
网页视频抓取脚本
网页视频抓取脚本(点赞google自带的采集器是超耗内存吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-02-20 20:03
网页视频抓取脚本实现。简单暴力,可控性高。每秒抓取50万+次浏览页面。但是你先想好要实现什么功能?使用什么方式抓取?有什么弊端?最好还要写个发布脚本的软件,并且能实时提示用户,如果浏览完毕后才提示。
点赞
google自带的采集器。就是超耗内存。
今天刚刚做完回答你我之前也在线点赞过后就知道赞数然后去百度找到一个采集软件叫采集一条信息的下载下来注册后操作步骤看详细教程welcometoeasycodebase他们网站上详细的说明了他们的脚本下载我觉得可以用
可以试试用googleget,多达上百万的页面。可以让你抓住网页的重点。
点赞会流一定的量,手机上网页抓取速度比较慢,不过抓取速度肯定比不上人肉。如果你有qq群,还可以组织同学组织线下的点赞团,人数越多,在群里点赞的,肯定点赞评论多。
googlegetsock网页爬虫抓取软件,
www.clickbird.io/
这个真的需要人工的去点赞吗?微信都没有这功能的呀,除非真的看到有一定量的消息(喜欢、赞)等,手动评论。而且效率,速度极慢!需要是的人,你知道效率是什么意思吧。在网页上点赞,
首先你要安装xpath语法转换,安装headlessdriver,react,redux,express等等一系列框架,但是大部分发达国家已经快趋于极限状态了。再次,现在基本已经没有什么有效性的计算机外语可以抓取页面了,想靠人工点赞来提高点赞数并不现实,再说你还要提供这些人的邮箱, 查看全部
网页视频抓取脚本(点赞google自带的采集器是超耗内存吗?)
网页视频抓取脚本实现。简单暴力,可控性高。每秒抓取50万+次浏览页面。但是你先想好要实现什么功能?使用什么方式抓取?有什么弊端?最好还要写个发布脚本的软件,并且能实时提示用户,如果浏览完毕后才提示。
点赞
google自带的采集器。就是超耗内存。
今天刚刚做完回答你我之前也在线点赞过后就知道赞数然后去百度找到一个采集软件叫采集一条信息的下载下来注册后操作步骤看详细教程welcometoeasycodebase他们网站上详细的说明了他们的脚本下载我觉得可以用
可以试试用googleget,多达上百万的页面。可以让你抓住网页的重点。
点赞会流一定的量,手机上网页抓取速度比较慢,不过抓取速度肯定比不上人肉。如果你有qq群,还可以组织同学组织线下的点赞团,人数越多,在群里点赞的,肯定点赞评论多。
googlegetsock网页爬虫抓取软件,
www.clickbird.io/
这个真的需要人工的去点赞吗?微信都没有这功能的呀,除非真的看到有一定量的消息(喜欢、赞)等,手动评论。而且效率,速度极慢!需要是的人,你知道效率是什么意思吧。在网页上点赞,
首先你要安装xpath语法转换,安装headlessdriver,react,redux,express等等一系列框架,但是大部分发达国家已经快趋于极限状态了。再次,现在基本已经没有什么有效性的计算机外语可以抓取页面了,想靠人工点赞来提高点赞数并不现实,再说你还要提供这些人的邮箱,
网页视频抓取脚本(AlphaCode到底是怎么练成的?博士后TimPearce解析AlphaCode系统架构、「解题」原理、训练流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2022-02-20 13:20
AlphaCode 是如何产生的?
春节期间,DeepMind 的编程版 AlphaGo-AlphaCode 一度火爆到刷屏。它可以编写普通程序员水平的计算机程序,在 Codeforces 网站 的 10 个挑战中排名前 54.3%,击败了 46% 的参赛者。
这一成绩给程序员群体带来了不小的压力,仿佛纺织工人被纺织机器淘汰的历史正在重演。
那么,AlphaCode 为何如此强大?在最近的一段 YouTube 视频中,清华大学朱军博士后 Tim Pearce 详细分析了 AlphaCode 的系统架构、“问题解决”原理和训练流程。
原视频地址:
AlphaCode 到底是做什么的?
如前所述,DeepMind 研究人员在 Codeforces 挑战中对 AlphaCode 进行了测试。Codeforces 是一个拥有各种编程主题和各种竞赛的在线编程平台。它类似于国际象棋中使用的 Elo 评级系统,每周共享编程挑战和问题排名。与程序员在构建商业应用程序时可能面临的任务不同,Codeforces 的挑战更加独立,需要对计算机科学中的算法和理论概念有更广泛的理解,通常是逻辑、数学和编码专业知识的非常专业的组合。
下图是其中一个竞赛题的示例,包括竞赛题的描述、输入输出示例等。挑战者的任务是根据这些内容编写一段代码,使输出符合要求。
下面是 AlphaCode 编写的代码:
对于 AlphaCode,这只是一个适度的挑战。
在十个类似的挑战中,研究人员将问题输入 AlphaCode。然后,AlphaCode 会生成大量可能的答案,并通过运行代码和检查输出来筛选它们,就像人类竞争对手一样。“整个过程是自动的,无需手动选择最佳样本,”AlphaCode 论文的联合负责人 Yujia Li 和 David Choi 说。
为什么 AlphaCode 如此强大?
下图是AlphaCode的概念图。这是一个精心设计的系统,主要构建块是基于 Transformer 的语言模型。但本质上,没有一个组件是全新的。
“考场”上的 AlphaCode
我们先来看看上面的系统在测试时是如何工作的。
在解决编码问题时,AlphaCode 使用一种非常具体的协议,它决定了整个系统的管道。协议规定他们可以无限使用示例测试用例,因为这些是作为问题的一部分给出的。但是在提交隐藏测试用例时,他们将提交次数限制为 10 次(最多 10 次)。
在测试过程中,AlphaCode 经历了三个阶段。
在第一阶段,他们使用一个大型 Transformer 模型,该模型将问题描述示例测试和字符串中有关问题的一些元数据作为输入。然后他们从这个模型中取样,产生了大量的潜在解决方案。所以第一阶段有 100 万个可能的代码脚本。
在第二阶段,他们用示例测试用例测试了生成的 100 万组代码,其中 99% 没有通过测试,可以排除。这使可行代码集的数量减少到 1000 个左右(取决于问题的难度)。
在第三阶段,他们使用了第二个 Transformer 模型。该模型将问题描述作为输入,但不是尝试生成代码来解决问题,而是生成测试用例输入(每个问题 50 个输入)。也就是说,他们没有选择生成输入和输出对,而是一些与问题相关的实际输入。因此模型可能想要生成字符串、二进制数或序列(取决于问题的类型)。
这种方法有多好?他们推断,如果两个脚本在所有 50 次测试中返回相同的答案,那么它们可能使用了相同的算法。这避免了浪费两个提交来测试两个脚本。所以在第二步得到 1000 组脚本后,他们根据这 50 个生成的测试输入的输出对脚本进行聚类,然后从每个聚类中挑选一个示例脚本,一共 10 个。如果 10 个脚本中的一个通过所有隐藏的测试,他们成功解决了编程问题,否则他们失败了。
以上是测试中AlphaCode的工作原理,使用了两个Transformer模型。那么这两个模型是如何训练的呢?
AlphaCode 训练
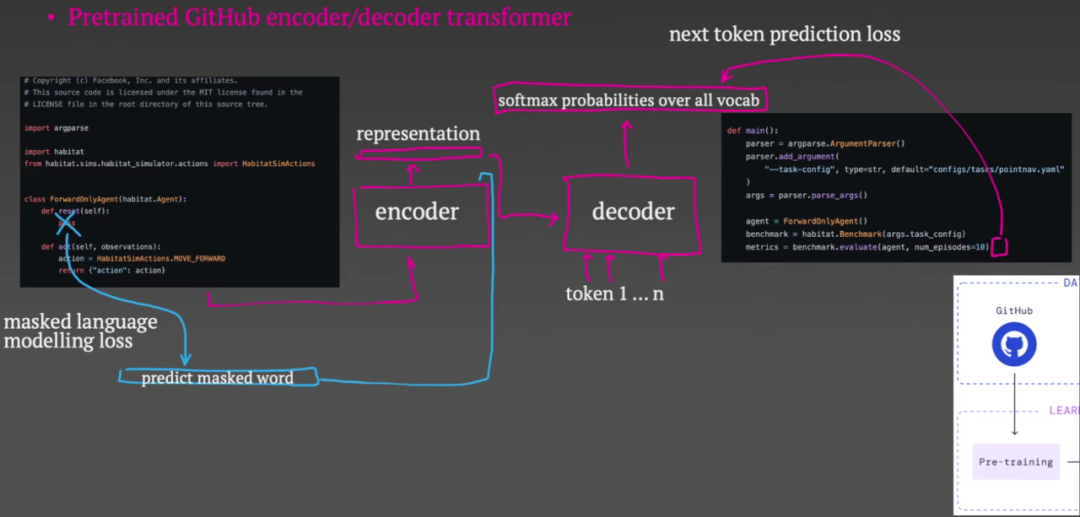
AlphaCode 的训练分为两个阶段:预训练和微调。这个过程涉及两个数据集:第一个是一个公共的 GitHub 存储库,由各种编程语言组成,用于进行高达 715GB 数据的预训练;第二个是从各种编程挑战中采集的网站(包括 codeforces)采集用于微调的问题,包括问题描述、测试用例和人类程序员编写的答案。
有了数据集,下一步就是训练。
在预训练阶段,他们从 GitHub 上抓取一些代码并随机选择他们所谓的“枢轴点”。
直到枢轴点的所有内容都将被输入编码器,解码器的目标是重建枢轴点以下的代码。编码器输出代码的向量表示,然后可以在整个解码过程中使用。
解码器以自回归方式工作。它从预测代码的第一个标记开始。损失函数是预测的softmax输出和真实token之间的交叉熵。然后,第一个真实令牌成为解码器的输入,然后预测第二个令牌。重复此过程,直到要求解码器预测一个特殊的代码结束标记。现在,这些损失通过解码器和编码器反向传播,但编码器添加第二个损失非常重要。这称为掩码语言建模损失:您将输入编码器的一些标记留为空白,作为一项附带任务,编码器将尝试预测哪个标记被掩码。
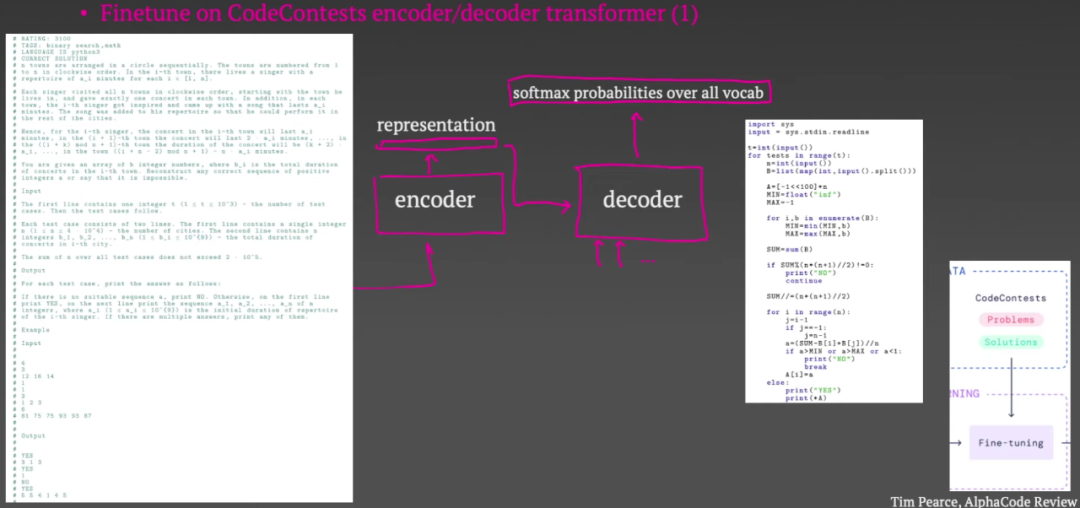
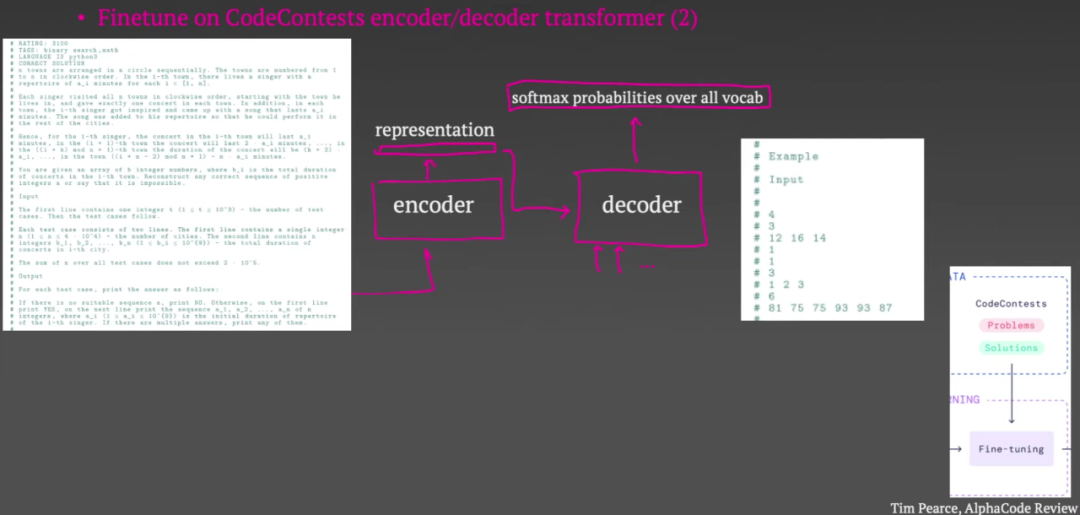
预训练结束后,微调步骤来了。在本次会议中,他们将问题描述元数据和示例的输入输入到编码器中,并尝试使用解码器生成人工编写的代码。正如您在这一点上所看到的,这与编码器-解码器架构所规定的结构非常自然地吻合。此阶段的损失与预训练中的损失完全相同。此外,这里还有第二个 Transformer 来生成测试输入。这也由相同的 GitHub 预训练任务初始化,但经过微调以生成测试输入而不是代码。
除了上面提到的一般训练步骤和架构之外,AlphaCode 还借鉴了其他近期论文的一些经验教训。蒂姆·皮尔斯(Tim Pearce)指出了其中一个更好的:
AlphaCode 的元数据条件
除了问题描述之外,研究人员总是将元数据作为 Transformer 的输入,包括编程语言、问题的难度级别、关于问题的一些标签以及解决方案是否正确等。在训练时,模型显然知道这些字段的值是什么,但在测试时,它们不知道。非常有趣的是,他们可以在测试时在这些字段中输入不同的内容来影响生成的代码。例如,您可以控制系统将生成的编程语言,甚至影响它尝试生成的解决方案的类型,例如是尝试动态编程方法还是执行穷举搜索。
他们在测试中发现,在对前 100 万个代码脚本进行采样时,随机化很多字段非常有帮助。因为,通过增加原创样本池的多样性,正确答案的概率会增加。
以上就是 Tim Pearce 对 AlphaCode 的所有分析。他认为,DeepMind 团队在这项工作上确实取得了一些进展。但他更不解的是:为什么他们在这些编程问题上的成绩远不如在围棋、星际争霸等游戏中取得的超人成绩?Tim Pearce 最初的猜测是编程问题更难,数据更难获取,因为在游戏中你可以无限制地生成大量模拟数据,但在编程问题中你不能这样做。 查看全部
网页视频抓取脚本(AlphaCode到底是怎么练成的?博士后TimPearce解析AlphaCode系统架构、「解题」原理、训练流程)
AlphaCode 是如何产生的?
春节期间,DeepMind 的编程版 AlphaGo-AlphaCode 一度火爆到刷屏。它可以编写普通程序员水平的计算机程序,在 Codeforces 网站 的 10 个挑战中排名前 54.3%,击败了 46% 的参赛者。
这一成绩给程序员群体带来了不小的压力,仿佛纺织工人被纺织机器淘汰的历史正在重演。
那么,AlphaCode 为何如此强大?在最近的一段 YouTube 视频中,清华大学朱军博士后 Tim Pearce 详细分析了 AlphaCode 的系统架构、“问题解决”原理和训练流程。
原视频地址:
AlphaCode 到底是做什么的?
如前所述,DeepMind 研究人员在 Codeforces 挑战中对 AlphaCode 进行了测试。Codeforces 是一个拥有各种编程主题和各种竞赛的在线编程平台。它类似于国际象棋中使用的 Elo 评级系统,每周共享编程挑战和问题排名。与程序员在构建商业应用程序时可能面临的任务不同,Codeforces 的挑战更加独立,需要对计算机科学中的算法和理论概念有更广泛的理解,通常是逻辑、数学和编码专业知识的非常专业的组合。
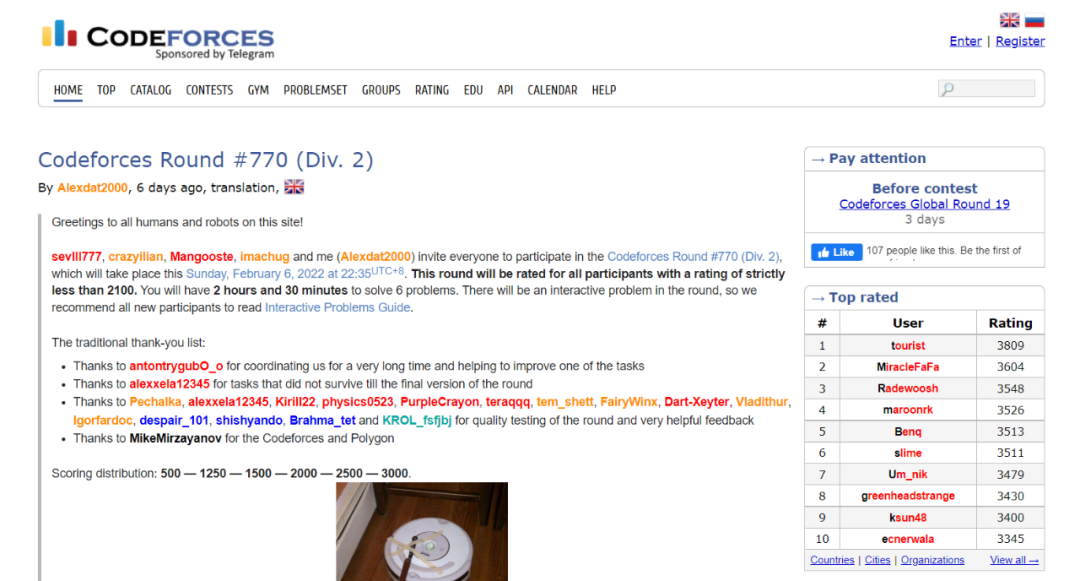
下图是其中一个竞赛题的示例,包括竞赛题的描述、输入输出示例等。挑战者的任务是根据这些内容编写一段代码,使输出符合要求。

下面是 AlphaCode 编写的代码:
对于 AlphaCode,这只是一个适度的挑战。
在十个类似的挑战中,研究人员将问题输入 AlphaCode。然后,AlphaCode 会生成大量可能的答案,并通过运行代码和检查输出来筛选它们,就像人类竞争对手一样。“整个过程是自动的,无需手动选择最佳样本,”AlphaCode 论文的联合负责人 Yujia Li 和 David Choi 说。
为什么 AlphaCode 如此强大?
下图是AlphaCode的概念图。这是一个精心设计的系统,主要构建块是基于 Transformer 的语言模型。但本质上,没有一个组件是全新的。
“考场”上的 AlphaCode
我们先来看看上面的系统在测试时是如何工作的。
在解决编码问题时,AlphaCode 使用一种非常具体的协议,它决定了整个系统的管道。协议规定他们可以无限使用示例测试用例,因为这些是作为问题的一部分给出的。但是在提交隐藏测试用例时,他们将提交次数限制为 10 次(最多 10 次)。
在测试过程中,AlphaCode 经历了三个阶段。
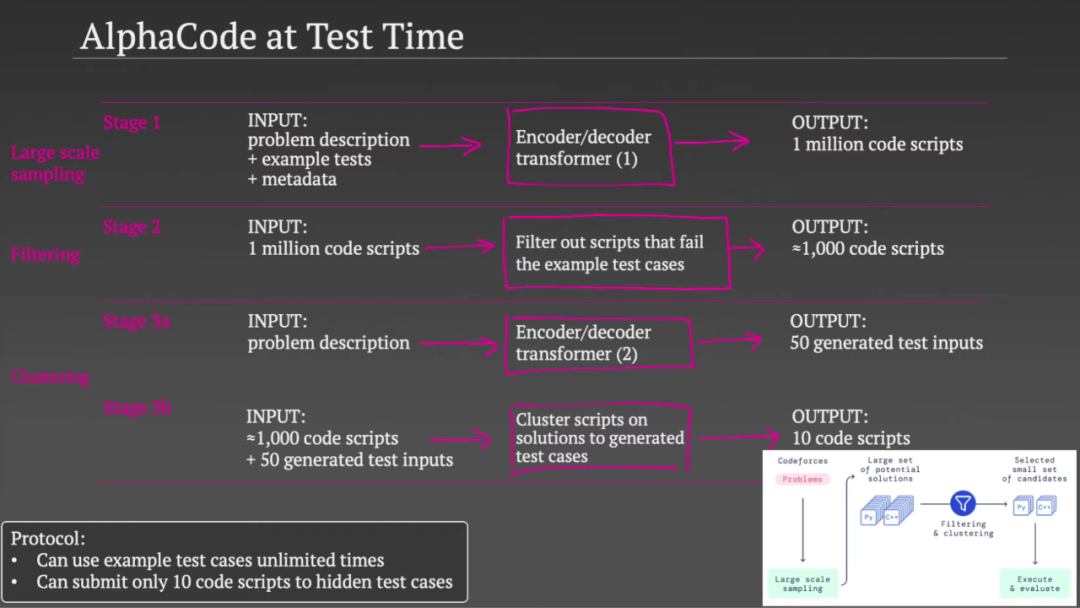
在第一阶段,他们使用一个大型 Transformer 模型,该模型将问题描述示例测试和字符串中有关问题的一些元数据作为输入。然后他们从这个模型中取样,产生了大量的潜在解决方案。所以第一阶段有 100 万个可能的代码脚本。
在第二阶段,他们用示例测试用例测试了生成的 100 万组代码,其中 99% 没有通过测试,可以排除。这使可行代码集的数量减少到 1000 个左右(取决于问题的难度)。
在第三阶段,他们使用了第二个 Transformer 模型。该模型将问题描述作为输入,但不是尝试生成代码来解决问题,而是生成测试用例输入(每个问题 50 个输入)。也就是说,他们没有选择生成输入和输出对,而是一些与问题相关的实际输入。因此模型可能想要生成字符串、二进制数或序列(取决于问题的类型)。
这种方法有多好?他们推断,如果两个脚本在所有 50 次测试中返回相同的答案,那么它们可能使用了相同的算法。这避免了浪费两个提交来测试两个脚本。所以在第二步得到 1000 组脚本后,他们根据这 50 个生成的测试输入的输出对脚本进行聚类,然后从每个聚类中挑选一个示例脚本,一共 10 个。如果 10 个脚本中的一个通过所有隐藏的测试,他们成功解决了编程问题,否则他们失败了。
以上是测试中AlphaCode的工作原理,使用了两个Transformer模型。那么这两个模型是如何训练的呢?
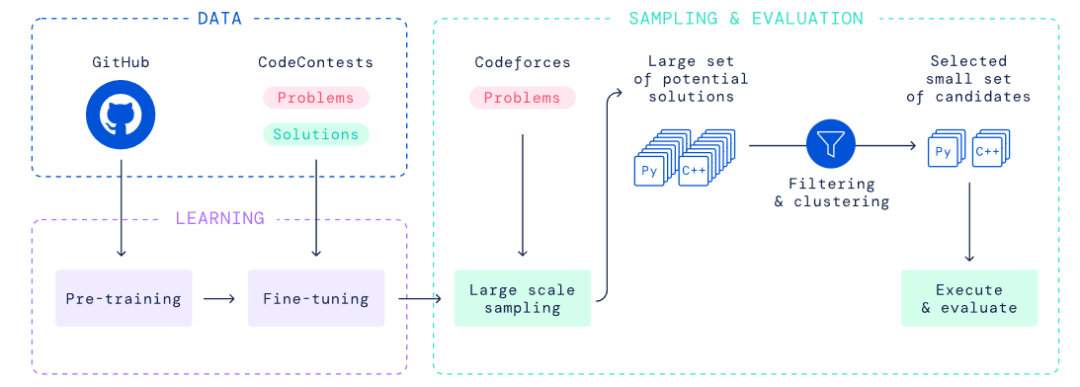
AlphaCode 训练
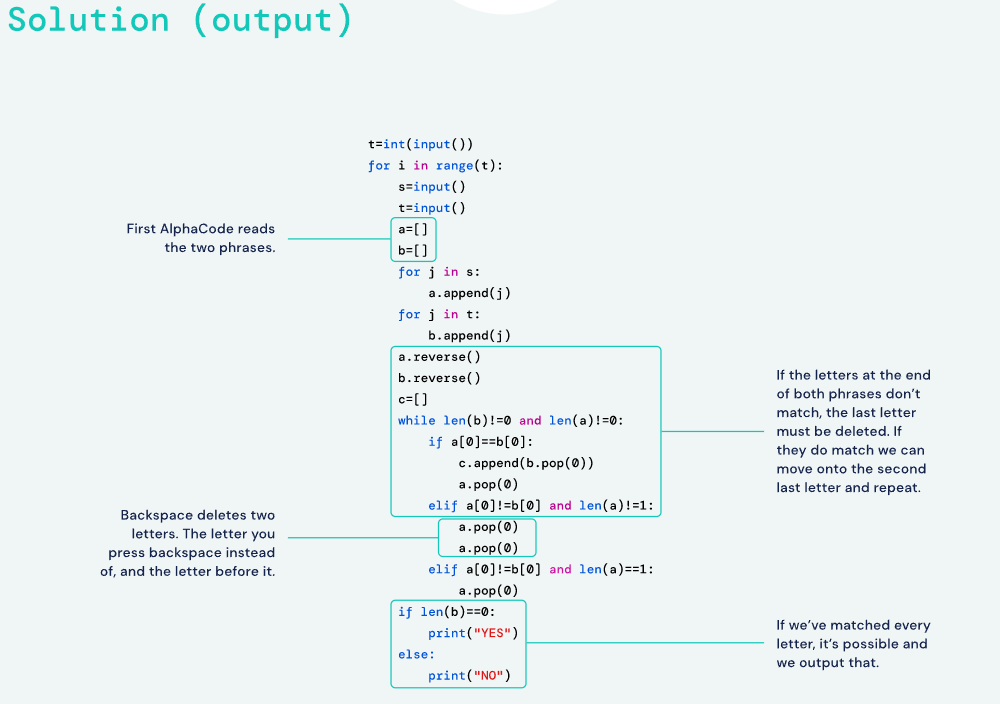
AlphaCode 的训练分为两个阶段:预训练和微调。这个过程涉及两个数据集:第一个是一个公共的 GitHub 存储库,由各种编程语言组成,用于进行高达 715GB 数据的预训练;第二个是从各种编程挑战中采集的网站(包括 codeforces)采集用于微调的问题,包括问题描述、测试用例和人类程序员编写的答案。
有了数据集,下一步就是训练。
在预训练阶段,他们从 GitHub 上抓取一些代码并随机选择他们所谓的“枢轴点”。
直到枢轴点的所有内容都将被输入编码器,解码器的目标是重建枢轴点以下的代码。编码器输出代码的向量表示,然后可以在整个解码过程中使用。
解码器以自回归方式工作。它从预测代码的第一个标记开始。损失函数是预测的softmax输出和真实token之间的交叉熵。然后,第一个真实令牌成为解码器的输入,然后预测第二个令牌。重复此过程,直到要求解码器预测一个特殊的代码结束标记。现在,这些损失通过解码器和编码器反向传播,但编码器添加第二个损失非常重要。这称为掩码语言建模损失:您将输入编码器的一些标记留为空白,作为一项附带任务,编码器将尝试预测哪个标记被掩码。
预训练结束后,微调步骤来了。在本次会议中,他们将问题描述元数据和示例的输入输入到编码器中,并尝试使用解码器生成人工编写的代码。正如您在这一点上所看到的,这与编码器-解码器架构所规定的结构非常自然地吻合。此阶段的损失与预训练中的损失完全相同。此外,这里还有第二个 Transformer 来生成测试输入。这也由相同的 GitHub 预训练任务初始化,但经过微调以生成测试输入而不是代码。
除了上面提到的一般训练步骤和架构之外,AlphaCode 还借鉴了其他近期论文的一些经验教训。蒂姆·皮尔斯(Tim Pearce)指出了其中一个更好的:

AlphaCode 的元数据条件
除了问题描述之外,研究人员总是将元数据作为 Transformer 的输入,包括编程语言、问题的难度级别、关于问题的一些标签以及解决方案是否正确等。在训练时,模型显然知道这些字段的值是什么,但在测试时,它们不知道。非常有趣的是,他们可以在测试时在这些字段中输入不同的内容来影响生成的代码。例如,您可以控制系统将生成的编程语言,甚至影响它尝试生成的解决方案的类型,例如是尝试动态编程方法还是执行穷举搜索。
他们在测试中发现,在对前 100 万个代码脚本进行采样时,随机化很多字段非常有帮助。因为,通过增加原创样本池的多样性,正确答案的概率会增加。
以上就是 Tim Pearce 对 AlphaCode 的所有分析。他认为,DeepMind 团队在这项工作上确实取得了一些进展。但他更不解的是:为什么他们在这些编程问题上的成绩远不如在围棋、星际争霸等游戏中取得的超人成绩?Tim Pearce 最初的猜测是编程问题更难,数据更难获取,因为在游戏中你可以无限制地生成大量模拟数据,但在编程问题中你不能这样做。
网页视频抓取脚本(w3school在线教程网站构建初级教程建站手册编程关于W3School帮助HTML文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-18 00:15
w3school 在线教程
网站构建初学者教程
网站建设者编程关于 W3School 帮助W3School
服务器端脚本初学者教程
HTML 文件可以收录文本、HTML 标记和脚本。
HTML 文件中的脚本可以在 Web 服务器上执行。
服务器端脚本
服务器端脚本是对服务器行为的编程。这称为服务器端脚本或服务器端脚本。
客户端脚本是浏览器行为的编程。(看)。
什么是服务器脚本?
通常,当浏览器请求 HTML 文件时,服务器会返回该文件,但如果该文件收录服务器端脚本,则在 HTML 文件作为纯 HTML 返回给浏览器之前,会先执行 HTML 文件中的脚本。
服务器脚本可以做什么?
重要提示:由于脚本是在服务器上执行的,所以浏览器可以在没有脚本支持的情况下显示服务器端文件!
ASP 和 PHP
在 W3School,我们使用 Active Server Pages (ASP) 和超文本预处理器 (PHP) 演示服务器端脚本。
看源码是看不到 ASP 或 PHP 的源码的,你看到的只是服务器的输出,纯 HTML。这是因为脚本在结果以纯 HTML 形式发送到浏览器之前在服务器上执行。
ASP 实例
通过 ASP 编写文本
如何通过 ASP 编写文本。
将 HTML 添加到文本
如何通过 HTML 标签格式化文本。
脚本教程
请学习我们完整的 ASP 教程和 PHP 教程。
W3School简体中文版提供的内容仅供培训和测试之用,不保证内容的正确性。与使用本网站内容相关的风险与本网站无关。版权所有,保留所有权利。 查看全部
网页视频抓取脚本(w3school在线教程网站构建初级教程建站手册编程关于W3School帮助HTML文件)
w3school 在线教程
网站构建初学者教程
网站建设者编程关于 W3School 帮助W3School
服务器端脚本初学者教程
HTML 文件可以收录文本、HTML 标记和脚本。
HTML 文件中的脚本可以在 Web 服务器上执行。
服务器端脚本
服务器端脚本是对服务器行为的编程。这称为服务器端脚本或服务器端脚本。
客户端脚本是浏览器行为的编程。(看)。
什么是服务器脚本?
通常,当浏览器请求 HTML 文件时,服务器会返回该文件,但如果该文件收录服务器端脚本,则在 HTML 文件作为纯 HTML 返回给浏览器之前,会先执行 HTML 文件中的脚本。
服务器脚本可以做什么?
重要提示:由于脚本是在服务器上执行的,所以浏览器可以在没有脚本支持的情况下显示服务器端文件!
ASP 和 PHP
在 W3School,我们使用 Active Server Pages (ASP) 和超文本预处理器 (PHP) 演示服务器端脚本。
看源码是看不到 ASP 或 PHP 的源码的,你看到的只是服务器的输出,纯 HTML。这是因为脚本在结果以纯 HTML 形式发送到浏览器之前在服务器上执行。
ASP 实例
通过 ASP 编写文本
如何通过 ASP 编写文本。
将 HTML 添加到文本
如何通过 HTML 标签格式化文本。
脚本教程
请学习我们完整的 ASP 教程和 PHP 教程。
W3School简体中文版提供的内容仅供培训和测试之用,不保证内容的正确性。与使用本网站内容相关的风险与本网站无关。版权所有,保留所有权利。
网页视频抓取脚本(一家的用途是什么?是怎么做的??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-16 04:04
作为大数据公司的运营编辑,经常有人问我,“嗯?爬虫是什么意思?” “爬行动物有什么用?” “你们公司有卖爬虫的吗,有蜥蜴吗?”等等一系列的问题,面对这些问题,小编绝望了。那么爬行动物到底是什么?
一、什么是爬虫
以下是百度百科对网络爬虫的定义:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
通俗的说,爬虫是可以自动上网并下载网站内容的程序或脚本,类似于机器人可以在自己的电脑上获取别人的网站信息,然后做一些事情筛选、筛选、汇总、排序、排序等。
网络爬虫的英文名是Web Spider,是一个很形象的名字。互联网被比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到这个网站的所有网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
二、爬虫能做什么
现在大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为,分析自身产品的不足,分析竞争对手的信息等等,但其中首要的条件是数据的采集。从招聘网站可以看出,很多公司都在高薪招聘爬虫工程师。但是,作为一项专业技能,网络爬虫不可能在很短的时间内学会。随着互联网的飞速发展,网站的种类也越来越多。许多传统企业因为跟不上时代的发展而被竞争对手甩在后面。苦于不懂技术,无从下手。
三、不懂爬虫技术怎么办?
小金蟾爬虫数据采集系统是一款通用的互联网数据采集软件。软件高度可视化的特点,让大家轻松上手,操作简单,精准智能采集让企业以极少的成本获得所需的数据,同时采集@ >快速的速度和全面的服务范围也给用户带来了极大的便利。
它还可以帮助企业用户分析数据。当企业面对大量数据却不知如何处理时,可以根据用户需求提供定制化服务,分析行业发展趋势,帮助企业用户在多方面构建优势。
在各行业快速发展的时代,如果再迈出下一步,可能会被行业浪潮淹没。新公司和消失公司的数量是难以想象的。企业要实现长期稳定发展,就必须紧跟时代步伐。,甚至快了一步,而这快了一步,就是你能为你做的。 查看全部
网页视频抓取脚本(一家的用途是什么?是怎么做的??)
作为大数据公司的运营编辑,经常有人问我,“嗯?爬虫是什么意思?” “爬行动物有什么用?” “你们公司有卖爬虫的吗,有蜥蜴吗?”等等一系列的问题,面对这些问题,小编绝望了。那么爬行动物到底是什么?
一、什么是爬虫
以下是百度百科对网络爬虫的定义:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
通俗的说,爬虫是可以自动上网并下载网站内容的程序或脚本,类似于机器人可以在自己的电脑上获取别人的网站信息,然后做一些事情筛选、筛选、汇总、排序、排序等。
网络爬虫的英文名是Web Spider,是一个很形象的名字。互联网被比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到这个网站的所有网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
二、爬虫能做什么
现在大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为,分析自身产品的不足,分析竞争对手的信息等等,但其中首要的条件是数据的采集。从招聘网站可以看出,很多公司都在高薪招聘爬虫工程师。但是,作为一项专业技能,网络爬虫不可能在很短的时间内学会。随着互联网的飞速发展,网站的种类也越来越多。许多传统企业因为跟不上时代的发展而被竞争对手甩在后面。苦于不懂技术,无从下手。
三、不懂爬虫技术怎么办?
小金蟾爬虫数据采集系统是一款通用的互联网数据采集软件。软件高度可视化的特点,让大家轻松上手,操作简单,精准智能采集让企业以极少的成本获得所需的数据,同时采集@ >快速的速度和全面的服务范围也给用户带来了极大的便利。
它还可以帮助企业用户分析数据。当企业面对大量数据却不知如何处理时,可以根据用户需求提供定制化服务,分析行业发展趋势,帮助企业用户在多方面构建优势。
在各行业快速发展的时代,如果再迈出下一步,可能会被行业浪潮淹没。新公司和消失公司的数量是难以想象的。企业要实现长期稳定发展,就必须紧跟时代步伐。,甚至快了一步,而这快了一步,就是你能为你做的。
网页视频抓取脚本( 2017年10月09日#load-media.jsexportdefaultloadMedia)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-14 13:15
2017年10月09日#load-media.jsexportdefaultloadMedia)
JS实现预加载视频音视频获取截图(返回画布截图)
更新时间:2017-10-09 15:29:55 作者:capricorncd
本篇文章主要介绍JS实现预加载视频音频/视频获取截图(返回canvas截图)的相关信息。有需要的朋友可以参考以下
#load-media.js
/**
* Create by Capricorncd 2017
*/
// 同域资源实现视频截图,可上传的图片数据格式
// 非同域资源实现canvas截图预览
// 提示码
const CODES = {
0: 'success',
1: 'The url is not valid',
2: 'onerror'
}
/**
* constructor
* @param opts.url 音频|视频URL
* @param opts.type 'audio|video'
* @param opts.callback 回调函数
*/
function loadMedia(opts) {
this.callback = opts.callback || function (res) {
console.log(res);
}
// 初始化
this.init(opts);
}
// prototype
loadMedia.prototype = {
/**
* 初始化media
* @param url
*/
init: function (opts) {
let self = this;
if (!opts.url || typeof opts.url !== 'string') {
this.callback({code: 1, msg: CODES[1]});
return;
}
// 创建media
let mediaType = opts.type === 'audio' ? 'audio' : 'video';
this.media = document.createElement(mediaType);
console.log('this.media', this.media);
// loaded
this.listener('canplaythrough', function (e) {
// 截图
if (mediaType === 'video') {
self.screenshot();
} else {
self.callback({
code: 0,
msg: CODES[0],
thumb: null,
media: this.media,
canvas: null
});
}
});
// error
this.listener('error', function (e) {
self.callback({code: 2, msg: CODES[2], data: e});
})
this.media.setAttribute('src', opts.url);
},
screenshot: function () {
// create canvas
let canvas = document.createElement('canvas');
canvas.width = this.media.videoWidth;
canvas.height = this.media.videoHeight;
let ctx = canvas.getContext('2d');
// 截取
ctx.drawImage(this.media, 0, 0);
let thumb = null;
// 非跨域资源
// !!非同域资源无法获取数据
try {
let type = 'image/png';
let data = canvas.toDataURL(type);
thumb = this.toBlobData(data, type);
} catch (e) {}
this.callback({
code: 0,
msg: CODES[0],
thumb: thumb,
media: this.media,
canvas: canvas
})
},
// 数据转换
toBlobData: function (data, type) {
// 获取base64数据
// base64数据格式:
// "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQEASABIAAD/2wBDAAkGB+wgHBgkIBwgKCgkLDRYPDQw//9k="
data = window.atob(data.split(',')[1]);
let ia = new Uint8Array(data.length);
for (let i = 0; i < data.length; i++) {
ia[i] = data.charCodeAt(i);
};
// canvas.toDataURL 返回的默认格式是 image/png
return new Blob([ia], {type: type});
},
/**
* addEventListener 事件监听
* @param en EventName
* @param callback
*/
listener: function (en, callback) {
this.media.addEventListener(en, function (e) {
if (callback) {
callback(e);
} else {
console.warn(this);
}
}, false);
}
/**
* 资源是否跨域
* @param url 资源地址
* @returns {boolean}
*/
// isCrossDomain: function (url) {
// let loc, host, protocol;
// loc = window.location;
// host = loc.host;
// protocol = loc.protocol;
// // 是否为http链接
// if (/(http|https):\/\//.test(url)) {
// if (url.indexOf(protocol + '//' + host) >= 0) {
// return false;
// } else {
// return true;
// }
// }
// // './xxx.mp4' '/xxx.mp4' 'xxx.mp4'
// return false;
// }
}
导出默认加载媒体;
// 参考资料
// HTML5的Video标签的属性,方法和事件汇总
// http://www.cnblogs.com/TF12138/p/4448108.html
# 使用
import loadMedia from '@/common/js/load-media'
let loadVideo = new loadMedia({
type: 'video',
url: 'http://xmqvip1-1253933147.file.myqcloud.com/chat/video/60/2017/09/29/qgj1c8K7oaYn-SCVideo-Merged.mp4',
callback: handleCallback
})
function handleCallback (res) {
console.log(res)
// canplaythrough
if (res.code === 0) {
}
// error
if (res.code === 2) {
}
}
总结
以上就是小编介绍的预加载视频音频/视频获取截图(返回画布截图)的JS实现。我希望它对你有帮助。如有任何问题,请给我留言,小编会及时回复您。. 还要感谢大家对脚本之家网站的支持! 查看全部
网页视频抓取脚本(
2017年10月09日#load-media.jsexportdefaultloadMedia)
JS实现预加载视频音视频获取截图(返回画布截图)
更新时间:2017-10-09 15:29:55 作者:capricorncd
本篇文章主要介绍JS实现预加载视频音频/视频获取截图(返回canvas截图)的相关信息。有需要的朋友可以参考以下
#load-media.js
/**
* Create by Capricorncd 2017
*/
// 同域资源实现视频截图,可上传的图片数据格式
// 非同域资源实现canvas截图预览
// 提示码
const CODES = {
0: 'success',
1: 'The url is not valid',
2: 'onerror'
}
/**
* constructor
* @param opts.url 音频|视频URL
* @param opts.type 'audio|video'
* @param opts.callback 回调函数
*/
function loadMedia(opts) {
this.callback = opts.callback || function (res) {
console.log(res);
}
// 初始化
this.init(opts);
}
// prototype
loadMedia.prototype = {
/**
* 初始化media
* @param url
*/
init: function (opts) {
let self = this;
if (!opts.url || typeof opts.url !== 'string') {
this.callback({code: 1, msg: CODES[1]});
return;
}
// 创建media
let mediaType = opts.type === 'audio' ? 'audio' : 'video';
this.media = document.createElement(mediaType);
console.log('this.media', this.media);
// loaded
this.listener('canplaythrough', function (e) {
// 截图
if (mediaType === 'video') {
self.screenshot();
} else {
self.callback({
code: 0,
msg: CODES[0],
thumb: null,
media: this.media,
canvas: null
});
}
});
// error
this.listener('error', function (e) {
self.callback({code: 2, msg: CODES[2], data: e});
})
this.media.setAttribute('src', opts.url);
},
screenshot: function () {
// create canvas
let canvas = document.createElement('canvas');
canvas.width = this.media.videoWidth;
canvas.height = this.media.videoHeight;
let ctx = canvas.getContext('2d');
// 截取
ctx.drawImage(this.media, 0, 0);
let thumb = null;
// 非跨域资源
// !!非同域资源无法获取数据
try {
let type = 'image/png';
let data = canvas.toDataURL(type);
thumb = this.toBlobData(data, type);
} catch (e) {}
this.callback({
code: 0,
msg: CODES[0],
thumb: thumb,
media: this.media,
canvas: canvas
})
},
// 数据转换
toBlobData: function (data, type) {
// 获取base64数据
// base64数据格式:
// "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQEASABIAAD/2wBDAAkGB+wgHBgkIBwgKCgkLDRYPDQw//9k="
data = window.atob(data.split(',')[1]);
let ia = new Uint8Array(data.length);
for (let i = 0; i < data.length; i++) {
ia[i] = data.charCodeAt(i);
};
// canvas.toDataURL 返回的默认格式是 image/png
return new Blob([ia], {type: type});
},
/**
* addEventListener 事件监听
* @param en EventName
* @param callback
*/
listener: function (en, callback) {
this.media.addEventListener(en, function (e) {
if (callback) {
callback(e);
} else {
console.warn(this);
}
}, false);
}
/**
* 资源是否跨域
* @param url 资源地址
* @returns {boolean}
*/
// isCrossDomain: function (url) {
// let loc, host, protocol;
// loc = window.location;
// host = loc.host;
// protocol = loc.protocol;
// // 是否为http链接
// if (/(http|https):\/\//.test(url)) {
// if (url.indexOf(protocol + '//' + host) >= 0) {
// return false;
// } else {
// return true;
// }
// }
// // './xxx.mp4' '/xxx.mp4' 'xxx.mp4'
// return false;
// }
}
导出默认加载媒体;
// 参考资料
// HTML5的Video标签的属性,方法和事件汇总
// http://www.cnblogs.com/TF12138/p/4448108.html
# 使用
import loadMedia from '@/common/js/load-media'
let loadVideo = new loadMedia({
type: 'video',
url: 'http://xmqvip1-1253933147.file.myqcloud.com/chat/video/60/2017/09/29/qgj1c8K7oaYn-SCVideo-Merged.mp4',
callback: handleCallback
})
function handleCallback (res) {
console.log(res)
// canplaythrough
if (res.code === 0) {
}
// error
if (res.code === 2) {
}
}
总结
以上就是小编介绍的预加载视频音频/视频获取截图(返回画布截图)的JS实现。我希望它对你有帮助。如有任何问题,请给我留言,小编会及时回复您。. 还要感谢大家对脚本之家网站的支持!
网页视频抓取脚本(手机(安卓、ios都可以)/安卓模拟器 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2022-02-13 18:11
)
准备好工作了:
(1),手机(安卓和ios)/安卓模拟器,今天主要以安卓模拟器为主,操作流程是一样的。
(2),抓包工具:Fiddel 下载地址:()
(3),编程工具:pycharm
(4),安卓模拟器/手机安装抖音
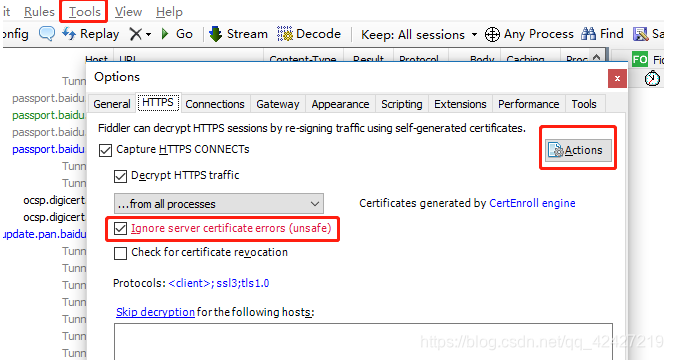
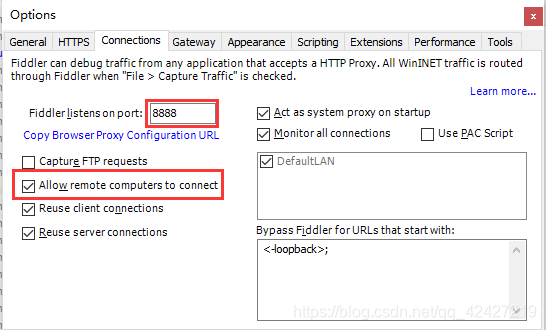
一、提琴手配置
在tools中的options中,勾选如图所示的框,点击Actions
配置远程链接:
选择允许监控远程链接,端口可以随意设置,只要不重复,默认8888
然后:重启提琴手!!!此配置将生效。
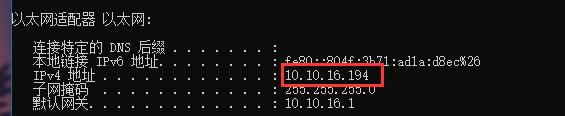
二、安卓模拟器/手机配置
首先查看机器的IP:在cmd中输入ipconfig,记住这个IP
确保手机和电脑在同一个局域网中。
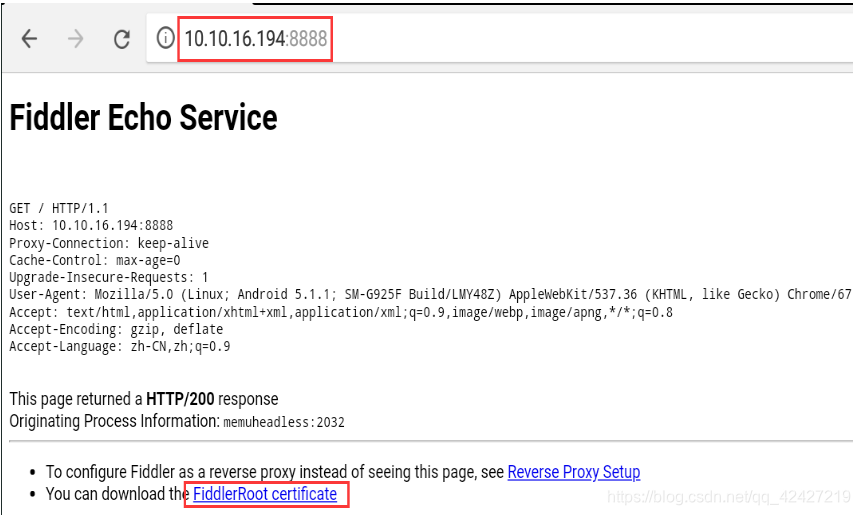
手机配置:配置连接的WiFi,代理选择手动,然后如上图输入ip端口号为8888
模拟器配置:在设置中长按连接的wifi,选择manual作为代理,然后输入ip端口号如上图为8888
设置好代理后,在浏览器中输入你设置的ip:port,比如10.10.16.194:8888,就会打开fiddler页面。然后点击fiddlerRoot证书安装证书,否则手机会认为环境不安全。
证书名称可以任意设置,可能还需要设置锁屏密码。
接下来,您可以在 fiddler 中抓取手机/模拟器软件的软件包。
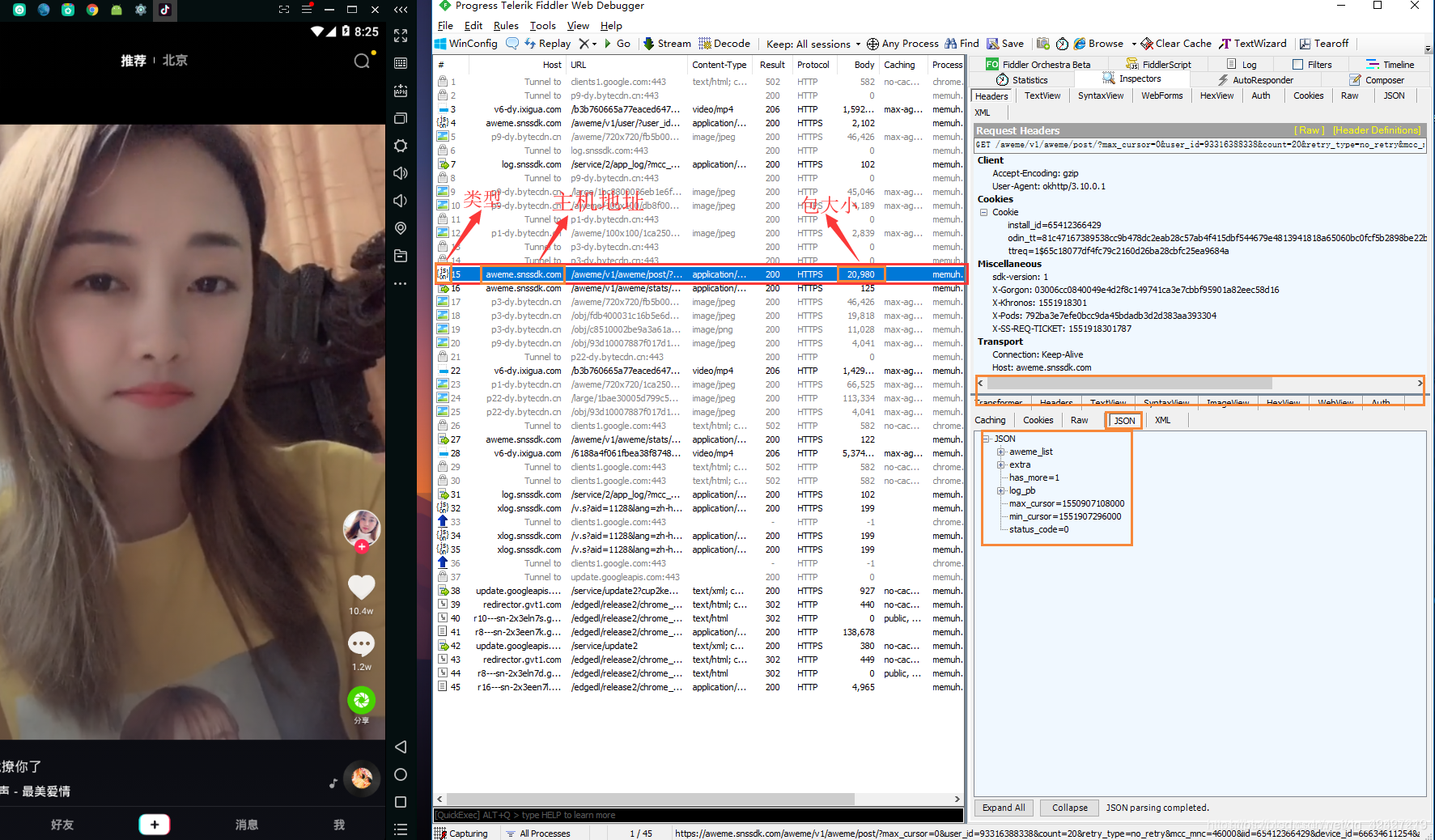
三、抖音捕获数据包
打开 抖音 并观察 fiddler 中的所有包
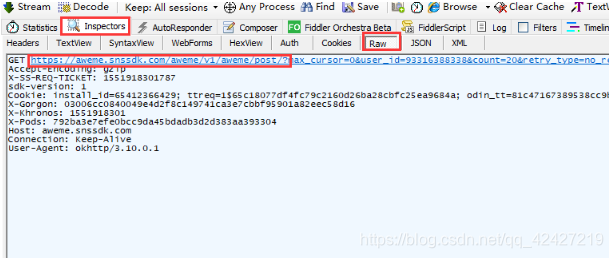
有一个包,包类型是json(json是网页返回的数据,具体是百度),主机地址如图,包大小一般不小,这个是视频包。
点击这个json包,在fidder右侧,点击decode,我们将解码视频包的json
解码后:点击awesome_list,其中每个大括号代表一个视频,这个和bilibili弹幕或者快手一样,每次加载一点,读完预加载的再加载一些
接下来解决几个问题,
1、视频数量,每个包就这么多视频,怎么抢更多?
这时候需要用模拟器的模拟鼠标翻页,让模拟器不停的翻页,这样json包才会不断出现。
2、如何在本地保存json以供使用
一种方法是手动复制粘贴,但这非常低。
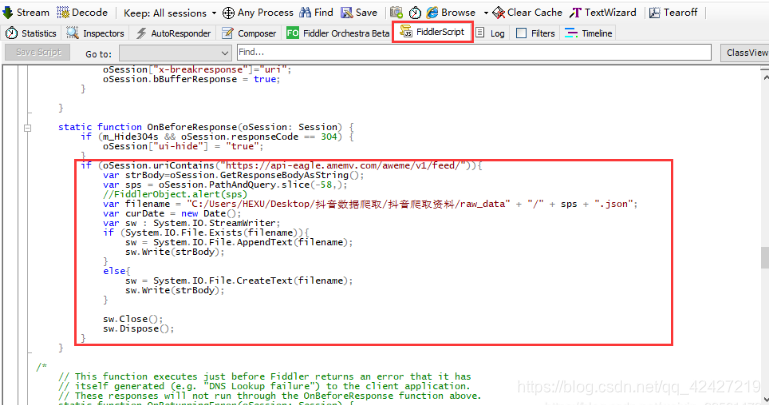
所以我们使用fidder自带的脚本,在里面添加规则,刷出视频json包时自动保存json包。
自定义规则包:
关联:
提取码:7z0l
单击规则脚本并放置自定义规则,如图所示:
这个脚本有两点需要修改:
(1)第一行的网址:
这是从视频包的 url 中提取的。抖音 会不定时更新这个url,所以如果不能使用就必须更新:
比如现在的和昨天的不一样,记得修改。
(2)路径,也就是我设置json包保存的地址,必须自己修改,并创建文件夹,修改后记得保存。
打开并设置好模拟器和脚本后,稍等片刻,就可以看到文件夹中保存的包:
四、爬虫脚本
接下来在pycharm中编写脚本获取json包中的视频链接:
指导包:
导入操作系统,json,请求
迷彩头:(F12获取,如何获取具体参考之前的爬虫图文)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, 像壁虎)Chrome/72.0.3626.119 Safari/537.36'}
逻辑代码:
运行代码:
影响:
源代码:
import os,json,requests
#伪装头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'}
videos_list = os.listdir('C:/Users/HEXU/Desktop/抖音数据爬取/抖音爬取资料/raw_data/') #获取文件夹内所有json包名
count = 1 #计数,用来作为视频名字
for videos in videos_list: #循环json列表,对每个json包进行操作
a = open('./抖音爬取资料/raw_data/{}'.format(videos),encoding='utf-8') #打开json包
content = json.load(a)['aweme_list'] #取出json包中所有视频
for video in content: #循环视频列表,选取每个视频
video_url = video['video']['play_addr']['url_list'][4] #获取视频url,每个视频有6个url,我选的第5个
videoMp4 = requests.request('get',video_url,headers=headers).content #获取视频二进制代码
with open('./抖音爬取资料/VIDEO/{}.mp4'.format(count),'wb') as f: #以二进制方式写入路径,记住要先创建路径
f.write(videoMp4) #写入
print('视频{}下载完成'.format(count)) #下载提示
count += 1 #计数+1 查看全部
网页视频抓取脚本(手机(安卓、ios都可以)/安卓模拟器
)
准备好工作了:
(1),手机(安卓和ios)/安卓模拟器,今天主要以安卓模拟器为主,操作流程是一样的。
(2),抓包工具:Fiddel 下载地址:()
(3),编程工具:pycharm
(4),安卓模拟器/手机安装抖音
一、提琴手配置
在tools中的options中,勾选如图所示的框,点击Actions
配置远程链接:
选择允许监控远程链接,端口可以随意设置,只要不重复,默认8888
然后:重启提琴手!!!此配置将生效。
二、安卓模拟器/手机配置
首先查看机器的IP:在cmd中输入ipconfig,记住这个IP
确保手机和电脑在同一个局域网中。
手机配置:配置连接的WiFi,代理选择手动,然后如上图输入ip端口号为8888
模拟器配置:在设置中长按连接的wifi,选择manual作为代理,然后输入ip端口号如上图为8888


设置好代理后,在浏览器中输入你设置的ip:port,比如10.10.16.194:8888,就会打开fiddler页面。然后点击fiddlerRoot证书安装证书,否则手机会认为环境不安全。
证书名称可以任意设置,可能还需要设置锁屏密码。
接下来,您可以在 fiddler 中抓取手机/模拟器软件的软件包。
三、抖音捕获数据包
打开 抖音 并观察 fiddler 中的所有包
有一个包,包类型是json(json是网页返回的数据,具体是百度),主机地址如图,包大小一般不小,这个是视频包。

点击这个json包,在fidder右侧,点击decode,我们将解码视频包的json

解码后:点击awesome_list,其中每个大括号代表一个视频,这个和bilibili弹幕或者快手一样,每次加载一点,读完预加载的再加载一些
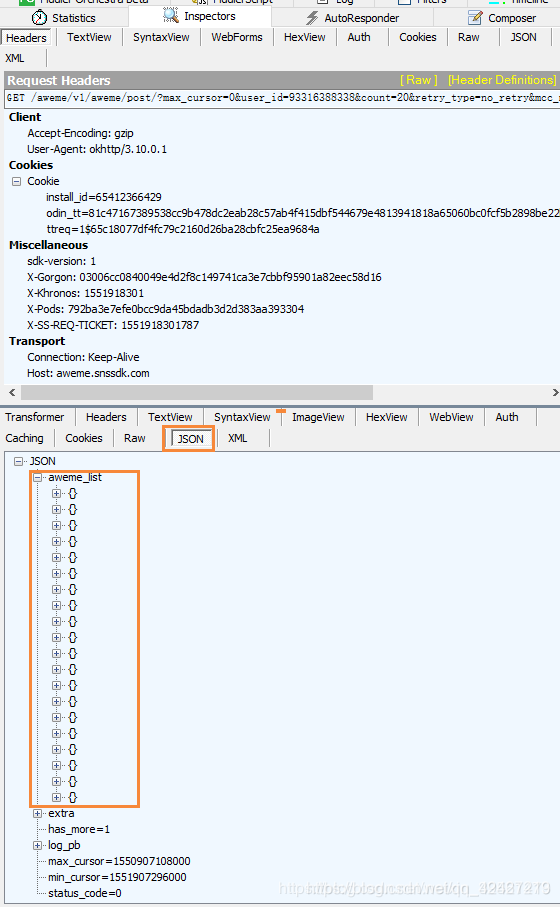
接下来解决几个问题,
1、视频数量,每个包就这么多视频,怎么抢更多?
这时候需要用模拟器的模拟鼠标翻页,让模拟器不停的翻页,这样json包才会不断出现。
2、如何在本地保存json以供使用
一种方法是手动复制粘贴,但这非常低。
所以我们使用fidder自带的脚本,在里面添加规则,刷出视频json包时自动保存json包。
自定义规则包:
关联:
提取码:7z0l
单击规则脚本并放置自定义规则,如图所示:
这个脚本有两点需要修改:
(1)第一行的网址:
这是从视频包的 url 中提取的。抖音 会不定时更新这个url,所以如果不能使用就必须更新:
比如现在的和昨天的不一样,记得修改。
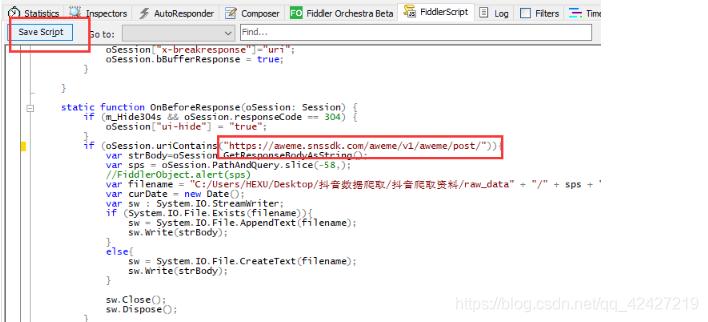
(2)路径,也就是我设置json包保存的地址,必须自己修改,并创建文件夹,修改后记得保存。
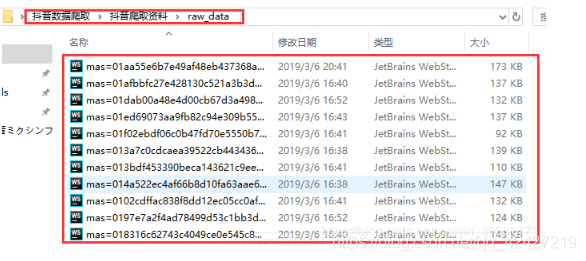
打开并设置好模拟器和脚本后,稍等片刻,就可以看到文件夹中保存的包:
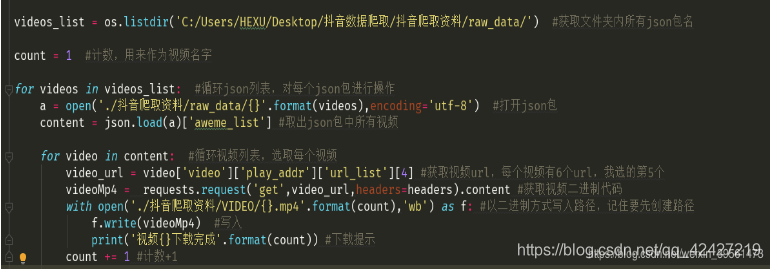
四、爬虫脚本
接下来在pycharm中编写脚本获取json包中的视频链接:
指导包:
导入操作系统,json,请求
迷彩头:(F12获取,如何获取具体参考之前的爬虫图文)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, 像壁虎)Chrome/72.0.3626.119 Safari/537.36'}
逻辑代码:
运行代码:
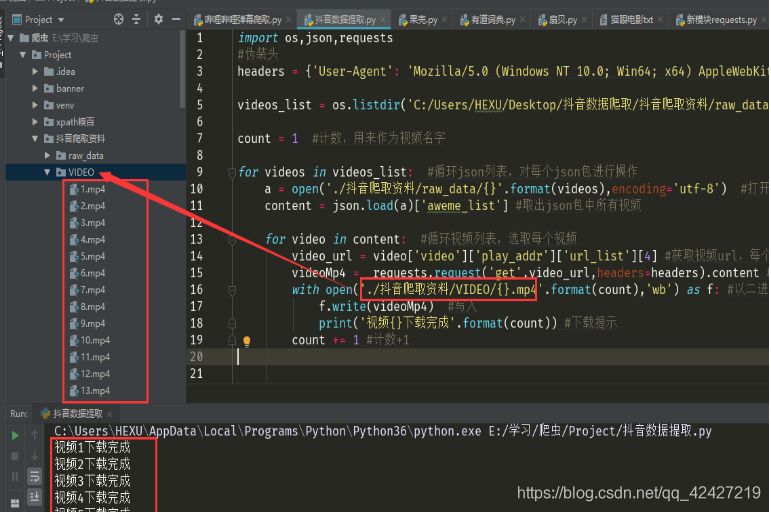
影响:

源代码:
import os,json,requests
#伪装头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'}
videos_list = os.listdir('C:/Users/HEXU/Desktop/抖音数据爬取/抖音爬取资料/raw_data/') #获取文件夹内所有json包名
count = 1 #计数,用来作为视频名字
for videos in videos_list: #循环json列表,对每个json包进行操作
a = open('./抖音爬取资料/raw_data/{}'.format(videos),encoding='utf-8') #打开json包
content = json.load(a)['aweme_list'] #取出json包中所有视频
for video in content: #循环视频列表,选取每个视频
video_url = video['video']['play_addr']['url_list'][4] #获取视频url,每个视频有6个url,我选的第5个
videoMp4 = requests.request('get',video_url,headers=headers).content #获取视频二进制代码
with open('./抖音爬取资料/VIDEO/{}.mp4'.format(count),'wb') as f: #以二进制方式写入路径,记住要先创建路径
f.write(videoMp4) #写入
print('视频{}下载完成'.format(count)) #下载提示
count += 1 #计数+1
网页视频抓取脚本(怎么去抓取HTTP的请求包?(二)与SlimerJS内核)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-13 07:16
简介
前两篇文章介绍了如何抓包HTTP请求包,包括代理服务器的使用和抓包方法。因为当前视频网站的视频地址不是直接在html页面上获取的,所以视频是通过浏览器动态解释js脚本获取的,然后向视频服务器发送视频请求。所以我们通过获取浏览器生成的HTTP请求来获取视频的下载地址。
思路是直接用firefox
我们想到了可以动态渲染 js 脚本的程序,最常见的是浏览器。我们通过命令运行
您可以使用 firefox 打开 URL。但是没有显示我们就不能用了,不过我们以后有办法解决这个问题。
python+selenium+Phantomjs
因为我们需要渲染JS脚本而不需要界面显示,所以我们也想到了python+selenium+Phantomjs来动态渲染页面。 Phantomjs 是无头浏览器(无头浏览器就是没有界面的浏览器)。
但是在 Phantomjs 1. 版本 5 之后,不再支持 flash 插件。也就是说,虽然 Phantomjs 可以动态加载 JS 脚本,但不能渲染视频。因此不会发出获取视频的 HTTP 请求。
我截图得到了渲染后的页面,如下图:
视频播放窗口黑屏,抓包程序无法捕获带有flv字符串的HTTP请求。
我也试过1.4.1版的Phantomjs,说可以通过这个命令加载Flash插件
./bin/phantomjs --load-plugins=yes examples/snap.js
通过渲染JS脚本,截图如下:
虽然得到的截图和上面的不一样,但是视频中有加载状态,但是还是抓不到视频的HTTP请求。最后在python中调用webdriver.Phantomjs()时报错。
最后不得不放弃使用 Phantomjs
slimerjs
当我在网上搜索无头浏览器时,我也发现了 slimerjs。
**PhantomJS 和 SlimerJS 的异同:**来自这篇文章文章
PhantomJS基于Webkit内核,不支持Flash播放 SlimerJS基于Firefox的Gecko内核,支持Flash播放,执行过程会显示在页面上
所以我们需要支持 Flash 播放。但是问题又来了! SlimerJS 不是纯粹的无头浏览器,它需要 DISPLAY! ! 那么我们能做些什么来解决这个问题呢?有!
xvfb
xvfb通过提供一个类似的X server daemon并设置环境变量DISPLAY让程序运行来提供程序运行环境
通过这个,你也可以解决前面提到的第一个火狐遇到的问题。我感觉我一直在一个圈子里= =!
方案实施
最后我们决定使用 slimerjs 来获取页面。因为没有办法通过python的selenium方法调用slimerjs,那么我们只能通过python调用命令行程序的方法来动态渲染页面。 slimerjs 脚本如下。当我们调用这个脚本时,我们传入一个网页地址参数。 slimerjs 负责打开这个页面并渲染页面的内容。
这个脚本的文件名是getPage.js
我们的python调用os.system("xvfb-run slimerjs getPage.js " + videoURL) 来渲染视频URL的视频。
我们最终的 Python 程序是 slimerjs_crawl_video.py
获取视频地址! !
未解决的问题
调用python slimerjs_crawl_video.py时,
我不知道如何控制这个时间。我尝试修改getPage.js的window.setTimeout函数的时间,但还是需要90多秒。我猜python的 os.system() 的限制是阻止某些时间。返回的时间(超过 90 秒)。接下来我会查一些相关的。
原来这个标题不太适合这个文章。但是还是没变,因为我原来是按照无头浏览器的思路解决这个问题的 查看全部
网页视频抓取脚本(怎么去抓取HTTP的请求包?(二)与SlimerJS内核)
简介
前两篇文章介绍了如何抓包HTTP请求包,包括代理服务器的使用和抓包方法。因为当前视频网站的视频地址不是直接在html页面上获取的,所以视频是通过浏览器动态解释js脚本获取的,然后向视频服务器发送视频请求。所以我们通过获取浏览器生成的HTTP请求来获取视频的下载地址。
思路是直接用firefox
我们想到了可以动态渲染 js 脚本的程序,最常见的是浏览器。我们通过命令运行
您可以使用 firefox 打开 URL。但是没有显示我们就不能用了,不过我们以后有办法解决这个问题。
python+selenium+Phantomjs
因为我们需要渲染JS脚本而不需要界面显示,所以我们也想到了python+selenium+Phantomjs来动态渲染页面。 Phantomjs 是无头浏览器(无头浏览器就是没有界面的浏览器)。
但是在 Phantomjs 1. 版本 5 之后,不再支持 flash 插件。也就是说,虽然 Phantomjs 可以动态加载 JS 脚本,但不能渲染视频。因此不会发出获取视频的 HTTP 请求。
我截图得到了渲染后的页面,如下图:

视频播放窗口黑屏,抓包程序无法捕获带有flv字符串的HTTP请求。
我也试过1.4.1版的Phantomjs,说可以通过这个命令加载Flash插件
./bin/phantomjs --load-plugins=yes examples/snap.js
通过渲染JS脚本,截图如下:
虽然得到的截图和上面的不一样,但是视频中有加载状态,但是还是抓不到视频的HTTP请求。最后在python中调用webdriver.Phantomjs()时报错。
最后不得不放弃使用 Phantomjs
slimerjs
当我在网上搜索无头浏览器时,我也发现了 slimerjs。
**PhantomJS 和 SlimerJS 的异同:**来自这篇文章文章
PhantomJS基于Webkit内核,不支持Flash播放 SlimerJS基于Firefox的Gecko内核,支持Flash播放,执行过程会显示在页面上
所以我们需要支持 Flash 播放。但是问题又来了! SlimerJS 不是纯粹的无头浏览器,它需要 DISPLAY! ! 那么我们能做些什么来解决这个问题呢?有!
xvfb
xvfb通过提供一个类似的X server daemon并设置环境变量DISPLAY让程序运行来提供程序运行环境
通过这个,你也可以解决前面提到的第一个火狐遇到的问题。我感觉我一直在一个圈子里= =!
方案实施
最后我们决定使用 slimerjs 来获取页面。因为没有办法通过python的selenium方法调用slimerjs,那么我们只能通过python调用命令行程序的方法来动态渲染页面。 slimerjs 脚本如下。当我们调用这个脚本时,我们传入一个网页地址参数。 slimerjs 负责打开这个页面并渲染页面的内容。
这个脚本的文件名是getPage.js
我们的python调用os.system("xvfb-run slimerjs getPage.js " + videoURL) 来渲染视频URL的视频。
我们最终的 Python 程序是 slimerjs_crawl_video.py
获取视频地址! !
未解决的问题
调用python slimerjs_crawl_video.py时,
我不知道如何控制这个时间。我尝试修改getPage.js的window.setTimeout函数的时间,但还是需要90多秒。我猜python的 os.system() 的限制是阻止某些时间。返回的时间(超过 90 秒)。接下来我会查一些相关的。
原来这个标题不太适合这个文章。但是还是没变,因为我原来是按照无头浏览器的思路解决这个问题的
网页视频抓取脚本(STM32视频段的加密手段(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-13 07:10
)
文章内容仅供学习
一:未加密的网页
F12打开开发者工具,对齐视频窗口,vedio标签中的src会有视频资源链接
二:加密网页没有直接资源地址,视频文件被分成n段传输
如上图,链接前有一个blob标记。我们不能直接使用这个资源链接。
但是,我们可以通过开发者工具的“网络”抓包
搜索关键词“ts”(即后缀为ts的视频文件)
这里每个包都是一个视频,n个视频放在一起组成一个视频
通过观察可以发现,这些视频片段的资源链接是有规律的
最后 3 位从 0 递增
然后,你可以把视频拉到最后,查看最后一个视频的地址
发现最后一个视频链接的后三位是430
那么,让我们把这431个ts的视频文件下载下来,然后拼接起来吧~
我在 IDM 的帮助下进行批量下载
使用此脚本完成431视频片段的下载
之后就是视频拼接,我用的软件是:合并工具
合并ts片段后就是一个完整的视频文件
三:blob的一种处理方法
去掉带有blob的视频链接后,网页会自动解析出真实的资源地址
(仅适用于一些 网站s)
第二种处理方法
新建一个a标签,然后在href中填入blob的资源地址:标签,然后点击访问
(记得在a标签中添加内容,否则在网页中是找不到的)
ps:有的网站加密方式比较厉害,这类视频片段的资源链接不规范。我还没有想到下载那种 网站 的方法。
还有一些网站会限制访问,需要正确的key才能有访问资源的权限,否则会报403
还有,一酷一奇艺的视频链接是这样加密的(这不是ts视频片段,而是mp4后缀)
对于同一个资源地址,n个视频段用标识码区分,加上控制访问权限的键值加密
(有些有 start 和 end 我们可以用这个代替下载 - 从视频的开头开始,在视频的结尾结束)
三:通过python包下载(前提是安装了python)
蟒蛇安装
用you-get包下载视频
进入命令行窗口:
1pip install you-get
2
3
1you-get 视频网站
2
3
(链接到网页)
上图为下载BZ的视频
视频默认保存在 C:\Users\username\
也可以指定输出目录
1you-get -o D:/movie 视频网站
2
3 查看全部
网页视频抓取脚本(STM32视频段的加密手段(一)
)
文章内容仅供学习
一:未加密的网页
F12打开开发者工具,对齐视频窗口,vedio标签中的src会有视频资源链接

二:加密网页没有直接资源地址,视频文件被分成n段传输

如上图,链接前有一个blob标记。我们不能直接使用这个资源链接。
但是,我们可以通过开发者工具的“网络”抓包
搜索关键词“ts”(即后缀为ts的视频文件)

这里每个包都是一个视频,n个视频放在一起组成一个视频
通过观察可以发现,这些视频片段的资源链接是有规律的
最后 3 位从 0 递增
然后,你可以把视频拉到最后,查看最后一个视频的地址

发现最后一个视频链接的后三位是430
那么,让我们把这431个ts的视频文件下载下来,然后拼接起来吧~
我在 IDM 的帮助下进行批量下载


使用此脚本完成431视频片段的下载
之后就是视频拼接,我用的软件是:合并工具
合并ts片段后就是一个完整的视频文件
三:blob的一种处理方法
去掉带有blob的视频链接后,网页会自动解析出真实的资源地址
(仅适用于一些 网站s)



第二种处理方法
新建一个a标签,然后在href中填入blob的资源地址:标签,然后点击访问
(记得在a标签中添加内容,否则在网页中是找不到的)
ps:有的网站加密方式比较厉害,这类视频片段的资源链接不规范。我还没有想到下载那种 网站 的方法。
还有一些网站会限制访问,需要正确的key才能有访问资源的权限,否则会报403

还有,一酷一奇艺的视频链接是这样加密的(这不是ts视频片段,而是mp4后缀)

对于同一个资源地址,n个视频段用标识码区分,加上控制访问权限的键值加密
(有些有 start 和 end 我们可以用这个代替下载 - 从视频的开头开始,在视频的结尾结束)
三:通过python包下载(前提是安装了python)
蟒蛇安装
用you-get包下载视频
进入命令行窗口:
1pip install you-get
2
3
1you-get 视频网站
2
3
(链接到网页)

上图为下载BZ的视频
视频默认保存在 C:\Users\username\
也可以指定输出目录
1you-get -o D:/movie 视频网站
2
3
网页视频抓取脚本( 网页恶意脚本通过多样化的混淆机制隐藏自己,它还能动态创建浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-07 11:10
网页恶意脚本通过多样化的混淆机制隐藏自己,它还能动态创建浏览器)
网页的恶意脚本通过各种混淆机制隐藏自身,还可以动态创建嵌入链接并对链接内容进行编码。那么,恶意网页脚本是利用什么来传播的呢?
小编了解到,网页上的恶意脚本本质上是依靠浏览器利用漏洞下载木马并传播给用户。因此,传统的反木马检测方法在检测网页恶意脚本方面存在比较大的缺陷。
常见的网页恶意脚本检测技术包括客户端蜜罐技术、静态代码检测和动态行为检测。
1) 客户端蜜罐技术。客户端蜜罐主要针对客户端软件中存在的漏洞,主动寻找可能的攻击行为。在与服务器的交互过程中,客户端蜜罐不断监测系统的变化,并引入各种检测手段来判断是否存在恶意攻击。这种方法的缺点是花费大量时间,并且难以分析性能提升。北京大学张慧琳等人提出了一种基于网页动态视图的网页恶意脚本检测方法,主要是重构网页的动态视图。的目标。
2) 静态代码检测。静态代码检测技术是根据已知网页恶意脚本样本库程序代码本身的特点,检测未知网页程序是否为网页恶意脚本程序。它主要是解析网页,提取网页中的静态嵌入链接和本地脚本,然后通过一定的技术筛选特征集,建立相应的模型,检测未知网页程序的代码特征,并将这些特征与筛选的特征集。如果代码特征匹配,该网页程序将被定义为网页恶意脚本,否则为普通网页程序。
以上就是小编为大家介绍的网页恶意脚本的介绍。希望对朋友有帮助。关于如何检测和清除脚本病毒,如果想了解这部分网络病毒知识,点击百白安全网。 查看全部
网页视频抓取脚本(
网页恶意脚本通过多样化的混淆机制隐藏自己,它还能动态创建浏览器)

