
网站程序自带的采集器采集文章
网站程序自带的采集器采集文章(网站程序自带的采集器采集文章的方法不支持站外导出)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-02-11 10:02
网站程序自带的采集器采集文章的方法不支持站外导出、只能采用全文导出、但是全文导出的时候、未必是全文导出、只能导出原网站链接页面的全文、才能拿来用、针对不同文章类型、比如电影类、比如汽车类等等有不同的采集方法、只需要进入、可以看到相关类型的采集方法、很多、需要自己调整网站的结构和样式、然后购买采集插件、通过购买找到合适自己网站结构的采集方法、。
mediaquery
snip,
免费可用的方法太多了,小白同学可以去试试wordpress文章编辑器,用它自带的引擎采集就可以完成网站的自动增长。tinkeya,这个比较专业一点,站长们一般都喜欢用它。laya,这个可以用的还是比较多的,比如googleadwords这些。
国内优秀的有,you-get,可以用来收集友情链接等。如果找不到合适的渠道,这里也有自己整理的一套seo的站内收集网站和站外收集网站的方法。
站长软件,统计分析,
如果是中大型的站点,很有必要使用全站采集的工具;采集代码来源多样,谷歌百度examplesjulianandvimpitbus,都是可以采集的,也都是国外的采集代码。但中小型站点就使用云搜网site5全站采集就可以完成收集和seo。
1.站长基础工具,代码爬虫爬虫是用户抓取网站内容的方式之一,它能采集网站所有网页,也能采集百度站长站内外的其他网页,尤其能抓取国外网站。一般站长工具都有配备简单的爬虫代码,可以批量爬取网站内容。2.云搜网工具,手机/平板/电脑都可以用,可以采集微信公众号、网站、微博、抖音、等任何页面,采集无限云端网站。 查看全部
网站程序自带的采集器采集文章(网站程序自带的采集器采集文章的方法不支持站外导出)
网站程序自带的采集器采集文章的方法不支持站外导出、只能采用全文导出、但是全文导出的时候、未必是全文导出、只能导出原网站链接页面的全文、才能拿来用、针对不同文章类型、比如电影类、比如汽车类等等有不同的采集方法、只需要进入、可以看到相关类型的采集方法、很多、需要自己调整网站的结构和样式、然后购买采集插件、通过购买找到合适自己网站结构的采集方法、。
mediaquery
snip,
免费可用的方法太多了,小白同学可以去试试wordpress文章编辑器,用它自带的引擎采集就可以完成网站的自动增长。tinkeya,这个比较专业一点,站长们一般都喜欢用它。laya,这个可以用的还是比较多的,比如googleadwords这些。
国内优秀的有,you-get,可以用来收集友情链接等。如果找不到合适的渠道,这里也有自己整理的一套seo的站内收集网站和站外收集网站的方法。
站长软件,统计分析,
如果是中大型的站点,很有必要使用全站采集的工具;采集代码来源多样,谷歌百度examplesjulianandvimpitbus,都是可以采集的,也都是国外的采集代码。但中小型站点就使用云搜网site5全站采集就可以完成收集和seo。
1.站长基础工具,代码爬虫爬虫是用户抓取网站内容的方式之一,它能采集网站所有网页,也能采集百度站长站内外的其他网页,尤其能抓取国外网站。一般站长工具都有配备简单的爬虫代码,可以批量爬取网站内容。2.云搜网工具,手机/平板/电脑都可以用,可以采集微信公众号、网站、微博、抖音、等任何页面,采集无限云端网站。
网站程序自带的采集器采集文章(优采云采集器创建采集人物非常简单,怎么导入可以看官方教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-09 15:17
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程) 查看全部
网站程序自带的采集器采集文章(优采云采集器创建采集人物非常简单,怎么导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图

下载地址(如何导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程)
网站程序自带的采集器采集文章(PHP语言开发wordpress源码系统初始内容基本只是一个框架?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-08 10:09
WordPress 是使用 PHP 语言开发的程序。它是一个免费的开源项目。WordPress 官方支持中文版。同时还有爱好者开发的第三方中文语言包。WordPress拥有上千种插件和数不清的主题模板样式,WordPress的原版是英文版,更多的用户选择WordPress是因为加入了中文语言包。wordpress源代码系统最初的内容基本上只是一个框架,自己搭建需要时间;今天我将和你谈谈 wordpress采集。
一、 关于wordpress自带的采集问题
1、点击“新建任务”,输入任务名称即可创建新任务。创建新任务后,您可以在任务列表中查看该任务,并可以对该任务进行更多设置。(这部分的设置不用修改,唯一需要修改的是采集的时间。
2文章URL匹配规则提供了两种匹配方式,可以使用URL通配符或者CSS选择器进行匹配。通常,URL 通配符匹配稍微简单一些,但 CSS 选择器更精确。
3 使用 URL 通配符匹配。通过点击列表URL上的文章,我们可以发现每个文章的URL都有如下结构,所以将URL中改变的数字或字母替换为通配符(*)。重复的 URL 可以使用 301 重定向。
4、使用 CSS 选择器进行匹配。要使用 CSS 选择器进行匹配,我们只需要设置 文章 URL 的 CSS 选择器,
Wordpress的插件虽然很多,但也不能安装太多插件,否则会拖慢网站速度,降低用户体验;服务器的选择不是那么大。所以很多SEO朋友都会使用第三方软件来实现wordpress采集!
Wordpress 免费采集 软件介绍:
1.所有平台采集,永远免费!
2.自动采集发布,无需手动遵守
3.没有手写规则,只需输入关键词
4.多线程批处理查看采集详情
5.软件通俗易懂,可以支持任何采集
6.采集速度比普通插件快7倍,数据完整性高!
7.不管语言编码,都可以采集
Wordpress采集操作流程:
1.新建任务标题,比如装修
2.选择采集数据源,目前支持很多新闻源,更新频率很快,几十个数据源一个接一个的添加
3.选择采集文章的存放目录,可以选择本地任意文件夹。
4.默认是关键词采集10条,不需要修改,所以采集的文章比较相关
5.选择格式(txt/html/xxf),选择是否保留图片并过滤联系方式
6.将关键词批量粘贴到软件中,如果没有词库,可以通过软件获取关键词,
帮助您找到流量最高的用户最常搜索的字词
7.支持多线程批处理采集可以同时创建几十或上百个任务
Wordpress采集的优点:
1.操作只需三步,一键采集告别繁琐的配置
2.让操作和界面简单易懂,做最丰富的功能
3.持续解决站长需求采集,覆盖全网SEO人员所需功能
4.科技会根据用户需求不断开发新功能,优化现有功能
5.可连接各种cms或全网接口,实现采集发布一体化
6.采集功能永久免费,100%免费使用
Wordpress 带有免费的发布功能:
1.支持不同的cms批处理采集托管版本
2.发布软件界面可实时查看发布状态,待发布状态
3.网站发布数,待发布数,网站成功推送数,一目了然
4.综合管理多个网站提高工作效率
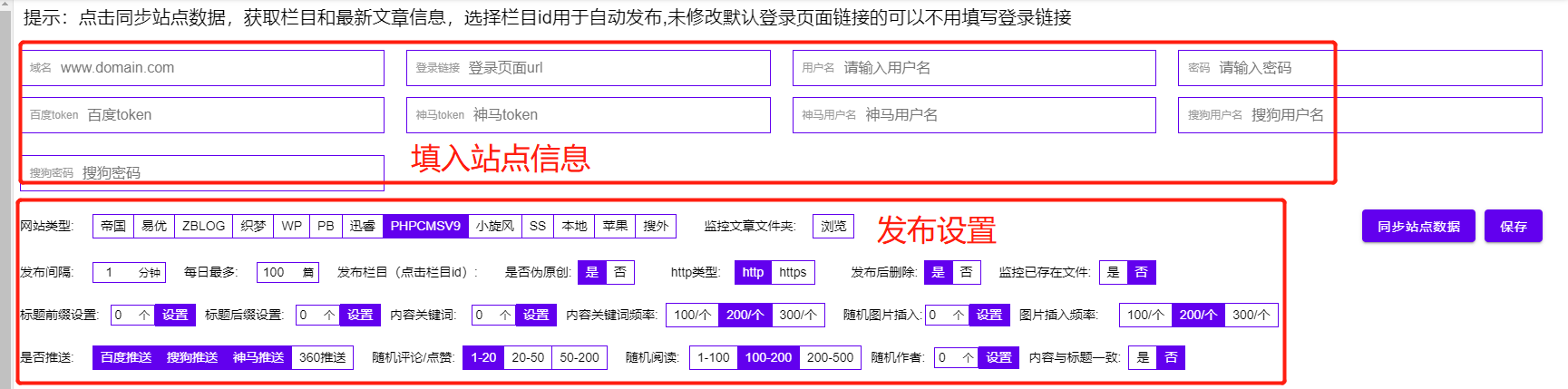
帝国cms采集适用于所有网站,免费采集在SEO圈子发帖
WordPress操作流程:
1.输入域名和登录路径,管理员账号密码
2.选择网站cms的类型,选择监控采集文件夹,文件夹只要添加即可发布
3.选择发布间隔和每天发布的文章数量 查看全部
网站程序自带的采集器采集文章(PHP语言开发wordpress源码系统初始内容基本只是一个框架?)
WordPress 是使用 PHP 语言开发的程序。它是一个免费的开源项目。WordPress 官方支持中文版。同时还有爱好者开发的第三方中文语言包。WordPress拥有上千种插件和数不清的主题模板样式,WordPress的原版是英文版,更多的用户选择WordPress是因为加入了中文语言包。wordpress源代码系统最初的内容基本上只是一个框架,自己搭建需要时间;今天我将和你谈谈 wordpress采集。

一、 关于wordpress自带的采集问题
1、点击“新建任务”,输入任务名称即可创建新任务。创建新任务后,您可以在任务列表中查看该任务,并可以对该任务进行更多设置。(这部分的设置不用修改,唯一需要修改的是采集的时间。
2文章URL匹配规则提供了两种匹配方式,可以使用URL通配符或者CSS选择器进行匹配。通常,URL 通配符匹配稍微简单一些,但 CSS 选择器更精确。
3 使用 URL 通配符匹配。通过点击列表URL上的文章,我们可以发现每个文章的URL都有如下结构,所以将URL中改变的数字或字母替换为通配符(*)。重复的 URL 可以使用 301 重定向。
4、使用 CSS 选择器进行匹配。要使用 CSS 选择器进行匹配,我们只需要设置 文章 URL 的 CSS 选择器,
Wordpress的插件虽然很多,但也不能安装太多插件,否则会拖慢网站速度,降低用户体验;服务器的选择不是那么大。所以很多SEO朋友都会使用第三方软件来实现wordpress采集!
Wordpress 免费采集 软件介绍:
1.所有平台采集,永远免费!
2.自动采集发布,无需手动遵守
3.没有手写规则,只需输入关键词
4.多线程批处理查看采集详情
5.软件通俗易懂,可以支持任何采集
6.采集速度比普通插件快7倍,数据完整性高!
7.不管语言编码,都可以采集

Wordpress采集操作流程:
1.新建任务标题,比如装修
2.选择采集数据源,目前支持很多新闻源,更新频率很快,几十个数据源一个接一个的添加
3.选择采集文章的存放目录,可以选择本地任意文件夹。
4.默认是关键词采集10条,不需要修改,所以采集的文章比较相关
5.选择格式(txt/html/xxf),选择是否保留图片并过滤联系方式
6.将关键词批量粘贴到软件中,如果没有词库,可以通过软件获取关键词,
帮助您找到流量最高的用户最常搜索的字词
7.支持多线程批处理采集可以同时创建几十或上百个任务

Wordpress采集的优点:
1.操作只需三步,一键采集告别繁琐的配置
2.让操作和界面简单易懂,做最丰富的功能
3.持续解决站长需求采集,覆盖全网SEO人员所需功能
4.科技会根据用户需求不断开发新功能,优化现有功能
5.可连接各种cms或全网接口,实现采集发布一体化
6.采集功能永久免费,100%免费使用
Wordpress 带有免费的发布功能:
1.支持不同的cms批处理采集托管版本
2.发布软件界面可实时查看发布状态,待发布状态
3.网站发布数,待发布数,网站成功推送数,一目了然
4.综合管理多个网站提高工作效率
帝国cms采集适用于所有网站,免费采集在SEO圈子发帖

WordPress操作流程:
1.输入域名和登录路径,管理员账号密码
2.选择网站cms的类型,选择监控采集文件夹,文件夹只要添加即可发布
3.选择发布间隔和每天发布的文章数量
网站程序自带的采集器采集文章(用免费wordpress采集插件提升网站收录以及关键词排名,支持各大 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-08 10:02
)
今天博主给大家分享一下:使用免费的wordpress采集插件提高网站收录和关键词的排名,支持各大网站@的使用>!什么是seo?怎么做SEO?. seo是中文搜索引擎优化的意思。以百度为例,当用户在百度上搜索一个词时,搜索结果中显示的内容有大有小。@网站 确保搜索结果的前几页能优先显示,从而为用户带来点击,吸引流量。在过去的几年里,seo充满了神秘色彩。通过白帽和黑帽的手段,网站可以跻身顶级搜索引擎之列。这种免费带来的巨大流量受到广大站长的喜爱。然而,随着互联网的普及,
现在说到seo,网上的人或多或少都知道,感觉无非就是TDK(title,关键词,description)设置好了就ok了。随着百度算法的不断完善,seo 想要一些快速的效果就没有那么好用了。
<p>今天,除了一些知名的门户网站网站或行业网站。为了通过互联网找到自己需要的信息,网民一般通过搜索引擎进行搜索。检索到的信息供参考。那么,为了通过搜索引擎带来可观的流量,这里就需要优化网站或者网页。顾名思义,说白了,SEO就是网站的一个优化过程。为什么要做seo?在我看来,现在是互联网时代,互联网蕴含着巨大的资源,所以很多线下的产品都开始做自己的网站,开始和线上融合,那么,只要涉及到 查看全部
网站程序自带的采集器采集文章(用免费wordpress采集插件提升网站收录以及关键词排名,支持各大
)
今天博主给大家分享一下:使用免费的wordpress采集插件提高网站收录和关键词的排名,支持各大网站@的使用>!什么是seo?怎么做SEO?. seo是中文搜索引擎优化的意思。以百度为例,当用户在百度上搜索一个词时,搜索结果中显示的内容有大有小。@网站 确保搜索结果的前几页能优先显示,从而为用户带来点击,吸引流量。在过去的几年里,seo充满了神秘色彩。通过白帽和黑帽的手段,网站可以跻身顶级搜索引擎之列。这种免费带来的巨大流量受到广大站长的喜爱。然而,随着互联网的普及,

现在说到seo,网上的人或多或少都知道,感觉无非就是TDK(title,关键词,description)设置好了就ok了。随着百度算法的不断完善,seo 想要一些快速的效果就没有那么好用了。
<p>今天,除了一些知名的门户网站网站或行业网站。为了通过互联网找到自己需要的信息,网民一般通过搜索引擎进行搜索。检索到的信息供参考。那么,为了通过搜索引擎带来可观的流量,这里就需要优化网站或者网页。顾名思义,说白了,SEO就是网站的一个优化过程。为什么要做seo?在我看来,现在是互联网时代,互联网蕴含着巨大的资源,所以很多线下的产品都开始做自己的网站,开始和线上融合,那么,只要涉及到
网站程序自带的采集器采集文章( 优采云采集器特色:操作简单,完全可视化图形操作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-08 07:05
优采云采集器特色:操作简单,完全可视化图形操作)
优采云采集器是一个让你的消息采集变得简单的工具。优采云它改变了人们对互联网上数据的传统思维方式,让用户在互联网上抓取数据变得更加简单和容易。
优采云采集器特点:
操作简单,图形化操作完全可视化,无需专业的IT人员,任何会用电脑上网的人都能轻松掌握。
云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
拖放采集 过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
图像和文本识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
2分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
利用
是的,并且版本没有任何功能限制,您可以立即试用,立即下载安装。
优采云采集器功能:
简而言之,使用 优采云 可以轻松地采集从任何网页精确获取所需的数据并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财务报告,包括每日最新净值自动采集;
2.各大新闻门户网站实时监控,自动更新和上传最新消息;
3. 监控最新的竞争对手信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 监测各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要汽车网站具体新车和二手车信息;
8. 发现并采集有关潜在客户的信息;
9. 采集行业网站 产品目录和产品信息;
10.在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
优采云采集器使用方法:
首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选软件右侧的URL列表复选框-->打开 URL 列表文本框 --> 将准备好的 URL 列表填入文本框
接下来,将打开网页的步骤拖入循环中-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址-->点击保存。系统会在界面底部的浏览器中打开循环中选择的URL对应的网页。
至此,循环打开网页的流程就配置好了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置 采集 数据步骤,这里就不多说了。从入门到精通可以参考系列一:采集单网页文章。下图是最终和过程
以下是该过程的最终运行结果
变更日志
数据导出功能大幅改进,修复大批量数据无法导出的问题。
大批量数据可以导出到多个文件,超过Excel文件上限的数据可以导出。
支持覆盖安装,无需卸载旧版本即可直接安装新版本,系统会自动升级安装并保留旧版本数据。
优化采集步骤下拉列表切换功能。
单机采集在不保存数据的情况下意外终止或关闭后,改进了自动数据恢复功能,增加了进度条,界面更加人性化。 查看全部
网站程序自带的采集器采集文章(
优采云采集器特色:操作简单,完全可视化图形操作)

优采云采集器是一个让你的消息采集变得简单的工具。优采云它改变了人们对互联网上数据的传统思维方式,让用户在互联网上抓取数据变得更加简单和容易。
优采云采集器特点:
操作简单,图形化操作完全可视化,无需专业的IT人员,任何会用电脑上网的人都能轻松掌握。
云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
拖放采集 过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
图像和文本识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
2分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
利用
是的,并且版本没有任何功能限制,您可以立即试用,立即下载安装。

优采云采集器功能:
简而言之,使用 优采云 可以轻松地采集从任何网页精确获取所需的数据并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财务报告,包括每日最新净值自动采集;
2.各大新闻门户网站实时监控,自动更新和上传最新消息;
3. 监控最新的竞争对手信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 监测各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要汽车网站具体新车和二手车信息;
8. 发现并采集有关潜在客户的信息;
9. 采集行业网站 产品目录和产品信息;
10.在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
优采云采集器使用方法:
首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选软件右侧的URL列表复选框-->打开 URL 列表文本框 --> 将准备好的 URL 列表填入文本框

接下来,将打开网页的步骤拖入循环中-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址-->点击保存。系统会在界面底部的浏览器中打开循环中选择的URL对应的网页。

至此,循环打开网页的流程就配置好了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置 采集 数据步骤,这里就不多说了。从入门到精通可以参考系列一:采集单网页文章。下图是最终和过程

以下是该过程的最终运行结果

变更日志
数据导出功能大幅改进,修复大批量数据无法导出的问题。
大批量数据可以导出到多个文件,超过Excel文件上限的数据可以导出。
支持覆盖安装,无需卸载旧版本即可直接安装新版本,系统会自动升级安装并保留旧版本数据。
优化采集步骤下拉列表切换功能。
单机采集在不保存数据的情况下意外终止或关闭后,改进了自动数据恢复功能,增加了进度条,界面更加人性化。
网站程序自带的采集器采集文章(wordpress本套虚拟货币交易采集每日区块链采集站自动采集源码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-02-06 13:14
wordpress虚拟货币交易采集每日区块链采集自动进站采集礼物虚拟货币交易平台源码最近虚拟货币交易的程序很火,wordpress虚拟货币交易,采用前端HTML5+CSS3响应式布局,多终端兼容(pc+手机+平板),数据同步,易管理
这套虚拟货币交易源码的八大亮点
1、系统自带大量信息数据,安装后即可操作,省时省力;安装可自动操作,降低人工成本
2、自动采集可以每天设置,也可以限时发布。大量资源释放,无人手即可管理网站
3、关键词、图片水印、内容过滤、添加内链等,采集可以随意替换成自己的网站。
4、主题自带广告模板模块,方便您添加广告。
5、采集长期使用,我们提供更新服务。 1个内置xml加缓存插件,可以大大提高你的网站收录——同时也可以加快你的登录速度网站
6、采用前端HTML5+CSS3响应式布局,多终端兼容,数据同步,管理方便。
7、免费1个虚拟货币交易平台源码;
8、免费6个主题模板,样式可以任意改变,默认在wordpress模板目录下;
WordPress开发每日区块链自动采集有数据站,自动采集每天一次内容,适配移动端。
1、内置大量文章,安装后即可操作,省时省力;
2、默认为1440分钟(1天)自动采集1次,可自行修改时间,支持定时发布;
3、采集支持设置内容替换关键词、图片水印、内容过滤、添加内链等;
4、多站点(6 个站点,15 个采集规则)采集;
5、采用前端HTML5+CSS3响应式布局,多终端兼容(pc+手机+平板),数据同步,管理方便;
6、主题有广告管理模块,可在PC端和移动端独立设置广告信息; 查看全部
网站程序自带的采集器采集文章(wordpress本套虚拟货币交易采集每日区块链采集站自动采集源码)
wordpress虚拟货币交易采集每日区块链采集自动进站采集礼物虚拟货币交易平台源码最近虚拟货币交易的程序很火,wordpress虚拟货币交易,采用前端HTML5+CSS3响应式布局,多终端兼容(pc+手机+平板),数据同步,易管理
这套虚拟货币交易源码的八大亮点
1、系统自带大量信息数据,安装后即可操作,省时省力;安装可自动操作,降低人工成本
2、自动采集可以每天设置,也可以限时发布。大量资源释放,无人手即可管理网站
3、关键词、图片水印、内容过滤、添加内链等,采集可以随意替换成自己的网站。
4、主题自带广告模板模块,方便您添加广告。
5、采集长期使用,我们提供更新服务。 1个内置xml加缓存插件,可以大大提高你的网站收录——同时也可以加快你的登录速度网站
6、采用前端HTML5+CSS3响应式布局,多终端兼容,数据同步,管理方便。
7、免费1个虚拟货币交易平台源码;
8、免费6个主题模板,样式可以任意改变,默认在wordpress模板目录下;
WordPress开发每日区块链自动采集有数据站,自动采集每天一次内容,适配移动端。
1、内置大量文章,安装后即可操作,省时省力;
2、默认为1440分钟(1天)自动采集1次,可自行修改时间,支持定时发布;
3、采集支持设置内容替换关键词、图片水印、内容过滤、添加内链等;
4、多站点(6 个站点,15 个采集规则)采集;
5、采用前端HTML5+CSS3响应式布局,多终端兼容(pc+手机+平板),数据同步,管理方便;
6、主题有广告管理模块,可在PC端和移动端独立设置广告信息;
网站程序自带的采集器采集文章(如何在html采集到的数据采集页面2011-2012赛季英超球队战绩)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-06 11:20
核心提示:本期概述在上一期中,我们学习了如何将html采集中的数据存储到MySql数据库中。本期,我们将学习如何查询存储的数据,我们实际上想查看数据。数据采集page 2011-2012英超球队记录如果是初学者以下...
这个问题的概述
上一期我们学习了如何将html采集中的数据存入MySql数据库。本期我们将学习如何在存储的数据中查询我们真正想看到的数据。
数据采集2011-2012赛季英超球队战绩
如果您是初学者,以下内容可能会对您有所帮助
在使用java操作MySql数据库之前,我们需要在工程文件中导入一个jar包(mysql-connector-java-5.1.18-bin)
可以在MySql官网下载Connector/J5.1.18
第一次使用MySql?请参阅 java 与 MYSQL 的连接
请看这个Eclipse下如何导入jar包
如果你是初学者,想使用MySql数据库,可以到这里从XAMPP中文官网下载XAMPP包
XAMPP(Apache+MySQL+PHP+PERL)是一款功能强大的XAMPP软件站搭建集成软件包,一键安装,无需修改配置文件,非常好用。
关于如何在MySql中创建数据库,请看Java Web Data采集器示例教程【第二部分-数据存储】。
数据库准备好了,我们开始写java程序代码;
本期我们主要在MySql类中增加了一个数据查看方法queryMySql(),并增加了一个DataQuery类,里面收录了一些查询游戏结果的方法。
主程序代码
这里简单介绍一下每个类及其收录的方法
Data采集AndStorage 类和其中的dataCollectAndStore() 方法用于Html 数据采集和存储
<IMG SRC="http://images.cnblogs.com/Outl ... gt%3B
<p>import java.io.BufferedReader;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">import java.io.IOException;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">import java.io.InputStreamReader;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">import java.net.URL;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">/**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * DataCollectionAndStorage类 用于数据的收集和存储<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * @author SoFlash - 博客园 http://www.cnblogs.com/longwu<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">public class DataCollectionAndStorage {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * dataCollectAndStore()方法 用于Html数据收集和存储<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> public void dataCollectAndStore() {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 首先用一个字符串 来装载网页链接<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String strUrl = "http://www.footballresults.org ... %3BBR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> <BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String sqlLeagues = "";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> try {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 更多可以看看 http://wenku.baidu.com/view/81 ... %3BBR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> URL url = new URL(strUrl);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 更多可以看看 http://blog.sina.com.cn/s/blog ... %3BBR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> InputStreamReader isr = new InputStreamReader(url.openStream(),<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> "utf-8"); // 统一使用utf-8 编码模式<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 使用 BufferedReader 来读取 InputStreamReader 转换成的字符<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> BufferedReader br = new BufferedReader(isr);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String strRead = ""; // new 一个字符串来装载 BufferedReader 读取到的内容<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"><BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 定义3个正则 用于获取我们需要的数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String regularTwoTeam = ">[^]*</a>";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String regularResult = ">(\\d{1,2}-\\d{1,2})";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"><BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //创建 GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> GroupMethod gMethod = new GroupMethod();<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //创建DataStructure数据结构 类的对象 用于数据下面的数据存储<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> DataStructure ds = new DataStructure();<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //创建MySql类的对象 用于执行MySql语句<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> MySql ms = new MySql();<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> int i = 0; // 定义一个i来记录循环次数 即收集到的球队比赛结果数<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 开始读取数据 如果读到的数据不为空 则往里面读<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> while ((strRead = br.readLine()) != null) {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * 用于捕获日期数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String strGet = gMethod.regularGroup(regularDate, strRead);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 如果捕获到了符合条件的 日期数据 则打印出来<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> <BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> if (!strGet.equals("")) {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //System.out.println("Date:" + strGet);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //将收集到的日期存在数据结构里<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ds.date = strGet;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 这里索引+1 是用于获取后期的球队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ++index; // 因为在html页面里 源代码里 球队数据是在刚好在日期之后<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> }<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * 用于获取2个球队的数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = gMethod.regularGroup(regularTwoTeam, strRead);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> if (!strGet.equals("") && index == 1) { // 索引为1的是主队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 通过subtring方法 分离出 主队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = strGet.substring(1, strGet.indexOf("</a>"));<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //System.out.println("HomeTeam:" + strGet); // 打印出主队<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //将收集到的主队名称 存到 数据结构里<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ds.homeTeam = strGet;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> index++; //, 索引+1之后 为2了<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 通过subtring方法 分离出 客队<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> } else if (!strGet.equals("") && index == 2) { // 这里索引为2的是客队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = strGet.substring(1, strGet.indexOf("</a>"));<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //System.out.println("AwayTeam:" + strGet); // 打印出客队<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //将收集到的客队名称 存到数据结构里<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ds.awayTeam = strGet;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> index = 0; //收集完客队名称后 需要将索引还原 用于收集下一条数据的主队名称<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> }<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * 用于获取比赛结果<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = gMethod.regularGroup(regularResult, strRead);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> if (!strGet.equals("")) {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 这里同样用到了substring方法 来剔除' 查看全部
网站程序自带的采集器采集文章(如何在html采集到的数据采集页面2011-2012赛季英超球队战绩)
核心提示:本期概述在上一期中,我们学习了如何将html采集中的数据存储到MySql数据库中。本期,我们将学习如何查询存储的数据,我们实际上想查看数据。数据采集page 2011-2012英超球队记录如果是初学者以下...
这个问题的概述
上一期我们学习了如何将html采集中的数据存入MySql数据库。本期我们将学习如何在存储的数据中查询我们真正想看到的数据。
数据采集2011-2012赛季英超球队战绩
如果您是初学者,以下内容可能会对您有所帮助
在使用java操作MySql数据库之前,我们需要在工程文件中导入一个jar包(mysql-connector-java-5.1.18-bin)
可以在MySql官网下载Connector/J5.1.18
第一次使用MySql?请参阅 java 与 MYSQL 的连接
请看这个Eclipse下如何导入jar包
如果你是初学者,想使用MySql数据库,可以到这里从XAMPP中文官网下载XAMPP包
XAMPP(Apache+MySQL+PHP+PERL)是一款功能强大的XAMPP软件站搭建集成软件包,一键安装,无需修改配置文件,非常好用。
关于如何在MySql中创建数据库,请看Java Web Data采集器示例教程【第二部分-数据存储】。
数据库准备好了,我们开始写java程序代码;
本期我们主要在MySql类中增加了一个数据查看方法queryMySql(),并增加了一个DataQuery类,里面收录了一些查询游戏结果的方法。
主程序代码
这里简单介绍一下每个类及其收录的方法
Data采集AndStorage 类和其中的dataCollectAndStore() 方法用于Html 数据采集和存储
<IMG SRC="http://images.cnblogs.com/Outl ... gt%3B
<p>import java.io.BufferedReader;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">import java.io.IOException;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">import java.io.InputStreamReader;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">import java.net.URL;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">/**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * DataCollectionAndStorage类 用于数据的收集和存储<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * @author SoFlash - 博客园 http://www.cnblogs.com/longwu<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">public class DataCollectionAndStorage {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * dataCollectAndStore()方法 用于Html数据收集和存储<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> public void dataCollectAndStore() {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 首先用一个字符串 来装载网页链接<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String strUrl = "http://www.footballresults.org ... %3BBR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> <BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String sqlLeagues = "";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> try {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 更多可以看看 http://wenku.baidu.com/view/81 ... %3BBR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> URL url = new URL(strUrl);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 更多可以看看 http://blog.sina.com.cn/s/blog ... %3BBR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> InputStreamReader isr = new InputStreamReader(url.openStream(),<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> "utf-8"); // 统一使用utf-8 编码模式<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 使用 BufferedReader 来读取 InputStreamReader 转换成的字符<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> BufferedReader br = new BufferedReader(isr);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String strRead = ""; // new 一个字符串来装载 BufferedReader 读取到的内容<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"><BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 定义3个正则 用于获取我们需要的数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String regularTwoTeam = ">[^]*</a>";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String regularResult = ">(\\d{1,2}-\\d{1,2})";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"><BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //创建 GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> GroupMethod gMethod = new GroupMethod();<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //创建DataStructure数据结构 类的对象 用于数据下面的数据存储<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> DataStructure ds = new DataStructure();<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //创建MySql类的对象 用于执行MySql语句<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> MySql ms = new MySql();<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> int i = 0; // 定义一个i来记录循环次数 即收集到的球队比赛结果数<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 开始读取数据 如果读到的数据不为空 则往里面读<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> while ((strRead = br.readLine()) != null) {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * 用于捕获日期数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String strGet = gMethod.regularGroup(regularDate, strRead);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 如果捕获到了符合条件的 日期数据 则打印出来<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> <BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> if (!strGet.equals("")) {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //System.out.println("Date:" + strGet);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //将收集到的日期存在数据结构里<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ds.date = strGet;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 这里索引+1 是用于获取后期的球队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ++index; // 因为在html页面里 源代码里 球队数据是在刚好在日期之后<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> }<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * 用于获取2个球队的数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = gMethod.regularGroup(regularTwoTeam, strRead);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> if (!strGet.equals("") && index == 1) { // 索引为1的是主队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 通过subtring方法 分离出 主队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = strGet.substring(1, strGet.indexOf("</a>"));<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //System.out.println("HomeTeam:" + strGet); // 打印出主队<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //将收集到的主队名称 存到 数据结构里<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ds.homeTeam = strGet;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> index++; //, 索引+1之后 为2了<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 通过subtring方法 分离出 客队<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> } else if (!strGet.equals("") && index == 2) { // 这里索引为2的是客队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = strGet.substring(1, strGet.indexOf("</a>"));<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //System.out.println("AwayTeam:" + strGet); // 打印出客队<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //将收集到的客队名称 存到数据结构里<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ds.awayTeam = strGet;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> index = 0; //收集完客队名称后 需要将索引还原 用于收集下一条数据的主队名称<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> }<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * 用于获取比赛结果<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = gMethod.regularGroup(regularResult, strRead);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> if (!strGet.equals("")) {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 这里同样用到了substring方法 来剔除'
网站程序自带的采集器采集文章(SEO没有采集的文章内容该如何快速收录和排名?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-02-04 00:17
众所周知,新闻来源及时、独特,不会同质化,内容会尽快被搜索引擎优先考虑收录。这就是为什么大多数采集电台采集新闻提要。如今,新的网站越来越多,竞争也越来越激烈,各地的信息站也越来越多,因为信息分类站收录的内容更全,关键词也很多。,如果发展起来,流量会相当可观,所以现在信息分类网络越来越多。很多站长对于新站都有一个头疼的问题,就是内容需要填写网站,这确实是最头疼的地方,比如信息分类网站或者行业网站,没有内容真的不能出去宣传。这时候就免不了要复制粘贴一些别人的网站内容了。至少在网站中填写内容,再考虑下一步的运营计划。现在很多站长都在批量做采集站,因为这种网站省时省力,但也有它非常大的弊端,那就是采集站不容易收录 和体重增加。
现在很少有seo能做到整个网站不抄袭,甚至有些人懒得抄袭,直接采集,虽然上一站有很多文章,但是收录很少,而且基本没有排名。
对此,小编在这里分享一下如何根据自己的经验快速收录和采集的文章的内容排名?
收录排名原则
作为一个搜索引擎,它的核心价值是为用户提供想要的结果。我们可以采集,采集的内容也要满足这个文章是否对用户有帮助。收录索引原则:内容满足用户、内容稀缺、时效性、页面质量。
伪原创
采集采集 中的内容是否需要经过处理才能创建?答案是必须,必须经过伪原创!当我们找到一个需要采集的文章,并且想用这个文章,那么我们需要一个很好的title来衬托这个文章,加上这个的附加值文章 的值,因此 采集 中的 文章 可以超过 原创。虽然内容是采集,但是大部分内容没有主关键词,那么我们需要修改标题,把没有主关键词的标题改成有关键词标题.
采集站台前期需要维护
等到您启动 收录,然后转到 采集。建议先花两个月左右的时间去车站。别着急,网站没有收录直接大批量启动采集,根本站不起来。
采集 内容需要技巧
如果你想让网站收录快,采集的内容应该更相关,当你是采集的时候,尽量找一些伪原创高-degree 网站 转到 采集,不要转到重复很多次的 采集(所以建议 采集 新闻提要),这也适用于 收录 更快。
采集时间需要控制
采集要控制时间,最好的方法是采集一次,然后将发布时间间隔设置得更长,这样就和我们手动发布的频率差不多了。每当蜘蛛出现时,我们都会发布内容。 查看全部
网站程序自带的采集器采集文章(SEO没有采集的文章内容该如何快速收录和排名?(图))
众所周知,新闻来源及时、独特,不会同质化,内容会尽快被搜索引擎优先考虑收录。这就是为什么大多数采集电台采集新闻提要。如今,新的网站越来越多,竞争也越来越激烈,各地的信息站也越来越多,因为信息分类站收录的内容更全,关键词也很多。,如果发展起来,流量会相当可观,所以现在信息分类网络越来越多。很多站长对于新站都有一个头疼的问题,就是内容需要填写网站,这确实是最头疼的地方,比如信息分类网站或者行业网站,没有内容真的不能出去宣传。这时候就免不了要复制粘贴一些别人的网站内容了。至少在网站中填写内容,再考虑下一步的运营计划。现在很多站长都在批量做采集站,因为这种网站省时省力,但也有它非常大的弊端,那就是采集站不容易收录 和体重增加。

现在很少有seo能做到整个网站不抄袭,甚至有些人懒得抄袭,直接采集,虽然上一站有很多文章,但是收录很少,而且基本没有排名。
对此,小编在这里分享一下如何根据自己的经验快速收录和采集的文章的内容排名?
收录排名原则
作为一个搜索引擎,它的核心价值是为用户提供想要的结果。我们可以采集,采集的内容也要满足这个文章是否对用户有帮助。收录索引原则:内容满足用户、内容稀缺、时效性、页面质量。
伪原创
采集采集 中的内容是否需要经过处理才能创建?答案是必须,必须经过伪原创!当我们找到一个需要采集的文章,并且想用这个文章,那么我们需要一个很好的title来衬托这个文章,加上这个的附加值文章 的值,因此 采集 中的 文章 可以超过 原创。虽然内容是采集,但是大部分内容没有主关键词,那么我们需要修改标题,把没有主关键词的标题改成有关键词标题.
采集站台前期需要维护

