
网站程序自带的采集器采集文章
实战:prometheus如何监控k8s集群里的node资源-2022.5
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-05-03 04:14
目录
关于我
最后
实验环境
k8s:v1.22.2(1 master,2 node)<br />containerd: v1.5.5<br />prometneus: docker.io/prom/prometheus:v2.34.0<br />
实验软件
链接:提取码:au4n2022.4.30-p8s监控k8s集群node资源-code
image-203369前置条件
关于如何将prometheus应用部署到k8s环境里,请查看我的另一篇文章,获取完整的部署方法!。
image-230811
image-222637基础知识
监控集群节点
前面我们和大家学习了怎样用 Promethues 来监控 Kubernetes 集群中的应用,但是对于 Kubernetes 集群本身的监控也是非常重要的,我们需要时时刻刻了解集群的运行状态。
对于集群的监控一般我们需要考虑以下几个方面:
Kubernetes 集群的监控方案目前主要有以下几种方案:
不过 kube-state-metrics 和 metrics-server 之间还是有很大不同的,二者的主要区别如下:
要监控节点其实我们已经有很多非常成熟的方案了,比如 Nagios、zabbix,甚至我们自己来收集数据也可以。我们这里通过 Prometheus 来采集节点的监控指标数据,可以通过 node_exporter 来获取,顾名思义,node_exporter 就是抓取用于采集服务器节点的各种运行指标,目前 node_exporter 支持几乎所有常见的监控点,比如 conntrack,cpu,diskstats,filesystem,loadavg,meminfo,netstat 等,详细的监控点列表可以参考其 Github 仓库。
我们可以通过 DaemonSet 控制器来部署该服务,这样每一个节点都会自动运行一个这样的 Pod,如果我们从集群中删除或者添加节点后,也会进行自动扩展。
1、创建daemonset资源
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-node-exporter.yaml
# prometheus-node-exporter.yaml<br />apiVersion: apps/v1<br />kind: DaemonSet<br />metadata:<br /> name: node-exporter<br /> namespace: monitor<br /> labels:<br /> app: node-exporter<br />spec:<br /> selector:<br /> matchLabels:<br /> app: node-exporter<br /> template:<br /> metadata:<br /> labels:<br /> app: node-exporter<br /> spec:<br /> hostPID: true<br /> hostIPC: true<br /> hostNetwork: true #因为这里用的是hostNetwortk模式,所以后面就不需要创建svc了!<br /> nodeSelector:<br /> kubernetes.io/os: linux<br /> containers:<br /> - name: node-exporter<br /> image: prom/node-exporter:v1.3.1<br /> args:<br /> - --web.listen-address=$(HOSTIP):9100<br /> - --path.procfs=/host/proc<br /> - --path.sysfs=/host/sys<br /> - --path.rootfs=/host/root<br /> - --no-collector.hwmon # 禁用不需要的一些采集器<br /> - --no-collector.nfs<br /> - --no-collector.nfsd<br /> - --no-collector.nvme<br /> - --no-collector.dmi<br /> - --no-collector.arp<br /> - --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/containerd/.+|/var/lib/docker/.+|var/lib/kubelet/pods/.+)($|/)<br /> - --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$<br /> ports:<br /> - containerPort: 9100<br /> env:<br /> - name: HOSTIP<br /> valueFrom:<br /> fieldRef:<br /> fieldPath: status.hostIP #Downward API<br /> resources:<br /> requests:<br /> cpu: 150m<br /> memory: 180Mi<br /> limits:<br /> cpu: 150m<br /> memory: 180Mi<br /> securityContext:<br /> runAsNonRoot: true<br /> runAsUser: 65534<br /> volumeMounts:<br /> - name: proc<br /> mountPath: /host/proc<br /> - name: sys<br /> mountPath: /host/sys<br /> - name: root<br /> mountPath: /host/root<br /> mountPropagation: HostToContainer<br /> readOnly: true<br /> tolerations:<br /> - operator: "Exists"<br /> volumes:<br /> - name: proc<br /> hostPath:<br /> path: /proc<br /> - name: dev<br /> hostPath:<br /> path: /dev<br /> - name: sys<br /> hostPath:<br /> path: /sys<br /> - name: root<br /> hostPath:<br /> path: /<br />
:warning: 注意:
image-225376
由于我们要获取到的数据是主机的监控指标数据,而我们的 node-exporter 是运行在容器中的,所以我们在 Pod 中需要配置一些 Pod 的安全策略,这里我们就添加了 hostPID: true、hostIPC: true、hostNetwork: true 3个策略,用来使用主机的 PID namespace、IPC namespace 以及主机网络,这些 namespace 就是用于容器隔离的关键技术,要注意这里的 namespace 和集群中的 namespace 是两个完全不相同的概念。
另外我们还将主机的 /dev、/proc、/sys这些目录挂载到容器中,这些因为我们采集的很多节点数据都是通过这些文件夹下面的文件来获取到的,比如我们在使用 top 命令可以查看当前 cpu 使用情况,数据就来源于文件 /proc/stat。使用 free 命令可以查看当前内存使用情况,其数据来源是来自 /proc/meminfo 文件。
另外由于我们集群使用的是 kubeadm 搭建的,所以如果希望 master 节点也一起被监控,则需要添加相应的容忍。
2、部署资源
[root@master1 p8s-example]#kubectl apply -f prometheus-node-exporter.yaml <br />daemonset.apps/node-exporter created<br /><br />[root@master1 p8s-example]#kubectl get pods -nmonitor -l app=node-exporter -o wide<br />NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES<br />node-exporter-6z7dx 1/1 Running 0 39s 172.29.9.52 node1 <br />node-exporter-bbsh6 1/1 Running 0 39s 172.29.9.51 master1 <br />node-exporter-lm46b 1/1 Running 0 39s 172.29.9.53 node2 <br />
image-225819
部署完成后,我们可以看到在几个节点上都运行了一个 Pod,由于我们指定了 hostNetwork=true,所以在每个节点上就会绑定一个端口 9100。
➜ curl 172.29.9.51:9100/metrics<br />...<br />node_filesystem_device_error{device="shm",fstype="tmpfs",mountpoint="/rootfs/var/lib/docker/containers/aefe8b1b63c3aa5f27766053ec817415faf8f6f417bb210d266fef0c2da64674/shm"} 1<br />node_filesystem_device_error{device="shm",fstype="tmpfs",mountpoint="/rootfs/var/lib/docker/containers/c8652ca72230496038a07e4fe4ee47046abb5f88d9d2440f0c8a923d5f3e133c/shm"} 1<br />node_filesystem_device_error{device="tmpfs",fstype="tmpfs",mountpoint="/dev"} 0<br />node_filesystem_device_error{device="tmpfs",fstype="tmpfs",mountpoint="/dev/shm"} 0<br />...<br />
image-255921
当然如果你觉得上面的手动安装方式比较麻烦,我们也可以使用 Helm 的方式来安装:
helm upgrade --install node-exporter --namespace monitor stable/prometheus-node-exporter<br />
3、服务发现
由于我们这里每个节点上面都运行了 node-exporter 程序,如果我们通过一个 Service 来将数据收集到一起用静态配置的方式配置到 Prometheus 去中,就只会显示一条数据,我们得自己在指标数据中去过滤每个节点的数据。当然我们也可以手动的把所有节点用静态的方式配置到 Prometheus 中去,但是以后要新增或者去掉节点的时候就还得手动去配置。那么有没有一种方式可以让 Prometheus 去自动发现我们节点的 node-exporter 程序,并且按节点进行分组呢?这就是 Prometheus 里面非常重要的服务发现功能了。
在 Kubernetes 下,Promethues 通过与 Kubernetes API 集成,主要支持5中服务发现模式,分别是:Node、Service、Pod、Endpoints、Ingress。
[root@master1 p8s-example]# kubectl get node<br />NAME STATUS ROLES AGE VERSION<br />master1 Ready control-plane,master 181d v1.22.2<br />node1 Ready 181d v1.22.2<br />node2 Ready 181d v1.22.2<br />
1.编写prometheus配置文件
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
# prometheus-cm.yaml<br />apiVersion: v1<br />kind: ConfigMap<br />metadata:<br /> name: prometheus-config<br /> namespace: monitor<br />data:<br /> prometheus.yml: |<br /> global:<br /> scrape_interval: 15s<br /> scrape_timeout: 15s<br /><br /> scrape_configs:<br /> - job_name: 'prometheus'<br /> static_configs:<br /> - targets: ['localhost:9090']<br /><br /> - job_name: 'coredns'<br /> static_configs:<br /> - targets: ['10.244.0.8:9153', '10.244.0.10:9153']<br /><br /> - job_name: 'redis'<br /> static_configs:<br /> - targets: ['redis:9121']<br /><br /> - job_name: 'nodes'<br /> kubernetes_sd_configs:<br /> - role: node<br />
image-207526
通过指定 kubernetes_sd_configs 的模式为 node,Prometheus 就会自动从 Kubernetes 中发现所有的 node 节点并作为当前 job 监控的目标实例,发现的节点 /metrics 接口是默认的 kubelet 的 HTTP 接口。
2.部署prometheus配置文件
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br /><br />[root@master1 p8s-example]#kubectl exec prometheus-698b6858c9-5xgsm -nmonitor -- cat /etc/prometheus/prometheus.yml<br />
可以看到prometheus pod的配置文件已经被更新了:
image-244290
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
image-237176
看了下prometheus pod日志没什么报错:
image-200878
[root@master1 p8s-example]#vim prometheus-rbac.yaml
image-254398
image-216722
image-242449
image-205240
server returned HTTP status 400 Bad Request<br />
这个是因为 prometheus 去发现 Node 模式的服务的时候,访问的端口默认是 10250,而默认是需要认证的 https 协议才有权访问的,但实际上我们并不是希望让去访问10250端口的 /metrics 接口,而是 node-exporter 绑定到节点的 9100 端口,所以我们应该将这里的 10250 替换成 9100,但是应该怎样替换呢?
3.使用 Prometheus 提供的 relabel_configs 中的 replace 能力
这里我们就需要使用到 Prometheus 提供的 relabel_configs 中的 replace 能力了,relabel 可以在 Prometheus 采集数据之前,通过 Target 实例的 Metadata 信息,动态重新写入 Label 的值。除此之外,我们还能根据 Target 实例的 Metadata 信息选择是否采集或者忽略该 Target 实例。比如我们这里就可以去匹配 __address__ 这个 Label 标签,然后替换掉其中的端口,如果你不知道有哪些 Label 标签可以操作的话,可以在 Service Discovery 页面获取到相关的元标签,这些标签都是我们可以进行 Relabel 的标签:
prometheus webui relabel before
image-202697
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
# prometheus-cm.yaml<br />apiVersion: v1<br />kind: ConfigMap<br />metadata:<br /> name: prometheus-config<br /> namespace: monitor<br />data:<br /> prometheus.yml: |<br /> global:<br /> scrape_interval: 15s<br /> scrape_timeout: 15s<br /><br /> scrape_configs:<br /> - job_name: 'prometheus'<br /> static_configs:<br /> - targets: ['localhost:9090']<br /><br /> - job_name: 'coredns'<br /> static_configs:<br /> - targets: ['10.244.0.8:9153', '10.244.0.10:9153']<br /><br /> - job_name: 'redis'<br /> static_configs:<br /> - targets: ['redis:9121']<br /><br /> - job_name: 'nodes'<br /> kubernetes_sd_configs:<br /> - role: node<br /> relabel_configs:<br /> - source_labels: [__address__]<br /> regex: '(.*):10250'<br /> replacement: '${1}:9100'<br /> target_label: __address__<br /> action: replace<br />
image-242968
这里就是一个正则表达式,去匹配 __address__ 这个标签,然后将 host 部分保留下来,port 替换成了 9100。
更新configmap文件:
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br />
image-257347
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
image-212315
我们可以看到现在已经正常了。
4.通过 labelmap 属性来将 Kubernetes 的 Label 标签添加为 Prometheus 的指标数据的标签
但是还有一个问题就是我们采集的指标数据 Label 标签就只有一个节点的 hostname,这对于我们在进行监控分组分类查询的时候带来了很多不方便的地方,要是我们能够将集群中 Node 节点的 Label 标签也能获取到就很好了。
image-247415
添加到prometheus-cm.yaml配置文件:
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
……<br />- job_name: 'kubernetes-nodes'<br /> kubernetes_sd_configs:<br /> - role: node<br /> relabel_configs:<br /> - source_labels: [__address__]<br /> regex: '(.*):10250'<br /> replacement: '${1}:9100'<br /> target_label: __address__<br /> action: replace<br /> - action: labelmap<br /> regex: __meta_kubernetes_node_label_(.+)<br />
image-236755
添加了一个 action 为 labelmap,正则表达式是 __meta_kubernetes_node_label_(.+) 的配置,这里的意思就是表达式中匹配都的数据也添加到指标数据的 Label 标签中去。
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br />
image-256974
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
image-205683
符合预期。
对于 kubernetes_sd_configs 下面可用的元信息标签如下:
关于 kubernets_sd_configs 更多信息可以查看官方文档:kubernetes_sd_config
5.把 kubelet 的监控任务也一并配置上
另外由于 kubelet 也自带了一些监控指标数据,就上面我们提到的 10250 端口,所以我们这里也把 kubelet 的监控任务也一并配置上:
添加到prometheus-cm.yaml配置文件:
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
……<br />- job_name: 'kubelet'<br /> kubernetes_sd_configs:<br /> - role: node<br /> scheme: https<br /> tls_config:<br /> ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt<br /> insecure_skip_verify: true<br /> bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token<br /> relabel_configs:<br /> - action: labelmap<br /> regex: __meta_kubernetes_node_label_(.+)<br />
image-205994
但是这里需要特别注意的是这里必须使用 https 协议访问,这样就必然需要提供证书,我们这里是通过配置 insecure_skip_verify: true 来跳过了证书校验。但是除此之外,要访问集群的资源,还必须要有对应的权限才可以,也就是对应的 ServiceAccount 棒的 权限允许才可以,我们这里部署的 prometheus 关联的 ServiceAccount 对象前面我们已经提到过了,这里我们只需要将 Pod 中自动注入的 /var/run/secrets/kubernetes.io/serviceaccount/ca.crt 和 /var/run/secrets/kubernetes.io/serviceaccount/token 文件配置上,就可以获取到对应的权限了。
以下不影响,是可以出效果的:
image-214497
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br />
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
现在我们再去更新下配置文件,执行 reload 操作,让配置生效,然后访问 Prometheus 的 Dashboard 查看 Targets 路径:
image-251917
现在可以看到我们上面添加的 kubernetes-kubelet 和 kubernetes-nodes 这两个 job 任务都已经配置成功了,而且二者的 Labels 标签都和集群的 node 节点标签保持一致了。
现在我们就可以切换到 Graph 路径下面查看采集的一些指标数据了,比如查询 node_load1 指标:
prometheus webui node load1
我们可以看到将几个节点对应的 node_load1 指标数据都查询出来了。
同样的,我们还可以使用 PromQL 语句来进行更复杂的一些聚合查询操作,还可以根据我们的 Labels 标签对指标数据进行聚合,比如我们这里只查询 node1 节点的数据,可以使用表达式 node_load1{instance="node1"} 来进行查询:
prometheus webui node1 load1
到这里我们就把 Kubernetes 集群节点使用 Prometheus 监控起来了,接下来我们再来和大家学习下怎样监控 Pod 或者 Service 之类的资源对象。
关于我
我的博客主旨: 查看全部
实战:prometheus如何监控k8s集群里的node资源-2022.5
目录
关于我
最后
实验环境
k8s:v1.22.2(1 master,2 node)<br />containerd: v1.5.5<br />prometneus: docker.io/prom/prometheus:v2.34.0<br />
实验软件
链接:提取码:au4n2022.4.30-p8s监控k8s集群node资源-code
image-203369前置条件
关于如何将prometheus应用部署到k8s环境里,请查看我的另一篇文章,获取完整的部署方法!。
image-230811
image-222637基础知识
监控集群节点
前面我们和大家学习了怎样用 Promethues 来监控 Kubernetes 集群中的应用,但是对于 Kubernetes 集群本身的监控也是非常重要的,我们需要时时刻刻了解集群的运行状态。
对于集群的监控一般我们需要考虑以下几个方面:
Kubernetes 集群的监控方案目前主要有以下几种方案:
不过 kube-state-metrics 和 metrics-server 之间还是有很大不同的,二者的主要区别如下:
要监控节点其实我们已经有很多非常成熟的方案了,比如 Nagios、zabbix,甚至我们自己来收集数据也可以。我们这里通过 Prometheus 来采集节点的监控指标数据,可以通过 node_exporter 来获取,顾名思义,node_exporter 就是抓取用于采集服务器节点的各种运行指标,目前 node_exporter 支持几乎所有常见的监控点,比如 conntrack,cpu,diskstats,filesystem,loadavg,meminfo,netstat 等,详细的监控点列表可以参考其 Github 仓库。
我们可以通过 DaemonSet 控制器来部署该服务,这样每一个节点都会自动运行一个这样的 Pod,如果我们从集群中删除或者添加节点后,也会进行自动扩展。
1、创建daemonset资源
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-node-exporter.yaml
# prometheus-node-exporter.yaml<br />apiVersion: apps/v1<br />kind: DaemonSet<br />metadata:<br /> name: node-exporter<br /> namespace: monitor<br /> labels:<br /> app: node-exporter<br />spec:<br /> selector:<br /> matchLabels:<br /> app: node-exporter<br /> template:<br /> metadata:<br /> labels:<br /> app: node-exporter<br /> spec:<br /> hostPID: true<br /> hostIPC: true<br /> hostNetwork: true #因为这里用的是hostNetwortk模式,所以后面就不需要创建svc了!<br /> nodeSelector:<br /> kubernetes.io/os: linux<br /> containers:<br /> - name: node-exporter<br /> image: prom/node-exporter:v1.3.1<br /> args:<br /> - --web.listen-address=$(HOSTIP):9100<br /> - --path.procfs=/host/proc<br /> - --path.sysfs=/host/sys<br /> - --path.rootfs=/host/root<br /> - --no-collector.hwmon # 禁用不需要的一些采集器<br /> - --no-collector.nfs<br /> - --no-collector.nfsd<br /> - --no-collector.nvme<br /> - --no-collector.dmi<br /> - --no-collector.arp<br /> - --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/containerd/.+|/var/lib/docker/.+|var/lib/kubelet/pods/.+)($|/)<br /> - --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$<br /> ports:<br /> - containerPort: 9100<br /> env:<br /> - name: HOSTIP<br /> valueFrom:<br /> fieldRef:<br /> fieldPath: status.hostIP #Downward API<br /> resources:<br /> requests:<br /> cpu: 150m<br /> memory: 180Mi<br /> limits:<br /> cpu: 150m<br /> memory: 180Mi<br /> securityContext:<br /> runAsNonRoot: true<br /> runAsUser: 65534<br /> volumeMounts:<br /> - name: proc<br /> mountPath: /host/proc<br /> - name: sys<br /> mountPath: /host/sys<br /> - name: root<br /> mountPath: /host/root<br /> mountPropagation: HostToContainer<br /> readOnly: true<br /> tolerations:<br /> - operator: "Exists"<br /> volumes:<br /> - name: proc<br /> hostPath:<br /> path: /proc<br /> - name: dev<br /> hostPath:<br /> path: /dev<br /> - name: sys<br /> hostPath:<br /> path: /sys<br /> - name: root<br /> hostPath:<br /> path: /<br />
:warning: 注意:
image-225376
由于我们要获取到的数据是主机的监控指标数据,而我们的 node-exporter 是运行在容器中的,所以我们在 Pod 中需要配置一些 Pod 的安全策略,这里我们就添加了 hostPID: true、hostIPC: true、hostNetwork: true 3个策略,用来使用主机的 PID namespace、IPC namespace 以及主机网络,这些 namespace 就是用于容器隔离的关键技术,要注意这里的 namespace 和集群中的 namespace 是两个完全不相同的概念。
另外我们还将主机的 /dev、/proc、/sys这些目录挂载到容器中,这些因为我们采集的很多节点数据都是通过这些文件夹下面的文件来获取到的,比如我们在使用 top 命令可以查看当前 cpu 使用情况,数据就来源于文件 /proc/stat。使用 free 命令可以查看当前内存使用情况,其数据来源是来自 /proc/meminfo 文件。
另外由于我们集群使用的是 kubeadm 搭建的,所以如果希望 master 节点也一起被监控,则需要添加相应的容忍。
2、部署资源
[root@master1 p8s-example]#kubectl apply -f prometheus-node-exporter.yaml <br />daemonset.apps/node-exporter created<br /><br />[root@master1 p8s-example]#kubectl get pods -nmonitor -l app=node-exporter -o wide<br />NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES<br />node-exporter-6z7dx 1/1 Running 0 39s 172.29.9.52 node1 <br />node-exporter-bbsh6 1/1 Running 0 39s 172.29.9.51 master1 <br />node-exporter-lm46b 1/1 Running 0 39s 172.29.9.53 node2 <br />
image-225819
部署完成后,我们可以看到在几个节点上都运行了一个 Pod,由于我们指定了 hostNetwork=true,所以在每个节点上就会绑定一个端口 9100。
➜ curl 172.29.9.51:9100/metrics<br />...<br />node_filesystem_device_error{device="shm",fstype="tmpfs",mountpoint="/rootfs/var/lib/docker/containers/aefe8b1b63c3aa5f27766053ec817415faf8f6f417bb210d266fef0c2da64674/shm"} 1<br />node_filesystem_device_error{device="shm",fstype="tmpfs",mountpoint="/rootfs/var/lib/docker/containers/c8652ca72230496038a07e4fe4ee47046abb5f88d9d2440f0c8a923d5f3e133c/shm"} 1<br />node_filesystem_device_error{device="tmpfs",fstype="tmpfs",mountpoint="/dev"} 0<br />node_filesystem_device_error{device="tmpfs",fstype="tmpfs",mountpoint="/dev/shm"} 0<br />...<br />
image-255921
当然如果你觉得上面的手动安装方式比较麻烦,我们也可以使用 Helm 的方式来安装:
helm upgrade --install node-exporter --namespace monitor stable/prometheus-node-exporter<br />
3、服务发现
由于我们这里每个节点上面都运行了 node-exporter 程序,如果我们通过一个 Service 来将数据收集到一起用静态配置的方式配置到 Prometheus 去中,就只会显示一条数据,我们得自己在指标数据中去过滤每个节点的数据。当然我们也可以手动的把所有节点用静态的方式配置到 Prometheus 中去,但是以后要新增或者去掉节点的时候就还得手动去配置。那么有没有一种方式可以让 Prometheus 去自动发现我们节点的 node-exporter 程序,并且按节点进行分组呢?这就是 Prometheus 里面非常重要的服务发现功能了。
在 Kubernetes 下,Promethues 通过与 Kubernetes API 集成,主要支持5中服务发现模式,分别是:Node、Service、Pod、Endpoints、Ingress。
[root@master1 p8s-example]# kubectl get node<br />NAME STATUS ROLES AGE VERSION<br />master1 Ready control-plane,master 181d v1.22.2<br />node1 Ready 181d v1.22.2<br />node2 Ready 181d v1.22.2<br />
1.编写prometheus配置文件
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
# prometheus-cm.yaml<br />apiVersion: v1<br />kind: ConfigMap<br />metadata:<br /> name: prometheus-config<br /> namespace: monitor<br />data:<br /> prometheus.yml: |<br /> global:<br /> scrape_interval: 15s<br /> scrape_timeout: 15s<br /><br /> scrape_configs:<br /> - job_name: 'prometheus'<br /> static_configs:<br /> - targets: ['localhost:9090']<br /><br /> - job_name: 'coredns'<br /> static_configs:<br /> - targets: ['10.244.0.8:9153', '10.244.0.10:9153']<br /><br /> - job_name: 'redis'<br /> static_configs:<br /> - targets: ['redis:9121']<br /><br /> - job_name: 'nodes'<br /> kubernetes_sd_configs:<br /> - role: node<br />
image-207526
通过指定 kubernetes_sd_configs 的模式为 node,Prometheus 就会自动从 Kubernetes 中发现所有的 node 节点并作为当前 job 监控的目标实例,发现的节点 /metrics 接口是默认的 kubelet 的 HTTP 接口。
2.部署prometheus配置文件
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br /><br />[root@master1 p8s-example]#kubectl exec prometheus-698b6858c9-5xgsm -nmonitor -- cat /etc/prometheus/prometheus.yml<br />
可以看到prometheus pod的配置文件已经被更新了:
image-244290
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
image-237176
看了下prometheus pod日志没什么报错:
image-200878
[root@master1 p8s-example]#vim prometheus-rbac.yaml
image-254398
image-216722
image-242449
image-205240
server returned HTTP status 400 Bad Request<br />
这个是因为 prometheus 去发现 Node 模式的服务的时候,访问的端口默认是 10250,而默认是需要认证的 https 协议才有权访问的,但实际上我们并不是希望让去访问10250端口的 /metrics 接口,而是 node-exporter 绑定到节点的 9100 端口,所以我们应该将这里的 10250 替换成 9100,但是应该怎样替换呢?
3.使用 Prometheus 提供的 relabel_configs 中的 replace 能力
这里我们就需要使用到 Prometheus 提供的 relabel_configs 中的 replace 能力了,relabel 可以在 Prometheus 采集数据之前,通过 Target 实例的 Metadata 信息,动态重新写入 Label 的值。除此之外,我们还能根据 Target 实例的 Metadata 信息选择是否采集或者忽略该 Target 实例。比如我们这里就可以去匹配 __address__ 这个 Label 标签,然后替换掉其中的端口,如果你不知道有哪些 Label 标签可以操作的话,可以在 Service Discovery 页面获取到相关的元标签,这些标签都是我们可以进行 Relabel 的标签:
prometheus webui relabel before
image-202697
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
# prometheus-cm.yaml<br />apiVersion: v1<br />kind: ConfigMap<br />metadata:<br /> name: prometheus-config<br /> namespace: monitor<br />data:<br /> prometheus.yml: |<br /> global:<br /> scrape_interval: 15s<br /> scrape_timeout: 15s<br /><br /> scrape_configs:<br /> - job_name: 'prometheus'<br /> static_configs:<br /> - targets: ['localhost:9090']<br /><br /> - job_name: 'coredns'<br /> static_configs:<br /> - targets: ['10.244.0.8:9153', '10.244.0.10:9153']<br /><br /> - job_name: 'redis'<br /> static_configs:<br /> - targets: ['redis:9121']<br /><br /> - job_name: 'nodes'<br /> kubernetes_sd_configs:<br /> - role: node<br /> relabel_configs:<br /> - source_labels: [__address__]<br /> regex: '(.*):10250'<br /> replacement: '${1}:9100'<br /> target_label: __address__<br /> action: replace<br />
image-242968
这里就是一个正则表达式,去匹配 __address__ 这个标签,然后将 host 部分保留下来,port 替换成了 9100。
更新configmap文件:
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br />
image-257347
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
image-212315
我们可以看到现在已经正常了。
4.通过 labelmap 属性来将 Kubernetes 的 Label 标签添加为 Prometheus 的指标数据的标签
但是还有一个问题就是我们采集的指标数据 Label 标签就只有一个节点的 hostname,这对于我们在进行监控分组分类查询的时候带来了很多不方便的地方,要是我们能够将集群中 Node 节点的 Label 标签也能获取到就很好了。
image-247415
添加到prometheus-cm.yaml配置文件:
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
……<br />- job_name: 'kubernetes-nodes'<br /> kubernetes_sd_configs:<br /> - role: node<br /> relabel_configs:<br /> - source_labels: [__address__]<br /> regex: '(.*):10250'<br /> replacement: '${1}:9100'<br /> target_label: __address__<br /> action: replace<br /> - action: labelmap<br /> regex: __meta_kubernetes_node_label_(.+)<br />
image-236755
添加了一个 action 为 labelmap,正则表达式是 __meta_kubernetes_node_label_(.+) 的配置,这里的意思就是表达式中匹配都的数据也添加到指标数据的 Label 标签中去。
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br />
image-256974
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
image-205683
符合预期。
对于 kubernetes_sd_configs 下面可用的元信息标签如下:
关于 kubernets_sd_configs 更多信息可以查看官方文档:kubernetes_sd_config
5.把 kubelet 的监控任务也一并配置上
另外由于 kubelet 也自带了一些监控指标数据,就上面我们提到的 10250 端口,所以我们这里也把 kubelet 的监控任务也一并配置上:
添加到prometheus-cm.yaml配置文件:
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
……<br />- job_name: 'kubelet'<br /> kubernetes_sd_configs:<br /> - role: node<br /> scheme: https<br /> tls_config:<br /> ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt<br /> insecure_skip_verify: true<br /> bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token<br /> relabel_configs:<br /> - action: labelmap<br /> regex: __meta_kubernetes_node_label_(.+)<br />
image-205994
但是这里需要特别注意的是这里必须使用 https 协议访问,这样就必然需要提供证书,我们这里是通过配置 insecure_skip_verify: true 来跳过了证书校验。但是除此之外,要访问集群的资源,还必须要有对应的权限才可以,也就是对应的 ServiceAccount 棒的 权限允许才可以,我们这里部署的 prometheus 关联的 ServiceAccount 对象前面我们已经提到过了,这里我们只需要将 Pod 中自动注入的 /var/run/secrets/kubernetes.io/serviceaccount/ca.crt 和 /var/run/secrets/kubernetes.io/serviceaccount/token 文件配置上,就可以获取到对应的权限了。
以下不影响,是可以出效果的:
image-214497
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br />
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
现在我们再去更新下配置文件,执行 reload 操作,让配置生效,然后访问 Prometheus 的 Dashboard 查看 Targets 路径:
image-251917
现在可以看到我们上面添加的 kubernetes-kubelet 和 kubernetes-nodes 这两个 job 任务都已经配置成功了,而且二者的 Labels 标签都和集群的 node 节点标签保持一致了。
现在我们就可以切换到 Graph 路径下面查看采集的一些指标数据了,比如查询 node_load1 指标:
prometheus webui node load1
我们可以看到将几个节点对应的 node_load1 指标数据都查询出来了。
同样的,我们还可以使用 PromQL 语句来进行更复杂的一些聚合查询操作,还可以根据我们的 Labels 标签对指标数据进行聚合,比如我们这里只查询 node1 节点的数据,可以使用表达式 node_load1{instance="node1"} 来进行查询:
prometheus webui node1 load1
到这里我们就把 Kubernetes 集群节点使用 Prometheus 监控起来了,接下来我们再来和大家学习下怎样监控 Pod 或者 Service 之类的资源对象。
关于我
我的博客主旨:
网站程序自带的采集器采集文章(新浪微博采集直发养号大师的软件用途及使用方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-20 03:26
新浪微博采集知发养豪大师是一款采集软件,可以定位采集你需要的微博内容,指定一个或几个大方向,软件会自动采集 @采集最热门的内容,可以直接发送,是营销的好工具,欢迎有需要的朋友下载使用!
主要功能
自动采集内容,即可使用微博内容和多个账号同时操作。
新浪微博自动发布
可以批量维护微博账号,定时发送微博。
不仅可以采集微博文字内容,还可以自动采集微博图片,自动采集微博视频,自动采集微博内容来源和作者信息。
软件使用
1)微博内容采集(包括文字、图片、头像、微博数量、关注人数、关注人数、是否加V、作者、博主昵称、博主头像、UID等)
2)微博内容自动批量发布,可批量指定多个账号和内容。原创微博,本软件也可用于微博账号维护,自动更新微博内容,减少工作量微博维护
3)采集微博昵称,UID(可以通过关键字搜索,提取某人粉丝的昵称UID,提取某人关注的昵称UID,通过高级搜索搜索)
4)采集微博转发内容,采集评论内容
5)昵称转UID(指定批次昵称转换为对应微博的UID)
6)您可以将数据采集传输到Mssql或MySQL数据库,并与您的网站进行批处理(站群的朋友们有福了)
7) 发完微博,立即评论微博,提升微博排名,轻松进入微博精选、热门微博、实时微博(评论可收录9个链接,主要应用场景:在微博内容中发图,在评论中有婴儿链接。)
8)微博内容自动同步,可以将大微博的内容自动同步到很多微博小号上的产品描述
9)。新浪微博超级话题关注签到,支持多号批量关注签到。
指示
1、账号分类管理
首先添加你的“账号”发布微博和采集微博内容。此功能还可用于批量管理您的N个新浪微博账号,维护您的新浪微博账号。可以自动检测你的微博账号是否异常,是否被新浪微博官方封禁等。
2、内容自动发布
查看微博内容和账号,点击“开始发送”发布微博。这里是自动即时发布或您的微博内容,真正 24 小时无人值守。让机器完全代替您的手动操作!该软件还支持定时和自动发微博。可以先设置一个时间点,时间点到了会自动发微博。
3、内容批量管理
您可以自行添加、修改和删除内容。采集微博的内容也可以在这里编辑。您可以批量导入和导出微博内容。
4、内容自动采集
通过指定采集一个人的微博,也可以通过关键字搜索采集对应的内容。
5、网管模式管理
软件可以通过代理IP和ADSL发布你的微博内容,防止账号被封的风险。
6、微博昵称采集
你可以在微博上采集活跃真实用户的昵称,然后在你自动发微博的时候,你可以在微博的内容里@一群人,从布上横向传递信息,让你的微博可以迅速将其影响向外扩散。力量!
7、操作帮助
设置后会自动采集新浪微博内容,不仅有采集文字,还有采集图片、采集视频、采集作者和源地址等. 您也可以将采集之后的内容发布到您指定的微博。新浪微博内容自动采集及发布工具,新浪微博内容自动采集及发布软件,新浪微博发布大师。 查看全部
网站程序自带的采集器采集文章(新浪微博采集直发养号大师的软件用途及使用方法介绍)
新浪微博采集知发养豪大师是一款采集软件,可以定位采集你需要的微博内容,指定一个或几个大方向,软件会自动采集 @采集最热门的内容,可以直接发送,是营销的好工具,欢迎有需要的朋友下载使用!

主要功能
自动采集内容,即可使用微博内容和多个账号同时操作。
新浪微博自动发布
可以批量维护微博账号,定时发送微博。
不仅可以采集微博文字内容,还可以自动采集微博图片,自动采集微博视频,自动采集微博内容来源和作者信息。
软件使用
1)微博内容采集(包括文字、图片、头像、微博数量、关注人数、关注人数、是否加V、作者、博主昵称、博主头像、UID等)
2)微博内容自动批量发布,可批量指定多个账号和内容。原创微博,本软件也可用于微博账号维护,自动更新微博内容,减少工作量微博维护
3)采集微博昵称,UID(可以通过关键字搜索,提取某人粉丝的昵称UID,提取某人关注的昵称UID,通过高级搜索搜索)
4)采集微博转发内容,采集评论内容
5)昵称转UID(指定批次昵称转换为对应微博的UID)
6)您可以将数据采集传输到Mssql或MySQL数据库,并与您的网站进行批处理(站群的朋友们有福了)
7) 发完微博,立即评论微博,提升微博排名,轻松进入微博精选、热门微博、实时微博(评论可收录9个链接,主要应用场景:在微博内容中发图,在评论中有婴儿链接。)
8)微博内容自动同步,可以将大微博的内容自动同步到很多微博小号上的产品描述
9)。新浪微博超级话题关注签到,支持多号批量关注签到。
指示
1、账号分类管理
首先添加你的“账号”发布微博和采集微博内容。此功能还可用于批量管理您的N个新浪微博账号,维护您的新浪微博账号。可以自动检测你的微博账号是否异常,是否被新浪微博官方封禁等。
2、内容自动发布
查看微博内容和账号,点击“开始发送”发布微博。这里是自动即时发布或您的微博内容,真正 24 小时无人值守。让机器完全代替您的手动操作!该软件还支持定时和自动发微博。可以先设置一个时间点,时间点到了会自动发微博。
3、内容批量管理
您可以自行添加、修改和删除内容。采集微博的内容也可以在这里编辑。您可以批量导入和导出微博内容。
4、内容自动采集
通过指定采集一个人的微博,也可以通过关键字搜索采集对应的内容。
5、网管模式管理
软件可以通过代理IP和ADSL发布你的微博内容,防止账号被封的风险。
6、微博昵称采集
你可以在微博上采集活跃真实用户的昵称,然后在你自动发微博的时候,你可以在微博的内容里@一群人,从布上横向传递信息,让你的微博可以迅速将其影响向外扩散。力量!
7、操作帮助
设置后会自动采集新浪微博内容,不仅有采集文字,还有采集图片、采集视频、采集作者和源地址等. 您也可以将采集之后的内容发布到您指定的微博。新浪微博内容自动采集及发布工具,新浪微博内容自动采集及发布软件,新浪微博发布大师。
网站程序自带的采集器采集文章( Wp网站建设的网站,我们应该怎么去优化呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-04-20 01:27
Wp网站建设的网站,我们应该怎么去优化呢?)
wp网站, wordpress网站 构建(免费 wordpress采集 教程)
光速SEO2022-04-18
wp网站,wordpress是很多站长建站选择的内容管理系统。wp网站constructed网站,我们应该如何优化呢?首先,wp网站SEO优化我们需要做好SEO站内优化和站外优化。具体可以走wordpress采集、wordpress伪原创、wordpress自动定时发布路线。
wp网站建站目标关键词确定后,wordpress采集会进行关键词挖矿。形成大量长尾关键词,然后根据这些长尾关键词进行全网文章关键词pan采集,接着是伪原创,最后自动批量发布。
那么我们如何确定哪个关键词应该在wp网站首页优化,哪个关键词应该在分类页面优化呢?首先,将目标关键词放到wordpress采集中,按照搜索量排序,搜索量最高的排在最前面。找到可以作为wp网站的分类页面的关键词,去掉搜索量低的关键词。
wp网站关键词 出现在文本中,文本的第一段自动加粗。当描述不太相关时,自动添加当前 采集 的 关键词。去掉分类页面和低搜索量关键词后,剩下的就是wp网站首页的关键词有待优化。首页优化关键词也有限,太多关键词无法优化。然后我们可以结合关键词来达到想要的SEO效果。
wp网站建一个网站,不管是服务器还是虚拟主机,稳定的服务器。要知道,搜索引擎蜘蛛会模拟用户浏览和抓取内容。如果出现断电或服务器宕机等问题,导致wp网站无法访问或浏览不稳定,那么搜索引擎蜘蛛将无法打开我们的wp网站,并将无法获取wp网站内容的网页,这会导致搜索引擎蜘蛛无法获取网页内容,更不用说收录了。
Wordpress采集可以同时选择多个新闻源关键词pan采集伪原创发布,提供各种SEO优化设置包括:百度、有道、147翻译、标题内容< @关键词 等等。Wordpress采集 的文本在随机位置自动插入到当前 关键词 集合中两次。当前采集的 关键词 在出现在文本中时会自动加粗。
其次,如果网站打开次数过多,搜索引擎也会判断网站不稳定或者网站没有内容可显示。这种情况会大大降低搜索引擎的友好度,甚至可能被评为死链接网站,导致网站无法参与排名。
相信很多站长都经历过wp网站被黑客攻击,而这一次也是考验服务器安全的时候了。一般来说,安全性差的服务器很容易被黑客攻击,导致来之不易的排名下滑。因此,必须保证服务器的安全。
wp网站的站外优化,需要我们做优秀的网站外链,你在行业中立于不败之地。你为什么这么说?wp网站优化的组件很多,其中内链占据非常重要的位置,因为它可以提升网站的排名,甚至整个网站的权重。不要忽视内部链接的重要性。
当 wp网站 构建的 网站 内链运行良好时,用户体验的作用可以通过观察数据来体现。内容被浏览的次数大大增加,不会有点击率。由于内容的可转移性,用户访问量迅速增加。
另外,wp网站合理的内链结构会引导蜘蛛爬行,大量的内链网络会大大增加网站的整体权重。只有不断优化内链,才能真正将权重提升到一个新的水平。通过分析wp网站的访问页面,我们可以知道用户访问了wp网站的哪些页面。
通过查看这些数据,我们可以微调 wp网站。通过分析门户页面,我们可以知道用户从哪个页面进入网站。点击页面地图,可以直观的分析出用户点击了哪些页面,页面点击量,喜欢什么内容,方便我们调整优化。今天关于wp网站的构造的解释就到这里了。下期分享更多SEO相关知识。 查看全部
网站程序自带的采集器采集文章(
Wp网站建设的网站,我们应该怎么去优化呢?)
wp网站, wordpress网站 构建(免费 wordpress采集 教程)
光速SEO2022-04-18
wp网站,wordpress是很多站长建站选择的内容管理系统。wp网站constructed网站,我们应该如何优化呢?首先,wp网站SEO优化我们需要做好SEO站内优化和站外优化。具体可以走wordpress采集、wordpress伪原创、wordpress自动定时发布路线。
wp网站建站目标关键词确定后,wordpress采集会进行关键词挖矿。形成大量长尾关键词,然后根据这些长尾关键词进行全网文章关键词pan采集,接着是伪原创,最后自动批量发布。
那么我们如何确定哪个关键词应该在wp网站首页优化,哪个关键词应该在分类页面优化呢?首先,将目标关键词放到wordpress采集中,按照搜索量排序,搜索量最高的排在最前面。找到可以作为wp网站的分类页面的关键词,去掉搜索量低的关键词。
wp网站关键词 出现在文本中,文本的第一段自动加粗。当描述不太相关时,自动添加当前 采集 的 关键词。去掉分类页面和低搜索量关键词后,剩下的就是wp网站首页的关键词有待优化。首页优化关键词也有限,太多关键词无法优化。然后我们可以结合关键词来达到想要的SEO效果。
wp网站建一个网站,不管是服务器还是虚拟主机,稳定的服务器。要知道,搜索引擎蜘蛛会模拟用户浏览和抓取内容。如果出现断电或服务器宕机等问题,导致wp网站无法访问或浏览不稳定,那么搜索引擎蜘蛛将无法打开我们的wp网站,并将无法获取wp网站内容的网页,这会导致搜索引擎蜘蛛无法获取网页内容,更不用说收录了。
Wordpress采集可以同时选择多个新闻源关键词pan采集伪原创发布,提供各种SEO优化设置包括:百度、有道、147翻译、标题内容< @关键词 等等。Wordpress采集 的文本在随机位置自动插入到当前 关键词 集合中两次。当前采集的 关键词 在出现在文本中时会自动加粗。
其次,如果网站打开次数过多,搜索引擎也会判断网站不稳定或者网站没有内容可显示。这种情况会大大降低搜索引擎的友好度,甚至可能被评为死链接网站,导致网站无法参与排名。
相信很多站长都经历过wp网站被黑客攻击,而这一次也是考验服务器安全的时候了。一般来说,安全性差的服务器很容易被黑客攻击,导致来之不易的排名下滑。因此,必须保证服务器的安全。
wp网站的站外优化,需要我们做优秀的网站外链,你在行业中立于不败之地。你为什么这么说?wp网站优化的组件很多,其中内链占据非常重要的位置,因为它可以提升网站的排名,甚至整个网站的权重。不要忽视内部链接的重要性。
当 wp网站 构建的 网站 内链运行良好时,用户体验的作用可以通过观察数据来体现。内容被浏览的次数大大增加,不会有点击率。由于内容的可转移性,用户访问量迅速增加。
另外,wp网站合理的内链结构会引导蜘蛛爬行,大量的内链网络会大大增加网站的整体权重。只有不断优化内链,才能真正将权重提升到一个新的水平。通过分析wp网站的访问页面,我们可以知道用户访问了wp网站的哪些页面。
通过查看这些数据,我们可以微调 wp网站。通过分析门户页面,我们可以知道用户从哪个页面进入网站。点击页面地图,可以直观的分析出用户点击了哪些页面,页面点击量,喜欢什么内容,方便我们调整优化。今天关于wp网站的构造的解释就到这里了。下期分享更多SEO相关知识。
网站程序自带的采集器采集文章(如何使用好网页采集器让网站更多的被搜索引擎收录)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-19 15:26
网页采集器,最近很多站长朋友问我怎么指定网站采集,市面上的网页采集工具基本都需要写采集规则,要求站长朋友了解正则表达式和html代码基础。这对于小白站长来说是一件非常困难的事情。网页采集器可视化批次采集指定网站采集并自动伪原创发布及一键自动百度、神马、360、搜狗推送.
