 抓取助手(SEO高级培训班第一期课程:SEO基础和实用操作老师:MOON)
SEO高级培训课程第一阶段
第一课:SEO基础与实操
老师:月亮
培训语录:很多朋友不明白为什么要讲这么基础的知识。读一篇文章就这么简单。没有必要谈论它。其实,要学好SEO,必须掌握大理的基本SEO“关键词”。在我们优化一个网站的过程中,如果你不好好学习关键词,那么你在接下来的工作中将一无所获。
课程关键词:SEO、UEO、PR值、搜狗值、SEM、目标关键词、长尾关键词、死链、反向链接、SEO黑帽、SEO白帽、沙盒沙盒、 Alexa排名、ALT属性、链接和域和站点、关键词热度分析、关键词密度分析、页面相关性、采集或重复内容、蜘蛛和搜索引擎、做站点SEO元素、搜索引擎封站点K站采摘、优质外链、站点相关性、站点收录、导出链接、交叉链接、关键词堆砌、隐藏文字、隐藏链接、隐藏页面、301重定向欺骗、搜索引擎惩罚、关键词 排名、机器人、站点地图、SEO 工具、HTTP 状态代码、div+css、元标签(MATE 标签)、数据 采集、伪原创、FLASH 和 JS 以及框架框架、TITLE、H 标签、URL 超文本链接、敏感词汇、服务器安全、服务器稳定性、FFA 链接工厂、Indexed Pages 索引页、Crawler、什么是nofollow、301 重定向、cms系统、PV、跳出率、404 页面、开源系统、Firefox 浏览器、Google网站管理员、阿里妈妈站长工具、webmaster-toolbox 站长工具箱、反向链接查询工具、PR劫持、SeoQuake工具、站点地图生成工具、反向链接查询工具、流量统计工具、谷歌炸弹、SEO助手、webmasterhome查询工具、雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,最好的迁移方式网站。跳出率、404页面、开源系统、火狐浏览器、Google网站管理员、阿里妈妈站长工具、webmaster-toolbox站长工具箱、反向链接查询工具、PR劫持、SeoQuake工具、站点地图生成工具、反向链接查询工具、流量统计工具,谷歌炸弹,SEO助手,站长首页查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,迁移网站的最佳方式。跳出率、404页面、开源系统、火狐浏览器、Google网站管理员、阿里妈妈站长工具、webmaster-toolbox站长工具箱、反向链接查询工具、PR劫持、SeoQuake工具、站点地图生成工具、反向链接查询工具、流量统计工具,谷歌炸弹,SEO助手,站长首页查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,迁移网站的最佳方式。webmasterhome查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,最好的迁移方式网站。webmasterhome查询工具,雅虎站长查询工具,网页死链断链检查工具,搜索引擎模拟爬取工具,链接交易,如何申请重复收录,如何处理恶意软件,最好的迁移方式网站。
SEO基本概念学习:
1. SEO究竟是什么,SEO的真正范围是什么?
答:很多朋友研究了很久,还是没有理解SEO的真正含义。我们现在通俗地讲的SEO指的是关键词排名优化和网站质量优化两大类。搜索引擎优化不是简单的字面解释,那么关键词优化是什么意思呢?是指站点可以定位到目标关键词,从而通过目标关键词在百度、谷歌或其他搜索引擎上可以找到该站点。网站的优化称为关键词优化。. 网站质量优化是指我们通过精心添加网站内容和网站模板操作布局和目录结构优化来改进网站的收录和内部页面关键词@。> 排名。
2. UEO是什么意思?怎么理解他?
答:UEO的意思是优化体验。我们在 UEO 理解的是如何让用户在 网站 上找到他们需要的东西,并以最低的成本让网站对用户产生吸引力。用最少的成本找到用户需要的东西,就是按用户分类(非分段)对网站信息进行布局。牵引力是指网站内容降低用户跳出率的能力。
3. PR值是多少?如何准确查询PR值
PR值是谷歌对网站质量和关键词进行排名的算法。通过这个算法,他可以判断网站的质量是高还是低。网站的好坏体现在PR值上,影响PR值的原因很多,反向链接、内链、内容。我们主要通过一些关键词查询工具来了解网站的PR值。
4. 什么是搜狗价值?
搜狗值和PR值是不同概念的算法。你为什么这么说?搜狗是搜索引擎的算法,但与谷歌的算法不同。他的比分是1-100,不是1-10.
5. 什么是扫描电镜?
SEM是指搜索引擎营销策略。其实就是指通过营销手段整合网站优化,或者说对网站关键词进行精准优化,达到触达流量,将流量收益最大化。我们称这样的程序为 SEM 策略。也就是说,我们可以通过这个策略优化网站,直接带来收益。
6.目标是什么关键词?
Goal 关键词 我们也称其为网站的核心关键词,即网站的主题关键词,那么具体是什么意思呢?让我们举一个例子。比如我们做一个服装网站,那么我们网站的主题就是服装,服装就是目标关键词。当然,可以有多个目标关键词。但这些必须是相关的。因为一个站点只能有一个主题。
7.什么是长尾关键词?
长尾关键词也称为相关关键词,指的是整个站点除核心关键词之外的所有相关关键词。我们都叫它长尾关键词,也就是关键词核心的长尾词。
8. 什么是死链接?
死链接是指网站上存在无效或不存在的 URL。一般站点的网页上都有一个URL路径,但是点击后,该路径不存在,或者已经移动或者动态路径失效。向上。这种链接的存在称为死链接。
9. 什么是反向链接?
反向链接实际上很容易解释。比如网页A和网页B,现在网页B中有一个指向网页A的链接,那么我们把网页B的链接称为网页A的反向链接。
10. 什么是导出链接?
导出链接也很容易理解。现在有两个站点 A 和 B。在站点 A 上,有一个指向站点 B 的链接(称为小 a)或指向站点 B 的链接。我们将站点 A 称为导出链接小 a。
11. 什么是导入链接?
导入链接也可以以站点 A 和站点 B 为例。现在站点 B 有一个到站点 A 的链接。我们称之为站点 A,站点 A 有一个名为 B 的导入链接。
12. 什么是内链?
我们将内部链接简称为内部链接。指站点内相互之间的链接。例如,如果站点A的目标关键词出现在站点A的某个页面上,那么我们将这个目标关键词用锚文本链接指向站点A的首页,那么这样的链接是称为内部链接。
13. 什么是超链接?
超文本链接是前面提到的锚文本链接。以文字形式参考上面的链接。例如,以下是一个超文本链接。昆明旅游的超文本为昆明旅游,网址为通用论坛的超文本,表示为昆明旅游的。意思是一样的。
14. 什么是隐藏链接?
