
网页数据抓取
网页数据抓取(四川网络推广优化人员需要注意其中更多的细节来帮助)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-01 06:21
众所周知,四川互联网推广网站结构搭建的越好,越能吸引蜘蛛爬行爬行,也能吸引用户浏览。四川网络推广优化人员也需要关注更多细节,帮助网站架构设计越来越好,从而帮助网站改进收录,增加排名,那么下面就带大家一探究竟。
1、页面设计
一个好的网站页面设计会给蜘蛛留下更好的印象,也会给用户留下更好的印象和体验,网站的点击率和跳出率数据也会是它会更好,所以蜘蛛的爬行频率会更高。一般情况下,蜘蛛爬取和用户反馈数据是相辅相成的。总之,页面设计越好,蜘蛛爬行就越有吸引力。
2、导航设计
导航设计是一个关键因素,可以很好的体现网站的核心。由于网站行业的类型不同,优化者也可以从用户的角度设计更加人性化的导航功能。 , 满足用户搜索、查找、浏览等需求,使导航更加结构化、层次化,为蜘蛛创造更便捷的爬行环境。另外,四川互联网推广提醒大家要注意导航设计要简洁明了,越简单越好。
3、展示优质内容
四川网推广表示,网站首页是SEO优化的重点,首页也是整个网站评分的重要组成部分,所以做好很重要在网站的内容展示中。因此,优化者必须以合理的方式在首页展示重要且优质的内容,这样既方便用户查看,也有助于蜘蛛更快地捕捉有价值的信息,自然会吸引蜘蛛爬行。
综上所述,以上就是四川网促为大家总结的几个优质的网站架构来吸引蜘蛛。相信你也会对此有更多的了解,做好相关的细节。吸引更多蜘蛛爬行爬行,帮助网站获得更高的排名。 查看全部
网页数据抓取(四川网络推广优化人员需要注意其中更多的细节来帮助)
众所周知,四川互联网推广网站结构搭建的越好,越能吸引蜘蛛爬行爬行,也能吸引用户浏览。四川网络推广优化人员也需要关注更多细节,帮助网站架构设计越来越好,从而帮助网站改进收录,增加排名,那么下面就带大家一探究竟。
1、页面设计
一个好的网站页面设计会给蜘蛛留下更好的印象,也会给用户留下更好的印象和体验,网站的点击率和跳出率数据也会是它会更好,所以蜘蛛的爬行频率会更高。一般情况下,蜘蛛爬取和用户反馈数据是相辅相成的。总之,页面设计越好,蜘蛛爬行就越有吸引力。
2、导航设计
导航设计是一个关键因素,可以很好的体现网站的核心。由于网站行业的类型不同,优化者也可以从用户的角度设计更加人性化的导航功能。 , 满足用户搜索、查找、浏览等需求,使导航更加结构化、层次化,为蜘蛛创造更便捷的爬行环境。另外,四川互联网推广提醒大家要注意导航设计要简洁明了,越简单越好。
3、展示优质内容
四川网推广表示,网站首页是SEO优化的重点,首页也是整个网站评分的重要组成部分,所以做好很重要在网站的内容展示中。因此,优化者必须以合理的方式在首页展示重要且优质的内容,这样既方便用户查看,也有助于蜘蛛更快地捕捉有价值的信息,自然会吸引蜘蛛爬行。
综上所述,以上就是四川网促为大家总结的几个优质的网站架构来吸引蜘蛛。相信你也会对此有更多的了解,做好相关的细节。吸引更多蜘蛛爬行爬行,帮助网站获得更高的排名。
网页数据抓取(直观强大的可视化网页抓取工具可以轻松地从网站上抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-28 02:15
)
直观而强大的可视化网络爬虫工具
您可以轻松地从网站抓取文本、HTML、图像、URL 和电子邮件,并将抓取的数据保存为各种格式。
非常好用,分分钟开始爬取数据
支持所有类型的网站。处理登录、表单提交等。
从多个页面、类别和关键字中获取数据
内置调度器、代理支持、智能帮助等...
轻松抓取网页
使用该软件的点击式界面可以轻松抓取网页。绝对不需要编写任何代码或脚本来抓取数据。您将使用该软件的内置浏览器来加载网站,您可以通过单击鼠标选择您要抓取的数据。就是这么简单!(视频)
智能模式检测
该软件会自动识别出现在网页中的数据模式。因此,如果您需要从网页中获取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,软件会自动抓取。
保存到文件或数据库
您可以以各种格式保存从网站上抓取的数据。当前版本允许您将捕获的数据保存为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
抓取多个页面
网站通常在多个页面上显示产品列表或搜索结果等数据。该软件可以从多个页面自动抓取和抓取数据。只需指出“加载下一页的链接”,软件就会自动从所有页面抓取数据。
提交关键词
通过自动向搜索表单提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以抓取所有输入关键字组合的搜索结果数据。
隐私保护
为了匿名抓取,防止网络爬虫软件被网络服务器拦截,您可以选择通过代理服务器或科学上网工具访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
分类爬取
该软件允许您从指向网站中类似页面/列表的链接列表中获取数据。这允许您使用单个配置来抓取站点内的类别和子类别。
常用表达
该软件允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并抓取匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
JavaScript 支持
在获取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互、修改 DOM 或调用已在目标页面中实现的 JavaScript 函数。
图像捕捉
您可以下载图像或获取图像 URL。该软件可以自动抓取显示在电子商务网站产品详情页面上的多张图片。
自动化浏览器任务
该软件可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面和打开弹出窗口。
原价:883
当前折扣价:88
如何下载
会员免费下载
普通用户请先付款后下载,付款后可见下载链接
查看全部
网页数据抓取(直观强大的可视化网页抓取工具可以轻松地从网站上抓取
)
直观而强大的可视化网络爬虫工具
您可以轻松地从网站抓取文本、HTML、图像、URL 和电子邮件,并将抓取的数据保存为各种格式。
非常好用,分分钟开始爬取数据
支持所有类型的网站。处理登录、表单提交等。
从多个页面、类别和关键字中获取数据
内置调度器、代理支持、智能帮助等...
轻松抓取网页
使用该软件的点击式界面可以轻松抓取网页。绝对不需要编写任何代码或脚本来抓取数据。您将使用该软件的内置浏览器来加载网站,您可以通过单击鼠标选择您要抓取的数据。就是这么简单!(视频)
智能模式检测
该软件会自动识别出现在网页中的数据模式。因此,如果您需要从网页中获取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,软件会自动抓取。
保存到文件或数据库
您可以以各种格式保存从网站上抓取的数据。当前版本允许您将捕获的数据保存为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
抓取多个页面
网站通常在多个页面上显示产品列表或搜索结果等数据。该软件可以从多个页面自动抓取和抓取数据。只需指出“加载下一页的链接”,软件就会自动从所有页面抓取数据。
提交关键词
通过自动向搜索表单提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以抓取所有输入关键字组合的搜索结果数据。
隐私保护
为了匿名抓取,防止网络爬虫软件被网络服务器拦截,您可以选择通过代理服务器或科学上网工具访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
分类爬取
该软件允许您从指向网站中类似页面/列表的链接列表中获取数据。这允许您使用单个配置来抓取站点内的类别和子类别。
常用表达
该软件允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并抓取匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
JavaScript 支持
在获取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互、修改 DOM 或调用已在目标页面中实现的 JavaScript 函数。
图像捕捉
您可以下载图像或获取图像 URL。该软件可以自动抓取显示在电子商务网站产品详情页面上的多张图片。
自动化浏览器任务
该软件可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面和打开弹出窗口。
原价:883
当前折扣价:88
如何下载
会员免费下载
普通用户请先付款后下载,付款后可见下载链接
 https://www.huahaikuajing.com/ ... 0.jpg 300w" />
https://www.huahaikuajing.com/ ... 0.jpg 300w" /> https://www.huahaikuajing.com/ ... 0.jpg 300w" />
https://www.huahaikuajing.com/ ... 0.jpg 300w" /> https://www.huahaikuajing.com/ ... 0.jpg 300w" />
https://www.huahaikuajing.com/ ... 0.jpg 300w" /> 网页数据抓取(如何吸引蜘蛛来抓取文章的内容,提高我们网站的收录量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-27 07:15
很多站长在分析网站数据时,都会关注自己网站的收录量。这个收录是网站优化排名中比较重要的一个因素,也比较直观。虽然并不是说你的网站收录越多,排名就越高,但收录和排名还是有关系的。收录
的内容越多,获得良好排名的机会就越大。怎样才能吸引蜘蛛抓取文章内容,增加我们网站的收录量?SEO会为你慢慢做!!!
第一:提交站点地图
我们每天更新网站文章后,需要更新网站地图,然后将地图提交给百度,以便百度可以通过地图访问您的网站。
二、 按照百度官方声明执行
1. 百度原创火星项目提到,只要你的文章是原创的,当用户搜索同一篇文章时,原创内容会优先显示。当然,最好是原创,但往往我们维护的客户网站都非常专业,水平有限,只能做伪原创。
2. 对于一些权重比较高的网站,如果采集
了一些小站的文章,那么百度可能不确定小站的情况,所以小站可以通过ping机制ping百度,这会帮助百度知道哪个是原创。
3. 作者一般是按照百度官网的说明,然后对外发布一些采集
速度更快、权重更高的网站,比如:a5,站长之家,还有新浪博客,天涯大博客、搜狐、中金博客等大型博客,利用外链吸引蜘蛛到我的网站抓取原创文章。
三、 发链接吸引蜘蛛
1. 就算很多站长用一个网站的首页网址发布外链,我觉得这个优化方法还是比较简单的。如果您的网站权重较低,更新不频繁,蜘蛛可能会链接到您的网站,不再深入抓取。
2. 一般文章更新后,可以去各大论坛和博客发表文章,然后带上刚刚发表的文章地址。这个效果相当不错,朋友可以试试。
四、 与一些经常更新的网站交换链接
每个人都知道友好链接的作用。友情链接对网站排名有一定的作用。同时,友情链接引导蜘蛛在网站之间来回爬行,对网站排名和收录非常有帮助。是的,所以我们必须与一些经常更新的网站交换链接。
五、 网站上文章之间的链接
无论是文章之间,还是栏目与网站首页之间,都必须有一个或多个链接路径。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,它也是一个允许用户点击的链接。其中,排名和权重提升都比较好。 查看全部
网页数据抓取(如何吸引蜘蛛来抓取文章的内容,提高我们网站的收录量)
很多站长在分析网站数据时,都会关注自己网站的收录量。这个收录是网站优化排名中比较重要的一个因素,也比较直观。虽然并不是说你的网站收录越多,排名就越高,但收录和排名还是有关系的。收录
的内容越多,获得良好排名的机会就越大。怎样才能吸引蜘蛛抓取文章内容,增加我们网站的收录量?SEO会为你慢慢做!!!

