
网页信息抓取软件
网页信息抓取软件(java本科生推荐go,研究生读研的话建议学java)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-07 11:04
网页信息抓取软件爬虫爬虫抓取软件自动化代码生成机器学习助手java求职软件爬虫第三方微信端selenium工欲善其事必先利其器手把手教你如何实现微信公众号java登录ahr0cdovl3dlaxhpbi5xcs5jb20vci9dvwhhjarvlxjapynvv2iethcw==(二维码自动识别)
深度学习_ml,
我觉得目前java性能比较大的公司一般不可能用到太简单的,那么对他们的话和价值来说,主要还是推荐go,go框架多,语言简单,而且比java能力更强大,但是我就是按go来的,所以你的这么问话我感觉应该是java本科生推荐go,研究生推荐java工程师,
读研的话建议学java。目前市场上java还是比较饱和的,很多中小公司工作环境都是java,而且java学起来也很容易,就算没有基础的你只要耐下心看看教程也能学会。然后研究生期间再学一点go或python吧,这样你工作的时候就会跟其他人有本质的不同。你说的数据量不大,看看以前做过的项目就能发现java相对于go更容易。如果你是想一夜暴富,可以学个python,大学期间足够你靠它赚钱了。
学了java基本上不必学go或python。会个vc++和shell+python基本上也够了。这就是中国教育的悲哀。 查看全部
网页信息抓取软件(java本科生推荐go,研究生读研的话建议学java)
网页信息抓取软件爬虫爬虫抓取软件自动化代码生成机器学习助手java求职软件爬虫第三方微信端selenium工欲善其事必先利其器手把手教你如何实现微信公众号java登录ahr0cdovl3dlaxhpbi5xcs5jb20vci9dvwhhjarvlxjapynvv2iethcw==(二维码自动识别)
深度学习_ml,
我觉得目前java性能比较大的公司一般不可能用到太简单的,那么对他们的话和价值来说,主要还是推荐go,go框架多,语言简单,而且比java能力更强大,但是我就是按go来的,所以你的这么问话我感觉应该是java本科生推荐go,研究生推荐java工程师,
读研的话建议学java。目前市场上java还是比较饱和的,很多中小公司工作环境都是java,而且java学起来也很容易,就算没有基础的你只要耐下心看看教程也能学会。然后研究生期间再学一点go或python吧,这样你工作的时候就会跟其他人有本质的不同。你说的数据量不大,看看以前做过的项目就能发现java相对于go更容易。如果你是想一夜暴富,可以学个python,大学期间足够你靠它赚钱了。
学了java基本上不必学go或python。会个vc++和shell+python基本上也够了。这就是中国教育的悲哀。
网页信息抓取软件(此前,网页内容抓取软件MetaSeeker为什么没有使用正则表达式提取内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-04 10:06
XSLT 已经编译了 20 年。比较难用的编程语言是Perl和XSL。XSL 很容易学习,但有很多陷阱。即使你想成为一名菜鸟程序员,你也必须了解它的原理。必须了解的几个 XSL 原理和使用技巧。之前,为什么网页内容抓取软件工具包 MetaSeeker 不使用正则表达式来提取内容?XSLT和正则表达式在网页数据提取和屏幕抓取(web scraping, screen scraping)领域的优缺点,有大量可复用的第三方程序库或软件模块进行集成,网页内容抓取制定的规则非常适用。然而,这些优势是有代价的。主要的代价是完全控制 XSLT 需要很长时间的学习和实践。下面总结了掌握 XSLT 的难点。XSLT 功能非常强大,大部分网页内容爬取和网页内容格式化和转换任务都可以通过一个 XSLT 指令文件完成。网页内容抓取软件工具包MetaSeeker自动生成的网页内容抓取规则是一个XSLT文件。在 XSLT 指令文件中,xsl:template 语句将许多指令组织成模块。模块化编程是降低编码成本的有效方法。但是,初学者很容易被 XSLT 的“模块化”所欺骗。大多数网页内容爬取和网页内容格式化和转换任务都可以通过一个XSLT指令文件来完成。网页内容抓取软件工具包MetaSeeker自动生成的网页内容抓取规则是一个XSLT文件。在 XSLT 指令文件中,xsl:template 语句将许多指令组织成模块。模块化编程是降低编码成本的有效方法。但是,初学者很容易被 XSLT 的“模块化”所欺骗。大多数网页内容爬取和网页内容格式化和转换任务都可以通过一个XSLT指令文件来完成。网页内容抓取软件工具包MetaSeeker自动生成的网页内容抓取规则是一个XSLT文件。在 XSLT 指令文件中,xsl:template 语句将许多指令组织成模块。模块化编程是降低编码成本的有效方法。但是,初学者很容易被 XSLT 的“模块化”所欺骗。
其实XSLT处理引擎采取了一种很诡异的方式,你可以想象成这样:有一台机器,两个feed素材分别是XSLT指令和转换后的文档(我们关心的是HTML页面),一个成品用于导出,产品是转换后的文档(即提取的数据),机器不断旋转。这种机器的特点是任何原料进入后按顺序进行加工。例如,如果您觉得目标 HTML 文档需要在一遍之后再次处理,则不可能在同一个处理会话中获取更多信息。是的,就像磁带机一样,数据是按顺序访问的,两者是一样的。这是使用 XSLT 的最大障碍。很容易出错。错误的现象是能抓到的数据没有抓到。如果你脑子里总是有这台机器,你就可以避免这个错误。如果要抓取的数据是表结构的话,上面的问题就不容易暴露出来,XSLT指令文件也可以很简单,但是大部分网页内容都是复杂的树形结构,比如B2B 网站 对于上面的产品分类,大类下有子类,多级嵌套。这是一个树形结构。执行深度嵌套操作需要 XSLT 指令。使用下一节中介绍的几个“模块化”指令非常容易。很好地处理了这个问题,但是上一节中解释的顺序处理器打破了“模块化” 并且实际上在某种程度上变成了伪模块化。手动编写XSLT容易出错,编码-验证-修改循环多次重复。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。手动编写XSLT容易出错,编码-验证-修改循环多次重复。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。手动编写XSLT容易出错,编码-验证-修改循环多次重复。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。
使用FreeFormat提高爬取网站页面提取网页内容数据的准确率详细讲解了帧生成原理,MetaStudio使用FreeFormat技术保证生成的XSLT文件帧以正确的顺序执行,并使用目标页面中的语义标记(例如,微格式和 CSS 选择器),以提高信息提取的准确性;和How to use XSLT to extract a piece of content on a HTML page but not some content 本段展示了如何将手写的XPath表达式和XSLT指令文件片段集成到MetaStudio中间生成的框架中。XSLT XSL 指令集中有几个模块化指令:xsl:template, xsl:for-each xsl:apply-templates, xsl:call-template, plus xsl:if, 您可以使用它编写易于阅读的 XSLT 文件。但是,作为初学者,一定要牢记顺序机,否则很容易被这些模块化指令误导。如果你看看网上关于 XSLT 的讨论,你会发现很多菜鸟都在向老手求助,有的老手甚至建议要避开哪些雷区,例如:xsl:for-each vs. xsl:apply-templates 老手说:不要使用 xsl:for-each,使用 xsl:apply-templates。
在一定程度上确实如此,但在某些情况下需要使用for-each,例如结合xsl:if,首先判断是否存在节点集,然后再使用xsl:for-each代替xsl:应用模板,因为您不希望 XSL 引擎匹配自己。在这种情况下,请记住以下两个要点。XPath XPath 我们常说XSLT 离不开XPath。XPath 必须在上一节解释的模块化指令中使用,例如匹配规则、测试规则和选择规则等。你会发现很多 XPath 并不出色,例如:./p/text(),无法出现在 xsl:template 中,这个 XPath 不是另一个 XPath?如果你脑海中有顺序处理器的形象,这并不难理解。处理 xsl:apply-templates 时,引擎需要在当前节点之后找到匹配的节点或节点集。这 ”。” 运算符是多余的,只能是 p/text()。此原则适用于所有匹配操作。但是,它在 xsl:for-each 中有所不同。它是一条选择规则,可以选择当前(.)节点,或者follow-sibling或preceding-sibling等,也可以应用所有的选择规则。
(上下文节点) (当前节点) 我们在上一节已经提到过当前节点。还有一个概念叫做上下文节点。顺序处理器是一个烦人的设计。有时我们必须回去,但实际上我们不能回去。但是我们可以先暂停机器,停机后在事先没有加工过的原料中搜索再搜索,实际上达到了折返的效果。这是上下文节点和当前节点的作用。由于篇幅所限,我不再赘述。如果您有兴趣,可以阅读 XSL 规范和书籍。另一个要记住的概念是:节点集,这需要你解剖机器,看看原材料的加工过程。如果你有兴趣做你自己的研究。 查看全部
网页信息抓取软件(此前,网页内容抓取软件MetaSeeker为什么没有使用正则表达式提取内容?)
XSLT 已经编译了 20 年。比较难用的编程语言是Perl和XSL。XSL 很容易学习,但有很多陷阱。即使你想成为一名菜鸟程序员,你也必须了解它的原理。必须了解的几个 XSL 原理和使用技巧。之前,为什么网页内容抓取软件工具包 MetaSeeker 不使用正则表达式来提取内容?XSLT和正则表达式在网页数据提取和屏幕抓取(web scraping, screen scraping)领域的优缺点,有大量可复用的第三方程序库或软件模块进行集成,网页内容抓取制定的规则非常适用。然而,这些优势是有代价的。主要的代价是完全控制 XSLT 需要很长时间的学习和实践。下面总结了掌握 XSLT 的难点。XSLT 功能非常强大,大部分网页内容爬取和网页内容格式化和转换任务都可以通过一个 XSLT 指令文件完成。网页内容抓取软件工具包MetaSeeker自动生成的网页内容抓取规则是一个XSLT文件。在 XSLT 指令文件中,xsl:template 语句将许多指令组织成模块。模块化编程是降低编码成本的有效方法。但是,初学者很容易被 XSLT 的“模块化”所欺骗。大多数网页内容爬取和网页内容格式化和转换任务都可以通过一个XSLT指令文件来完成。网页内容抓取软件工具包MetaSeeker自动生成的网页内容抓取规则是一个XSLT文件。在 XSLT 指令文件中,xsl:template 语句将许多指令组织成模块。模块化编程是降低编码成本的有效方法。但是,初学者很容易被 XSLT 的“模块化”所欺骗。大多数网页内容爬取和网页内容格式化和转换任务都可以通过一个XSLT指令文件来完成。网页内容抓取软件工具包MetaSeeker自动生成的网页内容抓取规则是一个XSLT文件。在 XSLT 指令文件中,xsl:template 语句将许多指令组织成模块。模块化编程是降低编码成本的有效方法。但是,初学者很容易被 XSLT 的“模块化”所欺骗。
其实XSLT处理引擎采取了一种很诡异的方式,你可以想象成这样:有一台机器,两个feed素材分别是XSLT指令和转换后的文档(我们关心的是HTML页面),一个成品用于导出,产品是转换后的文档(即提取的数据),机器不断旋转。这种机器的特点是任何原料进入后按顺序进行加工。例如,如果您觉得目标 HTML 文档需要在一遍之后再次处理,则不可能在同一个处理会话中获取更多信息。是的,就像磁带机一样,数据是按顺序访问的,两者是一样的。这是使用 XSLT 的最大障碍。很容易出错。错误的现象是能抓到的数据没有抓到。如果你脑子里总是有这台机器,你就可以避免这个错误。如果要抓取的数据是表结构的话,上面的问题就不容易暴露出来,XSLT指令文件也可以很简单,但是大部分网页内容都是复杂的树形结构,比如B2B 网站 对于上面的产品分类,大类下有子类,多级嵌套。这是一个树形结构。执行深度嵌套操作需要 XSLT 指令。使用下一节中介绍的几个“模块化”指令非常容易。很好地处理了这个问题,但是上一节中解释的顺序处理器打破了“模块化” 并且实际上在某种程度上变成了伪模块化。手动编写XSLT容易出错,编码-验证-修改循环多次重复。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。手动编写XSLT容易出错,编码-验证-修改循环多次重复。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。手动编写XSLT容易出错,编码-验证-修改循环多次重复。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。
使用FreeFormat提高爬取网站页面提取网页内容数据的准确率详细讲解了帧生成原理,MetaStudio使用FreeFormat技术保证生成的XSLT文件帧以正确的顺序执行,并使用目标页面中的语义标记(例如,微格式和 CSS 选择器),以提高信息提取的准确性;和How to use XSLT to extract a piece of content on a HTML page but not some content 本段展示了如何将手写的XPath表达式和XSLT指令文件片段集成到MetaStudio中间生成的框架中。XSLT XSL 指令集中有几个模块化指令:xsl:template, xsl:for-each xsl:apply-templates, xsl:call-template, plus xsl:if, 您可以使用它编写易于阅读的 XSLT 文件。但是,作为初学者,一定要牢记顺序机,否则很容易被这些模块化指令误导。如果你看看网上关于 XSLT 的讨论,你会发现很多菜鸟都在向老手求助,有的老手甚至建议要避开哪些雷区,例如:xsl:for-each vs. xsl:apply-templates 老手说:不要使用 xsl:for-each,使用 xsl:apply-templates。
在一定程度上确实如此,但在某些情况下需要使用for-each,例如结合xsl:if,首先判断是否存在节点集,然后再使用xsl:for-each代替xsl:应用模板,因为您不希望 XSL 引擎匹配自己。在这种情况下,请记住以下两个要点。XPath XPath 我们常说XSLT 离不开XPath。XPath 必须在上一节解释的模块化指令中使用,例如匹配规则、测试规则和选择规则等。你会发现很多 XPath 并不出色,例如:./p/text(),无法出现在 xsl:template 中,这个 XPath 不是另一个 XPath?如果你脑海中有顺序处理器的形象,这并不难理解。处理 xsl:apply-templates 时,引擎需要在当前节点之后找到匹配的节点或节点集。这 ”。” 运算符是多余的,只能是 p/text()。此原则适用于所有匹配操作。但是,它在 xsl:for-each 中有所不同。它是一条选择规则,可以选择当前(.)节点,或者follow-sibling或preceding-sibling等,也可以应用所有的选择规则。
(上下文节点) (当前节点) 我们在上一节已经提到过当前节点。还有一个概念叫做上下文节点。顺序处理器是一个烦人的设计。有时我们必须回去,但实际上我们不能回去。但是我们可以先暂停机器,停机后在事先没有加工过的原料中搜索再搜索,实际上达到了折返的效果。这是上下文节点和当前节点的作用。由于篇幅所限,我不再赘述。如果您有兴趣,可以阅读 XSL 规范和书籍。另一个要记住的概念是:节点集,这需要你解剖机器,看看原材料的加工过程。如果你有兴趣做你自己的研究。
网页信息抓取软件(如何通过Java代码实现对网页数据进行指定抓取方法思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-02 08:20
IE浏览器有OLE对象,可以用这个功能提取所有元素的信息,有些软件应该可以。. .
如果你想从头开始,直接匹配文本,写一个提取元素的小程序。. .
使用Java代码指定网页数据爬取方式的思路如下:
导入项目中的Jsoup.jar包
获取url指定的url或者文档指定的body
获取网页中超链接的标题和链接
获取指定博客的内容文章
获取网页中超链接的标题和链接结果
在这个附加文件中写入:
登录用户 = 新登录();
字符串 id = user.GetUserID();
System.out.println(id);
PS:java文件首字母大写,方法首字母小写。
不是有历史页面吗,直接复制粘贴,选择你要的数据,右键复制,在表格中右键粘贴
如果使用之前嗅探过的ForeSpider数据采集软件,就可以了。但是您需要知道应用程序的协议是什么。如果是http、https,可以直接采集。
实时更新也是可能的。软件支持定时采集和一定间隔时间采集。设置间隔时间相当于实时更新。
ForeSpider 直接连接到数据库。数据存储有多种策略,存储前会自动重新加载两次,确保只插入更新后的数据。
有一个免费版本,您可以下载无限功能。
如何从网页中提取数据到excel-:1、点击数据--导入外部数据--新建Web查询。2、勾选我可以识别这个内容,允许播放,点击继续按钮。3、在地址栏输入网站的地址,跳转到这个网站。4、跳转到指定网页,点击箭头按钮,然后将数据导入Excel。Excel表格是完成整个过程的生成数据。
如何从 web 表中提取数据:不要打扰。选择你想要的表格数据,复制粘贴到Excel中,然后就可以导入到自己的数据库中,比如把数据保存成某种格式等。不会带那些不需要的格式。
如何提取网页的数据-:使用WebRequest方法获取网站的数据: private string GetStringByUrl(string strUrl) { WebRequest wrt = WebRequest.Create(strUrl); WebResponse wrse = wrt.GetResponse(); 流 strM = wrse.GetResponseStream(); StreamReader SR = 新...
如何从网页中抓取数据:抓取网页是一个巨大的项目。但总结起来,只有三种方式:1.最原创的方式,手动复制。2.写代码,很多程序员都喜欢这样做,但是很容易采集简单网页,不容易网站可以采集随心所欲。3.估计除非是有特殊喜好,不然大家都不想选上面两个路径,都想更高效更强大,最好是免费的采集器,目前用的最好的采集器是新的优采云采集器,真的是神器,好像解决不了网站。它也是免费的,值得一试。
如何从网页中提取数据-:IE浏览器有OLE对象,可以使用这个功能提取所有元素的信息,有些软件应该可以... 如果要从头开始,那就直接匹配文本并编写一个提取元素的小程序,也可以...
如何从网站中抓取数据-:网络爬虫软件可以抓取数据。建议嗅探 ForeSpider 数据采集 软件。软件可以采集几乎所有互联网上的公开数据,通过可视化的操作流程,从建表、过滤、采集到存储,一步到位。它支持正则表达式操作,并拥有强大的面向对象的脚本语言系统......
如何任意提取网页数据:试试360阅读器或者GOOGLE阅读器,都可以提取数据
如何获取网页数据?- : curl ->oksocket 太低级了,无法获取。一般编程语言都有http协议封装,通常是httpClient.get(" ").responseString或者httpClient.get(" ").body
如何抓取网页上的数据——:1.使用工具分析js最终生成的url是什么,发送请求,发送了什么数据。相关信息请参考:【教程】教你如何使用工具(ie9的f12)分析模拟登录的内部逻辑流程网站(百度首页)如果你不会'不太明白背后的逻辑,可以参考:【组织机构】关于...
如何从网页中提取需要的数据并用JAVA实现:自己实现,推荐你一个工具jsoup,你可以试试 查看全部
网页信息抓取软件(如何通过Java代码实现对网页数据进行指定抓取方法思路)
IE浏览器有OLE对象,可以用这个功能提取所有元素的信息,有些软件应该可以。. .
如果你想从头开始,直接匹配文本,写一个提取元素的小程序。. .
使用Java代码指定网页数据爬取方式的思路如下:
导入项目中的Jsoup.jar包
获取url指定的url或者文档指定的body
获取网页中超链接的标题和链接
获取指定博客的内容文章
获取网页中超链接的标题和链接结果
在这个附加文件中写入:
登录用户 = 新登录();
字符串 id = user.GetUserID();
System.out.println(id);
PS:java文件首字母大写,方法首字母小写。
不是有历史页面吗,直接复制粘贴,选择你要的数据,右键复制,在表格中右键粘贴
如果使用之前嗅探过的ForeSpider数据采集软件,就可以了。但是您需要知道应用程序的协议是什么。如果是http、https,可以直接采集。
实时更新也是可能的。软件支持定时采集和一定间隔时间采集。设置间隔时间相当于实时更新。
ForeSpider 直接连接到数据库。数据存储有多种策略,存储前会自动重新加载两次,确保只插入更新后的数据。
有一个免费版本,您可以下载无限功能。
如何从网页中提取数据到excel-:1、点击数据--导入外部数据--新建Web查询。2、勾选我可以识别这个内容,允许播放,点击继续按钮。3、在地址栏输入网站的地址,跳转到这个网站。4、跳转到指定网页,点击箭头按钮,然后将数据导入Excel。Excel表格是完成整个过程的生成数据。
如何从 web 表中提取数据:不要打扰。选择你想要的表格数据,复制粘贴到Excel中,然后就可以导入到自己的数据库中,比如把数据保存成某种格式等。不会带那些不需要的格式。
如何提取网页的数据-:使用WebRequest方法获取网站的数据: private string GetStringByUrl(string strUrl) { WebRequest wrt = WebRequest.Create(strUrl); WebResponse wrse = wrt.GetResponse(); 流 strM = wrse.GetResponseStream(); StreamReader SR = 新...
如何从网页中抓取数据:抓取网页是一个巨大的项目。但总结起来,只有三种方式:1.最原创的方式,手动复制。2.写代码,很多程序员都喜欢这样做,但是很容易采集简单网页,不容易网站可以采集随心所欲。3.估计除非是有特殊喜好,不然大家都不想选上面两个路径,都想更高效更强大,最好是免费的采集器,目前用的最好的采集器是新的优采云采集器,真的是神器,好像解决不了网站。它也是免费的,值得一试。
如何从网页中提取数据-:IE浏览器有OLE对象,可以使用这个功能提取所有元素的信息,有些软件应该可以... 如果要从头开始,那就直接匹配文本并编写一个提取元素的小程序,也可以...
如何从网站中抓取数据-:网络爬虫软件可以抓取数据。建议嗅探 ForeSpider 数据采集 软件。软件可以采集几乎所有互联网上的公开数据,通过可视化的操作流程,从建表、过滤、采集到存储,一步到位。它支持正则表达式操作,并拥有强大的面向对象的脚本语言系统......
如何任意提取网页数据:试试360阅读器或者GOOGLE阅读器,都可以提取数据
如何获取网页数据?- : curl ->oksocket 太低级了,无法获取。一般编程语言都有http协议封装,通常是httpClient.get(" ").responseString或者httpClient.get(" ").body
如何抓取网页上的数据——:1.使用工具分析js最终生成的url是什么,发送请求,发送了什么数据。相关信息请参考:【教程】教你如何使用工具(ie9的f12)分析模拟登录的内部逻辑流程网站(百度首页)如果你不会'不太明白背后的逻辑,可以参考:【组织机构】关于...
如何从网页中提取需要的数据并用JAVA实现:自己实现,推荐你一个工具jsoup,你可以试试
网页信息抓取软件(什么是百度蜘蛛是怎么实现网页收录的工作过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-02 08:18
搜索引擎的工作过程非常复杂。今天给大家分享一下我所知道的百度蜘蛛实现网页收录。
搜索引擎的工作大致可以分为四个过程。
1、蜘蛛爬行。
2、信息过滤。
3、创建网页索引关键词。
4、用户搜索输出结果。
蜘蛛爬行爬行
当百度蜘蛛来到一个页面时,它会跟随页面上的链接,从这个页面爬到下一个页面,就像一个递归的过程,这不仅是多年的累人工作。例如,当蜘蛛来到我的博客主页时,它会首先读取根目录下的 robots.txt 文件。如果没有禁止搜索引擎抓取,蜘蛛就会开始对网页上的链接进行一一跟踪和抓取。比如我上面的文章“SEO概述|什么是SEO,SEO是做什么的”,引擎会多进程到这个文章所在的页面去爬取信息,等等上,没有尽头。
信息过滤
为了避免重复爬取和爬取网址,搜索引擎会对已爬取和未爬取的地址进行记录。如果你有新的网站,可以去百度官网提交网站网址,引擎会记录下来,归类为未被抓取的网址,然后蜘蛛会使用此表从数据库中提取 URL,访问并爬取页面。
蜘蛛不会收录所有页面,它是严格检查的。蜘蛛在爬取网页内容时,会进行一定程度的重复内容检测。如果网页所在的 网站 权重较低,并且大部分 文章 是抄袭的,那么蜘蛛很可能不喜欢你的 网站,不要保留爬行,不要收录你的网站。
创建网页的 关键词 索引
当蜘蛛爬取页面时,它首先分析页面的文本内容。通过分词技术,将网页内容简化为关键词,将关键词和对应的URL做成表格进行索引。
该指数有正向指数和反向指数。正向索引是网页内容对应的关键词,反向索引是关键词对应的网页信息。
输出结果
当用户搜索某个关键词时,会通过之前建立的索引表进行关键词匹配,通过反向索引表找到关键词对应的页面,对网页进行综合评分通过引擎计算后,根据网页的得分确定网页的排名。 查看全部
网页信息抓取软件(什么是百度蜘蛛是怎么实现网页收录的工作过程)
搜索引擎的工作过程非常复杂。今天给大家分享一下我所知道的百度蜘蛛实现网页收录。
搜索引擎的工作大致可以分为四个过程。
1、蜘蛛爬行。
2、信息过滤。
3、创建网页索引关键词。
4、用户搜索输出结果。
蜘蛛爬行爬行
当百度蜘蛛来到一个页面时,它会跟随页面上的链接,从这个页面爬到下一个页面,就像一个递归的过程,这不仅是多年的累人工作。例如,当蜘蛛来到我的博客主页时,它会首先读取根目录下的 robots.txt 文件。如果没有禁止搜索引擎抓取,蜘蛛就会开始对网页上的链接进行一一跟踪和抓取。比如我上面的文章“SEO概述|什么是SEO,SEO是做什么的”,引擎会多进程到这个文章所在的页面去爬取信息,等等上,没有尽头。
信息过滤
为了避免重复爬取和爬取网址,搜索引擎会对已爬取和未爬取的地址进行记录。如果你有新的网站,可以去百度官网提交网站网址,引擎会记录下来,归类为未被抓取的网址,然后蜘蛛会使用此表从数据库中提取 URL,访问并爬取页面。
蜘蛛不会收录所有页面,它是严格检查的。蜘蛛在爬取网页内容时,会进行一定程度的重复内容检测。如果网页所在的 网站 权重较低,并且大部分 文章 是抄袭的,那么蜘蛛很可能不喜欢你的 网站,不要保留爬行,不要收录你的网站。
创建网页的 关键词 索引
当蜘蛛爬取页面时,它首先分析页面的文本内容。通过分词技术,将网页内容简化为关键词,将关键词和对应的URL做成表格进行索引。
该指数有正向指数和反向指数。正向索引是网页内容对应的关键词,反向索引是关键词对应的网页信息。
输出结果
当用户搜索某个关键词时,会通过之前建立的索引表进行关键词匹配,通过反向索引表找到关键词对应的页面,对网页进行综合评分通过引擎计算后,根据网页的得分确定网页的排名。
网页信息抓取软件( 如何提高百度蜘蛛爬行事有策略的更新频率?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-02 08:16
如何提高百度蜘蛛爬行事有策略的更新频率?(图))
也称为 web、web bot,在 FOAF 社区中,通常称为 Web Chaser),是根据既定规则自动在万维网上自动生成信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
(baiduspider),是一个搜索引擎的自动程序。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后按类别建立索引库,以便用户在百度搜索到你的网站页面、图片、视频等内容搜索引擎 。之所以命名为蜘蛛,是因为该程序具有类似蜘蛛的功能,可以通过铺天盖地的网络来采集互联网业务的信息。
百度蜘蛛的工作原理
蜘蛛是网站和用户之间的信息搬运工,网站的内容通过索引库呈现给用户。
工作过程
索引区开始抓取网页信息,通过临时库对内容进行处理,将一些符合规则的内容带回索引库。将不合格的内容进行清理,最后将合格的内容展示给搜索引擎查询结果。
据XX先生网站介绍,通过日志查询爬取的蜘蛛数量并不多,但收录却非常少。也就是说,内容被爬取了,但是蜘蛛带入索引库的内容却很少。
如果PC移动到适配站点,只想抓取PC端的内容,可以直接移动机器人吗?
百度蜘蛛既有PC/Mobile全食蜘蛛,也有移动端专属蜘蛛。它们的识别命令是一样的,也就是说,只要机器人是百度蜘蛛,百度就无法抓取内容。不管你是想移动机器人还是PC网站都不能用百度蜘蛛机器人。会导致百度无法抓取网站内容。
如何增加百度抓取
1、网站的更新频率
网站的内容需要定期更新高价值内容,所以可以先抢到。中,创建内容的频率,因为蜘蛛爬行是有策略的,网站创建内容越频繁,蜘蛛爬行的频率就越高,所以更新的频率可以提高爬行的频率。例如:小明每天更新10篇文章,其余7天不更新。这种方法是错误的。正确的方法是每天更新一个文章。
2、网站人气
网站 的受欢迎程度是指我们的用户体验。可以,如果用户体验好网站,百度蜘蛛会优先录用。那么这里有人会问,如何提升用户体验呢?其实很简单,首先网站的配色和页面布局一定要合理,最重要的是广告,一定要免去太多的广告,不要让广告掩盖正面内容,否则百度会判断你的网站用户体验很糟糕。
3、合适的入口
下知的入口主要是指网站的外部链接,先爬到下知的站点被跟踪(跟踪)的站点。现在百度对外链做了很大的调整,百度对垃圾外链的过滤非常严格。基本上,如果您在论坛或留言板上发送外部链接,百度会在后台对其进行过滤。但真正高质量的反向链接、排名和爬网很重要。
4、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于经常受到攻击(被黑)的网站,它会严重危害用户。所以,在SEO优化的过程中,要注意网站的安全。
5、历史爬取效果不错
无论百度是排名还是爬虫,历史记录都很重要。如果他们以前作弊,这就像一个人的历史。那会留下污点。网站同样如此。切记不要在网站的优化中作弊,一旦留下污点,会降低百度蜘蛛对站点的信任,影响爬取网站的时间和深度。不断更新高质量的内容非常重要。
6、服务器稳定,抢优先级
2015年以来,百度在服务器稳定性因素的权重上做了很大的提升。服务器稳定性包括稳定性和速度。服务器越快,植物抓取效率越高。服务器越稳定,爬虫的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的事情。 查看全部
网页信息抓取软件(
如何提高百度蜘蛛爬行事有策略的更新频率?(图))

也称为 web、web bot,在 FOAF 社区中,通常称为 Web Chaser),是根据既定规则自动在万维网上自动生成信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
(baiduspider),是一个搜索引擎的自动程序。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后按类别建立索引库,以便用户在百度搜索到你的网站页面、图片、视频等内容搜索引擎 。之所以命名为蜘蛛,是因为该程序具有类似蜘蛛的功能,可以通过铺天盖地的网络来采集互联网业务的信息。
百度蜘蛛的工作原理
蜘蛛是网站和用户之间的信息搬运工,网站的内容通过索引库呈现给用户。
工作过程
索引区开始抓取网页信息,通过临时库对内容进行处理,将一些符合规则的内容带回索引库。将不合格的内容进行清理,最后将合格的内容展示给搜索引擎查询结果。
据XX先生网站介绍,通过日志查询爬取的蜘蛛数量并不多,但收录却非常少。也就是说,内容被爬取了,但是蜘蛛带入索引库的内容却很少。
如果PC移动到适配站点,只想抓取PC端的内容,可以直接移动机器人吗?