隐藏链接是指使用 CSS 或代码使其在浏览器中不可见。
事实上,它已经使用了颜色或将文本字体更改为 0 或负数,以使只有搜索引擎可以抓取
但是用户看不到它,这与隐藏文本相同。
15. SEO黑帽
SEO黑帽是指很多SEO人员(SEOER)通过搜索引擎算法的漏洞,进行非法、公平竞争的SEO优化,我们称之为黑帽收费,黑帽的方法有很多,比如301重定向欺骗,比如隐藏链接,隐藏文字是一种欺骗搜索引擎的方式,但是可以在短时间内达到排名的效果关键词16. SEO白帽
SEO白帽和黑帽是对立的。SEO白帽提倡使用健康的SEO技术优化网站,以获得良好的关键词排名和网站页面收录。它主要是通过优化网站内容和外链资源来达到效果。
17. 什么是沙盒效应?
新展在上线后的1-6个月内很难在谷歌上获得好的排名,甚至没有排名。我们称这种现象为:沙盒-沙盒效应。该信用期一般为6个月。即使你在过去6个月有很好的优化获得高权重,也不可能获得好的关键词排名。那么百度对于新网站也有一个信用期,就是3个月。所以现在很多站长为了优化,买老网站的域名,特别是买行业网站做SEO优化,是个不错的办法。
18. 什么是Alexa排名?有什么作用?
Alexa排名指的是全职网站质量排名。当然,质量包括很多指标。关键词的索引还是以网站的流量作为判断依据。很多朋友喜欢看Alexa排名。其实我们知道,如果Alexa排名不再在10000以内,那是没有意义的。一般来说,行业站点能达到50000以下就不错了。
19. 什么是ALT属性,ALT属性的作用是什么?
ALT 属性是一种
图片的一个注解属性,这个属性的作用是告诉所有来爬的图片搜索引擎如何对图片进行分类关键词
例如:
关键词1@>
然后当图片搜索引擎的蜘蛛爬取时,会对图片进行分类,进行关键词排名。
20.link与domain和site的区别
域:相关域,即您在互联网上搜索的相关站点
站点:指站点收录 数据链接:站点是指向您站点的所有外部链接
例如:
领域:
然后查询出来所有站点都收录此链接字母和组件。如果是做锚链接,是不可能显示出来的。如果直接做域名,可以不通过导出链接查询
21.什么是关键词热分析?
关键词 人气分析是指我们的SEO优化师需要分析哪些关键词属于热门关键词、超热门词、一般关键词、冷门关键词。这样就用定位关键词进行优化,也用很多专业的SEO优化器来给客户报价。
22. 关键词 什么是密度分析?
关键词 密度分析是指网页中某个关键词的总字数的密度。一般我们将密度定位为3%-8%,根据不同行业,密度有所区别。
23. 什么是页面相关性和站点相关性?
页面相关性是两个页面和两个站点是否属于两种类型的行业。例如,当我们要对信息进行分类时,网络技术、服装行业和化学行业有不同的类别。分类越详细,相关性越好。强大的。24. 采集 或重复内容是什么意思?
采集 内容或重复内容是指通过采集或复制等方式向网站添加内容的网站。这会导致大量的网站内容和互联网内容被复制,导致内容失去重要性。重复内容是指一个站点或不同站点上的重复内容。
25. 蜘蛛和搜索引擎
蜘蛛不是指真正的蜘蛛,而是百度、谷歌等搜索引擎的网络爬行程序。百度和谷歌使用这些程序来抓取互联网上的网站,并对它们进行收录 分类。我们称这种程序为蜘蛛。搜索引擎简称SE,是指搜索、采集、分类不同类型的引擎程序,为用户提供搜索。例如:百度、谷歌、雅虎、搜狗、搜搜等。
26. 网站SEO需要哪些要素和步骤?
(关键词9@>关键词分析定位(2)站点目录结构(3)内容添加布局(4)内部链布局(5)导入链接优化) ( 6)友情链接优化(7)提交给搜索引擎(8)谷歌管理工具分析)
27. 搜索引擎关掉K站是什么意思?
表示您的网站违反搜索引擎等相关规定或不符合搜索引擎的要求,被搜索引擎从您网站的所有收录页面中删除。
详情请见百度和谷歌的具体要求和规定。
28. 对优质外链的要求是什么?
优质外链的基本要素是,第一个必须是首页或目录页,或者有大量导入链接的内容页。第二是页面导入链接的数量和来源,是否是高PR值,导入的页面链接数量以及被百度快照快速纠正的导入链接数量。第三是这些目标链接页面是否与您现有的页面和站点特别相关。
29.站点收录是什么意思?
站点收录指的是搜索引擎,比如百度、谷歌收录你的站点在它的数据库中有多少页,可以查看具体站点:你的站点
30. 交叉链接是什么意思?
交叉链接是指A和B之间的链路交换。A有两个站a和b,B有一个站c。A用他的a站链接B的c站,并要求B的c站链接A站b。
31. 关键词 堆积是什么意思?
关键词Stuffing是搜索引擎作弊的一种形式,指的是在页面上重复某个关键词,使搜索引擎与其页面更相关。
32. 隐藏文字,隐藏页面?
隐藏文本和隐藏页面。前面提到隐藏链接的时间我已经解释过了,不再赘述。这两种都是SEO黑帽作弊方法。
33. 301转为欺骗是什么意思?
301重定向欺骗是指对某个站点进行优化,实现搜索引擎中的第一名关键词,然后通过301重定向到另一个站点,这样你一点击就跳转到另一个站点排名。
34. 什么是搜索引擎惩罚?
搜索引擎处罚是指您违反了搜索引擎网站的相关规定。搜索引擎采取降低您的站点权限或K站点的措施,例如降低您的关键词排名。降低你的 收录。
35. 关键词 排名是什么意思?
关键词 排名是指您的网站页面在搜索引擎关键词上的排名。当用户搜索此关键词时间时,您的网站将根据其权重排名在相关位置。
36. 什么是机器人?
Robots是搜索引擎公共协议,所有搜索引擎都支持。一般将robots.txt文本直接放在根目录下。我们可以使用robtos文本在网站上执行很多有用的操作,比如网站上没有内容
该页面被阻止。阻止论坛的垃圾邮件链接导出部分。
37. 什么是站点地图?
