
网页音频抓取
【音效】一个提供各种素材下载的网站
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-07-16 15:15
排版|设计|配图©孤狼小航
素材吧这个网站是一个提供各种素材下载的网站,里面的音效板块挺不错的
获取方式将网址直接复制浏览器即可
请将以上网址复制到自带的浏览器内(手机/电脑),请关注公众号“90技术控”查找历史记录,查阅更多的黑科技,获取你想要的内容。
温馨提示:
①“90技术控”公众号内提供的全部资源皆为无偿分享,资源都是来自于网络搜集和小伙伴们的提供(包含图片文字),仅供学习&交流(禁商用),本公众号不参与任何版权问题,如有侵权,请联系删除!
②每期文章底部都会有相应关键词,只有在关注完公众号内正确的回复关键词才会获得相关资源,搜索关键词必须为精确关键词!(你可以复制文章底部的关键词,不包括文章底部的符号)不能错一个字和字符,区分大小写,不能有多余的符号,感谢大家的支持与理解!
③如需遇到外文网站或其他语种网站,先在你打开的网站中寻找你能看懂的语言,同时,如果没有你想要的的语言,建议你可以利用自带翻译功能的浏览器进行翻译,如果打开链接公众号内容没有反应或者长时间打不开,建议先检查自己的网络原因,如果微信打不开的话建议把链接复制到(手机或者电脑)的自带浏览器进行查阅。
④由于我们公众号内部功能比较多,大家不懂得先可以尝试在菜单栏中找到对应的帮助,如果还不会的话可以咨询一下人工服务!感谢你的支持与理解!
“90技术控”
不一样的黑科技技术平台 查看全部
【音效】一个提供各种素材下载的网站
排版|设计|配图©孤狼小航
素材吧这个网站是一个提供各种素材下载的网站,里面的音效板块挺不错的

获取方式将网址直接复制浏览器即可
请将以上网址复制到自带的浏览器内(手机/电脑),请关注公众号“90技术控”查找历史记录,查阅更多的黑科技,获取你想要的内容。
温馨提示:
①“90技术控”公众号内提供的全部资源皆为无偿分享,资源都是来自于网络搜集和小伙伴们的提供(包含图片文字),仅供学习&交流(禁商用),本公众号不参与任何版权问题,如有侵权,请联系删除!

②每期文章底部都会有相应关键词,只有在关注完公众号内正确的回复关键词才会获得相关资源,搜索关键词必须为精确关键词!(你可以复制文章底部的关键词,不包括文章底部的符号)不能错一个字和字符,区分大小写,不能有多余的符号,感谢大家的支持与理解!
③如需遇到外文网站或其他语种网站,先在你打开的网站中寻找你能看懂的语言,同时,如果没有你想要的的语言,建议你可以利用自带翻译功能的浏览器进行翻译,如果打开链接公众号内容没有反应或者长时间打不开,建议先检查自己的网络原因,如果微信打不开的话建议把链接复制到(手机或者电脑)的自带浏览器进行查阅。
④由于我们公众号内部功能比较多,大家不懂得先可以尝试在菜单栏中找到对应的帮助,如果还不会的话可以咨询一下人工服务!感谢你的支持与理解!
“90技术控”
不一样的黑科技技术平台
【实用办公网站】即时工具网站(PDF、音视频、图片、办公辅助等236款工具)完全
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-06-17 22:01
下载须知:
1. 公众号所分享的软件都是已亲自测试,可放心使用,仅供学习交流,勿用于商业用途;如果觉得不错,欢迎将公众号推荐给您的朋友使用。
2.破解软件的签名和原官方软件不一致,会出现报毒!无需理会!放心使用。另破解软件有时效性,如出现无法使用请关注后续版本的更新。
3.获取链接后请复制到浏览器下载。如还是无法下载,请关闭纯净模式。
近期会将原工作黑科技公众号上的资源全部搬运至此公众号上,不过原来文章的图片都丢失了,只保留了文字部分。200多篇文章为了快速搬运,无法再补上图片了。
即时工具(网址)
即时工具网 是一款在线工具箱,内含很多种实用工具。通过首页我们可以看到,该平台推荐的一些工具都与我们生活息息相关,内置236款在线小工具,网站完全免费。其中的工具包括,办公辅助,设计工具,图片处理工具,视频处理工具,格式转换,教育学习,文本工具,开发工具,生活查询等等。
1、图片无损压缩-不改变图片尺寸、文件减小、无损压缩,支持40张批量处理。
2、视频修剪-在线视频修剪,同时可裁切、翻转、旋转、分辨率、倍速、循环、缩放等处理。
3、视频裁切-在线自定义裁切视频画面,可用于去水印、改分辨率等等操作。
4、视频格式转换-支持MP4、AVI、MPG、MOV、FLV、3GP、WEBM、MKV、WMV、GIF在线互转。
5、视频分辨率转换-支持超多分辨率预设转换,同时支持输入自定义分辨率。
6、视频压缩-不改变分辨率压缩视频,支持MP4、AVI、MPG、MOV、FLV、3GP、WEBM、MKV、WMV格式。
7、视频提取音频-支持主流视频格式在线提取音频,并且可以选择输出格式。
8、音频格式转换-支持mp3、wav、ogg、ac3、flac、opus、pcm、m4a、aac在线互转。
9、视频拼接-支持多个视频文件在线拼接,同时可选择多种输出格式。
10、音频调速-在线可视化音频调速,支持0.5倍到4倍速度调整。
网站适配多个主流浏览器,内置236个工具,同时也可看到工具的使用次数。
免责声明:0点黑科技公众号所分享的资源全部是来源于互联网公开分享的内容,仅用于个人学习使用,禁止用于其他商业用途和倒卖。如有条件请支持正版,谢谢。如软件失效、打不开等问题,请联系我处理,谢谢。
▌获取方式
先点击右下角的“在看” 查看全部
【实用办公网站】即时工具网站(PDF、音视频、图片、办公辅助等236款工具)完全
下载须知:
1. 公众号所分享的软件都是已亲自测试,可放心使用,仅供学习交流,勿用于商业用途;如果觉得不错,欢迎将公众号推荐给您的朋友使用。
2.破解软件的签名和原官方软件不一致,会出现报毒!无需理会!放心使用。另破解软件有时效性,如出现无法使用请关注后续版本的更新。
3.获取链接后请复制到浏览器下载。如还是无法下载,请关闭纯净模式。
近期会将原工作黑科技公众号上的资源全部搬运至此公众号上,不过原来文章的图片都丢失了,只保留了文字部分。200多篇文章为了快速搬运,无法再补上图片了。
即时工具(网址)
即时工具网 是一款在线工具箱,内含很多种实用工具。通过首页我们可以看到,该平台推荐的一些工具都与我们生活息息相关,内置236款在线小工具,网站完全免费。其中的工具包括,办公辅助,设计工具,图片处理工具,视频处理工具,格式转换,教育学习,文本工具,开发工具,生活查询等等。
1、图片无损压缩-不改变图片尺寸、文件减小、无损压缩,支持40张批量处理。
2、视频修剪-在线视频修剪,同时可裁切、翻转、旋转、分辨率、倍速、循环、缩放等处理。
3、视频裁切-在线自定义裁切视频画面,可用于去水印、改分辨率等等操作。
4、视频格式转换-支持MP4、AVI、MPG、MOV、FLV、3GP、WEBM、MKV、WMV、GIF在线互转。
5、视频分辨率转换-支持超多分辨率预设转换,同时支持输入自定义分辨率。
6、视频压缩-不改变分辨率压缩视频,支持MP4、AVI、MPG、MOV、FLV、3GP、WEBM、MKV、WMV格式。
7、视频提取音频-支持主流视频格式在线提取音频,并且可以选择输出格式。
8、音频格式转换-支持mp3、wav、ogg、ac3、flac、opus、pcm、m4a、aac在线互转。
9、视频拼接-支持多个视频文件在线拼接,同时可选择多种输出格式。
10、音频调速-在线可视化音频调速,支持0.5倍到4倍速度调整。
网站适配多个主流浏览器,内置236个工具,同时也可看到工具的使用次数。
免责声明:0点黑科技公众号所分享的资源全部是来源于互联网公开分享的内容,仅用于个人学习使用,禁止用于其他商业用途和倒卖。如有条件请支持正版,谢谢。如软件失效、打不开等问题,请联系我处理,谢谢。
▌获取方式
先点击右下角的“在看”
(Android)Top浏览器v3.0.8-极速移动浏览器
网站优化 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2022-05-23 17:41
OMG优质资源
公众号改推送机制了,以后可能收不到咱们消息了,不想错过优质的资源分享,请点左上角OMG优质资源,然后按下面步骤,设置星标★就可以优先推送了,谢谢大家的支持。下载提取码在文末哦!!!!!!!!!!!!!!另外破解软件有时效性,过一段时间会时效的,后续网盘会有更新新版本微信如果遇到无法访问蓝奏云连接,获取链接后复制到浏览器下载既可
产品简介Top浏览器是一款极速移动浏览器。
智能广告拦截,采用Adblock,自动更新规则,清爽界面,拒绝弹窗骚扰,任何的广告又或者是小的弹窗广告,都会进行删除。阅读模式,智能提取网页正文,下拉翻页,给你干净整洁的阅读体验,而且用户们还可以根据自己的需求,主动对界面进行管理。嗅探下载,准确抓取资源链接,支持音频、视频的下载,支持M3U8视频下载并自动转MP4,同时还可以在平台下载其他的文件。随时随地都可以浏览各种热点网页推荐视频等等。智能搜索功能,让你轻松查看到你感兴趣的内容。
产品特色
【最良心】不偷取用户数据,权限只必要;
【最快速】使用的webkit内核,原生体验;
【最强悍】各种设置项自定义,为你专属;
– 非常小巧,仅几百KB,该有的功能都有;
– 隐私保护、隐私防追踪、自定义浏览器标识ua;
– 支持广告拦截、自定义广告标记(可添加拦截规则)
– 支持沉浸式、支持定制主页风格、LOGO、搜索栏;
– 支持HTML5、插件管理、下载插件、下载链接解析;
– 书签可以登陆云同步,支持夜间模式,夜间模式、电脑模式、有图/无图模式;
– 支持翻译网页、离线网页、保存网页、查看网页源码、网页资源嗅探、网页内查找等;
– 支持自定义添加脚本(添加如:百度贴吧免登陆看更多回复、知乎免登陆看全文回答);
产品更新为了让更多的用户享受到舒适的便捷生活服务,用户们可以在平台上更加轻松地了解到众多的应用版块的使用方式,享受软件的操作性;
三无模式开启,你不想要的,我们通通都没有——无广告、无新闻、无推送,轻快简洁,还原浏览器本质,使用起来更加舒心;自由订阅功能,通过订阅获取网站更新内容,轻松实现追剧、追小说、追漫画…以订阅的方式“看”世界,各种各样的资讯都可以在线订阅
联系我们加入微群每天都有VIP优秀资源分享,欢迎大家加入,进群才有哦!由于群已满200人,无法进行扫码入群,现提供群主微信,(需要进群可加群主微信,拉你入群)广告别进 必T,广告别进 必T,广告别进 必T
下载地址
公众号内发送【198】点击下方公众号进入发送数字即可获取资源下载链接微信如果遇到无法访问蓝奏云连接,获取链接后复制到浏览器下载既可
好了,今天的分享就是这样,老规矩,获取软件前记得戳一些右下角的【在看】哦!你们的在看就是我更新的动力!拜 托戳 最 底加 个 鸡 腿吧
查看全部
(Android)Top浏览器v3.0.8-极速移动浏览器
OMG优质资源
公众号改推送机制了,以后可能收不到咱们消息了,不想错过优质的资源分享,请点左上角OMG优质资源,然后按下面步骤,设置星标★就可以优先推送了,谢谢大家的支持。下载提取码在文末哦!!!!!!!!!!!!!!另外破解软件有时效性,过一段时间会时效的,后续网盘会有更新新版本微信如果遇到无法访问蓝奏云连接,获取链接后复制到浏览器下载既可
产品简介Top浏览器是一款极速移动浏览器。
智能广告拦截,采用Adblock,自动更新规则,清爽界面,拒绝弹窗骚扰,任何的广告又或者是小的弹窗广告,都会进行删除。阅读模式,智能提取网页正文,下拉翻页,给你干净整洁的阅读体验,而且用户们还可以根据自己的需求,主动对界面进行管理。嗅探下载,准确抓取资源链接,支持音频、视频的下载,支持M3U8视频下载并自动转MP4,同时还可以在平台下载其他的文件。随时随地都可以浏览各种热点网页推荐视频等等。智能搜索功能,让你轻松查看到你感兴趣的内容。
产品特色
【最良心】不偷取用户数据,权限只必要;
【最快速】使用的webkit内核,原生体验;
【最强悍】各种设置项自定义,为你专属;
– 非常小巧,仅几百KB,该有的功能都有;
– 隐私保护、隐私防追踪、自定义浏览器标识ua;
– 支持广告拦截、自定义广告标记(可添加拦截规则)
– 支持沉浸式、支持定制主页风格、LOGO、搜索栏;
– 支持HTML5、插件管理、下载插件、下载链接解析;
– 书签可以登陆云同步,支持夜间模式,夜间模式、电脑模式、有图/无图模式;
– 支持翻译网页、离线网页、保存网页、查看网页源码、网页资源嗅探、网页内查找等;
– 支持自定义添加脚本(添加如:百度贴吧免登陆看更多回复、知乎免登陆看全文回答);
产品更新为了让更多的用户享受到舒适的便捷生活服务,用户们可以在平台上更加轻松地了解到众多的应用版块的使用方式,享受软件的操作性;
三无模式开启,你不想要的,我们通通都没有——无广告、无新闻、无推送,轻快简洁,还原浏览器本质,使用起来更加舒心;自由订阅功能,通过订阅获取网站更新内容,轻松实现追剧、追小说、追漫画…以订阅的方式“看”世界,各种各样的资讯都可以在线订阅
联系我们加入微群每天都有VIP优秀资源分享,欢迎大家加入,进群才有哦!由于群已满200人,无法进行扫码入群,现提供群主微信,(需要进群可加群主微信,拉你入群)广告别进 必T,广告别进 必T,广告别进 必T
下载地址
公众号内发送【198】点击下方公众号进入发送数字即可获取资源下载链接微信如果遇到无法访问蓝奏云连接,获取链接后复制到浏览器下载既可
好了,今天的分享就是这样,老规矩,获取软件前记得戳一些右下角的【在看】哦!你们的在看就是我更新的动力!拜 托戳 最 底加 个 鸡 腿吧
python爬虫学习教程之自动下载网页音频文件
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-05-12 14:43
2、BeautifulSoup
一个灵活又方便的网页解析库,处理高效,支持多种解析器。
利用它就不用编写正则表达式也能方便的实现网页信息的抓取。
3、安装和引入:
pip install requestspip install BeautifulSoup
import requestsfrom bs4 import BeautifulSoup as bf
二、目标网站
一个需要手动点击下载mp3文件的网站,因为需要下载几百个所以很难手动操作。
三:获取并解析网页源代码
1、使用requests获取目标网站的源代码
r = requests.get('http://www.goodkejian.com/ertonggushi.htm')
所有下载链接被存放在标签内,并且长度固定。该链接将其中的amp;去除后方可直接下载。
2、使用BeautifulSoup将网页内容解析并将其中的标签提取出来
soup = bf(r.text, 'html.parser')res = soup.find_all('a')
四:下载
经过上述步骤res就变成了包含所有目标标签的数组,要想下载网页上的所有mp3文件,只要循环把res中的元组转换为字符串,并经过筛选、裁剪等处理后变成链接就可以使用request访问了,并且返回值就是mp3文件的二进制表示,将其以二进制形式写进文件即可。
全部代码如下:
import requestsfrom bs4 import BeautifulSoup as bf<br />r = requests.get('http://www.goodkejian.com/ertonggushi.htm')<br />soup = bf(r.text, 'html.parser')res = soup.find_all('a')<br />recorder = 1# 长度为126的是要找的图标for i in res: dst = str(i) if dst.__len__() == 126: url1 = dst[9:53] url2 = dst[57:62] url = url1 + url2 print(url) xjh_request = requests.get(url) with open("./res/" + str(recorder) + ".rar", 'wb') as file: file.write(xjh_request.content) file.close() recorder += 1 print("ok")
以上就是使用python爬虫自动下载网页音频文件的思路和全部代码,大家可以套入代码尝试下载进行实战练习哦~
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权
查看全部
python爬虫学习教程之自动下载网页音频文件
2、BeautifulSoup
一个灵活又方便的网页解析库,处理高效,支持多种解析器。
利用它就不用编写正则表达式也能方便的实现网页信息的抓取。
3、安装和引入:
pip install requestspip install BeautifulSoup
import requestsfrom bs4 import BeautifulSoup as bf
二、目标网站
一个需要手动点击下载mp3文件的网站,因为需要下载几百个所以很难手动操作。
三:获取并解析网页源代码
1、使用requests获取目标网站的源代码
r = requests.get('http://www.goodkejian.com/ertonggushi.htm')
所有下载链接被存放在标签内,并且长度固定。该链接将其中的amp;去除后方可直接下载。
2、使用BeautifulSoup将网页内容解析并将其中的标签提取出来
soup = bf(r.text, 'html.parser')res = soup.find_all('a')
四:下载
经过上述步骤res就变成了包含所有目标标签的数组,要想下载网页上的所有mp3文件,只要循环把res中的元组转换为字符串,并经过筛选、裁剪等处理后变成链接就可以使用request访问了,并且返回值就是mp3文件的二进制表示,将其以二进制形式写进文件即可。
全部代码如下:
import requestsfrom bs4 import BeautifulSoup as bf<br />r = requests.get('http://www.goodkejian.com/ertonggushi.htm')<br />soup = bf(r.text, 'html.parser')res = soup.find_all('a')<br />recorder = 1# 长度为126的是要找的图标for i in res: dst = str(i) if dst.__len__() == 126: url1 = dst[9:53] url2 = dst[57:62] url = url1 + url2 print(url) xjh_request = requests.get(url) with open("./res/" + str(recorder) + ".rar", 'wb') as file: file.write(xjh_request.content) file.close() recorder += 1 print("ok")
以上就是使用python爬虫自动下载网页音频文件的思路和全部代码,大家可以套入代码尝试下载进行实战练习哦~
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权
网页音频抓取 基本请求库requests
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-05-04 06:23
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get")# 发起Post请求requests.post("https://www.httpbin.org/post")# 发起Put请求requests.put("https://www.httpbin.org/put")# 发起Delete请求requests.delete("https://www.httpbin.org/delete")
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/")# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证 查看全部
网页音频抓取 基本请求库requests
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get";)# 发起Post请求requests.post("https://www.httpbin.org/post";)# 发起Put请求requests.put("https://www.httpbin.org/put";)# 发起Delete请求requests.delete("https://www.httpbin.org/delete";)
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/";)# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证
网页音频抓取 基本请求库requests
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-05-03 22:38
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get")# 发起Post请求requests.post("https://www.httpbin.org/post")# 发起Put请求requests.put("https://www.httpbin.org/put")# 发起Delete请求requests.delete("https://www.httpbin.org/delete")
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/")# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证 查看全部
网页音频抓取 基本请求库requests
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get";)# 发起Post请求requests.post("https://www.httpbin.org/post";)# 发起Put请求requests.put("https://www.httpbin.org/put";)# 发起Delete请求requests.delete("https://www.httpbin.org/delete";)
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/";)# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证
网页音频抓取 基本请求库requests
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-05-03 14:54
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get")# 发起Post请求requests.post("https://www.httpbin.org/post")# 发起Put请求requests.put("https://www.httpbin.org/put")# 发起Delete请求requests.delete("https://www.httpbin.org/delete")
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/")# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证 查看全部
网页音频抓取 基本请求库requests
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get";)# 发起Post请求requests.post("https://www.httpbin.org/post";)# 发起Put请求requests.put("https://www.httpbin.org/put";)# 发起Delete请求requests.delete("https://www.httpbin.org/delete";)
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/";)# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证
《玩转无线投屏》连载№2:轻松地在PC上操作手机
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-05-02 22:06
引言
从苹果 Mac + iPhone 的接力/通用剪贴板,到华为的多屏协同,越来越多人意识到手机和电脑之间的交互如跨屏控制/同步剪贴板等功能确实能提高使用方便程度以及效率的。
小米12 Pro 骁龙8 Gen1 2K AMOLED 120Hz高刷 5000万疾速影像 120W小米澎湃秒充 12GB+256GB 黑色 5G手机
———————
京东价:¥5199.00
抢购链接:
那有没有什么办法通过软件打通限制,在电脑上更好的「玩」手机呢?
优爱酷今天分享的软件,可以轻松地在PC上操作手机,支持所有品牌的Android手机,WiFi和USB连接,多点触控,共享剪贴板等,且看
文末获取 工具下载链接
功能
所有Android手机
谷歌、HTC、华为、联想、Mi、OnePlus、Oppo、Realme、三星、索尼、Tecno、维梧等。
音频支持
你的电脑就是你的手机扬声器
键映射
帮助您在 PC 上玩移动 FPS 游戏。
屏幕录制
使用 AnLink 快速录制技术,减少 CPU 和 GPU 消耗。
键盘和输入法
使用键盘和输入法编辑器提高打字速度。
大而清晰
享受大屏体验,最清晰的镜像显示质量,支持硬件解码器以节省电池。
WiFi和USB
WiFi连接更方便,USB连接更流畅。
共享剪贴板
Ctrl+C和Ctrl+V也在手机和电脑之间工作。
多点触控
如果您可以触摸显示器屏幕,则支持手势。
文件管理器
通过拖放等方式在手机和PC之间传输文件。
“随心所欲 截您所需”
为批量截图而生,Chrome内核新版本发布啦!
IE内核版下载地址
https://gitee.com/uicoolcn/UiC ... eases
Chromium内核版下载地址
https://gitee.com/uicoolcn/UiC ... eases
优爱酷批量图像文字识别系统OCR
本软件与 “优爱酷批量长网页整页截图系统”配合使用,更加得心应手,只要是截得到的图,就可以用本软件进行批量OCR转为文字。
一款基于开放互操作人工智能的AI深度学习的OCR软件。
支持单图OCR 以及 自由截屏OCR识别、批量OCR、动态OCR(定时OCR);
支持五大场景结构化识别;
支持倾斜图像自动纠偏;
支持识别成文本文档(.txt)、Excel(.xlsx)格式;
支持表格图片识别成Word文档(.docx)格式,支持多表格识别。
优爱酷使用AI技术将无比庞大的文字识别功能从网络端,轻量化到桌面端,本地化OCR识别库,本地识别文字,使您无需顾虑涉密信息或隐私数据的泄露。
点击原文链接下载更多软件。
或直接免费下载地址:
https://gitee.com/uicoolcn/UiCoolOCR/releases
用法
帮助里可以选择多种手机品牌,之后,按步骤做即可,非常直观和易操作。
有线连接的话,插入数据线即可
连接中
连接成功
可选固定在窗口的位置
关注不迷路
∷
加个星标约定再见~
— 完 —
本文系新浪微博、知乎内容激励计划签约账号【】原创内容
© 本文著作权归优爱酷所有,未经优爱酷授权,禁止转载使用。
刮刮卡
微信扫码关注【优爱酷】回复【AnLink】获取直接下载链接
提示:手机上长按色块复制 查看全部
《玩转无线投屏》连载№2:轻松地在PC上操作手机
引言
从苹果 Mac + iPhone 的接力/通用剪贴板,到华为的多屏协同,越来越多人意识到手机和电脑之间的交互如跨屏控制/同步剪贴板等功能确实能提高使用方便程度以及效率的。
小米12 Pro 骁龙8 Gen1 2K AMOLED 120Hz高刷 5000万疾速影像 120W小米澎湃秒充 12GB+256GB 黑色 5G手机
———————
京东价:¥5199.00
抢购链接:
那有没有什么办法通过软件打通限制,在电脑上更好的「玩」手机呢?
优爱酷今天分享的软件,可以轻松地在PC上操作手机,支持所有品牌的Android手机,WiFi和USB连接,多点触控,共享剪贴板等,且看
文末获取 工具下载链接
功能
所有Android手机
谷歌、HTC、华为、联想、Mi、OnePlus、Oppo、Realme、三星、索尼、Tecno、维梧等。
音频支持
你的电脑就是你的手机扬声器
键映射
帮助您在 PC 上玩移动 FPS 游戏。
屏幕录制
使用 AnLink 快速录制技术,减少 CPU 和 GPU 消耗。
键盘和输入法
使用键盘和输入法编辑器提高打字速度。
大而清晰
享受大屏体验,最清晰的镜像显示质量,支持硬件解码器以节省电池。
WiFi和USB
WiFi连接更方便,USB连接更流畅。
共享剪贴板
Ctrl+C和Ctrl+V也在手机和电脑之间工作。
多点触控
如果您可以触摸显示器屏幕,则支持手势。
文件管理器
通过拖放等方式在手机和PC之间传输文件。
“随心所欲 截您所需”
为批量截图而生,Chrome内核新版本发布啦!
IE内核版下载地址
https://gitee.com/uicoolcn/UiC ... eases
Chromium内核版下载地址
https://gitee.com/uicoolcn/UiC ... eases
优爱酷批量图像文字识别系统OCR
本软件与 “优爱酷批量长网页整页截图系统”配合使用,更加得心应手,只要是截得到的图,就可以用本软件进行批量OCR转为文字。
一款基于开放互操作人工智能的AI深度学习的OCR软件。
支持单图OCR 以及 自由截屏OCR识别、批量OCR、动态OCR(定时OCR);
支持五大场景结构化识别;
支持倾斜图像自动纠偏;
支持识别成文本文档(.txt)、Excel(.xlsx)格式;
支持表格图片识别成Word文档(.docx)格式,支持多表格识别。
优爱酷使用AI技术将无比庞大的文字识别功能从网络端,轻量化到桌面端,本地化OCR识别库,本地识别文字,使您无需顾虑涉密信息或隐私数据的泄露。
点击原文链接下载更多软件。
或直接免费下载地址:
https://gitee.com/uicoolcn/UiCoolOCR/releases
用法
帮助里可以选择多种手机品牌,之后,按步骤做即可,非常直观和易操作。
有线连接的话,插入数据线即可
连接中
连接成功
可选固定在窗口的位置
关注不迷路
∷
加个星标约定再见~
— 完 —
本文系新浪微博、知乎内容激励计划签约账号【】原创内容
© 本文著作权归优爱酷所有,未经优爱酷授权,禁止转载使用。
刮刮卡
微信扫码关注【优爱酷】回复【AnLink】获取直接下载链接
提示:手机上长按色块复制
网页音频抓取 基本请求库requests
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-05-02 03:40
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get")# 发起Post请求requests.post("https://www.httpbin.org/post")# 发起Put请求requests.put("https://www.httpbin.org/put")# 发起Delete请求requests.delete("https://www.httpbin.org/delete")
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/")# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证 查看全部
网页音频抓取 基本请求库requests
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get";)# 发起Post请求requests.post("https://www.httpbin.org/post";)# 发起Put请求requests.put("https://www.httpbin.org/put";)# 发起Delete请求requests.delete("https://www.httpbin.org/delete";)
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/";)# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证
网页音频抓取(如何使用IDM批量下载网页上面的音乐、音效等素材)
网站优化 • 优采云 发表了文章 • 0 个评论 • 532 次浏览 • 2022-04-20 20:06
Internet Download Manager(简称IDM)是一款优秀的多线程下载工具。其受欢迎的原因是下载速度快,并且可以批量操作下载。
本期给大家讲讲如何使用IDM批量下载网页上的音乐、音效等素材。
一、点击打开软件进入网页
图 1:点击站点爬取
首先点击IDM软件,然后点击软件上的【Site Capture】功能,该功能可以直接保存网站上的任何信息、音频等资源。
图 2:复制链接
那我们以QQ浏览器为例,随机进入一个有音乐的页面。这里我们进入【音效素材下载-音效大全】页面。这个界面有很多音效,可以在线预览和下载。
二、复制网址,粘贴网址
图 3:粘贴 网站in
我们现在要做的就是复制页面的URL,并将其粘贴到IDM的[站点抓取功能]的第二列中。第一列是你的网站爬取方案的名称,最后会和你的设置一起保存在你需要存放的地方。建议将保存文件的名称更改为您需要的名称。
然后点击【转发】,根据需要保存需要的内容。除非有需要,这一步可以保持不变。
然后在此页面上,将[Explore specified link depth]更改为[3 root site link depth]。
图 4:调整根站点深度
这一步是获取音效下载页面的链接,因为在这个界面点击下载音乐会进入另一个界面下载。在这波操作中,我们直接把这三个接口的音频资源全部取回并下载。
然后点击【前进】进入下一波操作。
三、文件类型,等待下载
图 5:转换音频文件
最后一步是调整【文件类型】,因为我们是在下载音频资源,所以我们把这个界面第一栏的【所有文件】替换为【音频资源】,如果我们不做这一步,那么下载将是该界面的所有资源,包括图片、音频、视频、PDF、压缩包等文件。
图 6:等待下载和保存
当我们完成切换并点击【转发】后,该页面上的所有音频文件都会被下载。而且还可以抓取多个窗口,非常方便。但是需要注意的是网站音效资源必须是mp3、wma和waw这三种后缀格式,否则会因为IDM无法识别音频资源而导致保存失败。 查看全部
网页音频抓取(如何使用IDM批量下载网页上面的音乐、音效等素材)
Internet Download Manager(简称IDM)是一款优秀的多线程下载工具。其受欢迎的原因是下载速度快,并且可以批量操作下载。
本期给大家讲讲如何使用IDM批量下载网页上的音乐、音效等素材。
一、点击打开软件进入网页
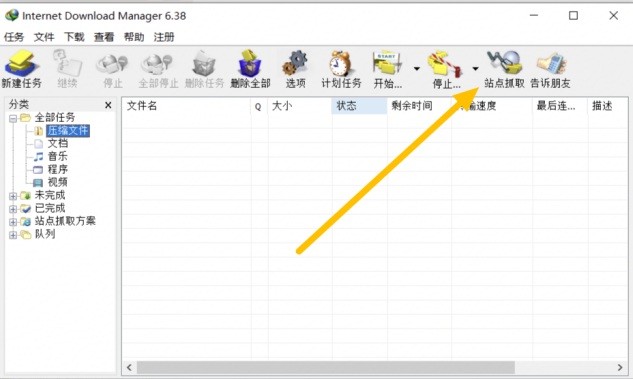
图 1:点击站点爬取
首先点击IDM软件,然后点击软件上的【Site Capture】功能,该功能可以直接保存网站上的任何信息、音频等资源。
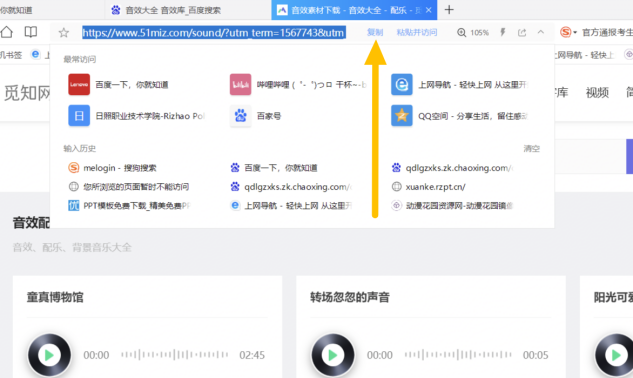
图 2:复制链接
那我们以QQ浏览器为例,随机进入一个有音乐的页面。这里我们进入【音效素材下载-音效大全】页面。这个界面有很多音效,可以在线预览和下载。
二、复制网址,粘贴网址
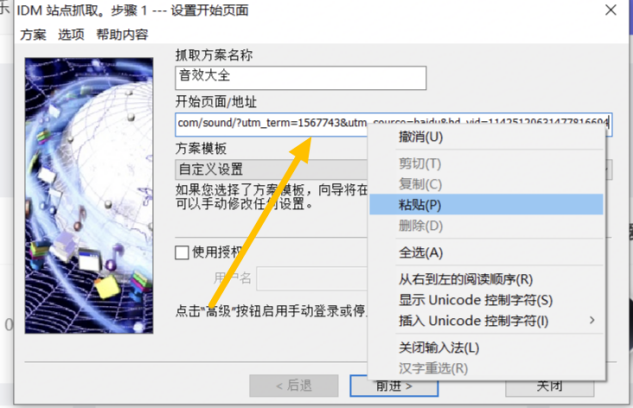
图 3:粘贴 网站in
我们现在要做的就是复制页面的URL,并将其粘贴到IDM的[站点抓取功能]的第二列中。第一列是你的网站爬取方案的名称,最后会和你的设置一起保存在你需要存放的地方。建议将保存文件的名称更改为您需要的名称。
然后点击【转发】,根据需要保存需要的内容。除非有需要,这一步可以保持不变。
然后在此页面上,将[Explore specified link depth]更改为[3 root site link depth]。
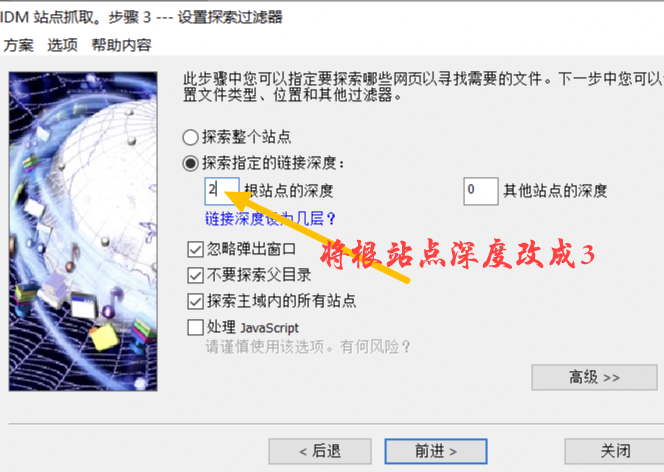
图 4:调整根站点深度
这一步是获取音效下载页面的链接,因为在这个界面点击下载音乐会进入另一个界面下载。在这波操作中,我们直接把这三个接口的音频资源全部取回并下载。
然后点击【前进】进入下一波操作。
三、文件类型,等待下载
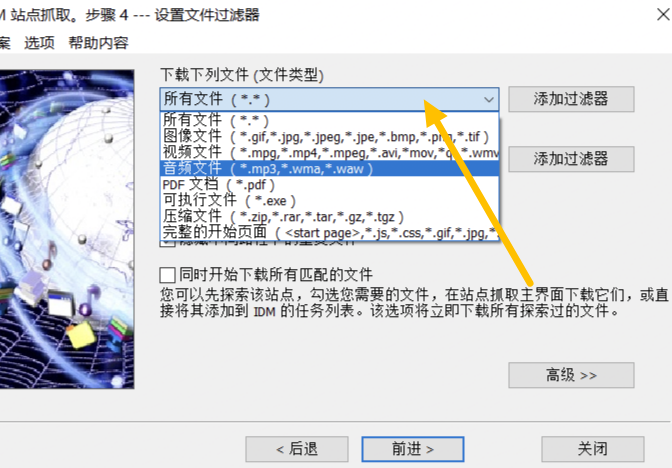
图 5:转换音频文件
最后一步是调整【文件类型】,因为我们是在下载音频资源,所以我们把这个界面第一栏的【所有文件】替换为【音频资源】,如果我们不做这一步,那么下载将是该界面的所有资源,包括图片、音频、视频、PDF、压缩包等文件。
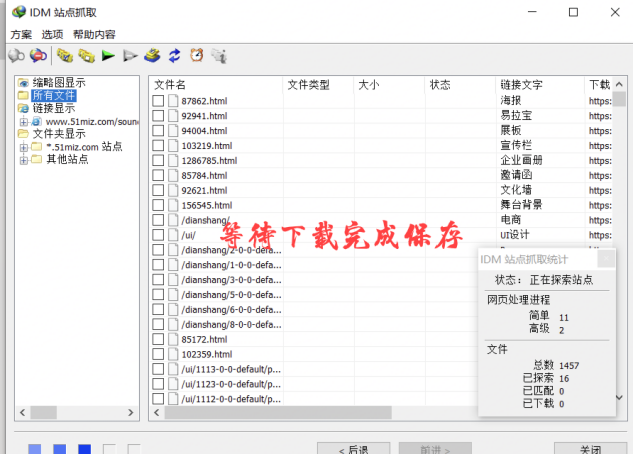
图 6:等待下载和保存
当我们完成切换并点击【转发】后,该页面上的所有音频文件都会被下载。而且还可以抓取多个窗口,非常方便。但是需要注意的是网站音效资源必须是mp3、wma和waw这三种后缀格式,否则会因为IDM无法识别音频资源而导致保存失败。
网页音频抓取( 猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-20 10:16
猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
猫抓
猫渣是一个支持所有Chrome核心浏览器的网络媒体嗅探和抓取的扩展。
可以一键抓取任意站点的任意视频/音频数据,使用非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮,就可以在这个页面看到资源信息了。
然后可以对资源进行三个操作:复制链接地址,小窗口播放,下载到本地电脑。
猫扎支持优酷、搜狐、腾讯、微博、B站等国内几乎所有网站的视频文件嗅探。
当您在同一页面上遇到多个属性时,您还可以对它们进行快速批量操作。
此类嗅探工具支持的短视频文件一般都是未加密的。面对一些加密视频时,会有一定的失败概率。
不过从市场反馈来看,猫爪可以抢到很多其他扩展,包括IDM都无法嗅到的媒体资源。
这就是它在竞争性扩展商店中拥有超过 50,000 名用户的原因之一。
此外,猫爪还支持所有音乐网站的音频文件嗅探,包括Qzone的SWF模块和音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,也支持使用正则表达式自定义采集的内容。
网络嗅探器原本是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。嗅探器也是许多程序员在编写网络程序时捕获和测试数据包的工具。
近年来,网络嗅探器已广泛应用于用户的日常行为,成为捕捉视频、音频等内容的工具。 查看全部
网页音频抓取(
猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)

