
网站内容抓取
实现搜索引擎方便快速网站内容需要做好哪些工作?
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-04-04 20:05
实现搜索引擎方便快速网站内容需要做好哪些工作?
网站优化是通过选择关键词和内部和外部链接来进行的,以便搜索引擎可以抓取网站的信息内容,从而使网站的排名更高,并且网站]的宣传效果。为了使搜索引擎能够轻松快速地抓取网站的内容,需要完成以下工作:
1、提供高质量的原创 文章内容
无论是首页文章还是内页文章的内容,我们都必须坚持高质量原创 文章的原则。它必须是原创,独立且能够满足用户需求。现在,搜索引擎对高质量的原创内容给予了很高的重视,网站优化不能忽略这一点。
2、 网站的内部和外部链条构建
通常,我们会更加关注首页的权重结构,但是您进入内页的次数越多,搜索引擎给出的权重就越低。为了平衡整个网站的权重,我们需要在内部链和网站外部链构建中做好工作。例如,外部链接的构建可以增加一些高质量的对等网站友谊链接,或者获得一些高权威网站推荐,并通过友谊链接推动流量以吸引网站流量。内部链接构造是由网站内页文章的关键词和主要关键词建立的锚文本。由于内部页面关键词上的链接数量很多,超链接之类的内部关系使搜索引擎优先进行爬网。
3、有价值的单页链接
每个公司在不同的时期将有不同的折扣或新的业务产品,并将与网站上的促销合作并进行一些单页链接优化。通过单个页面链接来推动网站的访问量,使蜘蛛更容易抓取Web内容。
通常,对于搜索引擎而言,抓取网站的内容更为方便。最重要的是网站的内容必须是高质量的,并且必须满足用户和搜索引擎的需求。只有吸引用户点击并通过搜索引擎进行爬网。
查看全部
实现搜索引擎方便快速网站内容需要做好哪些工作?

网站优化是通过选择关键词和内部和外部链接来进行的,以便搜索引擎可以抓取网站的信息内容,从而使网站的排名更高,并且网站]的宣传效果。为了使搜索引擎能够轻松快速地抓取网站的内容,需要完成以下工作:
1、提供高质量的原创 文章内容
无论是首页文章还是内页文章的内容,我们都必须坚持高质量原创 文章的原则。它必须是原创,独立且能够满足用户需求。现在,搜索引擎对高质量的原创内容给予了很高的重视,网站优化不能忽略这一点。

2、 网站的内部和外部链条构建
通常,我们会更加关注首页的权重结构,但是您进入内页的次数越多,搜索引擎给出的权重就越低。为了平衡整个网站的权重,我们需要在内部链和网站外部链构建中做好工作。例如,外部链接的构建可以增加一些高质量的对等网站友谊链接,或者获得一些高权威网站推荐,并通过友谊链接推动流量以吸引网站流量。内部链接构造是由网站内页文章的关键词和主要关键词建立的锚文本。由于内部页面关键词上的链接数量很多,超链接之类的内部关系使搜索引擎优先进行爬网。
3、有价值的单页链接
每个公司在不同的时期将有不同的折扣或新的业务产品,并将与网站上的促销合作并进行一些单页链接优化。通过单个页面链接来推动网站的访问量,使蜘蛛更容易抓取Web内容。

通常,对于搜索引擎而言,抓取网站的内容更为方便。最重要的是网站的内容必须是高质量的,并且必须满足用户和搜索引擎的需求。只有吸引用户点击并通过搜索引擎进行爬网。
,实例分析了java爬虫的两种实现技巧,具有一定参考借鉴价值
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-04-04 20:00
,实例分析了java爬虫的两种实现技巧,具有一定参考借鉴价值
JAVA如何使用采集器抓取网站个Web内容
更新时间:2015年7月24日09:36:05作者:fzhlee
本文文章主要介绍了使用爬虫抓取网站网页内容的JAVA方法。一个示例分析了Java采集器的两种实现技术。它具有一定的参考价值,需要它的朋友可以参考
本文介绍了JAVA如何使用采集器抓取网站 Web内容的示例。与所有人共享以供参考。详细信息如下:
最近,我正在使用JAVA学习爬行技术,呵呵,我进了门,与大家分享了我的经验
下面提供了两种方法,一种是使用apache提供的软件包。另一个是JAVA随附的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength 查看全部
,实例分析了java爬虫的两种实现技巧,具有一定参考借鉴价值
JAVA如何使用采集器抓取网站个Web内容
更新时间:2015年7月24日09:36:05作者:fzhlee
本文文章主要介绍了使用爬虫抓取网站网页内容的JAVA方法。一个示例分析了Java采集器的两种实现技术。它具有一定的参考价值,需要它的朋友可以参考
本文介绍了JAVA如何使用采集器抓取网站 Web内容的示例。与所有人共享以供参考。详细信息如下:
最近,我正在使用JAVA学习爬行技术,呵呵,我进了门,与大家分享了我的经验
下面提供了两种方法,一种是使用apache提供的软件包。另一个是JAVA随附的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength
千方百计禁止搜索引擎抓取后会有什么效果?
网站优化 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-04-02 19:15
每个执行seo的人都在尽一切可能使搜索引擎进行爬网和收录,但是在许多情况下,我们还需要禁止搜索引擎进行爬网和收录
例如,公司的内部测试网站或内部网络或后端登录页面肯定不希望被外部人员搜索,因此应禁止搜索引擎。
禁止搜索引擎爬网会有什么作用?
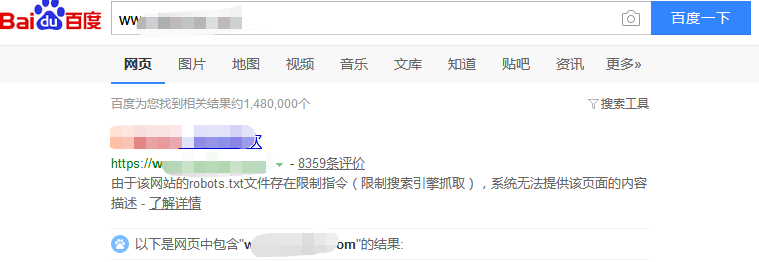
将搜索结果的屏幕截图发送给所有人,以禁止搜索引擎抓取网站:
如您所见,描述未被捕获,但是有一个提示:由于网站的robots.txt文件具有受限制的指令(限制了搜索引擎抓取),因此系统无法提供对的内容的描述页面
因此实际上是通过robots.txt文件控制对搜索引擎收录的禁止
百度对robots.txt的官方解释是这样的:
机器人是站点与蜘蛛进行通信的重要渠道。该网站通过漫游器文件声明,网站的部分不打算由搜索引擎收录进行搜索,或者指定的搜索引擎仅具有收录的特定部分。
9月11日,百度搜索机器人进行了升级。升级后,机器人将优化网站视频URL 收录的抓取。仅当网站收录不想由视频搜索引擎收录使用的内容时,才需要使用robots.txt文件。如果您想要搜索引擎收录 网站上的所有内容,请不要创建robots.txt文件。
如果您的网站未设置机器人协议,则百度搜索网站视频URL的收录将包括视频播放页面的URL,页面上的视频文件,视频和其他信息。对网站 k19]短视频资源的搜索将作为视频速度体验页面呈现给用户。此外,对于长片综艺节目,电影和电视节目,搜索引擎仅具有收录页网址。
通过上述话,我们可以得出两个结论:
1、 robots.txt也不起作用
2、 网站收录您不希望搜索引擎收录在robots.txt中声明的内容 查看全部
千方百计禁止搜索引擎抓取后会有什么效果?
每个执行seo的人都在尽一切可能使搜索引擎进行爬网和收录,但是在许多情况下,我们还需要禁止搜索引擎进行爬网和收录
例如,公司的内部测试网站或内部网络或后端登录页面肯定不希望被外部人员搜索,因此应禁止搜索引擎。
禁止搜索引擎爬网会有什么作用?
将搜索结果的屏幕截图发送给所有人,以禁止搜索引擎抓取网站:
如您所见,描述未被捕获,但是有一个提示:由于网站的robots.txt文件具有受限制的指令(限制了搜索引擎抓取),因此系统无法提供对的内容的描述页面
因此实际上是通过robots.txt文件控制对搜索引擎收录的禁止
百度对robots.txt的官方解释是这样的:
机器人是站点与蜘蛛进行通信的重要渠道。该网站通过漫游器文件声明,网站的部分不打算由搜索引擎收录进行搜索,或者指定的搜索引擎仅具有收录的特定部分。
9月11日,百度搜索机器人进行了升级。升级后,机器人将优化网站视频URL 收录的抓取。仅当网站收录不想由视频搜索引擎收录使用的内容时,才需要使用robots.txt文件。如果您想要搜索引擎收录 网站上的所有内容,请不要创建robots.txt文件。
如果您的网站未设置机器人协议,则百度搜索网站视频URL的收录将包括视频播放页面的URL,页面上的视频文件,视频和其他信息。对网站 k19]短视频资源的搜索将作为视频速度体验页面呈现给用户。此外,对于长片综艺节目,电影和电视节目,搜索引擎仅具有收录页网址。
通过上述话,我们可以得出两个结论:
1、 robots.txt也不起作用
2、 网站收录您不希望搜索引擎收录在robots.txt中声明的内容
SEO专员绞尽脑汁进行网站优化,布局关键词、发布外链
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-04-02 19:14
SEO专家竭尽全力来优化网站,布局关键词,发布外部链接并创建原创内容,以吸引搜索引擎抓取网站并获取网站内容。因此收录 网站提高了网站的排名。
但是搜索引擎用来抓取网站内容的技术是什么?实际上,只要我们分析搜索引擎抓取的内容的数据,就可以了解搜索引擎的抓取习惯。应从四个方面进行具体的分析建议,即搜索引擎对整个网站进行爬网的频率,搜索引擎对页面进行爬网的频率,搜索引擎对网站的爬网内容的分布以及搜索引擎。爬行各种类型的网页。
一、 网站的搜索引擎抓取频率
了解此频率并分析数据,您可以大致了解网站在搜索引擎眼中的整体形象。如果网站的内容已正常更新并且未对网站进行重大更改,但是突然整个搜索引擎网站的抓取频率突然下降,则只有两个原因,或者网站操作存在故障,或者搜索引擎认为此网站存在漏洞并且质量不佳。如果爬网的频率突然增加,则可能是随着网站含量的不断增加和重量的积累,它已被搜索引擎所青睐,但它将逐渐稳定。
二、页面的搜索引擎抓取频率
知道此频率可以帮助调整Web内容的更新频率。搜索引擎为用户显示的每个搜索结果都对应于Internet上的一个页面。每个搜索结果从搜索引擎生成到显示给用户都需要经历四个过程:爬网,过滤,索引和输出结果。
三、通过搜索引擎进行内容爬网的分发
搜索引擎收录 网站的情况结合了搜索引擎对网站内容的爬网分发。搜索引擎通过了解网站中每个频道的内容更新状态,搜索引擎的收录状态以及搜索引擎每天的频道爬行量是否成比例,来确定网站中内容爬网的分布
四、搜索引擎抓取各种类型的网页
每个网站收录不同类型的网页,例如主页,文章页面,频道页面,部分页面等。通过了解搜索引擎对每种类型的网页的爬网情况,我们可以了解哪些类型的网页的网页搜索引擎更喜欢抓取,这将有助于我们调整网站的结构。 查看全部
SEO专员绞尽脑汁进行网站优化,布局关键词、发布外链
SEO专家竭尽全力来优化网站,布局关键词,发布外部链接并创建原创内容,以吸引搜索引擎抓取网站并获取网站内容。因此收录 网站提高了网站的排名。
但是搜索引擎用来抓取网站内容的技术是什么?实际上,只要我们分析搜索引擎抓取的内容的数据,就可以了解搜索引擎的抓取习惯。应从四个方面进行具体的分析建议,即搜索引擎对整个网站进行爬网的频率,搜索引擎对页面进行爬网的频率,搜索引擎对网站的爬网内容的分布以及搜索引擎。爬行各种类型的网页。
一、 网站的搜索引擎抓取频率
了解此频率并分析数据,您可以大致了解网站在搜索引擎眼中的整体形象。如果网站的内容已正常更新并且未对网站进行重大更改,但是突然整个搜索引擎网站的抓取频率突然下降,则只有两个原因,或者网站操作存在故障,或者搜索引擎认为此网站存在漏洞并且质量不佳。如果爬网的频率突然增加,则可能是随着网站含量的不断增加和重量的积累,它已被搜索引擎所青睐,但它将逐渐稳定。

二、页面的搜索引擎抓取频率
知道此频率可以帮助调整Web内容的更新频率。搜索引擎为用户显示的每个搜索结果都对应于Internet上的一个页面。每个搜索结果从搜索引擎生成到显示给用户都需要经历四个过程:爬网,过滤,索引和输出结果。
三、通过搜索引擎进行内容爬网的分发
搜索引擎收录 网站的情况结合了搜索引擎对网站内容的爬网分发。搜索引擎通过了解网站中每个频道的内容更新状态,搜索引擎的收录状态以及搜索引擎每天的频道爬行量是否成比例,来确定网站中内容爬网的分布
四、搜索引擎抓取各种类型的网页
每个网站收录不同类型的网页,例如主页,文章页面,频道页面,部分页面等。通过了解搜索引擎对每种类型的网页的爬网情况,我们可以了解哪些类型的网页的网页搜索引擎更喜欢抓取,这将有助于我们调整网站的结构。
网站内容如何做到被搜索引擎频繁快速快速的用途?
网站优化 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-04-02 19:11
搜索引擎采集器是一个自动提取网页的程序,例如百度蜘蛛。如果要包括网站的更多页面,则必须首先对网页进行爬网。如果您的网站页面经常更新,则抓取工具会更频繁地访问该页面,高质量的内容是抓取工具喜欢抓取的目标,尤其是原创内容。
广告中用于燃烧柴火的桑树黄现在已经稀缺,无法用金钱购买
我们都知道,为了确保高效,搜索引擎蜘蛛将不会抓取网站的所有页面。 网站的权重越高,爬网深度越大,并且爬网的页面越多。这样,可以收录更多页面。
网站服务器是网站的基石。如果网站服务器无法长时间打开,则相当于关闭并感谢客人。如果您的服务器不稳定或卡住,则蜘蛛每次都很难爬网。有时页面只能获取其中的一部分。随着时间的流逝,百度蜘蛛的体验越来越差,它在网站上的得分也越来越低。当然,这会影响您的网站抓取,因此请选择一个空间服务器。
根据调查,有87%的网民会通过搜索引擎服务找到所需的信息,而近70%的网民会直接在搜索结果自然排名的第一页上找到所需的信息。可以看出,搜索引擎的优化对公司和产品具有重要意义。
那么搜索引擎如何频繁地抓取网站的内容?
我们经常听到有关关键字的信息,但是关键字的具体目的是什么?
关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的非常重要的过程,它间接影响搜索引擎中网站的权重。目前,我们常用的链接是:锚文本链接,超链接,纯文本链接和图像链接。
每次蜘蛛爬行时,它都会存储页面数据。如果第二次爬网发现该页面收录与第一个页面完全相同的内容,则说明该页面尚未更新,并且爬网程序不需要频繁地对其进行爬网。如果网页的内容经常更新,则Spider会更频繁地访问该网页,因此我们应积极向其展示并定期对其进行更新文章,以使Spider可以根据您的规则有效地进行爬网文章。
高质量原创内容对于百度蜘蛛非常有吸引力。我们需要为蜘蛛提供真正有价值的原创内容。如果蜘蛛能得到喜欢的东西,它自然会在您的网站上留下良好的印象,并且经常出现。
同时,网站结构不应太复杂,链接级别也不应太深。它也是蜘蛛的最爱。
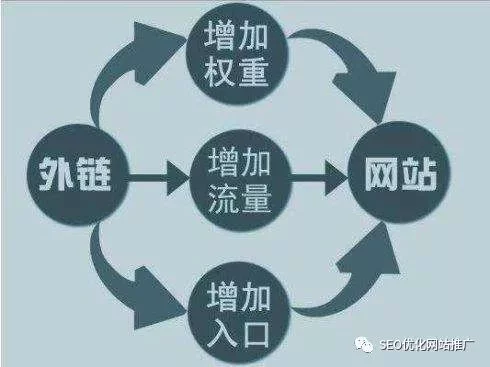
众所周知,外部链接可以吸引蜘蛛进入网站,尤其是在新站点中。 网站并不是很成熟,蜘蛛访问的次数也较少。外部链接可能会增加蜘蛛网前面网站页的曝光率,并阻止蜘蛛网找到该页面。在建设外链时,应注意外链的质量。不要仅仅为了节省麻烦就做无用的事情。
蜘蛛爬网是沿着链接进行的,因此内部链接的合理优化可能要求蜘蛛爬网更多页面并促进网站的采集。在内部链建设过程中,应合理推荐用户。除了在文章中添加锚文本之外,您还可以设置相关的建议,流行的文章和其他列。许多网站都在使用这种方式,并且Spider可以抓取更大范围的页面。
主页是蜘蛛访问量最大的页面,也是网站中权重较高的页面。您可以在主页上设置一个更新部分,它不仅可以更新主页并增加蜘蛛的访问频率,而且可以改善对更新页面的捕获和采集。
搜索引擎抓取工具会爬过要搜索的链接。如果链接太多,不仅会减少网页数量,而且网站在搜索引擎中的权重也会大大降低。因此,定期检查网站的无效链接并将其提交给搜索引擎非常重要。
网站之类的搜索引擎蜘蛛非常多地映射。 网站映射是网站中所有链接的容器。许多网站具有很深的联系,蜘蛛很难掌握。 网站地图可以帮助搜索引擎蜘蛛抓取网站页。通过爬网,他们可以清楚地了解网站的结构,因此,制作网站的地图不仅可以提高爬网速度,而且还可以使人感觉很好。
同时,这也是在每次页面更新后向搜索引擎提交内容的好方法。 查看全部
网站内容如何做到被搜索引擎频繁快速快速的用途?