我们将站点地图称为 网站 地图。网站 地图有两种类型。一种是HTML格式,这样不仅用户可以查看,搜索引擎也可以抓取站点目录。还有一种XML的形式,是专门为搜索引擎提供的,但在搜索引擎中只有Google、Yahoo等支持xml映射。比如百度不支持xml,那我们怎么操作呢?直接提交sitemap.xml给百度就很简单了,这样百度蜘蛛就可以抓取里面的链接了。
38. 什么SEO工具?有那些SEO工具
SEO工具是指帮助SEOER人员进行SEO优化检查的小助手,可以为SEOER节省大量时间。我们经常使用FLASH站长工具,阿里妈妈,雅虎站长工具等等。当然,还有SITEMAP工具、反向链接查询工具、友情链接检查工具等等。
网页css js 抓取助手(网站优化需求熟练把握查找引擎算法规矩,既要把握网站底层代码的标准性书写)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-07 18:02
网站优化
网站优化需要掌握搜索引擎算法规则,不仅要掌握网站底层代码的标准编写,还要掌握优秀的策划和排名能力,坚持专业的原创 高质量的内容更新。因此,网站 优化不应该马虎。这是一个专业和技术问题。通常需要优化团队协作。团队必须细心、耐心和负责。
网站构建
一、网站优化前提和基础环境:
(一)网站 域名先决条件:
1.网站域名选择:域名解释简单易记,网站内容相关性较好。网站 域名是否为常用后缀com、cn或net等,部分后缀域名国内搜索引擎不识别,不支持存档。域名过长必然会影响网站的链接。搜索引擎对 URL 的长度有限制。长度过长的 URL。不会被认出来。
2.网站域名记录:网站域名记录是搜索引擎对网站声望的评判标准。正规的大型企事业单位的官网会首先显示在搜索引擎首页和排行榜上,没有记录的网站将被识别为灰色网站或风险网站被搜索引擎@>,不利于网站的进入和排名。
(二)网站 服务器基础环境:
1.服务器环境设备:高性能、高带宽、独立的IP服务器,可以使网站稳定运行和发展,是寻找网站引擎得分的重要参考。一些功能低下、流量受限的虚拟主机往往被简单攻击,构成网站运行错误或无法打开,往往会受到搜索引擎的奖惩。
2.网站 运维操作:具有专业技能的程序员可以保证网站的正常运行和安全的数据备份。相反,网站经常遭受攻击或数据丢失,会给网站带来毁灭性的损失,更不用说网站优化了。
二、网站 优化方向:站内优化和站外优化
(一)站内优化:站内优化包括网站排版结构优化、网站底层代码优化、网页优化、网站程序优化、网站@ > 内链优化及网站原创内容更新。
(二)站外优化:站外优化包括网站的外链建设指导,站外渠道曝光网站信息,增加品牌搜索点击量。
三、网站 优化的基本操作细节:
(一)网站的生成规则:
1. URL 可以生成动态和静态。所谓静态网址的主要特征是htm、html、shtml、xml等以后缀结尾,而动态网址的主要特征是PHP、ASP、JSP、Perl等。最后不具备静态URL的后缀特性。虽然搜索引擎都表示对网页的布局不屑一顾,但静态页面在搜索引擎蜘蛛抓取和优化保护方面优势明显。例如网站数据库遭到恶意攻击,动态网站内容随机损坏或消失,静态网站仍然是保存完好的静态Web路径。前者随机出现大量404或网页乱码,
2.开启https网络协议和cdn加速:https与http网络数据传输安全通道相关,现在搜索引擎明确指出https站点有加权重和流量处理,优先显示网站排名,CDN加速还处理了由于地域或网络环境差异导致网页加载缓慢的问题,尤其是移动端网站。搜索引擎明确规定,打开速度直接影响网站的权重和流量。
(二)网站 标准编写代码:
1.网页标题和meta标签的标准书写:标题标签是网页内容信息介绍的重点,meta标签可以收录文章、关键词的描述、作者信息、版权信息、网页编码、图像识别阅读兼容方式、单页蜘蛛爬取约束,就像一个产品的参数和特性一样。标签只显示在源代码中,普通访问者看不到,但可以被搜索引擎蜘蛛识别。也是搜索引擎添加索引和查找词匹配的关键点。文字必须准确、有能力,并适合网页的内容。所有信息必须是唯一的和唯一的。
2.网站 标题H标签标准写法:h1-h6。h标签是网页要点分类的呈现和陈述,权重从h1递减到h6。搜索引擎蜘蛛可以识别网页内容的层次链接。h1 标题在单个网页中只能出现一次,就像 文章 的标题一样。
3. 锚文本的标准写法:锚文本是否习惯,加上title="title",可以引导蜘蛛理解链接的内容。如果不加,对蜘蛛来说就像一个灰色区域,是不知道的东西,这会降低蜘蛛的抓取速度,以及关于一些出站链接或敏感链接,是否已经做出了停止抓取的单一指令在锚文本中,rel="nofollow",写成ahref="/"Title="title" rel="nofollow"。对于一些站外链接,需要添加target=_blank作为新窗口打开,防止避免网站无法回源,减少流量损失,建议一个网页中不要收录相同的锚文本链接,
4.图片源img的标准书写:按照常规的标准书写格式,一张图片的格式应该是alt=\"portrait\", src=\"/\", width=\"\ ",height=\" \", 包括图片的描述、比例尺的大小、图片的来源地址、关于一些一般图片,甚至可以添加标题来引导访问者了解图片的含义,没有描述的图片,搜索引擎蜘蛛无法识别图片的内容和含义,没有比例标记,搜索引擎蜘蛛无法区分图片的正确比例,这会降低网页的摘要分数。
5. js和css的标准写法:一个网页最好只收录一个js或者css。太多js提倡合并和请求,可以减少网页加载的时间。对于一些相同的样式,css主张剪新的。如果js和css的内容比较大,可以进行压缩。对于js和css的样式编写,要进行兼容性测试,并添加兼容的样式,否则在单个用户的阅读器上可能会出现变形,不利于访问者的体验,反弹网站 的比率将被添加。
6. 网页代码紧缩:如果网页代码很多,可以进行代码紧缩。搜索引擎蜘蛛在识别网页代码方面是资源受限的。超过一定长度和超出内容,搜索引擎蜘蛛将难以识别并降低分数。
(三)词库构建及内链标准应用:
1.词库是一个网站有计划的长期优化方向。网站的权重是网站流量大小的标志,而网站的排名往往是指网站的权重。关键词文章具有搜索索引和排名,可以直接增加网站的流量,带来网站的权重,促进网站的自然排名。
2.网页内链设置及应用:网站系统的许多免费版本现在都有后台关键词保护、标签标签保护等功能,相关内链锚文本显示在网页内容 其中,可以提高访问者的停留时间和阅读深度,可以降低网站的跳出率。标签和内容页和列表页的标准应用可以提升搜索引擎蜘蛛的强度和频率。,不仅可以提高访问者的阅读量,还可以增加百度索引,提高内容进入次数和站外匹配搜索次数关键词。
(四)设置网站提交链接:
1.网站地图站点地图制作:站点地图收录两种格式,sitemap.xml和sitemap.html,列出了网站的所有内容和URL路径。sitemap.xml格式文件主要用于站长后台链接的提交和更新,包括网站内容更新网络频道、更新时间、作者和频率等信息,sitemap.html可用于访问者轻松阅读整个网站的栏目,有利于提高访问者的体验 作用也有利于搜索引擎蜘蛛的抓取。
2.网站内容自动推送:随着搜索引擎的发展和完善,现在各大搜索引擎的后台都有网站自动推送功能。界面根据搜索引擎提供的链接提交。使php链接自动推送的文件可以更快地被搜索引擎输入。
3.网站 内容自动推送:搜索引擎现在也推出了自动推送js功能。当访问者阅读网站的内容时,会自动触发提交链接信息,这也是一种适合访问者搜索体验的功能,可以配合自动推送和站点地图使用。
(五)URL路径长度的调整:
1.网站 方法的合理调整: 网站 方法代表了网站结构的层次区分。为此,搜索引擎蜘蛛给出了由大到小的权重,网站的结构清晰合理,手法得当,可以让搜索引擎更好地识别网站@的要点>. 比如网站系统的网站sitemap、rssmap、rss文件默认都在data库目录下,这个目录一般会被robots列为防止爬虫,因为它收录一个大量的数据库文件,以及一些数据库帐户密码和地址的敏感信息。因此,将此路径升级到网站的根目录
2.网站 栏目命名规则和简洁写法:搜索引擎对URL的长度有明确的要求。如果超过长度,URL 将难以识别和输入。因此,建议在列和子列之间简洁明了,命名简单,区分为最好。
(六)网站 功能页面设置:
1.网站404页面设置:网站内容难以防止代码错误的网页,删除的页面,404页面过多,会构成大量重复页面,搜索引擎将他们识别为网站作弊降低索引,减少进入和降低权限等。为此,制作一个定向404y页面并正确返回404状态码,不仅可以降低访问者的跳出率,但也要防止来自搜索引擎的奖励和惩罚。
<p>2.网站 301状态码的设置:网站 域名的顶级域名比二级以下域名的权重更重要。对于网站域名,访问者经常使用www的前两个。一级域名是习惯性的。为此,为了更好的承载前沿域名的重量,可以做301域名重定向。否则,网站很可能会显示网站的首页不在第一位,从而失去网站的权重,对 查看全部
网页css js 抓取助手(网站优化需求熟练把握查找引擎算法规矩,既要把握网站底层代码的标准性书写)
网站优化
网站优化需要掌握搜索引擎算法规则,不仅要掌握网站底层代码的标准编写,还要掌握优秀的策划和排名能力,坚持专业的原创 高质量的内容更新。因此,网站 优化不应该马虎。这是一个专业和技术问题。通常需要优化团队协作。团队必须细心、耐心和负责。
网站构建
一、网站优化前提和基础环境:
(一)网站 域名先决条件:
1.网站域名选择:域名解释简单易记,网站内容相关性较好。网站 域名是否为常用后缀com、cn或net等,部分后缀域名国内搜索引擎不识别,不支持存档。域名过长必然会影响网站的链接。搜索引擎对 URL 的长度有限制。长度过长的 URL。不会被认出来。
2.网站域名记录:网站域名记录是搜索引擎对网站声望的评判标准。正规的大型企事业单位的官网会首先显示在搜索引擎首页和排行榜上,没有记录的网站将被识别为灰色网站或风险网站被搜索引擎@>,不利于网站的进入和排名。
(二)网站 服务器基础环境:
1.服务器环境设备:高性能、高带宽、独立的IP服务器,可以使网站稳定运行和发展,是寻找网站引擎得分的重要参考。一些功能低下、流量受限的虚拟主机往往被简单攻击,构成网站运行错误或无法打开,往往会受到搜索引擎的奖惩。
2.网站 运维操作:具有专业技能的程序员可以保证网站的正常运行和安全的数据备份。相反,网站经常遭受攻击或数据丢失,会给网站带来毁灭性的损失,更不用说网站优化了。
二、网站 优化方向:站内优化和站外优化
(一)站内优化:站内优化包括网站排版结构优化、网站底层代码优化、网页优化、网站程序优化、网站@ > 内链优化及网站原创内容更新。
(二)站外优化:站外优化包括网站的外链建设指导,站外渠道曝光网站信息,增加品牌搜索点击量。
三、网站 优化的基本操作细节:
(一)网站的生成规则:
1. URL 可以生成动态和静态。所谓静态网址的主要特征是htm、html、shtml、xml等以后缀结尾,而动态网址的主要特征是PHP、ASP、JSP、Perl等。最后不具备静态URL的后缀特性。虽然搜索引擎都表示对网页的布局不屑一顾,但静态页面在搜索引擎蜘蛛抓取和优化保护方面优势明显。例如网站数据库遭到恶意攻击,动态网站内容随机损坏或消失,静态网站仍然是保存完好的静态Web路径。前者随机出现大量404或网页乱码,
2.开启https网络协议和cdn加速:https与http网络数据传输安全通道相关,现在搜索引擎明确指出https站点有加权重和流量处理,优先显示网站排名,CDN加速还处理了由于地域或网络环境差异导致网页加载缓慢的问题,尤其是移动端网站。搜索引擎明确规定,打开速度直接影响网站的权重和流量。
(二)网站 标准编写代码:
1.网页标题和meta标签的标准书写:标题标签是网页内容信息介绍的重点,meta标签可以收录文章、关键词的描述、作者信息、版权信息、网页编码、图像识别阅读兼容方式、单页蜘蛛爬取约束,就像一个产品的参数和特性一样。标签只显示在源代码中,普通访问者看不到,但可以被搜索引擎蜘蛛识别。也是搜索引擎添加索引和查找词匹配的关键点。文字必须准确、有能力,并适合网页的内容。所有信息必须是唯一的和唯一的。
2.网站 标题H标签标准写法:h1-h6。h标签是网页要点分类的呈现和陈述,权重从h1递减到h6。搜索引擎蜘蛛可以识别网页内容的层次链接。h1 标题在单个网页中只能出现一次,就像 文章 的标题一样。
3. 锚文本的标准写法:锚文本是否习惯,加上title="title",可以引导蜘蛛理解链接的内容。如果不加,对蜘蛛来说就像一个灰色区域,是不知道的东西,这会降低蜘蛛的抓取速度,以及关于一些出站链接或敏感链接,是否已经做出了停止抓取的单一指令在锚文本中,rel="nofollow",写成ahref="/"Title="title" rel="nofollow"。对于一些站外链接,需要添加target=_blank作为新窗口打开,防止避免网站无法回源,减少流量损失,建议一个网页中不要收录相同的锚文本链接,
4.图片源img的标准书写:按照常规的标准书写格式,一张图片的格式应该是alt=\"portrait\", src=\"/\", width=\"\ ",height=\" \", 包括图片的描述、比例尺的大小、图片的来源地址、关于一些一般图片,甚至可以添加标题来引导访问者了解图片的含义,没有描述的图片,搜索引擎蜘蛛无法识别图片的内容和含义,没有比例标记,搜索引擎蜘蛛无法区分图片的正确比例,这会降低网页的摘要分数。
