
网页音频抓取
网页音频抓取(玩转西藏【旅游攻略】的过程实现过程定义一个类)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-19 13:25
前言
眼睛习惯看文字,累了,转身用耳朵听世界。Himalaya FM,这里是我们想听的,用爬虫抓取我们想要的音频!这次要抢的是关于玩西藏[旅游攻略]的游记,感受高原风情,废话不多说。
环境
win10+python3.7+sublime text
指导包
导入请求---->网页请求和数据抓取
import json--->数据格式转换
from multiprocessing.pool import pool---->使用线程池
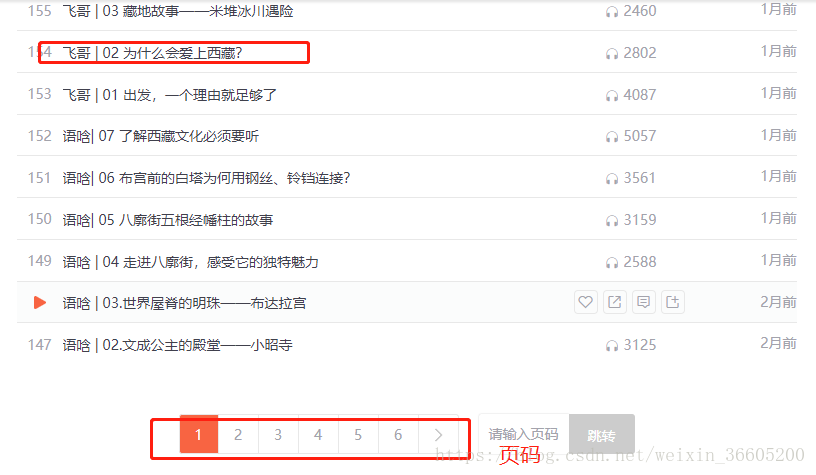
网页分析
,URL对应上图,下面是我们要查看的内容的地址。我们主要是把这些音频全部抓取到本地保存,但是我们并没有从这个地址抓取音频的src,而是直接在旅游文章上点击播放来播放西藏【旅游攻略】。在这个过程中,使用浏览器的开发者工具来获取相关信息的json数据。trackAudioPlay 字段收录我们想要的所有音频数据。需要实现以下代码。
抓包过程
定义一个类,在这个类中初始化请求头和请求的资源url,然后在requests对象中使用get()方法,因为网页的请求方法是get方法,然后判断对应的状态码,如果是200,则表示请求成功,然后对获取的内容进行解码。
def __init__(self,num,id):
self.headers={
'Host': 'www.ximalaya.com',
'Referer': 'https://www.ximalaya.com/lvyou/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36'
}
# albumId=5656303是该收听节目的id,页码:pageNum,一页多少条:pageSize=30
self.url='https://www.ximalaya.com/revis ... 2Bstr(id)+'&pageNum='+str(num)+'&pageSize=30'
def get_content(self):
response=requests.get(url=self.url,headers=self.headers)
# 判断响应的状态码
if response.status_code==200:
# 解码
return response.content.decode()
将获取的字符串数据转换成字典格式,方便获取里面的具体内容,获取相关的音频数据
def get_tracks(self,content):
try:
if content:
# 字符串转换为字典:json.loads()
# print(json.loads(content)['data']['tracksAudioPlay']),测试输出
return json.loads(content)['data']['tracksAudioPlay']
except Exception as e:
print(e)
pass
根据音频连接src重新请求资源,并下载到本地,其中trackName字段中的数据作为每个音频的名称,拼接字符串,更改扩展名为 .m4a 格式,并且在 Windows 系统中,文件名不能有一些特殊的字符串,如 | 和其他特殊字符,所以需要用特殊字符替换trackName字段的字符串数据。
def down_from_src(self,src,trackName):
response=requests.get(url=src)
if response.status_code==200:
# 去除特殊符号,因为windows的文件不能出现这些特殊字符
trackName=trackName.replace('|','').replace('?','').replace(':','').replace(' ','')
with open(trackName+'.m4a','wb') as f:
f.write(response.content)
需要判断url,因为对于vip音频,这里的url是空的,不存在的,所以无法直接抓取数据。
# 程序主入口
def main(i):
sipder=xizangSipder(i,5656303)
for tracksAudioPlay in sipder.get_tracks(sipder.get_content()):
try:
src,trackName=tracksAudioPlay['src'],tracksAudioPlay['trackName']
if src:
sipder.down_from_src(src,trackName)
except Exception as e:
print(e)
pass
if __name__=='__main__':
# 创建线程池
pool=Pool(5)
# 第一个参数是函数,第二个参数是一个迭代器,把迭代器的数字作为参数传进去
pool.map(main,[x for x in range(1,7)])
# 关闭线程池
pool.close()
# 主线程阻塞等待子线程的退出
pool.join()
达到效果
渲染(抓取 6 页音频)
总结:程序比较简单。只要知道资源连接在哪里,就可以通过资源url抓取,通过线程池提高程序效率。音频下载的VIP版还没有实现,下一步就是实现了(但是这样破解别人的VIP是违法的,小心点!)
项目链接:链接:提取码:b78t 查看全部
网页音频抓取(玩转西藏【旅游攻略】的过程实现过程定义一个类)
前言
眼睛习惯看文字,累了,转身用耳朵听世界。Himalaya FM,这里是我们想听的,用爬虫抓取我们想要的音频!这次要抢的是关于玩西藏[旅游攻略]的游记,感受高原风情,废话不多说。
环境
win10+python3.7+sublime text
指导包
导入请求---->网页请求和数据抓取
import json--->数据格式转换
from multiprocessing.pool import pool---->使用线程池
网页分析
,URL对应上图,下面是我们要查看的内容的地址。我们主要是把这些音频全部抓取到本地保存,但是我们并没有从这个地址抓取音频的src,而是直接在旅游文章上点击播放来播放西藏【旅游攻略】。在这个过程中,使用浏览器的开发者工具来获取相关信息的json数据。trackAudioPlay 字段收录我们想要的所有音频数据。需要实现以下代码。

抓包过程
定义一个类,在这个类中初始化请求头和请求的资源url,然后在requests对象中使用get()方法,因为网页的请求方法是get方法,然后判断对应的状态码,如果是200,则表示请求成功,然后对获取的内容进行解码。
def __init__(self,num,id):
self.headers={
'Host': 'www.ximalaya.com',
'Referer': 'https://www.ximalaya.com/lvyou/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36'
}
# albumId=5656303是该收听节目的id,页码:pageNum,一页多少条:pageSize=30
self.url='https://www.ximalaya.com/revis ... 2Bstr(id)+'&pageNum='+str(num)+'&pageSize=30'
def get_content(self):
response=requests.get(url=self.url,headers=self.headers)
# 判断响应的状态码
if response.status_code==200:
# 解码
return response.content.decode()
将获取的字符串数据转换成字典格式,方便获取里面的具体内容,获取相关的音频数据
def get_tracks(self,content):
try:
if content:
# 字符串转换为字典:json.loads()
# print(json.loads(content)['data']['tracksAudioPlay']),测试输出
return json.loads(content)['data']['tracksAudioPlay']
except Exception as e:
print(e)
pass
根据音频连接src重新请求资源,并下载到本地,其中trackName字段中的数据作为每个音频的名称,拼接字符串,更改扩展名为 .m4a 格式,并且在 Windows 系统中,文件名不能有一些特殊的字符串,如 | 和其他特殊字符,所以需要用特殊字符替换trackName字段的字符串数据。
def down_from_src(self,src,trackName):
response=requests.get(url=src)
if response.status_code==200:
# 去除特殊符号,因为windows的文件不能出现这些特殊字符
trackName=trackName.replace('|','').replace('?','').replace(':','').replace(' ','')
with open(trackName+'.m4a','wb') as f:
f.write(response.content)
需要判断url,因为对于vip音频,这里的url是空的,不存在的,所以无法直接抓取数据。
# 程序主入口
def main(i):
sipder=xizangSipder(i,5656303)
for tracksAudioPlay in sipder.get_tracks(sipder.get_content()):
try:
src,trackName=tracksAudioPlay['src'],tracksAudioPlay['trackName']
if src:
sipder.down_from_src(src,trackName)
except Exception as e:
print(e)
pass
if __name__=='__main__':
# 创建线程池
pool=Pool(5)
# 第一个参数是函数,第二个参数是一个迭代器,把迭代器的数字作为参数传进去
pool.map(main,[x for x in range(1,7)])
# 关闭线程池
pool.close()
# 主线程阻塞等待子线程的退出
pool.join()
达到效果
渲染(抓取 6 页音频)
总结:程序比较简单。只要知道资源连接在哪里,就可以通过资源url抓取,通过线程池提高程序效率。音频下载的VIP版还没有实现,下一步就是实现了(但是这样破解别人的VIP是违法的,小心点!)
项目链接:链接:提取码:b78t
网页音频抓取(我们有时想要将一段电影或视频中的背景音乐/对话提取出来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-18 12:05
有时我们想从电影或视频中提取背景音乐/对话进行采集,或者将美剧制作成MP3来练习英语听力等。今天介绍的软件可以帮助您简单方便地做到这一点。
Pazera Free Audio Extractor是一款完全免费的绿色通用音频提取软件和音频格式转换软件,可以从各种主流格式(AVI、FLV、MP4、MPG、MOV、RM、3GP、WMV、VOB等)中提取视频文件格式。无损提取其中的音频并保存,提取效率非常高,保存时可以选择将音频转换成MP3、AAC、AC3、WMA、FLAC、OGG、WAV等格式。非常实用...
Pazera Free Audio Extractor软件介绍及截图:
软件支持Windows 10、Win7、Vista,和XP,绿色安装免费,解压后即可使用。该软件使用起来也比较简单。将视频文件拖入列表后,选择输出目录和音频输出格式。如果不想导出整个视频的音频,可以设置开始和结束时间。PS:如果导出后发现音频质量变差,请尝试提高音频码率。
软件特点:
相关文件下载地址
官方网站:访问
软件性质:免费
提取密码:
下载 Pazera 免费音频提取器视频和音频提取器(64 位)| 32 位 | 更多音频相关 查看全部
网页音频抓取(我们有时想要将一段电影或视频中的背景音乐/对话提取出来)
有时我们想从电影或视频中提取背景音乐/对话进行采集,或者将美剧制作成MP3来练习英语听力等。今天介绍的软件可以帮助您简单方便地做到这一点。
Pazera Free Audio Extractor是一款完全免费的绿色通用音频提取软件和音频格式转换软件,可以从各种主流格式(AVI、FLV、MP4、MPG、MOV、RM、3GP、WMV、VOB等)中提取视频文件格式。无损提取其中的音频并保存,提取效率非常高,保存时可以选择将音频转换成MP3、AAC、AC3、WMA、FLAC、OGG、WAV等格式。非常实用...
Pazera Free Audio Extractor软件介绍及截图:
软件支持Windows 10、Win7、Vista,和XP,绿色安装免费,解压后即可使用。该软件使用起来也比较简单。将视频文件拖入列表后,选择输出目录和音频输出格式。如果不想导出整个视频的音频,可以设置开始和结束时间。PS:如果导出后发现音频质量变差,请尝试提高音频码率。
软件特点:
相关文件下载地址
官方网站:访问
软件性质:免费
提取密码:
下载 Pazera 免费音频提取器视频和音频提取器(64 位)| 32 位 | 更多音频相关
网页音频抓取(1.域名选择网站域名中的建议和建议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-07 00:02
1. 域选择
网站域名的选择,不仅可以让用户快速直观的了解网站的定位和域名设置,还会影响网站被搜索的抓取。因此,选择一个简单、易记、安全的域名是网站建设初期最重要的一步。
1.1 域名选择注意事项
网站建立之初,建议网站的域名独立好记;独立移动台的域名选择也遵循这个规则。
移动站的域名需要和PC站的域名分开。不建议移动站与PC站共享域名; Adaptive网站 可能不会考虑到这一点。
网站在域名选择上,主要有两个建议:
√ 建议使用比较常见的域名后缀,如.com\.cn\.net等;
√如果网站追求个性化使用稀有域名后缀,为了保证搜索效果,需要在站长平台进行站点验证。
1.2 使用子域或目录
网站是需要建立子域名还是划分多级目录,可以根据网站自身定位和网站内容量级来确定。一般来说,对于综合类或者内容比较多的网站,可以根据不同的二级域明确划分内容;而如果网站的内容较少,不建议打开太多的网站子域。
比如对于博客风格的网站,有的网站给每个博客作者一个单独的三级域,但是如果作者发表频率较低,整个三级域就处于低更新状态频率,太低的发布频率对搜索引擎不友好。
2 内容发布系统
所有发布系统,除了遵循有序、逻辑清晰的网站建设外,还应注意网站建设的安全问题,避免网站隐患,以更好地提升价值网站。
2.1自建内容发布系统
网站自建内容发布系统,注意事项包括:
√ 主要内容清晰,可以很好的识别和区分;
√ 不要在后台自行设置发布时间,按照发布时间和显示时间进行;
√ 内容发布系统中各个表单的设置合理。比如标签的设置不宜过多,不宜列出关键词;
√ 分类明确,分类主题的文章应在相应分类下公布;
√标题匹配,不卖狗肉,欺骗搜索引擎流量,损害用户体验;
√ 段落清晰合理,字体大小适中,字体颜色不宜使用与背景色相近的颜色;
√ 发布内容目录划分清晰。
2.2 第三方发布系统
使用第三方发布系统搭建网站,站长需要注意以下几点:
√ 不建议频繁更换模板主题;
√ 不建议使用过多的插件,会影响网页的打开速度;
√ URL 伪静态处理,命名约定,层次清晰;
√ 开源建站系统存在诸多安全隐患,使用过程中一定要做好一些安全设置和优化。
2.3 页面生成规范
无论网站自建发布系统还是网站使用第三方建站系统,网站页面生成时应注意以下几点:
√ 网页结构清晰,各分类名称设置醒目;
√ 导航和面包屑导航设置合理,机器可读,位置显着,用户在网站中可以轻松知道所访问页面的位置;
√ 没有遮挡主要内容的广告元素;
√没有三俗的图文元素;
关注网站构建系统安全问题,消除网站安全隐患。
3 网站结构
网站结构的合理设置是网站被快速抢占并获得搜索流量的基础;由于网站结构设置不合理,无法快速识别网站爬取案例在反馈中经常看到,而网站更改域名也会对网站造成一定损失@>,所以希望各位站长从建站之初就注意网站结构设置,以免造成不必要的损失。
3.1 URL结构设置
对URL构建是否有严格要求,请看以下几点:
√ 在构建网站的结构和制作网址时,尽量避免非主流设计,追求简洁美观。 ”,这会导致搜索引擎识别错误;
√ URL长度要求去掉协议头http(s)://后的URL长度不能超过256字节;
√ 慎用#参数,有效参数不能放在#后面;它们可能会被截断并导致异常的网络爬取。
3.2 目录结构设置
网站目录结构是否合理会影响搜索引擎对网站的抓取。这里需要提到的是网站目录结构是扁平的或者树状的。 ,一般搜索引擎都能找到,但有几点需要注意:
√ 建议将不同的内容放在不同的目录或子域中;
√ 不要使用孤岛链接,搜索引擎很难快速找到孤岛链接;如果网站有大量孤岛链接,建议使用搜索资源平台的链接提交工具向站长平台提交数据;
√ 重要内容不建议放在deep目录下。如果内容没有大量的内部链接,搜索引擎很难判断页面的重要性。
4 服务商/自建服务器
选择服务商或自建服务器是网站建设中非常重要和基础的一环;服务器的安全性和稳定性将直接影响百度搜索引擎对网站的整体判断。
4.1个域名服务4.1.1个域名服务&域名部署
关于域名服务和域名部署,以下注意事项:
√站长要注意域名部署的方方面面,不要出现域名部署错误;
√ 不建议网站进行一般分析。如果网站爆发大规模泛分析,影响不好,会被搜索策略压制;
√ 尽量选择优质的域名服务商。
4.2 个服务器
做网站还有一个很重要的部分,就是服务器的选择。在服务器的选择上,无论是虚拟主机、云主机还是独立服务器,都需要注意以下四点:
√中文网站不建议选择国外服务器;
√ 服务器的稳定性很重要。需要保持访问顺畅,服务器是否稳定。可以使用百站长平台爬取异常,爬取诊断工具进行检测和维护。 (服务器经常无法访问或崩溃,这对爬虫来说是致命的);
√ 服务器选择除了自身的稳定性外,还要考虑网站的业务量,比如带宽、内存、CPU能否承受流量,在情况下能否正常访问突然大流量;
√ 服务器主机设置,需要注意是否有禁止爬虫爬取的设置,或者404错误信息设置。这些情况都会造成不必要的搜索引擎爬取异常判断,从而给网站带来不必要的爬取损失。
4.2.1 个虚拟主机
一般来说,建议在购买虚拟主机时要特别注意:
√主机公司是否限制搜索引擎的访问;
√ 主办公司资质是否符合要求;
√主机公司技术沉淀是否充足,建议选择品牌较大的主机公司;
√ 主机公司托管的机房物理条件和网络条件是否足够好;
√ 托管公司的技术和客服支持是否足够好;
√ 东道公司是否会出现产能过剩;
√ 宿主公司是否非法访问高风险站点或同一IP下是否存在高风险站点;
√ 国内网站建议购买国内云主机建站。
4.2.2 台专用主机
独立托管给网站带来更宽松的使用环境和个性化的软件安装,所以独立托管需要站长具备一定的技术实力才能保证网站的正常运行和安全。
我们对网站管理员购买和托管专用主机的建议是:
√ 关注虚拟主机是否已将爬虫IP拉入黑名单;
√ 建议使用具有专用IP地址的主机;
√ 建议使用较大机构的主机,在安全配置和稳定性方面相对较好;
√IDC服务商的建设标准需要一定的考虑,比如防火、防盗、是否有UPS保障、室内温控、防火等;
√IDC服务商的服务质量和技术是否达标,是否24小时值班,是否能协助排除部分故障,免费重启重装系统等;
√IDC机房资质是否齐全,存储站点是否有高风险站点或服务器。
4.3 安全服务4.3.1 HTTPS 查看全部
网页音频抓取(1.域名选择网站域名中的建议和建议)
1. 域选择
网站域名的选择,不仅可以让用户快速直观的了解网站的定位和域名设置,还会影响网站被搜索的抓取。因此,选择一个简单、易记、安全的域名是网站建设初期最重要的一步。
1.1 域名选择注意事项
网站建立之初,建议网站的域名独立好记;独立移动台的域名选择也遵循这个规则。
移动站的域名需要和PC站的域名分开。不建议移动站与PC站共享域名; Adaptive网站 可能不会考虑到这一点。
网站在域名选择上,主要有两个建议:
√ 建议使用比较常见的域名后缀,如.com\.cn\.net等;
√如果网站追求个性化使用稀有域名后缀,为了保证搜索效果,需要在站长平台进行站点验证。
1.2 使用子域或目录
网站是需要建立子域名还是划分多级目录,可以根据网站自身定位和网站内容量级来确定。一般来说,对于综合类或者内容比较多的网站,可以根据不同的二级域明确划分内容;而如果网站的内容较少,不建议打开太多的网站子域。
比如对于博客风格的网站,有的网站给每个博客作者一个单独的三级域,但是如果作者发表频率较低,整个三级域就处于低更新状态频率,太低的发布频率对搜索引擎不友好。
2 内容发布系统
所有发布系统,除了遵循有序、逻辑清晰的网站建设外,还应注意网站建设的安全问题,避免网站隐患,以更好地提升价值网站。
2.1自建内容发布系统
网站自建内容发布系统,注意事项包括:
√ 主要内容清晰,可以很好的识别和区分;
√ 不要在后台自行设置发布时间,按照发布时间和显示时间进行;
√ 内容发布系统中各个表单的设置合理。比如标签的设置不宜过多,不宜列出关键词;
√ 分类明确,分类主题的文章应在相应分类下公布;
√标题匹配,不卖狗肉,欺骗搜索引擎流量,损害用户体验;
√ 段落清晰合理,字体大小适中,字体颜色不宜使用与背景色相近的颜色;
√ 发布内容目录划分清晰。
2.2 第三方发布系统
使用第三方发布系统搭建网站,站长需要注意以下几点:
√ 不建议频繁更换模板主题;
√ 不建议使用过多的插件,会影响网页的打开速度;
√ URL 伪静态处理,命名约定,层次清晰;
√ 开源建站系统存在诸多安全隐患,使用过程中一定要做好一些安全设置和优化。
2.3 页面生成规范
无论网站自建发布系统还是网站使用第三方建站系统,网站页面生成时应注意以下几点:
√ 网页结构清晰,各分类名称设置醒目;
√ 导航和面包屑导航设置合理,机器可读,位置显着,用户在网站中可以轻松知道所访问页面的位置;
√ 没有遮挡主要内容的广告元素;
√没有三俗的图文元素;
关注网站构建系统安全问题,消除网站安全隐患。
3 网站结构
网站结构的合理设置是网站被快速抢占并获得搜索流量的基础;由于网站结构设置不合理,无法快速识别网站爬取案例在反馈中经常看到,而网站更改域名也会对网站造成一定损失@>,所以希望各位站长从建站之初就注意网站结构设置,以免造成不必要的损失。
3.1 URL结构设置
对URL构建是否有严格要求,请看以下几点:
√ 在构建网站的结构和制作网址时,尽量避免非主流设计,追求简洁美观。 ”,这会导致搜索引擎识别错误;
√ URL长度要求去掉协议头http(s)://后的URL长度不能超过256字节;
√ 慎用#参数,有效参数不能放在#后面;它们可能会被截断并导致异常的网络爬取。
3.2 目录结构设置
网站目录结构是否合理会影响搜索引擎对网站的抓取。这里需要提到的是网站目录结构是扁平的或者树状的。 ,一般搜索引擎都能找到,但有几点需要注意:
√ 建议将不同的内容放在不同的目录或子域中;
√ 不要使用孤岛链接,搜索引擎很难快速找到孤岛链接;如果网站有大量孤岛链接,建议使用搜索资源平台的链接提交工具向站长平台提交数据;
√ 重要内容不建议放在deep目录下。如果内容没有大量的内部链接,搜索引擎很难判断页面的重要性。
4 服务商/自建服务器
选择服务商或自建服务器是网站建设中非常重要和基础的一环;服务器的安全性和稳定性将直接影响百度搜索引擎对网站的整体判断。
4.1个域名服务4.1.1个域名服务&域名部署
关于域名服务和域名部署,以下注意事项:
√站长要注意域名部署的方方面面,不要出现域名部署错误;
√ 不建议网站进行一般分析。如果网站爆发大规模泛分析,影响不好,会被搜索策略压制;
√ 尽量选择优质的域名服务商。
4.2 个服务器
做网站还有一个很重要的部分,就是服务器的选择。在服务器的选择上,无论是虚拟主机、云主机还是独立服务器,都需要注意以下四点:
√中文网站不建议选择国外服务器;
√ 服务器的稳定性很重要。需要保持访问顺畅,服务器是否稳定。可以使用百站长平台爬取异常,爬取诊断工具进行检测和维护。 (服务器经常无法访问或崩溃,这对爬虫来说是致命的);
√ 服务器选择除了自身的稳定性外,还要考虑网站的业务量,比如带宽、内存、CPU能否承受流量,在情况下能否正常访问突然大流量;
√ 服务器主机设置,需要注意是否有禁止爬虫爬取的设置,或者404错误信息设置。这些情况都会造成不必要的搜索引擎爬取异常判断,从而给网站带来不必要的爬取损失。
4.2.1 个虚拟主机
一般来说,建议在购买虚拟主机时要特别注意:
√主机公司是否限制搜索引擎的访问;
√ 主办公司资质是否符合要求;
√主机公司技术沉淀是否充足,建议选择品牌较大的主机公司;
√ 主机公司托管的机房物理条件和网络条件是否足够好;
√ 托管公司的技术和客服支持是否足够好;
√ 东道公司是否会出现产能过剩;
√ 宿主公司是否非法访问高风险站点或同一IP下是否存在高风险站点;
√ 国内网站建议购买国内云主机建站。
4.2.2 台专用主机
独立托管给网站带来更宽松的使用环境和个性化的软件安装,所以独立托管需要站长具备一定的技术实力才能保证网站的正常运行和安全。
我们对网站管理员购买和托管专用主机的建议是:
√ 关注虚拟主机是否已将爬虫IP拉入黑名单;
√ 建议使用具有专用IP地址的主机;
√ 建议使用较大机构的主机,在安全配置和稳定性方面相对较好;
√IDC服务商的建设标准需要一定的考虑,比如防火、防盗、是否有UPS保障、室内温控、防火等;
√IDC服务商的服务质量和技术是否达标,是否24小时值班,是否能协助排除部分故障,免费重启重装系统等;
√IDC机房资质是否齐全,存储站点是否有高风险站点或服务器。
4.3 安全服务4.3.1 HTTPS
网页音频抓取(BeautifulSoup文档bs4—BeautifulSoup4,BeautifulSoup是Python库!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-19 03:17
BeautifulSoup 文档
bs4 — BeautifulSoup 4,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,Beautiful Soup 文档,版本 4.4.0 Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中检索数据 提取数据。它与您最喜欢的解析器一起使用,提供一种惯用的方式来导航、搜索和修改解析树。. Beautiful Soup 文档,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索、.
Beautiful Soup 文档,Beautiful Soup 文档,4.4.0 版本 Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供一种惯用的方式来导航、搜索和修改解析树。Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索、. Beautiful Soup 4,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它可以与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,bs4 — BeautifulSoup 4¶。“Fish-Footman 开始从他的腋下生成一个大字母。Beautiful Soup 是一个用于拉取的 Python 库。
Beautiful Soup 4,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它可以与您最喜欢的解析器一起使用,提供惯用的导航、搜索、.Beautiful Soup 文档、bs4 — BeautifulSoup 4¶。“Fish-Footman 开始从他的腋下生成一封很棒的信。Beautiful Soup 是一个 Python 库,它拉动 Beautiful Soup 构造函数以获取 XML 作为字符串(或打开的文件类对象)或 HTML 文档。它解析文档并创建一种 。
Beautiful Soup 文档,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它可以与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,bs4 — BeautifulSoup 4¶。“Fish-Footman 开始从他的腋下生成一个很棒的字母。Beautiful Soup 是一个用于拉取的 Python 库。BeautifulSoup - bs4 - Python 文档,Beautiful Soup 构造函数打开一个字符串(或类似)对象中的文件)以获取 XML 或 HTML文档。它解析文档并创建一个 Beautiful Soup 文档 Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供了一种导航、搜索和修改解析树的惯用方式。它可以通常可以节省程序员数小时或数天的工作时间。
BeautifulSoup - bs4 - Python 文档,bs4 - BeautifulSoup 4¶。“Fish-Footman 从腋下写了一封很棒的信。Beautiful Soup 是一个 Python 库,用于引入 Beautiful Soup 的介绍,
BeautifulSoup 教程
使用 Python 和 Beautiful Soup 从 Web 采集数据,使用 BeautifulSoup 在 Python 中实现 Web Scraping · 如果存在 网站 的 API,请使用它。例如,Facebook 有 Facebook 安装解析器¶。Beautiful Soup 支持 Python 标准库中收录的 HTML 解析器,但它也支持许多第三方 Python 解析器。使用 BeautifulSoup 在 Python 中实现 Web Scraping,在本 Python 教程中,我们将使用 Beautiful Soup 模块采集和解析网页以获取数据,并将我们采集的信息写入代码以获取一些信息。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。.
使用 BeautifulSoup 在 Python 中进行 Web 抓取,安装 Parser¶。Beautiful Soup 支持 Python 标准库中收录的 HTML 解析器,但它也支持许多第三方 Python 解析器。在本 Python 教程中,我们将使用 Beautiful Soup 模块来采集和解析网页以获取数据并写入我们采集的信息。教程:Web Scraping with Python with Beautiful Soup,这是我们用来从 index.html 中检索数据的代码来获取文件中的一些信息。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。在本教程中,您将学习如何: 使用请求和 Beautiful Soup 从 Web 抓取和解析数据;
教程:使用 Beautiful Soup 使用 Python 进行 Web Scraping,在本 Python 教程中,我们将使用 Beautiful Soup 模块来采集和解析网页,以便抓取数据并将我们采集的信息写入 a 这是我们将使用的代码在我们的 index.html 文件中获取一些信息。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。. Beautiful Soup 教程,在本教程中,您将学习如何:使用请求和 Beautiful Soup 从 Web 抓取和解析数据;从一开始就从 Web 抓取管道导航到 Beautiful Soup 教程 - 在本教程中,
美丽的汤教程,这是我们用来从 index.html 文件中获取一些信息的代码。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。在本教程中,您将学习如何: 使用请求和 Beautiful Soup 从 Web 抓取和解析数据;从头到尾浏览。Beautiful Soup 教程 - Python 中的网页抓取,Beautiful Soup 教程 - 在本教程中,我们将向您展示如何使用 Beautiful Soup 4 在 Python 中执行网页抓取,以从 HTML、XML 中获取数据,学习新技能永远不会太晚!学习编码并加入我们的 45+ 百万用户。
Beautiful Soup 教程 - Python 中的 Web Scraping,Beautiful Soup 的 Web Scraping,
抓取 YouTube 视频 Python
如何在 Python 中抓取 Youtube 评论,我最近一直痴迷于对 youtube 视频的见解,所以我试图用我最喜欢的 python 包 - BeautifulSoup 来抓取 网站。可用的爬虫在这里做了我会看到如何下载视频。要从 youtube 中提取这些数据,需要进行一些网络抓取和网络抓取 - 确实如此。使用 BeautifulSoup (python) 抓取 Youtube 视频 跟随我使用 python 在 youtube 频道上抓取和可视化统计数据。加载自动播放启用自动播放后,接下来会自动播放建议的视频。这是介绍性网络抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es。
用 BeautifulSoup (python) 抓取 Youtube 视频,让我看看如何下载视频。要从 YouTube 中提取这些数据,需要进行一些网络抓取和网络抓取——当我使用 python 在 youtube 频道上抓取和可视化统计数据时,它会遵循。加载自动播放启用自动播放后,接下来会自动播放建议的视频。. 如何在 Python 中提取 YouTube 数据,介绍性网络抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es 谈到情感分析项目,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。.
如何在 Python 中提取 YouTube 数据,请跟随我使用 python 来抓取 youtube 频道上的统计数据并将其可视化。加载自动播放启用自动播放后,接下来会自动播放建议的视频。这是介绍性网络抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es。Python Tutorial: Web Scraping with Python,当谈到情感分析项目时,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。使用 requests_html 和 Beautiful Soup 库在 Python 中抓取 YouTube 视频并提取有用的视频信息,例如标题,总观看次数、发布日期、视频时长、标签、喜欢和不喜欢等等。Abdou Rockikz · 7 分钟阅读 · 2020 年 8 月更新 · 网页抓取 网页抓取正在从 网站 中提取数据。.
Python 教程:使用 Python 进行网页抓取,介绍性网页抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es 谈到情感分析项目,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。介绍使用 Python 和 Beautiful Soup 进行网页抓取,用 Python 抓取 YouTube 视频,并使用 requests_html 和 Beautiful Soup 库提取有用的视频信息,例如标题、总观看次数、发布日期、视频时长、标签、喜欢和不喜欢等。Abdou Rockikz · 7 分钟阅读 · 2020 年 8 月更新 · 网页抓取 网页抓取正在从 网站 中提取数据。在这里,我将看到如何下载视频。从 YouTube 中提取这些数据需要进行一些网络爬虫和网络抓取——这在 Python 中非常简单。特别是因为有很多图书馆可以帮助你。用于网页抓取的两个最流行的 Python 库是 BeautifulSoup 和 ScraPy。在这里,我将随机挑选和使用 BeautifulSoup。. 用于网页抓取的两个最流行的 Python 库是 BeautifulSoup 和 ScraPy。在这里,我将随机挑选和使用 BeautifulSoup。. 用于网页抓取的两个最流行的 Python 库是 BeautifulSoup 和 ScraPy。在这里,我将随机挑选和使用 BeautifulSoup。.
用 Python 和 Beautiful Soup 介绍 Web Scraping,谈到情感分析项目,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。使用python从youtube抓取视频信息,
BeautifulSoup 按类别查找
使用 Beautiful Soup 进行网页抓取,使用 select() 方法查找多个元素,并使用 select_one() 查找单个元素。基本示例:from bs4 import BeautifulSoup data = """ 查看全部
网页音频抓取(BeautifulSoup文档bs4—BeautifulSoup4,BeautifulSoup是Python库!)
BeautifulSoup 文档
bs4 — BeautifulSoup 4,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,Beautiful Soup 文档,版本 4.4.0 Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中检索数据 提取数据。它与您最喜欢的解析器一起使用,提供一种惯用的方式来导航、搜索和修改解析树。. Beautiful Soup 文档,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索、.
Beautiful Soup 文档,Beautiful Soup 文档,4.4.0 版本 Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供一种惯用的方式来导航、搜索和修改解析树。Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索、. Beautiful Soup 4,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它可以与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,bs4 — BeautifulSoup 4¶。“Fish-Footman 开始从他的腋下生成一个大字母。Beautiful Soup 是一个用于拉取的 Python 库。
Beautiful Soup 4,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它可以与您最喜欢的解析器一起使用,提供惯用的导航、搜索、.Beautiful Soup 文档、bs4 — BeautifulSoup 4¶。“Fish-Footman 开始从他的腋下生成一封很棒的信。Beautiful Soup 是一个 Python 库,它拉动 Beautiful Soup 构造函数以获取 XML 作为字符串(或打开的文件类对象)或 HTML 文档。它解析文档并创建一种 。
Beautiful Soup 文档,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它可以与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,bs4 — BeautifulSoup 4¶。“Fish-Footman 开始从他的腋下生成一个很棒的字母。Beautiful Soup 是一个用于拉取的 Python 库。BeautifulSoup - bs4 - Python 文档,Beautiful Soup 构造函数打开一个字符串(或类似)对象中的文件)以获取 XML 或 HTML文档。它解析文档并创建一个 Beautiful Soup 文档 Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供了一种导航、搜索和修改解析树的惯用方式。它可以通常可以节省程序员数小时或数天的工作时间。
BeautifulSoup - bs4 - Python 文档,bs4 - BeautifulSoup 4¶。“Fish-Footman 从腋下写了一封很棒的信。Beautiful Soup 是一个 Python 库,用于引入 Beautiful Soup 的介绍,
BeautifulSoup 教程
使用 Python 和 Beautiful Soup 从 Web 采集数据,使用 BeautifulSoup 在 Python 中实现 Web Scraping · 如果存在 网站 的 API,请使用它。例如,Facebook 有 Facebook 安装解析器¶。Beautiful Soup 支持 Python 标准库中收录的 HTML 解析器,但它也支持许多第三方 Python 解析器。使用 BeautifulSoup 在 Python 中实现 Web Scraping,在本 Python 教程中,我们将使用 Beautiful Soup 模块采集和解析网页以获取数据,并将我们采集的信息写入代码以获取一些信息。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。.
使用 BeautifulSoup 在 Python 中进行 Web 抓取,安装 Parser¶。Beautiful Soup 支持 Python 标准库中收录的 HTML 解析器,但它也支持许多第三方 Python 解析器。在本 Python 教程中,我们将使用 Beautiful Soup 模块来采集和解析网页以获取数据并写入我们采集的信息。教程:Web Scraping with Python with Beautiful Soup,这是我们用来从 index.html 中检索数据的代码来获取文件中的一些信息。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。在本教程中,您将学习如何: 使用请求和 Beautiful Soup 从 Web 抓取和解析数据;
教程:使用 Beautiful Soup 使用 Python 进行 Web Scraping,在本 Python 教程中,我们将使用 Beautiful Soup 模块来采集和解析网页,以便抓取数据并将我们采集的信息写入 a 这是我们将使用的代码在我们的 index.html 文件中获取一些信息。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。. Beautiful Soup 教程,在本教程中,您将学习如何:使用请求和 Beautiful Soup 从 Web 抓取和解析数据;从一开始就从 Web 抓取管道导航到 Beautiful Soup 教程 - 在本教程中,
美丽的汤教程,这是我们用来从 index.html 文件中获取一些信息的代码。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。在本教程中,您将学习如何: 使用请求和 Beautiful Soup 从 Web 抓取和解析数据;从头到尾浏览。Beautiful Soup 教程 - Python 中的网页抓取,Beautiful Soup 教程 - 在本教程中,我们将向您展示如何使用 Beautiful Soup 4 在 Python 中执行网页抓取,以从 HTML、XML 中获取数据,学习新技能永远不会太晚!学习编码并加入我们的 45+ 百万用户。
Beautiful Soup 教程 - Python 中的 Web Scraping,Beautiful Soup 的 Web Scraping,
抓取 YouTube 视频 Python
如何在 Python 中抓取 Youtube 评论,我最近一直痴迷于对 youtube 视频的见解,所以我试图用我最喜欢的 python 包 - BeautifulSoup 来抓取 网站。可用的爬虫在这里做了我会看到如何下载视频。要从 youtube 中提取这些数据,需要进行一些网络抓取和网络抓取 - 确实如此。使用 BeautifulSoup (python) 抓取 Youtube 视频 跟随我使用 python 在 youtube 频道上抓取和可视化统计数据。加载自动播放启用自动播放后,接下来会自动播放建议的视频。这是介绍性网络抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es。
用 BeautifulSoup (python) 抓取 Youtube 视频,让我看看如何下载视频。要从 YouTube 中提取这些数据,需要进行一些网络抓取和网络抓取——当我使用 python 在 youtube 频道上抓取和可视化统计数据时,它会遵循。加载自动播放启用自动播放后,接下来会自动播放建议的视频。. 如何在 Python 中提取 YouTube 数据,介绍性网络抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es 谈到情感分析项目,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。.
如何在 Python 中提取 YouTube 数据,请跟随我使用 python 来抓取 youtube 频道上的统计数据并将其可视化。加载自动播放启用自动播放后,接下来会自动播放建议的视频。这是介绍性网络抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es。Python Tutorial: Web Scraping with Python,当谈到情感分析项目时,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。使用 requests_html 和 Beautiful Soup 库在 Python 中抓取 YouTube 视频并提取有用的视频信息,例如标题,总观看次数、发布日期、视频时长、标签、喜欢和不喜欢等等。Abdou Rockikz · 7 分钟阅读 · 2020 年 8 月更新 · 网页抓取 网页抓取正在从 网站 中提取数据。.
Python 教程:使用 Python 进行网页抓取,介绍性网页抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es 谈到情感分析项目,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。介绍使用 Python 和 Beautiful Soup 进行网页抓取,用 Python 抓取 YouTube 视频,并使用 requests_html 和 Beautiful Soup 库提取有用的视频信息,例如标题、总观看次数、发布日期、视频时长、标签、喜欢和不喜欢等。Abdou Rockikz · 7 分钟阅读 · 2020 年 8 月更新 · 网页抓取 网页抓取正在从 网站 中提取数据。在这里,我将看到如何下载视频。从 YouTube 中提取这些数据需要进行一些网络爬虫和网络抓取——这在 Python 中非常简单。特别是因为有很多图书馆可以帮助你。用于网页抓取的两个最流行的 Python 库是 BeautifulSoup 和 ScraPy。在这里,我将随机挑选和使用 BeautifulSoup。. 用于网页抓取的两个最流行的 Python 库是 BeautifulSoup 和 ScraPy。在这里,我将随机挑选和使用 BeautifulSoup。. 用于网页抓取的两个最流行的 Python 库是 BeautifulSoup 和 ScraPy。在这里,我将随机挑选和使用 BeautifulSoup。.
用 Python 和 Beautiful Soup 介绍 Web Scraping,谈到情感分析项目,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。使用python从youtube抓取视频信息,
BeautifulSoup 按类别查找
使用 Beautiful Soup 进行网页抓取,使用 select() 方法查找多个元素,并使用 select_one() 查找单个元素。基本示例:from bs4 import BeautifulSoup data = """
网页音频抓取(Mozilla/5.0(WindowsNT)#递归删除目录树)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-18 02:03
导入异步
来自 bs4import BeautifulSoup
来自 lxmlimport etree
导入操作系统
导入关闭
filePath="D:\\temp_ximalaya_audio"
channelFilePath=""
#初始化文件目录
如果 os.path.isdir(filePath):
shutil.rmtree(filePath)#递归删除目录树
elif os.path.isfile(filePath):
os.remove(filePath)#删除文件
os.makedirs(filePath)#创建目录
#mongodb
#clients = pymongo.MongoClient('localhost')
#db = clients["XiMaLaYa"]
#col1 = db["album2"]
#col2 = db["detail2"]
UA_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/22.@ >0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11;CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome /20.0.1132.@>57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, 像 Gecko) Chrome/20.@ >0.1092.@>0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, 像壁虎) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/19.@ >77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, 像 Gecko) Chrome/19.@>0. 1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, 像壁虎) Chrome/19.@>0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1063.0 Safari/536.3",
"Mozilla/4.0(兼容;MSIE 7.0;Windows NT 5.1;Trident/4.0;SE 2.@>X MetaSr < @1.0; SE 2.@>X MetaSr 1.0; .NET CLR 2.@>0.50727; SE 2.@>X MetaSr 1.< @0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML,像壁虎) Chrome/19.@>0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML,像 Gecko) Chrome/19.@>0. 1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, 像 Gecko) Chrome/19.@ >0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/22.@ >0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11;CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome /20.0.1132.@>57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, 像 Gecko) Chrome/20.@ >0.1092.@>0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, 像壁虎) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/19.@ >77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, 像 Gecko) Chrome/19.@>0. 1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, 像壁虎) Chrome/19.@>0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, 像 Gecko) Chrome/19.@>0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML,像壁虎) Chrome/19.@>0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML,像 Gecko) Chrome/19.@>0. 1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, 像 Gecko) Chrome/19.@ >0.1055.1 Safari/535.24"
]
标题1 = {
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control':'max-age=0',
'代理连接':'keep-alive',
'Upgrade-Insecure-Requests':'1',
'用户代理':random.choice(UA_LIST)
}
headers2 = {
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control':'max-age=0',
'代理连接':'keep-alive',
'推荐人':'',
'Upgrade-Insecure-Requests':'1',
'用户代理':random.choice(UA_LIST)
}
def get_url():
#start_urls = ['{}'.format(num) for num in range(1, 85)]
start_urls = [""]
打印(start_urls)
对于 start_urlin start_urls:
打印(start_url)
print("==================开始 html===============")
html = requests.get(start_url,headers=headers1).text
print("html = {}".format(html))
print("================end html===============")
print("================开始汤=============")
soup = BeautifulSoup(html,'lxml')
打印(汤)
print("================结束汤============")
对于 itemin soup.find_all(class_="albumfaceOutter"):
print("================开始项目================")
打印(项目)
print("================结束项目========================= =")
print("================开始内容================")
内容 = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
打印(内容)
print("==================结束内容======================= ===")
#col1.插入(内容)
print('写一个频道' + item.a['href'])
子频道 = item.a['href']
print("============开始子频道=====================")
打印(子通道)
subchannelArr = subchannel.split("/")
打印(subchannelArr)
#channelFilePath = subchannelArr[len(subchannelArr) - 2]
channelFilePath = content['title']
打印(通道文件路径)
channelFilePath = filePath + os.sep + channelFilePath
打印(通道文件路径)
如果 os.path.isdir(channelFilePath):
shutil.rmtree(channelFilePath)#递归删除目录树
elif os.path.isfile(channelFilePath):
os.remove(channelFilePath)#删除文件
os.makedirs(channelFilePath)# 创建目录
print("============结束子频道=====================")
打印(内容)
另一个(channelFilePath, item.a['href'])
时间.sleep(1)
def another(channelFilePath, url):
print("========================开始另一个html================= === =====")
html = requests.get(url,headers=headers2).text
打印(html)
print("========================结束另一个html================= === =====")
print("=========================开始另一个 ifanother================ === =====")
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
打印(ifanother)
print("========================结束另一个 ifanother================= === =====")
如果 len(ifanother):
num = ifanother[0]
print('这个频道资源存在' + num + 'pages')
对于 nin range(1,int(num)):
print('开始解析{}中的第{}页'.format(num, n))
url2 = url +'?page={}'.format(n)
打印(网址)
打印(网址2)
get_m4a(channelFilePath, url2)
get_m4a(url)
def get_m4a(channelFilePath, url):
时间.sleep(1)
html = requests.get(url,headers=headers2).text
print("==============开始get_m4a======================")
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
打印(数字列表)
print("==============end get_m4a======================")
对于iin numlist:
print("==============开始 get_m4a murl======================") 查看全部
网页音频抓取(Mozilla/5.0(WindowsNT)#递归删除目录树)
导入异步
来自 bs4import BeautifulSoup
来自 lxmlimport etree
导入操作系统
导入关闭
filePath="D:\\temp_ximalaya_audio"
channelFilePath=""
#初始化文件目录
如果 os.path.isdir(filePath):
shutil.rmtree(filePath)#递归删除目录树
elif os.path.isfile(filePath):
os.remove(filePath)#删除文件
os.makedirs(filePath)#创建目录
#mongodb
#clients = pymongo.MongoClient('localhost')
#db = clients["XiMaLaYa"]
#col1 = db["album2"]
#col2 = db["detail2"]
UA_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/22.@ >0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11;CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome /20.0.1132.@>57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, 像 Gecko) Chrome/20.@ >0.1092.@>0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, 像壁虎) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/19.@ >77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, 像 Gecko) Chrome/19.@>0. 1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, 像壁虎) Chrome/19.@>0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1063.0 Safari/536.3",
"Mozilla/4.0(兼容;MSIE 7.0;Windows NT 5.1;Trident/4.0;SE 2.@>X MetaSr < @1.0; SE 2.@>X MetaSr 1.0; .NET CLR 2.@>0.50727; SE 2.@>X MetaSr 1.< @0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML,像壁虎) Chrome/19.@>0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML,像 Gecko) Chrome/19.@>0. 1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, 像 Gecko) Chrome/19.@ >0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/22.@ >0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11;CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome /20.0.1132.@>57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, 像 Gecko) Chrome/20.@ >0.1092.@>0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, 像壁虎) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/19.@ >77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, 像 Gecko) Chrome/19.@>0. 1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, 像壁虎) Chrome/19.@>0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, 像 Gecko) Chrome/19.@>0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML,像壁虎) Chrome/19.@>0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML,像 Gecko) Chrome/19.@>0. 1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, 像 Gecko) Chrome/19.@ >0.1055.1 Safari/535.24"
]
标题1 = {
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control':'max-age=0',
'代理连接':'keep-alive',
'Upgrade-Insecure-Requests':'1',
'用户代理':random.choice(UA_LIST)
}
headers2 = {
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control':'max-age=0',
'代理连接':'keep-alive',
'推荐人':'',
'Upgrade-Insecure-Requests':'1',
'用户代理':random.choice(UA_LIST)
}
def get_url():
#start_urls = ['{}'.format(num) for num in range(1, 85)]
start_urls = [""]
打印(start_urls)
对于 start_urlin start_urls:
打印(start_url)
print("==================开始 html===============")
html = requests.get(start_url,headers=headers1).text
print("html = {}".format(html))
print("================end html===============")
print("================开始汤=============")
soup = BeautifulSoup(html,'lxml')
打印(汤)
print("================结束汤============")
对于 itemin soup.find_all(class_="albumfaceOutter"):
print("================开始项目================")
打印(项目)
print("================结束项目========================= =")
print("================开始内容================")
内容 = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
打印(内容)
print("==================结束内容======================= ===")
#col1.插入(内容)
print('写一个频道' + item.a['href'])
子频道 = item.a['href']
print("============开始子频道=====================")
打印(子通道)
subchannelArr = subchannel.split("/")
打印(subchannelArr)
#channelFilePath = subchannelArr[len(subchannelArr) - 2]
channelFilePath = content['title']
打印(通道文件路径)
channelFilePath = filePath + os.sep + channelFilePath
打印(通道文件路径)
如果 os.path.isdir(channelFilePath):
shutil.rmtree(channelFilePath)#递归删除目录树
elif os.path.isfile(channelFilePath):
os.remove(channelFilePath)#删除文件
os.makedirs(channelFilePath)# 创建目录
print("============结束子频道=====================")
打印(内容)
另一个(channelFilePath, item.a['href'])
时间.sleep(1)
def another(channelFilePath, url):
print("========================开始另一个html================= === =====")
html = requests.get(url,headers=headers2).text
打印(html)
print("========================结束另一个html================= === =====")
print("=========================开始另一个 ifanother================ === =====")
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
打印(ifanother)
print("========================结束另一个 ifanother================= === =====")
如果 len(ifanother):
num = ifanother[0]
print('这个频道资源存在' + num + 'pages')
对于 nin range(1,int(num)):
print('开始解析{}中的第{}页'.format(num, n))
url2 = url +'?page={}'.format(n)
打印(网址)
打印(网址2)
get_m4a(channelFilePath, url2)
get_m4a(url)
def get_m4a(channelFilePath, url):
时间.sleep(1)
html = requests.get(url,headers=headers2).text
print("==============开始get_m4a======================")
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
打印(数字列表)
print("==============end get_m4a======================")
对于iin numlist:
print("==============开始 get_m4a murl======================")
网页音频抓取(ESFSoftURLSniffer播放 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-10 18:16
)
3、检测、识别、嗅探流媒体 FLV、F4V、SWF、MP4、MP3、WMV、ASF、RM、RAM、JPG。
4、查找隐藏在 Java 脚本或 ActiveX 脚本后面的流式音频和视频。
5、智能区分有效的媒体流URL链接。
6、快速实现 URL 嗅探。
7、任何下载管理器都允许下载流文件。
如何使用 ESFSoft URL 嗅探器:
1、运行 ESFSoft URL 嗅探器。
2、然后点击开始按钮,ESFSoft URL Sniffer就会开始从浏览器播放的音视频流中检测并嗅出相应的URL链接,包括FLV、MP4、MP3、WMV、ASF、RM、RAM 和一些文本链接。值得一提的是,ESFSoft URL Sniffer可以将有用的媒体流URL链接与一些不重要的文字图片链接区分开来,为广大网友省去了一些麻烦的步骤,即过滤掉所有抓取到的链接。有用的链接。
使用 ESFSoft URL Sniffer 的注意事项:
1、软件需要WinPcap支持才能运行,压缩包内有WinPcap4.1.3官方英文安装版,双击运行安装即可。
2、软件窗口中Start按钮的Start英文字符串和Top按钮的Top和NoTop英文字符串无法本地化,本地化会导致按钮失败。
界面预览:
查看全部
网页音频抓取(ESFSoftURLSniffer播放
)
3、检测、识别、嗅探流媒体 FLV、F4V、SWF、MP4、MP3、WMV、ASF、RM、RAM、JPG。
4、查找隐藏在 Java 脚本或 ActiveX 脚本后面的流式音频和视频。
5、智能区分有效的媒体流URL链接。
6、快速实现 URL 嗅探。
7、任何下载管理器都允许下载流文件。
如何使用 ESFSoft URL 嗅探器:
1、运行 ESFSoft URL 嗅探器。
2、然后点击开始按钮,ESFSoft URL Sniffer就会开始从浏览器播放的音视频流中检测并嗅出相应的URL链接,包括FLV、MP4、MP3、WMV、ASF、RM、RAM 和一些文本链接。值得一提的是,ESFSoft URL Sniffer可以将有用的媒体流URL链接与一些不重要的文字图片链接区分开来,为广大网友省去了一些麻烦的步骤,即过滤掉所有抓取到的链接。有用的链接。
使用 ESFSoft URL Sniffer 的注意事项:
1、软件需要WinPcap支持才能运行,压缩包内有WinPcap4.1.3官方英文安装版,双击运行安装即可。
2、软件窗口中Start按钮的Start英文字符串和Top按钮的Top和NoTop英文字符串无法本地化,本地化会导致按钮失败。
界面预览:
网页音频抓取(听有声小说的音频地址是什么?如何借鉴本文的思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-02-07 08:02
)
前言:
一个朋友最近沉迷于听有声小说,但是因为很多有声小说网站需要VIP才能听,所以他想让我帮他把小说下载下来,这样他就可以在手机上随时听了电话。我在网上搜了他听的这本小说,确实有很多大型听书网站需要VIP才能听,于是找了一个小网站帮他爬小说拿去向下。因为他听的小说是知名作者写的,为了保护作者的权益,本文的案例没有使用作者的小说进行爬取,而是使用了另一部小说进行爬取说明,大致爬取思路是一样的,大家可以借鉴这篇文章的思路。
本案网站:
一、分析网页
本案小说共有178章,对应178个音频数据。我们需要爬取小说的名字,每章的链接地址,然后分析每一个链接地址,找到真正的音频。数据地址。如图所示:
网页的链接可以通过查看开发者工具来分析,该网页是html数据网页,数据也在html网页的源码中。继续分析,随意点击一个章节链接,网页跳转到另一个窗口,然后自动播放。本章的小说,如图:
事实上,找到音频文件非常简单。只需找到网络下的媒体选项,就可以看到正在播放的音频数据,如图:
从图中可以看出,音频数据是m4a格式的音频数据,而这个URL是真正的音频地址,所以问题是,只有这个URL只能爬取一章的小说,我们的目的是爬取所有章节的小说,所以显然只知道小说的音频地址是没有用的。接下来,我们需要找出音频地址的来源。通过经验,我们可以搜索到音频地址后面的文件名。
通过搜索名称,我们找到了一个新的网页链接,如图:
可以清楚的看到和真实的音频地址是一样的,只是少了**.m4a**这几个字。我们大概断定这个网页就是收录真实音频数据的地址网页,但是这是一个新的,那么这个地址是从哪里来的呢?没关系,我们继续搜索这个地址试试。
可以看出,我们通过搜索找到了一个新的网页。里面有一个iframe标签,标签下面有一个src属性。里面的 URL 大概和我们之前搜索的网页的 URL 是一样的,但是这个 URL 并不完整。,只有URL的后半部分,前半部分不见了,我们只需要完成前半部分,通过这一系列的分析,大概确定这个URL就是收录上述URL的数据URL,最后我们只需要确定 URL 使用任何 URL 就足够了。确认后,URL为各章节的链接地址。即使完成了整个分析过程,小说的有声读物也基本可以爬取。
现在我们来谈谈爬行的想法。首先通过小说首页爬取每章的链接地址和小说名,然后通过爬下来的每章的链接找到链接地址中收录的另一个。一个收录真实音频数据的小说链接,通过这个链接找到真实的音频数据,最后保存数据。
在这种情况下使用的模块:
1import requests
2import parsel
3import re
4import os
5from urllib.request import urlretrieve
6from tqdm import tqdm
7
8
二、发送请求并获取响应数据
1 def parse_url(self, url, headers):
2 """
3 发送请求,获取响应数据的方法
4 :param url:
5 :param headers:
6 :return:
7 """
8 response = requests.get(url, headers=headers)
9 if response.status_code == 200:
10 return response.text
11 else:
12 print('请求失败')
13
14
三、提取小说各章链接地址
1 def get_chapter_url(self, html_str):
2 """
3 提取小说章节的url的方法
4 :param html_str:
5 :return:
6 """
7 html = parsel.Selector(html_str)
8 # 提取小说章节地址列表
9 chapter_urls = html.css('#playlist>ul>li>a::attr(href)').extract()
10 chapter_urls = [self.SHU_TEMP_URL.format(i) for i in chapter_urls]
11 # 提取小说名字
12 audio_shu_name = html.css('.book-title::text').extract_first().strip()
13 return chapter_urls, audio_shu_name
14
15
16
四、提取收录小说真实音频地址的链接地址
1 def get_audio_temp_url(self, html_str2):
2 """
3 提取含有小说真实地址的url的方法
4 :param html_str2:
5 :return:
6 """
7 html = parsel.Selector(html_str2)
8 audio_temp_url = html.css('iframe::attr(src)').extract_first()
9 audio_temp_url = self.SHU_TEMP_URL.format(audio_temp_url)
10 return audio_temp_url
11
12
五、提取该地址下的真实音频数据地址
1 def get_audio_url(self, html_str3):
2 """
3 提取小说真实的url地址的方法
4 :param html_str3:
5 :return:
6 """
7 audio_url = re.findall("mp3:'(.*?)'", html_str3, re.S)[0]
8 if 'm4a' in audio_url:
9 return audio_url
10 else:
11 return audio_url + '.m4a'
12
13
六、保存音频数据
1 def down_audio(self, audio_url, audio_shu_name, num):
2 """
3 下载有声小说的方法
4 :param audio_url:
5 :param audio_shu_name:
6 :param num:
7 :return:
8 """
9 path = f'{audio_shu_name}'
10 isExists = os.path.exists(path)
11 file_path = os.path.join(path, f'{audio_shu_name}_{num}.mp3')
12 if not isExists:
13 os.makedirs(path, exist_ok=True)
14 urlretrieve(audio_url, file_path)
15 print(f"{audio_shu_name}_{num}---下载完成")
16 else:
17 urlretrieve(audio_url, file_path)
18 print(f"{audio_shu_name}_{num}---下载完成")
19
20
七、实现逻辑思想的代码
1 def run(self):
2 """
3 实现主要逻辑思路
4 :return:
5 """
6 # 1.发送请求,获取响应数据
7 html_str = self.parse_url(self.SHU_URL, self.headers)
8 # 2.提取小说章节的url
9 chapter_urls, audio_shu_name = self.get_chapter_url(html_str)
10 tqdm_chapter_urls = tqdm(chapter_urls)
11 for num, chapter_url in enumerate(tqdm_chapter_urls):
12 # 3.对小说章节url发送请求,获取响应数据
13 html_str2 = self.parse_url(chapter_url, self.headers)
14 # 4.提取含有小说真实地址的url
15 audio_temp_url = self.get_audio_temp_url(html_str2)
16 # 5.对这个url地址发送请求,获取响应数据
17 html_str3 = self.parse_url(audio_temp_url, self.headers)
18 # 6.提取真实的url地址
19 audio_url = self.get_audio_url(html_str3)
20 # 7.下载小说
21 self.down_audio(audio_url, audio_shu_name, num + 1)
22
23
完成效果展示:
查看全部
网页音频抓取(听有声小说的音频地址是什么?如何借鉴本文的思路
)
前言:
一个朋友最近沉迷于听有声小说,但是因为很多有声小说网站需要VIP才能听,所以他想让我帮他把小说下载下来,这样他就可以在手机上随时听了电话。我在网上搜了他听的这本小说,确实有很多大型听书网站需要VIP才能听,于是找了一个小网站帮他爬小说拿去向下。因为他听的小说是知名作者写的,为了保护作者的权益,本文的案例没有使用作者的小说进行爬取,而是使用了另一部小说进行爬取说明,大致爬取思路是一样的,大家可以借鉴这篇文章的思路。
本案网站:
一、分析网页
本案小说共有178章,对应178个音频数据。我们需要爬取小说的名字,每章的链接地址,然后分析每一个链接地址,找到真正的音频。数据地址。如图所示:

网页的链接可以通过查看开发者工具来分析,该网页是html数据网页,数据也在html网页的源码中。继续分析,随意点击一个章节链接,网页跳转到另一个窗口,然后自动播放。本章的小说,如图:

事实上,找到音频文件非常简单。只需找到网络下的媒体选项,就可以看到正在播放的音频数据,如图:

从图中可以看出,音频数据是m4a格式的音频数据,而这个URL是真正的音频地址,所以问题是,只有这个URL只能爬取一章的小说,我们的目的是爬取所有章节的小说,所以显然只知道小说的音频地址是没有用的。接下来,我们需要找出音频地址的来源。通过经验,我们可以搜索到音频地址后面的文件名。

通过搜索名称,我们找到了一个新的网页链接,如图:

可以清楚的看到和真实的音频地址是一样的,只是少了**.m4a**这几个字。我们大概断定这个网页就是收录真实音频数据的地址网页,但是这是一个新的,那么这个地址是从哪里来的呢?没关系,我们继续搜索这个地址试试。

可以看出,我们通过搜索找到了一个新的网页。里面有一个iframe标签,标签下面有一个src属性。里面的 URL 大概和我们之前搜索的网页的 URL 是一样的,但是这个 URL 并不完整。,只有URL的后半部分,前半部分不见了,我们只需要完成前半部分,通过这一系列的分析,大概确定这个URL就是收录上述URL的数据URL,最后我们只需要确定 URL 使用任何 URL 就足够了。确认后,URL为各章节的链接地址。即使完成了整个分析过程,小说的有声读物也基本可以爬取。
现在我们来谈谈爬行的想法。首先通过小说首页爬取每章的链接地址和小说名,然后通过爬下来的每章的链接找到链接地址中收录的另一个。一个收录真实音频数据的小说链接,通过这个链接找到真实的音频数据,最后保存数据。
在这种情况下使用的模块:
1import requests
2import parsel
3import re
4import os
5from urllib.request import urlretrieve
6from tqdm import tqdm
7
8
二、发送请求并获取响应数据
1 def parse_url(self, url, headers):
2 """
3 发送请求,获取响应数据的方法
4 :param url:
5 :param headers:
6 :return:
7 """
8 response = requests.get(url, headers=headers)
9 if response.status_code == 200:
10 return response.text
11 else:
12 print('请求失败')
13
14
三、提取小说各章链接地址
1 def get_chapter_url(self, html_str):
2 """
3 提取小说章节的url的方法
4 :param html_str:
5 :return:
6 """
7 html = parsel.Selector(html_str)
8 # 提取小说章节地址列表
9 chapter_urls = html.css('#playlist>ul>li>a::attr(href)').extract()
10 chapter_urls = [self.SHU_TEMP_URL.format(i) for i in chapter_urls]
11 # 提取小说名字
12 audio_shu_name = html.css('.book-title::text').extract_first().strip()
13 return chapter_urls, audio_shu_name
14
15
16
四、提取收录小说真实音频地址的链接地址
1 def get_audio_temp_url(self, html_str2):
2 """
3 提取含有小说真实地址的url的方法
4 :param html_str2:
5 :return:
6 """
7 html = parsel.Selector(html_str2)
8 audio_temp_url = html.css('iframe::attr(src)').extract_first()
9 audio_temp_url = self.SHU_TEMP_URL.format(audio_temp_url)
10 return audio_temp_url
11
12
五、提取该地址下的真实音频数据地址
1 def get_audio_url(self, html_str3):
2 """
3 提取小说真实的url地址的方法
4 :param html_str3:
5 :return:
6 """
7 audio_url = re.findall("mp3:'(.*?)'", html_str3, re.S)[0]
8 if 'm4a' in audio_url:
9 return audio_url
10 else:
11 return audio_url + '.m4a'
12
13
六、保存音频数据
1 def down_audio(self, audio_url, audio_shu_name, num):
2 """
3 下载有声小说的方法
4 :param audio_url:
5 :param audio_shu_name:
6 :param num:
7 :return:
8 """
9 path = f'{audio_shu_name}'
10 isExists = os.path.exists(path)
11 file_path = os.path.join(path, f'{audio_shu_name}_{num}.mp3')
12 if not isExists:
13 os.makedirs(path, exist_ok=True)
14 urlretrieve(audio_url, file_path)
15 print(f"{audio_shu_name}_{num}---下载完成")
16 else:
17 urlretrieve(audio_url, file_path)
18 print(f"{audio_shu_name}_{num}---下载完成")
19
20
七、实现逻辑思想的代码
1 def run(self):
2 """
3 实现主要逻辑思路
4 :return:
5 """
6 # 1.发送请求,获取响应数据
7 html_str = self.parse_url(self.SHU_URL, self.headers)
8 # 2.提取小说章节的url
9 chapter_urls, audio_shu_name = self.get_chapter_url(html_str)
10 tqdm_chapter_urls = tqdm(chapter_urls)
11 for num, chapter_url in enumerate(tqdm_chapter_urls):
12 # 3.对小说章节url发送请求,获取响应数据
13 html_str2 = self.parse_url(chapter_url, self.headers)
14 # 4.提取含有小说真实地址的url
15 audio_temp_url = self.get_audio_temp_url(html_str2)
16 # 5.对这个url地址发送请求,获取响应数据
17 html_str3 = self.parse_url(audio_temp_url, self.headers)
18 # 6.提取真实的url地址
19 audio_url = self.get_audio_url(html_str3)
20 # 7.下载小说
21 self.down_audio(audio_url, audio_shu_name, num + 1)
22
23
完成效果展示:


网页音频抓取(试试,真正被今日头条收购的海外头条版(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-06 05:28
视频查看器
互动率
评论数
评价率
喜欢比
广告点击率
观众年龄分布
观众地域分布
最受欢迎的视频等
您可以通过电子邮件直接联系影响者
工具网址为:
2、互联网上最好的设计之一网站
这是一个非常丑陋的单页网站,每月浏览量接近10亿,聚合了其他新闻网站的链接,自制头条。从1995年开始,几乎只有一个人经营,现在每年的广告收入都在几千万美元。
与 Craigslist 类似,Drudge Report 已经运营了 20 多年,页面设计几乎没有变化,经受住了时间的考验。而且大部分访问者都是直接访问,不依赖搜索引擎来分流。我这里就不截图了,有兴趣的可以看看,网址是:
3、亚马逊美国前 250,000 个搜索词
该网站是:
4、今日头条海外版
海外版抖音TikTok最近越来越火了。如果你不擅长短视频,何不尝试通过文字和图片来获得一些流量。试试海外版的今日头条。
该网站是:
顺便说一句,真正被今日头条收购的海外头条版是
有兴趣的都可以试试
5、Free Standalone:用于生成隐私政策、使用条款等法律文件的工具。
我知道很多独立网站的运营商/站长基本上都是从外地抄袭隐私政策、使用条款等文件。同时,面对欧盟的GDPR政策,网站中的相关文案也不知道怎么解释。这个工具也许能帮到你。
我们来做一个简单的操作说明:
1)注册成功后(可以直接通过谷歌账号登录),进入如下界面。很多模板,同时告诉你免费版只能创建3个文件。
如果找不到想要的模板,可以点击模板市场
2)我们选择与“隐私政策”相关的模板
3)10步以上的选择题
最后,您到达一个需要填写几个字段的页面。设置完成后,即可将内容发送到您的邮箱。
单击“魔术”按钮后,将为您生成一个word文档。
工具网址为:
6、将音视频文件翻译成文本提取核心思想
这是一个刚刚开发的网站,连付费版的支付工具都没有准备好。
免费版目前支持90分钟,点击上传音视频
上传成功后,点击文件名:
默认显示翻译文本
点击“摘要”提取核心点
7、做点有趣的事网站:看死囚的遗言
8、不用学Python,用这个工具爬网
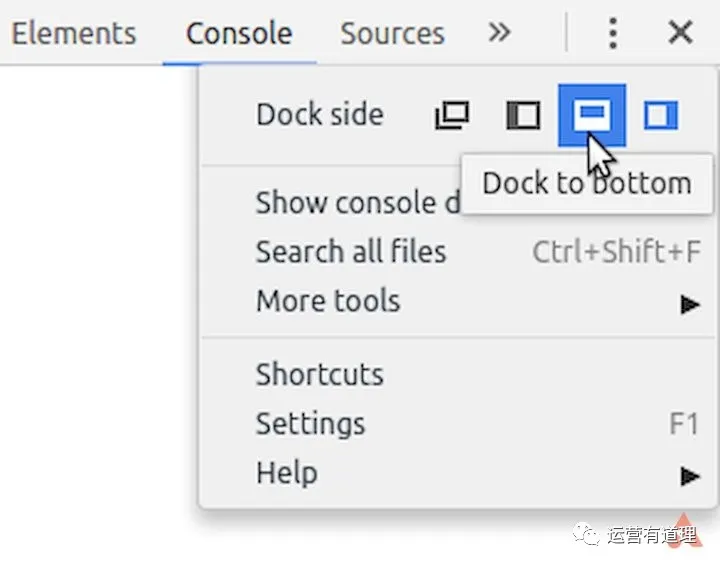
抓取页面多条信息——以bilibili排行榜为例
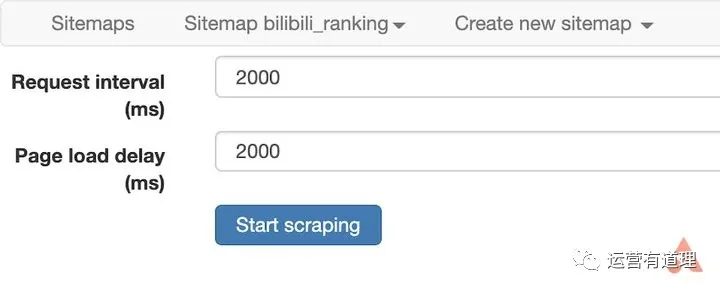
安装好“Web Scraper”后,按F12进入开发者模式,这样就可以在最后一个标签中看到“Web Scraper”菜单了。需要注意的是,如果开发者模式面板不在下方,会提示必须放在浏览器下方才能继续。
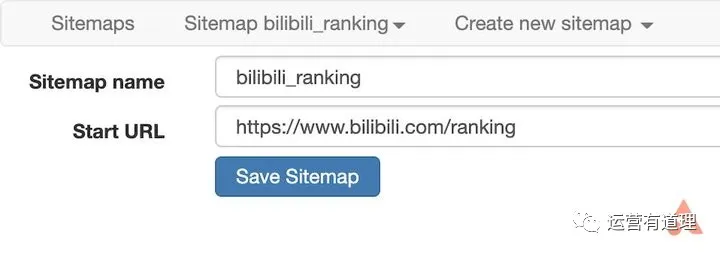
在菜单中选择“创建新站点地图-创建站点地图”创建新站点地图,填写名称和起始地址即可开始。这里以bilibili排名为例,介绍如何抓取页面上的多条信息。起始地址设置为
这里我们需要捕获“视频标题”、“播放量”、“弹幕数”、“up主”和“综合评分”,所以首先为每条记录创建一个wrapper。
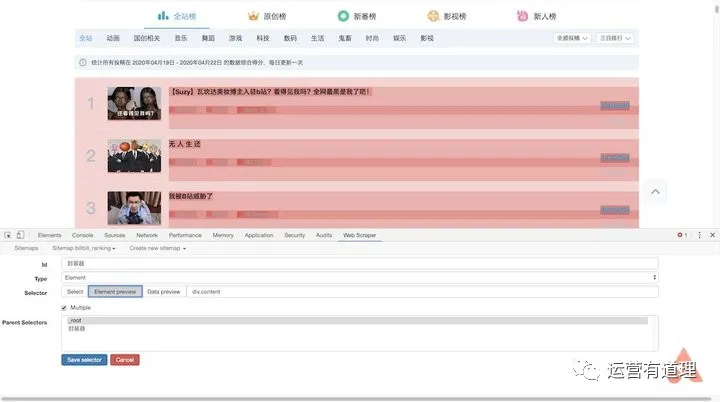
点击“添加新选择器”,id填写“packager”,type选择“element”,然后点击“selector”,选择一条记录的外框,外框需要收录以上所有信息,然后选择第二个,所以你会发现页面中的所有记录都被自动选中了,点击“Done selection”完成数据选择。还要记得勾选“Multiple”以确保捕获到多条记录,最后保存选择器。
返回后,点击刚才的wrapper,进入二级路径,创建“title”选择器,id填写“video title”,type选择“text”,点击“selector”找到第一条记录高亮显示。这是因为我们提前把它做成了包装器。在边界框中选择标题,然后单击“完成选择”完成标题的选择。注意这里不需要勾选“Multiple”,最后保存选择器。
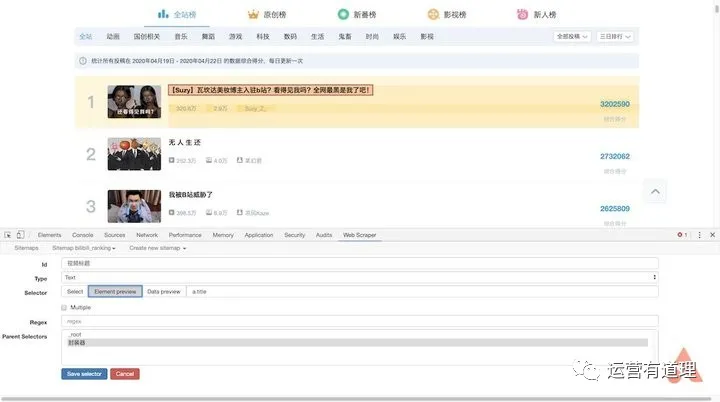
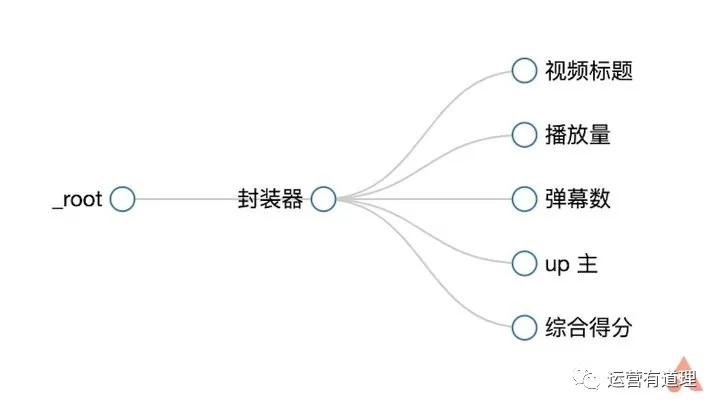
同样,我们为“播放量”、“弹幕数”、“up master”和“综合得分”创建选择器。选择后,可以通过“数据预览”预览是否选择了想要的内容。此外,您可以通过菜单栏中的“Sitemap bilibili_ranking - Selector graph”直观地查看树状结构。
继续选择刚才菜单下的“抓取”,开始创建抓取任务。可以默认单个网页的间隔时间和响应时间。点击“开始抓取”开始抓取。这时浏览器会自动打开一个新页面,停留几秒后会自动关闭,表示爬取完成。
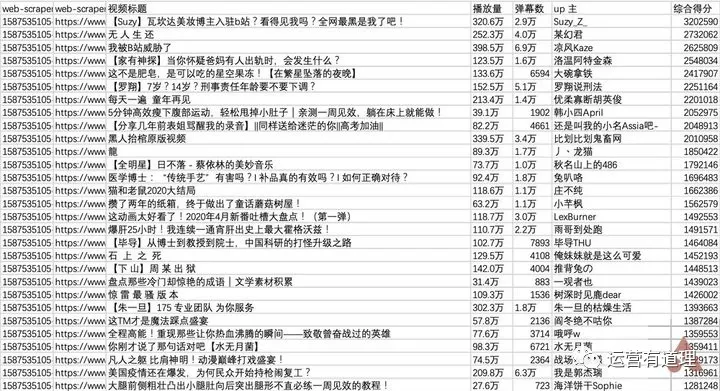
点击“刷新数据”刷新数据,或点击“Sitemap bilibili_ranking - 浏览”查看数据。您可以通过“Sitemap bilibili_ranking - 将数据导出为 CSV”将其下载为 CSV 文件。
▲bilibili排行榜
用 Excel 打开它。由于“Web Scraper”抓取的内容是乱序的,所以需要对“综合得分”进行降序排序,才能恢复原来排行榜的结果。
9、带有漂亮浏览器外壳的网页生成工具
输入任意 URL 生成带有 mac/win 风格的浏览器 shell 的图像
10、9 合 1 免费社交媒体分析工具
最强大的工具往往是最后出现的。Socialbakers 本身是一个强大的付费工具,但它提供了 9 个非常值得使用的免费工具。我们将一一介绍:
1)个人网上商城模板
2)网红搜索(只能看到部分数据)
3)网红标签搜索工具
4)facebook专页及竞争对手业绩分析报告
5)比较 Instagram 个人资料和竞争对手的影响力分析报告
6)比较 Instagram 个人资料和竞争对手的影响者分析报告
7)facebook 广告影响预测工具
8)facebook网红对比分析工具
9)Socialbakers 关于社会客户关怀的最新数据 查看全部
网页音频抓取(试试,真正被今日头条收购的海外头条版(组图))
视频查看器
互动率
评论数
评价率
喜欢比
广告点击率
观众年龄分布
观众地域分布
最受欢迎的视频等
您可以通过电子邮件直接联系影响者
工具网址为:
2、互联网上最好的设计之一网站
这是一个非常丑陋的单页网站,每月浏览量接近10亿,聚合了其他新闻网站的链接,自制头条。从1995年开始,几乎只有一个人经营,现在每年的广告收入都在几千万美元。
与 Craigslist 类似,Drudge Report 已经运营了 20 多年,页面设计几乎没有变化,经受住了时间的考验。而且大部分访问者都是直接访问,不依赖搜索引擎来分流。我这里就不截图了,有兴趣的可以看看,网址是:
3、亚马逊美国前 250,000 个搜索词
该网站是:
4、今日头条海外版
海外版抖音TikTok最近越来越火了。如果你不擅长短视频,何不尝试通过文字和图片来获得一些流量。试试海外版的今日头条。
该网站是:
顺便说一句,真正被今日头条收购的海外头条版是
有兴趣的都可以试试
5、Free Standalone:用于生成隐私政策、使用条款等法律文件的工具。
我知道很多独立网站的运营商/站长基本上都是从外地抄袭隐私政策、使用条款等文件。同时,面对欧盟的GDPR政策,网站中的相关文案也不知道怎么解释。这个工具也许能帮到你。
我们来做一个简单的操作说明:
1)注册成功后(可以直接通过谷歌账号登录),进入如下界面。很多模板,同时告诉你免费版只能创建3个文件。
如果找不到想要的模板,可以点击模板市场
2)我们选择与“隐私政策”相关的模板
3)10步以上的选择题
最后,您到达一个需要填写几个字段的页面。设置完成后,即可将内容发送到您的邮箱。
单击“魔术”按钮后,将为您生成一个word文档。
工具网址为:
6、将音视频文件翻译成文本提取核心思想
这是一个刚刚开发的网站,连付费版的支付工具都没有准备好。
免费版目前支持90分钟,点击上传音视频
上传成功后,点击文件名:
默认显示翻译文本
点击“摘要”提取核心点
7、做点有趣的事网站:看死囚的遗言
8、不用学Python,用这个工具爬网
抓取页面多条信息——以bilibili排行榜为例
安装好“Web Scraper”后,按F12进入开发者模式,这样就可以在最后一个标签中看到“Web Scraper”菜单了。需要注意的是,如果开发者模式面板不在下方,会提示必须放在浏览器下方才能继续。
在菜单中选择“创建新站点地图-创建站点地图”创建新站点地图,填写名称和起始地址即可开始。这里以bilibili排名为例,介绍如何抓取页面上的多条信息。起始地址设置为
这里我们需要捕获“视频标题”、“播放量”、“弹幕数”、“up主”和“综合评分”,所以首先为每条记录创建一个wrapper。
点击“添加新选择器”,id填写“packager”,type选择“element”,然后点击“selector”,选择一条记录的外框,外框需要收录以上所有信息,然后选择第二个,所以你会发现页面中的所有记录都被自动选中了,点击“Done selection”完成数据选择。还要记得勾选“Multiple”以确保捕获到多条记录,最后保存选择器。
返回后,点击刚才的wrapper,进入二级路径,创建“title”选择器,id填写“video title”,type选择“text”,点击“selector”找到第一条记录高亮显示。这是因为我们提前把它做成了包装器。在边界框中选择标题,然后单击“完成选择”完成标题的选择。注意这里不需要勾选“Multiple”,最后保存选择器。
同样,我们为“播放量”、“弹幕数”、“up master”和“综合得分”创建选择器。选择后,可以通过“数据预览”预览是否选择了想要的内容。此外,您可以通过菜单栏中的“Sitemap bilibili_ranking - Selector graph”直观地查看树状结构。
继续选择刚才菜单下的“抓取”,开始创建抓取任务。可以默认单个网页的间隔时间和响应时间。点击“开始抓取”开始抓取。这时浏览器会自动打开一个新页面,停留几秒后会自动关闭,表示爬取完成。
点击“刷新数据”刷新数据,或点击“Sitemap bilibili_ranking - 浏览”查看数据。您可以通过“Sitemap bilibili_ranking - 将数据导出为 CSV”将其下载为 CSV 文件。
▲bilibili排行榜
用 Excel 打开它。由于“Web Scraper”抓取的内容是乱序的,所以需要对“综合得分”进行降序排序,才能恢复原来排行榜的结果。
9、带有漂亮浏览器外壳的网页生成工具
输入任意 URL 生成带有 mac/win 风格的浏览器 shell 的图像
10、9 合 1 免费社交媒体分析工具
最强大的工具往往是最后出现的。Socialbakers 本身是一个强大的付费工具,但它提供了 9 个非常值得使用的免费工具。我们将一一介绍:
1)个人网上商城模板
2)网红搜索(只能看到部分数据)
3)网红标签搜索工具
4)facebook专页及竞争对手业绩分析报告
5)比较 Instagram 个人资料和竞争对手的影响力分析报告
6)比较 Instagram 个人资料和竞争对手的影响者分析报告
7)facebook 广告影响预测工具
8)facebook网红对比分析工具
9)Socialbakers 关于社会客户关怀的最新数据
网页音频抓取(总不能手工去网页源码吧?担心Python提供了许多库来帮助)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-06 05:27
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬取它相当于访问该页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,从而使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
爬虫概述
简单来说,爬虫是一个自动程序,它获取网页并提取和保存信息,如下所述。
1.获取网页
爬虫首先要做的是获取网页,这里是网页的源代码。源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如urllib、requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
2.提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
3.保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL和MongoDB,或者保存到远程服务器,比如使用SFTP操作。
4.自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们对应的是HTML代码,而最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据,爬虫就可以爬取。
页面的 JavaScript 渲染
有时候,当我们用 urllib 或者 requests 爬取网页时,得到的源代码其实和我们在浏览器中看到的不一样。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
This is a Demo
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开这个页面时,会先加载HTML内容,然后浏览器会发现里面已经引入了一个app.js文件,然后再去请求这个文件。获取文件后,它将执行 JavaScript 代码,JavaScript 更改 HTML 中的节点,向其中添加内容,最终得到一个完整的页面。
但是当用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载这个 JavaScript 文件,所以我们在浏览器中看不到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何用 采集JavaScript 渲染网页。
本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。
【上篇】《从零开始Python爬虫》2.2小白必备的网页基础知识 查看全部
网页音频抓取(总不能手工去网页源码吧?担心Python提供了许多库来帮助)
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬取它相当于访问该页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,从而使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
爬虫概述
简单来说,爬虫是一个自动程序,它获取网页并提取和保存信息,如下所述。
1.获取网页
爬虫首先要做的是获取网页,这里是网页的源代码。源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如urllib、requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
2.提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
3.保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL和MongoDB,或者保存到远程服务器,比如使用SFTP操作。
4.自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们对应的是HTML代码,而最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据,爬虫就可以爬取。
页面的 JavaScript 渲染
有时候,当我们用 urllib 或者 requests 爬取网页时,得到的源代码其实和我们在浏览器中看到的不一样。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
This is a Demo
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开这个页面时,会先加载HTML内容,然后浏览器会发现里面已经引入了一个app.js文件,然后再去请求这个文件。获取文件后,它将执行 JavaScript 代码,JavaScript 更改 HTML 中的节点,向其中添加内容,最终得到一个完整的页面。
但是当用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载这个 JavaScript 文件,所以我们在浏览器中看不到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何用 采集JavaScript 渲染网页。
本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。
【上篇】《从零开始Python爬虫》2.2小白必备的网页基础知识
网页音频抓取(4KYouTubeto提取YouTube或其他视频网站中的音频工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2022-02-04 19:25
4K YouTube to MP3 是一种从 YouTube 或其他视频中提取音频的工具 网站。4K YouTube 是一款通过从 YouTube、Vimeo、Facebook 和其他在线视频中提取音频来创建 MP3 文件的软件。没有复杂的设置,只有干净、简单、实用的界面。该软件使用方便:在浏览器中,复制并粘贴刚才视频链接的URL,就大功告成了。这是一个免费的 YouTube 到 MP3 转换器!随时随地享受您的音频,当然,即使您处于离线状态!
软件功能
从视频中提取音频并保存为 MP3、M4A 或 Ogg 高质量。
下载完整的 YouTube 播放列表或频道并生成 m3u 文件。
传输曲目会自动下载到 iTunes 中并上传到您的 iPhone 或 iPod。
听音乐是通过本地内置的音乐播放器。
从 SoundCloud、Vimeo、Flickr 和 Dailymotion 视频中下载和提取音轨。
从 YouTube 下载有声读物。
甚至从嵌入在 HTML 页面中的视频中提取音轨。
在您喜欢的 PC、Mac 或 Linux 操作系统上使用 4K 视频格式。
软件功能
1、界面简洁干净,没有复杂的设置,使用方便;
2、好用,打开视频网页,复制视频链接,网页音频提取软件可以抓取地址进行提取;
3、提取完成后,即使离线也能欣赏您的音频。 查看全部
网页音频抓取(4KYouTubeto提取YouTube或其他视频网站中的音频工具)
4K YouTube to MP3 是一种从 YouTube 或其他视频中提取音频的工具 网站。4K YouTube 是一款通过从 YouTube、Vimeo、Facebook 和其他在线视频中提取音频来创建 MP3 文件的软件。没有复杂的设置,只有干净、简单、实用的界面。该软件使用方便:在浏览器中,复制并粘贴刚才视频链接的URL,就大功告成了。这是一个免费的 YouTube 到 MP3 转换器!随时随地享受您的音频,当然,即使您处于离线状态!
软件功能
从视频中提取音频并保存为 MP3、M4A 或 Ogg 高质量。
下载完整的 YouTube 播放列表或频道并生成 m3u 文件。
传输曲目会自动下载到 iTunes 中并上传到您的 iPhone 或 iPod。
听音乐是通过本地内置的音乐播放器。
从 SoundCloud、Vimeo、Flickr 和 Dailymotion 视频中下载和提取音轨。
从 YouTube 下载有声读物。
甚至从嵌入在 HTML 页面中的视频中提取音轨。
在您喜欢的 PC、Mac 或 Linux 操作系统上使用 4K 视频格式。
软件功能
1、界面简洁干净,没有复杂的设置,使用方便;
2、好用,打开视频网页,复制视频链接,网页音频提取软件可以抓取地址进行提取;
3、提取完成后,即使离线也能欣赏您的音频。
网页音频抓取(有时候简单易用好上手的方法,一起来看下吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-29 06:06
在我们的日常工作和日常学习中,有时候一个视频除了音频还值得保留,而图片毫无意义,我们可以通过提取视频中的音频来提取音频,那么如何提取呢,可能有朋友说,我们可以用pr提取,但其实很多小伙伴都不会用,所以今天给大家分享两个好用又好用的方法,一起来看看吧!
方法一:使用风云视频转换器提取音频
风云视频转换器可以将视频转换成各种格式的视频文件,我们可以使用风云视频转换器将视频转换成MP3音频。首先需要下载这个软件,在浏览器或者软件管家中搜索就可以找到。
运行工具,进入主页面,主页面有各种视频处理功能,点击【视频转换】跳转到页面中的下一页!
点击页面中间的【添加文件】,将我们需要提取音频文件的视频添加到页面中,或者点击“添加文件夹”批量导入视频进行提取。
接下来,在页面底部,点击【输出格式】,在【音频】中选择【mp3】格式,同时设置音频质量。
然后我们设置文件输出路径,在输出目录后面查看输出目录。点击【全部转换】,从导入的视频中提取 MP3 音频!
方法二:使用风云音频处理大师从视频中提取音频
风云音频处理大师也可以提取视频。我们先搜索网页上的工具,下载到电脑上。
2、然后我们打开软件,在主界面选择点击音频提取功能。
3、接下来,点击“添加文件”,将需要提取音频的视频文件添加到软件中。
4、添加完视频后,我们需要圈出音频片段,选择音频片段范围,然后点击确定添加到输出列表中。
5、 接下来查看输出目录,点击开始处理,就可以解压视频和音频了。
6、解压完成后,点击打开文件,找到需要的音频文件。
7、我们点击属性查看。
好的!以上就是小编今天分享的如何从视频中提取音频文件的具体操作步骤!是不是很简单好用,有需要的朋友可以使用~ 查看全部
网页音频抓取(有时候简单易用好上手的方法,一起来看下吧!)
在我们的日常工作和日常学习中,有时候一个视频除了音频还值得保留,而图片毫无意义,我们可以通过提取视频中的音频来提取音频,那么如何提取呢,可能有朋友说,我们可以用pr提取,但其实很多小伙伴都不会用,所以今天给大家分享两个好用又好用的方法,一起来看看吧!
方法一:使用风云视频转换器提取音频
风云视频转换器可以将视频转换成各种格式的视频文件,我们可以使用风云视频转换器将视频转换成MP3音频。首先需要下载这个软件,在浏览器或者软件管家中搜索就可以找到。
运行工具,进入主页面,主页面有各种视频处理功能,点击【视频转换】跳转到页面中的下一页!
点击页面中间的【添加文件】,将我们需要提取音频文件的视频添加到页面中,或者点击“添加文件夹”批量导入视频进行提取。
接下来,在页面底部,点击【输出格式】,在【音频】中选择【mp3】格式,同时设置音频质量。
然后我们设置文件输出路径,在输出目录后面查看输出目录。点击【全部转换】,从导入的视频中提取 MP3 音频!
方法二:使用风云音频处理大师从视频中提取音频
风云音频处理大师也可以提取视频。我们先搜索网页上的工具,下载到电脑上。
2、然后我们打开软件,在主界面选择点击音频提取功能。
3、接下来,点击“添加文件”,将需要提取音频的视频文件添加到软件中。
4、添加完视频后,我们需要圈出音频片段,选择音频片段范围,然后点击确定添加到输出列表中。
5、 接下来查看输出目录,点击开始处理,就可以解压视频和音频了。
6、解压完成后,点击打开文件,找到需要的音频文件。
7、我们点击属性查看。
好的!以上就是小编今天分享的如何从视频中提取音频文件的具体操作步骤!是不是很简单好用,有需要的朋友可以使用~
网页音频抓取(白又白i--对你有用的话记得三连呦! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-23 00:15
)
大家好,我是白人。
如果对你有用,记得加三倍!
性能展示
抓取目标
网址:酷我音乐
工具使用
开发工具:pycharm
开发环境:python3.7、Windows10
使用工具包:requests, re
项目思路分析
找到需要解析的列表数据
随意点击一首歌曲,获取音乐的详细数据,通过抓包获取音乐播放数据
找到MP3的数据提交地址,mp3数据来自这个url地址
提交数据的网址:
/yy/index.ph…
比较多个网址数据,看看哪些参数需要自己修改
有3个url数据变化
_ 可以清楚的看到是时间戳。需要获取对应的hash和album_id值。到首页找到对应的歌曲id数据。发现数据来源于网页源代码
歌曲数据均来自网页源代码
梳理整体思路:简单源码分析
本章内容仅供学习,请勿用于其他用途! ! ! ! !
Pythonimport requestsimport reimport timedef Tools(url): headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.70' } response = requests.get(url, headers=headers) return responsedef Save(name, url): mp3 = Tools(url).content # 请求mp3地址链接 返回格式是16进制 f = open('./kugou/{}.mp3'.format(name), 'wb') # w 文件存在就写入 不存在就会创建 b进制读写 f.write(mp3) f.close() print('{}下载完成....'.format(name))url = 'https://www.kugou.com/yy/html/rank.html'response = Tools(url).textalbum_id = re.findall(r'"album_id":(\d*?),', response) # idHash = re.findall(r'"Hash":"(.*?)",', response) # hashfor a, h in zip(album_id, Hash): # 生成时间戳 time1 = int(time.time() * 1000) # 包含歌曲下载地址的url urls = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash={}&dfid=0zlWqK0UWNFa0weUnX0hjlFa&mid=f79511e2e86914b99e351c42ba1f8bc7&platid=4&album_id={}&_={}'.format(h, a, time1) response1 = Tools(urls).json() audio_name = response1['data']['audio_name'].split('-')[1] play_url = response1['data']['play_url'] Save(audio_name, play_url)复制代码
查看全部
网页音频抓取(白又白i--对你有用的话记得三连呦!
)
大家好,我是白人。
如果对你有用,记得加三倍!
性能展示

抓取目标
网址:酷我音乐

工具使用
开发工具:pycharm
开发环境:python3.7、Windows10
使用工具包:requests, re
项目思路分析
找到需要解析的列表数据

随意点击一首歌曲,获取音乐的详细数据,通过抓包获取音乐播放数据

找到MP3的数据提交地址,mp3数据来自这个url地址

提交数据的网址:
/yy/index.ph…
比较多个网址数据,看看哪些参数需要自己修改

有3个url数据变化
_ 可以清楚的看到是时间戳。需要获取对应的hash和album_id值。到首页找到对应的歌曲id数据。发现数据来源于网页源代码

歌曲数据均来自网页源代码

梳理整体思路:简单源码分析
本章内容仅供学习,请勿用于其他用途! ! ! ! !
Pythonimport requestsimport reimport timedef Tools(url): headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.70' } response = requests.get(url, headers=headers) return responsedef Save(name, url): mp3 = Tools(url).content # 请求mp3地址链接 返回格式是16进制 f = open('./kugou/{}.mp3'.format(name), 'wb') # w 文件存在就写入 不存在就会创建 b进制读写 f.write(mp3) f.close() print('{}下载完成....'.format(name))url = 'https://www.kugou.com/yy/html/rank.html'response = Tools(url).textalbum_id = re.findall(r'"album_id":(\d*?),', response) # idHash = re.findall(r'"Hash":"(.*?)",', response) # hashfor a, h in zip(album_id, Hash): # 生成时间戳 time1 = int(time.time() * 1000) # 包含歌曲下载地址的url urls = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash={}&dfid=0zlWqK0UWNFa0weUnX0hjlFa&mid=f79511e2e86914b99e351c42ba1f8bc7&platid=4&album_id={}&_={}'.format(h, a, time1) response1 = Tools(urls).json() audio_name = response1['data']['audio_name'].split('-')[1] play_url = response1['data']['play_url'] Save(audio_name, play_url)复制代码


网页音频抓取( 如何嵌入视频和音频在网页里嵌入HTML5音频播放器和视频播放器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-22 22:02
如何嵌入视频和音频在网页里嵌入HTML5音频播放器和视频播放器)
HTML5视频/音频的使用介绍
« 上一章
下一章 »
HTML5中引入的新标签,实现了HTML对视频播放和音频播放的原生支持,有了这个原生的HTML5视频播放器/音频播放器,我们不再需要flash技术,可以直接将视频/音频嵌入到网页中。
如何嵌入视频和音频
在网页中嵌入 HTML5 音频播放器和视频播放器的方法非常简单:
Your browser does not support the video element.
上面的示例展示了如何播放视频文件并公开视频播放控件。
下面是一个如何在 HTML 页面中嵌入音频音频的示例:
<p>Your browser does not support the audio element.
</p>
这里的 src 属性可以填写音视频 URL 或本地文件。
<p>Your browser does not support the audio element
</p>
这里是和两个标签上的控件属性的含义:
这里的 preload 属性是用来缓存大文件的。它具有三个可选值:
为了兼容各种浏览器对不同媒体类型的支持,我们可以使用多个元素来提供多种不同的媒体类型。例如:
Your browser does not support the video element.
支持 Ogg 格式视频流的浏览器可以播放 Ogg 文件。如果不支持,可以播放 MPEG-4 文件。要查看浏览器对各种媒体类型的支持,请查看此处。
我们还可以指定用于播放的编解码器(codecs);这使浏览器可以更准确地了解如何播放提供的视频:
Your browser does not support the video element.
上面,我们指定此视频需要使用 Dirac 和 Speex 编解码器。如果浏览器支持 Ogg 格式,但没有指定编解码器,则不会加载视频。
如果没有提供 type 属性,浏览器会向服务器询问媒体类型,看是否支持;如果没有,浏览器将转到下一个源属性。
使用 JavaScript 控制视频/音频播放
一旦视频文件被正确嵌入到 HTML 页面中,我们就可以使用控制它的 JavaScript 部分来获取其播放信息。例如,要使用 JavaScript 开始视频播放:
var v = document.getElementsByTagName("video")[0];
v.play();
使用 JavaScript 控制 HTML5 视频播放器的播放、暂停、快进、快退、音量等。
播放
暂停
降低音量
提高音量
停止下载视频文件
虽然我们可以使用 pause() 来停止播放视频文件,但浏览器不会停止下载媒体文件,除非它达到一定的缓存大小。
以下是告诉您的浏览器停止下载视频文件的方法:
var mediaElement = document.getElementById("myMediaElementID");
mediaElement.pause();
mediaElement.src='';
//或
mediaElement.removeAttribute("src");
通过删除 src 属性(或将其设置为空值),这将停止文件的网络下载。
设置播放时间点定位
我们可以通过设置 currentTime 属性来指定视频在特定时间、分钟和秒开始播放。
我们可以通过 seekable 属性获取视频的有效播放时间范围。它返回一个 TimeRanges 对象,告诉您有效的开始和结束时间。
var mediaElement = document.getElementById('mediaElementID');
mediaElement.seekable.start(0); // 返回开始时间 (秒)
mediaElement.seekable.end(0); // 返回结束时间 (秒)
mediaElement.currentTime = 122; // 定位到第 122 秒播放
mediaElement.played.end(0); // 返回已经播放的时间长度(秒)
设置播放范围
在网页中嵌入视频/音频文件时,或元素允许我们提供一些额外的信息来指定播放的时间段。执行此操作的方法是使用 ("#") 格式信息跟随媒体文件。
其具体语法如下:
#t=[开始时间][,结束时间]
时间可以用秒表示,或者您可以提供“时:分:秒”格式的时间(例如 2:05:01)。/p>
例子:
#t=10,20 查看全部
网页音频抓取(
如何嵌入视频和音频在网页里嵌入HTML5音频播放器和视频播放器)
HTML5视频/音频的使用介绍
« 上一章
下一章 »
HTML5中引入的新标签,实现了HTML对视频播放和音频播放的原生支持,有了这个原生的HTML5视频播放器/音频播放器,我们不再需要flash技术,可以直接将视频/音频嵌入到网页中。
如何嵌入视频和音频
在网页中嵌入 HTML5 音频播放器和视频播放器的方法非常简单:
Your browser does not support the video element.
上面的示例展示了如何播放视频文件并公开视频播放控件。
下面是一个如何在 HTML 页面中嵌入音频音频的示例:
<p>Your browser does not support the audio element.
</p>
这里的 src 属性可以填写音视频 URL 或本地文件。
<p>Your browser does not support the audio element
</p>
这里是和两个标签上的控件属性的含义:
这里的 preload 属性是用来缓存大文件的。它具有三个可选值:
为了兼容各种浏览器对不同媒体类型的支持,我们可以使用多个元素来提供多种不同的媒体类型。例如:
Your browser does not support the video element.
支持 Ogg 格式视频流的浏览器可以播放 Ogg 文件。如果不支持,可以播放 MPEG-4 文件。要查看浏览器对各种媒体类型的支持,请查看此处。
我们还可以指定用于播放的编解码器(codecs);这使浏览器可以更准确地了解如何播放提供的视频:
Your browser does not support the video element.
上面,我们指定此视频需要使用 Dirac 和 Speex 编解码器。如果浏览器支持 Ogg 格式,但没有指定编解码器,则不会加载视频。
如果没有提供 type 属性,浏览器会向服务器询问媒体类型,看是否支持;如果没有,浏览器将转到下一个源属性。
使用 JavaScript 控制视频/音频播放
一旦视频文件被正确嵌入到 HTML 页面中,我们就可以使用控制它的 JavaScript 部分来获取其播放信息。例如,要使用 JavaScript 开始视频播放:
var v = document.getElementsByTagName("video")[0];
v.play();
使用 JavaScript 控制 HTML5 视频播放器的播放、暂停、快进、快退、音量等。
播放
暂停
降低音量
提高音量
停止下载视频文件
虽然我们可以使用 pause() 来停止播放视频文件,但浏览器不会停止下载媒体文件,除非它达到一定的缓存大小。
以下是告诉您的浏览器停止下载视频文件的方法:
var mediaElement = document.getElementById("myMediaElementID");
mediaElement.pause();
mediaElement.src='';
//或
mediaElement.removeAttribute("src");
通过删除 src 属性(或将其设置为空值),这将停止文件的网络下载。
设置播放时间点定位
我们可以通过设置 currentTime 属性来指定视频在特定时间、分钟和秒开始播放。
我们可以通过 seekable 属性获取视频的有效播放时间范围。它返回一个 TimeRanges 对象,告诉您有效的开始和结束时间。
var mediaElement = document.getElementById('mediaElementID');
mediaElement.seekable.start(0); // 返回开始时间 (秒)
mediaElement.seekable.end(0); // 返回结束时间 (秒)
mediaElement.currentTime = 122; // 定位到第 122 秒播放
mediaElement.played.end(0); // 返回已经播放的时间长度(秒)
设置播放范围
在网页中嵌入视频/音频文件时,或元素允许我们提供一些额外的信息来指定播放的时间段。执行此操作的方法是使用 ("#") 格式信息跟随媒体文件。
其具体语法如下:
#t=[开始时间][,结束时间]
时间可以用秒表示,或者您可以提供“时:分:秒”格式的时间(例如 2:05:01)。/p>
例子:
#t=10,20
网页音频抓取(网站优化:TAG标签好处多你的网站用了吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-19 05:02
)
相关话题
git 拉取代码到本地
2/7/202018:02:55
git拉码到本地的方法是:先打开git命令窗口,输入命令【gitclonegithub仓库地址】;然后回车拉码到本地仓库。第一步:拉取远程代码 gitclone
如何善用博客或网站上的标签?
28/1/2010 08:55:00
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大网站已经熟练使用TAG标签了,今天想和大家讨论这个话题,因为很多中小网站经常忽略TAG标签的作用也不知道TAG标签能给网站带来什么好处,今天就和大家详细分享一下。
标签——push的基石和实现
18/5/2018 14:26:49
在任何一个网站上购物,不管是看文章,听音乐还是看视频,都会有一些相关的推送,还有对豆瓣、个人账号等社交网络感兴趣的朋友们网站 ,根据你在网站中的行为,推送越来越符合你的脾胃,这背后的英雄是Tag。
网站优化简化代码
21/11/2012 16:06:00
精简代码有很多好处。首先,从SEO理解的角度来看,搜索引擎预处理的第一步是提取文本内容。因此,我们应该尽量降低搜索引擎提取文本内容的难度,简化代码,从而提高文本内容的占比。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
2007 年 16 月 11 日 05:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
网站标签在优化中有什么用?
28/7/202018:07:22
tag标签是一种可以自行定义的关键词,比分类标签更具体准确,可以概括文章的主要内容。那么网站的优化中使用tag标签有什么用呢?
在 GTM 中指定标签依赖关系
26/10/201209:40:00
GoogleTagManager 方便了网站 分析师的工作,我一直认为它有一个局限性:Container 中的标签是异步加载的,标签之间没有顺序,所以如果之前有的标签有依赖关系,那就是如果Btag 必须在 ATag 执行后执行,才有效。
Tag标签SEO优化让网站快速排名收录!
2017 年 10 月 31 日 15:03:00
tag标签的作用:第一:提升用户体验和PV点击率。第二:增加内链有利于网页权重的相互传递。第三:增加百度收录,提升关键词的排名。为什么标签页的排名比 文章 页面好?原因是标签页关键词与文章页形成内部竞争,标签页接收到的内链远多于文章页,这些内链甚至是高度相关的,所以这是正常的
WP博客专栏,TAG URL链接加反斜杠代码
29/6/2012 14:22:00
WP博客的默认栏目、TAG、分页等url链接后面没有反斜杠“/”,但是一些SEOER常说没有反斜杠的URL不利于SEO优化。其实不管有没有反斜杠,搜索引擎都会一直收录,所以只要把URL规范化统一起来,对SE是有好处的。
网站优化指南:标签优化技巧分析
19/4/2010 10:51:00
如今,所有主要的cms 和博客系统都添加了标签。tag标签的意思是将相关的关键词聚合在一起。现在网站管理员使用 Tag 标签。标签无非就是两点 1:增强搜索引擎地收录。2:有利于用户体验。
关于webhooks服务器自动拉取代码phpthinkphp6
24/6/202118:16:07
thinkphp教程栏目介绍“webhooks服务器自动拉码phpthinkphp6”。Github准备1.在仓库设置中添加webhooks 以私有仓库为例:1.创建仓库后,点击设置。设置 w
查看全部
网页音频抓取(网站优化:TAG标签好处多你的网站用了吗?
)
相关话题
git 拉取代码到本地
2/7/202018:02:55
git拉码到本地的方法是:先打开git命令窗口,输入命令【gitclonegithub仓库地址】;然后回车拉码到本地仓库。第一步:拉取远程代码 gitclone