第一:提交站点地图
我们每天更新网站文章后,需要更新网站地图,然后将地图提交给百度,以便百度可以通过地图访问您的网站。
二、 按照百度官方声明执行
1. 百度原创火星项目提到,只要你的文章是原创的,当用户搜索同一篇文章时,原创内容会优先显示。当然,最好是原创,但往往我们维护的客户网站都非常专业,水平有限,只能做伪原创。
2. 对于一些权重比较高的网站,如果采集
了一些小站的文章,那么百度可能不确定小站的情况,所以小站可以通过ping机制ping百度,这会帮助百度知道哪个是原创。
3. 作者一般是按照百度官网的说明,然后对外发布一些采集
速度更快、权重更高的网站,比如:a5,站长之家,还有新浪博客,天涯大博客、搜狐、中金博客等大型博客,利用外链吸引蜘蛛到我的网站抓取原创文章。
三、 发链接吸引蜘蛛
1. 就算很多站长用一个网站的首页网址发布外链,我觉得这个优化方法还是比较简单的。如果您的网站权重较低,更新不频繁,蜘蛛可能会链接到您的网站,不再深入抓取。
2. 一般文章更新后,可以去各大论坛和博客发表文章,然后带上刚刚发表的文章地址。这个效果相当不错,朋友可以试试。
四、 与一些经常更新的网站交换链接
每个人都知道友好链接的作用。友情链接对网站排名有一定的作用。同时,友情链接引导蜘蛛在网站之间来回爬行,对网站排名和收录非常有帮助。是的,所以我们必须与一些经常更新的网站交换链接。
五、 网站上文章之间的链接
无论是文章之间,还是栏目与网站首页之间,都必须有一个或多个链接路径。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,它也是一个允许用户点击的链接。其中,排名和权重提升都比较好。
网页数据抓取( 网络爬虫就是获取网页信息的简单爬虫方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-26 14:15
网络爬虫就是获取网页信息的简单爬虫方法)
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数),一般网站默认端口号为80,例如百度的主机名是,这是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录
一些处理 URL 的模块,如下:
进群:960410445获取源码!
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录
了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录
一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们使用 urllib.request.urlopen() 接口函数来方便地打开一个网站,阅读和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这些,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后使用print()将读取的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。
当然,我们也可以从浏览器中查看这些代码。
比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,
比如中文网站起点付费章节就不行),以百度界面为例,截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(再次以百度翻译网站为例):
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,这个前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?
需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
这样,我们就知道了这个网站的编码方式,但这需要我们每次打开浏览器,查找编码方式。显然是有点麻烦。用几行代码来解决,更省事,更爽。
一种自动获取网页编码方式的方法
获取网页代码的方式有很多种,我个人更喜欢使用第三方库。
首先,我们需要安装第三方库chardet,这是一个用于确定编码的模块。安装方法如下图所示。只需输入命令:
安装后,我们可以使用chardet.detect()方法来判断网页的编码方式。
此时,我们可以编写一个小程序来判断网页的编码方式,新建文件名为chardet_test01.py:
运行程序,查看输出结果如下:
返回的是一个字典,让我们知道网页的编码方式,可以根据得到的信息使用不同的解码方式。 查看全部
网页数据抓取(
网络爬虫就是获取网页信息的简单爬虫方法)
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数),一般网站默认端口号为80,例如百度的主机名是,这是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录
一些处理 URL 的模块,如下:
进群:960410445获取源码!
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录
了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录
一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们使用 urllib.request.urlopen() 接口函数来方便地打开一个网站,阅读和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这些,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后使用print()将读取的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。
当然,我们也可以从浏览器中查看这些代码。
比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,
比如中文网站起点付费章节就不行),以百度界面为例,截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(再次以百度翻译网站为例):
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,这个前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?
需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
这样,我们就知道了这个网站的编码方式,但这需要我们每次打开浏览器,查找编码方式。显然是有点麻烦。用几行代码来解决,更省事,更爽。
一种自动获取网页编码方式的方法
获取网页代码的方式有很多种,我个人更喜欢使用第三方库。
首先,我们需要安装第三方库chardet,这是一个用于确定编码的模块。安装方法如下图所示。只需输入命令:
安装后,我们可以使用chardet.detect()方法来判断网页的编码方式。
此时,我们可以编写一个小程序来判断网页的编码方式,新建文件名为chardet_test01.py:
运行程序,查看输出结果如下:
返回的是一个字典,让我们知道网页的编码方式,可以根据得到的信息使用不同的解码方式。
网页数据抓取(我有一个excel文件,其中包含以下变量的数据框)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-25 10:16
我有一个 excel 文件,其中收录
需要通过 R 在 google 中搜索的某些关键字。要创建的输出是一个数据框,其中收录
以下变量: 搜索到的一些关键字。要创建的输出是数据收录
以下变量的框架:
Keyword;Position(url 在搜索结果中的位置);Title(第 i 个搜索结果的标题);Text(该搜索结果中的文本);URL;Domain 关键字和一些输出示例在以下链接:关键字;位置(网址在搜索结果中的位置); Title(第i个搜索结果的标题);文本(搜索结果中的文本);网址; Domain 下面的链接中给出了关键字和一些输出示例:
(工作表 1 有关键字,工作表 2 有示例输出)(工作表 1 有关键字,工作表 2 有示例输出)
我尝试创建类似的输出,但似乎有错误。我试图创建一个类似的输出,但似乎有一个错误。代码: 代码:
显示的错误是: 显示的错误是:
Error in match.names(clabs, nmi) : names do not match previous names
请帮助,我是 R 的新手。请帮助,我是 R 的新手。 查看全部
网页数据抓取(我有一个excel文件,其中包含以下变量的数据框)
我有一个 excel 文件,其中收录
需要通过 R 在 google 中搜索的某些关键字。要创建的输出是一个数据框,其中收录
以下变量: 搜索到的一些关键字。要创建的输出是数据收录
以下变量的框架:
Keyword;Position(url 在搜索结果中的位置);Title(第 i 个搜索结果的标题);Text(该搜索结果中的文本);URL;Domain 关键字和一些输出示例在以下链接:关键字;位置(网址在搜索结果中的位置); Title(第i个搜索结果的标题);文本(搜索结果中的文本);网址; Domain 下面的链接中给出了关键字和一些输出示例:
(工作表 1 有关键字,工作表 2 有示例输出)(工作表 1 有关键字,工作表 2 有示例输出)
我尝试创建类似的输出,但似乎有错误。我试图创建一个类似的输出,但似乎有一个错误。代码: 代码:
显示的错误是: 显示的错误是:
Error in match.names(clabs, nmi) : names do not match previous names
请帮助,我是 R 的新手。请帮助,我是 R 的新手。
网页数据抓取(拎起Python,说干就干程序想必如何解决?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-13 04:01
每个人都必须熟悉爬虫程序。随便写一个获取网页信息,甚至通过请求自动生成Python脚本[1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但是问题是没有抓取范围的限制,也就是说没有清晰的页面结构。
对于一个页面来说,除了核心的文章内容,还有headers、tails、左右列表列等等。有的页框使用div布局,有的使用table。即使两者都使用div,less网站的样式和布局是不同的。
但问题必须解决。我想,既然搜索引擎已经抓取了各种网页的核心内容,我们应该也能应付。拿起 Python 去做吧!
各种尝试
如何解决?
生成PDF
开始想到一个比较棘手的方法,就是用一个工具(wkhtmltopdf[2])生成目标网页的PDF文件。
好处是不需要关心页面的具体形式,就像给页面拍照一样,文章结构就完整了。
虽然可以在源码级别检索PDF,但是生成PDF有很多缺点:
计算资源消耗大,效率低,错误率高,体积过大。
几万条数据已经两百多G了,如果数据量上来存储,那就是大问题了。
提取 文章 内容
在不生成PDF的情况下,有一种简单的方法可以通过xpath[3]提取页面上的所有文本。
但是内容会失去结构,可读性会很差。更可怕的是,网页上有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。像搜索引擎一样学习,就是想办法识别页面的核心内容。
我们知道,一般情况下,页面的核心内容(比如文章部分)文字比较集中,可以从这个地方开始分析。
所以我写了一段代码。我使用 Scrapy[4] 作为爬虫框架。这里只截取了提取文章部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试几页真的很好。
但是,在提取大量页面时,发现很多页面无法提取数据。仔细一看,发现有两种情况。
一些文章的内容是放在标签里的,所以我没有拿到每个文章
外面裹了一个
, 所以 p 的个数和 div 的偏移量
再次调整策略,不再区分div,查看所有元素。
另外,先选择更多的p,然后在此基础上看更少的div。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
发现的文章主体不稳定,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,需要重新设计算法。
发现文字集中的地方往往是文章的主体。前面的方法没有考虑这个,而是机械地找到最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离p标签越近,越有可能成为文章的主题,也就是说离p越近的节点权重应该越大,离p越远的节点权重就越大p 时间,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度原理,就是离中心越近的地方,密度就越大,而远离中心的地方,密度会呈指数下降,这样密度中心就可以被过滤掉了。
50%的斜率是怎么得到的?
其实是通过实验确定的。一开始,我把它设置为90%,但结果是body节点总是最好的,因为body收录了所有的文本内容。
经过反复实验,确定 50% 是一个更好的值。如果它不适合您的应用程序,您可以进行调整。
总结
在描述了我如何选择文章的方法后,我没有意识到它实际上是一个非常简单的方法。而这次解题的经历,让我感受到了数学的魅力。
我一直认为,只要理解了常规的处理问题的方式,应付日常的编程就足够了。当遇到不确定的问题,又没有办法提取出简单的问题模型时,常规思维显然是不行的。
因此,我们通常应该看看一些数学上很强的方法来解决不确定的问题,以提高我们的编程适应性,扩大我们的技能范围。 查看全部
网页数据抓取(拎起Python,说干就干程序想必如何解决?(图))
每个人都必须熟悉爬虫程序。随便写一个获取网页信息,甚至通过请求自动生成Python脚本[1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但是问题是没有抓取范围的限制,也就是说没有清晰的页面结构。
对于一个页面来说,除了核心的文章内容,还有headers、tails、左右列表列等等。有的页框使用div布局,有的使用table。即使两者都使用div,less网站的样式和布局是不同的。
但问题必须解决。我想,既然搜索引擎已经抓取了各种网页的核心内容,我们应该也能应付。拿起 Python 去做吧!
各种尝试
如何解决?
生成PDF
开始想到一个比较棘手的方法,就是用一个工具(wkhtmltopdf[2])生成目标网页的PDF文件。
好处是不需要关心页面的具体形式,就像给页面拍照一样,文章结构就完整了。
虽然可以在源码级别检索PDF,但是生成PDF有很多缺点:
计算资源消耗大,效率低,错误率高,体积过大。
几万条数据已经两百多G了,如果数据量上来存储,那就是大问题了。
提取 文章 内容
在不生成PDF的情况下,有一种简单的方法可以通过xpath[3]提取页面上的所有文本。
但是内容会失去结构,可读性会很差。更可怕的是,网页上有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。像搜索引擎一样学习,就是想办法识别页面的核心内容。
我们知道,一般情况下,页面的核心内容(比如文章部分)文字比较集中,可以从这个地方开始分析。
所以我写了一段代码。我使用 Scrapy[4] 作为爬虫框架。这里只截取了提取文章部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试几页真的很好。
但是,在提取大量页面时,发现很多页面无法提取数据。仔细一看,发现有两种情况。
一些文章的内容是放在标签里的,所以我没有拿到每个文章
外面裹了一个
, 所以 p 的个数和 div 的偏移量
再次调整策略,不再区分div,查看所有元素。
另外,先选择更多的p,然后在此基础上看更少的div。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
发现的文章主体不稳定,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,需要重新设计算法。
发现文字集中的地方往往是文章的主体。前面的方法没有考虑这个,而是机械地找到最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离p标签越近,越有可能成为文章的主题,也就是说离p越近的节点权重应该越大,离p越远的节点权重就越大p 时间,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度原理,就是离中心越近的地方,密度就越大,而远离中心的地方,密度会呈指数下降,这样密度中心就可以被过滤掉了。
50%的斜率是怎么得到的?
其实是通过实验确定的。一开始,我把它设置为90%,但结果是body节点总是最好的,因为body收录了所有的文本内容。
经过反复实验,确定 50% 是一个更好的值。如果它不适合您的应用程序,您可以进行调整。
总结
在描述了我如何选择文章的方法后,我没有意识到它实际上是一个非常简单的方法。而这次解题的经历,让我感受到了数学的魅力。
我一直认为,只要理解了常规的处理问题的方式,应付日常的编程就足够了。当遇到不确定的问题,又没有办法提取出简单的问题模型时,常规思维显然是不行的。
因此,我们通常应该看看一些数学上很强的方法来解决不确定的问题,以提高我们的编程适应性,扩大我们的技能范围。
网页数据抓取(大数据时代,如何有效获取数据已成为驱动业务决策的关键技能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-12 21:37
站长之家注:大数据时代,如何有效获取数据成为驱动商业决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网络爬取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络抓取赚钱的方法。整个过程只需几个小时就可以学会,使用的代码不到50行。
通过自动化程序在 Airbnb 上最好的酒店花最少的钱
自动化程序可用于执行特定操作,您可以将它们出售给没有技术技能的人来赚钱。
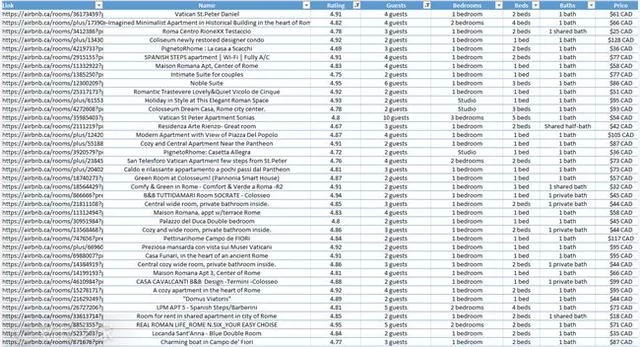
为了展示如何创建和销售自动化程序,Christopher Zita 创建了一个 Airbnb 自动爬虫。该程序允许用户输入位置,它将获取Airbnb在该位置提供的所有房屋数据,包括价格、评级和允许进入的客人数量。所有这一切都是通过在 Airbnb 上抓取数据来完成的。
为了演示程序的实际操作,Christopher Zita 在程序中进入罗马,然后在几秒钟内获得了 272 条 Airbnb 相关数据:
广告网站数据采集首选优采云采集器,支持一键批量网站数据采集,功能强大,免费下载^^-- - ---输入网站了解更多详情!
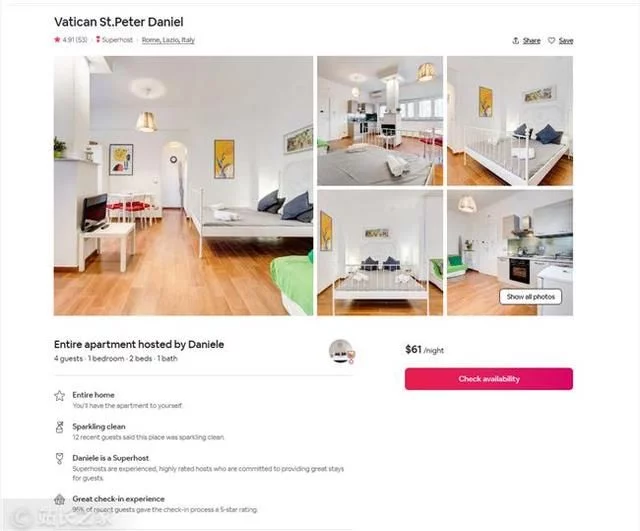
现在,查看所有房屋数据非常简单,过滤也容易得多。以克里斯托弗·齐塔 (Christopher Zita) 的家人为例。他们家有四口人。如果他们想去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床的酒店。得到这个表中的数据后,excel就可以很方便的进行过滤了。在这 272 条结果中,有 7 家酒店符合要求。
在这7家酒店中,Christopher Zita选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚只需61美元。选择所需链接后,只需将链接复制到浏览器中即可预订。
广告策略数据,深入洞察用户数据,帮助企业用数据驱动产品改进和运营监控,实现多维度、^^精细化统计分析。二级处理,实时更新,...
在度假旅行时,寻找酒店是一项艰巨的任务。出于这个原因,有人愿意花钱来简化这个过程。使用这个自动程序,您可以在短短 5 分钟内以低廉的价格预订一个令您满意的房间。
抓取特定产品的价格数据,以最低价格购买
网页抓取最常见的用途之一是从 网站 获取价格。通过创建一个程序来抓取特定产品的价格数据,当价格下降到一定水平时,它会在产品售罄之前自动购买该产品。
广告python爬虫入门教程,python_basic+爬虫+数据分析+人工智能,免费学习!^^科大讯飞高级技术讲师指导,14天轻...
接下来,Christopher Zita 将向您展示一种可以在赚钱的同时为您节省大量资金的方法:
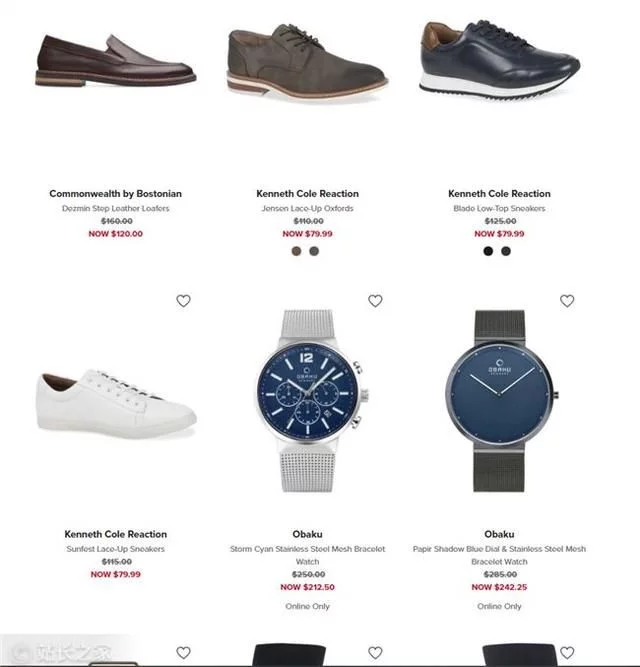
每个电商网站都会有限量的特价商品,他们会显示商品的原价和折扣价,但一般不会显示在原价的基础上打了多少折扣。举个例子,如果一只手表的初始价格是350美元,促销价是300美元,你会认为50美元的折扣不是小数目,但实际上只有14.@ > 2% 的折扣。而如果一件T恤的初始价是50美元,销售价是40美元,你会觉得它并没有便宜多少,但实际上它的折扣率比手表高出20%。因此,您可以通过购买折扣率最高的产品来省钱/赚钱。
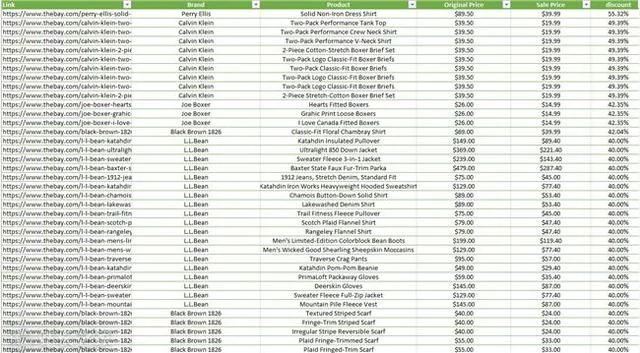
我们以百货公司Hudson's'Bay为例进行数据抓取实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
广告抓数据软件——大数据精准采集端口,全网采集行业精准人力资源,2021营销必备神器!^^ 掌握全国95%以上的大数据库,你要...
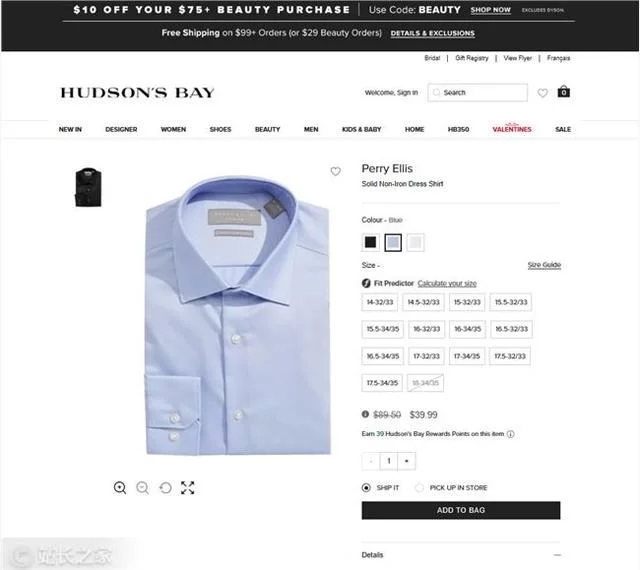
抓取网站的数据后,我们得到了900多种产品的数据,其中只有一种产品Perry Ellis纯色衬衫的折扣率超过50%。
广告GooSeeker免费提供采集电子商务、社交平台、房地产网站、科研网站等各种网站网络数据采集^^输出各种包括EXCEL数字...
由于限时优惠,这件衬衫的价格将很快回升至 90 美元左右。因此,如果您现在以 40 美元的价格购买并在限时优惠结束后以 60 美元的价格出售,您仍然可以赚取 20 美元。
这是一种方式,如果你找到合适的利基市场,你可能会赚很多钱。
抓取宣传数据并可视化
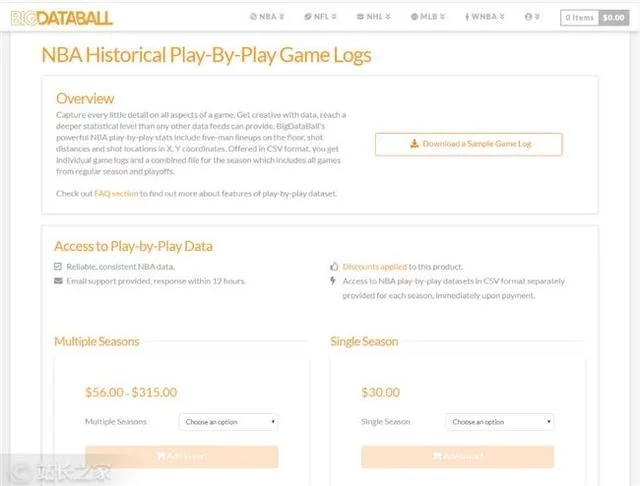
网络上有数百万个数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有一些数据不容易获取,可视化需要花费大量时间。这就是销售数据的演变方式。天眼查、七查查等公司专注于获取和可视化公司工商界的业务变化,然后以“买会员查”的形式销售给用户。
一个类似的模型是体育数据网站BigDataBall。网站通过出售玩家的各种游戏数据等统计信息,向用户收取每季30美元的费用。他们设定这个价格不是因为他们网站有数据,而是他们抓取数据后,对数据进行排序,然后以易于阅读和清晰的结构显示数据。
如何写爬虫python免费教程下载+0元直播课,进群交流学习,快速上手掌握,^^推荐就业,轻松进名企,选...
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,然后将其放入结构化数据集。BigDataBall 不是唯一拥有这些数据的 网站。它有相同的数据。但是,网站 并没有对数据进行结构化,用户很难过滤和下载所需的数据集。Christopher Zita 使用网络爬虫来捕获网络上的所有玩家数据。
30秒注册广告,一键发布“慧聪网”^^慧聪网中国商机信息网,2021年各行业商机+2000万产品信息+2700万注册用户=...
所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过16,000份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了这些数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络爬虫工具来寻找人工难以获取的数据,让计算机来完成工作,然后将数据可视化并出售给对数据感兴趣的人。
总结
如今,网络抓取已成为一种非常独特且新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
每天一个超级实用的创业案例,扫码关注【站长视野】↓↓↓ 查看全部
网页数据抓取(大数据时代,如何有效获取数据已成为驱动业务决策的关键技能)
站长之家注:大数据时代,如何有效获取数据成为驱动商业决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网络爬取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络抓取赚钱的方法。整个过程只需几个小时就可以学会,使用的代码不到50行。
通过自动化程序在 Airbnb 上最好的酒店花最少的钱
自动化程序可用于执行特定操作,您可以将它们出售给没有技术技能的人来赚钱。
为了展示如何创建和销售自动化程序,Christopher Zita 创建了一个 Airbnb 自动爬虫。该程序允许用户输入位置,它将获取Airbnb在该位置提供的所有房屋数据,包括价格、评级和允许进入的客人数量。所有这一切都是通过在 Airbnb 上抓取数据来完成的。
为了演示程序的实际操作,Christopher Zita 在程序中进入罗马,然后在几秒钟内获得了 272 条 Airbnb 相关数据:
广告网站数据采集首选优采云采集器,支持一键批量网站数据采集,功能强大,免费下载^^-- - ---输入网站了解更多详情!
现在,查看所有房屋数据非常简单,过滤也容易得多。以克里斯托弗·齐塔 (Christopher Zita) 的家人为例。他们家有四口人。如果他们想去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床的酒店。得到这个表中的数据后,excel就可以很方便的进行过滤了。在这 272 条结果中,有 7 家酒店符合要求。
在这7家酒店中,Christopher Zita选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚只需61美元。选择所需链接后,只需将链接复制到浏览器中即可预订。
广告策略数据,深入洞察用户数据,帮助企业用数据驱动产品改进和运营监控,实现多维度、^^精细化统计分析。二级处理,实时更新,...
在度假旅行时,寻找酒店是一项艰巨的任务。出于这个原因,有人愿意花钱来简化这个过程。使用这个自动程序,您可以在短短 5 分钟内以低廉的价格预订一个令您满意的房间。
抓取特定产品的价格数据,以最低价格购买
网页抓取最常见的用途之一是从 网站 获取价格。通过创建一个程序来抓取特定产品的价格数据,当价格下降到一定水平时,它会在产品售罄之前自动购买该产品。
广告python爬虫入门教程,python_basic+爬虫+数据分析+人工智能,免费学习!^^科大讯飞高级技术讲师指导,14天轻...
接下来,Christopher Zita 将向您展示一种可以在赚钱的同时为您节省大量资金的方法:
每个电商网站都会有限量的特价商品,他们会显示商品的原价和折扣价,但一般不会显示在原价的基础上打了多少折扣。举个例子,如果一只手表的初始价格是350美元,促销价是300美元,你会认为50美元的折扣不是小数目,但实际上只有14.@ > 2% 的折扣。而如果一件T恤的初始价是50美元,销售价是40美元,你会觉得它并没有便宜多少,但实际上它的折扣率比手表高出20%。因此,您可以通过购买折扣率最高的产品来省钱/赚钱。
我们以百货公司Hudson's'Bay为例进行数据抓取实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
广告抓数据软件——大数据精准采集端口,全网采集行业精准人力资源,2021营销必备神器!^^ 掌握全国95%以上的大数据库,你要...
抓取网站的数据后,我们得到了900多种产品的数据,其中只有一种产品Perry Ellis纯色衬衫的折扣率超过50%。
广告GooSeeker免费提供采集电子商务、社交平台、房地产网站、科研网站等各种网站网络数据采集^^输出各种包括EXCEL数字...
由于限时优惠,这件衬衫的价格将很快回升至 90 美元左右。因此,如果您现在以 40 美元的价格购买并在限时优惠结束后以 60 美元的价格出售,您仍然可以赚取 20 美元。
这是一种方式,如果你找到合适的利基市场,你可能会赚很多钱。
抓取宣传数据并可视化
网络上有数百万个数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有一些数据不容易获取,可视化需要花费大量时间。这就是销售数据的演变方式。天眼查、七查查等公司专注于获取和可视化公司工商界的业务变化,然后以“买会员查”的形式销售给用户。
一个类似的模型是体育数据网站BigDataBall。网站通过出售玩家的各种游戏数据等统计信息,向用户收取每季30美元的费用。他们设定这个价格不是因为他们网站有数据,而是他们抓取数据后,对数据进行排序,然后以易于阅读和清晰的结构显示数据。
如何写爬虫python免费教程下载+0元直播课,进群交流学习,快速上手掌握,^^推荐就业,轻松进名企,选...
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,然后将其放入结构化数据集。BigDataBall 不是唯一拥有这些数据的 网站。它有相同的数据。但是,网站 并没有对数据进行结构化,用户很难过滤和下载所需的数据集。Christopher Zita 使用网络爬虫来捕获网络上的所有玩家数据。

30秒注册广告,一键发布“慧聪网”^^慧聪网中国商机信息网,2021年各行业商机+2000万产品信息+2700万注册用户=...
所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过16,000份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了这些数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络爬虫工具来寻找人工难以获取的数据,让计算机来完成工作,然后将数据可视化并出售给对数据感兴趣的人。
总结
如今,网络抓取已成为一种非常独特且新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
每天一个超级实用的创业案例,扫码关注【站长视野】↓↓↓
网页数据抓取(开源的,httpd使用golang和java编写,tornado框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-10 04:02
<p>网页数据抓取很多人都会用到一个神器tornado,还有httpd。这两个都是开源的,httpd使用golang和java编写,tornado是前端开发语言iojs和lua实现的。这篇文章介绍httpd转flask的实现。httpd是一个轻量级的客户端/服务器并发(concurrent)框架。首先定义一个简单的工作页面,用express编写这个页面 查看全部
网页数据抓取(开源的,httpd使用golang和java编写,tornado框架)
<p>网页数据抓取很多人都会用到一个神器tornado,还有httpd。这两个都是开源的,httpd使用golang和java编写,tornado是前端开发语言iojs和lua实现的。这篇文章介绍httpd转flask的实现。httpd是一个轻量级的客户端/服务器并发(concurrent)框架。首先定义一个简单的工作页面,用express编写这个页面
网页数据抓取(2019独角兽企业重金招聘Python工程师标准(gt)(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-06 03:16
)
2019年独角兽企业重磅Python工程师招聘标准>>>
使用Selenium记录前端渲染数据
这几天打算用程序来抓取网站的下一个数据。具体哪个我就不说了,为了减少体力,省点力气。技术使用Java、Selenium、chromeDriver、系统ubuntu16.04
开始查网站的源码,看到了网站使用的模板方式,
> /etc/apt/sources.list.d/google.list'
sudo apt-get update
sudo apt-get install google-chrome-stable
测试chromeDriver是否正常运行。最初,阿里云ECS安装的是centos6.8系统。安装linux chrome并运行chromeDriver后,遇到各种找不到的库。我一直按照提示安装后,还是有问题。谷歌发现CentOS对chrome的支持不是很好(我没有继续追查原因,如果有懂的朋友希望澄清一下,谢谢),我换成了ubuntu 16.04 ,测试正常
root@iZj6c1imv6wpn7tfmm7nusZ:/work/fantasy# ./chromedriver
Starting ChromeDriver 2.37.544315 (730aa6a5fdba159ac9f4c1e8cbc59bf1b5ce12b7) on port 9515
Only local connections are allowed.
抓取页面的java代码,并使用chromeDriver进行渲染。您可以正常使用 xpath 来查找 html 元素。基本用法是使用By的搜索方法,可以通过id、class、tag等进行搜索。
这里有几点需要注意
需要设置选项,
准备工作做完了,可以抓数据了。摆脱手动定时查看,需要通知的时候可以使用bearychat向自己或团队发送通知,做一个快乐的程序员
java爬取分析代码
private WebDriver webDriver;
public XXXSpider() {
String driver = System.getProperty("webdriver.chrome.driver");
if (driver == null) {
logger.info("没有设置 driver 变量");
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/chengpanwang/Downloads/chromedriver");
} else {
logger.info("driver: {}", driver);
}
}
public BigDecimal pageDetail(String url) {
logger.info("详情页: {}", url);
........
try {
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
options.addArguments("--disable-gpu");
options.addArguments("--no-sandbox");
webDriver = new ChromeDriver(options);
webDriver.get(url);
WebElement webElement = webDriver.findElement(By.xpath("/html"));
WebElement roleSkill = webElement.findElement(By.id("role_skill"));
logger.info(roleSkill.getText());
logger.info("选中技术标签");
roleSkill.click();
WebElement skillTb = webElement.findElement(By.className("skillTb"));
for (WebElement item : skillTb.findElements(By.tagName("td"))) {
String level = item.findElement(By.tagName("p")).getText();
String h5 = item.findElement(By.tagName("h5")).getText();
.... 具体业务代码
}
webDriver.close();
} catch (Exception e) {
logger.error("", e);
}
return price;
} 查看全部
网页数据抓取(2019独角兽企业重金招聘Python工程师标准(gt)(组图)
)
2019年独角兽企业重磅Python工程师招聘标准>>>

