
网页信息抓取软件
网页信息抓取软件(如何使用类来首页的DOM树(如最新的头条新闻))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-14 02:20
我写了一个类,用于从网页中抓取信息(如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类从网页中抓取所需的信息。本文将以博客园首页的博客标题和链接为例:
上图是博客园首页的 DOM 树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
结果如下:
欢迎前端同学一起学习
前端学习交流QQ群:461593224 查看全部
网页信息抓取软件(如何使用类来首页的DOM树(如最新的头条新闻))
我写了一个类,用于从网页中抓取信息(如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类从网页中抓取所需的信息。本文将以博客园首页的博客标题和链接为例:

上图是博客园首页的 DOM 树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
结果如下:

欢迎前端同学一起学习
前端学习交流QQ群:461593224
网页信息抓取软件(网页信息抓取软件推荐beegirl爬取的时候考虑一个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-10 00:04
网页信息抓取软件推荐beegirl
爬取的时候,考虑一个问题。1.进行数据分析,用于建模。(比如进行归一化处理,log一类的,做数据分析或者测试)2.进行业务处理,比如你要找到精准广告投放的问题,那就可以对这个做研究。3.或者个人发博客,网页主要都是电商站点,可以看看优秀的博客内容,总结一下。(比如最近在研究百度首页的广告位。)但是,我觉得你不应该用网页数据分析来自学。
或者说,你完全没有意识到自己会学到什么东西。但凡接触点网页分析相关的东西,都是高端技术活,想自学网页分析还不如自己研究一些别的领域。建议你去学python,有很多相关内容的教程,然后自己实践。其实python就是numpy+pandas。多关注国内外的新兴技术和最近发展。
建议到看一下pandas的read_excel.sqlite的部分
推荐urllib,matplotlib之类的库可以处理网页的html与javascript文件,vue.js教程上提到python怎么处理百度广告的?跟你的情况差不多,
可以用tiobe推荐的网页信息分析工具包。pip安装tiobe提供的filter·tiobe有免费试用版本,特点是利用爬虫抓取网页,比如你想爬取知乎上有关化妆的各种问题的html地址,你可以用它。
简单的有techeel,复杂的有stock32。其实不要手动去爬。excel做个基本数据透视表就能爬了。 查看全部
网页信息抓取软件(网页信息抓取软件推荐beegirl爬取的时候考虑一个问题)
网页信息抓取软件推荐beegirl
爬取的时候,考虑一个问题。1.进行数据分析,用于建模。(比如进行归一化处理,log一类的,做数据分析或者测试)2.进行业务处理,比如你要找到精准广告投放的问题,那就可以对这个做研究。3.或者个人发博客,网页主要都是电商站点,可以看看优秀的博客内容,总结一下。(比如最近在研究百度首页的广告位。)但是,我觉得你不应该用网页数据分析来自学。
或者说,你完全没有意识到自己会学到什么东西。但凡接触点网页分析相关的东西,都是高端技术活,想自学网页分析还不如自己研究一些别的领域。建议你去学python,有很多相关内容的教程,然后自己实践。其实python就是numpy+pandas。多关注国内外的新兴技术和最近发展。
建议到看一下pandas的read_excel.sqlite的部分
推荐urllib,matplotlib之类的库可以处理网页的html与javascript文件,vue.js教程上提到python怎么处理百度广告的?跟你的情况差不多,
可以用tiobe推荐的网页信息分析工具包。pip安装tiobe提供的filter·tiobe有免费试用版本,特点是利用爬虫抓取网页,比如你想爬取知乎上有关化妆的各种问题的html地址,你可以用它。
简单的有techeel,复杂的有stock32。其实不要手动去爬。excel做个基本数据透视表就能爬了。
网页信息抓取软件(SysNucleusWebHarvy可以自动从网页中提取数据的工具介绍介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-09 18:00
SysNucleus WebHarvy 是一个用于抓取 Web 数据的工具。该软件可以帮助您自动从网页中提取数据,并将提取的内容以不同的格式保存。该软件可以自动抓取网页上的文字、图片、网址、邮件等内容。您也可以直接将整个网页保存为 HTML 格式,从而提取网页中的所有文字和图标内容。
软件特点:
1、SysNucleus WebHarvy 可让您分析网页上的数据
2、 可以显示来自 HTML 地址的解析连接数据
3、可以延伸到下一个网页
4、可以指定搜索数据的范围和内容
5、扫描的图片可以下载保存
6、支持浏览器复制链接搜索
7、支持配置对应资源项搜索
8、可以使用项目名和资源名来查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、提供更高级的多词搜索和多页搜索
特征:
1、可视点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
6、通过代理服务器提取 {pass}{filter}
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
8、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。 查看全部
网页信息抓取软件(SysNucleusWebHarvy可以自动从网页中提取数据的工具介绍介绍)
SysNucleus WebHarvy 是一个用于抓取 Web 数据的工具。该软件可以帮助您自动从网页中提取数据,并将提取的内容以不同的格式保存。该软件可以自动抓取网页上的文字、图片、网址、邮件等内容。您也可以直接将整个网页保存为 HTML 格式,从而提取网页中的所有文字和图标内容。
软件特点:
1、SysNucleus WebHarvy 可让您分析网页上的数据
2、 可以显示来自 HTML 地址的解析连接数据
3、可以延伸到下一个网页
4、可以指定搜索数据的范围和内容
5、扫描的图片可以下载保存
6、支持浏览器复制链接搜索
7、支持配置对应资源项搜索
8、可以使用项目名和资源名来查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、提供更高级的多词搜索和多页搜索
特征:
1、可视点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
6、通过代理服务器提取 {pass}{filter}
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
8、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
网页信息抓取软件(这是,小巧的工具,可以让你轻松抓取和复制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-09 17:14
这是一款网页文字抓取工具,一个小型的网页文字抓取工具,可以让您轻松抓取和复制网页上禁止选择和复制的文字。对于内容被大面积广告覆盖而看不到的网页,网页文字抓取器也是一个很好的解决方案,可以抓取并查看。
软件介绍
网页文字抓取就是网上有很多禁止复制的html文件,但是我们非常需要。我们应该做什么?小编找了很多软件尝试抓取网页中的文字,但都不好用。
终于找到了一个网页文字抓取器,非常好用,推荐给大家!
软件功能
1、一键保存页面文字
2、下载页面上的所有图片
3、保存页面的所有css
4、保存页面js文件
5、在一个页面上下载所有相关文档
6、保存带参数的css和js文件
7、生成单页index.html
相关说明
网页文字抓取v3.0正式版,网站抓取精灵是一款可以帮助用户提取完整网站内容的工具。用户可以下载到本地硬盘的网站内容将保持原来的HTML格式,文件名和目录结构不会改变,为您提供最准确的URL镜像。
软件截图
相关软件
网页文字抓取工具:这是网页文字抓取工具的下载。网页文字提取工具(网页文字抓取工具)是一款绿色、简单、功能强大的网页提取软件。该软件对搜狐、新浪和腾讯进行比较分析。、网易、中新网、百度、21cn、CDC等大型门户网站网站,详细分析其噪声数据的特点,然后根据超文本协议的结构特点,很方便的提取网页的正文。
Douding Text Grabber:这是Douding Text Grabber,一个伪装获取Douding文档文本的小程序。 查看全部
网页信息抓取软件(这是,小巧的工具,可以让你轻松抓取和复制)
这是一款网页文字抓取工具,一个小型的网页文字抓取工具,可以让您轻松抓取和复制网页上禁止选择和复制的文字。对于内容被大面积广告覆盖而看不到的网页,网页文字抓取器也是一个很好的解决方案,可以抓取并查看。
软件介绍
网页文字抓取就是网上有很多禁止复制的html文件,但是我们非常需要。我们应该做什么?小编找了很多软件尝试抓取网页中的文字,但都不好用。
终于找到了一个网页文字抓取器,非常好用,推荐给大家!
软件功能
1、一键保存页面文字
2、下载页面上的所有图片
3、保存页面的所有css
4、保存页面js文件
5、在一个页面上下载所有相关文档
6、保存带参数的css和js文件
7、生成单页index.html
相关说明
网页文字抓取v3.0正式版,网站抓取精灵是一款可以帮助用户提取完整网站内容的工具。用户可以下载到本地硬盘的网站内容将保持原来的HTML格式,文件名和目录结构不会改变,为您提供最准确的URL镜像。
软件截图

相关软件
网页文字抓取工具:这是网页文字抓取工具的下载。网页文字提取工具(网页文字抓取工具)是一款绿色、简单、功能强大的网页提取软件。该软件对搜狐、新浪和腾讯进行比较分析。、网易、中新网、百度、21cn、CDC等大型门户网站网站,详细分析其噪声数据的特点,然后根据超文本协议的结构特点,很方便的提取网页的正文。
Douding Text Grabber:这是Douding Text Grabber,一个伪装获取Douding文档文本的小程序。
网页信息抓取软件(科鼎网页抓包工具(网站抓取工具)手机版工具V1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-05 16:20
客鼎网页抓取工具(网站capture tool)手机版工具是一款(易)实用的IE网页数据分析工具。软件功能强大,可轻松查看科鼎网页抓包工具(网站Grab tool)移动版的实际网页,方便网页开发者和测试者分析网页数据,获取网页相关信息。 ,是一款功能强大的手机版科鼎网页抓取工具(网站抓取工具)。赶快下载体验吧!
手机版Keding网页抓取工具(网站抓取工具)介绍
1. 网页科鼎网页抓包工具(网站Grabber Tool)手机版工具,作为需要频繁分析网页发送的数据包的Web开发者/测试者使用。 IE强大的插件,简洁明了,可以很好的完成对URL请求的分析。主要功能是监控和分析浏览器发送的http请求。当您在浏览器的地址栏上请求一个URL或提交一个表单时,它会帮助您分析http请求的头部信息和访问页面的cookie。 Information、Get 和 Post 详细的数据包分析,集成在 Internet Explorer 工具栏中,包括网页摘要、Cookies 管理、缓存管理、消息头发送/接收、字符查询、POST 数据和目录管理功能。
手机版克定网页抓取工具(网站抓取工具)总结
客鼎网页抓取工具(网站抓取工具)V1.60是一款适用于安卓版的网络辅助手机软件。如果您喜欢这个软件,请下载链接分享给您的朋友: 查看全部
网页信息抓取软件(科鼎网页抓包工具(网站抓取工具)手机版工具V1)
客鼎网页抓取工具(网站capture tool)手机版工具是一款(易)实用的IE网页数据分析工具。软件功能强大,可轻松查看科鼎网页抓包工具(网站Grab tool)移动版的实际网页,方便网页开发者和测试者分析网页数据,获取网页相关信息。 ,是一款功能强大的手机版科鼎网页抓取工具(网站抓取工具)。赶快下载体验吧!
手机版Keding网页抓取工具(网站抓取工具)介绍
1. 网页科鼎网页抓包工具(网站Grabber Tool)手机版工具,作为需要频繁分析网页发送的数据包的Web开发者/测试者使用。 IE强大的插件,简洁明了,可以很好的完成对URL请求的分析。主要功能是监控和分析浏览器发送的http请求。当您在浏览器的地址栏上请求一个URL或提交一个表单时,它会帮助您分析http请求的头部信息和访问页面的cookie。 Information、Get 和 Post 详细的数据包分析,集成在 Internet Explorer 工具栏中,包括网页摘要、Cookies 管理、缓存管理、消息头发送/接收、字符查询、POST 数据和目录管理功能。
手机版克定网页抓取工具(网站抓取工具)总结
客鼎网页抓取工具(网站抓取工具)V1.60是一款适用于安卓版的网络辅助手机软件。如果您喜欢这个软件,请下载链接分享给您的朋友:
网页信息抓取软件(网页信息抓取软件,支持windows和mac平台,节省工作效率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-04 23:04
网页信息抓取软件,一款信息抓取软件,支持windows和mac平台,抓取信息流量,节省工作效率,赚取外快,是体力劳动也是脑力劳动。可自行录制文字,图片,3d,4d图形,制作成小程序,实现赚取更多的报酬。
互联网广告一般主要分为:信息流,电商,咨询,金融,社交。信息流是最为普遍的一种广告形式,意思是看不见摸不着的,可能是热点事件,也可能是演唱会、返奖券、自拍照等等,但是不同行业,同一个广告,在不同的平台效果差别挺大。
我是广告狗出身的,平时做的比较多的也就是网站上线,banner,flash,app,就是看不见,但是存在,所以你看到后习惯性的就点击或者收藏一下。目前做自媒体平台,很多平台主要是靠直接阅读、阅读量,今日头条算是ugc模式,提供文章给你看,还有像百家号这些等平台,你经常会有机会接触到很多。最近看到朋友圈的朋友在弄卖智能店内机器人,也是写点新闻给你看看,还卖个会员,不知道他们能赚多少钱呢?想了解更多的可以看看微信公众号,智能店内机器人,-oceanwg。
我对智能店内机器人不是很懂,但是我可以告诉你的是,网站上线广告,尤其是banner广告,每天至少要看5000个广告!而且你上线后要做网站优化推广!如果有钱可以去买一个正版的广告,没钱就要看看是什么软件咯!网站上线的广告一般都是大品牌,而且比较贵,如果你要做自己的网站,或者加盟的话, 查看全部
网页信息抓取软件(网页信息抓取软件,支持windows和mac平台,节省工作效率)
网页信息抓取软件,一款信息抓取软件,支持windows和mac平台,抓取信息流量,节省工作效率,赚取外快,是体力劳动也是脑力劳动。可自行录制文字,图片,3d,4d图形,制作成小程序,实现赚取更多的报酬。
互联网广告一般主要分为:信息流,电商,咨询,金融,社交。信息流是最为普遍的一种广告形式,意思是看不见摸不着的,可能是热点事件,也可能是演唱会、返奖券、自拍照等等,但是不同行业,同一个广告,在不同的平台效果差别挺大。
我是广告狗出身的,平时做的比较多的也就是网站上线,banner,flash,app,就是看不见,但是存在,所以你看到后习惯性的就点击或者收藏一下。目前做自媒体平台,很多平台主要是靠直接阅读、阅读量,今日头条算是ugc模式,提供文章给你看,还有像百家号这些等平台,你经常会有机会接触到很多。最近看到朋友圈的朋友在弄卖智能店内机器人,也是写点新闻给你看看,还卖个会员,不知道他们能赚多少钱呢?想了解更多的可以看看微信公众号,智能店内机器人,-oceanwg。
我对智能店内机器人不是很懂,但是我可以告诉你的是,网站上线广告,尤其是banner广告,每天至少要看5000个广告!而且你上线后要做网站优化推广!如果有钱可以去买一个正版的广告,没钱就要看看是什么软件咯!网站上线的广告一般都是大品牌,而且比较贵,如果你要做自己的网站,或者加盟的话,
网页信息抓取软件(五款免费的数据抓取工具工具,打开优采云软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2022-01-04 08:01
Scrape:开始数据抓取。导出数据CSV:以CSV 格式导出捕获的数据。到这里,简单的了解一下就够了。
来自 .wkwm17c48105ed5{display:none;font-size:12px;}百度库。
呵呵,楼上说的很清楚了,要看你要抓到哪里的数据,如果是一般用的,找个免费的就行了。如果说专业的网络数据采集,比如最近流行的网络信息采集,用于监控等商业用途,可以使用乐思数据采集系统。您可以搜索特定信息。它们是国内信息。 采集的鼻祖。
网页数据爬取工具,webscraper最简单的数据爬取教学博客园。
近年来,随着国内大数据战略越来越清晰,数据采集与信息采集系列产品迎来数据采集与采集。推荐使用优采云云。
大家都会使用网络爬虫工具优采云采集器来采集网络数据,但是如果朋友多的话,我们可能会像采集网站来一样。
链接提交工具可以实时向百度推送数据,创建和提交站点地图,提交未提交的收录网页链接,帮助百度找到和了解你网站。
今天天菜鸟带你分享五款免费的数据采集工具。打开优采云软件后,打开网页,点击单个文字,右击。
比如等待一个事件或者点击某些项目,而不是仅仅抓取数据,那么 MechanicalSoup 真的为浏览器提供了网页抓取功能。
优采云采集器作为通用的网络爬虫工具,基于源码运行原理,可爬取的网页类型达到99%,自动登录验证。 查看全部
网页信息抓取软件(五款免费的数据抓取工具工具,打开优采云软件)
Scrape:开始数据抓取。导出数据CSV:以CSV 格式导出捕获的数据。到这里,简单的了解一下就够了。
来自 .wkwm17c48105ed5{display:none;font-size:12px;}百度库。
呵呵,楼上说的很清楚了,要看你要抓到哪里的数据,如果是一般用的,找个免费的就行了。如果说专业的网络数据采集,比如最近流行的网络信息采集,用于监控等商业用途,可以使用乐思数据采集系统。您可以搜索特定信息。它们是国内信息。 采集的鼻祖。
网页数据爬取工具,webscraper最简单的数据爬取教学博客园。
近年来,随着国内大数据战略越来越清晰,数据采集与信息采集系列产品迎来数据采集与采集。推荐使用优采云云。

大家都会使用网络爬虫工具优采云采集器来采集网络数据,但是如果朋友多的话,我们可能会像采集网站来一样。
链接提交工具可以实时向百度推送数据,创建和提交站点地图,提交未提交的收录网页链接,帮助百度找到和了解你网站。