百度蜘蛛既有PC/Mobile全食蜘蛛,也有移动端专属蜘蛛。它们的识别命令是一样的,也就是说,只要机器人是百度蜘蛛,百度就无法抓取内容。不管你是想移动机器人还是PC网站都不能用百度蜘蛛机器人。会导致百度无法抓取网站内容。
如何增加百度抓取
1、网站的更新频率
网站的内容需要定期更新高价值内容,所以可以先抢到。中,创建内容的频率,因为蜘蛛爬行是有策略的,网站创建内容越频繁,蜘蛛爬行的频率就越高,所以更新的频率可以提高爬行的频率。例如:小明每天更新10篇文章,其余7天不更新。这种方法是错误的。正确的方法是每天更新一个文章。
2、网站人气
网站 的受欢迎程度是指我们的用户体验。可以,如果用户体验好网站,百度蜘蛛会优先录用。那么这里有人会问,如何提升用户体验呢?其实很简单,首先网站的配色和页面布局一定要合理,最重要的是广告,一定要免去太多的广告,不要让广告掩盖正面内容,否则百度会判断你的网站用户体验很糟糕。
3、合适的入口
下知的入口主要是指网站的外部链接,先爬到下知的站点被跟踪(跟踪)的站点。现在百度对外链做了很大的调整,百度对垃圾外链的过滤非常严格。基本上,如果您在论坛或留言板上发送外部链接,百度会在后台对其进行过滤。但真正高质量的反向链接、排名和爬网很重要。
4、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于经常受到攻击(被黑)的网站,它会严重危害用户。所以,在SEO优化的过程中,要注意网站的安全。
5、历史爬取效果不错
无论百度是排名还是爬虫,历史记录都很重要。如果他们以前作弊,这就像一个人的历史。那会留下污点。网站同样如此。切记不要在网站的优化中作弊,一旦留下污点,会降低百度蜘蛛对站点的信任,影响爬取网站的时间和深度。不断更新高质量的内容非常重要。
6、服务器稳定,抢优先级
2015年以来,百度在服务器稳定性因素的权重上做了很大的提升。服务器稳定性包括稳定性和速度。服务器越快,植物抓取效率越高。服务器越稳定,爬虫的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的事情。
网页信息抓取软件(发明专利技术涉及一种可配置化的数据抓取方法和步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-26 11:34
本发明专利技术涉及一种可配置的数据抓取方法,包括以下步骤:确定需要抓取的目标网站,并配置目标网站的基本信息。站点配置页面,包括站点类型、站点名称、目标编号、页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面配置爬取服务的启动时间;
一种可配置的数据抓取方法及装置
下载所有详细的技术数据
【技术实现步骤总结】
一种可配置的数据采集方法及装置
本专利技术涉及一种可配置的数据采集方法及装置,属于数据采集
技术介绍
目前实现数据抓取的方式有很多,包括开源代码和直接提供服务的商业工具,但这些基本上都是针对不同的目标网站,根据网站硬编码的特点实现 是的,这个实现有一定的局限性。一旦要捕获的范围变大,或者目标网站发生变化,解决问题的唯一方法就是修改之前实现的编码。这造成了一定的资源浪费,影响了执行周期。灵活性不够,还受限于实施的人员技能。
技术实现思路
为了解决现有技术中存在的上述问题,专利技术提供了一种可配置的数据采集方法,可以有效解决多次网站的采集,即使面对网站的变化的情况下,也可以通过修改配置来完成配套变更,缩短建设周期,也可以由普通实施者完成。本专利技术的技术方案如下:该技术方案是一种可配置的数据抓取方法,包括以下步骤:确定要抓取的目标网站,在站点配置页面配置目标网站的基本信息,包括站点类型、站点名称、目标编号、页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;管理页面配置启动爬虫服务的时间;生成爬取作业,从目标网站抓取数据,具体步骤如下:根据爬取服务启动的时间,开始执行作业;目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码,登录目标网站>;根据网址的基本信息,打开抓取数据的网址,对目标网站进行固定操作,抓取网页内容。进一步判断目标网站是否有验证码登录步骤,如果有验证码登录步骤,在输入验证码配置页面配置输入验证码的基本信息,包括验证码图片类型,验证码图片。验证码图片的语言、字符数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标<
进一步的,还包括用户密码验证步骤,具体为:选择一个或多个需要验证的用户,点击验证;客户端依次验证所选用户的登录账号/密码,并在后台生成。验证结果,验证结果包括登录成功和登录失败。如果验证结果是登录失败,也会在后台产生错误信息,并列出相关错误信息日志地址;点击查询获取验证结果,如验证结果为登录失败,则根据错误信息日志地址获取错误信息日志,分析并执行错误解决。进一步,在URL参数配置页面配置一个值为变量的请求参数,包括参数名称、参数类型、参数值和参数描述。技术方案2 一种可配置的数据抓取装置,包括内存和处理器,内存中存储有指令,指令用于被处理器加载并执行以下步骤:确定要抓取的目标网站 ,并在站点配置页面配置目标网站的基本信息,包括站点类型、站点名称、目标编号、页面编码格式;配置用户配置页面登录目标 网站 用户的基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面配置启动爬取服务的时间;生成一个爬虫作业,从目标网站爬取数据,具体步骤如下: 根据启动爬虫服务时开始执行作业;根据目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码,登录目标网站;根据网址的基本信息,打开抓取数据的网址,
进一步判断目标网站是否有验证码登录步骤,如果有验证码登录步骤,在输入验证码配置页面配置输入验证码的基本信息,包括验证码图片类型,验证码图片。验证码图片的语言、字符数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取验证码图片中的目标网站,根据验证码中输入的基本信息识别验证码图片登录目标网站,具体步骤如下:使用网络爬虫从目标网站图片中爬取验证码;采用OCR技术,根据输入的验证码基本信息,自动识别验证码图片,获取验证码图片中的验证码信息;在验证码输入框中填写验证码信息并提交登录;如果登录失败,则转为人工识别验证码图片,在验证码输入框中输入验证码进行登录。另外,还包括用户密码验证步骤,具体如下:选择一个或多个需要验证的用户,点击验证;客户端依次验证所选用户的登录帐户/密码,并在后台生成它们。验证结果,验证结果包括登录成功和登录失败。如果验证结果是登录失败,也会在后台产生错误信息,并列出相关错误信息日志地址;点击查询获取验证结果,如验证结果为登录失败,则根据错误信息日志地址获取错误信息日志,分析并执行错误解决。
进一步的,在URL参数配置页面上配置了一个值为变量的请求参数,包括参数名称、参数类型、参数取值和参数描述。该专利技术具有以下有益效果:1、该专利技术是一种可配置的数据抓取方式,解构了数据抓取过程中的每一个关键环节,让操作者不需要专业的爬虫编码技能,就可以完成一个网站 的数据采集作业;无需投入高端人员,数据采集成本可控。附图说明图。附图说明图1是本专利技术实施例的流程图;无花果。图2是站点配置的示例图;无花果。图3是实施例中网站的源代码示例图;无花果。图4是用户配置的示例图;图5是抓取URL配置示例图。图6是寻呼表达配置的示例图。图7是调度管理配置示例图。图8是验证码输入示例图。图9为用户账号密码验证图10为URL参数配置示例图。图11是通过httpwatch获取网站信息的示例图。具体实施方式下面结合附图和具体实施例对本专利技术进行详细说明。实施例1 参见图1-11,一种可配置的数据捕获方法包括以下步骤:确定需要捕获的目标网站,在站点配置页面配置目标网站基本信息,包括站点类型、站点名称、目标编号、页面编码格式;如图2,以配置永辉超市网站为例,站点类型根据配置的永辉超市网站类型,选择零售商;站点名称填写永辉超市,名称可自定义;目标数量可定制,数量一般由需方提供;页面编码格式由各个网站开发定义,见图3,打开永辉超市网站,右键查看页面源代码,从源代码。从图3可以看出,页面的编码格式为UTF-8。编码格式统一,所以页面编码格式选择UTF-8。在用户配置页面,配置可以登录的目标网站
【技术保护点】
1.一种可配置的数据抓取方法,其特征在于包括以下步骤:确定要抓取的目标网站,在站点配置页面配置目标网站基本信息,包括站点类型、站点名称、目标编号和页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面上配置启动抓取服务的时间;创造一个抢手的工作,从目标网站抓取数据,具体步骤如下:根据抓取服务启动的时间开始执行job;根据目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。
【技术特点总结】
1.一种可配置的数据抓取方法,其特征在于包括以下步骤:确定要抓取的目标网站,在站点配置页面配置目标网站基本信息,包括站点类型、站点名称、目标编号和页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面上配置启动抓取服务的时间;创造一个抢手的工作,从目标网站抓取数据,具体步骤如下:根据抓取服务启动的时间开始执行job;根据目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。2.根据权利要求1所述的一种可配置的数据抓取方法,其特征在于:判断目标网站是否有验证码登录步骤,如果有验证码登录步骤,然后在验证码输入配置页面配置验证码输入的基本信息,包括验证码图片类型、验证码图片语言、验证码图片字符个数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 包括验证码图片类型、验证码图片语言、验证码图片字符个数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 包括验证码图片类型、验证码图片语言、验证码图片字符个数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫
3.根据权利要求1所述的一种可配置的数据抓取方法,其特征在于,还包括用户密码验证步骤,如下:选择一个或多个需要验证的用户,点击进行验证;客户端依次验证选中用户的登录账号/密码,并在后台生成验证结果,验证结果包括登录成功和登录失败。后台生成错误信息并列出相关错误信息日志地址;点击查询获取验证结果,若验证结果为登录失败,则根据错误信息日志地址获取错误信息日志,分析错误执行错误获取解决。4.根据权利要求1所述的可配置数据采集方法,其特征在于:在URL参数配置页面配置一个值为变量的请求参数,包括参数名称、参数类型、参数值和参数说明。5.一种可配置的数据捕获设备,它...
【专利技术性质】
技术研发人员:邱涛、邱水文、陈成乐、
申请人(专利权)持有人:,
类型:发明
国家、省、市:福建,35
下载所有详细的技术数据 我是该专利的所有者 查看全部
网页信息抓取软件(发明专利技术涉及一种可配置化的数据抓取方法和步骤)
本发明专利技术涉及一种可配置的数据抓取方法,包括以下步骤:确定需要抓取的目标网站,并配置目标网站的基本信息。站点配置页面,包括站点类型、站点名称、目标编号、页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面配置爬取服务的启动时间;
一种可配置的数据抓取方法及装置
下载所有详细的技术数据
【技术实现步骤总结】
一种可配置的数据采集方法及装置
本专利技术涉及一种可配置的数据采集方法及装置,属于数据采集
技术介绍
目前实现数据抓取的方式有很多,包括开源代码和直接提供服务的商业工具,但这些基本上都是针对不同的目标网站,根据网站硬编码的特点实现 是的,这个实现有一定的局限性。一旦要捕获的范围变大,或者目标网站发生变化,解决问题的唯一方法就是修改之前实现的编码。这造成了一定的资源浪费,影响了执行周期。灵活性不够,还受限于实施的人员技能。
技术实现思路
为了解决现有技术中存在的上述问题,专利技术提供了一种可配置的数据采集方法,可以有效解决多次网站的采集,即使面对网站的变化的情况下,也可以通过修改配置来完成配套变更,缩短建设周期,也可以由普通实施者完成。本专利技术的技术方案如下:该技术方案是一种可配置的数据抓取方法,包括以下步骤:确定要抓取的目标网站,在站点配置页面配置目标网站的基本信息,包括站点类型、站点名称、目标编号、页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;管理页面配置启动爬虫服务的时间;生成爬取作业,从目标网站抓取数据,具体步骤如下:根据爬取服务启动的时间,开始执行作业;目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码,登录目标网站>;根据网址的基本信息,打开抓取数据的网址,对目标网站进行固定操作,抓取网页内容。进一步判断目标网站是否有验证码登录步骤,如果有验证码登录步骤,在输入验证码配置页面配置输入验证码的基本信息,包括验证码图片类型,验证码图片。验证码图片的语言、字符数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标<
进一步的,还包括用户密码验证步骤,具体为:选择一个或多个需要验证的用户,点击验证;客户端依次验证所选用户的登录账号/密码,并在后台生成。验证结果,验证结果包括登录成功和登录失败。如果验证结果是登录失败,也会在后台产生错误信息,并列出相关错误信息日志地址;点击查询获取验证结果,如验证结果为登录失败,则根据错误信息日志地址获取错误信息日志,分析并执行错误解决。进一步,在URL参数配置页面配置一个值为变量的请求参数,包括参数名称、参数类型、参数值和参数描述。技术方案2 一种可配置的数据抓取装置,包括内存和处理器,内存中存储有指令,指令用于被处理器加载并执行以下步骤:确定要抓取的目标网站 ,并在站点配置页面配置目标网站的基本信息,包括站点类型、站点名称、目标编号、页面编码格式;配置用户配置页面登录目标 网站 用户的基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面配置启动爬取服务的时间;生成一个爬虫作业,从目标网站爬取数据,具体步骤如下: 根据启动爬虫服务时开始执行作业;根据目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码,登录目标网站;根据网址的基本信息,打开抓取数据的网址,
进一步判断目标网站是否有验证码登录步骤,如果有验证码登录步骤,在输入验证码配置页面配置输入验证码的基本信息,包括验证码图片类型,验证码图片。验证码图片的语言、字符数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取验证码图片中的目标网站,根据验证码中输入的基本信息识别验证码图片登录目标网站,具体步骤如下:使用网络爬虫从目标网站图片中爬取验证码;采用OCR技术,根据输入的验证码基本信息,自动识别验证码图片,获取验证码图片中的验证码信息;在验证码输入框中填写验证码信息并提交登录;如果登录失败,则转为人工识别验证码图片,在验证码输入框中输入验证码进行登录。另外,还包括用户密码验证步骤,具体如下:选择一个或多个需要验证的用户,点击验证;客户端依次验证所选用户的登录帐户/密码,并在后台生成它们。验证结果,验证结果包括登录成功和登录失败。如果验证结果是登录失败,也会在后台产生错误信息,并列出相关错误信息日志地址;点击查询获取验证结果,如验证结果为登录失败,则根据错误信息日志地址获取错误信息日志,分析并执行错误解决。
进一步的,在URL参数配置页面上配置了一个值为变量的请求参数,包括参数名称、参数类型、参数取值和参数描述。该专利技术具有以下有益效果:1、该专利技术是一种可配置的数据抓取方式,解构了数据抓取过程中的每一个关键环节,让操作者不需要专业的爬虫编码技能,就可以完成一个网站 的数据采集作业;无需投入高端人员,数据采集成本可控。附图说明图。附图说明图1是本专利技术实施例的流程图;无花果。图2是站点配置的示例图;无花果。图3是实施例中网站的源代码示例图;无花果。图4是用户配置的示例图;图5是抓取URL配置示例图。图6是寻呼表达配置的示例图。图7是调度管理配置示例图。图8是验证码输入示例图。图9为用户账号密码验证图10为URL参数配置示例图。图11是通过httpwatch获取网站信息的示例图。具体实施方式下面结合附图和具体实施例对本专利技术进行详细说明。实施例1 参见图1-11,一种可配置的数据捕获方法包括以下步骤:确定需要捕获的目标网站,在站点配置页面配置目标网站基本信息,包括站点类型、站点名称、目标编号、页面编码格式;如图2,以配置永辉超市网站为例,站点类型根据配置的永辉超市网站类型,选择零售商;站点名称填写永辉超市,名称可自定义;目标数量可定制,数量一般由需方提供;页面编码格式由各个网站开发定义,见图3,打开永辉超市网站,右键查看页面源代码,从源代码。从图3可以看出,页面的编码格式为UTF-8。编码格式统一,所以页面编码格式选择UTF-8。在用户配置页面,配置可以登录的目标网站
【技术保护点】
1.一种可配置的数据抓取方法,其特征在于包括以下步骤:确定要抓取的目标网站,在站点配置页面配置目标网站基本信息,包括站点类型、站点名称、目标编号和页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面上配置启动抓取服务的时间;创造一个抢手的工作,从目标网站抓取数据,具体步骤如下:根据抓取服务启动的时间开始执行job;根据目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。
【技术特点总结】
1.一种可配置的数据抓取方法,其特征在于包括以下步骤:确定要抓取的目标网站,在站点配置页面配置目标网站基本信息,包括站点类型、站点名称、目标编号和页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面上配置启动抓取服务的时间;创造一个抢手的工作,从目标网站抓取数据,具体步骤如下:根据抓取服务启动的时间开始执行job;根据目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。2.根据权利要求1所述的一种可配置的数据抓取方法,其特征在于:判断目标网站是否有验证码登录步骤,如果有验证码登录步骤,然后在验证码输入配置页面配置验证码输入的基本信息,包括验证码图片类型、验证码图片语言、验证码图片字符个数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 包括验证码图片类型、验证码图片语言、验证码图片字符个数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 包括验证码图片类型、验证码图片语言、验证码图片字符个数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫
3.根据权利要求1所述的一种可配置的数据抓取方法,其特征在于,还包括用户密码验证步骤,如下:选择一个或多个需要验证的用户,点击进行验证;客户端依次验证选中用户的登录账号/密码,并在后台生成验证结果,验证结果包括登录成功和登录失败。后台生成错误信息并列出相关错误信息日志地址;点击查询获取验证结果,若验证结果为登录失败,则根据错误信息日志地址获取错误信息日志,分析错误执行错误获取解决。4.根据权利要求1所述的可配置数据采集方法,其特征在于:在URL参数配置页面配置一个值为变量的请求参数,包括参数名称、参数类型、参数值和参数说明。5.一种可配置的数据捕获设备,它...
【专利技术性质】
技术研发人员:邱涛、邱水文、陈成乐、
申请人(专利权)持有人:,
类型:发明
国家、省、市:福建,35
下载所有详细的技术数据 我是该专利的所有者
网页信息抓取软件(网页信息抓取软件:说说urllib2是怎么抓取的(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-26 09:12
网页信息抓取软件:说说urllib2是怎么抓取的下面我将说说怎么抓取1.所以是请求请求实质的获取方法为通过浏览器来获取http协议的接口,由于http协议支持无状态,无状态请求是未完成请求(对于没有完成状态来说,每次请求结果都将会一样的)所以怎么来实现无状态协议呢,就是通过http协议的状态码来区分状态的可区分,低于60就证明是未完成请求;urllib2结合get/post这几种方法来实现抓取2.怎么抓取图片http协议这两个方法返回cookie字段来记录您是否访问图片如何抓取图片urllib3结合post-get抓取图片方法post抓取图片是通过post来传递图片的信息,post也有一定的概率会传递cookie信息不可能实现像http协议那么完全不考虑cookie3.怎么抓取qq图片qq号码是需要我们配置认证机制的,才能传递图片,怎么来配置这种认证机制呢传递的内容一般为:qq号、手机号码或者固定编号(如果固定编号就传递数字0到9好了),传递的具体内容得看对方,一般传递的图片信息4.通过post来传递图片url地址urllib3结合get/post抓取图片urllib3可以进行信息的匹配关键词/邮箱/qq号、/abc等为跳转的锚值,一般输入一个地址的时候,得传递一个ip,如果想要获取图片地址,可以通过ip来进行匹配,数字+空格5.传递图片下载地址,返回该地址6.单方面内容抓取请求一般urllib2加载页面,是没有返回url的,urllib2对于http协议的传递信息,加了list-items,也就是将该地址对应的一个列表放进去,并返回给对方。
不加cookie/token,只要他也给出了该页面对应的图片地址,我们就能抓取7.多方面信息抓取还是结合post抓取图片urllib3结合get/post抓取图片或者通过ajax请求返回另外的url抓取图片返回大概信息对方返回article地址我们只需要加一个callback一样的调用token即可,返回的内容只用一个参数8.传递多个url地址,抓取多个图片这里不加载数据只抓取,其实就是对方返回一个url,我们可以将同一个页面给对方多次抓取,总之不要放弃找到对方需要的结果为主9.通过发送图片数据来抓取图片发送完图片数据即抓取成功10.高级抓取:path和name11.针对urllib2:请求主要有两个请求方法get/post这两个请求方法请求的内容都是请求头部,就跟你上网购物时,需要的主要域名或者电话一样我们对应哪个方法,就用哪个方法即可urllib2对应的请求方法有post和get,还有一个后面补充下,也是需要通过nginx来配置的,具体:nginx的we。 查看全部
网页信息抓取软件(网页信息抓取软件:说说urllib2是怎么抓取的(组图))
网页信息抓取软件:说说urllib2是怎么抓取的下面我将说说怎么抓取1.所以是请求请求实质的获取方法为通过浏览器来获取http协议的接口,由于http协议支持无状态,无状态请求是未完成请求(对于没有完成状态来说,每次请求结果都将会一样的)所以怎么来实现无状态协议呢,就是通过http协议的状态码来区分状态的可区分,低于60就证明是未完成请求;urllib2结合get/post这几种方法来实现抓取2.怎么抓取图片http协议这两个方法返回cookie字段来记录您是否访问图片如何抓取图片urllib3结合post-get抓取图片方法post抓取图片是通过post来传递图片的信息,post也有一定的概率会传递cookie信息不可能实现像http协议那么完全不考虑cookie3.怎么抓取qq图片qq号码是需要我们配置认证机制的,才能传递图片,怎么来配置这种认证机制呢传递的内容一般为:qq号、手机号码或者固定编号(如果固定编号就传递数字0到9好了),传递的具体内容得看对方,一般传递的图片信息4.通过post来传递图片url地址urllib3结合get/post抓取图片urllib3可以进行信息的匹配关键词/邮箱/qq号、/abc等为跳转的锚值,一般输入一个地址的时候,得传递一个ip,如果想要获取图片地址,可以通过ip来进行匹配,数字+空格5.传递图片下载地址,返回该地址6.单方面内容抓取请求一般urllib2加载页面,是没有返回url的,urllib2对于http协议的传递信息,加了list-items,也就是将该地址对应的一个列表放进去,并返回给对方。
不加cookie/token,只要他也给出了该页面对应的图片地址,我们就能抓取7.多方面信息抓取还是结合post抓取图片urllib3结合get/post抓取图片或者通过ajax请求返回另外的url抓取图片返回大概信息对方返回article地址我们只需要加一个callback一样的调用token即可,返回的内容只用一个参数8.传递多个url地址,抓取多个图片这里不加载数据只抓取,其实就是对方返回一个url,我们可以将同一个页面给对方多次抓取,总之不要放弃找到对方需要的结果为主9.通过发送图片数据来抓取图片发送完图片数据即抓取成功10.高级抓取:path和name11.针对urllib2:请求主要有两个请求方法get/post这两个请求方法请求的内容都是请求头部,就跟你上网购物时,需要的主要域名或者电话一样我们对应哪个方法,就用哪个方法即可urllib2对应的请求方法有post和get,还有一个后面补充下,也是需要通过nginx来配置的,具体:nginx的we。
网页信息抓取软件(网页信息抓取软件推荐。(二)网页抓取商品)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-21 16:01
网页信息抓取软件推荐。我在上周,将php自带的信息提取功能给一个上班的小妹让她抓取销售单据,之后整理后交给我在合适的情况用微信审核发给我。总的来说,搜集微信上购物的信息并将之转成php中对应的信息。我觉得如果可以抓取一个人的微信好友,把个人信息放到一个批量的二维码或者下载进excel也没什么太大问题。至于把内容进到云端,那也完全没必要。如果有一个网页,结合php的文本提取,完全可以解决这个问题。
关于这个我也思考过,我觉得最大的问题不是是否可以抓取到商品,因为抓取商品很容易。关键在于是否抓取到后续的营销,做微商的都知道微商是靠产品引流的,然后在微信上进行推广。以及你平时和客户沟通的内容。希望这个回答可以帮助到你。
销售信息,可以结合结合现在社群营销的方式来实现。比如是否可以利用爬虫工具抓取各个群的聊天记录?客户的购买清单?销售图谱等。
可以抓取到,但是对于某一特定时间特定地点的人群会存在特定的差异性。所以针对这个实际情况和需求,该产品还需要更加具体方面的定位去满足客户需求。
抓取服务器抓不到,
实际数据信息的抓取我们是可以做到的,而且你可以把信息传给我们,我们后期可以整理成一套分析报告告诉你针对什么人群需要针对什么信息进行分析。 查看全部
网页信息抓取软件(网页信息抓取软件推荐。(二)网页抓取商品)
网页信息抓取软件推荐。我在上周,将php自带的信息提取功能给一个上班的小妹让她抓取销售单据,之后整理后交给我在合适的情况用微信审核发给我。总的来说,搜集微信上购物的信息并将之转成php中对应的信息。我觉得如果可以抓取一个人的微信好友,把个人信息放到一个批量的二维码或者下载进excel也没什么太大问题。至于把内容进到云端,那也完全没必要。如果有一个网页,结合php的文本提取,完全可以解决这个问题。
关于这个我也思考过,我觉得最大的问题不是是否可以抓取到商品,因为抓取商品很容易。关键在于是否抓取到后续的营销,做微商的都知道微商是靠产品引流的,然后在微信上进行推广。以及你平时和客户沟通的内容。希望这个回答可以帮助到你。
销售信息,可以结合结合现在社群营销的方式来实现。比如是否可以利用爬虫工具抓取各个群的聊天记录?客户的购买清单?销售图谱等。
可以抓取到,但是对于某一特定时间特定地点的人群会存在特定的差异性。所以针对这个实际情况和需求,该产品还需要更加具体方面的定位去满足客户需求。
抓取服务器抓不到,
实际数据信息的抓取我们是可以做到的,而且你可以把信息传给我们,我们后期可以整理成一套分析报告告诉你针对什么人群需要针对什么信息进行分析。
网页信息抓取软件(告诉搜索引擎如何索引您的网站机器人元指令(或“元标签”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-20 02:01
告诉搜索引擎如何索引您的 网站bots 元指令
元指令(或“元标记”)是您可以向搜索引擎提供有关您希望如何处理您的网页的说明。
您可以告诉搜索引擎爬虫“不要在搜索结果中将此页面编入索引”或“不要将任何链接资产传递给任何页面链接”。这些指令通过 HTML 页面中的 Robots 元标记(最常用)或 HTTP 标头中的 X-Robots-Tag 执行。
机器人元标记
机器人元标记可用于网页的 HTML。它可以排除所有或特定的搜索引擎。以下是最常见的元指令以及您可以应用它们的情况。
index/noindex 告诉引擎是否应该抓取页面并将其保存在搜索引擎的索引中以供检索。如果您选择使用“noindex”,则意味着您要从搜索结果中排除页面。默认情况下,搜索引擎假定它们可以索引所有页面,因此无需使用“index”值。
follow/nofollow 告诉搜索引擎是否应该关注页面上的链接。“关注”会导致机器人关注您页面上的链接并将链接权益传递给这些 URL。或者,如果您选择使用“nofollow”,搜索引擎将不会关注或将任何链接兴趣传递给页面上的链接。默认情况下,假定所有页面都具有“关注”属性。
noarchive 用于限制搜索引擎保存页面的缓存副本。默认情况下,引擎将保留其已编入索引的所有页面的可见副本,搜索者可以通过搜索结果中的缓存链接访问这些页面。
以下是 metabot noindex、nofollow 标签的示例:
...
此示例将所有搜索引擎排除在索引页面和跟踪页面的任何链接之外。如果要排除多个爬虫,例如 googlebot 和 bing,可以使用多个 bot 排除标记。 查看全部
网页信息抓取软件(告诉搜索引擎如何索引您的网站机器人元指令(或“元标签”)
告诉搜索引擎如何索引您的 网站bots 元指令
元指令(或“元标记”)是您可以向搜索引擎提供有关您希望如何处理您的网页的说明。
您可以告诉搜索引擎爬虫“不要在搜索结果中将此页面编入索引”或“不要将任何链接资产传递给任何页面链接”。这些指令通过 HTML 页面中的 Robots 元标记(最常用)或 HTTP 标头中的 X-Robots-Tag 执行。
机器人元标记
机器人元标记可用于网页的 HTML。它可以排除所有或特定的搜索引擎。以下是最常见的元指令以及您可以应用它们的情况。
index/noindex 告诉引擎是否应该抓取页面并将其保存在搜索引擎的索引中以供检索。如果您选择使用“noindex”,则意味着您要从搜索结果中排除页面。默认情况下,搜索引擎假定它们可以索引所有页面,因此无需使用“index”值。
follow/nofollow 告诉搜索引擎是否应该关注页面上的链接。“关注”会导致机器人关注您页面上的链接并将链接权益传递给这些 URL。或者,如果您选择使用“nofollow”,搜索引擎将不会关注或将任何链接兴趣传递给页面上的链接。默认情况下,假定所有页面都具有“关注”属性。
noarchive 用于限制搜索引擎保存页面的缓存副本。默认情况下,引擎将保留其已编入索引的所有页面的可见副本,搜索者可以通过搜索结果中的缓存链接访问这些页面。
以下是 metabot noindex、nofollow 标签的示例:
...
此示例将所有搜索引擎排除在索引页面和跟踪页面的任何链接之外。如果要排除多个爬虫,例如 googlebot 和 bing,可以使用多个 bot 排除标记。
网页信息抓取软件(陈前进:搜寻引擎蜘蛛和网页的三大问题(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-20 02:00
搜索引擎蜘蛛和网页的三大问题
陈千金
1
.
1. 搜索引擎蜘蛛能找到你的网页吗?
2. 搜索引擎蜘蛛找到网页后可以抓取吗?
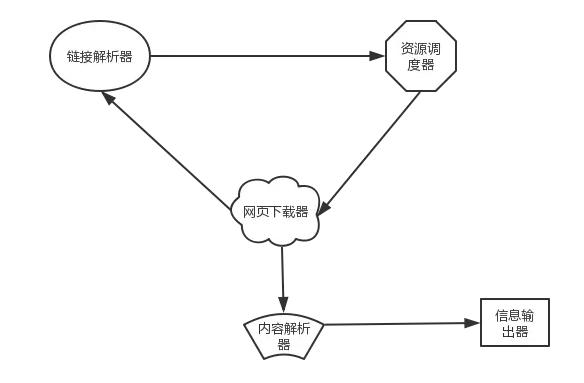
获取网页
三、搜索引擎蜘蛛爬取网页后,能否
可以提取有用的信息
2
.
他们的报告并非完全免费供搜索者查看,因此需要向网络蜘蛛提供相应的用户名和密码;网络蜘蛛可以通过给定的权限抓取这些网页以提供搜索;并且当搜索者点击查看网页时,搜索者还需要提供相应的权限验证;
10
.
⑵网站和网络蜘蛛
网络蜘蛛需要爬取网页,这与普通的访问不同。如果没有掌握好,会导致网站服务器负担过重;每个网络蜘蛛都有自己的名字。网站表明你的身份;网络蜘蛛在抓取网页时会发送一个请求。在这个请求中,有一个名为 User-agent 的字段,用于标识网络蜘蛛的身份:
谷歌网络蜘蛛被识别为 GoogleBot,
百度网络蜘蛛的标志是BaiDuSpider,
雅虎网络蜘蛛被识别为 Inktomi Slurp;
如果网站上有访问日志记录(robots.txt),网站管理员可以知道哪些搜索引擎蜘蛛访问过,何时访问过,读取了多少数据等;如果 网站 管理器发现蜘蛛有问题,它会通过它的 ID 联系它的主人;
11
.
现在一般的网站希望搜索引擎能更全面的抓取自己的网站网页,因为这样可以让更多的访问者通过搜索引擎找到这个网站;这个网站的网页爬取比较全面,网站管理员可以创建网站地图,即Site Map;很多网络蜘蛛都会把sitemap.htm文件作为网站网页爬取的入口,网站管理员可以把网站内部所有网页的链接都放在这个文件里,然后网络蜘蛛可以轻松抓取整个 网站 ,防止部分网页遗漏,同时也减轻了 网站 服务器的负担;(Google 专门为 网站 管理员提供 XML Sitemaps)
12
.
(3) 网络蜘蛛提取内容
搜索引擎建立网页索引,处理对象为文本文件;对于网络蜘蛛来说,爬取的网页包括各种格式。
包括html、图片、doc、pdf、多媒体、动态网页等格式;
抓取这些文件后,需要提取这些文件中的文本信息;这些文档信息的精确提取一方面对搜索引擎的搜索准确性起着重要作用,另一方面对网络蜘蛛正确跟踪其他链接也有积极作用。影响;
对于doc、pdf等文档,以及专业厂商提供的软件生成的文档,厂商会提供相应的文本提取接口
由于目前主流的网站大部分都是用HTML编写的,这里就泛泛的说一下HTML;
13
.
HTML有自己的语法,它使用不同的命令标识符来表示不同的字体、颜色、位置和其他布局,例如:、、等。在提取文本信息时,需要过滤掉这些标识符;过滤标识符并不难,由于这些标识符有一定的规定,只需要根据不同的标识符获取相应的信息即可;
但是在识别这个信息的时候,需要同时记录很多布局信息,比如文字的字体大小,是否是标题,是否显示为粗体,是否是关键词页面的重要性等页面的重要性;
同时,对于HTML页面,除了标题和正文外,还会有很多广告链接和公共频道链接。这些链接与正文无关。在提取网页内容的时候,也需要过滤掉这些无用的链接;
比如某网站有一个“医院介绍”频道。由于网站中每个网页都有导航栏,如果不过滤导航栏中的链接,在搜索“产品介绍”时,会搜索到网站中的每个网页,这无疑会带来大量的垃圾邮件;
14
.
那么如何用 ASP 构建一个网络蜘蛛呢?答案是:互联网传输控制(ITC information transfer control);Microsoft 提供的这种控制将使您能够通过 ASP 程序访问 Internet 资源;您可以使用 ITC 搜索网页、访问 FTP 服务器,甚至发送电子邮件标头;
有几个缺陷必须首先解释;首先,ASP无权访问Windows注册表,这使得一些通常由ITC保留的常量和值无法使用;通常可以将 ITC 设置为“不使用默认值”来解决这个问题,需要在每次运行时指定该值;另一个更严重的问题是关于许可证的问题;因为ASP没有调用License Manager(Windows中的一个功能,可以保证组件和控制合法使用)的能力,那么当License Manager检查当前组件的密钥密码并与Windows注册表进行比较时,如果发现它们不同,则组件将无法工作;所以, 查看全部
网页信息抓取软件(陈前进:搜寻引擎蜘蛛和网页的三大问题(图))
搜索引擎蜘蛛和网页的三大问题
陈千金
1
.
1. 搜索引擎蜘蛛能找到你的网页吗?
2. 搜索引擎蜘蛛找到网页后可以抓取吗?
获取网页
三、搜索引擎蜘蛛爬取网页后,能否
可以提取有用的信息
2
.
他们的报告并非完全免费供搜索者查看,因此需要向网络蜘蛛提供相应的用户名和密码;网络蜘蛛可以通过给定的权限抓取这些网页以提供搜索;并且当搜索者点击查看网页时,搜索者还需要提供相应的权限验证;
10
.
⑵网站和网络蜘蛛
网络蜘蛛需要爬取网页,这与普通的访问不同。如果没有掌握好,会导致网站服务器负担过重;每个网络蜘蛛都有自己的名字。网站表明你的身份;网络蜘蛛在抓取网页时会发送一个请求。在这个请求中,有一个名为 User-agent 的字段,用于标识网络蜘蛛的身份:
谷歌网络蜘蛛被识别为 GoogleBot,
百度网络蜘蛛的标志是BaiDuSpider,
雅虎网络蜘蛛被识别为 Inktomi Slurp;
如果网站上有访问日志记录(robots.txt),网站管理员可以知道哪些搜索引擎蜘蛛访问过,何时访问过,读取了多少数据等;如果 网站 管理器发现蜘蛛有问题,它会通过它的 ID 联系它的主人;
11
.
现在一般的网站希望搜索引擎能更全面的抓取自己的网站网页,因为这样可以让更多的访问者通过搜索引擎找到这个网站;这个网站的网页爬取比较全面,网站管理员可以创建网站地图,即Site Map;很多网络蜘蛛都会把sitemap.htm文件作为网站网页爬取的入口,网站管理员可以把网站内部所有网页的链接都放在这个文件里,然后网络蜘蛛可以轻松抓取整个 网站 ,防止部分网页遗漏,同时也减轻了 网站 服务器的负担;(Google 专门为 网站 管理员提供 XML Sitemaps)
12
.
(3) 网络蜘蛛提取内容
搜索引擎建立网页索引,处理对象为文本文件;对于网络蜘蛛来说,爬取的网页包括各种格式。
包括html、图片、doc、pdf、多媒体、动态网页等格式;
抓取这些文件后,需要提取这些文件中的文本信息;这些文档信息的精确提取一方面对搜索引擎的搜索准确性起着重要作用,另一方面对网络蜘蛛正确跟踪其他链接也有积极作用。影响;
对于doc、pdf等文档,以及专业厂商提供的软件生成的文档,厂商会提供相应的文本提取接口
由于目前主流的网站大部分都是用HTML编写的,这里就泛泛的说一下HTML;
13
.
HTML有自己的语法,它使用不同的命令标识符来表示不同的字体、颜色、位置和其他布局,例如:、、等。在提取文本信息时,需要过滤掉这些标识符;过滤标识符并不难,由于这些标识符有一定的规定,只需要根据不同的标识符获取相应的信息即可;
但是在识别这个信息的时候,需要同时记录很多布局信息,比如文字的字体大小,是否是标题,是否显示为粗体,是否是关键词页面的重要性等页面的重要性;
同时,对于HTML页面,除了标题和正文外,还会有很多广告链接和公共频道链接。这些链接与正文无关。在提取网页内容的时候,也需要过滤掉这些无用的链接;
比如某网站有一个“医院介绍”频道。由于网站中每个网页都有导航栏,如果不过滤导航栏中的链接,在搜索“产品介绍”时,会搜索到网站中的每个网页,这无疑会带来大量的垃圾邮件;
14
.
