
网页视频抓取脚本
网页视频抓取脚本(爬虫测试样例序言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-29 13:04
pip3安装请求
试样
此外,序言中还有16段视频。我们使用Python爬虫技术在本地批量下载它们
#/?vid=0
直链
首先,我们需要获得视频下载直链。右击选中,可以直接看到视频的直链
再看一下页面的源代码,发现缺少视频直链。视频直链的原创位置已成为JS脚本
如果我们直接使用请求库来请求URL,我们会得到源代码,但是源代码中没有视频直接链接,所以我们应该考虑改变我们的想法。为什么视频直链的位置被JS取代
当有更多的爬虫程序时,您将知道这是网页的动态加载。必须有一个JS文件来存储视频的直链。然后,每次加载网页时,通过JS脚本将视频的直链动态加载到HTML中
点击网络,过滤JS文件,找到三个JS文件。让我们看看第一个JS文件中是否有视频直链。搜索视频的标题,直接查找视频的直链,并找到视频的所有直链都保存到名为lesson_uuuList的文件中
第一课所有视频名称和视频直接链接信息都保存在列表中。为统一起见,序言改为第0节
#lesson_uuList.py
课程列表=[{
“名称”:“第0节vue.js简介”
“url”:“
“询问”:“77367”
},{
“名称”:“第1节安装和部署”
“url”:“
“询问”:“77369”
},{
“名称”:“第2节创建第一个Vue应用程序”
“url”:“
“询问”:“77370”
},{
“名称”:“第3节数据和方法”
“url”:“
“询问”:“77372”
},{
“名称”:“第4节生命周期”
“url”:“
“询问”:“77373”
},{
“名称”:“第5节模板语法-插值”
“url”:“
“询问”:“77375”
},{
“名称”:“第6节模板语法-说明”
“url”:“
“询问”:“77376”
},{
“名称”:“第7节装订类别和样式”
“url”:“
“询问”:“77377”
},{
“名称”:“第8节条件呈现”
“url”:“
“询问”:“77378”
},{
“名称”:“第9节列表呈现”
“url”:“
“询问”:“77380”
},{
“名称”:“第10节事件绑定”
“url”:“
“询问”:“77381”
},{
“名称”:“第11节表单输入绑定”
“url”:“
“询问”:“77382”
},{
“名称”:“第12节组件基础”
“url”:“
“询问”:“77383”
},{
“名称”:“第13节部件注册”
“url”:“
“询问”:“78520”
},{
“名称”:“第14节单文件组件”
“url”:“
“询问”:“78521”
},{
“名称”:“第15节无终端开发Vue应用程序”
“url”:“
“询问”:“81004”
}]
批量下载
在这里,使用for循环遍历每个下载链接,然后使用之前编写的多线程下载程序进行下载
从concurrent.futures导入ThreadPoolExecutor
从课程列表导入课程列表
从请求导入获取,头部
导入时间
类下载器:
定义初始化(self,url,num,name):
self.url=url
self.num=num
self.name=名称
self.getsize=0
r=头(self.url,allow_redirects=True)
self.size=int(r.headers['Content-Length'])
def下降(自身、开始、结束、块大小=10240):
headers={'range':f'bytes={start}-{end}
r=get(self.url,headers=headers,stream=True)
将open(self.name,“rb+”)作为f:
f、 搜索(开始)
对于r.iter\u内容中的块(块大小):
f、 写入(块)
self.getsize+=块大小
def主(自):
开始时间=time.time()
f=打开(self.name,“wb”)
f、 截断(自身大小)
f、 关闭()
tp=线程池执行器(最大工作线程数=self.num)
期货=[]
开始=0
对于范围内的i(self.num):
end=int((i+1)/self.num*self.size)
future=tp.submit(self.down、start、end)
futures.append(未来)
开始=结束+1
尽管如此:
进程=self.getsize/self.size*100
last=self.getsize
时间。睡眠(1)
curr=self.getsize
向下=(当前最后一次)/1024
如果下降>;1024:
速度=f'{down/1024:6.2f}MB/s'
其他:
速度=f'{down:6.2f}KB/s'
打印(f'process:{process:6.2f}%|速度:{speed}',end='r')
如果流程>;=100:
打印(进程:{100.00:6}%|速度:00.00KB/s',结束=“|”)
中断
结束时间=time.time()
总时间=结束时间-开始时间
平均速度=自身大小/总时间/1024/1024
打印(f'总时间:{总时间:{0f}s}平均速度:{平均速度:{2f}MB/s')
如果uuuu name uuuuuu='\uuuuuuu main\uuuuuuu':
对于课程列表中的课程:
url=课程['url']
名称=课程['name']
down=downloader(url,8,name+'.mp4')
down.main()
结果打印
在56秒内下载了16个视频,总计339mb
进程:100.0%|速度:00.00KB/s |总时间:2s |平均速度:47MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:6.62MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:72MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:72MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:85MB/s
进程:100.0%|速度:00.00KB/s |总时间:7s |平均速度:7.01MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:4.65MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:69MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:88MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:5.01MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:6.60MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:6.20MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:96MB/s
进程:100.0%|速度:00.00KB/s |总时间:2s |平均速度:64MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:6.02MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:80MB/s
总结与展望
有时候视频或图片的直接链接不一定需要爬网,可能在网页上加载的JS文件中就可以找到,既然可以直接找到,为什么要爬网呢?那么下载的时候一定要使用多线程,因为多线程可以占用宽带,全速下载 查看全部
网页视频抓取脚本(爬虫测试样例序言)
pip3安装请求
试样
此外,序言中还有16段视频。我们使用Python爬虫技术在本地批量下载它们
#/?vid=0
直链
首先,我们需要获得视频下载直链。右击选中,可以直接看到视频的直链
再看一下页面的源代码,发现缺少视频直链。视频直链的原创位置已成为JS脚本
如果我们直接使用请求库来请求URL,我们会得到源代码,但是源代码中没有视频直接链接,所以我们应该考虑改变我们的想法。为什么视频直链的位置被JS取代
当有更多的爬虫程序时,您将知道这是网页的动态加载。必须有一个JS文件来存储视频的直链。然后,每次加载网页时,通过JS脚本将视频的直链动态加载到HTML中
点击网络,过滤JS文件,找到三个JS文件。让我们看看第一个JS文件中是否有视频直链。搜索视频的标题,直接查找视频的直链,并找到视频的所有直链都保存到名为lesson_uuuList的文件中
第一课所有视频名称和视频直接链接信息都保存在列表中。为统一起见,序言改为第0节
#lesson_uuList.py
课程列表=[{
“名称”:“第0节vue.js简介”
“url”:“
“询问”:“77367”
},{
“名称”:“第1节安装和部署”
“url”:“
“询问”:“77369”
},{
“名称”:“第2节创建第一个Vue应用程序”
“url”:“
“询问”:“77370”
},{
“名称”:“第3节数据和方法”
“url”:“
“询问”:“77372”
},{
“名称”:“第4节生命周期”
“url”:“
“询问”:“77373”
},{
“名称”:“第5节模板语法-插值”
“url”:“
“询问”:“77375”
},{
“名称”:“第6节模板语法-说明”
“url”:“
“询问”:“77376”
},{
“名称”:“第7节装订类别和样式”
“url”:“
“询问”:“77377”
},{
“名称”:“第8节条件呈现”
“url”:“
“询问”:“77378”
},{
“名称”:“第9节列表呈现”
“url”:“
“询问”:“77380”
},{
“名称”:“第10节事件绑定”
“url”:“
“询问”:“77381”
},{
“名称”:“第11节表单输入绑定”
“url”:“
“询问”:“77382”
},{
“名称”:“第12节组件基础”
“url”:“
“询问”:“77383”
},{
“名称”:“第13节部件注册”
“url”:“
“询问”:“78520”
},{
“名称”:“第14节单文件组件”
“url”:“
“询问”:“78521”
},{
“名称”:“第15节无终端开发Vue应用程序”
“url”:“
“询问”:“81004”
}]
批量下载
在这里,使用for循环遍历每个下载链接,然后使用之前编写的多线程下载程序进行下载
从concurrent.futures导入ThreadPoolExecutor
从课程列表导入课程列表
从请求导入获取,头部
导入时间
类下载器:
定义初始化(self,url,num,name):
self.url=url
self.num=num
self.name=名称
self.getsize=0
r=头(self.url,allow_redirects=True)
self.size=int(r.headers['Content-Length'])
def下降(自身、开始、结束、块大小=10240):
headers={'range':f'bytes={start}-{end}
r=get(self.url,headers=headers,stream=True)
将open(self.name,“rb+”)作为f:
f、 搜索(开始)
对于r.iter\u内容中的块(块大小):
f、 写入(块)
self.getsize+=块大小
def主(自):
开始时间=time.time()
f=打开(self.name,“wb”)
f、 截断(自身大小)
f、 关闭()
tp=线程池执行器(最大工作线程数=self.num)
期货=[]
开始=0
对于范围内的i(self.num):
end=int((i+1)/self.num*self.size)
future=tp.submit(self.down、start、end)
futures.append(未来)
开始=结束+1
尽管如此:
进程=self.getsize/self.size*100
last=self.getsize
时间。睡眠(1)
curr=self.getsize
向下=(当前最后一次)/1024
如果下降>;1024:
速度=f'{down/1024:6.2f}MB/s'
其他:
速度=f'{down:6.2f}KB/s'
打印(f'process:{process:6.2f}%|速度:{speed}',end='r')
如果流程>;=100:
打印(进程:{100.00:6}%|速度:00.00KB/s',结束=“|”)
中断
结束时间=time.time()
总时间=结束时间-开始时间
平均速度=自身大小/总时间/1024/1024
打印(f'总时间:{总时间:{0f}s}平均速度:{平均速度:{2f}MB/s')
如果uuuu name uuuuuu='\uuuuuuu main\uuuuuuu':
对于课程列表中的课程:
url=课程['url']
名称=课程['name']
down=downloader(url,8,name+'.mp4')
down.main()
结果打印
在56秒内下载了16个视频,总计339mb
进程:100.0%|速度:00.00KB/s |总时间:2s |平均速度:47MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:6.62MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:72MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:72MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:85MB/s
进程:100.0%|速度:00.00KB/s |总时间:7s |平均速度:7.01MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:4.65MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:69MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:88MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:5.01MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:6.60MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:6.20MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:96MB/s
进程:100.0%|速度:00.00KB/s |总时间:2s |平均速度:64MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:6.02MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:80MB/s
总结与展望
有时候视频或图片的直接链接不一定需要爬网,可能在网页上加载的JS文件中就可以找到,既然可以直接找到,为什么要爬网呢?那么下载的时候一定要使用多线程,因为多线程可以占用宽带,全速下载
网页视频抓取脚本(视频链接下载链接显示出来就行;.fire )
网站优化 • 优采云 发表了文章 • 0 个评论 • 1176 次浏览 • 2021-09-27 06:03
)
思路:年龄使用的网盘下载链接经常被举报然后失效,但是可以在线观看,然后可以通过在线视频链接下载。
因此,我们只需要找到视频链接并显示即可;
第一步:找到对应的链接
这里我们可以通过F12找到对应的链接来查看元素
(Age网站 统一了review元素,在播放页面使用时会跳转到首页,所以一定要先停止网页跳转,再快速跳转)
通过对比可以发现,本身的id和上层的id不一样,上层的id是一样的,所以这个视频是个突破口。
第二步:油猴脚本编写
首先我们需要遍历视频,找到里面的src-writing
$("#video video").each(function() {
$(this).attr("src")
});
我们使用alert函数来显示
$("#video video").each(function() {
alert($(this).attr("src"))
});
测试
貌似测试成功了,但是这个有抄袭的缺陷,不美观。我通过百度了解了 Swal.fire。
第 3 步:将链接放入 Swal.fire 窗口
先引用对应的js
// @require https://cdn.jsdelivr.net/npm/sweetalert2@8
然后我们按照官方格式修改
$("#video video").each(function() {
Swal.fire({//使用Swal.fire窗口
title: '下载地址是', //窗口标题
text:$(this).attr("src"),//窗口内容 这里我们将上面的遍历放入
type:"info",//窗口图标
confirmButtonText: 'OK',//窗口按钮
confirmButtonColor: '#3085d6'//按钮颜色
});
});
测试
好像成功了
下面是我写的所有代码
(以上是初学者的尝试,老板们仁慈)
// ==UserScript==
// @icon https://www.agefans.net/favicon.ico
// @name Age在线视频 下载地址获取
// @author Mr
// @description 能够获取到age在线视频的地址 然后使用弹窗展示 初学者作者 不喜勿喷
// @match https://www.agefans.net/*
// @require http://cdn.bootcss.com/jquery/1.8.3/jquery.min.js
// @require https://cdn.jsdelivr.net/npm/sweetalert2@8
// @version 0.0.1
// ==/UserScript==
var src;
(function () {
'use strict';
a();
})();
function a() {
$("#video video").each(function() {
Swal.fire({
title: '下载地址是',
text:$(this).attr("src"),
type:"info",
confirmButtonText: 'OK',
confirmButtonColor: '#3085d6'
});
});
} 查看全部
网页视频抓取脚本(视频链接下载链接显示出来就行;.fire
)
思路:年龄使用的网盘下载链接经常被举报然后失效,但是可以在线观看,然后可以通过在线视频链接下载。
因此,我们只需要找到视频链接并显示即可;
第一步:找到对应的链接
这里我们可以通过F12找到对应的链接来查看元素
(Age网站 统一了review元素,在播放页面使用时会跳转到首页,所以一定要先停止网页跳转,再快速跳转)


通过对比可以发现,本身的id和上层的id不一样,上层的id是一样的,所以这个视频是个突破口。
第二步:油猴脚本编写
首先我们需要遍历视频,找到里面的src-writing
$("#video video").each(function() {
$(this).attr("src")
});
我们使用alert函数来显示
$("#video video").each(function() {
alert($(this).attr("src"))
});
测试
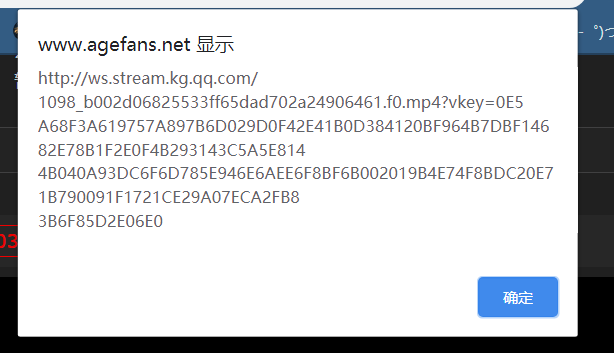
貌似测试成功了,但是这个有抄袭的缺陷,不美观。我通过百度了解了 Swal.fire。
第 3 步:将链接放入 Swal.fire 窗口
先引用对应的js
// @require https://cdn.jsdelivr.net/npm/sweetalert2@8
然后我们按照官方格式修改
$("#video video").each(function() {
Swal.fire({//使用Swal.fire窗口
title: '下载地址是', //窗口标题
text:$(this).attr("src"),//窗口内容 这里我们将上面的遍历放入
type:"info",//窗口图标
confirmButtonText: 'OK',//窗口按钮
confirmButtonColor: '#3085d6'//按钮颜色
});
});
测试
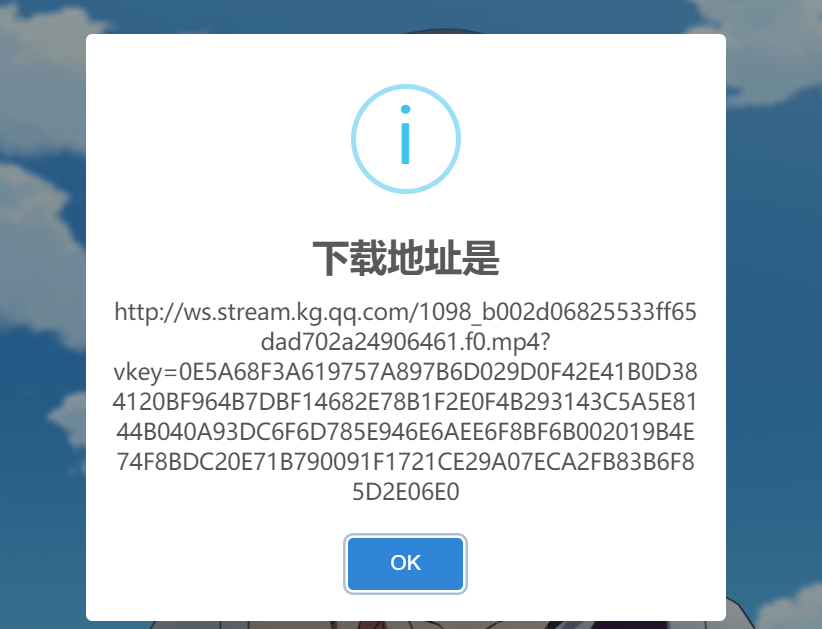
好像成功了
下面是我写的所有代码
(以上是初学者的尝试,老板们仁慈)
// ==UserScript==
// @icon https://www.agefans.net/favicon.ico
// @name Age在线视频 下载地址获取
// @author Mr
// @description 能够获取到age在线视频的地址 然后使用弹窗展示 初学者作者 不喜勿喷
// @match https://www.agefans.net/*
// @require http://cdn.bootcss.com/jquery/1.8.3/jquery.min.js
// @require https://cdn.jsdelivr.net/npm/sweetalert2@8
// @version 0.0.1
// ==/UserScript==
var src;
(function () {
'use strict';
a();
})();
function a() {
$("#video video").each(function() {
Swal.fire({
title: '下载地址是',
text:$(this).attr("src"),
type:"info",
confirmButtonText: 'OK',
confirmButtonColor: '#3085d6'
});
});
}
网页视频抓取脚本(弹幕,new返回xml数据使用正则表达式获取所有弹幕消息,匹配模式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-26 12:05
)
需要准备的环境:
A站B账号,需要先登录,否则无法查看历史弹幕记录
连接互联网的计算机和方便的浏览器,我使用 Chrome
Python3环境和请求模块,安装使用命令,改源码更快:
pip3 install request -i http://pypi.douban.com/simple
爬取步骤:登录后打开需要爬取的视频页面,打开开发者工具控制台,Chrome可以使用F12快捷键选择网络监听请求
点击查看历史弹幕并获取请求
rolldate后面的数字代表视频对应的弹幕编号。返回数据中,timestamp代表弹幕日期,new代表数字。
在查看历史弹幕中选择一天,勾选,会发出新的请求
dmroll,timestamp,弹幕数,表示获取该日期的弹幕,1507564800表示2017/10/10 0:0:0
请求返回xml数据
使用正则表达式获取所有弹幕消息并匹配模式
'(.*?)'
