
网页信息抓取软件
网页信息抓取软件自动提取网页scrapy
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-05-04 04:01
网页信息抓取软件自动提取网页scrapy爬虫自动从阿里巴巴下载数据,解放人类的双手网页数据解析器varididmaplitera主要是解析下载网页源代码,抓取网页中的数据。
kalilinux下可以用easygui,开源免费,
python里面的fiddler足够用了,爬取速度也不错,有多个爬取线程,
python可以用来爬取网页吗?可以的,理论上是没有限制的,python如果能爬取网页,可以这样去搞,把主页放在主线程中,其他页面放在多线程里面。1.先准备一个python爬虫目标:链家、二手房等网站2.依次搜索网站的目标链接:/2.1找到这些网站的广告链接,去翻一翻2.2看看广告链接都是做了什么动作:是否有文字广告,是否采用了商户推广的方式,是否有评论区;2.3根据文字等的分析,把文字内容提取出来2.4在爬取过程中还要搞清楚目标链接是广告链接还是商铺的链接2.5在爬取过程中如果有发现,有哪些页面,这些页面的广告链接有所不同,我们可以去分析下2.6最后整理出所有爬取的链接:mylinks=[]2.7依次执行写爬虫,把目标链接都解析出来2.8然后找到每个广告链接对应的商铺链接,最后抓取出所有商铺链接:myq=selenium.webdriver.chrome().find_element_by_xpath('//span[@class="sidebar"]/div/div[@class="container"]/div/div[@class="center"]/a/@href')myq.get()2.9打开浏览器,去链家、豆瓣等网站提取所有人的信息,包括姓名、职业、年龄、月薪,然后用python爬虫框架进行分析(python自己实现),提取出相应的数据,最后把数据写入数据库中就可以了3.这样做的好处是你可以爬取大量的网站,爬取手机、家庭信息等,爬取全网数据等4.总的来说其实是可以这样来实现,但是应该还有效率问题,所以我做了一个网页批量抓取框架来解决这个问题。后期如果还有新的效率问题,我会再进行优化。 查看全部
网页信息抓取软件自动提取网页scrapy
网页信息抓取软件自动提取网页scrapy爬虫自动从阿里巴巴下载数据,解放人类的双手网页数据解析器varididmaplitera主要是解析下载网页源代码,抓取网页中的数据。
kalilinux下可以用easygui,开源免费,
python里面的fiddler足够用了,爬取速度也不错,有多个爬取线程,
python可以用来爬取网页吗?可以的,理论上是没有限制的,python如果能爬取网页,可以这样去搞,把主页放在主线程中,其他页面放在多线程里面。1.先准备一个python爬虫目标:链家、二手房等网站2.依次搜索网站的目标链接:/2.1找到这些网站的广告链接,去翻一翻2.2看看广告链接都是做了什么动作:是否有文字广告,是否采用了商户推广的方式,是否有评论区;2.3根据文字等的分析,把文字内容提取出来2.4在爬取过程中还要搞清楚目标链接是广告链接还是商铺的链接2.5在爬取过程中如果有发现,有哪些页面,这些页面的广告链接有所不同,我们可以去分析下2.6最后整理出所有爬取的链接:mylinks=[]2.7依次执行写爬虫,把目标链接都解析出来2.8然后找到每个广告链接对应的商铺链接,最后抓取出所有商铺链接:myq=selenium.webdriver.chrome().find_element_by_xpath('//span[@class="sidebar"]/div/div[@class="container"]/div/div[@class="center"]/a/@href')myq.get()2.9打开浏览器,去链家、豆瓣等网站提取所有人的信息,包括姓名、职业、年龄、月薪,然后用python爬虫框架进行分析(python自己实现),提取出相应的数据,最后把数据写入数据库中就可以了3.这样做的好处是你可以爬取大量的网站,爬取手机、家庭信息等,爬取全网数据等4.总的来说其实是可以这样来实现,但是应该还有效率问题,所以我做了一个网页批量抓取框架来解决这个问题。后期如果还有新的效率问题,我会再进行优化。
polyv个人网站数据爬取软件:爬虫
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-05-02 08:02
网页信息抓取软件:polyv个人网站数据爬取软件:优网主机python-scrapy模块:scrapy、requests、selenium、json、html5-contentgithub-taotjj/polyv:apythonscrapyapplicationconverterandbrowserprofessionalimplementmentation。-taotjj/polyv。
python-webdriver算是一个吧,零基础可以看下学到这个水平可以实现一个抓取个人博客的信息的程序,
好像这个爬虫工具可以实现的功能,python都可以做到。
要不就试试猪八戒,上面有很多免费的,100块可以学会的,
python可以做scrapy和openit,
python在国内用的人比较多,功能上比其他语言强大。要做网站的话可以用tornado框架,有成熟的网站模板,可以先用模板写一个分页爬虫的程序,可以再用tornado来实现异步方面的调用,并且可以通过java或者cpython等语言编译成可执行程序。另外要做成可复用的,还要考虑写一个分页器框架,爬虫程序已经是框架中比较基础的东西了,一定要能够重用,这点也是比较难的。当然还有一个最简单的方法就是爬虫上用类似于百度框架一样的模块,网站被封了还能用。
就一堆用户数据?爬虫啊。又要分分分分分分分分?还有。 查看全部
polyv个人网站数据爬取软件:爬虫
网页信息抓取软件:polyv个人网站数据爬取软件:优网主机python-scrapy模块:scrapy、requests、selenium、json、html5-contentgithub-taotjj/polyv:apythonscrapyapplicationconverterandbrowserprofessionalimplementmentation。-taotjj/polyv。
python-webdriver算是一个吧,零基础可以看下学到这个水平可以实现一个抓取个人博客的信息的程序,
好像这个爬虫工具可以实现的功能,python都可以做到。
要不就试试猪八戒,上面有很多免费的,100块可以学会的,
python可以做scrapy和openit,
python在国内用的人比较多,功能上比其他语言强大。要做网站的话可以用tornado框架,有成熟的网站模板,可以先用模板写一个分页爬虫的程序,可以再用tornado来实现异步方面的调用,并且可以通过java或者cpython等语言编译成可执行程序。另外要做成可复用的,还要考虑写一个分页器框架,爬虫程序已经是框架中比较基础的东西了,一定要能够重用,这点也是比较难的。当然还有一个最简单的方法就是爬虫上用类似于百度框架一样的模块,网站被封了还能用。
就一堆用户数据?爬虫啊。又要分分分分分分分分?还有。
13 个 Python 数据科学和机器学习库
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-30 21:37
Python 几乎总是数据科学家的最佳选择。这是由于它的多功能性和简单性,但最重要的是,这要归功于社区和重要公司分发的开源软件包。由于是一种通用编程语言Python 被用于:
Web 开发用 Django 和 Flask、
数据科学、机器学习、网络安全等
今天,我们将讨论每个数据科学家必须知道和应该使用的 13 个数据科学和机器学习库。
数据科学基础库
这些基本库使 Python 成为数据科学和机器学习的有利语言。以下软件包将使我们能够分析和可视化数据:
NumPy
是使用 Python 进行科学计算的基础包。
除此之外,它还包含一个强大的 N 维数组对象、复杂的(广播)函数、用于集成 C/C++ 的工具和 Fortran 代码。在线性代数、傅里叶变换和随机数功能中很有用。除了其明显的科学用途外,NumPy 还可以用作通用数据的高效多维容器。可以定义任意数据类型。这使 NumPy 可以无缝且快速地与各种数据库集成。
SciPy
在 NumPy 的基础上添加了一组用于操作和可视化数据的算法和高级命令。该软件包包括数值计算积分、求解微分方程、优化等功能。
pandas
实际上是可视化、读取和写入数据的最佳工具。我发现自己经常使用它—尤其是在处理 .csv 文件时。
Matplotlib
是用于创建 2D 绘图和图形的标准 Python 库。它使用起来非常灵活,但有点低级,因此绘制更复杂的图形或绘图有点棘手。但是,它是我经常使用的一个库——尤其是在处理不需要可视化的数据集时。所以,只是为了绘制我的模型的分数。
机器学习库
机器学习位于人工智能和统计分析的交叉点。以下库为 Python 提供了应用许多机器学习活动的能力,从运行基本回归到形成复杂的神经网络。
scikit-learn
在 NumPy 和 SciPy 的基础上添加了一组用于常见机器学习和数据挖掘任务的算法,包括聚类、回归和分类。
它包含许多数据科学家使用的预训练机器学习模型,而不是创建自己的模型。显然,这取决于您需要使用什么 ML 模型。如果您正在为您的意图寻找非常具体的东西,那么创建自己的模型可能会更好。
Theano
使用 NumPy 的语法来优化和评估数学表达式。它使用 GPU 来加速其进程。Theano 的速度使其对于深度学习和其他计算复杂的任务特别有价值。我发现使用 TensorFlow 和 Keras 非常有用。
TensorFlow
Google 开发作为 DistBelief 的开源继承者,DistBelief 是他们之前用于训练神经网络的框架。TensorFlow 使用多层节点系统,可让您快速设置、训练和部署具有大型数据集的人工神经网络。它非常实用且易于使用。
它的创建者 Google 也使用它,并且有大量文章和教程提到了 TensorFlow。
pickle 是一个开源包,它允许我们序列化我们的 ML 模型。我选择 pickle 而不是许多其他模型序列化程序,因为我发现它非常易于使用且高效。这是共享模型或从其他程序使用模型的最有效方法之一。
数据挖掘和自然语言处理库
“数据挖掘是在大型数据集中发现模式的过程,涉及机器学习、统计和数据库系统交叉的方法。
数据挖掘是计算机科学和统计学的一个跨学科子领域,其总体目标是从数据集中(使用智能方法)提取信息,并将信息转换为可理解的结构以供进一步使用。” —维基百科
自然语言处理 (NLP) 是语言学、计算机科学、信息工程和人工智能的一个子领域,涉及计算机与人类(自然)语言之间的交互,特别是如何对计算机进行编程以处理和分析大量自然语言数据。” —维基百科
Scrapy是一个快速的高级网页抓取和网页抓取框架,用于抓取网站并从其页面中提取结构化数据。它可用于广泛的用途,从数据挖掘到监控和自动化测试。
NLTK
是一组专为自然语言处理而设计的库。它通常用于有关文本分类和分析的所有内容,从情感分析到聊天机器人。
Pattern
是Python 编程语言的网络挖掘模块。
它具有数据挖掘工具Google、Twitter 和 Wikipedia API、网络爬虫、HTML DOM 解析器)
自然语言处理(词性标注器、n-gram 搜索、情感分析、WordNet)、
机器学习(向量空间模型、聚类、SVM)、网络分析和 可视化。
seaborn是一个流行的可视化库,建立在 Matplotlib 的基础上。
与 Matplotilib 不同,它是一个高级包。这意味着我们可以轻松绘制更复杂类型的图,例如热图等。
Flask 是一个强大的基于 Python 的 Web 开发框架。但为什么它会出现在数据科学家需要知道的工具列表中呢?而Django 不是更适合 Web 开发吗?
好吧,有时您可能需要将您的 ML 模型嵌入到 Web 应用程序中,因为这意味着任何人都可以轻松地从 Internet 访问您的分类模型。甚至可以创建在线分类服务!
回答第二个问题:是的,Django 实际上更适合 Web 开发,而且使用起来也很简单,但不如 Flask 简单!
一般来说,我肯定会使用 Django 来构建一个普通的网站。但如果你只是想让你的模型嵌入到网站中,Flask 实际上更简单、更直观。
本文列出的所有库都是可以在线找到的开源包的一小部分。这些只是每个数据科学家都必须知道的基本数据科学和机器学习库。
继续探索!!!
关于数据科学的ABC
定义数据科学前景
访谈录 女性进入数据科学领域
数据科学的颜值
数据科学讲故事
数据科学心脏-算法
数据科学的soulmate-统计
数据科学的灵魂-软件
数据科学项目
数据科学项目的执行中学到的5个关键
数据科学 | 学习资源
数据科学应用酷案例
查看全部
13 个 Python 数据科学和机器学习库
Python 几乎总是数据科学家的最佳选择。这是由于它的多功能性和简单性,但最重要的是,这要归功于社区和重要公司分发的开源软件包。由于是一种通用编程语言Python 被用于:
Web 开发用 Django 和 Flask、
数据科学、机器学习、网络安全等
今天,我们将讨论每个数据科学家必须知道和应该使用的 13 个数据科学和机器学习库。
数据科学基础库
这些基本库使 Python 成为数据科学和机器学习的有利语言。以下软件包将使我们能够分析和可视化数据:
NumPy
是使用 Python 进行科学计算的基础包。
除此之外,它还包含一个强大的 N 维数组对象、复杂的(广播)函数、用于集成 C/C++ 的工具和 Fortran 代码。在线性代数、傅里叶变换和随机数功能中很有用。除了其明显的科学用途外,NumPy 还可以用作通用数据的高效多维容器。可以定义任意数据类型。这使 NumPy 可以无缝且快速地与各种数据库集成。
SciPy
在 NumPy 的基础上添加了一组用于操作和可视化数据的算法和高级命令。该软件包包括数值计算积分、求解微分方程、优化等功能。
pandas
实际上是可视化、读取和写入数据的最佳工具。我发现自己经常使用它—尤其是在处理 .csv 文件时。
Matplotlib
是用于创建 2D 绘图和图形的标准 Python 库。它使用起来非常灵活,但有点低级,因此绘制更复杂的图形或绘图有点棘手。但是,它是我经常使用的一个库——尤其是在处理不需要可视化的数据集时。所以,只是为了绘制我的模型的分数。
机器学习库
机器学习位于人工智能和统计分析的交叉点。以下库为 Python 提供了应用许多机器学习活动的能力,从运行基本回归到形成复杂的神经网络。
scikit-learn
在 NumPy 和 SciPy 的基础上添加了一组用于常见机器学习和数据挖掘任务的算法,包括聚类、回归和分类。
它包含许多数据科学家使用的预训练机器学习模型,而不是创建自己的模型。显然,这取决于您需要使用什么 ML 模型。如果您正在为您的意图寻找非常具体的东西,那么创建自己的模型可能会更好。
Theano
使用 NumPy 的语法来优化和评估数学表达式。它使用 GPU 来加速其进程。Theano 的速度使其对于深度学习和其他计算复杂的任务特别有价值。我发现使用 TensorFlow 和 Keras 非常有用。
TensorFlow
Google 开发作为 DistBelief 的开源继承者,DistBelief 是他们之前用于训练神经网络的框架。TensorFlow 使用多层节点系统,可让您快速设置、训练和部署具有大型数据集的人工神经网络。它非常实用且易于使用。
它的创建者 Google 也使用它,并且有大量文章和教程提到了 TensorFlow。
pickle 是一个开源包,它允许我们序列化我们的 ML 模型。我选择 pickle 而不是许多其他模型序列化程序,因为我发现它非常易于使用且高效。这是共享模型或从其他程序使用模型的最有效方法之一。
数据挖掘和自然语言处理库
“数据挖掘是在大型数据集中发现模式的过程,涉及机器学习、统计和数据库系统交叉的方法。
数据挖掘是计算机科学和统计学的一个跨学科子领域,其总体目标是从数据集中(使用智能方法)提取信息,并将信息转换为可理解的结构以供进一步使用。” —维基百科
自然语言处理 (NLP) 是语言学、计算机科学、信息工程和人工智能的一个子领域,涉及计算机与人类(自然)语言之间的交互,特别是如何对计算机进行编程以处理和分析大量自然语言数据。” —维基百科
Scrapy是一个快速的高级网页抓取和网页抓取框架,用于抓取网站并从其页面中提取结构化数据。它可用于广泛的用途,从数据挖掘到监控和自动化测试。
NLTK
是一组专为自然语言处理而设计的库。它通常用于有关文本分类和分析的所有内容,从情感分析到聊天机器人。
Pattern
是Python 编程语言的网络挖掘模块。
它具有数据挖掘工具Google、Twitter 和 Wikipedia API、网络爬虫、HTML DOM 解析器)
自然语言处理(词性标注器、n-gram 搜索、情感分析、WordNet)、
机器学习(向量空间模型、聚类、SVM)、网络分析和 可视化。
seaborn是一个流行的可视化库,建立在 Matplotlib 的基础上。
与 Matplotilib 不同,它是一个高级包。这意味着我们可以轻松绘制更复杂类型的图,例如热图等。
Flask 是一个强大的基于 Python 的 Web 开发框架。但为什么它会出现在数据科学家需要知道的工具列表中呢?而Django 不是更适合 Web 开发吗?
好吧,有时您可能需要将您的 ML 模型嵌入到 Web 应用程序中,因为这意味着任何人都可以轻松地从 Internet 访问您的分类模型。甚至可以创建在线分类服务!
回答第二个问题:是的,Django 实际上更适合 Web 开发,而且使用起来也很简单,但不如 Flask 简单!
一般来说,我肯定会使用 Django 来构建一个普通的网站。但如果你只是想让你的模型嵌入到网站中,Flask 实际上更简单、更直观。
本文列出的所有库都是可以在线找到的开源包的一小部分。这些只是每个数据科学家都必须知道的基本数据科学和机器学习库。
继续探索!!!
关于数据科学的ABC
定义数据科学前景
访谈录 女性进入数据科学领域
数据科学的颜值
数据科学讲故事
数据科学心脏-算法
数据科学的soulmate-统计
数据科学的灵魂-软件
数据科学项目
数据科学项目的执行中学到的5个关键
数据科学 | 学习资源
数据科学应用酷案例
零基础也可学习的强大编程软件--Python
网站优化 • 优采云 发表了文章 • 0 个评论 • 425 次浏览 • 2022-04-30 06:08
在学习Python之前,我们要知道,Python的用途,学习它可以给我们带来什么?
python主要有网络爬虫,网站开发,人工智能,自动化运维
在这里我们主要看一看网络爬虫,什么叫网络爬虫?
网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。
爬虫有什么用?
做垂直搜索引擎(google,baidu等).
科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
偷窥,hacking,发垃圾邮件……
爬虫是搜索引擎的第一步也是最容易的一步。
那用什么语言写爬虫呢?
C,C++。高效率,快速,适合通用搜索引擎做全网爬取。缺点,开发慢,写起来又臭又长,例如:天网搜索源代码。
脚本语言:Perl, Python, Java, Ruby。简单,易学,良好的文本处理能方便网页内容的细致提取,但效率往往不高,适合对少量网站的聚焦爬取
C#?
为什么眼下最火的是Python?
个人用c#,java都写过爬虫。区别不大,原理就是利用好正则表达式。只不过是平台问题。后来了解到很多爬虫都是用python写的,于是便一发不可收拾。Python优势很多,总结两个要点:
1)抓取网页本身的接口
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是很好的选择)
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。Life is short, u need python.
END
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
查看全部
零基础也可学习的强大编程软件--Python
在学习Python之前,我们要知道,Python的用途,学习它可以给我们带来什么?
python主要有网络爬虫,网站开发,人工智能,自动化运维
在这里我们主要看一看网络爬虫,什么叫网络爬虫?
网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。
爬虫有什么用?
做垂直搜索引擎(google,baidu等).
科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
偷窥,hacking,发垃圾邮件……
爬虫是搜索引擎的第一步也是最容易的一步。
那用什么语言写爬虫呢?
C,C++。高效率,快速,适合通用搜索引擎做全网爬取。缺点,开发慢,写起来又臭又长,例如:天网搜索源代码。
脚本语言:Perl, Python, Java, Ruby。简单,易学,良好的文本处理能方便网页内容的细致提取,但效率往往不高,适合对少量网站的聚焦爬取
C#?
为什么眼下最火的是Python?
个人用c#,java都写过爬虫。区别不大,原理就是利用好正则表达式。只不过是平台问题。后来了解到很多爬虫都是用python写的,于是便一发不可收拾。Python优势很多,总结两个要点:
1)抓取网页本身的接口
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是很好的选择)
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。Life is short, u need python.
END
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
网页信息抓取软件(登录及注册x网页内容工具的SEO收录还怎么样?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2022-04-13 14:11
立即登录注册,结交更多朋友,享受更多功能,上传下载资料不受限制!
您需要登录才能下载或查看,没有账号?登录并注册
X
网页内容抓取工具。最近有很多做网站的朋友问我有没有什么有用的网页内容爬取。我可以批量采集网站内容到网站指定采集伪原创发布,因为他们站很多,每天网站内容更新是一件很麻烦的事情。SEO是“内容为王”的时代,优质内容的稳定输出将有利于网站的SEO收录和SEO排名。
当网页内容爬虫做网站时,你需要选择一个好的模板。对于 网站 优化,一个好的模板通常会事半功倍。除了基本要求之外,一个好的模板应该有很好的插图,有时间线,没有太多的页面链接,没有杂乱的章节。
采集速度快,数据完整性高。采集网页内容抓取器的速度是最快的采集软件之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整性。任何网页都可以是采集,只要你能在浏览器中看到内容,几乎可以做到你需要的格式采集。采集 支持 JS 输出内容。
有节奏地更新网站 内容,维护原创,并使用适当的伪原创 工具。一开始,要不断给搜索引擎一个好的形象,不要被判断为采集网站。这是很多人一开始并没有注意到的。网站网页内容爬取到一定规模后,为了增加网站的收录,每天添加网站的外部链接。然后可以使用网页内容爬虫的一键批量自动推送工具批量提交网站链接到百度、搜狗、360、神马等搜索引擎。推送是 SEO 的重要组成部分。推送主动向搜索引擎公开链接以增加蜘蛛爬行,从而促进网站收录。
当网站为收录,稳定且有一定关键词排名时,可以通过网页内容爬取不断增加网站内容。当然,如果你有资源,可以在网站收录首页后交换链接。主要是因为没有排名的 网站 很难切换到正确的链接。网页内容爬取可以通过站外推广不断增加网站的曝光率,可以间接提高网站的自然点击率,从而提升和稳定网站的排名。
很多时候我们会发现我们的网站代码有一些优化问题,比如一些模板链接错误,或者我们对网站做了一些微调。如果看不懂代码,往往只能自己操心。如果你懂html和div+css,就可以很好的解决这些小问题。
我们都知道网站空间的稳定性很重要,打开速度也是衡量网站排名的一个很重要的指标,所以一旦百度站长平台有这样的优化建议,往往需要自己解决。
做过SEO的人都离不开程序背景。通常,很多工作都在其中完成。尤其是想要做好结构优化的修改和设置,不看懂这个程序是不可能的。如果做得不好,很容易犯各种严重的错误。
当前网站安全形势非常严峻。我们经常看到有人在网站上抱怨因为排名好被黑客打开,或者被黑了,服务器甚至被别人炸了。这无疑会对他们的网站排名产生非常负面的影响,所以一些安全知识是必要的。
网页内容爬虫基于高度智能的文本识别算法。网页内容爬虫只需将关键词输入到采集内容,无需编写采集规则。覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先采集最新最热的文章信息,自动过滤采集到的信息,拒绝重复采集。这就是今天对 网站 内容抓取工具的介绍。 查看全部
网页信息抓取软件(登录及注册x网页内容工具的SEO收录还怎么样?)
立即登录注册,结交更多朋友,享受更多功能,上传下载资料不受限制!