那么如何用 ASP 构建一个网络蜘蛛呢?答案是:互联网传输控制(ITC information transfer control);Microsoft 提供的这种控制将使您能够通过 ASP 程序访问 Internet 资源;您可以使用 ITC 搜索网页、访问 FTP 服务器,甚至发送电子邮件标头;
有几个缺陷必须首先解释;首先,ASP无权访问Windows注册表,这使得一些通常由ITC保留的常量和值无法使用;通常可以将 ITC 设置为“不使用默认值”来解决这个问题,需要在每次运行时指定该值;另一个更严重的问题是关于许可证的问题;因为ASP没有调用License Manager(Windows中的一个功能,可以保证组件和控制合法使用)的能力,那么当License Manager检查当前组件的密钥密码并与Windows注册表进行比较时,如果发现它们不同,则组件将无法工作;所以,
网页信息抓取软件(优采云网页数据采集器连续五年大数据采集领域排名领先)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-02-18 03:11
网站描述:优采云网页数据采集器,是一款简单强大的网络爬虫工具,全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取连续五年在大数据行业数据领域排名第一采集。
转到 网站
重量信息
搜索引擎优化信息
百度来源:732~988 IP 手机来源:27~37 IP 出站链接:6 主页内部链接:49
收录信息
百度收录: 264,000360收录: 3,820 神马收录:- 搜狗收录:- 谷歌收录:-
反向链接信息
百度外链:936,000360 外链:8,600 神马外链:- 搜狗外链:8,563 谷歌外链:-
排名信息
世界排名:19,832 国内排名:1,076 预计日均IP:60,000 预计日均PV:240,000
记录信息
备案号:粤ICP备14092314-1号性质:公司名称:审核时间:2021-10-20
域名信息
未找到whois信息
服务器信息
协议类型:HTTP/1.1 200 OK 页面类型:text/html;charset=utf-8 服务器类型:nginx/1.18.0 程序支持:- 连接 ID:- 消息发送:2022 年 2 月 16 日 17:42:18 GZIP 检测:未启用 GZIP 压缩率:估计 72.39% 最后修改:未知
网站评估
优采云采集器 - 免费网页爬虫软件_网页大数据爬取工具 2022-02-17 19:50:43收录正亚秒收录,目前一共有全球19832个,中国1076个,日均IP约6万个,备案号粤ICP备14092314-1号,本次评测参考包括优采云采集器 - 免费网络爬虫软件_网页大数据爬虫的搜索引擎权重、收录和反向链接、Alexa排名信息、服务器信息等互联网属性,不包括域名价值、品牌价值及其附加值。优采云采集器 - 免费网络爬虫软件_网络大数据爬虫工具的真正价值需要读者综合考虑实际情况,结果仅供参考。 查看全部
网页信息抓取软件(优采云网页数据采集器连续五年大数据采集领域排名领先)
网站描述:优采云网页数据采集器,是一款简单强大的网络爬虫工具,全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取连续五年在大数据行业数据领域排名第一采集。
转到 网站
重量信息






搜索引擎优化信息
百度来源:732~988 IP 手机来源:27~37 IP 出站链接:6 主页内部链接:49
收录信息
百度收录: 264,000360收录: 3,820 神马收录:- 搜狗收录:- 谷歌收录:-
反向链接信息
百度外链:936,000360 外链:8,600 神马外链:- 搜狗外链:8,563 谷歌外链:-
排名信息
世界排名:19,832 国内排名:1,076 预计日均IP:60,000 预计日均PV:240,000
记录信息
备案号:粤ICP备14092314-1号性质:公司名称:审核时间:2021-10-20
域名信息
未找到whois信息
服务器信息
协议类型:HTTP/1.1 200 OK 页面类型:text/html;charset=utf-8 服务器类型:nginx/1.18.0 程序支持:- 连接 ID:- 消息发送:2022 年 2 月 16 日 17:42:18 GZIP 检测:未启用 GZIP 压缩率:估计 72.39% 最后修改:未知
网站评估
优采云采集器 - 免费网页爬虫软件_网页大数据爬取工具 2022-02-17 19:50:43收录正亚秒收录,目前一共有全球19832个,中国1076个,日均IP约6万个,备案号粤ICP备14092314-1号,本次评测参考包括优采云采集器 - 免费网络爬虫软件_网页大数据爬虫的搜索引擎权重、收录和反向链接、Alexa排名信息、服务器信息等互联网属性,不包括域名价值、品牌价值及其附加值。优采云采集器 - 免费网络爬虫软件_网络大数据爬虫工具的真正价值需要读者综合考虑实际情况,结果仅供参考。
网页信息抓取软件(XPath的节点(Node)中的核心就是节点及其关系)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-14 16:11
在上一节中,我们详细介绍了 lxml.html 的各种操作。接下来,我们精通XPath,就可以熟练的提取网页内容了。
什么是 XPath?
XPath的全称是XML Path Language,即XML Path Language,是一种在XML(HTML)文档中查找信息的语言。它有4个特点:
我们从网页中提取数据,主要应用前两点。
XPath 路径表达式
使用XPath,我们可以很方便的定位到网页中的节点,也就是找到我们关心的数据。这些路径与计算机目录和 URL 的路径非常相似,路径的深度用 / 表示。
XPath 注释库
标头中有 100 多个内置函数。当然,我们用来提取数据的数据是有限的,所以我们不需要记住所有 100 多个函数。
Xpath 的节点
XPath的核心是节点(Node),它定义了7种不同类型的节点:元素(Element)、属性(Attribute)、文本(Text)、命名空间(Namespace)、处理指令(processing-instruction)、注释(Comment ) 和文档节点
这些节点组成一个节点树,树的根节点称为文档节点。
注释是html中的注释:``
命名空间、处理指令和网页数据提取基本无关,这里不再详述。
下面我们以一个简单的html文档为例来说明不同的节点及其关系。
ABC home python
此 html 中的节点是:
XPath 节点的关系
节点之间的关系完全复制了人类的代际关系,但只是直接关系,没有叔叔叔叔之类的旁系关系。
或者以上面的html文档为例来说明节点关系:
家长
每个元素节点(Element)及其属性都有一个父节点。
比如body的parent是html,body是div和ul的parent。
孩子们
每个元素节点可以有零个、一个或多个子节点。
例如,body 有两个孩子:div、ul,而 ul 也有两个孩子:两个 li。
兄弟
兄弟姐妹具有相同的父节点。
例如, div 和 ul 是兄弟姐妹。
祖先
一个节点的父节点和上面几代的节点。
比如li的父母是:ul, div, body, html
后裔
节点的子节点及其后代节点。
比如body的后代有:div、ul、li。
XPath 节点的选择
选择节点是通过路径表达式来实现的。这是我们从网页中提取数据的关键,我们必须掌握它。
下表是一个有用的路径表达式:
表达描述
节点名
选择当前节点的所有名为 nodename 的子节点。
/
从根节点中选择,在路径中间时表示一级路径
//
从当前节点开始选择文档中的一个节点,可以是多级路径
.
从当前节点挑选
..
从父节点挑选
@
按属性选择
接下来,我们将通过具体的例子加深对路径表达的理解:
路径表达式解释
/html/body/ul/li
根据从根节点开始的路径选择li元素。返回多个。
//ul/li[1]
li 元素仍然被选中,但路径多级跳转到 ul/li。[1] 表示只取第一个 li。
//li[last()]
还是选择了li,只是路径更加跳跃。[last()] 表示取最后一个 li 元素。
//li[@class]
选择名为 li 的具有类属性的根节点的所有后代。
//li[@class=”item”]
选择名称为 li 且类属性为 item 的根节点的所有后代。
//正文/*/li
选择body的名为li的孙节点。* 是通配符,表示任何节点。
//li[@*]
选择所有具有属性的 li 元素。
//body/div `
` //正文/ul
选择正文的所有 div 和 ul 元素。
身体/格
相对路径,选择当前节点body元素的子元素div。绝对路径以 / 开头。
XPath 函数
Xpath的功能很多,涉及到错误、值、字符串、时间等,但是我们在从网页中提取数据的时候只用到了几个。其中最重要的是与字符串相关的函数,例如 contains() 函数。
收录(a,b)
如果字符串 a 收录字符串 b,则返回 true,否则返回 false。
例如: contains('猿人学 Python', 'Python'),返回 true
那么什么时候使用呢?我们知道一个html标签的类可以有多个属性值,比如:
...
这个html中的div有三个class值,第一个表示是发布的消息,后两个是更多的格式设置。如果我们想提取网页中所有发布的消息,我们只需要匹配post-item,那么我们可以使用contains:
doc.xpath('//div[contains(@class, "post-item")]')
与 contains() 类似的字符串匹配函数有:
但是在lxml的xpath中使用ends-with(),matches()会报错
In [232]: doc.xpath('//ul[ends-with(@id, "u")]') --------------------------------------------------------------------------- XPathEvalError Traceback (most recent call last) in () ----> 1 doc.xpath('//ul[ends-with(@id, "u")]') src/lxml/etree.pyx in lxml.etree._Element.xpath() src/lxml/xpath.pxi in lxml.etree.XPathElementEvaluator.__call__() src/lxml/xpath.pxi in lxml.etree._XPathEvaluatorBase._handle_result() XPathEvalError: Unregistered function
lxml 不支持 end-with()、matches() 函数
去lxml官方网站看,原来只支持XPath1.0:
lxml 以符合标准的方式通过 libxml2 和 libxslt 支持 XPath 1.0、XSLT 1.0 和 EXSLT 扩展。
然后我在维基百科上找到了Xpath 2.0 和1.0 的区别,果然ends-with(),matches() 只属于2.0。下图中,粗体部分收录在1.0中,其他部分也收录在2.0中:
XPath 2.0 和 1.0 之间的区别
好了,Xpath在网页内容提取中用到的部分已经完成了。
来自“ITPUB博客”,链接:如需转载,请注明出处,否则追究法律责任。
转载于: 查看全部
网页信息抓取软件(XPath的节点(Node)中的核心就是节点及其关系)
在上一节中,我们详细介绍了 lxml.html 的各种操作。接下来,我们精通XPath,就可以熟练的提取网页内容了。
什么是 XPath?
XPath的全称是XML Path Language,即XML Path Language,是一种在XML(HTML)文档中查找信息的语言。它有4个特点:

我们从网页中提取数据,主要应用前两点。
XPath 路径表达式
使用XPath,我们可以很方便的定位到网页中的节点,也就是找到我们关心的数据。这些路径与计算机目录和 URL 的路径非常相似,路径的深度用 / 表示。
XPath 注释库
标头中有 100 多个内置函数。当然,我们用来提取数据的数据是有限的,所以我们不需要记住所有 100 多个函数。
Xpath 的节点
XPath的核心是节点(Node),它定义了7种不同类型的节点:元素(Element)、属性(Attribute)、文本(Text)、命名空间(Namespace)、处理指令(processing-instruction)、注释(Comment ) 和文档节点
这些节点组成一个节点树,树的根节点称为文档节点。
注释是html中的注释:``
命名空间、处理指令和网页数据提取基本无关,这里不再详述。
下面我们以一个简单的html文档为例来说明不同的节点及其关系。
ABC home python
此 html 中的节点是:
XPath 节点的关系
节点之间的关系完全复制了人类的代际关系,但只是直接关系,没有叔叔叔叔之类的旁系关系。
或者以上面的html文档为例来说明节点关系:
家长
每个元素节点(Element)及其属性都有一个父节点。
比如body的parent是html,body是div和ul的parent。
孩子们
每个元素节点可以有零个、一个或多个子节点。
例如,body 有两个孩子:div、ul,而 ul 也有两个孩子:两个 li。
兄弟
兄弟姐妹具有相同的父节点。
例如, div 和 ul 是兄弟姐妹。
祖先
一个节点的父节点和上面几代的节点。
比如li的父母是:ul, div, body, html
后裔
节点的子节点及其后代节点。
比如body的后代有:div、ul、li。
XPath 节点的选择
选择节点是通过路径表达式来实现的。这是我们从网页中提取数据的关键,我们必须掌握它。
下表是一个有用的路径表达式:
表达描述
节点名
选择当前节点的所有名为 nodename 的子节点。
/
从根节点中选择,在路径中间时表示一级路径
//
从当前节点开始选择文档中的一个节点,可以是多级路径
.
从当前节点挑选
..
从父节点挑选
@
按属性选择
接下来,我们将通过具体的例子加深对路径表达的理解:
路径表达式解释
/html/body/ul/li
根据从根节点开始的路径选择li元素。返回多个。
//ul/li[1]
li 元素仍然被选中,但路径多级跳转到 ul/li。[1] 表示只取第一个 li。
//li[last()]
还是选择了li,只是路径更加跳跃。[last()] 表示取最后一个 li 元素。
//li[@class]
选择名为 li 的具有类属性的根节点的所有后代。
//li[@class=”item”]
选择名称为 li 且类属性为 item 的根节点的所有后代。
//正文/*/li
选择body的名为li的孙节点。* 是通配符,表示任何节点。
//li[@*]
选择所有具有属性的 li 元素。
//body/div `
` //正文/ul
选择正文的所有 div 和 ul 元素。
身体/格
相对路径,选择当前节点body元素的子元素div。绝对路径以 / 开头。
XPath 函数
Xpath的功能很多,涉及到错误、值、字符串、时间等,但是我们在从网页中提取数据的时候只用到了几个。其中最重要的是与字符串相关的函数,例如 contains() 函数。
收录(a,b)
如果字符串 a 收录字符串 b,则返回 true,否则返回 false。
例如: contains('猿人学 Python', 'Python'),返回 true
那么什么时候使用呢?我们知道一个html标签的类可以有多个属性值,比如:
...
这个html中的div有三个class值,第一个表示是发布的消息,后两个是更多的格式设置。如果我们想提取网页中所有发布的消息,我们只需要匹配post-item,那么我们可以使用contains:
doc.xpath('//div[contains(@class, "post-item")]')
与 contains() 类似的字符串匹配函数有:
但是在lxml的xpath中使用ends-with(),matches()会报错
In [232]: doc.xpath('//ul[ends-with(@id, "u")]') --------------------------------------------------------------------------- XPathEvalError Traceback (most recent call last) in () ----> 1 doc.xpath('//ul[ends-with(@id, "u")]') src/lxml/etree.pyx in lxml.etree._Element.xpath() src/lxml/xpath.pxi in lxml.etree.XPathElementEvaluator.__call__() src/lxml/xpath.pxi in lxml.etree._XPathEvaluatorBase._handle_result() XPathEvalError: Unregistered function
lxml 不支持 end-with()、matches() 函数
去lxml官方网站看,原来只支持XPath1.0:
lxml 以符合标准的方式通过 libxml2 和 libxslt 支持 XPath 1.0、XSLT 1.0 和 EXSLT 扩展。
然后我在维基百科上找到了Xpath 2.0 和1.0 的区别,果然ends-with(),matches() 只属于2.0。下图中,粗体部分收录在1.0中,其他部分也收录在2.0中:

XPath 2.0 和 1.0 之间的区别
好了,Xpath在网页内容提取中用到的部分已经完成了。
来自“ITPUB博客”,链接:如需转载,请注明出处,否则追究法律责任。
转载于:
网页信息抓取软件(一下每项信息应该如何提取?class属性为哪般? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-02-14 13:20
)
通过昨天的分析,我们已经能够依次打开多个页面,接下来就是获取每个页面的宝贝信息了。
分析页面宝贝信息
【插入图片,宝贝信息的各种内容】
从图片来看,每个宝贝都有以下信息:价格、标题、url、交易金额、店铺、位置等6条信息,其中url代表宝贝的地址。
通过viewer分析,每个baby都在一个div中,这个div的class属性收录item。
并且所有的item都在一个div中,总div有items的class属性,也就是一个页面收录所有宝物的frame。
所以,只有当div已经加载完毕,才能断定可以提取页面的baby信息,所以在提取信息之前,我们要判断这个div的存在。
对于网页源码的解析,这次我们使用Pyquery,依次使用。感觉PyQuery比较好用,尤其是pyquery搜索到的对象都可以在这里搜索到,非常方便。
请参阅我之前的 文章 了解如何使用 Pyquery,或查看 API。
下面我们依次分析每条信息应该如何提取。
1、价格
【插图、价格】
可以看到价格信息在一个div中,并且有class属性price。如果我们通过文字得到,也会得到它前面的RMB符号,我们回去切片的时候可以把它剪掉。
2、成交金额
【插图,金额】
音量信息在另一个div标签中,class属性为deal-cnt,最后三个字符还是需要剪掉的。
3、标题
[插入图片,标题]
宝贝的title在一个div标签中,class属性为title,可以通过text获取。
4、商店
[插入图片、店铺和位置]
店铺名称在一个 div 标签中,其 class 属性为 shop。
5、位置
如上所示,类属性为位置。
6、网址
【插入图片,宝贝地址】
url地址在一个a标签里,class属性是pic-link,这个a标签的href属性就是url地址。
from pyquery import PyQuery as pq
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.grid > div:nth-child(1)')))
html=browser.page_source
doc=pq(html)
items=doc('div.item').items()#讲解一下
for item in items:
product={
'url':item('a.pic-link').attr('href'),
'price':item.find('.price').text()[1:],
'amount':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
#save_to_mongo(product)
save_to_csv(product)
这里说的是item的内容,看一下源码中的例子:
> d = PyQuery('foobar')
> [i.text() for i in d.items('span')]
['foo', 'bar']
>[i.text() for i in d('span').items()]
['foo', 'bar']
>list(d.items('a')) == list(d('a').items())
True
将数据保存到 MongoDb
如果我们拿到产品,想把它保存到MongoDb数据库中,其实很简单。设置数据库的url、数据库名、表名,通过pymongo链接到对应的数据库。
即使我们的数据库还没有建立,也没关系,表和数据会动态创建。
import pymongo
'''MONGO设置'''
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_Table=KEYWORD
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
def save_to_mongo(product):
try:
if db[MONGO_Table].insert(product):
print('保存成功',product)
except Exception:
print('保存出错',product)
pass
【插图,MongoDB数据】
将数据保存到 CSV 文件
其实也是一个文本文件,但是可以通过excel打开,方便我们做一些分析。
我这里就不赘述了,看代码就行了。
def save_to_csv(product):
with open(FileName,'a') as f:
s=product['title']+','+product['price']+','+product['amount']+','+product['location']+','+product['shop']+','+product['url']+'\n'
try:
f.write(s)
print('保存到csv成功!',product)
except:
pass
所有代码
只要更改KEYWORD关键字的内容,就可以搜索到不同的宝贝信息并保存。我们默认将其保存为 csv 文件。毕竟数据只有几千条,Excel方便。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
import re
import pymongo
from multiprocessing import Pool
'''要搜索的关键字'''
KEYWORD='Iphone8'
'''MONGO设置'''
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_Table=KEYWORD
'''要保存的csv文件'''
FileName=KEYWORD+'.csv'
'''PhantomJS参数'''
SERVICE_ARGS=['--load-images=false']#不加载图片,节省时间
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
#browser=webdriver.Firefox()
browser=webdriver.PhantomJS(service_args=SERVICE_ARGS)
browser.set_window_size(1400,900)
index_url='https://www.taobao.com/'
wait=WebDriverWait(browser, 10)
def search(keyword):
try:
browser.get(index_url)
#user_search_input=browser.find_element_by_css_selector('#q')
#user_search_button=browser.find_element_by_css_selector('.btn-search')
user_search_input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
user_search_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".btn-search")))
user_search_input.send_keys(keyword)
user_search_button.click()
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.total')))
total_page=re.compile(r'(\d+)').search(total.text).group(1)
print(total_page)
get_products()
return int(total_page)
except TimeoutException:
search(keyword)
def get_next_page(pageNum):
try:
user_page_input = wait.until(EC.presence_of_element_located((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/input")))
user_page_button = wait.until(EC.element_to_be_clickable((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/span[3]")))
user_page_input.clear()
user_page_input.send_keys(pageNum)
user_page_button.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'li.active > span:nth-child(1)'),str(pageNum)))
get_products()
except TimeoutException:
get_next_page(pageNum)
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.grid > div:nth-child(1)')))
html=browser.page_source
doc=pq(html)
items=doc('div.item').items()
for item in items:
product={
'url':item('a.pic-link').attr('href'),
'price':item.find('.price').text()[1:],
'amount':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
#save_to_mongo(product)
save_to_csv(product)
def save_to_csv(product):
with open(FileName,'a') as f:
s=product['title']+','+product['price']+','+product['amount']+','+product['location']+','+product['shop']+','+product['url']+'\n'
try:
f.write(s)
print('保存到csv成功!',product)
except:
pass
def save_to_mongo(product):
try:
if db[MONGO_Table].insert(product):
print('保存成功',product)
except Exception:
print('保存出错',product)
pass
def main():
total=search(KEYWORD)
# p=Pool()
# p.map(get_next_page,[i for i in range(2,total+1)])
for i in range(2,total+1):
get_next_page(i)
browser.close()
if __name__=='__main__':
main()
简单分析结果
【插入图片,结果分析示例】
月交易量最好的是一部老人手机,仅79元。. . .
在智能手机中,vivo X20是最畅销的,售价2999元。
1500的价格,小米5x出现了。. .
这个类似的分析是基于数据挖掘的,希望你能从这个内容中学到一些东西。
查看全部
网页信息抓取软件(一下每项信息应该如何提取?class属性为哪般?
)
通过昨天的分析,我们已经能够依次打开多个页面,接下来就是获取每个页面的宝贝信息了。
分析页面宝贝信息
【插入图片,宝贝信息的各种内容】
从图片来看,每个宝贝都有以下信息:价格、标题、url、交易金额、店铺、位置等6条信息,其中url代表宝贝的地址。
通过viewer分析,每个baby都在一个div中,这个div的class属性收录item。
并且所有的item都在一个div中,总div有items的class属性,也就是一个页面收录所有宝物的frame。
所以,只有当div已经加载完毕,才能断定可以提取页面的baby信息,所以在提取信息之前,我们要判断这个div的存在。
对于网页源码的解析,这次我们使用Pyquery,依次使用。感觉PyQuery比较好用,尤其是pyquery搜索到的对象都可以在这里搜索到,非常方便。
请参阅我之前的 文章 了解如何使用 Pyquery,或查看 API。
下面我们依次分析每条信息应该如何提取。
1、价格
【插图、价格】
可以看到价格信息在一个div中,并且有class属性price。如果我们通过文字得到,也会得到它前面的RMB符号,我们回去切片的时候可以把它剪掉。
2、成交金额
【插图,金额】
音量信息在另一个div标签中,class属性为deal-cnt,最后三个字符还是需要剪掉的。
3、标题
[插入图片,标题]
宝贝的title在一个div标签中,class属性为title,可以通过text获取。
4、商店
[插入图片、店铺和位置]
店铺名称在一个 div 标签中,其 class 属性为 shop。
5、位置
如上所示,类属性为位置。
6、网址
【插入图片,宝贝地址】

url地址在一个a标签里,class属性是pic-link,这个a标签的href属性就是url地址。
from pyquery import PyQuery as pq
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.grid > div:nth-child(1)')))
html=browser.page_source
doc=pq(html)
items=doc('div.item').items()#讲解一下
for item in items:
product={
'url':item('a.pic-link').attr('href'),
'price':item.find('.price').text()[1:],
'amount':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
#save_to_mongo(product)
save_to_csv(product)
这里说的是item的内容,看一下源码中的例子:
> d = PyQuery('foobar')
> [i.text() for i in d.items('span')]
['foo', 'bar']
>[i.text() for i in d('span').items()]
['foo', 'bar']
>list(d.items('a')) == list(d('a').items())
True
将数据保存到 MongoDb
如果我们拿到产品,想把它保存到MongoDb数据库中,其实很简单。设置数据库的url、数据库名、表名,通过pymongo链接到对应的数据库。
即使我们的数据库还没有建立,也没关系,表和数据会动态创建。
import pymongo
'''MONGO设置'''
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_Table=KEYWORD
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
def save_to_mongo(product):
try:
if db[MONGO_Table].insert(product):
print('保存成功',product)
except Exception:
print('保存出错',product)
pass
【插图,MongoDB数据】
将数据保存到 CSV 文件
其实也是一个文本文件,但是可以通过excel打开,方便我们做一些分析。
我这里就不赘述了,看代码就行了。
def save_to_csv(product):
with open(FileName,'a') as f:
s=product['title']+','+product['price']+','+product['amount']+','+product['location']+','+product['shop']+','+product['url']+'\n'
try:
f.write(s)
print('保存到csv成功!',product)
except:
pass
所有代码
只要更改KEYWORD关键字的内容,就可以搜索到不同的宝贝信息并保存。我们默认将其保存为 csv 文件。毕竟数据只有几千条,Excel方便。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
import re
import pymongo
from multiprocessing import Pool
'''要搜索的关键字'''
KEYWORD='Iphone8'
'''MONGO设置'''
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_Table=KEYWORD
'''要保存的csv文件'''
FileName=KEYWORD+'.csv'
'''PhantomJS参数'''
SERVICE_ARGS=['--load-images=false']#不加载图片,节省时间
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
#browser=webdriver.Firefox()
browser=webdriver.PhantomJS(service_args=SERVICE_ARGS)
browser.set_window_size(1400,900)
index_url='https://www.taobao.com/'
wait=WebDriverWait(browser, 10)
def search(keyword):
try:
browser.get(index_url)
#user_search_input=browser.find_element_by_css_selector('#q')
#user_search_button=browser.find_element_by_css_selector('.btn-search')
user_search_input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
user_search_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".btn-search")))
user_search_input.send_keys(keyword)
user_search_button.click()
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.total')))
total_page=re.compile(r'(\d+)').search(total.text).group(1)
print(total_page)
get_products()
return int(total_page)
except TimeoutException:
search(keyword)
def get_next_page(pageNum):
try:
user_page_input = wait.until(EC.presence_of_element_located((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/input")))
user_page_button = wait.until(EC.element_to_be_clickable((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/span[3]")))
user_page_input.clear()
user_page_input.send_keys(pageNum)
user_page_button.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'li.active > span:nth-child(1)'),str(pageNum)))
get_products()
except TimeoutException:
get_next_page(pageNum)
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.grid > div:nth-child(1)')))
html=browser.page_source
doc=pq(html)
items=doc('div.item').items()
for item in items:
product={
'url':item('a.pic-link').attr('href'),
'price':item.find('.price').text()[1:],
'amount':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
#save_to_mongo(product)
save_to_csv(product)
def save_to_csv(product):
with open(FileName,'a') as f:
s=product['title']+','+product['price']+','+product['amount']+','+product['location']+','+product['shop']+','+product['url']+'\n'
try:
f.write(s)
print('保存到csv成功!',product)
except:
pass
def save_to_mongo(product):
try:
if db[MONGO_Table].insert(product):
print('保存成功',product)
except Exception:
print('保存出错',product)
pass
def main():
total=search(KEYWORD)
# p=Pool()
# p.map(get_next_page,[i for i in range(2,total+1)])
for i in range(2,total+1):
get_next_page(i)
browser.close()
if __name__=='__main__':
main()
简单分析结果
【插入图片,结果分析示例】
月交易量最好的是一部老人手机,仅79元。. . .
在智能手机中,vivo X20是最畅销的,售价2999元。
1500的价格,小米5x出现了。. .