5. js和css的标准写法:一个网页最好只收录一个js或者css。太多js提倡合并和请求,可以减少网页加载的时间。对于一些相同的样式,css主张剪新的。如果js和css的内容比较大,可以进行压缩。对于js和css的样式编写,要进行兼容性测试,并添加兼容的样式,否则在单个用户的阅读器上可能会出现变形,不利于访问者的体验,反弹网站 的比率将被添加。
6. 网页代码紧缩:如果网页代码很多,可以进行代码紧缩。搜索引擎蜘蛛在识别网页代码方面是资源受限的。超过一定长度和超出内容,搜索引擎蜘蛛将难以识别并降低分数。
(三)词库构建及内链标准应用:
1.词库是一个网站有计划的长期优化方向。网站的权重是网站流量大小的标志,而网站的排名往往是指网站的权重。关键词文章具有搜索索引和排名,可以直接增加网站的流量,带来网站的权重,促进网站的自然排名。
2.网页内链设置及应用:网站系统的许多免费版本现在都有后台关键词保护、标签标签保护等功能,相关内链锚文本显示在网页内容 其中,可以提高访问者的停留时间和阅读深度,可以降低网站的跳出率。标签和内容页和列表页的标准应用可以提升搜索引擎蜘蛛的强度和频率。,不仅可以提高访问者的阅读量,还可以增加百度索引,提高内容进入次数和站外匹配搜索次数关键词。
(四)设置网站提交链接:
1.网站地图站点地图制作:站点地图收录两种格式,sitemap.xml和sitemap.html,列出了网站的所有内容和URL路径。sitemap.xml格式文件主要用于站长后台链接的提交和更新,包括网站内容更新网络频道、更新时间、作者和频率等信息,sitemap.html可用于访问者轻松阅读整个网站的栏目,有利于提高访问者的体验 作用也有利于搜索引擎蜘蛛的抓取。
2.网站内容自动推送:随着搜索引擎的发展和完善,现在各大搜索引擎的后台都有网站自动推送功能。界面根据搜索引擎提供的链接提交。使php链接自动推送的文件可以更快地被搜索引擎输入。
3.网站 内容自动推送:搜索引擎现在也推出了自动推送js功能。当访问者阅读网站的内容时,会自动触发提交链接信息,这也是一种适合访问者搜索体验的功能,可以配合自动推送和站点地图使用。
(五)URL路径长度的调整:
1.网站 方法的合理调整: 网站 方法代表了网站结构的层次区分。为此,搜索引擎蜘蛛给出了由大到小的权重,网站的结构清晰合理,手法得当,可以让搜索引擎更好地识别网站@的要点>. 比如网站系统的网站sitemap、rssmap、rss文件默认都在data库目录下,这个目录一般会被robots列为防止爬虫,因为它收录一个大量的数据库文件,以及一些数据库帐户密码和地址的敏感信息。因此,将此路径升级到网站的根目录
2.网站 栏目命名规则和简洁写法:搜索引擎对URL的长度有明确的要求。如果超过长度,URL 将难以识别和输入。因此,建议在列和子列之间简洁明了,命名简单,区分为最好。
(六)网站 功能页面设置:
1.网站404页面设置:网站内容难以防止代码错误的网页,删除的页面,404页面过多,会构成大量重复页面,搜索引擎将他们识别为网站作弊降低索引,减少进入和降低权限等。为此,制作一个定向404y页面并正确返回404状态码,不仅可以降低访问者的跳出率,但也要防止来自搜索引擎的奖励和惩罚。
<p>2.网站 301状态码的设置:网站 域名的顶级域名比二级以下域名的权重更重要。对于网站域名,访问者经常使用www的前两个。一级域名是习惯性的。为此,为了更好的承载前沿域名的重量,可以做301域名重定向。否则,网站很可能会显示网站的首页不在第一位,从而失去网站的权重,对
网页css js 抓取助手(智能模式检测WebHarvy自动识别网页数据采集器的软件特征及特征)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-27 09:23
SysNucleus WebHarvy 是一款非常优秀的网页数据采集器,旨在让您能够自动从网页中提取数据并将提取的内容以不同的格式保存。使用 WebHarvy,从网页捕获数据就像导航到收录数据的页面并单击要捕获的数据一样简单。欢迎有需要的朋友下载。
软件说明:
WebHarvy 是一个方便的应用程序,旨在使您能够自动从网页中提取数据并将提取的内容以不同的格式保存。使用 WebHarvy,从网页捕获数据就像导航到收录数据的页面并单击要捕获的数据一样简单。
WebHarvy 将智能识别出现在网页中的数据模式。使用WebHarvy,您可以从各种网站(如房地产、电子商务、学术研究、娱乐、科技等)中提取数据,例如产品目录或搜索结果。
从网页中提取的数据可以以多种格式保存。网页通常在多个页面中显示搜索结果等数据。WebHarvy 可以自动抓取网络并从多个页面中提取数据。
软件特点:
简单的网络搜索
WebHarvy 的点击式界面使 Web Scraping 变得容易。绝对不需要编写任何代码或脚本来抓取数据。您将使用WebHarvy 的内置浏览器加载网站,您可以通过单击鼠标选择要提取的数据。就是这么简单!(视频)
智能模式检测
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中获取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,WebHarvy 会自动抓取它。保存到文件或数据库
您可以以多种格式保存从网站 中提取的数据。当前版本的 WebHarvyWeb 搜索软件允许您将提取的数据保存为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。(了解更多)
获取多个页面
网站 产品列表或搜索结果等数据通常显示在多个页面上。WebHarvy 可以自动抓取网络并从多个页面中提取数据。只需指出“加载下一页的链接”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。(了解更多)
提交关键词
通过自动提交输入关键字列表来搜索表单来擦除数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以从所有输入关键字组合的搜索结果中提取数据。(了解更多)(视频)
隐私保护
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。(了解更多)
分类抓取
WebHarvyWeb 爬虫允许您从链接列表中抓取数据,这会导致网站 中出现类似的页面/列表。这允许您使用单个配置来抓取 网站 内的类别和子类别。(了解更多)(视频)
常用表达
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并抓取匹配的部分。这种强大的技术在您抓取数据时提供了更大的灵活性。(了解更多)(正则表达式教程)