网页采集器可以被任意网页数据抓取,所见即所得的操作方法只需点击几下鼠标即可轻松获取。那么我们如何使用好的网页来采集器网站更多的搜索引擎收录并获得好的SEO排名。
网页采集器要求我们能够清晰直观的网站定位会带来较高的客群转化率。我们的网站 目的是营销。我们的网站只有专注于一件事才能更好的展示出来,这样网站的内容搭建就会相当的简单。网页采集器基于高度智能的文本识别算法,根据关键词采集文章,无需编写采集规则。
页面采集器做网站SEO优化需要网站合理的结构。首先要提的是网站的结构要清晰,布局要合理,拒绝冗余代码,拒绝大量的JS脚本和FLASH动画,会影响网站 的打开速度。设置应清晰可见,便于客户导航。
和关键字描述信息。事实上,大多数人都知道 关键词 和描述对于一个 网站 非常重要,但是有些人忽略了这些信息。关键词 和 description 相当于一个搜索领导者提交的名片。有了这张卡片,人们就会更多地了解你的网站。
网页采集器可以通过长尾关键词做全网关键词文章pan采集,然后合并批量伪原创到网站 文章定期发布,让搜索引擎判断你的网站内容属于原创,更容易获得搜索引擎的青睐。还有一点要提醒大家,在网站收录之后,不要轻易改变你网站的关键词。所以一个好的关键词和描述也是一个网站的必要条件之一。网页采集器可以对文章的标题描述和内容进行相应的SEO优化设置。
网页采集器内置了很多网站优化方法。网页 采集器 支持自动内部链接。我们都知道网站的内链在一个网站中起着非常重要的作用,所以网站采集器内的网页会合理的安排内链。网页采集器伪原创文章也会大大提高网站SEO优化的指标。好的伪原创文章,对蜘蛛的吸引力很大。网页采集器自动全网采集,覆盖六大搜索引擎。自动过滤内容相关度和文章平滑度,只有采集高度相关和平滑度文章。
<p>当蜘蛛进入网站时,网站地图被视为很好的引导,蜘蛛可以轻松进入网站的每一个角落,网页采集器可以自动生成并更新网站的sitemap地图,让蜘蛛第一时间知道你网站的文章链接,可以方便蜘蛛抓取你 查看全部
网站程序自带的采集器采集文章(如何使用好网页采集器让网站更多的被搜索引擎收录)
网页采集器,最近很多站长朋友问我怎么指定网站采集,市面上的网页采集工具基本都需要写采集规则,要求站长朋友了解正则表达式和html代码基础。这对于小白站长来说是一件非常困难的事情。网页采集器可视化批次采集指定网站采集并自动伪原创发布及一键自动百度、神马、360、搜狗推送.
网页采集器可以被任意网页数据抓取,所见即所得的操作方法只需点击几下鼠标即可轻松获取。那么我们如何使用好的网页来采集器网站更多的搜索引擎收录并获得好的SEO排名。
网页采集器要求我们能够清晰直观的网站定位会带来较高的客群转化率。我们的网站 目的是营销。我们的网站只有专注于一件事才能更好的展示出来,这样网站的内容搭建就会相当的简单。网页采集器基于高度智能的文本识别算法,根据关键词采集文章,无需编写采集规则。
页面采集器做网站SEO优化需要网站合理的结构。首先要提的是网站的结构要清晰,布局要合理,拒绝冗余代码,拒绝大量的JS脚本和FLASH动画,会影响网站 的打开速度。设置应清晰可见,便于客户导航。
和关键字描述信息。事实上,大多数人都知道 关键词 和描述对于一个 网站 非常重要,但是有些人忽略了这些信息。关键词 和 description 相当于一个搜索领导者提交的名片。有了这张卡片,人们就会更多地了解你的网站。
网页采集器可以通过长尾关键词做全网关键词文章pan采集,然后合并批量伪原创到网站 文章定期发布,让搜索引擎判断你的网站内容属于原创,更容易获得搜索引擎的青睐。还有一点要提醒大家,在网站收录之后,不要轻易改变你网站的关键词。所以一个好的关键词和描述也是一个网站的必要条件之一。网页采集器可以对文章的标题描述和内容进行相应的SEO优化设置。
网页采集器内置了很多网站优化方法。网页 采集器 支持自动内部链接。我们都知道网站的内链在一个网站中起着非常重要的作用,所以网站采集器内的网页会合理的安排内链。网页采集器伪原创文章也会大大提高网站SEO优化的指标。好的伪原创文章,对蜘蛛的吸引力很大。网页采集器自动全网采集,覆盖六大搜索引擎。自动过滤内容相关度和文章平滑度,只有采集高度相关和平滑度文章。
<p>当蜘蛛进入网站时,网站地图被视为很好的引导,蜘蛛可以轻松进入网站的每一个角落,网页采集器可以自动生成并更新网站的sitemap地图,让蜘蛛第一时间知道你网站的文章链接,可以方便蜘蛛抓取你
网站程序自带的采集器采集文章(微信搜索微信指数文章网站程序/微博/公号助手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-18 05:23
热点指数
1文章网站节目,微博索引:/index
2、微信索引文章网站程序:微信搜索微信索引小程序
3、百度索引文章网站程序::///#/
4文章网站节目,今日头条指数:///
5、搜狗指数文章网站节目:/
公众号小助手
1、西瓜助手:/
2、新媒体经理::///index
3、合伙人:://yiban.io/
4、主机:/
5、新排名助手::///public/about/plugIn_introduce.html
6、滴滴微平台:://drip.im/
7、小宝:/
但是域名没变,301怎么办?
第一种方法(我也用过):在全站生成静态页面,然后保存静态页面和目录。后台更新、修订或程序更改后,请勿使用与之前同名的文件目录作为列。将之前生成的静态文件放回网站文件夹的原创位置。以上保证了上一页收录仍然存在。--------------- 前提是你的网站后台开启了静态生成功能,这样链接总是一样的,保存下来才有意义静态页面。---------------第二种方法:如果上不了路,就得301权重页面直接新的对应地址,比较繁琐但还是有效的在挽回损失。
查看原帖>>
但是域名没变,301怎么办?
第一种方法(我也用过):在全站生成静态页面,然后保存静态页面和目录。后台更新、修订或程序更改后,请勿使用与之前同名的文件目录作为列。将之前生成的静态文件放回网站文件夹的原创位置。以上保证了上一页收录仍然存在。--------------- 前提是你的网站后台开启了静态生成功能,这样链接总是一样的,保存下来才有意义静态页面。---------------第二种方法:如果上不了路,就得301权重页面直接新的对应地址,比较麻烦但是还是有效的在挽回损失。 查看全部
网站程序自带的采集器采集文章(微信搜索微信指数文章网站程序/微博/公号助手)
热点指数

1文章网站节目,微博索引:/index
2、微信索引文章网站程序:微信搜索微信索引小程序
3、百度索引文章网站程序::///#/
4文章网站节目,今日头条指数:///
5、搜狗指数文章网站节目:/
公众号小助手
1、西瓜助手:/
2、新媒体经理::///index
3、合伙人:://yiban.io/
4、主机:/
5、新排名助手::///public/about/plugIn_introduce.html
6、滴滴微平台:://drip.im/
7、小宝:/
但是域名没变,301怎么办?
第一种方法(我也用过):在全站生成静态页面,然后保存静态页面和目录。后台更新、修订或程序更改后,请勿使用与之前同名的文件目录作为列。将之前生成的静态文件放回网站文件夹的原创位置。以上保证了上一页收录仍然存在。--------------- 前提是你的网站后台开启了静态生成功能,这样链接总是一样的,保存下来才有意义静态页面。---------------第二种方法:如果上不了路,就得301权重页面直接新的对应地址,比较繁琐但还是有效的在挽回损失。
查看原帖>>
但是域名没变,301怎么办?
第一种方法(我也用过):在全站生成静态页面,然后保存静态页面和目录。后台更新、修订或程序更改后,请勿使用与之前同名的文件目录作为列。将之前生成的静态文件放回网站文件夹的原创位置。以上保证了上一页收录仍然存在。--------------- 前提是你的网站后台开启了静态生成功能,这样链接总是一样的,保存下来才有意义静态页面。---------------第二种方法:如果上不了路,就得301权重页面直接新的对应地址,比较麻烦但是还是有效的在挽回损失。
网站程序自带的采集器采集文章(SEO和网站运营经验文章,手写原创内容可以直接忽略)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-04-16 18:28
大家好,我叫熊晓峰。今天继续分享SEO和网站运营经验文章。因为昨天分享内容更新和原创处理的时候,只提到了框架,没有详细分享,所以,今天给大家详细分享一下如何处理获取到的文章内容使内容更好。
今天的内容主要针对采集内容,手写原创的内容可以直接忽略。
主要分为以下几个部分
1、过滤采集来源
2、采集工具介绍
3、采集文章处理中
1、采集来源
这个好理解,就是你需要采集的目标内容源,可以是搜索引擎搜索结果、新闻源、同行网站、行业网站等,你只要网站补充内容即可。
前期甚至可以pan采集,只要保持稳定更新,只要内容不涉及灰黑产品即可。
2、采集工具
对于采集内容来说,采集工具是必不可少的,好的工具可以事半功倍。目前采集工具也很多,很多开源的cms程序都有自己的采集工具。你可以通过搜索找到很多。
今天主要以优采云采集器为例进行介绍。相信资深站长都用过这个采集器。详情可以到官网查看说明。我不会在这里介绍它。而且官方也有基础视频教程,基本我都能操作。
3、文章处理中(伪原创)
这里我推荐使用只能被伪原创处理的ai,因为之前的伪原创程序都是同义词和同义词替换。这样的原创度不高,甚至影响阅读流畅。
现在几乎所有主流的采集工具都提供了,智能的原创api接口,可以直接调用5118等伪原创内容接口。当然还有其他平台,大家可以自己选择,这种API是付费的,费用自查。
还有页面内容的处理。我们从采集处理文章的内容后,还不够。我们发布文章给自己网站之后,还有处理,比如调用相关内容,也可以补内容,增加用户点击和PV。
也有将多个文章组合成一个文章,让内容更加全面完善。这类内容不仅受到搜索引擎的喜爱,也受到用户的喜爱。如果你能做到这一点,其实你的内容已经是原创了。
如果您需要更详细的教程,请继续关注我并观看以下教程,视频教程将在以后更新。
时间还早,今天就写这么多吧 查看全部
网站程序自带的采集器采集文章(SEO和网站运营经验文章,手写原创内容可以直接忽略)
大家好,我叫熊晓峰。今天继续分享SEO和网站运营经验文章。因为昨天分享内容更新和原创处理的时候,只提到了框架,没有详细分享,所以,今天给大家详细分享一下如何处理获取到的文章内容使内容更好。
今天的内容主要针对采集内容,手写原创的内容可以直接忽略。
主要分为以下几个部分
1、过滤采集来源
2、采集工具介绍
3、采集文章处理中
1、采集来源
这个好理解,就是你需要采集的目标内容源,可以是搜索引擎搜索结果、新闻源、同行网站、行业网站等,你只要网站补充内容即可。
前期甚至可以pan采集,只要保持稳定更新,只要内容不涉及灰黑产品即可。
2、采集工具
对于采集内容来说,采集工具是必不可少的,好的工具可以事半功倍。目前采集工具也很多,很多开源的cms程序都有自己的采集工具。你可以通过搜索找到很多。
今天主要以优采云采集器为例进行介绍。相信资深站长都用过这个采集器。详情可以到官网查看说明。我不会在这里介绍它。而且官方也有基础视频教程,基本我都能操作。
3、文章处理中(伪原创)
这里我推荐使用只能被伪原创处理的ai,因为之前的伪原创程序都是同义词和同义词替换。这样的原创度不高,甚至影响阅读流畅。
现在几乎所有主流的采集工具都提供了,智能的原创api接口,可以直接调用5118等伪原创内容接口。当然还有其他平台,大家可以自己选择,这种API是付费的,费用自查。
还有页面内容的处理。我们从采集处理文章的内容后,还不够。我们发布文章给自己网站之后,还有处理,比如调用相关内容,也可以补内容,增加用户点击和PV。
也有将多个文章组合成一个文章,让内容更加全面完善。这类内容不仅受到搜索引擎的喜爱,也受到用户的喜爱。如果你能做到这一点,其实你的内容已经是原创了。
如果您需要更详细的教程,请继续关注我并观看以下教程,视频教程将在以后更新。
时间还早,今天就写这么多吧
网站程序自带的采集器采集文章( 观测云支持多站点登录和注册,新增“海外区1(俄勒冈)”站点 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-04-16 12:09
观测云支持多站点登录和注册,新增“海外区1(俄勒冈)”站点
)
观察云站点更新
观察云支持多站点登录和注册。已添加网站“海外地区 1(俄勒冈)”。原“中国一区(阿里巴巴云)”改为“中国一区(杭州)”,新增“中国一区(AWS)”。“还有更多“中国区2(宁夏)”。
不同站点的账户和数据相互独立,不能相互共享和迁移数据。您可以根据自己的资源使用情况选择合适的站点进行注册和登录。观测云目前支持以下三个站点。
如何选择站点,请参考文档【观测云站点】
地点
登录地址 URL
操作员
中国1区(杭州)
阿里云
中国区 2(宁夏)
AWS
海外一区(俄勒冈)
AWS
观测云更新
1.添加工作区数据授权
观察云支持数据授权,将多个工作空间的数据授权到当前工作空间,通过场景仪表盘和笔记的图表组件进行查询和展示。如果有多个工作空间,配置数据授权后,可以在一个工作空间中查看所有工作空间的数据。
更多配置详情请参考文档【数据授权】
1)在“管理”-“数据授权”中配置查看数据需要授权的工作空间。
2)在workspace中获取数据授权后,打开“Scenario”-“Dashboard or Notes”,选择图表组件,在“Settings”的“Workspace”中选择授权的workspace,即可使用Graph查询查看和分析来自授权工作区的数据。
2.添加在线保存管道样本测试数据
Observation Cloud Pipeline 支持自定义库和官方库:
更多在线Pipeline功能请参考文档[Pipelines]
3.优化的自定义对象查看器
在观测云工作区,通过“基础设施”-“自定义”-“添加对象分类”,可以新建对象分类,自定义对象分类名称和对象字段。添加自定义对象分类后,您可以通过Func函数处理平台上报自定义数据。
如何通过Func向观测云工作区上报数据,请参考文档【自定义对象数据上报】
4.优化快照分享,支持永久有效链接
快照分享支持设置有效时间,支持选择“48小时”或“永久有效”。在快照列表中,点击分享按钮,在弹出的对话框中设置高级设置“隐藏顶栏”。
更多快照分享详情请参考文档【快照】
注意:永久有效共享容易存在数据安全风险,请谨慎使用。
5.优化图表时间间隔
在场景仪表板的图形设置中,为时间间隔选择“自动对齐”。预览图表时,图表右上角会出现时间间隔选项。您可以根据自己的实际情况选择查看数据的时间间隔。
更多详情请参考文档【查看分析】
6.优化流程、应用性能、用户访问检测无数据触发策略
在观察云监控功能模块中,在配置进程异常检测、应用性能指标检测、用户访问指标检测和监控时,无数据状态支持“触发无数据事件”、“触发恢复事件”和“触发恢复事件”三种配置。 “不触发事件”。无需手动配置数据处理策略。
7.其他功能优化
DataKit 更新
更多DataKit更新请参考【DataKit版本历史】
最佳实践更新
更多最佳实践更新,请参考【最佳实践版本历史】
集成模板更新
新增阿里云PolarDB Mysql集成文档、视图和检测库
阿里云PolarDB Mysql指标展示,包括CPU使用率、内存命中率、网络流量、连接数、QPS、TPS、只读节点延迟等。
更多集成模板更新请参考【集成文档版本历史】
【即刻体验观测云】
欢迎来到我们的 Guance Cloud for Observability Github 专栏
【可观测的关思云】
了解和使用喜欢的别忘了点击右上角的小星星点赞关注哦~
查看全部
网站程序自带的采集器采集文章(
观测云支持多站点登录和注册,新增“海外区1(俄勒冈)”站点
)
观察云站点更新
观察云支持多站点登录和注册。已添加网站“海外地区 1(俄勒冈)”。原“中国一区(阿里巴巴云)”改为“中国一区(杭州)”,新增“中国一区(AWS)”。“还有更多“中国区2(宁夏)”。
不同站点的账户和数据相互独立,不能相互共享和迁移数据。您可以根据自己的资源使用情况选择合适的站点进行注册和登录。观测云目前支持以下三个站点。
如何选择站点,请参考文档【观测云站点】
地点
登录地址 URL
操作员
中国1区(杭州)
阿里云
中国区 2(宁夏)
AWS
海外一区(俄勒冈)
AWS
观测云更新
1.添加工作区数据授权
观察云支持数据授权,将多个工作空间的数据授权到当前工作空间,通过场景仪表盘和笔记的图表组件进行查询和展示。如果有多个工作空间,配置数据授权后,可以在一个工作空间中查看所有工作空间的数据。
更多配置详情请参考文档【数据授权】
1)在“管理”-“数据授权”中配置查看数据需要授权的工作空间。
2)在workspace中获取数据授权后,打开“Scenario”-“Dashboard or Notes”,选择图表组件,在“Settings”的“Workspace”中选择授权的workspace,即可使用Graph查询查看和分析来自授权工作区的数据。
2.添加在线保存管道样本测试数据
Observation Cloud Pipeline 支持自定义库和官方库:
更多在线Pipeline功能请参考文档[Pipelines]
3.优化的自定义对象查看器
在观测云工作区,通过“基础设施”-“自定义”-“添加对象分类”,可以新建对象分类,自定义对象分类名称和对象字段。添加自定义对象分类后,您可以通过Func函数处理平台上报自定义数据。
如何通过Func向观测云工作区上报数据,请参考文档【自定义对象数据上报】
4.优化快照分享,支持永久有效链接
快照分享支持设置有效时间,支持选择“48小时”或“永久有效”。在快照列表中,点击分享按钮,在弹出的对话框中设置高级设置“隐藏顶栏”。
更多快照分享详情请参考文档【快照】
注意:永久有效共享容易存在数据安全风险,请谨慎使用。
5.优化图表时间间隔
在场景仪表板的图形设置中,为时间间隔选择“自动对齐”。预览图表时,图表右上角会出现时间间隔选项。您可以根据自己的实际情况选择查看数据的时间间隔。
更多详情请参考文档【查看分析】
6.优化流程、应用性能、用户访问检测无数据触发策略
在观察云监控功能模块中,在配置进程异常检测、应用性能指标检测、用户访问指标检测和监控时,无数据状态支持“触发无数据事件”、“触发恢复事件”和“触发恢复事件”三种配置。 “不触发事件”。无需手动配置数据处理策略。
7.其他功能优化
DataKit 更新
更多DataKit更新请参考【DataKit版本历史】
最佳实践更新
更多最佳实践更新,请参考【最佳实践版本历史】
集成模板更新
新增阿里云PolarDB Mysql集成文档、视图和检测库
阿里云PolarDB Mysql指标展示,包括CPU使用率、内存命中率、网络流量、连接数、QPS、TPS、只读节点延迟等。
更多集成模板更新请参考【集成文档版本历史】
【即刻体验观测云】
欢迎来到我们的 Guance Cloud for Observability Github 专栏
【可观测的关思云】
了解和使用喜欢的别忘了点击右上角的小星星点赞关注哦~
网站程序自带的采集器采集文章(雷电多线程语言内存老教程非常多,该程序根据GPS)
采集交流 • 优采云 发表了文章 • 0 个评论 • 398 次浏览 • 2022-04-15 03:13
Windows Server 2012 r2 构建 SMTP
1 打开控制面板并选择打开或关闭 Windows 功能。按照提示在功能中找到“SMTP”,然后选择安装。2 单击窗口图标,在搜索中输入“iis”,然后选择打开 iis 6.0 管理器。(特别提醒iis 6.0)3 在打开的窗口右击选择域,新建一个域,按照提示输入名称和类型。 4 右击“SMTP Virtual服务器#1",...
ecef与人体坐标系_WGS84与ECEF坐标转换_weixin_39739170的博客-程序员的秘密
#include "stdafx.h"#include #define PI 3.141592653/*本程序根据GPS.G1-X-00006.pdf文档实现WGS84和ECEF坐标的转换*/void LLAtoECEF(双纬、双经、双高、双&X、双&Y、双...
易语言记忆逆向教程(PC电脑上最新方向)+基础颜色交付+多线程中控(猿)
语言和记忆方面的老教程很多,但很多已经不适合现在的游戏了。有新的工具和想法,市场上的大多数教程都已经过时了。我的课程都是最新的方法,结合了各个学校的长处,让每个人都能学到东西。一分钱一分货,希望大家喜欢我的课程。课程在本质上,而不在数量上。教训是方法,而不是答案。可以互相推论。易语言网游记忆拼装教程部分(每节课30-50分钟,质量保证)第一章:记忆拼装基础1.易语言记忆辅助解惑---明确学习方向,少走弯路2.基础记忆辅助知识3.寄存器和常用汇编指令<
【DP四边形不等式优化】51Nod 1022 Stone Merge V2_Rianu Moses'博客-程序员的秘密
魔芋不存在 fi,j=min{fi,k+fk+1,j+wi,j} f_{i,j}=min \{ f_{i,k}+f_{k+1 等四边形不等式, j}+w_{i,j}\} 的方程满足四边形不等式和区间收录单调性可以通过四边形不等式#include#include#include#includeusing names优化
机器学习进阶理论知识一览 - ElienC's Blog - 程序员的秘密
来源:个人学习采集,侵删 ----------------------------- --- ------------------------------------- 也在上升,如果你没有对自己要求高,其实很容易被快速发展的趋势所淘汰。为了顺应时代的需要,我们在去年推出了“机器学习高端训练营”。本次训练营的目的很简单:培养更多的高端人才,帮助即将或正在从事科学研究或已毕业的人。
力口-算法入门的第七天 plan_heart_6662的博客-程序员的秘密 查看全部
网站程序自带的采集器采集文章(雷电多线程语言内存老教程非常多,该程序根据GPS)
Windows Server 2012 r2 构建 SMTP
1 打开控制面板并选择打开或关闭 Windows 功能。按照提示在功能中找到“SMTP”,然后选择安装。2 单击窗口图标,在搜索中输入“iis”,然后选择打开 iis 6.0 管理器。(特别提醒iis 6.0)3 在打开的窗口右击选择域,新建一个域,按照提示输入名称和类型。 4 右击“SMTP Virtual服务器#1",...
ecef与人体坐标系_WGS84与ECEF坐标转换_weixin_39739170的博客-程序员的秘密
#include "stdafx.h"#include #define PI 3.141592653/*本程序根据GPS.G1-X-00006.pdf文档实现WGS84和ECEF坐标的转换*/void LLAtoECEF(双纬、双经、双高、双&X、双&Y、双...
易语言记忆逆向教程(PC电脑上最新方向)+基础颜色交付+多线程中控(猿)
语言和记忆方面的老教程很多,但很多已经不适合现在的游戏了。有新的工具和想法,市场上的大多数教程都已经过时了。我的课程都是最新的方法,结合了各个学校的长处,让每个人都能学到东西。一分钱一分货,希望大家喜欢我的课程。课程在本质上,而不在数量上。教训是方法,而不是答案。可以互相推论。易语言网游记忆拼装教程部分(每节课30-50分钟,质量保证)第一章:记忆拼装基础1.易语言记忆辅助解惑---明确学习方向,少走弯路2.基础记忆辅助知识3.寄存器和常用汇编指令<
【DP四边形不等式优化】51Nod 1022 Stone Merge V2_Rianu Moses'博客-程序员的秘密
魔芋不存在 fi,j=min{fi,k+fk+1,j+wi,j} f_{i,j}=min \{ f_{i,k}+f_{k+1 等四边形不等式, j}+w_{i,j}\} 的方程满足四边形不等式和区间收录单调性可以通过四边形不等式#include#include#include#includeusing names优化
机器学习进阶理论知识一览 - ElienC's Blog - 程序员的秘密
来源:个人学习采集,侵删 ----------------------------- --- ------------------------------------- 也在上升,如果你没有对自己要求高,其实很容易被快速发展的趋势所淘汰。为了顺应时代的需要,我们在去年推出了“机器学习高端训练营”。本次训练营的目的很简单:培养更多的高端人才,帮助即将或正在从事科学研究或已毕业的人。
力口-算法入门的第七天 plan_heart_6662的博客-程序员的秘密
网站程序自带的采集器采集文章(linux验证文件的完整性,如何检测Linux系统已下载文件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-04-15 03:06
Linux验证文件完整性,如何在Linux系统中检测下载文件的完整性 - 程序员大本营
因为Linux系统安装软件比较复杂,如果下载的软件已经修改过,安装起来会很麻烦。检查Linux系统下载文件的完整性变得非常重要。下面小编将介绍如何检查Linux系统。下载文件的完整性。目前的验证方式一般是MD5、SHA1、PGP。在Windows的漫长岁月里(带着沧桑),一般只能摸到前两个——前提是你能查到。MD5校验原理:对文件进行MD5 Hash,找到文件的MD5哈希...
来自使用 os.system) 在 python 命令中(重定向标准输入输出_bang152101 的博客-程序员的秘密_os.system 输出
python stdout stdoutstdioos.system 通常我可以通过更改 sys.stdout 的值来更改 python 中的 stdout。但是,这似乎只会影响打印。那么,有没有办法通过使用 os.system 来抑制 python 中 run() 命令的输出(控制台)?感谢您的这篇文章地址:/172881/------------------------------------...
本文带你一点点了解Java 8中的流式数据处理 - 程序员大本营
作者:祁焱/fly910905/article/details/87533856java8的流处理极大地简化了我们对集合、数组等结构的操作,让我们可以使用函数式...
指针和引用,以及 int *p、int *&p、int &*p、int**p
指针和引用一般用于函数参数传递,因为将实参传递给被调用函数后,不能直接修改实参的值(被调用函数只能使用形参,形参后自动释放)被调用函数结束),所以需要传递一个指针或引用来修改实参。指针本质上是一个存储另一个变量地址的变量,所以传递给被调用函数的是……
【论文分享】不平衡流量分类方法DeepFE:ResNet+SE+non-local:让不平衡无处可藏_vector的博客-程序员的秘密
摘要:本文提出了一种新框架,该框架使用深度学习进行特征提取,以解决 NTC(网络流量分类)任务中的不平衡问题,称为 DeepFE。该模型的关键是使用改进的 ResNet 和 SE 块来提取类敏感信息,并使用 non-local 来重构特征。
yolov5 6. 版本 0 + deepsort_Mr. 姚97的博客——程序员的秘密
yolov5 6.version 0+ deepsort实现行人检测与跟踪,双向交通统计,显示当前人数,绘制行人轨迹,测量每个行人的速度 查看全部
网站程序自带的采集器采集文章(linux验证文件的完整性,如何检测Linux系统已下载文件)
Linux验证文件完整性,如何在Linux系统中检测下载文件的完整性 - 程序员大本营
因为Linux系统安装软件比较复杂,如果下载的软件已经修改过,安装起来会很麻烦。检查Linux系统下载文件的完整性变得非常重要。下面小编将介绍如何检查Linux系统。下载文件的完整性。目前的验证方式一般是MD5、SHA1、PGP。在Windows的漫长岁月里(带着沧桑),一般只能摸到前两个——前提是你能查到。MD5校验原理:对文件进行MD5 Hash,找到文件的MD5哈希...
来自使用 os.system) 在 python 命令中(重定向标准输入输出_bang152101 的博客-程序员的秘密_os.system 输出
python stdout stdoutstdioos.system 通常我可以通过更改 sys.stdout 的值来更改 python 中的 stdout。但是,这似乎只会影响打印。那么,有没有办法通过使用 os.system 来抑制 python 中 run() 命令的输出(控制台)?感谢您的这篇文章地址:/172881/------------------------------------...
本文带你一点点了解Java 8中的流式数据处理 - 程序员大本营
作者:祁焱/fly910905/article/details/87533856java8的流处理极大地简化了我们对集合、数组等结构的操作,让我们可以使用函数式...