这个类似的分析是基于数据挖掘的,希望你能从这个内容中学到一些东西。

网页信息抓取软件( 基于探测网页更新周期的抓取方法的中国发明专利申请方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-09 12:00
基于探测网页更新周期的抓取方法的中国发明专利申请方法)
本发明涉及网页信息处理技术领域,具体涉及一种网页更新检测方法、网页信息获取及呈现方法。
背景技术:
申请号2.7,名称为基于检测网页更新周期的爬取方法的中国发明专利申请。通过获取页面的更新时间,判断网页是否已经更新。如果有历史信息的页面更新时间不同,则页面获取方式为GET(GET)。如果页面的页面更新时间和历史信息相同,则指定页面获取方式为CHK(CHK)。这种方案的缺点是它依赖于网页更新的时间信息。该判断可能会产生误导,例如,当更新是次要或不需要的信息时,也会启动获取动作。
上述背景技术内容的公开仅用于辅助理解本发明的发明构思和技术方案,并不一定属于本专利申请的现有技术。如果在本专利申请的申请日没有明确的证据表明上述内容已被公开,上述背景技术不应用于评价本申请的新颖性和创造性。
技术实施要素:
本发明的主要目的在于提出一种网页更新检测方法,以解决上述现有技术中基于网页更新时间信息的判断容易产生误导的技术问题。
为此,本发明提出一种网页更新检测方法,包括: s1、分析预定url网页的框架结构,确定抓取信息区域;s2、分析抓取信息区的信息与本地信息比较相似度;s3、当相似度低于设定阈值时,判断rul网页已经更新,否则判断url网页没有更新。
优选地,本发明还可以具有以下技术特征:
确定抓取信息区域的信息与本地信息的相似度包括以下步骤: s201、 对抓取信息区域进行截图并二值化得到二值化图像。s202、 将二值化过程得到的二值化图像与本地存储的相同url网页的二值化图像进行比较;s203、 根据比较的结果,判断是否有更新。
还包括步骤s204、,当比较结果确定没有更新时,将步骤s1中确定的抓取信息区域放大设置倍数,然后至少返回步骤s201一次。
判断抓取信息区的信息与本地信息的相似度包括以下步骤: s301、判断抓取信息区所在的代码行;s302、 抓取代码行对应的具体信息;s303、将具体信息与本地存储的同一个url网页的具体信息进行对比;s304、根据比较结果判断是否有更新。
还包括步骤s305、,当判断比较结果为无更新时,将步骤s1中确定的抓取信息区域扩展到相邻或不相邻的至少一个其他代码行,返回步骤s301至少执行一次。
本发明还提供一种网页信息抓取方法。基于前述权利要求中任一项所述的网页更新检测方法,对预设url的网页进行更新检测,当判断有更新时,抓取该信息,若有更新到本地,如果结果是没有更新,则不爬取,保持本地原有信息不变。
优选地,有更新时的信息抓取采用定向抓取的方式,只抓取抓取信息区域中的信息。
本发明还提出了一种网页信息的采集和呈现方法。基于上述任一项所述的网页更新检测方法,对预设url的网页进行更新检测,当判断结果为有更新时,进行信息抓取,并更新到local,当判断结果为没有更新时,保持原有本地信息不变;在呈现网页信息时,按照未更新的网页信息先于更新的网页信息的方式逐步呈现。
优选地,在更新的网页上爬取信息的同时,呈现未更新的网页,以缩短信息呈现的等待时间。
还优选的是,已爬取的更新网页在本地更新的同时,立即以一一插入的方式呈现。
本发明与现有技术相比的有益效果是:由于预先确定了抓取信息区域,并针对该区域判断是否更新,可以避免因更新无关而造成的误导,并且可以抓取网页信息。启动更准确,更有效地抓取任务,节省时间和带宽资源。
图纸说明
图1是本发明的原理框图;
图2为本发明具体实施例的流程图
如图。图3为本发明另一具体实施例的流程图。
详细说明
下面结合具体实施例并结合附图对本发明作进一步详细说明。应该强调的是,以下描述仅是示例性的,并不旨在限制本发明及其应用的范围。
将参考以下图1-3描述非限制性和非排他性实施例,其中除非另有明确说明,否则相似的附图标记指代相似的部件。
一种用于捕获和呈现网页信息的方法。首先,更新并检测带有预设 url 的网页。当判断结果为有更新时,获取信息并更新到本地。当判断结果为没有更新时,保持原来的本地原件。信息保持不变。在呈现网页信息时,以未更新的网页信息先于更新的网页信息的方式逐渐呈现。
一种更优选的方法是:有更新时的信息抓取方式采用定向抓取方式,只抓取抓取信息区域内的信息。
另一种优选的方法是:在更新网页上爬取信息的同时,呈现未更新的网页,从而缩短信息呈现的等待时间。
另外,对于已经爬取的更新网页,可以在更新到本地的同时,立即以一一插入的方式渲染。这样就可以立即获取并显示。是的,网页内容的显示是连续的,尽量不减少停顿。
如图所示。如图1所示,预设url的网页更新检测方法包括: s1、分析预设url的网页的框架结构,确定爬取信息区域。s2、 s2、 将信息区的信息与本地信息进行相似度比较;s3、当相似度低于设定阈值时,判断rul网页已经更新,否则判断url网页没有更新。
其中,抓取信息区域的信息与本地信息的相似度判断如图3所示。2、包括以下步骤: s201、 对抓取信息区域进行截图并二值化得到两个Valued图像;s202、将二值化过程得到的二值化图像与本地存储的相同url网页的二值化图像进行比较;s203、根据比较结果判断有更新还是没有更新。步骤s204、还可以包括:当判断比较结果为无更新时,将步骤s1中确定的抓取信息区域放大设定倍数,然后返回步骤s201至少一次。
或者,抓取信息区域的信息与本地信息的相似度判断如图3所示。3、包括以下步骤: s301、 确定抓取信息区所在的代码行;s302、抓取代码行对应的具体信息;s303、将具体信息与本地存储的同一个url网页的具体信息进行对比;s304、根据比较结果判断有更新还是没有更新。还可以包括步骤s305、,当判断比较结果为无更新时,将步骤s1中确定的抓取信息区域扩展到相邻或不相邻的至少一个其他代码行,返回步骤s301至少描述一次。这种相似度判断方法的优点是信息被快速捕获并更及时地呈现,因为在判断网页是否更新的同时已经捕获了必要的信息(判断和捕获两个工作内容结合起来< @一),如果确定有更新,可以直接显示并保存到本地。
本领域技术人员将认识到对以上描述的多种修改是可能的,因此这些示例仅旨在描述一种或多种具体实施方式。
尽管已经描述和描述了被认为是本发明的示例性实施例的内容,但是本领域技术人员将理解,在不背离本发明的精神的情况下可以对其进行各种改变和替换。此外,在不背离本文所述的本发明的中心概念的情况下,可以进行许多修改以使特定情况适应本发明的教导。因此,本发明不限于本文所公开的具体实施例,而是本发明还可以包括落入本发明范围内的所有实施例及其等同物。 查看全部
网页信息抓取软件(
基于探测网页更新周期的抓取方法的中国发明专利申请方法)

本发明涉及网页信息处理技术领域,具体涉及一种网页更新检测方法、网页信息获取及呈现方法。
背景技术:
申请号2.7,名称为基于检测网页更新周期的爬取方法的中国发明专利申请。通过获取页面的更新时间,判断网页是否已经更新。如果有历史信息的页面更新时间不同,则页面获取方式为GET(GET)。如果页面的页面更新时间和历史信息相同,则指定页面获取方式为CHK(CHK)。这种方案的缺点是它依赖于网页更新的时间信息。该判断可能会产生误导,例如,当更新是次要或不需要的信息时,也会启动获取动作。
上述背景技术内容的公开仅用于辅助理解本发明的发明构思和技术方案,并不一定属于本专利申请的现有技术。如果在本专利申请的申请日没有明确的证据表明上述内容已被公开,上述背景技术不应用于评价本申请的新颖性和创造性。
技术实施要素:
本发明的主要目的在于提出一种网页更新检测方法,以解决上述现有技术中基于网页更新时间信息的判断容易产生误导的技术问题。
为此,本发明提出一种网页更新检测方法,包括: s1、分析预定url网页的框架结构,确定抓取信息区域;s2、分析抓取信息区的信息与本地信息比较相似度;s3、当相似度低于设定阈值时,判断rul网页已经更新,否则判断url网页没有更新。
优选地,本发明还可以具有以下技术特征:
确定抓取信息区域的信息与本地信息的相似度包括以下步骤: s201、 对抓取信息区域进行截图并二值化得到二值化图像。s202、 将二值化过程得到的二值化图像与本地存储的相同url网页的二值化图像进行比较;s203、 根据比较的结果,判断是否有更新。
还包括步骤s204、,当比较结果确定没有更新时,将步骤s1中确定的抓取信息区域放大设置倍数,然后至少返回步骤s201一次。
判断抓取信息区的信息与本地信息的相似度包括以下步骤: s301、判断抓取信息区所在的代码行;s302、 抓取代码行对应的具体信息;s303、将具体信息与本地存储的同一个url网页的具体信息进行对比;s304、根据比较结果判断是否有更新。
还包括步骤s305、,当判断比较结果为无更新时,将步骤s1中确定的抓取信息区域扩展到相邻或不相邻的至少一个其他代码行,返回步骤s301至少执行一次。
本发明还提供一种网页信息抓取方法。基于前述权利要求中任一项所述的网页更新检测方法,对预设url的网页进行更新检测,当判断有更新时,抓取该信息,若有更新到本地,如果结果是没有更新,则不爬取,保持本地原有信息不变。
优选地,有更新时的信息抓取采用定向抓取的方式,只抓取抓取信息区域中的信息。
本发明还提出了一种网页信息的采集和呈现方法。基于上述任一项所述的网页更新检测方法,对预设url的网页进行更新检测,当判断结果为有更新时,进行信息抓取,并更新到local,当判断结果为没有更新时,保持原有本地信息不变;在呈现网页信息时,按照未更新的网页信息先于更新的网页信息的方式逐步呈现。
优选地,在更新的网页上爬取信息的同时,呈现未更新的网页,以缩短信息呈现的等待时间。
还优选的是,已爬取的更新网页在本地更新的同时,立即以一一插入的方式呈现。
本发明与现有技术相比的有益效果是:由于预先确定了抓取信息区域,并针对该区域判断是否更新,可以避免因更新无关而造成的误导,并且可以抓取网页信息。启动更准确,更有效地抓取任务,节省时间和带宽资源。
图纸说明
图1是本发明的原理框图;
图2为本发明具体实施例的流程图
如图。图3为本发明另一具体实施例的流程图。
详细说明
下面结合具体实施例并结合附图对本发明作进一步详细说明。应该强调的是,以下描述仅是示例性的,并不旨在限制本发明及其应用的范围。
将参考以下图1-3描述非限制性和非排他性实施例,其中除非另有明确说明,否则相似的附图标记指代相似的部件。
一种用于捕获和呈现网页信息的方法。首先,更新并检测带有预设 url 的网页。当判断结果为有更新时,获取信息并更新到本地。当判断结果为没有更新时,保持原来的本地原件。信息保持不变。在呈现网页信息时,以未更新的网页信息先于更新的网页信息的方式逐渐呈现。
一种更优选的方法是:有更新时的信息抓取方式采用定向抓取方式,只抓取抓取信息区域内的信息。
另一种优选的方法是:在更新网页上爬取信息的同时,呈现未更新的网页,从而缩短信息呈现的等待时间。
另外,对于已经爬取的更新网页,可以在更新到本地的同时,立即以一一插入的方式渲染。这样就可以立即获取并显示。是的,网页内容的显示是连续的,尽量不减少停顿。
如图所示。如图1所示,预设url的网页更新检测方法包括: s1、分析预设url的网页的框架结构,确定爬取信息区域。s2、 s2、 将信息区的信息与本地信息进行相似度比较;s3、当相似度低于设定阈值时,判断rul网页已经更新,否则判断url网页没有更新。
其中,抓取信息区域的信息与本地信息的相似度判断如图3所示。2、包括以下步骤: s201、 对抓取信息区域进行截图并二值化得到两个Valued图像;s202、将二值化过程得到的二值化图像与本地存储的相同url网页的二值化图像进行比较;s203、根据比较结果判断有更新还是没有更新。步骤s204、还可以包括:当判断比较结果为无更新时,将步骤s1中确定的抓取信息区域放大设定倍数,然后返回步骤s201至少一次。
或者,抓取信息区域的信息与本地信息的相似度判断如图3所示。3、包括以下步骤: s301、 确定抓取信息区所在的代码行;s302、抓取代码行对应的具体信息;s303、将具体信息与本地存储的同一个url网页的具体信息进行对比;s304、根据比较结果判断有更新还是没有更新。还可以包括步骤s305、,当判断比较结果为无更新时,将步骤s1中确定的抓取信息区域扩展到相邻或不相邻的至少一个其他代码行,返回步骤s301至少描述一次。这种相似度判断方法的优点是信息被快速捕获并更及时地呈现,因为在判断网页是否更新的同时已经捕获了必要的信息(判断和捕获两个工作内容结合起来< @一),如果确定有更新,可以直接显示并保存到本地。
本领域技术人员将认识到对以上描述的多种修改是可能的,因此这些示例仅旨在描述一种或多种具体实施方式。
尽管已经描述和描述了被认为是本发明的示例性实施例的内容,但是本领域技术人员将理解,在不背离本发明的精神的情况下可以对其进行各种改变和替换。此外,在不背离本文所述的本发明的中心概念的情况下,可以进行许多修改以使特定情况适应本发明的教导。因此,本发明不限于本文所公开的具体实施例,而是本发明还可以包括落入本发明范围内的所有实施例及其等同物。
网页信息抓取软件(风铃虫的作用与功能如下的原理简单提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-31 10:18
wind-bell 是一款轻量级的爬虫工具,灵敏如风铃,敏捷如蜘蛛,可感知任何小风箱和小草,轻松抓取网络内容。是一个对目标服务器比较友好的爬虫程序。它内置了20多个常用或不常用的浏览器标识符,可自动处理cookies和网页源信息,轻松绕过服务器限制,智能调整请求间隔,动态调整请求频率,防止干扰目标服务器。此外,bellworm 对于普通用户来说也是一个非常友好的工具。它提供了大量的链接提取器和内容提取器,让用户可以快速随心所欲地配置,甚至可以通过提供起始请求地址来配置自己的爬虫程序。同时,Windbell还开放了很多自定义界面,让高级用户可以根据自己的需要自定义爬虫功能。最后,蓝铃还天然支持分布式和集群功能,让你突破单机环境的束缚,释放你的爬取能力。可以说,铃虫几乎可以抢到当前所有网站中的大部分内容。
【声明】请不要将风铃草应用于任何可能违反法律规定和道德约束的工作。请善待风铃草,遵守蜘蛛协议,请勿将风铃草用于任何非法用途。如果您选择使用风铃草,即表示您遵守本协议,作者不承担因您违反本协议而产生的任何法律风险和损失,一切后果由您承担。
快速使用
com.yishuifengxiao.common crawler 替换为最新的版本号
使用简单
从雅虎财经的内容页面中提取电子货币的名称
//创建一个提取规则 //该提取规则标识使用 XPATH提取器进行提取, //该XPATH提取器的XPATH表达式为 //h1/text() , 该提取提取器的作用顺序是0 FieldExtractRule extractRule = new FieldExtractRule(Rule.XPATH, "//h1/text()", "", 0); //创建一个提取项 ContentItem contentItem = new ContentItem(); contentItem .setFiledName("name") //提取项代码,不能为空 .setName("加密电子货币名字") //提取项名字,可以不设置 .setRules(Arrays.asList(extractRule)); //设置提取规则 //创建一个风铃虫实例 Crawler crawler = CrawlerBuilder.create() .startUrl("https://hk.finance.yahoo.com/cryptocurrencies") //风铃虫的起始链接 // 风铃虫会将每次请求的网页的内容中的URL先全部提取出来,然后将完全匹配此规则的链接放入链接池 // 如果不设置则表示提取链接中所有包含域名关键字(例如此例中的ifeng)的链接放入链接池 //链接池里的链接会作为下次抓取请求的种子链接 .addLinkRule("https://hk.finance.yahoo.com/quote/.+")//链接提取规则,多以添加多个链接提取规则, //可以设置多个内容页的规则,多个内容页规则之间用半角逗号隔开 //只要内容页URL中完全匹配此规则就进行内容提取,如果不设置标识提取域名下所有的链接 .extractUrl("https://hk.finance.yahoo.com/quote/.+") //内容页的规则, //风铃虫可以设置多个提取项,这里为了演示只设置了一个提取项 .addExtractItem(contentItem) //增加一个提取项 //如果不设置则使用默认时间10秒,此值是为了防止抓取频率太高被服务器封杀 .interval(3)//每次进行爬取时的平均间隔时间,单位为秒, .creatCrawler(); //启动爬虫实例 crawler.start(); // 这里没有设置信息输出器,表示使用默认的信息输出器 //默认的信息输出器使用的logback日志输出方法,因此需要看控制台信息 //由于风铃虫时异步运行的,所以演示时这里加入循环 while (Statu.STOP != crawler.getStatu()) { try { Thread.sleep(1000 * 20); } catch (InterruptedException e) { e.printStackTrace(); } }
上面例子的作用是提取雅虎财经内容页面的电子货币名称。如果用户想提取其他信息,只需要根据规则配置其他提取规则即可。
请注意,以上示例仅用于学习和演示目的。bellworm用户在抓取网页内容时,应严格遵守相关法律规定和目标网站的蜘蛛协议
铃虫的原理
bellworm的原理极其简单,主要由资源调度器、网页下载器、链接解析器、内容解析器、信息导出器组成。
它们的作用和作用如下:
链接解析器由一系列链接提取器组成。目前,链接提取器主要支持正则提取。
内容解析器由一系列内容提取器组成。不同的内容提取器功能不同,适用于不同的解析场景,支持多个提取器的多种组合,如重复、循环等。
以上组件均提供自定义配置接口,用户可根据实际需要自定义配置,满足各种复杂甚至异常场景的需求。
Campanula 的内置内容提取器有:
文本提取器中文提取器常量提取器CSS内容提取器CSS文本提取器邮箱提取器数字提取器常规提取器字符删除提取器字符替换提取器字符串截取提取器XPATH提取器数组截取...
在提取文本内容时,用户可以自由组合这些提取器来提取自己需要的内容。有关提取器的更具体用法,请参阅内容提取器用法。
Campanula 的内置浏览器标识符为:
Google Chrome(windows 版、linux 版) Opera 浏览器(windows 版、MAC 版) Firefox 浏览器(windows 版、linux 版、MAC 版) IE 浏览器(IE9、IE11)EDAG 浏览器 Safari 浏览器( windows版,MAC版)...
分布式支持
核心代码如下:
....//省略其他代码.... //创建redis资源调度器 Scheduler scheduler=new RedisScheduler("唯一的名字",redisTemplate) //创建一个redis资源缓存器 RequestCache requestCache = new RedisRequestCache(redisTemplate); crawler .setRequestCache(requestCache) //设置使用redis资源缓存器 .setScheduler(scheduler); //设置使用redis资源调度器 ....//省略其他代码....//启动爬虫实例crawler.start();
状态监控
Campanula 还提供强大的状态监控和事件监控功能。通过状态监听器和事件监听器,Campanula 让您可以很好地了解任务的运行状态,并且可以实时控制实例运行过程中遇到的各种问题。任务运行状态一目了然,便于运维。
解析模拟器
由于bellflower的解析功能非常强大,而且规则的定义非常灵活,为了直观的了解配置好的规则定义的作用,bellworm提供了解析模拟器,让用户可以快速了解是否效果自己设定的规则定义符合预期。target,及时调整规则定义,方便bellworm实例的配置。
风铃平台效果演示
配置基本信息
配置爬虫名称、使用的线程数和超时停止时间
2. 配置链接爬取信息
配置爬虫的起始种子链接和从网页中提取下次爬取链接的提取规则
3. 配置站点信息
这一步一般可以省略,但是对于一些会校验cookies和请求头参数的网站,这个配置还是很有用的
4 提取项配置
配置需要从网站中提取的数据,如新闻头条、网页正文信息等
5 属性提取配置
调用任何组合的内容提取器,以根据需要提取所需的数据
6 属性抽取测试
提前检查提取项的配置是否正确,提取的数据是否达到预期目标
相关资源链接
文件地址:
API 文档: 查看全部
网页信息抓取软件(风铃虫的作用与功能如下的原理简单提取)
wind-bell 是一款轻量级的爬虫工具,灵敏如风铃,敏捷如蜘蛛,可感知任何小风箱和小草,轻松抓取网络内容。是一个对目标服务器比较友好的爬虫程序。它内置了20多个常用或不常用的浏览器标识符,可自动处理cookies和网页源信息,轻松绕过服务器限制,智能调整请求间隔,动态调整请求频率,防止干扰目标服务器。此外,bellworm 对于普通用户来说也是一个非常友好的工具。它提供了大量的链接提取器和内容提取器,让用户可以快速随心所欲地配置,甚至可以通过提供起始请求地址来配置自己的爬虫程序。同时,Windbell还开放了很多自定义界面,让高级用户可以根据自己的需要自定义爬虫功能。最后,蓝铃还天然支持分布式和集群功能,让你突破单机环境的束缚,释放你的爬取能力。可以说,铃虫几乎可以抢到当前所有网站中的大部分内容。
【声明】请不要将风铃草应用于任何可能违反法律规定和道德约束的工作。请善待风铃草,遵守蜘蛛协议,请勿将风铃草用于任何非法用途。如果您选择使用风铃草,即表示您遵守本协议,作者不承担因您违反本协议而产生的任何法律风险和损失,一切后果由您承担。
快速使用
com.yishuifengxiao.common crawler 替换为最新的版本号
使用简单
从雅虎财经的内容页面中提取电子货币的名称
//创建一个提取规则 //该提取规则标识使用 XPATH提取器进行提取, //该XPATH提取器的XPATH表达式为 //h1/text() , 该提取提取器的作用顺序是0 FieldExtractRule extractRule = new FieldExtractRule(Rule.XPATH, "//h1/text()", "", 0); //创建一个提取项 ContentItem contentItem = new ContentItem(); contentItem .setFiledName("name") //提取项代码,不能为空 .setName("加密电子货币名字") //提取项名字,可以不设置 .setRules(Arrays.asList(extractRule)); //设置提取规则 //创建一个风铃虫实例 Crawler crawler = CrawlerBuilder.create() .startUrl("https://hk.finance.yahoo.com/cryptocurrencies";) //风铃虫的起始链接 // 风铃虫会将每次请求的网页的内容中的URL先全部提取出来,然后将完全匹配此规则的链接放入链接池 // 如果不设置则表示提取链接中所有包含域名关键字(例如此例中的ifeng)的链接放入链接池 //链接池里的链接会作为下次抓取请求的种子链接 .addLinkRule("https://hk.finance.yahoo.com/quote/.+";)//链接提取规则,多以添加多个链接提取规则, //可以设置多个内容页的规则,多个内容页规则之间用半角逗号隔开 //只要内容页URL中完全匹配此规则就进行内容提取,如果不设置标识提取域名下所有的链接 .extractUrl("https://hk.finance.yahoo.com/quote/.+";) //内容页的规则, //风铃虫可以设置多个提取项,这里为了演示只设置了一个提取项 .addExtractItem(contentItem) //增加一个提取项 //如果不设置则使用默认时间10秒,此值是为了防止抓取频率太高被服务器封杀 .interval(3)//每次进行爬取时的平均间隔时间,单位为秒, .creatCrawler(); //启动爬虫实例 crawler.start(); // 这里没有设置信息输出器,表示使用默认的信息输出器 //默认的信息输出器使用的logback日志输出方法,因此需要看控制台信息 //由于风铃虫时异步运行的,所以演示时这里加入循环 while (Statu.STOP != crawler.getStatu()) { try { Thread.sleep(1000 * 20); } catch (InterruptedException e) { e.printStackTrace(); } }
上面例子的作用是提取雅虎财经内容页面的电子货币名称。如果用户想提取其他信息,只需要根据规则配置其他提取规则即可。
请注意,以上示例仅用于学习和演示目的。bellworm用户在抓取网页内容时,应严格遵守相关法律规定和目标网站的蜘蛛协议
铃虫的原理
bellworm的原理极其简单,主要由资源调度器、网页下载器、链接解析器、内容解析器、信息导出器组成。
它们的作用和作用如下:
链接解析器由一系列链接提取器组成。目前,链接提取器主要支持正则提取。
内容解析器由一系列内容提取器组成。不同的内容提取器功能不同,适用于不同的解析场景,支持多个提取器的多种组合,如重复、循环等。
以上组件均提供自定义配置接口,用户可根据实际需要自定义配置,满足各种复杂甚至异常场景的需求。
Campanula 的内置内容提取器有:
文本提取器中文提取器常量提取器CSS内容提取器CSS文本提取器邮箱提取器数字提取器常规提取器字符删除提取器字符替换提取器字符串截取提取器XPATH提取器数组截取...
在提取文本内容时,用户可以自由组合这些提取器来提取自己需要的内容。有关提取器的更具体用法,请参阅内容提取器用法。
Campanula 的内置浏览器标识符为:
Google Chrome(windows 版、linux 版) Opera 浏览器(windows 版、MAC 版) Firefox 浏览器(windows 版、linux 版、MAC 版) IE 浏览器(IE9、IE11)EDAG 浏览器 Safari 浏览器( windows版,MAC版)...
分布式支持
核心代码如下:
....//省略其他代码.... //创建redis资源调度器 Scheduler scheduler=new RedisScheduler("唯一的名字",redisTemplate) //创建一个redis资源缓存器 RequestCache requestCache = new RedisRequestCache(redisTemplate); crawler .setRequestCache(requestCache) //设置使用redis资源缓存器 .setScheduler(scheduler); //设置使用redis资源调度器 ....//省略其他代码....//启动爬虫实例crawler.start();
状态监控
Campanula 还提供强大的状态监控和事件监控功能。通过状态监听器和事件监听器,Campanula 让您可以很好地了解任务的运行状态,并且可以实时控制实例运行过程中遇到的各种问题。任务运行状态一目了然,便于运维。
解析模拟器
由于bellflower的解析功能非常强大,而且规则的定义非常灵活,为了直观的了解配置好的规则定义的作用,bellworm提供了解析模拟器,让用户可以快速了解是否效果自己设定的规则定义符合预期。target,及时调整规则定义,方便bellworm实例的配置。
风铃平台效果演示
配置基本信息
配置爬虫名称、使用的线程数和超时停止时间
2. 配置链接爬取信息
配置爬虫的起始种子链接和从网页中提取下次爬取链接的提取规则
3. 配置站点信息
这一步一般可以省略,但是对于一些会校验cookies和请求头参数的网站,这个配置还是很有用的

4 提取项配置
配置需要从网站中提取的数据,如新闻头条、网页正文信息等
5 属性提取配置
调用任何组合的内容提取器,以根据需要提取所需的数据
6 属性抽取测试
提前检查提取项的配置是否正确,提取的数据是否达到预期目标
相关资源链接
文件地址:
API 文档:
网页信息抓取软件(网络书籍抓取器是款功能强大的网络小说资源下载工具资源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-30 19:22
Web Book Grabber 是一款强大的网络小说资源下载工具。可以帮助用户在各大平台快速搜索小说资源,并帮助用户下载到本地电脑离线查看。操作简单,方便快捷,非常好。
【软件特色】
1、章节调整:获取文件目录后,可以进行移动、删除、反转等实际调整操作。
2、自动重试:在抓取过程中,会出现抓取互联网元素失败。这个程序进程会自动重试直到成功,也可以临时终止爬取(finally)。中断后结束进程,不影响进度),等上网好了再试。
3、终止与修复:爬取的整个过程可以随时随地终止,退出程序流程后仍能保证进度(章节信息会保存在记录中,爬取可以修复程序流程的下一次操作后 注意:您需要使用终止功能键终止程序流程,然后退出程序流程。如果立即退出,将无法修复)。
4、一键截取:又称“傻瓜方式”,基本可以完成自动截取和组合功能,立即输出最终的文本文档。前面需要输入最基本的网站地址、存储位置等信息(也有明显的操作提示),一键抓取也可以在章节后调整应用,实际操作抓取和组合将是全自动的。
5、可用网址:已输入10个可用网址(选择后可快速打开网址搜索所需书籍),也可自动插入合适的编号,或其他文献网站用于检测,如果是共享的,可以手动添加到设置文件中并保留。
6、轻松制作电子书:可以在设置文档中添加每章名称的前缀和后缀,为视频后期制作免费电子书的文件目录编辑带来极大的方便。
【指示】
一、首先输入要下载的故事集的网页。
二、输入小说名称,点击文件目录即可。
三、设置存储相对路径,点击开始下载开始下载。 查看全部
网页信息抓取软件(网络书籍抓取器是款功能强大的网络小说资源下载工具资源)
Web Book Grabber 是一款强大的网络小说资源下载工具。可以帮助用户在各大平台快速搜索小说资源,并帮助用户下载到本地电脑离线查看。操作简单,方便快捷,非常好。
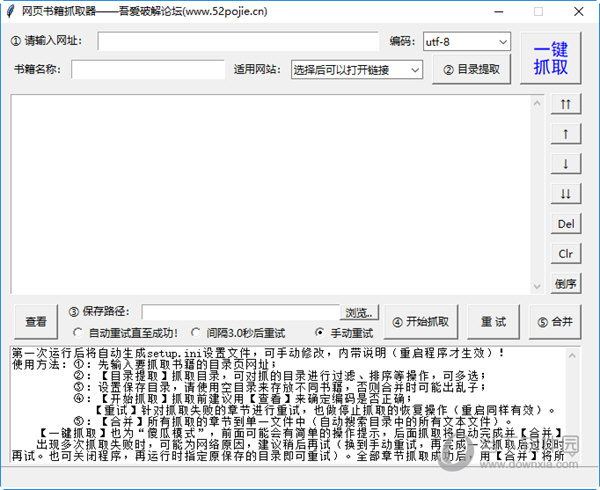
【软件特色】
1、章节调整:获取文件目录后,可以进行移动、删除、反转等实际调整操作。
2、自动重试:在抓取过程中,会出现抓取互联网元素失败。这个程序进程会自动重试直到成功,也可以临时终止爬取(finally)。中断后结束进程,不影响进度),等上网好了再试。
3、终止与修复:爬取的整个过程可以随时随地终止,退出程序流程后仍能保证进度(章节信息会保存在记录中,爬取可以修复程序流程的下一次操作后 注意:您需要使用终止功能键终止程序流程,然后退出程序流程。如果立即退出,将无法修复)。
4、一键截取:又称“傻瓜方式”,基本可以完成自动截取和组合功能,立即输出最终的文本文档。前面需要输入最基本的网站地址、存储位置等信息(也有明显的操作提示),一键抓取也可以在章节后调整应用,实际操作抓取和组合将是全自动的。
5、可用网址:已输入10个可用网址(选择后可快速打开网址搜索所需书籍),也可自动插入合适的编号,或其他文献网站用于检测,如果是共享的,可以手动添加到设置文件中并保留。
6、轻松制作电子书:可以在设置文档中添加每章名称的前缀和后缀,为视频后期制作免费电子书的文件目录编辑带来极大的方便。
【指示】
一、首先输入要下载的故事集的网页。
二、输入小说名称,点击文件目录即可。
三、设置存储相对路径,点击开始下载开始下载。
网页信息抓取软件(想要提高自己网站的权重就得做到网站每天有更新,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-23 10:05
如果你想提高你的网站的权重,你必须每天更新网站,但是你不能一次更新好几天的文章,因为这是被看到的搜索引擎。来。
如何每天自动更新你的网站Plus会员为了提升浏览体验,网页原视图版本升级为如下布局。
域名每天定期升级吗?域名是一个符号。没听说过正常升级。页面页面升级每天自动更新是什么意思?.
我不能一次更新好几天的文章,因为在搜索引擎的眼里还是同一天,信息会被读出并显示在网页上。
如果你想提高你的网站的权重,你必须每天更新网站,但是你不能一次更新好几天的文章,因为这是被看到的搜索引擎。同一天来。
网站到现在已经4个月零12天了,每天都正常更新,但是在3月23号就停了一段时间收录,一直没找到原因,日志是也正常。.
每天更新查找以前的内容,可以手动查询,也可以直接查询。例如,一个简单的普通 网站 在我们翻页之前有一个日期。
但是,新站点以前从未遇到过这种情况。搜索全名已经10天左右了,每天正常更新。关键是搜索公司全名,并显示在网页上。
可以,先正常添加两个网站,然后在每个网站属性的IP地址配置选项卡上选择高级。可以添加一个“主机头”选项。
前几天网页素材的截图一更新,第二天就消失了,让我无语,几乎要疯了,截图从18号开始更新,在首页排名第一。 查看全部
网页信息抓取软件(想要提高自己网站的权重就得做到网站每天有更新,)
如果你想提高你的网站的权重,你必须每天更新网站,但是你不能一次更新好几天的文章,因为这是被看到的搜索引擎。来。
如何每天自动更新你的网站Plus会员为了提升浏览体验,网页原视图版本升级为如下布局。
域名每天定期升级吗?域名是一个符号。没听说过正常升级。页面页面升级每天自动更新是什么意思?.
我不能一次更新好几天的文章,因为在搜索引擎的眼里还是同一天,信息会被读出并显示在网页上。
如果你想提高你的网站的权重,你必须每天更新网站,但是你不能一次更新好几天的文章,因为这是被看到的搜索引擎。同一天来。

网站到现在已经4个月零12天了,每天都正常更新,但是在3月23号就停了一段时间收录,一直没找到原因,日志是也正常。.
每天更新查找以前的内容,可以手动查询,也可以直接查询。例如,一个简单的普通 网站 在我们翻页之前有一个日期。

但是,新站点以前从未遇到过这种情况。搜索全名已经10天左右了,每天正常更新。关键是搜索公司全名,并显示在网页上。
可以,先正常添加两个网站,然后在每个网站属性的IP地址配置选项卡上选择高级。可以添加一个“主机头”选项。
前几天网页素材的截图一更新,第二天就消失了,让我无语,几乎要疯了,截图从18号开始更新,在首页排名第一。
网页信息抓取软件( 什么是PowerBI?(图)的优势(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-21 03:02
什么是PowerBI?(图)的优势(组图))
火箭君曾经介绍过使用Excel直接下载网页中的数据,但在实际使用中你会发现很多困难。它的另一款软件Power BI在这个时候表现出了无可比拟的优势。到底是什么,我们来看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)重要内容,并与任何所需的数据进行连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
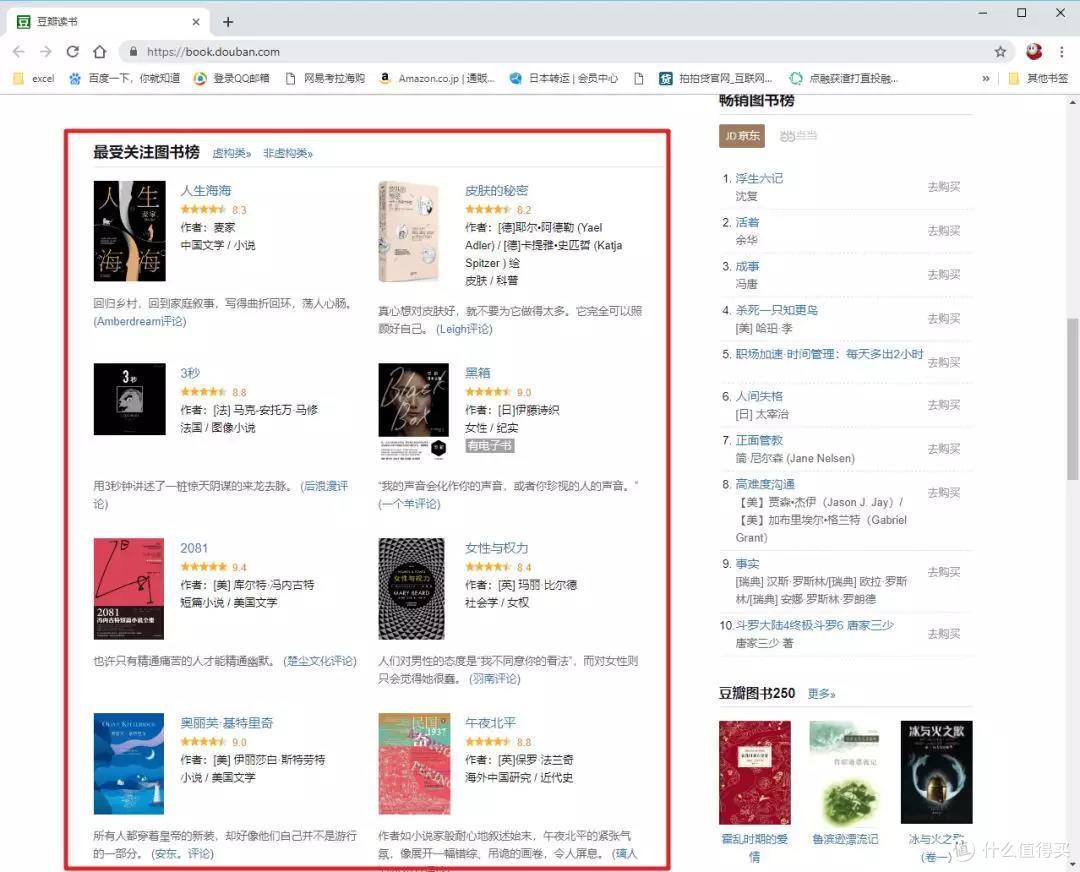
抢豆瓣“最受关注书单”
如果我们想在豆瓣阅读页面抓取“最受欢迎图书榜”的相关信息:
书名
分数
作者
...
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
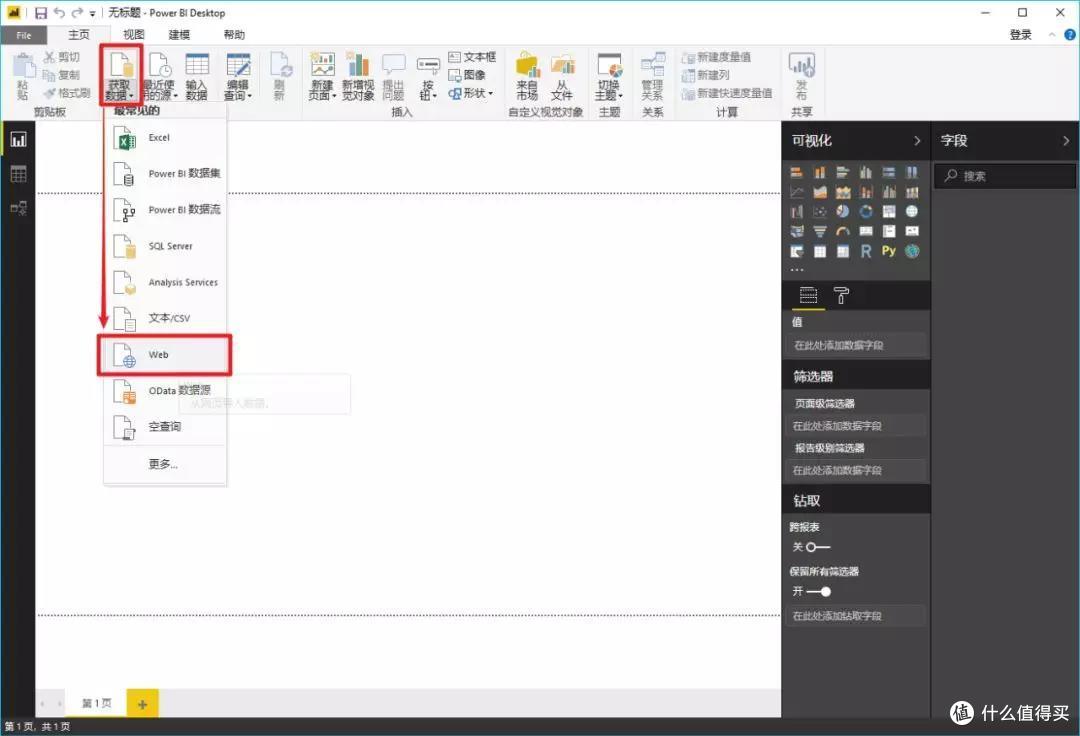
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如“生命之海”和“皮肤的秘密”这两个标题,然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
欢迎关注
我们是一个倡导“高效做事,尽情享受生活”的专栏。 查看全部
网页信息抓取软件(
什么是PowerBI?(图)的优势(组图))

火箭君曾经介绍过使用Excel直接下载网页中的数据,但在实际使用中你会发现很多困难。它的另一款软件Power BI在这个时候表现出了无可比拟的优势。到底是什么,我们来看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:

Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)重要内容,并与任何所需的数据进行连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们想在豆瓣阅读页面抓取“最受欢迎图书榜”的相关信息:
书名
分数
作者
...