网页的恶意脚本通过各种混淆机制隐藏自身,还可以动态创建嵌入链接并对链接内容进行编码。那么,恶意网页脚本是利用什么来传播的呢?
小编了解到,网页上的恶意脚本本质上是依靠浏览器利用漏洞下载木马并传播给用户。因此,传统的反木马检测方法在检测网页恶意脚本方面存在比较大的缺陷。
常见的网页恶意脚本检测技术包括客户端蜜罐技术、静态代码检测和动态行为检测。
1) 客户端蜜罐技术。客户端蜜罐主要针对客户端软件中存在的漏洞,主动寻找可能的攻击行为。在与服务器的交互过程中,客户端蜜罐不断监测系统的变化,并引入各种检测手段来判断是否存在恶意攻击。这种方法的缺点是花费大量时间,并且难以分析性能提升。北京大学张慧琳等人提出了一种基于网页动态视图的网页恶意脚本检测方法,主要是重构网页的动态视图。的目标。
2) 静态代码检测。静态代码检测技术是根据已知网页恶意脚本样本库程序代码本身的特点,检测未知网页程序是否为网页恶意脚本程序。它主要是解析网页,提取网页中的静态嵌入链接和本地脚本,然后通过一定的技术筛选特征集,建立相应的模型,检测未知网页程序的代码特征,并将这些特征与筛选的特征集。如果代码特征匹配,该网页程序将被定义为网页恶意脚本,否则为普通网页程序。
以上就是小编为大家介绍的网页恶意脚本的介绍。希望对朋友有帮助。关于如何检测和清除脚本病毒,如果想了解这部分网络病毒知识,点击百白安全网。
网页视频抓取脚本(如何用python3编写一个文件序列文件中的基因功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-31 04:16
操作说明
在基因组分析中,我们经常有这样的需求,需要从fasta文件中提取一些序列。有时这些序列是完整的序列,有时它们只是原创 fasta 文件中序列的一部分。尤其是数据量大的时候,用肉眼来选择序列会很困难,那么我们可以通过简单的编程来实现。
例如,一个物种的全基因组序列(0-refer/Bacillus_subtilis.str168.fasta)及其基因组gff注释文件(0-refer/Bacillus_subtilis.str168.gff)。这里假设我们对这个物种进行研究,通过gff注释文件中的基因功能描述字段定位一些特定的基因,加上相关数据的访问等。接下来,我们期望在全基因组序列中找到并提取这些基因fasta 文件根据 gff 文件中这些基因的位置描述,得到一个新的 fasta 文件,该文件只收录目标基因序列。
请使用python3编写一个可以做到这一点的脚本。
例子
示例脚本如下(见网盘附件“seq_select1.py”)。
为了达到上述目的,我们首先需要准备一个txt文件(以下简称list文件,示例list.txt可以在网盘附件中找到),根据记录的基因位置信息gff 文件,填写类似如下内容(列和列之间用制表符分隔)。
1.png
#将以下内容保存到list.txt
基因46 NC_000964.3 42917 43660 +
NP_387934.1 NC_000964.3 59504 60070 +
yfmC NC_000964.3 825787 826734 -
cds821 NC_000964.3 885844 886173 -
在第 1 列中,为要获得的新序列命名;
第二列,要获取的序列的原创序列ID;
第3列,原创序列中要获取的序列的起始位置;
第4列,原创序列中要得到的序列的终止位置;
在第 5 列中,要获得的序列位于原创序列的正 (+) 或负 (-) 链上。
然后根据输入文件编辑py脚本,即输入fasta文件和list文件中记录要获取的序列位置的内容。
打开fasta文件“Bacillus_subtilis.scaffolds.fasta”,使用循环逐行读取序列id和碱基序列,将每个序列的所有碱基组合成一个字符串;基本序列存储为字典(字典样式 {'id':'base'})。
打开列表文件“list.txt”,读取内容,存入字典。字典的键是列表文件中第一列的内容;字典的值是列表文件第2-5列的内容,除以tab得到一个列表,收录4个字符分别代表列表文件第2-5列的信息)。
最后根据read list文件中的序列位置信息,从read基因组中截取目标基因序列。由于某些基因序列可能位于基因组的负链中,因此需要取反向互补序列。因此,首先定义一个函数rev(),以便在后续调用中获取反向互补序列。在输出序列名称时,还可以选择是否将序列的位置信息一起输出(name_detail = True/False)。
#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
#初始通过命令
input_file = '枯草芽孢杆菌.str168.fasta'
list_file = 'list.txt'
output_file = 'gene.fasta'
name_detail = 真
##读取文件
#读取基因组序列
seq_file = {}
使用 open(input_file, 'r') 作为 input_fasta:
对于 input_fasta 中的行:
line = line.strip()
如果行 [0] == '>':
seq_id = line.split()[0]
seq_file[seq_id] = ''
别的:
seq_file[seq_id] += 行
input_fasta.close()
#读取列表文件
list_dict = {}
使用 open(list_file, 'r') 作为 list_table:
对于 list_table 中的行:
如果 line.strip():
line = line.strip().split('\t')
list_dict[line[0]] = [line[1], int(line[2]) - 1, int(line[3]), line[4]]
list_table.close()
##截取序列并输出
#定义一个截取逆补的函数
def rev(seq):
base_trans = {'A':'T', 'C':'G', 'T':'A', 'G':'C', 'N':'N', 'a':'t' , 'c':'g', 't':'a', 'g':'c', 'n':'n'}
rev_seq = 列表(反转(seq))
rev_seq_list = [base_trans[k] for k in rev_seq]
rev_seq = ''.join(rev_seq_list)
返回(rev_seq)
#截断序列并输出
output_fasta = 打开(输出文件,'w')
对于 list_dict.items() 中的键、值:
如果名称_详细信息:
print('>' + key, '[' + value[0], value[1] + 1, value[2], value[3] + ']', file = output_fasta)
别的:
打印('>' + 键,文件 = output_fasta)
seq = seq_file['>' + value[0]][value[1]:value[2]]
如果值 [3] == '+':
打印(序列,文件= output_fasta)
elif 值 [3] == '-':
seq = rev(seq)
打印(序列,文件= output_fasta)
output_fasta.close()
编辑好脚本后,运行并输出一个新的fasta文件“gene.fasta”,其序列就是我们要得到的目标基因序列。
2.png
延期:
网盘附件“seq_select.py”是一个python3脚本,增加了命令行传输线,可以直接在shell中对目标文件进行I/O处理。该脚本可以指定一个输入fasta序列文件和一个记录要提取的序列位置的列表文件,新的输出fasta文件就是提取的序列。
#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
#导入模块,初始传递命令、变量等
导入参数解析
parser = argparse.ArgumentParser(description = '\n该脚本用于截取基因组中特定位置的序列,并额外输入截取序列信息的列表文件', add_help = False, usage = '\npython3 seq_select.py -i [ input.fasta] -o [output.fasta] -l [list]\npython3 seq_select.py --input [input.fasta] --output [output.fasta] --list [list]')
required = parser.add_argument_group('必需选项')
可选 = parser.add_argument_group('可选')
required.add_argument('-i', '--input', metavar = '[input.fasta]', help = '输入文件, fasta 格式', required = True)
required.add_argument('-o', '--output', metavar = '[output.fasta]', help = '输出文件,fasta 格式', required = True)
required.add_argument('-l', '--list', metavar = '[list]', help = 'record "新序列名称/原序列的序列ID/序列起始位置/序列结束位置/正链( +) 或负链 (-)",以制表符分隔,必填 = True)
optional.add_argument('--detail', action = 'store_true', help = '如果该参数存在,则在输出fasta的每个sequence id中显示序列在原创fasta中的位置信息', required = False)
optional.add_argument('-h', '--help', action = 'help', help = '帮助信息')
args = parser.parse_args()
##读取文件
#读取基因组序列
seq_file = {}
使用 open(args.input, 'r') 作为 input_fasta:
对于 input_fasta 中的行:
line = line.strip()
如果行 [0] == '>':
seq_id = line.split()[0]
seq_file[seq_id] = ''
别的:
seq_file[seq_id] += 行
input_fasta.close()
#读取列表文件
list_dict = {}
使用 open(args.list, 'r') 作为 list_file:
对于 list_file 中的行:
如果 line.strip():
line = line.strip().split('\t')
list_dict[line[0]] = [line[1], int(line[2]) - 1, int(line[3]), line[4]]
list_file.close()
##截取序列并输出
#定义一个截取逆补的函数
def rev(seq):
base_trans = {'A':'T', 'C':'G', 'T':'A', 'G':'C', 'a':'t', 'c':'g' , 't':'a', 'g':'c'}
rev_seq = 列表(反转(seq))
rev_seq_list = [base_trans[k] for k in rev_seq]
rev_seq = ''.join(rev_seq_list)
返回(rev_seq)
#截断序列并输出
output_fasta = open(args.output, 'w')
对于 list_dict.items() 中的键、值:
如果 args.detail:
print('>' + key, '[' + value[0], value[1] + 1, value[2], value[3] + ']', file = output_fasta)
别的:
打印('>' + 键,文件 = output_fasta)
seq = seq_file['>' + value[0]][value[1]:value[2]]
如果值 [3] == '+':
打印(序列,文件= output_fasta)
elif 值 [3] == '-':
seq = rev(seq)
打印(序列,文件= output_fasta)
output_fasta.close()
使用上面示例中的测试文件,脚本运行如下。
#python3 seq_select.py -h
python3 seq_select.py -i Bacillus_subtilis.str168.fasta -l list.txt -o gene.fasta --detail
3.png 查看全部
网页视频抓取脚本(如何用python3编写一个文件序列文件中的基因功能)
操作说明
在基因组分析中,我们经常有这样的需求,需要从fasta文件中提取一些序列。有时这些序列是完整的序列,有时它们只是原创 fasta 文件中序列的一部分。尤其是数据量大的时候,用肉眼来选择序列会很困难,那么我们可以通过简单的编程来实现。
例如,一个物种的全基因组序列(0-refer/Bacillus_subtilis.str168.fasta)及其基因组gff注释文件(0-refer/Bacillus_subtilis.str168.gff)。这里假设我们对这个物种进行研究,通过gff注释文件中的基因功能描述字段定位一些特定的基因,加上相关数据的访问等。接下来,我们期望在全基因组序列中找到并提取这些基因fasta 文件根据 gff 文件中这些基因的位置描述,得到一个新的 fasta 文件,该文件只收录目标基因序列。
请使用python3编写一个可以做到这一点的脚本。
例子
示例脚本如下(见网盘附件“seq_select1.py”)。
为了达到上述目的,我们首先需要准备一个txt文件(以下简称list文件,示例list.txt可以在网盘附件中找到),根据记录的基因位置信息gff 文件,填写类似如下内容(列和列之间用制表符分隔)。
1.png
#将以下内容保存到list.txt
基因46 NC_000964.3 42917 43660 +
NP_387934.1 NC_000964.3 59504 60070 +
yfmC NC_000964.3 825787 826734 -
cds821 NC_000964.3 885844 886173 -
在第 1 列中,为要获得的新序列命名;
第二列,要获取的序列的原创序列ID;
第3列,原创序列中要获取的序列的起始位置;
第4列,原创序列中要得到的序列的终止位置;
在第 5 列中,要获得的序列位于原创序列的正 (+) 或负 (-) 链上。
然后根据输入文件编辑py脚本,即输入fasta文件和list文件中记录要获取的序列位置的内容。
打开fasta文件“Bacillus_subtilis.scaffolds.fasta”,使用循环逐行读取序列id和碱基序列,将每个序列的所有碱基组合成一个字符串;基本序列存储为字典(字典样式 {'id':'base'})。
打开列表文件“list.txt”,读取内容,存入字典。字典的键是列表文件中第一列的内容;字典的值是列表文件第2-5列的内容,除以tab得到一个列表,收录4个字符分别代表列表文件第2-5列的信息)。
最后根据read list文件中的序列位置信息,从read基因组中截取目标基因序列。由于某些基因序列可能位于基因组的负链中,因此需要取反向互补序列。因此,首先定义一个函数rev(),以便在后续调用中获取反向互补序列。在输出序列名称时,还可以选择是否将序列的位置信息一起输出(name_detail = True/False)。
#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
#初始通过命令
input_file = '枯草芽孢杆菌.str168.fasta'
list_file = 'list.txt'
output_file = 'gene.fasta'
name_detail = 真
##读取文件
#读取基因组序列
seq_file = {}
使用 open(input_file, 'r') 作为 input_fasta:
对于 input_fasta 中的行:
line = line.strip()
如果行 [0] == '>':
seq_id = line.split()[0]
seq_file[seq_id] = ''
别的:
seq_file[seq_id] += 行
input_fasta.close()
#读取列表文件
list_dict = {}
使用 open(list_file, 'r') 作为 list_table:
对于 list_table 中的行:
如果 line.strip():
line = line.strip().split('\t')
list_dict[line[0]] = [line[1], int(line[2]) - 1, int(line[3]), line[4]]
list_table.close()
##截取序列并输出
#定义一个截取逆补的函数
def rev(seq):
base_trans = {'A':'T', 'C':'G', 'T':'A', 'G':'C', 'N':'N', 'a':'t' , 'c':'g', 't':'a', 'g':'c', 'n':'n'}
rev_seq = 列表(反转(seq))
rev_seq_list = [base_trans[k] for k in rev_seq]
rev_seq = ''.join(rev_seq_list)
返回(rev_seq)
#截断序列并输出
output_fasta = 打开(输出文件,'w')
对于 list_dict.items() 中的键、值:
如果名称_详细信息:
print('>' + key, '[' + value[0], value[1] + 1, value[2], value[3] + ']', file = output_fasta)
别的:
打印('>' + 键,文件 = output_fasta)
seq = seq_file['>' + value[0]][value[1]:value[2]]
如果值 [3] == '+':
打印(序列,文件= output_fasta)
elif 值 [3] == '-':
seq = rev(seq)
打印(序列,文件= output_fasta)
output_fasta.close()
编辑好脚本后,运行并输出一个新的fasta文件“gene.fasta”,其序列就是我们要得到的目标基因序列。
2.png
延期:
网盘附件“seq_select.py”是一个python3脚本,增加了命令行传输线,可以直接在shell中对目标文件进行I/O处理。该脚本可以指定一个输入fasta序列文件和一个记录要提取的序列位置的列表文件,新的输出fasta文件就是提取的序列。
#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
#导入模块,初始传递命令、变量等
导入参数解析
parser = argparse.ArgumentParser(description = '\n该脚本用于截取基因组中特定位置的序列,并额外输入截取序列信息的列表文件', add_help = False, usage = '\npython3 seq_select.py -i [ input.fasta] -o [output.fasta] -l [list]\npython3 seq_select.py --input [input.fasta] --output [output.fasta] --list [list]')
required = parser.add_argument_group('必需选项')
可选 = parser.add_argument_group('可选')
required.add_argument('-i', '--input', metavar = '[input.fasta]', help = '输入文件, fasta 格式', required = True)
required.add_argument('-o', '--output', metavar = '[output.fasta]', help = '输出文件,fasta 格式', required = True)
required.add_argument('-l', '--list', metavar = '[list]', help = 'record "新序列名称/原序列的序列ID/序列起始位置/序列结束位置/正链( +) 或负链 (-)",以制表符分隔,必填 = True)
optional.add_argument('--detail', action = 'store_true', help = '如果该参数存在,则在输出fasta的每个sequence id中显示序列在原创fasta中的位置信息', required = False)
optional.add_argument('-h', '--help', action = 'help', help = '帮助信息')
args = parser.parse_args()
##读取文件
#读取基因组序列
seq_file = {}
使用 open(args.input, 'r') 作为 input_fasta:
对于 input_fasta 中的行:
line = line.strip()
如果行 [0] == '>':
seq_id = line.split()[0]
seq_file[seq_id] = ''
别的:
seq_file[seq_id] += 行
input_fasta.close()
#读取列表文件
list_dict = {}
使用 open(args.list, 'r') 作为 list_file:
对于 list_file 中的行:
如果 line.strip():
line = line.strip().split('\t')
list_dict[line[0]] = [line[1], int(line[2]) - 1, int(line[3]), line[4]]
list_file.close()
##截取序列并输出
#定义一个截取逆补的函数
def rev(seq):
base_trans = {'A':'T', 'C':'G', 'T':'A', 'G':'C', 'a':'t', 'c':'g' , 't':'a', 'g':'c'}
rev_seq = 列表(反转(seq))
rev_seq_list = [base_trans[k] for k in rev_seq]
rev_seq = ''.join(rev_seq_list)
返回(rev_seq)
#截断序列并输出
output_fasta = open(args.output, 'w')
对于 list_dict.items() 中的键、值:
如果 args.detail:
print('>' + key, '[' + value[0], value[1] + 1, value[2], value[3] + ']', file = output_fasta)
别的:
打印('>' + 键,文件 = output_fasta)
seq = seq_file['>' + value[0]][value[1]:value[2]]
如果值 [3] == '+':
打印(序列,文件= output_fasta)
elif 值 [3] == '-':
seq = rev(seq)
打印(序列,文件= output_fasta)
output_fasta.close()
使用上面示例中的测试文件,脚本运行如下。
#python3 seq_select.py -h
python3 seq_select.py -i Bacillus_subtilis.str168.fasta -l list.txt -o gene.fasta --detail
3.png
网页视频抓取脚本(B站视频内容(一)_e操盘_光明网(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-31 04:13
1、第三方库导入
from bs4 import BeautifulSoup # 解析网页
import re # 正则表达式,进行文字匹配
import urllib.request,urllib.error # 通过浏览器请求数据
import sqlite3 # 轻型数据库
import time # 获取当前时间
2、程序运行main函数
爬取过程主要包括声明爬取网页->爬取网页数据并解析->保存数据
def main():
#声明爬取网站
baseurl = "https://www.bilibili.com/v/popular/rank/all"
#爬取网页
datalist = getData(baseurl)
# print(datalist)
#保存数据
dbname = time.strftime("%Y-%m-%d", time.localtime())
dbpath = "BiliBiliTop100 " + dbname
saveData(datalist,dbpath)
(1)爬取过程中使用的技术是:伪装成浏览器请求数据;
(2)解析爬取网页源码时:使用Beautifulsoup解析出需要的数据,使用re正则表达式匹配数据;
(3)保存数据的时候,考虑到B站的排名每天都在刷新,可以用当前日期保存数据库名。
3、程序运行结果
数据库中收录的数据有:排名、视频链接、标题、播放量、评论量、作者、综合评分。
4、程序源代码
<p>
from bs4 import BeautifulSoup #解析网页
import re # 正则表达式,进行文字匹配
import urllib.request,urllib.error
import sqlite3
import time
def main():
#声明爬取网站
baseurl = "https://www.bilibili.com/v/popular/rank/all"
#爬取网页
datalist = getData(baseurl)
# print(datalist)
#保存数据
dbname = time.strftime("%Y-%m-%d", time.localtime())
dbpath = "BiliBiliTop100 " + dbname
saveData(datalist,dbpath)
#re正则表达式
findLink =re.compile(r' 查看全部
网页视频抓取脚本(B站视频内容(一)_e操盘_光明网(图))
1、第三方库导入
from bs4 import BeautifulSoup # 解析网页
import re # 正则表达式,进行文字匹配
import urllib.request,urllib.error # 通过浏览器请求数据
import sqlite3 # 轻型数据库
import time # 获取当前时间
2、程序运行main函数
爬取过程主要包括声明爬取网页->爬取网页数据并解析->保存数据
def main():
#声明爬取网站
baseurl = "https://www.bilibili.com/v/popular/rank/all"
#爬取网页
datalist = getData(baseurl)
# print(datalist)
#保存数据
dbname = time.strftime("%Y-%m-%d", time.localtime())
dbpath = "BiliBiliTop100 " + dbname
saveData(datalist,dbpath)
(1)爬取过程中使用的技术是:伪装成浏览器请求数据;
(2)解析爬取网页源码时:使用Beautifulsoup解析出需要的数据,使用re正则表达式匹配数据;
(3)保存数据的时候,考虑到B站的排名每天都在刷新,可以用当前日期保存数据库名。
3、程序运行结果

数据库中收录的数据有:排名、视频链接、标题、播放量、评论量、作者、综合评分。

4、程序源代码
<p>
from bs4 import BeautifulSoup #解析网页
import re # 正则表达式,进行文字匹配
import urllib.request,urllib.error
import sqlite3
import time
def main():
#声明爬取网站
baseurl = "https://www.bilibili.com/v/popular/rank/all"
#爬取网页
datalist = getData(baseurl)
# print(datalist)
#保存数据
dbname = time.strftime("%Y-%m-%d", time.localtime())
dbpath = "BiliBiliTop100 " + dbname
saveData(datalist,dbpath)
#re正则表达式
findLink =re.compile(r'
网页视频抓取脚本(如何采集爬取抖音用户信息,整理自己的思路?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2022-01-31 04:11
最近在学习python爬虫,想采集爬抖音用户信息,因为看到这个需要相关爬虫职位,心血来潮,分享一下经验,自己整理一下顺便说一句。首先是在B站看爬虫的短视频,心灵之王的插件,通过修改fidder函数将心灵之王的json数据包保存到本地,使用python脚本读取数据循环包,然后自动打开浏览器搜索主题。现在我想把这个想法扩展到 抖音 这里。
先安装最新的fidder,抖音用户的数据包传输协议是https。您需要下载 fidder 的证书并将其安装在您的手机或 Android 模拟器上。我用的模拟器,然后把安卓模拟器的代理IP设置为电脑的IP。现在模拟器的所有网络请求都是通过fidder获取的。现在我们只想抓到数据包,分析数据包,推荐一个分析json包的url,可以清晰的展示复杂难懂的数据段。模拟器刷到抖音json数据包的时候,我会一个一个复制过来看看。网址在图片中。.
下一步是想办法保存这个数据包。关键点是修改fiddler函数。fidder工具在做爬虫和插件的时候经常用到。我特地学会了这个提琴手的用法。修改fiiderscript,这个收录用户信息的json数据包的请求url和host是一样的,使用这个修改后的函数保存到本地文件夹。
fidder函数保存到本地的数据只能覆盖不能添加,所以只能通过脚本循环读取,所以用python写一个脚本,解析读取的数据,保存到本地数据库。
现在是最后一步,编写一个脚本来模拟手动滑动抖音。由于你用的是模拟器,如果要多开几个,保存数据会比较快,所以就写一个分辨率最小的。320*480分辨率,节省资源,抓取用户信息进入个人主页。思路是在抖音中向上滑动识别是广告还是直播,是广告然后往下,而不是点击头像,延迟返回,然后循环。打包成apk安装到模拟器上进行真机测试!速度还不错。继续优化脚本,设置清缓存功能。如果缓存太多,就会很卡。
其实抓包的过程中还有很多有趣的事情,比如抓包没有水印的视频链接,可以采集,哈哈。还有一些细节,没有写清楚。如果您有任何问题,您可以留言,我会认真回答。
最终附件代码包百度云链接:密码:hzn5。
此贴也发在My Love Cracked上,标题相同,以后可能会同步。 查看全部
网页视频抓取脚本(如何采集爬取抖音用户信息,整理自己的思路?)
最近在学习python爬虫,想采集爬抖音用户信息,因为看到这个需要相关爬虫职位,心血来潮,分享一下经验,自己整理一下顺便说一句。首先是在B站看爬虫的短视频,心灵之王的插件,通过修改fidder函数将心灵之王的json数据包保存到本地,使用python脚本读取数据循环包,然后自动打开浏览器搜索主题。现在我想把这个想法扩展到 抖音 这里。
先安装最新的fidder,抖音用户的数据包传输协议是https。您需要下载 fidder 的证书并将其安装在您的手机或 Android 模拟器上。我用的模拟器,然后把安卓模拟器的代理IP设置为电脑的IP。现在模拟器的所有网络请求都是通过fidder获取的。现在我们只想抓到数据包,分析数据包,推荐一个分析json包的url,可以清晰的展示复杂难懂的数据段。模拟器刷到抖音json数据包的时候,我会一个一个复制过来看看。网址在图片中。.


下一步是想办法保存这个数据包。关键点是修改fiddler函数。fidder工具在做爬虫和插件的时候经常用到。我特地学会了这个提琴手的用法。修改fiiderscript,这个收录用户信息的json数据包的请求url和host是一样的,使用这个修改后的函数保存到本地文件夹。

fidder函数保存到本地的数据只能覆盖不能添加,所以只能通过脚本循环读取,所以用python写一个脚本,解析读取的数据,保存到本地数据库。

现在是最后一步,编写一个脚本来模拟手动滑动抖音。由于你用的是模拟器,如果要多开几个,保存数据会比较快,所以就写一个分辨率最小的。320*480分辨率,节省资源,抓取用户信息进入个人主页。思路是在抖音中向上滑动识别是广告还是直播,是广告然后往下,而不是点击头像,延迟返回,然后循环。打包成apk安装到模拟器上进行真机测试!速度还不错。继续优化脚本,设置清缓存功能。如果缓存太多,就会很卡。


其实抓包的过程中还有很多有趣的事情,比如抓包没有水印的视频链接,可以采集,哈哈。还有一些细节,没有写清楚。如果您有任何问题,您可以留言,我会认真回答。
最终附件代码包百度云链接:密码:hzn5。
此贴也发在My Love Cracked上,标题相同,以后可能会同步。
网页视频抓取脚本(网络爬虫(ComputerRobot)(又被称为网页蜘蛛))
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-26 23:19
网络爬虫
计算机机器人(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常称为网络追逐者),是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
背景
随着网络的飞速发展,万维网已经成为大量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。搜索引擎(Search Engine),如传统的通用搜索引擎AltaVista、Yahoo!而谷歌等作为帮助人们检索信息的工具,已经成为用户访问万维网的门户和指南。但是,这些通用搜索引擎也有一定的局限性,例如:
(1)不同领域和背景的用户往往检索目的和需求不同,一般搜索引擎返回的结果中收录大量用户不关心的网页。
(2)一般搜索引擎的目标是最大化网络覆盖,有限的搜索引擎服务器资源和无限的网络数据资源之间的冲突将进一步加深。
(3)万维网数据形式的丰富和网络技术的不断发展,催生了图片、数据库、音频、视频、多媒体等大量不同的数据。一般搜索对于这些信息内容密集、结构一定的数据,引擎往往无能为力。
(4)一般搜索引擎大多提供基于关键词的检索,难以支持基于语义信息的查询。
网络爬虫
为了解决以上问题,定向爬取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一种自动下载网页的程序。它根据给定的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大覆盖,而是旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到系统达到一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。
2 爬取目标描述
现有的焦点爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
爬虫根据目标网页的特征爬取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页类别和类别对应的种子样本,如Yahoo!类别结构等;
(3) 由用户行为决定的抓取目标示例分为:
(a) 在用户浏览过程中显示标记的抓取样本;
(b) 通过用户日志挖掘获取访问模式和相关样本。
网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
技术研究
基于目标数据模式的爬虫针对网页上的数据,抓取到的数据一般都符合一定的模式,或者可以转化或映射成目标数据模式。
另一种描述方式是构建目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
网络搜索策略
网页抓取策略可以分为三种类型:深度优先、广度优先和最佳优先。深度优先在很多情况下会导致爬虫被困的问题。目前,广度优先和最佳优先方法很常见。
广度优先搜索
广度优先搜索策略是指在爬取过程中,完成当前一级搜索后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网页过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,
最好的第一次搜索
最佳优先级搜索策略是根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。在第 4 节中,将结合网页分析算法进行详细讨论。
深度优先搜索
深度优先搜索策略从起始页面开始,选择一个URL进入,分析该页面中的URL,选择一个进入。这样的链接被逐个链接地获取,直到在处理下一个路由之前处理了一个路由。深度优先策略设计相对简单。虽然门户网站 网站 倾向于提供最有价值的链接并具有较高的 PageRank,但页面价值和 PageRank 会随着每个级别的深入而相应降低。这意味着重要的页面通常更靠近种子,而爬得太深的页面价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,而抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
网页分析算法
网页分析算法可以分为三类:基于网络拓扑、基于网页内容和基于用户访问行为。
拓扑分析算法
基于网页之间的链接,通过已知的网页或数据,评估与其有直接或间接链接关系的对象(可以是网页或网站等)的算法。进一步分为三种:网页粒度、网站粒度和网页块粒度。
1 网页粒度分析算法
PageRank 和 HITS 算法是最常见的链接分析算法。两者都是通过网页间链接度的递归归一化计算得到每个网页的重要性。PageRank算法虽然考虑了用户访问行为的随机性和Sink网页的存在性,但忽略了大部分用户访问的目的性,即网页与查询主题链接的相关性。针对这个问题,HITS算法提出了两个关键概念:权威网页(authority)和中心网页(hub)。
基于链接的爬取问题是相关页面的主题组之间存在隧道现象,即爬取路径上很多偏离主题的页面也指向目标页面,局部评价策略中断了爬取行为当前路径。参考文献[21]提出了一种基于反向链接(BackLink)的层次上下文模型(Context Model),用于描述指向一定物理跳半径内的目标网页的网页拓扑图的中心Layer 0作为目标网页。网页根据指向目标网页的物理跳数进行层次划分,外层网页到内层网页的链接称为反向链接。
2 网站粒度分析算法
网站粒度资源发现和管理策略也比网页粒度更简单有效。网站粒度爬取的关键是站点的划分和SiteRank的计算。SiteRank的计算方法与PageRank类似,但需要对网站之间的链接进行一定程度的抽象,并在一定模型下计算链接的权重。
网站划分分为两种:按域名划分和按IP地址划分。参考文献[18]讨论了在分布式情况下,通过划分同一域名下不同主机和服务器的IP地址,构建站点地图,并采用类似于PageRank的方法评估SiteRank。同时,根据每个站点不同文件的分布情况,构建文档图,结合SiteRank分布式计算得到DocRank。参考文献[18]证明,使用分布式SiteRank计算不仅大大降低了单个站点的算法成本,而且克服了单个站点对全网覆盖范围有限的缺点。一个额外的好处是,常见的 PageRank 欺诈很难欺骗 SiteRank。
3 网页块粒度分析算法
一个页面往往收录多个指向其他页面的链接,而这些链接中只有一部分指向与主题相关的网页,或者根据网页的链接锚文本表明其重要性高。但是在PageRank和HITS算法中,这些链接是没有区分的,所以往往会给网页分析带来广告等噪声链接的干扰。页面块级(Block?级)链接分析算法的基本思想是通过VIPS页面分割算法将页面划分为不同的页面块(page blocks),然后创建page?to?block和block?block 用于这些页面块。to?page 的链接矩阵,? 分别表示为 Z 和 X。因此,page-to-page图上的page block level的PageRank为?W?p=X×Z;?Block?to?block 图上的BlockRank 是?W?b=Z×X。
网页分析算法
基于网页内容的分析算法是指利用网页内容的特征(文本、数据等资源)对网页进行评价。网页内容已经从基于超文本的内容演变为动态页面(或称为隐藏网页)数据,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的400~500%。次。另一方面,多媒体数据、Web Service等各种形式的网络资源日益丰富。因此,基于网页内容的分析算法也从最初的相对简单的文本检索方法发展到综合应用包括网页数据提取、机器学习、数据挖掘、语义理解等多种方法。本节根据网页数据的不同形式,基于网页内容的分析算法分为以下三类:第一类是针对以文本和超链接为主的非结构化或非常简单的网页;第二个是结构化网页。对于数据源(如RDBMS)动态生成的页面,不能直接批量访问数据;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。数据不能直接批量访问;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。数据不能直接批量访问;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。
基于文本的网页分析算法
1) 纯文本分类和聚类算法
它在很大程度上借鉴了文本检索的技术。文本分析算法可以快速有效地对网页进行分类和聚类,但很少单独使用,因为它们忽略了网页之间和网页内的结构信息。
2) 超文本分类和聚类算法
根据网页链接的网页的相关类型对网页进行分类,并通过关联的网页推断网页的类型。 查看全部
网页视频抓取脚本(网络爬虫(ComputerRobot)(又被称为网页蜘蛛))
网络爬虫
计算机机器人(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常称为网络追逐者),是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
背景
随着网络的飞速发展,万维网已经成为大量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。搜索引擎(Search Engine),如传统的通用搜索引擎AltaVista、Yahoo!而谷歌等作为帮助人们检索信息的工具,已经成为用户访问万维网的门户和指南。但是,这些通用搜索引擎也有一定的局限性,例如:
(1)不同领域和背景的用户往往检索目的和需求不同,一般搜索引擎返回的结果中收录大量用户不关心的网页。
(2)一般搜索引擎的目标是最大化网络覆盖,有限的搜索引擎服务器资源和无限的网络数据资源之间的冲突将进一步加深。
(3)万维网数据形式的丰富和网络技术的不断发展,催生了图片、数据库、音频、视频、多媒体等大量不同的数据。一般搜索对于这些信息内容密集、结构一定的数据,引擎往往无能为力。
(4)一般搜索引擎大多提供基于关键词的检索,难以支持基于语义信息的查询。
网络爬虫
为了解决以上问题,定向爬取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一种自动下载网页的程序。它根据给定的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大覆盖,而是旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到系统达到一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。

与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。
2 爬取目标描述
现有的焦点爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
爬虫根据目标网页的特征爬取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页类别和类别对应的种子样本,如Yahoo!类别结构等;
(3) 由用户行为决定的抓取目标示例分为:
(a) 在用户浏览过程中显示标记的抓取样本;
(b) 通过用户日志挖掘获取访问模式和相关样本。
网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
技术研究
基于目标数据模式的爬虫针对网页上的数据,抓取到的数据一般都符合一定的模式,或者可以转化或映射成目标数据模式。
另一种描述方式是构建目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
网络搜索策略
网页抓取策略可以分为三种类型:深度优先、广度优先和最佳优先。深度优先在很多情况下会导致爬虫被困的问题。目前,广度优先和最佳优先方法很常见。
广度优先搜索
广度优先搜索策略是指在爬取过程中,完成当前一级搜索后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网页过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,
最好的第一次搜索
最佳优先级搜索策略是根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。在第 4 节中,将结合网页分析算法进行详细讨论。
深度优先搜索
深度优先搜索策略从起始页面开始,选择一个URL进入,分析该页面中的URL,选择一个进入。这样的链接被逐个链接地获取,直到在处理下一个路由之前处理了一个路由。深度优先策略设计相对简单。虽然门户网站 网站 倾向于提供最有价值的链接并具有较高的 PageRank,但页面价值和 PageRank 会随着每个级别的深入而相应降低。这意味着重要的页面通常更靠近种子,而爬得太深的页面价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,而抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
网页分析算法
网页分析算法可以分为三类:基于网络拓扑、基于网页内容和基于用户访问行为。
拓扑分析算法
基于网页之间的链接,通过已知的网页或数据,评估与其有直接或间接链接关系的对象(可以是网页或网站等)的算法。进一步分为三种:网页粒度、网站粒度和网页块粒度。
1 网页粒度分析算法
PageRank 和 HITS 算法是最常见的链接分析算法。两者都是通过网页间链接度的递归归一化计算得到每个网页的重要性。PageRank算法虽然考虑了用户访问行为的随机性和Sink网页的存在性,但忽略了大部分用户访问的目的性,即网页与查询主题链接的相关性。针对这个问题,HITS算法提出了两个关键概念:权威网页(authority)和中心网页(hub)。
基于链接的爬取问题是相关页面的主题组之间存在隧道现象,即爬取路径上很多偏离主题的页面也指向目标页面,局部评价策略中断了爬取行为当前路径。参考文献[21]提出了一种基于反向链接(BackLink)的层次上下文模型(Context Model),用于描述指向一定物理跳半径内的目标网页的网页拓扑图的中心Layer 0作为目标网页。网页根据指向目标网页的物理跳数进行层次划分,外层网页到内层网页的链接称为反向链接。
2 网站粒度分析算法
网站粒度资源发现和管理策略也比网页粒度更简单有效。网站粒度爬取的关键是站点的划分和SiteRank的计算。SiteRank的计算方法与PageRank类似,但需要对网站之间的链接进行一定程度的抽象,并在一定模型下计算链接的权重。
网站划分分为两种:按域名划分和按IP地址划分。参考文献[18]讨论了在分布式情况下,通过划分同一域名下不同主机和服务器的IP地址,构建站点地图,并采用类似于PageRank的方法评估SiteRank。同时,根据每个站点不同文件的分布情况,构建文档图,结合SiteRank分布式计算得到DocRank。参考文献[18]证明,使用分布式SiteRank计算不仅大大降低了单个站点的算法成本,而且克服了单个站点对全网覆盖范围有限的缺点。一个额外的好处是,常见的 PageRank 欺诈很难欺骗 SiteRank。
3 网页块粒度分析算法
一个页面往往收录多个指向其他页面的链接,而这些链接中只有一部分指向与主题相关的网页,或者根据网页的链接锚文本表明其重要性高。但是在PageRank和HITS算法中,这些链接是没有区分的,所以往往会给网页分析带来广告等噪声链接的干扰。页面块级(Block?级)链接分析算法的基本思想是通过VIPS页面分割算法将页面划分为不同的页面块(page blocks),然后创建page?to?block和block?block 用于这些页面块。to?page 的链接矩阵,? 分别表示为 Z 和 X。因此,page-to-page图上的page block level的PageRank为?W?p=X×Z;?Block?to?block 图上的BlockRank 是?W?b=Z×X。
网页分析算法
基于网页内容的分析算法是指利用网页内容的特征(文本、数据等资源)对网页进行评价。网页内容已经从基于超文本的内容演变为动态页面(或称为隐藏网页)数据,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的400~500%。次。另一方面,多媒体数据、Web Service等各种形式的网络资源日益丰富。因此,基于网页内容的分析算法也从最初的相对简单的文本检索方法发展到综合应用包括网页数据提取、机器学习、数据挖掘、语义理解等多种方法。本节根据网页数据的不同形式,基于网页内容的分析算法分为以下三类:第一类是针对以文本和超链接为主的非结构化或非常简单的网页;第二个是结构化网页。对于数据源(如RDBMS)动态生成的页面,不能直接批量访问数据;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。数据不能直接批量访问;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。数据不能直接批量访问;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。
基于文本的网页分析算法
1) 纯文本分类和聚类算法
它在很大程度上借鉴了文本检索的技术。文本分析算法可以快速有效地对网页进行分类和聚类,但很少单独使用,因为它们忽略了网页之间和网页内的结构信息。
2) 超文本分类和聚类算法
根据网页链接的网页的相关类型对网页进行分类,并通过关联的网页推断网页的类型。
网页视频抓取脚本(配置文件技术点puppeteer官方APIpuppeteer提供一个高级API来控制Chrome或者Chromium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-26 02:03
介绍
批量爬取视频或图片的一般套路是使用爬虫获取一组文件链接,然后通过writeFile等方法将文件一个一个保存。但是,头条的视频无法捕捉到需要爬取的html文件(服务器端渲染输出)中的视频链接。视频链接是在客户端渲染页面时,通过一些js文件中的算法或解密方法,根据视频的已知key或hash值,动态计算并添加到video标签中的。这也是网站的防爬措施。
当我们浏览这些页面时,我们可以通过审计元素看到计算出来的文件地址。但是,在批量下载的时候,手动一个一个的获取视频链接显然是不可取的。令人高兴的是,puppeteer 提供了模拟访问 Chrome 的能力,允许我们抓取浏览器呈现的最终页面。
项目开始
命令
npm i
npm start
注意:安装puppeteer的过程有点慢,请耐心等待。
配置文件
// 配置相关
module.exports = {
originPath: 'https://www.ixigua.com', // 页面请求地址
savePath: 'D:/videoZZ' // 存放路径
}
技术点
傀儡师
官方API
puppeteer 提供了一个高级 API 来控制 Chrome 或 Chromium。
傀儡师的主要作用:
从网页生成 PDF 和图片
抓取 SPA 应用程序并生成预渲染内容(即“SSR”服务器端渲染)
可以从 网站 抓取内容
自动化表单提交、UI 测试、键盘输入等
使用的 API:
puppeteer.launch() 启动浏览器实例
browser.newPage() 创建一个新页面
page.goto() 转到指定网页
page.screenshot() 截图
page.waitFor() 页面等待,可以是时间,一个元素,一个函数
page.$eval() 获取指定元素,相当于 document.querySelector
page.$$eval() 获取某种类型的元素,相当于 document.querySelectorAll
page.$('#id .className') 获取文档中的一个元素,类似于jQuery
代码示例
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
视频文件下载方法
下载视频大师方法
const downloadVideo = async video => {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.src, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
获取视频数据
getVideoData (url, encoding) {
return new Promise((resolve, reject) => {
let req = http.get(url, function (res) {
let result = ''
encoding && res.setEncoding(encoding)
res.on('data', function (d) {
result += d
})
res.on('end', function () {
resolve(result)
})
res.on('error', function (e) {
reject(e)
})
})
req.end()
})
}
将视频数据保存到本地
savefileToPath (fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
目标网站:西瓜视频
项目功能:下载标题下的最新20个视频【微臣财经】
项目地址:Github地址 查看全部
网页视频抓取脚本(配置文件技术点puppeteer官方APIpuppeteer提供一个高级API来控制Chrome或者Chromium)
介绍
批量爬取视频或图片的一般套路是使用爬虫获取一组文件链接,然后通过writeFile等方法将文件一个一个保存。但是,头条的视频无法捕捉到需要爬取的html文件(服务器端渲染输出)中的视频链接。视频链接是在客户端渲染页面时,通过一些js文件中的算法或解密方法,根据视频的已知key或hash值,动态计算并添加到video标签中的。这也是网站的防爬措施。
当我们浏览这些页面时,我们可以通过审计元素看到计算出来的文件地址。但是,在批量下载的时候,手动一个一个的获取视频链接显然是不可取的。令人高兴的是,puppeteer 提供了模拟访问 Chrome 的能力,允许我们抓取浏览器呈现的最终页面。
项目开始
命令
npm i
npm start
注意:安装puppeteer的过程有点慢,请耐心等待。
配置文件
// 配置相关
module.exports = {
originPath: 'https://www.ixigua.com', // 页面请求地址
savePath: 'D:/videoZZ' // 存放路径
}
技术点
傀儡师
官方API
puppeteer 提供了一个高级 API 来控制 Chrome 或 Chromium。
傀儡师的主要作用:
从网页生成 PDF 和图片
抓取 SPA 应用程序并生成预渲染内容(即“SSR”服务器端渲染)
可以从 网站 抓取内容
自动化表单提交、UI 测试、键盘输入等
使用的 API:
puppeteer.launch() 启动浏览器实例
browser.newPage() 创建一个新页面
page.goto() 转到指定网页
page.screenshot() 截图
page.waitFor() 页面等待,可以是时间,一个元素,一个函数
page.$eval() 获取指定元素,相当于 document.querySelector
page.$$eval() 获取某种类型的元素,相当于 document.querySelectorAll
page.$('#id .className') 获取文档中的一个元素,类似于jQuery
代码示例
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
视频文件下载方法
下载视频大师方法
const downloadVideo = async video => {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.src, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
获取视频数据
getVideoData (url, encoding) {
return new Promise((resolve, reject) => {
let req = http.get(url, function (res) {
let result = ''
encoding && res.setEncoding(encoding)
res.on('data', function (d) {
result += d
})
res.on('end', function () {
resolve(result)
})
res.on('error', function (e) {
reject(e)
})
})
req.end()
})
}
将视频数据保存到本地
savefileToPath (fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
目标网站:西瓜视频
项目功能:下载标题下的最新20个视频【微臣财经】
项目地址:Github地址
网页视频抓取脚本( Android手机上的抖音爬取抖音视频内容怎么扩展?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-26 01:22
Android手机上的抖音爬取抖音视频内容怎么扩展?(图))
python爬取抖音视频实例分析
更新时间:2021年1月19日11:40:00 作者:十一
本文中,小编将整理一篇关于python爬取抖音视频案例分析的文章。有兴趣的朋友可以测试一下案例内容。
现在抖音的流行有目共睹。之前小编在网上找到有趣的东西,就是爬了一些网站,所以也考虑过要不要进行
@k8@上解决的案例,经过实际操作,真的实现了。使用自动化工具,可以轻松实现。后来有小伙伴提出,去除appium减肥后也可以实现。然后看详细操作。内容。
1、mitmproxy/mitmdump 捕获
import requests
path = 'D:/video/'
num = 1788
def response(flow):
global num
target_urls = ['url']
for url in target_urls:
if flow.request.url.startswith(url):
filename = path + str(num) + '.mp4
res = requests.get(flow.request.url, stream=True)
with open(filename, 'ab') as f:
f.write(res.content)
f.flush()
print(filename + '下载完成')
num += 1
2、Appium模拟手机操作
使用启动服务器按钮启动appium服务
再次点击Start Session,在Android手机上启动抖音app,进入启动页面
3、python脚本驱动app,直接在pycharm中运行即可
实例扩展:
import requests
import json
import re
import os
from pprint import pprint as pp
import queue
class DouYin:
header = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
}
def __init__(self, url=None):
self.url = self.get_RealAddress(url)
# 获取用户视频的url
self.user_video_url = 'https://www.douyin.com/aweme/v1/aweme/post/?{0}'
self.user_id = re.search(r'user/(.*)\?', self.url).group(1) # 用户id
requests.packages.urllib3.disable_warnings()
self.session = requests.Session()
self.target_folder = '' # 创建文件的路径
self.queue = queue.Queue() # 生成一个队列对象
def user_info(self):
self.mkdir_dir()
p = os.popen('node fuck.js %s' % self.user_id) # 获取加密的signature
signature = p.readlines()[0]
user_video_params = {
'user_id': str(self.user_id),
'count': '21',
'max_cursor': '0',
'aid': '1128',
'_signature': signature
}
# 获取下载视频的列表
def get_aweme_list(max_cursor=None):
if max_cursor:
user_video_params['max_cursor'] = str(max_cursor)
user_video_url = self.user_video_url.format(
'&'.join([key + '=' + user_video_params[key] for key in user_video_params])) # 拼接参数
response = requests.get(
url=user_video_url, headers=self.header, verify=False)
contentJson = json.loads(response.content.decode('utf-8')) # 将返回的进行utf8编码
aweme_list = contentJson.get('aweme_list', [])
for aweme in aweme_list:
video_name = aweme.get(
'share_info', None).get('share_desc', None) # 视频的名字
video_url = aweme.get('video', None).get('play_addr', None).get(
'url_list', None)[0].replace('playwm', 'play') # 视频链接
self.queue.put((video_name, video_url)) # 将数据进队列
if contentJson.get('has_more') == 1: # 判断后面是不是还有是1就是还有
return get_aweme_list(contentJson.get('max_cursor')) # 有的话获取参数max_cursor
get_aweme_list()
# 下载视频
def get_download(self):
while True:
video_name, video_url = self.queue.get()
file_name = video_name + '.mp4'
file_path = os.path.join(self.target_folder, file_name)
if not os.path.isfile(file_path):
print('download %s form %s.\n' % (file_name, video_url))
times = 0
while times < 10:
try:
response = requests.get(
url=video_url, stream=True, timeout=10, verify=False) # 开启流下载
with open(file_path, 'wb') as f:
for chunk in response.iter_content(1024): # 返回迭代对象
f.write(chunk)
print('下载成功')
break
except:
print('下载失败')
times += 1
# 创建对应的文件夹
def mkdir_dir(self):
current_folder = os.getcwd()
self.target_folder = os.path.join(
current_folder, 'download/%s' % self.user_id)
if not os.path.isdir(self.target_folder):
os.mkdir(self.target_folder)
# 短链接转长地址
def get_RealAddress(self, url):
if url.find('v.douyin.com') < 0:
return url
response = requests.get(
url=url, headers=self.header, allow_redirects=False) # allow_redirects 允许跳转
return response.headers['Location']
if __name__ == '__main__':
douyin = DouYin(url='http://v.douyin.com/J2B9Sk/')
douyin.user_info()
douyin.get_download()
这里是本文文章关于python爬取抖音视频实例分析的介绍。更多关于如何使用python爬取抖音视频内容,请搜索之前文章的脚本首页或继续浏览以下相关文章希望大家支持脚本未来的家! 查看全部
网页视频抓取脚本(
Android手机上的抖音爬取抖音视频内容怎么扩展?(图))
python爬取抖音视频实例分析
更新时间:2021年1月19日11:40:00 作者:十一
本文中,小编将整理一篇关于python爬取抖音视频案例分析的文章。有兴趣的朋友可以测试一下案例内容。
现在抖音的流行有目共睹。之前小编在网上找到有趣的东西,就是爬了一些网站,所以也考虑过要不要进行
@k8@上解决的案例,经过实际操作,真的实现了。使用自动化工具,可以轻松实现。后来有小伙伴提出,去除appium减肥后也可以实现。然后看详细操作。内容。
1、mitmproxy/mitmdump 捕获
import requests
path = 'D:/video/'
num = 1788
def response(flow):
global num
target_urls = ['url']
for url in target_urls:
if flow.request.url.startswith(url):
filename = path + str(num) + '.mp4
res = requests.get(flow.request.url, stream=True)
with open(filename, 'ab') as f:
f.write(res.content)
f.flush()
print(filename + '下载完成')
num += 1
2、Appium模拟手机操作
使用启动服务器按钮启动appium服务

