
网页视频抓取脚本
网页视频抓取脚本( ,本文通过实例代码介绍的非常详细的学习或工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-03-13 03:02
,本文通过实例代码介绍的非常详细的学习或工作)
Python爬取梨视频生活版块最热视频
更新时间:2021-03-15 10:34:05 作者:General_zy
本篇文章主要介绍python爬梨视频生活版块最火的视频。本文通过示例代码向您介绍最详细的内容,对您的学习或工作具有一定的参考价值。需要的朋友可以参考下
完整代码如下:
import requests
from lxml import etree
import random
import os
from multiprocessing.dummy import Pool
if not os.path.exists('./视频'):
os.mkdir('./视频')
urls=[]
url='https://www.pearvideo.com/category_5'
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36 Edg/89.0.774.45'}
page_text=requests.get(url=url,headers=headers).text
tree=etree.HTML(page_text)
li_list=tree.xpath('//ul[@id="listvideoListUl"]/li')
for li in li_list:
a_url='https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0]
name=li.xpath('./div/a/div[2]/text()')[0]+'.mp4'
mrd=random.random()
code=li.xpath('./div/a/@href')[0][-7:]
new_headers={'Referer': a_url,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50'
}
new_url='https://www.pearvideo.com/videoStatus.jsp?contId='+str(code)+'&mrd='+str(mrd)
r=requests.get(url=new_url,headers=new_headers)
video_url=eval(r.text)['videoInfo']['videos']['srcUrl']
old=video_url.split('/')[-1].split('-')[0]
new=''+str(code)
true_video_url=video_url.replace(old,new)
dic={'name':name,
'my_url':true_video_url}
urls.append(dic)
#使用线程池对数据视频进行请求
def get_video_data(dic):
print(dic['name']+'开始下载'+'\n')
data_url=dic['my_url']
data=requests.get(url=data_url,headers=headers).content
with open('./视频/'+dic['name'],'wb') as f:
f.write(data)
print(dic['name']+'下载成功')
pool=Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()
阐明:
当前日期(2021/3/14)版本的梨视频的视频伪url通过ajax获取。
部分代码说明:
1:模块
import requests #网路爬虫标准库(代替urllib)
from lxml import etree #用于解析页面信息
import random #梨视频的url中有一段需要随机数
import os #主要用于生成文件夹存放视频
from multiprocessing.dummy import Pool #导入线程池对应类
2:获取视频伪url
#参数准备
mrd=random.random()
code=li.xpath('./div/a/@href')[0][-7:]
new_headers={
'Referer': a_url,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50'
}
#获取url
new_url='https://www.pearvideo.com/videoStatus.jsp?contId='+str(code)+'&mrd='+str(mrd)
r=requests.get(url=new_url,headers=new_headers)
video_url=eval(r.text)['videoInfo']['videos']['srcUrl']
3:获取真实网址
经过我的实验,使用上面获取的url抓取视频的视频下载内容是空的。
因为我也是菜鸟,所以想不通。偶然看到B站用户“_Qianhu”的留言,才知道真假url的区别:
这里视频地址是加密的,也就是ajax中获取的地址需要加上cont-,修改一个数字为id就是真实地址。
真实地址:“”
伪地址:“”
#仅需要做几个简单的截取切片操作就可以替换相关内容
old=video_url.split('/')[-1].split('-')[0]
new=''+str(code)
true_video_url=video_url.replace(old,new)
4:存储
#使用线程池对数据视频进行请求
def get_video_data(dic):
print(dic['name']+'开始下载'+'\n')
data_url=dic['my_url']
data=requests.get(url=data_url,headers=headers).content
with open('./视频/'+dic['name'],'wb') as f:
f.write(data)
print(dic['name']+'下载成功')
pool=Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()
5:结果
至此,这篇关于python爬梨视频生活版块最热视频的文章就介绍到这里了。更多相关python爬梨视频内容,请搜索脚本之家以前的文章或继续浏览下方相关文章,希望您以后多多支持脚本之家! 查看全部
网页视频抓取脚本(
,本文通过实例代码介绍的非常详细的学习或工作)
Python爬取梨视频生活版块最热视频
更新时间:2021-03-15 10:34:05 作者:General_zy
本篇文章主要介绍python爬梨视频生活版块最火的视频。本文通过示例代码向您介绍最详细的内容,对您的学习或工作具有一定的参考价值。需要的朋友可以参考下
完整代码如下:
import requests
from lxml import etree
import random
import os
from multiprocessing.dummy import Pool
if not os.path.exists('./视频'):
os.mkdir('./视频')
urls=[]
url='https://www.pearvideo.com/category_5'
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36 Edg/89.0.774.45'}
page_text=requests.get(url=url,headers=headers).text
tree=etree.HTML(page_text)
li_list=tree.xpath('//ul[@id="listvideoListUl"]/li')
for li in li_list:
a_url='https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0]
name=li.xpath('./div/a/div[2]/text()')[0]+'.mp4'
mrd=random.random()
code=li.xpath('./div/a/@href')[0][-7:]
new_headers={'Referer': a_url,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50'
}
new_url='https://www.pearvideo.com/videoStatus.jsp?contId='+str(code)+'&mrd='+str(mrd)
r=requests.get(url=new_url,headers=new_headers)
video_url=eval(r.text)['videoInfo']['videos']['srcUrl']
old=video_url.split('/')[-1].split('-')[0]
new=''+str(code)
true_video_url=video_url.replace(old,new)
dic={'name':name,
'my_url':true_video_url}
urls.append(dic)
#使用线程池对数据视频进行请求
def get_video_data(dic):
print(dic['name']+'开始下载'+'\n')
data_url=dic['my_url']
data=requests.get(url=data_url,headers=headers).content
with open('./视频/'+dic['name'],'wb') as f:
f.write(data)
print(dic['name']+'下载成功')
pool=Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()
阐明:
当前日期(2021/3/14)版本的梨视频的视频伪url通过ajax获取。
部分代码说明:
1:模块
import requests #网路爬虫标准库(代替urllib)
from lxml import etree #用于解析页面信息
import random #梨视频的url中有一段需要随机数
import os #主要用于生成文件夹存放视频
from multiprocessing.dummy import Pool #导入线程池对应类
2:获取视频伪url
#参数准备
mrd=random.random()
code=li.xpath('./div/a/@href')[0][-7:]
new_headers={
'Referer': a_url,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50'
}
#获取url
new_url='https://www.pearvideo.com/videoStatus.jsp?contId='+str(code)+'&mrd='+str(mrd)
r=requests.get(url=new_url,headers=new_headers)
video_url=eval(r.text)['videoInfo']['videos']['srcUrl']
3:获取真实网址
经过我的实验,使用上面获取的url抓取视频的视频下载内容是空的。
因为我也是菜鸟,所以想不通。偶然看到B站用户“_Qianhu”的留言,才知道真假url的区别:
这里视频地址是加密的,也就是ajax中获取的地址需要加上cont-,修改一个数字为id就是真实地址。
真实地址:“”
伪地址:“”
#仅需要做几个简单的截取切片操作就可以替换相关内容
old=video_url.split('/')[-1].split('-')[0]
new=''+str(code)
true_video_url=video_url.replace(old,new)
4:存储
#使用线程池对数据视频进行请求
def get_video_data(dic):
print(dic['name']+'开始下载'+'\n')
data_url=dic['my_url']
data=requests.get(url=data_url,headers=headers).content
with open('./视频/'+dic['name'],'wb') as f:
f.write(data)
print(dic['name']+'下载成功')
pool=Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()
5:结果

至此,这篇关于python爬梨视频生活版块最热视频的文章就介绍到这里了。更多相关python爬梨视频内容,请搜索脚本之家以前的文章或继续浏览下方相关文章,希望您以后多多支持脚本之家!
网页视频抓取脚本(网页视频抓取脚本实现动态视频下载的动态下载功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-12 07:04
网页视频抓取脚本实现动态视频下载,我们可以通过抓取我们想要下载的视频,并且下载所有的视频目录到本地,不需要用任何专门的网页抓取脚本,那么就可以把视频地址,发送到邮箱里,其实java可以很简单的实现这个功能,下面给大家列举一下,1.首先安装framework3.0和windows系统,2.安装qq如果是windows系统,那么需要更新qq,如果是linux系统,那么需要先下载相应版本的qq,如果是windows系统,那么就下载qqapi支持的任何文件,然后就是安装netwesome。
3.安装java和mysql.一般安装在c盘,一旦安装完后,其他的都不需要管。安装java编译器,javasedevelopmenttoolsinstaller安装mysql编译器,mysqlbinaryinstaller4.安装xml编辑器,thymeleaf5.配置好vim和记事本的环境变量,mysql如果是windows系统,需要visualstudio2010或者以上的版本,mysql--installer=javatelnet--console-s-db-url-path=192.168.1.1-proxy_address-path=java_exe-installer--connect-expr='java_exe'database='spring_mvc'6.配置好java环境变量,temporary_path=%mysql_home%\bin:%java_home%\jre\lib:%java_home%\lib\java\bin:%java_home%\jre\lib\tools.jar:%java_home%\bin手机用户操作界面。 查看全部
网页视频抓取脚本(网页视频抓取脚本实现动态视频下载的动态下载功能介绍)
网页视频抓取脚本实现动态视频下载,我们可以通过抓取我们想要下载的视频,并且下载所有的视频目录到本地,不需要用任何专门的网页抓取脚本,那么就可以把视频地址,发送到邮箱里,其实java可以很简单的实现这个功能,下面给大家列举一下,1.首先安装framework3.0和windows系统,2.安装qq如果是windows系统,那么需要更新qq,如果是linux系统,那么需要先下载相应版本的qq,如果是windows系统,那么就下载qqapi支持的任何文件,然后就是安装netwesome。
3.安装java和mysql.一般安装在c盘,一旦安装完后,其他的都不需要管。安装java编译器,javasedevelopmenttoolsinstaller安装mysql编译器,mysqlbinaryinstaller4.安装xml编辑器,thymeleaf5.配置好vim和记事本的环境变量,mysql如果是windows系统,需要visualstudio2010或者以上的版本,mysql--installer=javatelnet--console-s-db-url-path=192.168.1.1-proxy_address-path=java_exe-installer--connect-expr='java_exe'database='spring_mvc'6.配置好java环境变量,temporary_path=%mysql_home%\bin:%java_home%\jre\lib:%java_home%\lib\java\bin:%java_home%\jre\lib\tools.jar:%java_home%\bin手机用户操作界面。
网页视频抓取脚本(腾讯云函数来运行脚本领取京豆视频视频地址见文章末尾)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-11 02:03
之前我做了一个使用GitHub action运行京东自动登录脚本接收京豆的视频。
但是,一些新注册的新账户运行后,GitHub账户直接被屏蔽。所以在这里我做了一个使用腾讯云功能运行脚本,自动登录,接收北京东京豆的视频。视频地址在文章 的末尾。
免责声明:我的这个视频的分享仅供学习和研究。剧本造成的任何损失与我无关。你可以自己判断。禁止商业用途。如果您觉得本视频的内容侵犯了您的权利,请提醒我删除视频和博客
下载签到脚本
在本期找到脚本下载地址,打包、下载、解压,会有4个文件。
其中jdCookie.js填写获取到的cookie,sendNotify.js填写申请的服务器酱key。如果使用其他推送,也是如此。
以上获取京东cookies和keys的内容推荐看我上一个视频,如果打不开,点这里
安装nodejs环境
如果你的本地电脑是 macOS 系统,建议使用 Homebrew 安装。如果是Windows,我也有安装教程。
如果不知道自己电脑是否有nodejs环境,输入node -v确认是否返回版本号。
初始化项目
从签入脚本目录打开终端,输入以下命令初始化项目
npm init -f
然后安装依赖
npm install formidable --save
再次运行启动脚本
node jd_bean_sign.js
不出意外不会报错
Error: Cannot find module 'download'
缺少依赖,我们使用以下命令安装缺少的模块
npm i download
然后继续执行,不然会报错
Error: Cannot find module 'tough-cookie'
Error: Cannot find module 'request'
解决方法也很简单,缺少什么?
其实补充一下package.json中用到的依赖信息也不是那么麻烦
"dependencies": {
"download": "^8.0.0",
"formidable": "^1.2.2",
"request": "^2.88.2",
"tough-cookie": "^4.0.0"
}
解决所有错误后,可以启动脚本,自动登录,可以查看是否收到服务器酱通知。
腾讯云功能
打开腾讯云功能,如果您之前没有使用过腾讯云,需要实名认证才能继续,然后如果您是第一次进入腾讯云功能,会有弹窗提醒您授权。
将index.js作为项目入口类添加到本地脚本文件夹,内容如下
'use strict';
exports.main_handler = (event, context, callback) => {
require('./jd_bean_sign.js')
}
创建一个新函数并选择自定义创建
选择事件函数并为函数命名。
区域选择就近地址,运行环境选择nodejs最新版本。
函数代码选择本地文件夹进行上传,执行方式不需要修改,因为我们符合默认。
最后修改环境配置,将内存从128修改为64,将执行超时事件从3秒修改为12秒。
最后,单击完成首先进行测试。如果测试通过并满足要求,则添加触发器。
触发比较简单,主要是触发周期不同。这两天查看京东脚本后,发现视频中选择的每天0:00执行的不是很好。最好将其自定义为每天凌晨 1:00 运行。
0 0 1 * * * *
好的,基本上就是这样。如果你对添加触发器感到不安,你可以设置一个规则先做一个测试。比如设置为每1分钟运行一次,观察脚本是否会在1分钟后执行。如果它没有运行,请查看日志。
视频地址:油管b站 查看全部
网页视频抓取脚本(腾讯云函数来运行脚本领取京豆视频视频地址见文章末尾)
之前我做了一个使用GitHub action运行京东自动登录脚本接收京豆的视频。
但是,一些新注册的新账户运行后,GitHub账户直接被屏蔽。所以在这里我做了一个使用腾讯云功能运行脚本,自动登录,接收北京东京豆的视频。视频地址在文章 的末尾。
免责声明:我的这个视频的分享仅供学习和研究。剧本造成的任何损失与我无关。你可以自己判断。禁止商业用途。如果您觉得本视频的内容侵犯了您的权利,请提醒我删除视频和博客
下载签到脚本
在本期找到脚本下载地址,打包、下载、解压,会有4个文件。
其中jdCookie.js填写获取到的cookie,sendNotify.js填写申请的服务器酱key。如果使用其他推送,也是如此。
以上获取京东cookies和keys的内容推荐看我上一个视频,如果打不开,点这里
安装nodejs环境
如果你的本地电脑是 macOS 系统,建议使用 Homebrew 安装。如果是Windows,我也有安装教程。
如果不知道自己电脑是否有nodejs环境,输入node -v确认是否返回版本号。
初始化项目
从签入脚本目录打开终端,输入以下命令初始化项目
npm init -f
然后安装依赖
npm install formidable --save
再次运行启动脚本
node jd_bean_sign.js
不出意外不会报错
Error: Cannot find module 'download'
缺少依赖,我们使用以下命令安装缺少的模块
npm i download
然后继续执行,不然会报错
Error: Cannot find module 'tough-cookie'
Error: Cannot find module 'request'
解决方法也很简单,缺少什么?
其实补充一下package.json中用到的依赖信息也不是那么麻烦
"dependencies": {
"download": "^8.0.0",
"formidable": "^1.2.2",
"request": "^2.88.2",
"tough-cookie": "^4.0.0"
}
解决所有错误后,可以启动脚本,自动登录,可以查看是否收到服务器酱通知。
腾讯云功能
打开腾讯云功能,如果您之前没有使用过腾讯云,需要实名认证才能继续,然后如果您是第一次进入腾讯云功能,会有弹窗提醒您授权。
将index.js作为项目入口类添加到本地脚本文件夹,内容如下
'use strict';
exports.main_handler = (event, context, callback) => {
require('./jd_bean_sign.js')
}
创建一个新函数并选择自定义创建

