
网页数据抓取
网页数据抓取(如何写好Python数据我用的是Python?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-14 17:14
)
最近发现数据在很多情况下变得越来越重要,我们经常发现一个网页上有大量我们想要的数据,但是一个一个下载太费力了。这时候就可以写一些简单的爬虫软件来帮助我们从网上抓取我们想要的数据
我使用 Python。这种语言比较简单。已经编写了很多工具包,可以直接使用。
开始---------------------------------------------- ----------
假设我们找到一个信息比较完整的网站,比如39养老网:
/findhomes/
点击打开任意一家养老院,如上海上大天平养老院
我们想获取这个网站的所有养老院信息,例如姓名、地址、机构性质等。
所需工具:
苹果或ubuntu操作系统,用windows的同学可以用虚拟机,推荐VMWARE Workstation
使用的语言是Python2.x,软件包需要美汤,请求,可以使用pip install安装
编程---------------------------------------------- --------------------
首先,一般这些网站页面和页面之间的url有一些相似之处,比如这个网站,如果你点击第二个页面,可以看到它的url是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_2.htm
第三页是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_3.htm
可以看到是最后一个数字决定显示哪个页面
经过尝试,我发现网站总共只有63页;这也说明我们可以写一个简单的for循环来快速访问每一页
知道如何翻页后,我们需要从当前页面找到各个养老院的链接
打开这个页面的html代码(每个预览器的打开方式不同)
我们看到一个类似的页面
/r/uXV0bFvEdQYKrR8P9yCr(自动识别二维码)
chrome 预览器在控制台的左上角有一个检查元素工具
我们可以用它在页面上找到我们感兴趣的部分
使用inspect工具,然后点击第一家养老院的信息,我们会发现html会显示相关的html信息
href表示这个网页点击链接后会跳转到的url,我们点击“上海上大天平疗养院”稍后发布
网址是/findhomes/tianping.htm
页面跳转到养老院信息页面
当前总结:目前我们知道如何使用程序在网站上翻页,以及如何找到各个疗养院的链接,我们来看看代码输入
代码第一步:导入相关的python库
我们需要的其实只是bs4的BeautifulSoup,和requests
第二部分代码:从每个页面链接中抓取相关页面上的养老院
正如我上面所说的,我们知道网站目前只有64页,所以我们可以写一个for循环,循环64次;
getLink的代码如下:
i 是一个整数,getLink 会返回给我们对应的页面 url,比如 i=1 时,getLink 会返回我们的第一页,当 i=2 时会返回给我们第二页
getFacilities的代码如下:
这个功能的主要作用是找出页面上所有养老院公寓的网址(我们刚刚看到的href)
getSoup是一个函数(BeautifulSoup库中的一个函数),我们给他一个url,他会返回一个处理后的网页html给我们搜索
<p>soup.find("ul"...) 的意思是在html中找到第一个符合"{...}"条件的"ul"标签,我们把这个信息存储在table_ul的变量中 查看全部
网页数据抓取(如何写好Python数据我用的是Python?(上)
)
最近发现数据在很多情况下变得越来越重要,我们经常发现一个网页上有大量我们想要的数据,但是一个一个下载太费力了。这时候就可以写一些简单的爬虫软件来帮助我们从网上抓取我们想要的数据
我使用 Python。这种语言比较简单。已经编写了很多工具包,可以直接使用。
开始---------------------------------------------- ----------
假设我们找到一个信息比较完整的网站,比如39养老网:
/findhomes/
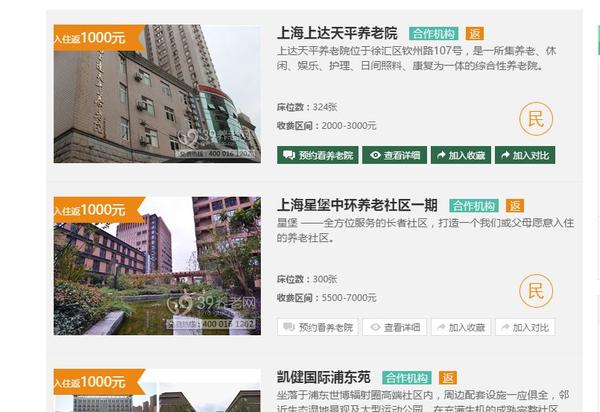
点击打开任意一家养老院,如上海上大天平养老院
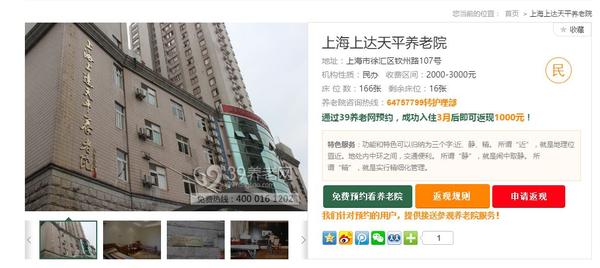
我们想获取这个网站的所有养老院信息,例如姓名、地址、机构性质等。
所需工具:
苹果或ubuntu操作系统,用windows的同学可以用虚拟机,推荐VMWARE Workstation
使用的语言是Python2.x,软件包需要美汤,请求,可以使用pip install安装
编程---------------------------------------------- --------------------
首先,一般这些网站页面和页面之间的url有一些相似之处,比如这个网站,如果你点击第二个页面,可以看到它的url是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_2.htm
第三页是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_3.htm
可以看到是最后一个数字决定显示哪个页面
经过尝试,我发现网站总共只有63页;这也说明我们可以写一个简单的for循环来快速访问每一页
知道如何翻页后,我们需要从当前页面找到各个养老院的链接
打开这个页面的html代码(每个预览器的打开方式不同)
我们看到一个类似的页面
/r/uXV0bFvEdQYKrR8P9yCr(自动识别二维码)
chrome 预览器在控制台的左上角有一个检查元素工具
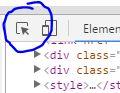
我们可以用它在页面上找到我们感兴趣的部分
使用inspect工具,然后点击第一家养老院的信息,我们会发现html会显示相关的html信息
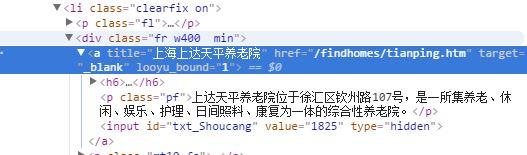
href表示这个网页点击链接后会跳转到的url,我们点击“上海上大天平疗养院”稍后发布
网址是/findhomes/tianping.htm
页面跳转到养老院信息页面
当前总结:目前我们知道如何使用程序在网站上翻页,以及如何找到各个疗养院的链接,我们来看看代码输入
代码第一步:导入相关的python库
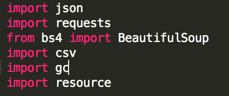
我们需要的其实只是bs4的BeautifulSoup,和requests
第二部分代码:从每个页面链接中抓取相关页面上的养老院
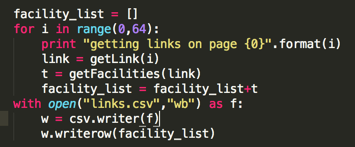
正如我上面所说的,我们知道网站目前只有64页,所以我们可以写一个for循环,循环64次;
getLink的代码如下:

i 是一个整数,getLink 会返回给我们对应的页面 url,比如 i=1 时,getLink 会返回我们的第一页,当 i=2 时会返回给我们第二页
getFacilities的代码如下:
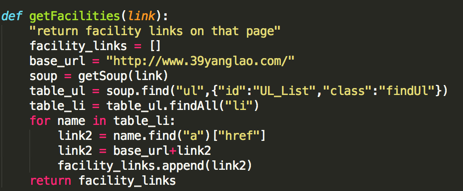
这个功能的主要作用是找出页面上所有养老院公寓的网址(我们刚刚看到的href)
getSoup是一个函数(BeautifulSoup库中的一个函数),我们给他一个url,他会返回一个处理后的网页html给我们搜索
<p>soup.find("ul"...) 的意思是在html中找到第一个符合"{...}"条件的"ul"标签,我们把这个信息存储在table_ul的变量中
网页数据抓取(没数据,数据不够不会Java不写爬虫工具怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-14 17:14
Web Scraper 爬虫工具是一个基于谷歌浏览器的插件。使用Web Scraper可以简单快速地抓取任何网站数据,不受网站反爬虫机制的影响。与Python等语言实现的爬虫工具相比,WebScraper具有先天优势。
Demo,简单吗?