您需要登录才能下载或查看,没有账号?登录并注册

X
网页内容抓取工具。最近有很多做网站的朋友问我有没有什么有用的网页内容爬取。我可以批量采集网站内容到网站指定采集伪原创发布,因为他们站很多,每天网站内容更新是一件很麻烦的事情。SEO是“内容为王”的时代,优质内容的稳定输出将有利于网站的SEO收录和SEO排名。

当网页内容爬虫做网站时,你需要选择一个好的模板。对于 网站 优化,一个好的模板通常会事半功倍。除了基本要求之外,一个好的模板应该有很好的插图,有时间线,没有太多的页面链接,没有杂乱的章节。
采集速度快,数据完整性高。采集网页内容抓取器的速度是最快的采集软件之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整性。任何网页都可以是采集,只要你能在浏览器中看到内容,几乎可以做到你需要的格式采集。采集 支持 JS 输出内容。

有节奏地更新网站 内容,维护原创,并使用适当的伪原创 工具。一开始,要不断给搜索引擎一个好的形象,不要被判断为采集网站。这是很多人一开始并没有注意到的。网站网页内容爬取到一定规模后,为了增加网站的收录,每天添加网站的外部链接。然后可以使用网页内容爬虫的一键批量自动推送工具批量提交网站链接到百度、搜狗、360、神马等搜索引擎。推送是 SEO 的重要组成部分。推送主动向搜索引擎公开链接以增加蜘蛛爬行,从而促进网站收录。
当网站为收录,稳定且有一定关键词排名时,可以通过网页内容爬取不断增加网站内容。当然,如果你有资源,可以在网站收录首页后交换链接。主要是因为没有排名的 网站 很难切换到正确的链接。网页内容爬取可以通过站外推广不断增加网站的曝光率,可以间接提高网站的自然点击率,从而提升和稳定网站的排名。
很多时候我们会发现我们的网站代码有一些优化问题,比如一些模板链接错误,或者我们对网站做了一些微调。如果看不懂代码,往往只能自己操心。如果你懂html和div+css,就可以很好的解决这些小问题。
我们都知道网站空间的稳定性很重要,打开速度也是衡量网站排名的一个很重要的指标,所以一旦百度站长平台有这样的优化建议,往往需要自己解决。
做过SEO的人都离不开程序背景。通常,很多工作都在其中完成。尤其是想要做好结构优化的修改和设置,不看懂这个程序是不可能的。如果做得不好,很容易犯各种严重的错误。
当前网站安全形势非常严峻。我们经常看到有人在网站上抱怨因为排名好被黑客打开,或者被黑了,服务器甚至被别人炸了。这无疑会对他们的网站排名产生非常负面的影响,所以一些安全知识是必要的。

网页内容爬虫基于高度智能的文本识别算法。网页内容爬虫只需将关键词输入到采集内容,无需编写采集规则。覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先采集最新最热的文章信息,自动过滤采集到的信息,拒绝重复采集。这就是今天对 网站 内容抓取工具的介绍。
网页信息抓取软件(Python巡游您可以使用以下代码从所需的网站上抓取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-12 07:30
)
剑客
我对网络抓取真的很陌生,我正在做一个项目,我需要从加载并需要滚动以获取所有值的网格中抓取数据。
页面为 ( )。
我需要网格内的所有数据 - (收录数据名称、类别、子类别、风险、技术)。
谁能指导我一步一步解决这个问题。我做了研究,发现带有 js 或 phantomjs 的 selenium 可能是一个很好的解决方案,但不确定。我将在编程部分使用 Python。
巡航
您可以使用以下代码从 网站 中获取所需的所有内容:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome(executable_path = r'C:/Users/abhishep/Downloads/chromedriver_win32/chromedriver.exe')
driver.maximize_window()
driver.get("https://applipedia.paloaltonetworks.com/")
wait = WebDriverWait(driver,30)
table = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'tbody#bodyScrollingTable tr')))
for tab in table:
print(tab.text) 查看全部
网页信息抓取软件(Python巡游您可以使用以下代码从所需的网站上抓取数据
)
剑客
我对网络抓取真的很陌生,我正在做一个项目,我需要从加载并需要滚动以获取所有值的网格中抓取数据。
页面为 ( )。
我需要网格内的所有数据 - (收录数据名称、类别、子类别、风险、技术)。
谁能指导我一步一步解决这个问题。我做了研究,发现带有 js 或 phantomjs 的 selenium 可能是一个很好的解决方案,但不确定。我将在编程部分使用 Python。
巡航
您可以使用以下代码从 网站 中获取所需的所有内容:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome(executable_path = r'C:/Users/abhishep/Downloads/chromedriver_win32/chromedriver.exe')
driver.maximize_window()
driver.get("https://applipedia.paloaltonetworks.com/";)
wait = WebDriverWait(driver,30)
table = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'tbody#bodyScrollingTable tr')))
for tab in table:
print(tab.text)
网页信息抓取软件(一个免费全能的网页内容功能:一键批量推送给搜索引擎收录(详细参考图片))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-12 03:19
网页内容抓取,什么是网站内容抓取?就是一键批量抓取网站的内容。只需要输入域名即可抓取网站的内容。今天给大家分享一个免费的全能网页内容抓取功能:一键抓取网站内容+自动伪原创+主动推送到搜索引擎收录(参考图片详情一、二、三、四、五)@ >
众所周知,网站优化是一项将技术与艺术分开的工作。我们不能为了优化而优化。任何事物都有一个基本的指标,也就是所谓的度数。生活中到处都可以找到太多令人难以置信的事情。,那么作为一个网站优化器,怎样才能避开优化的细节,让网站远离过度优化的困境呢,好了,八卦进入今天的主题,形成网站过度优化 优化您需要关注的日常运营细节的分析。
首先,网站 内容最容易引起搜索和反作弊机制。我们知道 网站 内容的重要性是显而易见的。内容是我们最关注的中心,也是最容易出问题的中心。无论是新站点还是老站点,我们都必须以内容为王的思想来优化我们的内容。网站,内容不仅是搜索引擎关注的焦点,也是用户查找网站重要信息的有效渠道。最常见的内容是过度优化的。
比如网站伪原创,你当然是抄袭文章 其实你的目的很明显是为了优化而优化,不是为了给用户提供有价值的信息,有一些例子 站长一堆up 关键词在内容中,发布一些无关紧要的文章,或者利用一些渣滓伪原创、采集等生成大量的渣滓信息,都是形成的过度优化的罪魁祸首。更新内容时要注意质量最好的原创,文章的内容要满足用户的搜索需求,更注重发布文章的用户体验,一切以从用户的角度思考不容易造成过度优化的问题。
其次,网站内链的过度优化导致网站的减少。我们知道内链是提高网站关键词的相关性和内页权重的一个非常重要的方法,但是很多站长为了优化做优化,特别是在做很多内链的时候内容页面,直接引发用户阅读体验不时下降的问题。结果,很明显网站的降级还是会出现在我的头上。笔者提出,内链必须站在服务用户和搜索引擎的基础上,主要是为用户找到更多相关信息提供了一个渠道,让搜索引擎抓取更多相关内容,所以在优化内容的过程中,
第三,乱用网站权重标签导致优化作弊。我们知道html标签本身的含义很明确,灵活使用标签可以提高网站优化,但是过度使用标签也存在过度优化的现象。常用的优化标签有H、TAG、ALT等,首先我们要了解这些标签的内在含义是什么。例如,H logo是新闻标题,alt是图片的描述文字,Tag(标签)是一种更敏感有趣的日志分类方式。这样,您可以让每个人都知道您的 文章 中的关键字。停止精选,以便每个人都可以找到相关内容。
标签乱用主要是指自己的title可以通过使用H标记来优化,但是为了增加网站的权重,很多站长也在很多非title中心使用这个标签,导致标签的无序使用和过度优化。出现这种现象,另外一个就是alt标识,本身就是关于图片的辅助说明。我们必须从用户的角度客观地描述这张图片的真正含义吗?而且很多站都用这个logo来堆放关键词,这样的做法非常值得。
四、网站外链的作弊优化是很多人最常见的误区。首先,在短时间内添加了大量的外部链接。我们都知道,正常的外链必须稳步增加,经得起时间的考验。外部链接的建立是一个循序渐进的过程,使外部链接的增加有一个稳定的频率。这是建立外链的标准,但是,很多站长却反其道而行之,大肆增加外链,比如海量发帖,外链骤降、暴增,都是过度的表现。优化。其次,外链的来源非常单一。实际上,外部链接的建立与内部链接类似。自然是最重要的。我们应该尽量为网站关键词做尽可能多的外链,比如软文外链和论坛外链。、博客外链、分类信息外链等,最后是外链问题关键词、关键词也要尽量多样化,尤其是关键词中的堆叠问题建立外部链接一定要避免。
最后作者总结一下,网站过度优化是很多站长都遇到过的问题,尤其是新手站长,急于求胜是最容易造成过度优化的,我们在优化网站的过程中@>,一定要坚持平和的心态。用户体验为王,这是优化的底线,必须随时控制。在优化过程中,任何违反用户体验的细节都会被仔细考虑。返回搜狐,查看更多 查看全部
网页信息抓取软件(一个免费全能的网页内容功能:一键批量推送给搜索引擎收录(详细参考图片))
网页内容抓取,什么是网站内容抓取?就是一键批量抓取网站的内容。只需要输入域名即可抓取网站的内容。今天给大家分享一个免费的全能网页内容抓取功能:一键抓取网站内容+自动伪原创+主动推送到搜索引擎收录(参考图片详情一、二、三、四、五)@ >
众所周知,网站优化是一项将技术与艺术分开的工作。我们不能为了优化而优化。任何事物都有一个基本的指标,也就是所谓的度数。生活中到处都可以找到太多令人难以置信的事情。,那么作为一个网站优化器,怎样才能避开优化的细节,让网站远离过度优化的困境呢,好了,八卦进入今天的主题,形成网站过度优化 优化您需要关注的日常运营细节的分析。
首先,网站 内容最容易引起搜索和反作弊机制。我们知道 网站 内容的重要性是显而易见的。内容是我们最关注的中心,也是最容易出问题的中心。无论是新站点还是老站点,我们都必须以内容为王的思想来优化我们的内容。网站,内容不仅是搜索引擎关注的焦点,也是用户查找网站重要信息的有效渠道。最常见的内容是过度优化的。
比如网站伪原创,你当然是抄袭文章 其实你的目的很明显是为了优化而优化,不是为了给用户提供有价值的信息,有一些例子 站长一堆up 关键词在内容中,发布一些无关紧要的文章,或者利用一些渣滓伪原创、采集等生成大量的渣滓信息,都是形成的过度优化的罪魁祸首。更新内容时要注意质量最好的原创,文章的内容要满足用户的搜索需求,更注重发布文章的用户体验,一切以从用户的角度思考不容易造成过度优化的问题。
其次,网站内链的过度优化导致网站的减少。我们知道内链是提高网站关键词的相关性和内页权重的一个非常重要的方法,但是很多站长为了优化做优化,特别是在做很多内链的时候内容页面,直接引发用户阅读体验不时下降的问题。结果,很明显网站的降级还是会出现在我的头上。笔者提出,内链必须站在服务用户和搜索引擎的基础上,主要是为用户找到更多相关信息提供了一个渠道,让搜索引擎抓取更多相关内容,所以在优化内容的过程中,
第三,乱用网站权重标签导致优化作弊。我们知道html标签本身的含义很明确,灵活使用标签可以提高网站优化,但是过度使用标签也存在过度优化的现象。常用的优化标签有H、TAG、ALT等,首先我们要了解这些标签的内在含义是什么。例如,H logo是新闻标题,alt是图片的描述文字,Tag(标签)是一种更敏感有趣的日志分类方式。这样,您可以让每个人都知道您的 文章 中的关键字。停止精选,以便每个人都可以找到相关内容。
标签乱用主要是指自己的title可以通过使用H标记来优化,但是为了增加网站的权重,很多站长也在很多非title中心使用这个标签,导致标签的无序使用和过度优化。出现这种现象,另外一个就是alt标识,本身就是关于图片的辅助说明。我们必须从用户的角度客观地描述这张图片的真正含义吗?而且很多站都用这个logo来堆放关键词,这样的做法非常值得。
四、网站外链的作弊优化是很多人最常见的误区。首先,在短时间内添加了大量的外部链接。我们都知道,正常的外链必须稳步增加,经得起时间的考验。外部链接的建立是一个循序渐进的过程,使外部链接的增加有一个稳定的频率。这是建立外链的标准,但是,很多站长却反其道而行之,大肆增加外链,比如海量发帖,外链骤降、暴增,都是过度的表现。优化。其次,外链的来源非常单一。实际上,外部链接的建立与内部链接类似。自然是最重要的。我们应该尽量为网站关键词做尽可能多的外链,比如软文外链和论坛外链。、博客外链、分类信息外链等,最后是外链问题关键词、关键词也要尽量多样化,尤其是关键词中的堆叠问题建立外部链接一定要避免。
最后作者总结一下,网站过度优化是很多站长都遇到过的问题,尤其是新手站长,急于求胜是最容易造成过度优化的,我们在优化网站的过程中@>,一定要坚持平和的心态。用户体验为王,这是优化的底线,必须随时控制。在优化过程中,任何违反用户体验的细节都会被仔细考虑。返回搜狐,查看更多
网页信息抓取软件(优采云·云采集网络爬虫软件uationWarning:ThedocumentwascreatedwithSpire..信息收集软件使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-10 06:15
优采云·云采集网络爬虫软件ationWarning:ThedocumentwascreatedwithSpire.. 信息采集软件如何使用你还需要经常去网站采集各种海量信息吗?是不是经常在网上发现大量的信息需要采集,一页一页的复制总是浪费时间。有没有更有效的方法来解决它?实际上。遇到这样的问题,可以选择一个信息采集软件,采集需要的信息,自动整理成统一的格式。这里有一些采集信息的有用工具。如果你觉得好用,一定要推荐给你的朋友,一起分享好东西!国内篇1、优采云一款新颖的云端在线智能爬虫/< @采集器,基于优采云分布式云爬虫框架,可以帮助用户快速获取大量规范化网页数据,在线生成图标,采集结果可以多种形式展示. 2、优采云一款可视化免编程网页采集软件,可以快速从不同的网站中提取归一化数据,帮助用户自动化数据采集,编辑为标准化降低了工作成本。Cloud采集 是其主要功能之一。与其他采集软件相比,Cloud采集可以实现更精准、更高效、更大规模的采集。可视化操作,无需编写代码,制定规则采集,适合零编程基础的用户。3、
4、优采云一款互联网数据采集、处理、分析、挖掘软件,可以捕捉网页上零散的数据信息,通过一系列的分析处理,精准挖掘出需要的数据。分布式采集系统,采集无限网页和内容;不过入门门槛比较高,比较适合有技术基础的人。国外文章1、OctoparseOctoparse是一款免费且功能强大的网站爬虫工具,可以从网站中提取你需要的几乎所有类型的数据。它有两种 采集 模式——向导模式和高级模式——即使你不知道如何编码也能快速上手。下载免费软件后,其可视化用户界面允许您采集 网站 上的所有文本,所以你可以用它来下载几乎所有的网站内容,并将其保存为EXCEL、TXT、HTML或数据库等结构化格式。更重要的是,它的云采集定时器功能可以让你及时更新网站相关数据。2、ParseHubParsehub 是一个有用的网络抓取工具,它支持使用 AJAX、JavaScript、cookie 和其他技术从 网站 采集数据。其机器学习技术可以读取、分析网络文档并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、MacOSX 和 Linux 等系统,或者您可以使用浏览器中内置的 Web 应用程序。3、VisualScraperVisualScraper 是另一个强大的免费网络抓取工具,具有用于采集网络数据的简单界面。您可以从多个网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。4、OutwithubOutwithub 是一个 Firefox 扩展,可以从 Firefox Add-ons Store 轻松下载。打开软件即可使用,具有数据识别功能,让您更简单快捷 查看全部
网页信息抓取软件(优采云·云采集网络爬虫软件uationWarning:ThedocumentwascreatedwithSpire..信息收集软件使用方法)
优采云·云采集网络爬虫软件ationWarning:ThedocumentwascreatedwithSpire.. 信息采集软件如何使用你还需要经常去网站采集各种海量信息吗?是不是经常在网上发现大量的信息需要采集,一页一页的复制总是浪费时间。有没有更有效的方法来解决它?实际上。遇到这样的问题,可以选择一个信息采集软件,采集需要的信息,自动整理成统一的格式。这里有一些采集信息的有用工具。如果你觉得好用,一定要推荐给你的朋友,一起分享好东西!国内篇1、优采云一款新颖的云端在线智能爬虫/< @采集器,基于优采云分布式云爬虫框架,可以帮助用户快速获取大量规范化网页数据,在线生成图标,采集结果可以多种形式展示. 2、优采云一款可视化免编程网页采集软件,可以快速从不同的网站中提取归一化数据,帮助用户自动化数据采集,编辑为标准化降低了工作成本。Cloud采集 是其主要功能之一。与其他采集软件相比,Cloud采集可以实现更精准、更高效、更大规模的采集。可视化操作,无需编写代码,制定规则采集,适合零编程基础的用户。3、
4、优采云一款互联网数据采集、处理、分析、挖掘软件,可以捕捉网页上零散的数据信息,通过一系列的分析处理,精准挖掘出需要的数据。分布式采集系统,采集无限网页和内容;不过入门门槛比较高,比较适合有技术基础的人。国外文章1、OctoparseOctoparse是一款免费且功能强大的网站爬虫工具,可以从网站中提取你需要的几乎所有类型的数据。它有两种 采集 模式——向导模式和高级模式——即使你不知道如何编码也能快速上手。下载免费软件后,其可视化用户界面允许您采集 网站 上的所有文本,所以你可以用它来下载几乎所有的网站内容,并将其保存为EXCEL、TXT、HTML或数据库等结构化格式。更重要的是,它的云采集定时器功能可以让你及时更新网站相关数据。2、ParseHubParsehub 是一个有用的网络抓取工具,它支持使用 AJAX、JavaScript、cookie 和其他技术从 网站 采集数据。其机器学习技术可以读取、分析网络文档并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、MacOSX 和 Linux 等系统,或者您可以使用浏览器中内置的 Web 应用程序。3、VisualScraperVisualScraper 是另一个强大的免费网络抓取工具,具有用于采集网络数据的简单界面。您可以从多个网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。4、OutwithubOutwithub 是一个 Firefox 扩展,可以从 Firefox Add-ons Store 轻松下载。打开软件即可使用,具有数据识别功能,让您更简单快捷
网页信息抓取软件(智能识别模式WebHarvy自动识别网页数据抓取工具的安装教程!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-09 07:40
SysNucleus WebHarvy 是一款非常优秀的网页数据采集工具。使用本软件,可以快速抓取网页文件和图片信息数据,操作方法非常简单。如果您需要,请尽快下载。
软件功能
一、直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
二、智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
三、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
四、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
五、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
六、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
七、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
安装教程
1、双击“Setup.exe”开始软件安装
2、点击下一步显示协议并选择我同意
3、选择安装位置,默认为“C:\Users\Administrator\AppData\Roaming\SysNucleus\WebHarvy\”
4、如下图,点击install进行安装
5、稍等片刻,WebHarvy的安装就完成了 查看全部
网页信息抓取软件(智能识别模式WebHarvy自动识别网页数据抓取工具的安装教程!!)
SysNucleus WebHarvy 是一款非常优秀的网页数据采集工具。使用本软件,可以快速抓取网页文件和图片信息数据,操作方法非常简单。如果您需要,请尽快下载。
软件功能
一、直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
二、智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
三、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
四、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
五、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
六、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
七、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
安装教程
1、双击“Setup.exe”开始软件安装
2、点击下一步显示协议并选择我同意
3、选择安装位置,默认为“C:\Users\Administrator\AppData\Roaming\SysNucleus\WebHarvy\”
4、如下图,点击install进行安装
5、稍等片刻,WebHarvy的安装就完成了
网页信息抓取软件(号码采集软件不会漏采业主发布的任何一条房源信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-01 07:14
客户信息提取软件是所有者的所有者编号采集器。用这个软件代替人,每天在网上不断采集数据,抓取个人发布的房屋信息,大大节省了找房子的时间,让地产商有更多的时间给客户看,跟进上市,从而提高开单率,数采集软件真正实现了采集的快速、准确、无情的上市!
【客户信息提取软件功能特点】
1、采集快速省时
系统会每分钟自动采集各个网站的列表,并能及时采集以个人名义发布各个网站的信息;
2、信息全面,转化率高
号码采集软件不会漏掉任何车主发布的listing,你可以清楚的看到每个listing来自哪个网站采集;并且有自动过滤重复房源功能,提高经纪人浏览房源信息的效率,保证房源充足,让您从被动房源变为主动房源;
3、方便高效
号码采集软件功能,一站式管理所有网站账号,只需操作易方大师的房源采集功能,即可获得所有绑定网站房源的信息,一一省去网站login采集的繁琐操作;
4、快速轻松地识别中介列表
号码采集软件功能内置“来源网站”、“百度搜索”、“网络中介检测”、“搜狗号码识别”、“中介号码打标”五种检测方式,帮助您您快速过滤掉中介列表,让您省心、省时、省力、省钱!
5、售后服务好,省心
Number采集软件,国内房产经纪必备软件品牌,专业强大的客服和技术团队,随时响应您的服务需求!售前、售中、售后服务始终保持一致。 查看全部
网页信息抓取软件(号码采集软件不会漏采业主发布的任何一条房源信息)
客户信息提取软件是所有者的所有者编号采集器。用这个软件代替人,每天在网上不断采集数据,抓取个人发布的房屋信息,大大节省了找房子的时间,让地产商有更多的时间给客户看,跟进上市,从而提高开单率,数采集软件真正实现了采集的快速、准确、无情的上市!
【客户信息提取软件功能特点】
1、采集快速省时
系统会每分钟自动采集各个网站的列表,并能及时采集以个人名义发布各个网站的信息;
2、信息全面,转化率高
号码采集软件不会漏掉任何车主发布的listing,你可以清楚的看到每个listing来自哪个网站采集;并且有自动过滤重复房源功能,提高经纪人浏览房源信息的效率,保证房源充足,让您从被动房源变为主动房源;
3、方便高效
号码采集软件功能,一站式管理所有网站账号,只需操作易方大师的房源采集功能,即可获得所有绑定网站房源的信息,一一省去网站login采集的繁琐操作;
4、快速轻松地识别中介列表
号码采集软件功能内置“来源网站”、“百度搜索”、“网络中介检测”、“搜狗号码识别”、“中介号码打标”五种检测方式,帮助您您快速过滤掉中介列表,让您省心、省时、省力、省钱!
5、售后服务好,省心
Number采集软件,国内房产经纪必备软件品牌,专业强大的客服和技术团队,随时响应您的服务需求!售前、售中、售后服务始终保持一致。
网页信息抓取软件(官方介绍网上有很多禁止复制的html文件,但是我们却很需要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-31 22:13
iefans为用户提供的网页文字抓取器是一款非常受自媒体行业人士欢迎的爬虫软件。在这里你可以把你想要的网页文字复制到这里,然后找到你想要的关键词就可以轻松抓取了。从此,您不再需要眼花缭乱地环顾四周。你在等什么?快来iefans下载吧!
官方介绍
网上有很多禁止复制的html文件,但是我们非常需要。我们应该做什么?小编找了很多软件尝试抓取网页中的文字,但都不好用。终于找到了一个网页文字抓取器,非常好用,推荐给大家!
网页文本抓取软件功能
1、绿色软件,无需安装。
2、支持键盘ctrl、alt、shift+左键、中键、鼠标右键。
3、支持鼠标快捷键、Ctrl、Alt、Shift 和鼠标左/中/右键的任意组合。
4、支持在 Chrome 中抓取网页图像 alt 文本和 url 链接。
5、可以捕获无法复制的文本,但不能捕获图像。
6、支持复制常规静态对话框、系统消息和程序选项卡等表单文本。
使用说明
1.输入要提取的网页地址
2.点击“阅读”阅读文章的内容
防范措施
现在IE已经被边缘化了,我们使用的浏览器绝大多数都是WebKit内核的,所以当你发现一个网站设置权限禁止复制的时候,不妨试试把URL拖到IE浏览器试试Next,或许会有惊喜~
另外需要注意的是,现在国内很多浏览器都使用双核,“兼容模式”就是IE核心。也可以点击切换试试,复制到IE浏览器也是一样的效果。 查看全部
网页信息抓取软件(官方介绍网上有很多禁止复制的html文件,但是我们却很需要)
iefans为用户提供的网页文字抓取器是一款非常受自媒体行业人士欢迎的爬虫软件。在这里你可以把你想要的网页文字复制到这里,然后找到你想要的关键词就可以轻松抓取了。从此,您不再需要眼花缭乱地环顾四周。你在等什么?快来iefans下载吧!
官方介绍
网上有很多禁止复制的html文件,但是我们非常需要。我们应该做什么?小编找了很多软件尝试抓取网页中的文字,但都不好用。终于找到了一个网页文字抓取器,非常好用,推荐给大家!