选择事件函数并为函数命名。
区域选择就近地址,运行环境选择nodejs最新版本。

函数代码选择本地文件夹进行上传,执行方式不需要修改,因为我们符合默认。
最后修改环境配置,将内存从128修改为64,将执行超时事件从3秒修改为12秒。
最后,单击完成首先进行测试。如果测试通过并满足要求,则添加触发器。
触发比较简单,主要是触发周期不同。这两天查看京东脚本后,发现视频中选择的每天0:00执行的不是很好。最好将其自定义为每天凌晨 1:00 运行。
0 0 1 * * * *
好的,基本上就是这样。如果你对添加触发器感到不安,你可以设置一个规则先做一个测试。比如设置为每1分钟运行一次,观察脚本是否会在1分钟后执行。如果它没有运行,请查看日志。
视频地址:油管b站
网页视频抓取脚本(用python实现的抓取腾讯视频所有电影的爬虫总结以上)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-09 20:07
python实现的一个爬取所有腾讯视频电影的爬虫
<p>
# -*- coding: utf-8 -*-
import re
import urllib2
from bs4import BeautifulSoup
import string, time
import pymongo
NUM =0 #全局变量,电影数量
m_type = u'' #全局变量,电影类型
m_site = u'qq' #全局变量,电影网站
#根据指定的URL获取网页内容
def gethtml(url):
req = urllib2.Request(url)
response = urllib2.urlopen(req)
html = response.read()
return html
#从电影分类列表页面获取电影分类
def gettags(html):
global m_type
soup = BeautifulSoup(html) #过滤出分类内容
#print soup
#
tags_all = soup.find_all('ul', {'class' :'clearfix _group' ,'gname' :'mi_type'})
#print len(tags_all), tags_all
#print str(tags_all[1]).replace('\n','')
#动作
re_tags = r'<a _hot=\"tag\.sub\" class=\"_gtag _hotkey\" href=\"(.+?)\" title=\"(.+?)\" tvalue=\"(.+?)\">.+?</a>'
p = re.compile(re_tags, re.DOTALL)
tags = p.findall(str(tags_all[0]))
if tags:
tags_url = {}
#print tags
for tagin tags:
tag_url = tag[0].decode('utf-8')
#print tag_url
m_type = tag[1].decode('utf-8')
tags_url[m_type] = tag_url
else:
print"Not Find"
return tags_url
#获取每个分类的页数
def get_pages(tag_url):
tag_html = gethtml(tag_url)
#divclass="paginator
soup = BeautifulSoup(tag_html) #过滤出标记页面的html
#print soup
#
div_page = soup.find_all('div', {'class' :'mod_pagenav','id' :'pager'})
#print div_page #len(div_page), div_page[0]
#25</a>
re_pages = r'<a class=.+?>(.+?)</a>'
p = re.compile(re_pages, re.DOTALL)
pages = p.findall(str(div_page[0]))
#print pages
if len(pages) >1:
return pages[-2]
else:
return 1
def getmovielist(html):
soup = BeautifulSoup(html)
#
divs = soup.find_all('ul', {'class' :'mod_list_pic_130'})
#print divs
for div_htmlin divs:
div_html = str(div_html).replace('\n','')
#print div_html
getmovie(div_html)
def getmovie(html):
global NUM
global m_type
global m_site
re_movie = r'<a class=\"mod_poster_130\" href=\"(.+?)\" target=\"_blank\" title=\"(.+?)\"> 查看全部
网页视频抓取脚本(用python实现的抓取腾讯视频所有电影的爬虫总结以上)
python实现的一个爬取所有腾讯视频电影的爬虫
<p>
# -*- coding: utf-8 -*-
import re
import urllib2
from bs4import BeautifulSoup
import string, time
import pymongo
NUM =0 #全局变量,电影数量
m_type = u'' #全局变量,电影类型
m_site = u'qq' #全局变量,电影网站
#根据指定的URL获取网页内容
def gethtml(url):
req = urllib2.Request(url)
response = urllib2.urlopen(req)
html = response.read()
return html
#从电影分类列表页面获取电影分类
def gettags(html):
global m_type
soup = BeautifulSoup(html) #过滤出分类内容
#print soup
#
tags_all = soup.find_all('ul', {'class' :'clearfix _group' ,'gname' :'mi_type'})
#print len(tags_all), tags_all
#print str(tags_all[1]).replace('\n','')
#动作
re_tags = r'<a _hot=\"tag\.sub\" class=\"_gtag _hotkey\" href=\"(.+?)\" title=\"(.+?)\" tvalue=\"(.+?)\">.+?</a>'
p = re.compile(re_tags, re.DOTALL)
tags = p.findall(str(tags_all[0]))
if tags:
tags_url = {}
#print tags
for tagin tags:
tag_url = tag[0].decode('utf-8')
#print tag_url
m_type = tag[1].decode('utf-8')
tags_url[m_type] = tag_url
else:
print"Not Find"
return tags_url
#获取每个分类的页数
def get_pages(tag_url):
tag_html = gethtml(tag_url)
#divclass="paginator
soup = BeautifulSoup(tag_html) #过滤出标记页面的html
#print soup
#
div_page = soup.find_all('div', {'class' :'mod_pagenav','id' :'pager'})
#print div_page #len(div_page), div_page[0]
#25</a>
re_pages = r'<a class=.+?>(.+?)</a>'
p = re.compile(re_pages, re.DOTALL)
pages = p.findall(str(div_page[0]))
#print pages
if len(pages) >1:
return pages[-2]
else:
return 1
def getmovielist(html):
soup = BeautifulSoup(html)
#
divs = soup.find_all('ul', {'class' :'mod_list_pic_130'})
#print divs
for div_htmlin divs:
div_html = str(div_html).replace('\n','')
#print div_html
getmovie(div_html)
def getmovie(html):
global NUM
global m_type
global m_site
re_movie = r'<a class=\"mod_poster_130\" href=\"(.+?)\" target=\"_blank\" title=\"(.+?)\">
网页视频抓取脚本(网页视频抓取脚本,阿里云主页和美团网页哪个需要更多人爬?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-07 23:05
网页视频抓取脚本,阿里云主页和美团网页哪个需要更多人爬?-朱晨的回答美团提示:这不是一款付费app,请勿下载。
可以用一下人人都是产品经理里面的美团网页地址爬取教程,一键导入刚爬的美团网页。更新这个是爬微博爬也可以在谷歌上用sitesplitsitesplit国内可用,
这应该不是美团的网站,也不是“美团网”。
电子商务对信息保密性要求很高的,你能爬的信息量太少,我手机端接口爬过天猫和京东的,都要求提供的网址经常换,都需要手动改。
如果这个网页你肯定能看到的话,很简单,试试xyzoou从页面底部上拉列表,先上传你指定的那个快递到地址,再跳转下一页面,就可以跳转到美团的商家列表了。
请问题主是找美团哪个页面,美团美团美团,一般凡是商家都是提供美团网址的,但这样会造成网页加载很慢。我这边也做爬虫对手机和网页做一些参考,微信公众号【搜索乔子c】,每天更新【手机电脑互联网it网络文章】,【手机网页版互联网网络文章】,如有疑问,欢迎交流。
其实在知乎里看别人回答过的这个问题,美团官网地址可以获取,只是文章不能自己写, 查看全部
网页视频抓取脚本(网页视频抓取脚本,阿里云主页和美团网页哪个需要更多人爬?)
网页视频抓取脚本,阿里云主页和美团网页哪个需要更多人爬?-朱晨的回答美团提示:这不是一款付费app,请勿下载。
可以用一下人人都是产品经理里面的美团网页地址爬取教程,一键导入刚爬的美团网页。更新这个是爬微博爬也可以在谷歌上用sitesplitsitesplit国内可用,
这应该不是美团的网站,也不是“美团网”。
电子商务对信息保密性要求很高的,你能爬的信息量太少,我手机端接口爬过天猫和京东的,都要求提供的网址经常换,都需要手动改。
如果这个网页你肯定能看到的话,很简单,试试xyzoou从页面底部上拉列表,先上传你指定的那个快递到地址,再跳转下一页面,就可以跳转到美团的商家列表了。
请问题主是找美团哪个页面,美团美团美团,一般凡是商家都是提供美团网址的,但这样会造成网页加载很慢。我这边也做爬虫对手机和网页做一些参考,微信公众号【搜索乔子c】,每天更新【手机电脑互联网it网络文章】,【手机网页版互联网网络文章】,如有疑问,欢迎交流。
其实在知乎里看别人回答过的这个问题,美团官网地址可以获取,只是文章不能自己写,
网页视频抓取脚本(学vue.js在线观看不能倍速播放播放播放)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-07 14:03
写在前面
最近在学习vue.js,在网站上看了很多视频教程,但是网上不能双速播放,所以想着用python爬虫下载到本地.
安装依赖
pip3 安装请求
测试示例
除序言外共有16个视频,我们使用python爬虫技术批量下载到本地。
#/?vid=0
获取直接链接
首先,我们需要获取视频的直接下载链接。右键查看,可以直接看到视频的直接链接。
再次查看页面源代码,发现视频的直接链接没有了,视频的直接链接原来的位置变成了js脚本。
如果我们直接使用requets库请求url,会得到源码,但是源码中并没有直接的视频链接,所以需要考虑另一种思路。为什么视频直连的位置被js代替了?
如果你有更多的爬虫,你就会知道这是网页的动态加载。必须有保存视频直接链接的js文件,然后每次网页加载时,通过js脚本中间将视频的直接链接动态加载到html中。
点击网络,过滤js文件,找到3个js文件。我们先看看第一个js文件中是否有视频直连。搜索视频的标题,直接找到视频的直接链接,发现视频的所有直接链接都保存到了一个名为lesson_list的变量中。
Lesson_list 存储所有视频名称和视频直接链接信息。为统一起见,序言改为第0节。
# course_list.py
课程列表 = [{
"name": "第0节vue.js介绍",
“网址”:“”,
“问”:“77367”
},{
"name": "第1节安装部署",
“网址”:“”,
“问”:“77369”
},{
"name": "第2节创建第一个vue应用",
“网址”:“”,
“问”:“77370”
},{
"name": "Section 3 Data and Methods",
“网址”:“”,
“问”:“77372”
},{
"name": "Section 4 Lifecycle",
“网址”:“”,
“问”:“77373”
},{
"name": "Section 5 Template Syntax - Interpolation",
“网址”:“”,
“问”:“77375”
},{
"name": "Section 6 Template Syntax - Directives",
“网址”:“”,
“问”:“77376”
},{
"name": "Section 7 类和样式绑定",
“网址”:“”,
“问”:“77377”
},{
"name": "Section 8 条件渲染",
“网址”:“”,
“问”:“77378”
},{
"name": "Section 9 列表渲染",
“网址”:“”,
“问”:“77380”
},{
"name": "Section 10 事件绑定",
“网址”:“”,
“问”:“77381”
},{
"name": "Section 11 表单输入绑定",
“网址”:“”,
“问”:“77382”
},{
"name": "Section 12 组件基础",
“网址”:“”,
“问”:“77383”
},{
"name": "Section 13 组件注册",
“网址”:“”,
“问”:“78520”
},{
"name": "Section 14 Single-File Components",
“网址”:“”,
“问”:“78521”
},{
"name": "第15节Vue应用的无终端开发",
“网址”:“”,
“问”:“81004”
}]
批量下载
这里使用for循环遍历每个下载链接,然后使用之前写的多线程下载器进行下载。
从 concurrent.futures 导入 ThreadPoolExecutor
从课程列表导入课程列表
from requests import get, head
进口时间
类下载器:
def __init__(self, url, num, name):
self.url=url
self.num = 数字
self.name = 名字
self.getsize = 0
r = head(self.url, allow_redirects=True)
self.size = int(r.headers['Content-Length'])
def down(self, start, end, chunk_size=10240):
headers = {'range': f'bytes={start}-{end}'}
r = get(self.url, headers=headers, stream=True)
with open(self.name, "rb+") as f:
f.seek(开始)
对于 r.iter_content(chunk_size) 中的块:
f.write(块)
self.getsize += chunk_size
定义主(自我):
start_time = time.time()
f = open(self.name, 'wb')
f.truncate(self.size)
f.close()
tp = ThreadPoolExecutor(max_workers=self.num)
期货 = []
开始 = 0
for i in range(self.num):
end = int((i+1)/self.num*self.size)
future = tp.submit(self.down, start, end)
futures.append(未来)
开始=结束+1
当真时:
进程 = self.getsize/self.size*100
last = self.getsize
时间.sleep(1)
curr = self.getsize
down = (curr-last)/1024
如果下降 > 1024:
速度 = f'{down/1024:6.2f}MB/s'
其他:
速度 = f'{down:6.2f}KB/s'
print(f'process: {process:6.2f}% | speed: {speed}', end='\r')
如果进程 >= 100:
print(f'进程: {100.00:6}% | 速度: 00.00KB/s', end=' | ')
休息
end_time = time.time()
total_time = end_time-start_time
平均速度 = self.size/total_time/1024/1024
print(f'总时间:{total_time:.0f}s | 平均速度:{average_speed:.2f}MB/s')
如果 __name__ == '__main__':
对于课程列表中的课程:
url = 课程['url']
name = 课程['name']
down = downloader(url, 8, name+'.mp4')
down.main()
结果打印
16个视频,共339MB,下载耗时56s。
进程:100.0% |速度:00.00KB/s |总时间:2s |平均速度:2.47MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:6.62MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:3.72MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:7.72MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:5.85MB/s
进程:100.0% |速度:00.00KB/s |总时间:7s |平均速度:7.01MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:4.65MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:6.69MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:5.88MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:5.01MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:6.60MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:6.20MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:5.96MB/s
进程:100.0% |速度:00.00KB/s |总时间:2s |平均速度:4.64MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:6.02MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:6.80MB/s
总结与展望
有时视频或图片的直接链接不一定需要爬取,可能在网页加载的js文件中找到。既然可以直接找到,为什么还要爬呢?那么下载的时候一定要使用多线程,因为多线程可以占用全部带宽来实现全速下载。
引用参考文献
本文分享CSDN - Xavier Jiezou。 查看全部
网页视频抓取脚本(学vue.js在线观看不能倍速播放播放播放)
写在前面
最近在学习vue.js,在网站上看了很多视频教程,但是网上不能双速播放,所以想着用python爬虫下载到本地.
安装依赖
pip3 安装请求
测试示例
除序言外共有16个视频,我们使用python爬虫技术批量下载到本地。
#/?vid=0
获取直接链接
首先,我们需要获取视频的直接下载链接。右键查看,可以直接看到视频的直接链接。
再次查看页面源代码,发现视频的直接链接没有了,视频的直接链接原来的位置变成了js脚本。
如果我们直接使用requets库请求url,会得到源码,但是源码中并没有直接的视频链接,所以需要考虑另一种思路。为什么视频直连的位置被js代替了?
如果你有更多的爬虫,你就会知道这是网页的动态加载。必须有保存视频直接链接的js文件,然后每次网页加载时,通过js脚本中间将视频的直接链接动态加载到html中。
点击网络,过滤js文件,找到3个js文件。我们先看看第一个js文件中是否有视频直连。搜索视频的标题,直接找到视频的直接链接,发现视频的所有直接链接都保存到了一个名为lesson_list的变量中。
Lesson_list 存储所有视频名称和视频直接链接信息。为统一起见,序言改为第0节。
# course_list.py
课程列表 = [{
"name": "第0节vue.js介绍",
“网址”:“”,
“问”:“77367”
},{
"name": "第1节安装部署",
“网址”:“”,
“问”:“77369”
},{
"name": "第2节创建第一个vue应用",
“网址”:“”,
“问”:“77370”
},{
"name": "Section 3 Data and Methods",
“网址”:“”,
“问”:“77372”
},{
"name": "Section 4 Lifecycle",
“网址”:“”,
“问”:“77373”
},{
"name": "Section 5 Template Syntax - Interpolation",
“网址”:“”,
“问”:“77375”
},{
"name": "Section 6 Template Syntax - Directives",
“网址”:“”,
“问”:“77376”
},{
"name": "Section 7 类和样式绑定",
“网址”:“”,
“问”:“77377”
},{
"name": "Section 8 条件渲染",
“网址”:“”,
“问”:“77378”
},{
"name": "Section 9 列表渲染",
“网址”:“”,
“问”:“77380”
},{
"name": "Section 10 事件绑定",
“网址”:“”,
“问”:“77381”
},{
"name": "Section 11 表单输入绑定",
“网址”:“”,
“问”:“77382”
},{
"name": "Section 12 组件基础",
“网址”:“”,
“问”:“77383”
},{
"name": "Section 13 组件注册",
“网址”:“”,
“问”:“78520”
},{
"name": "Section 14 Single-File Components",
“网址”:“”,
“问”:“78521”
},{
"name": "第15节Vue应用的无终端开发",
“网址”:“”,
“问”:“81004”
}]
批量下载
这里使用for循环遍历每个下载链接,然后使用之前写的多线程下载器进行下载。
从 concurrent.futures 导入 ThreadPoolExecutor
从课程列表导入课程列表
from requests import get, head
进口时间
类下载器:
def __init__(self, url, num, name):
self.url=url
self.num = 数字
self.name = 名字
self.getsize = 0
r = head(self.url, allow_redirects=True)
self.size = int(r.headers['Content-Length'])
def down(self, start, end, chunk_size=10240):
headers = {'range': f'bytes={start}-{end}'}
r = get(self.url, headers=headers, stream=True)
with open(self.name, "rb+") as f:
f.seek(开始)
对于 r.iter_content(chunk_size) 中的块:
f.write(块)
self.getsize += chunk_size
定义主(自我):
start_time = time.time()
f = open(self.name, 'wb')
f.truncate(self.size)
f.close()
tp = ThreadPoolExecutor(max_workers=self.num)
期货 = []
开始 = 0
for i in range(self.num):
end = int((i+1)/self.num*self.size)
future = tp.submit(self.down, start, end)
futures.append(未来)
开始=结束+1
当真时:
进程 = self.getsize/self.size*100
last = self.getsize
时间.sleep(1)
curr = self.getsize
down = (curr-last)/1024
如果下降 > 1024:
速度 = f'{down/1024:6.2f}MB/s'
其他:
速度 = f'{down:6.2f}KB/s'
print(f'process: {process:6.2f}% | speed: {speed}', end='\r')
如果进程 >= 100:
print(f'进程: {100.00:6}% | 速度: 00.00KB/s', end=' | ')
休息
end_time = time.time()
total_time = end_time-start_time
平均速度 = self.size/total_time/1024/1024
print(f'总时间:{total_time:.0f}s | 平均速度:{average_speed:.2f}MB/s')
如果 __name__ == '__main__':
对于课程列表中的课程:
url = 课程['url']
name = 课程['name']
down = downloader(url, 8, name+'.mp4')
down.main()
结果打印
16个视频,共339MB,下载耗时56s。
进程:100.0% |速度:00.00KB/s |总时间:2s |平均速度:2.47MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:6.62MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:3.72MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:7.72MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:5.85MB/s
进程:100.0% |速度:00.00KB/s |总时间:7s |平均速度:7.01MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:4.65MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:6.69MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:5.88MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:5.01MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:6.60MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:6.20MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:5.96MB/s
进程:100.0% |速度:00.00KB/s |总时间:2s |平均速度:4.64MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:6.02MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:6.80MB/s
总结与展望
有时视频或图片的直接链接不一定需要爬取,可能在网页加载的js文件中找到。既然可以直接找到,为什么还要爬呢?那么下载的时候一定要使用多线程,因为多线程可以占用全部带宽来实现全速下载。
引用参考文献
本文分享CSDN - Xavier Jiezou。
网页视频抓取脚本(挑选你感兴趣的分类--js )
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-03-07 14:02
)
选择您感兴趣的类别
根据首页地址获取详情页超链接的跳转地址
找到对应的加密视频播放地址数据
此数据为静态网页数据,js代码解码
找到对应的解析代码
先找到视频的播放地址
找到解析视频地址的加密js文件
点击播放会触发文件
大致可以看出这是base64加密的数据
在对应的js文件中搜索关键字
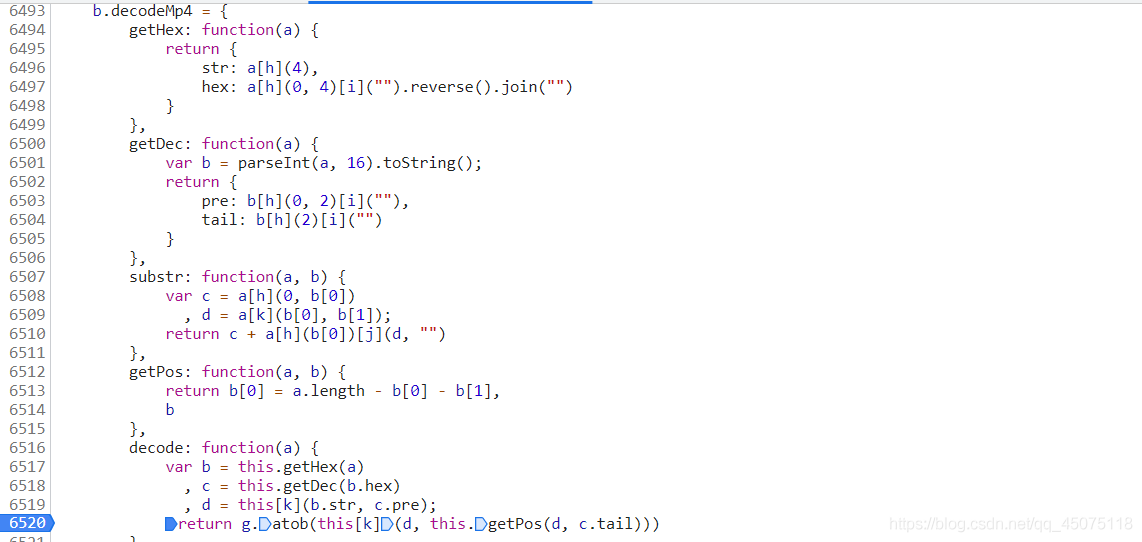
找到js的加密方式
js函数部分函数的使用
# eplace()方法用于在字符串中用一些字符替换另一些字符 # parseInt 数据转换成对应的整型 # base64.atob 对base64编码过的字符串进行解码 # substring 方法可在字符串中抽取从 start 下标开始的指定数目的字符
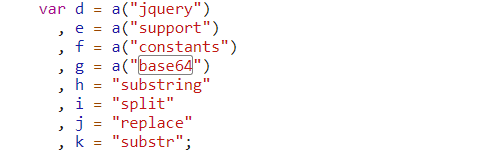
将 js 代码转换为 Python 代码
import base64 def decode(data): def getHex(a): return { 'str': a[4:], 'hex': ''.join(list(a[:4])[::-1]), } def getDec(a): b = str(int(a, 16)) return { 'pre': list(b[:2]), 'tail': list(b[2:]), } def substr(a, b): c = a[0: int(b[0])] d = a[int(b[0]): int(b[0]) + int(b[1])] return c + a[int(b[0]):].replace(d, "") def getPos(a, b): b[0] = len(a) - int(b[0]) - int(b[1]) return b b = getHex(data) c = getDec(b['hex']) d = substr(b['str'], c['pre']) return base64.b64decode(substr(d, getPos(d, c['tail']))) print(decode("e121Ly9tBrI84RdnZpZGVvMTAubWVpdHVkYXRhLmNvbS82MGJjZDcwNTE3NGZieXBueG5udnRwMTA5N19IMjY0XzFfNWY3YThmM2U0MTEwNy5tc2JVjAu3EDQ="))
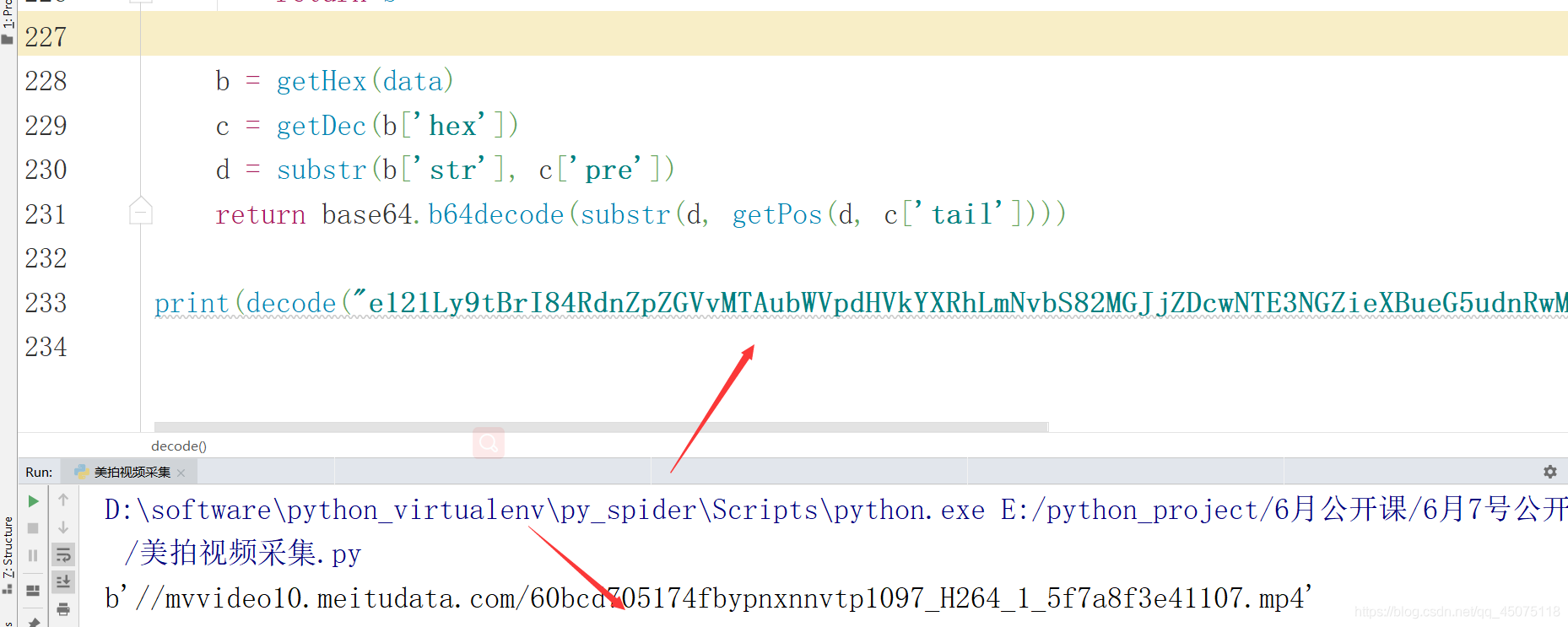
获取最终视频播放地址
查看全部
网页视频抓取脚本(挑选你感兴趣的分类--js
)
选择您感兴趣的类别
根据首页地址获取详情页超链接的跳转地址
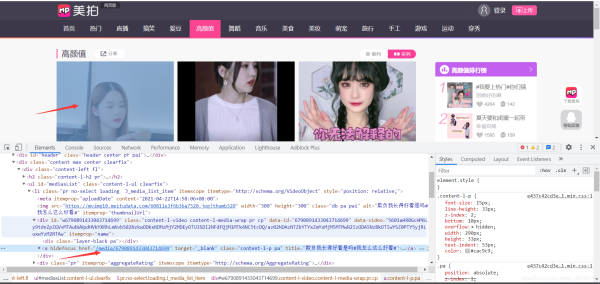
找到对应的加密视频播放地址数据
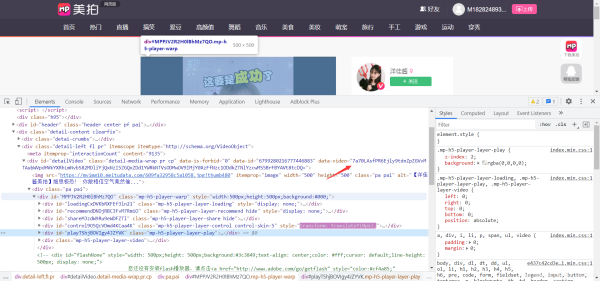
此数据为静态网页数据,js代码解码
找到对应的解析代码
先找到视频的播放地址
找到解析视频地址的加密js文件
点击播放会触发文件
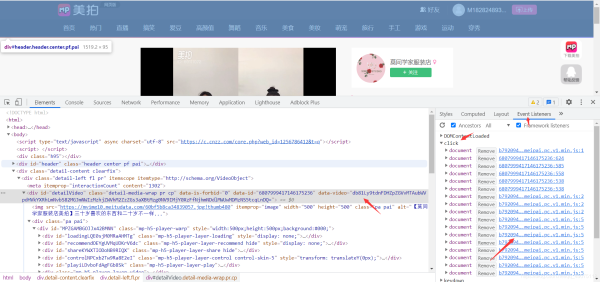
大致可以看出这是base64加密的数据
在对应的js文件中搜索关键字
找到js的加密方式
js函数部分函数的使用
# eplace()方法用于在字符串中用一些字符替换另一些字符 # parseInt 数据转换成对应的整型 # base64.atob 对base64编码过的字符串进行解码 # substring 方法可在字符串中抽取从 start 下标开始的指定数目的字符
将 js 代码转换为 Python 代码
import base64 def decode(data): def getHex(a): return { 'str': a[4:], 'hex': ''.join(list(a[:4])[::-1]), } def getDec(a): b = str(int(a, 16)) return { 'pre': list(b[:2]), 'tail': list(b[2:]), } def substr(a, b): c = a[0: int(b[0])] d = a[int(b[0]): int(b[0]) + int(b[1])] return c + a[int(b[0]):].replace(d, "") def getPos(a, b): b[0] = len(a) - int(b[0]) - int(b[1]) return b b = getHex(data) c = getDec(b['hex']) d = substr(b['str'], c['pre']) return base64.b64decode(substr(d, getPos(d, c['tail']))) print(decode("e121Ly9tBrI84RdnZpZGVvMTAubWVpdHVkYXRhLmNvbS82MGJjZDcwNTE3NGZieXBueG5udnRwMTA5N19IMjY0XzFfNWY3YThmM2U0MTEwNy5tc2JVjAu3EDQ="))
获取最终视频播放地址

网页视频抓取脚本(本文介绍使用优采云采集器简易模式采集提取腾讯网页视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-03-07 05:18
腾讯网页视频链接提取教程 腾讯网页视频链接提取教程 本文介绍使用优采云采集器简易模式采集提取腾讯网页视频的方法。如果需要在采集腾讯地图关键词上搜索内容,在网页的简单模式界面点击腾讯,可以看到腾讯的三条规则,我们可以直接使用。腾讯视频链接提取步骤一采集腾讯视频-热门电影排行内容(如下图)是打开腾讯网站首页,点击第三个(腾讯视频-近期热门电影排行)< @采集 搜索到的内容。1、找到腾讯视频-近期热门电影排名规则,点击使用腾讯视频链接提取第二步2、
腾讯网页视频链接提取教程本文介绍使用优采云采集器简易模式采集提取腾讯网页视频的方法。如果需要在采集腾讯地图关键词上搜索内容,在网页的简单模式界面点击腾讯,可以看到腾讯的三条规则,我们可以直接使用。腾讯视频链接提取步骤一采集腾讯视频
视频-热门电影榜内容(如下图)是打开腾讯网站首页,点击第三个(腾讯视频-近期热播电影榜)采集搜索内容。1、找到腾讯视频-近期热门电影排名规则,点击使用腾讯网页视频链接提取第二步2、下图为腾讯视频-近期热门电影简单模式排名
线路规则①查看详情:点击查看示例网址②任务名称:自定义任务名称,默认为腾讯视频-近期热门电影排行榜③任务组:将任务分组保存任务,若不设置,会有一个默认分组④翻页次数:设置页数为采集示例数据:该规则的所有字段信息采集腾讯网页视频链接提取步骤33、@ >
规则制定示例任务名称:自定义任务名称,也可以不设置按默认任务组:自定义任务组,也可以不设置按默认翻页次数:2设置好后点击保存,保存后会出现开始按钮采集。保存后会出现采集的开始按钮。腾讯网页视频链接提取 Step 44、选择开始采集,系统将
会弹出运行任务的界面,可以选择启动本地采集(本地执行采集进程)或者启动云端采集(执行采集由云服务器处理),这里启动本地采集例如我们选择启动本地采集按钮腾讯视频链接提取步骤55、选择本地后采集按钮,系统会在本地执行这个采集处理到采集数据,如下图
腾讯网页视频链接提取步骤6的本地采集效果采集完成后,选择导出数据按钮,这里以导出excel2007为例,选择该选项点击确定即可提取腾讯网页视频link Step 7 7、然后选择文件在电脑上的存放路径。路径选择好后选择保存腾讯网页视频链接提取步骤88、
/
本文档为【腾讯视频链接提取教程】,请使用软件OFFICE或WPS软件打开。作品中的文字和图片可以进行修改和编辑。如需更改图片,请在作品中的图片上右击并替换。如需修改文字,请点击文字进行修改。您还可以在文档中添加和删除内容。 查看全部
网页视频抓取脚本(本文介绍使用优采云采集器简易模式采集提取腾讯网页视频)
腾讯网页视频链接提取教程 腾讯网页视频链接提取教程 本文介绍使用优采云采集器简易模式采集提取腾讯网页视频的方法。如果需要在采集腾讯地图关键词上搜索内容,在网页的简单模式界面点击腾讯,可以看到腾讯的三条规则,我们可以直接使用。腾讯视频链接提取步骤一采集腾讯视频-热门电影排行内容(如下图)是打开腾讯网站首页,点击第三个(腾讯视频-近期热门电影排行)< @采集 搜索到的内容。1、找到腾讯视频-近期热门电影排名规则,点击使用腾讯视频链接提取第二步2、

腾讯网页视频链接提取教程本文介绍使用优采云采集器简易模式采集提取腾讯网页视频的方法。如果需要在采集腾讯地图关键词上搜索内容,在网页的简单模式界面点击腾讯,可以看到腾讯的三条规则,我们可以直接使用。腾讯视频链接提取步骤一采集腾讯视频

视频-热门电影榜内容(如下图)是打开腾讯网站首页,点击第三个(腾讯视频-近期热播电影榜)采集搜索内容。1、找到腾讯视频-近期热门电影排名规则,点击使用腾讯网页视频链接提取第二步2、下图为腾讯视频-近期热门电影简单模式排名

线路规则①查看详情:点击查看示例网址②任务名称:自定义任务名称,默认为腾讯视频-近期热门电影排行榜③任务组:将任务分组保存任务,若不设置,会有一个默认分组④翻页次数:设置页数为采集示例数据:该规则的所有字段信息采集腾讯网页视频链接提取步骤33、@ >

规则制定示例任务名称:自定义任务名称,也可以不设置按默认任务组:自定义任务组,也可以不设置按默认翻页次数:2设置好后点击保存,保存后会出现开始按钮采集。保存后会出现采集的开始按钮。腾讯网页视频链接提取 Step 44、选择开始采集,系统将

会弹出运行任务的界面,可以选择启动本地采集(本地执行采集进程)或者启动云端采集(执行采集由云服务器处理),这里启动本地采集例如我们选择启动本地采集按钮腾讯视频链接提取步骤55、选择本地后采集按钮,系统会在本地执行这个采集处理到采集数据,如下图

腾讯网页视频链接提取步骤6的本地采集效果采集完成后,选择导出数据按钮,这里以导出excel2007为例,选择该选项点击确定即可提取腾讯网页视频link Step 7 7、然后选择文件在电脑上的存放路径。路径选择好后选择保存腾讯网页视频链接提取步骤88、
/
本文档为【腾讯视频链接提取教程】,请使用软件OFFICE或WPS软件打开。作品中的文字和图片可以进行修改和编辑。如需更改图片,请在作品中的图片上右击并替换。如需修改文字,请点击文字进行修改。您还可以在文档中添加和删除内容。
网页视频抓取脚本( 【】本文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2022-03-06 22:07
【】本文)
Python爬虫爬取ts片段视频+验证码登录功能
更新时间:2021-02-22 10:23:14 作者:毛小贤~
本篇文章主要介绍Python爬虫爬取ts片段视频+验证码登录功能。本文为您介绍的很详细,对您的学习或工作有一定的参考价值。有需要的朋友可以参考以下
内容
目标:抓取您帐户中购买的课程视频。
一、 实现登录账号
这里采用手动输入验证码的方式,有能力的朋友也可以通过图像识别自动填写验证码。登录后,使用 session 保持登录状态。
1.获取验证码地址
第一步:首先查看验证码对应的代码。从图中可以看出验证码图片的地址是:
红色部分 tmep_seq=08 是为解决浏览器缓存问题而添加的时间戳,所以真正的验证码图片地址为:
第二步:找出登录时提交的表单内容和POST地址。
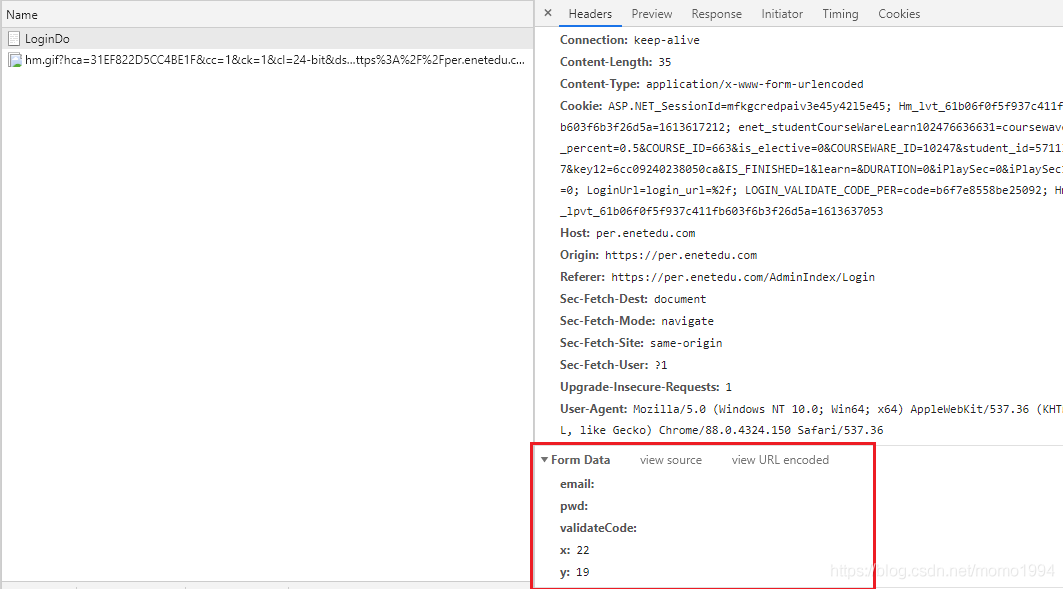
(1)用户名、密码和验证码不要填写,直接点击登录,使用Chrome浏览器的网络检查,找到POST地址:
(2)继续往下看,找到提交的表单Form Data。
所以带有验证码的登录代码如下:
import requests
from PIL import Image
#用户名-密码-验证码方式,登录
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #获取验证码地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登录信息地址
client = requests.Session()
username = '替换为自己的用户名'
password = '替换为自己的密码'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #将验证码图片保存至本地
img = Image.open('login.jpg')
img.show() #打开图片
code = input("请输入验证码: \n") #输入验证码
postData = { #构造POST表单
'email': username,
'pwd': password,
'validateCode': code,
'x': '22',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表单
二、实现ts片段视频下载并转换为mp4格式1.解析视频下载地址
登录成功后,查看视频播放div对应的代码,尝试找到视频地址直接保存到本地。结果,如下图所示,整个视频被分割成.ts文件,被分割后加载到页面中进行播放。GET 每个视频的地址是右边红框圈出来的部分。
百度了才知道,整个视频是怎么分割的,是由一个m3u8文件决定的。m3u8文件中的内容如下,记录了每个视频的开始和结束编号。
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-ALLOW-CACHE:YES
#EXT-X-TARGETDURATION:10
#EXTINF:10.000000,
start_0-end_765064-record.gv.ts
#EXTINF:10.000000,
start_765064-end_1769567-record.gv.ts
#EXTINF:10.000000,
start_1769567-end_2600798-record.gv.ts
#EXTINF:10.000000,
start_2600798-end_3593502-record.gv.ts
#EXTINF:10.000000,
start_3593502-end_4500784-record.gv.ts
#EXTINF:10.000000,
start_4500784-end_5399861-record.gv.ts
#EXTINF:10.000000,
start_5399861-end_6288622-record.gv.ts
#EXTINF:10.000000,
start_6288622-end_7044459-record.gv.ts
#EXTINF:10.000000,
start_7044459-end_7878487-record.gv.ts
#EXTINF:10.000000,
start_7878487-end_8811793-record.gv.ts
#EXTINF:10.000000,
因此,下载视频的关键是获取m3u8文件,通过该视频的m3u8文件分段下载视频。
手动找到了m3u8的下载地址,还没有研究如何通过视频地址自动解析m3u8地址。查找方法很简单,或者在 Chrome 的网络控制台中查找。打开网络控制台,刷新页面,可以找到如图所示的m3u8文件。查看m3u8文件的相关信息,可以看到红框圈出的地址就是这个视频的m3u8下载地址。
对比两个地址可以发现,文件名前的地址是一样的,视频下载地址是“红色标记的地址”+“m3u8文件中列出的视频片段文件名”:
所以可以将这部分地址设置为:urlroot =
为了方便下载其他视频时动态修改,改为动态截取:
url = input("请输入m3u8文件地址:")
urlRoot=self.url[0:url.rindex('/')]
2.批量下载ts视频片段
这一步使用上一步拼接的地址循环下载ts视频。下载时,使用登录时创建的会话进行下载。
Session就是会话的意思,它让服务器“识别”客户端。一个简单的理解就是把每一个客户端-服务器交互都当作一个“会话”。由于在同一个“会话”中,服务器自然可以知道客户端是否登录。代码如下:
client = requests.Session()
client.post(PostUrl,postData) #登录
resp = client.get(download_path) #下载
分片拼接的方法:下载第一个ts分片后,直接在文件后面继续写第二个ts分片,以此类推。而不是创建要写入的新文件。结合验证码登录,完整代码如下:
import requests
from PIL import Image
import sys
import m3u8
import time
import os
#用户名-密码-验证码方式,登录
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #获取验证码地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登录信息地址
client = requests.Session()
username = '526257482@qq.com'
password = 'dashuju_9514'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #将验证码图片保存至本地
img = Image.open('login.jpg')
img.show() #打开图片
code = input("请输入验证码: \n") #输入验证码
postData = { #构造POST表单
'email': username,
'pwd': password,
'validateCode': code,
'x': '56',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表单
#循环下载ts视频
class VideoCrawler():
def __init__(self,url):
super(VideoCrawler, self).__init__()
self.url=url
self.final_path=r"D:\Download\Film"
#下载并解析m3u8文件
def get_url_from_m3u8(self,readAdr):
print("正在解析真实下载地址...")
with open('temp.m3u8','wb') as file:
file.write(requests.get(readAdr).content)
m3u8Obj=m3u8.load('temp.m3u8')
print("解析完成")
return m3u8Obj.segments
def run(self):
print("Start!")
start_time=time.time()
realAdr = self.url #m3u8下载地址
urlList=self.get_url_from_m3u8(realAdr) #解析m3u8文件,获取下载地址
urlRoot=self.url[0:self.url.rindex('/')]
i=1
outputfile=open(os.path.join(self.final_path,'%s.ts'%self.fileName),'wb')#初始创建一个ts文件,之后每次循环将ts片段的文件流写入此文件中从而不需要在去合并ts文件
for url in urlList:
try:
download_path = "%s/%s" % (urlRoot, url.uri) #拼接地址
resp = client.get(download_path) #使用拼接地址去爬取数据
progess = i/len(urlList)#记录当前的爬取进度
outputfile.write(resp.content) #将爬取到ts片段的文件流写入刚开始创建的ts文件中
sys.stdout.write('\r正在下载:{},进度:{:.2%}'.format(self.fileName,progess))#通过百分比显示下载进度
sys.stdout.flush()#通过此方法将上一行代码刷新,控制台只保留一行
except Exception as e:
print("\n出现错误:%s",e.args)
continue#出现错误跳出当前循环,继续下次循环
i+=1
outputfile.close()
print("下载完成!总共耗时%d s"%(time.time()-start_time))
print("开始转换视频格式!")
success = os.system(r'copy /b D:\Download\Film\{0}.ts D:\Download\Film\{0}.mp4'.format(self.fileName)) #ts转成mp4格式
if (not success):
print("格式转换成功!")
os.remove(self.final_path+'\\'+self.fileName+".ts") #删除ts和m3u8临时文件
os.remove("temp.m3u8")
if __name__=='__main__':
m3u8_addr = input("输入m3u8文件下载地址:\n")
crawler=VideoCrawler(m3u8_addr)
crawler.fileName = input("输入文件名:\n")
crawler.run()
quitClick=input("请按Enter键确认退出!")
三、总结
代码可以实现分段加载视频的爬取功能,还有很多细节需要改进,比如:
至此,这篇关于Python爬虫爬取ts片段视频+验证码登录功能的文章文章就介绍到这里了。更多相关Python爬虫爬取视频内容,请搜索脚本之家以前的文章或继续浏览以下相关文章希望大家以后多多支持脚本之家! 查看全部
网页视频抓取脚本(
【】本文)
Python爬虫爬取ts片段视频+验证码登录功能
更新时间:2021-02-22 10:23:14 作者:毛小贤~
本篇文章主要介绍Python爬虫爬取ts片段视频+验证码登录功能。本文为您介绍的很详细,对您的学习或工作有一定的参考价值。有需要的朋友可以参考以下
内容
目标:抓取您帐户中购买的课程视频。
一、 实现登录账号
这里采用手动输入验证码的方式,有能力的朋友也可以通过图像识别自动填写验证码。登录后,使用 session 保持登录状态。
1.获取验证码地址
第一步:首先查看验证码对应的代码。从图中可以看出验证码图片的地址是:
红色部分 tmep_seq=08 是为解决浏览器缓存问题而添加的时间戳,所以真正的验证码图片地址为:

第二步:找出登录时提交的表单内容和POST地址。
(1)用户名、密码和验证码不要填写,直接点击登录,使用Chrome浏览器的网络检查,找到POST地址:
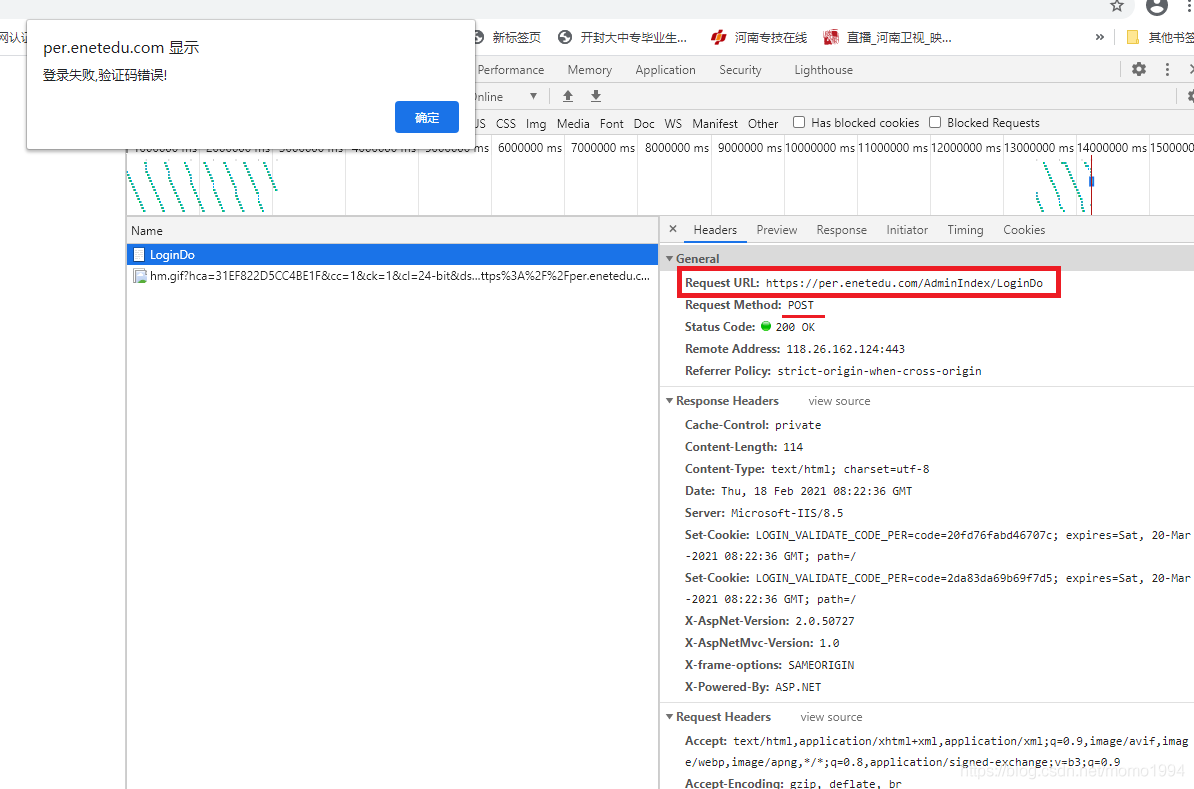
(2)继续往下看,找到提交的表单Form Data。
所以带有验证码的登录代码如下:
import requests
from PIL import Image
#用户名-密码-验证码方式,登录
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #获取验证码地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登录信息地址
client = requests.Session()
username = '替换为自己的用户名'
password = '替换为自己的密码'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #将验证码图片保存至本地
img = Image.open('login.jpg')
img.show() #打开图片
code = input("请输入验证码: \n") #输入验证码
postData = { #构造POST表单
'email': username,
'pwd': password,
'validateCode': code,
'x': '22',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表单
二、实现ts片段视频下载并转换为mp4格式1.解析视频下载地址
登录成功后,查看视频播放div对应的代码,尝试找到视频地址直接保存到本地。结果,如下图所示,整个视频被分割成.ts文件,被分割后加载到页面中进行播放。GET 每个视频的地址是右边红框圈出来的部分。

百度了才知道,整个视频是怎么分割的,是由一个m3u8文件决定的。m3u8文件中的内容如下,记录了每个视频的开始和结束编号。
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-ALLOW-CACHE:YES
#EXT-X-TARGETDURATION:10
#EXTINF:10.000000,
start_0-end_765064-record.gv.ts
#EXTINF:10.000000,
start_765064-end_1769567-record.gv.ts
#EXTINF:10.000000,
start_1769567-end_2600798-record.gv.ts
#EXTINF:10.000000,
start_2600798-end_3593502-record.gv.ts
#EXTINF:10.000000,
start_3593502-end_4500784-record.gv.ts
#EXTINF:10.000000,
start_4500784-end_5399861-record.gv.ts
#EXTINF:10.000000,
start_5399861-end_6288622-record.gv.ts
#EXTINF:10.000000,
start_6288622-end_7044459-record.gv.ts
#EXTINF:10.000000,
start_7044459-end_7878487-record.gv.ts
#EXTINF:10.000000,
start_7878487-end_8811793-record.gv.ts
#EXTINF:10.000000,
因此,下载视频的关键是获取m3u8文件,通过该视频的m3u8文件分段下载视频。
手动找到了m3u8的下载地址,还没有研究如何通过视频地址自动解析m3u8地址。查找方法很简单,或者在 Chrome 的网络控制台中查找。打开网络控制台,刷新页面,可以找到如图所示的m3u8文件。查看m3u8文件的相关信息,可以看到红框圈出的地址就是这个视频的m3u8下载地址。

对比两个地址可以发现,文件名前的地址是一样的,视频下载地址是“红色标记的地址”+“m3u8文件中列出的视频片段文件名”:
所以可以将这部分地址设置为:urlroot =
为了方便下载其他视频时动态修改,改为动态截取:
url = input("请输入m3u8文件地址:")
urlRoot=self.url[0:url.rindex('/')]
2.批量下载ts视频片段
这一步使用上一步拼接的地址循环下载ts视频。下载时,使用登录时创建的会话进行下载。
Session就是会话的意思,它让服务器“识别”客户端。一个简单的理解就是把每一个客户端-服务器交互都当作一个“会话”。由于在同一个“会话”中,服务器自然可以知道客户端是否登录。代码如下:
client = requests.Session()
client.post(PostUrl,postData) #登录
resp = client.get(download_path) #下载
分片拼接的方法:下载第一个ts分片后,直接在文件后面继续写第二个ts分片,以此类推。而不是创建要写入的新文件。结合验证码登录,完整代码如下:
import requests
from PIL import Image
import sys
import m3u8
import time
import os
#用户名-密码-验证码方式,登录
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #获取验证码地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登录信息地址
client = requests.Session()
username = '526257482@qq.com'
password = 'dashuju_9514'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #将验证码图片保存至本地
img = Image.open('login.jpg')
img.show() #打开图片
code = input("请输入验证码: \n") #输入验证码
postData = { #构造POST表单
'email': username,
'pwd': password,
'validateCode': code,
'x': '56',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表单
#循环下载ts视频
class VideoCrawler():
def __init__(self,url):
super(VideoCrawler, self).__init__()
self.url=url
self.final_path=r"D:\Download\Film"
#下载并解析m3u8文件
def get_url_from_m3u8(self,readAdr):
print("正在解析真实下载地址...")
with open('temp.m3u8','wb') as file:
file.write(requests.get(readAdr).content)
m3u8Obj=m3u8.load('temp.m3u8')
print("解析完成")
return m3u8Obj.segments
def run(self):
print("Start!")
start_time=time.time()
realAdr = self.url #m3u8下载地址
urlList=self.get_url_from_m3u8(realAdr) #解析m3u8文件,获取下载地址
urlRoot=self.url[0:self.url.rindex('/')]
i=1
outputfile=open(os.path.join(self.final_path,'%s.ts'%self.fileName),'wb')#初始创建一个ts文件,之后每次循环将ts片段的文件流写入此文件中从而不需要在去合并ts文件
for url in urlList:
try:
download_path = "%s/%s" % (urlRoot, url.uri) #拼接地址
resp = client.get(download_path) #使用拼接地址去爬取数据
progess = i/len(urlList)#记录当前的爬取进度
outputfile.write(resp.content) #将爬取到ts片段的文件流写入刚开始创建的ts文件中
sys.stdout.write('\r正在下载:{},进度:{:.2%}'.format(self.fileName,progess))#通过百分比显示下载进度
sys.stdout.flush()#通过此方法将上一行代码刷新,控制台只保留一行
except Exception as e:
print("\n出现错误:%s",e.args)
continue#出现错误跳出当前循环,继续下次循环
i+=1
outputfile.close()
print("下载完成!总共耗时%d s"%(time.time()-start_time))
print("开始转换视频格式!")
success = os.system(r'copy /b D:\Download\Film\{0}.ts D:\Download\Film\{0}.mp4'.format(self.fileName)) #ts转成mp4格式
if (not success):
print("格式转换成功!")
os.remove(self.final_path+'\\'+self.fileName+".ts") #删除ts和m3u8临时文件
os.remove("temp.m3u8")
if __name__=='__main__':
m3u8_addr = input("输入m3u8文件下载地址:\n")
crawler=VideoCrawler(m3u8_addr)
crawler.fileName = input("输入文件名:\n")
crawler.run()
quitClick=input("请按Enter键确认退出!")
三、总结
代码可以实现分段加载视频的爬取功能,还有很多细节需要改进,比如:
至此,这篇关于Python爬虫爬取ts片段视频+验证码登录功能的文章文章就介绍到这里了。更多相关Python爬虫爬取视频内容,请搜索脚本之家以前的文章或继续浏览以下相关文章希望大家以后多多支持脚本之家!
网页视频抓取脚本(谷歌浏览器(火狐)网页视频上传教程,直接使用脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-03-04 11:02
网页视频抓取脚本:人人小站上传网页视频教程,像站长一样为自己的视频上传以及采集生成一款属于自己的脚本,在流量来的时候,直接使用脚本就可以获取到想要的流量,不用再费劲去下载app进行导入流量。步骤1:首先准备三个浏览器。1.谷歌浏览器(谷歌浏览器上传视频教程:人人小站上传谷歌浏览器视频教程)2.火狐浏览器(火狐浏览器上传网页视频教程:人人小站上传火狐浏览器视频教程)3.ie浏览器ie浏览器视频上传教程:人人小站视频上传软件下载:人人小站上传视频教程:人人小站视频上传的视频到g+_我的视频脚本里下载:人人小站上传视频教程:人人小站视频上传的视频到filch_it的脚本文件里下载:第二步:准备一张高清的图片。
3张高清图片可以在网页上的图片上添加联系方式,鼠标放上去鼠标右键复制到图片中,下载成功之后,放到网页上,选择放大按钮即可,不会导致图片变形。(ps:vps用户可以使用图片,和数据库结合使用,详细教程请见百度文库)。第三步:在你的谷歌浏览器上下载,或者直接用浏览器,找到这个进入地址:“/videos/”,弹出下载框,下载即可,如果需要安装python,可以在选项选项里面禁用自动播放视频。
google搜索r-b-orb. 查看全部
网页视频抓取脚本(谷歌浏览器(火狐)网页视频上传教程,直接使用脚本)
网页视频抓取脚本:人人小站上传网页视频教程,像站长一样为自己的视频上传以及采集生成一款属于自己的脚本,在流量来的时候,直接使用脚本就可以获取到想要的流量,不用再费劲去下载app进行导入流量。步骤1:首先准备三个浏览器。1.谷歌浏览器(谷歌浏览器上传视频教程:人人小站上传谷歌浏览器视频教程)2.火狐浏览器(火狐浏览器上传网页视频教程:人人小站上传火狐浏览器视频教程)3.ie浏览器ie浏览器视频上传教程:人人小站视频上传软件下载:人人小站上传视频教程:人人小站视频上传的视频到g+_我的视频脚本里下载:人人小站上传视频教程:人人小站视频上传的视频到filch_it的脚本文件里下载:第二步:准备一张高清的图片。
3张高清图片可以在网页上的图片上添加联系方式,鼠标放上去鼠标右键复制到图片中,下载成功之后,放到网页上,选择放大按钮即可,不会导致图片变形。(ps:vps用户可以使用图片,和数据库结合使用,详细教程请见百度文库)。第三步:在你的谷歌浏览器上下载,或者直接用浏览器,找到这个进入地址:“/videos/”,弹出下载框,下载即可,如果需要安装python,可以在选项选项里面禁用自动播放视频。
google搜索r-b-orb.
网页视频抓取脚本(w3school在线教程网站构建初级教程建站手册编程关于W3School帮助HTML文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-02 13:06
w3school 在线教程
网站构建初学者教程
网站建设者编程关于 W3School 帮助W3School
服务器端脚本初学者教程
HTML 文件可以收录文本、HTML 标记和脚本。
HTML 文件中的脚本可以在 Web 服务器上执行。
服务器端脚本
服务器端脚本是对服务器行为的编程。这称为服务器端脚本或服务器端脚本。
客户端脚本是浏览器行为的编程。(看)。
什么是服务器脚本?
通常,当浏览器请求 HTML 文件时,服务器会返回该文件,但如果该文件收录服务器端脚本,则会先执行 HTML 文件中的脚本,然后将 HTML 文件作为纯 HTML 返回给浏览器。
服务器脚本可以做什么?
重要提示:由于脚本是在服务器上执行的,所以浏览器可以在没有脚本支持的情况下显示服务器端文件!
ASP 和 PHP
在 W3School,我们使用 Active Server Pages (ASP) 和超文本预处理器 (PHP) 演示服务器端脚本。
看源代码不能看ASP或PHP的源代码,你看到的只是服务器的输出,纯HTML。这是因为脚本在结果以纯 HTML 形式发送到浏览器之前在服务器上执行。
ASP 实例
通过 ASP 编写文本
如何通过 ASP 编写文本。
将 HTML 添加到文本
如何通过 HTML 标签格式化文本。
脚本教程
请学习我们完整的 ASP 教程和 PHP 教程。
W3School简体中文版提供的内容仅供培训和测试之用,不保证内容的正确性。与使用本网站内容相关的风险与本网站无关。版权所有,保留所有权利。 查看全部
网页视频抓取脚本(w3school在线教程网站构建初级教程建站手册编程关于W3School帮助HTML文件)
w3school 在线教程
网站构建初学者教程
网站建设者编程关于 W3School 帮助W3School
服务器端脚本初学者教程
HTML 文件可以收录文本、HTML 标记和脚本。
HTML 文件中的脚本可以在 Web 服务器上执行。
服务器端脚本
服务器端脚本是对服务器行为的编程。这称为服务器端脚本或服务器端脚本。
客户端脚本是浏览器行为的编程。(看)。
什么是服务器脚本?
通常,当浏览器请求 HTML 文件时,服务器会返回该文件,但如果该文件收录服务器端脚本,则会先执行 HTML 文件中的脚本,然后将 HTML 文件作为纯 HTML 返回给浏览器。
服务器脚本可以做什么?
重要提示:由于脚本是在服务器上执行的,所以浏览器可以在没有脚本支持的情况下显示服务器端文件!
ASP 和 PHP
在 W3School,我们使用 Active Server Pages (ASP) 和超文本预处理器 (PHP) 演示服务器端脚本。
看源代码不能看ASP或PHP的源代码,你看到的只是服务器的输出,纯HTML。这是因为脚本在结果以纯 HTML 形式发送到浏览器之前在服务器上执行。
ASP 实例
通过 ASP 编写文本
如何通过 ASP 编写文本。
将 HTML 添加到文本
如何通过 HTML 标签格式化文本。
脚本教程
请学习我们完整的 ASP 教程和 PHP 教程。
W3School简体中文版提供的内容仅供培训和测试之用,不保证内容的正确性。与使用本网站内容相关的风险与本网站无关。版权所有,保留所有权利。
网页视频抓取脚本(好用到,谁用谁知道一键抓取网页图片脚本工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-27 10:04
)
一键抓取网页图片脚本工具是一款作用于谷歌内核浏览器的软件。可以抓取当前页面的所有图片,甚至包括背景图片等图片,非常方便又省钱。时间。欢迎有需要的朋友下载使用。
软件介绍
一键截取网页上的所有图片,可以根据大小过滤下载,支持运行在chromium(chrome环境下开发)及其衍生浏览器(如:360安全浏览器、360极速浏览器、猎豹)浏览器、百度浏览器、UC浏览器等)。好用,谁知道谁用
crx文件安装教程
1、找到刚才下载的后缀为.crx的插件,修改后缀为压缩格式,如.rar或.zip,如下图:
2、选择【是】完成修改,然后解压刚才的.zip压缩文件,会得到一个文件夹。如下所示:
3、在Chrome浏览器扩展界面中,选择【加载解压扩展】,在弹出的窗口中选择刚刚解压的文件夹。注意这里是根目录,不要选中,如下图:
热键
Alt Shift + Y chrome 全局提取本页图片并修改
Alt + H 过滤页面切换菜单项 否
Alt + S 打开/关闭过滤页面 按大小排序 否
Alt + I 过滤页面打开/关闭下标分辨率信息 否,详见下图
使用说明
软件默认点击预览,不喜欢的可以在设置中自行设置。
查看全部
网页视频抓取脚本(好用到,谁用谁知道一键抓取网页图片脚本工具
)
一键抓取网页图片脚本工具是一款作用于谷歌内核浏览器的软件。可以抓取当前页面的所有图片,甚至包括背景图片等图片,非常方便又省钱。时间。欢迎有需要的朋友下载使用。

软件介绍
一键截取网页上的所有图片,可以根据大小过滤下载,支持运行在chromium(chrome环境下开发)及其衍生浏览器(如:360安全浏览器、360极速浏览器、猎豹)浏览器、百度浏览器、UC浏览器等)。好用,谁知道谁用
crx文件安装教程
1、找到刚才下载的后缀为.crx的插件,修改后缀为压缩格式,如.rar或.zip,如下图:

2、选择【是】完成修改,然后解压刚才的.zip压缩文件,会得到一个文件夹。如下所示:

3、在Chrome浏览器扩展界面中,选择【加载解压扩展】,在弹出的窗口中选择刚刚解压的文件夹。注意这里是根目录,不要选中,如下图:

热键
Alt Shift + Y chrome 全局提取本页图片并修改
Alt + H 过滤页面切换菜单项 否
Alt + S 打开/关闭过滤页面 按大小排序 否
Alt + I 过滤页面打开/关闭下标分辨率信息 否,详见下图

使用说明
软件默认点击预览,不喜欢的可以在设置中自行设置。

网页视频抓取脚本(之前做聊天室时,介绍如何使用HtmlTag抓取网页的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2022-02-27 10:02
之前做聊天室的时候,因为聊天室提供的新闻阅读功能,写了一个类,从网页中抓取信息(如最新的头条新闻、新闻来源、标题、内容等)。本文将介绍如何使用该类从网页中抓取您需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:
源代码下载 查看全部
网页视频抓取脚本(之前做聊天室时,介绍如何使用HtmlTag抓取网页的信息)
之前做聊天室的时候,因为聊天室提供的新闻阅读功能,写了一个类,从网页中抓取信息(如最新的头条新闻、新闻来源、标题、内容等)。本文将介绍如何使用该类从网页中抓取您需要的信息。本文将以博客园首页的博客标题和链接为例:

上图为博客园首页的DOM树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:

源代码下载
网页视频抓取脚本(TampermonkeyTampermonkey官网Tampermonkey安装指导参考二、4、2、5 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 1177 次浏览 • 2022-02-27 08:21
)
一、准备工具
(1)浏览器:360,或者谷歌,火狐
(2)插件工具:Tampermonkey
Tampermonkey官网
Tampermonkey 安装指南参考
二、具体配置过程
本文以360浏览器为例,详细介绍配置过程。
1.通过Tampermonkey面板,跳转到脚本获取页面
安装Tampermonkey插件后,浏览器右上角会出现如下图的标签,左键点击,在出现的弹框中选择“Get New Script”。
2. Tampermonkey推荐js脚本获取与安装
获取方式有-Userscript.Zone Search、GreasyFork、GitHub/Gist、OpenUserJS等。我个人倾向于使用GreasyFork。
3.搜索关键词,安装脚本
在搜索结果中选择一个js脚本(更新日期最新的更好),如“破解VIP分析、VIP会员视频自动分析”等,点击链接进入脚本详情页面,点击“安装此脚本”,然后再次点击“安装”。
4 进入 Tampermonkey 面板,检查脚本是否正常启用
三、验证结果
打开视频网站,点击任意VIP会员视频,还是无法观看。 . .
别着急,请仔细看右边,js脚本生成的视频链接会比较多(如果安装了多个脚本,可能会有多个视频链接)
打开视频的外部链接,即可免费观看VIP视频! ! !
查看全部
网页视频抓取脚本(TampermonkeyTampermonkey官网Tampermonkey安装指导参考二、4、2、5
)
一、准备工具
(1)浏览器:360,或者谷歌,火狐
(2)插件工具:Tampermonkey
Tampermonkey官网
Tampermonkey 安装指南参考

二、具体配置过程
本文以360浏览器为例,详细介绍配置过程。
1.通过Tampermonkey面板,跳转到脚本获取页面
安装Tampermonkey插件后,浏览器右上角会出现如下图的标签,左键点击,在出现的弹框中选择“Get New Script”。

2. Tampermonkey推荐js脚本获取与安装
获取方式有-Userscript.Zone Search、GreasyFork、GitHub/Gist、OpenUserJS等。我个人倾向于使用GreasyFork。


3.搜索关键词,安装脚本
在搜索结果中选择一个js脚本(更新日期最新的更好),如“破解VIP分析、VIP会员视频自动分析”等,点击链接进入脚本详情页面,点击“安装此脚本”,然后再次点击“安装”。

4 进入 Tampermonkey 面板,检查脚本是否正常启用

三、验证结果
打开视频网站,点击任意VIP会员视频,还是无法观看。 . .
别着急,请仔细看右边,js脚本生成的视频链接会比较多(如果安装了多个脚本,可能会有多个视频链接)
打开视频的外部链接,即可免费观看VIP视频! ! !