做科学研究和实验最痛苦的事情是什么?
没有数据,没有足够的数据
如果我不会 Python、不会 Java 并且不会编写爬虫怎么办?
查找:网络爬虫!
互联网上有海量的数据,每天都有各种各样的数据展现在我们面前。同时,金融、医学、计算机科学等诸多研究课题需要获取大量数据作为样本进行科学分析。传统的手动采集操作从根本上很难处理数据采集,即使可以采集,也需要花费大量的时间和成本。本教程的目的是让拥有采集数据需求的人能够在一小时内熟练使用“神器”Web Scraper插件。
让我们先了解一下爬行的简单原理,所谓“磨刀不误砍柴”,了解原理可以帮助我们事半功倍!
「抓取对象」
作为展示数据的平台,可以通过浏览器窗口浏览网页。从服务器数据库到浏览器窗口的显示,中间有一个复杂的过程。服务器数据库中存储的数据一般以某种编码形式存储。如果我们看这个时候的数据,我们看到的是一个这样或那样的纯文本类型。数据传输到浏览器后,浏览器将“数据信息”加载到设计者准备好的“网页模板”中,最终得到我们通过浏览器看到的一切。
我们看到的金融网站
我们看到的新闻网站
我们看到的博客
“了解网页的“层次””
各种网页都收录各种数据。网页组织数据收录在不同的“层”中(详细信息可以从html标签中了解)。当然,我们无法直观地看到所有这些层。
经过长时间的网页设计发展,到现在我们都是通过标准的html标签语言来设计网页的。在这套国际通用规则下,设计的过程就是逐层设计页面元素,让不同的内容可以更和谐的结合。虽然不同的网站设计风格不同,但每个网页都类似于一个“金字塔”结构,比如下面这个网页:
第一级:类似于一张桌子
第二层:标题栏和内容栏(类似Excel)
第三层:每一行的数据
第四层:每个单元格
第五层:文字
「Web Scraper 分层抓取页面元素」
Web Scraper作为一种自动化爬虫工具,它的爬取目标是页面数据,但是在爬取数据之前,我们需要定义一个“流程”,这个流程包括“动作”(模拟鼠标点击操作)和“页面元素” "(定义要爬取的页面元素)。
感觉好傻
实践是检验真理的唯一标准。这是爬行过程的结束。基本原理储备足够学习Web Scraper!
从下一节开始,我们正式进入Web Scraper的学习。
下一节《【网络爬虫教程02】安装网络爬虫插件》预览 查看全部
网页数据抓取(没数据,数据不够不会Java不写爬虫工具怎么办?)
Web Scraper 爬虫工具是一个基于谷歌浏览器的插件。使用Web Scraper可以简单快速地抓取任何网站数据,不受网站反爬虫机制的影响。与Python等语言实现的爬虫工具相比,WebScraper具有先天优势。
Demo,简单吗?
做科学研究和实验最痛苦的事情是什么?
没有数据,没有足够的数据
如果我不会 Python、不会 Java 并且不会编写爬虫怎么办?
查找:网络爬虫!
互联网上有海量的数据,每天都有各种各样的数据展现在我们面前。同时,金融、医学、计算机科学等诸多研究课题需要获取大量数据作为样本进行科学分析。传统的手动采集操作从根本上很难处理数据采集,即使可以采集,也需要花费大量的时间和成本。本教程的目的是让拥有采集数据需求的人能够在一小时内熟练使用“神器”Web Scraper插件。
让我们先了解一下爬行的简单原理,所谓“磨刀不误砍柴”,了解原理可以帮助我们事半功倍!
「抓取对象」
作为展示数据的平台,可以通过浏览器窗口浏览网页。从服务器数据库到浏览器窗口的显示,中间有一个复杂的过程。服务器数据库中存储的数据一般以某种编码形式存储。如果我们看这个时候的数据,我们看到的是一个这样或那样的纯文本类型。数据传输到浏览器后,浏览器将“数据信息”加载到设计者准备好的“网页模板”中,最终得到我们通过浏览器看到的一切。
我们看到的金融网站
我们看到的新闻网站
我们看到的博客
“了解网页的“层次””
各种网页都收录各种数据。网页组织数据收录在不同的“层”中(详细信息可以从html标签中了解)。当然,我们无法直观地看到所有这些层。
经过长时间的网页设计发展,到现在我们都是通过标准的html标签语言来设计网页的。在这套国际通用规则下,设计的过程就是逐层设计页面元素,让不同的内容可以更和谐的结合。虽然不同的网站设计风格不同,但每个网页都类似于一个“金字塔”结构,比如下面这个网页:
第一级:类似于一张桌子
第二层:标题栏和内容栏(类似Excel)
第三层:每一行的数据
第四层:每个单元格
第五层:文字
「Web Scraper 分层抓取页面元素」
Web Scraper作为一种自动化爬虫工具,它的爬取目标是页面数据,但是在爬取数据之前,我们需要定义一个“流程”,这个流程包括“动作”(模拟鼠标点击操作)和“页面元素” "(定义要爬取的页面元素)。
感觉好傻
实践是检验真理的唯一标准。这是爬行过程的结束。基本原理储备足够学习Web Scraper!
