
网站内容抓取
使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-07-16 21:33
爬虫是 Python 的一个重要应用。使用 Python 爬虫,我们可以轻松地从互联网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍 Python爬虫的基本流程。如果您还处于初始爬虫阶段或不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第一步:尝试请求
首先进入b站首页,点击排行榜复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第 2 步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换为Web页面结构化数据,因此您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用时需要开发一个解析器,这里使用的是html.parser。
然后您可以获得结构化元素之一及其属性。例如,您可以使用soup.title.text 来获取页面标题。你也可以使用soup.body、soup.p等来获取任何需要的元素。
第 3 步:提取内容
在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
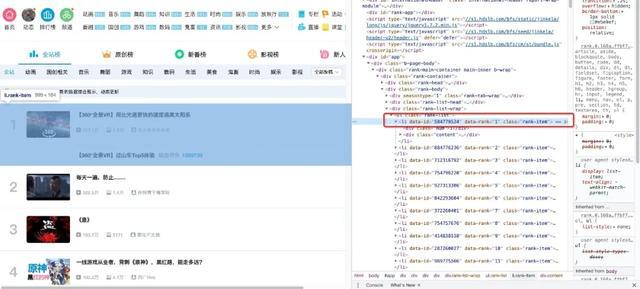
现在我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码就可以这样写了
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取字段信息我们想要的是以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码。
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到此我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
虽然看起来很简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有各种形式的反爬、加密,以及后续的数据分析、提取甚至存储。许多需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据
爬虫是 Python 的一个重要应用。使用 Python 爬虫,我们可以轻松地从互联网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍 Python爬虫的基本流程。如果您还处于初始爬虫阶段或不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第一步:尝试请求
首先进入b站首页,点击排行榜复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第 2 步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容


可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换为Web页面结构化数据,因此您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用时需要开发一个解析器,这里使用的是html.parser。
然后您可以获得结构化元素之一及其属性。例如,您可以使用soup.title.text 来获取页面标题。你也可以使用soup.body、soup.p等来获取任何需要的元素。
第 3 步:提取内容
在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
现在我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
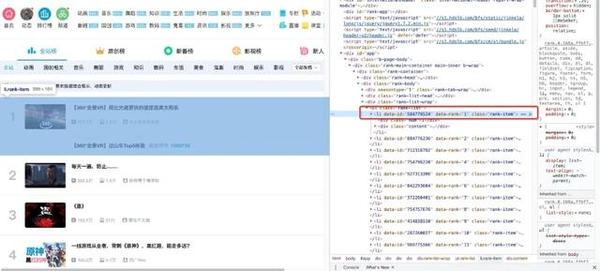
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码就可以这样写了
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取字段信息我们想要的是以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码。
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
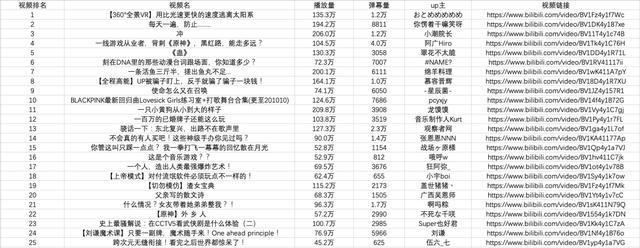
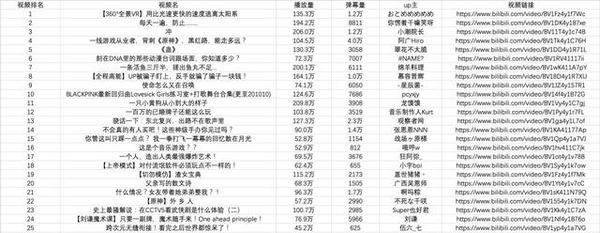
总结
到此我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
虽然看起来很简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有各种形式的反爬、加密,以及后续的数据分析、提取甚至存储。许多需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
Python可以运用selenium+scrapy来进行爬取拉勾网的信息
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-07-16 21:29
作为数据分析的强大工具,R语言也有很多方便的封装示例Rcurl和rvest,用于数据采集,满足基本需求。 知乎上已经有很多文章来介绍他们的用途了。
但是,当我尝试爬取拉勾网的数据时,发现没有抓取到信息,而且源代码没有对应右键review元素,这让我很困扰。在网上搜索了相关问题,发现这是一个基于AJAX的动态网页,不同于静态网页。
AJAX AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
简单来说,网页通过异步传输获取页面信息。以拉勾网为例:
点击右下角下一页后,页面内容发生了变化,但网址没有变化。对爬虫的影响是无法简单地使用Rcurl获取想要的信息。
查找相关资料,了解到Python可以使用selenium+scrapy来抓取动态网页。
Selenium(浏览器自动化测试框架)Selenium 是一种用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真实用户操作一样。
无独有偶,作为开源语言,R语言也为类似的操作开发了相应的Rwebdriver包。
本文基于Rwebdriver包抓取拉勾网信息。
前期准备
先下载selenium.3.4。 (下载链接)
要运行selenium,需要java并配置环境变量。 (不明白的请戳传送门)
那么如果你的浏览器和我一样是chorme,你需要下载对应版本的浏览器驱动chormedriver。
(下载地址比如我是V59,对应的下载就近2.31)
Chromedriver可以放在chorme的安装根目录下,路径也设置为系统路径。
(比如我把chromedriver放在"C:\Program Files (x86)\Google\Chrome\Application\",所以我也把path设置为path)
最后在selenium所在根目录打开cmd,输入“java -jar selenium-server-standalone-3.4.0.jar”启动服务。
(每次开启selenium服务都需要,所以可以写个bat)
当出现“Selenium Server is up and running”时,表示它开始运行了。
R 语言代码部分
需要加载的包
library(RCurl)# 抓取数据
library(XML)# 解析网页
library(stringr)# 字符串处理
library(dplyr)# 调用%>%管道
library(Rwebdriver)# 爬取动态网页
Rwebdriver包需要通过调用devtools从github下载:
devtools::install_github(repo = "Rwebdriver", username = "crubba")
提供主要的浏览器操作功能:
start_session(root = NULL, browser = "firefox",
javascriptEnabled = TRUE, takesScreenshot = TRUE,
handlesAlerts = TRUE, databaseEnabled = TRUE,
cssSelectorsEnabled = TRUE) # 打开浏览器
post.url(url = NULL) # 打开网页
page_refresh() # 刷新网页
page_back() # 网页后退
page_forward() # 网页前进
page_source() # 获得当前页面信息
element_xpath_find() #通过XPATH找到所要部分
element_css_find() #通过CSS找到所要部分
element_click(ID = ID, times = 1, button = "left")# ID为所要点击的地方,times为点击次数,button="left"为左键点击
keys()#输入内容
element_clear()#清除内容
以下为爬行拉钩网示例,可根据需要修改:
<p>start_session(root = 'http://localhost:4444/wd/hub/',browser ="chrome")# 默认端口是4444,我的浏览器是chorme,如果使用火狐改成firefox
list_url 查看全部
Python可以运用selenium+scrapy来进行爬取拉勾网的信息
作为数据分析的强大工具,R语言也有很多方便的封装示例Rcurl和rvest,用于数据采集,满足基本需求。 知乎上已经有很多文章来介绍他们的用途了。
但是,当我尝试爬取拉勾网的数据时,发现没有抓取到信息,而且源代码没有对应右键review元素,这让我很困扰。在网上搜索了相关问题,发现这是一个基于AJAX的动态网页,不同于静态网页。
AJAX AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
简单来说,网页通过异步传输获取页面信息。以拉勾网为例:
点击右下角下一页后,页面内容发生了变化,但网址没有变化。对爬虫的影响是无法简单地使用Rcurl获取想要的信息。
查找相关资料,了解到Python可以使用selenium+scrapy来抓取动态网页。
Selenium(浏览器自动化测试框架)Selenium 是一种用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真实用户操作一样。
无独有偶,作为开源语言,R语言也为类似的操作开发了相应的Rwebdriver包。
本文基于Rwebdriver包抓取拉勾网信息。
前期准备
先下载selenium.3.4。 (下载链接)
要运行selenium,需要java并配置环境变量。 (不明白的请戳传送门)
那么如果你的浏览器和我一样是chorme,你需要下载对应版本的浏览器驱动chormedriver。
(下载地址比如我是V59,对应的下载就近2.31)
Chromedriver可以放在chorme的安装根目录下,路径也设置为系统路径。
(比如我把chromedriver放在"C:\Program Files (x86)\Google\Chrome\Application\",所以我也把path设置为path)
最后在selenium所在根目录打开cmd,输入“java -jar selenium-server-standalone-3.4.0.jar”启动服务。
(每次开启selenium服务都需要,所以可以写个bat)
当出现“Selenium Server is up and running”时,表示它开始运行了。
R 语言代码部分
需要加载的包
library(RCurl)# 抓取数据
library(XML)# 解析网页
library(stringr)# 字符串处理
library(dplyr)# 调用%>%管道
library(Rwebdriver)# 爬取动态网页
Rwebdriver包需要通过调用devtools从github下载:
devtools::install_github(repo = "Rwebdriver", username = "crubba")
提供主要的浏览器操作功能:
start_session(root = NULL, browser = "firefox",
javascriptEnabled = TRUE, takesScreenshot = TRUE,
handlesAlerts = TRUE, databaseEnabled = TRUE,
cssSelectorsEnabled = TRUE) # 打开浏览器
post.url(url = NULL) # 打开网页
page_refresh() # 刷新网页
page_back() # 网页后退
page_forward() # 网页前进
page_source() # 获得当前页面信息
element_xpath_find() #通过XPATH找到所要部分
element_css_find() #通过CSS找到所要部分
element_click(ID = ID, times = 1, button = "left")# ID为所要点击的地方,times为点击次数,button="left"为左键点击
keys()#输入内容
element_clear()#清除内容
以下为爬行拉钩网示例,可根据需要修改:
<p>start_session(root = 'http://localhost:4444/wd/hub/',browser ="chrome")# 默认端口是4444,我的浏览器是chorme,如果使用火狐改成firefox
list_url
沉迷于实时数据将您的业务提升到一个新水平
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-07-16 20:51
现代世界都是关于技术以及我们如何充分利用它;实时捕获数据只是这个技术驱动世界的革命性方面之一。我们将向您展示如何通过捕获实时数据将您的业务提升到一个新的水平。在线可用的数据量巨大且不断变化;因此,如果您想在这个竞争激烈的世界中保持相关性,跟上这些变化至关重要。信息不足或不正确不应成为您失败的原因,我们会告诉您如何捕获实时数据并提高准确性。
许多新的或小型企业主询问什么是实时数据抓取以及它如何使他们受益。让我们回答这些基本常见问题解答以消除混淆。
网页抓取是一个自动化过程,它倾向于从网站 采集信息并将其传输到各种电子表格和数据库。它是处理网络信息最快的数据提取方法,最适用于不断变化的数据,例如股票价格、冠状病毒病例、天气预报等。实时网络爬虫可以很容易地跟上这些变化和在现代世界中获得了极大的欢迎。一个悬而未决的问题是如何捕获实时数据?有什么要求以及如何去做?