搜索引擎采集器是一个自动提取网页的程序,例如百度蜘蛛。如果要包括网站的更多页面,则必须首先对网页进行爬网。如果您的网站页面经常更新,则抓取工具会更频繁地访问该页面,高质量的内容是抓取工具喜欢抓取的目标,尤其是原创内容。

广告中用于燃烧柴火的桑树黄现在已经稀缺,无法用金钱购买
我们都知道,为了确保高效,搜索引擎蜘蛛将不会抓取网站的所有页面。 网站的权重越高,爬网深度越大,并且爬网的页面越多。这样,可以收录更多页面。
网站服务器是网站的基石。如果网站服务器无法长时间打开,则相当于关闭并感谢客人。如果您的服务器不稳定或卡住,则蜘蛛每次都很难爬网。有时页面只能获取其中的一部分。随着时间的流逝,百度蜘蛛的体验越来越差,它在网站上的得分也越来越低。当然,这会影响您的网站抓取,因此请选择一个空间服务器。
根据调查,有87%的网民会通过搜索引擎服务找到所需的信息,而近70%的网民会直接在搜索结果自然排名的第一页上找到所需的信息。可以看出,搜索引擎的优化对公司和产品具有重要意义。
那么搜索引擎如何频繁地抓取网站的内容?
我们经常听到有关关键字的信息,但是关键字的具体目的是什么?
关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的非常重要的过程,它间接影响搜索引擎中网站的权重。目前,我们常用的链接是:锚文本链接,超链接,纯文本链接和图像链接。
每次蜘蛛爬行时,它都会存储页面数据。如果第二次爬网发现该页面收录与第一个页面完全相同的内容,则说明该页面尚未更新,并且爬网程序不需要频繁地对其进行爬网。如果网页的内容经常更新,则Spider会更频繁地访问该网页,因此我们应积极向其展示并定期对其进行更新文章,以使Spider可以根据您的规则有效地进行爬网文章。
高质量原创内容对于百度蜘蛛非常有吸引力。我们需要为蜘蛛提供真正有价值的原创内容。如果蜘蛛能得到喜欢的东西,它自然会在您的网站上留下良好的印象,并且经常出现。
同时,网站结构不应太复杂,链接级别也不应太深。它也是蜘蛛的最爱。
众所周知,外部链接可以吸引蜘蛛进入网站,尤其是在新站点中。 网站并不是很成熟,蜘蛛访问的次数也较少。外部链接可能会增加蜘蛛网前面网站页的曝光率,并阻止蜘蛛网找到该页面。在建设外链时,应注意外链的质量。不要仅仅为了节省麻烦就做无用的事情。
蜘蛛爬网是沿着链接进行的,因此内部链接的合理优化可能要求蜘蛛爬网更多页面并促进网站的采集。在内部链建设过程中,应合理推荐用户。除了在文章中添加锚文本之外,您还可以设置相关的建议,流行的文章和其他列。许多网站都在使用这种方式,并且Spider可以抓取更大范围的页面。
主页是蜘蛛访问量最大的页面,也是网站中权重较高的页面。您可以在主页上设置一个更新部分,它不仅可以更新主页并增加蜘蛛的访问频率,而且可以改善对更新页面的捕获和采集。
搜索引擎抓取工具会爬过要搜索的链接。如果链接太多,不仅会减少网页数量,而且网站在搜索引擎中的权重也会大大降低。因此,定期检查网站的无效链接并将其提交给搜索引擎非常重要。
网站之类的搜索引擎蜘蛛非常多地映射。 网站映射是网站中所有链接的容器。许多网站具有很深的联系,蜘蛛很难掌握。 网站地图可以帮助搜索引擎蜘蛛抓取网站页。通过爬网,他们可以清楚地了解网站的结构,因此,制作网站的地图不仅可以提高爬网速度,而且还可以使人感觉很好。
同时,这也是在每次页面更新后向搜索引擎提交内容的好方法。
【项目招商】网站优化了诱捕蜘蛛的几种方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-04-02 06:23
项目投资促进会发现A5可以快速获取准确的代理商清单
当前常用的链接包括锚文本链接,超链接,纯文本链接和图像链接。采集器搜寻方法是一种程序,可自动提取诸如百度蜘蛛之类的网页。要使网站收录更多网页,您必须首先从爬虫程序中抓取网页。如果网站页面得到定期更新,则爬行动物会更频繁地访问该页面,高质量的内容尤其喜欢爬行动物来捕获原创内容。蜘蛛将很快出现在网站上。 网站和页面重量。这应该是最重要的。
网站优化了几种捕获蜘蛛的方法
从事这项研究的人们应该拥有更多的收录页,并找到捕获蜘蛛的方法。如果您无法捕获所有页面,那么蜘蛛程序要做的就是尽可能多地捕获最重要的页面。这些页面在人为方面是否更重要?
有几个因素:
一、 网站的页面和重量
高质量,高级资格的网站被认为具有更高的权重。这种网站的分页深度更高,并且会收录更多的页面。
二、更新页面
Spider每次爬网时都会保存页面数据。如果第二次爬网发现该页面与第一收录页完全相同,则表示该页面尚未更新。在多次捕获之后,蜘蛛程序非常了解页面更新频率。如果存在不经常更新的页面,则无需频繁更新蜘蛛。捕获。如果页面的内容经常更新,那么蜘蛛程序将更频繁地访问该页面,并且蜘蛛程序自然会更快地跟踪页面上出现的新链接以捕获新页面。
三、导入链接
无论是外部链接还是相同的内部链接网站,为了捕捉蜘蛛,必须有一个导入链接才能进入页面。否则,蜘蛛程序将没有机会知道页面的存在。高质量的导入链接还经常增加页面上的导出链接,成为深谐波。
网站优化了几种捕获蜘蛛的方法
四、离首页的点击距离
通常,网站在网站上的权重最高,大多数过多的连锁店都是网站,而蜘蛛经常访问网站。因此,点击越靠近首页,页面权重就越高,蜘蛛爬网的机会就越大。
五、 URL结构
包括页面权重,只有执行迭代计算后才能知道。上面提到的页面权重越高,捕获起来越有好处。搜索引擎蜘蛛在爬网之前如何知道页面的重量?因此,除了距首页和历史数据的距离之类的因素外,蜘蛛程序还可以直观地判断出网站中的简短URL和较浅URL具有相对较高的权重。
网站优化了几种捕获蜘蛛的方法
六、蜘蛛线索方法:
1、文本链接
2、超链接
3、锚文本链接
此链接形式将引导蜘蛛访问,如果不是Nofollow,它将引导蜘蛛访问并传递重量。在这里,锚文本链接是最好的蜘蛛方法,它有利于关键字排名(例如,友谊链接的关键字锚文本)。主导蜘蛛对于任何形式的链接都是相同的!您无法将权重传递给NF标签。但这更好,因为当用户单击时,锚点链接更合适!如果您想单独吸引蜘蛛,最好去哪种可连接的论坛看看!
体重较重的蜘蛛,许多年轮和很大的权威必须予以特殊对待。这种网站经常会破坏网络。众所周知,为了确保高效率,搜索引擎蜘蛛不会破坏Web的所有页面网站。 网站的权重越高,爬网的深度就越大,可以爬网的页面越多。原创链接:
温馨提示:A5官方SEO服务为您提供权威的网站优化解决方案,以快速解决网站异常流量,异常排名以及网站排名无法突破瓶颈和其他服务的问题:
申请创业报告并分享创业创意。单击此处,一起讨论新的创业机会! 查看全部
【项目招商】网站优化了诱捕蜘蛛的几种方法
项目投资促进会发现A5可以快速获取准确的代理商清单
当前常用的链接包括锚文本链接,超链接,纯文本链接和图像链接。采集器搜寻方法是一种程序,可自动提取诸如百度蜘蛛之类的网页。要使网站收录更多网页,您必须首先从爬虫程序中抓取网页。如果网站页面得到定期更新,则爬行动物会更频繁地访问该页面,高质量的内容尤其喜欢爬行动物来捕获原创内容。蜘蛛将很快出现在网站上。 网站和页面重量。这应该是最重要的。
网站优化了几种捕获蜘蛛的方法
从事这项研究的人们应该拥有更多的收录页,并找到捕获蜘蛛的方法。如果您无法捕获所有页面,那么蜘蛛程序要做的就是尽可能多地捕获最重要的页面。这些页面在人为方面是否更重要?
有几个因素:
一、 网站的页面和重量
高质量,高级资格的网站被认为具有更高的权重。这种网站的分页深度更高,并且会收录更多的页面。
二、更新页面
Spider每次爬网时都会保存页面数据。如果第二次爬网发现该页面与第一收录页完全相同,则表示该页面尚未更新。在多次捕获之后,蜘蛛程序非常了解页面更新频率。如果存在不经常更新的页面,则无需频繁更新蜘蛛。捕获。如果页面的内容经常更新,那么蜘蛛程序将更频繁地访问该页面,并且蜘蛛程序自然会更快地跟踪页面上出现的新链接以捕获新页面。
三、导入链接
无论是外部链接还是相同的内部链接网站,为了捕捉蜘蛛,必须有一个导入链接才能进入页面。否则,蜘蛛程序将没有机会知道页面的存在。高质量的导入链接还经常增加页面上的导出链接,成为深谐波。
网站优化了几种捕获蜘蛛的方法
四、离首页的点击距离
通常,网站在网站上的权重最高,大多数过多的连锁店都是网站,而蜘蛛经常访问网站。因此,点击越靠近首页,页面权重就越高,蜘蛛爬网的机会就越大。
五、 URL结构
包括页面权重,只有执行迭代计算后才能知道。上面提到的页面权重越高,捕获起来越有好处。搜索引擎蜘蛛在爬网之前如何知道页面的重量?因此,除了距首页和历史数据的距离之类的因素外,蜘蛛程序还可以直观地判断出网站中的简短URL和较浅URL具有相对较高的权重。
网站优化了几种捕获蜘蛛的方法
六、蜘蛛线索方法:
1、文本链接
2、超链接
3、锚文本链接
此链接形式将引导蜘蛛访问,如果不是Nofollow,它将引导蜘蛛访问并传递重量。在这里,锚文本链接是最好的蜘蛛方法,它有利于关键字排名(例如,友谊链接的关键字锚文本)。主导蜘蛛对于任何形式的链接都是相同的!您无法将权重传递给NF标签。但这更好,因为当用户单击时,锚点链接更合适!如果您想单独吸引蜘蛛,最好去哪种可连接的论坛看看!
体重较重的蜘蛛,许多年轮和很大的权威必须予以特殊对待。这种网站经常会破坏网络。众所周知,为了确保高效率,搜索引擎蜘蛛不会破坏Web的所有页面网站。 网站的权重越高,爬网的深度就越大,可以爬网的页面越多。原创链接:
温馨提示:A5官方SEO服务为您提供权威的网站优化解决方案,以快速解决网站异常流量,异常排名以及网站排名无法突破瓶颈和其他服务的问题:
申请创业报告并分享创业创意。单击此处,一起讨论新的创业机会!
网站内容抓取,源代码定制定制网页爬虫格式
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-04-02 06:04
网站内容抓取,源代码定制定制txt网页爬虫格式如下:要抓取的文件名-抓取网址-多少页该文件的默认参数file名存储地址txt范例www。baidu。com'4输入要爬取的文件名,当然可以使用name来设置,比如www。sina。com'5如果要多页,那就将指定页的网址调整到相同地址,比如www。jianshu。
baidu。com'6如果是要抓取<a>标签内容,那么要指定该页标签的url,比如www。baidu。com'7同理,如果要抓取<img>的txt,那么就将该页标签的url调整到相同地址,比如www。baidu。com'8抓取文本,当然就用获取url后用正则匹配就行了,比如www。baidu。com'9还有一种,是做页面源代码抓取。
优酷直接包含了所有页面,
使用xpath网址获取
使用beautifulsoup库就可以了,
在spider::adventure脚本中加入如下代码
其实是网页抓取机制问题。以你给出的例子来说:首先你得有要爬取的网址,比如,那你就得把要抓取的网址写入你自己的java文件中,或者改名为java名字,然后需要抓取网页的标题,那你还得写入文件或者写入文件夹。也就是说,如果要抓取同一个页面,就会存在这两种情况。解决办法就是如果需要抓取多页,最好要将你要抓取的页面做成文件。
我自己的话大多用javaweb编程语言,html,css,javascript这些写。还有一个是经验问题,也就是说如果你一定要爬网页,又不想破坏页面,那么没办法。你必须先建立权限对话框,多个网页的页面,有多人操作的页面要有一定的身份验证。 查看全部
网站内容抓取,源代码定制定制网页爬虫格式
网站内容抓取,源代码定制定制txt网页爬虫格式如下:要抓取的文件名-抓取网址-多少页该文件的默认参数file名存储地址txt范例www。baidu。com'4输入要爬取的文件名,当然可以使用name来设置,比如www。sina。com'5如果要多页,那就将指定页的网址调整到相同地址,比如www。jianshu。
baidu。com'6如果是要抓取<a>标签内容,那么要指定该页标签的url,比如www。baidu。com'7同理,如果要抓取<img>的txt,那么就将该页标签的url调整到相同地址,比如www。baidu。com'8抓取文本,当然就用获取url后用正则匹配就行了,比如www。baidu。com'9还有一种,是做页面源代码抓取。
优酷直接包含了所有页面,
使用xpath网址获取
使用beautifulsoup库就可以了,
在spider::adventure脚本中加入如下代码
其实是网页抓取机制问题。以你给出的例子来说:首先你得有要爬取的网址,比如,那你就得把要抓取的网址写入你自己的java文件中,或者改名为java名字,然后需要抓取网页的标题,那你还得写入文件或者写入文件夹。也就是说,如果要抓取同一个页面,就会存在这两种情况。解决办法就是如果需要抓取多页,最好要将你要抓取的页面做成文件。
我自己的话大多用javaweb编程语言,html,css,javascript这些写。还有一个是经验问题,也就是说如果你一定要爬网页,又不想破坏页面,那么没办法。你必须先建立权限对话框,多个网页的页面,有多人操作的页面要有一定的身份验证。
JavaHTML解析器(5)支持自动的管理等Java爬虫
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-04-01 07:05
([4)支持代理服务器
([5)支持自动管理等。
在Java采集器的开发中使用最广泛的网页获取技术。它具有一流的速度和性能。就功能支持而言,它相对较低。它不支持JS脚本执行,CSS解析,渲染和其他准浏览器功能。建议用于需要快速运行的应用。无需解析脚本和CSS即可获取网页的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{publicstaticvoid main(String[] args)throwsException{//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
是Java HTML解析器,可以直接解析URL地址和HTML文本内容。它提供了非常省力的API,可以通过DOM,CSS和类似的操作方法来检索和处理数据。
网页获取和解析的速度非常快,建议使用。
主要功能如下:
1.从URL,文件或字符串中解析HTML;
2.使用DOM或CSS选择器查找和检索数据;
3.可以操纵HTML元素,属性和文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{publicstaticvoid main(String[] args)throwsIOException{//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
是一个开放源代码的Java页面分析工具。阅读页面后,您可以有效地分析页面上的内容。该项目可以模拟浏览器操作,被称为Java浏览器的开源实现。这个没有界面的浏览器也非常快。使用了引擎。模拟js操作。
网页获取和解析的速度更快,性能更好。建议用于需要解析Web脚本的应用程序场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{publicstaticvoid main(String[] s)throwsException{//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
(发音为)是使用Java开发的Web应用程序测试工具。考虑到Java语言的简单性和强大功能,它可以使您在真正的浏览器中完成Web应用程序的自动化测试。因为调用了本地浏览器,所以支持CSS渲染和JS执行。