猫抓

猫渣是一个支持所有Chrome核心浏览器的网络媒体嗅探和抓取的扩展。
可以一键抓取任意站点的任意视频/音频数据,使用非常方便。

安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮,就可以在这个页面看到资源信息了。
然后可以对资源进行三个操作:复制链接地址,小窗口播放,下载到本地电脑。

猫扎支持优酷、搜狐、腾讯、微博、B站等国内几乎所有网站的视频文件嗅探。
当您在同一页面上遇到多个属性时,您还可以对它们进行快速批量操作。

此类嗅探工具支持的短视频文件一般都是未加密的。面对一些加密视频时,会有一定的失败概率。
不过从市场反馈来看,猫爪可以抢到很多其他扩展,包括IDM都无法嗅到的媒体资源。
这就是它在竞争性扩展商店中拥有超过 50,000 名用户的原因之一。

此外,猫爪还支持所有音乐网站的音频文件嗅探,包括Qzone的SWF模块和音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,也支持使用正则表达式自定义采集的内容。

网络嗅探器原本是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。嗅探器也是许多程序员在编写网络程序时捕获和测试数据包的工具。
近年来,网络嗅探器已广泛应用于用户的日常行为,成为捕捉视频、音频等内容的工具。
网页音频抓取(一个网络爬虫程序的基本执行流程可以总结框架简介)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-19 21:25
scrapy框架介绍
scrapy 是一个用 Python 语言编写的开源网络爬虫框架(基于 Twisted 框架),目前支持
由 scrapinghub Ltd. 维护。Scrapy 易于使用、灵活且可扩展,拥有活跃的开发社区,并且是跨平台的。适用于 Linux、MaxOS 和 Windows 平台。
网络爬虫
网络爬虫是一种自动爬取互联网上网站内容信息的程序,也称为网络蜘蛛或网络机器人。大型爬虫广泛应用于搜索引擎、数据挖掘等领域。个人用户或企业也可以使用爬虫为自己采集有价值的数据。
网络爬虫的基本执行过程可以概括为三个过程:请求数据、解析数据和保存数据
数据请求
请求的数据除了普通的HTML,还包括json数据、字符串数据、图片、视频、音频等。
解析数据
数据下载完成后,分析数据内容并提取所需数据。提取的数据可以以各种形式保存。数据格式有很多种,常见的有csv、json、pickle等。
保存数据
最后将数据以某种格式(CSV、JSON)写入文件,或存储在数据库(MySQL、MongoDB)中。同时保存为一个或多个。
通常我们要获取的数据不只是在一个页面中,而是分布在多个页面中,这些页面是相互关联的,一个页面可能收录一个或多个指向其他页面的链接,提取当前后页面中的数据,页面中的一些链接也被提取出来,然后对链接的页面进行爬取(循环1-3步)。
在设计爬虫程序时,还需要考虑防止对同一页面的重复爬取(URL去重)、网页搜索策略(深度优先或广度优先等)、限制访问等一系列问题。爬虫访问边界。
从头开始开发爬虫程序是一项乏味的任务。为了避免大量的时间花在制造轮子上,我们在实际应用中可以选择使用一些优秀的爬虫框架。使用框架可以降低开发成本并提高程序质量。让我们专注于业务逻辑(抓取有价值的数据)。接下来带大家学习一下非常流行的开源爬虫框架Scrapy。
scrapy 安装
scrapy官网:
scrapy中文文档:
安装方法
在任何操作系统上,都可以使用 pip 安装 Scrapy,例如:
pip install scrapy
安装完成后,我们需要测试是否安装成功,通过以下步骤确认:
测试scrapy命令是否可以在终端执行
scrapy 2.4.0 - no active project
usage:
scrapy [options] [args]
Available commands :
bench Run quick benchmark test
fetch Fetch a URL using the scrapy down1oader
genspider Generate new spider using pre-defined temp1ates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
she11 Interactive scraping console
startproject create new project
version Print scrapy version
view open URL in browser,as seen by scrapy
[ more ] More commands available when run from project directory
use "scrapy -h" to see more info about a command
进入scrapy bench测试连通性,如果出现以下情况,则安装成功:
图像.png
通过以上两项测试,说明Scrapy安装成功。如上图,我们安装了当前最新版本2.4.0.
注意:
在安装Scrapy的过程中,可能会遇到缺少VC++等错误,可以安装缺少模块的离线包
图像.png
安装成功后,在cmd下运行scrapy和上图并不是真的成功。检查scrapybench测试是否真的成功。如果没有错误,说明安装成功。
全局命令
scrapy 2.4.0 - no active project
usage:
scrapy [options] [args]
Available commands :
bench Run quick benchmark test #测试电脑性能
fetch Fetch a URL using the scrapy down1oader#将源代码下载下来并显示出来
genspider Generate new spider using pre-defined temp1ates#创建一个新的spider文件
runspider Run a self-contained spider (without creating a project)# 这个和通过craw1启动爬虫不同,scrapy runspider爬虫文件名称
settings Get settings values#获取当前的配置信息
she11 Interactive scraping console#进入scrapy 的交互模式
startproject create new project#创建爬虫项目
version Print scrapy version#显示scrapy框架的版本
view open URL in browser,as seen by scrapy#将网页document内容下载下来,并且在浏览器显示出来
[ more ] More commands available when run from project directory
use "scrapy -h" to see more info about a command
项目命令先scrapy爬虫项目要求
在网站()上爬取名言警句,专为爬虫初学者训练爬虫技术。
创建一个项目
在开始抓取之前,必须创建一个新的 Scrapy 项目。转到您打算存储代码的目录并运行以下命令:
(base) λ scrapy startproject quotes
New scrapy project 'quotes ', using template directory 'd: \anaconda3\lib\site-packages\scrapy\temp1ates\project ', created in:
D:\XXX
You can start your first spider with :
cd quotes
scrapy genspider example example. com
首先切换到新创建的爬虫项目目录,即/quotes目录。然后执行命令创建爬虫文件:
D:\XXX(master)
(base) λ cd quotes\
D:\XXX\quotes (master)
(base) λ scrapy genspider quotes quotes.com
cannot create a spider with the same name as your project
D :\XXX\quotes (master)
(base) λ scrapy genspider quote quotes.com
created spider 'quote' using template 'basic' in module:quotes.spiders.quote
此命令将创建一个收录以下内容的引号目录
robots.txt
robots协议,也叫robots.txt(统一小写),是一个ASCII编码的文本文件,存放在网站的根目录下,通常告诉网络搜索引擎的网络蜘蛛这个网站 哪些内容不应该被搜索引擎爬虫获取,哪些内容可以被爬虫获取。
机器人协议不是规范,而是约定。
#filename : settings.py
#obey robots.txt rules
ROBOTSTXT__OBEY = False
分析页面
在编写爬虫程序之前,首先需要对要爬取的页面进行分析。主流浏览器都有分析页面的工具或插件。这里我们使用Chrome浏览器的开发者工具(Tools→Developer tools)来分析页面。
数据信息
在 Chrome 中打开页面并选择“元素”以查看其 HTML 代码。
可以看到每个标签都包裹在里面
图像.png
写蜘蛛
分析完页面,接下来就是编写爬虫了。用 Scrapy 写蜘蛛,用 scrapy.Spider 写代码 蜘蛛是用户编写的一个类,用于从单个 网站(或 - 一些 网站)中抓取数据。
它收录一个用于下载的初始URL,如何跟随网页中的链接以及如何分析页面中的内容,提取生成项目的方法。
为了创建一个Spider,你必须扩展scrapy.Spider类并定义以下三个属性:
name:用于区分Spider。名称必须唯一,不能为不同的蜘蛛设置相同的名称。 start _urls:收录 Spider 在启动时爬取的 urs 列表。因此,
要获取的第一页将是其中之一。从初始 URL 获得的数据中提取后续 URL。 parse():是蜘蛛的一种方法。调用时,每个初始 URL 完成下载后生成的 Response 对象将作为唯一参数传递给此函数。该方法负责解析返回的数据(响应
data),提取数据(生成项目)并为需要进一步处理的 URL 生成 Request 对象。
import scrapy
class QuoteSpi der(scrapy . Spider):
name ='quote'
allowed_ domains = [' quotes. com ']
start_ urls = ['http://quotes . toscrape . com/']
def parse(self, response) :
pass
下面简单介绍一下quote的实现。
页面解析函数通常实现为生成器函数,从页面中提取的每一项数据以及对链接页面的每个下载请求都通过yield语句提交给Scrapy引擎。
解析数据
import scrapy
def parse(se1f,response) :
quotes = response.css('.quote ')
for quote in quotes:
text = quote.css( '.text: :text ' ).extract_first()
auth = quote.css( '.author : :text ' ).extract_first()
tages = quote.css('.tags a: :text' ).extract()
yield dict(text=text,auth=auth,tages=tages)
关键点:
response.css(response中的数据可以直接用css语法提取。start_ur1s中可以写多个url,可以拆分成列表格式。extract()就是提取css中的数据对象,提取后为List,否则为对象。而extract_first()是提取第一个运行的爬虫
运行/quotes目录下的scrapycrawlquotes,运行爬虫项目。
运行爬虫后发生了什么?
Scrapy 为 Spider 的 start_urls 属性中的每个 URL 创建一个 scrapy.Request 对象,并将 parse 方法分配给 Request 作为回调函数。
Request对象被调度,执行生成一个scrapy.http.Response对象并发回spider的parse()方法处理。
完成代码后,运行爬虫爬取数据,在shell中执行scrapy crawl命令运行爬虫'quote',并将爬取的数据存储在csv文件中:
(base) λ scrapy craw1 quote -o quotes.csv
2021-06-19 20:48:44 [scrapy.utils.log] INF0: Scrapy 1.8.0 started (bot: quotes)
等待爬虫运行结束后,会在当前目录生成一个quotes.csv文件,其中的数据已经以csv格式保存。
-o 支持保存为各种格式。保存的方式也很简单,只要给出文件的后缀名即可。 (csv、json、pickle等) 查看全部
网页音频抓取(一个网络爬虫程序的基本执行流程可以总结框架简介)
scrapy框架介绍
scrapy 是一个用 Python 语言编写的开源网络爬虫框架(基于 Twisted 框架),目前支持
由 scrapinghub Ltd. 维护。Scrapy 易于使用、灵活且可扩展,拥有活跃的开发社区,并且是跨平台的。适用于 Linux、MaxOS 和 Windows 平台。
网络爬虫
网络爬虫是一种自动爬取互联网上网站内容信息的程序,也称为网络蜘蛛或网络机器人。大型爬虫广泛应用于搜索引擎、数据挖掘等领域。个人用户或企业也可以使用爬虫为自己采集有价值的数据。
网络爬虫的基本执行过程可以概括为三个过程:请求数据、解析数据和保存数据
数据请求
请求的数据除了普通的HTML,还包括json数据、字符串数据、图片、视频、音频等。
解析数据
数据下载完成后,分析数据内容并提取所需数据。提取的数据可以以各种形式保存。数据格式有很多种,常见的有csv、json、pickle等。
保存数据
最后将数据以某种格式(CSV、JSON)写入文件,或存储在数据库(MySQL、MongoDB)中。同时保存为一个或多个。
通常我们要获取的数据不只是在一个页面中,而是分布在多个页面中,这些页面是相互关联的,一个页面可能收录一个或多个指向其他页面的链接,提取当前后页面中的数据,页面中的一些链接也被提取出来,然后对链接的页面进行爬取(循环1-3步)。
在设计爬虫程序时,还需要考虑防止对同一页面的重复爬取(URL去重)、网页搜索策略(深度优先或广度优先等)、限制访问等一系列问题。爬虫访问边界。
从头开始开发爬虫程序是一项乏味的任务。为了避免大量的时间花在制造轮子上,我们在实际应用中可以选择使用一些优秀的爬虫框架。使用框架可以降低开发成本并提高程序质量。让我们专注于业务逻辑(抓取有价值的数据)。接下来带大家学习一下非常流行的开源爬虫框架Scrapy。
scrapy 安装
scrapy官网:
scrapy中文文档:
安装方法
在任何操作系统上,都可以使用 pip 安装 Scrapy,例如:
pip install scrapy
安装完成后,我们需要测试是否安装成功,通过以下步骤确认:
测试scrapy命令是否可以在终端执行
scrapy 2.4.0 - no active project
usage:
scrapy [options] [args]
Available commands :
bench Run quick benchmark test
fetch Fetch a URL using the scrapy down1oader
genspider Generate new spider using pre-defined temp1ates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
she11 Interactive scraping console
startproject create new project
version Print scrapy version
view open URL in browser,as seen by scrapy
[ more ] More commands available when run from project directory
use "scrapy -h" to see more info about a command
进入scrapy bench测试连通性,如果出现以下情况,则安装成功:
图像.png
通过以上两项测试,说明Scrapy安装成功。如上图,我们安装了当前最新版本2.4.0.
注意:
在安装Scrapy的过程中,可能会遇到缺少VC++等错误,可以安装缺少模块的离线包
图像.png
安装成功后,在cmd下运行scrapy和上图并不是真的成功。检查scrapybench测试是否真的成功。如果没有错误,说明安装成功。
全局命令
scrapy 2.4.0 - no active project
usage:
scrapy [options] [args]
Available commands :
bench Run quick benchmark test #测试电脑性能
fetch Fetch a URL using the scrapy down1oader#将源代码下载下来并显示出来
genspider Generate new spider using pre-defined temp1ates#创建一个新的spider文件
runspider Run a self-contained spider (without creating a project)# 这个和通过craw1启动爬虫不同,scrapy runspider爬虫文件名称
settings Get settings values#获取当前的配置信息
she11 Interactive scraping console#进入scrapy 的交互模式
startproject create new project#创建爬虫项目
version Print scrapy version#显示scrapy框架的版本
view open URL in browser,as seen by scrapy#将网页document内容下载下来,并且在浏览器显示出来
[ more ] More commands available when run from project directory
use "scrapy -h" to see more info about a command
项目命令先scrapy爬虫项目要求
在网站()上爬取名言警句,专为爬虫初学者训练爬虫技术。
创建一个项目
在开始抓取之前,必须创建一个新的 Scrapy 项目。转到您打算存储代码的目录并运行以下命令:
(base) λ scrapy startproject quotes
New scrapy project 'quotes ', using template directory 'd: \anaconda3\lib\site-packages\scrapy\temp1ates\project ', created in:
D:\XXX
You can start your first spider with :
cd quotes
scrapy genspider example example. com
首先切换到新创建的爬虫项目目录,即/quotes目录。然后执行命令创建爬虫文件:
D:\XXX(master)
(base) λ cd quotes\
D:\XXX\quotes (master)
(base) λ scrapy genspider quotes quotes.com
cannot create a spider with the same name as your project
D :\XXX\quotes (master)
(base) λ scrapy genspider quote quotes.com
created spider 'quote' using template 'basic' in module:quotes.spiders.quote
此命令将创建一个收录以下内容的引号目录
robots.txt
robots协议,也叫robots.txt(统一小写),是一个ASCII编码的文本文件,存放在网站的根目录下,通常告诉网络搜索引擎的网络蜘蛛这个网站 哪些内容不应该被搜索引擎爬虫获取,哪些内容可以被爬虫获取。
机器人协议不是规范,而是约定。
#filename : settings.py
#obey robots.txt rules
ROBOTSTXT__OBEY = False
分析页面
在编写爬虫程序之前,首先需要对要爬取的页面进行分析。主流浏览器都有分析页面的工具或插件。这里我们使用Chrome浏览器的开发者工具(Tools→Developer tools)来分析页面。
数据信息
在 Chrome 中打开页面并选择“元素”以查看其 HTML 代码。
可以看到每个标签都包裹在里面
图像.png
写蜘蛛
分析完页面,接下来就是编写爬虫了。用 Scrapy 写蜘蛛,用 scrapy.Spider 写代码 蜘蛛是用户编写的一个类,用于从单个 网站(或 - 一些 网站)中抓取数据。
它收录一个用于下载的初始URL,如何跟随网页中的链接以及如何分析页面中的内容,提取生成项目的方法。
为了创建一个Spider,你必须扩展scrapy.Spider类并定义以下三个属性:
name:用于区分Spider。名称必须唯一,不能为不同的蜘蛛设置相同的名称。 start _urls:收录 Spider 在启动时爬取的 urs 列表。因此,
要获取的第一页将是其中之一。从初始 URL 获得的数据中提取后续 URL。 parse():是蜘蛛的一种方法。调用时,每个初始 URL 完成下载后生成的 Response 对象将作为唯一参数传递给此函数。该方法负责解析返回的数据(响应
data),提取数据(生成项目)并为需要进一步处理的 URL 生成 Request 对象。
import scrapy
class QuoteSpi der(scrapy . Spider):
name ='quote'
allowed_ domains = [' quotes. com ']
start_ urls = ['http://quotes . toscrape . com/']
def parse(self, response) :
pass
下面简单介绍一下quote的实现。
页面解析函数通常实现为生成器函数,从页面中提取的每一项数据以及对链接页面的每个下载请求都通过yield语句提交给Scrapy引擎。
解析数据
import scrapy
def parse(se1f,response) :
quotes = response.css('.quote ')
for quote in quotes:
text = quote.css( '.text: :text ' ).extract_first()
auth = quote.css( '.author : :text ' ).extract_first()
tages = quote.css('.tags a: :text' ).extract()
yield dict(text=text,auth=auth,tages=tages)
关键点:
response.css(response中的数据可以直接用css语法提取。start_ur1s中可以写多个url,可以拆分成列表格式。extract()就是提取css中的数据对象,提取后为List,否则为对象。而extract_first()是提取第一个运行的爬虫
运行/quotes目录下的scrapycrawlquotes,运行爬虫项目。
运行爬虫后发生了什么?
Scrapy 为 Spider 的 start_urls 属性中的每个 URL 创建一个 scrapy.Request 对象,并将 parse 方法分配给 Request 作为回调函数。
Request对象被调度,执行生成一个scrapy.http.Response对象并发回spider的parse()方法处理。
完成代码后,运行爬虫爬取数据,在shell中执行scrapy crawl命令运行爬虫'quote',并将爬取的数据存储在csv文件中:
(base) λ scrapy craw1 quote -o quotes.csv
2021-06-19 20:48:44 [scrapy.utils.log] INF0: Scrapy 1.8.0 started (bot: quotes)
等待爬虫运行结束后,会在当前目录生成一个quotes.csv文件,其中的数据已经以csv格式保存。
-o 支持保存为各种格式。保存的方式也很简单,只要给出文件的后缀名即可。 (csv、json、pickle等)
网页音频抓取(Python库:pyAudioAnalysis特征提取音频分析任务 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-15 22:22
)
pyAudioAnalysis 是一个开放的 Python 库,提供了许多与音频相关的功能,专注于特征提取、分类、分割和可视化问题。
特征
pyAudioAnalysis 是一个 Python 库,涵盖了广泛的音频分析任务。
使用 pyAudioAnalysis,您可以:
实用功能
将 Mp3 批量转换为 Wav
函数 convertDirMP3ToWav(dirName, Fs, nC, useMp3TagsAsName = False) 使用提供的采样率(第二个参数)和通道数(第三个参数)将文件夹 dirName 的所有 MP3 文件转换为 WAV 文件。如果最后一个参数 (useMp3TagsAsName) 设置为 True,则输出的 WAV 文件将使用 MP3 标签(艺术家和歌曲名称)命名,否则将使用 MP3 文件名(当然,扩展名为 .wav)
命令行使用示例
python audioAnalysis.py dirMp3toWav -i MusicData/ -r 16000 -c 1
或者,convertFsDirWavToWav() 函数可用于将存储在特定文件夹中的 WAV 列表转换为具有另一个采样率的相同信号的新列表(同样是 WAV 文件)。通讯示例:
python audioAnalysis.py dirWavResample -i MusicData/ -r 8000 -c 1
新文件存储在名为 Fs_Nc 的新文件夹下,例如 Fs8000_NC1
pyAudioAnalysis - Theodoros Giannakopoulos
下载并安装
下载包:pyAudioAnalysis模块下载
安装依赖: pip install -r ./requirements.txt
使用 pip 安装: pip install -e
音频分类示例
pyAudioAnalysis 提供易于调用的包装器来执行音频分析任务。例如,给定一组存储在文件夹中的 WAV 文件(每个文件夹代表不同的类别),此代码首先训练一个音频片段分类器,然后使用训练好的分类器对未知音频 WAV 文件进行分析分类:
aT.extract_features_and_train(["classifierData/music","classifierData/speech"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "svm", "svmSMtemp", False)aT.file_classification("data/doremi.wav", "svmSMtemp","svm")``` 查看全部
网页音频抓取(Python库:pyAudioAnalysis特征提取音频分析任务
)
pyAudioAnalysis 是一个开放的 Python 库,提供了许多与音频相关的功能,专注于特征提取、分类、分割和可视化问题。