使用Selenium记录前端渲染数据
这几天打算用程序来抓取网站的下一个数据。具体哪个我就不说了,为了减少体力,省点力气。技术使用Java、Selenium、chromeDriver、系统ubuntu16.04
开始查网站的源码,看到了网站使用的模板方式,
> /etc/apt/sources.list.d/google.list'
sudo apt-get update
sudo apt-get install google-chrome-stable
测试chromeDriver是否正常运行。最初,阿里云ECS安装的是centos6.8系统。安装linux chrome并运行chromeDriver后,遇到各种找不到的库。我一直按照提示安装后,还是有问题。谷歌发现CentOS对chrome的支持不是很好(我没有继续追查原因,如果有懂的朋友希望澄清一下,谢谢),我换成了ubuntu 16.04 ,测试正常
root@iZj6c1imv6wpn7tfmm7nusZ:/work/fantasy# ./chromedriver
Starting ChromeDriver 2.37.544315 (730aa6a5fdba159ac9f4c1e8cbc59bf1b5ce12b7) on port 9515
Only local connections are allowed.
抓取页面的java代码,并使用chromeDriver进行渲染。您可以正常使用 xpath 来查找 html 元素。基本用法是使用By的搜索方法,可以通过id、class、tag等进行搜索。
这里有几点需要注意
需要设置选项,
准备工作做完了,可以抓数据了。摆脱手动定时查看,需要通知的时候可以使用bearychat向自己或团队发送通知,做一个快乐的程序员
java爬取分析代码
private WebDriver webDriver;
public XXXSpider() {
String driver = System.getProperty("webdriver.chrome.driver");
if (driver == null) {
logger.info("没有设置 driver 变量");
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/chengpanwang/Downloads/chromedriver");
} else {
logger.info("driver: {}", driver);
}
}
public BigDecimal pageDetail(String url) {
logger.info("详情页: {}", url);
........
try {
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
options.addArguments("--disable-gpu");
options.addArguments("--no-sandbox");
webDriver = new ChromeDriver(options);
webDriver.get(url);
WebElement webElement = webDriver.findElement(By.xpath("/html"));
WebElement roleSkill = webElement.findElement(By.id("role_skill"));
logger.info(roleSkill.getText());
logger.info("选中技术标签");
roleSkill.click();
WebElement skillTb = webElement.findElement(By.className("skillTb"));
for (WebElement item : skillTb.findElements(By.tagName("td"))) {
String level = item.findElement(By.tagName("p")).getText();
String h5 = item.findElement(By.tagName("h5")).getText();
.... 具体业务代码
}
webDriver.close();
} catch (Exception e) {
logger.error("", e);
}
return price;
}
网页数据抓取(网页数据抓取功能常见有20多种方法,我简单介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-30 02:02
网页数据抓取功能常见有20多种方法,我简单介绍网页搜索,关键词百度搜索抓取,谷歌搜索抓取,比如你在谷歌搜索pythonscientificstatistics会跳出一大堆有关python中最出名的爬虫例子,点进去随便浏览一下再返回到谷歌页面去发现很多相关网页,点进去以后进入一个搜索框,搜索你要的内容,如nbaairline,再分别查看页面搜索结果中的每个页面的后缀是python那个的那些,就会得到你想要的内容了。还有其他的方法:搜索了一部手机型号,搜索了一个好像专辑,搜索了一个专辑,等等。
开始我是用一个爬虫工具来完成这一部分数据爬取的,不过你有没有想过,这样学习量产你对爬虫学习是不是太漫长了?你学习爬虫,又不是学习代码,对你来说会因为课本上的代码让你很舒适,而是通过完成一个个爬虫任务,不断复杂化和重构,通过达到工程上的复杂化,形成自己的一套规范,在解决问题,用实际任务去证明你对爬虫语言的掌握是不是可以吗?你学习爬虫,不需要通过网页划拉你眼睛都盯着哪里去,你学习的是如何组合方法进行数据爬取,而这种方法不需要你自己编写,是只要说明白大致的思路就行,所以你也能用语言中写的爬虫,也能用python来实现,但语言怎么说呢,就是一个工具。代码是死的,理论是活的,如果能活起来,就能产生最终的,具有自己价值的产品。 查看全部
网页数据抓取(网页数据抓取功能常见有20多种方法,我简单介绍)
网页数据抓取功能常见有20多种方法,我简单介绍网页搜索,关键词百度搜索抓取,谷歌搜索抓取,比如你在谷歌搜索pythonscientificstatistics会跳出一大堆有关python中最出名的爬虫例子,点进去随便浏览一下再返回到谷歌页面去发现很多相关网页,点进去以后进入一个搜索框,搜索你要的内容,如nbaairline,再分别查看页面搜索结果中的每个页面的后缀是python那个的那些,就会得到你想要的内容了。还有其他的方法:搜索了一部手机型号,搜索了一个好像专辑,搜索了一个专辑,等等。
开始我是用一个爬虫工具来完成这一部分数据爬取的,不过你有没有想过,这样学习量产你对爬虫学习是不是太漫长了?你学习爬虫,又不是学习代码,对你来说会因为课本上的代码让你很舒适,而是通过完成一个个爬虫任务,不断复杂化和重构,通过达到工程上的复杂化,形成自己的一套规范,在解决问题,用实际任务去证明你对爬虫语言的掌握是不是可以吗?你学习爬虫,不需要通过网页划拉你眼睛都盯着哪里去,你学习的是如何组合方法进行数据爬取,而这种方法不需要你自己编写,是只要说明白大致的思路就行,所以你也能用语言中写的爬虫,也能用python来实现,但语言怎么说呢,就是一个工具。代码是死的,理论是活的,如果能活起来,就能产生最终的,具有自己价值的产品。
网页数据抓取(网页数据抓取实战twopi成长计划项目是怎样进行的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-19 05:00
网页数据抓取实战twopi成长计划项目是这样进行的:从海量文本中提取有效信息作为分类输出(“清华大学计算机科学技术805实验室【是谁】”)。欢迎给作者投稿留言。
说一句冒犯人的话,根据楼主的描述,无论如何也不像是想使用类似“selenium+chromeflash+sublimetext”的技术,正经点吧,这种做法是走弯路的,不靠谱的,还不如自己做,开源的库不多,自己开发的库有海量,要你挑,如果你有兴趣可以去github看看,免费开源,也很不错的,最近天气那个,还有新闻微博那个。天气那个。
把今天所有的新闻及我所关注的话题全部爬下来,按人气排序,总会有几个靠前的。
可以选择网页的批量爬虫,推荐你使用蜂鸟全网爬虫工具箱,功能齐全易用,
首先上传数据,爬你感兴趣的东西啊,新闻,百科,贴吧,有可能会遇到反爬虫,把他爬到一定时间(多少自己试),然后就能输出一个txt格式的数据了。如果不想费事,找一个大网站的数据库手动下载下来,然后导入你的爬虫就ok了。wooyun不错,公共社区。比你自己玩强很多。
最近我自己用的是爬虫工具webpagetest()。
关键看是什么数据,必须要先数据可用。爬虫技术用处有限,适合复杂数据(字段比较多,组合方式比较复杂)。自己有一个简单的爬虫/反爬虫的模型就行了。最后说一句,爬虫是一个非常低效、不务正业、没有任何实际意义的工作,当前网站服务器对于爬虫是很敏感的, 查看全部
网页数据抓取(网页数据抓取实战twopi成长计划项目是怎样进行的?)
网页数据抓取实战twopi成长计划项目是这样进行的:从海量文本中提取有效信息作为分类输出(“清华大学计算机科学技术805实验室【是谁】”)。欢迎给作者投稿留言。
说一句冒犯人的话,根据楼主的描述,无论如何也不像是想使用类似“selenium+chromeflash+sublimetext”的技术,正经点吧,这种做法是走弯路的,不靠谱的,还不如自己做,开源的库不多,自己开发的库有海量,要你挑,如果你有兴趣可以去github看看,免费开源,也很不错的,最近天气那个,还有新闻微博那个。天气那个。
把今天所有的新闻及我所关注的话题全部爬下来,按人气排序,总会有几个靠前的。
可以选择网页的批量爬虫,推荐你使用蜂鸟全网爬虫工具箱,功能齐全易用,
首先上传数据,爬你感兴趣的东西啊,新闻,百科,贴吧,有可能会遇到反爬虫,把他爬到一定时间(多少自己试),然后就能输出一个txt格式的数据了。如果不想费事,找一个大网站的数据库手动下载下来,然后导入你的爬虫就ok了。wooyun不错,公共社区。比你自己玩强很多。
最近我自己用的是爬虫工具webpagetest()。
关键看是什么数据,必须要先数据可用。爬虫技术用处有限,适合复杂数据(字段比较多,组合方式比较复杂)。自己有一个简单的爬虫/反爬虫的模型就行了。最后说一句,爬虫是一个非常低效、不务正业、没有任何实际意义的工作,当前网站服务器对于爬虫是很敏感的,
网页数据抓取(java实现了一个简单的网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-18 07:08
最近,使用java实现了一个简单的网络数据捕获。下面是实现原理和实现代码:
原理:使用如下URL对象获取链接,下载目标网页的源码,使用jsoup解析源码中的数据,得到想要的内容
1.首先根据网址下载源码:
/**
* 根据网址和编码下载源代码
* @param url 目标网址
* @param encoding 编码
* @return
*/
public static String getHtmlResourceByURL(String url,String encoding){
//存储源代码容器
StringBuffer buffer = new StringBuffer();
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader br =null;
try {
//建立网络连接
urlObj = new URL(url);
//打开网络连接
uc = urlObj.openConnection();
//建立文件输入流
isr = new InputStreamReader(uc.getInputStream(),encoding);
InputStream is = uc.getInputStream();
//建立文件缓冲写入流
br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("F:\\java-study\\downImg\\index.txt");
//建立临时变量
String temp = null;
while((temp = br.readLine()) != null){
buffer.append(temp + "\n");
}
// fos.write(buffer.toString().getBytes());
// fos.close();
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("网络不给力,请检查网络设置。。。。");
}catch (IOException e){
e.printStackTrace();
System.out.println("你的网络连接打开失败,请稍后重新尝试!");
}finally {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return buffer.toString();
}
2.根据下载的源码分析数据得到你想要的内容,这里我拿图,你也可以在贴吧中得到邮箱、电话等
/**
* 获取图片路劲
* @param url 网络路径
* @param encoding 编码
*/
public static void downImg(String url,String encoding){
String resourceByURL = getHtmlResourceByURL(url, encoding);
//2.解析源代码,根据网络图像地址,下载到服务器
Document document = Jsoup.parse(resourceByURL);
//获取页面中所有的图片标签
Elements elements = document.getElementsByTag("img");
for(Element element:elements){
//获取图像地址
String src = element.attr("src");
//包含http开头
if (src.startsWith("http") && src.indexOf("jpg") != -1) {
getImg(src, "F:\\java-study\\downImg");
}
}
}
3. 根据获取到的图片路径下载图片,这里我下载的是携程网的内容
/**
* 下载图片
* @param imgUrl 图片地址
* @param filePath 存储路劲
*
*/
public static void getImg(String imgUrl,String filePath){
String fileName = imgUrl.substring(imgUrl.lastIndexOf("/"));
try {
//创建目录
File files = new File(filePath);
if (!files.exists()) {
files.mkdirs();
}
//获取地址
URL url = new URL(imgUrl);
//打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//获取输入流
InputStream is = connection.getInputStream();
File file = new File(filePath + fileName);
//建立问价输入流
FileOutputStream fos = new FileOutputStream(file);
int temp = 0;
while((temp = is.read()) != -1){
fos.write(temp);
}
is.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
最后是调用过程
public static void main(String[] args) {
//1.根据网址和页面编码集获取网页源代码
String encoding = "gbk";
String url = "http://vacations.ctrip.com/";
//2.解析源代码,根据网络图像地址,下载到服务器
downImg(url, encoding);
}
总结:根据上面实现的简单数据爬取,存在一些问题。我爬的旅游页面有很多图片。根据img属性,我在src里面拿到了下载图片的地址,但是页面图片很多。结果但是我只能爬到一小部分,如下图:
我把下载的源代码写成文件,和原来的网页对比。基本上,没有页面浏览的图片,也没有在源代码中。不知道为什么,求网友解答。 查看全部
网页数据抓取(java实现了一个简单的网页数据)
最近,使用java实现了一个简单的网络数据捕获。下面是实现原理和实现代码:
原理:使用如下URL对象获取链接,下载目标网页的源码,使用jsoup解析源码中的数据,得到想要的内容
1.首先根据网址下载源码:
/**
* 根据网址和编码下载源代码
* @param url 目标网址
* @param encoding 编码
* @return
*/
public static String getHtmlResourceByURL(String url,String encoding){
//存储源代码容器
StringBuffer buffer = new StringBuffer();
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader br =null;
try {
//建立网络连接
urlObj = new URL(url);
//打开网络连接
uc = urlObj.openConnection();
//建立文件输入流
isr = new InputStreamReader(uc.getInputStream(),encoding);
InputStream is = uc.getInputStream();
//建立文件缓冲写入流
br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("F:\\java-study\\downImg\\index.txt");
//建立临时变量
String temp = null;
while((temp = br.readLine()) != null){
buffer.append(temp + "\n");
}
// fos.write(buffer.toString().getBytes());
// fos.close();
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("网络不给力,请检查网络设置。。。。");
}catch (IOException e){
e.printStackTrace();
System.out.println("你的网络连接打开失败,请稍后重新尝试!");
}finally {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return buffer.toString();
}
2.根据下载的源码分析数据得到你想要的内容,这里我拿图,你也可以在贴吧中得到邮箱、电话等
/**
* 获取图片路劲
* @param url 网络路径
* @param encoding 编码
*/
public static void downImg(String url,String encoding){
String resourceByURL = getHtmlResourceByURL(url, encoding);
//2.解析源代码,根据网络图像地址,下载到服务器
Document document = Jsoup.parse(resourceByURL);
//获取页面中所有的图片标签
Elements elements = document.getElementsByTag("img");
for(Element element:elements){
//获取图像地址
String src = element.attr("src");
//包含http开头
if (src.startsWith("http") && src.indexOf("jpg") != -1) {
getImg(src, "F:\\java-study\\downImg");
}
}
}
3. 根据获取到的图片路径下载图片,这里我下载的是携程网的内容
/**
* 下载图片
* @param imgUrl 图片地址
* @param filePath 存储路劲
*
*/
public static void getImg(String imgUrl,String filePath){
String fileName = imgUrl.substring(imgUrl.lastIndexOf("/"));
try {
//创建目录
File files = new File(filePath);
if (!files.exists()) {
files.mkdirs();
}
//获取地址
URL url = new URL(imgUrl);
//打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//获取输入流
InputStream is = connection.getInputStream();
File file = new File(filePath + fileName);
//建立问价输入流
FileOutputStream fos = new FileOutputStream(file);
int temp = 0;
while((temp = is.read()) != -1){
fos.write(temp);
}
is.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
最后是调用过程
public static void main(String[] args) {
//1.根据网址和页面编码集获取网页源代码
String encoding = "gbk";
String url = "http://vacations.ctrip.com/";
//2.解析源代码,根据网络图像地址,下载到服务器
downImg(url, encoding);
}
总结:根据上面实现的简单数据爬取,存在一些问题。我爬的旅游页面有很多图片。根据img属性,我在src里面拿到了下载图片的地址,但是页面图片很多。结果但是我只能爬到一小部分,如下图:
我把下载的源代码写成文件,和原来的网页对比。基本上,没有页面浏览的图片,也没有在源代码中。不知道为什么,求网友解答。
网页数据抓取(自己边看边实践一些简单的实际应用,发现Python真的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-13 23:03
)
自己观看并练习一些简单的实际应用。下面的程序是从某个网站中获取需要的数据。
在写的过程中,通过学习学到了一些方法,发现Python真的很方便。
尤其是使用pandas获取网页中的表格数据,真的很方便!!!
程序可能不太好,但基本满足了它的需求。
希望有高手指点~~
Version 04 (Jan 12 2017) [获取表单信息推荐使用此方法]
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 import pandas as pd
6
7 url2 = 'http://www.bjets.com.cn/article/jyxx/?'
8 links = []
9 for n in range(2, 40):
10 # 页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
11 link = url2 + str(n)
12 links.append(link)
13 links.insert(0, url2)
14
15 df2 = pd.DataFrame() # creates a new dataframe that's empty
16 for url in links:
17 # 利用pandas获取数据,需要安装 html5lib模块
18 dfs = pd.read_html(url, header=0)
19 for df in dfs:
20 df2= df2.append(df, ignore_index= True)
21
22 # df2.to_excel('MktDataBJ.xlsx') # 将数据存储在excel文件里
23 df2.to_csv('MktDataBJ-1.csv') # 将数据存储在csv文件里
版本 03(201 年 1 月 12 日7)
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 from bs4 import BeautifulSoup
6 import requests
7 import csv
8
9 url2 = 'http://www.bjets.com.cn/article/jyxx/?'
10 links = []
11 for n in range(2, 40):
12 # 页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
13 link = url2 + str(n)
14 links.append(link)
15 links.insert(0, url2)
16
17 for url in links:
18 rep = requests.get(url)
19 # content = rep.text.encode(rep.encoding).decode('utf-8')
20 # # 直接用requests时,中文内容需要转码
21
22 soup = BeautifulSoup(rep.content, 'html.parser')
23
24 # table = soup.table
25 table = soup.find('table') # 两种方式都可以
26
27 trs = table.find_all('tr')
28 trs2 = trs[1:len(trs)]
29 list1 = []
30 for tr in trs2:
31 td = tr.find_all('td')
32 row = [i.text for i in td]
33 list1.append(row)
34
35 with open('MktDataBJ.csv', 'a', errors='ignore', newline='') as f:
36 f_csv = csv.writer(f)
37 f_csv.writerows(list1)
版本 02(201 年 1 月 9 日7)
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 from bs4 import BeautifulSoup
6 import requests
7 import csv
8
9 url2 = 'http://www.bjets.com.cn/article/jyxx/?'
10 links = []
11 for n in range(2, 40):
12 # 页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
13 link = url2 + str(n)
14 links.append(link)
15 links.insert(0, url2)
16 # print(links)
17
18 for url in links:
19 rep = requests.get(url)
20 # content = rep.text.encode(rep.encoding).decode('utf-8')
21 # # 直接用requests时,中文内容需要转码
22
23 soup = BeautifulSoup(rep.content, 'html.parser')
24 body = soup.body
25 data = body.find('div', {'class': 'list_right'})
26
27 quotes = data.find_all('tr')
28 quotes1 = quotes[1:len(quotes)]
29
30 list1 = []
31 for x in quotes1:
32 list2 = []
33 for y in x.find_all('td'):
34 list2.append(y.text) # 每日的数据做一个单独的list
35 list1.append(list2)
36 # print(list1) # list1为每日数据的总列表
37 with open('MktDataBJ.csv', 'a', errors='ignore', newline='') as f:
38 f_csv = csv.writer(f)
39 f_csv.writerows(list1)
版本 01(201 年 1 月 8 日7)
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 from bs4 import BeautifulSoup
6 import requests
7 import csv
8
9 urllink = 'http://www.bjets.com.cn/article/jyxx/?'
10 links = []
11 for n in range(2, 40):
12 #页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
13 link = urllink + str(n)
14 links.append(link)
15 links.insert(0, urllink)
16 # print(links)
17
18 for url in links:
19
20 rep = requests.get(url)
21 # content = rep.text.encode(rep.encoding).decode('utf-8')
22 # # 直接用requests时,中文内容需要转码
23
24 soup = BeautifulSoup(rep.content, 'html.parser')
25
26 # print(soup.prettify())
27 # # prettify()
28
29 body = soup.body
30 data = body.find('div', {'class': 'list_right'})
31
32 # table title
33 titles = data.find_all('th')
34
35 title = []
36 for x in titles:
37 title.append(x.text)
38 # print(title)
39
40 quotes = data.find_all('tr')
41 quotes1 = quotes[1:len(quotes)]
42 # print(quotes1)
43
44 list1 = []
45 for x in quotes1:
46 for y in x.find_all('td'):
47 list1.append(y.text)
48 # print(list1) # list为每日数据的总列表
49
50 date = []
51 volumes = []
52 meanprice = []
53 totalmoney = []
54
55 for i in range(0, len(list1)):
56 if i % 4 == 0:
57 date.append(list1[i])
58 elif i % 4 == 1:
59 volumes.append(list1[i])
60 elif i % 4 == 2:
61 meanprice.append(list1[i])
62 else:
63 totalmoney.append(list1[i])
64
65 # print(date)
66 # print(volumes)
67 # print(meanprice)
68 # print(totalmoney)
69
70 final = []
71 for i in range(0, len(date)):
72 temp = [date[i], volumes[i], meanprice[i], totalmoney[i]]
73 final.append(temp)
74 # print(final)
75 with open('bj_carbon.csv', 'a', errors='ignore', newline='') as f:
76 f_csv = csv.writer(f)
77 f_csv.writerows(final) 查看全部
网页数据抓取(自己边看边实践一些简单的实际应用,发现Python真的
)
自己观看并练习一些简单的实际应用。下面的程序是从某个网站中获取需要的数据。
在写的过程中,通过学习学到了一些方法,发现Python真的很方便。
尤其是使用pandas获取网页中的表格数据,真的很方便!!!
程序可能不太好,但基本满足了它的需求。
希望有高手指点~~
Version 04 (Jan 12 2017) [获取表单信息推荐使用此方法]
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 import pandas as pd
6
7 url2 = 'http://www.bjets.com.cn/article/jyxx/?'
8 links = []
9 for n in range(2, 40):
10 # 页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
11 link = url2 + str(n)
12 links.append(link)
13 links.insert(0, url2)
14
15 df2 = pd.DataFrame() # creates a new dataframe that's empty
16 for url in links:
17 # 利用pandas获取数据,需要安装 html5lib模块
18 dfs = pd.read_html(url, header=0)
19 for df in dfs:
20 df2= df2.append(df, ignore_index= True)
21
22 # df2.to_excel('MktDataBJ.xlsx') # 将数据存储在excel文件里
23 df2.to_csv('MktDataBJ-1.csv') # 将数据存储在csv文件里
版本 03(201 年 1 月 12 日7)
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 from bs4 import BeautifulSoup
6 import requests
7 import csv
8
9 url2 = 'http://www.bjets.com.cn/article/jyxx/?'
10 links = []
11 for n in range(2, 40):
12 # 页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
13 link = url2 + str(n)
14 links.append(link)
15 links.insert(0, url2)
16
17 for url in links:
18 rep = requests.get(url)
19 # content = rep.text.encode(rep.encoding).decode('utf-8')
20 # # 直接用requests时,中文内容需要转码
21
22 soup = BeautifulSoup(rep.content, 'html.parser')
23
24 # table = soup.table
25 table = soup.find('table') # 两种方式都可以
26
27 trs = table.find_all('tr')
28 trs2 = trs[1:len(trs)]
29 list1 = []
30 for tr in trs2:
31 td = tr.find_all('td')
32 row = [i.text for i in td]
33 list1.append(row)
34
35 with open('MktDataBJ.csv', 'a', errors='ignore', newline='') as f:
36 f_csv = csv.writer(f)
37 f_csv.writerows(list1)
版本 02(201 年 1 月 9 日7)
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 from bs4 import BeautifulSoup
6 import requests
7 import csv
8
9 url2 = 'http://www.bjets.com.cn/article/jyxx/?'
10 links = []
11 for n in range(2, 40):
12 # 页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
13 link = url2 + str(n)
14 links.append(link)
15 links.insert(0, url2)
16 # print(links)
17
18 for url in links:
19 rep = requests.get(url)
20 # content = rep.text.encode(rep.encoding).decode('utf-8')
21 # # 直接用requests时,中文内容需要转码
22
23 soup = BeautifulSoup(rep.content, 'html.parser')
24 body = soup.body
25 data = body.find('div', {'class': 'list_right'})
26
27 quotes = data.find_all('tr')
28 quotes1 = quotes[1:len(quotes)]
29
30 list1 = []
31 for x in quotes1:
32 list2 = []
33 for y in x.find_all('td'):
34 list2.append(y.text) # 每日的数据做一个单独的list
35 list1.append(list2)
36 # print(list1) # list1为每日数据的总列表
37 with open('MktDataBJ.csv', 'a', errors='ignore', newline='') as f:
38 f_csv = csv.writer(f)
39 f_csv.writerows(list1)
版本 01(201 年 1 月 8 日7)
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 from bs4 import BeautifulSoup
6 import requests
7 import csv
8
9 urllink = 'http://www.bjets.com.cn/article/jyxx/?'
10 links = []
11 for n in range(2, 40):
12 #页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
13 link = urllink + str(n)
14 links.append(link)
15 links.insert(0, urllink)
16 # print(links)
17
18 for url in links:
19
20 rep = requests.get(url)
21 # content = rep.text.encode(rep.encoding).decode('utf-8')
22 # # 直接用requests时,中文内容需要转码
23
24 soup = BeautifulSoup(rep.content, 'html.parser')
25
26 # print(soup.prettify())
27 # # prettify()
28
29 body = soup.body
30 data = body.find('div', {'class': 'list_right'})
31
32 # table title
33 titles = data.find_all('th')
34
35 title = []
36 for x in titles:
37 title.append(x.text)
38 # print(title)
39
40 quotes = data.find_all('tr')
41 quotes1 = quotes[1:len(quotes)]
42 # print(quotes1)
43
44 list1 = []
45 for x in quotes1:
46 for y in x.find_all('td'):
47 list1.append(y.text)
48 # print(list1) # list为每日数据的总列表
49
50 date = []
51 volumes = []
52 meanprice = []
53 totalmoney = []
54
55 for i in range(0, len(list1)):
56 if i % 4 == 0:
57 date.append(list1[i])
58 elif i % 4 == 1:
59 volumes.append(list1[i])
60 elif i % 4 == 2:
61 meanprice.append(list1[i])
62 else:
63 totalmoney.append(list1[i])
64
65 # print(date)
66 # print(volumes)
67 # print(meanprice)
68 # print(totalmoney)
69
70 final = []
71 for i in range(0, len(date)):
72 temp = [date[i], volumes[i], meanprice[i], totalmoney[i]]
73 final.append(temp)
74 # print(final)
75 with open('bj_carbon.csv', 'a', errors='ignore', newline='') as f:
76 f_csv = csv.writer(f)
77 f_csv.writerows(final)
网页数据抓取( 网页抓取工具助力传统企业弯道超车(2016.10.21))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-10 21:04
网页抓取工具助力传统企业弯道超车(2016.10.21))
获取大数据信息爬取的网络爬虫工具-微信公众Ping
600x450-45KB-JPEG
如何获取网页数据工具的内容
893x1462-47KB-PNG
网页抓取工具助力传统企业弯道超车-微信公众号
600x277-308KB-PNG
网页抓取工具助力传统企业弯道超车-微信公众号
432x324-266KB-PNG
网页抓取工具:详述未来的核心资产-
547x405-111KB-PNG
手机网页视频提取工具-安卓网页视频抓取工具
329x404-45KB-JPEG
网页抓取工具:大数据工作必不可少
487x326-34KB-JPEG
网页抓取工具:一个简单的文章采集示例(1)
893x2000-71KB-PNG
Web哈维中文| SysNucleus WebHarvy(页数
256x256-43KB-PNG
Python爬取动态网页内容程序详解
673x246-28KB-PNG
爬取网页数据工具优采云采集器插件说明
893x1744-72KB-PNG
抓取网页颜色的好工具--PickColor_Homepage_Production_
220x201-26KB-JPEG
[30P] 网页数据爬取工具-大网页数据爬取工具
550x349-28KB-JPEG
【全新Petal采集工具测试版上线】主要改进与
640x450-46KB-JPEG
【全新Petal采集工具测试版上线】主要改进与
640x1136-75KB-JPEG
抓取网页的指定内容(信息),获取网页中的图片,最近遇到同学反馈。网页中没有特征值的文本元素不是
优采云采集器是一套专业的网站内容采集实现网页内容的软件,支持各种论坛发帖和回复采集、网站@ >和博客文章
这种类型是专门为网页链接准备的,所以我们抓取数据的逻辑是这样的:从入口页面进入,获取当前页面已经加载
网页内容提取工具使用方法:2、点击抓取文本按钮,程序可以自动过滤网页,只提取文本内容,获取网页中的文本
本工具可以加快爬虫的抓取速度,不能解决网站内容是否为收录的问题2.百度搜索资源平台为站长提供了链接提交通道,各位
网页正文提取器是一种网页内容提取工具。该软件可以提前快速提取文章的正文和标题。
Import.io 是一个免费的在线网页 Mozenda 提供了数据提取工具,即使没有键盘,也可以轻松地从网页中抓取数据
我写的网络爬虫工具配置为只抓取某些论坛,你可以重写配置文件来抓取其他网页内容。
网页正文内容提取工具分析了新浪、搜狐、网易、腾讯、百度、中国新闻、中华网、21cn这8个网站。 查看全部
网页数据抓取(
网页抓取工具助力传统企业弯道超车(2016.10.21))