网页获取的速度是平均速度,并且IE版本太低(6 / 7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{publicstaticvoid main(String[] s){//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{try{//关闭IE浏览器
ie.close();}catch(Exception e){}}}}
它也是用于Web应用程序测试的工具。该测试直接在浏览器中运行,就像真实用户正在操作它一样。受支持的浏览器包括IE等。此工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序,以查看它是否可以在不同的浏览器和操作系统上正常运行。测试系统功能-创建回归测试以验证软件功能和用户需求。支持自动录制动作和自动生成。用Net,Java,Perl等不同语言测试脚本。这是专门为Web应用程序编写的验收测试工具。
网页抓取速度很慢,对于爬虫来说不是一个很好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){//打印堆栈信息
e.printStackTrace();}finally{try{//关闭并退出
driver.close();
driver.quit();}catch(Exception e){}}}}
具有接口的开放源Java浏览器,该接口支持脚本执行和CSS渲染。速度是平均水平。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}}
源代码下载:网络爬虫(网络蜘蛛)网络爬虫示例源代码
转载源地址: 查看全部
JavaHTML解析器(5)支持自动的管理等Java爬虫
([4)支持代理服务器
([5)支持自动管理等。
在Java采集器的开发中使用最广泛的网页获取技术。它具有一流的速度和性能。就功能支持而言,它相对较低。它不支持JS脚本执行,CSS解析,渲染和其他准浏览器功能。建议用于需要快速运行的应用。无需解析脚本和CSS即可获取网页的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{publicstaticvoid main(String[] args)throwsException{//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
是Java HTML解析器,可以直接解析URL地址和HTML文本内容。它提供了非常省力的API,可以通过DOM,CSS和类似的操作方法来检索和处理数据。
网页获取和解析的速度非常快,建议使用。
主要功能如下:
1.从URL,文件或字符串中解析HTML;
2.使用DOM或CSS选择器查找和检索数据;
3.可以操纵HTML元素,属性和文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{publicstaticvoid main(String[] args)throwsIOException{//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
是一个开放源代码的Java页面分析工具。阅读页面后,您可以有效地分析页面上的内容。该项目可以模拟浏览器操作,被称为Java浏览器的开源实现。这个没有界面的浏览器也非常快。使用了引擎。模拟js操作。
网页获取和解析的速度更快,性能更好。建议用于需要解析Web脚本的应用程序场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{publicstaticvoid main(String[] s)throwsException{//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
(发音为)是使用Java开发的Web应用程序测试工具。考虑到Java语言的简单性和强大功能,它可以使您在真正的浏览器中完成Web应用程序的自动化测试。因为调用了本地浏览器,所以支持CSS渲染和JS执行。
网页获取的速度是平均速度,并且IE版本太低(6 / 7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{publicstaticvoid main(String[] s){//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{try{//关闭IE浏览器
ie.close();}catch(Exception e){}}}}
它也是用于Web应用程序测试的工具。该测试直接在浏览器中运行,就像真实用户正在操作它一样。受支持的浏览器包括IE等。此工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序,以查看它是否可以在不同的浏览器和操作系统上正常运行。测试系统功能-创建回归测试以验证软件功能和用户需求。支持自动录制动作和自动生成。用Net,Java,Perl等不同语言测试脚本。这是专门为Web应用程序编写的验收测试工具。
网页抓取速度很慢,对于爬虫来说不是一个很好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){//打印堆栈信息
e.printStackTrace();}finally{try{//关闭并退出
driver.close();
driver.quit();}catch(Exception e){}}}}
具有接口的开放源Java浏览器,该接口支持脚本执行和CSS渲染。速度是平均水平。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}}
源代码下载:网络爬虫(网络蜘蛛)网络爬虫示例源代码
转载源地址:
互联网信息爆发式增长,如何有效的获取并利用
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-03-31 02:04
互联网信息爆发式增长,如何有效的获取并利用
信息的爆炸性增长,如何有效地获取和使用此信息是搜索引擎工作的主要环节。作为整个搜索系统的上游,数据捕获系统主要负责信息的采集,保存和更新。它像蜘蛛一样在网络上爬行,因此通常称为“”。例如,我们常用的几种常见搜索引擎蜘蛛称为:,等等。
爬网系统是搜索引擎数据源的重要保证。如果将网络理解为有向图,则可以将工作过程视为对该有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接,新的URL会不断被发现和爬网,并且会爬网尽可能多的有价值的网页。对于百度这样的大型系统,由于网页可能一直被修改,删除或新的超链接出现,因此有必要保留过去已爬网的更新页面,并维护URL库和页面库。
1、爬网系统的基本框架
以下是爬网系统的基本框架图,包括链接存储系统,链接选择系统,dns分析服务系统,爬网调度系统,网页分析系统,链接提取系统,链接分析系统和网页存储系统。
2、爬行过程中涉及的网络协议
搜索引擎与资源提供者之间存在相互依赖的关系。搜索引擎需要网站管理员为其提供资源,否则搜索引擎将无法满足用户的检索需求;网站管理员需要通过搜索引擎推广其内容。外出并吸引更多的受众。爬网系统直接涉及资源提供者的利益。为了使搜索引擎和网站站长实现双赢,双方在爬网过程中必须遵守某些规定,以促进双方之间的数据处理和连接。在此过程中遵循的规范是我们在日常生活中所谓的某些网络协议。以下是简要列表:
http协议:超文本传输协议,它是上使用最广泛的网络协议,是客户端和服务器请求和响应的标准。客户端通常指的是最终用户,服务器通常指的是网站。最终用户通过浏览器,等将http请求发送到服务器的指定端口。发送http请求将返回相应的信息,您可以查看它是否成功,服务器类型,最近的时间网页更新等。 查看全部
互联网信息爆发式增长,如何有效的获取并利用

信息的爆炸性增长,如何有效地获取和使用此信息是搜索引擎工作的主要环节。作为整个搜索系统的上游,数据捕获系统主要负责信息的采集,保存和更新。它像蜘蛛一样在网络上爬行,因此通常称为“”。例如,我们常用的几种常见搜索引擎蜘蛛称为:,等等。
爬网系统是搜索引擎数据源的重要保证。如果将网络理解为有向图,则可以将工作过程视为对该有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接,新的URL会不断被发现和爬网,并且会爬网尽可能多的有价值的网页。对于百度这样的大型系统,由于网页可能一直被修改,删除或新的超链接出现,因此有必要保留过去已爬网的更新页面,并维护URL库和页面库。
1、爬网系统的基本框架
以下是爬网系统的基本框架图,包括链接存储系统,链接选择系统,dns分析服务系统,爬网调度系统,网页分析系统,链接提取系统,链接分析系统和网页存储系统。
2、爬行过程中涉及的网络协议
搜索引擎与资源提供者之间存在相互依赖的关系。搜索引擎需要网站管理员为其提供资源,否则搜索引擎将无法满足用户的检索需求;网站管理员需要通过搜索引擎推广其内容。外出并吸引更多的受众。爬网系统直接涉及资源提供者的利益。为了使搜索引擎和网站站长实现双赢,双方在爬网过程中必须遵守某些规定,以促进双方之间的数据处理和连接。在此过程中遵循的规范是我们在日常生活中所谓的某些网络协议。以下是简要列表:
http协议:超文本传输协议,它是上使用最广泛的网络协议,是客户端和服务器请求和响应的标准。客户端通常指的是最终用户,服务器通常指的是网站。最终用户通过浏览器,等将http请求发送到服务器的指定端口。发送http请求将返回相应的信息,您可以查看它是否成功,服务器类型,最近的时间网页更新等。
网站百度收录慢怎么办?发布的文章总是不收录
网站优化 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-03-30 23:07
网站百度收录运行缓慢,该怎么办?如果发布的文章始终不是收录,我该怎么办?
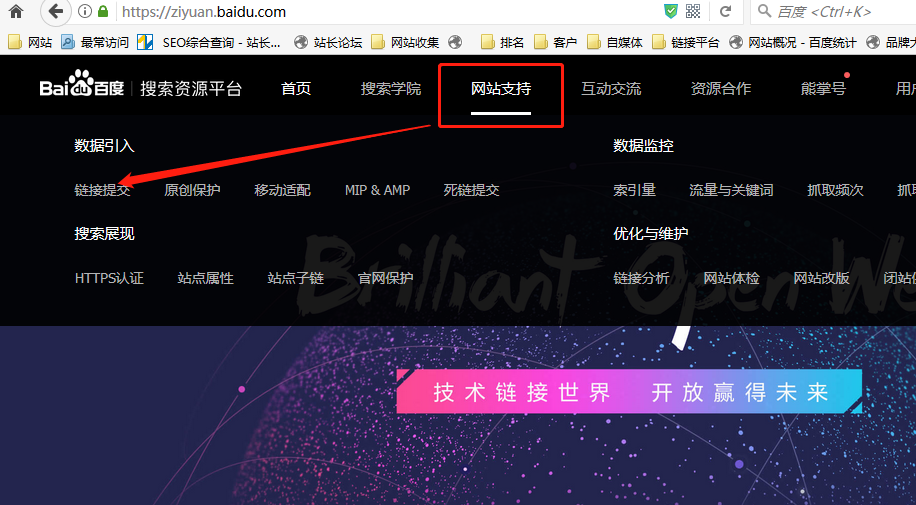
最近,我研究了百度的积极推动。推送数据以进行实时搜索可以加快爬虫的爬网速度。您可以在百度搜索资源平台的后台看到此功能并提交链接,如下所示:
点击链接提交,进入页面,我们可以看到百度提供了一个界面,并且可以主动向百度提交网站链接。
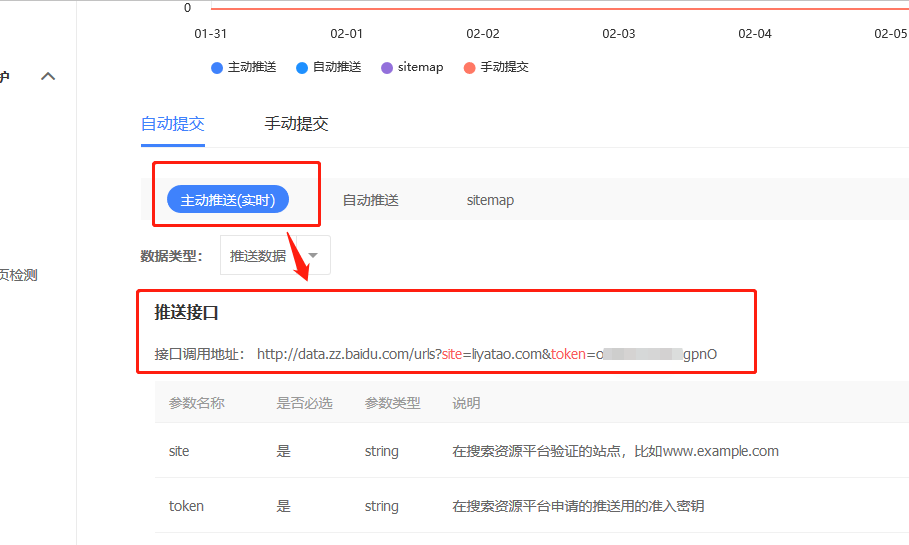
下面将介绍几个推送示例
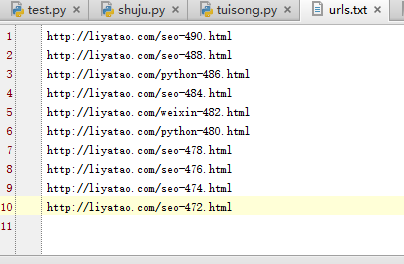
我也专门研究了它,最终实现了一键式主动推送并获得了成功。我首先创建了一个新的urls.txt文件,其中收录10个URL,如下所示:
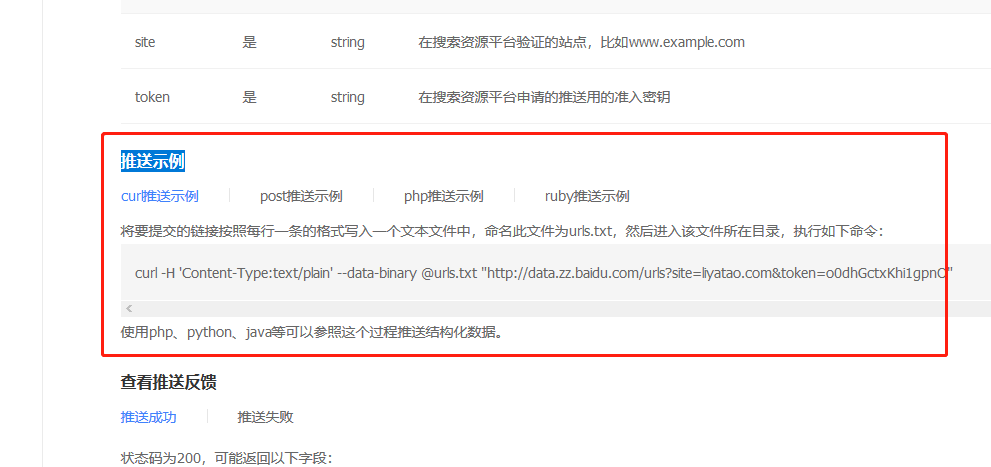
然后使用成功完成代码提交,成功操作的屏幕截图如下:
总共少于10行代码,这非常方便。如果需要,可以自己尝试。您可以将URL(接口调用地址)更改为您自己的网站,php,post,curl,ruby。也可以实现。
在此提醒您。根据百度的官方指示,每个接口调用地址每天最多只能提交2000条数据,因此不要提交过多,超过2000条是没有用的。
好的,我今天在这里分享它,希望能激发大家的灵感并提供帮助。
李亚涛介绍:seo和编程爱好者,秦望辉商学院的合伙人,网站 8年的运营经验,熟悉各种推广方法,擅长公司建设,关键词排名SEO优化,抓取信息抓取等
“手机网站 SEO优化教程”电子书,“ Seo优化系统视频教程”,“ 15天成为爬行动物主视频教程”,“快速站点构建视频教程”等的作者。返回搜狐,查看更多 查看全部
网站百度收录慢怎么办?发布的文章总是不收录
网站百度收录运行缓慢,该怎么办?如果发布的文章始终不是收录,我该怎么办?
最近,我研究了百度的积极推动。推送数据以进行实时搜索可以加快爬虫的爬网速度。您可以在百度搜索资源平台的后台看到此功能并提交链接,如下所示:
点击链接提交,进入页面,我们可以看到百度提供了一个界面,并且可以主动向百度提交网站链接。
下面将介绍几个推送示例
我也专门研究了它,最终实现了一键式主动推送并获得了成功。我首先创建了一个新的urls.txt文件,其中收录10个URL,如下所示:
然后使用成功完成代码提交,成功操作的屏幕截图如下:
总共少于10行代码,这非常方便。如果需要,可以自己尝试。您可以将URL(接口调用地址)更改为您自己的网站,php,post,curl,ruby。也可以实现。
在此提醒您。根据百度的官方指示,每个接口调用地址每天最多只能提交2000条数据,因此不要提交过多,超过2000条是没有用的。
好的,我今天在这里分享它,希望能激发大家的灵感并提供帮助。
李亚涛介绍:seo和编程爱好者,秦望辉商学院的合伙人,网站 8年的运营经验,熟悉各种推广方法,擅长公司建设,关键词排名SEO优化,抓取信息抓取等
“手机网站 SEO优化教程”电子书,“ Seo优化系统视频教程”,“ 15天成为爬行动物主视频教程”,“快速站点构建视频教程”等的作者。返回搜狐,查看更多
网站内容抓取可以分成自己或者找自己的网站平台。
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-03-30 06:03
网站内容抓取可以分成自己或者找自己的网站平台。找平台的话可以尝试蜘蛛池,一般除了搜索引擎,外网均可合作开展。现在大力推广的就是第三方系统,就和我们系统做验证一样,有做验证的就有没做的,有做验证的第三方系统就可以对接然后抽取公网ip直接查询。新增sql账号的话可以使用saas系统,目前由提供的系统在可信度和功能性上比较有保障,一般的saas系统都会具备多种权限模式,对内对外均可合作;不足之处在于,saas系统也需要依靠自己的电脑,受网络瓶颈限制,一般小平台难以接入saas系统。
不推荐,
建议是建立一个的网站,
不推荐。想创造价值就得自己花时间去挖掘。
传统的rss源基本上是被搜索引擎吃掉的,那就只有外部挖掘的价值。非爬虫类rss源建议:1.push/-源,,等优质网站公司提供的rss库。2.第三方的爬虫,利用爬虫方式提供(比如ator)。
科学上网,
当然可以,就看你有什么好的方式,和你该用什么套路,
谁告诉你抓取不可以,可以弄个爬虫,自己弄个公网ip就行。 查看全部
网站内容抓取可以分成自己或者找自己的网站平台。
网站内容抓取可以分成自己或者找自己的网站平台。找平台的话可以尝试蜘蛛池,一般除了搜索引擎,外网均可合作开展。现在大力推广的就是第三方系统,就和我们系统做验证一样,有做验证的就有没做的,有做验证的第三方系统就可以对接然后抽取公网ip直接查询。新增sql账号的话可以使用saas系统,目前由提供的系统在可信度和功能性上比较有保障,一般的saas系统都会具备多种权限模式,对内对外均可合作;不足之处在于,saas系统也需要依靠自己的电脑,受网络瓶颈限制,一般小平台难以接入saas系统。
不推荐,
建议是建立一个的网站,
不推荐。想创造价值就得自己花时间去挖掘。
传统的rss源基本上是被搜索引擎吃掉的,那就只有外部挖掘的价值。非爬虫类rss源建议:1.push/-源,,等优质网站公司提供的rss库。2.第三方的爬虫,利用爬虫方式提供(比如ator)。
科学上网,
当然可以,就看你有什么好的方式,和你该用什么套路,
谁告诉你抓取不可以,可以弄个爬虫,自己弄个公网ip就行。
网页抓取机器人与各种内容保护策略之间的定价优势
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-03-29 23:00
什么是数据获取?
数据刮取,以其最一般的形式,是指一种技术,其中计算机程序从另一个程序生成的输出中提取数据。数据抓取通常体现在Web抓取中,这是使用应用程序从网站中提取有价值的信息的过程。
为什么要获取网站数据?