今天天菜鸟带你分享五款免费的数据采集工具。打开优采云软件后,打开网页,点击单个文字,右击。
比如等待一个事件或者点击某些项目,而不是仅仅抓取数据,那么 MechanicalSoup 真的为浏览器提供了网页抓取功能。
优采云采集器作为通用的网络爬虫工具,基于源码运行原理,可爬取的网页类型达到99%,自动登录验证。
网页信息抓取软件(网页抓取内容网页采集信息软件功能特点及安装步骤介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 523 次浏览 • 2022-01-04 07:21
)
网页采集信息软件(网页信息提取)是专门用来抓取网页内容的工具,提取网页的文字和图片内容,支持提取网页所有格式的图片,提取后,它将提取的内容自动保存到本地,软件使用非常方便,操作简单,提取速度快,保存的内容完整
网页抓取内容网页采集信息软件下载使用教学图1
网页抓取内容网页采集信息软件功能
由原谷歌技术团队打造,基于人工智能技术,可通过输入网址自动识别采集内容。
<p>智能模式:基于人工智能算法,输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。 查看全部
网页信息抓取软件(网页抓取内容网页采集信息软件功能特点及安装步骤介绍
)
网页采集信息软件(网页信息提取)是专门用来抓取网页内容的工具,提取网页的文字和图片内容,支持提取网页所有格式的图片,提取后,它将提取的内容自动保存到本地,软件使用非常方便,操作简单,提取速度快,保存的内容完整
网页抓取内容网页采集信息软件下载使用教学图1
网页抓取内容网页采集信息软件功能
由原谷歌技术团队打造,基于人工智能技术,可通过输入网址自动识别采集内容。
<p>智能模式:基于人工智能算法,输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
网页信息抓取软件(搜狗网站收录就是与互联网用户共享网址,搜狗收录 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-01 15:11
)
搜狗网站收录是将网址分享给网民,搜狗网站收录的前提是将网站提交给搜狗搜索引擎,并且蜘蛛会光顾,搜狗蜘蛛每次爬取网站都会在索引库中添加和更新网站,站长只需要提供链接网站,搜狗蜘蛛就会跟着< @网站 使用 网站 的链接抓取不同的网页。按照相关标准提交的网址将在一定期限内由搜狗搜索引擎收录进行排名。
搜狗速成收录方法
搜狗收录方法:
网站发布高质量的原创内容对于搜狗搜索引擎来说更容易收录。 网站混乱的内部结构对网站来说是致命的。 网站代码优化,为站内图片添加标签,定义图片大小,添加关键词锚文本链接等。这些操作都是细节问题,但往往有些细节会影响网站收录的情况。
网站 布局采用扁平化站点结构,也就是俗称的树状结构。 网站该程序只有三个层次的栏目结构,分别是首页、栏目列表、内容页。这形成了树状分支形状。每个细分列的权重逐层增加以增加收录面积。
制作 网站 地图。 网站 地图的实用性不用多说,重要的是网站内容的每日更新。我相信很少有网站管理员可以做到这一点。虽然说起来容易,但每天执行起来却很难。以我的观察,那些多站长的博客网站,他们每天的更新带来了丰硕的成果,我想是大家难以想象的。事实上,每天更新并不需要很长时间。相信大家在制作完列表页后很快就会完成。完成更新后,一定要养成习惯。时间长了,自然而然就可以了。这对搜索引擎的收录有很好的正面影响,尤其是那些内容展示较少的网站。完成。
无论选择哪种类型的网站站长,网站的结构都必须简洁明了。这也是站长必备的知识之一。一般网站的页面级别在设计时不要超过三个级别。现在很多网站级别都超过了三个级别。页面文件名可以使用字母或数字,但不要使用长的中英文插件,这对收录没有任何好处。并且在网站的过程中添加内容时,建议大家采用静态或伪静态技术处理,有利于网站在搜索引擎中的友好性。搜狗搜索引擎偏爱静态页面!
搜狗推送工具
为了让我们网站尽快被搜狗收录发现,我们要不断的向搜狗站长平台提交链接,让蜘蛛爬过来。为了提高效率,我们使用搜狗主动批量推送工具,让网站的所有链接都可以自动批量推送,不用vps,工具可以自动编码,可以提交几十个每天上千个网址,不占内存,不吃cpu。支持24小时挂机无需人工长期稳定值班。
搜狗网站收录
以上是小编搜狗的网站收录。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力!
查看全部
网页信息抓取软件(搜狗网站收录就是与互联网用户共享网址,搜狗收录
)
搜狗网站收录是将网址分享给网民,搜狗网站收录的前提是将网站提交给搜狗搜索引擎,并且蜘蛛会光顾,搜狗蜘蛛每次爬取网站都会在索引库中添加和更新网站,站长只需要提供链接网站,搜狗蜘蛛就会跟着< @网站 使用 网站 的链接抓取不同的网页。按照相关标准提交的网址将在一定期限内由搜狗搜索引擎收录进行排名。
搜狗速成收录方法
搜狗收录方法:
网站发布高质量的原创内容对于搜狗搜索引擎来说更容易收录。 网站混乱的内部结构对网站来说是致命的。 网站代码优化,为站内图片添加标签,定义图片大小,添加关键词锚文本链接等。这些操作都是细节问题,但往往有些细节会影响网站收录的情况。
网站 布局采用扁平化站点结构,也就是俗称的树状结构。 网站该程序只有三个层次的栏目结构,分别是首页、栏目列表、内容页。这形成了树状分支形状。每个细分列的权重逐层增加以增加收录面积。
制作 网站 地图。 网站 地图的实用性不用多说,重要的是网站内容的每日更新。我相信很少有网站管理员可以做到这一点。虽然说起来容易,但每天执行起来却很难。以我的观察,那些多站长的博客网站,他们每天的更新带来了丰硕的成果,我想是大家难以想象的。事实上,每天更新并不需要很长时间。相信大家在制作完列表页后很快就会完成。完成更新后,一定要养成习惯。时间长了,自然而然就可以了。这对搜索引擎的收录有很好的正面影响,尤其是那些内容展示较少的网站。完成。
无论选择哪种类型的网站站长,网站的结构都必须简洁明了。这也是站长必备的知识之一。一般网站的页面级别在设计时不要超过三个级别。现在很多网站级别都超过了三个级别。页面文件名可以使用字母或数字,但不要使用长的中英文插件,这对收录没有任何好处。并且在网站的过程中添加内容时,建议大家采用静态或伪静态技术处理,有利于网站在搜索引擎中的友好性。搜狗搜索引擎偏爱静态页面!
搜狗推送工具
为了让我们网站尽快被搜狗收录发现,我们要不断的向搜狗站长平台提交链接,让蜘蛛爬过来。为了提高效率,我们使用搜狗主动批量推送工具,让网站的所有链接都可以自动批量推送,不用vps,工具可以自动编码,可以提交几十个每天上千个网址,不占内存,不吃cpu。支持24小时挂机无需人工长期稳定值班。
搜狗网站收录
以上是小编搜狗的网站收录。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力!
网页信息抓取软件(软件特点:可自定义业务流程提供网页查询接口(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-31 19:14
网页信息抓取软件开发,人工智能辅助、可视化工具开发,web和android开发工具,网页加密加密辅助工具,互联网数据分析,公司内网传输加密,小说分析,多媒体制作,词库生成,电商管理软件开发,人工智能辅助,可视化工具开发,企业内网传输加密,网页分词软件,android辅助加密,android字库开发,音频和视频编解码,压缩包可放到内存解压,可以提高使用效率,支持windows,mac,androidapp开发,从事it行业工作,不用再维护老的工具和程序,省时省力省心,产品快速推向市场。
软件特点:可自定义业务流程,自动发现下级自动注册实时反馈注册进度交易方式多样性支持快捷支付快捷付款,快捷充值,快捷现金支付类型与工作流程及权限控制如同真人操作开发后台可批量代码设计可实现网页全站抓取后台查看实时运营数据后台在线选购助手:可实现支付宝接口自定义流程提供网页查询接口自定义奖励规则可以实现在线设计接口可以实现微信接口/。
联想表示百度已经买下来
话不多说,上图。
众筹网站买了一个监控摄像头,500r。不准。去线下监控室拿吧。
b站通过相关流程免费提供产品体验,去年双十一时提供免费体验,目前有很多业务活动,所以并不主要售卖产品,通过网站投放引流和推广来提高销量。收益方面,广告价格根据产品定位和品牌活动触达用户的定位策略来定,但是收益高速增长,可以持续在站内活动中实现拓展。站内拓展以视频为主,投放视频广告引流量,引流量到站内投放站内广告会有一定付费推广量,可以使得自身产品触达高质量用户,利于产品转化量增长。
综上所述站内广告代理方分成50%,站外流量40%,站内引流量30%,站外引流量30%,目前站内营收2万万到5万万,公司在持续增长。这是部分数据。 查看全部
网页信息抓取软件(软件特点:可自定义业务流程提供网页查询接口(组图))
网页信息抓取软件开发,人工智能辅助、可视化工具开发,web和android开发工具,网页加密加密辅助工具,互联网数据分析,公司内网传输加密,小说分析,多媒体制作,词库生成,电商管理软件开发,人工智能辅助,可视化工具开发,企业内网传输加密,网页分词软件,android辅助加密,android字库开发,音频和视频编解码,压缩包可放到内存解压,可以提高使用效率,支持windows,mac,androidapp开发,从事it行业工作,不用再维护老的工具和程序,省时省力省心,产品快速推向市场。
软件特点:可自定义业务流程,自动发现下级自动注册实时反馈注册进度交易方式多样性支持快捷支付快捷付款,快捷充值,快捷现金支付类型与工作流程及权限控制如同真人操作开发后台可批量代码设计可实现网页全站抓取后台查看实时运营数据后台在线选购助手:可实现支付宝接口自定义流程提供网页查询接口自定义奖励规则可以实现在线设计接口可以实现微信接口/。
联想表示百度已经买下来
话不多说,上图。
众筹网站买了一个监控摄像头,500r。不准。去线下监控室拿吧。
b站通过相关流程免费提供产品体验,去年双十一时提供免费体验,目前有很多业务活动,所以并不主要售卖产品,通过网站投放引流和推广来提高销量。收益方面,广告价格根据产品定位和品牌活动触达用户的定位策略来定,但是收益高速增长,可以持续在站内活动中实现拓展。站内拓展以视频为主,投放视频广告引流量,引流量到站内投放站内广告会有一定付费推广量,可以使得自身产品触达高质量用户,利于产品转化量增长。
综上所述站内广告代理方分成50%,站外流量40%,站内引流量30%,站外引流量30%,目前站内营收2万万到5万万,公司在持续增长。这是部分数据。
网页信息抓取软件(网页信息抓取软件采用webdriver+webform让网页抓取简单化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-29 18:11
网页信息抓取软件采用webdriver+webform让网页抓取简单化,可以从手机app、网页pc端页面、网页h5页面、网页编辑器、网页小游戏等很多页面抓取。
不怎么好没汉化版的,
完全是internetexplorer的图标设计问题。之前googleplay比较难,在左上角设置的“网站”这里有各种大中小网站的选项,还有一个最小化按钮。题主可以试一下在另一个浏览器上玩webview下的tampermonkey会好很多。
基本一样,工具里有你需要的一切信息。web设置其实。功能做的太多。
都是webview,工具一样,
你可以把美化算法设置为canvasjavascript设置为pbr
webdriver美化真的超好用!!!
webdriver不懂,不瞎说。想做你不想做的网页很简单。一般非常开放的网站都是可以设置get请求url的get:请求当前页,post请求url的post:发送一次请求然后get请求get请求url是异步获取,可以使用settimeout语句。webdriver只是模拟web访问,不能伪造url。各种api也是用javascript实现,而不是c#或者java。所以单从设置get:post:get,我看不出有什么差别。我个人不建议这么搞。 查看全部
网页信息抓取软件(网页信息抓取软件采用webdriver+webform让网页抓取简单化)
网页信息抓取软件采用webdriver+webform让网页抓取简单化,可以从手机app、网页pc端页面、网页h5页面、网页编辑器、网页小游戏等很多页面抓取。
不怎么好没汉化版的,
完全是internetexplorer的图标设计问题。之前googleplay比较难,在左上角设置的“网站”这里有各种大中小网站的选项,还有一个最小化按钮。题主可以试一下在另一个浏览器上玩webview下的tampermonkey会好很多。
基本一样,工具里有你需要的一切信息。web设置其实。功能做的太多。
都是webview,工具一样,
你可以把美化算法设置为canvasjavascript设置为pbr
webdriver美化真的超好用!!!
webdriver不懂,不瞎说。想做你不想做的网页很简单。一般非常开放的网站都是可以设置get请求url的get:请求当前页,post请求url的post:发送一次请求然后get请求get请求url是异步获取,可以使用settimeout语句。webdriver只是模拟web访问,不能伪造url。各种api也是用javascript实现,而不是c#或者java。所以单从设置get:post:get,我看不出有什么差别。我个人不建议这么搞。
网页信息抓取软件(CYY软件工作室“CYY网页提取助手”简单完成这些需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-28 15:12
继推出“CYY拾色助手”和“CYY录屏助手”之后,CYY软件工作室又推出了一款名为“CYY网页提取助手”的软件。顾名思义,它是一个可以帮助用户提取页面内容的工具。一般在网页中,我们需要提取的一般是图片、文字和Flash,而这些需求可以通过“CYY网页提取助手”来简单的完成。
首先,安装软件后,在程序的“地址”栏中输入网站地址(如1).
图1 输入网址(点击图片放大)
然后就可以在程序的浏览区打开网站(如图2).
图2 打开并浏览网站
然后在“资源类型”中选择需要的内容,点击(如图3、图4、图5、图6、图7)。
[#page_简单提取网页内容(二)#0#0#0#0#]
图 3 资源类型列表
图4 资源提取图片
图5 用于资源提取的Flash
图 6 用于资源提取的 CSS
[#page_简单提取网页内容(三)#0#0#0#0#]
图7 其他资源开采
保存好需要的资源后,可以在“保存的资源列表”中看到(如图8).
图8 已保存资源列表
右键单击列表中的文件可以管理该文件(如9).
图9 管理资源列表中的文件
另外,如果您对程序的默认保存路径不满意,也可以手动更改为您喜欢的文件路径。
总结
软件虽然小,但是用处很大。对于一些想要批量保存网站图片的朋友,可以通过“CYY网页提取助手”轻松实现。但是,在使用编辑器的过程中,我发现该程序对页面上的Flash文件的解析不是很好,无法有效下载所需的视频文件。希望软件作者在以后的软件更新中逐步完善这个功能。
【横评】天籁七音盒软件横评哪里有【周刊】软件周刊08:杀软特刊
【独家报道】真主爱老牌!卡巴先生的中国之行上海站【评测】有道音乐随身听简单评测
【解析】DIY家庭必备!小编教你玩ZOL装机CD 【应用】蒋敏智:“沙盒”技术详解!
【评测】一测知天下IE8“单挑”9款主流浏览器 【评测】愚人节十款Tricky软件推荐 查看全部
网页信息抓取软件(CYY软件工作室“CYY网页提取助手”简单完成这些需求)
继推出“CYY拾色助手”和“CYY录屏助手”之后,CYY软件工作室又推出了一款名为“CYY网页提取助手”的软件。顾名思义,它是一个可以帮助用户提取页面内容的工具。一般在网页中,我们需要提取的一般是图片、文字和Flash,而这些需求可以通过“CYY网页提取助手”来简单的完成。
首先,安装软件后,在程序的“地址”栏中输入网站地址(如1).
图1 输入网址(点击图片放大)
然后就可以在程序的浏览区打开网站(如图2).

图2 打开并浏览网站
然后在“资源类型”中选择需要的内容,点击(如图3、图4、图5、图6、图7)。
[#page_简单提取网页内容(二)#0#0#0#0#]

图 3 资源类型列表

图4 资源提取图片

图5 用于资源提取的Flash

图 6 用于资源提取的 CSS
[#page_简单提取网页内容(三)#0#0#0#0#]

图7 其他资源开采
保存好需要的资源后,可以在“保存的资源列表”中看到(如图8).

图8 已保存资源列表
右键单击列表中的文件可以管理该文件(如9).