JavaScript 支持
在提取数据之前,请在浏览器中运行您自己的 JavaScript 代码。它可用于与页面元素进行交互、修改 DOM 或调用已在目标页面中实现的 JavaScript 函数。(了解更多)
图像提取
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站 产品详细信息页面中的多个图像。(了解更多)
自动化浏览器任务
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面和打开弹出窗口。
技术援助
购买 WebHarvy 后,您将在购买之日起 1 年内获得我们的免费更新和免费支持。
WebHarvy 入门:
1.首先,下载并安装WebHarvy的免费试用版。
2.在这里观看软件的基本演示视频。
3.观看更详细的视频教程。
4. 这里提供在线教程/功能帮助。
5. 尝试根据您的要求配置 WebHarvy 来提取数据,如果您遇到任何困难,请在此处联系我们的支持并提供必要的详细信息。
6.我们在这里的YouTube频道采集了大量视频,展示了各种网站的配置流程和数据提取要求。 查看全部
网页css js 抓取助手(智能模式检测WebHarvy自动识别网页数据采集器的软件特征及特征)
SysNucleus WebHarvy 是一款非常优秀的网页数据采集器,旨在让您能够自动从网页中提取数据并将提取的内容以不同的格式保存。使用 WebHarvy,从网页捕获数据就像导航到收录数据的页面并单击要捕获的数据一样简单。欢迎有需要的朋友下载。
软件说明:
WebHarvy 是一个方便的应用程序,旨在使您能够自动从网页中提取数据并将提取的内容以不同的格式保存。使用 WebHarvy,从网页捕获数据就像导航到收录数据的页面并单击要捕获的数据一样简单。
WebHarvy 将智能识别出现在网页中的数据模式。使用WebHarvy,您可以从各种网站(如房地产、电子商务、学术研究、娱乐、科技等)中提取数据,例如产品目录或搜索结果。
从网页中提取的数据可以以多种格式保存。网页通常在多个页面中显示搜索结果等数据。WebHarvy 可以自动抓取网络并从多个页面中提取数据。
软件特点:
简单的网络搜索
WebHarvy 的点击式界面使 Web Scraping 变得容易。绝对不需要编写任何代码或脚本来抓取数据。您将使用WebHarvy 的内置浏览器加载网站,您可以通过单击鼠标选择要提取的数据。就是这么简单!(视频)
智能模式检测
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中获取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,WebHarvy 会自动抓取它。保存到文件或数据库
您可以以多种格式保存从网站 中提取的数据。当前版本的 WebHarvyWeb 搜索软件允许您将提取的数据保存为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。(了解更多)
获取多个页面
网站 产品列表或搜索结果等数据通常显示在多个页面上。WebHarvy 可以自动抓取网络并从多个页面中提取数据。只需指出“加载下一页的链接”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。(了解更多)
提交关键词
通过自动提交输入关键字列表来搜索表单来擦除数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以从所有输入关键字组合的搜索结果中提取数据。(了解更多)(视频)
隐私保护
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。(了解更多)
分类抓取
WebHarvyWeb 爬虫允许您从链接列表中抓取数据,这会导致网站 中出现类似的页面/列表。这允许您使用单个配置来抓取 网站 内的类别和子类别。(了解更多)(视频)
常用表达
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并抓取匹配的部分。这种强大的技术在您抓取数据时提供了更大的灵活性。(了解更多)(正则表达式教程)
JavaScript 支持
在提取数据之前,请在浏览器中运行您自己的 JavaScript 代码。它可用于与页面元素进行交互、修改 DOM 或调用已在目标页面中实现的 JavaScript 函数。(了解更多)
图像提取
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站 产品详细信息页面中的多个图像。(了解更多)
自动化浏览器任务
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面和打开弹出窗口。
技术援助
购买 WebHarvy 后,您将在购买之日起 1 年内获得我们的免费更新和免费支持。
WebHarvy 入门:
1.首先,下载并安装WebHarvy的免费试用版。
2.在这里观看软件的基本演示视频。
3.观看更详细的视频教程。
4. 这里提供在线教程/功能帮助。
5. 尝试根据您的要求配置 WebHarvy 来提取数据,如果您遇到任何困难,请在此处联系我们的支持并提供必要的详细信息。
6.我们在这里的YouTube频道采集了大量视频,展示了各种网站的配置流程和数据提取要求。
网页css js 抓取助手(程序员最常用的工具利器介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-20 03:05
分为四类:
俗话说,工欲善其事,必先利其器。所以作为一个网页开发者,各种提高工作/学习效率的工具当然是必不可少的。给我们的程序员介绍一些最常用的开发工具。
一、小助手1.掘金
与第一个Infinity New Tab(首屏主题)插件类似,Nuggets是一款笔者认为前端开发者必备的好插件。只需打开新标签页就可以看到每天推荐的优质文章和GitHub项目,让开发者更好地了解技术的发展趋势。
2. 云 IDE:Repl.it
支持编译运行70多种语言,包括C、Python、JavaScript、Ruby等,无需下载,即刻使用。选择内容右键点击触发。非常方便,节省了打开编译器或搜索在线编译的时间网站。
如果有围墙,可以使用:le/22
3. 键盘派对:Vimium
如果你是 Linux 系统的爱好者,你一定知道 Vim 编辑器。这个 Vimium 插件继承了 vim 编辑器的常用操作。有了它,无论是浏览网页、切换标签页、搜索还是其他任何操作,都可以只用键盘来完成,是不是很hacky?