从下一节开始,我们正式进入Web Scraper的学习。
下一节《【网络爬虫教程02】安装网络爬虫插件》预览
网页数据抓取(1.外链,留下链接引导蜘蛛进入你的网站外链也不是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2021-09-12 12:10
1.sitemap
定期将网站链接放入Sitemap,然后将Sitemap提交给百度。百度会定期抓取检查您提交的Sitemap,并处理其中的链接,但收录比主动推送慢。
2.友链
友情链接一定要做好。一个新站想要快速站稳脚跟,快速成为收录,很大一部分需要友情链接,而且是优质友情链接。寻找友情链接的标准一定要及时更新内容,百度收录数量正常,网站好友链不多,内容质量高,权重不低于自己的网站做友链。记得及时查看好友链。
3.外链
除了朋友链,就是外链。发外链的目的是为了吸引蜘蛛来抓我们网站。将自己的优质外链发布到各大外链平台,留下链接引导蜘蛛进入你的网站,外链不随机。找相关网站发布外链,威力高,收录要快,快照需要及时更新网站,外链不能光看数量,最重要的是质量。
4.Push
主动推送可以让百度更快找到你的网站和收录。这也是最快的提交方式。网站上产生的新链接会立即通过这种方式推送给百度,以确保新链接及时被百度收录使用。
5.content
网站没有内容,不管做多少外链都是徒劳的。 网站的一个内容是吸引搜索引擎蜘蛛的根源。搜索引擎蜘蛛来你网站的原因是为了爬取优质内容。如果你的网站不做任何推广,你的网站内容质量很高,每天都准时更新,那么百度蜘蛛每天都会来到你的网站。
6.内链
这是大多数网站 忽略的事情。内部链接和内部链接的作用其实很重要。蜘蛛的爬行轨迹是跟随一个链接到另一个链接。我想让搜索引擎蜘蛛更好。地面爬行一般需要外链引导,但内页爬行需要良好的内链。如果不注意死链和断链的形成,蜘蛛就爬不上去,也没有好的收录NS。
7.update
这里所说的更新是指网站内容更新的频率和数量。为了让蜘蛛每天某个时间从你的网站抓取内容,你首先要有一个更新内容的规则。比如每天早上更新几篇文章,每天下午更新几篇文章。久而久之,搜索引擎蜘蛛找出你的更新规则后,就会按照你的规则来找你。 网站抢内容,三五天不更新,突然有一天你更新了很多内容。这样只会让搜索引擎蜘蛛想你很久,才会来你的网站一次。
上一篇:网站。如何快速成为百度收录?   |   下一篇:如何在百度搜索中排名第一? 查看全部
网页数据抓取(1.外链,留下链接引导蜘蛛进入你的网站外链也不是)
1.sitemap
定期将网站链接放入Sitemap,然后将Sitemap提交给百度。百度会定期抓取检查您提交的Sitemap,并处理其中的链接,但收录比主动推送慢。
2.友链
友情链接一定要做好。一个新站想要快速站稳脚跟,快速成为收录,很大一部分需要友情链接,而且是优质友情链接。寻找友情链接的标准一定要及时更新内容,百度收录数量正常,网站好友链不多,内容质量高,权重不低于自己的网站做友链。记得及时查看好友链。
3.外链
除了朋友链,就是外链。发外链的目的是为了吸引蜘蛛来抓我们网站。将自己的优质外链发布到各大外链平台,留下链接引导蜘蛛进入你的网站,外链不随机。找相关网站发布外链,威力高,收录要快,快照需要及时更新网站,外链不能光看数量,最重要的是质量。
4.Push
主动推送可以让百度更快找到你的网站和收录。这也是最快的提交方式。网站上产生的新链接会立即通过这种方式推送给百度,以确保新链接及时被百度收录使用。
5.content
网站没有内容,不管做多少外链都是徒劳的。 网站的一个内容是吸引搜索引擎蜘蛛的根源。搜索引擎蜘蛛来你网站的原因是为了爬取优质内容。如果你的网站不做任何推广,你的网站内容质量很高,每天都准时更新,那么百度蜘蛛每天都会来到你的网站。
6.内链
这是大多数网站 忽略的事情。内部链接和内部链接的作用其实很重要。蜘蛛的爬行轨迹是跟随一个链接到另一个链接。我想让搜索引擎蜘蛛更好。地面爬行一般需要外链引导,但内页爬行需要良好的内链。如果不注意死链和断链的形成,蜘蛛就爬不上去,也没有好的收录NS。
7.update
这里所说的更新是指网站内容更新的频率和数量。为了让蜘蛛每天某个时间从你的网站抓取内容,你首先要有一个更新内容的规则。比如每天早上更新几篇文章,每天下午更新几篇文章。久而久之,搜索引擎蜘蛛找出你的更新规则后,就会按照你的规则来找你。 网站抢内容,三五天不更新,突然有一天你更新了很多内容。这样只会让搜索引擎蜘蛛想你很久,才会来你的网站一次。