获取大数据信息爬取的网络爬虫工具-微信公众Ping
600x450-45KB-JPEG

如何获取网页数据工具的内容
893x1462-47KB-PNG

网页抓取工具助力传统企业弯道超车-微信公众号
600x277-308KB-PNG

网页抓取工具助力传统企业弯道超车-微信公众号
432x324-266KB-PNG

网页抓取工具:详述未来的核心资产-
547x405-111KB-PNG

手机网页视频提取工具-安卓网页视频抓取工具
329x404-45KB-JPEG

网页抓取工具:大数据工作必不可少
487x326-34KB-JPEG

网页抓取工具:一个简单的文章采集示例(1)
893x2000-71KB-PNG

Web哈维中文| SysNucleus WebHarvy(页数
256x256-43KB-PNG

Python爬取动态网页内容程序详解
673x246-28KB-PNG

爬取网页数据工具优采云采集器插件说明
893x1744-72KB-PNG
抓取网页颜色的好工具--PickColor_Homepage_Production_
220x201-26KB-JPEG

[30P] 网页数据爬取工具-大网页数据爬取工具
550x349-28KB-JPEG
【全新Petal采集工具测试版上线】主要改进与
640x450-46KB-JPEG
【全新Petal采集工具测试版上线】主要改进与
640x1136-75KB-JPEG
抓取网页的指定内容(信息),获取网页中的图片,最近遇到同学反馈。网页中没有特征值的文本元素不是
优采云采集器是一套专业的网站内容采集实现网页内容的软件,支持各种论坛发帖和回复采集、网站@ >和博客文章
这种类型是专门为网页链接准备的,所以我们抓取数据的逻辑是这样的:从入口页面进入,获取当前页面已经加载
网页内容提取工具使用方法:2、点击抓取文本按钮,程序可以自动过滤网页,只提取文本内容,获取网页中的文本
本工具可以加快爬虫的抓取速度,不能解决网站内容是否为收录的问题2.百度搜索资源平台为站长提供了链接提交通道,各位
网页正文提取器是一种网页内容提取工具。该软件可以提前快速提取文章的正文和标题。
Import.io 是一个免费的在线网页 Mozenda 提供了数据提取工具,即使没有键盘,也可以轻松地从网页中抓取数据
我写的网络爬虫工具配置为只抓取某些论坛,你可以重写配置文件来抓取其他网页内容。
网页正文内容提取工具分析了新浪、搜狐、网易、腾讯、百度、中国新闻、中华网、21cn这8个网站。
网页数据抓取(智能识别方式WebHarvy自动检索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-05 21:18
WebHarvy 是网页数据爬取的专用工具。该软件可以提取网页中的文字和图片,输入网址即可打开。默认设置为使用电脑内置浏览器,适合扩展分析,可自动获取类似连接列表。程序界面 可视化的实际操作很容易。【功能介绍】智能识别方法WebHarvy自动检索网页中出现的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则不需要做所有额外的准备工作。如果数据重复,WebHarvy 会自动抓取。导出捕获的数据可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy URL 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文档。您还可以抓取数据并将其导出到 SQL 数据库。从多个页面中提取通用网页显示信息数据,例如多个页面中的产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只强调“连接到下一页”,WebHarvy URL 抓取器会自动从所有页面抓取数据。可视化操作面板WebHarvy是一款用于数据可视化网页提取的专用工具。实际上,没有必要编写所有脚本。或者编码用于提取数据。使用 webharvy 的嵌入式计算机浏览器访问网页。您可以选择通过单击鼠标来提取数据。
这太容易了!根据关键词提取 根据关键词提取,可以抓取百度搜索页面关键词输入的列表数据。您创建的设备将自动重复输入所有输入 关键词 和发现的数据。能够指定一个随机的总输入 关键词 提取分类 WebHarvy URL 抓取器允许您从链接列表中提取数据,从而在 网站 内生成类似的页面。这使您能够在抓取的 URL 中应用单一类型或副标题。使用正则表达式提取 WebHarvy 可以在文本或网页的 HTML 源代码中使用正则表达式(正则表达式),并提取匹配的一部分。这种技术性很强,说明你协调能力很强,数据也很顶尖。[软件特点] WebHarvy 是一款视觉效果的网络爬虫。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。
您还可以将抓取到的数据导出到 SQL 数据库。通常,网页在多个页面上显示诸如信息产品列表之类的数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需强调“连接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。【版本更新】恢复页面启动时可以禁止使用链接。可以为page方法配备专用的接口方法。它可以自动检索可以在 HTML 上提供的资源。改进电脑键盘向下翻页功能改进基于Java脚本制作的下一页加载。添加URL设备后,可以在列表2搜索中输入关键词 查看全部
网页数据抓取(智能识别方式WebHarvy自动检索)
WebHarvy 是网页数据爬取的专用工具。该软件可以提取网页中的文字和图片,输入网址即可打开。默认设置为使用电脑内置浏览器,适合扩展分析,可自动获取类似连接列表。程序界面 可视化的实际操作很容易。【功能介绍】智能识别方法WebHarvy自动检索网页中出现的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则不需要做所有额外的准备工作。如果数据重复,WebHarvy 会自动抓取。导出捕获的数据可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy URL 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文档。您还可以抓取数据并将其导出到 SQL 数据库。从多个页面中提取通用网页显示信息数据,例如多个页面中的产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只强调“连接到下一页”,WebHarvy URL 抓取器会自动从所有页面抓取数据。可视化操作面板WebHarvy是一款用于数据可视化网页提取的专用工具。实际上,没有必要编写所有脚本。或者编码用于提取数据。使用 webharvy 的嵌入式计算机浏览器访问网页。您可以选择通过单击鼠标来提取数据。
这太容易了!根据关键词提取 根据关键词提取,可以抓取百度搜索页面关键词输入的列表数据。您创建的设备将自动重复输入所有输入 关键词 和发现的数据。能够指定一个随机的总输入 关键词 提取分类 WebHarvy URL 抓取器允许您从链接列表中提取数据,从而在 网站 内生成类似的页面。这使您能够在抓取的 URL 中应用单一类型或副标题。使用正则表达式提取 WebHarvy 可以在文本或网页的 HTML 源代码中使用正则表达式(正则表达式),并提取匹配的一部分。这种技术性很强,说明你协调能力很强,数据也很顶尖。[软件特点] WebHarvy 是一款视觉效果的网络爬虫。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。
您还可以将抓取到的数据导出到 SQL 数据库。通常,网页在多个页面上显示诸如信息产品列表之类的数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需强调“连接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。【版本更新】恢复页面启动时可以禁止使用链接。可以为page方法配备专用的接口方法。它可以自动检索可以在 HTML 上提供的资源。改进电脑键盘向下翻页功能改进基于Java脚本制作的下一页加载。添加URL设备后,可以在列表2搜索中输入关键词
网页数据抓取(智能识别方式WebHarvy自动检索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-05 21:14
WebHarvy 是网页数据爬取的专用工具。该软件可以提取网页中的文字和图片,输入网址即可打开。默认设置为使用电脑内置浏览器,适合扩展分析,可自动获取类似连接列表。程序界面 可视化的实际操作很容易。【功能介绍】智能识别方法WebHarvy自动检索网页中出现的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则不需要做所有额外的准备工作。如果数据重复,WebHarvy 会自动抓取。导出捕获的数据可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy URL 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文档。您还可以抓取数据并将其导出到 SQL 数据库。从多个页面中提取通用网页显示信息数据,例如多个页面中的产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只强调“连接到下一页”,WebHarvy URL 抓取器会自动从所有页面抓取数据。可视化操作面板WebHarvy是一款用于数据可视化网页提取的专用工具。实际上,没有必要编写所有脚本。或者编码用于提取数据。使用 webharvy 的嵌入式计算机浏览器访问网页。您可以选择通过单击鼠标来提取数据。
这太容易了!根据关键词提取 根据关键词提取,可以抓取百度搜索页面关键词输入的列表数据。您创建的设备将自动重复输入所有输入 关键词 和发现的数据。能够指定一个随机的总输入 关键词 提取分类 WebHarvy URL 抓取器允许您从链接列表中提取数据,从而在 网站 内生成类似的页面。这使您能够在抓取的 URL 中应用单一类型或副标题。使用正则表达式提取 WebHarvy 可以在文本或网页的 HTML 源代码中使用正则表达式(正则表达式),并提取匹配的一部分。这种技术性很强,说明你协调能力很强,数据也很顶尖。[软件特点] WebHarvy 是一款视觉效果的网络爬虫。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。
您还可以将抓取到的数据导出到 SQL 数据库。通常,网页在多个页面上显示诸如信息产品列表之类的数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需强调“连接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。【版本更新】恢复页面启动时可以禁止使用链接。可以为page方法配备专用的接口方法。它可以自动检索可以在 HTML 上提供的资源。改进电脑键盘向下翻页功能改进基于Java脚本制作的下一页加载。添加URL设备后,可以在列表2搜索中输入关键词 查看全部
网页数据抓取(智能识别方式WebHarvy自动检索)
WebHarvy 是网页数据爬取的专用工具。该软件可以提取网页中的文字和图片,输入网址即可打开。默认设置为使用电脑内置浏览器,适合扩展分析,可自动获取类似连接列表。程序界面 可视化的实际操作很容易。【功能介绍】智能识别方法WebHarvy自动检索网页中出现的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则不需要做所有额外的准备工作。如果数据重复,WebHarvy 会自动抓取。导出捕获的数据可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy URL 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文档。您还可以抓取数据并将其导出到 SQL 数据库。从多个页面中提取通用网页显示信息数据,例如多个页面中的产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只强调“连接到下一页”,WebHarvy URL 抓取器会自动从所有页面抓取数据。可视化操作面板WebHarvy是一款用于数据可视化网页提取的专用工具。实际上,没有必要编写所有脚本。或者编码用于提取数据。使用 webharvy 的嵌入式计算机浏览器访问网页。您可以选择通过单击鼠标来提取数据。
这太容易了!根据关键词提取 根据关键词提取,可以抓取百度搜索页面关键词输入的列表数据。您创建的设备将自动重复输入所有输入 关键词 和发现的数据。能够指定一个随机的总输入 关键词 提取分类 WebHarvy URL 抓取器允许您从链接列表中提取数据,从而在 网站 内生成类似的页面。这使您能够在抓取的 URL 中应用单一类型或副标题。使用正则表达式提取 WebHarvy 可以在文本或网页的 HTML 源代码中使用正则表达式(正则表达式),并提取匹配的一部分。这种技术性很强,说明你协调能力很强,数据也很顶尖。[软件特点] WebHarvy 是一款视觉效果的网络爬虫。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。
您还可以将抓取到的数据导出到 SQL 数据库。通常,网页在多个页面上显示诸如信息产品列表之类的数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需强调“连接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。【版本更新】恢复页面启动时可以禁止使用链接。可以为page方法配备专用的接口方法。它可以自动检索可以在 HTML 上提供的资源。改进电脑键盘向下翻页功能改进基于Java脚本制作的下一页加载。添加URL设备后,可以在列表2搜索中输入关键词
网页数据抓取(网页抓取工具优采云采集器中给出信息输出页后的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-03 06:14
当前的媒体状态,在一个焦点事件发生后或者在一个连续的话题中,形成一个媒体话题需要大量的人工操作,比如信息的采集和整理,及时更新等,但是高效的网络爬虫工具会为我们打造大数据智能媒体。
网络爬虫工具优采云采集器可以自动采集互联网焦点事件对应的舆情。例如,对于连续发生多天的事件,数据必须在每个重要节点的时间进行捕获和更新,那么您只需在优采云采集器中设置更新时间和频率。再比如我们关注的金融市场,也可以更新,自动整理成动态的媒体专栏。
对于焦点的某些方面的关注度,还可以根据网络爬虫抓取到的阅读或关注数据进行排名推荐和智能评分。我们甚至可以使用网络爬虫工具来维护智能媒体站。用户要做的就是锁定几个或多个信息输出页面,并在网络爬虫工具中给出信息优采云采集器 输出页面后,配置URL爬取和内容爬取的详细规则。获取到需要的数据后,可以对数据进行一系列的重新加权、过滤、清洗等处理,最后可以选择自动定时处理内容的精华发布到网站@指定栏目>.
未来的智能媒体必然是以大数据为引擎的媒体。核心要素是数据规模。我们要学会有效利用数据,发挥数据的价值。国内已经有基于媒体稿件大数据的高科技媒体产品,让人们更快更准确地了解信息,帮助人们更好地发现信息的价值和本质。
有专家指出,如果没有大数据的支持,很多新闻其实是无法启动的。传统媒体很难进行智能分析、预警或决策。因此,大数据智能化是必然趋势。
然而,目前网络大数据创造的智能媒体还不能完全取代人脑的工作,因为人脑有自我理解知识或事件的倾向,人工智能还需要继续探索语言和文本分析,以及大量枯燥的内容特定信息的整合和提取有朝一日可能会取代人脑来实现更复杂的原创。届时,智能媒体将更加个性化、定制化、高效化。 查看全部
网页数据抓取(网页抓取工具优采云采集器中给出信息输出页后的应用)
当前的媒体状态,在一个焦点事件发生后或者在一个连续的话题中,形成一个媒体话题需要大量的人工操作,比如信息的采集和整理,及时更新等,但是高效的网络爬虫工具会为我们打造大数据智能媒体。