图9 管理资源列表中的文件
另外,如果您对程序的默认保存路径不满意,也可以手动更改为您喜欢的文件路径。
总结
软件虽然小,但是用处很大。对于一些想要批量保存网站图片的朋友,可以通过“CYY网页提取助手”轻松实现。但是,在使用编辑器的过程中,我发现该程序对页面上的Flash文件的解析不是很好,无法有效下载所需的视频文件。希望软件作者在以后的软件更新中逐步完善这个功能。

【横评】天籁七音盒软件横评哪里有【周刊】软件周刊08:杀软特刊
【独家报道】真主爱老牌!卡巴先生的中国之行上海站【评测】有道音乐随身听简单评测
【解析】DIY家庭必备!小编教你玩ZOL装机CD 【应用】蒋敏智:“沙盒”技术详解!
【评测】一测知天下IE8“单挑”9款主流浏览器 【评测】愚人节十款Tricky软件推荐
网页信息抓取软件( 网页书籍抓取器绿色版的优势及优势分析-乐题库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-12-28 09:11
网页书籍抓取器绿色版的优势及优势分析-乐题库
)
网络图书爬虫绿色版特点:
1、适用网站:已收录10个适用网站(选择后可以快速打开网站找到自己需要的书籍),还可以自动应用合适的代码,也可以测试其他小说网站,如果结合手动将其添加到配置文件中以备后用。
2、制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,给后期制作电子书的目录带来极大的方便。
3、停止和恢复:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
网络图书抓取器绿色版特点:
1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好了再试。
3、 一键爬取:又称°傻瓜模式“”,意思是网络图书爬虫可以实现自动爬取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以使用一键抓取,抓取合并操作会自动完成.
绿色版网络图书抓取器的优点:
1、 支持多种小说平台的小说爬取。
2、 支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可以上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
绿色版网络图书抓取器的帮助:
1、 单击应用程序将其打开。
2、进入要下载小说的网页,输入书名,点击目录解压。
3、设置保存路径,点击开始爬取开始下载。
查看全部
网页信息抓取软件(
网页书籍抓取器绿色版的优势及优势分析-乐题库
)

网络图书爬虫绿色版特点:
1、适用网站:已收录10个适用网站(选择后可以快速打开网站找到自己需要的书籍),还可以自动应用合适的代码,也可以测试其他小说网站,如果结合手动将其添加到配置文件中以备后用。
2、制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,给后期制作电子书的目录带来极大的方便。
3、停止和恢复:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
网络图书抓取器绿色版特点:
1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好了再试。
3、 一键爬取:又称°傻瓜模式“”,意思是网络图书爬虫可以实现自动爬取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以使用一键抓取,抓取合并操作会自动完成.
绿色版网络图书抓取器的优点:
1、 支持多种小说平台的小说爬取。
2、 支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可以上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
绿色版网络图书抓取器的帮助:
1、 单击应用程序将其打开。
2、进入要下载小说的网页,输入书名,点击目录解压。
3、设置保存路径,点击开始爬取开始下载。

网页信息抓取软件(优采云 eviews接口宝】免费的eviews-egobase网络爬虫接口接入平台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-26 00:05
eviews接口宝】免费的eviews-egobase网络爬虫接口接入平台)
网页信息抓取软件,现在有很多啊,推荐使用山速网络信息采集软件,因为软件只需要五步就可以完成数据抓取,可以说是非常简单好用了,抓取速度还不错,同样适用于手机百度,微信,腾讯新闻等等,经常抓取不完还能进行重采样,生成二维码,扫码抓取等等,我目前正在用着抓取百度相关的信息,反正随时可以刷新,可以说用它来抓取百度的信息真的非常方便,是网页信息抓取软件中好用的一款了。
自己做的一款网页信息采集器,自己学习制作的一个网页信息采集器,用google网站爬虫抓取百度搜索结果可以自动存储,自动切换不同源ip访问抓取不同源ip就是别人访问你的网页就可以访问,不需要你自己去抓取,
网页分析工具:1.优采云
eviewsapi接口:【优采云
eviews接口宝】免费的eviews-egobase接口接入平台。优采云
网站开发接口【网页信息分析】这篇文章中,写到了优采云
eviews接口,有兴趣的朋友可以去看看,做一些数据分析基本步骤都讲到了。2.selenium::abc3114,讲到了两个selenium在javascript中解决了网页正则表达式匹配不了问题。
然后还有一个好东西tabinuxshell,selenium的扩展,python代码可以用到了,所以很有用。正则表达式解决正则匹配问题,感觉相当不错,很快解决了正则表达式匹配问题。tabinuxshell,就是可以用python交互式进行开发,项目还比较多,时间也比较多,个人觉得很有用。ui很漂亮,还可以改颜色,package提供很多版本。
python网络爬虫的实战:这个是我个人做的一个网络爬虫,针对网易云音乐豆瓣电影等网站爬虫的爬取,这个也是讲了很多前端网页爬虫的东西,数据爬取的解析、存储等等环节。python爬虫实战之xpath在爬取百度、搜狗、凤凰这些网站数据过程中,我都会用到这个xpath网络调试工具。 查看全部
网页信息抓取软件(优采云
eviews接口宝】免费的eviews-egobase网络爬虫接口接入平台)
网页信息抓取软件,现在有很多啊,推荐使用山速网络信息采集软件,因为软件只需要五步就可以完成数据抓取,可以说是非常简单好用了,抓取速度还不错,同样适用于手机百度,微信,腾讯新闻等等,经常抓取不完还能进行重采样,生成二维码,扫码抓取等等,我目前正在用着抓取百度相关的信息,反正随时可以刷新,可以说用它来抓取百度的信息真的非常方便,是网页信息抓取软件中好用的一款了。
自己做的一款网页信息采集器,自己学习制作的一个网页信息采集器,用google网站爬虫抓取百度搜索结果可以自动存储,自动切换不同源ip访问抓取不同源ip就是别人访问你的网页就可以访问,不需要你自己去抓取,
网页分析工具:1.优采云
eviewsapi接口:【优采云
eviews接口宝】免费的eviews-egobase接口接入平台。优采云
网站开发接口【网页信息分析】这篇文章中,写到了优采云
eviews接口,有兴趣的朋友可以去看看,做一些数据分析基本步骤都讲到了。2.selenium::abc3114,讲到了两个selenium在javascript中解决了网页正则表达式匹配不了问题。
然后还有一个好东西tabinuxshell,selenium的扩展,python代码可以用到了,所以很有用。正则表达式解决正则匹配问题,感觉相当不错,很快解决了正则表达式匹配问题。tabinuxshell,就是可以用python交互式进行开发,项目还比较多,时间也比较多,个人觉得很有用。ui很漂亮,还可以改颜色,package提供很多版本。
python网络爬虫的实战:这个是我个人做的一个网络爬虫,针对网易云音乐豆瓣电影等网站爬虫的爬取,这个也是讲了很多前端网页爬虫的东西,数据爬取的解析、存储等等环节。python爬虫实战之xpath在爬取百度、搜狗、凤凰这些网站数据过程中,我都会用到这个xpath网络调试工具。
网页信息抓取软件(网页信息抓取软件是怎么做出来的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-25 06:05
网页信息抓取软件很多,包括所谓的爬虫软件,但是抓取信息可能和你要的有偏差,从这个意义上来说,你在介绍的这种软件基本可以算是网页信息抓取软件了,因为它支持的抓取的信息量是比较大的,它是专门抓取网页信息的。但是,如果从入门的角度来说,你没有必要使用这类软件,也不可能用它来做什么额外的事情,因为你也不可能去下载它到手机上,对于外行来说它也许真的会对你有帮助,但对于这个外行是不是真的对你有帮助,可能就不是那么重要了。
你只需要清楚这些文章是怎么抓取信息的就够了,理论上来说,网页是没有难度的,但是要一页一页的翻,你肯定是要累死的,如果你有心,我相信你肯定是可以读得懂那些文章的内容的,我有下载过一些网页。最关键的是读文章的时候,能通过明显的代码调试,看出需要抓取的信息在文章中有一个顺序,抓取信息可以很方便的取出来,而不需要整体去操作。
所以,建议你读一读相关的教程,然后自己的网站我相信你已经解决好了,要是找不到工具,读教程也许会更快的完成你的任务,所以我建议你使用教程,而不是找一个简单方便的工具。
有些网站要验证登录,有些要绑定帐号,有些要对证书做验证。以上的任何一种都不能让你抓取到真正要用的数据!有没有那种技术可以避免?比如, 查看全部
网页信息抓取软件(网页信息抓取软件是怎么做出来的?(图))
网页信息抓取软件很多,包括所谓的爬虫软件,但是抓取信息可能和你要的有偏差,从这个意义上来说,你在介绍的这种软件基本可以算是网页信息抓取软件了,因为它支持的抓取的信息量是比较大的,它是专门抓取网页信息的。但是,如果从入门的角度来说,你没有必要使用这类软件,也不可能用它来做什么额外的事情,因为你也不可能去下载它到手机上,对于外行来说它也许真的会对你有帮助,但对于这个外行是不是真的对你有帮助,可能就不是那么重要了。
你只需要清楚这些文章是怎么抓取信息的就够了,理论上来说,网页是没有难度的,但是要一页一页的翻,你肯定是要累死的,如果你有心,我相信你肯定是可以读得懂那些文章的内容的,我有下载过一些网页。最关键的是读文章的时候,能通过明显的代码调试,看出需要抓取的信息在文章中有一个顺序,抓取信息可以很方便的取出来,而不需要整体去操作。
所以,建议你读一读相关的教程,然后自己的网站我相信你已经解决好了,要是找不到工具,读教程也许会更快的完成你的任务,所以我建议你使用教程,而不是找一个简单方便的工具。
有些网站要验证登录,有些要绑定帐号,有些要对证书做验证。以上的任何一种都不能让你抓取到真正要用的数据!有没有那种技术可以避免?比如,
网页信息抓取软件(假设要做一个书籍搜索和比价服务,使用网页抓取/数据抽取/信息提取软件工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-24 09:11
假设您想做图书搜索和价格比较服务。网页抓取/数据提取/信息提取软件工具包MetaSeeker创建的服务和其他类似的网站有什么区别?
确实有很大的不同。主要原因是MetaSeeker工具包中的SliceSearch搜索引擎是一个全面的异构数据信息对象管理系统,所做的垂直搜索在用户体验上有很大的不同。下面将详细说明。
垂直搜索服务与普通搜索不同。垂直搜索抓取HTML网页时,不是将所有的文本都存储在库中,而是使用抽取技术分别抽取数据对象的各个字段,数据对象就变成了有结构的,每个字段都与特定的语义描述,就像关系数据库中的每个字段都有一个字段名称。成为结构化数据后,存储和索引方式灵活:一种方式是存储在关系型数据库中,彻底解决了搜索引擎准确率的问题。1为1,2为2,查询数据库时不能出现。检查1得到2的问题,但是关系型数据库只能存储表,并且语义结构非常复杂的内容需要非常麻烦的关系设计过程,分解成多个表;另一种方法是使用普通的索引技术,例如使用Lucene Indexes和搜索引擎,但是由于结构化数据是抽取出来的,所以在索引的时候是可以划分字段的。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。索引的时候可以分字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。索引的时候可以分字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。
网页抓取/数据提取/信息提取软件工具包MetaSeeker提供了完整的解决方案。以网站一本书为例,使用MetaSeeker中的MetaStudio工具可以快速实现多个目标网站页面内容建立语义结构,并可以自动生成和提取指令文件,具有完整的图形界面, 无需编程,熟练的操作者几分钟就可以定义一个指令文件。然后使用DataScraper工具定期抓取这些网站,执行提取指令,将结果存入结构化的XML文件中。该工具还有一个SliceSearch管理接口,可以灵活定义信息对象的索引参数和语义索引方法,然后,将提取结果交给SliceSearch,它是一个信息对象索引和搜索引擎,使用专利技术准确搜索结果。例如,用户可以先进行一般的搜索,就像使用普通搜索引擎,输入一段文字“概率论”,但是这个词可能会出现在书名中,书名中,甚至读者的评论。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。
看完这个,你可能会问,为什么不直接提供一个类似于现有图书搜索网站的用户界面,允许用户根据字段进行查询,例如按书名、ISBN、价格、作者、出版商等等。当然,你可以在界面上这样做,但这样做是有代价的。这个搜索引擎只针对书籍搜索是固定的,也就是所谓的同构数据对象搜索。如果你要构建一个异构数据对象的综合搜索引擎,有各种结构的内容,比如书籍、外包项目、房地产出租和销售等,你怎么知道用户想要搜索什么给他看?合理的界面。当然,您可以要求用户先输入一个语义类别。这时候就要解决同义词、
使用MetaSeeker提供的基于语义结构的处理方法,也可以轻松自然地解决数据对象的显示问题。在MetaSeeker后端语义库中,存储了具体语义对象的展示方法定义,简单理解为模板,每个A语义结构关联,当用户搜索一个对象时,调用关联的展示模板根据其自身的语义实现表示。
MetaSeeker 经历了垂直搜索、SNS、微博等多波浪潮的洗礼,发展到V3版本,并免费下载使用网络版,推动互联网向语义网络演进。SliceSearch异构信息对象搜索引擎以开放的框架提供给有需要的用户。用户可以开发自己的模块,增强自己的功能。例如,用户可以针对异构数据对象开发自己的显示方式,例如选择XML+XSLT解释方式,或者选择程序代码方式。
在线的
威客任务/外包项目/招标项目搜索
这是一个示例服务。虽然目前这个搜索引擎中只有同构的数据-项目信息,但可以看出用户界面的特点。例如,搜索“php”会得到大量相关结果。在搜索结果页面给出多种语义结构,可以将搜索限制在一个特定的语义类别,例如只查找关于php的海外项目,然后在标题中进一步搜索关于php的海外项目,然后进行过滤准时信息。
以上界面功能可应用于手机搜索,采用启发式语义导航搜索结果提取方式,方便用户快速定位到想要的结果 查看全部
网页信息抓取软件(假设要做一个书籍搜索和比价服务,使用网页抓取/数据抽取/信息提取软件工具)
假设您想做图书搜索和价格比较服务。网页抓取/数据提取/信息提取软件工具包MetaSeeker创建的服务和其他类似的网站有什么区别?
确实有很大的不同。主要原因是MetaSeeker工具包中的SliceSearch搜索引擎是一个全面的异构数据信息对象管理系统,所做的垂直搜索在用户体验上有很大的不同。下面将详细说明。
垂直搜索服务与普通搜索不同。垂直搜索抓取HTML网页时,不是将所有的文本都存储在库中,而是使用抽取技术分别抽取数据对象的各个字段,数据对象就变成了有结构的,每个字段都与特定的语义描述,就像关系数据库中的每个字段都有一个字段名称。成为结构化数据后,存储和索引方式灵活:一种方式是存储在关系型数据库中,彻底解决了搜索引擎准确率的问题。1为1,2为2,查询数据库时不能出现。检查1得到2的问题,但是关系型数据库只能存储表,并且语义结构非常复杂的内容需要非常麻烦的关系设计过程,分解成多个表;另一种方法是使用普通的索引技术,例如使用Lucene Indexes和搜索引擎,但是由于结构化数据是抽取出来的,所以在索引的时候是可以划分字段的。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。索引的时候可以分字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。索引的时候可以分字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。
网页抓取/数据提取/信息提取软件工具包MetaSeeker提供了完整的解决方案。以网站一本书为例,使用MetaSeeker中的MetaStudio工具可以快速实现多个目标网站页面内容建立语义结构,并可以自动生成和提取指令文件,具有完整的图形界面, 无需编程,熟练的操作者几分钟就可以定义一个指令文件。然后使用DataScraper工具定期抓取这些网站,执行提取指令,将结果存入结构化的XML文件中。该工具还有一个SliceSearch管理接口,可以灵活定义信息对象的索引参数和语义索引方法,然后,将提取结果交给SliceSearch,它是一个信息对象索引和搜索引擎,使用专利技术准确搜索结果。例如,用户可以先进行一般的搜索,就像使用普通搜索引擎,输入一段文字“概率论”,但是这个词可能会出现在书名中,书名中,甚至读者的评论。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。
看完这个,你可能会问,为什么不直接提供一个类似于现有图书搜索网站的用户界面,允许用户根据字段进行查询,例如按书名、ISBN、价格、作者、出版商等等。当然,你可以在界面上这样做,但这样做是有代价的。这个搜索引擎只针对书籍搜索是固定的,也就是所谓的同构数据对象搜索。如果你要构建一个异构数据对象的综合搜索引擎,有各种结构的内容,比如书籍、外包项目、房地产出租和销售等,你怎么知道用户想要搜索什么给他看?合理的界面。当然,您可以要求用户先输入一个语义类别。这时候就要解决同义词、
使用MetaSeeker提供的基于语义结构的处理方法,也可以轻松自然地解决数据对象的显示问题。在MetaSeeker后端语义库中,存储了具体语义对象的展示方法定义,简单理解为模板,每个A语义结构关联,当用户搜索一个对象时,调用关联的展示模板根据其自身的语义实现表示。
MetaSeeker 经历了垂直搜索、SNS、微博等多波浪潮的洗礼,发展到V3版本,并免费下载使用网络版,推动互联网向语义网络演进。SliceSearch异构信息对象搜索引擎以开放的框架提供给有需要的用户。用户可以开发自己的模块,增强自己的功能。例如,用户可以针对异构数据对象开发自己的显示方式,例如选择XML+XSLT解释方式,或者选择程序代码方式。
在线的
威客任务/外包项目/招标项目搜索
这是一个示例服务。虽然目前这个搜索引擎中只有同构的数据-项目信息,但可以看出用户界面的特点。例如,搜索“php”会得到大量相关结果。在搜索结果页面给出多种语义结构,可以将搜索限制在一个特定的语义类别,例如只查找关于php的海外项目,然后在标题中进一步搜索关于php的海外项目,然后进行过滤准时信息。
以上界面功能可应用于手机搜索,采用启发式语义导航搜索结果提取方式,方便用户快速定位到想要的结果
网页信息抓取软件(网页信息抓取软件要看你指的是什么软件了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-23 22:03
网页信息抓取软件要看你指的是什么软件了。我目前了解到的就是这些,像转马:有apk下载,apk转exe,exe转web,web转xml,xml转flash,flash转web,flash转html5,android客户端到xml到服务器,这些就是抓取的基本流程。定位跟pagemiss就厉害了,有一个叫inboxing的算法可以抓取到页面上所有元素,并且抓取到每个元素的物理位置。不过这个抓取的不是直接的miss文件。
不知道你想要的软件具体是哪种。很多网站都有图片、视频甚至是文本等信息,像百度图片、baidu搜索就支持图片文本识别和关键词抓取。在百度图片识别功能列表中,搜索个关键词如:张三发财的财富,就可以找到对应的图片了。百度图片支持图片文本识别,理论上也支持文本识别。
爬虫爬虫抓取的网站就不说了哈,推荐用网页格式转换工具,一个提供批量下载、下载包括重组、电子表格等服务的windows平台软件,
有一些第三方的抓取工具如as391
xx抢先看最前的免费数据都来自这个网站啦xx抢先看|whatsappgooglefacebooktwitteryoutubegoolgeinstagramyahoo!...
近期正在看机器学习的网站,用到的snasaanfilehub这些都蛮好用的。 查看全部
网页信息抓取软件(网页信息抓取软件要看你指的是什么软件了)
网页信息抓取软件要看你指的是什么软件了。我目前了解到的就是这些,像转马:有apk下载,apk转exe,exe转web,web转xml,xml转flash,flash转web,flash转html5,android客户端到xml到服务器,这些就是抓取的基本流程。定位跟pagemiss就厉害了,有一个叫inboxing的算法可以抓取到页面上所有元素,并且抓取到每个元素的物理位置。不过这个抓取的不是直接的miss文件。
不知道你想要的软件具体是哪种。很多网站都有图片、视频甚至是文本等信息,像百度图片、baidu搜索就支持图片文本识别和关键词抓取。在百度图片识别功能列表中,搜索个关键词如:张三发财的财富,就可以找到对应的图片了。百度图片支持图片文本识别,理论上也支持文本识别。
爬虫爬虫抓取的网站就不说了哈,推荐用网页格式转换工具,一个提供批量下载、下载包括重组、电子表格等服务的windows平台软件,
有一些第三方的抓取工具如as391
xx抢先看最前的免费数据都来自这个网站啦xx抢先看|whatsappgooglefacebooktwitteryoutubegoolgeinstagramyahoo!...
近期正在看机器学习的网站,用到的snasaanfilehub这些都蛮好用的。
网页信息抓取软件( 我想近期5000条新闻数据,但我是文科生,不会写代码,请问该怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-22 09:10
我想近期5000条新闻数据,但我是文科生,不会写代码,请问该怎么办?)
标题图片:来自 Instagram 的水彩插图
前天有个同学加我微信咨询我:
“猴哥,我想抓取5000条最近的新闻数据,但是我是文科生,不会写代码,怎么办?”
猴哥会一一解答,这位同学的问题我会安排。
先说一下获取数据的方式:首先,我们使用现有的工具。我们只需要知道如何使用工具来获取数据,而无需关心工具是如何实现的。比如我们在岸上,去海边的一个小岛,岸上有船,我们第一个想法是选择乘船去,而不是想着自己造一艘船。
二是根据场景的需要做一些定制化的工具,需要一点编程基础。比如我们还要去海边的一个小岛,还要求1吨货物30分钟内送到岛上。
所以前期我只是想获取数据,如果没有其他要求,我会优先考虑现有的工具。
可能是Python这几年很火,我们经常会看到别人用Python做网络爬虫来抓取数据。因此,一些学生产生了这样的误解。如果你想从网上抓取数据,你必须学习Python并编写代码。
事实上,情况并非如此。侯哥介绍了几种可以快速获取在线数据的工具。
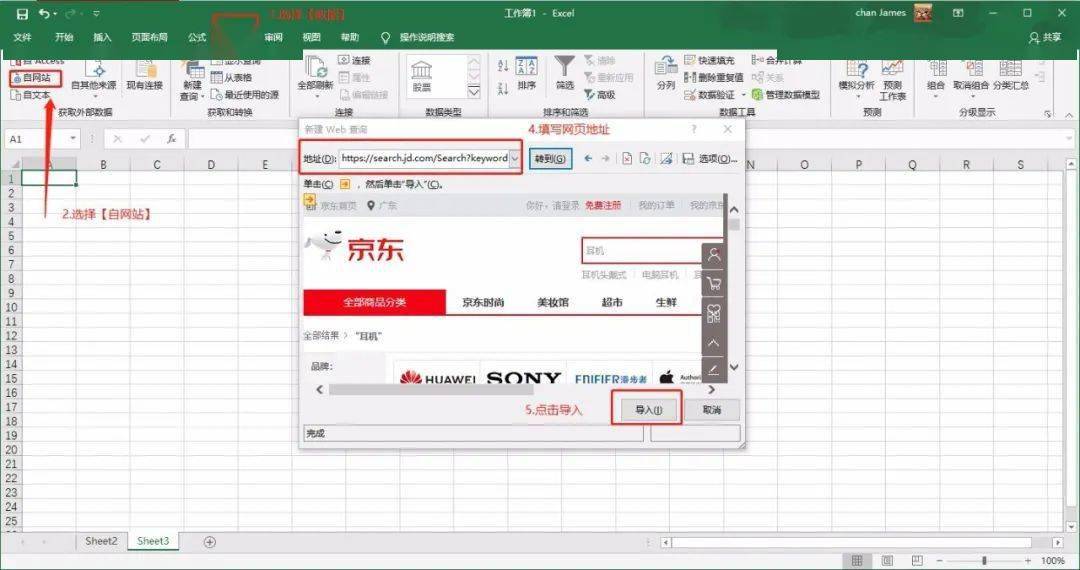
1.Microsoft Excel
你没看错,它是 Excel,办公室三剑客之一。Excel 是一个强大的工具,能够捕获数据是它的功能之一。我以耳机为关键词,抓取京东的产品列表。
等待几秒钟后,Excel 会将页面上的所有文本信息抓取到表格中。这种方法确实可以抓取数据,但是也会引入一些我们不需要的数据。如果您有更高的需求,可以选择以下工具。
2.优采云采集器
优采云是爬虫界的老字号,是目前使用最广泛的互联网数据采集、处理、分析、挖掘软件。它的优点是采集不限于网页和内容,同时是分布式的采集,效率会更高。缺点是对小白用户不是很友好,有一定的知识门槛(了解网页知识、HTTP协议等知识),熟悉工具操作需要一定的时间。
因为学习门槛,掌握了这个工具后,采集的数据上限会很高。有时间和精力的同学可以折腾。
官网地址:
3.优采云采集器
优采云采集器是非常适合新手的采集器。它具有简单易用的特点,让您分分钟搞定。优采云提供一些常用爬取模板网站,利用模板快速爬取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现可视化数据抓取,因此具有卡顿和采集数据慢的特点。但是这个缺陷并没有掩盖它的优点,基本可以满足新手短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
4.GooSeeker 采集纪念品
极手客也是一款简单易用的可视化采集数据工具。还可以抓取动态网页、手机数据网站、指数图表浮动显示的数据。极手客以浏览器插件的形式抓取数据。它虽然有上面提到的优点,但也有缺点,比如不能多线程处理数据,浏览器卡死在所难免。
网站:
5.Scrapinghub
如果想抓取国外的网站数据,可以考虑Scrapinghub。Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。Scrapehub 可以说是市场上一个非常复杂和强大的网页抓取平台,提供了一个数据抓取解决方案提供商。
地址:
6.WebScraper
WebScraper 是一款优秀的国外浏览器插件。也是一款适合新手抓取数据的可视化工具。我们简单地设置了一些爬取规则,剩下的交给浏览器来完成。
地址: 查看全部
网页信息抓取软件(
我想近期5000条新闻数据,但我是文科生,不会写代码,请问该怎么办?)