上一篇:网站。如何快速成为百度收录?   |   下一篇:如何在百度搜索中排名第一?
网页数据抓取(用网页抓取工具,大多还是免费的哦比import.io)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-12 12:08
今天给大家推荐几款非常实用的网络爬虫工具,大部分都是免费的!喜欢记得点赞。
1、Import.ioimport.io
用法很简单。注册后,在可视化界面输入URL链接过滤数据。操作也超级简单,如下图,唯一的缺点就是全英文,不过我们自己有,我们来看看第二个。
2、parsehubparsehub
与上述两种网页抓取不同,parsehub需要用户下载客户端才能使用。它像浏览器一样打开,然后输入 URL 以提取网页上所需的信息。
/ZTg4et(自动识别二维码)
3、80legs80legs
80legs 每天在由 50,000 台计算机组成的 Plura 网格上抓取 200 万个网页。但是,它可能不像以前那样容易使用。
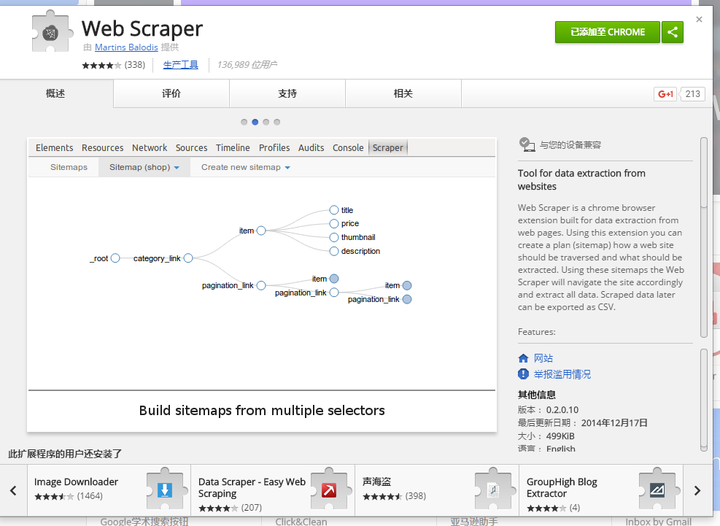
4、Web ScraperWeb Scraper
Web Scraper 是一个需要在 Google App Store 中安装的插件。基本步骤只是一点点。
详细教程可以看这里/article/241334
/ZTg4et(自动识别二维码)
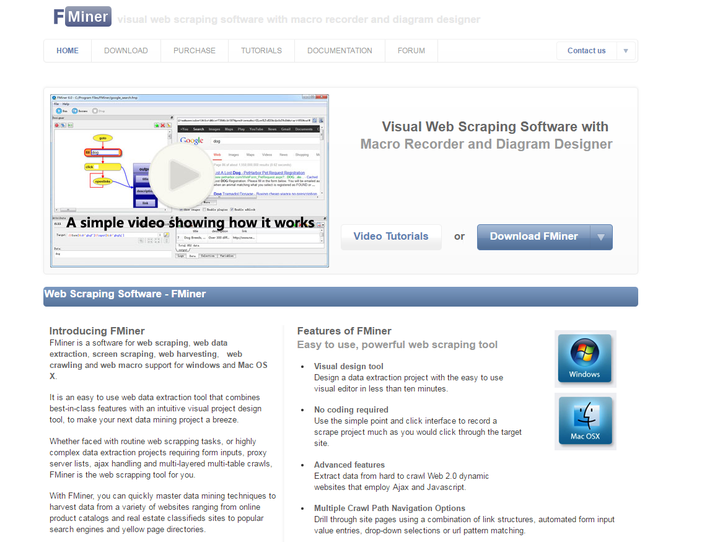
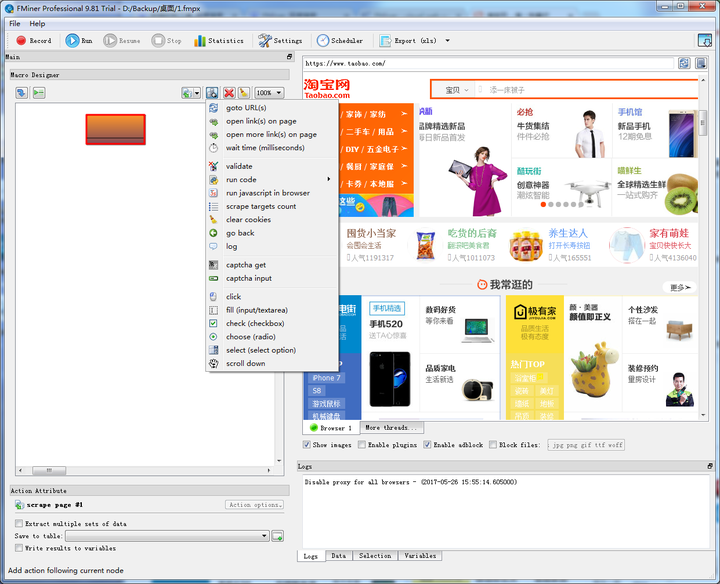
5、FMinerFMiner
FMiner 也需要下载客户端才能使用,但它是付费产品,有 15 天的免费使用期。
总结
以上工具都是国外工具。如果您更喜欢中文界面,可以来试试我们的产品。-深受广大爬虫爱好者喜爱的云爬虫。
左书比import.io更适合中国人。直接在原网页的基础上操作,也可以使用分布式爬取、深度爬取等,有数据需求的可以试试。
其实,网络爬虫的工具有很多,不必全部掌握。本文的目标是将它们用作工具来促进您的工作。
那么,您最喜欢使用哪一个?
下次见!
Meeting 在不断完善,变得越来越强大。数据采集这里! ! ! ! 查看全部
网页数据抓取(用网页抓取工具,大多还是免费的哦比import.io)
今天给大家推荐几款非常实用的网络爬虫工具,大部分都是免费的!喜欢记得点赞。

1、Import.ioimport.io
用法很简单。注册后,在可视化界面输入URL链接过滤数据。操作也超级简单,如下图,唯一的缺点就是全英文,不过我们自己有,我们来看看第二个。
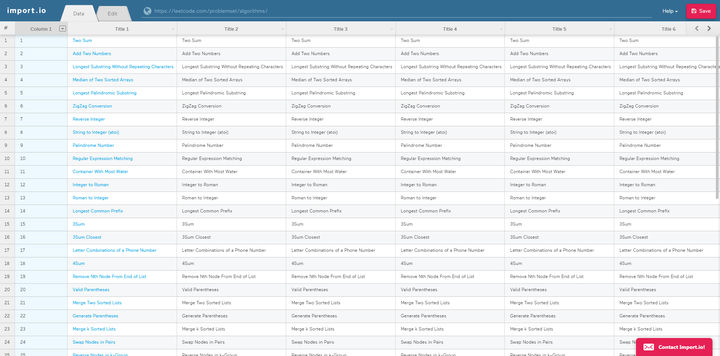
2、parsehubparsehub
与上述两种网页抓取不同,parsehub需要用户下载客户端才能使用。它像浏览器一样打开,然后输入 URL 以提取网页上所需的信息。
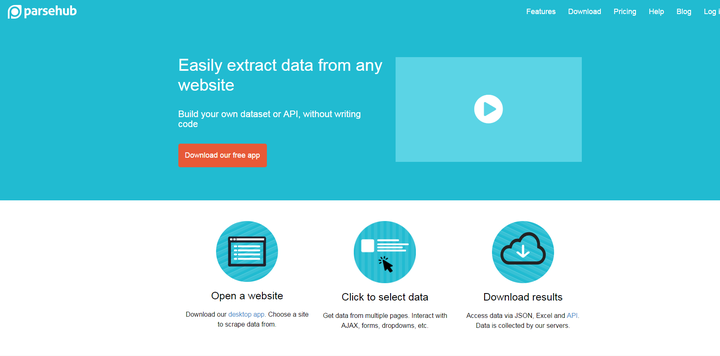
/ZTg4et(自动识别二维码)
3、80legs80legs
80legs 每天在由 50,000 台计算机组成的 Plura 网格上抓取 200 万个网页。但是,它可能不像以前那样容易使用。

4、Web ScraperWeb Scraper
Web Scraper 是一个需要在 Google App Store 中安装的插件。基本步骤只是一点点。
详细教程可以看这里/article/241334
/ZTg4et(自动识别二维码)
5、FMinerFMiner
FMiner 也需要下载客户端才能使用,但它是付费产品,有 15 天的免费使用期。
总结
以上工具都是国外工具。如果您更喜欢中文界面,可以来试试我们的产品。-深受广大爬虫爱好者喜爱的云爬虫。
左书比import.io更适合中国人。直接在原网页的基础上操作,也可以使用分布式爬取、深度爬取等,有数据需求的可以试试。
其实,网络爬虫的工具有很多,不必全部掌握。本文的目标是将它们用作工具来促进您的工作。
那么,您最喜欢使用哪一个?
下次见!
Meeting 在不断完善,变得越来越强大。数据采集这里! ! ! !