网络爬虫工具优采云采集器可以自动采集互联网焦点事件对应的舆情。例如,对于连续发生多天的事件,数据必须在每个重要节点的时间进行捕获和更新,那么您只需在优采云采集器中设置更新时间和频率。再比如我们关注的金融市场,也可以更新,自动整理成动态的媒体专栏。
对于焦点的某些方面的关注度,还可以根据网络爬虫抓取到的阅读或关注数据进行排名推荐和智能评分。我们甚至可以使用网络爬虫工具来维护智能媒体站。用户要做的就是锁定几个或多个信息输出页面,并在网络爬虫工具中给出信息优采云采集器 输出页面后,配置URL爬取和内容爬取的详细规则。获取到需要的数据后,可以对数据进行一系列的重新加权、过滤、清洗等处理,最后可以选择自动定时处理内容的精华发布到网站@指定栏目>.
未来的智能媒体必然是以大数据为引擎的媒体。核心要素是数据规模。我们要学会有效利用数据,发挥数据的价值。国内已经有基于媒体稿件大数据的高科技媒体产品,让人们更快更准确地了解信息,帮助人们更好地发现信息的价值和本质。
有专家指出,如果没有大数据的支持,很多新闻其实是无法启动的。传统媒体很难进行智能分析、预警或决策。因此,大数据智能化是必然趋势。
然而,目前网络大数据创造的智能媒体还不能完全取代人脑的工作,因为人脑有自我理解知识或事件的倾向,人工智能还需要继续探索语言和文本分析,以及大量枯燥的内容特定信息的整合和提取有朝一日可能会取代人脑来实现更复杂的原创。届时,智能媒体将更加个性化、定制化、高效化。
网页数据抓取(基于Python爬虫技术简单易用的特点,利用python语言编写爬虫程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-31 06:13
摘要:基于Python爬虫技术简单易用的特点,采用python语言编写了爬虫程序,对广电总局电视剧电子政务平台的电视剧记录数据进行爬取。此外,还对抓取的电视剧记录数据进行了统计分析,得出了相关结论。关键词:Python;爬虫;数据分析
中文图书馆分类号:TP311.11 文献识别码:A文章编号:1007-9416(2017)09-0035-021 爬虫技术简介
网络爬虫是一种通过既定规则自动抓取网络信息的计算机程序。爬虫的目的是将目标网页数据下载到本地进行后续的数据分析。爬虫技术的兴起源于海量网络数据的可用性。通过爬虫技术,我们可以轻松获取网络数据,通过数据分析得出有价值的结论。
Python语言简单易用,现成的爬虫框架和工具包降低了使用门槛。具体配合正则表达式的使用,使得数据采集工作生动有趣。2 案例研究 2.1 网页描述
目标数据是历年全国电视剧拍摄的记录数据。数据来源于国家广电总局电视剧电子政务平台公开信息,如图1所示。 具体网址:“http:
///tims/site/views/applications.shanty? 应用名称=注释”。
我们需要抓取历年各月的记录和公开信息列表数据,如图2所示,进行汇总分析。2.2 爬虫程序的设计与实现
首先,我们使用 BeautifulSoup 解析器来解析 URL 的文本信息。在分析了网页的 HTML 文本和页面规则后,我们制定了以下步骤来捕获目标数据。
①抓取第一页码和最后页码后,循环抓取列表页信息; 查看全部
网页数据抓取(基于Python爬虫技术简单易用的特点,利用python语言编写爬虫程序)
摘要:基于Python爬虫技术简单易用的特点,采用python语言编写了爬虫程序,对广电总局电视剧电子政务平台的电视剧记录数据进行爬取。此外,还对抓取的电视剧记录数据进行了统计分析,得出了相关结论。关键词:Python;爬虫;数据分析
中文图书馆分类号:TP311.11 文献识别码:A文章编号:1007-9416(2017)09-0035-021 爬虫技术简介
网络爬虫是一种通过既定规则自动抓取网络信息的计算机程序。爬虫的目的是将目标网页数据下载到本地进行后续的数据分析。爬虫技术的兴起源于海量网络数据的可用性。通过爬虫技术,我们可以轻松获取网络数据,通过数据分析得出有价值的结论。
Python语言简单易用,现成的爬虫框架和工具包降低了使用门槛。具体配合正则表达式的使用,使得数据采集工作生动有趣。2 案例研究 2.1 网页描述
目标数据是历年全国电视剧拍摄的记录数据。数据来源于国家广电总局电视剧电子政务平台公开信息,如图1所示。 具体网址:“http:
///tims/site/views/applications.shanty? 应用名称=注释”。
我们需要抓取历年各月的记录和公开信息列表数据,如图2所示,进行汇总分析。2.2 爬虫程序的设计与实现
首先,我们使用 BeautifulSoup 解析器来解析 URL 的文本信息。在分析了网页的 HTML 文本和页面规则后,我们制定了以下步骤来捕获目标数据。
①抓取第一页码和最后页码后,循环抓取列表页信息;
网页数据抓取(推荐你学习下flask+mongodb数据库抓取工具(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-30 13:03
网页数据抓取:到百度上,选择新闻,点开每个新闻后面有分类;选择“会员”类似这样:这里是选择“图书”点击后会跳转到“全部商品”页面,注意看你要分析的分类信息。点击商品名,会自动跳转到商品所属购买页面,到这一步有点复杂,容我上图注意“怎么获取对应的会员,如何验证这个会员”抓取模板页面数据:方法同上;同理前面页面也是;想抓取目标节点的其他页面,跳转至page120,得到页面内容,比如打开招聘网站,可以看到介绍后面的分类信息,点击,到下载即可得到对应的工作量有没有超过自己的预期?很多,很多,这种题用python动手太麻烦了,用flask框架快捷多了。
在别的方面需要大量的数据时,可以使用flask框架快速搭建个简单的网站抓取。推荐你学习下flask+mongodb数据库抓取工具。flask官方有很多非常好的教程与示例代码,想深入学习,可以看本网站的教程。
其实,目前的网站都有这个需求,而且近几年互联网增长最快的部分,正是图书和电商类的,所以公司比较看重抓取哪方面的数据。当然这类网站用lxml或xml+flask或者flask+mongodb数据库抓取工具也能完成,目前来说,flask+mongodb是最快捷、最灵活的方案,虽然功能上不如flask或者flask+lxml等,但确实目前性价比最高的,也是目前用最多的。
具体用什么做实现,你可以看一下flask+lxml或者flask+mongodb可以做什么?-flask,这是目前最新的两篇文章。 查看全部
网页数据抓取(推荐你学习下flask+mongodb数据库抓取工具(图))
网页数据抓取:到百度上,选择新闻,点开每个新闻后面有分类;选择“会员”类似这样:这里是选择“图书”点击后会跳转到“全部商品”页面,注意看你要分析的分类信息。点击商品名,会自动跳转到商品所属购买页面,到这一步有点复杂,容我上图注意“怎么获取对应的会员,如何验证这个会员”抓取模板页面数据:方法同上;同理前面页面也是;想抓取目标节点的其他页面,跳转至page120,得到页面内容,比如打开招聘网站,可以看到介绍后面的分类信息,点击,到下载即可得到对应的工作量有没有超过自己的预期?很多,很多,这种题用python动手太麻烦了,用flask框架快捷多了。
在别的方面需要大量的数据时,可以使用flask框架快速搭建个简单的网站抓取。推荐你学习下flask+mongodb数据库抓取工具。flask官方有很多非常好的教程与示例代码,想深入学习,可以看本网站的教程。
其实,目前的网站都有这个需求,而且近几年互联网增长最快的部分,正是图书和电商类的,所以公司比较看重抓取哪方面的数据。当然这类网站用lxml或xml+flask或者flask+mongodb数据库抓取工具也能完成,目前来说,flask+mongodb是最快捷、最灵活的方案,虽然功能上不如flask或者flask+lxml等,但确实目前性价比最高的,也是目前用最多的。
具体用什么做实现,你可以看一下flask+lxml或者flask+mongodb可以做什么?-flask,这是目前最新的两篇文章。
网页数据抓取(智教智道网页数据监控软件官方版(da)众需要的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-30 07:08
网探网页数据监控软件官方版是一款可以监控搜狐、天猫、微博、12306等的网页数据监控软件官方版网站,帮你抓拍网站重要访问URL,辽中大学(da)需要的抢先信息。智交智道真诚推荐!
网页数据监控软件正式版介绍
1. 多任务同时运行,无人值守长期运行。
2. 及时通知用户,新增程序设置对话框。
3. 增加定时关机等附加功能,对比验证网页数据监控软件正式版。
4. 资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行,修复bug。
Netexplorer网页数据监控软件正式版功能
1. 监控任务A(必须是网址)得到的结果可以转移到监控任务B执行,从而获得网页数据监控软件正式版更丰富的结果。网页数据监控软件正式版上线 各行各业都在应用互联网技术,互联网上的网页数据监控软件正式版也越来越丰富。一些在线数据监控软件正式版的价值与时间有关。早点知道会很有用,以后值可能为零。Netexploration软件就是来解决这类问题的,让您“永远领先一步”是我们的目标。
2. 打开通知界面,“人人为我,我为人” 分享任意网页的爬取公式,免去编辑公式的麻烦。.
3. 爬取公式网上分享,“文本匹配”和“文档结构分析”是网页数据监控软件正式版的两种爬取方法。它们可以单独使用,也可以组合使用,制作正式版的网络数据监控软件。爬行更容易,更准确。
4. 直接与您的服务器后端连接,后续流程自定义,实时高效接入官方版网页数据监控软件自动处理流程,自动判断官方版最新更新网页数据监测软件,支持自定义网页数据监测软件正式版对比验证公式,过滤出用户最感兴趣的网页数据监测软件正式版内容。
网页数据监控软件正式版特点
1. 任务之间的相互调用。用户注册后,可将已验证的网页数据监控软件正式版发送至用户邮箱,也可推送至用户指定的网页数据监控软件正式版界面。再次处理版本。
2. 基于IE浏览器爬取的网页网页数据监控软件正式版。
NetExplore网页数据监控软件正式版总结
NetExplore网络数据监控软件V1.20是一款适用于安卓版的办公软件手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
网页数据抓取(智教智道网页数据监控软件官方版(da)众需要的信息)
网探网页数据监控软件官方版是一款可以监控搜狐、天猫、微博、12306等的网页数据监控软件官方版网站,帮你抓拍网站重要访问URL,辽中大学(da)需要的抢先信息。智交智道真诚推荐!
网页数据监控软件正式版介绍
1. 多任务同时运行,无人值守长期运行。
2. 及时通知用户,新增程序设置对话框。
3. 增加定时关机等附加功能,对比验证网页数据监控软件正式版。
4. 资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行,修复bug。
Netexplorer网页数据监控软件正式版功能
1. 监控任务A(必须是网址)得到的结果可以转移到监控任务B执行,从而获得网页数据监控软件正式版更丰富的结果。网页数据监控软件正式版上线 各行各业都在应用互联网技术,互联网上的网页数据监控软件正式版也越来越丰富。一些在线数据监控软件正式版的价值与时间有关。早点知道会很有用,以后值可能为零。Netexploration软件就是来解决这类问题的,让您“永远领先一步”是我们的目标。
2. 打开通知界面,“人人为我,我为人” 分享任意网页的爬取公式,免去编辑公式的麻烦。.
3. 爬取公式网上分享,“文本匹配”和“文档结构分析”是网页数据监控软件正式版的两种爬取方法。它们可以单独使用,也可以组合使用,制作正式版的网络数据监控软件。爬行更容易,更准确。
4. 直接与您的服务器后端连接,后续流程自定义,实时高效接入官方版网页数据监控软件自动处理流程,自动判断官方版最新更新网页数据监测软件,支持自定义网页数据监测软件正式版对比验证公式,过滤出用户最感兴趣的网页数据监测软件正式版内容。
网页数据监控软件正式版特点
1. 任务之间的相互调用。用户注册后,可将已验证的网页数据监控软件正式版发送至用户邮箱,也可推送至用户指定的网页数据监控软件正式版界面。再次处理版本。
2. 基于IE浏览器爬取的网页网页数据监控软件正式版。
NetExplore网页数据监控软件正式版总结
NetExplore网络数据监控软件V1.20是一款适用于安卓版的办公软件手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
网页数据抓取(四川网络推广优化人员需要注意其中更多的细节来帮助)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-01 06:21
众所周知,四川互联网推广网站结构搭建的越好,越能吸引蜘蛛爬行爬行,也能吸引用户浏览。四川网络推广优化人员也需要关注更多细节,帮助网站架构设计越来越好,从而帮助网站改进收录,增加排名,那么下面就带大家一探究竟。
1、页面设计
一个好的网站页面设计会给蜘蛛留下更好的印象,也会给用户留下更好的印象和体验,网站的点击率和跳出率数据也会是它会更好,所以蜘蛛的爬行频率会更高。一般情况下,蜘蛛爬取和用户反馈数据是相辅相成的。总之,页面设计越好,蜘蛛爬行就越有吸引力。
2、导航设计
导航设计是一个关键因素,可以很好的体现网站的核心。由于网站行业的类型不同,优化者也可以从用户的角度设计更加人性化的导航功能。 , 满足用户搜索、查找、浏览等需求,使导航更加结构化、层次化,为蜘蛛创造更便捷的爬行环境。另外,四川互联网推广提醒大家要注意导航设计要简洁明了,越简单越好。
3、展示优质内容
四川网推广表示,网站首页是SEO优化的重点,首页也是整个网站评分的重要组成部分,所以做好很重要在网站的内容展示中。因此,优化者必须以合理的方式在首页展示重要且优质的内容,这样既方便用户查看,也有助于蜘蛛更快地捕捉有价值的信息,自然会吸引蜘蛛爬行。
综上所述,以上就是四川网促为大家总结的几个优质的网站架构来吸引蜘蛛。相信你也会对此有更多的了解,做好相关的细节。吸引更多蜘蛛爬行爬行,帮助网站获得更高的排名。 查看全部
网页数据抓取(四川网络推广优化人员需要注意其中更多的细节来帮助)
众所周知,四川互联网推广网站结构搭建的越好,越能吸引蜘蛛爬行爬行,也能吸引用户浏览。四川网络推广优化人员也需要关注更多细节,帮助网站架构设计越来越好,从而帮助网站改进收录,增加排名,那么下面就带大家一探究竟。
1、页面设计
一个好的网站页面设计会给蜘蛛留下更好的印象,也会给用户留下更好的印象和体验,网站的点击率和跳出率数据也会是它会更好,所以蜘蛛的爬行频率会更高。一般情况下,蜘蛛爬取和用户反馈数据是相辅相成的。总之,页面设计越好,蜘蛛爬行就越有吸引力。
2、导航设计
导航设计是一个关键因素,可以很好的体现网站的核心。由于网站行业的类型不同,优化者也可以从用户的角度设计更加人性化的导航功能。 , 满足用户搜索、查找、浏览等需求,使导航更加结构化、层次化,为蜘蛛创造更便捷的爬行环境。另外,四川互联网推广提醒大家要注意导航设计要简洁明了,越简单越好。
3、展示优质内容
四川网推广表示,网站首页是SEO优化的重点,首页也是整个网站评分的重要组成部分,所以做好很重要在网站的内容展示中。因此,优化者必须以合理的方式在首页展示重要且优质的内容,这样既方便用户查看,也有助于蜘蛛更快地捕捉有价值的信息,自然会吸引蜘蛛爬行。
综上所述,以上就是四川网促为大家总结的几个优质的网站架构来吸引蜘蛛。相信你也会对此有更多的了解,做好相关的细节。吸引更多蜘蛛爬行爬行,帮助网站获得更高的排名。
网页数据抓取(直观强大的可视化网页抓取工具可以轻松地从网站上抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-28 02:15
)
直观而强大的可视化网络爬虫工具
您可以轻松地从网站抓取文本、HTML、图像、URL 和电子邮件,并将抓取的数据保存为各种格式。
非常好用,分分钟开始爬取数据
支持所有类型的网站。处理登录、表单提交等。
从多个页面、类别和关键字中获取数据
内置调度器、代理支持、智能帮助等...
轻松抓取网页
使用该软件的点击式界面可以轻松抓取网页。绝对不需要编写任何代码或脚本来抓取数据。您将使用该软件的内置浏览器来加载网站,您可以通过单击鼠标选择您要抓取的数据。就是这么简单!(视频)
智能模式检测
该软件会自动识别出现在网页中的数据模式。因此,如果您需要从网页中获取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,软件会自动抓取。
保存到文件或数据库
您可以以各种格式保存从网站上抓取的数据。当前版本允许您将捕获的数据保存为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
抓取多个页面
网站通常在多个页面上显示产品列表或搜索结果等数据。该软件可以从多个页面自动抓取和抓取数据。只需指出“加载下一页的链接”,软件就会自动从所有页面抓取数据。
提交关键词
通过自动向搜索表单提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以抓取所有输入关键字组合的搜索结果数据。
隐私保护
为了匿名抓取,防止网络爬虫软件被网络服务器拦截,您可以选择通过代理服务器或科学上网工具访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
分类爬取
该软件允许您从指向网站中类似页面/列表的链接列表中获取数据。这允许您使用单个配置来抓取站点内的类别和子类别。
常用表达
该软件允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并抓取匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
JavaScript 支持
在获取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互、修改 DOM 或调用已在目标页面中实现的 JavaScript 函数。
图像捕捉
您可以下载图像或获取图像 URL。该软件可以自动抓取显示在电子商务网站产品详情页面上的多张图片。
自动化浏览器任务
该软件可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面和打开弹出窗口。
原价:883
当前折扣价:88
如何下载
会员免费下载
普通用户请先付款后下载,付款后可见下载链接
查看全部
网页数据抓取(直观强大的可视化网页抓取工具可以轻松地从网站上抓取
)
直观而强大的可视化网络爬虫工具
您可以轻松地从网站抓取文本、HTML、图像、URL 和电子邮件,并将抓取的数据保存为各种格式。
非常好用,分分钟开始爬取数据
支持所有类型的网站。处理登录、表单提交等。
从多个页面、类别和关键字中获取数据
内置调度器、代理支持、智能帮助等...
轻松抓取网页
使用该软件的点击式界面可以轻松抓取网页。绝对不需要编写任何代码或脚本来抓取数据。您将使用该软件的内置浏览器来加载网站,您可以通过单击鼠标选择您要抓取的数据。就是这么简单!(视频)
智能模式检测
该软件会自动识别出现在网页中的数据模式。因此,如果您需要从网页中获取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,软件会自动抓取。
保存到文件或数据库
您可以以各种格式保存从网站上抓取的数据。当前版本允许您将捕获的数据保存为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
抓取多个页面
网站通常在多个页面上显示产品列表或搜索结果等数据。该软件可以从多个页面自动抓取和抓取数据。只需指出“加载下一页的链接”,软件就会自动从所有页面抓取数据。
提交关键词
通过自动向搜索表单提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以抓取所有输入关键字组合的搜索结果数据。
隐私保护
为了匿名抓取,防止网络爬虫软件被网络服务器拦截,您可以选择通过代理服务器或科学上网工具访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
分类爬取
该软件允许您从指向网站中类似页面/列表的链接列表中获取数据。这允许您使用单个配置来抓取站点内的类别和子类别。
常用表达
该软件允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并抓取匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
JavaScript 支持
在获取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互、修改 DOM 或调用已在目标页面中实现的 JavaScript 函数。
图像捕捉
您可以下载图像或获取图像 URL。该软件可以自动抓取显示在电子商务网站产品详情页面上的多张图片。
自动化浏览器任务
该软件可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面和打开弹出窗口。
原价:883
当前折扣价:88
如何下载
会员免费下载
普通用户请先付款后下载,付款后可见下载链接
https://www.huahaikuajing.com/ ... 0.jpg 300w" />https://www.huahaikuajing.com/ ... 0.jpg 300w" />https://www.huahaikuajing.com/ ... 0.jpg 300w" /> 网页数据抓取(如何吸引蜘蛛来抓取文章的内容,提高我们网站的收录量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-27 07:15
很多站长在分析网站数据时,都会关注自己网站的收录量。这个收录是网站优化排名中比较重要的一个因素,也比较直观。虽然并不是说你的网站收录越多,排名就越高,但收录和排名还是有关系的。收录
的内容越多,获得良好排名的机会就越大。怎样才能吸引蜘蛛抓取文章内容,增加我们网站的收录量?SEO会为你慢慢做!!!
第一:提交站点地图
我们每天更新网站文章后,需要更新网站地图,然后将地图提交给百度,以便百度可以通过地图访问您的网站。
二、 按照百度官方声明执行
1. 百度原创火星项目提到,只要你的文章是原创的,当用户搜索同一篇文章时,原创内容会优先显示。当然,最好是原创,但往往我们维护的客户网站都非常专业,水平有限,只能做伪原创。
2. 对于一些权重比较高的网站,如果采集
了一些小站的文章,那么百度可能不确定小站的情况,所以小站可以通过ping机制ping百度,这会帮助百度知道哪个是原创。
3. 作者一般是按照百度官网的说明,然后对外发布一些采集
速度更快、权重更高的网站,比如:a5,站长之家,还有新浪博客,天涯大博客、搜狐、中金博客等大型博客,利用外链吸引蜘蛛到我的网站抓取原创文章。
三、 发链接吸引蜘蛛
1. 就算很多站长用一个网站的首页网址发布外链,我觉得这个优化方法还是比较简单的。如果您的网站权重较低,更新不频繁,蜘蛛可能会链接到您的网站,不再深入抓取。
2. 一般文章更新后,可以去各大论坛和博客发表文章,然后带上刚刚发表的文章地址。这个效果相当不错,朋友可以试试。
四、 与一些经常更新的网站交换链接
每个人都知道友好链接的作用。友情链接对网站排名有一定的作用。同时,友情链接引导蜘蛛在网站之间来回爬行,对网站排名和收录非常有帮助。是的,所以我们必须与一些经常更新的网站交换链接。
五、 网站上文章之间的链接
无论是文章之间,还是栏目与网站首页之间,都必须有一个或多个链接路径。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,它也是一个允许用户点击的链接。其中,排名和权重提升都比较好。 查看全部
网页数据抓取(如何吸引蜘蛛来抓取文章的内容,提高我们网站的收录量)
很多站长在分析网站数据时,都会关注自己网站的收录量。这个收录是网站优化排名中比较重要的一个因素,也比较直观。虽然并不是说你的网站收录越多,排名就越高,但收录和排名还是有关系的。收录
的内容越多,获得良好排名的机会就越大。怎样才能吸引蜘蛛抓取文章内容,增加我们网站的收录量?SEO会为你慢慢做!!!
第一:提交站点地图
我们每天更新网站文章后,需要更新网站地图,然后将地图提交给百度,以便百度可以通过地图访问您的网站。
二、 按照百度官方声明执行
1. 百度原创火星项目提到,只要你的文章是原创的,当用户搜索同一篇文章时,原创内容会优先显示。当然,最好是原创,但往往我们维护的客户网站都非常专业,水平有限,只能做伪原创。
2. 对于一些权重比较高的网站,如果采集
了一些小站的文章,那么百度可能不确定小站的情况,所以小站可以通过ping机制ping百度,这会帮助百度知道哪个是原创。
3. 作者一般是按照百度官网的说明,然后对外发布一些采集
速度更快、权重更高的网站,比如:a5,站长之家,还有新浪博客,天涯大博客、搜狐、中金博客等大型博客,利用外链吸引蜘蛛到我的网站抓取原创文章。
三、 发链接吸引蜘蛛
1. 就算很多站长用一个网站的首页网址发布外链,我觉得这个优化方法还是比较简单的。如果您的网站权重较低,更新不频繁,蜘蛛可能会链接到您的网站,不再深入抓取。
2. 一般文章更新后,可以去各大论坛和博客发表文章,然后带上刚刚发表的文章地址。这个效果相当不错,朋友可以试试。
四、 与一些经常更新的网站交换链接
每个人都知道友好链接的作用。友情链接对网站排名有一定的作用。同时,友情链接引导蜘蛛在网站之间来回爬行,对网站排名和收录非常有帮助。是的,所以我们必须与一些经常更新的网站交换链接。
五、 网站上文章之间的链接
无论是文章之间,还是栏目与网站首页之间,都必须有一个或多个链接路径。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,它也是一个允许用户点击的链接。其中,排名和权重提升都比较好。
网页数据抓取( 网络爬虫就是获取网页信息的简单爬虫方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-26 14:15
网络爬虫就是获取网页信息的简单爬虫方法)
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数),一般网站默认端口号为80,例如百度的主机名是,这是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录
一些处理 URL 的模块,如下:
进群:960410445获取源码!
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录
了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录
一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们使用 urllib.request.urlopen() 接口函数来方便地打开一个网站,阅读和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这些,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后使用print()将读取的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。
当然,我们也可以从浏览器中查看这些代码。
比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,
比如中文网站起点付费章节就不行),以百度界面为例,截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(再次以百度翻译网站为例):
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,这个前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?
需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
这样,我们就知道了这个网站的编码方式,但这需要我们每次打开浏览器,查找编码方式。显然是有点麻烦。用几行代码来解决,更省事,更爽。
一种自动获取网页编码方式的方法
获取网页代码的方式有很多种,我个人更喜欢使用第三方库。
首先,我们需要安装第三方库chardet,这是一个用于确定编码的模块。安装方法如下图所示。只需输入命令:
安装后,我们可以使用chardet.detect()方法来判断网页的编码方式。
此时,我们可以编写一个小程序来判断网页的编码方式,新建文件名为chardet_test01.py:
运行程序,查看输出结果如下:
返回的是一个字典,让我们知道网页的编码方式,可以根据得到的信息使用不同的解码方式。 查看全部
网页数据抓取(
网络爬虫就是获取网页信息的简单爬虫方法)
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数),一般网站默认端口号为80,例如百度的主机名是,这是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录
一些处理 URL 的模块,如下:
进群:960410445获取源码!
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录
了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录
一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们使用 urllib.request.urlopen() 接口函数来方便地打开一个网站,阅读和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这些,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后使用print()将读取的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。
当然,我们也可以从浏览器中查看这些代码。
比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,
比如中文网站起点付费章节就不行),以百度界面为例,截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(再次以百度翻译网站为例):
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,这个前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?
需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
这样,我们就知道了这个网站的编码方式,但这需要我们每次打开浏览器,查找编码方式。显然是有点麻烦。用几行代码来解决,更省事,更爽。
一种自动获取网页编码方式的方法
获取网页代码的方式有很多种,我个人更喜欢使用第三方库。
首先,我们需要安装第三方库chardet,这是一个用于确定编码的模块。安装方法如下图所示。只需输入命令:
安装后,我们可以使用chardet.detect()方法来判断网页的编码方式。
此时,我们可以编写一个小程序来判断网页的编码方式,新建文件名为chardet_test01.py:
运行程序,查看输出结果如下:
返回的是一个字典,让我们知道网页的编码方式,可以根据得到的信息使用不同的解码方式。
网页数据抓取(我有一个excel文件,其中包含以下变量的数据框)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-25 10:16
我有一个 excel 文件,其中收录
需要通过 R 在 google 中搜索的某些关键字。要创建的输出是一个数据框,其中收录
以下变量: 搜索到的一些关键字。要创建的输出是数据收录
以下变量的框架:
Keyword;Position(url 在搜索结果中的位置);Title(第 i 个搜索结果的标题);Text(该搜索结果中的文本);URL;Domain 关键字和一些输出示例在以下链接:关键字;位置(网址在搜索结果中的位置); Title(第i个搜索结果的标题);文本(搜索结果中的文本);网址; Domain 下面的链接中给出了关键字和一些输出示例:
(工作表 1 有关键字,工作表 2 有示例输出)(工作表 1 有关键字,工作表 2 有示例输出)
我尝试创建类似的输出,但似乎有错误。我试图创建一个类似的输出,但似乎有一个错误。代码: 代码:
显示的错误是: 显示的错误是:
Error in match.names(clabs, nmi) : names do not match previous names
请帮助,我是 R 的新手。请帮助,我是 R 的新手。 查看全部
网页数据抓取(我有一个excel文件,其中包含以下变量的数据框)
我有一个 excel 文件,其中收录
需要通过 R 在 google 中搜索的某些关键字。要创建的输出是一个数据框,其中收录
以下变量: 搜索到的一些关键字。要创建的输出是数据收录
以下变量的框架:
Keyword;Position(url 在搜索结果中的位置);Title(第 i 个搜索结果的标题);Text(该搜索结果中的文本);URL;Domain 关键字和一些输出示例在以下链接:关键字;位置(网址在搜索结果中的位置); Title(第i个搜索结果的标题);文本(搜索结果中的文本);网址; Domain 下面的链接中给出了关键字和一些输出示例:
(工作表 1 有关键字,工作表 2 有示例输出)(工作表 1 有关键字,工作表 2 有示例输出)
我尝试创建类似的输出,但似乎有错误。我试图创建一个类似的输出,但似乎有一个错误。代码: 代码:
显示的错误是: 显示的错误是:
Error in match.names(clabs, nmi) : names do not match previous names
请帮助,我是 R 的新手。请帮助,我是 R 的新手。
网页数据抓取(拎起Python,说干就干程序想必如何解决?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-13 04:01
每个人都必须熟悉爬虫程序。随便写一个获取网页信息,甚至通过请求自动生成Python脚本[1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但是问题是没有抓取范围的限制,也就是说没有清晰的页面结构。
对于一个页面来说,除了核心的文章内容,还有headers、tails、左右列表列等等。有的页框使用div布局,有的使用table。即使两者都使用div,less网站的样式和布局是不同的。
但问题必须解决。我想,既然搜索引擎已经抓取了各种网页的核心内容,我们应该也能应付。拿起 Python 去做吧!
各种尝试
如何解决?
生成PDF
开始想到一个比较棘手的方法,就是用一个工具(wkhtmltopdf[2])生成目标网页的PDF文件。
好处是不需要关心页面的具体形式,就像给页面拍照一样,文章结构就完整了。
虽然可以在源码级别检索PDF,但是生成PDF有很多缺点:
计算资源消耗大,效率低,错误率高,体积过大。
几万条数据已经两百多G了,如果数据量上来存储,那就是大问题了。
提取 文章 内容
在不生成PDF的情况下,有一种简单的方法可以通过xpath[3]提取页面上的所有文本。
但是内容会失去结构,可读性会很差。更可怕的是,网页上有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。像搜索引擎一样学习,就是想办法识别页面的核心内容。
我们知道,一般情况下,页面的核心内容(比如文章部分)文字比较集中,可以从这个地方开始分析。
所以我写了一段代码。我使用 Scrapy[4] 作为爬虫框架。这里只截取了提取文章部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试几页真的很好。
但是,在提取大量页面时,发现很多页面无法提取数据。仔细一看,发现有两种情况。
一些文章的内容是放在标签里的,所以我没有拿到每个文章
外面裹了一个
, 所以 p 的个数和 div 的偏移量
再次调整策略,不再区分div,查看所有元素。
另外,先选择更多的p,然后在此基础上看更少的div。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
发现的文章主体不稳定,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,需要重新设计算法。
发现文字集中的地方往往是文章的主体。前面的方法没有考虑这个,而是机械地找到最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离p标签越近,越有可能成为文章的主题,也就是说离p越近的节点权重应该越大,离p越远的节点权重就越大p 时间,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度原理,就是离中心越近的地方,密度就越大,而远离中心的地方,密度会呈指数下降,这样密度中心就可以被过滤掉了。
50%的斜率是怎么得到的?
其实是通过实验确定的。一开始,我把它设置为90%,但结果是body节点总是最好的,因为body收录了所有的文本内容。
经过反复实验,确定 50% 是一个更好的值。如果它不适合您的应用程序,您可以进行调整。
总结
在描述了我如何选择文章的方法后,我没有意识到它实际上是一个非常简单的方法。而这次解题的经历,让我感受到了数学的魅力。
我一直认为,只要理解了常规的处理问题的方式,应付日常的编程就足够了。当遇到不确定的问题,又没有办法提取出简单的问题模型时,常规思维显然是不行的。
因此,我们通常应该看看一些数学上很强的方法来解决不确定的问题,以提高我们的编程适应性,扩大我们的技能范围。 查看全部
网页数据抓取(拎起Python,说干就干程序想必如何解决?(图))
每个人都必须熟悉爬虫程序。随便写一个获取网页信息,甚至通过请求自动生成Python脚本[1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但是问题是没有抓取范围的限制,也就是说没有清晰的页面结构。
对于一个页面来说,除了核心的文章内容,还有headers、tails、左右列表列等等。有的页框使用div布局,有的使用table。即使两者都使用div,less网站的样式和布局是不同的。
但问题必须解决。我想,既然搜索引擎已经抓取了各种网页的核心内容,我们应该也能应付。拿起 Python 去做吧!
各种尝试
如何解决?
生成PDF
开始想到一个比较棘手的方法,就是用一个工具(wkhtmltopdf[2])生成目标网页的PDF文件。
好处是不需要关心页面的具体形式,就像给页面拍照一样,文章结构就完整了。
虽然可以在源码级别检索PDF,但是生成PDF有很多缺点:
计算资源消耗大,效率低,错误率高,体积过大。
几万条数据已经两百多G了,如果数据量上来存储,那就是大问题了。
提取 文章 内容
在不生成PDF的情况下,有一种简单的方法可以通过xpath[3]提取页面上的所有文本。
但是内容会失去结构,可读性会很差。更可怕的是,网页上有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。像搜索引擎一样学习,就是想办法识别页面的核心内容。
我们知道,一般情况下,页面的核心内容(比如文章部分)文字比较集中,可以从这个地方开始分析。
所以我写了一段代码。我使用 Scrapy[4] 作为爬虫框架。这里只截取了提取文章部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试几页真的很好。
但是,在提取大量页面时,发现很多页面无法提取数据。仔细一看,发现有两种情况。
一些文章的内容是放在标签里的,所以我没有拿到每个文章
外面裹了一个
, 所以 p 的个数和 div 的偏移量
再次调整策略,不再区分div,查看所有元素。
另外,先选择更多的p,然后在此基础上看更少的div。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
发现的文章主体不稳定,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,需要重新设计算法。
发现文字集中的地方往往是文章的主体。前面的方法没有考虑这个,而是机械地找到最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离p标签越近,越有可能成为文章的主题,也就是说离p越近的节点权重应该越大,离p越远的节点权重就越大p 时间,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度原理,就是离中心越近的地方,密度就越大,而远离中心的地方,密度会呈指数下降,这样密度中心就可以被过滤掉了。
50%的斜率是怎么得到的?
其实是通过实验确定的。一开始,我把它设置为90%,但结果是body节点总是最好的,因为body收录了所有的文本内容。
经过反复实验,确定 50% 是一个更好的值。如果它不适合您的应用程序,您可以进行调整。
总结
在描述了我如何选择文章的方法后,我没有意识到它实际上是一个非常简单的方法。而这次解题的经历,让我感受到了数学的魅力。
我一直认为,只要理解了常规的处理问题的方式,应付日常的编程就足够了。当遇到不确定的问题,又没有办法提取出简单的问题模型时,常规思维显然是不行的。
因此,我们通常应该看看一些数学上很强的方法来解决不确定的问题,以提高我们的编程适应性,扩大我们的技能范围。
网页数据抓取(大数据时代,如何有效获取数据已成为驱动业务决策的关键技能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-12 21:37
站长之家注:大数据时代,如何有效获取数据成为驱动商业决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网络爬取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络抓取赚钱的方法。整个过程只需几个小时就可以学会,使用的代码不到50行。
通过自动化程序在 Airbnb 上最好的酒店花最少的钱
自动化程序可用于执行特定操作,您可以将它们出售给没有技术技能的人来赚钱。
为了展示如何创建和销售自动化程序,Christopher Zita 创建了一个 Airbnb 自动爬虫。该程序允许用户输入位置,它将获取Airbnb在该位置提供的所有房屋数据,包括价格、评级和允许进入的客人数量。所有这一切都是通过在 Airbnb 上抓取数据来完成的。
为了演示程序的实际操作,Christopher Zita 在程序中进入罗马,然后在几秒钟内获得了 272 条 Airbnb 相关数据:
广告网站数据采集首选优采云采集器,支持一键批量网站数据采集,功能强大,免费下载^^-- - ---输入网站了解更多详情!
现在,查看所有房屋数据非常简单,过滤也容易得多。以克里斯托弗·齐塔 (Christopher Zita) 的家人为例。他们家有四口人。如果他们想去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床的酒店。得到这个表中的数据后,excel就可以很方便的进行过滤了。在这 272 条结果中,有 7 家酒店符合要求。
在这7家酒店中,Christopher Zita选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚只需61美元。选择所需链接后,只需将链接复制到浏览器中即可预订。
广告策略数据,深入洞察用户数据,帮助企业用数据驱动产品改进和运营监控,实现多维度、^^精细化统计分析。二级处理,实时更新,...
在度假旅行时,寻找酒店是一项艰巨的任务。出于这个原因,有人愿意花钱来简化这个过程。使用这个自动程序,您可以在短短 5 分钟内以低廉的价格预订一个令您满意的房间。
抓取特定产品的价格数据,以最低价格购买
网页抓取最常见的用途之一是从 网站 获取价格。通过创建一个程序来抓取特定产品的价格数据,当价格下降到一定水平时,它会在产品售罄之前自动购买该产品。
广告python爬虫入门教程,python_basic+爬虫+数据分析+人工智能,免费学习!^^科大讯飞高级技术讲师指导,14天轻...
接下来,Christopher Zita 将向您展示一种可以在赚钱的同时为您节省大量资金的方法:
每个电商网站都会有限量的特价商品,他们会显示商品的原价和折扣价,但一般不会显示在原价的基础上打了多少折扣。举个例子,如果一只手表的初始价格是350美元,促销价是300美元,你会认为50美元的折扣不是小数目,但实际上只有14.@ > 2% 的折扣。而如果一件T恤的初始价是50美元,销售价是40美元,你会觉得它并没有便宜多少,但实际上它的折扣率比手表高出20%。因此,您可以通过购买折扣率最高的产品来省钱/赚钱。
我们以百货公司Hudson's'Bay为例进行数据抓取实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
广告抓数据软件——大数据精准采集端口,全网采集行业精准人力资源,2021营销必备神器!^^ 掌握全国95%以上的大数据库,你要...
抓取网站的数据后,我们得到了900多种产品的数据,其中只有一种产品Perry Ellis纯色衬衫的折扣率超过50%。
广告GooSeeker免费提供采集电子商务、社交平台、房地产网站、科研网站等各种网站网络数据采集^^输出各种包括EXCEL数字...
由于限时优惠,这件衬衫的价格将很快回升至 90 美元左右。因此,如果您现在以 40 美元的价格购买并在限时优惠结束后以 60 美元的价格出售,您仍然可以赚取 20 美元。
这是一种方式,如果你找到合适的利基市场,你可能会赚很多钱。
抓取宣传数据并可视化
网络上有数百万个数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有一些数据不容易获取,可视化需要花费大量时间。这就是销售数据的演变方式。天眼查、七查查等公司专注于获取和可视化公司工商界的业务变化,然后以“买会员查”的形式销售给用户。
一个类似的模型是体育数据网站BigDataBall。网站通过出售玩家的各种游戏数据等统计信息,向用户收取每季30美元的费用。他们设定这个价格不是因为他们网站有数据,而是他们抓取数据后,对数据进行排序,然后以易于阅读和清晰的结构显示数据。
如何写爬虫python免费教程下载+0元直播课,进群交流学习,快速上手掌握,^^推荐就业,轻松进名企,选...
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,然后将其放入结构化数据集。BigDataBall 不是唯一拥有这些数据的 网站。它有相同的数据。但是,网站 并没有对数据进行结构化,用户很难过滤和下载所需的数据集。Christopher Zita 使用网络爬虫来捕获网络上的所有玩家数据。
30秒注册广告,一键发布“慧聪网”^^慧聪网中国商机信息网,2021年各行业商机+2000万产品信息+2700万注册用户=...
所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过16,000份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了这些数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络爬虫工具来寻找人工难以获取的数据,让计算机来完成工作,然后将数据可视化并出售给对数据感兴趣的人。
总结
如今,网络抓取已成为一种非常独特且新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
每天一个超级实用的创业案例,扫码关注【站长视野】↓↓↓ 查看全部
网页数据抓取(大数据时代,如何有效获取数据已成为驱动业务决策的关键技能)
站长之家注:大数据时代,如何有效获取数据成为驱动商业决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网络爬取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络抓取赚钱的方法。整个过程只需几个小时就可以学会,使用的代码不到50行。
通过自动化程序在 Airbnb 上最好的酒店花最少的钱
自动化程序可用于执行特定操作,您可以将它们出售给没有技术技能的人来赚钱。
为了展示如何创建和销售自动化程序,Christopher Zita 创建了一个 Airbnb 自动爬虫。该程序允许用户输入位置,它将获取Airbnb在该位置提供的所有房屋数据,包括价格、评级和允许进入的客人数量。所有这一切都是通过在 Airbnb 上抓取数据来完成的。
为了演示程序的实际操作,Christopher Zita 在程序中进入罗马,然后在几秒钟内获得了 272 条 Airbnb 相关数据:
广告网站数据采集首选优采云采集器,支持一键批量网站数据采集,功能强大,免费下载^^-- - ---输入网站了解更多详情!
现在,查看所有房屋数据非常简单,过滤也容易得多。以克里斯托弗·齐塔 (Christopher Zita) 的家人为例。他们家有四口人。如果他们想去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床的酒店。得到这个表中的数据后,excel就可以很方便的进行过滤了。在这 272 条结果中,有 7 家酒店符合要求。
在这7家酒店中,Christopher Zita选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚只需61美元。选择所需链接后,只需将链接复制到浏览器中即可预订。
广告策略数据,深入洞察用户数据,帮助企业用数据驱动产品改进和运营监控,实现多维度、^^精细化统计分析。二级处理,实时更新,...
在度假旅行时,寻找酒店是一项艰巨的任务。出于这个原因,有人愿意花钱来简化这个过程。使用这个自动程序,您可以在短短 5 分钟内以低廉的价格预订一个令您满意的房间。
抓取特定产品的价格数据,以最低价格购买
网页抓取最常见的用途之一是从 网站 获取价格。通过创建一个程序来抓取特定产品的价格数据,当价格下降到一定水平时,它会在产品售罄之前自动购买该产品。
广告python爬虫入门教程,python_basic+爬虫+数据分析+人工智能,免费学习!^^科大讯飞高级技术讲师指导,14天轻...
接下来,Christopher Zita 将向您展示一种可以在赚钱的同时为您节省大量资金的方法:
每个电商网站都会有限量的特价商品,他们会显示商品的原价和折扣价,但一般不会显示在原价的基础上打了多少折扣。举个例子,如果一只手表的初始价格是350美元,促销价是300美元,你会认为50美元的折扣不是小数目,但实际上只有14.@ > 2% 的折扣。而如果一件T恤的初始价是50美元,销售价是40美元,你会觉得它并没有便宜多少,但实际上它的折扣率比手表高出20%。因此,您可以通过购买折扣率最高的产品来省钱/赚钱。
我们以百货公司Hudson's'Bay为例进行数据抓取实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
广告抓数据软件——大数据精准采集端口,全网采集行业精准人力资源,2021营销必备神器!^^ 掌握全国95%以上的大数据库,你要...
抓取网站的数据后,我们得到了900多种产品的数据,其中只有一种产品Perry Ellis纯色衬衫的折扣率超过50%。
广告GooSeeker免费提供采集电子商务、社交平台、房地产网站、科研网站等各种网站网络数据采集^^输出各种包括EXCEL数字...
由于限时优惠,这件衬衫的价格将很快回升至 90 美元左右。因此,如果您现在以 40 美元的价格购买并在限时优惠结束后以 60 美元的价格出售,您仍然可以赚取 20 美元。
这是一种方式,如果你找到合适的利基市场,你可能会赚很多钱。
抓取宣传数据并可视化
网络上有数百万个数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有一些数据不容易获取,可视化需要花费大量时间。这就是销售数据的演变方式。天眼查、七查查等公司专注于获取和可视化公司工商界的业务变化,然后以“买会员查”的形式销售给用户。
一个类似的模型是体育数据网站BigDataBall。网站通过出售玩家的各种游戏数据等统计信息,向用户收取每季30美元的费用。他们设定这个价格不是因为他们网站有数据,而是他们抓取数据后,对数据进行排序,然后以易于阅读和清晰的结构显示数据。
如何写爬虫python免费教程下载+0元直播课,进群交流学习,快速上手掌握,^^推荐就业,轻松进名企,选...
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,然后将其放入结构化数据集。BigDataBall 不是唯一拥有这些数据的 网站。它有相同的数据。但是,网站 并没有对数据进行结构化,用户很难过滤和下载所需的数据集。Christopher Zita 使用网络爬虫来捕获网络上的所有玩家数据。
30秒注册广告,一键发布“慧聪网”^^慧聪网中国商机信息网,2021年各行业商机+2000万产品信息+2700万注册用户=...
所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过16,000份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了这些数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络爬虫工具来寻找人工难以获取的数据,让计算机来完成工作,然后将数据可视化并出售给对数据感兴趣的人。
总结
如今,网络抓取已成为一种非常独特且新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
每天一个超级实用的创业案例,扫码关注【站长视野】↓↓↓
网页数据抓取(开源的,httpd使用golang和java编写,tornado框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-10 04:02
<p>网页数据抓取很多人都会用到一个神器tornado,还有httpd。这两个都是开源的,httpd使用golang和java编写,tornado是前端开发语言iojs和lua实现的。这篇文章介绍httpd转flask的实现。httpd是一个轻量级的客户端/服务器并发(concurrent)框架。首先定义一个简单的工作页面,用express编写这个页面 查看全部
网页数据抓取(开源的,httpd使用golang和java编写,tornado框架)
<p>网页数据抓取很多人都会用到一个神器tornado,还有httpd。这两个都是开源的,httpd使用golang和java编写,tornado是前端开发语言iojs和lua实现的。这篇文章介绍httpd转flask的实现。httpd是一个轻量级的客户端/服务器并发(concurrent)框架。首先定义一个简单的工作页面,用express编写这个页面
网页数据抓取(2019独角兽企业重金招聘Python工程师标准(gt)(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-06 03:16
)
2019年独角兽企业重磅Python工程师招聘标准>>>
使用Selenium记录前端渲染数据
这几天打算用程序来抓取网站的下一个数据。具体哪个我就不说了,为了减少体力,省点力气。技术使用Java、Selenium、chromeDriver、系统ubuntu16.04
开始查网站的源码,看到了网站使用的模板方式,
> /etc/apt/sources.list.d/google.list'
sudo apt-get update
sudo apt-get install google-chrome-stable
测试chromeDriver是否正常运行。最初,阿里云ECS安装的是centos6.8系统。安装linux chrome并运行chromeDriver后,遇到各种找不到的库。我一直按照提示安装后,还是有问题。谷歌发现CentOS对chrome的支持不是很好(我没有继续追查原因,如果有懂的朋友希望澄清一下,谢谢),我换成了ubuntu 16.04 ,测试正常
root@iZj6c1imv6wpn7tfmm7nusZ:/work/fantasy# ./chromedriver
Starting ChromeDriver 2.37.544315 (730aa6a5fdba159ac9f4c1e8cbc59bf1b5ce12b7) on port 9515
Only local connections are allowed.
抓取页面的java代码,并使用chromeDriver进行渲染。您可以正常使用 xpath 来查找 html 元素。基本用法是使用By的搜索方法,可以通过id、class、tag等进行搜索。
这里有几点需要注意
需要设置选项,
准备工作做完了,可以抓数据了。摆脱手动定时查看,需要通知的时候可以使用bearychat向自己或团队发送通知,做一个快乐的程序员
java爬取分析代码
private WebDriver webDriver;
public XXXSpider() {
String driver = System.getProperty("webdriver.chrome.driver");
if (driver == null) {
logger.info("没有设置 driver 变量");
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/chengpanwang/Downloads/chromedriver");
} else {
logger.info("driver: {}", driver);
}
}
public BigDecimal pageDetail(String url) {
logger.info("详情页: {}", url);
........
try {
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
options.addArguments("--disable-gpu");
options.addArguments("--no-sandbox");
webDriver = new ChromeDriver(options);
webDriver.get(url);
WebElement webElement = webDriver.findElement(By.xpath("/html"));
WebElement roleSkill = webElement.findElement(By.id("role_skill"));
logger.info(roleSkill.getText());
logger.info("选中技术标签");
roleSkill.click();
WebElement skillTb = webElement.findElement(By.className("skillTb"));
for (WebElement item : skillTb.findElements(By.tagName("td"))) {
String level = item.findElement(By.tagName("p")).getText();
String h5 = item.findElement(By.tagName("h5")).getText();
.... 具体业务代码
}
webDriver.close();
} catch (Exception e) {
logger.error("", e);
}
return price;
} 查看全部
网页数据抓取(2019独角兽企业重金招聘Python工程师标准(gt)(组图)
)
2019年独角兽企业重磅Python工程师招聘标准>>>
使用Selenium记录前端渲染数据
这几天打算用程序来抓取网站的下一个数据。具体哪个我就不说了,为了减少体力,省点力气。技术使用Java、Selenium、chromeDriver、系统ubuntu16.04
开始查网站的源码,看到了网站使用的模板方式,
> /etc/apt/sources.list.d/google.list'
sudo apt-get update
sudo apt-get install google-chrome-stable
测试chromeDriver是否正常运行。最初,阿里云ECS安装的是centos6.8系统。安装linux chrome并运行chromeDriver后,遇到各种找不到的库。我一直按照提示安装后,还是有问题。谷歌发现CentOS对chrome的支持不是很好(我没有继续追查原因,如果有懂的朋友希望澄清一下,谢谢),我换成了ubuntu 16.04 ,测试正常
root@iZj6c1imv6wpn7tfmm7nusZ:/work/fantasy# ./chromedriver
Starting ChromeDriver 2.37.544315 (730aa6a5fdba159ac9f4c1e8cbc59bf1b5ce12b7) on port 9515
Only local connections are allowed.
抓取页面的java代码,并使用chromeDriver进行渲染。您可以正常使用 xpath 来查找 html 元素。基本用法是使用By的搜索方法,可以通过id、class、tag等进行搜索。
这里有几点需要注意
需要设置选项,
准备工作做完了,可以抓数据了。摆脱手动定时查看,需要通知的时候可以使用bearychat向自己或团队发送通知,做一个快乐的程序员
java爬取分析代码
private WebDriver webDriver;
public XXXSpider() {
String driver = System.getProperty("webdriver.chrome.driver");
if (driver == null) {
logger.info("没有设置 driver 变量");
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/chengpanwang/Downloads/chromedriver");
} else {
logger.info("driver: {}", driver);
}
}
public BigDecimal pageDetail(String url) {
logger.info("详情页: {}", url);
........
try {
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
options.addArguments("--disable-gpu");
options.addArguments("--no-sandbox");
webDriver = new ChromeDriver(options);
webDriver.get(url);
WebElement webElement = webDriver.findElement(By.xpath("/html"));
WebElement roleSkill = webElement.findElement(By.id("role_skill"));
logger.info(roleSkill.getText());
logger.info("选中技术标签");
roleSkill.click();
WebElement skillTb = webElement.findElement(By.className("skillTb"));
for (WebElement item : skillTb.findElements(By.tagName("td"))) {
String level = item.findElement(By.tagName("p")).getText();
String h5 = item.findElement(By.tagName("h5")).getText();
.... 具体业务代码
}
webDriver.close();
} catch (Exception e) {
logger.error("", e);
}
return price;
}
网页数据抓取(网页数据抓取功能常见有20多种方法,我简单介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-30 02:02
网页数据抓取功能常见有20多种方法,我简单介绍网页搜索,关键词百度搜索抓取,谷歌搜索抓取,比如你在谷歌搜索pythonscientificstatistics会跳出一大堆有关python中最出名的爬虫例子,点进去随便浏览一下再返回到谷歌页面去发现很多相关网页,点进去以后进入一个搜索框,搜索你要的内容,如nbaairline,再分别查看页面搜索结果中的每个页面的后缀是python那个的那些,就会得到你想要的内容了。还有其他的方法:搜索了一部手机型号,搜索了一个好像专辑,搜索了一个专辑,等等。
开始我是用一个爬虫工具来完成这一部分数据爬取的,不过你有没有想过,这样学习量产你对爬虫学习是不是太漫长了?你学习爬虫,又不是学习代码,对你来说会因为课本上的代码让你很舒适,而是通过完成一个个爬虫任务,不断复杂化和重构,通过达到工程上的复杂化,形成自己的一套规范,在解决问题,用实际任务去证明你对爬虫语言的掌握是不是可以吗?你学习爬虫,不需要通过网页划拉你眼睛都盯着哪里去,你学习的是如何组合方法进行数据爬取,而这种方法不需要你自己编写,是只要说明白大致的思路就行,所以你也能用语言中写的爬虫,也能用python来实现,但语言怎么说呢,就是一个工具。代码是死的,理论是活的,如果能活起来,就能产生最终的,具有自己价值的产品。 查看全部
网页数据抓取(网页数据抓取功能常见有20多种方法,我简单介绍)
网页数据抓取功能常见有20多种方法,我简单介绍网页搜索,关键词百度搜索抓取,谷歌搜索抓取,比如你在谷歌搜索pythonscientificstatistics会跳出一大堆有关python中最出名的爬虫例子,点进去随便浏览一下再返回到谷歌页面去发现很多相关网页,点进去以后进入一个搜索框,搜索你要的内容,如nbaairline,再分别查看页面搜索结果中的每个页面的后缀是python那个的那些,就会得到你想要的内容了。还有其他的方法:搜索了一部手机型号,搜索了一个好像专辑,搜索了一个专辑,等等。
开始我是用一个爬虫工具来完成这一部分数据爬取的,不过你有没有想过,这样学习量产你对爬虫学习是不是太漫长了?你学习爬虫,又不是学习代码,对你来说会因为课本上的代码让你很舒适,而是通过完成一个个爬虫任务,不断复杂化和重构,通过达到工程上的复杂化,形成自己的一套规范,在解决问题,用实际任务去证明你对爬虫语言的掌握是不是可以吗?你学习爬虫,不需要通过网页划拉你眼睛都盯着哪里去,你学习的是如何组合方法进行数据爬取,而这种方法不需要你自己编写,是只要说明白大致的思路就行,所以你也能用语言中写的爬虫,也能用python来实现,但语言怎么说呢,就是一个工具。代码是死的,理论是活的,如果能活起来,就能产生最终的,具有自己价值的产品。
网页数据抓取(网页数据抓取实战twopi成长计划项目是怎样进行的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-19 05:00