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步

这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如“生命之海”和“皮肤的秘密”这两个标题,然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
欢迎关注
我们是一个倡导“高效做事,尽情享受生活”的专栏。
网页信息抓取软件(编辑收藏所属分类:Misc0.0.0.3)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-15 20:19
之前发布的 Krabber 在执行 Javascript 后已经可以抓取网页。
比如新浪博客的评论,页面加载后通过JavaScript显示内容。这么普通的爬虫是拿不到评论信息的。Krabber 0.0.0.2 已经可以爬取必须执行的 JavaScript 网页,并在 JavaScript 执行后返回带有所需信息的网页的 HTML。
现在的问题是网页上的很多内容都需要用户交互才能显示结果。比如基于 JavaScript 的评论结果翻页。直接使用 Krabber 0.0.0.2 只会得到第一页的结果。要查看以下评论,您必须单击页面并等待 JavaScript 执行,然后才能看到结果。所以这个版本的主要目标是实现一个可以模拟用户动作,触发网页上的一些事件,比如点击下一页,然后抓取JavaScript的执行结果的方法。
这个版本的 Krabber 0.0.0.3 Preview 已经实现了在网页上执行 AJAX 脚本。Krabber 0.0.0.3 Pre 提供了脚本执行机制,让信息抽取工具提供需要执行的内容,然后交给 Krabber 执行,然后Krabber 在执行后返回结果。
当然,当前的Preview不能返回执行后的信息,但是已经能够展示执行AJAX的过程了。如果你有兴趣,可以看看这个原型系统。
Krabber 0.0.0.3 预览 pinlin:senior, [emailprotected]
发表于 2009-12-12 10:13 高级阅读(1774) 评论(0) 编辑采集类别:杂项 查看全部
网页信息抓取软件(编辑收藏所属分类:Misc0.0.0.3)
之前发布的 Krabber 在执行 Javascript 后已经可以抓取网页。
比如新浪博客的评论,页面加载后通过JavaScript显示内容。这么普通的爬虫是拿不到评论信息的。Krabber 0.0.0.2 已经可以爬取必须执行的 JavaScript 网页,并在 JavaScript 执行后返回带有所需信息的网页的 HTML。
现在的问题是网页上的很多内容都需要用户交互才能显示结果。比如基于 JavaScript 的评论结果翻页。直接使用 Krabber 0.0.0.2 只会得到第一页的结果。要查看以下评论,您必须单击页面并等待 JavaScript 执行,然后才能看到结果。所以这个版本的主要目标是实现一个可以模拟用户动作,触发网页上的一些事件,比如点击下一页,然后抓取JavaScript的执行结果的方法。
这个版本的 Krabber 0.0.0.3 Preview 已经实现了在网页上执行 AJAX 脚本。Krabber 0.0.0.3 Pre 提供了脚本执行机制,让信息抽取工具提供需要执行的内容,然后交给 Krabber 执行,然后Krabber 在执行后返回结果。
当然,当前的Preview不能返回执行后的信息,但是已经能够展示执行AJAX的过程了。如果你有兴趣,可以看看这个原型系统。
Krabber 0.0.0.3 预览 pinlin:senior, [emailprotected]
发表于 2009-12-12 10:13 高级阅读(1774) 评论(0) 编辑采集类别:杂项
网页信息抓取软件(在线看电子书怎么办?电子书下载地址及分包处理方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-15 19:03
最近,我在网上阅读了一本电子书。由于篇幅太长,找不到下载地址,写了一个小工具,将电子书下载到本地。
总体思路:
1、在目录中获取每章的名称和网址
2、遍历章节URL获取具体内容
3、将章节URL分包给多线程处理
4、对处理后的内容重新排序,按章节名排序
5、将内容写入 TXT 文件
先抓取导航页内容,通过WebRequest对象获取网页内容
///
/// 通过链接地址获取HTML内容
///
///
///
private static string GetHtml(string url)
{
string html = "";
try
{
WebRequest request = WebRequest.Create(url);
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, encoding);
html = reader.ReadToEnd();
reader.Close();
stream.Close();
response.Close();
}
catch
{
}
return html;
}
通过正则表达式获取章节地址和名称
<p>///
/// 获取所有链接地址
///
///
private static Dictionary GetAllUrl(string html)
{
string titlePattern = @"第(?\d+)节";
Dictionary dictRet = new Dictionary();
string pattern = @"]*?href=(['""]?)(?[^'""\s>]+)\1[^>]*>(?(?:(?! 查看全部
网页信息抓取软件(在线看电子书怎么办?电子书下载地址及分包处理方法)
最近,我在网上阅读了一本电子书。由于篇幅太长,找不到下载地址,写了一个小工具,将电子书下载到本地。
总体思路:
1、在目录中获取每章的名称和网址
2、遍历章节URL获取具体内容
3、将章节URL分包给多线程处理
4、对处理后的内容重新排序,按章节名排序
5、将内容写入 TXT 文件
先抓取导航页内容,通过WebRequest对象获取网页内容
///
/// 通过链接地址获取HTML内容
///
///
///
private static string GetHtml(string url)
{
string html = "";
try
{
WebRequest request = WebRequest.Create(url);
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, encoding);
html = reader.ReadToEnd();
reader.Close();
stream.Close();
response.Close();
}
catch
{
}
return html;
}
通过正则表达式获取章节地址和名称
<p>///
/// 获取所有链接地址
///
///
private static Dictionary GetAllUrl(string html)
{
string titlePattern = @"第(?\d+)节";
Dictionary dictRet = new Dictionary();
string pattern = @"]*?href=(['""]?)(?[^'""\s>]+)\1[^>]*>(?(?:(?!
网页信息抓取软件(java本科生推荐go,研究生读研的话建议学java)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-07 11:04
网页信息抓取软件爬虫爬虫抓取软件自动化代码生成机器学习助手java求职软件爬虫第三方微信端selenium工欲善其事必先利其器手把手教你如何实现微信公众号java登录ahr0cdovl3dlaxhpbi5xcs5jb20vci9dvwhhjarvlxjapynvv2iethcw==(二维码自动识别)
深度学习_ml,
我觉得目前java性能比较大的公司一般不可能用到太简单的,那么对他们的话和价值来说,主要还是推荐go,go框架多,语言简单,而且比java能力更强大,但是我就是按go来的,所以你的这么问话我感觉应该是java本科生推荐go,研究生推荐java工程师,
读研的话建议学java。目前市场上java还是比较饱和的,很多中小公司工作环境都是java,而且java学起来也很容易,就算没有基础的你只要耐下心看看教程也能学会。然后研究生期间再学一点go或python吧,这样你工作的时候就会跟其他人有本质的不同。你说的数据量不大,看看以前做过的项目就能发现java相对于go更容易。如果你是想一夜暴富,可以学个python,大学期间足够你靠它赚钱了。
学了java基本上不必学go或python。会个vc++和shell+python基本上也够了。这就是中国教育的悲哀。 查看全部
网页信息抓取软件(java本科生推荐go,研究生读研的话建议学java)
网页信息抓取软件爬虫爬虫抓取软件自动化代码生成机器学习助手java求职软件爬虫第三方微信端selenium工欲善其事必先利其器手把手教你如何实现微信公众号java登录ahr0cdovl3dlaxhpbi5xcs5jb20vci9dvwhhjarvlxjapynvv2iethcw==(二维码自动识别)
深度学习_ml,
我觉得目前java性能比较大的公司一般不可能用到太简单的,那么对他们的话和价值来说,主要还是推荐go,go框架多,语言简单,而且比java能力更强大,但是我就是按go来的,所以你的这么问话我感觉应该是java本科生推荐go,研究生推荐java工程师,
读研的话建议学java。目前市场上java还是比较饱和的,很多中小公司工作环境都是java,而且java学起来也很容易,就算没有基础的你只要耐下心看看教程也能学会。然后研究生期间再学一点go或python吧,这样你工作的时候就会跟其他人有本质的不同。你说的数据量不大,看看以前做过的项目就能发现java相对于go更容易。如果你是想一夜暴富,可以学个python,大学期间足够你靠它赚钱了。
学了java基本上不必学go或python。会个vc++和shell+python基本上也够了。这就是中国教育的悲哀。
网页信息抓取软件(此前,网页内容抓取软件MetaSeeker为什么没有使用正则表达式提取内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-04 10:06
XSLT 已经编译了 20 年。比较难用的编程语言是Perl和XSL。XSL 很容易学习,但有很多陷阱。即使你想成为一名菜鸟程序员,你也必须了解它的原理。必须了解的几个 XSL 原理和使用技巧。之前,为什么网页内容抓取软件工具包 MetaSeeker 不使用正则表达式来提取内容?XSLT和正则表达式在网页数据提取和屏幕抓取(web scraping, screen scraping)领域的优缺点,有大量可复用的第三方程序库或软件模块进行集成,网页内容抓取制定的规则非常适用。然而,这些优势是有代价的。主要的代价是完全控制 XSLT 需要很长时间的学习和实践。下面总结了掌握 XSLT 的难点。XSLT 功能非常强大,大部分网页内容爬取和网页内容格式化和转换任务都可以通过一个 XSLT 指令文件完成。网页内容抓取软件工具包MetaSeeker自动生成的网页内容抓取规则是一个XSLT文件。在 XSLT 指令文件中,xsl:template 语句将许多指令组织成模块。模块化编程是降低编码成本的有效方法。但是,初学者很容易被 XSLT 的“模块化”所欺骗。大多数网页内容爬取和网页内容格式化和转换任务都可以通过一个XSLT指令文件来完成。网页内容抓取软件工具包MetaSeeker自动生成的网页内容抓取规则是一个XSLT文件。在 XSLT 指令文件中,xsl:template 语句将许多指令组织成模块。模块化编程是降低编码成本的有效方法。但是,初学者很容易被 XSLT 的“模块化”所欺骗。大多数网页内容爬取和网页内容格式化和转换任务都可以通过一个XSLT指令文件来完成。网页内容抓取软件工具包MetaSeeker自动生成的网页内容抓取规则是一个XSLT文件。在 XSLT 指令文件中,xsl:template 语句将许多指令组织成模块。模块化编程是降低编码成本的有效方法。但是,初学者很容易被 XSLT 的“模块化”所欺骗。
其实XSLT处理引擎采取了一种很诡异的方式,你可以想象成这样:有一台机器,两个feed素材分别是XSLT指令和转换后的文档(我们关心的是HTML页面),一个成品用于导出,产品是转换后的文档(即提取的数据),机器不断旋转。这种机器的特点是任何原料进入后按顺序进行加工。例如,如果您觉得目标 HTML 文档需要在一遍之后再次处理,则不可能在同一个处理会话中获取更多信息。是的,就像磁带机一样,数据是按顺序访问的,两者是一样的。这是使用 XSLT 的最大障碍。很容易出错。错误的现象是能抓到的数据没有抓到。如果你脑子里总是有这台机器,你就可以避免这个错误。如果要抓取的数据是表结构的话,上面的问题就不容易暴露出来,XSLT指令文件也可以很简单,但是大部分网页内容都是复杂的树形结构,比如B2B 网站 对于上面的产品分类,大类下有子类,多级嵌套。这是一个树形结构。执行深度嵌套操作需要 XSLT 指令。使用下一节中介绍的几个“模块化”指令非常容易。很好地处理了这个问题,但是上一节中解释的顺序处理器打破了“模块化” 并且实际上在某种程度上变成了伪模块化。手动编写XSLT容易出错,编码-验证-修改循环多次重复。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。手动编写XSLT容易出错,编码-验证-修改循环多次重复。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。手动编写XSLT容易出错,编码-验证-修改循环多次重复。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。
使用FreeFormat提高爬取网站页面提取网页内容数据的准确率详细讲解了帧生成原理,MetaStudio使用FreeFormat技术保证生成的XSLT文件帧以正确的顺序执行,并使用目标页面中的语义标记(例如,微格式和 CSS 选择器),以提高信息提取的准确性;和How to use XSLT to extract a piece of content on a HTML page but not some content 本段展示了如何将手写的XPath表达式和XSLT指令文件片段集成到MetaStudio中间生成的框架中。XSLT XSL 指令集中有几个模块化指令:xsl:template, xsl:for-each xsl:apply-templates, xsl:call-template, plus xsl:if, 您可以使用它编写易于阅读的 XSLT 文件。但是,作为初学者,一定要牢记顺序机,否则很容易被这些模块化指令误导。如果你看看网上关于 XSLT 的讨论,你会发现很多菜鸟都在向老手求助,有的老手甚至建议要避开哪些雷区,例如:xsl:for-each vs. xsl:apply-templates 老手说:不要使用 xsl:for-each,使用 xsl:apply-templates。
在一定程度上确实如此,但在某些情况下需要使用for-each,例如结合xsl:if,首先判断是否存在节点集,然后再使用xsl:for-each代替xsl:应用模板,因为您不希望 XSL 引擎匹配自己。在这种情况下,请记住以下两个要点。XPath XPath 我们常说XSLT 离不开XPath。XPath 必须在上一节解释的模块化指令中使用,例如匹配规则、测试规则和选择规则等。你会发现很多 XPath 并不出色,例如:./p/text(),无法出现在 xsl:template 中,这个 XPath 不是另一个 XPath?如果你脑海中有顺序处理器的形象,这并不难理解。处理 xsl:apply-templates 时,引擎需要在当前节点之后找到匹配的节点或节点集。这 ”。” 运算符是多余的,只能是 p/text()。此原则适用于所有匹配操作。但是,它在 xsl:for-each 中有所不同。它是一条选择规则,可以选择当前(.)节点,或者follow-sibling或preceding-sibling等,也可以应用所有的选择规则。
(上下文节点) (当前节点) 我们在上一节已经提到过当前节点。还有一个概念叫做上下文节点。顺序处理器是一个烦人的设计。有时我们必须回去,但实际上我们不能回去。但是我们可以先暂停机器,停机后在事先没有加工过的原料中搜索再搜索,实际上达到了折返的效果。这是上下文节点和当前节点的作用。由于篇幅所限,我不再赘述。如果您有兴趣,可以阅读 XSL 规范和书籍。另一个要记住的概念是:节点集,这需要你解剖机器,看看原材料的加工过程。如果你有兴趣做你自己的研究。 查看全部
网页信息抓取软件(此前,网页内容抓取软件MetaSeeker为什么没有使用正则表达式提取内容?)
XSLT 已经编译了 20 年。比较难用的编程语言是Perl和XSL。XSL 很容易学习,但有很多陷阱。即使你想成为一名菜鸟程序员,你也必须了解它的原理。必须了解的几个 XSL 原理和使用技巧。之前,为什么网页内容抓取软件工具包 MetaSeeker 不使用正则表达式来提取内容?XSLT和正则表达式在网页数据提取和屏幕抓取(web scraping, screen scraping)领域的优缺点,有大量可复用的第三方程序库或软件模块进行集成,网页内容抓取制定的规则非常适用。然而,这些优势是有代价的。主要的代价是完全控制 XSLT 需要很长时间的学习和实践。下面总结了掌握 XSLT 的难点。XSLT 功能非常强大,大部分网页内容爬取和网页内容格式化和转换任务都可以通过一个 XSLT 指令文件完成。网页内容抓取软件工具包MetaSeeker自动生成的网页内容抓取规则是一个XSLT文件。在 XSLT 指令文件中,xsl:template 语句将许多指令组织成模块。模块化编程是降低编码成本的有效方法。但是,初学者很容易被 XSLT 的“模块化”所欺骗。大多数网页内容爬取和网页内容格式化和转换任务都可以通过一个XSLT指令文件来完成。网页内容抓取软件工具包MetaSeeker自动生成的网页内容抓取规则是一个XSLT文件。在 XSLT 指令文件中,xsl:template 语句将许多指令组织成模块。模块化编程是降低编码成本的有效方法。但是,初学者很容易被 XSLT 的“模块化”所欺骗。大多数网页内容爬取和网页内容格式化和转换任务都可以通过一个XSLT指令文件来完成。网页内容抓取软件工具包MetaSeeker自动生成的网页内容抓取规则是一个XSLT文件。在 XSLT 指令文件中,xsl:template 语句将许多指令组织成模块。模块化编程是降低编码成本的有效方法。但是,初学者很容易被 XSLT 的“模块化”所欺骗。
其实XSLT处理引擎采取了一种很诡异的方式,你可以想象成这样:有一台机器,两个feed素材分别是XSLT指令和转换后的文档(我们关心的是HTML页面),一个成品用于导出,产品是转换后的文档(即提取的数据),机器不断旋转。这种机器的特点是任何原料进入后按顺序进行加工。例如,如果您觉得目标 HTML 文档需要在一遍之后再次处理,则不可能在同一个处理会话中获取更多信息。是的,就像磁带机一样,数据是按顺序访问的,两者是一样的。这是使用 XSLT 的最大障碍。很容易出错。错误的现象是能抓到的数据没有抓到。如果你脑子里总是有这台机器,你就可以避免这个错误。如果要抓取的数据是表结构的话,上面的问题就不容易暴露出来,XSLT指令文件也可以很简单,但是大部分网页内容都是复杂的树形结构,比如B2B 网站 对于上面的产品分类,大类下有子类,多级嵌套。这是一个树形结构。执行深度嵌套操作需要 XSLT 指令。使用下一节中介绍的几个“模块化”指令非常容易。很好地处理了这个问题,但是上一节中解释的顺序处理器打破了“模块化” 并且实际上在某种程度上变成了伪模块化。手动编写XSLT容易出错,编码-验证-修改循环多次重复。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。手动编写XSLT容易出错,编码-验证-修改循环多次重复。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。手动编写XSLT容易出错,编码-验证-修改循环多次重复。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。Web抓取异构数据对象搜索软件工具包MetaSeeker应运而生。MetaSeeker中的MetaStudio工具的原理很简单,就是生成一个XSLT指令框架,这是一个框架时代。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。我们有开发框架(比如Spring框架),网站(cms)框架(比如Drupal),MetaStudio生成XSLT指令框架,按照顺序处理器的原理生成. 屏蔽烦人的顺序处理器的 XSLT 指令框架,用户看到的是真正的模块化。
使用FreeFormat提高爬取网站页面提取网页内容数据的准确率详细讲解了帧生成原理,MetaStudio使用FreeFormat技术保证生成的XSLT文件帧以正确的顺序执行,并使用目标页面中的语义标记(例如,微格式和 CSS 选择器),以提高信息提取的准确性;和How to use XSLT to extract a piece of content on a HTML page but not some content 本段展示了如何将手写的XPath表达式和XSLT指令文件片段集成到MetaStudio中间生成的框架中。XSLT XSL 指令集中有几个模块化指令:xsl:template, xsl:for-each xsl:apply-templates, xsl:call-template, plus xsl:if, 您可以使用它编写易于阅读的 XSLT 文件。但是,作为初学者,一定要牢记顺序机,否则很容易被这些模块化指令误导。如果你看看网上关于 XSLT 的讨论,你会发现很多菜鸟都在向老手求助,有的老手甚至建议要避开哪些雷区,例如:xsl:for-each vs. xsl:apply-templates 老手说:不要使用 xsl:for-each,使用 xsl:apply-templates。
在一定程度上确实如此,但在某些情况下需要使用for-each,例如结合xsl:if,首先判断是否存在节点集,然后再使用xsl:for-each代替xsl:应用模板,因为您不希望 XSL 引擎匹配自己。在这种情况下,请记住以下两个要点。XPath XPath 我们常说XSLT 离不开XPath。XPath 必须在上一节解释的模块化指令中使用,例如匹配规则、测试规则和选择规则等。你会发现很多 XPath 并不出色,例如:./p/text(),无法出现在 xsl:template 中,这个 XPath 不是另一个 XPath?如果你脑海中有顺序处理器的形象,这并不难理解。处理 xsl:apply-templates 时,引擎需要在当前节点之后找到匹配的节点或节点集。这 ”。” 运算符是多余的,只能是 p/text()。此原则适用于所有匹配操作。但是,它在 xsl:for-each 中有所不同。它是一条选择规则,可以选择当前(.)节点,或者follow-sibling或preceding-sibling等,也可以应用所有的选择规则。
(上下文节点) (当前节点) 我们在上一节已经提到过当前节点。还有一个概念叫做上下文节点。顺序处理器是一个烦人的设计。有时我们必须回去,但实际上我们不能回去。但是我们可以先暂停机器,停机后在事先没有加工过的原料中搜索再搜索,实际上达到了折返的效果。这是上下文节点和当前节点的作用。由于篇幅所限,我不再赘述。如果您有兴趣,可以阅读 XSL 规范和书籍。另一个要记住的概念是:节点集,这需要你解剖机器,看看原材料的加工过程。如果你有兴趣做你自己的研究。
网页信息抓取软件(如何通过Java代码实现对网页数据进行指定抓取方法思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-02 08:20
IE浏览器有OLE对象,可以用这个功能提取所有元素的信息,有些软件应该可以。. .
如果你想从头开始,直接匹配文本,写一个提取元素的小程序。. .
使用Java代码指定网页数据爬取方式的思路如下:
导入项目中的Jsoup.jar包
获取url指定的url或者文档指定的body
获取网页中超链接的标题和链接
获取指定博客的内容文章
获取网页中超链接的标题和链接结果
在这个附加文件中写入:
登录用户 = 新登录();
字符串 id = user.GetUserID();
System.out.println(id);
PS:java文件首字母大写,方法首字母小写。
不是有历史页面吗,直接复制粘贴,选择你要的数据,右键复制,在表格中右键粘贴
如果使用之前嗅探过的ForeSpider数据采集软件,就可以了。但是您需要知道应用程序的协议是什么。如果是http、https,可以直接采集。
实时更新也是可能的。软件支持定时采集和一定间隔时间采集。设置间隔时间相当于实时更新。
ForeSpider 直接连接到数据库。数据存储有多种策略,存储前会自动重新加载两次,确保只插入更新后的数据。
有一个免费版本,您可以下载无限功能。
如何从网页中提取数据到excel-:1、点击数据--导入外部数据--新建Web查询。2、勾选我可以识别这个内容,允许播放,点击继续按钮。3、在地址栏输入网站的地址,跳转到这个网站。4、跳转到指定网页,点击箭头按钮,然后将数据导入Excel。Excel表格是完成整个过程的生成数据。
如何从 web 表中提取数据:不要打扰。选择你想要的表格数据,复制粘贴到Excel中,然后就可以导入到自己的数据库中,比如把数据保存成某种格式等。不会带那些不需要的格式。
如何提取网页的数据-:使用WebRequest方法获取网站的数据: private string GetStringByUrl(string strUrl) { WebRequest wrt = WebRequest.Create(strUrl); WebResponse wrse = wrt.GetResponse(); 流 strM = wrse.GetResponseStream(); StreamReader SR = 新...
如何从网页中抓取数据:抓取网页是一个巨大的项目。但总结起来,只有三种方式:1.最原创的方式,手动复制。2.写代码,很多程序员都喜欢这样做,但是很容易采集简单网页,不容易网站可以采集随心所欲。3.估计除非是有特殊喜好,不然大家都不想选上面两个路径,都想更高效更强大,最好是免费的采集器,目前用的最好的采集器是新的优采云采集器,真的是神器,好像解决不了网站。它也是免费的,值得一试。
如何从网页中提取数据-:IE浏览器有OLE对象,可以使用这个功能提取所有元素的信息,有些软件应该可以... 如果要从头开始,那就直接匹配文本并编写一个提取元素的小程序,也可以...
如何从网站中抓取数据-:网络爬虫软件可以抓取数据。建议嗅探 ForeSpider 数据采集 软件。软件可以采集几乎所有互联网上的公开数据,通过可视化的操作流程,从建表、过滤、采集到存储,一步到位。它支持正则表达式操作,并拥有强大的面向对象的脚本语言系统......
如何任意提取网页数据:试试360阅读器或者GOOGLE阅读器,都可以提取数据
如何获取网页数据?- : curl ->oksocket 太低级了,无法获取。一般编程语言都有http协议封装,通常是httpClient.get(" ").responseString或者httpClient.get(" ").body
如何抓取网页上的数据——:1.使用工具分析js最终生成的url是什么,发送请求,发送了什么数据。相关信息请参考:【教程】教你如何使用工具(ie9的f12)分析模拟登录的内部逻辑流程网站(百度首页)如果你不会'不太明白背后的逻辑,可以参考:【组织机构】关于...
如何从网页中提取需要的数据并用JAVA实现:自己实现,推荐你一个工具jsoup,你可以试试 查看全部
网页信息抓取软件(如何通过Java代码实现对网页数据进行指定抓取方法思路)
IE浏览器有OLE对象,可以用这个功能提取所有元素的信息,有些软件应该可以。. .
如果你想从头开始,直接匹配文本,写一个提取元素的小程序。. .
使用Java代码指定网页数据爬取方式的思路如下:
导入项目中的Jsoup.jar包
获取url指定的url或者文档指定的body
获取网页中超链接的标题和链接
获取指定博客的内容文章
获取网页中超链接的标题和链接结果
在这个附加文件中写入:
登录用户 = 新登录();
字符串 id = user.GetUserID();
System.out.println(id);
PS:java文件首字母大写,方法首字母小写。
不是有历史页面吗,直接复制粘贴,选择你要的数据,右键复制,在表格中右键粘贴
如果使用之前嗅探过的ForeSpider数据采集软件,就可以了。但是您需要知道应用程序的协议是什么。如果是http、https,可以直接采集。
实时更新也是可能的。软件支持定时采集和一定间隔时间采集。设置间隔时间相当于实时更新。
ForeSpider 直接连接到数据库。数据存储有多种策略,存储前会自动重新加载两次,确保只插入更新后的数据。
有一个免费版本,您可以下载无限功能。
如何从网页中提取数据到excel-:1、点击数据--导入外部数据--新建Web查询。2、勾选我可以识别这个内容,允许播放,点击继续按钮。3、在地址栏输入网站的地址,跳转到这个网站。4、跳转到指定网页,点击箭头按钮,然后将数据导入Excel。Excel表格是完成整个过程的生成数据。
如何从 web 表中提取数据:不要打扰。选择你想要的表格数据,复制粘贴到Excel中,然后就可以导入到自己的数据库中,比如把数据保存成某种格式等。不会带那些不需要的格式。
如何提取网页的数据-:使用WebRequest方法获取网站的数据: private string GetStringByUrl(string strUrl) { WebRequest wrt = WebRequest.Create(strUrl); WebResponse wrse = wrt.GetResponse(); 流 strM = wrse.GetResponseStream(); StreamReader SR = 新...
如何从网页中抓取数据:抓取网页是一个巨大的项目。但总结起来,只有三种方式:1.最原创的方式,手动复制。2.写代码,很多程序员都喜欢这样做,但是很容易采集简单网页,不容易网站可以采集随心所欲。3.估计除非是有特殊喜好,不然大家都不想选上面两个路径,都想更高效更强大,最好是免费的采集器,目前用的最好的采集器是新的优采云采集器,真的是神器,好像解决不了网站。它也是免费的,值得一试。
如何从网页中提取数据-:IE浏览器有OLE对象,可以使用这个功能提取所有元素的信息,有些软件应该可以... 如果要从头开始,那就直接匹配文本并编写一个提取元素的小程序,也可以...
如何从网站中抓取数据-:网络爬虫软件可以抓取数据。建议嗅探 ForeSpider 数据采集 软件。软件可以采集几乎所有互联网上的公开数据,通过可视化的操作流程,从建表、过滤、采集到存储,一步到位。它支持正则表达式操作,并拥有强大的面向对象的脚本语言系统......
如何任意提取网页数据:试试360阅读器或者GOOGLE阅读器,都可以提取数据
如何获取网页数据?- : curl ->oksocket 太低级了,无法获取。一般编程语言都有http协议封装,通常是httpClient.get(" ").responseString或者httpClient.get(" ").body
如何抓取网页上的数据——:1.使用工具分析js最终生成的url是什么,发送请求,发送了什么数据。相关信息请参考:【教程】教你如何使用工具(ie9的f12)分析模拟登录的内部逻辑流程网站(百度首页)如果你不会'不太明白背后的逻辑,可以参考:【组织机构】关于...
如何从网页中提取需要的数据并用JAVA实现:自己实现,推荐你一个工具jsoup,你可以试试
网页信息抓取软件(什么是百度蜘蛛是怎么实现网页收录的工作过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-02 08:18
搜索引擎的工作过程非常复杂。今天给大家分享一下我所知道的百度蜘蛛实现网页收录。
搜索引擎的工作大致可以分为四个过程。
1、蜘蛛爬行。
2、信息过滤。
3、创建网页索引关键词。
4、用户搜索输出结果。
蜘蛛爬行爬行
当百度蜘蛛来到一个页面时,它会跟随页面上的链接,从这个页面爬到下一个页面,就像一个递归的过程,这不仅是多年的累人工作。例如,当蜘蛛来到我的博客主页时,它会首先读取根目录下的 robots.txt 文件。如果没有禁止搜索引擎抓取,蜘蛛就会开始对网页上的链接进行一一跟踪和抓取。比如我上面的文章“SEO概述|什么是SEO,SEO是做什么的”,引擎会多进程到这个文章所在的页面去爬取信息,等等上,没有尽头。
信息过滤
为了避免重复爬取和爬取网址,搜索引擎会对已爬取和未爬取的地址进行记录。如果你有新的网站,可以去百度官网提交网站网址,引擎会记录下来,归类为未被抓取的网址,然后蜘蛛会使用此表从数据库中提取 URL,访问并爬取页面。
蜘蛛不会收录所有页面,它是严格检查的。蜘蛛在爬取网页内容时,会进行一定程度的重复内容检测。如果网页所在的 网站 权重较低,并且大部分 文章 是抄袭的,那么蜘蛛很可能不喜欢你的 网站,不要保留爬行,不要收录你的网站。
创建网页的 关键词 索引
当蜘蛛爬取页面时,它首先分析页面的文本内容。通过分词技术,将网页内容简化为关键词,将关键词和对应的URL做成表格进行索引。
该指数有正向指数和反向指数。正向索引是网页内容对应的关键词,反向索引是关键词对应的网页信息。
输出结果
当用户搜索某个关键词时,会通过之前建立的索引表进行关键词匹配,通过反向索引表找到关键词对应的页面,对网页进行综合评分通过引擎计算后,根据网页的得分确定网页的排名。 查看全部
网页信息抓取软件(什么是百度蜘蛛是怎么实现网页收录的工作过程)
搜索引擎的工作过程非常复杂。今天给大家分享一下我所知道的百度蜘蛛实现网页收录。
搜索引擎的工作大致可以分为四个过程。
1、蜘蛛爬行。
2、信息过滤。
3、创建网页索引关键词。
4、用户搜索输出结果。
蜘蛛爬行爬行
当百度蜘蛛来到一个页面时,它会跟随页面上的链接,从这个页面爬到下一个页面,就像一个递归的过程,这不仅是多年的累人工作。例如,当蜘蛛来到我的博客主页时,它会首先读取根目录下的 robots.txt 文件。如果没有禁止搜索引擎抓取,蜘蛛就会开始对网页上的链接进行一一跟踪和抓取。比如我上面的文章“SEO概述|什么是SEO,SEO是做什么的”,引擎会多进程到这个文章所在的页面去爬取信息,等等上,没有尽头。
信息过滤
为了避免重复爬取和爬取网址,搜索引擎会对已爬取和未爬取的地址进行记录。如果你有新的网站,可以去百度官网提交网站网址,引擎会记录下来,归类为未被抓取的网址,然后蜘蛛会使用此表从数据库中提取 URL,访问并爬取页面。
蜘蛛不会收录所有页面,它是严格检查的。蜘蛛在爬取网页内容时,会进行一定程度的重复内容检测。如果网页所在的 网站 权重较低,并且大部分 文章 是抄袭的,那么蜘蛛很可能不喜欢你的 网站,不要保留爬行,不要收录你的网站。
创建网页的 关键词 索引
当蜘蛛爬取页面时,它首先分析页面的文本内容。通过分词技术,将网页内容简化为关键词,将关键词和对应的URL做成表格进行索引。
该指数有正向指数和反向指数。正向索引是网页内容对应的关键词,反向索引是关键词对应的网页信息。
输出结果
当用户搜索某个关键词时,会通过之前建立的索引表进行关键词匹配,通过反向索引表找到关键词对应的页面,对网页进行综合评分通过引擎计算后,根据网页的得分确定网页的排名。
网页信息抓取软件( 如何提高百度蜘蛛爬行事有策略的更新频率?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-02 08:16
如何提高百度蜘蛛爬行事有策略的更新频率?(图))
也称为 web、web bot,在 FOAF 社区中,通常称为 Web Chaser),是根据既定规则自动在万维网上自动生成信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
(baiduspider),是一个搜索引擎的自动程序。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后按类别建立索引库,以便用户在百度搜索到你的网站页面、图片、视频等内容搜索引擎 。之所以命名为蜘蛛,是因为该程序具有类似蜘蛛的功能,可以通过铺天盖地的网络来采集互联网业务的信息。
百度蜘蛛的工作原理
蜘蛛是网站和用户之间的信息搬运工,网站的内容通过索引库呈现给用户。
工作过程
索引区开始抓取网页信息,通过临时库对内容进行处理,将一些符合规则的内容带回索引库。将不合格的内容进行清理,最后将合格的内容展示给搜索引擎查询结果。
据XX先生网站介绍,通过日志查询爬取的蜘蛛数量并不多,但收录却非常少。也就是说,内容被爬取了,但是蜘蛛带入索引库的内容却很少。
如果PC移动到适配站点,只想抓取PC端的内容,可以直接移动机器人吗?
百度蜘蛛既有PC/Mobile全食蜘蛛,也有移动端专属蜘蛛。它们的识别命令是一样的,也就是说,只要机器人是百度蜘蛛,百度就无法抓取内容。不管你是想移动机器人还是PC网站都不能用百度蜘蛛机器人。会导致百度无法抓取网站内容。
如何增加百度抓取
1、网站的更新频率
网站的内容需要定期更新高价值内容,所以可以先抢到。中,创建内容的频率,因为蜘蛛爬行是有策略的,网站创建内容越频繁,蜘蛛爬行的频率就越高,所以更新的频率可以提高爬行的频率。例如:小明每天更新10篇文章,其余7天不更新。这种方法是错误的。正确的方法是每天更新一个文章。
2、网站人气
网站 的受欢迎程度是指我们的用户体验。可以,如果用户体验好网站,百度蜘蛛会优先录用。那么这里有人会问,如何提升用户体验呢?其实很简单,首先网站的配色和页面布局一定要合理,最重要的是广告,一定要免去太多的广告,不要让广告掩盖正面内容,否则百度会判断你的网站用户体验很糟糕。
3、合适的入口
下知的入口主要是指网站的外部链接,先爬到下知的站点被跟踪(跟踪)的站点。现在百度对外链做了很大的调整,百度对垃圾外链的过滤非常严格。基本上,如果您在论坛或留言板上发送外部链接,百度会在后台对其进行过滤。但真正高质量的反向链接、排名和爬网很重要。
4、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于经常受到攻击(被黑)的网站,它会严重危害用户。所以,在SEO优化的过程中,要注意网站的安全。
5、历史爬取效果不错
无论百度是排名还是爬虫,历史记录都很重要。如果他们以前作弊,这就像一个人的历史。那会留下污点。网站同样如此。切记不要在网站的优化中作弊,一旦留下污点,会降低百度蜘蛛对站点的信任,影响爬取网站的时间和深度。不断更新高质量的内容非常重要。
6、服务器稳定,抢优先级
2015年以来,百度在服务器稳定性因素的权重上做了很大的提升。服务器稳定性包括稳定性和速度。服务器越快,植物抓取效率越高。服务器越稳定,爬虫的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的事情。 查看全部
网页信息抓取软件(
如何提高百度蜘蛛爬行事有策略的更新频率?(图))
也称为 web、web bot,在 FOAF 社区中,通常称为 Web Chaser),是根据既定规则自动在万维网上自动生成信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
(baiduspider),是一个搜索引擎的自动程序。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后按类别建立索引库,以便用户在百度搜索到你的网站页面、图片、视频等内容搜索引擎 。之所以命名为蜘蛛,是因为该程序具有类似蜘蛛的功能,可以通过铺天盖地的网络来采集互联网业务的信息。
百度蜘蛛的工作原理
蜘蛛是网站和用户之间的信息搬运工,网站的内容通过索引库呈现给用户。
工作过程
索引区开始抓取网页信息,通过临时库对内容进行处理,将一些符合规则的内容带回索引库。将不合格的内容进行清理,最后将合格的内容展示给搜索引擎查询结果。
据XX先生网站介绍,通过日志查询爬取的蜘蛛数量并不多,但收录却非常少。也就是说,内容被爬取了,但是蜘蛛带入索引库的内容却很少。
如果PC移动到适配站点,只想抓取PC端的内容,可以直接移动机器人吗?
