
网页css js 抓取助手
网页css js 抓取助手(如何自定义一个chrome?最简单的chromeextend?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-09 14:16
如何自定义 chrome 扩展?
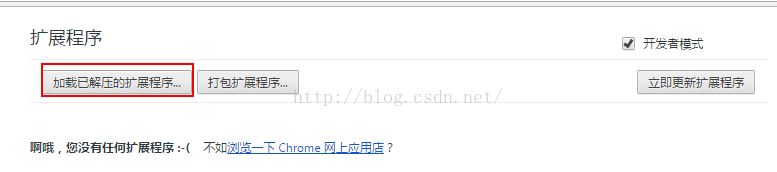
最简单的chrome extend由两个文件组成,一个是配置文件mainfest.json,另一个是运行js文件,在mainfest.js中有介绍。那么在chrome浏览器中引入插件的流程是:设置-扩展,然后点击“加载解压扩展”,选择已经编写好的程序,然后打开京东触发扩展。
下面是我写的操作京东的配置文件代码manifest.json:
{
"name": "jd-extends",
"manifest_version": 2,
"version": "1.0",
"description": "access www.jd.com,search goods.",
"browser_action": {
// "default_icon": "1.png"
"default_popup": "index.html"
},
"permissions": [
"tabs", "http://*/*","https://*/*"
],
"content_scripts": [
{
"matches": ["https://www.jd.com/*","https://search.jd.com/*","https://item.jd.com/*"],
"js": ["jquery.min.js","javascript.js"]
}
]
}
它主要是变量“content_scripts”。需要匹配的网页卸载匹配后,将操作该网页的js写入js文件并导入。可以导入多个网页和js。
如何使用JavaScript操作京东网页?
javascript.js 文件的代码
// var cycleNumber = $(".cycle-number").val();
if(window.location.host == "www.jd.com"){
// alert(cycleNumber);
clearCookie();
setInterval(function(){
if(Date.now()>=new Date("2016-10-23 01:04:00")){
// document.getElementById("key").value("韩版女装");
$("#key").val("韩版女装");
$("#key").parent().find("button").click();
}
},10)
}
if(window.location.host == "search.jd.com"){
$("#J_goodsList").find("li").find("img")[0].click();
// setTimeout("window.close()",12000)
}
if(window.location.host == "item.jd.com"){
if($(document).scrollTop() + $(window).height() < $(document).height()){
setInterval("moveScroll()",800);
}
setTimeout("closeChrome()",10000);
}
//the scroll move
function moveScroll(){
var h = $(document).height()-$(window).height();
$(document).scrollTop(h);
}
//close chrome
function closeChrome(){
clearCookie();
window.close();
}
//delete all cookie
function clearCookie(){
var keys=document.cookie.match(/[^ =;]+(?=\=)/g);
if (keys) {
for (var i = keys.length; i--;)
document.cookie=keys[i]+'=0;expires=' + new Date( 0).toUTCString()
}
}
以上操作流程主要是:在京东首页搜索“韩版女装”,然后点击搜索()跳转浏览搜索结果(),然后输入第一个搜索结果,然后浏览页面到底部,然后在关闭 page() 后停留 10000ms。因为操作了三个页面,所以每个页面在操作前都要进行相应的判断,否则会报错说找不到元素。 查看全部
网页css js 抓取助手(如何自定义一个chrome?最简单的chromeextend?)
如何自定义 chrome 扩展?
最简单的chrome extend由两个文件组成,一个是配置文件mainfest.json,另一个是运行js文件,在mainfest.js中有介绍。那么在chrome浏览器中引入插件的流程是:设置-扩展,然后点击“加载解压扩展”,选择已经编写好的程序,然后打开京东触发扩展。
下面是我写的操作京东的配置文件代码manifest.json:
{
"name": "jd-extends",
"manifest_version": 2,
"version": "1.0",
"description": "access www.jd.com,search goods.",
"browser_action": {
// "default_icon": "1.png"
"default_popup": "index.html"
},
"permissions": [
"tabs", "http://*/*","https://*/*"
],
"content_scripts": [
{
"matches": ["https://www.jd.com/*","https://search.jd.com/*","https://item.jd.com/*"],
"js": ["jquery.min.js","javascript.js"]
}
]
}
它主要是变量“content_scripts”。需要匹配的网页卸载匹配后,将操作该网页的js写入js文件并导入。可以导入多个网页和js。
如何使用JavaScript操作京东网页?
javascript.js 文件的代码
// var cycleNumber = $(".cycle-number").val();
if(window.location.host == "www.jd.com"){
// alert(cycleNumber);
clearCookie();
setInterval(function(){
if(Date.now()>=new Date("2016-10-23 01:04:00")){
// document.getElementById("key").value("韩版女装");
$("#key").val("韩版女装");
$("#key").parent().find("button").click();
}
},10)
}
if(window.location.host == "search.jd.com"){
$("#J_goodsList").find("li").find("img")[0].click();
// setTimeout("window.close()",12000)
}
if(window.location.host == "item.jd.com"){
if($(document).scrollTop() + $(window).height() < $(document).height()){
setInterval("moveScroll()",800);
}
setTimeout("closeChrome()",10000);
}
//the scroll move
function moveScroll(){
var h = $(document).height()-$(window).height();
$(document).scrollTop(h);
}
//close chrome
function closeChrome(){
clearCookie();
window.close();
}
//delete all cookie
function clearCookie(){
var keys=document.cookie.match(/[^ =;]+(?=\=)/g);
if (keys) {
for (var i = keys.length; i--;)
document.cookie=keys[i]+'=0;expires=' + new Date( 0).toUTCString()
}
}
以上操作流程主要是:在京东首页搜索“韩版女装”,然后点击搜索()跳转浏览搜索结果(),然后输入第一个搜索结果,然后浏览页面到底部,然后在关闭 page() 后停留 10000ms。因为操作了三个页面,所以每个页面在操作前都要进行相应的判断,否则会报错说找不到元素。
网页css js 抓取助手(如何提高网站百度蜘蛛量量?(组图)期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-02-06 05:10
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧
作者:迟到991人查看评论:04年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧
作者:熊哥 club903 浏览评论:05年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅
作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术,伪装指南,高级代码,让你惊叹不已。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直都是渣渣,我也无计可施。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?
作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛的数量之前,我们必须考虑:增加网站的开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)
作者:赖1681人查看评论:03年前
回顾旧的并保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前是 presto,现在改为 G
阅读全文
加快网站访问的9种方法
作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览
作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
网页css js 抓取助手(如何提高网站百度蜘蛛量量?(组图)期)
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取

推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧


作者:迟到991人查看评论:04年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧


作者:熊哥 club903 浏览评论:05年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅


作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术,伪装指南,高级代码,让你惊叹不已。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直都是渣渣,我也无计可施。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?

作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛的数量之前,我们必须考虑:增加网站的开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)


作者:赖1681人查看评论:03年前
回顾旧的并保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前是 presto,现在改为 G
阅读全文
加快网站访问的9种方法

作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序

作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览


作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑


作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
网页css js 抓取助手(什么是网站开放源代码?JS怎么获取css属性的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-02-06 05:09
相关话题
什么是网站开源?
2018 年 7 月 8 日 10:40:53
源代码是网站的核心,即网站程序代码,包括网站文件和目录结构。只有源代码可以拥有所有的网站。源代码决定了 网站 的所有权。传统的自助网站由于其SAAS模式,无法开源代码。本质上,用户每年支付租金来租用平台的使用权网站。网站 也不见了;而开源网站是拥有网站的用户的所有权,是买卖关系而不是
搜索引擎爬取JS代码实验
25/9/2007 13:47:00
页面中JavaScript的常用方式有两种,一种是把JS做成外部文件直接调用页面,另一种是直接在页面上写JS代码。搜索引擎如何识别这两种方法?
vue.js如何导入css文件
2015 年 9 月 11 日:06:27
vue.js中引入css文件的方法:1、在[main.js]中全局引入,代码为[import "./common/uni.css"];2、直接在组件中引入,代码为[@import"/common/uni.css";]。【相关文章推荐:vue.j
js如何获取css属性
2015 年 9 月 11 日:06:08
js获取css属性的方法:使用[getComputedStyle(div)]方法获取,代码为[vara=document.defaultView.getComputedStyle(div);]。【相关文章推荐:vue.js】js如何获取css属性
如何在js中导入css外部文件
25/11/202012:05:41
js引入外部css文件的方法:写成自定义函数,url为文件路径,后面元素调用,代码为[varscript=document.createElement('script')]。修改后的方法适用于所有品牌的电脑js
谷歌能否实现对JS的正确抓取未披露
2008 年 10 月 6 日 13:57:00
百度和谷歌作为国内最大的两家搜索引擎巨头,之前代码中出现 JS 的地方都没有爬过。也就是说,当遇到JS代码时,搜索引擎会跳过这部分,放弃收录。但是今天,通过对比研究,笔者得到了以下事实,谷歌终于率先实现了技术突破,有效识别了JS代码。
码农在网站的源码中吐槽老大,最后被炒了
17/1/2013 11:08:00
上周,一条关于网站源代码的微博给大家带来了欢乐。在某网站主页的源码中,程序员发泄了自己的不满,抱怨公司没有年终奖,并好心劝告不要指望任何想来公司的人。
kbengine0.4.20源码分析(一)
2018 年 4 月 3 日 01:14:49
总结:kbengine0.4.20源码分析(一)
【JS教程】 JS小功能代码片段(二)
2018 年 4 月 3 日 01:13:52
JS小功能代码片段(一)JS小功能代码片段(二)16、窗口滚动时自动加载内容) varloading=false;$(window).scroll(function() { if((($(window).scrollTop()+$(window).height())+250)>=$(document).height()){if(loadi
javaScript介绍介绍js代码
2021 年 4 月 2 日 10:31:05
免费学习推荐:js视频教程javaScript-如何直接引入js代码po代码和截图js01-如何引入js代码 查看全部
网页css js 抓取助手(什么是网站开放源代码?JS怎么获取css属性的方法)
相关话题
什么是网站开源?
2018 年 7 月 8 日 10:40:53
源代码是网站的核心,即网站程序代码,包括网站文件和目录结构。只有源代码可以拥有所有的网站。源代码决定了 网站 的所有权。传统的自助网站由于其SAAS模式,无法开源代码。本质上,用户每年支付租金来租用平台的使用权网站。网站 也不见了;而开源网站是拥有网站的用户的所有权,是买卖关系而不是

搜索引擎爬取JS代码实验
25/9/2007 13:47:00
页面中JavaScript的常用方式有两种,一种是把JS做成外部文件直接调用页面,另一种是直接在页面上写JS代码。搜索引擎如何识别这两种方法?
vue.js如何导入css文件
2015 年 9 月 11 日:06:27
vue.js中引入css文件的方法:1、在[main.js]中全局引入,代码为[import "./common/uni.css"];2、直接在组件中引入,代码为[@import"/common/uni.css";]。【相关文章推荐:vue.j
js如何获取css属性
2015 年 9 月 11 日:06:08
js获取css属性的方法:使用[getComputedStyle(div)]方法获取,代码为[vara=document.defaultView.getComputedStyle(div);]。【相关文章推荐:vue.js】js如何获取css属性
如何在js中导入css外部文件
25/11/202012:05:41
js引入外部css文件的方法:写成自定义函数,url为文件路径,后面元素调用,代码为[varscript=document.createElement('script')]。修改后的方法适用于所有品牌的电脑js
谷歌能否实现对JS的正确抓取未披露
2008 年 10 月 6 日 13:57:00
百度和谷歌作为国内最大的两家搜索引擎巨头,之前代码中出现 JS 的地方都没有爬过。也就是说,当遇到JS代码时,搜索引擎会跳过这部分,放弃收录。但是今天,通过对比研究,笔者得到了以下事实,谷歌终于率先实现了技术突破,有效识别了JS代码。
码农在网站的源码中吐槽老大,最后被炒了
17/1/2013 11:08:00
上周,一条关于网站源代码的微博给大家带来了欢乐。在某网站主页的源码中,程序员发泄了自己的不满,抱怨公司没有年终奖,并好心劝告不要指望任何想来公司的人。
kbengine0.4.20源码分析(一)
2018 年 4 月 3 日 01:14:49
总结:kbengine0.4.20源码分析(一)
【JS教程】 JS小功能代码片段(二)
2018 年 4 月 3 日 01:13:52
JS小功能代码片段(一)JS小功能代码片段(二)16、窗口滚动时自动加载内容) varloading=false;$(window).scroll(function() { if((($(window).scrollTop()+$(window).height())+250)>=$(document).height()){if(loadi
javaScript介绍介绍js代码
2021 年 4 月 2 日 10:31:05
免费学习推荐:js视频教程javaScript-如何直接引入js代码po代码和截图js01-如何引入js代码
网页css js 抓取助手(是否屏蔽蜘蛛抓取和JS和CSS文件?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-05 03:20
做过网站的人都知道,在查看日志的时候,会发现JS和CSS文件被蜘蛛爬取的非常频繁,所以有人考虑在robots.txt中阻止蜘蛛爬取js和css文件以节省资金。蜘蛛时间到其他页面。你会阻止蜘蛛抓取 JS 和 CSS 文件吗?我们采访了几位专业的 SEO 专家: Fuwei - SEOWHY 创始人 我认为“蜘蛛爬 网站 的时间是确定的,如果某个文件被限制爬取,它会有更多的时间来爬取它.如果“取另一个网页”不是真的,那么根本不需要屏蔽CSS和JS。如果是真的,需要屏蔽的不仅仅是CSS和JS,很多没有意义的文件都值得屏蔽. 张立波——麦步鞋业联合创始人兼COO。com 我觉得没必要屏蔽,因为搜索引擎会知道哪些是JS,CSS,哪些是web文件。爬js和css的爬虫应该不会影响网页的爬取频率。至于搜索引擎爬js和css,可能和snapshot有关,因为网站的页面大部分都是用div+css搭建的,如果没有css页面就惨了。所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。如果没有 css 页面将是可怕的。所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。如果没有 css 页面将是可怕的。所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。
Feng Han – 某大型B2B平台的seo负责人通过我的实验和跟踪数据表明: 1> 被屏蔽的js/css文件仍然会被大量的百度和google抓取。3>如果网站大部分js/css文件收录的url比较多,可以解封,蜘蛛可以边爬链接边爬js/css文件4>如果网站大部分js/css文件基本都是代码等,屏蔽也是可能的。没有发现明显的优点或缺点。国平老师认为,屏蔽此类文件不会对网站产生不良影响,相反可以推广其他页面的收录; 查看全部
网页css js 抓取助手(是否屏蔽蜘蛛抓取和JS和CSS文件?(组图))
做过网站的人都知道,在查看日志的时候,会发现JS和CSS文件被蜘蛛爬取的非常频繁,所以有人考虑在robots.txt中阻止蜘蛛爬取js和css文件以节省资金。蜘蛛时间到其他页面。你会阻止蜘蛛抓取 JS 和 CSS 文件吗?我们采访了几位专业的 SEO 专家: Fuwei - SEOWHY 创始人 我认为“蜘蛛爬 网站 的时间是确定的,如果某个文件被限制爬取,它会有更多的时间来爬取它.如果“取另一个网页”不是真的,那么根本不需要屏蔽CSS和JS。如果是真的,需要屏蔽的不仅仅是CSS和JS,很多没有意义的文件都值得屏蔽. 张立波——麦步鞋业联合创始人兼COO。com 我觉得没必要屏蔽,因为搜索引擎会知道哪些是JS,CSS,哪些是web文件。爬js和css的爬虫应该不会影响网页的爬取频率。至于搜索引擎爬js和css,可能和snapshot有关,因为网站的页面大部分都是用div+css搭建的,如果没有css页面就惨了。所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。如果没有 css 页面将是可怕的。所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。如果没有 css 页面将是可怕的。所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。

Feng Han – 某大型B2B平台的seo负责人通过我的实验和跟踪数据表明: 1> 被屏蔽的js/css文件仍然会被大量的百度和google抓取。3>如果网站大部分js/css文件收录的url比较多,可以解封,蜘蛛可以边爬链接边爬js/css文件4>如果网站大部分js/css文件基本都是代码等,屏蔽也是可能的。没有发现明显的优点或缺点。国平老师认为,屏蔽此类文件不会对网站产生不良影响,相反可以推广其他页面的收录;
网页css js 抓取助手(的是“小七烤地瓜编程助手中文便携版”介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-02-05 03:12
小七烤红薯编程助手绿色版这个软件大家都不陌生吧?是一款功能强大的专业辅助编程软件。软件界面简洁,没有多余的复杂功能,使用起来非常方便。此外,它还有强大的JS调试工具、后期调试、中英文翻译、编程转换等操作,可以帮助您轻松解决所有问题。此外,它还提供代码转换、窗口截图、图标提取等,多合一软件,非常强大。而今天带来的是《小七烤红薯编程助手中文便携版》,这个版本经过大神精心修改,无需安装,下载后双击即可使用。有了这个软件,您可以轻松地调制代码,非常方便。不仅如此,这款软件体积并不大,内存小的朋友可以轻松安装使用。此外,它还支持中文,对不擅长英语的人来说非常友好。感觉不错的小伙伴,还等什么,快来下载体验吧!
软件功能
1、正则调试:轻松调试正则表达式。
2、Web 数据包捕获:智能Web 数据包捕获,POSTGET 客户端数据包测试。
3、生成代码:找到指定的窗口控件,生成全智能易语言代码。
4、工具箱:屏幕颜色选择器、GET、POST 测试、客户端 cookie 测试。
5、资源采集:采集 网页上的 CSS、JS、图像、背景、媒体文件。
6、网页分析:通过框架对网页元素进行深入分析,让您在网页上填写表格更容易。
7、窗口检测:清晰分析窗口中各种控件的ID、句柄、标题、类名、位置、大小。
8、常用工具:中英文翻译、代码转换、窗口截图、图标提取、文本加解密等。
9、调试也支持一键生成对应的js算法,自动调用js调试工具调试和一些hmacsha算法。
软件优势
1、功能丰富,有很多常用的编程工具
2、常规内容可在软件中调试,表达式可在软件中分析
3、可以通过软件的语法提示编辑表达式,也可以在软件中匹配结果
4、支持关键词搜索,可以在软件中输入表达式,然后搜索指定内容
5、可以在软件中查看API内容,方便用户编辑API文档
6、还支持查看API相关案例学习如何制作开发文档
7、软件有很多功能,可以转换代码,提取哈希值,加密代码
8、如果你需要这个软件,可以直接下载,帮助你调试自己的js文件和post界面
变更日志
v2.6.4
修复加解密的bug 查看全部
网页css js 抓取助手(的是“小七烤地瓜编程助手中文便携版”介绍)
小七烤红薯编程助手绿色版这个软件大家都不陌生吧?是一款功能强大的专业辅助编程软件。软件界面简洁,没有多余的复杂功能,使用起来非常方便。此外,它还有强大的JS调试工具、后期调试、中英文翻译、编程转换等操作,可以帮助您轻松解决所有问题。此外,它还提供代码转换、窗口截图、图标提取等,多合一软件,非常强大。而今天带来的是《小七烤红薯编程助手中文便携版》,这个版本经过大神精心修改,无需安装,下载后双击即可使用。有了这个软件,您可以轻松地调制代码,非常方便。不仅如此,这款软件体积并不大,内存小的朋友可以轻松安装使用。此外,它还支持中文,对不擅长英语的人来说非常友好。感觉不错的小伙伴,还等什么,快来下载体验吧!

软件功能
1、正则调试:轻松调试正则表达式。
2、Web 数据包捕获:智能Web 数据包捕获,POSTGET 客户端数据包测试。
3、生成代码:找到指定的窗口控件,生成全智能易语言代码。
4、工具箱:屏幕颜色选择器、GET、POST 测试、客户端 cookie 测试。
5、资源采集:采集 网页上的 CSS、JS、图像、背景、媒体文件。
6、网页分析:通过框架对网页元素进行深入分析,让您在网页上填写表格更容易。
7、窗口检测:清晰分析窗口中各种控件的ID、句柄、标题、类名、位置、大小。
8、常用工具:中英文翻译、代码转换、窗口截图、图标提取、文本加解密等。
9、调试也支持一键生成对应的js算法,自动调用js调试工具调试和一些hmacsha算法。
软件优势
1、功能丰富,有很多常用的编程工具
2、常规内容可在软件中调试,表达式可在软件中分析
3、可以通过软件的语法提示编辑表达式,也可以在软件中匹配结果
4、支持关键词搜索,可以在软件中输入表达式,然后搜索指定内容
5、可以在软件中查看API内容,方便用户编辑API文档
6、还支持查看API相关案例学习如何制作开发文档
7、软件有很多功能,可以转换代码,提取哈希值,加密代码
8、如果你需要这个软件,可以直接下载,帮助你调试自己的js文件和post界面
变更日志
v2.6.4
修复加解密的bug
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-02 23:20
本文整理了25个前端相关学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望对大家有所帮助,下面就和千峰广州小编一起来看看吧!
CSS相关
1、CSS 之战 - 在线竞争 CSS
cssbattle.dev
CSS线上竞技,很有趣的竞技游戏,一共12关,需要用HTML和CSS来100%还原它给的页面,然后尽量减少代码,还可以查看全球排行榜,看解决方案。
2、学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
3、Flexbox Froggy - 一个学习 Flex 布局的小游戏
一款引导式学习flex布局游戏,使用flex布局让青蛙在荷叶上跳跃甚至完成,游戏收录了几乎所有常用的属性,所以学起来很有趣,形象好记,谁要flex 布局如果你熟悉的话,在这里多练习一下。
4、EnjoyCSS-在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件一样。
5、CSS 技巧 - CSS 技巧
这个网站 每天都会不断更新一些优秀的教程和CSS 技巧的技巧文章。
6、新拟态——实现新拟态效果
神经拟态.io
可以轻松实现新的模仿效果。不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数。同时可以直接复制CSS代码。
7、uiGradients - 共享渐变
提供渐变色效果的网站有近百种渐变色方案。可以根据自己的风格选择搭配,直接获取渐变色对应的CSS代码即可。
JS相关
8、JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。它主要写如何避免一些常见的错误,发现难以发现的错误,并深入了解 JavaScript 的语言特性。
9、JS 技巧 - JS 技巧
jstips.co
每天一点点的Javascript知识。
10、JSweekly - 科技周刊
专注于 Javascript 的技术周刊。
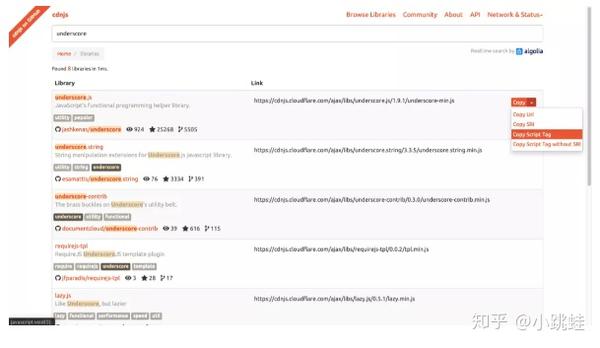
11、CDNJS - JavaScript 库
/图书馆
CDNJS为开发者提供最新的前端web开发资源,免费使用,没有使用限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端CDN服务中排名第二(第一是谷歌),性能优异。
12、美丽开放——开源JS库合集
采集各类优秀设计的开源项目,从cms内容管理系统到小型常用Javascript库,适合网站开发的用户使用。
13、JavaScript Fun - 代码库合集
最流行的 JavaScript 代码库集合,显示流行排名,开发者可以轻松找到最新的代码插件、工具和博客。
社区和博客
14、Stack Overflow - 程序员问答网络
全球IT界最火爆的技术问答网站,一个解决bug的社区,号称“100,000whys of programming”。
15、掘金-优质技术社区
绝进.im
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术 文章 包括 Android、iOS、前端和后端资源。
16、Codrops - 网页设计开发博客
发布技术文章和网络教程,提供经验,少踩坑,资源丰富。许多优秀的技术都来自这里。
在线IDE
17、代码笔
码笔.io
一个网站前端设计开发平台,一个网站前端代码工具,有各种效果的案例特效(炫技),你可以开发自己的前端设计基于他们的演示。
18、代码沙盒
码沙盒.io
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
19、JS 斌
另一个轻量级的在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
资源类
20、ICONSVG - 在线定制设计SVG图标素材
图标vg.xyz
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材是常用的图标。可以点击官方提供的素材进行二次设计,也可以导出设计好的图标。
21、OpenMoji - 免费表情符号库
提供带有源代码的表情符号库,可以免费下载使用。
22、分享图标 - 免费矢量素材库
一个提供超过250,000种ICON矢量图素材,120多个类别的网站,所有素材均以PNG和SVG格式提供,素材大小不一,包括512*512、256*256、 128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
23、tableconvert - 在线表格编辑器
一个强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的相互转换。当您需要转换表格,但无法使其变形时,请尝试使用此工具。
24、Feathericons - 极简ICON图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发。图标格式为 SVG。
25、HTML5 + CSS 3 免费模板
/
提供大量HTML5模板,用户可以自己分享和修改模板。 查看全部
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具)
本文整理了25个前端相关学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望对大家有所帮助,下面就和千峰广州小编一起来看看吧!
CSS相关
1、CSS 之战 - 在线竞争 CSS
cssbattle.dev
CSS线上竞技,很有趣的竞技游戏,一共12关,需要用HTML和CSS来100%还原它给的页面,然后尽量减少代码,还可以查看全球排行榜,看解决方案。
2、学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
3、Flexbox Froggy - 一个学习 Flex 布局的小游戏
一款引导式学习flex布局游戏,使用flex布局让青蛙在荷叶上跳跃甚至完成,游戏收录了几乎所有常用的属性,所以学起来很有趣,形象好记,谁要flex 布局如果你熟悉的话,在这里多练习一下。
4、EnjoyCSS-在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件一样。
5、CSS 技巧 - CSS 技巧
这个网站 每天都会不断更新一些优秀的教程和CSS 技巧的技巧文章。
6、新拟态——实现新拟态效果
神经拟态.io
可以轻松实现新的模仿效果。不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数。同时可以直接复制CSS代码。
7、uiGradients - 共享渐变
提供渐变色效果的网站有近百种渐变色方案。可以根据自己的风格选择搭配,直接获取渐变色对应的CSS代码即可。
JS相关
8、JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。它主要写如何避免一些常见的错误,发现难以发现的错误,并深入了解 JavaScript 的语言特性。
9、JS 技巧 - JS 技巧
jstips.co
每天一点点的Javascript知识。
10、JSweekly - 科技周刊
专注于 Javascript 的技术周刊。
11、CDNJS - JavaScript 库
/图书馆
CDNJS为开发者提供最新的前端web开发资源,免费使用,没有使用限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端CDN服务中排名第二(第一是谷歌),性能优异。
12、美丽开放——开源JS库合集
采集各类优秀设计的开源项目,从cms内容管理系统到小型常用Javascript库,适合网站开发的用户使用。
13、JavaScript Fun - 代码库合集
最流行的 JavaScript 代码库集合,显示流行排名,开发者可以轻松找到最新的代码插件、工具和博客。

