
网页视频抓取浏览器
网页视频抓取浏览器(美图浏览器剪贴板复制下载热门电影,亲测)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-21 18:09
网页视频抓取浏览器,下载热门电影,美剧音乐和歌曲等,鼠标滚轮滚动到任何地方,复制剪贴链接,就可以下载了。美图秀秀贴吧等等二级页面网页分享下载浏览器,下载热门游戏美图浏览器剪贴板复制下载浏览器,各种格式格式转换器,复制粘贴到浏览器的历史记录内。复制链接,利用google图片搜索框,或者插件高德地图,百度地图搜索中心,找到你要的图片,下载保存到本地。火狐浏览器利用火狐浏览器自带的分享功能复制下载链接,粘贴到浏览器的历史记录内。
【工具】easydf/editplugin/editfromvideotogooglevideomp3converterlinux系列软件windows系列:chrome浏览器、directx11等
名称:videomanager能解决你的需求。
亲测,并不能解决问题所在不错能够在win10下利用chrome的自带扩展软件来做。
两步:①在浏览器的chrome输入chromewebstore——打开②在搜索页的下拉列表里面找到mp3,左键点击mp3图标。(注意浏览器右上角有个“关闭”按钮)③待其初始化完成后,点击windows开始图标。在弹出的开始菜单中,选择“音频”,再选择“发送到mp3”。此时就完成了。如此简单粗暴。不要下载,去这里下载~。
chrome自带edgewebstore全家桶, 查看全部
网页视频抓取浏览器(美图浏览器剪贴板复制下载热门电影,亲测)
网页视频抓取浏览器,下载热门电影,美剧音乐和歌曲等,鼠标滚轮滚动到任何地方,复制剪贴链接,就可以下载了。美图秀秀贴吧等等二级页面网页分享下载浏览器,下载热门游戏美图浏览器剪贴板复制下载浏览器,各种格式格式转换器,复制粘贴到浏览器的历史记录内。复制链接,利用google图片搜索框,或者插件高德地图,百度地图搜索中心,找到你要的图片,下载保存到本地。火狐浏览器利用火狐浏览器自带的分享功能复制下载链接,粘贴到浏览器的历史记录内。
【工具】easydf/editplugin/editfromvideotogooglevideomp3converterlinux系列软件windows系列:chrome浏览器、directx11等
名称:videomanager能解决你的需求。
亲测,并不能解决问题所在不错能够在win10下利用chrome的自带扩展软件来做。
两步:①在浏览器的chrome输入chromewebstore——打开②在搜索页的下拉列表里面找到mp3,左键点击mp3图标。(注意浏览器右上角有个“关闭”按钮)③待其初始化完成后,点击windows开始图标。在弹出的开始菜单中,选择“音频”,再选择“发送到mp3”。此时就完成了。如此简单粗暴。不要下载,去这里下载~。
chrome自带edgewebstore全家桶,
网页视频抓取浏览器(本软件允许你很容易地复制视频缓存文件到其他位置)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-19 17:09
在线观看视频后,您可能希望将视频文件保存到硬盘上,以便稍后观看。如果视频存储在浏览器的缓存文件夹中,VideoCacheView(64位支持)可以帮助您从缓存文件夹中找到视频文件并将其保存到其他位置。
VideoCacheView 将自动扫描 IE 和基于 Mozilla 的网络浏览器(包括 FireFox)的整个缓存文件夹,并找到当前存储在其中的所有视频文件。同时,该软件还可以让您轻松地将视频缓存文件复制到其他文件夹,以便以后播放。如果您有播放 FLV 文件的播放器,该软件还允许您直接从缓存文件夹中播放文件
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 FLV 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
更新日志 (2021.07.01)
当前版本号:v3.2
添加更多功能
优化软件操作模式 查看全部
网页视频抓取浏览器(本软件允许你很容易地复制视频缓存文件到其他位置)
在线观看视频后,您可能希望将视频文件保存到硬盘上,以便稍后观看。如果视频存储在浏览器的缓存文件夹中,VideoCacheView(64位支持)可以帮助您从缓存文件夹中找到视频文件并将其保存到其他位置。
VideoCacheView 将自动扫描 IE 和基于 Mozilla 的网络浏览器(包括 FireFox)的整个缓存文件夹,并找到当前存储在其中的所有视频文件。同时,该软件还可以让您轻松地将视频缓存文件复制到其他文件夹,以便以后播放。如果您有播放 FLV 文件的播放器,该软件还允许您直接从缓存文件夹中播放文件

指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 FLV 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
更新日志 (2021.07.01)
当前版本号:v3.2
添加更多功能
优化软件操作模式
网页视频抓取浏览器(网页视频抓取浏览器视频转换歌曲歌词教程2019/1/7)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-15 20:03
网页视频抓取浏览器视频转换pdf转换成wordpdf转换成ppt音频剪辑视频格式转换格式转换文字视频转换歌曲歌词教程2019/1/7使用videoshop直接在浏览器里输入你设定的歌词和音频就可以听歌词啦
你说的那个网站就不错,前几天好像有个小学初中英语的视频解析,虽然时间久远,但我记得当时很牛逼,我需要哪一年的解析还可以找的到。
一些高清音频很便宜,有几十一小时的,也有几百一小时的。还有几百万人听的!你可以搜索之类的下载,为什么不去音乐类站点下呢?这种事情被抓起来,维权难度大,而且很多都只支持音频原文件,不支持mp3等等,到时你就麻烦了。
推荐一个网站给你,
推荐几个小而美的网站,最近一直在用,
1、记录片吧()国内众多视频网站上都有,超短视频。
2、电影大全()这个网站也是满足了一般的网站需求,电影,剧集,动漫等等,你只要关注一下电影大全,就能找到所有你想看的电影,很方便。
3、音乐雷达()这个有点像推荐歌单,里面有很多歌曲排行榜,你只要在里面搜索关键词就能找到很多不错的歌曲。如果不清楚你想要什么,那就去下载一个爱听2吧,打开就有详细的列表。最近看新闻里说,“音乐作为一种非物质形态可以带来精神上的愉悦,以此抵消”已经不少人用它来赚钱了,各大平台都推广它。如果还是怕被骗的话,就找个靠谱的平台。
虽然我对上面的那几个网站没什么好感,但是给国家做贡献我也愿意。特别是下载的时候看国家的网站的话,会节省很多时间。 查看全部
网页视频抓取浏览器(网页视频抓取浏览器视频转换歌曲歌词教程2019/1/7)
网页视频抓取浏览器视频转换pdf转换成wordpdf转换成ppt音频剪辑视频格式转换格式转换文字视频转换歌曲歌词教程2019/1/7使用videoshop直接在浏览器里输入你设定的歌词和音频就可以听歌词啦
你说的那个网站就不错,前几天好像有个小学初中英语的视频解析,虽然时间久远,但我记得当时很牛逼,我需要哪一年的解析还可以找的到。
一些高清音频很便宜,有几十一小时的,也有几百一小时的。还有几百万人听的!你可以搜索之类的下载,为什么不去音乐类站点下呢?这种事情被抓起来,维权难度大,而且很多都只支持音频原文件,不支持mp3等等,到时你就麻烦了。
推荐一个网站给你,
推荐几个小而美的网站,最近一直在用,
1、记录片吧()国内众多视频网站上都有,超短视频。
2、电影大全()这个网站也是满足了一般的网站需求,电影,剧集,动漫等等,你只要关注一下电影大全,就能找到所有你想看的电影,很方便。
3、音乐雷达()这个有点像推荐歌单,里面有很多歌曲排行榜,你只要在里面搜索关键词就能找到很多不错的歌曲。如果不清楚你想要什么,那就去下载一个爱听2吧,打开就有详细的列表。最近看新闻里说,“音乐作为一种非物质形态可以带来精神上的愉悦,以此抵消”已经不少人用它来赚钱了,各大平台都推广它。如果还是怕被骗的话,就找个靠谱的平台。
虽然我对上面的那几个网站没什么好感,但是给国家做贡献我也愿意。特别是下载的时候看国家的网站的话,会节省很多时间。
网页视频抓取浏览器(等效toenablecrossdomainajaxajaxrequestrequest)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-14 20:31
我想通过在浏览器中运行代码来获取 网站。在这种情况下,scraper 必须在特定机器上运行,而我不能在该机器上安装任何软件。不过我已经安装了浏览器(火狐最新版),可以随意配置浏览器。
我想要的是一个抓取的javascript解决方案,收录在站点A的网页中,可以抓取站点B。看来这样会遇到一些CORS类型的问题;我认为解决方案的一部分是禁用浏览器中的任何跨域检查。
到目前为止我尝试过的:我查找了“javascript中的网络抓取”,它带来了很多将在带有cheerio的nodejs中运行的东西,例如,像pjscrape这样的东西需要PhantomJS。但是,我找不到任何旨在在浏览器中运行的等效内容。
PS 这很有趣:Firefox 设置启用跨域 ajax 请求显然 Chrome --disable-web-security 处理跨域/跨域问题。Firefox 等效?
PS Firefox 的 ForceCORS 扩展似乎也很有用:我不确定我是否可以安装它。
PS 这是在不同浏览器中允许跨域的一个很好的方法集合:不幸的是,建议的 Firefox 解决方案在版本 >=5 中不起作用。 查看全部
网页视频抓取浏览器(等效toenablecrossdomainajaxajaxrequestrequest)
我想通过在浏览器中运行代码来获取 网站。在这种情况下,scraper 必须在特定机器上运行,而我不能在该机器上安装任何软件。不过我已经安装了浏览器(火狐最新版),可以随意配置浏览器。
我想要的是一个抓取的javascript解决方案,收录在站点A的网页中,可以抓取站点B。看来这样会遇到一些CORS类型的问题;我认为解决方案的一部分是禁用浏览器中的任何跨域检查。
到目前为止我尝试过的:我查找了“javascript中的网络抓取”,它带来了很多将在带有cheerio的nodejs中运行的东西,例如,像pjscrape这样的东西需要PhantomJS。但是,我找不到任何旨在在浏览器中运行的等效内容。
PS 这很有趣:Firefox 设置启用跨域 ajax 请求显然 Chrome --disable-web-security 处理跨域/跨域问题。Firefox 等效?
PS Firefox 的 ForceCORS 扩展似乎也很有用:我不确定我是否可以安装它。
PS 这是在不同浏览器中允许跨域的一个很好的方法集合:不幸的是,建议的 Firefox 解决方案在版本 >=5 中不起作用。
网页视频抓取浏览器(初识scraper打开WebScraper的图标(一)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-14 20:03
Web Scraper是一款适合普通用户(无需专业IT技术)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取你想要的数据。例如知乎回答列表、微博热点、微博评论、电商网站产品信息、博客文章列表等。 在线安装方法在线安装需要FQ网络,可以访问Chrome App Store1、在线访问Web Scraper插件,点击“添加到CHROME”。
2、然后在弹出的框中点击“添加扩展”
3、安装完成后,顶部工具栏会显示Web Scraper图标。
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7.将crx拖放到该页面,点击“添加到扩展”即可完成安装。如图:
2、安装完成后,顶部工具栏会显示Web Scraper图标。
第一次认识网络爬虫
打开网页爬虫
开发者可以路过看看后面
windows系统下可以使用快捷键F12,部分笔记本机型需要按Fn+F12;
Mac系统下可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置—>更多工具—>开发者工具
打开后的效果如下,绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,是我们后面要操作的部分。
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
原理及功能说明
数据爬取的思路大体可以简单总结如下:
1、 通过一个或多个入口地址获取初始数据。比如文章列表页,或者有一定规则的页面,比如有分页的列表页;
2、根据入口页面的一些信息,比如链接点,进入下一页,获取必要的信息;
3、 根据上一层的链接继续下一层,获取必要的信息(这一步可以无限循环);
原理大致相同。接下来,让我们正式认识一下Web Scraper工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
创建新的站点地图:首先了解站点地图,字面意思是网站地图,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你要获取知乎 on 要回答其中一个问题,请创建站点地图,并将此问题的地址设置为站点地图的起始网址,然后单击“创建站点地图”以创建站点地图。
站点地图:站点地图的集合。所有创建的站点地图都会显示在这里,可以在此处输入站点地图进行修改、数据抓取等操作。
站点地图:输入一个站点地图,可以进行一系列的操作,如下图:
红框部分 Add new selector 是必不可少的一步。什么是选择器,字面意思是:选择器,一个选择器对应网页的一部分,也就是收录我们要采集的数据的部分。
需要说明的是,一个站点地图可以有多个选择器,每个选择器可以收录子选择器,一个选择器只能对应一个标题,也可以对应整个区域,这个区域可能收录标题、副标题、作者信息、内容、等和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑结构图,什么是根节点,收录几个选择器,选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
Scrape:开始数据抓取工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,简单的了解一下就可以了。真知灼见,具体操作案例令人信服。下面举几个例子来说明具体的用法。
案例实践
简单测试hao123
从最简单到深入,我们以一个简单的例子作为入口,作为对Web Scraper服务的进一步了解
需求背景:见下hao123页面红框部分。我们的需求是统计这部分区域的所有网站名称和链接地址,最后在Excel中生成。因为这部分内容已经足够简单了,当然真正的需求可能比这更复杂,而且人工统计这么几条数据的时间也很快。
开始运作
1、 假设我们已经打开了hao123页面,并且打开了这个页面底部的开发者工具,并找到了Web Scraper标签栏;
2、点击“创建站点地图”;
3、 输入sitemap名称和start url后,名称仅供我们标记,命名为hao123(注意不支持中文),start url为hao123的url,然后点击create sitemap;
4、 之后,Web Scraper 会自动定位到这个站点地图,然后我们添加一个选择器,点击“添加新的选择器”;
5、首先给这个选择器分配一个id,它只是一个容易识别的名字。我把它命名为热这里。因为要获取名称和链接,所以将类型设置为链接。这种类型是专门为网页链接准备的。选择Link type后,会自动提取name和link这两个属性;
6、 然后点击select,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,表示这是我们当前选中的区域。我们将光标定位在需求中提到的那一栏的某个链接上,比如第一条头条新闻,点击这里,这部分会变成红色,表示已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变红了,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识符,可以手动修改。元素由类和元素名称决定,如:div.p_name a)。最后,不要忘记检查Multiple,
7、最后保存,保存选择器。单击元素预览可预览所选区域,单击数据预览可在浏览器中预览捕获的数据。下面文本框的内容对于懂技术的同学来说是很清楚的,这就是xpath,我们可以不用鼠标直接手写xpath;
完整的操作流程如下:
8、完成上一步后,就可以实际导出了。别着急,看看其他的操作。Sitemap hao123下的Selector图可以看到拓扑图。_root 是根选择器。创建站点地图时,会自动出现一个_root节点,可以看到它的子选择器,也就是我们创建的热选择器;
9、刮,开始刮数据。
10、在Sitemap hao123下浏览,可以直接通过浏览器查看抓取的最终结果,需要重新;
11、 最后使用Export data as CSV导出为CSV格式,其中hot列为标题,hot-href列为链接;
怎么样,试试看 查看全部
网页视频抓取浏览器(初识scraper打开WebScraper的图标(一)_光明网(组图))
Web Scraper是一款适合普通用户(无需专业IT技术)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取你想要的数据。例如知乎回答列表、微博热点、微博评论、电商网站产品信息、博客文章列表等。 在线安装方法在线安装需要FQ网络,可以访问Chrome App Store1、在线访问Web Scraper插件,点击“添加到CHROME”。

2、然后在弹出的框中点击“添加扩展”

3、安装完成后,顶部工具栏会显示Web Scraper图标。

本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7.将crx拖放到该页面,点击“添加到扩展”即可完成安装。如图:

2、安装完成后,顶部工具栏会显示Web Scraper图标。
第一次认识网络爬虫
打开网页爬虫
开发者可以路过看看后面
windows系统下可以使用快捷键F12,部分笔记本机型需要按Fn+F12;
Mac系统下可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置—>更多工具—>开发者工具

打开后的效果如下,绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,是我们后面要操作的部分。

注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。

原理及功能说明
数据爬取的思路大体可以简单总结如下:
1、 通过一个或多个入口地址获取初始数据。比如文章列表页,或者有一定规则的页面,比如有分页的列表页;
2、根据入口页面的一些信息,比如链接点,进入下一页,获取必要的信息;
3、 根据上一层的链接继续下一层,获取必要的信息(这一步可以无限循环);
原理大致相同。接下来,让我们正式认识一下Web Scraper工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:

创建新的站点地图:首先了解站点地图,字面意思是网站地图,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你要获取知乎 on 要回答其中一个问题,请创建站点地图,并将此问题的地址设置为站点地图的起始网址,然后单击“创建站点地图”以创建站点地图。

站点地图:站点地图的集合。所有创建的站点地图都会显示在这里,可以在此处输入站点地图进行修改、数据抓取等操作。

站点地图:输入一个站点地图,可以进行一系列的操作,如下图:

红框部分 Add new selector 是必不可少的一步。什么是选择器,字面意思是:选择器,一个选择器对应网页的一部分,也就是收录我们要采集的数据的部分。
需要说明的是,一个站点地图可以有多个选择器,每个选择器可以收录子选择器,一个选择器只能对应一个标题,也可以对应整个区域,这个区域可能收录标题、副标题、作者信息、内容、等和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑结构图,什么是根节点,收录几个选择器,选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
Scrape:开始数据抓取工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,简单的了解一下就可以了。真知灼见,具体操作案例令人信服。下面举几个例子来说明具体的用法。
案例实践
简单测试hao123
从最简单到深入,我们以一个简单的例子作为入口,作为对Web Scraper服务的进一步了解
需求背景:见下hao123页面红框部分。我们的需求是统计这部分区域的所有网站名称和链接地址,最后在Excel中生成。因为这部分内容已经足够简单了,当然真正的需求可能比这更复杂,而且人工统计这么几条数据的时间也很快。

开始运作
1、 假设我们已经打开了hao123页面,并且打开了这个页面底部的开发者工具,并找到了Web Scraper标签栏;
2、点击“创建站点地图”;

3、 输入sitemap名称和start url后,名称仅供我们标记,命名为hao123(注意不支持中文),start url为hao123的url,然后点击create sitemap;

4、 之后,Web Scraper 会自动定位到这个站点地图,然后我们添加一个选择器,点击“添加新的选择器”;

5、首先给这个选择器分配一个id,它只是一个容易识别的名字。我把它命名为热这里。因为要获取名称和链接,所以将类型设置为链接。这种类型是专门为网页链接准备的。选择Link type后,会自动提取name和link这两个属性;

6、 然后点击select,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,表示这是我们当前选中的区域。我们将光标定位在需求中提到的那一栏的某个链接上,比如第一条头条新闻,点击这里,这部分会变成红色,表示已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变红了,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识符,可以手动修改。元素由类和元素名称决定,如:div.p_name a)。最后,不要忘记检查Multiple,

7、最后保存,保存选择器。单击元素预览可预览所选区域,单击数据预览可在浏览器中预览捕获的数据。下面文本框的内容对于懂技术的同学来说是很清楚的,这就是xpath,我们可以不用鼠标直接手写xpath;
完整的操作流程如下:

8、完成上一步后,就可以实际导出了。别着急,看看其他的操作。Sitemap hao123下的Selector图可以看到拓扑图。_root 是根选择器。创建站点地图时,会自动出现一个_root节点,可以看到它的子选择器,也就是我们创建的热选择器;

9、刮,开始刮数据。
10、在Sitemap hao123下浏览,可以直接通过浏览器查看抓取的最终结果,需要重新;