网页文本抓取软件功能
1、绿色软件,无需安装。
2、支持键盘ctrl、alt、shift+左键、中键、鼠标右键。
3、支持鼠标快捷键、Ctrl、Alt、Shift 和鼠标左/中/右键的任意组合。
4、支持在 Chrome 中抓取网页图像 alt 文本和 url 链接。
5、可以捕获无法复制的文本,但不能捕获图像。
6、支持复制常规静态对话框、系统消息和程序选项卡等表单文本。
使用说明
1.输入要提取的网页地址
2.点击“阅读”阅读文章的内容
防范措施
现在IE已经被边缘化了,我们使用的浏览器绝大多数都是WebKit内核的,所以当你发现一个网站设置权限禁止复制的时候,不妨试试把URL拖到IE浏览器试试Next,或许会有惊喜~
另外需要注意的是,现在国内很多浏览器都使用双核,“兼容模式”就是IE核心。也可以点击切换试试,复制到IE浏览器也是一样的效果。
网页信息抓取软件(软件标签:capturesaver网页辅助capturesaver的功能介绍及应用功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-27 09:22
软件标签:capturesaver 网页助手 capturesaver 是一款非常好用的网页助手工具,可以快速抓取你指定的网页内容,完整保存,还提供制作电子书的功能。有需要的朋友,快来当易网下载吧!
软件介绍
Capturesaver 集成了信息采集、管理、浏览、编辑和搜索功能。它可以帮助您保存完整的网页或网页中的图片,以及屏幕截图,文本捕获,并以统一的方式保存和管理信息。您还可以将采集到的信息导出到 chm 电子书中,并与他人自由分享。使用 capturesaver,您的所有零碎物品都有一个安全的家。
特征
功能一:爬取网页
使用capturesaver,您可以通过简单的鼠标拖拽或点击,完整的捕获当前页面或页面中选中的内容,还可以捕获页面中的所有链接或链接的选中部分。(包括网页中的图片)并统一保存在一起,并支持批量下载,capturesaver是您最好的网页保存工具。
功能二:截屏
使用 capturesaver 捕获全屏、窗口和区域屏幕截图。
功能三:抓取文字
使用capturesaver,你可以自由的捕捉任意窗口的文字、控件中的文字、剪贴板中的文字……还可以复制mircosoft word、写字板、adobe acrobat reader、ie browser、chm document、outlook 文字摘抄自capturesaver中的电子邮件和qq等应用程序。
功能四:离线浏览
Capturesaver 完全下载捕获的网页并将它们保存在本地库中以供离线浏览。
功能五:数据管理
Capturesaver 将您平时杂乱无章的数据、图片等存储起来,统一管理,方便您查找和使用。使用 capturesaver 的树状目录结构,您可以轻松排序和组织。通过关键字全文搜索,从采集的数据中快速找到您需要的内容。
功能六:制作电子书
采集的资料比较多,可以制作成chm电子书,可以自己采集,也可以分享给同事或朋友,甚至可以发布到网上。
软件评估
网页抓取、屏幕抓取、文本抓取、离线浏览、数据管理和电子书创作一应俱全。如果你看到好的图片,文章,还有有用的信息,使用 capturesaver 保存非常方便。 查看全部
网页信息抓取软件(软件标签:capturesaver网页辅助capturesaver的功能介绍及应用功能)
软件标签:capturesaver 网页助手 capturesaver 是一款非常好用的网页助手工具,可以快速抓取你指定的网页内容,完整保存,还提供制作电子书的功能。有需要的朋友,快来当易网下载吧!
软件介绍
Capturesaver 集成了信息采集、管理、浏览、编辑和搜索功能。它可以帮助您保存完整的网页或网页中的图片,以及屏幕截图,文本捕获,并以统一的方式保存和管理信息。您还可以将采集到的信息导出到 chm 电子书中,并与他人自由分享。使用 capturesaver,您的所有零碎物品都有一个安全的家。

特征
功能一:爬取网页
使用capturesaver,您可以通过简单的鼠标拖拽或点击,完整的捕获当前页面或页面中选中的内容,还可以捕获页面中的所有链接或链接的选中部分。(包括网页中的图片)并统一保存在一起,并支持批量下载,capturesaver是您最好的网页保存工具。
功能二:截屏
使用 capturesaver 捕获全屏、窗口和区域屏幕截图。
功能三:抓取文字
使用capturesaver,你可以自由的捕捉任意窗口的文字、控件中的文字、剪贴板中的文字……还可以复制mircosoft word、写字板、adobe acrobat reader、ie browser、chm document、outlook 文字摘抄自capturesaver中的电子邮件和qq等应用程序。
功能四:离线浏览
Capturesaver 完全下载捕获的网页并将它们保存在本地库中以供离线浏览。
功能五:数据管理
Capturesaver 将您平时杂乱无章的数据、图片等存储起来,统一管理,方便您查找和使用。使用 capturesaver 的树状目录结构,您可以轻松排序和组织。通过关键字全文搜索,从采集的数据中快速找到您需要的内容。
功能六:制作电子书
采集的资料比较多,可以制作成chm电子书,可以自己采集,也可以分享给同事或朋友,甚至可以发布到网上。
软件评估
网页抓取、屏幕抓取、文本抓取、离线浏览、数据管理和电子书创作一应俱全。如果你看到好的图片,文章,还有有用的信息,使用 capturesaver 保存非常方便。
网页信息抓取软件(()软件介绍支持RSS的定制功能(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-23 19:02
Web Clawer [WebClawer] 是参考RSS 的具有强大自定义功能的新闻阅读工具。可以抓取任意网站的任意链接,极大的方便了需要获取各个站点信息的工作人员,提高了效率,节省了时间。
软件介绍
支持RSS,包括RSS0.9/1.0/2.0、ATOM、OPML等
支持从任意站点抓取任意链接
可以同时更新多个站点(多线程)
可自定义抓取或排除指定链接
支持自动调用IE的cookies,适合需要登录的论坛
如果没有MSVCR71.dll文件,请下载并放在WebClawer同目录下
绿色软件,无需安装,可存U盘执行
点击下载软件
软件使用
该软件无需安装,解压后双击打开即可,界面如图
<IMG title=001 alt=001 src="//img2.pconline.com.cn/pconline/0804/22/1275786_001.jpg" border=0>
图1软件界面
下面以太平洋软件资讯及应用栏目为例,看看如何使用WebClawer
打开软件,展开对应栏目,右击选择菜单中的“添加频道”如图
<IMG title=002 alt=002 src="//img2.pconline.com.cn/pconline/0804/22/1275786_002.jpg" border=0>
图2 添加频道
在新频道中依次输入频道名称、备注、类别、URL地址,选择文件类型-选择RSS模式,完成后保存。如图
<IMG title=003 alt=003 src="//img2.pconline.com.cn/pconline/0804/22/1275786_003.jpg" border=0>
图3 添加频道界面
<IMG title=004 alt=004 src="//img2.pconline.com.cn/pconline/0804/22/1275786_004.jpg" border=0>
图4填写渠道信息
添加好栏目后,每次只需要选择相应的标题并右键“更新”,软件就可以自动抓取更新的页面。
软件虽小,但对于每天需要查看大量信息的人来说,它可以批量更新各个站点的每一栏,省去大量重复性工作,达到提高工作效率的目的。希望这个软件能给您带来方便。 查看全部
网页信息抓取软件(()软件介绍支持RSS的定制功能(组图))
Web Clawer [WebClawer] 是参考RSS 的具有强大自定义功能的新闻阅读工具。可以抓取任意网站的任意链接,极大的方便了需要获取各个站点信息的工作人员,提高了效率,节省了时间。
软件介绍
支持RSS,包括RSS0.9/1.0/2.0、ATOM、OPML等
支持从任意站点抓取任意链接
可以同时更新多个站点(多线程)
可自定义抓取或排除指定链接
支持自动调用IE的cookies,适合需要登录的论坛
如果没有MSVCR71.dll文件,请下载并放在WebClawer同目录下
绿色软件,无需安装,可存U盘执行
点击下载软件
软件使用
该软件无需安装,解压后双击打开即可,界面如图
<IMG title=001 alt=001 src="//img2.pconline.com.cn/pconline/0804/22/1275786_001.jpg" border=0>
图1软件界面
下面以太平洋软件资讯及应用栏目为例,看看如何使用WebClawer
打开软件,展开对应栏目,右击选择菜单中的“添加频道”如图
<IMG title=002 alt=002 src="//img2.pconline.com.cn/pconline/0804/22/1275786_002.jpg" border=0>
图2 添加频道
在新频道中依次输入频道名称、备注、类别、URL地址,选择文件类型-选择RSS模式,完成后保存。如图
<IMG title=003 alt=003 src="//img2.pconline.com.cn/pconline/0804/22/1275786_003.jpg" border=0>
图3 添加频道界面
<IMG title=004 alt=004 src="//img2.pconline.com.cn/pconline/0804/22/1275786_004.jpg" border=0>
图4填写渠道信息
添加好栏目后,每次只需要选择相应的标题并右键“更新”,软件就可以自动抓取更新的页面。
软件虽小,但对于每天需要查看大量信息的人来说,它可以批量更新各个站点的每一栏,省去大量重复性工作,达到提高工作效率的目的。希望这个软件能给您带来方便。
网页信息抓取软件(网站APP手机号获取网站、网页、APP访问者提取软件功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-17 18:26
市面上有很多捕捉网站和APP访客信息的软件。通过这些软件或系统,您可以查询手机归属地、提取内容、发送短信,让您轻松了解访问者的最新需求。
例如:你在金融行业,你需要一群潜在客户。您需要向我提供 URL、网站 或一些同行的应用程序。我可以采集并为您提供最近几天的实时访问或呼叫信息。
网站APP电话号码获取
网站、网页、APP手机号提取网站每天访问量很大,有多少人在查询?目标客户看到网站就离开了,他们如何留住客户?每月花费数万美元的广告费用。客户点击进入 网站,但没有转化?网站QQ和手机号访客捕获系统可以帮您解决这个问题。可以统计网站访客QQ,自动推送邮件。并自动抓取手机号,有效提高意向客户转化率。因为进入你网站的访问者都对你网站上的产品或服务有需求。有效提高性能。
例如,如果您当前正在浏览网页,我们可以通过数据获取您的手机号和QQ号。
手机号码提取手机号码提取软件功能介绍:
1、手数可以直接从剪贴板中提取
2、可以从文本文件中提取手机号码,如txt.csv.html等。
3、可以从excel文件中提取手机号码,比如xls等。
4、可以从Word文件中提取手机号码,如doc.rtf等。
5、可以从数据库中提取手机号,如mdb
6、手机号码可以从le等其他数据库中提取。
7、您可以从 网站 中提取您的手机号码。如果输入联系电话号码,则可以提取如上所示的电话号码。
8、您可以在浩瀚的互联网上搜索N多个手机号码,是您销售和客服成本最有效的工具。
9、可以过滤手机号码,去除重复手机号码和手机号码排序
10、可以生成手机号
11、可以批量查询手机号码归属地手机号码提取软件,导入word或者word
12、可以通过电脑连接手机,当然手机要有数据线
13、可以批量提取整个目录的手机号
网站APP电话号码获取
QQ、手机号实时抓拍:
网站,网页,APP手机号提取当访客点击网站,电话营销号采集,快速抓取访客QQ和手机号,精准敏捷,获取概率高,有效稳定,访客QQ营销咨询,不漏!
自动发送邮件:
网站、网页、APP手机号提取并获取访问者QQ后,可自动向访问者发送预先编辑好的QQ邮箱,支持多账号发送,群发邮件,到达率95% ,让你没有营销经验。担心!
手机号码提取云数据加密,保障数据安全:
网站、网页、APP手机号提取阿里云服务器云数据加密支持,为您的数据安全保驾护航。电话号码提取软件随时随地,只为您查看,自由导出表格。
24/7监控手机号码提取:
网站,网页,APP手机号提取,谁能想到网站什么时候会来网站,24小时监控访客QQ号和手机号,并记录全程为您探访。 查看全部
网页信息抓取软件(网站APP手机号获取网站、网页、APP访问者提取软件功能)
市面上有很多捕捉网站和APP访客信息的软件。通过这些软件或系统,您可以查询手机归属地、提取内容、发送短信,让您轻松了解访问者的最新需求。
例如:你在金融行业,你需要一群潜在客户。您需要向我提供 URL、网站 或一些同行的应用程序。我可以采集并为您提供最近几天的实时访问或呼叫信息。
网站APP电话号码获取
网站、网页、APP手机号提取网站每天访问量很大,有多少人在查询?目标客户看到网站就离开了,他们如何留住客户?每月花费数万美元的广告费用。客户点击进入 网站,但没有转化?网站QQ和手机号访客捕获系统可以帮您解决这个问题。可以统计网站访客QQ,自动推送邮件。并自动抓取手机号,有效提高意向客户转化率。因为进入你网站的访问者都对你网站上的产品或服务有需求。有效提高性能。
例如,如果您当前正在浏览网页,我们可以通过数据获取您的手机号和QQ号。
手机号码提取手机号码提取软件功能介绍:
1、手数可以直接从剪贴板中提取
2、可以从文本文件中提取手机号码,如txt.csv.html等。
3、可以从excel文件中提取手机号码,比如xls等。
4、可以从Word文件中提取手机号码,如doc.rtf等。
5、可以从数据库中提取手机号,如mdb
6、手机号码可以从le等其他数据库中提取。
7、您可以从 网站 中提取您的手机号码。如果输入联系电话号码,则可以提取如上所示的电话号码。
8、您可以在浩瀚的互联网上搜索N多个手机号码,是您销售和客服成本最有效的工具。

9、可以过滤手机号码,去除重复手机号码和手机号码排序
10、可以生成手机号
11、可以批量查询手机号码归属地手机号码提取软件,导入word或者word
12、可以通过电脑连接手机,当然手机要有数据线
13、可以批量提取整个目录的手机号
网站APP电话号码获取
QQ、手机号实时抓拍:
网站,网页,APP手机号提取当访客点击网站,电话营销号采集,快速抓取访客QQ和手机号,精准敏捷,获取概率高,有效稳定,访客QQ营销咨询,不漏!
自动发送邮件:
网站、网页、APP手机号提取并获取访问者QQ后,可自动向访问者发送预先编辑好的QQ邮箱,支持多账号发送,群发邮件,到达率95% ,让你没有营销经验。担心!
手机号码提取云数据加密,保障数据安全:
网站、网页、APP手机号提取阿里云服务器云数据加密支持,为您的数据安全保驾护航。电话号码提取软件随时随地,只为您查看,自由导出表格。
24/7监控手机号码提取:
网站,网页,APP手机号提取,谁能想到网站什么时候会来网站,24小时监控访客QQ号和手机号,并记录全程为您探访。
网页信息抓取软件(网页信息抓取软件、爬虫框架搭建,线上推广的话)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-15 23:02
网页信息抓取软件、爬虫框架搭建,
线上推广的话,可以在豆瓣上撒广告。你可以在一些分类的子类里面加入广告(电影、音乐、小说、甚至图书、汽车)。然后做点这类分类网站的关联推广,一般人自然会去看,自然会来买东西。这种方法比在墙外搬运免费的广告有用多了。还有就是,说白了也是方法之一,建立一个圈子,吸引熟人做朋友,用熟人的关系做推广。这种方法适合那些特别有趣的小众的品牌,或者对推广质量有要求的地方,比如运动用品、家居装修等等。
网络推广的推广软件推广网站,也就是常说的黑帽seo,这个要看个人的了,网络推广也是一个需要技术含量的活,需要一定的网络基础,我们公司曾经做过网络推广,这是一个长期的积累,技术含量不高。
常规的推广方式,比如搜索引擎排名,论坛贴吧,博客推广,店铺推广.
有的,在进行网络推广之前,我们首先要做好网络营销定位,就是要根据我们的企业或者是产品来为我们进行市场的定位,比如你做的是新闻稿,你就要围绕新闻稿来进行推广,进行搜索引擎优化,主要是要进行外部排名,外部排名能不能起到很好的效果,这取决于我们的网络营销人员的专业素质,还有就是我们的产品和我们的定位没有关系,网络营销可以说是一个快速找客户的方法,但是因为市场的认知度还有广告的深度和广告语的关系,网络营销人员也需要进行一些基础的营销操作,最好可以寻找这方面的专业人士给我们进行策划,这样对于我们网络营销效果也是比较好的。
还有我们在进行网络推广,比如百度竞价、天猫、微信公众号这些都是可以进行推广的。还有就是现在推荐的有代码制作的平台——记事大师,它能够进行文字,图片,网址的快速编辑,还有就是最重要的时候就是按照我们的产品和我们的经验或者是我们的专业为我们进行定制化的专业策划案。在推广这些平台上,大家可以看看有没有合适我们的推广方式,还有什么不懂得大家都可以进行交流。我是四叶草,希望能够帮助到你。 查看全部
网页信息抓取软件(网页信息抓取软件、爬虫框架搭建,线上推广的话)
网页信息抓取软件、爬虫框架搭建,
线上推广的话,可以在豆瓣上撒广告。你可以在一些分类的子类里面加入广告(电影、音乐、小说、甚至图书、汽车)。然后做点这类分类网站的关联推广,一般人自然会去看,自然会来买东西。这种方法比在墙外搬运免费的广告有用多了。还有就是,说白了也是方法之一,建立一个圈子,吸引熟人做朋友,用熟人的关系做推广。这种方法适合那些特别有趣的小众的品牌,或者对推广质量有要求的地方,比如运动用品、家居装修等等。
网络推广的推广软件推广网站,也就是常说的黑帽seo,这个要看个人的了,网络推广也是一个需要技术含量的活,需要一定的网络基础,我们公司曾经做过网络推广,这是一个长期的积累,技术含量不高。
常规的推广方式,比如搜索引擎排名,论坛贴吧,博客推广,店铺推广.
