
网页css js 抓取助手
网页css js 抓取助手(在线版的CSS3代码生成工具,你get到了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2022-04-20 04:01
来自:南瓜编程公众号
我们整理了25个前端相关的学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望有可以帮到大家!
▍CSS相关
●1
CSSBattle-在线 CSS 大赛
Competition CSS Online,一款非常有趣的竞技游戏,共12个关卡,要求你使用HTML和CSS来100%还原它给出的页面,然后最小化代码,你也可以查看全球排行榜,看看解决办法。
●2
学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS的基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
●3
Flexbox Froggy - 一个学习Flex布局的小游戏
一个引导学习flex布局的游戏,用flex布局让青蛙跳到荷叶上就完成了,游戏收录了几乎所有常用的属性,很好学,形象好记,谁是Flex如果对布局不熟悉,这里多练习一下。
●4
EnjoyCSS-在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。就像在本地使用 PS 或 AI 软件一样。
●5
CSS-Tricks-CSS 技巧
此网站 会不断更新,提供一些关于 CSS 技术的优秀教程和技巧,每天更新文章。
●6
新拟态——实现新的模仿效果
可以轻松实现新的模仿效果,不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数,并提供CSS可以直接复制的代码。
●7
uiGradients-分享渐变
一个提供渐变色效果的网站,有近百种渐变色方案,可以根据自己的风格选择搭配,直接获取渐变色对应的CSS代码。
▍JS相关
●8
JavaScript 秘密花园
一个不断更新的JavaScript语法文档,主要写如何避免一些常见的错误,以及寻找难以发现的Bug,深入了解JavaScript的语言特性。
●9
JSTips-JS 技巧
每天都有一点 Javascript 知识。
●10
JSweekly - 科技周刊
每周专门讨论 Javascript 的技术期刊。
●11
CDNJS - JavaScript 库
CDNJS 为开发者提供最新的前端网页开发资源,免费使用,不受限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端的CDN服务中排名第二(第一是Google),性能优异。
●12
Beautiful Open - 开源 JS 库合集
采集各种设计优秀的开源项目,从cms内容管理系统到常用的Javascript库,适合网站开发的用户使用。
●13
JavaScript Fun - 代码库集合
目前最流行的 JavaScript 代码库合集,展示人气排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow - 程序员问答网络
全球 IT 社区中最受欢迎的技术问答之一网站,一个用于解决错误的社区,被称为“编程的 100,000 个为什么”。
●15
掘金 - 优质技术社区
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术文章包括Android、iOS、前端和后端资源。
●16
Codrops - 网页设计和开发博客
发布技术文章和网络教程,提供经验,避免陷阱,资源丰富。许多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码的工具,上面有各种效果的案例特效(炫技),可以自己开发基于他们的演示设计的前端。
●18
代码沙盒
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。 React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
●19
JSBin
又一款轻量级在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材都是常用的图标,可以点击官方提供的素材进行二次设计。同时还可以导出设计好的图标。
●21
OpenMoji - 免费表情符号库
提供源码表情库,免费下载使用。
● 22
分享图标 - 免费矢量素材库
提供超过250,000种ICON矢量图素材,120多个类别,所有素材均以PNG和SVG格式提供,素材有512*512、256*25等多种尺寸可供选择6、128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
● 23
tableconvert - 在线表格编辑器
强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的转换。当您需要转换表格,但又无法使其变形时,请尝试使用此工具。
● 24
Feathericons - 极简图标图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发,图标格式为SVG。
● 25
HTML5 + CSS 3 免费模板
提供大量HTML5模板,用户可以自己分享和修改模板。
本文推荐网站总结:
CSSbattle:
学习 CSS 布局:
Flexbox Froggy:
享受CSS:
CSS 技巧:
新拟态:
uiGradients:
JavaScript:
JS 提示:
JS 周刊:
CDNJS:
美丽的开放:
JavaScript 乐趣:
堆栈溢出:
掘金队:
Codrops:
代码笔:
代码沙盒:
JS斌:
图标:
OpenMoji:
分享图标:
表格转换:
羽毛图标:
HTML5UP: 查看全部
网页css js 抓取助手(在线版的CSS3代码生成工具,你get到了吗?)
来自:南瓜编程公众号
我们整理了25个前端相关的学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望有可以帮到大家!
▍CSS相关
●1
CSSBattle-在线 CSS 大赛
Competition CSS Online,一款非常有趣的竞技游戏,共12个关卡,要求你使用HTML和CSS来100%还原它给出的页面,然后最小化代码,你也可以查看全球排行榜,看看解决办法。
●2
学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS的基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
●3
Flexbox Froggy - 一个学习Flex布局的小游戏
一个引导学习flex布局的游戏,用flex布局让青蛙跳到荷叶上就完成了,游戏收录了几乎所有常用的属性,很好学,形象好记,谁是Flex如果对布局不熟悉,这里多练习一下。
●4
EnjoyCSS-在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。就像在本地使用 PS 或 AI 软件一样。
●5
CSS-Tricks-CSS 技巧
此网站 会不断更新,提供一些关于 CSS 技术的优秀教程和技巧,每天更新文章。
●6
新拟态——实现新的模仿效果
可以轻松实现新的模仿效果,不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数,并提供CSS可以直接复制的代码。
●7
uiGradients-分享渐变
一个提供渐变色效果的网站,有近百种渐变色方案,可以根据自己的风格选择搭配,直接获取渐变色对应的CSS代码。
▍JS相关
●8
JavaScript 秘密花园
一个不断更新的JavaScript语法文档,主要写如何避免一些常见的错误,以及寻找难以发现的Bug,深入了解JavaScript的语言特性。
●9
JSTips-JS 技巧
每天都有一点 Javascript 知识。
●10
JSweekly - 科技周刊
每周专门讨论 Javascript 的技术期刊。
●11
CDNJS - JavaScript 库
CDNJS 为开发者提供最新的前端网页开发资源,免费使用,不受限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端的CDN服务中排名第二(第一是Google),性能优异。
●12
Beautiful Open - 开源 JS 库合集
采集各种设计优秀的开源项目,从cms内容管理系统到常用的Javascript库,适合网站开发的用户使用。
●13
JavaScript Fun - 代码库集合
目前最流行的 JavaScript 代码库合集,展示人气排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow - 程序员问答网络
全球 IT 社区中最受欢迎的技术问答之一网站,一个用于解决错误的社区,被称为“编程的 100,000 个为什么”。
●15
掘金 - 优质技术社区
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术文章包括Android、iOS、前端和后端资源。
●16
Codrops - 网页设计和开发博客
发布技术文章和网络教程,提供经验,避免陷阱,资源丰富。许多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码的工具,上面有各种效果的案例特效(炫技),可以自己开发基于他们的演示设计的前端。
●18
代码沙盒
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。 React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
●19
JSBin
又一款轻量级在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材都是常用的图标,可以点击官方提供的素材进行二次设计。同时还可以导出设计好的图标。
●21
OpenMoji - 免费表情符号库
提供源码表情库,免费下载使用。
● 22
分享图标 - 免费矢量素材库
提供超过250,000种ICON矢量图素材,120多个类别,所有素材均以PNG和SVG格式提供,素材有512*512、256*25等多种尺寸可供选择6、128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
● 23
tableconvert - 在线表格编辑器
强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的转换。当您需要转换表格,但又无法使其变形时,请尝试使用此工具。
● 24
Feathericons - 极简图标图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发,图标格式为SVG。
● 25
HTML5 + CSS 3 免费模板
提供大量HTML5模板,用户可以自己分享和修改模板。
本文推荐网站总结:
CSSbattle:
学习 CSS 布局:
Flexbox Froggy:
享受CSS:
CSS 技巧:
新拟态:
uiGradients:
JavaScript:
JS 提示:
JS 周刊:
CDNJS:
美丽的开放:
JavaScript 乐趣:
堆栈溢出:
掘金队:
Codrops:
代码笔:
代码沙盒:
JS斌:
图标:
OpenMoji:
分享图标:
表格转换:
羽毛图标:
HTML5UP:
网页css js 抓取助手(SEO优化人员选择爬取数据保存路径使用教程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-11 16:23
选择保存爬取数据的路径
【相关新闻】
在当前的移动互联网时代,每个站长都会仔细分析各大搜索引擎的收录特征,其中百度搜索引擎占比较大。毕竟,对于今天的大多数人来说,很多人在日常生活中更多地使用百度搜索引擎。
所以很多SEO优化人员经常被告知要熟悉百度的算法和收录特性,并在此基础上对自己的工作进行相应的调整和安排,为了取悦百度搜索引擎,让内容被百度抓取。百度爬虫速度更快,提升网站在搜索引擎中的排名。
【更新内容】
BUG:修复了无效的 URI:URI 字符串太长。
【教程】
1、选择下载类型网站(移动站、PC站)
点击菜单栏上的“文件”,在PC站选择“Download Normal网站”,在移动站选择“Download Mobile网站”。
2、配置下载文件的保存目录
点击菜单栏上的“配置”,选择保存下载的静态文件的目录。
3、添加URL和文件存放目录
输入 URL:您要下载的 网站 的地址。
相对路径:相对于根目录的路径。
文件名:当前 URL 下载后保存的名称。
4、下载相关配置
路径设置:设置代码中引用文件的方式。
模拟抓图:PC端网站只显示PC端的User Agent,移动端只显示移动端的User Agent。
Cookie:登录信息字段。 查看全部
网页css js 抓取助手(SEO优化人员选择爬取数据保存路径使用教程-乐题库)
选择保存爬取数据的路径
【相关新闻】
在当前的移动互联网时代,每个站长都会仔细分析各大搜索引擎的收录特征,其中百度搜索引擎占比较大。毕竟,对于今天的大多数人来说,很多人在日常生活中更多地使用百度搜索引擎。
所以很多SEO优化人员经常被告知要熟悉百度的算法和收录特性,并在此基础上对自己的工作进行相应的调整和安排,为了取悦百度搜索引擎,让内容被百度抓取。百度爬虫速度更快,提升网站在搜索引擎中的排名。
【更新内容】
BUG:修复了无效的 URI:URI 字符串太长。
【教程】
1、选择下载类型网站(移动站、PC站)
点击菜单栏上的“文件”,在PC站选择“Download Normal网站”,在移动站选择“Download Mobile网站”。
2、配置下载文件的保存目录
点击菜单栏上的“配置”,选择保存下载的静态文件的目录。
3、添加URL和文件存放目录
输入 URL:您要下载的 网站 的地址。
相对路径:相对于根目录的路径。
文件名:当前 URL 下载后保存的名称。
4、下载相关配置
路径设置:设置代码中引用文件的方式。
模拟抓图:PC端网站只显示PC端的User Agent,移动端只显示移动端的User Agent。
Cookie:登录信息字段。
网页css js 抓取助手(()软件介绍支持RSS的定制功能(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-09 17:12
网络爬虫[WebClawer]是参考RSS的具有强大定制功能的新闻阅读工具。可以抓取任意网站的任意链接,极大的方便了需要获取各个站点信息的工作人员,提高了效率,节省了时间。
软件介绍
支持RSS,包括RSS0.9/1.0/2.0、ATOM、OPML等。
支持从任何站点抓取任何链接
可以同时更新多个站点(多线程处理)
可自定义抓取或排除特定链接
支持自动调用IE的cookies,适合需要登录的论坛
如果没有MSVCR71.dll文件,请下载并放在WebClawer同目录下
绿色软件,无需安装,可存U盘执行
点击下载软件
软件使用
该软件不需要安装。解压后,双击打开。界面如图所示。
<IMG title=001 alt=001 src="//img2.pconline.com.cn/pconline/0804/22/1275786_001.jpg" border=0>
图1 软件界面
下面以太平洋软件信息与应用为例,看看如何使用WebClawer
打开软件,展开对应栏目,右键选择菜单中的“添加频道”如图
<IMG title=002 alt=002 src="//img2.pconline.com.cn/pconline/0804/22/1275786_002.jpg" border=0>
图 2 添加通道
在新建频道中依次输入频道名称、备注、类别、URL地址,选择文件类型-选择RSS模式,完成后保存。如图所示
<IMG title=003 alt=003 src="//img2.pconline.com.cn/pconline/0804/22/1275786_003.jpg" border=0>
图3 添加频道界面
<IMG title=004 alt=004 src="//img2.pconline.com.cn/pconline/0804/22/1275786_004.jpg" border=0>
图4 填写渠道信息
添加好栏目后,每次只需要选择相应的标题并右键“更新”,软件就可以自动抓取更新的页面。
软件虽小,但对于每天需要查看大量信息的朋友来说,可以批量更新各个站点的每一栏,省去大量重复性工作,达到提高工作效率的目的。希望这个软件能给您带来方便。 查看全部
网页css js 抓取助手(()软件介绍支持RSS的定制功能(组图))
网络爬虫[WebClawer]是参考RSS的具有强大定制功能的新闻阅读工具。可以抓取任意网站的任意链接,极大的方便了需要获取各个站点信息的工作人员,提高了效率,节省了时间。
软件介绍
支持RSS,包括RSS0.9/1.0/2.0、ATOM、OPML等。
支持从任何站点抓取任何链接
可以同时更新多个站点(多线程处理)
可自定义抓取或排除特定链接
支持自动调用IE的cookies,适合需要登录的论坛
如果没有MSVCR71.dll文件,请下载并放在WebClawer同目录下
绿色软件,无需安装,可存U盘执行
点击下载软件
软件使用
该软件不需要安装。解压后,双击打开。界面如图所示。
<IMG title=001 alt=001 src="//img2.pconline.com.cn/pconline/0804/22/1275786_001.jpg" border=0>
图1 软件界面
下面以太平洋软件信息与应用为例,看看如何使用WebClawer
打开软件,展开对应栏目,右键选择菜单中的“添加频道”如图
<IMG title=002 alt=002 src="//img2.pconline.com.cn/pconline/0804/22/1275786_002.jpg" border=0>
图 2 添加通道
在新建频道中依次输入频道名称、备注、类别、URL地址,选择文件类型-选择RSS模式,完成后保存。如图所示
<IMG title=003 alt=003 src="//img2.pconline.com.cn/pconline/0804/22/1275786_003.jpg" border=0>
图3 添加频道界面
<IMG title=004 alt=004 src="//img2.pconline.com.cn/pconline/0804/22/1275786_004.jpg" border=0>
图4 填写渠道信息
添加好栏目后,每次只需要选择相应的标题并右键“更新”,软件就可以自动抓取更新的页面。
软件虽小,但对于每天需要查看大量信息的朋友来说,可以批量更新各个站点的每一栏,省去大量重复性工作,达到提高工作效率的目的。希望这个软件能给您带来方便。
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-07 04:00
为大家整理了25个前端相关学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望你能帮助大家!
▍CSS相关
●1
CSSBattle-在线竞争 CSS
CSS线上竞技,一款非常有趣的竞技游戏,一共12关,需要用HTML和CSS来100%还原它给出的页面,然后尽量减少代码,还可以查看全球排行榜,看解决方案。
●2
学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
●3
Flexbox Froggy - 一个学习 Flex 布局的小游戏
一款引导式学习flex布局游戏,使用flex布局让青蛙在荷叶上跳跃,就完成了。游戏中几乎收录了所有常用的属性,所以学习起来非常有趣,而且形象好记。如果您熟悉它,请在此处进行更多练习。
●4
EnjoyCSS - 在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件一样。
●5
CSS 技巧 - CSS 技巧
这个网站 每天都会不断更新一些优秀的教程和CSS 技巧的技巧文章。
●6
Neumorphism - 实现新的模拟效果
新的模仿效果可以轻松实现,不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数,并提供CSS代码可以可以直接复制。
●7
uiGradients - 共享渐变
网站上有近百种渐变配色方案,提供渐变色效果。可以根据自己的风格进行选择搭配,直接获取渐变配色对应的CSS代码即可。
▍JS相关
●8
JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。主要写如何避免一些常见的错误,发现难以发现的bug,深入了解JavaScript的语言特性。
●9
JSTips - JS 技巧
每天一点点的Javascript知识。
●10
JSweekly - 科技周刊
专注于 Javascript 的技术周刊。
●11
CDNJS - JavaScript 库
CDNJS为开发者提供最新的前端web开发资源,免费使用,没有使用限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端CDN服务中排名第二(第一是谷歌),性能优异。
●12
Beautiful Open - 开源 JS 库合集
采集各类设计优秀的开源项目,从cms内容管理系统到小型常用Javascript库,适合网站开发的用户使用。
●13
JavaScript Fun - 代码库集合
最流行的 JavaScript 代码库集合,显示流行排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow - 程序员问答网络
全球IT界最火爆的技术问答网站,一个解决bug的社区,号称“编程界的十万个为什么”。
●15
掘金 - 优质技术社区
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术 文章 包括 Android、iOS、前端和后端资源。
●16
Codrops - 网页设计开发博客
发布技术文章和网络教程,提供经验,避免陷阱,资源丰富。许多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码工具,有各种效果的案例特效(炫技),你可以开发自己的前端设计基于他们的演示。
●18
代码沙盒
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
●19
JSBin
另一个轻量级的在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材都是常用的图标,可以点击官方提供的素材进行二次设计,也可以导出设计好的图标。
●21
OpenMoji - 免费表情符号库
提供带有源代码的表情符号库,可以免费下载使用。
● 22
共享图标 - 免费矢量图片
一个提供超过250,000种ICON矢量图素材,120多个类别的网站,所有素材均以PNG和SVG格式提供,素材有多种尺寸可供选择,包括512*512、256*256、128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
● 23
tableconvert - 在线表格编辑器
一款功能强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的相互转换。当您需要转换表格,但无法使其变形时,请尝试使用此工具。
● 24
Feathericons-极简主义图标图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发。图标格式为 SVG。
● 25
HTML5 + CSS 3 免费模板
提供大量HTML5模板,用户可以自己分享和修改模板。
本文推荐的网站总结:
CSS战斗:
学习 CSS 布局:
Flexbox Froggy:
享受CSS:
CSS 技巧:
神经拟态:
ui渐变:
JavaScript:
JS 提示:
JS周刊:
CDNJS:
美丽的开放:
JavaScript 乐趣:
堆栈溢出:
掘金:
Codrops:
代码笔:
代码沙盒:
JS斌:
图标:
打开Moji:
分享图标:
表格转换:
羽毛图标:
HTML5UP:
❤️爱三合一
1.看到这里,点个关注支持一下,你们的“关注”就是我创作的动力。 查看全部
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具)
为大家整理了25个前端相关学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望你能帮助大家!
▍CSS相关
●1
CSSBattle-在线竞争 CSS
CSS线上竞技,一款非常有趣的竞技游戏,一共12关,需要用HTML和CSS来100%还原它给出的页面,然后尽量减少代码,还可以查看全球排行榜,看解决方案。
●2
学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
●3
Flexbox Froggy - 一个学习 Flex 布局的小游戏
一款引导式学习flex布局游戏,使用flex布局让青蛙在荷叶上跳跃,就完成了。游戏中几乎收录了所有常用的属性,所以学习起来非常有趣,而且形象好记。如果您熟悉它,请在此处进行更多练习。
●4
EnjoyCSS - 在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件一样。
●5
CSS 技巧 - CSS 技巧
这个网站 每天都会不断更新一些优秀的教程和CSS 技巧的技巧文章。
●6
Neumorphism - 实现新的模拟效果
新的模仿效果可以轻松实现,不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数,并提供CSS代码可以可以直接复制。
●7
uiGradients - 共享渐变
网站上有近百种渐变配色方案,提供渐变色效果。可以根据自己的风格进行选择搭配,直接获取渐变配色对应的CSS代码即可。
▍JS相关
●8
JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。主要写如何避免一些常见的错误,发现难以发现的bug,深入了解JavaScript的语言特性。
●9
JSTips - JS 技巧
每天一点点的Javascript知识。
●10
JSweekly - 科技周刊
专注于 Javascript 的技术周刊。
●11
CDNJS - JavaScript 库
CDNJS为开发者提供最新的前端web开发资源,免费使用,没有使用限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端CDN服务中排名第二(第一是谷歌),性能优异。
●12
Beautiful Open - 开源 JS 库合集
采集各类设计优秀的开源项目,从cms内容管理系统到小型常用Javascript库,适合网站开发的用户使用。
●13
JavaScript Fun - 代码库集合
最流行的 JavaScript 代码库集合,显示流行排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow - 程序员问答网络
全球IT界最火爆的技术问答网站,一个解决bug的社区,号称“编程界的十万个为什么”。
●15
掘金 - 优质技术社区
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术 文章 包括 Android、iOS、前端和后端资源。
●16
Codrops - 网页设计开发博客
发布技术文章和网络教程,提供经验,避免陷阱,资源丰富。许多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码工具,有各种效果的案例特效(炫技),你可以开发自己的前端设计基于他们的演示。
●18
代码沙盒
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
●19
JSBin
另一个轻量级的在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材都是常用的图标,可以点击官方提供的素材进行二次设计,也可以导出设计好的图标。
●21
OpenMoji - 免费表情符号库
提供带有源代码的表情符号库,可以免费下载使用。
● 22
共享图标 - 免费矢量图片
一个提供超过250,000种ICON矢量图素材,120多个类别的网站,所有素材均以PNG和SVG格式提供,素材有多种尺寸可供选择,包括512*512、256*256、128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
● 23
tableconvert - 在线表格编辑器
一款功能强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的相互转换。当您需要转换表格,但无法使其变形时,请尝试使用此工具。
● 24
Feathericons-极简主义图标图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发。图标格式为 SVG。
● 25
HTML5 + CSS 3 免费模板
提供大量HTML5模板,用户可以自己分享和修改模板。
本文推荐的网站总结:
CSS战斗:
学习 CSS 布局:
Flexbox Froggy:
享受CSS:
CSS 技巧:
神经拟态:
ui渐变:
JavaScript:
JS 提示:
JS周刊:
CDNJS:
美丽的开放:
JavaScript 乐趣:
堆栈溢出:
掘金:
Codrops:
代码笔:
代码沙盒:
JS斌:
图标:
打开Moji:
分享图标:
表格转换:
羽毛图标:
HTML5UP:
❤️爱三合一
1.看到这里,点个关注支持一下,你们的“关注”就是我创作的动力。
网页css js 抓取助手(一下这些API都应该怎么使用?(图)API)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-04 18:13
写了几篇关于微信内置浏览器(WebView)特有的Javascript API(Javascript接口)的文章文章,但是随着微信官方的调整,有些API已经不能直接使用了,比如直接分享对朋友圈WeixinJSBridge.invoke('shareTimeline',data,callback)这样的函数,直接调用会得到拒绝访问的响应。后来又重新研究了一下,整理出了一个WeixinAPI Javascript类库,分享给大家。如果你对微信公众平台的开发感兴趣,应该对你有用。
/**!
* 微信内置浏览器的Javascript API,功能包括:
*
* 1、分享到微信朋友圈
* 2、分享给微信好友
* 3、分享到腾讯微博
* 4、隐藏/显示右上角的菜单入口
* 5、隐藏/显示底部浏览器工具栏
* 6、获取当前的网络状态
* 7、调起微信客户端的图片播放组件
*
* @author zhaoxianlie(http://www.baidufe.com)
*/
var WeixinApi = (function () {
/* 这里省略了一堆代码……下面直接看调用接口 */
return {
ready :wxJsBridgeReady,
shareToTimeline :weixinShareTimeline,
shareToWeibo :weixinShareWeibo,
shareToFriend :weixinSendAppMessage,
showOptionMenu :showOptionMenu,
hideOptionMenu :hideOptionMenu,
showToolbar :showToolbar,
hideToolbar :hideToolbar,
getNetworkType :getNetworkType,
imagePreview :imagePreview
};
});
接下来,让我们看看这些API应该如何使用,从最简单的开始。
1、如果我想一打开网页就隐藏右上角的PopUp菜单项,隐藏浏览器底部的工具栏,同时也获取当前的网络状态,那么我们的代码可以是像这样写:
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api){
// 隐藏右上角popup菜单入口
Api.hideOptionMenu();
// 隐藏浏览器下方的工具栏
Api.hideToolbar();
// 获取网络状态
Api.getNetworkType(function(network){
// 拿到 network 以后,做任何你想做的事
});
});
如示例代码中的注释所示,所有函数执行都必须在 WeixinApi.ready 方法中执行,就像在使用 jQuery 时,通常需要使用 jQuery(document).ready(function(){ }) 一样. 为什么要这样做?相信不用我解释大家都能理解,因为我们必须保证在执行这些方法的时候,WebView中已经添加了WeixinJsBridge API!
2、再看一个分享的例子,如果用户在阅读我的文章(或使用我的产品)的过程中发现它有趣或有价值,他们一般会采集或分享(给朋友、朋友圈、微博等),那么现在我希望监控用户的分享行为,比如:自定义用户可以分享的内容,即使用户分享了,取消分享,分享失败,分享成功,整个分享操作过程就结束了,大家都做点什么。所以,我们可以这样写代码:
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api){
// 微信分享的数据
var wxData = {
"imgUrl":'http://www.baidufe.com/fe/blog ... 39%3B,
"link":'http://www.baidufe.com',
"desc":'大家好,我是Alien,Web前端&Android客户端码农,喜欢技术上的瞎倒腾!欢迎多交流',
"title":"大家好,我是赵先烈"
};
// 分享的回调
var wxCallbacks = {
// 分享操作开始之前
ready:function () {
// 你可以在这里对分享的数据进行重组
},
// 分享被用户自动取消
cancel:function (resp) {
// 你可以在你的页面上给用户一个小Tip,为什么要取消呢?
},
// 分享失败了
fail:function (resp) {
// 分享失败了,是不是可以告诉用户:不要紧,可能是网络问题,一会儿再试试?
},
// 分享成功
confirm:function (resp) {
// 分享成功了,我们是不是可以做一些分享统计呢?
},
// 整个分享过程结束
all:function (resp) {
// 如果你做的是一个鼓励用户进行分享的产品,在这里是不是可以给用户一些反馈了?
}
};
// 用户点开右上角popup菜单后,点击分享给好友,会执行下面这个代码
Api.shareToFriend(wxData, wxCallbacks);
// 点击分享到朋友圈,会执行下面这个代码
Api.shareToTimeline(wxData, wxCallbacks);
// 点击分享到腾讯微博,会执行下面这个代码
Api.shareToWeibo(wxData, wxCallbacks);
});
3、当然,如果你的业务需求比较复杂,比如你的产品是微信网页游戏(类似于“2048数字游戏微信版”),你希望用户分享的数据是截图一个网页,或者一个将用户当前的游戏状态发送回服务器,以动态生成可分享的内容;在这种情况下我们应该怎么做?看看下面的示例代码:
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api){
// 分享的回调
var wxCallbacks = {
// 分享过程需要异步执行
async : true,
// 分享操作开始之前
ready:function () {
var self = this;
// 假设你需要在这里发一个 ajax 请求去获取分享数据
$.post(yourServerUrl,yourPostData,function(responseData){
// 可以解析reponseData得到wxData
var wxData = responseData;
// 调用dataLoaded方法,会自动触发分享操作
// 注意,当且仅当 async为true时,wxCallbacks.dataLoaded才会被初始化,并调用
self.dataLoaded(wxData);
});
}
/* cancel、fail、confirm、all 方法同示例2,此处略掉 */
};
// 用户点开右上角popup菜单后,点击分享给好友,会执行下面这个代码
Api.shareToFriend({}, wxCallbacks);
});
唯一不同的是,在wxCallbacks中,配置项async被添加为true,表示共享进程是异步调用的。其实就是说ready方法是异步执行的。在这种情况下,我们需要在 ready 方法中显式调用它。wxCallbacks的dataLoaded方法保证共享进程可以继续执行。可能你会发现这个wxCallbacks里面并没有配置dataLoaded方法!是的,当 async 为 true 时,我会在 WeixinApi 中自动初始化。dataLoaded 方法需要一个参数,表示需要共享的数据!
4、当然,如果非要配置dataLoaded方法也没问题。您的配置也将被执行并且不会被覆盖。执行顺序为:用户配置优先。
以上是直接给出使用方法。也许您现在开始关心每个方法的参数列表是什么样的?我们以分享到朋友圈的方法为例,看看参数有哪些配置项:
/**
* 分享到微信朋友圈
* @param {Object} data 待分享的信息
* @p-config {String} appId 公众平台的appId(服务号可用)
* @p-config {String} imageUrl 图片地址
* @p-config {String} link 链接地址
* @p-config {String} desc 描述
* @p-config {String} title 分享的标题
*
* @param {Object} callbacks 相关回调方法
* @p-config {Boolean} async ready方法是否需要异步执行,默认false
* @p-config {Function} ready(argv) 就绪状态
* @p-config {Function} dataLoaded(data) 数据加载完成后调用,async为true时有用
* @p-config {Function} cancel(resp) 取消
* @p-config {Function} fail(resp) 失败
* @p-config {Function} confirm(resp) 成功
* @p-config {Function} all(resp) 无论成功失败都会执行的回调
*/
WeixinApi.shareToTimeline(data,callbacks);
分享给微信朋友和分享给腾讯微博的参数列表是一样的,这里就不一一列举了。
5、如果你的文章里面有很多图片,那么点击图片直接调出微信客户端自带的图片播放组件一定是件好事;你可以这样做 :
// 调起微信客户端的图片播放组件进行播放
WeixinApi.ready(function(Api){
var srcList = [];
$.each($('img'),function(i,item){
if(item.src) {
srcList.push(item.src);
$(item).click(function(e){
// 通过这个API就能直接调起微信客户端的图片播放组件了
Api.imagePreview(this.src,srcList);
});
}
});
});
就这么简单的一段代码,一切就搞定了!不过需要指出的是,Api.imagePreview的参数会被强检测:
/**
* 调起微信Native的图片播放组件。
* 这里必须对参数进行强检测,如果参数不合法,直接会导致微信客户端crash
*
* @param {String} curSrc 当前播放的图片地址
* @param {Array} srcList 图片地址列表
*/
function imagePreview(curSrc,srcList) ;
需要指出的是,微信公众平台并没有统一支持Android和iOS平台,比较费力。具体有:
期待早日正式实现各平台API的统一!!!
至于API内部是如何实现的,有兴趣的可以看下源码。如果您在使用过程中遇到任何错误,请来这里反馈。
为了方便Api的维护和分享,已经放到了Github上。让我们从这里开始: 查看全部
网页css js 抓取助手(一下这些API都应该怎么使用?(图)API)
写了几篇关于微信内置浏览器(WebView)特有的Javascript API(Javascript接口)的文章文章,但是随着微信官方的调整,有些API已经不能直接使用了,比如直接分享对朋友圈WeixinJSBridge.invoke('shareTimeline',data,callback)这样的函数,直接调用会得到拒绝访问的响应。后来又重新研究了一下,整理出了一个WeixinAPI Javascript类库,分享给大家。如果你对微信公众平台的开发感兴趣,应该对你有用。
/**!
* 微信内置浏览器的Javascript API,功能包括:
*
* 1、分享到微信朋友圈
* 2、分享给微信好友
* 3、分享到腾讯微博
* 4、隐藏/显示右上角的菜单入口
* 5、隐藏/显示底部浏览器工具栏
* 6、获取当前的网络状态
* 7、调起微信客户端的图片播放组件
*
* @author zhaoxianlie(http://www.baidufe.com)
*/
var WeixinApi = (function () {
/* 这里省略了一堆代码……下面直接看调用接口 */
return {
ready :wxJsBridgeReady,
shareToTimeline :weixinShareTimeline,
shareToWeibo :weixinShareWeibo,
shareToFriend :weixinSendAppMessage,
showOptionMenu :showOptionMenu,
hideOptionMenu :hideOptionMenu,
showToolbar :showToolbar,
hideToolbar :hideToolbar,
getNetworkType :getNetworkType,
imagePreview :imagePreview
};
});
接下来,让我们看看这些API应该如何使用,从最简单的开始。
1、如果我想一打开网页就隐藏右上角的PopUp菜单项,隐藏浏览器底部的工具栏,同时也获取当前的网络状态,那么我们的代码可以是像这样写:
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api){
// 隐藏右上角popup菜单入口
Api.hideOptionMenu();
// 隐藏浏览器下方的工具栏
Api.hideToolbar();
// 获取网络状态
Api.getNetworkType(function(network){
// 拿到 network 以后,做任何你想做的事
});
});
如示例代码中的注释所示,所有函数执行都必须在 WeixinApi.ready 方法中执行,就像在使用 jQuery 时,通常需要使用 jQuery(document).ready(function(){ }) 一样. 为什么要这样做?相信不用我解释大家都能理解,因为我们必须保证在执行这些方法的时候,WebView中已经添加了WeixinJsBridge API!
2、再看一个分享的例子,如果用户在阅读我的文章(或使用我的产品)的过程中发现它有趣或有价值,他们一般会采集或分享(给朋友、朋友圈、微博等),那么现在我希望监控用户的分享行为,比如:自定义用户可以分享的内容,即使用户分享了,取消分享,分享失败,分享成功,整个分享操作过程就结束了,大家都做点什么。所以,我们可以这样写代码:
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api){
// 微信分享的数据
var wxData = {
"imgUrl":'http://www.baidufe.com/fe/blog ... 39%3B,
"link":'http://www.baidufe.com',
"desc":'大家好,我是Alien,Web前端&Android客户端码农,喜欢技术上的瞎倒腾!欢迎多交流',
"title":"大家好,我是赵先烈"
};
// 分享的回调
var wxCallbacks = {
// 分享操作开始之前
ready:function () {
// 你可以在这里对分享的数据进行重组
},
// 分享被用户自动取消
cancel:function (resp) {
// 你可以在你的页面上给用户一个小Tip,为什么要取消呢?
},
// 分享失败了
fail:function (resp) {
// 分享失败了,是不是可以告诉用户:不要紧,可能是网络问题,一会儿再试试?
},
// 分享成功
confirm:function (resp) {
// 分享成功了,我们是不是可以做一些分享统计呢?
},
// 整个分享过程结束
all:function (resp) {
// 如果你做的是一个鼓励用户进行分享的产品,在这里是不是可以给用户一些反馈了?
}
};
// 用户点开右上角popup菜单后,点击分享给好友,会执行下面这个代码
Api.shareToFriend(wxData, wxCallbacks);
// 点击分享到朋友圈,会执行下面这个代码
Api.shareToTimeline(wxData, wxCallbacks);
// 点击分享到腾讯微博,会执行下面这个代码
Api.shareToWeibo(wxData, wxCallbacks);
});
3、当然,如果你的业务需求比较复杂,比如你的产品是微信网页游戏(类似于“2048数字游戏微信版”),你希望用户分享的数据是截图一个网页,或者一个将用户当前的游戏状态发送回服务器,以动态生成可分享的内容;在这种情况下我们应该怎么做?看看下面的示例代码:
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api){
// 分享的回调
var wxCallbacks = {
// 分享过程需要异步执行
async : true,
// 分享操作开始之前
ready:function () {
var self = this;
// 假设你需要在这里发一个 ajax 请求去获取分享数据
$.post(yourServerUrl,yourPostData,function(responseData){
// 可以解析reponseData得到wxData
var wxData = responseData;
// 调用dataLoaded方法,会自动触发分享操作
// 注意,当且仅当 async为true时,wxCallbacks.dataLoaded才会被初始化,并调用
self.dataLoaded(wxData);
});
}
/* cancel、fail、confirm、all 方法同示例2,此处略掉 */
};
// 用户点开右上角popup菜单后,点击分享给好友,会执行下面这个代码
Api.shareToFriend({}, wxCallbacks);
});
唯一不同的是,在wxCallbacks中,配置项async被添加为true,表示共享进程是异步调用的。其实就是说ready方法是异步执行的。在这种情况下,我们需要在 ready 方法中显式调用它。wxCallbacks的dataLoaded方法保证共享进程可以继续执行。可能你会发现这个wxCallbacks里面并没有配置dataLoaded方法!是的,当 async 为 true 时,我会在 WeixinApi 中自动初始化。dataLoaded 方法需要一个参数,表示需要共享的数据!
4、当然,如果非要配置dataLoaded方法也没问题。您的配置也将被执行并且不会被覆盖。执行顺序为:用户配置优先。
以上是直接给出使用方法。也许您现在开始关心每个方法的参数列表是什么样的?我们以分享到朋友圈的方法为例,看看参数有哪些配置项:
/**
* 分享到微信朋友圈
* @param {Object} data 待分享的信息
* @p-config {String} appId 公众平台的appId(服务号可用)
* @p-config {String} imageUrl 图片地址
* @p-config {String} link 链接地址
* @p-config {String} desc 描述
* @p-config {String} title 分享的标题
*
* @param {Object} callbacks 相关回调方法
* @p-config {Boolean} async ready方法是否需要异步执行,默认false
* @p-config {Function} ready(argv) 就绪状态
* @p-config {Function} dataLoaded(data) 数据加载完成后调用,async为true时有用
* @p-config {Function} cancel(resp) 取消
* @p-config {Function} fail(resp) 失败
* @p-config {Function} confirm(resp) 成功
* @p-config {Function} all(resp) 无论成功失败都会执行的回调
*/
WeixinApi.shareToTimeline(data,callbacks);
分享给微信朋友和分享给腾讯微博的参数列表是一样的,这里就不一一列举了。
5、如果你的文章里面有很多图片,那么点击图片直接调出微信客户端自带的图片播放组件一定是件好事;你可以这样做 :
// 调起微信客户端的图片播放组件进行播放
WeixinApi.ready(function(Api){
var srcList = [];
$.each($('img'),function(i,item){
if(item.src) {
srcList.push(item.src);
$(item).click(function(e){
// 通过这个API就能直接调起微信客户端的图片播放组件了
Api.imagePreview(this.src,srcList);
});
}
});
});
就这么简单的一段代码,一切就搞定了!不过需要指出的是,Api.imagePreview的参数会被强检测:
/**
* 调起微信Native的图片播放组件。
* 这里必须对参数进行强检测,如果参数不合法,直接会导致微信客户端crash
*
* @param {String} curSrc 当前播放的图片地址
* @param {Array} srcList 图片地址列表
*/
function imagePreview(curSrc,srcList) ;
需要指出的是,微信公众平台并没有统一支持Android和iOS平台,比较费力。具体有:
期待早日正式实现各平台API的统一!!!
至于API内部是如何实现的,有兴趣的可以看下源码。如果您在使用过程中遇到任何错误,请来这里反馈。
为了方便Api的维护和分享,已经放到了Github上。让我们从这里开始:
网页css js 抓取助手(WebMagic介绍项目代码分为核心和扩展两部分的区别 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-04 12:12
)
一、WebMagic介绍
WebMagic 项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分包括一些便利和实用的功能。
WebMagic 的设计目标是尽可能模块化,并体现爬虫的功能特点。这部分提供了一个非常简单灵活的API来编写爬虫,而无需基本改变开发模式。
扩展部分(webmagic-extension)提供了一些方便的功能,比如以注解方式编写爬虫。同时内置了一些常用的组件,方便爬虫开发。
1.1 架构介绍
WebMagic 的结构分为四大组件:Downloader、PageProcessor、Scheduler 和 Pipeline,它们由 Spider 组织。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。WebMagic 的设计参考了 Scapy,但实现更类似于 Java。
Spider 组织这些组件,以便它们可以相互交互并处理执行。可以认为Spider是一个大容器,也是WebMagic逻辑的核心。
WebMagic的整体架构图如下:
1.1.1 WebMagic 的四个组成部分
1、下载器
下载器负责从 Internet 下载页面以进行后续处理。WebMagic 默认使用 Apache HttpClient 作为下载工具。
2、页面处理器
PageProcessor 负责解析页面、提取有用信息和发现新链接。WebMagic 使用 Jsoup 作为 HTML 解析工具,并在其基础上开发了 Xsoup,一个解析 XPath 的工具。这四个组件中,PageProcessor对于每个站点的每个页面都是不同的,是需要用户自定义的部分。
3、调度器
Scheduler 负责管理要爬取的 URL,以及一些去重工作。WebMagic 默认提供 JDK 的内存队列来管理 URL,并使用集合进行去重。还支持使用 Redis 进行分布式管理。
4、管道
Pipeline负责提取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供两种结果处理方案:“输出到控制台”和“保存到文件”。
Pipeline 定义了保存结果的方式。如果要保存到指定的数据库,需要编写相应的Pipeline。通常,对于一类需求,只需要编写一个 Pipeline。
1.1.2 数据流对象
1、请求
Request是对URL地址的一层封装,一个Request对应一个URL地址。
它是PageProcessor 与Downloader 交互的载体,也是PageProcessor 控制Downloader 的唯一途径。
除了 URL 本身,它还收录一个 Key-Value 结构的额外字段。你可以额外保存一些特殊的属性,并在其他地方读取它们来完成不同的功能。例如,添加上一页的一些信息等。
2、页面
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
3、结果项
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。它的API和Map非常相似,值得注意的是它有一个字段skip,如果设置为true,它不应该被Pipeline处理。
1.2 入门案例
1.2.1 添加依赖
创建一个Maven项目并添加以下依赖项
注意:0.7.3 版本不支持 SSL。如果直接从Maven中央仓库下载依赖,爬取只支持SSL v1.2的网站,会抛出SSL异常。
1.2.2 添加个人资料
WebMagic 使用 slf4j-log4j12 作为 slf4j 的实现。
添加 log4j.properties 配置文件:
log4j.rootLogger=INFO,A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
1.2.3 案例实现
二、WebMagic 功能
2.1 实现 PageProcessor
2.1.1 提取元素可选
WebMagic 中使用了三种主要的提取技术:XPath、正则表达式和 CSS 选择器。另外,对于 JSON 格式的内容,可以使用 JsonPath 进行解析。
2.1.1.1 XPath
入口案例是获取属性class=mt的div标签和里面h1标签的内容
page.getHtml().xpath("//div[@class=mt]/h1/text()")
2.1.1.2 个 CSS 选择器
CSS 选择器是一种类似于 XPath 的语言。上一课我们学习了Jsoup的选择器。写起来比XPath简单,但是写更复杂的抽取规则就比较麻烦。
div.mt>h1 表示类为mt的div标签下的直接子元素h1标签
page.getHtml().css("div.mt>h1").toString()
2.1.1.3 正则表达式
正则表达式是一种通用的文本提取语言。这里一般用来获取url地址。
2.1.2 提取元素 API
可选相关提取元素链接 API 是 WebMagic 的核心功能。使用Selectable接口,可以直接完成页面元素的链式提取,无需关心提取的细节。
在刚才的例子中可以看到,page.getHtml()返回一个实现了Selectable接口的Html对象。该接口收录的方法分为两类:提取部分和获取结果部分。
2.1.3 获取结果 API
当链式调用结束时,我们一般希望得到一个字符串类型的结果。这时候就需要使用API来获取结果了。
我们知道,一条抽取规则,无论是 XPath、CSS 选择器还是正则表达式,总是可以抽取多个元素。WebMagic 将这些统一起来,可以通过不同的 API 获取一个或多个元素。
2.1.4 获取链接
有了处理页面的逻辑,我们的爬虫就差不多完成了,但是还有一个问题:一个站点的页面很多,我们不能一开始就全部列出来,那么如何找到后续的链接就是爬虫了不能缺少的部分
下面的例子就是获取这个页面
所有与 \\w+?.* 正则表达式匹配的 URL 地址,并将这些链接添加到要爬取的队列中。
查看全部
网页css js 抓取助手(WebMagic介绍项目代码分为核心和扩展两部分的区别
)
一、WebMagic介绍
WebMagic 项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分包括一些便利和实用的功能。
WebMagic 的设计目标是尽可能模块化,并体现爬虫的功能特点。这部分提供了一个非常简单灵活的API来编写爬虫,而无需基本改变开发模式。
扩展部分(webmagic-extension)提供了一些方便的功能,比如以注解方式编写爬虫。同时内置了一些常用的组件,方便爬虫开发。
1.1 架构介绍
WebMagic 的结构分为四大组件:Downloader、PageProcessor、Scheduler 和 Pipeline,它们由 Spider 组织。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。WebMagic 的设计参考了 Scapy,但实现更类似于 Java。
Spider 组织这些组件,以便它们可以相互交互并处理执行。可以认为Spider是一个大容器,也是WebMagic逻辑的核心。
WebMagic的整体架构图如下:
1.1.1 WebMagic 的四个组成部分
1、下载器
下载器负责从 Internet 下载页面以进行后续处理。WebMagic 默认使用 Apache HttpClient 作为下载工具。
2、页面处理器
PageProcessor 负责解析页面、提取有用信息和发现新链接。WebMagic 使用 Jsoup 作为 HTML 解析工具,并在其基础上开发了 Xsoup,一个解析 XPath 的工具。这四个组件中,PageProcessor对于每个站点的每个页面都是不同的,是需要用户自定义的部分。
3、调度器
Scheduler 负责管理要爬取的 URL,以及一些去重工作。WebMagic 默认提供 JDK 的内存队列来管理 URL,并使用集合进行去重。还支持使用 Redis 进行分布式管理。
4、管道
Pipeline负责提取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供两种结果处理方案:“输出到控制台”和“保存到文件”。
Pipeline 定义了保存结果的方式。如果要保存到指定的数据库,需要编写相应的Pipeline。通常,对于一类需求,只需要编写一个 Pipeline。
1.1.2 数据流对象
1、请求
Request是对URL地址的一层封装,一个Request对应一个URL地址。
它是PageProcessor 与Downloader 交互的载体,也是PageProcessor 控制Downloader 的唯一途径。
除了 URL 本身,它还收录一个 Key-Value 结构的额外字段。你可以额外保存一些特殊的属性,并在其他地方读取它们来完成不同的功能。例如,添加上一页的一些信息等。
2、页面
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
3、结果项
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。它的API和Map非常相似,值得注意的是它有一个字段skip,如果设置为true,它不应该被Pipeline处理。
1.2 入门案例
1.2.1 添加依赖
创建一个Maven项目并添加以下依赖项
注意:0.7.3 版本不支持 SSL。如果直接从Maven中央仓库下载依赖,爬取只支持SSL v1.2的网站,会抛出SSL异常。
1.2.2 添加个人资料
WebMagic 使用 slf4j-log4j12 作为 slf4j 的实现。
添加 log4j.properties 配置文件:
log4j.rootLogger=INFO,A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
1.2.3 案例实现
二、WebMagic 功能
2.1 实现 PageProcessor
2.1.1 提取元素可选
WebMagic 中使用了三种主要的提取技术:XPath、正则表达式和 CSS 选择器。另外,对于 JSON 格式的内容,可以使用 JsonPath 进行解析。
2.1.1.1 XPath
入口案例是获取属性class=mt的div标签和里面h1标签的内容
page.getHtml().xpath("//div[@class=mt]/h1/text()")
2.1.1.2 个 CSS 选择器
CSS 选择器是一种类似于 XPath 的语言。上一课我们学习了Jsoup的选择器。写起来比XPath简单,但是写更复杂的抽取规则就比较麻烦。
div.mt>h1 表示类为mt的div标签下的直接子元素h1标签
page.getHtml().css("div.mt>h1").toString()
2.1.1.3 正则表达式
正则表达式是一种通用的文本提取语言。这里一般用来获取url地址。
2.1.2 提取元素 API
可选相关提取元素链接 API 是 WebMagic 的核心功能。使用Selectable接口,可以直接完成页面元素的链式提取,无需关心提取的细节。
在刚才的例子中可以看到,page.getHtml()返回一个实现了Selectable接口的Html对象。该接口收录的方法分为两类:提取部分和获取结果部分。
2.1.3 获取结果 API
当链式调用结束时,我们一般希望得到一个字符串类型的结果。这时候就需要使用API来获取结果了。
我们知道,一条抽取规则,无论是 XPath、CSS 选择器还是正则表达式,总是可以抽取多个元素。WebMagic 将这些统一起来,可以通过不同的 API 获取一个或多个元素。
2.1.4 获取链接
有了处理页面的逻辑,我们的爬虫就差不多完成了,但是还有一个问题:一个站点的页面很多,我们不能一开始就全部列出来,那么如何找到后续的链接就是爬虫了不能缺少的部分
下面的例子就是获取这个页面
所有与 \\w+?.* 正则表达式匹配的 URL 地址,并将这些链接添加到要爬取的队列中。
网页css js 抓取助手(网站抓取是一个用Python编写的Web爬虫和Web框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-04 03:14
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以直接通过socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫采用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。 查看全部
网页css js 抓取助手(网站抓取是一个用Python编写的Web爬虫和Web框架)
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。