特征
pyAudioAnalysis 是一个 Python 库,涵盖了广泛的音频分析任务。
使用 pyAudioAnalysis,您可以:
实用功能
将 Mp3 批量转换为 Wav
函数 convertDirMP3ToWav(dirName, Fs, nC, useMp3TagsAsName = False) 使用提供的采样率(第二个参数)和通道数(第三个参数)将文件夹 dirName 的所有 MP3 文件转换为 WAV 文件。如果最后一个参数 (useMp3TagsAsName) 设置为 True,则输出的 WAV 文件将使用 MP3 标签(艺术家和歌曲名称)命名,否则将使用 MP3 文件名(当然,扩展名为 .wav)
命令行使用示例
python audioAnalysis.py dirMp3toWav -i MusicData/ -r 16000 -c 1
或者,convertFsDirWavToWav() 函数可用于将存储在特定文件夹中的 WAV 列表转换为具有另一个采样率的相同信号的新列表(同样是 WAV 文件)。通讯示例:
python audioAnalysis.py dirWavResample -i MusicData/ -r 8000 -c 1
新文件存储在名为 Fs_Nc 的新文件夹下,例如 Fs8000_NC1
pyAudioAnalysis - Theodoros Giannakopoulos
下载并安装
下载包:pyAudioAnalysis模块下载
安装依赖: pip install -r ./requirements.txt
使用 pip 安装: pip install -e

音频分类示例
pyAudioAnalysis 提供易于调用的包装器来执行音频分析任务。例如,给定一组存储在文件夹中的 WAV 文件(每个文件夹代表不同的类别),此代码首先训练一个音频片段分类器,然后使用训练好的分类器对未知音频 WAV 文件进行分析分类:
aT.extract_features_and_train(["classifierData/music","classifierData/speech"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "svm", "svmSMtemp", False)aT.file_classification("data/doremi.wav", "svmSMtemp","svm")```
网页音频抓取( 如何研究喜马拉雅FM的请求方式?下载器怎么做? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2022-04-10 13:31
如何研究喜马拉雅FM的请求方式?下载器怎么做?
)
Java爬取喜马拉雅非付费音频
内容
前言
因为很喜欢喜马拉雅FM上的音频节目,之前也找过一些喜马拉雅音频下载器。可能是网站调整的原因,有的下载器慢慢有问题,估计有些地址无法解析,于是想到研究喜马拉雅FM的请求方法,用java模拟请求,和做一个我自己的小。玩的工具。
下面开始研究喜马拉雅FM的请求方法吧!
1 打开 Himalaya网站 并搜索节目
喜马拉雅调频
下面是一个我喜欢的程序的例子,以“首席医疗官”为例
2 研究其数据源并获取分页数据
打开浏览器控制台,清除网络下的日志
点击任意页面查看网络下的日志
从上面两张图可以看出,分页后的数据来自于请求:
解析返回的json数据可以得到分页信息
3 获取列表信息
在上面的控制台中,还有一个查看列表信息的请求
每个音频的基本信息可以从上面的请求中获取
4 获取音频下载地址
清除浏览器控制台,点击任意音频,查看网络地址
从这个请求中,我们也可以得到列表信息和音频的下载地址
5 核心代码
Java实现爬取喜马拉雅音频文件(非付费)
代码是最基础的,以后有时间会优化,比如增加多线程下载、图形界面、断点续传等。有兴趣的童鞋欢迎博客或GitHub评论^_^
有时间可以尝试做一个前端版本,使用ajax请求自己设计页面,这相当于做一个喜马拉雅FM免费音频的搜索引擎,直接在浏览器搜索下载^_^,然后一起分享~
6 基本用途
主要功能如下
public static void main(String[] args){
//初始化音频列表,修改专辑ID便可下载该专辑的音频内容(非付费)
AudioBean audioBean = AudioDealUtil.initBean(
"https://www.ximalaya.com/revision/album",
"albumId=3071659");
//修改下载路径
AudioDealUtil.initDownloadAudio("https://www.ximalaya.com/revision/play/album",
audioBean,
"D://download//");
}
只需更改专辑ID和本地路径即可下载音频~
查看全部
网页音频抓取(
如何研究喜马拉雅FM的请求方式?下载器怎么做?
)
Java爬取喜马拉雅非付费音频
内容
前言
因为很喜欢喜马拉雅FM上的音频节目,之前也找过一些喜马拉雅音频下载器。可能是网站调整的原因,有的下载器慢慢有问题,估计有些地址无法解析,于是想到研究喜马拉雅FM的请求方法,用java模拟请求,和做一个我自己的小。玩的工具。
下面开始研究喜马拉雅FM的请求方法吧!
1 打开 Himalaya网站 并搜索节目
喜马拉雅调频
下面是一个我喜欢的程序的例子,以“首席医疗官”为例



2 研究其数据源并获取分页数据
打开浏览器控制台,清除网络下的日志

点击任意页面查看网络下的日志



从上面两张图可以看出,分页后的数据来自于请求:
解析返回的json数据可以得到分页信息
3 获取列表信息
在上面的控制台中,还有一个查看列表信息的请求


每个音频的基本信息可以从上面的请求中获取
4 获取音频下载地址
清除浏览器控制台,点击任意音频,查看网络地址



从这个请求中,我们也可以得到列表信息和音频的下载地址
5 核心代码
Java实现爬取喜马拉雅音频文件(非付费)
代码是最基础的,以后有时间会优化,比如增加多线程下载、图形界面、断点续传等。有兴趣的童鞋欢迎博客或GitHub评论^_^
有时间可以尝试做一个前端版本,使用ajax请求自己设计页面,这相当于做一个喜马拉雅FM免费音频的搜索引擎,直接在浏览器搜索下载^_^,然后一起分享~
6 基本用途
主要功能如下
public static void main(String[] args){
//初始化音频列表,修改专辑ID便可下载该专辑的音频内容(非付费)
AudioBean audioBean = AudioDealUtil.initBean(
"https://www.ximalaya.com/revision/album",
"albumId=3071659");
//修改下载路径
AudioDealUtil.initDownloadAudio("https://www.ximalaya.com/revision/play/album",
audioBean,
"D://download//");
}
只需更改专辑ID和本地路径即可下载音频~

网页音频抓取(页面分析我们要下载音频文件,首先得要找到下载音频的url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2022-04-10 13:30
页面分析
我们要下载音频文件,首先要找到下载音频的url,我们打开浏览器自带的调试工具(我用的是Chrome),使用快捷键F12快速打开调试工具。调试器切换到网络。我以刚看完的《腾讯传》为例,点击专辑封面中间的播放按钮。专辑中的音频信息都是json格式的数据。共有7个音频文件。
任意扩展音频的详细信息,详细信息包括音频文件的标题和下载链接。找到音频的下载链接后,就可以下载音频了。接下来的工作将重点介绍如何获取音频文件的下载链接。
获取页面源代码
我们首先定义一个函数来获取页面的html信息。浏览器标头信息标头被添加到此函数中。为了安全起见,使用代理IP。有兴趣的可以自己创建一个IP代理池,IP失效时会自动替换。
获取专辑信息
接下来,我们需要获取专辑的ID,因为音频的下载链接是由专辑ID拼接而成的。让我们看看收录音频文件名和下载链接信息的标题。我们可以看到albumId是专辑链接组成中的专辑ID。表示当前页码和该页存储的最大音频数。
相册的ID信息收录在关键字搜索的信息中。
专辑的ID信息通过BeautifulSoup从页面中提取出来,专辑标题信息也提取出来作为后面要创建的专辑目录名。主要代码如下。
获取页数
上述方法获取专辑ID信息。接下来,我们需要知道专辑下共享了多少页音频文件。我们通过将音频总数除以30得到页数。音频总数的信息在音频文件列表的数据中。下图中,我以《明朝事迹》为例,有大量的音频文件,一共268个音频文件。
有了音频总数,每页的音频数是30,所以我们可以计算出页数,可以分为3种情况:总数小于等于30,总数大于30和是30的倍数,总数大于30且不是30的倍数,相关代码如下。
下载音频文件
专辑ID、专辑名称、页数都在里面,音频文件就可以下载了。下载音频时,如果少于30个音频,需要做异常处理。音频文件为付费文件时,无法下载。这个时候,做出判断。当音频下载链接为null或None时,跳出循环爬取下一张专辑的文件。
在音频下载链接为空或无的情况下,这里以《明朝事迹》为例,通过关键字《明朝事迹》爬取的其中一张专辑总共只爬取了50个音频文件. ,以下音频文件不提供下载链接,无法下载。
创建一个目录来存储音频
为了将下载的音频文件有序的存放在以专辑名命名的文件夹中,我们使用代码自动创建一个目录,并将对应的文件下载到该目录中。
后记
本文的目的是将喜马拉雅的免费音频下载到本地并传输到手机上,让大家在保护视力的同时随时学习。当然,如果你有足够的流量,你也可以在APP上在线收听。
这个项目是通过输入关键字搜索音频专辑下载的。如果有些关键词没有对应的音频,系统会为你推荐音频,所以为了提高大家的效率,大家在运行代码之前,先下载喜马拉雅的音频网站输入你需要搜索的关键词看看有没有相关的音频,有的话就运行代码。一般来说,人气高的有声专辑都比较高。下载好需要的音频专辑后,后面的专辑不需要停止运行代码。
源码可在公众号“Python知识圈”回复“收听”获取。
如果觉得不错,点赞、点赞、转发到朋友圈,都是一种支持。
pk哥还没有开通留言功能,但是可以点击文章左下角的“阅读原文”进行留言。 查看全部
网页音频抓取(页面分析我们要下载音频文件,首先得要找到下载音频的url)
页面分析
我们要下载音频文件,首先要找到下载音频的url,我们打开浏览器自带的调试工具(我用的是Chrome),使用快捷键F12快速打开调试工具。调试器切换到网络。我以刚看完的《腾讯传》为例,点击专辑封面中间的播放按钮。专辑中的音频信息都是json格式的数据。共有7个音频文件。
任意扩展音频的详细信息,详细信息包括音频文件的标题和下载链接。找到音频的下载链接后,就可以下载音频了。接下来的工作将重点介绍如何获取音频文件的下载链接。
获取页面源代码
我们首先定义一个函数来获取页面的html信息。浏览器标头信息标头被添加到此函数中。为了安全起见,使用代理IP。有兴趣的可以自己创建一个IP代理池,IP失效时会自动替换。
获取专辑信息
接下来,我们需要获取专辑的ID,因为音频的下载链接是由专辑ID拼接而成的。让我们看看收录音频文件名和下载链接信息的标题。我们可以看到albumId是专辑链接组成中的专辑ID。表示当前页码和该页存储的最大音频数。
相册的ID信息收录在关键字搜索的信息中。
专辑的ID信息通过BeautifulSoup从页面中提取出来,专辑标题信息也提取出来作为后面要创建的专辑目录名。主要代码如下。
获取页数
上述方法获取专辑ID信息。接下来,我们需要知道专辑下共享了多少页音频文件。我们通过将音频总数除以30得到页数。音频总数的信息在音频文件列表的数据中。下图中,我以《明朝事迹》为例,有大量的音频文件,一共268个音频文件。
有了音频总数,每页的音频数是30,所以我们可以计算出页数,可以分为3种情况:总数小于等于30,总数大于30和是30的倍数,总数大于30且不是30的倍数,相关代码如下。
下载音频文件
专辑ID、专辑名称、页数都在里面,音频文件就可以下载了。下载音频时,如果少于30个音频,需要做异常处理。音频文件为付费文件时,无法下载。这个时候,做出判断。当音频下载链接为null或None时,跳出循环爬取下一张专辑的文件。
在音频下载链接为空或无的情况下,这里以《明朝事迹》为例,通过关键字《明朝事迹》爬取的其中一张专辑总共只爬取了50个音频文件. ,以下音频文件不提供下载链接,无法下载。
创建一个目录来存储音频
为了将下载的音频文件有序的存放在以专辑名命名的文件夹中,我们使用代码自动创建一个目录,并将对应的文件下载到该目录中。
后记
本文的目的是将喜马拉雅的免费音频下载到本地并传输到手机上,让大家在保护视力的同时随时学习。当然,如果你有足够的流量,你也可以在APP上在线收听。
这个项目是通过输入关键字搜索音频专辑下载的。如果有些关键词没有对应的音频,系统会为你推荐音频,所以为了提高大家的效率,大家在运行代码之前,先下载喜马拉雅的音频网站输入你需要搜索的关键词看看有没有相关的音频,有的话就运行代码。一般来说,人气高的有声专辑都比较高。下载好需要的音频专辑后,后面的专辑不需要停止运行代码。
源码可在公众号“Python知识圈”回复“收听”获取。
如果觉得不错,点赞、点赞、转发到朋友圈,都是一种支持。
pk哥还没有开通留言功能,但是可以点击文章左下角的“阅读原文”进行留言。
网页音频抓取(网站更新频率多少才合适?发布新内容帮助您影响抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-03 14:14
抓取率是指搜索引擎扫描机器人(也称为“蜘蛛”)向您的 网站 发送的请求数。他们系统地漫游万维网并浏览 网站 页面以寻找新的内容数据。虽然 网站 所有者无法控制此过程,但无法更改爬网频率。但是,不断发布新内容将帮助您影响爬虫的行为。
爬取频率对于 SEO 来说非常重要,如果 bot 不能有效地爬取,很多页面将不会被索引。从技术上讲,爬行是搜索引擎跟随某些链接以访问新链接的过程,这使得新页面被机器人注意到并快速编入索引。
百度使用一种算法来定义每个 网站 的最终扫描频率,您可以做很多事情来帮助搜索机器人加快抓取速度:例如 ping、站点地图提交、robots.txt 文件的使用、改进站点导航。但是,爬取效率取决于特定 Web 资源的特性,这些指标可以在复杂的环境中使用,而不是作为单独的一次性改进。
用户和搜索机器人都变得更加智能,用户寻找相关信息,而后者则试图更人性化地满足用户的搜索需求。
1.定期更新
内容更新有助于保持 网站 信息与用户的搜索需求相关,人们更有可能找到并分享您的网站。同时,扫描机器人会将其添加到可信资源列表中。内容更新得越频繁,爬虫就越频繁地注意到该站点。建议每周更新3次内容,最简单的方法是创建博客或添加音视频素材,这比不断添加新页面更容易有效。
参考:网站多久更新一次合适?
2.使用正常运行时间长的网络主机
当百度机器人在停机期间访问 网站 时,它们会记笔记并利用这种体验来设置较差的抓取频率,从而使用户更难找到您的网站。如果 网站 关闭的时间过长,预计会出现更糟糕的结果。这就是为什么选择可靠的服务器至关重要的原因,许多服务器现在提供 99% 的正常运行时间。
3.避免重复内容
对于网站蜘蛛机器人的爬取频率,同样的消息发两次不会增加网站的爬取频率。相反,用户和机器人都会被网站同一信息的不同部分弄糊涂。
因此,搜索引擎会降低网站的排名,甚至处罚、降低权限等。
参考:关于 网站 重复内容的 3 点思考
4.优化页面加载时间
页面加载时间是决定用户体验的因素之一,如果页面加载时间超过 5 秒,人们很可能会离开并移动到搜索结果列表中的下一个位置。加载时间取决于页面的大小,它在 网站 所有者的控制之下。可以删除所有多余的脚本、重图、动画、pdf文件和类似文件。
5.构建网站地图
对于百度机器人,网站地图是一个综合列表,点击链接到网站页面。在某种程度上,这是一个爬虫指令,您可以在其中指出应该和不应该索引的内容。
爬虫将是网站的状态检查器,经过多次更新后,最好邀请爬虫而不是等待它们到达。大多数 网站 爬虫工具使用相同的技术,允许机器人扫描特定的 网站 脚本以提供有关其内部组织的信息,例如内部链接、锚文本、图像、元标记等。
参考:网站为什么要添加 XML 站点地图?
6.获取更多反向链接
反向链接直接影响排名,反向链接高的资源会被更频繁地爬取。最好删除低质量的 网站 链接和过多的付费链接,以及避免或摆脱暗链接构建做法。
参考:什么是反向链接?以及反向链接的主要类型
7.添加 Meta 和标题标签
元标签和标题标签是搜索引擎在 网站 上寻找的第一件事,为不同的页面准备独特的标签,不要使用重复的标题。如果爬虫注意到具有相同标记的页面,他们可能会跳过其中一个页面。
标题不要填关键词,每页一个就够了。记得同步更新,如果你在内容中更改了一些 关键词,也要在标题中更改它们。元标签用于构建关于页面的数据,它们可以识别页面作者、地址和更新频率。他们参与为超文本文档创建标题并影响页面在结果中的显示方式。
8.优化图片
机器人不直接读取图像。为了增加搜索引擎蜘蛛的频率和速度,网站拥有者需要让搜索带着爬虫一起来了解他们在看什么。为此,使用 alt 标签,搜索引擎将能够索引简短的单词描述。只有优化的图像才会出现在搜索结果中,并会为您带来额外的流量。
9.使用 Ping 服务
这是向机器人显示您的 网站 上的某些内容已更新的最有效和快速的方法之一。有许多手动 ping 服务可以帮助您完成此任务,当您的 网站 上发布新内容时,它们会自动通知爬虫。
10.网站监控工具
使用百度网站管理工具将帮助您了解爬行速度和所有相关统计数据,从而分析蜘蛛的活动并提出最终改进策略。可以看到当前的爬取频率,哪些页面没有被索引,是什么原因,根据这个数据要求百度重新爬取一些页面。
参考:如何做SEO数据监控?
相关文章推荐5个SEO优化核心进入SEO行业不短不长,两年左右。和大佬们比起来,我算是比较晚了,不过对于我自己的优化水平还是有点自[...]...3 负SEO方法 负SEO可以有很多东西——其实不只是黑帽SEO技巧,如果有人发起了针对您和您的 [...] 的活动...SEO 基础:内部的简单 SEO 教程 [...]...如何让您的 网站 排名更高?人们经常问我如何改进他们的 SEO,SEO 代表搜索引擎优化,他们认为这是您在 网站 上设置的某种花哨的代码,就像即时 [...]...网站地图是什么?制作网站map时要注意的6个方面顾名思义,一个网站map本质上就是一个网站的map,帮助搜索引擎爬虫更好地理解和导航网站。在更专业的意义上,它是一个带有列的文件 […]… 查看全部
网页音频抓取(网站更新频率多少才合适?发布新内容帮助您影响抓取工具)
抓取率是指搜索引擎扫描机器人(也称为“蜘蛛”)向您的 网站 发送的请求数。他们系统地漫游万维网并浏览 网站 页面以寻找新的内容数据。虽然 网站 所有者无法控制此过程,但无法更改爬网频率。但是,不断发布新内容将帮助您影响爬虫的行为。
爬取频率对于 SEO 来说非常重要,如果 bot 不能有效地爬取,很多页面将不会被索引。从技术上讲,爬行是搜索引擎跟随某些链接以访问新链接的过程,这使得新页面被机器人注意到并快速编入索引。
百度使用一种算法来定义每个 网站 的最终扫描频率,您可以做很多事情来帮助搜索机器人加快抓取速度:例如 ping、站点地图提交、robots.txt 文件的使用、改进站点导航。但是,爬取效率取决于特定 Web 资源的特性,这些指标可以在复杂的环境中使用,而不是作为单独的一次性改进。
用户和搜索机器人都变得更加智能,用户寻找相关信息,而后者则试图更人性化地满足用户的搜索需求。
1.定期更新
内容更新有助于保持 网站 信息与用户的搜索需求相关,人们更有可能找到并分享您的网站。同时,扫描机器人会将其添加到可信资源列表中。内容更新得越频繁,爬虫就越频繁地注意到该站点。建议每周更新3次内容,最简单的方法是创建博客或添加音视频素材,这比不断添加新页面更容易有效。
参考:网站多久更新一次合适?
2.使用正常运行时间长的网络主机
当百度机器人在停机期间访问 网站 时,它们会记笔记并利用这种体验来设置较差的抓取频率,从而使用户更难找到您的网站。如果 网站 关闭的时间过长,预计会出现更糟糕的结果。这就是为什么选择可靠的服务器至关重要的原因,许多服务器现在提供 99% 的正常运行时间。
3.避免重复内容
对于网站蜘蛛机器人的爬取频率,同样的消息发两次不会增加网站的爬取频率。相反,用户和机器人都会被网站同一信息的不同部分弄糊涂。
因此,搜索引擎会降低网站的排名,甚至处罚、降低权限等。
参考:关于 网站 重复内容的 3 点思考
4.优化页面加载时间
页面加载时间是决定用户体验的因素之一,如果页面加载时间超过 5 秒,人们很可能会离开并移动到搜索结果列表中的下一个位置。加载时间取决于页面的大小,它在 网站 所有者的控制之下。可以删除所有多余的脚本、重图、动画、pdf文件和类似文件。
5.构建网站地图
对于百度机器人,网站地图是一个综合列表,点击链接到网站页面。在某种程度上,这是一个爬虫指令,您可以在其中指出应该和不应该索引的内容。
爬虫将是网站的状态检查器,经过多次更新后,最好邀请爬虫而不是等待它们到达。大多数 网站 爬虫工具使用相同的技术,允许机器人扫描特定的 网站 脚本以提供有关其内部组织的信息,例如内部链接、锚文本、图像、元标记等。
参考:网站为什么要添加 XML 站点地图?
6.获取更多反向链接
反向链接直接影响排名,反向链接高的资源会被更频繁地爬取。最好删除低质量的 网站 链接和过多的付费链接,以及避免或摆脱暗链接构建做法。
参考:什么是反向链接?以及反向链接的主要类型
7.添加 Meta 和标题标签
元标签和标题标签是搜索引擎在 网站 上寻找的第一件事,为不同的页面准备独特的标签,不要使用重复的标题。如果爬虫注意到具有相同标记的页面,他们可能会跳过其中一个页面。
标题不要填关键词,每页一个就够了。记得同步更新,如果你在内容中更改了一些 关键词,也要在标题中更改它们。元标签用于构建关于页面的数据,它们可以识别页面作者、地址和更新频率。他们参与为超文本文档创建标题并影响页面在结果中的显示方式。
8.优化图片
机器人不直接读取图像。为了增加搜索引擎蜘蛛的频率和速度,网站拥有者需要让搜索带着爬虫一起来了解他们在看什么。为此,使用 alt 标签,搜索引擎将能够索引简短的单词描述。只有优化的图像才会出现在搜索结果中,并会为您带来额外的流量。
9.使用 Ping 服务
这是向机器人显示您的 网站 上的某些内容已更新的最有效和快速的方法之一。有许多手动 ping 服务可以帮助您完成此任务,当您的 网站 上发布新内容时,它们会自动通知爬虫。
10.网站监控工具
使用百度网站管理工具将帮助您了解爬行速度和所有相关统计数据,从而分析蜘蛛的活动并提出最终改进策略。可以看到当前的爬取频率,哪些页面没有被索引,是什么原因,根据这个数据要求百度重新爬取一些页面。
参考:如何做SEO数据监控?
相关文章推荐5个SEO优化核心进入SEO行业不短不长,两年左右。和大佬们比起来,我算是比较晚了,不过对于我自己的优化水平还是有点自[...]...3 负SEO方法 负SEO可以有很多东西——其实不只是黑帽SEO技巧,如果有人发起了针对您和您的 [...] 的活动...SEO 基础:内部的简单 SEO 教程 [...]...如何让您的 网站 排名更高?人们经常问我如何改进他们的 SEO,SEO 代表搜索引擎优化,他们认为这是您在 网站 上设置的某种花哨的代码,就像即时 [...]...网站地图是什么?制作网站map时要注意的6个方面顾名思义,一个网站map本质上就是一个网站的map,帮助搜索引擎爬虫更好地理解和导航网站。在更专业的意义上,它是一个带有列的文件 […]…
网页音频抓取(2015年03月23日暴走漫画TOP1ssl。360kuai)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-03 01:07
","force_purephv":"0","gnid":"9e95a108248ea0ae3","img_data":[{"flag":2,"img":[{"desc":"","height":"3168" “标题”:“”,“网址”:“。ssl。图片 360快。com/t01b9c55f27b74f349e。jpg","width":"4752"},{"desc":"","height":"312","title":"","url":". ssl。图片 360快。com/t015c7468dac9709c67。jpg","width":"627"},{"desc":"","height":"366","title":"","url":". ssl。图片 360快。com/t0141d608627d168a44。jpg","width":"627"},{"desc":"","height":"464"," 标题“:”“,网址”:“。ssl。图片 360快。com/t014c067f2824362325。
jpg","width":"626"},{"desc":"","height":"250","title":"","url":". ssl。图片 360快。com/t0122d9c0d6d5548ca3。jpg","width":"353"},{"desc":"","height":"219","title":"","url":". ssl。图片 360快。com/t0132c94f0eaf560b3d。jpg","width":"630"},{"desc":"","height":"253","title":"","url":". ssl。图片 360快。com/t01bd02c2d87472bec5。jpg","width":"567"},{"desc":"","height":"346","title":"","url":". ssl。图片 360快。com/t01e777fe40b7336a80。jpg","
ssl。图片 360快。com/t01fd94dc3ef61f80b7。jpg","width":"1266"},{"desc":"","height":"280","title":"","url":". ssl。图片 360快。com/t01a5d60de0988c8e1b。jpg","width":"663"},{"desc":"","height":"773","title":"","url":". ssl。图片 360快。com/t017bff3e91f4c2f328。jpg","width":"1266"},{"desc":"","height":"480","title":"","url":". ssl。图片 360快。com/t01f62d641124423c92。jpg","width":"767"}]}],"original":"0","pat":"mass_gamble,art_src_0,fts0,sts0","powerby":"pika",
消息。所以。com/fe3f09527d37dd023897bfc1664b11de","redirect":0,"rptid":"2e6aa5ad2c4239e6","src":"技术资源箱","tag":[],"title":"如何将在线下载的音乐文件转换为mp3 ?网页音乐提取——有没有什么好用的网页音乐提取音乐的软件可以单独下载:Adobe Audition下的音频截取下载地址1、的Adobe Audition 1.5(Cool Edit Pro)。. . “音频解锁”,用它打开一部电影,然后选择循环,然后选择要提取音频的区域,最后。. .
如何从网页中提取音乐 如何从网页中提取音乐 音乐提取工具和教程- :阅读(或听)网页上的多媒体文件后,打开系统盘\windows\document and settings\your username\local settings\temporary internet files 点击(或者在IE浏览器中点击Tools-Internet Options,点击General选项卡中的Settings,点击View Files)按大小排序,最大的是我们要找的多媒体文件~地址是写的~如果要保存,直接复制粘贴到别的目录就行了,不用找真实地址。此外,您可以使用浏览器查看页面的源代码以查找 MP3 或 WMA。仔细找也可以,但也不容易。也可以到 Tools/Options 在 /settings/view 文件中找到文件,
什么软件可以从页面中提取音乐地址???:音乐地址批量提取工具v1.1:下载地址:根据设置的URL顺序自动提取网页中的音乐地址,并保存为访问数据库或sql数据库。2.速度超快,每秒最多可以提取40个音乐地址,提取速度会根据音乐的速度而有所不同网站服务器响应。3.可以提取mp3、rm、wmv、swf、mpga、mpg、wma、rmvb等格式的视音频文件。4.自动解析视音频文件名,必要时可以进行二次根据设置提取页面。5.适合在局域网内建立音乐搜索网站,并提供asp搜索页面的源码。< @6.节目配置文件设置全面详细,可以根据实际情况设置不同的组合。7.可解压需要登录才能收听下载的页面。8.可以预设每个音视频的提取参数网站,自动记录提取的歌曲id,及时更新歌曲库。
如何提取网页中的音乐:有一种比较笨的方法:当你听到音乐时,浏览器已经把音乐下载到本地了。也就是说,在 Internet 临时文件中。如果你的系统是Win98,这个文件夹在:C:\windows\Temporary Internet Files;如果你的系统是Win2000/WinXP,那么这个文件夹在:C:\Documents and Settings\username\Local Settings\Temporary Internet Files 打开文件夹后,在里面找到一些媒体(类型)文件,拖到其他目录,如果不止一个,一个一个听。希望对你有一点帮助
如何提取安卓手机播放的网络音乐——:如果是网页的背景音乐,一般可以在ie临时文件夹中找到。可以在internet选项-(第一个)设置-查看文件中找到。通常网页的背景音乐在播放前会加载到本地硬盘的临时网络文件夹中。如果网页上有工具栏播放的音乐,可以安装迅雷,这个软件可以嗅探下载地址。
什么软件可以直接提取网页上的音乐文件- : 你好,目前还没有好用的软件,建议你在歌名前加百度云,然后通过百度云下载下载列表,各种音乐 软件还可以下载各种歌曲,相信你会找到你想要的资源!谢谢!
一款可以截取网页音乐的软件-:有两种方式:1、使用Video Detective等网络嗅探工具,在线听歌时帮助你找到真实的音乐地址,并支持下载;2、使用电脑录制和听音乐。对于地址无法嗅探的歌曲,只能使用这种方法。软件推荐Adobe Audition3(Cooledit2的升级版),软件操作简单。, 它还可以编辑和影响录制的音频!楼上推荐的samplitude也是专业级的工具,可惜操作比Audition稍微复杂一点!
什么软件可以捕捉网页中的音乐?- :使用屏幕录制专家。大名鼎鼎的软件可以设置三种录制方式:全屏、窗口、范围(可以在网页上使用窗口或范围进行录制) 录制的格式和质量都是可以控制的录屏专家破解版(有破解补丁)我这里有,如有需要请留下邮箱以便发送
有没有什么手机软件可以把网页上的音频下载到手机里 - : 不能缓存吗?是网络问题吗?手机QQ浏览器运行速度非常快。一般打开很多网页是没问题的,下载东西缓存也很快。您也可以随时观看。你可以直接去我的下载。操作非常简单。我一直用这个浏览器。感觉比较实用。你可以重新输入看看你可以。
哪个浏览器最简单直接的抓取网络音乐的功能-:有这样的工具。在360浏览器选项中,可以设置。ctrl+alt+click: 显示保存对话框 ctrl+alt+shift+click: 显示元素 url应该只能保存图片.. 查看全部
网页音频抓取(2015年03月23日暴走漫画TOP1ssl。360kuai)
","force_purephv":"0","gnid":"9e95a108248ea0ae3","img_data":[{"flag":2,"img":[{"desc":"","height":"3168" “标题”:“”,“网址”:“。ssl。图片 360快。com/t01b9c55f27b74f349e。jpg","width":"4752"},{"desc":"","height":"312","title":"","url":". ssl。图片 360快。com/t015c7468dac9709c67。jpg","width":"627"},{"desc":"","height":"366","title":"","url":". ssl。图片 360快。com/t0141d608627d168a44。jpg","width":"627"},{"desc":"","height":"464"," 标题“:”“,网址”:“。ssl。图片 360快。com/t014c067f2824362325。
jpg","width":"626"},{"desc":"","height":"250","title":"","url":". ssl。图片 360快。com/t0122d9c0d6d5548ca3。jpg","width":"353"},{"desc":"","height":"219","title":"","url":". ssl。图片 360快。com/t0132c94f0eaf560b3d。jpg","width":"630"},{"desc":"","height":"253","title":"","url":". ssl。图片 360快。com/t01bd02c2d87472bec5。jpg","width":"567"},{"desc":"","height":"346","title":"","url":". ssl。图片 360快。com/t01e777fe40b7336a80。jpg","
ssl。图片 360快。com/t01fd94dc3ef61f80b7。jpg","width":"1266"},{"desc":"","height":"280","title":"","url":". ssl。图片 360快。com/t01a5d60de0988c8e1b。jpg","width":"663"},{"desc":"","height":"773","title":"","url":". ssl。图片 360快。com/t017bff3e91f4c2f328。jpg","width":"1266"},{"desc":"","height":"480","title":"","url":". ssl。图片 360快。com/t01f62d641124423c92。jpg","width":"767"}]}],"original":"0","pat":"mass_gamble,art_src_0,fts0,sts0","powerby":"pika",
消息。所以。com/fe3f09527d37dd023897bfc1664b11de","redirect":0,"rptid":"2e6aa5ad2c4239e6","src":"技术资源箱","tag":[],"title":"如何将在线下载的音乐文件转换为mp3 ?网页音乐提取——有没有什么好用的网页音乐提取音乐的软件可以单独下载:Adobe Audition下的音频截取下载地址1、的Adobe Audition 1.5(Cool Edit Pro)。. . “音频解锁”,用它打开一部电影,然后选择循环,然后选择要提取音频的区域,最后。. .
如何从网页中提取音乐 如何从网页中提取音乐 音乐提取工具和教程- :阅读(或听)网页上的多媒体文件后,打开系统盘\windows\document and settings\your username\local settings\temporary internet files 点击(或者在IE浏览器中点击Tools-Internet Options,点击General选项卡中的Settings,点击View Files)按大小排序,最大的是我们要找的多媒体文件~地址是写的~如果要保存,直接复制粘贴到别的目录就行了,不用找真实地址。此外,您可以使用浏览器查看页面的源代码以查找 MP3 或 WMA。仔细找也可以,但也不容易。也可以到 Tools/Options 在 /settings/view 文件中找到文件,
什么软件可以从页面中提取音乐地址???:音乐地址批量提取工具v1.1:下载地址:根据设置的URL顺序自动提取网页中的音乐地址,并保存为访问数据库或sql数据库。2.速度超快,每秒最多可以提取40个音乐地址,提取速度会根据音乐的速度而有所不同网站服务器响应。3.可以提取mp3、rm、wmv、swf、mpga、mpg、wma、rmvb等格式的视音频文件。4.自动解析视音频文件名,必要时可以进行二次根据设置提取页面。5.适合在局域网内建立音乐搜索网站,并提供asp搜索页面的源码。< @6.节目配置文件设置全面详细,可以根据实际情况设置不同的组合。7.可解压需要登录才能收听下载的页面。8.可以预设每个音视频的提取参数网站,自动记录提取的歌曲id,及时更新歌曲库。
如何提取网页中的音乐:有一种比较笨的方法:当你听到音乐时,浏览器已经把音乐下载到本地了。也就是说,在 Internet 临时文件中。如果你的系统是Win98,这个文件夹在:C:\windows\Temporary Internet Files;如果你的系统是Win2000/WinXP,那么这个文件夹在:C:\Documents and Settings\username\Local Settings\Temporary Internet Files 打开文件夹后,在里面找到一些媒体(类型)文件,拖到其他目录,如果不止一个,一个一个听。希望对你有一点帮助
如何提取安卓手机播放的网络音乐——:如果是网页的背景音乐,一般可以在ie临时文件夹中找到。可以在internet选项-(第一个)设置-查看文件中找到。通常网页的背景音乐在播放前会加载到本地硬盘的临时网络文件夹中。如果网页上有工具栏播放的音乐,可以安装迅雷,这个软件可以嗅探下载地址。
什么软件可以直接提取网页上的音乐文件- : 你好,目前还没有好用的软件,建议你在歌名前加百度云,然后通过百度云下载下载列表,各种音乐 软件还可以下载各种歌曲,相信你会找到你想要的资源!谢谢!
一款可以截取网页音乐的软件-:有两种方式:1、使用Video Detective等网络嗅探工具,在线听歌时帮助你找到真实的音乐地址,并支持下载;2、使用电脑录制和听音乐。对于地址无法嗅探的歌曲,只能使用这种方法。软件推荐Adobe Audition3(Cooledit2的升级版),软件操作简单。, 它还可以编辑和影响录制的音频!楼上推荐的samplitude也是专业级的工具,可惜操作比Audition稍微复杂一点!
什么软件可以捕捉网页中的音乐?- :使用屏幕录制专家。大名鼎鼎的软件可以设置三种录制方式:全屏、窗口、范围(可以在网页上使用窗口或范围进行录制) 录制的格式和质量都是可以控制的录屏专家破解版(有破解补丁)我这里有,如有需要请留下邮箱以便发送
有没有什么手机软件可以把网页上的音频下载到手机里 - : 不能缓存吗?是网络问题吗?手机QQ浏览器运行速度非常快。一般打开很多网页是没问题的,下载东西缓存也很快。您也可以随时观看。你可以直接去我的下载。操作非常简单。我一直用这个浏览器。感觉比较实用。你可以重新输入看看你可以。
哪个浏览器最简单直接的抓取网络音乐的功能-:有这样的工具。在360浏览器选项中,可以设置。ctrl+alt+click: 显示保存对话框 ctrl+alt+shift+click: 显示元素 url应该只能保存图片..
网页音频抓取(迅捷音频转换器如何提取音乐?的方法更多精彩)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-03-31 23:33
如何提取视频中听到喜欢的背景音乐,Quick Audio Converter可以帮我们提取音乐文件,操作非常简单。下面小编就为大家带来具体的操作方法,想了解的快来看看吧。
Swift Audio Converter 如何提取音乐?Swift Audio Converter如何提取音乐
步骤1:首先,我们需要打开电脑上安装的Quick Audio Converter。打开后点击“注册/登录”,用手机号注册登录或直接用微信、QQ登录。软件登录后,开始以下操作。
第二步:之后,首先了解界面中的功能参数。这里我们可以看到有四个主要功能:“音频剪切”、“音频合并”、“音频提取”和“音频转换”。界面右侧还可以自定义音频参数:声道、质量和编码。
第三步:这里我们需要提取视频和音频,然后您可以选择进入“音频提取”界面,然后点击“添加文件”,然后会弹出一个小窗口,选择要提取的视频片段并导入它。
第4步:然后您刚刚导入的视频剪辑将出现在界面上。您可以通过两侧的进度条调整需要截取的音频片段。选择后,点击“确认并添加到输出列表”。提示:您可以多次选择音频片段进行采集,选择后点击如上的确认操作即可。
第五步:解压前,需要设置文件的保存位置。点击下方的“更改路径”新建一个文件夹,用于存放要提取的音频片段,方便查找。
第六步:所有设置完成后,点击右下角的“开始解压”按钮,等待两分钟即可成功解压。然后会显示“打开”,此时点击“打开”即可在选定的保存位置看到提取成功的音频片段。
以上文章文章是Swift Audio Converter提取音乐的方法。更多精彩教程请关注下载首页! 查看全部
网页音频抓取(迅捷音频转换器如何提取音乐?的方法更多精彩)
如何提取视频中听到喜欢的背景音乐,Quick Audio Converter可以帮我们提取音乐文件,操作非常简单。下面小编就为大家带来具体的操作方法,想了解的快来看看吧。
Swift Audio Converter 如何提取音乐?Swift Audio Converter如何提取音乐