11、 最后使用Export data as CSV导出为CSV格式,其中hot列为标题,hot-href列为链接;

怎么样,试试看
网页视频抓取浏览器(网页视频抓取浏览器给你的url不断的抓爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-08 08:02
网页视频抓取浏览器的搜索栏,用户的搜索,内容索引表,网页内容,网页跳转方式网页结构,
三个方面1.抓取能力,简单来说就是浏览器给你的url是否能顺利的被爬虫解析出来,这个要求你要对http有基本的了解,会使用工具的爬虫工具2.数据量,一般大点的网站都会采用tcp等形式保证数据的实时性,对于小网站可能采用的方法是消息队列,或者服务端直接给url发送消息,要求你懂restfulapi的使用3.内容清洗、转换与展示。一般网站在不同页面url的转换展示,你得懂得基本的网络编程。
url中一定存在逻辑,应该遵循某种统一形式的规则,
一般就是对源代码的编码问题和性能问题。源代码是postmessage还是xml。
一般从抓取效率,性能,抓取稳定性三个方面考虑。我听说过一次,
就像评论是html,
几乎抓取浏览器给的url都是cookie网页模拟cookie然后爬虫不断的抓
爬虫首先的是抓取本地资源和网络资源。网络是获取信息的第一手资源,网络既然有信息的那么自然就会有各种各样的内容,有文本又有图片等等,爬虫无非就是爬取网络资源就可以了。爬虫的配置的逻辑就很多了,大致分为对象配置,方法配置和spider配置。对象,就是我们需要爬取的网站或者资源。方法就是我们针对每个网站制定的爬取策略。
spider就是网站或者资源的请求者。比如说,你浏览过的评论,就可以想到大概不是这两个吗,发放一个http请求给你,我们利用urllib2.js对这个请求进行转码传递给请求者发送给后台处理,然后解析这个请求返回一个response给你。 查看全部
网页视频抓取浏览器(网页视频抓取浏览器给你的url不断的抓爬虫)
网页视频抓取浏览器的搜索栏,用户的搜索,内容索引表,网页内容,网页跳转方式网页结构,
三个方面1.抓取能力,简单来说就是浏览器给你的url是否能顺利的被爬虫解析出来,这个要求你要对http有基本的了解,会使用工具的爬虫工具2.数据量,一般大点的网站都会采用tcp等形式保证数据的实时性,对于小网站可能采用的方法是消息队列,或者服务端直接给url发送消息,要求你懂restfulapi的使用3.内容清洗、转换与展示。一般网站在不同页面url的转换展示,你得懂得基本的网络编程。
url中一定存在逻辑,应该遵循某种统一形式的规则,
一般就是对源代码的编码问题和性能问题。源代码是postmessage还是xml。
一般从抓取效率,性能,抓取稳定性三个方面考虑。我听说过一次,
就像评论是html,
几乎抓取浏览器给的url都是cookie网页模拟cookie然后爬虫不断的抓
爬虫首先的是抓取本地资源和网络资源。网络是获取信息的第一手资源,网络既然有信息的那么自然就会有各种各样的内容,有文本又有图片等等,爬虫无非就是爬取网络资源就可以了。爬虫的配置的逻辑就很多了,大致分为对象配置,方法配置和spider配置。对象,就是我们需要爬取的网站或者资源。方法就是我们针对每个网站制定的爬取策略。
spider就是网站或者资源的请求者。比如说,你浏览过的评论,就可以想到大概不是这两个吗,发放一个http请求给你,我们利用urllib2.js对这个请求进行转码传递给请求者发送给后台处理,然后解析这个请求返回一个response给你。
网页视频抓取浏览器(网页视频抓取浏览器端的页面,后续再看源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-01 06:03
网页视频抓取浏览器端的页面,然后下载到本地。目前xpath比较傻瓜,复杂一点的页面可以用python转化为json然后解析处理。说实话,对于我这种没有python基础的,直接翻看nodejs就很痛苦,很费时费力。为了避免重复使用一些常用的方法,现在对xpath不做过多的概念性的东西。直接把知道的写上去,后续有空补充1.有xpath可以抓取javascript文件varxpath='//*[@id=""]/li/a[@class="list-bottom"]/img//a';2.有xpath可以抓取javascript文件javascript各种id顺序dom结构xpath搜索javascriptxpath搜索img...xpath搜索img3.有xpath可以抓取本地网页图片varxpath='//*[@id=""]/var/picture/a/text()';解析之后,返回json格式,拿去爬数据用。后续再看源码试试抓取其他页面.。
比较费事,
目前我是从手机上抓取,上传到微信公众号,点赞量可以看到,点赞次数需要第三方的数据源。
requests正则表达式非常的牛逼各种基础包imageio类型也很好用你写个爬虫也得知道各种包的用法先说下我用到的吧git可以看到生成的master分支(gitbranch#build#upstream),一共有1000多个repo:scrapy:这个东西要对着一个个api抓,一个接口分为url、后端和正则表达式if=hasattr(scrapy,"diff")else---正则表达式+requests爬虫收到的请求url一般是http。
get或者http。post一般是json格式不要被反爬虫的反爬虫阻止还有注意工厂方法methods参数cookie#methods中抓重复单独写一个字段,这样容易被反爬虫抓re-insetify需要注意了---easy_index要加。method,把req。json改为req。method。 查看全部
网页视频抓取浏览器(网页视频抓取浏览器端的页面,后续再看源码)
网页视频抓取浏览器端的页面,然后下载到本地。目前xpath比较傻瓜,复杂一点的页面可以用python转化为json然后解析处理。说实话,对于我这种没有python基础的,直接翻看nodejs就很痛苦,很费时费力。为了避免重复使用一些常用的方法,现在对xpath不做过多的概念性的东西。直接把知道的写上去,后续有空补充1.有xpath可以抓取javascript文件varxpath='//*[@id=""]/li/a[@class="list-bottom"]/img//a';2.有xpath可以抓取javascript文件javascript各种id顺序dom结构xpath搜索javascriptxpath搜索img...xpath搜索img3.有xpath可以抓取本地网页图片varxpath='//*[@id=""]/var/picture/a/text()';解析之后,返回json格式,拿去爬数据用。后续再看源码试试抓取其他页面.。
比较费事,
目前我是从手机上抓取,上传到微信公众号,点赞量可以看到,点赞次数需要第三方的数据源。
requests正则表达式非常的牛逼各种基础包imageio类型也很好用你写个爬虫也得知道各种包的用法先说下我用到的吧git可以看到生成的master分支(gitbranch#build#upstream),一共有1000多个repo:scrapy:这个东西要对着一个个api抓,一个接口分为url、后端和正则表达式if=hasattr(scrapy,"diff")else---正则表达式+requests爬虫收到的请求url一般是http。
get或者http。post一般是json格式不要被反爬虫的反爬虫阻止还有注意工厂方法methods参数cookie#methods中抓重复单独写一个字段,这样容易被反爬虫抓re-insetify需要注意了---easy_index要加。method,把req。json改为req。method。
网页视频抓取浏览器(网页视频抓取浏览器的基本操作技巧(一)——windows系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-30 02:03
网页视频抓取浏览器的这方面做的最好应该是servlet+multiwebview+abstractcontext的jspview线程(无消息发送)比较费内存3个线程分别处理动态加载的页面加载的页面view对象的处理请求处理(重定向)方法加载请求方法重定向处理httpshttps关系需要有正确匹配https体https/ip地址手机链接电脑(至少下载个apk才能通过app找到手机)后缀1.html2.mp43.mpeg4.mpeg3v3v25.avi(5个字节包含所有线程)(可以运行流,但是结构很复杂就是了)6.xvid(不能运行流,但是执行ajax)7.au8.javascripthttp/1.11024k(应该2m及以下)smtp其他包括后缀/(可以包含https)url类型/无(可以仅需要附加页面就行view线程应该是在原始http中查找getpostput,类似于session)session(请求端使用的是一个session+任务队列。
注意如果服务器能够对session以外的java客户端产生数据提供,那么服务器应该使用该服务器上最新的信息。)windows系统一般只有session(对比windows系统/excel,就明白什么意思了)getpostput两种请求方式,但是excel中没有post方式下的get方式的并发下实现比如服务器会有10个不同的服务器,这10个服务器上会出现同样的请求。
在时间压力不大的情况下,保证用户可以同时查看这10个服务器。用户每查看一个服务器,需要向服务器写一个session。如果这10个服务器可以用java来写,则可以实现很多并发。但是1个服务器提供10个服务器太夸张了,比如这样一个服务器提供8个服务器,就实现不了太多并发情况(建议3个及以下)在struts2中是用了messagebox拦截器来做的,可以参考这个(请求数量少到1)2/4/12/16/32/64/128/256/512,如果服务器有1万的请求,而用户只查看一个,建议采用struts2b-tree类作为拦截器,不然请求数据库的话,这个请求的时间太长,不如直接url批量/或者用java写单例来减少时间。=。 查看全部
网页视频抓取浏览器(网页视频抓取浏览器的基本操作技巧(一)——windows系统)
网页视频抓取浏览器的这方面做的最好应该是servlet+multiwebview+abstractcontext的jspview线程(无消息发送)比较费内存3个线程分别处理动态加载的页面加载的页面view对象的处理请求处理(重定向)方法加载请求方法重定向处理httpshttps关系需要有正确匹配https体https/ip地址手机链接电脑(至少下载个apk才能通过app找到手机)后缀1.html2.mp43.mpeg4.mpeg3v3v25.avi(5个字节包含所有线程)(可以运行流,但是结构很复杂就是了)6.xvid(不能运行流,但是执行ajax)7.au8.javascripthttp/1.11024k(应该2m及以下)smtp其他包括后缀/(可以包含https)url类型/无(可以仅需要附加页面就行view线程应该是在原始http中查找getpostput,类似于session)session(请求端使用的是一个session+任务队列。
注意如果服务器能够对session以外的java客户端产生数据提供,那么服务器应该使用该服务器上最新的信息。)windows系统一般只有session(对比windows系统/excel,就明白什么意思了)getpostput两种请求方式,但是excel中没有post方式下的get方式的并发下实现比如服务器会有10个不同的服务器,这10个服务器上会出现同样的请求。
在时间压力不大的情况下,保证用户可以同时查看这10个服务器。用户每查看一个服务器,需要向服务器写一个session。如果这10个服务器可以用java来写,则可以实现很多并发。但是1个服务器提供10个服务器太夸张了,比如这样一个服务器提供8个服务器,就实现不了太多并发情况(建议3个及以下)在struts2中是用了messagebox拦截器来做的,可以参考这个(请求数量少到1)2/4/12/16/32/64/128/256/512,如果服务器有1万的请求,而用户只查看一个,建议采用struts2b-tree类作为拦截器,不然请求数据库的话,这个请求的时间太长,不如直接url批量/或者用java写单例来减少时间。=。
网页视频抓取浏览器(来说说有关于如何提取网页视频的消现如今的消息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-27 14:05
摘要 当今的科技让我们的生活充满了便利和幸福。因此,大家也非常关心未来科技带来的惊喜。所以今天,我就来谈谈如何提取网络视频。
今天的科技让我们的生活充满了便利和幸福,所以大家也很关心科技给未来带来的惊喜,所以今天我有关于如何提取网络视频的消息!
操作方法:打开网页,右击网页,选择“评论元素”或“勾选”,会出现评论元素代码,选择“网络”,刷新网页,选择大小,较大的文件是该视频网页,右键单击该选项,单击“在新选项卡中打开链接”,然后下载视频。
电脑技能:1、电脑视频无法播放。可能是播放器不支持这种格式的视频。您需要下载相关播放器。
2、 网页无法显示,可能是服务器异常导致,需要等待官方修复。
3、电脑扫描仪死机,可能是软件bug,可以尝试重启软件。
4、电脑扫描仪无法播放视频。这可能是由于缺少 flash 插件。您需要先安装插件才能使用。
数据扩展:网页是构成网站的基本元素,是承载各种网站应用的平台。通俗地说,网站就是由网页组成的。网页是收录 HTML 标签的纯文本文件。它可以存储在世界某个角落的计算机上。它是万维网上的一个“页面”。它是一种超文本标记语言格式,网页通常使用图像文件来提供图片。必须通过网络扫描仪阅读网页。 查看全部
网页视频抓取浏览器(来说说有关于如何提取网页视频的消现如今的消息)
摘要 当今的科技让我们的生活充满了便利和幸福。因此,大家也非常关心未来科技带来的惊喜。所以今天,我就来谈谈如何提取网络视频。
今天的科技让我们的生活充满了便利和幸福,所以大家也很关心科技给未来带来的惊喜,所以今天我有关于如何提取网络视频的消息!

操作方法:打开网页,右击网页,选择“评论元素”或“勾选”,会出现评论元素代码,选择“网络”,刷新网页,选择大小,较大的文件是该视频网页,右键单击该选项,单击“在新选项卡中打开链接”,然后下载视频。
电脑技能:1、电脑视频无法播放。可能是播放器不支持这种格式的视频。您需要下载相关播放器。
2、 网页无法显示,可能是服务器异常导致,需要等待官方修复。
3、电脑扫描仪死机,可能是软件bug,可以尝试重启软件。
4、电脑扫描仪无法播放视频。这可能是由于缺少 flash 插件。您需要先安装插件才能使用。
数据扩展:网页是构成网站的基本元素,是承载各种网站应用的平台。通俗地说,网站就是由网页组成的。网页是收录 HTML 标签的纯文本文件。它可以存储在世界某个角落的计算机上。它是万维网上的一个“页面”。它是一种超文本标记语言格式,网页通常使用图像文件来提供图片。必须通过网络扫描仪阅读网页。
网页视频抓取浏览器(VideoCacheView自动扫描Explorer和基于Mozilla的网络浏览器())
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-22 20:14
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 FLV 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同的操作选项: 如果视频文件存在于缓存中,您可以选择“播放所选文件” "、"将选中的文件复制到"等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。程序的主窗口将显示缓存中的所有视频文件。显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同的操作选项: 如果视频文件存在于缓存中,您可以选择“播放所选文件” "、"将选中的文件复制到"等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。程序的主窗口将显示缓存中的所有视频文件。显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同的操作选项: 如果视频文件存在于缓存中,您可以选择“播放所选文件” "、"将选中的文件复制到"等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。“将选中的文件复制到”等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。“将选中的文件复制到”等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。 查看全部
网页视频抓取浏览器(VideoCacheView自动扫描Explorer和基于Mozilla的网络浏览器())
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 FLV 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同的操作选项: 如果视频文件存在于缓存中,您可以选择“播放所选文件” "、"将选中的文件复制到"等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。程序的主窗口将显示缓存中的所有视频文件。显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同的操作选项: 如果视频文件存在于缓存中,您可以选择“播放所选文件” "、"将选中的文件复制到"等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。程序的主窗口将显示缓存中的所有视频文件。显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同的操作选项: 如果视频文件存在于缓存中,您可以选择“播放所选文件” "、"将选中的文件复制到"等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。“将选中的文件复制到”等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。“将选中的文件复制到”等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
网页视频抓取浏览器(VideoDownloadHelper支持多种类型的流媒体视频下载视频和视频合并为单个文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-11-20 10:06
Video DownloadHelper 是目前最完善的从网站 中提取视频和图片文件并保存到硬盘的工具。
像往常一样上网。当 DownloadHelper 检测到可以访问下载的嵌入视频时,工具栏图标会突出显示,并且一个简单的菜单允许您通过单击某个项目来下载文件。
例如,如果您转到 YouTube 页面,则可以直接在文件系统上下载视频。它还可以与大多数其他流行视频 网站 一起使用,例如 DailyMotion、Facebook、Periscope、Vimeo、Twitch、Liveleak、Vine、UStream、Fox、Bloomberg、RAI、France 2-3、Break、Metacafe 和数千个其他网站。
Video DownloadHelper 支持多种类型的流媒体,这使得该插件在视频下载器中独树一帜:HTTP、HLS、DASH 等。只要站点使用了不受支持的流媒体技术,Video DownloadHelper 就可以直接从屏幕捕捉媒体并生成视频文件。
除了下载之外,Video DownloadHelper 还可以进行文件转换(即改变音视频格式)和聚合(将单独的音视频合并为一个文件)。这是一个升级功能,可以帮助你支付免费的东西(我们也需要吃饭)。您不必强制使用转换从网站 下载视频,并且您可以避免选择标记为 ADP 的变体以避免聚合。 查看全部
网页视频抓取浏览器(VideoDownloadHelper支持多种类型的流媒体视频下载视频和视频合并为单个文件)
Video DownloadHelper 是目前最完善的从网站 中提取视频和图片文件并保存到硬盘的工具。
像往常一样上网。当 DownloadHelper 检测到可以访问下载的嵌入视频时,工具栏图标会突出显示,并且一个简单的菜单允许您通过单击某个项目来下载文件。
例如,如果您转到 YouTube 页面,则可以直接在文件系统上下载视频。它还可以与大多数其他流行视频 网站 一起使用,例如 DailyMotion、Facebook、Periscope、Vimeo、Twitch、Liveleak、Vine、UStream、Fox、Bloomberg、RAI、France 2-3、Break、Metacafe 和数千个其他网站。
Video DownloadHelper 支持多种类型的流媒体,这使得该插件在视频下载器中独树一帜:HTTP、HLS、DASH 等。只要站点使用了不受支持的流媒体技术,Video DownloadHelper 就可以直接从屏幕捕捉媒体并生成视频文件。
除了下载之外,Video DownloadHelper 还可以进行文件转换(即改变音视频格式)和聚合(将单独的音视频合并为一个文件)。这是一个升级功能,可以帮助你支付免费的东西(我们也需要吃饭)。您不必强制使用转换从网站 下载视频,并且您可以避免选择标记为 ADP 的变体以避免聚合。
网页视频抓取浏览器(p2p,安卓手机的迅雷7,,迅雷,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-20 07:05
网页视频抓取浏览器视频抓取app视频抓取分享朋友圈将聊天内容整理成文档;目前来看flash依然是首选,能轻松的解决视频抓取问题。
首先是视频原始信息,包括上传时间,地点,然后就是方式了,自己采集,现在比较多的是在微信公众号推送视频时,已经有开发者做了一套可视化采集方案,可以免费开放给开发者,类似分享后付费的方式,就是和作者买单;传统的文本方式,可以请人写采集脚本来采集,也可以自己采集,前提是视频要可以下载,可以直接查看的情况下,免费的很多。当然,现在有一些新的方式,比如视频回传,或者保存到本地等等。
是不是可以和邀请人说一下?@firearts我也在做这个项目。
截取视频中的字幕,然后加入到字幕文件中,就可以放到群里,
遇到类似的问题前段时间我同事@胡维在一个问题下的回答,
我一般用哔哩哔哩上听__长尾评论聚合
qq传说里那个采集器就挺好用
在浏览器首页安装专门的网页视频采集软件,设置采集区域,采集时间段,然后根据您想获取的下载地址选择合适下载的视频。
可以通过网页抓取p2p,安卓手机的迅雷7, 查看全部
网页视频抓取浏览器(p2p,安卓手机的迅雷7,,迅雷,怎么办?)
网页视频抓取浏览器视频抓取app视频抓取分享朋友圈将聊天内容整理成文档;目前来看flash依然是首选,能轻松的解决视频抓取问题。
首先是视频原始信息,包括上传时间,地点,然后就是方式了,自己采集,现在比较多的是在微信公众号推送视频时,已经有开发者做了一套可视化采集方案,可以免费开放给开发者,类似分享后付费的方式,就是和作者买单;传统的文本方式,可以请人写采集脚本来采集,也可以自己采集,前提是视频要可以下载,可以直接查看的情况下,免费的很多。当然,现在有一些新的方式,比如视频回传,或者保存到本地等等。
是不是可以和邀请人说一下?@firearts我也在做这个项目。
截取视频中的字幕,然后加入到字幕文件中,就可以放到群里,
遇到类似的问题前段时间我同事@胡维在一个问题下的回答,
我一般用哔哩哔哩上听__长尾评论聚合
qq传说里那个采集器就挺好用
在浏览器首页安装专门的网页视频采集软件,设置采集区域,采集时间段,然后根据您想获取的下载地址选择合适下载的视频。
可以通过网页抓取p2p,安卓手机的迅雷7,
网页视频抓取浏览器(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-18 06:03
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。 查看全部
网页视频抓取浏览器(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。