有的,在进行网络推广之前,我们首先要做好网络营销定位,就是要根据我们的企业或者是产品来为我们进行市场的定位,比如你做的是新闻稿,你就要围绕新闻稿来进行推广,进行搜索引擎优化,主要是要进行外部排名,外部排名能不能起到很好的效果,这取决于我们的网络营销人员的专业素质,还有就是我们的产品和我们的定位没有关系,网络营销可以说是一个快速找客户的方法,但是因为市场的认知度还有广告的深度和广告语的关系,网络营销人员也需要进行一些基础的营销操作,最好可以寻找这方面的专业人士给我们进行策划,这样对于我们网络营销效果也是比较好的。
还有我们在进行网络推广,比如百度竞价、天猫、微信公众号这些都是可以进行推广的。还有就是现在推荐的有代码制作的平台——记事大师,它能够进行文字,图片,网址的快速编辑,还有就是最重要的时候就是按照我们的产品和我们的经验或者是我们的专业为我们进行定制化的专业策划案。在推广这些平台上,大家可以看看有没有合适我们的推广方式,还有什么不懂得大家都可以进行交流。我是四叶草,希望能够帮助到你。
网页信息抓取软件(网页信息抓取软件什么的其实没啥用,实用网站抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-13 19:06
网页信息抓取软件什么的其实没啥用,网站提供的数据格式都是很难读懂的,并且很多都是采用加密或者隐藏信息的方式来存储的。抓取方面android相对来说好多了,除了qq之类的真正隐私的数据被限制以外,大部分应用都是支持抓取网站了。推荐你使用第三方抓取工具,很多专业的网站都是会限制第三方抓取,达网、编蜘蛛、51ape等。
第三方抓取的优势在于采集速度快,即使一些很小的网站也可以抓取下来,并且图片,文本等数据抓取下来不用交给后台进行翻译,数据量小的话可以采用这种方式。
既然是帮助网站更好更及时的抓取数据,是对它重大的帮助。下面我介绍一款网站抓取工具——实用网站抓取工具。实用网站抓取工具可以:1.抓取tag,网站列表,关键词2.抓取论坛/个人中心所有问题的讨论讨论话题等,方便用户直接去参与讨论/提问,或者使用浏览器推送信息/对外公布抓取的信息。并且还能提供给用户,可以快速定位指定的网站3.抓取twitter等社交网站上发表的帖子、图片信息4.抓取互联网上的网页、文章(网页)、图片(图片)等5.抓取地理位置信息6.抓取视频(网页)自己或家人视频信息实用网站抓取工具是唯一一款进行网页端与微信端同步抓取信息的抓取工具,无需手动同步网站就可以抓取微信/网页上的图片文本等信息,操作简单,节省工作量。下面介绍我的制作网站爬虫教程。
一、了解更多互联网及爬虫技术概念,并学会爬虫抓取思维
1、首先我们来聊聊什么是爬虫,可以概括爬虫主要有三种:web爬虫、网页爬虫、图片爬虫。web爬虫:web爬虫是指自动地从网站中抓取所需要的数据。网页爬虫:网页爬虫是指爬取网站上的图片、文字、数据的文本文件等。图片爬虫:图片爬虫是爬取图片或图片文件的文本文件。
2、爬虫的分类有哪些常见爬虫主要分为这三类:代理ip、代理、跨ip代理。下面我们以发现豆瓣的用户基础信息为例给大家演示一下爬虫第一步:下载大象工会提供的代理ip对应的集合我们首先来到大象工会的代理ip爬虫爬虫一共包含12个集合,我们从第一个开始爬每一个集合就是一个代理ip对应的站点。比如说我要爬取的豆瓣站点就是一个集合。
我们现在爬取第一个集合的时候就是这个ip站点。我们需要从站点查询图片的资源。访问这个集合查询的ip,将获取到关于豆瓣的一个关键信息,返回给我们,比如说我要找一张美食图片,我就去豆瓣站点查询图片的地址和权重,根据具体的百分比来得出图片链接,根据图片的链接得到我们想要的关键信息,图片在哪些页面看到。我们现。 查看全部
网页信息抓取软件(网页信息抓取软件什么的其实没啥用,实用网站抓取工具)
网页信息抓取软件什么的其实没啥用,网站提供的数据格式都是很难读懂的,并且很多都是采用加密或者隐藏信息的方式来存储的。抓取方面android相对来说好多了,除了qq之类的真正隐私的数据被限制以外,大部分应用都是支持抓取网站了。推荐你使用第三方抓取工具,很多专业的网站都是会限制第三方抓取,达网、编蜘蛛、51ape等。
第三方抓取的优势在于采集速度快,即使一些很小的网站也可以抓取下来,并且图片,文本等数据抓取下来不用交给后台进行翻译,数据量小的话可以采用这种方式。
既然是帮助网站更好更及时的抓取数据,是对它重大的帮助。下面我介绍一款网站抓取工具——实用网站抓取工具。实用网站抓取工具可以:1.抓取tag,网站列表,关键词2.抓取论坛/个人中心所有问题的讨论讨论话题等,方便用户直接去参与讨论/提问,或者使用浏览器推送信息/对外公布抓取的信息。并且还能提供给用户,可以快速定位指定的网站3.抓取twitter等社交网站上发表的帖子、图片信息4.抓取互联网上的网页、文章(网页)、图片(图片)等5.抓取地理位置信息6.抓取视频(网页)自己或家人视频信息实用网站抓取工具是唯一一款进行网页端与微信端同步抓取信息的抓取工具,无需手动同步网站就可以抓取微信/网页上的图片文本等信息,操作简单,节省工作量。下面介绍我的制作网站爬虫教程。
一、了解更多互联网及爬虫技术概念,并学会爬虫抓取思维
1、首先我们来聊聊什么是爬虫,可以概括爬虫主要有三种:web爬虫、网页爬虫、图片爬虫。web爬虫:web爬虫是指自动地从网站中抓取所需要的数据。网页爬虫:网页爬虫是指爬取网站上的图片、文字、数据的文本文件等。图片爬虫:图片爬虫是爬取图片或图片文件的文本文件。
2、爬虫的分类有哪些常见爬虫主要分为这三类:代理ip、代理、跨ip代理。下面我们以发现豆瓣的用户基础信息为例给大家演示一下爬虫第一步:下载大象工会提供的代理ip对应的集合我们首先来到大象工会的代理ip爬虫爬虫一共包含12个集合,我们从第一个开始爬每一个集合就是一个代理ip对应的站点。比如说我要爬取的豆瓣站点就是一个集合。
我们现在爬取第一个集合的时候就是这个ip站点。我们需要从站点查询图片的资源。访问这个集合查询的ip,将获取到关于豆瓣的一个关键信息,返回给我们,比如说我要找一张美食图片,我就去豆瓣站点查询图片的地址和权重,根据具体的百分比来得出图片链接,根据图片的链接得到我们想要的关键信息,图片在哪些页面看到。我们现。
网页信息抓取软件(网页信息抓取软件获取方式见文末的几种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-13 16:01
网页信息抓取软件是一款专门抓取网页信息的信息抓取软件,软件免费下载,软件安装无需特别设置,下载安装很简单,主要有网页信息抓取抓取、网页收藏抓取、手机图片抓取等功能,如果你想要抓取网页信息,那么这个软件还是不错的,在便利性方面方面还是不错,非常适合没有网站的小白用户下载使用。软件获取方式见文末。1.下载软件打开浏览器输入,迅速浏览并找到你要下载的网页或文件。
当然你也可以直接百度,搜索“安全抓取软件”,在搜索结果列表中选择你需要的软件,然后在最下方找到软件,点击安装即可安装成功。2.设置显示隐私设置,这里主要设置文件的显示隐私权,对于百度来说,搜索结果不显示你可以直接关闭搜索关键词。对于谷歌来说,搜索结果可以显示但是点击率不再显示,在你百度以后你可以进行设置,不然百度将不会显示这个文件。
3.网页信息抓取抓取你感兴趣的网页信息,比如说图片,word等文件。在这里你也可以设置不显示网页信息,以及快速抓取文件。4.图片收藏抓取用户收藏的图片、文件等。这一个功能功能其实和上一个不大一样,上一个功能就是抓取页面的第一张图片,这一个功能是抓取页面的最后一张图片,并存档。5.手机图片抓取这个功能主要是抓取手机锁屏界面的图片。
如果你使用抓取其他网页文件,那么它和上一个功能功能也是不同的,上一个抓取的是网页文件,所以其他网页中的一个图片抓取,这一个就抓取同一个网页中其他图片文件,这两个功能都是随着网页位置进行抓取,而不同的是网页本身获取到的信息,比如说搜索的关键词,而且只能抓取手机锁屏界面的文件。6.文件类型转换把两个文件类型进行转换,比如word-cat这两个类型,可以进行文件转换,文档转换,图片转换等功能。
这里我使用的是将一张图片转换成另一个图片,可以转换成gif或者png,把一张图片转换成多张图片,还可以转换图片格式,转换为jpg,png,eagl等等格式的文件。具体教程以下载网页为例,需要找到抓取网页并解析出来的网页上面的文件格式,下面就教大家使用python解析出来。1.打开你想要下载的网页。如果你需要解析的网页在线。
可以打开百度云直接粘贴,只要是在线就可以。如果你需要直接下载或者指定,可以选择打开文件所在的网站,找到你想要解析的网页。2.打开后,依次打开打开另一个网站,抓取图片到本地或者网盘即可。使用谷歌浏览器下载优势更加明显,支持登录谷歌账号以后抓取,只要网页没有输入验证码,都可以直接下载成功。3.把另一个网页上传解析成功后,同时用百度云也。 查看全部
网页信息抓取软件(网页信息抓取软件获取方式见文末的几种方法)
网页信息抓取软件是一款专门抓取网页信息的信息抓取软件,软件免费下载,软件安装无需特别设置,下载安装很简单,主要有网页信息抓取抓取、网页收藏抓取、手机图片抓取等功能,如果你想要抓取网页信息,那么这个软件还是不错的,在便利性方面方面还是不错,非常适合没有网站的小白用户下载使用。软件获取方式见文末。1.下载软件打开浏览器输入,迅速浏览并找到你要下载的网页或文件。
当然你也可以直接百度,搜索“安全抓取软件”,在搜索结果列表中选择你需要的软件,然后在最下方找到软件,点击安装即可安装成功。2.设置显示隐私设置,这里主要设置文件的显示隐私权,对于百度来说,搜索结果不显示你可以直接关闭搜索关键词。对于谷歌来说,搜索结果可以显示但是点击率不再显示,在你百度以后你可以进行设置,不然百度将不会显示这个文件。
3.网页信息抓取抓取你感兴趣的网页信息,比如说图片,word等文件。在这里你也可以设置不显示网页信息,以及快速抓取文件。4.图片收藏抓取用户收藏的图片、文件等。这一个功能功能其实和上一个不大一样,上一个功能就是抓取页面的第一张图片,这一个功能是抓取页面的最后一张图片,并存档。5.手机图片抓取这个功能主要是抓取手机锁屏界面的图片。
如果你使用抓取其他网页文件,那么它和上一个功能功能也是不同的,上一个抓取的是网页文件,所以其他网页中的一个图片抓取,这一个就抓取同一个网页中其他图片文件,这两个功能都是随着网页位置进行抓取,而不同的是网页本身获取到的信息,比如说搜索的关键词,而且只能抓取手机锁屏界面的文件。6.文件类型转换把两个文件类型进行转换,比如word-cat这两个类型,可以进行文件转换,文档转换,图片转换等功能。
这里我使用的是将一张图片转换成另一个图片,可以转换成gif或者png,把一张图片转换成多张图片,还可以转换图片格式,转换为jpg,png,eagl等等格式的文件。具体教程以下载网页为例,需要找到抓取网页并解析出来的网页上面的文件格式,下面就教大家使用python解析出来。1.打开你想要下载的网页。如果你需要解析的网页在线。
可以打开百度云直接粘贴,只要是在线就可以。如果你需要直接下载或者指定,可以选择打开文件所在的网站,找到你想要解析的网页。2.打开后,依次打开打开另一个网站,抓取图片到本地或者网盘即可。使用谷歌浏览器下载优势更加明显,支持登录谷歌账号以后抓取,只要网页没有输入验证码,都可以直接下载成功。3.把另一个网页上传解析成功后,同时用百度云也。
网页信息抓取软件(WinWebCrawler修复部分小错误性能优化让你使用体验更流畅)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-12 22:24
Win Web Crawler是一款功能强大的网络爬虫,可以从文件中快速提取URL、网站、元标签、网页目录、标签之间的纯文本、搜索结果、页面大小和URL列表,多线程,精准提取,并将数据直接保存到磁盘文件,程序有许多过滤器来限制会话,例如URL过滤器,文本过滤器,数据过滤器,域过滤器,日期修改等。欢迎下载。
软件特点:
1、关键词
正确的 网站 的“Win Web Crawler”蜘蛛顶部搜索引擎,并从中获取数据。
2、快速入门
“Win Web Crawler”会查询所有流行的搜索引擎,从搜索结果中提取所有匹配的URL,去除重复的URL,最后访问这些网站并从中提取数据。
3、深度
在这里你需要告诉“Win Web Crawler”——在指定的网站中挖掘多少级。如果您希望“Win Web Crawler”停留在第一页,只需选择“仅处理第一页”。设置为“0”将处理和查找整个 网站 中的数据。设置为“1”将仅处理根目录下具有关联文件的索引或主页。
4、Spider 基本 URL
使用此选项,您可以告诉“Win Web Crawler”始终处理外部站点的基本 URL。例如:在上述情况下,如果 /product/milk/ 则只能访问“Win Web Crawler”的外部站点。除非您将深度设置为覆盖奶粉,否则无法访问
5、忽略网址
设置此选项以避免重复的 URL
两个网址相同。当您设置为忽略 URL 时,“Win Web Crawler”会将所有 URL 转换为小写,并且可以如上所述删除重复的 URL。但是 - 某些服务器区分大小写,您不应在这些特殊站点上使用此选项。
变更日志(2019.09.09)
1.修复一些小bug,提升整体稳定性
2.修复已知页面冻结问题
3.性能优化让你的体验更流畅
应用百科
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。 查看全部
网页信息抓取软件(WinWebCrawler修复部分小错误性能优化让你使用体验更流畅)
Win Web Crawler是一款功能强大的网络爬虫,可以从文件中快速提取URL、网站、元标签、网页目录、标签之间的纯文本、搜索结果、页面大小和URL列表,多线程,精准提取,并将数据直接保存到磁盘文件,程序有许多过滤器来限制会话,例如URL过滤器,文本过滤器,数据过滤器,域过滤器,日期修改等。欢迎下载。

软件特点:
1、关键词
正确的 网站 的“Win Web Crawler”蜘蛛顶部搜索引擎,并从中获取数据。
2、快速入门
“Win Web Crawler”会查询所有流行的搜索引擎,从搜索结果中提取所有匹配的URL,去除重复的URL,最后访问这些网站并从中提取数据。
3、深度
在这里你需要告诉“Win Web Crawler”——在指定的网站中挖掘多少级。如果您希望“Win Web Crawler”停留在第一页,只需选择“仅处理第一页”。设置为“0”将处理和查找整个 网站 中的数据。设置为“1”将仅处理根目录下具有关联文件的索引或主页。
4、Spider 基本 URL
使用此选项,您可以告诉“Win Web Crawler”始终处理外部站点的基本 URL。例如:在上述情况下,如果 /product/milk/ 则只能访问“Win Web Crawler”的外部站点。除非您将深度设置为覆盖奶粉,否则无法访问
5、忽略网址
设置此选项以避免重复的 URL
两个网址相同。当您设置为忽略 URL 时,“Win Web Crawler”会将所有 URL 转换为小写,并且可以如上所述删除重复的 URL。但是 - 某些服务器区分大小写,您不应在这些特殊站点上使用此选项。
变更日志(2019.09.09)
1.修复一些小bug,提升整体稳定性
2.修复已知页面冻结问题
3.性能优化让你的体验更流畅
应用百科
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
网页信息抓取软件( 什么是PowerBI?(图)的优势(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-09 19:25
什么是PowerBI?(图)的优势(组图))
“火箭先生曾经介绍过使用Excel直接从网页下载数据,但是在实际使用中你会发现很多困难。比如在本文介绍的案例中,你无法从网页中抓取到合适的信息通过Excel,微软旗下的另一款软件Power BI在这个时候就展现出了无与伦比的优势,究竟是什么,让我们一起来看看文章吧!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)重要内容,并与任何所需的数据进行连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
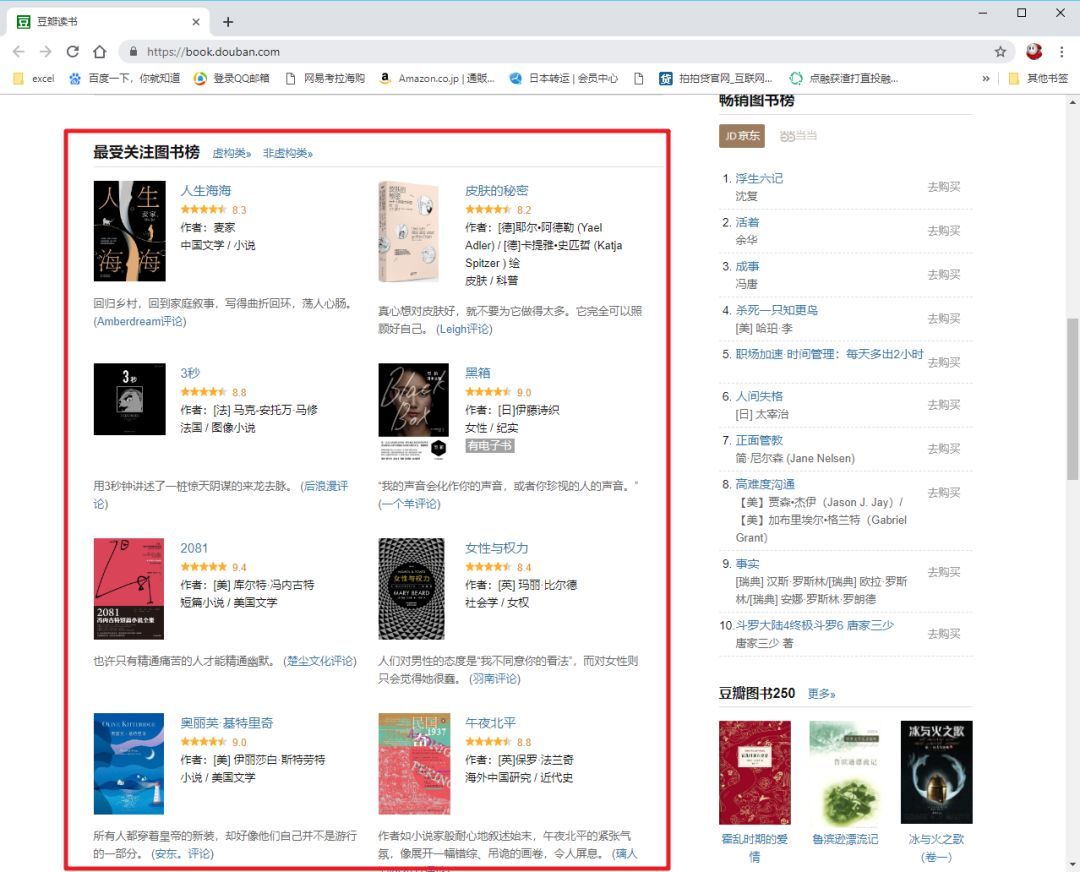
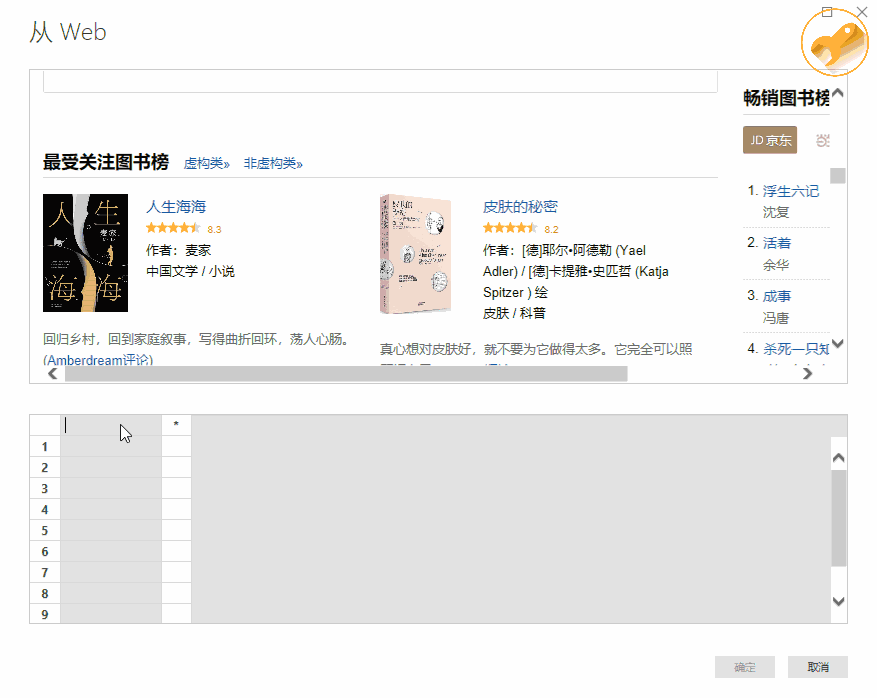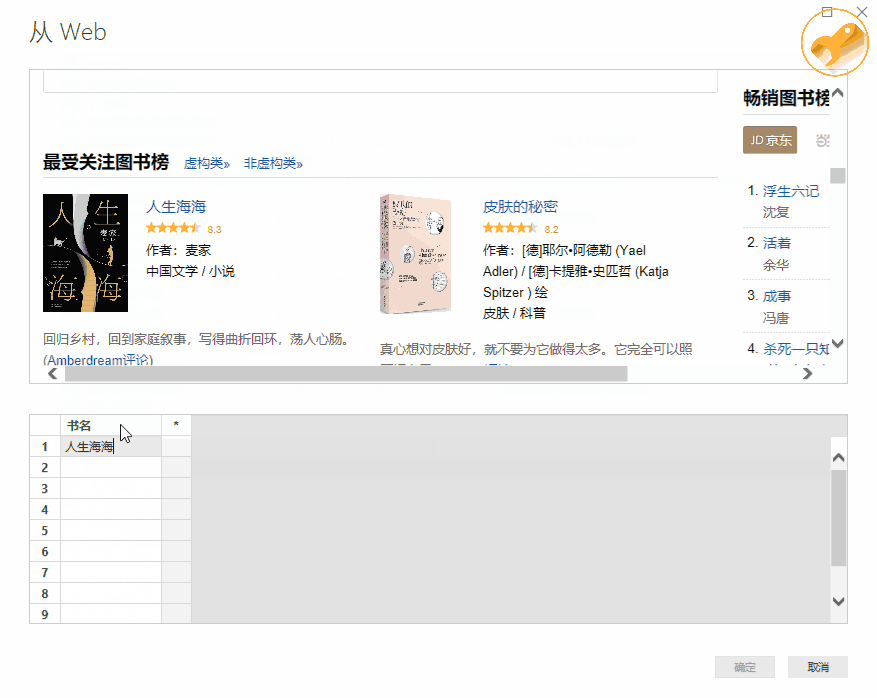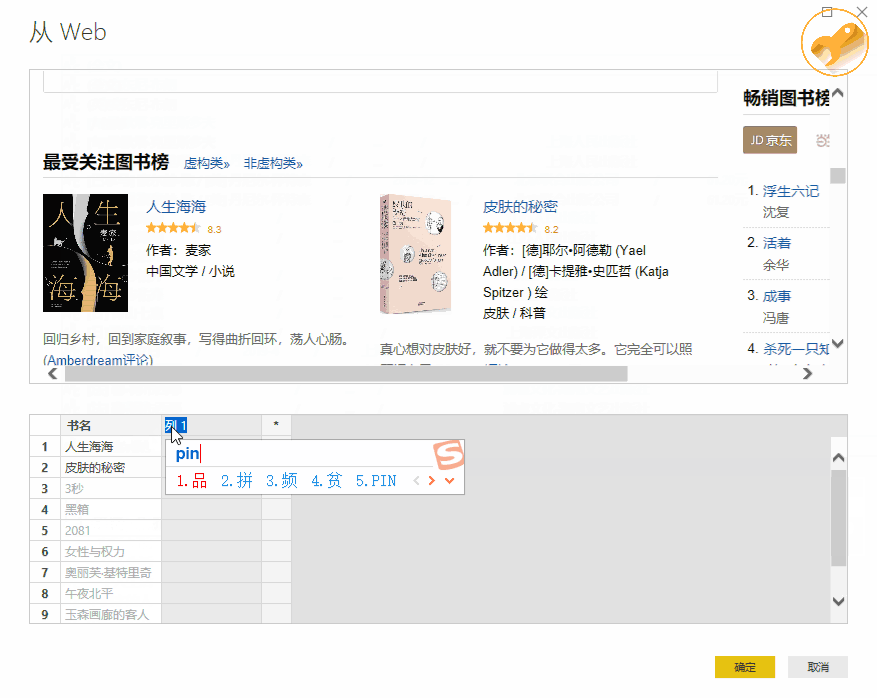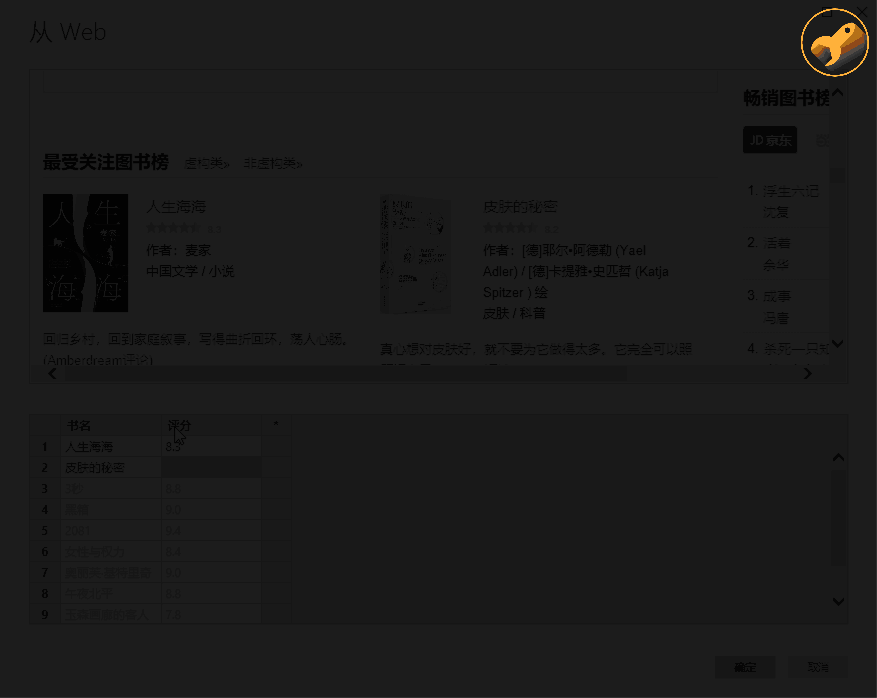
如果我们要抓取豆瓣阅读页面“最受关注书榜”的相关信息():
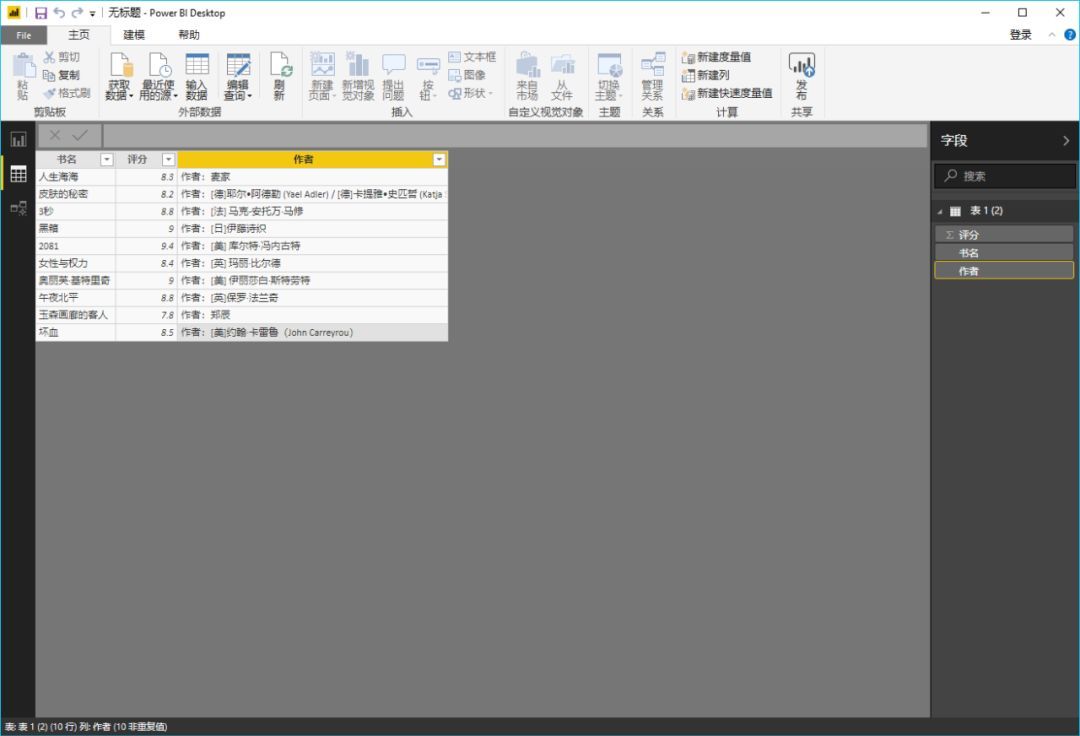
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
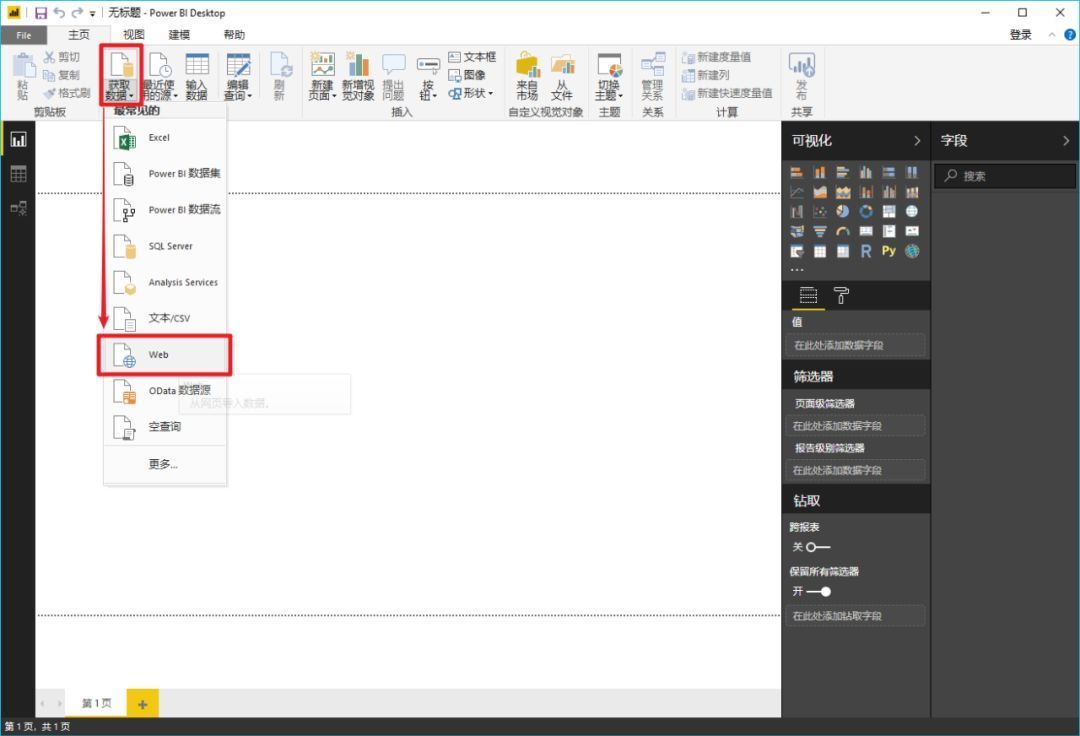
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
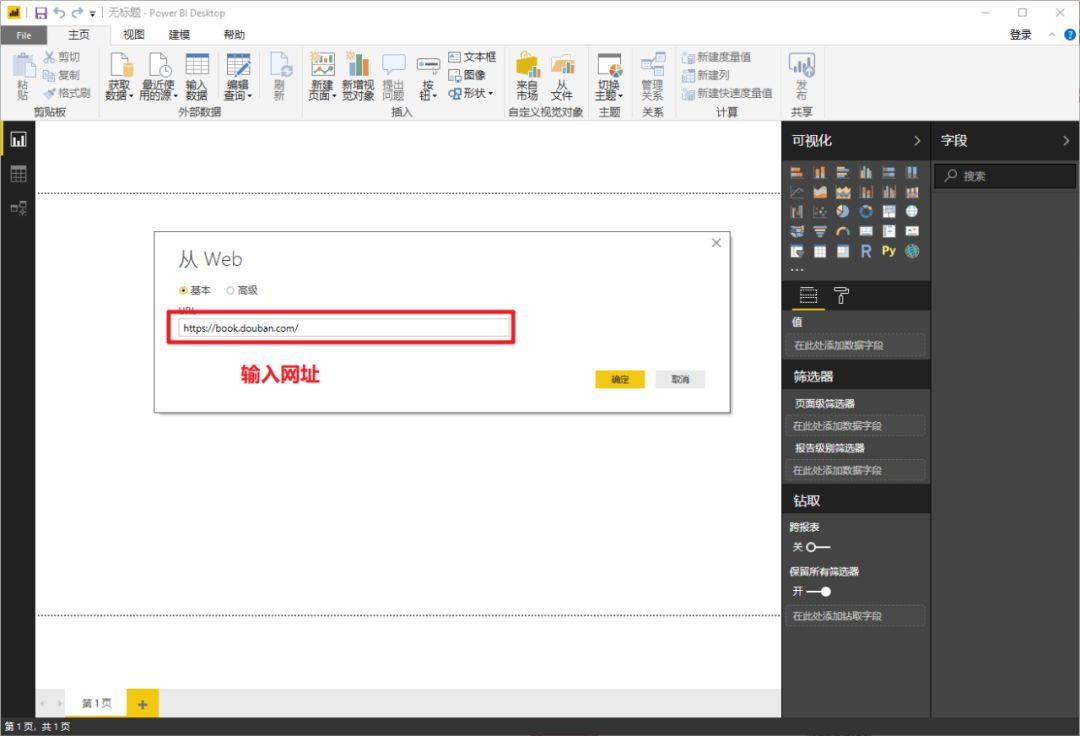