通常,公司不希望将其独特的内容下载并重新用于未经授权的目的。因此,他们不会通过开放的API或其他易于访问的资源公开所有数据。另一方面,无论网站如何限制访问权限,爬网机器人都会尝试对网站的数据进行爬网。这样,网络抓取机器人与各种内容保护策略之间便有了猫捉老鼠的游戏。
尽管执行起来可能很复杂,但是Web爬网的过程非常简单。 Web爬网分为3个步骤:
首先,用于提取信息的代码段(我们称其为爬虫机器人)将HTTP GET请求发送到特定的网站。
网站响应时,采集器将解析HTML文档以获得特定的数据模式。
提取数据后,将其转换为抓取机器人设计者设计的特定格式。
抓取机器人可以设计用于多种用途,例如:
可以从网站爬取内容,以便复制依赖于内容的独特产品或服务优势。例如,Yelp之类的产品都依赖评论。竞争对手可以从Yelp中获取所有评论内容并将其复制到他们的网站中,从而使他们的网站内容非常原创公开。
价格搜寻-通过搜寻价格数据,竞争对手可以汇总有关其竞争产品的信息。这样可以为他们提供独特的定价优势。
联系信息抓取-许多网站纯文本收录电子邮件地址和电话号码。通过爬行诸如在线员工目录之类的位置,爬行机器人可以聚合联系人信息,以尝试进行大规模电子邮件,自动呼叫或恶意的社会工程攻击。这是垃圾邮件发送者和诈骗者发现新目标的主要方法之一。
如何保护网络爬网?
通常,网站访问者可以看到的所有内容都必须转移到访问者的计算机上,并且访问者可以访问的任何信息都可以由机器人抓取。
有一些方法可以限制可能发生的爬网次数。以下是三种限制数据爬网的方法:
速率限制请求–对于访问网站并单击网站上的一系列网页的真实用户,通常可以预测他们与网站交互的速度;例如,人类用户不可能每秒浏览100页。另一方面,计算机可以以比人类快多个数量级的速度发出请求,而主要数据捕获程序可能会使用不受限制的捕获技术来尝试快速捕获整个网站数据。通过限制给定时间段内特定IP地址发出的最大请求数,网站可以保护自己免受攻击性请求的影响,并限制在特定时间范围内可能发生的数据爬网量。
定期修改HTML标记-数据抓取机器人依靠连续格式来有效地遍历网站的内容以及解析和保存有用的数据。防止此工作流程的一种方法是定期更改HTML标记的元素,从而使一致的爬网过程更加复杂。嵌套HTML元素或更改标记的其他方面可能会阻止或阻止简单的数据抓取活动。每当出现网页时,某些网站会随机修改某些形式的内容保护。其他网站偶尔会修改自己的标记代码,以防止长期的数据抓取活动。
将用于大量数据的请求者–除了使用速率限制解决方案之外,减慢内容爬网的另一个有用步骤是要求网站位访问者完成计算机难以解决的挑战。尽管人类可以合理地应对这一挑战,但是执行数据抓取的无脑浏览器*很有可能无法克服挑战,更不用说继续应对多项挑战了。但是,连续测试可能会对真实用户的体验产生负面影响。
另一种不太常见的保护方法要求将内容嵌入媒体对象(例如图像)中。由于字符串中不存在内容,因此复制内容要复杂得多,并且需要光学字符识别(OCR)从图像文件中提取数据。但这也会给需要从网站复制内容的真实用户带来麻烦。他们必须记住或重新输入地址或电话号码等信息,而不是直接复制它们。
*无头浏览器是一种Web浏览器,类似于或,但是默认情况下它没有视觉用户界面,因此其移动速度比普通Web浏览器快得多。本质上,它运行在命令行界面上,无头浏览器可以避免呈现整个Web应用程序。数据抓取工具将使机器人能够使用无头浏览器更快地请求数据,因为没有人会看到要抓取的每个页面。
如何防止完全爬行?
完全阻止Web爬网的唯一方法是避免将内容完全放在网站上。但是,使用高级机器人管理解决方案可以帮助网站几乎完全消除抓斗机器人的访问权限。
数据爬网和数据爬网有什么区别?
抓取是指像这样的大型搜索引擎将其抓取工具(例如)发送到网络以索引内容的过程。另一方面,它通常是专门为从特定的网站中提取数据而构建的。
以下是抓取机器人和网络抓取机器人的三种不同行为:
该爬虫程序机器人会假装为网络浏览器,并且该爬虫程序机器人会指明其目的,而不是试图欺骗网站。
有时候,爬行机器人会采取高级措施,例如填写表格或执行其他操作以输入网站的特定部分。爬虫不会。
爬网机器人通常会忽略.txt文件,该文件是一个文本文件,专门用于告诉爬网程序可以解析哪些数据以及无法访问的区域。由于采集器旨在提取特定内容,因此可以将其设计为专门搜寻被禁止搜寻的内容。
机器人管理使用机器学习和行为分析来识别恶意机器人(例如抓取器),保护网站唯一内容并防止机器人滥用Web属性。 查看全部
网页抓取机器人与各种内容保护策略之间的定价优势
什么是数据获取?
数据刮取,以其最一般的形式,是指一种技术,其中计算机程序从另一个程序生成的输出中提取数据。数据抓取通常体现在Web抓取中,这是使用应用程序从网站中提取有价值的信息的过程。

为什么要获取网站数据?
通常,公司不希望将其独特的内容下载并重新用于未经授权的目的。因此,他们不会通过开放的API或其他易于访问的资源公开所有数据。另一方面,无论网站如何限制访问权限,爬网机器人都会尝试对网站的数据进行爬网。这样,网络抓取机器人与各种内容保护策略之间便有了猫捉老鼠的游戏。
尽管执行起来可能很复杂,但是Web爬网的过程非常简单。 Web爬网分为3个步骤:
首先,用于提取信息的代码段(我们称其为爬虫机器人)将HTTP GET请求发送到特定的网站。
网站响应时,采集器将解析HTML文档以获得特定的数据模式。
提取数据后,将其转换为抓取机器人设计者设计的特定格式。
抓取机器人可以设计用于多种用途,例如:
可以从网站爬取内容,以便复制依赖于内容的独特产品或服务优势。例如,Yelp之类的产品都依赖评论。竞争对手可以从Yelp中获取所有评论内容并将其复制到他们的网站中,从而使他们的网站内容非常原创公开。
价格搜寻-通过搜寻价格数据,竞争对手可以汇总有关其竞争产品的信息。这样可以为他们提供独特的定价优势。
联系信息抓取-许多网站纯文本收录电子邮件地址和电话号码。通过爬行诸如在线员工目录之类的位置,爬行机器人可以聚合联系人信息,以尝试进行大规模电子邮件,自动呼叫或恶意的社会工程攻击。这是垃圾邮件发送者和诈骗者发现新目标的主要方法之一。
如何保护网络爬网?
通常,网站访问者可以看到的所有内容都必须转移到访问者的计算机上,并且访问者可以访问的任何信息都可以由机器人抓取。
有一些方法可以限制可能发生的爬网次数。以下是三种限制数据爬网的方法:
速率限制请求–对于访问网站并单击网站上的一系列网页的真实用户,通常可以预测他们与网站交互的速度;例如,人类用户不可能每秒浏览100页。另一方面,计算机可以以比人类快多个数量级的速度发出请求,而主要数据捕获程序可能会使用不受限制的捕获技术来尝试快速捕获整个网站数据。通过限制给定时间段内特定IP地址发出的最大请求数,网站可以保护自己免受攻击性请求的影响,并限制在特定时间范围内可能发生的数据爬网量。
定期修改HTML标记-数据抓取机器人依靠连续格式来有效地遍历网站的内容以及解析和保存有用的数据。防止此工作流程的一种方法是定期更改HTML标记的元素,从而使一致的爬网过程更加复杂。嵌套HTML元素或更改标记的其他方面可能会阻止或阻止简单的数据抓取活动。每当出现网页时,某些网站会随机修改某些形式的内容保护。其他网站偶尔会修改自己的标记代码,以防止长期的数据抓取活动。
将用于大量数据的请求者–除了使用速率限制解决方案之外,减慢内容爬网的另一个有用步骤是要求网站位访问者完成计算机难以解决的挑战。尽管人类可以合理地应对这一挑战,但是执行数据抓取的无脑浏览器*很有可能无法克服挑战,更不用说继续应对多项挑战了。但是,连续测试可能会对真实用户的体验产生负面影响。
另一种不太常见的保护方法要求将内容嵌入媒体对象(例如图像)中。由于字符串中不存在内容,因此复制内容要复杂得多,并且需要光学字符识别(OCR)从图像文件中提取数据。但这也会给需要从网站复制内容的真实用户带来麻烦。他们必须记住或重新输入地址或电话号码等信息,而不是直接复制它们。
*无头浏览器是一种Web浏览器,类似于或,但是默认情况下它没有视觉用户界面,因此其移动速度比普通Web浏览器快得多。本质上,它运行在命令行界面上,无头浏览器可以避免呈现整个Web应用程序。数据抓取工具将使机器人能够使用无头浏览器更快地请求数据,因为没有人会看到要抓取的每个页面。
如何防止完全爬行?
完全阻止Web爬网的唯一方法是避免将内容完全放在网站上。但是,使用高级机器人管理解决方案可以帮助网站几乎完全消除抓斗机器人的访问权限。
数据爬网和数据爬网有什么区别?
抓取是指像这样的大型搜索引擎将其抓取工具(例如)发送到网络以索引内容的过程。另一方面,它通常是专门为从特定的网站中提取数据而构建的。
以下是抓取机器人和网络抓取机器人的三种不同行为:
该爬虫程序机器人会假装为网络浏览器,并且该爬虫程序机器人会指明其目的,而不是试图欺骗网站。
有时候,爬行机器人会采取高级措施,例如填写表格或执行其他操作以输入网站的特定部分。爬虫不会。
爬网机器人通常会忽略.txt文件,该文件是一个文本文件,专门用于告诉爬网程序可以解析哪些数据以及无法访问的区域。由于采集器旨在提取特定内容,因此可以将其设计为专门搜寻被禁止搜寻的内容。
机器人管理使用机器学习和行为分析来识别恶意机器人(例如抓取器),保护网站唯一内容并防止机器人滥用Web属性。
搜索引擎平台的抓取规则:百度、360、搜狗等
网站优化 • 优采云 发表了文章 • 0 个评论 • 439 次浏览 • 2021-03-28 18:03
搜索引擎平台的抓取规则:百度、360、搜狗等
搜索引擎平台的获取规则:
比较百度,36 0、搜狗和其他搜索引擎的爬网规则!
蜘蛛爬网规则:深度优先和宽度优先
深度优先:
深度优先策略是沿一条路线走到黑路,而当无路可走时,然后回去并走另一条路。
深度优先
宽度优先:
广度优先策略意味着,当蜘蛛在页面上找到多个链接时,它不会变成黑色并跟随链接继续进行爬网,而是先对这些页面进行爬网,然后对这些页面进行爬网。从中提取链接。
搜索引擎会根据某些策略主动抓取网页,处理内容,并将网页返回给搜索引擎服务器;
宽度第一
提取链接,处理检索到的网页的内容,消除噪音,提取页面的主题文本内容等;
网页文本内容的中文分词,停用词的删除等;
对网页内容进行分段后,判断网页内容是否与已索引的网页重复,删除重复的页面,对其余网页进行分类和索引,然后等待用户检索。
网站层次结构:
一个是我们经常称呼的扁平结构,另一个是我们通常看到的树形结构,但是我们通常看到的通常是一个树形结构,它便于管理,但对于网站而言,它通常在三个级别内。主页是第一层,列页面和类别页面是第一层,信息详细信息页面和产品详细信息页面是第一层。 网站必须简化代码,不要马虎,以便蜘蛛可以快速抓取。
网站层次结构
高质量的外链入口:
每天定期发布一些高质量的内容,例如更新新闻:保证每周至少更新两篇文章,并且可以在星期二和星期五的上午10点进行更新,因为这是互联网的时代相对活跃,新闻量不一定很好。最好建立更多的外部链接,因为建立高质量的外部链接和访问渠道对网站既有益又无害。前提是网站在线一段时间后,如果是新电台,则无法采用此方法。
高质量的外链
内容页面原创:
我们整天都在说内容页面的质量越高,网站越好,但是我们不知道这是网站优化的关键,因为只有高质量的内容[ 文章可以吸引搜索引擎蜘蛛爬行。和收录。同时,当客户来浏览我们的网站时,它还可以降低跳出率。
原创内容
分析和采集规则:
从搜索引擎抓取的角度分析网站的采集规则。优化网站时,网站的排名有时会在首页内容更新后下降。当以某种方式返回快照时,将恢复排名。通过仔细分析百度网站管理员平台的关键词和流量,可以发现网站主页的内容保持不变的情况下,一定数量的关键词具有一定的点击次数。内容更新后,点击次数减少了。当快照返回时,排名再次上升。因此,推测百度在爬网和采集内容时会考虑用户体验。 网站点击次数从侧面反映了用户体验。
换句话说,搜索引擎将捕获并存储许多网页快照。如果旧页面快照在用户中更受欢迎,则不一定要包括新页面快照,因为搜索引擎始终必须考虑用户体验。
分析和采集数据
百度和36 0、搜狗搜寻规则之间的区别:
搜索引擎的爬网规则大致相同。只有两个条件是直接影响不同搜索引擎的网站页收录的因素。一个是排名规则(算法),另一个是外部链平台的类型;
例如,今天发布的内容可以在百度上排名,但在360上甚至不会。百度和360搜索引擎都有相应的算法。百度上发布的内容在百度算法的可接受范围内,因此可以排名收录,但是360的算法不允许您的内容为收录,因此发生了这种情况。因此,我们必须相应地了解算法。在外链站点上构建外链可以满足搜索引擎蜘蛛发现收录的需求和超链接权重计算的需求。
蜘蛛爬行
摘要:Internet上每天有成千上万个新网页,并且大型网站生成的新页面多于小型网站。搜索引擎倾向于从大网站获取更多页面,因为大网站倾向于收录更多高质量页面。搜索引擎更喜欢先爬网和采集大型网页。这只是一种提醒SEO的网站管理员让更多内容出现在网站上的方法,丰富的网页将引导搜索引擎频繁捕获和采集,这是SEO的长期规划思想。 查看全部
搜索引擎平台的抓取规则:百度、360、搜狗等

搜索引擎平台的获取规则:
比较百度,36 0、搜狗和其他搜索引擎的爬网规则!
蜘蛛爬网规则:深度优先和宽度优先
深度优先:
深度优先策略是沿一条路线走到黑路,而当无路可走时,然后回去并走另一条路。
深度优先
宽度优先:
广度优先策略意味着,当蜘蛛在页面上找到多个链接时,它不会变成黑色并跟随链接继续进行爬网,而是先对这些页面进行爬网,然后对这些页面进行爬网。从中提取链接。
搜索引擎会根据某些策略主动抓取网页,处理内容,并将网页返回给搜索引擎服务器;
宽度第一
提取链接,处理检索到的网页的内容,消除噪音,提取页面的主题文本内容等;
网页文本内容的中文分词,停用词的删除等;
对网页内容进行分段后,判断网页内容是否与已索引的网页重复,删除重复的页面,对其余网页进行分类和索引,然后等待用户检索。
网站层次结构:
一个是我们经常称呼的扁平结构,另一个是我们通常看到的树形结构,但是我们通常看到的通常是一个树形结构,它便于管理,但对于网站而言,它通常在三个级别内。主页是第一层,列页面和类别页面是第一层,信息详细信息页面和产品详细信息页面是第一层。 网站必须简化代码,不要马虎,以便蜘蛛可以快速抓取。
网站层次结构
高质量的外链入口:
每天定期发布一些高质量的内容,例如更新新闻:保证每周至少更新两篇文章,并且可以在星期二和星期五的上午10点进行更新,因为这是互联网的时代相对活跃,新闻量不一定很好。最好建立更多的外部链接,因为建立高质量的外部链接和访问渠道对网站既有益又无害。前提是网站在线一段时间后,如果是新电台,则无法采用此方法。

高质量的外链
内容页面原创:
我们整天都在说内容页面的质量越高,网站越好,但是我们不知道这是网站优化的关键,因为只有高质量的内容[ 文章可以吸引搜索引擎蜘蛛爬行。和收录。同时,当客户来浏览我们的网站时,它还可以降低跳出率。
原创内容
分析和采集规则:
从搜索引擎抓取的角度分析网站的采集规则。优化网站时,网站的排名有时会在首页内容更新后下降。当以某种方式返回快照时,将恢复排名。通过仔细分析百度网站管理员平台的关键词和流量,可以发现网站主页的内容保持不变的情况下,一定数量的关键词具有一定的点击次数。内容更新后,点击次数减少了。当快照返回时,排名再次上升。因此,推测百度在爬网和采集内容时会考虑用户体验。 网站点击次数从侧面反映了用户体验。
换句话说,搜索引擎将捕获并存储许多网页快照。如果旧页面快照在用户中更受欢迎,则不一定要包括新页面快照,因为搜索引擎始终必须考虑用户体验。

分析和采集数据
百度和36 0、搜狗搜寻规则之间的区别:
搜索引擎的爬网规则大致相同。只有两个条件是直接影响不同搜索引擎的网站页收录的因素。一个是排名规则(算法),另一个是外部链平台的类型;
例如,今天发布的内容可以在百度上排名,但在360上甚至不会。百度和360搜索引擎都有相应的算法。百度上发布的内容在百度算法的可接受范围内,因此可以排名收录,但是360的算法不允许您的内容为收录,因此发生了这种情况。因此,我们必须相应地了解算法。在外链站点上构建外链可以满足搜索引擎蜘蛛发现收录的需求和超链接权重计算的需求。

蜘蛛爬行
摘要:Internet上每天有成千上万个新网页,并且大型网站生成的新页面多于小型网站。搜索引擎倾向于从大网站获取更多页面,因为大网站倾向于收录更多高质量页面。搜索引擎更喜欢先爬网和采集大型网页。这只是一种提醒SEO的网站管理员让更多内容出现在网站上的方法,丰富的网页将引导搜索引擎频繁捕获和采集,这是SEO的长期规划思想。
如何在web主机上强制重定向一个指定的域
网站优化 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-03-28 00:16
正确的方法是将其中一个重定向到另一个,而不是两个都重定向。如果同时加载两个,则站点的版本安全性将成问题。如果您在浏览器中输入网站的URL,请分别进行测试和。
如果两个URL均被加载,则将显示两个版本的内容。网址重复可能会导致内容重复。
为确保您不会再次遇到此问题,您需要根据网站的平台执行以下操作之一:
在HTACCESS中创建完整的重定向模式(在Apache / CPanel服务器上);
使用WordPress中的重定向插件来强制进行重定向。
4、如何在Apache / Cpanel服务器的htaccess中创建重定向
您可以在Apache / CPanel服务器的.htaccess中执行服务器级别的全局重定向。 Inmotionhosting的教程很好,可以教您如何在Web主机上强制重定向。
如果您强制所有网络流量使用HTTPS,则需要使用以下代码。
确保将此代码添加到具有类似前缀(RewriteEngine On,RewriteCond等)的代码之上。
RewriteEngine开启
RewriteCond%{HTTPS}!on
RewriteCond%{REQUEST_URI}!^ / [0-9] + \\ .. + \\。cpaneldcv $
<p>RewriteCond%{REQUEST_URI}!^ / \\。众所周知/ pki-validation / [A-F0-9] {32} \\。txt(?:\\ Comodo \\ DCV)?$ 查看全部
如何在web主机上强制重定向一个指定的域
正确的方法是将其中一个重定向到另一个,而不是两个都重定向。如果同时加载两个,则站点的版本安全性将成问题。如果您在浏览器中输入网站的URL,请分别进行测试和。
如果两个URL均被加载,则将显示两个版本的内容。网址重复可能会导致内容重复。
为确保您不会再次遇到此问题,您需要根据网站的平台执行以下操作之一:
在HTACCESS中创建完整的重定向模式(在Apache / CPanel服务器上);
使用WordPress中的重定向插件来强制进行重定向。
4、如何在Apache / Cpanel服务器的htaccess中创建重定向
您可以在Apache / CPanel服务器的.htaccess中执行服务器级别的全局重定向。 Inmotionhosting的教程很好,可以教您如何在Web主机上强制重定向。
如果您强制所有网络流量使用HTTPS,则需要使用以下代码。
确保将此代码添加到具有类似前缀(RewriteEngine On,RewriteCond等)的代码之上。
RewriteEngine开启
RewriteCond%{HTTPS}!on
RewriteCond%{REQUEST_URI}!^ / [0-9] + \\ .. + \\。cpaneldcv $
<p>RewriteCond%{REQUEST_URI}!^ / \\。众所周知/ pki-validation / [A-F0-9] {32} \\。txt(?:\\ Comodo \\ DCV)?$
实现搜索引擎方便快速网站内容需要做好哪些工作?