网页视频抓取脚本(搜索引擎垃圾索引什么是搜索引擎营销营销营销营销)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-26 18:13
搜索引擎索引
搜索引擎索引搜索引擎索引采集、解析和存储数据以促进快速准确的信息检索。索引设计融合了语言学、认知心理学、数学、信息学和计算机科学的跨学科概念。在用于在 Internet 上查找网页的搜索引擎的上下文中,此过程的另一个名称是网络索引。流行的引擎专注于在线自然语言文档的全文索引...
搜索引擎垃圾邮件
什么是搜索引擎垃圾邮件索引?搜索引擎垃圾邮件索引,也称为引擎垃圾邮件,是搜索引擎被不恰当地定向到预定站点的情况,是黑帽SEO的常用方法之一。通过搜索引擎垃圾邮件索引,当用户在互联网上搜索时,他们访问了某些网站和网页,这种机制破坏了搜索结果的正常排名顺序,并显示了不相关的链接,违反了搜索引擎道德。坏的意思。搜索引擎垃圾邮件通常...
搜索引擎
搜索引擎定义搜索引擎是指按照一定的策略采集互联网上的信息并使用特定的计算机程序的系统。对信息进行组织处理后,是一个为用户提供检索服务的系统。搜索引擎由四部分组成:搜索器、索引器、爬虫和用户界面。搜索者的功能是漫游互联网,发现和采集信息。索引器的功能是了解搜索...
搜索引擎市场
搜索引擎营销 搜索引擎营销的基本思想是通过点击进入网站/网页,让用户发现信息,了解更多他需要的信息。在引入搜索引擎策略时,一般认为搜索引擎优化设计的主要目标有两个层次:被搜索引擎搜索收录,在搜索结果中排名靠前。这已经是常识问题,大多数网络营销人员和专业服务提供商都将搜索引擎的目标设定在这个级别。但是从... 查看全部
网页视频抓取脚本(搜索引擎垃圾索引什么是搜索引擎营销营销营销营销)
搜索引擎索引
搜索引擎索引搜索引擎索引采集、解析和存储数据以促进快速准确的信息检索。索引设计融合了语言学、认知心理学、数学、信息学和计算机科学的跨学科概念。在用于在 Internet 上查找网页的搜索引擎的上下文中,此过程的另一个名称是网络索引。流行的引擎专注于在线自然语言文档的全文索引...
搜索引擎垃圾邮件
什么是搜索引擎垃圾邮件索引?搜索引擎垃圾邮件索引,也称为引擎垃圾邮件,是搜索引擎被不恰当地定向到预定站点的情况,是黑帽SEO的常用方法之一。通过搜索引擎垃圾邮件索引,当用户在互联网上搜索时,他们访问了某些网站和网页,这种机制破坏了搜索结果的正常排名顺序,并显示了不相关的链接,违反了搜索引擎道德。坏的意思。搜索引擎垃圾邮件通常...
搜索引擎
搜索引擎定义搜索引擎是指按照一定的策略采集互联网上的信息并使用特定的计算机程序的系统。对信息进行组织处理后,是一个为用户提供检索服务的系统。搜索引擎由四部分组成:搜索器、索引器、爬虫和用户界面。搜索者的功能是漫游互联网,发现和采集信息。索引器的功能是了解搜索...
搜索引擎市场
搜索引擎营销 搜索引擎营销的基本思想是通过点击进入网站/网页,让用户发现信息,了解更多他需要的信息。在引入搜索引擎策略时,一般认为搜索引擎优化设计的主要目标有两个层次:被搜索引擎搜索收录,在搜索结果中排名靠前。这已经是常识问题,大多数网络营销人员和专业服务提供商都将搜索引擎的目标设定在这个级别。但是从...
网页视频抓取脚本( 2018年09月20日08:37:03投稿:laozhang爬取头条)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-23 07:27
2018年09月20日08:37:03投稿:laozhang爬取头条)
节点批量抓取头条视频并保存方法
更新时间:2018-09-20 08:37:03 投稿:老张
在这篇文章中,我们介绍节点抓取头条视频并批量保存的方法。有需要的朋友可以测试以下。
介绍
批量爬取视频或图片的一般套路是使用爬虫获取一组文件链接,然后通过writeFile等方法将文件一个一个保存。但是,头条的视频无法捕捉到需要爬取的html文件(服务器端渲染输出)中的视频链接。视频链接是在客户端渲染页面时,通过一些js文件中的算法或解密方法,根据视频的已知key或hash值,动态计算并添加到video标签中的。这也是网站的防爬措施。
当我们浏览这些页面时,我们可以通过审计元素看到计算出来的文件地址。但是,在批量下载的时候,手动一个一个的获取视频链接显然是不可取的。令人高兴的是,puppeteer 提供了模拟访问 Chrome 的能力,允许我们抓取浏览器呈现的最终页面。
项目开始
命令
npm i
npm start
注意:安装puppeteer的过程有点慢,请耐心等待。
配置文件
// 配置相关
module.exports = {
originPath: 'https://www.ixigua.com', // 页面请求地址
savePath: 'D:/videoZZ' // 存放路径
}
技术点
傀儡师
官方 API
puppeteer 提供了一个高级 API 来控制 Chrome 或 Chromium。
傀儡师的主要作用:
从网页生成 PDF 和图片
抓取 SPA 应用程序并生成预渲染内容(即“SSR”服务器端渲染)
可以从 网站 抓取内容
自动化表单提交、UI 测试、键盘输入等
使用的 API:
puppeteer.launch() 启动浏览器实例
browser.newPage() 创建一个新页面
page.goto() 转到指定网页
page.screenshot() 截图
page.waitFor() 页面等待,可以是时间,一个元素,一个函数
page.$eval() 获取指定元素,相当于 document.querySelector
page.$$eval() 获取某种类型的元素,相当于 document.querySelectorAll
page.$('#id .className') 获取文档中的一个元素,类似于jQuery
代码示例
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
视频文件下载方法
下载视频大师方法
const downloadVideo = async video => {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.src, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
获取视频数据
getVideoData (url, encoding) {
return new Promise((resolve, reject) => {
let req = http.get(url, function (res) {
let result = ''
encoding && res.setEncoding(encoding)
res.on('data', function (d) {
result += d
})
res.on('end', function () {
resolve(result)
})
res.on('error', function (e) {
reject(e)
})
})
req.end()
})
}
将视频数据保存到本地
savefileToPath (fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
目标网站:西瓜视频
项目功能:下载标题下的最新20个视频【微臣财经】
项目地址:Github地址 查看全部
网页视频抓取脚本(
2018年09月20日08:37:03投稿:laozhang爬取头条)
节点批量抓取头条视频并保存方法
更新时间:2018-09-20 08:37:03 投稿:老张
在这篇文章中,我们介绍节点抓取头条视频并批量保存的方法。有需要的朋友可以测试以下。
介绍
批量爬取视频或图片的一般套路是使用爬虫获取一组文件链接,然后通过writeFile等方法将文件一个一个保存。但是,头条的视频无法捕捉到需要爬取的html文件(服务器端渲染输出)中的视频链接。视频链接是在客户端渲染页面时,通过一些js文件中的算法或解密方法,根据视频的已知key或hash值,动态计算并添加到video标签中的。这也是网站的防爬措施。
当我们浏览这些页面时,我们可以通过审计元素看到计算出来的文件地址。但是,在批量下载的时候,手动一个一个的获取视频链接显然是不可取的。令人高兴的是,puppeteer 提供了模拟访问 Chrome 的能力,允许我们抓取浏览器呈现的最终页面。
项目开始
命令
npm i
npm start
注意:安装puppeteer的过程有点慢,请耐心等待。
配置文件
// 配置相关
module.exports = {
originPath: 'https://www.ixigua.com', // 页面请求地址
savePath: 'D:/videoZZ' // 存放路径
}
技术点
傀儡师
官方 API
puppeteer 提供了一个高级 API 来控制 Chrome 或 Chromium。
傀儡师的主要作用:
从网页生成 PDF 和图片
抓取 SPA 应用程序并生成预渲染内容(即“SSR”服务器端渲染)
可以从 网站 抓取内容
自动化表单提交、UI 测试、键盘输入等
使用的 API:
puppeteer.launch() 启动浏览器实例
browser.newPage() 创建一个新页面
page.goto() 转到指定网页
page.screenshot() 截图
page.waitFor() 页面等待,可以是时间,一个元素,一个函数
page.$eval() 获取指定元素,相当于 document.querySelector
page.$$eval() 获取某种类型的元素,相当于 document.querySelectorAll
page.$('#id .className') 获取文档中的一个元素,类似于jQuery
代码示例
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
视频文件下载方法
下载视频大师方法
const downloadVideo = async video => {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.src, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
获取视频数据
getVideoData (url, encoding) {
return new Promise((resolve, reject) => {
let req = http.get(url, function (res) {
let result = ''
encoding && res.setEncoding(encoding)
res.on('data', function (d) {
result += d
})
res.on('end', function () {
resolve(result)
})
res.on('error', function (e) {
reject(e)
})
})
req.end()
})
}
将视频数据保存到本地
savefileToPath (fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
目标网站:西瓜视频
项目功能:下载标题下的最新20个视频【微臣财经】
项目地址:Github地址
网页视频抓取脚本(爬取网站的几种应用框架,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-23 04:23
1、Scrapy
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。使用此框架可以轻松爬取亚马逊列表等数据。
2、PySpider
pyspider 是一个用 python 实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用通用数据库存储爬取结果。可以定期设置任务和任务优先级。
3、克劳利
Crawley可以高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
4、波西亚
Portia 是一个开源的可视化爬虫工具,让你无需任何编程知识即可爬取网站!只需对您感兴趣的页面进行注释,Portia 就会创建一个爬虫来从相似页面中提取数据。
5、报纸
报纸可用于提取新闻、文章 和内容分析。使用多线程,支持10多种语言等。
6美汤
Beautiful Soup 是一个 Python 库,用于从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的营业时间
7、抢
Grab 是一个用于构建网络爬虫的 Python 框架。使用 Grab,您可以构建各种复杂的网络爬虫,从简单的 5 行脚本到处理数百万网页的复杂异步网站爬虫。Grab 提供了一个用于执行网络请求和处理接收到的内容的 API,例如与 HTML 文档的 DOM 树进行交互。#grab-spider-用户手册
8、可乐
Cola 是一个分布式爬虫框架。对于用户来说,只需要编写几个具体的功能,无需关注分布式操作的细节。任务自动分发到多台机器上,整个过程对用户透明。 查看全部
网页视频抓取脚本(爬取网站的几种应用框架,你了解多少?)
1、Scrapy
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。使用此框架可以轻松爬取亚马逊列表等数据。
2、PySpider
pyspider 是一个用 python 实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用通用数据库存储爬取结果。可以定期设置任务和任务优先级。
3、克劳利
Crawley可以高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
4、波西亚
Portia 是一个开源的可视化爬虫工具,让你无需任何编程知识即可爬取网站!只需对您感兴趣的页面进行注释,Portia 就会创建一个爬虫来从相似页面中提取数据。
5、报纸
报纸可用于提取新闻、文章 和内容分析。使用多线程,支持10多种语言等。
6美汤
Beautiful Soup 是一个 Python 库,用于从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的营业时间
7、抢
Grab 是一个用于构建网络爬虫的 Python 框架。使用 Grab,您可以构建各种复杂的网络爬虫,从简单的 5 行脚本到处理数百万网页的复杂异步网站爬虫。Grab 提供了一个用于执行网络请求和处理接收到的内容的 API,例如与 HTML 文档的 DOM 树进行交互。#grab-spider-用户手册
8、可乐
Cola 是一个分布式爬虫框架。对于用户来说,只需要编写几个具体的功能,无需关注分布式操作的细节。任务自动分发到多台机器上,整个过程对用户透明。
网页视频抓取脚本(利用百度AI开发平台的OCR文字识别API也可以识别 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-22 13:22
)
一、Selenium 网页截图,图片定位二次精准截图
第三方模块“selenium”用于 Python 自动化与 Web 浏览器交互。
1.安装模块 pip install selenium
2.安装对应版本浏览器的驱动
谷歌查看浏览器版本访问“chrome://version/”
google驱动下载地址
注意下载解压后的驱动放在系统环境变量PATH的路径下
3. 代码如下:
# -*- coding:utf-8 -*-
from selenium import webdriver
import easyocr
import time
from PIL import Image
def screenshots(): # 访问网页截屏
driver = webdriver.Chrome() # 初始化一个谷歌浏览器实例
driver.maximize_window() # 打开最大窗口
driver.get("http://quote.eastmoney.com/sh600797.html") # 访问网页
js = "var q=document.documentElement.scrollTop=500" # 下拉500个像素
driver.execute_script(js) # 执行下拉500个像素操作
time.sleep(3)
driver.get_screenshot_as_file(
r"C:\Zzlong\%s.png" % time.strftime('%Y-%m-%d %H-%M', time.localtime(time.time()))
) # 截图保存为C:\Zzlong\2022-02-20 17-30.png
driver.quit() #关闭浏览器
# imgelement = driver.find_element_by_id('rgt1')
# imgelement = driver.find_element_by_class_name('line24')
# location = imgelement.location
# print(location) # {'x': 1104, 'y': 917}
# size = imgelement.size
# print(size) # {'height': 12, 'width': 26}
def crop(): # 定位 二次截图
picture = Image.open(
r"C:\Zzlong\%s.png" % time.strftime('%Y-%m-%d %H-%M', time.localtime(time.time()))
) # 打开第一次的截图
picture = picture.crop((1320,520,1450,550)) # 定位二次截图
# 注意: crop截图规则,(宽 - x坐标)为截图的宽位置 (高 - y坐标)为截图的高位置,坐标(0,0)位于左上角
picture.save(
r"C:\Zzlong\img%s.png" % time.strftime('%Y-%m-%d %H-%M', time.localtime(time.time()))
) # 保存图片
# print(picture.size) # 输出宽、高 (1920, 888)
# picture = picture.crop((0, 0, 1920, 888)) # 截取全图(x坐标,y坐标,宽,高)
二、easyocr 提取图片文本
Python-EasyOCR 中有一个很好的 OCR 库,在 GitHub 上有 9700stars。它可以在python中调用以识别图像中的文本并输出为文本。
安装过程比较简单,使用pip或者conda安装。
pip install easyocr
如果您使用 PyPl 源代码,安装可能需要一些时间。建议您使用清华源安装,几秒钟即可安装。
指示
EasyOCR的使用非常简单,分为三个步骤:
# 导入easyocr
import easyocr
# 创建reader对象
reader = easyocr.Reader(['ch_sim','en'])
# 读取图像
result = reader.readtext('test.jpg')
# 结果
print(result)
# 使用easyocr报错“Unknown C++ exception from OpenCV code,CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU. ”
# Python与CUDA版本不对应,导致Python安装的OpenCV版本与CUDA版本不照应
# pip install opencv-python==4.3.0.38 -i https://pypi.tuna.tsinghua.edu.cn/simple
这段代码有个参数['ch_sim','en'],就是要识别的语言列表(所有语言列表都放在文章的底部),因为里面有中文和英文路牌,所以将列表添加到列表 ch_sim(简体中文),en(英文)。
识别文本的准确率还是很高的,然后提取文本部分。
for i in result:
word = i[1]
print(word)
三、使用百度AI开发平台的OCR文字识别API也可以识别提取图片中的文字。
首先我们需要一个百度账号,然后打开百度AI开放平台()并登录,点击“控制台”,在左侧栏输入“文本识别”,创建一个应用,记住你的AppID、API Key和Secret Key .
然后,我们在cmd窗口中安装百度ai界面的库。
pip install baidu—aip
好了,基本的工作已经到这里了。接下来是文本识别和提取的核心部分:
def baiduOCR(picfile, outfile): #想要利用百度api识别文本,我们需要设置: #1、图片文件名为:picfile #2、输出文件为:outfile filename = path.basename(picfile) #接下来,我们需要将刚刚获取的ID、KEY和SECRECT KEY填入 APP_ID = '****' # 刚才获取的 ID,下同 API_KEY = '****' SECRECT_KEY = '****' client = AipOcr(APP_ID, API_KEY, SECRECT_KEY) #接下来,打开并识别图片信息 i = open(picfile, 'rb') img = i.read() print("正在识别图片:\t" + filename) #在这里,我们有两种识别方法:通用识别、高精度识别message = client.basicGeneral(img)#通用文字识别,每天50000次免费#message =client.basicAccurate(img)#通用文字高精度识别,每天800次免费 print("识别成功!") i.close();
以上就是使用百度api文本识别提取的识别部分。接下来,您只需要提取提取的文本。
要提取识别的文本,我们需要做以下设置:
with open(outfile, 'a+') as fo: fo.writelines("+" * 60 + '\n') fo.writelines("识别图片:\t" + filename + "\n" * 2) fo.writelines("文本内容:\n") # 输出文本内容 for text in message.get('words_result'): fo.writelines(text.get('words') + '\n') fo.writelines('\n'*2) print("文本导出成功!") print()
现在我们导入一张手机拍的照片:
识别结果:
从结果可以看出,精读的识别度非常高,效果非常好。
详细步骤请参考代码和注释:
import glob
from os import path
import os
from aip import AipOcr
from PIL import Image
def convertimg(picfile, outdir):
'''调整图片大小,对于过大的图片进行压缩
picfile: 图片路径
outdir:图片输出路径
'''
img = Image.open(picfile)
width, height = img.size
while(width*height > 4000000): # 该数值压缩后的图片大约两百多k
width = width // 2
height = height // 2
new_img=img.resize((width, height),Image.BILINEAR)
new_img.save(path.join(outdir,os.path.basename(picfile)))
def baiduOCR(picfile, outfile):
#想要利用百度api识别文本,我们需要设置:
#1、图片文件名为:picfile
#2、输出文件为:outfile
filename = path.basename(picfile)
#接下来,我们需要将刚刚获取的ID、KEY和SECRECT KEY填入
APP_ID = '****' # 刚才获取的 ID,下同
API_KEY = '****'
SECRECT_KEY = '****'
client = AipOcr(APP_ID, API_KEY, SECRECT_KEY)
#接下来,打开并识别图片信息
i = open(picfile, 'rb')
img = i.read()
print("正在识别图片:\t" + filename)
#在这里,我们有两种识别方法:通用识别、高精度识别
message = client.basicGeneral(img) # 通用文字识别,每天 50 000 次免费
#message = client.basicAccurate(img) # 通用文字高精度识别,每天 800 次免费
print("识别成功!")
i.close();
#以上即为识别过程
#想要将识别的文字提取出来,我们需要做以下设置:
with open(outfile, 'a+') as fo:
fo.writelines("+" * 60 + '\n')
fo.writelines("识别图片:\t" + filename + "\n" * 2)
fo.writelines("文本内容:\n")
# 输出文本内容
for text in message.get('words_result'):
fo.writelines(text.get('words') + '\n')
fo.writelines('\n'*2)
print("文本导出成功!")
print()
if __name__ == "__main__":
outfile = 'export.txt'
outdir = 'tmp'
if path.exists(outfile):
os.remove(outfile)
if not path.exists(outdir):
os.mkdir(outdir)
print("压缩过大的图片...")
#首先对过大的图片进行压缩,以提高识别速度,将压缩的图片保存与临时文件夹中
for picfile in glob.glob("picture/*"):
convertimg(picfile, outdir)
print("图片识别...")
for picfile in glob.glob("tmp/*"):
baiduOCR(picfile, outfile)
os.remove(picfile)
print('图片文本提取结束!文本输出结果位于 %s 文件中。' % outfile)
os.removedirs(outdir)
查看全部
网页视频抓取脚本(利用百度AI开发平台的OCR文字识别API也可以识别
)
一、Selenium 网页截图,图片定位二次精准截图
第三方模块“selenium”用于 Python 自动化与 Web 浏览器交互。
1.安装模块 pip install selenium
2.安装对应版本浏览器的驱动
谷歌查看浏览器版本访问“chrome://version/”
google驱动下载地址
注意下载解压后的驱动放在系统环境变量PATH的路径下
3. 代码如下:
# -*- coding:utf-8 -*-
from selenium import webdriver
import easyocr
import time
from PIL import Image
def screenshots(): # 访问网页截屏
driver = webdriver.Chrome() # 初始化一个谷歌浏览器实例
driver.maximize_window() # 打开最大窗口
driver.get("http://quote.eastmoney.com/sh600797.html";) # 访问网页
js = "var q=document.documentElement.scrollTop=500" # 下拉500个像素
driver.execute_script(js) # 执行下拉500个像素操作
time.sleep(3)
driver.get_screenshot_as_file(
r"C:\Zzlong\%s.png" % time.strftime('%Y-%m-%d %H-%M', time.localtime(time.time()))
) # 截图保存为C:\Zzlong\2022-02-20 17-30.png
driver.quit() #关闭浏览器
# imgelement = driver.find_element_by_id('rgt1')
# imgelement = driver.find_element_by_class_name('line24')
# location = imgelement.location
# print(location) # {'x': 1104, 'y': 917}
# size = imgelement.size
# print(size) # {'height': 12, 'width': 26}
def crop(): # 定位 二次截图
picture = Image.open(
r"C:\Zzlong\%s.png" % time.strftime('%Y-%m-%d %H-%M', time.localtime(time.time()))
) # 打开第一次的截图
picture = picture.crop((1320,520,1450,550)) # 定位二次截图
# 注意: crop截图规则,(宽 - x坐标)为截图的宽位置 (高 - y坐标)为截图的高位置,坐标(0,0)位于左上角
picture.save(
r"C:\Zzlong\img%s.png" % time.strftime('%Y-%m-%d %H-%M', time.localtime(time.time()))
) # 保存图片
# print(picture.size) # 输出宽、高 (1920, 888)
# picture = picture.crop((0, 0, 1920, 888)) # 截取全图(x坐标,y坐标,宽,高)
二、easyocr 提取图片文本
Python-EasyOCR 中有一个很好的 OCR 库,在 GitHub 上有 9700stars。它可以在python中调用以识别图像中的文本并输出为文本。
安装过程比较简单,使用pip或者conda安装。
pip install easyocr
如果您使用 PyPl 源代码,安装可能需要一些时间。建议您使用清华源安装,几秒钟即可安装。
指示
EasyOCR的使用非常简单,分为三个步骤:
# 导入easyocr
import easyocr
# 创建reader对象
reader = easyocr.Reader(['ch_sim','en'])
# 读取图像
result = reader.readtext('test.jpg')
# 结果
print(result)
# 使用easyocr报错“Unknown C++ exception from OpenCV code,CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU. ”
# Python与CUDA版本不对应,导致Python安装的OpenCV版本与CUDA版本不照应
# pip install opencv-python==4.3.0.38 -i https://pypi.tuna.tsinghua.edu.cn/simple
这段代码有个参数['ch_sim','en'],就是要识别的语言列表(所有语言列表都放在文章的底部),因为里面有中文和英文路牌,所以将列表添加到列表 ch_sim(简体中文),en(英文)。
识别文本的准确率还是很高的,然后提取文本部分。
for i in result:
word = i[1]
print(word)
三、使用百度AI开发平台的OCR文字识别API也可以识别提取图片中的文字。
首先我们需要一个百度账号,然后打开百度AI开放平台()并登录,点击“控制台”,在左侧栏输入“文本识别”,创建一个应用,记住你的AppID、API Key和Secret Key .
然后,我们在cmd窗口中安装百度ai界面的库。
pip install baidu—aip
好了,基本的工作已经到这里了。接下来是文本识别和提取的核心部分:
def baiduOCR(picfile, outfile): #想要利用百度api识别文本,我们需要设置: #1、图片文件名为:picfile #2、输出文件为:outfile filename = path.basename(picfile) #接下来,我们需要将刚刚获取的ID、KEY和SECRECT KEY填入 APP_ID = '****' # 刚才获取的 ID,下同 API_KEY = '****' SECRECT_KEY = '****' client = AipOcr(APP_ID, API_KEY, SECRECT_KEY) #接下来,打开并识别图片信息 i = open(picfile, 'rb') img = i.read() print("正在识别图片:\t" + filename) #在这里,我们有两种识别方法:通用识别、高精度识别message = client.basicGeneral(img)#通用文字识别,每天50000次免费#message =client.basicAccurate(img)#通用文字高精度识别,每天800次免费 print("识别成功!") i.close();
以上就是使用百度api文本识别提取的识别部分。接下来,您只需要提取提取的文本。
要提取识别的文本,我们需要做以下设置:
with open(outfile, 'a+') as fo: fo.writelines("+" * 60 + '\n') fo.writelines("识别图片:\t" + filename + "\n" * 2) fo.writelines("文本内容:\n") # 输出文本内容 for text in message.get('words_result'): fo.writelines(text.get('words') + '\n') fo.writelines('\n'*2) print("文本导出成功!") print()
现在我们导入一张手机拍的照片:

识别结果:
从结果可以看出,精读的识别度非常高,效果非常好。
详细步骤请参考代码和注释:
import glob
from os import path
import os
from aip import AipOcr
from PIL import Image
def convertimg(picfile, outdir):
'''调整图片大小,对于过大的图片进行压缩
picfile: 图片路径
outdir:图片输出路径
'''
img = Image.open(picfile)
width, height = img.size
while(width*height > 4000000): # 该数值压缩后的图片大约两百多k
width = width // 2
height = height // 2
new_img=img.resize((width, height),Image.BILINEAR)
new_img.save(path.join(outdir,os.path.basename(picfile)))
def baiduOCR(picfile, outfile):
#想要利用百度api识别文本,我们需要设置:
#1、图片文件名为:picfile
#2、输出文件为:outfile
filename = path.basename(picfile)
#接下来,我们需要将刚刚获取的ID、KEY和SECRECT KEY填入
APP_ID = '****' # 刚才获取的 ID,下同
API_KEY = '****'
SECRECT_KEY = '****'
client = AipOcr(APP_ID, API_KEY, SECRECT_KEY)
#接下来,打开并识别图片信息
i = open(picfile, 'rb')
img = i.read()
print("正在识别图片:\t" + filename)
#在这里,我们有两种识别方法:通用识别、高精度识别
message = client.basicGeneral(img) # 通用文字识别,每天 50 000 次免费
#message = client.basicAccurate(img) # 通用文字高精度识别,每天 800 次免费
print("识别成功!")
i.close();
#以上即为识别过程
#想要将识别的文字提取出来,我们需要做以下设置:
with open(outfile, 'a+') as fo:
fo.writelines("+" * 60 + '\n')
fo.writelines("识别图片:\t" + filename + "\n" * 2)
fo.writelines("文本内容:\n")
# 输出文本内容
for text in message.get('words_result'):
fo.writelines(text.get('words') + '\n')
fo.writelines('\n'*2)
print("文本导出成功!")
print()
if __name__ == "__main__":
outfile = 'export.txt'
outdir = 'tmp'
if path.exists(outfile):
os.remove(outfile)
if not path.exists(outdir):
os.mkdir(outdir)
print("压缩过大的图片...")
#首先对过大的图片进行压缩,以提高识别速度,将压缩的图片保存与临时文件夹中
for picfile in glob.glob("picture/*"):
convertimg(picfile, outdir)
print("图片识别...")
for picfile in glob.glob("tmp/*"):
baiduOCR(picfile, outfile)
os.remove(picfile)
print('图片文本提取结束!文本输出结果位于 %s 文件中。' % outfile)
os.removedirs(outdir)

网页视频抓取脚本( 阿里云盘下载不限速怎么办?Python模板文件小编.html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2022-02-22 13:19
阿里云盘下载不限速怎么办?Python模板文件小编.html)
使用Python抓取阿里云盘资源
更新时间:2022-02-22 09:50:12 作者:百胜酱
与百度云盘相比,阿里云盘拥有无限下载速度和大容量空间,深受大家的喜爱。本文将使用 Python 抓取阿里云盘的资源。有兴趣的可以学习一下
内容
前段时间,阿里云盘风靡一时,大量存储空间被送出。而且阿里云盘下载是无限的,比百度网盘好很多。这两天看到一个第三方网站可以在阿里云盘上搜索资源,但是它的资源没有按时间排序。这种情况会导致已经在队列中很长时间的资源成为过时的资源。小编这里使用python进行爬取和重排。
网页分析
这个 网站 有两条搜索线:搜索线一和搜索线二。这个 文章 使用第二行搜索。
打开控制面板下的网络,一眼就能看到一个sea.html的get请求。
有几个参数,四个关键参数:
同样在控制面板中,可以看到网页跳转到阿里云盘获取标题上方的真实链接。使用bs4解析页面上div(class=resource-itemborder-dashed-eee)标签下的a标签得到跳转网盘的地址,解析div下的p标签得到资源日期。
抓取和解析
首先安装解析页面需要的bs4第三方库。
pip3?install?bs4
下面是抓取并解析网页的脚本代码,最后按日期降序排序。
<p>import?requests
from?bs4?import?BeautifulSoup
import?string
word?=?input('请输入要搜索的资源名称:')
????
headers?=?{
????'User-Agent':?'Mozilla/5.0?(Windows?NT?10.0;?Win64;?x64)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/96.0.4664.45?Safari/537.36'
}
result_list?=?[]
for?i?in?range(1,?11):
????print('正在搜索第?{}?页'.format(i))
????params?=?{
????????'page':?i,
????????'keyword':?word,
????????'search_folder_or_file':?0,
????????'is_search_folder_content':?0,
????????'is_search_path_title':?0,
????????'category':?'all',
????????'file_extension':?'all',
????????'search_model':?0
????}
????response_html?=?requests.get('https://www.alipanso.com/search.html',?headers?=?headers,params=params)
????response_data?=?response_html.content.decode()
???
????soup?=?BeautifulSoup(response_data,?"html.parser");
????divs?=?soup.find_all('div',?class_='resource-item?border-dashed-eee')
????
????if?len(divs)? 查看全部
网页视频抓取脚本(
阿里云盘下载不限速怎么办?Python模板文件小编.html)
使用Python抓取阿里云盘资源
更新时间:2022-02-22 09:50:12 作者:百胜酱
与百度云盘相比,阿里云盘拥有无限下载速度和大容量空间,深受大家的喜爱。本文将使用 Python 抓取阿里云盘的资源。有兴趣的可以学习一下
内容
前段时间,阿里云盘风靡一时,大量存储空间被送出。而且阿里云盘下载是无限的,比百度网盘好很多。这两天看到一个第三方网站可以在阿里云盘上搜索资源,但是它的资源没有按时间排序。这种情况会导致已经在队列中很长时间的资源成为过时的资源。小编这里使用python进行爬取和重排。

网页分析
这个 网站 有两条搜索线:搜索线一和搜索线二。这个 文章 使用第二行搜索。

打开控制面板下的网络,一眼就能看到一个sea.html的get请求。

有几个参数,四个关键参数:
同样在控制面板中,可以看到网页跳转到阿里云盘获取标题上方的真实链接。使用bs4解析页面上div(class=resource-itemborder-dashed-eee)标签下的a标签得到跳转网盘的地址,解析div下的p标签得到资源日期。