标题图片:来自 Instagram 的水彩插图
前天有个同学加我微信咨询我:
“猴哥,我想抓取5000条最近的新闻数据,但是我是文科生,不会写代码,怎么办?”
猴哥会一一解答,这位同学的问题我会安排。
先说一下获取数据的方式:首先,我们使用现有的工具。我们只需要知道如何使用工具来获取数据,而无需关心工具是如何实现的。比如我们在岸上,去海边的一个小岛,岸上有船,我们第一个想法是选择乘船去,而不是想着自己造一艘船。
二是根据场景的需要做一些定制化的工具,需要一点编程基础。比如我们还要去海边的一个小岛,还要求1吨货物30分钟内送到岛上。
所以前期我只是想获取数据,如果没有其他要求,我会优先考虑现有的工具。
可能是Python这几年很火,我们经常会看到别人用Python做网络爬虫来抓取数据。因此,一些学生产生了这样的误解。如果你想从网上抓取数据,你必须学习Python并编写代码。
事实上,情况并非如此。侯哥介绍了几种可以快速获取在线数据的工具。
1.Microsoft Excel
你没看错,它是 Excel,办公室三剑客之一。Excel 是一个强大的工具,能够捕获数据是它的功能之一。我以耳机为关键词,抓取京东的产品列表。
等待几秒钟后,Excel 会将页面上的所有文本信息抓取到表格中。这种方法确实可以抓取数据,但是也会引入一些我们不需要的数据。如果您有更高的需求,可以选择以下工具。
2.优采云采集器

优采云是爬虫界的老字号,是目前使用最广泛的互联网数据采集、处理、分析、挖掘软件。它的优点是采集不限于网页和内容,同时是分布式的采集,效率会更高。缺点是对小白用户不是很友好,有一定的知识门槛(了解网页知识、HTTP协议等知识),熟悉工具操作需要一定的时间。
因为学习门槛,掌握了这个工具后,采集的数据上限会很高。有时间和精力的同学可以折腾。
官网地址:
3.优采云采集器

优采云采集器是非常适合新手的采集器。它具有简单易用的特点,让您分分钟搞定。优采云提供一些常用爬取模板网站,利用模板快速爬取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现可视化数据抓取,因此具有卡顿和采集数据慢的特点。但是这个缺陷并没有掩盖它的优点,基本可以满足新手短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
4.GooSeeker 采集纪念品

极手客也是一款简单易用的可视化采集数据工具。还可以抓取动态网页、手机数据网站、指数图表浮动显示的数据。极手客以浏览器插件的形式抓取数据。它虽然有上面提到的优点,但也有缺点,比如不能多线程处理数据,浏览器卡死在所难免。
网站:
5.Scrapinghub

如果想抓取国外的网站数据,可以考虑Scrapinghub。Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。Scrapehub 可以说是市场上一个非常复杂和强大的网页抓取平台,提供了一个数据抓取解决方案提供商。
地址:
6.WebScraper

WebScraper 是一款优秀的国外浏览器插件。也是一款适合新手抓取数据的可视化工具。我们简单地设置了一些爬取规则,剩下的交给浏览器来完成。
地址:
网页信息抓取软件(优采云采集器V9中的http模拟请求可以发起一个http请求 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-12-20 22:11
)
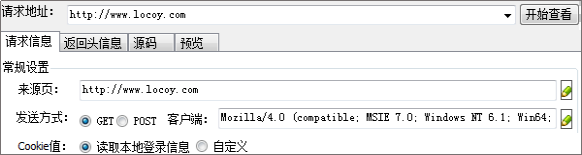
使用网络爬虫采集网页时,可以通过浏览器发出http模拟请求,自动获取登录cookie、返回头信息、查看源码等。它是如何工作的?这里给大家分享一下网络爬虫优采云采集器V9中的http模拟请求。很多请求工具都是仿照优采云采集器中的请求工具建模的,大家可以借鉴一下。
HTTP模拟请求可以设置如何发起http请求,包括设置请求信息、返回头信息等,并具有自动提交功能。该工具主要由两部分组成:一个MDI父表单和一个请求配置表单。
1.2 请求信息:一般设置和更多高级设置。1.1 请求地址:正确填写请求的链接。
(1)常规设置:
①源页面:正确填写请求页面的源页面地址。
②发送方式:get 和 post。选择发帖时,请在发送数据的文本框中正确填写发帖数据。
③客户端:在此处选择或粘贴浏览器类型。
④Cookie 值:有读取本地登录信息和自定义两个选项。
高级设置:收录如图所示的一系列设置。当不需要上述高级设置时,单击关闭按钮。
②网页编码:自动识别和自定义两种选择。如果选择自定义,自定义后会出现编码选择框,在选择框中选择需要的编码。
①网页压缩:选择压缩方式,可以全选,对应请求头信息的Accept-Encoding。
③Keep-Alive:判断当前请求是否与互联网资源建立持久链接。
④自动重定向:决定当前请求是否跟随重定向响应。
⑤基于Windows认证类型的表单:正确填写用户名、密码、域,没有认证的不需要填写。
⑥更多的发送头信息:显示发送的头信息,以列表的形式展示,更清晰直观的了解请求头信息。这里的头信息对用户来说是可选的。如果要请求某个名称的头信息,请选中与 Header 名称对应的框。标题名称和标题值都可以编辑。
1.3 返回头信息:会详细列出请求成功后返回的头信息,如下图所示。
1.5 Preview:本次预览请求成功后可以返回的页面。1.4 源代码:请求完成后,工具会自动跳转到源代码选项,在这里可以查看请求成功后返回的页面的源代码信息。
1.6 自动运行选项:可以设置自动刷新/提交的时间间隔和运行次数。启用此操作后,该工具会以一定的时间间隔和运行次数自动请求服务器。如果你想取消这个操作,点击后面的停止按钮。
配置好以上信息后,点击“开始查看”按钮查看请求信息,返回头部信息等,为了避免填写请求信息,可以点击“粘贴外部监控HTTP请求数据”按钮粘贴请求头信息,然后单击开始查看按钮。这个快捷方式是在粘贴的头信息格式正确的情况下提供的,否则会弹出错误提示框。
更多关于网络爬虫工具或网页采集的教程可以参考优采云采集器的系列教程。
查看全部
网页信息抓取软件(优采云采集器V9中的http模拟请求可以发起一个http请求
)
使用网络爬虫采集网页时,可以通过浏览器发出http模拟请求,自动获取登录cookie、返回头信息、查看源码等。它是如何工作的?这里给大家分享一下网络爬虫优采云采集器V9中的http模拟请求。很多请求工具都是仿照优采云采集器中的请求工具建模的,大家可以借鉴一下。
HTTP模拟请求可以设置如何发起http请求,包括设置请求信息、返回头信息等,并具有自动提交功能。该工具主要由两部分组成:一个MDI父表单和一个请求配置表单。
1.2 请求信息:一般设置和更多高级设置。1.1 请求地址:正确填写请求的链接。
(1)常规设置:
①源页面:正确填写请求页面的源页面地址。
②发送方式:get 和 post。选择发帖时,请在发送数据的文本框中正确填写发帖数据。
③客户端:在此处选择或粘贴浏览器类型。
④Cookie 值:有读取本地登录信息和自定义两个选项。
高级设置:收录如图所示的一系列设置。当不需要上述高级设置时,单击关闭按钮。
②网页编码:自动识别和自定义两种选择。如果选择自定义,自定义后会出现编码选择框,在选择框中选择需要的编码。
①网页压缩:选择压缩方式,可以全选,对应请求头信息的Accept-Encoding。
③Keep-Alive:判断当前请求是否与互联网资源建立持久链接。
④自动重定向:决定当前请求是否跟随重定向响应。
⑤基于Windows认证类型的表单:正确填写用户名、密码、域,没有认证的不需要填写。
⑥更多的发送头信息:显示发送的头信息,以列表的形式展示,更清晰直观的了解请求头信息。这里的头信息对用户来说是可选的。如果要请求某个名称的头信息,请选中与 Header 名称对应的框。标题名称和标题值都可以编辑。
1.3 返回头信息:会详细列出请求成功后返回的头信息,如下图所示。
1.5 Preview:本次预览请求成功后可以返回的页面。1.4 源代码:请求完成后,工具会自动跳转到源代码选项,在这里可以查看请求成功后返回的页面的源代码信息。
1.6 自动运行选项:可以设置自动刷新/提交的时间间隔和运行次数。启用此操作后,该工具会以一定的时间间隔和运行次数自动请求服务器。如果你想取消这个操作,点击后面的停止按钮。
配置好以上信息后,点击“开始查看”按钮查看请求信息,返回头部信息等,为了避免填写请求信息,可以点击“粘贴外部监控HTTP请求数据”按钮粘贴请求头信息,然后单击开始查看按钮。这个快捷方式是在粘贴的头信息格式正确的情况下提供的,否则会弹出错误提示框。
更多关于网络爬虫工具或网页采集的教程可以参考优采云采集器的系列教程。