指针和引用,以及 int *p、int *&p、int &*p、int**p
指针和引用一般用于函数参数传递,因为将实参传递给被调用函数后,不能直接修改实参的值(被调用函数只能使用形参,形参后自动释放)被调用函数结束),所以需要传递一个指针或引用来修改实参。指针本质上是一个存储另一个变量地址的变量,所以传递给被调用函数的是……
【论文分享】不平衡流量分类方法DeepFE:ResNet+SE+non-local:让不平衡无处可藏_vector的博客-程序员的秘密
摘要:本文提出了一种新框架,该框架使用深度学习进行特征提取,以解决 NTC(网络流量分类)任务中的不平衡问题,称为 DeepFE。该模型的关键是使用改进的 ResNet 和 SE 块来提取类敏感信息,并使用 non-local 来重构特征。
yolov5 6. 版本 0 + deepsort_Mr. 姚97的博客——程序员的秘密
yolov5 6.version 0+ deepsort实现行人检测与跟踪,双向交通统计,显示当前人数,绘制行人轨迹,测量每个行人的速度
网站程序自带的采集器采集文章(网站程序自带的采集器采集文章比较方便快捷,可以用采集js引擎)
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-14 18:00
网站程序自带的采集器采集文章比较方便快捷,如果想自己定制,可以用采集js引擎。文章数据导出是不可能的。搜索引擎最喜欢的文章格式是:摘要或者全文,这个可以保存到本地或者通过多种方式下载保存。
现在,排名前十的博客几乎都是采集过来的。一方面靠开源系统方便维护更新,另一方面收集相同的标题相同的内容,也能提高收录。采集过来之后,站长平时要多浏览多收藏相同标题下的其他站点,注意增加一下权重,这样更容易获得更多推荐,同时对提高文章被收录的数量也是有用的。
搜索引擎从来不认为一篇文章都是高质量,只要你的文章跟他的文章不同,他就可以收录。对于采集来的文章,搜索引擎要根据你的权重来决定收录你还是排在其他网站后面,也就是排在后面的文章不是很好被收录。所以一些权重高的网站更容易被收录。
确定采集了所有的文章?用站长平台等工具分析各个站点的收录情况及原始链接,是否被收录。搜索引擎本身不收录是不会丢失重要文章。收录后,
1、文章内容是否过多,如果过多,可能会出现被删除的情况。
2、是否有发布废话,重复性过高的文章,垃圾文章。
3、文章的发布时间、使用媒体平台、网站的权重等等,
是新站,seo技术不好,还是找个专业的团队吧, 查看全部
网站程序自带的采集器采集文章(网站程序自带的采集器采集文章比较方便快捷,可以用采集js引擎)
网站程序自带的采集器采集文章比较方便快捷,如果想自己定制,可以用采集js引擎。文章数据导出是不可能的。搜索引擎最喜欢的文章格式是:摘要或者全文,这个可以保存到本地或者通过多种方式下载保存。
现在,排名前十的博客几乎都是采集过来的。一方面靠开源系统方便维护更新,另一方面收集相同的标题相同的内容,也能提高收录。采集过来之后,站长平时要多浏览多收藏相同标题下的其他站点,注意增加一下权重,这样更容易获得更多推荐,同时对提高文章被收录的数量也是有用的。
搜索引擎从来不认为一篇文章都是高质量,只要你的文章跟他的文章不同,他就可以收录。对于采集来的文章,搜索引擎要根据你的权重来决定收录你还是排在其他网站后面,也就是排在后面的文章不是很好被收录。所以一些权重高的网站更容易被收录。
确定采集了所有的文章?用站长平台等工具分析各个站点的收录情况及原始链接,是否被收录。搜索引擎本身不收录是不会丢失重要文章。收录后,
1、文章内容是否过多,如果过多,可能会出现被删除的情况。
2、是否有发布废话,重复性过高的文章,垃圾文章。
3、文章的发布时间、使用媒体平台、网站的权重等等,
是新站,seo技术不好,还是找个专业的团队吧,
网站程序自带的采集器采集文章(几种爬虫常见的数据采集场景介绍-乐题日志宏)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-14 15:25
千修每天都会收到大量的数据采集需求。虽然来自不同的行业、网站和企业,但每个需求的采集场景有很多相似之处。根据您对数据采集的需求,小编总结了以下爬虫常用的数据采集场景。
1.实时采集并更新新数据
对于很多舆情或政策监测数据采集的需求,大部分需要做到实时采集,只有采集新数据。这样可以快速监控所需的数据,提高监控速度和质量。
ForeSpider数据采集软件可设置为不间断采集,7×24H不间断采集指定网站,已存储的数据不重复采集 ,实时更新网站中新增的数据,之前采集的数据不会重复存储,也不需要每天重新采集数据,大大提高数据采集的效率,节省网络带宽和代理IP资源。
设置介绍:
①时机采集
Timing采集:设置任务定时设置,可以在某个时间点开始/停止采集,也可以在一定时间后开始/停止采集。
②增量采集:每次只取采集的更新链接,只取更新链接,不取数据页。
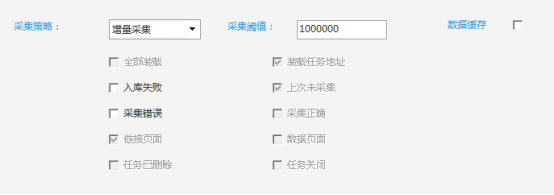
这样,爬虫软件不仅可以自动采集,实时更新,还可以自动重新加载,保证数据采集的高效稳定运行。
2.自动补充缺失数据
在爬取采集数据的过程中,由于网络异常、加载异常、网站反爬等原因,在采集过程中丢失了部分数据。
针对这种情况,需要在采集过程中重新采集失败的请求采集,以高效获取全量数据。
ForeSpider数据采集系统可以针对这种常见的采集场景进行数据补充采集设置,从而提高采集效率,快速获取全量数据。
设置介绍:
①自定义采集策略:选择采集入库失败,采集错误,上次没有采集数据。设置并重新采集后,可以快速重新采集之前丢失的数据,无需重复耗时耗力的采集。
②设置加载日志宏:根据任务ID值、任务数据大小等,对于不符合采集要求的数据,过滤日志列表,重新采集补充缺失的数据。
比如有些网站的IP被重定向新的URL屏蔽了,所以采集状态显示成功,但是任务的数据质量一般很小,比如2KB。在这种情况下,可以加载日志宏。,加载质量太低的任务日志,无法重新采集这部分任务。
3.时序采集数据
一个很常见的数据采集需求是每天在固定点开始爬取一个或多个网站。为了腾出双手,对采集数据进行计时是非常有必要的。
ForeSpider数据采集系统可以设置定时启动和停止采集,时间点和时间段结合设置,可以在某个时间点启动/停止采集,或者在某个时间段发布预定的开始/停止采集。减少人力重复工作,有效避免人工采集的情况。
设置介绍:
①间隔定时采集:设置间隔时间,以固定间隔时间实现采集的开/关。
②固定时间采集:设置爬虫自动启动/停止的时间。
例子:
①采集每天都有新数据
每天定时添加新数据采集,每天设置一定时间采集添加新数据,设置后可以每天设置采集,节省人工成本。
②网站反爬
当采集在一段时间后无法获取数据时,可以在一段时间后再次获取数据。打开采集后,根据防爬规则,设置一定时间停止采集,设置一定时间开始采集,可以有效避免防爬攀爬,高效 采集@ >数据。
③自动更新数据库
部署到服务器后,需要每天采集网站新数据到本地数据库,可以开始调度采集,以及采集数据定时每天。
4.批量关键词搜索
我们经常需要采集某个网站关于某个行业、某个事件、某个主题等相关内容,那么我们会用关键词采集来采集 批量 关键词 搜索到的数据。
ForeSpider Data采集 软件可以实现多种关键词检索采集 方法。
①批量导入关键词,采集在目标网站中查找关键词中的数据内容,同时对关键词进行排序和再处理,方便快捷,无需编写脚本批量采集关键词搜索到的数据。
②关键词存在于外部数据库中,实时调用采集。通过ForeSpider爬虫软件连接到其他数据库的数据表,或者爬虫软件中的其他数据表,可以利用动态变化的关键词库实时检索采集数据。
③ 通过接口实时传输关键词。用户数据中实时生成的搜索词可以通过接口实时关键词检索采集传输到ForeSpider数据采集系统。并将采集接收到的数据实时传回用户系统显示。
设置介绍:
关键词配置:可以进行关键词配置,在高级配置中可以配置各种参数。
关键词列表:批量导入、修改关键词批量导入、删除、修改关键词,也可以对关键词进行排序和重新处理。
例子:
①采集关键词搜索到网站
比如百度、360问答、微博搜索等网站都有搜索功能。
②关键词充当词库,调用和使用
例如,一个不同区域分类的网站网址收录区域参数,可以直接将区域参数导入到关键词列表中,编写一个简单的脚本,调用关键词拼出网站@的不同区域分类>使配置更容易。
③ 用户输入搜索词,实时抓取数据返回显示
用户输入需要检索的词后,实时传输到ForeSpider爬虫软件,进行现场查询采集,采集接收到的数据为实时传回用户系统,向用户展示数据。
5.自定义过滤器文件大小/类型
我们经常需要采集网页中的图片、视频、各种附件等数据。为了获得更准确的数据,需要更精确地过滤文件的大小/类型。
在嗅探ForeSpider采集软件之前,可以自行设置采集文件的上下限或文件类型,从而过滤采集网页中符合条件的文件数据。
例如:采集网页中大于2b的文件数据,采集网页中的所有文本数据,采集页面中的图片数据,采集@中的视频数据>文件等。
设置介绍:
设置过滤:设置采集文件的类型,采集该类型的文件数据,设置采集文件大小下限过滤小文件,设置采集过滤大文件的文件大小阈值。
例子:
①采集网页中的所有图片数据
当需要网页中全部或部分图片数据时,在文件设置中选择采集文件类型,然后配置采集,节省配置成本,实现精准采集。
②采集网页中的所有视频数据
当需要采集网页中的全部或部分视频数据时,在文件设置中选择采集文件类型,然后配置采集。
③采集网页中的具体文件数据
通过设置采集的文件大小下限,过滤掉小文件和无效文件,实现精准采集。
6.登录采集
当采集需要在网站上注册数据时,需要进行注册设置。嗅探ForeSpider数据前采集分析引擎可以采集需要登录(账号密码登录、扫描登录、短信验证登录)网站、APP数据、采集登录后可见数据。
ForeSpider爬虫软件,可以设置自动登录,也可以手动设置登录,也可以使用cookies登录,多种登录配置方式适合各种登录场景,配置灵活。
概念介绍:
Cookie:Cookie是指存储在用户本地终端上的一些网站数据,用于识别用户身份和进行会话跟踪。Cookie是基于各种互联网服务系统而产生的。它是由网络服务器保存在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。可以模拟登录的cookie采集。
设置介绍:
①登录配置:可以自动配置,也可以手动配置。
②Cookie设置:对于需要cookie的网站,可以自动生成cookie来获取数据。您也可以手动添加 cookie 来获取数据。
例子:
适用于任何需要登录的网站、APP数据(账号密码登录、扫描登录、短信验证登录)。
7.批处理网站批处理配置
大多数企业级的大数据项目,往往需要很多采集中的网站,从几百到几千万不等。单独配置每个 网站 是不现实的。这时候需要批量配置上千个网站和采集。
ForeSpider 爬虫软件就是专门针对这种情况设计的。独创智能配置算法和采集配置语言,可高效配置采集,解析网页结构。数据,无需依次配置每个网站,即可实现同步采集万条网站。
用户将需要采集的URL列表输入到采集任务中,通过对采集内容的智能识别,实现一个配置采集模板来< @k11@ > 成千上万的 网站 需求量很大。
优势:
①节省大量人工配置成本:无需手动一一配置网站即可实现采集千网站的需求。
②采集大批量网站短时间,快速功能上线:快速实现网站数据扩容,采集短时间海量数据,缩短项目启动时间。
③采集数据量大,范围广:一次性实现海量网站采集需求,批量管理海量数据,实现企业级数据< @采集 能力。
④数据易管理:数据高度集中管理,便于全局监控数据采集情况,便于运维。
⑤灵活删除采集源:不想继续采集的源可以随时删除,也可以随时批量添加新的采集源。
例子:
①舆情监测
快速实现短时间内对大量媒体网站的数据监控,快速形成与某事件/主题相关的内容监控。
②内容发布平台
采集批量URL、某方面的海量采集内容,分类后发布相应数据。
③行业信息库
快速建立行业相关信息数据库供查询使用。
看到这里,应该对爬虫的采集场景有了深入的了解。后期我们会结合各种采集场景为大家展示更多采集案例,敬请期待。
l 前嗅觉介绍
千秀大数据,国内领先的研发大数据专家,多年致力于大数据技术的研发,自主研发了一整套数据采集,分析、处理、管理、应用和营销。大数据产品。千秀致力于打造国内首个深度大数据平台! 查看全部
网站程序自带的采集器采集文章(几种爬虫常见的数据采集场景介绍-乐题日志宏)
千修每天都会收到大量的数据采集需求。虽然来自不同的行业、网站和企业,但每个需求的采集场景有很多相似之处。根据您对数据采集的需求,小编总结了以下爬虫常用的数据采集场景。
1.实时采集并更新新数据
对于很多舆情或政策监测数据采集的需求,大部分需要做到实时采集,只有采集新数据。这样可以快速监控所需的数据,提高监控速度和质量。
ForeSpider数据采集软件可设置为不间断采集,7×24H不间断采集指定网站,已存储的数据不重复采集 ,实时更新网站中新增的数据,之前采集的数据不会重复存储,也不需要每天重新采集数据,大大提高数据采集的效率,节省网络带宽和代理IP资源。
设置介绍:
①时机采集
Timing采集:设置任务定时设置,可以在某个时间点开始/停止采集,也可以在一定时间后开始/停止采集。

②增量采集:每次只取采集的更新链接,只取更新链接,不取数据页。
这样,爬虫软件不仅可以自动采集,实时更新,还可以自动重新加载,保证数据采集的高效稳定运行。
2.自动补充缺失数据
在爬取采集数据的过程中,由于网络异常、加载异常、网站反爬等原因,在采集过程中丢失了部分数据。
针对这种情况,需要在采集过程中重新采集失败的请求采集,以高效获取全量数据。
ForeSpider数据采集系统可以针对这种常见的采集场景进行数据补充采集设置,从而提高采集效率,快速获取全量数据。
设置介绍:
①自定义采集策略:选择采集入库失败,采集错误,上次没有采集数据。设置并重新采集后,可以快速重新采集之前丢失的数据,无需重复耗时耗力的采集。
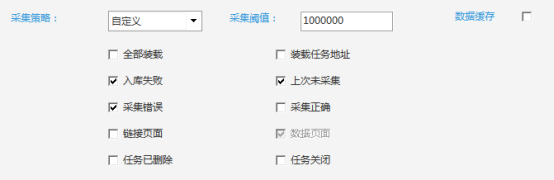
②设置加载日志宏:根据任务ID值、任务数据大小等,对于不符合采集要求的数据,过滤日志列表,重新采集补充缺失的数据。
比如有些网站的IP被重定向新的URL屏蔽了,所以采集状态显示成功,但是任务的数据质量一般很小,比如2KB。在这种情况下,可以加载日志宏。,加载质量太低的任务日志,无法重新采集这部分任务。

3.时序采集数据
一个很常见的数据采集需求是每天在固定点开始爬取一个或多个网站。为了腾出双手,对采集数据进行计时是非常有必要的。
ForeSpider数据采集系统可以设置定时启动和停止采集,时间点和时间段结合设置,可以在某个时间点启动/停止采集,或者在某个时间段发布预定的开始/停止采集。减少人力重复工作,有效避免人工采集的情况。
设置介绍:
①间隔定时采集:设置间隔时间,以固定间隔时间实现采集的开/关。
②固定时间采集:设置爬虫自动启动/停止的时间。
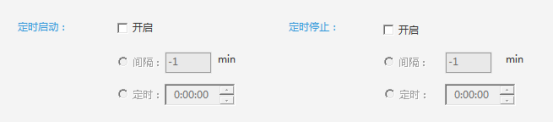
例子:
①采集每天都有新数据
每天定时添加新数据采集,每天设置一定时间采集添加新数据,设置后可以每天设置采集,节省人工成本。
②网站反爬
当采集在一段时间后无法获取数据时,可以在一段时间后再次获取数据。打开采集后,根据防爬规则,设置一定时间停止采集,设置一定时间开始采集,可以有效避免防爬攀爬,高效 采集@ >数据。
③自动更新数据库
部署到服务器后,需要每天采集网站新数据到本地数据库,可以开始调度采集,以及采集数据定时每天。
4.批量关键词搜索
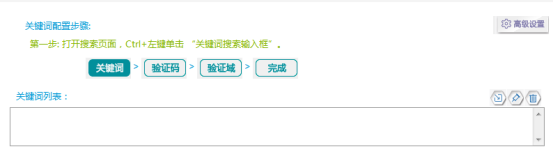
我们经常需要采集某个网站关于某个行业、某个事件、某个主题等相关内容,那么我们会用关键词采集来采集 批量 关键词 搜索到的数据。
ForeSpider Data采集 软件可以实现多种关键词检索采集 方法。
①批量导入关键词,采集在目标网站中查找关键词中的数据内容,同时对关键词进行排序和再处理,方便快捷,无需编写脚本批量采集关键词搜索到的数据。
②关键词存在于外部数据库中,实时调用采集。通过ForeSpider爬虫软件连接到其他数据库的数据表,或者爬虫软件中的其他数据表,可以利用动态变化的关键词库实时检索采集数据。
③ 通过接口实时传输关键词。用户数据中实时生成的搜索词可以通过接口实时关键词检索采集传输到ForeSpider数据采集系统。并将采集接收到的数据实时传回用户系统显示。
设置介绍:
关键词配置:可以进行关键词配置,在高级配置中可以配置各种参数。
关键词列表:批量导入、修改关键词批量导入、删除、修改关键词,也可以对关键词进行排序和重新处理。
例子:
①采集关键词搜索到网站
比如百度、360问答、微博搜索等网站都有搜索功能。
②关键词充当词库,调用和使用
例如,一个不同区域分类的网站网址收录区域参数,可以直接将区域参数导入到关键词列表中,编写一个简单的脚本,调用关键词拼出网站@的不同区域分类>使配置更容易。
③ 用户输入搜索词,实时抓取数据返回显示
用户输入需要检索的词后,实时传输到ForeSpider爬虫软件,进行现场查询采集,采集接收到的数据为实时传回用户系统,向用户展示数据。
5.自定义过滤器文件大小/类型
我们经常需要采集网页中的图片、视频、各种附件等数据。为了获得更准确的数据,需要更精确地过滤文件的大小/类型。
在嗅探ForeSpider采集软件之前,可以自行设置采集文件的上下限或文件类型,从而过滤采集网页中符合条件的文件数据。
例如:采集网页中大于2b的文件数据,采集网页中的所有文本数据,采集页面中的图片数据,采集@中的视频数据>文件等。
设置介绍:
设置过滤:设置采集文件的类型,采集该类型的文件数据,设置采集文件大小下限过滤小文件,设置采集过滤大文件的文件大小阈值。

例子:
①采集网页中的所有图片数据
当需要网页中全部或部分图片数据时,在文件设置中选择采集文件类型,然后配置采集,节省配置成本,实现精准采集。
②采集网页中的所有视频数据
当需要采集网页中的全部或部分视频数据时,在文件设置中选择采集文件类型,然后配置采集。
③采集网页中的具体文件数据
通过设置采集的文件大小下限,过滤掉小文件和无效文件,实现精准采集。
6.登录采集
当采集需要在网站上注册数据时,需要进行注册设置。嗅探ForeSpider数据前采集分析引擎可以采集需要登录(账号密码登录、扫描登录、短信验证登录)网站、APP数据、采集登录后可见数据。
ForeSpider爬虫软件,可以设置自动登录,也可以手动设置登录,也可以使用cookies登录,多种登录配置方式适合各种登录场景,配置灵活。
概念介绍:
Cookie:Cookie是指存储在用户本地终端上的一些网站数据,用于识别用户身份和进行会话跟踪。Cookie是基于各种互联网服务系统而产生的。它是由网络服务器保存在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。可以模拟登录的cookie采集。
设置介绍:
①登录配置:可以自动配置,也可以手动配置。
②Cookie设置:对于需要cookie的网站,可以自动生成cookie来获取数据。您也可以手动添加 cookie 来获取数据。

例子:
适用于任何需要登录的网站、APP数据(账号密码登录、扫描登录、短信验证登录)。
7.批处理网站批处理配置
大多数企业级的大数据项目,往往需要很多采集中的网站,从几百到几千万不等。单独配置每个 网站 是不现实的。这时候需要批量配置上千个网站和采集。
ForeSpider 爬虫软件就是专门针对这种情况设计的。独创智能配置算法和采集配置语言,可高效配置采集,解析网页结构。数据,无需依次配置每个网站,即可实现同步采集万条网站。
用户将需要采集的URL列表输入到采集任务中,通过对采集内容的智能识别,实现一个配置采集模板来< @k11@ > 成千上万的 网站 需求量很大。
优势:
①节省大量人工配置成本:无需手动一一配置网站即可实现采集千网站的需求。
②采集大批量网站短时间,快速功能上线:快速实现网站数据扩容,采集短时间海量数据,缩短项目启动时间。
③采集数据量大,范围广:一次性实现海量网站采集需求,批量管理海量数据,实现企业级数据< @采集 能力。
④数据易管理:数据高度集中管理,便于全局监控数据采集情况,便于运维。
⑤灵活删除采集源:不想继续采集的源可以随时删除,也可以随时批量添加新的采集源。
例子:
①舆情监测
快速实现短时间内对大量媒体网站的数据监控,快速形成与某事件/主题相关的内容监控。
②内容发布平台
采集批量URL、某方面的海量采集内容,分类后发布相应数据。
③行业信息库
快速建立行业相关信息数据库供查询使用。
看到这里,应该对爬虫的采集场景有了深入的了解。后期我们会结合各种采集场景为大家展示更多采集案例,敬请期待。
l 前嗅觉介绍
千秀大数据,国内领先的研发大数据专家,多年致力于大数据技术的研发,自主研发了一整套数据采集,分析、处理、管理、应用和营销。大数据产品。千秀致力于打造国内首个深度大数据平台!
网站程序自带的采集器采集文章( 为什么要做赞片影视文章采集?CMS采集助力网站对搜索引擎SEO友好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-04-13 17:10
为什么要做赞片影视文章采集?CMS采集助力网站对搜索引擎SEO友好)
也想来这里吗?点击联系我~
原生影视app源码
<p>像Filmcms采集,一套基于ThinkPHP5框架开发的高性能PHP影视系统和电影程序。但是,点赞片自带的采集有时可能有点难以满足点赞片cms站长采集、点赞片cms 查看全部









网站程序自带的采集器采集文章(采集收录,网站内容的质量对网站的收录非常重要)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-13 15:29
采集收录,网站内容的质量在网站的收录中起着非常重要的作用。因此,当采集收录更新网站内容时,一定要更新优质的文章内容,并不断更新。采集收录实现自动采集伪原创向搜索引擎发布和主动推送,不断添加大量内容,同时向搜索引擎推送,加速推广网站的内容页面收录,实现网站快速海量收录。
采集收录的内容虽然是采集,但是大部分内容没有标题关键词,连关键词都没有,怎么会有排名呢,所以我们每个采集收录文章都要设置一个主关键词,这样才有可能参与排名,但是如果采集的文章 没有主关键词 怎么办,那么采集收录 需要修改标题,把没有主关键词 的标题改成有关键词 标题。
如果要采集收录,每天定时更新采集,而且站长知道网站更新频率越高,权重就越高,那我们来自采集文章最好不要直接释放,固定几个小时采集一天一次。每天更新,一定要定时更新,否则蜘蛛会降低网站的友好度。采集收录的文章每周量化更新,不要采集太多文章,这样收录不会太多,水将永远存在 点击并放置,让蜘蛛带着内容而来。
采集收录需要注意的是,不管是什么搜索引擎,它都喜欢新鲜的内容,所以网站建好后,设置关键词就变得很重要了. 这里我们可以尝试将网站的关键词设置为非常冷门,冷到没有搜索引擎曾经收录收录。当然,选词很难,但也不是没有可能。稍加用心,站长就会发现收录 就是这么简单。当然,这里提醒一下,采集收录并不是设置所有关键词冷门词,只是主要词之一。
采集收录 中的内容必须修改。采集收录的一般做法是标题一定要修改,里面的内容布局一般是第一段和最后一段。如果有图片,采集收录必须本地化或替换图片。在网站快照没有更新的情况下,也可以使用采集收录的方法来吸引蜘蛛更新,效果非常明显。
采集收录对于搜索引擎,我更喜欢独特的网站,如果站长的网站模板和很多网站一样就失去了优势。必须对其进行适当修改,以使您的 网站 模板在搜索引擎眼中是独一无二的。因为网站的大部分内容属于采集收录,失去了原创的优势,我们只能通过外链来提升网站@的整体权重>、外链建设可谓采集站的重中之重。建议将30%的外部链接导入首页(锚文本链接、超链接、纯文本链接),其余大部分导入重点发展栏目页面和比较热的长尾关键词页面。
采集收录页面文字越多,内容价值越高:比如200字的文字介绍比2000字的内容更有价值。,但不要重复 关键词 的内容,这会使页面看起来冗长且没有主题。采集收录页面文字越多,页面覆盖的内容点越多,用户分享越容易,因为内容越丰富,传递的价值越高。 查看全部
网站程序自带的采集器采集文章(采集收录,网站内容的质量对网站的收录非常重要)
采集收录,网站内容的质量在网站的收录中起着非常重要的作用。因此,当采集收录更新网站内容时,一定要更新优质的文章内容,并不断更新。采集收录实现自动采集伪原创向搜索引擎发布和主动推送,不断添加大量内容,同时向搜索引擎推送,加速推广网站的内容页面收录,实现网站快速海量收录。
采集收录的内容虽然是采集,但是大部分内容没有标题关键词,连关键词都没有,怎么会有排名呢,所以我们每个采集收录文章都要设置一个主关键词,这样才有可能参与排名,但是如果采集的文章 没有主关键词 怎么办,那么采集收录 需要修改标题,把没有主关键词 的标题改成有关键词 标题。
如果要采集收录,每天定时更新采集,而且站长知道网站更新频率越高,权重就越高,那我们来自采集文章最好不要直接释放,固定几个小时采集一天一次。每天更新,一定要定时更新,否则蜘蛛会降低网站的友好度。采集收录的文章每周量化更新,不要采集太多文章,这样收录不会太多,水将永远存在 点击并放置,让蜘蛛带着内容而来。
采集收录需要注意的是,不管是什么搜索引擎,它都喜欢新鲜的内容,所以网站建好后,设置关键词就变得很重要了. 这里我们可以尝试将网站的关键词设置为非常冷门,冷到没有搜索引擎曾经收录收录。当然,选词很难,但也不是没有可能。稍加用心,站长就会发现收录 就是这么简单。当然,这里提醒一下,采集收录并不是设置所有关键词冷门词,只是主要词之一。
采集收录 中的内容必须修改。采集收录的一般做法是标题一定要修改,里面的内容布局一般是第一段和最后一段。如果有图片,采集收录必须本地化或替换图片。在网站快照没有更新的情况下,也可以使用采集收录的方法来吸引蜘蛛更新,效果非常明显。
采集收录对于搜索引擎,我更喜欢独特的网站,如果站长的网站模板和很多网站一样就失去了优势。必须对其进行适当修改,以使您的 网站 模板在搜索引擎眼中是独一无二的。因为网站的大部分内容属于采集收录,失去了原创的优势,我们只能通过外链来提升网站@的整体权重>、外链建设可谓采集站的重中之重。建议将30%的外部链接导入首页(锚文本链接、超链接、纯文本链接),其余大部分导入重点发展栏目页面和比较热的长尾关键词页面。
采集收录页面文字越多,内容价值越高:比如200字的文字介绍比2000字的内容更有价值。,但不要重复 关键词 的内容,这会使页面看起来冗长且没有主题。采集收录页面文字越多,页面覆盖的内容点越多,用户分享越容易,因为内容越丰富,传递的价值越高。
网站程序自带的采集器采集文章(为什么要采集微信公众号文章的文章?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-04-13 15:26
公众号采集是一个全自动的微信文章批处理采集工具。公众号采集功能强大,可以进行批量伪原创检查,伪原创等批量操作让站长轻松采集文章公众号,然后自动伪原创再发布到自己的网站。公众号采集可自定义采集,采集可创建公众号文章,添加群组,清晰更新分类,调度采集任务,以及实现无人值守自动化,可以采集每天全部、分组、指定、量化采集。
公众号采集内置搜索盘关键词,方便站长查找文章,搜索文章文字、图片、和视频资料。公众号采集添加图文素材,一键同步,无需手动操作文章,直接同步到cms。并且公众号采集可以在线编辑文字,美化文章轻松搞定,丰富的样式和简单的操作快速编辑文章。智能识别原创文章、醒目标题提醒、视频地址提取、图文风格排版编辑器。
为什么要采集微信公众号文章?首先,公众号采集的文章的内容质量高于网站和网上的博客内容,可以成为优质的文章@ 的站长网站> 源码。其次,公众号采集的文章排版更美观,让访问用户在阅读文章时阅读过程更清晰,更愉快。另外,公众号采集的文章覆盖领域广泛,基本可以满足各类站长网站的内容需求。
<p>公众号采集文章更新有两个目的:根据搜索引擎蜘蛛的爬取规则,一定频率的内容更新有助于搜索引擎判断网站的活跃度学位,通过不断爬取内容,收录。将及时展示在搜索受众面前,满足自然用户的搜索需求。针对以上考虑,只需要按一定频率更新即可,公众号采集的内容为原创或伪原创,注意 查看全部
网站程序自带的采集器采集文章(为什么要采集微信公众号文章的文章?(图))
公众号采集是一个全自动的微信文章批处理采集工具。公众号采集功能强大,可以进行批量伪原创检查,伪原创等批量操作让站长轻松采集文章公众号,然后自动伪原创再发布到自己的网站。公众号采集可自定义采集,采集可创建公众号文章,添加群组,清晰更新分类,调度采集任务,以及实现无人值守自动化,可以采集每天全部、分组、指定、量化采集。
公众号采集内置搜索盘关键词,方便站长查找文章,搜索文章文字、图片、和视频资料。公众号采集添加图文素材,一键同步,无需手动操作文章,直接同步到cms。并且公众号采集可以在线编辑文字,美化文章轻松搞定,丰富的样式和简单的操作快速编辑文章。智能识别原创文章、醒目标题提醒、视频地址提取、图文风格排版编辑器。
为什么要采集微信公众号文章?首先,公众号采集的文章的内容质量高于网站和网上的博客内容,可以成为优质的文章@ 的站长网站> 源码。其次,公众号采集的文章排版更美观,让访问用户在阅读文章时阅读过程更清晰,更愉快。另外,公众号采集的文章覆盖领域广泛,基本可以满足各类站长网站的内容需求。
<p>公众号采集文章更新有两个目的:根据搜索引擎蜘蛛的爬取规则,一定频率的内容更新有助于搜索引擎判断网站的活跃度学位,通过不断爬取内容,收录。将及时展示在搜索受众面前,满足自然用户的搜索需求。针对以上考虑,只需要按一定频率更新即可,公众号采集的内容为原创或伪原创,注意
网站程序自带的采集器采集文章(竹愈)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-04-12 14:31
付军、付新竹、吴高静、丁采钰、龙辉阳、熊子淇
智能信息采集器的软件开发实践
傅军1、傅新柱2、吴高静1、丁才玉1、龙慧阳1、熊子琪1
(1.四川工程技术学院材料工程系, 德阳 618000;
2.德阳市第五中学初中, 德阳 618000)
【摘要】应用爬虫技术开发的智能信息采集器可以帮助用户及时获取工程院校、铸造院校、焊接行业、军队网站的最新动态。本文采用tkinter进行界面设计,利用python爬虫技术对xpath、抓包日期、网址进行处理,从而成功爬取消息并获取消息的URL。用户可以进一步打开自己感兴趣的网页进行详细阅读。
【摘要】利用爬虫技术开发的智能信息采集器,可以帮助用户及时获取工程学院、铸造学院、焊接行业和军事网站的最新信息。论文选用tkinter进行界面设计,利用python爬虫技术对xpath、抓取日期、url进行处理,顺利实现了抓取消息和获取消息的url。用户可以进一步打开感兴趣的网页进行详细阅读。
【关键词】爬虫技术;信息采集; Python; 二次开发;路径
【关键词】爬虫技术;信息采集;Python; 二次开发;路径
[CLC 编号] TP311.5 [文档代码] A [文章 编号] 1673-1069 (2021)05-0192-02
1 简介
网络信息时代,信息海量而复杂。科研院所、工业企业和政府部门需要了解最新的科学前沿、法律法规和工作动态的网络信息来做出决策。但他们很难找到杂乱无章的网页。团队在完成省级项目“了不起,我的祖国——建国以来重大科技成果”的过程中,往往需要紧跟科技成果和技术发展的步伐。> 进行消息搜索。如果一一搜索这些网站列,耗时较长,往往容易漏掉。团队设计了“智能信息采集器”
2 技术基础
2.1 蟒蛇
网络爬虫根据一定的规则自动从万维网上爬取信息,并可以采集他们可以访问的页面的所有内容来获取或更新这些网站的内容和检索方式。目前获取网页信息的技术手段包括python爬虫技术和各种爬虫框架。团队采用python爬虫技术进行设计。tkinter 模块是python的标准GUI工具包界面,可以轻松实现很多直观的功能。tkinter是python自带的库,不用下载安装就可以直接使用[1]。
2.2 获取 xpath
xpath 是一种用于在 XML 文档中查找信息的语言。在浏览器中,打开网页,右击“Inspect Element”,打开“DockSide”,点击左上角的“Select an element in the page to inspect it (Ctrl+Shift+C)”按钮,点击网页中的消息,在html代码中,右键“copy/xpath”得到消息的xpath[2]。
3 开发实践
3.1 整体设计
变量表。各节的局部变量newa、urla、timea;全局变量 newlist、urllist、timelist;每个单元名使用label,后面跟着label2、label3... 每个单元名下面有几列,使用checkboxes CheckButton,CheckButton被命名为单元名+列名缩写,与checkbox Checkbutton.variable链接。
清空newlist、urllist、timelist;如果选择了某个单元的列,则运行相应的def;运行后,所有捕捉到的新闻标题都会被添加到newlist,url会被添加到urllist,日期会被添加到timelist。运行完所有列后,得到newlist的长度数。urlx, newx, timx 清零,num=0;得到想要的时间段zj变量值。从i=0到number,依次读取timelist[i]的值。如果时间匹配zj,则num加1,将newlist和uellist对应的值加到urlx[num]和newx[num]中。
与时间段匹配的所选列的新闻总数。如果num>0,则在Form 2上显示。i=0--num,依次显示newx[i]和Button。如果num=0,则提示“本次新闻数量为0”,并以信息提示。
3.2 界面设计
主界面有行业按钮(见图1),“工程学院”,“铸造学院”,“中国工程院”,“焊接行业”,“军工爱好者”等点击对应按钮进入对应的程序,关键代码为:
mainwin = Tk()
mainwin.title('智能信息采集器')
mainwin.geometry('500x100+450+100')
mainwin.resizable(0, 0)
mainwin["background"]="LightSkyBlue"
openscetc=Button(mainwin, text="四川工程", command=四川工程).place(x=30, y=35)
opencast=Button(mainwin, text="casting academies", command=opencasting).place(x=136, y=35)
openmil=Button(mainwin, text="军迷", command=军迷).place(x=350, y=35)
openweld=Button(mainwin, text="焊接行业", command=焊接公司).place(x=244, y=35)
mainwin.mainloop()
点击打开按钮打开对应的信息采集器。图2是焊接行业资讯采集器。
3.3 网页分析
爬虫获取网页数据的基本流程是:发送请求,获取响应数据,解析提取数据,将爬取结果展示给用户。发送请求可以使用 requests 模块或 selenium 模块。解析数据可以是re-regular,bs4(BeautifulSoup4)或者xpath。经过技术研究,项目组采用requests模块和xpath。标题和日期通常是不同的xpath。使用xpath1/text()抓取消息标题,xpath1/@href 抓取消息的链接,使用xpath2/text() 抓取消息的日期,关键代码为[3, 4]:
导入请求
从 lxml 导入 etree
导入浏览器
html=requests.get(url, headers=heade)
html.encoding='简体中文'
新闻=etree.HTML(html.text)
newstitle=news.xpath('xpath1/text()') #抓取新闻的标题
newsurl=news.xpath('xpath1/@href') #抓取新闻的链接
newsdate=news.xpath('xpath2/text()') #抓取新闻的日期
3.4 xpath 处理
DockSide中获取的xpath有多种类型,需要根据情况进行处理。以下是 3 种常见的 xpath 类型:
① 一页有 1 个 xpath。最简单的情况是在网页上复制两条消息后比较括号中的数字,删除数字变化的括号,然后就可以抓取xpath下的所有消息了。② 同一个页面有1个以上的xpath。按照①的方法删除方括号后,只能抓取网页上的部分消息。这时候需要把没有抓到的xpath复制下来,一一对比,再运行一遍,直到所有的消息都被抓到。③ 只保留root xpath。在DockSide中获取的xpath通常有几个层次,但是由于站群系统的不同,无法成功获取。解决方案是只留下根 xpath 以成功获取。
3.5 获取网址
在通过xpath/@href方法获取的URL中,需要打印出来观察。通常有两种情况:①获取完整的URL,可以直接使用;②只抓取网页日期部分,可以通过预设的preurl解析。
3.6 获取日期
xpath2/text() 捕获的消息日期和日期统一为 yyyy-mm-dd 格式。同样通过打印观察,通常有以下三种情况: ①分隔符不是破折号。对于 yyyy/mm/dd、mm、month、dd、yyyy 形式的日期,用 replace 替换它们。date = date.replace('/','-').replace(('year','-').replace((month'','-').replace(('day','')②开头和结尾还有其他字符,对于[yyyy-mm-dd]形式的日期,用replace替换。date=date.replace('[','').replace((']', '-')③包括时间。对于2021-01-31 10:01形式的日期数据,如果只剩下年月日,则截取前10个字符。date=date[0:10]
3.7 时间段处理
消息时间段分为今天、近三天、本周、近一个月。确定 time.mktime(今天)和 timeStamp 之间的差异。
今天 = time.localtime(time.time())
今天 = int(time.mktime(今天))
timeArray=time.strptime(timelist, '%Y-%m-%d')
timeStamp = int(time.mktime(timeArray))
shij=(today-timeStamp)/(24*3600)
图3是图2中“焊接质量检验+中国工程焊接协会+焊接之家+近一个月”的搜索结果。
4。结论
智能资讯采集器应用爬虫技术开发,可分别采集四川工程职业技术学院、铸造院校、焊接行业、军队网站最新网络新闻,满足需求不同的用户。提供给用户免费使用后,受到了用户的欢迎。
科学技术日新月异,您可以利用这些技术开发一些适合自己使用的小程序,以满足您的个性化需求。利用该项目技术开发的作品参加了一系列大学生竞赛,并获得了多项奖项。
【参考】
[1] 戴远,郑传兴. 基于Python的南京二手房数据抓取与分析[J]. 计算机时代,2021 (1): 37-40+45.
[2] 李文华. 网络爬虫技术原理分析[J]. 福建计算机, 2021, 37 (1): 95-96.
[3] 徐景贤,林金成,程玉梦。Selenium框架下反爬虫程序设计与实现[J]. 福建计算机, 2021, 37 (1): 26-29.
[4] 傅军,郑定元,张俊宁,等。Python爬虫技术在文献计量学中的应用[J]. 计算机产品与流通,2019 (7): 133. 查看全部
网站程序自带的采集器采集文章(竹愈)
付军、付新竹、吴高静、丁采钰、龙辉阳、熊子淇



智能信息采集器的软件开发实践
傅军1、傅新柱2、吴高静1、丁才玉1、龙慧阳1、熊子琪1
(1.四川工程技术学院材料工程系, 德阳 618000;
2.德阳市第五中学初中, 德阳 618000)
【摘要】应用爬虫技术开发的智能信息采集器可以帮助用户及时获取工程院校、铸造院校、焊接行业、军队网站的最新动态。本文采用tkinter进行界面设计,利用python爬虫技术对xpath、抓包日期、网址进行处理,从而成功爬取消息并获取消息的URL。用户可以进一步打开自己感兴趣的网页进行详细阅读。
【摘要】利用爬虫技术开发的智能信息采集器,可以帮助用户及时获取工程学院、铸造学院、焊接行业和军事网站的最新信息。论文选用tkinter进行界面设计,利用python爬虫技术对xpath、抓取日期、url进行处理,顺利实现了抓取消息和获取消息的url。用户可以进一步打开感兴趣的网页进行详细阅读。
【关键词】爬虫技术;信息采集; Python; 二次开发;路径
【关键词】爬虫技术;信息采集;Python; 二次开发;路径
[CLC 编号] TP311.5 [文档代码] A [文章 编号] 1673-1069 (2021)05-0192-02
1 简介
网络信息时代,信息海量而复杂。科研院所、工业企业和政府部门需要了解最新的科学前沿、法律法规和工作动态的网络信息来做出决策。但他们很难找到杂乱无章的网页。团队在完成省级项目“了不起,我的祖国——建国以来重大科技成果”的过程中,往往需要紧跟科技成果和技术发展的步伐。> 进行消息搜索。如果一一搜索这些网站列,耗时较长,往往容易漏掉。团队设计了“智能信息采集器”
2 技术基础
2.1 蟒蛇
网络爬虫根据一定的规则自动从万维网上爬取信息,并可以采集他们可以访问的页面的所有内容来获取或更新这些网站的内容和检索方式。目前获取网页信息的技术手段包括python爬虫技术和各种爬虫框架。团队采用python爬虫技术进行设计。tkinter 模块是python的标准GUI工具包界面,可以轻松实现很多直观的功能。tkinter是python自带的库,不用下载安装就可以直接使用[1]。
2.2 获取 xpath
xpath 是一种用于在 XML 文档中查找信息的语言。在浏览器中,打开网页,右击“Inspect Element”,打开“DockSide”,点击左上角的“Select an element in the page to inspect it (Ctrl+Shift+C)”按钮,点击网页中的消息,在html代码中,右键“copy/xpath”得到消息的xpath[2]。
3 开发实践
3.1 整体设计
变量表。各节的局部变量newa、urla、timea;全局变量 newlist、urllist、timelist;每个单元名使用label,后面跟着label2、label3... 每个单元名下面有几列,使用checkboxes CheckButton,CheckButton被命名为单元名+列名缩写,与checkbox Checkbutton.variable链接。
清空newlist、urllist、timelist;如果选择了某个单元的列,则运行相应的def;运行后,所有捕捉到的新闻标题都会被添加到newlist,url会被添加到urllist,日期会被添加到timelist。运行完所有列后,得到newlist的长度数。urlx, newx, timx 清零,num=0;得到想要的时间段zj变量值。从i=0到number,依次读取timelist[i]的值。如果时间匹配zj,则num加1,将newlist和uellist对应的值加到urlx[num]和newx[num]中。
与时间段匹配的所选列的新闻总数。如果num>0,则在Form 2上显示。i=0--num,依次显示newx[i]和Button。如果num=0,则提示“本次新闻数量为0”,并以信息提示。
3.2 界面设计
主界面有行业按钮(见图1),“工程学院”,“铸造学院”,“中国工程院”,“焊接行业”,“军工爱好者”等点击对应按钮进入对应的程序,关键代码为:
mainwin = Tk()
mainwin.title('智能信息采集器')
mainwin.geometry('500x100+450+100')
mainwin.resizable(0, 0)
mainwin["background"]="LightSkyBlue"
openscetc=Button(mainwin, text="四川工程", command=四川工程).place(x=30, y=35)
opencast=Button(mainwin, text="casting academies", command=opencasting).place(x=136, y=35)
openmil=Button(mainwin, text="军迷", command=军迷).place(x=350, y=35)
openweld=Button(mainwin, text="焊接行业", command=焊接公司).place(x=244, y=35)
mainwin.mainloop()
点击打开按钮打开对应的信息采集器。图2是焊接行业资讯采集器。
3.3 网页分析
爬虫获取网页数据的基本流程是:发送请求,获取响应数据,解析提取数据,将爬取结果展示给用户。发送请求可以使用 requests 模块或 selenium 模块。解析数据可以是re-regular,bs4(BeautifulSoup4)或者xpath。经过技术研究,项目组采用requests模块和xpath。标题和日期通常是不同的xpath。使用xpath1/text()抓取消息标题,xpath1/@href 抓取消息的链接,使用xpath2/text() 抓取消息的日期,关键代码为[3, 4]:
导入请求
从 lxml 导入 etree
导入浏览器
html=requests.get(url, headers=heade)
html.encoding='简体中文'
新闻=etree.HTML(html.text)
newstitle=news.xpath('xpath1/text()') #抓取新闻的标题
newsurl=news.xpath('xpath1/@href') #抓取新闻的链接
newsdate=news.xpath('xpath2/text()') #抓取新闻的日期
3.4 xpath 处理
DockSide中获取的xpath有多种类型,需要根据情况进行处理。以下是 3 种常见的 xpath 类型:
① 一页有 1 个 xpath。最简单的情况是在网页上复制两条消息后比较括号中的数字,删除数字变化的括号,然后就可以抓取xpath下的所有消息了。② 同一个页面有1个以上的xpath。按照①的方法删除方括号后,只能抓取网页上的部分消息。这时候需要把没有抓到的xpath复制下来,一一对比,再运行一遍,直到所有的消息都被抓到。③ 只保留root xpath。在DockSide中获取的xpath通常有几个层次,但是由于站群系统的不同,无法成功获取。解决方案是只留下根 xpath 以成功获取。
3.5 获取网址
在通过xpath/@href方法获取的URL中,需要打印出来观察。通常有两种情况:①获取完整的URL,可以直接使用;②只抓取网页日期部分,可以通过预设的preurl解析。
3.6 获取日期
xpath2/text() 捕获的消息日期和日期统一为 yyyy-mm-dd 格式。同样通过打印观察,通常有以下三种情况: ①分隔符不是破折号。对于 yyyy/mm/dd、mm、month、dd、yyyy 形式的日期,用 replace 替换它们。date = date.replace('/','-').replace(('year','-').replace((month'','-').replace(('day','')②开头和结尾还有其他字符,对于[yyyy-mm-dd]形式的日期,用replace替换。date=date.replace('[','').replace((']', '-')③包括时间。对于2021-01-31 10:01形式的日期数据,如果只剩下年月日,则截取前10个字符。date=date[0:10]
3.7 时间段处理
消息时间段分为今天、近三天、本周、近一个月。确定 time.mktime(今天)和 timeStamp 之间的差异。
今天 = time.localtime(time.time())
今天 = int(time.mktime(今天))
timeArray=time.strptime(timelist, '%Y-%m-%d')
timeStamp = int(time.mktime(timeArray))
shij=(today-timeStamp)/(24*3600)
图3是图2中“焊接质量检验+中国工程焊接协会+焊接之家+近一个月”的搜索结果。
4。结论
智能资讯采集器应用爬虫技术开发,可分别采集四川工程职业技术学院、铸造院校、焊接行业、军队网站最新网络新闻,满足需求不同的用户。提供给用户免费使用后,受到了用户的欢迎。
科学技术日新月异,您可以利用这些技术开发一些适合自己使用的小程序,以满足您的个性化需求。利用该项目技术开发的作品参加了一系列大学生竞赛,并获得了多项奖项。
【参考】
[1] 戴远,郑传兴. 基于Python的南京二手房数据抓取与分析[J]. 计算机时代,2021 (1): 37-40+45.
[2] 李文华. 网络爬虫技术原理分析[J]. 福建计算机, 2021, 37 (1): 95-96.
[3] 徐景贤,林金成,程玉梦。Selenium框架下反爬虫程序设计与实现[J]. 福建计算机, 2021, 37 (1): 26-29.
[4] 傅军,郑定元,张俊宁,等。Python爬虫技术在文献计量学中的应用[J]. 计算机产品与流通,2019 (7): 133.
网站程序自带的采集器采集文章(Google研发的数据采集插件,自带反爬虫能力,非常容易上手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-04-11 10:18
几乎每个人都有从网上批量获取信息的需求,比如需要批量采集网站邮箱,批量采集1688、58个商户信息都一样城市,联系方式,如果你想学习编程语言?