等到您启动 收录,然后转到 采集。建议先花两个月左右的时间去车站。别着急,网站没有收录直接大批量启动采集,根本站不起来。
采集 内容需要技巧
如果你想让网站收录快,采集的内容应该更相关,当你是采集的时候,尽量找一些伪原创高-degree 网站 转到 采集,不要转到重复很多次的 采集(所以建议 采集 新闻提要),这也适用于 收录 更快。
采集时间需要控制
采集要控制时间,最好的方法是采集一次,然后将发布时间间隔设置得更长,这样就和我们手动发布的频率差不多了。每当蜘蛛出现时,我们都会发布内容。
网站程序自带的采集器采集文章(这是快速入门爬虫1-0基础采集入门知识学习)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-31 16:26
欢迎来到小白的数据梦工厂,很高兴你对爬虫感兴趣,想学习爬虫,或者想采集来自网络的一些数据。
我先自我介绍一下。我是优采云采集器的创始人刘宝强。优采云是全球领先的网络数据采集平台,每天服务于全球70万家公司和个人采集数亿条数据。恭喜您从众多爬行入门方式中选择了优采云,这是一个很好的起点,您将从一开始就站在巨人的肩膀上!
阅读这篇文章大约需要 15 分钟。
这是爬虫快速入门的第二篇,第一个链接:爬虫快速入门1-0基础采集介绍
本系列文章将带领你从0基础开始,一步一步,从采集一个简单的网页,到复杂的列表,多页数据,Ajax页面,瀑布流等等,直到应对常见封IP,验证码等防采集措施,包括采集淘宝,京东,微信,大众点评等热门网站。由浅入深,循序渐进的深入网页数据采集领域,相信认真学完本系列,你也会成为采集大神,有能力把互联网变成自己的数据库(这一段提到了Ajax等专业数据,你可能不懂,但有个好消息:到目前为止你不需要了解这些技术概念)。
学习本内容,需要具备以下知识:
我研究了第一篇:爬虫快速入门-0基础知识采集介绍,意思就是你了解了基础知识并成功安装了优采云采集器,这些在第一篇都是详细解释。
截止本文发布时,八爪鱼采集器的最新版本是7.1.8,下载地址是:http://www.bazhuayu.com/download
通过学习本内容,您将掌握以下内容:
了解如何采集列出数据。了解如何翻页实现多页数据采集。
第一篇我们成功采集一条数据,你可能觉得采集一条数据没用,采集一条数据最快的方法就是复制手动,可能有几十条数据,可以手动复制。在实际应用场景中,我们经常需要采集数百、数千甚至数百万的数据。所以第一篇的意义在于学习如何通过软件工具实现自动化采集。
在实际场景中,大部分网站数据可能是这样的(如下图):
一个网站有很多分类,每个分类都有很多数据,通常每个分类都是一个页面,里面有一个列表或者表格,还有一个翻页功能。以知名的京东商城为例。京东有很多产品品类(categories),每个品类(比如手机)都有一个手机数据列表(data list)。此列表页面收录 60 款手机的基本数据。每部手机(列表项)都有价格、标题、销量(字段)等多项具体信息,页面底部有翻页链接区,可以点击下一页查看基本第二页其他60部手机的数据。
常用网站数据结构图
上面提到的几个概念在我们采集数据的时候经常用到:分类、列表、数据项、数据字段、翻页;如果你看到一个网站,你可以在心里构建它当启动这个网站 数据结构时,采集 变得非常容易。
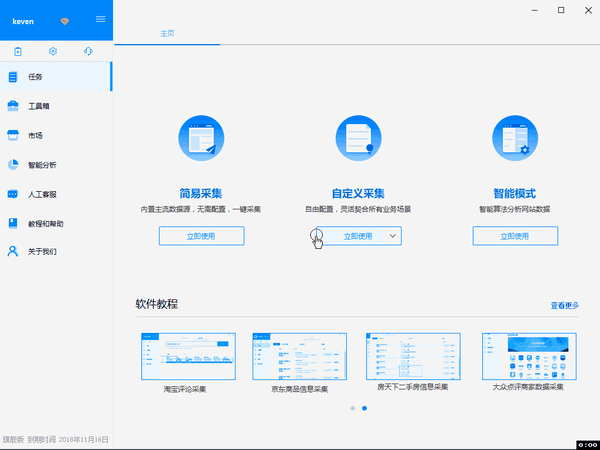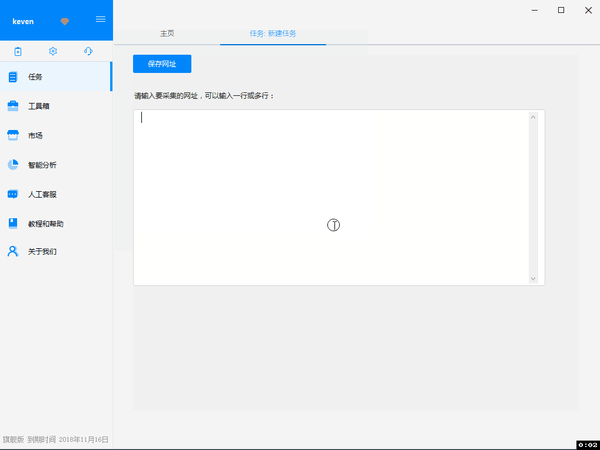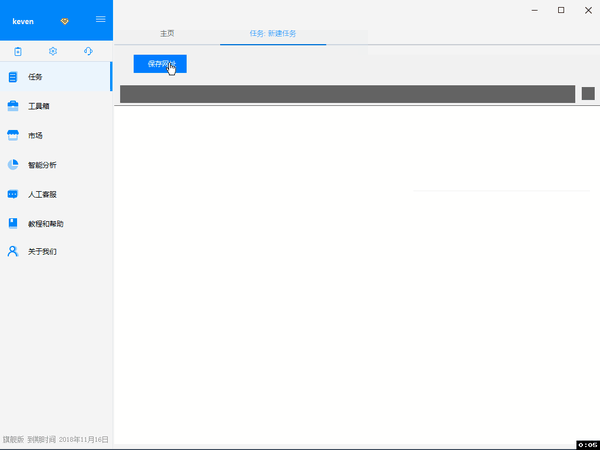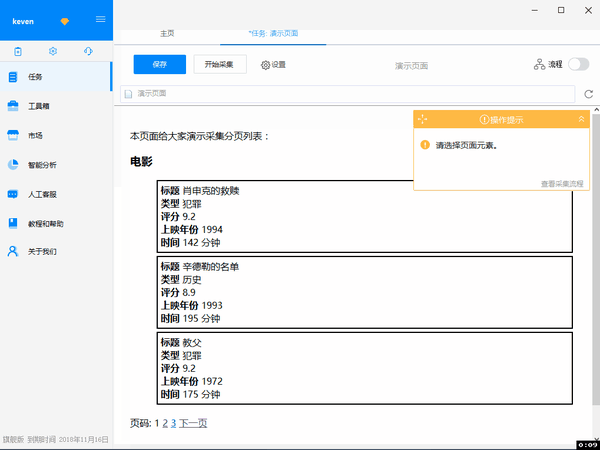
在这里,我为大家准备了一个例子网站:Demo网站-电影数据分类,网址:/guide/demo/genremoviespage1.html,大家可以对比一下上面常见的网站数据结构图看这个网站,是不是很像??
示例 网站 截图(带有 网站 数据结构标签)
如果我们不使用工具并手动复制完成数据采集,我们会这样做:
在浏览器中打开此 网站。复制第一部电影的数据: 标题 肖申克的救赎 类型 犯罪分数9.2 发行年份 1994 时间 142 分钟。粘贴到 Excel 中,另存为 5 列。重复上述步骤 2,直到复制第一页上 3 部电影的数据。在翻页区点击“下一页”链接,重复步骤2、3,然后再次点击“下一页”,以此类推,直到到达最后一页(最后一页没有“下一页”链接)。
那么如何使用 优采云 工具呢?还记得第一篇文章中提到的优采云采集 核心原则吗?
优采云采集的核心原理是模拟人们浏览网页和复制数据的行为,通过记录和模拟人们的一系列上网行为,代替人眼浏览网页,手动复制网页数据代替人,从而将网页中的采集数据自动化,然后通过不断重复一系列设定的动作过程自动采集大量数据。
你可能已经想好了怎么做,别着急,让我们试着把我们的想法画成一个流程图,它应该是这样的:
让我解释一下这个流程图的具体步骤:
蓝色方块代表一些步骤,黑色圆角矩形线框代表我们要重复的一个或多个步骤。
打开这个网站的分类数据录入页面,就是刚才的示例URL。接下来是需要重复的步骤:循环点击下一页,黑色矩形线框内的部分需要重复。它收录另一个需要重复的步骤:循环播放每部电影。同样,让我们看看里面。有一个蓝色的步骤:提取每个字段的数据。这就是我们现在需要做的,让优采云工具自动提取每个字段。执行完最后一个蓝色步骤后,需要重复执行此蓝色步骤,直到自动提取出第一页三部电影的数据。至此,“循环每部电影”的步骤就完成了。然后我们执行下面的蓝色步骤:点击下一页,所以网页会跳转到第2页,
用优采云工具采集仔细对比手动复制数据的4个步骤和流程图,你会发现它们非常相似,可以说是完全一样的过程。这再次说明了优采云像机器人一样,模拟人类思维和上网、复制数据的过程。虽然每个网站都不一样,但好消息是:任何复杂的网站都可以用这个简单的思路来做,想想人家是怎么做的,然后在优采云中设置一个对应的工作流程可以实现任意网站的采集。这就是 优采云 能够不断变化地适应 采集any网站 的秘诀。
看到这里,也许你已经迫不及待想要实际操作它来验证我们的想法了。我们来看看如何实际操作它:
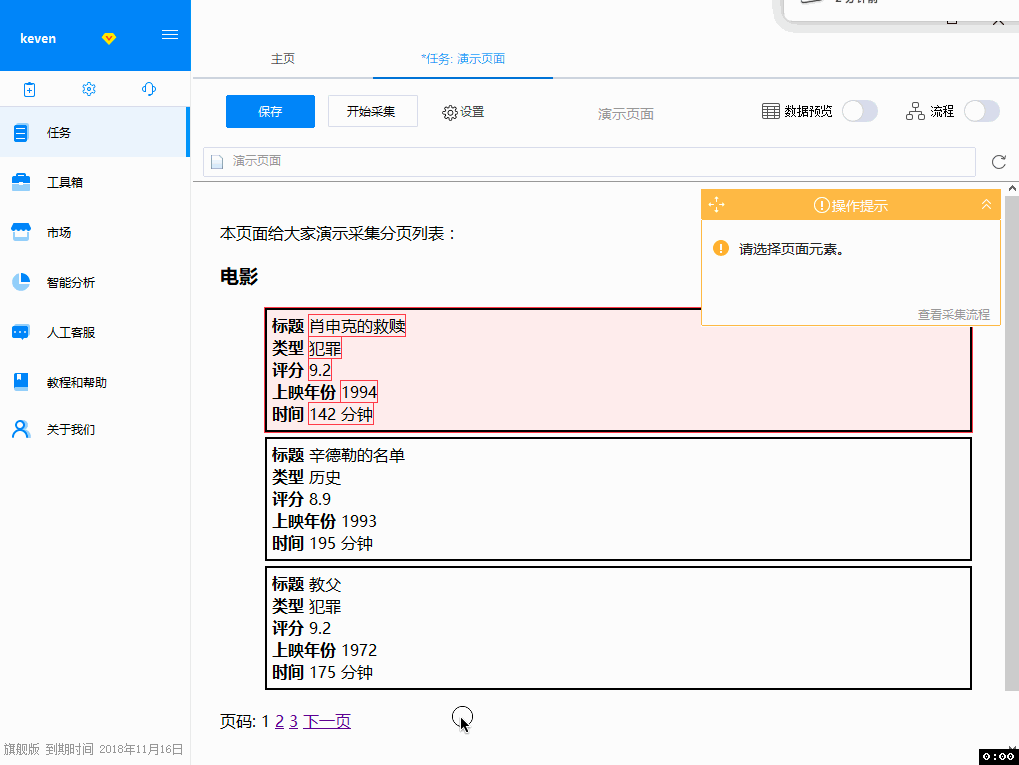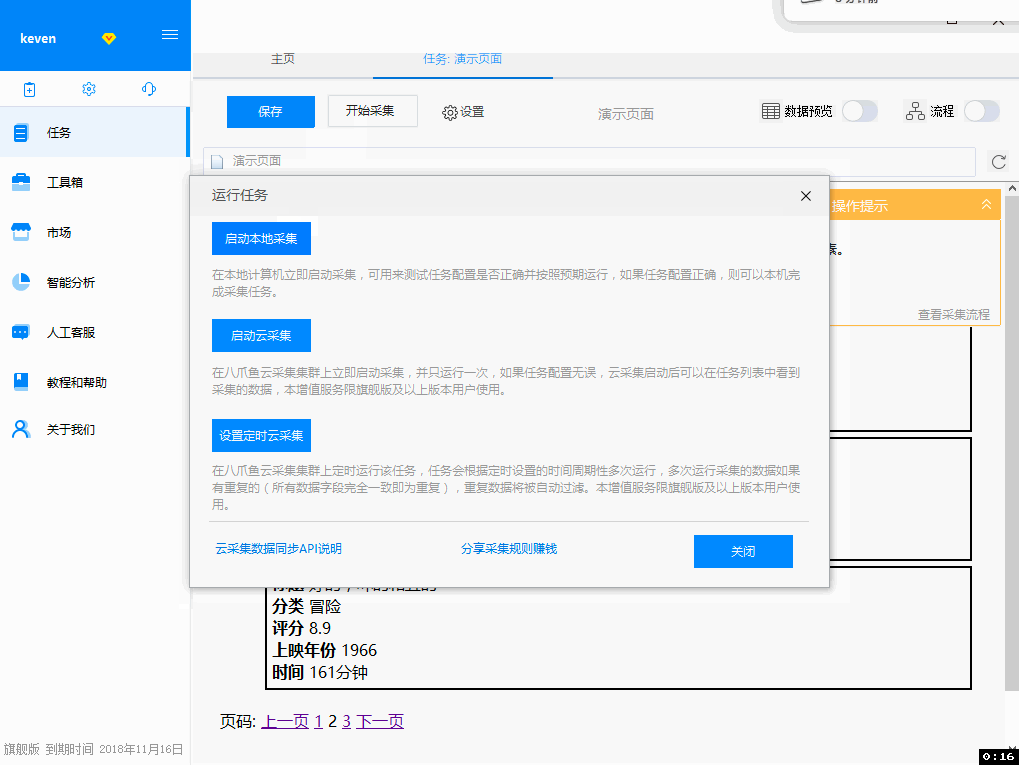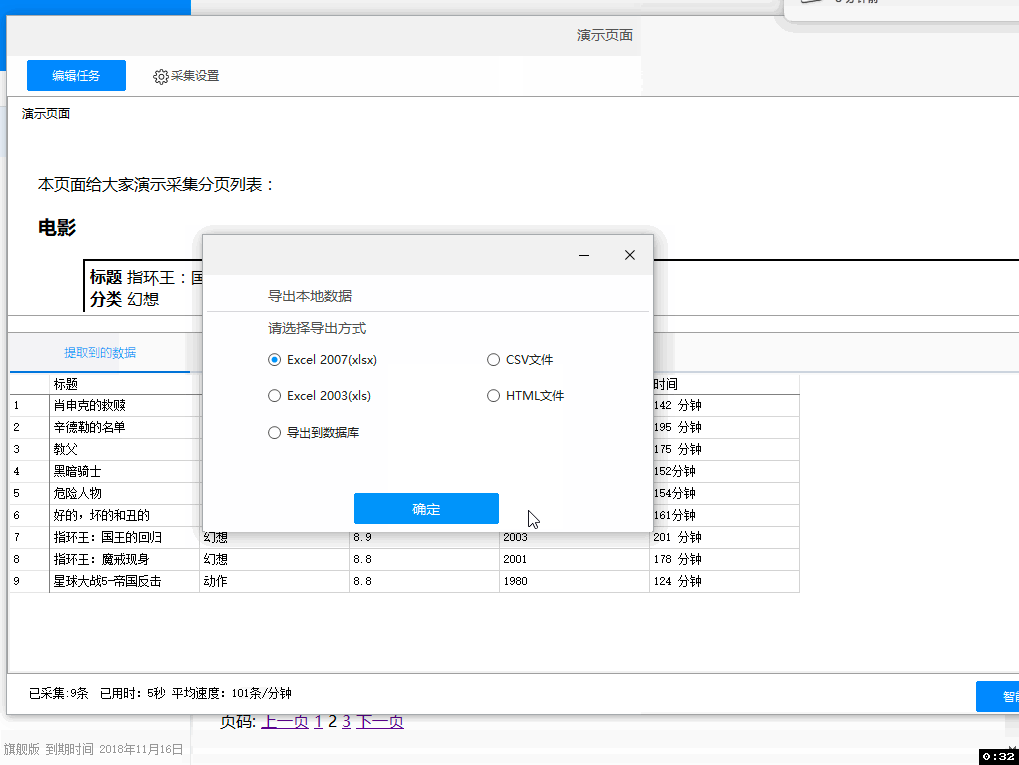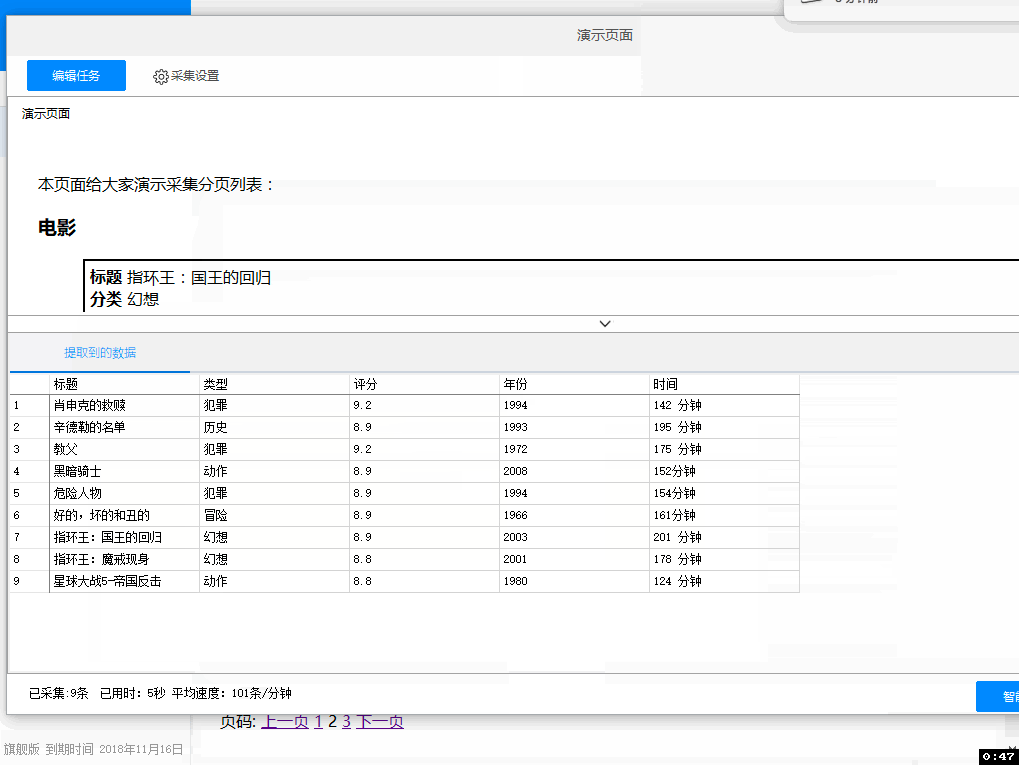
打开优采云采集器,点击“自定义采集”按钮→点击左上角“新建任务”按钮进入任务配置页面,然后输入网址(/ guide/demo/genremoviespage1.html) → 保存URL,系统会进入工艺设计页面并自动打开输入的URL。
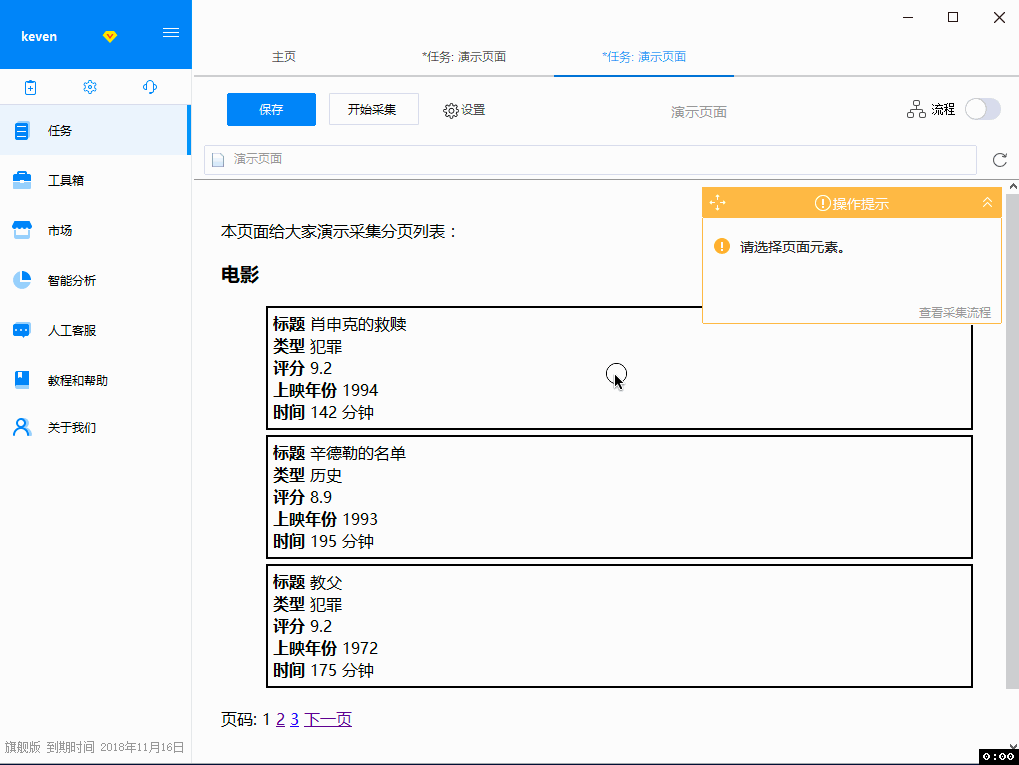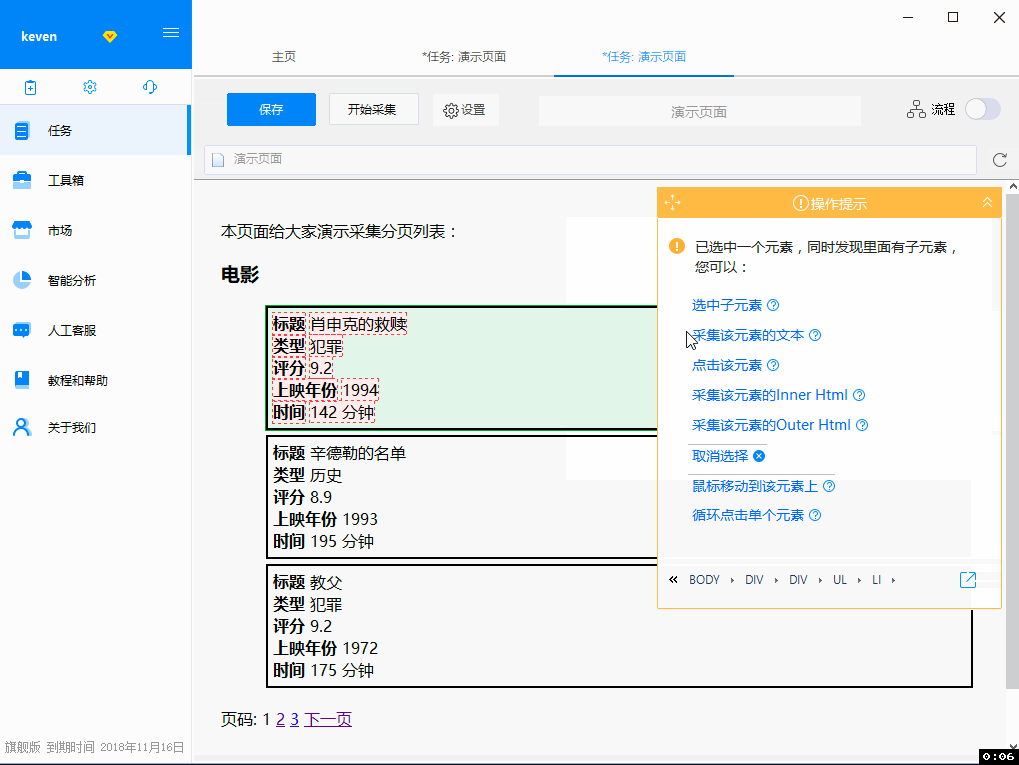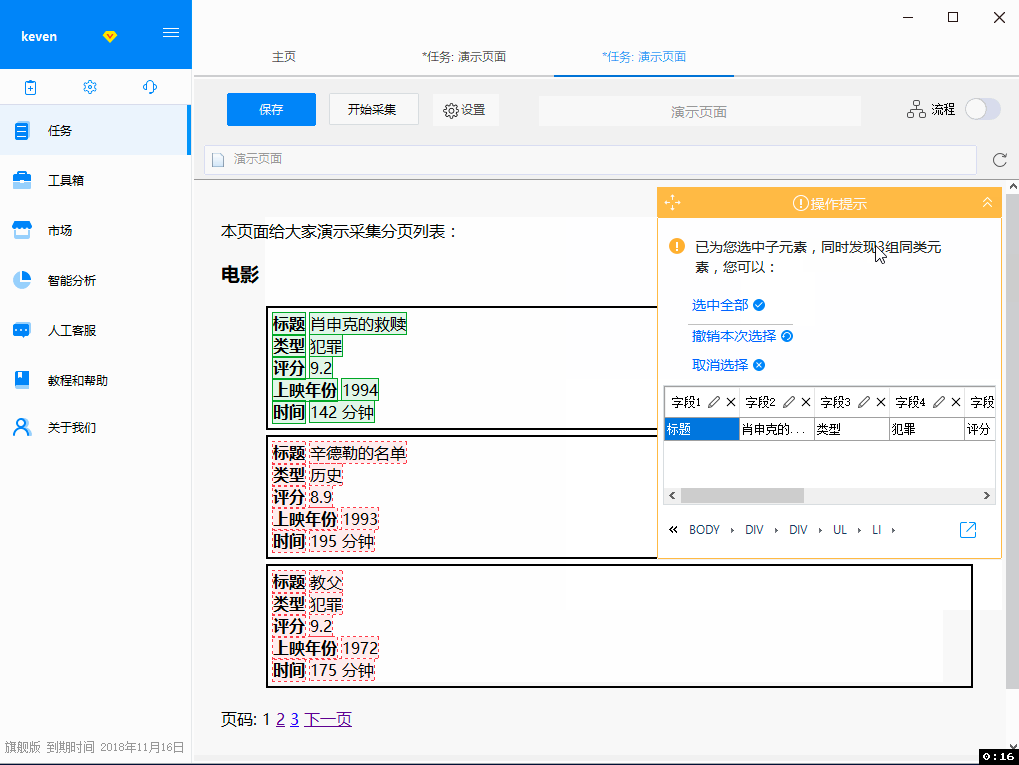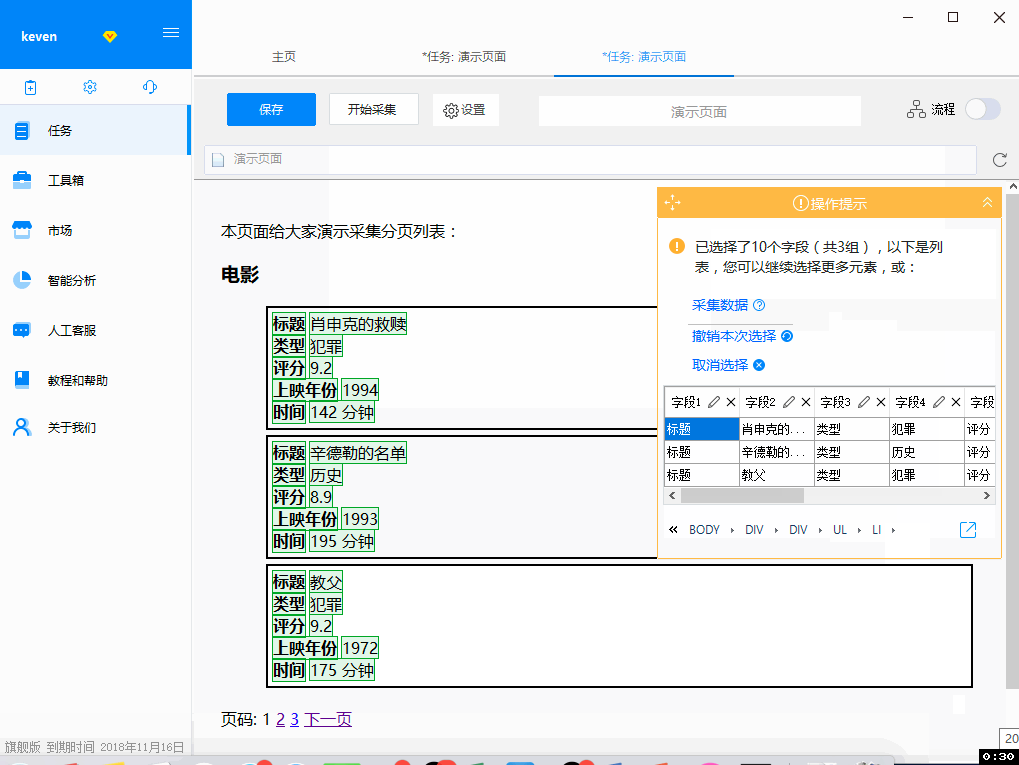
操作录屏 - 第一步
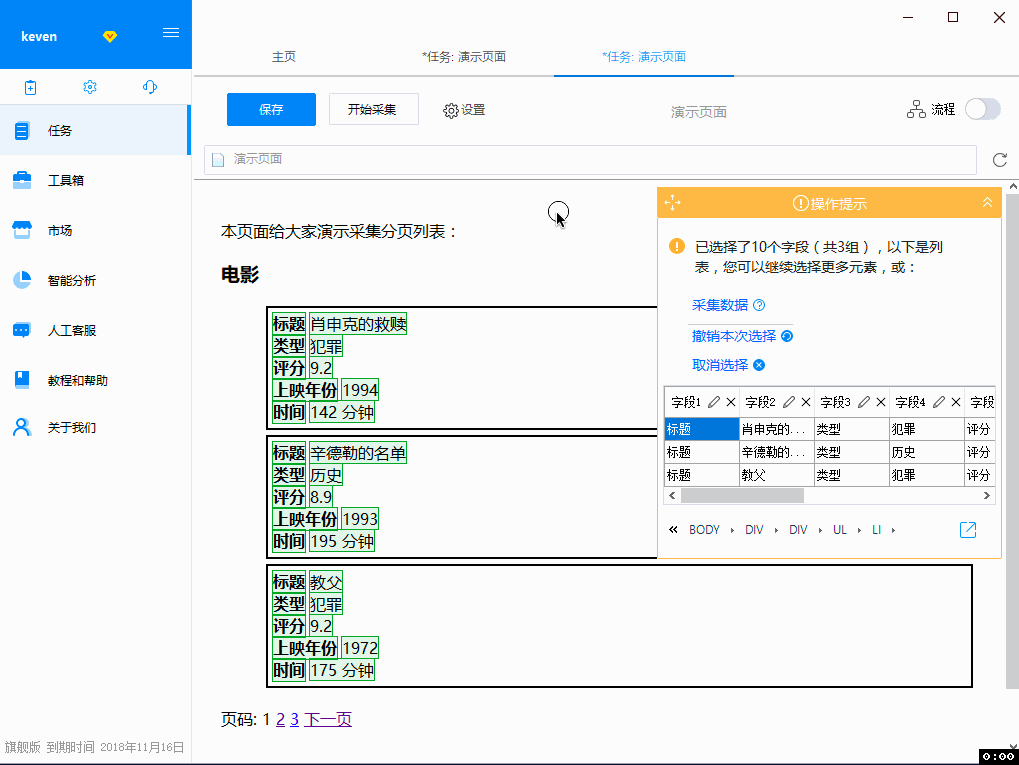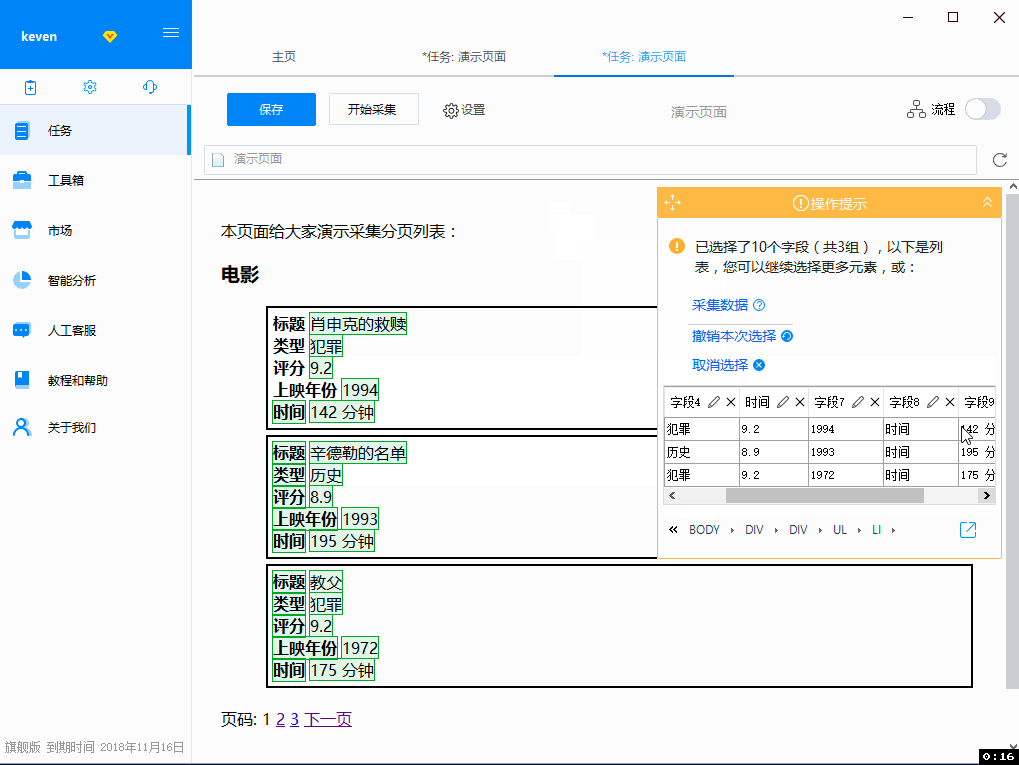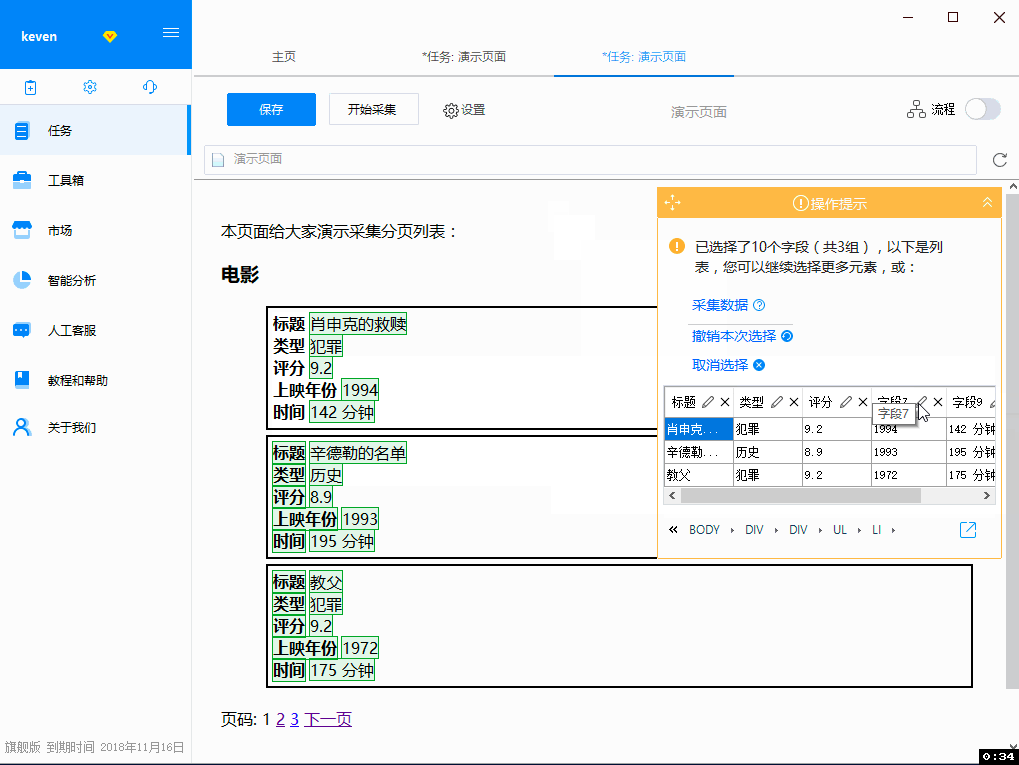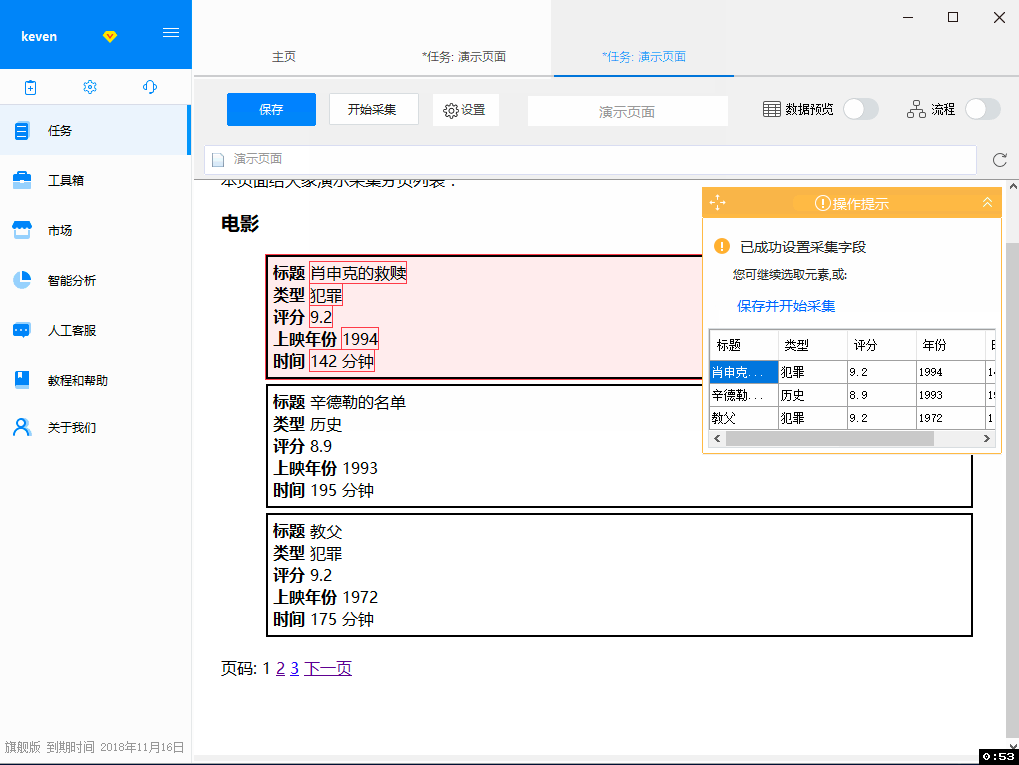
2. 网页打开后,随着鼠标的移动,会出现蓝色背景来表示内容。优采云 内置了专门为采集 数据开发的浏览器。除了像其他浏览器一样显示网页外,还增加了很多功能来支持采集,其中之一就是当鼠标移到不同的内容上时,对应的内容会自动标记为蓝色背景。当鼠标点击时,该区域将被选中并标为绿色,并弹出操作提示框。这里优采云已经自动识别出选中区域收录多个数值字段(子元素),并用红色虚线框标记(表示预选中),我们点击第一个选项“选择子元素”,那么刚刚预选的多个数据字段就会被正式选中并标记为绿色,并且这些字段也会在提示界面的表格中显示出来。. 然后优采云提醒我们:找到了3组相似的元素,也就是自动找到了另外2部电影的数据,也是用红色虚线框预选的,我们选择了第一个选项“全选” ,然后选择所有电影数据。
操作录屏 - 步骤 2
在第二步中,我们接触到了几个新的东西:子元素、智能提示框、各种颜色的选择提示。如果您有兴趣,可以阅读下面的详细说明。当然也可以直接跳到第3步操作。
智能工具提示:
为了记录人的步数采集数据,优采云会在用户选择要操作的网页内容时,让用户选择要进行的操作。例如,如果用户选择了一个链接,他可以选择提取该链接。文字、URL 链接、或点击此链接等。优采云 的智能提示不仅可以让用户选择操作,还可以为用户预测最有可能进行的下一步操作。通过网页数据的智能分析,优采云会自动发现数据字段和相似数据项,从而指导用户操作。4是不是4很聪明,很贴心?
选择提示颜色:
蓝色表示鼠标当前位于哪个内容区域。
绿色表示我们点击选中的内容。
红色虚线表示系统智能识别并预测您要选择的内容。
子元素:
当我们选择一个收录多个数据字段的区域时,优采云指的是我们选择的区域为一个“元素(English Element,这是一个技术术语)”,每个数据字段称为一个“子”元素,一个元素可能收录多个“子元素”。
3. 我们已经选择了上一步中的所有数据。在决定 采集 这些字段之前,让我们先检查一下表格。您会发现标题本身也被提取为字段。其实我们只需要真正的Title,不需要标题,所以我们可以直接删除提示框表单中的“字段1”,其他几个冗余字段同理删除,然后修改我们想要的字段的字段名. 单击 采集 确认数据字段。
操作录屏 - 步骤 3
4.我们现在采集第一页的所有数据,一共3页,然后我们设置翻页,点击下面的“下一页”按钮,优采云会自动识别这是下一页链接,我们选择“循环点击下一页”选项,系统会翻页,采集每一页直到最后一页。点击开始采集,在弹出的窗口中选择“开始本地采集”,会打开一个窗口继续采集。
操作录屏-第四步
概括:
恭喜!您已成功采集电影的所有数据网站,并且以同样的方式您将能够采集任何收录列表、表格和页面的网站,你在采集的路上又取得了一个里程碑,未来我们会继续学习更多的技能,一步步成为采集的大神。
如果您有任何问题或想法想与我分享,请在下面的评论部分留言。也可以关注我的知乎与我互动:点击关注“刘宝强的知乎”。同时,欢迎关注我的知乎栏目获取新的文章通知:点击关注“小白的数据梦工厂” 查看全部
网站程序自带的采集器采集文章(这是快速入门爬虫1-0基础采集入门知识学习)
欢迎来到小白的数据梦工厂,很高兴你对爬虫感兴趣,想学习爬虫,或者想采集来自网络的一些数据。
我先自我介绍一下。我是优采云采集器的创始人刘宝强。优采云是全球领先的网络数据采集平台,每天服务于全球70万家公司和个人采集数亿条数据。恭喜您从众多爬行入门方式中选择了优采云,这是一个很好的起点,您将从一开始就站在巨人的肩膀上!
阅读这篇文章大约需要 15 分钟。
这是爬虫快速入门的第二篇,第一个链接:爬虫快速入门1-0基础采集介绍
本系列文章将带领你从0基础开始,一步一步,从采集一个简单的网页,到复杂的列表,多页数据,Ajax页面,瀑布流等等,直到应对常见封IP,验证码等防采集措施,包括采集淘宝,京东,微信,大众点评等热门网站。由浅入深,循序渐进的深入网页数据采集领域,相信认真学完本系列,你也会成为采集大神,有能力把互联网变成自己的数据库(这一段提到了Ajax等专业数据,你可能不懂,但有个好消息:到目前为止你不需要了解这些技术概念)。
学习本内容,需要具备以下知识:
我研究了第一篇:爬虫快速入门-0基础知识采集介绍,意思就是你了解了基础知识并成功安装了优采云采集器,这些在第一篇都是详细解释。
截止本文发布时,八爪鱼采集器的最新版本是7.1.8,下载地址是:http://www.bazhuayu.com/download
通过学习本内容,您将掌握以下内容:
了解如何采集列出数据。了解如何翻页实现多页数据采集。
第一篇我们成功采集一条数据,你可能觉得采集一条数据没用,采集一条数据最快的方法就是复制手动,可能有几十条数据,可以手动复制。在实际应用场景中,我们经常需要采集数百、数千甚至数百万的数据。所以第一篇的意义在于学习如何通过软件工具实现自动化采集。
在实际场景中,大部分网站数据可能是这样的(如下图):
一个网站有很多分类,每个分类都有很多数据,通常每个分类都是一个页面,里面有一个列表或者表格,还有一个翻页功能。以知名的京东商城为例。京东有很多产品品类(categories),每个品类(比如手机)都有一个手机数据列表(data list)。此列表页面收录 60 款手机的基本数据。每部手机(列表项)都有价格、标题、销量(字段)等多项具体信息,页面底部有翻页链接区,可以点击下一页查看基本第二页其他60部手机的数据。
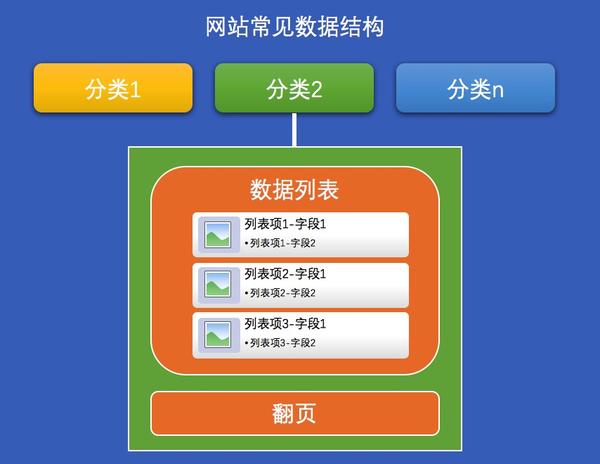
常用网站数据结构图
上面提到的几个概念在我们采集数据的时候经常用到:分类、列表、数据项、数据字段、翻页;如果你看到一个网站,你可以在心里构建它当启动这个网站 数据结构时,采集 变得非常容易。
在这里,我为大家准备了一个例子网站:Demo网站-电影数据分类,网址:/guide/demo/genremoviespage1.html,大家可以对比一下上面常见的网站数据结构图看这个网站,是不是很像??
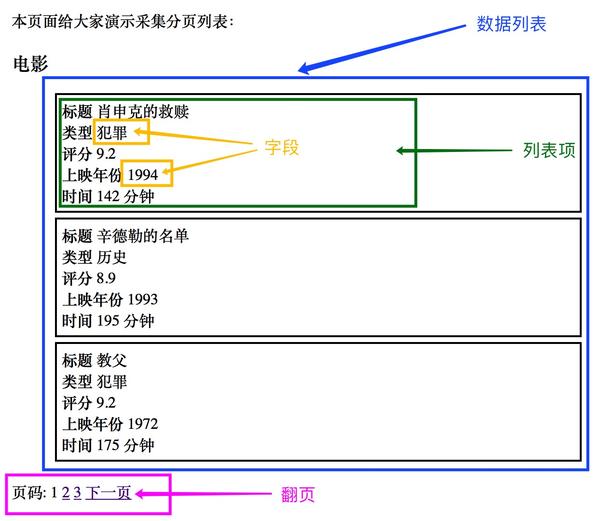
示例 网站 截图(带有 网站 数据结构标签)
如果我们不使用工具并手动复制完成数据采集,我们会这样做:
在浏览器中打开此 网站。复制第一部电影的数据: 标题 肖申克的救赎 类型 犯罪分数9.2 发行年份 1994 时间 142 分钟。粘贴到 Excel 中,另存为 5 列。重复上述步骤 2,直到复制第一页上 3 部电影的数据。在翻页区点击“下一页”链接,重复步骤2、3,然后再次点击“下一页”,以此类推,直到到达最后一页(最后一页没有“下一页”链接)。
那么如何使用 优采云 工具呢?还记得第一篇文章中提到的优采云采集 核心原则吗?
优采云采集的核心原理是模拟人们浏览网页和复制数据的行为,通过记录和模拟人们的一系列上网行为,代替人眼浏览网页,手动复制网页数据代替人,从而将网页中的采集数据自动化,然后通过不断重复一系列设定的动作过程自动采集大量数据。
你可能已经想好了怎么做,别着急,让我们试着把我们的想法画成一个流程图,它应该是这样的:
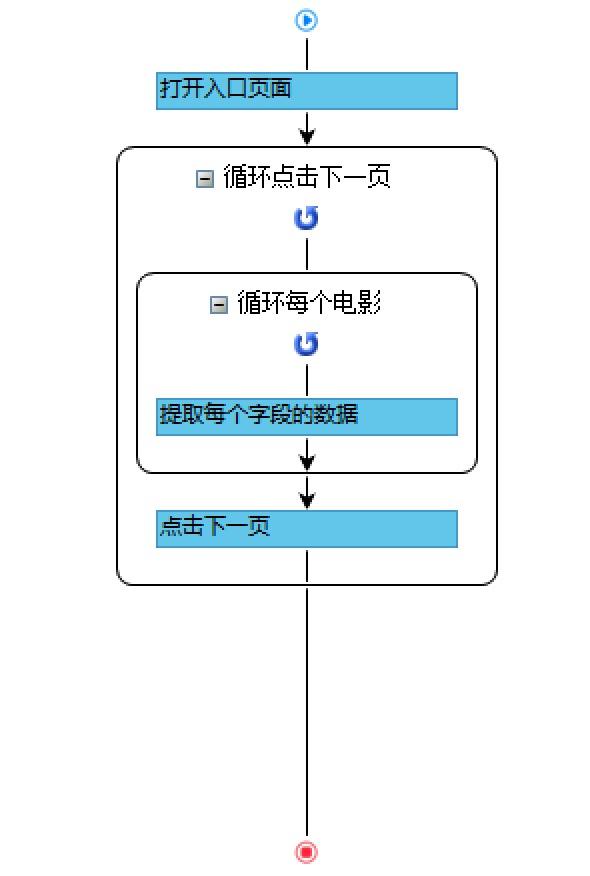
让我解释一下这个流程图的具体步骤:
蓝色方块代表一些步骤,黑色圆角矩形线框代表我们要重复的一个或多个步骤。
打开这个网站的分类数据录入页面,就是刚才的示例URL。接下来是需要重复的步骤:循环点击下一页,黑色矩形线框内的部分需要重复。它收录另一个需要重复的步骤:循环播放每部电影。同样,让我们看看里面。有一个蓝色的步骤:提取每个字段的数据。这就是我们现在需要做的,让优采云工具自动提取每个字段。执行完最后一个蓝色步骤后,需要重复执行此蓝色步骤,直到自动提取出第一页三部电影的数据。至此,“循环每部电影”的步骤就完成了。然后我们执行下面的蓝色步骤:点击下一页,所以网页会跳转到第2页,
用优采云工具采集仔细对比手动复制数据的4个步骤和流程图,你会发现它们非常相似,可以说是完全一样的过程。这再次说明了优采云像机器人一样,模拟人类思维和上网、复制数据的过程。虽然每个网站都不一样,但好消息是:任何复杂的网站都可以用这个简单的思路来做,想想人家是怎么做的,然后在优采云中设置一个对应的工作流程可以实现任意网站的采集。这就是 优采云 能够不断变化地适应 采集any网站 的秘诀。
看到这里,也许你已经迫不及待想要实际操作它来验证我们的想法了。我们来看看如何实际操作它:
打开优采云采集器,点击“自定义采集”按钮→点击左上角“新建任务”按钮进入任务配置页面,然后输入网址(/ guide/demo/genremoviespage1.html) → 保存URL,系统会进入工艺设计页面并自动打开输入的URL。
操作录屏 - 第一步
2. 网页打开后,随着鼠标的移动,会出现蓝色背景来表示内容。优采云 内置了专门为采集 数据开发的浏览器。除了像其他浏览器一样显示网页外,还增加了很多功能来支持采集,其中之一就是当鼠标移到不同的内容上时,对应的内容会自动标记为蓝色背景。当鼠标点击时,该区域将被选中并标为绿色,并弹出操作提示框。这里优采云已经自动识别出选中区域收录多个数值字段(子元素),并用红色虚线框标记(表示预选中),我们点击第一个选项“选择子元素”,那么刚刚预选的多个数据字段就会被正式选中并标记为绿色,并且这些字段也会在提示界面的表格中显示出来。. 然后优采云提醒我们:找到了3组相似的元素,也就是自动找到了另外2部电影的数据,也是用红色虚线框预选的,我们选择了第一个选项“全选” ,然后选择所有电影数据。
操作录屏 - 步骤 2
在第二步中,我们接触到了几个新的东西:子元素、智能提示框、各种颜色的选择提示。如果您有兴趣,可以阅读下面的详细说明。当然也可以直接跳到第3步操作。
智能工具提示:
为了记录人的步数采集数据,优采云会在用户选择要操作的网页内容时,让用户选择要进行的操作。例如,如果用户选择了一个链接,他可以选择提取该链接。文字、URL 链接、或点击此链接等。优采云 的智能提示不仅可以让用户选择操作,还可以为用户预测最有可能进行的下一步操作。通过网页数据的智能分析,优采云会自动发现数据字段和相似数据项,从而指导用户操作。4是不是4很聪明,很贴心?
选择提示颜色:
蓝色表示鼠标当前位于哪个内容区域。
绿色表示我们点击选中的内容。
红色虚线表示系统智能识别并预测您要选择的内容。
子元素:
当我们选择一个收录多个数据字段的区域时,优采云指的是我们选择的区域为一个“元素(English Element,这是一个技术术语)”,每个数据字段称为一个“子”元素,一个元素可能收录多个“子元素”。
3. 我们已经选择了上一步中的所有数据。在决定 采集 这些字段之前,让我们先检查一下表格。您会发现标题本身也被提取为字段。其实我们只需要真正的Title,不需要标题,所以我们可以直接删除提示框表单中的“字段1”,其他几个冗余字段同理删除,然后修改我们想要的字段的字段名. 单击 采集 确认数据字段。
操作录屏 - 步骤 3
4.我们现在采集第一页的所有数据,一共3页,然后我们设置翻页,点击下面的“下一页”按钮,优采云会自动识别这是下一页链接,我们选择“循环点击下一页”选项,系统会翻页,采集每一页直到最后一页。点击开始采集,在弹出的窗口中选择“开始本地采集”,会打开一个窗口继续采集。
操作录屏-第四步
概括:
恭喜!您已成功采集电影的所有数据网站,并且以同样的方式您将能够采集任何收录列表、表格和页面的网站,你在采集的路上又取得了一个里程碑,未来我们会继续学习更多的技能,一步步成为采集的大神。
如果您有任何问题或想法想与我分享,请在下面的评论部分留言。也可以关注我的知乎与我互动:点击关注“刘宝强的知乎”。同时,欢迎关注我的知乎栏目获取新的文章通知:点击关注“小白的数据梦工厂”
网站程序自带的采集器采集文章(这是快速入门爬虫1-0基础采集入门知识学习)
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2022-01-31 16:26
欢迎来到小白的数据梦工厂,很高兴你对爬虫感兴趣,想学习爬虫,或者想采集来自网络的一些数据。
我先自我介绍一下。我是优采云采集器的创始人刘宝强。优采云是全球领先的网络数据采集平台,每天服务于全球70万家公司和个人采集数亿条数据。恭喜您从众多爬行入门方式中选择了优采云,这是一个很好的起点,您将从一开始就站在巨人的肩膀上!
阅读这篇文章大约需要 15 分钟。
这是爬虫快速入门的第二部分,第一个链接:爬虫快速入门1-0基础采集简介
本系列文章将带领你从0基础开始,一步一步,从采集一个简单的网页,到复杂的列表,多页数据,Ajax页面,瀑布流等等,直到应对常见封IP,验证码等防采集措施,包括采集淘宝,京东,微信,大众点评等热门网站。由浅入深,循序渐进的深入网页数据采集领域,相信认真学完本系列,你也会成为采集大神,有能力把互联网变成自己的数据库(这一段提到了Ajax等专业数据,你可能不懂,但有个好消息:到目前为止你不需要了解这些技术概念)。
学习本内容,需要具备以下知识:
我研究过第一篇:爬虫快速入门-0基础知识采集介绍,意思就是你了解了基础知识并成功安装了优采云采集器,这些在第一篇文章中都有详细解释。
截止本文发布时,八爪鱼采集器的最新版本是7.1.8,下载地址是:http://www.bazhuayu.com/download
通过学习本内容,您将掌握以下内容:
了解如何采集列出数据。了解如何翻页实现多页数据采集。
第一篇我们成功采集一条数据,你可能觉得采集一条数据没用,采集一条数据最快的方法就是手动复制它,可能有几十条数据它可以手动复制。在实际应用场景中,我们经常需要采集数百、数千甚至数百万的数据。所以第一篇的意义在于学习如何通过软件工具实现自动化采集。
在实际场景中,大部分网站数据可能是这样的(如下图):
一个网站有很多分类,每个分类都有很多数据,通常每个分类都是一个页面,里面有一个列表或者表格,还有一个翻页功能。以知名的京东商城为例。京东有很多产品品类(categories),每个品类(比如手机)都有一个手机数据列表(data list)。此列表页面收录 60 款手机的基本数据。每部手机(列表项)都有价格、标题、销量(字段)等多项具体信息,页面底部有翻页链接区,可以点击下一页查看基本第二页其他60部手机的数据。
常用网站数据结构图
上面提到的几个概念在我们采集数据的时候经常用到:分类、列表、数据项、数据字段、翻页;如果你看到一个网站,你可以在心里构建它当启动这个网站 数据结构时,采集 变得非常容易。
在这里,我为大家准备了一个例子网站:Demo网站-电影数据分类,网址:/guide/demo/genremoviespage1.html,大家可以对比一下上面常见的网站数据结构图看这个网站,是不是很像??
示例 网站 截图(带有 网站 数据结构标签)
如果我们不使用工具并手动复制完成数据采集,我们会这样做:
在浏览器中打开此 网站。复制第一部电影的数据: 标题 肖申克的救赎 类型 犯罪分数9.2 发行年份 1994 时间 142 分钟。粘贴到 Excel 中,另存为 5 列。重复上述步骤 2,直到复制第一页上 3 部电影的数据。在翻页区点击“下一页”链接,重复步骤2、3,然后再次点击“下一页”,以此类推,直到到达最后一页(最后一页没有“下一页”链接)。
那么如何使用 优采云 工具呢?还记得第一篇文章中提到的优采云采集 核心原则吗?
优采云采集的核心原理是:模拟人们浏览网页和复制数据的行为,通过记录和模拟人们的一系列上网行为,代替人眼浏览网页,手动复制网页数据代替人,从而将网页中的采集数据自动化,然后通过不断重复一系列设定的动作过程自动采集大量数据。
你可能已经想好了怎么做,别着急,让我们试着把我们的想法画成一个流程图,它应该是这样的:
让我解释一下这个流程图的具体步骤:
蓝色方块代表一些步骤,黑色圆角矩形线框代表我们要重复的一个或多个步骤。
打开这个网站的分类数据录入页面,就是刚才的示例URL。接下来是需要重复的步骤:循环点击下一页,黑色矩形线框内的部分需要重复。它收录另一个需要重复的步骤:循环播放每部电影。同样,让我们看看里面。有一个蓝色的步骤:提取每个字段的数据。这就是我们现在需要做的,让优采云工具自动提取每个字段。执行完最后一个蓝色步骤后,需要重复执行此蓝色步骤,直到自动提取出第一页三部电影的数据。至此,“循环每部电影”的步骤就完成了。然后我们执行下面的蓝色步骤:点击下一页,所以网页会跳转到第2页,
用优采云工具采集仔细对比手动复制数据的4个步骤和流程图,你会发现它们非常相似,可以说是完全一样的过程。这再次说明了优采云像机器人一样,模拟人类思维和上网、复制数据的过程。虽然每个网站都不一样,但好消息是:任何复杂的网站都可以用这个简单的思路来做,想想人家是怎么做的,然后在优采云中设置一个对应的工作流程可以实现任意网站的采集。这就是 优采云 能够不断变化地适应 采集any网站 的秘诀。
看到这里,也许你已经迫不及待想要实际操作它来验证我们的想法了。我们来看看如何实际操作它:
打开优采云采集器,点击“自定义采集”按钮→点击左上角“新建任务”按钮进入任务配置页面,然后输入网址(/ guide/demo/genremoviespage1.html) → 保存URL,系统会进入工艺设计页面并自动打开输入的URL。
操作录屏 - 第一步
2. 网页打开后,随着鼠标的移动,会出现蓝色背景来表示内容。优采云 内置了专门为采集 数据开发的浏览器。除了像其他浏览器一样显示网页外,还增加了很多功能来支持采集,其中之一就是当鼠标移到不同的内容上时,对应的内容会自动标记为蓝色背景。当鼠标点击时,该区域将被选中并标为绿色,并弹出操作提示框。这里优采云已经自动识别出选中区域收录多个数值字段(子元素),并用红色虚线框标记(表示预选中),我们点击第一个选项“选择子元素”,那么刚刚预选的多个数据字段将被正式选中并标记为绿色,并且这些字段也将显示在提示界面的表格中。. 然后优采云提醒我们:找到了3组相似的元素,也就是自动找到了另外2部电影的数据,也是用红色虚线框预选的,我们选择了第一个选项“全选” ,然后选择所有电影数据。
操作录屏 - 步骤 2
在第二步中,我们接触到了几个新的东西:子元素、智能提示框、各种颜色的选择提示。如果您有兴趣,可以阅读下面的详细说明。当然也可以直接跳到第3步操作。
智能工具提示:
为了记录人的步数采集数据,优采云会在用户选择要操作的网页内容时,让用户选择要进行的操作。例如,如果用户选择了一个链接,他可以选择提取该链接。文字、URL 链接、或点击此链接等。优采云 的智能提示不仅可以让用户选择操作,还可以为用户预测最有可能进行的下一步操作。通过网页数据的智能分析,优采云会自动发现数据字段和相似数据项,从而指导用户操作。4是不是4很聪明,很贴心?
选择提示颜色:
蓝色表示鼠标当前位于哪个内容区域。
绿色表示我们点击选中的内容。
红色虚线表示系统智能识别并预测您要选择的内容。
子元素:
当我们选择一个收录多个数据字段的区域时,优采云指的是我们选择的区域为一个“元素(English Element,这是一个技术术语)”,每个数据字段称为一个“子”元素,一个元素可能收录多个“子元素”。
3. 我们已经选择了上一步中的所有数据。在决定 采集 这些字段之前,让我们先检查一下表格。您会发现标题本身也被提取为字段。其实我们只需要真正的Title,不需要标题,所以我们可以直接删除提示框表单中的“字段1”,其他几个冗余字段同理删除,然后修改我们想要的字段的字段名. 单击 采集 确认数据字段。
操作录屏 - 步骤 3
4.我们现在采集第一页的所有数据,一共3页,然后我们设置翻页,点击下面的“下一页”按钮,优采云会自动识别这是下一页链接,我们选择“循环点击下一页”选项,系统会翻页,采集每一页直到最后一页。点击开始采集,在弹出的窗口中选择“开始本地采集”,会打开一个窗口继续采集。
操作录屏-第四步
概括:
恭喜!您已成功采集电影的所有数据网站,并且以同样的方式您将能够采集任何收录列表、表格和页面的网站,你在采集的路上又取得了一个里程碑,未来我们会继续学习更多的技能,一步步成为采集的大神。
如果您有任何问题或想法想与我分享,请在下面的评论部分留言。也可以关注我的知乎与我互动:点击关注“刘宝强的知乎”。同时,欢迎关注我的知乎专栏,获取新的文章通知:点击关注“小白的数据梦工厂” 查看全部
网站程序自带的采集器采集文章(这是快速入门爬虫1-0基础采集入门知识学习)
欢迎来到小白的数据梦工厂,很高兴你对爬虫感兴趣,想学习爬虫,或者想采集来自网络的一些数据。
我先自我介绍一下。我是优采云采集器的创始人刘宝强。优采云是全球领先的网络数据采集平台,每天服务于全球70万家公司和个人采集数亿条数据。恭喜您从众多爬行入门方式中选择了优采云,这是一个很好的起点,您将从一开始就站在巨人的肩膀上!
阅读这篇文章大约需要 15 分钟。
这是爬虫快速入门的第二部分,第一个链接:爬虫快速入门1-0基础采集简介
本系列文章将带领你从0基础开始,一步一步,从采集一个简单的网页,到复杂的列表,多页数据,Ajax页面,瀑布流等等,直到应对常见封IP,验证码等防采集措施,包括采集淘宝,京东,微信,大众点评等热门网站。由浅入深,循序渐进的深入网页数据采集领域,相信认真学完本系列,你也会成为采集大神,有能力把互联网变成自己的数据库(这一段提到了Ajax等专业数据,你可能不懂,但有个好消息:到目前为止你不需要了解这些技术概念)。
学习本内容,需要具备以下知识:
我研究过第一篇:爬虫快速入门-0基础知识采集介绍,意思就是你了解了基础知识并成功安装了优采云采集器,这些在第一篇文章中都有详细解释。
截止本文发布时,八爪鱼采集器的最新版本是7.1.8,下载地址是:http://www.bazhuayu.com/download
通过学习本内容,您将掌握以下内容:
了解如何采集列出数据。了解如何翻页实现多页数据采集。
第一篇我们成功采集一条数据,你可能觉得采集一条数据没用,采集一条数据最快的方法就是手动复制它,可能有几十条数据它可以手动复制。在实际应用场景中,我们经常需要采集数百、数千甚至数百万的数据。所以第一篇的意义在于学习如何通过软件工具实现自动化采集。
在实际场景中,大部分网站数据可能是这样的(如下图):
一个网站有很多分类,每个分类都有很多数据,通常每个分类都是一个页面,里面有一个列表或者表格,还有一个翻页功能。以知名的京东商城为例。京东有很多产品品类(categories),每个品类(比如手机)都有一个手机数据列表(data list)。此列表页面收录 60 款手机的基本数据。每部手机(列表项)都有价格、标题、销量(字段)等多项具体信息,页面底部有翻页链接区,可以点击下一页查看基本第二页其他60部手机的数据。
常用网站数据结构图
上面提到的几个概念在我们采集数据的时候经常用到:分类、列表、数据项、数据字段、翻页;如果你看到一个网站,你可以在心里构建它当启动这个网站 数据结构时,采集 变得非常容易。
在这里,我为大家准备了一个例子网站:Demo网站-电影数据分类,网址:/guide/demo/genremoviespage1.html,大家可以对比一下上面常见的网站数据结构图看这个网站,是不是很像??
示例 网站 截图(带有 网站 数据结构标签)
如果我们不使用工具并手动复制完成数据采集,我们会这样做:
在浏览器中打开此 网站。复制第一部电影的数据: 标题 肖申克的救赎 类型 犯罪分数9.2 发行年份 1994 时间 142 分钟。粘贴到 Excel 中,另存为 5 列。重复上述步骤 2,直到复制第一页上 3 部电影的数据。在翻页区点击“下一页”链接,重复步骤2、3,然后再次点击“下一页”,以此类推,直到到达最后一页(最后一页没有“下一页”链接)。
那么如何使用 优采云 工具呢?还记得第一篇文章中提到的优采云采集 核心原则吗?
优采云采集的核心原理是:模拟人们浏览网页和复制数据的行为,通过记录和模拟人们的一系列上网行为,代替人眼浏览网页,手动复制网页数据代替人,从而将网页中的采集数据自动化,然后通过不断重复一系列设定的动作过程自动采集大量数据。
你可能已经想好了怎么做,别着急,让我们试着把我们的想法画成一个流程图,它应该是这样的:
让我解释一下这个流程图的具体步骤:
蓝色方块代表一些步骤,黑色圆角矩形线框代表我们要重复的一个或多个步骤。
打开这个网站的分类数据录入页面,就是刚才的示例URL。接下来是需要重复的步骤:循环点击下一页,黑色矩形线框内的部分需要重复。它收录另一个需要重复的步骤:循环播放每部电影。同样,让我们看看里面。有一个蓝色的步骤:提取每个字段的数据。这就是我们现在需要做的,让优采云工具自动提取每个字段。执行完最后一个蓝色步骤后,需要重复执行此蓝色步骤,直到自动提取出第一页三部电影的数据。至此,“循环每部电影”的步骤就完成了。然后我们执行下面的蓝色步骤:点击下一页,所以网页会跳转到第2页,
用优采云工具采集仔细对比手动复制数据的4个步骤和流程图,你会发现它们非常相似,可以说是完全一样的过程。这再次说明了优采云像机器人一样,模拟人类思维和上网、复制数据的过程。虽然每个网站都不一样,但好消息是:任何复杂的网站都可以用这个简单的思路来做,想想人家是怎么做的,然后在优采云中设置一个对应的工作流程可以实现任意网站的采集。这就是 优采云 能够不断变化地适应 采集any网站 的秘诀。
看到这里,也许你已经迫不及待想要实际操作它来验证我们的想法了。我们来看看如何实际操作它:
打开优采云采集器,点击“自定义采集”按钮→点击左上角“新建任务”按钮进入任务配置页面,然后输入网址(/ guide/demo/genremoviespage1.html) → 保存URL,系统会进入工艺设计页面并自动打开输入的URL。
操作录屏 - 第一步
2. 网页打开后,随着鼠标的移动,会出现蓝色背景来表示内容。优采云 内置了专门为采集 数据开发的浏览器。除了像其他浏览器一样显示网页外,还增加了很多功能来支持采集,其中之一就是当鼠标移到不同的内容上时,对应的内容会自动标记为蓝色背景。当鼠标点击时,该区域将被选中并标为绿色,并弹出操作提示框。这里优采云已经自动识别出选中区域收录多个数值字段(子元素),并用红色虚线框标记(表示预选中),我们点击第一个选项“选择子元素”,那么刚刚预选的多个数据字段将被正式选中并标记为绿色,并且这些字段也将显示在提示界面的表格中。. 然后优采云提醒我们:找到了3组相似的元素,也就是自动找到了另外2部电影的数据,也是用红色虚线框预选的,我们选择了第一个选项“全选” ,然后选择所有电影数据。
操作录屏 - 步骤 2
在第二步中,我们接触到了几个新的东西:子元素、智能提示框、各种颜色的选择提示。如果您有兴趣,可以阅读下面的详细说明。当然也可以直接跳到第3步操作。
智能工具提示:
为了记录人的步数采集数据,优采云会在用户选择要操作的网页内容时,让用户选择要进行的操作。例如,如果用户选择了一个链接,他可以选择提取该链接。文字、URL 链接、或点击此链接等。优采云 的智能提示不仅可以让用户选择操作,还可以为用户预测最有可能进行的下一步操作。通过网页数据的智能分析,优采云会自动发现数据字段和相似数据项,从而指导用户操作。4是不是4很聪明,很贴心?
选择提示颜色:
蓝色表示鼠标当前位于哪个内容区域。
绿色表示我们点击选中的内容。
红色虚线表示系统智能识别并预测您要选择的内容。
子元素:
当我们选择一个收录多个数据字段的区域时,优采云指的是我们选择的区域为一个“元素(English Element,这是一个技术术语)”,每个数据字段称为一个“子”元素,一个元素可能收录多个“子元素”。
3. 我们已经选择了上一步中的所有数据。在决定 采集 这些字段之前,让我们先检查一下表格。您会发现标题本身也被提取为字段。其实我们只需要真正的Title,不需要标题,所以我们可以直接删除提示框表单中的“字段1”,其他几个冗余字段同理删除,然后修改我们想要的字段的字段名. 单击 采集 确认数据字段。
操作录屏 - 步骤 3
4.我们现在采集第一页的所有数据,一共3页,然后我们设置翻页,点击下面的“下一页”按钮,优采云会自动识别这是下一页链接,我们选择“循环点击下一页”选项,系统会翻页,采集每一页直到最后一页。点击开始采集,在弹出的窗口中选择“开始本地采集”,会打开一个窗口继续采集。
操作录屏-第四步
概括:
恭喜!您已成功采集电影的所有数据网站,并且以同样的方式您将能够采集任何收录列表、表格和页面的网站,你在采集的路上又取得了一个里程碑,未来我们会继续学习更多的技能,一步步成为采集的大神。
如果您有任何问题或想法想与我分享,请在下面的评论部分留言。也可以关注我的知乎与我互动:点击关注“刘宝强的知乎”。同时,欢迎关注我的知乎专栏,获取新的文章通知:点击关注“小白的数据梦工厂”
网站程序自带的采集器采集文章(优采云采集程序负责根据工作流对网页数据采集(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-31 16:25
优采云采集原理
优采云网页数据采集客户端使用的开发语言为C#,运行于Windows系统。客户端主程序负责任务配置和管理、云采集任务控制、云集成数据管理(导出、清理、发布)。数据导出程序负责将数据导出为Excel、SQL、TXT、MYSQL等,支持一次导出百万级数据。本地采集程序负责按照工作流程打开、抓取、采集网页数据,通过正则表达式和Xpath原理快速获取网页数据。
整个采集过程是基于火狐内核浏览器,通过模拟人的思维方式(比如打开网页,点击网页中的按钮)自动提取网页内容。系统将流程操作完全可视化,无需专业知识,轻松实现数据采集。优采云通过准确定位网页源代码中每条数据的XPath路径,可以准确采集批量出用户需要的数据。
优采云实现的功能
优采云网页数据采集系统基于完全自主研发的分布式云计算平台,可在极短的时间内轻松获取各种网站或网页的大量数据. 规范化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率. 涉及政府、高校、企业、银行、电子商务、科研、汽车、房地产、媒体等众多行业和领域。
图 1:采集 示意图
优采云作为一般的网页数据采集器,并不针对某个网站某个行业进行采集数据,但是在网页上可以看到或者网页源码中几乎所有的文字信息都可以是采集,市面上98%的网页都可以是采集和优采云。
使用本地采集(单机采集),除了爬取大部分网页数据外,还可以对采集过程中的数据进行初步清洗。如果您使用程序自带的正则工具,请使用正则表达式来格式化数据。可以在数据源处实现去除空格、过滤日期等各种操作。其次,优采云还提供了分支判断功能,可以逻辑判断网页中的信息是否真实,从而实现用户的筛选需求。
Cloud采集不仅具备本地采集(单机采集)的所有功能,还可以实现定时采集、实时监控、自动去重和存储,增加数量采集,自动识别验证码,API接口多样化导出数据和修改参数。同时使用云端多个节点并发运行,采集速度会比本地采集(单机采集)快很多,多台自动切换任务启动时的IP也可以避免网站IP阻塞,实现采集对比数据。
图 2:时序云采集 查看全部
网站程序自带的采集器采集文章(优采云采集程序负责根据工作流对网页数据采集(组图))
优采云采集原理
优采云网页数据采集客户端使用的开发语言为C#,运行于Windows系统。客户端主程序负责任务配置和管理、云采集任务控制、云集成数据管理(导出、清理、发布)。数据导出程序负责将数据导出为Excel、SQL、TXT、MYSQL等,支持一次导出百万级数据。本地采集程序负责按照工作流程打开、抓取、采集网页数据,通过正则表达式和Xpath原理快速获取网页数据。
整个采集过程是基于火狐内核浏览器,通过模拟人的思维方式(比如打开网页,点击网页中的按钮)自动提取网页内容。系统将流程操作完全可视化,无需专业知识,轻松实现数据采集。优采云通过准确定位网页源代码中每条数据的XPath路径,可以准确采集批量出用户需要的数据。
优采云实现的功能
优采云网页数据采集系统基于完全自主研发的分布式云计算平台,可在极短的时间内轻松获取各种网站或网页的大量数据. 规范化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率. 涉及政府、高校、企业、银行、电子商务、科研、汽车、房地产、媒体等众多行业和领域。