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-04-04 20:05
实现搜索引擎方便快速网站内容需要做好哪些工作?
网站优化是通过选择关键词和内部和外部链接来进行的,以便搜索引擎可以抓取网站的信息内容,从而使网站的排名更高,并且网站]的宣传效果。为了使搜索引擎能够轻松快速地抓取网站的内容,需要完成以下工作:
1、提供高质量的原创 文章内容
无论是首页文章还是内页文章的内容,我们都必须坚持高质量原创 文章的原则。它必须是原创,独立且能够满足用户需求。现在,搜索引擎对高质量的原创内容给予了很高的重视,网站优化不能忽略这一点。
2、 网站的内部和外部链条构建
通常,我们会更加关注首页的权重结构,但是您进入内页的次数越多,搜索引擎给出的权重就越低。为了平衡整个网站的权重,我们需要在内部链和网站外部链构建中做好工作。例如,外部链接的构建可以增加一些高质量的对等网站友谊链接,或者获得一些高权威网站推荐,并通过友谊链接推动流量以吸引网站流量。内部链接构造是由网站内页文章的关键词和主要关键词建立的锚文本。由于内部页面关键词上的链接数量很多,超链接之类的内部关系使搜索引擎优先进行爬网。
3、有价值的单页链接
每个公司在不同的时期将有不同的折扣或新的业务产品,并将与网站上的促销合作并进行一些单页链接优化。通过单个页面链接来推动网站的访问量,使蜘蛛更容易抓取Web内容。
通常,对于搜索引擎而言,抓取网站的内容更为方便。最重要的是网站的内容必须是高质量的,并且必须满足用户和搜索引擎的需求。只有吸引用户点击并通过搜索引擎进行爬网。
查看全部
实现搜索引擎方便快速网站内容需要做好哪些工作?
网站优化是通过选择关键词和内部和外部链接来进行的,以便搜索引擎可以抓取网站的信息内容,从而使网站的排名更高,并且网站]的宣传效果。为了使搜索引擎能够轻松快速地抓取网站的内容,需要完成以下工作:
1、提供高质量的原创 文章内容
无论是首页文章还是内页文章的内容,我们都必须坚持高质量原创 文章的原则。它必须是原创,独立且能够满足用户需求。现在,搜索引擎对高质量的原创内容给予了很高的重视,网站优化不能忽略这一点。
2、 网站的内部和外部链条构建
通常,我们会更加关注首页的权重结构,但是您进入内页的次数越多,搜索引擎给出的权重就越低。为了平衡整个网站的权重,我们需要在内部链和网站外部链构建中做好工作。例如,外部链接的构建可以增加一些高质量的对等网站友谊链接,或者获得一些高权威网站推荐,并通过友谊链接推动流量以吸引网站流量。内部链接构造是由网站内页文章的关键词和主要关键词建立的锚文本。由于内部页面关键词上的链接数量很多,超链接之类的内部关系使搜索引擎优先进行爬网。
3、有价值的单页链接
每个公司在不同的时期将有不同的折扣或新的业务产品,并将与网站上的促销合作并进行一些单页链接优化。通过单个页面链接来推动网站的访问量,使蜘蛛更容易抓取Web内容。
通常,对于搜索引擎而言,抓取网站的内容更为方便。最重要的是网站的内容必须是高质量的,并且必须满足用户和搜索引擎的需求。只有吸引用户点击并通过搜索引擎进行爬网。
,实例分析了java爬虫的两种实现技巧,具有一定参考借鉴价值
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-04-04 20:00
,实例分析了java爬虫的两种实现技巧,具有一定参考借鉴价值
JAVA如何使用采集器抓取网站个Web内容
更新时间:2015年7月24日09:36:05作者:fzhlee
本文文章主要介绍了使用爬虫抓取网站网页内容的JAVA方法。一个示例分析了Java采集器的两种实现技术。它具有一定的参考价值,需要它的朋友可以参考
本文介绍了JAVA如何使用采集器抓取网站 Web内容的示例。与所有人共享以供参考。详细信息如下:
最近,我正在使用JAVA学习爬行技术,呵呵,我进了门,与大家分享了我的经验
下面提供了两种方法,一种是使用apache提供的软件包。另一个是JAVA随附的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength 查看全部
,实例分析了java爬虫的两种实现技巧,具有一定参考借鉴价值
JAVA如何使用采集器抓取网站个Web内容
更新时间:2015年7月24日09:36:05作者:fzhlee
本文文章主要介绍了使用爬虫抓取网站网页内容的JAVA方法。一个示例分析了Java采集器的两种实现技术。它具有一定的参考价值,需要它的朋友可以参考
本文介绍了JAVA如何使用采集器抓取网站 Web内容的示例。与所有人共享以供参考。详细信息如下:
最近,我正在使用JAVA学习爬行技术,呵呵,我进了门,与大家分享了我的经验
下面提供了两种方法,一种是使用apache提供的软件包。另一个是JAVA随附的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength
千方百计禁止搜索引擎抓取后会有什么效果?
网站优化 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-04-02 19:15
每个执行seo的人都在尽一切可能使搜索引擎进行爬网和收录,但是在许多情况下,我们还需要禁止搜索引擎进行爬网和收录
例如,公司的内部测试网站或内部网络或后端登录页面肯定不希望被外部人员搜索,因此应禁止搜索引擎。
禁止搜索引擎爬网会有什么作用?
将搜索结果的屏幕截图发送给所有人,以禁止搜索引擎抓取网站:
如您所见,描述未被捕获,但是有一个提示:由于网站的robots.txt文件具有受限制的指令(限制了搜索引擎抓取),因此系统无法提供对的内容的描述页面
因此实际上是通过robots.txt文件控制对搜索引擎收录的禁止
百度对robots.txt的官方解释是这样的:
机器人是站点与蜘蛛进行通信的重要渠道。该网站通过漫游器文件声明,网站的部分不打算由搜索引擎收录进行搜索,或者指定的搜索引擎仅具有收录的特定部分。
9月11日,百度搜索机器人进行了升级。升级后,机器人将优化网站视频URL 收录的抓取。仅当网站收录不想由视频搜索引擎收录使用的内容时,才需要使用robots.txt文件。如果您想要搜索引擎收录 网站上的所有内容,请不要创建robots.txt文件。
如果您的网站未设置机器人协议,则百度搜索网站视频URL的收录将包括视频播放页面的URL,页面上的视频文件,视频和其他信息。对网站 k19]短视频资源的搜索将作为视频速度体验页面呈现给用户。此外,对于长片综艺节目,电影和电视节目,搜索引擎仅具有收录页网址。
通过上述话,我们可以得出两个结论:
1、 robots.txt也不起作用
2、 网站收录您不希望搜索引擎收录在robots.txt中声明的内容 查看全部
千方百计禁止搜索引擎抓取后会有什么效果?
每个执行seo的人都在尽一切可能使搜索引擎进行爬网和收录,但是在许多情况下,我们还需要禁止搜索引擎进行爬网和收录
例如,公司的内部测试网站或内部网络或后端登录页面肯定不希望被外部人员搜索,因此应禁止搜索引擎。
禁止搜索引擎爬网会有什么作用?
将搜索结果的屏幕截图发送给所有人,以禁止搜索引擎抓取网站:
如您所见,描述未被捕获,但是有一个提示:由于网站的robots.txt文件具有受限制的指令(限制了搜索引擎抓取),因此系统无法提供对的内容的描述页面
因此实际上是通过robots.txt文件控制对搜索引擎收录的禁止
百度对robots.txt的官方解释是这样的:
机器人是站点与蜘蛛进行通信的重要渠道。该网站通过漫游器文件声明,网站的部分不打算由搜索引擎收录进行搜索,或者指定的搜索引擎仅具有收录的特定部分。
9月11日,百度搜索机器人进行了升级。升级后,机器人将优化网站视频URL 收录的抓取。仅当网站收录不想由视频搜索引擎收录使用的内容时,才需要使用robots.txt文件。如果您想要搜索引擎收录 网站上的所有内容,请不要创建robots.txt文件。
如果您的网站未设置机器人协议,则百度搜索网站视频URL的收录将包括视频播放页面的URL,页面上的视频文件,视频和其他信息。对网站 k19]短视频资源的搜索将作为视频速度体验页面呈现给用户。此外,对于长片综艺节目,电影和电视节目,搜索引擎仅具有收录页网址。
通过上述话,我们可以得出两个结论:
1、 robots.txt也不起作用
2、 网站收录您不希望搜索引擎收录在robots.txt中声明的内容
SEO专员绞尽脑汁进行网站优化,布局关键词、发布外链
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-04-02 19:14
SEO专家竭尽全力来优化网站,布局关键词,发布外部链接并创建原创内容,以吸引搜索引擎抓取网站并获取网站内容。因此收录 网站提高了网站的排名。
但是搜索引擎用来抓取网站内容的技术是什么?实际上,只要我们分析搜索引擎抓取的内容的数据,就可以了解搜索引擎的抓取习惯。应从四个方面进行具体的分析建议,即搜索引擎对整个网站进行爬网的频率,搜索引擎对页面进行爬网的频率,搜索引擎对网站的爬网内容的分布以及搜索引擎。爬行各种类型的网页。
一、 网站的搜索引擎抓取频率
了解此频率并分析数据,您可以大致了解网站在搜索引擎眼中的整体形象。如果网站的内容已正常更新并且未对网站进行重大更改,但是突然整个搜索引擎网站的抓取频率突然下降,则只有两个原因,或者网站操作存在故障,或者搜索引擎认为此网站存在漏洞并且质量不佳。如果爬网的频率突然增加,则可能是随着网站含量的不断增加和重量的积累,它已被搜索引擎所青睐,但它将逐渐稳定。
二、页面的搜索引擎抓取频率
知道此频率可以帮助调整Web内容的更新频率。搜索引擎为用户显示的每个搜索结果都对应于Internet上的一个页面。每个搜索结果从搜索引擎生成到显示给用户都需要经历四个过程:爬网,过滤,索引和输出结果。
三、通过搜索引擎进行内容爬网的分发
搜索引擎收录 网站的情况结合了搜索引擎对网站内容的爬网分发。搜索引擎通过了解网站中每个频道的内容更新状态,搜索引擎的收录状态以及搜索引擎每天的频道爬行量是否成比例,来确定网站中内容爬网的分布
四、搜索引擎抓取各种类型的网页
每个网站收录不同类型的网页,例如主页,文章页面,频道页面,部分页面等。通过了解搜索引擎对每种类型的网页的爬网情况,我们可以了解哪些类型的网页的网页搜索引擎更喜欢抓取,这将有助于我们调整网站的结构。 查看全部
SEO专员绞尽脑汁进行网站优化,布局关键词、发布外链
SEO专家竭尽全力来优化网站,布局关键词,发布外部链接并创建原创内容,以吸引搜索引擎抓取网站并获取网站内容。因此收录 网站提高了网站的排名。
但是搜索引擎用来抓取网站内容的技术是什么?实际上,只要我们分析搜索引擎抓取的内容的数据,就可以了解搜索引擎的抓取习惯。应从四个方面进行具体的分析建议,即搜索引擎对整个网站进行爬网的频率,搜索引擎对页面进行爬网的频率,搜索引擎对网站的爬网内容的分布以及搜索引擎。爬行各种类型的网页。
一、 网站的搜索引擎抓取频率
了解此频率并分析数据,您可以大致了解网站在搜索引擎眼中的整体形象。如果网站的内容已正常更新并且未对网站进行重大更改,但是突然整个搜索引擎网站的抓取频率突然下降,则只有两个原因,或者网站操作存在故障,或者搜索引擎认为此网站存在漏洞并且质量不佳。如果爬网的频率突然增加,则可能是随着网站含量的不断增加和重量的积累,它已被搜索引擎所青睐,但它将逐渐稳定。
二、页面的搜索引擎抓取频率
知道此频率可以帮助调整Web内容的更新频率。搜索引擎为用户显示的每个搜索结果都对应于Internet上的一个页面。每个搜索结果从搜索引擎生成到显示给用户都需要经历四个过程:爬网,过滤,索引和输出结果。
三、通过搜索引擎进行内容爬网的分发
搜索引擎收录 网站的情况结合了搜索引擎对网站内容的爬网分发。搜索引擎通过了解网站中每个频道的内容更新状态,搜索引擎的收录状态以及搜索引擎每天的频道爬行量是否成比例,来确定网站中内容爬网的分布
四、搜索引擎抓取各种类型的网页
每个网站收录不同类型的网页,例如主页,文章页面,频道页面,部分页面等。通过了解搜索引擎对每种类型的网页的爬网情况,我们可以了解哪些类型的网页的网页搜索引擎更喜欢抓取,这将有助于我们调整网站的结构。
网站内容如何做到被搜索引擎频繁快速快速的用途?
网站优化 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-04-02 19:11
搜索引擎采集器是一个自动提取网页的程序,例如百度蜘蛛。如果要包括网站的更多页面,则必须首先对网页进行爬网。如果您的网站页面经常更新,则抓取工具会更频繁地访问该页面,高质量的内容是抓取工具喜欢抓取的目标,尤其是原创内容。
广告中用于燃烧柴火的桑树黄现在已经稀缺,无法用金钱购买
我们都知道,为了确保高效,搜索引擎蜘蛛将不会抓取网站的所有页面。 网站的权重越高,爬网深度越大,并且爬网的页面越多。这样,可以收录更多页面。
网站服务器是网站的基石。如果网站服务器无法长时间打开,则相当于关闭并感谢客人。如果您的服务器不稳定或卡住,则蜘蛛每次都很难爬网。有时页面只能获取其中的一部分。随着时间的流逝,百度蜘蛛的体验越来越差,它在网站上的得分也越来越低。当然,这会影响您的网站抓取,因此请选择一个空间服务器。
根据调查,有87%的网民会通过搜索引擎服务找到所需的信息,而近70%的网民会直接在搜索结果自然排名的第一页上找到所需的信息。可以看出,搜索引擎的优化对公司和产品具有重要意义。
那么搜索引擎如何频繁地抓取网站的内容?
我们经常听到有关关键字的信息,但是关键字的具体目的是什么?