网页数据抓取(智能识别模式WebHarvy(网页数据抓取软件)功能介绍(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-11 15:13
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。易于使用。
WebHarvy(网页数据采集软件)
功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。软件功能
WebHarvy 是一个可视化的网络抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。更新日志
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
网页数据抓取(智能识别模式WebHarvy(网页数据抓取软件)功能介绍(组图))
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。易于使用。
WebHarvy(网页数据采集软件)
功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。软件功能
WebHarvy 是一个可视化的网络抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。更新日志
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
网页数据抓取(SysNucleusWebHarvy破解版自动提取文字、图片、网址和破解教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-09-10 04:01
SysNucleus WebHarvy 破解版是一款专业的网络数据采集工具。它可以自动从多个页面中抓取和提取数据。可以直接在网页上选择要选择的资源,也可以直接将整个网页保存为HTML格式,可以帮助用户快速从网页中提取数据并保存为不同的格式,让您可以导出将捕获的数据转换为 Excel、XML、CSV、JSON 或 TSV 文件。智能识别网页上出现的数据模式。 SysNucleus WebHarvy 破解版自动提取网站中的文字、图片、网址和邮件,并以多种格式保存内容。从网页上的采集 数据,导航到收录数据的网页就像单击捕获的数据一样简单。可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。使用该软件,您可以从各种网站中提取数据,例如产品目录或搜索结果,这些网站可能涉及房地产、电子商务、学术研究、娱乐、科技等不同类别。
破解教程1、下载并解压安装包,双击运行软件“Setup.exe”进行安装,进入安装向导,点击next进入下一步
2、同意用户协议,选择顶一个
3、设置安装目录,如果要更改,点击更改
4、确认软件安装无误后点击安装
5、安装成功,取消勾选立即运行软件,点击完成启动安装界面
6、将破解补丁“WebHarvy.exe”替换到原安装目录,点击复制替换
ps:如果找不到位置,可以返回桌面右击图标,选择位置打开文件。
7、破解成功,打开软件即可免费使用
功能1、webharvy 自动从网站 中提取文本、图片、URL 和电子邮件,并以各种格式保存内容。
2、非常好用,几分钟就能自动提取出来
3、 支持从多个页面/类别/关键字中提取数据
4、将提取的数据保存到文件或数据库中
5、内置调度器和代理支持
6、 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
7、自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
8、您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
9、通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
更新日志修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
网页数据抓取(SysNucleusWebHarvy破解版自动提取文字、图片、网址和破解教程)
SysNucleus WebHarvy 破解版是一款专业的网络数据采集工具。它可以自动从多个页面中抓取和提取数据。可以直接在网页上选择要选择的资源,也可以直接将整个网页保存为HTML格式,可以帮助用户快速从网页中提取数据并保存为不同的格式,让您可以导出将捕获的数据转换为 Excel、XML、CSV、JSON 或 TSV 文件。智能识别网页上出现的数据模式。 SysNucleus WebHarvy 破解版自动提取网站中的文字、图片、网址和邮件,并以多种格式保存内容。从网页上的采集 数据,导航到收录数据的网页就像单击捕获的数据一样简单。可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。使用该软件,您可以从各种网站中提取数据,例如产品目录或搜索结果,这些网站可能涉及房地产、电子商务、学术研究、娱乐、科技等不同类别。

破解教程1、下载并解压安装包,双击运行软件“Setup.exe”进行安装,进入安装向导,点击next进入下一步

2、同意用户协议,选择顶一个

3、设置安装目录,如果要更改,点击更改

4、确认软件安装无误后点击安装

5、安装成功,取消勾选立即运行软件,点击完成启动安装界面

6、将破解补丁“WebHarvy.exe”替换到原安装目录,点击复制替换

ps:如果找不到位置,可以返回桌面右击图标,选择位置打开文件。

7、破解成功,打开软件即可免费使用

功能1、webharvy 自动从网站 中提取文本、图片、URL 和电子邮件,并以各种格式保存内容。
2、非常好用,几分钟就能自动提取出来
3、 支持从多个页面/类别/关键字中提取数据
4、将提取的数据保存到文件或数据库中
5、内置调度器和代理支持
6、 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
7、自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
8、您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
9、通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
更新日志修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
网页数据抓取(如何写好Python数据我用的是Python?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-14 17:14
)
最近发现数据在很多情况下变得越来越重要,我们经常发现一个网页上有大量我们想要的数据,但是一个一个下载太费力了。这时候就可以写一些简单的爬虫软件来帮助我们从网上抓取我们想要的数据
我使用 Python。这种语言比较简单。已经编写了很多工具包,可以直接使用。
开始---------------------------------------------- ----------
假设我们找到一个信息比较完整的网站,比如39养老网:
/findhomes/
点击打开任意一家养老院,如上海上大天平养老院
我们想获取这个网站的所有养老院信息,例如姓名、地址、机构性质等。
所需工具:
苹果或ubuntu操作系统,用windows的同学可以用虚拟机,推荐VMWARE Workstation
使用的语言是Python2.x,软件包需要美汤,请求,可以使用pip install安装
编程---------------------------------------------- --------------------
首先,一般这些网站页面和页面之间的url有一些相似之处,比如这个网站,如果你点击第二个页面,可以看到它的url是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_2.htm
第三页是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_3.htm
可以看到是最后一个数字决定显示哪个页面
经过尝试,我发现网站总共只有63页;这也说明我们可以写一个简单的for循环来快速访问每一页
知道如何翻页后,我们需要从当前页面找到各个养老院的链接
打开这个页面的html代码(每个预览器的打开方式不同)
我们看到一个类似的页面
/r/uXV0bFvEdQYKrR8P9yCr(自动识别二维码)