社区和博客
14、Stack Overflow - 程序员问答网络
全球IT界最火爆的技术问答网站,一个解决bug的社区,号称“100,000whys of programming”。
15、掘金-优质技术社区
绝进.im
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术 文章 包括 Android、iOS、前端和后端资源。
16、Codrops - 网页设计开发博客
发布技术文章和网络教程,提供经验,少踩坑,资源丰富。许多优秀的技术都来自这里。
在线IDE
17、代码笔
码笔.io
一个网站前端设计开发平台,一个网站前端代码工具,有各种效果的案例特效(炫技),你可以开发自己的前端设计基于他们的演示。
18、代码沙盒
码沙盒.io
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
19、JS 斌
另一个轻量级的在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
资源类
20、ICONSVG - 在线定制设计SVG图标素材
图标vg.xyz
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材是常用的图标。可以点击官方提供的素材进行二次设计,也可以导出设计好的图标。
21、OpenMoji - 免费表情符号库
提供带有源代码的表情符号库,可以免费下载使用。
22、分享图标 - 免费矢量素材库
一个提供超过250,000种ICON矢量图素材,120多个类别的网站,所有素材均以PNG和SVG格式提供,素材大小不一,包括512*512、256*256、 128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
23、tableconvert - 在线表格编辑器
一个强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的相互转换。当您需要转换表格,但无法使其变形时,请尝试使用此工具。
24、Feathericons - 极简ICON图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发。图标格式为 SVG。
25、HTML5 + CSS 3 免费模板
/
提供大量HTML5模板,用户可以自己分享和修改模板。
网页css js 抓取助手(Python爬虫的详细用法,你都知道吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-02 23:19
为了正常显示中文,指定编码为UTF-8
5)链接标签
点击我,本窗口访问百度
点击我,新窗口访问百度
6)表格
功能:主要负责网页中的数据采集;
表单具有三个基本组件:
表单
2、css描述页面的布局
用于美化页面,布局页面,使显示的数据更好看;
例如,为下图中的文字添加特殊效果。
1)CSS的三种使用方式
这里主要讲CSS选择器。CSS 选择器用于选择所需元素的样式。
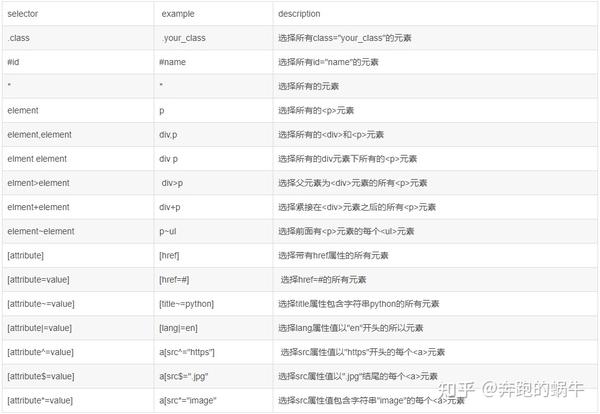
要通过 CSS 选择器抓取网页内容,首先需要学习 CSS 选择器的语法。
‘#’:代表选择id节点,‘.’:代表class的节点;
获取嵌套:加空格代表层级关系,不加空格代表并列关系;
2)选择器类型
① 元素选择器
使用 HTML 标签名作为选择器,按标签名分类,为页面上的某类标签指定统一的 CSS 样式。优点是可以快速定位页面中同类型的标签。
h1 {
color: #F00;
font-size: 50px;
}
hello
② id 选择器
选择具有特定id属性值的元素;id 名称是 HTML 元素的 id 属性值。大多数 HTML 元素都可以定义 id 属性。元素的 id 值是唯一的,只能对应文档中的特定项。, id 选择器优先于元素选择器。
#demo1 {
color: #0f0;
}
hello css
如果 id 选择器是唯一的,使用 # 来定位
post_urls = response.css("#archive .floated-thumb .post-thumb a::attr(href)").extract()
for post_url in post_urls:
print(post_url)
PS:
xpath 解析返回一个选择器列表;
extract()[0]:转换为Unicode字符串列表的第一个位置;
③ 类选择器
类名是 HTML 元素的类属性的值。大多数 HTML 元素都可以定义 class 属性。类选择器的最大优点是它可以为元素对象定义单独的或相同的样式。
.myClass {
font-size: 25px;
}
hello
3)CSS选择器的详细使用
#container:选择id为container的节点
.container:选取所有class包含container的节点
Li a : 选取所有li下的所有a节点
Ul + p :选择ul 后面的第一个p元素
Div#container>ul :选取id为container的div的第一个ul子元素
Ul ~ P :选取与ul相邻的所有p元素
a[title] :选取所有有title属性的a元素
a[href=’http://jobbole.com’]:选取所有href属性为jobbole.com值的a元素
a[href*=”jobole”]:选取所有href属性包含的jobbole的a元素;
a[href^=”http”] : 选取所有href属性值为http开头的a元素;
a[href$=”.jpg”];选取所有href属性值以.jpg结尾的a元素;
input[type=radio]:checked 选择选中的radio的元素;
div:not(#container): 选取所有id非container的div属性;
li:nth-child(3):选取第三个li元素;
tr: nth-child(2n):选取第偶数个tr;
CSS 应用示例
Tiltle = response.css(".entry-header h1::text").extract()#提取title:*(用到伪类选择器)
Create_data=response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace(“·”,” ”)
Comment_num = response.css("a[href='#article-comment'] span::text").extract()[0];
Content = response.css("div.entry").extract()[0]
Tags=response.css(".entry-meta-hide-on-mobile a::text").extract()[0]
4)Python爬虫常用的CSS选择器
3、JavaScript 网页的行为
控制页面的元素,使页面具有一定的动态效果;
JavaScript 被添加为脚本语言以使 HTML 具有交互性,JavaScript 既可以嵌入 HTML 中,也可以在外部链接到 HTML。
例如,设置点击标题的点击事件可以使用 JavaScript 来实现。
1)作文
2)基本语法
(1)变量
使用 JavaScript 时,需要遵循以下命名约定:
① 必须以字母或下划线开头,中间可以是数字、字符或下划线;
② 变量名不能收录空格等符号;
③ 不能使用 JavaScript 关键字作为变量名,如:function 4.JavaScript 严格区分大小写;
(2)数据类型
基本型
1.Undefined,Undefined类型只有⼀个值,即undefined。当声明的变量未初始化时,该变 量的默认值是undefined。
2.Null,只有⼀个专⽤值null,表示空,⼀个占位符。值undefined实际上是从值null派⽣来 的,因此ECMAScript把他们定义为相等的。
3.Boolean,有两个值true和false
4.Number,表示任意数字
5.String,字符串由双引号(")或单引号(')声明的。JavaScript没有字符类型
参考类型
1.引⽤类型通常叫做类(class),也就是说,遇到引⽤值,所处理的就是对象。
2.JavaScript是基于对象⽽不是⾯向对象。对象类型的默认值是null。
3.JavaScript提供众多预定义引⽤类型(内置对象)。
3)基本操作
① alert():在页面弹出提示框
② innerHTML:向页面上的一个元素写入一段内容,覆盖原有内容
③ document.write():将内容写入页面
④ window.setInterval(code, millisec) :按照指定的周期(interval)执行函数或代码段。clearInterval() : 取消 setInterval() 设置的超时时间。
⑤ setTimeout(code, millisec) :在指定的毫秒数后调用函数或执行代码段。clearTimeout() : 取消 setTimeout() 设置的超时时间。
4)Python爬取javascript动态网页的两种解决方案
(1)使用dryscrape库动态抓取页面
JS 脚本由浏览器执行并返回信息。因此,在JS执行完后,抓取页面最直接的方法之一就是使用python来模拟浏览器的行为。
WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js等的网页。
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页。虽然可以满足爬取动态页面的要求,但缺点是速度慢。
不过也有道理,python调用webkit请求页面,页面加载的时候,加载js文件,让js执行,返回执行的页面,确实比较慢。
除此之外,还有很多库可以调用webkit:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等也可以实现同样的功能。
(2)selenium web 测试框架
Selenium是一个web测试框架,可以调用本地浏览器引擎发送网页请求,也可以实现爬取页面的需求。
使用 selenium webdriver 可以工作,但会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
可以看作是治标不治本。还有一个类似selenium的风车,不过感觉稍微复杂一点。
对于动态网页的爬取,可以找一些网站来练习,对爬虫友好,控制爬虫的访问频率,不要让你的爬虫被封禁。新手可以移步下面的文章看看,老大会定期直播分享自己的实战项目,大家可以跟着实践。
总之,爬虫的学习也是需要积累的,并不是说一两天就能学会。想要进入这个行业,在学习基础知识点的基础上,还有很多东西需要深入补充。最好系统地学习它。 查看全部
网页css js 抓取助手(Python爬虫的详细用法,你都知道吗?(一))
为了正常显示中文,指定编码为UTF-8
5)链接标签
点击我,本窗口访问百度
点击我,新窗口访问百度
6)表格
功能:主要负责网页中的数据采集;
表单具有三个基本组件:
表单
2、css描述页面的布局
用于美化页面,布局页面,使显示的数据更好看;
例如,为下图中的文字添加特殊效果。
1)CSS的三种使用方式
这里主要讲CSS选择器。CSS 选择器用于选择所需元素的样式。
要通过 CSS 选择器抓取网页内容,首先需要学习 CSS 选择器的语法。
‘#’:代表选择id节点,‘.’:代表class的节点;
获取嵌套:加空格代表层级关系,不加空格代表并列关系;
2)选择器类型
① 元素选择器
使用 HTML 标签名作为选择器,按标签名分类,为页面上的某类标签指定统一的 CSS 样式。优点是可以快速定位页面中同类型的标签。
h1 {
color: #F00;
font-size: 50px;
}
hello
② id 选择器
选择具有特定id属性值的元素;id 名称是 HTML 元素的 id 属性值。大多数 HTML 元素都可以定义 id 属性。元素的 id 值是唯一的,只能对应文档中的特定项。, id 选择器优先于元素选择器。
#demo1 {
color: #0f0;
}
hello css
如果 id 选择器是唯一的,使用 # 来定位
post_urls = response.css("#archive .floated-thumb .post-thumb a::attr(href)").extract()
for post_url in post_urls:
print(post_url)
PS:
xpath 解析返回一个选择器列表;
extract()[0]:转换为Unicode字符串列表的第一个位置;
③ 类选择器
类名是 HTML 元素的类属性的值。大多数 HTML 元素都可以定义 class 属性。类选择器的最大优点是它可以为元素对象定义单独的或相同的样式。
.myClass {
font-size: 25px;
}
hello
3)CSS选择器的详细使用
#container:选择id为container的节点
.container:选取所有class包含container的节点
Li a : 选取所有li下的所有a节点
Ul + p :选择ul 后面的第一个p元素
Div#container>ul :选取id为container的div的第一个ul子元素
Ul ~ P :选取与ul相邻的所有p元素
a[title] :选取所有有title属性的a元素
a[href=’http://jobbole.com’]:选取所有href属性为jobbole.com值的a元素
a[href*=”jobole”]:选取所有href属性包含的jobbole的a元素;
a[href^=”http”] : 选取所有href属性值为http开头的a元素;
a[href$=”.jpg”];选取所有href属性值以.jpg结尾的a元素;
input[type=radio]:checked 选择选中的radio的元素;
div:not(#container): 选取所有id非container的div属性;
li:nth-child(3):选取第三个li元素;
tr: nth-child(2n):选取第偶数个tr;
CSS 应用示例
Tiltle = response.css(".entry-header h1::text").extract()#提取title:*(用到伪类选择器)
Create_data=response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace(“·”,” ”)
Comment_num = response.css("a[href='#article-comment'] span::text").extract()[0];
Content = response.css("div.entry").extract()[0]
Tags=response.css(".entry-meta-hide-on-mobile a::text").extract()[0]
4)Python爬虫常用的CSS选择器
3、JavaScript 网页的行为
控制页面的元素,使页面具有一定的动态效果;
JavaScript 被添加为脚本语言以使 HTML 具有交互性,JavaScript 既可以嵌入 HTML 中,也可以在外部链接到 HTML。
例如,设置点击标题的点击事件可以使用 JavaScript 来实现。
1)作文
2)基本语法
(1)变量
使用 JavaScript 时,需要遵循以下命名约定:
① 必须以字母或下划线开头,中间可以是数字、字符或下划线;
② 变量名不能收录空格等符号;
③ 不能使用 JavaScript 关键字作为变量名,如:function 4.JavaScript 严格区分大小写;
(2)数据类型
基本型
1.Undefined,Undefined类型只有⼀个值,即undefined。当声明的变量未初始化时,该变 量的默认值是undefined。
2.Null,只有⼀个专⽤值null,表示空,⼀个占位符。值undefined实际上是从值null派⽣来 的,因此ECMAScript把他们定义为相等的。
3.Boolean,有两个值true和false
4.Number,表示任意数字
5.String,字符串由双引号(")或单引号(')声明的。JavaScript没有字符类型
参考类型
1.引⽤类型通常叫做类(class),也就是说,遇到引⽤值,所处理的就是对象。
2.JavaScript是基于对象⽽不是⾯向对象。对象类型的默认值是null。
3.JavaScript提供众多预定义引⽤类型(内置对象)。
3)基本操作
① alert():在页面弹出提示框
② innerHTML:向页面上的一个元素写入一段内容,覆盖原有内容
③ document.write():将内容写入页面
④ window.setInterval(code, millisec) :按照指定的周期(interval)执行函数或代码段。clearInterval() : 取消 setInterval() 设置的超时时间。
⑤ setTimeout(code, millisec) :在指定的毫秒数后调用函数或执行代码段。clearTimeout() : 取消 setTimeout() 设置的超时时间。
4)Python爬取javascript动态网页的两种解决方案
(1)使用dryscrape库动态抓取页面
JS 脚本由浏览器执行并返回信息。因此,在JS执行完后,抓取页面最直接的方法之一就是使用python来模拟浏览器的行为。
WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js等的网页。
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页。虽然可以满足爬取动态页面的要求,但缺点是速度慢。
不过也有道理,python调用webkit请求页面,页面加载的时候,加载js文件,让js执行,返回执行的页面,确实比较慢。
除此之外,还有很多库可以调用webkit:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等也可以实现同样的功能。
(2)selenium web 测试框架
Selenium是一个web测试框架,可以调用本地浏览器引擎发送网页请求,也可以实现爬取页面的需求。
使用 selenium webdriver 可以工作,但会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
可以看作是治标不治本。还有一个类似selenium的风车,不过感觉稍微复杂一点。
对于动态网页的爬取,可以找一些网站来练习,对爬虫友好,控制爬虫的访问频率,不要让你的爬虫被封禁。新手可以移步下面的文章看看,老大会定期直播分享自己的实战项目,大家可以跟着实践。
总之,爬虫的学习也是需要积累的,并不是说一两天就能学会。想要进入这个行业,在学习基础知识点的基础上,还有很多东西需要深入补充。最好系统地学习它。
网页css js 抓取助手(如何更轻松的分析网页元素?ChromeSPY软件帮助你 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-02 08:08
)
Chrome SPY(网页元素分析助手)是一款非常好用的网页元素分析助手工具。如何更轻松地分析网页元素?小编带来的这款Chrome SPY软件可以帮到你,用户使用后可以更加轻松便捷的分析网页元素信息。该软件可以帮助有需要的谷歌浏览器用户对网页元素进行分析,轻松获取网页相关元素信息,绿色免费安装。欢迎有需要的朋友下载使用。
相关说明:
一个网页元素就是你在互联网上浏览时看到的每一个页面,称为一个网页,许多网页组成一个网站。网站 的第一页称为主页。
首页是所有网页的索引页,其他网页可以通过点击首页上的超链接打开。正是由于主页在网站中的特殊作用,人们经常用主页来指代所有的网页,而将个别的网站称为“个人主页”。主题 网站 称为“Web Production”。
网页元素包括:文本、图片、音频、动画和视频。文字,符合排版要求。图片、音频、动画、视频满足网络传输和专题需要,需要选择。
指示:
1、下载解压后的文件,解压后找到“Chrome_SPY.exe”,双击打开
2、稍等片刻就会出现界面,欢迎使用
软件介绍:
Chrome SPY是谷歌浏览器的网页元素分析工具,可以获取元素矩阵、元素坐标、参考代码、tagName、代码关键字等元素信息!
查看全部
网页css js 抓取助手(如何更轻松的分析网页元素?ChromeSPY软件帮助你
)
Chrome SPY(网页元素分析助手)是一款非常好用的网页元素分析助手工具。如何更轻松地分析网页元素?小编带来的这款Chrome SPY软件可以帮到你,用户使用后可以更加轻松便捷的分析网页元素信息。该软件可以帮助有需要的谷歌浏览器用户对网页元素进行分析,轻松获取网页相关元素信息,绿色免费安装。欢迎有需要的朋友下载使用。
相关说明:
一个网页元素就是你在互联网上浏览时看到的每一个页面,称为一个网页,许多网页组成一个网站。网站 的第一页称为主页。
首页是所有网页的索引页,其他网页可以通过点击首页上的超链接打开。正是由于主页在网站中的特殊作用,人们经常用主页来指代所有的网页,而将个别的网站称为“个人主页”。主题 网站 称为“Web Production”。
网页元素包括:文本、图片、音频、动画和视频。文字,符合排版要求。图片、音频、动画、视频满足网络传输和专题需要,需要选择。
指示:
1、下载解压后的文件,解压后找到“Chrome_SPY.exe”,双击打开
2、稍等片刻就会出现界面,欢迎使用
软件介绍:
Chrome SPY是谷歌浏览器的网页元素分析工具,可以获取元素矩阵、元素坐标、参考代码、tagName、代码关键字等元素信息!

网页css js 抓取助手(一个优化得比较完美的网站有必要屏蔽、哪些设置方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-02 06:22
经过良好优化的 网站 必须在根目录中收录 robots.txt 文件。这个文件的效果对于所有操作网站的朋友来说都不陌生,网上也有很多制作。robots.txt文件的方法和软件描述得恰当方便。但是,你真的知道网站的robots.txt文件设置是否合理,哪些文件或目录需要屏蔽,哪些设置方式有利于网站的运行?
那么,带着这些问题,杨紫会给出具体的解答,希望对菜鸟站长朋友们有所帮助,不要喷老鸟。
一、什么是 robots.txt
杨紫引用百度站长的中二段来澄清。搜索引擎使用蜘蛛程序自动访问互联网上的页面并获取页面信息。当蜘蛛访问一个网站时,它会首先检查网站的根域下是否有一个名为robots.txt的纯文本文件。此文件用于指定蜘蛛在您的 网站 爬网计划中。您可以在 网站 中创建 robots.txt,在文件中声明您不想被搜索引擎输入的 网站 的某些部分或指定搜索引擎只输入某些部分.
网站 二、robots.txt 文件的优缺点
1、快速添加网站权重和流量;
2、防止某些文件被搜索引擎索引,可以节省服务器带宽和网站访问速度;
3、为搜索引擎提供简洁明了的索引环境
三、哪些网站目录需要使用robots.txt文件来防止爬取
1),图片目录
图片是 网站 的主要组成部分。随着建站越来越方便,出现了很多cms,能打字就建一个网站,也正是因为这样的方便,出现了很多同质化的模板网上的网站,被反复使用,这样的网站搜索引擎肯定是不喜欢的,即使你的网站被输入了,那你的效果也很差。如果非要用这个网站,建议在robots.txt文件中屏蔽,常用的网站图片目录为:imags或img;
2), 网站 模板目录
正如上面图片目录中提到的,cms 的强大和灵活性也导致了许多同质的网站 模板的出现和乱用。高度重复的模板构成了一种搜索引擎。冗余,而且模板文件往往与生成的文件高度相似,同样容易构成相同内容的外观。对搜索引擎很不友好,直接被搜索引擎狠狠地放入冷宫,翻不过去。很多cms都有独立的模板存放目录,所以要屏蔽模板目录。通常模板目录的文件目录为:templets
3)、CSS、JS目录的屏蔽
CSS 目录文件在搜索引擎的抓取中没有用处,并且不提供有价值的信息。因此,强烈建议站长朋友在Robots.txt文件中屏蔽,以遍历搜索引擎的索引质量。为搜索引擎提供一个干净简洁的索引环境更容易网站友好。CSS样式的目录通常是:CSS或style
JS文件在搜索引擎中无法识别,这只是一个建议,可以屏蔽,这样做还有一个好处:为搜索引擎提供简洁明了的索引环境;
4),屏蔽双页内容
以 DEDEcms 为例。我们都知道 DEDEcms 可以使用静态和动态 URL 来访问相同的内容。如果生成静态站点范围,则必须阻止动态地址的 URL 连接。这里有两个好处:1、搜索引擎对静态网址更友好,比动态网址更容易进入;2、避免静态和动态网址可以访问相同的文章,搜索引擎判断重复内容。这样做有利于搜索引擎的友好性。
5),模板缓存目录
许多 cms 程序都有一个缓存目录。我认为我们不需要提及这个缓存目录的好处。提高网站 的访问速度和减少网站 的带宽非常有用。用户体验也很棒。但是这样的缓存目录也有一定的弊端,那就是会导致搜索引擎反复爬取。网站 中的内容重复也是一个很大的牺牲,这对网站 是有害的。很多用cms搭站的朋友都没有注意到,有必要关注一下。
6)已删除目录
过多的死链接对于搜索引擎优化来说是致命的。不能不引起站长的高度重视。在网站的打开过程中,目录的删除和调整在所难免。假设当时你的网站目录不存在,那么就需要为这个目录屏蔽robots并返回准确的目录。404错误页面(注意:在IIS中,有些朋友在设置404错误时对设置有疑问。在自定义错误页面中,404错误的精确设置应该选择:默认值或文件,而不是它应该是:url,避免搜索引擎返回200的状态码,至于怎么设置,网上教程很多,自己查)
这里有个有争议的问题,网站后台处理目录是否需要屏蔽,原来是可选的。只要能保证网站的安全,假设你的网站操作计划很小,即使网站处理目录出现在robots.txt文件中,也没有太大的疑问. 我也见过很多这样的 网站 设置;但是假设你的网站运营计划比较大,竞争也比较多,强烈建议不要显示你的网站后台处理目录的任何信息,以免被恶意利用人并损害您的利益;原来的搜索引擎越来越智能,网站的处理目录 仍然可以完美识别和丢弃。另外,我们在处理网站的后台时,还可以在页面元标记中添加:阻止搜索引擎的抓取。
毕竟需要澄清的是,很多站长朋友喜欢把sitemap地址放在robots.txt文件中。当然,这并不是要屏蔽搜索引擎,而是让搜索引擎在第一次对网站进行索引时,可以快速通过站点地图。抓取 网站 内容。这里需要注意:1、站点地图的制作一定要规范;2、网站一定要有优质的内容。 查看全部
网页css js 抓取助手(一个优化得比较完美的网站有必要屏蔽、哪些设置方法)
经过良好优化的 网站 必须在根目录中收录 robots.txt 文件。这个文件的效果对于所有操作网站的朋友来说都不陌生,网上也有很多制作。robots.txt文件的方法和软件描述得恰当方便。但是,你真的知道网站的robots.txt文件设置是否合理,哪些文件或目录需要屏蔽,哪些设置方式有利于网站的运行?
那么,带着这些问题,杨紫会给出具体的解答,希望对菜鸟站长朋友们有所帮助,不要喷老鸟。
一、什么是 robots.txt
杨紫引用百度站长的中二段来澄清。搜索引擎使用蜘蛛程序自动访问互联网上的页面并获取页面信息。当蜘蛛访问一个网站时,它会首先检查网站的根域下是否有一个名为robots.txt的纯文本文件。此文件用于指定蜘蛛在您的 网站 爬网计划中。您可以在 网站 中创建 robots.txt,在文件中声明您不想被搜索引擎输入的 网站 的某些部分或指定搜索引擎只输入某些部分.
网站 二、robots.txt 文件的优缺点
1、快速添加网站权重和流量;
2、防止某些文件被搜索引擎索引,可以节省服务器带宽和网站访问速度;
3、为搜索引擎提供简洁明了的索引环境
三、哪些网站目录需要使用robots.txt文件来防止爬取
1),图片目录
图片是 网站 的主要组成部分。随着建站越来越方便,出现了很多cms,能打字就建一个网站,也正是因为这样的方便,出现了很多同质化的模板网上的网站,被反复使用,这样的网站搜索引擎肯定是不喜欢的,即使你的网站被输入了,那你的效果也很差。如果非要用这个网站,建议在robots.txt文件中屏蔽,常用的网站图片目录为:imags或img;
2), 网站 模板目录
正如上面图片目录中提到的,cms 的强大和灵活性也导致了许多同质的网站 模板的出现和乱用。高度重复的模板构成了一种搜索引擎。冗余,而且模板文件往往与生成的文件高度相似,同样容易构成相同内容的外观。对搜索引擎很不友好,直接被搜索引擎狠狠地放入冷宫,翻不过去。很多cms都有独立的模板存放目录,所以要屏蔽模板目录。通常模板目录的文件目录为:templets
3)、CSS、JS目录的屏蔽
CSS 目录文件在搜索引擎的抓取中没有用处,并且不提供有价值的信息。因此,强烈建议站长朋友在Robots.txt文件中屏蔽,以遍历搜索引擎的索引质量。为搜索引擎提供一个干净简洁的索引环境更容易网站友好。CSS样式的目录通常是:CSS或style
JS文件在搜索引擎中无法识别,这只是一个建议,可以屏蔽,这样做还有一个好处:为搜索引擎提供简洁明了的索引环境;
4),屏蔽双页内容
以 DEDEcms 为例。我们都知道 DEDEcms 可以使用静态和动态 URL 来访问相同的内容。如果生成静态站点范围,则必须阻止动态地址的 URL 连接。这里有两个好处:1、搜索引擎对静态网址更友好,比动态网址更容易进入;2、避免静态和动态网址可以访问相同的文章,搜索引擎判断重复内容。这样做有利于搜索引擎的友好性。
5),模板缓存目录
许多 cms 程序都有一个缓存目录。我认为我们不需要提及这个缓存目录的好处。提高网站 的访问速度和减少网站 的带宽非常有用。用户体验也很棒。但是这样的缓存目录也有一定的弊端,那就是会导致搜索引擎反复爬取。网站 中的内容重复也是一个很大的牺牲,这对网站 是有害的。很多用cms搭站的朋友都没有注意到,有必要关注一下。
6)已删除目录
过多的死链接对于搜索引擎优化来说是致命的。不能不引起站长的高度重视。在网站的打开过程中,目录的删除和调整在所难免。假设当时你的网站目录不存在,那么就需要为这个目录屏蔽robots并返回准确的目录。404错误页面(注意:在IIS中,有些朋友在设置404错误时对设置有疑问。在自定义错误页面中,404错误的精确设置应该选择:默认值或文件,而不是它应该是:url,避免搜索引擎返回200的状态码,至于怎么设置,网上教程很多,自己查)
这里有个有争议的问题,网站后台处理目录是否需要屏蔽,原来是可选的。只要能保证网站的安全,假设你的网站操作计划很小,即使网站处理目录出现在robots.txt文件中,也没有太大的疑问. 我也见过很多这样的 网站 设置;但是假设你的网站运营计划比较大,竞争也比较多,强烈建议不要显示你的网站后台处理目录的任何信息,以免被恶意利用人并损害您的利益;原来的搜索引擎越来越智能,网站的处理目录 仍然可以完美识别和丢弃。另外,我们在处理网站的后台时,还可以在页面元标记中添加:阻止搜索引擎的抓取。
毕竟需要澄清的是,很多站长朋友喜欢把sitemap地址放在robots.txt文件中。当然,这并不是要屏蔽搜索引擎,而是让搜索引擎在第一次对网站进行索引时,可以快速通过站点地图。抓取 网站 内容。这里需要注意:1、站点地图的制作一定要规范;2、网站一定要有优质的内容。
网页css js 抓取助手(一下JS对SEO的影响有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-02 06:22
<p>在网站的优化中,一个网站需要从构建之初就安排好很多方面。搭建好框架后,我们需要对网站进行合理的优化,无论是站内优化还是站外优化,无论是链接还是代码,都是确定
网页css js 抓取助手(一下JS对SEO的影响有哪些?-八维教育)
<p>在网站的优化中,一个网站需要从构建之初就安排好很多方面。搭建好框架后,我们需要对网站进行合理的优化,无论是站内优化还是站外优化,无论是链接还是代码,都是确定
网页css js 抓取助手( 六九博客网站抓取精灵V1.0.0.0绿色版类别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-29 15:09
六九博客网站抓取精灵V1.0.0.0绿色版类别)
69 博客网站抓取精灵V1.0.0.0 绿色版
类别:上网辅助系统:WinAll 授权:免费更新:2019-08-07
六九博客网站爬虫精灵是一款非常实用的全站模板抓取工具。有了这个工具,我们可以轻松快速地抓取六九博客网站上的内容,它不仅支持全站下载功能,还可以像以前一样保存页面上的内容,非常简单操作。
点击下载(人气:1)
建站超级网站全站下载器5.2 正式版
类别:站长工具系统:WinAll授权:免费更新:2016-01-04
Site Builder Super 网站Whole Site Downloader是一个网站爬虫,可以下载动态网页,帮助你快速搭建和模仿你的网站。短时间内打造出高难度的精致网站。
点击下载(人气:51)
Yellow Pages Spider3.44位破解版
分类:站长工具 系统:WinAll 授权:破解更新:2016-03-07
YellowPagesSpider,做站长的朋友应该对这款软件比较熟悉。他可以在最流行的“黄页”目录中进行搜索,并提取重要信息,例如公司名称、地址、电话号码和电子邮件。Yellow Pages Spider 正在最流行的“黄页”目录中进行搜索并提取样本企业名称,
点击下载(人气:41)
Visual web scraper Visual Web Ripper 3.0.7破解版
分类:站长工具 系统:WinAll 授权:破解更新:2016-03-11
可视化网页抓取工具 VisualWebRipper 是一款功能强大且易于使用的数据提取软件,可以快速抓取网页中的数据。VisualWebRipper 可以自动“爬取”整个网站网页,从而采集网站的所有内容和结果,并存储在数据库或XML文档中
点击下载(人气:191)
网页抓取工具 Easy Web Extract 3.2.8破解版
分类:站长工具 系统:WinAll 授权:破解更新:2016-01-04
网页抓取工具 Easy Web Extract 是一款易于使用的网页抓取工具,只需点击几下即可提取网页中的内容(文本、URL、图片、文件)并将结果转换为各种格式。无需编程。使我们的网络爬虫易于使用作为它的名字
点击下载(人气:321)
网站爬取工具Teleport Pro破解版1.72专业版
分类:站长工具 系统:WinAll 授权:免费更新:2015-09-24
网站Crawler Teleport Pro 破解版是一款高级网站资料下载工具。来自一个 网站 或整个互联网。Teleport 可以做的就是将所有指定的网站下载到本地,即使没有网络也可以离线浏览这个网站。Teleport 不是一个简单的下载网络
点击下载(人气:649)
网站抓取精灵3.0 正式版
类别:其他应用系统:WinAll授权:免费更新:2014-03-01
网站抓取向导可以快速抓取网站页面中的所有图片、文字、css和js文件,并且可以生成单个index.html页面。软件功能1、下载页面所有图片2、保存带参数的css和js文件3、一键保存页面文字4、单页下载所有相关信息
点击下载(人气:282) 查看全部
网页css js 抓取助手(
六九博客网站抓取精灵V1.0.0.0绿色版类别)