步骤1:首先,我们需要打开电脑上安装的Quick Audio Converter。打开后点击“注册/登录”,用手机号注册登录或直接用微信、QQ登录。软件登录后,开始以下操作。
第二步:之后,首先了解界面中的功能参数。这里我们可以看到有四个主要功能:“音频剪切”、“音频合并”、“音频提取”和“音频转换”。界面右侧还可以自定义音频参数:声道、质量和编码。
第三步:这里我们需要提取视频和音频,然后您可以选择进入“音频提取”界面,然后点击“添加文件”,然后会弹出一个小窗口,选择要提取的视频片段并导入它。
第4步:然后您刚刚导入的视频剪辑将出现在界面上。您可以通过两侧的进度条调整需要截取的音频片段。选择后,点击“确认并添加到输出列表”。提示:您可以多次选择音频片段进行采集,选择后点击如上的确认操作即可。
第五步:解压前,需要设置文件的保存位置。点击下方的“更改路径”新建一个文件夹,用于存放要提取的音频片段,方便查找。
第六步:所有设置完成后,点击右下角的“开始解压”按钮,等待两分钟即可成功解压。然后会显示“打开”,此时点击“打开”即可在选定的保存位置看到提取成功的音频片段。
以上文章文章是Swift Audio Converter提取音乐的方法。更多精彩教程请关注下载首页!
网页音频抓取(示例下载朋友问到这样一个问题,需要实现如下功能(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-30 10:05
)
示例下载
有朋友问了这样一个问题,需要实现以下功能
1、打开一个空运公司的查询网页,比如,页面有两个文本框供用户输入业务代码,比如,
2、然后点击“Go”按钮,下一页显示查询结果
现在需要程序自动执行以上步骤,将查询结果提取出来做后续处理。
要完成这样的功能,首先要解决以下问题:
l 可以使用程序在后台向目标网页发布数据
l 可以接收对方返回的HTML结果页面
l 分析页面并提取所需结果的能力
经过一番研究和实验,我解决了上述问题,下面分别介绍。
1.使用程序将指定的数据post到目标网页,并接收结果网页
我首先使用网络嗅探器来捕捉浏览器与其他网页在使用IE手动查询时的HTTP协议交互过程。推荐使用Ultra Network Sniffer,它有连接监控功能,可以监控一个程序的所有连接,避免其他无关数据包的干扰。如图所示
在查询页面输入数据后,点击“Go”按钮,sniffer抓到的数据包如下图
请注意第三行,有一个Post包,这是我们需要的,
它发送的网页地址是:
它发布的数据是:awbpre=180&awbnum=36898035&x=17&y=9
显然180和36898035可以替换,需要注意的是,发送的目的网页不再是我们直接在浏览器中输入的初始页面
接下来我们使用程序发送这个数据,代码如下
public static string GetPage(string url, string postData,string encodeType,out string err)<br /><br /> {<br /><br /> Stream outstream = null;<br /><br /> Stream instream = null;<br /><br /> StreamReader sr = null;<br /><br /> HttpWebResponse response = null;<br /><br /> HttpWebRequest request = null;<br /><br /> Encoding encoding = Encoding.GetEncoding(encodeType);<br /><br /> byte[] data = encoding.GetBytes(postData);<br /><br /> // 准备请求...<br /><br /> try<br /><br /> { <br /><br /> // 设置参数<br /><br /> request = WebRequest.Create(url) as HttpWebRequest;<br /><br /> CookieContainer cookieContainer = new CookieContainer();<br /><br /> request.CookieContainer = cookieContainer;<br /><br /> request.AllowAutoRedirect = true;<br /><br /> request.Method = "POST";<br /><br /> request.ContentType = "application/x-www-form-urlencoded";<br /><br /> request.ContentLength = data.Length;<br /><br /> outstream = request.GetRequestStream();<br /><br /> outstream.Write(data,0,data.Length);<br /><br /> outstream.Close();<br /><br /> //发送请求并获取相应回应数据<br /><br /> response = request.GetResponse() as HttpWebResponse;<br /><br /> //直到request.GetResponse()程序才开始向目标网页发送Post请求<br /><br /> instream = response.GetResponseStream();<br /><br /> sr = new StreamReader( instream, encoding );<br /><br /> //返回结果网页(html)代码<br /><br />string content = sr.ReadToEnd();<br /><br /> err = string.Empty;<br /><br /> return content;<br /><br /> }<br /><br /> catch(Exception ex)<br /><br /> {<br /><br /> err = ex.Message;<br /><br /> return string.Empty;<br /><br /> }<br /><br />}
上面的代码通俗易懂,就不多废话了,简单说几个注意点:
如果你的程序需要保留SessionID,比如ASP.NET中的SessionID。比如自动登录后,可能需要进行后续处理,所以需要将上一个请求返回的cookieContainer分配给新的请求,然后再将请求发送到下一页,因为cookieContainer中预留了一个名为ASPNETSessionID的cookie。
如果你的 Post 的目标页面是 ASP.NET 页面,那么在要提交的 Form 中一般会有一个 __ViewState 隐藏的 Input 字段。服务器返回的网页源代码的ViewState示例如下,
<br /><br /><br /><br /><br /><br /><br /><br /><br /><br />
然而,嗅探器中捕获的 Post 数据是:
__VIEWSTATE=dDwtMzg4MDA0NzA7Oz7%2BjHQ0vF37%2Fga2CitRkQ3sfg%2BePg%3D%3D&用户名=管理员&密码=123&提交=按钮0
请注意,这里ViewState的数据和上一个有点不同。不同的是,“+/=”等符号已经转换成%2B、%2F、%3D等,实际上是URL ViewState Encoding的值,可以使用System.Web.HttpUtility.UrlEncode( ) 方法来做这个转换
当然,如果只需要一次性访问页面,就不用管这些了,根据sniffer抓到的结果发送数据即可,但如果需要根据ViewState动态处理页面返回的值,则需要注意这一点。
2.从 HTML 页面代码中提取信息
要从 HTML 网页中提取信息,您必须首先将网页代码格式化为 XML 文件,然后您可以使用 XPath 轻松提取您想要的信息。要将 HTML 格式化为 XML,目前有多种选择。
1、Chris Lovett 的 SgmlReader:
2、Simon Mourier 的 .NET Html 敏捷包
我选择了 SgmlReader。通过实际使用,我发现SgmlReader并不完美。有时候格式化的xml的嵌套关系会出错,但即便如此,根据他格式化的文本,提取数据就足够了。
public static DataSet ParsePage(string pageContent, string xpath, out string err)<br /><br /> {<br /><br /> err = string.Empty;<br /><br /> string pageContent = this.tbHTML.Text;<br /><br /> StreamReader streamReader = null;<br /><br /> StringWriter strWriter = null;<br /><br /> SgmlReader sgmlReader = null;<br /><br /> XmlTextWriter xmlWriter = null;<br /><br /> try<br /><br /> {<br /><br /> sgmlReader = new SgmlReader();<br /><br /> sgmlReader.DocType = "HTML";<br /><br /> sgmlReader.InputStream = new StringReader(pageContent);<br /><br /> strWriter = new StringWriter();<br /><br /> xmlWriter = new XmlTextWriter(strWriter);<br /><br /> xmlWriter.Formatting = Formatting.Indented;<br /><br /> while (sgmlReader.Read())<br /><br /> {<br /><br /> if (sgmlReader.NodeType != XmlNodeType.Whitespace)<br /><br /> {<br /><br /> xmlWriter.WriteNode(sgmlReader, true);<br /><br /> }<br /><br /> }<br /><br /> string wellFormedHTML = strWriter.ToString();<br /><br /> this.tbHTML.Text = wellFormedHTML;<br /><br /> string xpath = this.tbXPath.Text;<br /><br /> XPathDocument doc = new XPathDocument(new StringReader(wellFormedHTML));<br /><br /> XPathNavigator nav = doc.CreateNavigator();<br /><br /> XPathNodeIterator nodes = nav.Select(xpath);<br /><br /> while (nodes.MoveNext())<br /><br /> {<br /><br /> this.tbResult.Text += nodes.Current.Value+"\n";<br /><br /> }<br /><br /> }<br /><br /> catch (Exception exp)<br /><br /> {<br /><br /> string err = exp.Message;<br /><br /> MessageBox.Show("错误:"+err);<br /><br /> }<br /><br />}<br /><br />}
根据上面的代码,目前主要的问题是设置正确的XPath。有一篇关于代码项目 文章 的文章提供了一个简单的 XPath 查询工具。我对它做了一些修改,主要是增加了在节点的body中搜索某个字符串的功能,方便你根据得到的HTML页面查询XPath
调试 XPath 查询:
例如,下面是一个根据查询结果格式化的 XML 文本片段。信息的 XPath 是
//div[@class=”content”]/DIV[@id=”tblwithbck”]/TABLE/TR/TD/TABLE/TR/TD/DIV[@class=”data”]
需要注意的是,XPath中的每条路径都是区分大小写的,我只是一开始没有注意这个问题,犯了一些错误。
<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K departed on flight KE6316/04JUN from PVG to ICN<br /><br /><BR /><br /><br />Actual Time of Flight-Departure : 19:20<br /><br /><BR /><br /><br />Scheduled Time of Flight-Arrival : 21:55<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K departed on flight 9S0910/06JUN from ICN to DFW<br /><br /><BR /><br /><br />Actual Time of Flight-Departure : 22:15<br /><br /><BR /><br /><br />Scheduled Time of Flight-Arrival : 05:35+1<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K departed on flight 3A3617/07JUN from DFW to ELP<br /><br /><BR /><br /><br />Actual Time of Flight-Departure : 22:00<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K arrived in ELP from flight 3A3617<br /><br /><BR /><br /><br />Scheduled arrival : 08 JUN<br /><br /><BR /><br /><br />Goods checked in at : 11:00<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />Arrival docs delivered for 2 piece(s) 42 K on 09 JUN at 09:48 in ELP<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /> 查看全部
网页音频抓取(示例下载朋友问到这样一个问题,需要实现如下功能(图)
)
示例下载
有朋友问了这样一个问题,需要实现以下功能
1、打开一个空运公司的查询网页,比如,页面有两个文本框供用户输入业务代码,比如,
2、然后点击“Go”按钮,下一页显示查询结果
现在需要程序自动执行以上步骤,将查询结果提取出来做后续处理。
要完成这样的功能,首先要解决以下问题:
l 可以使用程序在后台向目标网页发布数据
l 可以接收对方返回的HTML结果页面
l 分析页面并提取所需结果的能力
经过一番研究和实验,我解决了上述问题,下面分别介绍。
1.使用程序将指定的数据post到目标网页,并接收结果网页
我首先使用网络嗅探器来捕捉浏览器与其他网页在使用IE手动查询时的HTTP协议交互过程。推荐使用Ultra Network Sniffer,它有连接监控功能,可以监控一个程序的所有连接,避免其他无关数据包的干扰。如图所示
在查询页面输入数据后,点击“Go”按钮,sniffer抓到的数据包如下图
请注意第三行,有一个Post包,这是我们需要的,
它发送的网页地址是:
它发布的数据是:awbpre=180&awbnum=36898035&x=17&y=9
显然180和36898035可以替换,需要注意的是,发送的目的网页不再是我们直接在浏览器中输入的初始页面
接下来我们使用程序发送这个数据,代码如下
public static string GetPage(string url, string postData,string encodeType,out string err)<br /><br /> {<br /><br /> Stream outstream = null;<br /><br /> Stream instream = null;<br /><br /> StreamReader sr = null;<br /><br /> HttpWebResponse response = null;<br /><br /> HttpWebRequest request = null;<br /><br /> Encoding encoding = Encoding.GetEncoding(encodeType);<br /><br /> byte[] data = encoding.GetBytes(postData);<br /><br /> // 准备请求...<br /><br /> try<br /><br /> { <br /><br /> // 设置参数<br /><br /> request = WebRequest.Create(url) as HttpWebRequest;<br /><br /> CookieContainer cookieContainer = new CookieContainer();<br /><br /> request.CookieContainer = cookieContainer;<br /><br /> request.AllowAutoRedirect = true;<br /><br /> request.Method = "POST";<br /><br /> request.ContentType = "application/x-www-form-urlencoded";<br /><br /> request.ContentLength = data.Length;<br /><br /> outstream = request.GetRequestStream();<br /><br /> outstream.Write(data,0,data.Length);<br /><br /> outstream.Close();<br /><br /> //发送请求并获取相应回应数据<br /><br /> response = request.GetResponse() as HttpWebResponse;<br /><br /> //直到request.GetResponse()程序才开始向目标网页发送Post请求<br /><br /> instream = response.GetResponseStream();<br /><br /> sr = new StreamReader( instream, encoding );<br /><br /> //返回结果网页(html)代码<br /><br />string content = sr.ReadToEnd();<br /><br /> err = string.Empty;<br /><br /> return content;<br /><br /> }<br /><br /> catch(Exception ex)<br /><br /> {<br /><br /> err = ex.Message;<br /><br /> return string.Empty;<br /><br /> }<br /><br />}
上面的代码通俗易懂,就不多废话了,简单说几个注意点:
如果你的程序需要保留SessionID,比如ASP.NET中的SessionID。比如自动登录后,可能需要进行后续处理,所以需要将上一个请求返回的cookieContainer分配给新的请求,然后再将请求发送到下一页,因为cookieContainer中预留了一个名为ASPNETSessionID的cookie。
如果你的 Post 的目标页面是 ASP.NET 页面,那么在要提交的 Form 中一般会有一个 __ViewState 隐藏的 Input 字段。服务器返回的网页源代码的ViewState示例如下,
<br /><br /><br /><br /><br /><br /><br /><br /><br /><br />
然而,嗅探器中捕获的 Post 数据是:
__VIEWSTATE=dDwtMzg4MDA0NzA7Oz7%2BjHQ0vF37%2Fga2CitRkQ3sfg%2BePg%3D%3D&用户名=管理员&密码=123&提交=按钮0
请注意,这里ViewState的数据和上一个有点不同。不同的是,“+/=”等符号已经转换成%2B、%2F、%3D等,实际上是URL ViewState Encoding的值,可以使用System.Web.HttpUtility.UrlEncode( ) 方法来做这个转换
当然,如果只需要一次性访问页面,就不用管这些了,根据sniffer抓到的结果发送数据即可,但如果需要根据ViewState动态处理页面返回的值,则需要注意这一点。
2.从 HTML 页面代码中提取信息
要从 HTML 网页中提取信息,您必须首先将网页代码格式化为 XML 文件,然后您可以使用 XPath 轻松提取您想要的信息。要将 HTML 格式化为 XML,目前有多种选择。
1、Chris Lovett 的 SgmlReader:
2、Simon Mourier 的 .NET Html 敏捷包
我选择了 SgmlReader。通过实际使用,我发现SgmlReader并不完美。有时候格式化的xml的嵌套关系会出错,但即便如此,根据他格式化的文本,提取数据就足够了。
public static DataSet ParsePage(string pageContent, string xpath, out string err)<br /><br /> {<br /><br /> err = string.Empty;<br /><br /> string pageContent = this.tbHTML.Text;<br /><br /> StreamReader streamReader = null;<br /><br /> StringWriter strWriter = null;<br /><br /> SgmlReader sgmlReader = null;<br /><br /> XmlTextWriter xmlWriter = null;<br /><br /> try<br /><br /> {<br /><br /> sgmlReader = new SgmlReader();<br /><br /> sgmlReader.DocType = "HTML";<br /><br /> sgmlReader.InputStream = new StringReader(pageContent);<br /><br /> strWriter = new StringWriter();<br /><br /> xmlWriter = new XmlTextWriter(strWriter);<br /><br /> xmlWriter.Formatting = Formatting.Indented;<br /><br /> while (sgmlReader.Read())<br /><br /> {<br /><br /> if (sgmlReader.NodeType != XmlNodeType.Whitespace)<br /><br /> {<br /><br /> xmlWriter.WriteNode(sgmlReader, true);<br /><br /> }<br /><br /> }<br /><br /> string wellFormedHTML = strWriter.ToString();<br /><br /> this.tbHTML.Text = wellFormedHTML;<br /><br /> string xpath = this.tbXPath.Text;<br /><br /> XPathDocument doc = new XPathDocument(new StringReader(wellFormedHTML));<br /><br /> XPathNavigator nav = doc.CreateNavigator();<br /><br /> XPathNodeIterator nodes = nav.Select(xpath);<br /><br /> while (nodes.MoveNext())<br /><br /> {<br /><br /> this.tbResult.Text += nodes.Current.Value+"\n";<br /><br /> }<br /><br /> }<br /><br /> catch (Exception exp)<br /><br /> {<br /><br /> string err = exp.Message;<br /><br /> MessageBox.Show("错误:"+err);<br /><br /> }<br /><br />}<br /><br />}
根据上面的代码,目前主要的问题是设置正确的XPath。有一篇关于代码项目 文章 的文章提供了一个简单的 XPath 查询工具。我对它做了一些修改,主要是增加了在节点的body中搜索某个字符串的功能,方便你根据得到的HTML页面查询XPath
调试 XPath 查询:
例如,下面是一个根据查询结果格式化的 XML 文本片段。信息的 XPath 是
//div[@class=”content”]/DIV[@id=”tblwithbck”]/TABLE/TR/TD/TABLE/TR/TD/DIV[@class=”data”]
需要注意的是,XPath中的每条路径都是区分大小写的,我只是一开始没有注意这个问题,犯了一些错误。
<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K departed on flight KE6316/04JUN from PVG to ICN<br /><br /><BR /><br /><br />Actual Time of Flight-Departure : 19:20<br /><br /><BR /><br /><br />Scheduled Time of Flight-Arrival : 21:55<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K departed on flight 9S0910/06JUN from ICN to DFW<br /><br /><BR /><br /><br />Actual Time of Flight-Departure : 22:15<br /><br /><BR /><br /><br />Scheduled Time of Flight-Arrival : 05:35+1<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K departed on flight 3A3617/07JUN from DFW to ELP<br /><br /><BR /><br /><br />Actual Time of Flight-Departure : 22:00<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K arrived in ELP from flight 3A3617<br /><br /><BR /><br /><br />Scheduled arrival : 08 JUN<br /><br /><BR /><br /><br />Goods checked in at : 11:00<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />Arrival docs delivered for 2 piece(s) 42 K on 09 JUN at 09:48 in ELP<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />
网页音频抓取(爬取喜马拉雅音频数据受害者(爬虫知识点)案例分析(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-19 13:27
前言
喜马拉雅是一个专业的音频分享平台,汇集了有声小说、有声读物、有声读物、FM收音机、儿童睡前故事、相声小品、鬼故事等数以亿计的音频,喜欢听民间故事和德云社会相声采集最多。,和你?
今天就带大家爬取喜马拉雅音频数据,一起期待吧!!
项目目标
爬取喜马拉雅音频数据
受害者地址
https://www.ximalaya.com/
本文知识点:
环境:
想法:(履带式案例)
案例思路:
开始写代码
先导入需要的模块
import requests
import parsel # 数据解析模块
import re
1.确定数据所在的链接地址(url) 反向分析网页性质(静态网页/动态网页)
打开开发者工具,播放一段音频,可以在Madie中找到一个数据包
复制网址,搜索
查找 id 值
继续搜索找到请求头参数
url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers)
html_data = response.text
3.分析数据(要的话就过滤)解析音频的id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li')
for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href)
m4a_id = href.split('/')[-1]
# print(href, m4a_id)
# 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revis ... id%3D{}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data)
# 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url)
# 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content
new_title = change_title(title)
4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)
最后,我们要处理文件名中的非法字符
def change_title(title):
pattern = re.compile(r"[\/\\\:\*\?\"\\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
完整代码
import re
import requests
import parsel # 数据解析模块
def change_title(title):
"""处理文件名非法字符的方法"""
pattern = re.compile(r"[\/\\\:\*\?\"\\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
for page in range(13, 33):
print('---------------正在爬取第{}页的数据----------------'.format(page))
# 1.确定数据所在的链接地址(url) 逆向分析 网页性质(静态网页/动态网页)
url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
# 2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers)
html_data = response.text
# print(html_data)
# 3.解析数据(要的, 筛选不要的) 解析音频的 id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li')
for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href)
m4a_id = href.split('/')[-1]
# print(href, m4a_id)
# 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revis ... id%3D{}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data)
# 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url)
# 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content
new_title = change_title(title)
# print(new_title)
# 4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)
except:
pass
运行代码,效果如下
本文文字和图片来源于网络,仅供学习交流,不具有任何商业用途。如有任何问题,请及时联系我们进行处理。 查看全部
网页音频抓取(爬取喜马拉雅音频数据受害者(爬虫知识点)案例分析(一))
前言
喜马拉雅是一个专业的音频分享平台,汇集了有声小说、有声读物、有声读物、FM收音机、儿童睡前故事、相声小品、鬼故事等数以亿计的音频,喜欢听民间故事和德云社会相声采集最多。,和你?
今天就带大家爬取喜马拉雅音频数据,一起期待吧!!
项目目标
爬取喜马拉雅音频数据
受害者地址
https://www.ximalaya.com/
本文知识点:
环境:
想法:(履带式案例)
案例思路:
开始写代码
先导入需要的模块
import requests
import parsel # 数据解析模块
import re
1.确定数据所在的链接地址(url) 反向分析网页性质(静态网页/动态网页)
打开开发者工具,播放一段音频,可以在Madie中找到一个数据包
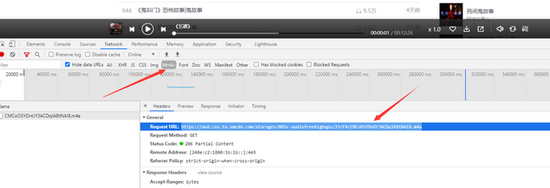
复制网址,搜索
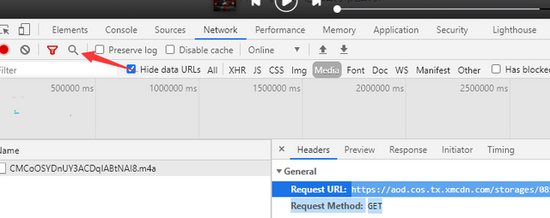
查找 id 值
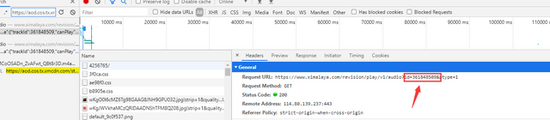
继续搜索找到请求头参数
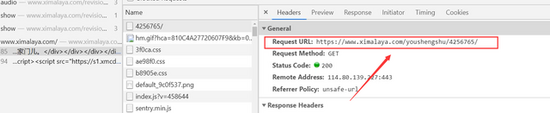
url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers)
html_data = response.text
3.分析数据(要的话就过滤)解析音频的id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li')
for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href)
m4a_id = href.split('/')[-1]
# print(href, m4a_id)
# 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revis ... id%3D{}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data)
# 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url)
# 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content
new_title = change_title(title)
4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)
最后,我们要处理文件名中的非法字符
def change_title(title):
pattern = re.compile(r"[\/\\\:\*\?\"\\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
完整代码
import re
import requests
import parsel # 数据解析模块
def change_title(title):
"""处理文件名非法字符的方法"""
pattern = re.compile(r"[\/\\\:\*\?\"\\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
for page in range(13, 33):
print('---------------正在爬取第{}页的数据----------------'.format(page))
# 1.确定数据所在的链接地址(url) 逆向分析 网页性质(静态网页/动态网页)
url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
# 2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers)
html_data = response.text
# print(html_data)
# 3.解析数据(要的, 筛选不要的) 解析音频的 id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li')
for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href)
m4a_id = href.split('/')[-1]
# print(href, m4a_id)
# 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revis ... id%3D{}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data)
# 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url)
# 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content
new_title = change_title(title)
# print(new_title)
# 4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)
except:
pass
运行代码,效果如下