抓取和解析
首先安装解析页面需要的bs4第三方库。
pip3?install?bs4
下面是抓取并解析网页的脚本代码,最后按日期降序排序。
<p>import?requests
from?bs4?import?BeautifulSoup
import?string
word?=?input('请输入要搜索的资源名称:')
????
headers?=?{
????'User-Agent':?'Mozilla/5.0?(Windows?NT?10.0;?Win64;?x64)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/96.0.4664.45?Safari/537.36'
}
result_list?=?[]
for?i?in?range(1,?11):
????print('正在搜索第?{}?页'.format(i))
????params?=?{
????????'page':?i,
????????'keyword':?word,
????????'search_folder_or_file':?0,
????????'is_search_folder_content':?0,
????????'is_search_path_title':?0,
????????'category':?'all',
????????'file_extension':?'all',
????????'search_model':?0
????}
????response_html?=?requests.get('https://www.alipanso.com/search.html',?headers?=?headers,params=params)
????response_data?=?response_html.content.decode()
???
????soup?=?BeautifulSoup(response_data,?"html.parser");
????divs?=?soup.find_all('div',?class_='resource-item?border-dashed-eee')
????
????if?len(divs)?
网页视频抓取脚本( 如何从网站免费获取所有链接并存储$(document))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-22 06:28
如何从网站免费获取所有链接并存储$(document))
从 网站 Chrome 扩展中提取所有链接
Link Grabber - Google Chrome,Link Klipper 是一个简单但非常强大的 chrome 扩展程序,可帮助您提取网页上的所有链接并将它们导出到文件中。不再需要从网页复制每个链接并存储 jQuery $(document).ready(function(){ $('a').each(function(){ console.log($(this).attr('href' ) ); }); });. 注意:在chrome中打开网站>>右键 >>检查>>去。Link Klipper - 提取所有链接 - Google Chrome,在单个页面上工作,但很容易被现代(不是纯 html 代码)跳过图像混淆。如果它可以拉出所有图像链接,肯定会给它 5 星,对于特定的 url 及其子页面甚至更好。如果要手动导出 Chrome 扩展程序,必须在浏览器中启用“开发者模式”,并将扩展程序打包成 CRX 文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该: .
Link Klipper - 提取所有链接 - Google Chrome, jQuery $(document).ready(function(){ $('a').each(function(){ console.log($(this).attr('href' ) ); }); });. 注意:在 chrome 中打开 网站 >> 右键单击 >> 检查 >> go 在单个页面上工作,但很容易现代化(不是纯 html 代码) 跳过图像混淆。如果它可以拉出所有图像链接并且更好地为特定的 url 及其子页面做这件事,肯定会给它 5 星。.Semalt:如何从网站免费获取所有链接,如果要手动导出Chrome扩展,必须在浏览器中启用“开发者模式”,并将扩展打包成CRX文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该:OutWit Hub 是一个强大的网页信息提取器,还可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。这。
Semalt:如何从 网站 免费获取所有链接,在单个页面上工作,但很容易被现代(非纯 html 代码)跳过图像混淆。如果它可以拉出所有图片链接,肯定会给它 5 颗星,并且更好地为特定的 url 及其子页面执行此操作。如果要手动导出 Chrome 扩展程序,必须在浏览器中启用“开发者模式”,并将扩展程序打包成 CRX 文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该: . 如何从网页中提取超链接地址,OutWit Hub 是一个强大的网页信息提取器,也可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。安装后,该扩展程序会自动将快捷方式图标添加到浏览器的多功能栏。现在,继续打开您喜欢的任何 网站 或页面(例如)。要从此页面中提取所有链接,只需单击浏览器多功能栏上的 Link Klipper 图标。接下来,单击“提取所有链接”按钮。.
如何从网页中提取超链接地址,如果要手动导出Chrome扩展程序,必须在浏览器中启用“开发者模式”并将扩展程序打包成CRX文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该: OutWit Hub 是一个功能强大的网页信息提取器,还可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。这。如何从html网站中提取href链接安装后,扩展程序会自动在浏览器的多功能栏中添加一个快捷方式图标。现在,继续打开您喜欢的任何 网站 或页面(例如)。要从此页面中提取所有链接,只需单击浏览器上的 Link Klipper 图标 s多功能酒吧。接下来,单击“提取所有链接”按钮。1. 安装 Link Klipper 浏览器扩展。2. 打开要从中提取链接的网页。3. CTRL 键(Mac 上的⌘)。
如何从html网站中提取href链接,OutWit Hub是一个强大的网页信息提取器,也可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。安装后,该扩展程序会自动将快捷方式图标添加到浏览器的多功能栏。现在,继续打开您喜欢的任何 网站 或页面(例如)。要从此页面中提取所有链接,只需单击浏览器多功能栏上的 Link Klipper 图标。接下来,单击“提取所有链接”按钮。. 链接地鼠,
从 网站Python 中提取所有链接
<p>如何使用Python构建一个URL爬虫来映射网站,提取一个网页的所有链接是网络爬虫中的常见任务,构建一个爬取某个 查看全部
网页视频抓取脚本(
如何从网站免费获取所有链接并存储$(document))
从 网站 Chrome 扩展中提取所有链接
Link Grabber - Google Chrome,Link Klipper 是一个简单但非常强大的 chrome 扩展程序,可帮助您提取网页上的所有链接并将它们导出到文件中。不再需要从网页复制每个链接并存储 jQuery $(document).ready(function(){ $('a').each(function(){ console.log($(this).attr('href' ) ); }); });. 注意:在chrome中打开网站>>右键 >>检查>>去。Link Klipper - 提取所有链接 - Google Chrome,在单个页面上工作,但很容易被现代(不是纯 html 代码)跳过图像混淆。如果它可以拉出所有图像链接,肯定会给它 5 星,对于特定的 url 及其子页面甚至更好。如果要手动导出 Chrome 扩展程序,必须在浏览器中启用“开发者模式”,并将扩展程序打包成 CRX 文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该: .
Link Klipper - 提取所有链接 - Google Chrome, jQuery $(document).ready(function(){ $('a').each(function(){ console.log($(this).attr('href' ) ); }); });. 注意:在 chrome 中打开 网站 >> 右键单击 >> 检查 >> go 在单个页面上工作,但很容易现代化(不是纯 html 代码) 跳过图像混淆。如果它可以拉出所有图像链接并且更好地为特定的 url 及其子页面做这件事,肯定会给它 5 星。.Semalt:如何从网站免费获取所有链接,如果要手动导出Chrome扩展,必须在浏览器中启用“开发者模式”,并将扩展打包成CRX文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该:OutWit Hub 是一个强大的网页信息提取器,还可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。这。
Semalt:如何从 网站 免费获取所有链接,在单个页面上工作,但很容易被现代(非纯 html 代码)跳过图像混淆。如果它可以拉出所有图片链接,肯定会给它 5 颗星,并且更好地为特定的 url 及其子页面执行此操作。如果要手动导出 Chrome 扩展程序,必须在浏览器中启用“开发者模式”,并将扩展程序打包成 CRX 文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该: . 如何从网页中提取超链接地址,OutWit Hub 是一个强大的网页信息提取器,也可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。安装后,该扩展程序会自动将快捷方式图标添加到浏览器的多功能栏。现在,继续打开您喜欢的任何 网站 或页面(例如)。要从此页面中提取所有链接,只需单击浏览器多功能栏上的 Link Klipper 图标。接下来,单击“提取所有链接”按钮。.
如何从网页中提取超链接地址,如果要手动导出Chrome扩展程序,必须在浏览器中启用“开发者模式”并将扩展程序打包成CRX文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该: OutWit Hub 是一个功能强大的网页信息提取器,还可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。这。如何从html网站中提取href链接安装后,扩展程序会自动在浏览器的多功能栏中添加一个快捷方式图标。现在,继续打开您喜欢的任何 网站 或页面(例如)。要从此页面中提取所有链接,只需单击浏览器上的 Link Klipper 图标 s多功能酒吧。接下来,单击“提取所有链接”按钮。1. 安装 Link Klipper 浏览器扩展。2. 打开要从中提取链接的网页。3. CTRL 键(Mac 上的⌘)。
如何从html网站中提取href链接,OutWit Hub是一个强大的网页信息提取器,也可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。安装后,该扩展程序会自动将快捷方式图标添加到浏览器的多功能栏。现在,继续打开您喜欢的任何 网站 或页面(例如)。要从此页面中提取所有链接,只需单击浏览器多功能栏上的 Link Klipper 图标。接下来,单击“提取所有链接”按钮。. 链接地鼠,
从 网站Python 中提取所有链接
<p>如何使用Python构建一个URL爬虫来映射网站,提取一个网页的所有链接是网络爬虫中的常见任务,构建一个爬取某个
网页视频抓取脚本( ,本文通过实例代码介绍的非常详细的学习或工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-03-13 03:02
,本文通过实例代码介绍的非常详细的学习或工作)
Python爬取梨视频生活版块最热视频
更新时间:2021-03-15 10:34:05 作者:General_zy
本篇文章主要介绍python爬梨视频生活版块最火的视频。本文通过示例代码向您介绍最详细的内容,对您的学习或工作具有一定的参考价值。需要的朋友可以参考下
完整代码如下:
import requests
from lxml import etree
import random
import os
from multiprocessing.dummy import Pool
if not os.path.exists('./视频'):
os.mkdir('./视频')
urls=[]
url='https://www.pearvideo.com/category_5'
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36 Edg/89.0.774.45'}
page_text=requests.get(url=url,headers=headers).text
tree=etree.HTML(page_text)
li_list=tree.xpath('//ul[@id="listvideoListUl"]/li')
for li in li_list:
a_url='https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0]
name=li.xpath('./div/a/div[2]/text()')[0]+'.mp4'
mrd=random.random()
code=li.xpath('./div/a/@href')[0][-7:]
new_headers={'Referer': a_url,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50'
}
new_url='https://www.pearvideo.com/videoStatus.jsp?contId='+str(code)+'&mrd='+str(mrd)
r=requests.get(url=new_url,headers=new_headers)
video_url=eval(r.text)['videoInfo']['videos']['srcUrl']
old=video_url.split('/')[-1].split('-')[0]
new=''+str(code)
true_video_url=video_url.replace(old,new)
dic={'name':name,
'my_url':true_video_url}
urls.append(dic)
#使用线程池对数据视频进行请求
def get_video_data(dic):
print(dic['name']+'开始下载'+'\n')
data_url=dic['my_url']
data=requests.get(url=data_url,headers=headers).content
with open('./视频/'+dic['name'],'wb') as f:
f.write(data)
print(dic['name']+'下载成功')
pool=Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()
阐明:
当前日期(2021/3/14)版本的梨视频的视频伪url通过ajax获取。
部分代码说明:
1:模块
import requests #网路爬虫标准库(代替urllib)
from lxml import etree #用于解析页面信息
import random #梨视频的url中有一段需要随机数
import os #主要用于生成文件夹存放视频
from multiprocessing.dummy import Pool #导入线程池对应类
2:获取视频伪url
#参数准备
mrd=random.random()
code=li.xpath('./div/a/@href')[0][-7:]
new_headers={
'Referer': a_url,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50'
}
#获取url
new_url='https://www.pearvideo.com/videoStatus.jsp?contId='+str(code)+'&mrd='+str(mrd)
r=requests.get(url=new_url,headers=new_headers)
video_url=eval(r.text)['videoInfo']['videos']['srcUrl']
3:获取真实网址
经过我的实验,使用上面获取的url抓取视频的视频下载内容是空的。
因为我也是菜鸟,所以想不通。偶然看到B站用户“_Qianhu”的留言,才知道真假url的区别:
这里视频地址是加密的,也就是ajax中获取的地址需要加上cont-,修改一个数字为id就是真实地址。
真实地址:“”
伪地址:“”
#仅需要做几个简单的截取切片操作就可以替换相关内容
old=video_url.split('/')[-1].split('-')[0]
new=''+str(code)
true_video_url=video_url.replace(old,new)
4:存储
#使用线程池对数据视频进行请求
def get_video_data(dic):
print(dic['name']+'开始下载'+'\n')
data_url=dic['my_url']
data=requests.get(url=data_url,headers=headers).content
with open('./视频/'+dic['name'],'wb') as f:
f.write(data)
print(dic['name']+'下载成功')
pool=Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()
5:结果
至此,这篇关于python爬梨视频生活版块最热视频的文章就介绍到这里了。更多相关python爬梨视频内容,请搜索脚本之家以前的文章或继续浏览下方相关文章,希望您以后多多支持脚本之家! 查看全部
网页视频抓取脚本(
,本文通过实例代码介绍的非常详细的学习或工作)
Python爬取梨视频生活版块最热视频
更新时间:2021-03-15 10:34:05 作者:General_zy
本篇文章主要介绍python爬梨视频生活版块最火的视频。本文通过示例代码向您介绍最详细的内容,对您的学习或工作具有一定的参考价值。需要的朋友可以参考下
完整代码如下:
import requests
from lxml import etree
import random
import os
from multiprocessing.dummy import Pool
if not os.path.exists('./视频'):
os.mkdir('./视频')
urls=[]
url='https://www.pearvideo.com/category_5'
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36 Edg/89.0.774.45'}
page_text=requests.get(url=url,headers=headers).text
tree=etree.HTML(page_text)
li_list=tree.xpath('//ul[@id="listvideoListUl"]/li')
for li in li_list:
a_url='https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0]
name=li.xpath('./div/a/div[2]/text()')[0]+'.mp4'
mrd=random.random()
code=li.xpath('./div/a/@href')[0][-7:]
new_headers={'Referer': a_url,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50'
}
new_url='https://www.pearvideo.com/videoStatus.jsp?contId='+str(code)+'&mrd='+str(mrd)
r=requests.get(url=new_url,headers=new_headers)
video_url=eval(r.text)['videoInfo']['videos']['srcUrl']
old=video_url.split('/')[-1].split('-')[0]
new=''+str(code)
true_video_url=video_url.replace(old,new)
dic={'name':name,
'my_url':true_video_url}
urls.append(dic)
#使用线程池对数据视频进行请求
def get_video_data(dic):
print(dic['name']+'开始下载'+'\n')
data_url=dic['my_url']
data=requests.get(url=data_url,headers=headers).content
with open('./视频/'+dic['name'],'wb') as f:
f.write(data)
print(dic['name']+'下载成功')
pool=Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()
阐明:
当前日期(2021/3/14)版本的梨视频的视频伪url通过ajax获取。
部分代码说明:
1:模块
import requests #网路爬虫标准库(代替urllib)
from lxml import etree #用于解析页面信息
import random #梨视频的url中有一段需要随机数
import os #主要用于生成文件夹存放视频
from multiprocessing.dummy import Pool #导入线程池对应类
2:获取视频伪url
#参数准备
mrd=random.random()
code=li.xpath('./div/a/@href')[0][-7:]
new_headers={
'Referer': a_url,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50'
}
#获取url
new_url='https://www.pearvideo.com/videoStatus.jsp?contId='+str(code)+'&mrd='+str(mrd)
r=requests.get(url=new_url,headers=new_headers)
video_url=eval(r.text)['videoInfo']['videos']['srcUrl']
3:获取真实网址
经过我的实验,使用上面获取的url抓取视频的视频下载内容是空的。
因为我也是菜鸟,所以想不通。偶然看到B站用户“_Qianhu”的留言,才知道真假url的区别:
这里视频地址是加密的,也就是ajax中获取的地址需要加上cont-,修改一个数字为id就是真实地址。
真实地址:“”
伪地址:“”
#仅需要做几个简单的截取切片操作就可以替换相关内容
old=video_url.split('/')[-1].split('-')[0]
new=''+str(code)
true_video_url=video_url.replace(old,new)
4:存储
#使用线程池对数据视频进行请求
def get_video_data(dic):
print(dic['name']+'开始下载'+'\n')
data_url=dic['my_url']
data=requests.get(url=data_url,headers=headers).content
with open('./视频/'+dic['name'],'wb') as f:
f.write(data)
print(dic['name']+'下载成功')
pool=Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()
5:结果
至此,这篇关于python爬梨视频生活版块最热视频的文章就介绍到这里了。更多相关python爬梨视频内容,请搜索脚本之家以前的文章或继续浏览下方相关文章,希望您以后多多支持脚本之家!
网页视频抓取脚本(网页视频抓取脚本实现动态视频下载的动态下载功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-12 07:04
网页视频抓取脚本实现动态视频下载,我们可以通过抓取我们想要下载的视频,并且下载所有的视频目录到本地,不需要用任何专门的网页抓取脚本,那么就可以把视频地址,发送到邮箱里,其实java可以很简单的实现这个功能,下面给大家列举一下,1.首先安装framework3.0和windows系统,2.安装qq如果是windows系统,那么需要更新qq,如果是linux系统,那么需要先下载相应版本的qq,如果是windows系统,那么就下载qqapi支持的任何文件,然后就是安装netwesome。
3.安装java和mysql.一般安装在c盘,一旦安装完后,其他的都不需要管。安装java编译器,javasedevelopmenttoolsinstaller安装mysql编译器,mysqlbinaryinstaller4.安装xml编辑器,thymeleaf5.配置好vim和记事本的环境变量,mysql如果是windows系统,需要visualstudio2010或者以上的版本,mysql--installer=javatelnet--console-s-db-url-path=192.168.1.1-proxy_address-path=java_exe-installer--connect-expr='java_exe'database='spring_mvc'6.配置好java环境变量,temporary_path=%mysql_home%\bin:%java_home%\jre\lib:%java_home%\lib\java\bin:%java_home%\jre\lib\tools.jar:%java_home%\bin手机用户操作界面。 查看全部
网页视频抓取脚本(网页视频抓取脚本实现动态视频下载的动态下载功能介绍)
网页视频抓取脚本实现动态视频下载,我们可以通过抓取我们想要下载的视频,并且下载所有的视频目录到本地,不需要用任何专门的网页抓取脚本,那么就可以把视频地址,发送到邮箱里,其实java可以很简单的实现这个功能,下面给大家列举一下,1.首先安装framework3.0和windows系统,2.安装qq如果是windows系统,那么需要更新qq,如果是linux系统,那么需要先下载相应版本的qq,如果是windows系统,那么就下载qqapi支持的任何文件,然后就是安装netwesome。
3.安装java和mysql.一般安装在c盘,一旦安装完后,其他的都不需要管。安装java编译器,javasedevelopmenttoolsinstaller安装mysql编译器,mysqlbinaryinstaller4.安装xml编辑器,thymeleaf5.配置好vim和记事本的环境变量,mysql如果是windows系统,需要visualstudio2010或者以上的版本,mysql--installer=javatelnet--console-s-db-url-path=192.168.1.1-proxy_address-path=java_exe-installer--connect-expr='java_exe'database='spring_mvc'6.配置好java环境变量,temporary_path=%mysql_home%\bin:%java_home%\jre\lib:%java_home%\lib\java\bin:%java_home%\jre\lib\tools.jar:%java_home%\bin手机用户操作界面。
网页视频抓取脚本(腾讯云函数来运行脚本领取京豆视频视频地址见文章末尾)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-11 02:03
之前我做了一个使用GitHub action运行京东自动登录脚本接收京豆的视频。
但是,一些新注册的新账户运行后,GitHub账户直接被屏蔽。所以在这里我做了一个使用腾讯云功能运行脚本,自动登录,接收北京东京豆的视频。视频地址在文章 的末尾。
免责声明:我的这个视频的分享仅供学习和研究。剧本造成的任何损失与我无关。你可以自己判断。禁止商业用途。如果您觉得本视频的内容侵犯了您的权利,请提醒我删除视频和博客
下载签到脚本
在本期找到脚本下载地址,打包、下载、解压,会有4个文件。
其中jdCookie.js填写获取到的cookie,sendNotify.js填写申请的服务器酱key。如果使用其他推送,也是如此。
以上获取京东cookies和keys的内容推荐看我上一个视频,如果打不开,点这里
安装nodejs环境
如果你的本地电脑是 macOS 系统,建议使用 Homebrew 安装。如果是Windows,我也有安装教程。
如果不知道自己电脑是否有nodejs环境,输入node -v确认是否返回版本号。
初始化项目
从签入脚本目录打开终端,输入以下命令初始化项目
npm init -f
然后安装依赖
npm install formidable --save
再次运行启动脚本
node jd_bean_sign.js
不出意外不会报错
Error: Cannot find module 'download'
缺少依赖,我们使用以下命令安装缺少的模块
npm i download
然后继续执行,不然会报错
Error: Cannot find module 'tough-cookie'
Error: Cannot find module 'request'
解决方法也很简单,缺少什么?
其实补充一下package.json中用到的依赖信息也不是那么麻烦
"dependencies": {
"download": "^8.0.0",
"formidable": "^1.2.2",
"request": "^2.88.2",
"tough-cookie": "^4.0.0"
}
解决所有错误后,可以启动脚本,自动登录,可以查看是否收到服务器酱通知。
腾讯云功能
打开腾讯云功能,如果您之前没有使用过腾讯云,需要实名认证才能继续,然后如果您是第一次进入腾讯云功能,会有弹窗提醒您授权。
将index.js作为项目入口类添加到本地脚本文件夹,内容如下
'use strict';
exports.main_handler = (event, context, callback) => {
require('./jd_bean_sign.js')
}
创建一个新函数并选择自定义创建
选择事件函数并为函数命名。
区域选择就近地址,运行环境选择nodejs最新版本。
函数代码选择本地文件夹进行上传,执行方式不需要修改,因为我们符合默认。
最后修改环境配置,将内存从128修改为64,将执行超时事件从3秒修改为12秒。
最后,单击完成首先进行测试。如果测试通过并满足要求,则添加触发器。
触发比较简单,主要是触发周期不同。这两天查看京东脚本后,发现视频中选择的每天0:00执行的不是很好。最好将其自定义为每天凌晨 1:00 运行。
0 0 1 * * * *
好的,基本上就是这样。如果你对添加触发器感到不安,你可以设置一个规则先做一个测试。比如设置为每1分钟运行一次,观察脚本是否会在1分钟后执行。如果它没有运行,请查看日志。
视频地址:油管b站 查看全部
网页视频抓取脚本(腾讯云函数来运行脚本领取京豆视频视频地址见文章末尾)
之前我做了一个使用GitHub action运行京东自动登录脚本接收京豆的视频。
但是,一些新注册的新账户运行后,GitHub账户直接被屏蔽。所以在这里我做了一个使用腾讯云功能运行脚本,自动登录,接收北京东京豆的视频。视频地址在文章 的末尾。
免责声明:我的这个视频的分享仅供学习和研究。剧本造成的任何损失与我无关。你可以自己判断。禁止商业用途。如果您觉得本视频的内容侵犯了您的权利,请提醒我删除视频和博客
下载签到脚本
在本期找到脚本下载地址,打包、下载、解压,会有4个文件。
其中jdCookie.js填写获取到的cookie,sendNotify.js填写申请的服务器酱key。如果使用其他推送,也是如此。
以上获取京东cookies和keys的内容推荐看我上一个视频,如果打不开,点这里
安装nodejs环境
如果你的本地电脑是 macOS 系统,建议使用 Homebrew 安装。如果是Windows,我也有安装教程。
如果不知道自己电脑是否有nodejs环境,输入node -v确认是否返回版本号。
初始化项目
从签入脚本目录打开终端,输入以下命令初始化项目
npm init -f
然后安装依赖
npm install formidable --save
再次运行启动脚本
node jd_bean_sign.js
不出意外不会报错
Error: Cannot find module 'download'
缺少依赖,我们使用以下命令安装缺少的模块
npm i download
然后继续执行,不然会报错
Error: Cannot find module 'tough-cookie'
Error: Cannot find module 'request'
解决方法也很简单,缺少什么?
其实补充一下package.json中用到的依赖信息也不是那么麻烦
"dependencies": {
"download": "^8.0.0",
"formidable": "^1.2.2",
"request": "^2.88.2",
"tough-cookie": "^4.0.0"
}
解决所有错误后,可以启动脚本,自动登录,可以查看是否收到服务器酱通知。
腾讯云功能
打开腾讯云功能,如果您之前没有使用过腾讯云,需要实名认证才能继续,然后如果您是第一次进入腾讯云功能,会有弹窗提醒您授权。
将index.js作为项目入口类添加到本地脚本文件夹,内容如下
'use strict';
exports.main_handler = (event, context, callback) => {
require('./jd_bean_sign.js')
}
创建一个新函数并选择自定义创建
选择事件函数并为函数命名。
区域选择就近地址,运行环境选择nodejs最新版本。
函数代码选择本地文件夹进行上传,执行方式不需要修改,因为我们符合默认。
最后修改环境配置,将内存从128修改为64,将执行超时事件从3秒修改为12秒。
最后,单击完成首先进行测试。如果测试通过并满足要求,则添加触发器。
触发比较简单,主要是触发周期不同。这两天查看京东脚本后,发现视频中选择的每天0:00执行的不是很好。最好将其自定义为每天凌晨 1:00 运行。
0 0 1 * * * *
好的,基本上就是这样。如果你对添加触发器感到不安,你可以设置一个规则先做一个测试。比如设置为每1分钟运行一次,观察脚本是否会在1分钟后执行。如果它没有运行,请查看日志。
视频地址:油管b站
网页视频抓取脚本(用python实现的抓取腾讯视频所有电影的爬虫总结以上)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-09 20:07
python实现的一个爬取所有腾讯视频电影的爬虫
<p>
# -*- coding: utf-8 -*-
import re
import urllib2
from bs4import BeautifulSoup
import string, time
import pymongo
NUM =0 #全局变量,电影数量
m_type = u'' #全局变量,电影类型
m_site = u'qq' #全局变量,电影网站
#根据指定的URL获取网页内容
def gethtml(url):
req = urllib2.Request(url)
response = urllib2.urlopen(req)
html = response.read()
return html
#从电影分类列表页面获取电影分类
def gettags(html):
global m_type
soup = BeautifulSoup(html) #过滤出分类内容
#print soup
#
tags_all = soup.find_all('ul', {'class' :'clearfix _group' ,'gname' :'mi_type'})
#print len(tags_all), tags_all
#print str(tags_all[1]).replace('\n','')
#动作
re_tags = r'<a _hot=\"tag\.sub\" class=\"_gtag _hotkey\" href=\"(.+?)\" title=\"(.+?)\" tvalue=\"(.+?)\">.+?</a>'
p = re.compile(re_tags, re.DOTALL)
tags = p.findall(str(tags_all[0]))
if tags:
tags_url = {}
#print tags
for tagin tags:
tag_url = tag[0].decode('utf-8')
#print tag_url
m_type = tag[1].decode('utf-8')
tags_url[m_type] = tag_url
else:
print"Not Find"
return tags_url
#获取每个分类的页数
def get_pages(tag_url):
tag_html = gethtml(tag_url)
#divclass="paginator
soup = BeautifulSoup(tag_html) #过滤出标记页面的html
#print soup
#
div_page = soup.find_all('div', {'class' :'mod_pagenav','id' :'pager'})
#print div_page #len(div_page), div_page[0]
#25</a>
re_pages = r'<a class=.+?>(.+?)</a>'
p = re.compile(re_pages, re.DOTALL)
pages = p.findall(str(div_page[0]))
#print pages
if len(pages) >1:
return pages[-2]
else:
return 1
def getmovielist(html):
soup = BeautifulSoup(html)
#
divs = soup.find_all('ul', {'class' :'mod_list_pic_130'})
#print divs
for div_htmlin divs:
div_html = str(div_html).replace('\n','')
#print div_html
getmovie(div_html)
def getmovie(html):
global NUM
global m_type
global m_site
re_movie = r'<a class=\"mod_poster_130\" href=\"(.+?)\" target=\"_blank\" title=\"(.+?)\"> 查看全部
网页视频抓取脚本(用python实现的抓取腾讯视频所有电影的爬虫总结以上)
python实现的一个爬取所有腾讯视频电影的爬虫
<p>
# -*- coding: utf-8 -*-
import re
import urllib2
from bs4import BeautifulSoup
import string, time
import pymongo
NUM =0 #全局变量,电影数量
m_type = u'' #全局变量,电影类型
m_site = u'qq' #全局变量,电影网站
#根据指定的URL获取网页内容
def gethtml(url):
req = urllib2.Request(url)
response = urllib2.urlopen(req)
html = response.read()
return html
#从电影分类列表页面获取电影分类
def gettags(html):
global m_type
soup = BeautifulSoup(html) #过滤出分类内容
#print soup