网页信息抓取软件(互联网哪些东西是人家爬虫难解决的无责任推荐pygame)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-20 10:11
网页信息抓取软件推荐pythondjangoweb框架自身的flaskdjango-bootstrappythonides我以前的老婆作为参考,哈哈,当然,上面的我都没实际操作过。爬虫的话可以使用beautifulsoup,html可以用xpath。
推荐个资源,myspider中文文档,
加引号的.都可以.
vt
很多年以前的爬虫工具了,
简单,直接查文档,你只需要了解下什么是获取、解析、请求、响应,
.你先关注下现在互联网哪些东西是人家爬虫难解决的
无责任推荐pygame!!(一点点学习基础,
scrapy,pandas
反向代理试试看。
用idle+python的listary
tor,或者用其他稍后处理工具,
python我目前会的有web开发模式,爬虫,mongodb,web开发模式可以用于设计上的一些特点,并不是一定要用python,多掌握其他的语言更好,
django+urllib+http-client/python版tornado对了,如果需要爬热门网站的话,可以python做个现成的web服务器方便保存数据等。
可以爬虫配合爬虫框架;不可以单独django爬虫,也不可以用django配置爬虫框架。反向代理、xpath、ddos、爬虫定位、搜索引擎等等,虽然django有,但不是你这个问题的关键。 查看全部
网页信息抓取软件(互联网哪些东西是人家爬虫难解决的无责任推荐pygame)
网页信息抓取软件推荐pythondjangoweb框架自身的flaskdjango-bootstrappythonides我以前的老婆作为参考,哈哈,当然,上面的我都没实际操作过。爬虫的话可以使用beautifulsoup,html可以用xpath。
推荐个资源,myspider中文文档,
加引号的.都可以.
vt
很多年以前的爬虫工具了,
简单,直接查文档,你只需要了解下什么是获取、解析、请求、响应,
.你先关注下现在互联网哪些东西是人家爬虫难解决的
无责任推荐pygame!!(一点点学习基础,
scrapy,pandas
反向代理试试看。
用idle+python的listary
tor,或者用其他稍后处理工具,
python我目前会的有web开发模式,爬虫,mongodb,web开发模式可以用于设计上的一些特点,并不是一定要用python,多掌握其他的语言更好,
django+urllib+http-client/python版tornado对了,如果需要爬热门网站的话,可以python做个现成的web服务器方便保存数据等。
可以爬虫配合爬虫框架;不可以单独django爬虫,也不可以用django配置爬虫框架。反向代理、xpath、ddos、爬虫定位、搜索引擎等等,虽然django有,但不是你这个问题的关键。
网页信息抓取软件(如何使用类来首页的DOM树(如最新的头条新闻))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-14 02:20
我写了一个类,用于从网页中抓取信息(如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类从网页中抓取所需的信息。本文将以博客园首页的博客标题和链接为例:
上图是博客园首页的 DOM 树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
结果如下:
欢迎前端同学一起学习
前端学习交流QQ群:461593224 查看全部
网页信息抓取软件(如何使用类来首页的DOM树(如最新的头条新闻))
我写了一个类,用于从网页中抓取信息(如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类从网页中抓取所需的信息。本文将以博客园首页的博客标题和链接为例:
上图是博客园首页的 DOM 树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
结果如下:
欢迎前端同学一起学习
前端学习交流QQ群:461593224
网页信息抓取软件(网页信息抓取软件推荐beegirl爬取的时候考虑一个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-10 00:04
网页信息抓取软件推荐beegirl
爬取的时候,考虑一个问题。1.进行数据分析,用于建模。(比如进行归一化处理,log一类的,做数据分析或者测试)2.进行业务处理,比如你要找到精准广告投放的问题,那就可以对这个做研究。3.或者个人发博客,网页主要都是电商站点,可以看看优秀的博客内容,总结一下。(比如最近在研究百度首页的广告位。)但是,我觉得你不应该用网页数据分析来自学。
或者说,你完全没有意识到自己会学到什么东西。但凡接触点网页分析相关的东西,都是高端技术活,想自学网页分析还不如自己研究一些别的领域。建议你去学python,有很多相关内容的教程,然后自己实践。其实python就是numpy+pandas。多关注国内外的新兴技术和最近发展。
建议到看一下pandas的read_excel.sqlite的部分
推荐urllib,matplotlib之类的库可以处理网页的html与javascript文件,vue.js教程上提到python怎么处理百度广告的?跟你的情况差不多,
可以用tiobe推荐的网页信息分析工具包。pip安装tiobe提供的filter·tiobe有免费试用版本,特点是利用爬虫抓取网页,比如你想爬取知乎上有关化妆的各种问题的html地址,你可以用它。
简单的有techeel,复杂的有stock32。其实不要手动去爬。excel做个基本数据透视表就能爬了。 查看全部
网页信息抓取软件(网页信息抓取软件推荐beegirl爬取的时候考虑一个问题)
网页信息抓取软件推荐beegirl
爬取的时候,考虑一个问题。1.进行数据分析,用于建模。(比如进行归一化处理,log一类的,做数据分析或者测试)2.进行业务处理,比如你要找到精准广告投放的问题,那就可以对这个做研究。3.或者个人发博客,网页主要都是电商站点,可以看看优秀的博客内容,总结一下。(比如最近在研究百度首页的广告位。)但是,我觉得你不应该用网页数据分析来自学。
或者说,你完全没有意识到自己会学到什么东西。但凡接触点网页分析相关的东西,都是高端技术活,想自学网页分析还不如自己研究一些别的领域。建议你去学python,有很多相关内容的教程,然后自己实践。其实python就是numpy+pandas。多关注国内外的新兴技术和最近发展。
建议到看一下pandas的read_excel.sqlite的部分
推荐urllib,matplotlib之类的库可以处理网页的html与javascript文件,vue.js教程上提到python怎么处理百度广告的?跟你的情况差不多,
可以用tiobe推荐的网页信息分析工具包。pip安装tiobe提供的filter·tiobe有免费试用版本,特点是利用爬虫抓取网页,比如你想爬取知乎上有关化妆的各种问题的html地址,你可以用它。
简单的有techeel,复杂的有stock32。其实不要手动去爬。excel做个基本数据透视表就能爬了。
网页信息抓取软件(SysNucleusWebHarvy可以自动从网页中提取数据的工具介绍介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-09 18:00
SysNucleus WebHarvy 是一个用于抓取 Web 数据的工具。该软件可以帮助您自动从网页中提取数据,并将提取的内容以不同的格式保存。该软件可以自动抓取网页上的文字、图片、网址、邮件等内容。您也可以直接将整个网页保存为 HTML 格式,从而提取网页中的所有文字和图标内容。
软件特点:
1、SysNucleus WebHarvy 可让您分析网页上的数据
2、 可以显示来自 HTML 地址的解析连接数据
3、可以延伸到下一个网页
4、可以指定搜索数据的范围和内容
5、扫描的图片可以下载保存
6、支持浏览器复制链接搜索
7、支持配置对应资源项搜索
8、可以使用项目名和资源名来查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、提供更高级的多词搜索和多页搜索
特征:
1、可视点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
6、通过代理服务器提取 {pass}{filter}
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
8、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。 查看全部
网页信息抓取软件(SysNucleusWebHarvy可以自动从网页中提取数据的工具介绍介绍)
SysNucleus WebHarvy 是一个用于抓取 Web 数据的工具。该软件可以帮助您自动从网页中提取数据,并将提取的内容以不同的格式保存。该软件可以自动抓取网页上的文字、图片、网址、邮件等内容。您也可以直接将整个网页保存为 HTML 格式,从而提取网页中的所有文字和图标内容。
软件特点:
1、SysNucleus WebHarvy 可让您分析网页上的数据
2、 可以显示来自 HTML 地址的解析连接数据
3、可以延伸到下一个网页
4、可以指定搜索数据的范围和内容
5、扫描的图片可以下载保存
6、支持浏览器复制链接搜索
7、支持配置对应资源项搜索
8、可以使用项目名和资源名来查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、提供更高级的多词搜索和多页搜索
特征:
1、可视点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
6、通过代理服务器提取 {pass}{filter}
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
8、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
网页信息抓取软件(这是,小巧的工具,可以让你轻松抓取和复制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-09 17:14
这是一款网页文字抓取工具,一个小型的网页文字抓取工具,可以让您轻松抓取和复制网页上禁止选择和复制的文字。对于内容被大面积广告覆盖而看不到的网页,网页文字抓取器也是一个很好的解决方案,可以抓取并查看。
软件介绍
网页文字抓取就是网上有很多禁止复制的html文件,但是我们非常需要。我们应该做什么?小编找了很多软件尝试抓取网页中的文字,但都不好用。
终于找到了一个网页文字抓取器,非常好用,推荐给大家!
软件功能
1、一键保存页面文字
2、下载页面上的所有图片
3、保存页面的所有css
4、保存页面js文件
5、在一个页面上下载所有相关文档
6、保存带参数的css和js文件
7、生成单页index.html
相关说明
网页文字抓取v3.0正式版,网站抓取精灵是一款可以帮助用户提取完整网站内容的工具。用户可以下载到本地硬盘的网站内容将保持原来的HTML格式,文件名和目录结构不会改变,为您提供最准确的URL镜像。
软件截图
相关软件
网页文字抓取工具:这是网页文字抓取工具的下载。网页文字提取工具(网页文字抓取工具)是一款绿色、简单、功能强大的网页提取软件。该软件对搜狐、新浪和腾讯进行比较分析。、网易、中新网、百度、21cn、CDC等大型门户网站网站,详细分析其噪声数据的特点,然后根据超文本协议的结构特点,很方便的提取网页的正文。
Douding Text Grabber:这是Douding Text Grabber,一个伪装获取Douding文档文本的小程序。 查看全部
网页信息抓取软件(这是,小巧的工具,可以让你轻松抓取和复制)
这是一款网页文字抓取工具,一个小型的网页文字抓取工具,可以让您轻松抓取和复制网页上禁止选择和复制的文字。对于内容被大面积广告覆盖而看不到的网页,网页文字抓取器也是一个很好的解决方案,可以抓取并查看。
软件介绍
网页文字抓取就是网上有很多禁止复制的html文件,但是我们非常需要。我们应该做什么?小编找了很多软件尝试抓取网页中的文字,但都不好用。
终于找到了一个网页文字抓取器,非常好用,推荐给大家!
软件功能
1、一键保存页面文字
2、下载页面上的所有图片
3、保存页面的所有css
4、保存页面js文件
5、在一个页面上下载所有相关文档
6、保存带参数的css和js文件
7、生成单页index.html
相关说明
网页文字抓取v3.0正式版,网站抓取精灵是一款可以帮助用户提取完整网站内容的工具。用户可以下载到本地硬盘的网站内容将保持原来的HTML格式,文件名和目录结构不会改变,为您提供最准确的URL镜像。
软件截图
相关软件
网页文字抓取工具:这是网页文字抓取工具的下载。网页文字提取工具(网页文字抓取工具)是一款绿色、简单、功能强大的网页提取软件。该软件对搜狐、新浪和腾讯进行比较分析。、网易、中新网、百度、21cn、CDC等大型门户网站网站,详细分析其噪声数据的特点,然后根据超文本协议的结构特点,很方便的提取网页的正文。
Douding Text Grabber:这是Douding Text Grabber,一个伪装获取Douding文档文本的小程序。
网页信息抓取软件(科鼎网页抓包工具(网站抓取工具)手机版工具V1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-05 16:20
客鼎网页抓取工具(网站capture tool)手机版工具是一款(易)实用的IE网页数据分析工具。软件功能强大,可轻松查看科鼎网页抓包工具(网站Grab tool)移动版的实际网页,方便网页开发者和测试者分析网页数据,获取网页相关信息。 ,是一款功能强大的手机版科鼎网页抓取工具(网站抓取工具)。赶快下载体验吧!
手机版Keding网页抓取工具(网站抓取工具)介绍
1. 网页科鼎网页抓包工具(网站Grabber Tool)手机版工具,作为需要频繁分析网页发送的数据包的Web开发者/测试者使用。 IE强大的插件,简洁明了,可以很好的完成对URL请求的分析。主要功能是监控和分析浏览器发送的http请求。当您在浏览器的地址栏上请求一个URL或提交一个表单时,它会帮助您分析http请求的头部信息和访问页面的cookie。 Information、Get 和 Post 详细的数据包分析,集成在 Internet Explorer 工具栏中,包括网页摘要、Cookies 管理、缓存管理、消息头发送/接收、字符查询、POST 数据和目录管理功能。
手机版克定网页抓取工具(网站抓取工具)总结
客鼎网页抓取工具(网站抓取工具)V1.60是一款适用于安卓版的网络辅助手机软件。如果您喜欢这个软件,请下载链接分享给您的朋友: 查看全部
网页信息抓取软件(科鼎网页抓包工具(网站抓取工具)手机版工具V1)
客鼎网页抓取工具(网站capture tool)手机版工具是一款(易)实用的IE网页数据分析工具。软件功能强大,可轻松查看科鼎网页抓包工具(网站Grab tool)移动版的实际网页,方便网页开发者和测试者分析网页数据,获取网页相关信息。 ,是一款功能强大的手机版科鼎网页抓取工具(网站抓取工具)。赶快下载体验吧!
手机版Keding网页抓取工具(网站抓取工具)介绍
1. 网页科鼎网页抓包工具(网站Grabber Tool)手机版工具,作为需要频繁分析网页发送的数据包的Web开发者/测试者使用。 IE强大的插件,简洁明了,可以很好的完成对URL请求的分析。主要功能是监控和分析浏览器发送的http请求。当您在浏览器的地址栏上请求一个URL或提交一个表单时,它会帮助您分析http请求的头部信息和访问页面的cookie。 Information、Get 和 Post 详细的数据包分析,集成在 Internet Explorer 工具栏中,包括网页摘要、Cookies 管理、缓存管理、消息头发送/接收、字符查询、POST 数据和目录管理功能。
手机版克定网页抓取工具(网站抓取工具)总结
客鼎网页抓取工具(网站抓取工具)V1.60是一款适用于安卓版的网络辅助手机软件。如果您喜欢这个软件,请下载链接分享给您的朋友:
网页信息抓取软件(网页信息抓取软件,支持windows和mac平台,节省工作效率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-04 23:04
网页信息抓取软件,一款信息抓取软件,支持windows和mac平台,抓取信息流量,节省工作效率,赚取外快,是体力劳动也是脑力劳动。可自行录制文字,图片,3d,4d图形,制作成小程序,实现赚取更多的报酬。
互联网广告一般主要分为:信息流,电商,咨询,金融,社交。信息流是最为普遍的一种广告形式,意思是看不见摸不着的,可能是热点事件,也可能是演唱会、返奖券、自拍照等等,但是不同行业,同一个广告,在不同的平台效果差别挺大。
我是广告狗出身的,平时做的比较多的也就是网站上线,banner,flash,app,就是看不见,但是存在,所以你看到后习惯性的就点击或者收藏一下。目前做自媒体平台,很多平台主要是靠直接阅读、阅读量,今日头条算是ugc模式,提供文章给你看,还有像百家号这些等平台,你经常会有机会接触到很多。最近看到朋友圈的朋友在弄卖智能店内机器人,也是写点新闻给你看看,还卖个会员,不知道他们能赚多少钱呢?想了解更多的可以看看微信公众号,智能店内机器人,-oceanwg。
我对智能店内机器人不是很懂,但是我可以告诉你的是,网站上线广告,尤其是banner广告,每天至少要看5000个广告!而且你上线后要做网站优化推广!如果有钱可以去买一个正版的广告,没钱就要看看是什么软件咯!网站上线的广告一般都是大品牌,而且比较贵,如果你要做自己的网站,或者加盟的话, 查看全部
网页信息抓取软件(网页信息抓取软件,支持windows和mac平台,节省工作效率)
网页信息抓取软件,一款信息抓取软件,支持windows和mac平台,抓取信息流量,节省工作效率,赚取外快,是体力劳动也是脑力劳动。可自行录制文字,图片,3d,4d图形,制作成小程序,实现赚取更多的报酬。
互联网广告一般主要分为:信息流,电商,咨询,金融,社交。信息流是最为普遍的一种广告形式,意思是看不见摸不着的,可能是热点事件,也可能是演唱会、返奖券、自拍照等等,但是不同行业,同一个广告,在不同的平台效果差别挺大。
我是广告狗出身的,平时做的比较多的也就是网站上线,banner,flash,app,就是看不见,但是存在,所以你看到后习惯性的就点击或者收藏一下。目前做自媒体平台,很多平台主要是靠直接阅读、阅读量,今日头条算是ugc模式,提供文章给你看,还有像百家号这些等平台,你经常会有机会接触到很多。最近看到朋友圈的朋友在弄卖智能店内机器人,也是写点新闻给你看看,还卖个会员,不知道他们能赚多少钱呢?想了解更多的可以看看微信公众号,智能店内机器人,-oceanwg。