图 1:采集 示意图
优采云作为一般的网页数据采集器,并不针对某个网站某个行业进行采集数据,但是在网页上可以看到或者网页源码中几乎所有的文字信息都可以是采集,市面上98%的网页都可以是采集和优采云。
使用本地采集(单机采集),除了爬取大部分网页数据外,还可以对采集过程中的数据进行初步清洗。如果您使用程序自带的正则工具,请使用正则表达式来格式化数据。可以在数据源处实现去除空格、过滤日期等各种操作。其次,优采云还提供了分支判断功能,可以逻辑判断网页中的信息是否真实,从而实现用户的筛选需求。
Cloud采集不仅具备本地采集(单机采集)的所有功能,还可以实现定时采集、实时监控、自动去重和存储,增加数量采集,自动识别验证码,API接口多样化导出数据和修改参数。同时使用云端多个节点并发运行,采集速度会比本地采集(单机采集)快很多,多台自动切换任务启动时的IP也可以避免网站IP阻塞,实现采集对比数据。
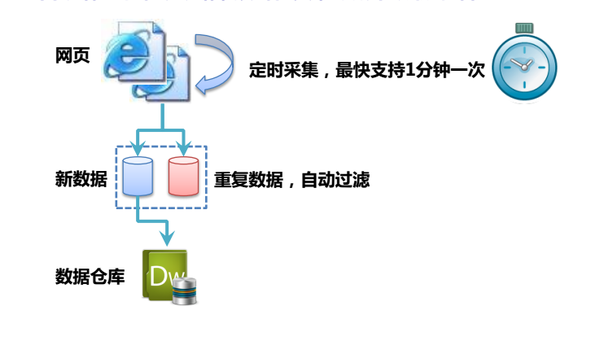
图 2:时序云采集
网站程序自带的采集器采集文章(一下来说胡乱采集新闻源软件的程序说明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-30 04:13
如果非要评论的话,应该算是随机的采集新闻源软件。现在有这么多采集器,我为什么要使用这个傻瓜式采集程序呢? .
但不能说这个软件没用。毕竟在使用站群堆放垃圾文章的时候,这个程序确实可以用,毕竟简单~
节目说明
第一百万新闻源文本采集软件
1、内置独家新闻挖掘接口数据
采集市面上有很多软件,采集软件可以很容易写,但技术点不是如何写程序逻辑,而是如何找到高质量的采集@ >消息源,骷髅采集夏能嗅探采集到国内消息源文章2005年到2019年,从文章的数据量来看,是远远满意的站群对文章的需求,对文章有严格要求的用户,对文章、骨架采集xia采集 是独一无二的,永不重复。 100万条头条数据足够你操作所有大数据站群,无论你是做内页站群,目录站群,搜狗新闻热词站群,这个软件可以满足您的要求。
软件深度批量采集后,会智能挂机,嗅探网上发布的最新新闻头条和热点头条,1秒内即可采集上你的服务器。保证资源的最大及时性。
软件支持自动挂机、循环嗅探、采集深度设置、简体中文自动转换为繁体。
如何使用软件
骷髅采集人分为两个软件,title采集和text采集,操作和使用完全一样,
1、设置参数
骷髅采集参数设置很简单,设置保存路径即可,采集生成的txt会自动保存在该路径下。
2、首字母采集
设置深度为21000,可以采集约100万条新闻,当你觉得采集的文章量满足你的需求时,关闭软件。初始的 采集 可以为您提供 采集 到基本的 文章txt 容量。比如你建一个蜘蛛池,5000个txt就够了,没必要深采集太多的txt
3、循环挂机
初始采集结束后,重启软件,设置采集深度为5,此时软件会自动扫描互联网新闻源发布的最新消息,执行采集.
下载链接
下载仅供技术交流学习讨论,请勿用于非法用途!请在下载后24小时内删除! 查看全部
网站程序自带的采集器采集文章(一下来说胡乱采集新闻源软件的程序说明)
如果非要评论的话,应该算是随机的采集新闻源软件。现在有这么多采集器,我为什么要使用这个傻瓜式采集程序呢? .
但不能说这个软件没用。毕竟在使用站群堆放垃圾文章的时候,这个程序确实可以用,毕竟简单~