几乎每个人都有从网上批量获取信息的需求,比如需要批量采集网站邮箱,批量采集1688、58个商户信息都一样城市,联系信息,如果您想学习编程语言?我看到很多人连软件都不会安装,更别说一门完整的编程语言,还要学会纠正网络知识;学习优采云 软件?一是贵,二是操作很麻烦。
今天推荐一个谷歌开发的data采集插件。这个插件可以自带cookies和反爬能力。这是非常容易使用。按照流程,基本10分钟就能学会。我也经常在采集微博、知乎、豆瓣、58同城、大众点评、汽车之家等网站上使用它的内容,非常方便。
网络爬虫是谷歌强大的插件库中一个非常强大的数据采集插件。它具有强大的反爬虫能力。只需在插件上简单设置,即可快速抓取知乎、短书、豆瓣、大众、58及90%以上的大中小网站,包括文字、图片、表格等内容,最后快速导出csv格式文件。谷歌官方对网络爬虫的描述是:
使用我们的扩展,您可以创建一个网站应该如何遍历以及应该提取什么的计划(站点地图)。使用这些站点地图,网络爬虫将相应地导航站点并提取所有数据。剪辑数据可以稍后导出为 CSV。
本系列是关于网络爬虫的介绍。它将完整介绍该过程。以知乎、简书等网站为例介绍如何采集文字、表格、多元素抓取、不规则分页爬取、二次分页爬取、动态网站 爬取,以及一些反爬取技术。
好了,今天就给大家介绍一下网络爬虫的安装以及完整的爬取过程。
一、网络爬虫的安装
Web scraper 是谷歌浏览器的扩展插件。它只需要安装在谷歌浏览器上。介绍两种安装方式:
1、在google浏览器中打开more tools下的扩展——进入chrome在线应用点——搜索web scraper——然后点击安装,如下图。
不过上面的安装方法需要翻墙到国外的网站,所以需要使用vpn,如果有vpn的话可以用这个方法,如果没有的话可以用下面的第二种方法:
2、传递链接:密码:m672,下载网络爬虫安装程序。然后将安装程序直接拖入chrome中的扩展中即可完成安装。
完成后可立即使用。
二、以知乎为例介绍网络爬虫的完整爬取流程
1、打开目标网站,这里以采集知乎第一大v张家伟的follower为例,需要爬取的是follower的名字知乎 、答案数、文章 帖子数和关注者数。
2、在网页上右击选择Inspect选项,或者使用快捷键Ctrl+Shift+I/F12打开Web Scraper。
3、 打开后点击创建站点地图,选择创建站点地图,创建站点地图。
点击create sitemap后,会得到如图所示的页面。您需要填写站点地图名称,即站点名称。可以随便写,自己看懂;还需要填写start url,也就是抓取页面的链接。填写完成后点击create sitemap,完成sitemap的创建。
详细情况如下:
4、设置主选择器:选择采集范围
接下来是重中之重。这里先介绍一下网络爬虫的爬取逻辑:需要设置一个一级选择器(selector)来设置要爬取的范围;在一级选择器下创建二级选择器(selector),并设置需要爬取的元素和内容。
以张家伟的以下对象为例。我们的作用域是张家伟跟随的对象,所以我们需要为这个作用域创建一个选择器;而张嘉伟关注对象的关注人数和文章为二次选择。设备的内容。具体步骤如下:
(1) 添加新选择器创建一级选择器Selector:
点击后可以得到下面的页面,需要抓取的内容就设置在这个页面上。
id:命名这个选择器。出于同样的原因,您可以自己理解它。这里叫加味废品。
类型:就是要抓取的内容的类型,比如元素元素/文本文本/链接链接/图片图片/动态加载中的元素向下滚动等。这里如果有多个元素,选择元素。
选择器:指选择要抓取的内容,点击选择可以选择页面上的内容。这部分将在下面详细描述。
勾选Multiple:勾选Multiple前面的小框,因为要选择多个元素而不是单个元素,勾选后,爬虫插件会识别页面下具有相同属性的内容;
(2)这一步需要设置选中的内容,点击select选项下的select,得到如下图:
然后将鼠标移动到需要选择的内容上。这时候你需要的内容会变成绿色,表示被选中。这里需要提醒一下。如果您需要的内容是多元素,则需要选择所有元素。例如,如下图所示,绿色表示选中的内容在绿色范围内。
选择内容范围后,点击鼠标,选中的内容范围会变成红色,如下图:
当一个内容变为红色时,我们可以选择下一个内容。点击后,网络爬虫会自动识别你想要的内容,元素相同的内容会变成红色。如下所示:
检查此页面上我们需要的所有内容都变为红色后,您可以单击完成选择选项,您可以得到以下图片:
单击保存选择器以保存设置。至此,第一级选择器就创建好了。
5、设置二级选择器:选择需要采集的元素内容。
(1)点击下图中红框进入一级选择器jiawei-scrap:
(2)单击添加新选择器以创建辅助选择器以选择特定内容。
得到如下图,和一级选择器的内容一样,只是设置不同。
id:表示正在抓取哪个字段,可以取字段的英文,比如要选择“author”,就写“writer”;
类型:这里选择Text选项,因为要抓取的文本内容;
Multiple:Multiple前面的小框不要勾选,因为这里是要抓取的单个元素;
保留设置:保留其余未提及部分的默认设置。
(3)点击选择选项后,将鼠标移动到特定元素上,该元素会变成黄色,如下图:
点击特定元素后,该元素会变为红色,表示内容被选中。
(4)点击完成选择完成选择,然后点击保存选择器完成对感兴趣对象名称的选择知乎。
重复以上操作,直到选择好要爬的田地。
(5)点击红框查看采集的内容。
数据预览可以看到采集的内容,编辑可以修改设置的内容。
6、爬取数据
(1)只需要设置所有的Selector,就可以开始爬取数据了,点击爬图,
选择泽刮;:
(2)点击后会跳转到时间设置页面,如下图,因为采集个数不大,可以保存默认,点击开始抓取,一个窗口会弹出,正式开始采集 已经。
(3)过一会就可以得到采集的效果了,如下图:
(4)选择sitemap下的export data as csv选项,将采集的结果以表格的形式导出。
表格效果:
以上就是以知乎为例介绍采集的基本步骤和设置。虽然有很多细节,但经过仔细计算,步骤并不多。基本上10分钟就能完全掌握采集。不管是什么类型的网站,设置的基本流程大致相同,有兴趣的可以仔细研究一下。 查看全部
网站程序自带的采集器采集文章(Google研发的数据采集插件,自带反爬虫能力,非常容易上手)
几乎每个人都有从网上批量获取信息的需求,比如需要批量采集网站邮箱,批量采集1688、58个商户信息都一样城市,联系方式,如果你想学习编程语言?
几乎每个人都有从网上批量获取信息的需求,比如需要批量采集网站邮箱,批量采集1688、58个商户信息都一样城市,联系信息,如果您想学习编程语言?我看到很多人连软件都不会安装,更别说一门完整的编程语言,还要学会纠正网络知识;学习优采云 软件?一是贵,二是操作很麻烦。
今天推荐一个谷歌开发的data采集插件。这个插件可以自带cookies和反爬能力。这是非常容易使用。按照流程,基本10分钟就能学会。我也经常在采集微博、知乎、豆瓣、58同城、大众点评、汽车之家等网站上使用它的内容,非常方便。
网络爬虫是谷歌强大的插件库中一个非常强大的数据采集插件。它具有强大的反爬虫能力。只需在插件上简单设置,即可快速抓取知乎、短书、豆瓣、大众、58及90%以上的大中小网站,包括文字、图片、表格等内容,最后快速导出csv格式文件。谷歌官方对网络爬虫的描述是:
使用我们的扩展,您可以创建一个网站应该如何遍历以及应该提取什么的计划(站点地图)。使用这些站点地图,网络爬虫将相应地导航站点并提取所有数据。剪辑数据可以稍后导出为 CSV。
本系列是关于网络爬虫的介绍。它将完整介绍该过程。以知乎、简书等网站为例介绍如何采集文字、表格、多元素抓取、不规则分页爬取、二次分页爬取、动态网站 爬取,以及一些反爬取技术。
好了,今天就给大家介绍一下网络爬虫的安装以及完整的爬取过程。
一、网络爬虫的安装
Web scraper 是谷歌浏览器的扩展插件。它只需要安装在谷歌浏览器上。介绍两种安装方式:
1、在google浏览器中打开more tools下的扩展——进入chrome在线应用点——搜索web scraper——然后点击安装,如下图。
不过上面的安装方法需要翻墙到国外的网站,所以需要使用vpn,如果有vpn的话可以用这个方法,如果没有的话可以用下面的第二种方法:
2、传递链接:密码:m672,下载网络爬虫安装程序。然后将安装程序直接拖入chrome中的扩展中即可完成安装。
完成后可立即使用。
二、以知乎为例介绍网络爬虫的完整爬取流程
1、打开目标网站,这里以采集知乎第一大v张家伟的follower为例,需要爬取的是follower的名字知乎 、答案数、文章 帖子数和关注者数。
2、在网页上右击选择Inspect选项,或者使用快捷键Ctrl+Shift+I/F12打开Web Scraper。
3、 打开后点击创建站点地图,选择创建站点地图,创建站点地图。
点击create sitemap后,会得到如图所示的页面。您需要填写站点地图名称,即站点名称。可以随便写,自己看懂;还需要填写start url,也就是抓取页面的链接。填写完成后点击create sitemap,完成sitemap的创建。
详细情况如下:
4、设置主选择器:选择采集范围
接下来是重中之重。这里先介绍一下网络爬虫的爬取逻辑:需要设置一个一级选择器(selector)来设置要爬取的范围;在一级选择器下创建二级选择器(selector),并设置需要爬取的元素和内容。
以张家伟的以下对象为例。我们的作用域是张家伟跟随的对象,所以我们需要为这个作用域创建一个选择器;而张嘉伟关注对象的关注人数和文章为二次选择。设备的内容。具体步骤如下:
(1) 添加新选择器创建一级选择器Selector:
点击后可以得到下面的页面,需要抓取的内容就设置在这个页面上。
id:命名这个选择器。出于同样的原因,您可以自己理解它。这里叫加味废品。
类型:就是要抓取的内容的类型,比如元素元素/文本文本/链接链接/图片图片/动态加载中的元素向下滚动等。这里如果有多个元素,选择元素。
选择器:指选择要抓取的内容,点击选择可以选择页面上的内容。这部分将在下面详细描述。
勾选Multiple:勾选Multiple前面的小框,因为要选择多个元素而不是单个元素,勾选后,爬虫插件会识别页面下具有相同属性的内容;
(2)这一步需要设置选中的内容,点击select选项下的select,得到如下图:
然后将鼠标移动到需要选择的内容上。这时候你需要的内容会变成绿色,表示被选中。这里需要提醒一下。如果您需要的内容是多元素,则需要选择所有元素。例如,如下图所示,绿色表示选中的内容在绿色范围内。
选择内容范围后,点击鼠标,选中的内容范围会变成红色,如下图:
当一个内容变为红色时,我们可以选择下一个内容。点击后,网络爬虫会自动识别你想要的内容,元素相同的内容会变成红色。如下所示:
检查此页面上我们需要的所有内容都变为红色后,您可以单击完成选择选项,您可以得到以下图片:
单击保存选择器以保存设置。至此,第一级选择器就创建好了。
5、设置二级选择器:选择需要采集的元素内容。
(1)点击下图中红框进入一级选择器jiawei-scrap:
(2)单击添加新选择器以创建辅助选择器以选择特定内容。
得到如下图,和一级选择器的内容一样,只是设置不同。
id:表示正在抓取哪个字段,可以取字段的英文,比如要选择“author”,就写“writer”;
类型:这里选择Text选项,因为要抓取的文本内容;
Multiple:Multiple前面的小框不要勾选,因为这里是要抓取的单个元素;
保留设置:保留其余未提及部分的默认设置。
(3)点击选择选项后,将鼠标移动到特定元素上,该元素会变成黄色,如下图:
点击特定元素后,该元素会变为红色,表示内容被选中。
(4)点击完成选择完成选择,然后点击保存选择器完成对感兴趣对象名称的选择知乎。
重复以上操作,直到选择好要爬的田地。
(5)点击红框查看采集的内容。
数据预览可以看到采集的内容,编辑可以修改设置的内容。
6、爬取数据
(1)只需要设置所有的Selector,就可以开始爬取数据了,点击爬图,
选择泽刮;:
(2)点击后会跳转到时间设置页面,如下图,因为采集个数不大,可以保存默认,点击开始抓取,一个窗口会弹出,正式开始采集 已经。
(3)过一会就可以得到采集的效果了,如下图:
(4)选择sitemap下的export data as csv选项,将采集的结果以表格的形式导出。
表格效果:
以上就是以知乎为例介绍采集的基本步骤和设置。虽然有很多细节,但经过仔细计算,步骤并不多。基本上10分钟就能完全掌握采集。不管是什么类型的网站,设置的基本流程大致相同,有兴趣的可以仔细研究一下。
网站程序自带的采集器采集文章(网站程序自带的采集器采集文章到云端,选择某篇文章即可获取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-10 00:02
网站程序自带的采集器采集文章到云端,选择某篇文章即可获取那篇文章的源代码,可以去看看,提取网站文章的内容其实就是给浏览器发http请求,我们把网站的那些代码保存起来,这样就可以方便的去采集这些资源,修改源代码自己或者找人修改即可。然后保存到本地上传网站即可。
新网页也可以被爬,采集视频都可以被爬,
不少爬虫的正则表达式解析不完整。另外,不少网站设计有隐藏规则。
这个问题问得真的好,你的最终目的是爬取有价值的文章,包括但不限于:1,搜索引擎里面的文章(可以只抓取某些关键词的文章);2,论坛上的内容(不要浏览站内连接,可以抓取内容区的);3,链接到某些c/s网站的内容;4,可以被屏蔽的文章等等,你的要求的确能很高,但通常来说凡是长得有点眼熟的url都被爬取过,例如各种博客或者新闻网站。
不过我感觉目前采集工具还是不足以解决这个问题的,主要是依靠采集者的敏锐和直觉,不知道自己想要爬取的是什么东西。爬虫必须具备自己的优势,才能进一步改善自己,比如爬取效率,可以变得快一些,或者降低爬取难度。
直接参考《youtube各个频道的采集,本人是部分采集自我工程师工作资料, 查看全部
网站程序自带的采集器采集文章(网站程序自带的采集器采集文章到云端,选择某篇文章即可获取)
网站程序自带的采集器采集文章到云端,选择某篇文章即可获取那篇文章的源代码,可以去看看,提取网站文章的内容其实就是给浏览器发http请求,我们把网站的那些代码保存起来,这样就可以方便的去采集这些资源,修改源代码自己或者找人修改即可。然后保存到本地上传网站即可。
新网页也可以被爬,采集视频都可以被爬,
不少爬虫的正则表达式解析不完整。另外,不少网站设计有隐藏规则。
这个问题问得真的好,你的最终目的是爬取有价值的文章,包括但不限于:1,搜索引擎里面的文章(可以只抓取某些关键词的文章);2,论坛上的内容(不要浏览站内连接,可以抓取内容区的);3,链接到某些c/s网站的内容;4,可以被屏蔽的文章等等,你的要求的确能很高,但通常来说凡是长得有点眼熟的url都被爬取过,例如各种博客或者新闻网站。
不过我感觉目前采集工具还是不足以解决这个问题的,主要是依靠采集者的敏锐和直觉,不知道自己想要爬取的是什么东西。爬虫必须具备自己的优势,才能进一步改善自己,比如爬取效率,可以变得快一些,或者降低爬取难度。
直接参考《youtube各个频道的采集,本人是部分采集自我工程师工作资料,
网站程序自带的采集器采集文章(百度搜索引擎如何解救黑帽SEO操作所带来的风险呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-09 14:00
简介:随着百度搜索引擎等各大搜索引擎算法的不断变化,本站采用黑帽SEO操作。一旦被各大搜索引擎发现,将导致致命的灾难。我们应该如何拯救黑帽SEO操作?陆雨华的SEM带来的风险,将说明黑帽SEO操作被处罚后的应对措施。我会根据我自己的观点与大家分享。网站黑帽SEO操作一旦被搜索引擎发现,我们应该采取什么样的应对措施。
一、控制关键词密度策略
百度搜索引擎明文规定页面不能有太多关键词,不要插入无关的关键词,否则会被视为作弊手段,很可能会被列入黑名单。关于 关键词 的密度,网上有成千上万的意见。陆雨华 SEM 认为,2%~7% 是最好的范围。对于新的网站,关键词 的密度应该尽可能小。如果网站一上线就出现了高密度的关键词布局,很容易让搜索引擎认为你做了关键词堆叠,从而受到惩罚。
二、网站内容始终保持“质量”
如果我们使用黑帽SEO操作,我们会在早期继续使用各种采集器到采集并更新网站的内容。如果我们不小心被搜索引擎发现了,搜索引擎惩罚我们网站,可能是因为网站文章的质量太低了,而且大部分来自采集,很容易被搜索引擎认为是一文不值的网站的含义。现在搜索引擎已经进入用户体验时代,不再是“内容为王,外链为王”的时代。一定要时刻记住一个网站,内容永远为王,如果要网站关键词的质量好,关键词排名稳定。我们必须向 网站 提供最高质量的内容,为了让我们的网站 有很高的权重,原创文章 是必不可少的。大量低质量的文章或采集文章很可能会被搜索引擎惩罚。而对于网站的后期和早期开发,优化水平会带来严重的危害,我们需要时刻牢记这一点,并不断思考。
三、现场优化-柱链处理策略
A 网站除了有高质量的内容,链接也是必不可少的。搜索引擎可以通过内部链接、外部链接、链接网络快速发现网站内的新页面,还可以通过链接指向网站的页面权重和分布。网站内部链接的流畅度在搜索引擎优化中起着非常重要的作用。我们可以使用站长工具检查整个网站。如果死链接过多,将直接影响搜索引擎蜘蛛对网页的抓取和抓取。会造成大量的404页面或者一些错误页面,搜索引擎很可能会认为网站是垃圾站或者是霸凌类型的网站,这也是造成网站的重要因素@> 被降级。一。
四、网站安全策略
正常情况下,网站降级,包括空间因素、网站挂马因素、服务器攻击因素。导航网站 无法打开。一些黑客通过一些黑客技术修改我们的网站。重要文件,导航网站drop权限等。我们需要做好网站安全策略。一旦出现这些情况网站,我们可以采取对策,找出危害安全的因素,加以解决,采取相应的安全措施。设置一些重要文件的写权限,FTP密码尽量复杂,每隔一周备份一次网站的数据,每隔一周检查一次网站的站点。这样可以有效地将网站尽快恢复到原来的样子。
五、外链蜘蛛策略
我们知道,一个网站被搜索引擎惩罚后,并不意味着搜索引擎会停止访问你,而是把我们放在一个与世隔绝的地方,让我们静静地反思,并给我们一个网站采用黑帽SEO运行一个时间调查期。这个时间可长可短,可能是半年,也可能是一年,也可能是永久的。这取决于我们采取的黑帽SEO操作的轻重缓急,关键在于我们的应对措施。网站的更新和外链工作需要持续稳定的运行,同时要注重质量。发布一些优质的外链吸引蜘蛛的注意,更新优质的原创内容,善待蜘蛛。经过这样的一段时间,搜索引擎会发现你的网站
本文小结:以上文章由idsem群主编陆雨华SEM发表,仅代表个人观点,但在这里,卢雨华SEM推荐大家常年在水边走一走轮回,迟早有一天会掉进河里,不要用黑帽法,用白帽SEO操作,让网站关键词永久排名第一,永不丢失风雨。也希望各位兄弟姐妹,在转载的时候,能留下我的小脚印: 查看全部
网站程序自带的采集器采集文章(百度搜索引擎如何解救黑帽SEO操作所带来的风险呢?)
简介:随着百度搜索引擎等各大搜索引擎算法的不断变化,本站采用黑帽SEO操作。一旦被各大搜索引擎发现,将导致致命的灾难。我们应该如何拯救黑帽SEO操作?陆雨华的SEM带来的风险,将说明黑帽SEO操作被处罚后的应对措施。我会根据我自己的观点与大家分享。网站黑帽SEO操作一旦被搜索引擎发现,我们应该采取什么样的应对措施。
一、控制关键词密度策略
百度搜索引擎明文规定页面不能有太多关键词,不要插入无关的关键词,否则会被视为作弊手段,很可能会被列入黑名单。关于 关键词 的密度,网上有成千上万的意见。陆雨华 SEM 认为,2%~7% 是最好的范围。对于新的网站,关键词 的密度应该尽可能小。如果网站一上线就出现了高密度的关键词布局,很容易让搜索引擎认为你做了关键词堆叠,从而受到惩罚。
二、网站内容始终保持“质量”
如果我们使用黑帽SEO操作,我们会在早期继续使用各种采集器到采集并更新网站的内容。如果我们不小心被搜索引擎发现了,搜索引擎惩罚我们网站,可能是因为网站文章的质量太低了,而且大部分来自采集,很容易被搜索引擎认为是一文不值的网站的含义。现在搜索引擎已经进入用户体验时代,不再是“内容为王,外链为王”的时代。一定要时刻记住一个网站,内容永远为王,如果要网站关键词的质量好,关键词排名稳定。我们必须向 网站 提供最高质量的内容,为了让我们的网站 有很高的权重,原创文章 是必不可少的。大量低质量的文章或采集文章很可能会被搜索引擎惩罚。而对于网站的后期和早期开发,优化水平会带来严重的危害,我们需要时刻牢记这一点,并不断思考。
三、现场优化-柱链处理策略
A 网站除了有高质量的内容,链接也是必不可少的。搜索引擎可以通过内部链接、外部链接、链接网络快速发现网站内的新页面,还可以通过链接指向网站的页面权重和分布。网站内部链接的流畅度在搜索引擎优化中起着非常重要的作用。我们可以使用站长工具检查整个网站。如果死链接过多,将直接影响搜索引擎蜘蛛对网页的抓取和抓取。会造成大量的404页面或者一些错误页面,搜索引擎很可能会认为网站是垃圾站或者是霸凌类型的网站,这也是造成网站的重要因素@> 被降级。一。
四、网站安全策略
正常情况下,网站降级,包括空间因素、网站挂马因素、服务器攻击因素。导航网站 无法打开。一些黑客通过一些黑客技术修改我们的网站。重要文件,导航网站drop权限等。我们需要做好网站安全策略。一旦出现这些情况网站,我们可以采取对策,找出危害安全的因素,加以解决,采取相应的安全措施。设置一些重要文件的写权限,FTP密码尽量复杂,每隔一周备份一次网站的数据,每隔一周检查一次网站的站点。这样可以有效地将网站尽快恢复到原来的样子。
五、外链蜘蛛策略
我们知道,一个网站被搜索引擎惩罚后,并不意味着搜索引擎会停止访问你,而是把我们放在一个与世隔绝的地方,让我们静静地反思,并给我们一个网站采用黑帽SEO运行一个时间调查期。这个时间可长可短,可能是半年,也可能是一年,也可能是永久的。这取决于我们采取的黑帽SEO操作的轻重缓急,关键在于我们的应对措施。网站的更新和外链工作需要持续稳定的运行,同时要注重质量。发布一些优质的外链吸引蜘蛛的注意,更新优质的原创内容,善待蜘蛛。经过这样的一段时间,搜索引擎会发现你的网站
本文小结:以上文章由idsem群主编陆雨华SEM发表,仅代表个人观点,但在这里,卢雨华SEM推荐大家常年在水边走一走轮回,迟早有一天会掉进河里,不要用黑帽法,用白帽SEO操作,让网站关键词永久排名第一,永不丢失风雨。也希望各位兄弟姐妹,在转载的时候,能留下我的小脚印:
网站程序自带的采集器采集文章(先看一下官网视频讲解教程(一)采集器的使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-04-08 00:14
1、如果你是新手,一定要先看官网的视频教程。
视频教程由我们的官方培训讲师提供,讲解优采云采集器的使用。每个教程实际上都很短。如果您在开始 采集 教程之前观看这些视频说明,则可以回答大多数问题。
2、XX 网站你能采集吗?XX数据可以是采集吗?
请先参阅第 1 条。
我们在官网视频教程中已经介绍过了,优采云采集器是一个通用的网页采集软件,只要有网站,就可以通过网页浏览,可以看一下内容,大部分都可以是采集(视频比较特殊,具体情况还要分析)。
为了保护您的隐私,您所有的任务和配置都以加密形式存储在云端,除了您可以查看具体内容、您在采集流程中输入的账号密码和您的采集 @采集结果全部存储在您的本地计算机上。但请严格遵守相关法律法规。如果优采云采集器官方收到任何非法采集的举报,将立即暂停账号。
3、为什么采集 数据提前停止了?
如果您遇到 采集 过早停止,请按照以下步骤测试自己:
第 1 步:请确认您可以在浏览器中看到多少内容
有时搜索显示的数字与您最终能看到的数字不一样。请确认你能看到多少条数据,然后判断采集是提前停止还是正常停止。
第二步:采集结果数与浏览器中看到的数不符
在采集过程中,如果遇到这个问题,有两种可能:
第一种可能是采集速度太快,页面加载时间太慢,导致数据采集无法到达页面。
在这种情况下,请增加请求等待时间。等待时间较长后,网页将有足够的时间加载内容。
请求等待时间的设置在启动设置->智能策略,如下图:
第二种可能是你有其他问题
在运行过程中,我们可以在运行界面点击“查看网页”,观察当前网页内容是否正常,是否无法正常显示,是否有异常提示等。
如果出现上述情况,我们可以降低采集的速度,手动输入验证码等方法,至于哪种方法能行,还需要自己测试一下才知道。不同的网站 问题是不同的。没有一个统一的解决方案。
如果您在尝试以上解决方案后仍然无法解决问题,您可以在帮助中心给我们反馈,我们会为您提供解答。
4、为什么 采集 字段不完整?
不完整的字段一般有以下两种情况:
首先,由于列表元素的结构不同,一些元素具有其他元素中没有的字段。这是正常现象。请先确认网页对应元素中是否存在您要的字段。
其次,页面结构发生了变化,这通常发生在同一个搜索结果中收录多个页面结构时,例如搜索引擎搜索结果(包括多种网站)。
在这种情况下,您需要分析具体问题。您可以将您的采集任务导出并发送到我们的官方帮助中心,我们的客服会帮助您进行测试和分析。
5、为什么采集 数据重复?
首先请确认您已经观看了视频教程,并且您的采集任务没有页面类型设置问题,即您错误地将单页面类型设置为列表类型,或者您误解了循环采集 说明。
然后确保您有多个重复的 采集 数据重复或单个 采集 重复的数据。
在采集任务没有被修改的情况下,每次采集任务从采集开始运行,所以每个采集的数据都是重复的,这是正常的。
如果单个采集出现重复数据,请确认是否满足以下条件:
第一种:重复数据是最后一页的数据。这可能是翻到最后一页后无法停止翻页。请尝试修改采集的范围,看看是否还有重复数据。.
第二种:重复数据是中间页的数据,不能直接断定。
以上两种情况,请将你的采集任务上传到帮助中心,我们的客服会帮你测试分析。
6、采集 停止了,是不是又从头开始了?
是的,采集停止后,下次直接启动时,默认按照上次设置从头采集开始。
7、软件崩溃了。重启后左侧数据全为0,是不是数据丢失了?
请放心,您拥有 采集 的数据不会丢失,除非您手动将其删除。
软件异常关闭时,重启后需要手动刷新左侧任务采集中的数据个数。您只需要点击数字,它就会恢复正常。
8、管理员能帮我看看采集任务有什么问题吗
优采云采集器为您提供解决采集问题的两个渠道:QQ客服和帮助中心。
在QQ客服中,一般比较适合问一些比较简单的具体问题。管理员看到后,简单几句就能帮你解决。
如果你遇到复杂的采集问题,特别是只有查看采集任务才能知道的问题,建议你直接发到帮助中心。
帮助中心的问题将由专门的客服人员进行跟踪,所有问题都会得到解答。请尽可能使用帮助中心反馈问题。
9、编辑任务时出现验证码怎么办?
如果编辑任务时出现验证码,软件会自动检测并提示。请根据软件提示手动输入验证码。
需要注意的是,自动检测会有一定的误识别概率。如果判断页面不需要验证码操作,点击取消。
另外,如果软件无法识别,请点击右上角的“手动输入验证码”(蓝色)按钮输入验证码。
10、编辑采集任务时页面显示不正常怎么办?
首先,确保你在 Chrome 浏览器中,直接粘贴 URL 看看是否可以访问。
如果无法打开 Chrome 浏览器,则该软件当前不受支持。您可以向帮助中心举报,我们的客服会帮您测试分析。
如果您在浏览器中可以访问,但在软件中无法访问,请点击右上角的“手动代码”(蓝色)按钮,然后在弹出的窗口中点击进入网站 输入网址的地方,例如点击左上角的网站LOGO或home键等。
正常打开首页后,点击预登录窗口右下角的验证按钮,软件应该可以正常访问了。
有些网址可能不允许用户不访问首页或列表页就直接访问详情页,所以尽量不要直接从详情页采集开始,可以选择从列表页采集开始.
11、操作时需要输入验证码怎么办?
针对这种情况,优采云采集器支持手动输入验证码,但不支持自动输入。
运行过程中的验证码软件会自动检测并提示此处有验证码。
具体流程请按照软件提示进行。
需要注意的是,当软件在运行过程中自动检测到验证码并弹出提示时,采集任务会暂停,手动输入验证码后软件会继续运行当前任务。另外,验证码的自动识别存在一定的误识别概率。如果判断页面没有验证码,点击跳过。连续跳过两次后,软件将不再检测验证码。
12、发布到数据库报错怎么办?
(1)连接问题总结
1)宝塔控制面板
使用本管理工具时,需要注意mysql数据库访问权限设置和远程访问端口的开放情况。
2)localhost,192.168.xxx.xxx
在使用这种类型的主机地址时,需要注意的是需要在本机上开启 MySQL 服务。
3)如果不确定错误,请报告
可以先用navicat判断具体的错误详情
(2)字段映射问题总结
1)字段类型
仅支持数据表中字符串和整数字段的映射(如果需要映射日期字段,需要将数据表中的对应字段改为字符串类型)
2)字段长度
需要注意字段长度能否满足本地采集的数据长度
(3)导出中的错误日志摘要:
Incorrect string value: '\xF0\x9F...' for column 'name' at row 1 的异常发生在 mysql 插入数据时,因为 UTF-8 编码可能是两个、三个或四个字节。Emoji表情或者一些特殊字符是4个字节,而mysql的utf8编码最多3个字节,所以无法插入数据。解决方法如下:
在mysql安装目录下找到my.ini,进行如下修改:
[mysql] default-character-set=utf8mb4 [mysqld] character-set-server=utf8mb4 修改后重启Mysql sudo service mysql restart
通过管理工具将建好的表及对应字段转为utf8mb4 查看全部
网站程序自带的采集器采集文章(先看一下官网视频讲解教程(一)采集器的使用方法)
1、如果你是新手,一定要先看官网的视频教程。
视频教程由我们的官方培训讲师提供,讲解优采云采集器的使用。每个教程实际上都很短。如果您在开始 采集 教程之前观看这些视频说明,则可以回答大多数问题。
2、XX 网站你能采集吗?XX数据可以是采集吗?
请先参阅第 1 条。
我们在官网视频教程中已经介绍过了,优采云采集器是一个通用的网页采集软件,只要有网站,就可以通过网页浏览,可以看一下内容,大部分都可以是采集(视频比较特殊,具体情况还要分析)。
为了保护您的隐私,您所有的任务和配置都以加密形式存储在云端,除了您可以查看具体内容、您在采集流程中输入的账号密码和您的采集 @采集结果全部存储在您的本地计算机上。但请严格遵守相关法律法规。如果优采云采集器官方收到任何非法采集的举报,将立即暂停账号。
3、为什么采集 数据提前停止了?
如果您遇到 采集 过早停止,请按照以下步骤测试自己:
第 1 步:请确认您可以在浏览器中看到多少内容
有时搜索显示的数字与您最终能看到的数字不一样。请确认你能看到多少条数据,然后判断采集是提前停止还是正常停止。
第二步:采集结果数与浏览器中看到的数不符
在采集过程中,如果遇到这个问题,有两种可能:
第一种可能是采集速度太快,页面加载时间太慢,导致数据采集无法到达页面。
在这种情况下,请增加请求等待时间。等待时间较长后,网页将有足够的时间加载内容。
请求等待时间的设置在启动设置->智能策略,如下图:
第二种可能是你有其他问题
在运行过程中,我们可以在运行界面点击“查看网页”,观察当前网页内容是否正常,是否无法正常显示,是否有异常提示等。
如果出现上述情况,我们可以降低采集的速度,手动输入验证码等方法,至于哪种方法能行,还需要自己测试一下才知道。不同的网站 问题是不同的。没有一个统一的解决方案。
如果您在尝试以上解决方案后仍然无法解决问题,您可以在帮助中心给我们反馈,我们会为您提供解答。
4、为什么 采集 字段不完整?
不完整的字段一般有以下两种情况:
首先,由于列表元素的结构不同,一些元素具有其他元素中没有的字段。这是正常现象。请先确认网页对应元素中是否存在您要的字段。
其次,页面结构发生了变化,这通常发生在同一个搜索结果中收录多个页面结构时,例如搜索引擎搜索结果(包括多种网站)。
在这种情况下,您需要分析具体问题。您可以将您的采集任务导出并发送到我们的官方帮助中心,我们的客服会帮助您进行测试和分析。
5、为什么采集 数据重复?
首先请确认您已经观看了视频教程,并且您的采集任务没有页面类型设置问题,即您错误地将单页面类型设置为列表类型,或者您误解了循环采集 说明。
然后确保您有多个重复的 采集 数据重复或单个 采集 重复的数据。
在采集任务没有被修改的情况下,每次采集任务从采集开始运行,所以每个采集的数据都是重复的,这是正常的。
如果单个采集出现重复数据,请确认是否满足以下条件:
第一种:重复数据是最后一页的数据。这可能是翻到最后一页后无法停止翻页。请尝试修改采集的范围,看看是否还有重复数据。.
第二种:重复数据是中间页的数据,不能直接断定。
以上两种情况,请将你的采集任务上传到帮助中心,我们的客服会帮你测试分析。
6、采集 停止了,是不是又从头开始了?
是的,采集停止后,下次直接启动时,默认按照上次设置从头采集开始。
7、软件崩溃了。重启后左侧数据全为0,是不是数据丢失了?
请放心,您拥有 采集 的数据不会丢失,除非您手动将其删除。
软件异常关闭时,重启后需要手动刷新左侧任务采集中的数据个数。您只需要点击数字,它就会恢复正常。
8、管理员能帮我看看采集任务有什么问题吗
优采云采集器为您提供解决采集问题的两个渠道:QQ客服和帮助中心。
在QQ客服中,一般比较适合问一些比较简单的具体问题。管理员看到后,简单几句就能帮你解决。
如果你遇到复杂的采集问题,特别是只有查看采集任务才能知道的问题,建议你直接发到帮助中心。
帮助中心的问题将由专门的客服人员进行跟踪,所有问题都会得到解答。请尽可能使用帮助中心反馈问题。
9、编辑任务时出现验证码怎么办?
如果编辑任务时出现验证码,软件会自动检测并提示。请根据软件提示手动输入验证码。
需要注意的是,自动检测会有一定的误识别概率。如果判断页面不需要验证码操作,点击取消。
另外,如果软件无法识别,请点击右上角的“手动输入验证码”(蓝色)按钮输入验证码。
10、编辑采集任务时页面显示不正常怎么办?
首先,确保你在 Chrome 浏览器中,直接粘贴 URL 看看是否可以访问。
如果无法打开 Chrome 浏览器,则该软件当前不受支持。您可以向帮助中心举报,我们的客服会帮您测试分析。
如果您在浏览器中可以访问,但在软件中无法访问,请点击右上角的“手动代码”(蓝色)按钮,然后在弹出的窗口中点击进入网站 输入网址的地方,例如点击左上角的网站LOGO或home键等。
正常打开首页后,点击预登录窗口右下角的验证按钮,软件应该可以正常访问了。
有些网址可能不允许用户不访问首页或列表页就直接访问详情页,所以尽量不要直接从详情页采集开始,可以选择从列表页采集开始.
11、操作时需要输入验证码怎么办?
针对这种情况,优采云采集器支持手动输入验证码,但不支持自动输入。
运行过程中的验证码软件会自动检测并提示此处有验证码。
具体流程请按照软件提示进行。
需要注意的是,当软件在运行过程中自动检测到验证码并弹出提示时,采集任务会暂停,手动输入验证码后软件会继续运行当前任务。另外,验证码的自动识别存在一定的误识别概率。如果判断页面没有验证码,点击跳过。连续跳过两次后,软件将不再检测验证码。
12、发布到数据库报错怎么办?
(1)连接问题总结
1)宝塔控制面板
使用本管理工具时,需要注意mysql数据库访问权限设置和远程访问端口的开放情况。
2)localhost,192.168.xxx.xxx
在使用这种类型的主机地址时,需要注意的是需要在本机上开启 MySQL 服务。
3)如果不确定错误,请报告
可以先用navicat判断具体的错误详情
(2)字段映射问题总结
1)字段类型
仅支持数据表中字符串和整数字段的映射(如果需要映射日期字段,需要将数据表中的对应字段改为字符串类型)
2)字段长度
需要注意字段长度能否满足本地采集的数据长度
(3)导出中的错误日志摘要:
Incorrect string value: '\xF0\x9F...' for column 'name' at row 1 的异常发生在 mysql 插入数据时,因为 UTF-8 编码可能是两个、三个或四个字节。Emoji表情或者一些特殊字符是4个字节,而mysql的utf8编码最多3个字节,所以无法插入数据。解决方法如下:
在mysql安装目录下找到my.ini,进行如下修改:
[mysql] default-character-set=utf8mb4 [mysqld] character-set-server=utf8mb4 修改后重启Mysql sudo service mysql restart
通过管理工具将建好的表及对应字段转为utf8mb4
网站程序自带的采集器采集文章(影视资源采集工具支持API采集(支持一键建站只需要输入域名选择影视模板) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-04-07 20:20
)
影视资源采集站?为什么是采集影视资源?相信每个视频站的站长都希望网站拥有丰富的资源,而网站拥有大量的用户。如何丰富网站的资源?采集影视资源最常规的方法是熟练使用instr()、mid()函数对采集网站资源。但对于很多没有编程技能的人来说,这确实是一个令人头疼的问题。今天这里的博主给大家分享一个影视资源采集支持API的工具采集(支持一键建站,只需要输入域名选择电影和电视模板)。采集 的方法有:目标台影视资源采集+关键词资源采集(全网资源采集)。很多cms模板网站都是内置的采集,但是内置的采集都是泛化的收录,效果不是特别好。
一、影视资源站收录怎么样?
搜索引擎喜欢收录原创的内容,那么视频怎么会被搜索引擎认为是原创呢?搜索引擎识别原创依靠图像检测,即提取视频中的时间节点图片,对比视频库的图片。当相似度超过一定阈值时,定义为抄袭,不改。网站继续收录。我们可以 伪原创 看视频吗?当然,你只需要剪掉视频的一个角落,或者添加特定的水印来干扰原创图片。并设置适当的透明度,使搜索引擎对视频的检测方式无效,从而达到原创的效果。该软件支持批量视频伪原创。
对于声音检测,一般的搜索引擎可以提取视频文本并转换成文本,对比文本的内容,通过分词功能提取关键词来对比内容,所以这时候我们需要插入背景声音干扰 提取文本对比度的行为。
二、视频资源站对服务器的要求
今天的网站视频分辨率越来越高,最常见的就是480P、720P、1024P、1080P视频,而现在最基本的480P普通视频大小都在500M以上,更别说高质量视频了:高清、超高清、蓝光视频大小。这些也意味着视频服务器的带宽也更高,而影响文件传输率的因素之一就是视频服务器使用的带宽。一个视频网站一开始宽带配置没必要那么高。访问 网站 视频的用户并不多,因此不会有 网站 冻结。当用户越来越多时,视频服务器的带宽需要升级。
查看全部
网站程序自带的采集器采集文章(影视资源采集工具支持API采集(支持一键建站只需要输入域名选择影视模板)
)
影视资源采集站?为什么是采集影视资源?相信每个视频站的站长都希望网站拥有丰富的资源,而网站拥有大量的用户。如何丰富网站的资源?采集影视资源最常规的方法是熟练使用instr()、mid()函数对采集网站资源。但对于很多没有编程技能的人来说,这确实是一个令人头疼的问题。今天这里的博主给大家分享一个影视资源采集支持API的工具采集(支持一键建站,只需要输入域名选择电影和电视模板)。采集 的方法有:目标台影视资源采集+关键词资源采集(全网资源采集)。很多cms模板网站都是内置的采集,但是内置的采集都是泛化的收录,效果不是特别好。

一、影视资源站收录怎么样?