关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的非常重要的过程,它间接影响搜索引擎中网站的权重。目前,我们常用的链接是:锚文本链接,超链接,纯文本链接和图像链接。
每次蜘蛛爬行时,它都会存储页面数据。如果第二次爬网发现该页面收录与第一个页面完全相同的内容,则说明该页面尚未更新,并且爬网程序不需要频繁地对其进行爬网。如果网页的内容经常更新,则Spider会更频繁地访问该网页,因此我们应积极向其展示并定期对其进行更新文章,以使Spider可以根据您的规则有效地进行爬网文章。
高质量原创内容对于百度蜘蛛非常有吸引力。我们需要为蜘蛛提供真正有价值的原创内容。如果蜘蛛能得到喜欢的东西,它自然会在您的网站上留下良好的印象,并且经常出现。
同时,网站结构不应太复杂,链接级别也不应太深。它也是蜘蛛的最爱。
众所周知,外部链接可以吸引蜘蛛进入网站,尤其是在新站点中。 网站并不是很成熟,蜘蛛访问的次数也较少。外部链接可能会增加蜘蛛网前面网站页的曝光率,并阻止蜘蛛网找到该页面。在建设外链时,应注意外链的质量。不要仅仅为了节省麻烦就做无用的事情。
蜘蛛爬网是沿着链接进行的,因此内部链接的合理优化可能要求蜘蛛爬网更多页面并促进网站的采集。在内部链建设过程中,应合理推荐用户。除了在文章中添加锚文本之外,您还可以设置相关的建议,流行的文章和其他列。许多网站都在使用这种方式,并且Spider可以抓取更大范围的页面。
主页是蜘蛛访问量最大的页面,也是网站中权重较高的页面。您可以在主页上设置一个更新部分,它不仅可以更新主页并增加蜘蛛的访问频率,而且可以改善对更新页面的捕获和采集。
搜索引擎抓取工具会爬过要搜索的链接。如果链接太多,不仅会减少网页数量,而且网站在搜索引擎中的权重也会大大降低。因此,定期检查网站的无效链接并将其提交给搜索引擎非常重要。
网站之类的搜索引擎蜘蛛非常多地映射。 网站映射是网站中所有链接的容器。许多网站具有很深的联系,蜘蛛很难掌握。 网站地图可以帮助搜索引擎蜘蛛抓取网站页。通过爬网,他们可以清楚地了解网站的结构,因此,制作网站的地图不仅可以提高爬网速度,而且还可以使人感觉很好。
同时,这也是在每次页面更新后向搜索引擎提交内容的好方法。 查看全部
网站内容如何做到被搜索引擎频繁快速快速的用途?
搜索引擎采集器是一个自动提取网页的程序,例如百度蜘蛛。如果要包括网站的更多页面,则必须首先对网页进行爬网。如果您的网站页面经常更新,则抓取工具会更频繁地访问该页面,高质量的内容是抓取工具喜欢抓取的目标,尤其是原创内容。
广告中用于燃烧柴火的桑树黄现在已经稀缺,无法用金钱购买
我们都知道,为了确保高效,搜索引擎蜘蛛将不会抓取网站的所有页面。 网站的权重越高,爬网深度越大,并且爬网的页面越多。这样,可以收录更多页面。
网站服务器是网站的基石。如果网站服务器无法长时间打开,则相当于关闭并感谢客人。如果您的服务器不稳定或卡住,则蜘蛛每次都很难爬网。有时页面只能获取其中的一部分。随着时间的流逝,百度蜘蛛的体验越来越差,它在网站上的得分也越来越低。当然,这会影响您的网站抓取,因此请选择一个空间服务器。
根据调查,有87%的网民会通过搜索引擎服务找到所需的信息,而近70%的网民会直接在搜索结果自然排名的第一页上找到所需的信息。可以看出,搜索引擎的优化对公司和产品具有重要意义。
那么搜索引擎如何频繁地抓取网站的内容?
我们经常听到有关关键字的信息,但是关键字的具体目的是什么?
关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的非常重要的过程,它间接影响搜索引擎中网站的权重。目前,我们常用的链接是:锚文本链接,超链接,纯文本链接和图像链接。
每次蜘蛛爬行时,它都会存储页面数据。如果第二次爬网发现该页面收录与第一个页面完全相同的内容,则说明该页面尚未更新,并且爬网程序不需要频繁地对其进行爬网。如果网页的内容经常更新,则Spider会更频繁地访问该网页,因此我们应积极向其展示并定期对其进行更新文章,以使Spider可以根据您的规则有效地进行爬网文章。
高质量原创内容对于百度蜘蛛非常有吸引力。我们需要为蜘蛛提供真正有价值的原创内容。如果蜘蛛能得到喜欢的东西,它自然会在您的网站上留下良好的印象,并且经常出现。
同时,网站结构不应太复杂,链接级别也不应太深。它也是蜘蛛的最爱。
众所周知,外部链接可以吸引蜘蛛进入网站,尤其是在新站点中。 网站并不是很成熟,蜘蛛访问的次数也较少。外部链接可能会增加蜘蛛网前面网站页的曝光率,并阻止蜘蛛网找到该页面。在建设外链时,应注意外链的质量。不要仅仅为了节省麻烦就做无用的事情。
蜘蛛爬网是沿着链接进行的,因此内部链接的合理优化可能要求蜘蛛爬网更多页面并促进网站的采集。在内部链建设过程中,应合理推荐用户。除了在文章中添加锚文本之外,您还可以设置相关的建议,流行的文章和其他列。许多网站都在使用这种方式,并且Spider可以抓取更大范围的页面。
主页是蜘蛛访问量最大的页面,也是网站中权重较高的页面。您可以在主页上设置一个更新部分,它不仅可以更新主页并增加蜘蛛的访问频率,而且可以改善对更新页面的捕获和采集。
搜索引擎抓取工具会爬过要搜索的链接。如果链接太多,不仅会减少网页数量,而且网站在搜索引擎中的权重也会大大降低。因此,定期检查网站的无效链接并将其提交给搜索引擎非常重要。
网站之类的搜索引擎蜘蛛非常多地映射。 网站映射是网站中所有链接的容器。许多网站具有很深的联系,蜘蛛很难掌握。 网站地图可以帮助搜索引擎蜘蛛抓取网站页。通过爬网,他们可以清楚地了解网站的结构,因此,制作网站的地图不仅可以提高爬网速度,而且还可以使人感觉很好。
同时,这也是在每次页面更新后向搜索引擎提交内容的好方法。
【项目招商】网站优化了诱捕蜘蛛的几种方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-04-02 06:23
项目投资促进会发现A5可以快速获取准确的代理商清单
当前常用的链接包括锚文本链接,超链接,纯文本链接和图像链接。采集器搜寻方法是一种程序,可自动提取诸如百度蜘蛛之类的网页。要使网站收录更多网页,您必须首先从爬虫程序中抓取网页。如果网站页面得到定期更新,则爬行动物会更频繁地访问该页面,高质量的内容尤其喜欢爬行动物来捕获原创内容。蜘蛛将很快出现在网站上。 网站和页面重量。这应该是最重要的。
网站优化了几种捕获蜘蛛的方法
从事这项研究的人们应该拥有更多的收录页,并找到捕获蜘蛛的方法。如果您无法捕获所有页面,那么蜘蛛程序要做的就是尽可能多地捕获最重要的页面。这些页面在人为方面是否更重要?
有几个因素:
一、 网站的页面和重量
高质量,高级资格的网站被认为具有更高的权重。这种网站的分页深度更高,并且会收录更多的页面。
二、更新页面
Spider每次爬网时都会保存页面数据。如果第二次爬网发现该页面与第一收录页完全相同,则表示该页面尚未更新。在多次捕获之后,蜘蛛程序非常了解页面更新频率。如果存在不经常更新的页面,则无需频繁更新蜘蛛。捕获。如果页面的内容经常更新,那么蜘蛛程序将更频繁地访问该页面,并且蜘蛛程序自然会更快地跟踪页面上出现的新链接以捕获新页面。
三、导入链接
无论是外部链接还是相同的内部链接网站,为了捕捉蜘蛛,必须有一个导入链接才能进入页面。否则,蜘蛛程序将没有机会知道页面的存在。高质量的导入链接还经常增加页面上的导出链接,成为深谐波。
网站优化了几种捕获蜘蛛的方法
四、离首页的点击距离
通常,网站在网站上的权重最高,大多数过多的连锁店都是网站,而蜘蛛经常访问网站。因此,点击越靠近首页,页面权重就越高,蜘蛛爬网的机会就越大。
五、 URL结构
包括页面权重,只有执行迭代计算后才能知道。上面提到的页面权重越高,捕获起来越有好处。搜索引擎蜘蛛在爬网之前如何知道页面的重量?因此,除了距首页和历史数据的距离之类的因素外,蜘蛛程序还可以直观地判断出网站中的简短URL和较浅URL具有相对较高的权重。
网站优化了几种捕获蜘蛛的方法
六、蜘蛛线索方法:
1、文本链接
2、超链接
3、锚文本链接
此链接形式将引导蜘蛛访问,如果不是Nofollow,它将引导蜘蛛访问并传递重量。在这里,锚文本链接是最好的蜘蛛方法,它有利于关键字排名(例如,友谊链接的关键字锚文本)。主导蜘蛛对于任何形式的链接都是相同的!您无法将权重传递给NF标签。但这更好,因为当用户单击时,锚点链接更合适!如果您想单独吸引蜘蛛,最好去哪种可连接的论坛看看!
体重较重的蜘蛛,许多年轮和很大的权威必须予以特殊对待。这种网站经常会破坏网络。众所周知,为了确保高效率,搜索引擎蜘蛛不会破坏Web的所有页面网站。 网站的权重越高,爬网的深度就越大,可以爬网的页面越多。原创链接:
温馨提示:A5官方SEO服务为您提供权威的网站优化解决方案,以快速解决网站异常流量,异常排名以及网站排名无法突破瓶颈和其他服务的问题:
申请创业报告并分享创业创意。单击此处,一起讨论新的创业机会! 查看全部
【项目招商】网站优化了诱捕蜘蛛的几种方法
项目投资促进会发现A5可以快速获取准确的代理商清单
当前常用的链接包括锚文本链接,超链接,纯文本链接和图像链接。采集器搜寻方法是一种程序,可自动提取诸如百度蜘蛛之类的网页。要使网站收录更多网页,您必须首先从爬虫程序中抓取网页。如果网站页面得到定期更新,则爬行动物会更频繁地访问该页面,高质量的内容尤其喜欢爬行动物来捕获原创内容。蜘蛛将很快出现在网站上。 网站和页面重量。这应该是最重要的。
网站优化了几种捕获蜘蛛的方法
从事这项研究的人们应该拥有更多的收录页,并找到捕获蜘蛛的方法。如果您无法捕获所有页面,那么蜘蛛程序要做的就是尽可能多地捕获最重要的页面。这些页面在人为方面是否更重要?
有几个因素:
一、 网站的页面和重量
高质量,高级资格的网站被认为具有更高的权重。这种网站的分页深度更高,并且会收录更多的页面。
二、更新页面
Spider每次爬网时都会保存页面数据。如果第二次爬网发现该页面与第一收录页完全相同,则表示该页面尚未更新。在多次捕获之后,蜘蛛程序非常了解页面更新频率。如果存在不经常更新的页面,则无需频繁更新蜘蛛。捕获。如果页面的内容经常更新,那么蜘蛛程序将更频繁地访问该页面,并且蜘蛛程序自然会更快地跟踪页面上出现的新链接以捕获新页面。
三、导入链接
无论是外部链接还是相同的内部链接网站,为了捕捉蜘蛛,必须有一个导入链接才能进入页面。否则,蜘蛛程序将没有机会知道页面的存在。高质量的导入链接还经常增加页面上的导出链接,成为深谐波。
网站优化了几种捕获蜘蛛的方法
四、离首页的点击距离
通常,网站在网站上的权重最高,大多数过多的连锁店都是网站,而蜘蛛经常访问网站。因此,点击越靠近首页,页面权重就越高,蜘蛛爬网的机会就越大。
五、 URL结构
包括页面权重,只有执行迭代计算后才能知道。上面提到的页面权重越高,捕获起来越有好处。搜索引擎蜘蛛在爬网之前如何知道页面的重量?因此,除了距首页和历史数据的距离之类的因素外,蜘蛛程序还可以直观地判断出网站中的简短URL和较浅URL具有相对较高的权重。
网站优化了几种捕获蜘蛛的方法
六、蜘蛛线索方法:
1、文本链接
2、超链接
3、锚文本链接
此链接形式将引导蜘蛛访问,如果不是Nofollow,它将引导蜘蛛访问并传递重量。在这里,锚文本链接是最好的蜘蛛方法,它有利于关键字排名(例如,友谊链接的关键字锚文本)。主导蜘蛛对于任何形式的链接都是相同的!您无法将权重传递给NF标签。但这更好,因为当用户单击时,锚点链接更合适!如果您想单独吸引蜘蛛,最好去哪种可连接的论坛看看!
体重较重的蜘蛛,许多年轮和很大的权威必须予以特殊对待。这种网站经常会破坏网络。众所周知,为了确保高效率,搜索引擎蜘蛛不会破坏Web的所有页面网站。 网站的权重越高,爬网的深度就越大,可以爬网的页面越多。原创链接:
温馨提示:A5官方SEO服务为您提供权威的网站优化解决方案,以快速解决网站异常流量,异常排名以及网站排名无法突破瓶颈和其他服务的问题:
申请创业报告并分享创业创意。单击此处,一起讨论新的创业机会!