节目说明
第一百万新闻源文本采集软件
1、内置独家新闻挖掘接口数据
采集市面上有很多软件,采集软件可以很容易写,但技术点不是如何写程序逻辑,而是如何找到高质量的采集@ >消息源,骷髅采集夏能嗅探采集到国内消息源文章2005年到2019年,从文章的数据量来看,是远远满意的站群对文章的需求,对文章有严格要求的用户,对文章、骨架采集xia采集 是独一无二的,永不重复。 100万条头条数据足够你操作所有大数据站群,无论你是做内页站群,目录站群,搜狗新闻热词站群,这个软件可以满足您的要求。
软件深度批量采集后,会智能挂机,嗅探网上发布的最新新闻头条和热点头条,1秒内即可采集上你的服务器。保证资源的最大及时性。
软件支持自动挂机、循环嗅探、采集深度设置、简体中文自动转换为繁体。
如何使用软件
骷髅采集人分为两个软件,title采集和text采集,操作和使用完全一样,
1、设置参数
骷髅采集参数设置很简单,设置保存路径即可,采集生成的txt会自动保存在该路径下。
2、首字母采集
设置深度为21000,可以采集约100万条新闻,当你觉得采集的文章量满足你的需求时,关闭软件。初始的 采集 可以为您提供 采集 到基本的 文章txt 容量。比如你建一个蜘蛛池,5000个txt就够了,没必要深采集太多的txt
3、循环挂机
初始采集结束后,重启软件,设置采集深度为5,此时软件会自动扫描互联网新闻源发布的最新消息,执行采集.
下载链接
下载仅供技术交流学习讨论,请勿用于非法用途!请在下载后24小时内删除!
网站程序自带的采集器采集文章(帝国cms具有如下的几个核心优点以及帝国CMS的采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2022-01-27 10:03
)
Empire 是一个免费的开源程序。相对来说,Empirecms的使用就没有那么直观方便了,上手也不容易(比如模板)。但世上没有烦恼。只要肯努力,铁杵可以磨成针!如果你玩过cms,基本上是一样的。我想对于有一定基础的人来说,熟悉Empirecms需要一周的时间。今天给大家讲讲Empirecms和Empirecms的采集的优势。
一、Empirescms 有几个核心优势。
1、最重要的事情说三遍,安全、安全、安全。在使用Empirecms的两年时间里,没有任何特殊的安全设置,运行中的网站没有受到木马的危害。
二、快速生成html。尤其是数据量大后更新html后,你会发现帝国cms速度非常快,而其他cms静态页面生成速度极慢。
3、便于二次开发的功能扩展。如果懂后端程序开发(主要是php),可以基于empirecms开发更多自定义的网站,比如网站有旅游路线和预订。
四、 Empirecms 是开源的。因为它是开源的,所以您可以放心使用它。
二、Empirecms静态化比较好
为了节省成本,服务器的配置相对较低。要想获得更好的访问效果,静态化更为关键。静态化一方面减少了服务器的消耗,另一方面对搜索引擎比较友好,同时可以支持大量的数据。
三、帝国cms自带采集:
1、打开帝国后台,点击上方栏目,左侧栏目管理中多了一个采集节点,进入。
2、中间的提示是选择你要创建的版块,然后点击你要创建的版块,比如国际新闻。好了,点进去。出现的界面有第一个节点的名字,因为上面创建了国际新闻,这里填写的是国际新闻的父节点(留空就好)。
3、在中间的提示中,选择要创建的栏目,点击你要创建的栏目,比如国际新闻。嗯,点进去。出现的界面有第一个节点的名字,因为上面创建了国际新闻,填国际新闻父节点就行了,不用管(就是留空)
4、页面采集的地址,你可以去新浪的国际新闻复制,比如国际新闻页面的地址,在地址栏复制就可以了。
5、采集页面地址方式2无需填写内容,页面地址前缀写为
6、图片/FLASH地址前缀(内容)~~~截取内容介绍,不介意从这里开始填写采集这个时候是正规内容,需要看源码网页注意-信息页面的常规链接
7、标题图片正则无标题正则:打开内容页,打开你刚才的大栏目中的文章
8、采集内容页面列表-采集内容页面页面-查看采集的信息并入库,点击库中所有信息的按钮-去到所有的采集信息都已经完成了。
四、第三方帝国采集软件兼容优势:
1、支持任何 PHP 版本
2、支持任意版本的Mysql
3、支持任何版本的 Nginx
4、支持任何 Empirecms 版本
采集 将因版本不匹配或服务器环境不支持等其他原因不可用
五、第三方帝国采集软件更易用
门槛低:无需花大量时间学习软件操作,一分钟即可上手,无需配置采集规则,输入关键词到采集即可,
高效:提供一站式网站文章解决方案,无需人工干预,设置任务自动执行采集releases。
零成本:几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
帝国的第三方采集软件很强大,只要输入关键词采集,完全可以通过软件自动采集发布文章采集@>,为了让搜索引擎收录你的网站,我们还可以设置自动下载图片和替换链接。图片存储方式支持:阿里云OSS、七牛对象存储、腾讯云、杂牌云。同时还配备了自动内链,在内容或标题前后插入一定的内容,形成“伪原创”。软件还有监控功能,可以直接通过软件查看文章采集的发布状态。看完这篇文章,如果你觉得不错,不妨采集起来或发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
查看全部
网站程序自带的采集器采集文章(帝国cms具有如下的几个核心优点以及帝国CMS的采集
)
Empire 是一个免费的开源程序。相对来说,Empirecms的使用就没有那么直观方便了,上手也不容易(比如模板)。但世上没有烦恼。只要肯努力,铁杵可以磨成针!如果你玩过cms,基本上是一样的。我想对于有一定基础的人来说,熟悉Empirecms需要一周的时间。今天给大家讲讲Empirecms和Empirecms的采集的优势。

一、Empirescms 有几个核心优势。
1、最重要的事情说三遍,安全、安全、安全。在使用Empirecms的两年时间里,没有任何特殊的安全设置,运行中的网站没有受到木马的危害。
二、快速生成html。尤其是数据量大后更新html后,你会发现帝国cms速度非常快,而其他cms静态页面生成速度极慢。
3、便于二次开发的功能扩展。如果懂后端程序开发(主要是php),可以基于empirecms开发更多自定义的网站,比如网站有旅游路线和预订。
四、 Empirecms 是开源的。因为它是开源的,所以您可以放心使用它。
二、Empirecms静态化比较好
为了节省成本,服务器的配置相对较低。要想获得更好的访问效果,静态化更为关键。静态化一方面减少了服务器的消耗,另一方面对搜索引擎比较友好,同时可以支持大量的数据。
三、帝国cms自带采集:
1、打开帝国后台,点击上方栏目,左侧栏目管理中多了一个采集节点,进入。
2、中间的提示是选择你要创建的版块,然后点击你要创建的版块,比如国际新闻。好了,点进去。出现的界面有第一个节点的名字,因为上面创建了国际新闻,这里填写的是国际新闻的父节点(留空就好)。
3、在中间的提示中,选择要创建的栏目,点击你要创建的栏目,比如国际新闻。嗯,点进去。出现的界面有第一个节点的名字,因为上面创建了国际新闻,填国际新闻父节点就行了,不用管(就是留空)
4、页面采集的地址,你可以去新浪的国际新闻复制,比如国际新闻页面的地址,在地址栏复制就可以了。
5、采集页面地址方式2无需填写内容,页面地址前缀写为
6、图片/FLASH地址前缀(内容)~~~截取内容介绍,不介意从这里开始填写采集这个时候是正规内容,需要看源码网页注意-信息页面的常规链接
7、标题图片正则无标题正则:打开内容页,打开你刚才的大栏目中的文章
8、采集内容页面列表-采集内容页面页面-查看采集的信息并入库,点击库中所有信息的按钮-去到所有的采集信息都已经完成了。
四、第三方帝国采集软件兼容优势:
1、支持任何 PHP 版本
2、支持任意版本的Mysql
3、支持任何版本的 Nginx
4、支持任何 Empirecms 版本
采集 将因版本不匹配或服务器环境不支持等其他原因不可用
五、第三方帝国采集软件更易用
门槛低:无需花大量时间学习软件操作,一分钟即可上手,无需配置采集规则,输入关键词到采集即可,
高效:提供一站式网站文章解决方案,无需人工干预,设置任务自动执行采集releases。
零成本:几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
帝国的第三方采集软件很强大,只要输入关键词采集,完全可以通过软件自动采集发布文章采集@>,为了让搜索引擎收录你的网站,我们还可以设置自动下载图片和替换链接。图片存储方式支持:阿里云OSS、七牛对象存储、腾讯云、杂牌云。同时还配备了自动内链,在内容或标题前后插入一定的内容,形成“伪原创”。软件还有监控功能,可以直接通过软件查看文章采集的发布状态。看完这篇文章,如果你觉得不错,不妨采集起来或发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!

网站程序自带的采集器采集文章(打造一个个人小说站源码上传的商家推荐:网站服务器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-27 04:09
这个文章收录了建立个人小说站的所有详细流程,避免了目前大部分的弯路,无需精通编程,小白也能用。如果你有兴趣搭建个人小说站,可以参考这篇教程完整,因为这里收录了所有相关的源码、规则、程序,你不需要去其他地方找. 另外,这些博主的源代码也被采集,不保证绝对安全,但保证正常使用。,请注意筛选。
注意红色编码部分是你要填写参数的部分
准备好工作了:
网站 大硬盘linux系统服务器(推荐debian8)
N个系统为win的采集服务器(可以是一个)
网站 的域名
服务器选择的一些建议:
因为需要使用多台服务器,所以最实惠的解决方案可能是选择国外服务器。网站最好选择西部的服务器。一方面是因为价格。将它们作为采集 的对象可以保证更快的速度。至于推荐的商家,我后面会补上,因为大硬盘VPS容易断货。
至于采集服务器,我个人推荐使用Vutlr,因为通过邀请注册可以额外获得$25的奖励,可用于开启多台机器同时执行采集,既保证速度又减少高架。,一般情况下,4台机器可以远程采集5条可用规则,一天可以采集1500-3000本书,内容大小在12-20G左右。
还有一点很重要,采集服务器必须靠近网站服务器,ping值最好小于2ms。
部分商家推荐:
网站服务器设置:
1.Linux服务器安装Lamp运行环境
这里需要注意的是php选择5.2,apache选择2.4,其他可以默认推荐。
2.在Liunx服务器上添加PC和手机域名,解析域名
分两步添加,先PC域名,记得建个数据库,再添加手机域名,一般格式为
然后在域名提供者上设置域名解析
3.网站将源码上传到服务器并配置目录的权限
使用Winscp将PC和WAP源代码和压缩包上传到对应的根目录并解压,然后修改目录权限
注意:将PC.zip解压到你的域名.com目录,WAP.zip解压到m.你的域名.com
相关命令示例:
解压解压PC.zip
修改权限 chmod -R 777 /home/wwwroot
修改所有者 chown -R www /home/wwwroot
4.配置站目录下的key文件
然后根据源码中的说明配置网站的配置文件。下面是需要修改配置文件的地方。它已用红色代码标记。@>留言
PC网站 目录下的 /configs/define.php:
WAP目录下(若乱码请改码):
5.进入网站后台输入相关配置
解析生效后,直接输入你的url访问网站,这里我们直接在url后面输入/admin,然后进入后台(用户名admin,密码admin2017).
只要修改的内容是之前设置的一些参数,以及网站相关的信息,这里用截图做个简单的识别:
然后执行命令清除自带的小说数据:
截断表
1`
jieqi_article_article
1`
;
截断表
1`
jieqi_article_chapter
1`
;
6.安装Samba并完成配置
执行命令安装 Samba:
apt-get install samba samba-common-bin
然后使用WinScp,找到目录/etc/samba/smb.conf,编辑这个配置文件并保存:
共享定义下的部分
[杰奇]
comment = jieqi (尽量用这个名字,方便以后参考教程)
path = /home/wwwroot/(这里填写你要分享的目录,分享整个PC网站目录)
有效用户 = 根
公开=不
可写=是
可打印=否
dos 字符集 = GB2312
unix 字符集 = GB2312
目录掩码 = 0777
强制目录模式 = 0777
目录安全掩码 = 0777
强制目录安全模式 = 0777
创建掩码 = 0777
强制创建模式 = 0777
安全面具 = 0777
强制安全模式 = 0777
然后重启 Samba 服务:
/etc/init.d/samba 重启
然后添加 Samba 用户:
smbpasswd -a 根
然后根据提示输入密码。
7.打开IPtable相关端口
先检查港口情况。如果 3306 端口被 DROP 丢弃,则需要释放该端口,并将序列号替换为要删除的序列号。
先检查端口规则
iptables -L -n --line-numbers
例如,要删除INPUT中序号为6的DROP规则(如果有DROP规则,如果没有则跳过),执行:
iptables -D 输入 6
然后添加以下规则:
iptables -A INPUT -p tcp --dport 3306 -j ACCEPT
iptables -A INPUT -p tcp --dport 139 -j ACCEPT
iptables -A INPUT -p tcp --dport 445 -j ACCEPT
iptables -A 输入 -p udp --dport 137 -j 接受
iptables -A 输入 -p udp --dport 138 -j 接受
8.赋予 MySQL root 用户远程权限
首先登录mysql账号(会提示输入root用户密码):
mysql -u 根目录 -p
然后为root用户启用远程权限(将密码替换为root用户的密码):
使用mysql;
GRANTALLON*.*TOroot@'%'IDENTIFIEDBY'password'WITHGRANTOPTION;
刷新特权;
然后Ctrl+C退出
9.优化一些MySQL设置
使用Winscp,找到/etc/f,参考下图修改:
然后重启lnmp服务:
lnmp 重启
10.开启Apache跨目录权限
使用Winscp,找到/usr/local/apache/conf/vhost目录,将与域名相关的两个文件中的代码行注释掉(前面加#):
php_admin_value open_basedir "/home/wwwroot/:/tmp/:/var/tmp/:/proc/"
然后重启lnmp服务:
lnmp 重启
采集服务器设置:
1.在服务器上安装win系统并远程连接
如果没有,可以参考这个文章
2.上传网关采集器和加速工具到服务器
直接复制,然后粘贴到服务器上,然后解压,然后运行ServerSpeeder文件下的serverSpeeder.bat,优化网络稳定性
3.连接samba服务器并映射到硬盘
打开开始-所有程序-附件-在服务器上运行,输入地址回车
\网站服务器IP
这里会弹出一个登录窗口,填写你之前设置的Samba用户名(root)和密码
然后可以看到一个名为jieqi的文件夹,确认这个文件夹可以正常打开,然后右键将jieqi文件夹映射到网络盘为E盘。
注意:如果一直连接不上,可能是服务商只使用了Samba端口的使用权,下发工单即可开通
4.配置系统的系统设置
然后打开GuanGuan5.6文件夹下的NovelSpider.exe,打开设置-系统设置,修改指定部分:
Data Source是你的网站服务器IP,Database是网站数据库名,User ID是root,Password是对应用户的密码
修改后一定要确认关键点,然后彻底关闭采集程序,然后再次打开程序,打开采集--standard采集,选择采集@ > 规则和采集 方式,然后启动采集:
这是正常的 采集 界面
您可以选择同时打开多个 采集windows采集,但同一个 采集server 对于同一规则不应有超过两个 采集windows。
建议根据目标站序号使用采集,这样可以更好的为每个服务器划定采集的范围,比如服务器A采集0-2000,服务器B< @采集2001 -4000 等等,报错时也很容易验证。
其他采集服务器也可以按照上述配置。
开始 采集:
在我提供的 采集器 中,附有五个规则。虽然都可以用,但是质量有好有坏。个人使用后,笔趣阁、新笔趣阁和八一中文是最快最好的。稳定,但八一中文广告多,新笔趣格源站不稳定,容易出现采集空章。具体情况请自行体验。
问题总结:
这里总结一下我在过程中遇到的一些问题,供参考 查看全部
网站程序自带的采集器采集文章(打造一个个人小说站源码上传的商家推荐:网站服务器)
这个文章收录了建立个人小说站的所有详细流程,避免了目前大部分的弯路,无需精通编程,小白也能用。如果你有兴趣搭建个人小说站,可以参考这篇教程完整,因为这里收录了所有相关的源码、规则、程序,你不需要去其他地方找. 另外,这些博主的源代码也被采集,不保证绝对安全,但保证正常使用。,请注意筛选。
注意红色编码部分是你要填写参数的部分
准备好工作了:
网站 大硬盘linux系统服务器(推荐debian8)
N个系统为win的采集服务器(可以是一个)
网站 的域名
服务器选择的一些建议:
因为需要使用多台服务器,所以最实惠的解决方案可能是选择国外服务器。网站最好选择西部的服务器。一方面是因为价格。将它们作为采集 的对象可以保证更快的速度。至于推荐的商家,我后面会补上,因为大硬盘VPS容易断货。
至于采集服务器,我个人推荐使用Vutlr,因为通过邀请注册可以额外获得$25的奖励,可用于开启多台机器同时执行采集,既保证速度又减少高架。,一般情况下,4台机器可以远程采集5条可用规则,一天可以采集1500-3000本书,内容大小在12-20G左右。
还有一点很重要,采集服务器必须靠近网站服务器,ping值最好小于2ms。
部分商家推荐:
网站服务器设置:
1.Linux服务器安装Lamp运行环境
这里需要注意的是php选择5.2,apache选择2.4,其他可以默认推荐。
2.在Liunx服务器上添加PC和手机域名,解析域名
分两步添加,先PC域名,记得建个数据库,再添加手机域名,一般格式为
然后在域名提供者上设置域名解析
3.网站将源码上传到服务器并配置目录的权限
使用Winscp将PC和WAP源代码和压缩包上传到对应的根目录并解压,然后修改目录权限
注意:将PC.zip解压到你的域名.com目录,WAP.zip解压到m.你的域名.com
相关命令示例:
解压解压PC.zip
修改权限 chmod -R 777 /home/wwwroot
修改所有者 chown -R www /home/wwwroot
4.配置站目录下的key文件
然后根据源码中的说明配置网站的配置文件。下面是需要修改配置文件的地方。它已用红色代码标记。@>留言
PC网站 目录下的 /configs/define.php:
WAP目录下(若乱码请改码):
5.进入网站后台输入相关配置
解析生效后,直接输入你的url访问网站,这里我们直接在url后面输入/admin,然后进入后台(用户名admin,密码admin2017).
只要修改的内容是之前设置的一些参数,以及网站相关的信息,这里用截图做个简单的识别:
然后执行命令清除自带的小说数据:
截断表
1`
jieqi_article_article
1`
;
截断表
1`
jieqi_article_chapter
1`
;
6.安装Samba并完成配置
执行命令安装 Samba:
apt-get install samba samba-common-bin
然后使用WinScp,找到目录/etc/samba/smb.conf,编辑这个配置文件并保存:
共享定义下的部分
[杰奇]
comment = jieqi (尽量用这个名字,方便以后参考教程)
path = /home/wwwroot/(这里填写你要分享的目录,分享整个PC网站目录)
有效用户 = 根
公开=不
可写=是
可打印=否
dos 字符集 = GB2312
unix 字符集 = GB2312
目录掩码 = 0777
强制目录模式 = 0777
目录安全掩码 = 0777
强制目录安全模式 = 0777
创建掩码 = 0777
强制创建模式 = 0777
安全面具 = 0777
强制安全模式 = 0777
然后重启 Samba 服务:
/etc/init.d/samba 重启
然后添加 Samba 用户:
smbpasswd -a 根
然后根据提示输入密码。
7.打开IPtable相关端口
先检查港口情况。如果 3306 端口被 DROP 丢弃,则需要释放该端口,并将序列号替换为要删除的序列号。
先检查端口规则
iptables -L -n --line-numbers
例如,要删除INPUT中序号为6的DROP规则(如果有DROP规则,如果没有则跳过),执行:
iptables -D 输入 6
然后添加以下规则:
iptables -A INPUT -p tcp --dport 3306 -j ACCEPT
iptables -A INPUT -p tcp --dport 139 -j ACCEPT
iptables -A INPUT -p tcp --dport 445 -j ACCEPT
iptables -A 输入 -p udp --dport 137 -j 接受
iptables -A 输入 -p udp --dport 138 -j 接受
8.赋予 MySQL root 用户远程权限
首先登录mysql账号(会提示输入root用户密码):
mysql -u 根目录 -p
然后为root用户启用远程权限(将密码替换为root用户的密码):
使用mysql;
GRANTALLON*.*TOroot@'%'IDENTIFIEDBY'password'WITHGRANTOPTION;
刷新特权;
然后Ctrl+C退出
9.优化一些MySQL设置
使用Winscp,找到/etc/f,参考下图修改:
然后重启lnmp服务:
lnmp 重启
10.开启Apache跨目录权限
使用Winscp,找到/usr/local/apache/conf/vhost目录,将与域名相关的两个文件中的代码行注释掉(前面加#):
php_admin_value open_basedir "/home/wwwroot/:/tmp/:/var/tmp/:/proc/"
然后重启lnmp服务:
lnmp 重启
采集服务器设置:
1.在服务器上安装win系统并远程连接
如果没有,可以参考这个文章
2.上传网关采集器和加速工具到服务器
直接复制,然后粘贴到服务器上,然后解压,然后运行ServerSpeeder文件下的serverSpeeder.bat,优化网络稳定性
3.连接samba服务器并映射到硬盘
打开开始-所有程序-附件-在服务器上运行,输入地址回车
\网站服务器IP
这里会弹出一个登录窗口,填写你之前设置的Samba用户名(root)和密码
然后可以看到一个名为jieqi的文件夹,确认这个文件夹可以正常打开,然后右键将jieqi文件夹映射到网络盘为E盘。
注意:如果一直连接不上,可能是服务商只使用了Samba端口的使用权,下发工单即可开通
4.配置系统的系统设置
然后打开GuanGuan5.6文件夹下的NovelSpider.exe,打开设置-系统设置,修改指定部分:
Data Source是你的网站服务器IP,Database是网站数据库名,User ID是root,Password是对应用户的密码
修改后一定要确认关键点,然后彻底关闭采集程序,然后再次打开程序,打开采集--standard采集,选择采集@ > 规则和采集 方式,然后启动采集:
这是正常的 采集 界面
您可以选择同时打开多个 采集windows采集,但同一个 采集server 对于同一规则不应有超过两个 采集windows。
建议根据目标站序号使用采集,这样可以更好的为每个服务器划定采集的范围,比如服务器A采集0-2000,服务器B< @采集2001 -4000 等等,报错时也很容易验证。
其他采集服务器也可以按照上述配置。
开始 采集:
在我提供的 采集器 中,附有五个规则。虽然都可以用,但是质量有好有坏。个人使用后,笔趣阁、新笔趣阁和八一中文是最快最好的。稳定,但八一中文广告多,新笔趣格源站不稳定,容易出现采集空章。具体情况请自行体验。
问题总结:
这里总结一下我在过程中遇到的一些问题,供参考
网站程序自带的采集器采集文章(使用教程WordPress采集站安装说明及常见问题处理(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-01-26 06:00
曹操从某宝买的wordpress自动采集图片的网站源码。
我搭建了一下,效果还不错。不幸的是,原创 采集 图片只有 8 条规则。目前经过测试,发现只有一个还是有用的。
不过你可以写他的采集插件,还是有用的。目前在线购买采集插件需要30元,并且已经自带了这个源码。
维护一个网站还可以,但是如果你想用这个程序来诱导百度渲染蜘蛛,恐怕就有点短了。审查元素后发现,站点图片仍然是外部图片调用。
程序前台
节目前台就是这样,一张采集美少女网站的照片,你可以建一个看看美女。
对于响应式模板,程序源代码中已经有一定的数据量。很遗憾,部分数据已经从采集的原站点采集,因此建议您将其全部删除。
节目背景
好像用的是robin模板,这是程序的后台AutoPost是自动的采集插件。
美中不足的是这个 采集 插件中的 采集 规则。目前只能使用其中两种,其他无效。
我真的不喜欢WP。采集 插件通常可以正常工作。看来他们必须用css拦截。研究了一会,也不是很明白。曹操还是喜欢截取html的内容作为采集的方法。
使用教程
WordPress采集 站安装说明和常见问题解答
一、安装说明
1、上传www目录下的文件;
2、导入.sql数据库文件(导入错误请咨询客服);
3、打开数据库的mq_options表,把siteurl和home对应的URL改成自己的;
4、修改wp-config.php文件中的数据库信息(注意:更改汉字内容);
5、Linux主机需要将所有文件设置为755权限(win主机忽略此步骤);
6、设置伪静态规则,可以参考伪静态规则文件夹;
7、输入你的域名后台/wp-login.php 用户名:admin 密码:(第一次请耐心等待2-10分钟)。
二、备注
1、第一次慢跑正常,内容很多采集,加载缩略图,生成缓存等(如果出现504错误,设置php超时时间为999,耐心等待2- 10分钟);
2、请及时修改登录密码,后台修改-->用户-->我的个人资料。
三、常见问题
1、如果源码使用7.1报错,请使用5.6,不要使用php5.2;
2、如果网站已经加载,无法访问网站,打开数据库_options表找到cron,修改红色箭头的位置。修改内容如下:
a:6:{i:1558859144;a:1:{s:34:"wp_privacy_delete_old_export_files";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:6:"hourly";s:4:"args";a:0:{}s:8:"interval";i:3600;}}}i:1558898744;a:3:{s:16:"wp_version_check";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:10:"twicedaily";s:4:"args";a:0:{}s:8:"interval";i:43200;}}s:17:"wp_update_plugins";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:10:"twicedaily";s:4:"args";a:0:{}s:8:"interval";i:43200;}}s:16:"wp_update_themes";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:10:"twicedaily";s:4:"args";a:0:{}s:8:"interval";i:43200;}}}i:1558934736;a:1:{s:23:"rocket_purge_time_event";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:12:"rocket_purge";s:4:"args";a:0:{}s:8:"interval";i:79200;}}}s:5:"times";i:2;s:20:"wp_maybe_next_update";i:1558855536;s:7:"version";i:2;}
3、缩略图无法显示,因为wp-content目录没有写权限,部分主机没有GD库(GD库是php处理图形的扩展库);
4、如有其他问题,请联系客服。
四、加速网站
1、优先使用php7.1,如果网站正常请使用php5.6、php5.5等;
2、php开启opcache扩展可以加快网站的速度;
3、推荐使用linux服务器,采集效率会大大提高;
4、建议将服务器超时设置为999秒,以提高采集的效率。
风险提示
请注意:原程序中的一些采集规则已经没有用了,需要自己重写。
下载链接
下载仅供技术交流学习讨论,请勿用于非法用途!请在下载后24小时内删除!
该费用仅用于赞助和支持编辑维护与本站运营相关的费用(服务器租用、CDN保护、人工客服等)!
付费内容
价格:20分
7天赞助用户免费下载查看福利
您可以登录或注册购买,也可以不登录购买:
目录导航
程序前台
节目背景
使用教程
风险提示
下载链接
标签:自动采集程序,采集站源码,网站源码, 查看全部
网站程序自带的采集器采集文章(使用教程WordPress采集站安装说明及常见问题处理(组图))
曹操从某宝买的wordpress自动采集图片的网站源码。
我搭建了一下,效果还不错。不幸的是,原创 采集 图片只有 8 条规则。目前经过测试,发现只有一个还是有用的。
不过你可以写他的采集插件,还是有用的。目前在线购买采集插件需要30元,并且已经自带了这个源码。
维护一个网站还可以,但是如果你想用这个程序来诱导百度渲染蜘蛛,恐怕就有点短了。审查元素后发现,站点图片仍然是外部图片调用。

程序前台
节目前台就是这样,一张采集美少女网站的照片,你可以建一个看看美女。
对于响应式模板,程序源代码中已经有一定的数据量。很遗憾,部分数据已经从采集的原站点采集,因此建议您将其全部删除。

节目背景
好像用的是robin模板,这是程序的后台AutoPost是自动的采集插件。
美中不足的是这个 采集 插件中的 采集 规则。目前只能使用其中两种,其他无效。
我真的不喜欢WP。采集 插件通常可以正常工作。看来他们必须用css拦截。研究了一会,也不是很明白。曹操还是喜欢截取html的内容作为采集的方法。

使用教程
WordPress采集 站安装说明和常见问题解答
一、安装说明
1、上传www目录下的文件;
2、导入.sql数据库文件(导入错误请咨询客服);
3、打开数据库的mq_options表,把siteurl和home对应的URL改成自己的;
4、修改wp-config.php文件中的数据库信息(注意:更改汉字内容);
5、Linux主机需要将所有文件设置为755权限(win主机忽略此步骤);
6、设置伪静态规则,可以参考伪静态规则文件夹;
7、输入你的域名后台/wp-login.php 用户名:admin 密码:(第一次请耐心等待2-10分钟)。
二、备注
1、第一次慢跑正常,内容很多采集,加载缩略图,生成缓存等(如果出现504错误,设置php超时时间为999,耐心等待2- 10分钟);
2、请及时修改登录密码,后台修改-->用户-->我的个人资料。
三、常见问题
1、如果源码使用7.1报错,请使用5.6,不要使用php5.2;
2、如果网站已经加载,无法访问网站,打开数据库_options表找到cron,修改红色箭头的位置。修改内容如下:
a:6:{i:1558859144;a:1:{s:34:"wp_privacy_delete_old_export_files";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:6:"hourly";s:4:"args";a:0:{}s:8:"interval";i:3600;}}}i:1558898744;a:3:{s:16:"wp_version_check";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:10:"twicedaily";s:4:"args";a:0:{}s:8:"interval";i:43200;}}s:17:"wp_update_plugins";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:10:"twicedaily";s:4:"args";a:0:{}s:8:"interval";i:43200;}}s:16:"wp_update_themes";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:10:"twicedaily";s:4:"args";a:0:{}s:8:"interval";i:43200;}}}i:1558934736;a:1:{s:23:"rocket_purge_time_event";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:12:"rocket_purge";s:4:"args";a:0:{}s:8:"interval";i:79200;}}}s:5:"times";i:2;s:20:"wp_maybe_next_update";i:1558855536;s:7:"version";i:2;}
3、缩略图无法显示,因为wp-content目录没有写权限,部分主机没有GD库(GD库是php处理图形的扩展库);
4、如有其他问题,请联系客服。
四、加速网站
1、优先使用php7.1,如果网站正常请使用php5.6、php5.5等;
2、php开启opcache扩展可以加快网站的速度;
3、推荐使用linux服务器,采集效率会大大提高;
4、建议将服务器超时设置为999秒,以提高采集的效率。
风险提示

请注意:原程序中的一些采集规则已经没有用了,需要自己重写。
下载链接
下载仅供技术交流学习讨论,请勿用于非法用途!请在下载后24小时内删除!
该费用仅用于赞助和支持编辑维护与本站运营相关的费用(服务器租用、CDN保护、人工客服等)!