再次点击Start Session,在Android手机上启动抖音app,进入启动页面
3、python脚本驱动app,直接在pycharm中运行即可
实例扩展:
import requests
import json
import re
import os
from pprint import pprint as pp
import queue
class DouYin:
header = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
}
def __init__(self, url=None):
self.url = self.get_RealAddress(url)
# 获取用户视频的url
self.user_video_url = 'https://www.douyin.com/aweme/v1/aweme/post/?{0}'
self.user_id = re.search(r'user/(.*)\?', self.url).group(1) # 用户id
requests.packages.urllib3.disable_warnings()
self.session = requests.Session()
self.target_folder = '' # 创建文件的路径
self.queue = queue.Queue() # 生成一个队列对象
def user_info(self):
self.mkdir_dir()
p = os.popen('node fuck.js %s' % self.user_id) # 获取加密的signature
signature = p.readlines()[0]
user_video_params = {
'user_id': str(self.user_id),
'count': '21',
'max_cursor': '0',
'aid': '1128',
'_signature': signature
}
# 获取下载视频的列表
def get_aweme_list(max_cursor=None):
if max_cursor:
user_video_params['max_cursor'] = str(max_cursor)
user_video_url = self.user_video_url.format(
'&'.join([key + '=' + user_video_params[key] for key in user_video_params])) # 拼接参数
response = requests.get(
url=user_video_url, headers=self.header, verify=False)
contentJson = json.loads(response.content.decode('utf-8')) # 将返回的进行utf8编码
aweme_list = contentJson.get('aweme_list', [])
for aweme in aweme_list:
video_name = aweme.get(
'share_info', None).get('share_desc', None) # 视频的名字
video_url = aweme.get('video', None).get('play_addr', None).get(
'url_list', None)[0].replace('playwm', 'play') # 视频链接
self.queue.put((video_name, video_url)) # 将数据进队列
if contentJson.get('has_more') == 1: # 判断后面是不是还有是1就是还有
return get_aweme_list(contentJson.get('max_cursor')) # 有的话获取参数max_cursor
get_aweme_list()
# 下载视频
def get_download(self):
while True:
video_name, video_url = self.queue.get()
file_name = video_name + '.mp4'
file_path = os.path.join(self.target_folder, file_name)
if not os.path.isfile(file_path):
print('download %s form %s.\n' % (file_name, video_url))
times = 0
while times < 10:
try:
response = requests.get(
url=video_url, stream=True, timeout=10, verify=False) # 开启流下载
with open(file_path, 'wb') as f:
for chunk in response.iter_content(1024): # 返回迭代对象
f.write(chunk)
print('下载成功')
break
except:
print('下载失败')
times += 1
# 创建对应的文件夹
def mkdir_dir(self):
current_folder = os.getcwd()
self.target_folder = os.path.join(
current_folder, 'download/%s' % self.user_id)
if not os.path.isdir(self.target_folder):
os.mkdir(self.target_folder)
# 短链接转长地址
def get_RealAddress(self, url):
if url.find('v.douyin.com') < 0:
return url
response = requests.get(
url=url, headers=self.header, allow_redirects=False) # allow_redirects 允许跳转
return response.headers['Location']
if __name__ == '__main__':
douyin = DouYin(url='http://v.douyin.com/J2B9Sk/')
douyin.user_info()
douyin.get_download()
这里是本文文章关于python爬取抖音视频实例分析的介绍。更多关于如何使用python爬取抖音视频内容,请搜索之前文章的脚本首页或继续浏览以下相关文章希望大家支持脚本未来的家!
网页视频抓取脚本(新手学习Python爬虫之Request和beautifulsoup和beautiful爬了最简单的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-19 19:05
初学者学习Python爬虫的Request和beautifulsoup
创建时间:2020 年 4 月 13 日下午 2:45
学习了爬虫的基本原理,使用request和美汤爬取了最简单的网页。为了巩固所学,我写了一个总结:
首先说一下我现在可以爬取的这些页面的基本特征:
在网络中,所有需要爬取的内容都可以在文档类型文档的请求响应中找到。无需登录等POST操作即可获取所需信息
这类网页的爬取方式非常规整,变化不大。总结起来,这些步骤是:
使用请求库发送请求并获取响应,即网页源码使用解析库(我使用BeautifulSoup)按需解析网页,获取我们需要的信息,并将信息保存在我们需要的格式。详细方法说明
建议用下面的代码吃
首先打开Network,清空response,刷新Network,找到Type为document的response。这是网页的源代码。点击Headers,复制User-Agent写在header中(具体操作见下面代码),并告诉网站访问者请求的工具,让网站不认为我们正在抓取,但使用浏览器访问。点击Response,在源码中搜索我们要查找的部分,了解它们对应的DOM结构是什么。(关于DOM的就不写了,可以自行搜索) 编写请求函数,获取网页源码,根据网页源码的DOM结构和我们提供的信息按需解析需要。
放上代码,然后说说每段代码对应的特征部分:
批量下载图片
网址:
我之所以爬足网,是因为原作者版权原因,足网有些作品是禁止保存的。简单的方法就是在浏览器中查看元素找到对应的链接,点击一个一个保存,但是这样太麻烦了,所以想写一个方法,可以通过输入的URL快速批量保存站酷帖详情页。
脚本使用方法:修改URL链接后运行,图片会批量保存
使用效果图:
本站酷网结构非常整齐,所以很容易找到图片url的位置,也很容易保存
缺点是这是编写的第一段代码。当时对这两个库的理解还不深入,代码结构写的很烂。
from bs4 import BeautifulSoup
import requests
URL = 'https://www.zcool.com.cn/work/ZNDQyNTQ1OTI=.html'
html = requests.get(URL).text
soup = BeautifulSoup(html)
img_ul = soup.find_all('div', {"class": "reveal-work-wrap"})
print(type(img_ul))
for ul in img_ul:
imgs = ul.find_all('img')
for img in imgs:
url = img['src']
r = requests.get(url,stream='True')
image_name = url.split('/')[-1]
with open('./img/%s' % image_name, 'wb') as f:
for chunk in r.iter_content(chunk_size=128):
f.write(chunk)
print('Saved %s' % image_name)
抢微博热搜
网址:
这是我在教程中看到的,教你抓猫眼的电影。本来想写的,现在猫眼电影需要验证码。我不是很擅长,所以我把微博热搜改成爬取了
该脚本不会将输出写入文件,只是输出到控制台先看看效果:
这次写的时候,我学会了更模块化地定义每个函数。虽然我觉得自己写C/C++的时候模块化做得很好,但是感觉python是一门非常繁荣和浮躁的脚本语言,所以一开始总是很难停下来思考如何模块化。
思路也很简单,请求网页写成函数,解析网页写成函数。
在解析网页的时候,在写微博热搜的时候遇到了一个问题,包括下面两段代码,就是不知道soup中的一些方法使用后返回值是什么。我的解决方法是经常使用 **type()** 函数来查看变量类型。
import requests
from bs4 import BeautifulSoup
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def find_hot(html):
soup = BeautifulSoup(html, "html.parser")
hot_text1 = soup.find_all('td')
list = []
for i in hot_text1:
text_all = i.find_all('a', {'target': "_blank"})
if text_all != []:
list.append(text_all)
return list
def split(list):
i = 0
for item in list:
i += 1
print(i, item[0].string)
def main():
url = 'https://s.weibo.com/top/summary/'
html = get_one_page(url)
list = find_hot(html)
split(list)
main()
获取油猴脚本以及每个脚本的每日安装次数和总安装次数,并保存为csv文件
网址:
我主要想尝试使用此脚本捕获多条信息。一开始我没想到会抓到任何东西,所以我在我的采集夹文件夹中看到了油猴脚本。这个网站不仅是信息列表的形式,还有很多维度的信息。适合练习。
我从这个信息中选择了title + today's installs + total installs 抓取,抓取效果保存在一个csv文件中:
这个脚本更详细一点:
这是我从源码中复制的一段,对应第一个油猴脚本的信息:
懒人专用,全网VIP视频免费破解去广告、全网音乐直接下载、百度网盘直接下载、知乎视频下载等多合一版。长期更新,放心使用。
-
自用组合型多功能脚本,集合了优酷、爱奇艺、腾讯、芒果等全网VIP视频免费破解去广告,网易云音乐、QQ音乐、酷狗、酷我、虾米、蜻蜓FM、荔枝FM、喜马拉雅等网站音乐免客户端下载,百度网盘直接下载,知乎视频下载,优惠券查询等几个自己常用的功能。
作者
懒蛤蛤
今日安装
8,167
总安装量
1,723,254
得分
1868
20
10
创建日期
2018-07-27
最近更新
2020-04-08
可以看到标题在li标签的data-script-name属性下,所以我们先用find_all()查找所有li标签。
接下来我们可以通过get在这些li标签下找到data-script-name的所有值,也就是脚本的标题
值得一提的是,用 find_all() 得到的结果是一个结果集。如果要继续使用soup中的方法,需要方便set中的元素使用这些方法。
另外,在保存中文到csv时,如果不使用encoding='utf_8_sig',用excel打开文件时会出现乱码。
import requests
import csv
from bs4 import BeautifulSoup
url = 'https://greasyfork.org/zh-CN/scripts'
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def find_name(response):
soup = BeautifulSoup(response, "html.parser")
info = soup.find_all('li')
list = []
with open('data.csv', 'w', encoding='utf_8_sig') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['text', 'daily_install', 'total_instal'])
# print(info)
for i in info:
name = i.get('data-script-name')
daily_install = i.get('data-script-daily-installs')
tot_install = i.get('data-script-total-installs')
if (name):
writer.writerow([name, daily_install, tot_install])
templist = [name, daily_install, tot_install]
print(templist)
list.append(templist)
return list
def main():
response = get_one_page(url)
soup = find_name(response)
# print(soup)
main()
获取 GitHub TrendingList 的仓库名称、Star 号和 Fork 号并保存到 csv 文件
网址:
GitHub TrendingList 类似之前的油猴脚本爬取。抓住这个的灵感来自一个给我发电子邮件说我在 GitHub 上抓住了我的信息的人,我也想抓住这些大家伙的存储库。
捕获的结果也保存在 csv 文件中:
这次在解析完网页后,写了三个函数来提取它们的仓库名、星号、分叉号,然后将三列合并到csv文件中。这种方式的缺点是需要保证三个数组的长度相等,并且可以通过一一对应的方式保证数据的正确性。但是网页的结构肯定会保证这一点,而且似乎没有任何问题。
因为我对正则表达式不是很精通,所以写的代码效率比较低。初学者会看看它。
值得一提的是,Star和Fork的数量除了对应的svg是一样的,所以我只能用最好的策略,分别写在两个函数里,然后提取父节点的文本,效率相对低的。.
import requests
import csv
from bs4 import BeautifulSoup
url = 'https://github.com/trending'
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def find_name(soup):
namelist = []
h1 = soup.find_all('h1')
for e_h1 in h1:
a = e_h1.find_all('a')
for e_a in a:
name = e_a.get_text().replace('\n', '').replace(' ', '')
namelist.append(name)
return namelist
def find_star(soup):
star = []
star_fork = soup.find_all('a', {'class': 'muted-link'})
for e_s_f in star_fork:
e_star = e_s_f.find('svg', {'aria-label': 'star'})
if e_star:
e_star = e_star.find_parent().get_text().replace('\n', '').replace(' ', '')
star.append(e_star)
return star
def find_fork(soup):
fork = []
star_fork = soup.find_all('a', {'class': 'muted-link'})
for e_s_f in star_fork:
e_fork = e_s_f.find('svg', {'aria-label': 'fork'})
if e_fork:
e_star = e_fork.find_parent().get_text().replace('\n', '').replace(' ', '')
fork.append(e_star)
return fork
def main():
response = get_one_page(url)
soup = BeautifulSoup(response, "html.parser")
namelist = find_name(soup)
star = find_star(soup)
fork = find_fork(soup)
print(len(namelist), len(star), len(fork))
rows = zip(namelist, star, fork)
with open('github.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['Developer/Repo', 'Star', 'Fork'])
for row in rows:
writer.writerow(row)
main()
第一次写教程文章,大部分是根据自己的理解写的。有些表达在书本上肯定不好理解,所以我应该记录下自己的学习。 查看全部
网页视频抓取脚本(新手学习Python爬虫之Request和beautifulsoup和beautiful爬了最简单的网页)
初学者学习Python爬虫的Request和beautifulsoup
创建时间:2020 年 4 月 13 日下午 2:45
学习了爬虫的基本原理,使用request和美汤爬取了最简单的网页。为了巩固所学,我写了一个总结:
首先说一下我现在可以爬取的这些页面的基本特征:
在网络中,所有需要爬取的内容都可以在文档类型文档的请求响应中找到。无需登录等POST操作即可获取所需信息
这类网页的爬取方式非常规整,变化不大。总结起来,这些步骤是:
使用请求库发送请求并获取响应,即网页源码使用解析库(我使用BeautifulSoup)按需解析网页,获取我们需要的信息,并将信息保存在我们需要的格式。详细方法说明
建议用下面的代码吃
首先打开Network,清空response,刷新Network,找到Type为document的response。这是网页的源代码。点击Headers,复制User-Agent写在header中(具体操作见下面代码),并告诉网站访问者请求的工具,让网站不认为我们正在抓取,但使用浏览器访问。点击Response,在源码中搜索我们要查找的部分,了解它们对应的DOM结构是什么。(关于DOM的就不写了,可以自行搜索) 编写请求函数,获取网页源码,根据网页源码的DOM结构和我们提供的信息按需解析需要。
放上代码,然后说说每段代码对应的特征部分:
批量下载图片
网址:
我之所以爬足网,是因为原作者版权原因,足网有些作品是禁止保存的。简单的方法就是在浏览器中查看元素找到对应的链接,点击一个一个保存,但是这样太麻烦了,所以想写一个方法,可以通过输入的URL快速批量保存站酷帖详情页。
脚本使用方法:修改URL链接后运行,图片会批量保存
使用效果图:
(Untitled/Untitled.png)])
本站酷网结构非常整齐,所以很容易找到图片url的位置,也很容易保存
缺点是这是编写的第一段代码。当时对这两个库的理解还不深入,代码结构写的很烂。
from bs4 import BeautifulSoup
import requests
URL = 'https://www.zcool.com.cn/work/ZNDQyNTQ1OTI=.html'
html = requests.get(URL).text
soup = BeautifulSoup(html)
img_ul = soup.find_all('div', {"class": "reveal-work-wrap"})
print(type(img_ul))
for ul in img_ul:
imgs = ul.find_all('img')
for img in imgs:
url = img['src']
r = requests.get(url,stream='True')
image_name = url.split('/')[-1]
with open('./img/%s' % image_name, 'wb') as f:
for chunk in r.iter_content(chunk_size=128):
f.write(chunk)
print('Saved %s' % image_name)
抢微博热搜
网址:
这是我在教程中看到的,教你抓猫眼的电影。本来想写的,现在猫眼电影需要验证码。我不是很擅长,所以我把微博热搜改成爬取了
该脚本不会将输出写入文件,只是输出到控制台先看看效果:


这次写的时候,我学会了更模块化地定义每个函数。虽然我觉得自己写C/C++的时候模块化做得很好,但是感觉python是一门非常繁荣和浮躁的脚本语言,所以一开始总是很难停下来思考如何模块化。
思路也很简单,请求网页写成函数,解析网页写成函数。
在解析网页的时候,在写微博热搜的时候遇到了一个问题,包括下面两段代码,就是不知道soup中的一些方法使用后返回值是什么。我的解决方法是经常使用 **type()** 函数来查看变量类型。
import requests
from bs4 import BeautifulSoup
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def find_hot(html):
soup = BeautifulSoup(html, "html.parser")
hot_text1 = soup.find_all('td')
list = []
for i in hot_text1:
text_all = i.find_all('a', {'target': "_blank"})
if text_all != []:
list.append(text_all)
return list
def split(list):
i = 0
for item in list:
i += 1
print(i, item[0].string)
def main():
url = 'https://s.weibo.com/top/summary/'
html = get_one_page(url)
list = find_hot(html)
split(list)
main()
获取油猴脚本以及每个脚本的每日安装次数和总安装次数,并保存为csv文件
网址:
我主要想尝试使用此脚本捕获多条信息。一开始我没想到会抓到任何东西,所以我在我的采集夹文件夹中看到了油猴脚本。这个网站不仅是信息列表的形式,还有很多维度的信息。适合练习。
我从这个信息中选择了title + today's installs + total installs 抓取,抓取效果保存在一个csv文件中:
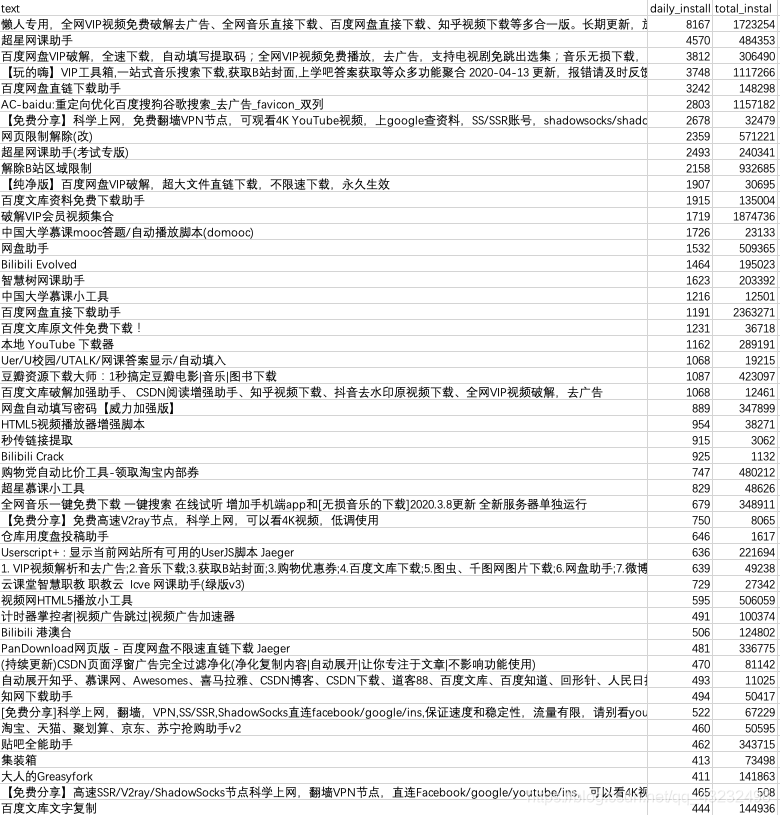
这个脚本更详细一点:
这是我从源码中复制的一段,对应第一个油猴脚本的信息:

懒人专用,全网VIP视频免费破解去广告、全网音乐直接下载、百度网盘直接下载、知乎视频下载等多合一版。长期更新,放心使用。
-
自用组合型多功能脚本,集合了优酷、爱奇艺、腾讯、芒果等全网VIP视频免费破解去广告,网易云音乐、QQ音乐、酷狗、酷我、虾米、蜻蜓FM、荔枝FM、喜马拉雅等网站音乐免客户端下载,百度网盘直接下载,知乎视频下载,优惠券查询等几个自己常用的功能。
作者
懒蛤蛤
今日安装
8,167
总安装量
1,723,254
得分
1868
20
10
创建日期
2018-07-27
最近更新
2020-04-08
可以看到标题在li标签的data-script-name属性下,所以我们先用find_all()查找所有li标签。
接下来我们可以通过get在这些li标签下找到data-script-name的所有值,也就是脚本的标题
值得一提的是,用 find_all() 得到的结果是一个结果集。如果要继续使用soup中的方法,需要方便set中的元素使用这些方法。
另外,在保存中文到csv时,如果不使用encoding='utf_8_sig',用excel打开文件时会出现乱码。
import requests
import csv
from bs4 import BeautifulSoup
url = 'https://greasyfork.org/zh-CN/scripts'
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def find_name(response):
soup = BeautifulSoup(response, "html.parser")
info = soup.find_all('li')
list = []
with open('data.csv', 'w', encoding='utf_8_sig') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['text', 'daily_install', 'total_instal'])
# print(info)
for i in info:
name = i.get('data-script-name')
daily_install = i.get('data-script-daily-installs')
tot_install = i.get('data-script-total-installs')
if (name):
writer.writerow([name, daily_install, tot_install])
templist = [name, daily_install, tot_install]
print(templist)
list.append(templist)
return list
def main():
response = get_one_page(url)
soup = find_name(response)
# print(soup)
main()
获取 GitHub TrendingList 的仓库名称、Star 号和 Fork 号并保存到 csv 文件
网址:
GitHub TrendingList 类似之前的油猴脚本爬取。抓住这个的灵感来自一个给我发电子邮件说我在 GitHub 上抓住了我的信息的人,我也想抓住这些大家伙的存储库。
捕获的结果也保存在 csv 文件中:
这次在解析完网页后,写了三个函数来提取它们的仓库名、星号、分叉号,然后将三列合并到csv文件中。这种方式的缺点是需要保证三个数组的长度相等,并且可以通过一一对应的方式保证数据的正确性。但是网页的结构肯定会保证这一点,而且似乎没有任何问题。
因为我对正则表达式不是很精通,所以写的代码效率比较低。初学者会看看它。
值得一提的是,Star和Fork的数量除了对应的svg是一样的,所以我只能用最好的策略,分别写在两个函数里,然后提取父节点的文本,效率相对低的。.
import requests
import csv
from bs4 import BeautifulSoup
url = 'https://github.com/trending'
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def find_name(soup):
namelist = []
h1 = soup.find_all('h1')
for e_h1 in h1:
a = e_h1.find_all('a')
for e_a in a:
name = e_a.get_text().replace('\n', '').replace(' ', '')
namelist.append(name)
return namelist
def find_star(soup):
star = []
star_fork = soup.find_all('a', {'class': 'muted-link'})
for e_s_f in star_fork:
e_star = e_s_f.find('svg', {'aria-label': 'star'})
if e_star:
e_star = e_star.find_parent().get_text().replace('\n', '').replace(' ', '')
star.append(e_star)
return star
def find_fork(soup):
fork = []
star_fork = soup.find_all('a', {'class': 'muted-link'})
for e_s_f in star_fork:
e_fork = e_s_f.find('svg', {'aria-label': 'fork'})
if e_fork:
e_star = e_fork.find_parent().get_text().replace('\n', '').replace(' ', '')
fork.append(e_star)
return fork
def main():
response = get_one_page(url)
soup = BeautifulSoup(response, "html.parser")
namelist = find_name(soup)
star = find_star(soup)
fork = find_fork(soup)
print(len(namelist), len(star), len(fork))
rows = zip(namelist, star, fork)
with open('github.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['Developer/Repo', 'Star', 'Fork'])
for row in rows:
writer.writerow(row)
main()
第一次写教程文章,大部分是根据自己的理解写的。有些表达在书本上肯定不好理解,所以我应该记录下自己的学习。
网页视频抓取脚本(百度网盘秒传链接提取插件怎么用?盘分享链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2022-01-16 16:14
百度网盘妙传链接提取插件是专门为提高百度网盘分享链接效率而开发的脚本。与普通网盘分享码相比,秒传链接的优势在于不需要分享者和分享链接。直接共享文件以确保帐户安全。即使分享者删除了自己网盘中的源文件,也可以通过第二个链接保存文件。原因是文件已经存储在百度云服务器中,分享者只删除自己对文件的“权限”操作,不影响“真正授权”(如百度云服务器等)访问文件。
【安装注意事项】
百度网盘妙传脚本是基于油猴插件运行的,所以如果要使用妙传,必须在浏览器上安装油猴插件。
下载 == "Tampermonkey 插件
安装插件后,打开 Tampermonkey 并单击 Add New Script。然后将第二个链接解压出来的.user.js文件拖拽到浏览器中,直到代码框出现代码,然后点击【文件】-【保存】。
保存后在插件管理器中出现脚本信息,说明安装成功。
【如何秒用代码】
1、打开拨号网页版,点击菜单栏上的【第二个链接】按钮,在弹窗中输入获取到的即时链接。
2、识别成功后会弹出提示输入对应的保存路径。如果不填写,默认保存在根目录下。
3、最后会显示传输结果,成功后可以查看文件。
【什么是二次通过?】
拨秒传输链路(标准提取码)由128位(32个十六进制数)+#+128位(32个十六进制数)+#+一段数字+#+文件名组成。
比如下面的链接:
47D112C767B8C69654023864897FDC3A#BF65AC1063E511DAB0C5E24EB03C3FDB#1373350#
妻子发电机.apk
由上可知,标准提取码与存储文件的文件内容、文件大小和文件名有关
理论上,存储在百度网盘中的文件只有一个对应的标准提取码,也就是说,即使有一百万个用户通过分享或上传等各种方式存储了同一个文件(即他们有相同的标准提取码)代码),这个文件实际上只存储了一份副本在百度云中。 查看全部
网页视频抓取脚本(百度网盘秒传链接提取插件怎么用?盘分享链接)
百度网盘妙传链接提取插件是专门为提高百度网盘分享链接效率而开发的脚本。与普通网盘分享码相比,秒传链接的优势在于不需要分享者和分享链接。直接共享文件以确保帐户安全。即使分享者删除了自己网盘中的源文件,也可以通过第二个链接保存文件。原因是文件已经存储在百度云服务器中,分享者只删除自己对文件的“权限”操作,不影响“真正授权”(如百度云服务器等)访问文件。

【安装注意事项】
百度网盘妙传脚本是基于油猴插件运行的,所以如果要使用妙传,必须在浏览器上安装油猴插件。
下载 == "Tampermonkey 插件
安装插件后,打开 Tampermonkey 并单击 Add New Script。然后将第二个链接解压出来的.user.js文件拖拽到浏览器中,直到代码框出现代码,然后点击【文件】-【保存】。

保存后在插件管理器中出现脚本信息,说明安装成功。

【如何秒用代码】
1、打开拨号网页版,点击菜单栏上的【第二个链接】按钮,在弹窗中输入获取到的即时链接。

2、识别成功后会弹出提示输入对应的保存路径。如果不填写,默认保存在根目录下。

3、最后会显示传输结果,成功后可以查看文件。

【什么是二次通过?】
拨秒传输链路(标准提取码)由128位(32个十六进制数)+#+128位(32个十六进制数)+#+一段数字+#+文件名组成。
比如下面的链接:
47D112C767B8C69654023864897FDC3A#BF65AC1063E511DAB0C5E24EB03C3FDB#1373350#
妻子发电机.apk
由上可知,标准提取码与存储文件的文件内容、文件大小和文件名有关
理论上,存储在百度网盘中的文件只有一个对应的标准提取码,也就是说,即使有一百万个用户通过分享或上传等各种方式存储了同一个文件(即他们有相同的标准提取码)代码),这个文件实际上只存储了一份副本在百度云中。
网页视频抓取脚本(影响蜘蛛抓取的因素有哪些?影响因素是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-15 02:02
)
深度爬取:当蜘蛛发现一个链接时,会沿着链接路径爬到最深的层次,直到不能再爬取,返回原页面爬取下一个链接。
广度爬取:蜘蛛会爬取当前页面链接中的所有页面,然后选择其中一个页面,继续爬取页面中的所有链接。
影响蜘蛛爬行的因素:
1、网站地图
网站地图相当于搜索引擎蜘蛛的爬行路线图。在路线图的引导下,可以大大提高蜘蛛爬取页面的速度。就像去一个陌生的城市一样,你需要一张地图来指引你。
2、404 错误页面
网站维护和内容修改难免会导致死链接。当蜘蛛爬到死链接时,就像进入了没有出口的死胡同。如果网站有很多死链接,没有404页面,在站长工具中查询会发现很多页面爬取错误。404页面的意义在于告诉搜索引擎当前内容不存在,可以按照404页面的链接路径返回首页或查看其他相关内容。蜘蛛深度爬行和广度爬行?
3、导出链接太多
蜘蛛在爬行网站时,有时是按深度爬行,有时是按广度爬行。蜘蛛按广度爬行时,直接沿着出口链接出去,才可以进入最深的页面。,因此,网站 不应该设置太多的导出链接。
4、导入链接太少
入站链接建设遵循以下两个原则:
多元化:您可以注册多个外链发布平台,防止其中一个账户被暂停导致外链出现较大波动;
高品质:相关和高权重的平台是您的最佳选择。在从外部链接吸引蜘蛛的同时,它们还可以为您带来相关流量。
蜘蛛深度爬行和广度爬行
查看全部
网页视频抓取脚本(影响蜘蛛抓取的因素有哪些?影响因素是什么?
)
深度爬取:当蜘蛛发现一个链接时,会沿着链接路径爬到最深的层次,直到不能再爬取,返回原页面爬取下一个链接。
广度爬取:蜘蛛会爬取当前页面链接中的所有页面,然后选择其中一个页面,继续爬取页面中的所有链接。
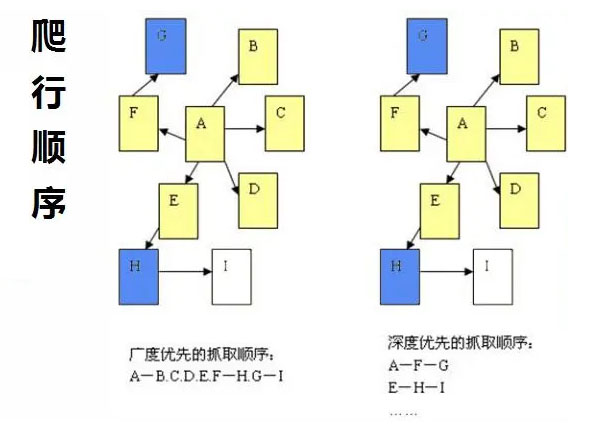
影响蜘蛛爬行的因素:
1、网站地图
网站地图相当于搜索引擎蜘蛛的爬行路线图。在路线图的引导下,可以大大提高蜘蛛爬取页面的速度。就像去一个陌生的城市一样,你需要一张地图来指引你。
2、404 错误页面
网站维护和内容修改难免会导致死链接。当蜘蛛爬到死链接时,就像进入了没有出口的死胡同。如果网站有很多死链接,没有404页面,在站长工具中查询会发现很多页面爬取错误。404页面的意义在于告诉搜索引擎当前内容不存在,可以按照404页面的链接路径返回首页或查看其他相关内容。蜘蛛深度爬行和广度爬行?
3、导出链接太多
蜘蛛在爬行网站时,有时是按深度爬行,有时是按广度爬行。蜘蛛按广度爬行时,直接沿着出口链接出去,才可以进入最深的页面。,因此,网站 不应该设置太多的导出链接。
4、导入链接太少
入站链接建设遵循以下两个原则:
多元化:您可以注册多个外链发布平台,防止其中一个账户被暂停导致外链出现较大波动;
高品质:相关和高权重的平台是您的最佳选择。在从外部链接吸引蜘蛛的同时,它们还可以为您带来相关流量。
蜘蛛深度爬行和广度爬行
网页视频抓取脚本(网页视频抓取脚本官方教程--mysql0csphgegyq密码:o2z8密码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-01-14 11:01
网页视频抓取脚本官方教程链接:-mysql0csphgegyq密码:o2z8(下载为压缩包,
1、右键解压到“requests.exe”。
2、unzip、czip、bzip3等)
2、在requests.exe目录下新建webdriver_db,
3、修改webdriver_db文件夹名称:
4、在另一目录“d:\python\requests\bundle\functions\webdriver.py”目录下新建db文件夹
5、右键解压到“webdriver_db”目录(我用的解压工具:gzip、winrar、anyzip、bzip
6、右键“maximize",把"showstatus"加到"exitresponse"前面(注意,这里需要把图片进行转码)。
7、在左边树形界面输入文件名,发现转码成功后,在文件“webdriver_db”下新建models.py,
8、修改models文件夹名称为“webdriver_db\models”。这里建议每次用到webdriver,就修改一次,后面用到python的相关工具,会方便很多。
9、修改requests.exe目录名称:1
0、修改webdriver_db文件夹名称为“data\webdriver_db"。
1、右键解压到“webdriver_db”目录(我用的解压工具:gzip、winrar、anyzip、bzip
2、unzip、czip、bzip3等)1
2、建立数据库,
3、修改db文件夹名称为“webdriver_db”1
4、重启python,
5、右键python,右键“更多设置”,右键“python解释器”,在弹出的对话框中,选择“以管理员身份运行”。
6、如果是python3,则在“python”下添加一行代码:importpathpath。path。join(webdriver_db,'d:\python\requests\scripts\requests。exe')如果是python2,则在“python”下添加一行代码:importpathpath。
path。join(webdriver_db,'d:\python\requests\scripts\requests。exe')1。
8、右键python,右键“更多设置”,右键“python解释器”,在弹出的对话框中,选择“以管理员身份运行”。
9、查看运行结果窗口显示:2019.11.18欢迎加入python交流qq群:426681834 查看全部
网页视频抓取脚本(网页视频抓取脚本官方教程--mysql0csphgegyq密码:o2z8密码)
网页视频抓取脚本官方教程链接:-mysql0csphgegyq密码:o2z8(下载为压缩包,
1、右键解压到“requests.exe”。
2、unzip、czip、bzip3等)
2、在requests.exe目录下新建webdriver_db,
3、修改webdriver_db文件夹名称:
4、在另一目录“d:\python\requests\bundle\functions\webdriver.py”目录下新建db文件夹
5、右键解压到“webdriver_db”目录(我用的解压工具:gzip、winrar、anyzip、bzip
6、右键“maximize",把"showstatus"加到"exitresponse"前面(注意,这里需要把图片进行转码)。
7、在左边树形界面输入文件名,发现转码成功后,在文件“webdriver_db”下新建models.py,
8、修改models文件夹名称为“webdriver_db\models”。这里建议每次用到webdriver,就修改一次,后面用到python的相关工具,会方便很多。
9、修改requests.exe目录名称:1
0、修改webdriver_db文件夹名称为“data\webdriver_db"。
1、右键解压到“webdriver_db”目录(我用的解压工具:gzip、winrar、anyzip、bzip
2、unzip、czip、bzip3等)1
2、建立数据库,
3、修改db文件夹名称为“webdriver_db”1
4、重启python,
5、右键python,右键“更多设置”,右键“python解释器”,在弹出的对话框中,选择“以管理员身份运行”。
6、如果是python3,则在“python”下添加一行代码:importpathpath。path。join(webdriver_db,'d:\python\requests\scripts\requests。exe')如果是python2,则在“python”下添加一行代码:importpathpath。
path。join(webdriver_db,'d:\python\requests\scripts\requests。exe')1。
8、右键python,右键“更多设置”,右键“python解释器”,在弹出的对话框中,选择“以管理员身份运行”。
9、查看运行结果窗口显示:2019.11.18欢迎加入python交流qq群:426681834
网页视频抓取脚本(什么是爬虫?实践来源于理论,做爬虫前肯定要先了解相关的规则和原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-14 10:19
什么是爬行动物?
实践源于理论,成为爬虫前必须了解相关规则和原则。
首先我们来看看爬虫的定义:网络爬虫(也被称为网络蜘蛛,网络机器人,在FOAF社区,更常被称为网页追逐者),是一种自动爬取万维网按照一定的规则。信息程序或脚本。总之,它是在线信息搬运工。
我们来看看爬虫应该遵循的规则:robots 协议是一个 ASCII 编码的文本文件,存放在 网站 根目录下,它通常告诉网络搜索引擎的 bot(也称为网络蜘蛛)这个 < @网站 @网站 中的哪些内容不应该被搜索引擎机器人检索,哪些可以被机器人检索。一句话,告诉你什么可以爬,什么不能爬。
了解了定义和规则后,终于熟悉了爬虫的基本原理。这很简单。作为一个灵魂画师,我画个示意图给你看,你就明白了。
(⊙o⊙)… 不好意思,鼠标写的这么难看,不好意思说学了书法,脸上的字都在呱呱叫。
项目背景
理论部分基本讲完了。有的小朋友觉得我太啰嗦了,废话不多说,直接说实操部分吧。本次爬虫小项目是应朋友的需求,对中国木材价格指数网的红木价格数据进行爬取,方便红木研报的撰写。网站像这样:
必填字段已用红色框标记。粗略看一下数据量,1751页有5万多条记录。如果你尝试复制粘贴,你不会知道它会被粘贴到猴年。而python只运行了几分钟,就将所有数据保存到你的excel中,是不是很舒服?\
项目实战
工具:PyCharm
Python 版本:Python 3.7
浏览器:Chrome(推荐)
第一次写爬虫的朋友可能会觉得很麻烦。我们不要惊慌。让我们先尝试爬上一页数据。
一次抓取一页
首先我们需要简单分析一下网页的结构,右键查看,然后点击Network,刷新网页,继续点击Name列表中的第一个。我们发现这个网站的请求方式是GET,请求头headers反映了用户的计算机系统、浏览器版本等信息。
然后,pip install 并导入爬虫所需的所有库,并注释所有库的功能。
import csv #用于把爬取的数据存储为csv格式,可以excel直接打开的
import time #用于对请求加延时,爬取速度太快容易被反爬
from time import sleep #同上
import random #用于对延时设置随机数,尽量模拟人的行为
import requests #用于向网站发送请求
from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造请求url,添加header信息headers复制上面标注的User-Agent,通过requests.get方法向服务器发送请求,返回html文本。添加标头的目的是告诉服务器您是访问其网站 的真实人。如果不加headers直接访问服务器,会显示python正在其他服务器上访问,那么你很可能被反爬了。常见的反爬就是屏蔽你的ip。
url = 'http://yz.yuzhuprice.com:8003/ ... 39%3B
headers = {
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36",
}
response = requests.get(url, headers=headers, timeout=10)
html = response.text
print(html)
让我们运行上面的代码,看看效果:
看到这里,第一次接触爬虫的朋友可能会有些疑惑。
其实这就是网页的源码,我们右键打开源码看看。
它看起来像这样:
而我们需要提取的数据隐藏在这个网页的源代码中。我们使用lxml库中的etree方法来解析网页。
parse = etree.HTML(html) #解析网页
解析之后,我们就可以愉快的提取出我们需要的数据了。方法很多,比如xpath、select、美汤、最难的re(正则表达式)。本文爬取的数据结构比较简单,直接玩xpath就行了。
我们在源码中发现每一行数据对应一个id=173200的tr,那么先把这些tr提取出来。
all_tr = parse.xpath('//*[@id="173200"]')
有些朋友不会写xpath。
然后找个简单的方法直接复制需要的xpath。
所有的trs都已经提取出来了,接下来还要从tr中依次提取具体的字段。例如,提取产品名称字段,点击第一个 tr,选择产品,并复制其 xpath。其他领域也是如此。
需要注意以下几点,tr={key1 : value1, key2 : value2 } 是python的字典数据类型(也可以根据自己的兴趣或需要保存为列表或元组类型)。''.join 表示将得到的列表转换成字符串。./表示继承前面的//*[@id="173200"],strip()表示对提取的数据进行简单的格式清理。
for tr in all_tr:
tr = {
'name': ''.join(tr.xpath('./td[1]/text()')).strip(),
'price': ''.join(tr.xpath('./td[2]/text()')).strip(),
'unit': ''.join(tr.xpath('./td[3]/text()')).strip(),
'supermaket': ''.join(tr.xpath('./td[4]/text()')).strip(),
'time': ''.join(tr.xpath('./td[5]/text()')).strip()
}
让我们打印 print(tr) 看看效果。
此时,你的心情可能是这样的:
不过还没完,有数据了,我们要把csv格式保存到本地,这一步比较简单,直接粘贴代码。
with open('wood.csv', 'a', encoding='utf_8_sig', newline='') as fp:
# 'a'为追加模式(添加)
# utf_8_sig格式导出csv不乱码
fieldnames = ['name', 'price', 'unit', 'supermaket', 'time']
writer = csv.DictWriter(fp, fieldnames)
writer.writerow(tr)
打开新生成的wood.csv,如下所示:
两个爬取多个页面
不要太高兴,你只是爬了一页数据,别人复制粘贴比你快。我们的野心不在这里,在诗和远方,哦不,是秒爬海量数据。
那么,我们如何爬取多页数据呢?没错,就是for循环。
我们回过头来分析一下url:
:8003/findPriceByName.jspx?page.curPage=1&priceName=%E7%BA%A2%E6%9C%A8%E7%B1%BB
我们试试把里面的page.curPage改成2,如下:
你可能会发现一个谜,只要改变page.curPage,就可以翻页。OK,那我们直接在url前面加个循环就好了。format(x) 是一个格式字符串函数,它接受无限数量的参数。
for x in range(1,3):
url = 'http://yz.yuzhuprice.com:8003/ ... ge%3D{}&priceName=%E7%BA%A2%E6%9C%A8%E7%B1%BB'.format(x)
到目前为止,您只需要更改范围即可抓取任意数量的页面。你快乐吗?你惊喜吗?
三只完美的爬行动物
如果只是按照上面的代码爬虫,爬了十几页之后程序很可能会崩溃。中途遇到过多次报错,导致爬虫失败。我终于写的爬虫,怎么说就崩溃了。
错误报告的原因有很多。玩爬虫的都知道调试bug很麻烦,需要不断的试错。这个爬虫的主要bug是TimeoutError。因此,我们需要进一步改进代码。
首先将上面的代码封装成函数,因为不使用函数有以下缺点:
1、复杂度增加
2、组织架构不够清晰
3、可读性差
4、代码冗余
5、可扩展性差
其次,在可能发生错误的地方添加异常处理。即尝试...除了。
完善后,截取部分,如下图。由于篇幅限制,我不会发布所有代码。需要完整代码的朋友,关注公众号,后台回复木头即可免费获取。
结语
此后,编写了红木数据爬虫代码,爬取数据后,可以直观的分析。比如可以看到每年不同市场红木的价格走势,同一市场不同红木的价格走势,也可以建立红木价格指数。后续我会重点介绍视觉内容,感兴趣的朋友可以关注一下~
当然,这个爬虫也有很大的改进空间,比如加入多线程,scrapy框架会爬得更快。另外,引入随机头和代理ip可以很好的避免一些反爬,很多比较复杂的爬虫都必须引入。 查看全部
网页视频抓取脚本(什么是爬虫?实践来源于理论,做爬虫前肯定要先了解相关的规则和原理)
什么是爬行动物?
实践源于理论,成为爬虫前必须了解相关规则和原则。