本文文字和图片来源于网络,仅供学习交流,不具有任何商业用途。如有任何问题,请及时联系我们进行处理。
【音效】一个提供各种素材下载的网站
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-07-16 15:15
排版|设计|配图©孤狼小航
素材吧这个网站是一个提供各种素材下载的网站,里面的音效板块挺不错的
获取方式将网址直接复制浏览器即可
请将以上网址复制到自带的浏览器内(手机/电脑),请关注公众号“90技术控”查找历史记录,查阅更多的黑科技,获取你想要的内容。
温馨提示:
①“90技术控”公众号内提供的全部资源皆为无偿分享,资源都是来自于网络搜集和小伙伴们的提供(包含图片文字),仅供学习&交流(禁商用),本公众号不参与任何版权问题,如有侵权,请联系删除!
②每期文章底部都会有相应关键词,只有在关注完公众号内正确的回复关键词才会获得相关资源,搜索关键词必须为精确关键词!(你可以复制文章底部的关键词,不包括文章底部的符号)不能错一个字和字符,区分大小写,不能有多余的符号,感谢大家的支持与理解!
③如需遇到外文网站或其他语种网站,先在你打开的网站中寻找你能看懂的语言,同时,如果没有你想要的的语言,建议你可以利用自带翻译功能的浏览器进行翻译,如果打开链接公众号内容没有反应或者长时间打不开,建议先检查自己的网络原因,如果微信打不开的话建议把链接复制到(手机或者电脑)的自带浏览器进行查阅。
④由于我们公众号内部功能比较多,大家不懂得先可以尝试在菜单栏中找到对应的帮助,如果还不会的话可以咨询一下人工服务!感谢你的支持与理解!
“90技术控”
不一样的黑科技技术平台 查看全部
【音效】一个提供各种素材下载的网站
排版|设计|配图©孤狼小航
素材吧这个网站是一个提供各种素材下载的网站,里面的音效板块挺不错的
获取方式将网址直接复制浏览器即可
请将以上网址复制到自带的浏览器内(手机/电脑),请关注公众号“90技术控”查找历史记录,查阅更多的黑科技,获取你想要的内容。
温馨提示:
①“90技术控”公众号内提供的全部资源皆为无偿分享,资源都是来自于网络搜集和小伙伴们的提供(包含图片文字),仅供学习&交流(禁商用),本公众号不参与任何版权问题,如有侵权,请联系删除!
②每期文章底部都会有相应关键词,只有在关注完公众号内正确的回复关键词才会获得相关资源,搜索关键词必须为精确关键词!(你可以复制文章底部的关键词,不包括文章底部的符号)不能错一个字和字符,区分大小写,不能有多余的符号,感谢大家的支持与理解!
③如需遇到外文网站或其他语种网站,先在你打开的网站中寻找你能看懂的语言,同时,如果没有你想要的的语言,建议你可以利用自带翻译功能的浏览器进行翻译,如果打开链接公众号内容没有反应或者长时间打不开,建议先检查自己的网络原因,如果微信打不开的话建议把链接复制到(手机或者电脑)的自带浏览器进行查阅。
④由于我们公众号内部功能比较多,大家不懂得先可以尝试在菜单栏中找到对应的帮助,如果还不会的话可以咨询一下人工服务!感谢你的支持与理解!
“90技术控”
不一样的黑科技技术平台
【实用办公网站】即时工具网站(PDF、音视频、图片、办公辅助等236款工具)完全
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-06-17 22:01
下载须知:
1. 公众号所分享的软件都是已亲自测试,可放心使用,仅供学习交流,勿用于商业用途;如果觉得不错,欢迎将公众号推荐给您的朋友使用。
2.破解软件的签名和原官方软件不一致,会出现报毒!无需理会!放心使用。另破解软件有时效性,如出现无法使用请关注后续版本的更新。
3.获取链接后请复制到浏览器下载。如还是无法下载,请关闭纯净模式。
近期会将原工作黑科技公众号上的资源全部搬运至此公众号上,不过原来文章的图片都丢失了,只保留了文字部分。200多篇文章为了快速搬运,无法再补上图片了。
即时工具(网址)
即时工具网 是一款在线工具箱,内含很多种实用工具。通过首页我们可以看到,该平台推荐的一些工具都与我们生活息息相关,内置236款在线小工具,网站完全免费。其中的工具包括,办公辅助,设计工具,图片处理工具,视频处理工具,格式转换,教育学习,文本工具,开发工具,生活查询等等。
1、图片无损压缩-不改变图片尺寸、文件减小、无损压缩,支持40张批量处理。
2、视频修剪-在线视频修剪,同时可裁切、翻转、旋转、分辨率、倍速、循环、缩放等处理。
3、视频裁切-在线自定义裁切视频画面,可用于去水印、改分辨率等等操作。
4、视频格式转换-支持MP4、AVI、MPG、MOV、FLV、3GP、WEBM、MKV、WMV、GIF在线互转。
5、视频分辨率转换-支持超多分辨率预设转换,同时支持输入自定义分辨率。
6、视频压缩-不改变分辨率压缩视频,支持MP4、AVI、MPG、MOV、FLV、3GP、WEBM、MKV、WMV格式。
7、视频提取音频-支持主流视频格式在线提取音频,并且可以选择输出格式。
8、音频格式转换-支持mp3、wav、ogg、ac3、flac、opus、pcm、m4a、aac在线互转。
9、视频拼接-支持多个视频文件在线拼接,同时可选择多种输出格式。
10、音频调速-在线可视化音频调速,支持0.5倍到4倍速度调整。
网站适配多个主流浏览器,内置236个工具,同时也可看到工具的使用次数。
免责声明:0点黑科技公众号所分享的资源全部是来源于互联网公开分享的内容,仅用于个人学习使用,禁止用于其他商业用途和倒卖。如有条件请支持正版,谢谢。如软件失效、打不开等问题,请联系我处理,谢谢。
▌获取方式
先点击右下角的“在看” 查看全部
【实用办公网站】即时工具网站(PDF、音视频、图片、办公辅助等236款工具)完全
下载须知:
1. 公众号所分享的软件都是已亲自测试,可放心使用,仅供学习交流,勿用于商业用途;如果觉得不错,欢迎将公众号推荐给您的朋友使用。
2.破解软件的签名和原官方软件不一致,会出现报毒!无需理会!放心使用。另破解软件有时效性,如出现无法使用请关注后续版本的更新。
3.获取链接后请复制到浏览器下载。如还是无法下载,请关闭纯净模式。
近期会将原工作黑科技公众号上的资源全部搬运至此公众号上,不过原来文章的图片都丢失了,只保留了文字部分。200多篇文章为了快速搬运,无法再补上图片了。
即时工具(网址)
即时工具网 是一款在线工具箱,内含很多种实用工具。通过首页我们可以看到,该平台推荐的一些工具都与我们生活息息相关,内置236款在线小工具,网站完全免费。其中的工具包括,办公辅助,设计工具,图片处理工具,视频处理工具,格式转换,教育学习,文本工具,开发工具,生活查询等等。
1、图片无损压缩-不改变图片尺寸、文件减小、无损压缩,支持40张批量处理。
2、视频修剪-在线视频修剪,同时可裁切、翻转、旋转、分辨率、倍速、循环、缩放等处理。
3、视频裁切-在线自定义裁切视频画面,可用于去水印、改分辨率等等操作。
4、视频格式转换-支持MP4、AVI、MPG、MOV、FLV、3GP、WEBM、MKV、WMV、GIF在线互转。
5、视频分辨率转换-支持超多分辨率预设转换,同时支持输入自定义分辨率。
6、视频压缩-不改变分辨率压缩视频,支持MP4、AVI、MPG、MOV、FLV、3GP、WEBM、MKV、WMV格式。
7、视频提取音频-支持主流视频格式在线提取音频,并且可以选择输出格式。
8、音频格式转换-支持mp3、wav、ogg、ac3、flac、opus、pcm、m4a、aac在线互转。
9、视频拼接-支持多个视频文件在线拼接,同时可选择多种输出格式。
10、音频调速-在线可视化音频调速,支持0.5倍到4倍速度调整。
网站适配多个主流浏览器,内置236个工具,同时也可看到工具的使用次数。
免责声明:0点黑科技公众号所分享的资源全部是来源于互联网公开分享的内容,仅用于个人学习使用,禁止用于其他商业用途和倒卖。如有条件请支持正版,谢谢。如软件失效、打不开等问题,请联系我处理,谢谢。
▌获取方式
先点击右下角的“在看”
(Android)Top浏览器v3.0.8-极速移动浏览器
网站优化 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2022-05-23 17:41
OMG优质资源
公众号改推送机制了,以后可能收不到咱们消息了,不想错过优质的资源分享,请点左上角OMG优质资源,然后按下面步骤,设置星标★就可以优先推送了,谢谢大家的支持。下载提取码在文末哦!!!!!!!!!!!!!!另外破解软件有时效性,过一段时间会时效的,后续网盘会有更新新版本微信如果遇到无法访问蓝奏云连接,获取链接后复制到浏览器下载既可
产品简介Top浏览器是一款极速移动浏览器。
智能广告拦截,采用Adblock,自动更新规则,清爽界面,拒绝弹窗骚扰,任何的广告又或者是小的弹窗广告,都会进行删除。阅读模式,智能提取网页正文,下拉翻页,给你干净整洁的阅读体验,而且用户们还可以根据自己的需求,主动对界面进行管理。嗅探下载,准确抓取资源链接,支持音频、视频的下载,支持M3U8视频下载并自动转MP4,同时还可以在平台下载其他的文件。随时随地都可以浏览各种热点网页推荐视频等等。智能搜索功能,让你轻松查看到你感兴趣的内容。
产品特色
【最良心】不偷取用户数据,权限只必要;
【最快速】使用的webkit内核,原生体验;
【最强悍】各种设置项自定义,为你专属;
– 非常小巧,仅几百KB,该有的功能都有;
– 隐私保护、隐私防追踪、自定义浏览器标识ua;
– 支持广告拦截、自定义广告标记(可添加拦截规则)
– 支持沉浸式、支持定制主页风格、LOGO、搜索栏;
– 支持HTML5、插件管理、下载插件、下载链接解析;
– 书签可以登陆云同步,支持夜间模式,夜间模式、电脑模式、有图/无图模式;
– 支持翻译网页、离线网页、保存网页、查看网页源码、网页资源嗅探、网页内查找等;
– 支持自定义添加脚本(添加如:百度贴吧免登陆看更多回复、知乎免登陆看全文回答);
产品更新为了让更多的用户享受到舒适的便捷生活服务,用户们可以在平台上更加轻松地了解到众多的应用版块的使用方式,享受软件的操作性;
三无模式开启,你不想要的,我们通通都没有——无广告、无新闻、无推送,轻快简洁,还原浏览器本质,使用起来更加舒心;自由订阅功能,通过订阅获取网站更新内容,轻松实现追剧、追小说、追漫画…以订阅的方式“看”世界,各种各样的资讯都可以在线订阅
联系我们加入微群每天都有VIP优秀资源分享,欢迎大家加入,进群才有哦!由于群已满200人,无法进行扫码入群,现提供群主微信,(需要进群可加群主微信,拉你入群)广告别进 必T,广告别进 必T,广告别进 必T
下载地址
公众号内发送【198】点击下方公众号进入发送数字即可获取资源下载链接微信如果遇到无法访问蓝奏云连接,获取链接后复制到浏览器下载既可
好了,今天的分享就是这样,老规矩,获取软件前记得戳一些右下角的【在看】哦!你们的在看就是我更新的动力!拜 托戳 最 底加 个 鸡 腿吧
查看全部
(Android)Top浏览器v3.0.8-极速移动浏览器
OMG优质资源
公众号改推送机制了,以后可能收不到咱们消息了,不想错过优质的资源分享,请点左上角OMG优质资源,然后按下面步骤,设置星标★就可以优先推送了,谢谢大家的支持。下载提取码在文末哦!!!!!!!!!!!!!!另外破解软件有时效性,过一段时间会时效的,后续网盘会有更新新版本微信如果遇到无法访问蓝奏云连接,获取链接后复制到浏览器下载既可
产品简介Top浏览器是一款极速移动浏览器。
智能广告拦截,采用Adblock,自动更新规则,清爽界面,拒绝弹窗骚扰,任何的广告又或者是小的弹窗广告,都会进行删除。阅读模式,智能提取网页正文,下拉翻页,给你干净整洁的阅读体验,而且用户们还可以根据自己的需求,主动对界面进行管理。嗅探下载,准确抓取资源链接,支持音频、视频的下载,支持M3U8视频下载并自动转MP4,同时还可以在平台下载其他的文件。随时随地都可以浏览各种热点网页推荐视频等等。智能搜索功能,让你轻松查看到你感兴趣的内容。
产品特色
【最良心】不偷取用户数据,权限只必要;
【最快速】使用的webkit内核,原生体验;
【最强悍】各种设置项自定义,为你专属;
– 非常小巧,仅几百KB,该有的功能都有;
– 隐私保护、隐私防追踪、自定义浏览器标识ua;
– 支持广告拦截、自定义广告标记(可添加拦截规则)
– 支持沉浸式、支持定制主页风格、LOGO、搜索栏;
– 支持HTML5、插件管理、下载插件、下载链接解析;
– 书签可以登陆云同步,支持夜间模式,夜间模式、电脑模式、有图/无图模式;
– 支持翻译网页、离线网页、保存网页、查看网页源码、网页资源嗅探、网页内查找等;
– 支持自定义添加脚本(添加如:百度贴吧免登陆看更多回复、知乎免登陆看全文回答);
产品更新为了让更多的用户享受到舒适的便捷生活服务,用户们可以在平台上更加轻松地了解到众多的应用版块的使用方式,享受软件的操作性;
三无模式开启,你不想要的,我们通通都没有——无广告、无新闻、无推送,轻快简洁,还原浏览器本质,使用起来更加舒心;自由订阅功能,通过订阅获取网站更新内容,轻松实现追剧、追小说、追漫画…以订阅的方式“看”世界,各种各样的资讯都可以在线订阅
联系我们加入微群每天都有VIP优秀资源分享,欢迎大家加入,进群才有哦!由于群已满200人,无法进行扫码入群,现提供群主微信,(需要进群可加群主微信,拉你入群)广告别进 必T,广告别进 必T,广告别进 必T
下载地址
公众号内发送【198】点击下方公众号进入发送数字即可获取资源下载链接微信如果遇到无法访问蓝奏云连接,获取链接后复制到浏览器下载既可
好了,今天的分享就是这样,老规矩,获取软件前记得戳一些右下角的【在看】哦!你们的在看就是我更新的动力!拜 托戳 最 底加 个 鸡 腿吧
python爬虫学习教程之自动下载网页音频文件
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-05-12 14:43
2、BeautifulSoup
一个灵活又方便的网页解析库,处理高效,支持多种解析器。
利用它就不用编写正则表达式也能方便的实现网页信息的抓取。
3、安装和引入:
pip install requestspip install BeautifulSoup
import requestsfrom bs4 import BeautifulSoup as bf
二、目标网站
一个需要手动点击下载mp3文件的网站,因为需要下载几百个所以很难手动操作。
三:获取并解析网页源代码
1、使用requests获取目标网站的源代码
r = requests.get('http://www.goodkejian.com/ertonggushi.htm')
所有下载链接被存放在标签内,并且长度固定。该链接将其中的amp;去除后方可直接下载。
2、使用BeautifulSoup将网页内容解析并将其中的标签提取出来
soup = bf(r.text, 'html.parser')res = soup.find_all('a')
四:下载
经过上述步骤res就变成了包含所有目标标签的数组,要想下载网页上的所有mp3文件,只要循环把res中的元组转换为字符串,并经过筛选、裁剪等处理后变成链接就可以使用request访问了,并且返回值就是mp3文件的二进制表示,将其以二进制形式写进文件即可。
全部代码如下:
import requestsfrom bs4 import BeautifulSoup as bf<br />r = requests.get('http://www.goodkejian.com/ertonggushi.htm')<br />soup = bf(r.text, 'html.parser')res = soup.find_all('a')<br />recorder = 1# 长度为126的是要找的图标for i in res: dst = str(i) if dst.__len__() == 126: url1 = dst[9:53] url2 = dst[57:62] url = url1 + url2 print(url) xjh_request = requests.get(url) with open("./res/" + str(recorder) + ".rar", 'wb') as file: file.write(xjh_request.content) file.close() recorder += 1 print("ok")
以上就是使用python爬虫自动下载网页音频文件的思路和全部代码,大家可以套入代码尝试下载进行实战练习哦~
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权
查看全部
python爬虫学习教程之自动下载网页音频文件
2、BeautifulSoup
一个灵活又方便的网页解析库,处理高效,支持多种解析器。
利用它就不用编写正则表达式也能方便的实现网页信息的抓取。
3、安装和引入:
pip install requestspip install BeautifulSoup
import requestsfrom bs4 import BeautifulSoup as bf
二、目标网站
一个需要手动点击下载mp3文件的网站,因为需要下载几百个所以很难手动操作。
三:获取并解析网页源代码
1、使用requests获取目标网站的源代码
r = requests.get('http://www.goodkejian.com/ertonggushi.htm')
所有下载链接被存放在标签内,并且长度固定。该链接将其中的amp;去除后方可直接下载。
2、使用BeautifulSoup将网页内容解析并将其中的标签提取出来
soup = bf(r.text, 'html.parser')res = soup.find_all('a')
四:下载
经过上述步骤res就变成了包含所有目标标签的数组,要想下载网页上的所有mp3文件,只要循环把res中的元组转换为字符串,并经过筛选、裁剪等处理后变成链接就可以使用request访问了,并且返回值就是mp3文件的二进制表示,将其以二进制形式写进文件即可。
全部代码如下:
import requestsfrom bs4 import BeautifulSoup as bf<br />r = requests.get('http://www.goodkejian.com/ertonggushi.htm')<br />soup = bf(r.text, 'html.parser')res = soup.find_all('a')<br />recorder = 1# 长度为126的是要找的图标for i in res: dst = str(i) if dst.__len__() == 126: url1 = dst[9:53] url2 = dst[57:62] url = url1 + url2 print(url) xjh_request = requests.get(url) with open("./res/" + str(recorder) + ".rar", 'wb') as file: file.write(xjh_request.content) file.close() recorder += 1 print("ok")
以上就是使用python爬虫自动下载网页音频文件的思路和全部代码,大家可以套入代码尝试下载进行实战练习哦~
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权
网页音频抓取 基本请求库requests
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-05-04 06:23
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get")# 发起Post请求requests.post("https://www.httpbin.org/post")# 发起Put请求requests.put("https://www.httpbin.org/put")# 发起Delete请求requests.delete("https://www.httpbin.org/delete")
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/")# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证 查看全部
网页音频抓取 基本请求库requests
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get";)# 发起Post请求requests.post("https://www.httpbin.org/post";)# 发起Put请求requests.put("https://www.httpbin.org/put";)# 发起Delete请求requests.delete("https://www.httpbin.org/delete";)
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/";)# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证
网页音频抓取 基本请求库requests
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-05-03 22:38
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get")# 发起Post请求requests.post("https://www.httpbin.org/post")# 发起Put请求requests.put("https://www.httpbin.org/put")# 发起Delete请求requests.delete("https://www.httpbin.org/delete")
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/")# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证 查看全部
网页音频抓取 基本请求库requests
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get";)# 发起Post请求requests.post("https://www.httpbin.org/post";)# 发起Put请求requests.put("https://www.httpbin.org/put";)# 发起Delete请求requests.delete("https://www.httpbin.org/delete";)
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/";)# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证
网页音频抓取 基本请求库requests
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-05-03 14:54
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get")# 发起Post请求requests.post("https://www.httpbin.org/post")# 发起Put请求requests.put("https://www.httpbin.org/put")# 发起Delete请求requests.delete("https://www.httpbin.org/delete")
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/")# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证 查看全部
网页音频抓取 基本请求库requests
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get";)# 发起Post请求requests.post("https://www.httpbin.org/post";)# 发起Put请求requests.put("https://www.httpbin.org/put";)# 发起Delete请求requests.delete("https://www.httpbin.org/delete";)
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/";)# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证
《玩转无线投屏》连载№2:轻松地在PC上操作手机
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-05-02 22:06
引言
从苹果 Mac + iPhone 的接力/通用剪贴板,到华为的多屏协同,越来越多人意识到手机和电脑之间的交互如跨屏控制/同步剪贴板等功能确实能提高使用方便程度以及效率的。
小米12 Pro 骁龙8 Gen1 2K AMOLED 120Hz高刷 5000万疾速影像 120W小米澎湃秒充 12GB+256GB 黑色 5G手机
———————
京东价:¥5199.00
抢购链接:
那有没有什么办法通过软件打通限制,在电脑上更好的「玩」手机呢?
优爱酷今天分享的软件,可以轻松地在PC上操作手机,支持所有品牌的Android手机,WiFi和USB连接,多点触控,共享剪贴板等,且看
文末获取 工具下载链接
功能
所有Android手机
谷歌、HTC、华为、联想、Mi、OnePlus、Oppo、Realme、三星、索尼、Tecno、维梧等。
音频支持
你的电脑就是你的手机扬声器
键映射
帮助您在 PC 上玩移动 FPS 游戏。
屏幕录制
使用 AnLink 快速录制技术,减少 CPU 和 GPU 消耗。
键盘和输入法
使用键盘和输入法编辑器提高打字速度。
大而清晰
享受大屏体验,最清晰的镜像显示质量,支持硬件解码器以节省电池。
WiFi和USB
WiFi连接更方便,USB连接更流畅。
共享剪贴板
Ctrl+C和Ctrl+V也在手机和电脑之间工作。
多点触控
如果您可以触摸显示器屏幕,则支持手势。
文件管理器
通过拖放等方式在手机和PC之间传输文件。
“随心所欲 截您所需”
为批量截图而生,Chrome内核新版本发布啦!
IE内核版下载地址
https://gitee.com/uicoolcn/UiC ... eases
Chromium内核版下载地址
https://gitee.com/uicoolcn/UiC ... eases
优爱酷批量图像文字识别系统OCR
本软件与 “优爱酷批量长网页整页截图系统”配合使用,更加得心应手,只要是截得到的图,就可以用本软件进行批量OCR转为文字。
一款基于开放互操作人工智能的AI深度学习的OCR软件。
支持单图OCR 以及 自由截屏OCR识别、批量OCR、动态OCR(定时OCR);
支持五大场景结构化识别;
支持倾斜图像自动纠偏;
支持识别成文本文档(.txt)、Excel(.xlsx)格式;
支持表格图片识别成Word文档(.docx)格式,支持多表格识别。
优爱酷使用AI技术将无比庞大的文字识别功能从网络端,轻量化到桌面端,本地化OCR识别库,本地识别文字,使您无需顾虑涉密信息或隐私数据的泄露。
点击原文链接下载更多软件。
或直接免费下载地址:
https://gitee.com/uicoolcn/UiCoolOCR/releases
用法
帮助里可以选择多种手机品牌,之后,按步骤做即可,非常直观和易操作。
有线连接的话,插入数据线即可
连接中
连接成功
可选固定在窗口的位置
关注不迷路
∷
加个星标约定再见~
— 完 —
本文系新浪微博、知乎内容激励计划签约账号【】原创内容
© 本文著作权归优爱酷所有,未经优爱酷授权,禁止转载使用。
刮刮卡
微信扫码关注【优爱酷】回复【AnLink】获取直接下载链接
提示:手机上长按色块复制 查看全部
《玩转无线投屏》连载№2:轻松地在PC上操作手机
引言
从苹果 Mac + iPhone 的接力/通用剪贴板,到华为的多屏协同,越来越多人意识到手机和电脑之间的交互如跨屏控制/同步剪贴板等功能确实能提高使用方便程度以及效率的。
小米12 Pro 骁龙8 Gen1 2K AMOLED 120Hz高刷 5000万疾速影像 120W小米澎湃秒充 12GB+256GB 黑色 5G手机
———————
京东价:¥5199.00
抢购链接:
那有没有什么办法通过软件打通限制,在电脑上更好的「玩」手机呢?
优爱酷今天分享的软件,可以轻松地在PC上操作手机,支持所有品牌的Android手机,WiFi和USB连接,多点触控,共享剪贴板等,且看
文末获取 工具下载链接
功能
所有Android手机
谷歌、HTC、华为、联想、Mi、OnePlus、Oppo、Realme、三星、索尼、Tecno、维梧等。
音频支持
你的电脑就是你的手机扬声器
键映射
帮助您在 PC 上玩移动 FPS 游戏。
屏幕录制
使用 AnLink 快速录制技术,减少 CPU 和 GPU 消耗。
键盘和输入法
使用键盘和输入法编辑器提高打字速度。
大而清晰
享受大屏体验,最清晰的镜像显示质量,支持硬件解码器以节省电池。
WiFi和USB
WiFi连接更方便,USB连接更流畅。
共享剪贴板
Ctrl+C和Ctrl+V也在手机和电脑之间工作。
多点触控
如果您可以触摸显示器屏幕,则支持手势。
文件管理器
通过拖放等方式在手机和PC之间传输文件。
“随心所欲 截您所需”
为批量截图而生,Chrome内核新版本发布啦!
IE内核版下载地址
https://gitee.com/uicoolcn/UiC ... eases
Chromium内核版下载地址
https://gitee.com/uicoolcn/UiC ... eases
优爱酷批量图像文字识别系统OCR
本软件与 “优爱酷批量长网页整页截图系统”配合使用,更加得心应手,只要是截得到的图,就可以用本软件进行批量OCR转为文字。
一款基于开放互操作人工智能的AI深度学习的OCR软件。
支持单图OCR 以及 自由截屏OCR识别、批量OCR、动态OCR(定时OCR);
支持五大场景结构化识别;
支持倾斜图像自动纠偏;
支持识别成文本文档(.txt)、Excel(.xlsx)格式;
支持表格图片识别成Word文档(.docx)格式,支持多表格识别。
优爱酷使用AI技术将无比庞大的文字识别功能从网络端,轻量化到桌面端,本地化OCR识别库,本地识别文字,使您无需顾虑涉密信息或隐私数据的泄露。
点击原文链接下载更多软件。
或直接免费下载地址:
https://gitee.com/uicoolcn/UiCoolOCR/releases
用法
帮助里可以选择多种手机品牌,之后,按步骤做即可,非常直观和易操作。
有线连接的话,插入数据线即可
连接中
连接成功
可选固定在窗口的位置
关注不迷路
∷
加个星标约定再见~
— 完 —
本文系新浪微博、知乎内容激励计划签约账号【】原创内容
© 本文著作权归优爱酷所有,未经优爱酷授权,禁止转载使用。
刮刮卡
微信扫码关注【优爱酷】回复【AnLink】获取直接下载链接
提示:手机上长按色块复制
网页音频抓取 基本请求库requests
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-05-02 03:40
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get")# 发起Post请求requests.post("https://www.httpbin.org/post")# 发起Put请求requests.put("https://www.httpbin.org/put")# 发起Delete请求requests.delete("https://www.httpbin.org/delete")
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/")# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证 查看全部
网页音频抓取 基本请求库requests
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get";)# 发起Post请求requests.post("https://www.httpbin.org/post";)# 发起Put请求requests.put("https://www.httpbin.org/put";)# 发起Delete请求requests.delete("https://www.httpbin.org/delete";)
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/";)# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证
网页音频抓取(如何使用IDM批量下载网页上面的音乐、音效等素材)
网站优化 • 优采云 发表了文章 • 0 个评论 • 532 次浏览 • 2022-04-20 20:06
Internet Download Manager(简称IDM)是一款优秀的多线程下载工具。其受欢迎的原因是下载速度快,并且可以批量操作下载。
本期给大家讲讲如何使用IDM批量下载网页上的音乐、音效等素材。
一、点击打开软件进入网页
图 1:点击站点爬取
首先点击IDM软件,然后点击软件上的【Site Capture】功能,该功能可以直接保存网站上的任何信息、音频等资源。
图 2:复制链接
那我们以QQ浏览器为例,随机进入一个有音乐的页面。这里我们进入【音效素材下载-音效大全】页面。这个界面有很多音效,可以在线预览和下载。
二、复制网址,粘贴网址
图 3:粘贴 网站in
我们现在要做的就是复制页面的URL,并将其粘贴到IDM的[站点抓取功能]的第二列中。第一列是你的网站爬取方案的名称,最后会和你的设置一起保存在你需要存放的地方。建议将保存文件的名称更改为您需要的名称。
然后点击【转发】,根据需要保存需要的内容。除非有需要,这一步可以保持不变。
然后在此页面上,将[Explore specified link depth]更改为[3 root site link depth]。
图 4:调整根站点深度
这一步是获取音效下载页面的链接,因为在这个界面点击下载音乐会进入另一个界面下载。在这波操作中,我们直接把这三个接口的音频资源全部取回并下载。
然后点击【前进】进入下一波操作。
三、文件类型,等待下载
图 5:转换音频文件
最后一步是调整【文件类型】,因为我们是在下载音频资源,所以我们把这个界面第一栏的【所有文件】替换为【音频资源】,如果我们不做这一步,那么下载将是该界面的所有资源,包括图片、音频、视频、PDF、压缩包等文件。
图 6:等待下载和保存
当我们完成切换并点击【转发】后,该页面上的所有音频文件都会被下载。而且还可以抓取多个窗口,非常方便。但是需要注意的是网站音效资源必须是mp3、wma和waw这三种后缀格式,否则会因为IDM无法识别音频资源而导致保存失败。 查看全部
网页音频抓取(如何使用IDM批量下载网页上面的音乐、音效等素材)
Internet Download Manager(简称IDM)是一款优秀的多线程下载工具。其受欢迎的原因是下载速度快,并且可以批量操作下载。
本期给大家讲讲如何使用IDM批量下载网页上的音乐、音效等素材。
一、点击打开软件进入网页
图 1:点击站点爬取
首先点击IDM软件,然后点击软件上的【Site Capture】功能,该功能可以直接保存网站上的任何信息、音频等资源。
图 2:复制链接
那我们以QQ浏览器为例,随机进入一个有音乐的页面。这里我们进入【音效素材下载-音效大全】页面。这个界面有很多音效,可以在线预览和下载。
二、复制网址,粘贴网址
图 3:粘贴 网站in
我们现在要做的就是复制页面的URL,并将其粘贴到IDM的[站点抓取功能]的第二列中。第一列是你的网站爬取方案的名称,最后会和你的设置一起保存在你需要存放的地方。建议将保存文件的名称更改为您需要的名称。
然后点击【转发】,根据需要保存需要的内容。除非有需要,这一步可以保持不变。
然后在此页面上,将[Explore specified link depth]更改为[3 root site link depth]。
图 4:调整根站点深度
这一步是获取音效下载页面的链接,因为在这个界面点击下载音乐会进入另一个界面下载。在这波操作中,我们直接把这三个接口的音频资源全部取回并下载。
然后点击【前进】进入下一波操作。
三、文件类型,等待下载
图 5:转换音频文件
最后一步是调整【文件类型】,因为我们是在下载音频资源,所以我们把这个界面第一栏的【所有文件】替换为【音频资源】,如果我们不做这一步,那么下载将是该界面的所有资源,包括图片、音频、视频、PDF、压缩包等文件。
图 6:等待下载和保存
当我们完成切换并点击【转发】后,该页面上的所有音频文件都会被下载。而且还可以抓取多个窗口,非常方便。但是需要注意的是网站音效资源必须是mp3、wma和waw这三种后缀格式,否则会因为IDM无法识别音频资源而导致保存失败。