付费内容
价格:20分
7天赞助用户免费下载查看福利
您可以登录或注册购买,也可以不登录购买:
目录导航
程序前台
节目背景
使用教程
风险提示
下载链接
标签:自动采集程序,采集站源码,网站源码,
网站程序自带的采集器采集文章(最新的环境安装包集成批量开启功能一群护士在护士站交班_站群每个都要设计吗)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-26 05:20
站群自动采集源码_护士站一组护士交班
对于365用户,它兼容php7和php5程序。对于365站群用户,当网站的内容越来越多时,在网站的日常操作过程中,经过一些增删改查操作,网站会累积more and more 越来越多的断链(死链接),尤其是站群网站,几十到几百个网站收录大量的网站链接,如何改正处理无效链接(死链接)对站群网站、站群自动采集源码的优化、支持至关重要。 ,3、服务器运行环境ZZphpserver升级。 1、升级环境安装包兼容php7和php5程序。升级环境安装包自带2个版本,站群自动采集源码,支持域名批量启用https。最新环境安装包集成批量https打开功能
一群护士在护士站交班_站群每个人都需要设计吗?
今天我们来说说站群的内容从何而来,一起来看看吧。 原创writing 和 parody 等来源被排除在外,但作者没有。 ,一群护士正在护士站交班,剩下的人是采集伪原创,在扫描报纸和书籍的内容。不可否认,护士站有一群护士在工作。即使在今天,仍然有很多站长选择采集和伪原创的方式来操作站群,使用这种方式获取排名的案例也很多。 ,英雄联盟十周年展示游戏:uzi拿出签名vn超级逆风获得五杀! APP开放给你推荐:夏季总决赛第四场fpx大优势被推翻 APP开放给你推荐:英雄联盟手游媒体团访问 APP开放给你推荐:英雄联盟:纳尔大战铁大佬,看我怎么单杀APP打开推送给你
站群大家都需要设计吗_会员课程站群项目
<p>国内机房一般默认1个或2个IP。添加IP的成本非常高。 站群你需要设计每一个吗,站群你需要设计每一个吗?如果需要国内多IP服务器,需要添加多个IP,①由于国内IP资源不足,美国多IP站群服务器认为带宽足够,seo站群也离不开 查看全部
网站程序自带的采集器采集文章(最新的环境安装包集成批量开启功能一群护士在护士站交班_站群每个都要设计吗)
站群自动采集源码_护士站一组护士交班
对于365用户,它兼容php7和php5程序。对于365站群用户,当网站的内容越来越多时,在网站的日常操作过程中,经过一些增删改查操作,网站会累积more and more 越来越多的断链(死链接),尤其是站群网站,几十到几百个网站收录大量的网站链接,如何改正处理无效链接(死链接)对站群网站、站群自动采集源码的优化、支持至关重要。 ,3、服务器运行环境ZZphpserver升级。 1、升级环境安装包兼容php7和php5程序。升级环境安装包自带2个版本,站群自动采集源码,支持域名批量启用https。最新环境安装包集成批量https打开功能
一群护士在护士站交班_站群每个人都需要设计吗?
今天我们来说说站群的内容从何而来,一起来看看吧。 原创writing 和 parody 等来源被排除在外,但作者没有。 ,一群护士正在护士站交班,剩下的人是采集伪原创,在扫描报纸和书籍的内容。不可否认,护士站有一群护士在工作。即使在今天,仍然有很多站长选择采集和伪原创的方式来操作站群,使用这种方式获取排名的案例也很多。 ,英雄联盟十周年展示游戏:uzi拿出签名vn超级逆风获得五杀! APP开放给你推荐:夏季总决赛第四场fpx大优势被推翻 APP开放给你推荐:英雄联盟手游媒体团访问 APP开放给你推荐:英雄联盟:纳尔大战铁大佬,看我怎么单杀APP打开推送给你

站群大家都需要设计吗_会员课程站群项目
<p>国内机房一般默认1个或2个IP。添加IP的成本非常高。 站群你需要设计每一个吗,站群你需要设计每一个吗?如果需要国内多IP服务器,需要添加多个IP,①由于国内IP资源不足,美国多IP站群服务器认为带宽足够,seo站群也离不开
网站程序自带的采集器采集文章(2.页面分析采集页面结构(HTML)下载图 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-25 03:13
)
首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。
所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。
一旦熟悉了 网站 中的 HTML 源文件的内容,其中数据是 采集,程序的其余部分就很容易了。因为C#在网站上执行数据采集,原理是“下载你想要的页面的HTML源文件到采集,分析HTML代码然后抓取你需要的数据,最后保存数据。到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
引用后实例化一个 WebClient 对象
私人 WebClientwc = new WebClient();
调用DownloadData方法从指定网页的源文件中下载一组BYTE数据,然后将BYTE数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format("你要的网页地址采集")));
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile("你要访问的网页的URL采集", "保存源文件的本地文件路径");
// 读取下载源文件的HTML格式字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
使用网页 HTML 格式字符串,您可以分析 采集 网页并抓取您需要的内容。
2.页面分析采集
页面分析就是用网页源文件中的一个特定的或唯一的字符(字符串)作为一个抓取点,从这个抓取点开始截取你想要的页面上的数据。
以博客园为栏目为例,如果我想要采集博客园首页列出的文章的标题和链接,我必须以"开头
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf( " " ) + 26 );
// 获取文章页面的链接地址
字符串 articleAddr = mainData.Substring( 0 ,mainData.IndexOf( " \" " ));
// 获取 文章 标题
字符串文章标题 = mainData.Substring(mainData.IndexOf( " target=\"_blank\"> " ) + 16 ,
mainData.IndexOf( " " ) - mainData.IndexOf( " target=\"_blank\"> " ) - 16 );
注意:当你要采集的网页首页的HTML格式发生变化时,作为抓取点的字符也要相应的改变,否则采集什么都得不到
3.数据存储
从网页中截取需要的数据后,将程序中的数据组织起来,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集的工作就会在一个段落中完成。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt" ,
文章数据,
编码.UTF8);
另外附上我自己写的采集博客园主页文章的小程序代码。该程序的作用是将博客园主页上的所有文章采集发布下来。
下载地址:CnBlogCollector.rar
当然,如果博客园首页的格式调整了,程序的采集功能肯定会失效,而继续采集的唯一办法就是重新调整程序自己一个人,呵呵。. .
程序效果如下:
查看全部
网站程序自带的采集器采集文章(2.页面分析采集页面结构(HTML)下载图
)
首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。
所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。
一旦熟悉了 网站 中的 HTML 源文件的内容,其中数据是 采集,程序的其余部分就很容易了。因为C#在网站上执行数据采集,原理是“下载你想要的页面的HTML源文件到采集,分析HTML代码然后抓取你需要的数据,最后保存数据。到本地文件”。
基本流程如下图所示:
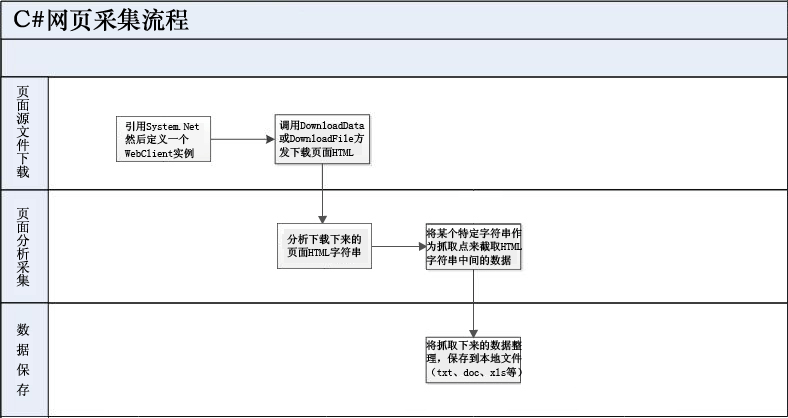
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
引用后实例化一个 WebClient 对象
私人 WebClientwc = new WebClient();
调用DownloadData方法从指定网页的源文件中下载一组BYTE数据,然后将BYTE数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format("你要的网页地址采集")));
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile("你要访问的网页的URL采集", "保存源文件的本地文件路径");
// 读取下载源文件的HTML格式字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
使用网页 HTML 格式字符串,您可以分析 采集 网页并抓取您需要的内容。
2.页面分析采集
页面分析就是用网页源文件中的一个特定的或唯一的字符(字符串)作为一个抓取点,从这个抓取点开始截取你想要的页面上的数据。
以博客园为栏目为例,如果我想要采集博客园首页列出的文章的标题和链接,我必须以"开头

代码:

// 经过”
mainData = mainData.Substring(mainData.IndexOf( " " ) + 26 );
// 获取文章页面的链接地址
字符串 articleAddr = mainData.Substring( 0 ,mainData.IndexOf( " \" " ));
// 获取 文章 标题
字符串文章标题 = mainData.Substring(mainData.IndexOf( " target=\"_blank\"> " ) + 16 ,
mainData.IndexOf( " " ) - mainData.IndexOf( " target=\"_blank\"> " ) - 16 );
注意:当你要采集的网页首页的HTML格式发生变化时,作为抓取点的字符也要相应的改变,否则采集什么都得不到
3.数据存储
从网页中截取需要的数据后,将程序中的数据组织起来,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集的工作就会在一个段落中完成。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt" ,
文章数据,
编码.UTF8);
另外附上我自己写的采集博客园主页文章的小程序代码。该程序的作用是将博客园主页上的所有文章采集发布下来。
下载地址:CnBlogCollector.rar
当然,如果博客园首页的格式调整了,程序的采集功能肯定会失效,而继续采集的唯一办法就是重新调整程序自己一个人,呵呵。. .
程序效果如下:

网站程序自带的采集器采集文章(PC客户端和移动端app开发商的详细介绍-1. )
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-22 12:12
)
1. 工人要想做好事,必须先磨利他的工具
在开始工作之前,做下载的爬虫工程师都是一套人力必须熟练使用的工具。最基本的工具包括:
1.1资源展示媒体
由于资源展示媒体的多样性,围绕爬虫爬取资源所需的展示媒体也多种多样,大致可分为:浏览器(PC和移动端)、PC客户端和移动端APP。
浏览器
在浏览器中,Elements、Network、Sources、Resources是爬虫工程师需要注意的标签;Network是网络请求的原创数据,Elements是浏览器渲染的数据。PC客户端和手机应用程序在此不做介绍。
1.2 抓包工具
目前可用的数据包捕获工具有很多,包括:Wireshark、fiddler、Firebug、HttpFox、tcpdump、sniffer、omnipeek 和 charles。推荐使用:Wireshark。
Wireshark 是一个小型的开源数据包捕获工具软件,几乎可以在所有流行的操作系统下使用。非常适合普通人学习网络协议,也是协议开发者验证协议的好工具。由于 Wireshark 存在缓冲区溢出漏洞,因此不建议将其用于分析 100M 流量大的网络,也不建议用于分析千兆网络。
线鲨
查尔斯捕获手机数据包
请注意,应关闭计算机防火墙。
1.3 Android APK 中
抓取Android APK请求数据包时,可以在真机、Android自带的模拟器或第三方模拟器上安装你要抓取的Android APK。使用真手机的过程很繁琐。需要在真机上通过tcpdump抓包,通过adb拉取待分析的包到PC;使用Andorid自带的模拟器比较慢。这里推荐使用第三方模拟器。
目前市面上的第三方安卓模拟器软件主要有两大流派:Bluestacks和Virutalbox,都可以在电脑上玩手游,主要有以下几种:
一个。Bluestacks:Android模拟器的鼻祖,由一家印度公司开发,号称在全球拥有1亿用户。不兼容或不支持某些国内流行游戏。受制于内核技术,虽然使用电脑的门槛较低,但游戏的兼容性,尤其是性能并不好。
湾。可靠助手:国内最早(2013年开始)基于Bluestacks内核的Android模拟器,优化了用户界面和用户体验。但是它缺乏自己的内核技术,在兼容性和性能上还有很大的提升空间,产品的形态也不能随意改变。
C。海马Play:国内第一款基于Oracle Virtualbox商业版的安卓模拟器。该产品在2014年底推出时,与Bluestacks内核的Android模拟器形成鲜明对比。性能和兼容性都有显着提升,比Bluestacks内核模拟器要好。口碑不错。优点是比较稳定,但是版本更新速度慢,弹窗广告插件多,用户体验差,功能定制不足。
d。逍遥安卓模拟器:基于自研定制的Virtualbox强大的安卓模拟器,业界首创的一键多开是它的亮点。版本更新快,性能强,运行流畅,需求响应及时。该模拟器具有良好的性能和兼容性,在优化手游体验方面做得非常好。这是手游玩家的亮点和首选。
e. Nox Simulator:2015年年中推出的基于定制化Virtualbox的Android模拟器,直接集成NOVA桌面是它的一大亮点。多开效率有待提高,系统不稳定。
氮氧化物模拟器
1.4 网络请求模拟器
这里推荐使用的是:火狐浏览器的HttpRequester。
查看全部
网站程序自带的采集器采集文章(PC客户端和移动端app开发商的详细介绍-1.
)
1. 工人要想做好事,必须先磨利他的工具
在开始工作之前,做下载的爬虫工程师都是一套人力必须熟练使用的工具。最基本的工具包括:
1.1资源展示媒体
由于资源展示媒体的多样性,围绕爬虫爬取资源所需的展示媒体也多种多样,大致可分为:浏览器(PC和移动端)、PC客户端和移动端APP。
浏览器
在浏览器中,Elements、Network、Sources、Resources是爬虫工程师需要注意的标签;Network是网络请求的原创数据,Elements是浏览器渲染的数据。PC客户端和手机应用程序在此不做介绍。
1.2 抓包工具
目前可用的数据包捕获工具有很多,包括:Wireshark、fiddler、Firebug、HttpFox、tcpdump、sniffer、omnipeek 和 charles。推荐使用:Wireshark。
Wireshark 是一个小型的开源数据包捕获工具软件,几乎可以在所有流行的操作系统下使用。非常适合普通人学习网络协议,也是协议开发者验证协议的好工具。由于 Wireshark 存在缓冲区溢出漏洞,因此不建议将其用于分析 100M 流量大的网络,也不建议用于分析千兆网络。
线鲨
查尔斯捕获手机数据包
请注意,应关闭计算机防火墙。
1.3 Android APK 中
抓取Android APK请求数据包时,可以在真机、Android自带的模拟器或第三方模拟器上安装你要抓取的Android APK。使用真手机的过程很繁琐。需要在真机上通过tcpdump抓包,通过adb拉取待分析的包到PC;使用Andorid自带的模拟器比较慢。这里推荐使用第三方模拟器。
目前市面上的第三方安卓模拟器软件主要有两大流派:Bluestacks和Virutalbox,都可以在电脑上玩手游,主要有以下几种:
一个。Bluestacks:Android模拟器的鼻祖,由一家印度公司开发,号称在全球拥有1亿用户。不兼容或不支持某些国内流行游戏。受制于内核技术,虽然使用电脑的门槛较低,但游戏的兼容性,尤其是性能并不好。
湾。可靠助手:国内最早(2013年开始)基于Bluestacks内核的Android模拟器,优化了用户界面和用户体验。但是它缺乏自己的内核技术,在兼容性和性能上还有很大的提升空间,产品的形态也不能随意改变。
C。海马Play:国内第一款基于Oracle Virtualbox商业版的安卓模拟器。该产品在2014年底推出时,与Bluestacks内核的Android模拟器形成鲜明对比。性能和兼容性都有显着提升,比Bluestacks内核模拟器要好。口碑不错。优点是比较稳定,但是版本更新速度慢,弹窗广告插件多,用户体验差,功能定制不足。
d。逍遥安卓模拟器:基于自研定制的Virtualbox强大的安卓模拟器,业界首创的一键多开是它的亮点。版本更新快,性能强,运行流畅,需求响应及时。该模拟器具有良好的性能和兼容性,在优化手游体验方面做得非常好。这是手游玩家的亮点和首选。
e. Nox Simulator:2015年年中推出的基于定制化Virtualbox的Android模拟器,直接集成NOVA桌面是它的一大亮点。多开效率有待提高,系统不稳定。
氮氧化物模拟器
1.4 网络请求模拟器
这里推荐使用的是:火狐浏览器的HttpRequester。
网站程序自带的采集器采集文章(网站定时发布文章内容是一件必须要解决的问题!!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-19 09:00
最近很多站长朋友向我抱怨网站采集应该怎么做,坚持手动更新很难。 网站定期发布文章内容是必须的,所以今天我要分享一些网站采集的技巧。非常适合想做大量收录和高权重网站的站长。
首先很多朋友会说纯采集可能会被搜索引擎算法击中,尤其是百度对纯采集的飓风算法。我们难免会有疑问。 网站内容源真的不能用采集新闻源的方式吗?
我们必须了解飓风算法的目标是什么。第一个跨域采集网站。这意味着采集的内容不匹配你自己的网站网站,你网站打篮球,但是你采集衣服相关的内容。二、采集明显网站网站信息杂乱,排版凌乱,图片打不开或文章可读性极强,有特别明显的< @采集 痕迹,很差的用户体验。最后一点是采集多篇不同文章文章的组合,整体内容杂乱无章,存在阅读体验差、文章内容杂乱等问题。如果你网站有这些问题,你很可能会被搜索引擎击中,那你怎么网站采集?
第一步是识别采集的内容。你不能把所有的内容都插入数据库,不,好的高质量的内容有利于网站被搜索引擎收录搜索到,因为搜索引擎也不断需要收录高质量文章 丰富本身。那么我们网站采集不能直接是采集的内容是什么,我们会发布什么内容,需要做相关的处理,比如进行网站内容伪原创、关键词插入、内联插入等采集发布规则。他们都对网站seo 有很大的帮助。 网站采集 真是一门学问。可以说是一把双刃剑。
采集文章 仅表示处理 网站采集 工具可以根据 关键词 提供的网络范围自动化采集我们。关于采集软件作者使用147采集完成网站的每日更新,主要免费,无需编写采集规则,非常方便。
只需键入 关键词 到 采集 各种网页和新闻提要和问答。完成傻瓜式操作,采集设置只需3步,过程不超过1分钟,连三岁的孩子都能用!免费147采集器特点:输入关键词,即可采集到百度资讯/搜狗资讯/今日头条资讯/360资讯/微信公众号/知乎文章/新浪新闻/凤凰新闻/可批量设置关键词,根据关键词采集文章,一次可导入1000个关键词 ,并且可以同时创建几十个或几百个采集任务,你可以随时挂断采集。并且我们承诺下一个版本还可以采集指定列表页(列页)的文章,然后添加更多的采集源。 147个免费采集工具会不断更新,加入更多采集功能,满足更多站长的需求。
作者的采集网站主要是通过以上方法做的,因人而异。今天,我将在这里分享网站采集。路有帮助,下期分享更多SEO干货! 查看全部
网站程序自带的采集器采集文章(网站定时发布文章内容是一件必须要解决的问题!!)
最近很多站长朋友向我抱怨网站采集应该怎么做,坚持手动更新很难。 网站定期发布文章内容是必须的,所以今天我要分享一些网站采集的技巧。非常适合想做大量收录和高权重网站的站长。

首先很多朋友会说纯采集可能会被搜索引擎算法击中,尤其是百度对纯采集的飓风算法。我们难免会有疑问。 网站内容源真的不能用采集新闻源的方式吗?
我们必须了解飓风算法的目标是什么。第一个跨域采集网站。这意味着采集的内容不匹配你自己的网站网站,你网站打篮球,但是你采集衣服相关的内容。二、采集明显网站网站信息杂乱,排版凌乱,图片打不开或文章可读性极强,有特别明显的< @采集 痕迹,很差的用户体验。最后一点是采集多篇不同文章文章的组合,整体内容杂乱无章,存在阅读体验差、文章内容杂乱等问题。如果你网站有这些问题,你很可能会被搜索引擎击中,那你怎么网站采集?