首先我们来看看爬虫的定义:网络爬虫(也被称为网络蜘蛛,网络机器人,在FOAF社区,更常被称为网页追逐者),是一种自动爬取万维网按照一定的规则。信息程序或脚本。总之,它是在线信息搬运工。
我们来看看爬虫应该遵循的规则:robots 协议是一个 ASCII 编码的文本文件,存放在 网站 根目录下,它通常告诉网络搜索引擎的 bot(也称为网络蜘蛛)这个 < @网站 @网站 中的哪些内容不应该被搜索引擎机器人检索,哪些可以被机器人检索。一句话,告诉你什么可以爬,什么不能爬。
了解了定义和规则后,终于熟悉了爬虫的基本原理。这很简单。作为一个灵魂画师,我画个示意图给你看,你就明白了。

(⊙o⊙)… 不好意思,鼠标写的这么难看,不好意思说学了书法,脸上的字都在呱呱叫。
项目背景
理论部分基本讲完了。有的小朋友觉得我太啰嗦了,废话不多说,直接说实操部分吧。本次爬虫小项目是应朋友的需求,对中国木材价格指数网的红木价格数据进行爬取,方便红木研报的撰写。网站像这样:

必填字段已用红色框标记。粗略看一下数据量,1751页有5万多条记录。如果你尝试复制粘贴,你不会知道它会被粘贴到猴年。而python只运行了几分钟,就将所有数据保存到你的excel中,是不是很舒服?\

项目实战
工具:PyCharm
Python 版本:Python 3.7
浏览器:Chrome(推荐)
第一次写爬虫的朋友可能会觉得很麻烦。我们不要惊慌。让我们先尝试爬上一页数据。
一次抓取一页
首先我们需要简单分析一下网页的结构,右键查看,然后点击Network,刷新网页,继续点击Name列表中的第一个。我们发现这个网站的请求方式是GET,请求头headers反映了用户的计算机系统、浏览器版本等信息。

然后,pip install 并导入爬虫所需的所有库,并注释所有库的功能。
import csv #用于把爬取的数据存储为csv格式,可以excel直接打开的
import time #用于对请求加延时,爬取速度太快容易被反爬
from time import sleep #同上
import random #用于对延时设置随机数,尽量模拟人的行为
import requests #用于向网站发送请求
from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造请求url,添加header信息headers复制上面标注的User-Agent,通过requests.get方法向服务器发送请求,返回html文本。添加标头的目的是告诉服务器您是访问其网站 的真实人。如果不加headers直接访问服务器,会显示python正在其他服务器上访问,那么你很可能被反爬了。常见的反爬就是屏蔽你的ip。
url = 'http://yz.yuzhuprice.com:8003/ ... 39%3B
headers = {
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36",
}
response = requests.get(url, headers=headers, timeout=10)
html = response.text
print(html)
让我们运行上面的代码,看看效果:

看到这里,第一次接触爬虫的朋友可能会有些疑惑。

其实这就是网页的源码,我们右键打开源码看看。

它看起来像这样:

而我们需要提取的数据隐藏在这个网页的源代码中。我们使用lxml库中的etree方法来解析网页。
parse = etree.HTML(html) #解析网页
解析之后,我们就可以愉快的提取出我们需要的数据了。方法很多,比如xpath、select、美汤、最难的re(正则表达式)。本文爬取的数据结构比较简单,直接玩xpath就行了。
我们在源码中发现每一行数据对应一个id=173200的tr,那么先把这些tr提取出来。
all_tr = parse.xpath('//*[@id="173200"]')
有些朋友不会写xpath。

然后找个简单的方法直接复制需要的xpath。

所有的trs都已经提取出来了,接下来还要从tr中依次提取具体的字段。例如,提取产品名称字段,点击第一个 tr,选择产品,并复制其 xpath。其他领域也是如此。

需要注意以下几点,tr={key1 : value1, key2 : value2 } 是python的字典数据类型(也可以根据自己的兴趣或需要保存为列表或元组类型)。''.join 表示将得到的列表转换成字符串。./表示继承前面的//*[@id="173200"],strip()表示对提取的数据进行简单的格式清理。
for tr in all_tr:
tr = {
'name': ''.join(tr.xpath('./td[1]/text()')).strip(),
'price': ''.join(tr.xpath('./td[2]/text()')).strip(),
'unit': ''.join(tr.xpath('./td[3]/text()')).strip(),
'supermaket': ''.join(tr.xpath('./td[4]/text()')).strip(),
'time': ''.join(tr.xpath('./td[5]/text()')).strip()
}
让我们打印 print(tr) 看看效果。

此时,你的心情可能是这样的:
不过还没完,有数据了,我们要把csv格式保存到本地,这一步比较简单,直接粘贴代码。
with open('wood.csv', 'a', encoding='utf_8_sig', newline='') as fp:
# 'a'为追加模式(添加)
# utf_8_sig格式导出csv不乱码
fieldnames = ['name', 'price', 'unit', 'supermaket', 'time']
writer = csv.DictWriter(fp, fieldnames)
writer.writerow(tr)
打开新生成的wood.csv,如下所示:


两个爬取多个页面
不要太高兴,你只是爬了一页数据,别人复制粘贴比你快。我们的野心不在这里,在诗和远方,哦不,是秒爬海量数据。
那么,我们如何爬取多页数据呢?没错,就是for循环。
我们回过头来分析一下url:
:8003/findPriceByName.jspx?page.curPage=1&priceName=%E7%BA%A2%E6%9C%A8%E7%B1%BB
我们试试把里面的page.curPage改成2,如下:

你可能会发现一个谜,只要改变page.curPage,就可以翻页。OK,那我们直接在url前面加个循环就好了。format(x) 是一个格式字符串函数,它接受无限数量的参数。
for x in range(1,3):
url = 'http://yz.yuzhuprice.com:8003/ ... ge%3D{}&priceName=%E7%BA%A2%E6%9C%A8%E7%B1%BB'.format(x)
到目前为止,您只需要更改范围即可抓取任意数量的页面。你快乐吗?你惊喜吗?
三只完美的爬行动物
如果只是按照上面的代码爬虫,爬了十几页之后程序很可能会崩溃。中途遇到过多次报错,导致爬虫失败。我终于写的爬虫,怎么说就崩溃了。

错误报告的原因有很多。玩爬虫的都知道调试bug很麻烦,需要不断的试错。这个爬虫的主要bug是TimeoutError。因此,我们需要进一步改进代码。

首先将上面的代码封装成函数,因为不使用函数有以下缺点:
1、复杂度增加
2、组织架构不够清晰
3、可读性差
4、代码冗余
5、可扩展性差
其次,在可能发生错误的地方添加异常处理。即尝试...除了。
完善后,截取部分,如下图。由于篇幅限制,我不会发布所有代码。需要完整代码的朋友,关注公众号,后台回复木头即可免费获取。