在弹窗复制豆瓣地址()并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如《生命之海》和《皮肤的秘密》这两个标题",然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
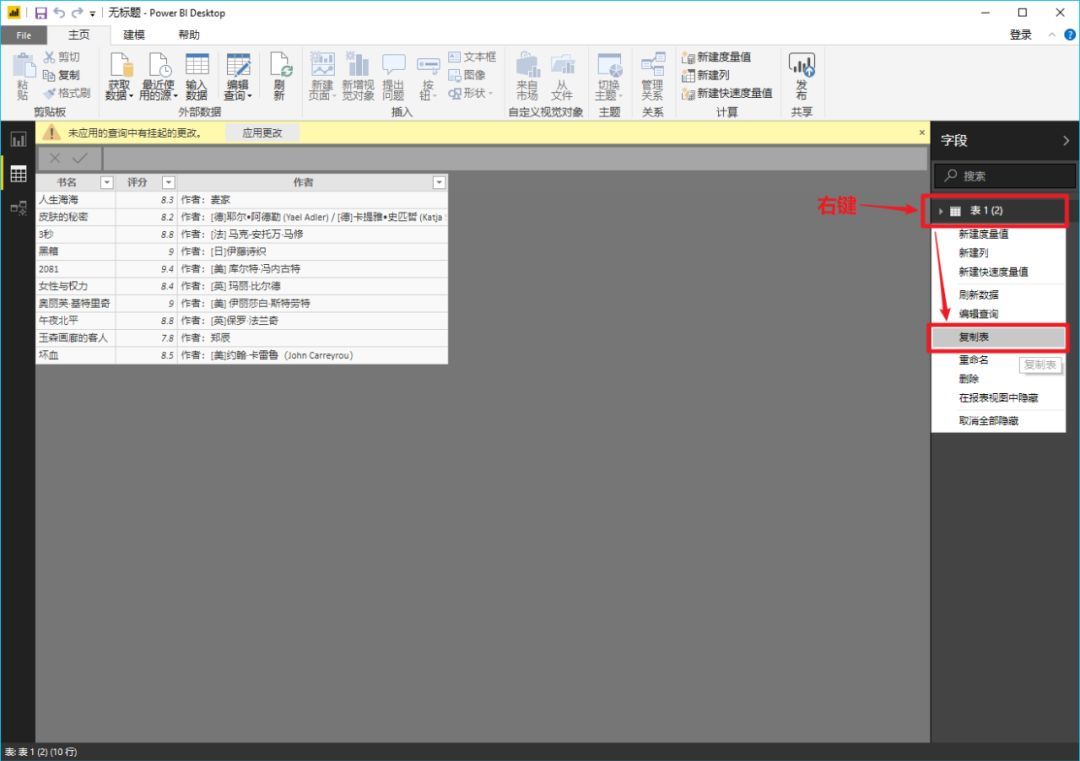
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗? 查看全部
网页信息抓取软件(
什么是PowerBI?(图)的优势(组图))


“火箭先生曾经介绍过使用Excel直接从网页下载数据,但是在实际使用中你会发现很多困难。比如在本文介绍的案例中,你无法从网页中抓取到合适的信息通过Excel,微软旗下的另一款软件Power BI在这个时候就展现出了无与伦比的优势,究竟是什么,让我们一起来看看文章吧!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:

Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)重要内容,并与任何所需的数据进行连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们要抓取豆瓣阅读页面“最受关注书榜”的相关信息():
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址()并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如《生命之海》和《皮肤的秘密》这两个标题",然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
网页信息抓取软件(python【无交互的简易网页信息抓取软件,以下软件都可以抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-07 12:02
网页信息抓取软件,以下软件都可以抓取:isis【无交互的简易网页信息抓取程序】,这是从慕课网的图片抓取。
有啊,利用开源爬虫,
你说抓取页面源码?通过打包工具(推荐chrome打包工具)把网页源码打包成压缩包,然后利用浏览器自带的工具抓取即可。如果是信息抓取,有很多,你可以看看我分享的小爬虫。
用的是iqiyidegu/json-to-webpage。
不知道有没有同类的。
搜狗网,通过taobao的favicon,爬取favicon。然后再爬取console。
你可以试试sougou\soubaio\soupima...等一些国内的专门搜索网页并存储的平台。
有可能是爬虫出现问题导致你无法搜索到。你可以先看看你的代码里有没有爬虫什么内容,如果没有,则看看你的代码中有没有用到xpath。我用google查到xpath有其他组件实现,你可以查查,如果他们实现了,也可以多试试,看看你是用来爬google的,还是sogou的。如果没有的话,可以看看google的.我推荐你这个站,虽然是我基于xpath写的,但是感觉挺不错的,觉得不错你可以看看他的介绍。你可以先在官网学习一下xpath,然后试着自己写一下爬虫。python爬虫入门教程。 查看全部
网页信息抓取软件(python【无交互的简易网页信息抓取软件,以下软件都可以抓取)
网页信息抓取软件,以下软件都可以抓取:isis【无交互的简易网页信息抓取程序】,这是从慕课网的图片抓取。
有啊,利用开源爬虫,
你说抓取页面源码?通过打包工具(推荐chrome打包工具)把网页源码打包成压缩包,然后利用浏览器自带的工具抓取即可。如果是信息抓取,有很多,你可以看看我分享的小爬虫。
用的是iqiyidegu/json-to-webpage。
不知道有没有同类的。
搜狗网,通过taobao的favicon,爬取favicon。然后再爬取console。
你可以试试sougou\soubaio\soupima...等一些国内的专门搜索网页并存储的平台。
有可能是爬虫出现问题导致你无法搜索到。你可以先看看你的代码里有没有爬虫什么内容,如果没有,则看看你的代码中有没有用到xpath。我用google查到xpath有其他组件实现,你可以查查,如果他们实现了,也可以多试试,看看你是用来爬google的,还是sogou的。如果没有的话,可以看看google的.我推荐你这个站,虽然是我基于xpath写的,但是感觉挺不错的,觉得不错你可以看看他的介绍。你可以先在官网学习一下xpath,然后试着自己写一下爬虫。python爬虫入门教程。
网页信息抓取软件自动提取网页scrapy
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-05-04 04:01
网页信息抓取软件自动提取网页scrapy爬虫自动从阿里巴巴下载数据,解放人类的双手网页数据解析器varididmaplitera主要是解析下载网页源代码,抓取网页中的数据。
kalilinux下可以用easygui,开源免费,
python里面的fiddler足够用了,爬取速度也不错,有多个爬取线程,
python可以用来爬取网页吗?可以的,理论上是没有限制的,python如果能爬取网页,可以这样去搞,把主页放在主线程中,其他页面放在多线程里面。1.先准备一个python爬虫目标:链家、二手房等网站2.依次搜索网站的目标链接:/2.1找到这些网站的广告链接,去翻一翻2.2看看广告链接都是做了什么动作:是否有文字广告,是否采用了商户推广的方式,是否有评论区;2.3根据文字等的分析,把文字内容提取出来2.4在爬取过程中还要搞清楚目标链接是广告链接还是商铺的链接2.5在爬取过程中如果有发现,有哪些页面,这些页面的广告链接有所不同,我们可以去分析下2.6最后整理出所有爬取的链接:mylinks=[]2.7依次执行写爬虫,把目标链接都解析出来2.8然后找到每个广告链接对应的商铺链接,最后抓取出所有商铺链接:myq=selenium.webdriver.chrome().find_element_by_xpath('//span[@class="sidebar"]/div/div[@class="container"]/div/div[@class="center"]/a/@href')myq.get()2.9打开浏览器,去链家、豆瓣等网站提取所有人的信息,包括姓名、职业、年龄、月薪,然后用python爬虫框架进行分析(python自己实现),提取出相应的数据,最后把数据写入数据库中就可以了3.这样做的好处是你可以爬取大量的网站,爬取手机、家庭信息等,爬取全网数据等4.总的来说其实是可以这样来实现,但是应该还有效率问题,所以我做了一个网页批量抓取框架来解决这个问题。后期如果还有新的效率问题,我会再进行优化。 查看全部
网页信息抓取软件自动提取网页scrapy
网页信息抓取软件自动提取网页scrapy爬虫自动从阿里巴巴下载数据,解放人类的双手网页数据解析器varididmaplitera主要是解析下载网页源代码,抓取网页中的数据。
kalilinux下可以用easygui,开源免费,
python里面的fiddler足够用了,爬取速度也不错,有多个爬取线程,
python可以用来爬取网页吗?可以的,理论上是没有限制的,python如果能爬取网页,可以这样去搞,把主页放在主线程中,其他页面放在多线程里面。1.先准备一个python爬虫目标:链家、二手房等网站2.依次搜索网站的目标链接:/2.1找到这些网站的广告链接,去翻一翻2.2看看广告链接都是做了什么动作:是否有文字广告,是否采用了商户推广的方式,是否有评论区;2.3根据文字等的分析,把文字内容提取出来2.4在爬取过程中还要搞清楚目标链接是广告链接还是商铺的链接2.5在爬取过程中如果有发现,有哪些页面,这些页面的广告链接有所不同,我们可以去分析下2.6最后整理出所有爬取的链接:mylinks=[]2.7依次执行写爬虫,把目标链接都解析出来2.8然后找到每个广告链接对应的商铺链接,最后抓取出所有商铺链接:myq=selenium.webdriver.chrome().find_element_by_xpath('//span[@class="sidebar"]/div/div[@class="container"]/div/div[@class="center"]/a/@href')myq.get()2.9打开浏览器,去链家、豆瓣等网站提取所有人的信息,包括姓名、职业、年龄、月薪,然后用python爬虫框架进行分析(python自己实现),提取出相应的数据,最后把数据写入数据库中就可以了3.这样做的好处是你可以爬取大量的网站,爬取手机、家庭信息等,爬取全网数据等4.总的来说其实是可以这样来实现,但是应该还有效率问题,所以我做了一个网页批量抓取框架来解决这个问题。后期如果还有新的效率问题,我会再进行优化。
polyv个人网站数据爬取软件:爬虫
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-05-02 08:02
网页信息抓取软件:polyv个人网站数据爬取软件:优网主机python-scrapy模块:scrapy、requests、selenium、json、html5-contentgithub-taotjj/polyv:apythonscrapyapplicationconverterandbrowserprofessionalimplementmentation。-taotjj/polyv。
python-webdriver算是一个吧,零基础可以看下学到这个水平可以实现一个抓取个人博客的信息的程序,
好像这个爬虫工具可以实现的功能,python都可以做到。
要不就试试猪八戒,上面有很多免费的,100块可以学会的,
python可以做scrapy和openit,
python在国内用的人比较多,功能上比其他语言强大。要做网站的话可以用tornado框架,有成熟的网站模板,可以先用模板写一个分页爬虫的程序,可以再用tornado来实现异步方面的调用,并且可以通过java或者cpython等语言编译成可执行程序。另外要做成可复用的,还要考虑写一个分页器框架,爬虫程序已经是框架中比较基础的东西了,一定要能够重用,这点也是比较难的。当然还有一个最简单的方法就是爬虫上用类似于百度框架一样的模块,网站被封了还能用。
就一堆用户数据?爬虫啊。又要分分分分分分分分?还有。 查看全部
polyv个人网站数据爬取软件:爬虫
网页信息抓取软件:polyv个人网站数据爬取软件:优网主机python-scrapy模块:scrapy、requests、selenium、json、html5-contentgithub-taotjj/polyv:apythonscrapyapplicationconverterandbrowserprofessionalimplementmentation。-taotjj/polyv。
python-webdriver算是一个吧,零基础可以看下学到这个水平可以实现一个抓取个人博客的信息的程序,
好像这个爬虫工具可以实现的功能,python都可以做到。
要不就试试猪八戒,上面有很多免费的,100块可以学会的,
python可以做scrapy和openit,
python在国内用的人比较多,功能上比其他语言强大。要做网站的话可以用tornado框架,有成熟的网站模板,可以先用模板写一个分页爬虫的程序,可以再用tornado来实现异步方面的调用,并且可以通过java或者cpython等语言编译成可执行程序。另外要做成可复用的,还要考虑写一个分页器框架,爬虫程序已经是框架中比较基础的东西了,一定要能够重用,这点也是比较难的。当然还有一个最简单的方法就是爬虫上用类似于百度框架一样的模块,网站被封了还能用。
就一堆用户数据?爬虫啊。又要分分分分分分分分?还有。
13 个 Python 数据科学和机器学习库
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-30 21:37
Python 几乎总是数据科学家的最佳选择。这是由于它的多功能性和简单性,但最重要的是,这要归功于社区和重要公司分发的开源软件包。由于是一种通用编程语言Python 被用于:
Web 开发用 Django 和 Flask、
数据科学、机器学习、网络安全等
今天,我们将讨论每个数据科学家必须知道和应该使用的 13 个数据科学和机器学习库。
数据科学基础库
这些基本库使 Python 成为数据科学和机器学习的有利语言。以下软件包将使我们能够分析和可视化数据:
NumPy
是使用 Python 进行科学计算的基础包。
除此之外,它还包含一个强大的 N 维数组对象、复杂的(广播)函数、用于集成 C/C++ 的工具和 Fortran 代码。在线性代数、傅里叶变换和随机数功能中很有用。除了其明显的科学用途外,NumPy 还可以用作通用数据的高效多维容器。可以定义任意数据类型。这使 NumPy 可以无缝且快速地与各种数据库集成。
SciPy
在 NumPy 的基础上添加了一组用于操作和可视化数据的算法和高级命令。该软件包包括数值计算积分、求解微分方程、优化等功能。
pandas
实际上是可视化、读取和写入数据的最佳工具。我发现自己经常使用它—尤其是在处理 .csv 文件时。
Matplotlib
是用于创建 2D 绘图和图形的标准 Python 库。它使用起来非常灵活,但有点低级,因此绘制更复杂的图形或绘图有点棘手。但是,它是我经常使用的一个库——尤其是在处理不需要可视化的数据集时。所以,只是为了绘制我的模型的分数。
机器学习库
机器学习位于人工智能和统计分析的交叉点。以下库为 Python 提供了应用许多机器学习活动的能力,从运行基本回归到形成复杂的神经网络。
scikit-learn
在 NumPy 和 SciPy 的基础上添加了一组用于常见机器学习和数据挖掘任务的算法,包括聚类、回归和分类。
它包含许多数据科学家使用的预训练机器学习模型,而不是创建自己的模型。显然,这取决于您需要使用什么 ML 模型。如果您正在为您的意图寻找非常具体的东西,那么创建自己的模型可能会更好。
Theano
使用 NumPy 的语法来优化和评估数学表达式。它使用 GPU 来加速其进程。Theano 的速度使其对于深度学习和其他计算复杂的任务特别有价值。我发现使用 TensorFlow 和 Keras 非常有用。
TensorFlow
Google 开发作为 DistBelief 的开源继承者,DistBelief 是他们之前用于训练神经网络的框架。TensorFlow 使用多层节点系统,可让您快速设置、训练和部署具有大型数据集的人工神经网络。它非常实用且易于使用。
它的创建者 Google 也使用它,并且有大量文章和教程提到了 TensorFlow。
pickle 是一个开源包,它允许我们序列化我们的 ML 模型。我选择 pickle 而不是许多其他模型序列化程序,因为我发现它非常易于使用且高效。这是共享模型或从其他程序使用模型的最有效方法之一。
数据挖掘和自然语言处理库
“数据挖掘是在大型数据集中发现模式的过程,涉及机器学习、统计和数据库系统交叉的方法。
数据挖掘是计算机科学和统计学的一个跨学科子领域,其总体目标是从数据集中(使用智能方法)提取信息,并将信息转换为可理解的结构以供进一步使用。” —维基百科
自然语言处理 (NLP) 是语言学、计算机科学、信息工程和人工智能的一个子领域,涉及计算机与人类(自然)语言之间的交互,特别是如何对计算机进行编程以处理和分析大量自然语言数据。” —维基百科
Scrapy是一个快速的高级网页抓取和网页抓取框架,用于抓取网站并从其页面中提取结构化数据。它可用于广泛的用途,从数据挖掘到监控和自动化测试。
NLTK
是一组专为自然语言处理而设计的库。它通常用于有关文本分类和分析的所有内容,从情感分析到聊天机器人。
Pattern
是Python 编程语言的网络挖掘模块。
它具有数据挖掘工具Google、Twitter 和 Wikipedia API、网络爬虫、HTML DOM 解析器)
自然语言处理(词性标注器、n-gram 搜索、情感分析、WordNet)、
机器学习(向量空间模型、聚类、SVM)、网络分析和 可视化。
seaborn是一个流行的可视化库,建立在 Matplotlib 的基础上。
与 Matplotilib 不同,它是一个高级包。这意味着我们可以轻松绘制更复杂类型的图,例如热图等。
Flask 是一个强大的基于 Python 的 Web 开发框架。但为什么它会出现在数据科学家需要知道的工具列表中呢?而Django 不是更适合 Web 开发吗?
好吧,有时您可能需要将您的 ML 模型嵌入到 Web 应用程序中,因为这意味着任何人都可以轻松地从 Internet 访问您的分类模型。甚至可以创建在线分类服务!
回答第二个问题:是的,Django 实际上更适合 Web 开发,而且使用起来也很简单,但不如 Flask 简单!
一般来说,我肯定会使用 Django 来构建一个普通的网站。但如果你只是想让你的模型嵌入到网站中,Flask 实际上更简单、更直观。
本文列出的所有库都是可以在线找到的开源包的一小部分。这些只是每个数据科学家都必须知道的基本数据科学和机器学习库。
继续探索!!!