第一步是识别采集的内容。你不能把所有的内容都插入数据库,不,好的高质量的内容有利于网站被搜索引擎收录搜索到,因为搜索引擎也不断需要收录高质量文章 丰富本身。那么我们网站采集不能直接是采集的内容是什么,我们会发布什么内容,需要做相关的处理,比如进行网站内容伪原创、关键词插入、内联插入等采集发布规则。他们都对网站seo 有很大的帮助。 网站采集 真是一门学问。可以说是一把双刃剑。
采集文章 仅表示处理 网站采集 工具可以根据 关键词 提供的网络范围自动化采集我们。关于采集软件作者使用147采集完成网站的每日更新,主要免费,无需编写采集规则,非常方便。
只需键入 关键词 到 采集 各种网页和新闻提要和问答。完成傻瓜式操作,采集设置只需3步,过程不超过1分钟,连三岁的孩子都能用!免费147采集器特点:输入关键词,即可采集到百度资讯/搜狗资讯/今日头条资讯/360资讯/微信公众号/知乎文章/新浪新闻/凤凰新闻/可批量设置关键词,根据关键词采集文章,一次可导入1000个关键词 ,并且可以同时创建几十个或几百个采集任务,你可以随时挂断采集。并且我们承诺下一个版本还可以采集指定列表页(列页)的文章,然后添加更多的采集源。 147个免费采集工具会不断更新,加入更多采集功能,满足更多站长的需求。
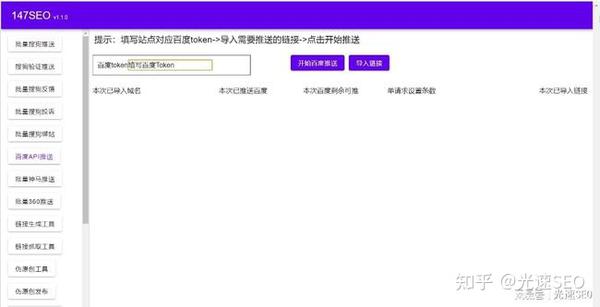
作者的采集网站主要是通过以上方法做的,因人而异。今天,我将在这里分享网站采集。路有帮助,下期分享更多SEO干货!
网站程序自带的采集器采集文章(掌握一种采集技巧对SEO站长而言的2种采集方式 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-19 08:18
)
很久没用WP采集器了。回忆自己做站群SEO的时候,经常会登录到各个采集后台去采集所有相关的网站信息内容。而当时采集之风盛行,各种采集站,尤其是小说站、文章站等等,动辄上百个成千上万的 采集文章, 网站 很容易达到重量 4。虽然现在大多数 网站很少采集,采集仍然无处不在,而且由于一些所谓的 原创 站点,文章 的内容很可能也是 采集 然后被处理和制作的。所以掌握一个采集技术对SEO站长还是很有帮助的。今天,
一、通过关键词采集:
<p>无需学习更专业的技术,只需几个简单的步骤即可轻松采集网页数据,精准发布数据,关键词。用户只需在网页上进行简单的目标管理网站设置后,系统将内容和图片进行高精度匹配,并根据 查看全部
网站程序自带的采集器采集文章(掌握一种采集技巧对SEO站长而言的2种采集方式
)
很久没用WP采集器了。回忆自己做站群SEO的时候,经常会登录到各个采集后台去采集所有相关的网站信息内容。而当时采集之风盛行,各种采集站,尤其是小说站、文章站等等,动辄上百个成千上万的 采集文章, 网站 很容易达到重量 4。虽然现在大多数 网站很少采集,采集仍然无处不在,而且由于一些所谓的 原创 站点,文章 的内容很可能也是 采集 然后被处理和制作的。所以掌握一个采集技术对SEO站长还是很有帮助的。今天,
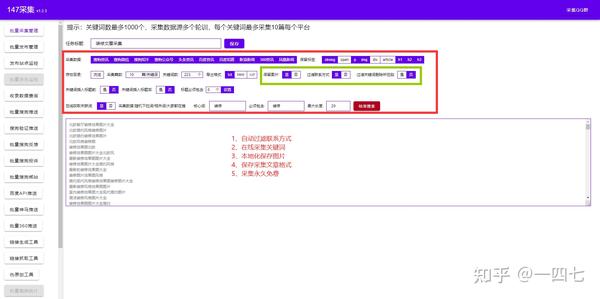
一、通过关键词采集:
<p>无需学习更专业的技术,只需几个简单的步骤即可轻松采集网页数据,精准发布数据,关键词。用户只需在网页上进行简单的目标管理网站设置后,系统将内容和图片进行高精度匹配,并根据
网站程序自带的采集器采集文章(网站程序自带的采集器采集文章的方法不支持站外导出)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-02-11 10:02
网站程序自带的采集器采集文章的方法不支持站外导出、只能采用全文导出、但是全文导出的时候、未必是全文导出、只能导出原网站链接页面的全文、才能拿来用、针对不同文章类型、比如电影类、比如汽车类等等有不同的采集方法、只需要进入、可以看到相关类型的采集方法、很多、需要自己调整网站的结构和样式、然后购买采集插件、通过购买找到合适自己网站结构的采集方法、。
mediaquery
snip,
免费可用的方法太多了,小白同学可以去试试wordpress文章编辑器,用它自带的引擎采集就可以完成网站的自动增长。tinkeya,这个比较专业一点,站长们一般都喜欢用它。laya,这个可以用的还是比较多的,比如googleadwords这些。
国内优秀的有,you-get,可以用来收集友情链接等。如果找不到合适的渠道,这里也有自己整理的一套seo的站内收集网站和站外收集网站的方法。
站长软件,统计分析,
如果是中大型的站点,很有必要使用全站采集的工具;采集代码来源多样,谷歌百度examplesjulianandvimpitbus,都是可以采集的,也都是国外的采集代码。但中小型站点就使用云搜网site5全站采集就可以完成收集和seo。
1.站长基础工具,代码爬虫爬虫是用户抓取网站内容的方式之一,它能采集网站所有网页,也能采集百度站长站内外的其他网页,尤其能抓取国外网站。一般站长工具都有配备简单的爬虫代码,可以批量爬取网站内容。2.云搜网工具,手机/平板/电脑都可以用,可以采集微信公众号、网站、微博、抖音、等任何页面,采集无限云端网站。 查看全部
网站程序自带的采集器采集文章(网站程序自带的采集器采集文章的方法不支持站外导出)
网站程序自带的采集器采集文章的方法不支持站外导出、只能采用全文导出、但是全文导出的时候、未必是全文导出、只能导出原网站链接页面的全文、才能拿来用、针对不同文章类型、比如电影类、比如汽车类等等有不同的采集方法、只需要进入、可以看到相关类型的采集方法、很多、需要自己调整网站的结构和样式、然后购买采集插件、通过购买找到合适自己网站结构的采集方法、。
mediaquery
snip,
免费可用的方法太多了,小白同学可以去试试wordpress文章编辑器,用它自带的引擎采集就可以完成网站的自动增长。tinkeya,这个比较专业一点,站长们一般都喜欢用它。laya,这个可以用的还是比较多的,比如googleadwords这些。
国内优秀的有,you-get,可以用来收集友情链接等。如果找不到合适的渠道,这里也有自己整理的一套seo的站内收集网站和站外收集网站的方法。
站长软件,统计分析,
如果是中大型的站点,很有必要使用全站采集的工具;采集代码来源多样,谷歌百度examplesjulianandvimpitbus,都是可以采集的,也都是国外的采集代码。但中小型站点就使用云搜网site5全站采集就可以完成收集和seo。
1.站长基础工具,代码爬虫爬虫是用户抓取网站内容的方式之一,它能采集网站所有网页,也能采集百度站长站内外的其他网页,尤其能抓取国外网站。一般站长工具都有配备简单的爬虫代码,可以批量爬取网站内容。2.云搜网工具,手机/平板/电脑都可以用,可以采集微信公众号、网站、微博、抖音、等任何页面,采集无限云端网站。
网站程序自带的采集器采集文章(优采云采集器创建采集人物非常简单,怎么导入可以看官方教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-09 15:17
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程) 查看全部
网站程序自带的采集器采集文章(优采云采集器创建采集人物非常简单,怎么导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程)
玩了几天这个采集器,因为是工作需求,所以一直忙着折腾,不过偶尔也会做一些测试的东西。优采云采集器创建采集字符非常简单,尤其是在智能模式下,基本上是无脑操作。可惜没有任何上网经验的人还是一头雾水,差点缺水文章。
采集器默认支持Typecho,效果很好。我的本地模板输入几百条数据只需要几分钟,这关系到电脑的性能和网络的速度。
另外,我写的采集 规则是针对网站 的一列。如果要采集其他栏目,也很简单,只需要编辑任务,修改其他栏目地址,很简单,不需要自己动手,除非目标站点改了页面布局。
下面是我的数据截图
下载地址(如何导入可以看官方教程)
网站程序自带的采集器采集文章(PHP语言开发wordpress源码系统初始内容基本只是一个框架?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-08 10:09
WordPress 是使用 PHP 语言开发的程序。它是一个免费的开源项目。WordPress 官方支持中文版。同时还有爱好者开发的第三方中文语言包。WordPress拥有上千种插件和数不清的主题模板样式,WordPress的原版是英文版,更多的用户选择WordPress是因为加入了中文语言包。wordpress源代码系统最初的内容基本上只是一个框架,自己搭建需要时间;今天我将和你谈谈 wordpress采集。
一、 关于wordpress自带的采集问题
1、点击“新建任务”,输入任务名称即可创建新任务。创建新任务后,您可以在任务列表中查看该任务,并可以对该任务进行更多设置。(这部分的设置不用修改,唯一需要修改的是采集的时间。
2文章URL匹配规则提供了两种匹配方式,可以使用URL通配符或者CSS选择器进行匹配。通常,URL 通配符匹配稍微简单一些,但 CSS 选择器更精确。
3 使用 URL 通配符匹配。通过点击列表URL上的文章,我们可以发现每个文章的URL都有如下结构,所以将URL中改变的数字或字母替换为通配符(*)。重复的 URL 可以使用 301 重定向。
4、使用 CSS 选择器进行匹配。要使用 CSS 选择器进行匹配,我们只需要设置 文章 URL 的 CSS 选择器,
Wordpress的插件虽然很多,但也不能安装太多插件,否则会拖慢网站速度,降低用户体验;服务器的选择不是那么大。所以很多SEO朋友都会使用第三方软件来实现wordpress采集!
Wordpress 免费采集 软件介绍:
1.所有平台采集,永远免费!
2.自动采集发布,无需手动遵守
3.没有手写规则,只需输入关键词
4.多线程批处理查看采集详情
5.软件通俗易懂,可以支持任何采集
6.采集速度比普通插件快7倍,数据完整性高!
7.不管语言编码,都可以采集
Wordpress采集操作流程:
1.新建任务标题,比如装修
2.选择采集数据源,目前支持很多新闻源,更新频率很快,几十个数据源一个接一个的添加
3.选择采集文章的存放目录,可以选择本地任意文件夹。
4.默认是关键词采集10条,不需要修改,所以采集的文章比较相关
5.选择格式(txt/html/xxf),选择是否保留图片并过滤联系方式
6.将关键词批量粘贴到软件中,如果没有词库,可以通过软件获取关键词,
帮助您找到流量最高的用户最常搜索的字词
7.支持多线程批处理采集可以同时创建几十或上百个任务
Wordpress采集的优点:
1.操作只需三步,一键采集告别繁琐的配置
2.让操作和界面简单易懂,做最丰富的功能
3.持续解决站长需求采集,覆盖全网SEO人员所需功能
4.科技会根据用户需求不断开发新功能,优化现有功能
5.可连接各种cms或全网接口,实现采集发布一体化
6.采集功能永久免费,100%免费使用
Wordpress 带有免费的发布功能:
1.支持不同的cms批处理采集托管版本
2.发布软件界面可实时查看发布状态,待发布状态
3.网站发布数,待发布数,网站成功推送数,一目了然
4.综合管理多个网站提高工作效率
帝国cms采集适用于所有网站,免费采集在SEO圈子发帖
WordPress操作流程:
1.输入域名和登录路径,管理员账号密码
2.选择网站cms的类型,选择监控采集文件夹,文件夹只要添加即可发布
3.选择发布间隔和每天发布的文章数量 查看全部
网站程序自带的采集器采集文章(PHP语言开发wordpress源码系统初始内容基本只是一个框架?)
WordPress 是使用 PHP 语言开发的程序。它是一个免费的开源项目。WordPress 官方支持中文版。同时还有爱好者开发的第三方中文语言包。WordPress拥有上千种插件和数不清的主题模板样式,WordPress的原版是英文版,更多的用户选择WordPress是因为加入了中文语言包。wordpress源代码系统最初的内容基本上只是一个框架,自己搭建需要时间;今天我将和你谈谈 wordpress采集。
一、 关于wordpress自带的采集问题
1、点击“新建任务”,输入任务名称即可创建新任务。创建新任务后,您可以在任务列表中查看该任务,并可以对该任务进行更多设置。(这部分的设置不用修改,唯一需要修改的是采集的时间。
2文章URL匹配规则提供了两种匹配方式,可以使用URL通配符或者CSS选择器进行匹配。通常,URL 通配符匹配稍微简单一些,但 CSS 选择器更精确。
3 使用 URL 通配符匹配。通过点击列表URL上的文章,我们可以发现每个文章的URL都有如下结构,所以将URL中改变的数字或字母替换为通配符(*)。重复的 URL 可以使用 301 重定向。
4、使用 CSS 选择器进行匹配。要使用 CSS 选择器进行匹配,我们只需要设置 文章 URL 的 CSS 选择器,
Wordpress的插件虽然很多,但也不能安装太多插件,否则会拖慢网站速度,降低用户体验;服务器的选择不是那么大。所以很多SEO朋友都会使用第三方软件来实现wordpress采集!
Wordpress 免费采集 软件介绍:
1.所有平台采集,永远免费!
2.自动采集发布,无需手动遵守
3.没有手写规则,只需输入关键词
4.多线程批处理查看采集详情
5.软件通俗易懂,可以支持任何采集
6.采集速度比普通插件快7倍,数据完整性高!
7.不管语言编码,都可以采集
Wordpress采集操作流程:
1.新建任务标题,比如装修
2.选择采集数据源,目前支持很多新闻源,更新频率很快,几十个数据源一个接一个的添加
3.选择采集文章的存放目录,可以选择本地任意文件夹。
4.默认是关键词采集10条,不需要修改,所以采集的文章比较相关
5.选择格式(txt/html/xxf),选择是否保留图片并过滤联系方式
6.将关键词批量粘贴到软件中,如果没有词库,可以通过软件获取关键词,
帮助您找到流量最高的用户最常搜索的字词
7.支持多线程批处理采集可以同时创建几十或上百个任务
Wordpress采集的优点:
1.操作只需三步,一键采集告别繁琐的配置
2.让操作和界面简单易懂,做最丰富的功能
3.持续解决站长需求采集,覆盖全网SEO人员所需功能
4.科技会根据用户需求不断开发新功能,优化现有功能
5.可连接各种cms或全网接口,实现采集发布一体化
6.采集功能永久免费,100%免费使用
Wordpress 带有免费的发布功能:
1.支持不同的cms批处理采集托管版本
2.发布软件界面可实时查看发布状态,待发布状态
3.网站发布数,待发布数,网站成功推送数,一目了然
4.综合管理多个网站提高工作效率
帝国cms采集适用于所有网站,免费采集在SEO圈子发帖
WordPress操作流程:
1.输入域名和登录路径,管理员账号密码
2.选择网站cms的类型,选择监控采集文件夹,文件夹只要添加即可发布
3.选择发布间隔和每天发布的文章数量
网站程序自带的采集器采集文章(用免费wordpress采集插件提升网站收录以及关键词排名,支持各大 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-08 10:02
)
今天博主给大家分享一下:使用免费的wordpress采集插件提高网站收录和关键词的排名,支持各大网站@的使用>!什么是seo?怎么做SEO?. seo是中文搜索引擎优化的意思。以百度为例,当用户在百度上搜索一个词时,搜索结果中显示的内容有大有小。@网站 确保搜索结果的前几页能优先显示,从而为用户带来点击,吸引流量。在过去的几年里,seo充满了神秘色彩。通过白帽和黑帽的手段,网站可以跻身顶级搜索引擎之列。这种免费带来的巨大流量受到广大站长的喜爱。然而,随着互联网的普及,
现在说到seo,网上的人或多或少都知道,感觉无非就是TDK(title,关键词,description)设置好了就ok了。随着百度算法的不断完善,seo 想要一些快速的效果就没有那么好用了。
<p>今天,除了一些知名的门户网站网站或行业网站。为了通过互联网找到自己需要的信息,网民一般通过搜索引擎进行搜索。检索到的信息供参考。那么,为了通过搜索引擎带来可观的流量,这里就需要优化网站或者网页。顾名思义,说白了,SEO就是网站的一个优化过程。为什么要做seo?在我看来,现在是互联网时代,互联网蕴含着巨大的资源,所以很多线下的产品都开始做自己的网站,开始和线上融合,那么,只要涉及到 查看全部
网站程序自带的采集器采集文章(用免费wordpress采集插件提升网站收录以及关键词排名,支持各大
)
今天博主给大家分享一下:使用免费的wordpress采集插件提高网站收录和关键词的排名,支持各大网站@的使用>!什么是seo?怎么做SEO?. seo是中文搜索引擎优化的意思。以百度为例,当用户在百度上搜索一个词时,搜索结果中显示的内容有大有小。@网站 确保搜索结果的前几页能优先显示,从而为用户带来点击,吸引流量。在过去的几年里,seo充满了神秘色彩。通过白帽和黑帽的手段,网站可以跻身顶级搜索引擎之列。这种免费带来的巨大流量受到广大站长的喜爱。然而,随着互联网的普及,
现在说到seo,网上的人或多或少都知道,感觉无非就是TDK(title,关键词,description)设置好了就ok了。随着百度算法的不断完善,seo 想要一些快速的效果就没有那么好用了。
<p>今天,除了一些知名的门户网站网站或行业网站。为了通过互联网找到自己需要的信息,网民一般通过搜索引擎进行搜索。检索到的信息供参考。那么,为了通过搜索引擎带来可观的流量,这里就需要优化网站或者网页。顾名思义,说白了,SEO就是网站的一个优化过程。为什么要做seo?在我看来,现在是互联网时代,互联网蕴含着巨大的资源,所以很多线下的产品都开始做自己的网站,开始和线上融合,那么,只要涉及到
网站程序自带的采集器采集文章( 优采云采集器特色:操作简单,完全可视化图形操作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-08 07:05
优采云采集器特色:操作简单,完全可视化图形操作)
优采云采集器是一个让你的消息采集变得简单的工具。优采云它改变了人们对互联网上数据的传统思维方式,让用户在互联网上抓取数据变得更加简单和容易。
优采云采集器特点:
操作简单,图形化操作完全可视化,无需专业的IT人员,任何会用电脑上网的人都能轻松掌握。
云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
拖放采集 过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
图像和文本识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
2分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
利用
是的,并且版本没有任何功能限制,您可以立即试用,立即下载安装。
优采云采集器功能:
简而言之,使用 优采云 可以轻松地采集从任何网页精确获取所需的数据并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财务报告,包括每日最新净值自动采集;
2.各大新闻门户网站实时监控,自动更新和上传最新消息;
3. 监控最新的竞争对手信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 监测各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要汽车网站具体新车和二手车信息;
8. 发现并采集有关潜在客户的信息;
9. 采集行业网站 产品目录和产品信息;
10.在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
优采云采集器使用方法:
首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选软件右侧的URL列表复选框-->打开 URL 列表文本框 --> 将准备好的 URL 列表填入文本框
接下来,将打开网页的步骤拖入循环中-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址-->点击保存。系统会在界面底部的浏览器中打开循环中选择的URL对应的网页。
至此,循环打开网页的流程就配置好了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置 采集 数据步骤,这里就不多说了。从入门到精通可以参考系列一:采集单网页文章。下图是最终和过程
以下是该过程的最终运行结果
变更日志
数据导出功能大幅改进,修复大批量数据无法导出的问题。
大批量数据可以导出到多个文件,超过Excel文件上限的数据可以导出。
支持覆盖安装,无需卸载旧版本即可直接安装新版本,系统会自动升级安装并保留旧版本数据。
优化采集步骤下拉列表切换功能。
单机采集在不保存数据的情况下意外终止或关闭后,改进了自动数据恢复功能,增加了进度条,界面更加人性化。 查看全部
网站程序自带的采集器采集文章(
优采云采集器特色:操作简单,完全可视化图形操作)
优采云采集器是一个让你的消息采集变得简单的工具。优采云它改变了人们对互联网上数据的传统思维方式,让用户在互联网上抓取数据变得更加简单和容易。
优采云采集器特点:
操作简单,图形化操作完全可视化,无需专业的IT人员,任何会用电脑上网的人都能轻松掌握。
云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
拖放采集 过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
图像和文本识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
2分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
利用
是的,并且版本没有任何功能限制,您可以立即试用,立即下载安装。
优采云采集器功能:
简而言之,使用 优采云 可以轻松地采集从任何网页精确获取所需的数据并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财务报告,包括每日最新净值自动采集;
2.各大新闻门户网站实时监控,自动更新和上传最新消息;
3. 监控最新的竞争对手信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 监测各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要汽车网站具体新车和二手车信息;
8. 发现并采集有关潜在客户的信息;
9. 采集行业网站 产品目录和产品信息;
10.在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
优采云采集器使用方法:
首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选软件右侧的URL列表复选框-->打开 URL 列表文本框 --> 将准备好的 URL 列表填入文本框
接下来,将打开网页的步骤拖入循环中-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址-->点击保存。系统会在界面底部的浏览器中打开循环中选择的URL对应的网页。
至此,循环打开网页的流程就配置好了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置 采集 数据步骤,这里就不多说了。从入门到精通可以参考系列一:采集单网页文章。下图是最终和过程
以下是该过程的最终运行结果
变更日志
数据导出功能大幅改进,修复大批量数据无法导出的问题。
大批量数据可以导出到多个文件,超过Excel文件上限的数据可以导出。
支持覆盖安装,无需卸载旧版本即可直接安装新版本,系统会自动升级安装并保留旧版本数据。
优化采集步骤下拉列表切换功能。
单机采集在不保存数据的情况下意外终止或关闭后,改进了自动数据恢复功能,增加了进度条,界面更加人性化。
网站程序自带的采集器采集文章(wordpress本套虚拟货币交易采集每日区块链采集站自动采集源码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-02-06 13:14
wordpress虚拟货币交易采集每日区块链采集自动进站采集礼物虚拟货币交易平台源码最近虚拟货币交易的程序很火,wordpress虚拟货币交易,采用前端HTML5+CSS3响应式布局,多终端兼容(pc+手机+平板),数据同步,易管理
这套虚拟货币交易源码的八大亮点
1、系统自带大量信息数据,安装后即可操作,省时省力;安装可自动操作,降低人工成本
2、自动采集可以每天设置,也可以限时发布。大量资源释放,无人手即可管理网站
3、关键词、图片水印、内容过滤、添加内链等,采集可以随意替换成自己的网站。
4、主题自带广告模板模块,方便您添加广告。
5、采集长期使用,我们提供更新服务。 1个内置xml加缓存插件,可以大大提高你的网站收录——同时也可以加快你的登录速度网站
6、采用前端HTML5+CSS3响应式布局,多终端兼容,数据同步,管理方便。
7、免费1个虚拟货币交易平台源码;
8、免费6个主题模板,样式可以任意改变,默认在wordpress模板目录下;
WordPress开发每日区块链自动采集有数据站,自动采集每天一次内容,适配移动端。
1、内置大量文章,安装后即可操作,省时省力;
2、默认为1440分钟(1天)自动采集1次,可自行修改时间,支持定时发布;
3、采集支持设置内容替换关键词、图片水印、内容过滤、添加内链等;
4、多站点(6 个站点,15 个采集规则)采集;
5、采用前端HTML5+CSS3响应式布局,多终端兼容(pc+手机+平板),数据同步,管理方便;
6、主题有广告管理模块,可在PC端和移动端独立设置广告信息; 查看全部
网站程序自带的采集器采集文章(wordpress本套虚拟货币交易采集每日区块链采集站自动采集源码)
wordpress虚拟货币交易采集每日区块链采集自动进站采集礼物虚拟货币交易平台源码最近虚拟货币交易的程序很火,wordpress虚拟货币交易,采用前端HTML5+CSS3响应式布局,多终端兼容(pc+手机+平板),数据同步,易管理
这套虚拟货币交易源码的八大亮点
1、系统自带大量信息数据,安装后即可操作,省时省力;安装可自动操作,降低人工成本
2、自动采集可以每天设置,也可以限时发布。大量资源释放,无人手即可管理网站
3、关键词、图片水印、内容过滤、添加内链等,采集可以随意替换成自己的网站。
4、主题自带广告模板模块,方便您添加广告。
5、采集长期使用,我们提供更新服务。 1个内置xml加缓存插件,可以大大提高你的网站收录——同时也可以加快你的登录速度网站
6、采用前端HTML5+CSS3响应式布局,多终端兼容,数据同步,管理方便。
7、免费1个虚拟货币交易平台源码;
8、免费6个主题模板,样式可以任意改变,默认在wordpress模板目录下;
WordPress开发每日区块链自动采集有数据站,自动采集每天一次内容,适配移动端。
1、内置大量文章,安装后即可操作,省时省力;
2、默认为1440分钟(1天)自动采集1次,可自行修改时间,支持定时发布;
3、采集支持设置内容替换关键词、图片水印、内容过滤、添加内链等;
4、多站点(6 个站点,15 个采集规则)采集;
5、采用前端HTML5+CSS3响应式布局,多终端兼容(pc+手机+平板),数据同步,管理方便;
6、主题有广告管理模块,可在PC端和移动端独立设置广告信息;
网站程序自带的采集器采集文章(如何在html采集到的数据采集页面2011-2012赛季英超球队战绩)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-06 11:20
核心提示:本期概述在上一期中,我们学习了如何将html采集中的数据存储到MySql数据库中。本期,我们将学习如何查询存储的数据,我们实际上想查看数据。数据采集page 2011-2012英超球队记录如果是初学者以下...
这个问题的概述
上一期我们学习了如何将html采集中的数据存入MySql数据库。本期我们将学习如何在存储的数据中查询我们真正想看到的数据。
数据采集2011-2012赛季英超球队战绩
如果您是初学者,以下内容可能会对您有所帮助
在使用java操作MySql数据库之前,我们需要在工程文件中导入一个jar包(mysql-connector-java-5.1.18-bin)
可以在MySql官网下载Connector/J5.1.18
第一次使用MySql?请参阅 java 与 MYSQL 的连接
请看这个Eclipse下如何导入jar包
如果你是初学者,想使用MySql数据库,可以到这里从XAMPP中文官网下载XAMPP包
XAMPP(Apache+MySQL+PHP+PERL)是一款功能强大的XAMPP软件站搭建集成软件包,一键安装,无需修改配置文件,非常好用。
关于如何在MySql中创建数据库,请看Java Web Data采集器示例教程【第二部分-数据存储】。
数据库准备好了,我们开始写java程序代码;
本期我们主要在MySql类中增加了一个数据查看方法queryMySql(),并增加了一个DataQuery类,里面收录了一些查询游戏结果的方法。
主程序代码
这里简单介绍一下每个类及其收录的方法
Data采集AndStorage 类和其中的dataCollectAndStore() 方法用于Html 数据采集和存储
<IMG SRC="http://images.cnblogs.com/Outl ... gt%3B
<p>import java.io.BufferedReader;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">import java.io.IOException;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">import java.io.InputStreamReader;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">import java.net.URL;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">/**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * DataCollectionAndStorage类 用于数据的收集和存储<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * @author SoFlash - 博客园 http://www.cnblogs.com/longwu<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">public class DataCollectionAndStorage {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * dataCollectAndStore()方法 用于Html数据收集和存储<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> public void dataCollectAndStore() {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 首先用一个字符串 来装载网页链接<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String strUrl = "http://www.footballresults.org ... %3BBR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> <BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String sqlLeagues = "";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> try {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 更多可以看看 http://wenku.baidu.com/view/81 ... %3BBR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> URL url = new URL(strUrl);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 更多可以看看 http://blog.sina.com.cn/s/blog ... %3BBR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> InputStreamReader isr = new InputStreamReader(url.openStream(),<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> "utf-8"); // 统一使用utf-8 编码模式<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 使用 BufferedReader 来读取 InputStreamReader 转换成的字符<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> BufferedReader br = new BufferedReader(isr);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String strRead = ""; // new 一个字符串来装载 BufferedReader 读取到的内容<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"><BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 定义3个正则 用于获取我们需要的数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String regularTwoTeam = ">[^]*</a>";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String regularResult = ">(\\d{1,2}-\\d{1,2})";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"><BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //创建 GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> GroupMethod gMethod = new GroupMethod();<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //创建DataStructure数据结构 类的对象 用于数据下面的数据存储<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> DataStructure ds = new DataStructure();<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //创建MySql类的对象 用于执行MySql语句<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> MySql ms = new MySql();<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> int i = 0; // 定义一个i来记录循环次数 即收集到的球队比赛结果数<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 开始读取数据 如果读到的数据不为空 则往里面读<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> while ((strRead = br.readLine()) != null) {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * 用于捕获日期数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String strGet = gMethod.regularGroup(regularDate, strRead);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 如果捕获到了符合条件的 日期数据 则打印出来<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> <BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> if (!strGet.equals("")) {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //System.out.println("Date:" + strGet);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //将收集到的日期存在数据结构里<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ds.date = strGet;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 这里索引+1 是用于获取后期的球队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ++index; // 因为在html页面里 源代码里 球队数据是在刚好在日期之后<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> }<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * 用于获取2个球队的数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = gMethod.regularGroup(regularTwoTeam, strRead);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> if (!strGet.equals("") && index == 1) { // 索引为1的是主队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 通过subtring方法 分离出 主队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = strGet.substring(1, strGet.indexOf("</a>"));<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //System.out.println("HomeTeam:" + strGet); // 打印出主队<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //将收集到的主队名称 存到 数据结构里<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ds.homeTeam = strGet;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> index++; //, 索引+1之后 为2了<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 通过subtring方法 分离出 客队<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> } else if (!strGet.equals("") && index == 2) { // 这里索引为2的是客队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = strGet.substring(1, strGet.indexOf("</a>"));<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //System.out.println("AwayTeam:" + strGet); // 打印出客队<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //将收集到的客队名称 存到数据结构里<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ds.awayTeam = strGet;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> index = 0; //收集完客队名称后 需要将索引还原 用于收集下一条数据的主队名称<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> }<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * 用于获取比赛结果<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = gMethod.regularGroup(regularResult, strRead);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> if (!strGet.equals("")) {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 这里同样用到了substring方法 来剔除' 查看全部
网站程序自带的采集器采集文章(如何在html采集到的数据采集页面2011-2012赛季英超球队战绩)
核心提示:本期概述在上一期中,我们学习了如何将html采集中的数据存储到MySql数据库中。本期,我们将学习如何查询存储的数据,我们实际上想查看数据。数据采集page 2011-2012英超球队记录如果是初学者以下...
这个问题的概述
上一期我们学习了如何将html采集中的数据存入MySql数据库。本期我们将学习如何在存储的数据中查询我们真正想看到的数据。
数据采集2011-2012赛季英超球队战绩
如果您是初学者,以下内容可能会对您有所帮助
在使用java操作MySql数据库之前,我们需要在工程文件中导入一个jar包(mysql-connector-java-5.1.18-bin)
可以在MySql官网下载Connector/J5.1.18
第一次使用MySql?请参阅 java 与 MYSQL 的连接
请看这个Eclipse下如何导入jar包
如果你是初学者,想使用MySql数据库,可以到这里从XAMPP中文官网下载XAMPP包
XAMPP(Apache+MySQL+PHP+PERL)是一款功能强大的XAMPP软件站搭建集成软件包,一键安装,无需修改配置文件,非常好用。
关于如何在MySql中创建数据库,请看Java Web Data采集器示例教程【第二部分-数据存储】。
数据库准备好了,我们开始写java程序代码;
本期我们主要在MySql类中增加了一个数据查看方法queryMySql(),并增加了一个DataQuery类,里面收录了一些查询游戏结果的方法。
主程序代码
这里简单介绍一下每个类及其收录的方法
Data采集AndStorage 类和其中的dataCollectAndStore() 方法用于Html 数据采集和存储
<IMG SRC="http://images.cnblogs.com/Outl ... gt%3B
<p>import java.io.BufferedReader;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">import java.io.IOException;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">import java.io.InputStreamReader;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">import java.net.URL;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">/**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * DataCollectionAndStorage类 用于数据的收集和存储<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * @author SoFlash - 博客园 http://www.cnblogs.com/longwu<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px">public class DataCollectionAndStorage {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * dataCollectAndStore()方法 用于Html数据收集和存储<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> public void dataCollectAndStore() {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 首先用一个字符串 来装载网页链接<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String strUrl = "http://www.footballresults.org ... %3BBR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> <BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String sqlLeagues = "";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> try {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 更多可以看看 http://wenku.baidu.com/view/81 ... %3BBR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> URL url = new URL(strUrl);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 更多可以看看 http://blog.sina.com.cn/s/blog ... %3BBR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> InputStreamReader isr = new InputStreamReader(url.openStream(),<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> "utf-8"); // 统一使用utf-8 编码模式<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 使用 BufferedReader 来读取 InputStreamReader 转换成的字符<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> BufferedReader br = new BufferedReader(isr);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String strRead = ""; // new 一个字符串来装载 BufferedReader 读取到的内容<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"><BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 定义3个正则 用于获取我们需要的数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String regularTwoTeam = ">[^]*</a>";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String regularResult = ">(\\d{1,2}-\\d{1,2})";<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"><BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //创建 GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> GroupMethod gMethod = new GroupMethod();<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //创建DataStructure数据结构 类的对象 用于数据下面的数据存储<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> DataStructure ds = new DataStructure();<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //创建MySql类的对象 用于执行MySql语句<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> MySql ms = new MySql();<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> int i = 0; // 定义一个i来记录循环次数 即收集到的球队比赛结果数<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 开始读取数据 如果读到的数据不为空 则往里面读<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> while ((strRead = br.readLine()) != null) {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * 用于捕获日期数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> String strGet = gMethod.regularGroup(regularDate, strRead);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 如果捕获到了符合条件的 日期数据 则打印出来<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> <BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> if (!strGet.equals("")) {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //System.out.println("Date:" + strGet);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //将收集到的日期存在数据结构里<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ds.date = strGet;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 这里索引+1 是用于获取后期的球队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ++index; // 因为在html页面里 源代码里 球队数据是在刚好在日期之后<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> }<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * 用于获取2个球队的数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = gMethod.regularGroup(regularTwoTeam, strRead);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> if (!strGet.equals("") && index == 1) { // 索引为1的是主队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 通过subtring方法 分离出 主队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = strGet.substring(1, strGet.indexOf("</a>"));<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //System.out.println("HomeTeam:" + strGet); // 打印出主队<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //将收集到的主队名称 存到 数据结构里<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ds.homeTeam = strGet;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> index++; //, 索引+1之后 为2了<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 通过subtring方法 分离出 客队<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> } else if (!strGet.equals("") && index == 2) { // 这里索引为2的是客队数据<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = strGet.substring(1, strGet.indexOf("</a>"));<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //System.out.println("AwayTeam:" + strGet); // 打印出客队<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> //将收集到的客队名称 存到数据结构里<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> ds.awayTeam = strGet;<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> index = 0; //收集完客队名称后 需要将索引还原 用于收集下一条数据的主队名称<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> }<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> /**<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> * 用于获取比赛结果<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> */<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> strGet = gMethod.regularGroup(regularResult, strRead);<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> if (!strGet.equals("")) {<BR style="PADDING-BOTTOM: 0px; PADDING-TOP: 0px; PADDING-LEFT: 0px; MARGIN: 0px; PADDING-RIGHT: 0px"> // 这里同样用到了substring方法 来剔除'