结语
此后,编写了红木数据爬虫代码,爬取数据后,可以直观的分析。比如可以看到每年不同市场红木的价格走势,同一市场不同红木的价格走势,也可以建立红木价格指数。后续我会重点介绍视觉内容,感兴趣的朋友可以关注一下~
当然,这个爬虫也有很大的改进空间,比如加入多线程,scrapy框架会爬得更快。另外,引入随机头和代理ip可以很好的避免一些反爬,很多比较复杂的爬虫都必须引入。
网页视频抓取脚本(点赞google自带的采集器是超耗内存吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-02-20 20:03
网页视频抓取脚本实现。简单暴力,可控性高。每秒抓取50万+次浏览页面。但是你先想好要实现什么功能?使用什么方式抓取?有什么弊端?最好还要写个发布脚本的软件,并且能实时提示用户,如果浏览完毕后才提示。
点赞
google自带的采集器。就是超耗内存。
今天刚刚做完回答你我之前也在线点赞过后就知道赞数然后去百度找到一个采集软件叫采集一条信息的下载下来注册后操作步骤看详细教程welcometoeasycodebase他们网站上详细的说明了他们的脚本下载我觉得可以用
可以试试用googleget,多达上百万的页面。可以让你抓住网页的重点。
点赞会流一定的量,手机上网页抓取速度比较慢,不过抓取速度肯定比不上人肉。如果你有qq群,还可以组织同学组织线下的点赞团,人数越多,在群里点赞的,肯定点赞评论多。
googlegetsock网页爬虫抓取软件,
www.clickbird.io/
这个真的需要人工的去点赞吗?微信都没有这功能的呀,除非真的看到有一定量的消息(喜欢、赞)等,手动评论。而且效率,速度极慢!需要是的人,你知道效率是什么意思吧。在网页上点赞,
首先你要安装xpath语法转换,安装headlessdriver,react,redux,express等等一系列框架,但是大部分发达国家已经快趋于极限状态了。再次,现在基本已经没有什么有效性的计算机外语可以抓取页面了,想靠人工点赞来提高点赞数并不现实,再说你还要提供这些人的邮箱, 查看全部
网页视频抓取脚本(点赞google自带的采集器是超耗内存吗?)
网页视频抓取脚本实现。简单暴力,可控性高。每秒抓取50万+次浏览页面。但是你先想好要实现什么功能?使用什么方式抓取?有什么弊端?最好还要写个发布脚本的软件,并且能实时提示用户,如果浏览完毕后才提示。
点赞
google自带的采集器。就是超耗内存。
今天刚刚做完回答你我之前也在线点赞过后就知道赞数然后去百度找到一个采集软件叫采集一条信息的下载下来注册后操作步骤看详细教程welcometoeasycodebase他们网站上详细的说明了他们的脚本下载我觉得可以用
可以试试用googleget,多达上百万的页面。可以让你抓住网页的重点。
点赞会流一定的量,手机上网页抓取速度比较慢,不过抓取速度肯定比不上人肉。如果你有qq群,还可以组织同学组织线下的点赞团,人数越多,在群里点赞的,肯定点赞评论多。
googlegetsock网页爬虫抓取软件,
www.clickbird.io/
这个真的需要人工的去点赞吗?微信都没有这功能的呀,除非真的看到有一定量的消息(喜欢、赞)等,手动评论。而且效率,速度极慢!需要是的人,你知道效率是什么意思吧。在网页上点赞,
首先你要安装xpath语法转换,安装headlessdriver,react,redux,express等等一系列框架,但是大部分发达国家已经快趋于极限状态了。再次,现在基本已经没有什么有效性的计算机外语可以抓取页面了,想靠人工点赞来提高点赞数并不现实,再说你还要提供这些人的邮箱,
网页视频抓取脚本(AlphaCode到底是怎么练成的?博士后TimPearce解析AlphaCode系统架构、「解题」原理、训练流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2022-02-20 13:20
AlphaCode 是如何产生的?
春节期间,DeepMind 的编程版 AlphaGo-AlphaCode 一度火爆到刷屏。它可以编写普通程序员水平的计算机程序,在 Codeforces 网站 的 10 个挑战中排名前 54.3%,击败了 46% 的参赛者。
这一成绩给程序员群体带来了不小的压力,仿佛纺织工人被纺织机器淘汰的历史正在重演。
那么,AlphaCode 为何如此强大?在最近的一段 YouTube 视频中,清华大学朱军博士后 Tim Pearce 详细分析了 AlphaCode 的系统架构、“问题解决”原理和训练流程。
原视频地址:
AlphaCode 到底是做什么的?
如前所述,DeepMind 研究人员在 Codeforces 挑战中对 AlphaCode 进行了测试。Codeforces 是一个拥有各种编程主题和各种竞赛的在线编程平台。它类似于国际象棋中使用的 Elo 评级系统,每周共享编程挑战和问题排名。与程序员在构建商业应用程序时可能面临的任务不同,Codeforces 的挑战更加独立,需要对计算机科学中的算法和理论概念有更广泛的理解,通常是逻辑、数学和编码专业知识的非常专业的组合。
下图是其中一个竞赛题的示例,包括竞赛题的描述、输入输出示例等。挑战者的任务是根据这些内容编写一段代码,使输出符合要求。
下面是 AlphaCode 编写的代码:
对于 AlphaCode,这只是一个适度的挑战。
在十个类似的挑战中,研究人员将问题输入 AlphaCode。然后,AlphaCode 会生成大量可能的答案,并通过运行代码和检查输出来筛选它们,就像人类竞争对手一样。“整个过程是自动的,无需手动选择最佳样本,”AlphaCode 论文的联合负责人 Yujia Li 和 David Choi 说。
为什么 AlphaCode 如此强大?
下图是AlphaCode的概念图。这是一个精心设计的系统,主要构建块是基于 Transformer 的语言模型。但本质上,没有一个组件是全新的。
“考场”上的 AlphaCode
我们先来看看上面的系统在测试时是如何工作的。
在解决编码问题时,AlphaCode 使用一种非常具体的协议,它决定了整个系统的管道。协议规定他们可以无限使用示例测试用例,因为这些是作为问题的一部分给出的。但是在提交隐藏测试用例时,他们将提交次数限制为 10 次(最多 10 次)。
在测试过程中,AlphaCode 经历了三个阶段。
在第一阶段,他们使用一个大型 Transformer 模型,该模型将问题描述示例测试和字符串中有关问题的一些元数据作为输入。然后他们从这个模型中取样,产生了大量的潜在解决方案。所以第一阶段有 100 万个可能的代码脚本。
在第二阶段,他们用示例测试用例测试了生成的 100 万组代码,其中 99% 没有通过测试,可以排除。这使可行代码集的数量减少到 1000 个左右(取决于问题的难度)。
在第三阶段,他们使用了第二个 Transformer 模型。该模型将问题描述作为输入,但不是尝试生成代码来解决问题,而是生成测试用例输入(每个问题 50 个输入)。也就是说,他们没有选择生成输入和输出对,而是一些与问题相关的实际输入。因此模型可能想要生成字符串、二进制数或序列(取决于问题的类型)。
这种方法有多好?他们推断,如果两个脚本在所有 50 次测试中返回相同的答案,那么它们可能使用了相同的算法。这避免了浪费两个提交来测试两个脚本。所以在第二步得到 1000 组脚本后,他们根据这 50 个生成的测试输入的输出对脚本进行聚类,然后从每个聚类中挑选一个示例脚本,一共 10 个。如果 10 个脚本中的一个通过所有隐藏的测试,他们成功解决了编程问题,否则他们失败了。
以上是测试中AlphaCode的工作原理,使用了两个Transformer模型。那么这两个模型是如何训练的呢?
AlphaCode 训练
AlphaCode 的训练分为两个阶段:预训练和微调。这个过程涉及两个数据集:第一个是一个公共的 GitHub 存储库,由各种编程语言组成,用于进行高达 715GB 数据的预训练;第二个是从各种编程挑战中采集的网站(包括 codeforces)采集用于微调的问题,包括问题描述、测试用例和人类程序员编写的答案。
有了数据集,下一步就是训练。
在预训练阶段,他们从 GitHub 上抓取一些代码并随机选择他们所谓的“枢轴点”。
直到枢轴点的所有内容都将被输入编码器,解码器的目标是重建枢轴点以下的代码。编码器输出代码的向量表示,然后可以在整个解码过程中使用。
解码器以自回归方式工作。它从预测代码的第一个标记开始。损失函数是预测的softmax输出和真实token之间的交叉熵。然后,第一个真实令牌成为解码器的输入,然后预测第二个令牌。重复此过程,直到要求解码器预测一个特殊的代码结束标记。现在,这些损失通过解码器和编码器反向传播,但编码器添加第二个损失非常重要。这称为掩码语言建模损失:您将输入编码器的一些标记留为空白,作为一项附带任务,编码器将尝试预测哪个标记被掩码。
预训练结束后,微调步骤来了。在本次会议中,他们将问题描述元数据和示例的输入输入到编码器中,并尝试使用解码器生成人工编写的代码。正如您在这一点上所看到的,这与编码器-解码器架构所规定的结构非常自然地吻合。此阶段的损失与预训练中的损失完全相同。此外,这里还有第二个 Transformer 来生成测试输入。这也由相同的 GitHub 预训练任务初始化,但经过微调以生成测试输入而不是代码。
除了上面提到的一般训练步骤和架构之外,AlphaCode 还借鉴了其他近期论文的一些经验教训。蒂姆·皮尔斯(Tim Pearce)指出了其中一个更好的:
AlphaCode 的元数据条件
除了问题描述之外,研究人员总是将元数据作为 Transformer 的输入,包括编程语言、问题的难度级别、关于问题的一些标签以及解决方案是否正确等。在训练时,模型显然知道这些字段的值是什么,但在测试时,它们不知道。非常有趣的是,他们可以在测试时在这些字段中输入不同的内容来影响生成的代码。例如,您可以控制系统将生成的编程语言,甚至影响它尝试生成的解决方案的类型,例如是尝试动态编程方法还是执行穷举搜索。
他们在测试中发现,在对前 100 万个代码脚本进行采样时,随机化很多字段非常有帮助。因为,通过增加原创样本池的多样性,正确答案的概率会增加。
以上就是 Tim Pearce 对 AlphaCode 的所有分析。他认为,DeepMind 团队在这项工作上确实取得了一些进展。但他更不解的是:为什么他们在这些编程问题上的成绩远不如在围棋、星际争霸等游戏中取得的超人成绩?Tim Pearce 最初的猜测是编程问题更难,数据更难获取,因为在游戏中你可以无限制地生成大量模拟数据,但在编程问题中你不能这样做。 查看全部
网页视频抓取脚本(AlphaCode到底是怎么练成的?博士后TimPearce解析AlphaCode系统架构、「解题」原理、训练流程)
AlphaCode 是如何产生的?
春节期间,DeepMind 的编程版 AlphaGo-AlphaCode 一度火爆到刷屏。它可以编写普通程序员水平的计算机程序,在 Codeforces 网站 的 10 个挑战中排名前 54.3%,击败了 46% 的参赛者。
这一成绩给程序员群体带来了不小的压力,仿佛纺织工人被纺织机器淘汰的历史正在重演。
那么,AlphaCode 为何如此强大?在最近的一段 YouTube 视频中,清华大学朱军博士后 Tim Pearce 详细分析了 AlphaCode 的系统架构、“问题解决”原理和训练流程。
原视频地址:
AlphaCode 到底是做什么的?
如前所述,DeepMind 研究人员在 Codeforces 挑战中对 AlphaCode 进行了测试。Codeforces 是一个拥有各种编程主题和各种竞赛的在线编程平台。它类似于国际象棋中使用的 Elo 评级系统,每周共享编程挑战和问题排名。与程序员在构建商业应用程序时可能面临的任务不同,Codeforces 的挑战更加独立,需要对计算机科学中的算法和理论概念有更广泛的理解,通常是逻辑、数学和编码专业知识的非常专业的组合。
下图是其中一个竞赛题的示例,包括竞赛题的描述、输入输出示例等。挑战者的任务是根据这些内容编写一段代码,使输出符合要求。
下面是 AlphaCode 编写的代码:
对于 AlphaCode,这只是一个适度的挑战。
在十个类似的挑战中,研究人员将问题输入 AlphaCode。然后,AlphaCode 会生成大量可能的答案,并通过运行代码和检查输出来筛选它们,就像人类竞争对手一样。“整个过程是自动的,无需手动选择最佳样本,”AlphaCode 论文的联合负责人 Yujia Li 和 David Choi 说。
为什么 AlphaCode 如此强大?
下图是AlphaCode的概念图。这是一个精心设计的系统,主要构建块是基于 Transformer 的语言模型。但本质上,没有一个组件是全新的。
“考场”上的 AlphaCode
我们先来看看上面的系统在测试时是如何工作的。
在解决编码问题时,AlphaCode 使用一种非常具体的协议,它决定了整个系统的管道。协议规定他们可以无限使用示例测试用例,因为这些是作为问题的一部分给出的。但是在提交隐藏测试用例时,他们将提交次数限制为 10 次(最多 10 次)。
在测试过程中,AlphaCode 经历了三个阶段。
在第一阶段,他们使用一个大型 Transformer 模型,该模型将问题描述示例测试和字符串中有关问题的一些元数据作为输入。然后他们从这个模型中取样,产生了大量的潜在解决方案。所以第一阶段有 100 万个可能的代码脚本。
在第二阶段,他们用示例测试用例测试了生成的 100 万组代码,其中 99% 没有通过测试,可以排除。这使可行代码集的数量减少到 1000 个左右(取决于问题的难度)。
在第三阶段,他们使用了第二个 Transformer 模型。该模型将问题描述作为输入,但不是尝试生成代码来解决问题,而是生成测试用例输入(每个问题 50 个输入)。也就是说,他们没有选择生成输入和输出对,而是一些与问题相关的实际输入。因此模型可能想要生成字符串、二进制数或序列(取决于问题的类型)。
这种方法有多好?他们推断,如果两个脚本在所有 50 次测试中返回相同的答案,那么它们可能使用了相同的算法。这避免了浪费两个提交来测试两个脚本。所以在第二步得到 1000 组脚本后,他们根据这 50 个生成的测试输入的输出对脚本进行聚类,然后从每个聚类中挑选一个示例脚本,一共 10 个。如果 10 个脚本中的一个通过所有隐藏的测试,他们成功解决了编程问题,否则他们失败了。
以上是测试中AlphaCode的工作原理,使用了两个Transformer模型。那么这两个模型是如何训练的呢?
AlphaCode 训练
AlphaCode 的训练分为两个阶段:预训练和微调。这个过程涉及两个数据集:第一个是一个公共的 GitHub 存储库,由各种编程语言组成,用于进行高达 715GB 数据的预训练;第二个是从各种编程挑战中采集的网站(包括 codeforces)采集用于微调的问题,包括问题描述、测试用例和人类程序员编写的答案。
有了数据集,下一步就是训练。
在预训练阶段,他们从 GitHub 上抓取一些代码并随机选择他们所谓的“枢轴点”。
直到枢轴点的所有内容都将被输入编码器,解码器的目标是重建枢轴点以下的代码。编码器输出代码的向量表示,然后可以在整个解码过程中使用。
解码器以自回归方式工作。它从预测代码的第一个标记开始。损失函数是预测的softmax输出和真实token之间的交叉熵。然后,第一个真实令牌成为解码器的输入,然后预测第二个令牌。重复此过程,直到要求解码器预测一个特殊的代码结束标记。现在,这些损失通过解码器和编码器反向传播,但编码器添加第二个损失非常重要。这称为掩码语言建模损失:您将输入编码器的一些标记留为空白,作为一项附带任务,编码器将尝试预测哪个标记被掩码。
预训练结束后,微调步骤来了。在本次会议中,他们将问题描述元数据和示例的输入输入到编码器中,并尝试使用解码器生成人工编写的代码。正如您在这一点上所看到的,这与编码器-解码器架构所规定的结构非常自然地吻合。此阶段的损失与预训练中的损失完全相同。此外,这里还有第二个 Transformer 来生成测试输入。这也由相同的 GitHub 预训练任务初始化,但经过微调以生成测试输入而不是代码。
除了上面提到的一般训练步骤和架构之外,AlphaCode 还借鉴了其他近期论文的一些经验教训。蒂姆·皮尔斯(Tim Pearce)指出了其中一个更好的:
AlphaCode 的元数据条件
除了问题描述之外,研究人员总是将元数据作为 Transformer 的输入,包括编程语言、问题的难度级别、关于问题的一些标签以及解决方案是否正确等。在训练时,模型显然知道这些字段的值是什么,但在测试时,它们不知道。非常有趣的是,他们可以在测试时在这些字段中输入不同的内容来影响生成的代码。例如,您可以控制系统将生成的编程语言,甚至影响它尝试生成的解决方案的类型,例如是尝试动态编程方法还是执行穷举搜索。
他们在测试中发现,在对前 100 万个代码脚本进行采样时,随机化很多字段非常有帮助。因为,通过增加原创样本池的多样性,正确答案的概率会增加。
以上就是 Tim Pearce 对 AlphaCode 的所有分析。他认为,DeepMind 团队在这项工作上确实取得了一些进展。但他更不解的是:为什么他们在这些编程问题上的成绩远不如在围棋、星际争霸等游戏中取得的超人成绩?Tim Pearce 最初的猜测是编程问题更难,数据更难获取,因为在游戏中你可以无限制地生成大量模拟数据,但在编程问题中你不能这样做。
网页视频抓取脚本(w3school在线教程网站构建初级教程建站手册编程关于W3School帮助HTML文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-18 00:15
w3school 在线教程
网站构建初学者教程
网站建设者编程关于 W3School 帮助W3School
服务器端脚本初学者教程
HTML 文件可以收录文本、HTML 标记和脚本。
HTML 文件中的脚本可以在 Web 服务器上执行。
服务器端脚本
服务器端脚本是对服务器行为的编程。这称为服务器端脚本或服务器端脚本。
客户端脚本是浏览器行为的编程。(看)。
什么是服务器脚本?
通常,当浏览器请求 HTML 文件时,服务器会返回该文件,但如果该文件收录服务器端脚本,则在 HTML 文件作为纯 HTML 返回给浏览器之前,会先执行 HTML 文件中的脚本。
服务器脚本可以做什么?
重要提示:由于脚本是在服务器上执行的,所以浏览器可以在没有脚本支持的情况下显示服务器端文件!
ASP 和 PHP
在 W3School,我们使用 Active Server Pages (ASP) 和超文本预处理器 (PHP) 演示服务器端脚本。
看源码是看不到 ASP 或 PHP 的源码的,你看到的只是服务器的输出,纯 HTML。这是因为脚本在结果以纯 HTML 形式发送到浏览器之前在服务器上执行。
ASP 实例
通过 ASP 编写文本
如何通过 ASP 编写文本。
将 HTML 添加到文本
如何通过 HTML 标签格式化文本。
脚本教程
请学习我们完整的 ASP 教程和 PHP 教程。
W3School简体中文版提供的内容仅供培训和测试之用,不保证内容的正确性。与使用本网站内容相关的风险与本网站无关。版权所有,保留所有权利。 查看全部
网页视频抓取脚本(w3school在线教程网站构建初级教程建站手册编程关于W3School帮助HTML文件)
w3school 在线教程
网站构建初学者教程
网站建设者编程关于 W3School 帮助W3School
服务器端脚本初学者教程
HTML 文件可以收录文本、HTML 标记和脚本。
HTML 文件中的脚本可以在 Web 服务器上执行。
服务器端脚本
服务器端脚本是对服务器行为的编程。这称为服务器端脚本或服务器端脚本。
客户端脚本是浏览器行为的编程。(看)。
什么是服务器脚本?
通常,当浏览器请求 HTML 文件时,服务器会返回该文件,但如果该文件收录服务器端脚本,则在 HTML 文件作为纯 HTML 返回给浏览器之前,会先执行 HTML 文件中的脚本。
服务器脚本可以做什么?
重要提示:由于脚本是在服务器上执行的,所以浏览器可以在没有脚本支持的情况下显示服务器端文件!
ASP 和 PHP
在 W3School,我们使用 Active Server Pages (ASP) 和超文本预处理器 (PHP) 演示服务器端脚本。
看源码是看不到 ASP 或 PHP 的源码的,你看到的只是服务器的输出,纯 HTML。这是因为脚本在结果以纯 HTML 形式发送到浏览器之前在服务器上执行。
ASP 实例
通过 ASP 编写文本
如何通过 ASP 编写文本。
将 HTML 添加到文本
如何通过 HTML 标签格式化文本。
脚本教程
请学习我们完整的 ASP 教程和 PHP 教程。
W3School简体中文版提供的内容仅供培训和测试之用,不保证内容的正确性。与使用本网站内容相关的风险与本网站无关。版权所有,保留所有权利。
网页视频抓取脚本(一家的用途是什么?是怎么做的??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-16 04:04
作为大数据公司的运营编辑,经常有人问我,“嗯?爬虫是什么意思?” “爬行动物有什么用?” “你们公司有卖爬虫的吗,有蜥蜴吗?”等等一系列的问题,面对这些问题,小编绝望了。那么爬行动物到底是什么?
一、什么是爬虫
以下是百度百科对网络爬虫的定义:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
通俗的说,爬虫是可以自动上网并下载网站内容的程序或脚本,类似于机器人可以在自己的电脑上获取别人的网站信息,然后做一些事情筛选、筛选、汇总、排序、排序等。
网络爬虫的英文名是Web Spider,是一个很形象的名字。互联网被比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到这个网站的所有网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
二、爬虫能做什么
现在大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为,分析自身产品的不足,分析竞争对手的信息等等,但其中首要的条件是数据的采集。从招聘网站可以看出,很多公司都在高薪招聘爬虫工程师。但是,作为一项专业技能,网络爬虫不可能在很短的时间内学会。随着互联网的飞速发展,网站的种类也越来越多。许多传统企业因为跟不上时代的发展而被竞争对手甩在后面。苦于不懂技术,无从下手。
三、不懂爬虫技术怎么办?
小金蟾爬虫数据采集系统是一款通用的互联网数据采集软件。软件高度可视化的特点,让大家轻松上手,操作简单,精准智能采集让企业以极少的成本获得所需的数据,同时采集@ >快速的速度和全面的服务范围也给用户带来了极大的便利。
它还可以帮助企业用户分析数据。当企业面对大量数据却不知如何处理时,可以根据用户需求提供定制化服务,分析行业发展趋势,帮助企业用户在多方面构建优势。
在各行业快速发展的时代,如果再迈出下一步,可能会被行业浪潮淹没。新公司和消失公司的数量是难以想象的。企业要实现长期稳定发展,就必须紧跟时代步伐。,甚至快了一步,而这快了一步,就是你能为你做的。 查看全部
网页视频抓取脚本(一家的用途是什么?是怎么做的??)
作为大数据公司的运营编辑,经常有人问我,“嗯?爬虫是什么意思?” “爬行动物有什么用?” “你们公司有卖爬虫的吗,有蜥蜴吗?”等等一系列的问题,面对这些问题,小编绝望了。那么爬行动物到底是什么?
一、什么是爬虫
以下是百度百科对网络爬虫的定义:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
通俗的说,爬虫是可以自动上网并下载网站内容的程序或脚本,类似于机器人可以在自己的电脑上获取别人的网站信息,然后做一些事情筛选、筛选、汇总、排序、排序等。
网络爬虫的英文名是Web Spider,是一个很形象的名字。互联网被比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到这个网站的所有网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
二、爬虫能做什么
现在大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为,分析自身产品的不足,分析竞争对手的信息等等,但其中首要的条件是数据的采集。从招聘网站可以看出,很多公司都在高薪招聘爬虫工程师。但是,作为一项专业技能,网络爬虫不可能在很短的时间内学会。随着互联网的飞速发展,网站的种类也越来越多。许多传统企业因为跟不上时代的发展而被竞争对手甩在后面。苦于不懂技术,无从下手。
三、不懂爬虫技术怎么办?
小金蟾爬虫数据采集系统是一款通用的互联网数据采集软件。软件高度可视化的特点,让大家轻松上手,操作简单,精准智能采集让企业以极少的成本获得所需的数据,同时采集@ >快速的速度和全面的服务范围也给用户带来了极大的便利。
它还可以帮助企业用户分析数据。当企业面对大量数据却不知如何处理时,可以根据用户需求提供定制化服务,分析行业发展趋势,帮助企业用户在多方面构建优势。
在各行业快速发展的时代,如果再迈出下一步,可能会被行业浪潮淹没。新公司和消失公司的数量是难以想象的。企业要实现长期稳定发展,就必须紧跟时代步伐。,甚至快了一步,而这快了一步,就是你能为你做的。
网页视频抓取脚本( 2017年10月09日#load-media.jsexportdefaultloadMedia)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-14 13:15
2017年10月09日#load-media.jsexportdefaultloadMedia)
JS实现预加载视频音视频获取截图(返回画布截图)
更新时间:2017-10-09 15:29:55 作者:capricorncd
本篇文章主要介绍JS实现预加载视频音频/视频获取截图(返回canvas截图)的相关信息。有需要的朋友可以参考以下
#load-media.js
/**
* Create by Capricorncd 2017
*/
// 同域资源实现视频截图,可上传的图片数据格式
// 非同域资源实现canvas截图预览
// 提示码
const CODES = {
0: 'success',
1: 'The url is not valid',
2: 'onerror'
}
/**
* constructor
* @param opts.url 音频|视频URL
* @param opts.type 'audio|video'
* @param opts.callback 回调函数
*/
function loadMedia(opts) {
this.callback = opts.callback || function (res) {
console.log(res);
}
// 初始化
this.init(opts);
}
// prototype
loadMedia.prototype = {
/**
* 初始化media
* @param url
*/
init: function (opts) {
let self = this;
if (!opts.url || typeof opts.url !== 'string') {
this.callback({code: 1, msg: CODES[1]});
return;
}
// 创建media
let mediaType = opts.type === 'audio' ? 'audio' : 'video';
this.media = document.createElement(mediaType);
console.log('this.media', this.media);
// loaded
this.listener('canplaythrough', function (e) {
// 截图
if (mediaType === 'video') {
self.screenshot();
} else {
self.callback({
code: 0,
msg: CODES[0],
thumb: null,
media: this.media,
canvas: null
});
}
});
// error
this.listener('error', function (e) {
self.callback({code: 2, msg: CODES[2], data: e});
})
this.media.setAttribute('src', opts.url);
},
screenshot: function () {
// create canvas
let canvas = document.createElement('canvas');
canvas.width = this.media.videoWidth;
canvas.height = this.media.videoHeight;
let ctx = canvas.getContext('2d');
// 截取
ctx.drawImage(this.media, 0, 0);
let thumb = null;
// 非跨域资源
// !!非同域资源无法获取数据
try {
let type = 'image/png';
let data = canvas.toDataURL(type);
thumb = this.toBlobData(data, type);
} catch (e) {}
this.callback({
code: 0,
msg: CODES[0],
thumb: thumb,
media: this.media,
canvas: canvas
})
},
// 数据转换
toBlobData: function (data, type) {
// 获取base64数据
// base64数据格式:
// "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQEASABIAAD/2wBDAAkGB+wgHBgkIBwgKCgkLDRYPDQw//9k="
data = window.atob(data.split(',')[1]);
let ia = new Uint8Array(data.length);
for (let i = 0; i < data.length; i++) {
ia[i] = data.charCodeAt(i);
};
// canvas.toDataURL 返回的默认格式是 image/png
return new Blob([ia], {type: type});
},
/**
* addEventListener 事件监听
* @param en EventName
* @param callback
*/
listener: function (en, callback) {
this.media.addEventListener(en, function (e) {
if (callback) {
callback(e);
} else {
console.warn(this);
}
}, false);
}
/**
* 资源是否跨域
* @param url 资源地址
* @returns {boolean}
*/
// isCrossDomain: function (url) {
// let loc, host, protocol;
// loc = window.location;
// host = loc.host;
// protocol = loc.protocol;
// // 是否为http链接
// if (/(http|https):\/\//.test(url)) {
// if (url.indexOf(protocol + '//' + host) >= 0) {
// return false;
// } else {
// return true;
// }
// }
// // './xxx.mp4' '/xxx.mp4' 'xxx.mp4'
// return false;
// }
}
导出默认加载媒体;
// 参考资料
// HTML5的Video标签的属性,方法和事件汇总
// http://www.cnblogs.com/TF12138/p/4448108.html
# 使用
import loadMedia from '@/common/js/load-media'
let loadVideo = new loadMedia({
type: 'video',
url: 'http://xmqvip1-1253933147.file.myqcloud.com/chat/video/60/2017/09/29/qgj1c8K7oaYn-SCVideo-Merged.mp4',
callback: handleCallback
})
function handleCallback (res) {
console.log(res)
// canplaythrough
if (res.code === 0) {
}
// error
if (res.code === 2) {
}
}
总结
以上就是小编介绍的预加载视频音频/视频获取截图(返回画布截图)的JS实现。我希望它对你有帮助。如有任何问题,请给我留言,小编会及时回复您。. 还要感谢大家对脚本之家网站的支持! 查看全部
网页视频抓取脚本(
2017年10月09日#load-media.jsexportdefaultloadMedia)
JS实现预加载视频音视频获取截图(返回画布截图)
更新时间:2017-10-09 15:29:55 作者:capricorncd
本篇文章主要介绍JS实现预加载视频音频/视频获取截图(返回canvas截图)的相关信息。有需要的朋友可以参考以下
#load-media.js
/**
* Create by Capricorncd 2017
*/
// 同域资源实现视频截图,可上传的图片数据格式
// 非同域资源实现canvas截图预览
// 提示码
const CODES = {
0: 'success',
1: 'The url is not valid',
2: 'onerror'
}
/**
* constructor
* @param opts.url 音频|视频URL
* @param opts.type 'audio|video'
* @param opts.callback 回调函数
*/
function loadMedia(opts) {
this.callback = opts.callback || function (res) {
console.log(res);
}
// 初始化
this.init(opts);
}
// prototype
loadMedia.prototype = {
/**
* 初始化media
* @param url
*/
init: function (opts) {
let self = this;
if (!opts.url || typeof opts.url !== 'string') {
this.callback({code: 1, msg: CODES[1]});
return;
}
// 创建media
let mediaType = opts.type === 'audio' ? 'audio' : 'video';
this.media = document.createElement(mediaType);
console.log('this.media', this.media);
// loaded
this.listener('canplaythrough', function (e) {
// 截图
if (mediaType === 'video') {
self.screenshot();
} else {
self.callback({
code: 0,
msg: CODES[0],
thumb: null,
media: this.media,
canvas: null
});
}
});
// error
this.listener('error', function (e) {
self.callback({code: 2, msg: CODES[2], data: e});
})
this.media.setAttribute('src', opts.url);
},
screenshot: function () {
// create canvas
let canvas = document.createElement('canvas');
canvas.width = this.media.videoWidth;
canvas.height = this.media.videoHeight;
let ctx = canvas.getContext('2d');
// 截取
ctx.drawImage(this.media, 0, 0);
let thumb = null;
// 非跨域资源
// !!非同域资源无法获取数据
try {
let type = 'image/png';
let data = canvas.toDataURL(type);
thumb = this.toBlobData(data, type);
} catch (e) {}
this.callback({
code: 0,
msg: CODES[0],
thumb: thumb,
media: this.media,
canvas: canvas
})
},
// 数据转换
toBlobData: function (data, type) {
// 获取base64数据
// base64数据格式:
// "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQEASABIAAD/2wBDAAkGB+wgHBgkIBwgKCgkLDRYPDQw//9k="
data = window.atob(data.split(',')[1]);
let ia = new Uint8Array(data.length);
for (let i = 0; i < data.length; i++) {
ia[i] = data.charCodeAt(i);
};
// canvas.toDataURL 返回的默认格式是 image/png
return new Blob([ia], {type: type});
},
/**
* addEventListener 事件监听
* @param en EventName
* @param callback
*/
listener: function (en, callback) {
this.media.addEventListener(en, function (e) {
if (callback) {
callback(e);
} else {
console.warn(this);
}
}, false);
}
/**
* 资源是否跨域
* @param url 资源地址
* @returns {boolean}
*/
// isCrossDomain: function (url) {
// let loc, host, protocol;
// loc = window.location;
// host = loc.host;
// protocol = loc.protocol;
// // 是否为http链接
// if (/(http|https):\/\//.test(url)) {
// if (url.indexOf(protocol + '//' + host) >= 0) {
// return false;
// } else {
// return true;
// }
// }
// // './xxx.mp4' '/xxx.mp4' 'xxx.mp4'
// return false;
// }
}
导出默认加载媒体;
// 参考资料
// HTML5的Video标签的属性,方法和事件汇总
// http://www.cnblogs.com/TF12138/p/4448108.html
# 使用
import loadMedia from '@/common/js/load-media'
let loadVideo = new loadMedia({
type: 'video',
url: 'http://xmqvip1-1253933147.file.myqcloud.com/chat/video/60/2017/09/29/qgj1c8K7oaYn-SCVideo-Merged.mp4',
callback: handleCallback
})
function handleCallback (res) {
console.log(res)
// canplaythrough
if (res.code === 0) {
}
// error
if (res.code === 2) {
}
}
总结
以上就是小编介绍的预加载视频音频/视频获取截图(返回画布截图)的JS实现。我希望它对你有帮助。如有任何问题,请给我留言,小编会及时回复您。. 还要感谢大家对脚本之家网站的支持!
网页视频抓取脚本(手机(安卓、ios都可以)/安卓模拟器 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2022-02-13 18:11
)
准备好工作了:
(1),手机(安卓和ios)/安卓模拟器,今天主要以安卓模拟器为主,操作流程是一样的。
(2),抓包工具:Fiddel 下载地址:()
(3),编程工具:pycharm
(4),安卓模拟器/手机安装抖音
一、提琴手配置
在tools中的options中,勾选如图所示的框,点击Actions
配置远程链接:
选择允许监控远程链接,端口可以随意设置,只要不重复,默认8888
然后:重启提琴手!!!此配置将生效。
二、安卓模拟器/手机配置
首先查看机器的IP:在cmd中输入ipconfig,记住这个IP
确保手机和电脑在同一个局域网中。
手机配置:配置连接的WiFi,代理选择手动,然后如上图输入ip端口号为8888
模拟器配置:在设置中长按连接的wifi,选择manual作为代理,然后输入ip端口号如上图为8888
设置好代理后,在浏览器中输入你设置的ip:port,比如10.10.16.194:8888,就会打开fiddler页面。然后点击fiddlerRoot证书安装证书,否则手机会认为环境不安全。
证书名称可以任意设置,可能还需要设置锁屏密码。
接下来,您可以在 fiddler 中抓取手机/模拟器软件的软件包。
三、抖音捕获数据包
打开 抖音 并观察 fiddler 中的所有包
有一个包,包类型是json(json是网页返回的数据,具体是百度),主机地址如图,包大小一般不小,这个是视频包。
点击这个json包,在fidder右侧,点击decode,我们将解码视频包的json
解码后:点击awesome_list,其中每个大括号代表一个视频,这个和bilibili弹幕或者快手一样,每次加载一点,读完预加载的再加载一些
接下来解决几个问题,
1、视频数量,每个包就这么多视频,怎么抢更多?
这时候需要用模拟器的模拟鼠标翻页,让模拟器不停的翻页,这样json包才会不断出现。
2、如何在本地保存json以供使用
一种方法是手动复制粘贴,但这非常低。
所以我们使用fidder自带的脚本,在里面添加规则,刷出视频json包时自动保存json包。
自定义规则包:
关联:
提取码:7z0l
单击规则脚本并放置自定义规则,如图所示:
这个脚本有两点需要修改:
(1)第一行的网址:
这是从视频包的 url 中提取的。抖音 会不定时更新这个url,所以如果不能使用就必须更新:
比如现在的和昨天的不一样,记得修改。
(2)路径,也就是我设置json包保存的地址,必须自己修改,并创建文件夹,修改后记得保存。
打开并设置好模拟器和脚本后,稍等片刻,就可以看到文件夹中保存的包:
四、爬虫脚本
接下来在pycharm中编写脚本获取json包中的视频链接:
指导包:
导入操作系统,json,请求
迷彩头:(F12获取,如何获取具体参考之前的爬虫图文)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, 像壁虎)Chrome/72.0.3626.119 Safari/537.36'}
逻辑代码:
运行代码:
影响:
源代码:
import os,json,requests
#伪装头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'}
videos_list = os.listdir('C:/Users/HEXU/Desktop/抖音数据爬取/抖音爬取资料/raw_data/') #获取文件夹内所有json包名
count = 1 #计数,用来作为视频名字
for videos in videos_list: #循环json列表,对每个json包进行操作
a = open('./抖音爬取资料/raw_data/{}'.format(videos),encoding='utf-8') #打开json包
content = json.load(a)['aweme_list'] #取出json包中所有视频
for video in content: #循环视频列表,选取每个视频
video_url = video['video']['play_addr']['url_list'][4] #获取视频url,每个视频有6个url,我选的第5个
videoMp4 = requests.request('get',video_url,headers=headers).content #获取视频二进制代码
with open('./抖音爬取资料/VIDEO/{}.mp4'.format(count),'wb') as f: #以二进制方式写入路径,记住要先创建路径
f.write(videoMp4) #写入
print('视频{}下载完成'.format(count)) #下载提示
count += 1 #计数+1 查看全部
网页视频抓取脚本(手机(安卓、ios都可以)/安卓模拟器
)
准备好工作了:
(1),手机(安卓和ios)/安卓模拟器,今天主要以安卓模拟器为主,操作流程是一样的。
(2),抓包工具:Fiddel 下载地址:()
(3),编程工具:pycharm
(4),安卓模拟器/手机安装抖音
一、提琴手配置
在tools中的options中,勾选如图所示的框,点击Actions
配置远程链接:
选择允许监控远程链接,端口可以随意设置,只要不重复,默认8888
然后:重启提琴手!!!此配置将生效。
二、安卓模拟器/手机配置
首先查看机器的IP:在cmd中输入ipconfig,记住这个IP
确保手机和电脑在同一个局域网中。
手机配置:配置连接的WiFi,代理选择手动,然后如上图输入ip端口号为8888
模拟器配置:在设置中长按连接的wifi,选择manual作为代理,然后输入ip端口号如上图为8888
设置好代理后,在浏览器中输入你设置的ip:port,比如10.10.16.194:8888,就会打开fiddler页面。然后点击fiddlerRoot证书安装证书,否则手机会认为环境不安全。
证书名称可以任意设置,可能还需要设置锁屏密码。
接下来,您可以在 fiddler 中抓取手机/模拟器软件的软件包。
三、抖音捕获数据包
打开 抖音 并观察 fiddler 中的所有包
有一个包,包类型是json(json是网页返回的数据,具体是百度),主机地址如图,包大小一般不小,这个是视频包。
点击这个json包,在fidder右侧,点击decode,我们将解码视频包的json
解码后:点击awesome_list,其中每个大括号代表一个视频,这个和bilibili弹幕或者快手一样,每次加载一点,读完预加载的再加载一些
接下来解决几个问题,
1、视频数量,每个包就这么多视频,怎么抢更多?
这时候需要用模拟器的模拟鼠标翻页,让模拟器不停的翻页,这样json包才会不断出现。
2、如何在本地保存json以供使用
一种方法是手动复制粘贴,但这非常低。
所以我们使用fidder自带的脚本,在里面添加规则,刷出视频json包时自动保存json包。
自定义规则包:
关联:
提取码:7z0l
单击规则脚本并放置自定义规则,如图所示:
这个脚本有两点需要修改:
(1)第一行的网址:
这是从视频包的 url 中提取的。抖音 会不定时更新这个url,所以如果不能使用就必须更新:
比如现在的和昨天的不一样,记得修改。
(2)路径,也就是我设置json包保存的地址,必须自己修改,并创建文件夹,修改后记得保存。
打开并设置好模拟器和脚本后,稍等片刻,就可以看到文件夹中保存的包:
四、爬虫脚本
接下来在pycharm中编写脚本获取json包中的视频链接:
指导包:
导入操作系统,json,请求
迷彩头:(F12获取,如何获取具体参考之前的爬虫图文)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, 像壁虎)Chrome/72.0.3626.119 Safari/537.36'}
逻辑代码:
运行代码:
影响:
源代码:
import os,json,requests
#伪装头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'}
videos_list = os.listdir('C:/Users/HEXU/Desktop/抖音数据爬取/抖音爬取资料/raw_data/') #获取文件夹内所有json包名
count = 1 #计数,用来作为视频名字
for videos in videos_list: #循环json列表,对每个json包进行操作
a = open('./抖音爬取资料/raw_data/{}'.format(videos),encoding='utf-8') #打开json包
content = json.load(a)['aweme_list'] #取出json包中所有视频
for video in content: #循环视频列表,选取每个视频
video_url = video['video']['play_addr']['url_list'][4] #获取视频url,每个视频有6个url,我选的第5个
videoMp4 = requests.request('get',video_url,headers=headers).content #获取视频二进制代码
with open('./抖音爬取资料/VIDEO/{}.mp4'.format(count),'wb') as f: #以二进制方式写入路径,记住要先创建路径
f.write(videoMp4) #写入
print('视频{}下载完成'.format(count)) #下载提示
count += 1 #计数+1
网页视频抓取脚本(怎么去抓取HTTP的请求包?(二)与SlimerJS内核)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-13 07:16
简介
前两篇文章介绍了如何抓包HTTP请求包,包括代理服务器的使用和抓包方法。因为当前视频网站的视频地址不是直接在html页面上获取的,所以视频是通过浏览器动态解释js脚本获取的,然后向视频服务器发送视频请求。所以我们通过获取浏览器生成的HTTP请求来获取视频的下载地址。
思路是直接用firefox
我们想到了可以动态渲染 js 脚本的程序,最常见的是浏览器。我们通过命令运行
您可以使用 firefox 打开 URL。但是没有显示我们就不能用了,不过我们以后有办法解决这个问题。
python+selenium+Phantomjs
因为我们需要渲染JS脚本而不需要界面显示,所以我们也想到了python+selenium+Phantomjs来动态渲染页面。 Phantomjs 是无头浏览器(无头浏览器就是没有界面的浏览器)。
但是在 Phantomjs 1. 版本 5 之后,不再支持 flash 插件。也就是说,虽然 Phantomjs 可以动态加载 JS 脚本,但不能渲染视频。因此不会发出获取视频的 HTTP 请求。
我截图得到了渲染后的页面,如下图:
视频播放窗口黑屏,抓包程序无法捕获带有flv字符串的HTTP请求。
我也试过1.4.1版的Phantomjs,说可以通过这个命令加载Flash插件
./bin/phantomjs --load-plugins=yes examples/snap.js
通过渲染JS脚本,截图如下:
虽然得到的截图和上面的不一样,但是视频中有加载状态,但是还是抓不到视频的HTTP请求。最后在python中调用webdriver.Phantomjs()时报错。
最后不得不放弃使用 Phantomjs
slimerjs
当我在网上搜索无头浏览器时,我也发现了 slimerjs。
**PhantomJS 和 SlimerJS 的异同:**来自这篇文章文章
PhantomJS基于Webkit内核,不支持Flash播放 SlimerJS基于Firefox的Gecko内核,支持Flash播放,执行过程会显示在页面上
所以我们需要支持 Flash 播放。但是问题又来了! SlimerJS 不是纯粹的无头浏览器,它需要 DISPLAY! ! 那么我们能做些什么来解决这个问题呢?有!
xvfb
xvfb通过提供一个类似的X server daemon并设置环境变量DISPLAY让程序运行来提供程序运行环境
通过这个,你也可以解决前面提到的第一个火狐遇到的问题。我感觉我一直在一个圈子里= =!
方案实施
最后我们决定使用 slimerjs 来获取页面。因为没有办法通过python的selenium方法调用slimerjs,那么我们只能通过python调用命令行程序的方法来动态渲染页面。 slimerjs 脚本如下。当我们调用这个脚本时,我们传入一个网页地址参数。 slimerjs 负责打开这个页面并渲染页面的内容。
这个脚本的文件名是getPage.js
我们的python调用os.system("xvfb-run slimerjs getPage.js " + videoURL) 来渲染视频URL的视频。
我们最终的 Python 程序是 slimerjs_crawl_video.py
获取视频地址! !
未解决的问题
调用python slimerjs_crawl_video.py时,
我不知道如何控制这个时间。我尝试修改getPage.js的window.setTimeout函数的时间,但还是需要90多秒。我猜python的 os.system() 的限制是阻止某些时间。返回的时间(超过 90 秒)。接下来我会查一些相关的。
原来这个标题不太适合这个文章。但是还是没变,因为我原来是按照无头浏览器的思路解决这个问题的 查看全部
网页视频抓取脚本(怎么去抓取HTTP的请求包?(二)与SlimerJS内核)
简介
前两篇文章介绍了如何抓包HTTP请求包,包括代理服务器的使用和抓包方法。因为当前视频网站的视频地址不是直接在html页面上获取的,所以视频是通过浏览器动态解释js脚本获取的,然后向视频服务器发送视频请求。所以我们通过获取浏览器生成的HTTP请求来获取视频的下载地址。
思路是直接用firefox
我们想到了可以动态渲染 js 脚本的程序,最常见的是浏览器。我们通过命令运行
您可以使用 firefox 打开 URL。但是没有显示我们就不能用了,不过我们以后有办法解决这个问题。
python+selenium+Phantomjs
因为我们需要渲染JS脚本而不需要界面显示,所以我们也想到了python+selenium+Phantomjs来动态渲染页面。 Phantomjs 是无头浏览器(无头浏览器就是没有界面的浏览器)。
但是在 Phantomjs 1. 版本 5 之后,不再支持 flash 插件。也就是说,虽然 Phantomjs 可以动态加载 JS 脚本,但不能渲染视频。因此不会发出获取视频的 HTTP 请求。
我截图得到了渲染后的页面,如下图:
视频播放窗口黑屏,抓包程序无法捕获带有flv字符串的HTTP请求。
我也试过1.4.1版的Phantomjs,说可以通过这个命令加载Flash插件
./bin/phantomjs --load-plugins=yes examples/snap.js
通过渲染JS脚本,截图如下:
虽然得到的截图和上面的不一样,但是视频中有加载状态,但是还是抓不到视频的HTTP请求。最后在python中调用webdriver.Phantomjs()时报错。
最后不得不放弃使用 Phantomjs
slimerjs
当我在网上搜索无头浏览器时,我也发现了 slimerjs。
**PhantomJS 和 SlimerJS 的异同:**来自这篇文章文章
PhantomJS基于Webkit内核,不支持Flash播放 SlimerJS基于Firefox的Gecko内核,支持Flash播放,执行过程会显示在页面上
所以我们需要支持 Flash 播放。但是问题又来了! SlimerJS 不是纯粹的无头浏览器,它需要 DISPLAY! ! 那么我们能做些什么来解决这个问题呢?有!
xvfb
xvfb通过提供一个类似的X server daemon并设置环境变量DISPLAY让程序运行来提供程序运行环境
通过这个,你也可以解决前面提到的第一个火狐遇到的问题。我感觉我一直在一个圈子里= =!
方案实施
最后我们决定使用 slimerjs 来获取页面。因为没有办法通过python的selenium方法调用slimerjs,那么我们只能通过python调用命令行程序的方法来动态渲染页面。 slimerjs 脚本如下。当我们调用这个脚本时,我们传入一个网页地址参数。 slimerjs 负责打开这个页面并渲染页面的内容。
这个脚本的文件名是getPage.js
我们的python调用os.system("xvfb-run slimerjs getPage.js " + videoURL) 来渲染视频URL的视频。
我们最终的 Python 程序是 slimerjs_crawl_video.py
获取视频地址! !
未解决的问题
调用python slimerjs_crawl_video.py时,
我不知道如何控制这个时间。我尝试修改getPage.js的window.setTimeout函数的时间,但还是需要90多秒。我猜python的 os.system() 的限制是阻止某些时间。返回的时间(超过 90 秒)。接下来我会查一些相关的。
原来这个标题不太适合这个文章。但是还是没变,因为我原来是按照无头浏览器的思路解决这个问题的
网页视频抓取脚本(STM32视频段的加密手段(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-13 07:10
)
文章内容仅供学习
一:未加密的网页
F12打开开发者工具,对齐视频窗口,vedio标签中的src会有视频资源链接
二:加密网页没有直接资源地址,视频文件被分成n段传输
如上图,链接前有一个blob标记。我们不能直接使用这个资源链接。
但是,我们可以通过开发者工具的“网络”抓包
搜索关键词“ts”(即后缀为ts的视频文件)
这里每个包都是一个视频,n个视频放在一起组成一个视频
通过观察可以发现,这些视频片段的资源链接是有规律的
最后 3 位从 0 递增
然后,你可以把视频拉到最后,查看最后一个视频的地址
发现最后一个视频链接的后三位是430
那么,让我们把这431个ts的视频文件下载下来,然后拼接起来吧~
我在 IDM 的帮助下进行批量下载
使用此脚本完成431视频片段的下载
之后就是视频拼接,我用的软件是:合并工具
合并ts片段后就是一个完整的视频文件
三:blob的一种处理方法
去掉带有blob的视频链接后,网页会自动解析出真实的资源地址
(仅适用于一些 网站s)
第二种处理方法
新建一个a标签,然后在href中填入blob的资源地址:标签,然后点击访问
(记得在a标签中添加内容,否则在网页中是找不到的)
ps:有的网站加密方式比较厉害,这类视频片段的资源链接不规范。我还没有想到下载那种 网站 的方法。
还有一些网站会限制访问,需要正确的key才能有访问资源的权限,否则会报403
还有,一酷一奇艺的视频链接是这样加密的(这不是ts视频片段,而是mp4后缀)
对于同一个资源地址,n个视频段用标识码区分,加上控制访问权限的键值加密
(有些有 start 和 end 我们可以用这个代替下载 - 从视频的开头开始,在视频的结尾结束)
三:通过python包下载(前提是安装了python)
蟒蛇安装
用you-get包下载视频
进入命令行窗口:
1pip install you-get
2
3
1you-get 视频网站
2
3
(链接到网页)
上图为下载BZ的视频
视频默认保存在 C:\Users\username\
也可以指定输出目录
1you-get -o D:/movie 视频网站
2
3 查看全部
网页视频抓取脚本(STM32视频段的加密手段(一)
)
文章内容仅供学习
一:未加密的网页
F12打开开发者工具,对齐视频窗口,vedio标签中的src会有视频资源链接
二:加密网页没有直接资源地址,视频文件被分成n段传输
如上图,链接前有一个blob标记。我们不能直接使用这个资源链接。
但是,我们可以通过开发者工具的“网络”抓包
搜索关键词“ts”(即后缀为ts的视频文件)
这里每个包都是一个视频,n个视频放在一起组成一个视频
通过观察可以发现,这些视频片段的资源链接是有规律的
最后 3 位从 0 递增
然后,你可以把视频拉到最后,查看最后一个视频的地址
发现最后一个视频链接的后三位是430
那么,让我们把这431个ts的视频文件下载下来,然后拼接起来吧~
我在 IDM 的帮助下进行批量下载
使用此脚本完成431视频片段的下载
之后就是视频拼接,我用的软件是:合并工具
合并ts片段后就是一个完整的视频文件
三:blob的一种处理方法
去掉带有blob的视频链接后,网页会自动解析出真实的资源地址
(仅适用于一些 网站s)
第二种处理方法
新建一个a标签,然后在href中填入blob的资源地址:标签,然后点击访问
(记得在a标签中添加内容,否则在网页中是找不到的)
ps:有的网站加密方式比较厉害,这类视频片段的资源链接不规范。我还没有想到下载那种 网站 的方法。
还有一些网站会限制访问,需要正确的key才能有访问资源的权限,否则会报403
还有,一酷一奇艺的视频链接是这样加密的(这不是ts视频片段,而是mp4后缀)
对于同一个资源地址,n个视频段用标识码区分,加上控制访问权限的键值加密
(有些有 start 和 end 我们可以用这个代替下载 - 从视频的开头开始,在视频的结尾结束)
三:通过python包下载(前提是安装了python)
蟒蛇安装
用you-get包下载视频
进入命令行窗口:
1pip install you-get
2
3
1you-get 视频网站
2
3
(链接到网页)
上图为下载BZ的视频
视频默认保存在 C:\Users\username\
也可以指定输出目录
1you-get -o D:/movie 视频网站
2
3
网页视频抓取脚本( 网页恶意脚本通过多样化的混淆机制隐藏自己,它还能动态创建浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-07 11:10
网页恶意脚本通过多样化的混淆机制隐藏自己,它还能动态创建浏览器)
网页的恶意脚本通过各种混淆机制隐藏自身,还可以动态创建嵌入链接并对链接内容进行编码。那么,恶意网页脚本是利用什么来传播的呢?
小编了解到,网页上的恶意脚本本质上是依靠浏览器利用漏洞下载木马并传播给用户。因此,传统的反木马检测方法在检测网页恶意脚本方面存在比较大的缺陷。
常见的网页恶意脚本检测技术包括客户端蜜罐技术、静态代码检测和动态行为检测。
1) 客户端蜜罐技术。客户端蜜罐主要针对客户端软件中存在的漏洞,主动寻找可能的攻击行为。在与服务器的交互过程中,客户端蜜罐不断监测系统的变化,并引入各种检测手段来判断是否存在恶意攻击。这种方法的缺点是花费大量时间,并且难以分析性能提升。北京大学张慧琳等人提出了一种基于网页动态视图的网页恶意脚本检测方法,主要是重构网页的动态视图。的目标。
2) 静态代码检测。静态代码检测技术是根据已知网页恶意脚本样本库程序代码本身的特点,检测未知网页程序是否为网页恶意脚本程序。它主要是解析网页,提取网页中的静态嵌入链接和本地脚本,然后通过一定的技术筛选特征集,建立相应的模型,检测未知网页程序的代码特征,并将这些特征与筛选的特征集。如果代码特征匹配,该网页程序将被定义为网页恶意脚本,否则为普通网页程序。
以上就是小编为大家介绍的网页恶意脚本的介绍。希望对朋友有帮助。关于如何检测和清除脚本病毒,如果想了解这部分网络病毒知识,点击百白安全网。 查看全部
网页视频抓取脚本(
网页恶意脚本通过多样化的混淆机制隐藏自己,它还能动态创建浏览器)
网页的恶意脚本通过各种混淆机制隐藏自身,还可以动态创建嵌入链接并对链接内容进行编码。那么,恶意网页脚本是利用什么来传播的呢?
小编了解到,网页上的恶意脚本本质上是依靠浏览器利用漏洞下载木马并传播给用户。因此,传统的反木马检测方法在检测网页恶意脚本方面存在比较大的缺陷。