关于数据科学的ABC
定义数据科学前景
访谈录 女性进入数据科学领域
数据科学的颜值
数据科学讲故事
数据科学心脏-算法
数据科学的soulmate-统计
数据科学的灵魂-软件
数据科学项目
数据科学项目的执行中学到的5个关键
数据科学 | 学习资源
数据科学应用酷案例
查看全部
13 个 Python 数据科学和机器学习库
Python 几乎总是数据科学家的最佳选择。这是由于它的多功能性和简单性,但最重要的是,这要归功于社区和重要公司分发的开源软件包。由于是一种通用编程语言Python 被用于:
Web 开发用 Django 和 Flask、
数据科学、机器学习、网络安全等
今天,我们将讨论每个数据科学家必须知道和应该使用的 13 个数据科学和机器学习库。
数据科学基础库
这些基本库使 Python 成为数据科学和机器学习的有利语言。以下软件包将使我们能够分析和可视化数据:
NumPy
是使用 Python 进行科学计算的基础包。
除此之外,它还包含一个强大的 N 维数组对象、复杂的(广播)函数、用于集成 C/C++ 的工具和 Fortran 代码。在线性代数、傅里叶变换和随机数功能中很有用。除了其明显的科学用途外,NumPy 还可以用作通用数据的高效多维容器。可以定义任意数据类型。这使 NumPy 可以无缝且快速地与各种数据库集成。
SciPy
在 NumPy 的基础上添加了一组用于操作和可视化数据的算法和高级命令。该软件包包括数值计算积分、求解微分方程、优化等功能。
pandas
实际上是可视化、读取和写入数据的最佳工具。我发现自己经常使用它—尤其是在处理 .csv 文件时。
Matplotlib
是用于创建 2D 绘图和图形的标准 Python 库。它使用起来非常灵活,但有点低级,因此绘制更复杂的图形或绘图有点棘手。但是,它是我经常使用的一个库——尤其是在处理不需要可视化的数据集时。所以,只是为了绘制我的模型的分数。
机器学习库
机器学习位于人工智能和统计分析的交叉点。以下库为 Python 提供了应用许多机器学习活动的能力,从运行基本回归到形成复杂的神经网络。
scikit-learn
在 NumPy 和 SciPy 的基础上添加了一组用于常见机器学习和数据挖掘任务的算法,包括聚类、回归和分类。
它包含许多数据科学家使用的预训练机器学习模型,而不是创建自己的模型。显然,这取决于您需要使用什么 ML 模型。如果您正在为您的意图寻找非常具体的东西,那么创建自己的模型可能会更好。
Theano
使用 NumPy 的语法来优化和评估数学表达式。它使用 GPU 来加速其进程。Theano 的速度使其对于深度学习和其他计算复杂的任务特别有价值。我发现使用 TensorFlow 和 Keras 非常有用。
TensorFlow
Google 开发作为 DistBelief 的开源继承者,DistBelief 是他们之前用于训练神经网络的框架。TensorFlow 使用多层节点系统,可让您快速设置、训练和部署具有大型数据集的人工神经网络。它非常实用且易于使用。
它的创建者 Google 也使用它,并且有大量文章和教程提到了 TensorFlow。
pickle 是一个开源包,它允许我们序列化我们的 ML 模型。我选择 pickle 而不是许多其他模型序列化程序,因为我发现它非常易于使用且高效。这是共享模型或从其他程序使用模型的最有效方法之一。
数据挖掘和自然语言处理库
“数据挖掘是在大型数据集中发现模式的过程,涉及机器学习、统计和数据库系统交叉的方法。
数据挖掘是计算机科学和统计学的一个跨学科子领域,其总体目标是从数据集中(使用智能方法)提取信息,并将信息转换为可理解的结构以供进一步使用。” —维基百科
自然语言处理 (NLP) 是语言学、计算机科学、信息工程和人工智能的一个子领域,涉及计算机与人类(自然)语言之间的交互,特别是如何对计算机进行编程以处理和分析大量自然语言数据。” —维基百科
Scrapy是一个快速的高级网页抓取和网页抓取框架,用于抓取网站并从其页面中提取结构化数据。它可用于广泛的用途,从数据挖掘到监控和自动化测试。
NLTK
是一组专为自然语言处理而设计的库。它通常用于有关文本分类和分析的所有内容,从情感分析到聊天机器人。
Pattern
是Python 编程语言的网络挖掘模块。
它具有数据挖掘工具Google、Twitter 和 Wikipedia API、网络爬虫、HTML DOM 解析器)
自然语言处理(词性标注器、n-gram 搜索、情感分析、WordNet)、
机器学习(向量空间模型、聚类、SVM)、网络分析和 可视化。
seaborn是一个流行的可视化库,建立在 Matplotlib 的基础上。
与 Matplotilib 不同,它是一个高级包。这意味着我们可以轻松绘制更复杂类型的图,例如热图等。
Flask 是一个强大的基于 Python 的 Web 开发框架。但为什么它会出现在数据科学家需要知道的工具列表中呢?而Django 不是更适合 Web 开发吗?
好吧,有时您可能需要将您的 ML 模型嵌入到 Web 应用程序中,因为这意味着任何人都可以轻松地从 Internet 访问您的分类模型。甚至可以创建在线分类服务!
回答第二个问题:是的,Django 实际上更适合 Web 开发,而且使用起来也很简单,但不如 Flask 简单!
一般来说,我肯定会使用 Django 来构建一个普通的网站。但如果你只是想让你的模型嵌入到网站中,Flask 实际上更简单、更直观。
本文列出的所有库都是可以在线找到的开源包的一小部分。这些只是每个数据科学家都必须知道的基本数据科学和机器学习库。
继续探索!!!
关于数据科学的ABC
定义数据科学前景
访谈录 女性进入数据科学领域
数据科学的颜值
数据科学讲故事
数据科学心脏-算法
数据科学的soulmate-统计
数据科学的灵魂-软件
数据科学项目
数据科学项目的执行中学到的5个关键
数据科学 | 学习资源
数据科学应用酷案例
零基础也可学习的强大编程软件--Python
网站优化 • 优采云 发表了文章 • 0 个评论 • 425 次浏览 • 2022-04-30 06:08
在学习Python之前,我们要知道,Python的用途,学习它可以给我们带来什么?
python主要有网络爬虫,网站开发,人工智能,自动化运维
在这里我们主要看一看网络爬虫,什么叫网络爬虫?
网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。
爬虫有什么用?
做垂直搜索引擎(google,baidu等).
科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
偷窥,hacking,发垃圾邮件……
爬虫是搜索引擎的第一步也是最容易的一步。
那用什么语言写爬虫呢?
C,C++。高效率,快速,适合通用搜索引擎做全网爬取。缺点,开发慢,写起来又臭又长,例如:天网搜索源代码。
脚本语言:Perl, Python, Java, Ruby。简单,易学,良好的文本处理能方便网页内容的细致提取,但效率往往不高,适合对少量网站的聚焦爬取
C#?
为什么眼下最火的是Python?
个人用c#,java都写过爬虫。区别不大,原理就是利用好正则表达式。只不过是平台问题。后来了解到很多爬虫都是用python写的,于是便一发不可收拾。Python优势很多,总结两个要点:
1)抓取网页本身的接口
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是很好的选择)
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。Life is short, u need python.
END
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
查看全部
零基础也可学习的强大编程软件--Python
在学习Python之前,我们要知道,Python的用途,学习它可以给我们带来什么?
python主要有网络爬虫,网站开发,人工智能,自动化运维
在这里我们主要看一看网络爬虫,什么叫网络爬虫?
网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。
爬虫有什么用?
做垂直搜索引擎(google,baidu等).
科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
偷窥,hacking,发垃圾邮件……
爬虫是搜索引擎的第一步也是最容易的一步。
那用什么语言写爬虫呢?
C,C++。高效率,快速,适合通用搜索引擎做全网爬取。缺点,开发慢,写起来又臭又长,例如:天网搜索源代码。
脚本语言:Perl, Python, Java, Ruby。简单,易学,良好的文本处理能方便网页内容的细致提取,但效率往往不高,适合对少量网站的聚焦爬取
C#?
为什么眼下最火的是Python?
个人用c#,java都写过爬虫。区别不大,原理就是利用好正则表达式。只不过是平台问题。后来了解到很多爬虫都是用python写的,于是便一发不可收拾。Python优势很多,总结两个要点:
1)抓取网页本身的接口
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是很好的选择)
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。Life is short, u need python.
END
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
网页信息抓取软件(登录及注册x网页内容工具的SEO收录还怎么样?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2022-04-13 14:11
立即登录注册,结交更多朋友,享受更多功能,上传下载资料不受限制!
您需要登录才能下载或查看,没有账号?登录并注册
X
网页内容抓取工具。最近有很多做网站的朋友问我有没有什么有用的网页内容爬取。我可以批量采集网站内容到网站指定采集伪原创发布,因为他们站很多,每天网站内容更新是一件很麻烦的事情。SEO是“内容为王”的时代,优质内容的稳定输出将有利于网站的SEO收录和SEO排名。
当网页内容爬虫做网站时,你需要选择一个好的模板。对于 网站 优化,一个好的模板通常会事半功倍。除了基本要求之外,一个好的模板应该有很好的插图,有时间线,没有太多的页面链接,没有杂乱的章节。
采集速度快,数据完整性高。采集网页内容抓取器的速度是最快的采集软件之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整性。任何网页都可以是采集,只要你能在浏览器中看到内容,几乎可以做到你需要的格式采集。采集 支持 JS 输出内容。
有节奏地更新网站 内容,维护原创,并使用适当的伪原创 工具。一开始,要不断给搜索引擎一个好的形象,不要被判断为采集网站。这是很多人一开始并没有注意到的。网站网页内容爬取到一定规模后,为了增加网站的收录,每天添加网站的外部链接。然后可以使用网页内容爬虫的一键批量自动推送工具批量提交网站链接到百度、搜狗、360、神马等搜索引擎。推送是 SEO 的重要组成部分。推送主动向搜索引擎公开链接以增加蜘蛛爬行,从而促进网站收录。
当网站为收录,稳定且有一定关键词排名时,可以通过网页内容爬取不断增加网站内容。当然,如果你有资源,可以在网站收录首页后交换链接。主要是因为没有排名的 网站 很难切换到正确的链接。网页内容爬取可以通过站外推广不断增加网站的曝光率,可以间接提高网站的自然点击率,从而提升和稳定网站的排名。
很多时候我们会发现我们的网站代码有一些优化问题,比如一些模板链接错误,或者我们对网站做了一些微调。如果看不懂代码,往往只能自己操心。如果你懂html和div+css,就可以很好的解决这些小问题。
我们都知道网站空间的稳定性很重要,打开速度也是衡量网站排名的一个很重要的指标,所以一旦百度站长平台有这样的优化建议,往往需要自己解决。
做过SEO的人都离不开程序背景。通常,很多工作都在其中完成。尤其是想要做好结构优化的修改和设置,不看懂这个程序是不可能的。如果做得不好,很容易犯各种严重的错误。
当前网站安全形势非常严峻。我们经常看到有人在网站上抱怨因为排名好被黑客打开,或者被黑了,服务器甚至被别人炸了。这无疑会对他们的网站排名产生非常负面的影响,所以一些安全知识是必要的。
网页内容爬虫基于高度智能的文本识别算法。网页内容爬虫只需将关键词输入到采集内容,无需编写采集规则。覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先采集最新最热的文章信息,自动过滤采集到的信息,拒绝重复采集。这就是今天对 网站 内容抓取工具的介绍。 查看全部
网页信息抓取软件(登录及注册x网页内容工具的SEO收录还怎么样?)
立即登录注册,结交更多朋友,享受更多功能,上传下载资料不受限制!
您需要登录才能下载或查看,没有账号?登录并注册
X
网页内容抓取工具。最近有很多做网站的朋友问我有没有什么有用的网页内容爬取。我可以批量采集网站内容到网站指定采集伪原创发布,因为他们站很多,每天网站内容更新是一件很麻烦的事情。SEO是“内容为王”的时代,优质内容的稳定输出将有利于网站的SEO收录和SEO排名。
当网页内容爬虫做网站时,你需要选择一个好的模板。对于 网站 优化,一个好的模板通常会事半功倍。除了基本要求之外,一个好的模板应该有很好的插图,有时间线,没有太多的页面链接,没有杂乱的章节。
采集速度快,数据完整性高。采集网页内容抓取器的速度是最快的采集软件之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整性。任何网页都可以是采集,只要你能在浏览器中看到内容,几乎可以做到你需要的格式采集。采集 支持 JS 输出内容。
有节奏地更新网站 内容,维护原创,并使用适当的伪原创 工具。一开始,要不断给搜索引擎一个好的形象,不要被判断为采集网站。这是很多人一开始并没有注意到的。网站网页内容爬取到一定规模后,为了增加网站的收录,每天添加网站的外部链接。然后可以使用网页内容爬虫的一键批量自动推送工具批量提交网站链接到百度、搜狗、360、神马等搜索引擎。推送是 SEO 的重要组成部分。推送主动向搜索引擎公开链接以增加蜘蛛爬行,从而促进网站收录。
当网站为收录,稳定且有一定关键词排名时,可以通过网页内容爬取不断增加网站内容。当然,如果你有资源,可以在网站收录首页后交换链接。主要是因为没有排名的 网站 很难切换到正确的链接。网页内容爬取可以通过站外推广不断增加网站的曝光率,可以间接提高网站的自然点击率,从而提升和稳定网站的排名。
很多时候我们会发现我们的网站代码有一些优化问题,比如一些模板链接错误,或者我们对网站做了一些微调。如果看不懂代码,往往只能自己操心。如果你懂html和div+css,就可以很好的解决这些小问题。
我们都知道网站空间的稳定性很重要,打开速度也是衡量网站排名的一个很重要的指标,所以一旦百度站长平台有这样的优化建议,往往需要自己解决。
做过SEO的人都离不开程序背景。通常,很多工作都在其中完成。尤其是想要做好结构优化的修改和设置,不看懂这个程序是不可能的。如果做得不好,很容易犯各种严重的错误。
当前网站安全形势非常严峻。我们经常看到有人在网站上抱怨因为排名好被黑客打开,或者被黑了,服务器甚至被别人炸了。这无疑会对他们的网站排名产生非常负面的影响,所以一些安全知识是必要的。
网页内容爬虫基于高度智能的文本识别算法。网页内容爬虫只需将关键词输入到采集内容,无需编写采集规则。覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先采集最新最热的文章信息,自动过滤采集到的信息,拒绝重复采集。这就是今天对 网站 内容抓取工具的介绍。
网页信息抓取软件(Python巡游您可以使用以下代码从所需的网站上抓取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-12 07:30
)
剑客
我对网络抓取真的很陌生,我正在做一个项目,我需要从加载并需要滚动以获取所有值的网格中抓取数据。
页面为 ( )。
我需要网格内的所有数据 - (收录数据名称、类别、子类别、风险、技术)。
谁能指导我一步一步解决这个问题。我做了研究,发现带有 js 或 phantomjs 的 selenium 可能是一个很好的解决方案,但不确定。我将在编程部分使用 Python。
巡航
您可以使用以下代码从 网站 中获取所需的所有内容:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome(executable_path = r'C:/Users/abhishep/Downloads/chromedriver_win32/chromedriver.exe')
driver.maximize_window()
driver.get("https://applipedia.paloaltonetworks.com/")
wait = WebDriverWait(driver,30)
table = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'tbody#bodyScrollingTable tr')))
for tab in table:
print(tab.text) 查看全部
网页信息抓取软件(Python巡游您可以使用以下代码从所需的网站上抓取数据
)
剑客
我对网络抓取真的很陌生,我正在做一个项目,我需要从加载并需要滚动以获取所有值的网格中抓取数据。
页面为 ( )。
我需要网格内的所有数据 - (收录数据名称、类别、子类别、风险、技术)。
谁能指导我一步一步解决这个问题。我做了研究,发现带有 js 或 phantomjs 的 selenium 可能是一个很好的解决方案,但不确定。我将在编程部分使用 Python。
巡航
您可以使用以下代码从 网站 中获取所需的所有内容:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome(executable_path = r'C:/Users/abhishep/Downloads/chromedriver_win32/chromedriver.exe')
driver.maximize_window()
driver.get("https://applipedia.paloaltonetworks.com/";)
wait = WebDriverWait(driver,30)
table = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'tbody#bodyScrollingTable tr')))
for tab in table:
print(tab.text)
网页信息抓取软件(一个免费全能的网页内容功能:一键批量推送给搜索引擎收录(详细参考图片))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-12 03:19
网页内容抓取,什么是网站内容抓取?就是一键批量抓取网站的内容。只需要输入域名即可抓取网站的内容。今天给大家分享一个免费的全能网页内容抓取功能:一键抓取网站内容+自动伪原创+主动推送到搜索引擎收录(参考图片详情一、二、三、四、五)@ >
众所周知,网站优化是一项将技术与艺术分开的工作。我们不能为了优化而优化。任何事物都有一个基本的指标,也就是所谓的度数。生活中到处都可以找到太多令人难以置信的事情。,那么作为一个网站优化器,怎样才能避开优化的细节,让网站远离过度优化的困境呢,好了,八卦进入今天的主题,形成网站过度优化 优化您需要关注的日常运营细节的分析。
首先,网站 内容最容易引起搜索和反作弊机制。我们知道 网站 内容的重要性是显而易见的。内容是我们最关注的中心,也是最容易出问题的中心。无论是新站点还是老站点,我们都必须以内容为王的思想来优化我们的内容。网站,内容不仅是搜索引擎关注的焦点,也是用户查找网站重要信息的有效渠道。最常见的内容是过度优化的。
比如网站伪原创,你当然是抄袭文章 其实你的目的很明显是为了优化而优化,不是为了给用户提供有价值的信息,有一些例子 站长一堆up 关键词在内容中,发布一些无关紧要的文章,或者利用一些渣滓伪原创、采集等生成大量的渣滓信息,都是形成的过度优化的罪魁祸首。更新内容时要注意质量最好的原创,文章的内容要满足用户的搜索需求,更注重发布文章的用户体验,一切以从用户的角度思考不容易造成过度优化的问题。
其次,网站内链的过度优化导致网站的减少。我们知道内链是提高网站关键词的相关性和内页权重的一个非常重要的方法,但是很多站长为了优化做优化,特别是在做很多内链的时候内容页面,直接引发用户阅读体验不时下降的问题。结果,很明显网站的降级还是会出现在我的头上。笔者提出,内链必须站在服务用户和搜索引擎的基础上,主要是为用户找到更多相关信息提供了一个渠道,让搜索引擎抓取更多相关内容,所以在优化内容的过程中,
第三,乱用网站权重标签导致优化作弊。我们知道html标签本身的含义很明确,灵活使用标签可以提高网站优化,但是过度使用标签也存在过度优化的现象。常用的优化标签有H、TAG、ALT等,首先我们要了解这些标签的内在含义是什么。例如,H logo是新闻标题,alt是图片的描述文字,Tag(标签)是一种更敏感有趣的日志分类方式。这样,您可以让每个人都知道您的 文章 中的关键字。停止精选,以便每个人都可以找到相关内容。
标签乱用主要是指自己的title可以通过使用H标记来优化,但是为了增加网站的权重,很多站长也在很多非title中心使用这个标签,导致标签的无序使用和过度优化。出现这种现象,另外一个就是alt标识,本身就是关于图片的辅助说明。我们必须从用户的角度客观地描述这张图片的真正含义吗?而且很多站都用这个logo来堆放关键词,这样的做法非常值得。
四、网站外链的作弊优化是很多人最常见的误区。首先,在短时间内添加了大量的外部链接。我们都知道,正常的外链必须稳步增加,经得起时间的考验。外部链接的建立是一个循序渐进的过程,使外部链接的增加有一个稳定的频率。这是建立外链的标准,但是,很多站长却反其道而行之,大肆增加外链,比如海量发帖,外链骤降、暴增,都是过度的表现。优化。其次,外链的来源非常单一。实际上,外部链接的建立与内部链接类似。自然是最重要的。我们应该尽量为网站关键词做尽可能多的外链,比如软文外链和论坛外链。、博客外链、分类信息外链等,最后是外链问题关键词、关键词也要尽量多样化,尤其是关键词中的堆叠问题建立外部链接一定要避免。
最后作者总结一下,网站过度优化是很多站长都遇到过的问题,尤其是新手站长,急于求胜是最容易造成过度优化的,我们在优化网站的过程中@>,一定要坚持平和的心态。用户体验为王,这是优化的底线,必须随时控制。在优化过程中,任何违反用户体验的细节都会被仔细考虑。返回搜狐,查看更多 查看全部
网页信息抓取软件(一个免费全能的网页内容功能:一键批量推送给搜索引擎收录(详细参考图片))
网页内容抓取,什么是网站内容抓取?就是一键批量抓取网站的内容。只需要输入域名即可抓取网站的内容。今天给大家分享一个免费的全能网页内容抓取功能:一键抓取网站内容+自动伪原创+主动推送到搜索引擎收录(参考图片详情一、二、三、四、五)@ >
众所周知,网站优化是一项将技术与艺术分开的工作。我们不能为了优化而优化。任何事物都有一个基本的指标,也就是所谓的度数。生活中到处都可以找到太多令人难以置信的事情。,那么作为一个网站优化器,怎样才能避开优化的细节,让网站远离过度优化的困境呢,好了,八卦进入今天的主题,形成网站过度优化 优化您需要关注的日常运营细节的分析。
首先,网站 内容最容易引起搜索和反作弊机制。我们知道 网站 内容的重要性是显而易见的。内容是我们最关注的中心,也是最容易出问题的中心。无论是新站点还是老站点,我们都必须以内容为王的思想来优化我们的内容。网站,内容不仅是搜索引擎关注的焦点,也是用户查找网站重要信息的有效渠道。最常见的内容是过度优化的。
比如网站伪原创,你当然是抄袭文章 其实你的目的很明显是为了优化而优化,不是为了给用户提供有价值的信息,有一些例子 站长一堆up 关键词在内容中,发布一些无关紧要的文章,或者利用一些渣滓伪原创、采集等生成大量的渣滓信息,都是形成的过度优化的罪魁祸首。更新内容时要注意质量最好的原创,文章的内容要满足用户的搜索需求,更注重发布文章的用户体验,一切以从用户的角度思考不容易造成过度优化的问题。
其次,网站内链的过度优化导致网站的减少。我们知道内链是提高网站关键词的相关性和内页权重的一个非常重要的方法,但是很多站长为了优化做优化,特别是在做很多内链的时候内容页面,直接引发用户阅读体验不时下降的问题。结果,很明显网站的降级还是会出现在我的头上。笔者提出,内链必须站在服务用户和搜索引擎的基础上,主要是为用户找到更多相关信息提供了一个渠道,让搜索引擎抓取更多相关内容,所以在优化内容的过程中,
第三,乱用网站权重标签导致优化作弊。我们知道html标签本身的含义很明确,灵活使用标签可以提高网站优化,但是过度使用标签也存在过度优化的现象。常用的优化标签有H、TAG、ALT等,首先我们要了解这些标签的内在含义是什么。例如,H logo是新闻标题,alt是图片的描述文字,Tag(标签)是一种更敏感有趣的日志分类方式。这样,您可以让每个人都知道您的 文章 中的关键字。停止精选,以便每个人都可以找到相关内容。
标签乱用主要是指自己的title可以通过使用H标记来优化,但是为了增加网站的权重,很多站长也在很多非title中心使用这个标签,导致标签的无序使用和过度优化。出现这种现象,另外一个就是alt标识,本身就是关于图片的辅助说明。我们必须从用户的角度客观地描述这张图片的真正含义吗?而且很多站都用这个logo来堆放关键词,这样的做法非常值得。
四、网站外链的作弊优化是很多人最常见的误区。首先,在短时间内添加了大量的外部链接。我们都知道,正常的外链必须稳步增加,经得起时间的考验。外部链接的建立是一个循序渐进的过程,使外部链接的增加有一个稳定的频率。这是建立外链的标准,但是,很多站长却反其道而行之,大肆增加外链,比如海量发帖,外链骤降、暴增,都是过度的表现。优化。其次,外链的来源非常单一。实际上,外部链接的建立与内部链接类似。自然是最重要的。我们应该尽量为网站关键词做尽可能多的外链,比如软文外链和论坛外链。、博客外链、分类信息外链等,最后是外链问题关键词、关键词也要尽量多样化,尤其是关键词中的堆叠问题建立外部链接一定要避免。
最后作者总结一下,网站过度优化是很多站长都遇到过的问题,尤其是新手站长,急于求胜是最容易造成过度优化的,我们在优化网站的过程中@>,一定要坚持平和的心态。用户体验为王,这是优化的底线,必须随时控制。在优化过程中,任何违反用户体验的细节都会被仔细考虑。返回搜狐,查看更多
网页信息抓取软件(优采云·云采集网络爬虫软件uationWarning:ThedocumentwascreatedwithSpire..信息收集软件使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-10 06:15
优采云·云采集网络爬虫软件ationWarning:ThedocumentwascreatedwithSpire.. 信息采集软件如何使用你还需要经常去网站采集各种海量信息吗?是不是经常在网上发现大量的信息需要采集,一页一页的复制总是浪费时间。有没有更有效的方法来解决它?实际上。遇到这样的问题,可以选择一个信息采集软件,采集需要的信息,自动整理成统一的格式。这里有一些采集信息的有用工具。如果你觉得好用,一定要推荐给你的朋友,一起分享好东西!国内篇1、优采云一款新颖的云端在线智能爬虫/< @采集器,基于优采云分布式云爬虫框架,可以帮助用户快速获取大量规范化网页数据,在线生成图标,采集结果可以多种形式展示. 2、优采云一款可视化免编程网页采集软件,可以快速从不同的网站中提取归一化数据,帮助用户自动化数据采集,编辑为标准化降低了工作成本。Cloud采集 是其主要功能之一。与其他采集软件相比,Cloud采集可以实现更精准、更高效、更大规模的采集。可视化操作,无需编写代码,制定规则采集,适合零编程基础的用户。3、
4、优采云一款互联网数据采集、处理、分析、挖掘软件,可以捕捉网页上零散的数据信息,通过一系列的分析处理,精准挖掘出需要的数据。分布式采集系统,采集无限网页和内容;不过入门门槛比较高,比较适合有技术基础的人。国外文章1、OctoparseOctoparse是一款免费且功能强大的网站爬虫工具,可以从网站中提取你需要的几乎所有类型的数据。它有两种 采集 模式——向导模式和高级模式——即使你不知道如何编码也能快速上手。下载免费软件后,其可视化用户界面允许您采集 网站 上的所有文本,所以你可以用它来下载几乎所有的网站内容,并将其保存为EXCEL、TXT、HTML或数据库等结构化格式。更重要的是,它的云采集定时器功能可以让你及时更新网站相关数据。2、ParseHubParsehub 是一个有用的网络抓取工具,它支持使用 AJAX、JavaScript、cookie 和其他技术从 网站 采集数据。其机器学习技术可以读取、分析网络文档并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、MacOSX 和 Linux 等系统,或者您可以使用浏览器中内置的 Web 应用程序。3、VisualScraperVisualScraper 是另一个强大的免费网络抓取工具,具有用于采集网络数据的简单界面。您可以从多个网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。4、OutwithubOutwithub 是一个 Firefox 扩展,可以从 Firefox Add-ons Store 轻松下载。打开软件即可使用,具有数据识别功能,让您更简单快捷 查看全部
网页信息抓取软件(优采云·云采集网络爬虫软件uationWarning:ThedocumentwascreatedwithSpire..信息收集软件使用方法)
优采云·云采集网络爬虫软件ationWarning:ThedocumentwascreatedwithSpire.. 信息采集软件如何使用你还需要经常去网站采集各种海量信息吗?是不是经常在网上发现大量的信息需要采集,一页一页的复制总是浪费时间。有没有更有效的方法来解决它?实际上。遇到这样的问题,可以选择一个信息采集软件,采集需要的信息,自动整理成统一的格式。这里有一些采集信息的有用工具。如果你觉得好用,一定要推荐给你的朋友,一起分享好东西!国内篇1、优采云一款新颖的云端在线智能爬虫/< @采集器,基于优采云分布式云爬虫框架,可以帮助用户快速获取大量规范化网页数据,在线生成图标,采集结果可以多种形式展示. 2、优采云一款可视化免编程网页采集软件,可以快速从不同的网站中提取归一化数据,帮助用户自动化数据采集,编辑为标准化降低了工作成本。Cloud采集 是其主要功能之一。与其他采集软件相比,Cloud采集可以实现更精准、更高效、更大规模的采集。可视化操作,无需编写代码,制定规则采集,适合零编程基础的用户。3、
4、优采云一款互联网数据采集、处理、分析、挖掘软件,可以捕捉网页上零散的数据信息,通过一系列的分析处理,精准挖掘出需要的数据。分布式采集系统,采集无限网页和内容;不过入门门槛比较高,比较适合有技术基础的人。国外文章1、OctoparseOctoparse是一款免费且功能强大的网站爬虫工具,可以从网站中提取你需要的几乎所有类型的数据。它有两种 采集 模式——向导模式和高级模式——即使你不知道如何编码也能快速上手。下载免费软件后,其可视化用户界面允许您采集 网站 上的所有文本,所以你可以用它来下载几乎所有的网站内容,并将其保存为EXCEL、TXT、HTML或数据库等结构化格式。更重要的是,它的云采集定时器功能可以让你及时更新网站相关数据。2、ParseHubParsehub 是一个有用的网络抓取工具,它支持使用 AJAX、JavaScript、cookie 和其他技术从 网站 采集数据。其机器学习技术可以读取、分析网络文档并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、MacOSX 和 Linux 等系统,或者您可以使用浏览器中内置的 Web 应用程序。3、VisualScraperVisualScraper 是另一个强大的免费网络抓取工具,具有用于采集网络数据的简单界面。您可以从多个网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。4、OutwithubOutwithub 是一个 Firefox 扩展,可以从 Firefox Add-ons Store 轻松下载。打开软件即可使用,具有数据识别功能,让您更简单快捷
网页信息抓取软件(智能识别模式WebHarvy自动识别网页数据抓取工具的安装教程!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-09 07:40
SysNucleus WebHarvy 是一款非常优秀的网页数据采集工具。使用本软件,可以快速抓取网页文件和图片信息数据,操作方法非常简单。如果您需要,请尽快下载。
软件功能
一、直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
二、智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
三、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
四、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
五、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
六、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
七、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
安装教程
1、双击“Setup.exe”开始软件安装
2、点击下一步显示协议并选择我同意
3、选择安装位置,默认为“C:\Users\Administrator\AppData\Roaming\SysNucleus\WebHarvy\”
4、如下图,点击install进行安装
5、稍等片刻,WebHarvy的安装就完成了 查看全部
网页信息抓取软件(智能识别模式WebHarvy自动识别网页数据抓取工具的安装教程!!)