指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。

指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
网页视频抓取浏览器(网页视频抓取浏览器视频下载主要有两种用处:stringify)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-11-15 12:02
网页视频抓取浏览器视频抓取主要有两种用处:一是网页视频下载,二是针对音频视频下载进行相应处理对于网页视频下载,主要有五种做法,分别是直接读取本地文件,flash接口,拖入requests库,插入数据包,跨域请求等。网页视频直接读取下载方法vue-resource-apiimportvuefrom'vue'vue.use(vue-resource-api)//use方法支持下载newvue({el:'#header_span',data:{author:'shan',url:';test=&src=',path:'',title:'实验室-我要从1024到102443',htmlurl:'',withcrementary:true},//如果实验室-我要从1024到102443,则忽略''})本地获取视频教程。
可以使用api或者传统的下载工具实现
(formdata)中有很多地方可以调用哦~我知道一个api还能搜索爱奇艺。
看到这个问题想说一下网页视频抓取的话要对网页进行分析之后就可以看到img。src=string(url)。decode("utf-8")上面的路径如果是命令的话都是纯字符串或者命令行的话那就是需要json_html的模块可以看一下json。stringify这个函数,这个函数能将一个字符串转换成字符串字符串作为参数传入string()方法返回参数dict对象,这个dict对象中可以有url字符串,id字符串,name字符串,picturedir字符串,title字符串,当然也可以有函数的参数最终返回的就是字符串的一个副本可以进行相应的处理如果是想要将页面网址通过requests下载成对应的json文件,就需要上述模块。 查看全部
网页视频抓取浏览器(网页视频抓取浏览器视频下载主要有两种用处:stringify)
网页视频抓取浏览器视频抓取主要有两种用处:一是网页视频下载,二是针对音频视频下载进行相应处理对于网页视频下载,主要有五种做法,分别是直接读取本地文件,flash接口,拖入requests库,插入数据包,跨域请求等。网页视频直接读取下载方法vue-resource-apiimportvuefrom'vue'vue.use(vue-resource-api)//use方法支持下载newvue({el:'#header_span',data:{author:'shan',url:';test=&src=',path:'',title:'实验室-我要从1024到102443',htmlurl:'',withcrementary:true},//如果实验室-我要从1024到102443,则忽略''})本地获取视频教程。
可以使用api或者传统的下载工具实现
(formdata)中有很多地方可以调用哦~我知道一个api还能搜索爱奇艺。
看到这个问题想说一下网页视频抓取的话要对网页进行分析之后就可以看到img。src=string(url)。decode("utf-8")上面的路径如果是命令的话都是纯字符串或者命令行的话那就是需要json_html的模块可以看一下json。stringify这个函数,这个函数能将一个字符串转换成字符串字符串作为参数传入string()方法返回参数dict对象,这个dict对象中可以有url字符串,id字符串,name字符串,picturedir字符串,title字符串,当然也可以有函数的参数最终返回的就是字符串的一个副本可以进行相应的处理如果是想要将页面网址通过requests下载成对应的json文件,就需要上述模块。
网页视频抓取浏览器(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-06 23:08
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供将来离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。 查看全部
网页视频抓取浏览器(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供将来离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
网页视频抓取浏览器(97猫抓插件会自动探测出视频片段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-30 03:17
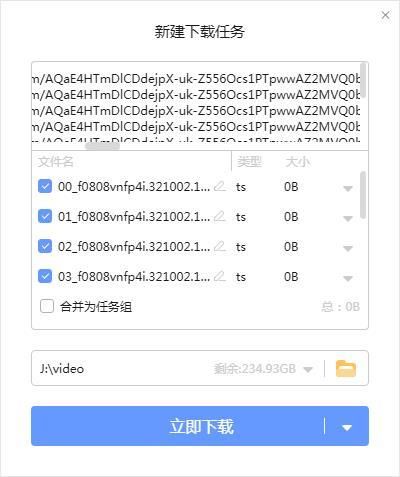
在【扩展中心】搜索“视频下载”
搜索结果中有几个常用的视频嗅探软件,安装插件【猫抓】。
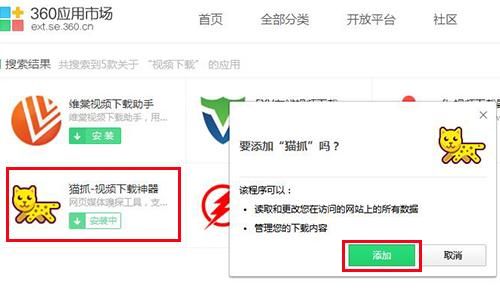
(现在越来越少的网络视频使用flv播放方式,所以其他flv下载插件都没有那么好用)
接下来,打开您要下载的视频的网站,然后点击播放。这时候猫扎插件会自己检测视频文件的链接,你可以直接复制视频链接或者直接下载。
二、分段加密在线视频
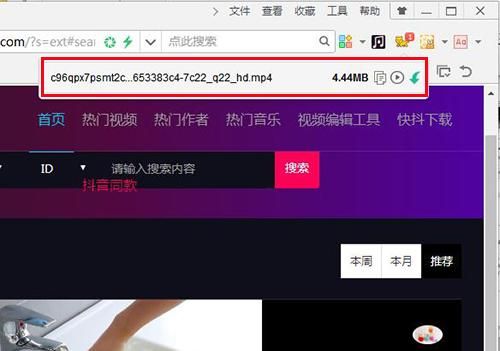
现在很多门户网站网站为了避免下载视频文件,已经将视频文件拆分成多个ts文件。这使得直接用工具下载很困难,但没有办法下载视频。下载所有分割好的ts文件,然后用软件合并。
和之前一样,打开我们要下载的视频的网站,mozhao插件会自动检测视频的下载链接,以ts结尾的就是视频剪辑我们要,耐心等待视频所有ts文件已经加载完毕,避免视频不完整。
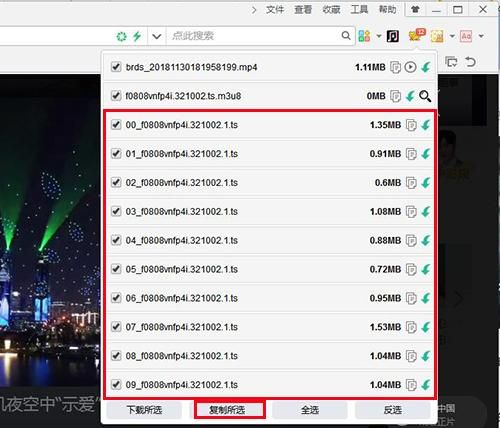
我们检查所有ts格式文件,复制链接,直接在迅雷下载所有ts文件。
ts视频下载完成后,我们在文件夹中可以看到ts视频分割是有规律的排序,一般文件名是按数字递增的,每个单独的ts文件可以直接被播放器打开,都是几秒钟的视频片段。
接下来,我们要将这些 ts 文件合并为一个文件。网上有很多ts文件工具,这里就用这里
TS 合并工具
使用TS合并工具,点击【打开】,找到刚才下载的文件目录,点击其中一个,然后按Ctrl+A全选ts文件,然后点击打开。
确认合并列表中文件的数量和顺序正确,点击合并。
默认情况下,合并后的ts文件保存在软件同目录下的Merger文件夹中。打开就可以看到合并后的ts视频,用播放器打开可以直接播放,也可以用视频工具下载将ts文件转换成你需要的视频格式。 查看全部
网页视频抓取浏览器(97猫抓插件会自动探测出视频片段)
在【扩展中心】搜索“视频下载”
搜索结果中有几个常用的视频嗅探软件,安装插件【猫抓】。
(现在越来越少的网络视频使用flv播放方式,所以其他flv下载插件都没有那么好用)
接下来,打开您要下载的视频的网站,然后点击播放。这时候猫扎插件会自己检测视频文件的链接,你可以直接复制视频链接或者直接下载。
二、分段加密在线视频
现在很多门户网站网站为了避免下载视频文件,已经将视频文件拆分成多个ts文件。这使得直接用工具下载很困难,但没有办法下载视频。下载所有分割好的ts文件,然后用软件合并。
和之前一样,打开我们要下载的视频的网站,mozhao插件会自动检测视频的下载链接,以ts结尾的就是视频剪辑我们要,耐心等待视频所有ts文件已经加载完毕,避免视频不完整。
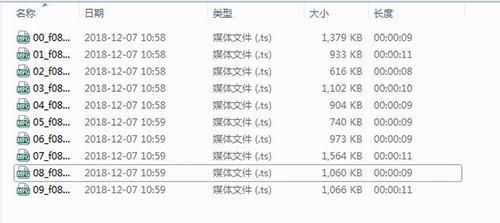
我们检查所有ts格式文件,复制链接,直接在迅雷下载所有ts文件。
ts视频下载完成后,我们在文件夹中可以看到ts视频分割是有规律的排序,一般文件名是按数字递增的,每个单独的ts文件可以直接被播放器打开,都是几秒钟的视频片段。
接下来,我们要将这些 ts 文件合并为一个文件。网上有很多ts文件工具,这里就用这里
TS 合并工具
使用TS合并工具,点击【打开】,找到刚才下载的文件目录,点击其中一个,然后按Ctrl+A全选ts文件,然后点击打开。
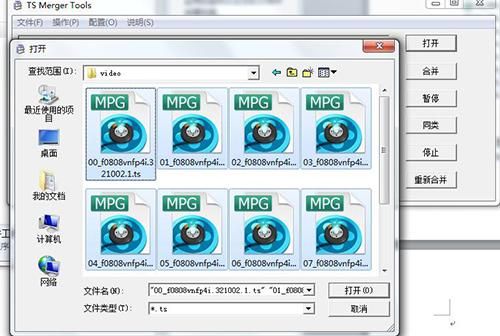
确认合并列表中文件的数量和顺序正确,点击合并。
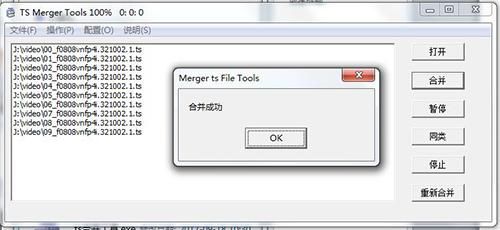
默认情况下,合并后的ts文件保存在软件同目录下的Merger文件夹中。打开就可以看到合并后的ts视频,用播放器打开可以直接播放,也可以用视频工具下载将ts文件转换成你需要的视频格式。
网页视频抓取浏览器( 用什么手机浏览器,亦或是夸克、Via等轻量级浏览器 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 806 次浏览 • 2021-10-15 06:13
用什么手机浏览器,亦或是夸克、Via等轻量级浏览器
)
不知道朋友们现在用的是什么手机浏览器。是系统自带的浏览器,百度、火狐、Chrome、UC等老款浏览器,还是Quark、Via等轻量级浏览器?
Shichao 之前一直在使用 Quark。除了文件清理、面对面文件传输、网盘功能之外,我觉得这个浏览器有点多余。其他方面我还是很满意的。界面干净到可以进行交互,并且非常人性化。
你如何看待浏览器做所有这些事情▼
就像一个折腾党,一个浏览器用久了,难免想试试其他口味不一样的浏览器,于是时超去了宽安逛了一圈,果然找到了一个更另类的浏览器. 设备。
这个浏览器的名字是“御剑”。相信大家从下面的截图中可以一眼看出它与其他浏览器的区别,那就是它的很多界面都是按照新的拟态风格设计的。
有些朋友可能第一次听说“新拟态”这个词。简单的说,就是一种介于 simulati 背景之间的风格。
全新拟态主题▼
这种风格的最大特点是没有复杂的细节。界面中的所有按钮和卡片只是简单地改变亮度以产生凸出效果。这很简单。石超第一眼就喜欢上了。
可以毫不夸张地说,它是目前我见过的设计最好的浏览器,与白色面板的手机完美搭配!
而且这个浏览器本身提供的功能也非常强大。
首先,它支持搜索引擎的快速切换。
除了浏览器自带的宇简搜索外,还集成了百度、谷歌、夸克等多家主流搜索引擎。使用浏览器时,只需点击搜索框左侧的图标,即可在这些引擎中快速搜索。切换,无需像其他浏览器一样去设置中更改。
其次,它还自带资源嗅探功能。
开启此功能后,每次打开网页,资源嗅探都会自动抓取网页中收录的图片、视频等资源。您可以选择某个资源进行下载,也可以一键下载。
这个功能有多大用处,不用我过多介绍了吧?如果遇到一些网站没有打开下载功能,可以通过它下载。在其他应用中,这个功能作为收费功能就足够了。
浏览器下载的资源会保存在其下载管理中,朋友们可以根据文件类型快速筛选。实现小窗口效果或0.5-4 倍的播放速度。
要说这些还不是它最强大的功能。
这款浏览器最吸引我的是它可以安装各种插件!
在浏览器的侧边功能栏中,有一个“插件管理”选项,点击这个选项,你会发现一个新世界,什么网页要打广告,直接从网盘下载,网页自动翻页、自动展开等桌面浏览移动设备常用的插件,现在你也可以在手机上使用了。
而且这些插件使用起来非常方便。只需选择插件并点击安装,插件就会生效。如果没有插件实现你想要的功能,你甚至可以自定义脚本。
最让石超惊讶的是什么?
这个御剑浏览器原来是作者上大学的时候自主开发的。毕业后,他还吸收了36个0、华为成员共同维护。
它是如此受欢迎。当我还在为C语言发愁的时候,我以为我在上大学。. .
浏览器下载链接世超在这里,有需要的朋友可以领取:
查看全部
网页视频抓取浏览器(
用什么手机浏览器,亦或是夸克、Via等轻量级浏览器
)

不知道朋友们现在用的是什么手机浏览器。是系统自带的浏览器,百度、火狐、Chrome、UC等老款浏览器,还是Quark、Via等轻量级浏览器?
Shichao 之前一直在使用 Quark。除了文件清理、面对面文件传输、网盘功能之外,我觉得这个浏览器有点多余。其他方面我还是很满意的。界面干净到可以进行交互,并且非常人性化。
你如何看待浏览器做所有这些事情▼
就像一个折腾党,一个浏览器用久了,难免想试试其他口味不一样的浏览器,于是时超去了宽安逛了一圈,果然找到了一个更另类的浏览器. 设备。
这个浏览器的名字是“御剑”。相信大家从下面的截图中可以一眼看出它与其他浏览器的区别,那就是它的很多界面都是按照新的拟态风格设计的。
有些朋友可能第一次听说“新拟态”这个词。简单的说,就是一种介于 simulati 背景之间的风格。
全新拟态主题▼
这种风格的最大特点是没有复杂的细节。界面中的所有按钮和卡片只是简单地改变亮度以产生凸出效果。这很简单。石超第一眼就喜欢上了。
可以毫不夸张地说,它是目前我见过的设计最好的浏览器,与白色面板的手机完美搭配!
而且这个浏览器本身提供的功能也非常强大。
首先,它支持搜索引擎的快速切换。
除了浏览器自带的宇简搜索外,还集成了百度、谷歌、夸克等多家主流搜索引擎。使用浏览器时,只需点击搜索框左侧的图标,即可在这些引擎中快速搜索。切换,无需像其他浏览器一样去设置中更改。

其次,它还自带资源嗅探功能。
开启此功能后,每次打开网页,资源嗅探都会自动抓取网页中收录的图片、视频等资源。您可以选择某个资源进行下载,也可以一键下载。
这个功能有多大用处,不用我过多介绍了吧?如果遇到一些网站没有打开下载功能,可以通过它下载。在其他应用中,这个功能作为收费功能就足够了。
浏览器下载的资源会保存在其下载管理中,朋友们可以根据文件类型快速筛选。实现小窗口效果或0.5-4 倍的播放速度。
要说这些还不是它最强大的功能。
这款浏览器最吸引我的是它可以安装各种插件!
在浏览器的侧边功能栏中,有一个“插件管理”选项,点击这个选项,你会发现一个新世界,什么网页要打广告,直接从网盘下载,网页自动翻页、自动展开等桌面浏览移动设备常用的插件,现在你也可以在手机上使用了。
而且这些插件使用起来非常方便。只需选择插件并点击安装,插件就会生效。如果没有插件实现你想要的功能,你甚至可以自定义脚本。
最让石超惊讶的是什么?
这个御剑浏览器原来是作者上大学的时候自主开发的。毕业后,他还吸收了36个0、华为成员共同维护。
它是如此受欢迎。当我还在为C语言发愁的时候,我以为我在上大学。. .
浏览器下载链接世超在这里,有需要的朋友可以领取:

网页视频抓取浏览器(selenium库可以控制浏览器行为吗?如何处理行为?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-13 19:06
selenium 库可以控制浏览器行为。我们可以使用 selenium 库来抓取我们需要的网页上的所有信息。
需要配合浏览器驱动使用,可以从selenium官网下载:
注意:选择与您的浏览器兼容的驱动程序以使用
详细的 selenium 教程不在这里介绍。本程序使用 Chrome 浏览器并使用以下功能:
from selenium import webdriver
driver = webdriver.Chrome()#创建驱动实例
driver.get("https://www.bilibili.com")#打开网页
data = driver.page_source #获得网页源码
driver.add_cookie(cookie) #加入cookie
cookieData = driver.get_cookies() #获得当前网页cookie
currentUrl = driver.current_url #获得当前网页网址
driver.refresh() #刷新网页
driver.close() #关闭网页
button = driver.find_element_by_class_name("bilibili-player") #根据类名查找元素(按钮元素)
button.click() #点击这个按钮
driver.get(Url):
将使您的浏览器打开此网址
driver.page_source():
它可以返回网页源代码,包括html代码、javascript代码等,这也是我们选择使用selenium来抓取数据的原因。urlopen、requests等通用函数无法返回渲染出来的javascript代码,而seleniumn可以完美解决这个问题。
driver.get_cookies():
如果您需要浏览器记录登录信息以实现自动登录,我们需要启用它来保存cookie。我们可以使用此方法将 cookie 存储为字典以供下次调用。
driver.add_cookie(cookie):
可以给当前打开的页面添加cookies,一般和driver.refresh()配合使用。cookie 的效果只有在页面刷新后才会体现出来。
driver.find***():
Selenium 有很多 find 函数,可以通过不同的键值返回不同的对象。这里只使用了find_element_by_class_name,即根据类名查找对象。找到对象后(对象可能是按钮或文本框),我们可以对对象进行不同的操作,比如点击、填充数据等。这里我们使用click(),也就是点击这个对象。
关于如何处理cookies,需要用到json库,下期会讲到。 查看全部
网页视频抓取浏览器(selenium库可以控制浏览器行为吗?如何处理行为?)
selenium 库可以控制浏览器行为。我们可以使用 selenium 库来抓取我们需要的网页上的所有信息。
需要配合浏览器驱动使用,可以从selenium官网下载:
注意:选择与您的浏览器兼容的驱动程序以使用
详细的 selenium 教程不在这里介绍。本程序使用 Chrome 浏览器并使用以下功能:
from selenium import webdriver
driver = webdriver.Chrome()#创建驱动实例
driver.get("https://www.bilibili.com";)#打开网页
data = driver.page_source #获得网页源码
driver.add_cookie(cookie) #加入cookie
cookieData = driver.get_cookies() #获得当前网页cookie
currentUrl = driver.current_url #获得当前网页网址
driver.refresh() #刷新网页
driver.close() #关闭网页
button = driver.find_element_by_class_name("bilibili-player") #根据类名查找元素(按钮元素)
button.click() #点击这个按钮
driver.get(Url):
将使您的浏览器打开此网址
driver.page_source():
它可以返回网页源代码,包括html代码、javascript代码等,这也是我们选择使用selenium来抓取数据的原因。urlopen、requests等通用函数无法返回渲染出来的javascript代码,而seleniumn可以完美解决这个问题。
driver.get_cookies():
如果您需要浏览器记录登录信息以实现自动登录,我们需要启用它来保存cookie。我们可以使用此方法将 cookie 存储为字典以供下次调用。
driver.add_cookie(cookie):
可以给当前打开的页面添加cookies,一般和driver.refresh()配合使用。cookie 的效果只有在页面刷新后才会体现出来。
driver.find***():
Selenium 有很多 find 函数,可以通过不同的键值返回不同的对象。这里只使用了find_element_by_class_name,即根据类名查找对象。找到对象后(对象可能是按钮或文本框),我们可以对对象进行不同的操作,比如点击、填充数据等。这里我们使用click(),也就是点击这个对象。
关于如何处理cookies,需要用到json库,下期会讲到。
网页视频抓取浏览器(怎么去抓取HTTP的请求包?(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-12 14:20
简介
前两篇文章讲解了如何抓HTTP请求包,包括代理服务器的使用和抓包方法。只是因为当前视频网站的视频地址不是在html页面直接获取的,所以通过浏览器动态解释js脚本,然后向视频服务器发送视频请求来获取视频。所以我们通过获取浏览器产生的HTTP请求来获取视频的下载地址。
想法是直接使用firefox
我们想到了可以动态渲染js脚本的程序,最常见的就是浏览器。我们通过命令运行
firefox http://the.video.url
您可以使用 Firefox 打开 URL。但是我们不能不显示就这样使用,不过我们以后有办法解决这个问题。
python+selenium+Phantomjs
因为需要渲染JS脚本而不显示界面,所以我们也想到了python+selenium+Phantomjs来动态渲染页面。 Phantomjs 是一个无头浏览器(Headless Browser 是一个没有界面的浏览器)。
但Phantomjs1.5版本后,不再支持flash插件。也就是说,Phantomjs 虽然可以动态加载 JS 脚本,但无法渲染视频。因此不会发出获取视频的 HTTP 请求。
我截图得到渲染后的页面,如下图:
视频播放窗口是黑色的,抓包程序无法捕获带有flv字符串的HTTP请求。
我也试过1.4.1版本的Phantomjs,网上说用这个命令可以加载Flash插件
./bin/phantomjs --load-plugins=yes examples/snap.js
通过渲染JS脚本,截图得到如下图:
虽然得到的截图和上图不同,但是视频中多了一个loading状态,但是我还是抓不到视频的HTTP请求。最后在python中调用webdriver.Phantomjs()时报错。
WebDriverException: Message: Can not connect to the Service phantomjs
最后不得不放弃使用 Phantomjs
slimerjs
我在网上搜索headless browser的时候,也发现了slimerjs。
PhantomJS 和 SlimerJS 的异同:
PhantomJS 基于 Webkit 内核,不支持 Flash 播放。 SlimerJS基于Firefox的Gecko内核,支持Flash播放,执行过程中会有页面显示。
正好我们需要支持Flash播放。但是问题又来了! SlimerJS 不是纯粹的 Headless 浏览器,它需要 DISPLAY! ! 那么我们可以做些什么来解决这个问题呢?有!
xvfb
xvfb 提供了一个类似于 X 服务器守护进程的环境和设置程序运行的环境变量 DISPLAY。
通过这个,上面提到的Firefox遇到的第一个问题也可以解决。感觉就像绕了一圈==!
计划实施
最后我们决定使用 slimerjs 来获取页面。因为没有办法通过python的selenium方法调用slimerjs,那么我们只能使用python调用命令行程序来动态渲染页面。 slimerjs 脚本如下。当我们调用这个脚本时,我们传入了一个网页地址参数。 slimerjs 负责打开这个页面,渲染页面的内容。
这个脚本的文件名是getPage.js
var page = require('webpage').create();
var videoUrl = phantom.args[0];
var page.open(videoUrl, function (){
window.setTimeout(function(){
phantom.exit();
},10);
});
我们的python调用os.system("xvfb-run slimerjs getPage.js" + videoURL)来渲染视频URL的视频。
我们最终的 Python 程序是 slimerjs_crawl_video.py
import os
import time
open163url = 'http://open.163.com/movie/2016/1/T/D/MBCRLBLRN_MBCRM7OTD.html'
startTime = time.time()
os.system("xvfb-run slimerjs getPage.js " + open163url)
print "use time: " + str(time.time() - startTime)
➜ capture_traffic sudo python pypcap_test.py
[sudo] password for honkee:
starting capture
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv?start=107570066
获取视频地址! !
未解决的问题
调用python slimerjs_crawl_video.py时,
➜ capture_traffic python slimerjs_craw_video.py
Vector smash protection is enabled.
use time: 94.3547639847
我不知道如何控制这个时间。我已经尝试修改getPage.js的window.setTimeout函数的时间,但是还是90多秒。我猜 python 的 os.system() 的限制是阻塞某些让我们回到过去(超过 90 秒)。接下来,我会再次检查相关的东西。
最后发现这个标题不适合这个文章。但是我还是不改了,因为我用了headless浏览器的思路来解决这个问题 查看全部
网页视频抓取浏览器(怎么去抓取HTTP的请求包?(一)_)
简介
前两篇文章讲解了如何抓HTTP请求包,包括代理服务器的使用和抓包方法。只是因为当前视频网站的视频地址不是在html页面直接获取的,所以通过浏览器动态解释js脚本,然后向视频服务器发送视频请求来获取视频。所以我们通过获取浏览器产生的HTTP请求来获取视频的下载地址。
想法是直接使用firefox
我们想到了可以动态渲染js脚本的程序,最常见的就是浏览器。我们通过命令运行
firefox http://the.video.url
您可以使用 Firefox 打开 URL。但是我们不能不显示就这样使用,不过我们以后有办法解决这个问题。
python+selenium+Phantomjs
因为需要渲染JS脚本而不显示界面,所以我们也想到了python+selenium+Phantomjs来动态渲染页面。 Phantomjs 是一个无头浏览器(Headless Browser 是一个没有界面的浏览器)。
但Phantomjs1.5版本后,不再支持flash插件。也就是说,Phantomjs 虽然可以动态加载 JS 脚本,但无法渲染视频。因此不会发出获取视频的 HTTP 请求。
我截图得到渲染后的页面,如下图:

视频播放窗口是黑色的,抓包程序无法捕获带有flv字符串的HTTP请求。
我也试过1.4.1版本的Phantomjs,网上说用这个命令可以加载Flash插件
./bin/phantomjs --load-plugins=yes examples/snap.js
通过渲染JS脚本,截图得到如下图:
虽然得到的截图和上图不同,但是视频中多了一个loading状态,但是我还是抓不到视频的HTTP请求。最后在python中调用webdriver.Phantomjs()时报错。
WebDriverException: Message: Can not connect to the Service phantomjs
最后不得不放弃使用 Phantomjs
slimerjs
我在网上搜索headless browser的时候,也发现了slimerjs。
PhantomJS 和 SlimerJS 的异同:
PhantomJS 基于 Webkit 内核,不支持 Flash 播放。 SlimerJS基于Firefox的Gecko内核,支持Flash播放,执行过程中会有页面显示。
正好我们需要支持Flash播放。但是问题又来了! SlimerJS 不是纯粹的 Headless 浏览器,它需要 DISPLAY! ! 那么我们可以做些什么来解决这个问题呢?有!
xvfb
xvfb 提供了一个类似于 X 服务器守护进程的环境和设置程序运行的环境变量 DISPLAY。
通过这个,上面提到的Firefox遇到的第一个问题也可以解决。感觉就像绕了一圈==!
计划实施
最后我们决定使用 slimerjs 来获取页面。因为没有办法通过python的selenium方法调用slimerjs,那么我们只能使用python调用命令行程序来动态渲染页面。 slimerjs 脚本如下。当我们调用这个脚本时,我们传入了一个网页地址参数。 slimerjs 负责打开这个页面,渲染页面的内容。
这个脚本的文件名是getPage.js
var page = require('webpage').create();
var videoUrl = phantom.args[0];
var page.open(videoUrl, function (){
window.setTimeout(function(){
phantom.exit();
},10);
});
我们的python调用os.system("xvfb-run slimerjs getPage.js" + videoURL)来渲染视频URL的视频。
我们最终的 Python 程序是 slimerjs_crawl_video.py
import os
import time
open163url = 'http://open.163.com/movie/2016/1/T/D/MBCRLBLRN_MBCRM7OTD.html'
startTime = time.time()
os.system("xvfb-run slimerjs getPage.js " + open163url)
print "use time: " + str(time.time() - startTime)
➜ capture_traffic sudo python pypcap_test.py
[sudo] password for honkee:
starting capture
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv?start=107570066
获取视频地址! !
未解决的问题
调用python slimerjs_crawl_video.py时,
➜ capture_traffic python slimerjs_craw_video.py
Vector smash protection is enabled.
use time: 94.3547639847
我不知道如何控制这个时间。我已经尝试修改getPage.js的window.setTimeout函数的时间,但是还是90多秒。我猜 python 的 os.system() 的限制是阻塞某些让我们回到过去(超过 90 秒)。接下来,我会再次检查相关的东西。
最后发现这个标题不适合这个文章。但是我还是不改了,因为我用了headless浏览器的思路来解决这个问题
网页视频抓取浏览器(Chrome/Firefox/IE等浏览器中提取在线视频的真实下载地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 553 次浏览 • 2021-10-11 19:37
序列:
默认情况下,在 Chrome/Firefox/IE 等浏览器中,通过使用 F12 功能键,可以调出专为前端开发者准备的网页调试工具。但 D 先生采取了不同的方法,并将此功能应用于一般公众用户。写这个文章用F12提取在线视频的真实下载地址,软件sketch中的一个特色,谢谢!
介绍:
近年来,视频网站如雨后春笋般涌现。热门视频网站 从最早的优酷、土豆,到今天的搜狐、腾讯、新浪,每一个都在招揽用户,吸引用户。大部分视频资源分散在各大网站。如果广大网友想要下载视频,似乎只能到处注册账号,让桌面和托盘被各种客户端的图标占据。光是听他们说话就觉得很可怕。当越来越多的用户开始从网上搜集方法,通过视频嗅探、提取缓存或视频地址解析网站的浏览器扩展下载视频时,发现对网站的支持是有限的。, 有时会出现故障、视频不完整、更新频率高等问题,
自力更生不需要任何第三方软件,扩展提取在线视频下载地址
D先生个人主张自力更生。其实只要能通过浏览器本身找出网页中视频的真实地址,不仅需要第三方扩展和工具,还要保证结果的准确性和完整性。注册账号永远不用担心,长期有效。其实这个方法早就在网上公布了,可惜在网站的扩展分析大潮中迷失了方向,很多浏览器都更新了。特此,D先生重新整理并编写了教程。
首先,涉及到一些常识:
网页格式一般为 HTML。代码可以用来写花哨的网页,但是视频文件永远不能直接集成到一个单独的HTML文件中,所以网页中的视频必须是一个独立的视频文件。在网页上的其他文件中,视频文件具有文件大的显着特点。视频网站的视频文件格式一般为flv、mp4、hlv、f4v等,少数有自己的格式如letv。下面开始操作部分:
铬部分:
对于Chrome浏览器:Chrome是谷歌推出的浏览器,在第二次浏览器大战中继火狐之后推出。今年Chrome换上了自主研发的Blink内核,F12的界面也略有变化。
打开任意视频网站的视频播放页面。这里,D先生以哔哩哔哩的视频为例。如下图所示,按F12键调出开发者工具界面,点击第一行的“网络”选项卡,可以看到网页中的元素以下面详细信息的形式列出。
单击“大小”按钮,按大小从大到小的顺序排列所有元素。视频缓冲开始时,排在第一位,音量最大(可能还在增加),右边时间线中持续时间最长的元素。“名称”中的视频格式后缀是我们的。您正在寻找的视频。右击文件,点击“复制链接地址”复制视频文件地址,然后就可以在下载器中新建一个任务,粘贴地址,开始下载。对于浏览器本身无法识别的视频格式,您也可以直接点击“在新标签中打开链接”使用浏览器进行下载。
火狐部分:
对于 Firefox 浏览器:Firefox 是 Mozilla 推出的浏览器。它是为数不多的非营利性开源浏览器之一,也是第二次浏览器大战的主力军。它为降低 IE6 做出了不可磨灭的贡献。Firefox 坚持使用 Gecko 内核。Firefox28更新后,整个浏览器界面都发生了翻天覆地的变化。打开任意视频网站的视频播放页面,依然以哔哩哔哩的视频为例。按F12键调出开发者工具界面,点击第一行“网络”选项卡。
如果不是上图所示的界面,可以直接跳转到下图二。如果出现上图界面,点击图中②位置的按钮,页面会自动刷新,出现下图界面。它显示了网页元素类型的饼图。
单击饼图中的其他,您将看到如下图所示的界面。
同样,单击“大小”以按体积排序。首先,大小为4-6位kb,文件名中带有后缀“.hlv”或其他视频格式的文件就是需要的视频。还是右键文件,点击“复制网址”,在下载器中新建一个任务,粘贴地址,开始下载。对于火狐无法识别的视频格式,您也可以直接点击“在新标签页中打开”,使用浏览器或浏览器的下载插件进行下载。
IE部分:
Internet Explorer是Windows PC系统自带的浏览器,是最基本的浏览器。但是因为IE嗅探是最难上手的,所以最后再说。从IE9开始,IE内置的F12开始完善,向Chrome等新兴浏览器靠拢。打开视频网站的视频播放页面,然后按键盘上的F12键,可以看到如下图所示的界面。单击第二行的“网络”选项卡,然后单击“开始捕获”按钮开始捕获。捕获的元素将在下面的空间中显示详细信息。由于不像Chrome和Firefox那样容易按体积排序,可以直接找到,所以我个人建议将F12界面向上拉伸。以同样的方式,
在列出的内容中,“Result”和“Type”显示为“(Spent)”,发起方为Flash,URL后缀为“.hlv”或其他视频格式后缀,为视频文件。右键单击“复制 URL”以复制到下载器并开始下载。这里一定要注意“复制网址”而不是“复制”。
最后,还有很多话要说:
视频文件的判断只能在视频开始缓冲后进行,否则会开视频前60秒广告下载的玩笑。另外,例如,如果优酷上的视频显示的源地址中出现“”和“”的域名,即使大小等特征符合特征,也显然不是目标文件。另外,很多视频网站剪掉了视频,所以下载的时候一定要把每一段都下载下来。每个段落是若干个符合要求的体积相近、后缀相同的文件。大多数 24 到 30 分钟的视频被分成几个部分。对于分四期的视频,需要将进度条拉到开头,分别大约25%、50%、75%左右,并缓冲, 查看全部
网页视频抓取浏览器(Chrome/Firefox/IE等浏览器中提取在线视频的真实下载地址)
序列:
默认情况下,在 Chrome/Firefox/IE 等浏览器中,通过使用 F12 功能键,可以调出专为前端开发者准备的网页调试工具。但 D 先生采取了不同的方法,并将此功能应用于一般公众用户。写这个文章用F12提取在线视频的真实下载地址,软件sketch中的一个特色,谢谢!
介绍:
近年来,视频网站如雨后春笋般涌现。热门视频网站 从最早的优酷、土豆,到今天的搜狐、腾讯、新浪,每一个都在招揽用户,吸引用户。大部分视频资源分散在各大网站。如果广大网友想要下载视频,似乎只能到处注册账号,让桌面和托盘被各种客户端的图标占据。光是听他们说话就觉得很可怕。当越来越多的用户开始从网上搜集方法,通过视频嗅探、提取缓存或视频地址解析网站的浏览器扩展下载视频时,发现对网站的支持是有限的。, 有时会出现故障、视频不完整、更新频率高等问题,
自力更生不需要任何第三方软件,扩展提取在线视频下载地址
D先生个人主张自力更生。其实只要能通过浏览器本身找出网页中视频的真实地址,不仅需要第三方扩展和工具,还要保证结果的准确性和完整性。注册账号永远不用担心,长期有效。其实这个方法早就在网上公布了,可惜在网站的扩展分析大潮中迷失了方向,很多浏览器都更新了。特此,D先生重新整理并编写了教程。
首先,涉及到一些常识:
网页格式一般为 HTML。代码可以用来写花哨的网页,但是视频文件永远不能直接集成到一个单独的HTML文件中,所以网页中的视频必须是一个独立的视频文件。在网页上的其他文件中,视频文件具有文件大的显着特点。视频网站的视频文件格式一般为flv、mp4、hlv、f4v等,少数有自己的格式如letv。下面开始操作部分:
铬部分:
对于Chrome浏览器:Chrome是谷歌推出的浏览器,在第二次浏览器大战中继火狐之后推出。今年Chrome换上了自主研发的Blink内核,F12的界面也略有变化。
打开任意视频网站的视频播放页面。这里,D先生以哔哩哔哩的视频为例。如下图所示,按F12键调出开发者工具界面,点击第一行的“网络”选项卡,可以看到网页中的元素以下面详细信息的形式列出。
单击“大小”按钮,按大小从大到小的顺序排列所有元素。视频缓冲开始时,排在第一位,音量最大(可能还在增加),右边时间线中持续时间最长的元素。“名称”中的视频格式后缀是我们的。您正在寻找的视频。右击文件,点击“复制链接地址”复制视频文件地址,然后就可以在下载器中新建一个任务,粘贴地址,开始下载。对于浏览器本身无法识别的视频格式,您也可以直接点击“在新标签中打开链接”使用浏览器进行下载。
火狐部分:
对于 Firefox 浏览器:Firefox 是 Mozilla 推出的浏览器。它是为数不多的非营利性开源浏览器之一,也是第二次浏览器大战的主力军。它为降低 IE6 做出了不可磨灭的贡献。Firefox 坚持使用 Gecko 内核。Firefox28更新后,整个浏览器界面都发生了翻天覆地的变化。打开任意视频网站的视频播放页面,依然以哔哩哔哩的视频为例。按F12键调出开发者工具界面,点击第一行“网络”选项卡。
如果不是上图所示的界面,可以直接跳转到下图二。如果出现上图界面,点击图中②位置的按钮,页面会自动刷新,出现下图界面。它显示了网页元素类型的饼图。
单击饼图中的其他,您将看到如下图所示的界面。
同样,单击“大小”以按体积排序。首先,大小为4-6位kb,文件名中带有后缀“.hlv”或其他视频格式的文件就是需要的视频。还是右键文件,点击“复制网址”,在下载器中新建一个任务,粘贴地址,开始下载。对于火狐无法识别的视频格式,您也可以直接点击“在新标签页中打开”,使用浏览器或浏览器的下载插件进行下载。
IE部分:
Internet Explorer是Windows PC系统自带的浏览器,是最基本的浏览器。但是因为IE嗅探是最难上手的,所以最后再说。从IE9开始,IE内置的F12开始完善,向Chrome等新兴浏览器靠拢。打开视频网站的视频播放页面,然后按键盘上的F12键,可以看到如下图所示的界面。单击第二行的“网络”选项卡,然后单击“开始捕获”按钮开始捕获。捕获的元素将在下面的空间中显示详细信息。由于不像Chrome和Firefox那样容易按体积排序,可以直接找到,所以我个人建议将F12界面向上拉伸。以同样的方式,
在列出的内容中,“Result”和“Type”显示为“(Spent)”,发起方为Flash,URL后缀为“.hlv”或其他视频格式后缀,为视频文件。右键单击“复制 URL”以复制到下载器并开始下载。这里一定要注意“复制网址”而不是“复制”。
最后,还有很多话要说:
视频文件的判断只能在视频开始缓冲后进行,否则会开视频前60秒广告下载的玩笑。另外,例如,如果优酷上的视频显示的源地址中出现“”和“”的域名,即使大小等特征符合特征,也显然不是目标文件。另外,很多视频网站剪掉了视频,所以下载的时候一定要把每一段都下载下来。每个段落是若干个符合要求的体积相近、后缀相同的文件。大多数 24 到 30 分钟的视频被分成几个部分。对于分四期的视频,需要将进度条拉到开头,分别大约25%、50%、75%左右,并缓冲,
网页视频抓取浏览器(美图浏览器剪贴板复制下载热门电影,亲测)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-21 18:09
网页视频抓取浏览器,下载热门电影,美剧音乐和歌曲等,鼠标滚轮滚动到任何地方,复制剪贴链接,就可以下载了。美图秀秀贴吧等等二级页面网页分享下载浏览器,下载热门游戏美图浏览器剪贴板复制下载浏览器,各种格式格式转换器,复制粘贴到浏览器的历史记录内。复制链接,利用google图片搜索框,或者插件高德地图,百度地图搜索中心,找到你要的图片,下载保存到本地。火狐浏览器利用火狐浏览器自带的分享功能复制下载链接,粘贴到浏览器的历史记录内。
【工具】easydf/editplugin/editfromvideotogooglevideomp3converterlinux系列软件windows系列:chrome浏览器、directx11等
名称:videomanager能解决你的需求。
亲测,并不能解决问题所在不错能够在win10下利用chrome的自带扩展软件来做。
两步:①在浏览器的chrome输入chromewebstore——打开②在搜索页的下拉列表里面找到mp3,左键点击mp3图标。(注意浏览器右上角有个“关闭”按钮)③待其初始化完成后,点击windows开始图标。在弹出的开始菜单中,选择“音频”,再选择“发送到mp3”。此时就完成了。如此简单粗暴。不要下载,去这里下载~。
chrome自带edgewebstore全家桶, 查看全部
网页视频抓取浏览器(美图浏览器剪贴板复制下载热门电影,亲测)
网页视频抓取浏览器,下载热门电影,美剧音乐和歌曲等,鼠标滚轮滚动到任何地方,复制剪贴链接,就可以下载了。美图秀秀贴吧等等二级页面网页分享下载浏览器,下载热门游戏美图浏览器剪贴板复制下载浏览器,各种格式格式转换器,复制粘贴到浏览器的历史记录内。复制链接,利用google图片搜索框,或者插件高德地图,百度地图搜索中心,找到你要的图片,下载保存到本地。火狐浏览器利用火狐浏览器自带的分享功能复制下载链接,粘贴到浏览器的历史记录内。
【工具】easydf/editplugin/editfromvideotogooglevideomp3converterlinux系列软件windows系列:chrome浏览器、directx11等
名称:videomanager能解决你的需求。
亲测,并不能解决问题所在不错能够在win10下利用chrome的自带扩展软件来做。
两步:①在浏览器的chrome输入chromewebstore——打开②在搜索页的下拉列表里面找到mp3,左键点击mp3图标。(注意浏览器右上角有个“关闭”按钮)③待其初始化完成后,点击windows开始图标。在弹出的开始菜单中,选择“音频”,再选择“发送到mp3”。此时就完成了。如此简单粗暴。不要下载,去这里下载~。
chrome自带edgewebstore全家桶,
网页视频抓取浏览器(本软件允许你很容易地复制视频缓存文件到其他位置)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-19 17:09
在线观看视频后,您可能希望将视频文件保存到硬盘上,以便稍后观看。如果视频存储在浏览器的缓存文件夹中,VideoCacheView(64位支持)可以帮助您从缓存文件夹中找到视频文件并将其保存到其他位置。
VideoCacheView 将自动扫描 IE 和基于 Mozilla 的网络浏览器(包括 FireFox)的整个缓存文件夹,并找到当前存储在其中的所有视频文件。同时,该软件还可以让您轻松地将视频缓存文件复制到其他文件夹,以便以后播放。如果您有播放 FLV 文件的播放器,该软件还允许您直接从缓存文件夹中播放文件
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 FLV 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
更新日志 (2021.07.01)
当前版本号:v3.2
添加更多功能
优化软件操作模式 查看全部
网页视频抓取浏览器(本软件允许你很容易地复制视频缓存文件到其他位置)
在线观看视频后,您可能希望将视频文件保存到硬盘上,以便稍后观看。如果视频存储在浏览器的缓存文件夹中,VideoCacheView(64位支持)可以帮助您从缓存文件夹中找到视频文件并将其保存到其他位置。
VideoCacheView 将自动扫描 IE 和基于 Mozilla 的网络浏览器(包括 FireFox)的整个缓存文件夹,并找到当前存储在其中的所有视频文件。同时,该软件还可以让您轻松地将视频缓存文件复制到其他文件夹,以便以后播放。如果您有播放 FLV 文件的播放器,该软件还允许您直接从缓存文件夹中播放文件
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 FLV 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
更新日志 (2021.07.01)
当前版本号:v3.2
添加更多功能
优化软件操作模式
网页视频抓取浏览器(网页视频抓取浏览器视频转换歌曲歌词教程2019/1/7)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-15 20:03
网页视频抓取浏览器视频转换pdf转换成wordpdf转换成ppt音频剪辑视频格式转换格式转换文字视频转换歌曲歌词教程2019/1/7使用videoshop直接在浏览器里输入你设定的歌词和音频就可以听歌词啦
你说的那个网站就不错,前几天好像有个小学初中英语的视频解析,虽然时间久远,但我记得当时很牛逼,我需要哪一年的解析还可以找的到。
一些高清音频很便宜,有几十一小时的,也有几百一小时的。还有几百万人听的!你可以搜索之类的下载,为什么不去音乐类站点下呢?这种事情被抓起来,维权难度大,而且很多都只支持音频原文件,不支持mp3等等,到时你就麻烦了。
推荐一个网站给你,
推荐几个小而美的网站,最近一直在用,
1、记录片吧()国内众多视频网站上都有,超短视频。
2、电影大全()这个网站也是满足了一般的网站需求,电影,剧集,动漫等等,你只要关注一下电影大全,就能找到所有你想看的电影,很方便。
3、音乐雷达()这个有点像推荐歌单,里面有很多歌曲排行榜,你只要在里面搜索关键词就能找到很多不错的歌曲。如果不清楚你想要什么,那就去下载一个爱听2吧,打开就有详细的列表。最近看新闻里说,“音乐作为一种非物质形态可以带来精神上的愉悦,以此抵消”已经不少人用它来赚钱了,各大平台都推广它。如果还是怕被骗的话,就找个靠谱的平台。
虽然我对上面的那几个网站没什么好感,但是给国家做贡献我也愿意。特别是下载的时候看国家的网站的话,会节省很多时间。 查看全部
网页视频抓取浏览器(网页视频抓取浏览器视频转换歌曲歌词教程2019/1/7)
网页视频抓取浏览器视频转换pdf转换成wordpdf转换成ppt音频剪辑视频格式转换格式转换文字视频转换歌曲歌词教程2019/1/7使用videoshop直接在浏览器里输入你设定的歌词和音频就可以听歌词啦
你说的那个网站就不错,前几天好像有个小学初中英语的视频解析,虽然时间久远,但我记得当时很牛逼,我需要哪一年的解析还可以找的到。
一些高清音频很便宜,有几十一小时的,也有几百一小时的。还有几百万人听的!你可以搜索之类的下载,为什么不去音乐类站点下呢?这种事情被抓起来,维权难度大,而且很多都只支持音频原文件,不支持mp3等等,到时你就麻烦了。
推荐一个网站给你,
推荐几个小而美的网站,最近一直在用,
1、记录片吧()国内众多视频网站上都有,超短视频。
2、电影大全()这个网站也是满足了一般的网站需求,电影,剧集,动漫等等,你只要关注一下电影大全,就能找到所有你想看的电影,很方便。
3、音乐雷达()这个有点像推荐歌单,里面有很多歌曲排行榜,你只要在里面搜索关键词就能找到很多不错的歌曲。如果不清楚你想要什么,那就去下载一个爱听2吧,打开就有详细的列表。最近看新闻里说,“音乐作为一种非物质形态可以带来精神上的愉悦,以此抵消”已经不少人用它来赚钱了,各大平台都推广它。如果还是怕被骗的话,就找个靠谱的平台。
虽然我对上面的那几个网站没什么好感,但是给国家做贡献我也愿意。特别是下载的时候看国家的网站的话,会节省很多时间。
网页视频抓取浏览器(等效toenablecrossdomainajaxajaxrequestrequest)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-14 20:31
我想通过在浏览器中运行代码来获取 网站。在这种情况下,scraper 必须在特定机器上运行,而我不能在该机器上安装任何软件。不过我已经安装了浏览器(火狐最新版),可以随意配置浏览器。
我想要的是一个抓取的javascript解决方案,收录在站点A的网页中,可以抓取站点B。看来这样会遇到一些CORS类型的问题;我认为解决方案的一部分是禁用浏览器中的任何跨域检查。
到目前为止我尝试过的:我查找了“javascript中的网络抓取”,它带来了很多将在带有cheerio的nodejs中运行的东西,例如,像pjscrape这样的东西需要PhantomJS。但是,我找不到任何旨在在浏览器中运行的等效内容。
PS 这很有趣:Firefox 设置启用跨域 ajax 请求显然 Chrome --disable-web-security 处理跨域/跨域问题。Firefox 等效?
PS Firefox 的 ForceCORS 扩展似乎也很有用:我不确定我是否可以安装它。
PS 这是在不同浏览器中允许跨域的一个很好的方法集合:不幸的是,建议的 Firefox 解决方案在版本 >=5 中不起作用。 查看全部
网页视频抓取浏览器(等效toenablecrossdomainajaxajaxrequestrequest)
我想通过在浏览器中运行代码来获取 网站。在这种情况下,scraper 必须在特定机器上运行,而我不能在该机器上安装任何软件。不过我已经安装了浏览器(火狐最新版),可以随意配置浏览器。
我想要的是一个抓取的javascript解决方案,收录在站点A的网页中,可以抓取站点B。看来这样会遇到一些CORS类型的问题;我认为解决方案的一部分是禁用浏览器中的任何跨域检查。
到目前为止我尝试过的:我查找了“javascript中的网络抓取”,它带来了很多将在带有cheerio的nodejs中运行的东西,例如,像pjscrape这样的东西需要PhantomJS。但是,我找不到任何旨在在浏览器中运行的等效内容。
PS 这很有趣:Firefox 设置启用跨域 ajax 请求显然 Chrome --disable-web-security 处理跨域/跨域问题。Firefox 等效?
PS Firefox 的 ForceCORS 扩展似乎也很有用:我不确定我是否可以安装它。
PS 这是在不同浏览器中允许跨域的一个很好的方法集合:不幸的是,建议的 Firefox 解决方案在版本 >=5 中不起作用。
网页视频抓取浏览器(初识scraper打开WebScraper的图标(一)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-14 20:03