网页音频抓取( 猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-20 10:16
猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
猫抓
猫渣是一个支持所有Chrome核心浏览器的网络媒体嗅探和抓取的扩展。
可以一键抓取任意站点的任意视频/音频数据,使用非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮,就可以在这个页面看到资源信息了。
然后可以对资源进行三个操作:复制链接地址,小窗口播放,下载到本地电脑。
猫扎支持优酷、搜狐、腾讯、微博、B站等国内几乎所有网站的视频文件嗅探。
当您在同一页面上遇到多个属性时,您还可以对它们进行快速批量操作。
此类嗅探工具支持的短视频文件一般都是未加密的。面对一些加密视频时,会有一定的失败概率。
不过从市场反馈来看,猫爪可以抢到很多其他扩展,包括IDM都无法嗅到的媒体资源。
这就是它在竞争性扩展商店中拥有超过 50,000 名用户的原因之一。
此外,猫爪还支持所有音乐网站的音频文件嗅探,包括Qzone的SWF模块和音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,也支持使用正则表达式自定义采集的内容。
网络嗅探器原本是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。嗅探器也是许多程序员在编写网络程序时捕获和测试数据包的工具。
近年来,网络嗅探器已广泛应用于用户的日常行为,成为捕捉视频、音频等内容的工具。 查看全部
网页音频抓取(
猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
猫抓
猫渣是一个支持所有Chrome核心浏览器的网络媒体嗅探和抓取的扩展。
可以一键抓取任意站点的任意视频/音频数据,使用非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮,就可以在这个页面看到资源信息了。
然后可以对资源进行三个操作:复制链接地址,小窗口播放,下载到本地电脑。
猫扎支持优酷、搜狐、腾讯、微博、B站等国内几乎所有网站的视频文件嗅探。
当您在同一页面上遇到多个属性时,您还可以对它们进行快速批量操作。
此类嗅探工具支持的短视频文件一般都是未加密的。面对一些加密视频时,会有一定的失败概率。
不过从市场反馈来看,猫爪可以抢到很多其他扩展,包括IDM都无法嗅到的媒体资源。
这就是它在竞争性扩展商店中拥有超过 50,000 名用户的原因之一。
此外,猫爪还支持所有音乐网站的音频文件嗅探,包括Qzone的SWF模块和音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,也支持使用正则表达式自定义采集的内容。
网络嗅探器原本是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。嗅探器也是许多程序员在编写网络程序时捕获和测试数据包的工具。
近年来,网络嗅探器已广泛应用于用户的日常行为,成为捕捉视频、音频等内容的工具。
网页音频抓取(一个网络爬虫程序的基本执行流程可以总结框架简介)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-19 21:25
scrapy框架介绍
scrapy 是一个用 Python 语言编写的开源网络爬虫框架(基于 Twisted 框架),目前支持
由 scrapinghub Ltd. 维护。Scrapy 易于使用、灵活且可扩展,拥有活跃的开发社区,并且是跨平台的。适用于 Linux、MaxOS 和 Windows 平台。
网络爬虫
网络爬虫是一种自动爬取互联网上网站内容信息的程序,也称为网络蜘蛛或网络机器人。大型爬虫广泛应用于搜索引擎、数据挖掘等领域。个人用户或企业也可以使用爬虫为自己采集有价值的数据。
网络爬虫的基本执行过程可以概括为三个过程:请求数据、解析数据和保存数据
数据请求
请求的数据除了普通的HTML,还包括json数据、字符串数据、图片、视频、音频等。
解析数据
数据下载完成后,分析数据内容并提取所需数据。提取的数据可以以各种形式保存。数据格式有很多种,常见的有csv、json、pickle等。
保存数据
最后将数据以某种格式(CSV、JSON)写入文件,或存储在数据库(MySQL、MongoDB)中。同时保存为一个或多个。
通常我们要获取的数据不只是在一个页面中,而是分布在多个页面中,这些页面是相互关联的,一个页面可能收录一个或多个指向其他页面的链接,提取当前后页面中的数据,页面中的一些链接也被提取出来,然后对链接的页面进行爬取(循环1-3步)。
在设计爬虫程序时,还需要考虑防止对同一页面的重复爬取(URL去重)、网页搜索策略(深度优先或广度优先等)、限制访问等一系列问题。爬虫访问边界。
从头开始开发爬虫程序是一项乏味的任务。为了避免大量的时间花在制造轮子上,我们在实际应用中可以选择使用一些优秀的爬虫框架。使用框架可以降低开发成本并提高程序质量。让我们专注于业务逻辑(抓取有价值的数据)。接下来带大家学习一下非常流行的开源爬虫框架Scrapy。
scrapy 安装
scrapy官网:
scrapy中文文档:
安装方法
在任何操作系统上,都可以使用 pip 安装 Scrapy,例如:
pip install scrapy
安装完成后,我们需要测试是否安装成功,通过以下步骤确认:
测试scrapy命令是否可以在终端执行
scrapy 2.4.0 - no active project
usage:
scrapy [options] [args]
Available commands :
bench Run quick benchmark test
fetch Fetch a URL using the scrapy down1oader
genspider Generate new spider using pre-defined temp1ates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
she11 Interactive scraping console
startproject create new project
version Print scrapy version
view open URL in browser,as seen by scrapy
[ more ] More commands available when run from project directory
use "scrapy -h" to see more info about a command
进入scrapy bench测试连通性,如果出现以下情况,则安装成功:
图像.png
通过以上两项测试,说明Scrapy安装成功。如上图,我们安装了当前最新版本2.4.0.
注意:
在安装Scrapy的过程中,可能会遇到缺少VC++等错误,可以安装缺少模块的离线包
图像.png
安装成功后,在cmd下运行scrapy和上图并不是真的成功。检查scrapybench测试是否真的成功。如果没有错误,说明安装成功。
全局命令
scrapy 2.4.0 - no active project
usage:
scrapy [options] [args]
Available commands :
bench Run quick benchmark test #测试电脑性能
fetch Fetch a URL using the scrapy down1oader#将源代码下载下来并显示出来
genspider Generate new spider using pre-defined temp1ates#创建一个新的spider文件
runspider Run a self-contained spider (without creating a project)# 这个和通过craw1启动爬虫不同,scrapy runspider爬虫文件名称
settings Get settings values#获取当前的配置信息
she11 Interactive scraping console#进入scrapy 的交互模式
startproject create new project#创建爬虫项目
version Print scrapy version#显示scrapy框架的版本
view open URL in browser,as seen by scrapy#将网页document内容下载下来,并且在浏览器显示出来
[ more ] More commands available when run from project directory
use "scrapy -h" to see more info about a command
项目命令先scrapy爬虫项目要求
在网站()上爬取名言警句,专为爬虫初学者训练爬虫技术。
创建一个项目
在开始抓取之前,必须创建一个新的 Scrapy 项目。转到您打算存储代码的目录并运行以下命令:
(base) λ scrapy startproject quotes
New scrapy project 'quotes ', using template directory 'd: \anaconda3\lib\site-packages\scrapy\temp1ates\project ', created in:
D:\XXX
You can start your first spider with :
cd quotes
scrapy genspider example example. com
首先切换到新创建的爬虫项目目录,即/quotes目录。然后执行命令创建爬虫文件:
D:\XXX(master)
(base) λ cd quotes\
D:\XXX\quotes (master)
(base) λ scrapy genspider quotes quotes.com
cannot create a spider with the same name as your project
D :\XXX\quotes (master)
(base) λ scrapy genspider quote quotes.com
created spider 'quote' using template 'basic' in module:quotes.spiders.quote
此命令将创建一个收录以下内容的引号目录
robots.txt
robots协议,也叫robots.txt(统一小写),是一个ASCII编码的文本文件,存放在网站的根目录下,通常告诉网络搜索引擎的网络蜘蛛这个网站 哪些内容不应该被搜索引擎爬虫获取,哪些内容可以被爬虫获取。
机器人协议不是规范,而是约定。
#filename : settings.py
#obey robots.txt rules
ROBOTSTXT__OBEY = False
分析页面
在编写爬虫程序之前,首先需要对要爬取的页面进行分析。主流浏览器都有分析页面的工具或插件。这里我们使用Chrome浏览器的开发者工具(Tools→Developer tools)来分析页面。
数据信息
在 Chrome 中打开页面并选择“元素”以查看其 HTML 代码。
可以看到每个标签都包裹在里面
图像.png
写蜘蛛
分析完页面,接下来就是编写爬虫了。用 Scrapy 写蜘蛛,用 scrapy.Spider 写代码 蜘蛛是用户编写的一个类,用于从单个 网站(或 - 一些 网站)中抓取数据。
它收录一个用于下载的初始URL,如何跟随网页中的链接以及如何分析页面中的内容,提取生成项目的方法。
为了创建一个Spider,你必须扩展scrapy.Spider类并定义以下三个属性:
name:用于区分Spider。名称必须唯一,不能为不同的蜘蛛设置相同的名称。 start _urls:收录 Spider 在启动时爬取的 urs 列表。因此,
要获取的第一页将是其中之一。从初始 URL 获得的数据中提取后续 URL。 parse():是蜘蛛的一种方法。调用时,每个初始 URL 完成下载后生成的 Response 对象将作为唯一参数传递给此函数。该方法负责解析返回的数据(响应
data),提取数据(生成项目)并为需要进一步处理的 URL 生成 Request 对象。
import scrapy
class QuoteSpi der(scrapy . Spider):
name ='quote'
allowed_ domains = [' quotes. com ']
start_ urls = ['http://quotes . toscrape . com/']
def parse(self, response) :
pass
下面简单介绍一下quote的实现。
页面解析函数通常实现为生成器函数,从页面中提取的每一项数据以及对链接页面的每个下载请求都通过yield语句提交给Scrapy引擎。
解析数据
import scrapy
def parse(se1f,response) :
quotes = response.css('.quote ')
for quote in quotes:
text = quote.css( '.text: :text ' ).extract_first()
auth = quote.css( '.author : :text ' ).extract_first()
tages = quote.css('.tags a: :text' ).extract()
yield dict(text=text,auth=auth,tages=tages)
关键点:
response.css(response中的数据可以直接用css语法提取。start_ur1s中可以写多个url,可以拆分成列表格式。extract()就是提取css中的数据对象,提取后为List,否则为对象。而extract_first()是提取第一个运行的爬虫
运行/quotes目录下的scrapycrawlquotes,运行爬虫项目。
运行爬虫后发生了什么?
Scrapy 为 Spider 的 start_urls 属性中的每个 URL 创建一个 scrapy.Request 对象,并将 parse 方法分配给 Request 作为回调函数。
Request对象被调度,执行生成一个scrapy.http.Response对象并发回spider的parse()方法处理。
完成代码后,运行爬虫爬取数据,在shell中执行scrapy crawl命令运行爬虫'quote',并将爬取的数据存储在csv文件中:
(base) λ scrapy craw1 quote -o quotes.csv
2021-06-19 20:48:44 [scrapy.utils.log] INF0: Scrapy 1.8.0 started (bot: quotes)
等待爬虫运行结束后,会在当前目录生成一个quotes.csv文件,其中的数据已经以csv格式保存。
-o 支持保存为各种格式。保存的方式也很简单,只要给出文件的后缀名即可。 (csv、json、pickle等) 查看全部
网页音频抓取(一个网络爬虫程序的基本执行流程可以总结框架简介)
scrapy框架介绍
scrapy 是一个用 Python 语言编写的开源网络爬虫框架(基于 Twisted 框架),目前支持
由 scrapinghub Ltd. 维护。Scrapy 易于使用、灵活且可扩展,拥有活跃的开发社区,并且是跨平台的。适用于 Linux、MaxOS 和 Windows 平台。
网络爬虫
网络爬虫是一种自动爬取互联网上网站内容信息的程序,也称为网络蜘蛛或网络机器人。大型爬虫广泛应用于搜索引擎、数据挖掘等领域。个人用户或企业也可以使用爬虫为自己采集有价值的数据。
网络爬虫的基本执行过程可以概括为三个过程:请求数据、解析数据和保存数据
数据请求
请求的数据除了普通的HTML,还包括json数据、字符串数据、图片、视频、音频等。
解析数据
数据下载完成后,分析数据内容并提取所需数据。提取的数据可以以各种形式保存。数据格式有很多种,常见的有csv、json、pickle等。
保存数据
最后将数据以某种格式(CSV、JSON)写入文件,或存储在数据库(MySQL、MongoDB)中。同时保存为一个或多个。
通常我们要获取的数据不只是在一个页面中,而是分布在多个页面中,这些页面是相互关联的,一个页面可能收录一个或多个指向其他页面的链接,提取当前后页面中的数据,页面中的一些链接也被提取出来,然后对链接的页面进行爬取(循环1-3步)。
在设计爬虫程序时,还需要考虑防止对同一页面的重复爬取(URL去重)、网页搜索策略(深度优先或广度优先等)、限制访问等一系列问题。爬虫访问边界。
从头开始开发爬虫程序是一项乏味的任务。为了避免大量的时间花在制造轮子上,我们在实际应用中可以选择使用一些优秀的爬虫框架。使用框架可以降低开发成本并提高程序质量。让我们专注于业务逻辑(抓取有价值的数据)。接下来带大家学习一下非常流行的开源爬虫框架Scrapy。
scrapy 安装
scrapy官网:
scrapy中文文档:
安装方法
在任何操作系统上,都可以使用 pip 安装 Scrapy,例如:
pip install scrapy
安装完成后,我们需要测试是否安装成功,通过以下步骤确认:
测试scrapy命令是否可以在终端执行
scrapy 2.4.0 - no active project
usage:
scrapy [options] [args]
Available commands :
bench Run quick benchmark test
fetch Fetch a URL using the scrapy down1oader
genspider Generate new spider using pre-defined temp1ates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
she11 Interactive scraping console
startproject create new project
version Print scrapy version
view open URL in browser,as seen by scrapy
[ more ] More commands available when run from project directory
use "scrapy -h" to see more info about a command
进入scrapy bench测试连通性,如果出现以下情况,则安装成功:
图像.png
通过以上两项测试,说明Scrapy安装成功。如上图,我们安装了当前最新版本2.4.0.
注意:
在安装Scrapy的过程中,可能会遇到缺少VC++等错误,可以安装缺少模块的离线包
图像.png
安装成功后,在cmd下运行scrapy和上图并不是真的成功。检查scrapybench测试是否真的成功。如果没有错误,说明安装成功。
全局命令
scrapy 2.4.0 - no active project
usage:
scrapy [options] [args]
Available commands :
bench Run quick benchmark test #测试电脑性能
fetch Fetch a URL using the scrapy down1oader#将源代码下载下来并显示出来
genspider Generate new spider using pre-defined temp1ates#创建一个新的spider文件
runspider Run a self-contained spider (without creating a project)# 这个和通过craw1启动爬虫不同,scrapy runspider爬虫文件名称
settings Get settings values#获取当前的配置信息
she11 Interactive scraping console#进入scrapy 的交互模式
startproject create new project#创建爬虫项目
version Print scrapy version#显示scrapy框架的版本
view open URL in browser,as seen by scrapy#将网页document内容下载下来,并且在浏览器显示出来
[ more ] More commands available when run from project directory
use "scrapy -h" to see more info about a command
项目命令先scrapy爬虫项目要求
在网站()上爬取名言警句,专为爬虫初学者训练爬虫技术。
创建一个项目
在开始抓取之前,必须创建一个新的 Scrapy 项目。转到您打算存储代码的目录并运行以下命令:
(base) λ scrapy startproject quotes
New scrapy project 'quotes ', using template directory 'd: \anaconda3\lib\site-packages\scrapy\temp1ates\project ', created in:
D:\XXX
You can start your first spider with :
cd quotes
scrapy genspider example example. com
首先切换到新创建的爬虫项目目录,即/quotes目录。然后执行命令创建爬虫文件:
D:\XXX(master)
(base) λ cd quotes\
D:\XXX\quotes (master)
(base) λ scrapy genspider quotes quotes.com
cannot create a spider with the same name as your project
D :\XXX\quotes (master)
(base) λ scrapy genspider quote quotes.com
created spider 'quote' using template 'basic' in module:quotes.spiders.quote
此命令将创建一个收录以下内容的引号目录
robots.txt
robots协议,也叫robots.txt(统一小写),是一个ASCII编码的文本文件,存放在网站的根目录下,通常告诉网络搜索引擎的网络蜘蛛这个网站 哪些内容不应该被搜索引擎爬虫获取,哪些内容可以被爬虫获取。
机器人协议不是规范,而是约定。
#filename : settings.py
#obey robots.txt rules
ROBOTSTXT__OBEY = False
分析页面
在编写爬虫程序之前,首先需要对要爬取的页面进行分析。主流浏览器都有分析页面的工具或插件。这里我们使用Chrome浏览器的开发者工具(Tools→Developer tools)来分析页面。
数据信息
在 Chrome 中打开页面并选择“元素”以查看其 HTML 代码。
可以看到每个标签都包裹在里面
图像.png
写蜘蛛
分析完页面,接下来就是编写爬虫了。用 Scrapy 写蜘蛛,用 scrapy.Spider 写代码 蜘蛛是用户编写的一个类,用于从单个 网站(或 - 一些 网站)中抓取数据。
它收录一个用于下载的初始URL,如何跟随网页中的链接以及如何分析页面中的内容,提取生成项目的方法。
为了创建一个Spider,你必须扩展scrapy.Spider类并定义以下三个属性:
name:用于区分Spider。名称必须唯一,不能为不同的蜘蛛设置相同的名称。 start _urls:收录 Spider 在启动时爬取的 urs 列表。因此,
要获取的第一页将是其中之一。从初始 URL 获得的数据中提取后续 URL。 parse():是蜘蛛的一种方法。调用时,每个初始 URL 完成下载后生成的 Response 对象将作为唯一参数传递给此函数。该方法负责解析返回的数据(响应
data),提取数据(生成项目)并为需要进一步处理的 URL 生成 Request 对象。
import scrapy
class QuoteSpi der(scrapy . Spider):
name ='quote'
allowed_ domains = [' quotes. com ']
start_ urls = ['http://quotes . toscrape . com/']
def parse(self, response) :
pass
下面简单介绍一下quote的实现。
页面解析函数通常实现为生成器函数,从页面中提取的每一项数据以及对链接页面的每个下载请求都通过yield语句提交给Scrapy引擎。
解析数据
import scrapy
def parse(se1f,response) :
quotes = response.css('.quote ')
for quote in quotes:
text = quote.css( '.text: :text ' ).extract_first()
auth = quote.css( '.author : :text ' ).extract_first()
tages = quote.css('.tags a: :text' ).extract()
yield dict(text=text,auth=auth,tages=tages)
关键点:
response.css(response中的数据可以直接用css语法提取。start_ur1s中可以写多个url,可以拆分成列表格式。extract()就是提取css中的数据对象,提取后为List,否则为对象。而extract_first()是提取第一个运行的爬虫
运行/quotes目录下的scrapycrawlquotes,运行爬虫项目。
运行爬虫后发生了什么?
Scrapy 为 Spider 的 start_urls 属性中的每个 URL 创建一个 scrapy.Request 对象,并将 parse 方法分配给 Request 作为回调函数。
Request对象被调度,执行生成一个scrapy.http.Response对象并发回spider的parse()方法处理。
完成代码后,运行爬虫爬取数据,在shell中执行scrapy crawl命令运行爬虫'quote',并将爬取的数据存储在csv文件中:
(base) λ scrapy craw1 quote -o quotes.csv
2021-06-19 20:48:44 [scrapy.utils.log] INF0: Scrapy 1.8.0 started (bot: quotes)
等待爬虫运行结束后,会在当前目录生成一个quotes.csv文件,其中的数据已经以csv格式保存。
-o 支持保存为各种格式。保存的方式也很简单,只要给出文件的后缀名即可。 (csv、json、pickle等)
网页音频抓取(Python库:pyAudioAnalysis特征提取音频分析任务 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-15 22:22
)
pyAudioAnalysis 是一个开放的 Python 库,提供了许多与音频相关的功能,专注于特征提取、分类、分割和可视化问题。
特征
pyAudioAnalysis 是一个 Python 库,涵盖了广泛的音频分析任务。
使用 pyAudioAnalysis,您可以:
实用功能
将 Mp3 批量转换为 Wav
函数 convertDirMP3ToWav(dirName, Fs, nC, useMp3TagsAsName = False) 使用提供的采样率(第二个参数)和通道数(第三个参数)将文件夹 dirName 的所有 MP3 文件转换为 WAV 文件。如果最后一个参数 (useMp3TagsAsName) 设置为 True,则输出的 WAV 文件将使用 MP3 标签(艺术家和歌曲名称)命名,否则将使用 MP3 文件名(当然,扩展名为 .wav)
命令行使用示例
python audioAnalysis.py dirMp3toWav -i MusicData/ -r 16000 -c 1
或者,convertFsDirWavToWav() 函数可用于将存储在特定文件夹中的 WAV 列表转换为具有另一个采样率的相同信号的新列表(同样是 WAV 文件)。通讯示例:
python audioAnalysis.py dirWavResample -i MusicData/ -r 8000 -c 1
新文件存储在名为 Fs_Nc 的新文件夹下,例如 Fs8000_NC1
pyAudioAnalysis - Theodoros Giannakopoulos
下载并安装
下载包:pyAudioAnalysis模块下载
安装依赖: pip install -r ./requirements.txt
使用 pip 安装: pip install -e
音频分类示例
pyAudioAnalysis 提供易于调用的包装器来执行音频分析任务。例如,给定一组存储在文件夹中的 WAV 文件(每个文件夹代表不同的类别),此代码首先训练一个音频片段分类器,然后使用训练好的分类器对未知音频 WAV 文件进行分析分类:
aT.extract_features_and_train(["classifierData/music","classifierData/speech"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "svm", "svmSMtemp", False)aT.file_classification("data/doremi.wav", "svmSMtemp","svm")``` 查看全部
网页音频抓取(Python库:pyAudioAnalysis特征提取音频分析任务
)
pyAudioAnalysis 是一个开放的 Python 库,提供了许多与音频相关的功能,专注于特征提取、分类、分割和可视化问题。
特征
pyAudioAnalysis 是一个 Python 库,涵盖了广泛的音频分析任务。
使用 pyAudioAnalysis,您可以:
实用功能
将 Mp3 批量转换为 Wav
函数 convertDirMP3ToWav(dirName, Fs, nC, useMp3TagsAsName = False) 使用提供的采样率(第二个参数)和通道数(第三个参数)将文件夹 dirName 的所有 MP3 文件转换为 WAV 文件。如果最后一个参数 (useMp3TagsAsName) 设置为 True,则输出的 WAV 文件将使用 MP3 标签(艺术家和歌曲名称)命名,否则将使用 MP3 文件名(当然,扩展名为 .wav)
命令行使用示例
python audioAnalysis.py dirMp3toWav -i MusicData/ -r 16000 -c 1
或者,convertFsDirWavToWav() 函数可用于将存储在特定文件夹中的 WAV 列表转换为具有另一个采样率的相同信号的新列表(同样是 WAV 文件)。通讯示例:
python audioAnalysis.py dirWavResample -i MusicData/ -r 8000 -c 1
新文件存储在名为 Fs_Nc 的新文件夹下,例如 Fs8000_NC1
pyAudioAnalysis - Theodoros Giannakopoulos
下载并安装
下载包:pyAudioAnalysis模块下载
安装依赖: pip install -r ./requirements.txt
使用 pip 安装: pip install -e
音频分类示例
pyAudioAnalysis 提供易于调用的包装器来执行音频分析任务。例如,给定一组存储在文件夹中的 WAV 文件(每个文件夹代表不同的类别),此代码首先训练一个音频片段分类器,然后使用训练好的分类器对未知音频 WAV 文件进行分析分类:
aT.extract_features_and_train(["classifierData/music","classifierData/speech"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "svm", "svmSMtemp", False)aT.file_classification("data/doremi.wav", "svmSMtemp","svm")```
网页音频抓取( 如何研究喜马拉雅FM的请求方式?下载器怎么做? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2022-04-10 13:31
如何研究喜马拉雅FM的请求方式?下载器怎么做?
)
Java爬取喜马拉雅非付费音频
内容
前言
因为很喜欢喜马拉雅FM上的音频节目,之前也找过一些喜马拉雅音频下载器。可能是网站调整的原因,有的下载器慢慢有问题,估计有些地址无法解析,于是想到研究喜马拉雅FM的请求方法,用java模拟请求,和做一个我自己的小。玩的工具。
下面开始研究喜马拉雅FM的请求方法吧!
1 打开 Himalaya网站 并搜索节目
喜马拉雅调频
下面是一个我喜欢的程序的例子,以“首席医疗官”为例
2 研究其数据源并获取分页数据
打开浏览器控制台,清除网络下的日志
点击任意页面查看网络下的日志
从上面两张图可以看出,分页后的数据来自于请求:
解析返回的json数据可以得到分页信息
3 获取列表信息
在上面的控制台中,还有一个查看列表信息的请求
每个音频的基本信息可以从上面的请求中获取
4 获取音频下载地址
清除浏览器控制台,点击任意音频,查看网络地址
从这个请求中,我们也可以得到列表信息和音频的下载地址
5 核心代码
Java实现爬取喜马拉雅音频文件(非付费)
代码是最基础的,以后有时间会优化,比如增加多线程下载、图形界面、断点续传等。有兴趣的童鞋欢迎博客或GitHub评论^_^
有时间可以尝试做一个前端版本,使用ajax请求自己设计页面,这相当于做一个喜马拉雅FM免费音频的搜索引擎,直接在浏览器搜索下载^_^,然后一起分享~
6 基本用途
主要功能如下
public static void main(String[] args){
//初始化音频列表,修改专辑ID便可下载该专辑的音频内容(非付费)
AudioBean audioBean = AudioDealUtil.initBean(
"https://www.ximalaya.com/revision/album",
"albumId=3071659");
//修改下载路径
AudioDealUtil.initDownloadAudio("https://www.ximalaya.com/revision/play/album",
audioBean,
"D://download//");
}
只需更改专辑ID和本地路径即可下载音频~
查看全部
网页音频抓取(
如何研究喜马拉雅FM的请求方式?下载器怎么做?
)
Java爬取喜马拉雅非付费音频
内容
前言
因为很喜欢喜马拉雅FM上的音频节目,之前也找过一些喜马拉雅音频下载器。可能是网站调整的原因,有的下载器慢慢有问题,估计有些地址无法解析,于是想到研究喜马拉雅FM的请求方法,用java模拟请求,和做一个我自己的小。玩的工具。
下面开始研究喜马拉雅FM的请求方法吧!
1 打开 Himalaya网站 并搜索节目
喜马拉雅调频
下面是一个我喜欢的程序的例子,以“首席医疗官”为例
2 研究其数据源并获取分页数据
打开浏览器控制台,清除网络下的日志
点击任意页面查看网络下的日志
从上面两张图可以看出,分页后的数据来自于请求:
解析返回的json数据可以得到分页信息
3 获取列表信息
在上面的控制台中,还有一个查看列表信息的请求
每个音频的基本信息可以从上面的请求中获取
4 获取音频下载地址
清除浏览器控制台,点击任意音频,查看网络地址
从这个请求中,我们也可以得到列表信息和音频的下载地址
5 核心代码
Java实现爬取喜马拉雅音频文件(非付费)
代码是最基础的,以后有时间会优化,比如增加多线程下载、图形界面、断点续传等。有兴趣的童鞋欢迎博客或GitHub评论^_^
有时间可以尝试做一个前端版本,使用ajax请求自己设计页面,这相当于做一个喜马拉雅FM免费音频的搜索引擎,直接在浏览器搜索下载^_^,然后一起分享~
6 基本用途
主要功能如下
public static void main(String[] args){
//初始化音频列表,修改专辑ID便可下载该专辑的音频内容(非付费)
AudioBean audioBean = AudioDealUtil.initBean(
"https://www.ximalaya.com/revision/album",
"albumId=3071659");
//修改下载路径
AudioDealUtil.initDownloadAudio("https://www.ximalaya.com/revision/play/album",
audioBean,