#
tags_all = soup.find_all('ul', {'class' :'clearfix _group' ,'gname' :'mi_type'})
#print len(tags_all), tags_all
#print str(tags_all[1]).replace('\n','')
#动作
re_tags = r'<a _hot=\"tag\.sub\" class=\"_gtag _hotkey\" href=\"(.+?)\" title=\"(.+?)\" tvalue=\"(.+?)\">.+?</a>'
p = re.compile(re_tags, re.DOTALL)
tags = p.findall(str(tags_all[0]))
if tags:
tags_url = {}
#print tags
for tagin tags:
tag_url = tag[0].decode('utf-8')
#print tag_url
m_type = tag[1].decode('utf-8')
tags_url[m_type] = tag_url
else:
print"Not Find"
return tags_url
#获取每个分类的页数
def get_pages(tag_url):
tag_html = gethtml(tag_url)
#divclass="paginator
soup = BeautifulSoup(tag_html) #过滤出标记页面的html
#print soup
#
div_page = soup.find_all('div', {'class' :'mod_pagenav','id' :'pager'})
#print div_page #len(div_page), div_page[0]
#25</a>
re_pages = r'<a class=.+?>(.+?)</a>'
p = re.compile(re_pages, re.DOTALL)
pages = p.findall(str(div_page[0]))
#print pages
if len(pages) >1:
return pages[-2]
else:
return 1
def getmovielist(html):
soup = BeautifulSoup(html)
#
divs = soup.find_all('ul', {'class' :'mod_list_pic_130'})
#print divs
for div_htmlin divs:
div_html = str(div_html).replace('\n','')
#print div_html
getmovie(div_html)
def getmovie(html):
global NUM
global m_type
global m_site
re_movie = r'<a class=\"mod_poster_130\" href=\"(.+?)\" target=\"_blank\" title=\"(.+?)\">
网页视频抓取脚本(网页视频抓取脚本,阿里云主页和美团网页哪个需要更多人爬?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-07 23:05
网页视频抓取脚本,阿里云主页和美团网页哪个需要更多人爬?-朱晨的回答美团提示:这不是一款付费app,请勿下载。
可以用一下人人都是产品经理里面的美团网页地址爬取教程,一键导入刚爬的美团网页。更新这个是爬微博爬也可以在谷歌上用sitesplitsitesplit国内可用,
这应该不是美团的网站,也不是“美团网”。
电子商务对信息保密性要求很高的,你能爬的信息量太少,我手机端接口爬过天猫和京东的,都要求提供的网址经常换,都需要手动改。
如果这个网页你肯定能看到的话,很简单,试试xyzoou从页面底部上拉列表,先上传你指定的那个快递到地址,再跳转下一页面,就可以跳转到美团的商家列表了。
请问题主是找美团哪个页面,美团美团美团,一般凡是商家都是提供美团网址的,但这样会造成网页加载很慢。我这边也做爬虫对手机和网页做一些参考,微信公众号【搜索乔子c】,每天更新【手机电脑互联网it网络文章】,【手机网页版互联网网络文章】,如有疑问,欢迎交流。
其实在知乎里看别人回答过的这个问题,美团官网地址可以获取,只是文章不能自己写, 查看全部
网页视频抓取脚本(网页视频抓取脚本,阿里云主页和美团网页哪个需要更多人爬?)
网页视频抓取脚本,阿里云主页和美团网页哪个需要更多人爬?-朱晨的回答美团提示:这不是一款付费app,请勿下载。
可以用一下人人都是产品经理里面的美团网页地址爬取教程,一键导入刚爬的美团网页。更新这个是爬微博爬也可以在谷歌上用sitesplitsitesplit国内可用,
这应该不是美团的网站,也不是“美团网”。
电子商务对信息保密性要求很高的,你能爬的信息量太少,我手机端接口爬过天猫和京东的,都要求提供的网址经常换,都需要手动改。
如果这个网页你肯定能看到的话,很简单,试试xyzoou从页面底部上拉列表,先上传你指定的那个快递到地址,再跳转下一页面,就可以跳转到美团的商家列表了。
请问题主是找美团哪个页面,美团美团美团,一般凡是商家都是提供美团网址的,但这样会造成网页加载很慢。我这边也做爬虫对手机和网页做一些参考,微信公众号【搜索乔子c】,每天更新【手机电脑互联网it网络文章】,【手机网页版互联网网络文章】,如有疑问,欢迎交流。
其实在知乎里看别人回答过的这个问题,美团官网地址可以获取,只是文章不能自己写,
网页视频抓取脚本(学vue.js在线观看不能倍速播放播放播放)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-07 14:03
写在前面
最近在学习vue.js,在网站上看了很多视频教程,但是网上不能双速播放,所以想着用python爬虫下载到本地.
安装依赖
pip3 安装请求
测试示例
除序言外共有16个视频,我们使用python爬虫技术批量下载到本地。
#/?vid=0
获取直接链接
首先,我们需要获取视频的直接下载链接。右键查看,可以直接看到视频的直接链接。
再次查看页面源代码,发现视频的直接链接没有了,视频的直接链接原来的位置变成了js脚本。
如果我们直接使用requets库请求url,会得到源码,但是源码中并没有直接的视频链接,所以需要考虑另一种思路。为什么视频直连的位置被js代替了?
如果你有更多的爬虫,你就会知道这是网页的动态加载。必须有保存视频直接链接的js文件,然后每次网页加载时,通过js脚本中间将视频的直接链接动态加载到html中。
点击网络,过滤js文件,找到3个js文件。我们先看看第一个js文件中是否有视频直连。搜索视频的标题,直接找到视频的直接链接,发现视频的所有直接链接都保存到了一个名为lesson_list的变量中。
Lesson_list 存储所有视频名称和视频直接链接信息。为统一起见,序言改为第0节。
# course_list.py
课程列表 = [{
"name": "第0节vue.js介绍",
“网址”:“”,
“问”:“77367”
},{
"name": "第1节安装部署",
“网址”:“”,
“问”:“77369”
},{
"name": "第2节创建第一个vue应用",
“网址”:“”,
“问”:“77370”
},{
"name": "Section 3 Data and Methods",
“网址”:“”,
“问”:“77372”
},{
"name": "Section 4 Lifecycle",
“网址”:“”,
“问”:“77373”
},{
"name": "Section 5 Template Syntax - Interpolation",
“网址”:“”,
“问”:“77375”
},{
"name": "Section 6 Template Syntax - Directives",
“网址”:“”,
“问”:“77376”
},{
"name": "Section 7 类和样式绑定",
“网址”:“”,
“问”:“77377”
},{
"name": "Section 8 条件渲染",
“网址”:“”,
“问”:“77378”
},{
"name": "Section 9 列表渲染",
“网址”:“”,
“问”:“77380”
},{
"name": "Section 10 事件绑定",
“网址”:“”,
“问”:“77381”
},{
"name": "Section 11 表单输入绑定",
“网址”:“”,
“问”:“77382”
},{
"name": "Section 12 组件基础",
“网址”:“”,
“问”:“77383”
},{
"name": "Section 13 组件注册",
“网址”:“”,
“问”:“78520”
},{
"name": "Section 14 Single-File Components",
“网址”:“”,
“问”:“78521”
},{
"name": "第15节Vue应用的无终端开发",
“网址”:“”,
“问”:“81004”
}]
批量下载
这里使用for循环遍历每个下载链接,然后使用之前写的多线程下载器进行下载。
从 concurrent.futures 导入 ThreadPoolExecutor
从课程列表导入课程列表
from requests import get, head
进口时间
类下载器:
def __init__(self, url, num, name):
self.url=url
self.num = 数字
self.name = 名字
self.getsize = 0
r = head(self.url, allow_redirects=True)
self.size = int(r.headers['Content-Length'])
def down(self, start, end, chunk_size=10240):
headers = {'range': f'bytes={start}-{end}'}
r = get(self.url, headers=headers, stream=True)
with open(self.name, "rb+") as f:
f.seek(开始)
对于 r.iter_content(chunk_size) 中的块:
f.write(块)
self.getsize += chunk_size
定义主(自我):
start_time = time.time()
f = open(self.name, 'wb')
f.truncate(self.size)
f.close()
tp = ThreadPoolExecutor(max_workers=self.num)
期货 = []
开始 = 0
for i in range(self.num):
end = int((i+1)/self.num*self.size)
future = tp.submit(self.down, start, end)
futures.append(未来)
开始=结束+1
当真时:
进程 = self.getsize/self.size*100
last = self.getsize
时间.sleep(1)
curr = self.getsize
down = (curr-last)/1024
如果下降 > 1024:
速度 = f'{down/1024:6.2f}MB/s'
其他:
速度 = f'{down:6.2f}KB/s'
print(f'process: {process:6.2f}% | speed: {speed}', end='\r')
如果进程 >= 100:
print(f'进程: {100.00:6}% | 速度: 00.00KB/s', end=' | ')
休息
end_time = time.time()
total_time = end_time-start_time
平均速度 = self.size/total_time/1024/1024
print(f'总时间:{total_time:.0f}s | 平均速度:{average_speed:.2f}MB/s')
如果 __name__ == '__main__':
对于课程列表中的课程:
url = 课程['url']
name = 课程['name']
down = downloader(url, 8, name+'.mp4')
down.main()
结果打印
16个视频,共339MB,下载耗时56s。
进程:100.0% |速度:00.00KB/s |总时间:2s |平均速度:2.47MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:6.62MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:3.72MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:7.72MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:5.85MB/s
进程:100.0% |速度:00.00KB/s |总时间:7s |平均速度:7.01MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:4.65MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:6.69MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:5.88MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:5.01MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:6.60MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:6.20MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:5.96MB/s
进程:100.0% |速度:00.00KB/s |总时间:2s |平均速度:4.64MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:6.02MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:6.80MB/s
总结与展望
有时视频或图片的直接链接不一定需要爬取,可能在网页加载的js文件中找到。既然可以直接找到,为什么还要爬呢?那么下载的时候一定要使用多线程,因为多线程可以占用全部带宽来实现全速下载。
引用参考文献
本文分享CSDN - Xavier Jiezou。 查看全部
网页视频抓取脚本(学vue.js在线观看不能倍速播放播放播放)
写在前面
最近在学习vue.js,在网站上看了很多视频教程,但是网上不能双速播放,所以想着用python爬虫下载到本地.
安装依赖
pip3 安装请求
测试示例
除序言外共有16个视频,我们使用python爬虫技术批量下载到本地。
#/?vid=0
获取直接链接
首先,我们需要获取视频的直接下载链接。右键查看,可以直接看到视频的直接链接。
再次查看页面源代码,发现视频的直接链接没有了,视频的直接链接原来的位置变成了js脚本。
如果我们直接使用requets库请求url,会得到源码,但是源码中并没有直接的视频链接,所以需要考虑另一种思路。为什么视频直连的位置被js代替了?
如果你有更多的爬虫,你就会知道这是网页的动态加载。必须有保存视频直接链接的js文件,然后每次网页加载时,通过js脚本中间将视频的直接链接动态加载到html中。
点击网络,过滤js文件,找到3个js文件。我们先看看第一个js文件中是否有视频直连。搜索视频的标题,直接找到视频的直接链接,发现视频的所有直接链接都保存到了一个名为lesson_list的变量中。
Lesson_list 存储所有视频名称和视频直接链接信息。为统一起见,序言改为第0节。
# course_list.py
课程列表 = [{
"name": "第0节vue.js介绍",
“网址”:“”,
“问”:“77367”
},{
"name": "第1节安装部署",
“网址”:“”,
“问”:“77369”
},{
"name": "第2节创建第一个vue应用",
“网址”:“”,
“问”:“77370”
},{
"name": "Section 3 Data and Methods",
“网址”:“”,
“问”:“77372”
},{
"name": "Section 4 Lifecycle",
“网址”:“”,
“问”:“77373”
},{
"name": "Section 5 Template Syntax - Interpolation",
“网址”:“”,
“问”:“77375”
},{
"name": "Section 6 Template Syntax - Directives",
“网址”:“”,
“问”:“77376”
},{
"name": "Section 7 类和样式绑定",
“网址”:“”,
“问”:“77377”
},{
"name": "Section 8 条件渲染",
“网址”:“”,
“问”:“77378”
},{
"name": "Section 9 列表渲染",
“网址”:“”,
“问”:“77380”
},{
"name": "Section 10 事件绑定",
“网址”:“”,
“问”:“77381”
},{
"name": "Section 11 表单输入绑定",
“网址”:“”,
“问”:“77382”
},{
"name": "Section 12 组件基础",
“网址”:“”,
“问”:“77383”
},{
"name": "Section 13 组件注册",
“网址”:“”,
“问”:“78520”
},{
"name": "Section 14 Single-File Components",
“网址”:“”,
“问”:“78521”
},{
"name": "第15节Vue应用的无终端开发",
“网址”:“”,
“问”:“81004”
}]
批量下载
这里使用for循环遍历每个下载链接,然后使用之前写的多线程下载器进行下载。
从 concurrent.futures 导入 ThreadPoolExecutor
从课程列表导入课程列表
from requests import get, head
进口时间
类下载器:
def __init__(self, url, num, name):
self.url=url
self.num = 数字
self.name = 名字
self.getsize = 0
r = head(self.url, allow_redirects=True)
self.size = int(r.headers['Content-Length'])
def down(self, start, end, chunk_size=10240):
headers = {'range': f'bytes={start}-{end}'}
r = get(self.url, headers=headers, stream=True)
with open(self.name, "rb+") as f:
f.seek(开始)
对于 r.iter_content(chunk_size) 中的块:
f.write(块)
self.getsize += chunk_size
定义主(自我):
start_time = time.time()
f = open(self.name, 'wb')
f.truncate(self.size)
f.close()
tp = ThreadPoolExecutor(max_workers=self.num)
期货 = []
开始 = 0
for i in range(self.num):
end = int((i+1)/self.num*self.size)
future = tp.submit(self.down, start, end)
futures.append(未来)
开始=结束+1
当真时:
进程 = self.getsize/self.size*100
last = self.getsize
时间.sleep(1)
curr = self.getsize
down = (curr-last)/1024
如果下降 > 1024:
速度 = f'{down/1024:6.2f}MB/s'
其他:
速度 = f'{down:6.2f}KB/s'
print(f'process: {process:6.2f}% | speed: {speed}', end='\r')
如果进程 >= 100:
print(f'进程: {100.00:6}% | 速度: 00.00KB/s', end=' | ')
休息
end_time = time.time()
total_time = end_time-start_time
平均速度 = self.size/total_time/1024/1024
print(f'总时间:{total_time:.0f}s | 平均速度:{average_speed:.2f}MB/s')
如果 __name__ == '__main__':
对于课程列表中的课程:
url = 课程['url']
name = 课程['name']
down = downloader(url, 8, name+'.mp4')
down.main()
结果打印
16个视频,共339MB,下载耗时56s。
进程:100.0% |速度:00.00KB/s |总时间:2s |平均速度:2.47MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:6.62MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:3.72MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:7.72MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:5.85MB/s
进程:100.0% |速度:00.00KB/s |总时间:7s |平均速度:7.01MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:4.65MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:6.69MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:5.88MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:5.01MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:6.60MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:6.20MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:5.96MB/s
进程:100.0% |速度:00.00KB/s |总时间:2s |平均速度:4.64MB/s
进程:100.0% |速度:00.00KB/s |总时间:3s |平均速度:6.02MB/s
进程:100.0% |速度:00.00KB/s |总时间:4s |平均速度:6.80MB/s
总结与展望
有时视频或图片的直接链接不一定需要爬取,可能在网页加载的js文件中找到。既然可以直接找到,为什么还要爬呢?那么下载的时候一定要使用多线程,因为多线程可以占用全部带宽来实现全速下载。
引用参考文献
本文分享CSDN - Xavier Jiezou。
网页视频抓取脚本(挑选你感兴趣的分类--js )
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-03-07 14:02
)
选择您感兴趣的类别
根据首页地址获取详情页超链接的跳转地址
找到对应的加密视频播放地址数据
此数据为静态网页数据,js代码解码
找到对应的解析代码
先找到视频的播放地址
找到解析视频地址的加密js文件
点击播放会触发文件
大致可以看出这是base64加密的数据
在对应的js文件中搜索关键字
找到js的加密方式
js函数部分函数的使用
# eplace()方法用于在字符串中用一些字符替换另一些字符 # parseInt 数据转换成对应的整型 # base64.atob 对base64编码过的字符串进行解码 # substring 方法可在字符串中抽取从 start 下标开始的指定数目的字符
将 js 代码转换为 Python 代码
import base64 def decode(data): def getHex(a): return { 'str': a[4:], 'hex': ''.join(list(a[:4])[::-1]), } def getDec(a): b = str(int(a, 16)) return { 'pre': list(b[:2]), 'tail': list(b[2:]), } def substr(a, b): c = a[0: int(b[0])] d = a[int(b[0]): int(b[0]) + int(b[1])] return c + a[int(b[0]):].replace(d, "") def getPos(a, b): b[0] = len(a) - int(b[0]) - int(b[1]) return b b = getHex(data) c = getDec(b['hex']) d = substr(b['str'], c['pre']) return base64.b64decode(substr(d, getPos(d, c['tail']))) print(decode("e121Ly9tBrI84RdnZpZGVvMTAubWVpdHVkYXRhLmNvbS82MGJjZDcwNTE3NGZieXBueG5udnRwMTA5N19IMjY0XzFfNWY3YThmM2U0MTEwNy5tc2JVjAu3EDQ="))
获取最终视频播放地址
查看全部
网页视频抓取脚本(挑选你感兴趣的分类--js
)
选择您感兴趣的类别
根据首页地址获取详情页超链接的跳转地址
找到对应的加密视频播放地址数据
此数据为静态网页数据,js代码解码
找到对应的解析代码
先找到视频的播放地址
找到解析视频地址的加密js文件
点击播放会触发文件
大致可以看出这是base64加密的数据
在对应的js文件中搜索关键字
找到js的加密方式
js函数部分函数的使用
# eplace()方法用于在字符串中用一些字符替换另一些字符 # parseInt 数据转换成对应的整型 # base64.atob 对base64编码过的字符串进行解码 # substring 方法可在字符串中抽取从 start 下标开始的指定数目的字符
将 js 代码转换为 Python 代码
import base64 def decode(data): def getHex(a): return { 'str': a[4:], 'hex': ''.join(list(a[:4])[::-1]), } def getDec(a): b = str(int(a, 16)) return { 'pre': list(b[:2]), 'tail': list(b[2:]), } def substr(a, b): c = a[0: int(b[0])] d = a[int(b[0]): int(b[0]) + int(b[1])] return c + a[int(b[0]):].replace(d, "") def getPos(a, b): b[0] = len(a) - int(b[0]) - int(b[1]) return b b = getHex(data) c = getDec(b['hex']) d = substr(b['str'], c['pre']) return base64.b64decode(substr(d, getPos(d, c['tail']))) print(decode("e121Ly9tBrI84RdnZpZGVvMTAubWVpdHVkYXRhLmNvbS82MGJjZDcwNTE3NGZieXBueG5udnRwMTA5N19IMjY0XzFfNWY3YThmM2U0MTEwNy5tc2JVjAu3EDQ="))
获取最终视频播放地址
网页视频抓取脚本(本文介绍使用优采云采集器简易模式采集提取腾讯网页视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-03-07 05:18
腾讯网页视频链接提取教程 腾讯网页视频链接提取教程 本文介绍使用优采云采集器简易模式采集提取腾讯网页视频的方法。如果需要在采集腾讯地图关键词上搜索内容,在网页的简单模式界面点击腾讯,可以看到腾讯的三条规则,我们可以直接使用。腾讯视频链接提取步骤一采集腾讯视频-热门电影排行内容(如下图)是打开腾讯网站首页,点击第三个(腾讯视频-近期热门电影排行)< @采集 搜索到的内容。1、找到腾讯视频-近期热门电影排名规则,点击使用腾讯视频链接提取第二步2、
腾讯网页视频链接提取教程本文介绍使用优采云采集器简易模式采集提取腾讯网页视频的方法。如果需要在采集腾讯地图关键词上搜索内容,在网页的简单模式界面点击腾讯,可以看到腾讯的三条规则,我们可以直接使用。腾讯视频链接提取步骤一采集腾讯视频
视频-热门电影榜内容(如下图)是打开腾讯网站首页,点击第三个(腾讯视频-近期热播电影榜)采集搜索内容。1、找到腾讯视频-近期热门电影排名规则,点击使用腾讯网页视频链接提取第二步2、下图为腾讯视频-近期热门电影简单模式排名
线路规则①查看详情:点击查看示例网址②任务名称:自定义任务名称,默认为腾讯视频-近期热门电影排行榜③任务组:将任务分组保存任务,若不设置,会有一个默认分组④翻页次数:设置页数为采集示例数据:该规则的所有字段信息采集腾讯网页视频链接提取步骤33、@ >
规则制定示例任务名称:自定义任务名称,也可以不设置按默认任务组:自定义任务组,也可以不设置按默认翻页次数:2设置好后点击保存,保存后会出现开始按钮采集。保存后会出现采集的开始按钮。腾讯网页视频链接提取 Step 44、选择开始采集,系统将
会弹出运行任务的界面,可以选择启动本地采集(本地执行采集进程)或者启动云端采集(执行采集由云服务器处理),这里启动本地采集例如我们选择启动本地采集按钮腾讯视频链接提取步骤55、选择本地后采集按钮,系统会在本地执行这个采集处理到采集数据,如下图
腾讯网页视频链接提取步骤6的本地采集效果采集完成后,选择导出数据按钮,这里以导出excel2007为例,选择该选项点击确定即可提取腾讯网页视频link Step 7 7、然后选择文件在电脑上的存放路径。路径选择好后选择保存腾讯网页视频链接提取步骤88、
/
本文档为【腾讯视频链接提取教程】,请使用软件OFFICE或WPS软件打开。作品中的文字和图片可以进行修改和编辑。如需更改图片,请在作品中的图片上右击并替换。如需修改文字,请点击文字进行修改。您还可以在文档中添加和删除内容。 查看全部
网页视频抓取脚本(本文介绍使用优采云采集器简易模式采集提取腾讯网页视频)
腾讯网页视频链接提取教程 腾讯网页视频链接提取教程 本文介绍使用优采云采集器简易模式采集提取腾讯网页视频的方法。如果需要在采集腾讯地图关键词上搜索内容,在网页的简单模式界面点击腾讯,可以看到腾讯的三条规则,我们可以直接使用。腾讯视频链接提取步骤一采集腾讯视频-热门电影排行内容(如下图)是打开腾讯网站首页,点击第三个(腾讯视频-近期热门电影排行)< @采集 搜索到的内容。1、找到腾讯视频-近期热门电影排名规则,点击使用腾讯视频链接提取第二步2、
腾讯网页视频链接提取教程本文介绍使用优采云采集器简易模式采集提取腾讯网页视频的方法。如果需要在采集腾讯地图关键词上搜索内容,在网页的简单模式界面点击腾讯,可以看到腾讯的三条规则,我们可以直接使用。腾讯视频链接提取步骤一采集腾讯视频
视频-热门电影榜内容(如下图)是打开腾讯网站首页,点击第三个(腾讯视频-近期热播电影榜)采集搜索内容。1、找到腾讯视频-近期热门电影排名规则,点击使用腾讯网页视频链接提取第二步2、下图为腾讯视频-近期热门电影简单模式排名
线路规则①查看详情:点击查看示例网址②任务名称:自定义任务名称,默认为腾讯视频-近期热门电影排行榜③任务组:将任务分组保存任务,若不设置,会有一个默认分组④翻页次数:设置页数为采集示例数据:该规则的所有字段信息采集腾讯网页视频链接提取步骤33、@ >
规则制定示例任务名称:自定义任务名称,也可以不设置按默认任务组:自定义任务组,也可以不设置按默认翻页次数:2设置好后点击保存,保存后会出现开始按钮采集。保存后会出现采集的开始按钮。腾讯网页视频链接提取 Step 44、选择开始采集,系统将
会弹出运行任务的界面,可以选择启动本地采集(本地执行采集进程)或者启动云端采集(执行采集由云服务器处理),这里启动本地采集例如我们选择启动本地采集按钮腾讯视频链接提取步骤55、选择本地后采集按钮,系统会在本地执行这个采集处理到采集数据,如下图
腾讯网页视频链接提取步骤6的本地采集效果采集完成后,选择导出数据按钮,这里以导出excel2007为例,选择该选项点击确定即可提取腾讯网页视频link Step 7 7、然后选择文件在电脑上的存放路径。路径选择好后选择保存腾讯网页视频链接提取步骤88、
/
本文档为【腾讯视频链接提取教程】,请使用软件OFFICE或WPS软件打开。作品中的文字和图片可以进行修改和编辑。如需更改图片,请在作品中的图片上右击并替换。如需修改文字,请点击文字进行修改。您还可以在文档中添加和删除内容。
网页视频抓取脚本( 【】本文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2022-03-06 22:07
【】本文)
Python爬虫爬取ts片段视频+验证码登录功能
更新时间:2021-02-22 10:23:14 作者:毛小贤~
本篇文章主要介绍Python爬虫爬取ts片段视频+验证码登录功能。本文为您介绍的很详细,对您的学习或工作有一定的参考价值。有需要的朋友可以参考以下
内容
目标:抓取您帐户中购买的课程视频。
一、 实现登录账号
这里采用手动输入验证码的方式,有能力的朋友也可以通过图像识别自动填写验证码。登录后,使用 session 保持登录状态。
1.获取验证码地址
第一步:首先查看验证码对应的代码。从图中可以看出验证码图片的地址是:
红色部分 tmep_seq=08 是为解决浏览器缓存问题而添加的时间戳,所以真正的验证码图片地址为:
第二步:找出登录时提交的表单内容和POST地址。
(1)用户名、密码和验证码不要填写,直接点击登录,使用Chrome浏览器的网络检查,找到POST地址:
(2)继续往下看,找到提交的表单Form Data。
所以带有验证码的登录代码如下:
import requests
from PIL import Image
#用户名-密码-验证码方式,登录
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #获取验证码地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登录信息地址
client = requests.Session()
username = '替换为自己的用户名'
password = '替换为自己的密码'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #将验证码图片保存至本地
img = Image.open('login.jpg')
img.show() #打开图片
code = input("请输入验证码: \n") #输入验证码
postData = { #构造POST表单
'email': username,
'pwd': password,
'validateCode': code,
'x': '22',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表单
二、实现ts片段视频下载并转换为mp4格式1.解析视频下载地址
登录成功后,查看视频播放div对应的代码,尝试找到视频地址直接保存到本地。结果,如下图所示,整个视频被分割成.ts文件,被分割后加载到页面中进行播放。GET 每个视频的地址是右边红框圈出来的部分。
百度了才知道,整个视频是怎么分割的,是由一个m3u8文件决定的。m3u8文件中的内容如下,记录了每个视频的开始和结束编号。
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-ALLOW-CACHE:YES
#EXT-X-TARGETDURATION:10
#EXTINF:10.000000,
start_0-end_765064-record.gv.ts
#EXTINF:10.000000,
start_765064-end_1769567-record.gv.ts
#EXTINF:10.000000,
start_1769567-end_2600798-record.gv.ts
#EXTINF:10.000000,
start_2600798-end_3593502-record.gv.ts
#EXTINF:10.000000,
start_3593502-end_4500784-record.gv.ts
#EXTINF:10.000000,
start_4500784-end_5399861-record.gv.ts
#EXTINF:10.000000,
start_5399861-end_6288622-record.gv.ts
#EXTINF:10.000000,
start_6288622-end_7044459-record.gv.ts
#EXTINF:10.000000,
start_7044459-end_7878487-record.gv.ts
#EXTINF:10.000000,
start_7878487-end_8811793-record.gv.ts
#EXTINF:10.000000,
因此,下载视频的关键是获取m3u8文件,通过该视频的m3u8文件分段下载视频。
手动找到了m3u8的下载地址,还没有研究如何通过视频地址自动解析m3u8地址。查找方法很简单,或者在 Chrome 的网络控制台中查找。打开网络控制台,刷新页面,可以找到如图所示的m3u8文件。查看m3u8文件的相关信息,可以看到红框圈出的地址就是这个视频的m3u8下载地址。
对比两个地址可以发现,文件名前的地址是一样的,视频下载地址是“红色标记的地址”+“m3u8文件中列出的视频片段文件名”:
所以可以将这部分地址设置为:urlroot =
为了方便下载其他视频时动态修改,改为动态截取:
url = input("请输入m3u8文件地址:")
urlRoot=self.url[0:url.rindex('/')]
2.批量下载ts视频片段
这一步使用上一步拼接的地址循环下载ts视频。下载时,使用登录时创建的会话进行下载。
Session就是会话的意思,它让服务器“识别”客户端。一个简单的理解就是把每一个客户端-服务器交互都当作一个“会话”。由于在同一个“会话”中,服务器自然可以知道客户端是否登录。代码如下:
client = requests.Session()
client.post(PostUrl,postData) #登录
resp = client.get(download_path) #下载
分片拼接的方法:下载第一个ts分片后,直接在文件后面继续写第二个ts分片,以此类推。而不是创建要写入的新文件。结合验证码登录,完整代码如下:
import requests
from PIL import Image
import sys
import m3u8
import time
import os
#用户名-密码-验证码方式,登录
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #获取验证码地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登录信息地址
client = requests.Session()
username = '526257482@qq.com'
password = 'dashuju_9514'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #将验证码图片保存至本地
img = Image.open('login.jpg')
img.show() #打开图片
code = input("请输入验证码: \n") #输入验证码
postData = { #构造POST表单
'email': username,
'pwd': password,
'validateCode': code,
'x': '56',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表单
#循环下载ts视频
class VideoCrawler():
def __init__(self,url):
super(VideoCrawler, self).__init__()
self.url=url
self.final_path=r"D:\Download\Film"