Web Scraper是一款适合普通用户(无需专业IT技术)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取你想要的数据。例如知乎回答列表、微博热点、微博评论、电商网站产品信息、博客文章列表等。 在线安装方法在线安装需要FQ网络,可以访问Chrome App Store1、在线访问Web Scraper插件,点击“添加到CHROME”。
2、然后在弹出的框中点击“添加扩展”
3、安装完成后,顶部工具栏会显示Web Scraper图标。
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7.将crx拖放到该页面,点击“添加到扩展”即可完成安装。如图:
2、安装完成后,顶部工具栏会显示Web Scraper图标。
第一次认识网络爬虫
打开网页爬虫
开发者可以路过看看后面
windows系统下可以使用快捷键F12,部分笔记本机型需要按Fn+F12;
Mac系统下可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置—>更多工具—>开发者工具
打开后的效果如下,绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,是我们后面要操作的部分。
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
原理及功能说明
数据爬取的思路大体可以简单总结如下:
1、 通过一个或多个入口地址获取初始数据。比如文章列表页,或者有一定规则的页面,比如有分页的列表页;
2、根据入口页面的一些信息,比如链接点,进入下一页,获取必要的信息;
3、 根据上一层的链接继续下一层,获取必要的信息(这一步可以无限循环);
原理大致相同。接下来,让我们正式认识一下Web Scraper工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
创建新的站点地图:首先了解站点地图,字面意思是网站地图,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你要获取知乎 on 要回答其中一个问题,请创建站点地图,并将此问题的地址设置为站点地图的起始网址,然后单击“创建站点地图”以创建站点地图。
站点地图:站点地图的集合。所有创建的站点地图都会显示在这里,可以在此处输入站点地图进行修改、数据抓取等操作。
站点地图:输入一个站点地图,可以进行一系列的操作,如下图:
红框部分 Add new selector 是必不可少的一步。什么是选择器,字面意思是:选择器,一个选择器对应网页的一部分,也就是收录我们要采集的数据的部分。
需要说明的是,一个站点地图可以有多个选择器,每个选择器可以收录子选择器,一个选择器只能对应一个标题,也可以对应整个区域,这个区域可能收录标题、副标题、作者信息、内容、等和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑结构图,什么是根节点,收录几个选择器,选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
Scrape:开始数据抓取工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,简单的了解一下就可以了。真知灼见,具体操作案例令人信服。下面举几个例子来说明具体的用法。
案例实践
简单测试hao123
从最简单到深入,我们以一个简单的例子作为入口,作为对Web Scraper服务的进一步了解
需求背景:见下hao123页面红框部分。我们的需求是统计这部分区域的所有网站名称和链接地址,最后在Excel中生成。因为这部分内容已经足够简单了,当然真正的需求可能比这更复杂,而且人工统计这么几条数据的时间也很快。
开始运作
1、 假设我们已经打开了hao123页面,并且打开了这个页面底部的开发者工具,并找到了Web Scraper标签栏;
2、点击“创建站点地图”;
3、 输入sitemap名称和start url后,名称仅供我们标记,命名为hao123(注意不支持中文),start url为hao123的url,然后点击create sitemap;
4、 之后,Web Scraper 会自动定位到这个站点地图,然后我们添加一个选择器,点击“添加新的选择器”;
5、首先给这个选择器分配一个id,它只是一个容易识别的名字。我把它命名为热这里。因为要获取名称和链接,所以将类型设置为链接。这种类型是专门为网页链接准备的。选择Link type后,会自动提取name和link这两个属性;
6、 然后点击select,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,表示这是我们当前选中的区域。我们将光标定位在需求中提到的那一栏的某个链接上,比如第一条头条新闻,点击这里,这部分会变成红色,表示已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变红了,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识符,可以手动修改。元素由类和元素名称决定,如:div.p_name a)。最后,不要忘记检查Multiple,
7、最后保存,保存选择器。单击元素预览可预览所选区域,单击数据预览可在浏览器中预览捕获的数据。下面文本框的内容对于懂技术的同学来说是很清楚的,这就是xpath,我们可以不用鼠标直接手写xpath;
完整的操作流程如下:
8、完成上一步后,就可以实际导出了。别着急,看看其他的操作。Sitemap hao123下的Selector图可以看到拓扑图。_root 是根选择器。创建站点地图时,会自动出现一个_root节点,可以看到它的子选择器,也就是我们创建的热选择器;
9、刮,开始刮数据。
10、在Sitemap hao123下浏览,可以直接通过浏览器查看抓取的最终结果,需要重新;
11、 最后使用Export data as CSV导出为CSV格式,其中hot列为标题,hot-href列为链接;
怎么样,试试看 查看全部
网页视频抓取浏览器(初识scraper打开WebScraper的图标(一)_光明网(组图))
Web Scraper是一款适合普通用户(无需专业IT技术)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取你想要的数据。例如知乎回答列表、微博热点、微博评论、电商网站产品信息、博客文章列表等。 在线安装方法在线安装需要FQ网络,可以访问Chrome App Store1、在线访问Web Scraper插件,点击“添加到CHROME”。
2、然后在弹出的框中点击“添加扩展”
3、安装完成后,顶部工具栏会显示Web Scraper图标。
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7.将crx拖放到该页面,点击“添加到扩展”即可完成安装。如图:
2、安装完成后,顶部工具栏会显示Web Scraper图标。
第一次认识网络爬虫
打开网页爬虫
开发者可以路过看看后面
windows系统下可以使用快捷键F12,部分笔记本机型需要按Fn+F12;
Mac系统下可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置—>更多工具—>开发者工具
打开后的效果如下,绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,是我们后面要操作的部分。
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
原理及功能说明
数据爬取的思路大体可以简单总结如下:
1、 通过一个或多个入口地址获取初始数据。比如文章列表页,或者有一定规则的页面,比如有分页的列表页;
2、根据入口页面的一些信息,比如链接点,进入下一页,获取必要的信息;
3、 根据上一层的链接继续下一层,获取必要的信息(这一步可以无限循环);
原理大致相同。接下来,让我们正式认识一下Web Scraper工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
创建新的站点地图:首先了解站点地图,字面意思是网站地图,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你要获取知乎 on 要回答其中一个问题,请创建站点地图,并将此问题的地址设置为站点地图的起始网址,然后单击“创建站点地图”以创建站点地图。
站点地图:站点地图的集合。所有创建的站点地图都会显示在这里,可以在此处输入站点地图进行修改、数据抓取等操作。
站点地图:输入一个站点地图,可以进行一系列的操作,如下图:
红框部分 Add new selector 是必不可少的一步。什么是选择器,字面意思是:选择器,一个选择器对应网页的一部分,也就是收录我们要采集的数据的部分。
需要说明的是,一个站点地图可以有多个选择器,每个选择器可以收录子选择器,一个选择器只能对应一个标题,也可以对应整个区域,这个区域可能收录标题、副标题、作者信息、内容、等和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑结构图,什么是根节点,收录几个选择器,选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
Scrape:开始数据抓取工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,简单的了解一下就可以了。真知灼见,具体操作案例令人信服。下面举几个例子来说明具体的用法。
案例实践
简单测试hao123
从最简单到深入,我们以一个简单的例子作为入口,作为对Web Scraper服务的进一步了解
需求背景:见下hao123页面红框部分。我们的需求是统计这部分区域的所有网站名称和链接地址,最后在Excel中生成。因为这部分内容已经足够简单了,当然真正的需求可能比这更复杂,而且人工统计这么几条数据的时间也很快。
开始运作
1、 假设我们已经打开了hao123页面,并且打开了这个页面底部的开发者工具,并找到了Web Scraper标签栏;
2、点击“创建站点地图”;
3、 输入sitemap名称和start url后,名称仅供我们标记,命名为hao123(注意不支持中文),start url为hao123的url,然后点击create sitemap;
4、 之后,Web Scraper 会自动定位到这个站点地图,然后我们添加一个选择器,点击“添加新的选择器”;
5、首先给这个选择器分配一个id,它只是一个容易识别的名字。我把它命名为热这里。因为要获取名称和链接,所以将类型设置为链接。这种类型是专门为网页链接准备的。选择Link type后,会自动提取name和link这两个属性;
6、 然后点击select,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,表示这是我们当前选中的区域。我们将光标定位在需求中提到的那一栏的某个链接上,比如第一条头条新闻,点击这里,这部分会变成红色,表示已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变红了,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识符,可以手动修改。元素由类和元素名称决定,如:div.p_name a)。最后,不要忘记检查Multiple,
7、最后保存,保存选择器。单击元素预览可预览所选区域,单击数据预览可在浏览器中预览捕获的数据。下面文本框的内容对于懂技术的同学来说是很清楚的,这就是xpath,我们可以不用鼠标直接手写xpath;
完整的操作流程如下:
8、完成上一步后,就可以实际导出了。别着急,看看其他的操作。Sitemap hao123下的Selector图可以看到拓扑图。_root 是根选择器。创建站点地图时,会自动出现一个_root节点,可以看到它的子选择器,也就是我们创建的热选择器;
9、刮,开始刮数据。
10、在Sitemap hao123下浏览,可以直接通过浏览器查看抓取的最终结果,需要重新;
11、 最后使用Export data as CSV导出为CSV格式,其中hot列为标题,hot-href列为链接;
怎么样,试试看
网页视频抓取浏览器(网页视频抓取浏览器给你的url不断的抓爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-08 08:02
网页视频抓取浏览器的搜索栏,用户的搜索,内容索引表,网页内容,网页跳转方式网页结构,
三个方面1.抓取能力,简单来说就是浏览器给你的url是否能顺利的被爬虫解析出来,这个要求你要对http有基本的了解,会使用工具的爬虫工具2.数据量,一般大点的网站都会采用tcp等形式保证数据的实时性,对于小网站可能采用的方法是消息队列,或者服务端直接给url发送消息,要求你懂restfulapi的使用3.内容清洗、转换与展示。一般网站在不同页面url的转换展示,你得懂得基本的网络编程。
url中一定存在逻辑,应该遵循某种统一形式的规则,
一般就是对源代码的编码问题和性能问题。源代码是postmessage还是xml。
一般从抓取效率,性能,抓取稳定性三个方面考虑。我听说过一次,
就像评论是html,
几乎抓取浏览器给的url都是cookie网页模拟cookie然后爬虫不断的抓
爬虫首先的是抓取本地资源和网络资源。网络是获取信息的第一手资源,网络既然有信息的那么自然就会有各种各样的内容,有文本又有图片等等,爬虫无非就是爬取网络资源就可以了。爬虫的配置的逻辑就很多了,大致分为对象配置,方法配置和spider配置。对象,就是我们需要爬取的网站或者资源。方法就是我们针对每个网站制定的爬取策略。
spider就是网站或者资源的请求者。比如说,你浏览过的评论,就可以想到大概不是这两个吗,发放一个http请求给你,我们利用urllib2.js对这个请求进行转码传递给请求者发送给后台处理,然后解析这个请求返回一个response给你。 查看全部
网页视频抓取浏览器(网页视频抓取浏览器给你的url不断的抓爬虫)
网页视频抓取浏览器的搜索栏,用户的搜索,内容索引表,网页内容,网页跳转方式网页结构,
三个方面1.抓取能力,简单来说就是浏览器给你的url是否能顺利的被爬虫解析出来,这个要求你要对http有基本的了解,会使用工具的爬虫工具2.数据量,一般大点的网站都会采用tcp等形式保证数据的实时性,对于小网站可能采用的方法是消息队列,或者服务端直接给url发送消息,要求你懂restfulapi的使用3.内容清洗、转换与展示。一般网站在不同页面url的转换展示,你得懂得基本的网络编程。
url中一定存在逻辑,应该遵循某种统一形式的规则,
一般就是对源代码的编码问题和性能问题。源代码是postmessage还是xml。
一般从抓取效率,性能,抓取稳定性三个方面考虑。我听说过一次,
就像评论是html,
几乎抓取浏览器给的url都是cookie网页模拟cookie然后爬虫不断的抓
爬虫首先的是抓取本地资源和网络资源。网络是获取信息的第一手资源,网络既然有信息的那么自然就会有各种各样的内容,有文本又有图片等等,爬虫无非就是爬取网络资源就可以了。爬虫的配置的逻辑就很多了,大致分为对象配置,方法配置和spider配置。对象,就是我们需要爬取的网站或者资源。方法就是我们针对每个网站制定的爬取策略。
spider就是网站或者资源的请求者。比如说,你浏览过的评论,就可以想到大概不是这两个吗,发放一个http请求给你,我们利用urllib2.js对这个请求进行转码传递给请求者发送给后台处理,然后解析这个请求返回一个response给你。
网页视频抓取浏览器(网页视频抓取浏览器端的页面,后续再看源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-01 06:03
网页视频抓取浏览器端的页面,然后下载到本地。目前xpath比较傻瓜,复杂一点的页面可以用python转化为json然后解析处理。说实话,对于我这种没有python基础的,直接翻看nodejs就很痛苦,很费时费力。为了避免重复使用一些常用的方法,现在对xpath不做过多的概念性的东西。直接把知道的写上去,后续有空补充1.有xpath可以抓取javascript文件varxpath='//*[@id=""]/li/a[@class="list-bottom"]/img//a';2.有xpath可以抓取javascript文件javascript各种id顺序dom结构xpath搜索javascriptxpath搜索img...xpath搜索img3.有xpath可以抓取本地网页图片varxpath='//*[@id=""]/var/picture/a/text()';解析之后,返回json格式,拿去爬数据用。后续再看源码试试抓取其他页面.。
比较费事,
目前我是从手机上抓取,上传到微信公众号,点赞量可以看到,点赞次数需要第三方的数据源。
requests正则表达式非常的牛逼各种基础包imageio类型也很好用你写个爬虫也得知道各种包的用法先说下我用到的吧git可以看到生成的master分支(gitbranch#build#upstream),一共有1000多个repo:scrapy:这个东西要对着一个个api抓,一个接口分为url、后端和正则表达式if=hasattr(scrapy,"diff")else---正则表达式+requests爬虫收到的请求url一般是http。
get或者http。post一般是json格式不要被反爬虫的反爬虫阻止还有注意工厂方法methods参数cookie#methods中抓重复单独写一个字段,这样容易被反爬虫抓re-insetify需要注意了---easy_index要加。method,把req。json改为req。method。 查看全部
网页视频抓取浏览器(网页视频抓取浏览器端的页面,后续再看源码)
网页视频抓取浏览器端的页面,然后下载到本地。目前xpath比较傻瓜,复杂一点的页面可以用python转化为json然后解析处理。说实话,对于我这种没有python基础的,直接翻看nodejs就很痛苦,很费时费力。为了避免重复使用一些常用的方法,现在对xpath不做过多的概念性的东西。直接把知道的写上去,后续有空补充1.有xpath可以抓取javascript文件varxpath='//*[@id=""]/li/a[@class="list-bottom"]/img//a';2.有xpath可以抓取javascript文件javascript各种id顺序dom结构xpath搜索javascriptxpath搜索img...xpath搜索img3.有xpath可以抓取本地网页图片varxpath='//*[@id=""]/var/picture/a/text()';解析之后,返回json格式,拿去爬数据用。后续再看源码试试抓取其他页面.。
比较费事,
目前我是从手机上抓取,上传到微信公众号,点赞量可以看到,点赞次数需要第三方的数据源。
requests正则表达式非常的牛逼各种基础包imageio类型也很好用你写个爬虫也得知道各种包的用法先说下我用到的吧git可以看到生成的master分支(gitbranch#build#upstream),一共有1000多个repo:scrapy:这个东西要对着一个个api抓,一个接口分为url、后端和正则表达式if=hasattr(scrapy,"diff")else---正则表达式+requests爬虫收到的请求url一般是http。
get或者http。post一般是json格式不要被反爬虫的反爬虫阻止还有注意工厂方法methods参数cookie#methods中抓重复单独写一个字段,这样容易被反爬虫抓re-insetify需要注意了---easy_index要加。method,把req。json改为req。method。
网页视频抓取浏览器(网页视频抓取浏览器的基本操作技巧(一)——windows系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-30 02:03
网页视频抓取浏览器的这方面做的最好应该是servlet+multiwebview+abstractcontext的jspview线程(无消息发送)比较费内存3个线程分别处理动态加载的页面加载的页面view对象的处理请求处理(重定向)方法加载请求方法重定向处理httpshttps关系需要有正确匹配https体https/ip地址手机链接电脑(至少下载个apk才能通过app找到手机)后缀1.html2.mp43.mpeg4.mpeg3v3v25.avi(5个字节包含所有线程)(可以运行流,但是结构很复杂就是了)6.xvid(不能运行流,但是执行ajax)7.au8.javascripthttp/1.11024k(应该2m及以下)smtp其他包括后缀/(可以包含https)url类型/无(可以仅需要附加页面就行view线程应该是在原始http中查找getpostput,类似于session)session(请求端使用的是一个session+任务队列。
注意如果服务器能够对session以外的java客户端产生数据提供,那么服务器应该使用该服务器上最新的信息。)windows系统一般只有session(对比windows系统/excel,就明白什么意思了)getpostput两种请求方式,但是excel中没有post方式下的get方式的并发下实现比如服务器会有10个不同的服务器,这10个服务器上会出现同样的请求。
在时间压力不大的情况下,保证用户可以同时查看这10个服务器。用户每查看一个服务器,需要向服务器写一个session。如果这10个服务器可以用java来写,则可以实现很多并发。但是1个服务器提供10个服务器太夸张了,比如这样一个服务器提供8个服务器,就实现不了太多并发情况(建议3个及以下)在struts2中是用了messagebox拦截器来做的,可以参考这个(请求数量少到1)2/4/12/16/32/64/128/256/512,如果服务器有1万的请求,而用户只查看一个,建议采用struts2b-tree类作为拦截器,不然请求数据库的话,这个请求的时间太长,不如直接url批量/或者用java写单例来减少时间。=。 查看全部
网页视频抓取浏览器(网页视频抓取浏览器的基本操作技巧(一)——windows系统)
网页视频抓取浏览器的这方面做的最好应该是servlet+multiwebview+abstractcontext的jspview线程(无消息发送)比较费内存3个线程分别处理动态加载的页面加载的页面view对象的处理请求处理(重定向)方法加载请求方法重定向处理httpshttps关系需要有正确匹配https体https/ip地址手机链接电脑(至少下载个apk才能通过app找到手机)后缀1.html2.mp43.mpeg4.mpeg3v3v25.avi(5个字节包含所有线程)(可以运行流,但是结构很复杂就是了)6.xvid(不能运行流,但是执行ajax)7.au8.javascripthttp/1.11024k(应该2m及以下)smtp其他包括后缀/(可以包含https)url类型/无(可以仅需要附加页面就行view线程应该是在原始http中查找getpostput,类似于session)session(请求端使用的是一个session+任务队列。
注意如果服务器能够对session以外的java客户端产生数据提供,那么服务器应该使用该服务器上最新的信息。)windows系统一般只有session(对比windows系统/excel,就明白什么意思了)getpostput两种请求方式,但是excel中没有post方式下的get方式的并发下实现比如服务器会有10个不同的服务器,这10个服务器上会出现同样的请求。
在时间压力不大的情况下,保证用户可以同时查看这10个服务器。用户每查看一个服务器,需要向服务器写一个session。如果这10个服务器可以用java来写,则可以实现很多并发。但是1个服务器提供10个服务器太夸张了,比如这样一个服务器提供8个服务器,就实现不了太多并发情况(建议3个及以下)在struts2中是用了messagebox拦截器来做的,可以参考这个(请求数量少到1)2/4/12/16/32/64/128/256/512,如果服务器有1万的请求,而用户只查看一个,建议采用struts2b-tree类作为拦截器,不然请求数据库的话,这个请求的时间太长,不如直接url批量/或者用java写单例来减少时间。=。
网页视频抓取浏览器(来说说有关于如何提取网页视频的消现如今的消息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-27 14:05
摘要 当今的科技让我们的生活充满了便利和幸福。因此,大家也非常关心未来科技带来的惊喜。所以今天,我就来谈谈如何提取网络视频。
今天的科技让我们的生活充满了便利和幸福,所以大家也很关心科技给未来带来的惊喜,所以今天我有关于如何提取网络视频的消息!
操作方法:打开网页,右击网页,选择“评论元素”或“勾选”,会出现评论元素代码,选择“网络”,刷新网页,选择大小,较大的文件是该视频网页,右键单击该选项,单击“在新选项卡中打开链接”,然后下载视频。
电脑技能:1、电脑视频无法播放。可能是播放器不支持这种格式的视频。您需要下载相关播放器。
2、 网页无法显示,可能是服务器异常导致,需要等待官方修复。
3、电脑扫描仪死机,可能是软件bug,可以尝试重启软件。
4、电脑扫描仪无法播放视频。这可能是由于缺少 flash 插件。您需要先安装插件才能使用。