chrome 预览器在控制台的左上角有一个检查元素工具
我们可以用它在页面上找到我们感兴趣的部分
使用inspect工具,然后点击第一家养老院的信息,我们会发现html会显示相关的html信息
href表示这个网页点击链接后会跳转到的url,我们点击“上海上大天平疗养院”稍后发布
网址是/findhomes/tianping.htm
页面跳转到养老院信息页面
当前总结:目前我们知道如何使用程序在网站上翻页,以及如何找到各个疗养院的链接,我们来看看代码输入
代码第一步:导入相关的python库
我们需要的其实只是bs4的BeautifulSoup,和requests
第二部分代码:从每个页面链接中抓取相关页面上的养老院
正如我上面所说的,我们知道网站目前只有64页,所以我们可以写一个for循环,循环64次;
getLink的代码如下:
i 是一个整数,getLink 会返回给我们对应的页面 url,比如 i=1 时,getLink 会返回我们的第一页,当 i=2 时会返回给我们第二页
getFacilities的代码如下:
这个功能的主要作用是找出页面上所有养老院公寓的网址(我们刚刚看到的href)
getSoup是一个函数(BeautifulSoup库中的一个函数),我们给他一个url,他会返回一个处理后的网页html给我们搜索
<p>soup.find("ul"...) 的意思是在html中找到第一个符合"{...}"条件的"ul"标签,我们把这个信息存储在table_ul的变量中 查看全部
网页数据抓取(如何写好Python数据我用的是Python?(上)
)
最近发现数据在很多情况下变得越来越重要,我们经常发现一个网页上有大量我们想要的数据,但是一个一个下载太费力了。这时候就可以写一些简单的爬虫软件来帮助我们从网上抓取我们想要的数据
我使用 Python。这种语言比较简单。已经编写了很多工具包,可以直接使用。
开始---------------------------------------------- ----------
假设我们找到一个信息比较完整的网站,比如39养老网:
/findhomes/
点击打开任意一家养老院,如上海上大天平养老院
我们想获取这个网站的所有养老院信息,例如姓名、地址、机构性质等。
所需工具:
苹果或ubuntu操作系统,用windows的同学可以用虚拟机,推荐VMWARE Workstation
使用的语言是Python2.x,软件包需要美汤,请求,可以使用pip install安装
编程---------------------------------------------- --------------------
首先,一般这些网站页面和页面之间的url有一些相似之处,比如这个网站,如果你点击第二个页面,可以看到它的url是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_2.htm
第三页是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_3.htm
可以看到是最后一个数字决定显示哪个页面
经过尝试,我发现网站总共只有63页;这也说明我们可以写一个简单的for循环来快速访问每一页
知道如何翻页后,我们需要从当前页面找到各个养老院的链接
打开这个页面的html代码(每个预览器的打开方式不同)
我们看到一个类似的页面
/r/uXV0bFvEdQYKrR8P9yCr(自动识别二维码)
chrome 预览器在控制台的左上角有一个检查元素工具
我们可以用它在页面上找到我们感兴趣的部分
使用inspect工具,然后点击第一家养老院的信息,我们会发现html会显示相关的html信息
href表示这个网页点击链接后会跳转到的url,我们点击“上海上大天平疗养院”稍后发布
网址是/findhomes/tianping.htm
页面跳转到养老院信息页面
当前总结:目前我们知道如何使用程序在网站上翻页,以及如何找到各个疗养院的链接,我们来看看代码输入
代码第一步:导入相关的python库
我们需要的其实只是bs4的BeautifulSoup,和requests
第二部分代码:从每个页面链接中抓取相关页面上的养老院
正如我上面所说的,我们知道网站目前只有64页,所以我们可以写一个for循环,循环64次;
getLink的代码如下:
i 是一个整数,getLink 会返回给我们对应的页面 url,比如 i=1 时,getLink 会返回我们的第一页,当 i=2 时会返回给我们第二页
getFacilities的代码如下:
这个功能的主要作用是找出页面上所有养老院公寓的网址(我们刚刚看到的href)
getSoup是一个函数(BeautifulSoup库中的一个函数),我们给他一个url,他会返回一个处理后的网页html给我们搜索
<p>soup.find("ul"...) 的意思是在html中找到第一个符合"{...}"条件的"ul"标签,我们把这个信息存储在table_ul的变量中
网页数据抓取(没数据,数据不够不会Java不写爬虫工具怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-14 17:14
Web Scraper 爬虫工具是一个基于谷歌浏览器的插件。使用Web Scraper可以简单快速地抓取任何网站数据,不受网站反爬虫机制的影响。与Python等语言实现的爬虫工具相比,WebScraper具有先天优势。
Demo,简单吗?
做科学研究和实验最痛苦的事情是什么?
没有数据,没有足够的数据
如果我不会 Python、不会 Java 并且不会编写爬虫怎么办?
查找:网络爬虫!
互联网上有海量的数据,每天都有各种各样的数据展现在我们面前。同时,金融、医学、计算机科学等诸多研究课题需要获取大量数据作为样本进行科学分析。传统的手动采集操作从根本上很难处理数据采集,即使可以采集,也需要花费大量的时间和成本。本教程的目的是让拥有采集数据需求的人能够在一小时内熟练使用“神器”Web Scraper插件。
让我们先了解一下爬行的简单原理,所谓“磨刀不误砍柴”,了解原理可以帮助我们事半功倍!
「抓取对象」
作为展示数据的平台,可以通过浏览器窗口浏览网页。从服务器数据库到浏览器窗口的显示,中间有一个复杂的过程。服务器数据库中存储的数据一般以某种编码形式存储。如果我们看这个时候的数据,我们看到的是一个这样或那样的纯文本类型。数据传输到浏览器后,浏览器将“数据信息”加载到设计者准备好的“网页模板”中,最终得到我们通过浏览器看到的一切。
我们看到的金融网站
我们看到的新闻网站
我们看到的博客
“了解网页的“层次””
各种网页都收录各种数据。网页组织数据收录在不同的“层”中(详细信息可以从html标签中了解)。当然,我们无法直观地看到所有这些层。
经过长时间的网页设计发展,到现在我们都是通过标准的html标签语言来设计网页的。在这套国际通用规则下,设计的过程就是逐层设计页面元素,让不同的内容可以更和谐的结合。虽然不同的网站设计风格不同,但每个网页都类似于一个“金字塔”结构,比如下面这个网页:
第一级:类似于一张桌子
第二层:标题栏和内容栏(类似Excel)
第三层:每一行的数据
第四层:每个单元格
第五层:文字
「Web Scraper 分层抓取页面元素」
Web Scraper作为一种自动化爬虫工具,它的爬取目标是页面数据,但是在爬取数据之前,我们需要定义一个“流程”,这个流程包括“动作”(模拟鼠标点击操作)和“页面元素” "(定义要爬取的页面元素)。
感觉好傻
实践是检验真理的唯一标准。这是爬行过程的结束。基本原理储备足够学习Web Scraper!
从下一节开始,我们正式进入Web Scraper的学习。
下一节《【网络爬虫教程02】安装网络爬虫插件》预览 查看全部
网页数据抓取(没数据,数据不够不会Java不写爬虫工具怎么办?)
Web Scraper 爬虫工具是一个基于谷歌浏览器的插件。使用Web Scraper可以简单快速地抓取任何网站数据,不受网站反爬虫机制的影响。与Python等语言实现的爬虫工具相比,WebScraper具有先天优势。
Demo,简单吗?
做科学研究和实验最痛苦的事情是什么?
没有数据,没有足够的数据
如果我不会 Python、不会 Java 并且不会编写爬虫怎么办?
查找:网络爬虫!
互联网上有海量的数据,每天都有各种各样的数据展现在我们面前。同时,金融、医学、计算机科学等诸多研究课题需要获取大量数据作为样本进行科学分析。传统的手动采集操作从根本上很难处理数据采集,即使可以采集,也需要花费大量的时间和成本。本教程的目的是让拥有采集数据需求的人能够在一小时内熟练使用“神器”Web Scraper插件。
让我们先了解一下爬行的简单原理,所谓“磨刀不误砍柴”,了解原理可以帮助我们事半功倍!