连接字符串并将所有项目符号屏幕保存到本地文件
with open('content.txt', mode='w+', encoding='utf8') as f: f.write(content)
参考代码如下,弹幕按日期保存为单个文件...因为太多...
import requests
import re
import time
"""
爬取哔哩哔哩视频弹幕信息
"""
# 2043618 是视频的弹幕标号,这个地址会返回时间列表
# https://www.bilibili.com/video/av1349282
url = 'https://comment.bilibili.com/rolldate,2043618'
# 获取弹幕的id 2043618
video_id = url.split(',')[-1]
print(video_id)
# 获取json文件
html = requests.get(url)
# print(html.json())
# 生成时间戳列表
time_list = [i['timestamp'] for i in html.json()]
# print(time_list)
# 获取弹幕网址格式 'https://comment.bilibili.com/dmroll,时间戳,弹幕号'
# 弹幕内容,由于总弹幕量太大,将每个弹幕文件分别保存
for i in time_list:
content = ''
j = 'https://comment.bilibili.com/dmroll,{0},{1}'.format(i, video_id)
print(j)
text = requests.get(j).text
# 匹配弹幕内容
res = re.findall('(.*?)', text)
# 将时间戳转化为日期形式,需要把字符串转为整数
timeArray = time.localtime(int(i))
date_time = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
print(date_time)
content += date_time + '\n'
for k in res:
content += k + '\n'
content += '\n'
file_path = 'txt/{}.txt'.format(time.strftime("%Y_%m_%d", timeArray))
print(file_path)
with open(file_path, mode='w+', encoding='utf8') as f:
f.write(content)
最终效果
之后就可以做一些分词来生成词云或者进行情感分析,有时间再聊...
可以在下方给小编留言学习心得,感谢大家的支持。
查看全部
网页视频抓取脚本(弹幕,new返回xml数据使用正则表达式获取所有弹幕消息,匹配模式
)
需要准备的环境:
A站B账号,需要先登录,否则无法查看历史弹幕记录
连接互联网的计算机和方便的浏览器,我使用 Chrome
Python3环境和请求模块,安装使用命令,改源码更快:
pip3 install request -i http://pypi.douban.com/simple
爬取步骤:登录后打开需要爬取的视频页面,打开开发者工具控制台,Chrome可以使用F12快捷键选择网络监听请求
点击查看历史弹幕并获取请求
rolldate后面的数字代表视频对应的弹幕编号。返回数据中,timestamp代表弹幕日期,new代表数字。
在查看历史弹幕中选择一天,勾选,会发出新的请求
dmroll,timestamp,弹幕数,表示获取该日期的弹幕,1507564800表示2017/10/10 0:0:0
请求返回xml数据
使用正则表达式获取所有弹幕消息并匹配模式
'(.*?)'
连接字符串并将所有项目符号屏幕保存到本地文件
with open('content.txt', mode='w+', encoding='utf8') as f: f.write(content)
参考代码如下,弹幕按日期保存为单个文件...因为太多...
import requests
import re
import time
"""
爬取哔哩哔哩视频弹幕信息
"""
# 2043618 是视频的弹幕标号,这个地址会返回时间列表
# https://www.bilibili.com/video/av1349282
url = 'https://comment.bilibili.com/rolldate,2043618'
# 获取弹幕的id 2043618
video_id = url.split(',')[-1]
print(video_id)
# 获取json文件
html = requests.get(url)
# print(html.json())
# 生成时间戳列表
time_list = [i['timestamp'] for i in html.json()]
# print(time_list)
# 获取弹幕网址格式 'https://comment.bilibili.com/dmroll,时间戳,弹幕号'
# 弹幕内容,由于总弹幕量太大,将每个弹幕文件分别保存
for i in time_list:
content = ''
j = 'https://comment.bilibili.com/dmroll,{0},{1}'.format(i, video_id)
print(j)
text = requests.get(j).text
# 匹配弹幕内容
res = re.findall('(.*?)', text)
# 将时间戳转化为日期形式,需要把字符串转为整数
timeArray = time.localtime(int(i))
date_time = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
print(date_time)
content += date_time + '\n'
for k in res:
content += k + '\n'
content += '\n'
file_path = 'txt/{}.txt'.format(time.strftime("%Y_%m_%d", timeArray))
print(file_path)
with open(file_path, mode='w+', encoding='utf8') as f:
f.write(content)
最终效果
之后就可以做一些分词来生成词云或者进行情感分析,有时间再聊...
可以在下方给小编留言学习心得,感谢大家的支持。

网页视频抓取脚本( 从左侧的菜单选择你需要的教程!JavaScriptJavaScript)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-26 02:01
从左侧的菜单选择你需要的教程!JavaScriptJavaScript)
浏览器脚本系列教程
从左侧的菜单中选择所需的教程
Java脚本
JavaScript是一种基于对象和事件驱动的脚本语言,具有相对的安全性。它广泛应用于客户端web开发,通常用于向HTML网页添加动态功能
ECMA国际已经开发了基于JavaScript的ECMAScript标准。JavaScript也可以用于其他情况,例如服务器端编程。完整的JavaScript实现由三部分组成:ECMAScript、文档对象模型和字节顺序标记
开始学习java脚本
HTML DOM
HTMLDOM定义了访问和操作HTML文档的标准方法。HTMLDOM将HTML文档表示为收录元素、属性和文本的树结构(节点树)
熟悉软件开发的人可以理解HTMLDOM作为网页的API。它将网页中的每个元素视为一个对象,这样网页中的元素也可以通过计算机语言获取或编辑。例如,JavaScript可以使用HTMLDOM动态修改网页
开始学习HTMLDOM
DHTML
DHTML是动态HTML的缩写,即动态HTML。与传统的静态HTML相比,它是一种制作网页的概念
DHTML是一种新的语言。它只是HTML、CSS和客户端脚本的集成,即一个页面收录HTML+CSS+JavaScript(或其他客户端脚本),其中CSS和客户端脚本直接写在页面上,而不是链接到相关文件
开始学习DHTML
VBScript
VBScript是Microsoft开发的一种分析服务器(也支持客户端)脚本语言。它可以看作是VB语言的简化版本,与VBA有着非常密切的关系
Vbsript是ASP动态网页的默认编程语言。通过ASP内置对象和ADO对象,用户可以快速掌握访问数据库的ASP动态网页开发技术
开始学习VBScript
阿贾克斯
AJAX是一种用于创建交互式web应用程序的web开发技术。Ajax指的是异步JavaScript和XML
AJAX的核心是JavaScript对象XMLHttpRequest。这个对象最初是在Internet Explorer 5中引入的。它是一种支持异步请求的技术。简而言之,XMLHttpRequest使您能够使用JavaScript向服务器发出请求并处理响应,而不会阻塞用户
开始学习ajax
JQuery
JQuery是一个优秀的JavaScript框架。它是一个轻量级JS库。它与CSS3和各种浏览器兼容
JQuery使用户能够更轻松地处理HTML文档和事件,实现动画效果,并轻松地为网站>提供Ajax交互。JQuery使用户能够更轻松地处理HTML文档和事件,实现动画效果,并为网站@>
开始学习jQuery
JSON
JSON(JavaScript对象表示法)是一种轻量级数据交换格式。它基于JavaScript的一个子集
JSON采用完全独立于语言的文本格式,但它也使用类似于C语言家族的习惯(包括C、C++、C#、Java、JavaScript、Perl、python等)。这些特性使JSON成为理想的数据交换语言。它便于人们读写,也便于机器分析和生成
开始学习JSON
E4X
E4X(ECMAScript for XML)是基于ECMAScript(包括ActionScript、JavaScript和其他语言实现)标准的动态XML支持的程序语言扩展
E4X是DOM接口的替代品。它使程序员能够通过ECMAScript脚本中更简洁的语法访问XML文档。E4X使用XML作为简单类型(相当于字符、整数或布尔值)。使用E4X,您可以像date或math对象一样声明XML对象
开始学习E4X
WML脚本
WML脚本是WML页面中使用的脚本语言。WML脚本是一种轻量级JavaScript语言
WML脚本不嵌入在WML页面中。WML页面仅收录对脚本URL的引用。WML脚本需要在服务器上编译成字节编码,然后才能在WAP浏览器中运行。WML是WAP规范的一部分
开始学习WML脚本 查看全部
网页视频抓取脚本(
从左侧的菜单选择你需要的教程!JavaScriptJavaScript)
浏览器脚本系列教程
从左侧的菜单中选择所需的教程
Java脚本
JavaScript是一种基于对象和事件驱动的脚本语言,具有相对的安全性。它广泛应用于客户端web开发,通常用于向HTML网页添加动态功能
ECMA国际已经开发了基于JavaScript的ECMAScript标准。JavaScript也可以用于其他情况,例如服务器端编程。完整的JavaScript实现由三部分组成:ECMAScript、文档对象模型和字节顺序标记
开始学习java脚本
HTML DOM
HTMLDOM定义了访问和操作HTML文档的标准方法。HTMLDOM将HTML文档表示为收录元素、属性和文本的树结构(节点树)
熟悉软件开发的人可以理解HTMLDOM作为网页的API。它将网页中的每个元素视为一个对象,这样网页中的元素也可以通过计算机语言获取或编辑。例如,JavaScript可以使用HTMLDOM动态修改网页
开始学习HTMLDOM
DHTML
DHTML是动态HTML的缩写,即动态HTML。与传统的静态HTML相比,它是一种制作网页的概念
DHTML是一种新的语言。它只是HTML、CSS和客户端脚本的集成,即一个页面收录HTML+CSS+JavaScript(或其他客户端脚本),其中CSS和客户端脚本直接写在页面上,而不是链接到相关文件
开始学习DHTML
VBScript
VBScript是Microsoft开发的一种分析服务器(也支持客户端)脚本语言。它可以看作是VB语言的简化版本,与VBA有着非常密切的关系
Vbsript是ASP动态网页的默认编程语言。通过ASP内置对象和ADO对象,用户可以快速掌握访问数据库的ASP动态网页开发技术
开始学习VBScript
阿贾克斯
AJAX是一种用于创建交互式web应用程序的web开发技术。Ajax指的是异步JavaScript和XML
AJAX的核心是JavaScript对象XMLHttpRequest。这个对象最初是在Internet Explorer 5中引入的。它是一种支持异步请求的技术。简而言之,XMLHttpRequest使您能够使用JavaScript向服务器发出请求并处理响应,而不会阻塞用户
开始学习ajax
JQuery
JQuery是一个优秀的JavaScript框架。它是一个轻量级JS库。它与CSS3和各种浏览器兼容
JQuery使用户能够更轻松地处理HTML文档和事件,实现动画效果,并轻松地为网站>提供Ajax交互。JQuery使用户能够更轻松地处理HTML文档和事件,实现动画效果,并为网站@>
开始学习jQuery
JSON
JSON(JavaScript对象表示法)是一种轻量级数据交换格式。它基于JavaScript的一个子集
JSON采用完全独立于语言的文本格式,但它也使用类似于C语言家族的习惯(包括C、C++、C#、Java、JavaScript、Perl、python等)。这些特性使JSON成为理想的数据交换语言。它便于人们读写,也便于机器分析和生成
开始学习JSON
E4X
E4X(ECMAScript for XML)是基于ECMAScript(包括ActionScript、JavaScript和其他语言实现)标准的动态XML支持的程序语言扩展
E4X是DOM接口的替代品。它使程序员能够通过ECMAScript脚本中更简洁的语法访问XML文档。E4X使用XML作为简单类型(相当于字符、整数或布尔值)。使用E4X,您可以像date或math对象一样声明XML对象
开始学习E4X
WML脚本
WML脚本是WML页面中使用的脚本语言。WML脚本是一种轻量级JavaScript语言
WML脚本不嵌入在WML页面中。WML页面仅收录对脚本URL的引用。WML脚本需要在服务器上编译成字节编码,然后才能在WAP浏览器中运行。WML是WAP规范的一部分
开始学习WML脚本
网页视频抓取脚本(制作自己的翻译脚本()(-))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-25 18:23
英语差一直是我的一个短板,尤其是在学习代码阶段。我经常需要检查各种错误,这很困难。一直想自己做一个翻译脚本,节省打开网页的时间,但是查询后发现网上的教程都是百度翻译改版之前的爬虫,只好自己动手了!
目标:制作自己的翻译脚本
网址:
前期准备:pycharm、python3.6、 库:requests、json
想法:
Lan是抓包直接提取后返回的内容
{"User-Agent":"Mozilla/5.0(Linux; Android 5.1.1; Nexus 6 Build/LYZ28E) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/63.0.3239.84 Mobile Safari/537.36"}
比如输入“python学习交流群:542110741”,返回内容:
Josn的内容如下:
{'errno':0,'from':'zh','to':'en','trans':[{'dst':'Python学习交流群:542110741','prefixWrap':0,'src ':'python学习交流群:542110741','relation':[],'result':[[0,'Python学习交流群:542110741',['0|32'],[],['0|32] '], ['0|46']]]}],'dict':[],'keywords': [{'means': ['giant snake, python'],'word':'python'} , {'means': ['study','learn','emulate','learning'],'word':'learning'}, {'means': ['exchange','interflow','interchange', 'alternating','AC(交流电)','communion'],'word':'沟通')))
我们可以分别抓取'trans'和'keywords'的值。我们需要的是这两个值。
好的,直接上传代码,运行结果
好了,内容就到这里了~如果对大家有帮助,请关注 查看全部
网页视频抓取脚本(制作自己的翻译脚本()(-))
英语差一直是我的一个短板,尤其是在学习代码阶段。我经常需要检查各种错误,这很困难。一直想自己做一个翻译脚本,节省打开网页的时间,但是查询后发现网上的教程都是百度翻译改版之前的爬虫,只好自己动手了!