如何善用博客或网站上的标签?
28/1/2010 08:55:00
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大网站已经熟练使用TAG标签了,今天想和大家讨论这个话题,因为很多中小网站经常忽略TAG标签的作用也不知道TAG标签能给网站带来什么好处,今天就和大家详细分享一下。
标签——push的基石和实现
18/5/2018 14:26:49
在任何一个网站上购物,不管是看文章,听音乐还是看视频,都会有一些相关的推送,还有对豆瓣、个人账号等社交网络感兴趣的朋友们网站 ,根据你在网站中的行为,推送越来越符合你的脾胃,这背后的英雄是Tag。
网站优化简化代码
21/11/2012 16:06:00
精简代码有很多好处。首先,从SEO理解的角度来看,搜索引擎预处理的第一步是提取文本内容。因此,我们应该尽量降低搜索引擎提取文本内容的难度,简化代码,从而提高文本内容的占比。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
2007 年 16 月 11 日 05:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
网站标签在优化中有什么用?
28/7/202018:07:22
tag标签是一种可以自行定义的关键词,比分类标签更具体准确,可以概括文章的主要内容。那么网站的优化中使用tag标签有什么用呢?
在 GTM 中指定标签依赖关系
26/10/201209:40:00
GoogleTagManager 方便了网站 分析师的工作,我一直认为它有一个局限性:Container 中的标签是异步加载的,标签之间没有顺序,所以如果之前有的标签有依赖关系,那就是如果Btag 必须在 ATag 执行后执行,才有效。
Tag标签SEO优化让网站快速排名收录!
2017 年 10 月 31 日 15:03:00
tag标签的作用:第一:提升用户体验和PV点击率。第二:增加内链有利于网页权重的相互传递。第三:增加百度收录,提升关键词的排名。为什么标签页的排名比 文章 页面好?原因是标签页关键词与文章页形成内部竞争,标签页接收到的内链远多于文章页,这些内链甚至是高度相关的,所以这是正常的
WP博客专栏,TAG URL链接加反斜杠代码
29/6/2012 14:22:00
WP博客的默认栏目、TAG、分页等url链接后面没有反斜杠“/”,但是一些SEOER常说没有反斜杠的URL不利于SEO优化。其实不管有没有反斜杠,搜索引擎都会一直收录,所以只要把URL规范化统一起来,对SE是有好处的。
网站优化指南:标签优化技巧分析
19/4/2010 10:51:00
如今,所有主要的cms 和博客系统都添加了标签。tag标签的意思是将相关的关键词聚合在一起。现在网站管理员使用 Tag 标签。标签无非就是两点 1:增强搜索引擎地收录。2:有利于用户体验。
关于webhooks服务器自动拉取代码phpthinkphp6
24/6/202118:16:07
thinkphp教程栏目介绍“webhooks服务器自动拉码phpthinkphp6”。Github准备1.在仓库设置中添加webhooks 以私有仓库为例:1.创建仓库后,点击设置。设置 w
网页音频抓取(私信小编001即可获取大量Python学习资料!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-29 08:07
今天,我们就打开爬虫的“工具箱”,把涉及到的技术盲点放在灯光下,让大家看得一清二楚。下面,本文将从这个角度来谈谈爬虫这个熟悉又陌生的技术。
“把你手里的密码放下,小心被抓住。”
最近程序员圈里不乏这样的笑话。
原因是近期司法部门对多家涉及爬虫技术的公司进行了立案调查。近日,51张信用卡被查处,曝光了暴力催收背后的丑闻:非法使用爬虫技术抓取个人隐私数据。
私信小编001可以获得大量Python学习资料!
一时间,“爬虫类”成为众矢之的。有的公司紧急下架爬虫类招聘信息,给大数据风控和人工智能从业者造成了不小的恐慌,又掉了几根头发。
事实上,大多数人都听说过爬虫,认为爬虫是在爬取其他网站的东西,窃取数据。甚至有人认为,只要有爬虫,任何数据都可以获得。
今天,我们就打开爬虫的“工具箱”,把涉及到的技术盲点放在灯光下,让大家看得一清二楚。下面,本文将从这个角度来谈谈爬虫这个熟悉又陌生的技术。
爬虫技术原理
搜索引擎在互联网上采集
信息的主要手段是网络爬虫(又称网络蜘蛛、网络机器人)。它是一种“自动浏览互联网”的程序,根据一定的规则,自动抓取互联网信息,如:网页、各种文档、图片、音频、视频等,搜索引擎通过索引技术将这些信息组织起来,并快速根据用户查询提供搜索结果。
想象一下,当我们浏览网页时,我们在做什么?
一般情况下,您首先会使用浏览器打开一个网站的首页,搜索页面上感兴趣的内容,然后点击该网站或页面上其他网站的链接,跳转到一个新的页面,阅读内容等。来回。如下所示:
图中带圆角的虚线矩形代表一个网站,每个实心矩形代表一个网页。可以看出,每个网站一般都以首页作为入口,链接到几个、几万甚至几千万个内部网页。同时,这些网页往往链接到许多外部网站。例如,某用户从苏宁财经的网页开始,浏览并找到PP视频的链接,点击跳转到PP视频首页,作为一名体育迷,在体育频道找到了相关的新浪微博内容,再次点击来到了PP视频主页。微博页面继续阅读,从而形成一条路径。如果您提供所有可能的路径,您将看到一个网络结构。
网络爬虫模拟人们浏览网页的行为,但用程序代替人工操作,在网页上进行广度和深度的遍历。如果将互联网上的网页或网站理解为节点,则大量网页或网站通过超链接形成网络结构。爬虫通过遍历网页上的链接从一个节点跳转到下一个节点,就像在巨大的网络上爬行一样,但它比人类更快,跳转的节点更全面,因此被形象地称为网络爬虫或网络蜘蛛。
爬行动物的历史
网络爬虫最早的用途是服务于搜索引擎的数据采集,现代意义上的搜索引擎的鼻祖是阿尔奇于1990年由加拿大麦吉尔大学的学生艾伦·埃姆塔奇(Alan Emtage)发明的。
人们使用FTP服务器来共享通信资源,大量的文件分散在各个FTP主机上,查询非常不方便。因此,他开发了一个系统,可以通过文件名搜索文件,定期采集
和分析FTP服务器上的文件名信息,并自动为这些文件建立索引。其工作原理与目前的搜索引擎非常接近,依靠脚本自动搜索分散在各个FTP主机上的文件,然后将相关信息编入索引,以一定的表达方式供用户查询。
世界上第一个网络爬虫“wwwwanderer”(“wwwwanderer”)是麻省理工学院的学生Matthew Gray于1993年编写的,一开始只是用来统计互联网上的服务器数量,后来发展到能够通过它检索网站域名。
随着互联网的快速发展,检索所有新网页变得越来越困难。因此,一些程序员在“网络漫游者”的基础上,改进了传统“蜘蛛”程序的工作原理。这个想法是因为所有网页都可能有到其他网站的链接,所以可以从跟踪到网站的链接开始检索整个互联网。
此后,无数的搜索引擎让爬虫变得越来越复杂,逐渐向多策略、负载均衡、大规模增量爬取的方向发展。爬虫工作的结果是搜索引擎可以遍历链接的网页,甚至可以通过“网页快照”功能访问已删除的网页。
网络爬虫的礼仪之一:robots.txt文件
每个行业都有其行为准则,它成为行为准则或行为准则。例如,如果您是某个协会的成员,则必须遵守该协会的行为准则。如果您违反行为准则,您将被踢出局。
最简单的例子就是你加入的很多微信群,一般的站长都会要求不要私下发广告。未经允许发广告会被直接踢出群,不过发个红包也没关系。这是行为准则。
爬虫也有行为准则。早在1994年,搜索引擎技术才刚刚兴起。当时,初创的搜索引擎公司,如AltaVista、DogPile,利用爬虫技术对整个互联网的资源进行采集,与雅虎等资源分类网站展开激烈竞争。随着互联网搜索规模的增长,爬虫采集
信息的能力也在飞速发展,网站开始考虑对搜索引擎爬取的信息进行限制,于是robots.txt应运而生,成为网络中的“君子协定”。爬虫世界。
robots.txt 文件是业界的通行做法,并非强制约束。robots.txt的格式如下:
在上面的 robots.txt 示例中,禁止所有爬虫访问网站上的任何内容。但是谷歌的爬虫机器人可以访问除私人位置以外的所有内容。如果网站上没有robots.txt,则认为默认允许爬虫抓取所有信息。如果robots.txt被限制访问,而爬虫不遵守,这不是技术实现上的简单问题。
礼仪二:控制爬行吞吐量
伪造谷歌搜索引擎的爬虫用于对网站进行 DDoS 攻击并使网站瘫痪。近年来,恶意爬虫引发的DDoS攻击不断增多,给大数据行业投下了爬虫的阴影。因为背后的恶意攻击者往往拥有更复杂、更专业的技术,可以绕过各种防御机制,使得防范此类攻击的难度更大。
礼仪三:做一个优雅的爬行者
优雅的履带车背后,必定有一个文明的人,或者文明的团队。他们会考虑自己编写的爬虫程序是否符合robots.txt协议,是否会影响被爬取的网站的性能,如何才能不侵犯知识产权人的权益和非常重要的个人隐私数据。
由于能力差异,并不是每个爬虫团队都能考虑这些问题。2018年,欧盟的《通用数据保护条例》(General Data Protection Regulation)发布了严格的数据保护指令。2019年5月28日,国家互联网信息办公室发布的《数据安全管理办法》(征求意见稿)对爬虫和个人信息安全做出了非常严格的规定。例如:
事实上,我国于2017年6月1日实施的《中华人民共和国网络安全法》第四章第四十一条和第四十四条,已经对个人隐私信息的采集
和使用作出了明确规定。与爬虫直接相关。
法律制度的颁布明确了技术的界限,技术的无罪不能作为技术实施者为自己辩解的理由。爬虫在满足自身需求的同时,必须严格遵守行为准则和法律法规。
各种反爬虫技术介绍
为了保护自己的合法权益不受恶意侵害,很多网站和APP都应用了大量的反爬技术。这使得爬虫技术衍生出反爬虫技术,如各种滑动拼图、文字点击、图标点击等验证码破解,相互促进,相互发展,相互伤害。
反爬虫的关键是防止爬虫批量抓取网站内容。反爬虫技术的核心是不断改变规则和各种验证方式。
这种技术的发展更是引人入胜,甚至比DOTA之战还要精彩。在波浪形文字验证码图形的伪装色中可以看到程序员的头发。
1、图片/Flash
这是一种比较常见的防爬方法。它将关键数据转换为图片并添加水印。即使使用了OCR(Optical Character Recognition),也无法识别,以至于爬虫拿到图片就得不到任何信息。这种方式在一些早期电子商务公司的价格标签中经常看到。
2、JavaScript 混淆技术
这是爬虫程序员遇到最多的反爬方法。简而言之,它实际上是一种致盲方法,本质上是一种加密技术。许多网页中的数据是使用 JavaScript 程序动态加载的。在抓取此类网页数据时,爬虫需要了解网页是如何加载数据的。这个过程称为逆向工程。为了防止逆向工程,使用了 JavaScript 混淆技术,并添加了 JavaScript 代码进行加密,使其他人无法理解。不过这种方法属于比较简单的防爬方法,属于履带工程师调平的初级阶段。
3、验证码
验证码是一个公开的全自动程序,用于区分用户是计算机还是人。也是我们经常遇到的一种网站访问验证的方法。它主要分为以下几种:
(1)输入类型验证码
这是最常见的。通过用户输入图片中的字母、数字、汉字等字符进行验证。
图中CAPTCHA的全称是(Completely Automated Public Turing test to tell Computers and Humans Apart),中文翻译为:自动图灵测试以区分计算机和人类。实现这一点的方法很简单,就是提出一个计算机无法回答但人类可以回答的问题。然而,目前的爬虫往往使用深度学习技术来破解这样的验证码,这样的图灵测试已经失效。
(2)滑块类型验证码
鉴于输入式图形验证码的缺点,容易被破解,有时还无法被人类识别。滑块验证码诞生了。这种验证码操作简单,破解难度大,迅速走红。破解滑块验证码有两大难点:一是要知道图形缺口在哪里,也就是要知道滑块在哪里滑动;另一种是模仿人类的滑动手势。这样的验证码增加了一定的难度,也给爬虫世界增添了不少乐趣。一时间出现了大量破解滑块验证码的技术。
(3)点击式图形验证和图标选择
图文验证是提醒用户点击图片中同一个词的位置进行文本验证。
图标选择是给出一组图片,根据需要点击其中一个或多个。
两种原理类似,只不过一种是给出文字,点击图片中的文字;另一个给出图片并点击与内容匹配的图片。这两种方式的共同点是体验不佳,广受诟病。
(4)手机验证码
对于一些重要敏感信息的访问,网站或APP一般会提供填写手机验证码的要求,手机接受网站发送的验证码,以便进一步访问。这种方法更利于数据隐私保护。
4、账号密码登录
网站可以通过账号登录来限制爬虫的访问权限。个人在使用很多网站服务时,一般都需要注册一个账号。使用时,他们需要使用帐户密码登录才能继续使用该服务。网站可以使用用户浏览器的cookie来识别用户的身份,并通过用户本地浏览器中存储的加密cookie数据跟踪用户的访问会话。这一般是作为之前防爬方法的补充。
履带技术的发展方向
传统网络爬虫最大的应用场景是搜索引擎,普通企业更多的是针对网站或者应用。后来随着网络数据分析的需要,以及互联网上层出不穷的舆论事件,对网络爬虫的需求量很大,主要采集的对象是新闻信息。
近年来,由于大数据处理和数据挖掘技术的发展,数据资产价值的概念深入人心,爬虫技术得到了更广泛深入的发展,采集
对象也越来越多。更丰富,高性能和并发技术指标也更高。.
围绕网络爬虫合法性的讨论依然存在,而且情况更为复杂。在目前的趋势下,很多法律问题还处于一个模糊的领域,往往取决于具体案件的影响。但是,可以肯定的是,只要有互联网,就会有网络爬虫。只有网络爬虫才能让庞大的互联网变得可搜索,让爆炸式增长的互联网更容易被访问和获取。在可预见的未来,互联网爬虫技术将不断发展。
作为人类历史上最大的知识仓库,互联网是非结构化或非标准化的。互联网上聚集了大量的文字、图片、多媒体等数据。虽然内容很有价值,但是提取知识的难度还是非常巨大的。语义互联网、知识共享等概念越来越流行,真正的语义互联网将成为网络爬虫的目标。此外,物联网技术的发展将是互联网的升级形态,也将是未来爬虫技术的发展方向。 查看全部
网页音频抓取(私信小编001即可获取大量Python学习资料!(组图))
今天,我们就打开爬虫的“工具箱”,把涉及到的技术盲点放在灯光下,让大家看得一清二楚。下面,本文将从这个角度来谈谈爬虫这个熟悉又陌生的技术。
“把你手里的密码放下,小心被抓住。”
最近程序员圈里不乏这样的笑话。
原因是近期司法部门对多家涉及爬虫技术的公司进行了立案调查。近日,51张信用卡被查处,曝光了暴力催收背后的丑闻:非法使用爬虫技术抓取个人隐私数据。
私信小编001可以获得大量Python学习资料!
一时间,“爬虫类”成为众矢之的。有的公司紧急下架爬虫类招聘信息,给大数据风控和人工智能从业者造成了不小的恐慌,又掉了几根头发。
事实上,大多数人都听说过爬虫,认为爬虫是在爬取其他网站的东西,窃取数据。甚至有人认为,只要有爬虫,任何数据都可以获得。
今天,我们就打开爬虫的“工具箱”,把涉及到的技术盲点放在灯光下,让大家看得一清二楚。下面,本文将从这个角度来谈谈爬虫这个熟悉又陌生的技术。
爬虫技术原理
搜索引擎在互联网上采集
信息的主要手段是网络爬虫(又称网络蜘蛛、网络机器人)。它是一种“自动浏览互联网”的程序,根据一定的规则,自动抓取互联网信息,如:网页、各种文档、图片、音频、视频等,搜索引擎通过索引技术将这些信息组织起来,并快速根据用户查询提供搜索结果。
想象一下,当我们浏览网页时,我们在做什么?
一般情况下,您首先会使用浏览器打开一个网站的首页,搜索页面上感兴趣的内容,然后点击该网站或页面上其他网站的链接,跳转到一个新的页面,阅读内容等。来回。如下所示:
图中带圆角的虚线矩形代表一个网站,每个实心矩形代表一个网页。可以看出,每个网站一般都以首页作为入口,链接到几个、几万甚至几千万个内部网页。同时,这些网页往往链接到许多外部网站。例如,某用户从苏宁财经的网页开始,浏览并找到PP视频的链接,点击跳转到PP视频首页,作为一名体育迷,在体育频道找到了相关的新浪微博内容,再次点击来到了PP视频主页。微博页面继续阅读,从而形成一条路径。如果您提供所有可能的路径,您将看到一个网络结构。
网络爬虫模拟人们浏览网页的行为,但用程序代替人工操作,在网页上进行广度和深度的遍历。如果将互联网上的网页或网站理解为节点,则大量网页或网站通过超链接形成网络结构。爬虫通过遍历网页上的链接从一个节点跳转到下一个节点,就像在巨大的网络上爬行一样,但它比人类更快,跳转的节点更全面,因此被形象地称为网络爬虫或网络蜘蛛。
爬行动物的历史
网络爬虫最早的用途是服务于搜索引擎的数据采集,现代意义上的搜索引擎的鼻祖是阿尔奇于1990年由加拿大麦吉尔大学的学生艾伦·埃姆塔奇(Alan Emtage)发明的。
人们使用FTP服务器来共享通信资源,大量的文件分散在各个FTP主机上,查询非常不方便。因此,他开发了一个系统,可以通过文件名搜索文件,定期采集
和分析FTP服务器上的文件名信息,并自动为这些文件建立索引。其工作原理与目前的搜索引擎非常接近,依靠脚本自动搜索分散在各个FTP主机上的文件,然后将相关信息编入索引,以一定的表达方式供用户查询。
世界上第一个网络爬虫“wwwwanderer”(“wwwwanderer”)是麻省理工学院的学生Matthew Gray于1993年编写的,一开始只是用来统计互联网上的服务器数量,后来发展到能够通过它检索网站域名。
随着互联网的快速发展,检索所有新网页变得越来越困难。因此,一些程序员在“网络漫游者”的基础上,改进了传统“蜘蛛”程序的工作原理。这个想法是因为所有网页都可能有到其他网站的链接,所以可以从跟踪到网站的链接开始检索整个互联网。
此后,无数的搜索引擎让爬虫变得越来越复杂,逐渐向多策略、负载均衡、大规模增量爬取的方向发展。爬虫工作的结果是搜索引擎可以遍历链接的网页,甚至可以通过“网页快照”功能访问已删除的网页。
网络爬虫的礼仪之一:robots.txt文件
每个行业都有其行为准则,它成为行为准则或行为准则。例如,如果您是某个协会的成员,则必须遵守该协会的行为准则。如果您违反行为准则,您将被踢出局。
最简单的例子就是你加入的很多微信群,一般的站长都会要求不要私下发广告。未经允许发广告会被直接踢出群,不过发个红包也没关系。这是行为准则。
爬虫也有行为准则。早在1994年,搜索引擎技术才刚刚兴起。当时,初创的搜索引擎公司,如AltaVista、DogPile,利用爬虫技术对整个互联网的资源进行采集,与雅虎等资源分类网站展开激烈竞争。随着互联网搜索规模的增长,爬虫采集
信息的能力也在飞速发展,网站开始考虑对搜索引擎爬取的信息进行限制,于是robots.txt应运而生,成为网络中的“君子协定”。爬虫世界。
robots.txt 文件是业界的通行做法,并非强制约束。robots.txt的格式如下:
在上面的 robots.txt 示例中,禁止所有爬虫访问网站上的任何内容。但是谷歌的爬虫机器人可以访问除私人位置以外的所有内容。如果网站上没有robots.txt,则认为默认允许爬虫抓取所有信息。如果robots.txt被限制访问,而爬虫不遵守,这不是技术实现上的简单问题。
礼仪二:控制爬行吞吐量
伪造谷歌搜索引擎的爬虫用于对网站进行 DDoS 攻击并使网站瘫痪。近年来,恶意爬虫引发的DDoS攻击不断增多,给大数据行业投下了爬虫的阴影。因为背后的恶意攻击者往往拥有更复杂、更专业的技术,可以绕过各种防御机制,使得防范此类攻击的难度更大。
礼仪三:做一个优雅的爬行者
优雅的履带车背后,必定有一个文明的人,或者文明的团队。他们会考虑自己编写的爬虫程序是否符合robots.txt协议,是否会影响被爬取的网站的性能,如何才能不侵犯知识产权人的权益和非常重要的个人隐私数据。
由于能力差异,并不是每个爬虫团队都能考虑这些问题。2018年,欧盟的《通用数据保护条例》(General Data Protection Regulation)发布了严格的数据保护指令。2019年5月28日,国家互联网信息办公室发布的《数据安全管理办法》(征求意见稿)对爬虫和个人信息安全做出了非常严格的规定。例如:
事实上,我国于2017年6月1日实施的《中华人民共和国网络安全法》第四章第四十一条和第四十四条,已经对个人隐私信息的采集
和使用作出了明确规定。与爬虫直接相关。
法律制度的颁布明确了技术的界限,技术的无罪不能作为技术实施者为自己辩解的理由。爬虫在满足自身需求的同时,必须严格遵守行为准则和法律法规。
各种反爬虫技术介绍
为了保护自己的合法权益不受恶意侵害,很多网站和APP都应用了大量的反爬技术。这使得爬虫技术衍生出反爬虫技术,如各种滑动拼图、文字点击、图标点击等验证码破解,相互促进,相互发展,相互伤害。
反爬虫的关键是防止爬虫批量抓取网站内容。反爬虫技术的核心是不断改变规则和各种验证方式。
这种技术的发展更是引人入胜,甚至比DOTA之战还要精彩。在波浪形文字验证码图形的伪装色中可以看到程序员的头发。
1、图片/Flash
这是一种比较常见的防爬方法。它将关键数据转换为图片并添加水印。即使使用了OCR(Optical Character Recognition),也无法识别,以至于爬虫拿到图片就得不到任何信息。这种方式在一些早期电子商务公司的价格标签中经常看到。
2、JavaScript 混淆技术
这是爬虫程序员遇到最多的反爬方法。简而言之,它实际上是一种致盲方法,本质上是一种加密技术。许多网页中的数据是使用 JavaScript 程序动态加载的。在抓取此类网页数据时,爬虫需要了解网页是如何加载数据的。这个过程称为逆向工程。为了防止逆向工程,使用了 JavaScript 混淆技术,并添加了 JavaScript 代码进行加密,使其他人无法理解。不过这种方法属于比较简单的防爬方法,属于履带工程师调平的初级阶段。
3、验证码
验证码是一个公开的全自动程序,用于区分用户是计算机还是人。也是我们经常遇到的一种网站访问验证的方法。它主要分为以下几种:
(1)输入类型验证码
这是最常见的。通过用户输入图片中的字母、数字、汉字等字符进行验证。
图中CAPTCHA的全称是(Completely Automated Public Turing test to tell Computers and Humans Apart),中文翻译为:自动图灵测试以区分计算机和人类。实现这一点的方法很简单,就是提出一个计算机无法回答但人类可以回答的问题。然而,目前的爬虫往往使用深度学习技术来破解这样的验证码,这样的图灵测试已经失效。
(2)滑块类型验证码
鉴于输入式图形验证码的缺点,容易被破解,有时还无法被人类识别。滑块验证码诞生了。这种验证码操作简单,破解难度大,迅速走红。破解滑块验证码有两大难点:一是要知道图形缺口在哪里,也就是要知道滑块在哪里滑动;另一种是模仿人类的滑动手势。这样的验证码增加了一定的难度,也给爬虫世界增添了不少乐趣。一时间出现了大量破解滑块验证码的技术。
(3)点击式图形验证和图标选择
图文验证是提醒用户点击图片中同一个词的位置进行文本验证。
图标选择是给出一组图片,根据需要点击其中一个或多个。
两种原理类似,只不过一种是给出文字,点击图片中的文字;另一个给出图片并点击与内容匹配的图片。这两种方式的共同点是体验不佳,广受诟病。
(4)手机验证码
对于一些重要敏感信息的访问,网站或APP一般会提供填写手机验证码的要求,手机接受网站发送的验证码,以便进一步访问。这种方法更利于数据隐私保护。
4、账号密码登录
网站可以通过账号登录来限制爬虫的访问权限。个人在使用很多网站服务时,一般都需要注册一个账号。使用时,他们需要使用帐户密码登录才能继续使用该服务。网站可以使用用户浏览器的cookie来识别用户的身份,并通过用户本地浏览器中存储的加密cookie数据跟踪用户的访问会话。这一般是作为之前防爬方法的补充。
履带技术的发展方向
传统网络爬虫最大的应用场景是搜索引擎,普通企业更多的是针对网站或者应用。后来随着网络数据分析的需要,以及互联网上层出不穷的舆论事件,对网络爬虫的需求量很大,主要采集的对象是新闻信息。
近年来,由于大数据处理和数据挖掘技术的发展,数据资产价值的概念深入人心,爬虫技术得到了更广泛深入的发展,采集
对象也越来越多。更丰富,高性能和并发技术指标也更高。.
围绕网络爬虫合法性的讨论依然存在,而且情况更为复杂。在目前的趋势下,很多法律问题还处于一个模糊的领域,往往取决于具体案件的影响。但是,可以肯定的是,只要有互联网,就会有网络爬虫。只有网络爬虫才能让庞大的互联网变得可搜索,让爆炸式增长的互联网更容易被访问和获取。在可预见的未来,互联网爬虫技术将不断发展。
作为人类历史上最大的知识仓库,互联网是非结构化或非标准化的。互联网上聚集了大量的文字、图片、多媒体等数据。虽然内容很有价值,但是提取知识的难度还是非常巨大的。语义互联网、知识共享等概念越来越流行,真正的语义互联网将成为网络爬虫的目标。此外,物联网技术的发展将是互联网的升级形态,也将是未来爬虫技术的发展方向。
网页音频抓取(几款高效实用、功能强大、速度极快的下载软件推荐!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-12-29 08:05
今天给大家介绍几款高效、实用、功能强大、速度极快的下载软件。如果对你有帮助,欢迎关注我们。你需要得到这3个下载工具,可以在我们的头条号“斜杠指南”中找到,私信号:23
1. IDM 下载器
Internet Download Manager,简称IDM,是一款国外优秀的下载工具。下载速度无可挑剔,下载速度轻松提升5倍。
安装浏览器插件一起使用,可以自动抓取浏览器的可下载资源,网页上的任何音视频都可以轻松下载,超级强大。有了这个下载神器,你可以立刻抛开某地雷!
此外,还有超多超实用的功能:定时下载、网盘下载、自动排列下载队列、批量下载、续传功能等。关于下载功能,似乎只有你想不到,没有它也做不到。强烈建议您使用它。
2. 免费下载管理器
FDM是一款轻量级强大的下载工具,支持windows和MacOS系统。特色功能包括:智能限速、定时任务、网页抓取、续传上传等;FDM还支持BT磁力链接,支持边下载边预览和播放音视频文件,支持直接浏览FTP服务器目录。
3. BitComet(比特彗星)
BitComet(比特彗星)是一款免费的HTTP/BT/FTP下载软件,功能强大,操作简单,速度够快,堪称BT资源下载工具!
可通过torrent文件和磁力链接下载,完美支持各种主流BT下载协议;解决了99%的下载经常卡在某些矿区的问题,下载速度更快!您也可以在下面观看并提取预览视频内容。 查看全部
网页音频抓取(几款高效实用、功能强大、速度极快的下载软件推荐!)
今天给大家介绍几款高效、实用、功能强大、速度极快的下载软件。如果对你有帮助,欢迎关注我们。你需要得到这3个下载工具,可以在我们的头条号“斜杠指南”中找到,私信号:23
1. IDM 下载器
Internet Download Manager,简称IDM,是一款国外优秀的下载工具。下载速度无可挑剔,下载速度轻松提升5倍。
安装浏览器插件一起使用,可以自动抓取浏览器的可下载资源,网页上的任何音视频都可以轻松下载,超级强大。有了这个下载神器,你可以立刻抛开某地雷!
此外,还有超多超实用的功能:定时下载、网盘下载、自动排列下载队列、批量下载、续传功能等。关于下载功能,似乎只有你想不到,没有它也做不到。强烈建议您使用它。
2. 免费下载管理器
FDM是一款轻量级强大的下载工具,支持windows和MacOS系统。特色功能包括:智能限速、定时任务、网页抓取、续传上传等;FDM还支持BT磁力链接,支持边下载边预览和播放音视频文件,支持直接浏览FTP服务器目录。
3. BitComet(比特彗星)
BitComet(比特彗星)是一款免费的HTTP/BT/FTP下载软件,功能强大,操作简单,速度够快,堪称BT资源下载工具!
可通过torrent文件和磁力链接下载,完美支持各种主流BT下载协议;解决了99%的下载经常卡在某些矿区的问题,下载速度更快!您也可以在下面观看并提取预览视频内容。
网页音频抓取( Python与其他语言的区别:4、Python生态圈:①WEB开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-29 08:04
Python与其他语言的区别:4、Python生态圈:①WEB开发)
Python 是一种优秀的综合语言。Python 的宗旨是简洁、优雅、强大。广泛应用于人工智能、云计算、金融分析、大数据开发、WEB开发、自动化运维、测试等领域。它已成为世界第 4 大最受欢迎的语言。
Python与其他语言的区别:
4、Python 生态系统:
①WEB开发。
最流行的 Python Web 框架 Django 支持异步和高并发 Tornado 框架。短小精悍的flask、bottle、Django官方口号将Django定义为完美主义者的框架,有期限(它是为完美主义者开发的高效web框架))。
②人工智能
谁将成为人工智能和大数据时代的第一开发语言?这已经是一个不需要争论的问题了。如果说三年前,Matlab、Scala、R、Java 和 Python 都有自己的机会,情况还不清楚,那么三年后,趋势就很明显了,尤其是在 Facebook 前两天开源 PyTorch 之后,Python 作为 AI时代顶级语言的地位基本确立,未来的悬念只有谁能保住第二名。(人工智能的转折点,2014年,著名科学家-吴恩达) ③云计算
目前最流行、最知名的云计算框架是OpenStack,而Python目前的流行很大程度上要归功于云计算。(云计算是按使用付费的模式。这种模式提供可用的、方便的、按需的网络访问,并进入一个可配置的计算资源共享池(资源包括网络、服务器、存储、应用软件和服务)。) ,这些资源可以快速提供,只需很少的管理工作或与服务提供商的很少互动。比如国内的“阿里巴巴云”和云谷公司的XenSystem,还有国外非常成熟的Intel和IBM。)
④财务分析
该公司编写的许多分析程序和高频交易软件都使用Python。到目前为止,Python 是金融分析和量化交易领域使用最多的语言。
⑤爬行动物
在爬虫领域,Python几乎占据主导地位。Scrapy、Request、BeautifuSoap、urllib等,想爬就爬。(网络爬虫,又称网络蜘蛛、网络机器人,在FOAF社区中更多的被称为网络追逐者。它们是按照一定的规则自动抓取万维网上信息的程序或脚本。应用在互联网领域. 搜索引擎利用网络爬虫抓取网页、文档甚至图片、音频、视频等资源,通过相应的索引技术将这些信息组织起来,提供给搜索用户查询。中型网站的一种有效方式。)
⑥自动化运维
请问国内的每一位运维人员,运维人员必须懂的语言是什么?10个人相信他们会给你同样的答案。它的名字是 Python。
⑦科学计算
自 1997 年以来,NASA 一直广泛使用 Python 来执行各种复杂的科学运算。随着 NumPy、SciPy、Matplotlib、Enthought 库等众多库的发展,Python 越来越适合于科学计算和绘图。高质量的 2D 和 3D 图像。与科学计算领域最流行的商业软件Matlab相比,Python是一种通用的编程语言,比Matlab使用的脚本语言有更广泛的应用。
⑧游戏开发
Python 在网络游戏开发方面也有很多应用。与Lua或C++相比,Python比Lua具有更高的抽象层次,可以用更少的代码来描述游戏业务逻辑。与Lua相比,Python更适合作为宿主语言,即程序的入口点在Python那端会更好,然后在需要的时候用C/C++写一些扩展。Python非常适合编写1万行以上的项目,在10万行代码以内可以很好的控制网络游戏项目的规模。此外,著名的游戏都是用 Python 编写的。
这么强大的编程语言,学会了,名利双收。阅读原文,让美女老师带你走进Python的殿堂。 查看全部
网页音频抓取(
Python与其他语言的区别:4、Python生态圈:①WEB开发)
Python 是一种优秀的综合语言。Python 的宗旨是简洁、优雅、强大。广泛应用于人工智能、云计算、金融分析、大数据开发、WEB开发、自动化运维、测试等领域。它已成为世界第 4 大最受欢迎的语言。
Python与其他语言的区别:
4、Python 生态系统:
①WEB开发。
最流行的 Python Web 框架 Django 支持异步和高并发 Tornado 框架。短小精悍的flask、bottle、Django官方口号将Django定义为完美主义者的框架,有期限(它是为完美主义者开发的高效web框架))。
②人工智能
谁将成为人工智能和大数据时代的第一开发语言?这已经是一个不需要争论的问题了。如果说三年前,Matlab、Scala、R、Java 和 Python 都有自己的机会,情况还不清楚,那么三年后,趋势就很明显了,尤其是在 Facebook 前两天开源 PyTorch 之后,Python 作为 AI时代顶级语言的地位基本确立,未来的悬念只有谁能保住第二名。(人工智能的转折点,2014年,著名科学家-吴恩达) ③云计算
目前最流行、最知名的云计算框架是OpenStack,而Python目前的流行很大程度上要归功于云计算。(云计算是按使用付费的模式。这种模式提供可用的、方便的、按需的网络访问,并进入一个可配置的计算资源共享池(资源包括网络、服务器、存储、应用软件和服务)。) ,这些资源可以快速提供,只需很少的管理工作或与服务提供商的很少互动。比如国内的“阿里巴巴云”和云谷公司的XenSystem,还有国外非常成熟的Intel和IBM。)
④财务分析
该公司编写的许多分析程序和高频交易软件都使用Python。到目前为止,Python 是金融分析和量化交易领域使用最多的语言。
⑤爬行动物
在爬虫领域,Python几乎占据主导地位。Scrapy、Request、BeautifuSoap、urllib等,想爬就爬。(网络爬虫,又称网络蜘蛛、网络机器人,在FOAF社区中更多的被称为网络追逐者。它们是按照一定的规则自动抓取万维网上信息的程序或脚本。应用在互联网领域. 搜索引擎利用网络爬虫抓取网页、文档甚至图片、音频、视频等资源,通过相应的索引技术将这些信息组织起来,提供给搜索用户查询。中型网站的一种有效方式。)
⑥自动化运维
请问国内的每一位运维人员,运维人员必须懂的语言是什么?10个人相信他们会给你同样的答案。它的名字是 Python。
⑦科学计算
自 1997 年以来,NASA 一直广泛使用 Python 来执行各种复杂的科学运算。随着 NumPy、SciPy、Matplotlib、Enthought 库等众多库的发展,Python 越来越适合于科学计算和绘图。高质量的 2D 和 3D 图像。与科学计算领域最流行的商业软件Matlab相比,Python是一种通用的编程语言,比Matlab使用的脚本语言有更广泛的应用。
⑧游戏开发
Python 在网络游戏开发方面也有很多应用。与Lua或C++相比,Python比Lua具有更高的抽象层次,可以用更少的代码来描述游戏业务逻辑。与Lua相比,Python更适合作为宿主语言,即程序的入口点在Python那端会更好,然后在需要的时候用C/C++写一些扩展。Python非常适合编写1万行以上的项目,在10万行代码以内可以很好的控制网络游戏项目的规模。此外,著名的游戏都是用 Python 编写的。
这么强大的编程语言,学会了,名利双收。阅读原文,让美女老师带你走进Python的殿堂。
网页音频抓取(一下如何用IDM巧妙的批量音效素材?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-27 00:24
IDM下载器的站点抓取功能可以抓取站点上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天我们就来看看如何使用IDM来巧妙的批量抓取声音素材。
1、进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站(进入网页后点击进入音效分类编译界面,即大量音效目录界面效果链接地址,然后复制该接口的链接地址。
图 1:音效采集
页面
2、 运行“网站抓取”功能抓取音效
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏中,然后点击下方的“Forward”按钮.
图2:网站抓取-链接输入页面
3、 建议将“探索指定链接深度”修改为“3”
在步骤2点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
图3:网站爬取界面
4、更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
图 4:文件类型更改页面
5、等待站点获取成功,并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
图5:文件捕获信息页面
经过上面的操作,已经下载了很多音效文件,并且可以使用站点抓取进行多窗口抓取,这样我们就可以同时抓取几个分类的音效文件,真的很方便!
但是一定要确保音效网站保存的音效文件格式为:mp3、wma或waw。如果网站的文件格式不是这三种后缀格式,IDM可能无法识别! 查看全部
网页音频抓取(一下如何用IDM巧妙的批量音效素材?(组图))
IDM下载器的站点抓取功能可以抓取站点上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天我们就来看看如何使用IDM来巧妙的批量抓取声音素材。
1、进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站(进入网页后点击进入音效分类编译界面,即大量音效目录界面效果链接地址,然后复制该接口的链接地址。
图 1:音效采集
页面
2、 运行“网站抓取”功能抓取音效
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏中,然后点击下方的“Forward”按钮.
图2:网站抓取-链接输入页面
3、 建议将“探索指定链接深度”修改为“3”
在步骤2点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
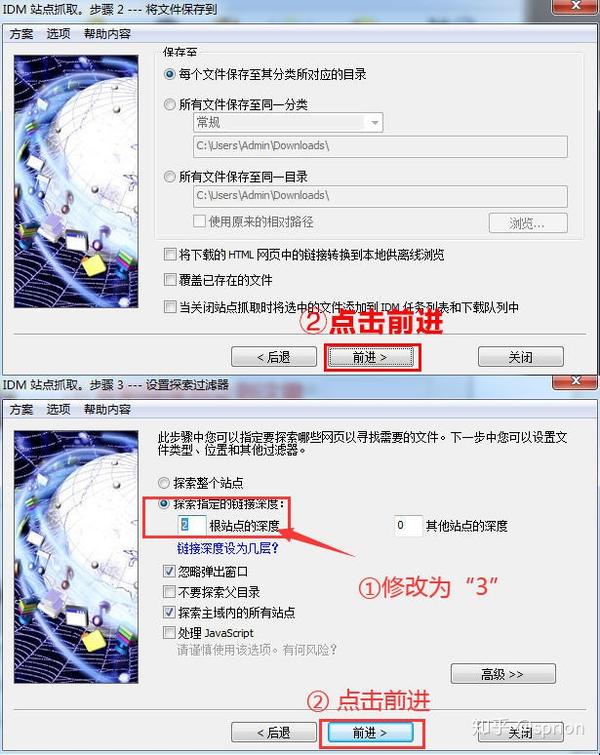
图3:网站爬取界面
4、更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
图 4:文件类型更改页面
5、等待站点获取成功,并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
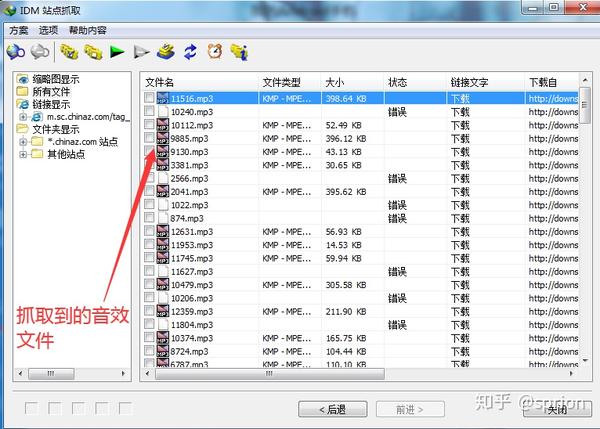
图5:文件捕获信息页面
经过上面的操作,已经下载了很多音效文件,并且可以使用站点抓取进行多窗口抓取,这样我们就可以同时抓取几个分类的音效文件,真的很方便!
但是一定要确保音效网站保存的音效文件格式为:mp3、wma或waw。如果网站的文件格式不是这三种后缀格式,IDM可能无法识别!
网页音频抓取(《暮光之城》不得不有版权有些居然还收费)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-19 00:17
趁着上周末看了《暮光之城》,不得不说这是一部非常好看的言情片。里面所有的歌曲,每次听都能深深地吸引我。记得卡伦一家和贝拉棒球的音乐很欢快,所以跑步的时候想下载下来保存一天,没想到这首歌有版权,有的被收费了,导致我很头疼。, 不过我终于想到了一个好办法,你想知道是什么吗?往下看你就明白了。音频转换软件...关于工具:
Fast Audio Converter 是一款多功能的音频编辑处理软件。该软件具有四种功能:音频剪切、音频提取、音频合并和音频转换。本工具操作简单,功能强大,可以多种方式分割音频 切割,操作简单的特点,支持和软件不仅支持单个文件操作,还支持文件批量操作!这是一个不错的选择。
打开工具
我们先准备好需要用到的工具和网页中的音频文件,最好放在一起,方便我们查找。添加音频文件
然后我们打开音频提取界面,点击添加文件或者添加文件夹,这里有多个文件夹,可以批量添加。添加和删除片段指南 片段指南
然后当我们提取音频时,点击添加片段指南。对于此添加,您可以拖动进度条选择要添加的时间段。如果删除它,单击 删除段指南。另外,您可以在下方设置当前时间点的音频的具体提取时间。开始和结束。最后点击确定。提取完成
确认后,界面上会出现提取的音频片段。稍等片刻。如果音频提取成功,会有一个小的复选标记图标。显示出来就说明提取成功了!是不是感觉非常简单快捷?有需要的可以试试编辑器的这个方法,挺好的。
【腾讯云】云产品限时秒杀,爆款1核2G云服务器,首年50元
阿里云限时Event-2核心2G-5M带宽-60G SSD-1000G包月流量,特价99元/年(原价1234.2元/年,可直接购买3年),快速抓取 查看全部
网页音频抓取(《暮光之城》不得不有版权有些居然还收费)
趁着上周末看了《暮光之城》,不得不说这是一部非常好看的言情片。里面所有的歌曲,每次听都能深深地吸引我。记得卡伦一家和贝拉棒球的音乐很欢快,所以跑步的时候想下载下来保存一天,没想到这首歌有版权,有的被收费了,导致我很头疼。, 不过我终于想到了一个好办法,你想知道是什么吗?往下看你就明白了。音频转换软件...关于工具:
Fast Audio Converter 是一款多功能的音频编辑处理软件。该软件具有四种功能:音频剪切、音频提取、音频合并和音频转换。本工具操作简单,功能强大,可以多种方式分割音频 切割,操作简单的特点,支持和软件不仅支持单个文件操作,还支持文件批量操作!这是一个不错的选择。
打开工具
我们先准备好需要用到的工具和网页中的音频文件,最好放在一起,方便我们查找。添加音频文件
然后我们打开音频提取界面,点击添加文件或者添加文件夹,这里有多个文件夹,可以批量添加。添加和删除片段指南 片段指南
然后当我们提取音频时,点击添加片段指南。对于此添加,您可以拖动进度条选择要添加的时间段。如果删除它,单击 删除段指南。另外,您可以在下方设置当前时间点的音频的具体提取时间。开始和结束。最后点击确定。提取完成
确认后,界面上会出现提取的音频片段。稍等片刻。如果音频提取成功,会有一个小的复选标记图标。显示出来就说明提取成功了!是不是感觉非常简单快捷?有需要的可以试试编辑器的这个方法,挺好的。
【腾讯云】云产品限时秒杀,爆款1核2G云服务器,首年50元
阿里云限时Event-2核心2G-5M带宽-60G SSD-1000G包月流量,特价99元/年(原价1234.2元/年,可直接购买3年),快速抓取
网页音频抓取(一款适合我们大众的工具,是什么工具呢??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-15 21:14
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候我们只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能音频编辑处理软件。该软件具有四个功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
第一步:打开工具
在网页上准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第 3 步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
点击“确定”后不要以为你饿了。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想查看就可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。 查看全部
网页音频抓取(一款适合我们大众的工具,是什么工具呢??)
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候我们只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能音频编辑处理软件。该软件具有四个功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
第一步:打开工具
在网页上准备好音乐,然后打开工具到界面,可以尝试简单了解一下。

第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。

第 3 步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。

第 4 步:设置保存提取音频的位置
点击“确定”后不要以为你饿了。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。

第五步成功
点击后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想查看就可以在你设置的文件中查看。

无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。
网页音频抓取(玩转西藏【旅游攻略】的过程实现过程定义一个类)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-19 13:25
前言
眼睛习惯看文字,累了,转身用耳朵听世界。Himalaya FM,这里是我们想听的,用爬虫抓取我们想要的音频!这次要抢的是关于玩西藏[旅游攻略]的游记,感受高原风情,废话不多说。
环境
win10+python3.7+sublime text
指导包
导入请求---->网页请求和数据抓取
import json--->数据格式转换
from multiprocessing.pool import pool---->使用线程池
网页分析
,URL对应上图,下面是我们要查看的内容的地址。我们主要是把这些音频全部抓取到本地保存,但是我们并没有从这个地址抓取音频的src,而是直接在旅游文章上点击播放来播放西藏【旅游攻略】。在这个过程中,使用浏览器的开发者工具来获取相关信息的json数据。trackAudioPlay 字段收录我们想要的所有音频数据。需要实现以下代码。
抓包过程
定义一个类,在这个类中初始化请求头和请求的资源url,然后在requests对象中使用get()方法,因为网页的请求方法是get方法,然后判断对应的状态码,如果是200,则表示请求成功,然后对获取的内容进行解码。
def __init__(self,num,id):
self.headers={
'Host': 'www.ximalaya.com',
'Referer': 'https://www.ximalaya.com/lvyou/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36'
}
# albumId=5656303是该收听节目的id,页码:pageNum,一页多少条:pageSize=30
self.url='https://www.ximalaya.com/revis ... 2Bstr(id)+'&pageNum='+str(num)+'&pageSize=30'
def get_content(self):
response=requests.get(url=self.url,headers=self.headers)
# 判断响应的状态码
if response.status_code==200:
# 解码
return response.content.decode()
将获取的字符串数据转换成字典格式,方便获取里面的具体内容,获取相关的音频数据
def get_tracks(self,content):
try:
if content:
# 字符串转换为字典:json.loads()
# print(json.loads(content)['data']['tracksAudioPlay']),测试输出
return json.loads(content)['data']['tracksAudioPlay']
except Exception as e:
print(e)
pass
根据音频连接src重新请求资源,并下载到本地,其中trackName字段中的数据作为每个音频的名称,拼接字符串,更改扩展名为 .m4a 格式,并且在 Windows 系统中,文件名不能有一些特殊的字符串,如 | 和其他特殊字符,所以需要用特殊字符替换trackName字段的字符串数据。
def down_from_src(self,src,trackName):
response=requests.get(url=src)
if response.status_code==200:
# 去除特殊符号,因为windows的文件不能出现这些特殊字符
trackName=trackName.replace('|','').replace('?','').replace(':','').replace(' ','')
with open(trackName+'.m4a','wb') as f:
f.write(response.content)
需要判断url,因为对于vip音频,这里的url是空的,不存在的,所以无法直接抓取数据。
# 程序主入口
def main(i):
sipder=xizangSipder(i,5656303)
for tracksAudioPlay in sipder.get_tracks(sipder.get_content()):
try:
src,trackName=tracksAudioPlay['src'],tracksAudioPlay['trackName']
if src:
sipder.down_from_src(src,trackName)
except Exception as e:
print(e)
pass
if __name__=='__main__':
# 创建线程池
pool=Pool(5)
# 第一个参数是函数,第二个参数是一个迭代器,把迭代器的数字作为参数传进去
pool.map(main,[x for x in range(1,7)])
# 关闭线程池
pool.close()
# 主线程阻塞等待子线程的退出
pool.join()
达到效果
渲染(抓取 6 页音频)
总结:程序比较简单。只要知道资源连接在哪里,就可以通过资源url抓取,通过线程池提高程序效率。音频下载的VIP版还没有实现,下一步就是实现了(但是这样破解别人的VIP是违法的,小心点!)
项目链接:链接:提取码:b78t 查看全部
网页音频抓取(玩转西藏【旅游攻略】的过程实现过程定义一个类)
前言
眼睛习惯看文字,累了,转身用耳朵听世界。Himalaya FM,这里是我们想听的,用爬虫抓取我们想要的音频!这次要抢的是关于玩西藏[旅游攻略]的游记,感受高原风情,废话不多说。
环境
win10+python3.7+sublime text
指导包
导入请求---->网页请求和数据抓取
import json--->数据格式转换
from multiprocessing.pool import pool---->使用线程池
网页分析
,URL对应上图,下面是我们要查看的内容的地址。我们主要是把这些音频全部抓取到本地保存,但是我们并没有从这个地址抓取音频的src,而是直接在旅游文章上点击播放来播放西藏【旅游攻略】。在这个过程中,使用浏览器的开发者工具来获取相关信息的json数据。trackAudioPlay 字段收录我们想要的所有音频数据。需要实现以下代码。
抓包过程
定义一个类,在这个类中初始化请求头和请求的资源url,然后在requests对象中使用get()方法,因为网页的请求方法是get方法,然后判断对应的状态码,如果是200,则表示请求成功,然后对获取的内容进行解码。
def __init__(self,num,id):
self.headers={
'Host': 'www.ximalaya.com',
'Referer': 'https://www.ximalaya.com/lvyou/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36'
}
# albumId=5656303是该收听节目的id,页码:pageNum,一页多少条:pageSize=30
self.url='https://www.ximalaya.com/revis ... 2Bstr(id)+'&pageNum='+str(num)+'&pageSize=30'
def get_content(self):
response=requests.get(url=self.url,headers=self.headers)
# 判断响应的状态码
if response.status_code==200:
# 解码
return response.content.decode()
将获取的字符串数据转换成字典格式,方便获取里面的具体内容,获取相关的音频数据
def get_tracks(self,content):
try:
if content:
# 字符串转换为字典:json.loads()
# print(json.loads(content)['data']['tracksAudioPlay']),测试输出
return json.loads(content)['data']['tracksAudioPlay']
except Exception as e:
print(e)
pass
根据音频连接src重新请求资源,并下载到本地,其中trackName字段中的数据作为每个音频的名称,拼接字符串,更改扩展名为 .m4a 格式,并且在 Windows 系统中,文件名不能有一些特殊的字符串,如 | 和其他特殊字符,所以需要用特殊字符替换trackName字段的字符串数据。
def down_from_src(self,src,trackName):
response=requests.get(url=src)
if response.status_code==200:
# 去除特殊符号,因为windows的文件不能出现这些特殊字符
trackName=trackName.replace('|','').replace('?','').replace(':','').replace(' ','')
with open(trackName+'.m4a','wb') as f:
f.write(response.content)
需要判断url,因为对于vip音频,这里的url是空的,不存在的,所以无法直接抓取数据。
# 程序主入口
def main(i):
sipder=xizangSipder(i,5656303)
for tracksAudioPlay in sipder.get_tracks(sipder.get_content()):
try:
src,trackName=tracksAudioPlay['src'],tracksAudioPlay['trackName']
if src:
sipder.down_from_src(src,trackName)
except Exception as e:
print(e)
pass
if __name__=='__main__':
# 创建线程池
pool=Pool(5)
# 第一个参数是函数,第二个参数是一个迭代器,把迭代器的数字作为参数传进去
pool.map(main,[x for x in range(1,7)])
# 关闭线程池
pool.close()
# 主线程阻塞等待子线程的退出
pool.join()
达到效果
渲染(抓取 6 页音频)
总结:程序比较简单。只要知道资源连接在哪里,就可以通过资源url抓取,通过线程池提高程序效率。音频下载的VIP版还没有实现,下一步就是实现了(但是这样破解别人的VIP是违法的,小心点!)
项目链接:链接:提取码:b78t
网页音频抓取(我们有时想要将一段电影或视频中的背景音乐/对话提取出来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-18 12:05
有时我们想从电影或视频中提取背景音乐/对话进行采集,或者将美剧制作成MP3来练习英语听力等。今天介绍的软件可以帮助您简单方便地做到这一点。
Pazera Free Audio Extractor是一款完全免费的绿色通用音频提取软件和音频格式转换软件,可以从各种主流格式(AVI、FLV、MP4、MPG、MOV、RM、3GP、WMV、VOB等)中提取视频文件格式。无损提取其中的音频并保存,提取效率非常高,保存时可以选择将音频转换成MP3、AAC、AC3、WMA、FLAC、OGG、WAV等格式。非常实用...
Pazera Free Audio Extractor软件介绍及截图:
软件支持Windows 10、Win7、Vista,和XP,绿色安装免费,解压后即可使用。该软件使用起来也比较简单。将视频文件拖入列表后,选择输出目录和音频输出格式。如果不想导出整个视频的音频,可以设置开始和结束时间。PS:如果导出后发现音频质量变差,请尝试提高音频码率。
软件特点:
相关文件下载地址
官方网站:访问
软件性质:免费
提取密码:
下载 Pazera 免费音频提取器视频和音频提取器(64 位)| 32 位 | 更多音频相关 查看全部
网页音频抓取(我们有时想要将一段电影或视频中的背景音乐/对话提取出来)
有时我们想从电影或视频中提取背景音乐/对话进行采集,或者将美剧制作成MP3来练习英语听力等。今天介绍的软件可以帮助您简单方便地做到这一点。
Pazera Free Audio Extractor是一款完全免费的绿色通用音频提取软件和音频格式转换软件,可以从各种主流格式(AVI、FLV、MP4、MPG、MOV、RM、3GP、WMV、VOB等)中提取视频文件格式。无损提取其中的音频并保存,提取效率非常高,保存时可以选择将音频转换成MP3、AAC、AC3、WMA、FLAC、OGG、WAV等格式。非常实用...
Pazera Free Audio Extractor软件介绍及截图:
软件支持Windows 10、Win7、Vista,和XP,绿色安装免费,解压后即可使用。该软件使用起来也比较简单。将视频文件拖入列表后,选择输出目录和音频输出格式。如果不想导出整个视频的音频,可以设置开始和结束时间。PS:如果导出后发现音频质量变差,请尝试提高音频码率。
软件特点:
相关文件下载地址
官方网站:访问
软件性质:免费
提取密码:
下载 Pazera 免费音频提取器视频和音频提取器(64 位)| 32 位 | 更多音频相关
网页音频抓取(1.域名选择网站域名中的建议和建议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-07 00:02
1. 域选择
网站域名的选择,不仅可以让用户快速直观的了解网站的定位和域名设置,还会影响网站被搜索的抓取。因此,选择一个简单、易记、安全的域名是网站建设初期最重要的一步。
1.1 域名选择注意事项
网站建立之初,建议网站的域名独立好记;独立移动台的域名选择也遵循这个规则。
移动站的域名需要和PC站的域名分开。不建议移动站与PC站共享域名; Adaptive网站 可能不会考虑到这一点。
网站在域名选择上,主要有两个建议:
√ 建议使用比较常见的域名后缀,如.com\.cn\.net等;
√如果网站追求个性化使用稀有域名后缀,为了保证搜索效果,需要在站长平台进行站点验证。
1.2 使用子域或目录
网站是需要建立子域名还是划分多级目录,可以根据网站自身定位和网站内容量级来确定。一般来说,对于综合类或者内容比较多的网站,可以根据不同的二级域明确划分内容;而如果网站的内容较少,不建议打开太多的网站子域。
比如对于博客风格的网站,有的网站给每个博客作者一个单独的三级域,但是如果作者发表频率较低,整个三级域就处于低更新状态频率,太低的发布频率对搜索引擎不友好。
2 内容发布系统
所有发布系统,除了遵循有序、逻辑清晰的网站建设外,还应注意网站建设的安全问题,避免网站隐患,以更好地提升价值网站。
2.1自建内容发布系统
网站自建内容发布系统,注意事项包括:
√ 主要内容清晰,可以很好的识别和区分;
√ 不要在后台自行设置发布时间,按照发布时间和显示时间进行;
√ 内容发布系统中各个表单的设置合理。比如标签的设置不宜过多,不宜列出关键词;
√ 分类明确,分类主题的文章应在相应分类下公布;
√标题匹配,不卖狗肉,欺骗搜索引擎流量,损害用户体验;
√ 段落清晰合理,字体大小适中,字体颜色不宜使用与背景色相近的颜色;
√ 发布内容目录划分清晰。
2.2 第三方发布系统
使用第三方发布系统搭建网站,站长需要注意以下几点:
√ 不建议频繁更换模板主题;
√ 不建议使用过多的插件,会影响网页的打开速度;
√ URL 伪静态处理,命名约定,层次清晰;
√ 开源建站系统存在诸多安全隐患,使用过程中一定要做好一些安全设置和优化。
2.3 页面生成规范
无论网站自建发布系统还是网站使用第三方建站系统,网站页面生成时应注意以下几点:
√ 网页结构清晰,各分类名称设置醒目;
√ 导航和面包屑导航设置合理,机器可读,位置显着,用户在网站中可以轻松知道所访问页面的位置;
√ 没有遮挡主要内容的广告元素;
√没有三俗的图文元素;
关注网站构建系统安全问题,消除网站安全隐患。
3 网站结构
网站结构的合理设置是网站被快速抢占并获得搜索流量的基础;由于网站结构设置不合理,无法快速识别网站爬取案例在反馈中经常看到,而网站更改域名也会对网站造成一定损失@>,所以希望各位站长从建站之初就注意网站结构设置,以免造成不必要的损失。
3.1 URL结构设置
对URL构建是否有严格要求,请看以下几点:
√ 在构建网站的结构和制作网址时,尽量避免非主流设计,追求简洁美观。 ”,这会导致搜索引擎识别错误;
√ URL长度要求去掉协议头http(s)://后的URL长度不能超过256字节;
√ 慎用#参数,有效参数不能放在#后面;它们可能会被截断并导致异常的网络爬取。
3.2 目录结构设置
网站目录结构是否合理会影响搜索引擎对网站的抓取。这里需要提到的是网站目录结构是扁平的或者树状的。 ,一般搜索引擎都能找到,但有几点需要注意:
√ 建议将不同的内容放在不同的目录或子域中;
√ 不要使用孤岛链接,搜索引擎很难快速找到孤岛链接;如果网站有大量孤岛链接,建议使用搜索资源平台的链接提交工具向站长平台提交数据;
√ 重要内容不建议放在deep目录下。如果内容没有大量的内部链接,搜索引擎很难判断页面的重要性。
4 服务商/自建服务器
选择服务商或自建服务器是网站建设中非常重要和基础的一环;服务器的安全性和稳定性将直接影响百度搜索引擎对网站的整体判断。
4.1个域名服务4.1.1个域名服务&域名部署
关于域名服务和域名部署,以下注意事项:
√站长要注意域名部署的方方面面,不要出现域名部署错误;
√ 不建议网站进行一般分析。如果网站爆发大规模泛分析,影响不好,会被搜索策略压制;
√ 尽量选择优质的域名服务商。
4.2 个服务器
做网站还有一个很重要的部分,就是服务器的选择。在服务器的选择上,无论是虚拟主机、云主机还是独立服务器,都需要注意以下四点:
√中文网站不建议选择国外服务器;
√ 服务器的稳定性很重要。需要保持访问顺畅,服务器是否稳定。可以使用百站长平台爬取异常,爬取诊断工具进行检测和维护。 (服务器经常无法访问或崩溃,这对爬虫来说是致命的);
√ 服务器选择除了自身的稳定性外,还要考虑网站的业务量,比如带宽、内存、CPU能否承受流量,在情况下能否正常访问突然大流量;
√ 服务器主机设置,需要注意是否有禁止爬虫爬取的设置,或者404错误信息设置。这些情况都会造成不必要的搜索引擎爬取异常判断,从而给网站带来不必要的爬取损失。
4.2.1 个虚拟主机
一般来说,建议在购买虚拟主机时要特别注意:
√主机公司是否限制搜索引擎的访问;
√ 主办公司资质是否符合要求;
√主机公司技术沉淀是否充足,建议选择品牌较大的主机公司;
√ 主机公司托管的机房物理条件和网络条件是否足够好;
√ 托管公司的技术和客服支持是否足够好;
√ 东道公司是否会出现产能过剩;
√ 宿主公司是否非法访问高风险站点或同一IP下是否存在高风险站点;
√ 国内网站建议购买国内云主机建站。
4.2.2 台专用主机
独立托管给网站带来更宽松的使用环境和个性化的软件安装,所以独立托管需要站长具备一定的技术实力才能保证网站的正常运行和安全。
我们对网站管理员购买和托管专用主机的建议是:
√ 关注虚拟主机是否已将爬虫IP拉入黑名单;
√ 建议使用具有专用IP地址的主机;
√ 建议使用较大机构的主机,在安全配置和稳定性方面相对较好;
√IDC服务商的建设标准需要一定的考虑,比如防火、防盗、是否有UPS保障、室内温控、防火等;
√IDC服务商的服务质量和技术是否达标,是否24小时值班,是否能协助排除部分故障,免费重启重装系统等;
√IDC机房资质是否齐全,存储站点是否有高风险站点或服务器。
4.3 安全服务4.3.1 HTTPS 查看全部
网页音频抓取(1.域名选择网站域名中的建议和建议)
1. 域选择
网站域名的选择,不仅可以让用户快速直观的了解网站的定位和域名设置,还会影响网站被搜索的抓取。因此,选择一个简单、易记、安全的域名是网站建设初期最重要的一步。
1.1 域名选择注意事项
网站建立之初,建议网站的域名独立好记;独立移动台的域名选择也遵循这个规则。
移动站的域名需要和PC站的域名分开。不建议移动站与PC站共享域名; Adaptive网站 可能不会考虑到这一点。
网站在域名选择上,主要有两个建议:
√ 建议使用比较常见的域名后缀,如.com\.cn\.net等;
√如果网站追求个性化使用稀有域名后缀,为了保证搜索效果,需要在站长平台进行站点验证。
1.2 使用子域或目录
网站是需要建立子域名还是划分多级目录,可以根据网站自身定位和网站内容量级来确定。一般来说,对于综合类或者内容比较多的网站,可以根据不同的二级域明确划分内容;而如果网站的内容较少,不建议打开太多的网站子域。
比如对于博客风格的网站,有的网站给每个博客作者一个单独的三级域,但是如果作者发表频率较低,整个三级域就处于低更新状态频率,太低的发布频率对搜索引擎不友好。
2 内容发布系统
所有发布系统,除了遵循有序、逻辑清晰的网站建设外,还应注意网站建设的安全问题,避免网站隐患,以更好地提升价值网站。
2.1自建内容发布系统
网站自建内容发布系统,注意事项包括:
√ 主要内容清晰,可以很好的识别和区分;
√ 不要在后台自行设置发布时间,按照发布时间和显示时间进行;
√ 内容发布系统中各个表单的设置合理。比如标签的设置不宜过多,不宜列出关键词;
√ 分类明确,分类主题的文章应在相应分类下公布;
√标题匹配,不卖狗肉,欺骗搜索引擎流量,损害用户体验;
√ 段落清晰合理,字体大小适中,字体颜色不宜使用与背景色相近的颜色;
√ 发布内容目录划分清晰。
2.2 第三方发布系统
使用第三方发布系统搭建网站,站长需要注意以下几点:
√ 不建议频繁更换模板主题;
√ 不建议使用过多的插件,会影响网页的打开速度;
√ URL 伪静态处理,命名约定,层次清晰;
√ 开源建站系统存在诸多安全隐患,使用过程中一定要做好一些安全设置和优化。
2.3 页面生成规范
无论网站自建发布系统还是网站使用第三方建站系统,网站页面生成时应注意以下几点:
√ 网页结构清晰,各分类名称设置醒目;
√ 导航和面包屑导航设置合理,机器可读,位置显着,用户在网站中可以轻松知道所访问页面的位置;
√ 没有遮挡主要内容的广告元素;
√没有三俗的图文元素;
关注网站构建系统安全问题,消除网站安全隐患。
3 网站结构
网站结构的合理设置是网站被快速抢占并获得搜索流量的基础;由于网站结构设置不合理,无法快速识别网站爬取案例在反馈中经常看到,而网站更改域名也会对网站造成一定损失@>,所以希望各位站长从建站之初就注意网站结构设置,以免造成不必要的损失。
3.1 URL结构设置
对URL构建是否有严格要求,请看以下几点:
√ 在构建网站的结构和制作网址时,尽量避免非主流设计,追求简洁美观。 ”,这会导致搜索引擎识别错误;
√ URL长度要求去掉协议头http(s)://后的URL长度不能超过256字节;
√ 慎用#参数,有效参数不能放在#后面;它们可能会被截断并导致异常的网络爬取。
3.2 目录结构设置
网站目录结构是否合理会影响搜索引擎对网站的抓取。这里需要提到的是网站目录结构是扁平的或者树状的。 ,一般搜索引擎都能找到,但有几点需要注意:
√ 建议将不同的内容放在不同的目录或子域中;
√ 不要使用孤岛链接,搜索引擎很难快速找到孤岛链接;如果网站有大量孤岛链接,建议使用搜索资源平台的链接提交工具向站长平台提交数据;
√ 重要内容不建议放在deep目录下。如果内容没有大量的内部链接,搜索引擎很难判断页面的重要性。
4 服务商/自建服务器
选择服务商或自建服务器是网站建设中非常重要和基础的一环;服务器的安全性和稳定性将直接影响百度搜索引擎对网站的整体判断。
4.1个域名服务4.1.1个域名服务&域名部署
关于域名服务和域名部署,以下注意事项:
√站长要注意域名部署的方方面面,不要出现域名部署错误;
√ 不建议网站进行一般分析。如果网站爆发大规模泛分析,影响不好,会被搜索策略压制;
√ 尽量选择优质的域名服务商。
4.2 个服务器
做网站还有一个很重要的部分,就是服务器的选择。在服务器的选择上,无论是虚拟主机、云主机还是独立服务器,都需要注意以下四点:
√中文网站不建议选择国外服务器;
√ 服务器的稳定性很重要。需要保持访问顺畅,服务器是否稳定。可以使用百站长平台爬取异常,爬取诊断工具进行检测和维护。 (服务器经常无法访问或崩溃,这对爬虫来说是致命的);
√ 服务器选择除了自身的稳定性外,还要考虑网站的业务量,比如带宽、内存、CPU能否承受流量,在情况下能否正常访问突然大流量;
√ 服务器主机设置,需要注意是否有禁止爬虫爬取的设置,或者404错误信息设置。这些情况都会造成不必要的搜索引擎爬取异常判断,从而给网站带来不必要的爬取损失。
4.2.1 个虚拟主机
一般来说,建议在购买虚拟主机时要特别注意:
√主机公司是否限制搜索引擎的访问;
√ 主办公司资质是否符合要求;
√主机公司技术沉淀是否充足,建议选择品牌较大的主机公司;
√ 主机公司托管的机房物理条件和网络条件是否足够好;
√ 托管公司的技术和客服支持是否足够好;
√ 东道公司是否会出现产能过剩;
√ 宿主公司是否非法访问高风险站点或同一IP下是否存在高风险站点;
√ 国内网站建议购买国内云主机建站。
4.2.2 台专用主机
独立托管给网站带来更宽松的使用环境和个性化的软件安装,所以独立托管需要站长具备一定的技术实力才能保证网站的正常运行和安全。
我们对网站管理员购买和托管专用主机的建议是:
√ 关注虚拟主机是否已将爬虫IP拉入黑名单;
√ 建议使用具有专用IP地址的主机;
√ 建议使用较大机构的主机,在安全配置和稳定性方面相对较好;
√IDC服务商的建设标准需要一定的考虑,比如防火、防盗、是否有UPS保障、室内温控、防火等;
√IDC服务商的服务质量和技术是否达标,是否24小时值班,是否能协助排除部分故障,免费重启重装系统等;
√IDC机房资质是否齐全,存储站点是否有高风险站点或服务器。
4.3 安全服务4.3.1 HTTPS
网页音频抓取(BeautifulSoup文档bs4—BeautifulSoup4,BeautifulSoup是Python库!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-19 03:17
BeautifulSoup 文档
bs4 — BeautifulSoup 4,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,Beautiful Soup 文档,版本 4.4.0 Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中检索数据 提取数据。它与您最喜欢的解析器一起使用,提供一种惯用的方式来导航、搜索和修改解析树。. Beautiful Soup 文档,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索、.
Beautiful Soup 文档,Beautiful Soup 文档,4.4.0 版本 Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供一种惯用的方式来导航、搜索和修改解析树。Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索、. Beautiful Soup 4,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它可以与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,bs4 — BeautifulSoup 4¶。“Fish-Footman 开始从他的腋下生成一个大字母。Beautiful Soup 是一个用于拉取的 Python 库。
Beautiful Soup 4,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它可以与您最喜欢的解析器一起使用,提供惯用的导航、搜索、.Beautiful Soup 文档、bs4 — BeautifulSoup 4¶。“Fish-Footman 开始从他的腋下生成一封很棒的信。Beautiful Soup 是一个 Python 库,它拉动 Beautiful Soup 构造函数以获取 XML 作为字符串(或打开的文件类对象)或 HTML 文档。它解析文档并创建一种 。
Beautiful Soup 文档,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它可以与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,bs4 — BeautifulSoup 4¶。“Fish-Footman 开始从他的腋下生成一个很棒的字母。Beautiful Soup 是一个用于拉取的 Python 库。BeautifulSoup - bs4 - Python 文档,Beautiful Soup 构造函数打开一个字符串(或类似)对象中的文件)以获取 XML 或 HTML文档。它解析文档并创建一个 Beautiful Soup 文档 Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供了一种导航、搜索和修改解析树的惯用方式。它可以通常可以节省程序员数小时或数天的工作时间。
BeautifulSoup - bs4 - Python 文档,bs4 - BeautifulSoup 4¶。“Fish-Footman 从腋下写了一封很棒的信。Beautiful Soup 是一个 Python 库,用于引入 Beautiful Soup 的介绍,
BeautifulSoup 教程
使用 Python 和 Beautiful Soup 从 Web 采集数据,使用 BeautifulSoup 在 Python 中实现 Web Scraping · 如果存在 网站 的 API,请使用它。例如,Facebook 有 Facebook 安装解析器¶。Beautiful Soup 支持 Python 标准库中收录的 HTML 解析器,但它也支持许多第三方 Python 解析器。使用 BeautifulSoup 在 Python 中实现 Web Scraping,在本 Python 教程中,我们将使用 Beautiful Soup 模块采集和解析网页以获取数据,并将我们采集的信息写入代码以获取一些信息。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。.
使用 BeautifulSoup 在 Python 中进行 Web 抓取,安装 Parser¶。Beautiful Soup 支持 Python 标准库中收录的 HTML 解析器,但它也支持许多第三方 Python 解析器。在本 Python 教程中,我们将使用 Beautiful Soup 模块来采集和解析网页以获取数据并写入我们采集的信息。教程:Web Scraping with Python with Beautiful Soup,这是我们用来从 index.html 中检索数据的代码来获取文件中的一些信息。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。在本教程中,您将学习如何: 使用请求和 Beautiful Soup 从 Web 抓取和解析数据;
教程:使用 Beautiful Soup 使用 Python 进行 Web Scraping,在本 Python 教程中,我们将使用 Beautiful Soup 模块来采集和解析网页,以便抓取数据并将我们采集的信息写入 a 这是我们将使用的代码在我们的 index.html 文件中获取一些信息。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。. Beautiful Soup 教程,在本教程中,您将学习如何:使用请求和 Beautiful Soup 从 Web 抓取和解析数据;从一开始就从 Web 抓取管道导航到 Beautiful Soup 教程 - 在本教程中,
美丽的汤教程,这是我们用来从 index.html 文件中获取一些信息的代码。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。在本教程中,您将学习如何: 使用请求和 Beautiful Soup 从 Web 抓取和解析数据;从头到尾浏览。Beautiful Soup 教程 - Python 中的网页抓取,Beautiful Soup 教程 - 在本教程中,我们将向您展示如何使用 Beautiful Soup 4 在 Python 中执行网页抓取,以从 HTML、XML 中获取数据,学习新技能永远不会太晚!学习编码并加入我们的 45+ 百万用户。
Beautiful Soup 教程 - Python 中的 Web Scraping,Beautiful Soup 的 Web Scraping,
抓取 YouTube 视频 Python
如何在 Python 中抓取 Youtube 评论,我最近一直痴迷于对 youtube 视频的见解,所以我试图用我最喜欢的 python 包 - BeautifulSoup 来抓取 网站。可用的爬虫在这里做了我会看到如何下载视频。要从 youtube 中提取这些数据,需要进行一些网络抓取和网络抓取 - 确实如此。使用 BeautifulSoup (python) 抓取 Youtube 视频 跟随我使用 python 在 youtube 频道上抓取和可视化统计数据。加载自动播放启用自动播放后,接下来会自动播放建议的视频。这是介绍性网络抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es。
用 BeautifulSoup (python) 抓取 Youtube 视频,让我看看如何下载视频。要从 YouTube 中提取这些数据,需要进行一些网络抓取和网络抓取——当我使用 python 在 youtube 频道上抓取和可视化统计数据时,它会遵循。加载自动播放启用自动播放后,接下来会自动播放建议的视频。. 如何在 Python 中提取 YouTube 数据,介绍性网络抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es 谈到情感分析项目,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。.
如何在 Python 中提取 YouTube 数据,请跟随我使用 python 来抓取 youtube 频道上的统计数据并将其可视化。加载自动播放启用自动播放后,接下来会自动播放建议的视频。这是介绍性网络抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es。Python Tutorial: Web Scraping with Python,当谈到情感分析项目时,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。使用 requests_html 和 Beautiful Soup 库在 Python 中抓取 YouTube 视频并提取有用的视频信息,例如标题,总观看次数、发布日期、视频时长、标签、喜欢和不喜欢等等。Abdou Rockikz · 7 分钟阅读 · 2020 年 8 月更新 · 网页抓取 网页抓取正在从 网站 中提取数据。.
Python 教程:使用 Python 进行网页抓取,介绍性网页抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es 谈到情感分析项目,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。介绍使用 Python 和 Beautiful Soup 进行网页抓取,用 Python 抓取 YouTube 视频,并使用 requests_html 和 Beautiful Soup 库提取有用的视频信息,例如标题、总观看次数、发布日期、视频时长、标签、喜欢和不喜欢等。Abdou Rockikz · 7 分钟阅读 · 2020 年 8 月更新 · 网页抓取 网页抓取正在从 网站 中提取数据。在这里,我将看到如何下载视频。从 YouTube 中提取这些数据需要进行一些网络爬虫和网络抓取——这在 Python 中非常简单。特别是因为有很多图书馆可以帮助你。用于网页抓取的两个最流行的 Python 库是 BeautifulSoup 和 ScraPy。在这里,我将随机挑选和使用 BeautifulSoup。. 用于网页抓取的两个最流行的 Python 库是 BeautifulSoup 和 ScraPy。在这里,我将随机挑选和使用 BeautifulSoup。. 用于网页抓取的两个最流行的 Python 库是 BeautifulSoup 和 ScraPy。在这里,我将随机挑选和使用 BeautifulSoup。.
用 Python 和 Beautiful Soup 介绍 Web Scraping,谈到情感分析项目,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。使用python从youtube抓取视频信息,
BeautifulSoup 按类别查找
使用 Beautiful Soup 进行网页抓取,使用 select() 方法查找多个元素,并使用 select_one() 查找单个元素。基本示例:from bs4 import BeautifulSoup data = """ 查看全部
网页音频抓取(BeautifulSoup文档bs4—BeautifulSoup4,BeautifulSoup是Python库!)
BeautifulSoup 文档
bs4 — BeautifulSoup 4,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,Beautiful Soup 文档,版本 4.4.0 Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中检索数据 提取数据。它与您最喜欢的解析器一起使用,提供一种惯用的方式来导航、搜索和修改解析树。. Beautiful Soup 文档,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索、.
Beautiful Soup 文档,Beautiful Soup 文档,4.4.0 版本 Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供一种惯用的方式来导航、搜索和修改解析树。Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索、. Beautiful Soup 4,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它可以与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,bs4 — BeautifulSoup 4¶。“Fish-Footman 开始从他的腋下生成一个大字母。Beautiful Soup 是一个用于拉取的 Python 库。
Beautiful Soup 4,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它可以与您最喜欢的解析器一起使用,提供惯用的导航、搜索、.Beautiful Soup 文档、bs4 — BeautifulSoup 4¶。“Fish-Footman 开始从他的腋下生成一封很棒的信。Beautiful Soup 是一个 Python 库,它拉动 Beautiful Soup 构造函数以获取 XML 作为字符串(或打开的文件类对象)或 HTML 文档。它解析文档并创建一种 。
Beautiful Soup 文档,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它可以与您最喜欢的解析器一起使用,提供惯用的导航、搜索方式,bs4 — BeautifulSoup 4¶。“Fish-Footman 开始从他的腋下生成一个很棒的字母。Beautiful Soup 是一个用于拉取的 Python 库。BeautifulSoup - bs4 - Python 文档,Beautiful Soup 构造函数打开一个字符串(或类似)对象中的文件)以获取 XML 或 HTML文档。它解析文档并创建一个 Beautiful Soup 文档 Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起使用,提供了一种导航、搜索和修改解析树的惯用方式。它可以通常可以节省程序员数小时或数天的工作时间。
BeautifulSoup - bs4 - Python 文档,bs4 - BeautifulSoup 4¶。“Fish-Footman 从腋下写了一封很棒的信。Beautiful Soup 是一个 Python 库,用于引入 Beautiful Soup 的介绍,
BeautifulSoup 教程
使用 Python 和 Beautiful Soup 从 Web 采集数据,使用 BeautifulSoup 在 Python 中实现 Web Scraping · 如果存在 网站 的 API,请使用它。例如,Facebook 有 Facebook 安装解析器¶。Beautiful Soup 支持 Python 标准库中收录的 HTML 解析器,但它也支持许多第三方 Python 解析器。使用 BeautifulSoup 在 Python 中实现 Web Scraping,在本 Python 教程中,我们将使用 Beautiful Soup 模块采集和解析网页以获取数据,并将我们采集的信息写入代码以获取一些信息。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。.
使用 BeautifulSoup 在 Python 中进行 Web 抓取,安装 Parser¶。Beautiful Soup 支持 Python 标准库中收录的 HTML 解析器,但它也支持许多第三方 Python 解析器。在本 Python 教程中,我们将使用 Beautiful Soup 模块来采集和解析网页以获取数据并写入我们采集的信息。教程:Web Scraping with Python with Beautiful Soup,这是我们用来从 index.html 中检索数据的代码来获取文件中的一些信息。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。在本教程中,您将学习如何: 使用请求和 Beautiful Soup 从 Web 抓取和解析数据;
教程:使用 Beautiful Soup 使用 Python 进行 Web Scraping,在本 Python 教程中,我们将使用 Beautiful Soup 模块来采集和解析网页,以便抓取数据并将我们采集的信息写入 a 这是我们将使用的代码在我们的 index.html 文件中获取一些信息。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。. Beautiful Soup 教程,在本教程中,您将学习如何:使用请求和 Beautiful Soup 从 Web 抓取和解析数据;从一开始就从 Web 抓取管道导航到 Beautiful Soup 教程 - 在本教程中,
美丽的汤教程,这是我们用来从 index.html 文件中获取一些信息的代码。从 bs4 导入 BeautifulSoup data = open("index.html").read() soup = BeautifulSoup(data, 'html.parser') print(soup.title.text) Python。这段非常基本的代码将从我们的 index.html 文档中获取标题标签文本。在本教程中,您将学习如何: 使用请求和 Beautiful Soup 从 Web 抓取和解析数据;从头到尾浏览。Beautiful Soup 教程 - Python 中的网页抓取,Beautiful Soup 教程 - 在本教程中,我们将向您展示如何使用 Beautiful Soup 4 在 Python 中执行网页抓取,以从 HTML、XML 中获取数据,学习新技能永远不会太晚!学习编码并加入我们的 45+ 百万用户。
Beautiful Soup 教程 - Python 中的 Web Scraping,Beautiful Soup 的 Web Scraping,
抓取 YouTube 视频 Python
如何在 Python 中抓取 Youtube 评论,我最近一直痴迷于对 youtube 视频的见解,所以我试图用我最喜欢的 python 包 - BeautifulSoup 来抓取 网站。可用的爬虫在这里做了我会看到如何下载视频。要从 youtube 中提取这些数据,需要进行一些网络抓取和网络抓取 - 确实如此。使用 BeautifulSoup (python) 抓取 Youtube 视频 跟随我使用 python 在 youtube 频道上抓取和可视化统计数据。加载自动播放启用自动播放后,接下来会自动播放建议的视频。这是介绍性网络抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es。
用 BeautifulSoup (python) 抓取 Youtube 视频,让我看看如何下载视频。要从 YouTube 中提取这些数据,需要进行一些网络抓取和网络抓取——当我使用 python 在 youtube 频道上抓取和可视化统计数据时,它会遵循。加载自动播放启用自动播放后,接下来会自动播放建议的视频。. 如何在 Python 中提取 YouTube 数据,介绍性网络抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es 谈到情感分析项目,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。.
如何在 Python 中提取 YouTube 数据,请跟随我使用 python 来抓取 youtube 频道上的统计数据并将其可视化。加载自动播放启用自动播放后,接下来会自动播放建议的视频。这是介绍性网络抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es。Python Tutorial: Web Scraping with Python,当谈到情感分析项目时,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。使用 requests_html 和 Beautiful Soup 库在 Python 中抓取 YouTube 视频并提取有用的视频信息,例如标题,总观看次数、发布日期、视频时长、标签、喜欢和不喜欢等等。Abdou Rockikz · 7 分钟阅读 · 2020 年 8 月更新 · 网页抓取 网页抓取正在从 网站 中提取数据。.
Python 教程:使用 Python 进行网页抓取,介绍性网页抓取教程的第 1 部分。在本视频中,您将了解什么是网络抓取以及它为何有用。同样,您将学习三个 es 谈到情感分析项目,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。介绍使用 Python 和 Beautiful Soup 进行网页抓取,用 Python 抓取 YouTube 视频,并使用 requests_html 和 Beautiful Soup 库提取有用的视频信息,例如标题、总观看次数、发布日期、视频时长、标签、喜欢和不喜欢等。Abdou Rockikz · 7 分钟阅读 · 2020 年 8 月更新 · 网页抓取 网页抓取正在从 网站 中提取数据。在这里,我将看到如何下载视频。从 YouTube 中提取这些数据需要进行一些网络爬虫和网络抓取——这在 Python 中非常简单。特别是因为有很多图书馆可以帮助你。用于网页抓取的两个最流行的 Python 库是 BeautifulSoup 和 ScraPy。在这里,我将随机挑选和使用 BeautifulSoup。. 用于网页抓取的两个最流行的 Python 库是 BeautifulSoup 和 ScraPy。在这里,我将随机挑选和使用 BeautifulSoup。. 用于网页抓取的两个最流行的 Python 库是 BeautifulSoup 和 ScraPy。在这里,我将随机挑选和使用 BeautifulSoup。.
用 Python 和 Beautiful Soup 介绍 Web Scraping,谈到情感分析项目,我觉得 Youtube 评论代表了一个很好且未被充分利用的数据源。您可以轻松访问所有观众对特定主题(即视频)的意见。了解了这一切,这里是如何一步一步地从 Youtube 视频中抓取评论。使用python从youtube抓取视频信息,
BeautifulSoup 按类别查找
使用 Beautiful Soup 进行网页抓取,使用 select() 方法查找多个元素,并使用 select_one() 查找单个元素。基本示例:from bs4 import BeautifulSoup data = """
网页音频抓取(Mozilla/5.0(WindowsNT)#递归删除目录树)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-18 02:03
导入异步
来自 bs4import BeautifulSoup
来自 lxmlimport etree
导入操作系统
导入关闭
filePath="D:\\temp_ximalaya_audio"
channelFilePath=""
#初始化文件目录
如果 os.path.isdir(filePath):
shutil.rmtree(filePath)#递归删除目录树
elif os.path.isfile(filePath):
os.remove(filePath)#删除文件
os.makedirs(filePath)#创建目录
#mongodb
#clients = pymongo.MongoClient('localhost')
#db = clients["XiMaLaYa"]
#col1 = db["album2"]
#col2 = db["detail2"]
UA_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/22.@ >0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11;CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome /20.0.1132.@>57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, 像 Gecko) Chrome/20.@ >0.1092.@>0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, 像壁虎) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/19.@ >77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, 像 Gecko) Chrome/19.@>0. 1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, 像壁虎) Chrome/19.@>0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1063.0 Safari/536.3",
"Mozilla/4.0(兼容;MSIE 7.0;Windows NT 5.1;Trident/4.0;SE 2.@>X MetaSr < @1.0; SE 2.@>X MetaSr 1.0; .NET CLR 2.@>0.50727; SE 2.@>X MetaSr 1.< @0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML,像壁虎) Chrome/19.@>0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML,像 Gecko) Chrome/19.@>0. 1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, 像 Gecko) Chrome/19.@ >0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/22.@ >0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11;CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome /20.0.1132.@>57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, 像 Gecko) Chrome/20.@ >0.1092.@>0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, 像壁虎) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/19.@ >77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, 像 Gecko) Chrome/19.@>0. 1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, 像壁虎) Chrome/19.@>0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, 像 Gecko) Chrome/19.@>0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML,像壁虎) Chrome/19.@>0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML,像 Gecko) Chrome/19.@>0. 1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, 像 Gecko) Chrome/19.@ >0.1055.1 Safari/535.24"
]
标题1 = {
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control':'max-age=0',
'代理连接':'keep-alive',
'Upgrade-Insecure-Requests':'1',
'用户代理':random.choice(UA_LIST)
}
headers2 = {
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control':'max-age=0',
'代理连接':'keep-alive',
'推荐人':'',
'Upgrade-Insecure-Requests':'1',
'用户代理':random.choice(UA_LIST)
}
def get_url():
#start_urls = ['{}'.format(num) for num in range(1, 85)]
start_urls = [""]
打印(start_urls)
对于 start_urlin start_urls:
打印(start_url)
print("==================开始 html===============")
html = requests.get(start_url,headers=headers1).text
print("html = {}".format(html))
print("================end html===============")
print("================开始汤=============")
soup = BeautifulSoup(html,'lxml')
打印(汤)
print("================结束汤============")
对于 itemin soup.find_all(class_="albumfaceOutter"):
print("================开始项目================")
打印(项目)
print("================结束项目========================= =")
print("================开始内容================")
内容 = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
打印(内容)
print("==================结束内容======================= ===")
#col1.插入(内容)
print('写一个频道' + item.a['href'])
子频道 = item.a['href']
print("============开始子频道=====================")
打印(子通道)
subchannelArr = subchannel.split("/")
打印(subchannelArr)
#channelFilePath = subchannelArr[len(subchannelArr) - 2]
channelFilePath = content['title']
打印(通道文件路径)
channelFilePath = filePath + os.sep + channelFilePath
打印(通道文件路径)
如果 os.path.isdir(channelFilePath):
shutil.rmtree(channelFilePath)#递归删除目录树
elif os.path.isfile(channelFilePath):
os.remove(channelFilePath)#删除文件
os.makedirs(channelFilePath)# 创建目录
print("============结束子频道=====================")
打印(内容)
另一个(channelFilePath, item.a['href'])
时间.sleep(1)
def another(channelFilePath, url):
print("========================开始另一个html================= === =====")
html = requests.get(url,headers=headers2).text
打印(html)
print("========================结束另一个html================= === =====")
print("=========================开始另一个 ifanother================ === =====")
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
打印(ifanother)
print("========================结束另一个 ifanother================= === =====")
如果 len(ifanother):
num = ifanother[0]
print('这个频道资源存在' + num + 'pages')
对于 nin range(1,int(num)):
print('开始解析{}中的第{}页'.format(num, n))
url2 = url +'?page={}'.format(n)
打印(网址)
打印(网址2)
get_m4a(channelFilePath, url2)
get_m4a(url)
def get_m4a(channelFilePath, url):
时间.sleep(1)
html = requests.get(url,headers=headers2).text
print("==============开始get_m4a======================")
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
打印(数字列表)
print("==============end get_m4a======================")
对于iin numlist:
print("==============开始 get_m4a murl======================") 查看全部
网页音频抓取(Mozilla/5.0(WindowsNT)#递归删除目录树)
导入异步
来自 bs4import BeautifulSoup
来自 lxmlimport etree
导入操作系统
导入关闭
filePath="D:\\temp_ximalaya_audio"
channelFilePath=""
#初始化文件目录
如果 os.path.isdir(filePath):
shutil.rmtree(filePath)#递归删除目录树
elif os.path.isfile(filePath):
os.remove(filePath)#删除文件
os.makedirs(filePath)#创建目录
#mongodb
#clients = pymongo.MongoClient('localhost')
#db = clients["XiMaLaYa"]
#col1 = db["album2"]
#col2 = db["detail2"]
UA_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/22.@ >0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11;CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome /20.0.1132.@>57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, 像 Gecko) Chrome/20.@ >0.1092.@>0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, 像壁虎) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/19.@ >77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, 像 Gecko) Chrome/19.@>0. 1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, 像壁虎) Chrome/19.@>0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1063.0 Safari/536.3",
"Mozilla/4.0(兼容;MSIE 7.0;Windows NT 5.1;Trident/4.0;SE 2.@>X MetaSr < @1.0; SE 2.@>X MetaSr 1.0; .NET CLR 2.@>0.50727; SE 2.@>X MetaSr 1.< @0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML,像壁虎) Chrome/19.@>0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML,像 Gecko) Chrome/19.@>0. 1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, 像 Gecko) Chrome/19.@ >0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/22.@ >0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11;CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome /20.0.1132.@>57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, 像 Gecko) Chrome/20.@ >0.1092.@>0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, 像壁虎) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, 像壁虎) Chrome/19.@ >77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, 像 Gecko) Chrome/19.@>0. 1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, 像壁虎) Chrome/19.@>0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, 像 Gecko) Chrome/19.@>0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1062.@>0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@ >0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML,像壁虎) Chrome/19.@>0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, 像壁虎) Chrome/19.@>0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML,像 Gecko) Chrome/19.@>0. 1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, 像 Gecko) Chrome/19.@ >0.1055.1 Safari/535.24"
]
标题1 = {
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control':'max-age=0',
'代理连接':'keep-alive',
'Upgrade-Insecure-Requests':'1',
'用户代理':random.choice(UA_LIST)
}
headers2 = {
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control':'max-age=0',
'代理连接':'keep-alive',
'推荐人':'',
'Upgrade-Insecure-Requests':'1',
'用户代理':random.choice(UA_LIST)
}
def get_url():
#start_urls = ['{}'.format(num) for num in range(1, 85)]
start_urls = [""]
打印(start_urls)
对于 start_urlin start_urls:
打印(start_url)
print("==================开始 html===============")
html = requests.get(start_url,headers=headers1).text
print("html = {}".format(html))
print("================end html===============")
print("================开始汤=============")
soup = BeautifulSoup(html,'lxml')
打印(汤)
print("================结束汤============")
对于 itemin soup.find_all(class_="albumfaceOutter"):
print("================开始项目================")
打印(项目)
print("================结束项目========================= =")
print("================开始内容================")
内容 = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
打印(内容)
print("==================结束内容======================= ===")
#col1.插入(内容)
print('写一个频道' + item.a['href'])
子频道 = item.a['href']
print("============开始子频道=====================")
打印(子通道)
subchannelArr = subchannel.split("/")
打印(subchannelArr)
#channelFilePath = subchannelArr[len(subchannelArr) - 2]
channelFilePath = content['title']
打印(通道文件路径)
channelFilePath = filePath + os.sep + channelFilePath
打印(通道文件路径)
如果 os.path.isdir(channelFilePath):
shutil.rmtree(channelFilePath)#递归删除目录树
elif os.path.isfile(channelFilePath):
os.remove(channelFilePath)#删除文件
os.makedirs(channelFilePath)# 创建目录
print("============结束子频道=====================")
打印(内容)
另一个(channelFilePath, item.a['href'])
时间.sleep(1)
def another(channelFilePath, url):
print("========================开始另一个html================= === =====")
html = requests.get(url,headers=headers2).text
打印(html)
print("========================结束另一个html================= === =====")
print("=========================开始另一个 ifanother================ === =====")
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
打印(ifanother)
print("========================结束另一个 ifanother================= === =====")
如果 len(ifanother):
num = ifanother[0]
print('这个频道资源存在' + num + 'pages')
对于 nin range(1,int(num)):
print('开始解析{}中的第{}页'.format(num, n))
url2 = url +'?page={}'.format(n)
打印(网址)
打印(网址2)
get_m4a(channelFilePath, url2)
get_m4a(url)
def get_m4a(channelFilePath, url):
时间.sleep(1)
html = requests.get(url,headers=headers2).text
print("==============开始get_m4a======================")
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
打印(数字列表)
print("==============end get_m4a======================")
对于iin numlist:
print("==============开始 get_m4a murl======================")
网页音频抓取(ESFSoftURLSniffer播放 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-10 18:16
)
3、检测、识别、嗅探流媒体 FLV、F4V、SWF、MP4、MP3、WMV、ASF、RM、RAM、JPG。
4、查找隐藏在 Java 脚本或 ActiveX 脚本后面的流式音频和视频。
5、智能区分有效的媒体流URL链接。
6、快速实现 URL 嗅探。
7、任何下载管理器都允许下载流文件。
如何使用 ESFSoft URL 嗅探器:
1、运行 ESFSoft URL 嗅探器。
2、然后点击开始按钮,ESFSoft URL Sniffer就会开始从浏览器播放的音视频流中检测并嗅出相应的URL链接,包括FLV、MP4、MP3、WMV、ASF、RM、RAM 和一些文本链接。值得一提的是,ESFSoft URL Sniffer可以将有用的媒体流URL链接与一些不重要的文字图片链接区分开来,为广大网友省去了一些麻烦的步骤,即过滤掉所有抓取到的链接。有用的链接。
使用 ESFSoft URL Sniffer 的注意事项:
1、软件需要WinPcap支持才能运行,压缩包内有WinPcap4.1.3官方英文安装版,双击运行安装即可。
2、软件窗口中Start按钮的Start英文字符串和Top按钮的Top和NoTop英文字符串无法本地化,本地化会导致按钮失败。
界面预览:
查看全部
网页音频抓取(ESFSoftURLSniffer播放
)
3、检测、识别、嗅探流媒体 FLV、F4V、SWF、MP4、MP3、WMV、ASF、RM、RAM、JPG。
4、查找隐藏在 Java 脚本或 ActiveX 脚本后面的流式音频和视频。
5、智能区分有效的媒体流URL链接。
6、快速实现 URL 嗅探。
7、任何下载管理器都允许下载流文件。
如何使用 ESFSoft URL 嗅探器:
1、运行 ESFSoft URL 嗅探器。
2、然后点击开始按钮,ESFSoft URL Sniffer就会开始从浏览器播放的音视频流中检测并嗅出相应的URL链接,包括FLV、MP4、MP3、WMV、ASF、RM、RAM 和一些文本链接。值得一提的是,ESFSoft URL Sniffer可以将有用的媒体流URL链接与一些不重要的文字图片链接区分开来,为广大网友省去了一些麻烦的步骤,即过滤掉所有抓取到的链接。有用的链接。
使用 ESFSoft URL Sniffer 的注意事项:
1、软件需要WinPcap支持才能运行,压缩包内有WinPcap4.1.3官方英文安装版,双击运行安装即可。
2、软件窗口中Start按钮的Start英文字符串和Top按钮的Top和NoTop英文字符串无法本地化,本地化会导致按钮失败。
界面预览:
网页音频抓取(听有声小说的音频地址是什么?如何借鉴本文的思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-02-07 08:02
)
前言:
一个朋友最近沉迷于听有声小说,但是因为很多有声小说网站需要VIP才能听,所以他想让我帮他把小说下载下来,这样他就可以在手机上随时听了电话。我在网上搜了他听的这本小说,确实有很多大型听书网站需要VIP才能听,于是找了一个小网站帮他爬小说拿去向下。因为他听的小说是知名作者写的,为了保护作者的权益,本文的案例没有使用作者的小说进行爬取,而是使用了另一部小说进行爬取说明,大致爬取思路是一样的,大家可以借鉴这篇文章的思路。
本案网站:
一、分析网页
本案小说共有178章,对应178个音频数据。我们需要爬取小说的名字,每章的链接地址,然后分析每一个链接地址,找到真正的音频。数据地址。如图所示:
网页的链接可以通过查看开发者工具来分析,该网页是html数据网页,数据也在html网页的源码中。继续分析,随意点击一个章节链接,网页跳转到另一个窗口,然后自动播放。本章的小说,如图:
事实上,找到音频文件非常简单。只需找到网络下的媒体选项,就可以看到正在播放的音频数据,如图:
从图中可以看出,音频数据是m4a格式的音频数据,而这个URL是真正的音频地址,所以问题是,只有这个URL只能爬取一章的小说,我们的目的是爬取所有章节的小说,所以显然只知道小说的音频地址是没有用的。接下来,我们需要找出音频地址的来源。通过经验,我们可以搜索到音频地址后面的文件名。
通过搜索名称,我们找到了一个新的网页链接,如图:
可以清楚的看到和真实的音频地址是一样的,只是少了**.m4a**这几个字。我们大概断定这个网页就是收录真实音频数据的地址网页,但是这是一个新的,那么这个地址是从哪里来的呢?没关系,我们继续搜索这个地址试试。
可以看出,我们通过搜索找到了一个新的网页。里面有一个iframe标签,标签下面有一个src属性。里面的 URL 大概和我们之前搜索的网页的 URL 是一样的,但是这个 URL 并不完整。,只有URL的后半部分,前半部分不见了,我们只需要完成前半部分,通过这一系列的分析,大概确定这个URL就是收录上述URL的数据URL,最后我们只需要确定 URL 使用任何 URL 就足够了。确认后,URL为各章节的链接地址。即使完成了整个分析过程,小说的有声读物也基本可以爬取。
现在我们来谈谈爬行的想法。首先通过小说首页爬取每章的链接地址和小说名,然后通过爬下来的每章的链接找到链接地址中收录的另一个。一个收录真实音频数据的小说链接,通过这个链接找到真实的音频数据,最后保存数据。
在这种情况下使用的模块:
1import requests
2import parsel
3import re
4import os
5from urllib.request import urlretrieve
6from tqdm import tqdm
7
8
二、发送请求并获取响应数据
1 def parse_url(self, url, headers):
2 """
3 发送请求,获取响应数据的方法
4 :param url:
5 :param headers:
6 :return:
7 """
8 response = requests.get(url, headers=headers)
9 if response.status_code == 200:
10 return response.text
11 else:
12 print('请求失败')
13
14
三、提取小说各章链接地址
1 def get_chapter_url(self, html_str):
2 """
3 提取小说章节的url的方法
4 :param html_str:
5 :return:
6 """
7 html = parsel.Selector(html_str)
8 # 提取小说章节地址列表
9 chapter_urls = html.css('#playlist>ul>li>a::attr(href)').extract()
10 chapter_urls = [self.SHU_TEMP_URL.format(i) for i in chapter_urls]
11 # 提取小说名字
12 audio_shu_name = html.css('.book-title::text').extract_first().strip()
13 return chapter_urls, audio_shu_name
14
15
16
四、提取收录小说真实音频地址的链接地址
1 def get_audio_temp_url(self, html_str2):
2 """
3 提取含有小说真实地址的url的方法
4 :param html_str2:
5 :return:
6 """
7 html = parsel.Selector(html_str2)
8 audio_temp_url = html.css('iframe::attr(src)').extract_first()
9 audio_temp_url = self.SHU_TEMP_URL.format(audio_temp_url)
10 return audio_temp_url
11
12
五、提取该地址下的真实音频数据地址
1 def get_audio_url(self, html_str3):
2 """
3 提取小说真实的url地址的方法
4 :param html_str3:
5 :return:
6 """
7 audio_url = re.findall("mp3:'(.*?)'", html_str3, re.S)[0]
8 if 'm4a' in audio_url:
9 return audio_url
10 else:
11 return audio_url + '.m4a'
12
13
六、保存音频数据
1 def down_audio(self, audio_url, audio_shu_name, num):
2 """
3 下载有声小说的方法
4 :param audio_url:
5 :param audio_shu_name:
6 :param num:
7 :return:
8 """
9 path = f'{audio_shu_name}'
10 isExists = os.path.exists(path)
11 file_path = os.path.join(path, f'{audio_shu_name}_{num}.mp3')
12 if not isExists:
13 os.makedirs(path, exist_ok=True)
14 urlretrieve(audio_url, file_path)
15 print(f"{audio_shu_name}_{num}---下载完成")
16 else:
17 urlretrieve(audio_url, file_path)
18 print(f"{audio_shu_name}_{num}---下载完成")
19
20
七、实现逻辑思想的代码
1 def run(self):
2 """
3 实现主要逻辑思路
4 :return:
5 """
6 # 1.发送请求,获取响应数据
7 html_str = self.parse_url(self.SHU_URL, self.headers)
8 # 2.提取小说章节的url
9 chapter_urls, audio_shu_name = self.get_chapter_url(html_str)
10 tqdm_chapter_urls = tqdm(chapter_urls)
11 for num, chapter_url in enumerate(tqdm_chapter_urls):
12 # 3.对小说章节url发送请求,获取响应数据
13 html_str2 = self.parse_url(chapter_url, self.headers)
14 # 4.提取含有小说真实地址的url
15 audio_temp_url = self.get_audio_temp_url(html_str2)
16 # 5.对这个url地址发送请求,获取响应数据
17 html_str3 = self.parse_url(audio_temp_url, self.headers)
18 # 6.提取真实的url地址
19 audio_url = self.get_audio_url(html_str3)
20 # 7.下载小说
21 self.down_audio(audio_url, audio_shu_name, num + 1)
22
23
完成效果展示:
查看全部
网页音频抓取(听有声小说的音频地址是什么?如何借鉴本文的思路
)
前言:
一个朋友最近沉迷于听有声小说,但是因为很多有声小说网站需要VIP才能听,所以他想让我帮他把小说下载下来,这样他就可以在手机上随时听了电话。我在网上搜了他听的这本小说,确实有很多大型听书网站需要VIP才能听,于是找了一个小网站帮他爬小说拿去向下。因为他听的小说是知名作者写的,为了保护作者的权益,本文的案例没有使用作者的小说进行爬取,而是使用了另一部小说进行爬取说明,大致爬取思路是一样的,大家可以借鉴这篇文章的思路。
本案网站:
一、分析网页
本案小说共有178章,对应178个音频数据。我们需要爬取小说的名字,每章的链接地址,然后分析每一个链接地址,找到真正的音频。数据地址。如图所示:
网页的链接可以通过查看开发者工具来分析,该网页是html数据网页,数据也在html网页的源码中。继续分析,随意点击一个章节链接,网页跳转到另一个窗口,然后自动播放。本章的小说,如图:
事实上,找到音频文件非常简单。只需找到网络下的媒体选项,就可以看到正在播放的音频数据,如图:
从图中可以看出,音频数据是m4a格式的音频数据,而这个URL是真正的音频地址,所以问题是,只有这个URL只能爬取一章的小说,我们的目的是爬取所有章节的小说,所以显然只知道小说的音频地址是没有用的。接下来,我们需要找出音频地址的来源。通过经验,我们可以搜索到音频地址后面的文件名。
通过搜索名称,我们找到了一个新的网页链接,如图:
可以清楚的看到和真实的音频地址是一样的,只是少了**.m4a**这几个字。我们大概断定这个网页就是收录真实音频数据的地址网页,但是这是一个新的,那么这个地址是从哪里来的呢?没关系,我们继续搜索这个地址试试。
可以看出,我们通过搜索找到了一个新的网页。里面有一个iframe标签,标签下面有一个src属性。里面的 URL 大概和我们之前搜索的网页的 URL 是一样的,但是这个 URL 并不完整。,只有URL的后半部分,前半部分不见了,我们只需要完成前半部分,通过这一系列的分析,大概确定这个URL就是收录上述URL的数据URL,最后我们只需要确定 URL 使用任何 URL 就足够了。确认后,URL为各章节的链接地址。即使完成了整个分析过程,小说的有声读物也基本可以爬取。
现在我们来谈谈爬行的想法。首先通过小说首页爬取每章的链接地址和小说名,然后通过爬下来的每章的链接找到链接地址中收录的另一个。一个收录真实音频数据的小说链接,通过这个链接找到真实的音频数据,最后保存数据。
在这种情况下使用的模块:
1import requests
2import parsel
3import re
4import os
5from urllib.request import urlretrieve
6from tqdm import tqdm
7
8
二、发送请求并获取响应数据
1 def parse_url(self, url, headers):
2 """
3 发送请求,获取响应数据的方法
4 :param url:
5 :param headers:
6 :return:
7 """
8 response = requests.get(url, headers=headers)
9 if response.status_code == 200:
10 return response.text
11 else:
12 print('请求失败')
13
14
三、提取小说各章链接地址
1 def get_chapter_url(self, html_str):
2 """
3 提取小说章节的url的方法
4 :param html_str:
5 :return:
6 """
7 html = parsel.Selector(html_str)
8 # 提取小说章节地址列表
9 chapter_urls = html.css('#playlist>ul>li>a::attr(href)').extract()
10 chapter_urls = [self.SHU_TEMP_URL.format(i) for i in chapter_urls]
11 # 提取小说名字
12 audio_shu_name = html.css('.book-title::text').extract_first().strip()
13 return chapter_urls, audio_shu_name
14
15
16
四、提取收录小说真实音频地址的链接地址
1 def get_audio_temp_url(self, html_str2):
2 """
3 提取含有小说真实地址的url的方法
4 :param html_str2:
5 :return:
6 """
7 html = parsel.Selector(html_str2)
8 audio_temp_url = html.css('iframe::attr(src)').extract_first()
9 audio_temp_url = self.SHU_TEMP_URL.format(audio_temp_url)
10 return audio_temp_url
11
12
五、提取该地址下的真实音频数据地址
1 def get_audio_url(self, html_str3):
2 """
3 提取小说真实的url地址的方法
4 :param html_str3:
5 :return:
6 """
7 audio_url = re.findall("mp3:'(.*?)'", html_str3, re.S)[0]
8 if 'm4a' in audio_url:
9 return audio_url
10 else:
11 return audio_url + '.m4a'
12
13
六、保存音频数据
1 def down_audio(self, audio_url, audio_shu_name, num):
2 """
3 下载有声小说的方法
4 :param audio_url:
5 :param audio_shu_name:
6 :param num:
7 :return:
8 """
9 path = f'{audio_shu_name}'
10 isExists = os.path.exists(path)
11 file_path = os.path.join(path, f'{audio_shu_name}_{num}.mp3')
12 if not isExists:
13 os.makedirs(path, exist_ok=True)
14 urlretrieve(audio_url, file_path)
15 print(f"{audio_shu_name}_{num}---下载完成")
16 else:
17 urlretrieve(audio_url, file_path)
18 print(f"{audio_shu_name}_{num}---下载完成")
19
20
七、实现逻辑思想的代码
1 def run(self):
2 """
3 实现主要逻辑思路
4 :return:
5 """
6 # 1.发送请求,获取响应数据
7 html_str = self.parse_url(self.SHU_URL, self.headers)
8 # 2.提取小说章节的url
9 chapter_urls, audio_shu_name = self.get_chapter_url(html_str)
10 tqdm_chapter_urls = tqdm(chapter_urls)
11 for num, chapter_url in enumerate(tqdm_chapter_urls):
12 # 3.对小说章节url发送请求,获取响应数据
13 html_str2 = self.parse_url(chapter_url, self.headers)
14 # 4.提取含有小说真实地址的url
15 audio_temp_url = self.get_audio_temp_url(html_str2)
16 # 5.对这个url地址发送请求,获取响应数据
17 html_str3 = self.parse_url(audio_temp_url, self.headers)
18 # 6.提取真实的url地址
19 audio_url = self.get_audio_url(html_str3)
20 # 7.下载小说
21 self.down_audio(audio_url, audio_shu_name, num + 1)
22
23
完成效果展示:
网页音频抓取(试试,真正被今日头条收购的海外头条版(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-06 05:28
视频查看器
互动率
评论数
评价率
喜欢比
广告点击率
观众年龄分布
观众地域分布
最受欢迎的视频等
您可以通过电子邮件直接联系影响者
工具网址为:
2、互联网上最好的设计之一网站
这是一个非常丑陋的单页网站,每月浏览量接近10亿,聚合了其他新闻网站的链接,自制头条。从1995年开始,几乎只有一个人经营,现在每年的广告收入都在几千万美元。
与 Craigslist 类似,Drudge Report 已经运营了 20 多年,页面设计几乎没有变化,经受住了时间的考验。而且大部分访问者都是直接访问,不依赖搜索引擎来分流。我这里就不截图了,有兴趣的可以看看,网址是:
3、亚马逊美国前 250,000 个搜索词
该网站是:
4、今日头条海外版
海外版抖音TikTok最近越来越火了。如果你不擅长短视频,何不尝试通过文字和图片来获得一些流量。试试海外版的今日头条。
该网站是:
顺便说一句,真正被今日头条收购的海外头条版是
有兴趣的都可以试试
5、Free Standalone:用于生成隐私政策、使用条款等法律文件的工具。
我知道很多独立网站的运营商/站长基本上都是从外地抄袭隐私政策、使用条款等文件。同时,面对欧盟的GDPR政策,网站中的相关文案也不知道怎么解释。这个工具也许能帮到你。
我们来做一个简单的操作说明:
1)注册成功后(可以直接通过谷歌账号登录),进入如下界面。很多模板,同时告诉你免费版只能创建3个文件。
如果找不到想要的模板,可以点击模板市场
2)我们选择与“隐私政策”相关的模板
3)10步以上的选择题
最后,您到达一个需要填写几个字段的页面。设置完成后,即可将内容发送到您的邮箱。
单击“魔术”按钮后,将为您生成一个word文档。
工具网址为:
6、将音视频文件翻译成文本提取核心思想
这是一个刚刚开发的网站,连付费版的支付工具都没有准备好。
免费版目前支持90分钟,点击上传音视频
上传成功后,点击文件名:
默认显示翻译文本
点击“摘要”提取核心点
7、做点有趣的事网站:看死囚的遗言
8、不用学Python,用这个工具爬网
抓取页面多条信息——以bilibili排行榜为例
安装好“Web Scraper”后,按F12进入开发者模式,这样就可以在最后一个标签中看到“Web Scraper”菜单了。需要注意的是,如果开发者模式面板不在下方,会提示必须放在浏览器下方才能继续。
在菜单中选择“创建新站点地图-创建站点地图”创建新站点地图,填写名称和起始地址即可开始。这里以bilibili排名为例,介绍如何抓取页面上的多条信息。起始地址设置为
这里我们需要捕获“视频标题”、“播放量”、“弹幕数”、“up主”和“综合评分”,所以首先为每条记录创建一个wrapper。
点击“添加新选择器”,id填写“packager”,type选择“element”,然后点击“selector”,选择一条记录的外框,外框需要收录以上所有信息,然后选择第二个,所以你会发现页面中的所有记录都被自动选中了,点击“Done selection”完成数据选择。还要记得勾选“Multiple”以确保捕获到多条记录,最后保存选择器。
返回后,点击刚才的wrapper,进入二级路径,创建“title”选择器,id填写“video title”,type选择“text”,点击“selector”找到第一条记录高亮显示。这是因为我们提前把它做成了包装器。在边界框中选择标题,然后单击“完成选择”完成标题的选择。注意这里不需要勾选“Multiple”,最后保存选择器。
同样,我们为“播放量”、“弹幕数”、“up master”和“综合得分”创建选择器。选择后,可以通过“数据预览”预览是否选择了想要的内容。此外,您可以通过菜单栏中的“Sitemap bilibili_ranking - Selector graph”直观地查看树状结构。
继续选择刚才菜单下的“抓取”,开始创建抓取任务。可以默认单个网页的间隔时间和响应时间。点击“开始抓取”开始抓取。这时浏览器会自动打开一个新页面,停留几秒后会自动关闭,表示爬取完成。
点击“刷新数据”刷新数据,或点击“Sitemap bilibili_ranking - 浏览”查看数据。您可以通过“Sitemap bilibili_ranking - 将数据导出为 CSV”将其下载为 CSV 文件。
▲bilibili排行榜
用 Excel 打开它。由于“Web Scraper”抓取的内容是乱序的,所以需要对“综合得分”进行降序排序,才能恢复原来排行榜的结果。
9、带有漂亮浏览器外壳的网页生成工具
输入任意 URL 生成带有 mac/win 风格的浏览器 shell 的图像
10、9 合 1 免费社交媒体分析工具
最强大的工具往往是最后出现的。Socialbakers 本身是一个强大的付费工具,但它提供了 9 个非常值得使用的免费工具。我们将一一介绍:
1)个人网上商城模板
2)网红搜索(只能看到部分数据)
3)网红标签搜索工具
4)facebook专页及竞争对手业绩分析报告
5)比较 Instagram 个人资料和竞争对手的影响力分析报告
6)比较 Instagram 个人资料和竞争对手的影响者分析报告
7)facebook 广告影响预测工具
8)facebook网红对比分析工具
9)Socialbakers 关于社会客户关怀的最新数据 查看全部
网页音频抓取(试试,真正被今日头条收购的海外头条版(组图))
视频查看器
互动率
评论数
评价率
喜欢比
广告点击率
观众年龄分布
观众地域分布
最受欢迎的视频等
您可以通过电子邮件直接联系影响者
工具网址为:
2、互联网上最好的设计之一网站
这是一个非常丑陋的单页网站,每月浏览量接近10亿,聚合了其他新闻网站的链接,自制头条。从1995年开始,几乎只有一个人经营,现在每年的广告收入都在几千万美元。
与 Craigslist 类似,Drudge Report 已经运营了 20 多年,页面设计几乎没有变化,经受住了时间的考验。而且大部分访问者都是直接访问,不依赖搜索引擎来分流。我这里就不截图了,有兴趣的可以看看,网址是:
3、亚马逊美国前 250,000 个搜索词
该网站是:
4、今日头条海外版
海外版抖音TikTok最近越来越火了。如果你不擅长短视频,何不尝试通过文字和图片来获得一些流量。试试海外版的今日头条。
该网站是:
顺便说一句,真正被今日头条收购的海外头条版是
有兴趣的都可以试试
5、Free Standalone:用于生成隐私政策、使用条款等法律文件的工具。
我知道很多独立网站的运营商/站长基本上都是从外地抄袭隐私政策、使用条款等文件。同时,面对欧盟的GDPR政策,网站中的相关文案也不知道怎么解释。这个工具也许能帮到你。
我们来做一个简单的操作说明:
1)注册成功后(可以直接通过谷歌账号登录),进入如下界面。很多模板,同时告诉你免费版只能创建3个文件。
如果找不到想要的模板,可以点击模板市场
2)我们选择与“隐私政策”相关的模板
3)10步以上的选择题
最后,您到达一个需要填写几个字段的页面。设置完成后,即可将内容发送到您的邮箱。
单击“魔术”按钮后,将为您生成一个word文档。
工具网址为:
6、将音视频文件翻译成文本提取核心思想
这是一个刚刚开发的网站,连付费版的支付工具都没有准备好。
免费版目前支持90分钟,点击上传音视频
上传成功后,点击文件名:
默认显示翻译文本
点击“摘要”提取核心点
7、做点有趣的事网站:看死囚的遗言
8、不用学Python,用这个工具爬网
抓取页面多条信息——以bilibili排行榜为例
安装好“Web Scraper”后,按F12进入开发者模式,这样就可以在最后一个标签中看到“Web Scraper”菜单了。需要注意的是,如果开发者模式面板不在下方,会提示必须放在浏览器下方才能继续。
在菜单中选择“创建新站点地图-创建站点地图”创建新站点地图,填写名称和起始地址即可开始。这里以bilibili排名为例,介绍如何抓取页面上的多条信息。起始地址设置为
这里我们需要捕获“视频标题”、“播放量”、“弹幕数”、“up主”和“综合评分”,所以首先为每条记录创建一个wrapper。
点击“添加新选择器”,id填写“packager”,type选择“element”,然后点击“selector”,选择一条记录的外框,外框需要收录以上所有信息,然后选择第二个,所以你会发现页面中的所有记录都被自动选中了,点击“Done selection”完成数据选择。还要记得勾选“Multiple”以确保捕获到多条记录,最后保存选择器。
返回后,点击刚才的wrapper,进入二级路径,创建“title”选择器,id填写“video title”,type选择“text”,点击“selector”找到第一条记录高亮显示。这是因为我们提前把它做成了包装器。在边界框中选择标题,然后单击“完成选择”完成标题的选择。注意这里不需要勾选“Multiple”,最后保存选择器。
同样,我们为“播放量”、“弹幕数”、“up master”和“综合得分”创建选择器。选择后,可以通过“数据预览”预览是否选择了想要的内容。此外,您可以通过菜单栏中的“Sitemap bilibili_ranking - Selector graph”直观地查看树状结构。
继续选择刚才菜单下的“抓取”,开始创建抓取任务。可以默认单个网页的间隔时间和响应时间。点击“开始抓取”开始抓取。这时浏览器会自动打开一个新页面,停留几秒后会自动关闭,表示爬取完成。
点击“刷新数据”刷新数据,或点击“Sitemap bilibili_ranking - 浏览”查看数据。您可以通过“Sitemap bilibili_ranking - 将数据导出为 CSV”将其下载为 CSV 文件。
▲bilibili排行榜
用 Excel 打开它。由于“Web Scraper”抓取的内容是乱序的,所以需要对“综合得分”进行降序排序,才能恢复原来排行榜的结果。
9、带有漂亮浏览器外壳的网页生成工具
输入任意 URL 生成带有 mac/win 风格的浏览器 shell 的图像
10、9 合 1 免费社交媒体分析工具
最强大的工具往往是最后出现的。Socialbakers 本身是一个强大的付费工具,但它提供了 9 个非常值得使用的免费工具。我们将一一介绍:
1)个人网上商城模板
2)网红搜索(只能看到部分数据)
3)网红标签搜索工具
4)facebook专页及竞争对手业绩分析报告
5)比较 Instagram 个人资料和竞争对手的影响力分析报告
6)比较 Instagram 个人资料和竞争对手的影响者分析报告
7)facebook 广告影响预测工具
8)facebook网红对比分析工具
9)Socialbakers 关于社会客户关怀的最新数据
网页音频抓取(总不能手工去网页源码吧?担心Python提供了许多库来帮助)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-06 05:27
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬取它相当于访问该页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,从而使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
爬虫概述
简单来说,爬虫是一个自动程序,它获取网页并提取和保存信息,如下所述。
1.获取网页
爬虫首先要做的是获取网页,这里是网页的源代码。源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如urllib、requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
2.提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
3.保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL和MongoDB,或者保存到远程服务器,比如使用SFTP操作。
4.自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们对应的是HTML代码,而最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据,爬虫就可以爬取。
页面的 JavaScript 渲染
有时候,当我们用 urllib 或者 requests 爬取网页时,得到的源代码其实和我们在浏览器中看到的不一样。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
This is a Demo
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开这个页面时,会先加载HTML内容,然后浏览器会发现里面已经引入了一个app.js文件,然后再去请求这个文件。获取文件后,它将执行 JavaScript 代码,JavaScript 更改 HTML 中的节点,向其中添加内容,最终得到一个完整的页面。
但是当用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载这个 JavaScript 文件,所以我们在浏览器中看不到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何用 采集JavaScript 渲染网页。
本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。
【上篇】《从零开始Python爬虫》2.2小白必备的网页基础知识 查看全部
网页音频抓取(总不能手工去网页源码吧?担心Python提供了许多库来帮助)
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬取它相当于访问该页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,从而使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
爬虫概述
简单来说,爬虫是一个自动程序,它获取网页并提取和保存信息,如下所述。
1.获取网页
爬虫首先要做的是获取网页,这里是网页的源代码。源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如urllib、requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
2.提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
3.保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL和MongoDB,或者保存到远程服务器,比如使用SFTP操作。
4.自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们对应的是HTML代码,而最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据,爬虫就可以爬取。
页面的 JavaScript 渲染
有时候,当我们用 urllib 或者 requests 爬取网页时,得到的源代码其实和我们在浏览器中看到的不一样。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
This is a Demo
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开这个页面时,会先加载HTML内容,然后浏览器会发现里面已经引入了一个app.js文件,然后再去请求这个文件。获取文件后,它将执行 JavaScript 代码,JavaScript 更改 HTML 中的节点,向其中添加内容,最终得到一个完整的页面。
但是当用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载这个 JavaScript 文件,所以我们在浏览器中看不到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何用 采集JavaScript 渲染网页。
本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。
【上篇】《从零开始Python爬虫》2.2小白必备的网页基础知识
网页音频抓取(4KYouTubeto提取YouTube或其他视频网站中的音频工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2022-02-04 19:25
4K YouTube to MP3 是一种从 YouTube 或其他视频中提取音频的工具 网站。4K YouTube 是一款通过从 YouTube、Vimeo、Facebook 和其他在线视频中提取音频来创建 MP3 文件的软件。没有复杂的设置,只有干净、简单、实用的界面。该软件使用方便:在浏览器中,复制并粘贴刚才视频链接的URL,就大功告成了。这是一个免费的 YouTube 到 MP3 转换器!随时随地享受您的音频,当然,即使您处于离线状态!
软件功能
从视频中提取音频并保存为 MP3、M4A 或 Ogg 高质量。
下载完整的 YouTube 播放列表或频道并生成 m3u 文件。
传输曲目会自动下载到 iTunes 中并上传到您的 iPhone 或 iPod。
听音乐是通过本地内置的音乐播放器。
从 SoundCloud、Vimeo、Flickr 和 Dailymotion 视频中下载和提取音轨。
从 YouTube 下载有声读物。
甚至从嵌入在 HTML 页面中的视频中提取音轨。
在您喜欢的 PC、Mac 或 Linux 操作系统上使用 4K 视频格式。
软件功能
1、界面简洁干净,没有复杂的设置,使用方便;
2、好用,打开视频网页,复制视频链接,网页音频提取软件可以抓取地址进行提取;
3、提取完成后,即使离线也能欣赏您的音频。 查看全部
网页音频抓取(4KYouTubeto提取YouTube或其他视频网站中的音频工具)
4K YouTube to MP3 是一种从 YouTube 或其他视频中提取音频的工具 网站。4K YouTube 是一款通过从 YouTube、Vimeo、Facebook 和其他在线视频中提取音频来创建 MP3 文件的软件。没有复杂的设置,只有干净、简单、实用的界面。该软件使用方便:在浏览器中,复制并粘贴刚才视频链接的URL,就大功告成了。这是一个免费的 YouTube 到 MP3 转换器!随时随地享受您的音频,当然,即使您处于离线状态!
软件功能
从视频中提取音频并保存为 MP3、M4A 或 Ogg 高质量。
下载完整的 YouTube 播放列表或频道并生成 m3u 文件。
传输曲目会自动下载到 iTunes 中并上传到您的 iPhone 或 iPod。
听音乐是通过本地内置的音乐播放器。
从 SoundCloud、Vimeo、Flickr 和 Dailymotion 视频中下载和提取音轨。
从 YouTube 下载有声读物。
甚至从嵌入在 HTML 页面中的视频中提取音轨。
在您喜欢的 PC、Mac 或 Linux 操作系统上使用 4K 视频格式。
软件功能
1、界面简洁干净,没有复杂的设置,使用方便;
2、好用,打开视频网页,复制视频链接,网页音频提取软件可以抓取地址进行提取;
3、提取完成后,即使离线也能欣赏您的音频。
网页音频抓取(有时候简单易用好上手的方法,一起来看下吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-29 06:06
在我们的日常工作和日常学习中,有时候一个视频除了音频还值得保留,而图片毫无意义,我们可以通过提取视频中的音频来提取音频,那么如何提取呢,可能有朋友说,我们可以用pr提取,但其实很多小伙伴都不会用,所以今天给大家分享两个好用又好用的方法,一起来看看吧!
方法一:使用风云视频转换器提取音频
风云视频转换器可以将视频转换成各种格式的视频文件,我们可以使用风云视频转换器将视频转换成MP3音频。首先需要下载这个软件,在浏览器或者软件管家中搜索就可以找到。
运行工具,进入主页面,主页面有各种视频处理功能,点击【视频转换】跳转到页面中的下一页!
点击页面中间的【添加文件】,将我们需要提取音频文件的视频添加到页面中,或者点击“添加文件夹”批量导入视频进行提取。
接下来,在页面底部,点击【输出格式】,在【音频】中选择【mp3】格式,同时设置音频质量。
然后我们设置文件输出路径,在输出目录后面查看输出目录。点击【全部转换】,从导入的视频中提取 MP3 音频!
方法二:使用风云音频处理大师从视频中提取音频
风云音频处理大师也可以提取视频。我们先搜索网页上的工具,下载到电脑上。
2、然后我们打开软件,在主界面选择点击音频提取功能。
3、接下来,点击“添加文件”,将需要提取音频的视频文件添加到软件中。
4、添加完视频后,我们需要圈出音频片段,选择音频片段范围,然后点击确定添加到输出列表中。
5、 接下来查看输出目录,点击开始处理,就可以解压视频和音频了。
6、解压完成后,点击打开文件,找到需要的音频文件。
7、我们点击属性查看。
好的!以上就是小编今天分享的如何从视频中提取音频文件的具体操作步骤!是不是很简单好用,有需要的朋友可以使用~ 查看全部
网页音频抓取(有时候简单易用好上手的方法,一起来看下吧!)
在我们的日常工作和日常学习中,有时候一个视频除了音频还值得保留,而图片毫无意义,我们可以通过提取视频中的音频来提取音频,那么如何提取呢,可能有朋友说,我们可以用pr提取,但其实很多小伙伴都不会用,所以今天给大家分享两个好用又好用的方法,一起来看看吧!
方法一:使用风云视频转换器提取音频
风云视频转换器可以将视频转换成各种格式的视频文件,我们可以使用风云视频转换器将视频转换成MP3音频。首先需要下载这个软件,在浏览器或者软件管家中搜索就可以找到。
运行工具,进入主页面,主页面有各种视频处理功能,点击【视频转换】跳转到页面中的下一页!
点击页面中间的【添加文件】,将我们需要提取音频文件的视频添加到页面中,或者点击“添加文件夹”批量导入视频进行提取。
接下来,在页面底部,点击【输出格式】,在【音频】中选择【mp3】格式,同时设置音频质量。
然后我们设置文件输出路径,在输出目录后面查看输出目录。点击【全部转换】,从导入的视频中提取 MP3 音频!
方法二:使用风云音频处理大师从视频中提取音频
风云音频处理大师也可以提取视频。我们先搜索网页上的工具,下载到电脑上。
2、然后我们打开软件,在主界面选择点击音频提取功能。
3、接下来,点击“添加文件”,将需要提取音频的视频文件添加到软件中。
4、添加完视频后,我们需要圈出音频片段,选择音频片段范围,然后点击确定添加到输出列表中。
5、 接下来查看输出目录,点击开始处理,就可以解压视频和音频了。
6、解压完成后,点击打开文件,找到需要的音频文件。
7、我们点击属性查看。
好的!以上就是小编今天分享的如何从视频中提取音频文件的具体操作步骤!是不是很简单好用,有需要的朋友可以使用~
网页音频抓取(白又白i--对你有用的话记得三连呦! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-23 00:15
)
大家好,我是白人。
如果对你有用,记得加三倍!
性能展示
抓取目标
网址:酷我音乐
工具使用
开发工具:pycharm
开发环境:python3.7、Windows10
使用工具包:requests, re
项目思路分析
找到需要解析的列表数据
随意点击一首歌曲,获取音乐的详细数据,通过抓包获取音乐播放数据
找到MP3的数据提交地址,mp3数据来自这个url地址
提交数据的网址:
/yy/index.ph…
比较多个网址数据,看看哪些参数需要自己修改
有3个url数据变化
_ 可以清楚的看到是时间戳。需要获取对应的hash和album_id值。到首页找到对应的歌曲id数据。发现数据来源于网页源代码
歌曲数据均来自网页源代码
梳理整体思路:简单源码分析
本章内容仅供学习,请勿用于其他用途! ! ! ! !
Pythonimport requestsimport reimport timedef Tools(url): headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.70' } response = requests.get(url, headers=headers) return responsedef Save(name, url): mp3 = Tools(url).content # 请求mp3地址链接 返回格式是16进制 f = open('./kugou/{}.mp3'.format(name), 'wb') # w 文件存在就写入 不存在就会创建 b进制读写 f.write(mp3) f.close() print('{}下载完成....'.format(name))url = 'https://www.kugou.com/yy/html/rank.html'response = Tools(url).textalbum_id = re.findall(r'"album_id":(\d*?),', response) # idHash = re.findall(r'"Hash":"(.*?)",', response) # hashfor a, h in zip(album_id, Hash): # 生成时间戳 time1 = int(time.time() * 1000) # 包含歌曲下载地址的url urls = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash={}&dfid=0zlWqK0UWNFa0weUnX0hjlFa&mid=f79511e2e86914b99e351c42ba1f8bc7&platid=4&album_id={}&_={}'.format(h, a, time1) response1 = Tools(urls).json() audio_name = response1['data']['audio_name'].split('-')[1] play_url = response1['data']['play_url'] Save(audio_name, play_url)复制代码
查看全部
网页音频抓取(白又白i--对你有用的话记得三连呦!
)
大家好,我是白人。
如果对你有用,记得加三倍!
性能展示
抓取目标
网址:酷我音乐
工具使用
开发工具:pycharm
开发环境:python3.7、Windows10
使用工具包:requests, re
项目思路分析
找到需要解析的列表数据
随意点击一首歌曲,获取音乐的详细数据,通过抓包获取音乐播放数据
找到MP3的数据提交地址,mp3数据来自这个url地址
提交数据的网址:
/yy/index.ph…
比较多个网址数据,看看哪些参数需要自己修改
有3个url数据变化
_ 可以清楚的看到是时间戳。需要获取对应的hash和album_id值。到首页找到对应的歌曲id数据。发现数据来源于网页源代码
歌曲数据均来自网页源代码
梳理整体思路:简单源码分析
本章内容仅供学习,请勿用于其他用途! ! ! ! !
Pythonimport requestsimport reimport timedef Tools(url): headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.70' } response = requests.get(url, headers=headers) return responsedef Save(name, url): mp3 = Tools(url).content # 请求mp3地址链接 返回格式是16进制 f = open('./kugou/{}.mp3'.format(name), 'wb') # w 文件存在就写入 不存在就会创建 b进制读写 f.write(mp3) f.close() print('{}下载完成....'.format(name))url = 'https://www.kugou.com/yy/html/rank.html'response = Tools(url).textalbum_id = re.findall(r'"album_id":(\d*?),', response) # idHash = re.findall(r'"Hash":"(.*?)",', response) # hashfor a, h in zip(album_id, Hash): # 生成时间戳 time1 = int(time.time() * 1000) # 包含歌曲下载地址的url urls = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash={}&dfid=0zlWqK0UWNFa0weUnX0hjlFa&mid=f79511e2e86914b99e351c42ba1f8bc7&platid=4&album_id={}&_={}'.format(h, a, time1) response1 = Tools(urls).json() audio_name = response1['data']['audio_name'].split('-')[1] play_url = response1['data']['play_url'] Save(audio_name, play_url)复制代码
网页音频抓取( 如何嵌入视频和音频在网页里嵌入HTML5音频播放器和视频播放器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-22 22:02
如何嵌入视频和音频在网页里嵌入HTML5音频播放器和视频播放器)
HTML5视频/音频的使用介绍
« 上一章
下一章 »
HTML5中引入的新标签,实现了HTML对视频播放和音频播放的原生支持,有了这个原生的HTML5视频播放器/音频播放器,我们不再需要flash技术,可以直接将视频/音频嵌入到网页中。
如何嵌入视频和音频
在网页中嵌入 HTML5 音频播放器和视频播放器的方法非常简单:
Your browser does not support the video element.
上面的示例展示了如何播放视频文件并公开视频播放控件。
下面是一个如何在 HTML 页面中嵌入音频音频的示例:
<p>Your browser does not support the audio element.
</p>
这里的 src 属性可以填写音视频 URL 或本地文件。
<p>Your browser does not support the audio element
</p>
这里是和两个标签上的控件属性的含义:
这里的 preload 属性是用来缓存大文件的。它具有三个可选值:
为了兼容各种浏览器对不同媒体类型的支持,我们可以使用多个元素来提供多种不同的媒体类型。例如:
Your browser does not support the video element.
支持 Ogg 格式视频流的浏览器可以播放 Ogg 文件。如果不支持,可以播放 MPEG-4 文件。要查看浏览器对各种媒体类型的支持,请查看此处。
我们还可以指定用于播放的编解码器(codecs);这使浏览器可以更准确地了解如何播放提供的视频:
Your browser does not support the video element.
上面,我们指定此视频需要使用 Dirac 和 Speex 编解码器。如果浏览器支持 Ogg 格式,但没有指定编解码器,则不会加载视频。
如果没有提供 type 属性,浏览器会向服务器询问媒体类型,看是否支持;如果没有,浏览器将转到下一个源属性。
使用 JavaScript 控制视频/音频播放
一旦视频文件被正确嵌入到 HTML 页面中,我们就可以使用控制它的 JavaScript 部分来获取其播放信息。例如,要使用 JavaScript 开始视频播放:
var v = document.getElementsByTagName("video")[0];
v.play();
使用 JavaScript 控制 HTML5 视频播放器的播放、暂停、快进、快退、音量等。
播放
暂停
降低音量
提高音量
停止下载视频文件
虽然我们可以使用 pause() 来停止播放视频文件,但浏览器不会停止下载媒体文件,除非它达到一定的缓存大小。
以下是告诉您的浏览器停止下载视频文件的方法:
var mediaElement = document.getElementById("myMediaElementID");
mediaElement.pause();
mediaElement.src='';
//或
mediaElement.removeAttribute("src");
通过删除 src 属性(或将其设置为空值),这将停止文件的网络下载。
设置播放时间点定位
我们可以通过设置 currentTime 属性来指定视频在特定时间、分钟和秒开始播放。
我们可以通过 seekable 属性获取视频的有效播放时间范围。它返回一个 TimeRanges 对象,告诉您有效的开始和结束时间。
var mediaElement = document.getElementById('mediaElementID');
mediaElement.seekable.start(0); // 返回开始时间 (秒)
mediaElement.seekable.end(0); // 返回结束时间 (秒)
mediaElement.currentTime = 122; // 定位到第 122 秒播放
mediaElement.played.end(0); // 返回已经播放的时间长度(秒)
设置播放范围
在网页中嵌入视频/音频文件时,或元素允许我们提供一些额外的信息来指定播放的时间段。执行此操作的方法是使用 ("#") 格式信息跟随媒体文件。
其具体语法如下:
#t=[开始时间][,结束时间]
时间可以用秒表示,或者您可以提供“时:分:秒”格式的时间(例如 2:05:01)。/p>
例子:
#t=10,20 查看全部
网页音频抓取(
如何嵌入视频和音频在网页里嵌入HTML5音频播放器和视频播放器)
HTML5视频/音频的使用介绍
« 上一章
下一章 »
HTML5中引入的新标签,实现了HTML对视频播放和音频播放的原生支持,有了这个原生的HTML5视频播放器/音频播放器,我们不再需要flash技术,可以直接将视频/音频嵌入到网页中。
如何嵌入视频和音频
在网页中嵌入 HTML5 音频播放器和视频播放器的方法非常简单:
Your browser does not support the video element.
上面的示例展示了如何播放视频文件并公开视频播放控件。
下面是一个如何在 HTML 页面中嵌入音频音频的示例:
<p>Your browser does not support the audio element.
</p>
这里的 src 属性可以填写音视频 URL 或本地文件。
<p>Your browser does not support the audio element
</p>
这里是和两个标签上的控件属性的含义:
这里的 preload 属性是用来缓存大文件的。它具有三个可选值:
为了兼容各种浏览器对不同媒体类型的支持,我们可以使用多个元素来提供多种不同的媒体类型。例如:
Your browser does not support the video element.
支持 Ogg 格式视频流的浏览器可以播放 Ogg 文件。如果不支持,可以播放 MPEG-4 文件。要查看浏览器对各种媒体类型的支持,请查看此处。
我们还可以指定用于播放的编解码器(codecs);这使浏览器可以更准确地了解如何播放提供的视频:
Your browser does not support the video element.
上面,我们指定此视频需要使用 Dirac 和 Speex 编解码器。如果浏览器支持 Ogg 格式,但没有指定编解码器,则不会加载视频。
如果没有提供 type 属性,浏览器会向服务器询问媒体类型,看是否支持;如果没有,浏览器将转到下一个源属性。
使用 JavaScript 控制视频/音频播放
一旦视频文件被正确嵌入到 HTML 页面中,我们就可以使用控制它的 JavaScript 部分来获取其播放信息。例如,要使用 JavaScript 开始视频播放:
var v = document.getElementsByTagName("video")[0];
v.play();
使用 JavaScript 控制 HTML5 视频播放器的播放、暂停、快进、快退、音量等。
播放
暂停
降低音量
提高音量
停止下载视频文件
虽然我们可以使用 pause() 来停止播放视频文件,但浏览器不会停止下载媒体文件,除非它达到一定的缓存大小。
以下是告诉您的浏览器停止下载视频文件的方法:
var mediaElement = document.getElementById("myMediaElementID");
mediaElement.pause();
mediaElement.src='';
//或
mediaElement.removeAttribute("src");
通过删除 src 属性(或将其设置为空值),这将停止文件的网络下载。
设置播放时间点定位
我们可以通过设置 currentTime 属性来指定视频在特定时间、分钟和秒开始播放。
我们可以通过 seekable 属性获取视频的有效播放时间范围。它返回一个 TimeRanges 对象,告诉您有效的开始和结束时间。
var mediaElement = document.getElementById('mediaElementID');
mediaElement.seekable.start(0); // 返回开始时间 (秒)
mediaElement.seekable.end(0); // 返回结束时间 (秒)
mediaElement.currentTime = 122; // 定位到第 122 秒播放
mediaElement.played.end(0); // 返回已经播放的时间长度(秒)
设置播放范围
在网页中嵌入视频/音频文件时,或元素允许我们提供一些额外的信息来指定播放的时间段。执行此操作的方法是使用 ("#") 格式信息跟随媒体文件。
其具体语法如下:
#t=[开始时间][,结束时间]
时间可以用秒表示,或者您可以提供“时:分:秒”格式的时间(例如 2:05:01)。/p>
例子:
#t=10,20
网页音频抓取(网站优化:TAG标签好处多你的网站用了吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-19 05:02
)
相关话题
git 拉取代码到本地
2/7/202018:02:55
git拉码到本地的方法是:先打开git命令窗口,输入命令【gitclonegithub仓库地址】;然后回车拉码到本地仓库。第一步:拉取远程代码 gitclone
如何善用博客或网站上的标签?
28/1/2010 08:55:00
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大网站已经熟练使用TAG标签了,今天想和大家讨论这个话题,因为很多中小网站经常忽略TAG标签的作用也不知道TAG标签能给网站带来什么好处,今天就和大家详细分享一下。
标签——push的基石和实现
18/5/2018 14:26:49
在任何一个网站上购物,不管是看文章,听音乐还是看视频,都会有一些相关的推送,还有对豆瓣、个人账号等社交网络感兴趣的朋友们网站 ,根据你在网站中的行为,推送越来越符合你的脾胃,这背后的英雄是Tag。
网站优化简化代码
21/11/2012 16:06:00
精简代码有很多好处。首先,从SEO理解的角度来看,搜索引擎预处理的第一步是提取文本内容。因此,我们应该尽量降低搜索引擎提取文本内容的难度,简化代码,从而提高文本内容的占比。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
2007 年 16 月 11 日 05:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
网站标签在优化中有什么用?
28/7/202018:07:22
tag标签是一种可以自行定义的关键词,比分类标签更具体准确,可以概括文章的主要内容。那么网站的优化中使用tag标签有什么用呢?
在 GTM 中指定标签依赖关系
26/10/201209:40:00
GoogleTagManager 方便了网站 分析师的工作,我一直认为它有一个局限性:Container 中的标签是异步加载的,标签之间没有顺序,所以如果之前有的标签有依赖关系,那就是如果Btag 必须在 ATag 执行后执行,才有效。
Tag标签SEO优化让网站快速排名收录!
2017 年 10 月 31 日 15:03:00
tag标签的作用:第一:提升用户体验和PV点击率。第二:增加内链有利于网页权重的相互传递。第三:增加百度收录,提升关键词的排名。为什么标签页的排名比 文章 页面好?原因是标签页关键词与文章页形成内部竞争,标签页接收到的内链远多于文章页,这些内链甚至是高度相关的,所以这是正常的
WP博客专栏,TAG URL链接加反斜杠代码
29/6/2012 14:22:00
WP博客的默认栏目、TAG、分页等url链接后面没有反斜杠“/”,但是一些SEOER常说没有反斜杠的URL不利于SEO优化。其实不管有没有反斜杠,搜索引擎都会一直收录,所以只要把URL规范化统一起来,对SE是有好处的。
网站优化指南:标签优化技巧分析
19/4/2010 10:51:00
如今,所有主要的cms 和博客系统都添加了标签。tag标签的意思是将相关的关键词聚合在一起。现在网站管理员使用 Tag 标签。标签无非就是两点 1:增强搜索引擎地收录。2:有利于用户体验。
关于webhooks服务器自动拉取代码phpthinkphp6
24/6/202118:16:07
thinkphp教程栏目介绍“webhooks服务器自动拉码phpthinkphp6”。Github准备1.在仓库设置中添加webhooks 以私有仓库为例:1.创建仓库后,点击设置。设置 w
查看全部
网页音频抓取(网站优化:TAG标签好处多你的网站用了吗?
)
相关话题
git 拉取代码到本地
2/7/202018:02:55
git拉码到本地的方法是:先打开git命令窗口,输入命令【gitclonegithub仓库地址】;然后回车拉码到本地仓库。第一步:拉取远程代码 gitclone
如何善用博客或网站上的标签?
28/1/2010 08:55:00
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大网站已经熟练使用TAG标签了,今天想和大家讨论这个话题,因为很多中小网站经常忽略TAG标签的作用也不知道TAG标签能给网站带来什么好处,今天就和大家详细分享一下。
标签——push的基石和实现
18/5/2018 14:26:49
在任何一个网站上购物,不管是看文章,听音乐还是看视频,都会有一些相关的推送,还有对豆瓣、个人账号等社交网络感兴趣的朋友们网站 ,根据你在网站中的行为,推送越来越符合你的脾胃,这背后的英雄是Tag。
网站优化简化代码
21/11/2012 16:06:00
精简代码有很多好处。首先,从SEO理解的角度来看,搜索引擎预处理的第一步是提取文本内容。因此,我们应该尽量降低搜索引擎提取文本内容的难度,简化代码,从而提高文本内容的占比。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
2007 年 16 月 11 日 05:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
网站标签在优化中有什么用?
28/7/202018:07:22
tag标签是一种可以自行定义的关键词,比分类标签更具体准确,可以概括文章的主要内容。那么网站的优化中使用tag标签有什么用呢?
在 GTM 中指定标签依赖关系
26/10/201209:40:00
GoogleTagManager 方便了网站 分析师的工作,我一直认为它有一个局限性:Container 中的标签是异步加载的,标签之间没有顺序,所以如果之前有的标签有依赖关系,那就是如果Btag 必须在 ATag 执行后执行,才有效。
Tag标签SEO优化让网站快速排名收录!
2017 年 10 月 31 日 15:03:00
tag标签的作用:第一:提升用户体验和PV点击率。第二:增加内链有利于网页权重的相互传递。第三:增加百度收录,提升关键词的排名。为什么标签页的排名比 文章 页面好?原因是标签页关键词与文章页形成内部竞争,标签页接收到的内链远多于文章页,这些内链甚至是高度相关的,所以这是正常的
WP博客专栏,TAG URL链接加反斜杠代码
29/6/2012 14:22:00
WP博客的默认栏目、TAG、分页等url链接后面没有反斜杠“/”,但是一些SEOER常说没有反斜杠的URL不利于SEO优化。其实不管有没有反斜杠,搜索引擎都会一直收录,所以只要把URL规范化统一起来,对SE是有好处的。
网站优化指南:标签优化技巧分析
19/4/2010 10:51:00
如今,所有主要的cms 和博客系统都添加了标签。tag标签的意思是将相关的关键词聚合在一起。现在网站管理员使用 Tag 标签。标签无非就是两点 1:增强搜索引擎地收录。2:有利于用户体验。
关于webhooks服务器自动拉取代码phpthinkphp6
24/6/202118:16:07
thinkphp教程栏目介绍“webhooks服务器自动拉码phpthinkphp6”。Github准备1.在仓库设置中添加webhooks 以私有仓库为例:1.创建仓库后,点击设置。设置 w
网页音频抓取(私信小编001即可获取大量Python学习资料!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-29 08:07
今天,我们就打开爬虫的“工具箱”,把涉及到的技术盲点放在灯光下,让大家看得一清二楚。下面,本文将从这个角度来谈谈爬虫这个熟悉又陌生的技术。
“把你手里的密码放下,小心被抓住。”
最近程序员圈里不乏这样的笑话。
原因是近期司法部门对多家涉及爬虫技术的公司进行了立案调查。近日,51张信用卡被查处,曝光了暴力催收背后的丑闻:非法使用爬虫技术抓取个人隐私数据。
私信小编001可以获得大量Python学习资料!
一时间,“爬虫类”成为众矢之的。有的公司紧急下架爬虫类招聘信息,给大数据风控和人工智能从业者造成了不小的恐慌,又掉了几根头发。
事实上,大多数人都听说过爬虫,认为爬虫是在爬取其他网站的东西,窃取数据。甚至有人认为,只要有爬虫,任何数据都可以获得。
今天,我们就打开爬虫的“工具箱”,把涉及到的技术盲点放在灯光下,让大家看得一清二楚。下面,本文将从这个角度来谈谈爬虫这个熟悉又陌生的技术。
爬虫技术原理
搜索引擎在互联网上采集
信息的主要手段是网络爬虫(又称网络蜘蛛、网络机器人)。它是一种“自动浏览互联网”的程序,根据一定的规则,自动抓取互联网信息,如:网页、各种文档、图片、音频、视频等,搜索引擎通过索引技术将这些信息组织起来,并快速根据用户查询提供搜索结果。
想象一下,当我们浏览网页时,我们在做什么?
一般情况下,您首先会使用浏览器打开一个网站的首页,搜索页面上感兴趣的内容,然后点击该网站或页面上其他网站的链接,跳转到一个新的页面,阅读内容等。来回。如下所示:
图中带圆角的虚线矩形代表一个网站,每个实心矩形代表一个网页。可以看出,每个网站一般都以首页作为入口,链接到几个、几万甚至几千万个内部网页。同时,这些网页往往链接到许多外部网站。例如,某用户从苏宁财经的网页开始,浏览并找到PP视频的链接,点击跳转到PP视频首页,作为一名体育迷,在体育频道找到了相关的新浪微博内容,再次点击来到了PP视频主页。微博页面继续阅读,从而形成一条路径。如果您提供所有可能的路径,您将看到一个网络结构。
网络爬虫模拟人们浏览网页的行为,但用程序代替人工操作,在网页上进行广度和深度的遍历。如果将互联网上的网页或网站理解为节点,则大量网页或网站通过超链接形成网络结构。爬虫通过遍历网页上的链接从一个节点跳转到下一个节点,就像在巨大的网络上爬行一样,但它比人类更快,跳转的节点更全面,因此被形象地称为网络爬虫或网络蜘蛛。
爬行动物的历史
网络爬虫最早的用途是服务于搜索引擎的数据采集,现代意义上的搜索引擎的鼻祖是阿尔奇于1990年由加拿大麦吉尔大学的学生艾伦·埃姆塔奇(Alan Emtage)发明的。
人们使用FTP服务器来共享通信资源,大量的文件分散在各个FTP主机上,查询非常不方便。因此,他开发了一个系统,可以通过文件名搜索文件,定期采集
和分析FTP服务器上的文件名信息,并自动为这些文件建立索引。其工作原理与目前的搜索引擎非常接近,依靠脚本自动搜索分散在各个FTP主机上的文件,然后将相关信息编入索引,以一定的表达方式供用户查询。
世界上第一个网络爬虫“wwwwanderer”(“wwwwanderer”)是麻省理工学院的学生Matthew Gray于1993年编写的,一开始只是用来统计互联网上的服务器数量,后来发展到能够通过它检索网站域名。
随着互联网的快速发展,检索所有新网页变得越来越困难。因此,一些程序员在“网络漫游者”的基础上,改进了传统“蜘蛛”程序的工作原理。这个想法是因为所有网页都可能有到其他网站的链接,所以可以从跟踪到网站的链接开始检索整个互联网。
此后,无数的搜索引擎让爬虫变得越来越复杂,逐渐向多策略、负载均衡、大规模增量爬取的方向发展。爬虫工作的结果是搜索引擎可以遍历链接的网页,甚至可以通过“网页快照”功能访问已删除的网页。
网络爬虫的礼仪之一:robots.txt文件
每个行业都有其行为准则,它成为行为准则或行为准则。例如,如果您是某个协会的成员,则必须遵守该协会的行为准则。如果您违反行为准则,您将被踢出局。
最简单的例子就是你加入的很多微信群,一般的站长都会要求不要私下发广告。未经允许发广告会被直接踢出群,不过发个红包也没关系。这是行为准则。
爬虫也有行为准则。早在1994年,搜索引擎技术才刚刚兴起。当时,初创的搜索引擎公司,如AltaVista、DogPile,利用爬虫技术对整个互联网的资源进行采集,与雅虎等资源分类网站展开激烈竞争。随着互联网搜索规模的增长,爬虫采集
信息的能力也在飞速发展,网站开始考虑对搜索引擎爬取的信息进行限制,于是robots.txt应运而生,成为网络中的“君子协定”。爬虫世界。
robots.txt 文件是业界的通行做法,并非强制约束。robots.txt的格式如下:
在上面的 robots.txt 示例中,禁止所有爬虫访问网站上的任何内容。但是谷歌的爬虫机器人可以访问除私人位置以外的所有内容。如果网站上没有robots.txt,则认为默认允许爬虫抓取所有信息。如果robots.txt被限制访问,而爬虫不遵守,这不是技术实现上的简单问题。
礼仪二:控制爬行吞吐量
伪造谷歌搜索引擎的爬虫用于对网站进行 DDoS 攻击并使网站瘫痪。近年来,恶意爬虫引发的DDoS攻击不断增多,给大数据行业投下了爬虫的阴影。因为背后的恶意攻击者往往拥有更复杂、更专业的技术,可以绕过各种防御机制,使得防范此类攻击的难度更大。
礼仪三:做一个优雅的爬行者
优雅的履带车背后,必定有一个文明的人,或者文明的团队。他们会考虑自己编写的爬虫程序是否符合robots.txt协议,是否会影响被爬取的网站的性能,如何才能不侵犯知识产权人的权益和非常重要的个人隐私数据。
由于能力差异,并不是每个爬虫团队都能考虑这些问题。2018年,欧盟的《通用数据保护条例》(General Data Protection Regulation)发布了严格的数据保护指令。2019年5月28日,国家互联网信息办公室发布的《数据安全管理办法》(征求意见稿)对爬虫和个人信息安全做出了非常严格的规定。例如:
事实上,我国于2017年6月1日实施的《中华人民共和国网络安全法》第四章第四十一条和第四十四条,已经对个人隐私信息的采集
和使用作出了明确规定。与爬虫直接相关。
法律制度的颁布明确了技术的界限,技术的无罪不能作为技术实施者为自己辩解的理由。爬虫在满足自身需求的同时,必须严格遵守行为准则和法律法规。
各种反爬虫技术介绍
为了保护自己的合法权益不受恶意侵害,很多网站和APP都应用了大量的反爬技术。这使得爬虫技术衍生出反爬虫技术,如各种滑动拼图、文字点击、图标点击等验证码破解,相互促进,相互发展,相互伤害。
反爬虫的关键是防止爬虫批量抓取网站内容。反爬虫技术的核心是不断改变规则和各种验证方式。
这种技术的发展更是引人入胜,甚至比DOTA之战还要精彩。在波浪形文字验证码图形的伪装色中可以看到程序员的头发。
1、图片/Flash
这是一种比较常见的防爬方法。它将关键数据转换为图片并添加水印。即使使用了OCR(Optical Character Recognition),也无法识别,以至于爬虫拿到图片就得不到任何信息。这种方式在一些早期电子商务公司的价格标签中经常看到。
2、JavaScript 混淆技术
这是爬虫程序员遇到最多的反爬方法。简而言之,它实际上是一种致盲方法,本质上是一种加密技术。许多网页中的数据是使用 JavaScript 程序动态加载的。在抓取此类网页数据时,爬虫需要了解网页是如何加载数据的。这个过程称为逆向工程。为了防止逆向工程,使用了 JavaScript 混淆技术,并添加了 JavaScript 代码进行加密,使其他人无法理解。不过这种方法属于比较简单的防爬方法,属于履带工程师调平的初级阶段。
3、验证码
验证码是一个公开的全自动程序,用于区分用户是计算机还是人。也是我们经常遇到的一种网站访问验证的方法。它主要分为以下几种:
(1)输入类型验证码
这是最常见的。通过用户输入图片中的字母、数字、汉字等字符进行验证。
图中CAPTCHA的全称是(Completely Automated Public Turing test to tell Computers and Humans Apart),中文翻译为:自动图灵测试以区分计算机和人类。实现这一点的方法很简单,就是提出一个计算机无法回答但人类可以回答的问题。然而,目前的爬虫往往使用深度学习技术来破解这样的验证码,这样的图灵测试已经失效。
(2)滑块类型验证码
鉴于输入式图形验证码的缺点,容易被破解,有时还无法被人类识别。滑块验证码诞生了。这种验证码操作简单,破解难度大,迅速走红。破解滑块验证码有两大难点:一是要知道图形缺口在哪里,也就是要知道滑块在哪里滑动;另一种是模仿人类的滑动手势。这样的验证码增加了一定的难度,也给爬虫世界增添了不少乐趣。一时间出现了大量破解滑块验证码的技术。
(3)点击式图形验证和图标选择
图文验证是提醒用户点击图片中同一个词的位置进行文本验证。
图标选择是给出一组图片,根据需要点击其中一个或多个。
两种原理类似,只不过一种是给出文字,点击图片中的文字;另一个给出图片并点击与内容匹配的图片。这两种方式的共同点是体验不佳,广受诟病。
(4)手机验证码
对于一些重要敏感信息的访问,网站或APP一般会提供填写手机验证码的要求,手机接受网站发送的验证码,以便进一步访问。这种方法更利于数据隐私保护。
4、账号密码登录
网站可以通过账号登录来限制爬虫的访问权限。个人在使用很多网站服务时,一般都需要注册一个账号。使用时,他们需要使用帐户密码登录才能继续使用该服务。网站可以使用用户浏览器的cookie来识别用户的身份,并通过用户本地浏览器中存储的加密cookie数据跟踪用户的访问会话。这一般是作为之前防爬方法的补充。
履带技术的发展方向
传统网络爬虫最大的应用场景是搜索引擎,普通企业更多的是针对网站或者应用。后来随着网络数据分析的需要,以及互联网上层出不穷的舆论事件,对网络爬虫的需求量很大,主要采集的对象是新闻信息。
近年来,由于大数据处理和数据挖掘技术的发展,数据资产价值的概念深入人心,爬虫技术得到了更广泛深入的发展,采集
对象也越来越多。更丰富,高性能和并发技术指标也更高。.
围绕网络爬虫合法性的讨论依然存在,而且情况更为复杂。在目前的趋势下,很多法律问题还处于一个模糊的领域,往往取决于具体案件的影响。但是,可以肯定的是,只要有互联网,就会有网络爬虫。只有网络爬虫才能让庞大的互联网变得可搜索,让爆炸式增长的互联网更容易被访问和获取。在可预见的未来,互联网爬虫技术将不断发展。
作为人类历史上最大的知识仓库,互联网是非结构化或非标准化的。互联网上聚集了大量的文字、图片、多媒体等数据。虽然内容很有价值,但是提取知识的难度还是非常巨大的。语义互联网、知识共享等概念越来越流行,真正的语义互联网将成为网络爬虫的目标。此外,物联网技术的发展将是互联网的升级形态,也将是未来爬虫技术的发展方向。 查看全部
网页音频抓取(私信小编001即可获取大量Python学习资料!(组图))
今天,我们就打开爬虫的“工具箱”,把涉及到的技术盲点放在灯光下,让大家看得一清二楚。下面,本文将从这个角度来谈谈爬虫这个熟悉又陌生的技术。
“把你手里的密码放下,小心被抓住。”
最近程序员圈里不乏这样的笑话。
原因是近期司法部门对多家涉及爬虫技术的公司进行了立案调查。近日,51张信用卡被查处,曝光了暴力催收背后的丑闻:非法使用爬虫技术抓取个人隐私数据。
私信小编001可以获得大量Python学习资料!
一时间,“爬虫类”成为众矢之的。有的公司紧急下架爬虫类招聘信息,给大数据风控和人工智能从业者造成了不小的恐慌,又掉了几根头发。
事实上,大多数人都听说过爬虫,认为爬虫是在爬取其他网站的东西,窃取数据。甚至有人认为,只要有爬虫,任何数据都可以获得。
今天,我们就打开爬虫的“工具箱”,把涉及到的技术盲点放在灯光下,让大家看得一清二楚。下面,本文将从这个角度来谈谈爬虫这个熟悉又陌生的技术。
爬虫技术原理
搜索引擎在互联网上采集
信息的主要手段是网络爬虫(又称网络蜘蛛、网络机器人)。它是一种“自动浏览互联网”的程序,根据一定的规则,自动抓取互联网信息,如:网页、各种文档、图片、音频、视频等,搜索引擎通过索引技术将这些信息组织起来,并快速根据用户查询提供搜索结果。
想象一下,当我们浏览网页时,我们在做什么?
一般情况下,您首先会使用浏览器打开一个网站的首页,搜索页面上感兴趣的内容,然后点击该网站或页面上其他网站的链接,跳转到一个新的页面,阅读内容等。来回。如下所示:
图中带圆角的虚线矩形代表一个网站,每个实心矩形代表一个网页。可以看出,每个网站一般都以首页作为入口,链接到几个、几万甚至几千万个内部网页。同时,这些网页往往链接到许多外部网站。例如,某用户从苏宁财经的网页开始,浏览并找到PP视频的链接,点击跳转到PP视频首页,作为一名体育迷,在体育频道找到了相关的新浪微博内容,再次点击来到了PP视频主页。微博页面继续阅读,从而形成一条路径。如果您提供所有可能的路径,您将看到一个网络结构。
网络爬虫模拟人们浏览网页的行为,但用程序代替人工操作,在网页上进行广度和深度的遍历。如果将互联网上的网页或网站理解为节点,则大量网页或网站通过超链接形成网络结构。爬虫通过遍历网页上的链接从一个节点跳转到下一个节点,就像在巨大的网络上爬行一样,但它比人类更快,跳转的节点更全面,因此被形象地称为网络爬虫或网络蜘蛛。
爬行动物的历史
网络爬虫最早的用途是服务于搜索引擎的数据采集,现代意义上的搜索引擎的鼻祖是阿尔奇于1990年由加拿大麦吉尔大学的学生艾伦·埃姆塔奇(Alan Emtage)发明的。
人们使用FTP服务器来共享通信资源,大量的文件分散在各个FTP主机上,查询非常不方便。因此,他开发了一个系统,可以通过文件名搜索文件,定期采集
和分析FTP服务器上的文件名信息,并自动为这些文件建立索引。其工作原理与目前的搜索引擎非常接近,依靠脚本自动搜索分散在各个FTP主机上的文件,然后将相关信息编入索引,以一定的表达方式供用户查询。
世界上第一个网络爬虫“wwwwanderer”(“wwwwanderer”)是麻省理工学院的学生Matthew Gray于1993年编写的,一开始只是用来统计互联网上的服务器数量,后来发展到能够通过它检索网站域名。
随着互联网的快速发展,检索所有新网页变得越来越困难。因此,一些程序员在“网络漫游者”的基础上,改进了传统“蜘蛛”程序的工作原理。这个想法是因为所有网页都可能有到其他网站的链接,所以可以从跟踪到网站的链接开始检索整个互联网。
此后,无数的搜索引擎让爬虫变得越来越复杂,逐渐向多策略、负载均衡、大规模增量爬取的方向发展。爬虫工作的结果是搜索引擎可以遍历链接的网页,甚至可以通过“网页快照”功能访问已删除的网页。
网络爬虫的礼仪之一:robots.txt文件
每个行业都有其行为准则,它成为行为准则或行为准则。例如,如果您是某个协会的成员,则必须遵守该协会的行为准则。如果您违反行为准则,您将被踢出局。
最简单的例子就是你加入的很多微信群,一般的站长都会要求不要私下发广告。未经允许发广告会被直接踢出群,不过发个红包也没关系。这是行为准则。
爬虫也有行为准则。早在1994年,搜索引擎技术才刚刚兴起。当时,初创的搜索引擎公司,如AltaVista、DogPile,利用爬虫技术对整个互联网的资源进行采集,与雅虎等资源分类网站展开激烈竞争。随着互联网搜索规模的增长,爬虫采集
信息的能力也在飞速发展,网站开始考虑对搜索引擎爬取的信息进行限制,于是robots.txt应运而生,成为网络中的“君子协定”。爬虫世界。
robots.txt 文件是业界的通行做法,并非强制约束。robots.txt的格式如下:
在上面的 robots.txt 示例中,禁止所有爬虫访问网站上的任何内容。但是谷歌的爬虫机器人可以访问除私人位置以外的所有内容。如果网站上没有robots.txt,则认为默认允许爬虫抓取所有信息。如果robots.txt被限制访问,而爬虫不遵守,这不是技术实现上的简单问题。
礼仪二:控制爬行吞吐量
伪造谷歌搜索引擎的爬虫用于对网站进行 DDoS 攻击并使网站瘫痪。近年来,恶意爬虫引发的DDoS攻击不断增多,给大数据行业投下了爬虫的阴影。因为背后的恶意攻击者往往拥有更复杂、更专业的技术,可以绕过各种防御机制,使得防范此类攻击的难度更大。
礼仪三:做一个优雅的爬行者
优雅的履带车背后,必定有一个文明的人,或者文明的团队。他们会考虑自己编写的爬虫程序是否符合robots.txt协议,是否会影响被爬取的网站的性能,如何才能不侵犯知识产权人的权益和非常重要的个人隐私数据。
由于能力差异,并不是每个爬虫团队都能考虑这些问题。2018年,欧盟的《通用数据保护条例》(General Data Protection Regulation)发布了严格的数据保护指令。2019年5月28日,国家互联网信息办公室发布的《数据安全管理办法》(征求意见稿)对爬虫和个人信息安全做出了非常严格的规定。例如:
事实上,我国于2017年6月1日实施的《中华人民共和国网络安全法》第四章第四十一条和第四十四条,已经对个人隐私信息的采集
和使用作出了明确规定。与爬虫直接相关。
法律制度的颁布明确了技术的界限,技术的无罪不能作为技术实施者为自己辩解的理由。爬虫在满足自身需求的同时,必须严格遵守行为准则和法律法规。
各种反爬虫技术介绍
为了保护自己的合法权益不受恶意侵害,很多网站和APP都应用了大量的反爬技术。这使得爬虫技术衍生出反爬虫技术,如各种滑动拼图、文字点击、图标点击等验证码破解,相互促进,相互发展,相互伤害。
反爬虫的关键是防止爬虫批量抓取网站内容。反爬虫技术的核心是不断改变规则和各种验证方式。
这种技术的发展更是引人入胜,甚至比DOTA之战还要精彩。在波浪形文字验证码图形的伪装色中可以看到程序员的头发。
1、图片/Flash
这是一种比较常见的防爬方法。它将关键数据转换为图片并添加水印。即使使用了OCR(Optical Character Recognition),也无法识别,以至于爬虫拿到图片就得不到任何信息。这种方式在一些早期电子商务公司的价格标签中经常看到。
2、JavaScript 混淆技术
这是爬虫程序员遇到最多的反爬方法。简而言之,它实际上是一种致盲方法,本质上是一种加密技术。许多网页中的数据是使用 JavaScript 程序动态加载的。在抓取此类网页数据时,爬虫需要了解网页是如何加载数据的。这个过程称为逆向工程。为了防止逆向工程,使用了 JavaScript 混淆技术,并添加了 JavaScript 代码进行加密,使其他人无法理解。不过这种方法属于比较简单的防爬方法,属于履带工程师调平的初级阶段。
3、验证码
验证码是一个公开的全自动程序,用于区分用户是计算机还是人。也是我们经常遇到的一种网站访问验证的方法。它主要分为以下几种:
(1)输入类型验证码
这是最常见的。通过用户输入图片中的字母、数字、汉字等字符进行验证。
图中CAPTCHA的全称是(Completely Automated Public Turing test to tell Computers and Humans Apart),中文翻译为:自动图灵测试以区分计算机和人类。实现这一点的方法很简单,就是提出一个计算机无法回答但人类可以回答的问题。然而,目前的爬虫往往使用深度学习技术来破解这样的验证码,这样的图灵测试已经失效。
(2)滑块类型验证码
鉴于输入式图形验证码的缺点,容易被破解,有时还无法被人类识别。滑块验证码诞生了。这种验证码操作简单,破解难度大,迅速走红。破解滑块验证码有两大难点:一是要知道图形缺口在哪里,也就是要知道滑块在哪里滑动;另一种是模仿人类的滑动手势。这样的验证码增加了一定的难度,也给爬虫世界增添了不少乐趣。一时间出现了大量破解滑块验证码的技术。
(3)点击式图形验证和图标选择
图文验证是提醒用户点击图片中同一个词的位置进行文本验证。
图标选择是给出一组图片,根据需要点击其中一个或多个。
两种原理类似,只不过一种是给出文字,点击图片中的文字;另一个给出图片并点击与内容匹配的图片。这两种方式的共同点是体验不佳,广受诟病。
(4)手机验证码
对于一些重要敏感信息的访问,网站或APP一般会提供填写手机验证码的要求,手机接受网站发送的验证码,以便进一步访问。这种方法更利于数据隐私保护。
4、账号密码登录
网站可以通过账号登录来限制爬虫的访问权限。个人在使用很多网站服务时,一般都需要注册一个账号。使用时,他们需要使用帐户密码登录才能继续使用该服务。网站可以使用用户浏览器的cookie来识别用户的身份,并通过用户本地浏览器中存储的加密cookie数据跟踪用户的访问会话。这一般是作为之前防爬方法的补充。
履带技术的发展方向
传统网络爬虫最大的应用场景是搜索引擎,普通企业更多的是针对网站或者应用。后来随着网络数据分析的需要,以及互联网上层出不穷的舆论事件,对网络爬虫的需求量很大,主要采集的对象是新闻信息。
近年来,由于大数据处理和数据挖掘技术的发展,数据资产价值的概念深入人心,爬虫技术得到了更广泛深入的发展,采集
对象也越来越多。更丰富,高性能和并发技术指标也更高。.
围绕网络爬虫合法性的讨论依然存在,而且情况更为复杂。在目前的趋势下,很多法律问题还处于一个模糊的领域,往往取决于具体案件的影响。但是,可以肯定的是,只要有互联网,就会有网络爬虫。只有网络爬虫才能让庞大的互联网变得可搜索,让爆炸式增长的互联网更容易被访问和获取。在可预见的未来,互联网爬虫技术将不断发展。
作为人类历史上最大的知识仓库,互联网是非结构化或非标准化的。互联网上聚集了大量的文字、图片、多媒体等数据。虽然内容很有价值,但是提取知识的难度还是非常巨大的。语义互联网、知识共享等概念越来越流行,真正的语义互联网将成为网络爬虫的目标。此外,物联网技术的发展将是互联网的升级形态,也将是未来爬虫技术的发展方向。
网页音频抓取(几款高效实用、功能强大、速度极快的下载软件推荐!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-12-29 08:05
今天给大家介绍几款高效、实用、功能强大、速度极快的下载软件。如果对你有帮助,欢迎关注我们。你需要得到这3个下载工具,可以在我们的头条号“斜杠指南”中找到,私信号:23
1. IDM 下载器
Internet Download Manager,简称IDM,是一款国外优秀的下载工具。下载速度无可挑剔,下载速度轻松提升5倍。
安装浏览器插件一起使用,可以自动抓取浏览器的可下载资源,网页上的任何音视频都可以轻松下载,超级强大。有了这个下载神器,你可以立刻抛开某地雷!
此外,还有超多超实用的功能:定时下载、网盘下载、自动排列下载队列、批量下载、续传功能等。关于下载功能,似乎只有你想不到,没有它也做不到。强烈建议您使用它。
2. 免费下载管理器
FDM是一款轻量级强大的下载工具,支持windows和MacOS系统。特色功能包括:智能限速、定时任务、网页抓取、续传上传等;FDM还支持BT磁力链接,支持边下载边预览和播放音视频文件,支持直接浏览FTP服务器目录。
3. BitComet(比特彗星)
BitComet(比特彗星)是一款免费的HTTP/BT/FTP下载软件,功能强大,操作简单,速度够快,堪称BT资源下载工具!
可通过torrent文件和磁力链接下载,完美支持各种主流BT下载协议;解决了99%的下载经常卡在某些矿区的问题,下载速度更快!您也可以在下面观看并提取预览视频内容。 查看全部
网页音频抓取(几款高效实用、功能强大、速度极快的下载软件推荐!)
今天给大家介绍几款高效、实用、功能强大、速度极快的下载软件。如果对你有帮助,欢迎关注我们。你需要得到这3个下载工具,可以在我们的头条号“斜杠指南”中找到,私信号:23
1. IDM 下载器
Internet Download Manager,简称IDM,是一款国外优秀的下载工具。下载速度无可挑剔,下载速度轻松提升5倍。
安装浏览器插件一起使用,可以自动抓取浏览器的可下载资源,网页上的任何音视频都可以轻松下载,超级强大。有了这个下载神器,你可以立刻抛开某地雷!
此外,还有超多超实用的功能:定时下载、网盘下载、自动排列下载队列、批量下载、续传功能等。关于下载功能,似乎只有你想不到,没有它也做不到。强烈建议您使用它。
2. 免费下载管理器
FDM是一款轻量级强大的下载工具,支持windows和MacOS系统。特色功能包括:智能限速、定时任务、网页抓取、续传上传等;FDM还支持BT磁力链接,支持边下载边预览和播放音视频文件,支持直接浏览FTP服务器目录。
3. BitComet(比特彗星)
BitComet(比特彗星)是一款免费的HTTP/BT/FTP下载软件,功能强大,操作简单,速度够快,堪称BT资源下载工具!
可通过torrent文件和磁力链接下载,完美支持各种主流BT下载协议;解决了99%的下载经常卡在某些矿区的问题,下载速度更快!您也可以在下面观看并提取预览视频内容。
网页音频抓取( Python与其他语言的区别:4、Python生态圈:①WEB开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-29 08:04
Python与其他语言的区别:4、Python生态圈:①WEB开发)
Python 是一种优秀的综合语言。Python 的宗旨是简洁、优雅、强大。广泛应用于人工智能、云计算、金融分析、大数据开发、WEB开发、自动化运维、测试等领域。它已成为世界第 4 大最受欢迎的语言。
Python与其他语言的区别:
4、Python 生态系统:
①WEB开发。
最流行的 Python Web 框架 Django 支持异步和高并发 Tornado 框架。短小精悍的flask、bottle、Django官方口号将Django定义为完美主义者的框架,有期限(它是为完美主义者开发的高效web框架))。
②人工智能
谁将成为人工智能和大数据时代的第一开发语言?这已经是一个不需要争论的问题了。如果说三年前,Matlab、Scala、R、Java 和 Python 都有自己的机会,情况还不清楚,那么三年后,趋势就很明显了,尤其是在 Facebook 前两天开源 PyTorch 之后,Python 作为 AI时代顶级语言的地位基本确立,未来的悬念只有谁能保住第二名。(人工智能的转折点,2014年,著名科学家-吴恩达) ③云计算
目前最流行、最知名的云计算框架是OpenStack,而Python目前的流行很大程度上要归功于云计算。(云计算是按使用付费的模式。这种模式提供可用的、方便的、按需的网络访问,并进入一个可配置的计算资源共享池(资源包括网络、服务器、存储、应用软件和服务)。) ,这些资源可以快速提供,只需很少的管理工作或与服务提供商的很少互动。比如国内的“阿里巴巴云”和云谷公司的XenSystem,还有国外非常成熟的Intel和IBM。)
④财务分析
该公司编写的许多分析程序和高频交易软件都使用Python。到目前为止,Python 是金融分析和量化交易领域使用最多的语言。
⑤爬行动物
在爬虫领域,Python几乎占据主导地位。Scrapy、Request、BeautifuSoap、urllib等,想爬就爬。(网络爬虫,又称网络蜘蛛、网络机器人,在FOAF社区中更多的被称为网络追逐者。它们是按照一定的规则自动抓取万维网上信息的程序或脚本。应用在互联网领域. 搜索引擎利用网络爬虫抓取网页、文档甚至图片、音频、视频等资源,通过相应的索引技术将这些信息组织起来,提供给搜索用户查询。中型网站的一种有效方式。)
⑥自动化运维
请问国内的每一位运维人员,运维人员必须懂的语言是什么?10个人相信他们会给你同样的答案。它的名字是 Python。
⑦科学计算
自 1997 年以来,NASA 一直广泛使用 Python 来执行各种复杂的科学运算。随着 NumPy、SciPy、Matplotlib、Enthought 库等众多库的发展,Python 越来越适合于科学计算和绘图。高质量的 2D 和 3D 图像。与科学计算领域最流行的商业软件Matlab相比,Python是一种通用的编程语言,比Matlab使用的脚本语言有更广泛的应用。
⑧游戏开发
Python 在网络游戏开发方面也有很多应用。与Lua或C++相比,Python比Lua具有更高的抽象层次,可以用更少的代码来描述游戏业务逻辑。与Lua相比,Python更适合作为宿主语言,即程序的入口点在Python那端会更好,然后在需要的时候用C/C++写一些扩展。Python非常适合编写1万行以上的项目,在10万行代码以内可以很好的控制网络游戏项目的规模。此外,著名的游戏都是用 Python 编写的。
这么强大的编程语言,学会了,名利双收。阅读原文,让美女老师带你走进Python的殿堂。 查看全部
网页音频抓取(
Python与其他语言的区别:4、Python生态圈:①WEB开发)
Python 是一种优秀的综合语言。Python 的宗旨是简洁、优雅、强大。广泛应用于人工智能、云计算、金融分析、大数据开发、WEB开发、自动化运维、测试等领域。它已成为世界第 4 大最受欢迎的语言。
Python与其他语言的区别:
4、Python 生态系统:
①WEB开发。
最流行的 Python Web 框架 Django 支持异步和高并发 Tornado 框架。短小精悍的flask、bottle、Django官方口号将Django定义为完美主义者的框架,有期限(它是为完美主义者开发的高效web框架))。
②人工智能
谁将成为人工智能和大数据时代的第一开发语言?这已经是一个不需要争论的问题了。如果说三年前,Matlab、Scala、R、Java 和 Python 都有自己的机会,情况还不清楚,那么三年后,趋势就很明显了,尤其是在 Facebook 前两天开源 PyTorch 之后,Python 作为 AI时代顶级语言的地位基本确立,未来的悬念只有谁能保住第二名。(人工智能的转折点,2014年,著名科学家-吴恩达) ③云计算
目前最流行、最知名的云计算框架是OpenStack,而Python目前的流行很大程度上要归功于云计算。(云计算是按使用付费的模式。这种模式提供可用的、方便的、按需的网络访问,并进入一个可配置的计算资源共享池(资源包括网络、服务器、存储、应用软件和服务)。) ,这些资源可以快速提供,只需很少的管理工作或与服务提供商的很少互动。比如国内的“阿里巴巴云”和云谷公司的XenSystem,还有国外非常成熟的Intel和IBM。)
④财务分析
该公司编写的许多分析程序和高频交易软件都使用Python。到目前为止,Python 是金融分析和量化交易领域使用最多的语言。
⑤爬行动物
在爬虫领域,Python几乎占据主导地位。Scrapy、Request、BeautifuSoap、urllib等,想爬就爬。(网络爬虫,又称网络蜘蛛、网络机器人,在FOAF社区中更多的被称为网络追逐者。它们是按照一定的规则自动抓取万维网上信息的程序或脚本。应用在互联网领域. 搜索引擎利用网络爬虫抓取网页、文档甚至图片、音频、视频等资源,通过相应的索引技术将这些信息组织起来,提供给搜索用户查询。中型网站的一种有效方式。)
⑥自动化运维
请问国内的每一位运维人员,运维人员必须懂的语言是什么?10个人相信他们会给你同样的答案。它的名字是 Python。
⑦科学计算
自 1997 年以来,NASA 一直广泛使用 Python 来执行各种复杂的科学运算。随着 NumPy、SciPy、Matplotlib、Enthought 库等众多库的发展,Python 越来越适合于科学计算和绘图。高质量的 2D 和 3D 图像。与科学计算领域最流行的商业软件Matlab相比,Python是一种通用的编程语言,比Matlab使用的脚本语言有更广泛的应用。
⑧游戏开发
Python 在网络游戏开发方面也有很多应用。与Lua或C++相比,Python比Lua具有更高的抽象层次,可以用更少的代码来描述游戏业务逻辑。与Lua相比,Python更适合作为宿主语言,即程序的入口点在Python那端会更好,然后在需要的时候用C/C++写一些扩展。Python非常适合编写1万行以上的项目,在10万行代码以内可以很好的控制网络游戏项目的规模。此外,著名的游戏都是用 Python 编写的。
这么强大的编程语言,学会了,名利双收。阅读原文,让美女老师带你走进Python的殿堂。
网页音频抓取(一下如何用IDM巧妙的批量音效素材?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-27 00:24
IDM下载器的站点抓取功能可以抓取站点上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天我们就来看看如何使用IDM来巧妙的批量抓取声音素材。
1、进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站(进入网页后点击进入音效分类编译界面,即大量音效目录界面效果链接地址,然后复制该接口的链接地址。
图 1:音效采集
页面
2、 运行“网站抓取”功能抓取音效
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏中,然后点击下方的“Forward”按钮.
图2:网站抓取-链接输入页面
3、 建议将“探索指定链接深度”修改为“3”
在步骤2点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
图3:网站爬取界面
4、更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
图 4:文件类型更改页面
5、等待站点获取成功,并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
图5:文件捕获信息页面
经过上面的操作,已经下载了很多音效文件,并且可以使用站点抓取进行多窗口抓取,这样我们就可以同时抓取几个分类的音效文件,真的很方便!
但是一定要确保音效网站保存的音效文件格式为:mp3、wma或waw。如果网站的文件格式不是这三种后缀格式,IDM可能无法识别! 查看全部
网页音频抓取(一下如何用IDM巧妙的批量音效素材?(组图))
IDM下载器的站点抓取功能可以抓取站点上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天我们就来看看如何使用IDM来巧妙的批量抓取声音素材。
1、进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站(进入网页后点击进入音效分类编译界面,即大量音效目录界面效果链接地址,然后复制该接口的链接地址。
图 1:音效采集
页面
2、 运行“网站抓取”功能抓取音效
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏中,然后点击下方的“Forward”按钮.
图2:网站抓取-链接输入页面
3、 建议将“探索指定链接深度”修改为“3”
在步骤2点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
图3:网站爬取界面
4、更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
图 4:文件类型更改页面
5、等待站点获取成功,并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
图5:文件捕获信息页面
经过上面的操作,已经下载了很多音效文件,并且可以使用站点抓取进行多窗口抓取,这样我们就可以同时抓取几个分类的音效文件,真的很方便!
但是一定要确保音效网站保存的音效文件格式为:mp3、wma或waw。如果网站的文件格式不是这三种后缀格式,IDM可能无法识别!
网页音频抓取(《暮光之城》不得不有版权有些居然还收费)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-19 00:17
趁着上周末看了《暮光之城》,不得不说这是一部非常好看的言情片。里面所有的歌曲,每次听都能深深地吸引我。记得卡伦一家和贝拉棒球的音乐很欢快,所以跑步的时候想下载下来保存一天,没想到这首歌有版权,有的被收费了,导致我很头疼。, 不过我终于想到了一个好办法,你想知道是什么吗?往下看你就明白了。音频转换软件...关于工具:
Fast Audio Converter 是一款多功能的音频编辑处理软件。该软件具有四种功能:音频剪切、音频提取、音频合并和音频转换。本工具操作简单,功能强大,可以多种方式分割音频 切割,操作简单的特点,支持和软件不仅支持单个文件操作,还支持文件批量操作!这是一个不错的选择。
打开工具
我们先准备好需要用到的工具和网页中的音频文件,最好放在一起,方便我们查找。添加音频文件
然后我们打开音频提取界面,点击添加文件或者添加文件夹,这里有多个文件夹,可以批量添加。添加和删除片段指南 片段指南
然后当我们提取音频时,点击添加片段指南。对于此添加,您可以拖动进度条选择要添加的时间段。如果删除它,单击 删除段指南。另外,您可以在下方设置当前时间点的音频的具体提取时间。开始和结束。最后点击确定。提取完成
确认后,界面上会出现提取的音频片段。稍等片刻。如果音频提取成功,会有一个小的复选标记图标。显示出来就说明提取成功了!是不是感觉非常简单快捷?有需要的可以试试编辑器的这个方法,挺好的。
【腾讯云】云产品限时秒杀,爆款1核2G云服务器,首年50元
阿里云限时Event-2核心2G-5M带宽-60G SSD-1000G包月流量,特价99元/年(原价1234.2元/年,可直接购买3年),快速抓取 查看全部
网页音频抓取(《暮光之城》不得不有版权有些居然还收费)
趁着上周末看了《暮光之城》,不得不说这是一部非常好看的言情片。里面所有的歌曲,每次听都能深深地吸引我。记得卡伦一家和贝拉棒球的音乐很欢快,所以跑步的时候想下载下来保存一天,没想到这首歌有版权,有的被收费了,导致我很头疼。, 不过我终于想到了一个好办法,你想知道是什么吗?往下看你就明白了。音频转换软件...关于工具:
Fast Audio Converter 是一款多功能的音频编辑处理软件。该软件具有四种功能:音频剪切、音频提取、音频合并和音频转换。本工具操作简单,功能强大,可以多种方式分割音频 切割,操作简单的特点,支持和软件不仅支持单个文件操作,还支持文件批量操作!这是一个不错的选择。
打开工具
我们先准备好需要用到的工具和网页中的音频文件,最好放在一起,方便我们查找。添加音频文件
然后我们打开音频提取界面,点击添加文件或者添加文件夹,这里有多个文件夹,可以批量添加。添加和删除片段指南 片段指南
然后当我们提取音频时,点击添加片段指南。对于此添加,您可以拖动进度条选择要添加的时间段。如果删除它,单击 删除段指南。另外,您可以在下方设置当前时间点的音频的具体提取时间。开始和结束。最后点击确定。提取完成
确认后,界面上会出现提取的音频片段。稍等片刻。如果音频提取成功,会有一个小的复选标记图标。显示出来就说明提取成功了!是不是感觉非常简单快捷?有需要的可以试试编辑器的这个方法,挺好的。
【腾讯云】云产品限时秒杀,爆款1核2G云服务器,首年50元
阿里云限时Event-2核心2G-5M带宽-60G SSD-1000G包月流量,特价99元/年(原价1234.2元/年,可直接购买3年),快速抓取
网页音频抓取(一款适合我们大众的工具,是什么工具呢??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-15 21:14
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候我们只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能音频编辑处理软件。该软件具有四个功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
第一步:打开工具
在网页上准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第 3 步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
点击“确定”后不要以为你饿了。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想查看就可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。 查看全部
网页音频抓取(一款适合我们大众的工具,是什么工具呢??)
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候我们只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能音频编辑处理软件。该软件具有四个功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
第一步:打开工具
在网页上准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第 3 步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
点击“确定”后不要以为你饿了。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想查看就可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。