69 博客网站抓取精灵V1.0.0.0 绿色版

类别:上网辅助系统:WinAll 授权:免费更新:2019-08-07
六九博客网站爬虫精灵是一款非常实用的全站模板抓取工具。有了这个工具,我们可以轻松快速地抓取六九博客网站上的内容,它不仅支持全站下载功能,还可以像以前一样保存页面上的内容,非常简单操作。
点击下载(人气:1)

建站超级网站全站下载器5.2 正式版
类别:站长工具系统:WinAll授权:免费更新:2016-01-04
Site Builder Super 网站Whole Site Downloader是一个网站爬虫,可以下载动态网页,帮助你快速搭建和模仿你的网站。短时间内打造出高难度的精致网站。
点击下载(人气:51)

Yellow Pages Spider3.44位破解版
分类:站长工具 系统:WinAll 授权:破解更新:2016-03-07
YellowPagesSpider,做站长的朋友应该对这款软件比较熟悉。他可以在最流行的“黄页”目录中进行搜索,并提取重要信息,例如公司名称、地址、电话号码和电子邮件。Yellow Pages Spider 正在最流行的“黄页”目录中进行搜索并提取样本企业名称,
点击下载(人气:41)

Visual web scraper Visual Web Ripper 3.0.7破解版
分类:站长工具 系统:WinAll 授权:破解更新:2016-03-11
可视化网页抓取工具 VisualWebRipper 是一款功能强大且易于使用的数据提取软件,可以快速抓取网页中的数据。VisualWebRipper 可以自动“爬取”整个网站网页,从而采集网站的所有内容和结果,并存储在数据库或XML文档中
点击下载(人气:191)

网页抓取工具 Easy Web Extract 3.2.8破解版
分类:站长工具 系统:WinAll 授权:破解更新:2016-01-04
网页抓取工具 Easy Web Extract 是一款易于使用的网页抓取工具,只需点击几下即可提取网页中的内容(文本、URL、图片、文件)并将结果转换为各种格式。无需编程。使我们的网络爬虫易于使用作为它的名字
点击下载(人气:321)

网站爬取工具Teleport Pro破解版1.72专业版
分类:站长工具 系统:WinAll 授权:免费更新:2015-09-24
网站Crawler Teleport Pro 破解版是一款高级网站资料下载工具。来自一个 网站 或整个互联网。Teleport 可以做的就是将所有指定的网站下载到本地,即使没有网络也可以离线浏览这个网站。Teleport 不是一个简单的下载网络
点击下载(人气:649)

网站抓取精灵3.0 正式版
类别:其他应用系统:WinAll授权:免费更新:2014-03-01
网站抓取向导可以快速抓取网站页面中的所有图片、文字、css和js文件,并且可以生成单个index.html页面。软件功能1、下载页面所有图片2、保存带参数的css和js文件3、一键保存页面文字4、单页下载所有相关信息
点击下载(人气:282)
网页css js 抓取助手(一个网站练习一下爬虫实现的功能全站获取CSS,JS,img等文件连接获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-28 23:18
闲暇之余,刚好找了一个网站来练习爬虫,总结一下写爬虫时遇到的知识点。
实现的功能
抓取站点范围的 URL
获取CSS、JS、img等文件连接
获取文件名
将文件保存到本地
使用的模块
urllib
BS4
回覆
操作系统
第 1 部分:抓取站点范围的 URL
先粘贴代码
# 获取当前页面子网站子网站
def get_urls(url, baseurl, urls):
with request.urlopen(url) as f:
data = f.read().decode('utf-8')
link = bs(data).find_all('a')
for i in link:
suffix = i.get('href')
# 设置排除写入的子连接
if suffix == '#' or suffix == '#carousel-example-generic' or 'javascript:void(0)' in suffix:
continue
else:
# 构建urls
childurl = baseurl + suffix
if childurl not in urls:
urls.append(childurl)
# 获取整个网站URL
def getallUrl(url, baseurl, urls):
get_urls(url, baseurl, urls)
end = len(urls)
start = 0
while(True):
if start == end:
break
for i in range(start, end):
get_urls(urls[i], baseurl, urls)
time.sleep(1)
start = end
end = len(urls)
通过urllib包中的请求,调用urlopen访问网站
首先从首页开始,首页一般收录各个子页面的url,将抓取到的url添加到一个列表中
然后读取这个列表的每个元素,依次访问,获取子页面的url连接,加入到列表中。
感觉这样抓取全站的url不是很靠谱,有时间再完善。
第二部分:获取css、js、img的连接
先粘贴代码
# 获取当前网页代码
with request.urlopen(url) as f:
html_source = f.read().decode()
<p> # css,js,img正则表达式,以获取文件相对路径
patterncss = ' 查看全部
网页css js 抓取助手(一个网站练习一下爬虫实现的功能全站获取CSS,JS,img等文件连接获取)
闲暇之余,刚好找了一个网站来练习爬虫,总结一下写爬虫时遇到的知识点。
实现的功能
抓取站点范围的 URL
获取CSS、JS、img等文件连接
获取文件名
将文件保存到本地
使用的模块
urllib
BS4
回覆
操作系统
第 1 部分:抓取站点范围的 URL
先粘贴代码
# 获取当前页面子网站子网站
def get_urls(url, baseurl, urls):
with request.urlopen(url) as f:
data = f.read().decode('utf-8')
link = bs(data).find_all('a')
for i in link:
suffix = i.get('href')
# 设置排除写入的子连接
if suffix == '#' or suffix == '#carousel-example-generic' or 'javascript:void(0)' in suffix:
continue
else:
# 构建urls
childurl = baseurl + suffix
if childurl not in urls:
urls.append(childurl)
# 获取整个网站URL
def getallUrl(url, baseurl, urls):
get_urls(url, baseurl, urls)
end = len(urls)
start = 0
while(True):
if start == end:
break
for i in range(start, end):
get_urls(urls[i], baseurl, urls)
time.sleep(1)
start = end
end = len(urls)
通过urllib包中的请求,调用urlopen访问网站
首先从首页开始,首页一般收录各个子页面的url,将抓取到的url添加到一个列表中
然后读取这个列表的每个元素,依次访问,获取子页面的url连接,加入到列表中。
感觉这样抓取全站的url不是很靠谱,有时间再完善。
第二部分:获取css、js、img的连接
先粘贴代码
# 获取当前网页代码
with request.urlopen(url) as f:
html_source = f.read().decode()
<p> # css,js,img正则表达式,以获取文件相对路径
patterncss = '
网页css js 抓取助手(如何提高网站百度蜘蛛量量?(组图)期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-28 04:00
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧
作者:迟到991人查看评论:04年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧
作者:熊哥 club903 浏览评论:05年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅
作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术、伪装指南、高级代码会让你惊叹。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直是渣渣,我也无计可施。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?
作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛的数量之前,我们必须考虑:增加网站的开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)
作者:赖1681人查看评论:03年前
刷新和学习新事物,保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前是 presto,现在改为 G
阅读全文
加快网站访问的9种方法
作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览
作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
网页css js 抓取助手(如何提高网站百度蜘蛛量量?(组图)期)
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧
作者:迟到991人查看评论:04年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧
作者:熊哥 club903 浏览评论:05年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅
作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术、伪装指南、高级代码会让你惊叹。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直是渣渣,我也无计可施。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?
作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛的数量之前,我们必须考虑:增加网站的开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)
作者:赖1681人查看评论:03年前
刷新和学习新事物,保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前是 presto,现在改为 G
阅读全文
加快网站访问的9种方法
作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览
作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
网页css js 抓取助手(基于文本密度的分析(DOM无关)的评分制筛选算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-22 05:16
评委,请轻拍。. .
我一直对抓取网页内容非常感兴趣。大约三年前,我曾经做过一个“新闻阅读器”。那个时候,我非常喜欢看新闻。嗯,所以我开发了一个浏览器书签插件,用js把页面的body提取出来,通过一个图层覆盖显示在页面上。当时只能想到通过正则表达式搜索目标dom,这也是爬虫最多的。取方法。
当时这个功能是在分析了网易、新浪、QQ、凤凰等各大门户网站后实现的。这是最笨的方法,但优点是准确率高,缺点是一旦目标页面修改了源代码,可能要重新匹配。
后来发现自己看的页面越来越多,上面的方法已经不适合我的需要了。但最近因为我开发并需要一个采集助手,我开始寻找解决方案。
我主要找到了3个解决方案:
1)基于dom节点的分数筛选算法
国外有一个叫可读的浏览器书签插件来实现这个,地址:,看到这个我印象很深刻,准确率很高。
2)基于文本密度的分析(DOM 无关)
这个方法的思路也很好,适用性也比较好。试过用JS来实现,但是能力有限,没有做出匹配度高的成品,所以放弃了。
3)基于图像识别
这与 AlphaGo 使用的方法非常接近。通过图像识别,只要对机器人进行足够的训练,就可以做到。其他领域已经有大量案例了,但是没有看到文本识别的具体实现(或者没有找到案例)。)。
以上是我找到的 3 个实现。
但是因为我只是一个web开发人员,所以对JS的理解也比较好,其他语言能力也很有限。于是我尝试了基于DOM的过滤,发现readable的实现比较复杂。我想知道是否有更有效的解决方案?
后来,我发现了一个规律。一般来说,body部分的p标签数量非常多,比其他部分多很多,因为网页的大部分内容都是通过WYSIWYG编辑器发布的,而这些编辑器会生成一个语义兼容的节点。
于是,我就利用这个规律,开发了一个小爬虫插件,效果还不错。当然,它还是很基础的,需要改进。
var pt = $doc.find("p").siblings().parent();
var l = pt.length - 1;
var e = l;
var arr = [];
while(l>=0){
arr[l] = $(pt[l]).find("p").length;
l--;
}
var temArr = arr.concat();
var newArr = arrSort(arr);
var c = temArr.indexOf(newArr[e]);
content = $(pt[c]).html();
代码很简单,但是经过我的测试,80%以上的网页(主要是文章页面)都可以爬取成功。基于此,我开发了 JSpapa 集合助手:
如果您对此有更好的解决方案,可以在下面进行探索。
如需转载本文请联系作者,并注明出处 查看全部
网页css js 抓取助手(基于文本密度的分析(DOM无关)的评分制筛选算法)
评委,请轻拍。. .
我一直对抓取网页内容非常感兴趣。大约三年前,我曾经做过一个“新闻阅读器”。那个时候,我非常喜欢看新闻。嗯,所以我开发了一个浏览器书签插件,用js把页面的body提取出来,通过一个图层覆盖显示在页面上。当时只能想到通过正则表达式搜索目标dom,这也是爬虫最多的。取方法。
当时这个功能是在分析了网易、新浪、QQ、凤凰等各大门户网站后实现的。这是最笨的方法,但优点是准确率高,缺点是一旦目标页面修改了源代码,可能要重新匹配。
后来发现自己看的页面越来越多,上面的方法已经不适合我的需要了。但最近因为我开发并需要一个采集助手,我开始寻找解决方案。
我主要找到了3个解决方案:
1)基于dom节点的分数筛选算法
国外有一个叫可读的浏览器书签插件来实现这个,地址:,看到这个我印象很深刻,准确率很高。
2)基于文本密度的分析(DOM 无关)
这个方法的思路也很好,适用性也比较好。试过用JS来实现,但是能力有限,没有做出匹配度高的成品,所以放弃了。
3)基于图像识别
这与 AlphaGo 使用的方法非常接近。通过图像识别,只要对机器人进行足够的训练,就可以做到。其他领域已经有大量案例了,但是没有看到文本识别的具体实现(或者没有找到案例)。)。
以上是我找到的 3 个实现。
但是因为我只是一个web开发人员,所以对JS的理解也比较好,其他语言能力也很有限。于是我尝试了基于DOM的过滤,发现readable的实现比较复杂。我想知道是否有更有效的解决方案?
后来,我发现了一个规律。一般来说,body部分的p标签数量非常多,比其他部分多很多,因为网页的大部分内容都是通过WYSIWYG编辑器发布的,而这些编辑器会生成一个语义兼容的节点。
于是,我就利用这个规律,开发了一个小爬虫插件,效果还不错。当然,它还是很基础的,需要改进。
var pt = $doc.find("p").siblings().parent();
var l = pt.length - 1;
var e = l;
var arr = [];
while(l>=0){
arr[l] = $(pt[l]).find("p").length;
l--;
}
var temArr = arr.concat();
var newArr = arrSort(arr);
var c = temArr.indexOf(newArr[e]);
content = $(pt[c]).html();
代码很简单,但是经过我的测试,80%以上的网页(主要是文章页面)都可以爬取成功。基于此,我开发了 JSpapa 集合助手:
如果您对此有更好的解决方案,可以在下面进行探索。
如需转载本文请联系作者,并注明出处
网页css js 抓取助手( 基于Selenium的库——Helium库简介—库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-01-19 12:11
基于Selenium的库——Helium库简介—库)
对于 Python 自动化测试或爬虫开发者来说,你一定听说过 selenium 库。Selenium 本身用作 Web 应用程序测试工具,但它作为爬虫工具也有广泛的用途。
尽管 Selenium 易于使用,但它大部分时间都在处理网页元素,并且需要了解 HTML 页面标签、CSS 选择器和其他知识。
虽然自动化程度很高,但使用起来还是不是很方便,上手也不是很容易。今天小编带大家认识一个基于Selenium的库——Helium。
Helium 库简介
Helium 库是基于 Selenium 的更高级的 Web 自动化工具,它可以通过网页上可以看到的标签和名称等信息实现用户交互。我们可以使用它来执行一系列的鼠标和键盘操作,比如在键盘上点击按键、点击标签、滚动鼠标。
Helium的安装也很简单,如下图所示:
只需要pip install Helium 即可安装,但需要注意的是普通的安装方式会很慢,所以小编使用清华镜像帮助下载,提高下载速度。
安装后,我们可以使用 Helium。首先,我们使用 Helium 登录 GitHub 账号。效果如下图所示:
上图中的程序跳转到GitHub登录界面,然后输入用户名和用户密码,最后点击Login登录GitHub账号。过程非常简单。我们来看看程序是怎么写的。
上面的程序只有短短的五行,每一行的意思都非常清楚,不含糊。
然后程序可以直接登录。下图是对应的selenium登录GitHub程序。
相比之下,可以看出 Helium 程序非常简洁易用。让大家对每一步操作都很清楚。
爬行的女孩图片
接下来,为了更好的展示Helium的强大,小编使用Helium自动抓取百度图片中的女生图片,看看我们是如何实现的,我们先介绍一下程序,按照自己想要的方式下载百度图片对程序的思考。
在上面的程序中,左边是我们的程序索引,右边是我们的程序。我们可以按照提取百度图片的思路看一下程序。小编一步步解释每一行代码:
上面的每一行都对应了程序中每条语句的含义,所以理解起来非常方便。
说实话,之前用过Selenium,但总觉得用起来太重,太贵。现在我有了这个神器,做了一些封装,为我们节省了很多东西。Python 这么有趣,你还在等什么?, 如果你有兴趣,请尝试一下。顺便转发+评论,小编会持续分享Python干货知识! 查看全部
网页css js 抓取助手(
基于Selenium的库——Helium库简介—库)
对于 Python 自动化测试或爬虫开发者来说,你一定听说过 selenium 库。Selenium 本身用作 Web 应用程序测试工具,但它作为爬虫工具也有广泛的用途。
尽管 Selenium 易于使用,但它大部分时间都在处理网页元素,并且需要了解 HTML 页面标签、CSS 选择器和其他知识。
虽然自动化程度很高,但使用起来还是不是很方便,上手也不是很容易。今天小编带大家认识一个基于Selenium的库——Helium。
Helium 库简介
Helium 库是基于 Selenium 的更高级的 Web 自动化工具,它可以通过网页上可以看到的标签和名称等信息实现用户交互。我们可以使用它来执行一系列的鼠标和键盘操作,比如在键盘上点击按键、点击标签、滚动鼠标。
Helium的安装也很简单,如下图所示:
只需要pip install Helium 即可安装,但需要注意的是普通的安装方式会很慢,所以小编使用清华镜像帮助下载,提高下载速度。
安装后,我们可以使用 Helium。首先,我们使用 Helium 登录 GitHub 账号。效果如下图所示:
上图中的程序跳转到GitHub登录界面,然后输入用户名和用户密码,最后点击Login登录GitHub账号。过程非常简单。我们来看看程序是怎么写的。
上面的程序只有短短的五行,每一行的意思都非常清楚,不含糊。
然后程序可以直接登录。下图是对应的selenium登录GitHub程序。
相比之下,可以看出 Helium 程序非常简洁易用。让大家对每一步操作都很清楚。
爬行的女孩图片
接下来,为了更好的展示Helium的强大,小编使用Helium自动抓取百度图片中的女生图片,看看我们是如何实现的,我们先介绍一下程序,按照自己想要的方式下载百度图片对程序的思考。
在上面的程序中,左边是我们的程序索引,右边是我们的程序。我们可以按照提取百度图片的思路看一下程序。小编一步步解释每一行代码:
上面的每一行都对应了程序中每条语句的含义,所以理解起来非常方便。
说实话,之前用过Selenium,但总觉得用起来太重,太贵。现在我有了这个神器,做了一些封装,为我们节省了很多东西。Python 这么有趣,你还在等什么?, 如果你有兴趣,请尝试一下。顺便转发+评论,小编会持续分享Python干货知识!
网页css js 抓取助手(前端已经被玩儿坏了了,瞬间GET了好多前端技能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-19 12:09
)
前端坏了!console.log() 可以将图片输出到控制台和其他很酷的东西,这已经不是什么新闻了。这是一个众所周知的旧消息,例如使用 || 运算符为变量分配默认值。今天在知乎上看到一个帖子。,一瞬间,我得到了一大堆前端技巧,有的是技巧,有的是闻所未闻的冷知识,一时消化不了。现将其分类整理分享给大家,也增加了一些平时的积累和拓展的一些内容。HTML文章浏览器地址栏运行JavaScript代码
很多人应该还知道,JavaScript 代码可以直接在浏览器地址栏中运行,以 javascript: 开头,后跟要执行的语句。例如:
javascript:alert('hello from address bar :)');
将以上代码粘贴到浏览器地址栏回车,alert正常执行,并出现弹窗。
需要注意的是,如果将代码复制粘贴到浏览器地址栏,IE和Chrome会自动去掉代码开头的javascript:,所以需要手动添加才能正确执行。尽管它不会在 Firefox 中自动删除,但它不会。不支持在地址栏运行JS代码,sigh~
这个技术在我的另一篇博文《让Chrome接管邮件连接,收发邮件更方便》中使用,使用浏览器地址栏中的JavaScript代码将Gmail设置为系统的邮件接管程序。
浏览器地址栏运行HTML代码
如果知道上面这个小秘密的人多,那么知道这个秘密的人就会少一些。HTML代码可以直接在非IE内核浏览器的地址栏中运行!
比如在地址栏输入如下代码,回车运行,就会出现指定的页面内容。
data:text/html,Hello, world!
做什么的,可以把浏览器当编辑器
或者在浏览器地址栏上做文章,将以下代码粘贴到地址栏运行,浏览器就变成了一个原创简单的编辑器,就像Windows自带的记事本一样,呵呵。
data:text/html,
毕竟,多亏了 HTML5 中新的 contenteditable 属性,当元素指定了这个属性时,元素的内容就变成了可编辑的。
通过扩展,在控制台中执行以下代码后,整个页面将变为可编辑状态,随意践踏吧~
document.body.contentEditable='true';
使用标签自动解析 URL
很多时候我们有从一个URL中提取域名、查询关键字、变量参数值等的需求,但是万万没想到浏览器可以轻松帮我们完成这个任务,而不需要我们编写规律来爬取。方法是先在JS代码中创建一个a标签,然后将要解析的URL赋值给a的href属性,然后得到我们想要的一切。
var a = document.createElement('a'); a.href = 'http://www.cnblogs.com/wayou/p/'; console.log(a.host);
使用这个原理并对其进行一些扩展,我们就有了一种更强大的解析 URL 部分的通用方法。下面的代码来自 James 的博客。
<p>function parseURL(url) { var a = document.createElement('a'); a.href = url; return { source: url, protocol: a.protocol.replace(':',''), host: a.hostname, port: a.port, query: a.search, params: (function(){ var ret = {}, seg =a.search.replace(/^\?/,'').split('&'), len = seg.length, i = 0, s; for (;i 查看全部
网页css js 抓取助手(前端已经被玩儿坏了了,瞬间GET了好多前端技能
)
前端坏了!console.log() 可以将图片输出到控制台和其他很酷的东西,这已经不是什么新闻了。这是一个众所周知的旧消息,例如使用 || 运算符为变量分配默认值。今天在知乎上看到一个帖子。,一瞬间,我得到了一大堆前端技巧,有的是技巧,有的是闻所未闻的冷知识,一时消化不了。现将其分类整理分享给大家,也增加了一些平时的积累和拓展的一些内容。HTML文章浏览器地址栏运行JavaScript代码
很多人应该还知道,JavaScript 代码可以直接在浏览器地址栏中运行,以 javascript: 开头,后跟要执行的语句。例如:
javascript:alert('hello from address bar :)');
将以上代码粘贴到浏览器地址栏回车,alert正常执行,并出现弹窗。
需要注意的是,如果将代码复制粘贴到浏览器地址栏,IE和Chrome会自动去掉代码开头的javascript:,所以需要手动添加才能正确执行。尽管它不会在 Firefox 中自动删除,但它不会。不支持在地址栏运行JS代码,sigh~
这个技术在我的另一篇博文《让Chrome接管邮件连接,收发邮件更方便》中使用,使用浏览器地址栏中的JavaScript代码将Gmail设置为系统的邮件接管程序。
浏览器地址栏运行HTML代码
如果知道上面这个小秘密的人多,那么知道这个秘密的人就会少一些。HTML代码可以直接在非IE内核浏览器的地址栏中运行!
比如在地址栏输入如下代码,回车运行,就会出现指定的页面内容。
data:text/html,Hello, world!
做什么的,可以把浏览器当编辑器
或者在浏览器地址栏上做文章,将以下代码粘贴到地址栏运行,浏览器就变成了一个原创简单的编辑器,就像Windows自带的记事本一样,呵呵。
data:text/html,
毕竟,多亏了 HTML5 中新的 contenteditable 属性,当元素指定了这个属性时,元素的内容就变成了可编辑的。
通过扩展,在控制台中执行以下代码后,整个页面将变为可编辑状态,随意践踏吧~
document.body.contentEditable='true';
使用标签自动解析 URL
很多时候我们有从一个URL中提取域名、查询关键字、变量参数值等的需求,但是万万没想到浏览器可以轻松帮我们完成这个任务,而不需要我们编写规律来爬取。方法是先在JS代码中创建一个a标签,然后将要解析的URL赋值给a的href属性,然后得到我们想要的一切。
var a = document.createElement('a'); a.href = 'http://www.cnblogs.com/wayou/p/'; console.log(a.host);
使用这个原理并对其进行一些扩展,我们就有了一种更强大的解析 URL 部分的通用方法。下面的代码来自 James 的博客。
<p>function parseURL(url) { var a = document.createElement('a'); a.href = url; return { source: url, protocol: a.protocol.replace(':',''), host: a.hostname, port: a.port, query: a.search, params: (function(){ var ret = {}, seg =a.search.replace(/^\?/,'').split('&'), len = seg.length, i = 0, s; for (;i
网页css js 抓取助手( Web狙击手的功能特点及功能介绍-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-18 17:19
Web狙击手的功能特点及功能介绍-上海怡健医学)
Web Sniper 是一个网站 模板批量下载工具。使用该工具可以自动抓取指定的网站页面及其收录的所有元素,如CSS、图片、JS等。分类下载,并支持嵌套网页的解析,帮助用户快速模仿< @网站,或者学习网页编辑。
只要看到你喜欢的网站,告诉网络狙击手地址,他会快速帮你按分类获取所有元素下载,并且支持嵌套和相对路径,让你获取资源完整,准确。
【特征】
1、暴力批量下载,手动下载模板的新替代品,只要输入目标页面URL,即可下载对应页面及其收录的各种元素。
2、Css、Img、Js、Jquery、Swf分类下载。除了下载分析网页加载的Jscss文件外,还可以分析嵌套在JsCss文件中的JsCss文件。
3、快速为用户节省建站时间,看到自己喜欢的页面,使用软件下载,简单修改即可上线。
4、100%第一时间提醒最新任务,任务提醒,获取全网第一手新任务订单,保障任务下达后第一时间通知及时响应。
【发行说明】
解决js文件本地化的bug
添加了 embedSWF 引用的 SWF 文件的下载
批量增加多页批量增加功能
解决js文件中url()引用的图片下载失败的问题
解决js文件中write()引用的js文件无法下载的问题
修复网页文件修改为无后缀下载失败的问题
解决@import引用的CSS文件无法下载的问题
增加软件反馈功能。问题反馈可直接在软件上进行
解决文件不存在时软件假死问题 查看全部
网页css js 抓取助手(
Web狙击手的功能特点及功能介绍-上海怡健医学)
Web Sniper 是一个网站 模板批量下载工具。使用该工具可以自动抓取指定的网站页面及其收录的所有元素,如CSS、图片、JS等。分类下载,并支持嵌套网页的解析,帮助用户快速模仿< @网站,或者学习网页编辑。
只要看到你喜欢的网站,告诉网络狙击手地址,他会快速帮你按分类获取所有元素下载,并且支持嵌套和相对路径,让你获取资源完整,准确。
【特征】
1、暴力批量下载,手动下载模板的新替代品,只要输入目标页面URL,即可下载对应页面及其收录的各种元素。
2、Css、Img、Js、Jquery、Swf分类下载。除了下载分析网页加载的Jscss文件外,还可以分析嵌套在JsCss文件中的JsCss文件。
3、快速为用户节省建站时间,看到自己喜欢的页面,使用软件下载,简单修改即可上线。
4、100%第一时间提醒最新任务,任务提醒,获取全网第一手新任务订单,保障任务下达后第一时间通知及时响应。
【发行说明】
解决js文件本地化的bug
添加了 embedSWF 引用的 SWF 文件的下载
批量增加多页批量增加功能
解决js文件中url()引用的图片下载失败的问题
解决js文件中write()引用的js文件无法下载的问题
修复网页文件修改为无后缀下载失败的问题
解决@import引用的CSS文件无法下载的问题
增加软件反馈功能。问题反馈可直接在软件上进行
解决文件不存在时软件假死问题
网页css js 抓取助手( 基于js代码是如何调用网页助手小精灵的呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-18 02:13
基于js代码是如何调用网页助手小精灵的呢?(图))
基于JS调用web助手向导实现导航栏的方法
更新时间:2016-06-17 14:55:25 作者:柯南&
为网站添加web助手精灵,当用户访问网站时,向用户打招呼,或者传递网站的一些重要信息,给用户带来极好的体验感,那么如何调用基于js代码的web助手精灵?让我们一起学习脚本屋编辑器
1.概览
为网站添加web助手向导,当用户访问网站时,向用户打招呼,或者传递网站的一些重要信息,不仅可以帮助用户快速了解网站 >,并且可以通过 网站 给用户留下深刻印象。本例将介绍通过 JavaScript 调用网络助手向导的方法。
2.技术要点
这个例子主要是通过微软的ActiveX组件Microsoft Agent来实现的。Microsoft Agent 提供了很多方法来控制 Agent 的角色,下面将详细介绍。
一个。load() 方法:用于读取要使用的角色,该方法收录两个参数,一个用于指定角色的名称,另一个用于指定角色存储的文件。
湾。Show() 方法:用于在屏幕上显示字符。
C。Hide() 方法:用于隐藏字符。
d。Speak() 方法:用于实现字符朗读,该方法有一个参数来指定朗读的内容。
e. MoveTo()方法:用于将字符移动到屏幕上的指定位置,该方法有两个参数,一个用于指定x轴坐标,另一个用于指定y轴坐标轴。
F。Play() 方法:用于指定要播放的动画。该方法只有一个参数,用于指定表示动画的字符串。它的值包括Announce、Explain、Congratulate、greet、Gestureright、Gestureleft、Gesturedown、Gestureup、Pleased和Read等。
3.具体实现
(1)在需要显示网络助手精灵的页面的标记中编写自定义JavaScript函数loadAgent()来加载要使用的角色。loadAgent()函数的具体代码如下:
function loadAgent(id){
try{
id=new ActiveXObject("Agent.Control.2"); //创建一个ActiveX控件
id.Connected = true;
id.Characters.Load("MrAgent","merlin.acs"); //装入要使用的角色
return id;
}catch (err){
return false;
}
}
(在2)loadAgent()函数后面写了一个自定义的JavaScript函数controlAgent()来调用和控制web助手向导,controlAgent()函数的具体代码如下:
function controlAgent(){
if (agent=loadAgent("agent")){
var mrAgentID="MrAgent";
mrAgent = agent.Characters.Character(mrAgentID); //获取助手对象
mrAgent.MoveTo(200,200); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Speak("欢迎来到明日科技网站!"); //提示语
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Play("Pleased"); //做请的手势
mrAgent.Speak("我们的网址:www.cccxy.com"); //提示语
mrAgent.Hide(); //隐藏助手
mrAgent.MoveTo(600,300); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Play("Read") //作出读书的动作
mrAgent.Speak("我们会热心解决您学习过程中遇到的疑问"); //提示语
mrAgent.Play("Idle1_1"); //做出无所事事的样子
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Speak("记住我们的网址:www.cccxy.com"); //提示语
mrAgent.Play("greet"); //问候
mrAgent.Speak("感谢您的到来"); //提示语
mrAgent.Play("Idle2_2"); //做出无所事事的样子
mrAgent.Hide(); //隐藏助手
}
}
(3)页面加载完成后编写JavaScript代码调用和控制web助手向导。具体代码如下:
window.onload=function(){
controlAgent(); //调用并控制网页助手小精灵
}
以上就是小编介绍的基于JS实现导航栏调用web助手精灵的方法。我希望它对你有帮助。如有任何问题,请给我留言,小编会及时回复您。还要感谢大家对脚本之家网站的支持! 查看全部
网页css js 抓取助手(
基于js代码是如何调用网页助手小精灵的呢?(图))
基于JS调用web助手向导实现导航栏的方法
更新时间:2016-06-17 14:55:25 作者:柯南&
为网站添加web助手精灵,当用户访问网站时,向用户打招呼,或者传递网站的一些重要信息,给用户带来极好的体验感,那么如何调用基于js代码的web助手精灵?让我们一起学习脚本屋编辑器
1.概览
为网站添加web助手向导,当用户访问网站时,向用户打招呼,或者传递网站的一些重要信息,不仅可以帮助用户快速了解网站 >,并且可以通过 网站 给用户留下深刻印象。本例将介绍通过 JavaScript 调用网络助手向导的方法。
2.技术要点
这个例子主要是通过微软的ActiveX组件Microsoft Agent来实现的。Microsoft Agent 提供了很多方法来控制 Agent 的角色,下面将详细介绍。
一个。load() 方法:用于读取要使用的角色,该方法收录两个参数,一个用于指定角色的名称,另一个用于指定角色存储的文件。
湾。Show() 方法:用于在屏幕上显示字符。
C。Hide() 方法:用于隐藏字符。
d。Speak() 方法:用于实现字符朗读,该方法有一个参数来指定朗读的内容。
e. MoveTo()方法:用于将字符移动到屏幕上的指定位置,该方法有两个参数,一个用于指定x轴坐标,另一个用于指定y轴坐标轴。
F。Play() 方法:用于指定要播放的动画。该方法只有一个参数,用于指定表示动画的字符串。它的值包括Announce、Explain、Congratulate、greet、Gestureright、Gestureleft、Gesturedown、Gestureup、Pleased和Read等。
3.具体实现
(1)在需要显示网络助手精灵的页面的标记中编写自定义JavaScript函数loadAgent()来加载要使用的角色。loadAgent()函数的具体代码如下:
function loadAgent(id){
try{
id=new ActiveXObject("Agent.Control.2"); //创建一个ActiveX控件
id.Connected = true;
id.Characters.Load("MrAgent","merlin.acs"); //装入要使用的角色
return id;
}catch (err){
return false;
}
}
(在2)loadAgent()函数后面写了一个自定义的JavaScript函数controlAgent()来调用和控制web助手向导,controlAgent()函数的具体代码如下:
function controlAgent(){
if (agent=loadAgent("agent")){
var mrAgentID="MrAgent";
mrAgent = agent.Characters.Character(mrAgentID); //获取助手对象
mrAgent.MoveTo(200,200); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Speak("欢迎来到明日科技网站!"); //提示语
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Play("Pleased"); //做请的手势
mrAgent.Speak("我们的网址:www.cccxy.com"); //提示语
mrAgent.Hide(); //隐藏助手
mrAgent.MoveTo(600,300); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Play("Read") //作出读书的动作
mrAgent.Speak("我们会热心解决您学习过程中遇到的疑问"); //提示语
mrAgent.Play("Idle1_1"); //做出无所事事的样子
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Speak("记住我们的网址:www.cccxy.com"); //提示语
mrAgent.Play("greet"); //问候
mrAgent.Speak("感谢您的到来"); //提示语
mrAgent.Play("Idle2_2"); //做出无所事事的样子
mrAgent.Hide(); //隐藏助手
}
}
(3)页面加载完成后编写JavaScript代码调用和控制web助手向导。具体代码如下:
window.onload=function(){
controlAgent(); //调用并控制网页助手小精灵
}
以上就是小编介绍的基于JS实现导航栏调用web助手精灵的方法。我希望它对你有帮助。如有任何问题,请给我留言,小编会及时回复您。还要感谢大家对脚本之家网站的支持!
网页css js 抓取助手(一个屏蔽CSDN博客页面多余内容的扩展吧这里插件名称填写 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-18 02:11
)
在阅读本章之前,请阅读自定义扩展部分
这种扩展方法是应用最广泛的扩展方法。通过将css和js注入到指定的网页中,可以改变网页的外观或者增强网页的功能。通过css和js注入可以实现非常强大的功能。理论上,你甚至可以通过开发扩展使百度页面与谷歌完全一样。
该扩展在用户打开网页时始终运行,运行过程如下
检测是否需要运行,主要是将打开页面的地址与预设的规则进行比较(如何添加规则后面会讲),将css代码注入页面,将js代码注入页
让我们通过一个演示来了解开发过程。
我们来写一个屏蔽CSDN博客页面冗余内容的扩展
此处填写插件名称 CSDN博客简洁版
通过切换css js标签页添加对应代码
在这个演示中,我们只需要添加 css 代码。
#recommend-right, .blog_container_aside {
display: none;
}
main {
box-shadow: rgb(199 184 184) 0px 0px 20px;
margin-top: 30px;
}
@media screen and (min-width: 1380px) {
.nodata .container.clearfix main {
width: 100%;
}
#rightAside {
display: none;
}
}
@media (min-width: 1320px) and (max-width: 1380px) {
.nodata .container.clearfix main {
width: 100%;
}
}
@media screen and (max-width: 1320px) {
.nodata .container.clearfix main {
width: 100%;
}
}
保存代码后,只需打开一个博客页面即可查看扩展效果
如您所见,没有左右两侧
这是没有扩展的样子
查看全部
网页css js 抓取助手(一个屏蔽CSDN博客页面多余内容的扩展吧这里插件名称填写
)
在阅读本章之前,请阅读自定义扩展部分
这种扩展方法是应用最广泛的扩展方法。通过将css和js注入到指定的网页中,可以改变网页的外观或者增强网页的功能。通过css和js注入可以实现非常强大的功能。理论上,你甚至可以通过开发扩展使百度页面与谷歌完全一样。
该扩展在用户打开网页时始终运行,运行过程如下
检测是否需要运行,主要是将打开页面的地址与预设的规则进行比较(如何添加规则后面会讲),将css代码注入页面,将js代码注入页
让我们通过一个演示来了解开发过程。
我们来写一个屏蔽CSDN博客页面冗余内容的扩展