常见的网页恶意脚本检测技术包括客户端蜜罐技术、静态代码检测和动态行为检测。
1) 客户端蜜罐技术。客户端蜜罐主要针对客户端软件中存在的漏洞,主动寻找可能的攻击行为。在与服务器的交互过程中,客户端蜜罐不断监测系统的变化,并引入各种检测手段来判断是否存在恶意攻击。这种方法的缺点是花费大量时间,并且难以分析性能提升。北京大学张慧琳等人提出了一种基于网页动态视图的网页恶意脚本检测方法,主要是重构网页的动态视图。的目标。
2) 静态代码检测。静态代码检测技术是根据已知网页恶意脚本样本库程序代码本身的特点,检测未知网页程序是否为网页恶意脚本程序。它主要是解析网页,提取网页中的静态嵌入链接和本地脚本,然后通过一定的技术筛选特征集,建立相应的模型,检测未知网页程序的代码特征,并将这些特征与筛选的特征集。如果代码特征匹配,该网页程序将被定义为网页恶意脚本,否则为普通网页程序。
以上就是小编为大家介绍的网页恶意脚本的介绍。希望对朋友有帮助。关于如何检测和清除脚本病毒,如果想了解这部分网络病毒知识,点击百白安全网。
网页视频抓取脚本(如何用python3编写一个文件序列文件中的基因功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-31 04:16
操作说明
在基因组分析中,我们经常有这样的需求,需要从fasta文件中提取一些序列。有时这些序列是完整的序列,有时它们只是原创 fasta 文件中序列的一部分。尤其是数据量大的时候,用肉眼来选择序列会很困难,那么我们可以通过简单的编程来实现。
例如,一个物种的全基因组序列(0-refer/Bacillus_subtilis.str168.fasta)及其基因组gff注释文件(0-refer/Bacillus_subtilis.str168.gff)。这里假设我们对这个物种进行研究,通过gff注释文件中的基因功能描述字段定位一些特定的基因,加上相关数据的访问等。接下来,我们期望在全基因组序列中找到并提取这些基因fasta 文件根据 gff 文件中这些基因的位置描述,得到一个新的 fasta 文件,该文件只收录目标基因序列。
请使用python3编写一个可以做到这一点的脚本。
例子
示例脚本如下(见网盘附件“seq_select1.py”)。
为了达到上述目的,我们首先需要准备一个txt文件(以下简称list文件,示例list.txt可以在网盘附件中找到),根据记录的基因位置信息gff 文件,填写类似如下内容(列和列之间用制表符分隔)。
1.png
#将以下内容保存到list.txt
基因46 NC_000964.3 42917 43660 +
NP_387934.1 NC_000964.3 59504 60070 +
yfmC NC_000964.3 825787 826734 -
cds821 NC_000964.3 885844 886173 -
在第 1 列中,为要获得的新序列命名;
第二列,要获取的序列的原创序列ID;
第3列,原创序列中要获取的序列的起始位置;
第4列,原创序列中要得到的序列的终止位置;
在第 5 列中,要获得的序列位于原创序列的正 (+) 或负 (-) 链上。
然后根据输入文件编辑py脚本,即输入fasta文件和list文件中记录要获取的序列位置的内容。
打开fasta文件“Bacillus_subtilis.scaffolds.fasta”,使用循环逐行读取序列id和碱基序列,将每个序列的所有碱基组合成一个字符串;基本序列存储为字典(字典样式 {'id':'base'})。
打开列表文件“list.txt”,读取内容,存入字典。字典的键是列表文件中第一列的内容;字典的值是列表文件第2-5列的内容,除以tab得到一个列表,收录4个字符分别代表列表文件第2-5列的信息)。
最后根据read list文件中的序列位置信息,从read基因组中截取目标基因序列。由于某些基因序列可能位于基因组的负链中,因此需要取反向互补序列。因此,首先定义一个函数rev(),以便在后续调用中获取反向互补序列。在输出序列名称时,还可以选择是否将序列的位置信息一起输出(name_detail = True/False)。
#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
#初始通过命令
input_file = '枯草芽孢杆菌.str168.fasta'
list_file = 'list.txt'
output_file = 'gene.fasta'
name_detail = 真
##读取文件
#读取基因组序列
seq_file = {}
使用 open(input_file, 'r') 作为 input_fasta:
对于 input_fasta 中的行:
line = line.strip()
如果行 [0] == '>':
seq_id = line.split()[0]
seq_file[seq_id] = ''
别的:
seq_file[seq_id] += 行
input_fasta.close()
#读取列表文件
list_dict = {}
使用 open(list_file, 'r') 作为 list_table:
对于 list_table 中的行:
如果 line.strip():
line = line.strip().split('\t')
list_dict[line[0]] = [line[1], int(line[2]) - 1, int(line[3]), line[4]]
list_table.close()
##截取序列并输出
#定义一个截取逆补的函数
def rev(seq):
base_trans = {'A':'T', 'C':'G', 'T':'A', 'G':'C', 'N':'N', 'a':'t' , 'c':'g', 't':'a', 'g':'c', 'n':'n'}
rev_seq = 列表(反转(seq))
rev_seq_list = [base_trans[k] for k in rev_seq]
rev_seq = ''.join(rev_seq_list)
返回(rev_seq)
#截断序列并输出
output_fasta = 打开(输出文件,'w')
对于 list_dict.items() 中的键、值:
如果名称_详细信息:
print('>' + key, '[' + value[0], value[1] + 1, value[2], value[3] + ']', file = output_fasta)
别的:
打印('>' + 键,文件 = output_fasta)
seq = seq_file['>' + value[0]][value[1]:value[2]]
如果值 [3] == '+':
打印(序列,文件= output_fasta)
elif 值 [3] == '-':
seq = rev(seq)
打印(序列,文件= output_fasta)
output_fasta.close()
编辑好脚本后,运行并输出一个新的fasta文件“gene.fasta”,其序列就是我们要得到的目标基因序列。
2.png
延期:
网盘附件“seq_select.py”是一个python3脚本,增加了命令行传输线,可以直接在shell中对目标文件进行I/O处理。该脚本可以指定一个输入fasta序列文件和一个记录要提取的序列位置的列表文件,新的输出fasta文件就是提取的序列。
#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
#导入模块,初始传递命令、变量等
导入参数解析
parser = argparse.ArgumentParser(description = '\n该脚本用于截取基因组中特定位置的序列,并额外输入截取序列信息的列表文件', add_help = False, usage = '\npython3 seq_select.py -i [ input.fasta] -o [output.fasta] -l [list]\npython3 seq_select.py --input [input.fasta] --output [output.fasta] --list [list]')
required = parser.add_argument_group('必需选项')
可选 = parser.add_argument_group('可选')
required.add_argument('-i', '--input', metavar = '[input.fasta]', help = '输入文件, fasta 格式', required = True)
required.add_argument('-o', '--output', metavar = '[output.fasta]', help = '输出文件,fasta 格式', required = True)
required.add_argument('-l', '--list', metavar = '[list]', help = 'record "新序列名称/原序列的序列ID/序列起始位置/序列结束位置/正链( +) 或负链 (-)",以制表符分隔,必填 = True)
optional.add_argument('--detail', action = 'store_true', help = '如果该参数存在,则在输出fasta的每个sequence id中显示序列在原创fasta中的位置信息', required = False)
optional.add_argument('-h', '--help', action = 'help', help = '帮助信息')
args = parser.parse_args()
##读取文件
#读取基因组序列
seq_file = {}
使用 open(args.input, 'r') 作为 input_fasta:
对于 input_fasta 中的行:
line = line.strip()
如果行 [0] == '>':
seq_id = line.split()[0]
seq_file[seq_id] = ''
别的:
seq_file[seq_id] += 行
input_fasta.close()
#读取列表文件
list_dict = {}
使用 open(args.list, 'r') 作为 list_file:
对于 list_file 中的行:
如果 line.strip():
line = line.strip().split('\t')
list_dict[line[0]] = [line[1], int(line[2]) - 1, int(line[3]), line[4]]
list_file.close()
##截取序列并输出
#定义一个截取逆补的函数
def rev(seq):
base_trans = {'A':'T', 'C':'G', 'T':'A', 'G':'C', 'a':'t', 'c':'g' , 't':'a', 'g':'c'}
rev_seq = 列表(反转(seq))
rev_seq_list = [base_trans[k] for k in rev_seq]
rev_seq = ''.join(rev_seq_list)
返回(rev_seq)
#截断序列并输出
output_fasta = open(args.output, 'w')
对于 list_dict.items() 中的键、值:
如果 args.detail:
print('>' + key, '[' + value[0], value[1] + 1, value[2], value[3] + ']', file = output_fasta)
别的:
打印('>' + 键,文件 = output_fasta)
seq = seq_file['>' + value[0]][value[1]:value[2]]
如果值 [3] == '+':
打印(序列,文件= output_fasta)
elif 值 [3] == '-':
seq = rev(seq)
打印(序列,文件= output_fasta)
output_fasta.close()
使用上面示例中的测试文件,脚本运行如下。
#python3 seq_select.py -h
python3 seq_select.py -i Bacillus_subtilis.str168.fasta -l list.txt -o gene.fasta --detail
3.png 查看全部
网页视频抓取脚本(如何用python3编写一个文件序列文件中的基因功能)
操作说明
在基因组分析中,我们经常有这样的需求,需要从fasta文件中提取一些序列。有时这些序列是完整的序列,有时它们只是原创 fasta 文件中序列的一部分。尤其是数据量大的时候,用肉眼来选择序列会很困难,那么我们可以通过简单的编程来实现。
例如,一个物种的全基因组序列(0-refer/Bacillus_subtilis.str168.fasta)及其基因组gff注释文件(0-refer/Bacillus_subtilis.str168.gff)。这里假设我们对这个物种进行研究,通过gff注释文件中的基因功能描述字段定位一些特定的基因,加上相关数据的访问等。接下来,我们期望在全基因组序列中找到并提取这些基因fasta 文件根据 gff 文件中这些基因的位置描述,得到一个新的 fasta 文件,该文件只收录目标基因序列。
请使用python3编写一个可以做到这一点的脚本。
例子
示例脚本如下(见网盘附件“seq_select1.py”)。
为了达到上述目的,我们首先需要准备一个txt文件(以下简称list文件,示例list.txt可以在网盘附件中找到),根据记录的基因位置信息gff 文件,填写类似如下内容(列和列之间用制表符分隔)。
1.png
#将以下内容保存到list.txt
基因46 NC_000964.3 42917 43660 +
NP_387934.1 NC_000964.3 59504 60070 +
yfmC NC_000964.3 825787 826734 -
cds821 NC_000964.3 885844 886173 -
在第 1 列中,为要获得的新序列命名;
第二列,要获取的序列的原创序列ID;
第3列,原创序列中要获取的序列的起始位置;
第4列,原创序列中要得到的序列的终止位置;
在第 5 列中,要获得的序列位于原创序列的正 (+) 或负 (-) 链上。
然后根据输入文件编辑py脚本,即输入fasta文件和list文件中记录要获取的序列位置的内容。
打开fasta文件“Bacillus_subtilis.scaffolds.fasta”,使用循环逐行读取序列id和碱基序列,将每个序列的所有碱基组合成一个字符串;基本序列存储为字典(字典样式 {'id':'base'})。
打开列表文件“list.txt”,读取内容,存入字典。字典的键是列表文件中第一列的内容;字典的值是列表文件第2-5列的内容,除以tab得到一个列表,收录4个字符分别代表列表文件第2-5列的信息)。
最后根据read list文件中的序列位置信息,从read基因组中截取目标基因序列。由于某些基因序列可能位于基因组的负链中,因此需要取反向互补序列。因此,首先定义一个函数rev(),以便在后续调用中获取反向互补序列。在输出序列名称时,还可以选择是否将序列的位置信息一起输出(name_detail = True/False)。
#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
#初始通过命令
input_file = '枯草芽孢杆菌.str168.fasta'
list_file = 'list.txt'
output_file = 'gene.fasta'
name_detail = 真
##读取文件
#读取基因组序列
seq_file = {}
使用 open(input_file, 'r') 作为 input_fasta:
对于 input_fasta 中的行:
line = line.strip()
如果行 [0] == '>':
seq_id = line.split()[0]
seq_file[seq_id] = ''
别的:
seq_file[seq_id] += 行
input_fasta.close()
#读取列表文件
list_dict = {}
使用 open(list_file, 'r') 作为 list_table:
对于 list_table 中的行:
如果 line.strip():
line = line.strip().split('\t')
list_dict[line[0]] = [line[1], int(line[2]) - 1, int(line[3]), line[4]]
list_table.close()
##截取序列并输出
#定义一个截取逆补的函数
def rev(seq):
base_trans = {'A':'T', 'C':'G', 'T':'A', 'G':'C', 'N':'N', 'a':'t' , 'c':'g', 't':'a', 'g':'c', 'n':'n'}
rev_seq = 列表(反转(seq))
rev_seq_list = [base_trans[k] for k in rev_seq]
rev_seq = ''.join(rev_seq_list)
返回(rev_seq)
#截断序列并输出
output_fasta = 打开(输出文件,'w')
对于 list_dict.items() 中的键、值:
如果名称_详细信息:
print('>' + key, '[' + value[0], value[1] + 1, value[2], value[3] + ']', file = output_fasta)
别的:
打印('>' + 键,文件 = output_fasta)
seq = seq_file['>' + value[0]][value[1]:value[2]]
如果值 [3] == '+':
打印(序列,文件= output_fasta)
elif 值 [3] == '-':
seq = rev(seq)
打印(序列,文件= output_fasta)
output_fasta.close()
编辑好脚本后,运行并输出一个新的fasta文件“gene.fasta”,其序列就是我们要得到的目标基因序列。
2.png
延期:
网盘附件“seq_select.py”是一个python3脚本,增加了命令行传输线,可以直接在shell中对目标文件进行I/O处理。该脚本可以指定一个输入fasta序列文件和一个记录要提取的序列位置的列表文件,新的输出fasta文件就是提取的序列。
#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
#导入模块,初始传递命令、变量等
导入参数解析
parser = argparse.ArgumentParser(description = '\n该脚本用于截取基因组中特定位置的序列,并额外输入截取序列信息的列表文件', add_help = False, usage = '\npython3 seq_select.py -i [ input.fasta] -o [output.fasta] -l [list]\npython3 seq_select.py --input [input.fasta] --output [output.fasta] --list [list]')
required = parser.add_argument_group('必需选项')
可选 = parser.add_argument_group('可选')
required.add_argument('-i', '--input', metavar = '[input.fasta]', help = '输入文件, fasta 格式', required = True)
required.add_argument('-o', '--output', metavar = '[output.fasta]', help = '输出文件,fasta 格式', required = True)
required.add_argument('-l', '--list', metavar = '[list]', help = 'record "新序列名称/原序列的序列ID/序列起始位置/序列结束位置/正链( +) 或负链 (-)",以制表符分隔,必填 = True)
optional.add_argument('--detail', action = 'store_true', help = '如果该参数存在,则在输出fasta的每个sequence id中显示序列在原创fasta中的位置信息', required = False)
optional.add_argument('-h', '--help', action = 'help', help = '帮助信息')
args = parser.parse_args()
##读取文件
#读取基因组序列
seq_file = {}
使用 open(args.input, 'r') 作为 input_fasta:
对于 input_fasta 中的行:
line = line.strip()
如果行 [0] == '>':
seq_id = line.split()[0]
seq_file[seq_id] = ''
别的:
seq_file[seq_id] += 行
input_fasta.close()
#读取列表文件
list_dict = {}
使用 open(args.list, 'r') 作为 list_file:
对于 list_file 中的行:
如果 line.strip():
line = line.strip().split('\t')
list_dict[line[0]] = [line[1], int(line[2]) - 1, int(line[3]), line[4]]
list_file.close()
##截取序列并输出
#定义一个截取逆补的函数
def rev(seq):
base_trans = {'A':'T', 'C':'G', 'T':'A', 'G':'C', 'a':'t', 'c':'g' , 't':'a', 'g':'c'}
rev_seq = 列表(反转(seq))
rev_seq_list = [base_trans[k] for k in rev_seq]
rev_seq = ''.join(rev_seq_list)
返回(rev_seq)
#截断序列并输出
output_fasta = open(args.output, 'w')
对于 list_dict.items() 中的键、值:
如果 args.detail:
print('>' + key, '[' + value[0], value[1] + 1, value[2], value[3] + ']', file = output_fasta)
别的:
打印('>' + 键,文件 = output_fasta)
seq = seq_file['>' + value[0]][value[1]:value[2]]
如果值 [3] == '+':
打印(序列,文件= output_fasta)
elif 值 [3] == '-':
seq = rev(seq)
打印(序列,文件= output_fasta)
output_fasta.close()
使用上面示例中的测试文件,脚本运行如下。
#python3 seq_select.py -h
python3 seq_select.py -i Bacillus_subtilis.str168.fasta -l list.txt -o gene.fasta --detail
3.png
网页视频抓取脚本(B站视频内容(一)_e操盘_光明网(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-31 04:13
1、第三方库导入
from bs4 import BeautifulSoup # 解析网页
import re # 正则表达式,进行文字匹配
import urllib.request,urllib.error # 通过浏览器请求数据
import sqlite3 # 轻型数据库
import time # 获取当前时间
2、程序运行main函数
爬取过程主要包括声明爬取网页->爬取网页数据并解析->保存数据
def main():
#声明爬取网站
baseurl = "https://www.bilibili.com/v/popular/rank/all"
#爬取网页
datalist = getData(baseurl)
# print(datalist)
#保存数据
dbname = time.strftime("%Y-%m-%d", time.localtime())
dbpath = "BiliBiliTop100 " + dbname
saveData(datalist,dbpath)
(1)爬取过程中使用的技术是:伪装成浏览器请求数据;
(2)解析爬取网页源码时:使用Beautifulsoup解析出需要的数据,使用re正则表达式匹配数据;
(3)保存数据的时候,考虑到B站的排名每天都在刷新,可以用当前日期保存数据库名。
3、程序运行结果
数据库中收录的数据有:排名、视频链接、标题、播放量、评论量、作者、综合评分。
4、程序源代码
<p>
from bs4 import BeautifulSoup #解析网页
import re # 正则表达式,进行文字匹配
import urllib.request,urllib.error
import sqlite3
import time
def main():
#声明爬取网站
baseurl = "https://www.bilibili.com/v/popular/rank/all"
#爬取网页
datalist = getData(baseurl)
# print(datalist)
#保存数据
dbname = time.strftime("%Y-%m-%d", time.localtime())
dbpath = "BiliBiliTop100 " + dbname
saveData(datalist,dbpath)
#re正则表达式
findLink =re.compile(r' 查看全部
网页视频抓取脚本(B站视频内容(一)_e操盘_光明网(图))
1、第三方库导入
from bs4 import BeautifulSoup # 解析网页
import re # 正则表达式,进行文字匹配
import urllib.request,urllib.error # 通过浏览器请求数据
import sqlite3 # 轻型数据库
import time # 获取当前时间
2、程序运行main函数
爬取过程主要包括声明爬取网页->爬取网页数据并解析->保存数据
def main():
#声明爬取网站
baseurl = "https://www.bilibili.com/v/popular/rank/all"
#爬取网页
datalist = getData(baseurl)
# print(datalist)
#保存数据
dbname = time.strftime("%Y-%m-%d", time.localtime())
dbpath = "BiliBiliTop100 " + dbname
saveData(datalist,dbpath)
(1)爬取过程中使用的技术是:伪装成浏览器请求数据;
(2)解析爬取网页源码时:使用Beautifulsoup解析出需要的数据,使用re正则表达式匹配数据;
(3)保存数据的时候,考虑到B站的排名每天都在刷新,可以用当前日期保存数据库名。
3、程序运行结果
数据库中收录的数据有:排名、视频链接、标题、播放量、评论量、作者、综合评分。
4、程序源代码
<p>
from bs4 import BeautifulSoup #解析网页
import re # 正则表达式,进行文字匹配
import urllib.request,urllib.error
import sqlite3
import time
def main():
#声明爬取网站
baseurl = "https://www.bilibili.com/v/popular/rank/all"
#爬取网页
datalist = getData(baseurl)
# print(datalist)
#保存数据
dbname = time.strftime("%Y-%m-%d", time.localtime())
dbpath = "BiliBiliTop100 " + dbname
saveData(datalist,dbpath)
#re正则表达式
findLink =re.compile(r'
网页视频抓取脚本(如何采集爬取抖音用户信息,整理自己的思路?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2022-01-31 04:11
最近在学习python爬虫,想采集爬抖音用户信息,因为看到这个需要相关爬虫职位,心血来潮,分享一下经验,自己整理一下顺便说一句。首先是在B站看爬虫的短视频,心灵之王的插件,通过修改fidder函数将心灵之王的json数据包保存到本地,使用python脚本读取数据循环包,然后自动打开浏览器搜索主题。现在我想把这个想法扩展到 抖音 这里。
先安装最新的fidder,抖音用户的数据包传输协议是https。您需要下载 fidder 的证书并将其安装在您的手机或 Android 模拟器上。我用的模拟器,然后把安卓模拟器的代理IP设置为电脑的IP。现在模拟器的所有网络请求都是通过fidder获取的。现在我们只想抓到数据包,分析数据包,推荐一个分析json包的url,可以清晰的展示复杂难懂的数据段。模拟器刷到抖音json数据包的时候,我会一个一个复制过来看看。网址在图片中。.
下一步是想办法保存这个数据包。关键点是修改fiddler函数。fidder工具在做爬虫和插件的时候经常用到。我特地学会了这个提琴手的用法。修改fiiderscript,这个收录用户信息的json数据包的请求url和host是一样的,使用这个修改后的函数保存到本地文件夹。
fidder函数保存到本地的数据只能覆盖不能添加,所以只能通过脚本循环读取,所以用python写一个脚本,解析读取的数据,保存到本地数据库。
现在是最后一步,编写一个脚本来模拟手动滑动抖音。由于你用的是模拟器,如果要多开几个,保存数据会比较快,所以就写一个分辨率最小的。320*480分辨率,节省资源,抓取用户信息进入个人主页。思路是在抖音中向上滑动识别是广告还是直播,是广告然后往下,而不是点击头像,延迟返回,然后循环。打包成apk安装到模拟器上进行真机测试!速度还不错。继续优化脚本,设置清缓存功能。如果缓存太多,就会很卡。
其实抓包的过程中还有很多有趣的事情,比如抓包没有水印的视频链接,可以采集,哈哈。还有一些细节,没有写清楚。如果您有任何问题,您可以留言,我会认真回答。
最终附件代码包百度云链接:密码:hzn5。
此贴也发在My Love Cracked上,标题相同,以后可能会同步。 查看全部
网页视频抓取脚本(如何采集爬取抖音用户信息,整理自己的思路?)
最近在学习python爬虫,想采集爬抖音用户信息,因为看到这个需要相关爬虫职位,心血来潮,分享一下经验,自己整理一下顺便说一句。首先是在B站看爬虫的短视频,心灵之王的插件,通过修改fidder函数将心灵之王的json数据包保存到本地,使用python脚本读取数据循环包,然后自动打开浏览器搜索主题。现在我想把这个想法扩展到 抖音 这里。
先安装最新的fidder,抖音用户的数据包传输协议是https。您需要下载 fidder 的证书并将其安装在您的手机或 Android 模拟器上。我用的模拟器,然后把安卓模拟器的代理IP设置为电脑的IP。现在模拟器的所有网络请求都是通过fidder获取的。现在我们只想抓到数据包,分析数据包,推荐一个分析json包的url,可以清晰的展示复杂难懂的数据段。模拟器刷到抖音json数据包的时候,我会一个一个复制过来看看。网址在图片中。.
下一步是想办法保存这个数据包。关键点是修改fiddler函数。fidder工具在做爬虫和插件的时候经常用到。我特地学会了这个提琴手的用法。修改fiiderscript,这个收录用户信息的json数据包的请求url和host是一样的,使用这个修改后的函数保存到本地文件夹。
fidder函数保存到本地的数据只能覆盖不能添加,所以只能通过脚本循环读取,所以用python写一个脚本,解析读取的数据,保存到本地数据库。
现在是最后一步,编写一个脚本来模拟手动滑动抖音。由于你用的是模拟器,如果要多开几个,保存数据会比较快,所以就写一个分辨率最小的。320*480分辨率,节省资源,抓取用户信息进入个人主页。思路是在抖音中向上滑动识别是广告还是直播,是广告然后往下,而不是点击头像,延迟返回,然后循环。打包成apk安装到模拟器上进行真机测试!速度还不错。继续优化脚本,设置清缓存功能。如果缓存太多,就会很卡。
其实抓包的过程中还有很多有趣的事情,比如抓包没有水印的视频链接,可以采集,哈哈。还有一些细节,没有写清楚。如果您有任何问题,您可以留言,我会认真回答。
最终附件代码包百度云链接:密码:hzn5。
此贴也发在My Love Cracked上,标题相同,以后可能会同步。
网页视频抓取脚本(网络爬虫(ComputerRobot)(又被称为网页蜘蛛))
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-26 23:19
网络爬虫
计算机机器人(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常称为网络追逐者),是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
背景
随着网络的飞速发展,万维网已经成为大量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。搜索引擎(Search Engine),如传统的通用搜索引擎AltaVista、Yahoo!而谷歌等作为帮助人们检索信息的工具,已经成为用户访问万维网的门户和指南。但是,这些通用搜索引擎也有一定的局限性,例如:
(1)不同领域和背景的用户往往检索目的和需求不同,一般搜索引擎返回的结果中收录大量用户不关心的网页。
(2)一般搜索引擎的目标是最大化网络覆盖,有限的搜索引擎服务器资源和无限的网络数据资源之间的冲突将进一步加深。
(3)万维网数据形式的丰富和网络技术的不断发展,催生了图片、数据库、音频、视频、多媒体等大量不同的数据。一般搜索对于这些信息内容密集、结构一定的数据,引擎往往无能为力。
(4)一般搜索引擎大多提供基于关键词的检索,难以支持基于语义信息的查询。
网络爬虫
为了解决以上问题,定向爬取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一种自动下载网页的程序。它根据给定的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大覆盖,而是旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到系统达到一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。
2 爬取目标描述
现有的焦点爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
爬虫根据目标网页的特征爬取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页类别和类别对应的种子样本,如Yahoo!类别结构等;
(3) 由用户行为决定的抓取目标示例分为:
(a) 在用户浏览过程中显示标记的抓取样本;
(b) 通过用户日志挖掘获取访问模式和相关样本。
网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
技术研究
基于目标数据模式的爬虫针对网页上的数据,抓取到的数据一般都符合一定的模式,或者可以转化或映射成目标数据模式。
另一种描述方式是构建目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
网络搜索策略
网页抓取策略可以分为三种类型:深度优先、广度优先和最佳优先。深度优先在很多情况下会导致爬虫被困的问题。目前,广度优先和最佳优先方法很常见。
广度优先搜索
广度优先搜索策略是指在爬取过程中,完成当前一级搜索后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网页过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,
最好的第一次搜索
最佳优先级搜索策略是根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。在第 4 节中,将结合网页分析算法进行详细讨论。
深度优先搜索
深度优先搜索策略从起始页面开始,选择一个URL进入,分析该页面中的URL,选择一个进入。这样的链接被逐个链接地获取,直到在处理下一个路由之前处理了一个路由。深度优先策略设计相对简单。虽然门户网站 网站 倾向于提供最有价值的链接并具有较高的 PageRank,但页面价值和 PageRank 会随着每个级别的深入而相应降低。这意味着重要的页面通常更靠近种子,而爬得太深的页面价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,而抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
网页分析算法
网页分析算法可以分为三类:基于网络拓扑、基于网页内容和基于用户访问行为。
拓扑分析算法
基于网页之间的链接,通过已知的网页或数据,评估与其有直接或间接链接关系的对象(可以是网页或网站等)的算法。进一步分为三种:网页粒度、网站粒度和网页块粒度。
1 网页粒度分析算法
PageRank 和 HITS 算法是最常见的链接分析算法。两者都是通过网页间链接度的递归归一化计算得到每个网页的重要性。PageRank算法虽然考虑了用户访问行为的随机性和Sink网页的存在性,但忽略了大部分用户访问的目的性,即网页与查询主题链接的相关性。针对这个问题,HITS算法提出了两个关键概念:权威网页(authority)和中心网页(hub)。
基于链接的爬取问题是相关页面的主题组之间存在隧道现象,即爬取路径上很多偏离主题的页面也指向目标页面,局部评价策略中断了爬取行为当前路径。参考文献[21]提出了一种基于反向链接(BackLink)的层次上下文模型(Context Model),用于描述指向一定物理跳半径内的目标网页的网页拓扑图的中心Layer 0作为目标网页。网页根据指向目标网页的物理跳数进行层次划分,外层网页到内层网页的链接称为反向链接。
2 网站粒度分析算法
网站粒度资源发现和管理策略也比网页粒度更简单有效。网站粒度爬取的关键是站点的划分和SiteRank的计算。SiteRank的计算方法与PageRank类似,但需要对网站之间的链接进行一定程度的抽象,并在一定模型下计算链接的权重。
网站划分分为两种:按域名划分和按IP地址划分。参考文献[18]讨论了在分布式情况下,通过划分同一域名下不同主机和服务器的IP地址,构建站点地图,并采用类似于PageRank的方法评估SiteRank。同时,根据每个站点不同文件的分布情况,构建文档图,结合SiteRank分布式计算得到DocRank。参考文献[18]证明,使用分布式SiteRank计算不仅大大降低了单个站点的算法成本,而且克服了单个站点对全网覆盖范围有限的缺点。一个额外的好处是,常见的 PageRank 欺诈很难欺骗 SiteRank。
3 网页块粒度分析算法
一个页面往往收录多个指向其他页面的链接,而这些链接中只有一部分指向与主题相关的网页,或者根据网页的链接锚文本表明其重要性高。但是在PageRank和HITS算法中,这些链接是没有区分的,所以往往会给网页分析带来广告等噪声链接的干扰。页面块级(Block?级)链接分析算法的基本思想是通过VIPS页面分割算法将页面划分为不同的页面块(page blocks),然后创建page?to?block和block?block 用于这些页面块。to?page 的链接矩阵,? 分别表示为 Z 和 X。因此,page-to-page图上的page block level的PageRank为?W?p=X×Z;?Block?to?block 图上的BlockRank 是?W?b=Z×X。
网页分析算法
基于网页内容的分析算法是指利用网页内容的特征(文本、数据等资源)对网页进行评价。网页内容已经从基于超文本的内容演变为动态页面(或称为隐藏网页)数据,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的400~500%。次。另一方面,多媒体数据、Web Service等各种形式的网络资源日益丰富。因此,基于网页内容的分析算法也从最初的相对简单的文本检索方法发展到综合应用包括网页数据提取、机器学习、数据挖掘、语义理解等多种方法。本节根据网页数据的不同形式,基于网页内容的分析算法分为以下三类:第一类是针对以文本和超链接为主的非结构化或非常简单的网页;第二个是结构化网页。对于数据源(如RDBMS)动态生成的页面,不能直接批量访问数据;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。数据不能直接批量访问;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。数据不能直接批量访问;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。
基于文本的网页分析算法
1) 纯文本分类和聚类算法
它在很大程度上借鉴了文本检索的技术。文本分析算法可以快速有效地对网页进行分类和聚类,但很少单独使用,因为它们忽略了网页之间和网页内的结构信息。
2) 超文本分类和聚类算法
根据网页链接的网页的相关类型对网页进行分类,并通过关联的网页推断网页的类型。 查看全部
网页视频抓取脚本(网络爬虫(ComputerRobot)(又被称为网页蜘蛛))
网络爬虫
计算机机器人(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常称为网络追逐者),是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
背景
随着网络的飞速发展,万维网已经成为大量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。搜索引擎(Search Engine),如传统的通用搜索引擎AltaVista、Yahoo!而谷歌等作为帮助人们检索信息的工具,已经成为用户访问万维网的门户和指南。但是,这些通用搜索引擎也有一定的局限性,例如:
(1)不同领域和背景的用户往往检索目的和需求不同,一般搜索引擎返回的结果中收录大量用户不关心的网页。
(2)一般搜索引擎的目标是最大化网络覆盖,有限的搜索引擎服务器资源和无限的网络数据资源之间的冲突将进一步加深。
(3)万维网数据形式的丰富和网络技术的不断发展,催生了图片、数据库、音频、视频、多媒体等大量不同的数据。一般搜索对于这些信息内容密集、结构一定的数据,引擎往往无能为力。
(4)一般搜索引擎大多提供基于关键词的检索,难以支持基于语义信息的查询。
网络爬虫
为了解决以上问题,定向爬取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一种自动下载网页的程序。它根据给定的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大覆盖,而是旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到系统达到一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。
2 爬取目标描述
现有的焦点爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
爬虫根据目标网页的特征爬取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页类别和类别对应的种子样本,如Yahoo!类别结构等;
(3) 由用户行为决定的抓取目标示例分为:
(a) 在用户浏览过程中显示标记的抓取样本;
(b) 通过用户日志挖掘获取访问模式和相关样本。
网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
技术研究
基于目标数据模式的爬虫针对网页上的数据,抓取到的数据一般都符合一定的模式,或者可以转化或映射成目标数据模式。
另一种描述方式是构建目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
网络搜索策略
网页抓取策略可以分为三种类型:深度优先、广度优先和最佳优先。深度优先在很多情况下会导致爬虫被困的问题。目前,广度优先和最佳优先方法很常见。
广度优先搜索
广度优先搜索策略是指在爬取过程中,完成当前一级搜索后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网页过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,
最好的第一次搜索
最佳优先级搜索策略是根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。在第 4 节中,将结合网页分析算法进行详细讨论。
深度优先搜索
深度优先搜索策略从起始页面开始,选择一个URL进入,分析该页面中的URL,选择一个进入。这样的链接被逐个链接地获取,直到在处理下一个路由之前处理了一个路由。深度优先策略设计相对简单。虽然门户网站 网站 倾向于提供最有价值的链接并具有较高的 PageRank,但页面价值和 PageRank 会随着每个级别的深入而相应降低。这意味着重要的页面通常更靠近种子,而爬得太深的页面价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,而抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
网页分析算法
网页分析算法可以分为三类:基于网络拓扑、基于网页内容和基于用户访问行为。
拓扑分析算法
基于网页之间的链接,通过已知的网页或数据,评估与其有直接或间接链接关系的对象(可以是网页或网站等)的算法。进一步分为三种:网页粒度、网站粒度和网页块粒度。
1 网页粒度分析算法
PageRank 和 HITS 算法是最常见的链接分析算法。两者都是通过网页间链接度的递归归一化计算得到每个网页的重要性。PageRank算法虽然考虑了用户访问行为的随机性和Sink网页的存在性,但忽略了大部分用户访问的目的性,即网页与查询主题链接的相关性。针对这个问题,HITS算法提出了两个关键概念:权威网页(authority)和中心网页(hub)。
基于链接的爬取问题是相关页面的主题组之间存在隧道现象,即爬取路径上很多偏离主题的页面也指向目标页面,局部评价策略中断了爬取行为当前路径。参考文献[21]提出了一种基于反向链接(BackLink)的层次上下文模型(Context Model),用于描述指向一定物理跳半径内的目标网页的网页拓扑图的中心Layer 0作为目标网页。网页根据指向目标网页的物理跳数进行层次划分,外层网页到内层网页的链接称为反向链接。
2 网站粒度分析算法
网站粒度资源发现和管理策略也比网页粒度更简单有效。网站粒度爬取的关键是站点的划分和SiteRank的计算。SiteRank的计算方法与PageRank类似,但需要对网站之间的链接进行一定程度的抽象,并在一定模型下计算链接的权重。
网站划分分为两种:按域名划分和按IP地址划分。参考文献[18]讨论了在分布式情况下,通过划分同一域名下不同主机和服务器的IP地址,构建站点地图,并采用类似于PageRank的方法评估SiteRank。同时,根据每个站点不同文件的分布情况,构建文档图,结合SiteRank分布式计算得到DocRank。参考文献[18]证明,使用分布式SiteRank计算不仅大大降低了单个站点的算法成本,而且克服了单个站点对全网覆盖范围有限的缺点。一个额外的好处是,常见的 PageRank 欺诈很难欺骗 SiteRank。
3 网页块粒度分析算法
一个页面往往收录多个指向其他页面的链接,而这些链接中只有一部分指向与主题相关的网页,或者根据网页的链接锚文本表明其重要性高。但是在PageRank和HITS算法中,这些链接是没有区分的,所以往往会给网页分析带来广告等噪声链接的干扰。页面块级(Block?级)链接分析算法的基本思想是通过VIPS页面分割算法将页面划分为不同的页面块(page blocks),然后创建page?to?block和block?block 用于这些页面块。to?page 的链接矩阵,? 分别表示为 Z 和 X。因此,page-to-page图上的page block level的PageRank为?W?p=X×Z;?Block?to?block 图上的BlockRank 是?W?b=Z×X。
网页分析算法
基于网页内容的分析算法是指利用网页内容的特征(文本、数据等资源)对网页进行评价。网页内容已经从基于超文本的内容演变为动态页面(或称为隐藏网页)数据,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的400~500%。次。另一方面,多媒体数据、Web Service等各种形式的网络资源日益丰富。因此,基于网页内容的分析算法也从最初的相对简单的文本检索方法发展到综合应用包括网页数据提取、机器学习、数据挖掘、语义理解等多种方法。本节根据网页数据的不同形式,基于网页内容的分析算法分为以下三类:第一类是针对以文本和超链接为主的非结构化或非常简单的网页;第二个是结构化网页。对于数据源(如RDBMS)动态生成的页面,不能直接批量访问数据;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。数据不能直接批量访问;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。数据不能直接批量访问;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。
基于文本的网页分析算法
1) 纯文本分类和聚类算法
它在很大程度上借鉴了文本检索的技术。文本分析算法可以快速有效地对网页进行分类和聚类,但很少单独使用,因为它们忽略了网页之间和网页内的结构信息。
2) 超文本分类和聚类算法
根据网页链接的网页的相关类型对网页进行分类,并通过关联的网页推断网页的类型。
网页视频抓取脚本(配置文件技术点puppeteer官方APIpuppeteer提供一个高级API来控制Chrome或者Chromium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-26 02:03
介绍
批量爬取视频或图片的一般套路是使用爬虫获取一组文件链接,然后通过writeFile等方法将文件一个一个保存。但是,头条的视频无法捕捉到需要爬取的html文件(服务器端渲染输出)中的视频链接。视频链接是在客户端渲染页面时,通过一些js文件中的算法或解密方法,根据视频的已知key或hash值,动态计算并添加到video标签中的。这也是网站的防爬措施。
当我们浏览这些页面时,我们可以通过审计元素看到计算出来的文件地址。但是,在批量下载的时候,手动一个一个的获取视频链接显然是不可取的。令人高兴的是,puppeteer 提供了模拟访问 Chrome 的能力,允许我们抓取浏览器呈现的最终页面。
项目开始
命令
npm i
npm start
注意:安装puppeteer的过程有点慢,请耐心等待。
配置文件
// 配置相关
module.exports = {
originPath: 'https://www.ixigua.com', // 页面请求地址
savePath: 'D:/videoZZ' // 存放路径
}
技术点
傀儡师
官方API
puppeteer 提供了一个高级 API 来控制 Chrome 或 Chromium。
傀儡师的主要作用:
从网页生成 PDF 和图片
抓取 SPA 应用程序并生成预渲染内容(即“SSR”服务器端渲染)
可以从 网站 抓取内容
自动化表单提交、UI 测试、键盘输入等
使用的 API:
puppeteer.launch() 启动浏览器实例
browser.newPage() 创建一个新页面
page.goto() 转到指定网页
page.screenshot() 截图
page.waitFor() 页面等待,可以是时间,一个元素,一个函数
page.$eval() 获取指定元素,相当于 document.querySelector
page.$$eval() 获取某种类型的元素,相当于 document.querySelectorAll
page.$('#id .className') 获取文档中的一个元素,类似于jQuery
代码示例
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
视频文件下载方法
下载视频大师方法
const downloadVideo = async video => {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.src, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
获取视频数据
getVideoData (url, encoding) {
return new Promise((resolve, reject) => {
let req = http.get(url, function (res) {
let result = ''
encoding && res.setEncoding(encoding)
res.on('data', function (d) {
result += d
})
res.on('end', function () {
resolve(result)
})
res.on('error', function (e) {
reject(e)
})
})
req.end()
})
}
将视频数据保存到本地
savefileToPath (fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
目标网站:西瓜视频
项目功能:下载标题下的最新20个视频【微臣财经】
项目地址:Github地址 查看全部
网页视频抓取脚本(配置文件技术点puppeteer官方APIpuppeteer提供一个高级API来控制Chrome或者Chromium)
介绍
批量爬取视频或图片的一般套路是使用爬虫获取一组文件链接,然后通过writeFile等方法将文件一个一个保存。但是,头条的视频无法捕捉到需要爬取的html文件(服务器端渲染输出)中的视频链接。视频链接是在客户端渲染页面时,通过一些js文件中的算法或解密方法,根据视频的已知key或hash值,动态计算并添加到video标签中的。这也是网站的防爬措施。
当我们浏览这些页面时,我们可以通过审计元素看到计算出来的文件地址。但是,在批量下载的时候,手动一个一个的获取视频链接显然是不可取的。令人高兴的是,puppeteer 提供了模拟访问 Chrome 的能力,允许我们抓取浏览器呈现的最终页面。
项目开始
命令
npm i
npm start
注意:安装puppeteer的过程有点慢,请耐心等待。
配置文件
// 配置相关
module.exports = {
originPath: 'https://www.ixigua.com', // 页面请求地址
savePath: 'D:/videoZZ' // 存放路径
}
技术点
傀儡师
官方API
puppeteer 提供了一个高级 API 来控制 Chrome 或 Chromium。
傀儡师的主要作用:
从网页生成 PDF 和图片
抓取 SPA 应用程序并生成预渲染内容(即“SSR”服务器端渲染)
可以从 网站 抓取内容
自动化表单提交、UI 测试、键盘输入等
使用的 API:
puppeteer.launch() 启动浏览器实例
browser.newPage() 创建一个新页面
page.goto() 转到指定网页
page.screenshot() 截图
page.waitFor() 页面等待,可以是时间,一个元素,一个函数
page.$eval() 获取指定元素,相当于 document.querySelector
page.$$eval() 获取某种类型的元素,相当于 document.querySelectorAll
page.$('#id .className') 获取文档中的一个元素,类似于jQuery
代码示例
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
视频文件下载方法
下载视频大师方法
const downloadVideo = async video => {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.src, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
获取视频数据
getVideoData (url, encoding) {
return new Promise((resolve, reject) => {
let req = http.get(url, function (res) {
let result = ''
encoding && res.setEncoding(encoding)
res.on('data', function (d) {
result += d
})
res.on('end', function () {
resolve(result)
})
res.on('error', function (e) {
reject(e)
})
})
req.end()
})
}
将视频数据保存到本地
savefileToPath (fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
目标网站:西瓜视频
项目功能:下载标题下的最新20个视频【微臣财经】
项目地址:Github地址
网页视频抓取脚本( Android手机上的抖音爬取抖音视频内容怎么扩展?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-26 01:22
Android手机上的抖音爬取抖音视频内容怎么扩展?(图))
python爬取抖音视频实例分析
更新时间:2021年1月19日11:40:00 作者:十一
本文中,小编将整理一篇关于python爬取抖音视频案例分析的文章。有兴趣的朋友可以测试一下案例内容。
现在抖音的流行有目共睹。之前小编在网上找到有趣的东西,就是爬了一些网站,所以也考虑过要不要进行
@k8@上解决的案例,经过实际操作,真的实现了。使用自动化工具,可以轻松实现。后来有小伙伴提出,去除appium减肥后也可以实现。然后看详细操作。内容。
1、mitmproxy/mitmdump 捕获
import requests
path = 'D:/video/'
num = 1788
def response(flow):
global num
target_urls = ['url']
for url in target_urls:
if flow.request.url.startswith(url):
filename = path + str(num) + '.mp4
res = requests.get(flow.request.url, stream=True)
with open(filename, 'ab') as f:
f.write(res.content)
f.flush()
print(filename + '下载完成')
num += 1
2、Appium模拟手机操作
使用启动服务器按钮启动appium服务
再次点击Start Session,在Android手机上启动抖音app,进入启动页面
3、python脚本驱动app,直接在pycharm中运行即可
实例扩展:
import requests
import json
import re
import os
from pprint import pprint as pp
import queue
class DouYin:
header = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
}
def __init__(self, url=None):
self.url = self.get_RealAddress(url)
# 获取用户视频的url
self.user_video_url = 'https://www.douyin.com/aweme/v1/aweme/post/?{0}'
self.user_id = re.search(r'user/(.*)\?', self.url).group(1) # 用户id
requests.packages.urllib3.disable_warnings()
self.session = requests.Session()
self.target_folder = '' # 创建文件的路径
self.queue = queue.Queue() # 生成一个队列对象
def user_info(self):
self.mkdir_dir()
p = os.popen('node fuck.js %s' % self.user_id) # 获取加密的signature
signature = p.readlines()[0]
user_video_params = {
'user_id': str(self.user_id),
'count': '21',
'max_cursor': '0',
'aid': '1128',
'_signature': signature
}
# 获取下载视频的列表
def get_aweme_list(max_cursor=None):
if max_cursor:
user_video_params['max_cursor'] = str(max_cursor)
user_video_url = self.user_video_url.format(
'&'.join([key + '=' + user_video_params[key] for key in user_video_params])) # 拼接参数
response = requests.get(
url=user_video_url, headers=self.header, verify=False)
contentJson = json.loads(response.content.decode('utf-8')) # 将返回的进行utf8编码
aweme_list = contentJson.get('aweme_list', [])
for aweme in aweme_list:
video_name = aweme.get(
'share_info', None).get('share_desc', None) # 视频的名字
video_url = aweme.get('video', None).get('play_addr', None).get(
'url_list', None)[0].replace('playwm', 'play') # 视频链接
self.queue.put((video_name, video_url)) # 将数据进队列
if contentJson.get('has_more') == 1: # 判断后面是不是还有是1就是还有
return get_aweme_list(contentJson.get('max_cursor')) # 有的话获取参数max_cursor
get_aweme_list()
# 下载视频
def get_download(self):
while True:
video_name, video_url = self.queue.get()
file_name = video_name + '.mp4'
file_path = os.path.join(self.target_folder, file_name)