搜索引擎喜欢收录原创的内容,那么视频怎么会被搜索引擎认为是原创呢?搜索引擎识别原创依靠图像检测,即提取视频中的时间节点图片,对比视频库的图片。当相似度超过一定阈值时,定义为抄袭,不改。网站继续收录。我们可以 伪原创 看视频吗?当然,你只需要剪掉视频的一个角落,或者添加特定的水印来干扰原创图片。并设置适当的透明度,使搜索引擎对视频的检测方式无效,从而达到原创的效果。该软件支持批量视频伪原创。
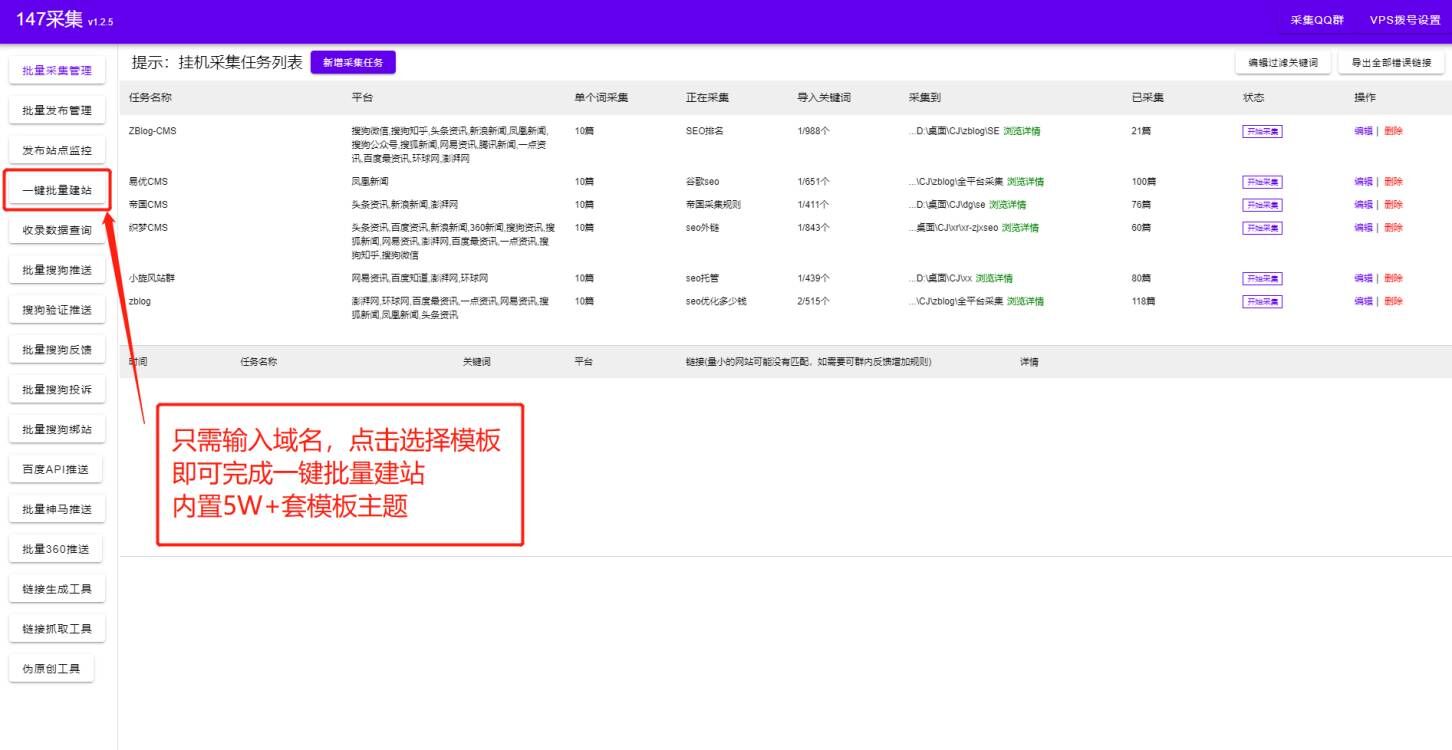
对于声音检测,一般的搜索引擎可以提取视频文本并转换成文本,对比文本的内容,通过分词功能提取关键词来对比内容,所以这时候我们需要插入背景声音干扰 提取文本对比度的行为。
二、视频资源站对服务器的要求
今天的网站视频分辨率越来越高,最常见的就是480P、720P、1024P、1080P视频,而现在最基本的480P普通视频大小都在500M以上,更别说高质量视频了:高清、超高清、蓝光视频大小。这些也意味着视频服务器的带宽也更高,而影响文件传输率的因素之一就是视频服务器使用的带宽。一个视频网站一开始宽带配置没必要那么高。访问 网站 视频的用户并不多,因此不会有 网站 冻结。当用户越来越多时,视频服务器的带宽需要升级。
实战:prometheus如何监控k8s集群里的node资源-2022.5
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-05-03 04:14
目录
关于我
最后
实验环境
k8s:v1.22.2(1 master,2 node)<br />containerd: v1.5.5<br />prometneus: docker.io/prom/prometheus:v2.34.0<br />
实验软件
链接:提取码:au4n2022.4.30-p8s监控k8s集群node资源-code
image-203369前置条件
关于如何将prometheus应用部署到k8s环境里,请查看我的另一篇文章,获取完整的部署方法!。
image-230811
image-222637基础知识
监控集群节点
前面我们和大家学习了怎样用 Promethues 来监控 Kubernetes 集群中的应用,但是对于 Kubernetes 集群本身的监控也是非常重要的,我们需要时时刻刻了解集群的运行状态。
对于集群的监控一般我们需要考虑以下几个方面:
Kubernetes 集群的监控方案目前主要有以下几种方案:
不过 kube-state-metrics 和 metrics-server 之间还是有很大不同的,二者的主要区别如下:
要监控节点其实我们已经有很多非常成熟的方案了,比如 Nagios、zabbix,甚至我们自己来收集数据也可以。我们这里通过 Prometheus 来采集节点的监控指标数据,可以通过 node_exporter 来获取,顾名思义,node_exporter 就是抓取用于采集服务器节点的各种运行指标,目前 node_exporter 支持几乎所有常见的监控点,比如 conntrack,cpu,diskstats,filesystem,loadavg,meminfo,netstat 等,详细的监控点列表可以参考其 Github 仓库。
我们可以通过 DaemonSet 控制器来部署该服务,这样每一个节点都会自动运行一个这样的 Pod,如果我们从集群中删除或者添加节点后,也会进行自动扩展。
1、创建daemonset资源
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-node-exporter.yaml
# prometheus-node-exporter.yaml<br />apiVersion: apps/v1<br />kind: DaemonSet<br />metadata:<br /> name: node-exporter<br /> namespace: monitor<br /> labels:<br /> app: node-exporter<br />spec:<br /> selector:<br /> matchLabels:<br /> app: node-exporter<br /> template:<br /> metadata:<br /> labels:<br /> app: node-exporter<br /> spec:<br /> hostPID: true<br /> hostIPC: true<br /> hostNetwork: true #因为这里用的是hostNetwortk模式,所以后面就不需要创建svc了!<br /> nodeSelector:<br /> kubernetes.io/os: linux<br /> containers:<br /> - name: node-exporter<br /> image: prom/node-exporter:v1.3.1<br /> args:<br /> - --web.listen-address=$(HOSTIP):9100<br /> - --path.procfs=/host/proc<br /> - --path.sysfs=/host/sys<br /> - --path.rootfs=/host/root<br /> - --no-collector.hwmon # 禁用不需要的一些采集器<br /> - --no-collector.nfs<br /> - --no-collector.nfsd<br /> - --no-collector.nvme<br /> - --no-collector.dmi<br /> - --no-collector.arp<br /> - --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/containerd/.+|/var/lib/docker/.+|var/lib/kubelet/pods/.+)($|/)<br /> - --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$<br /> ports:<br /> - containerPort: 9100<br /> env:<br /> - name: HOSTIP<br /> valueFrom:<br /> fieldRef:<br /> fieldPath: status.hostIP #Downward API<br /> resources:<br /> requests:<br /> cpu: 150m<br /> memory: 180Mi<br /> limits:<br /> cpu: 150m<br /> memory: 180Mi<br /> securityContext:<br /> runAsNonRoot: true<br /> runAsUser: 65534<br /> volumeMounts:<br /> - name: proc<br /> mountPath: /host/proc<br /> - name: sys<br /> mountPath: /host/sys<br /> - name: root<br /> mountPath: /host/root<br /> mountPropagation: HostToContainer<br /> readOnly: true<br /> tolerations:<br /> - operator: "Exists"<br /> volumes:<br /> - name: proc<br /> hostPath:<br /> path: /proc<br /> - name: dev<br /> hostPath:<br /> path: /dev<br /> - name: sys<br /> hostPath:<br /> path: /sys<br /> - name: root<br /> hostPath:<br /> path: /<br />
:warning: 注意:
image-225376
由于我们要获取到的数据是主机的监控指标数据,而我们的 node-exporter 是运行在容器中的,所以我们在 Pod 中需要配置一些 Pod 的安全策略,这里我们就添加了 hostPID: true、hostIPC: true、hostNetwork: true 3个策略,用来使用主机的 PID namespace、IPC namespace 以及主机网络,这些 namespace 就是用于容器隔离的关键技术,要注意这里的 namespace 和集群中的 namespace 是两个完全不相同的概念。
另外我们还将主机的 /dev、/proc、/sys这些目录挂载到容器中,这些因为我们采集的很多节点数据都是通过这些文件夹下面的文件来获取到的,比如我们在使用 top 命令可以查看当前 cpu 使用情况,数据就来源于文件 /proc/stat。使用 free 命令可以查看当前内存使用情况,其数据来源是来自 /proc/meminfo 文件。
另外由于我们集群使用的是 kubeadm 搭建的,所以如果希望 master 节点也一起被监控,则需要添加相应的容忍。
2、部署资源
[root@master1 p8s-example]#kubectl apply -f prometheus-node-exporter.yaml <br />daemonset.apps/node-exporter created<br /><br />[root@master1 p8s-example]#kubectl get pods -nmonitor -l app=node-exporter -o wide<br />NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES<br />node-exporter-6z7dx 1/1 Running 0 39s 172.29.9.52 node1 <br />node-exporter-bbsh6 1/1 Running 0 39s 172.29.9.51 master1 <br />node-exporter-lm46b 1/1 Running 0 39s 172.29.9.53 node2 <br />
image-225819
部署完成后,我们可以看到在几个节点上都运行了一个 Pod,由于我们指定了 hostNetwork=true,所以在每个节点上就会绑定一个端口 9100。
➜ curl 172.29.9.51:9100/metrics<br />...<br />node_filesystem_device_error{device="shm",fstype="tmpfs",mountpoint="/rootfs/var/lib/docker/containers/aefe8b1b63c3aa5f27766053ec817415faf8f6f417bb210d266fef0c2da64674/shm"} 1<br />node_filesystem_device_error{device="shm",fstype="tmpfs",mountpoint="/rootfs/var/lib/docker/containers/c8652ca72230496038a07e4fe4ee47046abb5f88d9d2440f0c8a923d5f3e133c/shm"} 1<br />node_filesystem_device_error{device="tmpfs",fstype="tmpfs",mountpoint="/dev"} 0<br />node_filesystem_device_error{device="tmpfs",fstype="tmpfs",mountpoint="/dev/shm"} 0<br />...<br />
image-255921
当然如果你觉得上面的手动安装方式比较麻烦,我们也可以使用 Helm 的方式来安装:
helm upgrade --install node-exporter --namespace monitor stable/prometheus-node-exporter<br />
3、服务发现
由于我们这里每个节点上面都运行了 node-exporter 程序,如果我们通过一个 Service 来将数据收集到一起用静态配置的方式配置到 Prometheus 去中,就只会显示一条数据,我们得自己在指标数据中去过滤每个节点的数据。当然我们也可以手动的把所有节点用静态的方式配置到 Prometheus 中去,但是以后要新增或者去掉节点的时候就还得手动去配置。那么有没有一种方式可以让 Prometheus 去自动发现我们节点的 node-exporter 程序,并且按节点进行分组呢?这就是 Prometheus 里面非常重要的服务发现功能了。
在 Kubernetes 下,Promethues 通过与 Kubernetes API 集成,主要支持5中服务发现模式,分别是:Node、Service、Pod、Endpoints、Ingress。
[root@master1 p8s-example]# kubectl get node<br />NAME STATUS ROLES AGE VERSION<br />master1 Ready control-plane,master 181d v1.22.2<br />node1 Ready 181d v1.22.2<br />node2 Ready 181d v1.22.2<br />
1.编写prometheus配置文件
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
# prometheus-cm.yaml<br />apiVersion: v1<br />kind: ConfigMap<br />metadata:<br /> name: prometheus-config<br /> namespace: monitor<br />data:<br /> prometheus.yml: |<br /> global:<br /> scrape_interval: 15s<br /> scrape_timeout: 15s<br /><br /> scrape_configs:<br /> - job_name: 'prometheus'<br /> static_configs:<br /> - targets: ['localhost:9090']<br /><br /> - job_name: 'coredns'<br /> static_configs:<br /> - targets: ['10.244.0.8:9153', '10.244.0.10:9153']<br /><br /> - job_name: 'redis'<br /> static_configs:<br /> - targets: ['redis:9121']<br /><br /> - job_name: 'nodes'<br /> kubernetes_sd_configs:<br /> - role: node<br />
image-207526
通过指定 kubernetes_sd_configs 的模式为 node,Prometheus 就会自动从 Kubernetes 中发现所有的 node 节点并作为当前 job 监控的目标实例,发现的节点 /metrics 接口是默认的 kubelet 的 HTTP 接口。
2.部署prometheus配置文件
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br /><br />[root@master1 p8s-example]#kubectl exec prometheus-698b6858c9-5xgsm -nmonitor -- cat /etc/prometheus/prometheus.yml<br />
可以看到prometheus pod的配置文件已经被更新了:
image-244290
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
image-237176
看了下prometheus pod日志没什么报错:
image-200878
[root@master1 p8s-example]#vim prometheus-rbac.yaml
image-254398
image-216722
image-242449
image-205240
server returned HTTP status 400 Bad Request<br />
这个是因为 prometheus 去发现 Node 模式的服务的时候,访问的端口默认是 10250,而默认是需要认证的 https 协议才有权访问的,但实际上我们并不是希望让去访问10250端口的 /metrics 接口,而是 node-exporter 绑定到节点的 9100 端口,所以我们应该将这里的 10250 替换成 9100,但是应该怎样替换呢?
3.使用 Prometheus 提供的 relabel_configs 中的 replace 能力
这里我们就需要使用到 Prometheus 提供的 relabel_configs 中的 replace 能力了,relabel 可以在 Prometheus 采集数据之前,通过 Target 实例的 Metadata 信息,动态重新写入 Label 的值。除此之外,我们还能根据 Target 实例的 Metadata 信息选择是否采集或者忽略该 Target 实例。比如我们这里就可以去匹配 __address__ 这个 Label 标签,然后替换掉其中的端口,如果你不知道有哪些 Label 标签可以操作的话,可以在 Service Discovery 页面获取到相关的元标签,这些标签都是我们可以进行 Relabel 的标签:
prometheus webui relabel before
image-202697
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
# prometheus-cm.yaml<br />apiVersion: v1<br />kind: ConfigMap<br />metadata:<br /> name: prometheus-config<br /> namespace: monitor<br />data:<br /> prometheus.yml: |<br /> global:<br /> scrape_interval: 15s<br /> scrape_timeout: 15s<br /><br /> scrape_configs:<br /> - job_name: 'prometheus'<br /> static_configs:<br /> - targets: ['localhost:9090']<br /><br /> - job_name: 'coredns'<br /> static_configs:<br /> - targets: ['10.244.0.8:9153', '10.244.0.10:9153']<br /><br /> - job_name: 'redis'<br /> static_configs:<br /> - targets: ['redis:9121']<br /><br /> - job_name: 'nodes'<br /> kubernetes_sd_configs:<br /> - role: node<br /> relabel_configs:<br /> - source_labels: [__address__]<br /> regex: '(.*):10250'<br /> replacement: '${1}:9100'<br /> target_label: __address__<br /> action: replace<br />
image-242968
这里就是一个正则表达式,去匹配 __address__ 这个标签,然后将 host 部分保留下来,port 替换成了 9100。
更新configmap文件:
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br />
image-257347
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
image-212315
我们可以看到现在已经正常了。
4.通过 labelmap 属性来将 Kubernetes 的 Label 标签添加为 Prometheus 的指标数据的标签
但是还有一个问题就是我们采集的指标数据 Label 标签就只有一个节点的 hostname,这对于我们在进行监控分组分类查询的时候带来了很多不方便的地方,要是我们能够将集群中 Node 节点的 Label 标签也能获取到就很好了。
image-247415
添加到prometheus-cm.yaml配置文件:
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
……<br />- job_name: 'kubernetes-nodes'<br /> kubernetes_sd_configs:<br /> - role: node<br /> relabel_configs:<br /> - source_labels: [__address__]<br /> regex: '(.*):10250'<br /> replacement: '${1}:9100'<br /> target_label: __address__<br /> action: replace<br /> - action: labelmap<br /> regex: __meta_kubernetes_node_label_(.+)<br />
image-236755
添加了一个 action 为 labelmap,正则表达式是 __meta_kubernetes_node_label_(.+) 的配置,这里的意思就是表达式中匹配都的数据也添加到指标数据的 Label 标签中去。
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br />
image-256974
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
image-205683
符合预期。
对于 kubernetes_sd_configs 下面可用的元信息标签如下:
关于 kubernets_sd_configs 更多信息可以查看官方文档:kubernetes_sd_config
5.把 kubelet 的监控任务也一并配置上
另外由于 kubelet 也自带了一些监控指标数据,就上面我们提到的 10250 端口,所以我们这里也把 kubelet 的监控任务也一并配置上:
添加到prometheus-cm.yaml配置文件:
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
……<br />- job_name: 'kubelet'<br /> kubernetes_sd_configs:<br /> - role: node<br /> scheme: https<br /> tls_config:<br /> ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt<br /> insecure_skip_verify: true<br /> bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token<br /> relabel_configs:<br /> - action: labelmap<br /> regex: __meta_kubernetes_node_label_(.+)<br />
image-205994
但是这里需要特别注意的是这里必须使用 https 协议访问,这样就必然需要提供证书,我们这里是通过配置 insecure_skip_verify: true 来跳过了证书校验。但是除此之外,要访问集群的资源,还必须要有对应的权限才可以,也就是对应的 ServiceAccount 棒的 权限允许才可以,我们这里部署的 prometheus 关联的 ServiceAccount 对象前面我们已经提到过了,这里我们只需要将 Pod 中自动注入的 /var/run/secrets/kubernetes.io/serviceaccount/ca.crt 和 /var/run/secrets/kubernetes.io/serviceaccount/token 文件配置上,就可以获取到对应的权限了。
以下不影响,是可以出效果的:
image-214497
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br />
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
现在我们再去更新下配置文件,执行 reload 操作,让配置生效,然后访问 Prometheus 的 Dashboard 查看 Targets 路径:
image-251917
现在可以看到我们上面添加的 kubernetes-kubelet 和 kubernetes-nodes 这两个 job 任务都已经配置成功了,而且二者的 Labels 标签都和集群的 node 节点标签保持一致了。
现在我们就可以切换到 Graph 路径下面查看采集的一些指标数据了,比如查询 node_load1 指标:
prometheus webui node load1
我们可以看到将几个节点对应的 node_load1 指标数据都查询出来了。
同样的,我们还可以使用 PromQL 语句来进行更复杂的一些聚合查询操作,还可以根据我们的 Labels 标签对指标数据进行聚合,比如我们这里只查询 node1 节点的数据,可以使用表达式 node_load1{instance="node1"} 来进行查询:
prometheus webui node1 load1
到这里我们就把 Kubernetes 集群节点使用 Prometheus 监控起来了,接下来我们再来和大家学习下怎样监控 Pod 或者 Service 之类的资源对象。
关于我
我的博客主旨: 查看全部
实战:prometheus如何监控k8s集群里的node资源-2022.5
目录
关于我
最后
实验环境
k8s:v1.22.2(1 master,2 node)<br />containerd: v1.5.5<br />prometneus: docker.io/prom/prometheus:v2.34.0<br />
实验软件
链接:提取码:au4n2022.4.30-p8s监控k8s集群node资源-code
image-203369前置条件
关于如何将prometheus应用部署到k8s环境里,请查看我的另一篇文章,获取完整的部署方法!。
image-230811
image-222637基础知识
监控集群节点
前面我们和大家学习了怎样用 Promethues 来监控 Kubernetes 集群中的应用,但是对于 Kubernetes 集群本身的监控也是非常重要的,我们需要时时刻刻了解集群的运行状态。
对于集群的监控一般我们需要考虑以下几个方面:
Kubernetes 集群的监控方案目前主要有以下几种方案:
不过 kube-state-metrics 和 metrics-server 之间还是有很大不同的,二者的主要区别如下:
要监控节点其实我们已经有很多非常成熟的方案了,比如 Nagios、zabbix,甚至我们自己来收集数据也可以。我们这里通过 Prometheus 来采集节点的监控指标数据,可以通过 node_exporter 来获取,顾名思义,node_exporter 就是抓取用于采集服务器节点的各种运行指标,目前 node_exporter 支持几乎所有常见的监控点,比如 conntrack,cpu,diskstats,filesystem,loadavg,meminfo,netstat 等,详细的监控点列表可以参考其 Github 仓库。
我们可以通过 DaemonSet 控制器来部署该服务,这样每一个节点都会自动运行一个这样的 Pod,如果我们从集群中删除或者添加节点后,也会进行自动扩展。
1、创建daemonset资源
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-node-exporter.yaml
# prometheus-node-exporter.yaml<br />apiVersion: apps/v1<br />kind: DaemonSet<br />metadata:<br /> name: node-exporter<br /> namespace: monitor<br /> labels:<br /> app: node-exporter<br />spec:<br /> selector:<br /> matchLabels:<br /> app: node-exporter<br /> template:<br /> metadata:<br /> labels:<br /> app: node-exporter<br /> spec:<br /> hostPID: true<br /> hostIPC: true<br /> hostNetwork: true #因为这里用的是hostNetwortk模式,所以后面就不需要创建svc了!<br /> nodeSelector:<br /> kubernetes.io/os: linux<br /> containers:<br /> - name: node-exporter<br /> image: prom/node-exporter:v1.3.1<br /> args:<br /> - --web.listen-address=$(HOSTIP):9100<br /> - --path.procfs=/host/proc<br /> - --path.sysfs=/host/sys<br /> - --path.rootfs=/host/root<br /> - --no-collector.hwmon # 禁用不需要的一些采集器<br /> - --no-collector.nfs<br /> - --no-collector.nfsd<br /> - --no-collector.nvme<br /> - --no-collector.dmi<br /> - --no-collector.arp<br /> - --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/containerd/.+|/var/lib/docker/.+|var/lib/kubelet/pods/.+)($|/)<br /> - --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$<br /> ports:<br /> - containerPort: 9100<br /> env:<br /> - name: HOSTIP<br /> valueFrom:<br /> fieldRef:<br /> fieldPath: status.hostIP #Downward API<br /> resources:<br /> requests:<br /> cpu: 150m<br /> memory: 180Mi<br /> limits:<br /> cpu: 150m<br /> memory: 180Mi<br /> securityContext:<br /> runAsNonRoot: true<br /> runAsUser: 65534<br /> volumeMounts:<br /> - name: proc<br /> mountPath: /host/proc<br /> - name: sys<br /> mountPath: /host/sys<br /> - name: root<br /> mountPath: /host/root<br /> mountPropagation: HostToContainer<br /> readOnly: true<br /> tolerations:<br /> - operator: "Exists"<br /> volumes:<br /> - name: proc<br /> hostPath:<br /> path: /proc<br /> - name: dev<br /> hostPath:<br /> path: /dev<br /> - name: sys<br /> hostPath:<br /> path: /sys<br /> - name: root<br /> hostPath:<br /> path: /<br />
:warning: 注意:
image-225376
由于我们要获取到的数据是主机的监控指标数据,而我们的 node-exporter 是运行在容器中的,所以我们在 Pod 中需要配置一些 Pod 的安全策略,这里我们就添加了 hostPID: true、hostIPC: true、hostNetwork: true 3个策略,用来使用主机的 PID namespace、IPC namespace 以及主机网络,这些 namespace 就是用于容器隔离的关键技术,要注意这里的 namespace 和集群中的 namespace 是两个完全不相同的概念。
另外我们还将主机的 /dev、/proc、/sys这些目录挂载到容器中,这些因为我们采集的很多节点数据都是通过这些文件夹下面的文件来获取到的,比如我们在使用 top 命令可以查看当前 cpu 使用情况,数据就来源于文件 /proc/stat。使用 free 命令可以查看当前内存使用情况,其数据来源是来自 /proc/meminfo 文件。
另外由于我们集群使用的是 kubeadm 搭建的,所以如果希望 master 节点也一起被监控,则需要添加相应的容忍。
2、部署资源
[root@master1 p8s-example]#kubectl apply -f prometheus-node-exporter.yaml <br />daemonset.apps/node-exporter created<br /><br />[root@master1 p8s-example]#kubectl get pods -nmonitor -l app=node-exporter -o wide<br />NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES<br />node-exporter-6z7dx 1/1 Running 0 39s 172.29.9.52 node1 <br />node-exporter-bbsh6 1/1 Running 0 39s 172.29.9.51 master1 <br />node-exporter-lm46b 1/1 Running 0 39s 172.29.9.53 node2 <br />
image-225819
部署完成后,我们可以看到在几个节点上都运行了一个 Pod,由于我们指定了 hostNetwork=true,所以在每个节点上就会绑定一个端口 9100。
➜ curl 172.29.9.51:9100/metrics<br />...<br />node_filesystem_device_error{device="shm",fstype="tmpfs",mountpoint="/rootfs/var/lib/docker/containers/aefe8b1b63c3aa5f27766053ec817415faf8f6f417bb210d266fef0c2da64674/shm"} 1<br />node_filesystem_device_error{device="shm",fstype="tmpfs",mountpoint="/rootfs/var/lib/docker/containers/c8652ca72230496038a07e4fe4ee47046abb5f88d9d2440f0c8a923d5f3e133c/shm"} 1<br />node_filesystem_device_error{device="tmpfs",fstype="tmpfs",mountpoint="/dev"} 0<br />node_filesystem_device_error{device="tmpfs",fstype="tmpfs",mountpoint="/dev/shm"} 0<br />...<br />
image-255921
当然如果你觉得上面的手动安装方式比较麻烦,我们也可以使用 Helm 的方式来安装:
helm upgrade --install node-exporter --namespace monitor stable/prometheus-node-exporter<br />
3、服务发现
由于我们这里每个节点上面都运行了 node-exporter 程序,如果我们通过一个 Service 来将数据收集到一起用静态配置的方式配置到 Prometheus 去中,就只会显示一条数据,我们得自己在指标数据中去过滤每个节点的数据。当然我们也可以手动的把所有节点用静态的方式配置到 Prometheus 中去,但是以后要新增或者去掉节点的时候就还得手动去配置。那么有没有一种方式可以让 Prometheus 去自动发现我们节点的 node-exporter 程序,并且按节点进行分组呢?这就是 Prometheus 里面非常重要的服务发现功能了。
在 Kubernetes 下,Promethues 通过与 Kubernetes API 集成,主要支持5中服务发现模式,分别是:Node、Service、Pod、Endpoints、Ingress。
[root@master1 p8s-example]# kubectl get node<br />NAME STATUS ROLES AGE VERSION<br />master1 Ready control-plane,master 181d v1.22.2<br />node1 Ready 181d v1.22.2<br />node2 Ready 181d v1.22.2<br />
1.编写prometheus配置文件
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
# prometheus-cm.yaml<br />apiVersion: v1<br />kind: ConfigMap<br />metadata:<br /> name: prometheus-config<br /> namespace: monitor<br />data:<br /> prometheus.yml: |<br /> global:<br /> scrape_interval: 15s<br /> scrape_timeout: 15s<br /><br /> scrape_configs:<br /> - job_name: 'prometheus'<br /> static_configs:<br /> - targets: ['localhost:9090']<br /><br /> - job_name: 'coredns'<br /> static_configs:<br /> - targets: ['10.244.0.8:9153', '10.244.0.10:9153']<br /><br /> - job_name: 'redis'<br /> static_configs:<br /> - targets: ['redis:9121']<br /><br /> - job_name: 'nodes'<br /> kubernetes_sd_configs:<br /> - role: node<br />
image-207526
通过指定 kubernetes_sd_configs 的模式为 node,Prometheus 就会自动从 Kubernetes 中发现所有的 node 节点并作为当前 job 监控的目标实例,发现的节点 /metrics 接口是默认的 kubelet 的 HTTP 接口。
2.部署prometheus配置文件
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br /><br />[root@master1 p8s-example]#kubectl exec prometheus-698b6858c9-5xgsm -nmonitor -- cat /etc/prometheus/prometheus.yml<br />
可以看到prometheus pod的配置文件已经被更新了:
image-244290
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
image-237176
看了下prometheus pod日志没什么报错:
image-200878
[root@master1 p8s-example]#vim prometheus-rbac.yaml
image-254398
image-216722
image-242449
image-205240
server returned HTTP status 400 Bad Request<br />
这个是因为 prometheus 去发现 Node 模式的服务的时候,访问的端口默认是 10250,而默认是需要认证的 https 协议才有权访问的,但实际上我们并不是希望让去访问10250端口的 /metrics 接口,而是 node-exporter 绑定到节点的 9100 端口,所以我们应该将这里的 10250 替换成 9100,但是应该怎样替换呢?
3.使用 Prometheus 提供的 relabel_configs 中的 replace 能力
这里我们就需要使用到 Prometheus 提供的 relabel_configs 中的 replace 能力了,relabel 可以在 Prometheus 采集数据之前,通过 Target 实例的 Metadata 信息,动态重新写入 Label 的值。除此之外,我们还能根据 Target 实例的 Metadata 信息选择是否采集或者忽略该 Target 实例。比如我们这里就可以去匹配 __address__ 这个 Label 标签,然后替换掉其中的端口,如果你不知道有哪些 Label 标签可以操作的话,可以在 Service Discovery 页面获取到相关的元标签,这些标签都是我们可以进行 Relabel 的标签:
prometheus webui relabel before
image-202697
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
# prometheus-cm.yaml<br />apiVersion: v1<br />kind: ConfigMap<br />metadata:<br /> name: prometheus-config<br /> namespace: monitor<br />data:<br /> prometheus.yml: |<br /> global:<br /> scrape_interval: 15s<br /> scrape_timeout: 15s<br /><br /> scrape_configs:<br /> - job_name: 'prometheus'<br /> static_configs:<br /> - targets: ['localhost:9090']<br /><br /> - job_name: 'coredns'<br /> static_configs:<br /> - targets: ['10.244.0.8:9153', '10.244.0.10:9153']<br /><br /> - job_name: 'redis'<br /> static_configs:<br /> - targets: ['redis:9121']<br /><br /> - job_name: 'nodes'<br /> kubernetes_sd_configs:<br /> - role: node<br /> relabel_configs:<br /> - source_labels: [__address__]<br /> regex: '(.*):10250'<br /> replacement: '${1}:9100'<br /> target_label: __address__<br /> action: replace<br />
image-242968
这里就是一个正则表达式,去匹配 __address__ 这个标签,然后将 host 部分保留下来,port 替换成了 9100。
更新configmap文件:
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br />
image-257347
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
image-212315
我们可以看到现在已经正常了。
4.通过 labelmap 属性来将 Kubernetes 的 Label 标签添加为 Prometheus 的指标数据的标签
但是还有一个问题就是我们采集的指标数据 Label 标签就只有一个节点的 hostname,这对于我们在进行监控分组分类查询的时候带来了很多不方便的地方,要是我们能够将集群中 Node 节点的 Label 标签也能获取到就很好了。
image-247415
添加到prometheus-cm.yaml配置文件:
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
……<br />- job_name: 'kubernetes-nodes'<br /> kubernetes_sd_configs:<br /> - role: node<br /> relabel_configs:<br /> - source_labels: [__address__]<br /> regex: '(.*):10250'<br /> replacement: '${1}:9100'<br /> target_label: __address__<br /> action: replace<br /> - action: labelmap<br /> regex: __meta_kubernetes_node_label_(.+)<br />
image-236755
添加了一个 action 为 labelmap,正则表达式是 __meta_kubernetes_node_label_(.+) 的配置,这里的意思就是表达式中匹配都的数据也添加到指标数据的 Label 标签中去。
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br />
image-256974
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
image-205683
符合预期。
对于 kubernetes_sd_configs 下面可用的元信息标签如下:
关于 kubernets_sd_configs 更多信息可以查看官方文档:kubernetes_sd_config
5.把 kubelet 的监控任务也一并配置上
另外由于 kubelet 也自带了一些监控指标数据,就上面我们提到的 10250 端口,所以我们这里也把 kubelet 的监控任务也一并配置上:
添加到prometheus-cm.yaml配置文件:
[root@master1 p8s-example]#pwd/root/p8s-example[root@master1 p8s-example]#vim prometheus-cm.yaml
……<br />- job_name: 'kubelet'<br /> kubernetes_sd_configs:<br /> - role: node<br /> scheme: https<br /> tls_config:<br /> ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt<br /> insecure_skip_verify: true<br /> bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token<br /> relabel_configs:<br /> - action: labelmap<br /> regex: __meta_kubernetes_node_label_(.+)<br />
image-205994
但是这里需要特别注意的是这里必须使用 https 协议访问,这样就必然需要提供证书,我们这里是通过配置 insecure_skip_verify: true 来跳过了证书校验。但是除此之外,要访问集群的资源,还必须要有对应的权限才可以,也就是对应的 ServiceAccount 棒的 权限允许才可以,我们这里部署的 prometheus 关联的 ServiceAccount 对象前面我们已经提到过了,这里我们只需要将 Pod 中自动注入的 /var/run/secrets/kubernetes.io/serviceaccount/ca.crt 和 /var/run/secrets/kubernetes.io/serviceaccount/token 文件配置上,就可以获取到对应的权限了。
以下不影响,是可以出效果的:
image-214497
[root@master1 p8s-example]#kubectl apply -f prometheus-cm.yaml <br />configmap/prometheus-config configured<br />
[root@master1 p8s-example]# curl -X POST "http://172.29.9.51:32700/-/reload"<br />
现在我们再去更新下配置文件,执行 reload 操作,让配置生效,然后访问 Prometheus 的 Dashboard 查看 Targets 路径:
image-251917
现在可以看到我们上面添加的 kubernetes-kubelet 和 kubernetes-nodes 这两个 job 任务都已经配置成功了,而且二者的 Labels 标签都和集群的 node 节点标签保持一致了。
现在我们就可以切换到 Graph 路径下面查看采集的一些指标数据了,比如查询 node_load1 指标:
prometheus webui node load1
我们可以看到将几个节点对应的 node_load1 指标数据都查询出来了。
同样的,我们还可以使用 PromQL 语句来进行更复杂的一些聚合查询操作,还可以根据我们的 Labels 标签对指标数据进行聚合,比如我们这里只查询 node1 节点的数据,可以使用表达式 node_load1{instance="node1"} 来进行查询:
prometheus webui node1 load1
到这里我们就把 Kubernetes 集群节点使用 Prometheus 监控起来了,接下来我们再来和大家学习下怎样监控 Pod 或者 Service 之类的资源对象。
关于我
我的博客主旨:
网站程序自带的采集器采集文章(新浪微博采集直发养号大师的软件用途及使用方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-20 03:26
新浪微博采集知发养豪大师是一款采集软件,可以定位采集你需要的微博内容,指定一个或几个大方向,软件会自动采集 @采集最热门的内容,可以直接发送,是营销的好工具,欢迎有需要的朋友下载使用!
主要功能
自动采集内容,即可使用微博内容和多个账号同时操作。
新浪微博自动发布
可以批量维护微博账号,定时发送微博。
不仅可以采集微博文字内容,还可以自动采集微博图片,自动采集微博视频,自动采集微博内容来源和作者信息。
软件使用
1)微博内容采集(包括文字、图片、头像、微博数量、关注人数、关注人数、是否加V、作者、博主昵称、博主头像、UID等)
2)微博内容自动批量发布,可批量指定多个账号和内容。原创微博,本软件也可用于微博账号维护,自动更新微博内容,减少工作量微博维护
3)采集微博昵称,UID(可以通过关键字搜索,提取某人粉丝的昵称UID,提取某人关注的昵称UID,通过高级搜索搜索)
4)采集微博转发内容,采集评论内容
5)昵称转UID(指定批次昵称转换为对应微博的UID)
6)您可以将数据采集传输到Mssql或MySQL数据库,并与您的网站进行批处理(站群的朋友们有福了)
7) 发完微博,立即评论微博,提升微博排名,轻松进入微博精选、热门微博、实时微博(评论可收录9个链接,主要应用场景:在微博内容中发图,在评论中有婴儿链接。)
8)微博内容自动同步,可以将大微博的内容自动同步到很多微博小号上的产品描述
9)。新浪微博超级话题关注签到,支持多号批量关注签到。
指示
1、账号分类管理
首先添加你的“账号”发布微博和采集微博内容。此功能还可用于批量管理您的N个新浪微博账号,维护您的新浪微博账号。可以自动检测你的微博账号是否异常,是否被新浪微博官方封禁等。
2、内容自动发布
查看微博内容和账号,点击“开始发送”发布微博。这里是自动即时发布或您的微博内容,真正 24 小时无人值守。让机器完全代替您的手动操作!该软件还支持定时和自动发微博。可以先设置一个时间点,时间点到了会自动发微博。
3、内容批量管理
您可以自行添加、修改和删除内容。采集微博的内容也可以在这里编辑。您可以批量导入和导出微博内容。
4、内容自动采集
通过指定采集一个人的微博,也可以通过关键字搜索采集对应的内容。
5、网管模式管理
软件可以通过代理IP和ADSL发布你的微博内容,防止账号被封的风险。
6、微博昵称采集
你可以在微博上采集活跃真实用户的昵称,然后在你自动发微博的时候,你可以在微博的内容里@一群人,从布上横向传递信息,让你的微博可以迅速将其影响向外扩散。力量!
7、操作帮助
设置后会自动采集新浪微博内容,不仅有采集文字,还有采集图片、采集视频、采集作者和源地址等. 您也可以将采集之后的内容发布到您指定的微博。新浪微博内容自动采集及发布工具,新浪微博内容自动采集及发布软件,新浪微博发布大师。 查看全部
网站程序自带的采集器采集文章(新浪微博采集直发养号大师的软件用途及使用方法介绍)
新浪微博采集知发养豪大师是一款采集软件,可以定位采集你需要的微博内容,指定一个或几个大方向,软件会自动采集 @采集最热门的内容,可以直接发送,是营销的好工具,欢迎有需要的朋友下载使用!
主要功能
自动采集内容,即可使用微博内容和多个账号同时操作。
新浪微博自动发布
可以批量维护微博账号,定时发送微博。
不仅可以采集微博文字内容,还可以自动采集微博图片,自动采集微博视频,自动采集微博内容来源和作者信息。
软件使用
1)微博内容采集(包括文字、图片、头像、微博数量、关注人数、关注人数、是否加V、作者、博主昵称、博主头像、UID等)
2)微博内容自动批量发布,可批量指定多个账号和内容。原创微博,本软件也可用于微博账号维护,自动更新微博内容,减少工作量微博维护
3)采集微博昵称,UID(可以通过关键字搜索,提取某人粉丝的昵称UID,提取某人关注的昵称UID,通过高级搜索搜索)
4)采集微博转发内容,采集评论内容
5)昵称转UID(指定批次昵称转换为对应微博的UID)
6)您可以将数据采集传输到Mssql或MySQL数据库,并与您的网站进行批处理(站群的朋友们有福了)
7) 发完微博,立即评论微博,提升微博排名,轻松进入微博精选、热门微博、实时微博(评论可收录9个链接,主要应用场景:在微博内容中发图,在评论中有婴儿链接。)
8)微博内容自动同步,可以将大微博的内容自动同步到很多微博小号上的产品描述
9)。新浪微博超级话题关注签到,支持多号批量关注签到。
指示
1、账号分类管理
首先添加你的“账号”发布微博和采集微博内容。此功能还可用于批量管理您的N个新浪微博账号,维护您的新浪微博账号。可以自动检测你的微博账号是否异常,是否被新浪微博官方封禁等。
2、内容自动发布
查看微博内容和账号,点击“开始发送”发布微博。这里是自动即时发布或您的微博内容,真正 24 小时无人值守。让机器完全代替您的手动操作!该软件还支持定时和自动发微博。可以先设置一个时间点,时间点到了会自动发微博。
3、内容批量管理
您可以自行添加、修改和删除内容。采集微博的内容也可以在这里编辑。您可以批量导入和导出微博内容。
4、内容自动采集
通过指定采集一个人的微博,也可以通过关键字搜索采集对应的内容。
5、网管模式管理
软件可以通过代理IP和ADSL发布你的微博内容,防止账号被封的风险。
6、微博昵称采集
你可以在微博上采集活跃真实用户的昵称,然后在你自动发微博的时候,你可以在微博的内容里@一群人,从布上横向传递信息,让你的微博可以迅速将其影响向外扩散。力量!