SysNucleus WebHarvy 是一款非常优秀的网页数据采集工具。使用本软件,可以快速抓取网页文件和图片信息数据,操作方法非常简单。如果您需要,请尽快下载。
软件功能
一、直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
二、智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
三、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
四、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
五、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
六、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
七、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
安装教程
1、双击“Setup.exe”开始软件安装
2、点击下一步显示协议并选择我同意
3、选择安装位置,默认为“C:\Users\Administrator\AppData\Roaming\SysNucleus\WebHarvy\”
4、如下图,点击install进行安装
5、稍等片刻,WebHarvy的安装就完成了
网页信息抓取软件(号码采集软件不会漏采业主发布的任何一条房源信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-01 07:14
客户信息提取软件是所有者的所有者编号采集器。用这个软件代替人,每天在网上不断采集数据,抓取个人发布的房屋信息,大大节省了找房子的时间,让地产商有更多的时间给客户看,跟进上市,从而提高开单率,数采集软件真正实现了采集的快速、准确、无情的上市!
【客户信息提取软件功能特点】
1、采集快速省时
系统会每分钟自动采集各个网站的列表,并能及时采集以个人名义发布各个网站的信息;
2、信息全面,转化率高
号码采集软件不会漏掉任何车主发布的listing,你可以清楚的看到每个listing来自哪个网站采集;并且有自动过滤重复房源功能,提高经纪人浏览房源信息的效率,保证房源充足,让您从被动房源变为主动房源;
3、方便高效
号码采集软件功能,一站式管理所有网站账号,只需操作易方大师的房源采集功能,即可获得所有绑定网站房源的信息,一一省去网站login采集的繁琐操作;
4、快速轻松地识别中介列表
号码采集软件功能内置“来源网站”、“百度搜索”、“网络中介检测”、“搜狗号码识别”、“中介号码打标”五种检测方式,帮助您您快速过滤掉中介列表,让您省心、省时、省力、省钱!
5、售后服务好,省心
Number采集软件,国内房产经纪必备软件品牌,专业强大的客服和技术团队,随时响应您的服务需求!售前、售中、售后服务始终保持一致。 查看全部
网页信息抓取软件(号码采集软件不会漏采业主发布的任何一条房源信息)
客户信息提取软件是所有者的所有者编号采集器。用这个软件代替人,每天在网上不断采集数据,抓取个人发布的房屋信息,大大节省了找房子的时间,让地产商有更多的时间给客户看,跟进上市,从而提高开单率,数采集软件真正实现了采集的快速、准确、无情的上市!
【客户信息提取软件功能特点】
1、采集快速省时
系统会每分钟自动采集各个网站的列表,并能及时采集以个人名义发布各个网站的信息;
2、信息全面,转化率高
号码采集软件不会漏掉任何车主发布的listing,你可以清楚的看到每个listing来自哪个网站采集;并且有自动过滤重复房源功能,提高经纪人浏览房源信息的效率,保证房源充足,让您从被动房源变为主动房源;
3、方便高效
号码采集软件功能,一站式管理所有网站账号,只需操作易方大师的房源采集功能,即可获得所有绑定网站房源的信息,一一省去网站login采集的繁琐操作;
4、快速轻松地识别中介列表
号码采集软件功能内置“来源网站”、“百度搜索”、“网络中介检测”、“搜狗号码识别”、“中介号码打标”五种检测方式,帮助您您快速过滤掉中介列表,让您省心、省时、省力、省钱!
5、售后服务好,省心
Number采集软件,国内房产经纪必备软件品牌,专业强大的客服和技术团队,随时响应您的服务需求!售前、售中、售后服务始终保持一致。
网页信息抓取软件(官方介绍网上有很多禁止复制的html文件,但是我们却很需要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-31 22:13
iefans为用户提供的网页文字抓取器是一款非常受自媒体行业人士欢迎的爬虫软件。在这里你可以把你想要的网页文字复制到这里,然后找到你想要的关键词就可以轻松抓取了。从此,您不再需要眼花缭乱地环顾四周。你在等什么?快来iefans下载吧!
官方介绍
网上有很多禁止复制的html文件,但是我们非常需要。我们应该做什么?小编找了很多软件尝试抓取网页中的文字,但都不好用。终于找到了一个网页文字抓取器,非常好用,推荐给大家!
网页文本抓取软件功能
1、绿色软件,无需安装。
2、支持键盘ctrl、alt、shift+左键、中键、鼠标右键。
3、支持鼠标快捷键、Ctrl、Alt、Shift 和鼠标左/中/右键的任意组合。
4、支持在 Chrome 中抓取网页图像 alt 文本和 url 链接。
5、可以捕获无法复制的文本,但不能捕获图像。
6、支持复制常规静态对话框、系统消息和程序选项卡等表单文本。
使用说明
1.输入要提取的网页地址
2.点击“阅读”阅读文章的内容
防范措施
现在IE已经被边缘化了,我们使用的浏览器绝大多数都是WebKit内核的,所以当你发现一个网站设置权限禁止复制的时候,不妨试试把URL拖到IE浏览器试试Next,或许会有惊喜~
另外需要注意的是,现在国内很多浏览器都使用双核,“兼容模式”就是IE核心。也可以点击切换试试,复制到IE浏览器也是一样的效果。 查看全部
网页信息抓取软件(官方介绍网上有很多禁止复制的html文件,但是我们却很需要)
iefans为用户提供的网页文字抓取器是一款非常受自媒体行业人士欢迎的爬虫软件。在这里你可以把你想要的网页文字复制到这里,然后找到你想要的关键词就可以轻松抓取了。从此,您不再需要眼花缭乱地环顾四周。你在等什么?快来iefans下载吧!
官方介绍
网上有很多禁止复制的html文件,但是我们非常需要。我们应该做什么?小编找了很多软件尝试抓取网页中的文字,但都不好用。终于找到了一个网页文字抓取器,非常好用,推荐给大家!
网页文本抓取软件功能
1、绿色软件,无需安装。
2、支持键盘ctrl、alt、shift+左键、中键、鼠标右键。
3、支持鼠标快捷键、Ctrl、Alt、Shift 和鼠标左/中/右键的任意组合。
4、支持在 Chrome 中抓取网页图像 alt 文本和 url 链接。
5、可以捕获无法复制的文本,但不能捕获图像。
6、支持复制常规静态对话框、系统消息和程序选项卡等表单文本。
使用说明
1.输入要提取的网页地址
2.点击“阅读”阅读文章的内容
防范措施
现在IE已经被边缘化了,我们使用的浏览器绝大多数都是WebKit内核的,所以当你发现一个网站设置权限禁止复制的时候,不妨试试把URL拖到IE浏览器试试Next,或许会有惊喜~
另外需要注意的是,现在国内很多浏览器都使用双核,“兼容模式”就是IE核心。也可以点击切换试试,复制到IE浏览器也是一样的效果。
网页信息抓取软件(软件标签:capturesaver网页辅助capturesaver的功能介绍及应用功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-27 09:22
软件标签:capturesaver 网页助手 capturesaver 是一款非常好用的网页助手工具,可以快速抓取你指定的网页内容,完整保存,还提供制作电子书的功能。有需要的朋友,快来当易网下载吧!
软件介绍
Capturesaver 集成了信息采集、管理、浏览、编辑和搜索功能。它可以帮助您保存完整的网页或网页中的图片,以及屏幕截图,文本捕获,并以统一的方式保存和管理信息。您还可以将采集到的信息导出到 chm 电子书中,并与他人自由分享。使用 capturesaver,您的所有零碎物品都有一个安全的家。
特征
功能一:爬取网页
使用capturesaver,您可以通过简单的鼠标拖拽或点击,完整的捕获当前页面或页面中选中的内容,还可以捕获页面中的所有链接或链接的选中部分。(包括网页中的图片)并统一保存在一起,并支持批量下载,capturesaver是您最好的网页保存工具。
功能二:截屏
使用 capturesaver 捕获全屏、窗口和区域屏幕截图。
功能三:抓取文字
使用capturesaver,你可以自由的捕捉任意窗口的文字、控件中的文字、剪贴板中的文字……还可以复制mircosoft word、写字板、adobe acrobat reader、ie browser、chm document、outlook 文字摘抄自capturesaver中的电子邮件和qq等应用程序。
功能四:离线浏览
Capturesaver 完全下载捕获的网页并将它们保存在本地库中以供离线浏览。
功能五:数据管理
Capturesaver 将您平时杂乱无章的数据、图片等存储起来,统一管理,方便您查找和使用。使用 capturesaver 的树状目录结构,您可以轻松排序和组织。通过关键字全文搜索,从采集的数据中快速找到您需要的内容。
功能六:制作电子书
采集的资料比较多,可以制作成chm电子书,可以自己采集,也可以分享给同事或朋友,甚至可以发布到网上。
软件评估
网页抓取、屏幕抓取、文本抓取、离线浏览、数据管理和电子书创作一应俱全。如果你看到好的图片,文章,还有有用的信息,使用 capturesaver 保存非常方便。 查看全部
网页信息抓取软件(软件标签:capturesaver网页辅助capturesaver的功能介绍及应用功能)
软件标签:capturesaver 网页助手 capturesaver 是一款非常好用的网页助手工具,可以快速抓取你指定的网页内容,完整保存,还提供制作电子书的功能。有需要的朋友,快来当易网下载吧!
软件介绍
Capturesaver 集成了信息采集、管理、浏览、编辑和搜索功能。它可以帮助您保存完整的网页或网页中的图片,以及屏幕截图,文本捕获,并以统一的方式保存和管理信息。您还可以将采集到的信息导出到 chm 电子书中,并与他人自由分享。使用 capturesaver,您的所有零碎物品都有一个安全的家。
特征
功能一:爬取网页
使用capturesaver,您可以通过简单的鼠标拖拽或点击,完整的捕获当前页面或页面中选中的内容,还可以捕获页面中的所有链接或链接的选中部分。(包括网页中的图片)并统一保存在一起,并支持批量下载,capturesaver是您最好的网页保存工具。
功能二:截屏
使用 capturesaver 捕获全屏、窗口和区域屏幕截图。
功能三:抓取文字
使用capturesaver,你可以自由的捕捉任意窗口的文字、控件中的文字、剪贴板中的文字……还可以复制mircosoft word、写字板、adobe acrobat reader、ie browser、chm document、outlook 文字摘抄自capturesaver中的电子邮件和qq等应用程序。
功能四:离线浏览
Capturesaver 完全下载捕获的网页并将它们保存在本地库中以供离线浏览。
功能五:数据管理
Capturesaver 将您平时杂乱无章的数据、图片等存储起来,统一管理,方便您查找和使用。使用 capturesaver 的树状目录结构,您可以轻松排序和组织。通过关键字全文搜索,从采集的数据中快速找到您需要的内容。
功能六:制作电子书
采集的资料比较多,可以制作成chm电子书,可以自己采集,也可以分享给同事或朋友,甚至可以发布到网上。
软件评估
网页抓取、屏幕抓取、文本抓取、离线浏览、数据管理和电子书创作一应俱全。如果你看到好的图片,文章,还有有用的信息,使用 capturesaver 保存非常方便。
网页信息抓取软件(()软件介绍支持RSS的定制功能(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-23 19:02
Web Clawer [WebClawer] 是参考RSS 的具有强大自定义功能的新闻阅读工具。可以抓取任意网站的任意链接,极大的方便了需要获取各个站点信息的工作人员,提高了效率,节省了时间。
软件介绍
支持RSS,包括RSS0.9/1.0/2.0、ATOM、OPML等
支持从任意站点抓取任意链接
可以同时更新多个站点(多线程)
可自定义抓取或排除指定链接
支持自动调用IE的cookies,适合需要登录的论坛
如果没有MSVCR71.dll文件,请下载并放在WebClawer同目录下
绿色软件,无需安装,可存U盘执行
点击下载软件
软件使用
该软件无需安装,解压后双击打开即可,界面如图
<IMG title=001 alt=001 src="//img2.pconline.com.cn/pconline/0804/22/1275786_001.jpg" border=0>
图1软件界面
下面以太平洋软件资讯及应用栏目为例,看看如何使用WebClawer
打开软件,展开对应栏目,右击选择菜单中的“添加频道”如图
<IMG title=002 alt=002 src="//img2.pconline.com.cn/pconline/0804/22/1275786_002.jpg" border=0>
图2 添加频道
在新频道中依次输入频道名称、备注、类别、URL地址,选择文件类型-选择RSS模式,完成后保存。如图
<IMG title=003 alt=003 src="//img2.pconline.com.cn/pconline/0804/22/1275786_003.jpg" border=0>
图3 添加频道界面
<IMG title=004 alt=004 src="//img2.pconline.com.cn/pconline/0804/22/1275786_004.jpg" border=0>
图4填写渠道信息
添加好栏目后,每次只需要选择相应的标题并右键“更新”,软件就可以自动抓取更新的页面。
软件虽小,但对于每天需要查看大量信息的人来说,它可以批量更新各个站点的每一栏,省去大量重复性工作,达到提高工作效率的目的。希望这个软件能给您带来方便。 查看全部
网页信息抓取软件(()软件介绍支持RSS的定制功能(组图))
Web Clawer [WebClawer] 是参考RSS 的具有强大自定义功能的新闻阅读工具。可以抓取任意网站的任意链接,极大的方便了需要获取各个站点信息的工作人员,提高了效率,节省了时间。
软件介绍
支持RSS,包括RSS0.9/1.0/2.0、ATOM、OPML等
支持从任意站点抓取任意链接
可以同时更新多个站点(多线程)
可自定义抓取或排除指定链接
支持自动调用IE的cookies,适合需要登录的论坛
如果没有MSVCR71.dll文件,请下载并放在WebClawer同目录下
绿色软件,无需安装,可存U盘执行
点击下载软件
软件使用
该软件无需安装,解压后双击打开即可,界面如图
<IMG title=001 alt=001 src="//img2.pconline.com.cn/pconline/0804/22/1275786_001.jpg" border=0>
图1软件界面
下面以太平洋软件资讯及应用栏目为例,看看如何使用WebClawer
打开软件,展开对应栏目,右击选择菜单中的“添加频道”如图
<IMG title=002 alt=002 src="//img2.pconline.com.cn/pconline/0804/22/1275786_002.jpg" border=0>
图2 添加频道
在新频道中依次输入频道名称、备注、类别、URL地址,选择文件类型-选择RSS模式,完成后保存。如图
<IMG title=003 alt=003 src="//img2.pconline.com.cn/pconline/0804/22/1275786_003.jpg" border=0>
图3 添加频道界面
<IMG title=004 alt=004 src="//img2.pconline.com.cn/pconline/0804/22/1275786_004.jpg" border=0>
图4填写渠道信息
添加好栏目后,每次只需要选择相应的标题并右键“更新”,软件就可以自动抓取更新的页面。
软件虽小,但对于每天需要查看大量信息的人来说,它可以批量更新各个站点的每一栏,省去大量重复性工作,达到提高工作效率的目的。希望这个软件能给您带来方便。
网页信息抓取软件(网站APP手机号获取网站、网页、APP访问者提取软件功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-17 18:26
市面上有很多捕捉网站和APP访客信息的软件。通过这些软件或系统,您可以查询手机归属地、提取内容、发送短信,让您轻松了解访问者的最新需求。
例如:你在金融行业,你需要一群潜在客户。您需要向我提供 URL、网站 或一些同行的应用程序。我可以采集并为您提供最近几天的实时访问或呼叫信息。
网站APP电话号码获取
网站、网页、APP手机号提取网站每天访问量很大,有多少人在查询?目标客户看到网站就离开了,他们如何留住客户?每月花费数万美元的广告费用。客户点击进入 网站,但没有转化?网站QQ和手机号访客捕获系统可以帮您解决这个问题。可以统计网站访客QQ,自动推送邮件。并自动抓取手机号,有效提高意向客户转化率。因为进入你网站的访问者都对你网站上的产品或服务有需求。有效提高性能。
例如,如果您当前正在浏览网页,我们可以通过数据获取您的手机号和QQ号。
手机号码提取手机号码提取软件功能介绍:
1、手数可以直接从剪贴板中提取
2、可以从文本文件中提取手机号码,如txt.csv.html等。
3、可以从excel文件中提取手机号码,比如xls等。
4、可以从Word文件中提取手机号码,如doc.rtf等。
5、可以从数据库中提取手机号,如mdb
6、手机号码可以从le等其他数据库中提取。
7、您可以从 网站 中提取您的手机号码。如果输入联系电话号码,则可以提取如上所示的电话号码。
8、您可以在浩瀚的互联网上搜索N多个手机号码,是您销售和客服成本最有效的工具。
9、可以过滤手机号码,去除重复手机号码和手机号码排序
10、可以生成手机号
11、可以批量查询手机号码归属地手机号码提取软件,导入word或者word
12、可以通过电脑连接手机,当然手机要有数据线
13、可以批量提取整个目录的手机号
网站APP电话号码获取
QQ、手机号实时抓拍:
网站,网页,APP手机号提取当访客点击网站,电话营销号采集,快速抓取访客QQ和手机号,精准敏捷,获取概率高,有效稳定,访客QQ营销咨询,不漏!
自动发送邮件:
网站、网页、APP手机号提取并获取访问者QQ后,可自动向访问者发送预先编辑好的QQ邮箱,支持多账号发送,群发邮件,到达率95% ,让你没有营销经验。担心!
手机号码提取云数据加密,保障数据安全:
网站、网页、APP手机号提取阿里云服务器云数据加密支持,为您的数据安全保驾护航。电话号码提取软件随时随地,只为您查看,自由导出表格。
24/7监控手机号码提取:
网站,网页,APP手机号提取,谁能想到网站什么时候会来网站,24小时监控访客QQ号和手机号,并记录全程为您探访。 查看全部
网页信息抓取软件(网站APP手机号获取网站、网页、APP访问者提取软件功能)
市面上有很多捕捉网站和APP访客信息的软件。通过这些软件或系统,您可以查询手机归属地、提取内容、发送短信,让您轻松了解访问者的最新需求。
例如:你在金融行业,你需要一群潜在客户。您需要向我提供 URL、网站 或一些同行的应用程序。我可以采集并为您提供最近几天的实时访问或呼叫信息。
网站APP电话号码获取
网站、网页、APP手机号提取网站每天访问量很大,有多少人在查询?目标客户看到网站就离开了,他们如何留住客户?每月花费数万美元的广告费用。客户点击进入 网站,但没有转化?网站QQ和手机号访客捕获系统可以帮您解决这个问题。可以统计网站访客QQ,自动推送邮件。并自动抓取手机号,有效提高意向客户转化率。因为进入你网站的访问者都对你网站上的产品或服务有需求。有效提高性能。
例如,如果您当前正在浏览网页,我们可以通过数据获取您的手机号和QQ号。
手机号码提取手机号码提取软件功能介绍:
1、手数可以直接从剪贴板中提取
2、可以从文本文件中提取手机号码,如txt.csv.html等。
3、可以从excel文件中提取手机号码,比如xls等。
4、可以从Word文件中提取手机号码,如doc.rtf等。
5、可以从数据库中提取手机号,如mdb
6、手机号码可以从le等其他数据库中提取。
7、您可以从 网站 中提取您的手机号码。如果输入联系电话号码,则可以提取如上所示的电话号码。
8、您可以在浩瀚的互联网上搜索N多个手机号码,是您销售和客服成本最有效的工具。
9、可以过滤手机号码,去除重复手机号码和手机号码排序
10、可以生成手机号
11、可以批量查询手机号码归属地手机号码提取软件,导入word或者word
12、可以通过电脑连接手机,当然手机要有数据线
13、可以批量提取整个目录的手机号
网站APP电话号码获取
QQ、手机号实时抓拍:
网站,网页,APP手机号提取当访客点击网站,电话营销号采集,快速抓取访客QQ和手机号,精准敏捷,获取概率高,有效稳定,访客QQ营销咨询,不漏!