if not os.path.isfile(file_path):
print('download %s form %s.\n' % (file_name, video_url))
times = 0
while times < 10:
try:
response = requests.get(
url=video_url, stream=True, timeout=10, verify=False) # 开启流下载
with open(file_path, 'wb') as f:
for chunk in response.iter_content(1024): # 返回迭代对象
f.write(chunk)
print('下载成功')
break
except:
print('下载失败')
times += 1
# 创建对应的文件夹
def mkdir_dir(self):
current_folder = os.getcwd()
self.target_folder = os.path.join(
current_folder, 'download/%s' % self.user_id)
if not os.path.isdir(self.target_folder):
os.mkdir(self.target_folder)
# 短链接转长地址
def get_RealAddress(self, url):
if url.find('v.douyin.com') < 0:
return url
response = requests.get(
url=url, headers=self.header, allow_redirects=False) # allow_redirects 允许跳转
return response.headers['Location']
if __name__ == '__main__':
douyin = DouYin(url='http://v.douyin.com/J2B9Sk/')
douyin.user_info()
douyin.get_download()
这里是本文文章关于python爬取抖音视频实例分析的介绍。更多关于如何使用python爬取抖音视频内容,请搜索之前文章的脚本首页或继续浏览以下相关文章希望大家支持脚本未来的家! 查看全部
网页视频抓取脚本(
Android手机上的抖音爬取抖音视频内容怎么扩展?(图))
python爬取抖音视频实例分析
更新时间:2021年1月19日11:40:00 作者:十一
本文中,小编将整理一篇关于python爬取抖音视频案例分析的文章。有兴趣的朋友可以测试一下案例内容。
现在抖音的流行有目共睹。之前小编在网上找到有趣的东西,就是爬了一些网站,所以也考虑过要不要进行
@k8@上解决的案例,经过实际操作,真的实现了。使用自动化工具,可以轻松实现。后来有小伙伴提出,去除appium减肥后也可以实现。然后看详细操作。内容。
1、mitmproxy/mitmdump 捕获
import requests
path = 'D:/video/'
num = 1788
def response(flow):
global num
target_urls = ['url']
for url in target_urls:
if flow.request.url.startswith(url):
filename = path + str(num) + '.mp4
res = requests.get(flow.request.url, stream=True)
with open(filename, 'ab') as f:
f.write(res.content)
f.flush()
print(filename + '下载完成')
num += 1
2、Appium模拟手机操作
使用启动服务器按钮启动appium服务
再次点击Start Session,在Android手机上启动抖音app,进入启动页面
3、python脚本驱动app,直接在pycharm中运行即可
实例扩展:
import requests
import json
import re
import os
from pprint import pprint as pp
import queue
class DouYin:
header = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
}
def __init__(self, url=None):
self.url = self.get_RealAddress(url)
# 获取用户视频的url
self.user_video_url = 'https://www.douyin.com/aweme/v1/aweme/post/?{0}'
self.user_id = re.search(r'user/(.*)\?', self.url).group(1) # 用户id
requests.packages.urllib3.disable_warnings()
self.session = requests.Session()
self.target_folder = '' # 创建文件的路径
self.queue = queue.Queue() # 生成一个队列对象
def user_info(self):
self.mkdir_dir()
p = os.popen('node fuck.js %s' % self.user_id) # 获取加密的signature
signature = p.readlines()[0]
user_video_params = {
'user_id': str(self.user_id),
'count': '21',
'max_cursor': '0',
'aid': '1128',
'_signature': signature
}
# 获取下载视频的列表
def get_aweme_list(max_cursor=None):
if max_cursor:
user_video_params['max_cursor'] = str(max_cursor)
user_video_url = self.user_video_url.format(
'&'.join([key + '=' + user_video_params[key] for key in user_video_params])) # 拼接参数
response = requests.get(
url=user_video_url, headers=self.header, verify=False)
contentJson = json.loads(response.content.decode('utf-8')) # 将返回的进行utf8编码
aweme_list = contentJson.get('aweme_list', [])
for aweme in aweme_list:
video_name = aweme.get(
'share_info', None).get('share_desc', None) # 视频的名字
video_url = aweme.get('video', None).get('play_addr', None).get(
'url_list', None)[0].replace('playwm', 'play') # 视频链接
self.queue.put((video_name, video_url)) # 将数据进队列
if contentJson.get('has_more') == 1: # 判断后面是不是还有是1就是还有
return get_aweme_list(contentJson.get('max_cursor')) # 有的话获取参数max_cursor
get_aweme_list()
# 下载视频
def get_download(self):
while True:
video_name, video_url = self.queue.get()
file_name = video_name + '.mp4'
file_path = os.path.join(self.target_folder, file_name)
if not os.path.isfile(file_path):
print('download %s form %s.\n' % (file_name, video_url))
times = 0
while times < 10:
try:
response = requests.get(
url=video_url, stream=True, timeout=10, verify=False) # 开启流下载
with open(file_path, 'wb') as f:
for chunk in response.iter_content(1024): # 返回迭代对象
f.write(chunk)
print('下载成功')
break
except:
print('下载失败')
times += 1
# 创建对应的文件夹
def mkdir_dir(self):
current_folder = os.getcwd()
self.target_folder = os.path.join(
current_folder, 'download/%s' % self.user_id)
if not os.path.isdir(self.target_folder):
os.mkdir(self.target_folder)
# 短链接转长地址
def get_RealAddress(self, url):
if url.find('v.douyin.com') < 0:
return url
response = requests.get(
url=url, headers=self.header, allow_redirects=False) # allow_redirects 允许跳转
return response.headers['Location']
if __name__ == '__main__':
douyin = DouYin(url='http://v.douyin.com/J2B9Sk/')
douyin.user_info()
douyin.get_download()
这里是本文文章关于python爬取抖音视频实例分析的介绍。更多关于如何使用python爬取抖音视频内容,请搜索之前文章的脚本首页或继续浏览以下相关文章希望大家支持脚本未来的家!
网页视频抓取脚本(新手学习Python爬虫之Request和beautifulsoup和beautiful爬了最简单的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-19 19:05
初学者学习Python爬虫的Request和beautifulsoup
创建时间:2020 年 4 月 13 日下午 2:45
学习了爬虫的基本原理,使用request和美汤爬取了最简单的网页。为了巩固所学,我写了一个总结:
首先说一下我现在可以爬取的这些页面的基本特征:
在网络中,所有需要爬取的内容都可以在文档类型文档的请求响应中找到。无需登录等POST操作即可获取所需信息
这类网页的爬取方式非常规整,变化不大。总结起来,这些步骤是:
使用请求库发送请求并获取响应,即网页源码使用解析库(我使用BeautifulSoup)按需解析网页,获取我们需要的信息,并将信息保存在我们需要的格式。详细方法说明
建议用下面的代码吃
首先打开Network,清空response,刷新Network,找到Type为document的response。这是网页的源代码。点击Headers,复制User-Agent写在header中(具体操作见下面代码),并告诉网站访问者请求的工具,让网站不认为我们正在抓取,但使用浏览器访问。点击Response,在源码中搜索我们要查找的部分,了解它们对应的DOM结构是什么。(关于DOM的就不写了,可以自行搜索) 编写请求函数,获取网页源码,根据网页源码的DOM结构和我们提供的信息按需解析需要。
放上代码,然后说说每段代码对应的特征部分:
批量下载图片
网址:
我之所以爬足网,是因为原作者版权原因,足网有些作品是禁止保存的。简单的方法就是在浏览器中查看元素找到对应的链接,点击一个一个保存,但是这样太麻烦了,所以想写一个方法,可以通过输入的URL快速批量保存站酷帖详情页。
脚本使用方法:修改URL链接后运行,图片会批量保存
使用效果图:
本站酷网结构非常整齐,所以很容易找到图片url的位置,也很容易保存
缺点是这是编写的第一段代码。当时对这两个库的理解还不深入,代码结构写的很烂。
from bs4 import BeautifulSoup
import requests
URL = 'https://www.zcool.com.cn/work/ZNDQyNTQ1OTI=.html'
html = requests.get(URL).text
soup = BeautifulSoup(html)
img_ul = soup.find_all('div', {"class": "reveal-work-wrap"})
print(type(img_ul))
for ul in img_ul:
imgs = ul.find_all('img')
for img in imgs:
url = img['src']
r = requests.get(url,stream='True')
image_name = url.split('/')[-1]
with open('./img/%s' % image_name, 'wb') as f:
for chunk in r.iter_content(chunk_size=128):
f.write(chunk)
print('Saved %s' % image_name)
抢微博热搜
网址:
这是我在教程中看到的,教你抓猫眼的电影。本来想写的,现在猫眼电影需要验证码。我不是很擅长,所以我把微博热搜改成爬取了
该脚本不会将输出写入文件,只是输出到控制台先看看效果:
这次写的时候,我学会了更模块化地定义每个函数。虽然我觉得自己写C/C++的时候模块化做得很好,但是感觉python是一门非常繁荣和浮躁的脚本语言,所以一开始总是很难停下来思考如何模块化。
思路也很简单,请求网页写成函数,解析网页写成函数。
在解析网页的时候,在写微博热搜的时候遇到了一个问题,包括下面两段代码,就是不知道soup中的一些方法使用后返回值是什么。我的解决方法是经常使用 **type()** 函数来查看变量类型。
import requests
from bs4 import BeautifulSoup
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def find_hot(html):
soup = BeautifulSoup(html, "html.parser")
hot_text1 = soup.find_all('td')
list = []
for i in hot_text1:
text_all = i.find_all('a', {'target': "_blank"})
if text_all != []:
list.append(text_all)
return list
def split(list):
i = 0
for item in list:
i += 1
print(i, item[0].string)
def main():
url = 'https://s.weibo.com/top/summary/'
html = get_one_page(url)
list = find_hot(html)
split(list)
main()
获取油猴脚本以及每个脚本的每日安装次数和总安装次数,并保存为csv文件
网址:
我主要想尝试使用此脚本捕获多条信息。一开始我没想到会抓到任何东西,所以我在我的采集夹文件夹中看到了油猴脚本。这个网站不仅是信息列表的形式,还有很多维度的信息。适合练习。
我从这个信息中选择了title + today's installs + total installs 抓取,抓取效果保存在一个csv文件中:
这个脚本更详细一点:
这是我从源码中复制的一段,对应第一个油猴脚本的信息:
懒人专用,全网VIP视频免费破解去广告、全网音乐直接下载、百度网盘直接下载、知乎视频下载等多合一版。长期更新,放心使用。
-
自用组合型多功能脚本,集合了优酷、爱奇艺、腾讯、芒果等全网VIP视频免费破解去广告,网易云音乐、QQ音乐、酷狗、酷我、虾米、蜻蜓FM、荔枝FM、喜马拉雅等网站音乐免客户端下载,百度网盘直接下载,知乎视频下载,优惠券查询等几个自己常用的功能。
作者
懒蛤蛤
今日安装
8,167
总安装量
1,723,254
得分
1868
20
10
创建日期
2018-07-27
最近更新
2020-04-08
可以看到标题在li标签的data-script-name属性下,所以我们先用find_all()查找所有li标签。
接下来我们可以通过get在这些li标签下找到data-script-name的所有值,也就是脚本的标题
值得一提的是,用 find_all() 得到的结果是一个结果集。如果要继续使用soup中的方法,需要方便set中的元素使用这些方法。
另外,在保存中文到csv时,如果不使用encoding='utf_8_sig',用excel打开文件时会出现乱码。
import requests
import csv
from bs4 import BeautifulSoup
url = 'https://greasyfork.org/zh-CN/scripts'
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def find_name(response):
soup = BeautifulSoup(response, "html.parser")
info = soup.find_all('li')
list = []
with open('data.csv', 'w', encoding='utf_8_sig') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['text', 'daily_install', 'total_instal'])
# print(info)
for i in info:
name = i.get('data-script-name')
daily_install = i.get('data-script-daily-installs')
tot_install = i.get('data-script-total-installs')
if (name):
writer.writerow([name, daily_install, tot_install])
templist = [name, daily_install, tot_install]
print(templist)
list.append(templist)
return list
def main():
response = get_one_page(url)
soup = find_name(response)
# print(soup)
main()
获取 GitHub TrendingList 的仓库名称、Star 号和 Fork 号并保存到 csv 文件
网址:
GitHub TrendingList 类似之前的油猴脚本爬取。抓住这个的灵感来自一个给我发电子邮件说我在 GitHub 上抓住了我的信息的人,我也想抓住这些大家伙的存储库。
捕获的结果也保存在 csv 文件中:
这次在解析完网页后,写了三个函数来提取它们的仓库名、星号、分叉号,然后将三列合并到csv文件中。这种方式的缺点是需要保证三个数组的长度相等,并且可以通过一一对应的方式保证数据的正确性。但是网页的结构肯定会保证这一点,而且似乎没有任何问题。
因为我对正则表达式不是很精通,所以写的代码效率比较低。初学者会看看它。
值得一提的是,Star和Fork的数量除了对应的svg是一样的,所以我只能用最好的策略,分别写在两个函数里,然后提取父节点的文本,效率相对低的。.
import requests
import csv
from bs4 import BeautifulSoup
url = 'https://github.com/trending'
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def find_name(soup):
namelist = []
h1 = soup.find_all('h1')
for e_h1 in h1:
a = e_h1.find_all('a')
for e_a in a:
name = e_a.get_text().replace('\n', '').replace(' ', '')
namelist.append(name)
return namelist
def find_star(soup):
star = []
star_fork = soup.find_all('a', {'class': 'muted-link'})
for e_s_f in star_fork:
e_star = e_s_f.find('svg', {'aria-label': 'star'})
if e_star:
e_star = e_star.find_parent().get_text().replace('\n', '').replace(' ', '')
star.append(e_star)
return star
def find_fork(soup):
fork = []
star_fork = soup.find_all('a', {'class': 'muted-link'})
for e_s_f in star_fork:
e_fork = e_s_f.find('svg', {'aria-label': 'fork'})
if e_fork:
e_star = e_fork.find_parent().get_text().replace('\n', '').replace(' ', '')
fork.append(e_star)
return fork
def main():
response = get_one_page(url)
soup = BeautifulSoup(response, "html.parser")
namelist = find_name(soup)
star = find_star(soup)
fork = find_fork(soup)
print(len(namelist), len(star), len(fork))
rows = zip(namelist, star, fork)
with open('github.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['Developer/Repo', 'Star', 'Fork'])
for row in rows:
writer.writerow(row)
main()
第一次写教程文章,大部分是根据自己的理解写的。有些表达在书本上肯定不好理解,所以我应该记录下自己的学习。 查看全部
网页视频抓取脚本(新手学习Python爬虫之Request和beautifulsoup和beautiful爬了最简单的网页)
初学者学习Python爬虫的Request和beautifulsoup
创建时间:2020 年 4 月 13 日下午 2:45
学习了爬虫的基本原理,使用request和美汤爬取了最简单的网页。为了巩固所学,我写了一个总结:
首先说一下我现在可以爬取的这些页面的基本特征:
在网络中,所有需要爬取的内容都可以在文档类型文档的请求响应中找到。无需登录等POST操作即可获取所需信息
这类网页的爬取方式非常规整,变化不大。总结起来,这些步骤是:
使用请求库发送请求并获取响应,即网页源码使用解析库(我使用BeautifulSoup)按需解析网页,获取我们需要的信息,并将信息保存在我们需要的格式。详细方法说明
建议用下面的代码吃
首先打开Network,清空response,刷新Network,找到Type为document的response。这是网页的源代码。点击Headers,复制User-Agent写在header中(具体操作见下面代码),并告诉网站访问者请求的工具,让网站不认为我们正在抓取,但使用浏览器访问。点击Response,在源码中搜索我们要查找的部分,了解它们对应的DOM结构是什么。(关于DOM的就不写了,可以自行搜索) 编写请求函数,获取网页源码,根据网页源码的DOM结构和我们提供的信息按需解析需要。
放上代码,然后说说每段代码对应的特征部分:
批量下载图片
网址:
我之所以爬足网,是因为原作者版权原因,足网有些作品是禁止保存的。简单的方法就是在浏览器中查看元素找到对应的链接,点击一个一个保存,但是这样太麻烦了,所以想写一个方法,可以通过输入的URL快速批量保存站酷帖详情页。
脚本使用方法:修改URL链接后运行,图片会批量保存
使用效果图:
本站酷网结构非常整齐,所以很容易找到图片url的位置,也很容易保存
缺点是这是编写的第一段代码。当时对这两个库的理解还不深入,代码结构写的很烂。
from bs4 import BeautifulSoup
import requests
URL = 'https://www.zcool.com.cn/work/ZNDQyNTQ1OTI=.html'
html = requests.get(URL).text
soup = BeautifulSoup(html)
img_ul = soup.find_all('div', {"class": "reveal-work-wrap"})
print(type(img_ul))
for ul in img_ul:
imgs = ul.find_all('img')
for img in imgs:
url = img['src']
r = requests.get(url,stream='True')
image_name = url.split('/')[-1]
with open('./img/%s' % image_name, 'wb') as f:
for chunk in r.iter_content(chunk_size=128):
f.write(chunk)
print('Saved %s' % image_name)
抢微博热搜
网址:
这是我在教程中看到的,教你抓猫眼的电影。本来想写的,现在猫眼电影需要验证码。我不是很擅长,所以我把微博热搜改成爬取了
该脚本不会将输出写入文件,只是输出到控制台先看看效果:
这次写的时候,我学会了更模块化地定义每个函数。虽然我觉得自己写C/C++的时候模块化做得很好,但是感觉python是一门非常繁荣和浮躁的脚本语言,所以一开始总是很难停下来思考如何模块化。
思路也很简单,请求网页写成函数,解析网页写成函数。
在解析网页的时候,在写微博热搜的时候遇到了一个问题,包括下面两段代码,就是不知道soup中的一些方法使用后返回值是什么。我的解决方法是经常使用 **type()** 函数来查看变量类型。
import requests
from bs4 import BeautifulSoup
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def find_hot(html):
soup = BeautifulSoup(html, "html.parser")
hot_text1 = soup.find_all('td')
list = []
for i in hot_text1:
text_all = i.find_all('a', {'target': "_blank"})
if text_all != []:
list.append(text_all)
return list
def split(list):
i = 0
for item in list:
i += 1
print(i, item[0].string)
def main():
url = 'https://s.weibo.com/top/summary/'
html = get_one_page(url)
list = find_hot(html)
split(list)
main()
获取油猴脚本以及每个脚本的每日安装次数和总安装次数,并保存为csv文件
网址:
我主要想尝试使用此脚本捕获多条信息。一开始我没想到会抓到任何东西,所以我在我的采集夹文件夹中看到了油猴脚本。这个网站不仅是信息列表的形式,还有很多维度的信息。适合练习。
我从这个信息中选择了title + today's installs + total installs 抓取,抓取效果保存在一个csv文件中:
这个脚本更详细一点:
这是我从源码中复制的一段,对应第一个油猴脚本的信息:
懒人专用,全网VIP视频免费破解去广告、全网音乐直接下载、百度网盘直接下载、知乎视频下载等多合一版。长期更新,放心使用。
-
自用组合型多功能脚本,集合了优酷、爱奇艺、腾讯、芒果等全网VIP视频免费破解去广告,网易云音乐、QQ音乐、酷狗、酷我、虾米、蜻蜓FM、荔枝FM、喜马拉雅等网站音乐免客户端下载,百度网盘直接下载,知乎视频下载,优惠券查询等几个自己常用的功能。
作者
懒蛤蛤
今日安装
8,167
总安装量
1,723,254
得分
1868
20
10
创建日期
2018-07-27
最近更新
2020-04-08
可以看到标题在li标签的data-script-name属性下,所以我们先用find_all()查找所有li标签。
接下来我们可以通过get在这些li标签下找到data-script-name的所有值,也就是脚本的标题
值得一提的是,用 find_all() 得到的结果是一个结果集。如果要继续使用soup中的方法,需要方便set中的元素使用这些方法。
另外,在保存中文到csv时,如果不使用encoding='utf_8_sig',用excel打开文件时会出现乱码。
import requests
import csv
from bs4 import BeautifulSoup
url = 'https://greasyfork.org/zh-CN/scripts'
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def find_name(response):
soup = BeautifulSoup(response, "html.parser")
info = soup.find_all('li')
list = []
with open('data.csv', 'w', encoding='utf_8_sig') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['text', 'daily_install', 'total_instal'])
# print(info)
for i in info:
name = i.get('data-script-name')
daily_install = i.get('data-script-daily-installs')
tot_install = i.get('data-script-total-installs')
if (name):
writer.writerow([name, daily_install, tot_install])
templist = [name, daily_install, tot_install]
print(templist)
list.append(templist)
return list
def main():
response = get_one_page(url)
soup = find_name(response)
# print(soup)
main()
获取 GitHub TrendingList 的仓库名称、Star 号和 Fork 号并保存到 csv 文件
网址:
GitHub TrendingList 类似之前的油猴脚本爬取。抓住这个的灵感来自一个给我发电子邮件说我在 GitHub 上抓住了我的信息的人,我也想抓住这些大家伙的存储库。
捕获的结果也保存在 csv 文件中:
这次在解析完网页后,写了三个函数来提取它们的仓库名、星号、分叉号,然后将三列合并到csv文件中。这种方式的缺点是需要保证三个数组的长度相等,并且可以通过一一对应的方式保证数据的正确性。但是网页的结构肯定会保证这一点,而且似乎没有任何问题。
因为我对正则表达式不是很精通,所以写的代码效率比较低。初学者会看看它。
值得一提的是,Star和Fork的数量除了对应的svg是一样的,所以我只能用最好的策略,分别写在两个函数里,然后提取父节点的文本,效率相对低的。.
import requests
import csv
from bs4 import BeautifulSoup
url = 'https://github.com/trending'
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def find_name(soup):
namelist = []
h1 = soup.find_all('h1')
for e_h1 in h1:
a = e_h1.find_all('a')
for e_a in a:
name = e_a.get_text().replace('\n', '').replace(' ', '')
namelist.append(name)
return namelist
def find_star(soup):
star = []
star_fork = soup.find_all('a', {'class': 'muted-link'})
for e_s_f in star_fork:
e_star = e_s_f.find('svg', {'aria-label': 'star'})
if e_star:
e_star = e_star.find_parent().get_text().replace('\n', '').replace(' ', '')
star.append(e_star)
return star
def find_fork(soup):
fork = []
star_fork = soup.find_all('a', {'class': 'muted-link'})
for e_s_f in star_fork:
e_fork = e_s_f.find('svg', {'aria-label': 'fork'})
if e_fork:
e_star = e_fork.find_parent().get_text().replace('\n', '').replace(' ', '')
fork.append(e_star)
return fork
def main():
response = get_one_page(url)
soup = BeautifulSoup(response, "html.parser")
namelist = find_name(soup)
star = find_star(soup)
fork = find_fork(soup)
print(len(namelist), len(star), len(fork))
rows = zip(namelist, star, fork)
with open('github.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['Developer/Repo', 'Star', 'Fork'])
for row in rows:
writer.writerow(row)
main()
第一次写教程文章,大部分是根据自己的理解写的。有些表达在书本上肯定不好理解,所以我应该记录下自己的学习。
网页视频抓取脚本(百度网盘秒传链接提取插件怎么用?盘分享链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2022-01-16 16:14
百度网盘妙传链接提取插件是专门为提高百度网盘分享链接效率而开发的脚本。与普通网盘分享码相比,秒传链接的优势在于不需要分享者和分享链接。直接共享文件以确保帐户安全。即使分享者删除了自己网盘中的源文件,也可以通过第二个链接保存文件。原因是文件已经存储在百度云服务器中,分享者只删除自己对文件的“权限”操作,不影响“真正授权”(如百度云服务器等)访问文件。
【安装注意事项】
百度网盘妙传脚本是基于油猴插件运行的,所以如果要使用妙传,必须在浏览器上安装油猴插件。
下载 == "Tampermonkey 插件
安装插件后,打开 Tampermonkey 并单击 Add New Script。然后将第二个链接解压出来的.user.js文件拖拽到浏览器中,直到代码框出现代码,然后点击【文件】-【保存】。
保存后在插件管理器中出现脚本信息,说明安装成功。
【如何秒用代码】
1、打开拨号网页版,点击菜单栏上的【第二个链接】按钮,在弹窗中输入获取到的即时链接。
2、识别成功后会弹出提示输入对应的保存路径。如果不填写,默认保存在根目录下。
3、最后会显示传输结果,成功后可以查看文件。
【什么是二次通过?】
拨秒传输链路(标准提取码)由128位(32个十六进制数)+#+128位(32个十六进制数)+#+一段数字+#+文件名组成。
比如下面的链接:
47D112C767B8C69654023864897FDC3A#BF65AC1063E511DAB0C5E24EB03C3FDB#1373350#
妻子发电机.apk
由上可知,标准提取码与存储文件的文件内容、文件大小和文件名有关
理论上,存储在百度网盘中的文件只有一个对应的标准提取码,也就是说,即使有一百万个用户通过分享或上传等各种方式存储了同一个文件(即他们有相同的标准提取码)代码),这个文件实际上只存储了一份副本在百度云中。 查看全部
网页视频抓取脚本(百度网盘秒传链接提取插件怎么用?盘分享链接)
百度网盘妙传链接提取插件是专门为提高百度网盘分享链接效率而开发的脚本。与普通网盘分享码相比,秒传链接的优势在于不需要分享者和分享链接。直接共享文件以确保帐户安全。即使分享者删除了自己网盘中的源文件,也可以通过第二个链接保存文件。原因是文件已经存储在百度云服务器中,分享者只删除自己对文件的“权限”操作,不影响“真正授权”(如百度云服务器等)访问文件。
【安装注意事项】
百度网盘妙传脚本是基于油猴插件运行的,所以如果要使用妙传,必须在浏览器上安装油猴插件。
下载 == "Tampermonkey 插件
安装插件后,打开 Tampermonkey 并单击 Add New Script。然后将第二个链接解压出来的.user.js文件拖拽到浏览器中,直到代码框出现代码,然后点击【文件】-【保存】。
保存后在插件管理器中出现脚本信息,说明安装成功。
【如何秒用代码】
1、打开拨号网页版,点击菜单栏上的【第二个链接】按钮,在弹窗中输入获取到的即时链接。
2、识别成功后会弹出提示输入对应的保存路径。如果不填写,默认保存在根目录下。
3、最后会显示传输结果,成功后可以查看文件。
【什么是二次通过?】
拨秒传输链路(标准提取码)由128位(32个十六进制数)+#+128位(32个十六进制数)+#+一段数字+#+文件名组成。
比如下面的链接:
47D112C767B8C69654023864897FDC3A#BF65AC1063E511DAB0C5E24EB03C3FDB#1373350#
妻子发电机.apk
由上可知,标准提取码与存储文件的文件内容、文件大小和文件名有关
理论上,存储在百度网盘中的文件只有一个对应的标准提取码,也就是说,即使有一百万个用户通过分享或上传等各种方式存储了同一个文件(即他们有相同的标准提取码)代码),这个文件实际上只存储了一份副本在百度云中。
网页视频抓取脚本(影响蜘蛛抓取的因素有哪些?影响因素是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-15 02:02
)
深度爬取:当蜘蛛发现一个链接时,会沿着链接路径爬到最深的层次,直到不能再爬取,返回原页面爬取下一个链接。
广度爬取:蜘蛛会爬取当前页面链接中的所有页面,然后选择其中一个页面,继续爬取页面中的所有链接。
影响蜘蛛爬行的因素:
1、网站地图
网站地图相当于搜索引擎蜘蛛的爬行路线图。在路线图的引导下,可以大大提高蜘蛛爬取页面的速度。就像去一个陌生的城市一样,你需要一张地图来指引你。
2、404 错误页面
网站维护和内容修改难免会导致死链接。当蜘蛛爬到死链接时,就像进入了没有出口的死胡同。如果网站有很多死链接,没有404页面,在站长工具中查询会发现很多页面爬取错误。404页面的意义在于告诉搜索引擎当前内容不存在,可以按照404页面的链接路径返回首页或查看其他相关内容。蜘蛛深度爬行和广度爬行?
3、导出链接太多
蜘蛛在爬行网站时,有时是按深度爬行,有时是按广度爬行。蜘蛛按广度爬行时,直接沿着出口链接出去,才可以进入最深的页面。,因此,网站 不应该设置太多的导出链接。
4、导入链接太少
入站链接建设遵循以下两个原则:
多元化:您可以注册多个外链发布平台,防止其中一个账户被暂停导致外链出现较大波动;
高品质:相关和高权重的平台是您的最佳选择。在从外部链接吸引蜘蛛的同时,它们还可以为您带来相关流量。
蜘蛛深度爬行和广度爬行
查看全部
网页视频抓取脚本(影响蜘蛛抓取的因素有哪些?影响因素是什么?
)
深度爬取:当蜘蛛发现一个链接时,会沿着链接路径爬到最深的层次,直到不能再爬取,返回原页面爬取下一个链接。
广度爬取:蜘蛛会爬取当前页面链接中的所有页面,然后选择其中一个页面,继续爬取页面中的所有链接。
影响蜘蛛爬行的因素:
1、网站地图
网站地图相当于搜索引擎蜘蛛的爬行路线图。在路线图的引导下,可以大大提高蜘蛛爬取页面的速度。就像去一个陌生的城市一样,你需要一张地图来指引你。
2、404 错误页面
网站维护和内容修改难免会导致死链接。当蜘蛛爬到死链接时,就像进入了没有出口的死胡同。如果网站有很多死链接,没有404页面,在站长工具中查询会发现很多页面爬取错误。404页面的意义在于告诉搜索引擎当前内容不存在,可以按照404页面的链接路径返回首页或查看其他相关内容。蜘蛛深度爬行和广度爬行?
3、导出链接太多
蜘蛛在爬行网站时,有时是按深度爬行,有时是按广度爬行。蜘蛛按广度爬行时,直接沿着出口链接出去,才可以进入最深的页面。,因此,网站 不应该设置太多的导出链接。
4、导入链接太少
入站链接建设遵循以下两个原则:
多元化:您可以注册多个外链发布平台,防止其中一个账户被暂停导致外链出现较大波动;
高品质:相关和高权重的平台是您的最佳选择。在从外部链接吸引蜘蛛的同时,它们还可以为您带来相关流量。
蜘蛛深度爬行和广度爬行
网页视频抓取脚本(网页视频抓取脚本官方教程--mysql0csphgegyq密码:o2z8密码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-01-14 11:01
网页视频抓取脚本官方教程链接:-mysql0csphgegyq密码:o2z8(下载为压缩包,
1、右键解压到“requests.exe”。
2、unzip、czip、bzip3等)
2、在requests.exe目录下新建webdriver_db,
3、修改webdriver_db文件夹名称:
4、在另一目录“d:\python\requests\bundle\functions\webdriver.py”目录下新建db文件夹
5、右键解压到“webdriver_db”目录(我用的解压工具:gzip、winrar、anyzip、bzip
6、右键“maximize",把"showstatus"加到"exitresponse"前面(注意,这里需要把图片进行转码)。
7、在左边树形界面输入文件名,发现转码成功后,在文件“webdriver_db”下新建models.py,
8、修改models文件夹名称为“webdriver_db\models”。这里建议每次用到webdriver,就修改一次,后面用到python的相关工具,会方便很多。
9、修改requests.exe目录名称:1
0、修改webdriver_db文件夹名称为“data\webdriver_db"。
1、右键解压到“webdriver_db”目录(我用的解压工具:gzip、winrar、anyzip、bzip
2、unzip、czip、bzip3等)1
2、建立数据库,
3、修改db文件夹名称为“webdriver_db”1
4、重启python,
5、右键python,右键“更多设置”,右键“python解释器”,在弹出的对话框中,选择“以管理员身份运行”。
6、如果是python3,则在“python”下添加一行代码:importpathpath。path。join(webdriver_db,'d:\python\requests\scripts\requests。exe')如果是python2,则在“python”下添加一行代码:importpathpath。
path。join(webdriver_db,'d:\python\requests\scripts\requests。exe')1。
8、右键python,右键“更多设置”,右键“python解释器”,在弹出的对话框中,选择“以管理员身份运行”。
9、查看运行结果窗口显示:2019.11.18欢迎加入python交流qq群:426681834 查看全部
网页视频抓取脚本(网页视频抓取脚本官方教程--mysql0csphgegyq密码:o2z8密码)
网页视频抓取脚本官方教程链接:-mysql0csphgegyq密码:o2z8(下载为压缩包,
1、右键解压到“requests.exe”。
2、unzip、czip、bzip3等)
2、在requests.exe目录下新建webdriver_db,
3、修改webdriver_db文件夹名称:
4、在另一目录“d:\python\requests\bundle\functions\webdriver.py”目录下新建db文件夹
5、右键解压到“webdriver_db”目录(我用的解压工具:gzip、winrar、anyzip、bzip
6、右键“maximize",把"showstatus"加到"exitresponse"前面(注意,这里需要把图片进行转码)。
7、在左边树形界面输入文件名,发现转码成功后,在文件“webdriver_db”下新建models.py,
8、修改models文件夹名称为“webdriver_db\models”。这里建议每次用到webdriver,就修改一次,后面用到python的相关工具,会方便很多。
9、修改requests.exe目录名称:1
0、修改webdriver_db文件夹名称为“data\webdriver_db"。
1、右键解压到“webdriver_db”目录(我用的解压工具:gzip、winrar、anyzip、bzip
2、unzip、czip、bzip3等)1
2、建立数据库,
3、修改db文件夹名称为“webdriver_db”1
4、重启python,
5、右键python,右键“更多设置”,右键“python解释器”,在弹出的对话框中,选择“以管理员身份运行”。
6、如果是python3,则在“python”下添加一行代码:importpathpath。path。join(webdriver_db,'d:\python\requests\scripts\requests。exe')如果是python2,则在“python”下添加一行代码:importpathpath。
path。join(webdriver_db,'d:\python\requests\scripts\requests。exe')1。
8、右键python,右键“更多设置”,右键“python解释器”,在弹出的对话框中,选择“以管理员身份运行”。
9、查看运行结果窗口显示:2019.11.18欢迎加入python交流qq群:426681834
网页视频抓取脚本(什么是爬虫?实践来源于理论,做爬虫前肯定要先了解相关的规则和原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-14 10:19
什么是爬行动物?
实践源于理论,成为爬虫前必须了解相关规则和原则。
首先我们来看看爬虫的定义:网络爬虫(也被称为网络蜘蛛,网络机器人,在FOAF社区,更常被称为网页追逐者),是一种自动爬取万维网按照一定的规则。信息程序或脚本。总之,它是在线信息搬运工。
我们来看看爬虫应该遵循的规则:robots 协议是一个 ASCII 编码的文本文件,存放在 网站 根目录下,它通常告诉网络搜索引擎的 bot(也称为网络蜘蛛)这个 < @网站 @网站 中的哪些内容不应该被搜索引擎机器人检索,哪些可以被机器人检索。一句话,告诉你什么可以爬,什么不能爬。
了解了定义和规则后,终于熟悉了爬虫的基本原理。这很简单。作为一个灵魂画师,我画个示意图给你看,你就明白了。
(⊙o⊙)… 不好意思,鼠标写的这么难看,不好意思说学了书法,脸上的字都在呱呱叫。
项目背景
理论部分基本讲完了。有的小朋友觉得我太啰嗦了,废话不多说,直接说实操部分吧。本次爬虫小项目是应朋友的需求,对中国木材价格指数网的红木价格数据进行爬取,方便红木研报的撰写。网站像这样:
必填字段已用红色框标记。粗略看一下数据量,1751页有5万多条记录。如果你尝试复制粘贴,你不会知道它会被粘贴到猴年。而python只运行了几分钟,就将所有数据保存到你的excel中,是不是很舒服?\
项目实战
工具:PyCharm
Python 版本:Python 3.7
浏览器:Chrome(推荐)
第一次写爬虫的朋友可能会觉得很麻烦。我们不要惊慌。让我们先尝试爬上一页数据。
一次抓取一页
首先我们需要简单分析一下网页的结构,右键查看,然后点击Network,刷新网页,继续点击Name列表中的第一个。我们发现这个网站的请求方式是GET,请求头headers反映了用户的计算机系统、浏览器版本等信息。
然后,pip install 并导入爬虫所需的所有库,并注释所有库的功能。
import csv #用于把爬取的数据存储为csv格式,可以excel直接打开的
import time #用于对请求加延时,爬取速度太快容易被反爬
from time import sleep #同上
import random #用于对延时设置随机数,尽量模拟人的行为
import requests #用于向网站发送请求
from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造请求url,添加header信息headers复制上面标注的User-Agent,通过requests.get方法向服务器发送请求,返回html文本。添加标头的目的是告诉服务器您是访问其网站 的真实人。如果不加headers直接访问服务器,会显示python正在其他服务器上访问,那么你很可能被反爬了。常见的反爬就是屏蔽你的ip。
url = 'http://yz.yuzhuprice.com:8003/ ... 39%3B
headers = {
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36",
}
response = requests.get(url, headers=headers, timeout=10)
html = response.text
print(html)
让我们运行上面的代码,看看效果:
看到这里,第一次接触爬虫的朋友可能会有些疑惑。
其实这就是网页的源码,我们右键打开源码看看。
它看起来像这样:
而我们需要提取的数据隐藏在这个网页的源代码中。我们使用lxml库中的etree方法来解析网页。
parse = etree.HTML(html) #解析网页
解析之后,我们就可以愉快的提取出我们需要的数据了。方法很多,比如xpath、select、美汤、最难的re(正则表达式)。本文爬取的数据结构比较简单,直接玩xpath就行了。
我们在源码中发现每一行数据对应一个id=173200的tr,那么先把这些tr提取出来。
all_tr = parse.xpath('//*[@id="173200"]')
有些朋友不会写xpath。
然后找个简单的方法直接复制需要的xpath。
所有的trs都已经提取出来了,接下来还要从tr中依次提取具体的字段。例如,提取产品名称字段,点击第一个 tr,选择产品,并复制其 xpath。其他领域也是如此。
需要注意以下几点,tr={key1 : value1, key2 : value2 } 是python的字典数据类型(也可以根据自己的兴趣或需要保存为列表或元组类型)。''.join 表示将得到的列表转换成字符串。./表示继承前面的//*[@id="173200"],strip()表示对提取的数据进行简单的格式清理。
for tr in all_tr:
tr = {
'name': ''.join(tr.xpath('./td[1]/text()')).strip(),
'price': ''.join(tr.xpath('./td[2]/text()')).strip(),
'unit': ''.join(tr.xpath('./td[3]/text()')).strip(),
'supermaket': ''.join(tr.xpath('./td[4]/text()')).strip(),
'time': ''.join(tr.xpath('./td[5]/text()')).strip()
}
让我们打印 print(tr) 看看效果。
此时,你的心情可能是这样的:
不过还没完,有数据了,我们要把csv格式保存到本地,这一步比较简单,直接粘贴代码。
with open('wood.csv', 'a', encoding='utf_8_sig', newline='') as fp:
# 'a'为追加模式(添加)
# utf_8_sig格式导出csv不乱码
fieldnames = ['name', 'price', 'unit', 'supermaket', 'time']
writer = csv.DictWriter(fp, fieldnames)
writer.writerow(tr)
打开新生成的wood.csv,如下所示:
两个爬取多个页面
不要太高兴,你只是爬了一页数据,别人复制粘贴比你快。我们的野心不在这里,在诗和远方,哦不,是秒爬海量数据。
那么,我们如何爬取多页数据呢?没错,就是for循环。
我们回过头来分析一下url:
:8003/findPriceByName.jspx?page.curPage=1&priceName=%E7%BA%A2%E6%9C%A8%E7%B1%BB
我们试试把里面的page.curPage改成2,如下:
你可能会发现一个谜,只要改变page.curPage,就可以翻页。OK,那我们直接在url前面加个循环就好了。format(x) 是一个格式字符串函数,它接受无限数量的参数。
for x in range(1,3):
url = 'http://yz.yuzhuprice.com:8003/ ... ge%3D{}&priceName=%E7%BA%A2%E6%9C%A8%E7%B1%BB'.format(x)
到目前为止,您只需要更改范围即可抓取任意数量的页面。你快乐吗?你惊喜吗?
三只完美的爬行动物
如果只是按照上面的代码爬虫,爬了十几页之后程序很可能会崩溃。中途遇到过多次报错,导致爬虫失败。我终于写的爬虫,怎么说就崩溃了。
错误报告的原因有很多。玩爬虫的都知道调试bug很麻烦,需要不断的试错。这个爬虫的主要bug是TimeoutError。因此,我们需要进一步改进代码。
首先将上面的代码封装成函数,因为不使用函数有以下缺点:
1、复杂度增加
2、组织架构不够清晰
3、可读性差
4、代码冗余
5、可扩展性差
其次,在可能发生错误的地方添加异常处理。即尝试...除了。
完善后,截取部分,如下图。由于篇幅限制,我不会发布所有代码。需要完整代码的朋友,关注公众号,后台回复木头即可免费获取。
结语
此后,编写了红木数据爬虫代码,爬取数据后,可以直观的分析。比如可以看到每年不同市场红木的价格走势,同一市场不同红木的价格走势,也可以建立红木价格指数。后续我会重点介绍视觉内容,感兴趣的朋友可以关注一下~
当然,这个爬虫也有很大的改进空间,比如加入多线程,scrapy框架会爬得更快。另外,引入随机头和代理ip可以很好的避免一些反爬,很多比较复杂的爬虫都必须引入。 查看全部
网页视频抓取脚本(什么是爬虫?实践来源于理论,做爬虫前肯定要先了解相关的规则和原理)
什么是爬行动物?
实践源于理论,成为爬虫前必须了解相关规则和原则。
首先我们来看看爬虫的定义:网络爬虫(也被称为网络蜘蛛,网络机器人,在FOAF社区,更常被称为网页追逐者),是一种自动爬取万维网按照一定的规则。信息程序或脚本。总之,它是在线信息搬运工。
我们来看看爬虫应该遵循的规则:robots 协议是一个 ASCII 编码的文本文件,存放在 网站 根目录下,它通常告诉网络搜索引擎的 bot(也称为网络蜘蛛)这个 < @网站 @网站 中的哪些内容不应该被搜索引擎机器人检索,哪些可以被机器人检索。一句话,告诉你什么可以爬,什么不能爬。
了解了定义和规则后,终于熟悉了爬虫的基本原理。这很简单。作为一个灵魂画师,我画个示意图给你看,你就明白了。
(⊙o⊙)… 不好意思,鼠标写的这么难看,不好意思说学了书法,脸上的字都在呱呱叫。
项目背景
理论部分基本讲完了。有的小朋友觉得我太啰嗦了,废话不多说,直接说实操部分吧。本次爬虫小项目是应朋友的需求,对中国木材价格指数网的红木价格数据进行爬取,方便红木研报的撰写。网站像这样:
必填字段已用红色框标记。粗略看一下数据量,1751页有5万多条记录。如果你尝试复制粘贴,你不会知道它会被粘贴到猴年。而python只运行了几分钟,就将所有数据保存到你的excel中,是不是很舒服?\
项目实战
工具:PyCharm
Python 版本:Python 3.7
浏览器:Chrome(推荐)
第一次写爬虫的朋友可能会觉得很麻烦。我们不要惊慌。让我们先尝试爬上一页数据。
一次抓取一页
首先我们需要简单分析一下网页的结构,右键查看,然后点击Network,刷新网页,继续点击Name列表中的第一个。我们发现这个网站的请求方式是GET,请求头headers反映了用户的计算机系统、浏览器版本等信息。
然后,pip install 并导入爬虫所需的所有库,并注释所有库的功能。
import csv #用于把爬取的数据存储为csv格式,可以excel直接打开的
import time #用于对请求加延时,爬取速度太快容易被反爬
from time import sleep #同上
import random #用于对延时设置随机数,尽量模拟人的行为
import requests #用于向网站发送请求
from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造请求url,添加header信息headers复制上面标注的User-Agent,通过requests.get方法向服务器发送请求,返回html文本。添加标头的目的是告诉服务器您是访问其网站 的真实人。如果不加headers直接访问服务器,会显示python正在其他服务器上访问,那么你很可能被反爬了。常见的反爬就是屏蔽你的ip。
url = 'http://yz.yuzhuprice.com:8003/ ... 39%3B
headers = {
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36",
}
response = requests.get(url, headers=headers, timeout=10)
html = response.text
print(html)
让我们运行上面的代码,看看效果:
看到这里,第一次接触爬虫的朋友可能会有些疑惑。
其实这就是网页的源码,我们右键打开源码看看。
它看起来像这样:
而我们需要提取的数据隐藏在这个网页的源代码中。我们使用lxml库中的etree方法来解析网页。
parse = etree.HTML(html) #解析网页
解析之后,我们就可以愉快的提取出我们需要的数据了。方法很多,比如xpath、select、美汤、最难的re(正则表达式)。本文爬取的数据结构比较简单,直接玩xpath就行了。
我们在源码中发现每一行数据对应一个id=173200的tr,那么先把这些tr提取出来。
all_tr = parse.xpath('//*[@id="173200"]')
有些朋友不会写xpath。
然后找个简单的方法直接复制需要的xpath。
所有的trs都已经提取出来了,接下来还要从tr中依次提取具体的字段。例如,提取产品名称字段,点击第一个 tr,选择产品,并复制其 xpath。其他领域也是如此。
需要注意以下几点,tr={key1 : value1, key2 : value2 } 是python的字典数据类型(也可以根据自己的兴趣或需要保存为列表或元组类型)。''.join 表示将得到的列表转换成字符串。./表示继承前面的//*[@id="173200"],strip()表示对提取的数据进行简单的格式清理。
for tr in all_tr:
tr = {
'name': ''.join(tr.xpath('./td[1]/text()')).strip(),
'price': ''.join(tr.xpath('./td[2]/text()')).strip(),
'unit': ''.join(tr.xpath('./td[3]/text()')).strip(),
'supermaket': ''.join(tr.xpath('./td[4]/text()')).strip(),
'time': ''.join(tr.xpath('./td[5]/text()')).strip()
}
让我们打印 print(tr) 看看效果。
此时,你的心情可能是这样的:
不过还没完,有数据了,我们要把csv格式保存到本地,这一步比较简单,直接粘贴代码。
with open('wood.csv', 'a', encoding='utf_8_sig', newline='') as fp:
# 'a'为追加模式(添加)
# utf_8_sig格式导出csv不乱码
fieldnames = ['name', 'price', 'unit', 'supermaket', 'time']
writer = csv.DictWriter(fp, fieldnames)
writer.writerow(tr)
打开新生成的wood.csv,如下所示:
两个爬取多个页面
不要太高兴,你只是爬了一页数据,别人复制粘贴比你快。我们的野心不在这里,在诗和远方,哦不,是秒爬海量数据。
那么,我们如何爬取多页数据呢?没错,就是for循环。
我们回过头来分析一下url:
:8003/findPriceByName.jspx?page.curPage=1&priceName=%E7%BA%A2%E6%9C%A8%E7%B1%BB
我们试试把里面的page.curPage改成2,如下:
你可能会发现一个谜,只要改变page.curPage,就可以翻页。OK,那我们直接在url前面加个循环就好了。format(x) 是一个格式字符串函数,它接受无限数量的参数。
for x in range(1,3):
url = 'http://yz.yuzhuprice.com:8003/ ... ge%3D{}&priceName=%E7%BA%A2%E6%9C%A8%E7%B1%BB'.format(x)
到目前为止,您只需要更改范围即可抓取任意数量的页面。你快乐吗?你惊喜吗?
三只完美的爬行动物
如果只是按照上面的代码爬虫,爬了十几页之后程序很可能会崩溃。中途遇到过多次报错,导致爬虫失败。我终于写的爬虫,怎么说就崩溃了。
错误报告的原因有很多。玩爬虫的都知道调试bug很麻烦,需要不断的试错。这个爬虫的主要bug是TimeoutError。因此,我们需要进一步改进代码。
首先将上面的代码封装成函数,因为不使用函数有以下缺点:
1、复杂度增加
2、组织架构不够清晰
3、可读性差
4、代码冗余
5、可扩展性差
其次,在可能发生错误的地方添加异常处理。即尝试...除了。
完善后,截取部分,如下图。由于篇幅限制,我不会发布所有代码。需要完整代码的朋友,关注公众号,后台回复木头即可免费获取。
结语
此后,编写了红木数据爬虫代码,爬取数据后,可以直观的分析。比如可以看到每年不同市场红木的价格走势,同一市场不同红木的价格走势,也可以建立红木价格指数。后续我会重点介绍视觉内容,感兴趣的朋友可以关注一下~
当然,这个爬虫也有很大的改进空间,比如加入多线程,scrapy框架会爬得更快。另外,引入随机头和代理ip可以很好的避免一些反爬,很多比较复杂的爬虫都必须引入。