翻页过程中:(按F/ESC键进入/退出键盘模式)
4. 排版转换:Markdown Here
作为程序员,写技术笔记总结文章当然少不了,但是作者一直习惯Markdown语法,微信不支持,怎么办?有了它,您可以随时将语法更改为兼容微信排版。
5. 前端助手:FeHelper.JSON
前端开发人员的福音,包括许多有用的小工具。右键单击以快速启动。
二、网页信息获取类1. 网页样式:CSSViewer
当我们要模仿或设计网页时,需要查看网站的CSS样式。有了它,您可以快速查看当前网页元素的各种 CSS 属性。
笔者专门测试了两个插件:另一个类似的插件是code cola,用户可以根据自己的需要进行选择。
点击插件图标触发,也可以设置快捷键
2. 网页标尺:尺寸
在网页上,我们经常需要测量页面上元素的大小。我们应该做什么?使用他。
笔者专门测试了两个插件: 另一个类似的插件是Page Ruler,用户可以根据自己的需要进行选择。
点击插件图标触发,也可以设置快捷键
3. 网页取色:ColorZilla
这个ColorZilla插件不仅弥补了之前CSSViewer插件无法选取图片的颜色,它还可以选取网页上任何元素的颜色。
对比一下ColorZilla、Eye Droppe和ColorPick Eyedropper的测试:第一个最方便,第二个最小,第三个最强大。作者推荐第一段。
4. 网页元素位置:农药
突出显示每个元素在页面上的位置,不同的线条颜色可以很好地识别父子元素和兄弟元素之间的关系。
5. 网络爬虫辅助:Xpath Helper
这是一个网络爬虫的解析工具。它可以轻松获取HTML元素的xPath,避免了搜索html源代码定位一些id和class找到对应的位置来解析网页。
6. 网络爬虫工具:Spider
插件名称为Spider——一款智能网页抓取工具。这是一款点击式插件,可以一键抓取网页结构化数据,生成JSON和CSV文件。无需编程经验,轻松抓取批量网站内容需求:如产品介绍、新闻标题、表格中的行列数据……有了它,你可以减少整理数据后的时间复制和粘贴。
7. Web 开发工具:Web Developer
功能非常强大,主要由以下几部分组成:禁用、Cookies、CSS、表单、图像、信息、杂项、大纲、调整大小、工具、查看源和选项。这里就不一一介绍了。
修改完成后刷新页面即可生效。我认为它可以取代仅对 cookie 进行操作的 EditThisCookie 插件。
8. 网站 技术分析:WhatRuns
单击以查找您访问的 网站 上涉及的任何技术,检测技术更改并接收通知。
虽然可以看懂网站的源码,但是效率不高,可能会漏掉一些技巧
三、网页调试类1.插件版邮递员:Talend API Tester
Talend API Tester 插件是一个类似于 Postman 的 api 接口测试工具,可以轻松测试 HTTP 和 REST API。与Postman相比,Talend API Tester无需安装本地客户端,即装即用,占用空间小,功能强大。
2. 网络代理:Proxy Switchy Omega
Proxy Switchy Omega插件用于代理一些国内无法访问的网站。支持多种模式,切换方便,规则编写简单,支持PAC、Switchy和AutoProxy列表。O|>|O
相关设置可以参考:
3. 多终端模拟:User Agent
Chrome 插件的 User Agent Switcher 可以将 Chrome 浏览器伪装成多种不同浏览器发送请求页面,让您轻松测试不同端页面之间的差异,避免安装和启动多个浏览器的麻烦。
其实Chrome浏览器也自带这个功能:开发者工具-->点击界面中的三个点-->更多工具-->网络条件-->取消勾选自动选择
4. IE核心操作:IE Tab
与上面的User Agent不同,IE Tab用IE内核实现了chrome选项卡中网页的正常显示,不仅方便开发和测试,还可以解决各种网银控件在chrome中无法使用的问题.
5. 调试 vue:Vue.js DevTools
Vue.js devtools 是一个开发者浏览器扩展,用于调试基于 google chrome 浏览器的 vue.js 应用程序。做前端开发的IT工程师应该对这个工具比较熟悉,可以边看边栏边的页面边检查代码。
Vue 是数据驱动的,在开发和调试的时候查看 DOM 结构是解析不出来的。所以你需要使用工具
6. 调试 React:React 开发人员
React Developer Tools 是由 facebook 开发的一个有用的 Chrome 浏览器扩展。通过它,我们可以查看应用程序的 React 组件层次结构,而不是更神秘的浏览器 DOM 表示。
7. 调试角度:AngularJS Batarang
angularjs batarang 是为谷歌浏览器用户创建的angular项目调试插件,与前两款机型类似。
四、Github 助手类
如果某些插件不能正常使用,可能需要到github设置访问令牌:github—>设置——>开发者设置——>个人访问令牌——>生成新令牌——>检查gist,repo—— >generate 将令牌值复制到插件配置选项中以显示它。
1. 文件下载助手:GitZip for github
打开GitHub上的项目,双击要下载的文件或文件夹的空白处,然后文件或文件夹前面会出现一个钩子,表示已被选中,并且会出现一个下载按钮浏览器的右下角。点击下载按钮下载对应的文件。
避免某个文件/文件夹下载整个仓库慢的尴尬
2. 单文件下载助手:增强型GitHub
显示 Github 当前仓库的整体大小和每个单独文件的文件大小。还增加了单个文件下载支持,也避免了某个文件整个仓库下载慢的尴尬情况。
要使用,去github设置token:github-->Settings-->Developer settings-->Personal access tokens--->Generate new token---> check gist, repo--->将生成的token值复制到插件配置选项 待显示。
3. 浮动快速预览:GitHub Hovercard
该插件为我们提供了鼠标悬停预览功能。每次查看其他个人信息、项目信息、问题信息时,都需要进入相关页面查看信息。国内访问github不快,所以很方便。
4. 显示文件树:Octotree
Octotree 插件可以让你像你的电脑文件夹一样在 GitHub 上快速浏览和搜索关键代码。由于国内访问github的速度不快,加载所有页面需要更多时间,非常方便。
5. 模拟 IDE:Sourcegraph
Sourcegraph 是一个 Chrome 扩展,它可以为 Github 上的代码添加即时文档和类型提示,并为每个标识符添加一个指向定义的链接。它允许您像浏览良好的 IDE 代码一样浏览源代码。
6. 浏览码工具:Octohint
功能比上面的Sourcegraph弱,但是加载速度更快。可以定位函数文件,高亮选中变量,显示变量类型等。
7.工作量:等距贡献
它可以将你每天贡献的数量(可以理解为向GitHub提交的数量)转换成不同颜色的三维直方图,并给出你自己的统计数据。
结束语
插件章节写了三章,近万字。插件都是作者这几年在使用过程中积累的。他们在工作和生活中都非常有帮助。有些零件以前没有使用过。我什至不知道如何非常方便地使用它。在编写Chrome插件文章的过程中,体会到了各种插件的强大。删除并整理了具有重复功能的插件。如果你觉得本章对你有帮助,请点赞/关注/转发到这里,以后会继续更新。当然,如果你觉得有更好的扩展需要推荐,请在下方留言给作者O|^|O。 查看全部
网页css js 抓取助手(程序员最常用的工具利器介绍)
分为四类:
俗话说,工欲善其事,必先利其器。所以作为一个网页开发者,各种提高工作/学习效率的工具当然是必不可少的。给我们的程序员介绍一些最常用的开发工具。
一、小助手1.掘金
与第一个Infinity New Tab(首屏主题)插件类似,Nuggets是一款笔者认为前端开发者必备的好插件。只需打开新标签页就可以看到每天推荐的优质文章和GitHub项目,让开发者更好地了解技术的发展趋势。
2. 云 IDE:Repl.it
支持编译运行70多种语言,包括C、Python、JavaScript、Ruby等,无需下载,即刻使用。选择内容右键点击触发。非常方便,节省了打开编译器或搜索在线编译的时间网站。
如果有围墙,可以使用:le/22
3. 键盘派对:Vimium
如果你是 Linux 系统的爱好者,你一定知道 Vim 编辑器。这个 Vimium 插件继承了 vim 编辑器的常用操作。有了它,无论是浏览网页、切换标签页、搜索还是其他任何操作,都可以只用键盘来完成,是不是很hacky?