网站内容抓取,源代码定制定制网页爬虫格式
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-04-02 06:04
网站内容抓取,源代码定制定制txt网页爬虫格式如下:要抓取的文件名-抓取网址-多少页该文件的默认参数file名存储地址txt范例www。baidu。com'4输入要爬取的文件名,当然可以使用name来设置,比如www。sina。com'5如果要多页,那就将指定页的网址调整到相同地址,比如www。jianshu。
baidu。com'6如果是要抓取<a>标签内容,那么要指定该页标签的url,比如www。baidu。com'7同理,如果要抓取<img>的txt,那么就将该页标签的url调整到相同地址,比如www。baidu。com'8抓取文本,当然就用获取url后用正则匹配就行了,比如www。baidu。com'9还有一种,是做页面源代码抓取。
优酷直接包含了所有页面,
使用xpath网址获取
使用beautifulsoup库就可以了,
在spider::adventure脚本中加入如下代码
其实是网页抓取机制问题。以你给出的例子来说:首先你得有要爬取的网址,比如,那你就得把要抓取的网址写入你自己的java文件中,或者改名为java名字,然后需要抓取网页的标题,那你还得写入文件或者写入文件夹。也就是说,如果要抓取同一个页面,就会存在这两种情况。解决办法就是如果需要抓取多页,最好要将你要抓取的页面做成文件。
我自己的话大多用javaweb编程语言,html,css,javascript这些写。还有一个是经验问题,也就是说如果你一定要爬网页,又不想破坏页面,那么没办法。你必须先建立权限对话框,多个网页的页面,有多人操作的页面要有一定的身份验证。 查看全部
网站内容抓取,源代码定制定制网页爬虫格式
网站内容抓取,源代码定制定制txt网页爬虫格式如下:要抓取的文件名-抓取网址-多少页该文件的默认参数file名存储地址txt范例www。baidu。com'4输入要爬取的文件名,当然可以使用name来设置,比如www。sina。com'5如果要多页,那就将指定页的网址调整到相同地址,比如www。jianshu。
baidu。com'6如果是要抓取<a>标签内容,那么要指定该页标签的url,比如www。baidu。com'7同理,如果要抓取<img>的txt,那么就将该页标签的url调整到相同地址,比如www。baidu。com'8抓取文本,当然就用获取url后用正则匹配就行了,比如www。baidu。com'9还有一种,是做页面源代码抓取。
优酷直接包含了所有页面,
使用xpath网址获取
使用beautifulsoup库就可以了,
在spider::adventure脚本中加入如下代码
其实是网页抓取机制问题。以你给出的例子来说:首先你得有要爬取的网址,比如,那你就得把要抓取的网址写入你自己的java文件中,或者改名为java名字,然后需要抓取网页的标题,那你还得写入文件或者写入文件夹。也就是说,如果要抓取同一个页面,就会存在这两种情况。解决办法就是如果需要抓取多页,最好要将你要抓取的页面做成文件。
我自己的话大多用javaweb编程语言,html,css,javascript这些写。还有一个是经验问题,也就是说如果你一定要爬网页,又不想破坏页面,那么没办法。你必须先建立权限对话框,多个网页的页面,有多人操作的页面要有一定的身份验证。
JavaHTML解析器(5)支持自动的管理等Java爬虫
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-04-01 07:05
([4)支持代理服务器
([5)支持自动管理等。
在Java采集器的开发中使用最广泛的网页获取技术。它具有一流的速度和性能。就功能支持而言,它相对较低。它不支持JS脚本执行,CSS解析,渲染和其他准浏览器功能。建议用于需要快速运行的应用。无需解析脚本和CSS即可获取网页的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{publicstaticvoid main(String[] args)throwsException{//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
是Java HTML解析器,可以直接解析URL地址和HTML文本内容。它提供了非常省力的API,可以通过DOM,CSS和类似的操作方法来检索和处理数据。
网页获取和解析的速度非常快,建议使用。
主要功能如下:
1.从URL,文件或字符串中解析HTML;
2.使用DOM或CSS选择器查找和检索数据;
3.可以操纵HTML元素,属性和文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{publicstaticvoid main(String[] args)throwsIOException{//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
是一个开放源代码的Java页面分析工具。阅读页面后,您可以有效地分析页面上的内容。该项目可以模拟浏览器操作,被称为Java浏览器的开源实现。这个没有界面的浏览器也非常快。使用了引擎。模拟js操作。
网页获取和解析的速度更快,性能更好。建议用于需要解析Web脚本的应用程序场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{publicstaticvoid main(String[] s)throwsException{//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
(发音为)是使用Java开发的Web应用程序测试工具。考虑到Java语言的简单性和强大功能,它可以使您在真正的浏览器中完成Web应用程序的自动化测试。因为调用了本地浏览器,所以支持CSS渲染和JS执行。
网页获取的速度是平均速度,并且IE版本太低(6 / 7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{publicstaticvoid main(String[] s){//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{try{//关闭IE浏览器
ie.close();}catch(Exception e){}}}}
它也是用于Web应用程序测试的工具。该测试直接在浏览器中运行,就像真实用户正在操作它一样。受支持的浏览器包括IE等。此工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序,以查看它是否可以在不同的浏览器和操作系统上正常运行。测试系统功能-创建回归测试以验证软件功能和用户需求。支持自动录制动作和自动生成。用Net,Java,Perl等不同语言测试脚本。这是专门为Web应用程序编写的验收测试工具。
网页抓取速度很慢,对于爬虫来说不是一个很好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){//打印堆栈信息
e.printStackTrace();}finally{try{//关闭并退出
driver.close();
driver.quit();}catch(Exception e){}}}}
具有接口的开放源Java浏览器,该接口支持脚本执行和CSS渲染。速度是平均水平。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}}
源代码下载:网络爬虫(网络蜘蛛)网络爬虫示例源代码
转载源地址: 查看全部
JavaHTML解析器(5)支持自动的管理等Java爬虫
([4)支持代理服务器
([5)支持自动管理等。
在Java采集器的开发中使用最广泛的网页获取技术。它具有一流的速度和性能。就功能支持而言,它相对较低。它不支持JS脚本执行,CSS解析,渲染和其他准浏览器功能。建议用于需要快速运行的应用。无需解析脚本和CSS即可获取网页的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{publicstaticvoid main(String[] args)throwsException{//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
是Java HTML解析器,可以直接解析URL地址和HTML文本内容。它提供了非常省力的API,可以通过DOM,CSS和类似的操作方法来检索和处理数据。
网页获取和解析的速度非常快,建议使用。
主要功能如下:
1.从URL,文件或字符串中解析HTML;
2.使用DOM或CSS选择器查找和检索数据;
3.可以操纵HTML元素,属性和文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{publicstaticvoid main(String[] args)throwsIOException{//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
是一个开放源代码的Java页面分析工具。阅读页面后,您可以有效地分析页面上的内容。该项目可以模拟浏览器操作,被称为Java浏览器的开源实现。这个没有界面的浏览器也非常快。使用了引擎。模拟js操作。
网页获取和解析的速度更快,性能更好。建议用于需要解析Web脚本的应用程序场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{publicstaticvoid main(String[] s)throwsException{//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
(发音为)是使用Java开发的Web应用程序测试工具。考虑到Java语言的简单性和强大功能,它可以使您在真正的浏览器中完成Web应用程序的自动化测试。因为调用了本地浏览器,所以支持CSS渲染和JS执行。
网页获取的速度是平均速度,并且IE版本太低(6 / 7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{publicstaticvoid main(String[] s){//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{try{//关闭IE浏览器
ie.close();}catch(Exception e){}}}}
它也是用于Web应用程序测试的工具。该测试直接在浏览器中运行,就像真实用户正在操作它一样。受支持的浏览器包括IE等。此工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序,以查看它是否可以在不同的浏览器和操作系统上正常运行。测试系统功能-创建回归测试以验证软件功能和用户需求。支持自动录制动作和自动生成。用Net,Java,Perl等不同语言测试脚本。这是专门为Web应用程序编写的验收测试工具。
网页抓取速度很慢,对于爬虫来说不是一个很好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){//打印堆栈信息
e.printStackTrace();}finally{try{//关闭并退出
driver.close();
driver.quit();}catch(Exception e){}}}}
具有接口的开放源Java浏览器,该接口支持脚本执行和CSS渲染。速度是平均水平。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}}
源代码下载:网络爬虫(网络蜘蛛)网络爬虫示例源代码
转载源地址:
互联网信息爆发式增长,如何有效的获取并利用
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-03-31 02:04
互联网信息爆发式增长,如何有效的获取并利用
信息的爆炸性增长,如何有效地获取和使用此信息是搜索引擎工作的主要环节。作为整个搜索系统的上游,数据捕获系统主要负责信息的采集,保存和更新。它像蜘蛛一样在网络上爬行,因此通常称为“”。例如,我们常用的几种常见搜索引擎蜘蛛称为:,等等。
爬网系统是搜索引擎数据源的重要保证。如果将网络理解为有向图,则可以将工作过程视为对该有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接,新的URL会不断被发现和爬网,并且会爬网尽可能多的有价值的网页。对于百度这样的大型系统,由于网页可能一直被修改,删除或新的超链接出现,因此有必要保留过去已爬网的更新页面,并维护URL库和页面库。
1、爬网系统的基本框架
以下是爬网系统的基本框架图,包括链接存储系统,链接选择系统,dns分析服务系统,爬网调度系统,网页分析系统,链接提取系统,链接分析系统和网页存储系统。
2、爬行过程中涉及的网络协议
搜索引擎与资源提供者之间存在相互依赖的关系。搜索引擎需要网站管理员为其提供资源,否则搜索引擎将无法满足用户的检索需求;网站管理员需要通过搜索引擎推广其内容。外出并吸引更多的受众。爬网系统直接涉及资源提供者的利益。为了使搜索引擎和网站站长实现双赢,双方在爬网过程中必须遵守某些规定,以促进双方之间的数据处理和连接。在此过程中遵循的规范是我们在日常生活中所谓的某些网络协议。以下是简要列表:
http协议:超文本传输协议,它是上使用最广泛的网络协议,是客户端和服务器请求和响应的标准。客户端通常指的是最终用户,服务器通常指的是网站。最终用户通过浏览器,等将http请求发送到服务器的指定端口。发送http请求将返回相应的信息,您可以查看它是否成功,服务器类型,最近的时间网页更新等。 查看全部
互联网信息爆发式增长,如何有效的获取并利用
信息的爆炸性增长,如何有效地获取和使用此信息是搜索引擎工作的主要环节。作为整个搜索系统的上游,数据捕获系统主要负责信息的采集,保存和更新。它像蜘蛛一样在网络上爬行,因此通常称为“”。例如,我们常用的几种常见搜索引擎蜘蛛称为:,等等。
爬网系统是搜索引擎数据源的重要保证。如果将网络理解为有向图,则可以将工作过程视为对该有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接,新的URL会不断被发现和爬网,并且会爬网尽可能多的有价值的网页。对于百度这样的大型系统,由于网页可能一直被修改,删除或新的超链接出现,因此有必要保留过去已爬网的更新页面,并维护URL库和页面库。
1、爬网系统的基本框架
以下是爬网系统的基本框架图,包括链接存储系统,链接选择系统,dns分析服务系统,爬网调度系统,网页分析系统,链接提取系统,链接分析系统和网页存储系统。
2、爬行过程中涉及的网络协议
搜索引擎与资源提供者之间存在相互依赖的关系。搜索引擎需要网站管理员为其提供资源,否则搜索引擎将无法满足用户的检索需求;网站管理员需要通过搜索引擎推广其内容。外出并吸引更多的受众。爬网系统直接涉及资源提供者的利益。为了使搜索引擎和网站站长实现双赢,双方在爬网过程中必须遵守某些规定,以促进双方之间的数据处理和连接。在此过程中遵循的规范是我们在日常生活中所谓的某些网络协议。以下是简要列表:
http协议:超文本传输协议,它是上使用最广泛的网络协议,是客户端和服务器请求和响应的标准。客户端通常指的是最终用户,服务器通常指的是网站。最终用户通过浏览器,等将http请求发送到服务器的指定端口。发送http请求将返回相应的信息,您可以查看它是否成功,服务器类型,最近的时间网页更新等。
网站百度收录慢怎么办?发布的文章总是不收录
网站优化 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-03-30 23:07
网站百度收录运行缓慢,该怎么办?如果发布的文章始终不是收录,我该怎么办?
最近,我研究了百度的积极推动。推送数据以进行实时搜索可以加快爬虫的爬网速度。您可以在百度搜索资源平台的后台看到此功能并提交链接,如下所示:
点击链接提交,进入页面,我们可以看到百度提供了一个界面,并且可以主动向百度提交网站链接。
下面将介绍几个推送示例
我也专门研究了它,最终实现了一键式主动推送并获得了成功。我首先创建了一个新的urls.txt文件,其中收录10个URL,如下所示:
然后使用成功完成代码提交,成功操作的屏幕截图如下:
总共少于10行代码,这非常方便。如果需要,可以自己尝试。您可以将URL(接口调用地址)更改为您自己的网站,php,post,curl,ruby。也可以实现。
在此提醒您。根据百度的官方指示,每个接口调用地址每天最多只能提交2000条数据,因此不要提交过多,超过2000条是没有用的。
好的,我今天在这里分享它,希望能激发大家的灵感并提供帮助。
李亚涛介绍:seo和编程爱好者,秦望辉商学院的合伙人,网站 8年的运营经验,熟悉各种推广方法,擅长公司建设,关键词排名SEO优化,抓取信息抓取等
“手机网站 SEO优化教程”电子书,“ Seo优化系统视频教程”,“ 15天成为爬行动物主视频教程”,“快速站点构建视频教程”等的作者。返回搜狐,查看更多 查看全部
网站百度收录慢怎么办?发布的文章总是不收录
网站百度收录运行缓慢,该怎么办?如果发布的文章始终不是收录,我该怎么办?
最近,我研究了百度的积极推动。推送数据以进行实时搜索可以加快爬虫的爬网速度。您可以在百度搜索资源平台的后台看到此功能并提交链接,如下所示:
点击链接提交,进入页面,我们可以看到百度提供了一个界面,并且可以主动向百度提交网站链接。
下面将介绍几个推送示例
我也专门研究了它,最终实现了一键式主动推送并获得了成功。我首先创建了一个新的urls.txt文件,其中收录10个URL,如下所示:
然后使用成功完成代码提交,成功操作的屏幕截图如下:
总共少于10行代码,这非常方便。如果需要,可以自己尝试。您可以将URL(接口调用地址)更改为您自己的网站,php,post,curl,ruby。也可以实现。
在此提醒您。根据百度的官方指示,每个接口调用地址每天最多只能提交2000条数据,因此不要提交过多,超过2000条是没有用的。
好的,我今天在这里分享它,希望能激发大家的灵感并提供帮助。
李亚涛介绍:seo和编程爱好者,秦望辉商学院的合伙人,网站 8年的运营经验,熟悉各种推广方法,擅长公司建设,关键词排名SEO优化,抓取信息抓取等
“手机网站 SEO优化教程”电子书,“ Seo优化系统视频教程”,“ 15天成为爬行动物主视频教程”,“快速站点构建视频教程”等的作者。返回搜狐,查看更多
网站内容抓取可以分成自己或者找自己的网站平台。
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-03-30 06:03
网站内容抓取可以分成自己或者找自己的网站平台。找平台的话可以尝试蜘蛛池,一般除了搜索引擎,外网均可合作开展。现在大力推广的就是第三方系统,就和我们系统做验证一样,有做验证的就有没做的,有做验证的第三方系统就可以对接然后抽取公网ip直接查询。新增sql账号的话可以使用saas系统,目前由提供的系统在可信度和功能性上比较有保障,一般的saas系统都会具备多种权限模式,对内对外均可合作;不足之处在于,saas系统也需要依靠自己的电脑,受网络瓶颈限制,一般小平台难以接入saas系统。
不推荐,
建议是建立一个的网站,
不推荐。想创造价值就得自己花时间去挖掘。
传统的rss源基本上是被搜索引擎吃掉的,那就只有外部挖掘的价值。非爬虫类rss源建议:1.push/-源,,等优质网站公司提供的rss库。2.第三方的爬虫,利用爬虫方式提供(比如ator)。
科学上网,
当然可以,就看你有什么好的方式,和你该用什么套路,
谁告诉你抓取不可以,可以弄个爬虫,自己弄个公网ip就行。 查看全部
网站内容抓取可以分成自己或者找自己的网站平台。
网站内容抓取可以分成自己或者找自己的网站平台。找平台的话可以尝试蜘蛛池,一般除了搜索引擎,外网均可合作开展。现在大力推广的就是第三方系统,就和我们系统做验证一样,有做验证的就有没做的,有做验证的第三方系统就可以对接然后抽取公网ip直接查询。新增sql账号的话可以使用saas系统,目前由提供的系统在可信度和功能性上比较有保障,一般的saas系统都会具备多种权限模式,对内对外均可合作;不足之处在于,saas系统也需要依靠自己的电脑,受网络瓶颈限制,一般小平台难以接入saas系统。
不推荐,
建议是建立一个的网站,
不推荐。想创造价值就得自己花时间去挖掘。
传统的rss源基本上是被搜索引擎吃掉的,那就只有外部挖掘的价值。非爬虫类rss源建议:1.push/-源,,等优质网站公司提供的rss库。2.第三方的爬虫,利用爬虫方式提供(比如ator)。
科学上网,
当然可以,就看你有什么好的方式,和你该用什么套路,
谁告诉你抓取不可以,可以弄个爬虫,自己弄个公网ip就行。
网页抓取机器人与各种内容保护策略之间的定价优势
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-03-29 23:00
什么是数据获取?
数据刮取,以其最一般的形式,是指一种技术,其中计算机程序从另一个程序生成的输出中提取数据。数据抓取通常体现在Web抓取中,这是使用应用程序从网站中提取有价值的信息的过程。
为什么要获取网站数据?
通常,公司不希望将其独特的内容下载并重新用于未经授权的目的。因此,他们不会通过开放的API或其他易于访问的资源公开所有数据。另一方面,无论网站如何限制访问权限,爬网机器人都会尝试对网站的数据进行爬网。这样,网络抓取机器人与各种内容保护策略之间便有了猫捉老鼠的游戏。
尽管执行起来可能很复杂,但是Web爬网的过程非常简单。 Web爬网分为3个步骤:
首先,用于提取信息的代码段(我们称其为爬虫机器人)将HTTP GET请求发送到特定的网站。
网站响应时,采集器将解析HTML文档以获得特定的数据模式。
提取数据后,将其转换为抓取机器人设计者设计的特定格式。
抓取机器人可以设计用于多种用途,例如:
可以从网站爬取内容,以便复制依赖于内容的独特产品或服务优势。例如,Yelp之类的产品都依赖评论。竞争对手可以从Yelp中获取所有评论内容并将其复制到他们的网站中,从而使他们的网站内容非常原创公开。
价格搜寻-通过搜寻价格数据,竞争对手可以汇总有关其竞争产品的信息。这样可以为他们提供独特的定价优势。
联系信息抓取-许多网站纯文本收录电子邮件地址和电话号码。通过爬行诸如在线员工目录之类的位置,爬行机器人可以聚合联系人信息,以尝试进行大规模电子邮件,自动呼叫或恶意的社会工程攻击。这是垃圾邮件发送者和诈骗者发现新目标的主要方法之一。
如何保护网络爬网?
通常,网站访问者可以看到的所有内容都必须转移到访问者的计算机上,并且访问者可以访问的任何信息都可以由机器人抓取。
有一些方法可以限制可能发生的爬网次数。以下是三种限制数据爬网的方法:
速率限制请求–对于访问网站并单击网站上的一系列网页的真实用户,通常可以预测他们与网站交互的速度;例如,人类用户不可能每秒浏览100页。另一方面,计算机可以以比人类快多个数量级的速度发出请求,而主要数据捕获程序可能会使用不受限制的捕获技术来尝试快速捕获整个网站数据。通过限制给定时间段内特定IP地址发出的最大请求数,网站可以保护自己免受攻击性请求的影响,并限制在特定时间范围内可能发生的数据爬网量。
定期修改HTML标记-数据抓取机器人依靠连续格式来有效地遍历网站的内容以及解析和保存有用的数据。防止此工作流程的一种方法是定期更改HTML标记的元素,从而使一致的爬网过程更加复杂。嵌套HTML元素或更改标记的其他方面可能会阻止或阻止简单的数据抓取活动。每当出现网页时,某些网站会随机修改某些形式的内容保护。其他网站偶尔会修改自己的标记代码,以防止长期的数据抓取活动。
将用于大量数据的请求者–除了使用速率限制解决方案之外,减慢内容爬网的另一个有用步骤是要求网站位访问者完成计算机难以解决的挑战。尽管人类可以合理地应对这一挑战,但是执行数据抓取的无脑浏览器*很有可能无法克服挑战,更不用说继续应对多项挑战了。但是,连续测试可能会对真实用户的体验产生负面影响。
另一种不太常见的保护方法要求将内容嵌入媒体对象(例如图像)中。由于字符串中不存在内容,因此复制内容要复杂得多,并且需要光学字符识别(OCR)从图像文件中提取数据。但这也会给需要从网站复制内容的真实用户带来麻烦。他们必须记住或重新输入地址或电话号码等信息,而不是直接复制它们。
*无头浏览器是一种Web浏览器,类似于或,但是默认情况下它没有视觉用户界面,因此其移动速度比普通Web浏览器快得多。本质上,它运行在命令行界面上,无头浏览器可以避免呈现整个Web应用程序。数据抓取工具将使机器人能够使用无头浏览器更快地请求数据,因为没有人会看到要抓取的每个页面。
如何防止完全爬行?