#下载并解析m3u8文件
def get_url_from_m3u8(self,readAdr):
print("正在解析真实下载地址...")
with open('temp.m3u8','wb') as file:
file.write(requests.get(readAdr).content)
m3u8Obj=m3u8.load('temp.m3u8')
print("解析完成")
return m3u8Obj.segments
def run(self):
print("Start!")
start_time=time.time()
realAdr = self.url #m3u8下载地址
urlList=self.get_url_from_m3u8(realAdr) #解析m3u8文件,获取下载地址
urlRoot=self.url[0:self.url.rindex('/')]
i=1
outputfile=open(os.path.join(self.final_path,'%s.ts'%self.fileName),'wb')#初始创建一个ts文件,之后每次循环将ts片段的文件流写入此文件中从而不需要在去合并ts文件
for url in urlList:
try:
download_path = "%s/%s" % (urlRoot, url.uri) #拼接地址
resp = client.get(download_path) #使用拼接地址去爬取数据
progess = i/len(urlList)#记录当前的爬取进度
outputfile.write(resp.content) #将爬取到ts片段的文件流写入刚开始创建的ts文件中
sys.stdout.write('\r正在下载:{},进度:{:.2%}'.format(self.fileName,progess))#通过百分比显示下载进度
sys.stdout.flush()#通过此方法将上一行代码刷新,控制台只保留一行
except Exception as e:
print("\n出现错误:%s",e.args)
continue#出现错误跳出当前循环,继续下次循环
i+=1
outputfile.close()
print("下载完成!总共耗时%d s"%(time.time()-start_time))
print("开始转换视频格式!")
success = os.system(r'copy /b D:\Download\Film\{0}.ts D:\Download\Film\{0}.mp4'.format(self.fileName)) #ts转成mp4格式
if (not success):
print("格式转换成功!")
os.remove(self.final_path+'\\'+self.fileName+".ts") #删除ts和m3u8临时文件
os.remove("temp.m3u8")
if __name__=='__main__':
m3u8_addr = input("输入m3u8文件下载地址:\n")
crawler=VideoCrawler(m3u8_addr)
crawler.fileName = input("输入文件名:\n")
crawler.run()
quitClick=input("请按Enter键确认退出!")
三、总结
代码可以实现分段加载视频的爬取功能,还有很多细节需要改进,比如:
至此,这篇关于Python爬虫爬取ts片段视频+验证码登录功能的文章文章就介绍到这里了。更多相关Python爬虫爬取视频内容,请搜索脚本之家以前的文章或继续浏览以下相关文章希望大家以后多多支持脚本之家! 查看全部
网页视频抓取脚本(
【】本文)
Python爬虫爬取ts片段视频+验证码登录功能
更新时间:2021-02-22 10:23:14 作者:毛小贤~
本篇文章主要介绍Python爬虫爬取ts片段视频+验证码登录功能。本文为您介绍的很详细,对您的学习或工作有一定的参考价值。有需要的朋友可以参考以下
内容
目标:抓取您帐户中购买的课程视频。
一、 实现登录账号
这里采用手动输入验证码的方式,有能力的朋友也可以通过图像识别自动填写验证码。登录后,使用 session 保持登录状态。
1.获取验证码地址
第一步:首先查看验证码对应的代码。从图中可以看出验证码图片的地址是:
红色部分 tmep_seq=08 是为解决浏览器缓存问题而添加的时间戳,所以真正的验证码图片地址为:
第二步:找出登录时提交的表单内容和POST地址。
(1)用户名、密码和验证码不要填写,直接点击登录,使用Chrome浏览器的网络检查,找到POST地址:
(2)继续往下看,找到提交的表单Form Data。
所以带有验证码的登录代码如下:
import requests
from PIL import Image
#用户名-密码-验证码方式,登录
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #获取验证码地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登录信息地址
client = requests.Session()
username = '替换为自己的用户名'
password = '替换为自己的密码'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #将验证码图片保存至本地
img = Image.open('login.jpg')
img.show() #打开图片
code = input("请输入验证码: \n") #输入验证码
postData = { #构造POST表单
'email': username,
'pwd': password,
'validateCode': code,
'x': '22',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表单
二、实现ts片段视频下载并转换为mp4格式1.解析视频下载地址
登录成功后,查看视频播放div对应的代码,尝试找到视频地址直接保存到本地。结果,如下图所示,整个视频被分割成.ts文件,被分割后加载到页面中进行播放。GET 每个视频的地址是右边红框圈出来的部分。
百度了才知道,整个视频是怎么分割的,是由一个m3u8文件决定的。m3u8文件中的内容如下,记录了每个视频的开始和结束编号。
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-ALLOW-CACHE:YES
#EXT-X-TARGETDURATION:10
#EXTINF:10.000000,
start_0-end_765064-record.gv.ts
#EXTINF:10.000000,
start_765064-end_1769567-record.gv.ts
#EXTINF:10.000000,
start_1769567-end_2600798-record.gv.ts
#EXTINF:10.000000,
start_2600798-end_3593502-record.gv.ts
#EXTINF:10.000000,
start_3593502-end_4500784-record.gv.ts
#EXTINF:10.000000,
start_4500784-end_5399861-record.gv.ts
#EXTINF:10.000000,
start_5399861-end_6288622-record.gv.ts
#EXTINF:10.000000,
start_6288622-end_7044459-record.gv.ts
#EXTINF:10.000000,
start_7044459-end_7878487-record.gv.ts
#EXTINF:10.000000,
start_7878487-end_8811793-record.gv.ts
#EXTINF:10.000000,
因此,下载视频的关键是获取m3u8文件,通过该视频的m3u8文件分段下载视频。
手动找到了m3u8的下载地址,还没有研究如何通过视频地址自动解析m3u8地址。查找方法很简单,或者在 Chrome 的网络控制台中查找。打开网络控制台,刷新页面,可以找到如图所示的m3u8文件。查看m3u8文件的相关信息,可以看到红框圈出的地址就是这个视频的m3u8下载地址。
对比两个地址可以发现,文件名前的地址是一样的,视频下载地址是“红色标记的地址”+“m3u8文件中列出的视频片段文件名”:
所以可以将这部分地址设置为:urlroot =
为了方便下载其他视频时动态修改,改为动态截取:
url = input("请输入m3u8文件地址:")
urlRoot=self.url[0:url.rindex('/')]
2.批量下载ts视频片段
这一步使用上一步拼接的地址循环下载ts视频。下载时,使用登录时创建的会话进行下载。
Session就是会话的意思,它让服务器“识别”客户端。一个简单的理解就是把每一个客户端-服务器交互都当作一个“会话”。由于在同一个“会话”中,服务器自然可以知道客户端是否登录。代码如下:
client = requests.Session()
client.post(PostUrl,postData) #登录
resp = client.get(download_path) #下载
分片拼接的方法:下载第一个ts分片后,直接在文件后面继续写第二个ts分片,以此类推。而不是创建要写入的新文件。结合验证码登录,完整代码如下:
import requests
from PIL import Image
import sys
import m3u8
import time
import os
#用户名-密码-验证码方式,登录
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #获取验证码地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登录信息地址
client = requests.Session()
username = '526257482@qq.com'
password = 'dashuju_9514'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #将验证码图片保存至本地
img = Image.open('login.jpg')
img.show() #打开图片
code = input("请输入验证码: \n") #输入验证码
postData = { #构造POST表单
'email': username,
'pwd': password,
'validateCode': code,
'x': '56',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表单
#循环下载ts视频
class VideoCrawler():
def __init__(self,url):
super(VideoCrawler, self).__init__()
self.url=url
self.final_path=r"D:\Download\Film"
#下载并解析m3u8文件
def get_url_from_m3u8(self,readAdr):
print("正在解析真实下载地址...")
with open('temp.m3u8','wb') as file:
file.write(requests.get(readAdr).content)
m3u8Obj=m3u8.load('temp.m3u8')
print("解析完成")
return m3u8Obj.segments
def run(self):
print("Start!")
start_time=time.time()
realAdr = self.url #m3u8下载地址
urlList=self.get_url_from_m3u8(realAdr) #解析m3u8文件,获取下载地址
urlRoot=self.url[0:self.url.rindex('/')]
i=1
outputfile=open(os.path.join(self.final_path,'%s.ts'%self.fileName),'wb')#初始创建一个ts文件,之后每次循环将ts片段的文件流写入此文件中从而不需要在去合并ts文件
for url in urlList:
try:
download_path = "%s/%s" % (urlRoot, url.uri) #拼接地址
resp = client.get(download_path) #使用拼接地址去爬取数据
progess = i/len(urlList)#记录当前的爬取进度
outputfile.write(resp.content) #将爬取到ts片段的文件流写入刚开始创建的ts文件中
sys.stdout.write('\r正在下载:{},进度:{:.2%}'.format(self.fileName,progess))#通过百分比显示下载进度
sys.stdout.flush()#通过此方法将上一行代码刷新,控制台只保留一行
except Exception as e:
print("\n出现错误:%s",e.args)
continue#出现错误跳出当前循环,继续下次循环
i+=1
outputfile.close()
print("下载完成!总共耗时%d s"%(time.time()-start_time))
print("开始转换视频格式!")
success = os.system(r'copy /b D:\Download\Film\{0}.ts D:\Download\Film\{0}.mp4'.format(self.fileName)) #ts转成mp4格式
if (not success):
print("格式转换成功!")
os.remove(self.final_path+'\\'+self.fileName+".ts") #删除ts和m3u8临时文件
os.remove("temp.m3u8")
if __name__=='__main__':
m3u8_addr = input("输入m3u8文件下载地址:\n")
crawler=VideoCrawler(m3u8_addr)
crawler.fileName = input("输入文件名:\n")
crawler.run()
quitClick=input("请按Enter键确认退出!")
三、总结
代码可以实现分段加载视频的爬取功能,还有很多细节需要改进,比如:
至此,这篇关于Python爬虫爬取ts片段视频+验证码登录功能的文章文章就介绍到这里了。更多相关Python爬虫爬取视频内容,请搜索脚本之家以前的文章或继续浏览以下相关文章希望大家以后多多支持脚本之家!
网页视频抓取脚本(谷歌浏览器(火狐)网页视频上传教程,直接使用脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-03-04 11:02
网页视频抓取脚本:人人小站上传网页视频教程,像站长一样为自己的视频上传以及采集生成一款属于自己的脚本,在流量来的时候,直接使用脚本就可以获取到想要的流量,不用再费劲去下载app进行导入流量。步骤1:首先准备三个浏览器。1.谷歌浏览器(谷歌浏览器上传视频教程:人人小站上传谷歌浏览器视频教程)2.火狐浏览器(火狐浏览器上传网页视频教程:人人小站上传火狐浏览器视频教程)3.ie浏览器ie浏览器视频上传教程:人人小站视频上传软件下载:人人小站上传视频教程:人人小站视频上传的视频到g+_我的视频脚本里下载:人人小站上传视频教程:人人小站视频上传的视频到filch_it的脚本文件里下载:第二步:准备一张高清的图片。
3张高清图片可以在网页上的图片上添加联系方式,鼠标放上去鼠标右键复制到图片中,下载成功之后,放到网页上,选择放大按钮即可,不会导致图片变形。(ps:vps用户可以使用图片,和数据库结合使用,详细教程请见百度文库)。第三步:在你的谷歌浏览器上下载,或者直接用浏览器,找到这个进入地址:“/videos/”,弹出下载框,下载即可,如果需要安装python,可以在选项选项里面禁用自动播放视频。
google搜索r-b-orb. 查看全部
网页视频抓取脚本(谷歌浏览器(火狐)网页视频上传教程,直接使用脚本)
网页视频抓取脚本:人人小站上传网页视频教程,像站长一样为自己的视频上传以及采集生成一款属于自己的脚本,在流量来的时候,直接使用脚本就可以获取到想要的流量,不用再费劲去下载app进行导入流量。步骤1:首先准备三个浏览器。1.谷歌浏览器(谷歌浏览器上传视频教程:人人小站上传谷歌浏览器视频教程)2.火狐浏览器(火狐浏览器上传网页视频教程:人人小站上传火狐浏览器视频教程)3.ie浏览器ie浏览器视频上传教程:人人小站视频上传软件下载:人人小站上传视频教程:人人小站视频上传的视频到g+_我的视频脚本里下载:人人小站上传视频教程:人人小站视频上传的视频到filch_it的脚本文件里下载:第二步:准备一张高清的图片。
3张高清图片可以在网页上的图片上添加联系方式,鼠标放上去鼠标右键复制到图片中,下载成功之后,放到网页上,选择放大按钮即可,不会导致图片变形。(ps:vps用户可以使用图片,和数据库结合使用,详细教程请见百度文库)。第三步:在你的谷歌浏览器上下载,或者直接用浏览器,找到这个进入地址:“/videos/”,弹出下载框,下载即可,如果需要安装python,可以在选项选项里面禁用自动播放视频。
google搜索r-b-orb.
网页视频抓取脚本(w3school在线教程网站构建初级教程建站手册编程关于W3School帮助HTML文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-02 13:06
w3school 在线教程
网站构建初学者教程
网站建设者编程关于 W3School 帮助W3School
服务器端脚本初学者教程
HTML 文件可以收录文本、HTML 标记和脚本。
HTML 文件中的脚本可以在 Web 服务器上执行。
服务器端脚本
服务器端脚本是对服务器行为的编程。这称为服务器端脚本或服务器端脚本。
客户端脚本是浏览器行为的编程。(看)。
什么是服务器脚本?
通常,当浏览器请求 HTML 文件时,服务器会返回该文件,但如果该文件收录服务器端脚本,则会先执行 HTML 文件中的脚本,然后将 HTML 文件作为纯 HTML 返回给浏览器。
服务器脚本可以做什么?
重要提示:由于脚本是在服务器上执行的,所以浏览器可以在没有脚本支持的情况下显示服务器端文件!
ASP 和 PHP
在 W3School,我们使用 Active Server Pages (ASP) 和超文本预处理器 (PHP) 演示服务器端脚本。
看源代码不能看ASP或PHP的源代码,你看到的只是服务器的输出,纯HTML。这是因为脚本在结果以纯 HTML 形式发送到浏览器之前在服务器上执行。
ASP 实例
通过 ASP 编写文本
如何通过 ASP 编写文本。
将 HTML 添加到文本
如何通过 HTML 标签格式化文本。
脚本教程
请学习我们完整的 ASP 教程和 PHP 教程。
W3School简体中文版提供的内容仅供培训和测试之用,不保证内容的正确性。与使用本网站内容相关的风险与本网站无关。版权所有,保留所有权利。 查看全部
网页视频抓取脚本(w3school在线教程网站构建初级教程建站手册编程关于W3School帮助HTML文件)
w3school 在线教程
网站构建初学者教程
网站建设者编程关于 W3School 帮助W3School
服务器端脚本初学者教程
HTML 文件可以收录文本、HTML 标记和脚本。
HTML 文件中的脚本可以在 Web 服务器上执行。
服务器端脚本
服务器端脚本是对服务器行为的编程。这称为服务器端脚本或服务器端脚本。
客户端脚本是浏览器行为的编程。(看)。
什么是服务器脚本?
通常,当浏览器请求 HTML 文件时,服务器会返回该文件,但如果该文件收录服务器端脚本,则会先执行 HTML 文件中的脚本,然后将 HTML 文件作为纯 HTML 返回给浏览器。
服务器脚本可以做什么?
重要提示:由于脚本是在服务器上执行的,所以浏览器可以在没有脚本支持的情况下显示服务器端文件!
ASP 和 PHP
在 W3School,我们使用 Active Server Pages (ASP) 和超文本预处理器 (PHP) 演示服务器端脚本。
看源代码不能看ASP或PHP的源代码,你看到的只是服务器的输出,纯HTML。这是因为脚本在结果以纯 HTML 形式发送到浏览器之前在服务器上执行。
ASP 实例
通过 ASP 编写文本
如何通过 ASP 编写文本。
将 HTML 添加到文本
如何通过 HTML 标签格式化文本。
脚本教程
请学习我们完整的 ASP 教程和 PHP 教程。
W3School简体中文版提供的内容仅供培训和测试之用,不保证内容的正确性。与使用本网站内容相关的风险与本网站无关。版权所有,保留所有权利。
网页视频抓取脚本(好用到,谁用谁知道一键抓取网页图片脚本工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-27 10:04
)
一键抓取网页图片脚本工具是一款作用于谷歌内核浏览器的软件。可以抓取当前页面的所有图片,甚至包括背景图片等图片,非常方便又省钱。时间。欢迎有需要的朋友下载使用。
软件介绍
一键截取网页上的所有图片,可以根据大小过滤下载,支持运行在chromium(chrome环境下开发)及其衍生浏览器(如:360安全浏览器、360极速浏览器、猎豹)浏览器、百度浏览器、UC浏览器等)。好用,谁知道谁用
crx文件安装教程
1、找到刚才下载的后缀为.crx的插件,修改后缀为压缩格式,如.rar或.zip,如下图:
2、选择【是】完成修改,然后解压刚才的.zip压缩文件,会得到一个文件夹。如下所示:
3、在Chrome浏览器扩展界面中,选择【加载解压扩展】,在弹出的窗口中选择刚刚解压的文件夹。注意这里是根目录,不要选中,如下图:
热键
Alt Shift + Y chrome 全局提取本页图片并修改
Alt + H 过滤页面切换菜单项 否
Alt + S 打开/关闭过滤页面 按大小排序 否
Alt + I 过滤页面打开/关闭下标分辨率信息 否,详见下图
使用说明
软件默认点击预览,不喜欢的可以在设置中自行设置。
查看全部
网页视频抓取脚本(好用到,谁用谁知道一键抓取网页图片脚本工具
)
一键抓取网页图片脚本工具是一款作用于谷歌内核浏览器的软件。可以抓取当前页面的所有图片,甚至包括背景图片等图片,非常方便又省钱。时间。欢迎有需要的朋友下载使用。
软件介绍
一键截取网页上的所有图片,可以根据大小过滤下载,支持运行在chromium(chrome环境下开发)及其衍生浏览器(如:360安全浏览器、360极速浏览器、猎豹)浏览器、百度浏览器、UC浏览器等)。好用,谁知道谁用
crx文件安装教程
1、找到刚才下载的后缀为.crx的插件,修改后缀为压缩格式,如.rar或.zip,如下图:
2、选择【是】完成修改,然后解压刚才的.zip压缩文件,会得到一个文件夹。如下所示:
3、在Chrome浏览器扩展界面中,选择【加载解压扩展】,在弹出的窗口中选择刚刚解压的文件夹。注意这里是根目录,不要选中,如下图:
热键
Alt Shift + Y chrome 全局提取本页图片并修改
Alt + H 过滤页面切换菜单项 否
Alt + S 打开/关闭过滤页面 按大小排序 否
Alt + I 过滤页面打开/关闭下标分辨率信息 否,详见下图
使用说明
软件默认点击预览,不喜欢的可以在设置中自行设置。
网页视频抓取脚本(之前做聊天室时,介绍如何使用HtmlTag抓取网页的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2022-02-27 10:02
之前做聊天室的时候,因为聊天室提供的新闻阅读功能,写了一个类,从网页中抓取信息(如最新的头条新闻、新闻来源、标题、内容等)。本文将介绍如何使用该类从网页中抓取您需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:
源代码下载 查看全部
网页视频抓取脚本(之前做聊天室时,介绍如何使用HtmlTag抓取网页的信息)
之前做聊天室的时候,因为聊天室提供的新闻阅读功能,写了一个类,从网页中抓取信息(如最新的头条新闻、新闻来源、标题、内容等)。本文将介绍如何使用该类从网页中抓取您需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:
源代码下载
网页视频抓取脚本(TampermonkeyTampermonkey官网Tampermonkey安装指导参考二、4、2、5 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 1177 次浏览 • 2022-02-27 08:21
)
一、准备工具
(1)浏览器:360,或者谷歌,火狐
(2)插件工具:Tampermonkey
Tampermonkey官网
Tampermonkey 安装指南参考
二、具体配置过程
本文以360浏览器为例,详细介绍配置过程。
1.通过Tampermonkey面板,跳转到脚本获取页面
安装Tampermonkey插件后,浏览器右上角会出现如下图的标签,左键点击,在出现的弹框中选择“Get New Script”。
2. Tampermonkey推荐js脚本获取与安装
获取方式有-Userscript.Zone Search、GreasyFork、GitHub/Gist、OpenUserJS等。我个人倾向于使用GreasyFork。
3.搜索关键词,安装脚本
在搜索结果中选择一个js脚本(更新日期最新的更好),如“破解VIP分析、VIP会员视频自动分析”等,点击链接进入脚本详情页面,点击“安装此脚本”,然后再次点击“安装”。
4 进入 Tampermonkey 面板,检查脚本是否正常启用
三、验证结果
打开视频网站,点击任意VIP会员视频,还是无法观看。 . .
别着急,请仔细看右边,js脚本生成的视频链接会比较多(如果安装了多个脚本,可能会有多个视频链接)
打开视频的外部链接,即可免费观看VIP视频! ! !
查看全部
网页视频抓取脚本(TampermonkeyTampermonkey官网Tampermonkey安装指导参考二、4、2、5
)
一、准备工具
(1)浏览器:360,或者谷歌,火狐
(2)插件工具:Tampermonkey
Tampermonkey官网
Tampermonkey 安装指南参考
二、具体配置过程
本文以360浏览器为例,详细介绍配置过程。
1.通过Tampermonkey面板,跳转到脚本获取页面
安装Tampermonkey插件后,浏览器右上角会出现如下图的标签,左键点击,在出现的弹框中选择“Get New Script”。
2. Tampermonkey推荐js脚本获取与安装
获取方式有-Userscript.Zone Search、GreasyFork、GitHub/Gist、OpenUserJS等。我个人倾向于使用GreasyFork。
3.搜索关键词,安装脚本
在搜索结果中选择一个js脚本(更新日期最新的更好),如“破解VIP分析、VIP会员视频自动分析”等,点击链接进入脚本详情页面,点击“安装此脚本”,然后再次点击“安装”。
4 进入 Tampermonkey 面板,检查脚本是否正常启用
三、验证结果
打开视频网站,点击任意VIP会员视频,还是无法观看。 . .
别着急,请仔细看右边,js脚本生成的视频链接会比较多(如果安装了多个脚本,可能会有多个视频链接)
打开视频的外部链接,即可免费观看VIP视频! ! !
网页视频抓取脚本(搜索引擎垃圾索引什么是搜索引擎营销营销营销营销)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-26 18:13
搜索引擎索引
搜索引擎索引搜索引擎索引采集、解析和存储数据以促进快速准确的信息检索。索引设计融合了语言学、认知心理学、数学、信息学和计算机科学的跨学科概念。在用于在 Internet 上查找网页的搜索引擎的上下文中,此过程的另一个名称是网络索引。流行的引擎专注于在线自然语言文档的全文索引...
搜索引擎垃圾邮件
什么是搜索引擎垃圾邮件索引?搜索引擎垃圾邮件索引,也称为引擎垃圾邮件,是搜索引擎被不恰当地定向到预定站点的情况,是黑帽SEO的常用方法之一。通过搜索引擎垃圾邮件索引,当用户在互联网上搜索时,他们访问了某些网站和网页,这种机制破坏了搜索结果的正常排名顺序,并显示了不相关的链接,违反了搜索引擎道德。坏的意思。搜索引擎垃圾邮件通常...
搜索引擎
搜索引擎定义搜索引擎是指按照一定的策略采集互联网上的信息并使用特定的计算机程序的系统。对信息进行组织处理后,是一个为用户提供检索服务的系统。搜索引擎由四部分组成:搜索器、索引器、爬虫和用户界面。搜索者的功能是漫游互联网,发现和采集信息。索引器的功能是了解搜索...
搜索引擎市场
搜索引擎营销 搜索引擎营销的基本思想是通过点击进入网站/网页,让用户发现信息,了解更多他需要的信息。在引入搜索引擎策略时,一般认为搜索引擎优化设计的主要目标有两个层次:被搜索引擎搜索收录,在搜索结果中排名靠前。这已经是常识问题,大多数网络营销人员和专业服务提供商都将搜索引擎的目标设定在这个级别。但是从... 查看全部
网页视频抓取脚本(搜索引擎垃圾索引什么是搜索引擎营销营销营销营销)
搜索引擎索引
搜索引擎索引搜索引擎索引采集、解析和存储数据以促进快速准确的信息检索。索引设计融合了语言学、认知心理学、数学、信息学和计算机科学的跨学科概念。在用于在 Internet 上查找网页的搜索引擎的上下文中,此过程的另一个名称是网络索引。流行的引擎专注于在线自然语言文档的全文索引...
搜索引擎垃圾邮件
什么是搜索引擎垃圾邮件索引?搜索引擎垃圾邮件索引,也称为引擎垃圾邮件,是搜索引擎被不恰当地定向到预定站点的情况,是黑帽SEO的常用方法之一。通过搜索引擎垃圾邮件索引,当用户在互联网上搜索时,他们访问了某些网站和网页,这种机制破坏了搜索结果的正常排名顺序,并显示了不相关的链接,违反了搜索引擎道德。坏的意思。搜索引擎垃圾邮件通常...
搜索引擎
搜索引擎定义搜索引擎是指按照一定的策略采集互联网上的信息并使用特定的计算机程序的系统。对信息进行组织处理后,是一个为用户提供检索服务的系统。搜索引擎由四部分组成:搜索器、索引器、爬虫和用户界面。搜索者的功能是漫游互联网,发现和采集信息。索引器的功能是了解搜索...
搜索引擎市场
搜索引擎营销 搜索引擎营销的基本思想是通过点击进入网站/网页,让用户发现信息,了解更多他需要的信息。在引入搜索引擎策略时,一般认为搜索引擎优化设计的主要目标有两个层次:被搜索引擎搜索收录,在搜索结果中排名靠前。这已经是常识问题,大多数网络营销人员和专业服务提供商都将搜索引擎的目标设定在这个级别。但是从...
网页视频抓取脚本( 2018年09月20日08:37:03投稿:laozhang爬取头条)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-23 07:27
2018年09月20日08:37:03投稿:laozhang爬取头条)
节点批量抓取头条视频并保存方法
更新时间:2018-09-20 08:37:03 投稿:老张
在这篇文章中,我们介绍节点抓取头条视频并批量保存的方法。有需要的朋友可以测试以下。
介绍
批量爬取视频或图片的一般套路是使用爬虫获取一组文件链接,然后通过writeFile等方法将文件一个一个保存。但是,头条的视频无法捕捉到需要爬取的html文件(服务器端渲染输出)中的视频链接。视频链接是在客户端渲染页面时,通过一些js文件中的算法或解密方法,根据视频的已知key或hash值,动态计算并添加到video标签中的。这也是网站的防爬措施。
当我们浏览这些页面时,我们可以通过审计元素看到计算出来的文件地址。但是,在批量下载的时候,手动一个一个的获取视频链接显然是不可取的。令人高兴的是,puppeteer 提供了模拟访问 Chrome 的能力,允许我们抓取浏览器呈现的最终页面。
项目开始
命令
npm i
npm start
注意:安装puppeteer的过程有点慢,请耐心等待。
配置文件
// 配置相关
module.exports = {
originPath: 'https://www.ixigua.com', // 页面请求地址
savePath: 'D:/videoZZ' // 存放路径
}
技术点
傀儡师
官方 API
puppeteer 提供了一个高级 API 来控制 Chrome 或 Chromium。
傀儡师的主要作用:
从网页生成 PDF 和图片
抓取 SPA 应用程序并生成预渲染内容(即“SSR”服务器端渲染)
可以从 网站 抓取内容
自动化表单提交、UI 测试、键盘输入等
使用的 API:
puppeteer.launch() 启动浏览器实例
browser.newPage() 创建一个新页面
page.goto() 转到指定网页
page.screenshot() 截图
page.waitFor() 页面等待,可以是时间,一个元素,一个函数
page.$eval() 获取指定元素,相当于 document.querySelector
page.$$eval() 获取某种类型的元素,相当于 document.querySelectorAll
page.$('#id .className') 获取文档中的一个元素,类似于jQuery
代码示例
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
视频文件下载方法
下载视频大师方法
const downloadVideo = async video => {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.src, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
获取视频数据
getVideoData (url, encoding) {
return new Promise((resolve, reject) => {
let req = http.get(url, function (res) {
let result = ''
encoding && res.setEncoding(encoding)
res.on('data', function (d) {
result += d
})
res.on('end', function () {
resolve(result)
})
res.on('error', function (e) {
reject(e)
})
})
req.end()
})
}
将视频数据保存到本地
savefileToPath (fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
目标网站:西瓜视频
项目功能:下载标题下的最新20个视频【微臣财经】
项目地址:Github地址 查看全部
网页视频抓取脚本(
2018年09月20日08:37:03投稿:laozhang爬取头条)
节点批量抓取头条视频并保存方法
更新时间:2018-09-20 08:37:03 投稿:老张
在这篇文章中,我们介绍节点抓取头条视频并批量保存的方法。有需要的朋友可以测试以下。
介绍
批量爬取视频或图片的一般套路是使用爬虫获取一组文件链接,然后通过writeFile等方法将文件一个一个保存。但是,头条的视频无法捕捉到需要爬取的html文件(服务器端渲染输出)中的视频链接。视频链接是在客户端渲染页面时,通过一些js文件中的算法或解密方法,根据视频的已知key或hash值,动态计算并添加到video标签中的。这也是网站的防爬措施。
当我们浏览这些页面时,我们可以通过审计元素看到计算出来的文件地址。但是,在批量下载的时候,手动一个一个的获取视频链接显然是不可取的。令人高兴的是,puppeteer 提供了模拟访问 Chrome 的能力,允许我们抓取浏览器呈现的最终页面。
项目开始
命令
npm i
npm start
注意:安装puppeteer的过程有点慢,请耐心等待。
配置文件
// 配置相关
module.exports = {
originPath: 'https://www.ixigua.com', // 页面请求地址
savePath: 'D:/videoZZ' // 存放路径
}
技术点
傀儡师
官方 API
puppeteer 提供了一个高级 API 来控制 Chrome 或 Chromium。
傀儡师的主要作用:
从网页生成 PDF 和图片
抓取 SPA 应用程序并生成预渲染内容(即“SSR”服务器端渲染)
可以从 网站 抓取内容
自动化表单提交、UI 测试、键盘输入等
使用的 API:
puppeteer.launch() 启动浏览器实例
browser.newPage() 创建一个新页面
page.goto() 转到指定网页
page.screenshot() 截图
page.waitFor() 页面等待,可以是时间,一个元素,一个函数
page.$eval() 获取指定元素,相当于 document.querySelector
page.$$eval() 获取某种类型的元素,相当于 document.querySelectorAll
page.$('#id .className') 获取文档中的一个元素,类似于jQuery
代码示例
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
视频文件下载方法
下载视频大师方法
const downloadVideo = async video => {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.src, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
获取视频数据
getVideoData (url, encoding) {
return new Promise((resolve, reject) => {
let req = http.get(url, function (res) {
let result = ''
encoding && res.setEncoding(encoding)
res.on('data', function (d) {
result += d
})
res.on('end', function () {
resolve(result)
})
res.on('error', function (e) {
reject(e)
})
})
req.end()
})
}
将视频数据保存到本地
savefileToPath (fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
目标网站:西瓜视频
项目功能:下载标题下的最新20个视频【微臣财经】
项目地址:Github地址
网页视频抓取脚本(爬取网站的几种应用框架,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-23 04:23
1、Scrapy
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。使用此框架可以轻松爬取亚马逊列表等数据。
2、PySpider
pyspider 是一个用 python 实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用通用数据库存储爬取结果。可以定期设置任务和任务优先级。
3、克劳利
Crawley可以高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
4、波西亚
Portia 是一个开源的可视化爬虫工具,让你无需任何编程知识即可爬取网站!只需对您感兴趣的页面进行注释,Portia 就会创建一个爬虫来从相似页面中提取数据。
5、报纸
报纸可用于提取新闻、文章 和内容分析。使用多线程,支持10多种语言等。
6美汤
Beautiful Soup 是一个 Python 库,用于从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的营业时间
7、抢
Grab 是一个用于构建网络爬虫的 Python 框架。使用 Grab,您可以构建各种复杂的网络爬虫,从简单的 5 行脚本到处理数百万网页的复杂异步网站爬虫。Grab 提供了一个用于执行网络请求和处理接收到的内容的 API,例如与 HTML 文档的 DOM 树进行交互。#grab-spider-用户手册
8、可乐
Cola 是一个分布式爬虫框架。对于用户来说,只需要编写几个具体的功能,无需关注分布式操作的细节。任务自动分发到多台机器上,整个过程对用户透明。 查看全部
网页视频抓取脚本(爬取网站的几种应用框架,你了解多少?)
1、Scrapy
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。使用此框架可以轻松爬取亚马逊列表等数据。
2、PySpider
pyspider 是一个用 python 实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用通用数据库存储爬取结果。可以定期设置任务和任务优先级。
3、克劳利
Crawley可以高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
4、波西亚