「抓取对象」
作为展示数据的平台,可以通过浏览器窗口浏览网页。从服务器数据库到浏览器窗口的显示,中间有一个复杂的过程。服务器数据库中存储的数据一般以某种编码形式存储。如果我们看这个时候的数据,我们看到的是一个这样或那样的纯文本类型。数据传输到浏览器后,浏览器将“数据信息”加载到设计者准备好的“网页模板”中,最终得到我们通过浏览器看到的一切。
我们看到的金融网站
我们看到的新闻网站
我们看到的博客
“了解网页的“层次””
各种网页都收录各种数据。网页组织数据收录在不同的“层”中(详细信息可以从html标签中了解)。当然,我们无法直观地看到所有这些层。
经过长时间的网页设计发展,到现在我们都是通过标准的html标签语言来设计网页的。在这套国际通用规则下,设计的过程就是逐层设计页面元素,让不同的内容可以更和谐的结合。虽然不同的网站设计风格不同,但每个网页都类似于一个“金字塔”结构,比如下面这个网页:
第一级:类似于一张桌子
第二层:标题栏和内容栏(类似Excel)
第三层:每一行的数据
第四层:每个单元格
第五层:文字
「Web Scraper 分层抓取页面元素」
Web Scraper作为一种自动化爬虫工具,它的爬取目标是页面数据,但是在爬取数据之前,我们需要定义一个“流程”,这个流程包括“动作”(模拟鼠标点击操作)和“页面元素” "(定义要爬取的页面元素)。
感觉好傻
实践是检验真理的唯一标准。这是爬行过程的结束。基本原理储备足够学习Web Scraper!
从下一节开始,我们正式进入Web Scraper的学习。
下一节《【网络爬虫教程02】安装网络爬虫插件》预览
网页数据抓取(1.外链,留下链接引导蜘蛛进入你的网站外链也不是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2021-09-12 12:10
1.sitemap
定期将网站链接放入Sitemap,然后将Sitemap提交给百度。百度会定期抓取检查您提交的Sitemap,并处理其中的链接,但收录比主动推送慢。
2.友链
友情链接一定要做好。一个新站想要快速站稳脚跟,快速成为收录,很大一部分需要友情链接,而且是优质友情链接。寻找友情链接的标准一定要及时更新内容,百度收录数量正常,网站好友链不多,内容质量高,权重不低于自己的网站做友链。记得及时查看好友链。
3.外链
除了朋友链,就是外链。发外链的目的是为了吸引蜘蛛来抓我们网站。将自己的优质外链发布到各大外链平台,留下链接引导蜘蛛进入你的网站,外链不随机。找相关网站发布外链,威力高,收录要快,快照需要及时更新网站,外链不能光看数量,最重要的是质量。
4.Push
主动推送可以让百度更快找到你的网站和收录。这也是最快的提交方式。网站上产生的新链接会立即通过这种方式推送给百度,以确保新链接及时被百度收录使用。
5.content
网站没有内容,不管做多少外链都是徒劳的。 网站的一个内容是吸引搜索引擎蜘蛛的根源。搜索引擎蜘蛛来你网站的原因是为了爬取优质内容。如果你的网站不做任何推广,你的网站内容质量很高,每天都准时更新,那么百度蜘蛛每天都会来到你的网站。
6.内链
这是大多数网站 忽略的事情。内部链接和内部链接的作用其实很重要。蜘蛛的爬行轨迹是跟随一个链接到另一个链接。我想让搜索引擎蜘蛛更好。地面爬行一般需要外链引导,但内页爬行需要良好的内链。如果不注意死链和断链的形成,蜘蛛就爬不上去,也没有好的收录NS。
7.update
这里所说的更新是指网站内容更新的频率和数量。为了让蜘蛛每天某个时间从你的网站抓取内容,你首先要有一个更新内容的规则。比如每天早上更新几篇文章,每天下午更新几篇文章。久而久之,搜索引擎蜘蛛找出你的更新规则后,就会按照你的规则来找你。 网站抢内容,三五天不更新,突然有一天你更新了很多内容。这样只会让搜索引擎蜘蛛想你很久,才会来你的网站一次。
上一篇:网站。如何快速成为百度收录?   |   下一篇:如何在百度搜索中排名第一? 查看全部
网页数据抓取(1.外链,留下链接引导蜘蛛进入你的网站外链也不是)
1.sitemap
定期将网站链接放入Sitemap,然后将Sitemap提交给百度。百度会定期抓取检查您提交的Sitemap,并处理其中的链接,但收录比主动推送慢。
2.友链
友情链接一定要做好。一个新站想要快速站稳脚跟,快速成为收录,很大一部分需要友情链接,而且是优质友情链接。寻找友情链接的标准一定要及时更新内容,百度收录数量正常,网站好友链不多,内容质量高,权重不低于自己的网站做友链。记得及时查看好友链。
3.外链
除了朋友链,就是外链。发外链的目的是为了吸引蜘蛛来抓我们网站。将自己的优质外链发布到各大外链平台,留下链接引导蜘蛛进入你的网站,外链不随机。找相关网站发布外链,威力高,收录要快,快照需要及时更新网站,外链不能光看数量,最重要的是质量。
4.Push
主动推送可以让百度更快找到你的网站和收录。这也是最快的提交方式。网站上产生的新链接会立即通过这种方式推送给百度,以确保新链接及时被百度收录使用。
5.content
网站没有内容,不管做多少外链都是徒劳的。 网站的一个内容是吸引搜索引擎蜘蛛的根源。搜索引擎蜘蛛来你网站的原因是为了爬取优质内容。如果你的网站不做任何推广,你的网站内容质量很高,每天都准时更新,那么百度蜘蛛每天都会来到你的网站。
6.内链
这是大多数网站 忽略的事情。内部链接和内部链接的作用其实很重要。蜘蛛的爬行轨迹是跟随一个链接到另一个链接。我想让搜索引擎蜘蛛更好。地面爬行一般需要外链引导,但内页爬行需要良好的内链。如果不注意死链和断链的形成,蜘蛛就爬不上去,也没有好的收录NS。
7.update
这里所说的更新是指网站内容更新的频率和数量。为了让蜘蛛每天某个时间从你的网站抓取内容,你首先要有一个更新内容的规则。比如每天早上更新几篇文章,每天下午更新几篇文章。久而久之,搜索引擎蜘蛛找出你的更新规则后,就会按照你的规则来找你。 网站抢内容,三五天不更新,突然有一天你更新了很多内容。这样只会让搜索引擎蜘蛛想你很久,才会来你的网站一次。
上一篇:网站。如何快速成为百度收录?   |   下一篇:如何在百度搜索中排名第一?