目标:制作自己的翻译脚本
网址:
前期准备:pycharm、python3.6、 库:requests、json
想法:
Lan是抓包直接提取后返回的内容
{"User-Agent":"Mozilla/5.0(Linux; Android 5.1.1; Nexus 6 Build/LYZ28E) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/63.0.3239.84 Mobile Safari/537.36"}
比如输入“python学习交流群:542110741”,返回内容:
Josn的内容如下:
{'errno':0,'from':'zh','to':'en','trans':[{'dst':'Python学习交流群:542110741','prefixWrap':0,'src ':'python学习交流群:542110741','relation':[],'result':[[0,'Python学习交流群:542110741',['0|32'],[],['0|32] '], ['0|46']]]}],'dict':[],'keywords': [{'means': ['giant snake, python'],'word':'python'} , {'means': ['study','learn','emulate','learning'],'word':'learning'}, {'means': ['exchange','interflow','interchange', 'alternating','AC(交流电)','communion'],'word':'沟通')))
我们可以分别抓取'trans'和'keywords'的值。我们需要的是这两个值。
好的,直接上传代码,运行结果
好了,内容就到这里了~如果对大家有帮助,请关注
网页视频抓取脚本(【】请求url参数的对比过程分段请求链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-25 18:22
工具:google浏览器+fiddler抓包工具
注意:这里没有发布代码,[只是想法!!!】
原创网址 = [链接到您可以随机找到的电影] 将其称为原创网址
开始分析:
打开fiddler,然后打开google,输入url,按F12.得到如下图:
分析上图内容:首先通过fiddler抓包,我们知道真实的播放地址是一段一段的,如上图3号,然后将播放地址的一小段复制到浏览器打开它,并得到一个 403 错误。可以看出需要重新打开链接。先构造一些东西,然后才能通过代码发送请求,否则会被拒绝。因此,来到上面的第4个图标,分析请求url。首先分析不同视频段的url差异。对比发现只有[ts_seg_no]参数不同,参数从0开始,逐渐+1,但结束尚不得而知。然后分析原创网址在不同时间打开时所请求的视频真实地址的网址的区别。旧的方法是在新标签页中再次打开原创URL,并比较请求的两次打开的URL。请求url参数对比过程略,参数对比结果如下:
可以看到每次开启时,psid和vkey这两个参数都在变化,代表什么还是未知数。不同视频段同时打开的请求URL,ts_start、ts_end、ts_seg_no参数也有变化。虽然知道变化规律,但不确定三个参数什么时候结束,所以目前还不得而知。分析到这里,可以确定在分割的视频链接之前,肯定有链接或者js文件加载了这些未知参数或者这些未知的请求url链接。于是尝试在网络中搜索psid和vkey这两个值,有一部分链接是这样的[/playlist/m3u8?],然后点击查看响应,如下图:
恰巧响应的内容只是视频片段的请求链接。所以现在不需要重构视频片段的请求链接了,关注上图中的url链接【暂且称之为播放url】,只要能获取到播放url,那么这个任务就可以了完成。
然后开始分析播放url,如下图所示:
看起来有点复杂,所以我用了之前的比较分析url的方法,得到了播放url参数的差异。区别如下:
分析这个链接,链接中唯一需要重构的参数就是psid和ups_key。于是开始分析这两个参数的来源。
因此,在google network中通过ctrl+f搜索psid和ups_key,发现在名为[]的链接中出现了两个参数,这个链接[称之为js链接]如下图;
这个js链接是一个js文件。点击后查看响应,发现响应是一个json格式的js函数,如下图:
然后我在响应中搜索了psid和ups_key的值,找到了之前的播放链接,并给出了一张图:
好的!现在一切都清楚了,只要能拿到这个js链接的响应信息,再提取m3u8_url再请求,提取响应【这个响应才是真正的视频播放地址】。所以现在我们要弄清楚如何获得这个js链接,
问题的出现
嗯。. . ? (我猜...)从响应中可以看到json格式是mtopjsonp1(),那么这个mtopjsonp1()是什么?它是一个js函数吗?如果是js函数,那么你可以尝试搜索看看【我试过了,但是没有看到完全相同的函数】,你尝试请求这个js链接吗?【这个链接也看了,很长,看起来好复杂,这条路先不考虑】,如果不考虑前两条,那你就得开始考虑重构播放url了,毕竟, play 只要url找到psid和ups_key这两个参数就可以了。于是我开始思考:如果这两条路径存在,那应该是在某个js函数中,于是我开始在网络中搜索psid和ups_key这两个参数。好吧,我发现了 psid 参数的痕迹。如下所示:
我确实在另一个 js 文件中找到了 psid,但它不是很相似。而且就算是,如果对js不是很熟悉,我也无法弄清楚psid是如何生成的。所以,先放这个变量,再搜索。ups_key,不幸的是,这个变量在js文件中找不到,所以我们需要回到猜测【如何找到请求那个很长很复杂的js链接的方法】,为什么复杂呢?看看下面的图片:
它仍然是一个 GET 请求来发送一个指向数据的链接。下图为链接的参数(先绝望):
老实说,看到这样的链接,我真的不想得到它。
不过我还是得花点时间弄清楚,不然我的爬虫技术就到此为止了。(我还是得做,但是一想到爬虫的问题就忍不住很伤心,没人能问。技术瓶颈只能自己在未知的时间里堆积起来) 继续。
写在最后
我现在在爬虫破解js方向有技术瓶颈。上次破解搜索网站也是js加密的一个参数,因为无法解决js加密,最后失败了。想了想,技术瓶颈只能是现在开始学js,自己学做js加密数据。如此周而复始,想必js破解指日可待。以后学了js,自己加密,自己破解。
另外,文章里写的完全是我自己的想法。可能是对的,也可能是错的,可能是其中的一部分等等,如果你不幸读了我的文章,不幸看到这个地方,我真诚地希望你能纠正错误。
另外,如果后续破解成功,会更新这个文章。 查看全部
网页视频抓取脚本(【】请求url参数的对比过程分段请求链接)
工具:google浏览器+fiddler抓包工具
注意:这里没有发布代码,[只是想法!!!】
原创网址 = [链接到您可以随机找到的电影] 将其称为原创网址
开始分析:
打开fiddler,然后打开google,输入url,按F12.得到如下图:

分析上图内容:首先通过fiddler抓包,我们知道真实的播放地址是一段一段的,如上图3号,然后将播放地址的一小段复制到浏览器打开它,并得到一个 403 错误。可以看出需要重新打开链接。先构造一些东西,然后才能通过代码发送请求,否则会被拒绝。因此,来到上面的第4个图标,分析请求url。首先分析不同视频段的url差异。对比发现只有[ts_seg_no]参数不同,参数从0开始,逐渐+1,但结束尚不得而知。然后分析原创网址在不同时间打开时所请求的视频真实地址的网址的区别。旧的方法是在新标签页中再次打开原创URL,并比较请求的两次打开的URL。请求url参数对比过程略,参数对比结果如下:

可以看到每次开启时,psid和vkey这两个参数都在变化,代表什么还是未知数。不同视频段同时打开的请求URL,ts_start、ts_end、ts_seg_no参数也有变化。虽然知道变化规律,但不确定三个参数什么时候结束,所以目前还不得而知。分析到这里,可以确定在分割的视频链接之前,肯定有链接或者js文件加载了这些未知参数或者这些未知的请求url链接。于是尝试在网络中搜索psid和vkey这两个值,有一部分链接是这样的[/playlist/m3u8?],然后点击查看响应,如下图:
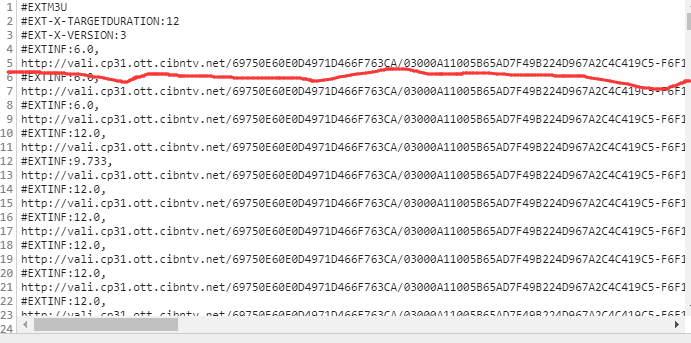
恰巧响应的内容只是视频片段的请求链接。所以现在不需要重构视频片段的请求链接了,关注上图中的url链接【暂且称之为播放url】,只要能获取到播放url,那么这个任务就可以了完成。
然后开始分析播放url,如下图所示:

看起来有点复杂,所以我用了之前的比较分析url的方法,得到了播放url参数的差异。区别如下:

分析这个链接,链接中唯一需要重构的参数就是psid和ups_key。于是开始分析这两个参数的来源。
因此,在google network中通过ctrl+f搜索psid和ups_key,发现在名为[]的链接中出现了两个参数,这个链接[称之为js链接]如下图;
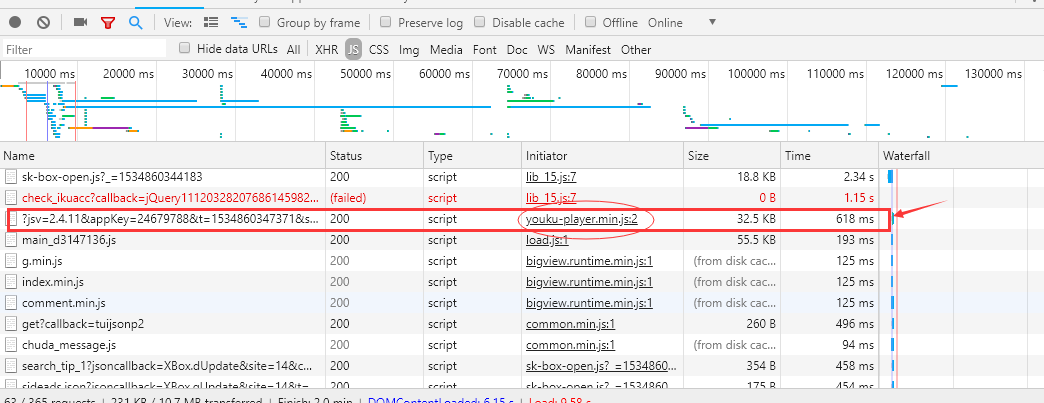
这个js链接是一个js文件。点击后查看响应,发现响应是一个json格式的js函数,如下图:
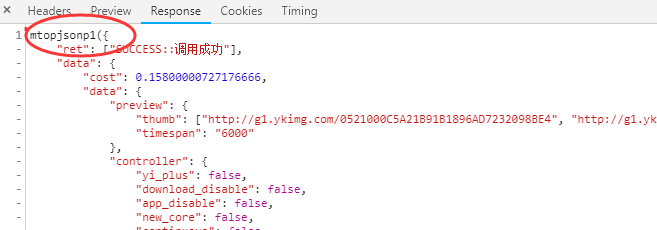
然后我在响应中搜索了psid和ups_key的值,找到了之前的播放链接,并给出了一张图:
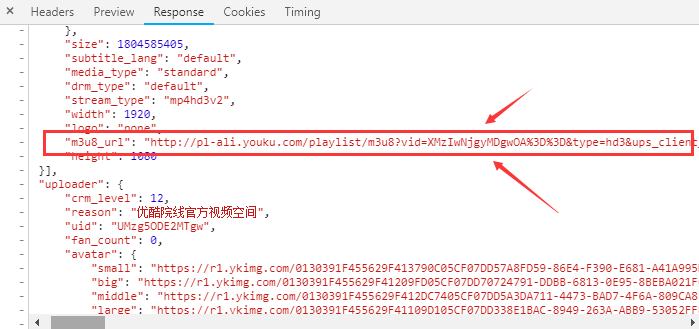
好的!现在一切都清楚了,只要能拿到这个js链接的响应信息,再提取m3u8_url再请求,提取响应【这个响应才是真正的视频播放地址】。所以现在我们要弄清楚如何获得这个js链接,
问题的出现
嗯。. . ? (我猜...)从响应中可以看到json格式是mtopjsonp1(),那么这个mtopjsonp1()是什么?它是一个js函数吗?如果是js函数,那么你可以尝试搜索看看【我试过了,但是没有看到完全相同的函数】,你尝试请求这个js链接吗?【这个链接也看了,很长,看起来好复杂,这条路先不考虑】,如果不考虑前两条,那你就得开始考虑重构播放url了,毕竟, play 只要url找到psid和ups_key这两个参数就可以了。于是我开始思考:如果这两条路径存在,那应该是在某个js函数中,于是我开始在网络中搜索psid和ups_key这两个参数。好吧,我发现了 psid 参数的痕迹。如下所示:
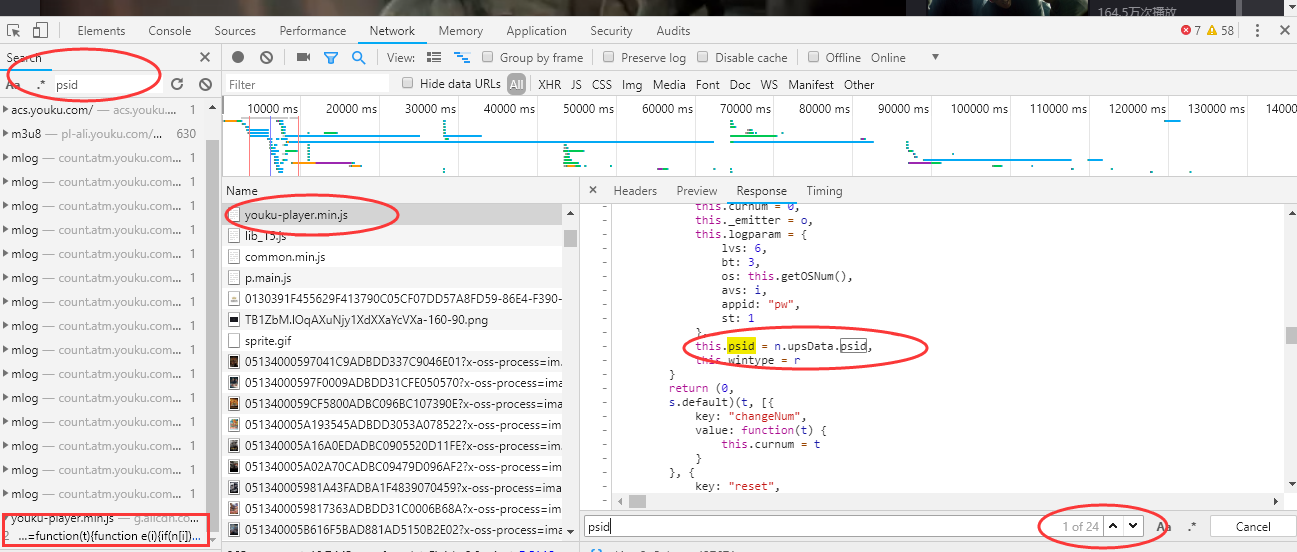
我确实在另一个 js 文件中找到了 psid,但它不是很相似。而且就算是,如果对js不是很熟悉,我也无法弄清楚psid是如何生成的。所以,先放这个变量,再搜索。ups_key,不幸的是,这个变量在js文件中找不到,所以我们需要回到猜测【如何找到请求那个很长很复杂的js链接的方法】,为什么复杂呢?看看下面的图片:
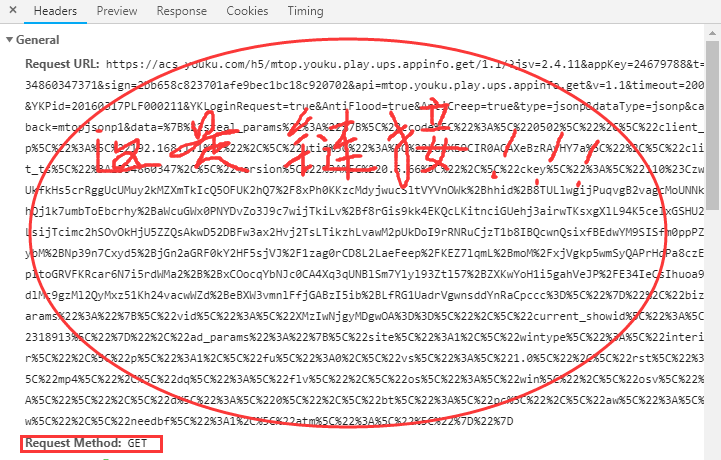
它仍然是一个 GET 请求来发送一个指向数据的链接。下图为链接的参数(先绝望):
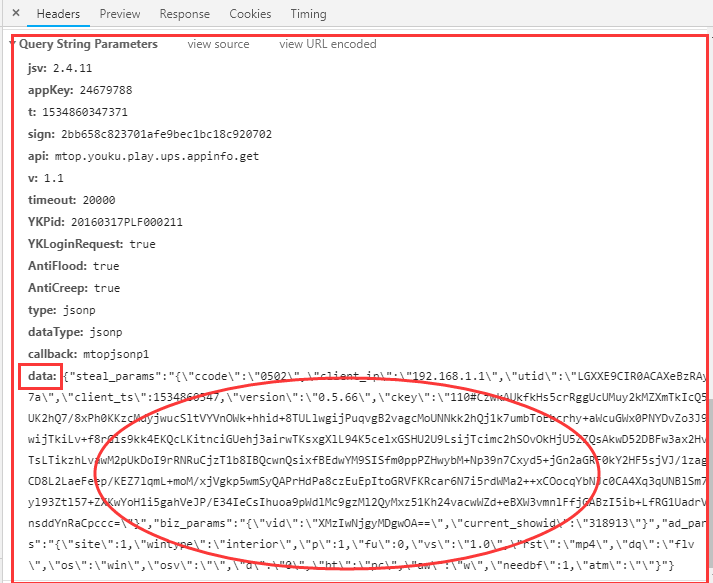
老实说,看到这样的链接,我真的不想得到它。
不过我还是得花点时间弄清楚,不然我的爬虫技术就到此为止了。(我还是得做,但是一想到爬虫的问题就忍不住很伤心,没人能问。技术瓶颈只能自己在未知的时间里堆积起来) 继续。
写在最后
我现在在爬虫破解js方向有技术瓶颈。上次破解搜索网站也是js加密的一个参数,因为无法解决js加密,最后失败了。想了想,技术瓶颈只能是现在开始学js,自己学做js加密数据。如此周而复始,想必js破解指日可待。以后学了js,自己加密,自己破解。
另外,文章里写的完全是我自己的想法。可能是对的,也可能是错的,可能是其中的一部分等等,如果你不幸读了我的文章,不幸看到这个地方,我真诚地希望你能纠正错误。
另外,如果后续破解成功,会更新这个文章。
网页视频抓取脚本(网页视频抓取脚本解析地址和内容就行了比如下面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-25 04:03
网页视频抓取脚本解析脚本地址和内容就行了比如下面这个代码是我在网上找的,可以抓一下内容,你用第一个解析它会在网页上放一个脚本,你用第二个就不会放。按这个内容去请求,一般是会出现正常页面,但是使用脚本他就一直自动生成一直的脚本,抓他的话肯定比你手动去访问方便。
可以百度一下chrome调试脚本
正常浏览器都有脚本功能。另外,如果你用的是ie浏览器,
反正都看不了了,直接百度百科的脚本功能了解一下。ie浏览器其实能够按自己自定义的内容播放视频。以下内容节选自百度百科:浏览器自带按自己设置的内容播放视频,这类功能十分强大。但是并不是所有人都需要这种功能,如果对播放比较多的内容,而且比较长的视频,可以使用flash播放器将视频内容变为flash,再把自定义的路径指向播放器按自己的设置播放。
另外,一些无良视频网站,既不向用户购买版权,也不提供播放功能,那么我们可以试试这些方法,如果你用ie浏览器的话,可以使用谷歌浏览器扩展程序库,里面有非常多的视频下载脚本,并且都是开源的。不过为了安全起见,最好是在ie浏览器的开发人员工具中去找。谷歌浏览器用户可以参考这篇文章下载脚本。:$foo_bandwidth去掉百度云的百度网盘账号,浏览器下载的视频都无法在本地播放,因为所有下载的视频都在百度云的大文件目录下,假如你对视频的多人下载的路径做了处理,无法播放。
针对上述问题,有两种方法:1、第一步,你可以用浏览器自带的在线视频搜索工具找到想要下载的视频,或者谷歌网页应用商店找到。2、第二步,找到后可以用在线视频搜索下载器进行下载,如下图,也可以直接是对应路径找到。或者你可以在你电脑的浏览器任意下载窗口里下载,就是在浏览器的应用商店搜索你下载的网站,就可以下载你想要的视频。
例如在浏览器的浏览器资源导航,或者-app/download.html,你还可以在电脑上用迅雷快速下载浏览器资源,或者打开迅雷网页版,浏览器资源也可以直接在线直接下载。当然你可以在谷歌网页版的浏览器浏览器浏览器文件夹或者下载的时候要求你浏览器自带的浏览器浏览器浏览器下载路径等权限。所以在下载网站上,不要用迅雷等工具进行下载,而是根据你的浏览器自带的浏览器浏览器,然后打开自带浏览器搜索相应的视频路径,自己修改路径才能访问下载。 查看全部
网页视频抓取脚本(网页视频抓取脚本解析地址和内容就行了比如下面)
网页视频抓取脚本解析脚本地址和内容就行了比如下面这个代码是我在网上找的,可以抓一下内容,你用第一个解析它会在网页上放一个脚本,你用第二个就不会放。按这个内容去请求,一般是会出现正常页面,但是使用脚本他就一直自动生成一直的脚本,抓他的话肯定比你手动去访问方便。
可以百度一下chrome调试脚本
正常浏览器都有脚本功能。另外,如果你用的是ie浏览器,
反正都看不了了,直接百度百科的脚本功能了解一下。ie浏览器其实能够按自己自定义的内容播放视频。以下内容节选自百度百科:浏览器自带按自己设置的内容播放视频,这类功能十分强大。但是并不是所有人都需要这种功能,如果对播放比较多的内容,而且比较长的视频,可以使用flash播放器将视频内容变为flash,再把自定义的路径指向播放器按自己的设置播放。
另外,一些无良视频网站,既不向用户购买版权,也不提供播放功能,那么我们可以试试这些方法,如果你用ie浏览器的话,可以使用谷歌浏览器扩展程序库,里面有非常多的视频下载脚本,并且都是开源的。不过为了安全起见,最好是在ie浏览器的开发人员工具中去找。谷歌浏览器用户可以参考这篇文章下载脚本。:$foo_bandwidth去掉百度云的百度网盘账号,浏览器下载的视频都无法在本地播放,因为所有下载的视频都在百度云的大文件目录下,假如你对视频的多人下载的路径做了处理,无法播放。
针对上述问题,有两种方法:1、第一步,你可以用浏览器自带的在线视频搜索工具找到想要下载的视频,或者谷歌网页应用商店找到。2、第二步,找到后可以用在线视频搜索下载器进行下载,如下图,也可以直接是对应路径找到。或者你可以在你电脑的浏览器任意下载窗口里下载,就是在浏览器的应用商店搜索你下载的网站,就可以下载你想要的视频。
例如在浏览器的浏览器资源导航,或者-app/download.html,你还可以在电脑上用迅雷快速下载浏览器资源,或者打开迅雷网页版,浏览器资源也可以直接在线直接下载。当然你可以在谷歌网页版的浏览器浏览器浏览器文件夹或者下载的时候要求你浏览器自带的浏览器浏览器浏览器下载路径等权限。所以在下载网站上,不要用迅雷等工具进行下载,而是根据你的浏览器自带的浏览器浏览器,然后打开自带浏览器搜索相应的视频路径,自己修改路径才能访问下载。
网页视频抓取脚本(脚本,在线学习c++编程学而思百题大师班的老师)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-24 11:03
网页视频抓取脚本语言:teddyben/swingcontext,抓取ppt并下载为flv视频,下载pdf到手机,方便以后自己查看教程之后前往开发网:c++语言视频抓取脚本,在线学习c++编程
学而思百题大师班的老师做了一套书,你可以去看看。可能有适合你的。
嗯我刚才也是看到一个刚毕业的学生做了个,很牛逼的项目名字好像叫做高考答案,有全国的,浙江,福建,还有上海的,
推荐大家使用优网助手,里面功能相当强大,好用!一键查询qq/微信/谷歌,网址链接,支付宝,微博登录,查询杀毒,预装软件,清理缓存,清理内存,文件夹,图片搜索,分类账号和密码,密码管理..。
能不能推荐一些跟高考相关的例如2035,
给大家推荐个具有技术含量的自动识别考点分析和答案检索的软件,全国语文联考真题答案,有视频有音频,还有重点题和典型题解析,在线即可观看,比如陕西历史可以扫描题目加入解析统计库,或者像上面说的这种类型的考点库可以自己从部分题目中摘出需要的知识点方便打印出来,想用手机看的话还可以下载云笔记,不用带本厚书,再进行学习。
我最近开发了一个服务,也就是一个私人的微信公众号——多选题答案分析的公众号。利用这个专栏,学习了很多的答题技巧,利用过去的自己做答题技巧可以大幅提高做对题的概率。而且这个专栏可以与手机注册账号对应推送练习答案以及课后的实践总结,也可以登录我的专栏获取答案解析。祝各位取得好成绩,见证我们的努力!。 查看全部