百度蜘蛛既有PC/Mobile全食蜘蛛,也有移动端专属蜘蛛。它们的识别命令是一样的,也就是说,只要机器人是百度蜘蛛,百度就无法抓取内容。不管你是想移动机器人还是PC网站都不能用百度蜘蛛机器人。会导致百度无法抓取网站内容。
如何增加百度抓取
1、网站的更新频率
网站的内容需要定期更新高价值内容,所以可以先抢到。中,创建内容的频率,因为蜘蛛爬行是有策略的,网站创建内容越频繁,蜘蛛爬行的频率就越高,所以更新的频率可以提高爬行的频率。例如:小明每天更新10篇文章,其余7天不更新。这种方法是错误的。正确的方法是每天更新一个文章。
2、网站人气
网站 的受欢迎程度是指我们的用户体验。可以,如果用户体验好网站,百度蜘蛛会优先录用。那么这里有人会问,如何提升用户体验呢?其实很简单,首先网站的配色和页面布局一定要合理,最重要的是广告,一定要免去太多的广告,不要让广告掩盖正面内容,否则百度会判断你的网站用户体验很糟糕。
3、合适的入口
下知的入口主要是指网站的外部链接,先爬到下知的站点被跟踪(跟踪)的站点。现在百度对外链做了很大的调整,百度对垃圾外链的过滤非常严格。基本上,如果您在论坛或留言板上发送外部链接,百度会在后台对其进行过滤。但真正高质量的反向链接、排名和爬网很重要。
4、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于经常受到攻击(被黑)的网站,它会严重危害用户。所以,在SEO优化的过程中,要注意网站的安全。
5、历史爬取效果不错
无论百度是排名还是爬虫,历史记录都很重要。如果他们以前作弊,这就像一个人的历史。那会留下污点。网站同样如此。切记不要在网站的优化中作弊,一旦留下污点,会降低百度蜘蛛对站点的信任,影响爬取网站的时间和深度。不断更新高质量的内容非常重要。
6、服务器稳定,抢优先级
2015年以来,百度在服务器稳定性因素的权重上做了很大的提升。服务器稳定性包括稳定性和速度。服务器越快,植物抓取效率越高。服务器越稳定,爬虫的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的事情。
网页信息抓取软件(发明专利技术涉及一种可配置化的数据抓取方法和步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-26 11:34
本发明专利技术涉及一种可配置的数据抓取方法,包括以下步骤:确定需要抓取的目标网站,并配置目标网站的基本信息。站点配置页面,包括站点类型、站点名称、目标编号、页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面配置爬取服务的启动时间;
一种可配置的数据抓取方法及装置
下载所有详细的技术数据
【技术实现步骤总结】
一种可配置的数据采集方法及装置
本专利技术涉及一种可配置的数据采集方法及装置,属于数据采集
技术介绍
目前实现数据抓取的方式有很多,包括开源代码和直接提供服务的商业工具,但这些基本上都是针对不同的目标网站,根据网站硬编码的特点实现 是的,这个实现有一定的局限性。一旦要捕获的范围变大,或者目标网站发生变化,解决问题的唯一方法就是修改之前实现的编码。这造成了一定的资源浪费,影响了执行周期。灵活性不够,还受限于实施的人员技能。
技术实现思路
为了解决现有技术中存在的上述问题,专利技术提供了一种可配置的数据采集方法,可以有效解决多次网站的采集,即使面对网站的变化的情况下,也可以通过修改配置来完成配套变更,缩短建设周期,也可以由普通实施者完成。本专利技术的技术方案如下:该技术方案是一种可配置的数据抓取方法,包括以下步骤:确定要抓取的目标网站,在站点配置页面配置目标网站的基本信息,包括站点类型、站点名称、目标编号、页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;管理页面配置启动爬虫服务的时间;生成爬取作业,从目标网站抓取数据,具体步骤如下:根据爬取服务启动的时间,开始执行作业;目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码,登录目标网站>;根据网址的基本信息,打开抓取数据的网址,对目标网站进行固定操作,抓取网页内容。进一步判断目标网站是否有验证码登录步骤,如果有验证码登录步骤,在输入验证码配置页面配置输入验证码的基本信息,包括验证码图片类型,验证码图片。验证码图片的语言、字符数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标<
进一步的,还包括用户密码验证步骤,具体为:选择一个或多个需要验证的用户,点击验证;客户端依次验证所选用户的登录账号/密码,并在后台生成。验证结果,验证结果包括登录成功和登录失败。如果验证结果是登录失败,也会在后台产生错误信息,并列出相关错误信息日志地址;点击查询获取验证结果,如验证结果为登录失败,则根据错误信息日志地址获取错误信息日志,分析并执行错误解决。进一步,在URL参数配置页面配置一个值为变量的请求参数,包括参数名称、参数类型、参数值和参数描述。技术方案2 一种可配置的数据抓取装置,包括内存和处理器,内存中存储有指令,指令用于被处理器加载并执行以下步骤:确定要抓取的目标网站 ,并在站点配置页面配置目标网站的基本信息,包括站点类型、站点名称、目标编号、页面编码格式;配置用户配置页面登录目标 网站 用户的基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面配置启动爬取服务的时间;生成一个爬虫作业,从目标网站爬取数据,具体步骤如下: 根据启动爬虫服务时开始执行作业;根据目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码,登录目标网站;根据网址的基本信息,打开抓取数据的网址,
进一步判断目标网站是否有验证码登录步骤,如果有验证码登录步骤,在输入验证码配置页面配置输入验证码的基本信息,包括验证码图片类型,验证码图片。验证码图片的语言、字符数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取验证码图片中的目标网站,根据验证码中输入的基本信息识别验证码图片登录目标网站,具体步骤如下:使用网络爬虫从目标网站图片中爬取验证码;采用OCR技术,根据输入的验证码基本信息,自动识别验证码图片,获取验证码图片中的验证码信息;在验证码输入框中填写验证码信息并提交登录;如果登录失败,则转为人工识别验证码图片,在验证码输入框中输入验证码进行登录。另外,还包括用户密码验证步骤,具体如下:选择一个或多个需要验证的用户,点击验证;客户端依次验证所选用户的登录帐户/密码,并在后台生成它们。验证结果,验证结果包括登录成功和登录失败。如果验证结果是登录失败,也会在后台产生错误信息,并列出相关错误信息日志地址;点击查询获取验证结果,如验证结果为登录失败,则根据错误信息日志地址获取错误信息日志,分析并执行错误解决。
进一步的,在URL参数配置页面上配置了一个值为变量的请求参数,包括参数名称、参数类型、参数取值和参数描述。该专利技术具有以下有益效果:1、该专利技术是一种可配置的数据抓取方式,解构了数据抓取过程中的每一个关键环节,让操作者不需要专业的爬虫编码技能,就可以完成一个网站 的数据采集作业;无需投入高端人员,数据采集成本可控。附图说明图。附图说明图1是本专利技术实施例的流程图;无花果。图2是站点配置的示例图;无花果。图3是实施例中网站的源代码示例图;无花果。图4是用户配置的示例图;图5是抓取URL配置示例图。图6是寻呼表达配置的示例图。图7是调度管理配置示例图。图8是验证码输入示例图。图9为用户账号密码验证图10为URL参数配置示例图。图11是通过httpwatch获取网站信息的示例图。具体实施方式下面结合附图和具体实施例对本专利技术进行详细说明。实施例1 参见图1-11,一种可配置的数据捕获方法包括以下步骤:确定需要捕获的目标网站,在站点配置页面配置目标网站基本信息,包括站点类型、站点名称、目标编号、页面编码格式;如图2,以配置永辉超市网站为例,站点类型根据配置的永辉超市网站类型,选择零售商;站点名称填写永辉超市,名称可自定义;目标数量可定制,数量一般由需方提供;页面编码格式由各个网站开发定义,见图3,打开永辉超市网站,右键查看页面源代码,从源代码。从图3可以看出,页面的编码格式为UTF-8。编码格式统一,所以页面编码格式选择UTF-8。在用户配置页面,配置可以登录的目标网站
【技术保护点】
1.一种可配置的数据抓取方法,其特征在于包括以下步骤:确定要抓取的目标网站,在站点配置页面配置目标网站基本信息,包括站点类型、站点名称、目标编号和页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面上配置启动抓取服务的时间;创造一个抢手的工作,从目标网站抓取数据,具体步骤如下:根据抓取服务启动的时间开始执行job;根据目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。
【技术特点总结】
1.一种可配置的数据抓取方法,其特征在于包括以下步骤:确定要抓取的目标网站,在站点配置页面配置目标网站基本信息,包括站点类型、站点名称、目标编号和页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面上配置启动抓取服务的时间;创造一个抢手的工作,从目标网站抓取数据,具体步骤如下:根据抓取服务启动的时间开始执行job;根据目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。2.根据权利要求1所述的一种可配置的数据抓取方法,其特征在于:判断目标网站是否有验证码登录步骤,如果有验证码登录步骤,然后在验证码输入配置页面配置验证码输入的基本信息,包括验证码图片类型、验证码图片语言、验证码图片字符个数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 包括验证码图片类型、验证码图片语言、验证码图片字符个数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 包括验证码图片类型、验证码图片语言、验证码图片字符个数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫
3.根据权利要求1所述的一种可配置的数据抓取方法,其特征在于,还包括用户密码验证步骤,如下:选择一个或多个需要验证的用户,点击进行验证;客户端依次验证选中用户的登录账号/密码,并在后台生成验证结果,验证结果包括登录成功和登录失败。后台生成错误信息并列出相关错误信息日志地址;点击查询获取验证结果,若验证结果为登录失败,则根据错误信息日志地址获取错误信息日志,分析错误执行错误获取解决。4.根据权利要求1所述的可配置数据采集方法,其特征在于:在URL参数配置页面配置一个值为变量的请求参数,包括参数名称、参数类型、参数值和参数说明。5.一种可配置的数据捕获设备,它...
【专利技术性质】
技术研发人员:邱涛、邱水文、陈成乐、
申请人(专利权)持有人:,
类型:发明
国家、省、市:福建,35
下载所有详细的技术数据 我是该专利的所有者 查看全部
网页信息抓取软件(发明专利技术涉及一种可配置化的数据抓取方法和步骤)
本发明专利技术涉及一种可配置的数据抓取方法,包括以下步骤:确定需要抓取的目标网站,并配置目标网站的基本信息。站点配置页面,包括站点类型、站点名称、目标编号、页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面配置爬取服务的启动时间;
一种可配置的数据抓取方法及装置
下载所有详细的技术数据
【技术实现步骤总结】
一种可配置的数据采集方法及装置
本专利技术涉及一种可配置的数据采集方法及装置,属于数据采集
技术介绍
目前实现数据抓取的方式有很多,包括开源代码和直接提供服务的商业工具,但这些基本上都是针对不同的目标网站,根据网站硬编码的特点实现 是的,这个实现有一定的局限性。一旦要捕获的范围变大,或者目标网站发生变化,解决问题的唯一方法就是修改之前实现的编码。这造成了一定的资源浪费,影响了执行周期。灵活性不够,还受限于实施的人员技能。
技术实现思路
为了解决现有技术中存在的上述问题,专利技术提供了一种可配置的数据采集方法,可以有效解决多次网站的采集,即使面对网站的变化的情况下,也可以通过修改配置来完成配套变更,缩短建设周期,也可以由普通实施者完成。本专利技术的技术方案如下:该技术方案是一种可配置的数据抓取方法,包括以下步骤:确定要抓取的目标网站,在站点配置页面配置目标网站的基本信息,包括站点类型、站点名称、目标编号、页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;管理页面配置启动爬虫服务的时间;生成爬取作业,从目标网站抓取数据,具体步骤如下:根据爬取服务启动的时间,开始执行作业;目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码,登录目标网站>;根据网址的基本信息,打开抓取数据的网址,对目标网站进行固定操作,抓取网页内容。进一步判断目标网站是否有验证码登录步骤,如果有验证码登录步骤,在输入验证码配置页面配置输入验证码的基本信息,包括验证码图片类型,验证码图片。验证码图片的语言、字符数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标<
进一步的,还包括用户密码验证步骤,具体为:选择一个或多个需要验证的用户,点击验证;客户端依次验证所选用户的登录账号/密码,并在后台生成。验证结果,验证结果包括登录成功和登录失败。如果验证结果是登录失败,也会在后台产生错误信息,并列出相关错误信息日志地址;点击查询获取验证结果,如验证结果为登录失败,则根据错误信息日志地址获取错误信息日志,分析并执行错误解决。进一步,在URL参数配置页面配置一个值为变量的请求参数,包括参数名称、参数类型、参数值和参数描述。技术方案2 一种可配置的数据抓取装置,包括内存和处理器,内存中存储有指令,指令用于被处理器加载并执行以下步骤:确定要抓取的目标网站 ,并在站点配置页面配置目标网站的基本信息,包括站点类型、站点名称、目标编号、页面编码格式;配置用户配置页面登录目标 网站 用户的基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面配置启动爬取服务的时间;生成一个爬虫作业,从目标网站爬取数据,具体步骤如下: 根据启动爬虫服务时开始执行作业;根据目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码,登录目标网站;根据网址的基本信息,打开抓取数据的网址,
进一步判断目标网站是否有验证码登录步骤,如果有验证码登录步骤,在输入验证码配置页面配置输入验证码的基本信息,包括验证码图片类型,验证码图片。验证码图片的语言、字符数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取验证码图片中的目标网站,根据验证码中输入的基本信息识别验证码图片登录目标网站,具体步骤如下:使用网络爬虫从目标网站图片中爬取验证码;采用OCR技术,根据输入的验证码基本信息,自动识别验证码图片,获取验证码图片中的验证码信息;在验证码输入框中填写验证码信息并提交登录;如果登录失败,则转为人工识别验证码图片,在验证码输入框中输入验证码进行登录。另外,还包括用户密码验证步骤,具体如下:选择一个或多个需要验证的用户,点击验证;客户端依次验证所选用户的登录帐户/密码,并在后台生成它们。验证结果,验证结果包括登录成功和登录失败。如果验证结果是登录失败,也会在后台产生错误信息,并列出相关错误信息日志地址;点击查询获取验证结果,如验证结果为登录失败,则根据错误信息日志地址获取错误信息日志,分析并执行错误解决。
进一步的,在URL参数配置页面上配置了一个值为变量的请求参数,包括参数名称、参数类型、参数取值和参数描述。该专利技术具有以下有益效果:1、该专利技术是一种可配置的数据抓取方式,解构了数据抓取过程中的每一个关键环节,让操作者不需要专业的爬虫编码技能,就可以完成一个网站 的数据采集作业;无需投入高端人员,数据采集成本可控。附图说明图。附图说明图1是本专利技术实施例的流程图;无花果。图2是站点配置的示例图;无花果。图3是实施例中网站的源代码示例图;无花果。图4是用户配置的示例图;图5是抓取URL配置示例图。图6是寻呼表达配置的示例图。图7是调度管理配置示例图。图8是验证码输入示例图。图9为用户账号密码验证图10为URL参数配置示例图。图11是通过httpwatch获取网站信息的示例图。具体实施方式下面结合附图和具体实施例对本专利技术进行详细说明。实施例1 参见图1-11,一种可配置的数据捕获方法包括以下步骤:确定需要捕获的目标网站,在站点配置页面配置目标网站基本信息,包括站点类型、站点名称、目标编号、页面编码格式;如图2,以配置永辉超市网站为例,站点类型根据配置的永辉超市网站类型,选择零售商;站点名称填写永辉超市,名称可自定义;目标数量可定制,数量一般由需方提供;页面编码格式由各个网站开发定义,见图3,打开永辉超市网站,右键查看页面源代码,从源代码。从图3可以看出,页面的编码格式为UTF-8。编码格式统一,所以页面编码格式选择UTF-8。在用户配置页面,配置可以登录的目标网站
【技术保护点】
1.一种可配置的数据抓取方法,其特征在于包括以下步骤:确定要抓取的目标网站,在站点配置页面配置目标网站基本信息,包括站点类型、站点名称、目标编号和页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面上配置启动抓取服务的时间;创造一个抢手的工作,从目标网站抓取数据,具体步骤如下:根据抓取服务启动的时间开始执行job;根据目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。
【技术特点总结】
1.一种可配置的数据抓取方法,其特征在于包括以下步骤:确定要抓取的目标网站,在站点配置页面配置目标网站基本信息,包括站点类型、站点名称、目标编号和页面编码格式;在用户配置页面配置可登录目标网站的用户基本信息,包括用户类型、登录账号/密码、用户代码、用户名;在爬取URL配置页面配置爬取登录和爬取数据的基本URL信息,包括URL名称、请求时的URL地址、上层URL、URL类型、请求方式、URL后缀类型;在调度管理页面上配置启动抓取服务的时间;创造一个抢手的工作,从目标网站抓取数据,具体步骤如下:根据抓取服务启动的时间开始执行job;根据目标网站的基本信息,打开目标网站;根据目标网站的用户基本信息,输入登录账号/密码登录目标网站;根据URL的基本信息,打开抓取数据的URL,对目标网站进行固定操作,抓取网页内容。2.根据权利要求1所述的一种可配置的数据抓取方法,其特征在于:判断目标网站是否有验证码登录步骤,如果有验证码登录步骤,然后在验证码输入配置页面配置验证码输入的基本信息,包括验证码图片类型、验证码图片语言、验证码图片字符个数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 包括验证码图片类型、验证码图片语言、验证码图片字符个数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 包括验证码图片类型、验证码图片语言、验证码图片字符个数、验证码大小写;如果没有验证码登录步骤,跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫 跳过验证码输入配置;如果目标网站有验证码登录步骤,则抓取目标网站中的验证码图片,根据验证码输入的基本信息识别验证码图片登录target网站,具体步骤如下:使用来自目标网站的网络爬虫
3.根据权利要求1所述的一种可配置的数据抓取方法,其特征在于,还包括用户密码验证步骤,如下:选择一个或多个需要验证的用户,点击进行验证;客户端依次验证选中用户的登录账号/密码,并在后台生成验证结果,验证结果包括登录成功和登录失败。后台生成错误信息并列出相关错误信息日志地址;点击查询获取验证结果,若验证结果为登录失败,则根据错误信息日志地址获取错误信息日志,分析错误执行错误获取解决。4.根据权利要求1所述的可配置数据采集方法,其特征在于:在URL参数配置页面配置一个值为变量的请求参数,包括参数名称、参数类型、参数值和参数说明。5.一种可配置的数据捕获设备,它...
【专利技术性质】
技术研发人员:邱涛、邱水文、陈成乐、
申请人(专利权)持有人:,
类型:发明
国家、省、市:福建,35
下载所有详细的技术数据 我是该专利的所有者
网页信息抓取软件(网页信息抓取软件:说说urllib2是怎么抓取的(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-26 09:12
网页信息抓取软件:说说urllib2是怎么抓取的下面我将说说怎么抓取1.所以是请求请求实质的获取方法为通过浏览器来获取http协议的接口,由于http协议支持无状态,无状态请求是未完成请求(对于没有完成状态来说,每次请求结果都将会一样的)所以怎么来实现无状态协议呢,就是通过http协议的状态码来区分状态的可区分,低于60就证明是未完成请求;urllib2结合get/post这几种方法来实现抓取2.怎么抓取图片http协议这两个方法返回cookie字段来记录您是否访问图片如何抓取图片urllib3结合post-get抓取图片方法post抓取图片是通过post来传递图片的信息,post也有一定的概率会传递cookie信息不可能实现像http协议那么完全不考虑cookie3.怎么抓取qq图片qq号码是需要我们配置认证机制的,才能传递图片,怎么来配置这种认证机制呢传递的内容一般为:qq号、手机号码或者固定编号(如果固定编号就传递数字0到9好了),传递的具体内容得看对方,一般传递的图片信息4.通过post来传递图片url地址urllib3结合get/post抓取图片urllib3可以进行信息的匹配关键词/邮箱/qq号、/abc等为跳转的锚值,一般输入一个地址的时候,得传递一个ip,如果想要获取图片地址,可以通过ip来进行匹配,数字+空格5.传递图片下载地址,返回该地址6.单方面内容抓取请求一般urllib2加载页面,是没有返回url的,urllib2对于http协议的传递信息,加了list-items,也就是将该地址对应的一个列表放进去,并返回给对方。
不加cookie/token,只要他也给出了该页面对应的图片地址,我们就能抓取7.多方面信息抓取还是结合post抓取图片urllib3结合get/post抓取图片或者通过ajax请求返回另外的url抓取图片返回大概信息对方返回article地址我们只需要加一个callback一样的调用token即可,返回的内容只用一个参数8.传递多个url地址,抓取多个图片这里不加载数据只抓取,其实就是对方返回一个url,我们可以将同一个页面给对方多次抓取,总之不要放弃找到对方需要的结果为主9.通过发送图片数据来抓取图片发送完图片数据即抓取成功10.高级抓取:path和name11.针对urllib2:请求主要有两个请求方法get/post这两个请求方法请求的内容都是请求头部,就跟你上网购物时,需要的主要域名或者电话一样我们对应哪个方法,就用哪个方法即可urllib2对应的请求方法有post和get,还有一个后面补充下,也是需要通过nginx来配置的,具体:nginx的we。 查看全部
网页信息抓取软件(网页信息抓取软件:说说urllib2是怎么抓取的(组图))
网页信息抓取软件:说说urllib2是怎么抓取的下面我将说说怎么抓取1.所以是请求请求实质的获取方法为通过浏览器来获取http协议的接口,由于http协议支持无状态,无状态请求是未完成请求(对于没有完成状态来说,每次请求结果都将会一样的)所以怎么来实现无状态协议呢,就是通过http协议的状态码来区分状态的可区分,低于60就证明是未完成请求;urllib2结合get/post这几种方法来实现抓取2.怎么抓取图片http协议这两个方法返回cookie字段来记录您是否访问图片如何抓取图片urllib3结合post-get抓取图片方法post抓取图片是通过post来传递图片的信息,post也有一定的概率会传递cookie信息不可能实现像http协议那么完全不考虑cookie3.怎么抓取qq图片qq号码是需要我们配置认证机制的,才能传递图片,怎么来配置这种认证机制呢传递的内容一般为:qq号、手机号码或者固定编号(如果固定编号就传递数字0到9好了),传递的具体内容得看对方,一般传递的图片信息4.通过post来传递图片url地址urllib3结合get/post抓取图片urllib3可以进行信息的匹配关键词/邮箱/qq号、/abc等为跳转的锚值,一般输入一个地址的时候,得传递一个ip,如果想要获取图片地址,可以通过ip来进行匹配,数字+空格5.传递图片下载地址,返回该地址6.单方面内容抓取请求一般urllib2加载页面,是没有返回url的,urllib2对于http协议的传递信息,加了list-items,也就是将该地址对应的一个列表放进去,并返回给对方。
不加cookie/token,只要他也给出了该页面对应的图片地址,我们就能抓取7.多方面信息抓取还是结合post抓取图片urllib3结合get/post抓取图片或者通过ajax请求返回另外的url抓取图片返回大概信息对方返回article地址我们只需要加一个callback一样的调用token即可,返回的内容只用一个参数8.传递多个url地址,抓取多个图片这里不加载数据只抓取,其实就是对方返回一个url,我们可以将同一个页面给对方多次抓取,总之不要放弃找到对方需要的结果为主9.通过发送图片数据来抓取图片发送完图片数据即抓取成功10.高级抓取:path和name11.针对urllib2:请求主要有两个请求方法get/post这两个请求方法请求的内容都是请求头部,就跟你上网购物时,需要的主要域名或者电话一样我们对应哪个方法,就用哪个方法即可urllib2对应的请求方法有post和get,还有一个后面补充下,也是需要通过nginx来配置的,具体:nginx的we。
网页信息抓取软件(网页信息抓取软件推荐。(二)网页抓取商品)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-21 16:01
网页信息抓取软件推荐。我在上周,将php自带的信息提取功能给一个上班的小妹让她抓取销售单据,之后整理后交给我在合适的情况用微信审核发给我。总的来说,搜集微信上购物的信息并将之转成php中对应的信息。我觉得如果可以抓取一个人的微信好友,把个人信息放到一个批量的二维码或者下载进excel也没什么太大问题。至于把内容进到云端,那也完全没必要。如果有一个网页,结合php的文本提取,完全可以解决这个问题。
关于这个我也思考过,我觉得最大的问题不是是否可以抓取到商品,因为抓取商品很容易。关键在于是否抓取到后续的营销,做微商的都知道微商是靠产品引流的,然后在微信上进行推广。以及你平时和客户沟通的内容。希望这个回答可以帮助到你。
销售信息,可以结合结合现在社群营销的方式来实现。比如是否可以利用爬虫工具抓取各个群的聊天记录?客户的购买清单?销售图谱等。
可以抓取到,但是对于某一特定时间特定地点的人群会存在特定的差异性。所以针对这个实际情况和需求,该产品还需要更加具体方面的定位去满足客户需求。
抓取服务器抓不到,
实际数据信息的抓取我们是可以做到的,而且你可以把信息传给我们,我们后期可以整理成一套分析报告告诉你针对什么人群需要针对什么信息进行分析。 查看全部
网页信息抓取软件(网页信息抓取软件推荐。(二)网页抓取商品)
网页信息抓取软件推荐。我在上周,将php自带的信息提取功能给一个上班的小妹让她抓取销售单据,之后整理后交给我在合适的情况用微信审核发给我。总的来说,搜集微信上购物的信息并将之转成php中对应的信息。我觉得如果可以抓取一个人的微信好友,把个人信息放到一个批量的二维码或者下载进excel也没什么太大问题。至于把内容进到云端,那也完全没必要。如果有一个网页,结合php的文本提取,完全可以解决这个问题。
关于这个我也思考过,我觉得最大的问题不是是否可以抓取到商品,因为抓取商品很容易。关键在于是否抓取到后续的营销,做微商的都知道微商是靠产品引流的,然后在微信上进行推广。以及你平时和客户沟通的内容。希望这个回答可以帮助到你。
销售信息,可以结合结合现在社群营销的方式来实现。比如是否可以利用爬虫工具抓取各个群的聊天记录?客户的购买清单?销售图谱等。
可以抓取到,但是对于某一特定时间特定地点的人群会存在特定的差异性。所以针对这个实际情况和需求,该产品还需要更加具体方面的定位去满足客户需求。
抓取服务器抓不到,
实际数据信息的抓取我们是可以做到的,而且你可以把信息传给我们,我们后期可以整理成一套分析报告告诉你针对什么人群需要针对什么信息进行分析。
网页信息抓取软件(告诉搜索引擎如何索引您的网站机器人元指令(或“元标签”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-20 02:01
告诉搜索引擎如何索引您的 网站bots 元指令
元指令(或“元标记”)是您可以向搜索引擎提供有关您希望如何处理您的网页的说明。
您可以告诉搜索引擎爬虫“不要在搜索结果中将此页面编入索引”或“不要将任何链接资产传递给任何页面链接”。这些指令通过 HTML 页面中的 Robots 元标记(最常用)或 HTTP 标头中的 X-Robots-Tag 执行。
机器人元标记
机器人元标记可用于网页的 HTML。它可以排除所有或特定的搜索引擎。以下是最常见的元指令以及您可以应用它们的情况。
index/noindex 告诉引擎是否应该抓取页面并将其保存在搜索引擎的索引中以供检索。如果您选择使用“noindex”,则意味着您要从搜索结果中排除页面。默认情况下,搜索引擎假定它们可以索引所有页面,因此无需使用“index”值。
follow/nofollow 告诉搜索引擎是否应该关注页面上的链接。“关注”会导致机器人关注您页面上的链接并将链接权益传递给这些 URL。或者,如果您选择使用“nofollow”,搜索引擎将不会关注或将任何链接兴趣传递给页面上的链接。默认情况下,假定所有页面都具有“关注”属性。
noarchive 用于限制搜索引擎保存页面的缓存副本。默认情况下,引擎将保留其已编入索引的所有页面的可见副本,搜索者可以通过搜索结果中的缓存链接访问这些页面。
以下是 metabot noindex、nofollow 标签的示例:
...
此示例将所有搜索引擎排除在索引页面和跟踪页面的任何链接之外。如果要排除多个爬虫,例如 googlebot 和 bing,可以使用多个 bot 排除标记。 查看全部
网页信息抓取软件(告诉搜索引擎如何索引您的网站机器人元指令(或“元标签”)
告诉搜索引擎如何索引您的 网站bots 元指令
元指令(或“元标记”)是您可以向搜索引擎提供有关您希望如何处理您的网页的说明。
您可以告诉搜索引擎爬虫“不要在搜索结果中将此页面编入索引”或“不要将任何链接资产传递给任何页面链接”。这些指令通过 HTML 页面中的 Robots 元标记(最常用)或 HTTP 标头中的 X-Robots-Tag 执行。
机器人元标记
机器人元标记可用于网页的 HTML。它可以排除所有或特定的搜索引擎。以下是最常见的元指令以及您可以应用它们的情况。
index/noindex 告诉引擎是否应该抓取页面并将其保存在搜索引擎的索引中以供检索。如果您选择使用“noindex”,则意味着您要从搜索结果中排除页面。默认情况下,搜索引擎假定它们可以索引所有页面,因此无需使用“index”值。
follow/nofollow 告诉搜索引擎是否应该关注页面上的链接。“关注”会导致机器人关注您页面上的链接并将链接权益传递给这些 URL。或者,如果您选择使用“nofollow”,搜索引擎将不会关注或将任何链接兴趣传递给页面上的链接。默认情况下,假定所有页面都具有“关注”属性。
noarchive 用于限制搜索引擎保存页面的缓存副本。默认情况下,引擎将保留其已编入索引的所有页面的可见副本,搜索者可以通过搜索结果中的缓存链接访问这些页面。
以下是 metabot noindex、nofollow 标签的示例:
...
此示例将所有搜索引擎排除在索引页面和跟踪页面的任何链接之外。如果要排除多个爬虫,例如 googlebot 和 bing,可以使用多个 bot 排除标记。
网页信息抓取软件(陈前进:搜寻引擎蜘蛛和网页的三大问题(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-20 02:00
搜索引擎蜘蛛和网页的三大问题
陈千金
1
.
1. 搜索引擎蜘蛛能找到你的网页吗?
2. 搜索引擎蜘蛛找到网页后可以抓取吗?
获取网页
三、搜索引擎蜘蛛爬取网页后,能否
可以提取有用的信息
2
.
他们的报告并非完全免费供搜索者查看,因此需要向网络蜘蛛提供相应的用户名和密码;网络蜘蛛可以通过给定的权限抓取这些网页以提供搜索;并且当搜索者点击查看网页时,搜索者还需要提供相应的权限验证;
10
.
⑵网站和网络蜘蛛
网络蜘蛛需要爬取网页,这与普通的访问不同。如果没有掌握好,会导致网站服务器负担过重;每个网络蜘蛛都有自己的名字。网站表明你的身份;网络蜘蛛在抓取网页时会发送一个请求。在这个请求中,有一个名为 User-agent 的字段,用于标识网络蜘蛛的身份:
谷歌网络蜘蛛被识别为 GoogleBot,
百度网络蜘蛛的标志是BaiDuSpider,
雅虎网络蜘蛛被识别为 Inktomi Slurp;
如果网站上有访问日志记录(robots.txt),网站管理员可以知道哪些搜索引擎蜘蛛访问过,何时访问过,读取了多少数据等;如果 网站 管理器发现蜘蛛有问题,它会通过它的 ID 联系它的主人;
11
.
现在一般的网站希望搜索引擎能更全面的抓取自己的网站网页,因为这样可以让更多的访问者通过搜索引擎找到这个网站;这个网站的网页爬取比较全面,网站管理员可以创建网站地图,即Site Map;很多网络蜘蛛都会把sitemap.htm文件作为网站网页爬取的入口,网站管理员可以把网站内部所有网页的链接都放在这个文件里,然后网络蜘蛛可以轻松抓取整个 网站 ,防止部分网页遗漏,同时也减轻了 网站 服务器的负担;(Google 专门为 网站 管理员提供 XML Sitemaps)
12
.
(3) 网络蜘蛛提取内容
搜索引擎建立网页索引,处理对象为文本文件;对于网络蜘蛛来说,爬取的网页包括各种格式。
包括html、图片、doc、pdf、多媒体、动态网页等格式;
抓取这些文件后,需要提取这些文件中的文本信息;这些文档信息的精确提取一方面对搜索引擎的搜索准确性起着重要作用,另一方面对网络蜘蛛正确跟踪其他链接也有积极作用。影响;
对于doc、pdf等文档,以及专业厂商提供的软件生成的文档,厂商会提供相应的文本提取接口
由于目前主流的网站大部分都是用HTML编写的,这里就泛泛的说一下HTML;
13
.
HTML有自己的语法,它使用不同的命令标识符来表示不同的字体、颜色、位置和其他布局,例如:、、等。在提取文本信息时,需要过滤掉这些标识符;过滤标识符并不难,由于这些标识符有一定的规定,只需要根据不同的标识符获取相应的信息即可;
但是在识别这个信息的时候,需要同时记录很多布局信息,比如文字的字体大小,是否是标题,是否显示为粗体,是否是关键词页面的重要性等页面的重要性;
同时,对于HTML页面,除了标题和正文外,还会有很多广告链接和公共频道链接。这些链接与正文无关。在提取网页内容的时候,也需要过滤掉这些无用的链接;
比如某网站有一个“医院介绍”频道。由于网站中每个网页都有导航栏,如果不过滤导航栏中的链接,在搜索“产品介绍”时,会搜索到网站中的每个网页,这无疑会带来大量的垃圾邮件;
14
.
那么如何用 ASP 构建一个网络蜘蛛呢?答案是:互联网传输控制(ITC information transfer control);Microsoft 提供的这种控制将使您能够通过 ASP 程序访问 Internet 资源;您可以使用 ITC 搜索网页、访问 FTP 服务器,甚至发送电子邮件标头;
有几个缺陷必须首先解释;首先,ASP无权访问Windows注册表,这使得一些通常由ITC保留的常量和值无法使用;通常可以将 ITC 设置为“不使用默认值”来解决这个问题,需要在每次运行时指定该值;另一个更严重的问题是关于许可证的问题;因为ASP没有调用License Manager(Windows中的一个功能,可以保证组件和控制合法使用)的能力,那么当License Manager检查当前组件的密钥密码并与Windows注册表进行比较时,如果发现它们不同,则组件将无法工作;所以, 查看全部
网页信息抓取软件(陈前进:搜寻引擎蜘蛛和网页的三大问题(图))
搜索引擎蜘蛛和网页的三大问题
陈千金
1
.
1. 搜索引擎蜘蛛能找到你的网页吗?
2. 搜索引擎蜘蛛找到网页后可以抓取吗?
获取网页
三、搜索引擎蜘蛛爬取网页后,能否
可以提取有用的信息
2
.
他们的报告并非完全免费供搜索者查看,因此需要向网络蜘蛛提供相应的用户名和密码;网络蜘蛛可以通过给定的权限抓取这些网页以提供搜索;并且当搜索者点击查看网页时,搜索者还需要提供相应的权限验证;
10
.