网页数据抓取(用网页抓取工具,大多还是免费的哦比import.io)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-12 12:08
今天给大家推荐几款非常实用的网络爬虫工具,大部分都是免费的!喜欢记得点赞。
1、Import.ioimport.io
用法很简单。注册后,在可视化界面输入URL链接过滤数据。操作也超级简单,如下图,唯一的缺点就是全英文,不过我们自己有,我们来看看第二个。
2、parsehubparsehub
与上述两种网页抓取不同,parsehub需要用户下载客户端才能使用。它像浏览器一样打开,然后输入 URL 以提取网页上所需的信息。
/ZTg4et(自动识别二维码)
3、80legs80legs
80legs 每天在由 50,000 台计算机组成的 Plura 网格上抓取 200 万个网页。但是,它可能不像以前那样容易使用。
4、Web ScraperWeb Scraper
Web Scraper 是一个需要在 Google App Store 中安装的插件。基本步骤只是一点点。
详细教程可以看这里/article/241334
/ZTg4et(自动识别二维码)
5、FMinerFMiner
FMiner 也需要下载客户端才能使用,但它是付费产品,有 15 天的免费使用期。
总结
以上工具都是国外工具。如果您更喜欢中文界面,可以来试试我们的产品。-深受广大爬虫爱好者喜爱的云爬虫。
左书比import.io更适合中国人。直接在原网页的基础上操作,也可以使用分布式爬取、深度爬取等,有数据需求的可以试试。
其实,网络爬虫的工具有很多,不必全部掌握。本文的目标是将它们用作工具来促进您的工作。
那么,您最喜欢使用哪一个?
下次见!
Meeting 在不断完善,变得越来越强大。数据采集这里! ! ! ! 查看全部
网页数据抓取(用网页抓取工具,大多还是免费的哦比import.io)
今天给大家推荐几款非常实用的网络爬虫工具,大部分都是免费的!喜欢记得点赞。
1、Import.ioimport.io
用法很简单。注册后,在可视化界面输入URL链接过滤数据。操作也超级简单,如下图,唯一的缺点就是全英文,不过我们自己有,我们来看看第二个。
2、parsehubparsehub
与上述两种网页抓取不同,parsehub需要用户下载客户端才能使用。它像浏览器一样打开,然后输入 URL 以提取网页上所需的信息。
/ZTg4et(自动识别二维码)
3、80legs80legs
80legs 每天在由 50,000 台计算机组成的 Plura 网格上抓取 200 万个网页。但是,它可能不像以前那样容易使用。
4、Web ScraperWeb Scraper
Web Scraper 是一个需要在 Google App Store 中安装的插件。基本步骤只是一点点。
详细教程可以看这里/article/241334
/ZTg4et(自动识别二维码)
5、FMinerFMiner
FMiner 也需要下载客户端才能使用,但它是付费产品,有 15 天的免费使用期。
总结
以上工具都是国外工具。如果您更喜欢中文界面,可以来试试我们的产品。-深受广大爬虫爱好者喜爱的云爬虫。
左书比import.io更适合中国人。直接在原网页的基础上操作,也可以使用分布式爬取、深度爬取等,有数据需求的可以试试。
其实,网络爬虫的工具有很多,不必全部掌握。本文的目标是将它们用作工具来促进您的工作。
那么,您最喜欢使用哪一个?
下次见!
Meeting 在不断完善,变得越来越强大。数据采集这里! ! ! !
网页数据抓取(智能识别模式WebHarvy(网页数据抓取软件)功能介绍(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-11 15:13
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。易于使用。
WebHarvy(网页数据采集软件)
功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。软件功能
WebHarvy 是一个可视化的网络抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。更新日志
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
网页数据抓取(智能识别模式WebHarvy(网页数据抓取软件)功能介绍(组图))
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。易于使用。
WebHarvy(网页数据采集软件)
功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。软件功能
WebHarvy 是一个可视化的网络抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。更新日志
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
网页数据抓取(SysNucleusWebHarvy破解版自动提取文字、图片、网址和破解教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-09-10 04:01
SysNucleus WebHarvy 破解版是一款专业的网络数据采集工具。它可以自动从多个页面中抓取和提取数据。可以直接在网页上选择要选择的资源,也可以直接将整个网页保存为HTML格式,可以帮助用户快速从网页中提取数据并保存为不同的格式,让您可以导出将捕获的数据转换为 Excel、XML、CSV、JSON 或 TSV 文件。智能识别网页上出现的数据模式。 SysNucleus WebHarvy 破解版自动提取网站中的文字、图片、网址和邮件,并以多种格式保存内容。从网页上的采集 数据,导航到收录数据的网页就像单击捕获的数据一样简单。可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。使用该软件,您可以从各种网站中提取数据,例如产品目录或搜索结果,这些网站可能涉及房地产、电子商务、学术研究、娱乐、科技等不同类别。
破解教程1、下载并解压安装包,双击运行软件“Setup.exe”进行安装,进入安装向导,点击next进入下一步
2、同意用户协议,选择顶一个
3、设置安装目录,如果要更改,点击更改
4、确认软件安装无误后点击安装
5、安装成功,取消勾选立即运行软件,点击完成启动安装界面
6、将破解补丁“WebHarvy.exe”替换到原安装目录,点击复制替换
ps:如果找不到位置,可以返回桌面右击图标,选择位置打开文件。
7、破解成功,打开软件即可免费使用
功能1、webharvy 自动从网站 中提取文本、图片、URL 和电子邮件,并以各种格式保存内容。
2、非常好用,几分钟就能自动提取出来
3、 支持从多个页面/类别/关键字中提取数据
4、将提取的数据保存到文件或数据库中
5、内置调度器和代理支持
6、 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
7、自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
8、您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
9、通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
更新日志修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
网页数据抓取(SysNucleusWebHarvy破解版自动提取文字、图片、网址和破解教程)
SysNucleus WebHarvy 破解版是一款专业的网络数据采集工具。它可以自动从多个页面中抓取和提取数据。可以直接在网页上选择要选择的资源,也可以直接将整个网页保存为HTML格式,可以帮助用户快速从网页中提取数据并保存为不同的格式,让您可以导出将捕获的数据转换为 Excel、XML、CSV、JSON 或 TSV 文件。智能识别网页上出现的数据模式。 SysNucleus WebHarvy 破解版自动提取网站中的文字、图片、网址和邮件,并以多种格式保存内容。从网页上的采集 数据,导航到收录数据的网页就像单击捕获的数据一样简单。可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。使用该软件,您可以从各种网站中提取数据,例如产品目录或搜索结果,这些网站可能涉及房地产、电子商务、学术研究、娱乐、科技等不同类别。
破解教程1、下载并解压安装包,双击运行软件“Setup.exe”进行安装,进入安装向导,点击next进入下一步
2、同意用户协议,选择顶一个
3、设置安装目录,如果要更改,点击更改
4、确认软件安装无误后点击安装
5、安装成功,取消勾选立即运行软件,点击完成启动安装界面
6、将破解补丁“WebHarvy.exe”替换到原安装目录,点击复制替换
ps:如果找不到位置,可以返回桌面右击图标,选择位置打开文件。
7、破解成功,打开软件即可免费使用
功能1、webharvy 自动从网站 中提取文本、图片、URL 和电子邮件,并以各种格式保存内容。
2、非常好用,几分钟就能自动提取出来
3、 支持从多个页面/类别/关键字中提取数据
4、将提取的数据保存到文件或数据库中
5、内置调度器和代理支持
6、 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
7、自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
8、您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
9、通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
更新日志修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源

