网页音频抓取(白又白i--对你有用的话记得三连呦! )
优采云 发布时间: 2022-01-23 00:15网页音频抓取(白又白i--对你有用的话记得三连呦!
)
大家好,我是白人。
如果对你有用,记得加三倍!
性能展示
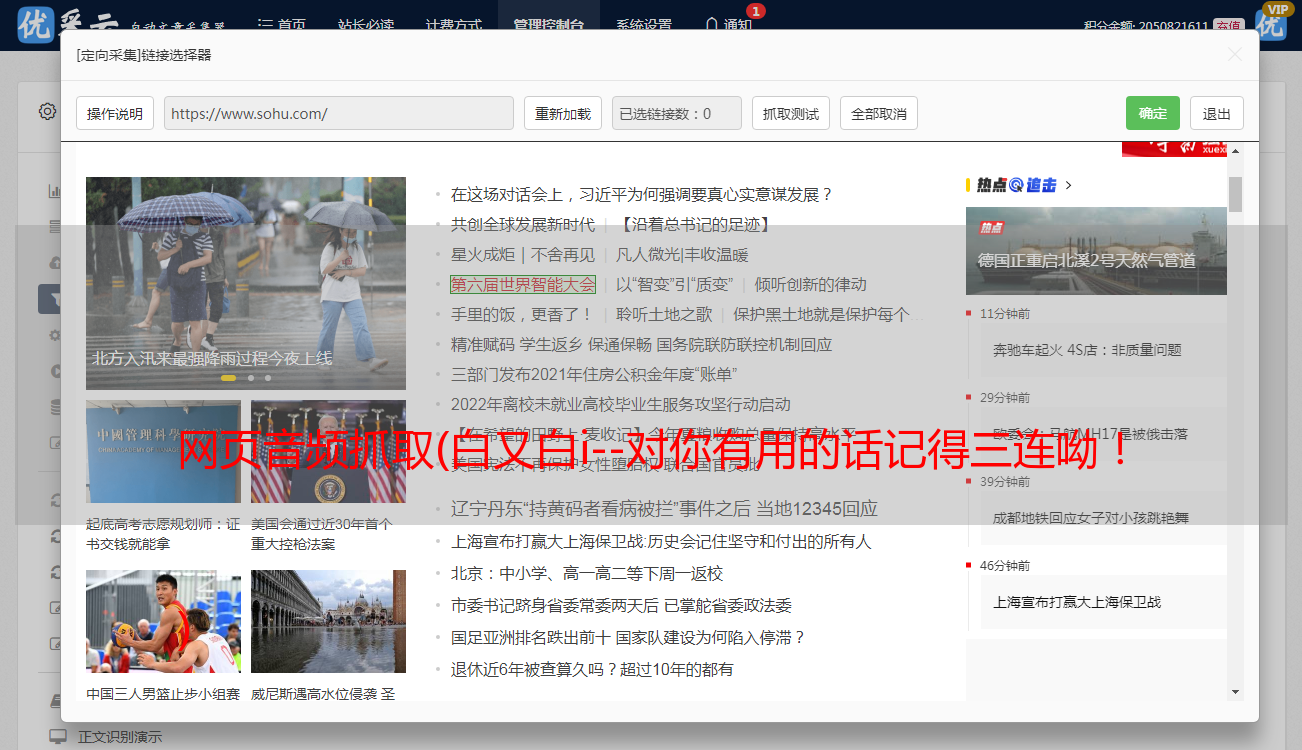
抓取目标
网址:酷我音乐
工具使用
开发工具:pycharm
开发环境:python3.7、Windows10
使用工具包:requests, re
项目思路分析
找到需要解析的列表数据
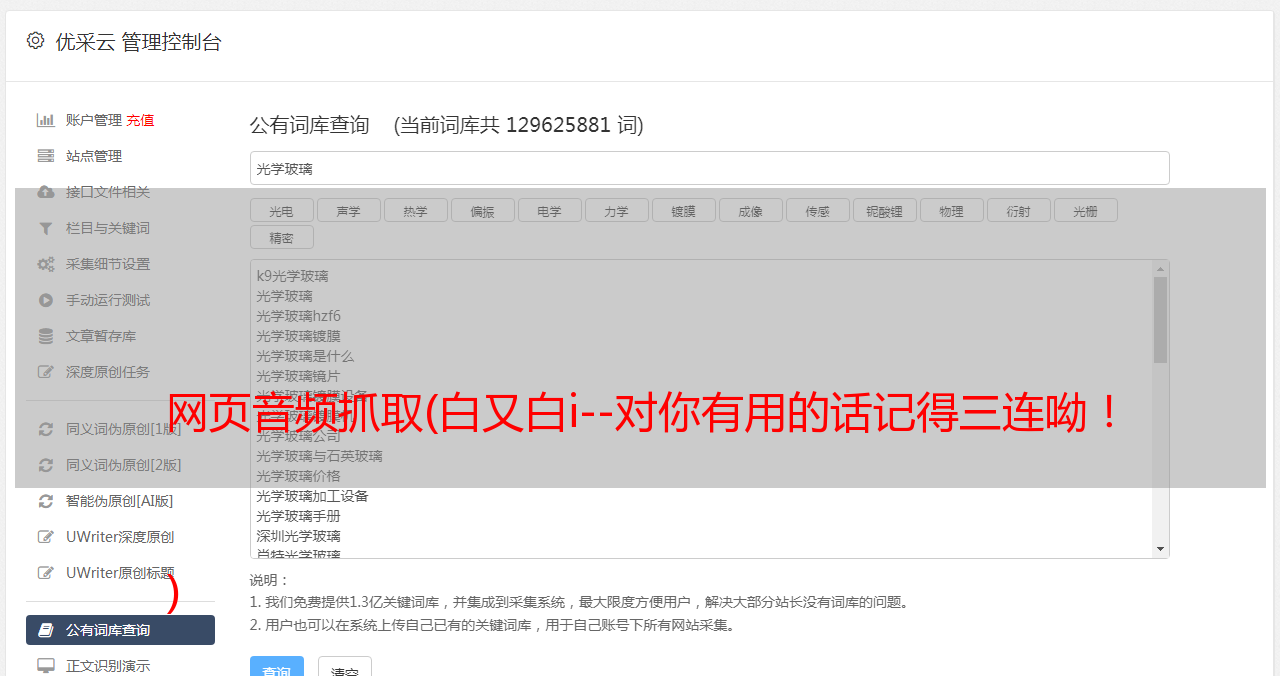
随意点击一首歌曲,获取音乐的详细数据,通过抓包获取音乐播放数据
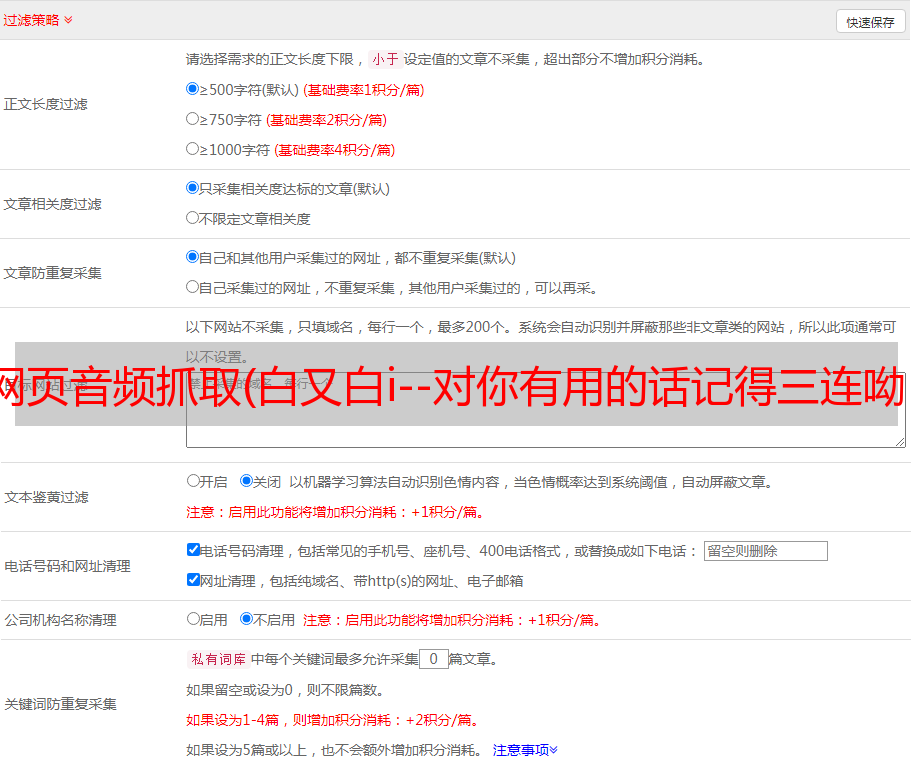
找到MP3的数据提交地址,mp3数据来自这个url地址
提交数据的网址:
/yy/index.ph…
比较多个网址数据,看看哪些参数需要自己修改
有3个url数据变化
_ 可以清楚的看到是时间戳。需要获取对应的hash和album_id值。到首页找到对应的歌曲id数据。发现数据来源于网页源代码
歌曲数据均来自网页源代码
梳理整体思路:简单源码分析
本章内容仅供学习,请勿用于其他用途! ! ! ! !
Pythonimport requestsimport reimport timedef Tools(url): headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.70' } response = requests.get(url, headers=headers) return responsedef Save(name, url): mp3 = Tools(url).content # 请求mp3地址链接 返回格式是16进制 f = open('./kugou/{}.mp3'.format(name), 'wb') # w 文件存在就写入 不存在就会创建 b进制读写 f.write(mp3) f.close() print('{}下载完成....'.format(name))url = 'https://www.kugou.com/yy/html/rank.html'response = Tools(url).textalbum_id = re.findall(r'"album_id":(\d*?),', response) # idHash = re.findall(r'"Hash":"(.*?)",', response) # hashfor a, h in zip(album_id, Hash): # 生成时间戳 time1 = int(time.time() * 1000) # 包含歌曲下载地址的url urls = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash={}&dfid=0zlWqK0UWNFa0weUnX0hjlFa&mid=f79511e2e86914b99e351c42ba1f8bc7&platid=4&album_id={}&_={}'.format(h, a, time1) response1 = Tools(urls).json() audio_name = response1['data']['audio_name'].split('-')[1] play_url = response1['data']['play_url'] Save(audio_name, play_url)复制代码