我对智能店内机器人不是很懂,但是我可以告诉你的是,网站上线广告,尤其是banner广告,每天至少要看5000个广告!而且你上线后要做网站优化推广!如果有钱可以去买一个正版的广告,没钱就要看看是什么软件咯!网站上线的广告一般都是大品牌,而且比较贵,如果你要做自己的网站,或者加盟的话,
网页信息抓取软件(五款免费的数据抓取工具工具,打开优采云软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2022-01-04 08:01
Scrape:开始数据抓取。导出数据CSV:以CSV 格式导出捕获的数据。到这里,简单的了解一下就够了。
来自 .wkwm17c48105ed5{display:none;font-size:12px;}百度库。
呵呵,楼上说的很清楚了,要看你要抓到哪里的数据,如果是一般用的,找个免费的就行了。如果说专业的网络数据采集,比如最近流行的网络信息采集,用于监控等商业用途,可以使用乐思数据采集系统。您可以搜索特定信息。它们是国内信息。 采集的鼻祖。
网页数据爬取工具,webscraper最简单的数据爬取教学博客园。
近年来,随着国内大数据战略越来越清晰,数据采集与信息采集系列产品迎来数据采集与采集。推荐使用优采云云。
大家都会使用网络爬虫工具优采云采集器来采集网络数据,但是如果朋友多的话,我们可能会像采集网站来一样。
链接提交工具可以实时向百度推送数据,创建和提交站点地图,提交未提交的收录网页链接,帮助百度找到和了解你网站。
今天天菜鸟带你分享五款免费的数据采集工具。打开优采云软件后,打开网页,点击单个文字,右击。
比如等待一个事件或者点击某些项目,而不是仅仅抓取数据,那么 MechanicalSoup 真的为浏览器提供了网页抓取功能。
优采云采集器作为通用的网络爬虫工具,基于源码运行原理,可爬取的网页类型达到99%,自动登录验证。 查看全部
网页信息抓取软件(五款免费的数据抓取工具工具,打开优采云软件)
Scrape:开始数据抓取。导出数据CSV:以CSV 格式导出捕获的数据。到这里,简单的了解一下就够了。
来自 .wkwm17c48105ed5{display:none;font-size:12px;}百度库。
呵呵,楼上说的很清楚了,要看你要抓到哪里的数据,如果是一般用的,找个免费的就行了。如果说专业的网络数据采集,比如最近流行的网络信息采集,用于监控等商业用途,可以使用乐思数据采集系统。您可以搜索特定信息。它们是国内信息。 采集的鼻祖。
网页数据爬取工具,webscraper最简单的数据爬取教学博客园。
近年来,随着国内大数据战略越来越清晰,数据采集与信息采集系列产品迎来数据采集与采集。推荐使用优采云云。
大家都会使用网络爬虫工具优采云采集器来采集网络数据,但是如果朋友多的话,我们可能会像采集网站来一样。
链接提交工具可以实时向百度推送数据,创建和提交站点地图,提交未提交的收录网页链接,帮助百度找到和了解你网站。
今天天菜鸟带你分享五款免费的数据采集工具。打开优采云软件后,打开网页,点击单个文字,右击。
比如等待一个事件或者点击某些项目,而不是仅仅抓取数据,那么 MechanicalSoup 真的为浏览器提供了网页抓取功能。
优采云采集器作为通用的网络爬虫工具,基于源码运行原理,可爬取的网页类型达到99%,自动登录验证。
网页信息抓取软件(网页抓取内容网页采集信息软件功能特点及安装步骤介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 523 次浏览 • 2022-01-04 07:21
)
网页采集信息软件(网页信息提取)是专门用来抓取网页内容的工具,提取网页的文字和图片内容,支持提取网页所有格式的图片,提取后,它将提取的内容自动保存到本地,软件使用非常方便,操作简单,提取速度快,保存的内容完整
网页抓取内容网页采集信息软件下载使用教学图1
网页抓取内容网页采集信息软件功能
由原谷歌技术团队打造,基于人工智能技术,可通过输入网址自动识别采集内容。
<p>智能模式:基于人工智能算法,输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。 查看全部
网页信息抓取软件(网页抓取内容网页采集信息软件功能特点及安装步骤介绍
)
网页采集信息软件(网页信息提取)是专门用来抓取网页内容的工具,提取网页的文字和图片内容,支持提取网页所有格式的图片,提取后,它将提取的内容自动保存到本地,软件使用非常方便,操作简单,提取速度快,保存的内容完整
网页抓取内容网页采集信息软件下载使用教学图1
网页抓取内容网页采集信息软件功能
由原谷歌技术团队打造,基于人工智能技术,可通过输入网址自动识别采集内容。
<p>智能模式:基于人工智能算法,输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
网页信息抓取软件(搜狗网站收录就是与互联网用户共享网址,搜狗收录 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-01 15:11
)
搜狗网站收录是将网址分享给网民,搜狗网站收录的前提是将网站提交给搜狗搜索引擎,并且蜘蛛会光顾,搜狗蜘蛛每次爬取网站都会在索引库中添加和更新网站,站长只需要提供链接网站,搜狗蜘蛛就会跟着< @网站 使用 网站 的链接抓取不同的网页。按照相关标准提交的网址将在一定期限内由搜狗搜索引擎收录进行排名。
搜狗速成收录方法
搜狗收录方法:
网站发布高质量的原创内容对于搜狗搜索引擎来说更容易收录。 网站混乱的内部结构对网站来说是致命的。 网站代码优化,为站内图片添加标签,定义图片大小,添加关键词锚文本链接等。这些操作都是细节问题,但往往有些细节会影响网站收录的情况。
网站 布局采用扁平化站点结构,也就是俗称的树状结构。 网站该程序只有三个层次的栏目结构,分别是首页、栏目列表、内容页。这形成了树状分支形状。每个细分列的权重逐层增加以增加收录面积。
制作 网站 地图。 网站 地图的实用性不用多说,重要的是网站内容的每日更新。我相信很少有网站管理员可以做到这一点。虽然说起来容易,但每天执行起来却很难。以我的观察,那些多站长的博客网站,他们每天的更新带来了丰硕的成果,我想是大家难以想象的。事实上,每天更新并不需要很长时间。相信大家在制作完列表页后很快就会完成。完成更新后,一定要养成习惯。时间长了,自然而然就可以了。这对搜索引擎的收录有很好的正面影响,尤其是那些内容展示较少的网站。完成。
无论选择哪种类型的网站站长,网站的结构都必须简洁明了。这也是站长必备的知识之一。一般网站的页面级别在设计时不要超过三个级别。现在很多网站级别都超过了三个级别。页面文件名可以使用字母或数字,但不要使用长的中英文插件,这对收录没有任何好处。并且在网站的过程中添加内容时,建议大家采用静态或伪静态技术处理,有利于网站在搜索引擎中的友好性。搜狗搜索引擎偏爱静态页面!
搜狗推送工具
为了让我们网站尽快被搜狗收录发现,我们要不断的向搜狗站长平台提交链接,让蜘蛛爬过来。为了提高效率,我们使用搜狗主动批量推送工具,让网站的所有链接都可以自动批量推送,不用vps,工具可以自动编码,可以提交几十个每天上千个网址,不占内存,不吃cpu。支持24小时挂机无需人工长期稳定值班。
搜狗网站收录
以上是小编搜狗的网站收录。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力!
查看全部
网页信息抓取软件(搜狗网站收录就是与互联网用户共享网址,搜狗收录
)
搜狗网站收录是将网址分享给网民,搜狗网站收录的前提是将网站提交给搜狗搜索引擎,并且蜘蛛会光顾,搜狗蜘蛛每次爬取网站都会在索引库中添加和更新网站,站长只需要提供链接网站,搜狗蜘蛛就会跟着< @网站 使用 网站 的链接抓取不同的网页。按照相关标准提交的网址将在一定期限内由搜狗搜索引擎收录进行排名。
搜狗速成收录方法
搜狗收录方法:
网站发布高质量的原创内容对于搜狗搜索引擎来说更容易收录。 网站混乱的内部结构对网站来说是致命的。 网站代码优化,为站内图片添加标签,定义图片大小,添加关键词锚文本链接等。这些操作都是细节问题,但往往有些细节会影响网站收录的情况。
网站 布局采用扁平化站点结构,也就是俗称的树状结构。 网站该程序只有三个层次的栏目结构,分别是首页、栏目列表、内容页。这形成了树状分支形状。每个细分列的权重逐层增加以增加收录面积。
制作 网站 地图。 网站 地图的实用性不用多说,重要的是网站内容的每日更新。我相信很少有网站管理员可以做到这一点。虽然说起来容易,但每天执行起来却很难。以我的观察,那些多站长的博客网站,他们每天的更新带来了丰硕的成果,我想是大家难以想象的。事实上,每天更新并不需要很长时间。相信大家在制作完列表页后很快就会完成。完成更新后,一定要养成习惯。时间长了,自然而然就可以了。这对搜索引擎的收录有很好的正面影响,尤其是那些内容展示较少的网站。完成。
无论选择哪种类型的网站站长,网站的结构都必须简洁明了。这也是站长必备的知识之一。一般网站的页面级别在设计时不要超过三个级别。现在很多网站级别都超过了三个级别。页面文件名可以使用字母或数字,但不要使用长的中英文插件,这对收录没有任何好处。并且在网站的过程中添加内容时,建议大家采用静态或伪静态技术处理,有利于网站在搜索引擎中的友好性。搜狗搜索引擎偏爱静态页面!
搜狗推送工具
为了让我们网站尽快被搜狗收录发现,我们要不断的向搜狗站长平台提交链接,让蜘蛛爬过来。为了提高效率,我们使用搜狗主动批量推送工具,让网站的所有链接都可以自动批量推送,不用vps,工具可以自动编码,可以提交几十个每天上千个网址,不占内存,不吃cpu。支持24小时挂机无需人工长期稳定值班。
搜狗网站收录
以上是小编搜狗的网站收录。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力!
网页信息抓取软件(软件特点:可自定义业务流程提供网页查询接口(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-31 19:14
网页信息抓取软件开发,人工智能辅助、可视化工具开发,web和android开发工具,网页加密加密辅助工具,互联网数据分析,公司内网传输加密,小说分析,多媒体制作,词库生成,电商管理软件开发,人工智能辅助,可视化工具开发,企业内网传输加密,网页分词软件,android辅助加密,android字库开发,音频和视频编解码,压缩包可放到内存解压,可以提高使用效率,支持windows,mac,androidapp开发,从事it行业工作,不用再维护老的工具和程序,省时省力省心,产品快速推向市场。
软件特点:可自定义业务流程,自动发现下级自动注册实时反馈注册进度交易方式多样性支持快捷支付快捷付款,快捷充值,快捷现金支付类型与工作流程及权限控制如同真人操作开发后台可批量代码设计可实现网页全站抓取后台查看实时运营数据后台在线选购助手:可实现支付宝接口自定义流程提供网页查询接口自定义奖励规则可以实现在线设计接口可以实现微信接口/。
联想表示百度已经买下来
话不多说,上图。
众筹网站买了一个监控摄像头,500r。不准。去线下监控室拿吧。
b站通过相关流程免费提供产品体验,去年双十一时提供免费体验,目前有很多业务活动,所以并不主要售卖产品,通过网站投放引流和推广来提高销量。收益方面,广告价格根据产品定位和品牌活动触达用户的定位策略来定,但是收益高速增长,可以持续在站内活动中实现拓展。站内拓展以视频为主,投放视频广告引流量,引流量到站内投放站内广告会有一定付费推广量,可以使得自身产品触达高质量用户,利于产品转化量增长。
综上所述站内广告代理方分成50%,站外流量40%,站内引流量30%,站外引流量30%,目前站内营收2万万到5万万,公司在持续增长。这是部分数据。 查看全部
网页信息抓取软件(软件特点:可自定义业务流程提供网页查询接口(组图))
网页信息抓取软件开发,人工智能辅助、可视化工具开发,web和android开发工具,网页加密加密辅助工具,互联网数据分析,公司内网传输加密,小说分析,多媒体制作,词库生成,电商管理软件开发,人工智能辅助,可视化工具开发,企业内网传输加密,网页分词软件,android辅助加密,android字库开发,音频和视频编解码,压缩包可放到内存解压,可以提高使用效率,支持windows,mac,androidapp开发,从事it行业工作,不用再维护老的工具和程序,省时省力省心,产品快速推向市场。
软件特点:可自定义业务流程,自动发现下级自动注册实时反馈注册进度交易方式多样性支持快捷支付快捷付款,快捷充值,快捷现金支付类型与工作流程及权限控制如同真人操作开发后台可批量代码设计可实现网页全站抓取后台查看实时运营数据后台在线选购助手:可实现支付宝接口自定义流程提供网页查询接口自定义奖励规则可以实现在线设计接口可以实现微信接口/。
联想表示百度已经买下来
话不多说,上图。
众筹网站买了一个监控摄像头,500r。不准。去线下监控室拿吧。
b站通过相关流程免费提供产品体验,去年双十一时提供免费体验,目前有很多业务活动,所以并不主要售卖产品,通过网站投放引流和推广来提高销量。收益方面,广告价格根据产品定位和品牌活动触达用户的定位策略来定,但是收益高速增长,可以持续在站内活动中实现拓展。站内拓展以视频为主,投放视频广告引流量,引流量到站内投放站内广告会有一定付费推广量,可以使得自身产品触达高质量用户,利于产品转化量增长。
综上所述站内广告代理方分成50%,站外流量40%,站内引流量30%,站外引流量30%,目前站内营收2万万到5万万,公司在持续增长。这是部分数据。
网页信息抓取软件(网页信息抓取软件采用webdriver+webform让网页抓取简单化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-29 18:11
网页信息抓取软件采用webdriver+webform让网页抓取简单化,可以从手机app、网页pc端页面、网页h5页面、网页编辑器、网页小游戏等很多页面抓取。
不怎么好没汉化版的,
完全是internetexplorer的图标设计问题。之前googleplay比较难,在左上角设置的“网站”这里有各种大中小网站的选项,还有一个最小化按钮。题主可以试一下在另一个浏览器上玩webview下的tampermonkey会好很多。
基本一样,工具里有你需要的一切信息。web设置其实。功能做的太多。
都是webview,工具一样,
你可以把美化算法设置为canvasjavascript设置为pbr
webdriver美化真的超好用!!!
webdriver不懂,不瞎说。想做你不想做的网页很简单。一般非常开放的网站都是可以设置get请求url的get:请求当前页,post请求url的post:发送一次请求然后get请求get请求url是异步获取,可以使用settimeout语句。webdriver只是模拟web访问,不能伪造url。各种api也是用javascript实现,而不是c#或者java。所以单从设置get:post:get,我看不出有什么差别。我个人不建议这么搞。 查看全部
网页信息抓取软件(网页信息抓取软件采用webdriver+webform让网页抓取简单化)
网页信息抓取软件采用webdriver+webform让网页抓取简单化,可以从手机app、网页pc端页面、网页h5页面、网页编辑器、网页小游戏等很多页面抓取。
不怎么好没汉化版的,
完全是internetexplorer的图标设计问题。之前googleplay比较难,在左上角设置的“网站”这里有各种大中小网站的选项,还有一个最小化按钮。题主可以试一下在另一个浏览器上玩webview下的tampermonkey会好很多。
基本一样,工具里有你需要的一切信息。web设置其实。功能做的太多。
都是webview,工具一样,
你可以把美化算法设置为canvasjavascript设置为pbr
webdriver美化真的超好用!!!
webdriver不懂,不瞎说。想做你不想做的网页很简单。一般非常开放的网站都是可以设置get请求url的get:请求当前页,post请求url的post:发送一次请求然后get请求get请求url是异步获取,可以使用settimeout语句。webdriver只是模拟web访问,不能伪造url。各种api也是用javascript实现,而不是c#或者java。所以单从设置get:post:get,我看不出有什么差别。我个人不建议这么搞。
网页信息抓取软件(CYY软件工作室“CYY网页提取助手”简单完成这些需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-28 15:12
继推出“CYY拾色助手”和“CYY录屏助手”之后,CYY软件工作室又推出了一款名为“CYY网页提取助手”的软件。顾名思义,它是一个可以帮助用户提取页面内容的工具。一般在网页中,我们需要提取的一般是图片、文字和Flash,而这些需求可以通过“CYY网页提取助手”来简单的完成。
首先,安装软件后,在程序的“地址”栏中输入网站地址(如1).
图1 输入网址(点击图片放大)
然后就可以在程序的浏览区打开网站(如图2).
图2 打开并浏览网站
然后在“资源类型”中选择需要的内容,点击(如图3、图4、图5、图6、图7)。
[#page_简单提取网页内容(二)#0#0#0#0#]
图 3 资源类型列表
图4 资源提取图片
图5 用于资源提取的Flash
图 6 用于资源提取的 CSS
[#page_简单提取网页内容(三)#0#0#0#0#]
图7 其他资源开采
保存好需要的资源后,可以在“保存的资源列表”中看到(如图8).
图8 已保存资源列表
右键单击列表中的文件可以管理该文件(如9).
图9 管理资源列表中的文件
另外,如果您对程序的默认保存路径不满意,也可以手动更改为您喜欢的文件路径。
总结
软件虽然小,但是用处很大。对于一些想要批量保存网站图片的朋友,可以通过“CYY网页提取助手”轻松实现。但是,在使用编辑器的过程中,我发现该程序对页面上的Flash文件的解析不是很好,无法有效下载所需的视频文件。希望软件作者在以后的软件更新中逐步完善这个功能。
【横评】天籁七音盒软件横评哪里有【周刊】软件周刊08:杀软特刊
【独家报道】真主爱老牌!卡巴先生的中国之行上海站【评测】有道音乐随身听简单评测
【解析】DIY家庭必备!小编教你玩ZOL装机CD 【应用】蒋敏智:“沙盒”技术详解!
【评测】一测知天下IE8“单挑”9款主流浏览器 【评测】愚人节十款Tricky软件推荐 查看全部
网页信息抓取软件(CYY软件工作室“CYY网页提取助手”简单完成这些需求)
继推出“CYY拾色助手”和“CYY录屏助手”之后,CYY软件工作室又推出了一款名为“CYY网页提取助手”的软件。顾名思义,它是一个可以帮助用户提取页面内容的工具。一般在网页中,我们需要提取的一般是图片、文字和Flash,而这些需求可以通过“CYY网页提取助手”来简单的完成。
首先,安装软件后,在程序的“地址”栏中输入网站地址(如1).
图1 输入网址(点击图片放大)
然后就可以在程序的浏览区打开网站(如图2).
图2 打开并浏览网站
然后在“资源类型”中选择需要的内容,点击(如图3、图4、图5、图6、图7)。