7、操作帮助
设置后会自动采集新浪微博内容,不仅有采集文字,还有采集图片、采集视频、采集作者和源地址等. 您也可以将采集之后的内容发布到您指定的微博。新浪微博内容自动采集及发布工具,新浪微博内容自动采集及发布软件,新浪微博发布大师。
网站程序自带的采集器采集文章( Wp网站建设的网站,我们应该怎么去优化呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-04-20 01:27
Wp网站建设的网站,我们应该怎么去优化呢?)
wp网站, wordpress网站 构建(免费 wordpress采集 教程)
光速SEO2022-04-18
wp网站,wordpress是很多站长建站选择的内容管理系统。wp网站constructed网站,我们应该如何优化呢?首先,wp网站SEO优化我们需要做好SEO站内优化和站外优化。具体可以走wordpress采集、wordpress伪原创、wordpress自动定时发布路线。
wp网站建站目标关键词确定后,wordpress采集会进行关键词挖矿。形成大量长尾关键词,然后根据这些长尾关键词进行全网文章关键词pan采集,接着是伪原创,最后自动批量发布。
那么我们如何确定哪个关键词应该在wp网站首页优化,哪个关键词应该在分类页面优化呢?首先,将目标关键词放到wordpress采集中,按照搜索量排序,搜索量最高的排在最前面。找到可以作为wp网站的分类页面的关键词,去掉搜索量低的关键词。
wp网站关键词 出现在文本中,文本的第一段自动加粗。当描述不太相关时,自动添加当前 采集 的 关键词。去掉分类页面和低搜索量关键词后,剩下的就是wp网站首页的关键词有待优化。首页优化关键词也有限,太多关键词无法优化。然后我们可以结合关键词来达到想要的SEO效果。
wp网站建一个网站,不管是服务器还是虚拟主机,稳定的服务器。要知道,搜索引擎蜘蛛会模拟用户浏览和抓取内容。如果出现断电或服务器宕机等问题,导致wp网站无法访问或浏览不稳定,那么搜索引擎蜘蛛将无法打开我们的wp网站,并将无法获取wp网站内容的网页,这会导致搜索引擎蜘蛛无法获取网页内容,更不用说收录了。
Wordpress采集可以同时选择多个新闻源关键词pan采集伪原创发布,提供各种SEO优化设置包括:百度、有道、147翻译、标题内容< @关键词 等等。Wordpress采集 的文本在随机位置自动插入到当前 关键词 集合中两次。当前采集的 关键词 在出现在文本中时会自动加粗。
其次,如果网站打开次数过多,搜索引擎也会判断网站不稳定或者网站没有内容可显示。这种情况会大大降低搜索引擎的友好度,甚至可能被评为死链接网站,导致网站无法参与排名。
相信很多站长都经历过wp网站被黑客攻击,而这一次也是考验服务器安全的时候了。一般来说,安全性差的服务器很容易被黑客攻击,导致来之不易的排名下滑。因此,必须保证服务器的安全。
wp网站的站外优化,需要我们做优秀的网站外链,你在行业中立于不败之地。你为什么这么说?wp网站优化的组件很多,其中内链占据非常重要的位置,因为它可以提升网站的排名,甚至整个网站的权重。不要忽视内部链接的重要性。
当 wp网站 构建的 网站 内链运行良好时,用户体验的作用可以通过观察数据来体现。内容被浏览的次数大大增加,不会有点击率。由于内容的可转移性,用户访问量迅速增加。
另外,wp网站合理的内链结构会引导蜘蛛爬行,大量的内链网络会大大增加网站的整体权重。只有不断优化内链,才能真正将权重提升到一个新的水平。通过分析wp网站的访问页面,我们可以知道用户访问了wp网站的哪些页面。
通过查看这些数据,我们可以微调 wp网站。通过分析门户页面,我们可以知道用户从哪个页面进入网站。点击页面地图,可以直观的分析出用户点击了哪些页面,页面点击量,喜欢什么内容,方便我们调整优化。今天关于wp网站的构造的解释就到这里了。下期分享更多SEO相关知识。 查看全部
网站程序自带的采集器采集文章(
Wp网站建设的网站,我们应该怎么去优化呢?)
wp网站, wordpress网站 构建(免费 wordpress采集 教程)
光速SEO2022-04-18
wp网站,wordpress是很多站长建站选择的内容管理系统。wp网站constructed网站,我们应该如何优化呢?首先,wp网站SEO优化我们需要做好SEO站内优化和站外优化。具体可以走wordpress采集、wordpress伪原创、wordpress自动定时发布路线。
wp网站建站目标关键词确定后,wordpress采集会进行关键词挖矿。形成大量长尾关键词,然后根据这些长尾关键词进行全网文章关键词pan采集,接着是伪原创,最后自动批量发布。
那么我们如何确定哪个关键词应该在wp网站首页优化,哪个关键词应该在分类页面优化呢?首先,将目标关键词放到wordpress采集中,按照搜索量排序,搜索量最高的排在最前面。找到可以作为wp网站的分类页面的关键词,去掉搜索量低的关键词。
wp网站关键词 出现在文本中,文本的第一段自动加粗。当描述不太相关时,自动添加当前 采集 的 关键词。去掉分类页面和低搜索量关键词后,剩下的就是wp网站首页的关键词有待优化。首页优化关键词也有限,太多关键词无法优化。然后我们可以结合关键词来达到想要的SEO效果。
wp网站建一个网站,不管是服务器还是虚拟主机,稳定的服务器。要知道,搜索引擎蜘蛛会模拟用户浏览和抓取内容。如果出现断电或服务器宕机等问题,导致wp网站无法访问或浏览不稳定,那么搜索引擎蜘蛛将无法打开我们的wp网站,并将无法获取wp网站内容的网页,这会导致搜索引擎蜘蛛无法获取网页内容,更不用说收录了。
Wordpress采集可以同时选择多个新闻源关键词pan采集伪原创发布,提供各种SEO优化设置包括:百度、有道、147翻译、标题内容< @关键词 等等。Wordpress采集 的文本在随机位置自动插入到当前 关键词 集合中两次。当前采集的 关键词 在出现在文本中时会自动加粗。
其次,如果网站打开次数过多,搜索引擎也会判断网站不稳定或者网站没有内容可显示。这种情况会大大降低搜索引擎的友好度,甚至可能被评为死链接网站,导致网站无法参与排名。
相信很多站长都经历过wp网站被黑客攻击,而这一次也是考验服务器安全的时候了。一般来说,安全性差的服务器很容易被黑客攻击,导致来之不易的排名下滑。因此,必须保证服务器的安全。
wp网站的站外优化,需要我们做优秀的网站外链,你在行业中立于不败之地。你为什么这么说?wp网站优化的组件很多,其中内链占据非常重要的位置,因为它可以提升网站的排名,甚至整个网站的权重。不要忽视内部链接的重要性。
当 wp网站 构建的 网站 内链运行良好时,用户体验的作用可以通过观察数据来体现。内容被浏览的次数大大增加,不会有点击率。由于内容的可转移性,用户访问量迅速增加。
另外,wp网站合理的内链结构会引导蜘蛛爬行,大量的内链网络会大大增加网站的整体权重。只有不断优化内链,才能真正将权重提升到一个新的水平。通过分析wp网站的访问页面,我们可以知道用户访问了wp网站的哪些页面。
通过查看这些数据,我们可以微调 wp网站。通过分析门户页面,我们可以知道用户从哪个页面进入网站。点击页面地图,可以直观的分析出用户点击了哪些页面,页面点击量,喜欢什么内容,方便我们调整优化。今天关于wp网站的构造的解释就到这里了。下期分享更多SEO相关知识。
网站程序自带的采集器采集文章(如何使用好网页采集器让网站更多的被搜索引擎收录)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-19 15:26
网页采集器,最近很多站长朋友问我怎么指定网站采集,市面上的网页采集工具基本都需要写采集规则,要求站长朋友了解正则表达式和html代码基础。这对于小白站长来说是一件非常困难的事情。网页采集器可视化批次采集指定网站采集并自动伪原创发布及一键自动百度、神马、360、搜狗推送.
网页采集器可以被任意网页数据抓取,所见即所得的操作方法只需点击几下鼠标即可轻松获取。那么我们如何使用好的网页来采集器网站更多的搜索引擎收录并获得好的SEO排名。
网页采集器要求我们能够清晰直观的网站定位会带来较高的客群转化率。我们的网站 目的是营销。我们的网站只有专注于一件事才能更好的展示出来,这样网站的内容搭建就会相当的简单。网页采集器基于高度智能的文本识别算法,根据关键词采集文章,无需编写采集规则。
页面采集器做网站SEO优化需要网站合理的结构。首先要提的是网站的结构要清晰,布局要合理,拒绝冗余代码,拒绝大量的JS脚本和FLASH动画,会影响网站 的打开速度。设置应清晰可见,便于客户导航。
和关键字描述信息。事实上,大多数人都知道 关键词 和描述对于一个 网站 非常重要,但是有些人忽略了这些信息。关键词 和 description 相当于一个搜索领导者提交的名片。有了这张卡片,人们就会更多地了解你的网站。
网页采集器可以通过长尾关键词做全网关键词文章pan采集,然后合并批量伪原创到网站 文章定期发布,让搜索引擎判断你的网站内容属于原创,更容易获得搜索引擎的青睐。还有一点要提醒大家,在网站收录之后,不要轻易改变你网站的关键词。所以一个好的关键词和描述也是一个网站的必要条件之一。网页采集器可以对文章的标题描述和内容进行相应的SEO优化设置。
网页采集器内置了很多网站优化方法。网页 采集器 支持自动内部链接。我们都知道网站的内链在一个网站中起着非常重要的作用,所以网站采集器内的网页会合理的安排内链。网页采集器伪原创文章也会大大提高网站SEO优化的指标。好的伪原创文章,对蜘蛛的吸引力很大。网页采集器自动全网采集,覆盖六大搜索引擎。自动过滤内容相关度和文章平滑度,只有采集高度相关和平滑度文章。
<p>当蜘蛛进入网站时,网站地图被视为很好的引导,蜘蛛可以轻松进入网站的每一个角落,网页采集器可以自动生成并更新网站的sitemap地图,让蜘蛛第一时间知道你网站的文章链接,可以方便蜘蛛抓取你 查看全部
网站程序自带的采集器采集文章(如何使用好网页采集器让网站更多的被搜索引擎收录)
网页采集器,最近很多站长朋友问我怎么指定网站采集,市面上的网页采集工具基本都需要写采集规则,要求站长朋友了解正则表达式和html代码基础。这对于小白站长来说是一件非常困难的事情。网页采集器可视化批次采集指定网站采集并自动伪原创发布及一键自动百度、神马、360、搜狗推送.
网页采集器可以被任意网页数据抓取,所见即所得的操作方法只需点击几下鼠标即可轻松获取。那么我们如何使用好的网页来采集器网站更多的搜索引擎收录并获得好的SEO排名。
网页采集器要求我们能够清晰直观的网站定位会带来较高的客群转化率。我们的网站 目的是营销。我们的网站只有专注于一件事才能更好的展示出来,这样网站的内容搭建就会相当的简单。网页采集器基于高度智能的文本识别算法,根据关键词采集文章,无需编写采集规则。
页面采集器做网站SEO优化需要网站合理的结构。首先要提的是网站的结构要清晰,布局要合理,拒绝冗余代码,拒绝大量的JS脚本和FLASH动画,会影响网站 的打开速度。设置应清晰可见,便于客户导航。
和关键字描述信息。事实上,大多数人都知道 关键词 和描述对于一个 网站 非常重要,但是有些人忽略了这些信息。关键词 和 description 相当于一个搜索领导者提交的名片。有了这张卡片,人们就会更多地了解你的网站。
网页采集器可以通过长尾关键词做全网关键词文章pan采集,然后合并批量伪原创到网站 文章定期发布,让搜索引擎判断你的网站内容属于原创,更容易获得搜索引擎的青睐。还有一点要提醒大家,在网站收录之后,不要轻易改变你网站的关键词。所以一个好的关键词和描述也是一个网站的必要条件之一。网页采集器可以对文章的标题描述和内容进行相应的SEO优化设置。
网页采集器内置了很多网站优化方法。网页 采集器 支持自动内部链接。我们都知道网站的内链在一个网站中起着非常重要的作用,所以网站采集器内的网页会合理的安排内链。网页采集器伪原创文章也会大大提高网站SEO优化的指标。好的伪原创文章,对蜘蛛的吸引力很大。网页采集器自动全网采集,覆盖六大搜索引擎。自动过滤内容相关度和文章平滑度,只有采集高度相关和平滑度文章。
<p>当蜘蛛进入网站时,网站地图被视为很好的引导,蜘蛛可以轻松进入网站的每一个角落,网页采集器可以自动生成并更新网站的sitemap地图,让蜘蛛第一时间知道你网站的文章链接,可以方便蜘蛛抓取你
网站程序自带的采集器采集文章(微信搜索微信指数文章网站程序/微博/公号助手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-18 05:23
热点指数
1文章网站节目,微博索引:/index
2、微信索引文章网站程序:微信搜索微信索引小程序
3、百度索引文章网站程序::///#/
4文章网站节目,今日头条指数:///
5、搜狗指数文章网站节目:/
公众号小助手
1、西瓜助手:/
2、新媒体经理::///index
3、合伙人:://yiban.io/
4、主机:/
5、新排名助手::///public/about/plugIn_introduce.html
6、滴滴微平台:://drip.im/
7、小宝:/
但是域名没变,301怎么办?
第一种方法(我也用过):在全站生成静态页面,然后保存静态页面和目录。后台更新、修订或程序更改后,请勿使用与之前同名的文件目录作为列。将之前生成的静态文件放回网站文件夹的原创位置。以上保证了上一页收录仍然存在。--------------- 前提是你的网站后台开启了静态生成功能,这样链接总是一样的,保存下来才有意义静态页面。---------------第二种方法:如果上不了路,就得301权重页面直接新的对应地址,比较繁琐但还是有效的在挽回损失。
查看原帖>>
但是域名没变,301怎么办?
第一种方法(我也用过):在全站生成静态页面,然后保存静态页面和目录。后台更新、修订或程序更改后,请勿使用与之前同名的文件目录作为列。将之前生成的静态文件放回网站文件夹的原创位置。以上保证了上一页收录仍然存在。--------------- 前提是你的网站后台开启了静态生成功能,这样链接总是一样的,保存下来才有意义静态页面。---------------第二种方法:如果上不了路,就得301权重页面直接新的对应地址,比较麻烦但是还是有效的在挽回损失。 查看全部
网站程序自带的采集器采集文章(微信搜索微信指数文章网站程序/微博/公号助手)
热点指数
1文章网站节目,微博索引:/index
2、微信索引文章网站程序:微信搜索微信索引小程序
3、百度索引文章网站程序::///#/
4文章网站节目,今日头条指数:///
5、搜狗指数文章网站节目:/
公众号小助手
1、西瓜助手:/
2、新媒体经理::///index
3、合伙人:://yiban.io/
4、主机:/
5、新排名助手::///public/about/plugIn_introduce.html
6、滴滴微平台:://drip.im/
7、小宝:/
但是域名没变,301怎么办?
第一种方法(我也用过):在全站生成静态页面,然后保存静态页面和目录。后台更新、修订或程序更改后,请勿使用与之前同名的文件目录作为列。将之前生成的静态文件放回网站文件夹的原创位置。以上保证了上一页收录仍然存在。--------------- 前提是你的网站后台开启了静态生成功能,这样链接总是一样的,保存下来才有意义静态页面。---------------第二种方法:如果上不了路,就得301权重页面直接新的对应地址,比较繁琐但还是有效的在挽回损失。
查看原帖>>
但是域名没变,301怎么办?
第一种方法(我也用过):在全站生成静态页面,然后保存静态页面和目录。后台更新、修订或程序更改后,请勿使用与之前同名的文件目录作为列。将之前生成的静态文件放回网站文件夹的原创位置。以上保证了上一页收录仍然存在。--------------- 前提是你的网站后台开启了静态生成功能,这样链接总是一样的,保存下来才有意义静态页面。---------------第二种方法:如果上不了路,就得301权重页面直接新的对应地址,比较麻烦但是还是有效的在挽回损失。
网站程序自带的采集器采集文章(SEO和网站运营经验文章,手写原创内容可以直接忽略)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-04-16 18:28
大家好,我叫熊晓峰。今天继续分享SEO和网站运营经验文章。因为昨天分享内容更新和原创处理的时候,只提到了框架,没有详细分享,所以,今天给大家详细分享一下如何处理获取到的文章内容使内容更好。
今天的内容主要针对采集内容,手写原创的内容可以直接忽略。
主要分为以下几个部分
1、过滤采集来源
2、采集工具介绍
3、采集文章处理中
1、采集来源
这个好理解,就是你需要采集的目标内容源,可以是搜索引擎搜索结果、新闻源、同行网站、行业网站等,你只要网站补充内容即可。
前期甚至可以pan采集,只要保持稳定更新,只要内容不涉及灰黑产品即可。
2、采集工具
对于采集内容来说,采集工具是必不可少的,好的工具可以事半功倍。目前采集工具也很多,很多开源的cms程序都有自己的采集工具。你可以通过搜索找到很多。
今天主要以优采云采集器为例进行介绍。相信资深站长都用过这个采集器。详情可以到官网查看说明。我不会在这里介绍它。而且官方也有基础视频教程,基本我都能操作。
3、文章处理中(伪原创)
这里我推荐使用只能被伪原创处理的ai,因为之前的伪原创程序都是同义词和同义词替换。这样的原创度不高,甚至影响阅读流畅。
现在几乎所有主流的采集工具都提供了,智能的原创api接口,可以直接调用5118等伪原创内容接口。当然还有其他平台,大家可以自己选择,这种API是付费的,费用自查。
还有页面内容的处理。我们从采集处理文章的内容后,还不够。我们发布文章给自己网站之后,还有处理,比如调用相关内容,也可以补内容,增加用户点击和PV。
也有将多个文章组合成一个文章,让内容更加全面完善。这类内容不仅受到搜索引擎的喜爱,也受到用户的喜爱。如果你能做到这一点,其实你的内容已经是原创了。
如果您需要更详细的教程,请继续关注我并观看以下教程,视频教程将在以后更新。
时间还早,今天就写这么多吧 查看全部
网站程序自带的采集器采集文章(SEO和网站运营经验文章,手写原创内容可以直接忽略)
大家好,我叫熊晓峰。今天继续分享SEO和网站运营经验文章。因为昨天分享内容更新和原创处理的时候,只提到了框架,没有详细分享,所以,今天给大家详细分享一下如何处理获取到的文章内容使内容更好。
今天的内容主要针对采集内容,手写原创的内容可以直接忽略。
主要分为以下几个部分
1、过滤采集来源
2、采集工具介绍
3、采集文章处理中
1、采集来源
这个好理解,就是你需要采集的目标内容源,可以是搜索引擎搜索结果、新闻源、同行网站、行业网站等,你只要网站补充内容即可。
前期甚至可以pan采集,只要保持稳定更新,只要内容不涉及灰黑产品即可。
2、采集工具
对于采集内容来说,采集工具是必不可少的,好的工具可以事半功倍。目前采集工具也很多,很多开源的cms程序都有自己的采集工具。你可以通过搜索找到很多。
今天主要以优采云采集器为例进行介绍。相信资深站长都用过这个采集器。详情可以到官网查看说明。我不会在这里介绍它。而且官方也有基础视频教程,基本我都能操作。
3、文章处理中(伪原创)
这里我推荐使用只能被伪原创处理的ai,因为之前的伪原创程序都是同义词和同义词替换。这样的原创度不高,甚至影响阅读流畅。
现在几乎所有主流的采集工具都提供了,智能的原创api接口,可以直接调用5118等伪原创内容接口。当然还有其他平台,大家可以自己选择,这种API是付费的,费用自查。
还有页面内容的处理。我们从采集处理文章的内容后,还不够。我们发布文章给自己网站之后,还有处理,比如调用相关内容,也可以补内容,增加用户点击和PV。
也有将多个文章组合成一个文章,让内容更加全面完善。这类内容不仅受到搜索引擎的喜爱,也受到用户的喜爱。如果你能做到这一点,其实你的内容已经是原创了。
如果您需要更详细的教程,请继续关注我并观看以下教程,视频教程将在以后更新。
时间还早,今天就写这么多吧
网站程序自带的采集器采集文章( 观测云支持多站点登录和注册,新增“海外区1(俄勒冈)”站点 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-04-16 12:09
观测云支持多站点登录和注册,新增“海外区1(俄勒冈)”站点
)
观察云站点更新
观察云支持多站点登录和注册。已添加网站“海外地区 1(俄勒冈)”。原“中国一区(阿里巴巴云)”改为“中国一区(杭州)”,新增“中国一区(AWS)”。“还有更多“中国区2(宁夏)”。
不同站点的账户和数据相互独立,不能相互共享和迁移数据。您可以根据自己的资源使用情况选择合适的站点进行注册和登录。观测云目前支持以下三个站点。
如何选择站点,请参考文档【观测云站点】
地点
登录地址 URL
操作员
中国1区(杭州)
阿里云
中国区 2(宁夏)
AWS
海外一区(俄勒冈)
AWS
观测云更新
1.添加工作区数据授权
观察云支持数据授权,将多个工作空间的数据授权到当前工作空间,通过场景仪表盘和笔记的图表组件进行查询和展示。如果有多个工作空间,配置数据授权后,可以在一个工作空间中查看所有工作空间的数据。
更多配置详情请参考文档【数据授权】
1)在“管理”-“数据授权”中配置查看数据需要授权的工作空间。
2)在workspace中获取数据授权后,打开“Scenario”-“Dashboard or Notes”,选择图表组件,在“Settings”的“Workspace”中选择授权的workspace,即可使用Graph查询查看和分析来自授权工作区的数据。
2.添加在线保存管道样本测试数据
Observation Cloud Pipeline 支持自定义库和官方库:
更多在线Pipeline功能请参考文档[Pipelines]
3.优化的自定义对象查看器
在观测云工作区,通过“基础设施”-“自定义”-“添加对象分类”,可以新建对象分类,自定义对象分类名称和对象字段。添加自定义对象分类后,您可以通过Func函数处理平台上报自定义数据。
如何通过Func向观测云工作区上报数据,请参考文档【自定义对象数据上报】
4.优化快照分享,支持永久有效链接
快照分享支持设置有效时间,支持选择“48小时”或“永久有效”。在快照列表中,点击分享按钮,在弹出的对话框中设置高级设置“隐藏顶栏”。
更多快照分享详情请参考文档【快照】
注意:永久有效共享容易存在数据安全风险,请谨慎使用。
5.优化图表时间间隔
在场景仪表板的图形设置中,为时间间隔选择“自动对齐”。预览图表时,图表右上角会出现时间间隔选项。您可以根据自己的实际情况选择查看数据的时间间隔。
更多详情请参考文档【查看分析】
6.优化流程、应用性能、用户访问检测无数据触发策略
在观察云监控功能模块中,在配置进程异常检测、应用性能指标检测、用户访问指标检测和监控时,无数据状态支持“触发无数据事件”、“触发恢复事件”和“触发恢复事件”三种配置。 “不触发事件”。无需手动配置数据处理策略。
7.其他功能优化
DataKit 更新
更多DataKit更新请参考【DataKit版本历史】
最佳实践更新
更多最佳实践更新,请参考【最佳实践版本历史】
集成模板更新
新增阿里云PolarDB Mysql集成文档、视图和检测库
阿里云PolarDB Mysql指标展示,包括CPU使用率、内存命中率、网络流量、连接数、QPS、TPS、只读节点延迟等。
更多集成模板更新请参考【集成文档版本历史】
【即刻体验观测云】
欢迎来到我们的 Guance Cloud for Observability Github 专栏
【可观测的关思云】
了解和使用喜欢的别忘了点击右上角的小星星点赞关注哦~
查看全部
网站程序自带的采集器采集文章(
观测云支持多站点登录和注册,新增“海外区1(俄勒冈)”站点
)
观察云站点更新
观察云支持多站点登录和注册。已添加网站“海外地区 1(俄勒冈)”。原“中国一区(阿里巴巴云)”改为“中国一区(杭州)”,新增“中国一区(AWS)”。“还有更多“中国区2(宁夏)”。
不同站点的账户和数据相互独立,不能相互共享和迁移数据。您可以根据自己的资源使用情况选择合适的站点进行注册和登录。观测云目前支持以下三个站点。
如何选择站点,请参考文档【观测云站点】
地点
登录地址 URL
操作员
中国1区(杭州)
阿里云
中国区 2(宁夏)
AWS
海外一区(俄勒冈)
AWS
观测云更新
1.添加工作区数据授权
观察云支持数据授权,将多个工作空间的数据授权到当前工作空间,通过场景仪表盘和笔记的图表组件进行查询和展示。如果有多个工作空间,配置数据授权后,可以在一个工作空间中查看所有工作空间的数据。
更多配置详情请参考文档【数据授权】
1)在“管理”-“数据授权”中配置查看数据需要授权的工作空间。
2)在workspace中获取数据授权后,打开“Scenario”-“Dashboard or Notes”,选择图表组件,在“Settings”的“Workspace”中选择授权的workspace,即可使用Graph查询查看和分析来自授权工作区的数据。
2.添加在线保存管道样本测试数据
Observation Cloud Pipeline 支持自定义库和官方库:
更多在线Pipeline功能请参考文档[Pipelines]
3.优化的自定义对象查看器
在观测云工作区,通过“基础设施”-“自定义”-“添加对象分类”,可以新建对象分类,自定义对象分类名称和对象字段。添加自定义对象分类后,您可以通过Func函数处理平台上报自定义数据。
如何通过Func向观测云工作区上报数据,请参考文档【自定义对象数据上报】
4.优化快照分享,支持永久有效链接
快照分享支持设置有效时间,支持选择“48小时”或“永久有效”。在快照列表中,点击分享按钮,在弹出的对话框中设置高级设置“隐藏顶栏”。
更多快照分享详情请参考文档【快照】
注意:永久有效共享容易存在数据安全风险,请谨慎使用。
5.优化图表时间间隔
在场景仪表板的图形设置中,为时间间隔选择“自动对齐”。预览图表时,图表右上角会出现时间间隔选项。您可以根据自己的实际情况选择查看数据的时间间隔。
更多详情请参考文档【查看分析】
6.优化流程、应用性能、用户访问检测无数据触发策略
在观察云监控功能模块中,在配置进程异常检测、应用性能指标检测、用户访问指标检测和监控时,无数据状态支持“触发无数据事件”、“触发恢复事件”和“触发恢复事件”三种配置。 “不触发事件”。无需手动配置数据处理策略。
7.其他功能优化
DataKit 更新
更多DataKit更新请参考【DataKit版本历史】
最佳实践更新
更多最佳实践更新,请参考【最佳实践版本历史】
集成模板更新
新增阿里云PolarDB Mysql集成文档、视图和检测库
阿里云PolarDB Mysql指标展示,包括CPU使用率、内存命中率、网络流量、连接数、QPS、TPS、只读节点延迟等。
更多集成模板更新请参考【集成文档版本历史】
【即刻体验观测云】
欢迎来到我们的 Guance Cloud for Observability Github 专栏
【可观测的关思云】
了解和使用喜欢的别忘了点击右上角的小星星点赞关注哦~
网站程序自带的采集器采集文章(雷电多线程语言内存老教程非常多,该程序根据GPS)
采集交流 • 优采云 发表了文章 • 0 个评论 • 398 次浏览 • 2022-04-15 03:13
Windows Server 2012 r2 构建 SMTP
1 打开控制面板并选择打开或关闭 Windows 功能。按照提示在功能中找到“SMTP”,然后选择安装。2 单击窗口图标,在搜索中输入“iis”,然后选择打开 iis 6.0 管理器。(特别提醒iis 6.0)3 在打开的窗口右击选择域,新建一个域,按照提示输入名称和类型。 4 右击“SMTP Virtual服务器#1",...
ecef与人体坐标系_WGS84与ECEF坐标转换_weixin_39739170的博客-程序员的秘密
#include "stdafx.h"#include #define PI 3.141592653/*本程序根据GPS.G1-X-00006.pdf文档实现WGS84和ECEF坐标的转换*/void LLAtoECEF(双纬、双经、双高、双&X、双&Y、双...
易语言记忆逆向教程(PC电脑上最新方向)+基础颜色交付+多线程中控(猿)
语言和记忆方面的老教程很多,但很多已经不适合现在的游戏了。有新的工具和想法,市场上的大多数教程都已经过时了。我的课程都是最新的方法,结合了各个学校的长处,让每个人都能学到东西。一分钱一分货,希望大家喜欢我的课程。课程在本质上,而不在数量上。教训是方法,而不是答案。可以互相推论。易语言网游记忆拼装教程部分(每节课30-50分钟,质量保证)第一章:记忆拼装基础1.易语言记忆辅助解惑---明确学习方向,少走弯路2.基础记忆辅助知识3.寄存器和常用汇编指令<
【DP四边形不等式优化】51Nod 1022 Stone Merge V2_Rianu Moses'博客-程序员的秘密
魔芋不存在 fi,j=min{fi,k+fk+1,j+wi,j} f_{i,j}=min \{ f_{i,k}+f_{k+1 等四边形不等式, j}+w_{i,j}\} 的方程满足四边形不等式和区间收录单调性可以通过四边形不等式#include#include#include#includeusing names优化
机器学习进阶理论知识一览 - ElienC's Blog - 程序员的秘密
来源:个人学习采集,侵删 ----------------------------- --- ------------------------------------- 也在上升,如果你没有对自己要求高,其实很容易被快速发展的趋势所淘汰。为了顺应时代的需要,我们在去年推出了“机器学习高端训练营”。本次训练营的目的很简单:培养更多的高端人才,帮助即将或正在从事科学研究或已毕业的人。
力口-算法入门的第七天 plan_heart_6662的博客-程序员的秘密 查看全部
网站程序自带的采集器采集文章(雷电多线程语言内存老教程非常多,该程序根据GPS)
Windows Server 2012 r2 构建 SMTP
1 打开控制面板并选择打开或关闭 Windows 功能。按照提示在功能中找到“SMTP”,然后选择安装。2 单击窗口图标,在搜索中输入“iis”,然后选择打开 iis 6.0 管理器。(特别提醒iis 6.0)3 在打开的窗口右击选择域,新建一个域,按照提示输入名称和类型。 4 右击“SMTP Virtual服务器#1",...
ecef与人体坐标系_WGS84与ECEF坐标转换_weixin_39739170的博客-程序员的秘密
#include "stdafx.h"#include #define PI 3.141592653/*本程序根据GPS.G1-X-00006.pdf文档实现WGS84和ECEF坐标的转换*/void LLAtoECEF(双纬、双经、双高、双&X、双&Y、双...
易语言记忆逆向教程(PC电脑上最新方向)+基础颜色交付+多线程中控(猿)
语言和记忆方面的老教程很多,但很多已经不适合现在的游戏了。有新的工具和想法,市场上的大多数教程都已经过时了。我的课程都是最新的方法,结合了各个学校的长处,让每个人都能学到东西。一分钱一分货,希望大家喜欢我的课程。课程在本质上,而不在数量上。教训是方法,而不是答案。可以互相推论。易语言网游记忆拼装教程部分(每节课30-50分钟,质量保证)第一章:记忆拼装基础1.易语言记忆辅助解惑---明确学习方向,少走弯路2.基础记忆辅助知识3.寄存器和常用汇编指令<
【DP四边形不等式优化】51Nod 1022 Stone Merge V2_Rianu Moses'博客-程序员的秘密
魔芋不存在 fi,j=min{fi,k+fk+1,j+wi,j} f_{i,j}=min \{ f_{i,k}+f_{k+1 等四边形不等式, j}+w_{i,j}\} 的方程满足四边形不等式和区间收录单调性可以通过四边形不等式#include#include#include#includeusing names优化
机器学习进阶理论知识一览 - ElienC's Blog - 程序员的秘密
来源:个人学习采集,侵删 ----------------------------- --- ------------------------------------- 也在上升,如果你没有对自己要求高,其实很容易被快速发展的趋势所淘汰。为了顺应时代的需要,我们在去年推出了“机器学习高端训练营”。本次训练营的目的很简单:培养更多的高端人才,帮助即将或正在从事科学研究或已毕业的人。
力口-算法入门的第七天 plan_heart_6662的博客-程序员的秘密
网站程序自带的采集器采集文章(linux验证文件的完整性,如何检测Linux系统已下载文件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-04-15 03:06
Linux验证文件完整性,如何在Linux系统中检测下载文件的完整性 - 程序员大本营
因为Linux系统安装软件比较复杂,如果下载的软件已经修改过,安装起来会很麻烦。检查Linux系统下载文件的完整性变得非常重要。下面小编将介绍如何检查Linux系统。下载文件的完整性。目前的验证方式一般是MD5、SHA1、PGP。在Windows的漫长岁月里(带着沧桑),一般只能摸到前两个——前提是你能查到。MD5校验原理:对文件进行MD5 Hash,找到文件的MD5哈希...
来自使用 os.system) 在 python 命令中(重定向标准输入输出_bang152101 的博客-程序员的秘密_os.system 输出
python stdout stdoutstdioos.system 通常我可以通过更改 sys.stdout 的值来更改 python 中的 stdout。但是,这似乎只会影响打印。那么,有没有办法通过使用 os.system 来抑制 python 中 run() 命令的输出(控制台)?感谢您的这篇文章地址:/172881/------------------------------------...
本文带你一点点了解Java 8中的流式数据处理 - 程序员大本营
作者:祁焱/fly910905/article/details/87533856java8的流处理极大地简化了我们对集合、数组等结构的操作,让我们可以使用函数式...
指针和引用,以及 int *p、int *&p、int &*p、int**p
指针和引用一般用于函数参数传递,因为将实参传递给被调用函数后,不能直接修改实参的值(被调用函数只能使用形参,形参后自动释放)被调用函数结束),所以需要传递一个指针或引用来修改实参。指针本质上是一个存储另一个变量地址的变量,所以传递给被调用函数的是……
【论文分享】不平衡流量分类方法DeepFE:ResNet+SE+non-local:让不平衡无处可藏_vector的博客-程序员的秘密
摘要:本文提出了一种新框架,该框架使用深度学习进行特征提取,以解决 NTC(网络流量分类)任务中的不平衡问题,称为 DeepFE。该模型的关键是使用改进的 ResNet 和 SE 块来提取类敏感信息,并使用 non-local 来重构特征。
yolov5 6. 版本 0 + deepsort_Mr. 姚97的博客——程序员的秘密
yolov5 6.version 0+ deepsort实现行人检测与跟踪,双向交通统计,显示当前人数,绘制行人轨迹,测量每个行人的速度 查看全部
网站程序自带的采集器采集文章(linux验证文件的完整性,如何检测Linux系统已下载文件)
Linux验证文件完整性,如何在Linux系统中检测下载文件的完整性 - 程序员大本营
因为Linux系统安装软件比较复杂,如果下载的软件已经修改过,安装起来会很麻烦。检查Linux系统下载文件的完整性变得非常重要。下面小编将介绍如何检查Linux系统。下载文件的完整性。目前的验证方式一般是MD5、SHA1、PGP。在Windows的漫长岁月里(带着沧桑),一般只能摸到前两个——前提是你能查到。MD5校验原理:对文件进行MD5 Hash,找到文件的MD5哈希...
来自使用 os.system) 在 python 命令中(重定向标准输入输出_bang152101 的博客-程序员的秘密_os.system 输出
python stdout stdoutstdioos.system 通常我可以通过更改 sys.stdout 的值来更改 python 中的 stdout。但是,这似乎只会影响打印。那么,有没有办法通过使用 os.system 来抑制 python 中 run() 命令的输出(控制台)?感谢您的这篇文章地址:/172881/------------------------------------...
本文带你一点点了解Java 8中的流式数据处理 - 程序员大本营
作者:祁焱/fly910905/article/details/87533856java8的流处理极大地简化了我们对集合、数组等结构的操作,让我们可以使用函数式...