完全阻止Web爬网的唯一方法是避免将内容完全放在网站上。但是,使用高级机器人管理解决方案可以帮助网站几乎完全消除抓斗机器人的访问权限。
数据爬网和数据爬网有什么区别?
抓取是指像这样的大型搜索引擎将其抓取工具(例如)发送到网络以索引内容的过程。另一方面,它通常是专门为从特定的网站中提取数据而构建的。
以下是抓取机器人和网络抓取机器人的三种不同行为:
该爬虫程序机器人会假装为网络浏览器,并且该爬虫程序机器人会指明其目的,而不是试图欺骗网站。
有时候,爬行机器人会采取高级措施,例如填写表格或执行其他操作以输入网站的特定部分。爬虫不会。
爬网机器人通常会忽略.txt文件,该文件是一个文本文件,专门用于告诉爬网程序可以解析哪些数据以及无法访问的区域。由于采集器旨在提取特定内容,因此可以将其设计为专门搜寻被禁止搜寻的内容。
机器人管理使用机器学习和行为分析来识别恶意机器人(例如抓取器),保护网站唯一内容并防止机器人滥用Web属性。 查看全部
网页抓取机器人与各种内容保护策略之间的定价优势
什么是数据获取?
数据刮取,以其最一般的形式,是指一种技术,其中计算机程序从另一个程序生成的输出中提取数据。数据抓取通常体现在Web抓取中,这是使用应用程序从网站中提取有价值的信息的过程。
为什么要获取网站数据?
通常,公司不希望将其独特的内容下载并重新用于未经授权的目的。因此,他们不会通过开放的API或其他易于访问的资源公开所有数据。另一方面,无论网站如何限制访问权限,爬网机器人都会尝试对网站的数据进行爬网。这样,网络抓取机器人与各种内容保护策略之间便有了猫捉老鼠的游戏。
尽管执行起来可能很复杂,但是Web爬网的过程非常简单。 Web爬网分为3个步骤:
首先,用于提取信息的代码段(我们称其为爬虫机器人)将HTTP GET请求发送到特定的网站。
网站响应时,采集器将解析HTML文档以获得特定的数据模式。
提取数据后,将其转换为抓取机器人设计者设计的特定格式。
抓取机器人可以设计用于多种用途,例如:
可以从网站爬取内容,以便复制依赖于内容的独特产品或服务优势。例如,Yelp之类的产品都依赖评论。竞争对手可以从Yelp中获取所有评论内容并将其复制到他们的网站中,从而使他们的网站内容非常原创公开。
价格搜寻-通过搜寻价格数据,竞争对手可以汇总有关其竞争产品的信息。这样可以为他们提供独特的定价优势。
联系信息抓取-许多网站纯文本收录电子邮件地址和电话号码。通过爬行诸如在线员工目录之类的位置,爬行机器人可以聚合联系人信息,以尝试进行大规模电子邮件,自动呼叫或恶意的社会工程攻击。这是垃圾邮件发送者和诈骗者发现新目标的主要方法之一。
如何保护网络爬网?
通常,网站访问者可以看到的所有内容都必须转移到访问者的计算机上,并且访问者可以访问的任何信息都可以由机器人抓取。
有一些方法可以限制可能发生的爬网次数。以下是三种限制数据爬网的方法:
速率限制请求–对于访问网站并单击网站上的一系列网页的真实用户,通常可以预测他们与网站交互的速度;例如,人类用户不可能每秒浏览100页。另一方面,计算机可以以比人类快多个数量级的速度发出请求,而主要数据捕获程序可能会使用不受限制的捕获技术来尝试快速捕获整个网站数据。通过限制给定时间段内特定IP地址发出的最大请求数,网站可以保护自己免受攻击性请求的影响,并限制在特定时间范围内可能发生的数据爬网量。
定期修改HTML标记-数据抓取机器人依靠连续格式来有效地遍历网站的内容以及解析和保存有用的数据。防止此工作流程的一种方法是定期更改HTML标记的元素,从而使一致的爬网过程更加复杂。嵌套HTML元素或更改标记的其他方面可能会阻止或阻止简单的数据抓取活动。每当出现网页时,某些网站会随机修改某些形式的内容保护。其他网站偶尔会修改自己的标记代码,以防止长期的数据抓取活动。
将用于大量数据的请求者–除了使用速率限制解决方案之外,减慢内容爬网的另一个有用步骤是要求网站位访问者完成计算机难以解决的挑战。尽管人类可以合理地应对这一挑战,但是执行数据抓取的无脑浏览器*很有可能无法克服挑战,更不用说继续应对多项挑战了。但是,连续测试可能会对真实用户的体验产生负面影响。
另一种不太常见的保护方法要求将内容嵌入媒体对象(例如图像)中。由于字符串中不存在内容,因此复制内容要复杂得多,并且需要光学字符识别(OCR)从图像文件中提取数据。但这也会给需要从网站复制内容的真实用户带来麻烦。他们必须记住或重新输入地址或电话号码等信息,而不是直接复制它们。
*无头浏览器是一种Web浏览器,类似于或,但是默认情况下它没有视觉用户界面,因此其移动速度比普通Web浏览器快得多。本质上,它运行在命令行界面上,无头浏览器可以避免呈现整个Web应用程序。数据抓取工具将使机器人能够使用无头浏览器更快地请求数据,因为没有人会看到要抓取的每个页面。
如何防止完全爬行?
完全阻止Web爬网的唯一方法是避免将内容完全放在网站上。但是,使用高级机器人管理解决方案可以帮助网站几乎完全消除抓斗机器人的访问权限。
数据爬网和数据爬网有什么区别?
抓取是指像这样的大型搜索引擎将其抓取工具(例如)发送到网络以索引内容的过程。另一方面,它通常是专门为从特定的网站中提取数据而构建的。
以下是抓取机器人和网络抓取机器人的三种不同行为:
该爬虫程序机器人会假装为网络浏览器,并且该爬虫程序机器人会指明其目的,而不是试图欺骗网站。
有时候,爬行机器人会采取高级措施,例如填写表格或执行其他操作以输入网站的特定部分。爬虫不会。
爬网机器人通常会忽略.txt文件,该文件是一个文本文件,专门用于告诉爬网程序可以解析哪些数据以及无法访问的区域。由于采集器旨在提取特定内容,因此可以将其设计为专门搜寻被禁止搜寻的内容。
机器人管理使用机器学习和行为分析来识别恶意机器人(例如抓取器),保护网站唯一内容并防止机器人滥用Web属性。
搜索引擎平台的抓取规则:百度、360、搜狗等
网站优化 • 优采云 发表了文章 • 0 个评论 • 439 次浏览 • 2021-03-28 18:03
搜索引擎平台的抓取规则:百度、360、搜狗等
搜索引擎平台的获取规则:
比较百度,36 0、搜狗和其他搜索引擎的爬网规则!
蜘蛛爬网规则:深度优先和宽度优先
深度优先:
深度优先策略是沿一条路线走到黑路,而当无路可走时,然后回去并走另一条路。
深度优先
宽度优先:
广度优先策略意味着,当蜘蛛在页面上找到多个链接时,它不会变成黑色并跟随链接继续进行爬网,而是先对这些页面进行爬网,然后对这些页面进行爬网。从中提取链接。
搜索引擎会根据某些策略主动抓取网页,处理内容,并将网页返回给搜索引擎服务器;
宽度第一
提取链接,处理检索到的网页的内容,消除噪音,提取页面的主题文本内容等;
网页文本内容的中文分词,停用词的删除等;
对网页内容进行分段后,判断网页内容是否与已索引的网页重复,删除重复的页面,对其余网页进行分类和索引,然后等待用户检索。
网站层次结构:
一个是我们经常称呼的扁平结构,另一个是我们通常看到的树形结构,但是我们通常看到的通常是一个树形结构,它便于管理,但对于网站而言,它通常在三个级别内。主页是第一层,列页面和类别页面是第一层,信息详细信息页面和产品详细信息页面是第一层。 网站必须简化代码,不要马虎,以便蜘蛛可以快速抓取。
网站层次结构
高质量的外链入口:
每天定期发布一些高质量的内容,例如更新新闻:保证每周至少更新两篇文章,并且可以在星期二和星期五的上午10点进行更新,因为这是互联网的时代相对活跃,新闻量不一定很好。最好建立更多的外部链接,因为建立高质量的外部链接和访问渠道对网站既有益又无害。前提是网站在线一段时间后,如果是新电台,则无法采用此方法。
高质量的外链
内容页面原创:
我们整天都在说内容页面的质量越高,网站越好,但是我们不知道这是网站优化的关键,因为只有高质量的内容[ 文章可以吸引搜索引擎蜘蛛爬行。和收录。同时,当客户来浏览我们的网站时,它还可以降低跳出率。
原创内容
分析和采集规则:
从搜索引擎抓取的角度分析网站的采集规则。优化网站时,网站的排名有时会在首页内容更新后下降。当以某种方式返回快照时,将恢复排名。通过仔细分析百度网站管理员平台的关键词和流量,可以发现网站主页的内容保持不变的情况下,一定数量的关键词具有一定的点击次数。内容更新后,点击次数减少了。当快照返回时,排名再次上升。因此,推测百度在爬网和采集内容时会考虑用户体验。 网站点击次数从侧面反映了用户体验。
换句话说,搜索引擎将捕获并存储许多网页快照。如果旧页面快照在用户中更受欢迎,则不一定要包括新页面快照,因为搜索引擎始终必须考虑用户体验。
分析和采集数据
百度和36 0、搜狗搜寻规则之间的区别:
搜索引擎的爬网规则大致相同。只有两个条件是直接影响不同搜索引擎的网站页收录的因素。一个是排名规则(算法),另一个是外部链平台的类型;
例如,今天发布的内容可以在百度上排名,但在360上甚至不会。百度和360搜索引擎都有相应的算法。百度上发布的内容在百度算法的可接受范围内,因此可以排名收录,但是360的算法不允许您的内容为收录,因此发生了这种情况。因此,我们必须相应地了解算法。在外链站点上构建外链可以满足搜索引擎蜘蛛发现收录的需求和超链接权重计算的需求。
蜘蛛爬行
摘要:Internet上每天有成千上万个新网页,并且大型网站生成的新页面多于小型网站。搜索引擎倾向于从大网站获取更多页面,因为大网站倾向于收录更多高质量页面。搜索引擎更喜欢先爬网和采集大型网页。这只是一种提醒SEO的网站管理员让更多内容出现在网站上的方法,丰富的网页将引导搜索引擎频繁捕获和采集,这是SEO的长期规划思想。 查看全部
搜索引擎平台的抓取规则:百度、360、搜狗等
搜索引擎平台的获取规则:
比较百度,36 0、搜狗和其他搜索引擎的爬网规则!
蜘蛛爬网规则:深度优先和宽度优先
深度优先:
深度优先策略是沿一条路线走到黑路,而当无路可走时,然后回去并走另一条路。
深度优先
宽度优先:
广度优先策略意味着,当蜘蛛在页面上找到多个链接时,它不会变成黑色并跟随链接继续进行爬网,而是先对这些页面进行爬网,然后对这些页面进行爬网。从中提取链接。
搜索引擎会根据某些策略主动抓取网页,处理内容,并将网页返回给搜索引擎服务器;
宽度第一
提取链接,处理检索到的网页的内容,消除噪音,提取页面的主题文本内容等;
网页文本内容的中文分词,停用词的删除等;
对网页内容进行分段后,判断网页内容是否与已索引的网页重复,删除重复的页面,对其余网页进行分类和索引,然后等待用户检索。
网站层次结构:
一个是我们经常称呼的扁平结构,另一个是我们通常看到的树形结构,但是我们通常看到的通常是一个树形结构,它便于管理,但对于网站而言,它通常在三个级别内。主页是第一层,列页面和类别页面是第一层,信息详细信息页面和产品详细信息页面是第一层。 网站必须简化代码,不要马虎,以便蜘蛛可以快速抓取。
网站层次结构
高质量的外链入口:
每天定期发布一些高质量的内容,例如更新新闻:保证每周至少更新两篇文章,并且可以在星期二和星期五的上午10点进行更新,因为这是互联网的时代相对活跃,新闻量不一定很好。最好建立更多的外部链接,因为建立高质量的外部链接和访问渠道对网站既有益又无害。前提是网站在线一段时间后,如果是新电台,则无法采用此方法。
高质量的外链
内容页面原创:
我们整天都在说内容页面的质量越高,网站越好,但是我们不知道这是网站优化的关键,因为只有高质量的内容[ 文章可以吸引搜索引擎蜘蛛爬行。和收录。同时,当客户来浏览我们的网站时,它还可以降低跳出率。
原创内容
分析和采集规则:
从搜索引擎抓取的角度分析网站的采集规则。优化网站时,网站的排名有时会在首页内容更新后下降。当以某种方式返回快照时,将恢复排名。通过仔细分析百度网站管理员平台的关键词和流量,可以发现网站主页的内容保持不变的情况下,一定数量的关键词具有一定的点击次数。内容更新后,点击次数减少了。当快照返回时,排名再次上升。因此,推测百度在爬网和采集内容时会考虑用户体验。 网站点击次数从侧面反映了用户体验。
换句话说,搜索引擎将捕获并存储许多网页快照。如果旧页面快照在用户中更受欢迎,则不一定要包括新页面快照,因为搜索引擎始终必须考虑用户体验。
分析和采集数据
百度和36 0、搜狗搜寻规则之间的区别:
搜索引擎的爬网规则大致相同。只有两个条件是直接影响不同搜索引擎的网站页收录的因素。一个是排名规则(算法),另一个是外部链平台的类型;
例如,今天发布的内容可以在百度上排名,但在360上甚至不会。百度和360搜索引擎都有相应的算法。百度上发布的内容在百度算法的可接受范围内,因此可以排名收录,但是360的算法不允许您的内容为收录,因此发生了这种情况。因此,我们必须相应地了解算法。在外链站点上构建外链可以满足搜索引擎蜘蛛发现收录的需求和超链接权重计算的需求。
蜘蛛爬行
摘要:Internet上每天有成千上万个新网页,并且大型网站生成的新页面多于小型网站。搜索引擎倾向于从大网站获取更多页面,因为大网站倾向于收录更多高质量页面。搜索引擎更喜欢先爬网和采集大型网页。这只是一种提醒SEO的网站管理员让更多内容出现在网站上的方法,丰富的网页将引导搜索引擎频繁捕获和采集,这是SEO的长期规划思想。
如何在web主机上强制重定向一个指定的域
网站优化 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-03-28 00:16
正确的方法是将其中一个重定向到另一个,而不是两个都重定向。如果同时加载两个,则站点的版本安全性将成问题。如果您在浏览器中输入网站的URL,请分别进行测试和。
如果两个URL均被加载,则将显示两个版本的内容。网址重复可能会导致内容重复。
为确保您不会再次遇到此问题,您需要根据网站的平台执行以下操作之一:
在HTACCESS中创建完整的重定向模式(在Apache / CPanel服务器上);
使用WordPress中的重定向插件来强制进行重定向。
4、如何在Apache / Cpanel服务器的htaccess中创建重定向
您可以在Apache / CPanel服务器的.htaccess中执行服务器级别的全局重定向。 Inmotionhosting的教程很好,可以教您如何在Web主机上强制重定向。
如果您强制所有网络流量使用HTTPS,则需要使用以下代码。
确保将此代码添加到具有类似前缀(RewriteEngine On,RewriteCond等)的代码之上。
RewriteEngine开启
RewriteCond%{HTTPS}!on
RewriteCond%{REQUEST_URI}!^ / [0-9] + \\ .. + \\。cpaneldcv $
<p>RewriteCond%{REQUEST_URI}!^ / \\。众所周知/ pki-validation / [A-F0-9] {32} \\。txt(?:\\ Comodo \\ DCV)?$ 查看全部
如何在web主机上强制重定向一个指定的域
正确的方法是将其中一个重定向到另一个,而不是两个都重定向。如果同时加载两个,则站点的版本安全性将成问题。如果您在浏览器中输入网站的URL,请分别进行测试和。
如果两个URL均被加载,则将显示两个版本的内容。网址重复可能会导致内容重复。
为确保您不会再次遇到此问题,您需要根据网站的平台执行以下操作之一:
在HTACCESS中创建完整的重定向模式(在Apache / CPanel服务器上);
使用WordPress中的重定向插件来强制进行重定向。
4、如何在Apache / Cpanel服务器的htaccess中创建重定向
您可以在Apache / CPanel服务器的.htaccess中执行服务器级别的全局重定向。 Inmotionhosting的教程很好,可以教您如何在Web主机上强制重定向。
如果您强制所有网络流量使用HTTPS,则需要使用以下代码。
确保将此代码添加到具有类似前缀(RewriteEngine On,RewriteCond等)的代码之上。
RewriteEngine开启
RewriteCond%{HTTPS}!on
RewriteCond%{REQUEST_URI}!^ / [0-9] + \\ .. + \\。cpaneldcv $
<p>RewriteCond%{REQUEST_URI}!^ / \\。众所周知/ pki-validation / [A-F0-9] {32} \\。txt(?:\\ Comodo \\ DCV)?$