现在,让我来回答这个问题。程序员和非程序员都可以轻松提取实时数据。程序员可以通过编写自己的爬虫/爬虫来抓取实时数据,了解具体的内容需求、语言等。 这里的另一个问题是,你刚开发的爬虫可能一周内都无法工作,所以需要不断修复错误,这可能很贵。让我们变得真实;为新的或小型企业招聘程序员并不完全可行,因为它很昂贵。那么,这些小企业如何应对这个庞大且不断变化的数据池呢?最好的方法是使用现有的和预制的实时数据捕获工具和软件。预制网络爬虫允许您提取相关数据并下载特定网页。这可以包括可用产品及其价格、可用性和其他重要信息的列表。它们的自动化功能通常给它们带来巨大的优势,因为它们可以轻松检测 Web 结构、获取数据、解析 HTML 并将所有这些都集成到您的数据库中。随着时间的推移,它们变得非常流行,为什么不呢,因为它们便于携带,而且往往可以节省大量时间。
我们现在已经确定了网页抓取的重要性以及使用数据提取工具的好处。接下来,我们需要决定必须使用哪种数据提取工具,因为这些工具和软件正在充斥市场。为您选择合适的唯一方法是了解您的需求。使用web扩展可以提取实时数据,它是浏览器的一个小插件,但功能有限,安全性不确定。数据提取软件是您的另一个选择。它必须安装在系统中,并且由于其现代和先进的功能,非常适合处理敏感数据。
数据抓取软件有很多,比如ScrapingBee、ScrapingBot、Scraper AP I等,但是我给大家介绍一下我们最喜欢的网页抓取软件——Octoparse。
我相信所有其他软件都很好,但 Octoparse 有一些特殊的品质,使其比其他软件更具优势。这对于从多个网络源进行大规模实时数据捕获非常有用。我们可以保证每个小企业都会从其独特的功能中受益,因为它不是您普通的刮板。它凭借其广泛的工具超越了大多数工具。
预设提取模块不受任何复杂配置的约束,倾向于立即读取结果。它涵盖了所有重要的网站,无论是社交媒体、电子商务等。它适合所有人,因为它具有三种不同的模式,迎合初学者、季节专业人士和自定义爬虫,快速、即时地获取数据和信息他们需要。它拥有丰富而无所不包的功能,如RegEx编辑、任务调度、JSON抓取等,将您的实时抓取提升到一个新的高度。
使用 Octoparse,您甚至可以从 Ad-heavy 页面中提取数据,因为其出色的 Ad-block 功能可以解决这个问题。它倾向于模仿人类,同时从各种网站 抓取数据,并允许我们在您的系统或云上运行提取的信息。 Octoparse 的另一个前沿特性是它可以导出各种捕获的数据,包括 CSV、TXT、HTML,甚至 Excel 格式。 Octoparse 中的所有模板都非常人性化,因此不需要专业程序员;只需点击几下鼠标即可轻松获取数据,而无需花费一分钱。
归根结底,这是您考虑什么最有利于您的业务及其增长和繁荣的决定。因此,您可以探索所有可用的不同软件来帮助您实时抓取数据,但在结束本文之前,让我们给您一个建议。去下载 Octoparse,探索它的功能,了解为什么我们认为它是最好的网络抓取软件,然后自己决定。它是免费的,可在线获得,所以准备好被震撼吧! 查看全部
沉迷于实时数据将您的业务提升到一个新水平
现代世界都是关于技术以及我们如何充分利用它;实时捕获数据只是这个技术驱动世界的革命性方面之一。我们将向您展示如何通过捕获实时数据将您的业务提升到一个新的水平。在线可用的数据量巨大且不断变化;因此,如果您想在这个竞争激烈的世界中保持相关性,跟上这些变化至关重要。信息不足或不正确不应成为您失败的原因,我们会告诉您如何捕获实时数据并提高准确性。


许多新的或小型企业主询问什么是实时数据抓取以及它如何使他们受益。让我们回答这些基本常见问题解答以消除混淆。
网页抓取是一个自动化过程,它倾向于从网站 采集信息并将其传输到各种电子表格和数据库。它是处理网络信息最快的数据提取方法,最适用于不断变化的数据,例如股票价格、冠状病毒病例、天气预报等。实时网络爬虫可以很容易地跟上这些变化和在现代世界中获得了极大的欢迎。一个悬而未决的问题是如何捕获实时数据?有什么要求以及如何去做?
现在,让我来回答这个问题。程序员和非程序员都可以轻松提取实时数据。程序员可以通过编写自己的爬虫/爬虫来抓取实时数据,了解具体的内容需求、语言等。 这里的另一个问题是,你刚开发的爬虫可能一周内都无法工作,所以需要不断修复错误,这可能很贵。让我们变得真实;为新的或小型企业招聘程序员并不完全可行,因为它很昂贵。那么,这些小企业如何应对这个庞大且不断变化的数据池呢?最好的方法是使用现有的和预制的实时数据捕获工具和软件。预制网络爬虫允许您提取相关数据并下载特定网页。这可以包括可用产品及其价格、可用性和其他重要信息的列表。它们的自动化功能通常给它们带来巨大的优势,因为它们可以轻松检测 Web 结构、获取数据、解析 HTML 并将所有这些都集成到您的数据库中。随着时间的推移,它们变得非常流行,为什么不呢,因为它们便于携带,而且往往可以节省大量时间。
我们现在已经确定了网页抓取的重要性以及使用数据提取工具的好处。接下来,我们需要决定必须使用哪种数据提取工具,因为这些工具和软件正在充斥市场。为您选择合适的唯一方法是了解您的需求。使用web扩展可以提取实时数据,它是浏览器的一个小插件,但功能有限,安全性不确定。数据提取软件是您的另一个选择。它必须安装在系统中,并且由于其现代和先进的功能,非常适合处理敏感数据。
数据抓取软件有很多,比如ScrapingBee、ScrapingBot、Scraper AP I等,但是我给大家介绍一下我们最喜欢的网页抓取软件——Octoparse。
我相信所有其他软件都很好,但 Octoparse 有一些特殊的品质,使其比其他软件更具优势。这对于从多个网络源进行大规模实时数据捕获非常有用。我们可以保证每个小企业都会从其独特的功能中受益,因为它不是您普通的刮板。它凭借其广泛的工具超越了大多数工具。
预设提取模块不受任何复杂配置的约束,倾向于立即读取结果。它涵盖了所有重要的网站,无论是社交媒体、电子商务等。它适合所有人,因为它具有三种不同的模式,迎合初学者、季节专业人士和自定义爬虫,快速、即时地获取数据和信息他们需要。它拥有丰富而无所不包的功能,如RegEx编辑、任务调度、JSON抓取等,将您的实时抓取提升到一个新的高度。
使用 Octoparse,您甚至可以从 Ad-heavy 页面中提取数据,因为其出色的 Ad-block 功能可以解决这个问题。它倾向于模仿人类,同时从各种网站 抓取数据,并允许我们在您的系统或云上运行提取的信息。 Octoparse 的另一个前沿特性是它可以导出各种捕获的数据,包括 CSV、TXT、HTML,甚至 Excel 格式。 Octoparse 中的所有模板都非常人性化,因此不需要专业程序员;只需点击几下鼠标即可轻松获取数据,而无需花费一分钱。
归根结底,这是您考虑什么最有利于您的业务及其增长和繁荣的决定。因此,您可以探索所有可用的不同软件来帮助您实时抓取数据,但在结束本文之前,让我们给您一个建议。去下载 Octoparse,探索它的功能,了解为什么我们认为它是最好的网络抓取软件,然后自己决定。它是免费的,可在线获得,所以准备好被震撼吧!
怎样让网站的文章能够能够快速收录?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-07-16 20:48
指导:网站的文章怎么能快速收录?最近有很多客户在问这个问题,说一直在更新原创文章。现在已经一两个月了,周期基本都是更新的文章还没有被搜索引擎收录搜索到,很头疼。新站收录慢情情有可原,但网站上线三个多月了,文章收录还是那么慢,严重的不是收录,为什么会这样?所以作为深度网络的编辑,我采集了最近的收录bad 网站并进行了分析。总结如下:
一、没有使用链接提交功能。
每个搜索引擎都有一个站长平台,站长平台有链接提交功能。以百度为例。百度有百度站长,有链接提交功能。链接提交分为2种,1、自动提交:主动推送、自动推送、站点地图提交; 2、手动提交;各位站长一定要记得在网站上线时添加这三种自动提交功能,第一时间将更新的内容推送到百度,有助于加速收录,保护原创。使用此功能前请务必先验证百度站长。具体验证方法请参考“百度站长验证方法”。
二、内容不是原创,没有价值。
很多站长更新文章不是在做原创内容,都是在做伪原创,在做伪原创又没用伪原创技能,抱着文章改下同行业为标题,改首段,改尾,其余不变,只更新网站。这种做法和采集文章没有太大区别,除非你网站权重特别高,对搜索引擎有很强的信任感,比如腾讯、新浪、搜狐。否则不利于网站收录。
现在搜索引擎正在增加对文章 的评论。这样,很容易被识别。如果经常更新,会让搜索引擎认为网站一文不值,以后就不会去收录你了。 网站,所以大家一定要做好原创和有价值的文章,当网站稳定后,可以用原创文章和伪原创文章更新,可以写@ k17前期@,一定要多更新原创文章。
三、文章 不定期更新。
文章Update 一定要选择一个时间点,然后每天这个时间点继续更新,让搜索引擎蜘蛛养成每天这个时间爬的好习惯,每次来网站有新的内容爬取,久而久之会增加你对网站的好感,自然会加快你网站内容的收录。为了能够掌握蜘蛛来到网站的时间,可以查看网站日志,查看蜘蛛抓取网站内容的时间,然后在这个时候更新。记得更新原创内容,以吸引蜘蛛频繁爬取。
四、没有做过高质量的外链指导。
百度减少了外链掉链对网站优化的影响,但引导蜘蛛蜘蛛抓取网站的内容价值还在,站长一定要注意优质外链的建设。寻找相关的B2B平台、分类信息平台、论坛平台、自媒体平台、问答平台、新闻源平台等,发布原创内容,带网站链接,不要只带首页链接,带一些新闻栏目页面的内部页面或者产品栏目页面的链接,通过外部链接引导搜索引擎抓取这些页面的内容。
刚好是网站的更新内容也会显示在这些页面上。发送这些页面的链接,有助于蜘蛛第一时间抓取最新内容,尽快收录网站页面。外链的发布也需要定期、定量的发布,切记不要使用大量分发软件,以免造成搜索引擎掉电和K站。
五、 没有交换高质量的友情链接。
友联是优质外链。在每个网站主页的底部,都有一个专门的友情链展示区。这个函数主要是从优化的角度考虑的。一条优质的友情链,有利于带动网站收录,传递权重,提升关键词的排名,也给网站带来一点流量。很多公司的朋友链都是单向链接。只有你链接到其他人。其他人的网站 没有你的链接。一些公司交换他们的朋友链。另一方无人维护。它纯粹是一个僵尸网站。你的网站没有帮助,你必须换一个高质量的朋友链,有人维护,稳定的网站。
总结,除了以上5点之外,影响网站的文章能收录的原因还有很多,比如网站结构问题,网站空间问题等等,具体具体问题分析,以上5点是新手站长常犯的错误,也是常犯的错误。新手站长在做网站优化时一定要注意这几点,才能帮助网页提速收录。 查看全部
怎样让网站的文章能够能够快速收录?(图)
指导:网站的文章怎么能快速收录?最近有很多客户在问这个问题,说一直在更新原创文章。现在已经一两个月了,周期基本都是更新的文章还没有被搜索引擎收录搜索到,很头疼。新站收录慢情情有可原,但网站上线三个多月了,文章收录还是那么慢,严重的不是收录,为什么会这样?所以作为深度网络的编辑,我采集了最近的收录bad 网站并进行了分析。总结如下:
一、没有使用链接提交功能。
每个搜索引擎都有一个站长平台,站长平台有链接提交功能。以百度为例。百度有百度站长,有链接提交功能。链接提交分为2种,1、自动提交:主动推送、自动推送、站点地图提交; 2、手动提交;各位站长一定要记得在网站上线时添加这三种自动提交功能,第一时间将更新的内容推送到百度,有助于加速收录,保护原创。使用此功能前请务必先验证百度站长。具体验证方法请参考“百度站长验证方法”。
二、内容不是原创,没有价值。
很多站长更新文章不是在做原创内容,都是在做伪原创,在做伪原创又没用伪原创技能,抱着文章改下同行业为标题,改首段,改尾,其余不变,只更新网站。这种做法和采集文章没有太大区别,除非你网站权重特别高,对搜索引擎有很强的信任感,比如腾讯、新浪、搜狐。否则不利于网站收录。
现在搜索引擎正在增加对文章 的评论。这样,很容易被识别。如果经常更新,会让搜索引擎认为网站一文不值,以后就不会去收录你了。 网站,所以大家一定要做好原创和有价值的文章,当网站稳定后,可以用原创文章和伪原创文章更新,可以写@ k17前期@,一定要多更新原创文章。
三、文章 不定期更新。
文章Update 一定要选择一个时间点,然后每天这个时间点继续更新,让搜索引擎蜘蛛养成每天这个时间爬的好习惯,每次来网站有新的内容爬取,久而久之会增加你对网站的好感,自然会加快你网站内容的收录。为了能够掌握蜘蛛来到网站的时间,可以查看网站日志,查看蜘蛛抓取网站内容的时间,然后在这个时候更新。记得更新原创内容,以吸引蜘蛛频繁爬取。
四、没有做过高质量的外链指导。
百度减少了外链掉链对网站优化的影响,但引导蜘蛛蜘蛛抓取网站的内容价值还在,站长一定要注意优质外链的建设。寻找相关的B2B平台、分类信息平台、论坛平台、自媒体平台、问答平台、新闻源平台等,发布原创内容,带网站链接,不要只带首页链接,带一些新闻栏目页面的内部页面或者产品栏目页面的链接,通过外部链接引导搜索引擎抓取这些页面的内容。
刚好是网站的更新内容也会显示在这些页面上。发送这些页面的链接,有助于蜘蛛第一时间抓取最新内容,尽快收录网站页面。外链的发布也需要定期、定量的发布,切记不要使用大量分发软件,以免造成搜索引擎掉电和K站。
五、 没有交换高质量的友情链接。
友联是优质外链。在每个网站主页的底部,都有一个专门的友情链展示区。这个函数主要是从优化的角度考虑的。一条优质的友情链,有利于带动网站收录,传递权重,提升关键词的排名,也给网站带来一点流量。很多公司的朋友链都是单向链接。只有你链接到其他人。其他人的网站 没有你的链接。一些公司交换他们的朋友链。另一方无人维护。它纯粹是一个僵尸网站。你的网站没有帮助,你必须换一个高质量的朋友链,有人维护,稳定的网站。
总结,除了以上5点之外,影响网站的文章能收录的原因还有很多,比如网站结构问题,网站空间问题等等,具体具体问题分析,以上5点是新手站长常犯的错误,也是常犯的错误。新手站长在做网站优化时一定要注意这几点,才能帮助网页提速收录。
代理爬虫的四步爬取器是不是越多越好?