指针和引用,以及 int *p、int *&p、int &*p、int**p
指针和引用一般用于函数参数传递,因为将实参传递给被调用函数后,不能直接修改实参的值(被调用函数只能使用形参,形参后自动释放)被调用函数结束),所以需要传递一个指针或引用来修改实参。指针本质上是一个存储另一个变量地址的变量,所以传递给被调用函数的是……
【论文分享】不平衡流量分类方法DeepFE:ResNet+SE+non-local:让不平衡无处可藏_vector的博客-程序员的秘密
摘要:本文提出了一种新框架,该框架使用深度学习进行特征提取,以解决 NTC(网络流量分类)任务中的不平衡问题,称为 DeepFE。该模型的关键是使用改进的 ResNet 和 SE 块来提取类敏感信息,并使用 non-local 来重构特征。
yolov5 6. 版本 0 + deepsort_Mr. 姚97的博客——程序员的秘密
yolov5 6.version 0+ deepsort实现行人检测与跟踪,双向交通统计,显示当前人数,绘制行人轨迹,测量每个行人的速度
网站程序自带的采集器采集文章(网站程序自带的采集器采集文章比较方便快捷,可以用采集js引擎)
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-14 18:00
网站程序自带的采集器采集文章比较方便快捷,如果想自己定制,可以用采集js引擎。文章数据导出是不可能的。搜索引擎最喜欢的文章格式是:摘要或者全文,这个可以保存到本地或者通过多种方式下载保存。
现在,排名前十的博客几乎都是采集过来的。一方面靠开源系统方便维护更新,另一方面收集相同的标题相同的内容,也能提高收录。采集过来之后,站长平时要多浏览多收藏相同标题下的其他站点,注意增加一下权重,这样更容易获得更多推荐,同时对提高文章被收录的数量也是有用的。
搜索引擎从来不认为一篇文章都是高质量,只要你的文章跟他的文章不同,他就可以收录。对于采集来的文章,搜索引擎要根据你的权重来决定收录你还是排在其他网站后面,也就是排在后面的文章不是很好被收录。所以一些权重高的网站更容易被收录。
确定采集了所有的文章?用站长平台等工具分析各个站点的收录情况及原始链接,是否被收录。搜索引擎本身不收录是不会丢失重要文章。收录后,
1、文章内容是否过多,如果过多,可能会出现被删除的情况。
2、是否有发布废话,重复性过高的文章,垃圾文章。
3、文章的发布时间、使用媒体平台、网站的权重等等,
是新站,seo技术不好,还是找个专业的团队吧, 查看全部
网站程序自带的采集器采集文章(网站程序自带的采集器采集文章比较方便快捷,可以用采集js引擎)
网站程序自带的采集器采集文章比较方便快捷,如果想自己定制,可以用采集js引擎。文章数据导出是不可能的。搜索引擎最喜欢的文章格式是:摘要或者全文,这个可以保存到本地或者通过多种方式下载保存。
现在,排名前十的博客几乎都是采集过来的。一方面靠开源系统方便维护更新,另一方面收集相同的标题相同的内容,也能提高收录。采集过来之后,站长平时要多浏览多收藏相同标题下的其他站点,注意增加一下权重,这样更容易获得更多推荐,同时对提高文章被收录的数量也是有用的。
搜索引擎从来不认为一篇文章都是高质量,只要你的文章跟他的文章不同,他就可以收录。对于采集来的文章,搜索引擎要根据你的权重来决定收录你还是排在其他网站后面,也就是排在后面的文章不是很好被收录。所以一些权重高的网站更容易被收录。
确定采集了所有的文章?用站长平台等工具分析各个站点的收录情况及原始链接,是否被收录。搜索引擎本身不收录是不会丢失重要文章。收录后,
1、文章内容是否过多,如果过多,可能会出现被删除的情况。
2、是否有发布废话,重复性过高的文章,垃圾文章。
3、文章的发布时间、使用媒体平台、网站的权重等等,
是新站,seo技术不好,还是找个专业的团队吧,
网站程序自带的采集器采集文章(几种爬虫常见的数据采集场景介绍-乐题日志宏)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-14 15:25
千修每天都会收到大量的数据采集需求。虽然来自不同的行业、网站和企业,但每个需求的采集场景有很多相似之处。根据您对数据采集的需求,小编总结了以下爬虫常用的数据采集场景。
1.实时采集并更新新数据
对于很多舆情或政策监测数据采集的需求,大部分需要做到实时采集,只有采集新数据。这样可以快速监控所需的数据,提高监控速度和质量。
ForeSpider数据采集软件可设置为不间断采集,7×24H不间断采集指定网站,已存储的数据不重复采集 ,实时更新网站中新增的数据,之前采集的数据不会重复存储,也不需要每天重新采集数据,大大提高数据采集的效率,节省网络带宽和代理IP资源。
设置介绍:
①时机采集
Timing采集:设置任务定时设置,可以在某个时间点开始/停止采集,也可以在一定时间后开始/停止采集。
②增量采集:每次只取采集的更新链接,只取更新链接,不取数据页。
这样,爬虫软件不仅可以自动采集,实时更新,还可以自动重新加载,保证数据采集的高效稳定运行。
2.自动补充缺失数据
在爬取采集数据的过程中,由于网络异常、加载异常、网站反爬等原因,在采集过程中丢失了部分数据。
针对这种情况,需要在采集过程中重新采集失败的请求采集,以高效获取全量数据。
ForeSpider数据采集系统可以针对这种常见的采集场景进行数据补充采集设置,从而提高采集效率,快速获取全量数据。
设置介绍:
①自定义采集策略:选择采集入库失败,采集错误,上次没有采集数据。设置并重新采集后,可以快速重新采集之前丢失的数据,无需重复耗时耗力的采集。
②设置加载日志宏:根据任务ID值、任务数据大小等,对于不符合采集要求的数据,过滤日志列表,重新采集补充缺失的数据。
比如有些网站的IP被重定向新的URL屏蔽了,所以采集状态显示成功,但是任务的数据质量一般很小,比如2KB。在这种情况下,可以加载日志宏。,加载质量太低的任务日志,无法重新采集这部分任务。
3.时序采集数据
一个很常见的数据采集需求是每天在固定点开始爬取一个或多个网站。为了腾出双手,对采集数据进行计时是非常有必要的。
ForeSpider数据采集系统可以设置定时启动和停止采集,时间点和时间段结合设置,可以在某个时间点启动/停止采集,或者在某个时间段发布预定的开始/停止采集。减少人力重复工作,有效避免人工采集的情况。
设置介绍:
①间隔定时采集:设置间隔时间,以固定间隔时间实现采集的开/关。
②固定时间采集:设置爬虫自动启动/停止的时间。
例子:
①采集每天都有新数据
每天定时添加新数据采集,每天设置一定时间采集添加新数据,设置后可以每天设置采集,节省人工成本。
②网站反爬
当采集在一段时间后无法获取数据时,可以在一段时间后再次获取数据。打开采集后,根据防爬规则,设置一定时间停止采集,设置一定时间开始采集,可以有效避免防爬攀爬,高效 采集@ >数据。
③自动更新数据库
部署到服务器后,需要每天采集网站新数据到本地数据库,可以开始调度采集,以及采集数据定时每天。
4.批量关键词搜索
我们经常需要采集某个网站关于某个行业、某个事件、某个主题等相关内容,那么我们会用关键词采集来采集 批量 关键词 搜索到的数据。
ForeSpider Data采集 软件可以实现多种关键词检索采集 方法。
①批量导入关键词,采集在目标网站中查找关键词中的数据内容,同时对关键词进行排序和再处理,方便快捷,无需编写脚本批量采集关键词搜索到的数据。
②关键词存在于外部数据库中,实时调用采集。通过ForeSpider爬虫软件连接到其他数据库的数据表,或者爬虫软件中的其他数据表,可以利用动态变化的关键词库实时检索采集数据。
③ 通过接口实时传输关键词。用户数据中实时生成的搜索词可以通过接口实时关键词检索采集传输到ForeSpider数据采集系统。并将采集接收到的数据实时传回用户系统显示。
设置介绍:
关键词配置:可以进行关键词配置,在高级配置中可以配置各种参数。
关键词列表:批量导入、修改关键词批量导入、删除、修改关键词,也可以对关键词进行排序和重新处理。
例子:
①采集关键词搜索到网站
比如百度、360问答、微博搜索等网站都有搜索功能。
②关键词充当词库,调用和使用
例如,一个不同区域分类的网站网址收录区域参数,可以直接将区域参数导入到关键词列表中,编写一个简单的脚本,调用关键词拼出网站@的不同区域分类>使配置更容易。
③ 用户输入搜索词,实时抓取数据返回显示
用户输入需要检索的词后,实时传输到ForeSpider爬虫软件,进行现场查询采集,采集接收到的数据为实时传回用户系统,向用户展示数据。
5.自定义过滤器文件大小/类型
我们经常需要采集网页中的图片、视频、各种附件等数据。为了获得更准确的数据,需要更精确地过滤文件的大小/类型。
在嗅探ForeSpider采集软件之前,可以自行设置采集文件的上下限或文件类型,从而过滤采集网页中符合条件的文件数据。
例如:采集网页中大于2b的文件数据,采集网页中的所有文本数据,采集页面中的图片数据,采集@中的视频数据>文件等。
设置介绍:
设置过滤:设置采集文件的类型,采集该类型的文件数据,设置采集文件大小下限过滤小文件,设置采集过滤大文件的文件大小阈值。
例子:
①采集网页中的所有图片数据
当需要网页中全部或部分图片数据时,在文件设置中选择采集文件类型,然后配置采集,节省配置成本,实现精准采集。
②采集网页中的所有视频数据
当需要采集网页中的全部或部分视频数据时,在文件设置中选择采集文件类型,然后配置采集。
③采集网页中的具体文件数据
通过设置采集的文件大小下限,过滤掉小文件和无效文件,实现精准采集。
6.登录采集
当采集需要在网站上注册数据时,需要进行注册设置。嗅探ForeSpider数据前采集分析引擎可以采集需要登录(账号密码登录、扫描登录、短信验证登录)网站、APP数据、采集登录后可见数据。
ForeSpider爬虫软件,可以设置自动登录,也可以手动设置登录,也可以使用cookies登录,多种登录配置方式适合各种登录场景,配置灵活。
概念介绍:
Cookie:Cookie是指存储在用户本地终端上的一些网站数据,用于识别用户身份和进行会话跟踪。Cookie是基于各种互联网服务系统而产生的。它是由网络服务器保存在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。可以模拟登录的cookie采集。
设置介绍:
①登录配置:可以自动配置,也可以手动配置。
②Cookie设置:对于需要cookie的网站,可以自动生成cookie来获取数据。您也可以手动添加 cookie 来获取数据。
例子:
适用于任何需要登录的网站、APP数据(账号密码登录、扫描登录、短信验证登录)。
7.批处理网站批处理配置
大多数企业级的大数据项目,往往需要很多采集中的网站,从几百到几千万不等。单独配置每个 网站 是不现实的。这时候需要批量配置上千个网站和采集。
ForeSpider 爬虫软件就是专门针对这种情况设计的。独创智能配置算法和采集配置语言,可高效配置采集,解析网页结构。数据,无需依次配置每个网站,即可实现同步采集万条网站。
用户将需要采集的URL列表输入到采集任务中,通过对采集内容的智能识别,实现一个配置采集模板来< @k11@ > 成千上万的 网站 需求量很大。
优势:
①节省大量人工配置成本:无需手动一一配置网站即可实现采集千网站的需求。
②采集大批量网站短时间,快速功能上线:快速实现网站数据扩容,采集短时间海量数据,缩短项目启动时间。
③采集数据量大,范围广:一次性实现海量网站采集需求,批量管理海量数据,实现企业级数据< @采集 能力。
④数据易管理:数据高度集中管理,便于全局监控数据采集情况,便于运维。
⑤灵活删除采集源:不想继续采集的源可以随时删除,也可以随时批量添加新的采集源。
例子:
①舆情监测
快速实现短时间内对大量媒体网站的数据监控,快速形成与某事件/主题相关的内容监控。
②内容发布平台
采集批量URL、某方面的海量采集内容,分类后发布相应数据。
③行业信息库
快速建立行业相关信息数据库供查询使用。
看到这里,应该对爬虫的采集场景有了深入的了解。后期我们会结合各种采集场景为大家展示更多采集案例,敬请期待。
l 前嗅觉介绍
千秀大数据,国内领先的研发大数据专家,多年致力于大数据技术的研发,自主研发了一整套数据采集,分析、处理、管理、应用和营销。大数据产品。千秀致力于打造国内首个深度大数据平台! 查看全部
网站程序自带的采集器采集文章(几种爬虫常见的数据采集场景介绍-乐题日志宏)
千修每天都会收到大量的数据采集需求。虽然来自不同的行业、网站和企业,但每个需求的采集场景有很多相似之处。根据您对数据采集的需求,小编总结了以下爬虫常用的数据采集场景。
1.实时采集并更新新数据
对于很多舆情或政策监测数据采集的需求,大部分需要做到实时采集,只有采集新数据。这样可以快速监控所需的数据,提高监控速度和质量。
ForeSpider数据采集软件可设置为不间断采集,7×24H不间断采集指定网站,已存储的数据不重复采集 ,实时更新网站中新增的数据,之前采集的数据不会重复存储,也不需要每天重新采集数据,大大提高数据采集的效率,节省网络带宽和代理IP资源。
设置介绍:
①时机采集
Timing采集:设置任务定时设置,可以在某个时间点开始/停止采集,也可以在一定时间后开始/停止采集。
②增量采集:每次只取采集的更新链接,只取更新链接,不取数据页。
这样,爬虫软件不仅可以自动采集,实时更新,还可以自动重新加载,保证数据采集的高效稳定运行。
2.自动补充缺失数据
在爬取采集数据的过程中,由于网络异常、加载异常、网站反爬等原因,在采集过程中丢失了部分数据。
针对这种情况,需要在采集过程中重新采集失败的请求采集,以高效获取全量数据。
ForeSpider数据采集系统可以针对这种常见的采集场景进行数据补充采集设置,从而提高采集效率,快速获取全量数据。
设置介绍:
①自定义采集策略:选择采集入库失败,采集错误,上次没有采集数据。设置并重新采集后,可以快速重新采集之前丢失的数据,无需重复耗时耗力的采集。
②设置加载日志宏:根据任务ID值、任务数据大小等,对于不符合采集要求的数据,过滤日志列表,重新采集补充缺失的数据。
比如有些网站的IP被重定向新的URL屏蔽了,所以采集状态显示成功,但是任务的数据质量一般很小,比如2KB。在这种情况下,可以加载日志宏。,加载质量太低的任务日志,无法重新采集这部分任务。
3.时序采集数据
一个很常见的数据采集需求是每天在固定点开始爬取一个或多个网站。为了腾出双手,对采集数据进行计时是非常有必要的。
ForeSpider数据采集系统可以设置定时启动和停止采集,时间点和时间段结合设置,可以在某个时间点启动/停止采集,或者在某个时间段发布预定的开始/停止采集。减少人力重复工作,有效避免人工采集的情况。
设置介绍:
①间隔定时采集:设置间隔时间,以固定间隔时间实现采集的开/关。
②固定时间采集:设置爬虫自动启动/停止的时间。
例子:
①采集每天都有新数据
每天定时添加新数据采集,每天设置一定时间采集添加新数据,设置后可以每天设置采集,节省人工成本。
②网站反爬
当采集在一段时间后无法获取数据时,可以在一段时间后再次获取数据。打开采集后,根据防爬规则,设置一定时间停止采集,设置一定时间开始采集,可以有效避免防爬攀爬,高效 采集@ >数据。
③自动更新数据库
部署到服务器后,需要每天采集网站新数据到本地数据库,可以开始调度采集,以及采集数据定时每天。
4.批量关键词搜索
我们经常需要采集某个网站关于某个行业、某个事件、某个主题等相关内容,那么我们会用关键词采集来采集 批量 关键词 搜索到的数据。
ForeSpider Data采集 软件可以实现多种关键词检索采集 方法。
①批量导入关键词,采集在目标网站中查找关键词中的数据内容,同时对关键词进行排序和再处理,方便快捷,无需编写脚本批量采集关键词搜索到的数据。
②关键词存在于外部数据库中,实时调用采集。通过ForeSpider爬虫软件连接到其他数据库的数据表,或者爬虫软件中的其他数据表,可以利用动态变化的关键词库实时检索采集数据。
③ 通过接口实时传输关键词。用户数据中实时生成的搜索词可以通过接口实时关键词检索采集传输到ForeSpider数据采集系统。并将采集接收到的数据实时传回用户系统显示。
设置介绍:
关键词配置:可以进行关键词配置,在高级配置中可以配置各种参数。
关键词列表:批量导入、修改关键词批量导入、删除、修改关键词,也可以对关键词进行排序和重新处理。
例子:
①采集关键词搜索到网站
比如百度、360问答、微博搜索等网站都有搜索功能。
②关键词充当词库,调用和使用
例如,一个不同区域分类的网站网址收录区域参数,可以直接将区域参数导入到关键词列表中,编写一个简单的脚本,调用关键词拼出网站@的不同区域分类>使配置更容易。
③ 用户输入搜索词,实时抓取数据返回显示
用户输入需要检索的词后,实时传输到ForeSpider爬虫软件,进行现场查询采集,采集接收到的数据为实时传回用户系统,向用户展示数据。
5.自定义过滤器文件大小/类型
我们经常需要采集网页中的图片、视频、各种附件等数据。为了获得更准确的数据,需要更精确地过滤文件的大小/类型。
在嗅探ForeSpider采集软件之前,可以自行设置采集文件的上下限或文件类型,从而过滤采集网页中符合条件的文件数据。
例如:采集网页中大于2b的文件数据,采集网页中的所有文本数据,采集页面中的图片数据,采集@中的视频数据>文件等。
设置介绍:
设置过滤:设置采集文件的类型,采集该类型的文件数据,设置采集文件大小下限过滤小文件,设置采集过滤大文件的文件大小阈值。
例子:
①采集网页中的所有图片数据
当需要网页中全部或部分图片数据时,在文件设置中选择采集文件类型,然后配置采集,节省配置成本,实现精准采集。
②采集网页中的所有视频数据
当需要采集网页中的全部或部分视频数据时,在文件设置中选择采集文件类型,然后配置采集。
③采集网页中的具体文件数据
通过设置采集的文件大小下限,过滤掉小文件和无效文件,实现精准采集。
6.登录采集
当采集需要在网站上注册数据时,需要进行注册设置。嗅探ForeSpider数据前采集分析引擎可以采集需要登录(账号密码登录、扫描登录、短信验证登录)网站、APP数据、采集登录后可见数据。
ForeSpider爬虫软件,可以设置自动登录,也可以手动设置登录,也可以使用cookies登录,多种登录配置方式适合各种登录场景,配置灵活。
概念介绍:
Cookie:Cookie是指存储在用户本地终端上的一些网站数据,用于识别用户身份和进行会话跟踪。Cookie是基于各种互联网服务系统而产生的。它是由网络服务器保存在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。可以模拟登录的cookie采集。
设置介绍:
①登录配置:可以自动配置,也可以手动配置。
②Cookie设置:对于需要cookie的网站,可以自动生成cookie来获取数据。您也可以手动添加 cookie 来获取数据。
例子:
适用于任何需要登录的网站、APP数据(账号密码登录、扫描登录、短信验证登录)。
7.批处理网站批处理配置
大多数企业级的大数据项目,往往需要很多采集中的网站,从几百到几千万不等。单独配置每个 网站 是不现实的。这时候需要批量配置上千个网站和采集。
ForeSpider 爬虫软件就是专门针对这种情况设计的。独创智能配置算法和采集配置语言,可高效配置采集,解析网页结构。数据,无需依次配置每个网站,即可实现同步采集万条网站。
用户将需要采集的URL列表输入到采集任务中,通过对采集内容的智能识别,实现一个配置采集模板来< @k11@ > 成千上万的 网站 需求量很大。
优势:
①节省大量人工配置成本:无需手动一一配置网站即可实现采集千网站的需求。
②采集大批量网站短时间,快速功能上线:快速实现网站数据扩容,采集短时间海量数据,缩短项目启动时间。
③采集数据量大,范围广:一次性实现海量网站采集需求,批量管理海量数据,实现企业级数据< @采集 能力。
④数据易管理:数据高度集中管理,便于全局监控数据采集情况,便于运维。
⑤灵活删除采集源:不想继续采集的源可以随时删除,也可以随时批量添加新的采集源。
例子:
①舆情监测
快速实现短时间内对大量媒体网站的数据监控,快速形成与某事件/主题相关的内容监控。
②内容发布平台
采集批量URL、某方面的海量采集内容,分类后发布相应数据。
③行业信息库
快速建立行业相关信息数据库供查询使用。
看到这里,应该对爬虫的采集场景有了深入的了解。后期我们会结合各种采集场景为大家展示更多采集案例,敬请期待。
l 前嗅觉介绍
千秀大数据,国内领先的研发大数据专家,多年致力于大数据技术的研发,自主研发了一整套数据采集,分析、处理、管理、应用和营销。大数据产品。千秀致力于打造国内首个深度大数据平台!
网站程序自带的采集器采集文章( 为什么要做赞片影视文章采集?CMS采集助力网站对搜索引擎SEO友好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-04-13 17:10
为什么要做赞片影视文章采集?CMS采集助力网站对搜索引擎SEO友好)
也想来这里吗?点击联系我~
原生影视app源码
<p>像Filmcms采集,一套基于ThinkPHP5框架开发的高性能PHP影视系统和电影程序。但是,点赞片自带的采集有时可能有点难以满足点赞片cms站长采集、点赞片cms 查看全部
网站程序自带的采集器采集文章(采集收录,网站内容的质量对网站的收录非常重要)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-13 15:29
采集收录,网站内容的质量在网站的收录中起着非常重要的作用。因此,当采集收录更新网站内容时,一定要更新优质的文章内容,并不断更新。采集收录实现自动采集伪原创向搜索引擎发布和主动推送,不断添加大量内容,同时向搜索引擎推送,加速推广网站的内容页面收录,实现网站快速海量收录。
采集收录的内容虽然是采集,但是大部分内容没有标题关键词,连关键词都没有,怎么会有排名呢,所以我们每个采集收录文章都要设置一个主关键词,这样才有可能参与排名,但是如果采集的文章 没有主关键词 怎么办,那么采集收录 需要修改标题,把没有主关键词 的标题改成有关键词 标题。
如果要采集收录,每天定时更新采集,而且站长知道网站更新频率越高,权重就越高,那我们来自采集文章最好不要直接释放,固定几个小时采集一天一次。每天更新,一定要定时更新,否则蜘蛛会降低网站的友好度。采集收录的文章每周量化更新,不要采集太多文章,这样收录不会太多,水将永远存在 点击并放置,让蜘蛛带着内容而来。
采集收录需要注意的是,不管是什么搜索引擎,它都喜欢新鲜的内容,所以网站建好后,设置关键词就变得很重要了. 这里我们可以尝试将网站的关键词设置为非常冷门,冷到没有搜索引擎曾经收录收录。当然,选词很难,但也不是没有可能。稍加用心,站长就会发现收录 就是这么简单。当然,这里提醒一下,采集收录并不是设置所有关键词冷门词,只是主要词之一。
采集收录 中的内容必须修改。采集收录的一般做法是标题一定要修改,里面的内容布局一般是第一段和最后一段。如果有图片,采集收录必须本地化或替换图片。在网站快照没有更新的情况下,也可以使用采集收录的方法来吸引蜘蛛更新,效果非常明显。
采集收录对于搜索引擎,我更喜欢独特的网站,如果站长的网站模板和很多网站一样就失去了优势。必须对其进行适当修改,以使您的 网站 模板在搜索引擎眼中是独一无二的。因为网站的大部分内容属于采集收录,失去了原创的优势,我们只能通过外链来提升网站@的整体权重>、外链建设可谓采集站的重中之重。建议将30%的外部链接导入首页(锚文本链接、超链接、纯文本链接),其余大部分导入重点发展栏目页面和比较热的长尾关键词页面。
采集收录页面文字越多,内容价值越高:比如200字的文字介绍比2000字的内容更有价值。,但不要重复 关键词 的内容,这会使页面看起来冗长且没有主题。采集收录页面文字越多,页面覆盖的内容点越多,用户分享越容易,因为内容越丰富,传递的价值越高。 查看全部
网站程序自带的采集器采集文章(采集收录,网站内容的质量对网站的收录非常重要)
采集收录,网站内容的质量在网站的收录中起着非常重要的作用。因此,当采集收录更新网站内容时,一定要更新优质的文章内容,并不断更新。采集收录实现自动采集伪原创向搜索引擎发布和主动推送,不断添加大量内容,同时向搜索引擎推送,加速推广网站的内容页面收录,实现网站快速海量收录。
采集收录的内容虽然是采集,但是大部分内容没有标题关键词,连关键词都没有,怎么会有排名呢,所以我们每个采集收录文章都要设置一个主关键词,这样才有可能参与排名,但是如果采集的文章 没有主关键词 怎么办,那么采集收录 需要修改标题,把没有主关键词 的标题改成有关键词 标题。
如果要采集收录,每天定时更新采集,而且站长知道网站更新频率越高,权重就越高,那我们来自采集文章最好不要直接释放,固定几个小时采集一天一次。每天更新,一定要定时更新,否则蜘蛛会降低网站的友好度。采集收录的文章每周量化更新,不要采集太多文章,这样收录不会太多,水将永远存在 点击并放置,让蜘蛛带着内容而来。
采集收录需要注意的是,不管是什么搜索引擎,它都喜欢新鲜的内容,所以网站建好后,设置关键词就变得很重要了. 这里我们可以尝试将网站的关键词设置为非常冷门,冷到没有搜索引擎曾经收录收录。当然,选词很难,但也不是没有可能。稍加用心,站长就会发现收录 就是这么简单。当然,这里提醒一下,采集收录并不是设置所有关键词冷门词,只是主要词之一。
采集收录 中的内容必须修改。采集收录的一般做法是标题一定要修改,里面的内容布局一般是第一段和最后一段。如果有图片,采集收录必须本地化或替换图片。在网站快照没有更新的情况下,也可以使用采集收录的方法来吸引蜘蛛更新,效果非常明显。
采集收录对于搜索引擎,我更喜欢独特的网站,如果站长的网站模板和很多网站一样就失去了优势。必须对其进行适当修改,以使您的 网站 模板在搜索引擎眼中是独一无二的。因为网站的大部分内容属于采集收录,失去了原创的优势,我们只能通过外链来提升网站@的整体权重>、外链建设可谓采集站的重中之重。建议将30%的外部链接导入首页(锚文本链接、超链接、纯文本链接),其余大部分导入重点发展栏目页面和比较热的长尾关键词页面。
采集收录页面文字越多,内容价值越高:比如200字的文字介绍比2000字的内容更有价值。,但不要重复 关键词 的内容,这会使页面看起来冗长且没有主题。采集收录页面文字越多,页面覆盖的内容点越多,用户分享越容易,因为内容越丰富,传递的价值越高。
网站程序自带的采集器采集文章(为什么要采集微信公众号文章的文章?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-04-13 15:26
公众号采集是一个全自动的微信文章批处理采集工具。公众号采集功能强大,可以进行批量伪原创检查,伪原创等批量操作让站长轻松采集文章公众号,然后自动伪原创再发布到自己的网站。公众号采集可自定义采集,采集可创建公众号文章,添加群组,清晰更新分类,调度采集任务,以及实现无人值守自动化,可以采集每天全部、分组、指定、量化采集。
公众号采集内置搜索盘关键词,方便站长查找文章,搜索文章文字、图片、和视频资料。公众号采集添加图文素材,一键同步,无需手动操作文章,直接同步到cms。并且公众号采集可以在线编辑文字,美化文章轻松搞定,丰富的样式和简单的操作快速编辑文章。智能识别原创文章、醒目标题提醒、视频地址提取、图文风格排版编辑器。
为什么要采集微信公众号文章?首先,公众号采集的文章的内容质量高于网站和网上的博客内容,可以成为优质的文章@ 的站长网站> 源码。其次,公众号采集的文章排版更美观,让访问用户在阅读文章时阅读过程更清晰,更愉快。另外,公众号采集的文章覆盖领域广泛,基本可以满足各类站长网站的内容需求。
<p>公众号采集文章更新有两个目的:根据搜索引擎蜘蛛的爬取规则,一定频率的内容更新有助于搜索引擎判断网站的活跃度学位,通过不断爬取内容,收录。将及时展示在搜索受众面前,满足自然用户的搜索需求。针对以上考虑,只需要按一定频率更新即可,公众号采集的内容为原创或伪原创,注意 查看全部
网站程序自带的采集器采集文章(为什么要采集微信公众号文章的文章?(图))
公众号采集是一个全自动的微信文章批处理采集工具。公众号采集功能强大,可以进行批量伪原创检查,伪原创等批量操作让站长轻松采集文章公众号,然后自动伪原创再发布到自己的网站。公众号采集可自定义采集,采集可创建公众号文章,添加群组,清晰更新分类,调度采集任务,以及实现无人值守自动化,可以采集每天全部、分组、指定、量化采集。
公众号采集内置搜索盘关键词,方便站长查找文章,搜索文章文字、图片、和视频资料。公众号采集添加图文素材,一键同步,无需手动操作文章,直接同步到cms。并且公众号采集可以在线编辑文字,美化文章轻松搞定,丰富的样式和简单的操作快速编辑文章。智能识别原创文章、醒目标题提醒、视频地址提取、图文风格排版编辑器。
为什么要采集微信公众号文章?首先,公众号采集的文章的内容质量高于网站和网上的博客内容,可以成为优质的文章@ 的站长网站> 源码。其次,公众号采集的文章排版更美观,让访问用户在阅读文章时阅读过程更清晰,更愉快。另外,公众号采集的文章覆盖领域广泛,基本可以满足各类站长网站的内容需求。
<p>公众号采集文章更新有两个目的:根据搜索引擎蜘蛛的爬取规则,一定频率的内容更新有助于搜索引擎判断网站的活跃度学位,通过不断爬取内容,收录。将及时展示在搜索受众面前,满足自然用户的搜索需求。针对以上考虑,只需要按一定频率更新即可,公众号采集的内容为原创或伪原创,注意
网站程序自带的采集器采集文章(竹愈)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-04-12 14:31
付军、付新竹、吴高静、丁采钰、龙辉阳、熊子淇
智能信息采集器的软件开发实践
傅军1、傅新柱2、吴高静1、丁才玉1、龙慧阳1、熊子琪1
(1.四川工程技术学院材料工程系, 德阳 618000;
2.德阳市第五中学初中, 德阳 618000)
【摘要】应用爬虫技术开发的智能信息采集器可以帮助用户及时获取工程院校、铸造院校、焊接行业、军队网站的最新动态。本文采用tkinter进行界面设计,利用python爬虫技术对xpath、抓包日期、网址进行处理,从而成功爬取消息并获取消息的URL。用户可以进一步打开自己感兴趣的网页进行详细阅读。
【摘要】利用爬虫技术开发的智能信息采集器,可以帮助用户及时获取工程学院、铸造学院、焊接行业和军事网站的最新信息。论文选用tkinter进行界面设计,利用python爬虫技术对xpath、抓取日期、url进行处理,顺利实现了抓取消息和获取消息的url。用户可以进一步打开感兴趣的网页进行详细阅读。
【关键词】爬虫技术;信息采集; Python; 二次开发;路径
【关键词】爬虫技术;信息采集;Python; 二次开发;路径
[CLC 编号] TP311.5 [文档代码] A [文章 编号] 1673-1069 (2021)05-0192-02
1 简介
网络信息时代,信息海量而复杂。科研院所、工业企业和政府部门需要了解最新的科学前沿、法律法规和工作动态的网络信息来做出决策。但他们很难找到杂乱无章的网页。团队在完成省级项目“了不起,我的祖国——建国以来重大科技成果”的过程中,往往需要紧跟科技成果和技术发展的步伐。> 进行消息搜索。如果一一搜索这些网站列,耗时较长,往往容易漏掉。团队设计了“智能信息采集器”
2 技术基础
2.1 蟒蛇
网络爬虫根据一定的规则自动从万维网上爬取信息,并可以采集他们可以访问的页面的所有内容来获取或更新这些网站的内容和检索方式。目前获取网页信息的技术手段包括python爬虫技术和各种爬虫框架。团队采用python爬虫技术进行设计。tkinter 模块是python的标准GUI工具包界面,可以轻松实现很多直观的功能。tkinter是python自带的库,不用下载安装就可以直接使用[1]。
2.2 获取 xpath
xpath 是一种用于在 XML 文档中查找信息的语言。在浏览器中,打开网页,右击“Inspect Element”,打开“DockSide”,点击左上角的“Select an element in the page to inspect it (Ctrl+Shift+C)”按钮,点击网页中的消息,在html代码中,右键“copy/xpath”得到消息的xpath[2]。
3 开发实践
3.1 整体设计
变量表。各节的局部变量newa、urla、timea;全局变量 newlist、urllist、timelist;每个单元名使用label,后面跟着label2、label3... 每个单元名下面有几列,使用checkboxes CheckButton,CheckButton被命名为单元名+列名缩写,与checkbox Checkbutton.variable链接。
清空newlist、urllist、timelist;如果选择了某个单元的列,则运行相应的def;运行后,所有捕捉到的新闻标题都会被添加到newlist,url会被添加到urllist,日期会被添加到timelist。运行完所有列后,得到newlist的长度数。urlx, newx, timx 清零,num=0;得到想要的时间段zj变量值。从i=0到number,依次读取timelist[i]的值。如果时间匹配zj,则num加1,将newlist和uellist对应的值加到urlx[num]和newx[num]中。
与时间段匹配的所选列的新闻总数。如果num>0,则在Form 2上显示。i=0--num,依次显示newx[i]和Button。如果num=0,则提示“本次新闻数量为0”,并以信息提示。
3.2 界面设计
主界面有行业按钮(见图1),“工程学院”,“铸造学院”,“中国工程院”,“焊接行业”,“军工爱好者”等点击对应按钮进入对应的程序,关键代码为:
mainwin = Tk()
mainwin.title('智能信息采集器')
mainwin.geometry('500x100+450+100')
mainwin.resizable(0, 0)
mainwin["background"]="LightSkyBlue"
openscetc=Button(mainwin, text="四川工程", command=四川工程).place(x=30, y=35)
opencast=Button(mainwin, text="casting academies", command=opencasting).place(x=136, y=35)
openmil=Button(mainwin, text="军迷", command=军迷).place(x=350, y=35)
openweld=Button(mainwin, text="焊接行业", command=焊接公司).place(x=244, y=35)
mainwin.mainloop()
点击打开按钮打开对应的信息采集器。图2是焊接行业资讯采集器。
3.3 网页分析
爬虫获取网页数据的基本流程是:发送请求,获取响应数据,解析提取数据,将爬取结果展示给用户。发送请求可以使用 requests 模块或 selenium 模块。解析数据可以是re-regular,bs4(BeautifulSoup4)或者xpath。经过技术研究,项目组采用requests模块和xpath。标题和日期通常是不同的xpath。使用xpath1/text()抓取消息标题,xpath1/@href 抓取消息的链接,使用xpath2/text() 抓取消息的日期,关键代码为[3, 4]:
导入请求
从 lxml 导入 etree
导入浏览器
html=requests.get(url, headers=heade)
html.encoding='简体中文'
新闻=etree.HTML(html.text)
newstitle=news.xpath('xpath1/text()') #抓取新闻的标题
newsurl=news.xpath('xpath1/@href') #抓取新闻的链接
newsdate=news.xpath('xpath2/text()') #抓取新闻的日期
3.4 xpath 处理
DockSide中获取的xpath有多种类型,需要根据情况进行处理。以下是 3 种常见的 xpath 类型:
① 一页有 1 个 xpath。最简单的情况是在网页上复制两条消息后比较括号中的数字,删除数字变化的括号,然后就可以抓取xpath下的所有消息了。② 同一个页面有1个以上的xpath。按照①的方法删除方括号后,只能抓取网页上的部分消息。这时候需要把没有抓到的xpath复制下来,一一对比,再运行一遍,直到所有的消息都被抓到。③ 只保留root xpath。在DockSide中获取的xpath通常有几个层次,但是由于站群系统的不同,无法成功获取。解决方案是只留下根 xpath 以成功获取。
3.5 获取网址
在通过xpath/@href方法获取的URL中,需要打印出来观察。通常有两种情况:①获取完整的URL,可以直接使用;②只抓取网页日期部分,可以通过预设的preurl解析。
3.6 获取日期
xpath2/text() 捕获的消息日期和日期统一为 yyyy-mm-dd 格式。同样通过打印观察,通常有以下三种情况: ①分隔符不是破折号。对于 yyyy/mm/dd、mm、month、dd、yyyy 形式的日期,用 replace 替换它们。date = date.replace('/','-').replace(('year','-').replace((month'','-').replace(('day','')②开头和结尾还有其他字符,对于[yyyy-mm-dd]形式的日期,用replace替换。date=date.replace('[','').replace((']', '-')③包括时间。对于2021-01-31 10:01形式的日期数据,如果只剩下年月日,则截取前10个字符。date=date[0:10]
3.7 时间段处理
消息时间段分为今天、近三天、本周、近一个月。确定 time.mktime(今天)和 timeStamp 之间的差异。
今天 = time.localtime(time.time())
今天 = int(time.mktime(今天))
timeArray=time.strptime(timelist, '%Y-%m-%d')
timeStamp = int(time.mktime(timeArray))
shij=(today-timeStamp)/(24*3600)
图3是图2中“焊接质量检验+中国工程焊接协会+焊接之家+近一个月”的搜索结果。
4。结论
智能资讯采集器应用爬虫技术开发,可分别采集四川工程职业技术学院、铸造院校、焊接行业、军队网站最新网络新闻,满足需求不同的用户。提供给用户免费使用后,受到了用户的欢迎。
科学技术日新月异,您可以利用这些技术开发一些适合自己使用的小程序,以满足您的个性化需求。利用该项目技术开发的作品参加了一系列大学生竞赛,并获得了多项奖项。
【参考】
[1] 戴远,郑传兴. 基于Python的南京二手房数据抓取与分析[J]. 计算机时代,2021 (1): 37-40+45.
[2] 李文华. 网络爬虫技术原理分析[J]. 福建计算机, 2021, 37 (1): 95-96.
[3] 徐景贤,林金成,程玉梦。Selenium框架下反爬虫程序设计与实现[J]. 福建计算机, 2021, 37 (1): 26-29.
[4] 傅军,郑定元,张俊宁,等。Python爬虫技术在文献计量学中的应用[J]. 计算机产品与流通,2019 (7): 133. 查看全部
网站程序自带的采集器采集文章(竹愈)
付军、付新竹、吴高静、丁采钰、龙辉阳、熊子淇
智能信息采集器的软件开发实践
傅军1、傅新柱2、吴高静1、丁才玉1、龙慧阳1、熊子琪1
(1.四川工程技术学院材料工程系, 德阳 618000;
2.德阳市第五中学初中, 德阳 618000)
【摘要】应用爬虫技术开发的智能信息采集器可以帮助用户及时获取工程院校、铸造院校、焊接行业、军队网站的最新动态。本文采用tkinter进行界面设计,利用python爬虫技术对xpath、抓包日期、网址进行处理,从而成功爬取消息并获取消息的URL。用户可以进一步打开自己感兴趣的网页进行详细阅读。
【摘要】利用爬虫技术开发的智能信息采集器,可以帮助用户及时获取工程学院、铸造学院、焊接行业和军事网站的最新信息。论文选用tkinter进行界面设计,利用python爬虫技术对xpath、抓取日期、url进行处理,顺利实现了抓取消息和获取消息的url。用户可以进一步打开感兴趣的网页进行详细阅读。
【关键词】爬虫技术;信息采集; Python; 二次开发;路径
【关键词】爬虫技术;信息采集;Python; 二次开发;路径
[CLC 编号] TP311.5 [文档代码] A [文章 编号] 1673-1069 (2021)05-0192-02
1 简介
网络信息时代,信息海量而复杂。科研院所、工业企业和政府部门需要了解最新的科学前沿、法律法规和工作动态的网络信息来做出决策。但他们很难找到杂乱无章的网页。团队在完成省级项目“了不起,我的祖国——建国以来重大科技成果”的过程中,往往需要紧跟科技成果和技术发展的步伐。> 进行消息搜索。如果一一搜索这些网站列,耗时较长,往往容易漏掉。团队设计了“智能信息采集器”
2 技术基础
2.1 蟒蛇
网络爬虫根据一定的规则自动从万维网上爬取信息,并可以采集他们可以访问的页面的所有内容来获取或更新这些网站的内容和检索方式。目前获取网页信息的技术手段包括python爬虫技术和各种爬虫框架。团队采用python爬虫技术进行设计。tkinter 模块是python的标准GUI工具包界面,可以轻松实现很多直观的功能。tkinter是python自带的库,不用下载安装就可以直接使用[1]。
2.2 获取 xpath
xpath 是一种用于在 XML 文档中查找信息的语言。在浏览器中,打开网页,右击“Inspect Element”,打开“DockSide”,点击左上角的“Select an element in the page to inspect it (Ctrl+Shift+C)”按钮,点击网页中的消息,在html代码中,右键“copy/xpath”得到消息的xpath[2]。
3 开发实践
3.1 整体设计
变量表。各节的局部变量newa、urla、timea;全局变量 newlist、urllist、timelist;每个单元名使用label,后面跟着label2、label3... 每个单元名下面有几列,使用checkboxes CheckButton,CheckButton被命名为单元名+列名缩写,与checkbox Checkbutton.variable链接。
清空newlist、urllist、timelist;如果选择了某个单元的列,则运行相应的def;运行后,所有捕捉到的新闻标题都会被添加到newlist,url会被添加到urllist,日期会被添加到timelist。运行完所有列后,得到newlist的长度数。urlx, newx, timx 清零,num=0;得到想要的时间段zj变量值。从i=0到number,依次读取timelist[i]的值。如果时间匹配zj,则num加1,将newlist和uellist对应的值加到urlx[num]和newx[num]中。
与时间段匹配的所选列的新闻总数。如果num>0,则在Form 2上显示。i=0--num,依次显示newx[i]和Button。如果num=0,则提示“本次新闻数量为0”,并以信息提示。
3.2 界面设计
主界面有行业按钮(见图1),“工程学院”,“铸造学院”,“中国工程院”,“焊接行业”,“军工爱好者”等点击对应按钮进入对应的程序,关键代码为:
mainwin = Tk()
mainwin.title('智能信息采集器')
mainwin.geometry('500x100+450+100')
mainwin.resizable(0, 0)
mainwin["background"]="LightSkyBlue"
openscetc=Button(mainwin, text="四川工程", command=四川工程).place(x=30, y=35)
opencast=Button(mainwin, text="casting academies", command=opencasting).place(x=136, y=35)
openmil=Button(mainwin, text="军迷", command=军迷).place(x=350, y=35)
openweld=Button(mainwin, text="焊接行业", command=焊接公司).place(x=244, y=35)
mainwin.mainloop()
点击打开按钮打开对应的信息采集器。图2是焊接行业资讯采集器。
3.3 网页分析
爬虫获取网页数据的基本流程是:发送请求,获取响应数据,解析提取数据,将爬取结果展示给用户。发送请求可以使用 requests 模块或 selenium 模块。解析数据可以是re-regular,bs4(BeautifulSoup4)或者xpath。经过技术研究,项目组采用requests模块和xpath。标题和日期通常是不同的xpath。使用xpath1/text()抓取消息标题,xpath1/@href 抓取消息的链接,使用xpath2/text() 抓取消息的日期,关键代码为[3, 4]:
导入请求
从 lxml 导入 etree
导入浏览器
html=requests.get(url, headers=heade)
html.encoding='简体中文'
新闻=etree.HTML(html.text)
newstitle=news.xpath('xpath1/text()') #抓取新闻的标题
newsurl=news.xpath('xpath1/@href') #抓取新闻的链接
newsdate=news.xpath('xpath2/text()') #抓取新闻的日期
3.4 xpath 处理
DockSide中获取的xpath有多种类型,需要根据情况进行处理。以下是 3 种常见的 xpath 类型:
① 一页有 1 个 xpath。最简单的情况是在网页上复制两条消息后比较括号中的数字,删除数字变化的括号,然后就可以抓取xpath下的所有消息了。② 同一个页面有1个以上的xpath。按照①的方法删除方括号后,只能抓取网页上的部分消息。这时候需要把没有抓到的xpath复制下来,一一对比,再运行一遍,直到所有的消息都被抓到。③ 只保留root xpath。在DockSide中获取的xpath通常有几个层次,但是由于站群系统的不同,无法成功获取。解决方案是只留下根 xpath 以成功获取。
3.5 获取网址
在通过xpath/@href方法获取的URL中,需要打印出来观察。通常有两种情况:①获取完整的URL,可以直接使用;②只抓取网页日期部分,可以通过预设的preurl解析。
3.6 获取日期
xpath2/text() 捕获的消息日期和日期统一为 yyyy-mm-dd 格式。同样通过打印观察,通常有以下三种情况: ①分隔符不是破折号。对于 yyyy/mm/dd、mm、month、dd、yyyy 形式的日期,用 replace 替换它们。date = date.replace('/','-').replace(('year','-').replace((month'','-').replace(('day','')②开头和结尾还有其他字符,对于[yyyy-mm-dd]形式的日期,用replace替换。date=date.replace('[','').replace((']', '-')③包括时间。对于2021-01-31 10:01形式的日期数据,如果只剩下年月日,则截取前10个字符。date=date[0:10]
3.7 时间段处理
消息时间段分为今天、近三天、本周、近一个月。确定 time.mktime(今天)和 timeStamp 之间的差异。
今天 = time.localtime(time.time())
今天 = int(time.mktime(今天))
timeArray=time.strptime(timelist, '%Y-%m-%d')
timeStamp = int(time.mktime(timeArray))
shij=(today-timeStamp)/(24*3600)
图3是图2中“焊接质量检验+中国工程焊接协会+焊接之家+近一个月”的搜索结果。
4。结论
智能资讯采集器应用爬虫技术开发,可分别采集四川工程职业技术学院、铸造院校、焊接行业、军队网站最新网络新闻,满足需求不同的用户。提供给用户免费使用后,受到了用户的欢迎。
科学技术日新月异,您可以利用这些技术开发一些适合自己使用的小程序,以满足您的个性化需求。利用该项目技术开发的作品参加了一系列大学生竞赛,并获得了多项奖项。
【参考】
[1] 戴远,郑传兴. 基于Python的南京二手房数据抓取与分析[J]. 计算机时代,2021 (1): 37-40+45.
[2] 李文华. 网络爬虫技术原理分析[J]. 福建计算机, 2021, 37 (1): 95-96.
[3] 徐景贤,林金成,程玉梦。Selenium框架下反爬虫程序设计与实现[J]. 福建计算机, 2021, 37 (1): 26-29.
[4] 傅军,郑定元,张俊宁,等。Python爬虫技术在文献计量学中的应用[J]. 计算机产品与流通,2019 (7): 133.
网站程序自带的采集器采集文章(Google研发的数据采集插件,自带反爬虫能力,非常容易上手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-04-11 10:18
几乎每个人都有从网上批量获取信息的需求,比如需要批量采集网站邮箱,批量采集1688、58个商户信息都一样城市,联系方式,如果你想学习编程语言?