网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。

网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以直接通过socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。

网站爬虫采用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。
网页css js 抓取助手(这里有新鲜出炉的Javascript教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-25 05:15
这里有新鲜出炉的Javascript教程,程序狗速来了!
JavaScript 客户端脚本语言 JavaScript 是一种原型继承的基于对象的动态类型区分大小写的客户端脚本语言,由 Netscape 的 LiveScript 开发。主要目的是解决服务器端语言,如Perl,遗留速度问题,为客户提供更流畅的浏览效果。
如果您想在保留文件或在执行阶段对代码进行 lint,则 linting 工具也可以做您想做的事情。这取决于个人选择。如果您正在寻找适用于 CSS 和 JavaScript 的最佳 linting 工具,请继续阅读
审查和测试代码以发现任何潜在的错误,从而在将错误发布到 网站 之前及时消除错误,这是一个非常重要的过程。代码检查的过程通常也称为网页设计师和开发人员之间的 linting。作为设计师,如果你想编写高度优化的代码,那么你肯定需要 linting 工具。有两种类型的代码检查工具。一种是在执行时检查代码中的错误和错误。另一种是使用静态代码分析技术,在执行前检查代码。后者显然更好,因为它可以节省时间和麻烦。
事实上,linting 可以放在不同的阶段。如果您想在键入时测试代码,则可以使用 lint 工具。当然,如果您想在保存文件或在执行阶段对代码进行 lint,那么 linting 工具可以满足您的需求。这取决于个人选择。如果您正在寻找适用于 CSS 和 JavaScript 的最佳 linting 工具,请继续阅读。
1.CSSLint
诚然,CSSLint 会“伤害你的感情”,但作为交换,它会“大大改善你的代码”。CSSLint 目前引领着 CSSlinting 市场。用 JavaScript 编写,不仅是开源的,而且还带有很多配置选项。
2.SublimeLinter CSSLint
CSSLint 曾经是一个如此高效的 CSSlinting 工具,以至于很难找到可以与之匹敌的竞争对手。也许这就是 SublimeLinterlinting 框架在 CSSLint 之上构建其 CSSlinting 插件的原因。SublimeLinter 是一个 SublimeText 插件,它为用户提供了一种 lint 代码(CSS、PHP、Python、Java、Ruby 等)的方法。
3.StyleLint
StyleLint 帮助开发人员避免 CSS、SCSS 或任何其他可解析的 PostCSS 中的语法错误。StyleLint 测试了一百多个规则,您可以选择要切换到哪些规则(请参阅此示例配置)。
4.W3C CSS 验证器
虽然 W3C 的 CSS Validator 通常不被视为 linting 工具,但它为开发人员提供了一个很好的机会来检查 CSS 代码是否符合官方 W3C 标准。W3C 构建了自己的验证器,旨在为 C 语言提供类似于 Lint 程序检查器的工具。
5.脏标记
Dirty Markup 清理、格式化和验证您的 HTML、CSS 和 JavaScript 代码。如果您喜欢简单直接的设计并想要快速解决方案,那么这是正确的选择。当您在编辑器中编写或修改代码时,脏标记可以实时抛出错误消息和通知。
6.JSLint
JSLint 最初是由 Douglas Crockford 于 2002 年发布的,从那时起已经有了很多生命,所以你可以放心地认为它是一个稳定可靠的 JavaScript linting 工具。
7.JSHint
JSHint 是一个社区驱动的项目,最初是为了创建一个更可配置、更不固执的 JSLint 版本。JSHint 允许开发人员配置其任何 linting 选项,然后将自定义配置放入单个文件中,这使得该工具易于重用,因此非常适合大型项目。
8.ESLint
ESLint 是 JavaScript linting 领域中最新的一件大事。它因其高度灵活的特性而广受欢迎。您不仅可以自定义大量前沿的 linting 规则,将其与所有主流代码编辑器集成,还可以通过添加不同的插件轻松扩展其功能。
9.JSCS
JSCS 或 JavaScript 代码样式是用于检查代码格式规则的 JavaScript 的可插入代码样式 linter。JSCS 的目标是提供一种以编程方式强制遵守编码风格指南的方法。尽管 JSCS 不检查 bug 和错误,但它仍然被许多高科技行业的参与者使用,例如 Google、AirBnB 和 AngularJS,因为它可以帮助开发人员保持高度可读和一致的代码库。
10.标准JS
StandardJS,或 JavaScript 标准样式,是一种代码样式 linter,有点像 JSCS,但区别更简单、更直接。如果您不想花时间在配置上,而只是想要一个开箱即用的高效工具,那么 StandardJS 是一个不错的选择。
翻译链接:
英文原文: 查看全部
网页css js 抓取助手(这里有新鲜出炉的Javascript教程,程序狗速度看过来!)
这里有新鲜出炉的Javascript教程,程序狗速来了!
JavaScript 客户端脚本语言 JavaScript 是一种原型继承的基于对象的动态类型区分大小写的客户端脚本语言,由 Netscape 的 LiveScript 开发。主要目的是解决服务器端语言,如Perl,遗留速度问题,为客户提供更流畅的浏览效果。
如果您想在保留文件或在执行阶段对代码进行 lint,则 linting 工具也可以做您想做的事情。这取决于个人选择。如果您正在寻找适用于 CSS 和 JavaScript 的最佳 linting 工具,请继续阅读
审查和测试代码以发现任何潜在的错误,从而在将错误发布到 网站 之前及时消除错误,这是一个非常重要的过程。代码检查的过程通常也称为网页设计师和开发人员之间的 linting。作为设计师,如果你想编写高度优化的代码,那么你肯定需要 linting 工具。有两种类型的代码检查工具。一种是在执行时检查代码中的错误和错误。另一种是使用静态代码分析技术,在执行前检查代码。后者显然更好,因为它可以节省时间和麻烦。
事实上,linting 可以放在不同的阶段。如果您想在键入时测试代码,则可以使用 lint 工具。当然,如果您想在保存文件或在执行阶段对代码进行 lint,那么 linting 工具可以满足您的需求。这取决于个人选择。如果您正在寻找适用于 CSS 和 JavaScript 的最佳 linting 工具,请继续阅读。
1.CSSLint
诚然,CSSLint 会“伤害你的感情”,但作为交换,它会“大大改善你的代码”。CSSLint 目前引领着 CSSlinting 市场。用 JavaScript 编写,不仅是开源的,而且还带有很多配置选项。

2.SublimeLinter CSSLint
CSSLint 曾经是一个如此高效的 CSSlinting 工具,以至于很难找到可以与之匹敌的竞争对手。也许这就是 SublimeLinterlinting 框架在 CSSLint 之上构建其 CSSlinting 插件的原因。SublimeLinter 是一个 SublimeText 插件,它为用户提供了一种 lint 代码(CSS、PHP、Python、Java、Ruby 等)的方法。
3.StyleLint
StyleLint 帮助开发人员避免 CSS、SCSS 或任何其他可解析的 PostCSS 中的语法错误。StyleLint 测试了一百多个规则,您可以选择要切换到哪些规则(请参阅此示例配置)。
4.W3C CSS 验证器
虽然 W3C 的 CSS Validator 通常不被视为 linting 工具,但它为开发人员提供了一个很好的机会来检查 CSS 代码是否符合官方 W3C 标准。W3C 构建了自己的验证器,旨在为 C 语言提供类似于 Lint 程序检查器的工具。

5.脏标记
Dirty Markup 清理、格式化和验证您的 HTML、CSS 和 JavaScript 代码。如果您喜欢简单直接的设计并想要快速解决方案,那么这是正确的选择。当您在编辑器中编写或修改代码时,脏标记可以实时抛出错误消息和通知。
6.JSLint
JSLint 最初是由 Douglas Crockford 于 2002 年发布的,从那时起已经有了很多生命,所以你可以放心地认为它是一个稳定可靠的 JavaScript linting 工具。

7.JSHint
JSHint 是一个社区驱动的项目,最初是为了创建一个更可配置、更不固执的 JSLint 版本。JSHint 允许开发人员配置其任何 linting 选项,然后将自定义配置放入单个文件中,这使得该工具易于重用,因此非常适合大型项目。
8.ESLint
ESLint 是 JavaScript linting 领域中最新的一件大事。它因其高度灵活的特性而广受欢迎。您不仅可以自定义大量前沿的 linting 规则,将其与所有主流代码编辑器集成,还可以通过添加不同的插件轻松扩展其功能。
9.JSCS
JSCS 或 JavaScript 代码样式是用于检查代码格式规则的 JavaScript 的可插入代码样式 linter。JSCS 的目标是提供一种以编程方式强制遵守编码风格指南的方法。尽管 JSCS 不检查 bug 和错误,但它仍然被许多高科技行业的参与者使用,例如 Google、AirBnB 和 AngularJS,因为它可以帮助开发人员保持高度可读和一致的代码库。

10.标准JS
StandardJS,或 JavaScript 标准样式,是一种代码样式 linter,有点像 JSCS,但区别更简单、更直接。如果您不想花时间在配置上,而只是想要一个开箱即用的高效工具,那么 StandardJS 是一个不错的选择。

翻译链接:
英文原文:
网页css js 抓取助手(HTMLPad代码编辑的优势及优势优势介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-20 07:21
HTMLPad是一个非常强大的代码编辑器,支持html5、CSS3、js代码,软件非常智能,自带导航和建议功能,可以大大提高代码编辑效率,并且在同时,也减少了错误,另外还有复用、浏览、验证和部署功能,让您轻松完成相关的开发任务。
HTMLPad的主要特点
1、快速轻量级
加载速度比具有类似功能的其他编辑器或 IDE 快得多。
2、强大的语法高亮
支持 HTML、CSS、JavaScript、PHP、XML、ASP、Perl 等。
3、代码智能
智能代码完成、导航和建议功能。
4、智能代码复用
带有可分配快捷方式的代码片段库和代码模板。
5、HTML5 和 CSS3 就绪
编码功能符合现代 HTML5 和 CSS3 标准。
6、直接FTP/SFTP/FTPS
直接在您的 Web 服务器上编辑或单击一下即可发布本地开发副本更新。
7、浏览器预览
内置多浏览器预览、分屏模式、屏幕大小测试、XRay。
8、高级搜索和替换
转到任何内容、快速搜索、详细搜索、文件搜索、正则表达式、详细结果等。
9、强大的 HTML 工具
标签匹配、HTML Tidy、HTML Inspector、HTML Helper 等等。
10、强大的CSS特性
CSS Inspector、Compatibility Watch、Prefix、Shadow Assistant、Box Assistant 等等。
11、强大的JavaScript编辑器
JavaScript 编辑器、自动完成、语言工具等。
12、综合验证
拼写检查器、W3 HTML 和 CSS 验证器、CSS 检查器、JSLint JavaScript 检查器。
HTMLPad 优势
1、节省时间并提高生产力
HTMLPad 将简单编辑器的速度与全尺寸开发环境的强大功能相结合,让您的工作更快。
2、简单切换
界面和行为与其他编辑器一致。所有基本特征都应该是正确的。
3、完全可定制
您可以调整文本编辑器、菜单、工具栏、快捷键和其他一切,以完全满足您的需求。
4、令人难以置信的一体式包装
在单个程序中创建、编辑、验证和管理 HTML、CSS、JavaScript!
5、更快的启动
与其他 Web 开发编辑器不同,您无需等待它加载。
6、没有混淆
HTMLPad 快速、干净且轻巧。它非常强大,但没有塞满无用的按钮或面板。
7、注意细节
HTMLPad 功能经过精心设计,考虑到了速度和生产力。
8、卓越的 FTP/SFTP/FTPS 功能
只需单击几下即可上传/更新您的在线 网站 文件。
9、许多集成工具
语法检查器、验证器、调试器、美化器、CSS 前缀等。
html5编辑器代码编辑器 查看全部
网页css js 抓取助手(HTMLPad代码编辑的优势及优势优势介绍)
HTMLPad是一个非常强大的代码编辑器,支持html5、CSS3、js代码,软件非常智能,自带导航和建议功能,可以大大提高代码编辑效率,并且在同时,也减少了错误,另外还有复用、浏览、验证和部署功能,让您轻松完成相关的开发任务。

HTMLPad的主要特点
1、快速轻量级
加载速度比具有类似功能的其他编辑器或 IDE 快得多。
2、强大的语法高亮
支持 HTML、CSS、JavaScript、PHP、XML、ASP、Perl 等。
3、代码智能
智能代码完成、导航和建议功能。
4、智能代码复用
带有可分配快捷方式的代码片段库和代码模板。
5、HTML5 和 CSS3 就绪
编码功能符合现代 HTML5 和 CSS3 标准。
6、直接FTP/SFTP/FTPS
直接在您的 Web 服务器上编辑或单击一下即可发布本地开发副本更新。
7、浏览器预览
内置多浏览器预览、分屏模式、屏幕大小测试、XRay。
8、高级搜索和替换
转到任何内容、快速搜索、详细搜索、文件搜索、正则表达式、详细结果等。
9、强大的 HTML 工具
标签匹配、HTML Tidy、HTML Inspector、HTML Helper 等等。
10、强大的CSS特性
CSS Inspector、Compatibility Watch、Prefix、Shadow Assistant、Box Assistant 等等。
11、强大的JavaScript编辑器
JavaScript 编辑器、自动完成、语言工具等。
12、综合验证
拼写检查器、W3 HTML 和 CSS 验证器、CSS 检查器、JSLint JavaScript 检查器。
HTMLPad 优势
1、节省时间并提高生产力
HTMLPad 将简单编辑器的速度与全尺寸开发环境的强大功能相结合,让您的工作更快。
2、简单切换
界面和行为与其他编辑器一致。所有基本特征都应该是正确的。
3、完全可定制
您可以调整文本编辑器、菜单、工具栏、快捷键和其他一切,以完全满足您的需求。
4、令人难以置信的一体式包装
在单个程序中创建、编辑、验证和管理 HTML、CSS、JavaScript!
5、更快的启动
与其他 Web 开发编辑器不同,您无需等待它加载。
6、没有混淆
HTMLPad 快速、干净且轻巧。它非常强大,但没有塞满无用的按钮或面板。
7、注意细节
HTMLPad 功能经过精心设计,考虑到了速度和生产力。
8、卓越的 FTP/SFTP/FTPS 功能
只需单击几下即可上传/更新您的在线 网站 文件。
9、许多集成工具
语法检查器、验证器、调试器、美化器、CSS 前缀等。

html5编辑器代码编辑器
网页css js 抓取助手(如何提高网站百度蜘蛛量量?(组图)期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-18 11:16
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧
作者:迟到991人查看评论:04年前
了解什么是保证金崩溃。与许多其他属性不同的是,盒子模型中的垂直边距在相遇时会塌陷,即当一个元素的下边距与另一个元素的上边距相邻时,只保留两个较大的值,即可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧
作者:熊哥 club903 浏览评论:05年前
了解什么是保证金崩溃。与许多其他属性不同的是,盒子模型中的垂直边距在相遇时会塌陷,即当一个元素的下边距与另一个元素的上边距相邻时,只保留两个较大的值,即可以从这个简单的例子中学到: ? .
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅
作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术、伪装指南、优质代码会让你惊叹不已。没想到会受到大家的欢迎。我也可以整理出一些CSS的黑魔法,可惜我的CSS一直都是渣渣,无事可做。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?
作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛数量之前,我们必须考虑:增加网站数量开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)
作者:赖1681人查看评论:03年前
刷新和学习新事物,保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前的 presto,现在的 Gecko
阅读全文
加快网站访问的9种方法
作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览
作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
网页css js 抓取助手(如何提高网站百度蜘蛛量量?(组图)期)
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取

推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧


作者:迟到991人查看评论:04年前
了解什么是保证金崩溃。与许多其他属性不同的是,盒子模型中的垂直边距在相遇时会塌陷,即当一个元素的下边距与另一个元素的上边距相邻时,只保留两个较大的值,即可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧


作者:熊哥 club903 浏览评论:05年前
了解什么是保证金崩溃。与许多其他属性不同的是,盒子模型中的垂直边距在相遇时会塌陷,即当一个元素的下边距与另一个元素的上边距相邻时,只保留两个较大的值,即可以从这个简单的例子中学到: ? .
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅


作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术、伪装指南、优质代码会让你惊叹不已。没想到会受到大家的欢迎。我也可以整理出一些CSS的黑魔法,可惜我的CSS一直都是渣渣,无事可做。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?