翻页过程中:(按F/ESC键进入/退出键盘模式)
4. 排版转换:Markdown Here
作为程序员,写技术笔记总结文章当然少不了,但是作者一直习惯Markdown语法,微信不支持,怎么办?有了它,您可以随时将语法更改为兼容微信排版。
5. 前端助手:FeHelper.JSON
前端开发人员的福音,包括许多有用的小工具。右键单击以快速启动。
二、网页信息获取类1. 网页样式:CSSViewer
当我们要模仿或设计网页时,需要查看网站的CSS样式。有了它,您可以快速查看当前网页元素的各种 CSS 属性。
笔者专门测试了两个插件:另一个类似的插件是code cola,用户可以根据自己的需要进行选择。
点击插件图标触发,也可以设置快捷键
2. 网页标尺:尺寸
在网页上,我们经常需要测量页面上元素的大小。我们应该做什么?使用他。
笔者专门测试了两个插件: 另一个类似的插件是Page Ruler,用户可以根据自己的需要进行选择。
点击插件图标触发,也可以设置快捷键
3. 网页取色:ColorZilla
这个ColorZilla插件不仅弥补了之前CSSViewer插件无法选取图片的颜色,它还可以选取网页上任何元素的颜色。
对比一下ColorZilla、Eye Droppe和ColorPick Eyedropper的测试:第一个最方便,第二个最小,第三个最强大。作者推荐第一段。
4. 网页元素位置:农药
突出显示每个元素在页面上的位置,不同的线条颜色可以很好地识别父子元素和兄弟元素之间的关系。
5. 网络爬虫辅助:Xpath Helper
这是一个网络爬虫的解析工具。它可以轻松获取HTML元素的xPath,避免了搜索html源代码定位一些id和class找到对应的位置来解析网页。
6. 网络爬虫工具:Spider
插件名称为Spider——一款智能网页抓取工具。这是一款点击式插件,可以一键抓取网页结构化数据,生成JSON和CSV文件。无需编程经验,轻松抓取批量网站内容需求:如产品介绍、新闻标题、表格中的行列数据……有了它,你可以减少整理数据后的时间复制和粘贴。
7. Web 开发工具:Web Developer
功能非常强大,主要由以下几部分组成:禁用、Cookies、CSS、表单、图像、信息、杂项、大纲、调整大小、工具、查看源和选项。这里就不一一介绍了。
修改完成后刷新页面即可生效。我认为它可以取代仅对 cookie 进行操作的 EditThisCookie 插件。
8. 网站 技术分析:WhatRuns
单击以查找您访问的 网站 上涉及的任何技术,检测技术更改并接收通知。
虽然可以看懂网站的源码,但是效率不高,可能会漏掉一些技巧
三、网页调试类1.插件版邮递员:Talend API Tester
Talend API Tester 插件是一个类似于 Postman 的 api 接口测试工具,可以轻松测试 HTTP 和 REST API。与Postman相比,Talend API Tester无需安装本地客户端,即装即用,占用空间小,功能强大。
2. 网络代理:Proxy Switchy Omega
Proxy Switchy Omega插件用于代理一些国内无法访问的网站。支持多种模式,切换方便,规则编写简单,支持PAC、Switchy和AutoProxy列表。O|>|O
相关设置可以参考:
3. 多终端模拟:User Agent
Chrome 插件的 User Agent Switcher 可以将 Chrome 浏览器伪装成多种不同浏览器发送请求页面,让您轻松测试不同端页面之间的差异,避免安装和启动多个浏览器的麻烦。
其实Chrome浏览器也自带这个功能:开发者工具-->点击界面中的三个点-->更多工具-->网络条件-->取消勾选自动选择
4. IE核心操作:IE Tab
与上面的User Agent不同,IE Tab用IE内核实现了chrome选项卡中网页的正常显示,不仅方便开发和测试,还可以解决各种网银控件在chrome中无法使用的问题.
5. 调试 vue:Vue.js DevTools
Vue.js devtools 是一个开发者浏览器扩展,用于调试基于 google chrome 浏览器的 vue.js 应用程序。做前端开发的IT工程师应该对这个工具比较熟悉,可以边看边栏边的页面边检查代码。
Vue 是数据驱动的,在开发和调试的时候查看 DOM 结构是解析不出来的。所以你需要使用工具
6. 调试 React:React 开发人员
React Developer Tools 是由 facebook 开发的一个有用的 Chrome 浏览器扩展。通过它,我们可以查看应用程序的 React 组件层次结构,而不是更神秘的浏览器 DOM 表示。
7. 调试角度:AngularJS Batarang
angularjs batarang 是为谷歌浏览器用户创建的angular项目调试插件,与前两款机型类似。
四、Github 助手类
如果某些插件不能正常使用,可能需要到github设置访问令牌:github—>设置——>开发者设置——>个人访问令牌——>生成新令牌——>检查gist,repo—— >generate 将令牌值复制到插件配置选项中以显示它。
1. 文件下载助手:GitZip for github
打开GitHub上的项目,双击要下载的文件或文件夹的空白处,然后文件或文件夹前面会出现一个钩子,表示已被选中,并且会出现一个下载按钮浏览器的右下角。点击下载按钮下载对应的文件。
避免某个文件/文件夹下载整个仓库慢的尴尬
2. 单文件下载助手:增强型GitHub
显示 Github 当前仓库的整体大小和每个单独文件的文件大小。还增加了单个文件下载支持,也避免了某个文件整个仓库下载慢的尴尬情况。
要使用,去github设置token:github-->Settings-->Developer settings-->Personal access tokens--->Generate new token---> check gist, repo--->将生成的token值复制到插件配置选项 待显示。
3. 浮动快速预览:GitHub Hovercard
该插件为我们提供了鼠标悬停预览功能。每次查看其他个人信息、项目信息、问题信息时,都需要进入相关页面查看信息。国内访问github不快,所以很方便。
4. 显示文件树:Octotree
Octotree 插件可以让你像你的电脑文件夹一样在 GitHub 上快速浏览和搜索关键代码。由于国内访问github的速度不快,加载所有页面需要更多时间,非常方便。
5. 模拟 IDE:Sourcegraph
Sourcegraph 是一个 Chrome 扩展,它可以为 Github 上的代码添加即时文档和类型提示,并为每个标识符添加一个指向定义的链接。它允许您像浏览良好的 IDE 代码一样浏览源代码。
6. 浏览码工具:Octohint
功能比上面的Sourcegraph弱,但是加载速度更快。可以定位函数文件,高亮选中变量,显示变量类型等。
7.工作量:等距贡献
它可以将你每天贡献的数量(可以理解为向GitHub提交的数量)转换成不同颜色的三维直方图,并给出你自己的统计数据。
结束语
插件章节写了三章,近万字。插件都是作者这几年在使用过程中积累的。他们在工作和生活中都非常有帮助。有些零件以前没有使用过。我什至不知道如何非常方便地使用它。在编写Chrome插件文章的过程中,体会到了各种插件的强大。删除并整理了具有重复功能的插件。如果你觉得本章对你有帮助,请点赞/关注/转发到这里,以后会继续更新。当然,如果你觉得有更好的扩展需要推荐,请在下方留言给作者O|^|O。