此处填写插件名称 CSDN博客简洁版

通过切换css js标签页添加对应代码
在这个演示中,我们只需要添加 css 代码。
#recommend-right, .blog_container_aside {
display: none;
}
main {
box-shadow: rgb(199 184 184) 0px 0px 20px;
margin-top: 30px;
}
@media screen and (min-width: 1380px) {
.nodata .container.clearfix main {
width: 100%;
}
#rightAside {
display: none;
}
}
@media (min-width: 1320px) and (max-width: 1380px) {
.nodata .container.clearfix main {
width: 100%;
}
}
@media screen and (max-width: 1320px) {
.nodata .container.clearfix main {
width: 100%;
}
}

保存代码后,只需打开一个博客页面即可查看扩展效果
如您所见,没有左右两侧

这是没有扩展的样子

网页css js 抓取助手(2.作品整体构思及网站(网页)的主体构想(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-18 02:08
**
1.作品总体构思及网站主要构思(网页)
**
我的网站的想法是基于HTML5、JavaScript和CSS3的web开发应用技术构建一个网页。网站的主题是相助60年,民族团结大家庭。网站包括首页、成就、广西福利、民族活动、展望未来、关于。网站最大的特点是借助CSS3的网页布局应用技术,使网页界面更具可读性,从而使网页具有亲和力。
2.作品整体设计方案及制作思路
在制作网页之前,我确定了制作网页的五个步骤:
一、确定网站主题:网站主题是要建立的网站的主要内容。网站 必须有明确的主题。在这里我的网站主题是60年互相帮助,把国家团结成一个大家庭。
二、采集素材:确定网站的主题后,就开始围绕主题采集素材。材料可以从书籍、报纸、多媒体中获取,也可以从互联网上采集,然后将采集到的材料从原石中提取出来,将赝品作为制作自己网页的材料保存下来。在这里采集了很多关于广西建国60周年的图片和资料,并前往官网进行了详细了解。
三、策划网站:网站设计的成功很大程度上取决于设计师的策划水平。规划网站就像设计一座建筑,设计好图纸后,就可以建造一座漂亮的建筑。网站策划收录了很多内容,比如网站的结构、栏目的设置、网站的风格、配色、布局、文字和图片的使用等等。考虑到所有这些方面,我们可以在生产中精通和自信。只有这样制作出来的网页才能具有个性、特色和吸引力。在规划上,我将网站的结构做成一页收录所有内容,栏目设置和最常见的网站没有区别,但网站的整体风格 @网站 还是比较新颖的,比如 网站 的布局经过精心设计,采用 CSS3 网页布局技术,达到完美效果。通过点击网站的顶部或底部一列,您可以立即转到该列的详细信息。我觉得这是这个页面最吸引人的特效。
四、选择合适的创作工具:虽然您选择的工具不会影响您的网页设计,但功能强大、易于使用的软件通常可以事半功倍。网页设计基于使用 CSS3 网页开发技术。我使用WebStorm,这是当今开发网页的主流软件。WebStorm 是 jetbrains 公司的 JavaScript 开发工具。目前已被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。它与 IntelliJ IDEA 同源,继承了 IntelliJ IDEA 强大的 JS 部分的功能。由于支持智能代码补全,支持不同浏览器的提示,并且还包括所有用户定义的函数(在项目中),代码完成包括所有流行的库,例如:JQuery、YUI、Dojo、Prototype、Mootools 和 Bindows。代码格式化,代码不仅可以格式化,所有的规则都可以自己定义。HTML提示,人们经常用js代码写HTML代码,一般来说是很痛苦的,但是有了智能提示,就好玩多了。并且在html中有js提示。关联查询,只需按Ctrl键点击某个函数或变量等,即可直接跳转到定义处;您可以在整个项目中搜索函数或变量,也可以找到并使用它们并突出显示它们。代码导航和用法查询,代码重构,这个操作有点类似于Resharper,代码检查和快速修复,可以快速发现代码中的错误或需要优化的地方,并给出快速修复的修改建议。代码调试,支持代码调试,界面类似IDEA,非常方便。代码结构浏览,可以快速浏览定位。代码折叠,虽然功能小,但比方便高效的打包或移除外设代码,自动提示打包或移除外设代码,一键完成。代码检查和快速修复,可以快速发现代码中的错误或需要优化的地方,并给出快速修复的修改建议。代码调试,支持代码调试,界面类似IDEA,非常方便。代码结构浏览,可以快速浏览定位。代码折叠,虽然功能小,但比方便高效的打包或移除外设代码,自动提示打包或移除外设代码,一键完成。
五、创建网页:材料可用并选择工具。接下来,你需要按照计划,一步一步把你的想法变成现实。这是一个复杂而细致的过程。然后小,先简单,然后复杂。所谓“先大后小”,是指在制作网页时,先设计大结构,再逐步完善小结构设计。所谓先简单,后复杂,就是先设计简单的内容,再设计复杂的内容,这样有问题的时候可以很方便的修改。制作网页时要灵活,灵活使用模板,可以大大提高生产效率。
网站包括首页、成就、广西福利、民族活动、展望未来、关于。想出点子,可以参考一些网页的排版,把对应的代码组合在一起,注入自己的编程设计,去理解和组成你看到的网页。
3.主要技术和知识点的应用,疑难问题的解决
在这里,我将介绍网页创建过程中使用的主要技术和知识点,以及解决难题的方法。
3.1 网页整体布局设计
作为一种视觉语言,网页设计应该注重布局和布局。主页的设计与平面设计虽然不一样,但它们有很多相似之处,应该充分利用和借鉴。版面设计通过文字和图形的空间结合表现出和谐与美感。一个好的网页设计师还应该知道哪一段文字和图形应该落入,以使整个网页熠熠生辉。多页面网站的页面布局和设计要求体现页面之间的有机联系,特别是要处理好页面之间和页面内部的顺序和内容的关系。尤其是当我们用网页效果来体现主题的时候,我们应该更加注重整体布局的合理性,以达到最佳的视觉表现。提供广西主页、广西成就、广西福利、广西民族活动、展望我们的未来、介绍信息。应该如何安排,让观者有一个流畅的视觉体验,以利于他对事物的理解,促进他的认知和参与。
3.2 网页设计中色彩的运用
色彩是艺术表现的要素之一。在网页设计中,根据和谐、平衡、强调的原则,将不同的颜色组合搭配,形成一个漂亮的页面。根据色彩对人心理的影响,合理使用。根据色彩记忆原理,一般暖色比冷色记忆力强。颜色还具有联想性和象征性,如红色象征血液、太阳、中国和民族;蓝色象征着大海、天空和水面。因此,在设计民族活动时,要使用红色活泼的色彩,使人们在心理上接近平和,增强人们对广西的热爱,达到良好的视觉效果。还需要注意的是,虽然网页上对颜色的应用没有限制,但不能无节制地使用多种颜色。一般来说,应根据整体风格的要求,先确定一种或两种主色。在使用颜色的过程中,另一个需要注意的问题是:由于国家、种族、宗教信仰的不同,以及生活的地理位置、文化修养的差异等,不同的人群有对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。应先根据整体风格的要求确定一种或两种主色。在使用颜色的过程中,另一个需要注意的问题是:由于国家、种族、宗教信仰的不同,以及生活的地理位置、文化修养的差异等,不同的人群有对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。应先根据整体风格的要求确定一种或两种主色。在使用颜色的过程中,另一个需要注意的问题是:由于国家、种族、宗教信仰的不同,以及生活的地理位置、文化修养的差异等,不同的人群有对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。不同的人群对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。不同的人群对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。
3.3 网页形式和内容统一
要将丰富的含义和各种形式组织成统一的页面结构,形式语言必须符合页面内容,体现内容的丰富含义。通过对比与和谐、对称与平衡、韵律与韵律、留白,通过空间、文字与图形的关系建立整体平衡,形成和谐的美感。比如在对称原则的页面设计中,它的平衡有时会让页面显得死板,但是如果你添加一些动态的文字、图案,或者使用夸张的方法来表达内在
4.工作完成后的总结和感受
总的来说,通过这次对网页设计的学习,有收获,也有遗憾,也有不足,但我认为自己已经踏入了网页设计的大门。只要我努力学习和提高,依靠我对网页设计的热情和执着,我未来设计的网页会更加专业和完美。也希望老师在以后的日子里给予更多的指导。网页设计中还有更多的技能需要我们去挖掘和研究。由于平时课程比较忙,学习时间也比较少,网页设计软件的强大功能都没有得到充分利用。不知不觉中,网页设计课程就要结束了,这门课程的内容比我想象的还要丰富。
5.了解HTML等Web前端知识5、CSS3、JavaScript
HTML5:万维网的核心语言,标准通用标记语言下超文本标记语言(HTML)的第五次重大修订,网页前端的标准编写;越来越多的行业巨头不断对 HTML5 看好。除了苹果、微软、黑莓之外,谷歌的 Youtube 也部分使用了 HTML5;Chrome 浏览器宣布全面支持 HTML5;Facebook 不遗余力地传播 HTML5。一切正如正义无线总裁王国春所说:“HTML5代表了移动互联网发展的趋势,总有一天它会成为主流技术。”
CSS 代表层叠样式表。在网页制作中使用级联样式表技术,可以有效实现对页面布局、字体、颜色、背景等效果的更精准控制。通过对相应代码的一些简单修改,您可以更改同一页面的不同部分或具有不同页数的页面的外观和格式。CSS3 是 CSS 技术的升级版,CSS3 语言开发正朝着模块化方向发展。以前的规范作为一个模块太大太复杂了,所以,把它分解成更小的模块,增加了更多的新模块。这些模块包括:框模型、列表模块、超链接模式、语言模块、背景和边框、文字效果、多栏布局等。
JavaScript 是一种文字脚本语言,是一种动态类型、弱类型、基于原型的语言,具有对类型的内置支持。它的解释器称为 JavaScript 引擎,它是浏览器的一部分,广泛用于客户端脚本语言。它最初用于 HTML(标准通用标记语言下的应用程序)网页,为 HTML5 网页添加动态功能。.
如图所示
作品的源代码在我的下载资源中。 查看全部
网页css js 抓取助手(2.作品整体构思及网站(网页)的主体构想(图))
**
1.作品总体构思及网站主要构思(网页)
**
我的网站的想法是基于HTML5、JavaScript和CSS3的web开发应用技术构建一个网页。网站的主题是相助60年,民族团结大家庭。网站包括首页、成就、广西福利、民族活动、展望未来、关于。网站最大的特点是借助CSS3的网页布局应用技术,使网页界面更具可读性,从而使网页具有亲和力。
2.作品整体设计方案及制作思路
在制作网页之前,我确定了制作网页的五个步骤:
一、确定网站主题:网站主题是要建立的网站的主要内容。网站 必须有明确的主题。在这里我的网站主题是60年互相帮助,把国家团结成一个大家庭。
二、采集素材:确定网站的主题后,就开始围绕主题采集素材。材料可以从书籍、报纸、多媒体中获取,也可以从互联网上采集,然后将采集到的材料从原石中提取出来,将赝品作为制作自己网页的材料保存下来。在这里采集了很多关于广西建国60周年的图片和资料,并前往官网进行了详细了解。
三、策划网站:网站设计的成功很大程度上取决于设计师的策划水平。规划网站就像设计一座建筑,设计好图纸后,就可以建造一座漂亮的建筑。网站策划收录了很多内容,比如网站的结构、栏目的设置、网站的风格、配色、布局、文字和图片的使用等等。考虑到所有这些方面,我们可以在生产中精通和自信。只有这样制作出来的网页才能具有个性、特色和吸引力。在规划上,我将网站的结构做成一页收录所有内容,栏目设置和最常见的网站没有区别,但网站的整体风格 @网站 还是比较新颖的,比如 网站 的布局经过精心设计,采用 CSS3 网页布局技术,达到完美效果。通过点击网站的顶部或底部一列,您可以立即转到该列的详细信息。我觉得这是这个页面最吸引人的特效。
四、选择合适的创作工具:虽然您选择的工具不会影响您的网页设计,但功能强大、易于使用的软件通常可以事半功倍。网页设计基于使用 CSS3 网页开发技术。我使用WebStorm,这是当今开发网页的主流软件。WebStorm 是 jetbrains 公司的 JavaScript 开发工具。目前已被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。它与 IntelliJ IDEA 同源,继承了 IntelliJ IDEA 强大的 JS 部分的功能。由于支持智能代码补全,支持不同浏览器的提示,并且还包括所有用户定义的函数(在项目中),代码完成包括所有流行的库,例如:JQuery、YUI、Dojo、Prototype、Mootools 和 Bindows。代码格式化,代码不仅可以格式化,所有的规则都可以自己定义。HTML提示,人们经常用js代码写HTML代码,一般来说是很痛苦的,但是有了智能提示,就好玩多了。并且在html中有js提示。关联查询,只需按Ctrl键点击某个函数或变量等,即可直接跳转到定义处;您可以在整个项目中搜索函数或变量,也可以找到并使用它们并突出显示它们。代码导航和用法查询,代码重构,这个操作有点类似于Resharper,代码检查和快速修复,可以快速发现代码中的错误或需要优化的地方,并给出快速修复的修改建议。代码调试,支持代码调试,界面类似IDEA,非常方便。代码结构浏览,可以快速浏览定位。代码折叠,虽然功能小,但比方便高效的打包或移除外设代码,自动提示打包或移除外设代码,一键完成。代码检查和快速修复,可以快速发现代码中的错误或需要优化的地方,并给出快速修复的修改建议。代码调试,支持代码调试,界面类似IDEA,非常方便。代码结构浏览,可以快速浏览定位。代码折叠,虽然功能小,但比方便高效的打包或移除外设代码,自动提示打包或移除外设代码,一键完成。
五、创建网页:材料可用并选择工具。接下来,你需要按照计划,一步一步把你的想法变成现实。这是一个复杂而细致的过程。然后小,先简单,然后复杂。所谓“先大后小”,是指在制作网页时,先设计大结构,再逐步完善小结构设计。所谓先简单,后复杂,就是先设计简单的内容,再设计复杂的内容,这样有问题的时候可以很方便的修改。制作网页时要灵活,灵活使用模板,可以大大提高生产效率。
网站包括首页、成就、广西福利、民族活动、展望未来、关于。想出点子,可以参考一些网页的排版,把对应的代码组合在一起,注入自己的编程设计,去理解和组成你看到的网页。
3.主要技术和知识点的应用,疑难问题的解决
在这里,我将介绍网页创建过程中使用的主要技术和知识点,以及解决难题的方法。
3.1 网页整体布局设计
作为一种视觉语言,网页设计应该注重布局和布局。主页的设计与平面设计虽然不一样,但它们有很多相似之处,应该充分利用和借鉴。版面设计通过文字和图形的空间结合表现出和谐与美感。一个好的网页设计师还应该知道哪一段文字和图形应该落入,以使整个网页熠熠生辉。多页面网站的页面布局和设计要求体现页面之间的有机联系,特别是要处理好页面之间和页面内部的顺序和内容的关系。尤其是当我们用网页效果来体现主题的时候,我们应该更加注重整体布局的合理性,以达到最佳的视觉表现。提供广西主页、广西成就、广西福利、广西民族活动、展望我们的未来、介绍信息。应该如何安排,让观者有一个流畅的视觉体验,以利于他对事物的理解,促进他的认知和参与。
3.2 网页设计中色彩的运用
色彩是艺术表现的要素之一。在网页设计中,根据和谐、平衡、强调的原则,将不同的颜色组合搭配,形成一个漂亮的页面。根据色彩对人心理的影响,合理使用。根据色彩记忆原理,一般暖色比冷色记忆力强。颜色还具有联想性和象征性,如红色象征血液、太阳、中国和民族;蓝色象征着大海、天空和水面。因此,在设计民族活动时,要使用红色活泼的色彩,使人们在心理上接近平和,增强人们对广西的热爱,达到良好的视觉效果。还需要注意的是,虽然网页上对颜色的应用没有限制,但不能无节制地使用多种颜色。一般来说,应根据整体风格的要求,先确定一种或两种主色。在使用颜色的过程中,另一个需要注意的问题是:由于国家、种族、宗教信仰的不同,以及生活的地理位置、文化修养的差异等,不同的人群有对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。应先根据整体风格的要求确定一种或两种主色。在使用颜色的过程中,另一个需要注意的问题是:由于国家、种族、宗教信仰的不同,以及生活的地理位置、文化修养的差异等,不同的人群有对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。应先根据整体风格的要求确定一种或两种主色。在使用颜色的过程中,另一个需要注意的问题是:由于国家、种族、宗教信仰的不同,以及生活的地理位置、文化修养的差异等,不同的人群有对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。不同的人群对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。不同的人群对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。
3.3 网页形式和内容统一
要将丰富的含义和各种形式组织成统一的页面结构,形式语言必须符合页面内容,体现内容的丰富含义。通过对比与和谐、对称与平衡、韵律与韵律、留白,通过空间、文字与图形的关系建立整体平衡,形成和谐的美感。比如在对称原则的页面设计中,它的平衡有时会让页面显得死板,但是如果你添加一些动态的文字、图案,或者使用夸张的方法来表达内在
4.工作完成后的总结和感受
总的来说,通过这次对网页设计的学习,有收获,也有遗憾,也有不足,但我认为自己已经踏入了网页设计的大门。只要我努力学习和提高,依靠我对网页设计的热情和执着,我未来设计的网页会更加专业和完美。也希望老师在以后的日子里给予更多的指导。网页设计中还有更多的技能需要我们去挖掘和研究。由于平时课程比较忙,学习时间也比较少,网页设计软件的强大功能都没有得到充分利用。不知不觉中,网页设计课程就要结束了,这门课程的内容比我想象的还要丰富。
5.了解HTML等Web前端知识5、CSS3、JavaScript
HTML5:万维网的核心语言,标准通用标记语言下超文本标记语言(HTML)的第五次重大修订,网页前端的标准编写;越来越多的行业巨头不断对 HTML5 看好。除了苹果、微软、黑莓之外,谷歌的 Youtube 也部分使用了 HTML5;Chrome 浏览器宣布全面支持 HTML5;Facebook 不遗余力地传播 HTML5。一切正如正义无线总裁王国春所说:“HTML5代表了移动互联网发展的趋势,总有一天它会成为主流技术。”
CSS 代表层叠样式表。在网页制作中使用级联样式表技术,可以有效实现对页面布局、字体、颜色、背景等效果的更精准控制。通过对相应代码的一些简单修改,您可以更改同一页面的不同部分或具有不同页数的页面的外观和格式。CSS3 是 CSS 技术的升级版,CSS3 语言开发正朝着模块化方向发展。以前的规范作为一个模块太大太复杂了,所以,把它分解成更小的模块,增加了更多的新模块。这些模块包括:框模型、列表模块、超链接模式、语言模块、背景和边框、文字效果、多栏布局等。
JavaScript 是一种文字脚本语言,是一种动态类型、弱类型、基于原型的语言,具有对类型的内置支持。它的解释器称为 JavaScript 引擎,它是浏览器的一部分,广泛用于客户端脚本语言。它最初用于 HTML(标准通用标记语言下的应用程序)网页,为 HTML5 网页添加动态功能。.
如图所示
作品的源代码在我的下载资源中。
网页css js 抓取助手(如何自定义一个chrome?最简单的chromeextend?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-09 14:16
如何自定义 chrome 扩展?
最简单的chrome extend由两个文件组成,一个是配置文件mainfest.json,另一个是运行js文件,在mainfest.js中有介绍。那么在chrome浏览器中引入插件的流程是:设置-扩展,然后点击“加载解压扩展”,选择已经编写好的程序,然后打开京东触发扩展。
下面是我写的操作京东的配置文件代码manifest.json:
{
"name": "jd-extends",
"manifest_version": 2,
"version": "1.0",
"description": "access www.jd.com,search goods.",
"browser_action": {
// "default_icon": "1.png"
"default_popup": "index.html"
},
"permissions": [
"tabs", "http://*/*","https://*/*"
],
"content_scripts": [
{
"matches": ["https://www.jd.com/*","https://search.jd.com/*","https://item.jd.com/*"],
"js": ["jquery.min.js","javascript.js"]
}
]
}
它主要是变量“content_scripts”。需要匹配的网页卸载匹配后,将操作该网页的js写入js文件并导入。可以导入多个网页和js。
如何使用JavaScript操作京东网页?
javascript.js 文件的代码
// var cycleNumber = $(".cycle-number").val();
if(window.location.host == "www.jd.com"){
// alert(cycleNumber);
clearCookie();
setInterval(function(){
if(Date.now()>=new Date("2016-10-23 01:04:00")){
// document.getElementById("key").value("韩版女装");
$("#key").val("韩版女装");
$("#key").parent().find("button").click();
}
},10)
}
if(window.location.host == "search.jd.com"){
$("#J_goodsList").find("li").find("img")[0].click();
// setTimeout("window.close()",12000)
}
if(window.location.host == "item.jd.com"){
if($(document).scrollTop() + $(window).height() < $(document).height()){
setInterval("moveScroll()",800);
}
setTimeout("closeChrome()",10000);
}
//the scroll move
function moveScroll(){
var h = $(document).height()-$(window).height();
$(document).scrollTop(h);
}
//close chrome
function closeChrome(){
clearCookie();
window.close();
}
//delete all cookie
function clearCookie(){
var keys=document.cookie.match(/[^ =;]+(?=\=)/g);
if (keys) {
for (var i = keys.length; i--;)
document.cookie=keys[i]+'=0;expires=' + new Date( 0).toUTCString()
}
}
以上操作流程主要是:在京东首页搜索“韩版女装”,然后点击搜索()跳转浏览搜索结果(),然后输入第一个搜索结果,然后浏览页面到底部,然后在关闭 page() 后停留 10000ms。因为操作了三个页面,所以每个页面在操作前都要进行相应的判断,否则会报错说找不到元素。 查看全部
网页css js 抓取助手(如何自定义一个chrome?最简单的chromeextend?)
如何自定义 chrome 扩展?
最简单的chrome extend由两个文件组成,一个是配置文件mainfest.json,另一个是运行js文件,在mainfest.js中有介绍。那么在chrome浏览器中引入插件的流程是:设置-扩展,然后点击“加载解压扩展”,选择已经编写好的程序,然后打开京东触发扩展。
下面是我写的操作京东的配置文件代码manifest.json:
{
"name": "jd-extends",
"manifest_version": 2,
"version": "1.0",
"description": "access www.jd.com,search goods.",
"browser_action": {
// "default_icon": "1.png"
"default_popup": "index.html"
},
"permissions": [
"tabs", "http://*/*","https://*/*"
],
"content_scripts": [
{
"matches": ["https://www.jd.com/*","https://search.jd.com/*","https://item.jd.com/*"],
"js": ["jquery.min.js","javascript.js"]
}
]
}
它主要是变量“content_scripts”。需要匹配的网页卸载匹配后,将操作该网页的js写入js文件并导入。可以导入多个网页和js。
如何使用JavaScript操作京东网页?
javascript.js 文件的代码
// var cycleNumber = $(".cycle-number").val();
if(window.location.host == "www.jd.com"){
// alert(cycleNumber);
clearCookie();
setInterval(function(){
if(Date.now()>=new Date("2016-10-23 01:04:00")){
// document.getElementById("key").value("韩版女装");
$("#key").val("韩版女装");
$("#key").parent().find("button").click();
}
},10)
}
if(window.location.host == "search.jd.com"){
$("#J_goodsList").find("li").find("img")[0].click();
// setTimeout("window.close()",12000)
}
if(window.location.host == "item.jd.com"){
if($(document).scrollTop() + $(window).height() < $(document).height()){
setInterval("moveScroll()",800);
}
setTimeout("closeChrome()",10000);
}
//the scroll move
function moveScroll(){
var h = $(document).height()-$(window).height();
$(document).scrollTop(h);
}
//close chrome
function closeChrome(){
clearCookie();
window.close();
}
//delete all cookie
function clearCookie(){
var keys=document.cookie.match(/[^ =;]+(?=\=)/g);
if (keys) {
for (var i = keys.length; i--;)
document.cookie=keys[i]+'=0;expires=' + new Date( 0).toUTCString()
}
}
以上操作流程主要是:在京东首页搜索“韩版女装”,然后点击搜索()跳转浏览搜索结果(),然后输入第一个搜索结果,然后浏览页面到底部,然后在关闭 page() 后停留 10000ms。因为操作了三个页面,所以每个页面在操作前都要进行相应的判断,否则会报错说找不到元素。
网页css js 抓取助手(如何提高网站百度蜘蛛量量?(组图)期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-02-06 05:10
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧
作者:迟到991人查看评论:04年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧
作者:熊哥 club903 浏览评论:05年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅
作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术,伪装指南,高级代码,让你惊叹不已。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直都是渣渣,我也无计可施。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?
作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛的数量之前,我们必须考虑:增加网站的开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)
作者:赖1681人查看评论:03年前
回顾旧的并保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前是 presto,现在改为 G
阅读全文
加快网站访问的9种方法
作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览
作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
网页css js 抓取助手(如何提高网站百度蜘蛛量量?(组图)期)
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧
作者:迟到991人查看评论:04年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧
作者:熊哥 club903 浏览评论:05年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅
作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术,伪装指南,高级代码,让你惊叹不已。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直都是渣渣,我也无计可施。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?
作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛的数量之前,我们必须考虑:增加网站的开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)
作者:赖1681人查看评论:03年前
回顾旧的并保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前是 presto,现在改为 G
阅读全文
加快网站访问的9种方法
作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览
作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
网页css js 抓取助手(什么是网站开放源代码?JS怎么获取css属性的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-02-06 05:09
相关话题
什么是网站开源?
2018 年 7 月 8 日 10:40:53
源代码是网站的核心,即网站程序代码,包括网站文件和目录结构。只有源代码可以拥有所有的网站。源代码决定了 网站 的所有权。传统的自助网站由于其SAAS模式,无法开源代码。本质上,用户每年支付租金来租用平台的使用权网站。网站 也不见了;而开源网站是拥有网站的用户的所有权,是买卖关系而不是
搜索引擎爬取JS代码实验
25/9/2007 13:47:00
页面中JavaScript的常用方式有两种,一种是把JS做成外部文件直接调用页面,另一种是直接在页面上写JS代码。搜索引擎如何识别这两种方法?
vue.js如何导入css文件
2015 年 9 月 11 日:06:27
vue.js中引入css文件的方法:1、在[main.js]中全局引入,代码为[import "./common/uni.css"];2、直接在组件中引入,代码为[@import"/common/uni.css";]。【相关文章推荐:vue.j
js如何获取css属性
2015 年 9 月 11 日:06:08
js获取css属性的方法:使用[getComputedStyle(div)]方法获取,代码为[vara=document.defaultView.getComputedStyle(div);]。【相关文章推荐:vue.js】js如何获取css属性
如何在js中导入css外部文件
25/11/202012:05:41
js引入外部css文件的方法:写成自定义函数,url为文件路径,后面元素调用,代码为[varscript=document.createElement('script')]。修改后的方法适用于所有品牌的电脑js
谷歌能否实现对JS的正确抓取未披露
2008 年 10 月 6 日 13:57:00
百度和谷歌作为国内最大的两家搜索引擎巨头,之前代码中出现 JS 的地方都没有爬过。也就是说,当遇到JS代码时,搜索引擎会跳过这部分,放弃收录。但是今天,通过对比研究,笔者得到了以下事实,谷歌终于率先实现了技术突破,有效识别了JS代码。
码农在网站的源码中吐槽老大,最后被炒了
17/1/2013 11:08:00
上周,一条关于网站源代码的微博给大家带来了欢乐。在某网站主页的源码中,程序员发泄了自己的不满,抱怨公司没有年终奖,并好心劝告不要指望任何想来公司的人。
kbengine0.4.20源码分析(一)
2018 年 4 月 3 日 01:14:49
总结:kbengine0.4.20源码分析(一)
【JS教程】 JS小功能代码片段(二)
2018 年 4 月 3 日 01:13:52
JS小功能代码片段(一)JS小功能代码片段(二)16、窗口滚动时自动加载内容) varloading=false;$(window).scroll(function() { if((($(window).scrollTop()+$(window).height())+250)>=$(document).height()){if(loadi
javaScript介绍介绍js代码
2021 年 4 月 2 日 10:31:05
免费学习推荐:js视频教程javaScript-如何直接引入js代码po代码和截图js01-如何引入js代码 查看全部
网页css js 抓取助手(什么是网站开放源代码?JS怎么获取css属性的方法)
相关话题
什么是网站开源?
2018 年 7 月 8 日 10:40:53
源代码是网站的核心,即网站程序代码,包括网站文件和目录结构。只有源代码可以拥有所有的网站。源代码决定了 网站 的所有权。传统的自助网站由于其SAAS模式,无法开源代码。本质上,用户每年支付租金来租用平台的使用权网站。网站 也不见了;而开源网站是拥有网站的用户的所有权,是买卖关系而不是
搜索引擎爬取JS代码实验
25/9/2007 13:47:00
页面中JavaScript的常用方式有两种,一种是把JS做成外部文件直接调用页面,另一种是直接在页面上写JS代码。搜索引擎如何识别这两种方法?
vue.js如何导入css文件
2015 年 9 月 11 日:06:27
vue.js中引入css文件的方法:1、在[main.js]中全局引入,代码为[import "./common/uni.css"];2、直接在组件中引入,代码为[@import"/common/uni.css";]。【相关文章推荐:vue.j
js如何获取css属性
2015 年 9 月 11 日:06:08
js获取css属性的方法:使用[getComputedStyle(div)]方法获取,代码为[vara=document.defaultView.getComputedStyle(div);]。【相关文章推荐:vue.js】js如何获取css属性
如何在js中导入css外部文件
25/11/202012:05:41
js引入外部css文件的方法:写成自定义函数,url为文件路径,后面元素调用,代码为[varscript=document.createElement('script')]。修改后的方法适用于所有品牌的电脑js
谷歌能否实现对JS的正确抓取未披露
2008 年 10 月 6 日 13:57:00
百度和谷歌作为国内最大的两家搜索引擎巨头,之前代码中出现 JS 的地方都没有爬过。也就是说,当遇到JS代码时,搜索引擎会跳过这部分,放弃收录。但是今天,通过对比研究,笔者得到了以下事实,谷歌终于率先实现了技术突破,有效识别了JS代码。
码农在网站的源码中吐槽老大,最后被炒了
17/1/2013 11:08:00
上周,一条关于网站源代码的微博给大家带来了欢乐。在某网站主页的源码中,程序员发泄了自己的不满,抱怨公司没有年终奖,并好心劝告不要指望任何想来公司的人。
kbengine0.4.20源码分析(一)
2018 年 4 月 3 日 01:14:49
总结:kbengine0.4.20源码分析(一)
【JS教程】 JS小功能代码片段(二)
2018 年 4 月 3 日 01:13:52
JS小功能代码片段(一)JS小功能代码片段(二)16、窗口滚动时自动加载内容) varloading=false;$(window).scroll(function() { if((($(window).scrollTop()+$(window).height())+250)>=$(document).height()){if(loadi
javaScript介绍介绍js代码
2021 年 4 月 2 日 10:31:05
免费学习推荐:js视频教程javaScript-如何直接引入js代码po代码和截图js01-如何引入js代码
网页css js 抓取助手(是否屏蔽蜘蛛抓取和JS和CSS文件?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-05 03:20
做过网站的人都知道,在查看日志的时候,会发现JS和CSS文件被蜘蛛爬取的非常频繁,所以有人考虑在robots.txt中阻止蜘蛛爬取js和css文件以节省资金。蜘蛛时间到其他页面。你会阻止蜘蛛抓取 JS 和 CSS 文件吗?我们采访了几位专业的 SEO 专家: Fuwei - SEOWHY 创始人 我认为“蜘蛛爬 网站 的时间是确定的,如果某个文件被限制爬取,它会有更多的时间来爬取它.如果“取另一个网页”不是真的,那么根本不需要屏蔽CSS和JS。如果是真的,需要屏蔽的不仅仅是CSS和JS,很多没有意义的文件都值得屏蔽. 张立波——麦步鞋业联合创始人兼COO。com 我觉得没必要屏蔽,因为搜索引擎会知道哪些是JS,CSS,哪些是web文件。爬js和css的爬虫应该不会影响网页的爬取频率。至于搜索引擎爬js和css,可能和snapshot有关,因为网站的页面大部分都是用div+css搭建的,如果没有css页面就惨了。所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。如果没有 css 页面将是可怕的。所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。如果没有 css 页面将是可怕的。所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。
Feng Han – 某大型B2B平台的seo负责人通过我的实验和跟踪数据表明: 1> 被屏蔽的js/css文件仍然会被大量的百度和google抓取。3>如果网站大部分js/css文件收录的url比较多,可以解封,蜘蛛可以边爬链接边爬js/css文件4>如果网站大部分js/css文件基本都是代码等,屏蔽也是可能的。没有发现明显的优点或缺点。国平老师认为,屏蔽此类文件不会对网站产生不良影响,相反可以推广其他页面的收录; 查看全部
网页css js 抓取助手(是否屏蔽蜘蛛抓取和JS和CSS文件?(组图))
做过网站的人都知道,在查看日志的时候,会发现JS和CSS文件被蜘蛛爬取的非常频繁,所以有人考虑在robots.txt中阻止蜘蛛爬取js和css文件以节省资金。蜘蛛时间到其他页面。你会阻止蜘蛛抓取 JS 和 CSS 文件吗?我们采访了几位专业的 SEO 专家: Fuwei - SEOWHY 创始人 我认为“蜘蛛爬 网站 的时间是确定的,如果某个文件被限制爬取,它会有更多的时间来爬取它.如果“取另一个网页”不是真的,那么根本不需要屏蔽CSS和JS。如果是真的,需要屏蔽的不仅仅是CSS和JS,很多没有意义的文件都值得屏蔽. 张立波——麦步鞋业联合创始人兼COO。com 我觉得没必要屏蔽,因为搜索引擎会知道哪些是JS,CSS,哪些是web文件。爬js和css的爬虫应该不会影响网页的爬取频率。至于搜索引擎爬js和css,可能和snapshot有关,因为网站的页面大部分都是用div+css搭建的,如果没有css页面就惨了。所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。如果没有 css 页面将是可怕的。所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。如果没有 css 页面将是可怕的。所以不排除搜索引擎试图解释JS和CSS文件来丰富网页内容,让搜索更加精准。
Feng Han – 某大型B2B平台的seo负责人通过我的实验和跟踪数据表明: 1> 被屏蔽的js/css文件仍然会被大量的百度和google抓取。3>如果网站大部分js/css文件收录的url比较多,可以解封,蜘蛛可以边爬链接边爬js/css文件4>如果网站大部分js/css文件基本都是代码等,屏蔽也是可能的。没有发现明显的优点或缺点。国平老师认为,屏蔽此类文件不会对网站产生不良影响,相反可以推广其他页面的收录;
网页css js 抓取助手(的是“小七烤地瓜编程助手中文便携版”介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-02-05 03:12
小七烤红薯编程助手绿色版这个软件大家都不陌生吧?是一款功能强大的专业辅助编程软件。软件界面简洁,没有多余的复杂功能,使用起来非常方便。此外,它还有强大的JS调试工具、后期调试、中英文翻译、编程转换等操作,可以帮助您轻松解决所有问题。此外,它还提供代码转换、窗口截图、图标提取等,多合一软件,非常强大。而今天带来的是《小七烤红薯编程助手中文便携版》,这个版本经过大神精心修改,无需安装,下载后双击即可使用。有了这个软件,您可以轻松地调制代码,非常方便。不仅如此,这款软件体积并不大,内存小的朋友可以轻松安装使用。此外,它还支持中文,对不擅长英语的人来说非常友好。感觉不错的小伙伴,还等什么,快来下载体验吧!
软件功能
1、正则调试:轻松调试正则表达式。
2、Web 数据包捕获:智能Web 数据包捕获,POSTGET 客户端数据包测试。
3、生成代码:找到指定的窗口控件,生成全智能易语言代码。
4、工具箱:屏幕颜色选择器、GET、POST 测试、客户端 cookie 测试。
5、资源采集:采集 网页上的 CSS、JS、图像、背景、媒体文件。
6、网页分析:通过框架对网页元素进行深入分析,让您在网页上填写表格更容易。
7、窗口检测:清晰分析窗口中各种控件的ID、句柄、标题、类名、位置、大小。
8、常用工具:中英文翻译、代码转换、窗口截图、图标提取、文本加解密等。
9、调试也支持一键生成对应的js算法,自动调用js调试工具调试和一些hmacsha算法。
软件优势
1、功能丰富,有很多常用的编程工具
2、常规内容可在软件中调试,表达式可在软件中分析
3、可以通过软件的语法提示编辑表达式,也可以在软件中匹配结果
4、支持关键词搜索,可以在软件中输入表达式,然后搜索指定内容
5、可以在软件中查看API内容,方便用户编辑API文档
6、还支持查看API相关案例学习如何制作开发文档
7、软件有很多功能,可以转换代码,提取哈希值,加密代码
8、如果你需要这个软件,可以直接下载,帮助你调试自己的js文件和post界面
变更日志
v2.6.4
修复加解密的bug 查看全部
网页css js 抓取助手(的是“小七烤地瓜编程助手中文便携版”介绍)
小七烤红薯编程助手绿色版这个软件大家都不陌生吧?是一款功能强大的专业辅助编程软件。软件界面简洁,没有多余的复杂功能,使用起来非常方便。此外,它还有强大的JS调试工具、后期调试、中英文翻译、编程转换等操作,可以帮助您轻松解决所有问题。此外,它还提供代码转换、窗口截图、图标提取等,多合一软件,非常强大。而今天带来的是《小七烤红薯编程助手中文便携版》,这个版本经过大神精心修改,无需安装,下载后双击即可使用。有了这个软件,您可以轻松地调制代码,非常方便。不仅如此,这款软件体积并不大,内存小的朋友可以轻松安装使用。此外,它还支持中文,对不擅长英语的人来说非常友好。感觉不错的小伙伴,还等什么,快来下载体验吧!
软件功能
1、正则调试:轻松调试正则表达式。
2、Web 数据包捕获:智能Web 数据包捕获,POSTGET 客户端数据包测试。
3、生成代码:找到指定的窗口控件,生成全智能易语言代码。
4、工具箱:屏幕颜色选择器、GET、POST 测试、客户端 cookie 测试。
5、资源采集:采集 网页上的 CSS、JS、图像、背景、媒体文件。
6、网页分析:通过框架对网页元素进行深入分析,让您在网页上填写表格更容易。
7、窗口检测:清晰分析窗口中各种控件的ID、句柄、标题、类名、位置、大小。
8、常用工具:中英文翻译、代码转换、窗口截图、图标提取、文本加解密等。
9、调试也支持一键生成对应的js算法,自动调用js调试工具调试和一些hmacsha算法。
软件优势
1、功能丰富,有很多常用的编程工具
2、常规内容可在软件中调试,表达式可在软件中分析
3、可以通过软件的语法提示编辑表达式,也可以在软件中匹配结果
4、支持关键词搜索,可以在软件中输入表达式,然后搜索指定内容
5、可以在软件中查看API内容,方便用户编辑API文档
6、还支持查看API相关案例学习如何制作开发文档
7、软件有很多功能,可以转换代码,提取哈希值,加密代码
8、如果你需要这个软件,可以直接下载,帮助你调试自己的js文件和post界面
变更日志
v2.6.4
修复加解密的bug
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-02 23:20
本文整理了25个前端相关学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望对大家有所帮助,下面就和千峰广州小编一起来看看吧!
CSS相关
1、CSS 之战 - 在线竞争 CSS
cssbattle.dev
CSS线上竞技,很有趣的竞技游戏,一共12关,需要用HTML和CSS来100%还原它给的页面,然后尽量减少代码,还可以查看全球排行榜,看解决方案。
2、学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
3、Flexbox Froggy - 一个学习 Flex 布局的小游戏
一款引导式学习flex布局游戏,使用flex布局让青蛙在荷叶上跳跃甚至完成,游戏收录了几乎所有常用的属性,所以学起来很有趣,形象好记,谁要flex 布局如果你熟悉的话,在这里多练习一下。
4、EnjoyCSS-在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件一样。
5、CSS 技巧 - CSS 技巧
这个网站 每天都会不断更新一些优秀的教程和CSS 技巧的技巧文章。
6、新拟态——实现新拟态效果
神经拟态.io
可以轻松实现新的模仿效果。不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数。同时可以直接复制CSS代码。
7、uiGradients - 共享渐变
提供渐变色效果的网站有近百种渐变色方案。可以根据自己的风格选择搭配,直接获取渐变色对应的CSS代码即可。
JS相关
8、JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。它主要写如何避免一些常见的错误,发现难以发现的错误,并深入了解 JavaScript 的语言特性。
9、JS 技巧 - JS 技巧
jstips.co
每天一点点的Javascript知识。
10、JSweekly - 科技周刊
专注于 Javascript 的技术周刊。
11、CDNJS - JavaScript 库
/图书馆
CDNJS为开发者提供最新的前端web开发资源,免费使用,没有使用限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端CDN服务中排名第二(第一是谷歌),性能优异。
12、美丽开放——开源JS库合集
采集各类优秀设计的开源项目,从cms内容管理系统到小型常用Javascript库,适合网站开发的用户使用。
13、JavaScript Fun - 代码库合集
最流行的 JavaScript 代码库集合,显示流行排名,开发者可以轻松找到最新的代码插件、工具和博客。
社区和博客
14、Stack Overflow - 程序员问答网络
全球IT界最火爆的技术问答网站,一个解决bug的社区,号称“100,000whys of programming”。
15、掘金-优质技术社区
绝进.im
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术 文章 包括 Android、iOS、前端和后端资源。
16、Codrops - 网页设计开发博客
发布技术文章和网络教程,提供经验,少踩坑,资源丰富。许多优秀的技术都来自这里。
在线IDE
17、代码笔
码笔.io
一个网站前端设计开发平台,一个网站前端代码工具,有各种效果的案例特效(炫技),你可以开发自己的前端设计基于他们的演示。
18、代码沙盒
码沙盒.io
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
19、JS 斌
另一个轻量级的在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
资源类
20、ICONSVG - 在线定制设计SVG图标素材
图标vg.xyz
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材是常用的图标。可以点击官方提供的素材进行二次设计,也可以导出设计好的图标。
21、OpenMoji - 免费表情符号库
提供带有源代码的表情符号库,可以免费下载使用。
22、分享图标 - 免费矢量素材库
一个提供超过250,000种ICON矢量图素材,120多个类别的网站,所有素材均以PNG和SVG格式提供,素材大小不一,包括512*512、256*256、 128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
23、tableconvert - 在线表格编辑器
一个强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的相互转换。当您需要转换表格,但无法使其变形时,请尝试使用此工具。
24、Feathericons - 极简ICON图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发。图标格式为 SVG。
25、HTML5 + CSS 3 免费模板
/
提供大量HTML5模板,用户可以自己分享和修改模板。 查看全部
网页css js 抓取助手(25个前端相关的学习网站和一些靠谱的小工具)
本文整理了25个前端相关学习网站和一些靠谱的小工具,包括一些小游戏、教程、社区网站和博客,还有一些资源网站,希望对大家有所帮助,下面就和千峰广州小编一起来看看吧!
CSS相关
1、CSS 之战 - 在线竞争 CSS
cssbattle.dev
CSS线上竞技,很有趣的竞技游戏,一共12关,需要用HTML和CSS来100%还原它给的页面,然后尽量减少代码,还可以查看全球排行榜,看解决方案。
2、学习 CSS 布局 - 学习 CSS 布局
在线CSS布局学习,将引导初学者逐步学习CSS基础知识,帮助初学者在实践中掌握CSS布局知识,提高初学者的CSS书写习惯和正确方法。
3、Flexbox Froggy - 一个学习 Flex 布局的小游戏
一款引导式学习flex布局游戏,使用flex布局让青蛙在荷叶上跳跃甚至完成,游戏收录了几乎所有常用的属性,所以学起来很有趣,形象好记,谁要flex 布局如果你熟悉的话,在这里多练习一下。
4、EnjoyCSS-在线 CSS 代码可视化工具
CSS3代码生成工具在线版,基于可视化操作,可以在非编码环境下快速调整网页效果和图形样式。这就像在本地使用 PS 或 AI 软件一样。
5、CSS 技巧 - CSS 技巧
这个网站 每天都会不断更新一些优秀的教程和CSS 技巧的技巧文章。
6、新拟态——实现新拟态效果
神经拟态.io
可以轻松实现新的模仿效果。不仅可以修改颜色或填充颜色值,还可以修改大小、半径、距离、强度、模糊效果、形状等参数。同时可以直接复制CSS代码。
7、uiGradients - 共享渐变
提供渐变色效果的网站有近百种渐变色方案。可以根据自己的风格选择搭配,直接获取渐变色对应的CSS代码即可。
JS相关
8、JavaScript 秘密花园
一直在更新的 JavaScript 语法文档。它主要写如何避免一些常见的错误,发现难以发现的错误,并深入了解 JavaScript 的语言特性。
9、JS 技巧 - JS 技巧
jstips.co
每天一点点的Javascript知识。
10、JSweekly - 科技周刊
专注于 Javascript 的技术周刊。
11、CDNJS - JavaScript 库
/图书馆
CDNJS为开发者提供最新的前端web开发资源,免费使用,没有使用限制。您可以在自己的网页上直接引用这些 JS 文件。进入CDNJS网站后,搜索你要的资源库,找到,点击项目后面的【复制脚本标签】,粘贴即可使用。目前CDNJS在Web前端CDN服务中排名第二(第一是谷歌),性能优异。
12、美丽开放——开源JS库合集
采集各类优秀设计的开源项目,从cms内容管理系统到小型常用Javascript库,适合网站开发的用户使用。
13、JavaScript Fun - 代码库合集
最流行的 JavaScript 代码库集合,显示流行排名,开发者可以轻松找到最新的代码插件、工具和博客。
社区和博客
14、Stack Overflow - 程序员问答网络
全球IT界最火爆的技术问答网站,一个解决bug的社区,号称“100,000whys of programming”。
15、掘金-优质技术社区
绝进.im
掘金技术社区是一个优质的技术分享社区,由技术专家和极客编辑筛选的优质干货。这些技术 文章 包括 Android、iOS、前端和后端资源。
16、Codrops - 网页设计开发博客
发布技术文章和网络教程,提供经验,少踩坑,资源丰富。许多优秀的技术都来自这里。
在线IDE
17、代码笔
码笔.io
一个网站前端设计开发平台,一个网站前端代码工具,有各种效果的案例特效(炫技),你可以开发自己的前端设计基于他们的演示。
18、代码沙盒
码沙盒.io
顾名思义,CodeSandBox 网站 提供了一个在线开发环境的“沙盒”。React、Vue、Angular等主流框架开箱即用,实时编译预览,非常方便。
19、JS 斌
另一个轻量级的在线编辑器网站,界面简洁干净,如果临时想调试简单的HTML或者JS代码,可以在这里试试。
资源类
20、ICONSVG - 在线定制设计SVG图标素材
图标vg.xyz
是一款在线定制设计的SVG图标素材网站,帮助前端设计师找到想要的图标素材。这些图标素材是常用的图标。可以点击官方提供的素材进行二次设计,也可以导出设计好的图标。
21、OpenMoji - 免费表情符号库
提供带有源代码的表情符号库,可以免费下载使用。
22、分享图标 - 免费矢量素材库
一个提供超过250,000种ICON矢量图素材,120多个类别的网站,所有素材均以PNG和SVG格式提供,素材大小不一,包括512*512、256*256、 128*128、64*64、32*32、16*16等,非常适合前端设计师采集和储备。
23、tableconvert - 在线表格编辑器
一个强大的在线表格编辑器,支持Excel、Markdown、JSON、CSV、HTML等格式的相互转换。当您需要转换表格,但无法使其变形时,请尝试使用此工具。
24、Feathericons - 极简ICON图标集
一个免费开源的简单漂亮的ICON图标集合,主要针对应用系统、媒体控制、位置、天气、箭头、标志等设计,可用于移动应用开发。图标格式为 SVG。
25、HTML5 + CSS 3 免费模板
/
提供大量HTML5模板,用户可以自己分享和修改模板。
网页css js 抓取助手(Python爬虫的详细用法,你都知道吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-02 23:19
为了正常显示中文,指定编码为UTF-8
5)链接标签
点击我,本窗口访问百度
点击我,新窗口访问百度
6)表格
功能:主要负责网页中的数据采集;
表单具有三个基本组件:
表单
2、css描述页面的布局
用于美化页面,布局页面,使显示的数据更好看;
例如,为下图中的文字添加特殊效果。
1)CSS的三种使用方式
这里主要讲CSS选择器。CSS 选择器用于选择所需元素的样式。
要通过 CSS 选择器抓取网页内容,首先需要学习 CSS 选择器的语法。
‘#’:代表选择id节点,‘.’:代表class的节点;
获取嵌套:加空格代表层级关系,不加空格代表并列关系;
2)选择器类型
① 元素选择器
使用 HTML 标签名作为选择器,按标签名分类,为页面上的某类标签指定统一的 CSS 样式。优点是可以快速定位页面中同类型的标签。
h1 {
color: #F00;
font-size: 50px;
}
hello
② id 选择器
选择具有特定id属性值的元素;id 名称是 HTML 元素的 id 属性值。大多数 HTML 元素都可以定义 id 属性。元素的 id 值是唯一的,只能对应文档中的特定项。, id 选择器优先于元素选择器。
#demo1 {
color: #0f0;
}
hello css
如果 id 选择器是唯一的,使用 # 来定位
post_urls = response.css("#archive .floated-thumb .post-thumb a::attr(href)").extract()
for post_url in post_urls:
print(post_url)
PS:
xpath 解析返回一个选择器列表;
extract()[0]:转换为Unicode字符串列表的第一个位置;
③ 类选择器
类名是 HTML 元素的类属性的值。大多数 HTML 元素都可以定义 class 属性。类选择器的最大优点是它可以为元素对象定义单独的或相同的样式。
.myClass {
font-size: 25px;
}
hello
3)CSS选择器的详细使用
#container:选择id为container的节点
.container:选取所有class包含container的节点
Li a : 选取所有li下的所有a节点
Ul + p :选择ul 后面的第一个p元素
Div#container>ul :选取id为container的div的第一个ul子元素
Ul ~ P :选取与ul相邻的所有p元素
a[title] :选取所有有title属性的a元素
a[href=’http://jobbole.com’]:选取所有href属性为jobbole.com值的a元素
a[href*=”jobole”]:选取所有href属性包含的jobbole的a元素;
a[href^=”http”] : 选取所有href属性值为http开头的a元素;
a[href$=”.jpg”];选取所有href属性值以.jpg结尾的a元素;
input[type=radio]:checked 选择选中的radio的元素;
div:not(#container): 选取所有id非container的div属性;
li:nth-child(3):选取第三个li元素;
tr: nth-child(2n):选取第偶数个tr;
CSS 应用示例
Tiltle = response.css(".entry-header h1::text").extract()#提取title:*(用到伪类选择器)
Create_data=response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace(“·”,” ”)
Comment_num = response.css("a[href='#article-comment'] span::text").extract()[0];
Content = response.css("div.entry").extract()[0]