网页数据抓取实战twopi成长计划项目是这样进行的:从海量文本中提取有效信息作为分类输出(“清华大学计算机科学技术805实验室【是谁】”)。欢迎给作者投稿留言。
说一句冒犯人的话,根据楼主的描述,无论如何也不像是想使用类似“selenium+chromeflash+sublimetext”的技术,正经点吧,这种做法是走弯路的,不靠谱的,还不如自己做,开源的库不多,自己开发的库有海量,要你挑,如果你有兴趣可以去github看看,免费开源,也很不错的,最近天气那个,还有新闻微博那个。天气那个。
把今天所有的新闻及我所关注的话题全部爬下来,按人气排序,总会有几个靠前的。
可以选择网页的批量爬虫,推荐你使用蜂鸟全网爬虫工具箱,功能齐全易用,
首先上传数据,爬你感兴趣的东西啊,新闻,百科,贴吧,有可能会遇到反爬虫,把他爬到一定时间(多少自己试),然后就能输出一个txt格式的数据了。如果不想费事,找一个大网站的数据库手动下载下来,然后导入你的爬虫就ok了。wooyun不错,公共社区。比你自己玩强很多。
最近我自己用的是爬虫工具webpagetest()。
关键看是什么数据,必须要先数据可用。爬虫技术用处有限,适合复杂数据(字段比较多,组合方式比较复杂)。自己有一个简单的爬虫/反爬虫的模型就行了。最后说一句,爬虫是一个非常低效、不务正业、没有任何实际意义的工作,当前网站服务器对于爬虫是很敏感的, 查看全部
网页数据抓取(网页数据抓取实战twopi成长计划项目是怎样进行的?)
网页数据抓取实战twopi成长计划项目是这样进行的:从海量文本中提取有效信息作为分类输出(“清华大学计算机科学技术805实验室【是谁】”)。欢迎给作者投稿留言。
说一句冒犯人的话,根据楼主的描述,无论如何也不像是想使用类似“selenium+chromeflash+sublimetext”的技术,正经点吧,这种做法是走弯路的,不靠谱的,还不如自己做,开源的库不多,自己开发的库有海量,要你挑,如果你有兴趣可以去github看看,免费开源,也很不错的,最近天气那个,还有新闻微博那个。天气那个。
把今天所有的新闻及我所关注的话题全部爬下来,按人气排序,总会有几个靠前的。
可以选择网页的批量爬虫,推荐你使用蜂鸟全网爬虫工具箱,功能齐全易用,
首先上传数据,爬你感兴趣的东西啊,新闻,百科,贴吧,有可能会遇到反爬虫,把他爬到一定时间(多少自己试),然后就能输出一个txt格式的数据了。如果不想费事,找一个大网站的数据库手动下载下来,然后导入你的爬虫就ok了。wooyun不错,公共社区。比你自己玩强很多。
最近我自己用的是爬虫工具webpagetest()。
关键看是什么数据,必须要先数据可用。爬虫技术用处有限,适合复杂数据(字段比较多,组合方式比较复杂)。自己有一个简单的爬虫/反爬虫的模型就行了。最后说一句,爬虫是一个非常低效、不务正业、没有任何实际意义的工作,当前网站服务器对于爬虫是很敏感的,
网页数据抓取(java实现了一个简单的网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-18 07:08
最近,使用java实现了一个简单的网络数据捕获。下面是实现原理和实现代码:
原理:使用如下URL对象获取链接,下载目标网页的源码,使用jsoup解析源码中的数据,得到想要的内容
1.首先根据网址下载源码:
/**
* 根据网址和编码下载源代码
* @param url 目标网址
* @param encoding 编码
* @return
*/
public static String getHtmlResourceByURL(String url,String encoding){
//存储源代码容器
StringBuffer buffer = new StringBuffer();
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader br =null;
try {
//建立网络连接
urlObj = new URL(url);
//打开网络连接
uc = urlObj.openConnection();
//建立文件输入流
isr = new InputStreamReader(uc.getInputStream(),encoding);
InputStream is = uc.getInputStream();
//建立文件缓冲写入流
br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("F:\\java-study\\downImg\\index.txt");
//建立临时变量
String temp = null;
while((temp = br.readLine()) != null){
buffer.append(temp + "\n");
}
// fos.write(buffer.toString().getBytes());
// fos.close();
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("网络不给力,请检查网络设置。。。。");
}catch (IOException e){
e.printStackTrace();
System.out.println("你的网络连接打开失败,请稍后重新尝试!");
}finally {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return buffer.toString();
}
2.根据下载的源码分析数据得到你想要的内容,这里我拿图,你也可以在贴吧中得到邮箱、电话等
/**
* 获取图片路劲
* @param url 网络路径
* @param encoding 编码
*/
public static void downImg(String url,String encoding){
String resourceByURL = getHtmlResourceByURL(url, encoding);
//2.解析源代码,根据网络图像地址,下载到服务器
Document document = Jsoup.parse(resourceByURL);
//获取页面中所有的图片标签
Elements elements = document.getElementsByTag("img");
for(Element element:elements){
//获取图像地址
String src = element.attr("src");
//包含http开头
if (src.startsWith("http") && src.indexOf("jpg") != -1) {
getImg(src, "F:\\java-study\\downImg");
}
}
}
3. 根据获取到的图片路径下载图片,这里我下载的是携程网的内容
/**
* 下载图片
* @param imgUrl 图片地址
* @param filePath 存储路劲
*
*/
public static void getImg(String imgUrl,String filePath){
String fileName = imgUrl.substring(imgUrl.lastIndexOf("/"));
try {
//创建目录
File files = new File(filePath);
if (!files.exists()) {
files.mkdirs();
}
//获取地址
URL url = new URL(imgUrl);
//打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//获取输入流
InputStream is = connection.getInputStream();
File file = new File(filePath + fileName);
//建立问价输入流
FileOutputStream fos = new FileOutputStream(file);
int temp = 0;
while((temp = is.read()) != -1){
fos.write(temp);
}
is.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
最后是调用过程
public static void main(String[] args) {
//1.根据网址和页面编码集获取网页源代码
String encoding = "gbk";
String url = "http://vacations.ctrip.com/";
//2.解析源代码,根据网络图像地址,下载到服务器
downImg(url, encoding);
}
总结:根据上面实现的简单数据爬取,存在一些问题。我爬的旅游页面有很多图片。根据img属性,我在src里面拿到了下载图片的地址,但是页面图片很多。结果但是我只能爬到一小部分,如下图:
我把下载的源代码写成文件,和原来的网页对比。基本上,没有页面浏览的图片,也没有在源代码中。不知道为什么,求网友解答。 查看全部
网页数据抓取(java实现了一个简单的网页数据)
最近,使用java实现了一个简单的网络数据捕获。下面是实现原理和实现代码:
原理:使用如下URL对象获取链接,下载目标网页的源码,使用jsoup解析源码中的数据,得到想要的内容
1.首先根据网址下载源码:
/**
* 根据网址和编码下载源代码
* @param url 目标网址
* @param encoding 编码
* @return
*/
public static String getHtmlResourceByURL(String url,String encoding){
//存储源代码容器
StringBuffer buffer = new StringBuffer();
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader br =null;
try {
//建立网络连接
urlObj = new URL(url);
//打开网络连接
uc = urlObj.openConnection();
//建立文件输入流
isr = new InputStreamReader(uc.getInputStream(),encoding);
InputStream is = uc.getInputStream();
//建立文件缓冲写入流
br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("F:\\java-study\\downImg\\index.txt");
//建立临时变量
String temp = null;
while((temp = br.readLine()) != null){
buffer.append(temp + "\n");
}
// fos.write(buffer.toString().getBytes());
// fos.close();
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("网络不给力,请检查网络设置。。。。");
}catch (IOException e){
e.printStackTrace();
System.out.println("你的网络连接打开失败,请稍后重新尝试!");
}finally {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return buffer.toString();
}
2.根据下载的源码分析数据得到你想要的内容,这里我拿图,你也可以在贴吧中得到邮箱、电话等
/**
* 获取图片路劲
* @param url 网络路径
* @param encoding 编码
*/
public static void downImg(String url,String encoding){
String resourceByURL = getHtmlResourceByURL(url, encoding);
//2.解析源代码,根据网络图像地址,下载到服务器
Document document = Jsoup.parse(resourceByURL);
//获取页面中所有的图片标签
Elements elements = document.getElementsByTag("img");
for(Element element:elements){
//获取图像地址
String src = element.attr("src");
//包含http开头
if (src.startsWith("http") && src.indexOf("jpg") != -1) {
getImg(src, "F:\\java-study\\downImg");
}
}
}
3. 根据获取到的图片路径下载图片,这里我下载的是携程网的内容
/**
* 下载图片
* @param imgUrl 图片地址
* @param filePath 存储路劲
*
*/
public static void getImg(String imgUrl,String filePath){
String fileName = imgUrl.substring(imgUrl.lastIndexOf("/"));
try {
//创建目录
File files = new File(filePath);
if (!files.exists()) {
files.mkdirs();
}
//获取地址
URL url = new URL(imgUrl);
//打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//获取输入流
InputStream is = connection.getInputStream();
File file = new File(filePath + fileName);
//建立问价输入流
FileOutputStream fos = new FileOutputStream(file);
int temp = 0;
while((temp = is.read()) != -1){
fos.write(temp);
}
is.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
最后是调用过程
public static void main(String[] args) {
//1.根据网址和页面编码集获取网页源代码
String encoding = "gbk";
String url = "http://vacations.ctrip.com/";
//2.解析源代码,根据网络图像地址,下载到服务器
downImg(url, encoding);
}
总结:根据上面实现的简单数据爬取,存在一些问题。我爬的旅游页面有很多图片。根据img属性,我在src里面拿到了下载图片的地址,但是页面图片很多。结果但是我只能爬到一小部分,如下图:
我把下载的源代码写成文件,和原来的网页对比。基本上,没有页面浏览的图片,也没有在源代码中。不知道为什么,求网友解答。
网页数据抓取(自己边看边实践一些简单的实际应用,发现Python真的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-13 23:03
)
自己观看并练习一些简单的实际应用。下面的程序是从某个网站中获取需要的数据。
在写的过程中,通过学习学到了一些方法,发现Python真的很方便。
尤其是使用pandas获取网页中的表格数据,真的很方便!!!
程序可能不太好,但基本满足了它的需求。
希望有高手指点~~
Version 04 (Jan 12 2017) [获取表单信息推荐使用此方法]
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 import pandas as pd
6
7 url2 = 'http://www.bjets.com.cn/article/jyxx/?'
8 links = []
9 for n in range(2, 40):
10 # 页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
11 link = url2 + str(n)
12 links.append(link)
13 links.insert(0, url2)
14
15 df2 = pd.DataFrame() # creates a new dataframe that's empty
16 for url in links:
17 # 利用pandas获取数据,需要安装 html5lib模块
18 dfs = pd.read_html(url, header=0)
19 for df in dfs:
20 df2= df2.append(df, ignore_index= True)
21
22 # df2.to_excel('MktDataBJ.xlsx') # 将数据存储在excel文件里
23 df2.to_csv('MktDataBJ-1.csv') # 将数据存储在csv文件里
版本 03(201 年 1 月 12 日7)
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 from bs4 import BeautifulSoup
6 import requests
7 import csv
8
9 url2 = 'http://www.bjets.com.cn/article/jyxx/?'
10 links = []
11 for n in range(2, 40):
12 # 页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
13 link = url2 + str(n)
14 links.append(link)
15 links.insert(0, url2)
16
17 for url in links:
18 rep = requests.get(url)
19 # content = rep.text.encode(rep.encoding).decode('utf-8')
20 # # 直接用requests时,中文内容需要转码
21
22 soup = BeautifulSoup(rep.content, 'html.parser')
23
24 # table = soup.table
25 table = soup.find('table') # 两种方式都可以
26
27 trs = table.find_all('tr')
28 trs2 = trs[1:len(trs)]
29 list1 = []
30 for tr in trs2:
31 td = tr.find_all('td')
32 row = [i.text for i in td]
33 list1.append(row)
34
35 with open('MktDataBJ.csv', 'a', errors='ignore', newline='') as f:
36 f_csv = csv.writer(f)
37 f_csv.writerows(list1)
版本 02(201 年 1 月 9 日7)
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 from bs4 import BeautifulSoup
6 import requests
7 import csv
8
9 url2 = 'http://www.bjets.com.cn/article/jyxx/?'
10 links = []
11 for n in range(2, 40):
12 # 页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
13 link = url2 + str(n)
14 links.append(link)
15 links.insert(0, url2)
16 # print(links)
17
18 for url in links:
19 rep = requests.get(url)
20 # content = rep.text.encode(rep.encoding).decode('utf-8')
21 # # 直接用requests时,中文内容需要转码
22
23 soup = BeautifulSoup(rep.content, 'html.parser')
24 body = soup.body
25 data = body.find('div', {'class': 'list_right'})
26
27 quotes = data.find_all('tr')
28 quotes1 = quotes[1:len(quotes)]
29
30 list1 = []
31 for x in quotes1:
32 list2 = []
33 for y in x.find_all('td'):
34 list2.append(y.text) # 每日的数据做一个单独的list
35 list1.append(list2)
36 # print(list1) # list1为每日数据的总列表
37 with open('MktDataBJ.csv', 'a', errors='ignore', newline='') as f:
38 f_csv = csv.writer(f)
39 f_csv.writerows(list1)
版本 01(201 年 1 月 8 日7)
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 from bs4 import BeautifulSoup
6 import requests
7 import csv
8
9 urllink = 'http://www.bjets.com.cn/article/jyxx/?'
10 links = []
11 for n in range(2, 40):
12 #页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
13 link = urllink + str(n)
14 links.append(link)
15 links.insert(0, urllink)
16 # print(links)
17
18 for url in links:
19
20 rep = requests.get(url)
21 # content = rep.text.encode(rep.encoding).decode('utf-8')
22 # # 直接用requests时,中文内容需要转码
23
24 soup = BeautifulSoup(rep.content, 'html.parser')
25
26 # print(soup.prettify())
27 # # prettify()
28
29 body = soup.body
30 data = body.find('div', {'class': 'list_right'})
31
32 # table title
33 titles = data.find_all('th')
34
35 title = []
36 for x in titles:
37 title.append(x.text)
38 # print(title)
39
40 quotes = data.find_all('tr')
41 quotes1 = quotes[1:len(quotes)]
42 # print(quotes1)
43
44 list1 = []
45 for x in quotes1:
46 for y in x.find_all('td'):
47 list1.append(y.text)
48 # print(list1) # list为每日数据的总列表
49
50 date = []
51 volumes = []
52 meanprice = []
53 totalmoney = []
54
55 for i in range(0, len(list1)):
56 if i % 4 == 0:
57 date.append(list1[i])
58 elif i % 4 == 1:
59 volumes.append(list1[i])
60 elif i % 4 == 2:
61 meanprice.append(list1[i])
62 else:
63 totalmoney.append(list1[i])
64
65 # print(date)
66 # print(volumes)
67 # print(meanprice)
68 # print(totalmoney)
69
70 final = []
71 for i in range(0, len(date)):
72 temp = [date[i], volumes[i], meanprice[i], totalmoney[i]]
73 final.append(temp)
74 # print(final)
75 with open('bj_carbon.csv', 'a', errors='ignore', newline='') as f:
76 f_csv = csv.writer(f)
77 f_csv.writerows(final) 查看全部
网页数据抓取(自己边看边实践一些简单的实际应用,发现Python真的
)
自己观看并练习一些简单的实际应用。下面的程序是从某个网站中获取需要的数据。
在写的过程中,通过学习学到了一些方法,发现Python真的很方便。
尤其是使用pandas获取网页中的表格数据,真的很方便!!!
程序可能不太好,但基本满足了它的需求。
希望有高手指点~~
Version 04 (Jan 12 2017) [获取表单信息推荐使用此方法]
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 import pandas as pd
6
7 url2 = 'http://www.bjets.com.cn/article/jyxx/?'
8 links = []
9 for n in range(2, 40):
10 # 页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
11 link = url2 + str(n)
12 links.append(link)
13 links.insert(0, url2)
14
15 df2 = pd.DataFrame() # creates a new dataframe that's empty
16 for url in links:
17 # 利用pandas获取数据,需要安装 html5lib模块
18 dfs = pd.read_html(url, header=0)
19 for df in dfs:
20 df2= df2.append(df, ignore_index= True)
21
22 # df2.to_excel('MktDataBJ.xlsx') # 将数据存储在excel文件里
23 df2.to_csv('MktDataBJ-1.csv') # 将数据存储在csv文件里
版本 03(201 年 1 月 12 日7)
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 from bs4 import BeautifulSoup
6 import requests
7 import csv
8
9 url2 = 'http://www.bjets.com.cn/article/jyxx/?'
10 links = []
11 for n in range(2, 40):
12 # 页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
13 link = url2 + str(n)
14 links.append(link)
15 links.insert(0, url2)
16
17 for url in links:
18 rep = requests.get(url)
19 # content = rep.text.encode(rep.encoding).decode('utf-8')
20 # # 直接用requests时,中文内容需要转码
21
22 soup = BeautifulSoup(rep.content, 'html.parser')
23
24 # table = soup.table
25 table = soup.find('table') # 两种方式都可以
26
27 trs = table.find_all('tr')
28 trs2 = trs[1:len(trs)]
29 list1 = []
30 for tr in trs2:
31 td = tr.find_all('td')
32 row = [i.text for i in td]
33 list1.append(row)
34
35 with open('MktDataBJ.csv', 'a', errors='ignore', newline='') as f:
36 f_csv = csv.writer(f)
37 f_csv.writerows(list1)
版本 02(201 年 1 月 9 日7)
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 from bs4 import BeautifulSoup
6 import requests
7 import csv
8
9 url2 = 'http://www.bjets.com.cn/article/jyxx/?'
10 links = []
11 for n in range(2, 40):
12 # 页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
13 link = url2 + str(n)
14 links.append(link)
15 links.insert(0, url2)
16 # print(links)
17
18 for url in links:
19 rep = requests.get(url)
20 # content = rep.text.encode(rep.encoding).decode('utf-8')
21 # # 直接用requests时,中文内容需要转码
22
23 soup = BeautifulSoup(rep.content, 'html.parser')
24 body = soup.body
25 data = body.find('div', {'class': 'list_right'})
26
27 quotes = data.find_all('tr')
28 quotes1 = quotes[1:len(quotes)]
29
30 list1 = []
31 for x in quotes1:
32 list2 = []
33 for y in x.find_all('td'):
34 list2.append(y.text) # 每日的数据做一个单独的list
35 list1.append(list2)
36 # print(list1) # list1为每日数据的总列表
37 with open('MktDataBJ.csv', 'a', errors='ignore', newline='') as f:
38 f_csv = csv.writer(f)
39 f_csv.writerows(list1)
版本 01(201 年 1 月 8 日7)
1 # Code based on Python 3.x
2 # _*_ coding: utf-8 _*_
3 # __Author: "LEMON"
4
5 from bs4 import BeautifulSoup
6 import requests
7 import csv
8
9 urllink = 'http://www.bjets.com.cn/article/jyxx/?'
10 links = []
11 for n in range(2, 40):
12 #页面总数为39页,需要自己先从网页判断,也可以从页面抓取,后续可以完善
13 link = urllink + str(n)
14 links.append(link)
15 links.insert(0, urllink)
16 # print(links)
17
18 for url in links:
19
20 rep = requests.get(url)
21 # content = rep.text.encode(rep.encoding).decode('utf-8')
22 # # 直接用requests时,中文内容需要转码
23
24 soup = BeautifulSoup(rep.content, 'html.parser')
25
26 # print(soup.prettify())
27 # # prettify()
28
29 body = soup.body
30 data = body.find('div', {'class': 'list_right'})
31
32 # table title
33 titles = data.find_all('th')
34
35 title = []
36 for x in titles:
37 title.append(x.text)
38 # print(title)
39
40 quotes = data.find_all('tr')
41 quotes1 = quotes[1:len(quotes)]
42 # print(quotes1)
43
44 list1 = []
45 for x in quotes1:
46 for y in x.find_all('td'):
47 list1.append(y.text)
48 # print(list1) # list为每日数据的总列表
49
50 date = []
51 volumes = []
52 meanprice = []
53 totalmoney = []
54
55 for i in range(0, len(list1)):
56 if i % 4 == 0:
57 date.append(list1[i])
58 elif i % 4 == 1:
59 volumes.append(list1[i])
60 elif i % 4 == 2:
61 meanprice.append(list1[i])
62 else:
63 totalmoney.append(list1[i])
64
65 # print(date)
66 # print(volumes)
67 # print(meanprice)
68 # print(totalmoney)
69
70 final = []
71 for i in range(0, len(date)):
72 temp = [date[i], volumes[i], meanprice[i], totalmoney[i]]
73 final.append(temp)
74 # print(final)
75 with open('bj_carbon.csv', 'a', errors='ignore', newline='') as f:
76 f_csv = csv.writer(f)
77 f_csv.writerows(final)
网页数据抓取( 网页抓取工具助力传统企业弯道超车(2016.10.21))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-10 21:04
网页抓取工具助力传统企业弯道超车(2016.10.21))
获取大数据信息爬取的网络爬虫工具-微信公众Ping
600x450-45KB-JPEG
如何获取网页数据工具的内容
893x1462-47KB-PNG
网页抓取工具助力传统企业弯道超车-微信公众号
600x277-308KB-PNG
网页抓取工具助力传统企业弯道超车-微信公众号
432x324-266KB-PNG
网页抓取工具:详述未来的核心资产-
547x405-111KB-PNG
手机网页视频提取工具-安卓网页视频抓取工具
329x404-45KB-JPEG
网页抓取工具:大数据工作必不可少
487x326-34KB-JPEG
网页抓取工具:一个简单的文章采集示例(1)
893x2000-71KB-PNG
Web哈维中文| SysNucleus WebHarvy(页数
256x256-43KB-PNG
Python爬取动态网页内容程序详解
673x246-28KB-PNG
爬取网页数据工具优采云采集器插件说明
893x1744-72KB-PNG
抓取网页颜色的好工具--PickColor_Homepage_Production_
220x201-26KB-JPEG
[30P] 网页数据爬取工具-大网页数据爬取工具
550x349-28KB-JPEG
【全新Petal采集工具测试版上线】主要改进与
640x450-46KB-JPEG
【全新Petal采集工具测试版上线】主要改进与
640x1136-75KB-JPEG
抓取网页的指定内容(信息),获取网页中的图片,最近遇到同学反馈。网页中没有特征值的文本元素不是
优采云采集器是一套专业的网站内容采集实现网页内容的软件,支持各种论坛发帖和回复采集、网站@ >和博客文章
这种类型是专门为网页链接准备的,所以我们抓取数据的逻辑是这样的:从入口页面进入,获取当前页面已经加载
网页内容提取工具使用方法:2、点击抓取文本按钮,程序可以自动过滤网页,只提取文本内容,获取网页中的文本
本工具可以加快爬虫的抓取速度,不能解决网站内容是否为收录的问题2.百度搜索资源平台为站长提供了链接提交通道,各位
网页正文提取器是一种网页内容提取工具。该软件可以提前快速提取文章的正文和标题。
Import.io 是一个免费的在线网页 Mozenda 提供了数据提取工具,即使没有键盘,也可以轻松地从网页中抓取数据
我写的网络爬虫工具配置为只抓取某些论坛,你可以重写配置文件来抓取其他网页内容。
网页正文内容提取工具分析了新浪、搜狐、网易、腾讯、百度、中国新闻、中华网、21cn这8个网站。 查看全部
网页数据抓取(
网页抓取工具助力传统企业弯道超车(2016.10.21))
获取大数据信息爬取的网络爬虫工具-微信公众Ping
600x450-45KB-JPEG
如何获取网页数据工具的内容
893x1462-47KB-PNG
网页抓取工具助力传统企业弯道超车-微信公众号
600x277-308KB-PNG
网页抓取工具助力传统企业弯道超车-微信公众号
432x324-266KB-PNG
网页抓取工具:详述未来的核心资产-
547x405-111KB-PNG
手机网页视频提取工具-安卓网页视频抓取工具
329x404-45KB-JPEG
网页抓取工具:大数据工作必不可少
487x326-34KB-JPEG
网页抓取工具:一个简单的文章采集示例(1)
893x2000-71KB-PNG
Web哈维中文| SysNucleus WebHarvy(页数
256x256-43KB-PNG
Python爬取动态网页内容程序详解
673x246-28KB-PNG
爬取网页数据工具优采云采集器插件说明
893x1744-72KB-PNG
抓取网页颜色的好工具--PickColor_Homepage_Production_
220x201-26KB-JPEG
[30P] 网页数据爬取工具-大网页数据爬取工具
550x349-28KB-JPEG
【全新Petal采集工具测试版上线】主要改进与
640x450-46KB-JPEG
【全新Petal采集工具测试版上线】主要改进与
640x1136-75KB-JPEG
抓取网页的指定内容(信息),获取网页中的图片,最近遇到同学反馈。网页中没有特征值的文本元素不是
优采云采集器是一套专业的网站内容采集实现网页内容的软件,支持各种论坛发帖和回复采集、网站@ >和博客文章
这种类型是专门为网页链接准备的,所以我们抓取数据的逻辑是这样的:从入口页面进入,获取当前页面已经加载
网页内容提取工具使用方法:2、点击抓取文本按钮,程序可以自动过滤网页,只提取文本内容,获取网页中的文本
本工具可以加快爬虫的抓取速度,不能解决网站内容是否为收录的问题2.百度搜索资源平台为站长提供了链接提交通道,各位
网页正文提取器是一种网页内容提取工具。该软件可以提前快速提取文章的正文和标题。
Import.io 是一个免费的在线网页 Mozenda 提供了数据提取工具,即使没有键盘,也可以轻松地从网页中抓取数据
我写的网络爬虫工具配置为只抓取某些论坛,你可以重写配置文件来抓取其他网页内容。
网页正文内容提取工具分析了新浪、搜狐、网易、腾讯、百度、中国新闻、中华网、21cn这8个网站。
网页数据抓取(智能识别方式WebHarvy自动检索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-05 21:18
WebHarvy 是网页数据爬取的专用工具。该软件可以提取网页中的文字和图片,输入网址即可打开。默认设置为使用电脑内置浏览器,适合扩展分析,可自动获取类似连接列表。程序界面 可视化的实际操作很容易。【功能介绍】智能识别方法WebHarvy自动检索网页中出现的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则不需要做所有额外的准备工作。如果数据重复,WebHarvy 会自动抓取。导出捕获的数据可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy URL 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文档。您还可以抓取数据并将其导出到 SQL 数据库。从多个页面中提取通用网页显示信息数据,例如多个页面中的产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只强调“连接到下一页”,WebHarvy URL 抓取器会自动从所有页面抓取数据。可视化操作面板WebHarvy是一款用于数据可视化网页提取的专用工具。实际上,没有必要编写所有脚本。或者编码用于提取数据。使用 webharvy 的嵌入式计算机浏览器访问网页。您可以选择通过单击鼠标来提取数据。
这太容易了!根据关键词提取 根据关键词提取,可以抓取百度搜索页面关键词输入的列表数据。您创建的设备将自动重复输入所有输入 关键词 和发现的数据。能够指定一个随机的总输入 关键词 提取分类 WebHarvy URL 抓取器允许您从链接列表中提取数据,从而在 网站 内生成类似的页面。这使您能够在抓取的 URL 中应用单一类型或副标题。使用正则表达式提取 WebHarvy 可以在文本或网页的 HTML 源代码中使用正则表达式(正则表达式),并提取匹配的一部分。这种技术性很强,说明你协调能力很强,数据也很顶尖。[软件特点] WebHarvy 是一款视觉效果的网络爬虫。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。
您还可以将抓取到的数据导出到 SQL 数据库。通常,网页在多个页面上显示诸如信息产品列表之类的数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需强调“连接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。【版本更新】恢复页面启动时可以禁止使用链接。可以为page方法配备专用的接口方法。它可以自动检索可以在 HTML 上提供的资源。改进电脑键盘向下翻页功能改进基于Java脚本制作的下一页加载。添加URL设备后,可以在列表2搜索中输入关键词 查看全部
网页数据抓取(智能识别方式WebHarvy自动检索)
WebHarvy 是网页数据爬取的专用工具。该软件可以提取网页中的文字和图片,输入网址即可打开。默认设置为使用电脑内置浏览器,适合扩展分析,可自动获取类似连接列表。程序界面 可视化的实际操作很容易。【功能介绍】智能识别方法WebHarvy自动检索网页中出现的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则不需要做所有额外的准备工作。如果数据重复,WebHarvy 会自动抓取。导出捕获的数据可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy URL 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文档。您还可以抓取数据并将其导出到 SQL 数据库。从多个页面中提取通用网页显示信息数据,例如多个页面中的产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只强调“连接到下一页”,WebHarvy URL 抓取器会自动从所有页面抓取数据。可视化操作面板WebHarvy是一款用于数据可视化网页提取的专用工具。实际上,没有必要编写所有脚本。或者编码用于提取数据。使用 webharvy 的嵌入式计算机浏览器访问网页。您可以选择通过单击鼠标来提取数据。
这太容易了!根据关键词提取 根据关键词提取,可以抓取百度搜索页面关键词输入的列表数据。您创建的设备将自动重复输入所有输入 关键词 和发现的数据。能够指定一个随机的总输入 关键词 提取分类 WebHarvy URL 抓取器允许您从链接列表中提取数据,从而在 网站 内生成类似的页面。这使您能够在抓取的 URL 中应用单一类型或副标题。使用正则表达式提取 WebHarvy 可以在文本或网页的 HTML 源代码中使用正则表达式(正则表达式),并提取匹配的一部分。这种技术性很强,说明你协调能力很强,数据也很顶尖。[软件特点] WebHarvy 是一款视觉效果的网络爬虫。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。
您还可以将抓取到的数据导出到 SQL 数据库。通常,网页在多个页面上显示诸如信息产品列表之类的数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需强调“连接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。【版本更新】恢复页面启动时可以禁止使用链接。可以为page方法配备专用的接口方法。它可以自动检索可以在 HTML 上提供的资源。改进电脑键盘向下翻页功能改进基于Java脚本制作的下一页加载。添加URL设备后,可以在列表2搜索中输入关键词
网页数据抓取(智能识别方式WebHarvy自动检索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-05 21:14
WebHarvy 是网页数据爬取的专用工具。该软件可以提取网页中的文字和图片,输入网址即可打开。默认设置为使用电脑内置浏览器,适合扩展分析,可自动获取类似连接列表。程序界面 可视化的实际操作很容易。【功能介绍】智能识别方法WebHarvy自动检索网页中出现的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则不需要做所有额外的准备工作。如果数据重复,WebHarvy 会自动抓取。导出捕获的数据可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy URL 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文档。您还可以抓取数据并将其导出到 SQL 数据库。从多个页面中提取通用网页显示信息数据,例如多个页面中的产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只强调“连接到下一页”,WebHarvy URL 抓取器会自动从所有页面抓取数据。可视化操作面板WebHarvy是一款用于数据可视化网页提取的专用工具。实际上,没有必要编写所有脚本。或者编码用于提取数据。使用 webharvy 的嵌入式计算机浏览器访问网页。您可以选择通过单击鼠标来提取数据。
这太容易了!根据关键词提取 根据关键词提取,可以抓取百度搜索页面关键词输入的列表数据。您创建的设备将自动重复输入所有输入 关键词 和发现的数据。能够指定一个随机的总输入 关键词 提取分类 WebHarvy URL 抓取器允许您从链接列表中提取数据,从而在 网站 内生成类似的页面。这使您能够在抓取的 URL 中应用单一类型或副标题。使用正则表达式提取 WebHarvy 可以在文本或网页的 HTML 源代码中使用正则表达式(正则表达式),并提取匹配的一部分。这种技术性很强,说明你协调能力很强,数据也很顶尖。[软件特点] WebHarvy 是一款视觉效果的网络爬虫。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。
您还可以将抓取到的数据导出到 SQL 数据库。通常,网页在多个页面上显示诸如信息产品列表之类的数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需强调“连接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。【版本更新】恢复页面启动时可以禁止使用链接。可以为page方法配备专用的接口方法。它可以自动检索可以在 HTML 上提供的资源。改进电脑键盘向下翻页功能改进基于Java脚本制作的下一页加载。添加URL设备后,可以在列表2搜索中输入关键词 查看全部
网页数据抓取(智能识别方式WebHarvy自动检索)
WebHarvy 是网页数据爬取的专用工具。该软件可以提取网页中的文字和图片,输入网址即可打开。默认设置为使用电脑内置浏览器,适合扩展分析,可自动获取类似连接列表。程序界面 可视化的实际操作很容易。【功能介绍】智能识别方法WebHarvy自动检索网页中出现的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则不需要做所有额外的准备工作。如果数据重复,WebHarvy 会自动抓取。导出捕获的数据可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy URL 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文档。您还可以抓取数据并将其导出到 SQL 数据库。从多个页面中提取通用网页显示信息数据,例如多个页面中的产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只强调“连接到下一页”,WebHarvy URL 抓取器会自动从所有页面抓取数据。可视化操作面板WebHarvy是一款用于数据可视化网页提取的专用工具。实际上,没有必要编写所有脚本。或者编码用于提取数据。使用 webharvy 的嵌入式计算机浏览器访问网页。您可以选择通过单击鼠标来提取数据。
这太容易了!根据关键词提取 根据关键词提取,可以抓取百度搜索页面关键词输入的列表数据。您创建的设备将自动重复输入所有输入 关键词 和发现的数据。能够指定一个随机的总输入 关键词 提取分类 WebHarvy URL 抓取器允许您从链接列表中提取数据,从而在 网站 内生成类似的页面。这使您能够在抓取的 URL 中应用单一类型或副标题。使用正则表达式提取 WebHarvy 可以在文本或网页的 HTML 源代码中使用正则表达式(正则表达式),并提取匹配的一部分。这种技术性很强,说明你协调能力很强,数据也很顶尖。[软件特点] WebHarvy 是一款视觉效果的网络爬虫。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。绝对不需要编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择关键数据。这很容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。非常容易!WebHarvy 自动检索网页中生成的数据。因此,如果您必须从网页中抓取新项目的列表(名称、完整地址、电子邮件地址、价格等),则无需实施所有其他设备。如果数据重复,WebHarvy 会自动删除它。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您可以以各种文件格式存储从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。
您还可以将抓取到的数据导出到 SQL 数据库。通常,网页在多个页面上显示诸如信息产品列表之类的数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需强调“连接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。【版本更新】恢复页面启动时可以禁止使用链接。可以为page方法配备专用的接口方法。它可以自动检索可以在 HTML 上提供的资源。改进电脑键盘向下翻页功能改进基于Java脚本制作的下一页加载。添加URL设备后,可以在列表2搜索中输入关键词
网页数据抓取(网页抓取工具优采云采集器中给出信息输出页后的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-03 06:14
当前的媒体状态,在一个焦点事件发生后或者在一个连续的话题中,形成一个媒体话题需要大量的人工操作,比如信息的采集和整理,及时更新等,但是高效的网络爬虫工具会为我们打造大数据智能媒体。
网络爬虫工具优采云采集器可以自动采集互联网焦点事件对应的舆情。例如,对于连续发生多天的事件,数据必须在每个重要节点的时间进行捕获和更新,那么您只需在优采云采集器中设置更新时间和频率。再比如我们关注的金融市场,也可以更新,自动整理成动态的媒体专栏。
对于焦点的某些方面的关注度,还可以根据网络爬虫抓取到的阅读或关注数据进行排名推荐和智能评分。我们甚至可以使用网络爬虫工具来维护智能媒体站。用户要做的就是锁定几个或多个信息输出页面,并在网络爬虫工具中给出信息优采云采集器 输出页面后,配置URL爬取和内容爬取的详细规则。获取到需要的数据后,可以对数据进行一系列的重新加权、过滤、清洗等处理,最后可以选择自动定时处理内容的精华发布到网站@指定栏目>.
未来的智能媒体必然是以大数据为引擎的媒体。核心要素是数据规模。我们要学会有效利用数据,发挥数据的价值。国内已经有基于媒体稿件大数据的高科技媒体产品,让人们更快更准确地了解信息,帮助人们更好地发现信息的价值和本质。
有专家指出,如果没有大数据的支持,很多新闻其实是无法启动的。传统媒体很难进行智能分析、预警或决策。因此,大数据智能化是必然趋势。
然而,目前网络大数据创造的智能媒体还不能完全取代人脑的工作,因为人脑有自我理解知识或事件的倾向,人工智能还需要继续探索语言和文本分析,以及大量枯燥的内容特定信息的整合和提取有朝一日可能会取代人脑来实现更复杂的原创。届时,智能媒体将更加个性化、定制化、高效化。 查看全部
网页数据抓取(网页抓取工具优采云采集器中给出信息输出页后的应用)
当前的媒体状态,在一个焦点事件发生后或者在一个连续的话题中,形成一个媒体话题需要大量的人工操作,比如信息的采集和整理,及时更新等,但是高效的网络爬虫工具会为我们打造大数据智能媒体。
网络爬虫工具优采云采集器可以自动采集互联网焦点事件对应的舆情。例如,对于连续发生多天的事件,数据必须在每个重要节点的时间进行捕获和更新,那么您只需在优采云采集器中设置更新时间和频率。再比如我们关注的金融市场,也可以更新,自动整理成动态的媒体专栏。
对于焦点的某些方面的关注度,还可以根据网络爬虫抓取到的阅读或关注数据进行排名推荐和智能评分。我们甚至可以使用网络爬虫工具来维护智能媒体站。用户要做的就是锁定几个或多个信息输出页面,并在网络爬虫工具中给出信息优采云采集器 输出页面后,配置URL爬取和内容爬取的详细规则。获取到需要的数据后,可以对数据进行一系列的重新加权、过滤、清洗等处理,最后可以选择自动定时处理内容的精华发布到网站@指定栏目>.
未来的智能媒体必然是以大数据为引擎的媒体。核心要素是数据规模。我们要学会有效利用数据,发挥数据的价值。国内已经有基于媒体稿件大数据的高科技媒体产品,让人们更快更准确地了解信息,帮助人们更好地发现信息的价值和本质。
有专家指出,如果没有大数据的支持,很多新闻其实是无法启动的。传统媒体很难进行智能分析、预警或决策。因此,大数据智能化是必然趋势。
然而,目前网络大数据创造的智能媒体还不能完全取代人脑的工作,因为人脑有自我理解知识或事件的倾向,人工智能还需要继续探索语言和文本分析,以及大量枯燥的内容特定信息的整合和提取有朝一日可能会取代人脑来实现更复杂的原创。届时,智能媒体将更加个性化、定制化、高效化。
网页数据抓取(基于Python爬虫技术简单易用的特点,利用python语言编写爬虫程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-31 06:13
摘要:基于Python爬虫技术简单易用的特点,采用python语言编写了爬虫程序,对广电总局电视剧电子政务平台的电视剧记录数据进行爬取。此外,还对抓取的电视剧记录数据进行了统计分析,得出了相关结论。关键词:Python;爬虫;数据分析
中文图书馆分类号:TP311.11 文献识别码:A文章编号:1007-9416(2017)09-0035-021 爬虫技术简介
网络爬虫是一种通过既定规则自动抓取网络信息的计算机程序。爬虫的目的是将目标网页数据下载到本地进行后续的数据分析。爬虫技术的兴起源于海量网络数据的可用性。通过爬虫技术,我们可以轻松获取网络数据,通过数据分析得出有价值的结论。
Python语言简单易用,现成的爬虫框架和工具包降低了使用门槛。具体配合正则表达式的使用,使得数据采集工作生动有趣。2 案例研究 2.1 网页描述
目标数据是历年全国电视剧拍摄的记录数据。数据来源于国家广电总局电视剧电子政务平台公开信息,如图1所示。 具体网址:“http:
///tims/site/views/applications.shanty? 应用名称=注释”。
我们需要抓取历年各月的记录和公开信息列表数据,如图2所示,进行汇总分析。2.2 爬虫程序的设计与实现
首先,我们使用 BeautifulSoup 解析器来解析 URL 的文本信息。在分析了网页的 HTML 文本和页面规则后,我们制定了以下步骤来捕获目标数据。
①抓取第一页码和最后页码后,循环抓取列表页信息; 查看全部
网页数据抓取(基于Python爬虫技术简单易用的特点,利用python语言编写爬虫程序)
摘要:基于Python爬虫技术简单易用的特点,采用python语言编写了爬虫程序,对广电总局电视剧电子政务平台的电视剧记录数据进行爬取。此外,还对抓取的电视剧记录数据进行了统计分析,得出了相关结论。关键词:Python;爬虫;数据分析
中文图书馆分类号:TP311.11 文献识别码:A文章编号:1007-9416(2017)09-0035-021 爬虫技术简介
网络爬虫是一种通过既定规则自动抓取网络信息的计算机程序。爬虫的目的是将目标网页数据下载到本地进行后续的数据分析。爬虫技术的兴起源于海量网络数据的可用性。通过爬虫技术,我们可以轻松获取网络数据,通过数据分析得出有价值的结论。
Python语言简单易用,现成的爬虫框架和工具包降低了使用门槛。具体配合正则表达式的使用,使得数据采集工作生动有趣。2 案例研究 2.1 网页描述
目标数据是历年全国电视剧拍摄的记录数据。数据来源于国家广电总局电视剧电子政务平台公开信息,如图1所示。 具体网址:“http:
///tims/site/views/applications.shanty? 应用名称=注释”。
我们需要抓取历年各月的记录和公开信息列表数据,如图2所示,进行汇总分析。2.2 爬虫程序的设计与实现
首先,我们使用 BeautifulSoup 解析器来解析 URL 的文本信息。在分析了网页的 HTML 文本和页面规则后,我们制定了以下步骤来捕获目标数据。
①抓取第一页码和最后页码后,循环抓取列表页信息;
网页数据抓取(推荐你学习下flask+mongodb数据库抓取工具(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-30 13:03
网页数据抓取:到百度上,选择新闻,点开每个新闻后面有分类;选择“会员”类似这样:这里是选择“图书”点击后会跳转到“全部商品”页面,注意看你要分析的分类信息。点击商品名,会自动跳转到商品所属购买页面,到这一步有点复杂,容我上图注意“怎么获取对应的会员,如何验证这个会员”抓取模板页面数据:方法同上;同理前面页面也是;想抓取目标节点的其他页面,跳转至page120,得到页面内容,比如打开招聘网站,可以看到介绍后面的分类信息,点击,到下载即可得到对应的工作量有没有超过自己的预期?很多,很多,这种题用python动手太麻烦了,用flask框架快捷多了。
在别的方面需要大量的数据时,可以使用flask框架快速搭建个简单的网站抓取。推荐你学习下flask+mongodb数据库抓取工具。flask官方有很多非常好的教程与示例代码,想深入学习,可以看本网站的教程。
其实,目前的网站都有这个需求,而且近几年互联网增长最快的部分,正是图书和电商类的,所以公司比较看重抓取哪方面的数据。当然这类网站用lxml或xml+flask或者flask+mongodb数据库抓取工具也能完成,目前来说,flask+mongodb是最快捷、最灵活的方案,虽然功能上不如flask或者flask+lxml等,但确实目前性价比最高的,也是目前用最多的。
具体用什么做实现,你可以看一下flask+lxml或者flask+mongodb可以做什么?-flask,这是目前最新的两篇文章。 查看全部
网页数据抓取(推荐你学习下flask+mongodb数据库抓取工具(图))
网页数据抓取:到百度上,选择新闻,点开每个新闻后面有分类;选择“会员”类似这样:这里是选择“图书”点击后会跳转到“全部商品”页面,注意看你要分析的分类信息。点击商品名,会自动跳转到商品所属购买页面,到这一步有点复杂,容我上图注意“怎么获取对应的会员,如何验证这个会员”抓取模板页面数据:方法同上;同理前面页面也是;想抓取目标节点的其他页面,跳转至page120,得到页面内容,比如打开招聘网站,可以看到介绍后面的分类信息,点击,到下载即可得到对应的工作量有没有超过自己的预期?很多,很多,这种题用python动手太麻烦了,用flask框架快捷多了。
在别的方面需要大量的数据时,可以使用flask框架快速搭建个简单的网站抓取。推荐你学习下flask+mongodb数据库抓取工具。flask官方有很多非常好的教程与示例代码,想深入学习,可以看本网站的教程。
其实,目前的网站都有这个需求,而且近几年互联网增长最快的部分,正是图书和电商类的,所以公司比较看重抓取哪方面的数据。当然这类网站用lxml或xml+flask或者flask+mongodb数据库抓取工具也能完成,目前来说,flask+mongodb是最快捷、最灵活的方案,虽然功能上不如flask或者flask+lxml等,但确实目前性价比最高的,也是目前用最多的。
具体用什么做实现,你可以看一下flask+lxml或者flask+mongodb可以做什么?-flask,这是目前最新的两篇文章。
网页数据抓取(智教智道网页数据监控软件官方版(da)众需要的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-30 07:08
网探网页数据监控软件官方版是一款可以监控搜狐、天猫、微博、12306等的网页数据监控软件官方版网站,帮你抓拍网站重要访问URL,辽中大学(da)需要的抢先信息。智交智道真诚推荐!
网页数据监控软件正式版介绍
1. 多任务同时运行,无人值守长期运行。
2. 及时通知用户,新增程序设置对话框。
3. 增加定时关机等附加功能,对比验证网页数据监控软件正式版。
4. 资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行,修复bug。
Netexplorer网页数据监控软件正式版功能
1. 监控任务A(必须是网址)得到的结果可以转移到监控任务B执行,从而获得网页数据监控软件正式版更丰富的结果。网页数据监控软件正式版上线 各行各业都在应用互联网技术,互联网上的网页数据监控软件正式版也越来越丰富。一些在线数据监控软件正式版的价值与时间有关。早点知道会很有用,以后值可能为零。Netexploration软件就是来解决这类问题的,让您“永远领先一步”是我们的目标。
2. 打开通知界面,“人人为我,我为人” 分享任意网页的爬取公式,免去编辑公式的麻烦。.
3. 爬取公式网上分享,“文本匹配”和“文档结构分析”是网页数据监控软件正式版的两种爬取方法。它们可以单独使用,也可以组合使用,制作正式版的网络数据监控软件。爬行更容易,更准确。
4. 直接与您的服务器后端连接,后续流程自定义,实时高效接入官方版网页数据监控软件自动处理流程,自动判断官方版最新更新网页数据监测软件,支持自定义网页数据监测软件正式版对比验证公式,过滤出用户最感兴趣的网页数据监测软件正式版内容。
网页数据监控软件正式版特点
1. 任务之间的相互调用。用户注册后,可将已验证的网页数据监控软件正式版发送至用户邮箱,也可推送至用户指定的网页数据监控软件正式版界面。再次处理版本。
2. 基于IE浏览器爬取的网页网页数据监控软件正式版。
NetExplore网页数据监控软件正式版总结
NetExplore网络数据监控软件V1.20是一款适用于安卓版的办公软件手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
网页数据抓取(智教智道网页数据监控软件官方版(da)众需要的信息)
网探网页数据监控软件官方版是一款可以监控搜狐、天猫、微博、12306等的网页数据监控软件官方版网站,帮你抓拍网站重要访问URL,辽中大学(da)需要的抢先信息。智交智道真诚推荐!
网页数据监控软件正式版介绍
1. 多任务同时运行,无人值守长期运行。
2. 及时通知用户,新增程序设置对话框。
3. 增加定时关机等附加功能,对比验证网页数据监控软件正式版。
4. 资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行,修复bug。
Netexplorer网页数据监控软件正式版功能
1. 监控任务A(必须是网址)得到的结果可以转移到监控任务B执行,从而获得网页数据监控软件正式版更丰富的结果。网页数据监控软件正式版上线 各行各业都在应用互联网技术,互联网上的网页数据监控软件正式版也越来越丰富。一些在线数据监控软件正式版的价值与时间有关。早点知道会很有用,以后值可能为零。Netexploration软件就是来解决这类问题的,让您“永远领先一步”是我们的目标。
2. 打开通知界面,“人人为我,我为人” 分享任意网页的爬取公式,免去编辑公式的麻烦。.
3. 爬取公式网上分享,“文本匹配”和“文档结构分析”是网页数据监控软件正式版的两种爬取方法。它们可以单独使用,也可以组合使用,制作正式版的网络数据监控软件。爬行更容易,更准确。
4. 直接与您的服务器后端连接,后续流程自定义,实时高效接入官方版网页数据监控软件自动处理流程,自动判断官方版最新更新网页数据监测软件,支持自定义网页数据监测软件正式版对比验证公式,过滤出用户最感兴趣的网页数据监测软件正式版内容。
网页数据监控软件正式版特点
1. 任务之间的相互调用。用户注册后,可将已验证的网页数据监控软件正式版发送至用户邮箱,也可推送至用户指定的网页数据监控软件正式版界面。再次处理版本。
2. 基于IE浏览器爬取的网页网页数据监控软件正式版。
NetExplore网页数据监控软件正式版总结
NetExplore网络数据监控软件V1.20是一款适用于安卓版的办公软件手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:

