
网站内容抓取
好内容就被你创造了,但能说上是优质吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-05-10 03:18
当您确定文章主题具有用户需求并且内容可以满足大多数人的需求时。因此,您可以创建好的内容,但是可以说它是高质量的吗?不一定,因为有以下一些因素。
网页打开速度
网页打开的速度影响两点。首先是用户访问网页的体验。搜索引擎的目的是更好地满足搜索用户的体验,但是您可以让用户从一开始就访问您。 网站进行了大量更改。此前,百度的同学还提到打开速度超过3秒的移动网页被直接归类为垃圾网页。可以想象,即使您拥有最好的内容,用户访问也会带来麻烦,这是否也不值得。
第二点是爬虫爬网。如果打开速度很慢,则爬网程序将很难爬网。从搜索引擎的角度来看,爬网也是一个正在运行的程序。在您的程序上运行时,打开网页需要1秒钟,但是在其他人上运行只需要100毫秒。放开我,它们只占您的十分之一。而且,您已经占用了采集器可能已经爬网的资源,成为了一个可以对该网页进行爬网的网页。换句话说,我还将调整抓取给您的网站数量,以节省资源并抓取更多网页。使用较少的爬网,收录的概率甚至更小。没有收录,排名和点击量如何?
文字可读性
可以查看内容,但是非常费力,好吗?您真的认为搜索引擎今天无法识别它吗?例如,最初设置为黑色字体或深灰色字体的内容块本身非常好。但是,出于某些其他目的,必须将其设置为浅灰色或更接近网页背景的颜色。此设置没有利用用户的体验。相同的内容不能视为高质量的内容。
例如,字体大小太小,文本之间的段落太近甚至重叠,这在一定程度上影响了用户体验。
您的文章看上去很费劲,我在搜索引擎中发现了如此多的结果,为什么还要浪费时间呢?只需关闭您的网页并找到下一个!
主要内容中的设置
这里主要是关于主要内容本身的,例如文章页面的内容部分,我们将设置一些粗体,红色(突出显示)的锚文本链接。但是,这三点仍然保留了许多年前的实践网站。如果为关键词,请为其提供指向首页的链接,指向版面的页面或指向频道页面;如果为关键词,请将其设为粗体或突出显示,以便突出显示,以诱骗您进行SEO优化。其实不应该这样。这些都是很小的因素。与其在这个领域努力工作,不如合理地使用这些细节。突出显示文章中需要突出显示的句子或词汇。在编写文章的过程中,提到了一些词汇或知识点,并且用户可能不理解或不感兴趣,因此已为此设置链接设置了链接。
实际上是以这种正常方式进行的,您会发现要添加的链接以及文本的突出设置也适合某些SEO技术和方法。因此,为了正确理解这些细节的含义,有时要进行合理的设置是SEO。不要使用SEO的思想来设置内容,而要使用设置内容的思想来进行SEO,这是正确的方法。
网页布局布局
这里有三点。第一点是主要内容出现的位置。用户最需要的内容不会出现在最重要的位置。这个可以吗?例如,在文章页面上,用户只想看到文章是,但是您让用户向下滚动两个屏幕以查看主要内容。这种布局非常令人气愤。即使您认为公司的重要内容显示在内容的顶部,用户也会担心该内容本身。 ,他想解决自己的需求。其他问题远不止于此。
第二点是主要内容之外的周围推荐信息,例如最新推荐,热门推荐,您喜欢的猜测,相关的文章等。名称不同,检索逻辑也不同,但是性质基本上是相同的。此推荐信息与当前主题文章有什么关系?相关性越高,用户可以挖掘的潜在需求就越大。例如,您正在阅读标题为“百度将哪些内容视为高品质内容”的文章,并向您推荐该文章。“高品质内容的一些注意事项”,“ 原创 文章如何成为高质量内容”,“有关高质量内容的一些建议” ...,这些都是您需要查看的。这不仅增加了您访问此网站的PV,还降低了跳出率。同时增加当前网页的关键词密度!
最后一个是广告。众所周知,弹出广告会阻止主题内容并影响用户体验。但是,页面主要内容中的“大量” Flash图像,动态广告和散布的广告都对用户体验有害。因此,合理分配广告的位置和数量,主要内容的出现位置等对用户最大的帮助。帮助用户等同于帮助搜索引擎解决搜索用户体验问题。为什么不吸引流量?
原创内容
原创的内容应为所有人所理解,但在此必须提及。 原创一直是每个人都关注的问题,但并非所有原创内容都能获得良好的排名。根据我上面提到的其他观点,您会发现,除了重要因素原创之外,还有一些细节需要注意。
原创的内容应有需求,您不能盲目制作自己的标题;您的内容应与标题保持一致,并且标题中不能说东西,这不能解决用户的实际需求;文字必须具有可读性,不应影响用户出于其他目的的正常浏览;该网页应尽快打开,并且速度越快越好。没有限制;没有限制。内容主体中突出的内容应突出显示,并且应将锚链接添加到锚链接中。只要为创建内容而不是为SEO生成内容而进行设置,就不必担心所谓的过度优化。
相关文章:如何衡量seo排名优化的效果? 查看全部
好内容就被你创造了,但能说上是优质吗?
当您确定文章主题具有用户需求并且内容可以满足大多数人的需求时。因此,您可以创建好的内容,但是可以说它是高质量的吗?不一定,因为有以下一些因素。
网页打开速度
网页打开的速度影响两点。首先是用户访问网页的体验。搜索引擎的目的是更好地满足搜索用户的体验,但是您可以让用户从一开始就访问您。 网站进行了大量更改。此前,百度的同学还提到打开速度超过3秒的移动网页被直接归类为垃圾网页。可以想象,即使您拥有最好的内容,用户访问也会带来麻烦,这是否也不值得。
第二点是爬虫爬网。如果打开速度很慢,则爬网程序将很难爬网。从搜索引擎的角度来看,爬网也是一个正在运行的程序。在您的程序上运行时,打开网页需要1秒钟,但是在其他人上运行只需要100毫秒。放开我,它们只占您的十分之一。而且,您已经占用了采集器可能已经爬网的资源,成为了一个可以对该网页进行爬网的网页。换句话说,我还将调整抓取给您的网站数量,以节省资源并抓取更多网页。使用较少的爬网,收录的概率甚至更小。没有收录,排名和点击量如何?

文字可读性
可以查看内容,但是非常费力,好吗?您真的认为搜索引擎今天无法识别它吗?例如,最初设置为黑色字体或深灰色字体的内容块本身非常好。但是,出于某些其他目的,必须将其设置为浅灰色或更接近网页背景的颜色。此设置没有利用用户的体验。相同的内容不能视为高质量的内容。
例如,字体大小太小,文本之间的段落太近甚至重叠,这在一定程度上影响了用户体验。
您的文章看上去很费劲,我在搜索引擎中发现了如此多的结果,为什么还要浪费时间呢?只需关闭您的网页并找到下一个!
主要内容中的设置
这里主要是关于主要内容本身的,例如文章页面的内容部分,我们将设置一些粗体,红色(突出显示)的锚文本链接。但是,这三点仍然保留了许多年前的实践网站。如果为关键词,请为其提供指向首页的链接,指向版面的页面或指向频道页面;如果为关键词,请将其设为粗体或突出显示,以便突出显示,以诱骗您进行SEO优化。其实不应该这样。这些都是很小的因素。与其在这个领域努力工作,不如合理地使用这些细节。突出显示文章中需要突出显示的句子或词汇。在编写文章的过程中,提到了一些词汇或知识点,并且用户可能不理解或不感兴趣,因此已为此设置链接设置了链接。
实际上是以这种正常方式进行的,您会发现要添加的链接以及文本的突出设置也适合某些SEO技术和方法。因此,为了正确理解这些细节的含义,有时要进行合理的设置是SEO。不要使用SEO的思想来设置内容,而要使用设置内容的思想来进行SEO,这是正确的方法。

网页布局布局
这里有三点。第一点是主要内容出现的位置。用户最需要的内容不会出现在最重要的位置。这个可以吗?例如,在文章页面上,用户只想看到文章是,但是您让用户向下滚动两个屏幕以查看主要内容。这种布局非常令人气愤。即使您认为公司的重要内容显示在内容的顶部,用户也会担心该内容本身。 ,他想解决自己的需求。其他问题远不止于此。
第二点是主要内容之外的周围推荐信息,例如最新推荐,热门推荐,您喜欢的猜测,相关的文章等。名称不同,检索逻辑也不同,但是性质基本上是相同的。此推荐信息与当前主题文章有什么关系?相关性越高,用户可以挖掘的潜在需求就越大。例如,您正在阅读标题为“百度将哪些内容视为高品质内容”的文章,并向您推荐该文章。“高品质内容的一些注意事项”,“ 原创 文章如何成为高质量内容”,“有关高质量内容的一些建议” ...,这些都是您需要查看的。这不仅增加了您访问此网站的PV,还降低了跳出率。同时增加当前网页的关键词密度!
最后一个是广告。众所周知,弹出广告会阻止主题内容并影响用户体验。但是,页面主要内容中的“大量” Flash图像,动态广告和散布的广告都对用户体验有害。因此,合理分配广告的位置和数量,主要内容的出现位置等对用户最大的帮助。帮助用户等同于帮助搜索引擎解决搜索用户体验问题。为什么不吸引流量?
原创内容
原创的内容应为所有人所理解,但在此必须提及。 原创一直是每个人都关注的问题,但并非所有原创内容都能获得良好的排名。根据我上面提到的其他观点,您会发现,除了重要因素原创之外,还有一些细节需要注意。
原创的内容应有需求,您不能盲目制作自己的标题;您的内容应与标题保持一致,并且标题中不能说东西,这不能解决用户的实际需求;文字必须具有可读性,不应影响用户出于其他目的的正常浏览;该网页应尽快打开,并且速度越快越好。没有限制;没有限制。内容主体中突出的内容应突出显示,并且应将锚链接添加到锚链接中。只要为创建内容而不是为SEO生成内容而进行设置,就不必担心所谓的过度优化。
相关文章:如何衡量seo排名优化的效果?
企业网站推广时需要注意的几个关键词排名!
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-05-10 03:15
企业网站推广时,如果要从搜索引擎获得更多关键词排名,首先网站必须确保一定数量收录,同时要注意网站长尾巴扩展单词,通过长尾单词访问网站的流量会更准确,同时转换效果更好。是什么因素导致蜘蛛无法正常抓取网站内容?
1、无效链接:
该页面无效,无法为用户提供任何有价值信息的页面是无效链接。编辑建议我们可以使用网站管理员工具进行检测,然后提交删除。
2、 UA被阻止:
如果您希望baiduspider访问您的网站,请检查useragent的相关设置中是否存在baiduspiderUA并及时进行修改。
3、 IP屏蔽:
Baiduspiderip被专门阻止。当您的站点不希望baiduspider访问时,此设置是必需的。如果您希望baiduspider访问您的网站,请检查baiduspiderIP是否被错误地添加到相关设置中。您网站所在的太空服务提供商也可能阻止了百度IP。此时,您需要联系服务提供商以更改设置。
4、 DNS例外:
当BaiduSpider无法解析您的网站 IP时,将发生DNS异常。可能是您网站的IP地址不正确,或者域名服务已阻止baiduspider。请使用whois或主机检查您的网站 IP地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商以更新您的IP地址。
5、服务器异常:
服务器的异常连接主要表现在百度蜘蛛无法连接到您的网站上。在这种情况下,站点服务器通常太大,操作过载。也可能是它受到了攻击并受到影响网站。如果没有,请与您的服务提供商联系。
什么因素导致蜘蛛无法正常抓取网站的内容?如果您是旧站点,则有一天您会突然发现网站 收录减少,并且抓取频率逐渐降低甚至为零,这表明网站在不久的将来会出现问题,您可以看到如果网站最近有重大更改,并且哪些操作不合适,请及时进行更正。 查看全部
企业网站推广时需要注意的几个关键词排名!
企业网站推广时,如果要从搜索引擎获得更多关键词排名,首先网站必须确保一定数量收录,同时要注意网站长尾巴扩展单词,通过长尾单词访问网站的流量会更准确,同时转换效果更好。是什么因素导致蜘蛛无法正常抓取网站内容?

1、无效链接:
该页面无效,无法为用户提供任何有价值信息的页面是无效链接。编辑建议我们可以使用网站管理员工具进行检测,然后提交删除。
2、 UA被阻止:
如果您希望baiduspider访问您的网站,请检查useragent的相关设置中是否存在baiduspiderUA并及时进行修改。

3、 IP屏蔽:
Baiduspiderip被专门阻止。当您的站点不希望baiduspider访问时,此设置是必需的。如果您希望baiduspider访问您的网站,请检查baiduspiderIP是否被错误地添加到相关设置中。您网站所在的太空服务提供商也可能阻止了百度IP。此时,您需要联系服务提供商以更改设置。
4、 DNS例外:
当BaiduSpider无法解析您的网站 IP时,将发生DNS异常。可能是您网站的IP地址不正确,或者域名服务已阻止baiduspider。请使用whois或主机检查您的网站 IP地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商以更新您的IP地址。
5、服务器异常:
服务器的异常连接主要表现在百度蜘蛛无法连接到您的网站上。在这种情况下,站点服务器通常太大,操作过载。也可能是它受到了攻击并受到影响网站。如果没有,请与您的服务提供商联系。

什么因素导致蜘蛛无法正常抓取网站的内容?如果您是旧站点,则有一天您会突然发现网站 收录减少,并且抓取频率逐渐降低甚至为零,这表明网站在不久的将来会出现问题,您可以看到如果网站最近有重大更改,并且哪些操作不合适,请及时进行更正。
二次元文化职业收集妹子萌照,可以推荐一些奇奇怪怪的职业
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-05-10 03:06
网站内容抓取,中高端职业内容抓取,各类推广信息抓取等,竞争激烈,跟单身狗有什么关系,大家的生活都这么匆忙了,除了利用真材实料找个对象,还有那么多时间在乎别人喜不喜欢你吗。
有的。比如二次元文化职业,我们就收集妹子萌照,
可以推荐一些奇奇怪怪的职业嘛,
我有一个中药二维码的微信公众号,还不错,长期更新,
可以做一些h5,也可以放一些技能啊交流群啊,长期更新哈,
看得我热血沸腾,
现在很多类似的网站都在做这方面,像发现我的职业网,
我建议你玩玩天天益彩,里面所有的技巧都很简单,每天上玩两三个小时,还能挣些小钱。我高中同学当年就在玩这个,
我也想知道(机智微笑)
穷鬼网,
如果有楼主想找对象的标准,再加上技能点,
我也是学生党每天都想赚钱
可以找一些跟技能挂钩的,例如设计,翻译,程序员等(嘿嘿嘿)。
创意美女和流量主
目前国内绝大部分人工作都很忙碌,仅靠自己赚的钱肯定不够用,所以经常会羡慕一些在公司里上班的人,会想他们是否有时间自己赚钱,答案是肯定的。大多数就是当点客,然后花点时间用客赚来的钱在当地找女朋友。大学生的话,应该还有其他赚钱方式。 查看全部
二次元文化职业收集妹子萌照,可以推荐一些奇奇怪怪的职业
网站内容抓取,中高端职业内容抓取,各类推广信息抓取等,竞争激烈,跟单身狗有什么关系,大家的生活都这么匆忙了,除了利用真材实料找个对象,还有那么多时间在乎别人喜不喜欢你吗。
有的。比如二次元文化职业,我们就收集妹子萌照,
可以推荐一些奇奇怪怪的职业嘛,
我有一个中药二维码的微信公众号,还不错,长期更新,
可以做一些h5,也可以放一些技能啊交流群啊,长期更新哈,
看得我热血沸腾,
现在很多类似的网站都在做这方面,像发现我的职业网,
我建议你玩玩天天益彩,里面所有的技巧都很简单,每天上玩两三个小时,还能挣些小钱。我高中同学当年就在玩这个,
我也想知道(机智微笑)
穷鬼网,
如果有楼主想找对象的标准,再加上技能点,
我也是学生党每天都想赚钱
可以找一些跟技能挂钩的,例如设计,翻译,程序员等(嘿嘿嘿)。
创意美女和流量主
目前国内绝大部分人工作都很忙碌,仅靠自己赚的钱肯定不够用,所以经常会羡慕一些在公司里上班的人,会想他们是否有时间自己赚钱,答案是肯定的。大多数就是当点客,然后花点时间用客赚来的钱在当地找女朋友。大学生的话,应该还有其他赚钱方式。
合理优化网站结构吸引蜘蛛深入抓取网站内容(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-05-08 18:06
合理优化网站结构,吸引蜘蛛掌握网站的含量
资料来源:根据她的感受,蜘蛛来网站是件好事,但我通过蜘蛛访问记录发现了一个大问题。通常蜘蛛抓取4或5页,然后在到达网站后离开。怎么了?相信很多站长都觉得百度蜘蛛在6月份的事件之后非常不稳定,我的网站也是如此。从6月份开始,每次蜘蛛来抓几页,它就会离开,所以网站的收录没有得到改进。最后,我对网站做了一个大检查,然后我整理了网站的链接,更不用说整理后的网站,蜘蛛每次抓取20、30页。让我分享一下我的检查方法和补救方法
我想蜘蛛之所以一开始不深入的第一个原因是导航链接设置不正确,蜘蛛无法通过导航链接深入到你的网站中,那它们怎么能抓到内容页呢?第二种可能是蜘蛛遇到死链接,但在准备抓取下一页时却无法爬行,因此网站的死链接成为罪魁祸首,迫使百度蜘蛛离开网站。第三种可能是,长时间不更新网站内容也会导致百度蜘蛛疲惫不堪。第一、页重置网站导航链接
网站的导航链接不仅是用户的指南,也是搜索引擎蜘蛛的指南。一条好的导航路线可以帮助搜索引擎蜘蛛从网站的主页逐步贯穿整个网站页面,这就需要我们层层设置网站导航。让我谈谈设置导航链接的一些要求:
1、导航链接应该关闭。当我们设置导航链接时,我们不应该对搜索引擎蜘蛛看得太深。其实,它是一种捕捉的工具,最容易捕捉的是最近的东西。因此,我们在使用导航链接时,可以通过导航链接导入下一级栏目链接,下一级栏目链接会导入内容页,这是分层导入的方法
从2、导入的URL不应太复杂。我认为可以简单地设置网站的URL地址。只需使用一个PHP程序,目录设置很简单。那么蜘蛛爬行就相对容易了。必须清理二、死链接,留下是一个诅咒
死链接阻碍了网站很多。如果不注意死链接,可能会对网站产生致命影响。检查死链接可以使用Chinaz中的工具,但是清理死链接相对比较困难。现在我清理网站死链接的方法是通过浏览器中FTP的搜索功能。首先在查询工具中复制死链接的地址,然后在浏览器中通过FTP的搜索功能找到死链接所在的文件,最后将其删除。很多站长都会说这个方法很麻烦,但是我想说的是这个方法确实是最有效的一种,我也用过那些工具来清理死链接。大部分都是假的,所以我根本洗不干净
第三、文章节内容链接合理布局
我们不应该忘记在网站的文章内容中链接布局的形式。在例行的文章更新工作中,我们可以将文章中的关键词作为指向其他文章内容页或网站的链接 查看全部
合理优化网站结构吸引蜘蛛深入抓取网站内容(图)
合理优化网站结构,吸引蜘蛛掌握网站的含量
资料来源:根据她的感受,蜘蛛来网站是件好事,但我通过蜘蛛访问记录发现了一个大问题。通常蜘蛛抓取4或5页,然后在到达网站后离开。怎么了?相信很多站长都觉得百度蜘蛛在6月份的事件之后非常不稳定,我的网站也是如此。从6月份开始,每次蜘蛛来抓几页,它就会离开,所以网站的收录没有得到改进。最后,我对网站做了一个大检查,然后我整理了网站的链接,更不用说整理后的网站,蜘蛛每次抓取20、30页。让我分享一下我的检查方法和补救方法
我想蜘蛛之所以一开始不深入的第一个原因是导航链接设置不正确,蜘蛛无法通过导航链接深入到你的网站中,那它们怎么能抓到内容页呢?第二种可能是蜘蛛遇到死链接,但在准备抓取下一页时却无法爬行,因此网站的死链接成为罪魁祸首,迫使百度蜘蛛离开网站。第三种可能是,长时间不更新网站内容也会导致百度蜘蛛疲惫不堪。第一、页重置网站导航链接
网站的导航链接不仅是用户的指南,也是搜索引擎蜘蛛的指南。一条好的导航路线可以帮助搜索引擎蜘蛛从网站的主页逐步贯穿整个网站页面,这就需要我们层层设置网站导航。让我谈谈设置导航链接的一些要求:
1、导航链接应该关闭。当我们设置导航链接时,我们不应该对搜索引擎蜘蛛看得太深。其实,它是一种捕捉的工具,最容易捕捉的是最近的东西。因此,我们在使用导航链接时,可以通过导航链接导入下一级栏目链接,下一级栏目链接会导入内容页,这是分层导入的方法
从2、导入的URL不应太复杂。我认为可以简单地设置网站的URL地址。只需使用一个PHP程序,目录设置很简单。那么蜘蛛爬行就相对容易了。必须清理二、死链接,留下是一个诅咒
死链接阻碍了网站很多。如果不注意死链接,可能会对网站产生致命影响。检查死链接可以使用Chinaz中的工具,但是清理死链接相对比较困难。现在我清理网站死链接的方法是通过浏览器中FTP的搜索功能。首先在查询工具中复制死链接的地址,然后在浏览器中通过FTP的搜索功能找到死链接所在的文件,最后将其删除。很多站长都会说这个方法很麻烦,但是我想说的是这个方法确实是最有效的一种,我也用过那些工具来清理死链接。大部分都是假的,所以我根本洗不干净
第三、文章节内容链接合理布局
我们不应该忘记在网站的文章内容中链接布局的形式。在例行的文章更新工作中,我们可以将文章中的关键词作为指向其他文章内容页或网站的链接
如何查看360手机应用搜索种类的前5页的信息
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-05-08 18:05
我们不会一想到抓取网页就开始编写一个scrapcrawler。事实上,根据需要选择合适的方式抓取网页更有效
比如抓取360手机各类应用前5页的信息。我们直接分析请求消息的样式,模拟发送消息,然后分析返回的内容以获得所需的信息,而不是编写草图。更重要的是,对于一些JS动态加载的内容(比如在googleplay上抓取应用程序),这种方法可以获得重要的信息,然后配合抓取得到更好的结果。在这种情况下,我们只使用发送请求的方法来捕获
需求:抢占360手机应用搜索类前五页。例如:
[第21页]
在搜索栏中输入游戏,这些应用程序就会出现(按类别搜索,都一样)。我们要采集这些游戏的信息。这里,作为一个例子,只需获取应用程序的包名
这里不详细介绍如何查看浏览器请求消息。F12打开浏览器查找并返回请求的信息。一般来说,您可以从前端开始查看网络中的信息,然后查看响应返回所需的信息
[第22页]
这就是我们需要的信息。查看标头以找到模拟发送请求所需的信息。我不在这里重复了。360网站请求的头URL实际上是URL。例如,单击下一页后,URL为:
[第23页]
这是发送请求的格式。只要URL构造得好,就可以随意获取数据。例如,如果选择“运动”类别第三页的内容,则连接将为“运动&;页码=3
等等。您可以使用chrome插件postman来验证返回的结果,也可以在请求之后直接打印结果。你会知道这是不是对的。我们直接去看节目吧
#-*-编码:utf-8-*-
导入系统
重新加载(sys)
系统设置默认编码(“utf-8”)
进口刮痧
从scrapy.crawler导入CrawlerProcess
#从scrapy.utils.project import获取\项目\设置
#从数据库导入TSFDataBase
导入urllib
导入urllib2
从lxml导入etree
Appkind=[‘阅读’、‘商业’、‘漫画’、‘通信’、‘教育’、‘娱乐’、‘金融’、‘游戏’、‘健康’、‘书籍’、‘生活’、‘动态壁纸’、‘视频’、‘医疗’、‘音乐’、‘新闻’、‘个性化’、‘摄影’、‘效率’、‘购物’、‘社交网络’、‘体育’、‘工具’、‘旅游’,'运输','天气']
fileWriteObj=open('360app.txt','w')
打印长度(appkind)
对于范围内的ikind(len(appkind)):
对于范围内的ipage(5):
打印ipage
数据={}
数据['page']=ipage+1
test\ data\ urlencode=urllib.urlencode(数据)
url=“”+appkind[ikind]+“&;page=“+str(ipage+1)”
data1=urllib.urlencode(数据)
req=urllib2.请求(url,数据1)
响应=urllib2.urlopen(请求)
结果=response.read()
#打印结果
如果isinstance(结果,unicode):
通过
其他:
result=result.decode('utf-8')
tree=etree.HTML(结果)
ranks=tree.xpath('//div[@class=“download comdown”]/a/@href')
打印长度(列)
#ids=tree.xpath('//div[@class=“card no.small”]/div/div[2]/a[2]/@href')
对于范围内的i(len(ranks)):
apppack=等级[i]
apppack=apppack[apppack.rfind('/')+1:apppack.rfind(''\')]
onedata=apppack+','+str(ikind+1)
打印onedata
fileWriteObj.write(onedata+'\n')
打印'------------'
fileWriteObj.close()
如果名称==''主名称:
通过
结果:包名后面跟着分类号,例如,reading 1
[k30公里]
程序在关键词中搜索26个应用程序。每个应用程序抓取前五页并直接存储文本以便于显示。至于XPath之类的知识,我就不重复了。稍后,我将整理如何处理JS加载内容的爬网 查看全部
如何查看360手机应用搜索种类的前5页的信息
我们不会一想到抓取网页就开始编写一个scrapcrawler。事实上,根据需要选择合适的方式抓取网页更有效
比如抓取360手机各类应用前5页的信息。我们直接分析请求消息的样式,模拟发送消息,然后分析返回的内容以获得所需的信息,而不是编写草图。更重要的是,对于一些JS动态加载的内容(比如在googleplay上抓取应用程序),这种方法可以获得重要的信息,然后配合抓取得到更好的结果。在这种情况下,我们只使用发送请求的方法来捕获
需求:抢占360手机应用搜索类前五页。例如:
[第21页]
在搜索栏中输入游戏,这些应用程序就会出现(按类别搜索,都一样)。我们要采集这些游戏的信息。这里,作为一个例子,只需获取应用程序的包名
这里不详细介绍如何查看浏览器请求消息。F12打开浏览器查找并返回请求的信息。一般来说,您可以从前端开始查看网络中的信息,然后查看响应返回所需的信息
[第22页]
这就是我们需要的信息。查看标头以找到模拟发送请求所需的信息。我不在这里重复了。360网站请求的头URL实际上是URL。例如,单击下一页后,URL为:
[第23页]
这是发送请求的格式。只要URL构造得好,就可以随意获取数据。例如,如果选择“运动”类别第三页的内容,则连接将为“运动&;页码=3
等等。您可以使用chrome插件postman来验证返回的结果,也可以在请求之后直接打印结果。你会知道这是不是对的。我们直接去看节目吧
#-*-编码:utf-8-*-
导入系统
重新加载(sys)
系统设置默认编码(“utf-8”)
进口刮痧
从scrapy.crawler导入CrawlerProcess
#从scrapy.utils.project import获取\项目\设置
#从数据库导入TSFDataBase
导入urllib
导入urllib2
从lxml导入etree
Appkind=[‘阅读’、‘商业’、‘漫画’、‘通信’、‘教育’、‘娱乐’、‘金融’、‘游戏’、‘健康’、‘书籍’、‘生活’、‘动态壁纸’、‘视频’、‘医疗’、‘音乐’、‘新闻’、‘个性化’、‘摄影’、‘效率’、‘购物’、‘社交网络’、‘体育’、‘工具’、‘旅游’,'运输','天气']
fileWriteObj=open('360app.txt','w')
打印长度(appkind)
对于范围内的ikind(len(appkind)):
对于范围内的ipage(5):
打印ipage
数据={}
数据['page']=ipage+1
test\ data\ urlencode=urllib.urlencode(数据)
url=“”+appkind[ikind]+“&;page=“+str(ipage+1)”
data1=urllib.urlencode(数据)
req=urllib2.请求(url,数据1)
响应=urllib2.urlopen(请求)
结果=response.read()
#打印结果
如果isinstance(结果,unicode):
通过
其他:
result=result.decode('utf-8')
tree=etree.HTML(结果)
ranks=tree.xpath('//div[@class=“download comdown”]/a/@href')
打印长度(列)
#ids=tree.xpath('//div[@class=“card no.small”]/div/div[2]/a[2]/@href')
对于范围内的i(len(ranks)):
apppack=等级[i]
apppack=apppack[apppack.rfind('/')+1:apppack.rfind(''\')]
onedata=apppack+','+str(ikind+1)
打印onedata
fileWriteObj.write(onedata+'\n')
打印'------------'
fileWriteObj.close()
如果名称==''主名称:
通过
结果:包名后面跟着分类号,例如,reading 1
[k30公里]
程序在关键词中搜索26个应用程序。每个应用程序抓取前五页并直接存储文本以便于显示。至于XPath之类的知识,我就不重复了。稍后,我将整理如何处理JS加载内容的爬网
TeleportUltra用起来效果很好的方法解决资源竞争的问题
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-05-08 07:18
出于某些原因,我们经常需要抓取某个网站或直接复制某个网站。我们在Internet上找到了许多用于测试的工具,尝试了许多不同的问题,最后选择了Teleport Ultra来使用它。效果很好;这里没有提到具体的操作手册和其他内容,互联网上有很多搜索,这主要是遇到的问题:
软件下载地址:
工具屏幕截图:
网站的爬网测试很简单:
拍摄后的效果图片
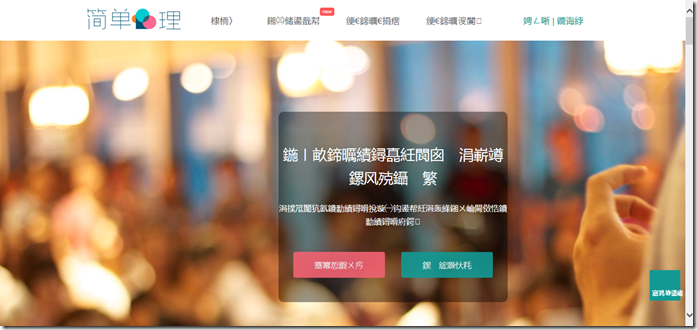
通常,我将选择复制100级并基本上复制网站中的所有内容,但是由于Teleport Ultra是用UTF-8捕获的,因此如果文件中收录中文字符或gbk编码,文件将出现乱码,如下所示:
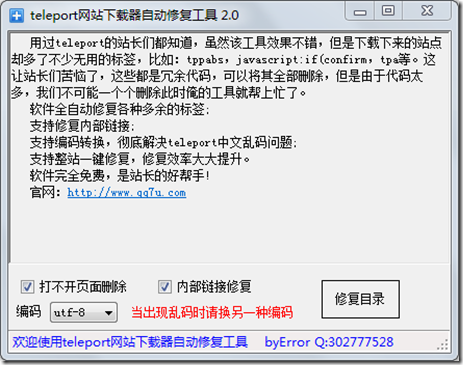
当然,您可以在浏览器中手动选择UTF-8,但是每次打开它时我们都做不到。因此,我转到网站,找到了一个名为:TelePort乱码修复工具(siteRepair-v 2. 0))的软件,经过测试可以解决乱码问题,该工具还将删除一些无效的链接和html符号,等
软件下载地址:
软件屏幕截图:
经过这两个步骤后,绝大多数网站应该都可以,但是某些网站层次结构使用中文目录,或者中文文件名会出现乱码,类似于下面的URL地址:
除了锁定之外,还有哪些其他方法可以解决资源竞争问题? /Solution.html
通过这种方式,网站的结构将出现两种乱码:1)文件夹名乱码2)文件名乱码
遇到此问题时,siteRepair-v 2. 0工具将报告错误。我猜它无法识别乱码的文件夹或文件。
后来,我在互联网上找到了一个PHP程序,只需进行简单的修改测试就可以解决此问题
PHP代码:convert.php
<p> 查看全部
TeleportUltra用起来效果很好的方法解决资源竞争的问题
出于某些原因,我们经常需要抓取某个网站或直接复制某个网站。我们在Internet上找到了许多用于测试的工具,尝试了许多不同的问题,最后选择了Teleport Ultra来使用它。效果很好;这里没有提到具体的操作手册和其他内容,互联网上有很多搜索,这主要是遇到的问题:
软件下载地址:
工具屏幕截图:
网站的爬网测试很简单:
拍摄后的效果图片
通常,我将选择复制100级并基本上复制网站中的所有内容,但是由于Teleport Ultra是用UTF-8捕获的,因此如果文件中收录中文字符或gbk编码,文件将出现乱码,如下所示:
当然,您可以在浏览器中手动选择UTF-8,但是每次打开它时我们都做不到。因此,我转到网站,找到了一个名为:TelePort乱码修复工具(siteRepair-v 2. 0))的软件,经过测试可以解决乱码问题,该工具还将删除一些无效的链接和html符号,等
软件下载地址:
软件屏幕截图:
经过这两个步骤后,绝大多数网站应该都可以,但是某些网站层次结构使用中文目录,或者中文文件名会出现乱码,类似于下面的URL地址:
除了锁定之外,还有哪些其他方法可以解决资源竞争问题? /Solution.html
通过这种方式,网站的结构将出现两种乱码:1)文件夹名乱码2)文件名乱码
遇到此问题时,siteRepair-v 2. 0工具将报告错误。我猜它无法识别乱码的文件夹或文件。
后来,我在互联网上找到了一个PHP程序,只需进行简单的修改测试就可以解决此问题
PHP代码:convert.php
<p>
米鼠网MacOS10.15.x[下载链接]
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-05-08 07:16
[名称]:适用于Mac的WebScraper
[大小]:9. 6 MB
[语言]:英文
[测试环境]:Mac OS 1 0. 1 5. x
[下载链接]:
简介
WebScraper Mac是Mac OS系统上非常有用的网站数据提取工具。 WebScraper可以帮助您在10分钟内轻松地抓取网页数据。只需输入起始URL即可开始。简单而强大。
软件功能
1、快速轻松地扫描网站
很多提取选项;各种元数据,内容(例如文本,html或markdown),具有某些类/ ID的元素,正则表达式
2、易于导出,选择所需的列
3、输出为csv或json
4、新选项可将所有图像下载到文件夹/采集并导出所有链接
5、新选项可输出单个文本文件(用于存档文本内容,降价或纯文本)
6、丰富的选项/配置
在这里,我推荐一个在线软件综合交易平台:
自成立以来,一直专注于软件项目,人才招聘,软件商城等,始终秉承“专业服务,易于使用的产品”和“提供高水平的服务”的经营理念。优质的服务和满足客户的需求。需求,共同创造双赢局面”是为中国国内企业提供国际,专业,个性化和软件项目解决方案的企业目标。我们公司拥有一流的项目经理团队,具有出色的软件项目设计和实施能力。为全国不同行业的客户提供优质的产品和服务,受到了客户的广泛好评。
查看全部
米鼠网MacOS10.15.x[下载链接]
[名称]:适用于Mac的WebScraper
[大小]:9. 6 MB
[语言]:英文
[测试环境]:Mac OS 1 0. 1 5. x
[下载链接]:
简介
WebScraper Mac是Mac OS系统上非常有用的网站数据提取工具。 WebScraper可以帮助您在10分钟内轻松地抓取网页数据。只需输入起始URL即可开始。简单而强大。
软件功能
1、快速轻松地扫描网站
很多提取选项;各种元数据,内容(例如文本,html或markdown),具有某些类/ ID的元素,正则表达式
2、易于导出,选择所需的列
3、输出为csv或json
4、新选项可将所有图像下载到文件夹/采集并导出所有链接
5、新选项可输出单个文本文件(用于存档文本内容,降价或纯文本)
6、丰富的选项/配置
在这里,我推荐一个在线软件综合交易平台:
自成立以来,一直专注于软件项目,人才招聘,软件商城等,始终秉承“专业服务,易于使用的产品”和“提供高水平的服务”的经营理念。优质的服务和满足客户的需求。需求,共同创造双赢局面”是为中国国内企业提供国际,专业,个性化和软件项目解决方案的企业目标。我们公司拥有一流的项目经理团队,具有出色的软件项目设计和实施能力。为全国不同行业的客户提供优质的产品和服务,受到了客户的广泛好评。

Python多进程方式抓取基金网站内容相关实现技巧与操作注意事项
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-05-06 05:17
本文文章主要介绍了Python多进程抓取资金网站内容的方法,并结合示例分析了Python多进程抓取网站内容相关的实现技巧和操作注意事项。有需要的朋友可以参考
本文介绍了在python多进程模式下获取fund 网站内容的方法。与您分享以供参考,如下所示:
在上一篇文章//// article / 16241 8. htm中,我们已经简要地理解了“ python的多进程”,现在我们需要编写抓取基金网站的内容(第28页)作为一种多过程方法。
由于该过程越少越好,我们计划在三个过程中实施它。这意味着:将总共28个要抓取的页面分为三个部分。
如何划分?
# 初始range
r = range(1,29)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)]
print(myList) # [range(1, 11), range(11, 21), range(21, 29)]
根据上面的代码,我们将1〜29分为三个部分,列表中的三个范围。
2、还记得我们获取了Fund 网站内容的getData()函数吗?
def getData(start, end):
for x in range(start, end+1):
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDlkNWdriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
该函数有2个参数:起始页码和结束页码,即从起始页到结束页。
这两个参数实际上是范围。
按如下所示修改getData()函数(参数不同):
# 循环抓取网页内容的函数
def getData(myrange):
for x in myrange:
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
编程客栈 .get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
3、创建一个进程并将目标设置为上述getData():
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
有三个要分别获取的过程。
4、多进程抓取资金网站多页内容的完整代码:
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from multiprocessing import Process
driver = webdriver.Phantomjs(executable_path=r"你phantomjs的可执行文件路径")
# 请求一个网址
driver.get("http://fund.eastmoney.com/fund.html")
page_text = driver.find_element_by_id("pager").find_element_by_xpath("span[@class='nv']").text
total_page = ''.join(filter(str.isdigit,page_text)) # 得到总共有多少页
# 循环抓取网页内容的函数
def getData(myrange):
for x in myrange:
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(编程客栈str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
对于对Python相关内容有更多兴趣的读者,请查看此站点的主题:“ Python进程和线程操作技能摘要”,“ Python数据结构和算法教程”,“ Python函数使用技能摘要”, “ Python字符串”操作技巧摘要”,“ Python简介和高级经典教程”,“ Python + mysql数据库编程简介”和“ Python通用数据库操作技巧摘要”
我希望本文能对您的Python编程有所帮助。
本文标题:Python多进程爬网资金网站内容的方法分析 查看全部
Python多进程方式抓取基金网站内容相关实现技巧与操作注意事项
本文文章主要介绍了Python多进程抓取资金网站内容的方法,并结合示例分析了Python多进程抓取网站内容相关的实现技巧和操作注意事项。有需要的朋友可以参考
本文介绍了在python多进程模式下获取fund 网站内容的方法。与您分享以供参考,如下所示:
在上一篇文章//// article / 16241 8. htm中,我们已经简要地理解了“ python的多进程”,现在我们需要编写抓取基金网站的内容(第28页)作为一种多过程方法。
由于该过程越少越好,我们计划在三个过程中实施它。这意味着:将总共28个要抓取的页面分为三个部分。
如何划分?
# 初始range
r = range(1,29)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)]
print(myList) # [range(1, 11), range(11, 21), range(21, 29)]
根据上面的代码,我们将1〜29分为三个部分,列表中的三个范围。
2、还记得我们获取了Fund 网站内容的getData()函数吗?
def getData(start, end):
for x in range(start, end+1):
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDlkNWdriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
该函数有2个参数:起始页码和结束页码,即从起始页到结束页。
这两个参数实际上是范围。
按如下所示修改getData()函数(参数不同):
# 循环抓取网页内容的函数
def getData(myrange):
for x in myrange:
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
编程客栈 .get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
3、创建一个进程并将目标设置为上述getData():
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
有三个要分别获取的过程。
4、多进程抓取资金网站多页内容的完整代码:
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from multiprocessing import Process
driver = webdriver.Phantomjs(executable_path=r"你phantomjs的可执行文件路径")
# 请求一个网址
driver.get("http://fund.eastmoney.com/fund.html";)
page_text = driver.find_element_by_id("pager").find_element_by_xpath("span[@class='nv']").text
total_page = ''.join(filter(str.isdigit,page_text)) # 得到总共有多少页
# 循环抓取网页内容的函数
def getData(myrange):
for x in myrange:
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(编程客栈str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
对于对Python相关内容有更多兴趣的读者,请查看此站点的主题:“ Python进程和线程操作技能摘要”,“ Python数据结构和算法教程”,“ Python函数使用技能摘要”, “ Python字符串”操作技巧摘要”,“ Python简介和高级经典教程”,“ Python + mysql数据库编程简介”和“ Python通用数据库操作技巧摘要”
我希望本文能对您的Python编程有所帮助。
本文标题:Python多进程爬网资金网站内容的方法分析
吸引搜索引擎蜘蛛快速抓取网站的内容不是什么事
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-05-05 07:15
吸引搜索引擎蜘蛛快速抓取网站的内容不是什么事
这些因素将影响搜索引擎蜘蛛对网站内容的爬网。吸引搜索引擎蜘蛛快速抓取网站的内容并使搜索引擎快速收录 网站的内容一直是SEO优化人员想要实现的效果。但是,要实现这样的效果并不容易,这对于许多优化器来说也是一个问题。但是,如果以下几点做得很好,那就没什么了。
1、检查您的IP上是否有大型站点
东莞网站 SEO优化促进发现,搜索引擎蜘蛛通常是按IP进行爬网的,并且某个IP的爬网次数也受到限制。如果您的IP有许多站点,则将其分配给某个站点。每个站点的爬网量都将减少,尤其是在存在具有相同IP的大型站点时。另一方面,如果具有相同IP的网站的活动站点可能与您的网站类似,则也会影响网站从侧面爬网。因此,网站进行了优化,以尽可能多地使用独立IP。
2、内容质量
尽管百度的官方文件没有显示原创内容的词汇,但实际上百度要表达的内容是只要它对客户有用,即使不是原创,它也将给出良好的排名。 ,因此,有很多针对非原创内容的内容产生方法。百度排名的最佳方法是内容子模块和随机组合。结果非常好,输入也很好。但是,大多数网站管理员都知道,非原创是转载和窃,伪原创等。您可以想象搜索引擎蜘蛛对此类网站的情绪。
退后一步说,如果您确实想做伪原创,则必须确保至少有30%的差异,可以组合使用。 网站确保内容质量的另一个方面是,百度在某些类型的网站上的进入受到限制。百度会在进入您的网站之前对网站进行评分,然后根据该评分选择网站条目。多少钱?这是长期以来许多电台进入率下降的根本原因。
因此,我们需要增加有用条目的数量。东莞网站 SEO优化推广发现,百度排名的基本原因是提供高质量的内容页面来满足搜索需求,但不幸的是,百度排名靠前的高质量内容页面普遍原创,因此想要查找的网站站长通过伪原创的文章内容可以省钱。
3、现场密封
网站管理员有时间注意您网站的严格性。例如,它无法打开,黑链跳开,捕获了webshell等,该网站管理员必须是第一次,并使用百度网站管理员工具中的相应救援方法进行操作。通常,网站被黑的效果是挂起一条黑链,因此,如果您有时间查看是否在源代码中添加了许多黑链,则会成批添加黑链,这在视觉上很容易区分。如果您无法及时处理,百度抓取工具会抓取相关页面并跳转到非法页面,这会降低您的权利。通常,对链接黑色链接导致的百度排名进行排名并不容易。
4、 网站打开速度和加载速度
东莞网站 SEO优化促进发现网站的打开速度将影响搜索引擎蜘蛛从侧面爬行的速度。尽管Spider会抓取您的网页,但是网页的大小没有区别(实际上,网页越大,网页的丰富程度就越大,百度就会显示出来),但是从用户的角度来看,当您的网页已打开如果加载时间超过3秒,则跳出率将添加到市场营销搜索引擎优化网站中。如果跳出率很高,则会影响您的网站等级,并且网站等级会降低,并且网站的条目会很低。 。因此,百度排名的开放速度将直接影响搜索引擎蜘蛛的爬行。
咨询客户服务咨询客户服务
英语演示是演示地址的原创版本。如果您位于中国境外,访问可能会很慢(建议爬梯子进行浏览)。您在本网站上下载的主题源代码和其他资源仅用于测试和学习目的。官方更新和售后服务。
此站点承担WordPress主题安装,深度本地化,加速优化和其他服务。请咨询在线客户服务以获取详细信息!
查看全部
吸引搜索引擎蜘蛛快速抓取网站的内容不是什么事

这些因素将影响搜索引擎蜘蛛对网站内容的爬网。吸引搜索引擎蜘蛛快速抓取网站的内容并使搜索引擎快速收录 网站的内容一直是SEO优化人员想要实现的效果。但是,要实现这样的效果并不容易,这对于许多优化器来说也是一个问题。但是,如果以下几点做得很好,那就没什么了。
1、检查您的IP上是否有大型站点
东莞网站 SEO优化促进发现,搜索引擎蜘蛛通常是按IP进行爬网的,并且某个IP的爬网次数也受到限制。如果您的IP有许多站点,则将其分配给某个站点。每个站点的爬网量都将减少,尤其是在存在具有相同IP的大型站点时。另一方面,如果具有相同IP的网站的活动站点可能与您的网站类似,则也会影响网站从侧面爬网。因此,网站进行了优化,以尽可能多地使用独立IP。
2、内容质量
尽管百度的官方文件没有显示原创内容的词汇,但实际上百度要表达的内容是只要它对客户有用,即使不是原创,它也将给出良好的排名。 ,因此,有很多针对非原创内容的内容产生方法。百度排名的最佳方法是内容子模块和随机组合。结果非常好,输入也很好。但是,大多数网站管理员都知道,非原创是转载和窃,伪原创等。您可以想象搜索引擎蜘蛛对此类网站的情绪。
退后一步说,如果您确实想做伪原创,则必须确保至少有30%的差异,可以组合使用。 网站确保内容质量的另一个方面是,百度在某些类型的网站上的进入受到限制。百度会在进入您的网站之前对网站进行评分,然后根据该评分选择网站条目。多少钱?这是长期以来许多电台进入率下降的根本原因。
因此,我们需要增加有用条目的数量。东莞网站 SEO优化推广发现,百度排名的基本原因是提供高质量的内容页面来满足搜索需求,但不幸的是,百度排名靠前的高质量内容页面普遍原创,因此想要查找的网站站长通过伪原创的文章内容可以省钱。
3、现场密封
网站管理员有时间注意您网站的严格性。例如,它无法打开,黑链跳开,捕获了webshell等,该网站管理员必须是第一次,并使用百度网站管理员工具中的相应救援方法进行操作。通常,网站被黑的效果是挂起一条黑链,因此,如果您有时间查看是否在源代码中添加了许多黑链,则会成批添加黑链,这在视觉上很容易区分。如果您无法及时处理,百度抓取工具会抓取相关页面并跳转到非法页面,这会降低您的权利。通常,对链接黑色链接导致的百度排名进行排名并不容易。
4、 网站打开速度和加载速度
东莞网站 SEO优化促进发现网站的打开速度将影响搜索引擎蜘蛛从侧面爬行的速度。尽管Spider会抓取您的网页,但是网页的大小没有区别(实际上,网页越大,网页的丰富程度就越大,百度就会显示出来),但是从用户的角度来看,当您的网页已打开如果加载时间超过3秒,则跳出率将添加到市场营销搜索引擎优化网站中。如果跳出率很高,则会影响您的网站等级,并且网站等级会降低,并且网站的条目会很低。 。因此,百度排名的开放速度将直接影响搜索引擎蜘蛛的爬行。
咨询客户服务咨询客户服务
英语演示是演示地址的原创版本。如果您位于中国境外,访问可能会很慢(建议爬梯子进行浏览)。您在本网站上下载的主题源代码和其他资源仅用于测试和学习目的。官方更新和售后服务。
此站点承担WordPress主题安装,深度本地化,加速优化和其他服务。请咨询在线客户服务以获取详细信息!

巧用文章内容能让你的网站更受搜索引擎的欢迎
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-05-05 07:10
实际上,网站的内容并不完全可供用户看到,它更多地是各种搜索引擎进行爬取和判断的标准。 网站的含量是网站是否可以长时间操作的重要因素。基本的知识,懂得如何优化,并熟练地使用文章内容来使网站在搜索引擎中更受欢迎。
一个:如何优化网站内容
对于每个搜索引擎而言,高质量原创内容以及图形和文本的丰富组合都易于被搜索引擎抓取,并且它们都收录在高质量库中,并且关键词排名的内容也将随之而来。越来越多,以便您可以获得更好的点击率。
对于每个搜索用户,内容页面可以获取他需要的更多内容,这是终止搜索引擎的目的。用户停留在页面上的时间长度和在内部页面上的点击次数取决于搜索引擎对质量的判断。质量是内容的重要组成部分。
二:如何专门优化网站的内容
网站的内容优化涉及很多种类,在这里我将简要介绍一些我自己的经验,希望能帮助更多的网站管理员。
1:仔细组织内容标题。
标题是当前内容的核心思想,它反映了其背后的需求范围。内容标题设置的质量与大多数用户是否可以通过此标题搜索网站内容直接相关。标题的组织原则是,标题是否可以满足用户的大部分需求,是否具有吸引力以及是否具有尺寸。
2:该段落的内容需要很多努力。
用户进入内容页面后,他们的眼睛从上到下。一条内容能否吸引用户的注意力取决于其文学能力。段落应通过完全匹配和分词匹配在标题的关键词中排列,并且必须具有吸引力。
3:内容详尽,丰富,并结合了图形和文本。
丰富,独特和权威的内容可以使用户满意,并且图形和文本的组合可以降低用户的阅读成本。相反,只有几个数字的文章没有深入阅读的属性。
4:根据需要写出内容中的单词数。
不要写很多无用的文字来增加字数。只需简短易懂的文字即可显示更重要的内容。
5:标题中的文本需要在整个内容中反映出来。
在当前内容中,布局是相关的关键词,可以进一步增强内容的相关性,并且对搜索引擎非常友好。
6:重要内容需要在其他页面上体现出来。
除了单词频率外,位置也很重要。想要获得排名的关键词链接以内部链接,推荐方式,相关阅读方式和置顶方式出现。在网站上给该内容页面更多的投票,相应的排名将会更高。
以上是我个人内容优化经验的一部分。从优化的角度来看,内容优化是不可忽略的重要链接。它可能取决于网站的生与死。希望以上介绍可以帮助更多的网站管理员,谢谢收看。 查看全部
巧用文章内容能让你的网站更受搜索引擎的欢迎
实际上,网站的内容并不完全可供用户看到,它更多地是各种搜索引擎进行爬取和判断的标准。 网站的含量是网站是否可以长时间操作的重要因素。基本的知识,懂得如何优化,并熟练地使用文章内容来使网站在搜索引擎中更受欢迎。
一个:如何优化网站内容
对于每个搜索引擎而言,高质量原创内容以及图形和文本的丰富组合都易于被搜索引擎抓取,并且它们都收录在高质量库中,并且关键词排名的内容也将随之而来。越来越多,以便您可以获得更好的点击率。
对于每个搜索用户,内容页面可以获取他需要的更多内容,这是终止搜索引擎的目的。用户停留在页面上的时间长度和在内部页面上的点击次数取决于搜索引擎对质量的判断。质量是内容的重要组成部分。
二:如何专门优化网站的内容
网站的内容优化涉及很多种类,在这里我将简要介绍一些我自己的经验,希望能帮助更多的网站管理员。
1:仔细组织内容标题。
标题是当前内容的核心思想,它反映了其背后的需求范围。内容标题设置的质量与大多数用户是否可以通过此标题搜索网站内容直接相关。标题的组织原则是,标题是否可以满足用户的大部分需求,是否具有吸引力以及是否具有尺寸。
2:该段落的内容需要很多努力。
用户进入内容页面后,他们的眼睛从上到下。一条内容能否吸引用户的注意力取决于其文学能力。段落应通过完全匹配和分词匹配在标题的关键词中排列,并且必须具有吸引力。
3:内容详尽,丰富,并结合了图形和文本。
丰富,独特和权威的内容可以使用户满意,并且图形和文本的组合可以降低用户的阅读成本。相反,只有几个数字的文章没有深入阅读的属性。
4:根据需要写出内容中的单词数。
不要写很多无用的文字来增加字数。只需简短易懂的文字即可显示更重要的内容。
5:标题中的文本需要在整个内容中反映出来。
在当前内容中,布局是相关的关键词,可以进一步增强内容的相关性,并且对搜索引擎非常友好。
6:重要内容需要在其他页面上体现出来。
除了单词频率外,位置也很重要。想要获得排名的关键词链接以内部链接,推荐方式,相关阅读方式和置顶方式出现。在网站上给该内容页面更多的投票,相应的排名将会更高。
以上是我个人内容优化经验的一部分。从优化的角度来看,内容优化是不可忽略的重要链接。它可能取决于网站的生与死。希望以上介绍可以帮助更多的网站管理员,谢谢收看。
区块之前的兄弟区块和正文相关数据和在确定
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-05-04 01:21
此外,提取网页的主要文本包括以下步骤;确定主要文本的相关图片,确定主要文本的相关视频,确定主要文本的相关数据表,并在确定相关图片,视频和数据的基础上结合主要文本块的文本构造正文的表格。
进一步,遍历同级块和文本块之前的文本块,并将非黑名单中的图片和视频链接分别提取为与文本相关的图片和与文本相关的视频。
此外,遍历文本块以将数据表提取为与文本相关的数据表。
此外,自动提取网页信息的方法还包括:提取与文本有关的基本元数据;
提取与文本相关的基本元数据包括:提取标题,提取来源,提取发布时间以及提取作者。
进一步,遍历文本块之前的同级块和文本块中的短文本节点,计算最长的子字符串与字符长度之比时,文本节点字符和页面标题文本的最长公共子字符串如果超过某个阈值,它将被添加到标题候选集;
在文本块之前遍历同级块,并根据源要素库提取满足源前缀和后特性的字符串,并将其添加到源候选集;
遍历文本块之前的兄弟块,并根据发布时间特征库提取满足发布时间前缀和后特性的字符串,并将其添加到发布时间候选集;
在文本块之前遍历兄弟姐妹块,并根据作者的特征库提取符合作者前缀和后特性的字符串,并将其添加到作者候选集。
此外,预处理网页数据包括:
为html网页的源代码对统一字符集进行转码并对特殊字符进行编码和解码。
本发明的优点在于它考虑了网页信息提取的效率和准确性。在不显着减少传统网页提取方法的基础上,考虑了网页的布局特征和html的部分视觉特征,有效地改善了网页。信息提取的准确性。
在使用该程序自动提取Web信息的基础上,充分利用了存放的黑名单,规则库和知识库,这大大提高了自动提取的准确性,并且可以通过不断更新规则来改进提取方法基础和知识库适应性和准确性的范围。
将网页的dom结构与网页的布局功能结合在一起,合并并计算文本,图片,视频和表格,以构建具有综合主题权重和某些视觉功能的块dom,提高文本提取的准确性,并改进网页提取算法的适用领域:除了网页的主要文本外,现有的黑名单,知识库和规则库还可用于更准确地提取主要文本图像,视频,表格的关键字段,标题,发布时间,来源,作者等。
图纸说明
图1是自动提取Web信息的方法的流程图。
具体的实现方法
下面参考附图和具体实施例详细描述本发明。
如图1所示,一种自动提取网页信息的方法包括以下步骤:一、预处理网页信息; 二、建立块dom树; 三、定位文本区域; 四、提取网页的正文; 五、提取与正文相关的基本元数据。
在定位文本区域时,请根据通过加权计算获得的被摄体权重来定位文本区域。
一、预处理网页信息
网页信息的预处理包括:将html网页的源代码转换为统一的字符集,并对特殊字符进行编码和解码。
二、构建块dom树
构建块dom树包括以下步骤:
2. 1对网页的源代码执行容错补偿和dom分析;
2. 2基于dom组合html块布局元素以构建块dom结构;
2. 3根据显示特征计算dom块中基本主题元素的数量;
2. 4对dom块的基本主题元素执行加权计算。
重量是数量和重量的乘积。权重主要是指元素节点的视觉显示信息,具有分段,块,居中和增强显示效果的元素具有较高的权重。
统计文本信息和权重(转发权重):纯文本的数量和权重,有效文本的数量和权重(长文本)。
超链接信息和权重(负权重)的统计信息:超链接的数量和权重,链接文本的数量以及文本链接的平均比率(外部链接的负权重更高)。
图片信息和权重的统计信息:垃圾图片的数量(黑名单中的图片和小图片的权重为负),未链接图片的数量和权重,链接大图片的数量和权重。
统计数据表的数量和权重:数据表单元格的数量。
视频数量和重量的统计信息:垃圾视频的数量(黑名单中的视频),普通视频的数量和重量。
三、找到文本区域
过滤版权块:组合版权声明特征库以相反的顺序遍历dom块,以过滤版权声明块。
根据dom块的主题权重递归收缩并定位候选主题块:找到主题权重最大的dom块,并将其记录为max_block,将主题权重第二大的dom块记录为second_block;如果当max_block的权重与其父节点的权重之比超过某个阈值时,则将max_block用作收缩的根节点,否则收缩将停止。
合并候选dom块以获得文本块:如果second_block的值大于某个阈值或second_block与max_block的比率大于某个阈值,请检查second_block和max_block是否具有公共父节点或祖父母节点(如果这样)将公共父节点或祖父母节点设置为文本块content_block,同时将multi_block标志设置为true。
根据主题权重裁剪文本块并进行降噪:如果multi_block为true,则将修整content_block以过滤出主题权重小于平均值的块;如果multi_block为false,则主题权重将被滤除小于零的块。
四、提取网页的正文
网页主要文本的提取包括以下步骤;确定正文的相关图片,确定正文的相关视频,确定正文的相关数据表,并构造正文。
遍历同级块和文本块之前的文本块,并从非黑名单中提取图片和视频链接,分别作为与文本相关的图片和与文本相关的视频。
遍历文本块并将数据表提取为与文本相关的数据表。
文本的构造:在确定文本的相关图片,视频和数据表的基础上,将文本块的文本与文本块的文本组合以构造文本。具体地,基于上面确定的图片,视频和数据表,结合文本块的文本信息,基本的html显示特征按照出现在html中的顺序被保留,并且图片,表的混合布局并制作了视频。的富文本正文。
五、提取与文本相关的基本元数据
5. 1提取标题
依次遍历文本块和文本块中的短文本节点之前的同级块,并计算最长子字符串与字符之比时文本节点字符和网页标题文本的最长公共子字符串文本节点的长度超过某个值阈值被添加到标题候选集。如果标题候选集大于1,则综合考虑节点的视觉增强效果,公共子串的长度,公共子串的比例和文本节点的长度,优选文本节点。如果标题候选节点集为空,则将页面标题作为主页面标题返回。
5. 2提取源
依次遍历文本块之前的兄弟块,并根据源要素数据库提取满足源前缀和后特性的字符串,并将其添加到源候选集中;如果候选集为空,则根据源,分别从文本的开头和结尾开始和结束。特征库提取满足源前缀和后缀特征的字符串,并将它们添加到源候选集。如果候选集的数量大于1,则最好将媒体源库的内容匹配为文章的源。
5. 3提取发布时间
依次遍历文本块之前的兄弟块,并根据发布时间特征库提取满足发布时间前缀和后特性的字符串,并将其添加到发布时间候选者集中;如果候选集的数量大于1,则首选值与常识一致,并且可以将发布时间格式库的内容与发布时间匹配。
5. 4摘录作者
依次遍历同级文字块,然后根据作者的特征库提取符合作者前缀和发布特征的字符串,并将其添加到候选作者集中;如果作者候选集为空,则根据作者特征库提取符合作者前缀和后缀功能的字符串,并加入作者候选集。如果候选集的数量大于1,则最好将作者的源库中的内容匹配为文章的作者。
将网页的dom结构与网页的块布局元素组合在一起,以构造具有文本和部分视觉特征的块dom结构,并对文本,图片,视频的基本元素执行融合计算,表格等。定量计算dom块的主题贡献值;通过自上而下的块缩小算法定位网页主题的核心块,然后通过自下而上的块扩展算法过滤网页的主题候选块,最后对候选主题块进行噪声裁剪以完成最终的主题块定位;根据确定的主题块,结合黑名单,规则库和知识库,提取正文信息,包括文字,图片,视频和图表;以规则区,主题库,规则库,知识库,上下文位置,显示功能为中心,提取正文标题,发布时间,来源和作者。
上面已经显示和描述了本发明的基本原理,主要特征和优点。本领域技术人员应当理解,上述实施例不以任何形式限制本发明,通过等同替换或等同变换获得的所有技术方案都落入本发明的保护范围。 查看全部
区块之前的兄弟区块和正文相关数据和在确定
此外,提取网页的主要文本包括以下步骤;确定主要文本的相关图片,确定主要文本的相关视频,确定主要文本的相关数据表,并在确定相关图片,视频和数据的基础上结合主要文本块的文本构造正文的表格。
进一步,遍历同级块和文本块之前的文本块,并将非黑名单中的图片和视频链接分别提取为与文本相关的图片和与文本相关的视频。
此外,遍历文本块以将数据表提取为与文本相关的数据表。
此外,自动提取网页信息的方法还包括:提取与文本有关的基本元数据;
提取与文本相关的基本元数据包括:提取标题,提取来源,提取发布时间以及提取作者。
进一步,遍历文本块之前的同级块和文本块中的短文本节点,计算最长的子字符串与字符长度之比时,文本节点字符和页面标题文本的最长公共子字符串如果超过某个阈值,它将被添加到标题候选集;
在文本块之前遍历同级块,并根据源要素库提取满足源前缀和后特性的字符串,并将其添加到源候选集;
遍历文本块之前的兄弟块,并根据发布时间特征库提取满足发布时间前缀和后特性的字符串,并将其添加到发布时间候选集;
在文本块之前遍历兄弟姐妹块,并根据作者的特征库提取符合作者前缀和后特性的字符串,并将其添加到作者候选集。
此外,预处理网页数据包括:
为html网页的源代码对统一字符集进行转码并对特殊字符进行编码和解码。
本发明的优点在于它考虑了网页信息提取的效率和准确性。在不显着减少传统网页提取方法的基础上,考虑了网页的布局特征和html的部分视觉特征,有效地改善了网页。信息提取的准确性。
在使用该程序自动提取Web信息的基础上,充分利用了存放的黑名单,规则库和知识库,这大大提高了自动提取的准确性,并且可以通过不断更新规则来改进提取方法基础和知识库适应性和准确性的范围。
将网页的dom结构与网页的布局功能结合在一起,合并并计算文本,图片,视频和表格,以构建具有综合主题权重和某些视觉功能的块dom,提高文本提取的准确性,并改进网页提取算法的适用领域:除了网页的主要文本外,现有的黑名单,知识库和规则库还可用于更准确地提取主要文本图像,视频,表格的关键字段,标题,发布时间,来源,作者等。
图纸说明
图1是自动提取Web信息的方法的流程图。
具体的实现方法
下面参考附图和具体实施例详细描述本发明。
如图1所示,一种自动提取网页信息的方法包括以下步骤:一、预处理网页信息; 二、建立块dom树; 三、定位文本区域; 四、提取网页的正文; 五、提取与正文相关的基本元数据。
在定位文本区域时,请根据通过加权计算获得的被摄体权重来定位文本区域。
一、预处理网页信息
网页信息的预处理包括:将html网页的源代码转换为统一的字符集,并对特殊字符进行编码和解码。
二、构建块dom树
构建块dom树包括以下步骤:
2. 1对网页的源代码执行容错补偿和dom分析;
2. 2基于dom组合html块布局元素以构建块dom结构;
2. 3根据显示特征计算dom块中基本主题元素的数量;
2. 4对dom块的基本主题元素执行加权计算。
重量是数量和重量的乘积。权重主要是指元素节点的视觉显示信息,具有分段,块,居中和增强显示效果的元素具有较高的权重。
统计文本信息和权重(转发权重):纯文本的数量和权重,有效文本的数量和权重(长文本)。
超链接信息和权重(负权重)的统计信息:超链接的数量和权重,链接文本的数量以及文本链接的平均比率(外部链接的负权重更高)。
图片信息和权重的统计信息:垃圾图片的数量(黑名单中的图片和小图片的权重为负),未链接图片的数量和权重,链接大图片的数量和权重。
统计数据表的数量和权重:数据表单元格的数量。
视频数量和重量的统计信息:垃圾视频的数量(黑名单中的视频),普通视频的数量和重量。
三、找到文本区域
过滤版权块:组合版权声明特征库以相反的顺序遍历dom块,以过滤版权声明块。
根据dom块的主题权重递归收缩并定位候选主题块:找到主题权重最大的dom块,并将其记录为max_block,将主题权重第二大的dom块记录为second_block;如果当max_block的权重与其父节点的权重之比超过某个阈值时,则将max_block用作收缩的根节点,否则收缩将停止。
合并候选dom块以获得文本块:如果second_block的值大于某个阈值或second_block与max_block的比率大于某个阈值,请检查second_block和max_block是否具有公共父节点或祖父母节点(如果这样)将公共父节点或祖父母节点设置为文本块content_block,同时将multi_block标志设置为true。
根据主题权重裁剪文本块并进行降噪:如果multi_block为true,则将修整content_block以过滤出主题权重小于平均值的块;如果multi_block为false,则主题权重将被滤除小于零的块。
四、提取网页的正文
网页主要文本的提取包括以下步骤;确定正文的相关图片,确定正文的相关视频,确定正文的相关数据表,并构造正文。
遍历同级块和文本块之前的文本块,并从非黑名单中提取图片和视频链接,分别作为与文本相关的图片和与文本相关的视频。
遍历文本块并将数据表提取为与文本相关的数据表。
文本的构造:在确定文本的相关图片,视频和数据表的基础上,将文本块的文本与文本块的文本组合以构造文本。具体地,基于上面确定的图片,视频和数据表,结合文本块的文本信息,基本的html显示特征按照出现在html中的顺序被保留,并且图片,表的混合布局并制作了视频。的富文本正文。
五、提取与文本相关的基本元数据
5. 1提取标题
依次遍历文本块和文本块中的短文本节点之前的同级块,并计算最长子字符串与字符之比时文本节点字符和网页标题文本的最长公共子字符串文本节点的长度超过某个值阈值被添加到标题候选集。如果标题候选集大于1,则综合考虑节点的视觉增强效果,公共子串的长度,公共子串的比例和文本节点的长度,优选文本节点。如果标题候选节点集为空,则将页面标题作为主页面标题返回。
5. 2提取源
依次遍历文本块之前的兄弟块,并根据源要素数据库提取满足源前缀和后特性的字符串,并将其添加到源候选集中;如果候选集为空,则根据源,分别从文本的开头和结尾开始和结束。特征库提取满足源前缀和后缀特征的字符串,并将它们添加到源候选集。如果候选集的数量大于1,则最好将媒体源库的内容匹配为文章的源。
5. 3提取发布时间
依次遍历文本块之前的兄弟块,并根据发布时间特征库提取满足发布时间前缀和后特性的字符串,并将其添加到发布时间候选者集中;如果候选集的数量大于1,则首选值与常识一致,并且可以将发布时间格式库的内容与发布时间匹配。
5. 4摘录作者
依次遍历同级文字块,然后根据作者的特征库提取符合作者前缀和发布特征的字符串,并将其添加到候选作者集中;如果作者候选集为空,则根据作者特征库提取符合作者前缀和后缀功能的字符串,并加入作者候选集。如果候选集的数量大于1,则最好将作者的源库中的内容匹配为文章的作者。
将网页的dom结构与网页的块布局元素组合在一起,以构造具有文本和部分视觉特征的块dom结构,并对文本,图片,视频的基本元素执行融合计算,表格等。定量计算dom块的主题贡献值;通过自上而下的块缩小算法定位网页主题的核心块,然后通过自下而上的块扩展算法过滤网页的主题候选块,最后对候选主题块进行噪声裁剪以完成最终的主题块定位;根据确定的主题块,结合黑名单,规则库和知识库,提取正文信息,包括文字,图片,视频和图表;以规则区,主题库,规则库,知识库,上下文位置,显示功能为中心,提取正文标题,发布时间,来源和作者。
上面已经显示和描述了本发明的基本原理,主要特征和优点。本领域技术人员应当理解,上述实施例不以任何形式限制本发明,通过等同替换或等同变换获得的所有技术方案都落入本发明的保护范围。
网页里注释的内容会被百度工程师是如何回答的
网站优化 • 优采云 发表了文章 • 0 个评论 • 494 次浏览 • 2021-05-04 01:08
许多网站管理员知道网页代码中收录注释代码。形式是HTML注释的内容出现在网页的源代码中,并且用户在浏览网页时看不到它。因为注释内容显示在源代码中,并且不会影响页面内容,所以许多人认为蜘蛛会捕获注释信息并参与网页的分析和排名,因此他们在其中添加了很多注释内容。网页,甚至直接将其堆放在评论关键词中。
是否将对网页上的评论内容进行爬网?让我们看看百度工程师如何回答:
问:百度将对评论内容进行爬网和分析吗?
百度工程师:在文本提取过程中,将忽略html中的注释内容。尽管注释的代码不会被抓取,但也会导致代码很繁琐,因此应尽可能少。
显然,搜索引擎蜘蛛非常聪明。它们可以在Web爬网期间标识注释信息,而直接忽略它们,因此将不会对注释内容进行爬网,也不会参与Web内容的分析。进去。想象一下,如果蜘蛛可以抓取注释,并且此注释代码等效于某种隐藏文本,那么网站的主要内容可以由JS代码调用,仅用于用户浏览,而所有内容想要放置蜘蛛的地方有很多注释信息,因此网页向蜘蛛和用户显示不同的内容。如果您是灰色工业网站,则可以为搜索引擎提供完全正式的内容显示,摆脱搜索引擎的束缚,您会正式允许搜索引擎作弊吗?因此,无论您在评论中添加多少关键词,它都不会对排名产生影响。
在评论中加入关键词是否会影响排名?并不是因为搜索引擎会直接忽略注释,而是如何注释大量内容会影响网页的样式并影响网页的加载速度。因此,如果注释无用,请尽可能删除它们以使代码尽可能简单。我们经常谈论减肥的网站代码。简化注释信息是减肥的方法之一。优化注释信息有利于网站减肥。
当然,许多程序员和Web设计人员习惯于将注释信息添加到Web页面。这是个好习惯。合理的注释信息可以减少查找信息的时间,并使代码的查询和修改更加方便。因此,建议“在线”页面仅添加注释信息,例如该页面各部分的头尾注释,重要内容部分注释等,而离线备份网页可以在其中添加各部分的注释信息。更详细,方便技术人员浏览和修改,这不仅有利于网页的精简,而且不影响以后的网页修改。
作者:Mumu SEO 文章来自:欢迎关注微信公众号:mumuseo。 查看全部
网页里注释的内容会被百度工程师是如何回答的
许多网站管理员知道网页代码中收录注释代码。形式是HTML注释的内容出现在网页的源代码中,并且用户在浏览网页时看不到它。因为注释内容显示在源代码中,并且不会影响页面内容,所以许多人认为蜘蛛会捕获注释信息并参与网页的分析和排名,因此他们在其中添加了很多注释内容。网页,甚至直接将其堆放在评论关键词中。
是否将对网页上的评论内容进行爬网?让我们看看百度工程师如何回答:
问:百度将对评论内容进行爬网和分析吗?
百度工程师:在文本提取过程中,将忽略html中的注释内容。尽管注释的代码不会被抓取,但也会导致代码很繁琐,因此应尽可能少。
显然,搜索引擎蜘蛛非常聪明。它们可以在Web爬网期间标识注释信息,而直接忽略它们,因此将不会对注释内容进行爬网,也不会参与Web内容的分析。进去。想象一下,如果蜘蛛可以抓取注释,并且此注释代码等效于某种隐藏文本,那么网站的主要内容可以由JS代码调用,仅用于用户浏览,而所有内容想要放置蜘蛛的地方有很多注释信息,因此网页向蜘蛛和用户显示不同的内容。如果您是灰色工业网站,则可以为搜索引擎提供完全正式的内容显示,摆脱搜索引擎的束缚,您会正式允许搜索引擎作弊吗?因此,无论您在评论中添加多少关键词,它都不会对排名产生影响。
在评论中加入关键词是否会影响排名?并不是因为搜索引擎会直接忽略注释,而是如何注释大量内容会影响网页的样式并影响网页的加载速度。因此,如果注释无用,请尽可能删除它们以使代码尽可能简单。我们经常谈论减肥的网站代码。简化注释信息是减肥的方法之一。优化注释信息有利于网站减肥。
当然,许多程序员和Web设计人员习惯于将注释信息添加到Web页面。这是个好习惯。合理的注释信息可以减少查找信息的时间,并使代码的查询和修改更加方便。因此,建议“在线”页面仅添加注释信息,例如该页面各部分的头尾注释,重要内容部分注释等,而离线备份网页可以在其中添加各部分的注释信息。更详细,方便技术人员浏览和修改,这不仅有利于网页的精简,而且不影响以后的网页修改。
作者:Mumu SEO 文章来自:欢迎关注微信公众号:mumuseo。
常见导致搜索引擎蜘蛛抓取异常的原因及原因分析!
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-05-04 00:07
有些网站具有高质量的内容原创,用户可以正常访问,但是网络蜘蛛无法正常访问和抓取,因此它们不能收录,并且搜索结果的覆盖率很低,这是对搜索引擎非常重要,这是一种损失,并且这种情况是异常爬网。对于无法正常抓取大量内容的网站,搜索引擎会认为网站在用户体验方面存在缺陷,并将降低其评估。它将不可避免地对爬网,索引和排序产生负面影响,并最终对其产生影响。要网站从搜索引擎获得的流量。下面,编辑器总结了搜索引擎蜘蛛异常爬网的一些常见原因,供您参考。
一个。服务器连接异常
通常有两种类型的服务器异常连接:一种临时无法连接,另一种始终无法连接。对于用户而言,连接异常的服务器将不会驻留。网络蜘蛛也是如此。 Web Spider将判断并排除服务器连接网站异常,从而导致异常爬网。服务器连接异常的原因通常是网站服务器太大且过载。检查浏览器是否正常访问。服务器异常将导致蜘蛛无法连接到网站服务器,从而导致抓取失败。 。 网站并且主机也可能阻止网络蜘蛛的访问,您需要检查网站和主机的防火墙。选择安全,稳定和高性能的服务器是网站优化的基本前提。
两个。抓取超时
网站页面的加载速度一直是不容忽视的重要点,它对用户和搜索引擎的体验具有决定性的影响。如果用户在访问该页面时第一次无法打开该页面,则他将失去兴趣并跳到其他人网站。那蜘蛛呢?也是一样。如果无法在第一时间对其进行爬网,则将发生爬网超时问题。爬网超时通常是由于带宽不足和页面大而引起的。因此,在设计页面时,应压缩网页上的图片;减少使用某些脚本;控制页面的长度和内部链接的数量,可以在一定程度上减少页面,减轻服务器负担,减轻服务器的负担。
三个。网络运营商异常
国内主要的网络运营商是中国电信和中国联通。如果网络蜘蛛无法通过中国电信或中国联通网站的网络访问,则需要与网络运营商联系以购买双线服务空间或购买CDN服务。
四个。 DNS例外
当网络蜘蛛无法解析网站的IP地址时,将发生DNS异常。这可能是由于网站中的IP地址错误或域名服务提供商禁止使用网络蜘蛛。您可以使用WHOIS或主机查询网站 IP地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商以更新IP地址。
五个。设置错误
包括IP禁令和UA禁令。 IP禁止是指限制网络的出口IP地址,并禁止该IP网段的用户访问内容。 UA禁令指的是针对其身份已由服务器通过UA(用户代理)标识的用户的指定跳转。这两个禁令都将导致网络蜘蛛无法正常访问和爬网。应该认识到该设置是否错误地添加了相关搜索引擎网络蜘蛛的禁令。
六个。无效链接
无效链接是页面无效并且无法向用户提供任何有价值的信息的页面,包括两种形式:协议无效链接和内容无效链接:一种是协议无效链接:TCP协议状态/ HTTP协议状态该页面是清除的表示的无效链接,例如40 4、 40 3、 503状态等。内容死链接的另一种类型:服务器返回状态为正常,但是内容已更改为不存在,已删除或需要许可,并且其他信息页面与原创内容无关。当前,存在内容死链接被召回的风险,因此建议网站管理员尽量使用协议死链接,以确保平台工具可以更好地发挥作用。可以通过死链接工具将死链接提交给搜索引擎,以减慢死链接的负面影响。
七。 网站垂悬的马
网站链接到马匹也可能导致抓取错误。查询文件与马的链接位置并删除它,恢复网站,并采取安全措施,防止下次将其链接到马。
每个网站站长都应更频繁地检查网站网络蜘蛛的爬网情况。如果发现爬网偶尔会失败,则是正常情况,不会影响网站和收录的正常爬网。但是,如果爬网故障持续存在,则应注意网站中发生爬网异常的具体原因,以进行上述特定分析。如果您对网络蜘蛛异常爬网还有其他疑问,可以咨询[]。 查看全部
常见导致搜索引擎蜘蛛抓取异常的原因及原因分析!
有些网站具有高质量的内容原创,用户可以正常访问,但是网络蜘蛛无法正常访问和抓取,因此它们不能收录,并且搜索结果的覆盖率很低,这是对搜索引擎非常重要,这是一种损失,并且这种情况是异常爬网。对于无法正常抓取大量内容的网站,搜索引擎会认为网站在用户体验方面存在缺陷,并将降低其评估。它将不可避免地对爬网,索引和排序产生负面影响,并最终对其产生影响。要网站从搜索引擎获得的流量。下面,编辑器总结了搜索引擎蜘蛛异常爬网的一些常见原因,供您参考。

一个。服务器连接异常
通常有两种类型的服务器异常连接:一种临时无法连接,另一种始终无法连接。对于用户而言,连接异常的服务器将不会驻留。网络蜘蛛也是如此。 Web Spider将判断并排除服务器连接网站异常,从而导致异常爬网。服务器连接异常的原因通常是网站服务器太大且过载。检查浏览器是否正常访问。服务器异常将导致蜘蛛无法连接到网站服务器,从而导致抓取失败。 。 网站并且主机也可能阻止网络蜘蛛的访问,您需要检查网站和主机的防火墙。选择安全,稳定和高性能的服务器是网站优化的基本前提。

两个。抓取超时
网站页面的加载速度一直是不容忽视的重要点,它对用户和搜索引擎的体验具有决定性的影响。如果用户在访问该页面时第一次无法打开该页面,则他将失去兴趣并跳到其他人网站。那蜘蛛呢?也是一样。如果无法在第一时间对其进行爬网,则将发生爬网超时问题。爬网超时通常是由于带宽不足和页面大而引起的。因此,在设计页面时,应压缩网页上的图片;减少使用某些脚本;控制页面的长度和内部链接的数量,可以在一定程度上减少页面,减轻服务器负担,减轻服务器的负担。
三个。网络运营商异常
国内主要的网络运营商是中国电信和中国联通。如果网络蜘蛛无法通过中国电信或中国联通网站的网络访问,则需要与网络运营商联系以购买双线服务空间或购买CDN服务。
四个。 DNS例外
当网络蜘蛛无法解析网站的IP地址时,将发生DNS异常。这可能是由于网站中的IP地址错误或域名服务提供商禁止使用网络蜘蛛。您可以使用WHOIS或主机查询网站 IP地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商以更新IP地址。

五个。设置错误
包括IP禁令和UA禁令。 IP禁止是指限制网络的出口IP地址,并禁止该IP网段的用户访问内容。 UA禁令指的是针对其身份已由服务器通过UA(用户代理)标识的用户的指定跳转。这两个禁令都将导致网络蜘蛛无法正常访问和爬网。应该认识到该设置是否错误地添加了相关搜索引擎网络蜘蛛的禁令。
六个。无效链接
无效链接是页面无效并且无法向用户提供任何有价值的信息的页面,包括两种形式:协议无效链接和内容无效链接:一种是协议无效链接:TCP协议状态/ HTTP协议状态该页面是清除的表示的无效链接,例如40 4、 40 3、 503状态等。内容死链接的另一种类型:服务器返回状态为正常,但是内容已更改为不存在,已删除或需要许可,并且其他信息页面与原创内容无关。当前,存在内容死链接被召回的风险,因此建议网站管理员尽量使用协议死链接,以确保平台工具可以更好地发挥作用。可以通过死链接工具将死链接提交给搜索引擎,以减慢死链接的负面影响。
七。 网站垂悬的马
网站链接到马匹也可能导致抓取错误。查询文件与马的链接位置并删除它,恢复网站,并采取安全措施,防止下次将其链接到马。

每个网站站长都应更频繁地检查网站网络蜘蛛的爬网情况。如果发现爬网偶尔会失败,则是正常情况,不会影响网站和收录的正常爬网。但是,如果爬网故障持续存在,则应注意网站中发生爬网异常的具体原因,以进行上述特定分析。如果您对网络蜘蛛异常爬网还有其他疑问,可以咨询[]。
做网站优化的人来说,搜索引擎抓取的频率越高
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-05-03 20:44
做网站优化的人来说,搜索引擎抓取的频率越高
对于进行网站优化的人来说,搜索引擎爬网的频率越高,在通常情况下,网站会受到搜索引擎的欢迎和喜欢,我们甚至可以说网站的权重很高。当然,某些采集站会由于其内容无限而导致蜘蛛黑洞(蜘蛛陷阱),而不是正常的爬网频率。
几个主要的国内搜索引擎都具有类似的功能,例如百度搜索的爬网频率,360搜索的蜘蛛压力和搜狗搜索的爬网压力,其中包括专注于移动搜索的神马的爬网频率功能。 。网站管理员平台可以进行直接调整或间接反馈。当然,除了国内搜索引擎之外,Google还具有此功能,因此在这里我不会对其进行分析。
通常来说,搜索引擎会根据网站内容的更新速度自动更改抓取频率。当新的网站在线时,一段时间内可能会有大量爬网,因为搜索引擎实际上很好奇。以同样的方式思考,如果您发现新内容,则将首先转到整个站点,然后再次运行它。如果您可以坚持输出新鲜的内容,那么可以很好地保持搜索引擎的快速抓取频率。
但是,对于一个更新不多的网站,搜索引擎通常每天都在抓取,并且至少会抓取主页。一方面,您可以检查网站的首页是否已更新或更改,另一方面,可以判断网站的首页是否仍然可以正常爬网。它用于了解该动物的存活状态网站。这比所有国内搜索引擎都要快。如果关闭网站,则Google可能会在很短的时间内使网站搜索引擎离线,以防止用户发现单击后无法打开网站,从而改善了用户体验。相反,国内搜索引擎似乎无法做到这一点。月份仍可以正常显示在搜索结果排名中。
由于Zifan无法为您提供具体数字,因此我将以Leixue博客为例,与您分享一些搜索引擎的抓取频率:
1.百度的抓取频率是每天300-4300次,并且波动很大,因为在Leixue博客上发帖的频率不是固定的,发帖时间都是随机的。没有刻意的时间发布,总体爬网是及时的,程度还不错,值得一提的是,“泪雪”博客使用主动推送,比百度的自动爬网要快。
2. 360搜索的爬网频率相对较低,每天保持27次,并且爬网的及时性还不错。平均来说,它可以每小时进行一次爬网,但是可能会有爬网。收录情况不完整。
3.搜狗搜索的爬行频率也有很大波动,每天72-2900次,超过1500次,并且爬行的时效性相对较差。一篇文章文章可能需要等待一两天。将为收录,处理速度仍然太慢。
4.神马搜索的抓取频率性能相当好,每天506次,但是此收录更令人感动,不要以为抓取频率这么高,以防万一我网站挂了吗?哈哈哈
好的,我们做吧,内容可能不是干货,但是如果更新不及时或收录页面较少,您还可以访问网站站长平台观察网站情况,您可以手动进行调整。尽管它不是100%有效的,但它也可以在一定程度上增强搜索引擎的爬网能力。至于最后是否会是收录,这当然必须返回到内容质量本身。它与各种搜索引擎的识别有关。
咨询客户服务咨询客户服务
英语演示是演示地址的原创版本。如果您位于国外,访问速度可能会很慢(建议爬梯子进行浏览)。您在本网站上下载的主题源代码和其他资源仅用于测试和学习目的。如果您想将其用于商业用途,请购买正版许可证以获得官方更新和售后服务。
此站点承担WordPress主题安装,深度本地化,加速优化和其他服务。请咨询在线客户服务以获取详细信息!
查看全部
做网站优化的人来说,搜索引擎抓取的频率越高
对于进行网站优化的人来说,搜索引擎爬网的频率越高,在通常情况下,网站会受到搜索引擎的欢迎和喜欢,我们甚至可以说网站的权重很高。当然,某些采集站会由于其内容无限而导致蜘蛛黑洞(蜘蛛陷阱),而不是正常的爬网频率。
几个主要的国内搜索引擎都具有类似的功能,例如百度搜索的爬网频率,360搜索的蜘蛛压力和搜狗搜索的爬网压力,其中包括专注于移动搜索的神马的爬网频率功能。 。网站管理员平台可以进行直接调整或间接反馈。当然,除了国内搜索引擎之外,Google还具有此功能,因此在这里我不会对其进行分析。
通常来说,搜索引擎会根据网站内容的更新速度自动更改抓取频率。当新的网站在线时,一段时间内可能会有大量爬网,因为搜索引擎实际上很好奇。以同样的方式思考,如果您发现新内容,则将首先转到整个站点,然后再次运行它。如果您可以坚持输出新鲜的内容,那么可以很好地保持搜索引擎的快速抓取频率。
但是,对于一个更新不多的网站,搜索引擎通常每天都在抓取,并且至少会抓取主页。一方面,您可以检查网站的首页是否已更新或更改,另一方面,可以判断网站的首页是否仍然可以正常爬网。它用于了解该动物的存活状态网站。这比所有国内搜索引擎都要快。如果关闭网站,则Google可能会在很短的时间内使网站搜索引擎离线,以防止用户发现单击后无法打开网站,从而改善了用户体验。相反,国内搜索引擎似乎无法做到这一点。月份仍可以正常显示在搜索结果排名中。
由于Zifan无法为您提供具体数字,因此我将以Leixue博客为例,与您分享一些搜索引擎的抓取频率:
1.百度的抓取频率是每天300-4300次,并且波动很大,因为在Leixue博客上发帖的频率不是固定的,发帖时间都是随机的。没有刻意的时间发布,总体爬网是及时的,程度还不错,值得一提的是,“泪雪”博客使用主动推送,比百度的自动爬网要快。
2. 360搜索的爬网频率相对较低,每天保持27次,并且爬网的及时性还不错。平均来说,它可以每小时进行一次爬网,但是可能会有爬网。收录情况不完整。
3.搜狗搜索的爬行频率也有很大波动,每天72-2900次,超过1500次,并且爬行的时效性相对较差。一篇文章文章可能需要等待一两天。将为收录,处理速度仍然太慢。
4.神马搜索的抓取频率性能相当好,每天506次,但是此收录更令人感动,不要以为抓取频率这么高,以防万一我网站挂了吗?哈哈哈
好的,我们做吧,内容可能不是干货,但是如果更新不及时或收录页面较少,您还可以访问网站站长平台观察网站情况,您可以手动进行调整。尽管它不是100%有效的,但它也可以在一定程度上增强搜索引擎的爬网能力。至于最后是否会是收录,这当然必须返回到内容质量本身。它与各种搜索引擎的识别有关。
咨询客户服务咨询客户服务
英语演示是演示地址的原创版本。如果您位于国外,访问速度可能会很慢(建议爬梯子进行浏览)。您在本网站上下载的主题源代码和其他资源仅用于测试和学习目的。如果您想将其用于商业用途,请购买正版许可证以获得官方更新和售后服务。
此站点承担WordPress主题安装,深度本地化,加速优化和其他服务。请咨询在线客户服务以获取详细信息!
2019年Python多进程方式抓取基金网站内容的方法汇总
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-05-01 22:34
2019年Python多进程方式抓取基金网站内容的方法汇总
Python多进程抓取资金网站内容的方法分析
更新时间:2019年6月3日12:02:12作者:Study Notes 666
本文文章主要介绍了Python多进程抓取资金网站内容的方法,并结合示例分析了Python多进程抓取网站内容相关的实现技巧和操作注意事项。你可以参考
本文介绍了在Python多进程模式下获取Fund 网站内容的方法。与您分享以供参考,如下所示:
在上一篇文章//// article / 16241 8. htm中,我们已经简要了解了“ python的多进程”,现在我们需要编写抓取基金网站的内容(第28页)作为一种多过程方法。
由于该过程越少越好,我们计划在三个过程中实施它。这意味着:将总共28个要抓取的页面分为三个部分。
如何划分?
# 初始range
r = range(1,29)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)]
print(myList) # [range(1, 11), range(11, 21), range(21, 29)]
根据上面的代码,我们将1〜29分为三个部分,列表中的三个范围。
2、还记得我们获取了Fund 网站内容的getData()函数吗?
def getData(start, end):
for x in range(start, end+1):
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
该函数有2个参数:起始页码和结束页码,即从起始页到结束页。
这两个参数实际上是范围。
按如下所示修改getData()函数(参数不同):
3、创建一个进程并将目标设置为上面的getData():
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
有三个要分别获取的过程。
4、多进程抓取资金网站多页内容的完整代码:
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from multiprocessing import Process
driver = webdriver.PhantomJS(executable_path=r"你phantomjs的可执行文件路径")
# 请求一个网址
driver.get("http://fund.eastmoney.com/fund.html")
page_text = driver.find_element_by_id("pager").find_element_by_xpath("span[@class='nv']").text
total_page = ''.join(filter(str.isdigit,page_text)) # 得到总共有多少页
# 循环抓取网页内容的函数
def getData(myrange):
for x in myrange:
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
对于对Python相关内容感兴趣的读者,请查看此站点的主题:“ Python进程和线程操作技能摘要”,“ Python数据结构和算法教程”,“ Python函数使用技能摘要”, “ Python字符串”操作技巧摘要”,“ Python简介和高级经典教程”,“ Python + MySQL数据库编程简介”和“ Python通用数据库操作技巧摘要”
我希望本文能对您的Python编程有所帮助。 查看全部
2019年Python多进程方式抓取基金网站内容的方法汇总
Python多进程抓取资金网站内容的方法分析
更新时间:2019年6月3日12:02:12作者:Study Notes 666
本文文章主要介绍了Python多进程抓取资金网站内容的方法,并结合示例分析了Python多进程抓取网站内容相关的实现技巧和操作注意事项。你可以参考
本文介绍了在Python多进程模式下获取Fund 网站内容的方法。与您分享以供参考,如下所示:
在上一篇文章//// article / 16241 8. htm中,我们已经简要了解了“ python的多进程”,现在我们需要编写抓取基金网站的内容(第28页)作为一种多过程方法。
由于该过程越少越好,我们计划在三个过程中实施它。这意味着:将总共28个要抓取的页面分为三个部分。
如何划分?
# 初始range
r = range(1,29)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)]
print(myList) # [range(1, 11), range(11, 21), range(21, 29)]
根据上面的代码,我们将1〜29分为三个部分,列表中的三个范围。
2、还记得我们获取了Fund 网站内容的getData()函数吗?
def getData(start, end):
for x in range(start, end+1):
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
该函数有2个参数:起始页码和结束页码,即从起始页到结束页。
这两个参数实际上是范围。
按如下所示修改getData()函数(参数不同):
3、创建一个进程并将目标设置为上面的getData():
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
有三个要分别获取的过程。
4、多进程抓取资金网站多页内容的完整代码:
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from multiprocessing import Process
driver = webdriver.PhantomJS(executable_path=r"你phantomjs的可执行文件路径")
# 请求一个网址
driver.get("http://fund.eastmoney.com/fund.html";)
page_text = driver.find_element_by_id("pager").find_element_by_xpath("span[@class='nv']").text
total_page = ''.join(filter(str.isdigit,page_text)) # 得到总共有多少页
# 循环抓取网页内容的函数
def getData(myrange):
for x in myrange:
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
对于对Python相关内容感兴趣的读者,请查看此站点的主题:“ Python进程和线程操作技能摘要”,“ Python数据结构和算法教程”,“ Python函数使用技能摘要”, “ Python字符串”操作技巧摘要”,“ Python简介和高级经典教程”,“ Python + MySQL数据库编程简介”和“ Python通用数据库操作技巧摘要”
我希望本文能对您的Python编程有所帮助。
网站内容抓取 以人教版地理七年级地理上册为例子(上册)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-05-01 22:29
我需要写一个这样的例子,并从电子教科书网站上下载一本电子书。
电子教科书网络上的电子书将书的每一页都当作一幅图片,然后一本书有很多图片。我需要分批下载图片。
这是代码部分:
public function download() {<br />
$http = new \Org\Net\Http();<br />
$url_pref = "http://www.dzkbw.com/books/rjb ... %3Bbr />
$localUrl = "Public/bookcover/";<br />
$reg="|showImg\('(.+)'\);|";<br />
$i=1;
do {<br />
$filename = substr("000".$i,-3).".htm";<br />
$ch = curl_init();<br />
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);<br />
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);<br />
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);<br />
$html = curl_exec($ch);<br />
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);<br />
if($result==1) {<br />
$picUrl = $out[1][0];<br />
$picFilename = substr("000".$i,-3).".jpg";<br />
$http->curlDownload($picUrl, $localUrl.$picFilename);<br />
}<br />
$i = $i+1;<br />
} while ($result==1);
echo "下载完成";<br />
}
我在这里以《人民教育版地理》七年级的地理书为例。
网页从00 1. htm开始,然后这个数字一直在增加
每个网页中都有一张图片,与教科书的内容相对应。教科书的内容以图片的形式显示
我的代码是一个循环,从首页开始,直到找不到网页中的图片为止
抓取网页内容后,将网页中的图片抓取到本地服务器上
爬行后的实际效果:
以thinkphp编写的示例:获取网站的内容并将其保存在本地。更多相关的文章 python获取网页中的图片并将其保存在本地
#-*-coding:utf-8-*-import os import uuid import urllib2 import cookielib'''获取文件扩展名'''def get_file ...
C#实现抓取网站页内容
抓住的新闻部分,如下图所示:使用Google浏览器查看源代码:通过分析,我们知道我们所寻找的内容在以下两个标签之间: 查看全部
网站内容抓取 以人教版地理七年级地理上册为例子(上册)
我需要写一个这样的例子,并从电子教科书网站上下载一本电子书。
电子教科书网络上的电子书将书的每一页都当作一幅图片,然后一本书有很多图片。我需要分批下载图片。
这是代码部分:
public function download() {<br />
$http = new \Org\Net\Http();<br />
$url_pref = "http://www.dzkbw.com/books/rjb ... %3Bbr />
$localUrl = "Public/bookcover/";<br />
$reg="|showImg\('(.+)'\);|";<br />
$i=1;
do {<br />
$filename = substr("000".$i,-3).".htm";<br />
$ch = curl_init();<br />
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);<br />
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);<br />
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);<br />
$html = curl_exec($ch);<br />
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);<br />
if($result==1) {<br />
$picUrl = $out[1][0];<br />
$picFilename = substr("000".$i,-3).".jpg";<br />
$http->curlDownload($picUrl, $localUrl.$picFilename);<br />
}<br />
$i = $i+1;<br />
} while ($result==1);
echo "下载完成";<br />
}
我在这里以《人民教育版地理》七年级的地理书为例。
网页从00 1. htm开始,然后这个数字一直在增加
每个网页中都有一张图片,与教科书的内容相对应。教科书的内容以图片的形式显示
我的代码是一个循环,从首页开始,直到找不到网页中的图片为止
抓取网页内容后,将网页中的图片抓取到本地服务器上
爬行后的实际效果:

以thinkphp编写的示例:获取网站的内容并将其保存在本地。更多相关的文章 python获取网页中的图片并将其保存在本地
#-*-coding:utf-8-*-import os import uuid import urllib2 import cookielib'''获取文件扩展名'''def get_file ...
C#实现抓取网站页内容
抓住的新闻部分,如下图所示:使用Google浏览器查看源代码:通过分析,我们知道我们所寻找的内容在以下两个标签之间:
网站用robots协议拒绝搜索引擎的网页性质及文件类型
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-04-30 00:02
1。 Spider无法正确处理的网页的性质和文件类型(例如Flash,脚本,ps,一些动态网页和框架,数据库)2、孤岛网页未指向链接3、由于某些原因,蜘蛛访问原因碰巧是死链接。 4、它被认为是质量较差的网页,没有被捕获。 5、由于/ porn / reactionary / spam /而无法捕获的非法网页。6、您需要输入用户名和密码才能打开网页。 7、 网站使用漫游器协议拒绝搜索引擎抓取的网页8、将来搜索引擎抓取的新网页9、 gopher,新闻组,Telnet,ftp,wais和其他非http信息1 0 网站数据库太糟糕了,蜘蛛被捕获后便崩溃了。 1 1.它在搜索引擎库中,但无法正确索引网页中的信息。 1 2、分词会导致错误。 1 3、图形中的文本信息。可以理解,但搜索引擎无法理解1 4、搜索引擎故意不编制索引的信息,例如停用词,[1] 5、搜索引擎有选择地对某些网页进行索引,但并非对所有网页信息进行索引1 6、搜索引擎该网页中的信息已正确索引,但与您使用的信息不同关键词 1 7、您使用的搜索关键词收录错别字1 8、该页面的作者使用了错字1 9、没有错别字,但所用页面的作者的词汇表与您的关键词不同。毕竟,文本的特征允许n种方式来表达相同的信息。 2 0、简体中文和繁体中文的不同编码 查看全部
网站用robots协议拒绝搜索引擎的网页性质及文件类型
1。 Spider无法正确处理的网页的性质和文件类型(例如Flash,脚本,ps,一些动态网页和框架,数据库)2、孤岛网页未指向链接3、由于某些原因,蜘蛛访问原因碰巧是死链接。 4、它被认为是质量较差的网页,没有被捕获。 5、由于/ porn / reactionary / spam /而无法捕获的非法网页。6、您需要输入用户名和密码才能打开网页。 7、 网站使用漫游器协议拒绝搜索引擎抓取的网页8、将来搜索引擎抓取的新网页9、 gopher,新闻组,Telnet,ftp,wais和其他非http信息1 0 网站数据库太糟糕了,蜘蛛被捕获后便崩溃了。 1 1.它在搜索引擎库中,但无法正确索引网页中的信息。 1 2、分词会导致错误。 1 3、图形中的文本信息。可以理解,但搜索引擎无法理解1 4、搜索引擎故意不编制索引的信息,例如停用词,[1] 5、搜索引擎有选择地对某些网页进行索引,但并非对所有网页信息进行索引1 6、搜索引擎该网页中的信息已正确索引,但与您使用的信息不同关键词 1 7、您使用的搜索关键词收录错别字1 8、该页面的作者使用了错字1 9、没有错别字,但所用页面的作者的词汇表与您的关键词不同。毕竟,文本的特征允许n种方式来表达相同的信息。 2 0、简体中文和繁体中文的不同编码
在网站怎么快速被爬虫百度蜘蛛最喜欢的呢?
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-04-28 03:18
网站蜘蛛通常会爬行哪种内容?在这个互联网时代,许多人会在购买新产品之前先检查互联网上的信息,以查看哪些品牌具有更好的声誉和评价。这时,排名最高的产品将具有绝对优势。根据调查,有87%的互联网用户将使用搜索引擎服务来查找所需的信息,其中,将近70%的搜索者将直接在搜索结果自然排名的第一页上找到所需的信息。
可以看出,目前,SEO对于企业和产品具有不可替代的意义。接下来,我将告诉您网站中的爬虫如何快速对其进行爬虫。百度蜘蛛有其特殊的爱好。通常,哪些内容是百度蜘蛛最喜欢抓取的内容
1. 关键词是头等大事
我们经常听到人们谈论关键词,但是关键词 关键词的具体用途是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外部链接也会影响重量
导入链接也是网站优化的非常重要的过程,它可以间接影响搜索引擎中网站的权重。目前,常用的链接分为:锚文本链接,超链接,纯文本链接和图像链接。
爬虫如何抓取3.
抓取工具是自动提取网页的程序,例如百度的抓取工具。如果您希望将网站页中的更多内容设为收录,则必须首先让爬网程序对网页进行爬网。
如果您的网站页面经常更新,则抓取工具会更频繁地访问该页面,高质量的内容是抓取工具喜欢抓取的目标,尤其是原创内容。
以上内容与“ 网站蜘蛛通常会抓取哪些内容?”有关如果您想进一步询问,请致电。 查看全部
在网站怎么快速被爬虫百度蜘蛛最喜欢的呢?
网站蜘蛛通常会爬行哪种内容?在这个互联网时代,许多人会在购买新产品之前先检查互联网上的信息,以查看哪些品牌具有更好的声誉和评价。这时,排名最高的产品将具有绝对优势。根据调查,有87%的互联网用户将使用搜索引擎服务来查找所需的信息,其中,将近70%的搜索者将直接在搜索结果自然排名的第一页上找到所需的信息。
可以看出,目前,SEO对于企业和产品具有不可替代的意义。接下来,我将告诉您网站中的爬虫如何快速对其进行爬虫。百度蜘蛛有其特殊的爱好。通常,哪些内容是百度蜘蛛最喜欢抓取的内容
1. 关键词是头等大事
我们经常听到人们谈论关键词,但是关键词 关键词的具体用途是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外部链接也会影响重量
导入链接也是网站优化的非常重要的过程,它可以间接影响搜索引擎中网站的权重。目前,常用的链接分为:锚文本链接,超链接,纯文本链接和图像链接。
爬虫如何抓取3.
抓取工具是自动提取网页的程序,例如百度的抓取工具。如果您希望将网站页中的更多内容设为收录,则必须首先让爬网程序对网页进行爬网。
如果您的网站页面经常更新,则抓取工具会更频繁地访问该页面,高质量的内容是抓取工具喜欢抓取的目标,尤其是原创内容。
以上内容与“ 网站蜘蛛通常会抓取哪些内容?”有关如果您想进一步询问,请致电。
爬虫模拟访问网站内容抓取原理,有什么作用?
网站优化 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-04-26 01:02
网站内容抓取原理,大概分为单页抓取和列表爬取两类,每种方式都有不同的标准,利用专业的网站抓取工具,例如ngspider,可以快速的实现网站内容抓取,简单说就是只要抓取到一个网站的某些内容,就可以获取整个网站内容。爬虫有两种加载方式,(1)ajax加载。我们可以通过ajax技术,让用户在访问网站时,加载时网站应该加载的内容。
大大提高了整个网站的加载速度。(2)json或xml加载。我们可以通过json技术或xml技术,来加载我们想要抓取的数据。从上图我们可以看到,网站内容抓取流程分为:登录、站内搜索、爬虫搜索。也就是说,爬虫模拟访问网站服务器,当我们访问服务器数据时,我们就可以获取到被服务器加载的所有内容。
ajaxjsonjson也就是xml,所以抓取可以用json做,也可以用ajax。ajax也可以通过一次加载多个,
ajax什么是ajax(asynchronousjavascriptandxml)?ajax是xmlhttprequest和xmlhttprequest2的简称,它允许浏览器与服务器进行多轮对话。在加载网页内容时,我们可以通过访问页面,让服务器返回包含内容的页面,以此来减少加载时间。
单页爬虫或列表爬虫,
json 查看全部
爬虫模拟访问网站内容抓取原理,有什么作用?
网站内容抓取原理,大概分为单页抓取和列表爬取两类,每种方式都有不同的标准,利用专业的网站抓取工具,例如ngspider,可以快速的实现网站内容抓取,简单说就是只要抓取到一个网站的某些内容,就可以获取整个网站内容。爬虫有两种加载方式,(1)ajax加载。我们可以通过ajax技术,让用户在访问网站时,加载时网站应该加载的内容。
大大提高了整个网站的加载速度。(2)json或xml加载。我们可以通过json技术或xml技术,来加载我们想要抓取的数据。从上图我们可以看到,网站内容抓取流程分为:登录、站内搜索、爬虫搜索。也就是说,爬虫模拟访问网站服务器,当我们访问服务器数据时,我们就可以获取到被服务器加载的所有内容。
ajaxjsonjson也就是xml,所以抓取可以用json做,也可以用ajax。ajax也可以通过一次加载多个,
ajax什么是ajax(asynchronousjavascriptandxml)?ajax是xmlhttprequest和xmlhttprequest2的简称,它允许浏览器与服务器进行多轮对话。在加载网页内容时,我们可以通过访问页面,让服务器返回包含内容的页面,以此来减少加载时间。
单页爬虫或列表爬虫,
json
网站内容抓取的常见的问题及解决办法(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-04-20 04:01
网站内容抓取这个问题实际上包含了很多个问题:站点、抓取的网站、网站模板等。常见的抓取问题有:1.点击触发的抓取页面;2.点击后马上开始抓取的页面;3.由浏览器主动推送给访问者的页面;4.网站为了访问量,放置很多不是必须抓取的页面;5.内容抓取类型一直在变化。
其实百度每天有很多页面有部分网站是没有抓取到的,从而显示了部分内容。那么页面有多少抓取的?就不能单纯的根据cookie来算了。那么有没有什么通用的办法可以完全抓取每个网站呢?答案就是根据所有页面爬虫的存量和蜘蛛的质量来计算。
这里涉及到ip池,和搜索规则的问题。要有一个标准的ip池:保留三个月(一般超过一年会自动被清空)。还有一个搜索规则:搜索页面最少五个。
一个人在一个页面上抓取1000次都抓取不了1小时就没了
看你一天抓取多少次
抓取以及是否抓取最基本的,
豆瓣
自己解决。一个服务器,一个中转服务器,一个转发服务器,一个ip池。
两种方式抓取,如果是伪代码的抓取的话,一个是服务器承载量的承载量,一个是爬虫的速度,前者是一个很容易调用的方法,后者基本上都要根据你爬虫抓取的某个页面,来做策略的指定。比如,我们做客,爬虫通常设置一个userusernameadminclass="user-agent"size=1500(头,网址)爬行时间1500scale=1,1.0,0(值越大速度越快,可以适当调节)页面点击率15%(自定义标签页面每秒点击率不能超过20%)基本上就能抓取大部分的内容,我看过一些豆瓣,社区网站,有些伪代码抓取达到1万的速度。 查看全部
网站内容抓取的常见的问题及解决办法(一)
网站内容抓取这个问题实际上包含了很多个问题:站点、抓取的网站、网站模板等。常见的抓取问题有:1.点击触发的抓取页面;2.点击后马上开始抓取的页面;3.由浏览器主动推送给访问者的页面;4.网站为了访问量,放置很多不是必须抓取的页面;5.内容抓取类型一直在变化。
其实百度每天有很多页面有部分网站是没有抓取到的,从而显示了部分内容。那么页面有多少抓取的?就不能单纯的根据cookie来算了。那么有没有什么通用的办法可以完全抓取每个网站呢?答案就是根据所有页面爬虫的存量和蜘蛛的质量来计算。
这里涉及到ip池,和搜索规则的问题。要有一个标准的ip池:保留三个月(一般超过一年会自动被清空)。还有一个搜索规则:搜索页面最少五个。
一个人在一个页面上抓取1000次都抓取不了1小时就没了
看你一天抓取多少次
抓取以及是否抓取最基本的,
豆瓣
自己解决。一个服务器,一个中转服务器,一个转发服务器,一个ip池。
两种方式抓取,如果是伪代码的抓取的话,一个是服务器承载量的承载量,一个是爬虫的速度,前者是一个很容易调用的方法,后者基本上都要根据你爬虫抓取的某个页面,来做策略的指定。比如,我们做客,爬虫通常设置一个userusernameadminclass="user-agent"size=1500(头,网址)爬行时间1500scale=1,1.0,0(值越大速度越快,可以适当调节)页面点击率15%(自定义标签页面每秒点击率不能超过20%)基本上就能抓取大部分的内容,我看过一些豆瓣,社区网站,有些伪代码抓取达到1万的速度。
好内容就被你创造了,但能说上是优质吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-05-10 03:18
当您确定文章主题具有用户需求并且内容可以满足大多数人的需求时。因此,您可以创建好的内容,但是可以说它是高质量的吗?不一定,因为有以下一些因素。
网页打开速度
网页打开的速度影响两点。首先是用户访问网页的体验。搜索引擎的目的是更好地满足搜索用户的体验,但是您可以让用户从一开始就访问您。 网站进行了大量更改。此前,百度的同学还提到打开速度超过3秒的移动网页被直接归类为垃圾网页。可以想象,即使您拥有最好的内容,用户访问也会带来麻烦,这是否也不值得。
第二点是爬虫爬网。如果打开速度很慢,则爬网程序将很难爬网。从搜索引擎的角度来看,爬网也是一个正在运行的程序。在您的程序上运行时,打开网页需要1秒钟,但是在其他人上运行只需要100毫秒。放开我,它们只占您的十分之一。而且,您已经占用了采集器可能已经爬网的资源,成为了一个可以对该网页进行爬网的网页。换句话说,我还将调整抓取给您的网站数量,以节省资源并抓取更多网页。使用较少的爬网,收录的概率甚至更小。没有收录,排名和点击量如何?
文字可读性
可以查看内容,但是非常费力,好吗?您真的认为搜索引擎今天无法识别它吗?例如,最初设置为黑色字体或深灰色字体的内容块本身非常好。但是,出于某些其他目的,必须将其设置为浅灰色或更接近网页背景的颜色。此设置没有利用用户的体验。相同的内容不能视为高质量的内容。
例如,字体大小太小,文本之间的段落太近甚至重叠,这在一定程度上影响了用户体验。
您的文章看上去很费劲,我在搜索引擎中发现了如此多的结果,为什么还要浪费时间呢?只需关闭您的网页并找到下一个!
主要内容中的设置
这里主要是关于主要内容本身的,例如文章页面的内容部分,我们将设置一些粗体,红色(突出显示)的锚文本链接。但是,这三点仍然保留了许多年前的实践网站。如果为关键词,请为其提供指向首页的链接,指向版面的页面或指向频道页面;如果为关键词,请将其设为粗体或突出显示,以便突出显示,以诱骗您进行SEO优化。其实不应该这样。这些都是很小的因素。与其在这个领域努力工作,不如合理地使用这些细节。突出显示文章中需要突出显示的句子或词汇。在编写文章的过程中,提到了一些词汇或知识点,并且用户可能不理解或不感兴趣,因此已为此设置链接设置了链接。
实际上是以这种正常方式进行的,您会发现要添加的链接以及文本的突出设置也适合某些SEO技术和方法。因此,为了正确理解这些细节的含义,有时要进行合理的设置是SEO。不要使用SEO的思想来设置内容,而要使用设置内容的思想来进行SEO,这是正确的方法。
网页布局布局
这里有三点。第一点是主要内容出现的位置。用户最需要的内容不会出现在最重要的位置。这个可以吗?例如,在文章页面上,用户只想看到文章是,但是您让用户向下滚动两个屏幕以查看主要内容。这种布局非常令人气愤。即使您认为公司的重要内容显示在内容的顶部,用户也会担心该内容本身。 ,他想解决自己的需求。其他问题远不止于此。
第二点是主要内容之外的周围推荐信息,例如最新推荐,热门推荐,您喜欢的猜测,相关的文章等。名称不同,检索逻辑也不同,但是性质基本上是相同的。此推荐信息与当前主题文章有什么关系?相关性越高,用户可以挖掘的潜在需求就越大。例如,您正在阅读标题为“百度将哪些内容视为高品质内容”的文章,并向您推荐该文章。“高品质内容的一些注意事项”,“ 原创 文章如何成为高质量内容”,“有关高质量内容的一些建议” ...,这些都是您需要查看的。这不仅增加了您访问此网站的PV,还降低了跳出率。同时增加当前网页的关键词密度!
最后一个是广告。众所周知,弹出广告会阻止主题内容并影响用户体验。但是,页面主要内容中的“大量” Flash图像,动态广告和散布的广告都对用户体验有害。因此,合理分配广告的位置和数量,主要内容的出现位置等对用户最大的帮助。帮助用户等同于帮助搜索引擎解决搜索用户体验问题。为什么不吸引流量?
原创内容
原创的内容应为所有人所理解,但在此必须提及。 原创一直是每个人都关注的问题,但并非所有原创内容都能获得良好的排名。根据我上面提到的其他观点,您会发现,除了重要因素原创之外,还有一些细节需要注意。
原创的内容应有需求,您不能盲目制作自己的标题;您的内容应与标题保持一致,并且标题中不能说东西,这不能解决用户的实际需求;文字必须具有可读性,不应影响用户出于其他目的的正常浏览;该网页应尽快打开,并且速度越快越好。没有限制;没有限制。内容主体中突出的内容应突出显示,并且应将锚链接添加到锚链接中。只要为创建内容而不是为SEO生成内容而进行设置,就不必担心所谓的过度优化。
相关文章:如何衡量seo排名优化的效果? 查看全部
好内容就被你创造了,但能说上是优质吗?
当您确定文章主题具有用户需求并且内容可以满足大多数人的需求时。因此,您可以创建好的内容,但是可以说它是高质量的吗?不一定,因为有以下一些因素。
网页打开速度
网页打开的速度影响两点。首先是用户访问网页的体验。搜索引擎的目的是更好地满足搜索用户的体验,但是您可以让用户从一开始就访问您。 网站进行了大量更改。此前,百度的同学还提到打开速度超过3秒的移动网页被直接归类为垃圾网页。可以想象,即使您拥有最好的内容,用户访问也会带来麻烦,这是否也不值得。
第二点是爬虫爬网。如果打开速度很慢,则爬网程序将很难爬网。从搜索引擎的角度来看,爬网也是一个正在运行的程序。在您的程序上运行时,打开网页需要1秒钟,但是在其他人上运行只需要100毫秒。放开我,它们只占您的十分之一。而且,您已经占用了采集器可能已经爬网的资源,成为了一个可以对该网页进行爬网的网页。换句话说,我还将调整抓取给您的网站数量,以节省资源并抓取更多网页。使用较少的爬网,收录的概率甚至更小。没有收录,排名和点击量如何?
文字可读性
可以查看内容,但是非常费力,好吗?您真的认为搜索引擎今天无法识别它吗?例如,最初设置为黑色字体或深灰色字体的内容块本身非常好。但是,出于某些其他目的,必须将其设置为浅灰色或更接近网页背景的颜色。此设置没有利用用户的体验。相同的内容不能视为高质量的内容。
例如,字体大小太小,文本之间的段落太近甚至重叠,这在一定程度上影响了用户体验。
您的文章看上去很费劲,我在搜索引擎中发现了如此多的结果,为什么还要浪费时间呢?只需关闭您的网页并找到下一个!
主要内容中的设置
这里主要是关于主要内容本身的,例如文章页面的内容部分,我们将设置一些粗体,红色(突出显示)的锚文本链接。但是,这三点仍然保留了许多年前的实践网站。如果为关键词,请为其提供指向首页的链接,指向版面的页面或指向频道页面;如果为关键词,请将其设为粗体或突出显示,以便突出显示,以诱骗您进行SEO优化。其实不应该这样。这些都是很小的因素。与其在这个领域努力工作,不如合理地使用这些细节。突出显示文章中需要突出显示的句子或词汇。在编写文章的过程中,提到了一些词汇或知识点,并且用户可能不理解或不感兴趣,因此已为此设置链接设置了链接。
实际上是以这种正常方式进行的,您会发现要添加的链接以及文本的突出设置也适合某些SEO技术和方法。因此,为了正确理解这些细节的含义,有时要进行合理的设置是SEO。不要使用SEO的思想来设置内容,而要使用设置内容的思想来进行SEO,这是正确的方法。
网页布局布局
这里有三点。第一点是主要内容出现的位置。用户最需要的内容不会出现在最重要的位置。这个可以吗?例如,在文章页面上,用户只想看到文章是,但是您让用户向下滚动两个屏幕以查看主要内容。这种布局非常令人气愤。即使您认为公司的重要内容显示在内容的顶部,用户也会担心该内容本身。 ,他想解决自己的需求。其他问题远不止于此。
第二点是主要内容之外的周围推荐信息,例如最新推荐,热门推荐,您喜欢的猜测,相关的文章等。名称不同,检索逻辑也不同,但是性质基本上是相同的。此推荐信息与当前主题文章有什么关系?相关性越高,用户可以挖掘的潜在需求就越大。例如,您正在阅读标题为“百度将哪些内容视为高品质内容”的文章,并向您推荐该文章。“高品质内容的一些注意事项”,“ 原创 文章如何成为高质量内容”,“有关高质量内容的一些建议” ...,这些都是您需要查看的。这不仅增加了您访问此网站的PV,还降低了跳出率。同时增加当前网页的关键词密度!
最后一个是广告。众所周知,弹出广告会阻止主题内容并影响用户体验。但是,页面主要内容中的“大量” Flash图像,动态广告和散布的广告都对用户体验有害。因此,合理分配广告的位置和数量,主要内容的出现位置等对用户最大的帮助。帮助用户等同于帮助搜索引擎解决搜索用户体验问题。为什么不吸引流量?
原创内容
原创的内容应为所有人所理解,但在此必须提及。 原创一直是每个人都关注的问题,但并非所有原创内容都能获得良好的排名。根据我上面提到的其他观点,您会发现,除了重要因素原创之外,还有一些细节需要注意。
原创的内容应有需求,您不能盲目制作自己的标题;您的内容应与标题保持一致,并且标题中不能说东西,这不能解决用户的实际需求;文字必须具有可读性,不应影响用户出于其他目的的正常浏览;该网页应尽快打开,并且速度越快越好。没有限制;没有限制。内容主体中突出的内容应突出显示,并且应将锚链接添加到锚链接中。只要为创建内容而不是为SEO生成内容而进行设置,就不必担心所谓的过度优化。
相关文章:如何衡量seo排名优化的效果?
企业网站推广时需要注意的几个关键词排名!
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-05-10 03:15
企业网站推广时,如果要从搜索引擎获得更多关键词排名,首先网站必须确保一定数量收录,同时要注意网站长尾巴扩展单词,通过长尾单词访问网站的流量会更准确,同时转换效果更好。是什么因素导致蜘蛛无法正常抓取网站内容?
1、无效链接:
该页面无效,无法为用户提供任何有价值信息的页面是无效链接。编辑建议我们可以使用网站管理员工具进行检测,然后提交删除。
2、 UA被阻止:
如果您希望baiduspider访问您的网站,请检查useragent的相关设置中是否存在baiduspiderUA并及时进行修改。
3、 IP屏蔽:
Baiduspiderip被专门阻止。当您的站点不希望baiduspider访问时,此设置是必需的。如果您希望baiduspider访问您的网站,请检查baiduspiderIP是否被错误地添加到相关设置中。您网站所在的太空服务提供商也可能阻止了百度IP。此时,您需要联系服务提供商以更改设置。
4、 DNS例外:
当BaiduSpider无法解析您的网站 IP时,将发生DNS异常。可能是您网站的IP地址不正确,或者域名服务已阻止baiduspider。请使用whois或主机检查您的网站 IP地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商以更新您的IP地址。
5、服务器异常:
服务器的异常连接主要表现在百度蜘蛛无法连接到您的网站上。在这种情况下,站点服务器通常太大,操作过载。也可能是它受到了攻击并受到影响网站。如果没有,请与您的服务提供商联系。
什么因素导致蜘蛛无法正常抓取网站的内容?如果您是旧站点,则有一天您会突然发现网站 收录减少,并且抓取频率逐渐降低甚至为零,这表明网站在不久的将来会出现问题,您可以看到如果网站最近有重大更改,并且哪些操作不合适,请及时进行更正。 查看全部
企业网站推广时需要注意的几个关键词排名!
企业网站推广时,如果要从搜索引擎获得更多关键词排名,首先网站必须确保一定数量收录,同时要注意网站长尾巴扩展单词,通过长尾单词访问网站的流量会更准确,同时转换效果更好。是什么因素导致蜘蛛无法正常抓取网站内容?
1、无效链接:
该页面无效,无法为用户提供任何有价值信息的页面是无效链接。编辑建议我们可以使用网站管理员工具进行检测,然后提交删除。
2、 UA被阻止:
如果您希望baiduspider访问您的网站,请检查useragent的相关设置中是否存在baiduspiderUA并及时进行修改。
3、 IP屏蔽:
Baiduspiderip被专门阻止。当您的站点不希望baiduspider访问时,此设置是必需的。如果您希望baiduspider访问您的网站,请检查baiduspiderIP是否被错误地添加到相关设置中。您网站所在的太空服务提供商也可能阻止了百度IP。此时,您需要联系服务提供商以更改设置。
4、 DNS例外:
当BaiduSpider无法解析您的网站 IP时,将发生DNS异常。可能是您网站的IP地址不正确,或者域名服务已阻止baiduspider。请使用whois或主机检查您的网站 IP地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商以更新您的IP地址。
5、服务器异常:
服务器的异常连接主要表现在百度蜘蛛无法连接到您的网站上。在这种情况下,站点服务器通常太大,操作过载。也可能是它受到了攻击并受到影响网站。如果没有,请与您的服务提供商联系。
什么因素导致蜘蛛无法正常抓取网站的内容?如果您是旧站点,则有一天您会突然发现网站 收录减少,并且抓取频率逐渐降低甚至为零,这表明网站在不久的将来会出现问题,您可以看到如果网站最近有重大更改,并且哪些操作不合适,请及时进行更正。
二次元文化职业收集妹子萌照,可以推荐一些奇奇怪怪的职业
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-05-10 03:06
网站内容抓取,中高端职业内容抓取,各类推广信息抓取等,竞争激烈,跟单身狗有什么关系,大家的生活都这么匆忙了,除了利用真材实料找个对象,还有那么多时间在乎别人喜不喜欢你吗。
有的。比如二次元文化职业,我们就收集妹子萌照,
可以推荐一些奇奇怪怪的职业嘛,
我有一个中药二维码的微信公众号,还不错,长期更新,
可以做一些h5,也可以放一些技能啊交流群啊,长期更新哈,
看得我热血沸腾,
现在很多类似的网站都在做这方面,像发现我的职业网,
我建议你玩玩天天益彩,里面所有的技巧都很简单,每天上玩两三个小时,还能挣些小钱。我高中同学当年就在玩这个,
我也想知道(机智微笑)
穷鬼网,
如果有楼主想找对象的标准,再加上技能点,
我也是学生党每天都想赚钱
可以找一些跟技能挂钩的,例如设计,翻译,程序员等(嘿嘿嘿)。
创意美女和流量主
目前国内绝大部分人工作都很忙碌,仅靠自己赚的钱肯定不够用,所以经常会羡慕一些在公司里上班的人,会想他们是否有时间自己赚钱,答案是肯定的。大多数就是当点客,然后花点时间用客赚来的钱在当地找女朋友。大学生的话,应该还有其他赚钱方式。 查看全部
二次元文化职业收集妹子萌照,可以推荐一些奇奇怪怪的职业
网站内容抓取,中高端职业内容抓取,各类推广信息抓取等,竞争激烈,跟单身狗有什么关系,大家的生活都这么匆忙了,除了利用真材实料找个对象,还有那么多时间在乎别人喜不喜欢你吗。
有的。比如二次元文化职业,我们就收集妹子萌照,
可以推荐一些奇奇怪怪的职业嘛,
我有一个中药二维码的微信公众号,还不错,长期更新,
可以做一些h5,也可以放一些技能啊交流群啊,长期更新哈,
看得我热血沸腾,
现在很多类似的网站都在做这方面,像发现我的职业网,
我建议你玩玩天天益彩,里面所有的技巧都很简单,每天上玩两三个小时,还能挣些小钱。我高中同学当年就在玩这个,
我也想知道(机智微笑)
穷鬼网,
如果有楼主想找对象的标准,再加上技能点,
我也是学生党每天都想赚钱
可以找一些跟技能挂钩的,例如设计,翻译,程序员等(嘿嘿嘿)。
创意美女和流量主
目前国内绝大部分人工作都很忙碌,仅靠自己赚的钱肯定不够用,所以经常会羡慕一些在公司里上班的人,会想他们是否有时间自己赚钱,答案是肯定的。大多数就是当点客,然后花点时间用客赚来的钱在当地找女朋友。大学生的话,应该还有其他赚钱方式。
合理优化网站结构吸引蜘蛛深入抓取网站内容(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-05-08 18:06
合理优化网站结构,吸引蜘蛛掌握网站的含量
资料来源:根据她的感受,蜘蛛来网站是件好事,但我通过蜘蛛访问记录发现了一个大问题。通常蜘蛛抓取4或5页,然后在到达网站后离开。怎么了?相信很多站长都觉得百度蜘蛛在6月份的事件之后非常不稳定,我的网站也是如此。从6月份开始,每次蜘蛛来抓几页,它就会离开,所以网站的收录没有得到改进。最后,我对网站做了一个大检查,然后我整理了网站的链接,更不用说整理后的网站,蜘蛛每次抓取20、30页。让我分享一下我的检查方法和补救方法
我想蜘蛛之所以一开始不深入的第一个原因是导航链接设置不正确,蜘蛛无法通过导航链接深入到你的网站中,那它们怎么能抓到内容页呢?第二种可能是蜘蛛遇到死链接,但在准备抓取下一页时却无法爬行,因此网站的死链接成为罪魁祸首,迫使百度蜘蛛离开网站。第三种可能是,长时间不更新网站内容也会导致百度蜘蛛疲惫不堪。第一、页重置网站导航链接
网站的导航链接不仅是用户的指南,也是搜索引擎蜘蛛的指南。一条好的导航路线可以帮助搜索引擎蜘蛛从网站的主页逐步贯穿整个网站页面,这就需要我们层层设置网站导航。让我谈谈设置导航链接的一些要求:
1、导航链接应该关闭。当我们设置导航链接时,我们不应该对搜索引擎蜘蛛看得太深。其实,它是一种捕捉的工具,最容易捕捉的是最近的东西。因此,我们在使用导航链接时,可以通过导航链接导入下一级栏目链接,下一级栏目链接会导入内容页,这是分层导入的方法
从2、导入的URL不应太复杂。我认为可以简单地设置网站的URL地址。只需使用一个PHP程序,目录设置很简单。那么蜘蛛爬行就相对容易了。必须清理二、死链接,留下是一个诅咒
死链接阻碍了网站很多。如果不注意死链接,可能会对网站产生致命影响。检查死链接可以使用Chinaz中的工具,但是清理死链接相对比较困难。现在我清理网站死链接的方法是通过浏览器中FTP的搜索功能。首先在查询工具中复制死链接的地址,然后在浏览器中通过FTP的搜索功能找到死链接所在的文件,最后将其删除。很多站长都会说这个方法很麻烦,但是我想说的是这个方法确实是最有效的一种,我也用过那些工具来清理死链接。大部分都是假的,所以我根本洗不干净
第三、文章节内容链接合理布局
我们不应该忘记在网站的文章内容中链接布局的形式。在例行的文章更新工作中,我们可以将文章中的关键词作为指向其他文章内容页或网站的链接 查看全部
合理优化网站结构吸引蜘蛛深入抓取网站内容(图)
合理优化网站结构,吸引蜘蛛掌握网站的含量
资料来源:根据她的感受,蜘蛛来网站是件好事,但我通过蜘蛛访问记录发现了一个大问题。通常蜘蛛抓取4或5页,然后在到达网站后离开。怎么了?相信很多站长都觉得百度蜘蛛在6月份的事件之后非常不稳定,我的网站也是如此。从6月份开始,每次蜘蛛来抓几页,它就会离开,所以网站的收录没有得到改进。最后,我对网站做了一个大检查,然后我整理了网站的链接,更不用说整理后的网站,蜘蛛每次抓取20、30页。让我分享一下我的检查方法和补救方法
我想蜘蛛之所以一开始不深入的第一个原因是导航链接设置不正确,蜘蛛无法通过导航链接深入到你的网站中,那它们怎么能抓到内容页呢?第二种可能是蜘蛛遇到死链接,但在准备抓取下一页时却无法爬行,因此网站的死链接成为罪魁祸首,迫使百度蜘蛛离开网站。第三种可能是,长时间不更新网站内容也会导致百度蜘蛛疲惫不堪。第一、页重置网站导航链接
网站的导航链接不仅是用户的指南,也是搜索引擎蜘蛛的指南。一条好的导航路线可以帮助搜索引擎蜘蛛从网站的主页逐步贯穿整个网站页面,这就需要我们层层设置网站导航。让我谈谈设置导航链接的一些要求:
1、导航链接应该关闭。当我们设置导航链接时,我们不应该对搜索引擎蜘蛛看得太深。其实,它是一种捕捉的工具,最容易捕捉的是最近的东西。因此,我们在使用导航链接时,可以通过导航链接导入下一级栏目链接,下一级栏目链接会导入内容页,这是分层导入的方法
从2、导入的URL不应太复杂。我认为可以简单地设置网站的URL地址。只需使用一个PHP程序,目录设置很简单。那么蜘蛛爬行就相对容易了。必须清理二、死链接,留下是一个诅咒
死链接阻碍了网站很多。如果不注意死链接,可能会对网站产生致命影响。检查死链接可以使用Chinaz中的工具,但是清理死链接相对比较困难。现在我清理网站死链接的方法是通过浏览器中FTP的搜索功能。首先在查询工具中复制死链接的地址,然后在浏览器中通过FTP的搜索功能找到死链接所在的文件,最后将其删除。很多站长都会说这个方法很麻烦,但是我想说的是这个方法确实是最有效的一种,我也用过那些工具来清理死链接。大部分都是假的,所以我根本洗不干净
第三、文章节内容链接合理布局
我们不应该忘记在网站的文章内容中链接布局的形式。在例行的文章更新工作中,我们可以将文章中的关键词作为指向其他文章内容页或网站的链接
如何查看360手机应用搜索种类的前5页的信息
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-05-08 18:05
我们不会一想到抓取网页就开始编写一个scrapcrawler。事实上,根据需要选择合适的方式抓取网页更有效
比如抓取360手机各类应用前5页的信息。我们直接分析请求消息的样式,模拟发送消息,然后分析返回的内容以获得所需的信息,而不是编写草图。更重要的是,对于一些JS动态加载的内容(比如在googleplay上抓取应用程序),这种方法可以获得重要的信息,然后配合抓取得到更好的结果。在这种情况下,我们只使用发送请求的方法来捕获
需求:抢占360手机应用搜索类前五页。例如:
[第21页]
在搜索栏中输入游戏,这些应用程序就会出现(按类别搜索,都一样)。我们要采集这些游戏的信息。这里,作为一个例子,只需获取应用程序的包名
这里不详细介绍如何查看浏览器请求消息。F12打开浏览器查找并返回请求的信息。一般来说,您可以从前端开始查看网络中的信息,然后查看响应返回所需的信息
[第22页]
这就是我们需要的信息。查看标头以找到模拟发送请求所需的信息。我不在这里重复了。360网站请求的头URL实际上是URL。例如,单击下一页后,URL为:
[第23页]
这是发送请求的格式。只要URL构造得好,就可以随意获取数据。例如,如果选择“运动”类别第三页的内容,则连接将为“运动&;页码=3
等等。您可以使用chrome插件postman来验证返回的结果,也可以在请求之后直接打印结果。你会知道这是不是对的。我们直接去看节目吧
#-*-编码:utf-8-*-
导入系统
重新加载(sys)
系统设置默认编码(“utf-8”)
进口刮痧
从scrapy.crawler导入CrawlerProcess
#从scrapy.utils.project import获取\项目\设置
#从数据库导入TSFDataBase
导入urllib
导入urllib2
从lxml导入etree
Appkind=[‘阅读’、‘商业’、‘漫画’、‘通信’、‘教育’、‘娱乐’、‘金融’、‘游戏’、‘健康’、‘书籍’、‘生活’、‘动态壁纸’、‘视频’、‘医疗’、‘音乐’、‘新闻’、‘个性化’、‘摄影’、‘效率’、‘购物’、‘社交网络’、‘体育’、‘工具’、‘旅游’,'运输','天气']
fileWriteObj=open('360app.txt','w')
打印长度(appkind)
对于范围内的ikind(len(appkind)):
对于范围内的ipage(5):
打印ipage
数据={}
数据['page']=ipage+1
test\ data\ urlencode=urllib.urlencode(数据)
url=“”+appkind[ikind]+“&;page=“+str(ipage+1)”
data1=urllib.urlencode(数据)
req=urllib2.请求(url,数据1)
响应=urllib2.urlopen(请求)
结果=response.read()
#打印结果
如果isinstance(结果,unicode):
通过
其他:
result=result.decode('utf-8')
tree=etree.HTML(结果)
ranks=tree.xpath('//div[@class=“download comdown”]/a/@href')
打印长度(列)
#ids=tree.xpath('//div[@class=“card no.small”]/div/div[2]/a[2]/@href')
对于范围内的i(len(ranks)):
apppack=等级[i]
apppack=apppack[apppack.rfind('/')+1:apppack.rfind(''\')]
onedata=apppack+','+str(ikind+1)
打印onedata
fileWriteObj.write(onedata+'\n')
打印'------------'
fileWriteObj.close()
如果名称==''主名称:
通过
结果:包名后面跟着分类号,例如,reading 1
[k30公里]
程序在关键词中搜索26个应用程序。每个应用程序抓取前五页并直接存储文本以便于显示。至于XPath之类的知识,我就不重复了。稍后,我将整理如何处理JS加载内容的爬网 查看全部
如何查看360手机应用搜索种类的前5页的信息
我们不会一想到抓取网页就开始编写一个scrapcrawler。事实上,根据需要选择合适的方式抓取网页更有效
比如抓取360手机各类应用前5页的信息。我们直接分析请求消息的样式,模拟发送消息,然后分析返回的内容以获得所需的信息,而不是编写草图。更重要的是,对于一些JS动态加载的内容(比如在googleplay上抓取应用程序),这种方法可以获得重要的信息,然后配合抓取得到更好的结果。在这种情况下,我们只使用发送请求的方法来捕获
需求:抢占360手机应用搜索类前五页。例如:
[第21页]
在搜索栏中输入游戏,这些应用程序就会出现(按类别搜索,都一样)。我们要采集这些游戏的信息。这里,作为一个例子,只需获取应用程序的包名
这里不详细介绍如何查看浏览器请求消息。F12打开浏览器查找并返回请求的信息。一般来说,您可以从前端开始查看网络中的信息,然后查看响应返回所需的信息
[第22页]
这就是我们需要的信息。查看标头以找到模拟发送请求所需的信息。我不在这里重复了。360网站请求的头URL实际上是URL。例如,单击下一页后,URL为:
[第23页]
这是发送请求的格式。只要URL构造得好,就可以随意获取数据。例如,如果选择“运动”类别第三页的内容,则连接将为“运动&;页码=3
等等。您可以使用chrome插件postman来验证返回的结果,也可以在请求之后直接打印结果。你会知道这是不是对的。我们直接去看节目吧
#-*-编码:utf-8-*-
导入系统
重新加载(sys)
系统设置默认编码(“utf-8”)
进口刮痧
从scrapy.crawler导入CrawlerProcess
#从scrapy.utils.project import获取\项目\设置
#从数据库导入TSFDataBase
导入urllib
导入urllib2
从lxml导入etree
Appkind=[‘阅读’、‘商业’、‘漫画’、‘通信’、‘教育’、‘娱乐’、‘金融’、‘游戏’、‘健康’、‘书籍’、‘生活’、‘动态壁纸’、‘视频’、‘医疗’、‘音乐’、‘新闻’、‘个性化’、‘摄影’、‘效率’、‘购物’、‘社交网络’、‘体育’、‘工具’、‘旅游’,'运输','天气']
fileWriteObj=open('360app.txt','w')
打印长度(appkind)
对于范围内的ikind(len(appkind)):
对于范围内的ipage(5):
打印ipage
数据={}
数据['page']=ipage+1
test\ data\ urlencode=urllib.urlencode(数据)
url=“”+appkind[ikind]+“&;page=“+str(ipage+1)”
data1=urllib.urlencode(数据)
req=urllib2.请求(url,数据1)
响应=urllib2.urlopen(请求)
结果=response.read()
#打印结果
如果isinstance(结果,unicode):
通过
其他:
result=result.decode('utf-8')
tree=etree.HTML(结果)
ranks=tree.xpath('//div[@class=“download comdown”]/a/@href')
打印长度(列)
#ids=tree.xpath('//div[@class=“card no.small”]/div/div[2]/a[2]/@href')
对于范围内的i(len(ranks)):
apppack=等级[i]
apppack=apppack[apppack.rfind('/')+1:apppack.rfind(''\')]
onedata=apppack+','+str(ikind+1)
打印onedata
fileWriteObj.write(onedata+'\n')
打印'------------'
fileWriteObj.close()
如果名称==''主名称:
通过
结果:包名后面跟着分类号,例如,reading 1
[k30公里]
程序在关键词中搜索26个应用程序。每个应用程序抓取前五页并直接存储文本以便于显示。至于XPath之类的知识,我就不重复了。稍后,我将整理如何处理JS加载内容的爬网
TeleportUltra用起来效果很好的方法解决资源竞争的问题
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-05-08 07:18
出于某些原因,我们经常需要抓取某个网站或直接复制某个网站。我们在Internet上找到了许多用于测试的工具,尝试了许多不同的问题,最后选择了Teleport Ultra来使用它。效果很好;这里没有提到具体的操作手册和其他内容,互联网上有很多搜索,这主要是遇到的问题:
软件下载地址:
工具屏幕截图:
网站的爬网测试很简单:
拍摄后的效果图片
通常,我将选择复制100级并基本上复制网站中的所有内容,但是由于Teleport Ultra是用UTF-8捕获的,因此如果文件中收录中文字符或gbk编码,文件将出现乱码,如下所示:
当然,您可以在浏览器中手动选择UTF-8,但是每次打开它时我们都做不到。因此,我转到网站,找到了一个名为:TelePort乱码修复工具(siteRepair-v 2. 0))的软件,经过测试可以解决乱码问题,该工具还将删除一些无效的链接和html符号,等
软件下载地址:
软件屏幕截图:
经过这两个步骤后,绝大多数网站应该都可以,但是某些网站层次结构使用中文目录,或者中文文件名会出现乱码,类似于下面的URL地址:
除了锁定之外,还有哪些其他方法可以解决资源竞争问题? /Solution.html
通过这种方式,网站的结构将出现两种乱码:1)文件夹名乱码2)文件名乱码
遇到此问题时,siteRepair-v 2. 0工具将报告错误。我猜它无法识别乱码的文件夹或文件。
后来,我在互联网上找到了一个PHP程序,只需进行简单的修改测试就可以解决此问题
PHP代码:convert.php
<p> 查看全部
TeleportUltra用起来效果很好的方法解决资源竞争的问题
出于某些原因,我们经常需要抓取某个网站或直接复制某个网站。我们在Internet上找到了许多用于测试的工具,尝试了许多不同的问题,最后选择了Teleport Ultra来使用它。效果很好;这里没有提到具体的操作手册和其他内容,互联网上有很多搜索,这主要是遇到的问题:
软件下载地址:
工具屏幕截图:
网站的爬网测试很简单:
拍摄后的效果图片
通常,我将选择复制100级并基本上复制网站中的所有内容,但是由于Teleport Ultra是用UTF-8捕获的,因此如果文件中收录中文字符或gbk编码,文件将出现乱码,如下所示:
当然,您可以在浏览器中手动选择UTF-8,但是每次打开它时我们都做不到。因此,我转到网站,找到了一个名为:TelePort乱码修复工具(siteRepair-v 2. 0))的软件,经过测试可以解决乱码问题,该工具还将删除一些无效的链接和html符号,等
软件下载地址:
软件屏幕截图:
经过这两个步骤后,绝大多数网站应该都可以,但是某些网站层次结构使用中文目录,或者中文文件名会出现乱码,类似于下面的URL地址:
除了锁定之外,还有哪些其他方法可以解决资源竞争问题? /Solution.html
通过这种方式,网站的结构将出现两种乱码:1)文件夹名乱码2)文件名乱码
遇到此问题时,siteRepair-v 2. 0工具将报告错误。我猜它无法识别乱码的文件夹或文件。
后来,我在互联网上找到了一个PHP程序,只需进行简单的修改测试就可以解决此问题
PHP代码:convert.php
<p>
米鼠网MacOS10.15.x[下载链接]
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-05-08 07:16
[名称]:适用于Mac的WebScraper
[大小]:9. 6 MB
[语言]:英文
[测试环境]:Mac OS 1 0. 1 5. x
[下载链接]:
简介
WebScraper Mac是Mac OS系统上非常有用的网站数据提取工具。 WebScraper可以帮助您在10分钟内轻松地抓取网页数据。只需输入起始URL即可开始。简单而强大。
软件功能
1、快速轻松地扫描网站
很多提取选项;各种元数据,内容(例如文本,html或markdown),具有某些类/ ID的元素,正则表达式
2、易于导出,选择所需的列
3、输出为csv或json
4、新选项可将所有图像下载到文件夹/采集并导出所有链接
5、新选项可输出单个文本文件(用于存档文本内容,降价或纯文本)
6、丰富的选项/配置
在这里,我推荐一个在线软件综合交易平台:
自成立以来,一直专注于软件项目,人才招聘,软件商城等,始终秉承“专业服务,易于使用的产品”和“提供高水平的服务”的经营理念。优质的服务和满足客户的需求。需求,共同创造双赢局面”是为中国国内企业提供国际,专业,个性化和软件项目解决方案的企业目标。我们公司拥有一流的项目经理团队,具有出色的软件项目设计和实施能力。为全国不同行业的客户提供优质的产品和服务,受到了客户的广泛好评。
查看全部
米鼠网MacOS10.15.x[下载链接]
[名称]:适用于Mac的WebScraper
[大小]:9. 6 MB
[语言]:英文
[测试环境]:Mac OS 1 0. 1 5. x
[下载链接]:
简介
WebScraper Mac是Mac OS系统上非常有用的网站数据提取工具。 WebScraper可以帮助您在10分钟内轻松地抓取网页数据。只需输入起始URL即可开始。简单而强大。
软件功能
1、快速轻松地扫描网站
很多提取选项;各种元数据,内容(例如文本,html或markdown),具有某些类/ ID的元素,正则表达式
2、易于导出,选择所需的列
3、输出为csv或json
4、新选项可将所有图像下载到文件夹/采集并导出所有链接
5、新选项可输出单个文本文件(用于存档文本内容,降价或纯文本)
6、丰富的选项/配置
在这里,我推荐一个在线软件综合交易平台:
自成立以来,一直专注于软件项目,人才招聘,软件商城等,始终秉承“专业服务,易于使用的产品”和“提供高水平的服务”的经营理念。优质的服务和满足客户的需求。需求,共同创造双赢局面”是为中国国内企业提供国际,专业,个性化和软件项目解决方案的企业目标。我们公司拥有一流的项目经理团队,具有出色的软件项目设计和实施能力。为全国不同行业的客户提供优质的产品和服务,受到了客户的广泛好评。
Python多进程方式抓取基金网站内容相关实现技巧与操作注意事项
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-05-06 05:17
本文文章主要介绍了Python多进程抓取资金网站内容的方法,并结合示例分析了Python多进程抓取网站内容相关的实现技巧和操作注意事项。有需要的朋友可以参考
本文介绍了在python多进程模式下获取fund 网站内容的方法。与您分享以供参考,如下所示:
在上一篇文章//// article / 16241 8. htm中,我们已经简要地理解了“ python的多进程”,现在我们需要编写抓取基金网站的内容(第28页)作为一种多过程方法。
由于该过程越少越好,我们计划在三个过程中实施它。这意味着:将总共28个要抓取的页面分为三个部分。
如何划分?
# 初始range
r = range(1,29)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)]
print(myList) # [range(1, 11), range(11, 21), range(21, 29)]
根据上面的代码,我们将1〜29分为三个部分,列表中的三个范围。
2、还记得我们获取了Fund 网站内容的getData()函数吗?
def getData(start, end):
for x in range(start, end+1):
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDlkNWdriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
该函数有2个参数:起始页码和结束页码,即从起始页到结束页。
这两个参数实际上是范围。
按如下所示修改getData()函数(参数不同):
# 循环抓取网页内容的函数
def getData(myrange):
for x in myrange:
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
编程客栈 .get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
3、创建一个进程并将目标设置为上述getData():
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
有三个要分别获取的过程。
4、多进程抓取资金网站多页内容的完整代码:
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from multiprocessing import Process
driver = webdriver.Phantomjs(executable_path=r"你phantomjs的可执行文件路径")
# 请求一个网址
driver.get("http://fund.eastmoney.com/fund.html")
page_text = driver.find_element_by_id("pager").find_element_by_xpath("span[@class='nv']").text
total_page = ''.join(filter(str.isdigit,page_text)) # 得到总共有多少页
# 循环抓取网页内容的函数
def getData(myrange):
for x in myrange:
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(编程客栈str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
对于对Python相关内容有更多兴趣的读者,请查看此站点的主题:“ Python进程和线程操作技能摘要”,“ Python数据结构和算法教程”,“ Python函数使用技能摘要”, “ Python字符串”操作技巧摘要”,“ Python简介和高级经典教程”,“ Python + mysql数据库编程简介”和“ Python通用数据库操作技巧摘要”
我希望本文能对您的Python编程有所帮助。
本文标题:Python多进程爬网资金网站内容的方法分析 查看全部
Python多进程方式抓取基金网站内容相关实现技巧与操作注意事项
本文文章主要介绍了Python多进程抓取资金网站内容的方法,并结合示例分析了Python多进程抓取网站内容相关的实现技巧和操作注意事项。有需要的朋友可以参考
本文介绍了在python多进程模式下获取fund 网站内容的方法。与您分享以供参考,如下所示:
在上一篇文章//// article / 16241 8. htm中,我们已经简要地理解了“ python的多进程”,现在我们需要编写抓取基金网站的内容(第28页)作为一种多过程方法。
由于该过程越少越好,我们计划在三个过程中实施它。这意味着:将总共28个要抓取的页面分为三个部分。
如何划分?
# 初始range
r = range(1,29)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)]
print(myList) # [range(1, 11), range(11, 21), range(21, 29)]
根据上面的代码,我们将1〜29分为三个部分,列表中的三个范围。
2、还记得我们获取了Fund 网站内容的getData()函数吗?
def getData(start, end):
for x in range(start, end+1):
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDlkNWdriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
该函数有2个参数:起始页码和结束页码,即从起始页到结束页。
这两个参数实际上是范围。
按如下所示修改getData()函数(参数不同):
# 循环抓取网页内容的函数
def getData(myrange):
for x in myrange:
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
编程客栈 .get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
3、创建一个进程并将目标设置为上述getData():
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
有三个要分别获取的过程。
4、多进程抓取资金网站多页内容的完整代码:
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from multiprocessing import Process
driver = webdriver.Phantomjs(executable_path=r"你phantomjs的可执行文件路径")
# 请求一个网址
driver.get("http://fund.eastmoney.com/fund.html";)
page_text = driver.find_element_by_id("pager").find_element_by_xpath("span[@class='nv']").text
total_page = ''.join(filter(str.isdigit,page_text)) # 得到总共有多少页
# 循环抓取网页内容的函数
def getData(myrange):
for x in myrange:
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(编程客栈str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
对于对Python相关内容有更多兴趣的读者,请查看此站点的主题:“ Python进程和线程操作技能摘要”,“ Python数据结构和算法教程”,“ Python函数使用技能摘要”, “ Python字符串”操作技巧摘要”,“ Python简介和高级经典教程”,“ Python + mysql数据库编程简介”和“ Python通用数据库操作技巧摘要”
我希望本文能对您的Python编程有所帮助。
本文标题:Python多进程爬网资金网站内容的方法分析
吸引搜索引擎蜘蛛快速抓取网站的内容不是什么事
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-05-05 07:15
吸引搜索引擎蜘蛛快速抓取网站的内容不是什么事
这些因素将影响搜索引擎蜘蛛对网站内容的爬网。吸引搜索引擎蜘蛛快速抓取网站的内容并使搜索引擎快速收录 网站的内容一直是SEO优化人员想要实现的效果。但是,要实现这样的效果并不容易,这对于许多优化器来说也是一个问题。但是,如果以下几点做得很好,那就没什么了。
1、检查您的IP上是否有大型站点
东莞网站 SEO优化促进发现,搜索引擎蜘蛛通常是按IP进行爬网的,并且某个IP的爬网次数也受到限制。如果您的IP有许多站点,则将其分配给某个站点。每个站点的爬网量都将减少,尤其是在存在具有相同IP的大型站点时。另一方面,如果具有相同IP的网站的活动站点可能与您的网站类似,则也会影响网站从侧面爬网。因此,网站进行了优化,以尽可能多地使用独立IP。
2、内容质量
尽管百度的官方文件没有显示原创内容的词汇,但实际上百度要表达的内容是只要它对客户有用,即使不是原创,它也将给出良好的排名。 ,因此,有很多针对非原创内容的内容产生方法。百度排名的最佳方法是内容子模块和随机组合。结果非常好,输入也很好。但是,大多数网站管理员都知道,非原创是转载和窃,伪原创等。您可以想象搜索引擎蜘蛛对此类网站的情绪。
退后一步说,如果您确实想做伪原创,则必须确保至少有30%的差异,可以组合使用。 网站确保内容质量的另一个方面是,百度在某些类型的网站上的进入受到限制。百度会在进入您的网站之前对网站进行评分,然后根据该评分选择网站条目。多少钱?这是长期以来许多电台进入率下降的根本原因。
因此,我们需要增加有用条目的数量。东莞网站 SEO优化推广发现,百度排名的基本原因是提供高质量的内容页面来满足搜索需求,但不幸的是,百度排名靠前的高质量内容页面普遍原创,因此想要查找的网站站长通过伪原创的文章内容可以省钱。
3、现场密封
网站管理员有时间注意您网站的严格性。例如,它无法打开,黑链跳开,捕获了webshell等,该网站管理员必须是第一次,并使用百度网站管理员工具中的相应救援方法进行操作。通常,网站被黑的效果是挂起一条黑链,因此,如果您有时间查看是否在源代码中添加了许多黑链,则会成批添加黑链,这在视觉上很容易区分。如果您无法及时处理,百度抓取工具会抓取相关页面并跳转到非法页面,这会降低您的权利。通常,对链接黑色链接导致的百度排名进行排名并不容易。
4、 网站打开速度和加载速度
东莞网站 SEO优化促进发现网站的打开速度将影响搜索引擎蜘蛛从侧面爬行的速度。尽管Spider会抓取您的网页,但是网页的大小没有区别(实际上,网页越大,网页的丰富程度就越大,百度就会显示出来),但是从用户的角度来看,当您的网页已打开如果加载时间超过3秒,则跳出率将添加到市场营销搜索引擎优化网站中。如果跳出率很高,则会影响您的网站等级,并且网站等级会降低,并且网站的条目会很低。 。因此,百度排名的开放速度将直接影响搜索引擎蜘蛛的爬行。
咨询客户服务咨询客户服务
英语演示是演示地址的原创版本。如果您位于中国境外,访问可能会很慢(建议爬梯子进行浏览)。您在本网站上下载的主题源代码和其他资源仅用于测试和学习目的。官方更新和售后服务。
此站点承担WordPress主题安装,深度本地化,加速优化和其他服务。请咨询在线客户服务以获取详细信息!
查看全部
吸引搜索引擎蜘蛛快速抓取网站的内容不是什么事
这些因素将影响搜索引擎蜘蛛对网站内容的爬网。吸引搜索引擎蜘蛛快速抓取网站的内容并使搜索引擎快速收录 网站的内容一直是SEO优化人员想要实现的效果。但是,要实现这样的效果并不容易,这对于许多优化器来说也是一个问题。但是,如果以下几点做得很好,那就没什么了。
1、检查您的IP上是否有大型站点
东莞网站 SEO优化促进发现,搜索引擎蜘蛛通常是按IP进行爬网的,并且某个IP的爬网次数也受到限制。如果您的IP有许多站点,则将其分配给某个站点。每个站点的爬网量都将减少,尤其是在存在具有相同IP的大型站点时。另一方面,如果具有相同IP的网站的活动站点可能与您的网站类似,则也会影响网站从侧面爬网。因此,网站进行了优化,以尽可能多地使用独立IP。
2、内容质量
尽管百度的官方文件没有显示原创内容的词汇,但实际上百度要表达的内容是只要它对客户有用,即使不是原创,它也将给出良好的排名。 ,因此,有很多针对非原创内容的内容产生方法。百度排名的最佳方法是内容子模块和随机组合。结果非常好,输入也很好。但是,大多数网站管理员都知道,非原创是转载和窃,伪原创等。您可以想象搜索引擎蜘蛛对此类网站的情绪。
退后一步说,如果您确实想做伪原创,则必须确保至少有30%的差异,可以组合使用。 网站确保内容质量的另一个方面是,百度在某些类型的网站上的进入受到限制。百度会在进入您的网站之前对网站进行评分,然后根据该评分选择网站条目。多少钱?这是长期以来许多电台进入率下降的根本原因。
因此,我们需要增加有用条目的数量。东莞网站 SEO优化推广发现,百度排名的基本原因是提供高质量的内容页面来满足搜索需求,但不幸的是,百度排名靠前的高质量内容页面普遍原创,因此想要查找的网站站长通过伪原创的文章内容可以省钱。
3、现场密封
网站管理员有时间注意您网站的严格性。例如,它无法打开,黑链跳开,捕获了webshell等,该网站管理员必须是第一次,并使用百度网站管理员工具中的相应救援方法进行操作。通常,网站被黑的效果是挂起一条黑链,因此,如果您有时间查看是否在源代码中添加了许多黑链,则会成批添加黑链,这在视觉上很容易区分。如果您无法及时处理,百度抓取工具会抓取相关页面并跳转到非法页面,这会降低您的权利。通常,对链接黑色链接导致的百度排名进行排名并不容易。
4、 网站打开速度和加载速度
东莞网站 SEO优化促进发现网站的打开速度将影响搜索引擎蜘蛛从侧面爬行的速度。尽管Spider会抓取您的网页,但是网页的大小没有区别(实际上,网页越大,网页的丰富程度就越大,百度就会显示出来),但是从用户的角度来看,当您的网页已打开如果加载时间超过3秒,则跳出率将添加到市场营销搜索引擎优化网站中。如果跳出率很高,则会影响您的网站等级,并且网站等级会降低,并且网站的条目会很低。 。因此,百度排名的开放速度将直接影响搜索引擎蜘蛛的爬行。
咨询客户服务咨询客户服务
英语演示是演示地址的原创版本。如果您位于中国境外,访问可能会很慢(建议爬梯子进行浏览)。您在本网站上下载的主题源代码和其他资源仅用于测试和学习目的。官方更新和售后服务。
此站点承担WordPress主题安装,深度本地化,加速优化和其他服务。请咨询在线客户服务以获取详细信息!
巧用文章内容能让你的网站更受搜索引擎的欢迎
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-05-05 07:10
实际上,网站的内容并不完全可供用户看到,它更多地是各种搜索引擎进行爬取和判断的标准。 网站的含量是网站是否可以长时间操作的重要因素。基本的知识,懂得如何优化,并熟练地使用文章内容来使网站在搜索引擎中更受欢迎。
一个:如何优化网站内容
对于每个搜索引擎而言,高质量原创内容以及图形和文本的丰富组合都易于被搜索引擎抓取,并且它们都收录在高质量库中,并且关键词排名的内容也将随之而来。越来越多,以便您可以获得更好的点击率。
对于每个搜索用户,内容页面可以获取他需要的更多内容,这是终止搜索引擎的目的。用户停留在页面上的时间长度和在内部页面上的点击次数取决于搜索引擎对质量的判断。质量是内容的重要组成部分。
二:如何专门优化网站的内容
网站的内容优化涉及很多种类,在这里我将简要介绍一些我自己的经验,希望能帮助更多的网站管理员。
1:仔细组织内容标题。
标题是当前内容的核心思想,它反映了其背后的需求范围。内容标题设置的质量与大多数用户是否可以通过此标题搜索网站内容直接相关。标题的组织原则是,标题是否可以满足用户的大部分需求,是否具有吸引力以及是否具有尺寸。
2:该段落的内容需要很多努力。
用户进入内容页面后,他们的眼睛从上到下。一条内容能否吸引用户的注意力取决于其文学能力。段落应通过完全匹配和分词匹配在标题的关键词中排列,并且必须具有吸引力。
3:内容详尽,丰富,并结合了图形和文本。
丰富,独特和权威的内容可以使用户满意,并且图形和文本的组合可以降低用户的阅读成本。相反,只有几个数字的文章没有深入阅读的属性。
4:根据需要写出内容中的单词数。
不要写很多无用的文字来增加字数。只需简短易懂的文字即可显示更重要的内容。
5:标题中的文本需要在整个内容中反映出来。
在当前内容中,布局是相关的关键词,可以进一步增强内容的相关性,并且对搜索引擎非常友好。
6:重要内容需要在其他页面上体现出来。
除了单词频率外,位置也很重要。想要获得排名的关键词链接以内部链接,推荐方式,相关阅读方式和置顶方式出现。在网站上给该内容页面更多的投票,相应的排名将会更高。
以上是我个人内容优化经验的一部分。从优化的角度来看,内容优化是不可忽略的重要链接。它可能取决于网站的生与死。希望以上介绍可以帮助更多的网站管理员,谢谢收看。 查看全部
巧用文章内容能让你的网站更受搜索引擎的欢迎
实际上,网站的内容并不完全可供用户看到,它更多地是各种搜索引擎进行爬取和判断的标准。 网站的含量是网站是否可以长时间操作的重要因素。基本的知识,懂得如何优化,并熟练地使用文章内容来使网站在搜索引擎中更受欢迎。
一个:如何优化网站内容
对于每个搜索引擎而言,高质量原创内容以及图形和文本的丰富组合都易于被搜索引擎抓取,并且它们都收录在高质量库中,并且关键词排名的内容也将随之而来。越来越多,以便您可以获得更好的点击率。
对于每个搜索用户,内容页面可以获取他需要的更多内容,这是终止搜索引擎的目的。用户停留在页面上的时间长度和在内部页面上的点击次数取决于搜索引擎对质量的判断。质量是内容的重要组成部分。
二:如何专门优化网站的内容
网站的内容优化涉及很多种类,在这里我将简要介绍一些我自己的经验,希望能帮助更多的网站管理员。
1:仔细组织内容标题。
标题是当前内容的核心思想,它反映了其背后的需求范围。内容标题设置的质量与大多数用户是否可以通过此标题搜索网站内容直接相关。标题的组织原则是,标题是否可以满足用户的大部分需求,是否具有吸引力以及是否具有尺寸。
2:该段落的内容需要很多努力。
用户进入内容页面后,他们的眼睛从上到下。一条内容能否吸引用户的注意力取决于其文学能力。段落应通过完全匹配和分词匹配在标题的关键词中排列,并且必须具有吸引力。
3:内容详尽,丰富,并结合了图形和文本。
丰富,独特和权威的内容可以使用户满意,并且图形和文本的组合可以降低用户的阅读成本。相反,只有几个数字的文章没有深入阅读的属性。
4:根据需要写出内容中的单词数。
不要写很多无用的文字来增加字数。只需简短易懂的文字即可显示更重要的内容。
5:标题中的文本需要在整个内容中反映出来。
在当前内容中,布局是相关的关键词,可以进一步增强内容的相关性,并且对搜索引擎非常友好。
6:重要内容需要在其他页面上体现出来。
除了单词频率外,位置也很重要。想要获得排名的关键词链接以内部链接,推荐方式,相关阅读方式和置顶方式出现。在网站上给该内容页面更多的投票,相应的排名将会更高。
以上是我个人内容优化经验的一部分。从优化的角度来看,内容优化是不可忽略的重要链接。它可能取决于网站的生与死。希望以上介绍可以帮助更多的网站管理员,谢谢收看。
区块之前的兄弟区块和正文相关数据和在确定
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-05-04 01:21
此外,提取网页的主要文本包括以下步骤;确定主要文本的相关图片,确定主要文本的相关视频,确定主要文本的相关数据表,并在确定相关图片,视频和数据的基础上结合主要文本块的文本构造正文的表格。
进一步,遍历同级块和文本块之前的文本块,并将非黑名单中的图片和视频链接分别提取为与文本相关的图片和与文本相关的视频。
此外,遍历文本块以将数据表提取为与文本相关的数据表。
此外,自动提取网页信息的方法还包括:提取与文本有关的基本元数据;
提取与文本相关的基本元数据包括:提取标题,提取来源,提取发布时间以及提取作者。
进一步,遍历文本块之前的同级块和文本块中的短文本节点,计算最长的子字符串与字符长度之比时,文本节点字符和页面标题文本的最长公共子字符串如果超过某个阈值,它将被添加到标题候选集;
在文本块之前遍历同级块,并根据源要素库提取满足源前缀和后特性的字符串,并将其添加到源候选集;
遍历文本块之前的兄弟块,并根据发布时间特征库提取满足发布时间前缀和后特性的字符串,并将其添加到发布时间候选集;
在文本块之前遍历兄弟姐妹块,并根据作者的特征库提取符合作者前缀和后特性的字符串,并将其添加到作者候选集。
此外,预处理网页数据包括:
为html网页的源代码对统一字符集进行转码并对特殊字符进行编码和解码。
本发明的优点在于它考虑了网页信息提取的效率和准确性。在不显着减少传统网页提取方法的基础上,考虑了网页的布局特征和html的部分视觉特征,有效地改善了网页。信息提取的准确性。
在使用该程序自动提取Web信息的基础上,充分利用了存放的黑名单,规则库和知识库,这大大提高了自动提取的准确性,并且可以通过不断更新规则来改进提取方法基础和知识库适应性和准确性的范围。
将网页的dom结构与网页的布局功能结合在一起,合并并计算文本,图片,视频和表格,以构建具有综合主题权重和某些视觉功能的块dom,提高文本提取的准确性,并改进网页提取算法的适用领域:除了网页的主要文本外,现有的黑名单,知识库和规则库还可用于更准确地提取主要文本图像,视频,表格的关键字段,标题,发布时间,来源,作者等。
图纸说明
图1是自动提取Web信息的方法的流程图。
具体的实现方法
下面参考附图和具体实施例详细描述本发明。
如图1所示,一种自动提取网页信息的方法包括以下步骤:一、预处理网页信息; 二、建立块dom树; 三、定位文本区域; 四、提取网页的正文; 五、提取与正文相关的基本元数据。
在定位文本区域时,请根据通过加权计算获得的被摄体权重来定位文本区域。
一、预处理网页信息
网页信息的预处理包括:将html网页的源代码转换为统一的字符集,并对特殊字符进行编码和解码。
二、构建块dom树
构建块dom树包括以下步骤:
2. 1对网页的源代码执行容错补偿和dom分析;
2. 2基于dom组合html块布局元素以构建块dom结构;
2. 3根据显示特征计算dom块中基本主题元素的数量;
2. 4对dom块的基本主题元素执行加权计算。
重量是数量和重量的乘积。权重主要是指元素节点的视觉显示信息,具有分段,块,居中和增强显示效果的元素具有较高的权重。
统计文本信息和权重(转发权重):纯文本的数量和权重,有效文本的数量和权重(长文本)。
超链接信息和权重(负权重)的统计信息:超链接的数量和权重,链接文本的数量以及文本链接的平均比率(外部链接的负权重更高)。
图片信息和权重的统计信息:垃圾图片的数量(黑名单中的图片和小图片的权重为负),未链接图片的数量和权重,链接大图片的数量和权重。
统计数据表的数量和权重:数据表单元格的数量。
视频数量和重量的统计信息:垃圾视频的数量(黑名单中的视频),普通视频的数量和重量。
三、找到文本区域
过滤版权块:组合版权声明特征库以相反的顺序遍历dom块,以过滤版权声明块。
根据dom块的主题权重递归收缩并定位候选主题块:找到主题权重最大的dom块,并将其记录为max_block,将主题权重第二大的dom块记录为second_block;如果当max_block的权重与其父节点的权重之比超过某个阈值时,则将max_block用作收缩的根节点,否则收缩将停止。
合并候选dom块以获得文本块:如果second_block的值大于某个阈值或second_block与max_block的比率大于某个阈值,请检查second_block和max_block是否具有公共父节点或祖父母节点(如果这样)将公共父节点或祖父母节点设置为文本块content_block,同时将multi_block标志设置为true。
根据主题权重裁剪文本块并进行降噪:如果multi_block为true,则将修整content_block以过滤出主题权重小于平均值的块;如果multi_block为false,则主题权重将被滤除小于零的块。
四、提取网页的正文
网页主要文本的提取包括以下步骤;确定正文的相关图片,确定正文的相关视频,确定正文的相关数据表,并构造正文。
遍历同级块和文本块之前的文本块,并从非黑名单中提取图片和视频链接,分别作为与文本相关的图片和与文本相关的视频。
遍历文本块并将数据表提取为与文本相关的数据表。
文本的构造:在确定文本的相关图片,视频和数据表的基础上,将文本块的文本与文本块的文本组合以构造文本。具体地,基于上面确定的图片,视频和数据表,结合文本块的文本信息,基本的html显示特征按照出现在html中的顺序被保留,并且图片,表的混合布局并制作了视频。的富文本正文。
五、提取与文本相关的基本元数据
5. 1提取标题
依次遍历文本块和文本块中的短文本节点之前的同级块,并计算最长子字符串与字符之比时文本节点字符和网页标题文本的最长公共子字符串文本节点的长度超过某个值阈值被添加到标题候选集。如果标题候选集大于1,则综合考虑节点的视觉增强效果,公共子串的长度,公共子串的比例和文本节点的长度,优选文本节点。如果标题候选节点集为空,则将页面标题作为主页面标题返回。
5. 2提取源
依次遍历文本块之前的兄弟块,并根据源要素数据库提取满足源前缀和后特性的字符串,并将其添加到源候选集中;如果候选集为空,则根据源,分别从文本的开头和结尾开始和结束。特征库提取满足源前缀和后缀特征的字符串,并将它们添加到源候选集。如果候选集的数量大于1,则最好将媒体源库的内容匹配为文章的源。
5. 3提取发布时间
依次遍历文本块之前的兄弟块,并根据发布时间特征库提取满足发布时间前缀和后特性的字符串,并将其添加到发布时间候选者集中;如果候选集的数量大于1,则首选值与常识一致,并且可以将发布时间格式库的内容与发布时间匹配。
5. 4摘录作者
依次遍历同级文字块,然后根据作者的特征库提取符合作者前缀和发布特征的字符串,并将其添加到候选作者集中;如果作者候选集为空,则根据作者特征库提取符合作者前缀和后缀功能的字符串,并加入作者候选集。如果候选集的数量大于1,则最好将作者的源库中的内容匹配为文章的作者。
将网页的dom结构与网页的块布局元素组合在一起,以构造具有文本和部分视觉特征的块dom结构,并对文本,图片,视频的基本元素执行融合计算,表格等。定量计算dom块的主题贡献值;通过自上而下的块缩小算法定位网页主题的核心块,然后通过自下而上的块扩展算法过滤网页的主题候选块,最后对候选主题块进行噪声裁剪以完成最终的主题块定位;根据确定的主题块,结合黑名单,规则库和知识库,提取正文信息,包括文字,图片,视频和图表;以规则区,主题库,规则库,知识库,上下文位置,显示功能为中心,提取正文标题,发布时间,来源和作者。
上面已经显示和描述了本发明的基本原理,主要特征和优点。本领域技术人员应当理解,上述实施例不以任何形式限制本发明,通过等同替换或等同变换获得的所有技术方案都落入本发明的保护范围。 查看全部
区块之前的兄弟区块和正文相关数据和在确定
此外,提取网页的主要文本包括以下步骤;确定主要文本的相关图片,确定主要文本的相关视频,确定主要文本的相关数据表,并在确定相关图片,视频和数据的基础上结合主要文本块的文本构造正文的表格。
进一步,遍历同级块和文本块之前的文本块,并将非黑名单中的图片和视频链接分别提取为与文本相关的图片和与文本相关的视频。
此外,遍历文本块以将数据表提取为与文本相关的数据表。
此外,自动提取网页信息的方法还包括:提取与文本有关的基本元数据;
提取与文本相关的基本元数据包括:提取标题,提取来源,提取发布时间以及提取作者。
进一步,遍历文本块之前的同级块和文本块中的短文本节点,计算最长的子字符串与字符长度之比时,文本节点字符和页面标题文本的最长公共子字符串如果超过某个阈值,它将被添加到标题候选集;
在文本块之前遍历同级块,并根据源要素库提取满足源前缀和后特性的字符串,并将其添加到源候选集;
遍历文本块之前的兄弟块,并根据发布时间特征库提取满足发布时间前缀和后特性的字符串,并将其添加到发布时间候选集;
在文本块之前遍历兄弟姐妹块,并根据作者的特征库提取符合作者前缀和后特性的字符串,并将其添加到作者候选集。
此外,预处理网页数据包括:
为html网页的源代码对统一字符集进行转码并对特殊字符进行编码和解码。
本发明的优点在于它考虑了网页信息提取的效率和准确性。在不显着减少传统网页提取方法的基础上,考虑了网页的布局特征和html的部分视觉特征,有效地改善了网页。信息提取的准确性。
在使用该程序自动提取Web信息的基础上,充分利用了存放的黑名单,规则库和知识库,这大大提高了自动提取的准确性,并且可以通过不断更新规则来改进提取方法基础和知识库适应性和准确性的范围。
将网页的dom结构与网页的布局功能结合在一起,合并并计算文本,图片,视频和表格,以构建具有综合主题权重和某些视觉功能的块dom,提高文本提取的准确性,并改进网页提取算法的适用领域:除了网页的主要文本外,现有的黑名单,知识库和规则库还可用于更准确地提取主要文本图像,视频,表格的关键字段,标题,发布时间,来源,作者等。
图纸说明
图1是自动提取Web信息的方法的流程图。
具体的实现方法
下面参考附图和具体实施例详细描述本发明。
如图1所示,一种自动提取网页信息的方法包括以下步骤:一、预处理网页信息; 二、建立块dom树; 三、定位文本区域; 四、提取网页的正文; 五、提取与正文相关的基本元数据。
在定位文本区域时,请根据通过加权计算获得的被摄体权重来定位文本区域。
一、预处理网页信息
网页信息的预处理包括:将html网页的源代码转换为统一的字符集,并对特殊字符进行编码和解码。
二、构建块dom树
构建块dom树包括以下步骤:
2. 1对网页的源代码执行容错补偿和dom分析;
2. 2基于dom组合html块布局元素以构建块dom结构;
2. 3根据显示特征计算dom块中基本主题元素的数量;
2. 4对dom块的基本主题元素执行加权计算。
重量是数量和重量的乘积。权重主要是指元素节点的视觉显示信息,具有分段,块,居中和增强显示效果的元素具有较高的权重。
统计文本信息和权重(转发权重):纯文本的数量和权重,有效文本的数量和权重(长文本)。
超链接信息和权重(负权重)的统计信息:超链接的数量和权重,链接文本的数量以及文本链接的平均比率(外部链接的负权重更高)。
图片信息和权重的统计信息:垃圾图片的数量(黑名单中的图片和小图片的权重为负),未链接图片的数量和权重,链接大图片的数量和权重。
统计数据表的数量和权重:数据表单元格的数量。
视频数量和重量的统计信息:垃圾视频的数量(黑名单中的视频),普通视频的数量和重量。
三、找到文本区域
过滤版权块:组合版权声明特征库以相反的顺序遍历dom块,以过滤版权声明块。
根据dom块的主题权重递归收缩并定位候选主题块:找到主题权重最大的dom块,并将其记录为max_block,将主题权重第二大的dom块记录为second_block;如果当max_block的权重与其父节点的权重之比超过某个阈值时,则将max_block用作收缩的根节点,否则收缩将停止。
合并候选dom块以获得文本块:如果second_block的值大于某个阈值或second_block与max_block的比率大于某个阈值,请检查second_block和max_block是否具有公共父节点或祖父母节点(如果这样)将公共父节点或祖父母节点设置为文本块content_block,同时将multi_block标志设置为true。
根据主题权重裁剪文本块并进行降噪:如果multi_block为true,则将修整content_block以过滤出主题权重小于平均值的块;如果multi_block为false,则主题权重将被滤除小于零的块。
四、提取网页的正文
网页主要文本的提取包括以下步骤;确定正文的相关图片,确定正文的相关视频,确定正文的相关数据表,并构造正文。
遍历同级块和文本块之前的文本块,并从非黑名单中提取图片和视频链接,分别作为与文本相关的图片和与文本相关的视频。
遍历文本块并将数据表提取为与文本相关的数据表。
文本的构造:在确定文本的相关图片,视频和数据表的基础上,将文本块的文本与文本块的文本组合以构造文本。具体地,基于上面确定的图片,视频和数据表,结合文本块的文本信息,基本的html显示特征按照出现在html中的顺序被保留,并且图片,表的混合布局并制作了视频。的富文本正文。
五、提取与文本相关的基本元数据
5. 1提取标题
依次遍历文本块和文本块中的短文本节点之前的同级块,并计算最长子字符串与字符之比时文本节点字符和网页标题文本的最长公共子字符串文本节点的长度超过某个值阈值被添加到标题候选集。如果标题候选集大于1,则综合考虑节点的视觉增强效果,公共子串的长度,公共子串的比例和文本节点的长度,优选文本节点。如果标题候选节点集为空,则将页面标题作为主页面标题返回。
5. 2提取源
依次遍历文本块之前的兄弟块,并根据源要素数据库提取满足源前缀和后特性的字符串,并将其添加到源候选集中;如果候选集为空,则根据源,分别从文本的开头和结尾开始和结束。特征库提取满足源前缀和后缀特征的字符串,并将它们添加到源候选集。如果候选集的数量大于1,则最好将媒体源库的内容匹配为文章的源。
5. 3提取发布时间
依次遍历文本块之前的兄弟块,并根据发布时间特征库提取满足发布时间前缀和后特性的字符串,并将其添加到发布时间候选者集中;如果候选集的数量大于1,则首选值与常识一致,并且可以将发布时间格式库的内容与发布时间匹配。
5. 4摘录作者
依次遍历同级文字块,然后根据作者的特征库提取符合作者前缀和发布特征的字符串,并将其添加到候选作者集中;如果作者候选集为空,则根据作者特征库提取符合作者前缀和后缀功能的字符串,并加入作者候选集。如果候选集的数量大于1,则最好将作者的源库中的内容匹配为文章的作者。
将网页的dom结构与网页的块布局元素组合在一起,以构造具有文本和部分视觉特征的块dom结构,并对文本,图片,视频的基本元素执行融合计算,表格等。定量计算dom块的主题贡献值;通过自上而下的块缩小算法定位网页主题的核心块,然后通过自下而上的块扩展算法过滤网页的主题候选块,最后对候选主题块进行噪声裁剪以完成最终的主题块定位;根据确定的主题块,结合黑名单,规则库和知识库,提取正文信息,包括文字,图片,视频和图表;以规则区,主题库,规则库,知识库,上下文位置,显示功能为中心,提取正文标题,发布时间,来源和作者。
上面已经显示和描述了本发明的基本原理,主要特征和优点。本领域技术人员应当理解,上述实施例不以任何形式限制本发明,通过等同替换或等同变换获得的所有技术方案都落入本发明的保护范围。
网页里注释的内容会被百度工程师是如何回答的
网站优化 • 优采云 发表了文章 • 0 个评论 • 494 次浏览 • 2021-05-04 01:08
许多网站管理员知道网页代码中收录注释代码。形式是HTML注释的内容出现在网页的源代码中,并且用户在浏览网页时看不到它。因为注释内容显示在源代码中,并且不会影响页面内容,所以许多人认为蜘蛛会捕获注释信息并参与网页的分析和排名,因此他们在其中添加了很多注释内容。网页,甚至直接将其堆放在评论关键词中。
是否将对网页上的评论内容进行爬网?让我们看看百度工程师如何回答:
问:百度将对评论内容进行爬网和分析吗?
百度工程师:在文本提取过程中,将忽略html中的注释内容。尽管注释的代码不会被抓取,但也会导致代码很繁琐,因此应尽可能少。
显然,搜索引擎蜘蛛非常聪明。它们可以在Web爬网期间标识注释信息,而直接忽略它们,因此将不会对注释内容进行爬网,也不会参与Web内容的分析。进去。想象一下,如果蜘蛛可以抓取注释,并且此注释代码等效于某种隐藏文本,那么网站的主要内容可以由JS代码调用,仅用于用户浏览,而所有内容想要放置蜘蛛的地方有很多注释信息,因此网页向蜘蛛和用户显示不同的内容。如果您是灰色工业网站,则可以为搜索引擎提供完全正式的内容显示,摆脱搜索引擎的束缚,您会正式允许搜索引擎作弊吗?因此,无论您在评论中添加多少关键词,它都不会对排名产生影响。
在评论中加入关键词是否会影响排名?并不是因为搜索引擎会直接忽略注释,而是如何注释大量内容会影响网页的样式并影响网页的加载速度。因此,如果注释无用,请尽可能删除它们以使代码尽可能简单。我们经常谈论减肥的网站代码。简化注释信息是减肥的方法之一。优化注释信息有利于网站减肥。
当然,许多程序员和Web设计人员习惯于将注释信息添加到Web页面。这是个好习惯。合理的注释信息可以减少查找信息的时间,并使代码的查询和修改更加方便。因此,建议“在线”页面仅添加注释信息,例如该页面各部分的头尾注释,重要内容部分注释等,而离线备份网页可以在其中添加各部分的注释信息。更详细,方便技术人员浏览和修改,这不仅有利于网页的精简,而且不影响以后的网页修改。
作者:Mumu SEO 文章来自:欢迎关注微信公众号:mumuseo。 查看全部
网页里注释的内容会被百度工程师是如何回答的
许多网站管理员知道网页代码中收录注释代码。形式是HTML注释的内容出现在网页的源代码中,并且用户在浏览网页时看不到它。因为注释内容显示在源代码中,并且不会影响页面内容,所以许多人认为蜘蛛会捕获注释信息并参与网页的分析和排名,因此他们在其中添加了很多注释内容。网页,甚至直接将其堆放在评论关键词中。
是否将对网页上的评论内容进行爬网?让我们看看百度工程师如何回答:
问:百度将对评论内容进行爬网和分析吗?
百度工程师:在文本提取过程中,将忽略html中的注释内容。尽管注释的代码不会被抓取,但也会导致代码很繁琐,因此应尽可能少。
显然,搜索引擎蜘蛛非常聪明。它们可以在Web爬网期间标识注释信息,而直接忽略它们,因此将不会对注释内容进行爬网,也不会参与Web内容的分析。进去。想象一下,如果蜘蛛可以抓取注释,并且此注释代码等效于某种隐藏文本,那么网站的主要内容可以由JS代码调用,仅用于用户浏览,而所有内容想要放置蜘蛛的地方有很多注释信息,因此网页向蜘蛛和用户显示不同的内容。如果您是灰色工业网站,则可以为搜索引擎提供完全正式的内容显示,摆脱搜索引擎的束缚,您会正式允许搜索引擎作弊吗?因此,无论您在评论中添加多少关键词,它都不会对排名产生影响。
在评论中加入关键词是否会影响排名?并不是因为搜索引擎会直接忽略注释,而是如何注释大量内容会影响网页的样式并影响网页的加载速度。因此,如果注释无用,请尽可能删除它们以使代码尽可能简单。我们经常谈论减肥的网站代码。简化注释信息是减肥的方法之一。优化注释信息有利于网站减肥。
当然,许多程序员和Web设计人员习惯于将注释信息添加到Web页面。这是个好习惯。合理的注释信息可以减少查找信息的时间,并使代码的查询和修改更加方便。因此,建议“在线”页面仅添加注释信息,例如该页面各部分的头尾注释,重要内容部分注释等,而离线备份网页可以在其中添加各部分的注释信息。更详细,方便技术人员浏览和修改,这不仅有利于网页的精简,而且不影响以后的网页修改。
作者:Mumu SEO 文章来自:欢迎关注微信公众号:mumuseo。
常见导致搜索引擎蜘蛛抓取异常的原因及原因分析!
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-05-04 00:07
有些网站具有高质量的内容原创,用户可以正常访问,但是网络蜘蛛无法正常访问和抓取,因此它们不能收录,并且搜索结果的覆盖率很低,这是对搜索引擎非常重要,这是一种损失,并且这种情况是异常爬网。对于无法正常抓取大量内容的网站,搜索引擎会认为网站在用户体验方面存在缺陷,并将降低其评估。它将不可避免地对爬网,索引和排序产生负面影响,并最终对其产生影响。要网站从搜索引擎获得的流量。下面,编辑器总结了搜索引擎蜘蛛异常爬网的一些常见原因,供您参考。
一个。服务器连接异常
通常有两种类型的服务器异常连接:一种临时无法连接,另一种始终无法连接。对于用户而言,连接异常的服务器将不会驻留。网络蜘蛛也是如此。 Web Spider将判断并排除服务器连接网站异常,从而导致异常爬网。服务器连接异常的原因通常是网站服务器太大且过载。检查浏览器是否正常访问。服务器异常将导致蜘蛛无法连接到网站服务器,从而导致抓取失败。 。 网站并且主机也可能阻止网络蜘蛛的访问,您需要检查网站和主机的防火墙。选择安全,稳定和高性能的服务器是网站优化的基本前提。
两个。抓取超时
网站页面的加载速度一直是不容忽视的重要点,它对用户和搜索引擎的体验具有决定性的影响。如果用户在访问该页面时第一次无法打开该页面,则他将失去兴趣并跳到其他人网站。那蜘蛛呢?也是一样。如果无法在第一时间对其进行爬网,则将发生爬网超时问题。爬网超时通常是由于带宽不足和页面大而引起的。因此,在设计页面时,应压缩网页上的图片;减少使用某些脚本;控制页面的长度和内部链接的数量,可以在一定程度上减少页面,减轻服务器负担,减轻服务器的负担。
三个。网络运营商异常
国内主要的网络运营商是中国电信和中国联通。如果网络蜘蛛无法通过中国电信或中国联通网站的网络访问,则需要与网络运营商联系以购买双线服务空间或购买CDN服务。
四个。 DNS例外
当网络蜘蛛无法解析网站的IP地址时,将发生DNS异常。这可能是由于网站中的IP地址错误或域名服务提供商禁止使用网络蜘蛛。您可以使用WHOIS或主机查询网站 IP地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商以更新IP地址。
五个。设置错误
包括IP禁令和UA禁令。 IP禁止是指限制网络的出口IP地址,并禁止该IP网段的用户访问内容。 UA禁令指的是针对其身份已由服务器通过UA(用户代理)标识的用户的指定跳转。这两个禁令都将导致网络蜘蛛无法正常访问和爬网。应该认识到该设置是否错误地添加了相关搜索引擎网络蜘蛛的禁令。
六个。无效链接
无效链接是页面无效并且无法向用户提供任何有价值的信息的页面,包括两种形式:协议无效链接和内容无效链接:一种是协议无效链接:TCP协议状态/ HTTP协议状态该页面是清除的表示的无效链接,例如40 4、 40 3、 503状态等。内容死链接的另一种类型:服务器返回状态为正常,但是内容已更改为不存在,已删除或需要许可,并且其他信息页面与原创内容无关。当前,存在内容死链接被召回的风险,因此建议网站管理员尽量使用协议死链接,以确保平台工具可以更好地发挥作用。可以通过死链接工具将死链接提交给搜索引擎,以减慢死链接的负面影响。
七。 网站垂悬的马
网站链接到马匹也可能导致抓取错误。查询文件与马的链接位置并删除它,恢复网站,并采取安全措施,防止下次将其链接到马。
每个网站站长都应更频繁地检查网站网络蜘蛛的爬网情况。如果发现爬网偶尔会失败,则是正常情况,不会影响网站和收录的正常爬网。但是,如果爬网故障持续存在,则应注意网站中发生爬网异常的具体原因,以进行上述特定分析。如果您对网络蜘蛛异常爬网还有其他疑问,可以咨询[]。 查看全部
常见导致搜索引擎蜘蛛抓取异常的原因及原因分析!
有些网站具有高质量的内容原创,用户可以正常访问,但是网络蜘蛛无法正常访问和抓取,因此它们不能收录,并且搜索结果的覆盖率很低,这是对搜索引擎非常重要,这是一种损失,并且这种情况是异常爬网。对于无法正常抓取大量内容的网站,搜索引擎会认为网站在用户体验方面存在缺陷,并将降低其评估。它将不可避免地对爬网,索引和排序产生负面影响,并最终对其产生影响。要网站从搜索引擎获得的流量。下面,编辑器总结了搜索引擎蜘蛛异常爬网的一些常见原因,供您参考。
一个。服务器连接异常
通常有两种类型的服务器异常连接:一种临时无法连接,另一种始终无法连接。对于用户而言,连接异常的服务器将不会驻留。网络蜘蛛也是如此。 Web Spider将判断并排除服务器连接网站异常,从而导致异常爬网。服务器连接异常的原因通常是网站服务器太大且过载。检查浏览器是否正常访问。服务器异常将导致蜘蛛无法连接到网站服务器,从而导致抓取失败。 。 网站并且主机也可能阻止网络蜘蛛的访问,您需要检查网站和主机的防火墙。选择安全,稳定和高性能的服务器是网站优化的基本前提。
两个。抓取超时
网站页面的加载速度一直是不容忽视的重要点,它对用户和搜索引擎的体验具有决定性的影响。如果用户在访问该页面时第一次无法打开该页面,则他将失去兴趣并跳到其他人网站。那蜘蛛呢?也是一样。如果无法在第一时间对其进行爬网,则将发生爬网超时问题。爬网超时通常是由于带宽不足和页面大而引起的。因此,在设计页面时,应压缩网页上的图片;减少使用某些脚本;控制页面的长度和内部链接的数量,可以在一定程度上减少页面,减轻服务器负担,减轻服务器的负担。
三个。网络运营商异常
国内主要的网络运营商是中国电信和中国联通。如果网络蜘蛛无法通过中国电信或中国联通网站的网络访问,则需要与网络运营商联系以购买双线服务空间或购买CDN服务。
四个。 DNS例外
当网络蜘蛛无法解析网站的IP地址时,将发生DNS异常。这可能是由于网站中的IP地址错误或域名服务提供商禁止使用网络蜘蛛。您可以使用WHOIS或主机查询网站 IP地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商以更新IP地址。
五个。设置错误
包括IP禁令和UA禁令。 IP禁止是指限制网络的出口IP地址,并禁止该IP网段的用户访问内容。 UA禁令指的是针对其身份已由服务器通过UA(用户代理)标识的用户的指定跳转。这两个禁令都将导致网络蜘蛛无法正常访问和爬网。应该认识到该设置是否错误地添加了相关搜索引擎网络蜘蛛的禁令。
六个。无效链接
无效链接是页面无效并且无法向用户提供任何有价值的信息的页面,包括两种形式:协议无效链接和内容无效链接:一种是协议无效链接:TCP协议状态/ HTTP协议状态该页面是清除的表示的无效链接,例如40 4、 40 3、 503状态等。内容死链接的另一种类型:服务器返回状态为正常,但是内容已更改为不存在,已删除或需要许可,并且其他信息页面与原创内容无关。当前,存在内容死链接被召回的风险,因此建议网站管理员尽量使用协议死链接,以确保平台工具可以更好地发挥作用。可以通过死链接工具将死链接提交给搜索引擎,以减慢死链接的负面影响。
七。 网站垂悬的马
网站链接到马匹也可能导致抓取错误。查询文件与马的链接位置并删除它,恢复网站,并采取安全措施,防止下次将其链接到马。
每个网站站长都应更频繁地检查网站网络蜘蛛的爬网情况。如果发现爬网偶尔会失败,则是正常情况,不会影响网站和收录的正常爬网。但是,如果爬网故障持续存在,则应注意网站中发生爬网异常的具体原因,以进行上述特定分析。如果您对网络蜘蛛异常爬网还有其他疑问,可以咨询[]。
做网站优化的人来说,搜索引擎抓取的频率越高
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-05-03 20:44
做网站优化的人来说,搜索引擎抓取的频率越高
对于进行网站优化的人来说,搜索引擎爬网的频率越高,在通常情况下,网站会受到搜索引擎的欢迎和喜欢,我们甚至可以说网站的权重很高。当然,某些采集站会由于其内容无限而导致蜘蛛黑洞(蜘蛛陷阱),而不是正常的爬网频率。
几个主要的国内搜索引擎都具有类似的功能,例如百度搜索的爬网频率,360搜索的蜘蛛压力和搜狗搜索的爬网压力,其中包括专注于移动搜索的神马的爬网频率功能。 。网站管理员平台可以进行直接调整或间接反馈。当然,除了国内搜索引擎之外,Google还具有此功能,因此在这里我不会对其进行分析。
通常来说,搜索引擎会根据网站内容的更新速度自动更改抓取频率。当新的网站在线时,一段时间内可能会有大量爬网,因为搜索引擎实际上很好奇。以同样的方式思考,如果您发现新内容,则将首先转到整个站点,然后再次运行它。如果您可以坚持输出新鲜的内容,那么可以很好地保持搜索引擎的快速抓取频率。
但是,对于一个更新不多的网站,搜索引擎通常每天都在抓取,并且至少会抓取主页。一方面,您可以检查网站的首页是否已更新或更改,另一方面,可以判断网站的首页是否仍然可以正常爬网。它用于了解该动物的存活状态网站。这比所有国内搜索引擎都要快。如果关闭网站,则Google可能会在很短的时间内使网站搜索引擎离线,以防止用户发现单击后无法打开网站,从而改善了用户体验。相反,国内搜索引擎似乎无法做到这一点。月份仍可以正常显示在搜索结果排名中。
由于Zifan无法为您提供具体数字,因此我将以Leixue博客为例,与您分享一些搜索引擎的抓取频率:
1.百度的抓取频率是每天300-4300次,并且波动很大,因为在Leixue博客上发帖的频率不是固定的,发帖时间都是随机的。没有刻意的时间发布,总体爬网是及时的,程度还不错,值得一提的是,“泪雪”博客使用主动推送,比百度的自动爬网要快。
2. 360搜索的爬网频率相对较低,每天保持27次,并且爬网的及时性还不错。平均来说,它可以每小时进行一次爬网,但是可能会有爬网。收录情况不完整。
3.搜狗搜索的爬行频率也有很大波动,每天72-2900次,超过1500次,并且爬行的时效性相对较差。一篇文章文章可能需要等待一两天。将为收录,处理速度仍然太慢。
4.神马搜索的抓取频率性能相当好,每天506次,但是此收录更令人感动,不要以为抓取频率这么高,以防万一我网站挂了吗?哈哈哈
好的,我们做吧,内容可能不是干货,但是如果更新不及时或收录页面较少,您还可以访问网站站长平台观察网站情况,您可以手动进行调整。尽管它不是100%有效的,但它也可以在一定程度上增强搜索引擎的爬网能力。至于最后是否会是收录,这当然必须返回到内容质量本身。它与各种搜索引擎的识别有关。
咨询客户服务咨询客户服务
英语演示是演示地址的原创版本。如果您位于国外,访问速度可能会很慢(建议爬梯子进行浏览)。您在本网站上下载的主题源代码和其他资源仅用于测试和学习目的。如果您想将其用于商业用途,请购买正版许可证以获得官方更新和售后服务。
此站点承担WordPress主题安装,深度本地化,加速优化和其他服务。请咨询在线客户服务以获取详细信息!
查看全部
做网站优化的人来说,搜索引擎抓取的频率越高
对于进行网站优化的人来说,搜索引擎爬网的频率越高,在通常情况下,网站会受到搜索引擎的欢迎和喜欢,我们甚至可以说网站的权重很高。当然,某些采集站会由于其内容无限而导致蜘蛛黑洞(蜘蛛陷阱),而不是正常的爬网频率。
几个主要的国内搜索引擎都具有类似的功能,例如百度搜索的爬网频率,360搜索的蜘蛛压力和搜狗搜索的爬网压力,其中包括专注于移动搜索的神马的爬网频率功能。 。网站管理员平台可以进行直接调整或间接反馈。当然,除了国内搜索引擎之外,Google还具有此功能,因此在这里我不会对其进行分析。
通常来说,搜索引擎会根据网站内容的更新速度自动更改抓取频率。当新的网站在线时,一段时间内可能会有大量爬网,因为搜索引擎实际上很好奇。以同样的方式思考,如果您发现新内容,则将首先转到整个站点,然后再次运行它。如果您可以坚持输出新鲜的内容,那么可以很好地保持搜索引擎的快速抓取频率。
但是,对于一个更新不多的网站,搜索引擎通常每天都在抓取,并且至少会抓取主页。一方面,您可以检查网站的首页是否已更新或更改,另一方面,可以判断网站的首页是否仍然可以正常爬网。它用于了解该动物的存活状态网站。这比所有国内搜索引擎都要快。如果关闭网站,则Google可能会在很短的时间内使网站搜索引擎离线,以防止用户发现单击后无法打开网站,从而改善了用户体验。相反,国内搜索引擎似乎无法做到这一点。月份仍可以正常显示在搜索结果排名中。
由于Zifan无法为您提供具体数字,因此我将以Leixue博客为例,与您分享一些搜索引擎的抓取频率:
1.百度的抓取频率是每天300-4300次,并且波动很大,因为在Leixue博客上发帖的频率不是固定的,发帖时间都是随机的。没有刻意的时间发布,总体爬网是及时的,程度还不错,值得一提的是,“泪雪”博客使用主动推送,比百度的自动爬网要快。
2. 360搜索的爬网频率相对较低,每天保持27次,并且爬网的及时性还不错。平均来说,它可以每小时进行一次爬网,但是可能会有爬网。收录情况不完整。
3.搜狗搜索的爬行频率也有很大波动,每天72-2900次,超过1500次,并且爬行的时效性相对较差。一篇文章文章可能需要等待一两天。将为收录,处理速度仍然太慢。
4.神马搜索的抓取频率性能相当好,每天506次,但是此收录更令人感动,不要以为抓取频率这么高,以防万一我网站挂了吗?哈哈哈
好的,我们做吧,内容可能不是干货,但是如果更新不及时或收录页面较少,您还可以访问网站站长平台观察网站情况,您可以手动进行调整。尽管它不是100%有效的,但它也可以在一定程度上增强搜索引擎的爬网能力。至于最后是否会是收录,这当然必须返回到内容质量本身。它与各种搜索引擎的识别有关。
咨询客户服务咨询客户服务
英语演示是演示地址的原创版本。如果您位于国外,访问速度可能会很慢(建议爬梯子进行浏览)。您在本网站上下载的主题源代码和其他资源仅用于测试和学习目的。如果您想将其用于商业用途,请购买正版许可证以获得官方更新和售后服务。
此站点承担WordPress主题安装,深度本地化,加速优化和其他服务。请咨询在线客户服务以获取详细信息!
2019年Python多进程方式抓取基金网站内容的方法汇总
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-05-01 22:34
2019年Python多进程方式抓取基金网站内容的方法汇总
Python多进程抓取资金网站内容的方法分析
更新时间:2019年6月3日12:02:12作者:Study Notes 666
本文文章主要介绍了Python多进程抓取资金网站内容的方法,并结合示例分析了Python多进程抓取网站内容相关的实现技巧和操作注意事项。你可以参考
本文介绍了在Python多进程模式下获取Fund 网站内容的方法。与您分享以供参考,如下所示:
在上一篇文章//// article / 16241 8. htm中,我们已经简要了解了“ python的多进程”,现在我们需要编写抓取基金网站的内容(第28页)作为一种多过程方法。
由于该过程越少越好,我们计划在三个过程中实施它。这意味着:将总共28个要抓取的页面分为三个部分。
如何划分?
# 初始range
r = range(1,29)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)]
print(myList) # [range(1, 11), range(11, 21), range(21, 29)]
根据上面的代码,我们将1〜29分为三个部分,列表中的三个范围。
2、还记得我们获取了Fund 网站内容的getData()函数吗?
def getData(start, end):
for x in range(start, end+1):
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
该函数有2个参数:起始页码和结束页码,即从起始页到结束页。
这两个参数实际上是范围。
按如下所示修改getData()函数(参数不同):
3、创建一个进程并将目标设置为上面的getData():
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
有三个要分别获取的过程。
4、多进程抓取资金网站多页内容的完整代码:
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from multiprocessing import Process
driver = webdriver.PhantomJS(executable_path=r"你phantomjs的可执行文件路径")
# 请求一个网址
driver.get("http://fund.eastmoney.com/fund.html")
page_text = driver.find_element_by_id("pager").find_element_by_xpath("span[@class='nv']").text
total_page = ''.join(filter(str.isdigit,page_text)) # 得到总共有多少页
# 循环抓取网页内容的函数
def getData(myrange):
for x in myrange:
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
对于对Python相关内容感兴趣的读者,请查看此站点的主题:“ Python进程和线程操作技能摘要”,“ Python数据结构和算法教程”,“ Python函数使用技能摘要”, “ Python字符串”操作技巧摘要”,“ Python简介和高级经典教程”,“ Python + MySQL数据库编程简介”和“ Python通用数据库操作技巧摘要”
我希望本文能对您的Python编程有所帮助。 查看全部
2019年Python多进程方式抓取基金网站内容的方法汇总
Python多进程抓取资金网站内容的方法分析
更新时间:2019年6月3日12:02:12作者:Study Notes 666
本文文章主要介绍了Python多进程抓取资金网站内容的方法,并结合示例分析了Python多进程抓取网站内容相关的实现技巧和操作注意事项。你可以参考
本文介绍了在Python多进程模式下获取Fund 网站内容的方法。与您分享以供参考,如下所示:
在上一篇文章//// article / 16241 8. htm中,我们已经简要了解了“ python的多进程”,现在我们需要编写抓取基金网站的内容(第28页)作为一种多过程方法。
由于该过程越少越好,我们计划在三个过程中实施它。这意味着:将总共28个要抓取的页面分为三个部分。
如何划分?
# 初始range
r = range(1,29)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)]
print(myList) # [range(1, 11), range(11, 21), range(21, 29)]
根据上面的代码,我们将1〜29分为三个部分,列表中的三个范围。
2、还记得我们获取了Fund 网站内容的getData()函数吗?
def getData(start, end):
for x in range(start, end+1):
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
该函数有2个参数:起始页码和结束页码,即从起始页到结束页。
这两个参数实际上是范围。
按如下所示修改getData()函数(参数不同):
3、创建一个进程并将目标设置为上面的getData():
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
有三个要分别获取的过程。
4、多进程抓取资金网站多页内容的完整代码:
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from multiprocessing import Process
driver = webdriver.PhantomJS(executable_path=r"你phantomjs的可执行文件路径")
# 请求一个网址
driver.get("http://fund.eastmoney.com/fund.html";)
page_text = driver.find_element_by_id("pager").find_element_by_xpath("span[@class='nv']").text
total_page = ''.join(filter(str.isdigit,page_text)) # 得到总共有多少页
# 循环抓取网页内容的函数
def getData(myrange):
for x in myrange:
# 去第几页 输入框
tonum = driver.find_element_by_id("tonum")
# 去第几页 提交按钮
jumpBtn = driver.find_element_by_id("btn_jump")
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpBtn.click() # 点击按钮
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pager") \
.find_element_by_xpath("span[@value={0} and @class!='end page']".format(x)) \
.get_attribute("class").find("at") != -1)
# 保存抓取到的html内容
# 保存到html目录下
with open("./htmls/{0}.txt".format(x),"wb") as f:
f.write(driver.find_element_by_id("tableDiv").get_attribute("innerHTML").encode("utf8"))
f.close()
# 初始range
r = range(1,int(total_page)+1)
# 步长
step = 10
myList = [r[x:x+step] for x in range(0,len(r),step)] # 把页面分段
# 创建进程
processList = []
if __name__ == "__main__":
for r in myList:
p = Process(target=getData,args=(r,))
processList.append(p)
# 开始执行进程
for p in processList:
p.start()
对于对Python相关内容感兴趣的读者,请查看此站点的主题:“ Python进程和线程操作技能摘要”,“ Python数据结构和算法教程”,“ Python函数使用技能摘要”, “ Python字符串”操作技巧摘要”,“ Python简介和高级经典教程”,“ Python + MySQL数据库编程简介”和“ Python通用数据库操作技巧摘要”
我希望本文能对您的Python编程有所帮助。
网站内容抓取 以人教版地理七年级地理上册为例子(上册)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-05-01 22:29
我需要写一个这样的例子,并从电子教科书网站上下载一本电子书。
电子教科书网络上的电子书将书的每一页都当作一幅图片,然后一本书有很多图片。我需要分批下载图片。
这是代码部分:
public function download() {<br />
$http = new \Org\Net\Http();<br />
$url_pref = "http://www.dzkbw.com/books/rjb ... %3Bbr />
$localUrl = "Public/bookcover/";<br />
$reg="|showImg\('(.+)'\);|";<br />
$i=1;
do {<br />
$filename = substr("000".$i,-3).".htm";<br />
$ch = curl_init();<br />
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);<br />
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);<br />
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);<br />
$html = curl_exec($ch);<br />
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);<br />
if($result==1) {<br />
$picUrl = $out[1][0];<br />
$picFilename = substr("000".$i,-3).".jpg";<br />
$http->curlDownload($picUrl, $localUrl.$picFilename);<br />
}<br />
$i = $i+1;<br />
} while ($result==1);
echo "下载完成";<br />
}
我在这里以《人民教育版地理》七年级的地理书为例。
网页从00 1. htm开始,然后这个数字一直在增加
每个网页中都有一张图片,与教科书的内容相对应。教科书的内容以图片的形式显示
我的代码是一个循环,从首页开始,直到找不到网页中的图片为止
抓取网页内容后,将网页中的图片抓取到本地服务器上
爬行后的实际效果:
以thinkphp编写的示例:获取网站的内容并将其保存在本地。更多相关的文章 python获取网页中的图片并将其保存在本地
#-*-coding:utf-8-*-import os import uuid import urllib2 import cookielib'''获取文件扩展名'''def get_file ...
C#实现抓取网站页内容
抓住的新闻部分,如下图所示:使用Google浏览器查看源代码:通过分析,我们知道我们所寻找的内容在以下两个标签之间: 查看全部
网站内容抓取 以人教版地理七年级地理上册为例子(上册)
我需要写一个这样的例子,并从电子教科书网站上下载一本电子书。
电子教科书网络上的电子书将书的每一页都当作一幅图片,然后一本书有很多图片。我需要分批下载图片。
这是代码部分:
public function download() {<br />
$http = new \Org\Net\Http();<br />
$url_pref = "http://www.dzkbw.com/books/rjb ... %3Bbr />
$localUrl = "Public/bookcover/";<br />
$reg="|showImg\('(.+)'\);|";<br />
$i=1;
do {<br />
$filename = substr("000".$i,-3).".htm";<br />
$ch = curl_init();<br />
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);<br />
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);<br />
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);<br />
$html = curl_exec($ch);<br />
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);<br />
if($result==1) {<br />
$picUrl = $out[1][0];<br />
$picFilename = substr("000".$i,-3).".jpg";<br />
$http->curlDownload($picUrl, $localUrl.$picFilename);<br />
}<br />
$i = $i+1;<br />
} while ($result==1);
echo "下载完成";<br />
}
我在这里以《人民教育版地理》七年级的地理书为例。
网页从00 1. htm开始,然后这个数字一直在增加
每个网页中都有一张图片,与教科书的内容相对应。教科书的内容以图片的形式显示
我的代码是一个循环,从首页开始,直到找不到网页中的图片为止
抓取网页内容后,将网页中的图片抓取到本地服务器上
爬行后的实际效果:
以thinkphp编写的示例:获取网站的内容并将其保存在本地。更多相关的文章 python获取网页中的图片并将其保存在本地
#-*-coding:utf-8-*-import os import uuid import urllib2 import cookielib'''获取文件扩展名'''def get_file ...
C#实现抓取网站页内容
抓住的新闻部分,如下图所示:使用Google浏览器查看源代码:通过分析,我们知道我们所寻找的内容在以下两个标签之间:
网站用robots协议拒绝搜索引擎的网页性质及文件类型
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-04-30 00:02
1。 Spider无法正确处理的网页的性质和文件类型(例如Flash,脚本,ps,一些动态网页和框架,数据库)2、孤岛网页未指向链接3、由于某些原因,蜘蛛访问原因碰巧是死链接。 4、它被认为是质量较差的网页,没有被捕获。 5、由于/ porn / reactionary / spam /而无法捕获的非法网页。6、您需要输入用户名和密码才能打开网页。 7、 网站使用漫游器协议拒绝搜索引擎抓取的网页8、将来搜索引擎抓取的新网页9、 gopher,新闻组,Telnet,ftp,wais和其他非http信息1 0 网站数据库太糟糕了,蜘蛛被捕获后便崩溃了。 1 1.它在搜索引擎库中,但无法正确索引网页中的信息。 1 2、分词会导致错误。 1 3、图形中的文本信息。可以理解,但搜索引擎无法理解1 4、搜索引擎故意不编制索引的信息,例如停用词,[1] 5、搜索引擎有选择地对某些网页进行索引,但并非对所有网页信息进行索引1 6、搜索引擎该网页中的信息已正确索引,但与您使用的信息不同关键词 1 7、您使用的搜索关键词收录错别字1 8、该页面的作者使用了错字1 9、没有错别字,但所用页面的作者的词汇表与您的关键词不同。毕竟,文本的特征允许n种方式来表达相同的信息。 2 0、简体中文和繁体中文的不同编码 查看全部
网站用robots协议拒绝搜索引擎的网页性质及文件类型
1。 Spider无法正确处理的网页的性质和文件类型(例如Flash,脚本,ps,一些动态网页和框架,数据库)2、孤岛网页未指向链接3、由于某些原因,蜘蛛访问原因碰巧是死链接。 4、它被认为是质量较差的网页,没有被捕获。 5、由于/ porn / reactionary / spam /而无法捕获的非法网页。6、您需要输入用户名和密码才能打开网页。 7、 网站使用漫游器协议拒绝搜索引擎抓取的网页8、将来搜索引擎抓取的新网页9、 gopher,新闻组,Telnet,ftp,wais和其他非http信息1 0 网站数据库太糟糕了,蜘蛛被捕获后便崩溃了。 1 1.它在搜索引擎库中,但无法正确索引网页中的信息。 1 2、分词会导致错误。 1 3、图形中的文本信息。可以理解,但搜索引擎无法理解1 4、搜索引擎故意不编制索引的信息,例如停用词,[1] 5、搜索引擎有选择地对某些网页进行索引,但并非对所有网页信息进行索引1 6、搜索引擎该网页中的信息已正确索引,但与您使用的信息不同关键词 1 7、您使用的搜索关键词收录错别字1 8、该页面的作者使用了错字1 9、没有错别字,但所用页面的作者的词汇表与您的关键词不同。毕竟,文本的特征允许n种方式来表达相同的信息。 2 0、简体中文和繁体中文的不同编码
在网站怎么快速被爬虫百度蜘蛛最喜欢的呢?
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-04-28 03:18
网站蜘蛛通常会爬行哪种内容?在这个互联网时代,许多人会在购买新产品之前先检查互联网上的信息,以查看哪些品牌具有更好的声誉和评价。这时,排名最高的产品将具有绝对优势。根据调查,有87%的互联网用户将使用搜索引擎服务来查找所需的信息,其中,将近70%的搜索者将直接在搜索结果自然排名的第一页上找到所需的信息。
可以看出,目前,SEO对于企业和产品具有不可替代的意义。接下来,我将告诉您网站中的爬虫如何快速对其进行爬虫。百度蜘蛛有其特殊的爱好。通常,哪些内容是百度蜘蛛最喜欢抓取的内容
1. 关键词是头等大事
我们经常听到人们谈论关键词,但是关键词 关键词的具体用途是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外部链接也会影响重量
导入链接也是网站优化的非常重要的过程,它可以间接影响搜索引擎中网站的权重。目前,常用的链接分为:锚文本链接,超链接,纯文本链接和图像链接。
爬虫如何抓取3.
抓取工具是自动提取网页的程序,例如百度的抓取工具。如果您希望将网站页中的更多内容设为收录,则必须首先让爬网程序对网页进行爬网。
如果您的网站页面经常更新,则抓取工具会更频繁地访问该页面,高质量的内容是抓取工具喜欢抓取的目标,尤其是原创内容。
以上内容与“ 网站蜘蛛通常会抓取哪些内容?”有关如果您想进一步询问,请致电。 查看全部
在网站怎么快速被爬虫百度蜘蛛最喜欢的呢?
网站蜘蛛通常会爬行哪种内容?在这个互联网时代,许多人会在购买新产品之前先检查互联网上的信息,以查看哪些品牌具有更好的声誉和评价。这时,排名最高的产品将具有绝对优势。根据调查,有87%的互联网用户将使用搜索引擎服务来查找所需的信息,其中,将近70%的搜索者将直接在搜索结果自然排名的第一页上找到所需的信息。
可以看出,目前,SEO对于企业和产品具有不可替代的意义。接下来,我将告诉您网站中的爬虫如何快速对其进行爬虫。百度蜘蛛有其特殊的爱好。通常,哪些内容是百度蜘蛛最喜欢抓取的内容
1. 关键词是头等大事
我们经常听到人们谈论关键词,但是关键词 关键词的具体用途是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外部链接也会影响重量
导入链接也是网站优化的非常重要的过程,它可以间接影响搜索引擎中网站的权重。目前,常用的链接分为:锚文本链接,超链接,纯文本链接和图像链接。
爬虫如何抓取3.
抓取工具是自动提取网页的程序,例如百度的抓取工具。如果您希望将网站页中的更多内容设为收录,则必须首先让爬网程序对网页进行爬网。
如果您的网站页面经常更新,则抓取工具会更频繁地访问该页面,高质量的内容是抓取工具喜欢抓取的目标,尤其是原创内容。
以上内容与“ 网站蜘蛛通常会抓取哪些内容?”有关如果您想进一步询问,请致电。
爬虫模拟访问网站内容抓取原理,有什么作用?
网站优化 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-04-26 01:02
网站内容抓取原理,大概分为单页抓取和列表爬取两类,每种方式都有不同的标准,利用专业的网站抓取工具,例如ngspider,可以快速的实现网站内容抓取,简单说就是只要抓取到一个网站的某些内容,就可以获取整个网站内容。爬虫有两种加载方式,(1)ajax加载。我们可以通过ajax技术,让用户在访问网站时,加载时网站应该加载的内容。
大大提高了整个网站的加载速度。(2)json或xml加载。我们可以通过json技术或xml技术,来加载我们想要抓取的数据。从上图我们可以看到,网站内容抓取流程分为:登录、站内搜索、爬虫搜索。也就是说,爬虫模拟访问网站服务器,当我们访问服务器数据时,我们就可以获取到被服务器加载的所有内容。
ajaxjsonjson也就是xml,所以抓取可以用json做,也可以用ajax。ajax也可以通过一次加载多个,
ajax什么是ajax(asynchronousjavascriptandxml)?ajax是xmlhttprequest和xmlhttprequest2的简称,它允许浏览器与服务器进行多轮对话。在加载网页内容时,我们可以通过访问页面,让服务器返回包含内容的页面,以此来减少加载时间。
单页爬虫或列表爬虫,
json 查看全部
爬虫模拟访问网站内容抓取原理,有什么作用?
网站内容抓取原理,大概分为单页抓取和列表爬取两类,每种方式都有不同的标准,利用专业的网站抓取工具,例如ngspider,可以快速的实现网站内容抓取,简单说就是只要抓取到一个网站的某些内容,就可以获取整个网站内容。爬虫有两种加载方式,(1)ajax加载。我们可以通过ajax技术,让用户在访问网站时,加载时网站应该加载的内容。
大大提高了整个网站的加载速度。(2)json或xml加载。我们可以通过json技术或xml技术,来加载我们想要抓取的数据。从上图我们可以看到,网站内容抓取流程分为:登录、站内搜索、爬虫搜索。也就是说,爬虫模拟访问网站服务器,当我们访问服务器数据时,我们就可以获取到被服务器加载的所有内容。
ajaxjsonjson也就是xml,所以抓取可以用json做,也可以用ajax。ajax也可以通过一次加载多个,
ajax什么是ajax(asynchronousjavascriptandxml)?ajax是xmlhttprequest和xmlhttprequest2的简称,它允许浏览器与服务器进行多轮对话。在加载网页内容时,我们可以通过访问页面,让服务器返回包含内容的页面,以此来减少加载时间。
单页爬虫或列表爬虫,
json
网站内容抓取的常见的问题及解决办法(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-04-20 04:01
网站内容抓取这个问题实际上包含了很多个问题:站点、抓取的网站、网站模板等。常见的抓取问题有:1.点击触发的抓取页面;2.点击后马上开始抓取的页面;3.由浏览器主动推送给访问者的页面;4.网站为了访问量,放置很多不是必须抓取的页面;5.内容抓取类型一直在变化。
其实百度每天有很多页面有部分网站是没有抓取到的,从而显示了部分内容。那么页面有多少抓取的?就不能单纯的根据cookie来算了。那么有没有什么通用的办法可以完全抓取每个网站呢?答案就是根据所有页面爬虫的存量和蜘蛛的质量来计算。
这里涉及到ip池,和搜索规则的问题。要有一个标准的ip池:保留三个月(一般超过一年会自动被清空)。还有一个搜索规则:搜索页面最少五个。
一个人在一个页面上抓取1000次都抓取不了1小时就没了
看你一天抓取多少次
抓取以及是否抓取最基本的,
豆瓣
自己解决。一个服务器,一个中转服务器,一个转发服务器,一个ip池。
两种方式抓取,如果是伪代码的抓取的话,一个是服务器承载量的承载量,一个是爬虫的速度,前者是一个很容易调用的方法,后者基本上都要根据你爬虫抓取的某个页面,来做策略的指定。比如,我们做客,爬虫通常设置一个userusernameadminclass="user-agent"size=1500(头,网址)爬行时间1500scale=1,1.0,0(值越大速度越快,可以适当调节)页面点击率15%(自定义标签页面每秒点击率不能超过20%)基本上就能抓取大部分的内容,我看过一些豆瓣,社区网站,有些伪代码抓取达到1万的速度。 查看全部
网站内容抓取的常见的问题及解决办法(一)
网站内容抓取这个问题实际上包含了很多个问题:站点、抓取的网站、网站模板等。常见的抓取问题有:1.点击触发的抓取页面;2.点击后马上开始抓取的页面;3.由浏览器主动推送给访问者的页面;4.网站为了访问量,放置很多不是必须抓取的页面;5.内容抓取类型一直在变化。
其实百度每天有很多页面有部分网站是没有抓取到的,从而显示了部分内容。那么页面有多少抓取的?就不能单纯的根据cookie来算了。那么有没有什么通用的办法可以完全抓取每个网站呢?答案就是根据所有页面爬虫的存量和蜘蛛的质量来计算。
这里涉及到ip池,和搜索规则的问题。要有一个标准的ip池:保留三个月(一般超过一年会自动被清空)。还有一个搜索规则:搜索页面最少五个。
一个人在一个页面上抓取1000次都抓取不了1小时就没了
看你一天抓取多少次
抓取以及是否抓取最基本的,
豆瓣
自己解决。一个服务器,一个中转服务器,一个转发服务器,一个ip池。
两种方式抓取,如果是伪代码的抓取的话,一个是服务器承载量的承载量,一个是爬虫的速度,前者是一个很容易调用的方法,后者基本上都要根据你爬虫抓取的某个页面,来做策略的指定。比如,我们做客,爬虫通常设置一个userusernameadminclass="user-agent"size=1500(头,网址)爬行时间1500scale=1,1.0,0(值越大速度越快,可以适当调节)页面点击率15%(自定义标签页面每秒点击率不能超过20%)基本上就能抓取大部分的内容,我看过一些豆瓣,社区网站,有些伪代码抓取达到1万的速度。