自动发送邮件:
网站、网页、APP手机号提取并获取访问者QQ后,可自动向访问者发送预先编辑好的QQ邮箱,支持多账号发送,群发邮件,到达率95% ,让你没有营销经验。担心!
手机号码提取云数据加密,保障数据安全:
网站、网页、APP手机号提取阿里云服务器云数据加密支持,为您的数据安全保驾护航。电话号码提取软件随时随地,只为您查看,自由导出表格。
24/7监控手机号码提取:
网站,网页,APP手机号提取,谁能想到网站什么时候会来网站,24小时监控访客QQ号和手机号,并记录全程为您探访。
网页信息抓取软件(网页信息抓取软件、爬虫框架搭建,线上推广的话)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-15 23:02
网页信息抓取软件、爬虫框架搭建,
线上推广的话,可以在豆瓣上撒广告。你可以在一些分类的子类里面加入广告(电影、音乐、小说、甚至图书、汽车)。然后做点这类分类网站的关联推广,一般人自然会去看,自然会来买东西。这种方法比在墙外搬运免费的广告有用多了。还有就是,说白了也是方法之一,建立一个圈子,吸引熟人做朋友,用熟人的关系做推广。这种方法适合那些特别有趣的小众的品牌,或者对推广质量有要求的地方,比如运动用品、家居装修等等。
网络推广的推广软件推广网站,也就是常说的黑帽seo,这个要看个人的了,网络推广也是一个需要技术含量的活,需要一定的网络基础,我们公司曾经做过网络推广,这是一个长期的积累,技术含量不高。
常规的推广方式,比如搜索引擎排名,论坛贴吧,博客推广,店铺推广.
有的,在进行网络推广之前,我们首先要做好网络营销定位,就是要根据我们的企业或者是产品来为我们进行市场的定位,比如你做的是新闻稿,你就要围绕新闻稿来进行推广,进行搜索引擎优化,主要是要进行外部排名,外部排名能不能起到很好的效果,这取决于我们的网络营销人员的专业素质,还有就是我们的产品和我们的定位没有关系,网络营销可以说是一个快速找客户的方法,但是因为市场的认知度还有广告的深度和广告语的关系,网络营销人员也需要进行一些基础的营销操作,最好可以寻找这方面的专业人士给我们进行策划,这样对于我们网络营销效果也是比较好的。
还有我们在进行网络推广,比如百度竞价、天猫、微信公众号这些都是可以进行推广的。还有就是现在推荐的有代码制作的平台——记事大师,它能够进行文字,图片,网址的快速编辑,还有就是最重要的时候就是按照我们的产品和我们的经验或者是我们的专业为我们进行定制化的专业策划案。在推广这些平台上,大家可以看看有没有合适我们的推广方式,还有什么不懂得大家都可以进行交流。我是四叶草,希望能够帮助到你。 查看全部
网页信息抓取软件(网页信息抓取软件、爬虫框架搭建,线上推广的话)
网页信息抓取软件、爬虫框架搭建,
线上推广的话,可以在豆瓣上撒广告。你可以在一些分类的子类里面加入广告(电影、音乐、小说、甚至图书、汽车)。然后做点这类分类网站的关联推广,一般人自然会去看,自然会来买东西。这种方法比在墙外搬运免费的广告有用多了。还有就是,说白了也是方法之一,建立一个圈子,吸引熟人做朋友,用熟人的关系做推广。这种方法适合那些特别有趣的小众的品牌,或者对推广质量有要求的地方,比如运动用品、家居装修等等。
网络推广的推广软件推广网站,也就是常说的黑帽seo,这个要看个人的了,网络推广也是一个需要技术含量的活,需要一定的网络基础,我们公司曾经做过网络推广,这是一个长期的积累,技术含量不高。
常规的推广方式,比如搜索引擎排名,论坛贴吧,博客推广,店铺推广.
有的,在进行网络推广之前,我们首先要做好网络营销定位,就是要根据我们的企业或者是产品来为我们进行市场的定位,比如你做的是新闻稿,你就要围绕新闻稿来进行推广,进行搜索引擎优化,主要是要进行外部排名,外部排名能不能起到很好的效果,这取决于我们的网络营销人员的专业素质,还有就是我们的产品和我们的定位没有关系,网络营销可以说是一个快速找客户的方法,但是因为市场的认知度还有广告的深度和广告语的关系,网络营销人员也需要进行一些基础的营销操作,最好可以寻找这方面的专业人士给我们进行策划,这样对于我们网络营销效果也是比较好的。
还有我们在进行网络推广,比如百度竞价、天猫、微信公众号这些都是可以进行推广的。还有就是现在推荐的有代码制作的平台——记事大师,它能够进行文字,图片,网址的快速编辑,还有就是最重要的时候就是按照我们的产品和我们的经验或者是我们的专业为我们进行定制化的专业策划案。在推广这些平台上,大家可以看看有没有合适我们的推广方式,还有什么不懂得大家都可以进行交流。我是四叶草,希望能够帮助到你。
网页信息抓取软件(网页信息抓取软件什么的其实没啥用,实用网站抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-13 19:06
网页信息抓取软件什么的其实没啥用,网站提供的数据格式都是很难读懂的,并且很多都是采用加密或者隐藏信息的方式来存储的。抓取方面android相对来说好多了,除了qq之类的真正隐私的数据被限制以外,大部分应用都是支持抓取网站了。推荐你使用第三方抓取工具,很多专业的网站都是会限制第三方抓取,达网、编蜘蛛、51ape等。
第三方抓取的优势在于采集速度快,即使一些很小的网站也可以抓取下来,并且图片,文本等数据抓取下来不用交给后台进行翻译,数据量小的话可以采用这种方式。
既然是帮助网站更好更及时的抓取数据,是对它重大的帮助。下面我介绍一款网站抓取工具——实用网站抓取工具。实用网站抓取工具可以:1.抓取tag,网站列表,关键词2.抓取论坛/个人中心所有问题的讨论讨论话题等,方便用户直接去参与讨论/提问,或者使用浏览器推送信息/对外公布抓取的信息。并且还能提供给用户,可以快速定位指定的网站3.抓取twitter等社交网站上发表的帖子、图片信息4.抓取互联网上的网页、文章(网页)、图片(图片)等5.抓取地理位置信息6.抓取视频(网页)自己或家人视频信息实用网站抓取工具是唯一一款进行网页端与微信端同步抓取信息的抓取工具,无需手动同步网站就可以抓取微信/网页上的图片文本等信息,操作简单,节省工作量。下面介绍我的制作网站爬虫教程。
一、了解更多互联网及爬虫技术概念,并学会爬虫抓取思维
1、首先我们来聊聊什么是爬虫,可以概括爬虫主要有三种:web爬虫、网页爬虫、图片爬虫。web爬虫:web爬虫是指自动地从网站中抓取所需要的数据。网页爬虫:网页爬虫是指爬取网站上的图片、文字、数据的文本文件等。图片爬虫:图片爬虫是爬取图片或图片文件的文本文件。
2、爬虫的分类有哪些常见爬虫主要分为这三类:代理ip、代理、跨ip代理。下面我们以发现豆瓣的用户基础信息为例给大家演示一下爬虫第一步:下载大象工会提供的代理ip对应的集合我们首先来到大象工会的代理ip爬虫爬虫一共包含12个集合,我们从第一个开始爬每一个集合就是一个代理ip对应的站点。比如说我要爬取的豆瓣站点就是一个集合。
我们现在爬取第一个集合的时候就是这个ip站点。我们需要从站点查询图片的资源。访问这个集合查询的ip,将获取到关于豆瓣的一个关键信息,返回给我们,比如说我要找一张美食图片,我就去豆瓣站点查询图片的地址和权重,根据具体的百分比来得出图片链接,根据图片的链接得到我们想要的关键信息,图片在哪些页面看到。我们现。 查看全部
网页信息抓取软件(网页信息抓取软件什么的其实没啥用,实用网站抓取工具)
网页信息抓取软件什么的其实没啥用,网站提供的数据格式都是很难读懂的,并且很多都是采用加密或者隐藏信息的方式来存储的。抓取方面android相对来说好多了,除了qq之类的真正隐私的数据被限制以外,大部分应用都是支持抓取网站了。推荐你使用第三方抓取工具,很多专业的网站都是会限制第三方抓取,达网、编蜘蛛、51ape等。
第三方抓取的优势在于采集速度快,即使一些很小的网站也可以抓取下来,并且图片,文本等数据抓取下来不用交给后台进行翻译,数据量小的话可以采用这种方式。
既然是帮助网站更好更及时的抓取数据,是对它重大的帮助。下面我介绍一款网站抓取工具——实用网站抓取工具。实用网站抓取工具可以:1.抓取tag,网站列表,关键词2.抓取论坛/个人中心所有问题的讨论讨论话题等,方便用户直接去参与讨论/提问,或者使用浏览器推送信息/对外公布抓取的信息。并且还能提供给用户,可以快速定位指定的网站3.抓取twitter等社交网站上发表的帖子、图片信息4.抓取互联网上的网页、文章(网页)、图片(图片)等5.抓取地理位置信息6.抓取视频(网页)自己或家人视频信息实用网站抓取工具是唯一一款进行网页端与微信端同步抓取信息的抓取工具,无需手动同步网站就可以抓取微信/网页上的图片文本等信息,操作简单,节省工作量。下面介绍我的制作网站爬虫教程。
一、了解更多互联网及爬虫技术概念,并学会爬虫抓取思维
1、首先我们来聊聊什么是爬虫,可以概括爬虫主要有三种:web爬虫、网页爬虫、图片爬虫。web爬虫:web爬虫是指自动地从网站中抓取所需要的数据。网页爬虫:网页爬虫是指爬取网站上的图片、文字、数据的文本文件等。图片爬虫:图片爬虫是爬取图片或图片文件的文本文件。
2、爬虫的分类有哪些常见爬虫主要分为这三类:代理ip、代理、跨ip代理。下面我们以发现豆瓣的用户基础信息为例给大家演示一下爬虫第一步:下载大象工会提供的代理ip对应的集合我们首先来到大象工会的代理ip爬虫爬虫一共包含12个集合,我们从第一个开始爬每一个集合就是一个代理ip对应的站点。比如说我要爬取的豆瓣站点就是一个集合。
我们现在爬取第一个集合的时候就是这个ip站点。我们需要从站点查询图片的资源。访问这个集合查询的ip,将获取到关于豆瓣的一个关键信息,返回给我们,比如说我要找一张美食图片,我就去豆瓣站点查询图片的地址和权重,根据具体的百分比来得出图片链接,根据图片的链接得到我们想要的关键信息,图片在哪些页面看到。我们现。
网页信息抓取软件(网页信息抓取软件获取方式见文末的几种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-13 16:01
网页信息抓取软件是一款专门抓取网页信息的信息抓取软件,软件免费下载,软件安装无需特别设置,下载安装很简单,主要有网页信息抓取抓取、网页收藏抓取、手机图片抓取等功能,如果你想要抓取网页信息,那么这个软件还是不错的,在便利性方面方面还是不错,非常适合没有网站的小白用户下载使用。软件获取方式见文末。1.下载软件打开浏览器输入,迅速浏览并找到你要下载的网页或文件。
当然你也可以直接百度,搜索“安全抓取软件”,在搜索结果列表中选择你需要的软件,然后在最下方找到软件,点击安装即可安装成功。2.设置显示隐私设置,这里主要设置文件的显示隐私权,对于百度来说,搜索结果不显示你可以直接关闭搜索关键词。对于谷歌来说,搜索结果可以显示但是点击率不再显示,在你百度以后你可以进行设置,不然百度将不会显示这个文件。
3.网页信息抓取抓取你感兴趣的网页信息,比如说图片,word等文件。在这里你也可以设置不显示网页信息,以及快速抓取文件。4.图片收藏抓取用户收藏的图片、文件等。这一个功能功能其实和上一个不大一样,上一个功能就是抓取页面的第一张图片,这一个功能是抓取页面的最后一张图片,并存档。5.手机图片抓取这个功能主要是抓取手机锁屏界面的图片。
如果你使用抓取其他网页文件,那么它和上一个功能功能也是不同的,上一个抓取的是网页文件,所以其他网页中的一个图片抓取,这一个就抓取同一个网页中其他图片文件,这两个功能都是随着网页位置进行抓取,而不同的是网页本身获取到的信息,比如说搜索的关键词,而且只能抓取手机锁屏界面的文件。6.文件类型转换把两个文件类型进行转换,比如word-cat这两个类型,可以进行文件转换,文档转换,图片转换等功能。
这里我使用的是将一张图片转换成另一个图片,可以转换成gif或者png,把一张图片转换成多张图片,还可以转换图片格式,转换为jpg,png,eagl等等格式的文件。具体教程以下载网页为例,需要找到抓取网页并解析出来的网页上面的文件格式,下面就教大家使用python解析出来。1.打开你想要下载的网页。如果你需要解析的网页在线。
可以打开百度云直接粘贴,只要是在线就可以。如果你需要直接下载或者指定,可以选择打开文件所在的网站,找到你想要解析的网页。2.打开后,依次打开打开另一个网站,抓取图片到本地或者网盘即可。使用谷歌浏览器下载优势更加明显,支持登录谷歌账号以后抓取,只要网页没有输入验证码,都可以直接下载成功。3.把另一个网页上传解析成功后,同时用百度云也。 查看全部
网页信息抓取软件(网页信息抓取软件获取方式见文末的几种方法)
网页信息抓取软件是一款专门抓取网页信息的信息抓取软件,软件免费下载,软件安装无需特别设置,下载安装很简单,主要有网页信息抓取抓取、网页收藏抓取、手机图片抓取等功能,如果你想要抓取网页信息,那么这个软件还是不错的,在便利性方面方面还是不错,非常适合没有网站的小白用户下载使用。软件获取方式见文末。1.下载软件打开浏览器输入,迅速浏览并找到你要下载的网页或文件。
当然你也可以直接百度,搜索“安全抓取软件”,在搜索结果列表中选择你需要的软件,然后在最下方找到软件,点击安装即可安装成功。2.设置显示隐私设置,这里主要设置文件的显示隐私权,对于百度来说,搜索结果不显示你可以直接关闭搜索关键词。对于谷歌来说,搜索结果可以显示但是点击率不再显示,在你百度以后你可以进行设置,不然百度将不会显示这个文件。
3.网页信息抓取抓取你感兴趣的网页信息,比如说图片,word等文件。在这里你也可以设置不显示网页信息,以及快速抓取文件。4.图片收藏抓取用户收藏的图片、文件等。这一个功能功能其实和上一个不大一样,上一个功能就是抓取页面的第一张图片,这一个功能是抓取页面的最后一张图片,并存档。5.手机图片抓取这个功能主要是抓取手机锁屏界面的图片。
如果你使用抓取其他网页文件,那么它和上一个功能功能也是不同的,上一个抓取的是网页文件,所以其他网页中的一个图片抓取,这一个就抓取同一个网页中其他图片文件,这两个功能都是随着网页位置进行抓取,而不同的是网页本身获取到的信息,比如说搜索的关键词,而且只能抓取手机锁屏界面的文件。6.文件类型转换把两个文件类型进行转换,比如word-cat这两个类型,可以进行文件转换,文档转换,图片转换等功能。
这里我使用的是将一张图片转换成另一个图片,可以转换成gif或者png,把一张图片转换成多张图片,还可以转换图片格式,转换为jpg,png,eagl等等格式的文件。具体教程以下载网页为例,需要找到抓取网页并解析出来的网页上面的文件格式,下面就教大家使用python解析出来。1.打开你想要下载的网页。如果你需要解析的网页在线。
可以打开百度云直接粘贴,只要是在线就可以。如果你需要直接下载或者指定,可以选择打开文件所在的网站,找到你想要解析的网页。2.打开后,依次打开打开另一个网站,抓取图片到本地或者网盘即可。使用谷歌浏览器下载优势更加明显,支持登录谷歌账号以后抓取,只要网页没有输入验证码,都可以直接下载成功。3.把另一个网页上传解析成功后,同时用百度云也。
网页信息抓取软件(WinWebCrawler修复部分小错误性能优化让你使用体验更流畅)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-12 22:24
Win Web Crawler是一款功能强大的网络爬虫,可以从文件中快速提取URL、网站、元标签、网页目录、标签之间的纯文本、搜索结果、页面大小和URL列表,多线程,精准提取,并将数据直接保存到磁盘文件,程序有许多过滤器来限制会话,例如URL过滤器,文本过滤器,数据过滤器,域过滤器,日期修改等。欢迎下载。
软件特点:
1、关键词
正确的 网站 的“Win Web Crawler”蜘蛛顶部搜索引擎,并从中获取数据。
2、快速入门
“Win Web Crawler”会查询所有流行的搜索引擎,从搜索结果中提取所有匹配的URL,去除重复的URL,最后访问这些网站并从中提取数据。
3、深度
在这里你需要告诉“Win Web Crawler”——在指定的网站中挖掘多少级。如果您希望“Win Web Crawler”停留在第一页,只需选择“仅处理第一页”。设置为“0”将处理和查找整个 网站 中的数据。设置为“1”将仅处理根目录下具有关联文件的索引或主页。
4、Spider 基本 URL
使用此选项,您可以告诉“Win Web Crawler”始终处理外部站点的基本 URL。例如:在上述情况下,如果 /product/milk/ 则只能访问“Win Web Crawler”的外部站点。除非您将深度设置为覆盖奶粉,否则无法访问
5、忽略网址
设置此选项以避免重复的 URL
两个网址相同。当您设置为忽略 URL 时,“Win Web Crawler”会将所有 URL 转换为小写,并且可以如上所述删除重复的 URL。但是 - 某些服务器区分大小写,您不应在这些特殊站点上使用此选项。
变更日志(2019.09.09)
1.修复一些小bug,提升整体稳定性
2.修复已知页面冻结问题
3.性能优化让你的体验更流畅
应用百科
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。 查看全部
网页信息抓取软件(WinWebCrawler修复部分小错误性能优化让你使用体验更流畅)
Win Web Crawler是一款功能强大的网络爬虫,可以从文件中快速提取URL、网站、元标签、网页目录、标签之间的纯文本、搜索结果、页面大小和URL列表,多线程,精准提取,并将数据直接保存到磁盘文件,程序有许多过滤器来限制会话,例如URL过滤器,文本过滤器,数据过滤器,域过滤器,日期修改等。欢迎下载。
软件特点:
1、关键词
正确的 网站 的“Win Web Crawler”蜘蛛顶部搜索引擎,并从中获取数据。
2、快速入门
“Win Web Crawler”会查询所有流行的搜索引擎,从搜索结果中提取所有匹配的URL,去除重复的URL,最后访问这些网站并从中提取数据。
3、深度
在这里你需要告诉“Win Web Crawler”——在指定的网站中挖掘多少级。如果您希望“Win Web Crawler”停留在第一页,只需选择“仅处理第一页”。设置为“0”将处理和查找整个 网站 中的数据。设置为“1”将仅处理根目录下具有关联文件的索引或主页。
4、Spider 基本 URL
使用此选项,您可以告诉“Win Web Crawler”始终处理外部站点的基本 URL。例如:在上述情况下,如果 /product/milk/ 则只能访问“Win Web Crawler”的外部站点。除非您将深度设置为覆盖奶粉,否则无法访问
5、忽略网址
设置此选项以避免重复的 URL
两个网址相同。当您设置为忽略 URL 时,“Win Web Crawler”会将所有 URL 转换为小写,并且可以如上所述删除重复的 URL。但是 - 某些服务器区分大小写,您不应在这些特殊站点上使用此选项。
变更日志(2019.09.09)
1.修复一些小bug,提升整体稳定性
2.修复已知页面冻结问题
3.性能优化让你的体验更流畅
应用百科
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
网页信息抓取软件( 什么是PowerBI?(图)的优势(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-09 19:25
什么是PowerBI?(图)的优势(组图))
“火箭先生曾经介绍过使用Excel直接从网页下载数据,但是在实际使用中你会发现很多困难。比如在本文介绍的案例中,你无法从网页中抓取到合适的信息通过Excel,微软旗下的另一款软件Power BI在这个时候就展现出了无与伦比的优势,究竟是什么,让我们一起来看看文章吧!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)重要内容,并与任何所需的数据进行连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们要抓取豆瓣阅读页面“最受关注书榜”的相关信息():
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址()并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如《生命之海》和《皮肤的秘密》这两个标题",然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗? 查看全部
网页信息抓取软件(
什么是PowerBI?(图)的优势(组图))
“火箭先生曾经介绍过使用Excel直接从网页下载数据,但是在实际使用中你会发现很多困难。比如在本文介绍的案例中,你无法从网页中抓取到合适的信息通过Excel,微软旗下的另一款软件Power BI在这个时候就展现出了无与伦比的优势,究竟是什么,让我们一起来看看文章吧!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)重要内容,并与任何所需的数据进行连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们要抓取豆瓣阅读页面“最受关注书榜”的相关信息():
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址()并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如《生命之海》和《皮肤的秘密》这两个标题",然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
网页信息抓取软件(python【无交互的简易网页信息抓取软件,以下软件都可以抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-07 12:02
网页信息抓取软件,以下软件都可以抓取:isis【无交互的简易网页信息抓取程序】,这是从慕课网的图片抓取。
有啊,利用开源爬虫,
你说抓取页面源码?通过打包工具(推荐chrome打包工具)把网页源码打包成压缩包,然后利用浏览器自带的工具抓取即可。如果是信息抓取,有很多,你可以看看我分享的小爬虫。
用的是iqiyidegu/json-to-webpage。
不知道有没有同类的。
搜狗网,通过taobao的favicon,爬取favicon。然后再爬取console。
你可以试试sougou\soubaio\soupima...等一些国内的专门搜索网页并存储的平台。
有可能是爬虫出现问题导致你无法搜索到。你可以先看看你的代码里有没有爬虫什么内容,如果没有,则看看你的代码中有没有用到xpath。我用google查到xpath有其他组件实现,你可以查查,如果他们实现了,也可以多试试,看看你是用来爬google的,还是sogou的。如果没有的话,可以看看google的.我推荐你这个站,虽然是我基于xpath写的,但是感觉挺不错的,觉得不错你可以看看他的介绍。你可以先在官网学习一下xpath,然后试着自己写一下爬虫。python爬虫入门教程。 查看全部
网页信息抓取软件(python【无交互的简易网页信息抓取软件,以下软件都可以抓取)
网页信息抓取软件,以下软件都可以抓取:isis【无交互的简易网页信息抓取程序】,这是从慕课网的图片抓取。
有啊,利用开源爬虫,
你说抓取页面源码?通过打包工具(推荐chrome打包工具)把网页源码打包成压缩包,然后利用浏览器自带的工具抓取即可。如果是信息抓取,有很多,你可以看看我分享的小爬虫。
用的是iqiyidegu/json-to-webpage。
不知道有没有同类的。
搜狗网,通过taobao的favicon,爬取favicon。然后再爬取console。
你可以试试sougou\soubaio\soupima...等一些国内的专门搜索网页并存储的平台。
有可能是爬虫出现问题导致你无法搜索到。你可以先看看你的代码里有没有爬虫什么内容,如果没有,则看看你的代码中有没有用到xpath。我用google查到xpath有其他组件实现,你可以查查,如果他们实现了,也可以多试试,看看你是用来爬google的,还是sogou的。如果没有的话,可以看看google的.我推荐你这个站,虽然是我基于xpath写的,但是感觉挺不错的,觉得不错你可以看看他的介绍。你可以先在官网学习一下xpath,然后试着自己写一下爬虫。python爬虫入门教程。