⑵网站和网络蜘蛛
网络蜘蛛需要爬取网页,这与普通的访问不同。如果没有掌握好,会导致网站服务器负担过重;每个网络蜘蛛都有自己的名字。网站表明你的身份;网络蜘蛛在抓取网页时会发送一个请求。在这个请求中,有一个名为 User-agent 的字段,用于标识网络蜘蛛的身份:
谷歌网络蜘蛛被识别为 GoogleBot,
百度网络蜘蛛的标志是BaiDuSpider,
雅虎网络蜘蛛被识别为 Inktomi Slurp;
如果网站上有访问日志记录(robots.txt),网站管理员可以知道哪些搜索引擎蜘蛛访问过,何时访问过,读取了多少数据等;如果 网站 管理器发现蜘蛛有问题,它会通过它的 ID 联系它的主人;
11
.
现在一般的网站希望搜索引擎能更全面的抓取自己的网站网页,因为这样可以让更多的访问者通过搜索引擎找到这个网站;这个网站的网页爬取比较全面,网站管理员可以创建网站地图,即Site Map;很多网络蜘蛛都会把sitemap.htm文件作为网站网页爬取的入口,网站管理员可以把网站内部所有网页的链接都放在这个文件里,然后网络蜘蛛可以轻松抓取整个 网站 ,防止部分网页遗漏,同时也减轻了 网站 服务器的负担;(Google 专门为 网站 管理员提供 XML Sitemaps)
12
.
(3) 网络蜘蛛提取内容
搜索引擎建立网页索引,处理对象为文本文件;对于网络蜘蛛来说,爬取的网页包括各种格式。
包括html、图片、doc、pdf、多媒体、动态网页等格式;
抓取这些文件后,需要提取这些文件中的文本信息;这些文档信息的精确提取一方面对搜索引擎的搜索准确性起着重要作用,另一方面对网络蜘蛛正确跟踪其他链接也有积极作用。影响;
对于doc、pdf等文档,以及专业厂商提供的软件生成的文档,厂商会提供相应的文本提取接口
由于目前主流的网站大部分都是用HTML编写的,这里就泛泛的说一下HTML;
13
.
HTML有自己的语法,它使用不同的命令标识符来表示不同的字体、颜色、位置和其他布局,例如:、、等。在提取文本信息时,需要过滤掉这些标识符;过滤标识符并不难,由于这些标识符有一定的规定,只需要根据不同的标识符获取相应的信息即可;
但是在识别这个信息的时候,需要同时记录很多布局信息,比如文字的字体大小,是否是标题,是否显示为粗体,是否是关键词页面的重要性等页面的重要性;
同时,对于HTML页面,除了标题和正文外,还会有很多广告链接和公共频道链接。这些链接与正文无关。在提取网页内容的时候,也需要过滤掉这些无用的链接;
比如某网站有一个“医院介绍”频道。由于网站中每个网页都有导航栏,如果不过滤导航栏中的链接,在搜索“产品介绍”时,会搜索到网站中的每个网页,这无疑会带来大量的垃圾邮件;
14
.
那么如何用 ASP 构建一个网络蜘蛛呢?答案是:互联网传输控制(ITC information transfer control);Microsoft 提供的这种控制将使您能够通过 ASP 程序访问 Internet 资源;您可以使用 ITC 搜索网页、访问 FTP 服务器,甚至发送电子邮件标头;
有几个缺陷必须首先解释;首先,ASP无权访问Windows注册表,这使得一些通常由ITC保留的常量和值无法使用;通常可以将 ITC 设置为“不使用默认值”来解决这个问题,需要在每次运行时指定该值;另一个更严重的问题是关于许可证的问题;因为ASP没有调用License Manager(Windows中的一个功能,可以保证组件和控制合法使用)的能力,那么当License Manager检查当前组件的密钥密码并与Windows注册表进行比较时,如果发现它们不同,则组件将无法工作;所以,
网页信息抓取软件(优采云网页数据采集器连续五年大数据采集领域排名领先)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-02-18 03:11
网站描述:优采云网页数据采集器,是一款简单强大的网络爬虫工具,全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取连续五年在大数据行业数据领域排名第一采集。
转到 网站
重量信息
搜索引擎优化信息
百度来源:732~988 IP 手机来源:27~37 IP 出站链接:6 主页内部链接:49
收录信息
百度收录: 264,000360收录: 3,820 神马收录:- 搜狗收录:- 谷歌收录:-
反向链接信息
百度外链:936,000360 外链:8,600 神马外链:- 搜狗外链:8,563 谷歌外链:-
排名信息
世界排名:19,832 国内排名:1,076 预计日均IP:60,000 预计日均PV:240,000
记录信息
备案号:粤ICP备14092314-1号性质:公司名称:审核时间:2021-10-20
域名信息
未找到whois信息
服务器信息
协议类型:HTTP/1.1 200 OK 页面类型:text/html;charset=utf-8 服务器类型:nginx/1.18.0 程序支持:- 连接 ID:- 消息发送:2022 年 2 月 16 日 17:42:18 GZIP 检测:未启用 GZIP 压缩率:估计 72.39% 最后修改:未知
网站评估
优采云采集器 - 免费网页爬虫软件_网页大数据爬取工具 2022-02-17 19:50:43收录正亚秒收录,目前一共有全球19832个,中国1076个,日均IP约6万个,备案号粤ICP备14092314-1号,本次评测参考包括优采云采集器 - 免费网络爬虫软件_网页大数据爬虫的搜索引擎权重、收录和反向链接、Alexa排名信息、服务器信息等互联网属性,不包括域名价值、品牌价值及其附加值。优采云采集器 - 免费网络爬虫软件_网络大数据爬虫工具的真正价值需要读者综合考虑实际情况,结果仅供参考。 查看全部
网页信息抓取软件(优采云网页数据采集器连续五年大数据采集领域排名领先)
网站描述:优采云网页数据采集器,是一款简单强大的网络爬虫工具,全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取连续五年在大数据行业数据领域排名第一采集。
转到 网站
重量信息
搜索引擎优化信息
百度来源:732~988 IP 手机来源:27~37 IP 出站链接:6 主页内部链接:49
收录信息
百度收录: 264,000360收录: 3,820 神马收录:- 搜狗收录:- 谷歌收录:-
反向链接信息
百度外链:936,000360 外链:8,600 神马外链:- 搜狗外链:8,563 谷歌外链:-
排名信息
世界排名:19,832 国内排名:1,076 预计日均IP:60,000 预计日均PV:240,000
记录信息
备案号:粤ICP备14092314-1号性质:公司名称:审核时间:2021-10-20
域名信息
未找到whois信息
服务器信息
协议类型:HTTP/1.1 200 OK 页面类型:text/html;charset=utf-8 服务器类型:nginx/1.18.0 程序支持:- 连接 ID:- 消息发送:2022 年 2 月 16 日 17:42:18 GZIP 检测:未启用 GZIP 压缩率:估计 72.39% 最后修改:未知
网站评估
优采云采集器 - 免费网页爬虫软件_网页大数据爬取工具 2022-02-17 19:50:43收录正亚秒收录,目前一共有全球19832个,中国1076个,日均IP约6万个,备案号粤ICP备14092314-1号,本次评测参考包括优采云采集器 - 免费网络爬虫软件_网页大数据爬虫的搜索引擎权重、收录和反向链接、Alexa排名信息、服务器信息等互联网属性,不包括域名价值、品牌价值及其附加值。优采云采集器 - 免费网络爬虫软件_网络大数据爬虫工具的真正价值需要读者综合考虑实际情况,结果仅供参考。
网页信息抓取软件(XPath的节点(Node)中的核心就是节点及其关系)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-14 16:11
在上一节中,我们详细介绍了 lxml.html 的各种操作。接下来,我们精通XPath,就可以熟练的提取网页内容了。
什么是 XPath?
XPath的全称是XML Path Language,即XML Path Language,是一种在XML(HTML)文档中查找信息的语言。它有4个特点:
我们从网页中提取数据,主要应用前两点。
XPath 路径表达式
使用XPath,我们可以很方便的定位到网页中的节点,也就是找到我们关心的数据。这些路径与计算机目录和 URL 的路径非常相似,路径的深度用 / 表示。
XPath 注释库
标头中有 100 多个内置函数。当然,我们用来提取数据的数据是有限的,所以我们不需要记住所有 100 多个函数。
Xpath 的节点
XPath的核心是节点(Node),它定义了7种不同类型的节点:元素(Element)、属性(Attribute)、文本(Text)、命名空间(Namespace)、处理指令(processing-instruction)、注释(Comment ) 和文档节点
这些节点组成一个节点树,树的根节点称为文档节点。
注释是html中的注释:``
命名空间、处理指令和网页数据提取基本无关,这里不再详述。
下面我们以一个简单的html文档为例来说明不同的节点及其关系。
ABC home python
此 html 中的节点是:
XPath 节点的关系
节点之间的关系完全复制了人类的代际关系,但只是直接关系,没有叔叔叔叔之类的旁系关系。
或者以上面的html文档为例来说明节点关系:
家长
每个元素节点(Element)及其属性都有一个父节点。
比如body的parent是html,body是div和ul的parent。
孩子们
每个元素节点可以有零个、一个或多个子节点。
例如,body 有两个孩子:div、ul,而 ul 也有两个孩子:两个 li。
兄弟
兄弟姐妹具有相同的父节点。
例如, div 和 ul 是兄弟姐妹。
祖先
一个节点的父节点和上面几代的节点。
比如li的父母是:ul, div, body, html
后裔
节点的子节点及其后代节点。
比如body的后代有:div、ul、li。
XPath 节点的选择
选择节点是通过路径表达式来实现的。这是我们从网页中提取数据的关键,我们必须掌握它。
下表是一个有用的路径表达式:
表达描述
节点名
选择当前节点的所有名为 nodename 的子节点。
/
从根节点中选择,在路径中间时表示一级路径
//
从当前节点开始选择文档中的一个节点,可以是多级路径
.
从当前节点挑选
..
从父节点挑选
@
按属性选择
接下来,我们将通过具体的例子加深对路径表达的理解:
路径表达式解释
/html/body/ul/li
根据从根节点开始的路径选择li元素。返回多个。
//ul/li[1]
li 元素仍然被选中,但路径多级跳转到 ul/li。[1] 表示只取第一个 li。
//li[last()]
还是选择了li,只是路径更加跳跃。[last()] 表示取最后一个 li 元素。
//li[@class]
选择名为 li 的具有类属性的根节点的所有后代。
//li[@class=”item”]
选择名称为 li 且类属性为 item 的根节点的所有后代。
//正文/*/li
选择body的名为li的孙节点。* 是通配符,表示任何节点。
//li[@*]
选择所有具有属性的 li 元素。
//body/div `
` //正文/ul
选择正文的所有 div 和 ul 元素。
身体/格
相对路径,选择当前节点body元素的子元素div。绝对路径以 / 开头。
XPath 函数
Xpath的功能很多,涉及到错误、值、字符串、时间等,但是我们在从网页中提取数据的时候只用到了几个。其中最重要的是与字符串相关的函数,例如 contains() 函数。
收录(a,b)
如果字符串 a 收录字符串 b,则返回 true,否则返回 false。
例如: contains('猿人学 Python', 'Python'),返回 true
那么什么时候使用呢?我们知道一个html标签的类可以有多个属性值,比如:
...
这个html中的div有三个class值,第一个表示是发布的消息,后两个是更多的格式设置。如果我们想提取网页中所有发布的消息,我们只需要匹配post-item,那么我们可以使用contains:
doc.xpath('//div[contains(@class, "post-item")]')
与 contains() 类似的字符串匹配函数有:
但是在lxml的xpath中使用ends-with(),matches()会报错
In [232]: doc.xpath('//ul[ends-with(@id, "u")]') --------------------------------------------------------------------------- XPathEvalError Traceback (most recent call last) in () ----> 1 doc.xpath('//ul[ends-with(@id, "u")]') src/lxml/etree.pyx in lxml.etree._Element.xpath() src/lxml/xpath.pxi in lxml.etree.XPathElementEvaluator.__call__() src/lxml/xpath.pxi in lxml.etree._XPathEvaluatorBase._handle_result() XPathEvalError: Unregistered function
lxml 不支持 end-with()、matches() 函数
去lxml官方网站看,原来只支持XPath1.0:
lxml 以符合标准的方式通过 libxml2 和 libxslt 支持 XPath 1.0、XSLT 1.0 和 EXSLT 扩展。
然后我在维基百科上找到了Xpath 2.0 和1.0 的区别,果然ends-with(),matches() 只属于2.0。下图中,粗体部分收录在1.0中,其他部分也收录在2.0中:
XPath 2.0 和 1.0 之间的区别
好了,Xpath在网页内容提取中用到的部分已经完成了。
来自“ITPUB博客”,链接:如需转载,请注明出处,否则追究法律责任。
转载于: 查看全部
网页信息抓取软件(XPath的节点(Node)中的核心就是节点及其关系)
在上一节中,我们详细介绍了 lxml.html 的各种操作。接下来,我们精通XPath,就可以熟练的提取网页内容了。
什么是 XPath?
XPath的全称是XML Path Language,即XML Path Language,是一种在XML(HTML)文档中查找信息的语言。它有4个特点:
我们从网页中提取数据,主要应用前两点。
XPath 路径表达式
使用XPath,我们可以很方便的定位到网页中的节点,也就是找到我们关心的数据。这些路径与计算机目录和 URL 的路径非常相似,路径的深度用 / 表示。
XPath 注释库
标头中有 100 多个内置函数。当然,我们用来提取数据的数据是有限的,所以我们不需要记住所有 100 多个函数。
Xpath 的节点
XPath的核心是节点(Node),它定义了7种不同类型的节点:元素(Element)、属性(Attribute)、文本(Text)、命名空间(Namespace)、处理指令(processing-instruction)、注释(Comment ) 和文档节点
这些节点组成一个节点树,树的根节点称为文档节点。
注释是html中的注释:``
命名空间、处理指令和网页数据提取基本无关,这里不再详述。
下面我们以一个简单的html文档为例来说明不同的节点及其关系。
ABC home python
此 html 中的节点是:
XPath 节点的关系
节点之间的关系完全复制了人类的代际关系,但只是直接关系,没有叔叔叔叔之类的旁系关系。
或者以上面的html文档为例来说明节点关系:
家长
每个元素节点(Element)及其属性都有一个父节点。
比如body的parent是html,body是div和ul的parent。
孩子们
每个元素节点可以有零个、一个或多个子节点。
例如,body 有两个孩子:div、ul,而 ul 也有两个孩子:两个 li。
兄弟
兄弟姐妹具有相同的父节点。
例如, div 和 ul 是兄弟姐妹。
祖先
一个节点的父节点和上面几代的节点。
比如li的父母是:ul, div, body, html
后裔
节点的子节点及其后代节点。
比如body的后代有:div、ul、li。
XPath 节点的选择
选择节点是通过路径表达式来实现的。这是我们从网页中提取数据的关键,我们必须掌握它。
下表是一个有用的路径表达式:
表达描述
节点名
选择当前节点的所有名为 nodename 的子节点。
/
从根节点中选择,在路径中间时表示一级路径
//
从当前节点开始选择文档中的一个节点,可以是多级路径
.
从当前节点挑选
..
从父节点挑选
@
按属性选择
接下来,我们将通过具体的例子加深对路径表达的理解:
路径表达式解释
/html/body/ul/li
根据从根节点开始的路径选择li元素。返回多个。
//ul/li[1]
li 元素仍然被选中,但路径多级跳转到 ul/li。[1] 表示只取第一个 li。
//li[last()]
还是选择了li,只是路径更加跳跃。[last()] 表示取最后一个 li 元素。
//li[@class]
选择名为 li 的具有类属性的根节点的所有后代。
//li[@class=”item”]
选择名称为 li 且类属性为 item 的根节点的所有后代。
//正文/*/li
选择body的名为li的孙节点。* 是通配符,表示任何节点。
//li[@*]
选择所有具有属性的 li 元素。
//body/div `
` //正文/ul
选择正文的所有 div 和 ul 元素。
身体/格
相对路径,选择当前节点body元素的子元素div。绝对路径以 / 开头。
XPath 函数
Xpath的功能很多,涉及到错误、值、字符串、时间等,但是我们在从网页中提取数据的时候只用到了几个。其中最重要的是与字符串相关的函数,例如 contains() 函数。
收录(a,b)
如果字符串 a 收录字符串 b,则返回 true,否则返回 false。
例如: contains('猿人学 Python', 'Python'),返回 true
那么什么时候使用呢?我们知道一个html标签的类可以有多个属性值,比如:
...
这个html中的div有三个class值,第一个表示是发布的消息,后两个是更多的格式设置。如果我们想提取网页中所有发布的消息,我们只需要匹配post-item,那么我们可以使用contains:
doc.xpath('//div[contains(@class, "post-item")]')
与 contains() 类似的字符串匹配函数有:
但是在lxml的xpath中使用ends-with(),matches()会报错
In [232]: doc.xpath('//ul[ends-with(@id, "u")]') --------------------------------------------------------------------------- XPathEvalError Traceback (most recent call last) in () ----> 1 doc.xpath('//ul[ends-with(@id, "u")]') src/lxml/etree.pyx in lxml.etree._Element.xpath() src/lxml/xpath.pxi in lxml.etree.XPathElementEvaluator.__call__() src/lxml/xpath.pxi in lxml.etree._XPathEvaluatorBase._handle_result() XPathEvalError: Unregistered function
lxml 不支持 end-with()、matches() 函数
去lxml官方网站看,原来只支持XPath1.0:
lxml 以符合标准的方式通过 libxml2 和 libxslt 支持 XPath 1.0、XSLT 1.0 和 EXSLT 扩展。
然后我在维基百科上找到了Xpath 2.0 和1.0 的区别,果然ends-with(),matches() 只属于2.0。下图中,粗体部分收录在1.0中,其他部分也收录在2.0中:
XPath 2.0 和 1.0 之间的区别
好了,Xpath在网页内容提取中用到的部分已经完成了。
来自“ITPUB博客”,链接:如需转载,请注明出处,否则追究法律责任。
转载于:
网页信息抓取软件(一下每项信息应该如何提取?class属性为哪般? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-02-14 13:20
)
通过昨天的分析,我们已经能够依次打开多个页面,接下来就是获取每个页面的宝贝信息了。
分析页面宝贝信息
【插入图片,宝贝信息的各种内容】
从图片来看,每个宝贝都有以下信息:价格、标题、url、交易金额、店铺、位置等6条信息,其中url代表宝贝的地址。
通过viewer分析,每个baby都在一个div中,这个div的class属性收录item。
并且所有的item都在一个div中,总div有items的class属性,也就是一个页面收录所有宝物的frame。
所以,只有当div已经加载完毕,才能断定可以提取页面的baby信息,所以在提取信息之前,我们要判断这个div的存在。
对于网页源码的解析,这次我们使用Pyquery,依次使用。感觉PyQuery比较好用,尤其是pyquery搜索到的对象都可以在这里搜索到,非常方便。
请参阅我之前的 文章 了解如何使用 Pyquery,或查看 API。
下面我们依次分析每条信息应该如何提取。
1、价格
【插图、价格】
可以看到价格信息在一个div中,并且有class属性price。如果我们通过文字得到,也会得到它前面的RMB符号,我们回去切片的时候可以把它剪掉。
2、成交金额
【插图,金额】
音量信息在另一个div标签中,class属性为deal-cnt,最后三个字符还是需要剪掉的。
3、标题
[插入图片,标题]
宝贝的title在一个div标签中,class属性为title,可以通过text获取。
4、商店
[插入图片、店铺和位置]
店铺名称在一个 div 标签中,其 class 属性为 shop。
5、位置
如上所示,类属性为位置。
6、网址
【插入图片,宝贝地址】
url地址在一个a标签里,class属性是pic-link,这个a标签的href属性就是url地址。
from pyquery import PyQuery as pq
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.grid > div:nth-child(1)')))
html=browser.page_source
doc=pq(html)
items=doc('div.item').items()#讲解一下
for item in items:
product={
'url':item('a.pic-link').attr('href'),
'price':item.find('.price').text()[1:],
'amount':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
#save_to_mongo(product)
save_to_csv(product)
这里说的是item的内容,看一下源码中的例子:
> d = PyQuery('foobar')
> [i.text() for i in d.items('span')]
['foo', 'bar']
>[i.text() for i in d('span').items()]
['foo', 'bar']
>list(d.items('a')) == list(d('a').items())
True
将数据保存到 MongoDb
如果我们拿到产品,想把它保存到MongoDb数据库中,其实很简单。设置数据库的url、数据库名、表名,通过pymongo链接到对应的数据库。
即使我们的数据库还没有建立,也没关系,表和数据会动态创建。
import pymongo
'''MONGO设置'''
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_Table=KEYWORD
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
def save_to_mongo(product):
try:
if db[MONGO_Table].insert(product):
print('保存成功',product)
except Exception:
print('保存出错',product)
pass
【插图,MongoDB数据】
将数据保存到 CSV 文件
其实也是一个文本文件,但是可以通过excel打开,方便我们做一些分析。
我这里就不赘述了,看代码就行了。
def save_to_csv(product):
with open(FileName,'a') as f:
s=product['title']+','+product['price']+','+product['amount']+','+product['location']+','+product['shop']+','+product['url']+'\n'
try:
f.write(s)
print('保存到csv成功!',product)
except:
pass
所有代码
只要更改KEYWORD关键字的内容,就可以搜索到不同的宝贝信息并保存。我们默认将其保存为 csv 文件。毕竟数据只有几千条,Excel方便。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
import re
import pymongo
from multiprocessing import Pool
'''要搜索的关键字'''
KEYWORD='Iphone8'
'''MONGO设置'''
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_Table=KEYWORD
'''要保存的csv文件'''
FileName=KEYWORD+'.csv'
'''PhantomJS参数'''
SERVICE_ARGS=['--load-images=false']#不加载图片,节省时间
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
#browser=webdriver.Firefox()
browser=webdriver.PhantomJS(service_args=SERVICE_ARGS)
browser.set_window_size(1400,900)
index_url='https://www.taobao.com/'
wait=WebDriverWait(browser, 10)
def search(keyword):
try:
browser.get(index_url)
#user_search_input=browser.find_element_by_css_selector('#q')
#user_search_button=browser.find_element_by_css_selector('.btn-search')
user_search_input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
user_search_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".btn-search")))
user_search_input.send_keys(keyword)
user_search_button.click()
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.total')))
total_page=re.compile(r'(\d+)').search(total.text).group(1)
print(total_page)
get_products()
return int(total_page)
except TimeoutException:
search(keyword)
def get_next_page(pageNum):
try:
user_page_input = wait.until(EC.presence_of_element_located((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/input")))
user_page_button = wait.until(EC.element_to_be_clickable((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/span[3]")))
user_page_input.clear()
user_page_input.send_keys(pageNum)
user_page_button.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'li.active > span:nth-child(1)'),str(pageNum)))
get_products()
except TimeoutException:
get_next_page(pageNum)
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.grid > div:nth-child(1)')))
html=browser.page_source
doc=pq(html)
items=doc('div.item').items()
for item in items:
product={
'url':item('a.pic-link').attr('href'),
'price':item.find('.price').text()[1:],
'amount':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
#save_to_mongo(product)
save_to_csv(product)
def save_to_csv(product):
with open(FileName,'a') as f:
s=product['title']+','+product['price']+','+product['amount']+','+product['location']+','+product['shop']+','+product['url']+'\n'
try:
f.write(s)
print('保存到csv成功!',product)
except:
pass
def save_to_mongo(product):
try:
if db[MONGO_Table].insert(product):
print('保存成功',product)
except Exception:
print('保存出错',product)
pass
def main():
total=search(KEYWORD)
# p=Pool()
# p.map(get_next_page,[i for i in range(2,total+1)])
for i in range(2,total+1):
get_next_page(i)
browser.close()
if __name__=='__main__':
main()
简单分析结果
【插入图片,结果分析示例】
月交易量最好的是一部老人手机,仅79元。. . .
在智能手机中,vivo X20是最畅销的,售价2999元。
1500的价格,小米5x出现了。. .
这个类似的分析是基于数据挖掘的,希望你能从这个内容中学到一些东西。
查看全部
网页信息抓取软件(一下每项信息应该如何提取?class属性为哪般?
)
通过昨天的分析,我们已经能够依次打开多个页面,接下来就是获取每个页面的宝贝信息了。
分析页面宝贝信息
【插入图片,宝贝信息的各种内容】
从图片来看,每个宝贝都有以下信息:价格、标题、url、交易金额、店铺、位置等6条信息,其中url代表宝贝的地址。
通过viewer分析,每个baby都在一个div中,这个div的class属性收录item。
并且所有的item都在一个div中,总div有items的class属性,也就是一个页面收录所有宝物的frame。
所以,只有当div已经加载完毕,才能断定可以提取页面的baby信息,所以在提取信息之前,我们要判断这个div的存在。
对于网页源码的解析,这次我们使用Pyquery,依次使用。感觉PyQuery比较好用,尤其是pyquery搜索到的对象都可以在这里搜索到,非常方便。
请参阅我之前的 文章 了解如何使用 Pyquery,或查看 API。
下面我们依次分析每条信息应该如何提取。
1、价格
【插图、价格】
可以看到价格信息在一个div中,并且有class属性price。如果我们通过文字得到,也会得到它前面的RMB符号,我们回去切片的时候可以把它剪掉。
2、成交金额
【插图,金额】
音量信息在另一个div标签中,class属性为deal-cnt,最后三个字符还是需要剪掉的。
3、标题
[插入图片,标题]
宝贝的title在一个div标签中,class属性为title,可以通过text获取。
4、商店
[插入图片、店铺和位置]
店铺名称在一个 div 标签中,其 class 属性为 shop。
5、位置
如上所示,类属性为位置。
6、网址
【插入图片,宝贝地址】
url地址在一个a标签里,class属性是pic-link,这个a标签的href属性就是url地址。
from pyquery import PyQuery as pq
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.grid > div:nth-child(1)')))
html=browser.page_source
doc=pq(html)
items=doc('div.item').items()#讲解一下
for item in items:
product={
'url':item('a.pic-link').attr('href'),
'price':item.find('.price').text()[1:],
'amount':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
#save_to_mongo(product)
save_to_csv(product)
这里说的是item的内容,看一下源码中的例子:
> d = PyQuery('foobar')
> [i.text() for i in d.items('span')]
['foo', 'bar']
>[i.text() for i in d('span').items()]
['foo', 'bar']
>list(d.items('a')) == list(d('a').items())
True
将数据保存到 MongoDb
如果我们拿到产品,想把它保存到MongoDb数据库中,其实很简单。设置数据库的url、数据库名、表名,通过pymongo链接到对应的数据库。
即使我们的数据库还没有建立,也没关系,表和数据会动态创建。
import pymongo
'''MONGO设置'''
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_Table=KEYWORD
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
def save_to_mongo(product):
try:
if db[MONGO_Table].insert(product):
print('保存成功',product)
except Exception:
print('保存出错',product)
pass
【插图,MongoDB数据】
将数据保存到 CSV 文件
其实也是一个文本文件,但是可以通过excel打开,方便我们做一些分析。
我这里就不赘述了,看代码就行了。
def save_to_csv(product):
with open(FileName,'a') as f:
s=product['title']+','+product['price']+','+product['amount']+','+product['location']+','+product['shop']+','+product['url']+'\n'
try:
f.write(s)
print('保存到csv成功!',product)
except:
pass
所有代码
只要更改KEYWORD关键字的内容,就可以搜索到不同的宝贝信息并保存。我们默认将其保存为 csv 文件。毕竟数据只有几千条,Excel方便。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
import re
import pymongo
from multiprocessing import Pool
'''要搜索的关键字'''
KEYWORD='Iphone8'
'''MONGO设置'''
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_Table=KEYWORD
'''要保存的csv文件'''
FileName=KEYWORD+'.csv'
'''PhantomJS参数'''
SERVICE_ARGS=['--load-images=false']#不加载图片,节省时间
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
#browser=webdriver.Firefox()
browser=webdriver.PhantomJS(service_args=SERVICE_ARGS)
browser.set_window_size(1400,900)
index_url='https://www.taobao.com/'
wait=WebDriverWait(browser, 10)
def search(keyword):
try:
browser.get(index_url)
#user_search_input=browser.find_element_by_css_selector('#q')
#user_search_button=browser.find_element_by_css_selector('.btn-search')
user_search_input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
user_search_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".btn-search")))
user_search_input.send_keys(keyword)
user_search_button.click()
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.total')))
total_page=re.compile(r'(\d+)').search(total.text).group(1)
print(total_page)
get_products()
return int(total_page)
except TimeoutException:
search(keyword)
def get_next_page(pageNum):
try:
user_page_input = wait.until(EC.presence_of_element_located((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/input")))
user_page_button = wait.until(EC.element_to_be_clickable((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/span[3]")))
user_page_input.clear()
user_page_input.send_keys(pageNum)
user_page_button.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'li.active > span:nth-child(1)'),str(pageNum)))
get_products()
except TimeoutException:
get_next_page(pageNum)
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.grid > div:nth-child(1)')))
html=browser.page_source
doc=pq(html)
items=doc('div.item').items()
for item in items:
product={
'url':item('a.pic-link').attr('href'),
'price':item.find('.price').text()[1:],
'amount':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
#save_to_mongo(product)
save_to_csv(product)
def save_to_csv(product):
with open(FileName,'a') as f:
s=product['title']+','+product['price']+','+product['amount']+','+product['location']+','+product['shop']+','+product['url']+'\n'
try:
f.write(s)
print('保存到csv成功!',product)
except:
pass
def save_to_mongo(product):
try:
if db[MONGO_Table].insert(product):
print('保存成功',product)
except Exception:
print('保存出错',product)
pass
def main():
total=search(KEYWORD)
# p=Pool()
# p.map(get_next_page,[i for i in range(2,total+1)])
for i in range(2,total+1):
get_next_page(i)
browser.close()
if __name__=='__main__':
main()
简单分析结果
【插入图片,结果分析示例】
月交易量最好的是一部老人手机,仅79元。. . .
在智能手机中,vivo X20是最畅销的,售价2999元。
1500的价格,小米5x出现了。. .