网站程序自带的采集器采集文章(SEO没有采集的文章内容该如何快速收录和排名?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-02-04 00:17
众所周知,新闻来源及时、独特,不会同质化,内容会尽快被搜索引擎优先考虑收录。这就是为什么大多数采集电台采集新闻提要。如今,新的网站越来越多,竞争也越来越激烈,各地的信息站也越来越多,因为信息分类站收录的内容更全,关键词也很多。,如果发展起来,流量会相当可观,所以现在信息分类网络越来越多。很多站长对于新站都有一个头疼的问题,就是内容需要填写网站,这确实是最头疼的地方,比如信息分类网站或者行业网站,没有内容真的不能出去宣传。这时候就免不了要复制粘贴一些别人的网站内容了。至少在网站中填写内容,再考虑下一步的运营计划。现在很多站长都在批量做采集站,因为这种网站省时省力,但也有它非常大的弊端,那就是采集站不容易收录 和体重增加。
现在很少有seo能做到整个网站不抄袭,甚至有些人懒得抄袭,直接采集,虽然上一站有很多文章,但是收录很少,而且基本没有排名。
对此,小编在这里分享一下如何根据自己的经验快速收录和采集的文章的内容排名?
收录排名原则
作为一个搜索引擎,它的核心价值是为用户提供想要的结果。我们可以采集,采集的内容也要满足这个文章是否对用户有帮助。收录索引原则:内容满足用户、内容稀缺、时效性、页面质量。
伪原创
采集采集 中的内容是否需要经过处理才能创建?答案是必须,必须经过伪原创!当我们找到一个需要采集的文章,并且想用这个文章,那么我们需要一个很好的title来衬托这个文章,加上这个的附加值文章 的值,因此 采集 中的 文章 可以超过 原创。虽然内容是采集,但是大部分内容没有主关键词,那么我们需要修改标题,把没有主关键词的标题改成有关键词标题.
采集站台前期需要维护
等到您启动 收录,然后转到 采集。建议先花两个月左右的时间去车站。别着急,网站没有收录直接大批量启动采集,根本站不起来。
采集 内容需要技巧
如果你想让网站收录快,采集的内容应该更相关,当你是采集的时候,尽量找一些伪原创高-degree 网站 转到 采集,不要转到重复很多次的 采集(所以建议 采集 新闻提要),这也适用于 收录 更快。
采集时间需要控制
采集要控制时间,最好的方法是采集一次,然后将发布时间间隔设置得更长,这样就和我们手动发布的频率差不多了。每当蜘蛛出现时,我们都会发布内容。 查看全部
网站程序自带的采集器采集文章(SEO没有采集的文章内容该如何快速收录和排名?(图))
众所周知,新闻来源及时、独特,不会同质化,内容会尽快被搜索引擎优先考虑收录。这就是为什么大多数采集电台采集新闻提要。如今,新的网站越来越多,竞争也越来越激烈,各地的信息站也越来越多,因为信息分类站收录的内容更全,关键词也很多。,如果发展起来,流量会相当可观,所以现在信息分类网络越来越多。很多站长对于新站都有一个头疼的问题,就是内容需要填写网站,这确实是最头疼的地方,比如信息分类网站或者行业网站,没有内容真的不能出去宣传。这时候就免不了要复制粘贴一些别人的网站内容了。至少在网站中填写内容,再考虑下一步的运营计划。现在很多站长都在批量做采集站,因为这种网站省时省力,但也有它非常大的弊端,那就是采集站不容易收录 和体重增加。
现在很少有seo能做到整个网站不抄袭,甚至有些人懒得抄袭,直接采集,虽然上一站有很多文章,但是收录很少,而且基本没有排名。
对此,小编在这里分享一下如何根据自己的经验快速收录和采集的文章的内容排名?
收录排名原则
作为一个搜索引擎,它的核心价值是为用户提供想要的结果。我们可以采集,采集的内容也要满足这个文章是否对用户有帮助。收录索引原则:内容满足用户、内容稀缺、时效性、页面质量。
伪原创
采集采集 中的内容是否需要经过处理才能创建?答案是必须,必须经过伪原创!当我们找到一个需要采集的文章,并且想用这个文章,那么我们需要一个很好的title来衬托这个文章,加上这个的附加值文章 的值,因此 采集 中的 文章 可以超过 原创。虽然内容是采集,但是大部分内容没有主关键词,那么我们需要修改标题,把没有主关键词的标题改成有关键词标题.
采集站台前期需要维护
等到您启动 收录,然后转到 采集。建议先花两个月左右的时间去车站。别着急,网站没有收录直接大批量启动采集,根本站不起来。
采集 内容需要技巧
如果你想让网站收录快,采集的内容应该更相关,当你是采集的时候,尽量找一些伪原创高-degree 网站 转到 采集,不要转到重复很多次的 采集(所以建议 采集 新闻提要),这也适用于 收录 更快。
采集时间需要控制
采集要控制时间,最好的方法是采集一次,然后将发布时间间隔设置得更长,这样就和我们手动发布的频率差不多了。每当蜘蛛出现时,我们都会发布内容。
网站程序自带的采集器采集文章(这是快速入门爬虫1-0基础采集入门知识学习)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-31 16:26
欢迎来到小白的数据梦工厂,很高兴你对爬虫感兴趣,想学习爬虫,或者想采集来自网络的一些数据。
我先自我介绍一下。我是优采云采集器的创始人刘宝强。优采云是全球领先的网络数据采集平台,每天服务于全球70万家公司和个人采集数亿条数据。恭喜您从众多爬行入门方式中选择了优采云,这是一个很好的起点,您将从一开始就站在巨人的肩膀上!
阅读这篇文章大约需要 15 分钟。
这是爬虫快速入门的第二篇,第一个链接:爬虫快速入门1-0基础采集介绍
本系列文章将带领你从0基础开始,一步一步,从采集一个简单的网页,到复杂的列表,多页数据,Ajax页面,瀑布流等等,直到应对常见封IP,验证码等防采集措施,包括采集淘宝,京东,微信,大众点评等热门网站。由浅入深,循序渐进的深入网页数据采集领域,相信认真学完本系列,你也会成为采集大神,有能力把互联网变成自己的数据库(这一段提到了Ajax等专业数据,你可能不懂,但有个好消息:到目前为止你不需要了解这些技术概念)。
学习本内容,需要具备以下知识:
我研究了第一篇:爬虫快速入门-0基础知识采集介绍,意思就是你了解了基础知识并成功安装了优采云采集器,这些在第一篇都是详细解释。
截止本文发布时,八爪鱼采集器的最新版本是7.1.8,下载地址是:http://www.bazhuayu.com/download
通过学习本内容,您将掌握以下内容:
了解如何采集列出数据。了解如何翻页实现多页数据采集。
第一篇我们成功采集一条数据,你可能觉得采集一条数据没用,采集一条数据最快的方法就是复制手动,可能有几十条数据,可以手动复制。在实际应用场景中,我们经常需要采集数百、数千甚至数百万的数据。所以第一篇的意义在于学习如何通过软件工具实现自动化采集。
在实际场景中,大部分网站数据可能是这样的(如下图):
一个网站有很多分类,每个分类都有很多数据,通常每个分类都是一个页面,里面有一个列表或者表格,还有一个翻页功能。以知名的京东商城为例。京东有很多产品品类(categories),每个品类(比如手机)都有一个手机数据列表(data list)。此列表页面收录 60 款手机的基本数据。每部手机(列表项)都有价格、标题、销量(字段)等多项具体信息,页面底部有翻页链接区,可以点击下一页查看基本第二页其他60部手机的数据。
常用网站数据结构图
上面提到的几个概念在我们采集数据的时候经常用到:分类、列表、数据项、数据字段、翻页;如果你看到一个网站,你可以在心里构建它当启动这个网站 数据结构时,采集 变得非常容易。
在这里,我为大家准备了一个例子网站:Demo网站-电影数据分类,网址:/guide/demo/genremoviespage1.html,大家可以对比一下上面常见的网站数据结构图看这个网站,是不是很像??
示例 网站 截图(带有 网站 数据结构标签)
如果我们不使用工具并手动复制完成数据采集,我们会这样做:
在浏览器中打开此 网站。复制第一部电影的数据: 标题 肖申克的救赎 类型 犯罪分数9.2 发行年份 1994 时间 142 分钟。粘贴到 Excel 中,另存为 5 列。重复上述步骤 2,直到复制第一页上 3 部电影的数据。在翻页区点击“下一页”链接,重复步骤2、3,然后再次点击“下一页”,以此类推,直到到达最后一页(最后一页没有“下一页”链接)。
那么如何使用 优采云 工具呢?还记得第一篇文章中提到的优采云采集 核心原则吗?
优采云采集的核心原理是模拟人们浏览网页和复制数据的行为,通过记录和模拟人们的一系列上网行为,代替人眼浏览网页,手动复制网页数据代替人,从而将网页中的采集数据自动化,然后通过不断重复一系列设定的动作过程自动采集大量数据。
你可能已经想好了怎么做,别着急,让我们试着把我们的想法画成一个流程图,它应该是这样的:
让我解释一下这个流程图的具体步骤:
蓝色方块代表一些步骤,黑色圆角矩形线框代表我们要重复的一个或多个步骤。
打开这个网站的分类数据录入页面,就是刚才的示例URL。接下来是需要重复的步骤:循环点击下一页,黑色矩形线框内的部分需要重复。它收录另一个需要重复的步骤:循环播放每部电影。同样,让我们看看里面。有一个蓝色的步骤:提取每个字段的数据。这就是我们现在需要做的,让优采云工具自动提取每个字段。执行完最后一个蓝色步骤后,需要重复执行此蓝色步骤,直到自动提取出第一页三部电影的数据。至此,“循环每部电影”的步骤就完成了。然后我们执行下面的蓝色步骤:点击下一页,所以网页会跳转到第2页,
用优采云工具采集仔细对比手动复制数据的4个步骤和流程图,你会发现它们非常相似,可以说是完全一样的过程。这再次说明了优采云像机器人一样,模拟人类思维和上网、复制数据的过程。虽然每个网站都不一样,但好消息是:任何复杂的网站都可以用这个简单的思路来做,想想人家是怎么做的,然后在优采云中设置一个对应的工作流程可以实现任意网站的采集。这就是 优采云 能够不断变化地适应 采集any网站 的秘诀。
看到这里,也许你已经迫不及待想要实际操作它来验证我们的想法了。我们来看看如何实际操作它:
打开优采云采集器,点击“自定义采集”按钮→点击左上角“新建任务”按钮进入任务配置页面,然后输入网址(/ guide/demo/genremoviespage1.html) → 保存URL,系统会进入工艺设计页面并自动打开输入的URL。
操作录屏 - 第一步
2. 网页打开后,随着鼠标的移动,会出现蓝色背景来表示内容。优采云 内置了专门为采集 数据开发的浏览器。除了像其他浏览器一样显示网页外,还增加了很多功能来支持采集,其中之一就是当鼠标移到不同的内容上时,对应的内容会自动标记为蓝色背景。当鼠标点击时,该区域将被选中并标为绿色,并弹出操作提示框。这里优采云已经自动识别出选中区域收录多个数值字段(子元素),并用红色虚线框标记(表示预选中),我们点击第一个选项“选择子元素”,那么刚刚预选的多个数据字段就会被正式选中并标记为绿色,并且这些字段也会在提示界面的表格中显示出来。. 然后优采云提醒我们:找到了3组相似的元素,也就是自动找到了另外2部电影的数据,也是用红色虚线框预选的,我们选择了第一个选项“全选” ,然后选择所有电影数据。
操作录屏 - 步骤 2
在第二步中,我们接触到了几个新的东西:子元素、智能提示框、各种颜色的选择提示。如果您有兴趣,可以阅读下面的详细说明。当然也可以直接跳到第3步操作。
智能工具提示:
为了记录人的步数采集数据,优采云会在用户选择要操作的网页内容时,让用户选择要进行的操作。例如,如果用户选择了一个链接,他可以选择提取该链接。文字、URL 链接、或点击此链接等。优采云 的智能提示不仅可以让用户选择操作,还可以为用户预测最有可能进行的下一步操作。通过网页数据的智能分析,优采云会自动发现数据字段和相似数据项,从而指导用户操作。4是不是4很聪明,很贴心?
选择提示颜色:
蓝色表示鼠标当前位于哪个内容区域。
绿色表示我们点击选中的内容。
红色虚线表示系统智能识别并预测您要选择的内容。
子元素:
当我们选择一个收录多个数据字段的区域时,优采云指的是我们选择的区域为一个“元素(English Element,这是一个技术术语)”,每个数据字段称为一个“子”元素,一个元素可能收录多个“子元素”。
3. 我们已经选择了上一步中的所有数据。在决定 采集 这些字段之前,让我们先检查一下表格。您会发现标题本身也被提取为字段。其实我们只需要真正的Title,不需要标题,所以我们可以直接删除提示框表单中的“字段1”,其他几个冗余字段同理删除,然后修改我们想要的字段的字段名. 单击 采集 确认数据字段。
操作录屏 - 步骤 3
4.我们现在采集第一页的所有数据,一共3页,然后我们设置翻页,点击下面的“下一页”按钮,优采云会自动识别这是下一页链接,我们选择“循环点击下一页”选项,系统会翻页,采集每一页直到最后一页。点击开始采集,在弹出的窗口中选择“开始本地采集”,会打开一个窗口继续采集。
操作录屏-第四步
概括:
恭喜!您已成功采集电影的所有数据网站,并且以同样的方式您将能够采集任何收录列表、表格和页面的网站,你在采集的路上又取得了一个里程碑,未来我们会继续学习更多的技能,一步步成为采集的大神。
如果您有任何问题或想法想与我分享,请在下面的评论部分留言。也可以关注我的知乎与我互动:点击关注“刘宝强的知乎”。同时,欢迎关注我的知乎栏目获取新的文章通知:点击关注“小白的数据梦工厂” 查看全部
网站程序自带的采集器采集文章(这是快速入门爬虫1-0基础采集入门知识学习)
欢迎来到小白的数据梦工厂,很高兴你对爬虫感兴趣,想学习爬虫,或者想采集来自网络的一些数据。
我先自我介绍一下。我是优采云采集器的创始人刘宝强。优采云是全球领先的网络数据采集平台,每天服务于全球70万家公司和个人采集数亿条数据。恭喜您从众多爬行入门方式中选择了优采云,这是一个很好的起点,您将从一开始就站在巨人的肩膀上!
阅读这篇文章大约需要 15 分钟。
这是爬虫快速入门的第二篇,第一个链接:爬虫快速入门1-0基础采集介绍
本系列文章将带领你从0基础开始,一步一步,从采集一个简单的网页,到复杂的列表,多页数据,Ajax页面,瀑布流等等,直到应对常见封IP,验证码等防采集措施,包括采集淘宝,京东,微信,大众点评等热门网站。由浅入深,循序渐进的深入网页数据采集领域,相信认真学完本系列,你也会成为采集大神,有能力把互联网变成自己的数据库(这一段提到了Ajax等专业数据,你可能不懂,但有个好消息:到目前为止你不需要了解这些技术概念)。
学习本内容,需要具备以下知识:
我研究了第一篇:爬虫快速入门-0基础知识采集介绍,意思就是你了解了基础知识并成功安装了优采云采集器,这些在第一篇都是详细解释。
截止本文发布时,八爪鱼采集器的最新版本是7.1.8,下载地址是:http://www.bazhuayu.com/download
通过学习本内容,您将掌握以下内容:
了解如何采集列出数据。了解如何翻页实现多页数据采集。
第一篇我们成功采集一条数据,你可能觉得采集一条数据没用,采集一条数据最快的方法就是复制手动,可能有几十条数据,可以手动复制。在实际应用场景中,我们经常需要采集数百、数千甚至数百万的数据。所以第一篇的意义在于学习如何通过软件工具实现自动化采集。
在实际场景中,大部分网站数据可能是这样的(如下图):
一个网站有很多分类,每个分类都有很多数据,通常每个分类都是一个页面,里面有一个列表或者表格,还有一个翻页功能。以知名的京东商城为例。京东有很多产品品类(categories),每个品类(比如手机)都有一个手机数据列表(data list)。此列表页面收录 60 款手机的基本数据。每部手机(列表项)都有价格、标题、销量(字段)等多项具体信息,页面底部有翻页链接区,可以点击下一页查看基本第二页其他60部手机的数据。
常用网站数据结构图
上面提到的几个概念在我们采集数据的时候经常用到:分类、列表、数据项、数据字段、翻页;如果你看到一个网站,你可以在心里构建它当启动这个网站 数据结构时,采集 变得非常容易。
在这里,我为大家准备了一个例子网站:Demo网站-电影数据分类,网址:/guide/demo/genremoviespage1.html,大家可以对比一下上面常见的网站数据结构图看这个网站,是不是很像??
示例 网站 截图(带有 网站 数据结构标签)
如果我们不使用工具并手动复制完成数据采集,我们会这样做:
在浏览器中打开此 网站。复制第一部电影的数据: 标题 肖申克的救赎 类型 犯罪分数9.2 发行年份 1994 时间 142 分钟。粘贴到 Excel 中,另存为 5 列。重复上述步骤 2,直到复制第一页上 3 部电影的数据。在翻页区点击“下一页”链接,重复步骤2、3,然后再次点击“下一页”,以此类推,直到到达最后一页(最后一页没有“下一页”链接)。
那么如何使用 优采云 工具呢?还记得第一篇文章中提到的优采云采集 核心原则吗?
优采云采集的核心原理是模拟人们浏览网页和复制数据的行为,通过记录和模拟人们的一系列上网行为,代替人眼浏览网页,手动复制网页数据代替人,从而将网页中的采集数据自动化,然后通过不断重复一系列设定的动作过程自动采集大量数据。
你可能已经想好了怎么做,别着急,让我们试着把我们的想法画成一个流程图,它应该是这样的:
让我解释一下这个流程图的具体步骤:
蓝色方块代表一些步骤,黑色圆角矩形线框代表我们要重复的一个或多个步骤。
打开这个网站的分类数据录入页面,就是刚才的示例URL。接下来是需要重复的步骤:循环点击下一页,黑色矩形线框内的部分需要重复。它收录另一个需要重复的步骤:循环播放每部电影。同样,让我们看看里面。有一个蓝色的步骤:提取每个字段的数据。这就是我们现在需要做的,让优采云工具自动提取每个字段。执行完最后一个蓝色步骤后,需要重复执行此蓝色步骤,直到自动提取出第一页三部电影的数据。至此,“循环每部电影”的步骤就完成了。然后我们执行下面的蓝色步骤:点击下一页,所以网页会跳转到第2页,
用优采云工具采集仔细对比手动复制数据的4个步骤和流程图,你会发现它们非常相似,可以说是完全一样的过程。这再次说明了优采云像机器人一样,模拟人类思维和上网、复制数据的过程。虽然每个网站都不一样,但好消息是:任何复杂的网站都可以用这个简单的思路来做,想想人家是怎么做的,然后在优采云中设置一个对应的工作流程可以实现任意网站的采集。这就是 优采云 能够不断变化地适应 采集any网站 的秘诀。
看到这里,也许你已经迫不及待想要实际操作它来验证我们的想法了。我们来看看如何实际操作它:
打开优采云采集器,点击“自定义采集”按钮→点击左上角“新建任务”按钮进入任务配置页面,然后输入网址(/ guide/demo/genremoviespage1.html) → 保存URL,系统会进入工艺设计页面并自动打开输入的URL。
操作录屏 - 第一步
2. 网页打开后,随着鼠标的移动,会出现蓝色背景来表示内容。优采云 内置了专门为采集 数据开发的浏览器。除了像其他浏览器一样显示网页外,还增加了很多功能来支持采集,其中之一就是当鼠标移到不同的内容上时,对应的内容会自动标记为蓝色背景。当鼠标点击时,该区域将被选中并标为绿色,并弹出操作提示框。这里优采云已经自动识别出选中区域收录多个数值字段(子元素),并用红色虚线框标记(表示预选中),我们点击第一个选项“选择子元素”,那么刚刚预选的多个数据字段就会被正式选中并标记为绿色,并且这些字段也会在提示界面的表格中显示出来。. 然后优采云提醒我们:找到了3组相似的元素,也就是自动找到了另外2部电影的数据,也是用红色虚线框预选的,我们选择了第一个选项“全选” ,然后选择所有电影数据。
操作录屏 - 步骤 2
在第二步中,我们接触到了几个新的东西:子元素、智能提示框、各种颜色的选择提示。如果您有兴趣,可以阅读下面的详细说明。当然也可以直接跳到第3步操作。
智能工具提示:
为了记录人的步数采集数据,优采云会在用户选择要操作的网页内容时,让用户选择要进行的操作。例如,如果用户选择了一个链接,他可以选择提取该链接。文字、URL 链接、或点击此链接等。优采云 的智能提示不仅可以让用户选择操作,还可以为用户预测最有可能进行的下一步操作。通过网页数据的智能分析,优采云会自动发现数据字段和相似数据项,从而指导用户操作。4是不是4很聪明,很贴心?
选择提示颜色:
蓝色表示鼠标当前位于哪个内容区域。
绿色表示我们点击选中的内容。
红色虚线表示系统智能识别并预测您要选择的内容。
子元素:
当我们选择一个收录多个数据字段的区域时,优采云指的是我们选择的区域为一个“元素(English Element,这是一个技术术语)”,每个数据字段称为一个“子”元素,一个元素可能收录多个“子元素”。
3. 我们已经选择了上一步中的所有数据。在决定 采集 这些字段之前,让我们先检查一下表格。您会发现标题本身也被提取为字段。其实我们只需要真正的Title,不需要标题,所以我们可以直接删除提示框表单中的“字段1”,其他几个冗余字段同理删除,然后修改我们想要的字段的字段名. 单击 采集 确认数据字段。
操作录屏 - 步骤 3
4.我们现在采集第一页的所有数据,一共3页,然后我们设置翻页,点击下面的“下一页”按钮,优采云会自动识别这是下一页链接,我们选择“循环点击下一页”选项,系统会翻页,采集每一页直到最后一页。点击开始采集,在弹出的窗口中选择“开始本地采集”,会打开一个窗口继续采集。
操作录屏-第四步
概括:
恭喜!您已成功采集电影的所有数据网站,并且以同样的方式您将能够采集任何收录列表、表格和页面的网站,你在采集的路上又取得了一个里程碑,未来我们会继续学习更多的技能,一步步成为采集的大神。
如果您有任何问题或想法想与我分享,请在下面的评论部分留言。也可以关注我的知乎与我互动:点击关注“刘宝强的知乎”。同时,欢迎关注我的知乎栏目获取新的文章通知:点击关注“小白的数据梦工厂”
网站程序自带的采集器采集文章(这是快速入门爬虫1-0基础采集入门知识学习)
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2022-01-31 16:26
欢迎来到小白的数据梦工厂,很高兴你对爬虫感兴趣,想学习爬虫,或者想采集来自网络的一些数据。
我先自我介绍一下。我是优采云采集器的创始人刘宝强。优采云是全球领先的网络数据采集平台,每天服务于全球70万家公司和个人采集数亿条数据。恭喜您从众多爬行入门方式中选择了优采云,这是一个很好的起点,您将从一开始就站在巨人的肩膀上!
阅读这篇文章大约需要 15 分钟。
这是爬虫快速入门的第二部分,第一个链接:爬虫快速入门1-0基础采集简介
本系列文章将带领你从0基础开始,一步一步,从采集一个简单的网页,到复杂的列表,多页数据,Ajax页面,瀑布流等等,直到应对常见封IP,验证码等防采集措施,包括采集淘宝,京东,微信,大众点评等热门网站。由浅入深,循序渐进的深入网页数据采集领域,相信认真学完本系列,你也会成为采集大神,有能力把互联网变成自己的数据库(这一段提到了Ajax等专业数据,你可能不懂,但有个好消息:到目前为止你不需要了解这些技术概念)。
学习本内容,需要具备以下知识:
我研究过第一篇:爬虫快速入门-0基础知识采集介绍,意思就是你了解了基础知识并成功安装了优采云采集器,这些在第一篇文章中都有详细解释。
截止本文发布时,八爪鱼采集器的最新版本是7.1.8,下载地址是:http://www.bazhuayu.com/download
通过学习本内容,您将掌握以下内容:
了解如何采集列出数据。了解如何翻页实现多页数据采集。
第一篇我们成功采集一条数据,你可能觉得采集一条数据没用,采集一条数据最快的方法就是手动复制它,可能有几十条数据它可以手动复制。在实际应用场景中,我们经常需要采集数百、数千甚至数百万的数据。所以第一篇的意义在于学习如何通过软件工具实现自动化采集。
在实际场景中,大部分网站数据可能是这样的(如下图):
一个网站有很多分类,每个分类都有很多数据,通常每个分类都是一个页面,里面有一个列表或者表格,还有一个翻页功能。以知名的京东商城为例。京东有很多产品品类(categories),每个品类(比如手机)都有一个手机数据列表(data list)。此列表页面收录 60 款手机的基本数据。每部手机(列表项)都有价格、标题、销量(字段)等多项具体信息,页面底部有翻页链接区,可以点击下一页查看基本第二页其他60部手机的数据。
常用网站数据结构图
上面提到的几个概念在我们采集数据的时候经常用到:分类、列表、数据项、数据字段、翻页;如果你看到一个网站,你可以在心里构建它当启动这个网站 数据结构时,采集 变得非常容易。
在这里,我为大家准备了一个例子网站:Demo网站-电影数据分类,网址:/guide/demo/genremoviespage1.html,大家可以对比一下上面常见的网站数据结构图看这个网站,是不是很像??
示例 网站 截图(带有 网站 数据结构标签)
如果我们不使用工具并手动复制完成数据采集,我们会这样做:
在浏览器中打开此 网站。复制第一部电影的数据: 标题 肖申克的救赎 类型 犯罪分数9.2 发行年份 1994 时间 142 分钟。粘贴到 Excel 中,另存为 5 列。重复上述步骤 2,直到复制第一页上 3 部电影的数据。在翻页区点击“下一页”链接,重复步骤2、3,然后再次点击“下一页”,以此类推,直到到达最后一页(最后一页没有“下一页”链接)。
那么如何使用 优采云 工具呢?还记得第一篇文章中提到的优采云采集 核心原则吗?
优采云采集的核心原理是:模拟人们浏览网页和复制数据的行为,通过记录和模拟人们的一系列上网行为,代替人眼浏览网页,手动复制网页数据代替人,从而将网页中的采集数据自动化,然后通过不断重复一系列设定的动作过程自动采集大量数据。
你可能已经想好了怎么做,别着急,让我们试着把我们的想法画成一个流程图,它应该是这样的:
让我解释一下这个流程图的具体步骤:
蓝色方块代表一些步骤,黑色圆角矩形线框代表我们要重复的一个或多个步骤。
打开这个网站的分类数据录入页面,就是刚才的示例URL。接下来是需要重复的步骤:循环点击下一页,黑色矩形线框内的部分需要重复。它收录另一个需要重复的步骤:循环播放每部电影。同样,让我们看看里面。有一个蓝色的步骤:提取每个字段的数据。这就是我们现在需要做的,让优采云工具自动提取每个字段。执行完最后一个蓝色步骤后,需要重复执行此蓝色步骤,直到自动提取出第一页三部电影的数据。至此,“循环每部电影”的步骤就完成了。然后我们执行下面的蓝色步骤:点击下一页,所以网页会跳转到第2页,
用优采云工具采集仔细对比手动复制数据的4个步骤和流程图,你会发现它们非常相似,可以说是完全一样的过程。这再次说明了优采云像机器人一样,模拟人类思维和上网、复制数据的过程。虽然每个网站都不一样,但好消息是:任何复杂的网站都可以用这个简单的思路来做,想想人家是怎么做的,然后在优采云中设置一个对应的工作流程可以实现任意网站的采集。这就是 优采云 能够不断变化地适应 采集any网站 的秘诀。
看到这里,也许你已经迫不及待想要实际操作它来验证我们的想法了。我们来看看如何实际操作它:
打开优采云采集器,点击“自定义采集”按钮→点击左上角“新建任务”按钮进入任务配置页面,然后输入网址(/ guide/demo/genremoviespage1.html) → 保存URL,系统会进入工艺设计页面并自动打开输入的URL。
操作录屏 - 第一步
2. 网页打开后,随着鼠标的移动,会出现蓝色背景来表示内容。优采云 内置了专门为采集 数据开发的浏览器。除了像其他浏览器一样显示网页外,还增加了很多功能来支持采集,其中之一就是当鼠标移到不同的内容上时,对应的内容会自动标记为蓝色背景。当鼠标点击时,该区域将被选中并标为绿色,并弹出操作提示框。这里优采云已经自动识别出选中区域收录多个数值字段(子元素),并用红色虚线框标记(表示预选中),我们点击第一个选项“选择子元素”,那么刚刚预选的多个数据字段将被正式选中并标记为绿色,并且这些字段也将显示在提示界面的表格中。. 然后优采云提醒我们:找到了3组相似的元素,也就是自动找到了另外2部电影的数据,也是用红色虚线框预选的,我们选择了第一个选项“全选” ,然后选择所有电影数据。
操作录屏 - 步骤 2
在第二步中,我们接触到了几个新的东西:子元素、智能提示框、各种颜色的选择提示。如果您有兴趣,可以阅读下面的详细说明。当然也可以直接跳到第3步操作。
智能工具提示:
为了记录人的步数采集数据,优采云会在用户选择要操作的网页内容时,让用户选择要进行的操作。例如,如果用户选择了一个链接,他可以选择提取该链接。文字、URL 链接、或点击此链接等。优采云 的智能提示不仅可以让用户选择操作,还可以为用户预测最有可能进行的下一步操作。通过网页数据的智能分析,优采云会自动发现数据字段和相似数据项,从而指导用户操作。4是不是4很聪明,很贴心?
选择提示颜色:
蓝色表示鼠标当前位于哪个内容区域。
绿色表示我们点击选中的内容。
红色虚线表示系统智能识别并预测您要选择的内容。
子元素:
当我们选择一个收录多个数据字段的区域时,优采云指的是我们选择的区域为一个“元素(English Element,这是一个技术术语)”,每个数据字段称为一个“子”元素,一个元素可能收录多个“子元素”。
3. 我们已经选择了上一步中的所有数据。在决定 采集 这些字段之前,让我们先检查一下表格。您会发现标题本身也被提取为字段。其实我们只需要真正的Title,不需要标题,所以我们可以直接删除提示框表单中的“字段1”,其他几个冗余字段同理删除,然后修改我们想要的字段的字段名. 单击 采集 确认数据字段。
操作录屏 - 步骤 3
4.我们现在采集第一页的所有数据,一共3页,然后我们设置翻页,点击下面的“下一页”按钮,优采云会自动识别这是下一页链接,我们选择“循环点击下一页”选项,系统会翻页,采集每一页直到最后一页。点击开始采集,在弹出的窗口中选择“开始本地采集”,会打开一个窗口继续采集。
操作录屏-第四步
概括:
恭喜!您已成功采集电影的所有数据网站,并且以同样的方式您将能够采集任何收录列表、表格和页面的网站,你在采集的路上又取得了一个里程碑,未来我们会继续学习更多的技能,一步步成为采集的大神。
如果您有任何问题或想法想与我分享,请在下面的评论部分留言。也可以关注我的知乎与我互动:点击关注“刘宝强的知乎”。同时,欢迎关注我的知乎专栏,获取新的文章通知:点击关注“小白的数据梦工厂” 查看全部
网站程序自带的采集器采集文章(这是快速入门爬虫1-0基础采集入门知识学习)
欢迎来到小白的数据梦工厂,很高兴你对爬虫感兴趣,想学习爬虫,或者想采集来自网络的一些数据。
我先自我介绍一下。我是优采云采集器的创始人刘宝强。优采云是全球领先的网络数据采集平台,每天服务于全球70万家公司和个人采集数亿条数据。恭喜您从众多爬行入门方式中选择了优采云,这是一个很好的起点,您将从一开始就站在巨人的肩膀上!
阅读这篇文章大约需要 15 分钟。
这是爬虫快速入门的第二部分,第一个链接:爬虫快速入门1-0基础采集简介
本系列文章将带领你从0基础开始,一步一步,从采集一个简单的网页,到复杂的列表,多页数据,Ajax页面,瀑布流等等,直到应对常见封IP,验证码等防采集措施,包括采集淘宝,京东,微信,大众点评等热门网站。由浅入深,循序渐进的深入网页数据采集领域,相信认真学完本系列,你也会成为采集大神,有能力把互联网变成自己的数据库(这一段提到了Ajax等专业数据,你可能不懂,但有个好消息:到目前为止你不需要了解这些技术概念)。
学习本内容,需要具备以下知识:
我研究过第一篇:爬虫快速入门-0基础知识采集介绍,意思就是你了解了基础知识并成功安装了优采云采集器,这些在第一篇文章中都有详细解释。
截止本文发布时,八爪鱼采集器的最新版本是7.1.8,下载地址是:http://www.bazhuayu.com/download
通过学习本内容,您将掌握以下内容:
了解如何采集列出数据。了解如何翻页实现多页数据采集。
第一篇我们成功采集一条数据,你可能觉得采集一条数据没用,采集一条数据最快的方法就是手动复制它,可能有几十条数据它可以手动复制。在实际应用场景中,我们经常需要采集数百、数千甚至数百万的数据。所以第一篇的意义在于学习如何通过软件工具实现自动化采集。
在实际场景中,大部分网站数据可能是这样的(如下图):
一个网站有很多分类,每个分类都有很多数据,通常每个分类都是一个页面,里面有一个列表或者表格,还有一个翻页功能。以知名的京东商城为例。京东有很多产品品类(categories),每个品类(比如手机)都有一个手机数据列表(data list)。此列表页面收录 60 款手机的基本数据。每部手机(列表项)都有价格、标题、销量(字段)等多项具体信息,页面底部有翻页链接区,可以点击下一页查看基本第二页其他60部手机的数据。
常用网站数据结构图
上面提到的几个概念在我们采集数据的时候经常用到:分类、列表、数据项、数据字段、翻页;如果你看到一个网站,你可以在心里构建它当启动这个网站 数据结构时,采集 变得非常容易。
在这里,我为大家准备了一个例子网站:Demo网站-电影数据分类,网址:/guide/demo/genremoviespage1.html,大家可以对比一下上面常见的网站数据结构图看这个网站,是不是很像??
示例 网站 截图(带有 网站 数据结构标签)
如果我们不使用工具并手动复制完成数据采集,我们会这样做:
在浏览器中打开此 网站。复制第一部电影的数据: 标题 肖申克的救赎 类型 犯罪分数9.2 发行年份 1994 时间 142 分钟。粘贴到 Excel 中,另存为 5 列。重复上述步骤 2,直到复制第一页上 3 部电影的数据。在翻页区点击“下一页”链接,重复步骤2、3,然后再次点击“下一页”,以此类推,直到到达最后一页(最后一页没有“下一页”链接)。
那么如何使用 优采云 工具呢?还记得第一篇文章中提到的优采云采集 核心原则吗?
优采云采集的核心原理是:模拟人们浏览网页和复制数据的行为,通过记录和模拟人们的一系列上网行为,代替人眼浏览网页,手动复制网页数据代替人,从而将网页中的采集数据自动化,然后通过不断重复一系列设定的动作过程自动采集大量数据。
你可能已经想好了怎么做,别着急,让我们试着把我们的想法画成一个流程图,它应该是这样的:
让我解释一下这个流程图的具体步骤:
蓝色方块代表一些步骤,黑色圆角矩形线框代表我们要重复的一个或多个步骤。
打开这个网站的分类数据录入页面,就是刚才的示例URL。接下来是需要重复的步骤:循环点击下一页,黑色矩形线框内的部分需要重复。它收录另一个需要重复的步骤:循环播放每部电影。同样,让我们看看里面。有一个蓝色的步骤:提取每个字段的数据。这就是我们现在需要做的,让优采云工具自动提取每个字段。执行完最后一个蓝色步骤后,需要重复执行此蓝色步骤,直到自动提取出第一页三部电影的数据。至此,“循环每部电影”的步骤就完成了。然后我们执行下面的蓝色步骤:点击下一页,所以网页会跳转到第2页,
用优采云工具采集仔细对比手动复制数据的4个步骤和流程图,你会发现它们非常相似,可以说是完全一样的过程。这再次说明了优采云像机器人一样,模拟人类思维和上网、复制数据的过程。虽然每个网站都不一样,但好消息是:任何复杂的网站都可以用这个简单的思路来做,想想人家是怎么做的,然后在优采云中设置一个对应的工作流程可以实现任意网站的采集。这就是 优采云 能够不断变化地适应 采集any网站 的秘诀。
看到这里,也许你已经迫不及待想要实际操作它来验证我们的想法了。我们来看看如何实际操作它:
打开优采云采集器,点击“自定义采集”按钮→点击左上角“新建任务”按钮进入任务配置页面,然后输入网址(/ guide/demo/genremoviespage1.html) → 保存URL,系统会进入工艺设计页面并自动打开输入的URL。
操作录屏 - 第一步
2. 网页打开后,随着鼠标的移动,会出现蓝色背景来表示内容。优采云 内置了专门为采集 数据开发的浏览器。除了像其他浏览器一样显示网页外,还增加了很多功能来支持采集,其中之一就是当鼠标移到不同的内容上时,对应的内容会自动标记为蓝色背景。当鼠标点击时,该区域将被选中并标为绿色,并弹出操作提示框。这里优采云已经自动识别出选中区域收录多个数值字段(子元素),并用红色虚线框标记(表示预选中),我们点击第一个选项“选择子元素”,那么刚刚预选的多个数据字段将被正式选中并标记为绿色,并且这些字段也将显示在提示界面的表格中。. 然后优采云提醒我们:找到了3组相似的元素,也就是自动找到了另外2部电影的数据,也是用红色虚线框预选的,我们选择了第一个选项“全选” ,然后选择所有电影数据。
操作录屏 - 步骤 2
在第二步中,我们接触到了几个新的东西:子元素、智能提示框、各种颜色的选择提示。如果您有兴趣,可以阅读下面的详细说明。当然也可以直接跳到第3步操作。
智能工具提示:
为了记录人的步数采集数据,优采云会在用户选择要操作的网页内容时,让用户选择要进行的操作。例如,如果用户选择了一个链接,他可以选择提取该链接。文字、URL 链接、或点击此链接等。优采云 的智能提示不仅可以让用户选择操作,还可以为用户预测最有可能进行的下一步操作。通过网页数据的智能分析,优采云会自动发现数据字段和相似数据项,从而指导用户操作。4是不是4很聪明,很贴心?
选择提示颜色:
蓝色表示鼠标当前位于哪个内容区域。
绿色表示我们点击选中的内容。
红色虚线表示系统智能识别并预测您要选择的内容。
子元素:
当我们选择一个收录多个数据字段的区域时,优采云指的是我们选择的区域为一个“元素(English Element,这是一个技术术语)”,每个数据字段称为一个“子”元素,一个元素可能收录多个“子元素”。
3. 我们已经选择了上一步中的所有数据。在决定 采集 这些字段之前,让我们先检查一下表格。您会发现标题本身也被提取为字段。其实我们只需要真正的Title,不需要标题,所以我们可以直接删除提示框表单中的“字段1”,其他几个冗余字段同理删除,然后修改我们想要的字段的字段名. 单击 采集 确认数据字段。
操作录屏 - 步骤 3
4.我们现在采集第一页的所有数据,一共3页,然后我们设置翻页,点击下面的“下一页”按钮,优采云会自动识别这是下一页链接,我们选择“循环点击下一页”选项,系统会翻页,采集每一页直到最后一页。点击开始采集,在弹出的窗口中选择“开始本地采集”,会打开一个窗口继续采集。
操作录屏-第四步
概括:
恭喜!您已成功采集电影的所有数据网站,并且以同样的方式您将能够采集任何收录列表、表格和页面的网站,你在采集的路上又取得了一个里程碑,未来我们会继续学习更多的技能,一步步成为采集的大神。
如果您有任何问题或想法想与我分享,请在下面的评论部分留言。也可以关注我的知乎与我互动:点击关注“刘宝强的知乎”。同时,欢迎关注我的知乎专栏,获取新的文章通知:点击关注“小白的数据梦工厂”
网站程序自带的采集器采集文章(优采云采集程序负责根据工作流对网页数据采集(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-31 16:25
优采云采集原理
优采云网页数据采集客户端使用的开发语言为C#,运行于Windows系统。客户端主程序负责任务配置和管理、云采集任务控制、云集成数据管理(导出、清理、发布)。数据导出程序负责将数据导出为Excel、SQL、TXT、MYSQL等,支持一次导出百万级数据。本地采集程序负责按照工作流程打开、抓取、采集网页数据,通过正则表达式和Xpath原理快速获取网页数据。
整个采集过程是基于火狐内核浏览器,通过模拟人的思维方式(比如打开网页,点击网页中的按钮)自动提取网页内容。系统将流程操作完全可视化,无需专业知识,轻松实现数据采集。优采云通过准确定位网页源代码中每条数据的XPath路径,可以准确采集批量出用户需要的数据。
优采云实现的功能
优采云网页数据采集系统基于完全自主研发的分布式云计算平台,可在极短的时间内轻松获取各种网站或网页的大量数据. 规范化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率. 涉及政府、高校、企业、银行、电子商务、科研、汽车、房地产、媒体等众多行业和领域。
图 1:采集 示意图
优采云作为一般的网页数据采集器,并不针对某个网站某个行业进行采集数据,但是在网页上可以看到或者网页源码中几乎所有的文字信息都可以是采集,市面上98%的网页都可以是采集和优采云。
使用本地采集(单机采集),除了爬取大部分网页数据外,还可以对采集过程中的数据进行初步清洗。如果您使用程序自带的正则工具,请使用正则表达式来格式化数据。可以在数据源处实现去除空格、过滤日期等各种操作。其次,优采云还提供了分支判断功能,可以逻辑判断网页中的信息是否真实,从而实现用户的筛选需求。
Cloud采集不仅具备本地采集(单机采集)的所有功能,还可以实现定时采集、实时监控、自动去重和存储,增加数量采集,自动识别验证码,API接口多样化导出数据和修改参数。同时使用云端多个节点并发运行,采集速度会比本地采集(单机采集)快很多,多台自动切换任务启动时的IP也可以避免网站IP阻塞,实现采集对比数据。
图 2:时序云采集 查看全部
网站程序自带的采集器采集文章(优采云采集程序负责根据工作流对网页数据采集(组图))
优采云采集原理
优采云网页数据采集客户端使用的开发语言为C#,运行于Windows系统。客户端主程序负责任务配置和管理、云采集任务控制、云集成数据管理(导出、清理、发布)。数据导出程序负责将数据导出为Excel、SQL、TXT、MYSQL等,支持一次导出百万级数据。本地采集程序负责按照工作流程打开、抓取、采集网页数据,通过正则表达式和Xpath原理快速获取网页数据。
整个采集过程是基于火狐内核浏览器,通过模拟人的思维方式(比如打开网页,点击网页中的按钮)自动提取网页内容。系统将流程操作完全可视化,无需专业知识,轻松实现数据采集。优采云通过准确定位网页源代码中每条数据的XPath路径,可以准确采集批量出用户需要的数据。
优采云实现的功能
优采云网页数据采集系统基于完全自主研发的分布式云计算平台,可在极短的时间内轻松获取各种网站或网页的大量数据. 规范化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率. 涉及政府、高校、企业、银行、电子商务、科研、汽车、房地产、媒体等众多行业和领域。
图 1:采集 示意图
优采云作为一般的网页数据采集器,并不针对某个网站某个行业进行采集数据,但是在网页上可以看到或者网页源码中几乎所有的文字信息都可以是采集,市面上98%的网页都可以是采集和优采云。
使用本地采集(单机采集),除了爬取大部分网页数据外,还可以对采集过程中的数据进行初步清洗。如果您使用程序自带的正则工具,请使用正则表达式来格式化数据。可以在数据源处实现去除空格、过滤日期等各种操作。其次,优采云还提供了分支判断功能,可以逻辑判断网页中的信息是否真实,从而实现用户的筛选需求。
Cloud采集不仅具备本地采集(单机采集)的所有功能,还可以实现定时采集、实时监控、自动去重和存储,增加数量采集,自动识别验证码,API接口多样化导出数据和修改参数。同时使用云端多个节点并发运行,采集速度会比本地采集(单机采集)快很多,多台自动切换任务启动时的IP也可以避免网站IP阻塞,实现采集对比数据。
图 2:时序云采集
网站程序自带的采集器采集文章(一下来说胡乱采集新闻源软件的程序说明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-30 04:13
如果非要评论的话,应该算是随机的采集新闻源软件。现在有这么多采集器,我为什么要使用这个傻瓜式采集程序呢? .
但不能说这个软件没用。毕竟在使用站群堆放垃圾文章的时候,这个程序确实可以用,毕竟简单~
节目说明
第一百万新闻源文本采集软件
1、内置独家新闻挖掘接口数据
采集市面上有很多软件,采集软件可以很容易写,但技术点不是如何写程序逻辑,而是如何找到高质量的采集@ >消息源,骷髅采集夏能嗅探采集到国内消息源文章2005年到2019年,从文章的数据量来看,是远远满意的站群对文章的需求,对文章有严格要求的用户,对文章、骨架采集xia采集 是独一无二的,永不重复。 100万条头条数据足够你操作所有大数据站群,无论你是做内页站群,目录站群,搜狗新闻热词站群,这个软件可以满足您的要求。
软件深度批量采集后,会智能挂机,嗅探网上发布的最新新闻头条和热点头条,1秒内即可采集上你的服务器。保证资源的最大及时性。
软件支持自动挂机、循环嗅探、采集深度设置、简体中文自动转换为繁体。
如何使用软件
骷髅采集人分为两个软件,title采集和text采集,操作和使用完全一样,
1、设置参数
骷髅采集参数设置很简单,设置保存路径即可,采集生成的txt会自动保存在该路径下。
2、首字母采集
设置深度为21000,可以采集约100万条新闻,当你觉得采集的文章量满足你的需求时,关闭软件。初始的 采集 可以为您提供 采集 到基本的 文章txt 容量。比如你建一个蜘蛛池,5000个txt就够了,没必要深采集太多的txt
3、循环挂机
初始采集结束后,重启软件,设置采集深度为5,此时软件会自动扫描互联网新闻源发布的最新消息,执行采集.
下载链接
下载仅供技术交流学习讨论,请勿用于非法用途!请在下载后24小时内删除! 查看全部
网站程序自带的采集器采集文章(一下来说胡乱采集新闻源软件的程序说明)
如果非要评论的话,应该算是随机的采集新闻源软件。现在有这么多采集器,我为什么要使用这个傻瓜式采集程序呢? .
但不能说这个软件没用。毕竟在使用站群堆放垃圾文章的时候,这个程序确实可以用,毕竟简单~
节目说明
第一百万新闻源文本采集软件
1、内置独家新闻挖掘接口数据
采集市面上有很多软件,采集软件可以很容易写,但技术点不是如何写程序逻辑,而是如何找到高质量的采集@ >消息源,骷髅采集夏能嗅探采集到国内消息源文章2005年到2019年,从文章的数据量来看,是远远满意的站群对文章的需求,对文章有严格要求的用户,对文章、骨架采集xia采集 是独一无二的,永不重复。 100万条头条数据足够你操作所有大数据站群,无论你是做内页站群,目录站群,搜狗新闻热词站群,这个软件可以满足您的要求。
软件深度批量采集后,会智能挂机,嗅探网上发布的最新新闻头条和热点头条,1秒内即可采集上你的服务器。保证资源的最大及时性。
软件支持自动挂机、循环嗅探、采集深度设置、简体中文自动转换为繁体。
如何使用软件
骷髅采集人分为两个软件,title采集和text采集,操作和使用完全一样,
1、设置参数
骷髅采集参数设置很简单,设置保存路径即可,采集生成的txt会自动保存在该路径下。
2、首字母采集
设置深度为21000,可以采集约100万条新闻,当你觉得采集的文章量满足你的需求时,关闭软件。初始的 采集 可以为您提供 采集 到基本的 文章txt 容量。比如你建一个蜘蛛池,5000个txt就够了,没必要深采集太多的txt
3、循环挂机
初始采集结束后,重启软件,设置采集深度为5,此时软件会自动扫描互联网新闻源发布的最新消息,执行采集.
下载链接
下载仅供技术交流学习讨论,请勿用于非法用途!请在下载后24小时内删除!
网站程序自带的采集器采集文章(帝国cms具有如下的几个核心优点以及帝国CMS的采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2022-01-27 10:03
)
Empire 是一个免费的开源程序。相对来说,Empirecms的使用就没有那么直观方便了,上手也不容易(比如模板)。但世上没有烦恼。只要肯努力,铁杵可以磨成针!如果你玩过cms,基本上是一样的。我想对于有一定基础的人来说,熟悉Empirecms需要一周的时间。今天给大家讲讲Empirecms和Empirecms的采集的优势。
一、Empirescms 有几个核心优势。
1、最重要的事情说三遍,安全、安全、安全。在使用Empirecms的两年时间里,没有任何特殊的安全设置,运行中的网站没有受到木马的危害。
二、快速生成html。尤其是数据量大后更新html后,你会发现帝国cms速度非常快,而其他cms静态页面生成速度极慢。
3、便于二次开发的功能扩展。如果懂后端程序开发(主要是php),可以基于empirecms开发更多自定义的网站,比如网站有旅游路线和预订。
四、 Empirecms 是开源的。因为它是开源的,所以您可以放心使用它。
二、Empirecms静态化比较好
为了节省成本,服务器的配置相对较低。要想获得更好的访问效果,静态化更为关键。静态化一方面减少了服务器的消耗,另一方面对搜索引擎比较友好,同时可以支持大量的数据。
三、帝国cms自带采集:
1、打开帝国后台,点击上方栏目,左侧栏目管理中多了一个采集节点,进入。
2、中间的提示是选择你要创建的版块,然后点击你要创建的版块,比如国际新闻。好了,点进去。出现的界面有第一个节点的名字,因为上面创建了国际新闻,这里填写的是国际新闻的父节点(留空就好)。
3、在中间的提示中,选择要创建的栏目,点击你要创建的栏目,比如国际新闻。嗯,点进去。出现的界面有第一个节点的名字,因为上面创建了国际新闻,填国际新闻父节点就行了,不用管(就是留空)
4、页面采集的地址,你可以去新浪的国际新闻复制,比如国际新闻页面的地址,在地址栏复制就可以了。
5、采集页面地址方式2无需填写内容,页面地址前缀写为
6、图片/FLASH地址前缀(内容)~~~截取内容介绍,不介意从这里开始填写采集这个时候是正规内容,需要看源码网页注意-信息页面的常规链接
7、标题图片正则无标题正则:打开内容页,打开你刚才的大栏目中的文章
8、采集内容页面列表-采集内容页面页面-查看采集的信息并入库,点击库中所有信息的按钮-去到所有的采集信息都已经完成了。
四、第三方帝国采集软件兼容优势:
1、支持任何 PHP 版本
2、支持任意版本的Mysql
3、支持任何版本的 Nginx
4、支持任何 Empirecms 版本
采集 将因版本不匹配或服务器环境不支持等其他原因不可用
五、第三方帝国采集软件更易用
门槛低:无需花大量时间学习软件操作,一分钟即可上手,无需配置采集规则,输入关键词到采集即可,
高效:提供一站式网站文章解决方案,无需人工干预,设置任务自动执行采集releases。
零成本:几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
帝国的第三方采集软件很强大,只要输入关键词采集,完全可以通过软件自动采集发布文章采集@>,为了让搜索引擎收录你的网站,我们还可以设置自动下载图片和替换链接。图片存储方式支持:阿里云OSS、七牛对象存储、腾讯云、杂牌云。同时还配备了自动内链,在内容或标题前后插入一定的内容,形成“伪原创”。软件还有监控功能,可以直接通过软件查看文章采集的发布状态。看完这篇文章,如果你觉得不错,不妨采集起来或发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