Tags=response.css(".entry-meta-hide-on-mobile a::text").extract()[0]
4)Python爬虫常用的CSS选择器
3、JavaScript 网页的行为
控制页面的元素,使页面具有一定的动态效果;
JavaScript 被添加为脚本语言以使 HTML 具有交互性,JavaScript 既可以嵌入 HTML 中,也可以在外部链接到 HTML。
例如,设置点击标题的点击事件可以使用 JavaScript 来实现。
1)作文
2)基本语法
(1)变量
使用 JavaScript 时,需要遵循以下命名约定:
① 必须以字母或下划线开头,中间可以是数字、字符或下划线;
② 变量名不能收录空格等符号;
③ 不能使用 JavaScript 关键字作为变量名,如:function 4.JavaScript 严格区分大小写;
(2)数据类型
基本型
1.Undefined,Undefined类型只有⼀个值,即undefined。当声明的变量未初始化时,该变 量的默认值是undefined。
2.Null,只有⼀个专⽤值null,表示空,⼀个占位符。值undefined实际上是从值null派⽣来 的,因此ECMAScript把他们定义为相等的。
3.Boolean,有两个值true和false
4.Number,表示任意数字
5.String,字符串由双引号(")或单引号(')声明的。JavaScript没有字符类型
参考类型
1.引⽤类型通常叫做类(class),也就是说,遇到引⽤值,所处理的就是对象。
2.JavaScript是基于对象⽽不是⾯向对象。对象类型的默认值是null。
3.JavaScript提供众多预定义引⽤类型(内置对象)。
3)基本操作
① alert():在页面弹出提示框
② innerHTML:向页面上的一个元素写入一段内容,覆盖原有内容
③ document.write():将内容写入页面
④ window.setInterval(code, millisec) :按照指定的周期(interval)执行函数或代码段。clearInterval() : 取消 setInterval() 设置的超时时间。
⑤ setTimeout(code, millisec) :在指定的毫秒数后调用函数或执行代码段。clearTimeout() : 取消 setTimeout() 设置的超时时间。
4)Python爬取javascript动态网页的两种解决方案
(1)使用dryscrape库动态抓取页面
JS 脚本由浏览器执行并返回信息。因此,在JS执行完后,抓取页面最直接的方法之一就是使用python来模拟浏览器的行为。
WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js等的网页。
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页。虽然可以满足爬取动态页面的要求,但缺点是速度慢。
不过也有道理,python调用webkit请求页面,页面加载的时候,加载js文件,让js执行,返回执行的页面,确实比较慢。
除此之外,还有很多库可以调用webkit:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等也可以实现同样的功能。
(2)selenium web 测试框架
Selenium是一个web测试框架,可以调用本地浏览器引擎发送网页请求,也可以实现爬取页面的需求。
使用 selenium webdriver 可以工作,但会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
可以看作是治标不治本。还有一个类似selenium的风车,不过感觉稍微复杂一点。
对于动态网页的爬取,可以找一些网站来练习,对爬虫友好,控制爬虫的访问频率,不要让你的爬虫被封禁。新手可以移步下面的文章看看,老大会定期直播分享自己的实战项目,大家可以跟着实践。
总之,爬虫的学习也是需要积累的,并不是说一两天就能学会。想要进入这个行业,在学习基础知识点的基础上,还有很多东西需要深入补充。最好系统地学习它。 查看全部
网页css js 抓取助手(Python爬虫的详细用法,你都知道吗?(一))
为了正常显示中文,指定编码为UTF-8
5)链接标签
点击我,本窗口访问百度
点击我,新窗口访问百度
6)表格
功能:主要负责网页中的数据采集;
表单具有三个基本组件:
表单
2、css描述页面的布局
用于美化页面,布局页面,使显示的数据更好看;
例如,为下图中的文字添加特殊效果。
1)CSS的三种使用方式
这里主要讲CSS选择器。CSS 选择器用于选择所需元素的样式。
要通过 CSS 选择器抓取网页内容,首先需要学习 CSS 选择器的语法。
‘#’:代表选择id节点,‘.’:代表class的节点;
获取嵌套:加空格代表层级关系,不加空格代表并列关系;
2)选择器类型
① 元素选择器
使用 HTML 标签名作为选择器,按标签名分类,为页面上的某类标签指定统一的 CSS 样式。优点是可以快速定位页面中同类型的标签。
h1 {
color: #F00;
font-size: 50px;
}
hello
② id 选择器
选择具有特定id属性值的元素;id 名称是 HTML 元素的 id 属性值。大多数 HTML 元素都可以定义 id 属性。元素的 id 值是唯一的,只能对应文档中的特定项。, id 选择器优先于元素选择器。
#demo1 {
color: #0f0;
}
hello css
如果 id 选择器是唯一的,使用 # 来定位
post_urls = response.css("#archive .floated-thumb .post-thumb a::attr(href)").extract()
for post_url in post_urls:
print(post_url)
PS:
xpath 解析返回一个选择器列表;
extract()[0]:转换为Unicode字符串列表的第一个位置;
③ 类选择器
类名是 HTML 元素的类属性的值。大多数 HTML 元素都可以定义 class 属性。类选择器的最大优点是它可以为元素对象定义单独的或相同的样式。
.myClass {
font-size: 25px;
}
hello
3)CSS选择器的详细使用
#container:选择id为container的节点
.container:选取所有class包含container的节点
Li a : 选取所有li下的所有a节点
Ul + p :选择ul 后面的第一个p元素
Div#container>ul :选取id为container的div的第一个ul子元素
Ul ~ P :选取与ul相邻的所有p元素
a[title] :选取所有有title属性的a元素
a[href=’http://jobbole.com’]:选取所有href属性为jobbole.com值的a元素
a[href*=”jobole”]:选取所有href属性包含的jobbole的a元素;
a[href^=”http”] : 选取所有href属性值为http开头的a元素;
a[href$=”.jpg”];选取所有href属性值以.jpg结尾的a元素;
input[type=radio]:checked 选择选中的radio的元素;
div:not(#container): 选取所有id非container的div属性;
li:nth-child(3):选取第三个li元素;
tr: nth-child(2n):选取第偶数个tr;
CSS 应用示例
Tiltle = response.css(".entry-header h1::text").extract()#提取title:*(用到伪类选择器)
Create_data=response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace(“·”,” ”)
Comment_num = response.css("a[href='#article-comment'] span::text").extract()[0];
Content = response.css("div.entry").extract()[0]
Tags=response.css(".entry-meta-hide-on-mobile a::text").extract()[0]
4)Python爬虫常用的CSS选择器
3、JavaScript 网页的行为
控制页面的元素,使页面具有一定的动态效果;
JavaScript 被添加为脚本语言以使 HTML 具有交互性,JavaScript 既可以嵌入 HTML 中,也可以在外部链接到 HTML。
例如,设置点击标题的点击事件可以使用 JavaScript 来实现。
1)作文
2)基本语法
(1)变量
使用 JavaScript 时,需要遵循以下命名约定:
① 必须以字母或下划线开头,中间可以是数字、字符或下划线;
② 变量名不能收录空格等符号;
③ 不能使用 JavaScript 关键字作为变量名,如:function 4.JavaScript 严格区分大小写;
(2)数据类型
基本型
1.Undefined,Undefined类型只有⼀个值,即undefined。当声明的变量未初始化时,该变 量的默认值是undefined。
2.Null,只有⼀个专⽤值null,表示空,⼀个占位符。值undefined实际上是从值null派⽣来 的,因此ECMAScript把他们定义为相等的。
3.Boolean,有两个值true和false
4.Number,表示任意数字
5.String,字符串由双引号(")或单引号(')声明的。JavaScript没有字符类型
参考类型
1.引⽤类型通常叫做类(class),也就是说,遇到引⽤值,所处理的就是对象。
2.JavaScript是基于对象⽽不是⾯向对象。对象类型的默认值是null。
3.JavaScript提供众多预定义引⽤类型(内置对象)。
3)基本操作
① alert():在页面弹出提示框
② innerHTML:向页面上的一个元素写入一段内容,覆盖原有内容
③ document.write():将内容写入页面
④ window.setInterval(code, millisec) :按照指定的周期(interval)执行函数或代码段。clearInterval() : 取消 setInterval() 设置的超时时间。
⑤ setTimeout(code, millisec) :在指定的毫秒数后调用函数或执行代码段。clearTimeout() : 取消 setTimeout() 设置的超时时间。
4)Python爬取javascript动态网页的两种解决方案
(1)使用dryscrape库动态抓取页面
JS 脚本由浏览器执行并返回信息。因此,在JS执行完后,抓取页面最直接的方法之一就是使用python来模拟浏览器的行为。
WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js等的网页。
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页。虽然可以满足爬取动态页面的要求,但缺点是速度慢。
不过也有道理,python调用webkit请求页面,页面加载的时候,加载js文件,让js执行,返回执行的页面,确实比较慢。
除此之外,还有很多库可以调用webkit:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等也可以实现同样的功能。
(2)selenium web 测试框架
Selenium是一个web测试框架,可以调用本地浏览器引擎发送网页请求,也可以实现爬取页面的需求。
使用 selenium webdriver 可以工作,但会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
可以看作是治标不治本。还有一个类似selenium的风车,不过感觉稍微复杂一点。
对于动态网页的爬取,可以找一些网站来练习,对爬虫友好,控制爬虫的访问频率,不要让你的爬虫被封禁。新手可以移步下面的文章看看,老大会定期直播分享自己的实战项目,大家可以跟着实践。
总之,爬虫的学习也是需要积累的,并不是说一两天就能学会。想要进入这个行业,在学习基础知识点的基础上,还有很多东西需要深入补充。最好系统地学习它。
网页css js 抓取助手(如何更轻松的分析网页元素?ChromeSPY软件帮助你 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-02 08:08
)
Chrome SPY(网页元素分析助手)是一款非常好用的网页元素分析助手工具。如何更轻松地分析网页元素?小编带来的这款Chrome SPY软件可以帮到你,用户使用后可以更加轻松便捷的分析网页元素信息。该软件可以帮助有需要的谷歌浏览器用户对网页元素进行分析,轻松获取网页相关元素信息,绿色免费安装。欢迎有需要的朋友下载使用。
相关说明:
一个网页元素就是你在互联网上浏览时看到的每一个页面,称为一个网页,许多网页组成一个网站。网站 的第一页称为主页。
首页是所有网页的索引页,其他网页可以通过点击首页上的超链接打开。正是由于主页在网站中的特殊作用,人们经常用主页来指代所有的网页,而将个别的网站称为“个人主页”。主题 网站 称为“Web Production”。
网页元素包括:文本、图片、音频、动画和视频。文字,符合排版要求。图片、音频、动画、视频满足网络传输和专题需要,需要选择。
指示:
1、下载解压后的文件,解压后找到“Chrome_SPY.exe”,双击打开
2、稍等片刻就会出现界面,欢迎使用
软件介绍:
Chrome SPY是谷歌浏览器的网页元素分析工具,可以获取元素矩阵、元素坐标、参考代码、tagName、代码关键字等元素信息!
查看全部
网页css js 抓取助手(如何更轻松的分析网页元素?ChromeSPY软件帮助你
)
Chrome SPY(网页元素分析助手)是一款非常好用的网页元素分析助手工具。如何更轻松地分析网页元素?小编带来的这款Chrome SPY软件可以帮到你,用户使用后可以更加轻松便捷的分析网页元素信息。该软件可以帮助有需要的谷歌浏览器用户对网页元素进行分析,轻松获取网页相关元素信息,绿色免费安装。欢迎有需要的朋友下载使用。
相关说明:
一个网页元素就是你在互联网上浏览时看到的每一个页面,称为一个网页,许多网页组成一个网站。网站 的第一页称为主页。
首页是所有网页的索引页,其他网页可以通过点击首页上的超链接打开。正是由于主页在网站中的特殊作用,人们经常用主页来指代所有的网页,而将个别的网站称为“个人主页”。主题 网站 称为“Web Production”。
网页元素包括:文本、图片、音频、动画和视频。文字,符合排版要求。图片、音频、动画、视频满足网络传输和专题需要,需要选择。
指示:
1、下载解压后的文件,解压后找到“Chrome_SPY.exe”,双击打开
2、稍等片刻就会出现界面,欢迎使用
软件介绍:
Chrome SPY是谷歌浏览器的网页元素分析工具,可以获取元素矩阵、元素坐标、参考代码、tagName、代码关键字等元素信息!
网页css js 抓取助手(一个优化得比较完美的网站有必要屏蔽、哪些设置方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-02 06:22
经过良好优化的 网站 必须在根目录中收录 robots.txt 文件。这个文件的效果对于所有操作网站的朋友来说都不陌生,网上也有很多制作。robots.txt文件的方法和软件描述得恰当方便。但是,你真的知道网站的robots.txt文件设置是否合理,哪些文件或目录需要屏蔽,哪些设置方式有利于网站的运行?
那么,带着这些问题,杨紫会给出具体的解答,希望对菜鸟站长朋友们有所帮助,不要喷老鸟。
一、什么是 robots.txt
杨紫引用百度站长的中二段来澄清。搜索引擎使用蜘蛛程序自动访问互联网上的页面并获取页面信息。当蜘蛛访问一个网站时,它会首先检查网站的根域下是否有一个名为robots.txt的纯文本文件。此文件用于指定蜘蛛在您的 网站 爬网计划中。您可以在 网站 中创建 robots.txt,在文件中声明您不想被搜索引擎输入的 网站 的某些部分或指定搜索引擎只输入某些部分.
网站 二、robots.txt 文件的优缺点
1、快速添加网站权重和流量;
2、防止某些文件被搜索引擎索引,可以节省服务器带宽和网站访问速度;
3、为搜索引擎提供简洁明了的索引环境
三、哪些网站目录需要使用robots.txt文件来防止爬取
1),图片目录
图片是 网站 的主要组成部分。随着建站越来越方便,出现了很多cms,能打字就建一个网站,也正是因为这样的方便,出现了很多同质化的模板网上的网站,被反复使用,这样的网站搜索引擎肯定是不喜欢的,即使你的网站被输入了,那你的效果也很差。如果非要用这个网站,建议在robots.txt文件中屏蔽,常用的网站图片目录为:imags或img;
2), 网站 模板目录
正如上面图片目录中提到的,cms 的强大和灵活性也导致了许多同质的网站 模板的出现和乱用。高度重复的模板构成了一种搜索引擎。冗余,而且模板文件往往与生成的文件高度相似,同样容易构成相同内容的外观。对搜索引擎很不友好,直接被搜索引擎狠狠地放入冷宫,翻不过去。很多cms都有独立的模板存放目录,所以要屏蔽模板目录。通常模板目录的文件目录为:templets
3)、CSS、JS目录的屏蔽
CSS 目录文件在搜索引擎的抓取中没有用处,并且不提供有价值的信息。因此,强烈建议站长朋友在Robots.txt文件中屏蔽,以遍历搜索引擎的索引质量。为搜索引擎提供一个干净简洁的索引环境更容易网站友好。CSS样式的目录通常是:CSS或style
JS文件在搜索引擎中无法识别,这只是一个建议,可以屏蔽,这样做还有一个好处:为搜索引擎提供简洁明了的索引环境;
4),屏蔽双页内容
以 DEDEcms 为例。我们都知道 DEDEcms 可以使用静态和动态 URL 来访问相同的内容。如果生成静态站点范围,则必须阻止动态地址的 URL 连接。这里有两个好处:1、搜索引擎对静态网址更友好,比动态网址更容易进入;2、避免静态和动态网址可以访问相同的文章,搜索引擎判断重复内容。这样做有利于搜索引擎的友好性。
5),模板缓存目录
许多 cms 程序都有一个缓存目录。我认为我们不需要提及这个缓存目录的好处。提高网站 的访问速度和减少网站 的带宽非常有用。用户体验也很棒。但是这样的缓存目录也有一定的弊端,那就是会导致搜索引擎反复爬取。网站 中的内容重复也是一个很大的牺牲,这对网站 是有害的。很多用cms搭站的朋友都没有注意到,有必要关注一下。
6)已删除目录
过多的死链接对于搜索引擎优化来说是致命的。不能不引起站长的高度重视。在网站的打开过程中,目录的删除和调整在所难免。假设当时你的网站目录不存在,那么就需要为这个目录屏蔽robots并返回准确的目录。404错误页面(注意:在IIS中,有些朋友在设置404错误时对设置有疑问。在自定义错误页面中,404错误的精确设置应该选择:默认值或文件,而不是它应该是:url,避免搜索引擎返回200的状态码,至于怎么设置,网上教程很多,自己查)
这里有个有争议的问题,网站后台处理目录是否需要屏蔽,原来是可选的。只要能保证网站的安全,假设你的网站操作计划很小,即使网站处理目录出现在robots.txt文件中,也没有太大的疑问. 我也见过很多这样的 网站 设置;但是假设你的网站运营计划比较大,竞争也比较多,强烈建议不要显示你的网站后台处理目录的任何信息,以免被恶意利用人并损害您的利益;原来的搜索引擎越来越智能,网站的处理目录 仍然可以完美识别和丢弃。另外,我们在处理网站的后台时,还可以在页面元标记中添加:阻止搜索引擎的抓取。
毕竟需要澄清的是,很多站长朋友喜欢把sitemap地址放在robots.txt文件中。当然,这并不是要屏蔽搜索引擎,而是让搜索引擎在第一次对网站进行索引时,可以快速通过站点地图。抓取 网站 内容。这里需要注意:1、站点地图的制作一定要规范;2、网站一定要有优质的内容。 查看全部
网页css js 抓取助手(一个优化得比较完美的网站有必要屏蔽、哪些设置方法)
经过良好优化的 网站 必须在根目录中收录 robots.txt 文件。这个文件的效果对于所有操作网站的朋友来说都不陌生,网上也有很多制作。robots.txt文件的方法和软件描述得恰当方便。但是,你真的知道网站的robots.txt文件设置是否合理,哪些文件或目录需要屏蔽,哪些设置方式有利于网站的运行?
那么,带着这些问题,杨紫会给出具体的解答,希望对菜鸟站长朋友们有所帮助,不要喷老鸟。
一、什么是 robots.txt
杨紫引用百度站长的中二段来澄清。搜索引擎使用蜘蛛程序自动访问互联网上的页面并获取页面信息。当蜘蛛访问一个网站时,它会首先检查网站的根域下是否有一个名为robots.txt的纯文本文件。此文件用于指定蜘蛛在您的 网站 爬网计划中。您可以在 网站 中创建 robots.txt,在文件中声明您不想被搜索引擎输入的 网站 的某些部分或指定搜索引擎只输入某些部分.
网站 二、robots.txt 文件的优缺点
1、快速添加网站权重和流量;
2、防止某些文件被搜索引擎索引,可以节省服务器带宽和网站访问速度;
3、为搜索引擎提供简洁明了的索引环境
三、哪些网站目录需要使用robots.txt文件来防止爬取
1),图片目录
图片是 网站 的主要组成部分。随着建站越来越方便,出现了很多cms,能打字就建一个网站,也正是因为这样的方便,出现了很多同质化的模板网上的网站,被反复使用,这样的网站搜索引擎肯定是不喜欢的,即使你的网站被输入了,那你的效果也很差。如果非要用这个网站,建议在robots.txt文件中屏蔽,常用的网站图片目录为:imags或img;
2), 网站 模板目录
正如上面图片目录中提到的,cms 的强大和灵活性也导致了许多同质的网站 模板的出现和乱用。高度重复的模板构成了一种搜索引擎。冗余,而且模板文件往往与生成的文件高度相似,同样容易构成相同内容的外观。对搜索引擎很不友好,直接被搜索引擎狠狠地放入冷宫,翻不过去。很多cms都有独立的模板存放目录,所以要屏蔽模板目录。通常模板目录的文件目录为:templets
3)、CSS、JS目录的屏蔽
CSS 目录文件在搜索引擎的抓取中没有用处,并且不提供有价值的信息。因此,强烈建议站长朋友在Robots.txt文件中屏蔽,以遍历搜索引擎的索引质量。为搜索引擎提供一个干净简洁的索引环境更容易网站友好。CSS样式的目录通常是:CSS或style
JS文件在搜索引擎中无法识别,这只是一个建议,可以屏蔽,这样做还有一个好处:为搜索引擎提供简洁明了的索引环境;
4),屏蔽双页内容
以 DEDEcms 为例。我们都知道 DEDEcms 可以使用静态和动态 URL 来访问相同的内容。如果生成静态站点范围,则必须阻止动态地址的 URL 连接。这里有两个好处:1、搜索引擎对静态网址更友好,比动态网址更容易进入;2、避免静态和动态网址可以访问相同的文章,搜索引擎判断重复内容。这样做有利于搜索引擎的友好性。
5),模板缓存目录
许多 cms 程序都有一个缓存目录。我认为我们不需要提及这个缓存目录的好处。提高网站 的访问速度和减少网站 的带宽非常有用。用户体验也很棒。但是这样的缓存目录也有一定的弊端,那就是会导致搜索引擎反复爬取。网站 中的内容重复也是一个很大的牺牲,这对网站 是有害的。很多用cms搭站的朋友都没有注意到,有必要关注一下。
6)已删除目录
过多的死链接对于搜索引擎优化来说是致命的。不能不引起站长的高度重视。在网站的打开过程中,目录的删除和调整在所难免。假设当时你的网站目录不存在,那么就需要为这个目录屏蔽robots并返回准确的目录。404错误页面(注意:在IIS中,有些朋友在设置404错误时对设置有疑问。在自定义错误页面中,404错误的精确设置应该选择:默认值或文件,而不是它应该是:url,避免搜索引擎返回200的状态码,至于怎么设置,网上教程很多,自己查)
这里有个有争议的问题,网站后台处理目录是否需要屏蔽,原来是可选的。只要能保证网站的安全,假设你的网站操作计划很小,即使网站处理目录出现在robots.txt文件中,也没有太大的疑问. 我也见过很多这样的 网站 设置;但是假设你的网站运营计划比较大,竞争也比较多,强烈建议不要显示你的网站后台处理目录的任何信息,以免被恶意利用人并损害您的利益;原来的搜索引擎越来越智能,网站的处理目录 仍然可以完美识别和丢弃。另外,我们在处理网站的后台时,还可以在页面元标记中添加:阻止搜索引擎的抓取。
毕竟需要澄清的是,很多站长朋友喜欢把sitemap地址放在robots.txt文件中。当然,这并不是要屏蔽搜索引擎,而是让搜索引擎在第一次对网站进行索引时,可以快速通过站点地图。抓取 网站 内容。这里需要注意:1、站点地图的制作一定要规范;2、网站一定要有优质的内容。
网页css js 抓取助手(一下JS对SEO的影响有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-02 06:22
<p>在网站的优化中,一个网站需要从构建之初就安排好很多方面。搭建好框架后,我们需要对网站进行合理的优化,无论是站内优化还是站外优化,无论是链接还是代码,都是确定
网页css js 抓取助手(一下JS对SEO的影响有哪些?-八维教育)
<p>在网站的优化中,一个网站需要从构建之初就安排好很多方面。搭建好框架后,我们需要对网站进行合理的优化,无论是站内优化还是站外优化,无论是链接还是代码,都是确定
网页css js 抓取助手( 六九博客网站抓取精灵V1.0.0.0绿色版类别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-29 15:09
六九博客网站抓取精灵V1.0.0.0绿色版类别)
69 博客网站抓取精灵V1.0.0.0 绿色版
类别:上网辅助系统:WinAll 授权:免费更新:2019-08-07
六九博客网站爬虫精灵是一款非常实用的全站模板抓取工具。有了这个工具,我们可以轻松快速地抓取六九博客网站上的内容,它不仅支持全站下载功能,还可以像以前一样保存页面上的内容,非常简单操作。
点击下载(人气:1)
建站超级网站全站下载器5.2 正式版
类别:站长工具系统:WinAll授权:免费更新:2016-01-04
Site Builder Super 网站Whole Site Downloader是一个网站爬虫,可以下载动态网页,帮助你快速搭建和模仿你的网站。短时间内打造出高难度的精致网站。
点击下载(人气:51)
Yellow Pages Spider3.44位破解版
分类:站长工具 系统:WinAll 授权:破解更新:2016-03-07
YellowPagesSpider,做站长的朋友应该对这款软件比较熟悉。他可以在最流行的“黄页”目录中进行搜索,并提取重要信息,例如公司名称、地址、电话号码和电子邮件。Yellow Pages Spider 正在最流行的“黄页”目录中进行搜索并提取样本企业名称,
点击下载(人气:41)
Visual web scraper Visual Web Ripper 3.0.7破解版
分类:站长工具 系统:WinAll 授权:破解更新:2016-03-11
可视化网页抓取工具 VisualWebRipper 是一款功能强大且易于使用的数据提取软件,可以快速抓取网页中的数据。VisualWebRipper 可以自动“爬取”整个网站网页,从而采集网站的所有内容和结果,并存储在数据库或XML文档中
点击下载(人气:191)
网页抓取工具 Easy Web Extract 3.2.8破解版
分类:站长工具 系统:WinAll 授权:破解更新:2016-01-04
网页抓取工具 Easy Web Extract 是一款易于使用的网页抓取工具,只需点击几下即可提取网页中的内容(文本、URL、图片、文件)并将结果转换为各种格式。无需编程。使我们的网络爬虫易于使用作为它的名字
点击下载(人气:321)
网站爬取工具Teleport Pro破解版1.72专业版
分类:站长工具 系统:WinAll 授权:免费更新:2015-09-24
网站Crawler Teleport Pro 破解版是一款高级网站资料下载工具。来自一个 网站 或整个互联网。Teleport 可以做的就是将所有指定的网站下载到本地,即使没有网络也可以离线浏览这个网站。Teleport 不是一个简单的下载网络
点击下载(人气:649)
网站抓取精灵3.0 正式版
类别:其他应用系统:WinAll授权:免费更新:2014-03-01
网站抓取向导可以快速抓取网站页面中的所有图片、文字、css和js文件,并且可以生成单个index.html页面。软件功能1、下载页面所有图片2、保存带参数的css和js文件3、一键保存页面文字4、单页下载所有相关信息
点击下载(人气:282) 查看全部
网页css js 抓取助手(
六九博客网站抓取精灵V1.0.0.0绿色版类别)
69 博客网站抓取精灵V1.0.0.0 绿色版
类别:上网辅助系统:WinAll 授权:免费更新:2019-08-07
六九博客网站爬虫精灵是一款非常实用的全站模板抓取工具。有了这个工具,我们可以轻松快速地抓取六九博客网站上的内容,它不仅支持全站下载功能,还可以像以前一样保存页面上的内容,非常简单操作。
点击下载(人气:1)
建站超级网站全站下载器5.2 正式版
类别:站长工具系统:WinAll授权:免费更新:2016-01-04
Site Builder Super 网站Whole Site Downloader是一个网站爬虫,可以下载动态网页,帮助你快速搭建和模仿你的网站。短时间内打造出高难度的精致网站。
点击下载(人气:51)
Yellow Pages Spider3.44位破解版
分类:站长工具 系统:WinAll 授权:破解更新:2016-03-07
YellowPagesSpider,做站长的朋友应该对这款软件比较熟悉。他可以在最流行的“黄页”目录中进行搜索,并提取重要信息,例如公司名称、地址、电话号码和电子邮件。Yellow Pages Spider 正在最流行的“黄页”目录中进行搜索并提取样本企业名称,
点击下载(人气:41)
Visual web scraper Visual Web Ripper 3.0.7破解版
分类:站长工具 系统:WinAll 授权:破解更新:2016-03-11
可视化网页抓取工具 VisualWebRipper 是一款功能强大且易于使用的数据提取软件,可以快速抓取网页中的数据。VisualWebRipper 可以自动“爬取”整个网站网页,从而采集网站的所有内容和结果,并存储在数据库或XML文档中
点击下载(人气:191)
网页抓取工具 Easy Web Extract 3.2.8破解版
分类:站长工具 系统:WinAll 授权:破解更新:2016-01-04
网页抓取工具 Easy Web Extract 是一款易于使用的网页抓取工具,只需点击几下即可提取网页中的内容(文本、URL、图片、文件)并将结果转换为各种格式。无需编程。使我们的网络爬虫易于使用作为它的名字
点击下载(人气:321)
网站爬取工具Teleport Pro破解版1.72专业版
分类:站长工具 系统:WinAll 授权:免费更新:2015-09-24
网站Crawler Teleport Pro 破解版是一款高级网站资料下载工具。来自一个 网站 或整个互联网。Teleport 可以做的就是将所有指定的网站下载到本地,即使没有网络也可以离线浏览这个网站。Teleport 不是一个简单的下载网络
点击下载(人气:649)
网站抓取精灵3.0 正式版
类别:其他应用系统:WinAll授权:免费更新:2014-03-01