网页视频抓取脚本(脚本,在线学习c++编程学而思百题大师班的老师)
网页视频抓取脚本语言:teddyben/swingcontext,抓取ppt并下载为flv视频,下载pdf到手机,方便以后自己查看教程之后前往开发网:c++语言视频抓取脚本,在线学习c++编程
学而思百题大师班的老师做了一套书,你可以去看看。可能有适合你的。
嗯我刚才也是看到一个刚毕业的学生做了个,很牛逼的项目名字好像叫做高考答案,有全国的,浙江,福建,还有上海的,
推荐大家使用优网助手,里面功能相当强大,好用!一键查询qq/微信/谷歌,网址链接,支付宝,微博登录,查询杀毒,预装软件,清理缓存,清理内存,文件夹,图片搜索,分类账号和密码,密码管理..。
能不能推荐一些跟高考相关的例如2035,
给大家推荐个具有技术含量的自动识别考点分析和答案检索的软件,全国语文联考真题答案,有视频有音频,还有重点题和典型题解析,在线即可观看,比如陕西历史可以扫描题目加入解析统计库,或者像上面说的这种类型的考点库可以自己从部分题目中摘出需要的知识点方便打印出来,想用手机看的话还可以下载云笔记,不用带本厚书,再进行学习。
我最近开发了一个服务,也就是一个私人的微信公众号——多选题答案分析的公众号。利用这个专栏,学习了很多的答题技巧,利用过去的自己做答题技巧可以大幅提高做对题的概率。而且这个专栏可以与手机注册账号对应推送练习答案以及课后的实践总结,也可以登录我的专栏获取答案解析。祝各位取得好成绩,见证我们的努力!。
网页视频抓取脚本(网页视频抓取脚本录制软件-上海怡健医学培训学校)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-24 08:04
网页视频抓取脚本录制软件:easydlpythonpython实现电商网页视频播放功能第一步需要添加三个注册weixin123的网站和下载指定歌曲软件:免费|easydlpython视频下载抓取脚本第二步第三步第四步
自己动手写个爬虫,爬爬她的歌单,然后去下载--用以下网址:com.easyday.starm.jack-fantastic,收集下载youtubeyoutube在线视频高清无水印字幕的资源、音乐以及有水印的资源,一个专门的资源网,分享国外视频和文字。
有点困难,刚开始一个要下七八首歌才能满足。1.歌曲选择听着舒服的。千万不要听着很好听但是不适合你的歌,会弄巧成拙的。2.歌手选择有创意的。千万不要找很老的歌手,多看看mv,根据mv内容选择。3.歌曲前段选择合适的字幕。这就很考验英语功底了,新概念或者voa都可以。你可以找些歌词,有很多可以从google或者百度上搜,或者自己手动翻译。
4.歌词选择视频推荐乐库/,比较满意,但是你要先搜歌名再点乐库,不然找不到。5.资源选择音乐选择以下资源大,或者其他你喜欢的,以搜索引擎为准,里面有收集很多资源。6.歌单地址,字幕,都可以放进去,作为关键字可以找到一些你需要的资源,你可以发送网址,我也是easydl的员工,所以有上传歌单到乐库,或者地址给你。 查看全部
网页视频抓取脚本(网页视频抓取脚本录制软件-上海怡健医学培训学校)
网页视频抓取脚本录制软件:easydlpythonpython实现电商网页视频播放功能第一步需要添加三个注册weixin123的网站和下载指定歌曲软件:免费|easydlpython视频下载抓取脚本第二步第三步第四步
自己动手写个爬虫,爬爬她的歌单,然后去下载--用以下网址:com.easyday.starm.jack-fantastic,收集下载youtubeyoutube在线视频高清无水印字幕的资源、音乐以及有水印的资源,一个专门的资源网,分享国外视频和文字。
有点困难,刚开始一个要下七八首歌才能满足。1.歌曲选择听着舒服的。千万不要听着很好听但是不适合你的歌,会弄巧成拙的。2.歌手选择有创意的。千万不要找很老的歌手,多看看mv,根据mv内容选择。3.歌曲前段选择合适的字幕。这就很考验英语功底了,新概念或者voa都可以。你可以找些歌词,有很多可以从google或者百度上搜,或者自己手动翻译。
4.歌词选择视频推荐乐库/,比较满意,但是你要先搜歌名再点乐库,不然找不到。5.资源选择音乐选择以下资源大,或者其他你喜欢的,以搜索引擎为准,里面有收集很多资源。6.歌单地址,字幕,都可以放进去,作为关键字可以找到一些你需要的资源,你可以发送网址,我也是easydl的员工,所以有上传歌单到乐库,或者地址给你。
网页视频抓取脚本( 一起进步网页抓取工具我用的使用经验分享(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-14 11:19
一起进步网页抓取工具我用的使用经验分享(图))
教你使用网络爬虫工具下载图片。现在内容里有图片的网页已经很常见了,所以图片的采集也很重要,但是一张一张的点击下载很麻烦,所以我们爬网的时候一定要学会。当我抓取图片到我的采集 内容时,我会同时下载图片和缩略图采集。这个很有用,但是一开始图片总是采集不全。缩略图无法取下。现在我将我的经验分享给大家。让我们改进网络爬虫工具。我用的是优采云采集器,最新版本V9。因为功能比较全,速度也快,我会在优采云采集器中设置采集规则后输入内容优采云@k0采集rules这里的准备,大家要注意在编辑标签的数据处理中有一个文件下载选项。有四个选项,其中之一是下载图片。
一看就明白可以通过勾选来下载图片,但是如果只这样的话,只能采集到部分图片,因为优采云采集器这里是默认的图片下载带有html标签,所以对于没有html标签的图片,比如缩略图,检查检测文件并下载。然后优采云采集器会自动检测这种图片文件并下载采集。下载采集时,对不同类型的图片分别设置标签。只需下载并选择测试此页面上的5张图片是否已被优采云采集器下载。你觉得很简单吗?像优采云采集器这样的网络爬虫就是这样的。学习以后如何使用它非常容易上手,它确实可以解决很多问题,并且可以大大提高我们的工作效率。这就是人类智慧所在。 查看全部
网页视频抓取脚本(
一起进步网页抓取工具我用的使用经验分享(图))

教你使用网络爬虫工具下载图片。现在内容里有图片的网页已经很常见了,所以图片的采集也很重要,但是一张一张的点击下载很麻烦,所以我们爬网的时候一定要学会。当我抓取图片到我的采集 内容时,我会同时下载图片和缩略图采集。这个很有用,但是一开始图片总是采集不全。缩略图无法取下。现在我将我的经验分享给大家。让我们改进网络爬虫工具。我用的是优采云采集器,最新版本V9。因为功能比较全,速度也快,我会在优采云采集器中设置采集规则后输入内容优采云@k0采集rules这里的准备,大家要注意在编辑标签的数据处理中有一个文件下载选项。有四个选项,其中之一是下载图片。

一看就明白可以通过勾选来下载图片,但是如果只这样的话,只能采集到部分图片,因为优采云采集器这里是默认的图片下载带有html标签,所以对于没有html标签的图片,比如缩略图,检查检测文件并下载。然后优采云采集器会自动检测这种图片文件并下载采集。下载采集时,对不同类型的图片分别设置标签。只需下载并选择测试此页面上的5张图片是否已被优采云采集器下载。你觉得很简单吗?像优采云采集器这样的网络爬虫就是这样的。学习以后如何使用它非常容易上手,它确实可以解决很多问题,并且可以大大提高我们的工作效率。这就是人类智慧所在。
网页视频抓取脚本(2016年最适合你的网页刮刀取决于你需要的web抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-14 06:21
如今,市场上出现了各种网络抓取工具,当您必须选择其中一种工具时,您可能会感到困惑。最适合您的网页抓取工具取决于您的需求。这里有一些强烈推荐的网页抓取工具。其中一些是免费的,而有些则有试用期和高级计划。在做出决定之前,请仔细阅读以下所有信息。
ParseHub
ParseHub 是一款免费、可靠且功能强大的网页抓取工具。它用于使用 JS、AJAX、会话、cookie 和重定向来抓取单个和多个 网站。使用 Parsehub,您可以轻松地从任何网站 获取数据,因为您无需编写代码。您只需要打开目标网站 并开始单击要提取的数据。此工具可帮助您在服务器上自动采集和存储数据。其简单的 AIP 允许用户在任何地方集成他们提取的数据。
Parsehub 在爬取网站 时使用了大量代理,因此 IP 地址总是在旋转。
八字解析
Octopus 是一种现代视觉网络爬虫软件。对于那些无需编码即可从网站 获取数据的人来说,这是一个完美的选择。多亏了“点击”界面,用户使用起来不会有任何困难。八达通模仿人类活动,例如浏览网站、登录帐户等。它几乎可以从每个站点获取数据,即使它是使用 AJAX 或 JS 动态获取的。
免费版八达通允许用户提取几乎所有网站。只需点击几下鼠标,它就可以将网页变成结构化的电子表格。
Diffbot
Diffbot 是一种非常高效的数据提取工具,它使用互联网让个人和企业能够获取他们需要的任何信息。可广泛应用于市场营销、商业智能、销售和招聘等领域。它提供 API 来提取和理解对象,使用 Al 和计算机视觉从网站 中提取数据。使用 Diffbot,用户不再需要进行任何手动数据提取或互联网研究,因为数据可以自动保存到文件或数据库中。
Diffbot 服务虽然价格偏高,但质量确实非常出色。
冬天
WINTR 也是一个强大的抓取工具。它是一种网页抓取和解析服务,其 API 允许公司和开发人员将任何网页转换为自定义数据集。提供数据采集、数据分析、请求代理、请求定制等多种服务。使用 WINTR 保存请求。如果您的目标网站 将来更改其结构,您将不需要修改您的应用程序代码。
这是一个全面的工具,可帮助您的网页抓取变得简单。您可以试用它的免费版本,它提供 500 个 API 点。
Mozenda
Mozenda 是一个非常有用的数据提取工具,它避免了编写脚本或聘请开发人员的需要。它使中型软件和 IT 公司能够从任何来源自动提取网站 数据。此工具允许企业客户在其强大的云平台上运行网络抓取工具。
可以从 Excel、Word 和 PDF 等格式中提取数据。当Mozenda的“机器人”在页面上快速准确地抓取数据时,它得到结果的速度非常快。它也以多任务处理而闻名。 查看全部
网页视频抓取脚本(2016年最适合你的网页刮刀取决于你需要的web抓取工具)
如今,市场上出现了各种网络抓取工具,当您必须选择其中一种工具时,您可能会感到困惑。最适合您的网页抓取工具取决于您的需求。这里有一些强烈推荐的网页抓取工具。其中一些是免费的,而有些则有试用期和高级计划。在做出决定之前,请仔细阅读以下所有信息。
ParseHub
ParseHub 是一款免费、可靠且功能强大的网页抓取工具。它用于使用 JS、AJAX、会话、cookie 和重定向来抓取单个和多个 网站。使用 Parsehub,您可以轻松地从任何网站 获取数据,因为您无需编写代码。您只需要打开目标网站 并开始单击要提取的数据。此工具可帮助您在服务器上自动采集和存储数据。其简单的 AIP 允许用户在任何地方集成他们提取的数据。
Parsehub 在爬取网站 时使用了大量代理,因此 IP 地址总是在旋转。
八字解析
Octopus 是一种现代视觉网络爬虫软件。对于那些无需编码即可从网站 获取数据的人来说,这是一个完美的选择。多亏了“点击”界面,用户使用起来不会有任何困难。八达通模仿人类活动,例如浏览网站、登录帐户等。它几乎可以从每个站点获取数据,即使它是使用 AJAX 或 JS 动态获取的。
免费版八达通允许用户提取几乎所有网站。只需点击几下鼠标,它就可以将网页变成结构化的电子表格。
Diffbot
Diffbot 是一种非常高效的数据提取工具,它使用互联网让个人和企业能够获取他们需要的任何信息。可广泛应用于市场营销、商业智能、销售和招聘等领域。它提供 API 来提取和理解对象,使用 Al 和计算机视觉从网站 中提取数据。使用 Diffbot,用户不再需要进行任何手动数据提取或互联网研究,因为数据可以自动保存到文件或数据库中。
Diffbot 服务虽然价格偏高,但质量确实非常出色。
冬天
WINTR 也是一个强大的抓取工具。它是一种网页抓取和解析服务,其 API 允许公司和开发人员将任何网页转换为自定义数据集。提供数据采集、数据分析、请求代理、请求定制等多种服务。使用 WINTR 保存请求。如果您的目标网站 将来更改其结构,您将不需要修改您的应用程序代码。
这是一个全面的工具,可帮助您的网页抓取变得简单。您可以试用它的免费版本,它提供 500 个 API 点。
Mozenda
Mozenda 是一个非常有用的数据提取工具,它避免了编写脚本或聘请开发人员的需要。它使中型软件和 IT 公司能够从任何来源自动提取网站 数据。此工具允许企业客户在其强大的云平台上运行网络抓取工具。
可以从 Excel、Word 和 PDF 等格式中提取数据。当Mozenda的“机器人”在页面上快速准确地抓取数据时,它得到结果的速度非常快。它也以多任务处理而闻名。
网页视频抓取脚本( WebHarvy网站刮板的功能介绍及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-09-14 01:07
WebHarvy网站刮板的功能介绍及应用)
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。易于使用。
【功能介绍】
智能识别模式:WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据:您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取:通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面:WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取:基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取类别:WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取:WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
[软件功能]
WebHarvy 是一个可视化的网络抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
[更新日志]
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
网页视频抓取脚本(
WebHarvy网站刮板的功能介绍及应用)

WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。易于使用。
【功能介绍】
智能识别模式:WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据:您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取:通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面:WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取:基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取类别:WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取:WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
[软件功能]
WebHarvy 是一个可视化的网络抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
[更新日志]
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
网页视频抓取脚本(爬虫测试样例序言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-29 13:04
pip3安装请求
试样
此外,序言中还有16段视频。我们使用Python爬虫技术在本地批量下载它们
#/?vid=0
直链
首先,我们需要获得视频下载直链。右击选中,可以直接看到视频的直链
再看一下页面的源代码,发现缺少视频直链。视频直链的原创位置已成为JS脚本
如果我们直接使用请求库来请求URL,我们会得到源代码,但是源代码中没有视频直接链接,所以我们应该考虑改变我们的想法。为什么视频直链的位置被JS取代
当有更多的爬虫程序时,您将知道这是网页的动态加载。必须有一个JS文件来存储视频的直链。然后,每次加载网页时,通过JS脚本将视频的直链动态加载到HTML中
点击网络,过滤JS文件,找到三个JS文件。让我们看看第一个JS文件中是否有视频直链。搜索视频的标题,直接查找视频的直链,并找到视频的所有直链都保存到名为lesson_uuuList的文件中
第一课所有视频名称和视频直接链接信息都保存在列表中。为统一起见,序言改为第0节
#lesson_uuList.py
课程列表=[{
“名称”:“第0节vue.js简介”
“url”:“
“询问”:“77367”
},{
“名称”:“第1节安装和部署”
“url”:“
“询问”:“77369”
},{
“名称”:“第2节创建第一个Vue应用程序”
“url”:“
“询问”:“77370”
},{
“名称”:“第3节数据和方法”
“url”:“
“询问”:“77372”
},{
“名称”:“第4节生命周期”
“url”:“
“询问”:“77373”
},{
“名称”:“第5节模板语法-插值”
“url”:“
“询问”:“77375”
},{
“名称”:“第6节模板语法-说明”
“url”:“
“询问”:“77376”
},{
“名称”:“第7节装订类别和样式”
“url”:“
“询问”:“77377”
},{
“名称”:“第8节条件呈现”
“url”:“
“询问”:“77378”
},{
“名称”:“第9节列表呈现”
“url”:“