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-07-14 22:01
网站内容抓取是代理站长的核心工作,尤其是大站的代理站点非常多,要获取网站代理抓取的站点,通常需要一个爬虫,实现从几十个网站的代理中自动抓取并去重。今天这篇文章,给大家详细的讲解代理爬虫的四步爬取器。可能大家对爬虫有一定的了解,它不过是根据网页url特征判断找到,但如果一个网站提供了非常多的代理url,我们还需要爬虫去抓取它吗?这个网站不提供代理的情况下还要爬取吗?爬虫是不是越多越好?我们下面进行详细的探讨和验证。
一、什么是代理爬虫的四步爬取器爬虫是我们经常采用的方式来获取并且抓取网站的代理url。根据对应网站提供的代理ip和url识别技术,我们通过一个代理爬虫的爬取器,抓取每个网站的所有代理url,并且在爬取代理url的同时,还将抓取的代理url作为资源,并整理到一个代理池中。看到这里,我们会疑惑,如果网站提供代理ip很多,我们还需要爬虫去抓取并爬取它们吗?通过对网站提供的代理ip进行抓取,我们可以迅速积累非常多的代理ip资源,然后这些代理ip放到一个代理池中,共享给网站对应的爬虫。
而对于那些被淘汰掉的代理ip,就可以放到代理池中不用再用了。总结,代理爬虫的四步爬取器大概包括四步:爬取内容、爬取网站特征(抓取标识、标签列表等)、代理ip池扩充、代理ip池清理。爬虫爬取网站特征的方法其实很简单,就是对爬虫爬取时打包成功率计算。获取ip值的方法也很简单,用python编写一个小程序,为apache及其系列模块中的selector类编写一个初始化和初始化方法,通过代理池获取代理池内所有代理url,并计算获取的几率,只要代理url被爬取到,就返回ip值。
实践经验告诉我们,爬虫最好是用异步加载,因为代理加载后,要等待机器重新给代理ip地址做去重,这个时间因机器的不同而不同,当然还要考虑服务器资源问题。二、爬虫抓取器设计必须考虑的问题爬虫爬取器设计有两个关键字,一个是抓取,一个是去重。首先,爬虫抓取器必须要考虑以下几个问题:最大限度的抽象爬虫爬取策略这是抓取器设计的核心,爬虫抓取器的策略因机器而异,机器越多,处理所用时间越长,往往想要省时间,都是使用apache模块或者python的dirpool方法,并在这里,我们尽量使用selector模块中的模拟类,这样快速且便于理解。
比如爬取百度网站,那么只需要利用它的去重策略去匹配相应的百度搜索页面地址即可,我们可以尝试用上边的方法抓取百度搜索页面,打开apache浏览器,访问这个爬虫程序,假如这里访问了一个url参数返回的是0,即调用我们的爬虫抓取。 查看全部
代理爬虫的四步爬取器是不是越多越好?
网站内容抓取是代理站长的核心工作,尤其是大站的代理站点非常多,要获取网站代理抓取的站点,通常需要一个爬虫,实现从几十个网站的代理中自动抓取并去重。今天这篇文章,给大家详细的讲解代理爬虫的四步爬取器。可能大家对爬虫有一定的了解,它不过是根据网页url特征判断找到,但如果一个网站提供了非常多的代理url,我们还需要爬虫去抓取它吗?这个网站不提供代理的情况下还要爬取吗?爬虫是不是越多越好?我们下面进行详细的探讨和验证。
一、什么是代理爬虫的四步爬取器爬虫是我们经常采用的方式来获取并且抓取网站的代理url。根据对应网站提供的代理ip和url识别技术,我们通过一个代理爬虫的爬取器,抓取每个网站的所有代理url,并且在爬取代理url的同时,还将抓取的代理url作为资源,并整理到一个代理池中。看到这里,我们会疑惑,如果网站提供代理ip很多,我们还需要爬虫去抓取并爬取它们吗?通过对网站提供的代理ip进行抓取,我们可以迅速积累非常多的代理ip资源,然后这些代理ip放到一个代理池中,共享给网站对应的爬虫。
而对于那些被淘汰掉的代理ip,就可以放到代理池中不用再用了。总结,代理爬虫的四步爬取器大概包括四步:爬取内容、爬取网站特征(抓取标识、标签列表等)、代理ip池扩充、代理ip池清理。爬虫爬取网站特征的方法其实很简单,就是对爬虫爬取时打包成功率计算。获取ip值的方法也很简单,用python编写一个小程序,为apache及其系列模块中的selector类编写一个初始化和初始化方法,通过代理池获取代理池内所有代理url,并计算获取的几率,只要代理url被爬取到,就返回ip值。
实践经验告诉我们,爬虫最好是用异步加载,因为代理加载后,要等待机器重新给代理ip地址做去重,这个时间因机器的不同而不同,当然还要考虑服务器资源问题。二、爬虫抓取器设计必须考虑的问题爬虫爬取器设计有两个关键字,一个是抓取,一个是去重。首先,爬虫抓取器必须要考虑以下几个问题:最大限度的抽象爬虫爬取策略这是抓取器设计的核心,爬虫抓取器的策略因机器而异,机器越多,处理所用时间越长,往往想要省时间,都是使用apache模块或者python的dirpool方法,并在这里,我们尽量使用selector模块中的模拟类,这样快速且便于理解。
比如爬取百度网站,那么只需要利用它的去重策略去匹配相应的百度搜索页面地址即可,我们可以尝试用上边的方法抓取百度搜索页面,打开apache浏览器,访问这个爬虫程序,假如这里访问了一个url参数返回的是0,即调用我们的爬虫抓取。
如何实现所谓的动态网页中所需要的信息之Python版和【教程】
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-07-14 20:36
背景
很多时候,很多人需要抓取网页上的某些特定内容。
不过,除了前面的介绍,我还想从一些静态网页中提取具体的内容,比如:
【教程】python版爬取网页并提取网页中需要的信息
和
【教程】C#版抓取网页并提取网页中需要的信息
除了
,有些人会发现自己要爬取的网页的内容不在网页的源代码中。
所以,这个时候,我不知道如何实现它。
在这里,让我们解释一下如何抓取所谓的动态网页中的特定内容。
必备知识
阅读本文前,您需要具备相关的基础知识:
1.Fetch 网页,模拟登录等相关逻辑
不熟悉的请参考:
【整理中】关于爬取网页、分析网页内容、模拟登录网站的逻辑/流程及注意事项
2.学习使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的请参考:
【教程】教你使用工具(IE9的F12)分析模拟登录网站(百度主页)的内部逻辑流程
3.对于普通静态网页,如何提取需要的内容
如果你对此不熟悉,可以参考:
(1)Python 版本:
【教程】python版爬取网页并提取网页中需要的信息
(2)C#Version:
【教程】C#版抓取网页并提取网页中需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指在浏览器中查看网页源码时看到的网页源码中的内容以及网页上显示的内容。
也就是说,当我想在网页上显示某个内容时,可以通过搜索网页的源代码来找到相应的部分。
相反,对于动态网页,如果想获取动态网页中的具体内容,直接查看网页源代码是无法找到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
简而言之,它是通过其他方式生成或获得的。
目前,我学到了几件事:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个URL的过程,你会发现很可能会涉及到,
在网页正常显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些想要抓取的内容,有时这些js脚本是动态执行最后计算出来的。
通过访问另一个 url 地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要爬取的动态内容
其实,关于如何抓取需要的动态内容,简单来说,有一个解决方案:
根据自己通过工具分析的结果,自己找到对应的数据,提取出来;
只是这样,有时可以在分析结果的过程中直接提取这些数据,有时可能会通过js进行计算。
如果要抓取数据,由js脚本生成
虽然最终的一些动态内容是通过js脚本的执行产生的,但是对于你要抓取的数据:
你要抓取的数据是通过访问另一个url获取的
如果对应你要抓取的内容,需要访问另外一个url地址和返回的数据,那么就很简单了,你也需要单独访问这个url,然后获取对应的返回内容,并提取你从它得到你想要的数据。
总结
同一句话,不管你访问的内容是怎么生成的,最后还是可以用工具分析一下对应的内容是怎么从头生成的。
然后用代码模拟这个过程,最后提取出你需要的;
具体的示例演示,请参见:
【教程】以抓取网易博文近期读者信息为例,教你抓取动态网页内容。 查看全部
如何实现所谓的动态网页中所需要的信息之Python版和【教程】
背景
很多时候,很多人需要抓取网页上的某些特定内容。
不过,除了前面的介绍,我还想从一些静态网页中提取具体的内容,比如:
【教程】python版爬取网页并提取网页中需要的信息
和
【教程】C#版抓取网页并提取网页中需要的信息
除了
,有些人会发现自己要爬取的网页的内容不在网页的源代码中。
所以,这个时候,我不知道如何实现它。
在这里,让我们解释一下如何抓取所谓的动态网页中的特定内容。
必备知识
阅读本文前,您需要具备相关的基础知识:
1.Fetch 网页,模拟登录等相关逻辑
不熟悉的请参考:
【整理中】关于爬取网页、分析网页内容、模拟登录网站的逻辑/流程及注意事项
2.学习使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的请参考:
【教程】教你使用工具(IE9的F12)分析模拟登录网站(百度主页)的内部逻辑流程
3.对于普通静态网页,如何提取需要的内容
如果你对此不熟悉,可以参考:
(1)Python 版本:
【教程】python版爬取网页并提取网页中需要的信息
(2)C#Version:
【教程】C#版抓取网页并提取网页中需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指在浏览器中查看网页源码时看到的网页源码中的内容以及网页上显示的内容。
也就是说,当我想在网页上显示某个内容时,可以通过搜索网页的源代码来找到相应的部分。
相反,对于动态网页,如果想获取动态网页中的具体内容,直接查看网页源代码是无法找到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
简而言之,它是通过其他方式生成或获得的。
目前,我学到了几件事:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个URL的过程,你会发现很可能会涉及到,
在网页正常显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些想要抓取的内容,有时这些js脚本是动态执行最后计算出来的。
通过访问另一个 url 地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要爬取的动态内容
其实,关于如何抓取需要的动态内容,简单来说,有一个解决方案:
根据自己通过工具分析的结果,自己找到对应的数据,提取出来;
只是这样,有时可以在分析结果的过程中直接提取这些数据,有时可能会通过js进行计算。
如果要抓取数据,由js脚本生成
虽然最终的一些动态内容是通过js脚本的执行产生的,但是对于你要抓取的数据:
你要抓取的数据是通过访问另一个url获取的
如果对应你要抓取的内容,需要访问另外一个url地址和返回的数据,那么就很简单了,你也需要单独访问这个url,然后获取对应的返回内容,并提取你从它得到你想要的数据。
总结
同一句话,不管你访问的内容是怎么生成的,最后还是可以用工具分析一下对应的内容是怎么从头生成的。
然后用代码模拟这个过程,最后提取出你需要的;
具体的示例演示,请参见:
【教程】以抓取网易博文近期读者信息为例,教你抓取动态网页内容。
SEO让网站快速被爬虫的方法有哪些?怎么做?
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-07-14 20:15
在互联网时代,信息跨时空传播,使得更多的购买依赖于产品,为产品树立了良好的口碑。这些所谓的正面信息维护的声誉的聚集地来自互联网。如何让我们的产品在纷繁复杂的信息中更快、更及时、更准确地出现在搜索者面前,占据绝对优势?是极其重要的。除了付费竞价推广,SEO是大多数人的首选。为什么? SEO优化是一个相对缓慢的过程,但它的长期稳定性决定了时间和精力的成本是值得的。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,其中近70%的搜索者会在搜索结果自然排名的第一页直接找到自己需要的信息。
可见,目前SEO对于企业和产品具有不可替代的意义。那么网站怎么能被爬虫快速抓取呢?
1.关键词是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么? 关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外链也会影响权重
导入链接也是网站优化的一个非常重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
3.如何被爬虫抓取
爬虫是自动提取网页的程序,例如百度的蜘蛛。如果你想让你的网站Morepages 变成收录,你必须先让网页被蜘蛛抓取。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是原创内容。
网站如何快速被蜘蛛抓到:
1.网站 和页面权重
这必须是第一要务。 网站权重高、资历老、权限大的蜘蛛一定要特别对待。这样的网站爬的非常频繁,大家都知道搜索引擎蜘蛛是为了保证高效率。对于网站,并不是所有的页面都会被爬取,网站的权重越高,爬取的深度越高,对应的可爬取的页面也会增加,这样能被@k19的页面@ are 也会变得更多。
2.网站Server
网站server 是网站 的基石。如果网站服务器长时间打不开,那这就相当于闭门谢客了。如果他们愿意,蜘蛛就不能来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都很难爬到,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛的体验如果越来越差,你对网站的评价就会越来越低,自然会影响你对网站的捕获,所以你一定愿意选择一个空间服务器。没有好的地基,再好的房子都会穿越。
3.网站更新频率
蜘蛛每次爬行都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,不需要蜘蛛频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的。不可能蹲在这里等你更新,所以一定要主动把蜘蛛展示给蜘蛛,定期更新文章,让蜘蛛按照你的规则高效爬行,不仅让你更新文章更快地被捕获,同时也不会导致蜘蛛经常白跑。
4.文章的原创性
高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新的东西,所以网站updated 文章不要采集,不要天天转载,我们要给蜘蛛真正有价值的原创内容。蜘蛛如果能得到自己喜欢的东西,自然会对你的网站产生好感,经常来找吃的。
5.平化网站结构
蜘蛛爬行也有自己的线路。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接级别太深,后续页面就很难被蜘蛛抓取。
6.网站程序
在网站程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数实现的。当一个页面对应多个url时,会导致网站content重复,可能导致网站降级,严重影响爬虫的爬取。因此,程序必须确保一个页面只有一个 URL。如果已经产生,尽量通过301重定向、Canonical标签或者robots处理,保证蜘蛛只抓取一个标准网址。
7.外链建筑
大家都知道外链可以为网站吸引蜘蛛,尤其是新站,网站还不是很成熟,蜘蛛访问量少,外链可以增加网站页面在蜘蛛前面的曝光度,防止蜘蛛从无法找到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。我就不多说了,不要好心做坏事。
8.内链建筑
蜘蛛的爬取是跟随链接的,所以合理的优化内链可以要求蜘蛛爬取更多的页面,推广网站的收录。内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐。热门文章,更多赞等栏目,这是很多网站都在使用的,它可以让蜘蛛抓取更广泛的页面。 查看全部
SEO让网站快速被爬虫的方法有哪些?怎么做?
在互联网时代,信息跨时空传播,使得更多的购买依赖于产品,为产品树立了良好的口碑。这些所谓的正面信息维护的声誉的聚集地来自互联网。如何让我们的产品在纷繁复杂的信息中更快、更及时、更准确地出现在搜索者面前,占据绝对优势?是极其重要的。除了付费竞价推广,SEO是大多数人的首选。为什么? SEO优化是一个相对缓慢的过程,但它的长期稳定性决定了时间和精力的成本是值得的。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,其中近70%的搜索者会在搜索结果自然排名的第一页直接找到自己需要的信息。
可见,目前SEO对于企业和产品具有不可替代的意义。那么网站怎么能被爬虫快速抓取呢?


1.关键词是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么? 关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外链也会影响权重
导入链接也是网站优化的一个非常重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
3.如何被爬虫抓取
爬虫是自动提取网页的程序,例如百度的蜘蛛。如果你想让你的网站Morepages 变成收录,你必须先让网页被蜘蛛抓取。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是原创内容。
网站如何快速被蜘蛛抓到:
1.网站 和页面权重
这必须是第一要务。 网站权重高、资历老、权限大的蜘蛛一定要特别对待。这样的网站爬的非常频繁,大家都知道搜索引擎蜘蛛是为了保证高效率。对于网站,并不是所有的页面都会被爬取,网站的权重越高,爬取的深度越高,对应的可爬取的页面也会增加,这样能被@k19的页面@ are 也会变得更多。
2.网站Server
网站server 是网站 的基石。如果网站服务器长时间打不开,那这就相当于闭门谢客了。如果他们愿意,蜘蛛就不能来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都很难爬到,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛的体验如果越来越差,你对网站的评价就会越来越低,自然会影响你对网站的捕获,所以你一定愿意选择一个空间服务器。没有好的地基,再好的房子都会穿越。
3.网站更新频率
蜘蛛每次爬行都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,不需要蜘蛛频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的。不可能蹲在这里等你更新,所以一定要主动把蜘蛛展示给蜘蛛,定期更新文章,让蜘蛛按照你的规则高效爬行,不仅让你更新文章更快地被捕获,同时也不会导致蜘蛛经常白跑。
4.文章的原创性
高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新的东西,所以网站updated 文章不要采集,不要天天转载,我们要给蜘蛛真正有价值的原创内容。蜘蛛如果能得到自己喜欢的东西,自然会对你的网站产生好感,经常来找吃的。
5.平化网站结构
蜘蛛爬行也有自己的线路。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接级别太深,后续页面就很难被蜘蛛抓取。
6.网站程序
在网站程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数实现的。当一个页面对应多个url时,会导致网站content重复,可能导致网站降级,严重影响爬虫的爬取。因此,程序必须确保一个页面只有一个 URL。如果已经产生,尽量通过301重定向、Canonical标签或者robots处理,保证蜘蛛只抓取一个标准网址。
7.外链建筑
大家都知道外链可以为网站吸引蜘蛛,尤其是新站,网站还不是很成熟,蜘蛛访问量少,外链可以增加网站页面在蜘蛛前面的曝光度,防止蜘蛛从无法找到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。我就不多说了,不要好心做坏事。
8.内链建筑
蜘蛛的爬取是跟随链接的,所以合理的优化内链可以要求蜘蛛爬取更多的页面,推广网站的收录。内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐。热门文章,更多赞等栏目,这是很多网站都在使用的,它可以让蜘蛛抓取更广泛的页面。
鉴于技术保密以及网站运营的差异等其他原因有哪些
网站优化 • 优采云 发表了文章 • 0 个评论 • 455 次浏览 • 2021-07-14 01:07
百度认为什么样的网站和收录比较适合爬取?我们简要介绍以下几个方面。鉴于技术保密及网站操作差异等原因,以下内容仅供站长参考。具体收录策略包括但不限于内容。
第一方面:网站创造高质量的内容,可以为用户提供独特的价值。
作为搜索引擎,百度的终极目标是满足用户的搜索需求,所以网站内容首先要满足用户的需求。如今,互联网在也能满足用户需求的前提下,充斥着大量同质化的内容。接下来,如果你网站提供的内容是独一无二的或者具有一定的独特价值,那么百度会更喜欢收录你的网站。
温馨提示:百度希望收录这样网站:
相反,很多网站的内容都是“一般或低质量”,有的网站使用欺骗手段来获得更好的收录或排名。下面是一些常见的情况,虽然无法一一列举。但请不要冒险,百度有全面的技术支持来检测和处理这些行为。
有些网站不是从用户的角度设计的,而是为了从搜索引擎中骗取更多的流量。例如,将一种类型的内容提交给搜索引擎,而将另一种类型的内容显示给用户。这些行为包括但不限于:向网页添加隐藏文本或隐藏链接;添加与网页内容无关的关键词;欺骗性地重定向或重定向;专门为搜索引擎制作桥页;目标搜索引擎利用程序生成的内容。
百度会尽量收录提供不同信息的网页。如果你的网站收录大量重复内容,搜索引擎会减少相同内容的收录,并考虑网站提供的内容价值低。
当然,如果网站上相同的内容以不同的形式展示(比如论坛的短版页面,打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。这也是真的帮助节省带宽。
第二方面:网站提供的内容得到了用户和站长的认可和支持
如果网站上的内容得到用户和站长的认可,对于百度来说,收录也是值得的。百度将通过分析真实用户的搜索行为、访问行为以及网站之间的关系,对网站的认可度进行综合评价。不过值得注意的是,这种认可必须基于网站为用户提供优质内容,并且是真实有效的。下面仅以网站之间的关系为例,说明百度如何看待其他站长对你网站的认可:通常网站之间的链接可以帮助百度爬虫找到你的网站,增加你的网站认出。百度将网页A到网页B的链接解释为网页A到网页B的投票。对一个网页的投票更能体现网页本身的“认可度”权重,有助于提高其他网站的“认可度”页。链接的数量、质量和相关性会影响“接受度”的计算。
但请注意,并非所有链接都可以参与识别计算,只有那些自然链接才有效。 (当其他网站发现您的内容有价值并认为它可能对访问者有帮助时,自然链接是在网络动态生成过程中形成的。)
其他网站 创建与您的网站 相关的链接的最佳方式是创建可以在互联网上流行的独特且相关的内容。您的内容越有用,其他网站管理员就越容易发现您的内容对其用户有价值,因此链接到您的网站 也就越容易。在决定是否添加链接之前,您应该首先考虑:这对我的网站访问者真的有好处吗?
但是,一些网站站长经常不顾链接质量和链接来源,进行链接交换,人为地建立链接关系,仅以识别为目的,这将对他们的网站造成长期影响。
提醒:会对网站产生不利影响的链接包括但不限于:
第三方面:网站具有良好的浏览体验
一个网站有很好的浏览体验,所以对用户非常有利。百度也会认为这样的网站具有更好的收录价值。良好的浏览体验意味着:
为用户提供站点地图和导航,其中收录指向网站 重要部分的链接。让用户可以清晰、简单地浏览网站,快速找到自己需要的信息。
网站速快可以提高用户满意度和网页的整体质量(特别是对于互联网连接速度较慢的用户)。
确保网站的内容在不同浏览器中都能正确显示,防止部分用户正常访问。
广告是网站 的重要收入来源。 网站含有广告是很合理的现象,但是如果广告太多,会影响用户的浏览;或者网站有太多不相关的弹窗和浮动窗口广告可能会冒犯用户。
百度的目标是为用户提供最相关的搜索结果和最佳的用户体验。如果广告对用户体验造成损害,那么百度抓取时需要减少此类网站。
网站的注册权限等权限可以增加网站的注册用户,保证网站的内容质量,但是过多的权限设置可能会让新用户失去耐心,给用户带来不好的体验。从百度的角度来看,它希望减少对用户获取信息过于昂贵的网页的提供。 查看全部
鉴于技术保密以及网站运营的差异等其他原因有哪些
百度认为什么样的网站和收录比较适合爬取?我们简要介绍以下几个方面。鉴于技术保密及网站操作差异等原因,以下内容仅供站长参考。具体收录策略包括但不限于内容。

第一方面:网站创造高质量的内容,可以为用户提供独特的价值。
作为搜索引擎,百度的终极目标是满足用户的搜索需求,所以网站内容首先要满足用户的需求。如今,互联网在也能满足用户需求的前提下,充斥着大量同质化的内容。接下来,如果你网站提供的内容是独一无二的或者具有一定的独特价值,那么百度会更喜欢收录你的网站。
温馨提示:百度希望收录这样网站:
相反,很多网站的内容都是“一般或低质量”,有的网站使用欺骗手段来获得更好的收录或排名。下面是一些常见的情况,虽然无法一一列举。但请不要冒险,百度有全面的技术支持来检测和处理这些行为。
有些网站不是从用户的角度设计的,而是为了从搜索引擎中骗取更多的流量。例如,将一种类型的内容提交给搜索引擎,而将另一种类型的内容显示给用户。这些行为包括但不限于:向网页添加隐藏文本或隐藏链接;添加与网页内容无关的关键词;欺骗性地重定向或重定向;专门为搜索引擎制作桥页;目标搜索引擎利用程序生成的内容。
百度会尽量收录提供不同信息的网页。如果你的网站收录大量重复内容,搜索引擎会减少相同内容的收录,并考虑网站提供的内容价值低。
当然,如果网站上相同的内容以不同的形式展示(比如论坛的短版页面,打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。这也是真的帮助节省带宽。
第二方面:网站提供的内容得到了用户和站长的认可和支持
如果网站上的内容得到用户和站长的认可,对于百度来说,收录也是值得的。百度将通过分析真实用户的搜索行为、访问行为以及网站之间的关系,对网站的认可度进行综合评价。不过值得注意的是,这种认可必须基于网站为用户提供优质内容,并且是真实有效的。下面仅以网站之间的关系为例,说明百度如何看待其他站长对你网站的认可:通常网站之间的链接可以帮助百度爬虫找到你的网站,增加你的网站认出。百度将网页A到网页B的链接解释为网页A到网页B的投票。对一个网页的投票更能体现网页本身的“认可度”权重,有助于提高其他网站的“认可度”页。链接的数量、质量和相关性会影响“接受度”的计算。
但请注意,并非所有链接都可以参与识别计算,只有那些自然链接才有效。 (当其他网站发现您的内容有价值并认为它可能对访问者有帮助时,自然链接是在网络动态生成过程中形成的。)
其他网站 创建与您的网站 相关的链接的最佳方式是创建可以在互联网上流行的独特且相关的内容。您的内容越有用,其他网站管理员就越容易发现您的内容对其用户有价值,因此链接到您的网站 也就越容易。在决定是否添加链接之前,您应该首先考虑:这对我的网站访问者真的有好处吗?
但是,一些网站站长经常不顾链接质量和链接来源,进行链接交换,人为地建立链接关系,仅以识别为目的,这将对他们的网站造成长期影响。
提醒:会对网站产生不利影响的链接包括但不限于:
第三方面:网站具有良好的浏览体验
一个网站有很好的浏览体验,所以对用户非常有利。百度也会认为这样的网站具有更好的收录价值。良好的浏览体验意味着:
为用户提供站点地图和导航,其中收录指向网站 重要部分的链接。让用户可以清晰、简单地浏览网站,快速找到自己需要的信息。
网站速快可以提高用户满意度和网页的整体质量(特别是对于互联网连接速度较慢的用户)。
确保网站的内容在不同浏览器中都能正确显示,防止部分用户正常访问。
广告是网站 的重要收入来源。 网站含有广告是很合理的现象,但是如果广告太多,会影响用户的浏览;或者网站有太多不相关的弹窗和浮动窗口广告可能会冒犯用户。
百度的目标是为用户提供最相关的搜索结果和最佳的用户体验。如果广告对用户体验造成损害,那么百度抓取时需要减少此类网站。
网站的注册权限等权限可以增加网站的注册用户,保证网站的内容质量,但是过多的权限设置可能会让新用户失去耐心,给用户带来不好的体验。从百度的角度来看,它希望减少对用户获取信息过于昂贵的网页的提供。
山西事业单位考试:动态网页抓取(解析真实地址+selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-07-14 01:04
第四章:动态网页爬取(解析真实地址+selenium)
由于网易云线程服务暂停,新写的第4章现更新到这里。请参考文章:
之前抓取的网页都是静态网页,浏览器中显示的此类网页的内容都在HTML源代码中。但是,由于主流的网站使用JavaScript来展示网页内容,与静态网页不同,使用JavaScript时,很多内容不会出现在HTML源代码中,因此抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网络爬虫:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的例子,让读者了解什么是动态抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态捕捉示例
在抓取动态网页之前,我们还需要了解一种异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于通过后台与服务器的少量数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果需要更新传统网页的内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更用户友好。但是AJAX网页的抓取过程比较麻烦。
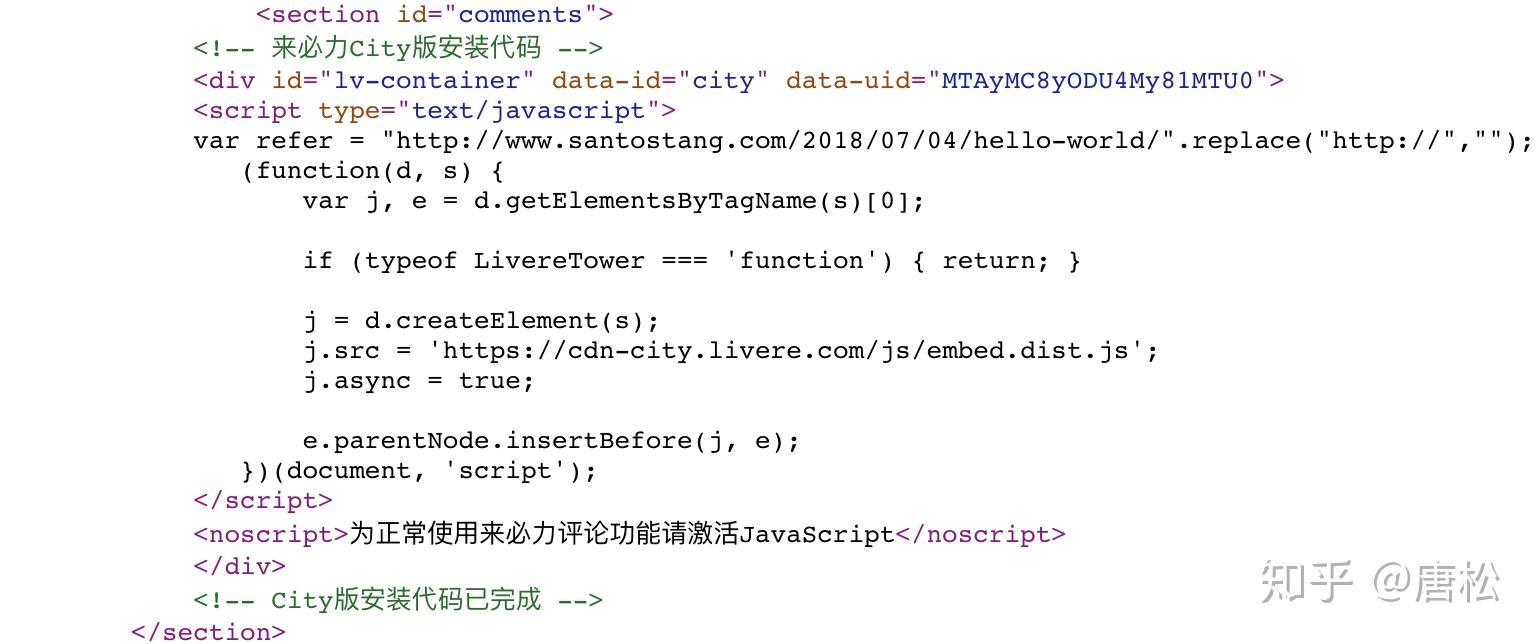
首先,让我们看一个动态网页的例子。在作者的博客上打开Hello World文章,文章地址:/2018/07/04/hello-world/。网站可能有变动,请到作者官网查找Hello World文章地址。如图4-1所示,页面下方的评论加载了JavaScript,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的源代码。如图4-2所示,放置注释的代码中没有注释数据。只有一段 JavaScript 代码。最后呈现的数据是通过JavaScript提取出来的,加载到源代码中进行呈现。
除了作者的博客,你还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评价”,可以发现上面的URL地址没有变化,整个网页没有重新加载,网页的评论部分有已更新,如图 4-3 所示。显示。
如图4-4所示,我们也可以查看该产品网页的源码。里面没有用户评论,这段内容是空白的。
如果使用 AJAX 加载的动态网页,如何抓取动态加载的内容?有两种方式:
(1)通过浏览器评论元素解析地址。
(2)Selenium 模拟浏览器爬行。
请查看第四章的其他章节
4.2 解析真实地址爬取
4.3 通过 selenium 模拟浏览器爬行 查看全部
山西事业单位考试:动态网页抓取(解析真实地址+selenium)
第四章:动态网页爬取(解析真实地址+selenium)
由于网易云线程服务暂停,新写的第4章现更新到这里。请参考文章:
之前抓取的网页都是静态网页,浏览器中显示的此类网页的内容都在HTML源代码中。但是,由于主流的网站使用JavaScript来展示网页内容,与静态网页不同,使用JavaScript时,很多内容不会出现在HTML源代码中,因此抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网络爬虫:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的例子,让读者了解什么是动态抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态捕捉示例
在抓取动态网页之前,我们还需要了解一种异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于通过后台与服务器的少量数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果需要更新传统网页的内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更用户友好。但是AJAX网页的抓取过程比较麻烦。
首先,让我们看一个动态网页的例子。在作者的博客上打开Hello World文章,文章地址:/2018/07/04/hello-world/。网站可能有变动,请到作者官网查找Hello World文章地址。如图4-1所示,页面下方的评论加载了JavaScript,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的源代码。如图4-2所示,放置注释的代码中没有注释数据。只有一段 JavaScript 代码。最后呈现的数据是通过JavaScript提取出来的,加载到源代码中进行呈现。
除了作者的博客,你还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评价”,可以发现上面的URL地址没有变化,整个网页没有重新加载,网页的评论部分有已更新,如图 4-3 所示。显示。
如图4-4所示,我们也可以查看该产品网页的源码。里面没有用户评论,这段内容是空白的。

如果使用 AJAX 加载的动态网页,如何抓取动态加载的内容?有两种方式:
(1)通过浏览器评论元素解析地址。
(2)Selenium 模拟浏览器爬行。
请查看第四章的其他章节
4.2 解析真实地址爬取
4.3 通过 selenium 模拟浏览器爬行
杭州SEO:搜索引擎优化对企业和产品都具有重要的意义
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-07-12 19:03
在这个互联网时代,很多人在购买新产品之前都会上网查看信息内容,看看哪些品牌的口碑和评价更好。这时候,好的产品就会有好的优势。调查显示,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会在搜索结果自然排名的第一页直接找到自己需要的信息。
因此,可见搜索引擎优化对企业和产品的意义重大。杭州SEO告诉你如何在网站上快速爬取。
我们经常听到关键字,但关键字的具体主要用途是什么? 关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的一个非常重要的过程,它会间接影响网站在搜索引擎中的权重。现阶段我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
crawler 是一个自动提取网页的程序,比如百度的蜘蛛。如果你想收录更多网站的页面,一定要先爬网。
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是最原创的内容。
这一定是第一件事。对权势大、资历大、权威大的蜘蛛,必须采取特殊的处理方法。这种网站的爬取频率非常高。我们都知道,搜索引擎蜘蛛为了保证高效,不会抓取网站的所有页面。 网站的权重越高,爬取深度越高,爬取的页面也就越多。这样,可以收录更多的页面。
网站server 是网站 的基石。如果网站服务器长时间打不开,那么就相当于关机谢客了。如果蜘蛛想来,他就不能来。百度蜘蛛也是这个网站的访客。如果你的服务器不稳定或卡住,蜘蛛每次都很难爬行。有时一个页面只能抓取其中的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的分数也越来越低。自然会影响你的网站爬取,所以选择空间服务器。我们必须放弃。没有好的地基,再好的房子也会过马路。
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次的内容完全一样,说明页面没有更新,蜘蛛不需要经常爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问网页,但蜘蛛不是你自己的,所以不可能蹲在这里等你更新。因此,我们应该主动向蜘蛛展示并及时更新文章,这样蜘蛛就会按照你的规则有效地爬取文章,这样不仅会让你更新的文章更快,不会让蜘蛛白跑。
高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新事物。所以网站更新的文章不能天天采集或者转载。我们需要给蜘蛛提供真正有价值的原创 内容。如果一只蜘蛛能得到它喜欢的东西,它自然会给你的网站留下好印象,它也会经常来觅食。
蜘蛛也有自己的捕食方法。在为他们铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接级别太深,蜘蛛将难以抓取下面的页面。
在网站程序中,有很多程序可以生成大量的重复页面,而这些页面一般都是通过参数来实现的。当一个页面对应大量的URL时,会导致网站内容重复,从而可能导致网站降级,严重影响蜘蛛抓取。因此,程序必须确保页面只有一个 URL(如果它被生成)。尝试通过 301 重定向、规范标签或机器人来处理它,以确保蜘蛛只捕获标准 URL。
大家都知道外链可以把蜘蛛吸引到网站,尤其是在新站里,网站还不是很成熟,蜘蛛的访问量也比较少,外链可以增加网站页面前面的曝光率蜘蛛 防止蜘蛛发现页面。在外链建设过程中,要注意外链的质量。不要为了避免麻烦而做无用的事情。百度现在相信大家都知道外链的管理,就不多说了。善良不做坏事。
蜘蛛沿着链接爬行,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的采集。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这是很多网站 正在使用的,蜘蛛可以抓取更广泛的页面。
首页是蜘蛛访问量最大的页面,也是网站权重好的页面。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛的访问频率,还可以提高对更新页面的抓取和采集。栏目页面也可以这样做。
搜索引擎蜘蛛抓取链接进行搜索。如果链接太多,不仅网页数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。当蜘蛛碰到死链时,它就像一个死胡同。他们不得不回去再回来,这大大降低了蜘蛛爬行网站的效率。所以一定要及时检查网站的死链接,提交给搜索引擎。同时还要做好网站404页面的处理,告知搜索引擎错误的页面。
很多网站有意无意地直接在robots文件中屏蔽了百度或网站的某些页面,但他们一直在寻找蜘蛛整天不爬我的页面的原因。百度会因此受到指责吗?如果你不让别人进来,那百度收录你的页面呢?所以如果有必要,请经常检查网站的robots文件是否正常。
搜索引擎蜘蛛非常喜欢网站map。 网站map 是网站 的所有链接的容器。很多网站都有很深的链接,蜘蛛很难掌握。 网站map 可以方便搜索引擎蜘蛛抓取网站页面。通过爬网,他们可以清楚地掌握网站的结构,所以网站地图的建立不仅可以提高爬网率,还可以很好地获得蜘蛛的感觉。
这也是在每次页面更新后向搜索引擎提交内容的好方法,但不要总是在没有内容的情况下提交。只需提交一次。接受程度取决于搜索引擎。 查看全部
杭州SEO:搜索引擎优化对企业和产品都具有重要的意义
在这个互联网时代,很多人在购买新产品之前都会上网查看信息内容,看看哪些品牌的口碑和评价更好。这时候,好的产品就会有好的优势。调查显示,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会在搜索结果自然排名的第一页直接找到自己需要的信息。
因此,可见搜索引擎优化对企业和产品的意义重大。杭州SEO告诉你如何在网站上快速爬取。
我们经常听到关键字,但关键字的具体主要用途是什么? 关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。

导入链接也是网站优化的一个非常重要的过程,它会间接影响网站在搜索引擎中的权重。现阶段我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
crawler 是一个自动提取网页的程序,比如百度的蜘蛛。如果你想收录更多网站的页面,一定要先爬网。
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是最原创的内容。
这一定是第一件事。对权势大、资历大、权威大的蜘蛛,必须采取特殊的处理方法。这种网站的爬取频率非常高。我们都知道,搜索引擎蜘蛛为了保证高效,不会抓取网站的所有页面。 网站的权重越高,爬取深度越高,爬取的页面也就越多。这样,可以收录更多的页面。
网站server 是网站 的基石。如果网站服务器长时间打不开,那么就相当于关机谢客了。如果蜘蛛想来,他就不能来。百度蜘蛛也是这个网站的访客。如果你的服务器不稳定或卡住,蜘蛛每次都很难爬行。有时一个页面只能抓取其中的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的分数也越来越低。自然会影响你的网站爬取,所以选择空间服务器。我们必须放弃。没有好的地基,再好的房子也会过马路。
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次的内容完全一样,说明页面没有更新,蜘蛛不需要经常爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问网页,但蜘蛛不是你自己的,所以不可能蹲在这里等你更新。因此,我们应该主动向蜘蛛展示并及时更新文章,这样蜘蛛就会按照你的规则有效地爬取文章,这样不仅会让你更新的文章更快,不会让蜘蛛白跑。
高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新事物。所以网站更新的文章不能天天采集或者转载。我们需要给蜘蛛提供真正有价值的原创 内容。如果一只蜘蛛能得到它喜欢的东西,它自然会给你的网站留下好印象,它也会经常来觅食。

蜘蛛也有自己的捕食方法。在为他们铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接级别太深,蜘蛛将难以抓取下面的页面。
在网站程序中,有很多程序可以生成大量的重复页面,而这些页面一般都是通过参数来实现的。当一个页面对应大量的URL时,会导致网站内容重复,从而可能导致网站降级,严重影响蜘蛛抓取。因此,程序必须确保页面只有一个 URL(如果它被生成)。尝试通过 301 重定向、规范标签或机器人来处理它,以确保蜘蛛只捕获标准 URL。
大家都知道外链可以把蜘蛛吸引到网站,尤其是在新站里,网站还不是很成熟,蜘蛛的访问量也比较少,外链可以增加网站页面前面的曝光率蜘蛛 防止蜘蛛发现页面。在外链建设过程中,要注意外链的质量。不要为了避免麻烦而做无用的事情。百度现在相信大家都知道外链的管理,就不多说了。善良不做坏事。
蜘蛛沿着链接爬行,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的采集。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这是很多网站 正在使用的,蜘蛛可以抓取更广泛的页面。
首页是蜘蛛访问量最大的页面,也是网站权重好的页面。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛的访问频率,还可以提高对更新页面的抓取和采集。栏目页面也可以这样做。
搜索引擎蜘蛛抓取链接进行搜索。如果链接太多,不仅网页数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。当蜘蛛碰到死链时,它就像一个死胡同。他们不得不回去再回来,这大大降低了蜘蛛爬行网站的效率。所以一定要及时检查网站的死链接,提交给搜索引擎。同时还要做好网站404页面的处理,告知搜索引擎错误的页面。
很多网站有意无意地直接在robots文件中屏蔽了百度或网站的某些页面,但他们一直在寻找蜘蛛整天不爬我的页面的原因。百度会因此受到指责吗?如果你不让别人进来,那百度收录你的页面呢?所以如果有必要,请经常检查网站的robots文件是否正常。
搜索引擎蜘蛛非常喜欢网站map。 网站map 是网站 的所有链接的容器。很多网站都有很深的链接,蜘蛛很难掌握。 网站map 可以方便搜索引擎蜘蛛抓取网站页面。通过爬网,他们可以清楚地掌握网站的结构,所以网站地图的建立不仅可以提高爬网率,还可以很好地获得蜘蛛的感觉。
这也是在每次页面更新后向搜索引擎提交内容的好方法,但不要总是在没有内容的情况下提交。只需提交一次。接受程度取决于搜索引擎。
3种抓取其中数据的方法,你get到了吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-07-08 23:03
3 种捕获数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1正则表达式
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re
>>> from chp1.advanced_link_crawler import download>>> url = 'http://example.python-scraping.com/view/UnitedKingdom-239'>>> html = download(url)>>> re.findall(r'(.*?)', html)['', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', '<a>EU</a>', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]d{2}[A-Z]{2})|([A-Z]d{3}[A-Z]{2})|([A-Z]{2}d{2} [A-Z]{2})|([A-Z]{2}d{3}[A-Z]{2})|([A-Z]d[A-Z]d[A-Z]{2}) |([A-Z]{2}d[A-Z]d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', '<a>IE </a>']
点击并拖拽以移动
从上面的结果可以看出,多个国家(或地区)属性使用了``标签。如果我们只想捕获国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个计划,但是如果页面发生变化,该计划很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望在未来的某个时间点再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加明确,我们还可以添加其父元素。因为这个元素有一个 ID 属性,所以它应该是唯一的。
>>> re.findall('Area:
(.*?)', html)['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)
['244,820 square kilometres']
这个正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加title 属性,或者为tr 和td` 元素修改其CSS 类或ID。
从这个例子中可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,而且很容易在网页更新后出现问题。幸运的是,还有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签打开和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。下面我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> from pprint import pprint>>> broken_html = 'AreaPopulation'>>> # parse the HTML>>> soup = BeautifulSoup(broken_html, 'html.parser')>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
我们可以看到,使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装 LXML(详见2.2.3 部分),或者使用 html5lib。要安装 html5lib,只需使用 pip。
pip install html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>> soup = BeautifulSoup(broken_html, 'html5lib')
>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
此时使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加&标签使其成为完整的HTML文档。当你使用 lxml 时,你可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country_or_district'})
>>> ul.find('li') # returns just the first matchArea>>> ul.find_all('li') # returns all matches[Area, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.python-scraping.com/places/view/United-Kingdom-239'>>> html = download(url)>>> soup = BeautifulSoup(html)>>> # locate the area row>>> tr = soup.find(attrs={'id':'places_area__row'})>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the data element>>> area = td.text # extract the text from the data element>>> print(area)244,820 square kilometres
虽然这段代码比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的网站 代码中提取数据。
3Lxml
Lxml
它是一个基于 libxml2 构建的 Python 库,一个 XML 解析库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用Anaconda的快速安装会将你的PYTHON_PATH设置为Conda的Python安装位置。
和 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。下面是使用该模块解析同样不完整的 HTML 的示例。
>>> from lxml.html import fromstring, tostring
>>> broken_html = 'AreaPopulation'>>> tree = fromstring(broken_html) # parse the HTML>>> fixed_html = tostring(tree, pretty_print=True)>>> print(fixed_html) Area Population
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验,或者它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip install cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]>>> area = td.text_content()>>> print(area)244,820 square kilometres
通过代码树上的cssselect方法,我们可以使用CSS语法来选择表中id为places_area__row的行元素,然后是w2p_fw类的子表数据标签。由于cssselect返回的是一个列表,所以我们需要获取第一个结果并调用text_content方法遍历所有子元素,并返回每个元素的相关文本。 查看全部
3种抓取其中数据的方法,你get到了吗?
3 种捕获数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1正则表达式
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re
>>> from chp1.advanced_link_crawler import download>>> url = 'http://example.python-scraping.com/view/UnitedKingdom-239'>>> html = download(url)>>> re.findall(r'(.*?)', html)['', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', '<a>EU</a>', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]d{2}[A-Z]{2})|([A-Z]d{3}[A-Z]{2})|([A-Z]{2}d{2} [A-Z]{2})|([A-Z]{2}d{3}[A-Z]{2})|([A-Z]d[A-Z]d[A-Z]{2}) |([A-Z]{2}d[A-Z]d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', '<a>IE </a>']
点击并拖拽以移动
从上面的结果可以看出,多个国家(或地区)属性使用了``标签。如果我们只想捕获国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个计划,但是如果页面发生变化,该计划很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望在未来的某个时间点再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加明确,我们还可以添加其父元素。因为这个元素有一个 ID 属性,所以它应该是唯一的。
>>> re.findall('Area:
(.*?)', html)['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)
['244,820 square kilometres']
这个正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加title 属性,或者为tr 和td` 元素修改其CSS 类或ID。
从这个例子中可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,而且很容易在网页更新后出现问题。幸运的是,还有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签打开和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。下面我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> from pprint import pprint>>> broken_html = 'AreaPopulation'>>> # parse the HTML>>> soup = BeautifulSoup(broken_html, 'html.parser')>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
我们可以看到,使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装 LXML(详见2.2.3 部分),或者使用 html5lib。要安装 html5lib,只需使用 pip。
pip install html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>> soup = BeautifulSoup(broken_html, 'html5lib')
>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
此时使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加&标签使其成为完整的HTML文档。当你使用 lxml 时,你可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country_or_district'})
>>> ul.find('li') # returns just the first matchArea>>> ul.find_all('li') # returns all matches[Area, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.python-scraping.com/places/view/United-Kingdom-239'>>> html = download(url)>>> soup = BeautifulSoup(html)>>> # locate the area row>>> tr = soup.find(attrs={'id':'places_area__row'})>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the data element>>> area = td.text # extract the text from the data element>>> print(area)244,820 square kilometres
虽然这段代码比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的网站 代码中提取数据。
3Lxml
Lxml
它是一个基于 libxml2 构建的 Python 库,一个 XML 解析库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用Anaconda的快速安装会将你的PYTHON_PATH设置为Conda的Python安装位置。
和 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。下面是使用该模块解析同样不完整的 HTML 的示例。
>>> from lxml.html import fromstring, tostring
>>> broken_html = 'AreaPopulation'>>> tree = fromstring(broken_html) # parse the HTML>>> fixed_html = tostring(tree, pretty_print=True)>>> print(fixed_html) Area Population
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验,或者它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip install cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]>>> area = td.text_content()>>> print(area)244,820 square kilometres
通过代码树上的cssselect方法,我们可以使用CSS语法来选择表中id为places_area__row的行元素,然后是w2p_fw类的子表数据标签。由于cssselect返回的是一个列表,所以我们需要获取第一个结果并调用text_content方法遍历所有子元素,并返回每个元素的相关文本。
维基百科:Web搜寻器开发的免费开放源代码(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-07-08 22:52
来自维基百科
网络爬虫(有时称为蜘蛛)是互联网机器人,通常系统地浏览网络索引以进行网络索引。
网络爬虫从要访问的 URL 列表(称为种子)开始。当爬虫访问这些 URL 时,它会识别页面中的所有超链接,并将它们添加到要访问的 URL 列表中。如果爬虫正在执行网站的归档,它会复制并保存信息。存档称为存储库,旨在存储和管理网页集合。存储库类似于任何其他存储数据的系统,例如现代数据库。
让我们开始吧! !
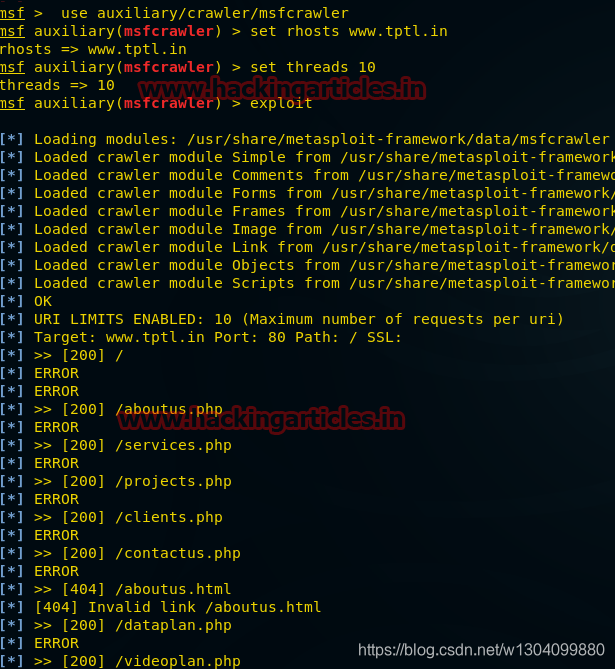
Metasploit
这个辅助模块是一个模块化的网络爬虫,可以与wmap(有时)或独立使用。
使用辅助/爬虫/msfcrawler
msf 辅助(msfcrawler)> 设置 rhosts
msf 辅助(msfcrawler)> 漏洞利用
从截图中可以看到截图已经加载了搜索引擎,这样就可以对任何网站准确隐藏文件,比如about.php、jquery联系表单、html等,同时使用浏览器无法准确隐藏网站。为了采集任何网站信息,我们可以使用它。
Httrack
HTTrack 是 Xavier Roche 开发的免费开源网络搜索器和离线浏览器
它可以让你将网上的wanwei网站dots下载到本地目录,递归构建所有目录,从服务器获取HTML、图片等文件到电脑。 HTTrack 整理原站的相对链接结构。
在终端输入以下命令
httrack –O /root/Desktop/file
它将输出保存在给定的目录 /root/Desktop/file 中。
从给定的屏幕截图中,您可以观察到这一点,它使网站 信息包括 html 文件以及 JavaScript 和 jquery 变得愚蠢
黑寡妇
此Web Spider实用程序检测并显示用户选择的网页的详细信息,并提供其他网络工具。
BlackWidow 干净、合乎逻辑的标签式界面足够简单,适合中级用户,但在底部足以满足高级用户的需求。只需输入您选择的 URL,然后按 Go。 BlackWidow 使用多线程快速下载所有文件和测试链接。对于小网站,这个操作只需要几分钟。
您可以从这里下载。
在地址字段中输入您的 URL,然后按 Go。
点击开始按钮开始扫描左边的网址,然后选择一个文件夹来保存输出文件按钮。
从截图中可以看出,我浏览了 C:\Users\RAJ\Desktop\tptl 以便将输出文件存储在其中。
打开目标文件夹tptl,会得到网站图片或内容的完整数据,html文件、php文件和JavaScript都存储在里面。
网站开膛手复印机
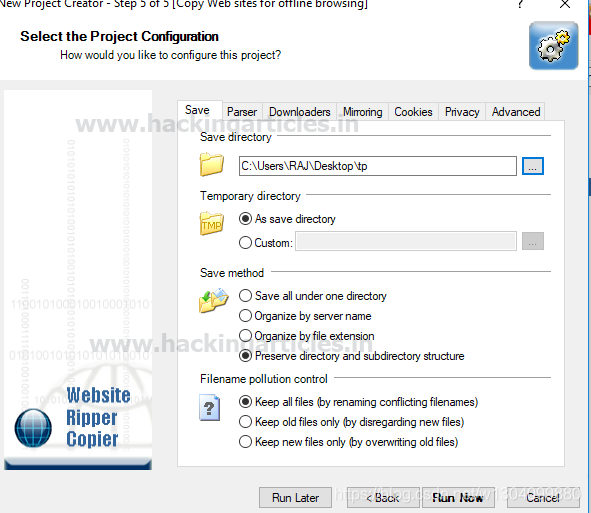
Website Ripper Copier (WRC) 是一种通用高速网站downloader 软件,用于保存网站 数据。 WRC 可以将网站 文件下载到本地驱动器进行离线浏览,提取特定大小和类型的网站 文件,例如图像、视频、图片、电影和音乐,并充当具有恢复支持的下载管理器 检索大量的文件和镜像站点。 WRC 还是站点链接验证器、资源管理器和选项卡式反弹网页/离线浏览器。
Website Ripper Copier 是唯一可以从 HTTP、HTTPS 和 FTP 连接恢复中断下载、访问受密码保护的 网站、支持 Web Cookie、分析脚本、更新检索到的 网站 或文件并启动 50 @K14 的下载用于多个检索线程的@downloader 工具
您可以从这里下载。
选择“离线浏览网站(网站)”选项。
输入网站URL 并点击下一步。
提取目录路径保存输出结果,然后点击立即运行。
当你打开选定的文件夹 tp 时,你会在其中看到 CSS、php、html 和 js 文件。
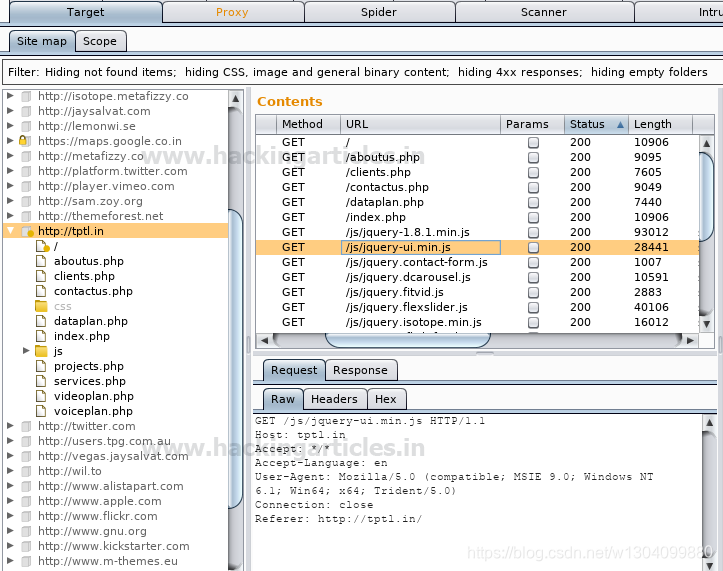
Burp Suite Spider
Burp Spider 是一款自动抓取 Web 应用程序的工具。通常最好手动映射应用程序,但对于非常大的应用程序或时间不足的情况,可以使用 Burp Spider 来部分自动化此过程。
欲了解更多详情,请从这里阅读我们之前的文章。
从给定的截图中,您可以观察到我获得的http请求;现在它在“Operation”标签的帮助下发送给Spider。
Target网站 已添加到站点地图中“目标”选项卡下的位置,作为网络爬行的新范围。从截图中可以看出,它启动了对目标网站 的网络爬虫。在这个网站中,它以php、html和js的形式采集了网站信息。
作者:Aarti Singh 是 Hacking Articles(信息安全顾问、社交媒体爱好者和小工具)的研究员和技术作家。入侵 查看全部
维基百科:Web搜寻器开发的免费开放源代码(图)
来自维基百科
网络爬虫(有时称为蜘蛛)是互联网机器人,通常系统地浏览网络索引以进行网络索引。
网络爬虫从要访问的 URL 列表(称为种子)开始。当爬虫访问这些 URL 时,它会识别页面中的所有超链接,并将它们添加到要访问的 URL 列表中。如果爬虫正在执行网站的归档,它会复制并保存信息。存档称为存储库,旨在存储和管理网页集合。存储库类似于任何其他存储数据的系统,例如现代数据库。
让我们开始吧! !