Portia 是一个开源的可视化爬虫工具,让你无需任何编程知识即可爬取网站!只需对您感兴趣的页面进行注释,Portia 就会创建一个爬虫来从相似页面中提取数据。
5、报纸
报纸可用于提取新闻、文章 和内容分析。使用多线程,支持10多种语言等。
6美汤
Beautiful Soup 是一个 Python 库,用于从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的营业时间
7、抢
Grab 是一个用于构建网络爬虫的 Python 框架。使用 Grab,您可以构建各种复杂的网络爬虫,从简单的 5 行脚本到处理数百万网页的复杂异步网站爬虫。Grab 提供了一个用于执行网络请求和处理接收到的内容的 API,例如与 HTML 文档的 DOM 树进行交互。#grab-spider-用户手册
8、可乐
Cola 是一个分布式爬虫框架。对于用户来说,只需要编写几个具体的功能,无需关注分布式操作的细节。任务自动分发到多台机器上,整个过程对用户透明。
网页视频抓取脚本(利用百度AI开发平台的OCR文字识别API也可以识别 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-22 13:22
)
一、Selenium 网页截图,图片定位二次精准截图
第三方模块“selenium”用于 Python 自动化与 Web 浏览器交互。
1.安装模块 pip install selenium
2.安装对应版本浏览器的驱动
谷歌查看浏览器版本访问“chrome://version/”
google驱动下载地址
注意下载解压后的驱动放在系统环境变量PATH的路径下
3. 代码如下:
# -*- coding:utf-8 -*-
from selenium import webdriver
import easyocr
import time
from PIL import Image
def screenshots(): # 访问网页截屏
driver = webdriver.Chrome() # 初始化一个谷歌浏览器实例
driver.maximize_window() # 打开最大窗口
driver.get("http://quote.eastmoney.com/sh600797.html") # 访问网页
js = "var q=document.documentElement.scrollTop=500" # 下拉500个像素
driver.execute_script(js) # 执行下拉500个像素操作
time.sleep(3)
driver.get_screenshot_as_file(
r"C:\Zzlong\%s.png" % time.strftime('%Y-%m-%d %H-%M', time.localtime(time.time()))
) # 截图保存为C:\Zzlong\2022-02-20 17-30.png
driver.quit() #关闭浏览器
# imgelement = driver.find_element_by_id('rgt1')
# imgelement = driver.find_element_by_class_name('line24')
# location = imgelement.location
# print(location) # {'x': 1104, 'y': 917}
# size = imgelement.size
# print(size) # {'height': 12, 'width': 26}
def crop(): # 定位 二次截图
picture = Image.open(
r"C:\Zzlong\%s.png" % time.strftime('%Y-%m-%d %H-%M', time.localtime(time.time()))
) # 打开第一次的截图
picture = picture.crop((1320,520,1450,550)) # 定位二次截图
# 注意: crop截图规则,(宽 - x坐标)为截图的宽位置 (高 - y坐标)为截图的高位置,坐标(0,0)位于左上角
picture.save(
r"C:\Zzlong\img%s.png" % time.strftime('%Y-%m-%d %H-%M', time.localtime(time.time()))
) # 保存图片
# print(picture.size) # 输出宽、高 (1920, 888)
# picture = picture.crop((0, 0, 1920, 888)) # 截取全图(x坐标,y坐标,宽,高)
二、easyocr 提取图片文本
Python-EasyOCR 中有一个很好的 OCR 库,在 GitHub 上有 9700stars。它可以在python中调用以识别图像中的文本并输出为文本。
安装过程比较简单,使用pip或者conda安装。
pip install easyocr
如果您使用 PyPl 源代码,安装可能需要一些时间。建议您使用清华源安装,几秒钟即可安装。
指示
EasyOCR的使用非常简单,分为三个步骤:
# 导入easyocr
import easyocr
# 创建reader对象
reader = easyocr.Reader(['ch_sim','en'])
# 读取图像
result = reader.readtext('test.jpg')
# 结果
print(result)
# 使用easyocr报错“Unknown C++ exception from OpenCV code,CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU. ”
# Python与CUDA版本不对应,导致Python安装的OpenCV版本与CUDA版本不照应
# pip install opencv-python==4.3.0.38 -i https://pypi.tuna.tsinghua.edu.cn/simple
这段代码有个参数['ch_sim','en'],就是要识别的语言列表(所有语言列表都放在文章的底部),因为里面有中文和英文路牌,所以将列表添加到列表 ch_sim(简体中文),en(英文)。
识别文本的准确率还是很高的,然后提取文本部分。
for i in result:
word = i[1]
print(word)
三、使用百度AI开发平台的OCR文字识别API也可以识别提取图片中的文字。
首先我们需要一个百度账号,然后打开百度AI开放平台()并登录,点击“控制台”,在左侧栏输入“文本识别”,创建一个应用,记住你的AppID、API Key和Secret Key .
然后,我们在cmd窗口中安装百度ai界面的库。
pip install baidu—aip
好了,基本的工作已经到这里了。接下来是文本识别和提取的核心部分:
def baiduOCR(picfile, outfile): #想要利用百度api识别文本,我们需要设置: #1、图片文件名为:picfile #2、输出文件为:outfile filename = path.basename(picfile) #接下来,我们需要将刚刚获取的ID、KEY和SECRECT KEY填入 APP_ID = '****' # 刚才获取的 ID,下同 API_KEY = '****' SECRECT_KEY = '****' client = AipOcr(APP_ID, API_KEY, SECRECT_KEY) #接下来,打开并识别图片信息 i = open(picfile, 'rb') img = i.read() print("正在识别图片:\t" + filename) #在这里,我们有两种识别方法:通用识别、高精度识别message = client.basicGeneral(img)#通用文字识别,每天50000次免费#message =client.basicAccurate(img)#通用文字高精度识别,每天800次免费 print("识别成功!") i.close();
以上就是使用百度api文本识别提取的识别部分。接下来,您只需要提取提取的文本。
要提取识别的文本,我们需要做以下设置:
with open(outfile, 'a+') as fo: fo.writelines("+" * 60 + '\n') fo.writelines("识别图片:\t" + filename + "\n" * 2) fo.writelines("文本内容:\n") # 输出文本内容 for text in message.get('words_result'): fo.writelines(text.get('words') + '\n') fo.writelines('\n'*2) print("文本导出成功!") print()
现在我们导入一张手机拍的照片:
识别结果:
从结果可以看出,精读的识别度非常高,效果非常好。
详细步骤请参考代码和注释:
import glob
from os import path
import os
from aip import AipOcr
from PIL import Image
def convertimg(picfile, outdir):
'''调整图片大小,对于过大的图片进行压缩
picfile: 图片路径
outdir:图片输出路径
'''
img = Image.open(picfile)
width, height = img.size
while(width*height > 4000000): # 该数值压缩后的图片大约两百多k
width = width // 2
height = height // 2
new_img=img.resize((width, height),Image.BILINEAR)
new_img.save(path.join(outdir,os.path.basename(picfile)))
def baiduOCR(picfile, outfile):
#想要利用百度api识别文本,我们需要设置:
#1、图片文件名为:picfile
#2、输出文件为:outfile
filename = path.basename(picfile)
#接下来,我们需要将刚刚获取的ID、KEY和SECRECT KEY填入
APP_ID = '****' # 刚才获取的 ID,下同
API_KEY = '****'
SECRECT_KEY = '****'
client = AipOcr(APP_ID, API_KEY, SECRECT_KEY)
#接下来,打开并识别图片信息
i = open(picfile, 'rb')
img = i.read()
print("正在识别图片:\t" + filename)
#在这里,我们有两种识别方法:通用识别、高精度识别
message = client.basicGeneral(img) # 通用文字识别,每天 50 000 次免费
#message = client.basicAccurate(img) # 通用文字高精度识别,每天 800 次免费
print("识别成功!")
i.close();
#以上即为识别过程
#想要将识别的文字提取出来,我们需要做以下设置:
with open(outfile, 'a+') as fo:
fo.writelines("+" * 60 + '\n')
fo.writelines("识别图片:\t" + filename + "\n" * 2)
fo.writelines("文本内容:\n")
# 输出文本内容
for text in message.get('words_result'):
fo.writelines(text.get('words') + '\n')
fo.writelines('\n'*2)
print("文本导出成功!")
print()
if __name__ == "__main__":
outfile = 'export.txt'
outdir = 'tmp'
if path.exists(outfile):
os.remove(outfile)
if not path.exists(outdir):
os.mkdir(outdir)
print("压缩过大的图片...")
#首先对过大的图片进行压缩,以提高识别速度,将压缩的图片保存与临时文件夹中
for picfile in glob.glob("picture/*"):
convertimg(picfile, outdir)
print("图片识别...")
for picfile in glob.glob("tmp/*"):
baiduOCR(picfile, outfile)
os.remove(picfile)
print('图片文本提取结束!文本输出结果位于 %s 文件中。' % outfile)
os.removedirs(outdir)
查看全部
网页视频抓取脚本(利用百度AI开发平台的OCR文字识别API也可以识别
)
一、Selenium 网页截图,图片定位二次精准截图
第三方模块“selenium”用于 Python 自动化与 Web 浏览器交互。
1.安装模块 pip install selenium
2.安装对应版本浏览器的驱动
谷歌查看浏览器版本访问“chrome://version/”
google驱动下载地址
注意下载解压后的驱动放在系统环境变量PATH的路径下
3. 代码如下:
# -*- coding:utf-8 -*-
from selenium import webdriver
import easyocr
import time
from PIL import Image
def screenshots(): # 访问网页截屏
driver = webdriver.Chrome() # 初始化一个谷歌浏览器实例
driver.maximize_window() # 打开最大窗口
driver.get("http://quote.eastmoney.com/sh600797.html";) # 访问网页
js = "var q=document.documentElement.scrollTop=500" # 下拉500个像素
driver.execute_script(js) # 执行下拉500个像素操作
time.sleep(3)
driver.get_screenshot_as_file(
r"C:\Zzlong\%s.png" % time.strftime('%Y-%m-%d %H-%M', time.localtime(time.time()))
) # 截图保存为C:\Zzlong\2022-02-20 17-30.png
driver.quit() #关闭浏览器
# imgelement = driver.find_element_by_id('rgt1')
# imgelement = driver.find_element_by_class_name('line24')
# location = imgelement.location
# print(location) # {'x': 1104, 'y': 917}
# size = imgelement.size
# print(size) # {'height': 12, 'width': 26}
def crop(): # 定位 二次截图
picture = Image.open(
r"C:\Zzlong\%s.png" % time.strftime('%Y-%m-%d %H-%M', time.localtime(time.time()))
) # 打开第一次的截图
picture = picture.crop((1320,520,1450,550)) # 定位二次截图
# 注意: crop截图规则,(宽 - x坐标)为截图的宽位置 (高 - y坐标)为截图的高位置,坐标(0,0)位于左上角
picture.save(
r"C:\Zzlong\img%s.png" % time.strftime('%Y-%m-%d %H-%M', time.localtime(time.time()))
) # 保存图片
# print(picture.size) # 输出宽、高 (1920, 888)
# picture = picture.crop((0, 0, 1920, 888)) # 截取全图(x坐标,y坐标,宽,高)
二、easyocr 提取图片文本
Python-EasyOCR 中有一个很好的 OCR 库,在 GitHub 上有 9700stars。它可以在python中调用以识别图像中的文本并输出为文本。
安装过程比较简单,使用pip或者conda安装。
pip install easyocr
如果您使用 PyPl 源代码,安装可能需要一些时间。建议您使用清华源安装,几秒钟即可安装。
指示
EasyOCR的使用非常简单,分为三个步骤:
# 导入easyocr
import easyocr
# 创建reader对象
reader = easyocr.Reader(['ch_sim','en'])
# 读取图像
result = reader.readtext('test.jpg')
# 结果
print(result)
# 使用easyocr报错“Unknown C++ exception from OpenCV code,CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU. ”
# Python与CUDA版本不对应,导致Python安装的OpenCV版本与CUDA版本不照应
# pip install opencv-python==4.3.0.38 -i https://pypi.tuna.tsinghua.edu.cn/simple
这段代码有个参数['ch_sim','en'],就是要识别的语言列表(所有语言列表都放在文章的底部),因为里面有中文和英文路牌,所以将列表添加到列表 ch_sim(简体中文),en(英文)。
识别文本的准确率还是很高的,然后提取文本部分。
for i in result:
word = i[1]
print(word)
三、使用百度AI开发平台的OCR文字识别API也可以识别提取图片中的文字。
首先我们需要一个百度账号,然后打开百度AI开放平台()并登录,点击“控制台”,在左侧栏输入“文本识别”,创建一个应用,记住你的AppID、API Key和Secret Key .
然后,我们在cmd窗口中安装百度ai界面的库。
pip install baidu—aip
好了,基本的工作已经到这里了。接下来是文本识别和提取的核心部分:
def baiduOCR(picfile, outfile): #想要利用百度api识别文本,我们需要设置: #1、图片文件名为:picfile #2、输出文件为:outfile filename = path.basename(picfile) #接下来,我们需要将刚刚获取的ID、KEY和SECRECT KEY填入 APP_ID = '****' # 刚才获取的 ID,下同 API_KEY = '****' SECRECT_KEY = '****' client = AipOcr(APP_ID, API_KEY, SECRECT_KEY) #接下来,打开并识别图片信息 i = open(picfile, 'rb') img = i.read() print("正在识别图片:\t" + filename) #在这里,我们有两种识别方法:通用识别、高精度识别message = client.basicGeneral(img)#通用文字识别,每天50000次免费#message =client.basicAccurate(img)#通用文字高精度识别,每天800次免费 print("识别成功!") i.close();
以上就是使用百度api文本识别提取的识别部分。接下来,您只需要提取提取的文本。
要提取识别的文本,我们需要做以下设置:
with open(outfile, 'a+') as fo: fo.writelines("+" * 60 + '\n') fo.writelines("识别图片:\t" + filename + "\n" * 2) fo.writelines("文本内容:\n") # 输出文本内容 for text in message.get('words_result'): fo.writelines(text.get('words') + '\n') fo.writelines('\n'*2) print("文本导出成功!") print()
现在我们导入一张手机拍的照片:
识别结果:
从结果可以看出,精读的识别度非常高,效果非常好。
详细步骤请参考代码和注释:
import glob
from os import path
import os
from aip import AipOcr
from PIL import Image
def convertimg(picfile, outdir):
'''调整图片大小,对于过大的图片进行压缩
picfile: 图片路径
outdir:图片输出路径
'''
img = Image.open(picfile)
width, height = img.size
while(width*height > 4000000): # 该数值压缩后的图片大约两百多k
width = width // 2
height = height // 2
new_img=img.resize((width, height),Image.BILINEAR)
new_img.save(path.join(outdir,os.path.basename(picfile)))
def baiduOCR(picfile, outfile):
#想要利用百度api识别文本,我们需要设置:
#1、图片文件名为:picfile
#2、输出文件为:outfile
filename = path.basename(picfile)
#接下来,我们需要将刚刚获取的ID、KEY和SECRECT KEY填入
APP_ID = '****' # 刚才获取的 ID,下同
API_KEY = '****'
SECRECT_KEY = '****'
client = AipOcr(APP_ID, API_KEY, SECRECT_KEY)
#接下来,打开并识别图片信息
i = open(picfile, 'rb')
img = i.read()
print("正在识别图片:\t" + filename)
#在这里,我们有两种识别方法:通用识别、高精度识别
message = client.basicGeneral(img) # 通用文字识别,每天 50 000 次免费
#message = client.basicAccurate(img) # 通用文字高精度识别,每天 800 次免费
print("识别成功!")
i.close();
#以上即为识别过程
#想要将识别的文字提取出来,我们需要做以下设置:
with open(outfile, 'a+') as fo:
fo.writelines("+" * 60 + '\n')
fo.writelines("识别图片:\t" + filename + "\n" * 2)
fo.writelines("文本内容:\n")
# 输出文本内容
for text in message.get('words_result'):
fo.writelines(text.get('words') + '\n')
fo.writelines('\n'*2)
print("文本导出成功!")
print()
if __name__ == "__main__":
outfile = 'export.txt'
outdir = 'tmp'
if path.exists(outfile):
os.remove(outfile)
if not path.exists(outdir):
os.mkdir(outdir)
print("压缩过大的图片...")
#首先对过大的图片进行压缩,以提高识别速度,将压缩的图片保存与临时文件夹中
for picfile in glob.glob("picture/*"):
convertimg(picfile, outdir)
print("图片识别...")
for picfile in glob.glob("tmp/*"):
baiduOCR(picfile, outfile)
os.remove(picfile)
print('图片文本提取结束!文本输出结果位于 %s 文件中。' % outfile)
os.removedirs(outdir)
网页视频抓取脚本( 阿里云盘下载不限速怎么办?Python模板文件小编.html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2022-02-22 13:19
阿里云盘下载不限速怎么办?Python模板文件小编.html)
使用Python抓取阿里云盘资源
更新时间:2022-02-22 09:50:12 作者:百胜酱
与百度云盘相比,阿里云盘拥有无限下载速度和大容量空间,深受大家的喜爱。本文将使用 Python 抓取阿里云盘的资源。有兴趣的可以学习一下
内容
前段时间,阿里云盘风靡一时,大量存储空间被送出。而且阿里云盘下载是无限的,比百度网盘好很多。这两天看到一个第三方网站可以在阿里云盘上搜索资源,但是它的资源没有按时间排序。这种情况会导致已经在队列中很长时间的资源成为过时的资源。小编这里使用python进行爬取和重排。
网页分析
这个 网站 有两条搜索线:搜索线一和搜索线二。这个 文章 使用第二行搜索。
打开控制面板下的网络,一眼就能看到一个sea.html的get请求。
有几个参数,四个关键参数:
同样在控制面板中,可以看到网页跳转到阿里云盘获取标题上方的真实链接。使用bs4解析页面上div(class=resource-itemborder-dashed-eee)标签下的a标签得到跳转网盘的地址,解析div下的p标签得到资源日期。
抓取和解析
首先安装解析页面需要的bs4第三方库。
pip3?install?bs4
下面是抓取并解析网页的脚本代码,最后按日期降序排序。
<p>import?requests
from?bs4?import?BeautifulSoup
import?string
word?=?input('请输入要搜索的资源名称:')
????
headers?=?{
????'User-Agent':?'Mozilla/5.0?(Windows?NT?10.0;?Win64;?x64)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/96.0.4664.45?Safari/537.36'
}
result_list?=?[]
for?i?in?range(1,?11):
????print('正在搜索第?{}?页'.format(i))
????params?=?{
????????'page':?i,
????????'keyword':?word,
????????'search_folder_or_file':?0,
????????'is_search_folder_content':?0,
????????'is_search_path_title':?0,
????????'category':?'all',
????????'file_extension':?'all',
????????'search_model':?0
????}
????response_html?=?requests.get('https://www.alipanso.com/search.html',?headers?=?headers,params=params)
????response_data?=?response_html.content.decode()
???
????soup?=?BeautifulSoup(response_data,?"html.parser");
????divs?=?soup.find_all('div',?class_='resource-item?border-dashed-eee')
????
????if?len(divs)? 查看全部
网页视频抓取脚本(
阿里云盘下载不限速怎么办?Python模板文件小编.html)
使用Python抓取阿里云盘资源
更新时间:2022-02-22 09:50:12 作者:百胜酱
与百度云盘相比,阿里云盘拥有无限下载速度和大容量空间,深受大家的喜爱。本文将使用 Python 抓取阿里云盘的资源。有兴趣的可以学习一下
内容
前段时间,阿里云盘风靡一时,大量存储空间被送出。而且阿里云盘下载是无限的,比百度网盘好很多。这两天看到一个第三方网站可以在阿里云盘上搜索资源,但是它的资源没有按时间排序。这种情况会导致已经在队列中很长时间的资源成为过时的资源。小编这里使用python进行爬取和重排。
网页分析
这个 网站 有两条搜索线:搜索线一和搜索线二。这个 文章 使用第二行搜索。
打开控制面板下的网络,一眼就能看到一个sea.html的get请求。
有几个参数,四个关键参数:
同样在控制面板中,可以看到网页跳转到阿里云盘获取标题上方的真实链接。使用bs4解析页面上div(class=resource-itemborder-dashed-eee)标签下的a标签得到跳转网盘的地址,解析div下的p标签得到资源日期。
抓取和解析
首先安装解析页面需要的bs4第三方库。
pip3?install?bs4
下面是抓取并解析网页的脚本代码,最后按日期降序排序。
<p>import?requests
from?bs4?import?BeautifulSoup
import?string
word?=?input('请输入要搜索的资源名称:')
????
headers?=?{
????'User-Agent':?'Mozilla/5.0?(Windows?NT?10.0;?Win64;?x64)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/96.0.4664.45?Safari/537.36'
}
result_list?=?[]
for?i?in?range(1,?11):
????print('正在搜索第?{}?页'.format(i))
????params?=?{
????????'page':?i,
????????'keyword':?word,
????????'search_folder_or_file':?0,
????????'is_search_folder_content':?0,
????????'is_search_path_title':?0,
????????'category':?'all',
????????'file_extension':?'all',
????????'search_model':?0
????}
????response_html?=?requests.get('https://www.alipanso.com/search.html',?headers?=?headers,params=params)
????response_data?=?response_html.content.decode()
???
????soup?=?BeautifulSoup(response_data,?"html.parser");
????divs?=?soup.find_all('div',?class_='resource-item?border-dashed-eee')
????
????if?len(divs)?
网页视频抓取脚本( 如何从网站免费获取所有链接并存储$(document))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-22 06:28
如何从网站免费获取所有链接并存储$(document))
从 网站 Chrome 扩展中提取所有链接
Link Grabber - Google Chrome,Link Klipper 是一个简单但非常强大的 chrome 扩展程序,可帮助您提取网页上的所有链接并将它们导出到文件中。不再需要从网页复制每个链接并存储 jQuery $(document).ready(function(){ $('a').each(function(){ console.log($(this).attr('href' ) ); }); });. 注意:在chrome中打开网站>>右键 >>检查>>去。Link Klipper - 提取所有链接 - Google Chrome,在单个页面上工作,但很容易被现代(不是纯 html 代码)跳过图像混淆。如果它可以拉出所有图像链接,肯定会给它 5 星,对于特定的 url 及其子页面甚至更好。如果要手动导出 Chrome 扩展程序,必须在浏览器中启用“开发者模式”,并将扩展程序打包成 CRX 文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该: .
Link Klipper - 提取所有链接 - Google Chrome, jQuery $(document).ready(function(){ $('a').each(function(){ console.log($(this).attr('href' ) ); }); });. 注意:在 chrome 中打开 网站 >> 右键单击 >> 检查 >> go 在单个页面上工作,但很容易现代化(不是纯 html 代码) 跳过图像混淆。如果它可以拉出所有图像链接并且更好地为特定的 url 及其子页面做这件事,肯定会给它 5 星。.Semalt:如何从网站免费获取所有链接,如果要手动导出Chrome扩展,必须在浏览器中启用“开发者模式”,并将扩展打包成CRX文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该:OutWit Hub 是一个强大的网页信息提取器,还可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。这。
Semalt:如何从 网站 免费获取所有链接,在单个页面上工作,但很容易被现代(非纯 html 代码)跳过图像混淆。如果它可以拉出所有图片链接,肯定会给它 5 颗星,并且更好地为特定的 url 及其子页面执行此操作。如果要手动导出 Chrome 扩展程序,必须在浏览器中启用“开发者模式”,并将扩展程序打包成 CRX 文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该: . 如何从网页中提取超链接地址,OutWit Hub 是一个强大的网页信息提取器,也可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。安装后,该扩展程序会自动将快捷方式图标添加到浏览器的多功能栏。现在,继续打开您喜欢的任何 网站 或页面(例如)。要从此页面中提取所有链接,只需单击浏览器多功能栏上的 Link Klipper 图标。接下来,单击“提取所有链接”按钮。.
如何从网页中提取超链接地址,如果要手动导出Chrome扩展程序,必须在浏览器中启用“开发者模式”并将扩展程序打包成CRX文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该: OutWit Hub 是一个功能强大的网页信息提取器,还可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。这。如何从html网站中提取href链接安装后,扩展程序会自动在浏览器的多功能栏中添加一个快捷方式图标。现在,继续打开您喜欢的任何 网站 或页面(例如)。要从此页面中提取所有链接,只需单击浏览器上的 Link Klipper 图标 s多功能酒吧。接下来,单击“提取所有链接”按钮。1. 安装 Link Klipper 浏览器扩展。2. 打开要从中提取链接的网页。3. CTRL 键(Mac 上的⌘)。
如何从html网站中提取href链接,OutWit Hub是一个强大的网页信息提取器,也可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。安装后,该扩展程序会自动将快捷方式图标添加到浏览器的多功能栏。现在,继续打开您喜欢的任何 网站 或页面(例如)。要从此页面中提取所有链接,只需单击浏览器多功能栏上的 Link Klipper 图标。接下来,单击“提取所有链接”按钮。. 链接地鼠,
从 网站Python 中提取所有链接
<p>如何使用Python构建一个URL爬虫来映射网站,提取一个网页的所有链接是网络爬虫中的常见任务,构建一个爬取某个 查看全部
网页视频抓取脚本(
如何从网站免费获取所有链接并存储$(document))
从 网站 Chrome 扩展中提取所有链接
Link Grabber - Google Chrome,Link Klipper 是一个简单但非常强大的 chrome 扩展程序,可帮助您提取网页上的所有链接并将它们导出到文件中。不再需要从网页复制每个链接并存储 jQuery $(document).ready(function(){ $('a').each(function(){ console.log($(this).attr('href' ) ); }); });. 注意:在chrome中打开网站>>右键 >>检查>>去。Link Klipper - 提取所有链接 - Google Chrome,在单个页面上工作,但很容易被现代(不是纯 html 代码)跳过图像混淆。如果它可以拉出所有图像链接,肯定会给它 5 星,对于特定的 url 及其子页面甚至更好。如果要手动导出 Chrome 扩展程序,必须在浏览器中启用“开发者模式”,并将扩展程序打包成 CRX 文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该: .
Link Klipper - 提取所有链接 - Google Chrome, jQuery $(document).ready(function(){ $('a').each(function(){ console.log($(this).attr('href' ) ); }); });. 注意:在 chrome 中打开 网站 >> 右键单击 >> 检查 >> go 在单个页面上工作,但很容易现代化(不是纯 html 代码) 跳过图像混淆。如果它可以拉出所有图像链接并且更好地为特定的 url 及其子页面做这件事,肯定会给它 5 星。.Semalt:如何从网站免费获取所有链接,如果要手动导出Chrome扩展,必须在浏览器中启用“开发者模式”,并将扩展打包成CRX文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该:OutWit Hub 是一个强大的网页信息提取器,还可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。这。
Semalt:如何从 网站 免费获取所有链接,在单个页面上工作,但很容易被现代(非纯 html 代码)跳过图像混淆。如果它可以拉出所有图片链接,肯定会给它 5 颗星,并且更好地为特定的 url 及其子页面执行此操作。如果要手动导出 Chrome 扩展程序,必须在浏览器中启用“开发者模式”,并将扩展程序打包成 CRX 文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该: . 如何从网页中提取超链接地址,OutWit Hub 是一个强大的网页信息提取器,也可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。安装后,该扩展程序会自动将快捷方式图标添加到浏览器的多功能栏。现在,继续打开您喜欢的任何 网站 或页面(例如)。要从此页面中提取所有链接,只需单击浏览器多功能栏上的 Link Klipper 图标。接下来,单击“提取所有链接”按钮。.
如何从网页中提取超链接地址,如果要手动导出Chrome扩展程序,必须在浏览器中启用“开发者模式”并将扩展程序打包成CRX文件。CRX 是 Chrome 在您添加扩展程序时自动下载和安装的文件。为此,您应该: OutWit Hub 是一个功能强大的网页信息提取器,还可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。这。如何从html网站中提取href链接安装后,扩展程序会自动在浏览器的多功能栏中添加一个快捷方式图标。现在,继续打开您喜欢的任何 网站 或页面(例如)。要从此页面中提取所有链接,只需单击浏览器上的 Link Klipper 图标 s多功能酒吧。接下来,单击“提取所有链接”按钮。1. 安装 Link Klipper 浏览器扩展。2. 打开要从中提取链接的网页。3. CTRL 键(Mac 上的⌘)。
如何从html网站中提取href链接,OutWit Hub是一个强大的网页信息提取器,也可以提取链接。它具有许多高级功能,并且可以通过多种方式进行配置(包括对自定义刮板的支持)。安装后,该扩展程序会自动将快捷方式图标添加到浏览器的多功能栏。现在,继续打开您喜欢的任何 网站 或页面(例如)。要从此页面中提取所有链接,只需单击浏览器多功能栏上的 Link Klipper 图标。接下来,单击“提取所有链接”按钮。. 链接地鼠,
从 网站Python 中提取所有链接
<p>如何使用Python构建一个URL爬虫来映射网站,提取一个网页的所有链接是网络爬虫中的常见任务,构建一个爬取某个