“询问”:“77380”
},{
“名称”:“第10节事件绑定”
“url”:“
“询问”:“77381”
},{
“名称”:“第11节表单输入绑定”
“url”:“
“询问”:“77382”
},{
“名称”:“第12节组件基础”
“url”:“
“询问”:“77383”
},{
“名称”:“第13节部件注册”
“url”:“
“询问”:“78520”
},{
“名称”:“第14节单文件组件”
“url”:“
“询问”:“78521”
},{
“名称”:“第15节无终端开发Vue应用程序”
“url”:“
“询问”:“81004”
}]
批量下载
在这里,使用for循环遍历每个下载链接,然后使用之前编写的多线程下载程序进行下载
从concurrent.futures导入ThreadPoolExecutor
从课程列表导入课程列表
从请求导入获取,头部
导入时间
类下载器:
定义初始化(self,url,num,name):
self.url=url
self.num=num
self.name=名称
self.getsize=0
r=头(self.url,allow_redirects=True)
self.size=int(r.headers['Content-Length'])
def下降(自身、开始、结束、块大小=10240):
headers={'range':f'bytes={start}-{end}
r=get(self.url,headers=headers,stream=True)
将open(self.name,“rb+”)作为f:
f、 搜索(开始)
对于r.iter\u内容中的块(块大小):
f、 写入(块)
self.getsize+=块大小
def主(自):
开始时间=time.time()
f=打开(self.name,“wb”)
f、 截断(自身大小)
f、 关闭()
tp=线程池执行器(最大工作线程数=self.num)
期货=[]
开始=0
对于范围内的i(self.num):
end=int((i+1)/self.num*self.size)
future=tp.submit(self.down、start、end)
futures.append(未来)
开始=结束+1
尽管如此:
进程=self.getsize/self.size*100
last=self.getsize
时间。睡眠(1)
curr=self.getsize
向下=(当前最后一次)/1024
如果下降>;1024:
速度=f'{down/1024:6.2f}MB/s'
其他:
速度=f'{down:6.2f}KB/s'
打印(f'process:{process:6.2f}%|速度:{speed}',end='r')
如果流程>;=100:
打印(进程:{100.00:6}%|速度:00.00KB/s',结束=“|”)
中断
结束时间=time.time()
总时间=结束时间-开始时间
平均速度=自身大小/总时间/1024/1024
打印(f'总时间:{总时间:{0f}s}平均速度:{平均速度:{2f}MB/s')
如果uuuu name uuuuuu='\uuuuuuu main\uuuuuuu':
对于课程列表中的课程:
url=课程['url']
名称=课程['name']
down=downloader(url,8,name+'.mp4')
down.main()
结果打印
在56秒内下载了16个视频,总计339mb
进程:100.0%|速度:00.00KB/s |总时间:2s |平均速度:47MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:6.62MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:72MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:72MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:85MB/s
进程:100.0%|速度:00.00KB/s |总时间:7s |平均速度:7.01MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:4.65MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:69MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:88MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:5.01MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:6.60MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:6.20MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:96MB/s
进程:100.0%|速度:00.00KB/s |总时间:2s |平均速度:64MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:6.02MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:80MB/s
总结与展望
有时候视频或图片的直接链接不一定需要爬网,可能在网页上加载的JS文件中就可以找到,既然可以直接找到,为什么要爬网呢?那么下载的时候一定要使用多线程,因为多线程可以占用宽带,全速下载 查看全部
网页视频抓取脚本(爬虫测试样例序言)
pip3安装请求
试样
此外,序言中还有16段视频。我们使用Python爬虫技术在本地批量下载它们
#/?vid=0
直链
首先,我们需要获得视频下载直链。右击选中,可以直接看到视频的直链
再看一下页面的源代码,发现缺少视频直链。视频直链的原创位置已成为JS脚本
如果我们直接使用请求库来请求URL,我们会得到源代码,但是源代码中没有视频直接链接,所以我们应该考虑改变我们的想法。为什么视频直链的位置被JS取代
当有更多的爬虫程序时,您将知道这是网页的动态加载。必须有一个JS文件来存储视频的直链。然后,每次加载网页时,通过JS脚本将视频的直链动态加载到HTML中
点击网络,过滤JS文件,找到三个JS文件。让我们看看第一个JS文件中是否有视频直链。搜索视频的标题,直接查找视频的直链,并找到视频的所有直链都保存到名为lesson_uuuList的文件中
第一课所有视频名称和视频直接链接信息都保存在列表中。为统一起见,序言改为第0节
#lesson_uuList.py
课程列表=[{
“名称”:“第0节vue.js简介”
“url”:“
“询问”:“77367”
},{
“名称”:“第1节安装和部署”
“url”:“
“询问”:“77369”
},{
“名称”:“第2节创建第一个Vue应用程序”
“url”:“
“询问”:“77370”
},{
“名称”:“第3节数据和方法”
“url”:“
“询问”:“77372”
},{
“名称”:“第4节生命周期”
“url”:“
“询问”:“77373”
},{
“名称”:“第5节模板语法-插值”
“url”:“
“询问”:“77375”
},{
“名称”:“第6节模板语法-说明”
“url”:“
“询问”:“77376”
},{
“名称”:“第7节装订类别和样式”
“url”:“
“询问”:“77377”
},{
“名称”:“第8节条件呈现”
“url”:“
“询问”:“77378”
},{
“名称”:“第9节列表呈现”
“url”:“
“询问”:“77380”
},{
“名称”:“第10节事件绑定”
“url”:“
“询问”:“77381”
},{
“名称”:“第11节表单输入绑定”
“url”:“
“询问”:“77382”
},{
“名称”:“第12节组件基础”
“url”:“
“询问”:“77383”
},{
“名称”:“第13节部件注册”
“url”:“
“询问”:“78520”
},{
“名称”:“第14节单文件组件”
“url”:“
“询问”:“78521”
},{
“名称”:“第15节无终端开发Vue应用程序”
“url”:“
“询问”:“81004”
}]
批量下载
在这里,使用for循环遍历每个下载链接,然后使用之前编写的多线程下载程序进行下载
从concurrent.futures导入ThreadPoolExecutor
从课程列表导入课程列表
从请求导入获取,头部
导入时间
类下载器:
定义初始化(self,url,num,name):
self.url=url
self.num=num
self.name=名称
self.getsize=0
r=头(self.url,allow_redirects=True)
self.size=int(r.headers['Content-Length'])
def下降(自身、开始、结束、块大小=10240):
headers={'range':f'bytes={start}-{end}
r=get(self.url,headers=headers,stream=True)
将open(self.name,“rb+”)作为f:
f、 搜索(开始)
对于r.iter\u内容中的块(块大小):
f、 写入(块)
self.getsize+=块大小
def主(自):
开始时间=time.time()
f=打开(self.name,“wb”)
f、 截断(自身大小)
f、 关闭()
tp=线程池执行器(最大工作线程数=self.num)
期货=[]
开始=0
对于范围内的i(self.num):
end=int((i+1)/self.num*self.size)
future=tp.submit(self.down、start、end)
futures.append(未来)
开始=结束+1
尽管如此:
进程=self.getsize/self.size*100
last=self.getsize
时间。睡眠(1)
curr=self.getsize
向下=(当前最后一次)/1024
如果下降>;1024:
速度=f'{down/1024:6.2f}MB/s'
其他:
速度=f'{down:6.2f}KB/s'
打印(f'process:{process:6.2f}%|速度:{speed}',end='r')
如果流程>;=100:
打印(进程:{100.00:6}%|速度:00.00KB/s',结束=“|”)
中断
结束时间=time.time()
总时间=结束时间-开始时间
平均速度=自身大小/总时间/1024/1024
打印(f'总时间:{总时间:{0f}s}平均速度:{平均速度:{2f}MB/s')
如果uuuu name uuuuuu='\uuuuuuu main\uuuuuuu':
对于课程列表中的课程:
url=课程['url']
名称=课程['name']
down=downloader(url,8,name+'.mp4')
down.main()
结果打印
在56秒内下载了16个视频,总计339mb
进程:100.0%|速度:00.00KB/s |总时间:2s |平均速度:47MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:6.62MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:72MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:72MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:85MB/s
进程:100.0%|速度:00.00KB/s |总时间:7s |平均速度:7.01MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:4.65MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:69MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:88MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:5.01MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:6.60MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:6.20MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:96MB/s
进程:100.0%|速度:00.00KB/s |总时间:2s |平均速度:64MB/s
进程:100.0%|速度:00.00KB/s |总时间:3s |平均速度:6.02MB/s
进程:100.0%|速度:00.00KB/s |总时间:4s |平均速度:80MB/s
总结与展望
有时候视频或图片的直接链接不一定需要爬网,可能在网页上加载的JS文件中就可以找到,既然可以直接找到,为什么要爬网呢?那么下载的时候一定要使用多线程,因为多线程可以占用宽带,全速下载
网页视频抓取脚本(视频链接下载链接显示出来就行;.fire )
网站优化 • 优采云 发表了文章 • 0 个评论 • 1176 次浏览 • 2021-09-27 06:03
)
思路:年龄使用的网盘下载链接经常被举报然后失效,但是可以在线观看,然后可以通过在线视频链接下载。
因此,我们只需要找到视频链接并显示即可;
第一步:找到对应的链接
这里我们可以通过F12找到对应的链接来查看元素
(Age网站 统一了review元素,在播放页面使用时会跳转到首页,所以一定要先停止网页跳转,再快速跳转)
通过对比可以发现,本身的id和上层的id不一样,上层的id是一样的,所以这个视频是个突破口。
第二步:油猴脚本编写
首先我们需要遍历视频,找到里面的src-writing
$("#video video").each(function() {
$(this).attr("src")
});
我们使用alert函数来显示
$("#video video").each(function() {
alert($(this).attr("src"))
});
测试
貌似测试成功了,但是这个有抄袭的缺陷,不美观。我通过百度了解了 Swal.fire。
第 3 步:将链接放入 Swal.fire 窗口
先引用对应的js
// @require https://cdn.jsdelivr.net/npm/sweetalert2@8
然后我们按照官方格式修改
$("#video video").each(function() {
Swal.fire({//使用Swal.fire窗口
title: '下载地址是', //窗口标题
text:$(this).attr("src"),//窗口内容 这里我们将上面的遍历放入
type:"info",//窗口图标
confirmButtonText: 'OK',//窗口按钮
confirmButtonColor: '#3085d6'//按钮颜色
});
});
测试
好像成功了
下面是我写的所有代码
(以上是初学者的尝试,老板们仁慈)
// ==UserScript==
// @icon https://www.agefans.net/favicon.ico
// @name Age在线视频 下载地址获取
// @author Mr
// @description 能够获取到age在线视频的地址 然后使用弹窗展示 初学者作者 不喜勿喷
// @match https://www.agefans.net/*
// @require http://cdn.bootcss.com/jquery/1.8.3/jquery.min.js
// @require https://cdn.jsdelivr.net/npm/sweetalert2@8
// @version 0.0.1
// ==/UserScript==
var src;
(function () {
'use strict';
a();
})();
function a() {
$("#video video").each(function() {
Swal.fire({
title: '下载地址是',
text:$(this).attr("src"),
type:"info",
confirmButtonText: 'OK',
confirmButtonColor: '#3085d6'
});
});
} 查看全部
网页视频抓取脚本(视频链接下载链接显示出来就行;.fire
)
思路:年龄使用的网盘下载链接经常被举报然后失效,但是可以在线观看,然后可以通过在线视频链接下载。
因此,我们只需要找到视频链接并显示即可;
第一步:找到对应的链接
这里我们可以通过F12找到对应的链接来查看元素
(Age网站 统一了review元素,在播放页面使用时会跳转到首页,所以一定要先停止网页跳转,再快速跳转)
通过对比可以发现,本身的id和上层的id不一样,上层的id是一样的,所以这个视频是个突破口。
第二步:油猴脚本编写
首先我们需要遍历视频,找到里面的src-writing
$("#video video").each(function() {
$(this).attr("src")
});
我们使用alert函数来显示
$("#video video").each(function() {
alert($(this).attr("src"))
});
测试
貌似测试成功了,但是这个有抄袭的缺陷,不美观。我通过百度了解了 Swal.fire。
第 3 步:将链接放入 Swal.fire 窗口
先引用对应的js
// @require https://cdn.jsdelivr.net/npm/sweetalert2@8
然后我们按照官方格式修改
$("#video video").each(function() {