查看全部
网站程序自带的采集器采集文章(帝国cms具有如下的几个核心优点以及帝国CMS的采集
)
Empire 是一个免费的开源程序。相对来说,Empirecms的使用就没有那么直观方便了,上手也不容易(比如模板)。但世上没有烦恼。只要肯努力,铁杵可以磨成针!如果你玩过cms,基本上是一样的。我想对于有一定基础的人来说,熟悉Empirecms需要一周的时间。今天给大家讲讲Empirecms和Empirecms的采集的优势。
一、Empirescms 有几个核心优势。
1、最重要的事情说三遍,安全、安全、安全。在使用Empirecms的两年时间里,没有任何特殊的安全设置,运行中的网站没有受到木马的危害。
二、快速生成html。尤其是数据量大后更新html后,你会发现帝国cms速度非常快,而其他cms静态页面生成速度极慢。
3、便于二次开发的功能扩展。如果懂后端程序开发(主要是php),可以基于empirecms开发更多自定义的网站,比如网站有旅游路线和预订。
四、 Empirecms 是开源的。因为它是开源的,所以您可以放心使用它。
二、Empirecms静态化比较好
为了节省成本,服务器的配置相对较低。要想获得更好的访问效果,静态化更为关键。静态化一方面减少了服务器的消耗,另一方面对搜索引擎比较友好,同时可以支持大量的数据。
三、帝国cms自带采集:
1、打开帝国后台,点击上方栏目,左侧栏目管理中多了一个采集节点,进入。
2、中间的提示是选择你要创建的版块,然后点击你要创建的版块,比如国际新闻。好了,点进去。出现的界面有第一个节点的名字,因为上面创建了国际新闻,这里填写的是国际新闻的父节点(留空就好)。
3、在中间的提示中,选择要创建的栏目,点击你要创建的栏目,比如国际新闻。嗯,点进去。出现的界面有第一个节点的名字,因为上面创建了国际新闻,填国际新闻父节点就行了,不用管(就是留空)
4、页面采集的地址,你可以去新浪的国际新闻复制,比如国际新闻页面的地址,在地址栏复制就可以了。
5、采集页面地址方式2无需填写内容,页面地址前缀写为
6、图片/FLASH地址前缀(内容)~~~截取内容介绍,不介意从这里开始填写采集这个时候是正规内容,需要看源码网页注意-信息页面的常规链接
7、标题图片正则无标题正则:打开内容页,打开你刚才的大栏目中的文章
8、采集内容页面列表-采集内容页面页面-查看采集的信息并入库,点击库中所有信息的按钮-去到所有的采集信息都已经完成了。
四、第三方帝国采集软件兼容优势:
1、支持任何 PHP 版本
2、支持任意版本的Mysql
3、支持任何版本的 Nginx
4、支持任何 Empirecms 版本
采集 将因版本不匹配或服务器环境不支持等其他原因不可用
五、第三方帝国采集软件更易用
门槛低:无需花大量时间学习软件操作,一分钟即可上手,无需配置采集规则,输入关键词到采集即可,
高效:提供一站式网站文章解决方案,无需人工干预,设置任务自动执行采集releases。
零成本:几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
帝国的第三方采集软件很强大,只要输入关键词采集,完全可以通过软件自动采集发布文章采集@>,为了让搜索引擎收录你的网站,我们还可以设置自动下载图片和替换链接。图片存储方式支持:阿里云OSS、七牛对象存储、腾讯云、杂牌云。同时还配备了自动内链,在内容或标题前后插入一定的内容,形成“伪原创”。软件还有监控功能,可以直接通过软件查看文章采集的发布状态。看完这篇文章,如果你觉得不错,不妨采集起来或发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
网站程序自带的采集器采集文章(打造一个个人小说站源码上传的商家推荐:网站服务器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-27 04:09
这个文章收录了建立个人小说站的所有详细流程,避免了目前大部分的弯路,无需精通编程,小白也能用。如果你有兴趣搭建个人小说站,可以参考这篇教程完整,因为这里收录了所有相关的源码、规则、程序,你不需要去其他地方找. 另外,这些博主的源代码也被采集,不保证绝对安全,但保证正常使用。,请注意筛选。
注意红色编码部分是你要填写参数的部分
准备好工作了:
网站 大硬盘linux系统服务器(推荐debian8)
N个系统为win的采集服务器(可以是一个)
网站 的域名
服务器选择的一些建议:
因为需要使用多台服务器,所以最实惠的解决方案可能是选择国外服务器。网站最好选择西部的服务器。一方面是因为价格。将它们作为采集 的对象可以保证更快的速度。至于推荐的商家,我后面会补上,因为大硬盘VPS容易断货。
至于采集服务器,我个人推荐使用Vutlr,因为通过邀请注册可以额外获得$25的奖励,可用于开启多台机器同时执行采集,既保证速度又减少高架。,一般情况下,4台机器可以远程采集5条可用规则,一天可以采集1500-3000本书,内容大小在12-20G左右。
还有一点很重要,采集服务器必须靠近网站服务器,ping值最好小于2ms。
部分商家推荐:
网站服务器设置:
1.Linux服务器安装Lamp运行环境
这里需要注意的是php选择5.2,apache选择2.4,其他可以默认推荐。
2.在Liunx服务器上添加PC和手机域名,解析域名
分两步添加,先PC域名,记得建个数据库,再添加手机域名,一般格式为
然后在域名提供者上设置域名解析
3.网站将源码上传到服务器并配置目录的权限
使用Winscp将PC和WAP源代码和压缩包上传到对应的根目录并解压,然后修改目录权限
注意:将PC.zip解压到你的域名.com目录,WAP.zip解压到m.你的域名.com
相关命令示例:
解压解压PC.zip
修改权限 chmod -R 777 /home/wwwroot
修改所有者 chown -R www /home/wwwroot
4.配置站目录下的key文件
然后根据源码中的说明配置网站的配置文件。下面是需要修改配置文件的地方。它已用红色代码标记。@>留言
PC网站 目录下的 /configs/define.php:
WAP目录下(若乱码请改码):
5.进入网站后台输入相关配置
解析生效后,直接输入你的url访问网站,这里我们直接在url后面输入/admin,然后进入后台(用户名admin,密码admin2017).
只要修改的内容是之前设置的一些参数,以及网站相关的信息,这里用截图做个简单的识别:
然后执行命令清除自带的小说数据:
截断表
1`
jieqi_article_article
1`
;
截断表
1`
jieqi_article_chapter
1`
;
6.安装Samba并完成配置
执行命令安装 Samba:
apt-get install samba samba-common-bin
然后使用WinScp,找到目录/etc/samba/smb.conf,编辑这个配置文件并保存:
共享定义下的部分
[杰奇]
comment = jieqi (尽量用这个名字,方便以后参考教程)
path = /home/wwwroot/(这里填写你要分享的目录,分享整个PC网站目录)
有效用户 = 根
公开=不
可写=是
可打印=否
dos 字符集 = GB2312
unix 字符集 = GB2312
目录掩码 = 0777
强制目录模式 = 0777
目录安全掩码 = 0777
强制目录安全模式 = 0777
创建掩码 = 0777
强制创建模式 = 0777
安全面具 = 0777
强制安全模式 = 0777
然后重启 Samba 服务:
/etc/init.d/samba 重启
然后添加 Samba 用户:
smbpasswd -a 根
然后根据提示输入密码。
7.打开IPtable相关端口
先检查港口情况。如果 3306 端口被 DROP 丢弃,则需要释放该端口,并将序列号替换为要删除的序列号。
先检查端口规则
iptables -L -n --line-numbers
例如,要删除INPUT中序号为6的DROP规则(如果有DROP规则,如果没有则跳过),执行:
iptables -D 输入 6
然后添加以下规则:
iptables -A INPUT -p tcp --dport 3306 -j ACCEPT
iptables -A INPUT -p tcp --dport 139 -j ACCEPT
iptables -A INPUT -p tcp --dport 445 -j ACCEPT
iptables -A 输入 -p udp --dport 137 -j 接受
iptables -A 输入 -p udp --dport 138 -j 接受
8.赋予 MySQL root 用户远程权限
首先登录mysql账号(会提示输入root用户密码):
mysql -u 根目录 -p
然后为root用户启用远程权限(将密码替换为root用户的密码):
使用mysql;
GRANTALLON*.*TOroot@'%'IDENTIFIEDBY'password'WITHGRANTOPTION;
刷新特权;
然后Ctrl+C退出
9.优化一些MySQL设置
使用Winscp,找到/etc/f,参考下图修改:
然后重启lnmp服务:
lnmp 重启
10.开启Apache跨目录权限
使用Winscp,找到/usr/local/apache/conf/vhost目录,将与域名相关的两个文件中的代码行注释掉(前面加#):
php_admin_value open_basedir "/home/wwwroot/:/tmp/:/var/tmp/:/proc/"
然后重启lnmp服务:
lnmp 重启
采集服务器设置:
1.在服务器上安装win系统并远程连接
如果没有,可以参考这个文章
2.上传网关采集器和加速工具到服务器
直接复制,然后粘贴到服务器上,然后解压,然后运行ServerSpeeder文件下的serverSpeeder.bat,优化网络稳定性
3.连接samba服务器并映射到硬盘
打开开始-所有程序-附件-在服务器上运行,输入地址回车
\网站服务器IP
这里会弹出一个登录窗口,填写你之前设置的Samba用户名(root)和密码
然后可以看到一个名为jieqi的文件夹,确认这个文件夹可以正常打开,然后右键将jieqi文件夹映射到网络盘为E盘。
注意:如果一直连接不上,可能是服务商只使用了Samba端口的使用权,下发工单即可开通
4.配置系统的系统设置
然后打开GuanGuan5.6文件夹下的NovelSpider.exe,打开设置-系统设置,修改指定部分:
Data Source是你的网站服务器IP,Database是网站数据库名,User ID是root,Password是对应用户的密码
修改后一定要确认关键点,然后彻底关闭采集程序,然后再次打开程序,打开采集--standard采集,选择采集@ > 规则和采集 方式,然后启动采集:
这是正常的 采集 界面
您可以选择同时打开多个 采集windows采集,但同一个 采集server 对于同一规则不应有超过两个 采集windows。
建议根据目标站序号使用采集,这样可以更好的为每个服务器划定采集的范围,比如服务器A采集0-2000,服务器B< @采集2001 -4000 等等,报错时也很容易验证。
其他采集服务器也可以按照上述配置。
开始 采集:
在我提供的 采集器 中,附有五个规则。虽然都可以用,但是质量有好有坏。个人使用后,笔趣阁、新笔趣阁和八一中文是最快最好的。稳定,但八一中文广告多,新笔趣格源站不稳定,容易出现采集空章。具体情况请自行体验。
问题总结:
这里总结一下我在过程中遇到的一些问题,供参考 查看全部
网站程序自带的采集器采集文章(打造一个个人小说站源码上传的商家推荐:网站服务器)
这个文章收录了建立个人小说站的所有详细流程,避免了目前大部分的弯路,无需精通编程,小白也能用。如果你有兴趣搭建个人小说站,可以参考这篇教程完整,因为这里收录了所有相关的源码、规则、程序,你不需要去其他地方找. 另外,这些博主的源代码也被采集,不保证绝对安全,但保证正常使用。,请注意筛选。
注意红色编码部分是你要填写参数的部分
准备好工作了:
网站 大硬盘linux系统服务器(推荐debian8)
N个系统为win的采集服务器(可以是一个)
网站 的域名
服务器选择的一些建议:
因为需要使用多台服务器,所以最实惠的解决方案可能是选择国外服务器。网站最好选择西部的服务器。一方面是因为价格。将它们作为采集 的对象可以保证更快的速度。至于推荐的商家,我后面会补上,因为大硬盘VPS容易断货。
至于采集服务器,我个人推荐使用Vutlr,因为通过邀请注册可以额外获得$25的奖励,可用于开启多台机器同时执行采集,既保证速度又减少高架。,一般情况下,4台机器可以远程采集5条可用规则,一天可以采集1500-3000本书,内容大小在12-20G左右。
还有一点很重要,采集服务器必须靠近网站服务器,ping值最好小于2ms。
部分商家推荐:
网站服务器设置:
1.Linux服务器安装Lamp运行环境
这里需要注意的是php选择5.2,apache选择2.4,其他可以默认推荐。
2.在Liunx服务器上添加PC和手机域名,解析域名
分两步添加,先PC域名,记得建个数据库,再添加手机域名,一般格式为
然后在域名提供者上设置域名解析
3.网站将源码上传到服务器并配置目录的权限
使用Winscp将PC和WAP源代码和压缩包上传到对应的根目录并解压,然后修改目录权限
注意:将PC.zip解压到你的域名.com目录,WAP.zip解压到m.你的域名.com
相关命令示例:
解压解压PC.zip
修改权限 chmod -R 777 /home/wwwroot
修改所有者 chown -R www /home/wwwroot
4.配置站目录下的key文件
然后根据源码中的说明配置网站的配置文件。下面是需要修改配置文件的地方。它已用红色代码标记。@>留言
PC网站 目录下的 /configs/define.php:
WAP目录下(若乱码请改码):
5.进入网站后台输入相关配置
解析生效后,直接输入你的url访问网站,这里我们直接在url后面输入/admin,然后进入后台(用户名admin,密码admin2017).
只要修改的内容是之前设置的一些参数,以及网站相关的信息,这里用截图做个简单的识别:
然后执行命令清除自带的小说数据:
截断表
1`
jieqi_article_article
1`
;
截断表
1`
jieqi_article_chapter
1`
;
6.安装Samba并完成配置
执行命令安装 Samba:
apt-get install samba samba-common-bin
然后使用WinScp,找到目录/etc/samba/smb.conf,编辑这个配置文件并保存:
共享定义下的部分
[杰奇]
comment = jieqi (尽量用这个名字,方便以后参考教程)
path = /home/wwwroot/(这里填写你要分享的目录,分享整个PC网站目录)
有效用户 = 根
公开=不
可写=是
可打印=否
dos 字符集 = GB2312
unix 字符集 = GB2312
目录掩码 = 0777
强制目录模式 = 0777
目录安全掩码 = 0777
强制目录安全模式 = 0777
创建掩码 = 0777
强制创建模式 = 0777
安全面具 = 0777
强制安全模式 = 0777
然后重启 Samba 服务:
/etc/init.d/samba 重启
然后添加 Samba 用户:
smbpasswd -a 根
然后根据提示输入密码。
7.打开IPtable相关端口
先检查港口情况。如果 3306 端口被 DROP 丢弃,则需要释放该端口,并将序列号替换为要删除的序列号。
先检查端口规则
iptables -L -n --line-numbers
例如,要删除INPUT中序号为6的DROP规则(如果有DROP规则,如果没有则跳过),执行:
iptables -D 输入 6
然后添加以下规则:
iptables -A INPUT -p tcp --dport 3306 -j ACCEPT
iptables -A INPUT -p tcp --dport 139 -j ACCEPT
iptables -A INPUT -p tcp --dport 445 -j ACCEPT
iptables -A 输入 -p udp --dport 137 -j 接受
iptables -A 输入 -p udp --dport 138 -j 接受
8.赋予 MySQL root 用户远程权限
首先登录mysql账号(会提示输入root用户密码):
mysql -u 根目录 -p
然后为root用户启用远程权限(将密码替换为root用户的密码):
使用mysql;
GRANTALLON*.*TOroot@'%'IDENTIFIEDBY'password'WITHGRANTOPTION;
刷新特权;
然后Ctrl+C退出
9.优化一些MySQL设置
使用Winscp,找到/etc/f,参考下图修改:
然后重启lnmp服务:
lnmp 重启
10.开启Apache跨目录权限
使用Winscp,找到/usr/local/apache/conf/vhost目录,将与域名相关的两个文件中的代码行注释掉(前面加#):
php_admin_value open_basedir "/home/wwwroot/:/tmp/:/var/tmp/:/proc/"
然后重启lnmp服务:
lnmp 重启
采集服务器设置:
1.在服务器上安装win系统并远程连接
如果没有,可以参考这个文章
2.上传网关采集器和加速工具到服务器
直接复制,然后粘贴到服务器上,然后解压,然后运行ServerSpeeder文件下的serverSpeeder.bat,优化网络稳定性
3.连接samba服务器并映射到硬盘
打开开始-所有程序-附件-在服务器上运行,输入地址回车
\网站服务器IP
这里会弹出一个登录窗口,填写你之前设置的Samba用户名(root)和密码
然后可以看到一个名为jieqi的文件夹,确认这个文件夹可以正常打开,然后右键将jieqi文件夹映射到网络盘为E盘。
注意:如果一直连接不上,可能是服务商只使用了Samba端口的使用权,下发工单即可开通
4.配置系统的系统设置
然后打开GuanGuan5.6文件夹下的NovelSpider.exe,打开设置-系统设置,修改指定部分:
Data Source是你的网站服务器IP,Database是网站数据库名,User ID是root,Password是对应用户的密码
修改后一定要确认关键点,然后彻底关闭采集程序,然后再次打开程序,打开采集--standard采集,选择采集@ > 规则和采集 方式,然后启动采集:
这是正常的 采集 界面
您可以选择同时打开多个 采集windows采集,但同一个 采集server 对于同一规则不应有超过两个 采集windows。
建议根据目标站序号使用采集,这样可以更好的为每个服务器划定采集的范围,比如服务器A采集0-2000,服务器B< @采集2001 -4000 等等,报错时也很容易验证。
其他采集服务器也可以按照上述配置。
开始 采集:
在我提供的 采集器 中,附有五个规则。虽然都可以用,但是质量有好有坏。个人使用后,笔趣阁、新笔趣阁和八一中文是最快最好的。稳定,但八一中文广告多,新笔趣格源站不稳定,容易出现采集空章。具体情况请自行体验。
问题总结:
这里总结一下我在过程中遇到的一些问题,供参考
网站程序自带的采集器采集文章(使用教程WordPress采集站安装说明及常见问题处理(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-01-26 06:00
曹操从某宝买的wordpress自动采集图片的网站源码。
我搭建了一下,效果还不错。不幸的是,原创 采集 图片只有 8 条规则。目前经过测试,发现只有一个还是有用的。
不过你可以写他的采集插件,还是有用的。目前在线购买采集插件需要30元,并且已经自带了这个源码。
维护一个网站还可以,但是如果你想用这个程序来诱导百度渲染蜘蛛,恐怕就有点短了。审查元素后发现,站点图片仍然是外部图片调用。
程序前台
节目前台就是这样,一张采集美少女网站的照片,你可以建一个看看美女。
对于响应式模板,程序源代码中已经有一定的数据量。很遗憾,部分数据已经从采集的原站点采集,因此建议您将其全部删除。
节目背景
好像用的是robin模板,这是程序的后台AutoPost是自动的采集插件。
美中不足的是这个 采集 插件中的 采集 规则。目前只能使用其中两种,其他无效。
我真的不喜欢WP。采集 插件通常可以正常工作。看来他们必须用css拦截。研究了一会,也不是很明白。曹操还是喜欢截取html的内容作为采集的方法。
使用教程
WordPress采集 站安装说明和常见问题解答
一、安装说明
1、上传www目录下的文件;
2、导入.sql数据库文件(导入错误请咨询客服);
3、打开数据库的mq_options表,把siteurl和home对应的URL改成自己的;
4、修改wp-config.php文件中的数据库信息(注意:更改汉字内容);
5、Linux主机需要将所有文件设置为755权限(win主机忽略此步骤);
6、设置伪静态规则,可以参考伪静态规则文件夹;
7、输入你的域名后台/wp-login.php 用户名:admin 密码:(第一次请耐心等待2-10分钟)。
二、备注
1、第一次慢跑正常,内容很多采集,加载缩略图,生成缓存等(如果出现504错误,设置php超时时间为999,耐心等待2- 10分钟);
2、请及时修改登录密码,后台修改-->用户-->我的个人资料。
三、常见问题
1、如果源码使用7.1报错,请使用5.6,不要使用php5.2;
2、如果网站已经加载,无法访问网站,打开数据库_options表找到cron,修改红色箭头的位置。修改内容如下:
a:6:{i:1558859144;a:1:{s:34:"wp_privacy_delete_old_export_files";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:6:"hourly";s:4:"args";a:0:{}s:8:"interval";i:3600;}}}i:1558898744;a:3:{s:16:"wp_version_check";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:10:"twicedaily";s:4:"args";a:0:{}s:8:"interval";i:43200;}}s:17:"wp_update_plugins";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:10:"twicedaily";s:4:"args";a:0:{}s:8:"interval";i:43200;}}s:16:"wp_update_themes";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:10:"twicedaily";s:4:"args";a:0:{}s:8:"interval";i:43200;}}}i:1558934736;a:1:{s:23:"rocket_purge_time_event";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:12:"rocket_purge";s:4:"args";a:0:{}s:8:"interval";i:79200;}}}s:5:"times";i:2;s:20:"wp_maybe_next_update";i:1558855536;s:7:"version";i:2;}
3、缩略图无法显示,因为wp-content目录没有写权限,部分主机没有GD库(GD库是php处理图形的扩展库);
4、如有其他问题,请联系客服。
四、加速网站
1、优先使用php7.1,如果网站正常请使用php5.6、php5.5等;
2、php开启opcache扩展可以加快网站的速度;
3、推荐使用linux服务器,采集效率会大大提高;
4、建议将服务器超时设置为999秒,以提高采集的效率。
风险提示
请注意:原程序中的一些采集规则已经没有用了,需要自己重写。
下载链接
下载仅供技术交流学习讨论,请勿用于非法用途!请在下载后24小时内删除!
该费用仅用于赞助和支持编辑维护与本站运营相关的费用(服务器租用、CDN保护、人工客服等)!
付费内容
价格:20分
7天赞助用户免费下载查看福利
您可以登录或注册购买,也可以不登录购买:
目录导航
程序前台
节目背景
使用教程
风险提示
下载链接
标签:自动采集程序,采集站源码,网站源码, 查看全部
网站程序自带的采集器采集文章(使用教程WordPress采集站安装说明及常见问题处理(组图))
曹操从某宝买的wordpress自动采集图片的网站源码。
我搭建了一下,效果还不错。不幸的是,原创 采集 图片只有 8 条规则。目前经过测试,发现只有一个还是有用的。
不过你可以写他的采集插件,还是有用的。目前在线购买采集插件需要30元,并且已经自带了这个源码。
维护一个网站还可以,但是如果你想用这个程序来诱导百度渲染蜘蛛,恐怕就有点短了。审查元素后发现,站点图片仍然是外部图片调用。
程序前台
节目前台就是这样,一张采集美少女网站的照片,你可以建一个看看美女。
对于响应式模板,程序源代码中已经有一定的数据量。很遗憾,部分数据已经从采集的原站点采集,因此建议您将其全部删除。
节目背景
好像用的是robin模板,这是程序的后台AutoPost是自动的采集插件。
美中不足的是这个 采集 插件中的 采集 规则。目前只能使用其中两种,其他无效。
我真的不喜欢WP。采集 插件通常可以正常工作。看来他们必须用css拦截。研究了一会,也不是很明白。曹操还是喜欢截取html的内容作为采集的方法。
使用教程
WordPress采集 站安装说明和常见问题解答
一、安装说明
1、上传www目录下的文件;
2、导入.sql数据库文件(导入错误请咨询客服);
3、打开数据库的mq_options表,把siteurl和home对应的URL改成自己的;
4、修改wp-config.php文件中的数据库信息(注意:更改汉字内容);
5、Linux主机需要将所有文件设置为755权限(win主机忽略此步骤);
6、设置伪静态规则,可以参考伪静态规则文件夹;
7、输入你的域名后台/wp-login.php 用户名:admin 密码:(第一次请耐心等待2-10分钟)。
二、备注
1、第一次慢跑正常,内容很多采集,加载缩略图,生成缓存等(如果出现504错误,设置php超时时间为999,耐心等待2- 10分钟);
2、请及时修改登录密码,后台修改-->用户-->我的个人资料。
三、常见问题
1、如果源码使用7.1报错,请使用5.6,不要使用php5.2;
2、如果网站已经加载,无法访问网站,打开数据库_options表找到cron,修改红色箭头的位置。修改内容如下:
a:6:{i:1558859144;a:1:{s:34:"wp_privacy_delete_old_export_files";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:6:"hourly";s:4:"args";a:0:{}s:8:"interval";i:3600;}}}i:1558898744;a:3:{s:16:"wp_version_check";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:10:"twicedaily";s:4:"args";a:0:{}s:8:"interval";i:43200;}}s:17:"wp_update_plugins";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:10:"twicedaily";s:4:"args";a:0:{}s:8:"interval";i:43200;}}s:16:"wp_update_themes";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:10:"twicedaily";s:4:"args";a:0:{}s:8:"interval";i:43200;}}}i:1558934736;a:1:{s:23:"rocket_purge_time_event";a:1:{s:32:"40cd750bba9870f18aada2478b24840a";a:3:{s:8:"schedule";s:12:"rocket_purge";s:4:"args";a:0:{}s:8:"interval";i:79200;}}}s:5:"times";i:2;s:20:"wp_maybe_next_update";i:1558855536;s:7:"version";i:2;}
3、缩略图无法显示,因为wp-content目录没有写权限,部分主机没有GD库(GD库是php处理图形的扩展库);
4、如有其他问题,请联系客服。
四、加速网站
1、优先使用php7.1,如果网站正常请使用php5.6、php5.5等;
2、php开启opcache扩展可以加快网站的速度;
3、推荐使用linux服务器,采集效率会大大提高;
4、建议将服务器超时设置为999秒,以提高采集的效率。
风险提示
请注意:原程序中的一些采集规则已经没有用了,需要自己重写。
下载链接
下载仅供技术交流学习讨论,请勿用于非法用途!请在下载后24小时内删除!
该费用仅用于赞助和支持编辑维护与本站运营相关的费用(服务器租用、CDN保护、人工客服等)!
付费内容
价格:20分
7天赞助用户免费下载查看福利
您可以登录或注册购买,也可以不登录购买:
目录导航
程序前台
节目背景
使用教程
风险提示
下载链接
标签:自动采集程序,采集站源码,网站源码,
网站程序自带的采集器采集文章(最新的环境安装包集成批量开启功能一群护士在护士站交班_站群每个都要设计吗)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-26 05:20
站群自动采集源码_护士站一组护士交班
对于365用户,它兼容php7和php5程序。对于365站群用户,当网站的内容越来越多时,在网站的日常操作过程中,经过一些增删改查操作,网站会累积more and more 越来越多的断链(死链接),尤其是站群网站,几十到几百个网站收录大量的网站链接,如何改正处理无效链接(死链接)对站群网站、站群自动采集源码的优化、支持至关重要。 ,3、服务器运行环境ZZphpserver升级。 1、升级环境安装包兼容php7和php5程序。升级环境安装包自带2个版本,站群自动采集源码,支持域名批量启用https。最新环境安装包集成批量https打开功能
一群护士在护士站交班_站群每个人都需要设计吗?
今天我们来说说站群的内容从何而来,一起来看看吧。 原创writing 和 parody 等来源被排除在外,但作者没有。 ,一群护士正在护士站交班,剩下的人是采集伪原创,在扫描报纸和书籍的内容。不可否认,护士站有一群护士在工作。即使在今天,仍然有很多站长选择采集和伪原创的方式来操作站群,使用这种方式获取排名的案例也很多。 ,英雄联盟十周年展示游戏:uzi拿出签名vn超级逆风获得五杀! APP开放给你推荐:夏季总决赛第四场fpx大优势被推翻 APP开放给你推荐:英雄联盟手游媒体团访问 APP开放给你推荐:英雄联盟:纳尔大战铁大佬,看我怎么单杀APP打开推送给你
站群大家都需要设计吗_会员课程站群项目
<p>国内机房一般默认1个或2个IP。添加IP的成本非常高。 站群你需要设计每一个吗,站群你需要设计每一个吗?如果需要国内多IP服务器,需要添加多个IP,①由于国内IP资源不足,美国多IP站群服务器认为带宽足够,seo站群也离不开 查看全部
网站程序自带的采集器采集文章(最新的环境安装包集成批量开启功能一群护士在护士站交班_站群每个都要设计吗)
站群自动采集源码_护士站一组护士交班
对于365用户,它兼容php7和php5程序。对于365站群用户,当网站的内容越来越多时,在网站的日常操作过程中,经过一些增删改查操作,网站会累积more and more 越来越多的断链(死链接),尤其是站群网站,几十到几百个网站收录大量的网站链接,如何改正处理无效链接(死链接)对站群网站、站群自动采集源码的优化、支持至关重要。 ,3、服务器运行环境ZZphpserver升级。 1、升级环境安装包兼容php7和php5程序。升级环境安装包自带2个版本,站群自动采集源码,支持域名批量启用https。最新环境安装包集成批量https打开功能
一群护士在护士站交班_站群每个人都需要设计吗?
今天我们来说说站群的内容从何而来,一起来看看吧。 原创writing 和 parody 等来源被排除在外,但作者没有。 ,一群护士正在护士站交班,剩下的人是采集伪原创,在扫描报纸和书籍的内容。不可否认,护士站有一群护士在工作。即使在今天,仍然有很多站长选择采集和伪原创的方式来操作站群,使用这种方式获取排名的案例也很多。 ,英雄联盟十周年展示游戏:uzi拿出签名vn超级逆风获得五杀! APP开放给你推荐:夏季总决赛第四场fpx大优势被推翻 APP开放给你推荐:英雄联盟手游媒体团访问 APP开放给你推荐:英雄联盟:纳尔大战铁大佬,看我怎么单杀APP打开推送给你
站群大家都需要设计吗_会员课程站群项目
<p>国内机房一般默认1个或2个IP。添加IP的成本非常高。 站群你需要设计每一个吗,站群你需要设计每一个吗?如果需要国内多IP服务器,需要添加多个IP,①由于国内IP资源不足,美国多IP站群服务器认为带宽足够,seo站群也离不开
网站程序自带的采集器采集文章(2.页面分析采集页面结构(HTML)下载图 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-25 03:13
)
首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。
所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。
一旦熟悉了 网站 中的 HTML 源文件的内容,其中数据是 采集,程序的其余部分就很容易了。因为C#在网站上执行数据采集,原理是“下载你想要的页面的HTML源文件到采集,分析HTML代码然后抓取你需要的数据,最后保存数据。到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
引用后实例化一个 WebClient 对象
私人 WebClientwc = new WebClient();
调用DownloadData方法从指定网页的源文件中下载一组BYTE数据,然后将BYTE数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format("你要的网页地址采集")));
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile("你要访问的网页的URL采集", "保存源文件的本地文件路径");
// 读取下载源文件的HTML格式字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
使用网页 HTML 格式字符串,您可以分析 采集 网页并抓取您需要的内容。
2.页面分析采集
页面分析就是用网页源文件中的一个特定的或唯一的字符(字符串)作为一个抓取点,从这个抓取点开始截取你想要的页面上的数据。
以博客园为栏目为例,如果我想要采集博客园首页列出的文章的标题和链接,我必须以"开头
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf( " " ) + 26 );
// 获取文章页面的链接地址
字符串 articleAddr = mainData.Substring( 0 ,mainData.IndexOf( " \" " ));
// 获取 文章 标题
字符串文章标题 = mainData.Substring(mainData.IndexOf( " target=\"_blank\"> " ) + 16 ,
mainData.IndexOf( " " ) - mainData.IndexOf( " target=\"_blank\"> " ) - 16 );
注意:当你要采集的网页首页的HTML格式发生变化时,作为抓取点的字符也要相应的改变,否则采集什么都得不到
3.数据存储
从网页中截取需要的数据后,将程序中的数据组织起来,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集的工作就会在一个段落中完成。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt" ,
文章数据,
编码.UTF8);
另外附上我自己写的采集博客园主页文章的小程序代码。该程序的作用是将博客园主页上的所有文章采集发布下来。
下载地址:CnBlogCollector.rar
当然,如果博客园首页的格式调整了,程序的采集功能肯定会失效,而继续采集的唯一办法就是重新调整程序自己一个人,呵呵。. .
程序效果如下:
查看全部
网站程序自带的采集器采集文章(2.页面分析采集页面结构(HTML)下载图
)
首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。
所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。
一旦熟悉了 网站 中的 HTML 源文件的内容,其中数据是 采集,程序的其余部分就很容易了。因为C#在网站上执行数据采集,原理是“下载你想要的页面的HTML源文件到采集,分析HTML代码然后抓取你需要的数据,最后保存数据。到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
引用后实例化一个 WebClient 对象
私人 WebClientwc = new WebClient();
调用DownloadData方法从指定网页的源文件中下载一组BYTE数据,然后将BYTE数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format("你要的网页地址采集")));
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile("你要访问的网页的URL采集", "保存源文件的本地文件路径");
// 读取下载源文件的HTML格式字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
使用网页 HTML 格式字符串,您可以分析 采集 网页并抓取您需要的内容。
2.页面分析采集
页面分析就是用网页源文件中的一个特定的或唯一的字符(字符串)作为一个抓取点,从这个抓取点开始截取你想要的页面上的数据。
以博客园为栏目为例,如果我想要采集博客园首页列出的文章的标题和链接,我必须以"开头
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf( " " ) + 26 );
// 获取文章页面的链接地址
字符串 articleAddr = mainData.Substring( 0 ,mainData.IndexOf( " \" " ));
// 获取 文章 标题
字符串文章标题 = mainData.Substring(mainData.IndexOf( " target=\"_blank\"> " ) + 16 ,
mainData.IndexOf( " " ) - mainData.IndexOf( " target=\"_blank\"> " ) - 16 );
注意:当你要采集的网页首页的HTML格式发生变化时,作为抓取点的字符也要相应的改变,否则采集什么都得不到
3.数据存储
从网页中截取需要的数据后,将程序中的数据组织起来,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集的工作就会在一个段落中完成。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt" ,
文章数据,
编码.UTF8);
另外附上我自己写的采集博客园主页文章的小程序代码。该程序的作用是将博客园主页上的所有文章采集发布下来。
下载地址:CnBlogCollector.rar
当然,如果博客园首页的格式调整了,程序的采集功能肯定会失效,而继续采集的唯一办法就是重新调整程序自己一个人,呵呵。. .
程序效果如下:
网站程序自带的采集器采集文章(PC客户端和移动端app开发商的详细介绍-1. )
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-22 12:12
)
1. 工人要想做好事,必须先磨利他的工具
在开始工作之前,做下载的爬虫工程师都是一套人力必须熟练使用的工具。最基本的工具包括:
1.1资源展示媒体
由于资源展示媒体的多样性,围绕爬虫爬取资源所需的展示媒体也多种多样,大致可分为:浏览器(PC和移动端)、PC客户端和移动端APP。
浏览器
在浏览器中,Elements、Network、Sources、Resources是爬虫工程师需要注意的标签;Network是网络请求的原创数据,Elements是浏览器渲染的数据。PC客户端和手机应用程序在此不做介绍。
1.2 抓包工具
目前可用的数据包捕获工具有很多,包括:Wireshark、fiddler、Firebug、HttpFox、tcpdump、sniffer、omnipeek 和 charles。推荐使用:Wireshark。
Wireshark 是一个小型的开源数据包捕获工具软件,几乎可以在所有流行的操作系统下使用。非常适合普通人学习网络协议,也是协议开发者验证协议的好工具。由于 Wireshark 存在缓冲区溢出漏洞,因此不建议将其用于分析 100M 流量大的网络,也不建议用于分析千兆网络。
线鲨
查尔斯捕获手机数据包
请注意,应关闭计算机防火墙。
1.3 Android APK 中
抓取Android APK请求数据包时,可以在真机、Android自带的模拟器或第三方模拟器上安装你要抓取的Android APK。使用真手机的过程很繁琐。需要在真机上通过tcpdump抓包,通过adb拉取待分析的包到PC;使用Andorid自带的模拟器比较慢。这里推荐使用第三方模拟器。
目前市面上的第三方安卓模拟器软件主要有两大流派:Bluestacks和Virutalbox,都可以在电脑上玩手游,主要有以下几种:
一个。Bluestacks:Android模拟器的鼻祖,由一家印度公司开发,号称在全球拥有1亿用户。不兼容或不支持某些国内流行游戏。受制于内核技术,虽然使用电脑的门槛较低,但游戏的兼容性,尤其是性能并不好。
湾。可靠助手:国内最早(2013年开始)基于Bluestacks内核的Android模拟器,优化了用户界面和用户体验。但是它缺乏自己的内核技术,在兼容性和性能上还有很大的提升空间,产品的形态也不能随意改变。
C。海马Play:国内第一款基于Oracle Virtualbox商业版的安卓模拟器。该产品在2014年底推出时,与Bluestacks内核的Android模拟器形成鲜明对比。性能和兼容性都有显着提升,比Bluestacks内核模拟器要好。口碑不错。优点是比较稳定,但是版本更新速度慢,弹窗广告插件多,用户体验差,功能定制不足。
d。逍遥安卓模拟器:基于自研定制的Virtualbox强大的安卓模拟器,业界首创的一键多开是它的亮点。版本更新快,性能强,运行流畅,需求响应及时。该模拟器具有良好的性能和兼容性,在优化手游体验方面做得非常好。这是手游玩家的亮点和首选。
e. Nox Simulator:2015年年中推出的基于定制化Virtualbox的Android模拟器,直接集成NOVA桌面是它的一大亮点。多开效率有待提高,系统不稳定。
氮氧化物模拟器
1.4 网络请求模拟器
这里推荐使用的是:火狐浏览器的HttpRequester。
查看全部
网站程序自带的采集器采集文章(PC客户端和移动端app开发商的详细介绍-1.
)
1. 工人要想做好事,必须先磨利他的工具
在开始工作之前,做下载的爬虫工程师都是一套人力必须熟练使用的工具。最基本的工具包括:
1.1资源展示媒体
由于资源展示媒体的多样性,围绕爬虫爬取资源所需的展示媒体也多种多样,大致可分为:浏览器(PC和移动端)、PC客户端和移动端APP。
浏览器
在浏览器中,Elements、Network、Sources、Resources是爬虫工程师需要注意的标签;Network是网络请求的原创数据,Elements是浏览器渲染的数据。PC客户端和手机应用程序在此不做介绍。
1.2 抓包工具
目前可用的数据包捕获工具有很多,包括:Wireshark、fiddler、Firebug、HttpFox、tcpdump、sniffer、omnipeek 和 charles。推荐使用:Wireshark。
Wireshark 是一个小型的开源数据包捕获工具软件,几乎可以在所有流行的操作系统下使用。非常适合普通人学习网络协议,也是协议开发者验证协议的好工具。由于 Wireshark 存在缓冲区溢出漏洞,因此不建议将其用于分析 100M 流量大的网络,也不建议用于分析千兆网络。
线鲨
查尔斯捕获手机数据包
请注意,应关闭计算机防火墙。
1.3 Android APK 中
抓取Android APK请求数据包时,可以在真机、Android自带的模拟器或第三方模拟器上安装你要抓取的Android APK。使用真手机的过程很繁琐。需要在真机上通过tcpdump抓包,通过adb拉取待分析的包到PC;使用Andorid自带的模拟器比较慢。这里推荐使用第三方模拟器。
目前市面上的第三方安卓模拟器软件主要有两大流派:Bluestacks和Virutalbox,都可以在电脑上玩手游,主要有以下几种:
一个。Bluestacks:Android模拟器的鼻祖,由一家印度公司开发,号称在全球拥有1亿用户。不兼容或不支持某些国内流行游戏。受制于内核技术,虽然使用电脑的门槛较低,但游戏的兼容性,尤其是性能并不好。
湾。可靠助手:国内最早(2013年开始)基于Bluestacks内核的Android模拟器,优化了用户界面和用户体验。但是它缺乏自己的内核技术,在兼容性和性能上还有很大的提升空间,产品的形态也不能随意改变。
C。海马Play:国内第一款基于Oracle Virtualbox商业版的安卓模拟器。该产品在2014年底推出时,与Bluestacks内核的Android模拟器形成鲜明对比。性能和兼容性都有显着提升,比Bluestacks内核模拟器要好。口碑不错。优点是比较稳定,但是版本更新速度慢,弹窗广告插件多,用户体验差,功能定制不足。
d。逍遥安卓模拟器:基于自研定制的Virtualbox强大的安卓模拟器,业界首创的一键多开是它的亮点。版本更新快,性能强,运行流畅,需求响应及时。该模拟器具有良好的性能和兼容性,在优化手游体验方面做得非常好。这是手游玩家的亮点和首选。
e. Nox Simulator:2015年年中推出的基于定制化Virtualbox的Android模拟器,直接集成NOVA桌面是它的一大亮点。多开效率有待提高,系统不稳定。
氮氧化物模拟器
1.4 网络请求模拟器
这里推荐使用的是:火狐浏览器的HttpRequester。
网站程序自带的采集器采集文章(网站定时发布文章内容是一件必须要解决的问题!!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-19 09:00
最近很多站长朋友向我抱怨网站采集应该怎么做,坚持手动更新很难。 网站定期发布文章内容是必须的,所以今天我要分享一些网站采集的技巧。非常适合想做大量收录和高权重网站的站长。
首先很多朋友会说纯采集可能会被搜索引擎算法击中,尤其是百度对纯采集的飓风算法。我们难免会有疑问。 网站内容源真的不能用采集新闻源的方式吗?
我们必须了解飓风算法的目标是什么。第一个跨域采集网站。这意味着采集的内容不匹配你自己的网站网站,你网站打篮球,但是你采集衣服相关的内容。二、采集明显网站网站信息杂乱,排版凌乱,图片打不开或文章可读性极强,有特别明显的< @采集 痕迹,很差的用户体验。最后一点是采集多篇不同文章文章的组合,整体内容杂乱无章,存在阅读体验差、文章内容杂乱等问题。如果你网站有这些问题,你很可能会被搜索引擎击中,那你怎么网站采集?
第一步是识别采集的内容。你不能把所有的内容都插入数据库,不,好的高质量的内容有利于网站被搜索引擎收录搜索到,因为搜索引擎也不断需要收录高质量文章 丰富本身。那么我们网站采集不能直接是采集的内容是什么,我们会发布什么内容,需要做相关的处理,比如进行网站内容伪原创、关键词插入、内联插入等采集发布规则。他们都对网站seo 有很大的帮助。 网站采集 真是一门学问。可以说是一把双刃剑。
采集文章 仅表示处理 网站采集 工具可以根据 关键词 提供的网络范围自动化采集我们。关于采集软件作者使用147采集完成网站的每日更新,主要免费,无需编写采集规则,非常方便。
只需键入 关键词 到 采集 各种网页和新闻提要和问答。完成傻瓜式操作,采集设置只需3步,过程不超过1分钟,连三岁的孩子都能用!免费147采集器特点:输入关键词,即可采集到百度资讯/搜狗资讯/今日头条资讯/360资讯/微信公众号/知乎文章/新浪新闻/凤凰新闻/可批量设置关键词,根据关键词采集文章,一次可导入1000个关键词 ,并且可以同时创建几十个或几百个采集任务,你可以随时挂断采集。并且我们承诺下一个版本还可以采集指定列表页(列页)的文章,然后添加更多的采集源。 147个免费采集工具会不断更新,加入更多采集功能,满足更多站长的需求。
作者的采集网站主要是通过以上方法做的,因人而异。今天,我将在这里分享网站采集。路有帮助,下期分享更多SEO干货! 查看全部
网站程序自带的采集器采集文章(网站定时发布文章内容是一件必须要解决的问题!!)
最近很多站长朋友向我抱怨网站采集应该怎么做,坚持手动更新很难。 网站定期发布文章内容是必须的,所以今天我要分享一些网站采集的技巧。非常适合想做大量收录和高权重网站的站长。
首先很多朋友会说纯采集可能会被搜索引擎算法击中,尤其是百度对纯采集的飓风算法。我们难免会有疑问。 网站内容源真的不能用采集新闻源的方式吗?
我们必须了解飓风算法的目标是什么。第一个跨域采集网站。这意味着采集的内容不匹配你自己的网站网站,你网站打篮球,但是你采集衣服相关的内容。二、采集明显网站网站信息杂乱,排版凌乱,图片打不开或文章可读性极强,有特别明显的< @采集 痕迹,很差的用户体验。最后一点是采集多篇不同文章文章的组合,整体内容杂乱无章,存在阅读体验差、文章内容杂乱等问题。如果你网站有这些问题,你很可能会被搜索引擎击中,那你怎么网站采集?
第一步是识别采集的内容。你不能把所有的内容都插入数据库,不,好的高质量的内容有利于网站被搜索引擎收录搜索到,因为搜索引擎也不断需要收录高质量文章 丰富本身。那么我们网站采集不能直接是采集的内容是什么,我们会发布什么内容,需要做相关的处理,比如进行网站内容伪原创、关键词插入、内联插入等采集发布规则。他们都对网站seo 有很大的帮助。 网站采集 真是一门学问。可以说是一把双刃剑。
采集文章 仅表示处理 网站采集 工具可以根据 关键词 提供的网络范围自动化采集我们。关于采集软件作者使用147采集完成网站的每日更新,主要免费,无需编写采集规则,非常方便。
只需键入 关键词 到 采集 各种网页和新闻提要和问答。完成傻瓜式操作,采集设置只需3步,过程不超过1分钟,连三岁的孩子都能用!免费147采集器特点:输入关键词,即可采集到百度资讯/搜狗资讯/今日头条资讯/360资讯/微信公众号/知乎文章/新浪新闻/凤凰新闻/可批量设置关键词,根据关键词采集文章,一次可导入1000个关键词 ,并且可以同时创建几十个或几百个采集任务,你可以随时挂断采集。并且我们承诺下一个版本还可以采集指定列表页(列页)的文章,然后添加更多的采集源。 147个免费采集工具会不断更新,加入更多采集功能,满足更多站长的需求。
作者的采集网站主要是通过以上方法做的,因人而异。今天,我将在这里分享网站采集。路有帮助,下期分享更多SEO干货!
网站程序自带的采集器采集文章(掌握一种采集技巧对SEO站长而言的2种采集方式 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-19 08:18
)
很久没用WP采集器了。回忆自己做站群SEO的时候,经常会登录到各个采集后台去采集所有相关的网站信息内容。而当时采集之风盛行,各种采集站,尤其是小说站、文章站等等,动辄上百个成千上万的 采集文章, 网站 很容易达到重量 4。虽然现在大多数 网站很少采集,采集仍然无处不在,而且由于一些所谓的 原创 站点,文章 的内容很可能也是 采集 然后被处理和制作的。所以掌握一个采集技术对SEO站长还是很有帮助的。今天,
一、通过关键词采集:
<p>无需学习更专业的技术,只需几个简单的步骤即可轻松采集网页数据,精准发布数据,关键词。用户只需在网页上进行简单的目标管理网站设置后,系统将内容和图片进行高精度匹配,并根据 查看全部
网站程序自带的采集器采集文章(掌握一种采集技巧对SEO站长而言的2种采集方式
)
很久没用WP采集器了。回忆自己做站群SEO的时候,经常会登录到各个采集后台去采集所有相关的网站信息内容。而当时采集之风盛行,各种采集站,尤其是小说站、文章站等等,动辄上百个成千上万的 采集文章, 网站 很容易达到重量 4。虽然现在大多数 网站很少采集,采集仍然无处不在,而且由于一些所谓的 原创 站点,文章 的内容很可能也是 采集 然后被处理和制作的。所以掌握一个采集技术对SEO站长还是很有帮助的。今天,
一、通过关键词采集:
<p>无需学习更专业的技术,只需几个简单的步骤即可轻松采集网页数据,精准发布数据,关键词。用户只需在网页上进行简单的目标管理网站设置后,系统将内容和图片进行高精度匹配,并根据