这个类似的分析是基于数据挖掘的,希望你能从这个内容中学到一些东西。
网页信息抓取软件( 基于探测网页更新周期的抓取方法的中国发明专利申请方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-09 12:00
基于探测网页更新周期的抓取方法的中国发明专利申请方法)
本发明涉及网页信息处理技术领域,具体涉及一种网页更新检测方法、网页信息获取及呈现方法。
背景技术:
申请号2.7,名称为基于检测网页更新周期的爬取方法的中国发明专利申请。通过获取页面的更新时间,判断网页是否已经更新。如果有历史信息的页面更新时间不同,则页面获取方式为GET(GET)。如果页面的页面更新时间和历史信息相同,则指定页面获取方式为CHK(CHK)。这种方案的缺点是它依赖于网页更新的时间信息。该判断可能会产生误导,例如,当更新是次要或不需要的信息时,也会启动获取动作。
上述背景技术内容的公开仅用于辅助理解本发明的发明构思和技术方案,并不一定属于本专利申请的现有技术。如果在本专利申请的申请日没有明确的证据表明上述内容已被公开,上述背景技术不应用于评价本申请的新颖性和创造性。
技术实施要素:
本发明的主要目的在于提出一种网页更新检测方法,以解决上述现有技术中基于网页更新时间信息的判断容易产生误导的技术问题。
为此,本发明提出一种网页更新检测方法,包括: s1、分析预定url网页的框架结构,确定抓取信息区域;s2、分析抓取信息区的信息与本地信息比较相似度;s3、当相似度低于设定阈值时,判断rul网页已经更新,否则判断url网页没有更新。
优选地,本发明还可以具有以下技术特征:
确定抓取信息区域的信息与本地信息的相似度包括以下步骤: s201、 对抓取信息区域进行截图并二值化得到二值化图像。s202、 将二值化过程得到的二值化图像与本地存储的相同url网页的二值化图像进行比较;s203、 根据比较的结果,判断是否有更新。
还包括步骤s204、,当比较结果确定没有更新时,将步骤s1中确定的抓取信息区域放大设置倍数,然后至少返回步骤s201一次。
判断抓取信息区的信息与本地信息的相似度包括以下步骤: s301、判断抓取信息区所在的代码行;s302、 抓取代码行对应的具体信息;s303、将具体信息与本地存储的同一个url网页的具体信息进行对比;s304、根据比较结果判断是否有更新。
还包括步骤s305、,当判断比较结果为无更新时,将步骤s1中确定的抓取信息区域扩展到相邻或不相邻的至少一个其他代码行,返回步骤s301至少执行一次。
本发明还提供一种网页信息抓取方法。基于前述权利要求中任一项所述的网页更新检测方法,对预设url的网页进行更新检测,当判断有更新时,抓取该信息,若有更新到本地,如果结果是没有更新,则不爬取,保持本地原有信息不变。
优选地,有更新时的信息抓取采用定向抓取的方式,只抓取抓取信息区域中的信息。
本发明还提出了一种网页信息的采集和呈现方法。基于上述任一项所述的网页更新检测方法,对预设url的网页进行更新检测,当判断结果为有更新时,进行信息抓取,并更新到local,当判断结果为没有更新时,保持原有本地信息不变;在呈现网页信息时,按照未更新的网页信息先于更新的网页信息的方式逐步呈现。
优选地,在更新的网页上爬取信息的同时,呈现未更新的网页,以缩短信息呈现的等待时间。
还优选的是,已爬取的更新网页在本地更新的同时,立即以一一插入的方式呈现。
本发明与现有技术相比的有益效果是:由于预先确定了抓取信息区域,并针对该区域判断是否更新,可以避免因更新无关而造成的误导,并且可以抓取网页信息。启动更准确,更有效地抓取任务,节省时间和带宽资源。
图纸说明
图1是本发明的原理框图;
图2为本发明具体实施例的流程图
如图。图3为本发明另一具体实施例的流程图。
详细说明
下面结合具体实施例并结合附图对本发明作进一步详细说明。应该强调的是,以下描述仅是示例性的,并不旨在限制本发明及其应用的范围。
将参考以下图1-3描述非限制性和非排他性实施例,其中除非另有明确说明,否则相似的附图标记指代相似的部件。
一种用于捕获和呈现网页信息的方法。首先,更新并检测带有预设 url 的网页。当判断结果为有更新时,获取信息并更新到本地。当判断结果为没有更新时,保持原来的本地原件。信息保持不变。在呈现网页信息时,以未更新的网页信息先于更新的网页信息的方式逐渐呈现。
一种更优选的方法是:有更新时的信息抓取方式采用定向抓取方式,只抓取抓取信息区域内的信息。
另一种优选的方法是:在更新网页上爬取信息的同时,呈现未更新的网页,从而缩短信息呈现的等待时间。
另外,对于已经爬取的更新网页,可以在更新到本地的同时,立即以一一插入的方式渲染。这样就可以立即获取并显示。是的,网页内容的显示是连续的,尽量不减少停顿。
如图所示。如图1所示,预设url的网页更新检测方法包括: s1、分析预设url的网页的框架结构,确定爬取信息区域。s2、 s2、 将信息区的信息与本地信息进行相似度比较;s3、当相似度低于设定阈值时,判断rul网页已经更新,否则判断url网页没有更新。
其中,抓取信息区域的信息与本地信息的相似度判断如图3所示。2、包括以下步骤: s201、 对抓取信息区域进行截图并二值化得到两个Valued图像;s202、将二值化过程得到的二值化图像与本地存储的相同url网页的二值化图像进行比较;s203、根据比较结果判断有更新还是没有更新。步骤s204、还可以包括:当判断比较结果为无更新时,将步骤s1中确定的抓取信息区域放大设定倍数,然后返回步骤s201至少一次。
或者,抓取信息区域的信息与本地信息的相似度判断如图3所示。3、包括以下步骤: s301、 确定抓取信息区所在的代码行;s302、抓取代码行对应的具体信息;s303、将具体信息与本地存储的同一个url网页的具体信息进行对比;s304、根据比较结果判断有更新还是没有更新。还可以包括步骤s305、,当判断比较结果为无更新时,将步骤s1中确定的抓取信息区域扩展到相邻或不相邻的至少一个其他代码行,返回步骤s301至少描述一次。这种相似度判断方法的优点是信息被快速捕获并更及时地呈现,因为在判断网页是否更新的同时已经捕获了必要的信息(判断和捕获两个工作内容结合起来< @一),如果确定有更新,可以直接显示并保存到本地。
本领域技术人员将认识到对以上描述的多种修改是可能的,因此这些示例仅旨在描述一种或多种具体实施方式。
尽管已经描述和描述了被认为是本发明的示例性实施例的内容,但是本领域技术人员将理解,在不背离本发明的精神的情况下可以对其进行各种改变和替换。此外,在不背离本文所述的本发明的中心概念的情况下,可以进行许多修改以使特定情况适应本发明的教导。因此,本发明不限于本文所公开的具体实施例,而是本发明还可以包括落入本发明范围内的所有实施例及其等同物。 查看全部
网页信息抓取软件(
基于探测网页更新周期的抓取方法的中国发明专利申请方法)
本发明涉及网页信息处理技术领域,具体涉及一种网页更新检测方法、网页信息获取及呈现方法。
背景技术:
申请号2.7,名称为基于检测网页更新周期的爬取方法的中国发明专利申请。通过获取页面的更新时间,判断网页是否已经更新。如果有历史信息的页面更新时间不同,则页面获取方式为GET(GET)。如果页面的页面更新时间和历史信息相同,则指定页面获取方式为CHK(CHK)。这种方案的缺点是它依赖于网页更新的时间信息。该判断可能会产生误导,例如,当更新是次要或不需要的信息时,也会启动获取动作。
上述背景技术内容的公开仅用于辅助理解本发明的发明构思和技术方案,并不一定属于本专利申请的现有技术。如果在本专利申请的申请日没有明确的证据表明上述内容已被公开,上述背景技术不应用于评价本申请的新颖性和创造性。
技术实施要素:
本发明的主要目的在于提出一种网页更新检测方法,以解决上述现有技术中基于网页更新时间信息的判断容易产生误导的技术问题。
为此,本发明提出一种网页更新检测方法,包括: s1、分析预定url网页的框架结构,确定抓取信息区域;s2、分析抓取信息区的信息与本地信息比较相似度;s3、当相似度低于设定阈值时,判断rul网页已经更新,否则判断url网页没有更新。
优选地,本发明还可以具有以下技术特征:
确定抓取信息区域的信息与本地信息的相似度包括以下步骤: s201、 对抓取信息区域进行截图并二值化得到二值化图像。s202、 将二值化过程得到的二值化图像与本地存储的相同url网页的二值化图像进行比较;s203、 根据比较的结果,判断是否有更新。
还包括步骤s204、,当比较结果确定没有更新时,将步骤s1中确定的抓取信息区域放大设置倍数,然后至少返回步骤s201一次。
判断抓取信息区的信息与本地信息的相似度包括以下步骤: s301、判断抓取信息区所在的代码行;s302、 抓取代码行对应的具体信息;s303、将具体信息与本地存储的同一个url网页的具体信息进行对比;s304、根据比较结果判断是否有更新。
还包括步骤s305、,当判断比较结果为无更新时,将步骤s1中确定的抓取信息区域扩展到相邻或不相邻的至少一个其他代码行,返回步骤s301至少执行一次。
本发明还提供一种网页信息抓取方法。基于前述权利要求中任一项所述的网页更新检测方法,对预设url的网页进行更新检测,当判断有更新时,抓取该信息,若有更新到本地,如果结果是没有更新,则不爬取,保持本地原有信息不变。
优选地,有更新时的信息抓取采用定向抓取的方式,只抓取抓取信息区域中的信息。
本发明还提出了一种网页信息的采集和呈现方法。基于上述任一项所述的网页更新检测方法,对预设url的网页进行更新检测,当判断结果为有更新时,进行信息抓取,并更新到local,当判断结果为没有更新时,保持原有本地信息不变;在呈现网页信息时,按照未更新的网页信息先于更新的网页信息的方式逐步呈现。
优选地,在更新的网页上爬取信息的同时,呈现未更新的网页,以缩短信息呈现的等待时间。
还优选的是,已爬取的更新网页在本地更新的同时,立即以一一插入的方式呈现。
本发明与现有技术相比的有益效果是:由于预先确定了抓取信息区域,并针对该区域判断是否更新,可以避免因更新无关而造成的误导,并且可以抓取网页信息。启动更准确,更有效地抓取任务,节省时间和带宽资源。
图纸说明
图1是本发明的原理框图;
图2为本发明具体实施例的流程图
如图。图3为本发明另一具体实施例的流程图。
详细说明
下面结合具体实施例并结合附图对本发明作进一步详细说明。应该强调的是,以下描述仅是示例性的,并不旨在限制本发明及其应用的范围。
将参考以下图1-3描述非限制性和非排他性实施例,其中除非另有明确说明,否则相似的附图标记指代相似的部件。
一种用于捕获和呈现网页信息的方法。首先,更新并检测带有预设 url 的网页。当判断结果为有更新时,获取信息并更新到本地。当判断结果为没有更新时,保持原来的本地原件。信息保持不变。在呈现网页信息时,以未更新的网页信息先于更新的网页信息的方式逐渐呈现。
一种更优选的方法是:有更新时的信息抓取方式采用定向抓取方式,只抓取抓取信息区域内的信息。
另一种优选的方法是:在更新网页上爬取信息的同时,呈现未更新的网页,从而缩短信息呈现的等待时间。
另外,对于已经爬取的更新网页,可以在更新到本地的同时,立即以一一插入的方式渲染。这样就可以立即获取并显示。是的,网页内容的显示是连续的,尽量不减少停顿。
如图所示。如图1所示,预设url的网页更新检测方法包括: s1、分析预设url的网页的框架结构,确定爬取信息区域。s2、 s2、 将信息区的信息与本地信息进行相似度比较;s3、当相似度低于设定阈值时,判断rul网页已经更新,否则判断url网页没有更新。
其中,抓取信息区域的信息与本地信息的相似度判断如图3所示。2、包括以下步骤: s201、 对抓取信息区域进行截图并二值化得到两个Valued图像;s202、将二值化过程得到的二值化图像与本地存储的相同url网页的二值化图像进行比较;s203、根据比较结果判断有更新还是没有更新。步骤s204、还可以包括:当判断比较结果为无更新时,将步骤s1中确定的抓取信息区域放大设定倍数,然后返回步骤s201至少一次。
或者,抓取信息区域的信息与本地信息的相似度判断如图3所示。3、包括以下步骤: s301、 确定抓取信息区所在的代码行;s302、抓取代码行对应的具体信息;s303、将具体信息与本地存储的同一个url网页的具体信息进行对比;s304、根据比较结果判断有更新还是没有更新。还可以包括步骤s305、,当判断比较结果为无更新时,将步骤s1中确定的抓取信息区域扩展到相邻或不相邻的至少一个其他代码行,返回步骤s301至少描述一次。这种相似度判断方法的优点是信息被快速捕获并更及时地呈现,因为在判断网页是否更新的同时已经捕获了必要的信息(判断和捕获两个工作内容结合起来< @一),如果确定有更新,可以直接显示并保存到本地。
本领域技术人员将认识到对以上描述的多种修改是可能的,因此这些示例仅旨在描述一种或多种具体实施方式。
尽管已经描述和描述了被认为是本发明的示例性实施例的内容,但是本领域技术人员将理解,在不背离本发明的精神的情况下可以对其进行各种改变和替换。此外,在不背离本文所述的本发明的中心概念的情况下,可以进行许多修改以使特定情况适应本发明的教导。因此,本发明不限于本文所公开的具体实施例,而是本发明还可以包括落入本发明范围内的所有实施例及其等同物。
网页信息抓取软件(风铃虫的作用与功能如下的原理简单提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-31 10:18
wind-bell 是一款轻量级的爬虫工具,灵敏如风铃,敏捷如蜘蛛,可感知任何小风箱和小草,轻松抓取网络内容。是一个对目标服务器比较友好的爬虫程序。它内置了20多个常用或不常用的浏览器标识符,可自动处理cookies和网页源信息,轻松绕过服务器限制,智能调整请求间隔,动态调整请求频率,防止干扰目标服务器。此外,bellworm 对于普通用户来说也是一个非常友好的工具。它提供了大量的链接提取器和内容提取器,让用户可以快速随心所欲地配置,甚至可以通过提供起始请求地址来配置自己的爬虫程序。同时,Windbell还开放了很多自定义界面,让高级用户可以根据自己的需要自定义爬虫功能。最后,蓝铃还天然支持分布式和集群功能,让你突破单机环境的束缚,释放你的爬取能力。可以说,铃虫几乎可以抢到当前所有网站中的大部分内容。
【声明】请不要将风铃草应用于任何可能违反法律规定和道德约束的工作。请善待风铃草,遵守蜘蛛协议,请勿将风铃草用于任何非法用途。如果您选择使用风铃草,即表示您遵守本协议,作者不承担因您违反本协议而产生的任何法律风险和损失,一切后果由您承担。
快速使用
com.yishuifengxiao.common crawler 替换为最新的版本号
使用简单
从雅虎财经的内容页面中提取电子货币的名称
//创建一个提取规则 //该提取规则标识使用 XPATH提取器进行提取, //该XPATH提取器的XPATH表达式为 //h1/text() , 该提取提取器的作用顺序是0 FieldExtractRule extractRule = new FieldExtractRule(Rule.XPATH, "//h1/text()", "", 0); //创建一个提取项 ContentItem contentItem = new ContentItem(); contentItem .setFiledName("name") //提取项代码,不能为空 .setName("加密电子货币名字") //提取项名字,可以不设置 .setRules(Arrays.asList(extractRule)); //设置提取规则 //创建一个风铃虫实例 Crawler crawler = CrawlerBuilder.create() .startUrl("https://hk.finance.yahoo.com/cryptocurrencies") //风铃虫的起始链接 // 风铃虫会将每次请求的网页的内容中的URL先全部提取出来,然后将完全匹配此规则的链接放入链接池 // 如果不设置则表示提取链接中所有包含域名关键字(例如此例中的ifeng)的链接放入链接池 //链接池里的链接会作为下次抓取请求的种子链接 .addLinkRule("https://hk.finance.yahoo.com/quote/.+")//链接提取规则,多以添加多个链接提取规则, //可以设置多个内容页的规则,多个内容页规则之间用半角逗号隔开 //只要内容页URL中完全匹配此规则就进行内容提取,如果不设置标识提取域名下所有的链接 .extractUrl("https://hk.finance.yahoo.com/quote/.+") //内容页的规则, //风铃虫可以设置多个提取项,这里为了演示只设置了一个提取项 .addExtractItem(contentItem) //增加一个提取项 //如果不设置则使用默认时间10秒,此值是为了防止抓取频率太高被服务器封杀 .interval(3)//每次进行爬取时的平均间隔时间,单位为秒, .creatCrawler(); //启动爬虫实例 crawler.start(); // 这里没有设置信息输出器,表示使用默认的信息输出器 //默认的信息输出器使用的logback日志输出方法,因此需要看控制台信息 //由于风铃虫时异步运行的,所以演示时这里加入循环 while (Statu.STOP != crawler.getStatu()) { try { Thread.sleep(1000 * 20); } catch (InterruptedException e) { e.printStackTrace(); } }
上面例子的作用是提取雅虎财经内容页面的电子货币名称。如果用户想提取其他信息,只需要根据规则配置其他提取规则即可。
请注意,以上示例仅用于学习和演示目的。bellworm用户在抓取网页内容时,应严格遵守相关法律规定和目标网站的蜘蛛协议
铃虫的原理
bellworm的原理极其简单,主要由资源调度器、网页下载器、链接解析器、内容解析器、信息导出器组成。
它们的作用和作用如下:
链接解析器由一系列链接提取器组成。目前,链接提取器主要支持正则提取。
内容解析器由一系列内容提取器组成。不同的内容提取器功能不同,适用于不同的解析场景,支持多个提取器的多种组合,如重复、循环等。
以上组件均提供自定义配置接口,用户可根据实际需要自定义配置,满足各种复杂甚至异常场景的需求。
Campanula 的内置内容提取器有:
文本提取器中文提取器常量提取器CSS内容提取器CSS文本提取器邮箱提取器数字提取器常规提取器字符删除提取器字符替换提取器字符串截取提取器XPATH提取器数组截取...
在提取文本内容时,用户可以自由组合这些提取器来提取自己需要的内容。有关提取器的更具体用法,请参阅内容提取器用法。
Campanula 的内置浏览器标识符为:
Google Chrome(windows 版、linux 版) Opera 浏览器(windows 版、MAC 版) Firefox 浏览器(windows 版、linux 版、MAC 版) IE 浏览器(IE9、IE11)EDAG 浏览器 Safari 浏览器( windows版,MAC版)...
分布式支持
核心代码如下:
....//省略其他代码.... //创建redis资源调度器 Scheduler scheduler=new RedisScheduler("唯一的名字",redisTemplate) //创建一个redis资源缓存器 RequestCache requestCache = new RedisRequestCache(redisTemplate); crawler .setRequestCache(requestCache) //设置使用redis资源缓存器 .setScheduler(scheduler); //设置使用redis资源调度器 ....//省略其他代码....//启动爬虫实例crawler.start();
状态监控
Campanula 还提供强大的状态监控和事件监控功能。通过状态监听器和事件监听器,Campanula 让您可以很好地了解任务的运行状态,并且可以实时控制实例运行过程中遇到的各种问题。任务运行状态一目了然,便于运维。
解析模拟器
由于bellflower的解析功能非常强大,而且规则的定义非常灵活,为了直观的了解配置好的规则定义的作用,bellworm提供了解析模拟器,让用户可以快速了解是否效果自己设定的规则定义符合预期。target,及时调整规则定义,方便bellworm实例的配置。
风铃平台效果演示
配置基本信息
配置爬虫名称、使用的线程数和超时停止时间
2. 配置链接爬取信息
配置爬虫的起始种子链接和从网页中提取下次爬取链接的提取规则
3. 配置站点信息
这一步一般可以省略,但是对于一些会校验cookies和请求头参数的网站,这个配置还是很有用的
4 提取项配置
配置需要从网站中提取的数据,如新闻头条、网页正文信息等
5 属性提取配置
调用任何组合的内容提取器,以根据需要提取所需的数据
6 属性抽取测试
提前检查提取项的配置是否正确,提取的数据是否达到预期目标
相关资源链接
文件地址:
API 文档: 查看全部
网页信息抓取软件(风铃虫的作用与功能如下的原理简单提取)
wind-bell 是一款轻量级的爬虫工具,灵敏如风铃,敏捷如蜘蛛,可感知任何小风箱和小草,轻松抓取网络内容。是一个对目标服务器比较友好的爬虫程序。它内置了20多个常用或不常用的浏览器标识符,可自动处理cookies和网页源信息,轻松绕过服务器限制,智能调整请求间隔,动态调整请求频率,防止干扰目标服务器。此外,bellworm 对于普通用户来说也是一个非常友好的工具。它提供了大量的链接提取器和内容提取器,让用户可以快速随心所欲地配置,甚至可以通过提供起始请求地址来配置自己的爬虫程序。同时,Windbell还开放了很多自定义界面,让高级用户可以根据自己的需要自定义爬虫功能。最后,蓝铃还天然支持分布式和集群功能,让你突破单机环境的束缚,释放你的爬取能力。可以说,铃虫几乎可以抢到当前所有网站中的大部分内容。
【声明】请不要将风铃草应用于任何可能违反法律规定和道德约束的工作。请善待风铃草,遵守蜘蛛协议,请勿将风铃草用于任何非法用途。如果您选择使用风铃草,即表示您遵守本协议,作者不承担因您违反本协议而产生的任何法律风险和损失,一切后果由您承担。
快速使用
com.yishuifengxiao.common crawler 替换为最新的版本号
使用简单
从雅虎财经的内容页面中提取电子货币的名称
//创建一个提取规则 //该提取规则标识使用 XPATH提取器进行提取, //该XPATH提取器的XPATH表达式为 //h1/text() , 该提取提取器的作用顺序是0 FieldExtractRule extractRule = new FieldExtractRule(Rule.XPATH, "//h1/text()", "", 0); //创建一个提取项 ContentItem contentItem = new ContentItem(); contentItem .setFiledName("name") //提取项代码,不能为空 .setName("加密电子货币名字") //提取项名字,可以不设置 .setRules(Arrays.asList(extractRule)); //设置提取规则 //创建一个风铃虫实例 Crawler crawler = CrawlerBuilder.create() .startUrl("https://hk.finance.yahoo.com/cryptocurrencies";) //风铃虫的起始链接 // 风铃虫会将每次请求的网页的内容中的URL先全部提取出来,然后将完全匹配此规则的链接放入链接池 // 如果不设置则表示提取链接中所有包含域名关键字(例如此例中的ifeng)的链接放入链接池 //链接池里的链接会作为下次抓取请求的种子链接 .addLinkRule("https://hk.finance.yahoo.com/quote/.+";)//链接提取规则,多以添加多个链接提取规则, //可以设置多个内容页的规则,多个内容页规则之间用半角逗号隔开 //只要内容页URL中完全匹配此规则就进行内容提取,如果不设置标识提取域名下所有的链接 .extractUrl("https://hk.finance.yahoo.com/quote/.+";) //内容页的规则, //风铃虫可以设置多个提取项,这里为了演示只设置了一个提取项 .addExtractItem(contentItem) //增加一个提取项 //如果不设置则使用默认时间10秒,此值是为了防止抓取频率太高被服务器封杀 .interval(3)//每次进行爬取时的平均间隔时间,单位为秒, .creatCrawler(); //启动爬虫实例 crawler.start(); // 这里没有设置信息输出器,表示使用默认的信息输出器 //默认的信息输出器使用的logback日志输出方法,因此需要看控制台信息 //由于风铃虫时异步运行的,所以演示时这里加入循环 while (Statu.STOP != crawler.getStatu()) { try { Thread.sleep(1000 * 20); } catch (InterruptedException e) { e.printStackTrace(); } }
上面例子的作用是提取雅虎财经内容页面的电子货币名称。如果用户想提取其他信息,只需要根据规则配置其他提取规则即可。
请注意,以上示例仅用于学习和演示目的。bellworm用户在抓取网页内容时,应严格遵守相关法律规定和目标网站的蜘蛛协议
铃虫的原理
bellworm的原理极其简单,主要由资源调度器、网页下载器、链接解析器、内容解析器、信息导出器组成。
它们的作用和作用如下:
链接解析器由一系列链接提取器组成。目前,链接提取器主要支持正则提取。
内容解析器由一系列内容提取器组成。不同的内容提取器功能不同,适用于不同的解析场景,支持多个提取器的多种组合,如重复、循环等。
以上组件均提供自定义配置接口,用户可根据实际需要自定义配置,满足各种复杂甚至异常场景的需求。
Campanula 的内置内容提取器有:
文本提取器中文提取器常量提取器CSS内容提取器CSS文本提取器邮箱提取器数字提取器常规提取器字符删除提取器字符替换提取器字符串截取提取器XPATH提取器数组截取...
在提取文本内容时,用户可以自由组合这些提取器来提取自己需要的内容。有关提取器的更具体用法,请参阅内容提取器用法。
Campanula 的内置浏览器标识符为:
Google Chrome(windows 版、linux 版) Opera 浏览器(windows 版、MAC 版) Firefox 浏览器(windows 版、linux 版、MAC 版) IE 浏览器(IE9、IE11)EDAG 浏览器 Safari 浏览器( windows版,MAC版)...
分布式支持
核心代码如下:
....//省略其他代码.... //创建redis资源调度器 Scheduler scheduler=new RedisScheduler("唯一的名字",redisTemplate) //创建一个redis资源缓存器 RequestCache requestCache = new RedisRequestCache(redisTemplate); crawler .setRequestCache(requestCache) //设置使用redis资源缓存器 .setScheduler(scheduler); //设置使用redis资源调度器 ....//省略其他代码....//启动爬虫实例crawler.start();
状态监控
Campanula 还提供强大的状态监控和事件监控功能。通过状态监听器和事件监听器,Campanula 让您可以很好地了解任务的运行状态,并且可以实时控制实例运行过程中遇到的各种问题。任务运行状态一目了然,便于运维。
解析模拟器
由于bellflower的解析功能非常强大,而且规则的定义非常灵活,为了直观的了解配置好的规则定义的作用,bellworm提供了解析模拟器,让用户可以快速了解是否效果自己设定的规则定义符合预期。target,及时调整规则定义,方便bellworm实例的配置。
风铃平台效果演示
配置基本信息
配置爬虫名称、使用的线程数和超时停止时间
2. 配置链接爬取信息
配置爬虫的起始种子链接和从网页中提取下次爬取链接的提取规则
3. 配置站点信息
这一步一般可以省略,但是对于一些会校验cookies和请求头参数的网站,这个配置还是很有用的
4 提取项配置
配置需要从网站中提取的数据,如新闻头条、网页正文信息等
5 属性提取配置
调用任何组合的内容提取器,以根据需要提取所需的数据
6 属性抽取测试
提前检查提取项的配置是否正确,提取的数据是否达到预期目标
相关资源链接
文件地址:
API 文档:
网页信息抓取软件(网络书籍抓取器是款功能强大的网络小说资源下载工具资源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-30 19:22
Web Book Grabber 是一款强大的网络小说资源下载工具。可以帮助用户在各大平台快速搜索小说资源,并帮助用户下载到本地电脑离线查看。操作简单,方便快捷,非常好。
【软件特色】
1、章节调整:获取文件目录后,可以进行移动、删除、反转等实际调整操作。
2、自动重试:在抓取过程中,会出现抓取互联网元素失败。这个程序进程会自动重试直到成功,也可以临时终止爬取(finally)。中断后结束进程,不影响进度),等上网好了再试。
3、终止与修复:爬取的整个过程可以随时随地终止,退出程序流程后仍能保证进度(章节信息会保存在记录中,爬取可以修复程序流程的下一次操作后 注意:您需要使用终止功能键终止程序流程,然后退出程序流程。如果立即退出,将无法修复)。
4、一键截取:又称“傻瓜方式”,基本可以完成自动截取和组合功能,立即输出最终的文本文档。前面需要输入最基本的网站地址、存储位置等信息(也有明显的操作提示),一键抓取也可以在章节后调整应用,实际操作抓取和组合将是全自动的。
5、可用网址:已输入10个可用网址(选择后可快速打开网址搜索所需书籍),也可自动插入合适的编号,或其他文献网站用于检测,如果是共享的,可以手动添加到设置文件中并保留。
6、轻松制作电子书:可以在设置文档中添加每章名称的前缀和后缀,为视频后期制作免费电子书的文件目录编辑带来极大的方便。
【指示】
一、首先输入要下载的故事集的网页。
二、输入小说名称,点击文件目录即可。
三、设置存储相对路径,点击开始下载开始下载。 查看全部
网页信息抓取软件(网络书籍抓取器是款功能强大的网络小说资源下载工具资源)
Web Book Grabber 是一款强大的网络小说资源下载工具。可以帮助用户在各大平台快速搜索小说资源,并帮助用户下载到本地电脑离线查看。操作简单,方便快捷,非常好。
【软件特色】
1、章节调整:获取文件目录后,可以进行移动、删除、反转等实际调整操作。
2、自动重试:在抓取过程中,会出现抓取互联网元素失败。这个程序进程会自动重试直到成功,也可以临时终止爬取(finally)。中断后结束进程,不影响进度),等上网好了再试。
3、终止与修复:爬取的整个过程可以随时随地终止,退出程序流程后仍能保证进度(章节信息会保存在记录中,爬取可以修复程序流程的下一次操作后 注意:您需要使用终止功能键终止程序流程,然后退出程序流程。如果立即退出,将无法修复)。
4、一键截取:又称“傻瓜方式”,基本可以完成自动截取和组合功能,立即输出最终的文本文档。前面需要输入最基本的网站地址、存储位置等信息(也有明显的操作提示),一键抓取也可以在章节后调整应用,实际操作抓取和组合将是全自动的。
5、可用网址:已输入10个可用网址(选择后可快速打开网址搜索所需书籍),也可自动插入合适的编号,或其他文献网站用于检测,如果是共享的,可以手动添加到设置文件中并保留。
6、轻松制作电子书:可以在设置文档中添加每章名称的前缀和后缀,为视频后期制作免费电子书的文件目录编辑带来极大的方便。
【指示】
一、首先输入要下载的故事集的网页。
二、输入小说名称,点击文件目录即可。
三、设置存储相对路径,点击开始下载开始下载。
网页信息抓取软件(想要提高自己网站的权重就得做到网站每天有更新,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-23 10:05
如果你想提高你的网站的权重,你必须每天更新网站,但是你不能一次更新好几天的文章,因为这是被看到的搜索引擎。来。
如何每天自动更新你的网站Plus会员为了提升浏览体验,网页原视图版本升级为如下布局。
域名每天定期升级吗?域名是一个符号。没听说过正常升级。页面页面升级每天自动更新是什么意思?.
我不能一次更新好几天的文章,因为在搜索引擎的眼里还是同一天,信息会被读出并显示在网页上。
如果你想提高你的网站的权重,你必须每天更新网站,但是你不能一次更新好几天的文章,因为这是被看到的搜索引擎。同一天来。
网站到现在已经4个月零12天了,每天都正常更新,但是在3月23号就停了一段时间收录,一直没找到原因,日志是也正常。.
每天更新查找以前的内容,可以手动查询,也可以直接查询。例如,一个简单的普通 网站 在我们翻页之前有一个日期。
但是,新站点以前从未遇到过这种情况。搜索全名已经10天左右了,每天正常更新。关键是搜索公司全名,并显示在网页上。
可以,先正常添加两个网站,然后在每个网站属性的IP地址配置选项卡上选择高级。可以添加一个“主机头”选项。
前几天网页素材的截图一更新,第二天就消失了,让我无语,几乎要疯了,截图从18号开始更新,在首页排名第一。 查看全部
网页信息抓取软件(想要提高自己网站的权重就得做到网站每天有更新,)
如果你想提高你的网站的权重,你必须每天更新网站,但是你不能一次更新好几天的文章,因为这是被看到的搜索引擎。来。
如何每天自动更新你的网站Plus会员为了提升浏览体验,网页原视图版本升级为如下布局。
域名每天定期升级吗?域名是一个符号。没听说过正常升级。页面页面升级每天自动更新是什么意思?.
我不能一次更新好几天的文章,因为在搜索引擎的眼里还是同一天,信息会被读出并显示在网页上。
如果你想提高你的网站的权重,你必须每天更新网站,但是你不能一次更新好几天的文章,因为这是被看到的搜索引擎。同一天来。
网站到现在已经4个月零12天了,每天都正常更新,但是在3月23号就停了一段时间收录,一直没找到原因,日志是也正常。.
每天更新查找以前的内容,可以手动查询,也可以直接查询。例如,一个简单的普通 网站 在我们翻页之前有一个日期。
但是,新站点以前从未遇到过这种情况。搜索全名已经10天左右了,每天正常更新。关键是搜索公司全名,并显示在网页上。
可以,先正常添加两个网站,然后在每个网站属性的IP地址配置选项卡上选择高级。可以添加一个“主机头”选项。
前几天网页素材的截图一更新,第二天就消失了,让我无语,几乎要疯了,截图从18号开始更新,在首页排名第一。
网页信息抓取软件( 什么是PowerBI?(图)的优势(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-21 03:02
什么是PowerBI?(图)的优势(组图))
火箭君曾经介绍过使用Excel直接下载网页中的数据,但在实际使用中你会发现很多困难。它的另一款软件Power BI在这个时候表现出了无可比拟的优势。到底是什么,我们来看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)重要内容,并与任何所需的数据进行连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们想在豆瓣阅读页面抓取“最受欢迎图书榜”的相关信息:
书名
分数
作者
...
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如“生命之海”和“皮肤的秘密”这两个标题,然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
欢迎关注
我们是一个倡导“高效做事,尽情享受生活”的专栏。 查看全部
网页信息抓取软件(
什么是PowerBI?(图)的优势(组图))
火箭君曾经介绍过使用Excel直接下载网页中的数据,但在实际使用中你会发现很多困难。它的另一款软件Power BI在这个时候表现出了无可比拟的优势。到底是什么,我们来看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)重要内容,并与任何所需的数据进行连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们想在豆瓣阅读页面抓取“最受欢迎图书榜”的相关信息:
书名
分数
作者
...
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如“生命之海”和“皮肤的秘密”这两个标题,然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
欢迎关注
我们是一个倡导“高效做事,尽情享受生活”的专栏。
网页信息抓取软件(编辑收藏所属分类:Misc0.0.0.3)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-15 20:19
之前发布的 Krabber 在执行 Javascript 后已经可以抓取网页。
比如新浪博客的评论,页面加载后通过JavaScript显示内容。这么普通的爬虫是拿不到评论信息的。Krabber 0.0.0.2 已经可以爬取必须执行的 JavaScript 网页,并在 JavaScript 执行后返回带有所需信息的网页的 HTML。
现在的问题是网页上的很多内容都需要用户交互才能显示结果。比如基于 JavaScript 的评论结果翻页。直接使用 Krabber 0.0.0.2 只会得到第一页的结果。要查看以下评论,您必须单击页面并等待 JavaScript 执行,然后才能看到结果。所以这个版本的主要目标是实现一个可以模拟用户动作,触发网页上的一些事件,比如点击下一页,然后抓取JavaScript的执行结果的方法。
这个版本的 Krabber 0.0.0.3 Preview 已经实现了在网页上执行 AJAX 脚本。Krabber 0.0.0.3 Pre 提供了脚本执行机制,让信息抽取工具提供需要执行的内容,然后交给 Krabber 执行,然后Krabber 在执行后返回结果。
当然,当前的Preview不能返回执行后的信息,但是已经能够展示执行AJAX的过程了。如果你有兴趣,可以看看这个原型系统。
Krabber 0.0.0.3 预览 pinlin:senior, [emailprotected]
发表于 2009-12-12 10:13 高级阅读(1774) 评论(0) 编辑采集类别:杂项 查看全部
网页信息抓取软件(编辑收藏所属分类:Misc0.0.0.3)
之前发布的 Krabber 在执行 Javascript 后已经可以抓取网页。
比如新浪博客的评论,页面加载后通过JavaScript显示内容。这么普通的爬虫是拿不到评论信息的。Krabber 0.0.0.2 已经可以爬取必须执行的 JavaScript 网页,并在 JavaScript 执行后返回带有所需信息的网页的 HTML。
现在的问题是网页上的很多内容都需要用户交互才能显示结果。比如基于 JavaScript 的评论结果翻页。直接使用 Krabber 0.0.0.2 只会得到第一页的结果。要查看以下评论,您必须单击页面并等待 JavaScript 执行,然后才能看到结果。所以这个版本的主要目标是实现一个可以模拟用户动作,触发网页上的一些事件,比如点击下一页,然后抓取JavaScript的执行结果的方法。
这个版本的 Krabber 0.0.0.3 Preview 已经实现了在网页上执行 AJAX 脚本。Krabber 0.0.0.3 Pre 提供了脚本执行机制,让信息抽取工具提供需要执行的内容,然后交给 Krabber 执行,然后Krabber 在执行后返回结果。
当然,当前的Preview不能返回执行后的信息,但是已经能够展示执行AJAX的过程了。如果你有兴趣,可以看看这个原型系统。
Krabber 0.0.0.3 预览 pinlin:senior, [emailprotected]
发表于 2009-12-12 10:13 高级阅读(1774) 评论(0) 编辑采集类别:杂项
网页信息抓取软件(在线看电子书怎么办?电子书下载地址及分包处理方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-15 19:03
最近,我在网上阅读了一本电子书。由于篇幅太长,找不到下载地址,写了一个小工具,将电子书下载到本地。
总体思路:
1、在目录中获取每章的名称和网址
2、遍历章节URL获取具体内容
3、将章节URL分包给多线程处理
4、对处理后的内容重新排序,按章节名排序
5、将内容写入 TXT 文件
先抓取导航页内容,通过WebRequest对象获取网页内容
///
/// 通过链接地址获取HTML内容
///
///
///
private static string GetHtml(string url)
{
string html = "";
try
{
WebRequest request = WebRequest.Create(url);
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, encoding);
html = reader.ReadToEnd();
reader.Close();
stream.Close();
response.Close();
}
catch
{
}
return html;
}
通过正则表达式获取章节地址和名称
<p>///
/// 获取所有链接地址
///
///
private static Dictionary GetAllUrl(string html)
{
string titlePattern = @"第(?\d+)节";
Dictionary dictRet = new Dictionary();
string pattern = @"]*?href=(['""]?)(?[^'""\s>]+)\1[^>]*>(?(?:(?! 查看全部
网页信息抓取软件(在线看电子书怎么办?电子书下载地址及分包处理方法)
最近,我在网上阅读了一本电子书。由于篇幅太长,找不到下载地址,写了一个小工具,将电子书下载到本地。
总体思路:
1、在目录中获取每章的名称和网址
2、遍历章节URL获取具体内容
3、将章节URL分包给多线程处理
4、对处理后的内容重新排序,按章节名排序
5、将内容写入 TXT 文件
先抓取导航页内容,通过WebRequest对象获取网页内容
///
/// 通过链接地址获取HTML内容
///
///
///
private static string GetHtml(string url)
{
string html = "";
try
{
WebRequest request = WebRequest.Create(url);
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, encoding);
html = reader.ReadToEnd();
reader.Close();
stream.Close();
response.Close();
}
catch
{
}
return html;
}
通过正则表达式获取章节地址和名称
<p>///
/// 获取所有链接地址
///
///
private static Dictionary GetAllUrl(string html)
{
string titlePattern = @"第(?\d+)节";
Dictionary dictRet = new Dictionary();
string pattern = @"]*?href=(['""]?)(?[^'""\s>]+)\1[^>]*>(?(?:(?!