Swal.fire({//使用Swal.fire窗口
title: '下载地址是', //窗口标题
text:$(this).attr("src"),//窗口内容 这里我们将上面的遍历放入
type:"info",//窗口图标
confirmButtonText: 'OK',//窗口按钮
confirmButtonColor: '#3085d6'//按钮颜色
});
});
测试
好像成功了
下面是我写的所有代码
(以上是初学者的尝试,老板们仁慈)
// ==UserScript==
// @icon https://www.agefans.net/favicon.ico
// @name Age在线视频 下载地址获取
// @author Mr
// @description 能够获取到age在线视频的地址 然后使用弹窗展示 初学者作者 不喜勿喷
// @match https://www.agefans.net/*
// @require http://cdn.bootcss.com/jquery/1.8.3/jquery.min.js
// @require https://cdn.jsdelivr.net/npm/sweetalert2@8
// @version 0.0.1
// ==/UserScript==
var src;
(function () {
'use strict';
a();
})();
function a() {
$("#video video").each(function() {
Swal.fire({
title: '下载地址是',
text:$(this).attr("src"),
type:"info",
confirmButtonText: 'OK',
confirmButtonColor: '#3085d6'
});
});
}
网页视频抓取脚本(弹幕,new返回xml数据使用正则表达式获取所有弹幕消息,匹配模式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-26 12:05
)
需要准备的环境:
A站B账号,需要先登录,否则无法查看历史弹幕记录
连接互联网的计算机和方便的浏览器,我使用 Chrome
Python3环境和请求模块,安装使用命令,改源码更快:
pip3 install request -i http://pypi.douban.com/simple
爬取步骤:登录后打开需要爬取的视频页面,打开开发者工具控制台,Chrome可以使用F12快捷键选择网络监听请求
点击查看历史弹幕并获取请求
rolldate后面的数字代表视频对应的弹幕编号。返回数据中,timestamp代表弹幕日期,new代表数字。
在查看历史弹幕中选择一天,勾选,会发出新的请求
dmroll,timestamp,弹幕数,表示获取该日期的弹幕,1507564800表示2017/10/10 0:0:0
请求返回xml数据
使用正则表达式获取所有弹幕消息并匹配模式
'(.*?)'
连接字符串并将所有项目符号屏幕保存到本地文件
with open('content.txt', mode='w+', encoding='utf8') as f: f.write(content)
参考代码如下,弹幕按日期保存为单个文件...因为太多...
import requests
import re
import time
"""
爬取哔哩哔哩视频弹幕信息
"""
# 2043618 是视频的弹幕标号,这个地址会返回时间列表
# https://www.bilibili.com/video/av1349282
url = 'https://comment.bilibili.com/rolldate,2043618'
# 获取弹幕的id 2043618
video_id = url.split(',')[-1]
print(video_id)
# 获取json文件
html = requests.get(url)
# print(html.json())
# 生成时间戳列表
time_list = [i['timestamp'] for i in html.json()]
# print(time_list)
# 获取弹幕网址格式 'https://comment.bilibili.com/dmroll,时间戳,弹幕号'
# 弹幕内容,由于总弹幕量太大,将每个弹幕文件分别保存
for i in time_list:
content = ''
j = 'https://comment.bilibili.com/dmroll,{0},{1}'.format(i, video_id)
print(j)
text = requests.get(j).text
# 匹配弹幕内容
res = re.findall('(.*?)', text)
# 将时间戳转化为日期形式,需要把字符串转为整数
timeArray = time.localtime(int(i))
date_time = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
print(date_time)
content += date_time + '\n'
for k in res:
content += k + '\n'
content += '\n'
file_path = 'txt/{}.txt'.format(time.strftime("%Y_%m_%d", timeArray))
print(file_path)
with open(file_path, mode='w+', encoding='utf8') as f:
f.write(content)
最终效果
之后就可以做一些分词来生成词云或者进行情感分析,有时间再聊...
可以在下方给小编留言学习心得,感谢大家的支持。
查看全部
网页视频抓取脚本(弹幕,new返回xml数据使用正则表达式获取所有弹幕消息,匹配模式
)
需要准备的环境:
A站B账号,需要先登录,否则无法查看历史弹幕记录
连接互联网的计算机和方便的浏览器,我使用 Chrome
Python3环境和请求模块,安装使用命令,改源码更快:
pip3 install request -i http://pypi.douban.com/simple
爬取步骤:登录后打开需要爬取的视频页面,打开开发者工具控制台,Chrome可以使用F12快捷键选择网络监听请求
点击查看历史弹幕并获取请求
rolldate后面的数字代表视频对应的弹幕编号。返回数据中,timestamp代表弹幕日期,new代表数字。
在查看历史弹幕中选择一天,勾选,会发出新的请求
dmroll,timestamp,弹幕数,表示获取该日期的弹幕,1507564800表示2017/10/10 0:0:0
请求返回xml数据
使用正则表达式获取所有弹幕消息并匹配模式
'(.*?)'
连接字符串并将所有项目符号屏幕保存到本地文件
with open('content.txt', mode='w+', encoding='utf8') as f: f.write(content)
参考代码如下,弹幕按日期保存为单个文件...因为太多...
import requests
import re
import time
"""
爬取哔哩哔哩视频弹幕信息
"""
# 2043618 是视频的弹幕标号,这个地址会返回时间列表
# https://www.bilibili.com/video/av1349282
url = 'https://comment.bilibili.com/rolldate,2043618'
# 获取弹幕的id 2043618
video_id = url.split(',')[-1]
print(video_id)
# 获取json文件
html = requests.get(url)
# print(html.json())
# 生成时间戳列表
time_list = [i['timestamp'] for i in html.json()]
# print(time_list)
# 获取弹幕网址格式 'https://comment.bilibili.com/dmroll,时间戳,弹幕号'
# 弹幕内容,由于总弹幕量太大,将每个弹幕文件分别保存
for i in time_list:
content = ''
j = 'https://comment.bilibili.com/dmroll,{0},{1}'.format(i, video_id)
print(j)
text = requests.get(j).text
# 匹配弹幕内容
res = re.findall('(.*?)', text)
# 将时间戳转化为日期形式,需要把字符串转为整数
timeArray = time.localtime(int(i))
date_time = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
print(date_time)
content += date_time + '\n'
for k in res:
content += k + '\n'
content += '\n'
file_path = 'txt/{}.txt'.format(time.strftime("%Y_%m_%d", timeArray))
print(file_path)
with open(file_path, mode='w+', encoding='utf8') as f:
f.write(content)
最终效果
之后就可以做一些分词来生成词云或者进行情感分析,有时间再聊...
可以在下方给小编留言学习心得,感谢大家的支持。
网页视频抓取脚本( 从左侧的菜单选择你需要的教程!JavaScriptJavaScript)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-26 02:01
从左侧的菜单选择你需要的教程!JavaScriptJavaScript)
浏览器脚本系列教程
从左侧的菜单中选择所需的教程
Java脚本
JavaScript是一种基于对象和事件驱动的脚本语言,具有相对的安全性。它广泛应用于客户端web开发,通常用于向HTML网页添加动态功能
ECMA国际已经开发了基于JavaScript的ECMAScript标准。JavaScript也可以用于其他情况,例如服务器端编程。完整的JavaScript实现由三部分组成:ECMAScript、文档对象模型和字节顺序标记
开始学习java脚本
HTML DOM
HTMLDOM定义了访问和操作HTML文档的标准方法。HTMLDOM将HTML文档表示为收录元素、属性和文本的树结构(节点树)
熟悉软件开发的人可以理解HTMLDOM作为网页的API。它将网页中的每个元素视为一个对象,这样网页中的元素也可以通过计算机语言获取或编辑。例如,JavaScript可以使用HTMLDOM动态修改网页
开始学习HTMLDOM
DHTML
DHTML是动态HTML的缩写,即动态HTML。与传统的静态HTML相比,它是一种制作网页的概念
DHTML是一种新的语言。它只是HTML、CSS和客户端脚本的集成,即一个页面收录HTML+CSS+JavaScript(或其他客户端脚本),其中CSS和客户端脚本直接写在页面上,而不是链接到相关文件
开始学习DHTML
VBScript
VBScript是Microsoft开发的一种分析服务器(也支持客户端)脚本语言。它可以看作是VB语言的简化版本,与VBA有着非常密切的关系
Vbsript是ASP动态网页的默认编程语言。通过ASP内置对象和ADO对象,用户可以快速掌握访问数据库的ASP动态网页开发技术
开始学习VBScript
阿贾克斯
AJAX是一种用于创建交互式web应用程序的web开发技术。Ajax指的是异步JavaScript和XML
AJAX的核心是JavaScript对象XMLHttpRequest。这个对象最初是在Internet Explorer 5中引入的。它是一种支持异步请求的技术。简而言之,XMLHttpRequest使您能够使用JavaScript向服务器发出请求并处理响应,而不会阻塞用户
开始学习ajax
JQuery
JQuery是一个优秀的JavaScript框架。它是一个轻量级JS库。它与CSS3和各种浏览器兼容
JQuery使用户能够更轻松地处理HTML文档和事件,实现动画效果,并轻松地为网站>提供Ajax交互。JQuery使用户能够更轻松地处理HTML文档和事件,实现动画效果,并为网站@>
开始学习jQuery
JSON
JSON(JavaScript对象表示法)是一种轻量级数据交换格式。它基于JavaScript的一个子集
JSON采用完全独立于语言的文本格式,但它也使用类似于C语言家族的习惯(包括C、C++、C#、Java、JavaScript、Perl、python等)。这些特性使JSON成为理想的数据交换语言。它便于人们读写,也便于机器分析和生成
开始学习JSON
E4X
E4X(ECMAScript for XML)是基于ECMAScript(包括ActionScript、JavaScript和其他语言实现)标准的动态XML支持的程序语言扩展
E4X是DOM接口的替代品。它使程序员能够通过ECMAScript脚本中更简洁的语法访问XML文档。E4X使用XML作为简单类型(相当于字符、整数或布尔值)。使用E4X,您可以像date或math对象一样声明XML对象
开始学习E4X
WML脚本
WML脚本是WML页面中使用的脚本语言。WML脚本是一种轻量级JavaScript语言
WML脚本不嵌入在WML页面中。WML页面仅收录对脚本URL的引用。WML脚本需要在服务器上编译成字节编码,然后才能在WAP浏览器中运行。WML是WAP规范的一部分
开始学习WML脚本 查看全部
网页视频抓取脚本(
从左侧的菜单选择你需要的教程!JavaScriptJavaScript)
浏览器脚本系列教程
从左侧的菜单中选择所需的教程
Java脚本
JavaScript是一种基于对象和事件驱动的脚本语言,具有相对的安全性。它广泛应用于客户端web开发,通常用于向HTML网页添加动态功能
ECMA国际已经开发了基于JavaScript的ECMAScript标准。JavaScript也可以用于其他情况,例如服务器端编程。完整的JavaScript实现由三部分组成:ECMAScript、文档对象模型和字节顺序标记
开始学习java脚本
HTML DOM
HTMLDOM定义了访问和操作HTML文档的标准方法。HTMLDOM将HTML文档表示为收录元素、属性和文本的树结构(节点树)
熟悉软件开发的人可以理解HTMLDOM作为网页的API。它将网页中的每个元素视为一个对象,这样网页中的元素也可以通过计算机语言获取或编辑。例如,JavaScript可以使用HTMLDOM动态修改网页
开始学习HTMLDOM
DHTML
DHTML是动态HTML的缩写,即动态HTML。与传统的静态HTML相比,它是一种制作网页的概念
DHTML是一种新的语言。它只是HTML、CSS和客户端脚本的集成,即一个页面收录HTML+CSS+JavaScript(或其他客户端脚本),其中CSS和客户端脚本直接写在页面上,而不是链接到相关文件
开始学习DHTML
VBScript
VBScript是Microsoft开发的一种分析服务器(也支持客户端)脚本语言。它可以看作是VB语言的简化版本,与VBA有着非常密切的关系
Vbsript是ASP动态网页的默认编程语言。通过ASP内置对象和ADO对象,用户可以快速掌握访问数据库的ASP动态网页开发技术
开始学习VBScript
阿贾克斯
AJAX是一种用于创建交互式web应用程序的web开发技术。Ajax指的是异步JavaScript和XML
AJAX的核心是JavaScript对象XMLHttpRequest。这个对象最初是在Internet Explorer 5中引入的。它是一种支持异步请求的技术。简而言之,XMLHttpRequest使您能够使用JavaScript向服务器发出请求并处理响应,而不会阻塞用户
开始学习ajax
JQuery
JQuery是一个优秀的JavaScript框架。它是一个轻量级JS库。它与CSS3和各种浏览器兼容
JQuery使用户能够更轻松地处理HTML文档和事件,实现动画效果,并轻松地为网站>提供Ajax交互。JQuery使用户能够更轻松地处理HTML文档和事件,实现动画效果,并为网站@>
开始学习jQuery
JSON
JSON(JavaScript对象表示法)是一种轻量级数据交换格式。它基于JavaScript的一个子集
JSON采用完全独立于语言的文本格式,但它也使用类似于C语言家族的习惯(包括C、C++、C#、Java、JavaScript、Perl、python等)。这些特性使JSON成为理想的数据交换语言。它便于人们读写,也便于机器分析和生成
开始学习JSON
E4X
E4X(ECMAScript for XML)是基于ECMAScript(包括ActionScript、JavaScript和其他语言实现)标准的动态XML支持的程序语言扩展
E4X是DOM接口的替代品。它使程序员能够通过ECMAScript脚本中更简洁的语法访问XML文档。E4X使用XML作为简单类型(相当于字符、整数或布尔值)。使用E4X,您可以像date或math对象一样声明XML对象
开始学习E4X
WML脚本
WML脚本是WML页面中使用的脚本语言。WML脚本是一种轻量级JavaScript语言
WML脚本不嵌入在WML页面中。WML页面仅收录对脚本URL的引用。WML脚本需要在服务器上编译成字节编码,然后才能在WAP浏览器中运行。WML是WAP规范的一部分
开始学习WML脚本
网页视频抓取脚本(制作自己的翻译脚本()(-))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-25 18:23
英语差一直是我的一个短板,尤其是在学习代码阶段。我经常需要检查各种错误,这很困难。一直想自己做一个翻译脚本,节省打开网页的时间,但是查询后发现网上的教程都是百度翻译改版之前的爬虫,只好自己动手了!
目标:制作自己的翻译脚本
网址:
前期准备:pycharm、python3.6、 库:requests、json
想法:
Lan是抓包直接提取后返回的内容
{"User-Agent":"Mozilla/5.0(Linux; Android 5.1.1; Nexus 6 Build/LYZ28E) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/63.0.3239.84 Mobile Safari/537.36"}
比如输入“python学习交流群:542110741”,返回内容:
Josn的内容如下:
{'errno':0,'from':'zh','to':'en','trans':[{'dst':'Python学习交流群:542110741','prefixWrap':0,'src ':'python学习交流群:542110741','relation':[],'result':[[0,'Python学习交流群:542110741',['0|32'],[],['0|32] '], ['0|46']]]}],'dict':[],'keywords': [{'means': ['giant snake, python'],'word':'python'} , {'means': ['study','learn','emulate','learning'],'word':'learning'}, {'means': ['exchange','interflow','interchange', 'alternating','AC(交流电)','communion'],'word':'沟通')))
我们可以分别抓取'trans'和'keywords'的值。我们需要的是这两个值。
好的,直接上传代码,运行结果
好了,内容就到这里了~如果对大家有帮助,请关注 查看全部
网页视频抓取脚本(制作自己的翻译脚本()(-))
英语差一直是我的一个短板,尤其是在学习代码阶段。我经常需要检查各种错误,这很困难。一直想自己做一个翻译脚本,节省打开网页的时间,但是查询后发现网上的教程都是百度翻译改版之前的爬虫,只好自己动手了!
目标:制作自己的翻译脚本
网址:
前期准备:pycharm、python3.6、 库:requests、json
想法:
Lan是抓包直接提取后返回的内容
{"User-Agent":"Mozilla/5.0(Linux; Android 5.1.1; Nexus 6 Build/LYZ28E) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/63.0.3239.84 Mobile Safari/537.36"}
比如输入“python学习交流群:542110741”,返回内容:
Josn的内容如下:
{'errno':0,'from':'zh','to':'en','trans':[{'dst':'Python学习交流群:542110741','prefixWrap':0,'src ':'python学习交流群:542110741','relation':[],'result':[[0,'Python学习交流群:542110741',['0|32'],[],['0|32] '], ['0|46']]]}],'dict':[],'keywords': [{'means': ['giant snake, python'],'word':'python'} , {'means': ['study','learn','emulate','learning'],'word':'learning'}, {'means': ['exchange','interflow','interchange', 'alternating','AC(交流电)','communion'],'word':'沟通')))
我们可以分别抓取'trans'和'keywords'的值。我们需要的是这两个值。
好的,直接上传代码,运行结果
好了,内容就到这里了~如果对大家有帮助,请关注
网页视频抓取脚本(【】请求url参数的对比过程分段请求链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-25 18:22
工具:google浏览器+fiddler抓包工具
注意:这里没有发布代码,[只是想法!!!】
原创网址 = [链接到您可以随机找到的电影] 将其称为原创网址
开始分析:
打开fiddler,然后打开google,输入url,按F12.得到如下图:
分析上图内容:首先通过fiddler抓包,我们知道真实的播放地址是一段一段的,如上图3号,然后将播放地址的一小段复制到浏览器打开它,并得到一个 403 错误。可以看出需要重新打开链接。先构造一些东西,然后才能通过代码发送请求,否则会被拒绝。因此,来到上面的第4个图标,分析请求url。首先分析不同视频段的url差异。对比发现只有[ts_seg_no]参数不同,参数从0开始,逐渐+1,但结束尚不得而知。然后分析原创网址在不同时间打开时所请求的视频真实地址的网址的区别。旧的方法是在新标签页中再次打开原创URL,并比较请求的两次打开的URL。请求url参数对比过程略,参数对比结果如下:
可以看到每次开启时,psid和vkey这两个参数都在变化,代表什么还是未知数。不同视频段同时打开的请求URL,ts_start、ts_end、ts_seg_no参数也有变化。虽然知道变化规律,但不确定三个参数什么时候结束,所以目前还不得而知。分析到这里,可以确定在分割的视频链接之前,肯定有链接或者js文件加载了这些未知参数或者这些未知的请求url链接。于是尝试在网络中搜索psid和vkey这两个值,有一部分链接是这样的[/playlist/m3u8?],然后点击查看响应,如下图:
恰巧响应的内容只是视频片段的请求链接。所以现在不需要重构视频片段的请求链接了,关注上图中的url链接【暂且称之为播放url】,只要能获取到播放url,那么这个任务就可以了完成。
然后开始分析播放url,如下图所示:
看起来有点复杂,所以我用了之前的比较分析url的方法,得到了播放url参数的差异。区别如下:
分析这个链接,链接中唯一需要重构的参数就是psid和ups_key。于是开始分析这两个参数的来源。
因此,在google network中通过ctrl+f搜索psid和ups_key,发现在名为[]的链接中出现了两个参数,这个链接[称之为js链接]如下图;
这个js链接是一个js文件。点击后查看响应,发现响应是一个json格式的js函数,如下图:
然后我在响应中搜索了psid和ups_key的值,找到了之前的播放链接,并给出了一张图:
好的!现在一切都清楚了,只要能拿到这个js链接的响应信息,再提取m3u8_url再请求,提取响应【这个响应才是真正的视频播放地址】。所以现在我们要弄清楚如何获得这个js链接,
问题的出现
嗯。. . ? (我猜...)从响应中可以看到json格式是mtopjsonp1(),那么这个mtopjsonp1()是什么?它是一个js函数吗?如果是js函数,那么你可以尝试搜索看看【我试过了,但是没有看到完全相同的函数】,你尝试请求这个js链接吗?【这个链接也看了,很长,看起来好复杂,这条路先不考虑】,如果不考虑前两条,那你就得开始考虑重构播放url了,毕竟, play 只要url找到psid和ups_key这两个参数就可以了。于是我开始思考:如果这两条路径存在,那应该是在某个js函数中,于是我开始在网络中搜索psid和ups_key这两个参数。好吧,我发现了 psid 参数的痕迹。如下所示:
我确实在另一个 js 文件中找到了 psid,但它不是很相似。而且就算是,如果对js不是很熟悉,我也无法弄清楚psid是如何生成的。所以,先放这个变量,再搜索。ups_key,不幸的是,这个变量在js文件中找不到,所以我们需要回到猜测【如何找到请求那个很长很复杂的js链接的方法】,为什么复杂呢?看看下面的图片:
它仍然是一个 GET 请求来发送一个指向数据的链接。下图为链接的参数(先绝望):
老实说,看到这样的链接,我真的不想得到它。
不过我还是得花点时间弄清楚,不然我的爬虫技术就到此为止了。(我还是得做,但是一想到爬虫的问题就忍不住很伤心,没人能问。技术瓶颈只能自己在未知的时间里堆积起来) 继续。
写在最后
我现在在爬虫破解js方向有技术瓶颈。上次破解搜索网站也是js加密的一个参数,因为无法解决js加密,最后失败了。想了想,技术瓶颈只能是现在开始学js,自己学做js加密数据。如此周而复始,想必js破解指日可待。以后学了js,自己加密,自己破解。
另外,文章里写的完全是我自己的想法。可能是对的,也可能是错的,可能是其中的一部分等等,如果你不幸读了我的文章,不幸看到这个地方,我真诚地希望你能纠正错误。
另外,如果后续破解成功,会更新这个文章。 查看全部
网页视频抓取脚本(【】请求url参数的对比过程分段请求链接)
工具:google浏览器+fiddler抓包工具
注意:这里没有发布代码,[只是想法!!!】
原创网址 = [链接到您可以随机找到的电影] 将其称为原创网址
开始分析:
打开fiddler,然后打开google,输入url,按F12.得到如下图:
分析上图内容:首先通过fiddler抓包,我们知道真实的播放地址是一段一段的,如上图3号,然后将播放地址的一小段复制到浏览器打开它,并得到一个 403 错误。可以看出需要重新打开链接。先构造一些东西,然后才能通过代码发送请求,否则会被拒绝。因此,来到上面的第4个图标,分析请求url。首先分析不同视频段的url差异。对比发现只有[ts_seg_no]参数不同,参数从0开始,逐渐+1,但结束尚不得而知。然后分析原创网址在不同时间打开时所请求的视频真实地址的网址的区别。旧的方法是在新标签页中再次打开原创URL,并比较请求的两次打开的URL。请求url参数对比过程略,参数对比结果如下:
可以看到每次开启时,psid和vkey这两个参数都在变化,代表什么还是未知数。不同视频段同时打开的请求URL,ts_start、ts_end、ts_seg_no参数也有变化。虽然知道变化规律,但不确定三个参数什么时候结束,所以目前还不得而知。分析到这里,可以确定在分割的视频链接之前,肯定有链接或者js文件加载了这些未知参数或者这些未知的请求url链接。于是尝试在网络中搜索psid和vkey这两个值,有一部分链接是这样的[/playlist/m3u8?],然后点击查看响应,如下图:
恰巧响应的内容只是视频片段的请求链接。所以现在不需要重构视频片段的请求链接了,关注上图中的url链接【暂且称之为播放url】,只要能获取到播放url,那么这个任务就可以了完成。
然后开始分析播放url,如下图所示:
看起来有点复杂,所以我用了之前的比较分析url的方法,得到了播放url参数的差异。区别如下:
分析这个链接,链接中唯一需要重构的参数就是psid和ups_key。于是开始分析这两个参数的来源。
因此,在google network中通过ctrl+f搜索psid和ups_key,发现在名为[]的链接中出现了两个参数,这个链接[称之为js链接]如下图;
这个js链接是一个js文件。点击后查看响应,发现响应是一个json格式的js函数,如下图:
然后我在响应中搜索了psid和ups_key的值,找到了之前的播放链接,并给出了一张图:
好的!现在一切都清楚了,只要能拿到这个js链接的响应信息,再提取m3u8_url再请求,提取响应【这个响应才是真正的视频播放地址】。所以现在我们要弄清楚如何获得这个js链接,
问题的出现
嗯。. . ? (我猜...)从响应中可以看到json格式是mtopjsonp1(),那么这个mtopjsonp1()是什么?它是一个js函数吗?如果是js函数,那么你可以尝试搜索看看【我试过了,但是没有看到完全相同的函数】,你尝试请求这个js链接吗?【这个链接也看了,很长,看起来好复杂,这条路先不考虑】,如果不考虑前两条,那你就得开始考虑重构播放url了,毕竟, play 只要url找到psid和ups_key这两个参数就可以了。于是我开始思考:如果这两条路径存在,那应该是在某个js函数中,于是我开始在网络中搜索psid和ups_key这两个参数。好吧,我发现了 psid 参数的痕迹。如下所示:
我确实在另一个 js 文件中找到了 psid,但它不是很相似。而且就算是,如果对js不是很熟悉,我也无法弄清楚psid是如何生成的。所以,先放这个变量,再搜索。ups_key,不幸的是,这个变量在js文件中找不到,所以我们需要回到猜测【如何找到请求那个很长很复杂的js链接的方法】,为什么复杂呢?看看下面的图片:
它仍然是一个 GET 请求来发送一个指向数据的链接。下图为链接的参数(先绝望):
老实说,看到这样的链接,我真的不想得到它。
不过我还是得花点时间弄清楚,不然我的爬虫技术就到此为止了。(我还是得做,但是一想到爬虫的问题就忍不住很伤心,没人能问。技术瓶颈只能自己在未知的时间里堆积起来) 继续。
写在最后
我现在在爬虫破解js方向有技术瓶颈。上次破解搜索网站也是js加密的一个参数,因为无法解决js加密,最后失败了。想了想,技术瓶颈只能是现在开始学js,自己学做js加密数据。如此周而复始,想必js破解指日可待。以后学了js,自己加密,自己破解。
另外,文章里写的完全是我自己的想法。可能是对的,也可能是错的,可能是其中的一部分等等,如果你不幸读了我的文章,不幸看到这个地方,我真诚地希望你能纠正错误。
另外,如果后续破解成功,会更新这个文章。
网页视频抓取脚本(网页视频抓取脚本解析地址和内容就行了比如下面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-25 04:03
网页视频抓取脚本解析脚本地址和内容就行了比如下面这个代码是我在网上找的,可以抓一下内容,你用第一个解析它会在网页上放一个脚本,你用第二个就不会放。按这个内容去请求,一般是会出现正常页面,但是使用脚本他就一直自动生成一直的脚本,抓他的话肯定比你手动去访问方便。
可以百度一下chrome调试脚本
正常浏览器都有脚本功能。另外,如果你用的是ie浏览器,
反正都看不了了,直接百度百科的脚本功能了解一下。ie浏览器其实能够按自己自定义的内容播放视频。以下内容节选自百度百科:浏览器自带按自己设置的内容播放视频,这类功能十分强大。但是并不是所有人都需要这种功能,如果对播放比较多的内容,而且比较长的视频,可以使用flash播放器将视频内容变为flash,再把自定义的路径指向播放器按自己的设置播放。
另外,一些无良视频网站,既不向用户购买版权,也不提供播放功能,那么我们可以试试这些方法,如果你用ie浏览器的话,可以使用谷歌浏览器扩展程序库,里面有非常多的视频下载脚本,并且都是开源的。不过为了安全起见,最好是在ie浏览器的开发人员工具中去找。谷歌浏览器用户可以参考这篇文章下载脚本。:$foo_bandwidth去掉百度云的百度网盘账号,浏览器下载的视频都无法在本地播放,因为所有下载的视频都在百度云的大文件目录下,假如你对视频的多人下载的路径做了处理,无法播放。
针对上述问题,有两种方法:1、第一步,你可以用浏览器自带的在线视频搜索工具找到想要下载的视频,或者谷歌网页应用商店找到。2、第二步,找到后可以用在线视频搜索下载器进行下载,如下图,也可以直接是对应路径找到。或者你可以在你电脑的浏览器任意下载窗口里下载,就是在浏览器的应用商店搜索你下载的网站,就可以下载你想要的视频。
例如在浏览器的浏览器资源导航,或者-app/download.html,你还可以在电脑上用迅雷快速下载浏览器资源,或者打开迅雷网页版,浏览器资源也可以直接在线直接下载。当然你可以在谷歌网页版的浏览器浏览器浏览器文件夹或者下载的时候要求你浏览器自带的浏览器浏览器浏览器下载路径等权限。所以在下载网站上,不要用迅雷等工具进行下载,而是根据你的浏览器自带的浏览器浏览器,然后打开自带浏览器搜索相应的视频路径,自己修改路径才能访问下载。 查看全部
网页视频抓取脚本(网页视频抓取脚本解析地址和内容就行了比如下面)
网页视频抓取脚本解析脚本地址和内容就行了比如下面这个代码是我在网上找的,可以抓一下内容,你用第一个解析它会在网页上放一个脚本,你用第二个就不会放。按这个内容去请求,一般是会出现正常页面,但是使用脚本他就一直自动生成一直的脚本,抓他的话肯定比你手动去访问方便。
可以百度一下chrome调试脚本
正常浏览器都有脚本功能。另外,如果你用的是ie浏览器,
反正都看不了了,直接百度百科的脚本功能了解一下。ie浏览器其实能够按自己自定义的内容播放视频。以下内容节选自百度百科:浏览器自带按自己设置的内容播放视频,这类功能十分强大。但是并不是所有人都需要这种功能,如果对播放比较多的内容,而且比较长的视频,可以使用flash播放器将视频内容变为flash,再把自定义的路径指向播放器按自己的设置播放。
另外,一些无良视频网站,既不向用户购买版权,也不提供播放功能,那么我们可以试试这些方法,如果你用ie浏览器的话,可以使用谷歌浏览器扩展程序库,里面有非常多的视频下载脚本,并且都是开源的。不过为了安全起见,最好是在ie浏览器的开发人员工具中去找。谷歌浏览器用户可以参考这篇文章下载脚本。:$foo_bandwidth去掉百度云的百度网盘账号,浏览器下载的视频都无法在本地播放,因为所有下载的视频都在百度云的大文件目录下,假如你对视频的多人下载的路径做了处理,无法播放。
针对上述问题,有两种方法:1、第一步,你可以用浏览器自带的在线视频搜索工具找到想要下载的视频,或者谷歌网页应用商店找到。2、第二步,找到后可以用在线视频搜索下载器进行下载,如下图,也可以直接是对应路径找到。或者你可以在你电脑的浏览器任意下载窗口里下载,就是在浏览器的应用商店搜索你下载的网站,就可以下载你想要的视频。