"D://download//");
}
只需更改专辑ID和本地路径即可下载音频~
网页音频抓取(页面分析我们要下载音频文件,首先得要找到下载音频的url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2022-04-10 13:30
页面分析
我们要下载音频文件,首先要找到下载音频的url,我们打开浏览器自带的调试工具(我用的是Chrome),使用快捷键F12快速打开调试工具。调试器切换到网络。我以刚看完的《腾讯传》为例,点击专辑封面中间的播放按钮。专辑中的音频信息都是json格式的数据。共有7个音频文件。
任意扩展音频的详细信息,详细信息包括音频文件的标题和下载链接。找到音频的下载链接后,就可以下载音频了。接下来的工作将重点介绍如何获取音频文件的下载链接。
获取页面源代码
我们首先定义一个函数来获取页面的html信息。浏览器标头信息标头被添加到此函数中。为了安全起见,使用代理IP。有兴趣的可以自己创建一个IP代理池,IP失效时会自动替换。
获取专辑信息
接下来,我们需要获取专辑的ID,因为音频的下载链接是由专辑ID拼接而成的。让我们看看收录音频文件名和下载链接信息的标题。我们可以看到albumId是专辑链接组成中的专辑ID。表示当前页码和该页存储的最大音频数。
相册的ID信息收录在关键字搜索的信息中。
专辑的ID信息通过BeautifulSoup从页面中提取出来,专辑标题信息也提取出来作为后面要创建的专辑目录名。主要代码如下。
获取页数
上述方法获取专辑ID信息。接下来,我们需要知道专辑下共享了多少页音频文件。我们通过将音频总数除以30得到页数。音频总数的信息在音频文件列表的数据中。下图中,我以《明朝事迹》为例,有大量的音频文件,一共268个音频文件。
有了音频总数,每页的音频数是30,所以我们可以计算出页数,可以分为3种情况:总数小于等于30,总数大于30和是30的倍数,总数大于30且不是30的倍数,相关代码如下。
下载音频文件
专辑ID、专辑名称、页数都在里面,音频文件就可以下载了。下载音频时,如果少于30个音频,需要做异常处理。音频文件为付费文件时,无法下载。这个时候,做出判断。当音频下载链接为null或None时,跳出循环爬取下一张专辑的文件。
在音频下载链接为空或无的情况下,这里以《明朝事迹》为例,通过关键字《明朝事迹》爬取的其中一张专辑总共只爬取了50个音频文件. ,以下音频文件不提供下载链接,无法下载。
创建一个目录来存储音频
为了将下载的音频文件有序的存放在以专辑名命名的文件夹中,我们使用代码自动创建一个目录,并将对应的文件下载到该目录中。
后记
本文的目的是将喜马拉雅的免费音频下载到本地并传输到手机上,让大家在保护视力的同时随时学习。当然,如果你有足够的流量,你也可以在APP上在线收听。
这个项目是通过输入关键字搜索音频专辑下载的。如果有些关键词没有对应的音频,系统会为你推荐音频,所以为了提高大家的效率,大家在运行代码之前,先下载喜马拉雅的音频网站输入你需要搜索的关键词看看有没有相关的音频,有的话就运行代码。一般来说,人气高的有声专辑都比较高。下载好需要的音频专辑后,后面的专辑不需要停止运行代码。
源码可在公众号“Python知识圈”回复“收听”获取。
如果觉得不错,点赞、点赞、转发到朋友圈,都是一种支持。
pk哥还没有开通留言功能,但是可以点击文章左下角的“阅读原文”进行留言。 查看全部
网页音频抓取(页面分析我们要下载音频文件,首先得要找到下载音频的url)
页面分析
我们要下载音频文件,首先要找到下载音频的url,我们打开浏览器自带的调试工具(我用的是Chrome),使用快捷键F12快速打开调试工具。调试器切换到网络。我以刚看完的《腾讯传》为例,点击专辑封面中间的播放按钮。专辑中的音频信息都是json格式的数据。共有7个音频文件。
任意扩展音频的详细信息,详细信息包括音频文件的标题和下载链接。找到音频的下载链接后,就可以下载音频了。接下来的工作将重点介绍如何获取音频文件的下载链接。
获取页面源代码
我们首先定义一个函数来获取页面的html信息。浏览器标头信息标头被添加到此函数中。为了安全起见,使用代理IP。有兴趣的可以自己创建一个IP代理池,IP失效时会自动替换。
获取专辑信息
接下来,我们需要获取专辑的ID,因为音频的下载链接是由专辑ID拼接而成的。让我们看看收录音频文件名和下载链接信息的标题。我们可以看到albumId是专辑链接组成中的专辑ID。表示当前页码和该页存储的最大音频数。
相册的ID信息收录在关键字搜索的信息中。
专辑的ID信息通过BeautifulSoup从页面中提取出来,专辑标题信息也提取出来作为后面要创建的专辑目录名。主要代码如下。
获取页数
上述方法获取专辑ID信息。接下来,我们需要知道专辑下共享了多少页音频文件。我们通过将音频总数除以30得到页数。音频总数的信息在音频文件列表的数据中。下图中,我以《明朝事迹》为例,有大量的音频文件,一共268个音频文件。
有了音频总数,每页的音频数是30,所以我们可以计算出页数,可以分为3种情况:总数小于等于30,总数大于30和是30的倍数,总数大于30且不是30的倍数,相关代码如下。
下载音频文件
专辑ID、专辑名称、页数都在里面,音频文件就可以下载了。下载音频时,如果少于30个音频,需要做异常处理。音频文件为付费文件时,无法下载。这个时候,做出判断。当音频下载链接为null或None时,跳出循环爬取下一张专辑的文件。
在音频下载链接为空或无的情况下,这里以《明朝事迹》为例,通过关键字《明朝事迹》爬取的其中一张专辑总共只爬取了50个音频文件. ,以下音频文件不提供下载链接,无法下载。
创建一个目录来存储音频
为了将下载的音频文件有序的存放在以专辑名命名的文件夹中,我们使用代码自动创建一个目录,并将对应的文件下载到该目录中。
后记
本文的目的是将喜马拉雅的免费音频下载到本地并传输到手机上,让大家在保护视力的同时随时学习。当然,如果你有足够的流量,你也可以在APP上在线收听。
这个项目是通过输入关键字搜索音频专辑下载的。如果有些关键词没有对应的音频,系统会为你推荐音频,所以为了提高大家的效率,大家在运行代码之前,先下载喜马拉雅的音频网站输入你需要搜索的关键词看看有没有相关的音频,有的话就运行代码。一般来说,人气高的有声专辑都比较高。下载好需要的音频专辑后,后面的专辑不需要停止运行代码。
源码可在公众号“Python知识圈”回复“收听”获取。
如果觉得不错,点赞、点赞、转发到朋友圈,都是一种支持。
pk哥还没有开通留言功能,但是可以点击文章左下角的“阅读原文”进行留言。
网页音频抓取(网站更新频率多少才合适?发布新内容帮助您影响抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-03 14:14
抓取率是指搜索引擎扫描机器人(也称为“蜘蛛”)向您的 网站 发送的请求数。他们系统地漫游万维网并浏览 网站 页面以寻找新的内容数据。虽然 网站 所有者无法控制此过程,但无法更改爬网频率。但是,不断发布新内容将帮助您影响爬虫的行为。
爬取频率对于 SEO 来说非常重要,如果 bot 不能有效地爬取,很多页面将不会被索引。从技术上讲,爬行是搜索引擎跟随某些链接以访问新链接的过程,这使得新页面被机器人注意到并快速编入索引。
百度使用一种算法来定义每个 网站 的最终扫描频率,您可以做很多事情来帮助搜索机器人加快抓取速度:例如 ping、站点地图提交、robots.txt 文件的使用、改进站点导航。但是,爬取效率取决于特定 Web 资源的特性,这些指标可以在复杂的环境中使用,而不是作为单独的一次性改进。
用户和搜索机器人都变得更加智能,用户寻找相关信息,而后者则试图更人性化地满足用户的搜索需求。
1.定期更新
内容更新有助于保持 网站 信息与用户的搜索需求相关,人们更有可能找到并分享您的网站。同时,扫描机器人会将其添加到可信资源列表中。内容更新得越频繁,爬虫就越频繁地注意到该站点。建议每周更新3次内容,最简单的方法是创建博客或添加音视频素材,这比不断添加新页面更容易有效。
参考:网站多久更新一次合适?
2.使用正常运行时间长的网络主机
当百度机器人在停机期间访问 网站 时,它们会记笔记并利用这种体验来设置较差的抓取频率,从而使用户更难找到您的网站。如果 网站 关闭的时间过长,预计会出现更糟糕的结果。这就是为什么选择可靠的服务器至关重要的原因,许多服务器现在提供 99% 的正常运行时间。
3.避免重复内容
对于网站蜘蛛机器人的爬取频率,同样的消息发两次不会增加网站的爬取频率。相反,用户和机器人都会被网站同一信息的不同部分弄糊涂。
因此,搜索引擎会降低网站的排名,甚至处罚、降低权限等。
参考:关于 网站 重复内容的 3 点思考
4.优化页面加载时间
页面加载时间是决定用户体验的因素之一,如果页面加载时间超过 5 秒,人们很可能会离开并移动到搜索结果列表中的下一个位置。加载时间取决于页面的大小,它在 网站 所有者的控制之下。可以删除所有多余的脚本、重图、动画、pdf文件和类似文件。
5.构建网站地图
对于百度机器人,网站地图是一个综合列表,点击链接到网站页面。在某种程度上,这是一个爬虫指令,您可以在其中指出应该和不应该索引的内容。
爬虫将是网站的状态检查器,经过多次更新后,最好邀请爬虫而不是等待它们到达。大多数 网站 爬虫工具使用相同的技术,允许机器人扫描特定的 网站 脚本以提供有关其内部组织的信息,例如内部链接、锚文本、图像、元标记等。
参考:网站为什么要添加 XML 站点地图?
6.获取更多反向链接
反向链接直接影响排名,反向链接高的资源会被更频繁地爬取。最好删除低质量的 网站 链接和过多的付费链接,以及避免或摆脱暗链接构建做法。
参考:什么是反向链接?以及反向链接的主要类型
7.添加 Meta 和标题标签
元标签和标题标签是搜索引擎在 网站 上寻找的第一件事,为不同的页面准备独特的标签,不要使用重复的标题。如果爬虫注意到具有相同标记的页面,他们可能会跳过其中一个页面。
标题不要填关键词,每页一个就够了。记得同步更新,如果你在内容中更改了一些 关键词,也要在标题中更改它们。元标签用于构建关于页面的数据,它们可以识别页面作者、地址和更新频率。他们参与为超文本文档创建标题并影响页面在结果中的显示方式。
8.优化图片
机器人不直接读取图像。为了增加搜索引擎蜘蛛的频率和速度,网站拥有者需要让搜索带着爬虫一起来了解他们在看什么。为此,使用 alt 标签,搜索引擎将能够索引简短的单词描述。只有优化的图像才会出现在搜索结果中,并会为您带来额外的流量。
9.使用 Ping 服务
这是向机器人显示您的 网站 上的某些内容已更新的最有效和快速的方法之一。有许多手动 ping 服务可以帮助您完成此任务,当您的 网站 上发布新内容时,它们会自动通知爬虫。
10.网站监控工具
使用百度网站管理工具将帮助您了解爬行速度和所有相关统计数据,从而分析蜘蛛的活动并提出最终改进策略。可以看到当前的爬取频率,哪些页面没有被索引,是什么原因,根据这个数据要求百度重新爬取一些页面。
参考:如何做SEO数据监控?
相关文章推荐5个SEO优化核心进入SEO行业不短不长,两年左右。和大佬们比起来,我算是比较晚了,不过对于我自己的优化水平还是有点自[...]...3 负SEO方法 负SEO可以有很多东西——其实不只是黑帽SEO技巧,如果有人发起了针对您和您的 [...] 的活动...SEO 基础:内部的简单 SEO 教程 [...]...如何让您的 网站 排名更高?人们经常问我如何改进他们的 SEO,SEO 代表搜索引擎优化,他们认为这是您在 网站 上设置的某种花哨的代码,就像即时 [...]...网站地图是什么?制作网站map时要注意的6个方面顾名思义,一个网站map本质上就是一个网站的map,帮助搜索引擎爬虫更好地理解和导航网站。在更专业的意义上,它是一个带有列的文件 […]… 查看全部
网页音频抓取(网站更新频率多少才合适?发布新内容帮助您影响抓取工具)
抓取率是指搜索引擎扫描机器人(也称为“蜘蛛”)向您的 网站 发送的请求数。他们系统地漫游万维网并浏览 网站 页面以寻找新的内容数据。虽然 网站 所有者无法控制此过程,但无法更改爬网频率。但是,不断发布新内容将帮助您影响爬虫的行为。
爬取频率对于 SEO 来说非常重要,如果 bot 不能有效地爬取,很多页面将不会被索引。从技术上讲,爬行是搜索引擎跟随某些链接以访问新链接的过程,这使得新页面被机器人注意到并快速编入索引。
百度使用一种算法来定义每个 网站 的最终扫描频率,您可以做很多事情来帮助搜索机器人加快抓取速度:例如 ping、站点地图提交、robots.txt 文件的使用、改进站点导航。但是,爬取效率取决于特定 Web 资源的特性,这些指标可以在复杂的环境中使用,而不是作为单独的一次性改进。
用户和搜索机器人都变得更加智能,用户寻找相关信息,而后者则试图更人性化地满足用户的搜索需求。
1.定期更新
内容更新有助于保持 网站 信息与用户的搜索需求相关,人们更有可能找到并分享您的网站。同时,扫描机器人会将其添加到可信资源列表中。内容更新得越频繁,爬虫就越频繁地注意到该站点。建议每周更新3次内容,最简单的方法是创建博客或添加音视频素材,这比不断添加新页面更容易有效。
参考:网站多久更新一次合适?
2.使用正常运行时间长的网络主机
当百度机器人在停机期间访问 网站 时,它们会记笔记并利用这种体验来设置较差的抓取频率,从而使用户更难找到您的网站。如果 网站 关闭的时间过长,预计会出现更糟糕的结果。这就是为什么选择可靠的服务器至关重要的原因,许多服务器现在提供 99% 的正常运行时间。
3.避免重复内容
对于网站蜘蛛机器人的爬取频率,同样的消息发两次不会增加网站的爬取频率。相反,用户和机器人都会被网站同一信息的不同部分弄糊涂。
因此,搜索引擎会降低网站的排名,甚至处罚、降低权限等。
参考:关于 网站 重复内容的 3 点思考
4.优化页面加载时间
页面加载时间是决定用户体验的因素之一,如果页面加载时间超过 5 秒,人们很可能会离开并移动到搜索结果列表中的下一个位置。加载时间取决于页面的大小,它在 网站 所有者的控制之下。可以删除所有多余的脚本、重图、动画、pdf文件和类似文件。
5.构建网站地图
对于百度机器人,网站地图是一个综合列表,点击链接到网站页面。在某种程度上,这是一个爬虫指令,您可以在其中指出应该和不应该索引的内容。
爬虫将是网站的状态检查器,经过多次更新后,最好邀请爬虫而不是等待它们到达。大多数 网站 爬虫工具使用相同的技术,允许机器人扫描特定的 网站 脚本以提供有关其内部组织的信息,例如内部链接、锚文本、图像、元标记等。
参考:网站为什么要添加 XML 站点地图?
6.获取更多反向链接
反向链接直接影响排名,反向链接高的资源会被更频繁地爬取。最好删除低质量的 网站 链接和过多的付费链接,以及避免或摆脱暗链接构建做法。
参考:什么是反向链接?以及反向链接的主要类型
7.添加 Meta 和标题标签
元标签和标题标签是搜索引擎在 网站 上寻找的第一件事,为不同的页面准备独特的标签,不要使用重复的标题。如果爬虫注意到具有相同标记的页面,他们可能会跳过其中一个页面。
标题不要填关键词,每页一个就够了。记得同步更新,如果你在内容中更改了一些 关键词,也要在标题中更改它们。元标签用于构建关于页面的数据,它们可以识别页面作者、地址和更新频率。他们参与为超文本文档创建标题并影响页面在结果中的显示方式。
8.优化图片
机器人不直接读取图像。为了增加搜索引擎蜘蛛的频率和速度,网站拥有者需要让搜索带着爬虫一起来了解他们在看什么。为此,使用 alt 标签,搜索引擎将能够索引简短的单词描述。只有优化的图像才会出现在搜索结果中,并会为您带来额外的流量。
9.使用 Ping 服务
这是向机器人显示您的 网站 上的某些内容已更新的最有效和快速的方法之一。有许多手动 ping 服务可以帮助您完成此任务,当您的 网站 上发布新内容时,它们会自动通知爬虫。
10.网站监控工具
使用百度网站管理工具将帮助您了解爬行速度和所有相关统计数据,从而分析蜘蛛的活动并提出最终改进策略。可以看到当前的爬取频率,哪些页面没有被索引,是什么原因,根据这个数据要求百度重新爬取一些页面。
参考:如何做SEO数据监控?
相关文章推荐5个SEO优化核心进入SEO行业不短不长,两年左右。和大佬们比起来,我算是比较晚了,不过对于我自己的优化水平还是有点自[...]...3 负SEO方法 负SEO可以有很多东西——其实不只是黑帽SEO技巧,如果有人发起了针对您和您的 [...] 的活动...SEO 基础:内部的简单 SEO 教程 [...]...如何让您的 网站 排名更高?人们经常问我如何改进他们的 SEO,SEO 代表搜索引擎优化,他们认为这是您在 网站 上设置的某种花哨的代码,就像即时 [...]...网站地图是什么?制作网站map时要注意的6个方面顾名思义,一个网站map本质上就是一个网站的map,帮助搜索引擎爬虫更好地理解和导航网站。在更专业的意义上,它是一个带有列的文件 […]…
网页音频抓取(2015年03月23日暴走漫画TOP1ssl。360kuai)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-03 01:07
","force_purephv":"0","gnid":"9e95a108248ea0ae3","img_data":[{"flag":2,"img":[{"desc":"","height":"3168" “标题”:“”,“网址”:“。ssl。图片 360快。com/t01b9c55f27b74f349e。jpg","width":"4752"},{"desc":"","height":"312","title":"","url":". ssl。图片 360快。com/t015c7468dac9709c67。jpg","width":"627"},{"desc":"","height":"366","title":"","url":". ssl。图片 360快。com/t0141d608627d168a44。jpg","width":"627"},{"desc":"","height":"464"," 标题“:”“,网址”:“。ssl。图片 360快。com/t014c067f2824362325。
jpg","width":"626"},{"desc":"","height":"250","title":"","url":". ssl。图片 360快。com/t0122d9c0d6d5548ca3。jpg","width":"353"},{"desc":"","height":"219","title":"","url":". ssl。图片 360快。com/t0132c94f0eaf560b3d。jpg","width":"630"},{"desc":"","height":"253","title":"","url":". ssl。图片 360快。com/t01bd02c2d87472bec5。jpg","width":"567"},{"desc":"","height":"346","title":"","url":". ssl。图片 360快。com/t01e777fe40b7336a80。jpg","
ssl。图片 360快。com/t01fd94dc3ef61f80b7。jpg","width":"1266"},{"desc":"","height":"280","title":"","url":". ssl。图片 360快。com/t01a5d60de0988c8e1b。jpg","width":"663"},{"desc":"","height":"773","title":"","url":". ssl。图片 360快。com/t017bff3e91f4c2f328。jpg","width":"1266"},{"desc":"","height":"480","title":"","url":". ssl。图片 360快。com/t01f62d641124423c92。jpg","width":"767"}]}],"original":"0","pat":"mass_gamble,art_src_0,fts0,sts0","powerby":"pika",
消息。所以。com/fe3f09527d37dd023897bfc1664b11de","redirect":0,"rptid":"2e6aa5ad2c4239e6","src":"技术资源箱","tag":[],"title":"如何将在线下载的音乐文件转换为mp3 ?网页音乐提取——有没有什么好用的网页音乐提取音乐的软件可以单独下载:Adobe Audition下的音频截取下载地址1、的Adobe Audition 1.5(Cool Edit Pro)。. . “音频解锁”,用它打开一部电影,然后选择循环,然后选择要提取音频的区域,最后。. .
如何从网页中提取音乐 如何从网页中提取音乐 音乐提取工具和教程- :阅读(或听)网页上的多媒体文件后,打开系统盘\windows\document and settings\your username\local settings\temporary internet files 点击(或者在IE浏览器中点击Tools-Internet Options,点击General选项卡中的Settings,点击View Files)按大小排序,最大的是我们要找的多媒体文件~地址是写的~如果要保存,直接复制粘贴到别的目录就行了,不用找真实地址。此外,您可以使用浏览器查看页面的源代码以查找 MP3 或 WMA。仔细找也可以,但也不容易。也可以到 Tools/Options 在 /settings/view 文件中找到文件,
什么软件可以从页面中提取音乐地址???:音乐地址批量提取工具v1.1:下载地址:根据设置的URL顺序自动提取网页中的音乐地址,并保存为访问数据库或sql数据库。2.速度超快,每秒最多可以提取40个音乐地址,提取速度会根据音乐的速度而有所不同网站服务器响应。3.可以提取mp3、rm、wmv、swf、mpga、mpg、wma、rmvb等格式的视音频文件。4.自动解析视音频文件名,必要时可以进行二次根据设置提取页面。5.适合在局域网内建立音乐搜索网站,并提供asp搜索页面的源码。< @6.节目配置文件设置全面详细,可以根据实际情况设置不同的组合。7.可解压需要登录才能收听下载的页面。8.可以预设每个音视频的提取参数网站,自动记录提取的歌曲id,及时更新歌曲库。
如何提取网页中的音乐:有一种比较笨的方法:当你听到音乐时,浏览器已经把音乐下载到本地了。也就是说,在 Internet 临时文件中。如果你的系统是Win98,这个文件夹在:C:\windows\Temporary Internet Files;如果你的系统是Win2000/WinXP,那么这个文件夹在:C:\Documents and Settings\username\Local Settings\Temporary Internet Files 打开文件夹后,在里面找到一些媒体(类型)文件,拖到其他目录,如果不止一个,一个一个听。希望对你有一点帮助
如何提取安卓手机播放的网络音乐——:如果是网页的背景音乐,一般可以在ie临时文件夹中找到。可以在internet选项-(第一个)设置-查看文件中找到。通常网页的背景音乐在播放前会加载到本地硬盘的临时网络文件夹中。如果网页上有工具栏播放的音乐,可以安装迅雷,这个软件可以嗅探下载地址。
什么软件可以直接提取网页上的音乐文件- : 你好,目前还没有好用的软件,建议你在歌名前加百度云,然后通过百度云下载下载列表,各种音乐 软件还可以下载各种歌曲,相信你会找到你想要的资源!谢谢!
一款可以截取网页音乐的软件-:有两种方式:1、使用Video Detective等网络嗅探工具,在线听歌时帮助你找到真实的音乐地址,并支持下载;2、使用电脑录制和听音乐。对于地址无法嗅探的歌曲,只能使用这种方法。软件推荐Adobe Audition3(Cooledit2的升级版),软件操作简单。, 它还可以编辑和影响录制的音频!楼上推荐的samplitude也是专业级的工具,可惜操作比Audition稍微复杂一点!
什么软件可以捕捉网页中的音乐?- :使用屏幕录制专家。大名鼎鼎的软件可以设置三种录制方式:全屏、窗口、范围(可以在网页上使用窗口或范围进行录制) 录制的格式和质量都是可以控制的录屏专家破解版(有破解补丁)我这里有,如有需要请留下邮箱以便发送
有没有什么手机软件可以把网页上的音频下载到手机里 - : 不能缓存吗?是网络问题吗?手机QQ浏览器运行速度非常快。一般打开很多网页是没问题的,下载东西缓存也很快。您也可以随时观看。你可以直接去我的下载。操作非常简单。我一直用这个浏览器。感觉比较实用。你可以重新输入看看你可以。
哪个浏览器最简单直接的抓取网络音乐的功能-:有这样的工具。在360浏览器选项中,可以设置。ctrl+alt+click: 显示保存对话框 ctrl+alt+shift+click: 显示元素 url应该只能保存图片.. 查看全部
网页音频抓取(2015年03月23日暴走漫画TOP1ssl。360kuai)
","force_purephv":"0","gnid":"9e95a108248ea0ae3","img_data":[{"flag":2,"img":[{"desc":"","height":"3168" “标题”:“”,“网址”:“。ssl。图片 360快。com/t01b9c55f27b74f349e。jpg","width":"4752"},{"desc":"","height":"312","title":"","url":". ssl。图片 360快。com/t015c7468dac9709c67。jpg","width":"627"},{"desc":"","height":"366","title":"","url":". ssl。图片 360快。com/t0141d608627d168a44。jpg","width":"627"},{"desc":"","height":"464"," 标题“:”“,网址”:“。ssl。图片 360快。com/t014c067f2824362325。
jpg","width":"626"},{"desc":"","height":"250","title":"","url":". ssl。图片 360快。com/t0122d9c0d6d5548ca3。jpg","width":"353"},{"desc":"","height":"219","title":"","url":". ssl。图片 360快。com/t0132c94f0eaf560b3d。jpg","width":"630"},{"desc":"","height":"253","title":"","url":". ssl。图片 360快。com/t01bd02c2d87472bec5。jpg","width":"567"},{"desc":"","height":"346","title":"","url":". ssl。图片 360快。com/t01e777fe40b7336a80。jpg","
ssl。图片 360快。com/t01fd94dc3ef61f80b7。jpg","width":"1266"},{"desc":"","height":"280","title":"","url":". ssl。图片 360快。com/t01a5d60de0988c8e1b。jpg","width":"663"},{"desc":"","height":"773","title":"","url":". ssl。图片 360快。com/t017bff3e91f4c2f328。jpg","width":"1266"},{"desc":"","height":"480","title":"","url":". ssl。图片 360快。com/t01f62d641124423c92。jpg","width":"767"}]}],"original":"0","pat":"mass_gamble,art_src_0,fts0,sts0","powerby":"pika",
消息。所以。com/fe3f09527d37dd023897bfc1664b11de","redirect":0,"rptid":"2e6aa5ad2c4239e6","src":"技术资源箱","tag":[],"title":"如何将在线下载的音乐文件转换为mp3 ?网页音乐提取——有没有什么好用的网页音乐提取音乐的软件可以单独下载:Adobe Audition下的音频截取下载地址1、的Adobe Audition 1.5(Cool Edit Pro)。. . “音频解锁”,用它打开一部电影,然后选择循环,然后选择要提取音频的区域,最后。. .
如何从网页中提取音乐 如何从网页中提取音乐 音乐提取工具和教程- :阅读(或听)网页上的多媒体文件后,打开系统盘\windows\document and settings\your username\local settings\temporary internet files 点击(或者在IE浏览器中点击Tools-Internet Options,点击General选项卡中的Settings,点击View Files)按大小排序,最大的是我们要找的多媒体文件~地址是写的~如果要保存,直接复制粘贴到别的目录就行了,不用找真实地址。此外,您可以使用浏览器查看页面的源代码以查找 MP3 或 WMA。仔细找也可以,但也不容易。也可以到 Tools/Options 在 /settings/view 文件中找到文件,
什么软件可以从页面中提取音乐地址???:音乐地址批量提取工具v1.1:下载地址:根据设置的URL顺序自动提取网页中的音乐地址,并保存为访问数据库或sql数据库。2.速度超快,每秒最多可以提取40个音乐地址,提取速度会根据音乐的速度而有所不同网站服务器响应。3.可以提取mp3、rm、wmv、swf、mpga、mpg、wma、rmvb等格式的视音频文件。4.自动解析视音频文件名,必要时可以进行二次根据设置提取页面。5.适合在局域网内建立音乐搜索网站,并提供asp搜索页面的源码。< @6.节目配置文件设置全面详细,可以根据实际情况设置不同的组合。7.可解压需要登录才能收听下载的页面。8.可以预设每个音视频的提取参数网站,自动记录提取的歌曲id,及时更新歌曲库。
如何提取网页中的音乐:有一种比较笨的方法:当你听到音乐时,浏览器已经把音乐下载到本地了。也就是说,在 Internet 临时文件中。如果你的系统是Win98,这个文件夹在:C:\windows\Temporary Internet Files;如果你的系统是Win2000/WinXP,那么这个文件夹在:C:\Documents and Settings\username\Local Settings\Temporary Internet Files 打开文件夹后,在里面找到一些媒体(类型)文件,拖到其他目录,如果不止一个,一个一个听。希望对你有一点帮助
如何提取安卓手机播放的网络音乐——:如果是网页的背景音乐,一般可以在ie临时文件夹中找到。可以在internet选项-(第一个)设置-查看文件中找到。通常网页的背景音乐在播放前会加载到本地硬盘的临时网络文件夹中。如果网页上有工具栏播放的音乐,可以安装迅雷,这个软件可以嗅探下载地址。
什么软件可以直接提取网页上的音乐文件- : 你好,目前还没有好用的软件,建议你在歌名前加百度云,然后通过百度云下载下载列表,各种音乐 软件还可以下载各种歌曲,相信你会找到你想要的资源!谢谢!
一款可以截取网页音乐的软件-:有两种方式:1、使用Video Detective等网络嗅探工具,在线听歌时帮助你找到真实的音乐地址,并支持下载;2、使用电脑录制和听音乐。对于地址无法嗅探的歌曲,只能使用这种方法。软件推荐Adobe Audition3(Cooledit2的升级版),软件操作简单。, 它还可以编辑和影响录制的音频!楼上推荐的samplitude也是专业级的工具,可惜操作比Audition稍微复杂一点!
什么软件可以捕捉网页中的音乐?- :使用屏幕录制专家。大名鼎鼎的软件可以设置三种录制方式:全屏、窗口、范围(可以在网页上使用窗口或范围进行录制) 录制的格式和质量都是可以控制的录屏专家破解版(有破解补丁)我这里有,如有需要请留下邮箱以便发送
有没有什么手机软件可以把网页上的音频下载到手机里 - : 不能缓存吗?是网络问题吗?手机QQ浏览器运行速度非常快。一般打开很多网页是没问题的,下载东西缓存也很快。您也可以随时观看。你可以直接去我的下载。操作非常简单。我一直用这个浏览器。感觉比较实用。你可以重新输入看看你可以。
哪个浏览器最简单直接的抓取网络音乐的功能-:有这样的工具。在360浏览器选项中,可以设置。ctrl+alt+click: 显示保存对话框 ctrl+alt+shift+click: 显示元素 url应该只能保存图片..
网页音频抓取(迅捷音频转换器如何提取音乐?的方法更多精彩)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-03-31 23:33
如何提取视频中听到喜欢的背景音乐,Quick Audio Converter可以帮我们提取音乐文件,操作非常简单。下面小编就为大家带来具体的操作方法,想了解的快来看看吧。
Swift Audio Converter 如何提取音乐?Swift Audio Converter如何提取音乐
步骤1:首先,我们需要打开电脑上安装的Quick Audio Converter。打开后点击“注册/登录”,用手机号注册登录或直接用微信、QQ登录。软件登录后,开始以下操作。
第二步:之后,首先了解界面中的功能参数。这里我们可以看到有四个主要功能:“音频剪切”、“音频合并”、“音频提取”和“音频转换”。界面右侧还可以自定义音频参数:声道、质量和编码。
第三步:这里我们需要提取视频和音频,然后您可以选择进入“音频提取”界面,然后点击“添加文件”,然后会弹出一个小窗口,选择要提取的视频片段并导入它。
第4步:然后您刚刚导入的视频剪辑将出现在界面上。您可以通过两侧的进度条调整需要截取的音频片段。选择后,点击“确认并添加到输出列表”。提示:您可以多次选择音频片段进行采集,选择后点击如上的确认操作即可。
第五步:解压前,需要设置文件的保存位置。点击下方的“更改路径”新建一个文件夹,用于存放要提取的音频片段,方便查找。
第六步:所有设置完成后,点击右下角的“开始解压”按钮,等待两分钟即可成功解压。然后会显示“打开”,此时点击“打开”即可在选定的保存位置看到提取成功的音频片段。
以上文章文章是Swift Audio Converter提取音乐的方法。更多精彩教程请关注下载首页! 查看全部
网页音频抓取(迅捷音频转换器如何提取音乐?的方法更多精彩)
如何提取视频中听到喜欢的背景音乐,Quick Audio Converter可以帮我们提取音乐文件,操作非常简单。下面小编就为大家带来具体的操作方法,想了解的快来看看吧。
Swift Audio Converter 如何提取音乐?Swift Audio Converter如何提取音乐
步骤1:首先,我们需要打开电脑上安装的Quick Audio Converter。打开后点击“注册/登录”,用手机号注册登录或直接用微信、QQ登录。软件登录后,开始以下操作。
第二步:之后,首先了解界面中的功能参数。这里我们可以看到有四个主要功能:“音频剪切”、“音频合并”、“音频提取”和“音频转换”。界面右侧还可以自定义音频参数:声道、质量和编码。
第三步:这里我们需要提取视频和音频,然后您可以选择进入“音频提取”界面,然后点击“添加文件”,然后会弹出一个小窗口,选择要提取的视频片段并导入它。
第4步:然后您刚刚导入的视频剪辑将出现在界面上。您可以通过两侧的进度条调整需要截取的音频片段。选择后,点击“确认并添加到输出列表”。提示:您可以多次选择音频片段进行采集,选择后点击如上的确认操作即可。
第五步:解压前,需要设置文件的保存位置。点击下方的“更改路径”新建一个文件夹,用于存放要提取的音频片段,方便查找。
第六步:所有设置完成后,点击右下角的“开始解压”按钮,等待两分钟即可成功解压。然后会显示“打开”,此时点击“打开”即可在选定的保存位置看到提取成功的音频片段。
以上文章文章是Swift Audio Converter提取音乐的方法。更多精彩教程请关注下载首页!
网页音频抓取(示例下载朋友问到这样一个问题,需要实现如下功能(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-30 10:05
)
示例下载
有朋友问了这样一个问题,需要实现以下功能
1、打开一个空运公司的查询网页,比如,页面有两个文本框供用户输入业务代码,比如,
2、然后点击“Go”按钮,下一页显示查询结果
现在需要程序自动执行以上步骤,将查询结果提取出来做后续处理。
要完成这样的功能,首先要解决以下问题:
l 可以使用程序在后台向目标网页发布数据
l 可以接收对方返回的HTML结果页面
l 分析页面并提取所需结果的能力
经过一番研究和实验,我解决了上述问题,下面分别介绍。
1.使用程序将指定的数据post到目标网页,并接收结果网页
我首先使用网络嗅探器来捕捉浏览器与其他网页在使用IE手动查询时的HTTP协议交互过程。推荐使用Ultra Network Sniffer,它有连接监控功能,可以监控一个程序的所有连接,避免其他无关数据包的干扰。如图所示
在查询页面输入数据后,点击“Go”按钮,sniffer抓到的数据包如下图
请注意第三行,有一个Post包,这是我们需要的,