网站抓取向导可以快速抓取网站页面中的所有图片、文字、css和js文件,并且可以生成单个index.html页面。软件功能1、下载页面所有图片2、保存带参数的css和js文件3、一键保存页面文字4、单页下载所有相关信息
点击下载(人气:282)
网页css js 抓取助手(一个网站练习一下爬虫实现的功能全站获取CSS,JS,img等文件连接获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-28 23:18
闲暇之余,刚好找了一个网站来练习爬虫,总结一下写爬虫时遇到的知识点。
实现的功能
抓取站点范围的 URL
获取CSS、JS、img等文件连接
获取文件名
将文件保存到本地
使用的模块
urllib
BS4
回覆
操作系统
第 1 部分:抓取站点范围的 URL
先粘贴代码
# 获取当前页面子网站子网站
def get_urls(url, baseurl, urls):
with request.urlopen(url) as f:
data = f.read().decode('utf-8')
link = bs(data).find_all('a')
for i in link:
suffix = i.get('href')
# 设置排除写入的子连接
if suffix == '#' or suffix == '#carousel-example-generic' or 'javascript:void(0)' in suffix:
continue
else:
# 构建urls
childurl = baseurl + suffix
if childurl not in urls:
urls.append(childurl)
# 获取整个网站URL
def getallUrl(url, baseurl, urls):
get_urls(url, baseurl, urls)
end = len(urls)
start = 0
while(True):
if start == end:
break
for i in range(start, end):
get_urls(urls[i], baseurl, urls)
time.sleep(1)
start = end
end = len(urls)
通过urllib包中的请求,调用urlopen访问网站
首先从首页开始,首页一般收录各个子页面的url,将抓取到的url添加到一个列表中
然后读取这个列表的每个元素,依次访问,获取子页面的url连接,加入到列表中。
感觉这样抓取全站的url不是很靠谱,有时间再完善。
第二部分:获取css、js、img的连接
先粘贴代码
# 获取当前网页代码
with request.urlopen(url) as f:
html_source = f.read().decode()
<p> # css,js,img正则表达式,以获取文件相对路径
patterncss = ' 查看全部
网页css js 抓取助手(一个网站练习一下爬虫实现的功能全站获取CSS,JS,img等文件连接获取)
闲暇之余,刚好找了一个网站来练习爬虫,总结一下写爬虫时遇到的知识点。
实现的功能
抓取站点范围的 URL
获取CSS、JS、img等文件连接
获取文件名
将文件保存到本地
使用的模块
urllib
BS4
回覆
操作系统
第 1 部分:抓取站点范围的 URL
先粘贴代码
# 获取当前页面子网站子网站
def get_urls(url, baseurl, urls):
with request.urlopen(url) as f:
data = f.read().decode('utf-8')
link = bs(data).find_all('a')
for i in link:
suffix = i.get('href')
# 设置排除写入的子连接
if suffix == '#' or suffix == '#carousel-example-generic' or 'javascript:void(0)' in suffix:
continue
else:
# 构建urls
childurl = baseurl + suffix
if childurl not in urls:
urls.append(childurl)
# 获取整个网站URL
def getallUrl(url, baseurl, urls):
get_urls(url, baseurl, urls)
end = len(urls)
start = 0
while(True):
if start == end:
break
for i in range(start, end):
get_urls(urls[i], baseurl, urls)
time.sleep(1)
start = end
end = len(urls)
通过urllib包中的请求,调用urlopen访问网站
首先从首页开始,首页一般收录各个子页面的url,将抓取到的url添加到一个列表中
然后读取这个列表的每个元素,依次访问,获取子页面的url连接,加入到列表中。
感觉这样抓取全站的url不是很靠谱,有时间再完善。
第二部分:获取css、js、img的连接
先粘贴代码
# 获取当前网页代码
with request.urlopen(url) as f:
html_source = f.read().decode()
<p> # css,js,img正则表达式,以获取文件相对路径
patterncss = '
网页css js 抓取助手(如何提高网站百度蜘蛛量量?(组图)期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-28 04:00
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧
作者:迟到991人查看评论:04年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧
作者:熊哥 club903 浏览评论:05年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅
作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术、伪装指南、高级代码会让你惊叹。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直是渣渣,我也无计可施。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?
作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛的数量之前,我们必须考虑:增加网站的开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)
作者:赖1681人查看评论:03年前
刷新和学习新事物,保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前是 presto,现在改为 G
阅读全文
加快网站访问的9种方法
作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览
作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
网页css js 抓取助手(如何提高网站百度蜘蛛量量?(组图)期)
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧
作者:迟到991人查看评论:04年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧
作者:熊哥 club903 浏览评论:05年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅
作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术、伪装指南、高级代码会让你惊叹。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直是渣渣,我也无计可施。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?
作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛的数量之前,我们必须考虑:增加网站的开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)
作者:赖1681人查看评论:03年前
刷新和学习新事物,保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前是 presto,现在改为 G
阅读全文
加快网站访问的9种方法
作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览
作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
网页css js 抓取助手(基于文本密度的分析(DOM无关)的评分制筛选算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-22 05:16
评委,请轻拍。. .
我一直对抓取网页内容非常感兴趣。大约三年前,我曾经做过一个“新闻阅读器”。那个时候,我非常喜欢看新闻。嗯,所以我开发了一个浏览器书签插件,用js把页面的body提取出来,通过一个图层覆盖显示在页面上。当时只能想到通过正则表达式搜索目标dom,这也是爬虫最多的。取方法。
当时这个功能是在分析了网易、新浪、QQ、凤凰等各大门户网站后实现的。这是最笨的方法,但优点是准确率高,缺点是一旦目标页面修改了源代码,可能要重新匹配。
后来发现自己看的页面越来越多,上面的方法已经不适合我的需要了。但最近因为我开发并需要一个采集助手,我开始寻找解决方案。
我主要找到了3个解决方案:
1)基于dom节点的分数筛选算法
国外有一个叫可读的浏览器书签插件来实现这个,地址:,看到这个我印象很深刻,准确率很高。
2)基于文本密度的分析(DOM 无关)
这个方法的思路也很好,适用性也比较好。试过用JS来实现,但是能力有限,没有做出匹配度高的成品,所以放弃了。
3)基于图像识别
这与 AlphaGo 使用的方法非常接近。通过图像识别,只要对机器人进行足够的训练,就可以做到。其他领域已经有大量案例了,但是没有看到文本识别的具体实现(或者没有找到案例)。)。
以上是我找到的 3 个实现。
但是因为我只是一个web开发人员,所以对JS的理解也比较好,其他语言能力也很有限。于是我尝试了基于DOM的过滤,发现readable的实现比较复杂。我想知道是否有更有效的解决方案?
后来,我发现了一个规律。一般来说,body部分的p标签数量非常多,比其他部分多很多,因为网页的大部分内容都是通过WYSIWYG编辑器发布的,而这些编辑器会生成一个语义兼容的节点。
于是,我就利用这个规律,开发了一个小爬虫插件,效果还不错。当然,它还是很基础的,需要改进。
var pt = $doc.find("p").siblings().parent();
var l = pt.length - 1;
var e = l;
var arr = [];
while(l>=0){
arr[l] = $(pt[l]).find("p").length;
l--;
}
var temArr = arr.concat();
var newArr = arrSort(arr);
var c = temArr.indexOf(newArr[e]);
content = $(pt[c]).html();
代码很简单,但是经过我的测试,80%以上的网页(主要是文章页面)都可以爬取成功。基于此,我开发了 JSpapa 集合助手:
如果您对此有更好的解决方案,可以在下面进行探索。
如需转载本文请联系作者,并注明出处 查看全部
网页css js 抓取助手(基于文本密度的分析(DOM无关)的评分制筛选算法)
评委,请轻拍。. .
我一直对抓取网页内容非常感兴趣。大约三年前,我曾经做过一个“新闻阅读器”。那个时候,我非常喜欢看新闻。嗯,所以我开发了一个浏览器书签插件,用js把页面的body提取出来,通过一个图层覆盖显示在页面上。当时只能想到通过正则表达式搜索目标dom,这也是爬虫最多的。取方法。
当时这个功能是在分析了网易、新浪、QQ、凤凰等各大门户网站后实现的。这是最笨的方法,但优点是准确率高,缺点是一旦目标页面修改了源代码,可能要重新匹配。
后来发现自己看的页面越来越多,上面的方法已经不适合我的需要了。但最近因为我开发并需要一个采集助手,我开始寻找解决方案。
我主要找到了3个解决方案:
1)基于dom节点的分数筛选算法
国外有一个叫可读的浏览器书签插件来实现这个,地址:,看到这个我印象很深刻,准确率很高。
2)基于文本密度的分析(DOM 无关)
这个方法的思路也很好,适用性也比较好。试过用JS来实现,但是能力有限,没有做出匹配度高的成品,所以放弃了。
3)基于图像识别
这与 AlphaGo 使用的方法非常接近。通过图像识别,只要对机器人进行足够的训练,就可以做到。其他领域已经有大量案例了,但是没有看到文本识别的具体实现(或者没有找到案例)。)。
以上是我找到的 3 个实现。
但是因为我只是一个web开发人员,所以对JS的理解也比较好,其他语言能力也很有限。于是我尝试了基于DOM的过滤,发现readable的实现比较复杂。我想知道是否有更有效的解决方案?
后来,我发现了一个规律。一般来说,body部分的p标签数量非常多,比其他部分多很多,因为网页的大部分内容都是通过WYSIWYG编辑器发布的,而这些编辑器会生成一个语义兼容的节点。
于是,我就利用这个规律,开发了一个小爬虫插件,效果还不错。当然,它还是很基础的,需要改进。
var pt = $doc.find("p").siblings().parent();
var l = pt.length - 1;
var e = l;
var arr = [];
while(l>=0){
arr[l] = $(pt[l]).find("p").length;
l--;
}
var temArr = arr.concat();
var newArr = arrSort(arr);
var c = temArr.indexOf(newArr[e]);
content = $(pt[c]).html();
代码很简单,但是经过我的测试,80%以上的网页(主要是文章页面)都可以爬取成功。基于此,我开发了 JSpapa 集合助手:
如果您对此有更好的解决方案,可以在下面进行探索。
如需转载本文请联系作者,并注明出处
网页css js 抓取助手( 基于Selenium的库——Helium库简介—库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-01-19 12:11
基于Selenium的库——Helium库简介—库)
对于 Python 自动化测试或爬虫开发者来说,你一定听说过 selenium 库。Selenium 本身用作 Web 应用程序测试工具,但它作为爬虫工具也有广泛的用途。
尽管 Selenium 易于使用,但它大部分时间都在处理网页元素,并且需要了解 HTML 页面标签、CSS 选择器和其他知识。
虽然自动化程度很高,但使用起来还是不是很方便,上手也不是很容易。今天小编带大家认识一个基于Selenium的库——Helium。
Helium 库简介
Helium 库是基于 Selenium 的更高级的 Web 自动化工具,它可以通过网页上可以看到的标签和名称等信息实现用户交互。我们可以使用它来执行一系列的鼠标和键盘操作,比如在键盘上点击按键、点击标签、滚动鼠标。
Helium的安装也很简单,如下图所示:
只需要pip install Helium 即可安装,但需要注意的是普通的安装方式会很慢,所以小编使用清华镜像帮助下载,提高下载速度。
安装后,我们可以使用 Helium。首先,我们使用 Helium 登录 GitHub 账号。效果如下图所示:
上图中的程序跳转到GitHub登录界面,然后输入用户名和用户密码,最后点击Login登录GitHub账号。过程非常简单。我们来看看程序是怎么写的。
上面的程序只有短短的五行,每一行的意思都非常清楚,不含糊。
然后程序可以直接登录。下图是对应的selenium登录GitHub程序。
相比之下,可以看出 Helium 程序非常简洁易用。让大家对每一步操作都很清楚。
爬行的女孩图片
接下来,为了更好的展示Helium的强大,小编使用Helium自动抓取百度图片中的女生图片,看看我们是如何实现的,我们先介绍一下程序,按照自己想要的方式下载百度图片对程序的思考。
在上面的程序中,左边是我们的程序索引,右边是我们的程序。我们可以按照提取百度图片的思路看一下程序。小编一步步解释每一行代码:
上面的每一行都对应了程序中每条语句的含义,所以理解起来非常方便。
说实话,之前用过Selenium,但总觉得用起来太重,太贵。现在我有了这个神器,做了一些封装,为我们节省了很多东西。Python 这么有趣,你还在等什么?, 如果你有兴趣,请尝试一下。顺便转发+评论,小编会持续分享Python干货知识! 查看全部
网页css js 抓取助手(
基于Selenium的库——Helium库简介—库)
对于 Python 自动化测试或爬虫开发者来说,你一定听说过 selenium 库。Selenium 本身用作 Web 应用程序测试工具,但它作为爬虫工具也有广泛的用途。
尽管 Selenium 易于使用,但它大部分时间都在处理网页元素,并且需要了解 HTML 页面标签、CSS 选择器和其他知识。
虽然自动化程度很高,但使用起来还是不是很方便,上手也不是很容易。今天小编带大家认识一个基于Selenium的库——Helium。
Helium 库简介
Helium 库是基于 Selenium 的更高级的 Web 自动化工具,它可以通过网页上可以看到的标签和名称等信息实现用户交互。我们可以使用它来执行一系列的鼠标和键盘操作,比如在键盘上点击按键、点击标签、滚动鼠标。
Helium的安装也很简单,如下图所示:
只需要pip install Helium 即可安装,但需要注意的是普通的安装方式会很慢,所以小编使用清华镜像帮助下载,提高下载速度。
安装后,我们可以使用 Helium。首先,我们使用 Helium 登录 GitHub 账号。效果如下图所示:
上图中的程序跳转到GitHub登录界面,然后输入用户名和用户密码,最后点击Login登录GitHub账号。过程非常简单。我们来看看程序是怎么写的。
上面的程序只有短短的五行,每一行的意思都非常清楚,不含糊。
然后程序可以直接登录。下图是对应的selenium登录GitHub程序。
相比之下,可以看出 Helium 程序非常简洁易用。让大家对每一步操作都很清楚。
爬行的女孩图片
接下来,为了更好的展示Helium的强大,小编使用Helium自动抓取百度图片中的女生图片,看看我们是如何实现的,我们先介绍一下程序,按照自己想要的方式下载百度图片对程序的思考。
在上面的程序中,左边是我们的程序索引,右边是我们的程序。我们可以按照提取百度图片的思路看一下程序。小编一步步解释每一行代码:
上面的每一行都对应了程序中每条语句的含义,所以理解起来非常方便。
说实话,之前用过Selenium,但总觉得用起来太重,太贵。现在我有了这个神器,做了一些封装,为我们节省了很多东西。Python 这么有趣,你还在等什么?, 如果你有兴趣,请尝试一下。顺便转发+评论,小编会持续分享Python干货知识!
网页css js 抓取助手(前端已经被玩儿坏了了,瞬间GET了好多前端技能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-19 12:09
)
前端坏了!console.log() 可以将图片输出到控制台和其他很酷的东西,这已经不是什么新闻了。这是一个众所周知的旧消息,例如使用 || 运算符为变量分配默认值。今天在知乎上看到一个帖子。,一瞬间,我得到了一大堆前端技巧,有的是技巧,有的是闻所未闻的冷知识,一时消化不了。现将其分类整理分享给大家,也增加了一些平时的积累和拓展的一些内容。HTML文章浏览器地址栏运行JavaScript代码
很多人应该还知道,JavaScript 代码可以直接在浏览器地址栏中运行,以 javascript: 开头,后跟要执行的语句。例如:
javascript:alert('hello from address bar :)');
将以上代码粘贴到浏览器地址栏回车,alert正常执行,并出现弹窗。
需要注意的是,如果将代码复制粘贴到浏览器地址栏,IE和Chrome会自动去掉代码开头的javascript:,所以需要手动添加才能正确执行。尽管它不会在 Firefox 中自动删除,但它不会。不支持在地址栏运行JS代码,sigh~
这个技术在我的另一篇博文《让Chrome接管邮件连接,收发邮件更方便》中使用,使用浏览器地址栏中的JavaScript代码将Gmail设置为系统的邮件接管程序。
浏览器地址栏运行HTML代码
如果知道上面这个小秘密的人多,那么知道这个秘密的人就会少一些。HTML代码可以直接在非IE内核浏览器的地址栏中运行!
比如在地址栏输入如下代码,回车运行,就会出现指定的页面内容。
data:text/html,Hello, world!
做什么的,可以把浏览器当编辑器
或者在浏览器地址栏上做文章,将以下代码粘贴到地址栏运行,浏览器就变成了一个原创简单的编辑器,就像Windows自带的记事本一样,呵呵。
data:text/html,
毕竟,多亏了 HTML5 中新的 contenteditable 属性,当元素指定了这个属性时,元素的内容就变成了可编辑的。
通过扩展,在控制台中执行以下代码后,整个页面将变为可编辑状态,随意践踏吧~
document.body.contentEditable='true';
使用标签自动解析 URL
很多时候我们有从一个URL中提取域名、查询关键字、变量参数值等的需求,但是万万没想到浏览器可以轻松帮我们完成这个任务,而不需要我们编写规律来爬取。方法是先在JS代码中创建一个a标签,然后将要解析的URL赋值给a的href属性,然后得到我们想要的一切。
var a = document.createElement('a'); a.href = 'http://www.cnblogs.com/wayou/p/'; console.log(a.host);
使用这个原理并对其进行一些扩展,我们就有了一种更强大的解析 URL 部分的通用方法。下面的代码来自 James 的博客。
<p>function parseURL(url) { var a = document.createElement('a'); a.href = url; return { source: url, protocol: a.protocol.replace(':',''), host: a.hostname, port: a.port, query: a.search, params: (function(){ var ret = {}, seg =a.search.replace(/^\?/,'').split('&'), len = seg.length, i = 0, s; for (;i 查看全部
网页css js 抓取助手(前端已经被玩儿坏了了,瞬间GET了好多前端技能
)
前端坏了!console.log() 可以将图片输出到控制台和其他很酷的东西,这已经不是什么新闻了。这是一个众所周知的旧消息,例如使用 || 运算符为变量分配默认值。今天在知乎上看到一个帖子。,一瞬间,我得到了一大堆前端技巧,有的是技巧,有的是闻所未闻的冷知识,一时消化不了。现将其分类整理分享给大家,也增加了一些平时的积累和拓展的一些内容。HTML文章浏览器地址栏运行JavaScript代码
很多人应该还知道,JavaScript 代码可以直接在浏览器地址栏中运行,以 javascript: 开头,后跟要执行的语句。例如:
javascript:alert('hello from address bar :)');
将以上代码粘贴到浏览器地址栏回车,alert正常执行,并出现弹窗。
需要注意的是,如果将代码复制粘贴到浏览器地址栏,IE和Chrome会自动去掉代码开头的javascript:,所以需要手动添加才能正确执行。尽管它不会在 Firefox 中自动删除,但它不会。不支持在地址栏运行JS代码,sigh~
这个技术在我的另一篇博文《让Chrome接管邮件连接,收发邮件更方便》中使用,使用浏览器地址栏中的JavaScript代码将Gmail设置为系统的邮件接管程序。
浏览器地址栏运行HTML代码
如果知道上面这个小秘密的人多,那么知道这个秘密的人就会少一些。HTML代码可以直接在非IE内核浏览器的地址栏中运行!
比如在地址栏输入如下代码,回车运行,就会出现指定的页面内容。
data:text/html,Hello, world!
做什么的,可以把浏览器当编辑器
或者在浏览器地址栏上做文章,将以下代码粘贴到地址栏运行,浏览器就变成了一个原创简单的编辑器,就像Windows自带的记事本一样,呵呵。
data:text/html,
毕竟,多亏了 HTML5 中新的 contenteditable 属性,当元素指定了这个属性时,元素的内容就变成了可编辑的。
通过扩展,在控制台中执行以下代码后,整个页面将变为可编辑状态,随意践踏吧~
document.body.contentEditable='true';
使用标签自动解析 URL
很多时候我们有从一个URL中提取域名、查询关键字、变量参数值等的需求,但是万万没想到浏览器可以轻松帮我们完成这个任务,而不需要我们编写规律来爬取。方法是先在JS代码中创建一个a标签,然后将要解析的URL赋值给a的href属性,然后得到我们想要的一切。
var a = document.createElement('a'); a.href = 'http://www.cnblogs.com/wayou/p/'; console.log(a.host);
使用这个原理并对其进行一些扩展,我们就有了一种更强大的解析 URL 部分的通用方法。下面的代码来自 James 的博客。
<p>function parseURL(url) { var a = document.createElement('a'); a.href = url; return { source: url, protocol: a.protocol.replace(':',''), host: a.hostname, port: a.port, query: a.search, params: (function(){ var ret = {}, seg =a.search.replace(/^\?/,'').split('&'), len = seg.length, i = 0, s; for (;i
网页css js 抓取助手( Web狙击手的功能特点及功能介绍-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-18 17:19
Web狙击手的功能特点及功能介绍-上海怡健医学)
Web Sniper 是一个网站 模板批量下载工具。使用该工具可以自动抓取指定的网站页面及其收录的所有元素,如CSS、图片、JS等。分类下载,并支持嵌套网页的解析,帮助用户快速模仿< @网站,或者学习网页编辑。
只要看到你喜欢的网站,告诉网络狙击手地址,他会快速帮你按分类获取所有元素下载,并且支持嵌套和相对路径,让你获取资源完整,准确。
【特征】
1、暴力批量下载,手动下载模板的新替代品,只要输入目标页面URL,即可下载对应页面及其收录的各种元素。
2、Css、Img、Js、Jquery、Swf分类下载。除了下载分析网页加载的Jscss文件外,还可以分析嵌套在JsCss文件中的JsCss文件。
3、快速为用户节省建站时间,看到自己喜欢的页面,使用软件下载,简单修改即可上线。
4、100%第一时间提醒最新任务,任务提醒,获取全网第一手新任务订单,保障任务下达后第一时间通知及时响应。
【发行说明】
解决js文件本地化的bug
添加了 embedSWF 引用的 SWF 文件的下载
批量增加多页批量增加功能
解决js文件中url()引用的图片下载失败的问题
解决js文件中write()引用的js文件无法下载的问题
修复网页文件修改为无后缀下载失败的问题
解决@import引用的CSS文件无法下载的问题
增加软件反馈功能。问题反馈可直接在软件上进行
解决文件不存在时软件假死问题 查看全部
网页css js 抓取助手(
Web狙击手的功能特点及功能介绍-上海怡健医学)
Web Sniper 是一个网站 模板批量下载工具。使用该工具可以自动抓取指定的网站页面及其收录的所有元素,如CSS、图片、JS等。分类下载,并支持嵌套网页的解析,帮助用户快速模仿< @网站,或者学习网页编辑。
只要看到你喜欢的网站,告诉网络狙击手地址,他会快速帮你按分类获取所有元素下载,并且支持嵌套和相对路径,让你获取资源完整,准确。
【特征】
1、暴力批量下载,手动下载模板的新替代品,只要输入目标页面URL,即可下载对应页面及其收录的各种元素。
2、Css、Img、Js、Jquery、Swf分类下载。除了下载分析网页加载的Jscss文件外,还可以分析嵌套在JsCss文件中的JsCss文件。
3、快速为用户节省建站时间,看到自己喜欢的页面,使用软件下载,简单修改即可上线。
4、100%第一时间提醒最新任务,任务提醒,获取全网第一手新任务订单,保障任务下达后第一时间通知及时响应。
【发行说明】
解决js文件本地化的bug
添加了 embedSWF 引用的 SWF 文件的下载
批量增加多页批量增加功能
解决js文件中url()引用的图片下载失败的问题
解决js文件中write()引用的js文件无法下载的问题
修复网页文件修改为无后缀下载失败的问题
解决@import引用的CSS文件无法下载的问题
增加软件反馈功能。问题反馈可直接在软件上进行
解决文件不存在时软件假死问题
网页css js 抓取助手( 基于js代码是如何调用网页助手小精灵的呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-18 02:13
基于js代码是如何调用网页助手小精灵的呢?(图))
基于JS调用web助手向导实现导航栏的方法
更新时间:2016-06-17 14:55:25 作者:柯南&
为网站添加web助手精灵,当用户访问网站时,向用户打招呼,或者传递网站的一些重要信息,给用户带来极好的体验感,那么如何调用基于js代码的web助手精灵?让我们一起学习脚本屋编辑器
1.概览
为网站添加web助手向导,当用户访问网站时,向用户打招呼,或者传递网站的一些重要信息,不仅可以帮助用户快速了解网站 >,并且可以通过 网站 给用户留下深刻印象。本例将介绍通过 JavaScript 调用网络助手向导的方法。
2.技术要点
这个例子主要是通过微软的ActiveX组件Microsoft Agent来实现的。Microsoft Agent 提供了很多方法来控制 Agent 的角色,下面将详细介绍。
一个。load() 方法:用于读取要使用的角色,该方法收录两个参数,一个用于指定角色的名称,另一个用于指定角色存储的文件。
湾。Show() 方法:用于在屏幕上显示字符。
C。Hide() 方法:用于隐藏字符。
d。Speak() 方法:用于实现字符朗读,该方法有一个参数来指定朗读的内容。
e. MoveTo()方法:用于将字符移动到屏幕上的指定位置,该方法有两个参数,一个用于指定x轴坐标,另一个用于指定y轴坐标轴。
F。Play() 方法:用于指定要播放的动画。该方法只有一个参数,用于指定表示动画的字符串。它的值包括Announce、Explain、Congratulate、greet、Gestureright、Gestureleft、Gesturedown、Gestureup、Pleased和Read等。
3.具体实现
(1)在需要显示网络助手精灵的页面的标记中编写自定义JavaScript函数loadAgent()来加载要使用的角色。loadAgent()函数的具体代码如下:
function loadAgent(id){
try{
id=new ActiveXObject("Agent.Control.2"); //创建一个ActiveX控件
id.Connected = true;
id.Characters.Load("MrAgent","merlin.acs"); //装入要使用的角色
return id;
}catch (err){
return false;
}
}
(在2)loadAgent()函数后面写了一个自定义的JavaScript函数controlAgent()来调用和控制web助手向导,controlAgent()函数的具体代码如下:
function controlAgent(){
if (agent=loadAgent("agent")){
var mrAgentID="MrAgent";
mrAgent = agent.Characters.Character(mrAgentID); //获取助手对象
mrAgent.MoveTo(200,200); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Speak("欢迎来到明日科技网站!"); //提示语
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Play("Pleased"); //做请的手势
mrAgent.Speak("我们的网址:www.cccxy.com"); //提示语
mrAgent.Hide(); //隐藏助手
mrAgent.MoveTo(600,300); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Play("Read") //作出读书的动作
mrAgent.Speak("我们会热心解决您学习过程中遇到的疑问"); //提示语
mrAgent.Play("Idle1_1"); //做出无所事事的样子
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Speak("记住我们的网址:www.cccxy.com"); //提示语
mrAgent.Play("greet"); //问候
mrAgent.Speak("感谢您的到来"); //提示语
mrAgent.Play("Idle2_2"); //做出无所事事的样子
mrAgent.Hide(); //隐藏助手
}
}
(3)页面加载完成后编写JavaScript代码调用和控制web助手向导。具体代码如下:
window.onload=function(){
controlAgent(); //调用并控制网页助手小精灵
}
以上就是小编介绍的基于JS实现导航栏调用web助手精灵的方法。我希望它对你有帮助。如有任何问题,请给我留言,小编会及时回复您。还要感谢大家对脚本之家网站的支持! 查看全部
网页css js 抓取助手(
基于js代码是如何调用网页助手小精灵的呢?(图))
基于JS调用web助手向导实现导航栏的方法
更新时间:2016-06-17 14:55:25 作者:柯南&
为网站添加web助手精灵,当用户访问网站时,向用户打招呼,或者传递网站的一些重要信息,给用户带来极好的体验感,那么如何调用基于js代码的web助手精灵?让我们一起学习脚本屋编辑器
1.概览
为网站添加web助手向导,当用户访问网站时,向用户打招呼,或者传递网站的一些重要信息,不仅可以帮助用户快速了解网站 >,并且可以通过 网站 给用户留下深刻印象。本例将介绍通过 JavaScript 调用网络助手向导的方法。
2.技术要点
这个例子主要是通过微软的ActiveX组件Microsoft Agent来实现的。Microsoft Agent 提供了很多方法来控制 Agent 的角色,下面将详细介绍。
一个。load() 方法:用于读取要使用的角色,该方法收录两个参数,一个用于指定角色的名称,另一个用于指定角色存储的文件。
湾。Show() 方法:用于在屏幕上显示字符。
C。Hide() 方法:用于隐藏字符。
d。Speak() 方法:用于实现字符朗读,该方法有一个参数来指定朗读的内容。
e. MoveTo()方法:用于将字符移动到屏幕上的指定位置,该方法有两个参数,一个用于指定x轴坐标,另一个用于指定y轴坐标轴。
F。Play() 方法:用于指定要播放的动画。该方法只有一个参数,用于指定表示动画的字符串。它的值包括Announce、Explain、Congratulate、greet、Gestureright、Gestureleft、Gesturedown、Gestureup、Pleased和Read等。
3.具体实现
(1)在需要显示网络助手精灵的页面的标记中编写自定义JavaScript函数loadAgent()来加载要使用的角色。loadAgent()函数的具体代码如下:
function loadAgent(id){
try{
id=new ActiveXObject("Agent.Control.2"); //创建一个ActiveX控件
id.Connected = true;
id.Characters.Load("MrAgent","merlin.acs"); //装入要使用的角色
return id;
}catch (err){
return false;
}
}
(在2)loadAgent()函数后面写了一个自定义的JavaScript函数controlAgent()来调用和控制web助手向导,controlAgent()函数的具体代码如下:
function controlAgent(){
if (agent=loadAgent("agent")){
var mrAgentID="MrAgent";
mrAgent = agent.Characters.Character(mrAgentID); //获取助手对象
mrAgent.MoveTo(200,200); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Speak("欢迎来到明日科技网站!"); //提示语
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Play("Pleased"); //做请的手势
mrAgent.Speak("我们的网址:www.cccxy.com"); //提示语
mrAgent.Hide(); //隐藏助手
mrAgent.MoveTo(600,300); //移动助手
mrAgent.Show(); //显示助手
mrAgent.Play("Explain"); //做解释的手势
mrAgent.Play("Read") //作出读书的动作
mrAgent.Speak("我们会热心解决您学习过程中遇到的疑问"); //提示语
mrAgent.Play("Idle1_1"); //做出无所事事的样子
mrAgent.Play("Gestureright"); //右手做手势
mrAgent.Speak("记住我们的网址:www.cccxy.com"); //提示语
mrAgent.Play("greet"); //问候
mrAgent.Speak("感谢您的到来"); //提示语
mrAgent.Play("Idle2_2"); //做出无所事事的样子
mrAgent.Hide(); //隐藏助手
}
}
(3)页面加载完成后编写JavaScript代码调用和控制web助手向导。具体代码如下:
window.onload=function(){
controlAgent(); //调用并控制网页助手小精灵
}
以上就是小编介绍的基于JS实现导航栏调用web助手精灵的方法。我希望它对你有帮助。如有任何问题,请给我留言,小编会及时回复您。还要感谢大家对脚本之家网站的支持!
网页css js 抓取助手(一个屏蔽CSDN博客页面多余内容的扩展吧这里插件名称填写 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-18 02:11
)
在阅读本章之前,请阅读自定义扩展部分
这种扩展方法是应用最广泛的扩展方法。通过将css和js注入到指定的网页中,可以改变网页的外观或者增强网页的功能。通过css和js注入可以实现非常强大的功能。理论上,你甚至可以通过开发扩展使百度页面与谷歌完全一样。
该扩展在用户打开网页时始终运行,运行过程如下
检测是否需要运行,主要是将打开页面的地址与预设的规则进行比较(如何添加规则后面会讲),将css代码注入页面,将js代码注入页
让我们通过一个演示来了解开发过程。
我们来写一个屏蔽CSDN博客页面冗余内容的扩展
此处填写插件名称 CSDN博客简洁版
通过切换css js标签页添加对应代码
在这个演示中,我们只需要添加 css 代码。
#recommend-right, .blog_container_aside {
display: none;
}
main {
box-shadow: rgb(199 184 184) 0px 0px 20px;
margin-top: 30px;
}
@media screen and (min-width: 1380px) {
.nodata .container.clearfix main {
width: 100%;
}
#rightAside {
display: none;
}
}
@media (min-width: 1320px) and (max-width: 1380px) {
.nodata .container.clearfix main {
width: 100%;
}
}
@media screen and (max-width: 1320px) {
.nodata .container.clearfix main {
width: 100%;
}
}
保存代码后,只需打开一个博客页面即可查看扩展效果
如您所见,没有左右两侧
这是没有扩展的样子
查看全部
网页css js 抓取助手(一个屏蔽CSDN博客页面多余内容的扩展吧这里插件名称填写
)
在阅读本章之前,请阅读自定义扩展部分
这种扩展方法是应用最广泛的扩展方法。通过将css和js注入到指定的网页中,可以改变网页的外观或者增强网页的功能。通过css和js注入可以实现非常强大的功能。理论上,你甚至可以通过开发扩展使百度页面与谷歌完全一样。
该扩展在用户打开网页时始终运行,运行过程如下
检测是否需要运行,主要是将打开页面的地址与预设的规则进行比较(如何添加规则后面会讲),将css代码注入页面,将js代码注入页
让我们通过一个演示来了解开发过程。
我们来写一个屏蔽CSDN博客页面冗余内容的扩展
此处填写插件名称 CSDN博客简洁版
通过切换css js标签页添加对应代码
在这个演示中,我们只需要添加 css 代码。
#recommend-right, .blog_container_aside {
display: none;
}
main {
box-shadow: rgb(199 184 184) 0px 0px 20px;
margin-top: 30px;
}
@media screen and (min-width: 1380px) {
.nodata .container.clearfix main {
width: 100%;
}
#rightAside {
display: none;
}
}
@media (min-width: 1320px) and (max-width: 1380px) {
.nodata .container.clearfix main {
width: 100%;
}
}
@media screen and (max-width: 1320px) {
.nodata .container.clearfix main {
width: 100%;
}
}
保存代码后,只需打开一个博客页面即可查看扩展效果
如您所见,没有左右两侧
这是没有扩展的样子
网页css js 抓取助手(2.作品整体构思及网站(网页)的主体构想(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-18 02:08
**
1.作品总体构思及网站主要构思(网页)
**
我的网站的想法是基于HTML5、JavaScript和CSS3的web开发应用技术构建一个网页。网站的主题是相助60年,民族团结大家庭。网站包括首页、成就、广西福利、民族活动、展望未来、关于。网站最大的特点是借助CSS3的网页布局应用技术,使网页界面更具可读性,从而使网页具有亲和力。
2.作品整体设计方案及制作思路
在制作网页之前,我确定了制作网页的五个步骤:
一、确定网站主题:网站主题是要建立的网站的主要内容。网站 必须有明确的主题。在这里我的网站主题是60年互相帮助,把国家团结成一个大家庭。
二、采集素材:确定网站的主题后,就开始围绕主题采集素材。材料可以从书籍、报纸、多媒体中获取,也可以从互联网上采集,然后将采集到的材料从原石中提取出来,将赝品作为制作自己网页的材料保存下来。在这里采集了很多关于广西建国60周年的图片和资料,并前往官网进行了详细了解。
三、策划网站:网站设计的成功很大程度上取决于设计师的策划水平。规划网站就像设计一座建筑,设计好图纸后,就可以建造一座漂亮的建筑。网站策划收录了很多内容,比如网站的结构、栏目的设置、网站的风格、配色、布局、文字和图片的使用等等。考虑到所有这些方面,我们可以在生产中精通和自信。只有这样制作出来的网页才能具有个性、特色和吸引力。在规划上,我将网站的结构做成一页收录所有内容,栏目设置和最常见的网站没有区别,但网站的整体风格 @网站 还是比较新颖的,比如 网站 的布局经过精心设计,采用 CSS3 网页布局技术,达到完美效果。通过点击网站的顶部或底部一列,您可以立即转到该列的详细信息。我觉得这是这个页面最吸引人的特效。
四、选择合适的创作工具:虽然您选择的工具不会影响您的网页设计,但功能强大、易于使用的软件通常可以事半功倍。网页设计基于使用 CSS3 网页开发技术。我使用WebStorm,这是当今开发网页的主流软件。WebStorm 是 jetbrains 公司的 JavaScript 开发工具。目前已被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。它与 IntelliJ IDEA 同源,继承了 IntelliJ IDEA 强大的 JS 部分的功能。由于支持智能代码补全,支持不同浏览器的提示,并且还包括所有用户定义的函数(在项目中),代码完成包括所有流行的库,例如:JQuery、YUI、Dojo、Prototype、Mootools 和 Bindows。代码格式化,代码不仅可以格式化,所有的规则都可以自己定义。HTML提示,人们经常用js代码写HTML代码,一般来说是很痛苦的,但是有了智能提示,就好玩多了。并且在html中有js提示。关联查询,只需按Ctrl键点击某个函数或变量等,即可直接跳转到定义处;您可以在整个项目中搜索函数或变量,也可以找到并使用它们并突出显示它们。代码导航和用法查询,代码重构,这个操作有点类似于Resharper,代码检查和快速修复,可以快速发现代码中的错误或需要优化的地方,并给出快速修复的修改建议。代码调试,支持代码调试,界面类似IDEA,非常方便。代码结构浏览,可以快速浏览定位。代码折叠,虽然功能小,但比方便高效的打包或移除外设代码,自动提示打包或移除外设代码,一键完成。代码检查和快速修复,可以快速发现代码中的错误或需要优化的地方,并给出快速修复的修改建议。代码调试,支持代码调试,界面类似IDEA,非常方便。代码结构浏览,可以快速浏览定位。代码折叠,虽然功能小,但比方便高效的打包或移除外设代码,自动提示打包或移除外设代码,一键完成。
五、创建网页:材料可用并选择工具。接下来,你需要按照计划,一步一步把你的想法变成现实。这是一个复杂而细致的过程。然后小,先简单,然后复杂。所谓“先大后小”,是指在制作网页时,先设计大结构,再逐步完善小结构设计。所谓先简单,后复杂,就是先设计简单的内容,再设计复杂的内容,这样有问题的时候可以很方便的修改。制作网页时要灵活,灵活使用模板,可以大大提高生产效率。
网站包括首页、成就、广西福利、民族活动、展望未来、关于。想出点子,可以参考一些网页的排版,把对应的代码组合在一起,注入自己的编程设计,去理解和组成你看到的网页。
3.主要技术和知识点的应用,疑难问题的解决
在这里,我将介绍网页创建过程中使用的主要技术和知识点,以及解决难题的方法。
3.1 网页整体布局设计
作为一种视觉语言,网页设计应该注重布局和布局。主页的设计与平面设计虽然不一样,但它们有很多相似之处,应该充分利用和借鉴。版面设计通过文字和图形的空间结合表现出和谐与美感。一个好的网页设计师还应该知道哪一段文字和图形应该落入,以使整个网页熠熠生辉。多页面网站的页面布局和设计要求体现页面之间的有机联系,特别是要处理好页面之间和页面内部的顺序和内容的关系。尤其是当我们用网页效果来体现主题的时候,我们应该更加注重整体布局的合理性,以达到最佳的视觉表现。提供广西主页、广西成就、广西福利、广西民族活动、展望我们的未来、介绍信息。应该如何安排,让观者有一个流畅的视觉体验,以利于他对事物的理解,促进他的认知和参与。
3.2 网页设计中色彩的运用
色彩是艺术表现的要素之一。在网页设计中,根据和谐、平衡、强调的原则,将不同的颜色组合搭配,形成一个漂亮的页面。根据色彩对人心理的影响,合理使用。根据色彩记忆原理,一般暖色比冷色记忆力强。颜色还具有联想性和象征性,如红色象征血液、太阳、中国和民族;蓝色象征着大海、天空和水面。因此,在设计民族活动时,要使用红色活泼的色彩,使人们在心理上接近平和,增强人们对广西的热爱,达到良好的视觉效果。还需要注意的是,虽然网页上对颜色的应用没有限制,但不能无节制地使用多种颜色。一般来说,应根据整体风格的要求,先确定一种或两种主色。在使用颜色的过程中,另一个需要注意的问题是:由于国家、种族、宗教信仰的不同,以及生活的地理位置、文化修养的差异等,不同的人群有对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。应先根据整体风格的要求确定一种或两种主色。在使用颜色的过程中,另一个需要注意的问题是:由于国家、种族、宗教信仰的不同,以及生活的地理位置、文化修养的差异等,不同的人群有对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。应先根据整体风格的要求确定一种或两种主色。在使用颜色的过程中,另一个需要注意的问题是:由于国家、种族、宗教信仰的不同,以及生活的地理位置、文化修养的差异等,不同的人群有对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。不同的人群对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。不同的人群对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。
3.3 网页形式和内容统一
要将丰富的含义和各种形式组织成统一的页面结构,形式语言必须符合页面内容,体现内容的丰富含义。通过对比与和谐、对称与平衡、韵律与韵律、留白,通过空间、文字与图形的关系建立整体平衡,形成和谐的美感。比如在对称原则的页面设计中,它的平衡有时会让页面显得死板,但是如果你添加一些动态的文字、图案,或者使用夸张的方法来表达内在
4.工作完成后的总结和感受
总的来说,通过这次对网页设计的学习,有收获,也有遗憾,也有不足,但我认为自己已经踏入了网页设计的大门。只要我努力学习和提高,依靠我对网页设计的热情和执着,我未来设计的网页会更加专业和完美。也希望老师在以后的日子里给予更多的指导。网页设计中还有更多的技能需要我们去挖掘和研究。由于平时课程比较忙,学习时间也比较少,网页设计软件的强大功能都没有得到充分利用。不知不觉中,网页设计课程就要结束了,这门课程的内容比我想象的还要丰富。
5.了解HTML等Web前端知识5、CSS3、JavaScript
HTML5:万维网的核心语言,标准通用标记语言下超文本标记语言(HTML)的第五次重大修订,网页前端的标准编写;越来越多的行业巨头不断对 HTML5 看好。除了苹果、微软、黑莓之外,谷歌的 Youtube 也部分使用了 HTML5;Chrome 浏览器宣布全面支持 HTML5;Facebook 不遗余力地传播 HTML5。一切正如正义无线总裁王国春所说:“HTML5代表了移动互联网发展的趋势,总有一天它会成为主流技术。”
CSS 代表层叠样式表。在网页制作中使用级联样式表技术,可以有效实现对页面布局、字体、颜色、背景等效果的更精准控制。通过对相应代码的一些简单修改,您可以更改同一页面的不同部分或具有不同页数的页面的外观和格式。CSS3 是 CSS 技术的升级版,CSS3 语言开发正朝着模块化方向发展。以前的规范作为一个模块太大太复杂了,所以,把它分解成更小的模块,增加了更多的新模块。这些模块包括:框模型、列表模块、超链接模式、语言模块、背景和边框、文字效果、多栏布局等。
JavaScript 是一种文字脚本语言,是一种动态类型、弱类型、基于原型的语言,具有对类型的内置支持。它的解释器称为 JavaScript 引擎,它是浏览器的一部分,广泛用于客户端脚本语言。它最初用于 HTML(标准通用标记语言下的应用程序)网页,为 HTML5 网页添加动态功能。.
如图所示
作品的源代码在我的下载资源中。 查看全部
网页css js 抓取助手(2.作品整体构思及网站(网页)的主体构想(图))
**
1.作品总体构思及网站主要构思(网页)
**
我的网站的想法是基于HTML5、JavaScript和CSS3的web开发应用技术构建一个网页。网站的主题是相助60年,民族团结大家庭。网站包括首页、成就、广西福利、民族活动、展望未来、关于。网站最大的特点是借助CSS3的网页布局应用技术,使网页界面更具可读性,从而使网页具有亲和力。
2.作品整体设计方案及制作思路
在制作网页之前,我确定了制作网页的五个步骤:
一、确定网站主题:网站主题是要建立的网站的主要内容。网站 必须有明确的主题。在这里我的网站主题是60年互相帮助,把国家团结成一个大家庭。
二、采集素材:确定网站的主题后,就开始围绕主题采集素材。材料可以从书籍、报纸、多媒体中获取,也可以从互联网上采集,然后将采集到的材料从原石中提取出来,将赝品作为制作自己网页的材料保存下来。在这里采集了很多关于广西建国60周年的图片和资料,并前往官网进行了详细了解。
三、策划网站:网站设计的成功很大程度上取决于设计师的策划水平。规划网站就像设计一座建筑,设计好图纸后,就可以建造一座漂亮的建筑。网站策划收录了很多内容,比如网站的结构、栏目的设置、网站的风格、配色、布局、文字和图片的使用等等。考虑到所有这些方面,我们可以在生产中精通和自信。只有这样制作出来的网页才能具有个性、特色和吸引力。在规划上,我将网站的结构做成一页收录所有内容,栏目设置和最常见的网站没有区别,但网站的整体风格 @网站 还是比较新颖的,比如 网站 的布局经过精心设计,采用 CSS3 网页布局技术,达到完美效果。通过点击网站的顶部或底部一列,您可以立即转到该列的详细信息。我觉得这是这个页面最吸引人的特效。
四、选择合适的创作工具:虽然您选择的工具不会影响您的网页设计,但功能强大、易于使用的软件通常可以事半功倍。网页设计基于使用 CSS3 网页开发技术。我使用WebStorm,这是当今开发网页的主流软件。WebStorm 是 jetbrains 公司的 JavaScript 开发工具。目前已被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。它与 IntelliJ IDEA 同源,继承了 IntelliJ IDEA 强大的 JS 部分的功能。由于支持智能代码补全,支持不同浏览器的提示,并且还包括所有用户定义的函数(在项目中),代码完成包括所有流行的库,例如:JQuery、YUI、Dojo、Prototype、Mootools 和 Bindows。代码格式化,代码不仅可以格式化,所有的规则都可以自己定义。HTML提示,人们经常用js代码写HTML代码,一般来说是很痛苦的,但是有了智能提示,就好玩多了。并且在html中有js提示。关联查询,只需按Ctrl键点击某个函数或变量等,即可直接跳转到定义处;您可以在整个项目中搜索函数或变量,也可以找到并使用它们并突出显示它们。代码导航和用法查询,代码重构,这个操作有点类似于Resharper,代码检查和快速修复,可以快速发现代码中的错误或需要优化的地方,并给出快速修复的修改建议。代码调试,支持代码调试,界面类似IDEA,非常方便。代码结构浏览,可以快速浏览定位。代码折叠,虽然功能小,但比方便高效的打包或移除外设代码,自动提示打包或移除外设代码,一键完成。代码检查和快速修复,可以快速发现代码中的错误或需要优化的地方,并给出快速修复的修改建议。代码调试,支持代码调试,界面类似IDEA,非常方便。代码结构浏览,可以快速浏览定位。代码折叠,虽然功能小,但比方便高效的打包或移除外设代码,自动提示打包或移除外设代码,一键完成。
五、创建网页:材料可用并选择工具。接下来,你需要按照计划,一步一步把你的想法变成现实。这是一个复杂而细致的过程。然后小,先简单,然后复杂。所谓“先大后小”,是指在制作网页时,先设计大结构,再逐步完善小结构设计。所谓先简单,后复杂,就是先设计简单的内容,再设计复杂的内容,这样有问题的时候可以很方便的修改。制作网页时要灵活,灵活使用模板,可以大大提高生产效率。
网站包括首页、成就、广西福利、民族活动、展望未来、关于。想出点子,可以参考一些网页的排版,把对应的代码组合在一起,注入自己的编程设计,去理解和组成你看到的网页。
3.主要技术和知识点的应用,疑难问题的解决
在这里,我将介绍网页创建过程中使用的主要技术和知识点,以及解决难题的方法。
3.1 网页整体布局设计
作为一种视觉语言,网页设计应该注重布局和布局。主页的设计与平面设计虽然不一样,但它们有很多相似之处,应该充分利用和借鉴。版面设计通过文字和图形的空间结合表现出和谐与美感。一个好的网页设计师还应该知道哪一段文字和图形应该落入,以使整个网页熠熠生辉。多页面网站的页面布局和设计要求体现页面之间的有机联系,特别是要处理好页面之间和页面内部的顺序和内容的关系。尤其是当我们用网页效果来体现主题的时候,我们应该更加注重整体布局的合理性,以达到最佳的视觉表现。提供广西主页、广西成就、广西福利、广西民族活动、展望我们的未来、介绍信息。应该如何安排,让观者有一个流畅的视觉体验,以利于他对事物的理解,促进他的认知和参与。
3.2 网页设计中色彩的运用
色彩是艺术表现的要素之一。在网页设计中,根据和谐、平衡、强调的原则,将不同的颜色组合搭配,形成一个漂亮的页面。根据色彩对人心理的影响,合理使用。根据色彩记忆原理,一般暖色比冷色记忆力强。颜色还具有联想性和象征性,如红色象征血液、太阳、中国和民族;蓝色象征着大海、天空和水面。因此,在设计民族活动时,要使用红色活泼的色彩,使人们在心理上接近平和,增强人们对广西的热爱,达到良好的视觉效果。还需要注意的是,虽然网页上对颜色的应用没有限制,但不能无节制地使用多种颜色。一般来说,应根据整体风格的要求,先确定一种或两种主色。在使用颜色的过程中,另一个需要注意的问题是:由于国家、种族、宗教信仰的不同,以及生活的地理位置、文化修养的差异等,不同的人群有对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。应先根据整体风格的要求确定一种或两种主色。在使用颜色的过程中,另一个需要注意的问题是:由于国家、种族、宗教信仰的不同,以及生活的地理位置、文化修养的差异等,不同的人群有对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。应先根据整体风格的要求确定一种或两种主色。在使用颜色的过程中,另一个需要注意的问题是:由于国家、种族、宗教信仰的不同,以及生活的地理位置、文化修养的差异等,不同的人群有对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。不同的人群对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。不同的人群对颜色有很大的偏好。不同之处。设计中有很多因素需要考虑。在我的网页设计中,红色是主色调,红色代表发展和成长。
3.3 网页形式和内容统一
要将丰富的含义和各种形式组织成统一的页面结构,形式语言必须符合页面内容,体现内容的丰富含义。通过对比与和谐、对称与平衡、韵律与韵律、留白,通过空间、文字与图形的关系建立整体平衡,形成和谐的美感。比如在对称原则的页面设计中,它的平衡有时会让页面显得死板,但是如果你添加一些动态的文字、图案,或者使用夸张的方法来表达内在
4.工作完成后的总结和感受
总的来说,通过这次对网页设计的学习,有收获,也有遗憾,也有不足,但我认为自己已经踏入了网页设计的大门。只要我努力学习和提高,依靠我对网页设计的热情和执着,我未来设计的网页会更加专业和完美。也希望老师在以后的日子里给予更多的指导。网页设计中还有更多的技能需要我们去挖掘和研究。由于平时课程比较忙,学习时间也比较少,网页设计软件的强大功能都没有得到充分利用。不知不觉中,网页设计课程就要结束了,这门课程的内容比我想象的还要丰富。
5.了解HTML等Web前端知识5、CSS3、JavaScript
HTML5:万维网的核心语言,标准通用标记语言下超文本标记语言(HTML)的第五次重大修订,网页前端的标准编写;越来越多的行业巨头不断对 HTML5 看好。除了苹果、微软、黑莓之外,谷歌的 Youtube 也部分使用了 HTML5;Chrome 浏览器宣布全面支持 HTML5;Facebook 不遗余力地传播 HTML5。一切正如正义无线总裁王国春所说:“HTML5代表了移动互联网发展的趋势,总有一天它会成为主流技术。”
CSS 代表层叠样式表。在网页制作中使用级联样式表技术,可以有效实现对页面布局、字体、颜色、背景等效果的更精准控制。通过对相应代码的一些简单修改,您可以更改同一页面的不同部分或具有不同页数的页面的外观和格式。CSS3 是 CSS 技术的升级版,CSS3 语言开发正朝着模块化方向发展。以前的规范作为一个模块太大太复杂了,所以,把它分解成更小的模块,增加了更多的新模块。这些模块包括:框模型、列表模块、超链接模式、语言模块、背景和边框、文字效果、多栏布局等。
JavaScript 是一种文字脚本语言,是一种动态类型、弱类型、基于原型的语言,具有对类型的内置支持。它的解释器称为 JavaScript 引擎,它是浏览器的一部分,广泛用于客户端脚本语言。它最初用于 HTML(标准通用标记语言下的应用程序)网页,为 HTML5 网页添加动态功能。.
如图所示
作品的源代码在我的下载资源中。