数据扩展:网页是构成网站的基本元素,是承载各种网站应用的平台。通俗地说,网站就是由网页组成的。网页是收录 HTML 标签的纯文本文件。它可以存储在世界某个角落的计算机上。它是万维网上的一个“页面”。它是一种超文本标记语言格式,网页通常使用图像文件来提供图片。必须通过网络扫描仪阅读网页。 查看全部
网页视频抓取浏览器(来说说有关于如何提取网页视频的消现如今的消息)
摘要 当今的科技让我们的生活充满了便利和幸福。因此,大家也非常关心未来科技带来的惊喜。所以今天,我就来谈谈如何提取网络视频。
今天的科技让我们的生活充满了便利和幸福,所以大家也很关心科技给未来带来的惊喜,所以今天我有关于如何提取网络视频的消息!
操作方法:打开网页,右击网页,选择“评论元素”或“勾选”,会出现评论元素代码,选择“网络”,刷新网页,选择大小,较大的文件是该视频网页,右键单击该选项,单击“在新选项卡中打开链接”,然后下载视频。
电脑技能:1、电脑视频无法播放。可能是播放器不支持这种格式的视频。您需要下载相关播放器。
2、 网页无法显示,可能是服务器异常导致,需要等待官方修复。
3、电脑扫描仪死机,可能是软件bug,可以尝试重启软件。
4、电脑扫描仪无法播放视频。这可能是由于缺少 flash 插件。您需要先安装插件才能使用。
数据扩展:网页是构成网站的基本元素,是承载各种网站应用的平台。通俗地说,网站就是由网页组成的。网页是收录 HTML 标签的纯文本文件。它可以存储在世界某个角落的计算机上。它是万维网上的一个“页面”。它是一种超文本标记语言格式,网页通常使用图像文件来提供图片。必须通过网络扫描仪阅读网页。
网页视频抓取浏览器(VideoCacheView自动扫描Explorer和基于Mozilla的网络浏览器())
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-22 20:14
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 FLV 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同的操作选项: 如果视频文件存在于缓存中,您可以选择“播放所选文件” "、"将选中的文件复制到"等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。程序的主窗口将显示缓存中的所有视频文件。显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同的操作选项: 如果视频文件存在于缓存中,您可以选择“播放所选文件” "、"将选中的文件复制到"等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。程序的主窗口将显示缓存中的所有视频文件。显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同的操作选项: 如果视频文件存在于缓存中,您可以选择“播放所选文件” "、"将选中的文件复制到"等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。“将选中的文件复制到”等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。“将选中的文件复制到”等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。 查看全部
网页视频抓取浏览器(VideoCacheView自动扫描Explorer和基于Mozilla的网络浏览器())
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 FLV 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同的操作选项: 如果视频文件存在于缓存中,您可以选择“播放所选文件” "、"将选中的文件复制到"等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。程序的主窗口将显示缓存中的所有视频文件。显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同的操作选项: 如果视频文件存在于缓存中,您可以选择“播放所选文件” "、"将选中的文件复制到"等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。程序的主窗口将显示缓存中的所有视频文件。显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同的操作选项: 如果视频文件存在于缓存中,您可以选择“播放所选文件” "、"将选中的文件复制到"等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。“将选中的文件复制到”等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。“将选中的文件复制到”等操作;如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
网页视频抓取浏览器(VideoDownloadHelper支持多种类型的流媒体视频下载视频和视频合并为单个文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-11-20 10:06
Video DownloadHelper 是目前最完善的从网站 中提取视频和图片文件并保存到硬盘的工具。
像往常一样上网。当 DownloadHelper 检测到可以访问下载的嵌入视频时,工具栏图标会突出显示,并且一个简单的菜单允许您通过单击某个项目来下载文件。
例如,如果您转到 YouTube 页面,则可以直接在文件系统上下载视频。它还可以与大多数其他流行视频 网站 一起使用,例如 DailyMotion、Facebook、Periscope、Vimeo、Twitch、Liveleak、Vine、UStream、Fox、Bloomberg、RAI、France 2-3、Break、Metacafe 和数千个其他网站。
Video DownloadHelper 支持多种类型的流媒体,这使得该插件在视频下载器中独树一帜:HTTP、HLS、DASH 等。只要站点使用了不受支持的流媒体技术,Video DownloadHelper 就可以直接从屏幕捕捉媒体并生成视频文件。
除了下载之外,Video DownloadHelper 还可以进行文件转换(即改变音视频格式)和聚合(将单独的音视频合并为一个文件)。这是一个升级功能,可以帮助你支付免费的东西(我们也需要吃饭)。您不必强制使用转换从网站 下载视频,并且您可以避免选择标记为 ADP 的变体以避免聚合。 查看全部
网页视频抓取浏览器(VideoDownloadHelper支持多种类型的流媒体视频下载视频和视频合并为单个文件)
Video DownloadHelper 是目前最完善的从网站 中提取视频和图片文件并保存到硬盘的工具。
像往常一样上网。当 DownloadHelper 检测到可以访问下载的嵌入视频时,工具栏图标会突出显示,并且一个简单的菜单允许您通过单击某个项目来下载文件。
例如,如果您转到 YouTube 页面,则可以直接在文件系统上下载视频。它还可以与大多数其他流行视频 网站 一起使用,例如 DailyMotion、Facebook、Periscope、Vimeo、Twitch、Liveleak、Vine、UStream、Fox、Bloomberg、RAI、France 2-3、Break、Metacafe 和数千个其他网站。
Video DownloadHelper 支持多种类型的流媒体,这使得该插件在视频下载器中独树一帜:HTTP、HLS、DASH 等。只要站点使用了不受支持的流媒体技术,Video DownloadHelper 就可以直接从屏幕捕捉媒体并生成视频文件。
除了下载之外,Video DownloadHelper 还可以进行文件转换(即改变音视频格式)和聚合(将单独的音视频合并为一个文件)。这是一个升级功能,可以帮助你支付免费的东西(我们也需要吃饭)。您不必强制使用转换从网站 下载视频,并且您可以避免选择标记为 ADP 的变体以避免聚合。
网页视频抓取浏览器(p2p,安卓手机的迅雷7,,迅雷,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-20 07:05
网页视频抓取浏览器视频抓取app视频抓取分享朋友圈将聊天内容整理成文档;目前来看flash依然是首选,能轻松的解决视频抓取问题。
首先是视频原始信息,包括上传时间,地点,然后就是方式了,自己采集,现在比较多的是在微信公众号推送视频时,已经有开发者做了一套可视化采集方案,可以免费开放给开发者,类似分享后付费的方式,就是和作者买单;传统的文本方式,可以请人写采集脚本来采集,也可以自己采集,前提是视频要可以下载,可以直接查看的情况下,免费的很多。当然,现在有一些新的方式,比如视频回传,或者保存到本地等等。
是不是可以和邀请人说一下?@firearts我也在做这个项目。
截取视频中的字幕,然后加入到字幕文件中,就可以放到群里,
遇到类似的问题前段时间我同事@胡维在一个问题下的回答,
我一般用哔哩哔哩上听__长尾评论聚合
qq传说里那个采集器就挺好用
在浏览器首页安装专门的网页视频采集软件,设置采集区域,采集时间段,然后根据您想获取的下载地址选择合适下载的视频。
可以通过网页抓取p2p,安卓手机的迅雷7, 查看全部
网页视频抓取浏览器(p2p,安卓手机的迅雷7,,迅雷,怎么办?)
网页视频抓取浏览器视频抓取app视频抓取分享朋友圈将聊天内容整理成文档;目前来看flash依然是首选,能轻松的解决视频抓取问题。
首先是视频原始信息,包括上传时间,地点,然后就是方式了,自己采集,现在比较多的是在微信公众号推送视频时,已经有开发者做了一套可视化采集方案,可以免费开放给开发者,类似分享后付费的方式,就是和作者买单;传统的文本方式,可以请人写采集脚本来采集,也可以自己采集,前提是视频要可以下载,可以直接查看的情况下,免费的很多。当然,现在有一些新的方式,比如视频回传,或者保存到本地等等。
是不是可以和邀请人说一下?@firearts我也在做这个项目。
截取视频中的字幕,然后加入到字幕文件中,就可以放到群里,
遇到类似的问题前段时间我同事@胡维在一个问题下的回答,
我一般用哔哩哔哩上听__长尾评论聚合
qq传说里那个采集器就挺好用
在浏览器首页安装专门的网页视频采集软件,设置采集区域,采集时间段,然后根据您想获取的下载地址选择合适下载的视频。
可以通过网页抓取p2p,安卓手机的迅雷7,
网页视频抓取浏览器(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-18 06:03
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。 查看全部
网页视频抓取浏览器(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
网页视频抓取浏览器(网页视频抓取浏览器视频下载主要有两种用处:stringify)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-11-15 12:02
网页视频抓取浏览器视频抓取主要有两种用处:一是网页视频下载,二是针对音频视频下载进行相应处理对于网页视频下载,主要有五种做法,分别是直接读取本地文件,flash接口,拖入requests库,插入数据包,跨域请求等。网页视频直接读取下载方法vue-resource-apiimportvuefrom'vue'vue.use(vue-resource-api)//use方法支持下载newvue({el:'#header_span',data:{author:'shan',url:';test=&src=',path:'',title:'实验室-我要从1024到102443',htmlurl:'',withcrementary:true},//如果实验室-我要从1024到102443,则忽略''})本地获取视频教程。
可以使用api或者传统的下载工具实现
(formdata)中有很多地方可以调用哦~我知道一个api还能搜索爱奇艺。
看到这个问题想说一下网页视频抓取的话要对网页进行分析之后就可以看到img。src=string(url)。decode("utf-8")上面的路径如果是命令的话都是纯字符串或者命令行的话那就是需要json_html的模块可以看一下json。stringify这个函数,这个函数能将一个字符串转换成字符串字符串作为参数传入string()方法返回参数dict对象,这个dict对象中可以有url字符串,id字符串,name字符串,picturedir字符串,title字符串,当然也可以有函数的参数最终返回的就是字符串的一个副本可以进行相应的处理如果是想要将页面网址通过requests下载成对应的json文件,就需要上述模块。 查看全部
网页视频抓取浏览器(网页视频抓取浏览器视频下载主要有两种用处:stringify)
网页视频抓取浏览器视频抓取主要有两种用处:一是网页视频下载,二是针对音频视频下载进行相应处理对于网页视频下载,主要有五种做法,分别是直接读取本地文件,flash接口,拖入requests库,插入数据包,跨域请求等。网页视频直接读取下载方法vue-resource-apiimportvuefrom'vue'vue.use(vue-resource-api)//use方法支持下载newvue({el:'#header_span',data:{author:'shan',url:';test=&src=',path:'',title:'实验室-我要从1024到102443',htmlurl:'',withcrementary:true},//如果实验室-我要从1024到102443,则忽略''})本地获取视频教程。
可以使用api或者传统的下载工具实现
(formdata)中有很多地方可以调用哦~我知道一个api还能搜索爱奇艺。
看到这个问题想说一下网页视频抓取的话要对网页进行分析之后就可以看到img。src=string(url)。decode("utf-8")上面的路径如果是命令的话都是纯字符串或者命令行的话那就是需要json_html的模块可以看一下json。stringify这个函数,这个函数能将一个字符串转换成字符串字符串作为参数传入string()方法返回参数dict对象,这个dict对象中可以有url字符串,id字符串,name字符串,picturedir字符串,title字符串,当然也可以有函数的参数最终返回的就是字符串的一个副本可以进行相应的处理如果是想要将页面网址通过requests下载成对应的json文件,就需要上述模块。
网页视频抓取浏览器(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-06 23:08
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供将来离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。 查看全部
网页视频抓取浏览器(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供将来离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
网页视频抓取浏览器(97猫抓插件会自动探测出视频片段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-30 03:17
在【扩展中心】搜索“视频下载”
搜索结果中有几个常用的视频嗅探软件,安装插件【猫抓】。
(现在越来越少的网络视频使用flv播放方式,所以其他flv下载插件都没有那么好用)
接下来,打开您要下载的视频的网站,然后点击播放。这时候猫扎插件会自己检测视频文件的链接,你可以直接复制视频链接或者直接下载。
二、分段加密在线视频
现在很多门户网站网站为了避免下载视频文件,已经将视频文件拆分成多个ts文件。这使得直接用工具下载很困难,但没有办法下载视频。下载所有分割好的ts文件,然后用软件合并。
和之前一样,打开我们要下载的视频的网站,mozhao插件会自动检测视频的下载链接,以ts结尾的就是视频剪辑我们要,耐心等待视频所有ts文件已经加载完毕,避免视频不完整。
我们检查所有ts格式文件,复制链接,直接在迅雷下载所有ts文件。
ts视频下载完成后,我们在文件夹中可以看到ts视频分割是有规律的排序,一般文件名是按数字递增的,每个单独的ts文件可以直接被播放器打开,都是几秒钟的视频片段。
接下来,我们要将这些 ts 文件合并为一个文件。网上有很多ts文件工具,这里就用这里
TS 合并工具
使用TS合并工具,点击【打开】,找到刚才下载的文件目录,点击其中一个,然后按Ctrl+A全选ts文件,然后点击打开。
确认合并列表中文件的数量和顺序正确,点击合并。
默认情况下,合并后的ts文件保存在软件同目录下的Merger文件夹中。打开就可以看到合并后的ts视频,用播放器打开可以直接播放,也可以用视频工具下载将ts文件转换成你需要的视频格式。 查看全部
网页视频抓取浏览器(97猫抓插件会自动探测出视频片段)
在【扩展中心】搜索“视频下载”
搜索结果中有几个常用的视频嗅探软件,安装插件【猫抓】。
(现在越来越少的网络视频使用flv播放方式,所以其他flv下载插件都没有那么好用)
接下来,打开您要下载的视频的网站,然后点击播放。这时候猫扎插件会自己检测视频文件的链接,你可以直接复制视频链接或者直接下载。
二、分段加密在线视频
现在很多门户网站网站为了避免下载视频文件,已经将视频文件拆分成多个ts文件。这使得直接用工具下载很困难,但没有办法下载视频。下载所有分割好的ts文件,然后用软件合并。
和之前一样,打开我们要下载的视频的网站,mozhao插件会自动检测视频的下载链接,以ts结尾的就是视频剪辑我们要,耐心等待视频所有ts文件已经加载完毕,避免视频不完整。
我们检查所有ts格式文件,复制链接,直接在迅雷下载所有ts文件。
ts视频下载完成后,我们在文件夹中可以看到ts视频分割是有规律的排序,一般文件名是按数字递增的,每个单独的ts文件可以直接被播放器打开,都是几秒钟的视频片段。
接下来,我们要将这些 ts 文件合并为一个文件。网上有很多ts文件工具,这里就用这里
TS 合并工具
使用TS合并工具,点击【打开】,找到刚才下载的文件目录,点击其中一个,然后按Ctrl+A全选ts文件,然后点击打开。
确认合并列表中文件的数量和顺序正确,点击合并。
默认情况下,合并后的ts文件保存在软件同目录下的Merger文件夹中。打开就可以看到合并后的ts视频,用播放器打开可以直接播放,也可以用视频工具下载将ts文件转换成你需要的视频格式。
网页视频抓取浏览器( 用什么手机浏览器,亦或是夸克、Via等轻量级浏览器 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 806 次浏览 • 2021-10-15 06:13
用什么手机浏览器,亦或是夸克、Via等轻量级浏览器
)
不知道朋友们现在用的是什么手机浏览器。是系统自带的浏览器,百度、火狐、Chrome、UC等老款浏览器,还是Quark、Via等轻量级浏览器?
Shichao 之前一直在使用 Quark。除了文件清理、面对面文件传输、网盘功能之外,我觉得这个浏览器有点多余。其他方面我还是很满意的。界面干净到可以进行交互,并且非常人性化。
你如何看待浏览器做所有这些事情▼
就像一个折腾党,一个浏览器用久了,难免想试试其他口味不一样的浏览器,于是时超去了宽安逛了一圈,果然找到了一个更另类的浏览器. 设备。
这个浏览器的名字是“御剑”。相信大家从下面的截图中可以一眼看出它与其他浏览器的区别,那就是它的很多界面都是按照新的拟态风格设计的。
有些朋友可能第一次听说“新拟态”这个词。简单的说,就是一种介于 simulati 背景之间的风格。
全新拟态主题▼
这种风格的最大特点是没有复杂的细节。界面中的所有按钮和卡片只是简单地改变亮度以产生凸出效果。这很简单。石超第一眼就喜欢上了。
可以毫不夸张地说,它是目前我见过的设计最好的浏览器,与白色面板的手机完美搭配!
而且这个浏览器本身提供的功能也非常强大。
首先,它支持搜索引擎的快速切换。
除了浏览器自带的宇简搜索外,还集成了百度、谷歌、夸克等多家主流搜索引擎。使用浏览器时,只需点击搜索框左侧的图标,即可在这些引擎中快速搜索。切换,无需像其他浏览器一样去设置中更改。
其次,它还自带资源嗅探功能。
开启此功能后,每次打开网页,资源嗅探都会自动抓取网页中收录的图片、视频等资源。您可以选择某个资源进行下载,也可以一键下载。
这个功能有多大用处,不用我过多介绍了吧?如果遇到一些网站没有打开下载功能,可以通过它下载。在其他应用中,这个功能作为收费功能就足够了。
浏览器下载的资源会保存在其下载管理中,朋友们可以根据文件类型快速筛选。实现小窗口效果或0.5-4 倍的播放速度。
要说这些还不是它最强大的功能。
这款浏览器最吸引我的是它可以安装各种插件!
在浏览器的侧边功能栏中,有一个“插件管理”选项,点击这个选项,你会发现一个新世界,什么网页要打广告,直接从网盘下载,网页自动翻页、自动展开等桌面浏览移动设备常用的插件,现在你也可以在手机上使用了。
而且这些插件使用起来非常方便。只需选择插件并点击安装,插件就会生效。如果没有插件实现你想要的功能,你甚至可以自定义脚本。
最让石超惊讶的是什么?
这个御剑浏览器原来是作者上大学的时候自主开发的。毕业后,他还吸收了36个0、华为成员共同维护。
它是如此受欢迎。当我还在为C语言发愁的时候,我以为我在上大学。. .
浏览器下载链接世超在这里,有需要的朋友可以领取:
查看全部
网页视频抓取浏览器(
用什么手机浏览器,亦或是夸克、Via等轻量级浏览器
)
不知道朋友们现在用的是什么手机浏览器。是系统自带的浏览器,百度、火狐、Chrome、UC等老款浏览器,还是Quark、Via等轻量级浏览器?
Shichao 之前一直在使用 Quark。除了文件清理、面对面文件传输、网盘功能之外,我觉得这个浏览器有点多余。其他方面我还是很满意的。界面干净到可以进行交互,并且非常人性化。
你如何看待浏览器做所有这些事情▼
就像一个折腾党,一个浏览器用久了,难免想试试其他口味不一样的浏览器,于是时超去了宽安逛了一圈,果然找到了一个更另类的浏览器. 设备。
这个浏览器的名字是“御剑”。相信大家从下面的截图中可以一眼看出它与其他浏览器的区别,那就是它的很多界面都是按照新的拟态风格设计的。
有些朋友可能第一次听说“新拟态”这个词。简单的说,就是一种介于 simulati 背景之间的风格。
全新拟态主题▼
这种风格的最大特点是没有复杂的细节。界面中的所有按钮和卡片只是简单地改变亮度以产生凸出效果。这很简单。石超第一眼就喜欢上了。
可以毫不夸张地说,它是目前我见过的设计最好的浏览器,与白色面板的手机完美搭配!
而且这个浏览器本身提供的功能也非常强大。
首先,它支持搜索引擎的快速切换。
除了浏览器自带的宇简搜索外,还集成了百度、谷歌、夸克等多家主流搜索引擎。使用浏览器时,只需点击搜索框左侧的图标,即可在这些引擎中快速搜索。切换,无需像其他浏览器一样去设置中更改。
其次,它还自带资源嗅探功能。
开启此功能后,每次打开网页,资源嗅探都会自动抓取网页中收录的图片、视频等资源。您可以选择某个资源进行下载,也可以一键下载。
这个功能有多大用处,不用我过多介绍了吧?如果遇到一些网站没有打开下载功能,可以通过它下载。在其他应用中,这个功能作为收费功能就足够了。
浏览器下载的资源会保存在其下载管理中,朋友们可以根据文件类型快速筛选。实现小窗口效果或0.5-4 倍的播放速度。
要说这些还不是它最强大的功能。
这款浏览器最吸引我的是它可以安装各种插件!
在浏览器的侧边功能栏中,有一个“插件管理”选项,点击这个选项,你会发现一个新世界,什么网页要打广告,直接从网盘下载,网页自动翻页、自动展开等桌面浏览移动设备常用的插件,现在你也可以在手机上使用了。
而且这些插件使用起来非常方便。只需选择插件并点击安装,插件就会生效。如果没有插件实现你想要的功能,你甚至可以自定义脚本。
最让石超惊讶的是什么?
这个御剑浏览器原来是作者上大学的时候自主开发的。毕业后,他还吸收了36个0、华为成员共同维护。
它是如此受欢迎。当我还在为C语言发愁的时候,我以为我在上大学。. .
浏览器下载链接世超在这里,有需要的朋友可以领取:
网页视频抓取浏览器(selenium库可以控制浏览器行为吗?如何处理行为?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-13 19:06
selenium 库可以控制浏览器行为。我们可以使用 selenium 库来抓取我们需要的网页上的所有信息。
需要配合浏览器驱动使用,可以从selenium官网下载:
注意:选择与您的浏览器兼容的驱动程序以使用
详细的 selenium 教程不在这里介绍。本程序使用 Chrome 浏览器并使用以下功能:
from selenium import webdriver
driver = webdriver.Chrome()#创建驱动实例
driver.get("https://www.bilibili.com")#打开网页
data = driver.page_source #获得网页源码
driver.add_cookie(cookie) #加入cookie
cookieData = driver.get_cookies() #获得当前网页cookie
currentUrl = driver.current_url #获得当前网页网址
driver.refresh() #刷新网页
driver.close() #关闭网页