它发送的网页地址是:
它发布的数据是:awbpre=180&awbnum=36898035&x=17&y=9
显然180和36898035可以替换,需要注意的是,发送的目的网页不再是我们直接在浏览器中输入的初始页面
接下来我们使用程序发送这个数据,代码如下
public static string GetPage(string url, string postData,string encodeType,out string err)<br /><br /> {<br /><br /> Stream outstream = null;<br /><br /> Stream instream = null;<br /><br /> StreamReader sr = null;<br /><br /> HttpWebResponse response = null;<br /><br /> HttpWebRequest request = null;<br /><br /> Encoding encoding = Encoding.GetEncoding(encodeType);<br /><br /> byte[] data = encoding.GetBytes(postData);<br /><br /> // 准备请求...<br /><br /> try<br /><br /> { <br /><br /> // 设置参数<br /><br /> request = WebRequest.Create(url) as HttpWebRequest;<br /><br /> CookieContainer cookieContainer = new CookieContainer();<br /><br /> request.CookieContainer = cookieContainer;<br /><br /> request.AllowAutoRedirect = true;<br /><br /> request.Method = "POST";<br /><br /> request.ContentType = "application/x-www-form-urlencoded";<br /><br /> request.ContentLength = data.Length;<br /><br /> outstream = request.GetRequestStream();<br /><br /> outstream.Write(data,0,data.Length);<br /><br /> outstream.Close();<br /><br /> //发送请求并获取相应回应数据<br /><br /> response = request.GetResponse() as HttpWebResponse;<br /><br /> //直到request.GetResponse()程序才开始向目标网页发送Post请求<br /><br /> instream = response.GetResponseStream();<br /><br /> sr = new StreamReader( instream, encoding );<br /><br /> //返回结果网页(html)代码<br /><br />string content = sr.ReadToEnd();<br /><br /> err = string.Empty;<br /><br /> return content;<br /><br /> }<br /><br /> catch(Exception ex)<br /><br /> {<br /><br /> err = ex.Message;<br /><br /> return string.Empty;<br /><br /> }<br /><br />}
上面的代码通俗易懂,就不多废话了,简单说几个注意点:
如果你的程序需要保留SessionID,比如ASP.NET中的SessionID。比如自动登录后,可能需要进行后续处理,所以需要将上一个请求返回的cookieContainer分配给新的请求,然后再将请求发送到下一页,因为cookieContainer中预留了一个名为ASPNETSessionID的cookie。
如果你的 Post 的目标页面是 ASP.NET 页面,那么在要提交的 Form 中一般会有一个 __ViewState 隐藏的 Input 字段。服务器返回的网页源代码的ViewState示例如下,
<br /><br /><br /><br /><br /><br /><br /><br /><br /><br />
然而,嗅探器中捕获的 Post 数据是:
__VIEWSTATE=dDwtMzg4MDA0NzA7Oz7%2BjHQ0vF37%2Fga2CitRkQ3sfg%2BePg%3D%3D&用户名=管理员&密码=123&提交=按钮0
请注意,这里ViewState的数据和上一个有点不同。不同的是,“+/=”等符号已经转换成%2B、%2F、%3D等,实际上是URL ViewState Encoding的值,可以使用System.Web.HttpUtility.UrlEncode( ) 方法来做这个转换
当然,如果只需要一次性访问页面,就不用管这些了,根据sniffer抓到的结果发送数据即可,但如果需要根据ViewState动态处理页面返回的值,则需要注意这一点。
2.从 HTML 页面代码中提取信息
要从 HTML 网页中提取信息,您必须首先将网页代码格式化为 XML 文件,然后您可以使用 XPath 轻松提取您想要的信息。要将 HTML 格式化为 XML,目前有多种选择。
1、Chris Lovett 的 SgmlReader:
2、Simon Mourier 的 .NET Html 敏捷包
我选择了 SgmlReader。通过实际使用,我发现SgmlReader并不完美。有时候格式化的xml的嵌套关系会出错,但即便如此,根据他格式化的文本,提取数据就足够了。
public static DataSet ParsePage(string pageContent, string xpath, out string err)<br /><br /> {<br /><br /> err = string.Empty;<br /><br /> string pageContent = this.tbHTML.Text;<br /><br /> StreamReader streamReader = null;<br /><br /> StringWriter strWriter = null;<br /><br /> SgmlReader sgmlReader = null;<br /><br /> XmlTextWriter xmlWriter = null;<br /><br /> try<br /><br /> {<br /><br /> sgmlReader = new SgmlReader();<br /><br /> sgmlReader.DocType = "HTML";<br /><br /> sgmlReader.InputStream = new StringReader(pageContent);<br /><br /> strWriter = new StringWriter();<br /><br /> xmlWriter = new XmlTextWriter(strWriter);<br /><br /> xmlWriter.Formatting = Formatting.Indented;<br /><br /> while (sgmlReader.Read())<br /><br /> {<br /><br /> if (sgmlReader.NodeType != XmlNodeType.Whitespace)<br /><br /> {<br /><br /> xmlWriter.WriteNode(sgmlReader, true);<br /><br /> }<br /><br /> }<br /><br /> string wellFormedHTML = strWriter.ToString();<br /><br /> this.tbHTML.Text = wellFormedHTML;<br /><br /> string xpath = this.tbXPath.Text;<br /><br /> XPathDocument doc = new XPathDocument(new StringReader(wellFormedHTML));<br /><br /> XPathNavigator nav = doc.CreateNavigator();<br /><br /> XPathNodeIterator nodes = nav.Select(xpath);<br /><br /> while (nodes.MoveNext())<br /><br /> {<br /><br /> this.tbResult.Text += nodes.Current.Value+"\n";<br /><br /> }<br /><br /> }<br /><br /> catch (Exception exp)<br /><br /> {<br /><br /> string err = exp.Message;<br /><br /> MessageBox.Show("错误:"+err);<br /><br /> }<br /><br />}<br /><br />}
根据上面的代码,目前主要的问题是设置正确的XPath。有一篇关于代码项目 文章 的文章提供了一个简单的 XPath 查询工具。我对它做了一些修改,主要是增加了在节点的body中搜索某个字符串的功能,方便你根据得到的HTML页面查询XPath
调试 XPath 查询:
例如,下面是一个根据查询结果格式化的 XML 文本片段。信息的 XPath 是
//div[@class=”content”]/DIV[@id=”tblwithbck”]/TABLE/TR/TD/TABLE/TR/TD/DIV[@class=”data”]
需要注意的是,XPath中的每条路径都是区分大小写的,我只是一开始没有注意这个问题,犯了一些错误。
<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K departed on flight KE6316/04JUN from PVG to ICN<br /><br /><BR /><br /><br />Actual Time of Flight-Departure : 19:20<br /><br /><BR /><br /><br />Scheduled Time of Flight-Arrival : 21:55<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K departed on flight 9S0910/06JUN from ICN to DFW<br /><br /><BR /><br /><br />Actual Time of Flight-Departure : 22:15<br /><br /><BR /><br /><br />Scheduled Time of Flight-Arrival : 05:35+1<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K departed on flight 3A3617/07JUN from DFW to ELP<br /><br /><BR /><br /><br />Actual Time of Flight-Departure : 22:00<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K arrived in ELP from flight 3A3617<br /><br /><BR /><br /><br />Scheduled arrival : 08 JUN<br /><br /><BR /><br /><br />Goods checked in at : 11:00<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />Arrival docs delivered for 2 piece(s) 42 K on 09 JUN at 09:48 in ELP<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /> 查看全部
网页音频抓取(示例下载朋友问到这样一个问题,需要实现如下功能(图)
)
示例下载
有朋友问了这样一个问题,需要实现以下功能
1、打开一个空运公司的查询网页,比如,页面有两个文本框供用户输入业务代码,比如,
2、然后点击“Go”按钮,下一页显示查询结果
现在需要程序自动执行以上步骤,将查询结果提取出来做后续处理。
要完成这样的功能,首先要解决以下问题:
l 可以使用程序在后台向目标网页发布数据
l 可以接收对方返回的HTML结果页面
l 分析页面并提取所需结果的能力
经过一番研究和实验,我解决了上述问题,下面分别介绍。
1.使用程序将指定的数据post到目标网页,并接收结果网页
我首先使用网络嗅探器来捕捉浏览器与其他网页在使用IE手动查询时的HTTP协议交互过程。推荐使用Ultra Network Sniffer,它有连接监控功能,可以监控一个程序的所有连接,避免其他无关数据包的干扰。如图所示
在查询页面输入数据后,点击“Go”按钮,sniffer抓到的数据包如下图
请注意第三行,有一个Post包,这是我们需要的,
它发送的网页地址是:
它发布的数据是:awbpre=180&awbnum=36898035&x=17&y=9
显然180和36898035可以替换,需要注意的是,发送的目的网页不再是我们直接在浏览器中输入的初始页面
接下来我们使用程序发送这个数据,代码如下
public static string GetPage(string url, string postData,string encodeType,out string err)<br /><br /> {<br /><br /> Stream outstream = null;<br /><br /> Stream instream = null;<br /><br /> StreamReader sr = null;<br /><br /> HttpWebResponse response = null;<br /><br /> HttpWebRequest request = null;<br /><br /> Encoding encoding = Encoding.GetEncoding(encodeType);<br /><br /> byte[] data = encoding.GetBytes(postData);<br /><br /> // 准备请求...<br /><br /> try<br /><br /> { <br /><br /> // 设置参数<br /><br /> request = WebRequest.Create(url) as HttpWebRequest;<br /><br /> CookieContainer cookieContainer = new CookieContainer();<br /><br /> request.CookieContainer = cookieContainer;<br /><br /> request.AllowAutoRedirect = true;<br /><br /> request.Method = "POST";<br /><br /> request.ContentType = "application/x-www-form-urlencoded";<br /><br /> request.ContentLength = data.Length;<br /><br /> outstream = request.GetRequestStream();<br /><br /> outstream.Write(data,0,data.Length);<br /><br /> outstream.Close();<br /><br /> //发送请求并获取相应回应数据<br /><br /> response = request.GetResponse() as HttpWebResponse;<br /><br /> //直到request.GetResponse()程序才开始向目标网页发送Post请求<br /><br /> instream = response.GetResponseStream();<br /><br /> sr = new StreamReader( instream, encoding );<br /><br /> //返回结果网页(html)代码<br /><br />string content = sr.ReadToEnd();<br /><br /> err = string.Empty;<br /><br /> return content;<br /><br /> }<br /><br /> catch(Exception ex)<br /><br /> {<br /><br /> err = ex.Message;<br /><br /> return string.Empty;<br /><br /> }<br /><br />}
上面的代码通俗易懂,就不多废话了,简单说几个注意点:
如果你的程序需要保留SessionID,比如ASP.NET中的SessionID。比如自动登录后,可能需要进行后续处理,所以需要将上一个请求返回的cookieContainer分配给新的请求,然后再将请求发送到下一页,因为cookieContainer中预留了一个名为ASPNETSessionID的cookie。
如果你的 Post 的目标页面是 ASP.NET 页面,那么在要提交的 Form 中一般会有一个 __ViewState 隐藏的 Input 字段。服务器返回的网页源代码的ViewState示例如下,
<br /><br /><br /><br /><br /><br /><br /><br /><br /><br />
然而,嗅探器中捕获的 Post 数据是:
__VIEWSTATE=dDwtMzg4MDA0NzA7Oz7%2BjHQ0vF37%2Fga2CitRkQ3sfg%2BePg%3D%3D&用户名=管理员&密码=123&提交=按钮0
请注意,这里ViewState的数据和上一个有点不同。不同的是,“+/=”等符号已经转换成%2B、%2F、%3D等,实际上是URL ViewState Encoding的值,可以使用System.Web.HttpUtility.UrlEncode( ) 方法来做这个转换
当然,如果只需要一次性访问页面,就不用管这些了,根据sniffer抓到的结果发送数据即可,但如果需要根据ViewState动态处理页面返回的值,则需要注意这一点。
2.从 HTML 页面代码中提取信息
要从 HTML 网页中提取信息,您必须首先将网页代码格式化为 XML 文件,然后您可以使用 XPath 轻松提取您想要的信息。要将 HTML 格式化为 XML,目前有多种选择。
1、Chris Lovett 的 SgmlReader:
2、Simon Mourier 的 .NET Html 敏捷包
我选择了 SgmlReader。通过实际使用,我发现SgmlReader并不完美。有时候格式化的xml的嵌套关系会出错,但即便如此,根据他格式化的文本,提取数据就足够了。
public static DataSet ParsePage(string pageContent, string xpath, out string err)<br /><br /> {<br /><br /> err = string.Empty;<br /><br /> string pageContent = this.tbHTML.Text;<br /><br /> StreamReader streamReader = null;<br /><br /> StringWriter strWriter = null;<br /><br /> SgmlReader sgmlReader = null;<br /><br /> XmlTextWriter xmlWriter = null;<br /><br /> try<br /><br /> {<br /><br /> sgmlReader = new SgmlReader();<br /><br /> sgmlReader.DocType = "HTML";<br /><br /> sgmlReader.InputStream = new StringReader(pageContent);<br /><br /> strWriter = new StringWriter();<br /><br /> xmlWriter = new XmlTextWriter(strWriter);<br /><br /> xmlWriter.Formatting = Formatting.Indented;<br /><br /> while (sgmlReader.Read())<br /><br /> {<br /><br /> if (sgmlReader.NodeType != XmlNodeType.Whitespace)<br /><br /> {<br /><br /> xmlWriter.WriteNode(sgmlReader, true);<br /><br /> }<br /><br /> }<br /><br /> string wellFormedHTML = strWriter.ToString();<br /><br /> this.tbHTML.Text = wellFormedHTML;<br /><br /> string xpath = this.tbXPath.Text;<br /><br /> XPathDocument doc = new XPathDocument(new StringReader(wellFormedHTML));<br /><br /> XPathNavigator nav = doc.CreateNavigator();<br /><br /> XPathNodeIterator nodes = nav.Select(xpath);<br /><br /> while (nodes.MoveNext())<br /><br /> {<br /><br /> this.tbResult.Text += nodes.Current.Value+"\n";<br /><br /> }<br /><br /> }<br /><br /> catch (Exception exp)<br /><br /> {<br /><br /> string err = exp.Message;<br /><br /> MessageBox.Show("错误:"+err);<br /><br /> }<br /><br />}<br /><br />}
根据上面的代码,目前主要的问题是设置正确的XPath。有一篇关于代码项目 文章 的文章提供了一个简单的 XPath 查询工具。我对它做了一些修改,主要是增加了在节点的body中搜索某个字符串的功能,方便你根据得到的HTML页面查询XPath
调试 XPath 查询:
例如,下面是一个根据查询结果格式化的 XML 文本片段。信息的 XPath 是
//div[@class=”content”]/DIV[@id=”tblwithbck”]/TABLE/TR/TD/TABLE/TR/TD/DIV[@class=”data”]
需要注意的是,XPath中的每条路径都是区分大小写的,我只是一开始没有注意这个问题,犯了一些错误。
<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K departed on flight KE6316/04JUN from PVG to ICN<br /><br /><BR /><br /><br />Actual Time of Flight-Departure : 19:20<br /><br /><BR /><br /><br />Scheduled Time of Flight-Arrival : 21:55<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K departed on flight 9S0910/06JUN from ICN to DFW<br /><br /><BR /><br /><br />Actual Time of Flight-Departure : 22:15<br /><br /><BR /><br /><br />Scheduled Time of Flight-Arrival : 05:35+1<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K departed on flight 3A3617/07JUN from DFW to ELP<br /><br /><BR /><br /><br />Actual Time of Flight-Departure : 22:00<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />2 piece(s) 42 K arrived in ELP from flight 3A3617<br /><br /><BR /><br /><br />Scheduled arrival : 08 JUN<br /><br /><BR /><br /><br />Goods checked in at : 11:00<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />Arrival docs delivered for 2 piece(s) 42 K on 09 JUN at 09:48 in ELP<br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br /><br />
网页音频抓取(爬取喜马拉雅音频数据受害者(爬虫知识点)案例分析(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-19 13:27
前言
喜马拉雅是一个专业的音频分享平台,汇集了有声小说、有声读物、有声读物、FM收音机、儿童睡前故事、相声小品、鬼故事等数以亿计的音频,喜欢听民间故事和德云社会相声采集最多。,和你?
今天就带大家爬取喜马拉雅音频数据,一起期待吧!!
项目目标
爬取喜马拉雅音频数据
受害者地址
https://www.ximalaya.com/
本文知识点:
环境:
想法:(履带式案例)
案例思路:
开始写代码
先导入需要的模块
import requests
import parsel # 数据解析模块
import re
1.确定数据所在的链接地址(url) 反向分析网页性质(静态网页/动态网页)
打开开发者工具,播放一段音频,可以在Madie中找到一个数据包
复制网址,搜索
查找 id 值
继续搜索找到请求头参数
url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers)
html_data = response.text
3.分析数据(要的话就过滤)解析音频的id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li')
for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href)
m4a_id = href.split('/')[-1]
# print(href, m4a_id)
# 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revis ... id%3D{}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data)
# 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url)
# 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content
new_title = change_title(title)
4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)
最后,我们要处理文件名中的非法字符
def change_title(title):
pattern = re.compile(r"[\/\\\:\*\?\"\\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
完整代码
import re
import requests
import parsel # 数据解析模块
def change_title(title):
"""处理文件名非法字符的方法"""
pattern = re.compile(r"[\/\\\:\*\?\"\\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
for page in range(13, 33):
print('---------------正在爬取第{}页的数据----------------'.format(page))
# 1.确定数据所在的链接地址(url) 逆向分析 网页性质(静态网页/动态网页)
url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
# 2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers)
html_data = response.text
# print(html_data)
# 3.解析数据(要的, 筛选不要的) 解析音频的 id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li')
for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href)
m4a_id = href.split('/')[-1]
# print(href, m4a_id)
# 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revis ... id%3D{}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data)
# 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url)
# 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content
new_title = change_title(title)
# print(new_title)
# 4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)
except:
pass
运行代码,效果如下
本文文字和图片来源于网络,仅供学习交流,不具有任何商业用途。如有任何问题,请及时联系我们进行处理。 查看全部
网页音频抓取(爬取喜马拉雅音频数据受害者(爬虫知识点)案例分析(一))
前言
喜马拉雅是一个专业的音频分享平台,汇集了有声小说、有声读物、有声读物、FM收音机、儿童睡前故事、相声小品、鬼故事等数以亿计的音频,喜欢听民间故事和德云社会相声采集最多。,和你?
今天就带大家爬取喜马拉雅音频数据,一起期待吧!!
项目目标
爬取喜马拉雅音频数据
受害者地址
https://www.ximalaya.com/
本文知识点:
环境:
想法:(履带式案例)
案例思路:
开始写代码
先导入需要的模块
import requests
import parsel # 数据解析模块
import re
1.确定数据所在的链接地址(url) 反向分析网页性质(静态网页/动态网页)
打开开发者工具,播放一段音频,可以在Madie中找到一个数据包
复制网址,搜索
查找 id 值
继续搜索找到请求头参数
url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers)
html_data = response.text
3.分析数据(要的话就过滤)解析音频的id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li')
for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href)
m4a_id = href.split('/')[-1]
# print(href, m4a_id)
# 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revis ... id%3D{}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data)
# 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url)
# 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content
new_title = change_title(title)
4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)
最后,我们要处理文件名中的非法字符
def change_title(title):
pattern = re.compile(r"[\/\\\:\*\?\"\\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
完整代码
import re
import requests
import parsel # 数据解析模块
def change_title(title):
"""处理文件名非法字符的方法"""
pattern = re.compile(r"[\/\\\:\*\?\"\\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
for page in range(13, 33):
print('---------------正在爬取第{}页的数据----------------'.format(page))
# 1.确定数据所在的链接地址(url) 逆向分析 网页性质(静态网页/动态网页)
url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
# 2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers)
html_data = response.text
# print(html_data)
# 3.解析数据(要的, 筛选不要的) 解析音频的 id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li')
for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href)
m4a_id = href.split('/')[-1]
# print(href, m4a_id)
# 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revis ... id%3D{}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data)
# 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url)
# 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content
new_title = change_title(title)
# print(new_title)
# 4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)
except:
pass
运行代码,效果如下
本文文字和图片来源于网络,仅供学习交流,不具有任何商业用途。如有任何问题,请及时联系我们进行处理。