几乎每个人都有从网上批量获取信息的需求,比如需要批量采集网站邮箱,批量采集1688、58个商户信息都一样城市,联系信息,如果您想学习编程语言?我看到很多人连软件都不会安装,更别说一门完整的编程语言,还要学会纠正网络知识;学习优采云 软件?一是贵,二是操作很麻烦。
今天推荐一个谷歌开发的data采集插件。这个插件可以自带cookies和反爬能力。这是非常容易使用。按照流程,基本10分钟就能学会。我也经常在采集微博、知乎、豆瓣、58同城、大众点评、汽车之家等网站上使用它的内容,非常方便。
网络爬虫是谷歌强大的插件库中一个非常强大的数据采集插件。它具有强大的反爬虫能力。只需在插件上简单设置,即可快速抓取知乎、短书、豆瓣、大众、58及90%以上的大中小网站,包括文字、图片、表格等内容,最后快速导出csv格式文件。谷歌官方对网络爬虫的描述是:
使用我们的扩展,您可以创建一个网站应该如何遍历以及应该提取什么的计划(站点地图)。使用这些站点地图,网络爬虫将相应地导航站点并提取所有数据。剪辑数据可以稍后导出为 CSV。
本系列是关于网络爬虫的介绍。它将完整介绍该过程。以知乎、简书等网站为例介绍如何采集文字、表格、多元素抓取、不规则分页爬取、二次分页爬取、动态网站 爬取,以及一些反爬取技术。
好了,今天就给大家介绍一下网络爬虫的安装以及完整的爬取过程。
一、网络爬虫的安装
Web scraper 是谷歌浏览器的扩展插件。它只需要安装在谷歌浏览器上。介绍两种安装方式:
1、在google浏览器中打开more tools下的扩展——进入chrome在线应用点——搜索web scraper——然后点击安装,如下图。
不过上面的安装方法需要翻墙到国外的网站,所以需要使用vpn,如果有vpn的话可以用这个方法,如果没有的话可以用下面的第二种方法:
2、传递链接:密码:m672,下载网络爬虫安装程序。然后将安装程序直接拖入chrome中的扩展中即可完成安装。
完成后可立即使用。
二、以知乎为例介绍网络爬虫的完整爬取流程
1、打开目标网站,这里以采集知乎第一大v张家伟的follower为例,需要爬取的是follower的名字知乎 、答案数、文章 帖子数和关注者数。
2、在网页上右击选择Inspect选项,或者使用快捷键Ctrl+Shift+I/F12打开Web Scraper。
3、 打开后点击创建站点地图,选择创建站点地图,创建站点地图。
点击create sitemap后,会得到如图所示的页面。您需要填写站点地图名称,即站点名称。可以随便写,自己看懂;还需要填写start url,也就是抓取页面的链接。填写完成后点击create sitemap,完成sitemap的创建。
详细情况如下:
4、设置主选择器:选择采集范围
接下来是重中之重。这里先介绍一下网络爬虫的爬取逻辑:需要设置一个一级选择器(selector)来设置要爬取的范围;在一级选择器下创建二级选择器(selector),并设置需要爬取的元素和内容。
以张家伟的以下对象为例。我们的作用域是张家伟跟随的对象,所以我们需要为这个作用域创建一个选择器;而张嘉伟关注对象的关注人数和文章为二次选择。设备的内容。具体步骤如下:
(1) 添加新选择器创建一级选择器Selector:
点击后可以得到下面的页面,需要抓取的内容就设置在这个页面上。
id:命名这个选择器。出于同样的原因,您可以自己理解它。这里叫加味废品。
类型:就是要抓取的内容的类型,比如元素元素/文本文本/链接链接/图片图片/动态加载中的元素向下滚动等。这里如果有多个元素,选择元素。
选择器:指选择要抓取的内容,点击选择可以选择页面上的内容。这部分将在下面详细描述。
勾选Multiple:勾选Multiple前面的小框,因为要选择多个元素而不是单个元素,勾选后,爬虫插件会识别页面下具有相同属性的内容;
(2)这一步需要设置选中的内容,点击select选项下的select,得到如下图:
然后将鼠标移动到需要选择的内容上。这时候你需要的内容会变成绿色,表示被选中。这里需要提醒一下。如果您需要的内容是多元素,则需要选择所有元素。例如,如下图所示,绿色表示选中的内容在绿色范围内。
选择内容范围后,点击鼠标,选中的内容范围会变成红色,如下图:
当一个内容变为红色时,我们可以选择下一个内容。点击后,网络爬虫会自动识别你想要的内容,元素相同的内容会变成红色。如下所示:
检查此页面上我们需要的所有内容都变为红色后,您可以单击完成选择选项,您可以得到以下图片:
单击保存选择器以保存设置。至此,第一级选择器就创建好了。
5、设置二级选择器:选择需要采集的元素内容。
(1)点击下图中红框进入一级选择器jiawei-scrap:
(2)单击添加新选择器以创建辅助选择器以选择特定内容。
得到如下图,和一级选择器的内容一样,只是设置不同。
id:表示正在抓取哪个字段,可以取字段的英文,比如要选择“author”,就写“writer”;
类型:这里选择Text选项,因为要抓取的文本内容;
Multiple:Multiple前面的小框不要勾选,因为这里是要抓取的单个元素;
保留设置:保留其余未提及部分的默认设置。
(3)点击选择选项后,将鼠标移动到特定元素上,该元素会变成黄色,如下图:
点击特定元素后,该元素会变为红色,表示内容被选中。
(4)点击完成选择完成选择,然后点击保存选择器完成对感兴趣对象名称的选择知乎。
重复以上操作,直到选择好要爬的田地。
(5)点击红框查看采集的内容。
数据预览可以看到采集的内容,编辑可以修改设置的内容。
6、爬取数据
(1)只需要设置所有的Selector,就可以开始爬取数据了,点击爬图,
选择泽刮;:
(2)点击后会跳转到时间设置页面,如下图,因为采集个数不大,可以保存默认,点击开始抓取,一个窗口会弹出,正式开始采集 已经。
(3)过一会就可以得到采集的效果了,如下图:
(4)选择sitemap下的export data as csv选项,将采集的结果以表格的形式导出。
表格效果:
以上就是以知乎为例介绍采集的基本步骤和设置。虽然有很多细节,但经过仔细计算,步骤并不多。基本上10分钟就能完全掌握采集。不管是什么类型的网站,设置的基本流程大致相同,有兴趣的可以仔细研究一下。 查看全部
网站程序自带的采集器采集文章(Google研发的数据采集插件,自带反爬虫能力,非常容易上手)
几乎每个人都有从网上批量获取信息的需求,比如需要批量采集网站邮箱,批量采集1688、58个商户信息都一样城市,联系方式,如果你想学习编程语言?
几乎每个人都有从网上批量获取信息的需求,比如需要批量采集网站邮箱,批量采集1688、58个商户信息都一样城市,联系信息,如果您想学习编程语言?我看到很多人连软件都不会安装,更别说一门完整的编程语言,还要学会纠正网络知识;学习优采云 软件?一是贵,二是操作很麻烦。
今天推荐一个谷歌开发的data采集插件。这个插件可以自带cookies和反爬能力。这是非常容易使用。按照流程,基本10分钟就能学会。我也经常在采集微博、知乎、豆瓣、58同城、大众点评、汽车之家等网站上使用它的内容,非常方便。
网络爬虫是谷歌强大的插件库中一个非常强大的数据采集插件。它具有强大的反爬虫能力。只需在插件上简单设置,即可快速抓取知乎、短书、豆瓣、大众、58及90%以上的大中小网站,包括文字、图片、表格等内容,最后快速导出csv格式文件。谷歌官方对网络爬虫的描述是:
使用我们的扩展,您可以创建一个网站应该如何遍历以及应该提取什么的计划(站点地图)。使用这些站点地图,网络爬虫将相应地导航站点并提取所有数据。剪辑数据可以稍后导出为 CSV。
本系列是关于网络爬虫的介绍。它将完整介绍该过程。以知乎、简书等网站为例介绍如何采集文字、表格、多元素抓取、不规则分页爬取、二次分页爬取、动态网站 爬取,以及一些反爬取技术。
好了,今天就给大家介绍一下网络爬虫的安装以及完整的爬取过程。
一、网络爬虫的安装
Web scraper 是谷歌浏览器的扩展插件。它只需要安装在谷歌浏览器上。介绍两种安装方式:
1、在google浏览器中打开more tools下的扩展——进入chrome在线应用点——搜索web scraper——然后点击安装,如下图。
不过上面的安装方法需要翻墙到国外的网站,所以需要使用vpn,如果有vpn的话可以用这个方法,如果没有的话可以用下面的第二种方法:
2、传递链接:密码:m672,下载网络爬虫安装程序。然后将安装程序直接拖入chrome中的扩展中即可完成安装。
完成后可立即使用。
二、以知乎为例介绍网络爬虫的完整爬取流程
1、打开目标网站,这里以采集知乎第一大v张家伟的follower为例,需要爬取的是follower的名字知乎 、答案数、文章 帖子数和关注者数。
2、在网页上右击选择Inspect选项,或者使用快捷键Ctrl+Shift+I/F12打开Web Scraper。
3、 打开后点击创建站点地图,选择创建站点地图,创建站点地图。
点击create sitemap后,会得到如图所示的页面。您需要填写站点地图名称,即站点名称。可以随便写,自己看懂;还需要填写start url,也就是抓取页面的链接。填写完成后点击create sitemap,完成sitemap的创建。
详细情况如下:
4、设置主选择器:选择采集范围
接下来是重中之重。这里先介绍一下网络爬虫的爬取逻辑:需要设置一个一级选择器(selector)来设置要爬取的范围;在一级选择器下创建二级选择器(selector),并设置需要爬取的元素和内容。
以张家伟的以下对象为例。我们的作用域是张家伟跟随的对象,所以我们需要为这个作用域创建一个选择器;而张嘉伟关注对象的关注人数和文章为二次选择。设备的内容。具体步骤如下:
(1) 添加新选择器创建一级选择器Selector:
点击后可以得到下面的页面,需要抓取的内容就设置在这个页面上。
id:命名这个选择器。出于同样的原因,您可以自己理解它。这里叫加味废品。
类型:就是要抓取的内容的类型,比如元素元素/文本文本/链接链接/图片图片/动态加载中的元素向下滚动等。这里如果有多个元素,选择元素。
选择器:指选择要抓取的内容,点击选择可以选择页面上的内容。这部分将在下面详细描述。
勾选Multiple:勾选Multiple前面的小框,因为要选择多个元素而不是单个元素,勾选后,爬虫插件会识别页面下具有相同属性的内容;
(2)这一步需要设置选中的内容,点击select选项下的select,得到如下图:
然后将鼠标移动到需要选择的内容上。这时候你需要的内容会变成绿色,表示被选中。这里需要提醒一下。如果您需要的内容是多元素,则需要选择所有元素。例如,如下图所示,绿色表示选中的内容在绿色范围内。
选择内容范围后,点击鼠标,选中的内容范围会变成红色,如下图:
当一个内容变为红色时,我们可以选择下一个内容。点击后,网络爬虫会自动识别你想要的内容,元素相同的内容会变成红色。如下所示:
检查此页面上我们需要的所有内容都变为红色后,您可以单击完成选择选项,您可以得到以下图片:
单击保存选择器以保存设置。至此,第一级选择器就创建好了。
5、设置二级选择器:选择需要采集的元素内容。
(1)点击下图中红框进入一级选择器jiawei-scrap:
(2)单击添加新选择器以创建辅助选择器以选择特定内容。
得到如下图,和一级选择器的内容一样,只是设置不同。
id:表示正在抓取哪个字段,可以取字段的英文,比如要选择“author”,就写“writer”;
类型:这里选择Text选项,因为要抓取的文本内容;
Multiple:Multiple前面的小框不要勾选,因为这里是要抓取的单个元素;
保留设置:保留其余未提及部分的默认设置。
(3)点击选择选项后,将鼠标移动到特定元素上,该元素会变成黄色,如下图:
点击特定元素后,该元素会变为红色,表示内容被选中。
(4)点击完成选择完成选择,然后点击保存选择器完成对感兴趣对象名称的选择知乎。
重复以上操作,直到选择好要爬的田地。
(5)点击红框查看采集的内容。
数据预览可以看到采集的内容,编辑可以修改设置的内容。
6、爬取数据
(1)只需要设置所有的Selector,就可以开始爬取数据了,点击爬图,
选择泽刮;:
(2)点击后会跳转到时间设置页面,如下图,因为采集个数不大,可以保存默认,点击开始抓取,一个窗口会弹出,正式开始采集 已经。
(3)过一会就可以得到采集的效果了,如下图:
(4)选择sitemap下的export data as csv选项,将采集的结果以表格的形式导出。
表格效果:
以上就是以知乎为例介绍采集的基本步骤和设置。虽然有很多细节,但经过仔细计算,步骤并不多。基本上10分钟就能完全掌握采集。不管是什么类型的网站,设置的基本流程大致相同,有兴趣的可以仔细研究一下。
网站程序自带的采集器采集文章(网站程序自带的采集器采集文章到云端,选择某篇文章即可获取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-10 00:02
网站程序自带的采集器采集文章到云端,选择某篇文章即可获取那篇文章的源代码,可以去看看,提取网站文章的内容其实就是给浏览器发http请求,我们把网站的那些代码保存起来,这样就可以方便的去采集这些资源,修改源代码自己或者找人修改即可。然后保存到本地上传网站即可。
新网页也可以被爬,采集视频都可以被爬,
不少爬虫的正则表达式解析不完整。另外,不少网站设计有隐藏规则。
这个问题问得真的好,你的最终目的是爬取有价值的文章,包括但不限于:1,搜索引擎里面的文章(可以只抓取某些关键词的文章);2,论坛上的内容(不要浏览站内连接,可以抓取内容区的);3,链接到某些c/s网站的内容;4,可以被屏蔽的文章等等,你的要求的确能很高,但通常来说凡是长得有点眼熟的url都被爬取过,例如各种博客或者新闻网站。
不过我感觉目前采集工具还是不足以解决这个问题的,主要是依靠采集者的敏锐和直觉,不知道自己想要爬取的是什么东西。爬虫必须具备自己的优势,才能进一步改善自己,比如爬取效率,可以变得快一些,或者降低爬取难度。
直接参考《youtube各个频道的采集,本人是部分采集自我工程师工作资料, 查看全部
网站程序自带的采集器采集文章(网站程序自带的采集器采集文章到云端,选择某篇文章即可获取)
网站程序自带的采集器采集文章到云端,选择某篇文章即可获取那篇文章的源代码,可以去看看,提取网站文章的内容其实就是给浏览器发http请求,我们把网站的那些代码保存起来,这样就可以方便的去采集这些资源,修改源代码自己或者找人修改即可。然后保存到本地上传网站即可。
新网页也可以被爬,采集视频都可以被爬,
不少爬虫的正则表达式解析不完整。另外,不少网站设计有隐藏规则。
这个问题问得真的好,你的最终目的是爬取有价值的文章,包括但不限于:1,搜索引擎里面的文章(可以只抓取某些关键词的文章);2,论坛上的内容(不要浏览站内连接,可以抓取内容区的);3,链接到某些c/s网站的内容;4,可以被屏蔽的文章等等,你的要求的确能很高,但通常来说凡是长得有点眼熟的url都被爬取过,例如各种博客或者新闻网站。
不过我感觉目前采集工具还是不足以解决这个问题的,主要是依靠采集者的敏锐和直觉,不知道自己想要爬取的是什么东西。爬虫必须具备自己的优势,才能进一步改善自己,比如爬取效率,可以变得快一些,或者降低爬取难度。
直接参考《youtube各个频道的采集,本人是部分采集自我工程师工作资料,
网站程序自带的采集器采集文章(百度搜索引擎如何解救黑帽SEO操作所带来的风险呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-09 14:00
简介:随着百度搜索引擎等各大搜索引擎算法的不断变化,本站采用黑帽SEO操作。一旦被各大搜索引擎发现,将导致致命的灾难。我们应该如何拯救黑帽SEO操作?陆雨华的SEM带来的风险,将说明黑帽SEO操作被处罚后的应对措施。我会根据我自己的观点与大家分享。网站黑帽SEO操作一旦被搜索引擎发现,我们应该采取什么样的应对措施。
一、控制关键词密度策略
百度搜索引擎明文规定页面不能有太多关键词,不要插入无关的关键词,否则会被视为作弊手段,很可能会被列入黑名单。关于 关键词 的密度,网上有成千上万的意见。陆雨华 SEM 认为,2%~7% 是最好的范围。对于新的网站,关键词 的密度应该尽可能小。如果网站一上线就出现了高密度的关键词布局,很容易让搜索引擎认为你做了关键词堆叠,从而受到惩罚。
二、网站内容始终保持“质量”
如果我们使用黑帽SEO操作,我们会在早期继续使用各种采集器到采集并更新网站的内容。如果我们不小心被搜索引擎发现了,搜索引擎惩罚我们网站,可能是因为网站文章的质量太低了,而且大部分来自采集,很容易被搜索引擎认为是一文不值的网站的含义。现在搜索引擎已经进入用户体验时代,不再是“内容为王,外链为王”的时代。一定要时刻记住一个网站,内容永远为王,如果要网站关键词的质量好,关键词排名稳定。我们必须向 网站 提供最高质量的内容,为了让我们的网站 有很高的权重,原创文章 是必不可少的。大量低质量的文章或采集文章很可能会被搜索引擎惩罚。而对于网站的后期和早期开发,优化水平会带来严重的危害,我们需要时刻牢记这一点,并不断思考。
三、现场优化-柱链处理策略
A 网站除了有高质量的内容,链接也是必不可少的。搜索引擎可以通过内部链接、外部链接、链接网络快速发现网站内的新页面,还可以通过链接指向网站的页面权重和分布。网站内部链接的流畅度在搜索引擎优化中起着非常重要的作用。我们可以使用站长工具检查整个网站。如果死链接过多,将直接影响搜索引擎蜘蛛对网页的抓取和抓取。会造成大量的404页面或者一些错误页面,搜索引擎很可能会认为网站是垃圾站或者是霸凌类型的网站,这也是造成网站的重要因素@> 被降级。一。
四、网站安全策略
正常情况下,网站降级,包括空间因素、网站挂马因素、服务器攻击因素。导航网站 无法打开。一些黑客通过一些黑客技术修改我们的网站。重要文件,导航网站drop权限等。我们需要做好网站安全策略。一旦出现这些情况网站,我们可以采取对策,找出危害安全的因素,加以解决,采取相应的安全措施。设置一些重要文件的写权限,FTP密码尽量复杂,每隔一周备份一次网站的数据,每隔一周检查一次网站的站点。这样可以有效地将网站尽快恢复到原来的样子。
五、外链蜘蛛策略
我们知道,一个网站被搜索引擎惩罚后,并不意味着搜索引擎会停止访问你,而是把我们放在一个与世隔绝的地方,让我们静静地反思,并给我们一个网站采用黑帽SEO运行一个时间调查期。这个时间可长可短,可能是半年,也可能是一年,也可能是永久的。这取决于我们采取的黑帽SEO操作的轻重缓急,关键在于我们的应对措施。网站的更新和外链工作需要持续稳定的运行,同时要注重质量。发布一些优质的外链吸引蜘蛛的注意,更新优质的原创内容,善待蜘蛛。经过这样的一段时间,搜索引擎会发现你的网站
本文小结:以上文章由idsem群主编陆雨华SEM发表,仅代表个人观点,但在这里,卢雨华SEM推荐大家常年在水边走一走轮回,迟早有一天会掉进河里,不要用黑帽法,用白帽SEO操作,让网站关键词永久排名第一,永不丢失风雨。也希望各位兄弟姐妹,在转载的时候,能留下我的小脚印: 查看全部
网站程序自带的采集器采集文章(百度搜索引擎如何解救黑帽SEO操作所带来的风险呢?)
简介:随着百度搜索引擎等各大搜索引擎算法的不断变化,本站采用黑帽SEO操作。一旦被各大搜索引擎发现,将导致致命的灾难。我们应该如何拯救黑帽SEO操作?陆雨华的SEM带来的风险,将说明黑帽SEO操作被处罚后的应对措施。我会根据我自己的观点与大家分享。网站黑帽SEO操作一旦被搜索引擎发现,我们应该采取什么样的应对措施。
一、控制关键词密度策略
百度搜索引擎明文规定页面不能有太多关键词,不要插入无关的关键词,否则会被视为作弊手段,很可能会被列入黑名单。关于 关键词 的密度,网上有成千上万的意见。陆雨华 SEM 认为,2%~7% 是最好的范围。对于新的网站,关键词 的密度应该尽可能小。如果网站一上线就出现了高密度的关键词布局,很容易让搜索引擎认为你做了关键词堆叠,从而受到惩罚。
二、网站内容始终保持“质量”
如果我们使用黑帽SEO操作,我们会在早期继续使用各种采集器到采集并更新网站的内容。如果我们不小心被搜索引擎发现了,搜索引擎惩罚我们网站,可能是因为网站文章的质量太低了,而且大部分来自采集,很容易被搜索引擎认为是一文不值的网站的含义。现在搜索引擎已经进入用户体验时代,不再是“内容为王,外链为王”的时代。一定要时刻记住一个网站,内容永远为王,如果要网站关键词的质量好,关键词排名稳定。我们必须向 网站 提供最高质量的内容,为了让我们的网站 有很高的权重,原创文章 是必不可少的。大量低质量的文章或采集文章很可能会被搜索引擎惩罚。而对于网站的后期和早期开发,优化水平会带来严重的危害,我们需要时刻牢记这一点,并不断思考。
三、现场优化-柱链处理策略
A 网站除了有高质量的内容,链接也是必不可少的。搜索引擎可以通过内部链接、外部链接、链接网络快速发现网站内的新页面,还可以通过链接指向网站的页面权重和分布。网站内部链接的流畅度在搜索引擎优化中起着非常重要的作用。我们可以使用站长工具检查整个网站。如果死链接过多,将直接影响搜索引擎蜘蛛对网页的抓取和抓取。会造成大量的404页面或者一些错误页面,搜索引擎很可能会认为网站是垃圾站或者是霸凌类型的网站,这也是造成网站的重要因素@> 被降级。一。
四、网站安全策略
正常情况下,网站降级,包括空间因素、网站挂马因素、服务器攻击因素。导航网站 无法打开。一些黑客通过一些黑客技术修改我们的网站。重要文件,导航网站drop权限等。我们需要做好网站安全策略。一旦出现这些情况网站,我们可以采取对策,找出危害安全的因素,加以解决,采取相应的安全措施。设置一些重要文件的写权限,FTP密码尽量复杂,每隔一周备份一次网站的数据,每隔一周检查一次网站的站点。这样可以有效地将网站尽快恢复到原来的样子。
五、外链蜘蛛策略
我们知道,一个网站被搜索引擎惩罚后,并不意味着搜索引擎会停止访问你,而是把我们放在一个与世隔绝的地方,让我们静静地反思,并给我们一个网站采用黑帽SEO运行一个时间调查期。这个时间可长可短,可能是半年,也可能是一年,也可能是永久的。这取决于我们采取的黑帽SEO操作的轻重缓急,关键在于我们的应对措施。网站的更新和外链工作需要持续稳定的运行,同时要注重质量。发布一些优质的外链吸引蜘蛛的注意,更新优质的原创内容,善待蜘蛛。经过这样的一段时间,搜索引擎会发现你的网站
本文小结:以上文章由idsem群主编陆雨华SEM发表,仅代表个人观点,但在这里,卢雨华SEM推荐大家常年在水边走一走轮回,迟早有一天会掉进河里,不要用黑帽法,用白帽SEO操作,让网站关键词永久排名第一,永不丢失风雨。也希望各位兄弟姐妹,在转载的时候,能留下我的小脚印:
网站程序自带的采集器采集文章(先看一下官网视频讲解教程(一)采集器的使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-04-08 00:14
1、如果你是新手,一定要先看官网的视频教程。
视频教程由我们的官方培训讲师提供,讲解优采云采集器的使用。每个教程实际上都很短。如果您在开始 采集 教程之前观看这些视频说明,则可以回答大多数问题。
2、XX 网站你能采集吗?XX数据可以是采集吗?
请先参阅第 1 条。
我们在官网视频教程中已经介绍过了,优采云采集器是一个通用的网页采集软件,只要有网站,就可以通过网页浏览,可以看一下内容,大部分都可以是采集(视频比较特殊,具体情况还要分析)。
为了保护您的隐私,您所有的任务和配置都以加密形式存储在云端,除了您可以查看具体内容、您在采集流程中输入的账号密码和您的采集 @采集结果全部存储在您的本地计算机上。但请严格遵守相关法律法规。如果优采云采集器官方收到任何非法采集的举报,将立即暂停账号。
3、为什么采集 数据提前停止了?
如果您遇到 采集 过早停止,请按照以下步骤测试自己:
第 1 步:请确认您可以在浏览器中看到多少内容
有时搜索显示的数字与您最终能看到的数字不一样。请确认你能看到多少条数据,然后判断采集是提前停止还是正常停止。
第二步:采集结果数与浏览器中看到的数不符
在采集过程中,如果遇到这个问题,有两种可能:
第一种可能是采集速度太快,页面加载时间太慢,导致数据采集无法到达页面。
在这种情况下,请增加请求等待时间。等待时间较长后,网页将有足够的时间加载内容。
请求等待时间的设置在启动设置->智能策略,如下图:
第二种可能是你有其他问题
在运行过程中,我们可以在运行界面点击“查看网页”,观察当前网页内容是否正常,是否无法正常显示,是否有异常提示等。
如果出现上述情况,我们可以降低采集的速度,手动输入验证码等方法,至于哪种方法能行,还需要自己测试一下才知道。不同的网站 问题是不同的。没有一个统一的解决方案。
如果您在尝试以上解决方案后仍然无法解决问题,您可以在帮助中心给我们反馈,我们会为您提供解答。
4、为什么 采集 字段不完整?
不完整的字段一般有以下两种情况:
首先,由于列表元素的结构不同,一些元素具有其他元素中没有的字段。这是正常现象。请先确认网页对应元素中是否存在您要的字段。
其次,页面结构发生了变化,这通常发生在同一个搜索结果中收录多个页面结构时,例如搜索引擎搜索结果(包括多种网站)。
在这种情况下,您需要分析具体问题。您可以将您的采集任务导出并发送到我们的官方帮助中心,我们的客服会帮助您进行测试和分析。
5、为什么采集 数据重复?
首先请确认您已经观看了视频教程,并且您的采集任务没有页面类型设置问题,即您错误地将单页面类型设置为列表类型,或者您误解了循环采集 说明。
然后确保您有多个重复的 采集 数据重复或单个 采集 重复的数据。
在采集任务没有被修改的情况下,每次采集任务从采集开始运行,所以每个采集的数据都是重复的,这是正常的。
如果单个采集出现重复数据,请确认是否满足以下条件:
第一种:重复数据是最后一页的数据。这可能是翻到最后一页后无法停止翻页。请尝试修改采集的范围,看看是否还有重复数据。.
第二种:重复数据是中间页的数据,不能直接断定。
以上两种情况,请将你的采集任务上传到帮助中心,我们的客服会帮你测试分析。
6、采集 停止了,是不是又从头开始了?
是的,采集停止后,下次直接启动时,默认按照上次设置从头采集开始。
7、软件崩溃了。重启后左侧数据全为0,是不是数据丢失了?
请放心,您拥有 采集 的数据不会丢失,除非您手动将其删除。
软件异常关闭时,重启后需要手动刷新左侧任务采集中的数据个数。您只需要点击数字,它就会恢复正常。
8、管理员能帮我看看采集任务有什么问题吗
优采云采集器为您提供解决采集问题的两个渠道:QQ客服和帮助中心。
在QQ客服中,一般比较适合问一些比较简单的具体问题。管理员看到后,简单几句就能帮你解决。
如果你遇到复杂的采集问题,特别是只有查看采集任务才能知道的问题,建议你直接发到帮助中心。
帮助中心的问题将由专门的客服人员进行跟踪,所有问题都会得到解答。请尽可能使用帮助中心反馈问题。
9、编辑任务时出现验证码怎么办?
如果编辑任务时出现验证码,软件会自动检测并提示。请根据软件提示手动输入验证码。
需要注意的是,自动检测会有一定的误识别概率。如果判断页面不需要验证码操作,点击取消。
另外,如果软件无法识别,请点击右上角的“手动输入验证码”(蓝色)按钮输入验证码。
10、编辑采集任务时页面显示不正常怎么办?
首先,确保你在 Chrome 浏览器中,直接粘贴 URL 看看是否可以访问。
如果无法打开 Chrome 浏览器,则该软件当前不受支持。您可以向帮助中心举报,我们的客服会帮您测试分析。
如果您在浏览器中可以访问,但在软件中无法访问,请点击右上角的“手动代码”(蓝色)按钮,然后在弹出的窗口中点击进入网站 输入网址的地方,例如点击左上角的网站LOGO或home键等。
正常打开首页后,点击预登录窗口右下角的验证按钮,软件应该可以正常访问了。
有些网址可能不允许用户不访问首页或列表页就直接访问详情页,所以尽量不要直接从详情页采集开始,可以选择从列表页采集开始.
11、操作时需要输入验证码怎么办?
针对这种情况,优采云采集器支持手动输入验证码,但不支持自动输入。
运行过程中的验证码软件会自动检测并提示此处有验证码。
具体流程请按照软件提示进行。
需要注意的是,当软件在运行过程中自动检测到验证码并弹出提示时,采集任务会暂停,手动输入验证码后软件会继续运行当前任务。另外,验证码的自动识别存在一定的误识别概率。如果判断页面没有验证码,点击跳过。连续跳过两次后,软件将不再检测验证码。
12、发布到数据库报错怎么办?
(1)连接问题总结
1)宝塔控制面板
使用本管理工具时,需要注意mysql数据库访问权限设置和远程访问端口的开放情况。
2)localhost,192.168.xxx.xxx
在使用这种类型的主机地址时,需要注意的是需要在本机上开启 MySQL 服务。
3)如果不确定错误,请报告
可以先用navicat判断具体的错误详情
(2)字段映射问题总结
1)字段类型
仅支持数据表中字符串和整数字段的映射(如果需要映射日期字段,需要将数据表中的对应字段改为字符串类型)
2)字段长度
需要注意字段长度能否满足本地采集的数据长度
(3)导出中的错误日志摘要:
Incorrect string value: '\xF0\x9F...' for column 'name' at row 1 的异常发生在 mysql 插入数据时,因为 UTF-8 编码可能是两个、三个或四个字节。Emoji表情或者一些特殊字符是4个字节,而mysql的utf8编码最多3个字节,所以无法插入数据。解决方法如下:
在mysql安装目录下找到my.ini,进行如下修改:
[mysql] default-character-set=utf8mb4 [mysqld] character-set-server=utf8mb4 修改后重启Mysql sudo service mysql restart
通过管理工具将建好的表及对应字段转为utf8mb4 查看全部
网站程序自带的采集器采集文章(先看一下官网视频讲解教程(一)采集器的使用方法)
1、如果你是新手,一定要先看官网的视频教程。
视频教程由我们的官方培训讲师提供,讲解优采云采集器的使用。每个教程实际上都很短。如果您在开始 采集 教程之前观看这些视频说明,则可以回答大多数问题。
2、XX 网站你能采集吗?XX数据可以是采集吗?
请先参阅第 1 条。
我们在官网视频教程中已经介绍过了,优采云采集器是一个通用的网页采集软件,只要有网站,就可以通过网页浏览,可以看一下内容,大部分都可以是采集(视频比较特殊,具体情况还要分析)。
为了保护您的隐私,您所有的任务和配置都以加密形式存储在云端,除了您可以查看具体内容、您在采集流程中输入的账号密码和您的采集 @采集结果全部存储在您的本地计算机上。但请严格遵守相关法律法规。如果优采云采集器官方收到任何非法采集的举报,将立即暂停账号。
3、为什么采集 数据提前停止了?
如果您遇到 采集 过早停止,请按照以下步骤测试自己:
第 1 步:请确认您可以在浏览器中看到多少内容
有时搜索显示的数字与您最终能看到的数字不一样。请确认你能看到多少条数据,然后判断采集是提前停止还是正常停止。
第二步:采集结果数与浏览器中看到的数不符
在采集过程中,如果遇到这个问题,有两种可能:
第一种可能是采集速度太快,页面加载时间太慢,导致数据采集无法到达页面。
在这种情况下,请增加请求等待时间。等待时间较长后,网页将有足够的时间加载内容。
请求等待时间的设置在启动设置->智能策略,如下图:
第二种可能是你有其他问题
在运行过程中,我们可以在运行界面点击“查看网页”,观察当前网页内容是否正常,是否无法正常显示,是否有异常提示等。
如果出现上述情况,我们可以降低采集的速度,手动输入验证码等方法,至于哪种方法能行,还需要自己测试一下才知道。不同的网站 问题是不同的。没有一个统一的解决方案。
如果您在尝试以上解决方案后仍然无法解决问题,您可以在帮助中心给我们反馈,我们会为您提供解答。
4、为什么 采集 字段不完整?
不完整的字段一般有以下两种情况:
首先,由于列表元素的结构不同,一些元素具有其他元素中没有的字段。这是正常现象。请先确认网页对应元素中是否存在您要的字段。
其次,页面结构发生了变化,这通常发生在同一个搜索结果中收录多个页面结构时,例如搜索引擎搜索结果(包括多种网站)。
在这种情况下,您需要分析具体问题。您可以将您的采集任务导出并发送到我们的官方帮助中心,我们的客服会帮助您进行测试和分析。
5、为什么采集 数据重复?
首先请确认您已经观看了视频教程,并且您的采集任务没有页面类型设置问题,即您错误地将单页面类型设置为列表类型,或者您误解了循环采集 说明。
然后确保您有多个重复的 采集 数据重复或单个 采集 重复的数据。
在采集任务没有被修改的情况下,每次采集任务从采集开始运行,所以每个采集的数据都是重复的,这是正常的。
如果单个采集出现重复数据,请确认是否满足以下条件:
第一种:重复数据是最后一页的数据。这可能是翻到最后一页后无法停止翻页。请尝试修改采集的范围,看看是否还有重复数据。.
第二种:重复数据是中间页的数据,不能直接断定。
以上两种情况,请将你的采集任务上传到帮助中心,我们的客服会帮你测试分析。
6、采集 停止了,是不是又从头开始了?
是的,采集停止后,下次直接启动时,默认按照上次设置从头采集开始。
7、软件崩溃了。重启后左侧数据全为0,是不是数据丢失了?
请放心,您拥有 采集 的数据不会丢失,除非您手动将其删除。
软件异常关闭时,重启后需要手动刷新左侧任务采集中的数据个数。您只需要点击数字,它就会恢复正常。
8、管理员能帮我看看采集任务有什么问题吗
优采云采集器为您提供解决采集问题的两个渠道:QQ客服和帮助中心。
在QQ客服中,一般比较适合问一些比较简单的具体问题。管理员看到后,简单几句就能帮你解决。
如果你遇到复杂的采集问题,特别是只有查看采集任务才能知道的问题,建议你直接发到帮助中心。
帮助中心的问题将由专门的客服人员进行跟踪,所有问题都会得到解答。请尽可能使用帮助中心反馈问题。
9、编辑任务时出现验证码怎么办?
如果编辑任务时出现验证码,软件会自动检测并提示。请根据软件提示手动输入验证码。
需要注意的是,自动检测会有一定的误识别概率。如果判断页面不需要验证码操作,点击取消。
另外,如果软件无法识别,请点击右上角的“手动输入验证码”(蓝色)按钮输入验证码。
10、编辑采集任务时页面显示不正常怎么办?
首先,确保你在 Chrome 浏览器中,直接粘贴 URL 看看是否可以访问。
如果无法打开 Chrome 浏览器,则该软件当前不受支持。您可以向帮助中心举报,我们的客服会帮您测试分析。
如果您在浏览器中可以访问,但在软件中无法访问,请点击右上角的“手动代码”(蓝色)按钮,然后在弹出的窗口中点击进入网站 输入网址的地方,例如点击左上角的网站LOGO或home键等。
正常打开首页后,点击预登录窗口右下角的验证按钮,软件应该可以正常访问了。
有些网址可能不允许用户不访问首页或列表页就直接访问详情页,所以尽量不要直接从详情页采集开始,可以选择从列表页采集开始.
11、操作时需要输入验证码怎么办?
针对这种情况,优采云采集器支持手动输入验证码,但不支持自动输入。
运行过程中的验证码软件会自动检测并提示此处有验证码。
具体流程请按照软件提示进行。
需要注意的是,当软件在运行过程中自动检测到验证码并弹出提示时,采集任务会暂停,手动输入验证码后软件会继续运行当前任务。另外,验证码的自动识别存在一定的误识别概率。如果判断页面没有验证码,点击跳过。连续跳过两次后,软件将不再检测验证码。
12、发布到数据库报错怎么办?
(1)连接问题总结
1)宝塔控制面板
使用本管理工具时,需要注意mysql数据库访问权限设置和远程访问端口的开放情况。
2)localhost,192.168.xxx.xxx
在使用这种类型的主机地址时,需要注意的是需要在本机上开启 MySQL 服务。
3)如果不确定错误,请报告
可以先用navicat判断具体的错误详情
(2)字段映射问题总结
1)字段类型
仅支持数据表中字符串和整数字段的映射(如果需要映射日期字段,需要将数据表中的对应字段改为字符串类型)
2)字段长度
需要注意字段长度能否满足本地采集的数据长度
(3)导出中的错误日志摘要:
Incorrect string value: '\xF0\x9F...' for column 'name' at row 1 的异常发生在 mysql 插入数据时,因为 UTF-8 编码可能是两个、三个或四个字节。Emoji表情或者一些特殊字符是4个字节,而mysql的utf8编码最多3个字节,所以无法插入数据。解决方法如下:
在mysql安装目录下找到my.ini,进行如下修改:
[mysql] default-character-set=utf8mb4 [mysqld] character-set-server=utf8mb4 修改后重启Mysql sudo service mysql restart
通过管理工具将建好的表及对应字段转为utf8mb4
网站程序自带的采集器采集文章(影视资源采集工具支持API采集(支持一键建站只需要输入域名选择影视模板) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-04-07 20:20
)
影视资源采集站?为什么是采集影视资源?相信每个视频站的站长都希望网站拥有丰富的资源,而网站拥有大量的用户。如何丰富网站的资源?采集影视资源最常规的方法是熟练使用instr()、mid()函数对采集网站资源。但对于很多没有编程技能的人来说,这确实是一个令人头疼的问题。今天这里的博主给大家分享一个影视资源采集支持API的工具采集(支持一键建站,只需要输入域名选择电影和电视模板)。采集 的方法有:目标台影视资源采集+关键词资源采集(全网资源采集)。很多cms模板网站都是内置的采集,但是内置的采集都是泛化的收录,效果不是特别好。
一、影视资源站收录怎么样?
搜索引擎喜欢收录原创的内容,那么视频怎么会被搜索引擎认为是原创呢?搜索引擎识别原创依靠图像检测,即提取视频中的时间节点图片,对比视频库的图片。当相似度超过一定阈值时,定义为抄袭,不改。网站继续收录。我们可以 伪原创 看视频吗?当然,你只需要剪掉视频的一个角落,或者添加特定的水印来干扰原创图片。并设置适当的透明度,使搜索引擎对视频的检测方式无效,从而达到原创的效果。该软件支持批量视频伪原创。
对于声音检测,一般的搜索引擎可以提取视频文本并转换成文本,对比文本的内容,通过分词功能提取关键词来对比内容,所以这时候我们需要插入背景声音干扰 提取文本对比度的行为。
二、视频资源站对服务器的要求
今天的网站视频分辨率越来越高,最常见的就是480P、720P、1024P、1080P视频,而现在最基本的480P普通视频大小都在500M以上,更别说高质量视频了:高清、超高清、蓝光视频大小。这些也意味着视频服务器的带宽也更高,而影响文件传输率的因素之一就是视频服务器使用的带宽。一个视频网站一开始宽带配置没必要那么高。访问 网站 视频的用户并不多,因此不会有 网站 冻结。当用户越来越多时,视频服务器的带宽需要升级。
查看全部
网站程序自带的采集器采集文章(影视资源采集工具支持API采集(支持一键建站只需要输入域名选择影视模板)
)
影视资源采集站?为什么是采集影视资源?相信每个视频站的站长都希望网站拥有丰富的资源,而网站拥有大量的用户。如何丰富网站的资源?采集影视资源最常规的方法是熟练使用instr()、mid()函数对采集网站资源。但对于很多没有编程技能的人来说,这确实是一个令人头疼的问题。今天这里的博主给大家分享一个影视资源采集支持API的工具采集(支持一键建站,只需要输入域名选择电影和电视模板)。采集 的方法有:目标台影视资源采集+关键词资源采集(全网资源采集)。很多cms模板网站都是内置的采集,但是内置的采集都是泛化的收录,效果不是特别好。
一、影视资源站收录怎么样?
搜索引擎喜欢收录原创的内容,那么视频怎么会被搜索引擎认为是原创呢?搜索引擎识别原创依靠图像检测,即提取视频中的时间节点图片,对比视频库的图片。当相似度超过一定阈值时,定义为抄袭,不改。网站继续收录。我们可以 伪原创 看视频吗?当然,你只需要剪掉视频的一个角落,或者添加特定的水印来干扰原创图片。并设置适当的透明度,使搜索引擎对视频的检测方式无效,从而达到原创的效果。该软件支持批量视频伪原创。
对于声音检测,一般的搜索引擎可以提取视频文本并转换成文本,对比文本的内容,通过分词功能提取关键词来对比内容,所以这时候我们需要插入背景声音干扰 提取文本对比度的行为。
二、视频资源站对服务器的要求
今天的网站视频分辨率越来越高,最常见的就是480P、720P、1024P、1080P视频,而现在最基本的480P普通视频大小都在500M以上,更别说高质量视频了:高清、超高清、蓝光视频大小。这些也意味着视频服务器的带宽也更高,而影响文件传输率的因素之一就是视频服务器使用的带宽。一个视频网站一开始宽带配置没必要那么高。访问 网站 视频的用户并不多,因此不会有 网站 冻结。当用户越来越多时,视频服务器的带宽需要升级。