button = driver.find_element_by_class_name("bilibili-player") #根据类名查找元素(按钮元素)
button.click() #点击这个按钮
driver.get(Url):
将使您的浏览器打开此网址
driver.page_source():
它可以返回网页源代码,包括html代码、javascript代码等,这也是我们选择使用selenium来抓取数据的原因。urlopen、requests等通用函数无法返回渲染出来的javascript代码,而seleniumn可以完美解决这个问题。
driver.get_cookies():
如果您需要浏览器记录登录信息以实现自动登录,我们需要启用它来保存cookie。我们可以使用此方法将 cookie 存储为字典以供下次调用。
driver.add_cookie(cookie):
可以给当前打开的页面添加cookies,一般和driver.refresh()配合使用。cookie 的效果只有在页面刷新后才会体现出来。
driver.find***():
Selenium 有很多 find 函数,可以通过不同的键值返回不同的对象。这里只使用了find_element_by_class_name,即根据类名查找对象。找到对象后(对象可能是按钮或文本框),我们可以对对象进行不同的操作,比如点击、填充数据等。这里我们使用click(),也就是点击这个对象。
关于如何处理cookies,需要用到json库,下期会讲到。 查看全部
网页视频抓取浏览器(selenium库可以控制浏览器行为吗?如何处理行为?)
selenium 库可以控制浏览器行为。我们可以使用 selenium 库来抓取我们需要的网页上的所有信息。
需要配合浏览器驱动使用,可以从selenium官网下载:
注意:选择与您的浏览器兼容的驱动程序以使用
详细的 selenium 教程不在这里介绍。本程序使用 Chrome 浏览器并使用以下功能:
from selenium import webdriver
driver = webdriver.Chrome()#创建驱动实例
driver.get("https://www.bilibili.com";)#打开网页
data = driver.page_source #获得网页源码
driver.add_cookie(cookie) #加入cookie
cookieData = driver.get_cookies() #获得当前网页cookie
currentUrl = driver.current_url #获得当前网页网址
driver.refresh() #刷新网页
driver.close() #关闭网页
button = driver.find_element_by_class_name("bilibili-player") #根据类名查找元素(按钮元素)
button.click() #点击这个按钮
driver.get(Url):
将使您的浏览器打开此网址
driver.page_source():
它可以返回网页源代码,包括html代码、javascript代码等,这也是我们选择使用selenium来抓取数据的原因。urlopen、requests等通用函数无法返回渲染出来的javascript代码,而seleniumn可以完美解决这个问题。
driver.get_cookies():
如果您需要浏览器记录登录信息以实现自动登录,我们需要启用它来保存cookie。我们可以使用此方法将 cookie 存储为字典以供下次调用。
driver.add_cookie(cookie):
可以给当前打开的页面添加cookies,一般和driver.refresh()配合使用。cookie 的效果只有在页面刷新后才会体现出来。
driver.find***():
Selenium 有很多 find 函数,可以通过不同的键值返回不同的对象。这里只使用了find_element_by_class_name,即根据类名查找对象。找到对象后(对象可能是按钮或文本框),我们可以对对象进行不同的操作,比如点击、填充数据等。这里我们使用click(),也就是点击这个对象。
关于如何处理cookies,需要用到json库,下期会讲到。
网页视频抓取浏览器(怎么去抓取HTTP的请求包?(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-12 14:20
简介
前两篇文章讲解了如何抓HTTP请求包,包括代理服务器的使用和抓包方法。只是因为当前视频网站的视频地址不是在html页面直接获取的,所以通过浏览器动态解释js脚本,然后向视频服务器发送视频请求来获取视频。所以我们通过获取浏览器产生的HTTP请求来获取视频的下载地址。
想法是直接使用firefox
我们想到了可以动态渲染js脚本的程序,最常见的就是浏览器。我们通过命令运行
firefox http://the.video.url
您可以使用 Firefox 打开 URL。但是我们不能不显示就这样使用,不过我们以后有办法解决这个问题。
python+selenium+Phantomjs
因为需要渲染JS脚本而不显示界面,所以我们也想到了python+selenium+Phantomjs来动态渲染页面。 Phantomjs 是一个无头浏览器(Headless Browser 是一个没有界面的浏览器)。
但Phantomjs1.5版本后,不再支持flash插件。也就是说,Phantomjs 虽然可以动态加载 JS 脚本,但无法渲染视频。因此不会发出获取视频的 HTTP 请求。
我截图得到渲染后的页面,如下图:
视频播放窗口是黑色的,抓包程序无法捕获带有flv字符串的HTTP请求。
我也试过1.4.1版本的Phantomjs,网上说用这个命令可以加载Flash插件
./bin/phantomjs --load-plugins=yes examples/snap.js
通过渲染JS脚本,截图得到如下图:
虽然得到的截图和上图不同,但是视频中多了一个loading状态,但是我还是抓不到视频的HTTP请求。最后在python中调用webdriver.Phantomjs()时报错。
WebDriverException: Message: Can not connect to the Service phantomjs
最后不得不放弃使用 Phantomjs
slimerjs
我在网上搜索headless browser的时候,也发现了slimerjs。
PhantomJS 和 SlimerJS 的异同:
PhantomJS 基于 Webkit 内核,不支持 Flash 播放。 SlimerJS基于Firefox的Gecko内核,支持Flash播放,执行过程中会有页面显示。
正好我们需要支持Flash播放。但是问题又来了! SlimerJS 不是纯粹的 Headless 浏览器,它需要 DISPLAY! ! 那么我们可以做些什么来解决这个问题呢?有!
xvfb
xvfb 提供了一个类似于 X 服务器守护进程的环境和设置程序运行的环境变量 DISPLAY。
通过这个,上面提到的Firefox遇到的第一个问题也可以解决。感觉就像绕了一圈==!
计划实施
最后我们决定使用 slimerjs 来获取页面。因为没有办法通过python的selenium方法调用slimerjs,那么我们只能使用python调用命令行程序来动态渲染页面。 slimerjs 脚本如下。当我们调用这个脚本时,我们传入了一个网页地址参数。 slimerjs 负责打开这个页面,渲染页面的内容。
这个脚本的文件名是getPage.js
var page = require('webpage').create();
var videoUrl = phantom.args[0];
var page.open(videoUrl, function (){
window.setTimeout(function(){
phantom.exit();
},10);
});
我们的python调用os.system("xvfb-run slimerjs getPage.js" + videoURL)来渲染视频URL的视频。
我们最终的 Python 程序是 slimerjs_crawl_video.py
import os
import time
open163url = 'http://open.163.com/movie/2016/1/T/D/MBCRLBLRN_MBCRM7OTD.html'
startTime = time.time()
os.system("xvfb-run slimerjs getPage.js " + open163url)
print "use time: " + str(time.time() - startTime)
➜ capture_traffic sudo python pypcap_test.py
[sudo] password for honkee:
starting capture
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv?start=107570066
获取视频地址! !
未解决的问题
调用python slimerjs_crawl_video.py时,
➜ capture_traffic python slimerjs_craw_video.py
Vector smash protection is enabled.
use time: 94.3547639847
我不知道如何控制这个时间。我已经尝试修改getPage.js的window.setTimeout函数的时间,但是还是90多秒。我猜 python 的 os.system() 的限制是阻塞某些让我们回到过去(超过 90 秒)。接下来,我会再次检查相关的东西。
最后发现这个标题不适合这个文章。但是我还是不改了,因为我用了headless浏览器的思路来解决这个问题 查看全部
网页视频抓取浏览器(怎么去抓取HTTP的请求包?(一)_)
简介
前两篇文章讲解了如何抓HTTP请求包,包括代理服务器的使用和抓包方法。只是因为当前视频网站的视频地址不是在html页面直接获取的,所以通过浏览器动态解释js脚本,然后向视频服务器发送视频请求来获取视频。所以我们通过获取浏览器产生的HTTP请求来获取视频的下载地址。
想法是直接使用firefox
我们想到了可以动态渲染js脚本的程序,最常见的就是浏览器。我们通过命令运行
firefox http://the.video.url
您可以使用 Firefox 打开 URL。但是我们不能不显示就这样使用,不过我们以后有办法解决这个问题。
python+selenium+Phantomjs
因为需要渲染JS脚本而不显示界面,所以我们也想到了python+selenium+Phantomjs来动态渲染页面。 Phantomjs 是一个无头浏览器(Headless Browser 是一个没有界面的浏览器)。
但Phantomjs1.5版本后,不再支持flash插件。也就是说,Phantomjs 虽然可以动态加载 JS 脚本,但无法渲染视频。因此不会发出获取视频的 HTTP 请求。
我截图得到渲染后的页面,如下图:
视频播放窗口是黑色的,抓包程序无法捕获带有flv字符串的HTTP请求。
我也试过1.4.1版本的Phantomjs,网上说用这个命令可以加载Flash插件
./bin/phantomjs --load-plugins=yes examples/snap.js
通过渲染JS脚本,截图得到如下图:
虽然得到的截图和上图不同,但是视频中多了一个loading状态,但是我还是抓不到视频的HTTP请求。最后在python中调用webdriver.Phantomjs()时报错。
WebDriverException: Message: Can not connect to the Service phantomjs
最后不得不放弃使用 Phantomjs
slimerjs
我在网上搜索headless browser的时候,也发现了slimerjs。
PhantomJS 和 SlimerJS 的异同:
PhantomJS 基于 Webkit 内核,不支持 Flash 播放。 SlimerJS基于Firefox的Gecko内核,支持Flash播放,执行过程中会有页面显示。
正好我们需要支持Flash播放。但是问题又来了! SlimerJS 不是纯粹的 Headless 浏览器,它需要 DISPLAY! ! 那么我们可以做些什么来解决这个问题呢?有!
xvfb
xvfb 提供了一个类似于 X 服务器守护进程的环境和设置程序运行的环境变量 DISPLAY。
通过这个,上面提到的Firefox遇到的第一个问题也可以解决。感觉就像绕了一圈==!
计划实施
最后我们决定使用 slimerjs 来获取页面。因为没有办法通过python的selenium方法调用slimerjs,那么我们只能使用python调用命令行程序来动态渲染页面。 slimerjs 脚本如下。当我们调用这个脚本时,我们传入了一个网页地址参数。 slimerjs 负责打开这个页面,渲染页面的内容。
这个脚本的文件名是getPage.js
var page = require('webpage').create();
var videoUrl = phantom.args[0];
var page.open(videoUrl, function (){
window.setTimeout(function(){
phantom.exit();
},10);
});
我们的python调用os.system("xvfb-run slimerjs getPage.js" + videoURL)来渲染视频URL的视频。
我们最终的 Python 程序是 slimerjs_crawl_video.py
import os
import time
open163url = 'http://open.163.com/movie/2016/1/T/D/MBCRLBLRN_MBCRM7OTD.html'
startTime = time.time()
os.system("xvfb-run slimerjs getPage.js " + open163url)
print "use time: " + str(time.time() - startTime)
➜ capture_traffic sudo python pypcap_test.py
[sudo] password for honkee:
starting capture
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv?start=107570066
获取视频地址! !
未解决的问题
调用python slimerjs_crawl_video.py时,
➜ capture_traffic python slimerjs_craw_video.py
Vector smash protection is enabled.
use time: 94.3547639847
我不知道如何控制这个时间。我已经尝试修改getPage.js的window.setTimeout函数的时间,但是还是90多秒。我猜 python 的 os.system() 的限制是阻塞某些让我们回到过去(超过 90 秒)。接下来,我会再次检查相关的东西。
最后发现这个标题不适合这个文章。但是我还是不改了,因为我用了headless浏览器的思路来解决这个问题
网页视频抓取浏览器(Chrome/Firefox/IE等浏览器中提取在线视频的真实下载地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 553 次浏览 • 2021-10-11 19:37
序列:
默认情况下,在 Chrome/Firefox/IE 等浏览器中,通过使用 F12 功能键,可以调出专为前端开发者准备的网页调试工具。但 D 先生采取了不同的方法,并将此功能应用于一般公众用户。写这个文章用F12提取在线视频的真实下载地址,软件sketch中的一个特色,谢谢!
介绍:
近年来,视频网站如雨后春笋般涌现。热门视频网站 从最早的优酷、土豆,到今天的搜狐、腾讯、新浪,每一个都在招揽用户,吸引用户。大部分视频资源分散在各大网站。如果广大网友想要下载视频,似乎只能到处注册账号,让桌面和托盘被各种客户端的图标占据。光是听他们说话就觉得很可怕。当越来越多的用户开始从网上搜集方法,通过视频嗅探、提取缓存或视频地址解析网站的浏览器扩展下载视频时,发现对网站的支持是有限的。, 有时会出现故障、视频不完整、更新频率高等问题,
自力更生不需要任何第三方软件,扩展提取在线视频下载地址
D先生个人主张自力更生。其实只要能通过浏览器本身找出网页中视频的真实地址,不仅需要第三方扩展和工具,还要保证结果的准确性和完整性。注册账号永远不用担心,长期有效。其实这个方法早就在网上公布了,可惜在网站的扩展分析大潮中迷失了方向,很多浏览器都更新了。特此,D先生重新整理并编写了教程。
首先,涉及到一些常识:
网页格式一般为 HTML。代码可以用来写花哨的网页,但是视频文件永远不能直接集成到一个单独的HTML文件中,所以网页中的视频必须是一个独立的视频文件。在网页上的其他文件中,视频文件具有文件大的显着特点。视频网站的视频文件格式一般为flv、mp4、hlv、f4v等,少数有自己的格式如letv。下面开始操作部分:
铬部分:
对于Chrome浏览器:Chrome是谷歌推出的浏览器,在第二次浏览器大战中继火狐之后推出。今年Chrome换上了自主研发的Blink内核,F12的界面也略有变化。
打开任意视频网站的视频播放页面。这里,D先生以哔哩哔哩的视频为例。如下图所示,按F12键调出开发者工具界面,点击第一行的“网络”选项卡,可以看到网页中的元素以下面详细信息的形式列出。
单击“大小”按钮,按大小从大到小的顺序排列所有元素。视频缓冲开始时,排在第一位,音量最大(可能还在增加),右边时间线中持续时间最长的元素。“名称”中的视频格式后缀是我们的。您正在寻找的视频。右击文件,点击“复制链接地址”复制视频文件地址,然后就可以在下载器中新建一个任务,粘贴地址,开始下载。对于浏览器本身无法识别的视频格式,您也可以直接点击“在新标签中打开链接”使用浏览器进行下载。
火狐部分:
对于 Firefox 浏览器:Firefox 是 Mozilla 推出的浏览器。它是为数不多的非营利性开源浏览器之一,也是第二次浏览器大战的主力军。它为降低 IE6 做出了不可磨灭的贡献。Firefox 坚持使用 Gecko 内核。Firefox28更新后,整个浏览器界面都发生了翻天覆地的变化。打开任意视频网站的视频播放页面,依然以哔哩哔哩的视频为例。按F12键调出开发者工具界面,点击第一行“网络”选项卡。
如果不是上图所示的界面,可以直接跳转到下图二。如果出现上图界面,点击图中②位置的按钮,页面会自动刷新,出现下图界面。它显示了网页元素类型的饼图。
单击饼图中的其他,您将看到如下图所示的界面。
同样,单击“大小”以按体积排序。首先,大小为4-6位kb,文件名中带有后缀“.hlv”或其他视频格式的文件就是需要的视频。还是右键文件,点击“复制网址”,在下载器中新建一个任务,粘贴地址,开始下载。对于火狐无法识别的视频格式,您也可以直接点击“在新标签页中打开”,使用浏览器或浏览器的下载插件进行下载。
IE部分:
Internet Explorer是Windows PC系统自带的浏览器,是最基本的浏览器。但是因为IE嗅探是最难上手的,所以最后再说。从IE9开始,IE内置的F12开始完善,向Chrome等新兴浏览器靠拢。打开视频网站的视频播放页面,然后按键盘上的F12键,可以看到如下图所示的界面。单击第二行的“网络”选项卡,然后单击“开始捕获”按钮开始捕获。捕获的元素将在下面的空间中显示详细信息。由于不像Chrome和Firefox那样容易按体积排序,可以直接找到,所以我个人建议将F12界面向上拉伸。以同样的方式,
在列出的内容中,“Result”和“Type”显示为“(Spent)”,发起方为Flash,URL后缀为“.hlv”或其他视频格式后缀,为视频文件。右键单击“复制 URL”以复制到下载器并开始下载。这里一定要注意“复制网址”而不是“复制”。
最后,还有很多话要说:
视频文件的判断只能在视频开始缓冲后进行,否则会开视频前60秒广告下载的玩笑。另外,例如,如果优酷上的视频显示的源地址中出现“”和“”的域名,即使大小等特征符合特征,也显然不是目标文件。另外,很多视频网站剪掉了视频,所以下载的时候一定要把每一段都下载下来。每个段落是若干个符合要求的体积相近、后缀相同的文件。大多数 24 到 30 分钟的视频被分成几个部分。对于分四期的视频,需要将进度条拉到开头,分别大约25%、50%、75%左右,并缓冲, 查看全部
网页视频抓取浏览器(Chrome/Firefox/IE等浏览器中提取在线视频的真实下载地址)
序列:
默认情况下,在 Chrome/Firefox/IE 等浏览器中,通过使用 F12 功能键,可以调出专为前端开发者准备的网页调试工具。但 D 先生采取了不同的方法,并将此功能应用于一般公众用户。写这个文章用F12提取在线视频的真实下载地址,软件sketch中的一个特色,谢谢!
介绍:
近年来,视频网站如雨后春笋般涌现。热门视频网站 从最早的优酷、土豆,到今天的搜狐、腾讯、新浪,每一个都在招揽用户,吸引用户。大部分视频资源分散在各大网站。如果广大网友想要下载视频,似乎只能到处注册账号,让桌面和托盘被各种客户端的图标占据。光是听他们说话就觉得很可怕。当越来越多的用户开始从网上搜集方法,通过视频嗅探、提取缓存或视频地址解析网站的浏览器扩展下载视频时,发现对网站的支持是有限的。, 有时会出现故障、视频不完整、更新频率高等问题,
自力更生不需要任何第三方软件,扩展提取在线视频下载地址
D先生个人主张自力更生。其实只要能通过浏览器本身找出网页中视频的真实地址,不仅需要第三方扩展和工具,还要保证结果的准确性和完整性。注册账号永远不用担心,长期有效。其实这个方法早就在网上公布了,可惜在网站的扩展分析大潮中迷失了方向,很多浏览器都更新了。特此,D先生重新整理并编写了教程。
首先,涉及到一些常识:
网页格式一般为 HTML。代码可以用来写花哨的网页,但是视频文件永远不能直接集成到一个单独的HTML文件中,所以网页中的视频必须是一个独立的视频文件。在网页上的其他文件中,视频文件具有文件大的显着特点。视频网站的视频文件格式一般为flv、mp4、hlv、f4v等,少数有自己的格式如letv。下面开始操作部分:
铬部分:
对于Chrome浏览器:Chrome是谷歌推出的浏览器,在第二次浏览器大战中继火狐之后推出。今年Chrome换上了自主研发的Blink内核,F12的界面也略有变化。
打开任意视频网站的视频播放页面。这里,D先生以哔哩哔哩的视频为例。如下图所示,按F12键调出开发者工具界面,点击第一行的“网络”选项卡,可以看到网页中的元素以下面详细信息的形式列出。
单击“大小”按钮,按大小从大到小的顺序排列所有元素。视频缓冲开始时,排在第一位,音量最大(可能还在增加),右边时间线中持续时间最长的元素。“名称”中的视频格式后缀是我们的。您正在寻找的视频。右击文件,点击“复制链接地址”复制视频文件地址,然后就可以在下载器中新建一个任务,粘贴地址,开始下载。对于浏览器本身无法识别的视频格式,您也可以直接点击“在新标签中打开链接”使用浏览器进行下载。
火狐部分:
对于 Firefox 浏览器:Firefox 是 Mozilla 推出的浏览器。它是为数不多的非营利性开源浏览器之一,也是第二次浏览器大战的主力军。它为降低 IE6 做出了不可磨灭的贡献。Firefox 坚持使用 Gecko 内核。Firefox28更新后,整个浏览器界面都发生了翻天覆地的变化。打开任意视频网站的视频播放页面,依然以哔哩哔哩的视频为例。按F12键调出开发者工具界面,点击第一行“网络”选项卡。
如果不是上图所示的界面,可以直接跳转到下图二。如果出现上图界面,点击图中②位置的按钮,页面会自动刷新,出现下图界面。它显示了网页元素类型的饼图。
单击饼图中的其他,您将看到如下图所示的界面。
同样,单击“大小”以按体积排序。首先,大小为4-6位kb,文件名中带有后缀“.hlv”或其他视频格式的文件就是需要的视频。还是右键文件,点击“复制网址”,在下载器中新建一个任务,粘贴地址,开始下载。对于火狐无法识别的视频格式,您也可以直接点击“在新标签页中打开”,使用浏览器或浏览器的下载插件进行下载。
IE部分:
Internet Explorer是Windows PC系统自带的浏览器,是最基本的浏览器。但是因为IE嗅探是最难上手的,所以最后再说。从IE9开始,IE内置的F12开始完善,向Chrome等新兴浏览器靠拢。打开视频网站的视频播放页面,然后按键盘上的F12键,可以看到如下图所示的界面。单击第二行的“网络”选项卡,然后单击“开始捕获”按钮开始捕获。捕获的元素将在下面的空间中显示详细信息。由于不像Chrome和Firefox那样容易按体积排序,可以直接找到,所以我个人建议将F12界面向上拉伸。以同样的方式,
在列出的内容中,“Result”和“Type”显示为“(Spent)”,发起方为Flash,URL后缀为“.hlv”或其他视频格式后缀,为视频文件。右键单击“复制 URL”以复制到下载器并开始下载。这里一定要注意“复制网址”而不是“复制”。
最后,还有很多话要说:
视频文件的判断只能在视频开始缓冲后进行,否则会开视频前60秒广告下载的玩笑。另外,例如,如果优酷上的视频显示的源地址中出现“”和“”的域名,即使大小等特征符合特征,也显然不是目标文件。另外,很多视频网站剪掉了视频,所以下载的时候一定要把每一段都下载下来。每个段落是若干个符合要求的体积相近、后缀相同的文件。大多数 24 到 30 分钟的视频被分成几个部分。对于分四期的视频,需要将进度条拉到开头,分别大约25%、50%、75%左右,并缓冲,