作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛数量之前,我们必须考虑:增加网站数量开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)


作者:赖1681人查看评论:03年前
刷新和学习新事物,保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前的 presto,现在的 Gecko
阅读全文
加快网站访问的9种方法

作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序

作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览


作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑


作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
网页css js 抓取助手( 百度快照入口快照更新的速度和网站的权重存在关系)
网站优化 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2022-03-13 23:11
百度快照入口快照更新的速度和网站的权重存在关系)
什么是百度快照
百度快照是搜索引擎在抓取页面时保留的纯文本文档。它不会收录任何图片、视频资源,甚至不会收录页面中引用的 css 和 js 文件。
但是我们经常看到的快照是图片和样式。这是因为对于快照来说,虽然只保留了文本文档,但是只要网站的服务器当前页面的资源可以访问,快照中就可以引用对应的资源地址;
但是如果你删除了网站对应的资源,或者我们的网站是不可访问的,那么你看到的快照页面就是一个极其丑陋的纯文本页面。
百度快照的作用
即当网站不可访问时,访问者可以通过快照了解页面的基本内容;或者当你现在的网络环境很差的时候,因为百度快照是纯文本内容,你可以在速度慢的时候,依然可以流畅的打开快照页面。
百度快照入口
快照更新时间
很多人认为快照的更新速度和网站的权重有关系,但这其实是一种错误的理解。按照这个逻辑,一个网站是如何阻止搜索引擎创建快照的,也就是说一个没有快照的网站是不是会瘦下来影响排名呢?实际情况是,即使快照被屏蔽,对网站的显示排名也没有影响。
为此,我们首先要了解为什么要更新快照。一般来说,快照的更新速度取决于网站的内容更新速度。
简单来说,搜索引擎了解网站页面的更新频率,然后按照一定的时间频率检查页面是否有变化,及时更新页面。当然,这个动作不是实时的,快照不会立即为你更新。
它更多地取决于您的 网站 内容的属性。对于时间敏感的网站内容,比如新闻和资讯,这种网站往往会更新快照的速度。会更快。
因此,我们不能说网站更快的快照更新比更慢的快照更新更重要。至于权重,快照的更新速度就更没有直接关系了。
收录正常的新站点很多,因为之前的站长更新比较用心,同时网站页面不多,但是可以开发的整体页面快照网站 都处于比较快的时效性。我们能说这个新站的权重很高吗?
快照时间倒退
网站有时更新快照不会用新数据替换旧数据。对于一些更重要的页面,搜索引擎更经常保留在不同时间捕获的几个快照。在某些特殊情况下,可能会显示比较旧的快照,也可能会向后查看快照时间。
有些人会担心这个和网站的权重排名。事实上,我们不需要过多关注快照。这只是一个没有劫持快照的正常更新。基本上,当我们优化 网站 时,快照不是关注点。
版权提醒:原创未经授权请勿复制、转载内容。违者必究,全网自动搜索识别类似抄袭!!! 查看全部
网页css js 抓取助手(
百度快照入口快照更新的速度和网站的权重存在关系)

什么是百度快照
百度快照是搜索引擎在抓取页面时保留的纯文本文档。它不会收录任何图片、视频资源,甚至不会收录页面中引用的 css 和 js 文件。
但是我们经常看到的快照是图片和样式。这是因为对于快照来说,虽然只保留了文本文档,但是只要网站的服务器当前页面的资源可以访问,快照中就可以引用对应的资源地址;
但是如果你删除了网站对应的资源,或者我们的网站是不可访问的,那么你看到的快照页面就是一个极其丑陋的纯文本页面。
百度快照的作用
即当网站不可访问时,访问者可以通过快照了解页面的基本内容;或者当你现在的网络环境很差的时候,因为百度快照是纯文本内容,你可以在速度慢的时候,依然可以流畅的打开快照页面。
百度快照入口
快照更新时间
很多人认为快照的更新速度和网站的权重有关系,但这其实是一种错误的理解。按照这个逻辑,一个网站是如何阻止搜索引擎创建快照的,也就是说一个没有快照的网站是不是会瘦下来影响排名呢?实际情况是,即使快照被屏蔽,对网站的显示排名也没有影响。
为此,我们首先要了解为什么要更新快照。一般来说,快照的更新速度取决于网站的内容更新速度。
简单来说,搜索引擎了解网站页面的更新频率,然后按照一定的时间频率检查页面是否有变化,及时更新页面。当然,这个动作不是实时的,快照不会立即为你更新。

它更多地取决于您的 网站 内容的属性。对于时间敏感的网站内容,比如新闻和资讯,这种网站往往会更新快照的速度。会更快。
因此,我们不能说网站更快的快照更新比更慢的快照更新更重要。至于权重,快照的更新速度就更没有直接关系了。
收录正常的新站点很多,因为之前的站长更新比较用心,同时网站页面不多,但是可以开发的整体页面快照网站 都处于比较快的时效性。我们能说这个新站的权重很高吗?
快照时间倒退
网站有时更新快照不会用新数据替换旧数据。对于一些更重要的页面,搜索引擎更经常保留在不同时间捕获的几个快照。在某些特殊情况下,可能会显示比较旧的快照,也可能会向后查看快照时间。
有些人会担心这个和网站的权重排名。事实上,我们不需要过多关注快照。这只是一个没有劫持快照的正常更新。基本上,当我们优化 网站 时,快照不是关注点。

版权提醒:原创未经授权请勿复制、转载内容。违者必究,全网自动搜索识别类似抄袭!!!
网页css js 抓取助手(网站页面代码该如何做优化?听听重庆SEO技术人员的相关介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-11 07:25
作为一名网站SEO优化者,必须了解网站的代码,这是网站优化的必备要素之一。如果 网站promotions 想要获得良好的性能,源代码非常重要。挑剔的搜索引擎蜘蛛对简洁的网站代码情有独钟,这就要求我们对网站代码进行简化和优化。网站如何优化页面代码?听听重庆SEO技术人员的相关介绍。
网站页面代码应该如何优化?网页的简化就是简单的网站代码优化,去掉网站冗余代码,减小网站大小,提高网站加载速度和用户体验。
网站代码优化是站长必须掌握的一项基本技能。这与搜索引擎蜘蛛是否会对您的网站 感兴趣有关。冗长无用的代码会让蜘蛛难以理解,增加蜘蛛的抓地力。取网站的难易程度,同时网页的精简也与网站的加载速度有关,这对用户体验非常重要。
网站如何优化页面代码?
1、HEAD 零件代码规范化
代码的HEAD部分是搜索引擎爬取网站的入口部分。现在很多网站头代码都比较统一,刻板印象效果很明显。这样的网站代码就像一个模板框架,不被蜘蛛喜欢,我们要做的就是规范网站的代码,建立一个唯一的网站头部,以及让搜索引擎新鲜,从而吸引蜘蛛爬行
2、使用DIV+CSS布局网页
虽然现在div+css已经很成熟了,但是考虑到网页的兼容性和布局的简洁性,很多网页设计师可能还是会使用老式的表格布局。表格布局虽然很方便,但缺点也很明显。大大增加了网页的大小,尤其是多层表格的嵌套。这样的布局不仅会增加体积,嵌套过多还会影响搜索引擎的爬取和网站的收录。
另外,有的网站会使用外部文件,把css和js放在外部文件中,只需要在页面的html中放入相同的代码即可调用,有时我们会看到很多源码的时候我们检查 CSS 代码和 javasript 代码,将 javascript 放在 网站 页面的 html 文件的最前面,将一些真正可以使用的文本部分推到 html 的后面。重庆SEO认为,这类代码需要精简。
3、CSS 优化
CSS 是页面渲染中非常重要的一部分,包括颜色、大小、背景和字体。编写 CSS 简单易行,但编写可靠的 CSS 代码有很多技巧。
(1), CSS 位置
如果CSS描述出现在网站之后,需要重新渲染页面,会影响打开速度。所有 CSS 定义代码的位置都应该放在 网站 之前。
(2), css sprite 技术
网站 上的部分图片可以使用 CSS sprite 技术进行组合,减少加载请求的数量,从而提高网页的加载速度。
(3), CSS 代码优化
通过 CSS 代码属性的简写、去除冗余结构(frameworks)和重置(resets)等一系列方法和技术,简化 CSS 代码,减小 CSS 文件的大小。
(4),尽量不要使用内联CSS
内联 CSS 有两种,一种是头部区域内的普通内联;另一个是出现在标签中的内联内联 CSS。无论使用什么内联 CSS 方法,结果都会增加页面的体积。,我们可以尝试使用外部调整的 CSS 来缩小网站页面的大小。
4、JS优化
JS 优化还是和其他语言的优化差不多。JS优化的关键还是要关注最关键的地方,也就是瓶颈。一般来说,瓶颈总是发生在大规模循环中。,这并不是说循环本身存在性能问题,而是说循环可以迅速放大可能的性能问题。
(1), JS 位置
在优化网页代码中的js时,重庆SEO建议将js放在页面末尾,这样可以加快页面打开速度。
(2), 合并 JS
合并同域名下的js,通过减少网络连接数来提高网页的打开速度。
(3),LazyLoad 技术
Lazy Load 是一个用 JavaScript 编写的 jQuery 插件。它可以延迟加载长页面中的图像。在用户将页面滚动到它们所在的位置之前,不会加载浏览器可见区域之外的图像。
(4),调用外部JS代码
我们知道目前的搜索引擎仍然无法识别 JS 代码。如果 网站 中出现大量 JS 代码,那么 网站 就很难在 收录 上,而我们要做的就是将 Javascript 代码以 external 的形式调用网站,可以简化搜索引擎的工作,不会无形中推导出涉及网站的无效代码。
不仅如此,您还可以使用 css 代码进行外部调用。网站开头可以在css代码文件中定义网站的文字和颜色,尽量不要在页面代码中出现过多的样式代码。
(5),减少页面对JS的依赖
现在,JS 对搜索引擎并不友好。虽然据说搜索引擎不讨厌 JS,但还是少做点比较好。虽然 JS 可以产生很多效果,但是网页中的 JS 还是很多的。会影响蜘蛛对页面的抓取,增加网页的体积,尤其是导航栏等页面的关键位置,尽量使用DIV+CSS的设计方式。
5、TABLE 标签缩减
表格标签是大部分在线网站中最常见的代码形式。原因是创建网站的时候表比较快,但这也影响了后期对网站的优化。
与div+css布局的简化代码网站相比,占用空间比较大。因此,在建网站时,尽量少用表格。即使要使用表格,也应尽可能使用嵌套表格。谨慎使用以避免冗余代码
那么,当前的 网站 做了什么?很多程序员首先想到用CSS来做,用CSS来排版。这种做法大大减少了页面中的表格,但是在重庆SEO看来,网站不能没有表格。有些东西是必须要用的。可以使用表。但是很多网站使用嵌套表。一般这样的表会给网站生成大量的垃圾代码,而这些垃圾代码都是没有用的代码,而这类代码也是我们网站需要精简的代码之一.
6、代码注释省略
许多程序员习惯于在编写代码时在别人看不懂的地方给出注释。这些代码通常用于几个程序员之间的协作工作,对局外人和搜索引擎没有用处。相反,它们会给搜索引擎蜘蛛带来一些麻烦。
在打开页面代码的时候,我们经常会看到一些注释代码,它们是程序员为了表明代码含义所做的注释。其实这些开孔都不是必须的,因为对于搜索引擎来说,它们没有任何意义,反而会增加页数。代码的容量,所以对网站没有好处,直接省略比较好。
7、去除页面中的冗余代码
有的网站认为作者的代码编写习惯有问题,页面上会出现很多空白代码,比如:空白代码,重复定义样式和字体的代码,不要小看这些小代码,他们积累了很多,也让我们的网站异常臃肿。
很多网站使用DIV+CSS,在CSS中定义了文本的字体、颜色和页面布局,但是在网站的其他地方,style和font用来重新定义Font字体,这些代码不需要重复定义,都是可以简化的代码。
8、将 HTML 控件转换为 CSS 控件
许多网页设计师习惯于控制标签内的内容。例如,在img标签中,宽度和高度用于控制图像的大小。尝试将这些代码转换为外部调整的 CSS 以使网页代码更苗条。
9、缓存静态资源
通过在浏览器端设置浏览器缓存,缓存css、js等更新频率较低的文件,这样当同一个访问者再次访问你的网站时,浏览器就可以从浏览器的缓存中获取css、js等,不用每次都从你的服务器读取,在一定程度上加快了网站的打开速度,节省了你的服务器流量。
10、网页压缩技术
对于网页压缩,相信各位站长都不陌生。主要是启用服务器Gzip,对页面进行Gzip压缩,减小元素大小,从而减少数据传输,提高网页加载速度。这个功能需要你的服务器是的,GZIP压缩一般可以将网页压缩30%-80%,这是最重要的优化效果。
网站如何优化页面代码?重庆SEO提醒网站页面代码的SEO优化,不仅可以提高页面的打开速度,还可以提升用户的访问体验。同时,从SEO的角度,还可以提高蜘蛛的访问速度,有助于网站的搜索引擎的索引体验。 查看全部
网页css js 抓取助手(网站页面代码该如何做优化?听听重庆SEO技术人员的相关介绍)
作为一名网站SEO优化者,必须了解网站的代码,这是网站优化的必备要素之一。如果 网站promotions 想要获得良好的性能,源代码非常重要。挑剔的搜索引擎蜘蛛对简洁的网站代码情有独钟,这就要求我们对网站代码进行简化和优化。网站如何优化页面代码?听听重庆SEO技术人员的相关介绍。

网站页面代码应该如何优化?网页的简化就是简单的网站代码优化,去掉网站冗余代码,减小网站大小,提高网站加载速度和用户体验。
网站代码优化是站长必须掌握的一项基本技能。这与搜索引擎蜘蛛是否会对您的网站 感兴趣有关。冗长无用的代码会让蜘蛛难以理解,增加蜘蛛的抓地力。取网站的难易程度,同时网页的精简也与网站的加载速度有关,这对用户体验非常重要。
网站如何优化页面代码?
1、HEAD 零件代码规范化
代码的HEAD部分是搜索引擎爬取网站的入口部分。现在很多网站头代码都比较统一,刻板印象效果很明显。这样的网站代码就像一个模板框架,不被蜘蛛喜欢,我们要做的就是规范网站的代码,建立一个唯一的网站头部,以及让搜索引擎新鲜,从而吸引蜘蛛爬行
2、使用DIV+CSS布局网页
虽然现在div+css已经很成熟了,但是考虑到网页的兼容性和布局的简洁性,很多网页设计师可能还是会使用老式的表格布局。表格布局虽然很方便,但缺点也很明显。大大增加了网页的大小,尤其是多层表格的嵌套。这样的布局不仅会增加体积,嵌套过多还会影响搜索引擎的爬取和网站的收录。
另外,有的网站会使用外部文件,把css和js放在外部文件中,只需要在页面的html中放入相同的代码即可调用,有时我们会看到很多源码的时候我们检查 CSS 代码和 javasript 代码,将 javascript 放在 网站 页面的 html 文件的最前面,将一些真正可以使用的文本部分推到 html 的后面。重庆SEO认为,这类代码需要精简。
3、CSS 优化
CSS 是页面渲染中非常重要的一部分,包括颜色、大小、背景和字体。编写 CSS 简单易行,但编写可靠的 CSS 代码有很多技巧。
(1), CSS 位置
如果CSS描述出现在网站之后,需要重新渲染页面,会影响打开速度。所有 CSS 定义代码的位置都应该放在 网站 之前。
(2), css sprite 技术
网站 上的部分图片可以使用 CSS sprite 技术进行组合,减少加载请求的数量,从而提高网页的加载速度。
(3), CSS 代码优化
通过 CSS 代码属性的简写、去除冗余结构(frameworks)和重置(resets)等一系列方法和技术,简化 CSS 代码,减小 CSS 文件的大小。
(4),尽量不要使用内联CSS
内联 CSS 有两种,一种是头部区域内的普通内联;另一个是出现在标签中的内联内联 CSS。无论使用什么内联 CSS 方法,结果都会增加页面的体积。,我们可以尝试使用外部调整的 CSS 来缩小网站页面的大小。
4、JS优化
JS 优化还是和其他语言的优化差不多。JS优化的关键还是要关注最关键的地方,也就是瓶颈。一般来说,瓶颈总是发生在大规模循环中。,这并不是说循环本身存在性能问题,而是说循环可以迅速放大可能的性能问题。
(1), JS 位置
在优化网页代码中的js时,重庆SEO建议将js放在页面末尾,这样可以加快页面打开速度。

(2), 合并 JS
合并同域名下的js,通过减少网络连接数来提高网页的打开速度。
(3),LazyLoad 技术
Lazy Load 是一个用 JavaScript 编写的 jQuery 插件。它可以延迟加载长页面中的图像。在用户将页面滚动到它们所在的位置之前,不会加载浏览器可见区域之外的图像。
(4),调用外部JS代码
我们知道目前的搜索引擎仍然无法识别 JS 代码。如果 网站 中出现大量 JS 代码,那么 网站 就很难在 收录 上,而我们要做的就是将 Javascript 代码以 external 的形式调用网站,可以简化搜索引擎的工作,不会无形中推导出涉及网站的无效代码。
不仅如此,您还可以使用 css 代码进行外部调用。网站开头可以在css代码文件中定义网站的文字和颜色,尽量不要在页面代码中出现过多的样式代码。
(5),减少页面对JS的依赖
现在,JS 对搜索引擎并不友好。虽然据说搜索引擎不讨厌 JS,但还是少做点比较好。虽然 JS 可以产生很多效果,但是网页中的 JS 还是很多的。会影响蜘蛛对页面的抓取,增加网页的体积,尤其是导航栏等页面的关键位置,尽量使用DIV+CSS的设计方式。
5、TABLE 标签缩减
表格标签是大部分在线网站中最常见的代码形式。原因是创建网站的时候表比较快,但这也影响了后期对网站的优化。
与div+css布局的简化代码网站相比,占用空间比较大。因此,在建网站时,尽量少用表格。即使要使用表格,也应尽可能使用嵌套表格。谨慎使用以避免冗余代码
那么,当前的 网站 做了什么?很多程序员首先想到用CSS来做,用CSS来排版。这种做法大大减少了页面中的表格,但是在重庆SEO看来,网站不能没有表格。有些东西是必须要用的。可以使用表。但是很多网站使用嵌套表。一般这样的表会给网站生成大量的垃圾代码,而这些垃圾代码都是没有用的代码,而这类代码也是我们网站需要精简的代码之一.
6、代码注释省略
许多程序员习惯于在编写代码时在别人看不懂的地方给出注释。这些代码通常用于几个程序员之间的协作工作,对局外人和搜索引擎没有用处。相反,它们会给搜索引擎蜘蛛带来一些麻烦。
在打开页面代码的时候,我们经常会看到一些注释代码,它们是程序员为了表明代码含义所做的注释。其实这些开孔都不是必须的,因为对于搜索引擎来说,它们没有任何意义,反而会增加页数。代码的容量,所以对网站没有好处,直接省略比较好。
7、去除页面中的冗余代码
有的网站认为作者的代码编写习惯有问题,页面上会出现很多空白代码,比如:空白代码,重复定义样式和字体的代码,不要小看这些小代码,他们积累了很多,也让我们的网站异常臃肿。
很多网站使用DIV+CSS,在CSS中定义了文本的字体、颜色和页面布局,但是在网站的其他地方,style和font用来重新定义Font字体,这些代码不需要重复定义,都是可以简化的代码。
8、将 HTML 控件转换为 CSS 控件
许多网页设计师习惯于控制标签内的内容。例如,在img标签中,宽度和高度用于控制图像的大小。尝试将这些代码转换为外部调整的 CSS 以使网页代码更苗条。
9、缓存静态资源
通过在浏览器端设置浏览器缓存,缓存css、js等更新频率较低的文件,这样当同一个访问者再次访问你的网站时,浏览器就可以从浏览器的缓存中获取css、js等,不用每次都从你的服务器读取,在一定程度上加快了网站的打开速度,节省了你的服务器流量。
10、网页压缩技术
对于网页压缩,相信各位站长都不陌生。主要是启用服务器Gzip,对页面进行Gzip压缩,减小元素大小,从而减少数据传输,提高网页加载速度。这个功能需要你的服务器是的,GZIP压缩一般可以将网页压缩30%-80%,这是最重要的优化效果。

网站如何优化页面代码?重庆SEO提醒网站页面代码的SEO优化,不仅可以提高页面的打开速度,还可以提升用户的访问体验。同时,从SEO的角度,还可以提高蜘蛛的访问速度,有助于网站的搜索引擎的索引体验。
网页css js 抓取助手( Python爬虫下我尉(同英):2763177065请求头注意)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-11 07:25
Python爬虫下我尉(同英):2763177065请求头注意)
请求:用户通过浏览器(socket客户端)将自己的信息发送到服务器(socket server)
响应:服务器收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后会解析其内容展示给用户,爬虫程序模拟浏览器发送请求再接收Response后提取有用的数据。对于想要更轻松地学习Python基础、Python爬虫、Web开发、大数据、数据分析、人工智能等技术的新手小白,这里把系统教学资源分享给大家,下面展开列表:2763177065 [教程] /工具/方法/疑问]
四、 请求
1、请求方法:
常用请求方式:GET/POST
2、请求的 URL
url 全局统一资源定位器用于定义 Internet 上的唯一资源。比如一张图片、一个文件、一个视频都可以通过url唯一标识
网址编码
图片
图像将被编码(参见示例代码)
一个网页的加载过程是:
加载网页时,通常首先加载文档文档。
解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(一些大的网站会使用Referrer进行防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问的浏览器(需添加否则视为爬虫)
(3)cookie:注意要携带请求头
4、请求正文
如果请求体在get方法中,则请求体是没有内容的(get请求的请求体放在url后面的参数中,可以直接看到)。如果是在post方法中,请求体为格式数据ps:1、登录窗口,文件上传等,信息会附在请求体中2、登录,输入错误的用户名和密码,然后提交,就可以看到帖子了,正确登录后,页面一般会跳转,帖子抓不到
五、 响应
1、响应状态码
200:代表成功
301:代表跳跃
404:文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能有多个,告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬虫流程总结:
抓取 -> 解析 -> 存储
2、爬虫需要的工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(有用和无用的网页都会被加载);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis 查看全部
网页css js 抓取助手(
Python爬虫下我尉(同英):2763177065请求头注意)
请求:用户通过浏览器(socket客户端)将自己的信息发送到服务器(socket server)
响应:服务器收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后会解析其内容展示给用户,爬虫程序模拟浏览器发送请求再接收Response后提取有用的数据。对于想要更轻松地学习Python基础、Python爬虫、Web开发、大数据、数据分析、人工智能等技术的新手小白,这里把系统教学资源分享给大家,下面展开列表:2763177065 [教程] /工具/方法/疑问]
四、 请求
1、请求方法:
常用请求方式:GET/POST
2、请求的 URL
url 全局统一资源定位器用于定义 Internet 上的唯一资源。比如一张图片、一个文件、一个视频都可以通过url唯一标识
网址编码
图片
图像将被编码(参见示例代码)
一个网页的加载过程是:
加载网页时,通常首先加载文档文档。
解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(一些大的网站会使用Referrer进行防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问的浏览器(需添加否则视为爬虫)
(3)cookie:注意要携带请求头
4、请求正文
如果请求体在get方法中,则请求体是没有内容的(get请求的请求体放在url后面的参数中,可以直接看到)。如果是在post方法中,请求体为格式数据ps:1、登录窗口,文件上传等,信息会附在请求体中2、登录,输入错误的用户名和密码,然后提交,就可以看到帖子了,正确登录后,页面一般会跳转,帖子抓不到
五、 响应
1、响应状态码
200:代表成功
301:代表跳跃
404:文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能有多个,告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬虫流程总结:
抓取 -> 解析 -> 存储
2、爬虫需要的工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(有用和无用的网页都会被加载);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
网页css js 抓取助手( JS、CSS文件被蜘蛛抓取的频率特别高,你们怎么看?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-02 12:14
JS、CSS文件被蜘蛛抓取的频率特别高,你们怎么看?)
很多 网站 正在查看日志,
你会发现JS和CSS文件被蜘蛛爬取的频率特别高。
于是有人考虑阻止蜘蛛抓取robots.txt中的js和css文件,
将蜘蛛时间节省到其他页面。
国平老师认为,屏蔽这种文件不会对网站造成不良影响,反而可以促进其他页面的收录;
但同时也有很多人认为屏蔽这两个文件很容易被搜索引擎判断为网站作弊。
元芳,你怎么看?
福威 说道:
以下说法值得商榷:
“蜘蛛爬取网站的时间是确定的,如果某个文件被限制爬取,它将有更多时间爬取其他网页”
如果没有,则根本没有必要阻止 CSS 和 JS。
如果是真的,那么需要屏蔽的不仅仅是 CSS 和 JS。许多没有意义的文件值得阻止。
因此,上述论点值得更多讨论。
张立波说:
我觉得没必要屏蔽,因为搜索引擎会知道哪些是JS,CSS,哪些是网页文件。爬js和css的爬虫应该不会影响网页的爬取频率。
至于搜索引擎爬js和css,可能和snapshot有关,因为网站的页面大部分都是用div+css搭建的,如果没有css页面就惨了。
所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。
为了使搜索结果更准确,这是个人猜测,但可能是真正的原因。
周围的王说:
就前面的操作流程来说,我个人并没有屏蔽过js和css文件。
关于网站的性能,只推荐js和css分开集成,css放在头,js放在最后,防止网站加载时出现混乱和阻塞。
目前似乎没有任何区域的信息说js和css必须被屏蔽。
粗略地说,遵循两点就足够了:
1:整合css文件,通过压缩缩小大小,放在头部;
2:整合js文件,通过压缩缩小体积,放在最后;
在其他代码区,尽量不要有单独的css和js代码,这样更符合标准。
冯寒说道:
经过测试和跟踪数据表明:
1> 被屏蔽的JS/css文件仍然会被百度和google抓取
2> 跟踪观察屏蔽后其他页面类型蜘蛛的爬取量,发现并没有增加
3>如果网站大部分js/css文件收录较多的url,可以解封,蜘蛛在爬js/css文件的同时可以爬取里面的链接
4>如果网站大部分js/css文件基本都是code之类的,屏蔽也可以,没有明显的优点,也没有发现缺点。
王丹说:
我屏蔽了,傅伟老师发现你回答很多问题都很“谨慎”。
回答的时候可以添加一些自己或者朋友的正常操作方法。
我记得听傅伟老师说他上课要被堵了。
程大虾说道:
一个搜索引擎可以爬取的页面量远大于我们拥有的数据量网站,所以爬css还是JS都无所谓
陈福山 说:
现在搜索引擎可以识别 JS CSS 文件,它们是否被阻止并不重要。
只要你的网站压力不受限,服务器还不算太差。
屏幕与否无关紧要。
我的网站检测JS N收录照常,快照照常更新
胡小义 说:
这取决于页数,如果页数小到可以被任何蜘蛛任意爬取,那么这是没有必要的。
相反,如果网页数量太大,蜘蛛无法抓取,则需要删除 Nofollow,而 Robots 会删除一些东西。
陈超 说道:
在我看来:
1、以后css文件会成为搜索引擎判断一个页面的参考因素;
2、也许现在搜索引擎可以简单地使用 css 文件来理解页面结构。
小龙 说道:
假设这句话是真的:“蜘蛛爬取网站的时间是确定的。如果某个文件被限制爬取,它就有更多的时间爬取其他网页”
对于较大的 网站,仍然需要阻止 CSS 和 JS 文件。
对于中小网站,完全没有必要。
吴兴说:
JS和css在网页头部设置了Cache-Control,不需要在Robots.txt中添加。
刘先森说:
你先尝试阻塞一个部分,看看网站的整体情况和日志分析。
不过建议等12月百度调整后再试。
于冰妍 说道:
屏蔽页面对于搜索引擎来说是很正常的事情,否则就不会有Robots.txt等用户制定的爬取规则。
本文提供的信息仅供参考,请自行查看。 查看全部
网页css js 抓取助手(
JS、CSS文件被蜘蛛抓取的频率特别高,你们怎么看?)

很多 网站 正在查看日志,
你会发现JS和CSS文件被蜘蛛爬取的频率特别高。
于是有人考虑阻止蜘蛛抓取robots.txt中的js和css文件,
将蜘蛛时间节省到其他页面。
国平老师认为,屏蔽这种文件不会对网站造成不良影响,反而可以促进其他页面的收录;
但同时也有很多人认为屏蔽这两个文件很容易被搜索引擎判断为网站作弊。
元芳,你怎么看?
福威 说道:
以下说法值得商榷:
“蜘蛛爬取网站的时间是确定的,如果某个文件被限制爬取,它将有更多时间爬取其他网页”
如果没有,则根本没有必要阻止 CSS 和 JS。
如果是真的,那么需要屏蔽的不仅仅是 CSS 和 JS。许多没有意义的文件值得阻止。
因此,上述论点值得更多讨论。
张立波说:
我觉得没必要屏蔽,因为搜索引擎会知道哪些是JS,CSS,哪些是网页文件。爬js和css的爬虫应该不会影响网页的爬取频率。
至于搜索引擎爬js和css,可能和snapshot有关,因为网站的页面大部分都是用div+css搭建的,如果没有css页面就惨了。
所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。
为了使搜索结果更准确,这是个人猜测,但可能是真正的原因。
周围的王说:
就前面的操作流程来说,我个人并没有屏蔽过js和css文件。
关于网站的性能,只推荐js和css分开集成,css放在头,js放在最后,防止网站加载时出现混乱和阻塞。
目前似乎没有任何区域的信息说js和css必须被屏蔽。
粗略地说,遵循两点就足够了:
1:整合css文件,通过压缩缩小大小,放在头部;
2:整合js文件,通过压缩缩小体积,放在最后;
在其他代码区,尽量不要有单独的css和js代码,这样更符合标准。
冯寒说道:
经过测试和跟踪数据表明:
1> 被屏蔽的JS/css文件仍然会被百度和google抓取
2> 跟踪观察屏蔽后其他页面类型蜘蛛的爬取量,发现并没有增加
3>如果网站大部分js/css文件收录较多的url,可以解封,蜘蛛在爬js/css文件的同时可以爬取里面的链接
4>如果网站大部分js/css文件基本都是code之类的,屏蔽也可以,没有明显的优点,也没有发现缺点。
王丹说:
我屏蔽了,傅伟老师发现你回答很多问题都很“谨慎”。
回答的时候可以添加一些自己或者朋友的正常操作方法。
我记得听傅伟老师说他上课要被堵了。
程大虾说道:
一个搜索引擎可以爬取的页面量远大于我们拥有的数据量网站,所以爬css还是JS都无所谓
陈福山 说:
现在搜索引擎可以识别 JS CSS 文件,它们是否被阻止并不重要。
只要你的网站压力不受限,服务器还不算太差。
屏幕与否无关紧要。
我的网站检测JS N收录照常,快照照常更新
胡小义 说:
这取决于页数,如果页数小到可以被任何蜘蛛任意爬取,那么这是没有必要的。
相反,如果网页数量太大,蜘蛛无法抓取,则需要删除 Nofollow,而 Robots 会删除一些东西。
陈超 说道:
在我看来:
1、以后css文件会成为搜索引擎判断一个页面的参考因素;
2、也许现在搜索引擎可以简单地使用 css 文件来理解页面结构。
小龙 说道:
假设这句话是真的:“蜘蛛爬取网站的时间是确定的。如果某个文件被限制爬取,它就有更多的时间爬取其他网页”
对于较大的 网站,仍然需要阻止 CSS 和 JS 文件。
对于中小网站,完全没有必要。
吴兴说:
JS和css在网页头部设置了Cache-Control,不需要在Robots.txt中添加。
刘先森说:
你先尝试阻塞一个部分,看看网站的整体情况和日志分析。
不过建议等12月百度调整后再试。
于冰妍 说道:
屏蔽页面对于搜索引擎来说是很正常的事情,否则就不会有Robots.txt等用户制定的爬取规则。
本文提供的信息仅供参考,请自行查看。
网页css js 抓取助手(一个网站练习一下爬虫实现的功能全站获取CSS,JS,img等文件连接获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-28 19:09
闲暇之余,刚好找了一个网站来练习爬虫,总结一下写爬虫时遇到的知识点。
实现的功能
抓取站点范围的 URL
获取CSS、JS、img等文件连接
获取文件名
将文件保存到本地
使用的模块
urllib
BS4
回覆
操作系统
第 1 部分:抓取站点范围的 URL
先粘贴代码
# 获取当前页面子网站子网站
def get_urls(url, baseurl, urls):
with request.urlopen(url) as f:
data = f.read().decode('utf-8')
link = bs(data).find_all('a')
for i in link:
suffix = i.get('href')
# 设置排除写入的子连接
if suffix == '#' or suffix == '#carousel-example-generic' or 'javascript:void(0)' in suffix:
continue
else:
# 构建urls
childurl = baseurl + suffix
if childurl not in urls:
urls.append(childurl)
# 获取整个网站URL
def getallUrl(url, baseurl, urls):
get_urls(url, baseurl, urls)
end = len(urls)
start = 0
while(True):
if start == end:
break
for i in range(start, end):
get_urls(urls[i], baseurl, urls)
time.sleep(1)
start = end
end = len(urls)
通过urllib包中的请求,调用urlopen访问网站
首先从首页开始,首页一般收录各个子页面的url,将抓取到的url添加到一个列表中
然后读取这个列表的每个元素,依次访问,获取子页面的url连接,加入到列表中。
感觉这样抓取全站的url不是很靠谱,有时间再完善。
第二部分:获取css、js、img的连接
先粘贴代码
# 获取当前网页代码
with request.urlopen(url) as f:
html_source = f.read().decode()
<p> # css,js,img正则表达式,以获取文件相对路径
patterncss = ' 查看全部
网页css js 抓取助手(一个网站练习一下爬虫实现的功能全站获取CSS,JS,img等文件连接获取)
闲暇之余,刚好找了一个网站来练习爬虫,总结一下写爬虫时遇到的知识点。
实现的功能
抓取站点范围的 URL
获取CSS、JS、img等文件连接
获取文件名
将文件保存到本地
使用的模块
urllib
BS4
回覆
操作系统
第 1 部分:抓取站点范围的 URL
先粘贴代码
# 获取当前页面子网站子网站
def get_urls(url, baseurl, urls):
with request.urlopen(url) as f:
data = f.read().decode('utf-8')
link = bs(data).find_all('a')
for i in link:
suffix = i.get('href')
# 设置排除写入的子连接
if suffix == '#' or suffix == '#carousel-example-generic' or 'javascript:void(0)' in suffix:
continue
else:
# 构建urls
childurl = baseurl + suffix
if childurl not in urls:
urls.append(childurl)
# 获取整个网站URL
def getallUrl(url, baseurl, urls):
get_urls(url, baseurl, urls)
end = len(urls)
start = 0
while(True):
if start == end:
break
for i in range(start, end):
get_urls(urls[i], baseurl, urls)
time.sleep(1)
start = end
end = len(urls)
通过urllib包中的请求,调用urlopen访问网站
首先从首页开始,首页一般收录各个子页面的url,将抓取到的url添加到一个列表中
然后读取这个列表的每个元素,依次访问,获取子页面的url连接,加入到列表中。
感觉这样抓取全站的url不是很靠谱,有时间再完善。
第二部分:获取css、js、img的连接
先粘贴代码
# 获取当前网页代码
with request.urlopen(url) as f:
html_source = f.read().decode()
<p> # css,js,img正则表达式,以获取文件相对路径
patterncss = '
网页css js 抓取助手(晚来风急4年前99120个现代CSS代码的建议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-27 09:22
网站js css代码爬取相关博客
编写现代 CSS 代码的 20 个技巧
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇的时候会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
风来已晚 4年前 991
编写现代 CSS 代码的 20 个技巧
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇的时候会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
熊哥俱乐部 5年前 903
CSS黑魔法,让你少写不必要的JS,代码更优雅
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术、伪装指南、高级代码会让你惊叹。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直是渣渣,我也无计可施。我最近写了一篇Ch
沃克·武松 4年前 1735
百度网站优化:如何增加蜘蛛爬取量?
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛数量之前,我们必须考虑:增加网站数量开启速度。百度网站优化:如何增加爬虫
蝙蝠侠 it3 年前 1205
前端面试题总结(HTML和CSS)
刷新和学习新事物,保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前的 presto,现在的 Gecko
赖同学 3年前 1681年
加快网站访问的9种方法
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
风来得太晚4年前1068
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
我是小助理3年前2146
HTML5 和 CSS3 新特性一览
HTML5 和 CSS3 新特性一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
云栖大讲堂3年前4140
网站js css代码爬取相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
管理员 宝贝 3 年前 5207 查看全部
网页css js 抓取助手(晚来风急4年前99120个现代CSS代码的建议)
网站js css代码爬取相关博客
编写现代 CSS 代码的 20 个技巧

了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇的时候会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
风来已晚 4年前 991
编写现代 CSS 代码的 20 个技巧

了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇的时候会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
熊哥俱乐部 5年前 903
CSS黑魔法,让你少写不必要的JS,代码更优雅

前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术、伪装指南、高级代码会让你惊叹。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直是渣渣,我也无计可施。我最近写了一篇Ch
沃克·武松 4年前 1735
百度网站优化:如何增加蜘蛛爬取量?
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛数量之前,我们必须考虑:增加网站数量开启速度。百度网站优化:如何增加爬虫
蝙蝠侠 it3 年前 1205
前端面试题总结(HTML和CSS)

刷新和学习新事物,保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前的 presto,现在的 Gecko
赖同学 3年前 1681年
加快网站访问的9种方法

一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
风来得太晚4年前1068
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
我是小助理3年前2146
HTML5 和 CSS3 新特性一览

HTML5 和 CSS3 新特性一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
云栖大讲堂3年前4140
网站js css代码爬取相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑

阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
管理员 宝贝 3 年前 5207
网页css js 抓取助手(是否屏蔽蜘蛛抓取一个JS和CSS文件?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-26 10:28
做过网站的人都知道,在查看日志的时候,会发现JS和CSS文件被蜘蛛爬取的非常频繁,所以有人考虑在robots.txt中阻止蜘蛛爬取js和css文件以节省资金。蜘蛛时间到其他页面。你会阻止蜘蛛抓取 JS 和 CSS 文件吗?我们采访了几位专业的SEO专家:
傅伟——
SEOWHY创始人
我认为“蜘蛛抓取 网站 的时间是确定的。如果限制抓取某个文件,它将有更多时间抓取其他网页”
如果没有,则根本没有必要阻止 CSS 和 JS。
如果是真的,那么需要屏蔽的不仅仅是 CSS 和 JS。许多没有意义的文件值得阻止。
张立波——
迈步鞋网联合创始人兼COO
我觉得没必要屏蔽,因为搜索引擎会知道哪些是JS,CSS,哪些是网页文件。爬js和css的爬虫应该不会影响网页的爬取频率。
至于搜索引擎爬js和css,可能和snapshot有关,因为网站的页面大部分都是用div+css搭建的,如果没有css页面就惨了。
所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。
冯寒——
大型B2B平台的SEO负责人
经过我的实验和跟踪数据显示:
1> 被屏蔽的js/css文件还是会被百度和google抓取
2> 跟踪观察屏蔽后其他页面类型蜘蛛的爬取量,发现并没有增加
3>如果网站大部分js/css文件收录较多的url,可以解封,蜘蛛在爬js/css文件的同时可以爬取里面的链接
4>如果网站大部分js/css文件基本都是code之类的,屏蔽也可以,没有明显的优点,也没有发现缺点。
国平老师认为,屏蔽这种文件不会对网站造成不良影响,反而可以促进其他页面的收录;
免责声明:本文由(李竹平)原创编译,转载请保留链接:是否屏蔽百度蜘蛛抓取JS和CSS文件 查看全部
网页css js 抓取助手(是否屏蔽蜘蛛抓取一个JS和CSS文件?(组图))
做过网站的人都知道,在查看日志的时候,会发现JS和CSS文件被蜘蛛爬取的非常频繁,所以有人考虑在robots.txt中阻止蜘蛛爬取js和css文件以节省资金。蜘蛛时间到其他页面。你会阻止蜘蛛抓取 JS 和 CSS 文件吗?我们采访了几位专业的SEO专家:

傅伟——
SEOWHY创始人
我认为“蜘蛛抓取 网站 的时间是确定的。如果限制抓取某个文件,它将有更多时间抓取其他网页”
如果没有,则根本没有必要阻止 CSS 和 JS。
如果是真的,那么需要屏蔽的不仅仅是 CSS 和 JS。许多没有意义的文件值得阻止。
张立波——
迈步鞋网联合创始人兼COO
我觉得没必要屏蔽,因为搜索引擎会知道哪些是JS,CSS,哪些是网页文件。爬js和css的爬虫应该不会影响网页的爬取频率。
至于搜索引擎爬js和css,可能和snapshot有关,因为网站的页面大部分都是用div+css搭建的,如果没有css页面就惨了。
所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。
冯寒——
大型B2B平台的SEO负责人
经过我的实验和跟踪数据显示:
1> 被屏蔽的js/css文件还是会被百度和google抓取
2> 跟踪观察屏蔽后其他页面类型蜘蛛的爬取量,发现并没有增加
3>如果网站大部分js/css文件收录较多的url,可以解封,蜘蛛在爬js/css文件的同时可以爬取里面的链接
4>如果网站大部分js/css文件基本都是code之类的,屏蔽也可以,没有明显的优点,也没有发现缺点。
国平老师认为,屏蔽这种文件不会对网站造成不良影响,反而可以促进其他页面的收录;
免责声明:本文由(李竹平)原创编译,转载请保留链接:是否屏蔽百度蜘蛛抓取JS和CSS文件
网页css js 抓取助手(什么是HTML?渲染网页的步骤机制及优化方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-24 23:23
)
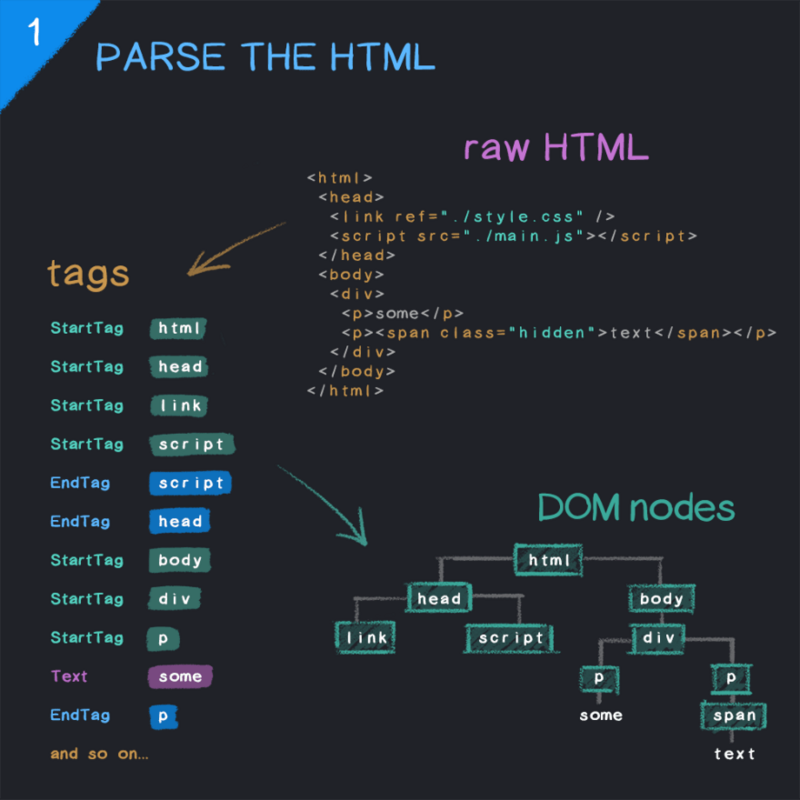
我的想法:如果我要构建快速可靠的网站,我需要真正了解浏览器如何在每一步呈现页面,以便在开发过程中优化每一步。这个 文章 是我对端到端流程的高级学习总结。
好吧,事不宜迟,让我们开始吧。这个过程可以分为以下几个主要阶段:
开始解析 HTML 获取外部资源 解析 CSS 并构建 CSSOM 执行 JavaScript 合并 DOM 和 CSSOM 构建渲染树 计算布局并绘制 1.开始解析 HTML
当浏览器通过网络接收到页面的 HTML 数据时,它会立即设置解析器以将 HTML 转换为文档对象模型 (DOM)。
文档对象模型 (DOM) 是 HTML 和 XML 文档的编程接口。它提供了文档的结构化表示,并定义了从程序访问该结构以更改文档的结构、样式和内容的方法。DOM 将文档解析为节点和对象(收录属性和方法的对象)的结构化集合。简而言之,它将网页与脚本或编程语言联系起来。
解析过程的第一步是将 HTML 分解并表示为开始标记、结束标记及其内容标记,然后可以构造 DOM。
2. 获取外部资源
当解析器遇到外部资源(例如 CSS 或 JavaScript 文件)时,解析器将提取这些文件。解析器在加载 CSS 文件时继续运行,此时页面被阻止呈现,直到资源被加载和解析(稍后会详细介绍)。
JavaScript 文件略有不同 - 默认情况下,解析器会在加载 JS 文件然后解析它们时阻止解析 HTML。可以向脚本标签添加两个属性来缓解这种情况:延迟和异步。两者都允许解析器在后台加载 JavaScript 文件时继续运行,但它们的做法不同。稍后会详细介绍,但总的来说:
defer 意味着文件的执行将被延迟,直到文档解析完成。如果多个文件具有 defer 属性,它们将按照页面放置的顺序依次执行。
async 表示文件一加载就执行,可能是在解析过程中,也可能是在解析过程之后,所以不保证异步脚本的执行顺序。
预加载资源
元素的 rel 属性的属性值 preload 允许你在 HTML 页面的元素内部编写一些声明性的资源获取请求,这可以指示页面加载后立即需要哪些资源。
对于这样一个立即需要的资源,您可能希望在页面加载生命周期的早期开始获取它,在浏览器的主要呈现机制参与之前预加载它。这种机制可以让资源更早地加载和可用,并且不太可能阻塞页面的初始渲染,从而提高性能。
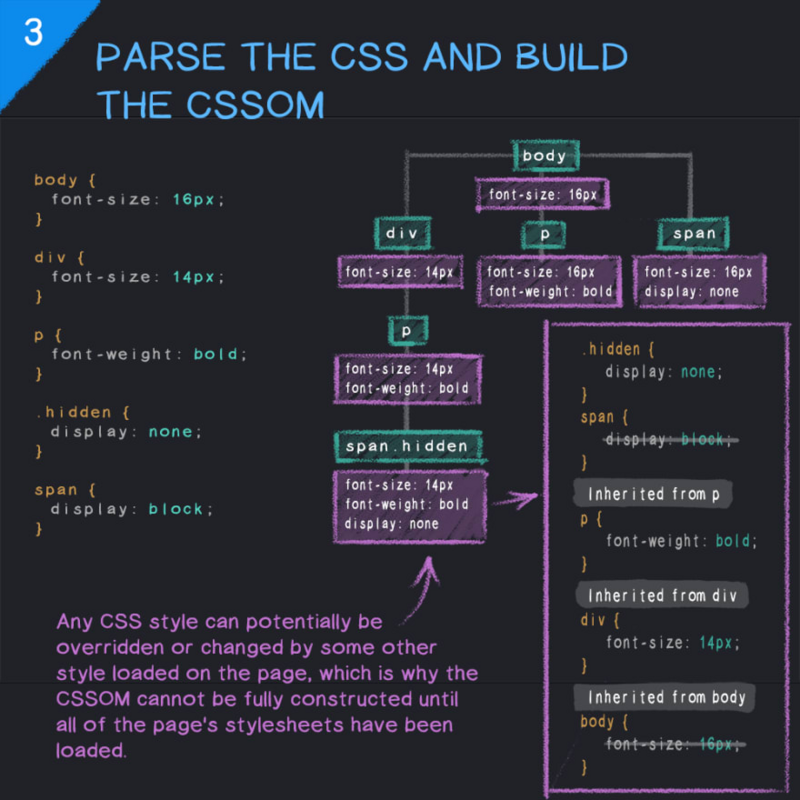
3.解析 CSS 并构建 CSSOM
你可能知道 DOM 很长时间了,但你可能对 CSSOM(CSS 对象模型)的了解较少,反正我也没听过几次。
CSS 对象模型 (CSSOM) 是所有 CSS 选择器和每个选择器的关联属性的映射,以树的形式存在,具有树的根节点、兄弟姐妹、后代、孩子和其他关系。CSSOM 与文档对象模型 (DOM) 非常相似。两者都是关键渲染路径的一部分,必须采取一系列步骤才能正确渲染 网站。
CSSOM 与 DOM 一起构建渲染树,浏览器依次使用它来布局和绘制网页。
与 HTML 文件和 DOM 类似,当 CSS 文件被加载时,它们必须被解析并转换成一棵树——这次是 CSSOM。它描述了页面上的所有 CSS 选择器、它们的层次结构和属性。
CSSOM 与 DOM 的不同之处在于它不能增量构建,因为 CSS 规则由于其特殊性而可以在不同的点上相互覆盖。这就是 CSS 渲染阻塞的原因,因为浏览器无法知道每个元素在屏幕上的位置,直到所有 CSS 被解析并构建 CSSOM。
4.执行 JavaScript
不同的浏览器有不同的 JS 引擎来执行这个任务。从计算机资源的角度来看,解析 JS 可能是一个昂贵的过程,比其他类型的资源更昂贵,因此优化它对于良好的性能非常重要。
加载事件
当加载的 JS 和 DOM 完全解析并准备好时,会发生 emitdocument.DOMContentLoaded 事件。对于需要访问 DOM 的任何脚本,例如以某种方式执行操作或侦听用户交互事件,在执行脚本之前等待此事件是一种很好的做法。
document.addEventListener(
'DOMContentLoaded',
(event) => {
// 这里面可以安全地访问DOM了
});
window.load 事件在所有其他内容(例如异步 JavaScript、图像等)完成加载后触发。
window.addEventListener(
'load',
(event) => {
// 页面现已完全加载
});
5.合并DOM和CSSOM构建渲染树
渲染树是 DOM 和 CSSOM 的组合,表示将渲染到页面上的所有内容。这并不一定意味着渲染树中的所有节点都将被可视化渲染,例如将收录 opacity: 0 或 visibility: hidden 并且仍然可以被屏幕阅读器读取的样式的节点等,而 display: none 不包括任何内容。此外,诸如此类不收录任何视觉信息的标签将始终被忽略。
和 JS 引擎一样,不同的浏览器有不同的渲染引擎。
6. 计算布局并绘制
现在我们有了完整的渲染树,浏览器知道要渲染什么,但不知道在哪里。因此,必须计算页面的布局(即每个节点的位置和大小)。渲染引擎从顶部一直向下遍历渲染树,计算应该显示每个节点的坐标。
完成后,最后一步是获取布局信息并将像素绘制到屏幕上。
查看全部
网页css js 抓取助手(什么是HTML?渲染网页的步骤机制及优化方法
)
我的想法:如果我要构建快速可靠的网站,我需要真正了解浏览器如何在每一步呈现页面,以便在开发过程中优化每一步。这个 文章 是我对端到端流程的高级学习总结。
好吧,事不宜迟,让我们开始吧。这个过程可以分为以下几个主要阶段:
开始解析 HTML 获取外部资源 解析 CSS 并构建 CSSOM 执行 JavaScript 合并 DOM 和 CSSOM 构建渲染树 计算布局并绘制 1.开始解析 HTML
当浏览器通过网络接收到页面的 HTML 数据时,它会立即设置解析器以将 HTML 转换为文档对象模型 (DOM)。
文档对象模型 (DOM) 是 HTML 和 XML 文档的编程接口。它提供了文档的结构化表示,并定义了从程序访问该结构以更改文档的结构、样式和内容的方法。DOM 将文档解析为节点和对象(收录属性和方法的对象)的结构化集合。简而言之,它将网页与脚本或编程语言联系起来。
解析过程的第一步是将 HTML 分解并表示为开始标记、结束标记及其内容标记,然后可以构造 DOM。
2. 获取外部资源
当解析器遇到外部资源(例如 CSS 或 JavaScript 文件)时,解析器将提取这些文件。解析器在加载 CSS 文件时继续运行,此时页面被阻止呈现,直到资源被加载和解析(稍后会详细介绍)。
JavaScript 文件略有不同 - 默认情况下,解析器会在加载 JS 文件然后解析它们时阻止解析 HTML。可以向脚本标签添加两个属性来缓解这种情况:延迟和异步。两者都允许解析器在后台加载 JavaScript 文件时继续运行,但它们的做法不同。稍后会详细介绍,但总的来说:
defer 意味着文件的执行将被延迟,直到文档解析完成。如果多个文件具有 defer 属性,它们将按照页面放置的顺序依次执行。
async 表示文件一加载就执行,可能是在解析过程中,也可能是在解析过程之后,所以不保证异步脚本的执行顺序。
预加载资源
元素的 rel 属性的属性值 preload 允许你在 HTML 页面的元素内部编写一些声明性的资源获取请求,这可以指示页面加载后立即需要哪些资源。
对于这样一个立即需要的资源,您可能希望在页面加载生命周期的早期开始获取它,在浏览器的主要呈现机制参与之前预加载它。这种机制可以让资源更早地加载和可用,并且不太可能阻塞页面的初始渲染,从而提高性能。

3.解析 CSS 并构建 CSSOM
你可能知道 DOM 很长时间了,但你可能对 CSSOM(CSS 对象模型)的了解较少,反正我也没听过几次。
CSS 对象模型 (CSSOM) 是所有 CSS 选择器和每个选择器的关联属性的映射,以树的形式存在,具有树的根节点、兄弟姐妹、后代、孩子和其他关系。CSSOM 与文档对象模型 (DOM) 非常相似。两者都是关键渲染路径的一部分,必须采取一系列步骤才能正确渲染 网站。
CSSOM 与 DOM 一起构建渲染树,浏览器依次使用它来布局和绘制网页。
与 HTML 文件和 DOM 类似,当 CSS 文件被加载时,它们必须被解析并转换成一棵树——这次是 CSSOM。它描述了页面上的所有 CSS 选择器、它们的层次结构和属性。
CSSOM 与 DOM 的不同之处在于它不能增量构建,因为 CSS 规则由于其特殊性而可以在不同的点上相互覆盖。这就是 CSS 渲染阻塞的原因,因为浏览器无法知道每个元素在屏幕上的位置,直到所有 CSS 被解析并构建 CSSOM。
4.执行 JavaScript
不同的浏览器有不同的 JS 引擎来执行这个任务。从计算机资源的角度来看,解析 JS 可能是一个昂贵的过程,比其他类型的资源更昂贵,因此优化它对于良好的性能非常重要。
加载事件
当加载的 JS 和 DOM 完全解析并准备好时,会发生 emitdocument.DOMContentLoaded 事件。对于需要访问 DOM 的任何脚本,例如以某种方式执行操作或侦听用户交互事件,在执行脚本之前等待此事件是一种很好的做法。
document.addEventListener(
'DOMContentLoaded',
(event) => {
// 这里面可以安全地访问DOM了
});
window.load 事件在所有其他内容(例如异步 JavaScript、图像等)完成加载后触发。
window.addEventListener(
'load',
(event) => {
// 页面现已完全加载
});

5.合并DOM和CSSOM构建渲染树
渲染树是 DOM 和 CSSOM 的组合,表示将渲染到页面上的所有内容。这并不一定意味着渲染树中的所有节点都将被可视化渲染,例如将收录 opacity: 0 或 visibility: hidden 并且仍然可以被屏幕阅读器读取的样式的节点等,而 display: none 不包括任何内容。此外,诸如此类不收录任何视觉信息的标签将始终被忽略。
和 JS 引擎一样,不同的浏览器有不同的渲染引擎。
6. 计算布局并绘制
现在我们有了完整的渲染树,浏览器知道要渲染什么,但不知道在哪里。因此,必须计算页面的布局(即每个节点的位置和大小)。渲染引擎从顶部一直向下遍历渲染树,计算应该显示每个节点的坐标。
完成后,最后一步是获取布局信息并将像素绘制到屏幕上。

网页css js 抓取助手(脚本助手--上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-15 22:16
ExcelWeb 脚本助手是一个可以自定义脚本来控制 Excel 和浏览器的工具。提供简单实用的Excel和浏览器API调用,可通过自建脚本或自建项目随意定制。 jQuery
根据Excel中的数据批量操作网页,将Excel数据填入网页,从浏览器获取数据到Excel,非常方便。当然也可以单独使用,脚本可以单独操作Excel或者浏览器。浏览器
在一定程度上替代了VBA,选择C#和VBNET语言,自带脚本编辑器、智能提示、代码高亮、编译提示,可以定义和使用其他IDE,让代码更方便。编辑器
主界面如下:工具
软件自带示例,双击试试。温泉
使用三方开源IDE:SharpDevelop,小而强大,非常适合写小项目。调试
当然你也可以在设置中自定义更强大的IDE,比如:visual studioorm
使用 IDE 调试和运行:博客
Excel操作示例代码:索引
Command.Excel.Activate();
var CurrentDirecotry = System.IO.Directory.GetCurrentDirectory();
var DemoPath = System.IO.Path.Combine(CurrentDirecotry,"Demo.xlsx");
var workbook = Command.Excel.OpenExcel(DemoPath);
var name = workbook.ActiveSheet.Name;
var row1 = workbook.ActiveSheet.Rows[1];
row1.BackColor = Color.Red;
Console.WriteLine("我是第" + row1.RowNumber + "行.我是否可见:" + row1.Visible.ToString());
var Cell1A = workbook.ActiveSheet.Rows[1].Cells["A"];
Console.WriteLine("1A的值为" + Cell1A.ToString() + ",行序号:" + Cell1A.RowNumber + ",列字符:" + Cell1A.ColumnChar);
Cell1A.Value = "我是新的值";
//--------------新增sheet
var sheetindex = workbook.Sheets.Add();
var NewSheet = workbook.Sheets[sheetindex];
NewSheet.Activate();
Console.WriteLine("新建Sheet成功,SheetName:" + NewSheet.Name + ",索引:" + NewSheet.SheetIndex);
//------------删除sheet
Console.WriteLine("按任意键删除新增的Sheet");
Console.ReadKey();
workbook.Sheets.RemoveAt(sheetindex);
Console.WriteLine("删除成功");
浏览器:获取
浏览器提供常用的js方法直接调用,jquery直接调用。
例子:
var page = Command.Browser.AddPage("www.baidu.com");///打开一个网页
page.Query("#kw").val("我不作大哥好多年");///用jQuery获取元素.Jqueery会等待网页加载.不用调用WaitForFormLoad
page.Query("#su").click();///jquery获取按钮,并单击
Wait(2000);///等待2秒
page.LoadURl("www.baidu.com");
page.WaitForPageLoadEnd();///等待网页加载完成.不用Jquery方法时要等待网页加载完成.或用Wait()等待必定时间
page.getElementById("kw").Value = "床沿冰冷哦好难";
page.getElementById("su").click();
Wait(2000);///等待2秒
page.Close();///关网页
试用版正式发布,免费使用。 查看全部
网页css js 抓取助手(脚本助手--上海怡健医学)
ExcelWeb 脚本助手是一个可以自定义脚本来控制 Excel 和浏览器的工具。提供简单实用的Excel和浏览器API调用,可通过自建脚本或自建项目随意定制。 jQuery
根据Excel中的数据批量操作网页,将Excel数据填入网页,从浏览器获取数据到Excel,非常方便。当然也可以单独使用,脚本可以单独操作Excel或者浏览器。浏览器
在一定程度上替代了VBA,选择C#和VBNET语言,自带脚本编辑器、智能提示、代码高亮、编译提示,可以定义和使用其他IDE,让代码更方便。编辑器
主界面如下:工具

软件自带示例,双击试试。温泉
使用三方开源IDE:SharpDevelop,小而强大,非常适合写小项目。调试
当然你也可以在设置中自定义更强大的IDE,比如:visual studioorm
使用 IDE 调试和运行:博客
Excel操作示例代码:索引
Command.Excel.Activate();
var CurrentDirecotry = System.IO.Directory.GetCurrentDirectory();
var DemoPath = System.IO.Path.Combine(CurrentDirecotry,"Demo.xlsx");
var workbook = Command.Excel.OpenExcel(DemoPath);
var name = workbook.ActiveSheet.Name;
var row1 = workbook.ActiveSheet.Rows[1];
row1.BackColor = Color.Red;
Console.WriteLine("我是第" + row1.RowNumber + "行.我是否可见:" + row1.Visible.ToString());
var Cell1A = workbook.ActiveSheet.Rows[1].Cells["A"];
Console.WriteLine("1A的值为" + Cell1A.ToString() + ",行序号:" + Cell1A.RowNumber + ",列字符:" + Cell1A.ColumnChar);
Cell1A.Value = "我是新的值";
//--------------新增sheet
var sheetindex = workbook.Sheets.Add();
var NewSheet = workbook.Sheets[sheetindex];
NewSheet.Activate();
Console.WriteLine("新建Sheet成功,SheetName:" + NewSheet.Name + ",索引:" + NewSheet.SheetIndex);
//------------删除sheet
Console.WriteLine("按任意键删除新增的Sheet");
Console.ReadKey();
workbook.Sheets.RemoveAt(sheetindex);
Console.WriteLine("删除成功");
浏览器:获取
浏览器提供常用的js方法直接调用,jquery直接调用。
例子:
var page = Command.Browser.AddPage("www.baidu.com");///打开一个网页
page.Query("#kw").val("我不作大哥好多年");///用jQuery获取元素.Jqueery会等待网页加载.不用调用WaitForFormLoad
page.Query("#su").click();///jquery获取按钮,并单击
Wait(2000);///等待2秒
page.LoadURl("www.baidu.com");
page.WaitForPageLoadEnd();///等待网页加载完成.不用Jquery方法时要等待网页加载完成.或用Wait()等待必定时间
page.getElementById("kw").Value = "床沿冰冷哦好难";
page.getElementById("su").click();
Wait(2000);///等待2秒
page.Close();///关网页
试用版正式发布,免费使用。
网页css js 抓取助手(Python公众号学的值得收藏|菜鸟学Python【入门文章大全】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-13 05:05
一直有一个传说,世界上有两种程序员:一种是程序员,另一种是女程序员。如果你的女票是程序员,那么恭喜你好运!请多加小心,否则,我分分钟教你怎么做人。
私信小编01获取大量python学习资源
前段时间,助教和我聊天,吐了一大口苦水,说女人懂Python太可怕了。到底是怎么回事,我们来详细说一下。
1.事件起因
小马哥的女朋友也是懂Python的程序员(据说刚开始看我的菜鸟学Python公众号也值得采集|菜鸟学Python【简介文章大全】),相处后时间长了,生活中难免会有一点小摩擦。前不久,我熬夜打游戏打电脑,没精力陪女朋友逛街看电视剧,让她不开心,情绪激动。
我去洗了个澡,偷偷打开他的电脑看看他整天在看什么。你为什么不考虑妇女的选票?没想到女票只用了一行Python代码就获取了浏览器历史记录,让小马的上网记录一目了然。事发后,一切安好,没有危险。今天给大家介绍一下这款神器。
1.神库浏览器历史库介绍
browserhistory 是 Python 的第三方库 browserhistory。获取浏览器的历史记录非常方便。Python真是无所不能,现成的轮子太多了,你只需要学会组装。
对于 browserhistory 的安装,可以使用命令 pip install browserhistory 来安装。
Browserhistory是一个简单的python脚本库,支持linux、Mac和Windows系统,支持火狐、谷歌和Safari浏览器的历史记录。使用的方法非常简单。
2.如何使用
我们先来看看 browserhistory 的简单用法。需要注意的是,在使用浏览器历史库之前需要关闭浏览器。一个简单的应用程序如下所示:
程序首先导入 browserhistory 库,然后使用 get_browserhistory 函数获取浏览器的历史记录。dict_obj.keys() 返回要抓取的浏览器类型。爬取的浏览器历史记录收录网页地址和网页标题。
3.抓取浏览记录并写入本地文件
browserhistory库有四个函数,我们主要用到两个:
get_browserhistory 函数是获取浏览器的历史记录;write_browserhistory_csv函数是将获取的历史浏览记录写入本地csv文件。
get_database_paths函数用于输出浏览器的历史存储路径,get_username用于获取用户名。
我们可以直接使用browserhistory.write_browserhistory_csv,一行代码就可以将浏览器的历史写入本地。
4.窥探历史
获得上述浏览器历史记录后,可以通过简单的数据分析进一步窥探秘密。
1)。用五行代码统计你经常浏览的网址的域名:
程序使用urlparse解析网页地址,输入网页地址的域名(netloc)。接下来,您可以进行统计并获取浏览时间最长的网页的域名。
2)。使用 Pyecharts 进行可视化分析
为了更好的展示,可以使用pyecharts库进行可视化展示。结果如下所示:
可以看出,访问量最大的网页域名是虎扑域名。当他的女朋友检查并分析了他的浏览器历史时,她终于满意地笑了,一个潜在的危机解决了。
所以,一个友好的提醒,不要继续一些奇怪的网站。另外,记得及时清理你的历史!友情提示,没事的话,回去看看浏览器记录吧!
好了,今天的分享就到这里了,欢迎大家在评论区吆喝~记得给个三连哦! 查看全部
网页css js 抓取助手(Python公众号学的值得收藏|菜鸟学Python【入门文章大全】)
一直有一个传说,世界上有两种程序员:一种是程序员,另一种是女程序员。如果你的女票是程序员,那么恭喜你好运!请多加小心,否则,我分分钟教你怎么做人。
私信小编01获取大量python学习资源
前段时间,助教和我聊天,吐了一大口苦水,说女人懂Python太可怕了。到底是怎么回事,我们来详细说一下。
1.事件起因
小马哥的女朋友也是懂Python的程序员(据说刚开始看我的菜鸟学Python公众号也值得采集|菜鸟学Python【简介文章大全】),相处后时间长了,生活中难免会有一点小摩擦。前不久,我熬夜打游戏打电脑,没精力陪女朋友逛街看电视剧,让她不开心,情绪激动。
我去洗了个澡,偷偷打开他的电脑看看他整天在看什么。你为什么不考虑妇女的选票?没想到女票只用了一行Python代码就获取了浏览器历史记录,让小马的上网记录一目了然。事发后,一切安好,没有危险。今天给大家介绍一下这款神器。
1.神库浏览器历史库介绍
browserhistory 是 Python 的第三方库 browserhistory。获取浏览器的历史记录非常方便。Python真是无所不能,现成的轮子太多了,你只需要学会组装。
对于 browserhistory 的安装,可以使用命令 pip install browserhistory 来安装。
Browserhistory是一个简单的python脚本库,支持linux、Mac和Windows系统,支持火狐、谷歌和Safari浏览器的历史记录。使用的方法非常简单。
2.如何使用
我们先来看看 browserhistory 的简单用法。需要注意的是,在使用浏览器历史库之前需要关闭浏览器。一个简单的应用程序如下所示:
程序首先导入 browserhistory 库,然后使用 get_browserhistory 函数获取浏览器的历史记录。dict_obj.keys() 返回要抓取的浏览器类型。爬取的浏览器历史记录收录网页地址和网页标题。
3.抓取浏览记录并写入本地文件
browserhistory库有四个函数,我们主要用到两个:
get_browserhistory 函数是获取浏览器的历史记录;write_browserhistory_csv函数是将获取的历史浏览记录写入本地csv文件。
get_database_paths函数用于输出浏览器的历史存储路径,get_username用于获取用户名。
我们可以直接使用browserhistory.write_browserhistory_csv,一行代码就可以将浏览器的历史写入本地。
4.窥探历史
获得上述浏览器历史记录后,可以通过简单的数据分析进一步窥探秘密。
1)。用五行代码统计你经常浏览的网址的域名:
程序使用urlparse解析网页地址,输入网页地址的域名(netloc)。接下来,您可以进行统计并获取浏览时间最长的网页的域名。
2)。使用 Pyecharts 进行可视化分析
为了更好的展示,可以使用pyecharts库进行可视化展示。结果如下所示:
可以看出,访问量最大的网页域名是虎扑域名。当他的女朋友检查并分析了他的浏览器历史时,她终于满意地笑了,一个潜在的危机解决了。
所以,一个友好的提醒,不要继续一些奇怪的网站。另外,记得及时清理你的历史!友情提示,没事的话,回去看看浏览器记录吧!
好了,今天的分享就到这里了,欢迎大家在评论区吆喝~记得给个三连哦!
网页css js 抓取助手(在线版的CSS3代码生成工具,你get到了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2022-04-20 04:01
来自:南瓜编程公众号
我们整理了25个前端相关的学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望有可以帮到大家!
▍CSS相关
●1
CSSBattle-在线 CSS 大赛
Competition CSS Online,一款非常有趣的竞技游戏,共12个关卡,要求你使用HTML和CSS来100%还原它给出的页面,然后最小化代码,你也可以查看全球排行榜,看看解决办法。
●2
学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS的基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
●3
Flexbox Froggy - 一个学习Flex布局的小游戏
一个引导学习flex布局的游戏,用flex布局让青蛙跳到荷叶上就完成了,游戏收录了几乎所有常用的属性,很好学,形象好记,谁是Flex如果对布局不熟悉,这里多练习一下。
●4
EnjoyCSS-在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。就像在本地使用 PS 或 AI 软件一样。
●5
CSS-Tricks-CSS 技巧
此网站 会不断更新,提供一些关于 CSS 技术的优秀教程和技巧,每天更新文章。
●6
新拟态——实现新的模仿效果
可以轻松实现新的模仿效果,不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数,并提供CSS可以直接复制的代码。
●7
uiGradients-分享渐变
一个提供渐变色效果的网站,有近百种渐变色方案,可以根据自己的风格选择搭配,直接获取渐变色对应的CSS代码。
▍JS相关
●8
JavaScript 秘密花园
一个不断更新的JavaScript语法文档,主要写如何避免一些常见的错误,以及寻找难以发现的Bug,深入了解JavaScript的语言特性。
●9
JSTips-JS 技巧
每天都有一点 Javascript 知识。
●10
JSweekly - 科技周刊
每周专门讨论 Javascript 的技术期刊。
●11
CDNJS - JavaScript 库
CDNJS 为开发者提供最新的前端网页开发资源,免费使用,不受限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端的CDN服务中排名第二(第一是Google),性能优异。
●12
Beautiful Open - 开源 JS 库合集
采集各种设计优秀的开源项目,从cms内容管理系统到常用的Javascript库,适合网站开发的用户使用。
●13
JavaScript Fun - 代码库集合
目前最流行的 JavaScript 代码库合集,展示人气排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow - 程序员问答网络
全球 IT 社区中最受欢迎的技术问答之一网站,一个用于解决错误的社区,被称为“编程的 100,000 个为什么”。
●15
掘金 - 优质技术社区
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术文章包括Android、iOS、前端和后端资源。
●16
Codrops - 网页设计和开发博客
发布技术文章和网络教程,提供经验,避免陷阱,资源丰富。许多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码的工具,上面有各种效果的案例特效(炫技),可以自己开发基于他们的演示设计的前端。
●18
代码沙盒
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。 React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
●19
JSBin
又一款轻量级在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材都是常用的图标,可以点击官方提供的素材进行二次设计。同时还可以导出设计好的图标。
●21
OpenMoji - 免费表情符号库
提供源码表情库,免费下载使用。
● 22
分享图标 - 免费矢量素材库
提供超过250,000种ICON矢量图素材,120多个类别,所有素材均以PNG和SVG格式提供,素材有512*512、256*25等多种尺寸可供选择6、128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
● 23
tableconvert - 在线表格编辑器
强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的转换。当您需要转换表格,但又无法使其变形时,请尝试使用此工具。
● 24
Feathericons - 极简图标图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发,图标格式为SVG。
● 25
HTML5 + CSS 3 免费模板
提供大量HTML5模板,用户可以自己分享和修改模板。
本文推荐网站总结:
CSSbattle:
学习 CSS 布局:
Flexbox Froggy:
享受CSS:
CSS 技巧:
新拟态:
uiGradients:
JavaScript:
JS 提示:
JS 周刊:
CDNJS:
美丽的开放:
JavaScript 乐趣:
堆栈溢出:
掘金队:
Codrops:
代码笔:
代码沙盒:
JS斌:
图标:
OpenMoji:
分享图标:
表格转换:
羽毛图标:
HTML5UP: 查看全部
网页css js 抓取助手(在线版的CSS3代码生成工具,你get到了吗?)
来自:南瓜编程公众号
我们整理了25个前端相关的学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望有可以帮到大家!
▍CSS相关
●1
CSSBattle-在线 CSS 大赛
Competition CSS Online,一款非常有趣的竞技游戏,共12个关卡,要求你使用HTML和CSS来100%还原它给出的页面,然后最小化代码,你也可以查看全球排行榜,看看解决办法。
●2
学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS的基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
●3
Flexbox Froggy - 一个学习Flex布局的小游戏
一个引导学习flex布局的游戏,用flex布局让青蛙跳到荷叶上就完成了,游戏收录了几乎所有常用的属性,很好学,形象好记,谁是Flex如果对布局不熟悉,这里多练习一下。
●4
EnjoyCSS-在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。就像在本地使用 PS 或 AI 软件一样。
●5
CSS-Tricks-CSS 技巧
此网站 会不断更新,提供一些关于 CSS 技术的优秀教程和技巧,每天更新文章。
●6
新拟态——实现新的模仿效果
可以轻松实现新的模仿效果,不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数,并提供CSS可以直接复制的代码。
●7
uiGradients-分享渐变
一个提供渐变色效果的网站,有近百种渐变色方案,可以根据自己的风格选择搭配,直接获取渐变色对应的CSS代码。
▍JS相关
●8
JavaScript 秘密花园
一个不断更新的JavaScript语法文档,主要写如何避免一些常见的错误,以及寻找难以发现的Bug,深入了解JavaScript的语言特性。
●9
JSTips-JS 技巧
每天都有一点 Javascript 知识。
●10
JSweekly - 科技周刊
每周专门讨论 Javascript 的技术期刊。
●11
CDNJS - JavaScript 库
CDNJS 为开发者提供最新的前端网页开发资源,免费使用,不受限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端的CDN服务中排名第二(第一是Google),性能优异。
●12
Beautiful Open - 开源 JS 库合集
采集各种设计优秀的开源项目,从cms内容管理系统到常用的Javascript库,适合网站开发的用户使用。
●13
JavaScript Fun - 代码库集合
目前最流行的 JavaScript 代码库合集,展示人气排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow - 程序员问答网络
全球 IT 社区中最受欢迎的技术问答之一网站,一个用于解决错误的社区,被称为“编程的 100,000 个为什么”。
●15
掘金 - 优质技术社区
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术文章包括Android、iOS、前端和后端资源。
●16
Codrops - 网页设计和开发博客
发布技术文章和网络教程,提供经验,避免陷阱,资源丰富。许多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码的工具,上面有各种效果的案例特效(炫技),可以自己开发基于他们的演示设计的前端。
●18
代码沙盒
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。 React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
●19
JSBin
又一款轻量级在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材都是常用的图标,可以点击官方提供的素材进行二次设计。同时还可以导出设计好的图标。
●21
OpenMoji - 免费表情符号库
提供源码表情库,免费下载使用。
● 22
分享图标 - 免费矢量素材库
提供超过250,000种ICON矢量图素材,120多个类别,所有素材均以PNG和SVG格式提供,素材有512*512、256*25等多种尺寸可供选择6、128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
● 23
tableconvert - 在线表格编辑器
强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的转换。当您需要转换表格,但又无法使其变形时,请尝试使用此工具。
● 24
Feathericons - 极简图标图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发,图标格式为SVG。
● 25
HTML5 + CSS 3 免费模板
提供大量HTML5模板,用户可以自己分享和修改模板。
本文推荐网站总结:
CSSbattle:
学习 CSS 布局:
Flexbox Froggy:
享受CSS:
CSS 技巧:
新拟态:
uiGradients:
JavaScript:
JS 提示:
JS 周刊:
CDNJS:
美丽的开放:
JavaScript 乐趣:
堆栈溢出:
掘金队:
Codrops:
代码笔:
代码沙盒:
JS斌:
图标:
OpenMoji:
分享图标:
表格转换:
羽毛图标:
HTML5UP:
网页css js 抓取助手(SEO优化人员选择爬取数据保存路径使用教程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-11 16:23
选择保存爬取数据的路径
【相关新闻】
在当前的移动互联网时代,每个站长都会仔细分析各大搜索引擎的收录特征,其中百度搜索引擎占比较大。毕竟,对于今天的大多数人来说,很多人在日常生活中更多地使用百度搜索引擎。
所以很多SEO优化人员经常被告知要熟悉百度的算法和收录特性,并在此基础上对自己的工作进行相应的调整和安排,为了取悦百度搜索引擎,让内容被百度抓取。百度爬虫速度更快,提升网站在搜索引擎中的排名。
【更新内容】
BUG:修复了无效的 URI:URI 字符串太长。
【教程】
1、选择下载类型网站(移动站、PC站)
点击菜单栏上的“文件”,在PC站选择“Download Normal网站”,在移动站选择“Download Mobile网站”。
2、配置下载文件的保存目录
点击菜单栏上的“配置”,选择保存下载的静态文件的目录。
3、添加URL和文件存放目录
输入 URL:您要下载的 网站 的地址。
相对路径:相对于根目录的路径。
文件名:当前 URL 下载后保存的名称。
4、下载相关配置
路径设置:设置代码中引用文件的方式。
模拟抓图:PC端网站只显示PC端的User Agent,移动端只显示移动端的User Agent。
Cookie:登录信息字段。 查看全部
网页css js 抓取助手(SEO优化人员选择爬取数据保存路径使用教程-乐题库)
选择保存爬取数据的路径
【相关新闻】
在当前的移动互联网时代,每个站长都会仔细分析各大搜索引擎的收录特征,其中百度搜索引擎占比较大。毕竟,对于今天的大多数人来说,很多人在日常生活中更多地使用百度搜索引擎。
所以很多SEO优化人员经常被告知要熟悉百度的算法和收录特性,并在此基础上对自己的工作进行相应的调整和安排,为了取悦百度搜索引擎,让内容被百度抓取。百度爬虫速度更快,提升网站在搜索引擎中的排名。
【更新内容】
BUG:修复了无效的 URI:URI 字符串太长。
【教程】
1、选择下载类型网站(移动站、PC站)
点击菜单栏上的“文件”,在PC站选择“Download Normal网站”,在移动站选择“Download Mobile网站”。
2、配置下载文件的保存目录
点击菜单栏上的“配置”,选择保存下载的静态文件的目录。
3、添加URL和文件存放目录
输入 URL:您要下载的 网站 的地址。
相对路径:相对于根目录的路径。
文件名:当前 URL 下载后保存的名称。
4、下载相关配置
路径设置:设置代码中引用文件的方式。
模拟抓图:PC端网站只显示PC端的User Agent,移动端只显示移动端的User Agent。
Cookie:登录信息字段。
网页css js 抓取助手(()软件介绍支持RSS的定制功能(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-09 17:12
网络爬虫[WebClawer]是参考RSS的具有强大定制功能的新闻阅读工具。可以抓取任意网站的任意链接,极大的方便了需要获取各个站点信息的工作人员,提高了效率,节省了时间。
软件介绍
支持RSS,包括RSS0.9/1.0/2.0、ATOM、OPML等。
支持从任何站点抓取任何链接
可以同时更新多个站点(多线程处理)
可自定义抓取或排除特定链接
支持自动调用IE的cookies,适合需要登录的论坛
如果没有MSVCR71.dll文件,请下载并放在WebClawer同目录下
绿色软件,无需安装,可存U盘执行
点击下载软件
软件使用
该软件不需要安装。解压后,双击打开。界面如图所示。
<IMG title=001 alt=001 src="//img2.pconline.com.cn/pconline/0804/22/1275786_001.jpg" border=0>
图1 软件界面
下面以太平洋软件信息与应用为例,看看如何使用WebClawer
打开软件,展开对应栏目,右键选择菜单中的“添加频道”如图
<IMG title=002 alt=002 src="//img2.pconline.com.cn/pconline/0804/22/1275786_002.jpg" border=0>
图 2 添加通道
在新建频道中依次输入频道名称、备注、类别、URL地址,选择文件类型-选择RSS模式,完成后保存。如图所示
<IMG title=003 alt=003 src="//img2.pconline.com.cn/pconline/0804/22/1275786_003.jpg" border=0>
图3 添加频道界面
<IMG title=004 alt=004 src="//img2.pconline.com.cn/pconline/0804/22/1275786_004.jpg" border=0>
图4 填写渠道信息
添加好栏目后,每次只需要选择相应的标题并右键“更新”,软件就可以自动抓取更新的页面。
软件虽小,但对于每天需要查看大量信息的朋友来说,可以批量更新各个站点的每一栏,省去大量重复性工作,达到提高工作效率的目的。希望这个软件能给您带来方便。 查看全部
网页css js 抓取助手(()软件介绍支持RSS的定制功能(组图))
网络爬虫[WebClawer]是参考RSS的具有强大定制功能的新闻阅读工具。可以抓取任意网站的任意链接,极大的方便了需要获取各个站点信息的工作人员,提高了效率,节省了时间。
软件介绍
支持RSS,包括RSS0.9/1.0/2.0、ATOM、OPML等。
支持从任何站点抓取任何链接
可以同时更新多个站点(多线程处理)
可自定义抓取或排除特定链接
支持自动调用IE的cookies,适合需要登录的论坛
如果没有MSVCR71.dll文件,请下载并放在WebClawer同目录下
绿色软件,无需安装,可存U盘执行
点击下载软件
软件使用
该软件不需要安装。解压后,双击打开。界面如图所示。
<IMG title=001 alt=001 src="//img2.pconline.com.cn/pconline/0804/22/1275786_001.jpg" border=0>
图1 软件界面
下面以太平洋软件信息与应用为例,看看如何使用WebClawer
打开软件,展开对应栏目,右键选择菜单中的“添加频道”如图
<IMG title=002 alt=002 src="//img2.pconline.com.cn/pconline/0804/22/1275786_002.jpg" border=0>
图 2 添加通道
在新建频道中依次输入频道名称、备注、类别、URL地址,选择文件类型-选择RSS模式,完成后保存。如图所示
<IMG title=003 alt=003 src="//img2.pconline.com.cn/pconline/0804/22/1275786_003.jpg" border=0>
图3 添加频道界面
<IMG title=004 alt=004 src="//img2.pconline.com.cn/pconline/0804/22/1275786_004.jpg" border=0>
图4 填写渠道信息
添加好栏目后,每次只需要选择相应的标题并右键“更新”,软件就可以自动抓取更新的页面。
软件虽小,但对于每天需要查看大量信息的朋友来说,可以批量更新各个站点的每一栏,省去大量重复性工作,达到提高工作效率的目的。希望这个软件能给您带来方便。
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-07 04:00
为大家整理了25个前端相关学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望你能帮助大家!
▍CSS相关
●1
CSSBattle-在线竞争 CSS
CSS线上竞技,一款非常有趣的竞技游戏,一共12关,需要用HTML和CSS来100%还原它给出的页面,然后尽量减少代码,还可以查看全球排行榜,看解决方案。
●2
学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
●3
Flexbox Froggy - 一个学习 Flex 布局的小游戏
一款引导式学习flex布局游戏,使用flex布局让青蛙在荷叶上跳跃,就完成了。游戏中几乎收录了所有常用的属性,所以学习起来非常有趣,而且形象好记。如果您熟悉它,请在此处进行更多练习。
●4
EnjoyCSS - 在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件一样。
●5
CSS 技巧 - CSS 技巧
这个网站 每天都会不断更新一些优秀的教程和CSS 技巧的技巧文章。
●6
Neumorphism - 实现新的模拟效果
新的模仿效果可以轻松实现,不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数,并提供CSS代码可以可以直接复制。
●7
uiGradients - 共享渐变
网站上有近百种渐变配色方案,提供渐变色效果。可以根据自己的风格进行选择搭配,直接获取渐变配色对应的CSS代码即可。
▍JS相关
●8
JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。主要写如何避免一些常见的错误,发现难以发现的bug,深入了解JavaScript的语言特性。
●9
JSTips - JS 技巧
每天一点点的Javascript知识。
●10
JSweekly - 科技周刊
专注于 Javascript 的技术周刊。
●11
CDNJS - JavaScript 库
CDNJS为开发者提供最新的前端web开发资源,免费使用,没有使用限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端CDN服务中排名第二(第一是谷歌),性能优异。
●12
Beautiful Open - 开源 JS 库合集
采集各类设计优秀的开源项目,从cms内容管理系统到小型常用Javascript库,适合网站开发的用户使用。
●13
JavaScript Fun - 代码库集合
最流行的 JavaScript 代码库集合,显示流行排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow - 程序员问答网络
全球IT界最火爆的技术问答网站,一个解决bug的社区,号称“编程界的十万个为什么”。
●15
掘金 - 优质技术社区
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术 文章 包括 Android、iOS、前端和后端资源。
●16
Codrops - 网页设计开发博客
发布技术文章和网络教程,提供经验,避免陷阱,资源丰富。许多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码工具,有各种效果的案例特效(炫技),你可以开发自己的前端设计基于他们的演示。
●18
代码沙盒
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
●19
JSBin
另一个轻量级的在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材都是常用的图标,可以点击官方提供的素材进行二次设计,也可以导出设计好的图标。
●21
OpenMoji - 免费表情符号库
提供带有源代码的表情符号库,可以免费下载使用。
● 22
共享图标 - 免费矢量图片
一个提供超过250,000种ICON矢量图素材,120多个类别的网站,所有素材均以PNG和SVG格式提供,素材有多种尺寸可供选择,包括512*512、256*256、128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
● 23
tableconvert - 在线表格编辑器
一款功能强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的相互转换。当您需要转换表格,但无法使其变形时,请尝试使用此工具。
● 24
Feathericons-极简主义图标图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发。图标格式为 SVG。
● 25
HTML5 + CSS 3 免费模板
提供大量HTML5模板,用户可以自己分享和修改模板。
本文推荐的网站总结:
CSS战斗:
学习 CSS 布局:
Flexbox Froggy:
享受CSS:
CSS 技巧:
神经拟态:
ui渐变:
JavaScript:
JS 提示:
JS周刊:
CDNJS:
美丽的开放:
JavaScript 乐趣:
堆栈溢出:
掘金:
Codrops:
代码笔:
代码沙盒:
JS斌:
图标:
打开Moji:
分享图标:
表格转换:
羽毛图标:
HTML5UP:
❤️爱三合一
1.看到这里,点个关注支持一下,你们的“关注”就是我创作的动力。 查看全部
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具)
为大家整理了25个前端相关学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望你能帮助大家!
▍CSS相关
●1
CSSBattle-在线竞争 CSS
CSS线上竞技,一款非常有趣的竞技游戏,一共12关,需要用HTML和CSS来100%还原它给出的页面,然后尽量减少代码,还可以查看全球排行榜,看解决方案。
●2
学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
●3
Flexbox Froggy - 一个学习 Flex 布局的小游戏
一款引导式学习flex布局游戏,使用flex布局让青蛙在荷叶上跳跃,就完成了。游戏中几乎收录了所有常用的属性,所以学习起来非常有趣,而且形象好记。如果您熟悉它,请在此处进行更多练习。
●4
EnjoyCSS - 在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件一样。
●5
CSS 技巧 - CSS 技巧
这个网站 每天都会不断更新一些优秀的教程和CSS 技巧的技巧文章。
●6
Neumorphism - 实现新的模拟效果
新的模仿效果可以轻松实现,不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数,并提供CSS代码可以可以直接复制。
●7
uiGradients - 共享渐变
网站上有近百种渐变配色方案,提供渐变色效果。可以根据自己的风格进行选择搭配,直接获取渐变配色对应的CSS代码即可。
▍JS相关
●8
JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。主要写如何避免一些常见的错误,发现难以发现的bug,深入了解JavaScript的语言特性。
●9
JSTips - JS 技巧
每天一点点的Javascript知识。
●10
JSweekly - 科技周刊
专注于 Javascript 的技术周刊。
●11
CDNJS - JavaScript 库
CDNJS为开发者提供最新的前端web开发资源,免费使用,没有使用限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端CDN服务中排名第二(第一是谷歌),性能优异。
●12
Beautiful Open - 开源 JS 库合集
采集各类设计优秀的开源项目,从cms内容管理系统到小型常用Javascript库,适合网站开发的用户使用。
●13
JavaScript Fun - 代码库集合
最流行的 JavaScript 代码库集合,显示流行排名,开发者可以轻松找到最新的代码插件、工具和博客。
▍社区和博客
●14
Stack Overflow - 程序员问答网络
全球IT界最火爆的技术问答网站,一个解决bug的社区,号称“编程界的十万个为什么”。
●15
掘金 - 优质技术社区
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术 文章 包括 Android、iOS、前端和后端资源。
●16
Codrops - 网页设计开发博客
发布技术文章和网络教程,提供经验,避免陷阱,资源丰富。许多优秀的技术都来自这里。
▍在线IDE
●17
代码笔
一个网站前端设计开发平台,一个网站前端代码工具,有各种效果的案例特效(炫技),你可以开发自己的前端设计基于他们的演示。
●18
代码沙盒
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
●19
JSBin
另一个轻量级的在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
▍资源
● 20
ICONSVG-在线定制设计SVG图标素材
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材都是常用的图标,可以点击官方提供的素材进行二次设计,也可以导出设计好的图标。
●21
OpenMoji - 免费表情符号库
提供带有源代码的表情符号库,可以免费下载使用。
● 22
共享图标 - 免费矢量图片
一个提供超过250,000种ICON矢量图素材,120多个类别的网站,所有素材均以PNG和SVG格式提供,素材有多种尺寸可供选择,包括512*512、256*256、128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
● 23
tableconvert - 在线表格编辑器
一款功能强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的相互转换。当您需要转换表格,但无法使其变形时,请尝试使用此工具。
● 24
Feathericons-极简主义图标图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发。图标格式为 SVG。
● 25
HTML5 + CSS 3 免费模板
提供大量HTML5模板,用户可以自己分享和修改模板。
本文推荐的网站总结:
CSS战斗:
学习 CSS 布局:
Flexbox Froggy:
享受CSS:
CSS 技巧:
神经拟态:
ui渐变:
JavaScript:
JS 提示:
JS周刊:
CDNJS:
美丽的开放:
JavaScript 乐趣:
堆栈溢出:
掘金:
Codrops:
代码笔:
代码沙盒:
JS斌:
图标:
打开Moji:
分享图标:
表格转换:
羽毛图标:
HTML5UP:
❤️爱三合一
1.看到这里,点个关注支持一下,你们的“关注”就是我创作的动力。
网页css js 抓取助手(一下这些API都应该怎么使用?(图)API)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-04 18:13
写了几篇关于微信内置浏览器(WebView)特有的Javascript API(Javascript接口)的文章文章,但是随着微信官方的调整,有些API已经不能直接使用了,比如直接分享对朋友圈WeixinJSBridge.invoke('shareTimeline',data,callback)这样的函数,直接调用会得到拒绝访问的响应。后来又重新研究了一下,整理出了一个WeixinAPI Javascript类库,分享给大家。如果你对微信公众平台的开发感兴趣,应该对你有用。
/**!
* 微信内置浏览器的Javascript API,功能包括:
*
* 1、分享到微信朋友圈
* 2、分享给微信好友
* 3、分享到腾讯微博
* 4、隐藏/显示右上角的菜单入口
* 5、隐藏/显示底部浏览器工具栏
* 6、获取当前的网络状态
* 7、调起微信客户端的图片播放组件
*
* @author zhaoxianlie(http://www.baidufe.com)
*/
var WeixinApi = (function () {
/* 这里省略了一堆代码……下面直接看调用接口 */
return {
ready :wxJsBridgeReady,
shareToTimeline :weixinShareTimeline,
shareToWeibo :weixinShareWeibo,
shareToFriend :weixinSendAppMessage,
showOptionMenu :showOptionMenu,
hideOptionMenu :hideOptionMenu,
showToolbar :showToolbar,
hideToolbar :hideToolbar,
getNetworkType :getNetworkType,
imagePreview :imagePreview
};
});
接下来,让我们看看这些API应该如何使用,从最简单的开始。
1、如果我想一打开网页就隐藏右上角的PopUp菜单项,隐藏浏览器底部的工具栏,同时也获取当前的网络状态,那么我们的代码可以是像这样写:
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api){
// 隐藏右上角popup菜单入口
Api.hideOptionMenu();
// 隐藏浏览器下方的工具栏
Api.hideToolbar();
// 获取网络状态
Api.getNetworkType(function(network){
// 拿到 network 以后,做任何你想做的事
});
});
如示例代码中的注释所示,所有函数执行都必须在 WeixinApi.ready 方法中执行,就像在使用 jQuery 时,通常需要使用 jQuery(document).ready(function(){ }) 一样. 为什么要这样做?相信不用我解释大家都能理解,因为我们必须保证在执行这些方法的时候,WebView中已经添加了WeixinJsBridge API!
2、再看一个分享的例子,如果用户在阅读我的文章(或使用我的产品)的过程中发现它有趣或有价值,他们一般会采集或分享(给朋友、朋友圈、微博等),那么现在我希望监控用户的分享行为,比如:自定义用户可以分享的内容,即使用户分享了,取消分享,分享失败,分享成功,整个分享操作过程就结束了,大家都做点什么。所以,我们可以这样写代码:
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api){
// 微信分享的数据
var wxData = {
"imgUrl":'http://www.baidufe.com/fe/blog ... 39%3B,
"link":'http://www.baidufe.com',
"desc":'大家好,我是Alien,Web前端&Android客户端码农,喜欢技术上的瞎倒腾!欢迎多交流',
"title":"大家好,我是赵先烈"
};
// 分享的回调
var wxCallbacks = {
// 分享操作开始之前
ready:function () {
// 你可以在这里对分享的数据进行重组
},
// 分享被用户自动取消
cancel:function (resp) {
// 你可以在你的页面上给用户一个小Tip,为什么要取消呢?
},
// 分享失败了
fail:function (resp) {
// 分享失败了,是不是可以告诉用户:不要紧,可能是网络问题,一会儿再试试?
},
// 分享成功
confirm:function (resp) {
// 分享成功了,我们是不是可以做一些分享统计呢?
},
// 整个分享过程结束
all:function (resp) {
// 如果你做的是一个鼓励用户进行分享的产品,在这里是不是可以给用户一些反馈了?
}
};
// 用户点开右上角popup菜单后,点击分享给好友,会执行下面这个代码
Api.shareToFriend(wxData, wxCallbacks);
// 点击分享到朋友圈,会执行下面这个代码
Api.shareToTimeline(wxData, wxCallbacks);
// 点击分享到腾讯微博,会执行下面这个代码
Api.shareToWeibo(wxData, wxCallbacks);
});
3、当然,如果你的业务需求比较复杂,比如你的产品是微信网页游戏(类似于“2048数字游戏微信版”),你希望用户分享的数据是截图一个网页,或者一个将用户当前的游戏状态发送回服务器,以动态生成可分享的内容;在这种情况下我们应该怎么做?看看下面的示例代码:
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api){
// 分享的回调
var wxCallbacks = {
// 分享过程需要异步执行
async : true,
// 分享操作开始之前
ready:function () {
var self = this;
// 假设你需要在这里发一个 ajax 请求去获取分享数据
$.post(yourServerUrl,yourPostData,function(responseData){
// 可以解析reponseData得到wxData
var wxData = responseData;
// 调用dataLoaded方法,会自动触发分享操作
// 注意,当且仅当 async为true时,wxCallbacks.dataLoaded才会被初始化,并调用
self.dataLoaded(wxData);
});
}
/* cancel、fail、confirm、all 方法同示例2,此处略掉 */
};
// 用户点开右上角popup菜单后,点击分享给好友,会执行下面这个代码
Api.shareToFriend({}, wxCallbacks);
});
唯一不同的是,在wxCallbacks中,配置项async被添加为true,表示共享进程是异步调用的。其实就是说ready方法是异步执行的。在这种情况下,我们需要在 ready 方法中显式调用它。wxCallbacks的dataLoaded方法保证共享进程可以继续执行。可能你会发现这个wxCallbacks里面并没有配置dataLoaded方法!是的,当 async 为 true 时,我会在 WeixinApi 中自动初始化。dataLoaded 方法需要一个参数,表示需要共享的数据!
4、当然,如果非要配置dataLoaded方法也没问题。您的配置也将被执行并且不会被覆盖。执行顺序为:用户配置优先。
以上是直接给出使用方法。也许您现在开始关心每个方法的参数列表是什么样的?我们以分享到朋友圈的方法为例,看看参数有哪些配置项:
/**
* 分享到微信朋友圈
* @param {Object} data 待分享的信息
* @p-config {String} appId 公众平台的appId(服务号可用)
* @p-config {String} imageUrl 图片地址
* @p-config {String} link 链接地址
* @p-config {String} desc 描述
* @p-config {String} title 分享的标题
*
* @param {Object} callbacks 相关回调方法
* @p-config {Boolean} async ready方法是否需要异步执行,默认false
* @p-config {Function} ready(argv) 就绪状态
* @p-config {Function} dataLoaded(data) 数据加载完成后调用,async为true时有用
* @p-config {Function} cancel(resp) 取消
* @p-config {Function} fail(resp) 失败
* @p-config {Function} confirm(resp) 成功
* @p-config {Function} all(resp) 无论成功失败都会执行的回调
*/
WeixinApi.shareToTimeline(data,callbacks);
分享给微信朋友和分享给腾讯微博的参数列表是一样的,这里就不一一列举了。
5、如果你的文章里面有很多图片,那么点击图片直接调出微信客户端自带的图片播放组件一定是件好事;你可以这样做 :
// 调起微信客户端的图片播放组件进行播放
WeixinApi.ready(function(Api){
var srcList = [];
$.each($('img'),function(i,item){
if(item.src) {
srcList.push(item.src);
$(item).click(function(e){
// 通过这个API就能直接调起微信客户端的图片播放组件了
Api.imagePreview(this.src,srcList);
});
}
});
});
就这么简单的一段代码,一切就搞定了!不过需要指出的是,Api.imagePreview的参数会被强检测:
/**
* 调起微信Native的图片播放组件。
* 这里必须对参数进行强检测,如果参数不合法,直接会导致微信客户端crash
*
* @param {String} curSrc 当前播放的图片地址
* @param {Array} srcList 图片地址列表
*/
function imagePreview(curSrc,srcList) ;
需要指出的是,微信公众平台并没有统一支持Android和iOS平台,比较费力。具体有:
期待早日正式实现各平台API的统一!!!
至于API内部是如何实现的,有兴趣的可以看下源码。如果您在使用过程中遇到任何错误,请来这里反馈。
为了方便Api的维护和分享,已经放到了Github上。让我们从这里开始: 查看全部
网页css js 抓取助手(一下这些API都应该怎么使用?(图)API)
写了几篇关于微信内置浏览器(WebView)特有的Javascript API(Javascript接口)的文章文章,但是随着微信官方的调整,有些API已经不能直接使用了,比如直接分享对朋友圈WeixinJSBridge.invoke('shareTimeline',data,callback)这样的函数,直接调用会得到拒绝访问的响应。后来又重新研究了一下,整理出了一个WeixinAPI Javascript类库,分享给大家。如果你对微信公众平台的开发感兴趣,应该对你有用。
/**!
* 微信内置浏览器的Javascript API,功能包括:
*
* 1、分享到微信朋友圈
* 2、分享给微信好友
* 3、分享到腾讯微博
* 4、隐藏/显示右上角的菜单入口
* 5、隐藏/显示底部浏览器工具栏
* 6、获取当前的网络状态
* 7、调起微信客户端的图片播放组件
*
* @author zhaoxianlie(http://www.baidufe.com)
*/
var WeixinApi = (function () {
/* 这里省略了一堆代码……下面直接看调用接口 */
return {
ready :wxJsBridgeReady,
shareToTimeline :weixinShareTimeline,
shareToWeibo :weixinShareWeibo,
shareToFriend :weixinSendAppMessage,
showOptionMenu :showOptionMenu,
hideOptionMenu :hideOptionMenu,
showToolbar :showToolbar,
hideToolbar :hideToolbar,
getNetworkType :getNetworkType,
imagePreview :imagePreview
};
});
接下来,让我们看看这些API应该如何使用,从最简单的开始。
1、如果我想一打开网页就隐藏右上角的PopUp菜单项,隐藏浏览器底部的工具栏,同时也获取当前的网络状态,那么我们的代码可以是像这样写:
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api){
// 隐藏右上角popup菜单入口
Api.hideOptionMenu();
// 隐藏浏览器下方的工具栏
Api.hideToolbar();
// 获取网络状态
Api.getNetworkType(function(network){
// 拿到 network 以后,做任何你想做的事
});
});
如示例代码中的注释所示,所有函数执行都必须在 WeixinApi.ready 方法中执行,就像在使用 jQuery 时,通常需要使用 jQuery(document).ready(function(){ }) 一样. 为什么要这样做?相信不用我解释大家都能理解,因为我们必须保证在执行这些方法的时候,WebView中已经添加了WeixinJsBridge API!
2、再看一个分享的例子,如果用户在阅读我的文章(或使用我的产品)的过程中发现它有趣或有价值,他们一般会采集或分享(给朋友、朋友圈、微博等),那么现在我希望监控用户的分享行为,比如:自定义用户可以分享的内容,即使用户分享了,取消分享,分享失败,分享成功,整个分享操作过程就结束了,大家都做点什么。所以,我们可以这样写代码:
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api){
// 微信分享的数据
var wxData = {
"imgUrl":'http://www.baidufe.com/fe/blog ... 39%3B,
"link":'http://www.baidufe.com',
"desc":'大家好,我是Alien,Web前端&Android客户端码农,喜欢技术上的瞎倒腾!欢迎多交流',
"title":"大家好,我是赵先烈"
};
// 分享的回调
var wxCallbacks = {
// 分享操作开始之前
ready:function () {
// 你可以在这里对分享的数据进行重组
},
// 分享被用户自动取消
cancel:function (resp) {
// 你可以在你的页面上给用户一个小Tip,为什么要取消呢?
},
// 分享失败了
fail:function (resp) {
// 分享失败了,是不是可以告诉用户:不要紧,可能是网络问题,一会儿再试试?
},
// 分享成功
confirm:function (resp) {
// 分享成功了,我们是不是可以做一些分享统计呢?
},
// 整个分享过程结束
all:function (resp) {
// 如果你做的是一个鼓励用户进行分享的产品,在这里是不是可以给用户一些反馈了?
}
};
// 用户点开右上角popup菜单后,点击分享给好友,会执行下面这个代码
Api.shareToFriend(wxData, wxCallbacks);
// 点击分享到朋友圈,会执行下面这个代码
Api.shareToTimeline(wxData, wxCallbacks);
// 点击分享到腾讯微博,会执行下面这个代码
Api.shareToWeibo(wxData, wxCallbacks);
});
3、当然,如果你的业务需求比较复杂,比如你的产品是微信网页游戏(类似于“2048数字游戏微信版”),你希望用户分享的数据是截图一个网页,或者一个将用户当前的游戏状态发送回服务器,以动态生成可分享的内容;在这种情况下我们应该怎么做?看看下面的示例代码:
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api){
// 分享的回调
var wxCallbacks = {
// 分享过程需要异步执行
async : true,
// 分享操作开始之前
ready:function () {
var self = this;
// 假设你需要在这里发一个 ajax 请求去获取分享数据
$.post(yourServerUrl,yourPostData,function(responseData){
// 可以解析reponseData得到wxData
var wxData = responseData;
// 调用dataLoaded方法,会自动触发分享操作
// 注意,当且仅当 async为true时,wxCallbacks.dataLoaded才会被初始化,并调用
self.dataLoaded(wxData);
});
}
/* cancel、fail、confirm、all 方法同示例2,此处略掉 */
};
// 用户点开右上角popup菜单后,点击分享给好友,会执行下面这个代码
Api.shareToFriend({}, wxCallbacks);
});
唯一不同的是,在wxCallbacks中,配置项async被添加为true,表示共享进程是异步调用的。其实就是说ready方法是异步执行的。在这种情况下,我们需要在 ready 方法中显式调用它。wxCallbacks的dataLoaded方法保证共享进程可以继续执行。可能你会发现这个wxCallbacks里面并没有配置dataLoaded方法!是的,当 async 为 true 时,我会在 WeixinApi 中自动初始化。dataLoaded 方法需要一个参数,表示需要共享的数据!
4、当然,如果非要配置dataLoaded方法也没问题。您的配置也将被执行并且不会被覆盖。执行顺序为:用户配置优先。
以上是直接给出使用方法。也许您现在开始关心每个方法的参数列表是什么样的?我们以分享到朋友圈的方法为例,看看参数有哪些配置项:
/**
* 分享到微信朋友圈
* @param {Object} data 待分享的信息
* @p-config {String} appId 公众平台的appId(服务号可用)
* @p-config {String} imageUrl 图片地址
* @p-config {String} link 链接地址
* @p-config {String} desc 描述
* @p-config {String} title 分享的标题
*
* @param {Object} callbacks 相关回调方法
* @p-config {Boolean} async ready方法是否需要异步执行,默认false
* @p-config {Function} ready(argv) 就绪状态
* @p-config {Function} dataLoaded(data) 数据加载完成后调用,async为true时有用
* @p-config {Function} cancel(resp) 取消
* @p-config {Function} fail(resp) 失败
* @p-config {Function} confirm(resp) 成功
* @p-config {Function} all(resp) 无论成功失败都会执行的回调
*/
WeixinApi.shareToTimeline(data,callbacks);
分享给微信朋友和分享给腾讯微博的参数列表是一样的,这里就不一一列举了。
5、如果你的文章里面有很多图片,那么点击图片直接调出微信客户端自带的图片播放组件一定是件好事;你可以这样做 :
// 调起微信客户端的图片播放组件进行播放
WeixinApi.ready(function(Api){
var srcList = [];
$.each($('img'),function(i,item){
if(item.src) {
srcList.push(item.src);
$(item).click(function(e){
// 通过这个API就能直接调起微信客户端的图片播放组件了
Api.imagePreview(this.src,srcList);
});
}
});
});
就这么简单的一段代码,一切就搞定了!不过需要指出的是,Api.imagePreview的参数会被强检测:
/**
* 调起微信Native的图片播放组件。
* 这里必须对参数进行强检测,如果参数不合法,直接会导致微信客户端crash
*
* @param {String} curSrc 当前播放的图片地址
* @param {Array} srcList 图片地址列表
*/
function imagePreview(curSrc,srcList) ;
需要指出的是,微信公众平台并没有统一支持Android和iOS平台,比较费力。具体有:
期待早日正式实现各平台API的统一!!!
至于API内部是如何实现的,有兴趣的可以看下源码。如果您在使用过程中遇到任何错误,请来这里反馈。
为了方便Api的维护和分享,已经放到了Github上。让我们从这里开始:
网页css js 抓取助手(WebMagic介绍项目代码分为核心和扩展两部分的区别 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-04 12:12
)
一、WebMagic介绍
WebMagic 项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分包括一些便利和实用的功能。
WebMagic 的设计目标是尽可能模块化,并体现爬虫的功能特点。这部分提供了一个非常简单灵活的API来编写爬虫,而无需基本改变开发模式。
扩展部分(webmagic-extension)提供了一些方便的功能,比如以注解方式编写爬虫。同时内置了一些常用的组件,方便爬虫开发。
1.1 架构介绍
WebMagic 的结构分为四大组件:Downloader、PageProcessor、Scheduler 和 Pipeline,它们由 Spider 组织。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。WebMagic 的设计参考了 Scapy,但实现更类似于 Java。
Spider 组织这些组件,以便它们可以相互交互并处理执行。可以认为Spider是一个大容器,也是WebMagic逻辑的核心。
WebMagic的整体架构图如下:
1.1.1 WebMagic 的四个组成部分
1、下载器
下载器负责从 Internet 下载页面以进行后续处理。WebMagic 默认使用 Apache HttpClient 作为下载工具。
2、页面处理器
PageProcessor 负责解析页面、提取有用信息和发现新链接。WebMagic 使用 Jsoup 作为 HTML 解析工具,并在其基础上开发了 Xsoup,一个解析 XPath 的工具。这四个组件中,PageProcessor对于每个站点的每个页面都是不同的,是需要用户自定义的部分。
3、调度器
Scheduler 负责管理要爬取的 URL,以及一些去重工作。WebMagic 默认提供 JDK 的内存队列来管理 URL,并使用集合进行去重。还支持使用 Redis 进行分布式管理。
4、管道
Pipeline负责提取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供两种结果处理方案:“输出到控制台”和“保存到文件”。
Pipeline 定义了保存结果的方式。如果要保存到指定的数据库,需要编写相应的Pipeline。通常,对于一类需求,只需要编写一个 Pipeline。
1.1.2 数据流对象
1、请求
Request是对URL地址的一层封装,一个Request对应一个URL地址。
它是PageProcessor 与Downloader 交互的载体,也是PageProcessor 控制Downloader 的唯一途径。
除了 URL 本身,它还收录一个 Key-Value 结构的额外字段。你可以额外保存一些特殊的属性,并在其他地方读取它们来完成不同的功能。例如,添加上一页的一些信息等。
2、页面
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
3、结果项
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。它的API和Map非常相似,值得注意的是它有一个字段skip,如果设置为true,它不应该被Pipeline处理。
1.2 入门案例
1.2.1 添加依赖
创建一个Maven项目并添加以下依赖项
注意:0.7.3 版本不支持 SSL。如果直接从Maven中央仓库下载依赖,爬取只支持SSL v1.2的网站,会抛出SSL异常。
1.2.2 添加个人资料
WebMagic 使用 slf4j-log4j12 作为 slf4j 的实现。
添加 log4j.properties 配置文件:
log4j.rootLogger=INFO,A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
1.2.3 案例实现
二、WebMagic 功能
2.1 实现 PageProcessor
2.1.1 提取元素可选
WebMagic 中使用了三种主要的提取技术:XPath、正则表达式和 CSS 选择器。另外,对于 JSON 格式的内容,可以使用 JsonPath 进行解析。
2.1.1.1 XPath
入口案例是获取属性class=mt的div标签和里面h1标签的内容
page.getHtml().xpath("//div[@class=mt]/h1/text()")
2.1.1.2 个 CSS 选择器
CSS 选择器是一种类似于 XPath 的语言。上一课我们学习了Jsoup的选择器。写起来比XPath简单,但是写更复杂的抽取规则就比较麻烦。
div.mt>h1 表示类为mt的div标签下的直接子元素h1标签
page.getHtml().css("div.mt>h1").toString()
2.1.1.3 正则表达式
正则表达式是一种通用的文本提取语言。这里一般用来获取url地址。
2.1.2 提取元素 API
可选相关提取元素链接 API 是 WebMagic 的核心功能。使用Selectable接口,可以直接完成页面元素的链式提取,无需关心提取的细节。
在刚才的例子中可以看到,page.getHtml()返回一个实现了Selectable接口的Html对象。该接口收录的方法分为两类:提取部分和获取结果部分。
2.1.3 获取结果 API
当链式调用结束时,我们一般希望得到一个字符串类型的结果。这时候就需要使用API来获取结果了。
我们知道,一条抽取规则,无论是 XPath、CSS 选择器还是正则表达式,总是可以抽取多个元素。WebMagic 将这些统一起来,可以通过不同的 API 获取一个或多个元素。
2.1.4 获取链接
有了处理页面的逻辑,我们的爬虫就差不多完成了,但是还有一个问题:一个站点的页面很多,我们不能一开始就全部列出来,那么如何找到后续的链接就是爬虫了不能缺少的部分
下面的例子就是获取这个页面
所有与 \\w+?.* 正则表达式匹配的 URL 地址,并将这些链接添加到要爬取的队列中。
查看全部
网页css js 抓取助手(WebMagic介绍项目代码分为核心和扩展两部分的区别
)
一、WebMagic介绍
WebMagic 项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分包括一些便利和实用的功能。
WebMagic 的设计目标是尽可能模块化,并体现爬虫的功能特点。这部分提供了一个非常简单灵活的API来编写爬虫,而无需基本改变开发模式。
扩展部分(webmagic-extension)提供了一些方便的功能,比如以注解方式编写爬虫。同时内置了一些常用的组件,方便爬虫开发。
1.1 架构介绍
WebMagic 的结构分为四大组件:Downloader、PageProcessor、Scheduler 和 Pipeline,它们由 Spider 组织。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。WebMagic 的设计参考了 Scapy,但实现更类似于 Java。
Spider 组织这些组件,以便它们可以相互交互并处理执行。可以认为Spider是一个大容器,也是WebMagic逻辑的核心。
WebMagic的整体架构图如下:
1.1.1 WebMagic 的四个组成部分
1、下载器
下载器负责从 Internet 下载页面以进行后续处理。WebMagic 默认使用 Apache HttpClient 作为下载工具。
2、页面处理器
PageProcessor 负责解析页面、提取有用信息和发现新链接。WebMagic 使用 Jsoup 作为 HTML 解析工具,并在其基础上开发了 Xsoup,一个解析 XPath 的工具。这四个组件中,PageProcessor对于每个站点的每个页面都是不同的,是需要用户自定义的部分。
3、调度器
Scheduler 负责管理要爬取的 URL,以及一些去重工作。WebMagic 默认提供 JDK 的内存队列来管理 URL,并使用集合进行去重。还支持使用 Redis 进行分布式管理。
4、管道
Pipeline负责提取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供两种结果处理方案:“输出到控制台”和“保存到文件”。
Pipeline 定义了保存结果的方式。如果要保存到指定的数据库,需要编写相应的Pipeline。通常,对于一类需求,只需要编写一个 Pipeline。
1.1.2 数据流对象
1、请求
Request是对URL地址的一层封装,一个Request对应一个URL地址。
它是PageProcessor 与Downloader 交互的载体,也是PageProcessor 控制Downloader 的唯一途径。
除了 URL 本身,它还收录一个 Key-Value 结构的额外字段。你可以额外保存一些特殊的属性,并在其他地方读取它们来完成不同的功能。例如,添加上一页的一些信息等。
2、页面
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
3、结果项
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。它的API和Map非常相似,值得注意的是它有一个字段skip,如果设置为true,它不应该被Pipeline处理。
1.2 入门案例
1.2.1 添加依赖
创建一个Maven项目并添加以下依赖项
注意:0.7.3 版本不支持 SSL。如果直接从Maven中央仓库下载依赖,爬取只支持SSL v1.2的网站,会抛出SSL异常。
1.2.2 添加个人资料
WebMagic 使用 slf4j-log4j12 作为 slf4j 的实现。
添加 log4j.properties 配置文件:
log4j.rootLogger=INFO,A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
1.2.3 案例实现
二、WebMagic 功能
2.1 实现 PageProcessor
2.1.1 提取元素可选
WebMagic 中使用了三种主要的提取技术:XPath、正则表达式和 CSS 选择器。另外,对于 JSON 格式的内容,可以使用 JsonPath 进行解析。
2.1.1.1 XPath
入口案例是获取属性class=mt的div标签和里面h1标签的内容
page.getHtml().xpath("//div[@class=mt]/h1/text()")
2.1.1.2 个 CSS 选择器
CSS 选择器是一种类似于 XPath 的语言。上一课我们学习了Jsoup的选择器。写起来比XPath简单,但是写更复杂的抽取规则就比较麻烦。
div.mt>h1 表示类为mt的div标签下的直接子元素h1标签
page.getHtml().css("div.mt>h1").toString()
2.1.1.3 正则表达式
正则表达式是一种通用的文本提取语言。这里一般用来获取url地址。
2.1.2 提取元素 API
可选相关提取元素链接 API 是 WebMagic 的核心功能。使用Selectable接口,可以直接完成页面元素的链式提取,无需关心提取的细节。
在刚才的例子中可以看到,page.getHtml()返回一个实现了Selectable接口的Html对象。该接口收录的方法分为两类:提取部分和获取结果部分。
2.1.3 获取结果 API
当链式调用结束时,我们一般希望得到一个字符串类型的结果。这时候就需要使用API来获取结果了。
我们知道,一条抽取规则,无论是 XPath、CSS 选择器还是正则表达式,总是可以抽取多个元素。WebMagic 将这些统一起来,可以通过不同的 API 获取一个或多个元素。
2.1.4 获取链接
有了处理页面的逻辑,我们的爬虫就差不多完成了,但是还有一个问题:一个站点的页面很多,我们不能一开始就全部列出来,那么如何找到后续的链接就是爬虫了不能缺少的部分
下面的例子就是获取这个页面
所有与 \\w+?.* 正则表达式匹配的 URL 地址,并将这些链接添加到要爬取的队列中。
网页css js 抓取助手(网站抓取是一个用Python编写的Web爬虫和Web框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-04 03:14
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以直接通过socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫采用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。 查看全部
网页css js 抓取助手(网站抓取是一个用Python编写的Web爬虫和Web框架)
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以直接通过socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫采用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。
网页css js 抓取助手(这里有新鲜出炉的Javascript教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-25 05:15
这里有新鲜出炉的Javascript教程,程序狗速来了!
JavaScript 客户端脚本语言 JavaScript 是一种原型继承的基于对象的动态类型区分大小写的客户端脚本语言,由 Netscape 的 LiveScript 开发。主要目的是解决服务器端语言,如Perl,遗留速度问题,为客户提供更流畅的浏览效果。
如果您想在保留文件或在执行阶段对代码进行 lint,则 linting 工具也可以做您想做的事情。这取决于个人选择。如果您正在寻找适用于 CSS 和 JavaScript 的最佳 linting 工具,请继续阅读
审查和测试代码以发现任何潜在的错误,从而在将错误发布到 网站 之前及时消除错误,这是一个非常重要的过程。代码检查的过程通常也称为网页设计师和开发人员之间的 linting。作为设计师,如果你想编写高度优化的代码,那么你肯定需要 linting 工具。有两种类型的代码检查工具。一种是在执行时检查代码中的错误和错误。另一种是使用静态代码分析技术,在执行前检查代码。后者显然更好,因为它可以节省时间和麻烦。
事实上,linting 可以放在不同的阶段。如果您想在键入时测试代码,则可以使用 lint 工具。当然,如果您想在保存文件或在执行阶段对代码进行 lint,那么 linting 工具可以满足您的需求。这取决于个人选择。如果您正在寻找适用于 CSS 和 JavaScript 的最佳 linting 工具,请继续阅读。
1.CSSLint
诚然,CSSLint 会“伤害你的感情”,但作为交换,它会“大大改善你的代码”。CSSLint 目前引领着 CSSlinting 市场。用 JavaScript 编写,不仅是开源的,而且还带有很多配置选项。
2.SublimeLinter CSSLint
CSSLint 曾经是一个如此高效的 CSSlinting 工具,以至于很难找到可以与之匹敌的竞争对手。也许这就是 SublimeLinterlinting 框架在 CSSLint 之上构建其 CSSlinting 插件的原因。SublimeLinter 是一个 SublimeText 插件,它为用户提供了一种 lint 代码(CSS、PHP、Python、Java、Ruby 等)的方法。
3.StyleLint
StyleLint 帮助开发人员避免 CSS、SCSS 或任何其他可解析的 PostCSS 中的语法错误。StyleLint 测试了一百多个规则,您可以选择要切换到哪些规则(请参阅此示例配置)。
4.W3C CSS 验证器
虽然 W3C 的 CSS Validator 通常不被视为 linting 工具,但它为开发人员提供了一个很好的机会来检查 CSS 代码是否符合官方 W3C 标准。W3C 构建了自己的验证器,旨在为 C 语言提供类似于 Lint 程序检查器的工具。
5.脏标记
Dirty Markup 清理、格式化和验证您的 HTML、CSS 和 JavaScript 代码。如果您喜欢简单直接的设计并想要快速解决方案,那么这是正确的选择。当您在编辑器中编写或修改代码时,脏标记可以实时抛出错误消息和通知。
6.JSLint
JSLint 最初是由 Douglas Crockford 于 2002 年发布的,从那时起已经有了很多生命,所以你可以放心地认为它是一个稳定可靠的 JavaScript linting 工具。
7.JSHint
JSHint 是一个社区驱动的项目,最初是为了创建一个更可配置、更不固执的 JSLint 版本。JSHint 允许开发人员配置其任何 linting 选项,然后将自定义配置放入单个文件中,这使得该工具易于重用,因此非常适合大型项目。
8.ESLint
ESLint 是 JavaScript linting 领域中最新的一件大事。它因其高度灵活的特性而广受欢迎。您不仅可以自定义大量前沿的 linting 规则,将其与所有主流代码编辑器集成,还可以通过添加不同的插件轻松扩展其功能。
9.JSCS
JSCS 或 JavaScript 代码样式是用于检查代码格式规则的 JavaScript 的可插入代码样式 linter。JSCS 的目标是提供一种以编程方式强制遵守编码风格指南的方法。尽管 JSCS 不检查 bug 和错误,但它仍然被许多高科技行业的参与者使用,例如 Google、AirBnB 和 AngularJS,因为它可以帮助开发人员保持高度可读和一致的代码库。
10.标准JS
StandardJS,或 JavaScript 标准样式,是一种代码样式 linter,有点像 JSCS,但区别更简单、更直接。如果您不想花时间在配置上,而只是想要一个开箱即用的高效工具,那么 StandardJS 是一个不错的选择。
翻译链接:
英文原文: 查看全部
网页css js 抓取助手(这里有新鲜出炉的Javascript教程,程序狗速度看过来!)
这里有新鲜出炉的Javascript教程,程序狗速来了!
JavaScript 客户端脚本语言 JavaScript 是一种原型继承的基于对象的动态类型区分大小写的客户端脚本语言,由 Netscape 的 LiveScript 开发。主要目的是解决服务器端语言,如Perl,遗留速度问题,为客户提供更流畅的浏览效果。
如果您想在保留文件或在执行阶段对代码进行 lint,则 linting 工具也可以做您想做的事情。这取决于个人选择。如果您正在寻找适用于 CSS 和 JavaScript 的最佳 linting 工具,请继续阅读
审查和测试代码以发现任何潜在的错误,从而在将错误发布到 网站 之前及时消除错误,这是一个非常重要的过程。代码检查的过程通常也称为网页设计师和开发人员之间的 linting。作为设计师,如果你想编写高度优化的代码,那么你肯定需要 linting 工具。有两种类型的代码检查工具。一种是在执行时检查代码中的错误和错误。另一种是使用静态代码分析技术,在执行前检查代码。后者显然更好,因为它可以节省时间和麻烦。
事实上,linting 可以放在不同的阶段。如果您想在键入时测试代码,则可以使用 lint 工具。当然,如果您想在保存文件或在执行阶段对代码进行 lint,那么 linting 工具可以满足您的需求。这取决于个人选择。如果您正在寻找适用于 CSS 和 JavaScript 的最佳 linting 工具,请继续阅读。
1.CSSLint
诚然,CSSLint 会“伤害你的感情”,但作为交换,它会“大大改善你的代码”。CSSLint 目前引领着 CSSlinting 市场。用 JavaScript 编写,不仅是开源的,而且还带有很多配置选项。
2.SublimeLinter CSSLint
CSSLint 曾经是一个如此高效的 CSSlinting 工具,以至于很难找到可以与之匹敌的竞争对手。也许这就是 SublimeLinterlinting 框架在 CSSLint 之上构建其 CSSlinting 插件的原因。SublimeLinter 是一个 SublimeText 插件,它为用户提供了一种 lint 代码(CSS、PHP、Python、Java、Ruby 等)的方法。
3.StyleLint
StyleLint 帮助开发人员避免 CSS、SCSS 或任何其他可解析的 PostCSS 中的语法错误。StyleLint 测试了一百多个规则,您可以选择要切换到哪些规则(请参阅此示例配置)。
4.W3C CSS 验证器
虽然 W3C 的 CSS Validator 通常不被视为 linting 工具,但它为开发人员提供了一个很好的机会来检查 CSS 代码是否符合官方 W3C 标准。W3C 构建了自己的验证器,旨在为 C 语言提供类似于 Lint 程序检查器的工具。
5.脏标记
Dirty Markup 清理、格式化和验证您的 HTML、CSS 和 JavaScript 代码。如果您喜欢简单直接的设计并想要快速解决方案,那么这是正确的选择。当您在编辑器中编写或修改代码时,脏标记可以实时抛出错误消息和通知。
6.JSLint
JSLint 最初是由 Douglas Crockford 于 2002 年发布的,从那时起已经有了很多生命,所以你可以放心地认为它是一个稳定可靠的 JavaScript linting 工具。
7.JSHint
JSHint 是一个社区驱动的项目,最初是为了创建一个更可配置、更不固执的 JSLint 版本。JSHint 允许开发人员配置其任何 linting 选项,然后将自定义配置放入单个文件中,这使得该工具易于重用,因此非常适合大型项目。
8.ESLint
ESLint 是 JavaScript linting 领域中最新的一件大事。它因其高度灵活的特性而广受欢迎。您不仅可以自定义大量前沿的 linting 规则,将其与所有主流代码编辑器集成,还可以通过添加不同的插件轻松扩展其功能。
9.JSCS
JSCS 或 JavaScript 代码样式是用于检查代码格式规则的 JavaScript 的可插入代码样式 linter。JSCS 的目标是提供一种以编程方式强制遵守编码风格指南的方法。尽管 JSCS 不检查 bug 和错误,但它仍然被许多高科技行业的参与者使用,例如 Google、AirBnB 和 AngularJS,因为它可以帮助开发人员保持高度可读和一致的代码库。
10.标准JS
StandardJS,或 JavaScript 标准样式,是一种代码样式 linter,有点像 JSCS,但区别更简单、更直接。如果您不想花时间在配置上,而只是想要一个开箱即用的高效工具,那么 StandardJS 是一个不错的选择。
翻译链接:
英文原文:
网页css js 抓取助手(HTMLPad代码编辑的优势及优势优势介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-20 07:21
HTMLPad是一个非常强大的代码编辑器,支持html5、CSS3、js代码,软件非常智能,自带导航和建议功能,可以大大提高代码编辑效率,并且在同时,也减少了错误,另外还有复用、浏览、验证和部署功能,让您轻松完成相关的开发任务。
HTMLPad的主要特点
1、快速轻量级
加载速度比具有类似功能的其他编辑器或 IDE 快得多。
2、强大的语法高亮
支持 HTML、CSS、JavaScript、PHP、XML、ASP、Perl 等。
3、代码智能
智能代码完成、导航和建议功能。
4、智能代码复用
带有可分配快捷方式的代码片段库和代码模板。
5、HTML5 和 CSS3 就绪
编码功能符合现代 HTML5 和 CSS3 标准。
6、直接FTP/SFTP/FTPS
直接在您的 Web 服务器上编辑或单击一下即可发布本地开发副本更新。
7、浏览器预览
内置多浏览器预览、分屏模式、屏幕大小测试、XRay。
8、高级搜索和替换
转到任何内容、快速搜索、详细搜索、文件搜索、正则表达式、详细结果等。
9、强大的 HTML 工具
标签匹配、HTML Tidy、HTML Inspector、HTML Helper 等等。
10、强大的CSS特性
CSS Inspector、Compatibility Watch、Prefix、Shadow Assistant、Box Assistant 等等。
11、强大的JavaScript编辑器
JavaScript 编辑器、自动完成、语言工具等。
12、综合验证
拼写检查器、W3 HTML 和 CSS 验证器、CSS 检查器、JSLint JavaScript 检查器。
HTMLPad 优势
1、节省时间并提高生产力
HTMLPad 将简单编辑器的速度与全尺寸开发环境的强大功能相结合,让您的工作更快。
2、简单切换
界面和行为与其他编辑器一致。所有基本特征都应该是正确的。
3、完全可定制
您可以调整文本编辑器、菜单、工具栏、快捷键和其他一切,以完全满足您的需求。
4、令人难以置信的一体式包装
在单个程序中创建、编辑、验证和管理 HTML、CSS、JavaScript!
5、更快的启动
与其他 Web 开发编辑器不同,您无需等待它加载。
6、没有混淆
HTMLPad 快速、干净且轻巧。它非常强大,但没有塞满无用的按钮或面板。
7、注意细节
HTMLPad 功能经过精心设计,考虑到了速度和生产力。
8、卓越的 FTP/SFTP/FTPS 功能
只需单击几下即可上传/更新您的在线 网站 文件。
9、许多集成工具
语法检查器、验证器、调试器、美化器、CSS 前缀等。
html5编辑器代码编辑器 查看全部
网页css js 抓取助手(HTMLPad代码编辑的优势及优势优势介绍)
HTMLPad是一个非常强大的代码编辑器,支持html5、CSS3、js代码,软件非常智能,自带导航和建议功能,可以大大提高代码编辑效率,并且在同时,也减少了错误,另外还有复用、浏览、验证和部署功能,让您轻松完成相关的开发任务。
HTMLPad的主要特点
1、快速轻量级
加载速度比具有类似功能的其他编辑器或 IDE 快得多。
2、强大的语法高亮
支持 HTML、CSS、JavaScript、PHP、XML、ASP、Perl 等。
3、代码智能
智能代码完成、导航和建议功能。
4、智能代码复用
带有可分配快捷方式的代码片段库和代码模板。
5、HTML5 和 CSS3 就绪
编码功能符合现代 HTML5 和 CSS3 标准。
6、直接FTP/SFTP/FTPS
直接在您的 Web 服务器上编辑或单击一下即可发布本地开发副本更新。
7、浏览器预览
内置多浏览器预览、分屏模式、屏幕大小测试、XRay。
8、高级搜索和替换
转到任何内容、快速搜索、详细搜索、文件搜索、正则表达式、详细结果等。
9、强大的 HTML 工具
标签匹配、HTML Tidy、HTML Inspector、HTML Helper 等等。
10、强大的CSS特性
CSS Inspector、Compatibility Watch、Prefix、Shadow Assistant、Box Assistant 等等。
11、强大的JavaScript编辑器
JavaScript 编辑器、自动完成、语言工具等。
12、综合验证
拼写检查器、W3 HTML 和 CSS 验证器、CSS 检查器、JSLint JavaScript 检查器。
HTMLPad 优势
1、节省时间并提高生产力
HTMLPad 将简单编辑器的速度与全尺寸开发环境的强大功能相结合,让您的工作更快。
2、简单切换
界面和行为与其他编辑器一致。所有基本特征都应该是正确的。
3、完全可定制
您可以调整文本编辑器、菜单、工具栏、快捷键和其他一切,以完全满足您的需求。
4、令人难以置信的一体式包装
在单个程序中创建、编辑、验证和管理 HTML、CSS、JavaScript!
5、更快的启动
与其他 Web 开发编辑器不同,您无需等待它加载。
6、没有混淆
HTMLPad 快速、干净且轻巧。它非常强大,但没有塞满无用的按钮或面板。
7、注意细节
HTMLPad 功能经过精心设计,考虑到了速度和生产力。
8、卓越的 FTP/SFTP/FTPS 功能
只需单击几下即可上传/更新您的在线 网站 文件。
9、许多集成工具
语法检查器、验证器、调试器、美化器、CSS 前缀等。
html5编辑器代码编辑器
网页css js 抓取助手(如何提高网站百度蜘蛛量量?(组图)期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-18 11:16
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧
作者:迟到991人查看评论:04年前
了解什么是保证金崩溃。与许多其他属性不同的是,盒子模型中的垂直边距在相遇时会塌陷,即当一个元素的下边距与另一个元素的上边距相邻时,只保留两个较大的值,即可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧
作者:熊哥 club903 浏览评论:05年前
了解什么是保证金崩溃。与许多其他属性不同的是,盒子模型中的垂直边距在相遇时会塌陷,即当一个元素的下边距与另一个元素的上边距相邻时,只保留两个较大的值,即可以从这个简单的例子中学到: ? .
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅
作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术、伪装指南、优质代码会让你惊叹不已。没想到会受到大家的欢迎。我也可以整理出一些CSS的黑魔法,可惜我的CSS一直都是渣渣,无事可做。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?
作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛数量之前,我们必须考虑:增加网站数量开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)
作者:赖1681人查看评论:03年前
刷新和学习新事物,保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前的 presto,现在的 Gecko
阅读全文
加快网站访问的9种方法
作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览
作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
网页css js 抓取助手(如何提高网站百度蜘蛛量量?(组图)期)
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧
作者:迟到991人查看评论:04年前
了解什么是保证金崩溃。与许多其他属性不同的是,盒子模型中的垂直边距在相遇时会塌陷,即当一个元素的下边距与另一个元素的上边距相邻时,只保留两个较大的值,即可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧
作者:熊哥 club903 浏览评论:05年前
了解什么是保证金崩溃。与许多其他属性不同的是,盒子模型中的垂直边距在相遇时会塌陷,即当一个元素的下边距与另一个元素的上边距相邻时,只保留两个较大的值,即可以从这个简单的例子中学到: ? .
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅
作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术、伪装指南、优质代码会让你惊叹不已。没想到会受到大家的欢迎。我也可以整理出一些CSS的黑魔法,可惜我的CSS一直都是渣渣,无事可做。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?
作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛数量之前,我们必须考虑:增加网站数量开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)
作者:赖1681人查看评论:03年前
刷新和学习新事物,保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前的 presto,现在的 Gecko
阅读全文
加快网站访问的9种方法
作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览
作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
网页css js 抓取助手( 百度快照入口快照更新的速度和网站的权重存在关系)
网站优化 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2022-03-13 23:11
百度快照入口快照更新的速度和网站的权重存在关系)
什么是百度快照
百度快照是搜索引擎在抓取页面时保留的纯文本文档。它不会收录任何图片、视频资源,甚至不会收录页面中引用的 css 和 js 文件。
但是我们经常看到的快照是图片和样式。这是因为对于快照来说,虽然只保留了文本文档,但是只要网站的服务器当前页面的资源可以访问,快照中就可以引用对应的资源地址;
但是如果你删除了网站对应的资源,或者我们的网站是不可访问的,那么你看到的快照页面就是一个极其丑陋的纯文本页面。
百度快照的作用
即当网站不可访问时,访问者可以通过快照了解页面的基本内容;或者当你现在的网络环境很差的时候,因为百度快照是纯文本内容,你可以在速度慢的时候,依然可以流畅的打开快照页面。
百度快照入口
快照更新时间
很多人认为快照的更新速度和网站的权重有关系,但这其实是一种错误的理解。按照这个逻辑,一个网站是如何阻止搜索引擎创建快照的,也就是说一个没有快照的网站是不是会瘦下来影响排名呢?实际情况是,即使快照被屏蔽,对网站的显示排名也没有影响。
为此,我们首先要了解为什么要更新快照。一般来说,快照的更新速度取决于网站的内容更新速度。
简单来说,搜索引擎了解网站页面的更新频率,然后按照一定的时间频率检查页面是否有变化,及时更新页面。当然,这个动作不是实时的,快照不会立即为你更新。
它更多地取决于您的 网站 内容的属性。对于时间敏感的网站内容,比如新闻和资讯,这种网站往往会更新快照的速度。会更快。
因此,我们不能说网站更快的快照更新比更慢的快照更新更重要。至于权重,快照的更新速度就更没有直接关系了。
收录正常的新站点很多,因为之前的站长更新比较用心,同时网站页面不多,但是可以开发的整体页面快照网站 都处于比较快的时效性。我们能说这个新站的权重很高吗?
快照时间倒退
网站有时更新快照不会用新数据替换旧数据。对于一些更重要的页面,搜索引擎更经常保留在不同时间捕获的几个快照。在某些特殊情况下,可能会显示比较旧的快照,也可能会向后查看快照时间。
有些人会担心这个和网站的权重排名。事实上,我们不需要过多关注快照。这只是一个没有劫持快照的正常更新。基本上,当我们优化 网站 时,快照不是关注点。
版权提醒:原创未经授权请勿复制、转载内容。违者必究,全网自动搜索识别类似抄袭!!! 查看全部
网页css js 抓取助手(
百度快照入口快照更新的速度和网站的权重存在关系)
什么是百度快照
百度快照是搜索引擎在抓取页面时保留的纯文本文档。它不会收录任何图片、视频资源,甚至不会收录页面中引用的 css 和 js 文件。
但是我们经常看到的快照是图片和样式。这是因为对于快照来说,虽然只保留了文本文档,但是只要网站的服务器当前页面的资源可以访问,快照中就可以引用对应的资源地址;
但是如果你删除了网站对应的资源,或者我们的网站是不可访问的,那么你看到的快照页面就是一个极其丑陋的纯文本页面。
百度快照的作用
即当网站不可访问时,访问者可以通过快照了解页面的基本内容;或者当你现在的网络环境很差的时候,因为百度快照是纯文本内容,你可以在速度慢的时候,依然可以流畅的打开快照页面。
百度快照入口
快照更新时间
很多人认为快照的更新速度和网站的权重有关系,但这其实是一种错误的理解。按照这个逻辑,一个网站是如何阻止搜索引擎创建快照的,也就是说一个没有快照的网站是不是会瘦下来影响排名呢?实际情况是,即使快照被屏蔽,对网站的显示排名也没有影响。
为此,我们首先要了解为什么要更新快照。一般来说,快照的更新速度取决于网站的内容更新速度。
简单来说,搜索引擎了解网站页面的更新频率,然后按照一定的时间频率检查页面是否有变化,及时更新页面。当然,这个动作不是实时的,快照不会立即为你更新。
它更多地取决于您的 网站 内容的属性。对于时间敏感的网站内容,比如新闻和资讯,这种网站往往会更新快照的速度。会更快。
因此,我们不能说网站更快的快照更新比更慢的快照更新更重要。至于权重,快照的更新速度就更没有直接关系了。
收录正常的新站点很多,因为之前的站长更新比较用心,同时网站页面不多,但是可以开发的整体页面快照网站 都处于比较快的时效性。我们能说这个新站的权重很高吗?
快照时间倒退
网站有时更新快照不会用新数据替换旧数据。对于一些更重要的页面,搜索引擎更经常保留在不同时间捕获的几个快照。在某些特殊情况下,可能会显示比较旧的快照,也可能会向后查看快照时间。
有些人会担心这个和网站的权重排名。事实上,我们不需要过多关注快照。这只是一个没有劫持快照的正常更新。基本上,当我们优化 网站 时,快照不是关注点。
版权提醒:原创未经授权请勿复制、转载内容。违者必究,全网自动搜索识别类似抄袭!!!
网页css js 抓取助手(网站页面代码该如何做优化?听听重庆SEO技术人员的相关介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-11 07:25
作为一名网站SEO优化者,必须了解网站的代码,这是网站优化的必备要素之一。如果 网站promotions 想要获得良好的性能,源代码非常重要。挑剔的搜索引擎蜘蛛对简洁的网站代码情有独钟,这就要求我们对网站代码进行简化和优化。网站如何优化页面代码?听听重庆SEO技术人员的相关介绍。
网站页面代码应该如何优化?网页的简化就是简单的网站代码优化,去掉网站冗余代码,减小网站大小,提高网站加载速度和用户体验。
网站代码优化是站长必须掌握的一项基本技能。这与搜索引擎蜘蛛是否会对您的网站 感兴趣有关。冗长无用的代码会让蜘蛛难以理解,增加蜘蛛的抓地力。取网站的难易程度,同时网页的精简也与网站的加载速度有关,这对用户体验非常重要。
网站如何优化页面代码?
1、HEAD 零件代码规范化
代码的HEAD部分是搜索引擎爬取网站的入口部分。现在很多网站头代码都比较统一,刻板印象效果很明显。这样的网站代码就像一个模板框架,不被蜘蛛喜欢,我们要做的就是规范网站的代码,建立一个唯一的网站头部,以及让搜索引擎新鲜,从而吸引蜘蛛爬行
2、使用DIV+CSS布局网页
虽然现在div+css已经很成熟了,但是考虑到网页的兼容性和布局的简洁性,很多网页设计师可能还是会使用老式的表格布局。表格布局虽然很方便,但缺点也很明显。大大增加了网页的大小,尤其是多层表格的嵌套。这样的布局不仅会增加体积,嵌套过多还会影响搜索引擎的爬取和网站的收录。
另外,有的网站会使用外部文件,把css和js放在外部文件中,只需要在页面的html中放入相同的代码即可调用,有时我们会看到很多源码的时候我们检查 CSS 代码和 javasript 代码,将 javascript 放在 网站 页面的 html 文件的最前面,将一些真正可以使用的文本部分推到 html 的后面。重庆SEO认为,这类代码需要精简。
3、CSS 优化
CSS 是页面渲染中非常重要的一部分,包括颜色、大小、背景和字体。编写 CSS 简单易行,但编写可靠的 CSS 代码有很多技巧。
(1), CSS 位置
如果CSS描述出现在网站之后,需要重新渲染页面,会影响打开速度。所有 CSS 定义代码的位置都应该放在 网站 之前。
(2), css sprite 技术
网站 上的部分图片可以使用 CSS sprite 技术进行组合,减少加载请求的数量,从而提高网页的加载速度。
(3), CSS 代码优化
通过 CSS 代码属性的简写、去除冗余结构(frameworks)和重置(resets)等一系列方法和技术,简化 CSS 代码,减小 CSS 文件的大小。
(4),尽量不要使用内联CSS
内联 CSS 有两种,一种是头部区域内的普通内联;另一个是出现在标签中的内联内联 CSS。无论使用什么内联 CSS 方法,结果都会增加页面的体积。,我们可以尝试使用外部调整的 CSS 来缩小网站页面的大小。
4、JS优化
JS 优化还是和其他语言的优化差不多。JS优化的关键还是要关注最关键的地方,也就是瓶颈。一般来说,瓶颈总是发生在大规模循环中。,这并不是说循环本身存在性能问题,而是说循环可以迅速放大可能的性能问题。
(1), JS 位置
在优化网页代码中的js时,重庆SEO建议将js放在页面末尾,这样可以加快页面打开速度。
(2), 合并 JS
合并同域名下的js,通过减少网络连接数来提高网页的打开速度。
(3),LazyLoad 技术
Lazy Load 是一个用 JavaScript 编写的 jQuery 插件。它可以延迟加载长页面中的图像。在用户将页面滚动到它们所在的位置之前,不会加载浏览器可见区域之外的图像。
(4),调用外部JS代码
我们知道目前的搜索引擎仍然无法识别 JS 代码。如果 网站 中出现大量 JS 代码,那么 网站 就很难在 收录 上,而我们要做的就是将 Javascript 代码以 external 的形式调用网站,可以简化搜索引擎的工作,不会无形中推导出涉及网站的无效代码。
不仅如此,您还可以使用 css 代码进行外部调用。网站开头可以在css代码文件中定义网站的文字和颜色,尽量不要在页面代码中出现过多的样式代码。
(5),减少页面对JS的依赖
现在,JS 对搜索引擎并不友好。虽然据说搜索引擎不讨厌 JS,但还是少做点比较好。虽然 JS 可以产生很多效果,但是网页中的 JS 还是很多的。会影响蜘蛛对页面的抓取,增加网页的体积,尤其是导航栏等页面的关键位置,尽量使用DIV+CSS的设计方式。
5、TABLE 标签缩减
表格标签是大部分在线网站中最常见的代码形式。原因是创建网站的时候表比较快,但这也影响了后期对网站的优化。
与div+css布局的简化代码网站相比,占用空间比较大。因此,在建网站时,尽量少用表格。即使要使用表格,也应尽可能使用嵌套表格。谨慎使用以避免冗余代码
那么,当前的 网站 做了什么?很多程序员首先想到用CSS来做,用CSS来排版。这种做法大大减少了页面中的表格,但是在重庆SEO看来,网站不能没有表格。有些东西是必须要用的。可以使用表。但是很多网站使用嵌套表。一般这样的表会给网站生成大量的垃圾代码,而这些垃圾代码都是没有用的代码,而这类代码也是我们网站需要精简的代码之一.
6、代码注释省略
许多程序员习惯于在编写代码时在别人看不懂的地方给出注释。这些代码通常用于几个程序员之间的协作工作,对局外人和搜索引擎没有用处。相反,它们会给搜索引擎蜘蛛带来一些麻烦。
在打开页面代码的时候,我们经常会看到一些注释代码,它们是程序员为了表明代码含义所做的注释。其实这些开孔都不是必须的,因为对于搜索引擎来说,它们没有任何意义,反而会增加页数。代码的容量,所以对网站没有好处,直接省略比较好。
7、去除页面中的冗余代码
有的网站认为作者的代码编写习惯有问题,页面上会出现很多空白代码,比如:空白代码,重复定义样式和字体的代码,不要小看这些小代码,他们积累了很多,也让我们的网站异常臃肿。
很多网站使用DIV+CSS,在CSS中定义了文本的字体、颜色和页面布局,但是在网站的其他地方,style和font用来重新定义Font字体,这些代码不需要重复定义,都是可以简化的代码。
8、将 HTML 控件转换为 CSS 控件
许多网页设计师习惯于控制标签内的内容。例如,在img标签中,宽度和高度用于控制图像的大小。尝试将这些代码转换为外部调整的 CSS 以使网页代码更苗条。
9、缓存静态资源
通过在浏览器端设置浏览器缓存,缓存css、js等更新频率较低的文件,这样当同一个访问者再次访问你的网站时,浏览器就可以从浏览器的缓存中获取css、js等,不用每次都从你的服务器读取,在一定程度上加快了网站的打开速度,节省了你的服务器流量。
10、网页压缩技术
对于网页压缩,相信各位站长都不陌生。主要是启用服务器Gzip,对页面进行Gzip压缩,减小元素大小,从而减少数据传输,提高网页加载速度。这个功能需要你的服务器是的,GZIP压缩一般可以将网页压缩30%-80%,这是最重要的优化效果。
网站如何优化页面代码?重庆SEO提醒网站页面代码的SEO优化,不仅可以提高页面的打开速度,还可以提升用户的访问体验。同时,从SEO的角度,还可以提高蜘蛛的访问速度,有助于网站的搜索引擎的索引体验。 查看全部
网页css js 抓取助手(网站页面代码该如何做优化?听听重庆SEO技术人员的相关介绍)
作为一名网站SEO优化者,必须了解网站的代码,这是网站优化的必备要素之一。如果 网站promotions 想要获得良好的性能,源代码非常重要。挑剔的搜索引擎蜘蛛对简洁的网站代码情有独钟,这就要求我们对网站代码进行简化和优化。网站如何优化页面代码?听听重庆SEO技术人员的相关介绍。
网站页面代码应该如何优化?网页的简化就是简单的网站代码优化,去掉网站冗余代码,减小网站大小,提高网站加载速度和用户体验。
网站代码优化是站长必须掌握的一项基本技能。这与搜索引擎蜘蛛是否会对您的网站 感兴趣有关。冗长无用的代码会让蜘蛛难以理解,增加蜘蛛的抓地力。取网站的难易程度,同时网页的精简也与网站的加载速度有关,这对用户体验非常重要。
网站如何优化页面代码?
1、HEAD 零件代码规范化
代码的HEAD部分是搜索引擎爬取网站的入口部分。现在很多网站头代码都比较统一,刻板印象效果很明显。这样的网站代码就像一个模板框架,不被蜘蛛喜欢,我们要做的就是规范网站的代码,建立一个唯一的网站头部,以及让搜索引擎新鲜,从而吸引蜘蛛爬行
2、使用DIV+CSS布局网页
虽然现在div+css已经很成熟了,但是考虑到网页的兼容性和布局的简洁性,很多网页设计师可能还是会使用老式的表格布局。表格布局虽然很方便,但缺点也很明显。大大增加了网页的大小,尤其是多层表格的嵌套。这样的布局不仅会增加体积,嵌套过多还会影响搜索引擎的爬取和网站的收录。
另外,有的网站会使用外部文件,把css和js放在外部文件中,只需要在页面的html中放入相同的代码即可调用,有时我们会看到很多源码的时候我们检查 CSS 代码和 javasript 代码,将 javascript 放在 网站 页面的 html 文件的最前面,将一些真正可以使用的文本部分推到 html 的后面。重庆SEO认为,这类代码需要精简。
3、CSS 优化
CSS 是页面渲染中非常重要的一部分,包括颜色、大小、背景和字体。编写 CSS 简单易行,但编写可靠的 CSS 代码有很多技巧。
(1), CSS 位置
如果CSS描述出现在网站之后,需要重新渲染页面,会影响打开速度。所有 CSS 定义代码的位置都应该放在 网站 之前。
(2), css sprite 技术
网站 上的部分图片可以使用 CSS sprite 技术进行组合,减少加载请求的数量,从而提高网页的加载速度。
(3), CSS 代码优化
通过 CSS 代码属性的简写、去除冗余结构(frameworks)和重置(resets)等一系列方法和技术,简化 CSS 代码,减小 CSS 文件的大小。
(4),尽量不要使用内联CSS
内联 CSS 有两种,一种是头部区域内的普通内联;另一个是出现在标签中的内联内联 CSS。无论使用什么内联 CSS 方法,结果都会增加页面的体积。,我们可以尝试使用外部调整的 CSS 来缩小网站页面的大小。
4、JS优化
JS 优化还是和其他语言的优化差不多。JS优化的关键还是要关注最关键的地方,也就是瓶颈。一般来说,瓶颈总是发生在大规模循环中。,这并不是说循环本身存在性能问题,而是说循环可以迅速放大可能的性能问题。
(1), JS 位置
在优化网页代码中的js时,重庆SEO建议将js放在页面末尾,这样可以加快页面打开速度。
(2), 合并 JS
合并同域名下的js,通过减少网络连接数来提高网页的打开速度。
(3),LazyLoad 技术
Lazy Load 是一个用 JavaScript 编写的 jQuery 插件。它可以延迟加载长页面中的图像。在用户将页面滚动到它们所在的位置之前,不会加载浏览器可见区域之外的图像。
(4),调用外部JS代码
我们知道目前的搜索引擎仍然无法识别 JS 代码。如果 网站 中出现大量 JS 代码,那么 网站 就很难在 收录 上,而我们要做的就是将 Javascript 代码以 external 的形式调用网站,可以简化搜索引擎的工作,不会无形中推导出涉及网站的无效代码。
不仅如此,您还可以使用 css 代码进行外部调用。网站开头可以在css代码文件中定义网站的文字和颜色,尽量不要在页面代码中出现过多的样式代码。
(5),减少页面对JS的依赖
现在,JS 对搜索引擎并不友好。虽然据说搜索引擎不讨厌 JS,但还是少做点比较好。虽然 JS 可以产生很多效果,但是网页中的 JS 还是很多的。会影响蜘蛛对页面的抓取,增加网页的体积,尤其是导航栏等页面的关键位置,尽量使用DIV+CSS的设计方式。
5、TABLE 标签缩减
表格标签是大部分在线网站中最常见的代码形式。原因是创建网站的时候表比较快,但这也影响了后期对网站的优化。
与div+css布局的简化代码网站相比,占用空间比较大。因此,在建网站时,尽量少用表格。即使要使用表格,也应尽可能使用嵌套表格。谨慎使用以避免冗余代码
那么,当前的 网站 做了什么?很多程序员首先想到用CSS来做,用CSS来排版。这种做法大大减少了页面中的表格,但是在重庆SEO看来,网站不能没有表格。有些东西是必须要用的。可以使用表。但是很多网站使用嵌套表。一般这样的表会给网站生成大量的垃圾代码,而这些垃圾代码都是没有用的代码,而这类代码也是我们网站需要精简的代码之一.
6、代码注释省略
许多程序员习惯于在编写代码时在别人看不懂的地方给出注释。这些代码通常用于几个程序员之间的协作工作,对局外人和搜索引擎没有用处。相反,它们会给搜索引擎蜘蛛带来一些麻烦。
在打开页面代码的时候,我们经常会看到一些注释代码,它们是程序员为了表明代码含义所做的注释。其实这些开孔都不是必须的,因为对于搜索引擎来说,它们没有任何意义,反而会增加页数。代码的容量,所以对网站没有好处,直接省略比较好。
7、去除页面中的冗余代码
有的网站认为作者的代码编写习惯有问题,页面上会出现很多空白代码,比如:空白代码,重复定义样式和字体的代码,不要小看这些小代码,他们积累了很多,也让我们的网站异常臃肿。
很多网站使用DIV+CSS,在CSS中定义了文本的字体、颜色和页面布局,但是在网站的其他地方,style和font用来重新定义Font字体,这些代码不需要重复定义,都是可以简化的代码。
8、将 HTML 控件转换为 CSS 控件
许多网页设计师习惯于控制标签内的内容。例如,在img标签中,宽度和高度用于控制图像的大小。尝试将这些代码转换为外部调整的 CSS 以使网页代码更苗条。
9、缓存静态资源
通过在浏览器端设置浏览器缓存,缓存css、js等更新频率较低的文件,这样当同一个访问者再次访问你的网站时,浏览器就可以从浏览器的缓存中获取css、js等,不用每次都从你的服务器读取,在一定程度上加快了网站的打开速度,节省了你的服务器流量。
10、网页压缩技术
对于网页压缩,相信各位站长都不陌生。主要是启用服务器Gzip,对页面进行Gzip压缩,减小元素大小,从而减少数据传输,提高网页加载速度。这个功能需要你的服务器是的,GZIP压缩一般可以将网页压缩30%-80%,这是最重要的优化效果。
网站如何优化页面代码?重庆SEO提醒网站页面代码的SEO优化,不仅可以提高页面的打开速度,还可以提升用户的访问体验。同时,从SEO的角度,还可以提高蜘蛛的访问速度,有助于网站的搜索引擎的索引体验。
网页css js 抓取助手( Python爬虫下我尉(同英):2763177065请求头注意)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-11 07:25
Python爬虫下我尉(同英):2763177065请求头注意)
请求:用户通过浏览器(socket客户端)将自己的信息发送到服务器(socket server)
响应:服务器收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后会解析其内容展示给用户,爬虫程序模拟浏览器发送请求再接收Response后提取有用的数据。对于想要更轻松地学习Python基础、Python爬虫、Web开发、大数据、数据分析、人工智能等技术的新手小白,这里把系统教学资源分享给大家,下面展开列表:2763177065 [教程] /工具/方法/疑问]
四、 请求
1、请求方法:
常用请求方式:GET/POST
2、请求的 URL
url 全局统一资源定位器用于定义 Internet 上的唯一资源。比如一张图片、一个文件、一个视频都可以通过url唯一标识
网址编码
图片
图像将被编码(参见示例代码)
一个网页的加载过程是:
加载网页时,通常首先加载文档文档。
解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(一些大的网站会使用Referrer进行防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问的浏览器(需添加否则视为爬虫)
(3)cookie:注意要携带请求头
4、请求正文
如果请求体在get方法中,则请求体是没有内容的(get请求的请求体放在url后面的参数中,可以直接看到)。如果是在post方法中,请求体为格式数据ps:1、登录窗口,文件上传等,信息会附在请求体中2、登录,输入错误的用户名和密码,然后提交,就可以看到帖子了,正确登录后,页面一般会跳转,帖子抓不到
五、 响应
1、响应状态码
200:代表成功
301:代表跳跃
404:文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能有多个,告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬虫流程总结:
抓取 -> 解析 -> 存储
2、爬虫需要的工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(有用和无用的网页都会被加载);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis 查看全部
网页css js 抓取助手(
Python爬虫下我尉(同英):2763177065请求头注意)
请求:用户通过浏览器(socket客户端)将自己的信息发送到服务器(socket server)
响应:服务器收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后会解析其内容展示给用户,爬虫程序模拟浏览器发送请求再接收Response后提取有用的数据。对于想要更轻松地学习Python基础、Python爬虫、Web开发、大数据、数据分析、人工智能等技术的新手小白,这里把系统教学资源分享给大家,下面展开列表:2763177065 [教程] /工具/方法/疑问]
四、 请求
1、请求方法:
常用请求方式:GET/POST
2、请求的 URL
url 全局统一资源定位器用于定义 Internet 上的唯一资源。比如一张图片、一个文件、一个视频都可以通过url唯一标识
网址编码
图片
图像将被编码(参见示例代码)
一个网页的加载过程是:
加载网页时,通常首先加载文档文档。
解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(一些大的网站会使用Referrer进行防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问的浏览器(需添加否则视为爬虫)
(3)cookie:注意要携带请求头
4、请求正文
如果请求体在get方法中,则请求体是没有内容的(get请求的请求体放在url后面的参数中,可以直接看到)。如果是在post方法中,请求体为格式数据ps:1、登录窗口,文件上传等,信息会附在请求体中2、登录,输入错误的用户名和密码,然后提交,就可以看到帖子了,正确登录后,页面一般会跳转,帖子抓不到
五、 响应
1、响应状态码
200:代表成功
301:代表跳跃
404:文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能有多个,告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬虫流程总结:
抓取 -> 解析 -> 存储
2、爬虫需要的工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(有用和无用的网页都会被加载);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
网页css js 抓取助手( JS、CSS文件被蜘蛛抓取的频率特别高,你们怎么看?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-02 12:14
JS、CSS文件被蜘蛛抓取的频率特别高,你们怎么看?)
很多 网站 正在查看日志,
你会发现JS和CSS文件被蜘蛛爬取的频率特别高。
于是有人考虑阻止蜘蛛抓取robots.txt中的js和css文件,
将蜘蛛时间节省到其他页面。
国平老师认为,屏蔽这种文件不会对网站造成不良影响,反而可以促进其他页面的收录;
但同时也有很多人认为屏蔽这两个文件很容易被搜索引擎判断为网站作弊。
元芳,你怎么看?
福威 说道:
以下说法值得商榷:
“蜘蛛爬取网站的时间是确定的,如果某个文件被限制爬取,它将有更多时间爬取其他网页”
如果没有,则根本没有必要阻止 CSS 和 JS。
如果是真的,那么需要屏蔽的不仅仅是 CSS 和 JS。许多没有意义的文件值得阻止。
因此,上述论点值得更多讨论。
张立波说:
我觉得没必要屏蔽,因为搜索引擎会知道哪些是JS,CSS,哪些是网页文件。爬js和css的爬虫应该不会影响网页的爬取频率。
至于搜索引擎爬js和css,可能和snapshot有关,因为网站的页面大部分都是用div+css搭建的,如果没有css页面就惨了。
所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。
为了使搜索结果更准确,这是个人猜测,但可能是真正的原因。
周围的王说:
就前面的操作流程来说,我个人并没有屏蔽过js和css文件。
关于网站的性能,只推荐js和css分开集成,css放在头,js放在最后,防止网站加载时出现混乱和阻塞。
目前似乎没有任何区域的信息说js和css必须被屏蔽。
粗略地说,遵循两点就足够了:
1:整合css文件,通过压缩缩小大小,放在头部;
2:整合js文件,通过压缩缩小体积,放在最后;
在其他代码区,尽量不要有单独的css和js代码,这样更符合标准。
冯寒说道:
经过测试和跟踪数据表明:
1> 被屏蔽的JS/css文件仍然会被百度和google抓取
2> 跟踪观察屏蔽后其他页面类型蜘蛛的爬取量,发现并没有增加
3>如果网站大部分js/css文件收录较多的url,可以解封,蜘蛛在爬js/css文件的同时可以爬取里面的链接
4>如果网站大部分js/css文件基本都是code之类的,屏蔽也可以,没有明显的优点,也没有发现缺点。
王丹说:
我屏蔽了,傅伟老师发现你回答很多问题都很“谨慎”。
回答的时候可以添加一些自己或者朋友的正常操作方法。
我记得听傅伟老师说他上课要被堵了。
程大虾说道:
一个搜索引擎可以爬取的页面量远大于我们拥有的数据量网站,所以爬css还是JS都无所谓
陈福山 说:
现在搜索引擎可以识别 JS CSS 文件,它们是否被阻止并不重要。
只要你的网站压力不受限,服务器还不算太差。
屏幕与否无关紧要。
我的网站检测JS N收录照常,快照照常更新
胡小义 说:
这取决于页数,如果页数小到可以被任何蜘蛛任意爬取,那么这是没有必要的。
相反,如果网页数量太大,蜘蛛无法抓取,则需要删除 Nofollow,而 Robots 会删除一些东西。
陈超 说道:
在我看来:
1、以后css文件会成为搜索引擎判断一个页面的参考因素;
2、也许现在搜索引擎可以简单地使用 css 文件来理解页面结构。
小龙 说道:
假设这句话是真的:“蜘蛛爬取网站的时间是确定的。如果某个文件被限制爬取,它就有更多的时间爬取其他网页”
对于较大的 网站,仍然需要阻止 CSS 和 JS 文件。
对于中小网站,完全没有必要。
吴兴说:
JS和css在网页头部设置了Cache-Control,不需要在Robots.txt中添加。
刘先森说:
你先尝试阻塞一个部分,看看网站的整体情况和日志分析。
不过建议等12月百度调整后再试。
于冰妍 说道:
屏蔽页面对于搜索引擎来说是很正常的事情,否则就不会有Robots.txt等用户制定的爬取规则。
本文提供的信息仅供参考,请自行查看。 查看全部
网页css js 抓取助手(
JS、CSS文件被蜘蛛抓取的频率特别高,你们怎么看?)
很多 网站 正在查看日志,
你会发现JS和CSS文件被蜘蛛爬取的频率特别高。
于是有人考虑阻止蜘蛛抓取robots.txt中的js和css文件,
将蜘蛛时间节省到其他页面。
国平老师认为,屏蔽这种文件不会对网站造成不良影响,反而可以促进其他页面的收录;
但同时也有很多人认为屏蔽这两个文件很容易被搜索引擎判断为网站作弊。
元芳,你怎么看?
福威 说道:
以下说法值得商榷:
“蜘蛛爬取网站的时间是确定的,如果某个文件被限制爬取,它将有更多时间爬取其他网页”
如果没有,则根本没有必要阻止 CSS 和 JS。
如果是真的,那么需要屏蔽的不仅仅是 CSS 和 JS。许多没有意义的文件值得阻止。
因此,上述论点值得更多讨论。
张立波说:
我觉得没必要屏蔽,因为搜索引擎会知道哪些是JS,CSS,哪些是网页文件。爬js和css的爬虫应该不会影响网页的爬取频率。
至于搜索引擎爬js和css,可能和snapshot有关,因为网站的页面大部分都是用div+css搭建的,如果没有css页面就惨了。
所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。
为了使搜索结果更准确,这是个人猜测,但可能是真正的原因。
周围的王说:
就前面的操作流程来说,我个人并没有屏蔽过js和css文件。
关于网站的性能,只推荐js和css分开集成,css放在头,js放在最后,防止网站加载时出现混乱和阻塞。
目前似乎没有任何区域的信息说js和css必须被屏蔽。
粗略地说,遵循两点就足够了:
1:整合css文件,通过压缩缩小大小,放在头部;
2:整合js文件,通过压缩缩小体积,放在最后;
在其他代码区,尽量不要有单独的css和js代码,这样更符合标准。
冯寒说道:
经过测试和跟踪数据表明:
1> 被屏蔽的JS/css文件仍然会被百度和google抓取