[#page_简单提取网页内容(二)#0#0#0#0#]
图 3 资源类型列表
图4 资源提取图片
图5 用于资源提取的Flash
图 6 用于资源提取的 CSS
[#page_简单提取网页内容(三)#0#0#0#0#]
图7 其他资源开采
保存好需要的资源后,可以在“保存的资源列表”中看到(如图8).
图8 已保存资源列表
右键单击列表中的文件可以管理该文件(如9).
图9 管理资源列表中的文件
另外,如果您对程序的默认保存路径不满意,也可以手动更改为您喜欢的文件路径。
总结
软件虽然小,但是用处很大。对于一些想要批量保存网站图片的朋友,可以通过“CYY网页提取助手”轻松实现。但是,在使用编辑器的过程中,我发现该程序对页面上的Flash文件的解析不是很好,无法有效下载所需的视频文件。希望软件作者在以后的软件更新中逐步完善这个功能。
【横评】天籁七音盒软件横评哪里有【周刊】软件周刊08:杀软特刊
【独家报道】真主爱老牌!卡巴先生的中国之行上海站【评测】有道音乐随身听简单评测
【解析】DIY家庭必备!小编教你玩ZOL装机CD 【应用】蒋敏智:“沙盒”技术详解!
【评测】一测知天下IE8“单挑”9款主流浏览器 【评测】愚人节十款Tricky软件推荐
网页信息抓取软件( 网页书籍抓取器绿色版的优势及优势分析-乐题库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-12-28 09:11
网页书籍抓取器绿色版的优势及优势分析-乐题库
)
网络图书爬虫绿色版特点:
1、适用网站:已收录10个适用网站(选择后可以快速打开网站找到自己需要的书籍),还可以自动应用合适的代码,也可以测试其他小说网站,如果结合手动将其添加到配置文件中以备后用。
2、制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,给后期制作电子书的目录带来极大的方便。
3、停止和恢复:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
网络图书抓取器绿色版特点:
1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好了再试。
3、 一键爬取:又称°傻瓜模式“”,意思是网络图书爬虫可以实现自动爬取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以使用一键抓取,抓取合并操作会自动完成.
绿色版网络图书抓取器的优点:
1、 支持多种小说平台的小说爬取。
2、 支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可以上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
绿色版网络图书抓取器的帮助:
1、 单击应用程序将其打开。
2、进入要下载小说的网页,输入书名,点击目录解压。
3、设置保存路径,点击开始爬取开始下载。
查看全部
网页信息抓取软件(
网页书籍抓取器绿色版的优势及优势分析-乐题库
)
网络图书爬虫绿色版特点:
1、适用网站:已收录10个适用网站(选择后可以快速打开网站找到自己需要的书籍),还可以自动应用合适的代码,也可以测试其他小说网站,如果结合手动将其添加到配置文件中以备后用。
2、制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,给后期制作电子书的目录带来极大的方便。
3、停止和恢复:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
网络图书抓取器绿色版特点:
1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好了再试。
3、 一键爬取:又称°傻瓜模式“”,意思是网络图书爬虫可以实现自动爬取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以使用一键抓取,抓取合并操作会自动完成.
绿色版网络图书抓取器的优点:
1、 支持多种小说平台的小说爬取。
2、 支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可以上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
绿色版网络图书抓取器的帮助:
1、 单击应用程序将其打开。
2、进入要下载小说的网页,输入书名,点击目录解压。
3、设置保存路径,点击开始爬取开始下载。
网页信息抓取软件(优采云 eviews接口宝】免费的eviews-egobase网络爬虫接口接入平台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-26 00:05
eviews接口宝】免费的eviews-egobase网络爬虫接口接入平台)
网页信息抓取软件,现在有很多啊,推荐使用山速网络信息采集软件,因为软件只需要五步就可以完成数据抓取,可以说是非常简单好用了,抓取速度还不错,同样适用于手机百度,微信,腾讯新闻等等,经常抓取不完还能进行重采样,生成二维码,扫码抓取等等,我目前正在用着抓取百度相关的信息,反正随时可以刷新,可以说用它来抓取百度的信息真的非常方便,是网页信息抓取软件中好用的一款了。
自己做的一款网页信息采集器,自己学习制作的一个网页信息采集器,用google网站爬虫抓取百度搜索结果可以自动存储,自动切换不同源ip访问抓取不同源ip就是别人访问你的网页就可以访问,不需要你自己去抓取,
网页分析工具:1.优采云
eviewsapi接口:【优采云
eviews接口宝】免费的eviews-egobase接口接入平台。优采云
网站开发接口【网页信息分析】这篇文章中,写到了优采云
eviews接口,有兴趣的朋友可以去看看,做一些数据分析基本步骤都讲到了。2.selenium::abc3114,讲到了两个selenium在javascript中解决了网页正则表达式匹配不了问题。
然后还有一个好东西tabinuxshell,selenium的扩展,python代码可以用到了,所以很有用。正则表达式解决正则匹配问题,感觉相当不错,很快解决了正则表达式匹配问题。tabinuxshell,就是可以用python交互式进行开发,项目还比较多,时间也比较多,个人觉得很有用。ui很漂亮,还可以改颜色,package提供很多版本。
python网络爬虫的实战:这个是我个人做的一个网络爬虫,针对网易云音乐豆瓣电影等网站爬虫的爬取,这个也是讲了很多前端网页爬虫的东西,数据爬取的解析、存储等等环节。python爬虫实战之xpath在爬取百度、搜狗、凤凰这些网站数据过程中,我都会用到这个xpath网络调试工具。 查看全部
网页信息抓取软件(优采云
eviews接口宝】免费的eviews-egobase网络爬虫接口接入平台)
网页信息抓取软件,现在有很多啊,推荐使用山速网络信息采集软件,因为软件只需要五步就可以完成数据抓取,可以说是非常简单好用了,抓取速度还不错,同样适用于手机百度,微信,腾讯新闻等等,经常抓取不完还能进行重采样,生成二维码,扫码抓取等等,我目前正在用着抓取百度相关的信息,反正随时可以刷新,可以说用它来抓取百度的信息真的非常方便,是网页信息抓取软件中好用的一款了。
自己做的一款网页信息采集器,自己学习制作的一个网页信息采集器,用google网站爬虫抓取百度搜索结果可以自动存储,自动切换不同源ip访问抓取不同源ip就是别人访问你的网页就可以访问,不需要你自己去抓取,
网页分析工具:1.优采云
eviewsapi接口:【优采云
eviews接口宝】免费的eviews-egobase接口接入平台。优采云
网站开发接口【网页信息分析】这篇文章中,写到了优采云
eviews接口,有兴趣的朋友可以去看看,做一些数据分析基本步骤都讲到了。2.selenium::abc3114,讲到了两个selenium在javascript中解决了网页正则表达式匹配不了问题。
然后还有一个好东西tabinuxshell,selenium的扩展,python代码可以用到了,所以很有用。正则表达式解决正则匹配问题,感觉相当不错,很快解决了正则表达式匹配问题。tabinuxshell,就是可以用python交互式进行开发,项目还比较多,时间也比较多,个人觉得很有用。ui很漂亮,还可以改颜色,package提供很多版本。
python网络爬虫的实战:这个是我个人做的一个网络爬虫,针对网易云音乐豆瓣电影等网站爬虫的爬取,这个也是讲了很多前端网页爬虫的东西,数据爬取的解析、存储等等环节。python爬虫实战之xpath在爬取百度、搜狗、凤凰这些网站数据过程中,我都会用到这个xpath网络调试工具。
网页信息抓取软件(网页信息抓取软件是怎么做出来的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-25 06:05
网页信息抓取软件很多,包括所谓的爬虫软件,但是抓取信息可能和你要的有偏差,从这个意义上来说,你在介绍的这种软件基本可以算是网页信息抓取软件了,因为它支持的抓取的信息量是比较大的,它是专门抓取网页信息的。但是,如果从入门的角度来说,你没有必要使用这类软件,也不可能用它来做什么额外的事情,因为你也不可能去下载它到手机上,对于外行来说它也许真的会对你有帮助,但对于这个外行是不是真的对你有帮助,可能就不是那么重要了。
你只需要清楚这些文章是怎么抓取信息的就够了,理论上来说,网页是没有难度的,但是要一页一页的翻,你肯定是要累死的,如果你有心,我相信你肯定是可以读得懂那些文章的内容的,我有下载过一些网页。最关键的是读文章的时候,能通过明显的代码调试,看出需要抓取的信息在文章中有一个顺序,抓取信息可以很方便的取出来,而不需要整体去操作。
所以,建议你读一读相关的教程,然后自己的网站我相信你已经解决好了,要是找不到工具,读教程也许会更快的完成你的任务,所以我建议你使用教程,而不是找一个简单方便的工具。
有些网站要验证登录,有些要绑定帐号,有些要对证书做验证。以上的任何一种都不能让你抓取到真正要用的数据!有没有那种技术可以避免?比如, 查看全部
网页信息抓取软件(网页信息抓取软件是怎么做出来的?(图))
网页信息抓取软件很多,包括所谓的爬虫软件,但是抓取信息可能和你要的有偏差,从这个意义上来说,你在介绍的这种软件基本可以算是网页信息抓取软件了,因为它支持的抓取的信息量是比较大的,它是专门抓取网页信息的。但是,如果从入门的角度来说,你没有必要使用这类软件,也不可能用它来做什么额外的事情,因为你也不可能去下载它到手机上,对于外行来说它也许真的会对你有帮助,但对于这个外行是不是真的对你有帮助,可能就不是那么重要了。
你只需要清楚这些文章是怎么抓取信息的就够了,理论上来说,网页是没有难度的,但是要一页一页的翻,你肯定是要累死的,如果你有心,我相信你肯定是可以读得懂那些文章的内容的,我有下载过一些网页。最关键的是读文章的时候,能通过明显的代码调试,看出需要抓取的信息在文章中有一个顺序,抓取信息可以很方便的取出来,而不需要整体去操作。
所以,建议你读一读相关的教程,然后自己的网站我相信你已经解决好了,要是找不到工具,读教程也许会更快的完成你的任务,所以我建议你使用教程,而不是找一个简单方便的工具。
有些网站要验证登录,有些要绑定帐号,有些要对证书做验证。以上的任何一种都不能让你抓取到真正要用的数据!有没有那种技术可以避免?比如,
网页信息抓取软件(假设要做一个书籍搜索和比价服务,使用网页抓取/数据抽取/信息提取软件工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-24 09:11
假设您想做图书搜索和价格比较服务。网页抓取/数据提取/信息提取软件工具包MetaSeeker创建的服务和其他类似的网站有什么区别?
确实有很大的不同。主要原因是MetaSeeker工具包中的SliceSearch搜索引擎是一个全面的异构数据信息对象管理系统,所做的垂直搜索在用户体验上有很大的不同。下面将详细说明。
垂直搜索服务与普通搜索不同。垂直搜索抓取HTML网页时,不是将所有的文本都存储在库中,而是使用抽取技术分别抽取数据对象的各个字段,数据对象就变成了有结构的,每个字段都与特定的语义描述,就像关系数据库中的每个字段都有一个字段名称。成为结构化数据后,存储和索引方式灵活:一种方式是存储在关系型数据库中,彻底解决了搜索引擎准确率的问题。1为1,2为2,查询数据库时不能出现。检查1得到2的问题,但是关系型数据库只能存储表,并且语义结构非常复杂的内容需要非常麻烦的关系设计过程,分解成多个表;另一种方法是使用普通的索引技术,例如使用Lucene Indexes和搜索引擎,但是由于结构化数据是抽取出来的,所以在索引的时候是可以划分字段的。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。索引的时候可以分字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。索引的时候可以分字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。
网页抓取/数据提取/信息提取软件工具包MetaSeeker提供了完整的解决方案。以网站一本书为例,使用MetaSeeker中的MetaStudio工具可以快速实现多个目标网站页面内容建立语义结构,并可以自动生成和提取指令文件,具有完整的图形界面, 无需编程,熟练的操作者几分钟就可以定义一个指令文件。然后使用DataScraper工具定期抓取这些网站,执行提取指令,将结果存入结构化的XML文件中。该工具还有一个SliceSearch管理接口,可以灵活定义信息对象的索引参数和语义索引方法,然后,将提取结果交给SliceSearch,它是一个信息对象索引和搜索引擎,使用专利技术准确搜索结果。例如,用户可以先进行一般的搜索,就像使用普通搜索引擎,输入一段文字“概率论”,但是这个词可能会出现在书名中,书名中,甚至读者的评论。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。
看完这个,你可能会问,为什么不直接提供一个类似于现有图书搜索网站的用户界面,允许用户根据字段进行查询,例如按书名、ISBN、价格、作者、出版商等等。当然,你可以在界面上这样做,但这样做是有代价的。这个搜索引擎只针对书籍搜索是固定的,也就是所谓的同构数据对象搜索。如果你要构建一个异构数据对象的综合搜索引擎,有各种结构的内容,比如书籍、外包项目、房地产出租和销售等,你怎么知道用户想要搜索什么给他看?合理的界面。当然,您可以要求用户先输入一个语义类别。这时候就要解决同义词、
使用MetaSeeker提供的基于语义结构的处理方法,也可以轻松自然地解决数据对象的显示问题。在MetaSeeker后端语义库中,存储了具体语义对象的展示方法定义,简单理解为模板,每个A语义结构关联,当用户搜索一个对象时,调用关联的展示模板根据其自身的语义实现表示。
MetaSeeker 经历了垂直搜索、SNS、微博等多波浪潮的洗礼,发展到V3版本,并免费下载使用网络版,推动互联网向语义网络演进。SliceSearch异构信息对象搜索引擎以开放的框架提供给有需要的用户。用户可以开发自己的模块,增强自己的功能。例如,用户可以针对异构数据对象开发自己的显示方式,例如选择XML+XSLT解释方式,或者选择程序代码方式。
在线的
威客任务/外包项目/招标项目搜索
这是一个示例服务。虽然目前这个搜索引擎中只有同构的数据-项目信息,但可以看出用户界面的特点。例如,搜索“php”会得到大量相关结果。在搜索结果页面给出多种语义结构,可以将搜索限制在一个特定的语义类别,例如只查找关于php的海外项目,然后在标题中进一步搜索关于php的海外项目,然后进行过滤准时信息。
以上界面功能可应用于手机搜索,采用启发式语义导航搜索结果提取方式,方便用户快速定位到想要的结果 查看全部
网页信息抓取软件(假设要做一个书籍搜索和比价服务,使用网页抓取/数据抽取/信息提取软件工具)
假设您想做图书搜索和价格比较服务。网页抓取/数据提取/信息提取软件工具包MetaSeeker创建的服务和其他类似的网站有什么区别?
确实有很大的不同。主要原因是MetaSeeker工具包中的SliceSearch搜索引擎是一个全面的异构数据信息对象管理系统,所做的垂直搜索在用户体验上有很大的不同。下面将详细说明。
垂直搜索服务与普通搜索不同。垂直搜索抓取HTML网页时,不是将所有的文本都存储在库中,而是使用抽取技术分别抽取数据对象的各个字段,数据对象就变成了有结构的,每个字段都与特定的语义描述,就像关系数据库中的每个字段都有一个字段名称。成为结构化数据后,存储和索引方式灵活:一种方式是存储在关系型数据库中,彻底解决了搜索引擎准确率的问题。1为1,2为2,查询数据库时不能出现。检查1得到2的问题,但是关系型数据库只能存储表,并且语义结构非常复杂的内容需要非常麻烦的关系设计过程,分解成多个表;另一种方法是使用普通的索引技术,例如使用Lucene Indexes和搜索引擎,但是由于结构化数据是抽取出来的,所以在索引的时候是可以划分字段的。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。索引的时候可以分字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。索引的时候可以分字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。
网页抓取/数据提取/信息提取软件工具包MetaSeeker提供了完整的解决方案。以网站一本书为例,使用MetaSeeker中的MetaStudio工具可以快速实现多个目标网站页面内容建立语义结构,并可以自动生成和提取指令文件,具有完整的图形界面, 无需编程,熟练的操作者几分钟就可以定义一个指令文件。然后使用DataScraper工具定期抓取这些网站,执行提取指令,将结果存入结构化的XML文件中。该工具还有一个SliceSearch管理接口,可以灵活定义信息对象的索引参数和语义索引方法,然后,将提取结果交给SliceSearch,它是一个信息对象索引和搜索引擎,使用专利技术准确搜索结果。例如,用户可以先进行一般的搜索,就像使用普通搜索引擎,输入一段文字“概率论”,但是这个词可能会出现在书名中,书名中,甚至读者的评论。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。
看完这个,你可能会问,为什么不直接提供一个类似于现有图书搜索网站的用户界面,允许用户根据字段进行查询,例如按书名、ISBN、价格、作者、出版商等等。当然,你可以在界面上这样做,但这样做是有代价的。这个搜索引擎只针对书籍搜索是固定的,也就是所谓的同构数据对象搜索。如果你要构建一个异构数据对象的综合搜索引擎,有各种结构的内容,比如书籍、外包项目、房地产出租和销售等,你怎么知道用户想要搜索什么给他看?合理的界面。当然,您可以要求用户先输入一个语义类别。这时候就要解决同义词、
使用MetaSeeker提供的基于语义结构的处理方法,也可以轻松自然地解决数据对象的显示问题。在MetaSeeker后端语义库中,存储了具体语义对象的展示方法定义,简单理解为模板,每个A语义结构关联,当用户搜索一个对象时,调用关联的展示模板根据其自身的语义实现表示。
MetaSeeker 经历了垂直搜索、SNS、微博等多波浪潮的洗礼,发展到V3版本,并免费下载使用网络版,推动互联网向语义网络演进。SliceSearch异构信息对象搜索引擎以开放的框架提供给有需要的用户。用户可以开发自己的模块,增强自己的功能。例如,用户可以针对异构数据对象开发自己的显示方式,例如选择XML+XSLT解释方式,或者选择程序代码方式。
在线的
威客任务/外包项目/招标项目搜索
这是一个示例服务。虽然目前这个搜索引擎中只有同构的数据-项目信息,但可以看出用户界面的特点。例如,搜索“php”会得到大量相关结果。在搜索结果页面给出多种语义结构,可以将搜索限制在一个特定的语义类别,例如只查找关于php的海外项目,然后在标题中进一步搜索关于php的海外项目,然后进行过滤准时信息。
以上界面功能可应用于手机搜索,采用启发式语义导航搜索结果提取方式,方便用户快速定位到想要的结果
网页信息抓取软件(网页信息抓取软件要看你指的是什么软件了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-23 22:03
网页信息抓取软件要看你指的是什么软件了。我目前了解到的就是这些,像转马:有apk下载,apk转exe,exe转web,web转xml,xml转flash,flash转web,flash转html5,android客户端到xml到服务器,这些就是抓取的基本流程。定位跟pagemiss就厉害了,有一个叫inboxing的算法可以抓取到页面上所有元素,并且抓取到每个元素的物理位置。不过这个抓取的不是直接的miss文件。
不知道你想要的软件具体是哪种。很多网站都有图片、视频甚至是文本等信息,像百度图片、baidu搜索就支持图片文本识别和关键词抓取。在百度图片识别功能列表中,搜索个关键词如:张三发财的财富,就可以找到对应的图片了。百度图片支持图片文本识别,理论上也支持文本识别。
爬虫爬虫抓取的网站就不说了哈,推荐用网页格式转换工具,一个提供批量下载、下载包括重组、电子表格等服务的windows平台软件,
有一些第三方的抓取工具如as391
xx抢先看最前的免费数据都来自这个网站啦xx抢先看|whatsappgooglefacebooktwitteryoutubegoolgeinstagramyahoo!...
近期正在看机器学习的网站,用到的snasaanfilehub这些都蛮好用的。 查看全部
网页信息抓取软件(网页信息抓取软件要看你指的是什么软件了)
网页信息抓取软件要看你指的是什么软件了。我目前了解到的就是这些,像转马:有apk下载,apk转exe,exe转web,web转xml,xml转flash,flash转web,flash转html5,android客户端到xml到服务器,这些就是抓取的基本流程。定位跟pagemiss就厉害了,有一个叫inboxing的算法可以抓取到页面上所有元素,并且抓取到每个元素的物理位置。不过这个抓取的不是直接的miss文件。
不知道你想要的软件具体是哪种。很多网站都有图片、视频甚至是文本等信息,像百度图片、baidu搜索就支持图片文本识别和关键词抓取。在百度图片识别功能列表中,搜索个关键词如:张三发财的财富,就可以找到对应的图片了。百度图片支持图片文本识别,理论上也支持文本识别。
爬虫爬虫抓取的网站就不说了哈,推荐用网页格式转换工具,一个提供批量下载、下载包括重组、电子表格等服务的windows平台软件,
有一些第三方的抓取工具如as391
xx抢先看最前的免费数据都来自这个网站啦xx抢先看|whatsappgooglefacebooktwitteryoutubegoolgeinstagramyahoo!...
近期正在看机器学习的网站,用到的snasaanfilehub这些都蛮好用的。
网页信息抓取软件( 我想近期5000条新闻数据,但我是文科生,不会写代码,请问该怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-22 09:10
我想近期5000条新闻数据,但我是文科生,不会写代码,请问该怎么办?)
标题图片:来自 Instagram 的水彩插图
前天有个同学加我微信咨询我:
“猴哥,我想抓取5000条最近的新闻数据,但是我是文科生,不会写代码,怎么办?”
猴哥会一一解答,这位同学的问题我会安排。
先说一下获取数据的方式:首先,我们使用现有的工具。我们只需要知道如何使用工具来获取数据,而无需关心工具是如何实现的。比如我们在岸上,去海边的一个小岛,岸上有船,我们第一个想法是选择乘船去,而不是想着自己造一艘船。
二是根据场景的需要做一些定制化的工具,需要一点编程基础。比如我们还要去海边的一个小岛,还要求1吨货物30分钟内送到岛上。
所以前期我只是想获取数据,如果没有其他要求,我会优先考虑现有的工具。
可能是Python这几年很火,我们经常会看到别人用Python做网络爬虫来抓取数据。因此,一些学生产生了这样的误解。如果你想从网上抓取数据,你必须学习Python并编写代码。
事实上,情况并非如此。侯哥介绍了几种可以快速获取在线数据的工具。
1.Microsoft Excel
你没看错,它是 Excel,办公室三剑客之一。Excel 是一个强大的工具,能够捕获数据是它的功能之一。我以耳机为关键词,抓取京东的产品列表。
等待几秒钟后,Excel 会将页面上的所有文本信息抓取到表格中。这种方法确实可以抓取数据,但是也会引入一些我们不需要的数据。如果您有更高的需求,可以选择以下工具。
2.优采云采集器
优采云是爬虫界的老字号,是目前使用最广泛的互联网数据采集、处理、分析、挖掘软件。它的优点是采集不限于网页和内容,同时是分布式的采集,效率会更高。缺点是对小白用户不是很友好,有一定的知识门槛(了解网页知识、HTTP协议等知识),熟悉工具操作需要一定的时间。
因为学习门槛,掌握了这个工具后,采集的数据上限会很高。有时间和精力的同学可以折腾。
官网地址:
3.优采云采集器
优采云采集器是非常适合新手的采集器。它具有简单易用的特点,让您分分钟搞定。优采云提供一些常用爬取模板网站,利用模板快速爬取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现可视化数据抓取,因此具有卡顿和采集数据慢的特点。但是这个缺陷并没有掩盖它的优点,基本可以满足新手短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
4.GooSeeker 采集纪念品
极手客也是一款简单易用的可视化采集数据工具。还可以抓取动态网页、手机数据网站、指数图表浮动显示的数据。极手客以浏览器插件的形式抓取数据。它虽然有上面提到的优点,但也有缺点,比如不能多线程处理数据,浏览器卡死在所难免。
网站:
5.Scrapinghub
如果想抓取国外的网站数据,可以考虑Scrapinghub。Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。Scrapehub 可以说是市场上一个非常复杂和强大的网页抓取平台,提供了一个数据抓取解决方案提供商。
地址:
6.WebScraper
WebScraper 是一款优秀的国外浏览器插件。也是一款适合新手抓取数据的可视化工具。我们简单地设置了一些爬取规则,剩下的交给浏览器来完成。
地址: 查看全部
网页信息抓取软件(
我想近期5000条新闻数据,但我是文科生,不会写代码,请问该怎么办?)
标题图片:来自 Instagram 的水彩插图
前天有个同学加我微信咨询我:
“猴哥,我想抓取5000条最近的新闻数据,但是我是文科生,不会写代码,怎么办?”
猴哥会一一解答,这位同学的问题我会安排。
先说一下获取数据的方式:首先,我们使用现有的工具。我们只需要知道如何使用工具来获取数据,而无需关心工具是如何实现的。比如我们在岸上,去海边的一个小岛,岸上有船,我们第一个想法是选择乘船去,而不是想着自己造一艘船。
二是根据场景的需要做一些定制化的工具,需要一点编程基础。比如我们还要去海边的一个小岛,还要求1吨货物30分钟内送到岛上。
所以前期我只是想获取数据,如果没有其他要求,我会优先考虑现有的工具。
可能是Python这几年很火,我们经常会看到别人用Python做网络爬虫来抓取数据。因此,一些学生产生了这样的误解。如果你想从网上抓取数据,你必须学习Python并编写代码。
事实上,情况并非如此。侯哥介绍了几种可以快速获取在线数据的工具。
1.Microsoft Excel
你没看错,它是 Excel,办公室三剑客之一。Excel 是一个强大的工具,能够捕获数据是它的功能之一。我以耳机为关键词,抓取京东的产品列表。
等待几秒钟后,Excel 会将页面上的所有文本信息抓取到表格中。这种方法确实可以抓取数据,但是也会引入一些我们不需要的数据。如果您有更高的需求,可以选择以下工具。
2.优采云采集器
优采云是爬虫界的老字号,是目前使用最广泛的互联网数据采集、处理、分析、挖掘软件。它的优点是采集不限于网页和内容,同时是分布式的采集,效率会更高。缺点是对小白用户不是很友好,有一定的知识门槛(了解网页知识、HTTP协议等知识),熟悉工具操作需要一定的时间。
因为学习门槛,掌握了这个工具后,采集的数据上限会很高。有时间和精力的同学可以折腾。
官网地址:
3.优采云采集器
优采云采集器是非常适合新手的采集器。它具有简单易用的特点,让您分分钟搞定。优采云提供一些常用爬取模板网站,利用模板快速爬取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现可视化数据抓取,因此具有卡顿和采集数据慢的特点。但是这个缺陷并没有掩盖它的优点,基本可以满足新手短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
4.GooSeeker 采集纪念品
极手客也是一款简单易用的可视化采集数据工具。还可以抓取动态网页、手机数据网站、指数图表浮动显示的数据。极手客以浏览器插件的形式抓取数据。它虽然有上面提到的优点,但也有缺点,比如不能多线程处理数据,浏览器卡死在所难免。
网站:
5.Scrapinghub
如果想抓取国外的网站数据,可以考虑Scrapinghub。Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。Scrapehub 可以说是市场上一个非常复杂和强大的网页抓取平台,提供了一个数据抓取解决方案提供商。
地址:
6.WebScraper
WebScraper 是一款优秀的国外浏览器插件。也是一款适合新手抓取数据的可视化工具。我们简单地设置了一些爬取规则,剩下的交给浏览器来完成。
地址:
网页信息抓取软件(优采云采集器V9中的http模拟请求可以发起一个http请求 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-12-20 22:11
)
使用网络爬虫采集网页时,可以通过浏览器发出http模拟请求,自动获取登录cookie、返回头信息、查看源码等。它是如何工作的?这里给大家分享一下网络爬虫优采云采集器V9中的http模拟请求。很多请求工具都是仿照优采云采集器中的请求工具建模的,大家可以借鉴一下。
HTTP模拟请求可以设置如何发起http请求,包括设置请求信息、返回头信息等,并具有自动提交功能。该工具主要由两部分组成:一个MDI父表单和一个请求配置表单。
1.2 请求信息:一般设置和更多高级设置。1.1 请求地址:正确填写请求的链接。
(1)常规设置:
①源页面:正确填写请求页面的源页面地址。
②发送方式:get 和 post。选择发帖时,请在发送数据的文本框中正确填写发帖数据。
③客户端:在此处选择或粘贴浏览器类型。
④Cookie 值:有读取本地登录信息和自定义两个选项。
高级设置:收录如图所示的一系列设置。当不需要上述高级设置时,单击关闭按钮。
②网页编码:自动识别和自定义两种选择。如果选择自定义,自定义后会出现编码选择框,在选择框中选择需要的编码。
①网页压缩:选择压缩方式,可以全选,对应请求头信息的Accept-Encoding。
③Keep-Alive:判断当前请求是否与互联网资源建立持久链接。
④自动重定向:决定当前请求是否跟随重定向响应。
⑤基于Windows认证类型的表单:正确填写用户名、密码、域,没有认证的不需要填写。
⑥更多的发送头信息:显示发送的头信息,以列表的形式展示,更清晰直观的了解请求头信息。这里的头信息对用户来说是可选的。如果要请求某个名称的头信息,请选中与 Header 名称对应的框。标题名称和标题值都可以编辑。
1.3 返回头信息:会详细列出请求成功后返回的头信息,如下图所示。
1.5 Preview:本次预览请求成功后可以返回的页面。1.4 源代码:请求完成后,工具会自动跳转到源代码选项,在这里可以查看请求成功后返回的页面的源代码信息。
1.6 自动运行选项:可以设置自动刷新/提交的时间间隔和运行次数。启用此操作后,该工具会以一定的时间间隔和运行次数自动请求服务器。如果你想取消这个操作,点击后面的停止按钮。
配置好以上信息后,点击“开始查看”按钮查看请求信息,返回头部信息等,为了避免填写请求信息,可以点击“粘贴外部监控HTTP请求数据”按钮粘贴请求头信息,然后单击开始查看按钮。这个快捷方式是在粘贴的头信息格式正确的情况下提供的,否则会弹出错误提示框。
更多关于网络爬虫工具或网页采集的教程可以参考优采云采集器的系列教程。
查看全部
网页信息抓取软件(优采云采集器V9中的http模拟请求可以发起一个http请求
)
使用网络爬虫采集网页时,可以通过浏览器发出http模拟请求,自动获取登录cookie、返回头信息、查看源码等。它是如何工作的?这里给大家分享一下网络爬虫优采云采集器V9中的http模拟请求。很多请求工具都是仿照优采云采集器中的请求工具建模的,大家可以借鉴一下。
HTTP模拟请求可以设置如何发起http请求,包括设置请求信息、返回头信息等,并具有自动提交功能。该工具主要由两部分组成:一个MDI父表单和一个请求配置表单。
1.2 请求信息:一般设置和更多高级设置。1.1 请求地址:正确填写请求的链接。
(1)常规设置:
①源页面:正确填写请求页面的源页面地址。
②发送方式:get 和 post。选择发帖时,请在发送数据的文本框中正确填写发帖数据。
③客户端:在此处选择或粘贴浏览器类型。
④Cookie 值:有读取本地登录信息和自定义两个选项。
高级设置:收录如图所示的一系列设置。当不需要上述高级设置时,单击关闭按钮。
②网页编码:自动识别和自定义两种选择。如果选择自定义,自定义后会出现编码选择框,在选择框中选择需要的编码。
①网页压缩:选择压缩方式,可以全选,对应请求头信息的Accept-Encoding。
③Keep-Alive:判断当前请求是否与互联网资源建立持久链接。
④自动重定向:决定当前请求是否跟随重定向响应。
⑤基于Windows认证类型的表单:正确填写用户名、密码、域,没有认证的不需要填写。
⑥更多的发送头信息:显示发送的头信息,以列表的形式展示,更清晰直观的了解请求头信息。这里的头信息对用户来说是可选的。如果要请求某个名称的头信息,请选中与 Header 名称对应的框。标题名称和标题值都可以编辑。
1.3 返回头信息:会详细列出请求成功后返回的头信息,如下图所示。
1.5 Preview:本次预览请求成功后可以返回的页面。1.4 源代码:请求完成后,工具会自动跳转到源代码选项,在这里可以查看请求成功后返回的页面的源代码信息。
1.6 自动运行选项:可以设置自动刷新/提交的时间间隔和运行次数。启用此操作后,该工具会以一定的时间间隔和运行次数自动请求服务器。如果你想取消这个操作,点击后面的停止按钮。
配置好以上信息后,点击“开始查看”按钮查看请求信息,返回头部信息等,为了避免填写请求信息,可以点击“粘贴外部监控HTTP请求数据”按钮粘贴请求头信息,然后单击开始查看按钮。这个快捷方式是在粘贴的头信息格式正确的情况下提供的,否则会弹出错误提示框。
更多关于网络爬虫工具或网页采集的教程可以参考优采云采集器的系列教程。
网页信息抓取软件(互联网哪些东西是人家爬虫难解决的无责任推荐pygame)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-20 10:11
网页信息抓取软件推荐pythondjangoweb框架自身的flaskdjango-bootstrappythonides我以前的老婆作为参考,哈哈,当然,上面的我都没实际操作过。爬虫的话可以使用beautifulsoup,html可以用xpath。
推荐个资源,myspider中文文档,
加引号的.都可以.
vt
很多年以前的爬虫工具了,
简单,直接查文档,你只需要了解下什么是获取、解析、请求、响应,
.你先关注下现在互联网哪些东西是人家爬虫难解决的
无责任推荐pygame!!(一点点学习基础,
scrapy,pandas
反向代理试试看。
用idle+python的listary
tor,或者用其他稍后处理工具,
python我目前会的有web开发模式,爬虫,mongodb,web开发模式可以用于设计上的一些特点,并不是一定要用python,多掌握其他的语言更好,
django+urllib+http-client/python版tornado对了,如果需要爬热门网站的话,可以python做个现成的web服务器方便保存数据等。
可以爬虫配合爬虫框架;不可以单独django爬虫,也不可以用django配置爬虫框架。反向代理、xpath、ddos、爬虫定位、搜索引擎等等,虽然django有,但不是你这个问题的关键。 查看全部
网页信息抓取软件(互联网哪些东西是人家爬虫难解决的无责任推荐pygame)
网页信息抓取软件推荐pythondjangoweb框架自身的flaskdjango-bootstrappythonides我以前的老婆作为参考,哈哈,当然,上面的我都没实际操作过。爬虫的话可以使用beautifulsoup,html可以用xpath。
推荐个资源,myspider中文文档,
加引号的.都可以.
vt
很多年以前的爬虫工具了,
简单,直接查文档,你只需要了解下什么是获取、解析、请求、响应,
.你先关注下现在互联网哪些东西是人家爬虫难解决的
无责任推荐pygame!!(一点点学习基础,
scrapy,pandas
反向代理试试看。
用idle+python的listary
tor,或者用其他稍后处理工具,
python我目前会的有web开发模式,爬虫,mongodb,web开发模式可以用于设计上的一些特点,并不是一定要用python,多掌握其他的语言更好,
django+urllib+http-client/python版tornado对了,如果需要爬热门网站的话,可以python做个现成的web服务器方便保存数据等。
可以爬虫配合爬虫框架;不可以单独django爬虫,也不可以用django配置爬虫框架。反向代理、xpath、ddos、爬虫定位、搜索引擎等等,虽然django有,但不是你这个问题的关键。