例如在浏览器的浏览器资源导航,或者-app/download.html,你还可以在电脑上用迅雷快速下载浏览器资源,或者打开迅雷网页版,浏览器资源也可以直接在线直接下载。当然你可以在谷歌网页版的浏览器浏览器浏览器文件夹或者下载的时候要求你浏览器自带的浏览器浏览器浏览器下载路径等权限。所以在下载网站上,不要用迅雷等工具进行下载,而是根据你的浏览器自带的浏览器浏览器,然后打开自带浏览器搜索相应的视频路径,自己修改路径才能访问下载。
网页视频抓取脚本(脚本,在线学习c++编程学而思百题大师班的老师)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-24 11:03
网页视频抓取脚本语言:teddyben/swingcontext,抓取ppt并下载为flv视频,下载pdf到手机,方便以后自己查看教程之后前往开发网:c++语言视频抓取脚本,在线学习c++编程
学而思百题大师班的老师做了一套书,你可以去看看。可能有适合你的。
嗯我刚才也是看到一个刚毕业的学生做了个,很牛逼的项目名字好像叫做高考答案,有全国的,浙江,福建,还有上海的,
推荐大家使用优网助手,里面功能相当强大,好用!一键查询qq/微信/谷歌,网址链接,支付宝,微博登录,查询杀毒,预装软件,清理缓存,清理内存,文件夹,图片搜索,分类账号和密码,密码管理..。
能不能推荐一些跟高考相关的例如2035,
给大家推荐个具有技术含量的自动识别考点分析和答案检索的软件,全国语文联考真题答案,有视频有音频,还有重点题和典型题解析,在线即可观看,比如陕西历史可以扫描题目加入解析统计库,或者像上面说的这种类型的考点库可以自己从部分题目中摘出需要的知识点方便打印出来,想用手机看的话还可以下载云笔记,不用带本厚书,再进行学习。
我最近开发了一个服务,也就是一个私人的微信公众号——多选题答案分析的公众号。利用这个专栏,学习了很多的答题技巧,利用过去的自己做答题技巧可以大幅提高做对题的概率。而且这个专栏可以与手机注册账号对应推送练习答案以及课后的实践总结,也可以登录我的专栏获取答案解析。祝各位取得好成绩,见证我们的努力!。 查看全部
网页视频抓取脚本(脚本,在线学习c++编程学而思百题大师班的老师)
网页视频抓取脚本语言:teddyben/swingcontext,抓取ppt并下载为flv视频,下载pdf到手机,方便以后自己查看教程之后前往开发网:c++语言视频抓取脚本,在线学习c++编程
学而思百题大师班的老师做了一套书,你可以去看看。可能有适合你的。
嗯我刚才也是看到一个刚毕业的学生做了个,很牛逼的项目名字好像叫做高考答案,有全国的,浙江,福建,还有上海的,
推荐大家使用优网助手,里面功能相当强大,好用!一键查询qq/微信/谷歌,网址链接,支付宝,微博登录,查询杀毒,预装软件,清理缓存,清理内存,文件夹,图片搜索,分类账号和密码,密码管理..。
能不能推荐一些跟高考相关的例如2035,
给大家推荐个具有技术含量的自动识别考点分析和答案检索的软件,全国语文联考真题答案,有视频有音频,还有重点题和典型题解析,在线即可观看,比如陕西历史可以扫描题目加入解析统计库,或者像上面说的这种类型的考点库可以自己从部分题目中摘出需要的知识点方便打印出来,想用手机看的话还可以下载云笔记,不用带本厚书,再进行学习。
我最近开发了一个服务,也就是一个私人的微信公众号——多选题答案分析的公众号。利用这个专栏,学习了很多的答题技巧,利用过去的自己做答题技巧可以大幅提高做对题的概率。而且这个专栏可以与手机注册账号对应推送练习答案以及课后的实践总结,也可以登录我的专栏获取答案解析。祝各位取得好成绩,见证我们的努力!。
网页视频抓取脚本(网页视频抓取脚本录制软件-上海怡健医学培训学校)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-24 08:04
网页视频抓取脚本录制软件:easydlpythonpython实现电商网页视频播放功能第一步需要添加三个注册weixin123的网站和下载指定歌曲软件:免费|easydlpython视频下载抓取脚本第二步第三步第四步
自己动手写个爬虫,爬爬她的歌单,然后去下载--用以下网址:com.easyday.starm.jack-fantastic,收集下载youtubeyoutube在线视频高清无水印字幕的资源、音乐以及有水印的资源,一个专门的资源网,分享国外视频和文字。
有点困难,刚开始一个要下七八首歌才能满足。1.歌曲选择听着舒服的。千万不要听着很好听但是不适合你的歌,会弄巧成拙的。2.歌手选择有创意的。千万不要找很老的歌手,多看看mv,根据mv内容选择。3.歌曲前段选择合适的字幕。这就很考验英语功底了,新概念或者voa都可以。你可以找些歌词,有很多可以从google或者百度上搜,或者自己手动翻译。
4.歌词选择视频推荐乐库/,比较满意,但是你要先搜歌名再点乐库,不然找不到。5.资源选择音乐选择以下资源大,或者其他你喜欢的,以搜索引擎为准,里面有收集很多资源。6.歌单地址,字幕,都可以放进去,作为关键字可以找到一些你需要的资源,你可以发送网址,我也是easydl的员工,所以有上传歌单到乐库,或者地址给你。 查看全部
网页视频抓取脚本(网页视频抓取脚本录制软件-上海怡健医学培训学校)
网页视频抓取脚本录制软件:easydlpythonpython实现电商网页视频播放功能第一步需要添加三个注册weixin123的网站和下载指定歌曲软件:免费|easydlpython视频下载抓取脚本第二步第三步第四步
自己动手写个爬虫,爬爬她的歌单,然后去下载--用以下网址:com.easyday.starm.jack-fantastic,收集下载youtubeyoutube在线视频高清无水印字幕的资源、音乐以及有水印的资源,一个专门的资源网,分享国外视频和文字。
有点困难,刚开始一个要下七八首歌才能满足。1.歌曲选择听着舒服的。千万不要听着很好听但是不适合你的歌,会弄巧成拙的。2.歌手选择有创意的。千万不要找很老的歌手,多看看mv,根据mv内容选择。3.歌曲前段选择合适的字幕。这就很考验英语功底了,新概念或者voa都可以。你可以找些歌词,有很多可以从google或者百度上搜,或者自己手动翻译。
4.歌词选择视频推荐乐库/,比较满意,但是你要先搜歌名再点乐库,不然找不到。5.资源选择音乐选择以下资源大,或者其他你喜欢的,以搜索引擎为准,里面有收集很多资源。6.歌单地址,字幕,都可以放进去,作为关键字可以找到一些你需要的资源,你可以发送网址,我也是easydl的员工,所以有上传歌单到乐库,或者地址给你。
网页视频抓取脚本( 一起进步网页抓取工具我用的使用经验分享(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-14 11:19
一起进步网页抓取工具我用的使用经验分享(图))
教你使用网络爬虫工具下载图片。现在内容里有图片的网页已经很常见了,所以图片的采集也很重要,但是一张一张的点击下载很麻烦,所以我们爬网的时候一定要学会。当我抓取图片到我的采集 内容时,我会同时下载图片和缩略图采集。这个很有用,但是一开始图片总是采集不全。缩略图无法取下。现在我将我的经验分享给大家。让我们改进网络爬虫工具。我用的是优采云采集器,最新版本V9。因为功能比较全,速度也快,我会在优采云采集器中设置采集规则后输入内容优采云@k0采集rules这里的准备,大家要注意在编辑标签的数据处理中有一个文件下载选项。有四个选项,其中之一是下载图片。
一看就明白可以通过勾选来下载图片,但是如果只这样的话,只能采集到部分图片,因为优采云采集器这里是默认的图片下载带有html标签,所以对于没有html标签的图片,比如缩略图,检查检测文件并下载。然后优采云采集器会自动检测这种图片文件并下载采集。下载采集时,对不同类型的图片分别设置标签。只需下载并选择测试此页面上的5张图片是否已被优采云采集器下载。你觉得很简单吗?像优采云采集器这样的网络爬虫就是这样的。学习以后如何使用它非常容易上手,它确实可以解决很多问题,并且可以大大提高我们的工作效率。这就是人类智慧所在。 查看全部
网页视频抓取脚本(
一起进步网页抓取工具我用的使用经验分享(图))
教你使用网络爬虫工具下载图片。现在内容里有图片的网页已经很常见了,所以图片的采集也很重要,但是一张一张的点击下载很麻烦,所以我们爬网的时候一定要学会。当我抓取图片到我的采集 内容时,我会同时下载图片和缩略图采集。这个很有用,但是一开始图片总是采集不全。缩略图无法取下。现在我将我的经验分享给大家。让我们改进网络爬虫工具。我用的是优采云采集器,最新版本V9。因为功能比较全,速度也快,我会在优采云采集器中设置采集规则后输入内容优采云@k0采集rules这里的准备,大家要注意在编辑标签的数据处理中有一个文件下载选项。有四个选项,其中之一是下载图片。
一看就明白可以通过勾选来下载图片,但是如果只这样的话,只能采集到部分图片,因为优采云采集器这里是默认的图片下载带有html标签,所以对于没有html标签的图片,比如缩略图,检查检测文件并下载。然后优采云采集器会自动检测这种图片文件并下载采集。下载采集时,对不同类型的图片分别设置标签。只需下载并选择测试此页面上的5张图片是否已被优采云采集器下载。你觉得很简单吗?像优采云采集器这样的网络爬虫就是这样的。学习以后如何使用它非常容易上手,它确实可以解决很多问题,并且可以大大提高我们的工作效率。这就是人类智慧所在。
网页视频抓取脚本(2016年最适合你的网页刮刀取决于你需要的web抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-14 06:21
如今,市场上出现了各种网络抓取工具,当您必须选择其中一种工具时,您可能会感到困惑。最适合您的网页抓取工具取决于您的需求。这里有一些强烈推荐的网页抓取工具。其中一些是免费的,而有些则有试用期和高级计划。在做出决定之前,请仔细阅读以下所有信息。
ParseHub
ParseHub 是一款免费、可靠且功能强大的网页抓取工具。它用于使用 JS、AJAX、会话、cookie 和重定向来抓取单个和多个 网站。使用 Parsehub,您可以轻松地从任何网站 获取数据,因为您无需编写代码。您只需要打开目标网站 并开始单击要提取的数据。此工具可帮助您在服务器上自动采集和存储数据。其简单的 AIP 允许用户在任何地方集成他们提取的数据。
Parsehub 在爬取网站 时使用了大量代理,因此 IP 地址总是在旋转。
八字解析
Octopus 是一种现代视觉网络爬虫软件。对于那些无需编码即可从网站 获取数据的人来说,这是一个完美的选择。多亏了“点击”界面,用户使用起来不会有任何困难。八达通模仿人类活动,例如浏览网站、登录帐户等。它几乎可以从每个站点获取数据,即使它是使用 AJAX 或 JS 动态获取的。
免费版八达通允许用户提取几乎所有网站。只需点击几下鼠标,它就可以将网页变成结构化的电子表格。
Diffbot
Diffbot 是一种非常高效的数据提取工具,它使用互联网让个人和企业能够获取他们需要的任何信息。可广泛应用于市场营销、商业智能、销售和招聘等领域。它提供 API 来提取和理解对象,使用 Al 和计算机视觉从网站 中提取数据。使用 Diffbot,用户不再需要进行任何手动数据提取或互联网研究,因为数据可以自动保存到文件或数据库中。
Diffbot 服务虽然价格偏高,但质量确实非常出色。
冬天
WINTR 也是一个强大的抓取工具。它是一种网页抓取和解析服务,其 API 允许公司和开发人员将任何网页转换为自定义数据集。提供数据采集、数据分析、请求代理、请求定制等多种服务。使用 WINTR 保存请求。如果您的目标网站 将来更改其结构,您将不需要修改您的应用程序代码。
这是一个全面的工具,可帮助您的网页抓取变得简单。您可以试用它的免费版本,它提供 500 个 API 点。
Mozenda
Mozenda 是一个非常有用的数据提取工具,它避免了编写脚本或聘请开发人员的需要。它使中型软件和 IT 公司能够从任何来源自动提取网站 数据。此工具允许企业客户在其强大的云平台上运行网络抓取工具。
可以从 Excel、Word 和 PDF 等格式中提取数据。当Mozenda的“机器人”在页面上快速准确地抓取数据时,它得到结果的速度非常快。它也以多任务处理而闻名。 查看全部
网页视频抓取脚本(2016年最适合你的网页刮刀取决于你需要的web抓取工具)
如今,市场上出现了各种网络抓取工具,当您必须选择其中一种工具时,您可能会感到困惑。最适合您的网页抓取工具取决于您的需求。这里有一些强烈推荐的网页抓取工具。其中一些是免费的,而有些则有试用期和高级计划。在做出决定之前,请仔细阅读以下所有信息。
ParseHub
ParseHub 是一款免费、可靠且功能强大的网页抓取工具。它用于使用 JS、AJAX、会话、cookie 和重定向来抓取单个和多个 网站。使用 Parsehub,您可以轻松地从任何网站 获取数据,因为您无需编写代码。您只需要打开目标网站 并开始单击要提取的数据。此工具可帮助您在服务器上自动采集和存储数据。其简单的 AIP 允许用户在任何地方集成他们提取的数据。
Parsehub 在爬取网站 时使用了大量代理,因此 IP 地址总是在旋转。
八字解析
Octopus 是一种现代视觉网络爬虫软件。对于那些无需编码即可从网站 获取数据的人来说,这是一个完美的选择。多亏了“点击”界面,用户使用起来不会有任何困难。八达通模仿人类活动,例如浏览网站、登录帐户等。它几乎可以从每个站点获取数据,即使它是使用 AJAX 或 JS 动态获取的。
免费版八达通允许用户提取几乎所有网站。只需点击几下鼠标,它就可以将网页变成结构化的电子表格。
Diffbot
Diffbot 是一种非常高效的数据提取工具,它使用互联网让个人和企业能够获取他们需要的任何信息。可广泛应用于市场营销、商业智能、销售和招聘等领域。它提供 API 来提取和理解对象,使用 Al 和计算机视觉从网站 中提取数据。使用 Diffbot,用户不再需要进行任何手动数据提取或互联网研究,因为数据可以自动保存到文件或数据库中。
Diffbot 服务虽然价格偏高,但质量确实非常出色。
冬天
WINTR 也是一个强大的抓取工具。它是一种网页抓取和解析服务,其 API 允许公司和开发人员将任何网页转换为自定义数据集。提供数据采集、数据分析、请求代理、请求定制等多种服务。使用 WINTR 保存请求。如果您的目标网站 将来更改其结构,您将不需要修改您的应用程序代码。
这是一个全面的工具,可帮助您的网页抓取变得简单。您可以试用它的免费版本,它提供 500 个 API 点。
Mozenda
Mozenda 是一个非常有用的数据提取工具,它避免了编写脚本或聘请开发人员的需要。它使中型软件和 IT 公司能够从任何来源自动提取网站 数据。此工具允许企业客户在其强大的云平台上运行网络抓取工具。
可以从 Excel、Word 和 PDF 等格式中提取数据。当Mozenda的“机器人”在页面上快速准确地抓取数据时,它得到结果的速度非常快。它也以多任务处理而闻名。
网页视频抓取脚本( WebHarvy网站刮板的功能介绍及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-09-14 01:07
WebHarvy网站刮板的功能介绍及应用)
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。易于使用。
【功能介绍】
智能识别模式:WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据:您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取:通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面:WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取:基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取类别:WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取:WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
[软件功能]
WebHarvy 是一个可视化的网络抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
[更新日志]
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
网页视频抓取脚本(
WebHarvy网站刮板的功能介绍及应用)
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。易于使用。
【功能介绍】
智能识别模式:WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据:您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取:通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面:WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取:基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取类别:WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取:WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
[软件功能]
WebHarvy 是一个可视化的网络抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
[更新日志]
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源