2> 跟踪观察屏蔽后其他页面类型蜘蛛的爬取量,发现并没有增加
3>如果网站大部分js/css文件收录较多的url,可以解封,蜘蛛在爬js/css文件的同时可以爬取里面的链接
4>如果网站大部分js/css文件基本都是code之类的,屏蔽也可以,没有明显的优点,也没有发现缺点。
王丹说:
我屏蔽了,傅伟老师发现你回答很多问题都很“谨慎”。
回答的时候可以添加一些自己或者朋友的正常操作方法。
我记得听傅伟老师说他上课要被堵了。
程大虾说道:
一个搜索引擎可以爬取的页面量远大于我们拥有的数据量网站,所以爬css还是JS都无所谓
陈福山 说:
现在搜索引擎可以识别 JS CSS 文件,它们是否被阻止并不重要。
只要你的网站压力不受限,服务器还不算太差。
屏幕与否无关紧要。
我的网站检测JS N收录照常,快照照常更新
胡小义 说:
这取决于页数,如果页数小到可以被任何蜘蛛任意爬取,那么这是没有必要的。
相反,如果网页数量太大,蜘蛛无法抓取,则需要删除 Nofollow,而 Robots 会删除一些东西。
陈超 说道:
在我看来:
1、以后css文件会成为搜索引擎判断一个页面的参考因素;
2、也许现在搜索引擎可以简单地使用 css 文件来理解页面结构。
小龙 说道:
假设这句话是真的:“蜘蛛爬取网站的时间是确定的。如果某个文件被限制爬取,它就有更多的时间爬取其他网页”
对于较大的 网站,仍然需要阻止 CSS 和 JS 文件。
对于中小网站,完全没有必要。
吴兴说:
JS和css在网页头部设置了Cache-Control,不需要在Robots.txt中添加。
刘先森说:
你先尝试阻塞一个部分,看看网站的整体情况和日志分析。
不过建议等12月百度调整后再试。
于冰妍 说道:
屏蔽页面对于搜索引擎来说是很正常的事情,否则就不会有Robots.txt等用户制定的爬取规则。
本文提供的信息仅供参考,请自行查看。
网页css js 抓取助手(一个网站练习一下爬虫实现的功能全站获取CSS,JS,img等文件连接获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-28 19:09
闲暇之余,刚好找了一个网站来练习爬虫,总结一下写爬虫时遇到的知识点。
实现的功能
抓取站点范围的 URL
获取CSS、JS、img等文件连接
获取文件名
将文件保存到本地
使用的模块
urllib
BS4
回覆
操作系统
第 1 部分:抓取站点范围的 URL
先粘贴代码
# 获取当前页面子网站子网站
def get_urls(url, baseurl, urls):
with request.urlopen(url) as f:
data = f.read().decode('utf-8')
link = bs(data).find_all('a')
for i in link:
suffix = i.get('href')
# 设置排除写入的子连接
if suffix == '#' or suffix == '#carousel-example-generic' or 'javascript:void(0)' in suffix:
continue
else:
# 构建urls
childurl = baseurl + suffix
if childurl not in urls:
urls.append(childurl)
# 获取整个网站URL
def getallUrl(url, baseurl, urls):
get_urls(url, baseurl, urls)
end = len(urls)
start = 0
while(True):
if start == end:
break
for i in range(start, end):
get_urls(urls[i], baseurl, urls)
time.sleep(1)
start = end
end = len(urls)
通过urllib包中的请求,调用urlopen访问网站
首先从首页开始,首页一般收录各个子页面的url,将抓取到的url添加到一个列表中
然后读取这个列表的每个元素,依次访问,获取子页面的url连接,加入到列表中。
感觉这样抓取全站的url不是很靠谱,有时间再完善。
第二部分:获取css、js、img的连接
先粘贴代码
# 获取当前网页代码
with request.urlopen(url) as f:
html_source = f.read().decode()
<p> # css,js,img正则表达式,以获取文件相对路径
patterncss = ' 查看全部
网页css js 抓取助手(一个网站练习一下爬虫实现的功能全站获取CSS,JS,img等文件连接获取)
闲暇之余,刚好找了一个网站来练习爬虫,总结一下写爬虫时遇到的知识点。
实现的功能
抓取站点范围的 URL
获取CSS、JS、img等文件连接
获取文件名
将文件保存到本地
使用的模块
urllib
BS4
回覆
操作系统
第 1 部分:抓取站点范围的 URL
先粘贴代码
# 获取当前页面子网站子网站
def get_urls(url, baseurl, urls):
with request.urlopen(url) as f:
data = f.read().decode('utf-8')
link = bs(data).find_all('a')
for i in link:
suffix = i.get('href')
# 设置排除写入的子连接
if suffix == '#' or suffix == '#carousel-example-generic' or 'javascript:void(0)' in suffix:
continue
else:
# 构建urls
childurl = baseurl + suffix
if childurl not in urls:
urls.append(childurl)
# 获取整个网站URL
def getallUrl(url, baseurl, urls):
get_urls(url, baseurl, urls)
end = len(urls)
start = 0
while(True):
if start == end:
break
for i in range(start, end):
get_urls(urls[i], baseurl, urls)
time.sleep(1)
start = end
end = len(urls)
通过urllib包中的请求,调用urlopen访问网站
首先从首页开始,首页一般收录各个子页面的url,将抓取到的url添加到一个列表中
然后读取这个列表的每个元素,依次访问,获取子页面的url连接,加入到列表中。
感觉这样抓取全站的url不是很靠谱,有时间再完善。
第二部分:获取css、js、img的连接
先粘贴代码
# 获取当前网页代码
with request.urlopen(url) as f:
html_source = f.read().decode()
<p> # css,js,img正则表达式,以获取文件相对路径
patterncss = '
网页css js 抓取助手(晚来风急4年前99120个现代CSS代码的建议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-27 09:22
网站js css代码爬取相关博客
编写现代 CSS 代码的 20 个技巧
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇的时候会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
风来已晚 4年前 991
编写现代 CSS 代码的 20 个技巧
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇的时候会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
熊哥俱乐部 5年前 903
CSS黑魔法,让你少写不必要的JS,代码更优雅
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术、伪装指南、高级代码会让你惊叹。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直是渣渣,我也无计可施。我最近写了一篇Ch
沃克·武松 4年前 1735
百度网站优化:如何增加蜘蛛爬取量?
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛数量之前,我们必须考虑:增加网站数量开启速度。百度网站优化:如何增加爬虫
蝙蝠侠 it3 年前 1205
前端面试题总结(HTML和CSS)
刷新和学习新事物,保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前的 presto,现在的 Gecko
赖同学 3年前 1681年
加快网站访问的9种方法
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
风来得太晚4年前1068
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
我是小助理3年前2146
HTML5 和 CSS3 新特性一览
HTML5 和 CSS3 新特性一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
云栖大讲堂3年前4140
网站js css代码爬取相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
管理员 宝贝 3 年前 5207 查看全部
网页css js 抓取助手(晚来风急4年前99120个现代CSS代码的建议)
网站js css代码爬取相关博客
编写现代 CSS 代码的 20 个技巧
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇的时候会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
风来已晚 4年前 991
编写现代 CSS 代码的 20 个技巧
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇的时候会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
熊哥俱乐部 5年前 903
CSS黑魔法,让你少写不必要的JS,代码更优雅
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术、伪装指南、高级代码会让你惊叹。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直是渣渣,我也无计可施。我最近写了一篇Ch
沃克·武松 4年前 1735
百度网站优化:如何增加蜘蛛爬取量?
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛数量之前,我们必须考虑:增加网站数量开启速度。百度网站优化:如何增加爬虫
蝙蝠侠 it3 年前 1205
前端面试题总结(HTML和CSS)
刷新和学习新事物,保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前的 presto,现在的 Gecko
赖同学 3年前 1681年
加快网站访问的9种方法
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
风来得太晚4年前1068
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
我是小助理3年前2146
HTML5 和 CSS3 新特性一览
HTML5 和 CSS3 新特性一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
云栖大讲堂3年前4140
网站js css代码爬取相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
管理员 宝贝 3 年前 5207
网页css js 抓取助手(是否屏蔽蜘蛛抓取一个JS和CSS文件?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-26 10:28
做过网站的人都知道,在查看日志的时候,会发现JS和CSS文件被蜘蛛爬取的非常频繁,所以有人考虑在robots.txt中阻止蜘蛛爬取js和css文件以节省资金。蜘蛛时间到其他页面。你会阻止蜘蛛抓取 JS 和 CSS 文件吗?我们采访了几位专业的SEO专家:
傅伟——
SEOWHY创始人
我认为“蜘蛛抓取 网站 的时间是确定的。如果限制抓取某个文件,它将有更多时间抓取其他网页”
如果没有,则根本没有必要阻止 CSS 和 JS。
如果是真的,那么需要屏蔽的不仅仅是 CSS 和 JS。许多没有意义的文件值得阻止。
张立波——
迈步鞋网联合创始人兼COO
我觉得没必要屏蔽,因为搜索引擎会知道哪些是JS,CSS,哪些是网页文件。爬js和css的爬虫应该不会影响网页的爬取频率。
至于搜索引擎爬js和css,可能和snapshot有关,因为网站的页面大部分都是用div+css搭建的,如果没有css页面就惨了。
所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。
冯寒——
大型B2B平台的SEO负责人
经过我的实验和跟踪数据显示:
1> 被屏蔽的js/css文件还是会被百度和google抓取
2> 跟踪观察屏蔽后其他页面类型蜘蛛的爬取量,发现并没有增加
3>如果网站大部分js/css文件收录较多的url,可以解封,蜘蛛在爬js/css文件的同时可以爬取里面的链接
4>如果网站大部分js/css文件基本都是code之类的,屏蔽也可以,没有明显的优点,也没有发现缺点。
国平老师认为,屏蔽这种文件不会对网站造成不良影响,反而可以促进其他页面的收录;
免责声明:本文由(李竹平)原创编译,转载请保留链接:是否屏蔽百度蜘蛛抓取JS和CSS文件 查看全部
网页css js 抓取助手(是否屏蔽蜘蛛抓取一个JS和CSS文件?(组图))
做过网站的人都知道,在查看日志的时候,会发现JS和CSS文件被蜘蛛爬取的非常频繁,所以有人考虑在robots.txt中阻止蜘蛛爬取js和css文件以节省资金。蜘蛛时间到其他页面。你会阻止蜘蛛抓取 JS 和 CSS 文件吗?我们采访了几位专业的SEO专家:
傅伟——
SEOWHY创始人
我认为“蜘蛛抓取 网站 的时间是确定的。如果限制抓取某个文件,它将有更多时间抓取其他网页”
如果没有,则根本没有必要阻止 CSS 和 JS。
如果是真的,那么需要屏蔽的不仅仅是 CSS 和 JS。许多没有意义的文件值得阻止。
张立波——
迈步鞋网联合创始人兼COO
我觉得没必要屏蔽,因为搜索引擎会知道哪些是JS,CSS,哪些是网页文件。爬js和css的爬虫应该不会影响网页的爬取频率。
至于搜索引擎爬js和css,可能和snapshot有关,因为网站的页面大部分都是用div+css搭建的,如果没有css页面就惨了。
所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。
冯寒——
大型B2B平台的SEO负责人
经过我的实验和跟踪数据显示:
1> 被屏蔽的js/css文件还是会被百度和google抓取
2> 跟踪观察屏蔽后其他页面类型蜘蛛的爬取量,发现并没有增加
3>如果网站大部分js/css文件收录较多的url,可以解封,蜘蛛在爬js/css文件的同时可以爬取里面的链接
4>如果网站大部分js/css文件基本都是code之类的,屏蔽也可以,没有明显的优点,也没有发现缺点。
国平老师认为,屏蔽这种文件不会对网站造成不良影响,反而可以促进其他页面的收录;
免责声明:本文由(李竹平)原创编译,转载请保留链接:是否屏蔽百度蜘蛛抓取JS和CSS文件
网页css js 抓取助手(什么是HTML?渲染网页的步骤机制及优化方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-24 23:23
)
我的想法:如果我要构建快速可靠的网站,我需要真正了解浏览器如何在每一步呈现页面,以便在开发过程中优化每一步。这个 文章 是我对端到端流程的高级学习总结。
好吧,事不宜迟,让我们开始吧。这个过程可以分为以下几个主要阶段:
开始解析 HTML 获取外部资源 解析 CSS 并构建 CSSOM 执行 JavaScript 合并 DOM 和 CSSOM 构建渲染树 计算布局并绘制 1.开始解析 HTML
当浏览器通过网络接收到页面的 HTML 数据时,它会立即设置解析器以将 HTML 转换为文档对象模型 (DOM)。
文档对象模型 (DOM) 是 HTML 和 XML 文档的编程接口。它提供了文档的结构化表示,并定义了从程序访问该结构以更改文档的结构、样式和内容的方法。DOM 将文档解析为节点和对象(收录属性和方法的对象)的结构化集合。简而言之,它将网页与脚本或编程语言联系起来。
解析过程的第一步是将 HTML 分解并表示为开始标记、结束标记及其内容标记,然后可以构造 DOM。
2. 获取外部资源
当解析器遇到外部资源(例如 CSS 或 JavaScript 文件)时,解析器将提取这些文件。解析器在加载 CSS 文件时继续运行,此时页面被阻止呈现,直到资源被加载和解析(稍后会详细介绍)。
JavaScript 文件略有不同 - 默认情况下,解析器会在加载 JS 文件然后解析它们时阻止解析 HTML。可以向脚本标签添加两个属性来缓解这种情况:延迟和异步。两者都允许解析器在后台加载 JavaScript 文件时继续运行,但它们的做法不同。稍后会详细介绍,但总的来说:
defer 意味着文件的执行将被延迟,直到文档解析完成。如果多个文件具有 defer 属性,它们将按照页面放置的顺序依次执行。
async 表示文件一加载就执行,可能是在解析过程中,也可能是在解析过程之后,所以不保证异步脚本的执行顺序。
预加载资源
元素的 rel 属性的属性值 preload 允许你在 HTML 页面的元素内部编写一些声明性的资源获取请求,这可以指示页面加载后立即需要哪些资源。
对于这样一个立即需要的资源,您可能希望在页面加载生命周期的早期开始获取它,在浏览器的主要呈现机制参与之前预加载它。这种机制可以让资源更早地加载和可用,并且不太可能阻塞页面的初始渲染,从而提高性能。
3.解析 CSS 并构建 CSSOM
你可能知道 DOM 很长时间了,但你可能对 CSSOM(CSS 对象模型)的了解较少,反正我也没听过几次。
CSS 对象模型 (CSSOM) 是所有 CSS 选择器和每个选择器的关联属性的映射,以树的形式存在,具有树的根节点、兄弟姐妹、后代、孩子和其他关系。CSSOM 与文档对象模型 (DOM) 非常相似。两者都是关键渲染路径的一部分,必须采取一系列步骤才能正确渲染 网站。
CSSOM 与 DOM 一起构建渲染树,浏览器依次使用它来布局和绘制网页。
与 HTML 文件和 DOM 类似,当 CSS 文件被加载时,它们必须被解析并转换成一棵树——这次是 CSSOM。它描述了页面上的所有 CSS 选择器、它们的层次结构和属性。
CSSOM 与 DOM 的不同之处在于它不能增量构建,因为 CSS 规则由于其特殊性而可以在不同的点上相互覆盖。这就是 CSS 渲染阻塞的原因,因为浏览器无法知道每个元素在屏幕上的位置,直到所有 CSS 被解析并构建 CSSOM。
4.执行 JavaScript
不同的浏览器有不同的 JS 引擎来执行这个任务。从计算机资源的角度来看,解析 JS 可能是一个昂贵的过程,比其他类型的资源更昂贵,因此优化它对于良好的性能非常重要。
加载事件
当加载的 JS 和 DOM 完全解析并准备好时,会发生 emitdocument.DOMContentLoaded 事件。对于需要访问 DOM 的任何脚本,例如以某种方式执行操作或侦听用户交互事件,在执行脚本之前等待此事件是一种很好的做法。
document.addEventListener(
'DOMContentLoaded',
(event) => {
// 这里面可以安全地访问DOM了
});
window.load 事件在所有其他内容(例如异步 JavaScript、图像等)完成加载后触发。
window.addEventListener(
'load',
(event) => {
// 页面现已完全加载
});
5.合并DOM和CSSOM构建渲染树
渲染树是 DOM 和 CSSOM 的组合,表示将渲染到页面上的所有内容。这并不一定意味着渲染树中的所有节点都将被可视化渲染,例如将收录 opacity: 0 或 visibility: hidden 并且仍然可以被屏幕阅读器读取的样式的节点等,而 display: none 不包括任何内容。此外,诸如此类不收录任何视觉信息的标签将始终被忽略。
和 JS 引擎一样,不同的浏览器有不同的渲染引擎。
6. 计算布局并绘制
现在我们有了完整的渲染树,浏览器知道要渲染什么,但不知道在哪里。因此,必须计算页面的布局(即每个节点的位置和大小)。渲染引擎从顶部一直向下遍历渲染树,计算应该显示每个节点的坐标。
完成后,最后一步是获取布局信息并将像素绘制到屏幕上。
查看全部
网页css js 抓取助手(什么是HTML?渲染网页的步骤机制及优化方法
)
我的想法:如果我要构建快速可靠的网站,我需要真正了解浏览器如何在每一步呈现页面,以便在开发过程中优化每一步。这个 文章 是我对端到端流程的高级学习总结。
好吧,事不宜迟,让我们开始吧。这个过程可以分为以下几个主要阶段:
开始解析 HTML 获取外部资源 解析 CSS 并构建 CSSOM 执行 JavaScript 合并 DOM 和 CSSOM 构建渲染树 计算布局并绘制 1.开始解析 HTML
当浏览器通过网络接收到页面的 HTML 数据时,它会立即设置解析器以将 HTML 转换为文档对象模型 (DOM)。
文档对象模型 (DOM) 是 HTML 和 XML 文档的编程接口。它提供了文档的结构化表示,并定义了从程序访问该结构以更改文档的结构、样式和内容的方法。DOM 将文档解析为节点和对象(收录属性和方法的对象)的结构化集合。简而言之,它将网页与脚本或编程语言联系起来。
解析过程的第一步是将 HTML 分解并表示为开始标记、结束标记及其内容标记,然后可以构造 DOM。
2. 获取外部资源
当解析器遇到外部资源(例如 CSS 或 JavaScript 文件)时,解析器将提取这些文件。解析器在加载 CSS 文件时继续运行,此时页面被阻止呈现,直到资源被加载和解析(稍后会详细介绍)。
JavaScript 文件略有不同 - 默认情况下,解析器会在加载 JS 文件然后解析它们时阻止解析 HTML。可以向脚本标签添加两个属性来缓解这种情况:延迟和异步。两者都允许解析器在后台加载 JavaScript 文件时继续运行,但它们的做法不同。稍后会详细介绍,但总的来说:
defer 意味着文件的执行将被延迟,直到文档解析完成。如果多个文件具有 defer 属性,它们将按照页面放置的顺序依次执行。
async 表示文件一加载就执行,可能是在解析过程中,也可能是在解析过程之后,所以不保证异步脚本的执行顺序。
预加载资源
元素的 rel 属性的属性值 preload 允许你在 HTML 页面的元素内部编写一些声明性的资源获取请求,这可以指示页面加载后立即需要哪些资源。
对于这样一个立即需要的资源,您可能希望在页面加载生命周期的早期开始获取它,在浏览器的主要呈现机制参与之前预加载它。这种机制可以让资源更早地加载和可用,并且不太可能阻塞页面的初始渲染,从而提高性能。
3.解析 CSS 并构建 CSSOM
你可能知道 DOM 很长时间了,但你可能对 CSSOM(CSS 对象模型)的了解较少,反正我也没听过几次。
CSS 对象模型 (CSSOM) 是所有 CSS 选择器和每个选择器的关联属性的映射,以树的形式存在,具有树的根节点、兄弟姐妹、后代、孩子和其他关系。CSSOM 与文档对象模型 (DOM) 非常相似。两者都是关键渲染路径的一部分,必须采取一系列步骤才能正确渲染 网站。
CSSOM 与 DOM 一起构建渲染树,浏览器依次使用它来布局和绘制网页。
与 HTML 文件和 DOM 类似,当 CSS 文件被加载时,它们必须被解析并转换成一棵树——这次是 CSSOM。它描述了页面上的所有 CSS 选择器、它们的层次结构和属性。
CSSOM 与 DOM 的不同之处在于它不能增量构建,因为 CSS 规则由于其特殊性而可以在不同的点上相互覆盖。这就是 CSS 渲染阻塞的原因,因为浏览器无法知道每个元素在屏幕上的位置,直到所有 CSS 被解析并构建 CSSOM。
4.执行 JavaScript
不同的浏览器有不同的 JS 引擎来执行这个任务。从计算机资源的角度来看,解析 JS 可能是一个昂贵的过程,比其他类型的资源更昂贵,因此优化它对于良好的性能非常重要。
加载事件
当加载的 JS 和 DOM 完全解析并准备好时,会发生 emitdocument.DOMContentLoaded 事件。对于需要访问 DOM 的任何脚本,例如以某种方式执行操作或侦听用户交互事件,在执行脚本之前等待此事件是一种很好的做法。
document.addEventListener(
'DOMContentLoaded',
(event) => {
// 这里面可以安全地访问DOM了
});
window.load 事件在所有其他内容(例如异步 JavaScript、图像等)完成加载后触发。
window.addEventListener(
'load',
(event) => {
// 页面现已完全加载
});
5.合并DOM和CSSOM构建渲染树
渲染树是 DOM 和 CSSOM 的组合,表示将渲染到页面上的所有内容。这并不一定意味着渲染树中的所有节点都将被可视化渲染,例如将收录 opacity: 0 或 visibility: hidden 并且仍然可以被屏幕阅读器读取的样式的节点等,而 display: none 不包括任何内容。此外,诸如此类不收录任何视觉信息的标签将始终被忽略。
和 JS 引擎一样,不同的浏览器有不同的渲染引擎。
6. 计算布局并绘制
现在我们有了完整的渲染树,浏览器知道要渲染什么,但不知道在哪里。因此,必须计算页面的布局(即每个节点的位置和大小)。渲染引擎从顶部一直向下遍历渲染树,计算应该显示每个节点的坐标。
完成后,最后一步是获取布局信息并将像素绘制到屏幕上。
网页css js 抓取助手(脚本助手--上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-15 22:16
ExcelWeb 脚本助手是一个可以自定义脚本来控制 Excel 和浏览器的工具。提供简单实用的Excel和浏览器API调用,可通过自建脚本或自建项目随意定制。 jQuery
根据Excel中的数据批量操作网页,将Excel数据填入网页,从浏览器获取数据到Excel,非常方便。当然也可以单独使用,脚本可以单独操作Excel或者浏览器。浏览器
在一定程度上替代了VBA,选择C#和VBNET语言,自带脚本编辑器、智能提示、代码高亮、编译提示,可以定义和使用其他IDE,让代码更方便。编辑器
主界面如下:工具
软件自带示例,双击试试。温泉
使用三方开源IDE:SharpDevelop,小而强大,非常适合写小项目。调试
当然你也可以在设置中自定义更强大的IDE,比如:visual studioorm
使用 IDE 调试和运行:博客
Excel操作示例代码:索引
Command.Excel.Activate();
var CurrentDirecotry = System.IO.Directory.GetCurrentDirectory();
var DemoPath = System.IO.Path.Combine(CurrentDirecotry,"Demo.xlsx");
var workbook = Command.Excel.OpenExcel(DemoPath);
var name = workbook.ActiveSheet.Name;
var row1 = workbook.ActiveSheet.Rows[1];
row1.BackColor = Color.Red;
Console.WriteLine("我是第" + row1.RowNumber + "行.我是否可见:" + row1.Visible.ToString());
var Cell1A = workbook.ActiveSheet.Rows[1].Cells["A"];
Console.WriteLine("1A的值为" + Cell1A.ToString() + ",行序号:" + Cell1A.RowNumber + ",列字符:" + Cell1A.ColumnChar);
Cell1A.Value = "我是新的值";
//--------------新增sheet
var sheetindex = workbook.Sheets.Add();
var NewSheet = workbook.Sheets[sheetindex];
NewSheet.Activate();
Console.WriteLine("新建Sheet成功,SheetName:" + NewSheet.Name + ",索引:" + NewSheet.SheetIndex);
//------------删除sheet
Console.WriteLine("按任意键删除新增的Sheet");
Console.ReadKey();
workbook.Sheets.RemoveAt(sheetindex);
Console.WriteLine("删除成功");
浏览器:获取
浏览器提供常用的js方法直接调用,jquery直接调用。
例子:
var page = Command.Browser.AddPage("www.baidu.com");///打开一个网页
page.Query("#kw").val("我不作大哥好多年");///用jQuery获取元素.Jqueery会等待网页加载.不用调用WaitForFormLoad
page.Query("#su").click();///jquery获取按钮,并单击
Wait(2000);///等待2秒
page.LoadURl("www.baidu.com");
page.WaitForPageLoadEnd();///等待网页加载完成.不用Jquery方法时要等待网页加载完成.或用Wait()等待必定时间
page.getElementById("kw").Value = "床沿冰冷哦好难";
page.getElementById("su").click();
Wait(2000);///等待2秒
page.Close();///关网页
试用版正式发布,免费使用。 查看全部
网页css js 抓取助手(脚本助手--上海怡健医学)
ExcelWeb 脚本助手是一个可以自定义脚本来控制 Excel 和浏览器的工具。提供简单实用的Excel和浏览器API调用,可通过自建脚本或自建项目随意定制。 jQuery
根据Excel中的数据批量操作网页,将Excel数据填入网页,从浏览器获取数据到Excel,非常方便。当然也可以单独使用,脚本可以单独操作Excel或者浏览器。浏览器
在一定程度上替代了VBA,选择C#和VBNET语言,自带脚本编辑器、智能提示、代码高亮、编译提示,可以定义和使用其他IDE,让代码更方便。编辑器
主界面如下:工具
软件自带示例,双击试试。温泉
使用三方开源IDE:SharpDevelop,小而强大,非常适合写小项目。调试
当然你也可以在设置中自定义更强大的IDE,比如:visual studioorm
使用 IDE 调试和运行:博客
Excel操作示例代码:索引
Command.Excel.Activate();
var CurrentDirecotry = System.IO.Directory.GetCurrentDirectory();
var DemoPath = System.IO.Path.Combine(CurrentDirecotry,"Demo.xlsx");
var workbook = Command.Excel.OpenExcel(DemoPath);
var name = workbook.ActiveSheet.Name;
var row1 = workbook.ActiveSheet.Rows[1];
row1.BackColor = Color.Red;
Console.WriteLine("我是第" + row1.RowNumber + "行.我是否可见:" + row1.Visible.ToString());
var Cell1A = workbook.ActiveSheet.Rows[1].Cells["A"];
Console.WriteLine("1A的值为" + Cell1A.ToString() + ",行序号:" + Cell1A.RowNumber + ",列字符:" + Cell1A.ColumnChar);
Cell1A.Value = "我是新的值";
//--------------新增sheet
var sheetindex = workbook.Sheets.Add();
var NewSheet = workbook.Sheets[sheetindex];
NewSheet.Activate();
Console.WriteLine("新建Sheet成功,SheetName:" + NewSheet.Name + ",索引:" + NewSheet.SheetIndex);
//------------删除sheet
Console.WriteLine("按任意键删除新增的Sheet");
Console.ReadKey();
workbook.Sheets.RemoveAt(sheetindex);
Console.WriteLine("删除成功");
浏览器:获取
浏览器提供常用的js方法直接调用,jquery直接调用。
例子:
var page = Command.Browser.AddPage("www.baidu.com");///打开一个网页
page.Query("#kw").val("我不作大哥好多年");///用jQuery获取元素.Jqueery会等待网页加载.不用调用WaitForFormLoad
page.Query("#su").click();///jquery获取按钮,并单击
Wait(2000);///等待2秒
page.LoadURl("www.baidu.com");
page.WaitForPageLoadEnd();///等待网页加载完成.不用Jquery方法时要等待网页加载完成.或用Wait()等待必定时间
page.getElementById("kw").Value = "床沿冰冷哦好难";
page.getElementById("su").click();
Wait(2000);///等待2秒
page.Close();///关网页
试用版正式发布,免费使用。
网页css js 抓取助手(Python公众号学的值得收藏|菜鸟学Python【入门文章大全】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-13 05:05
一直有一个传说,世界上有两种程序员:一种是程序员,另一种是女程序员。如果你的女票是程序员,那么恭喜你好运!请多加小心,否则,我分分钟教你怎么做人。
私信小编01获取大量python学习资源
前段时间,助教和我聊天,吐了一大口苦水,说女人懂Python太可怕了。到底是怎么回事,我们来详细说一下。
1.事件起因
小马哥的女朋友也是懂Python的程序员(据说刚开始看我的菜鸟学Python公众号也值得采集|菜鸟学Python【简介文章大全】),相处后时间长了,生活中难免会有一点小摩擦。前不久,我熬夜打游戏打电脑,没精力陪女朋友逛街看电视剧,让她不开心,情绪激动。
我去洗了个澡,偷偷打开他的电脑看看他整天在看什么。你为什么不考虑妇女的选票?没想到女票只用了一行Python代码就获取了浏览器历史记录,让小马的上网记录一目了然。事发后,一切安好,没有危险。今天给大家介绍一下这款神器。
1.神库浏览器历史库介绍
browserhistory 是 Python 的第三方库 browserhistory。获取浏览器的历史记录非常方便。Python真是无所不能,现成的轮子太多了,你只需要学会组装。
对于 browserhistory 的安装,可以使用命令 pip install browserhistory 来安装。
Browserhistory是一个简单的python脚本库,支持linux、Mac和Windows系统,支持火狐、谷歌和Safari浏览器的历史记录。使用的方法非常简单。
2.如何使用
我们先来看看 browserhistory 的简单用法。需要注意的是,在使用浏览器历史库之前需要关闭浏览器。一个简单的应用程序如下所示:
程序首先导入 browserhistory 库,然后使用 get_browserhistory 函数获取浏览器的历史记录。dict_obj.keys() 返回要抓取的浏览器类型。爬取的浏览器历史记录收录网页地址和网页标题。
3.抓取浏览记录并写入本地文件
browserhistory库有四个函数,我们主要用到两个:
get_browserhistory 函数是获取浏览器的历史记录;write_browserhistory_csv函数是将获取的历史浏览记录写入本地csv文件。
get_database_paths函数用于输出浏览器的历史存储路径,get_username用于获取用户名。
我们可以直接使用browserhistory.write_browserhistory_csv,一行代码就可以将浏览器的历史写入本地。
4.窥探历史
获得上述浏览器历史记录后,可以通过简单的数据分析进一步窥探秘密。
1)。用五行代码统计你经常浏览的网址的域名:
程序使用urlparse解析网页地址,输入网页地址的域名(netloc)。接下来,您可以进行统计并获取浏览时间最长的网页的域名。
2)。使用 Pyecharts 进行可视化分析
为了更好的展示,可以使用pyecharts库进行可视化展示。结果如下所示:
可以看出,访问量最大的网页域名是虎扑域名。当他的女朋友检查并分析了他的浏览器历史时,她终于满意地笑了,一个潜在的危机解决了。
所以,一个友好的提醒,不要继续一些奇怪的网站。另外,记得及时清理你的历史!友情提示,没事的话,回去看看浏览器记录吧!
好了,今天的分享就到这里了,欢迎大家在评论区吆喝~记得给个三连哦! 查看全部
网页css js 抓取助手(Python公众号学的值得收藏|菜鸟学Python【入门文章大全】)
一直有一个传说,世界上有两种程序员:一种是程序员,另一种是女程序员。如果你的女票是程序员,那么恭喜你好运!请多加小心,否则,我分分钟教你怎么做人。
私信小编01获取大量python学习资源
前段时间,助教和我聊天,吐了一大口苦水,说女人懂Python太可怕了。到底是怎么回事,我们来详细说一下。
1.事件起因
小马哥的女朋友也是懂Python的程序员(据说刚开始看我的菜鸟学Python公众号也值得采集|菜鸟学Python【简介文章大全】),相处后时间长了,生活中难免会有一点小摩擦。前不久,我熬夜打游戏打电脑,没精力陪女朋友逛街看电视剧,让她不开心,情绪激动。
我去洗了个澡,偷偷打开他的电脑看看他整天在看什么。你为什么不考虑妇女的选票?没想到女票只用了一行Python代码就获取了浏览器历史记录,让小马的上网记录一目了然。事发后,一切安好,没有危险。今天给大家介绍一下这款神器。
1.神库浏览器历史库介绍
browserhistory 是 Python 的第三方库 browserhistory。获取浏览器的历史记录非常方便。Python真是无所不能,现成的轮子太多了,你只需要学会组装。
对于 browserhistory 的安装,可以使用命令 pip install browserhistory 来安装。
Browserhistory是一个简单的python脚本库,支持linux、Mac和Windows系统,支持火狐、谷歌和Safari浏览器的历史记录。使用的方法非常简单。
2.如何使用
我们先来看看 browserhistory 的简单用法。需要注意的是,在使用浏览器历史库之前需要关闭浏览器。一个简单的应用程序如下所示:
程序首先导入 browserhistory 库,然后使用 get_browserhistory 函数获取浏览器的历史记录。dict_obj.keys() 返回要抓取的浏览器类型。爬取的浏览器历史记录收录网页地址和网页标题。
3.抓取浏览记录并写入本地文件
browserhistory库有四个函数,我们主要用到两个:
get_browserhistory 函数是获取浏览器的历史记录;write_browserhistory_csv函数是将获取的历史浏览记录写入本地csv文件。
get_database_paths函数用于输出浏览器的历史存储路径,get_username用于获取用户名。
我们可以直接使用browserhistory.write_browserhistory_csv,一行代码就可以将浏览器的历史写入本地。
4.窥探历史
获得上述浏览器历史记录后,可以通过简单的数据分析进一步窥探秘密。
1)。用五行代码统计你经常浏览的网址的域名:
程序使用urlparse解析网页地址,输入网页地址的域名(netloc)。接下来,您可以进行统计并获取浏览时间最长的网页的域名。
2)。使用 Pyecharts 进行可视化分析
为了更好的展示,可以使用pyecharts库进行可视化展示。结果如下所示:
可以看出,访问量最大的网页域名是虎扑域名。当他的女朋友检查并分析了他的浏览器历史时,她终于满意地笑了,一个潜在的危机解决了。
所以,一个友好的提醒,不要继续一些奇怪的网站。另外,记得及时清理你的历史!友情提示,没事的话,回去看看浏览器记录吧!
好了,今天的分享就到这里了,欢迎大家在评论区吆喝~记得给个三连哦!