Metasploit
这个辅助模块是一个模块化的网络爬虫,可以与wmap(有时)或独立使用。
使用辅助/爬虫/msfcrawler
msf 辅助(msfcrawler)> 设置 rhosts
msf 辅助(msfcrawler)> 漏洞利用
从截图中可以看到截图已经加载了搜索引擎,这样就可以对任何网站准确隐藏文件,比如about.php、jquery联系表单、html等,同时使用浏览器无法准确隐藏网站。为了采集任何网站信息,我们可以使用它。
Httrack
HTTrack 是 Xavier Roche 开发的免费开源网络搜索器和离线浏览器
它可以让你将网上的wanwei网站dots下载到本地目录,递归构建所有目录,从服务器获取HTML、图片等文件到电脑。 HTTrack 整理原站的相对链接结构。
在终端输入以下命令
httrack –O /root/Desktop/file
它将输出保存在给定的目录 /root/Desktop/file 中。

从给定的屏幕截图中,您可以观察到这一点,它使网站 信息包括 html 文件以及 JavaScript 和 jquery 变得愚蠢
黑寡妇
此Web Spider实用程序检测并显示用户选择的网页的详细信息,并提供其他网络工具。
BlackWidow 干净、合乎逻辑的标签式界面足够简单,适合中级用户,但在底部足以满足高级用户的需求。只需输入您选择的 URL,然后按 Go。 BlackWidow 使用多线程快速下载所有文件和测试链接。对于小网站,这个操作只需要几分钟。
您可以从这里下载。
在地址字段中输入您的 URL,然后按 Go。

点击开始按钮开始扫描左边的网址,然后选择一个文件夹来保存输出文件按钮。
从截图中可以看出,我浏览了 C:\Users\RAJ\Desktop\tptl 以便将输出文件存储在其中。

打开目标文件夹tptl,会得到网站图片或内容的完整数据,html文件、php文件和JavaScript都存储在里面。
网站开膛手复印机
Website Ripper Copier (WRC) 是一种通用高速网站downloader 软件,用于保存网站 数据。 WRC 可以将网站 文件下载到本地驱动器进行离线浏览,提取特定大小和类型的网站 文件,例如图像、视频、图片、电影和音乐,并充当具有恢复支持的下载管理器 检索大量的文件和镜像站点。 WRC 还是站点链接验证器、资源管理器和选项卡式反弹网页/离线浏览器。
Website Ripper Copier 是唯一可以从 HTTP、HTTPS 和 FTP 连接恢复中断下载、访问受密码保护的 网站、支持 Web Cookie、分析脚本、更新检索到的 网站 或文件并启动 50 @K14 的下载用于多个检索线程的@downloader 工具
您可以从这里下载。
选择“离线浏览网站(网站)”选项。

输入网站URL 并点击下一步。

提取目录路径保存输出结果,然后点击立即运行。
当你打开选定的文件夹 tp 时,你会在其中看到 CSS、php、html 和 js 文件。

Burp Suite Spider
Burp Spider 是一款自动抓取 Web 应用程序的工具。通常最好手动映射应用程序,但对于非常大的应用程序或时间不足的情况,可以使用 Burp Spider 来部分自动化此过程。
欲了解更多详情,请从这里阅读我们之前的文章。
从给定的截图中,您可以观察到我获得的http请求;现在它在“Operation”标签的帮助下发送给Spider。

Target网站 已添加到站点地图中“目标”选项卡下的位置,作为网络爬行的新范围。从截图中可以看出,它启动了对目标网站 的网络爬虫。在这个网站中,它以php、html和js的形式采集了网站信息。
作者:Aarti Singh 是 Hacking Articles(信息安全顾问、社交媒体爱好者和小工具)的研究员和技术作家。入侵
正则表达式国家(或地区)面积数据抓取其中数据的方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-07-08 01:39
3 种捕获数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1正则表达式
如果你不熟悉正则表达式或者需要一些提示,那么你可以查看完整的介绍。即使你用过其他编程语言的正则表达式,我还是建议你一步一步复习Python中正则表达式的编写。
因为每一章都可能构建或使用前几章的内容,所以建议你遵循类似于本书代码库的文件结构。所有代码都可以从代码库的代码目录运行,这样导入才能正常进行。如果要创建不同的结构,请注意其他章节的所有导入操作都需要更改(例如以下代码中的chp1.advanced_link_crawler)。
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re>>> from chp1.advanced_link_crawler import download>>> url ='#39;>>> html = download(url)>>> re.findall(r'(.*? )', html)['
','244,820 平方公里','62,348,447','GB','英国','伦敦','EU','.uk','GBP','英镑','44',' @##@@|@###@@|@@##@@|@@###@@|@#@ #@@|@@#@ #@@|GIR0AA','^(( [AZ]d{2}[AZ]{2})|([AZ]d{3}[AZ]{2})|([AZ]{2}d{2} [AZ]{2})| ([AZ]{2}d{3}[AZ]{2})|([AZ]d[AZ]d[AZ]{2})|([AZ]{2}d[AZ]d[AZ] ]{2})|(GIR0AA))$','en-GB,cy-GB,gd','
浏览器
']
从上面的结果可以看出,多个国家(或地区)属性使用了``标签。如果我们只想捕获国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]'244,820 平方公里'
虽然现在可以使用这个计划,但是如果页面发生变化,该计划很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望能够在未来的某个时刻再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加明确,我们还可以添加其父元素。因为这个元素有一个 ID 属性,所以它应该是唯一的。
>>> re.findall('(.*?)', html)['244,820 平方公里']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)['244,820平方公里']
这个正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加title 属性,或者为tr 和td` 元素修改其CSS 类或ID。
从这个例子中可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,而且很容易在网页更新后出现问题。幸运的是,还有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签打开和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。下面我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup>>> from pprint import pprint>>>broken_html =''>>> # 解析HTML>>>soup = BeautifulSoup(broken_html,'html.parser')>>> fixed_html =soup.prettify()>>> pprint(fixed_html)
我们可以看到,使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装 LXML(详见2.2.3 部分),或者使用 html5lib。要安装 html5lib,只需使用 pip。
pip 安装 html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>>soup = BeautifulSoup(broken_html,'html5lib')>>> fixed_html = soup.prettify()>>> pprint(fixed_html)
此时使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加&标签使其成为完整的HTML文档。当你使用 lxml 时,你可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs=('class':'country_or_district'))>>> ul.find('li') # 只返回第一个匹配区域>>> ul. find_all('li') # 返回所有匹配项[Area, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup>>> url ='#39;>>> html = download(url)>>> soup = BeautifulSoup(html)>>> # 定位区域行>>> tr = soup.find(attrs={'id':'places_area__row'})>>>td = tr.find(attrs={'class':'w2p_fw'}) # 定位数据元素>>> area = td.text # 从数据元素中提取文本>>> print(area)244,820 平方公里
虽然这段代码比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的网站 代码中提取数据。
3Lxml
Lxml
它是一个基于 libxml2 构建的 Python 库,一个 XML 解析库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。您可以参考最新的安装说明。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用Anaconda的快速安装会将你的PYTHON_PATH设置为Conda的Python安装位置。
和 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。下面是使用该模块解析同样不完整的 HTML 的示例。
>>> from lxml.html import fromstring, tostring>>>broken_html =''>>> tree = fromstring(broken_html) # 解析HTML>>>fixed_html = tostring(tree,pretty_print=True)>>>打印(fixed_html)
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验或它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip 安装 cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)>>> td = tree.cssselect('tr#places_area__row> td.w2p_fw')[0]>>> area = td.text_content()>>> print(area )244,820 平方公里
通过在代码树上使用cssselect方法,我们可以使用CSS语法选择表中ID为places_area__row的行元素,然后选择类w2p_fw的子表数据标签。由于cssselect返回的是一个列表,我们需要获取第一个结果并调用text_content方法迭代所有子元素并返回每个元素的相关文本。在这个例子中,虽然我们只有一个元素,但这个特征对于更复杂的提取例子非常有用。
本文摘自:《Writing Web Crawlers in Python (2nd Edition)》
作者:[德国]凯瑟琳·贾穆尔(Katharine Jarmul)、[澳大利亚]理查德·劳森(Richard Lawson)
译者:李斌
为 Python 3.6 版本编写。
提供示例完整源代码和示例网站构建源代码,确保用户在本地成功重现爬取网站环境,并保证网站的稳定性和可靠性以及代码运行结果的可复现性。
互联网收录大量有用的数据,其中大部分是免费且可公开访问的。然而,这些数据并不容易使用。它们嵌入在网站的结构和样式中,提取时需要小心。作为一种采集和了解 Internet 上信息量的方法,网络抓取技术正变得越来越有用。
本书是使用Python3.6的新特性爬取网络数据的入门指南。本书解释了如何从静态网站中提取数据,以及如何使用数据库和文件缓存技术来节省时间和管理服务器负载,然后介绍如何使用浏览器、爬虫和并发爬虫来开发更复杂的爬虫。
借助 PyQt 和 Selenium,您可以决定何时以及如何从依赖 JavaScript 的 网站 抓取数据,并更好地了解如何在受 CAPTCHA 保护的复杂 网站 上提交表单。书中还讲解了如何使用Python包(如mechanize)进行自动化处理,如何使用Scrapy库创建基于类的爬虫,以及如何实现在真实网站上学到的爬虫技巧。
在本书的最后,它还涵盖了使用爬虫测试网站、远程爬虫技术、图像处理和其他相关主题。 查看全部
正则表达式国家(或地区)面积数据抓取其中数据的方法
3 种捕获数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1正则表达式
如果你不熟悉正则表达式或者需要一些提示,那么你可以查看完整的介绍。即使你用过其他编程语言的正则表达式,我还是建议你一步一步复习Python中正则表达式的编写。
因为每一章都可能构建或使用前几章的内容,所以建议你遵循类似于本书代码库的文件结构。所有代码都可以从代码库的代码目录运行,这样导入才能正常进行。如果要创建不同的结构,请注意其他章节的所有导入操作都需要更改(例如以下代码中的chp1.advanced_link_crawler)。
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re>>> from chp1.advanced_link_crawler import download>>> url ='#39;>>> html = download(url)>>> re.findall(r'(.*? )', html)['
','244,820 平方公里','62,348,447','GB','英国','伦敦','EU','.uk','GBP','英镑','44',' @##@@|@###@@|@@##@@|@@###@@|@#@ #@@|@@#@ #@@|GIR0AA','^(( [AZ]d{2}[AZ]{2})|([AZ]d{3}[AZ]{2})|([AZ]{2}d{2} [AZ]{2})| ([AZ]{2}d{3}[AZ]{2})|([AZ]d[AZ]d[AZ]{2})|([AZ]{2}d[AZ]d[AZ] ]{2})|(GIR0AA))$','en-GB,cy-GB,gd','
浏览器
']
从上面的结果可以看出,多个国家(或地区)属性使用了``标签。如果我们只想捕获国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]'244,820 平方公里'
虽然现在可以使用这个计划,但是如果页面发生变化,该计划很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望能够在未来的某个时刻再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加明确,我们还可以添加其父元素。因为这个元素有一个 ID 属性,所以它应该是唯一的。
>>> re.findall('(.*?)', html)['244,820 平方公里']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)['244,820平方公里']
这个正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加title 属性,或者为tr 和td` 元素修改其CSS 类或ID。
从这个例子中可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,而且很容易在网页更新后出现问题。幸运的是,还有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签打开和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。下面我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup>>> from pprint import pprint>>>broken_html =''>>> # 解析HTML>>>soup = BeautifulSoup(broken_html,'html.parser')>>> fixed_html =soup.prettify()>>> pprint(fixed_html)
我们可以看到,使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装 LXML(详见2.2.3 部分),或者使用 html5lib。要安装 html5lib,只需使用 pip。
pip 安装 html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>>soup = BeautifulSoup(broken_html,'html5lib')>>> fixed_html = soup.prettify()>>> pprint(fixed_html)
此时使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加&标签使其成为完整的HTML文档。当你使用 lxml 时,你可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs=('class':'country_or_district'))>>> ul.find('li') # 只返回第一个匹配区域>>> ul. find_all('li') # 返回所有匹配项[Area, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup>>> url ='#39;>>> html = download(url)>>> soup = BeautifulSoup(html)>>> # 定位区域行>>> tr = soup.find(attrs={'id':'places_area__row'})>>>td = tr.find(attrs={'class':'w2p_fw'}) # 定位数据元素>>> area = td.text # 从数据元素中提取文本>>> print(area)244,820 平方公里
虽然这段代码比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的网站 代码中提取数据。
3Lxml
Lxml
它是一个基于 libxml2 构建的 Python 库,一个 XML 解析库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。您可以参考最新的安装说明。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用Anaconda的快速安装会将你的PYTHON_PATH设置为Conda的Python安装位置。
和 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。下面是使用该模块解析同样不完整的 HTML 的示例。
>>> from lxml.html import fromstring, tostring>>>broken_html =''>>> tree = fromstring(broken_html) # 解析HTML>>>fixed_html = tostring(tree,pretty_print=True)>>>打印(fixed_html)
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验或它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip 安装 cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)>>> td = tree.cssselect('tr#places_area__row> td.w2p_fw')[0]>>> area = td.text_content()>>> print(area )244,820 平方公里
通过在代码树上使用cssselect方法,我们可以使用CSS语法选择表中ID为places_area__row的行元素,然后选择类w2p_fw的子表数据标签。由于cssselect返回的是一个列表,我们需要获取第一个结果并调用text_content方法迭代所有子元素并返回每个元素的相关文本。在这个例子中,虽然我们只有一个元素,但这个特征对于更复杂的提取例子非常有用。
本文摘自:《Writing Web Crawlers in Python (2nd Edition)》
作者:[德国]凯瑟琳·贾穆尔(Katharine Jarmul)、[澳大利亚]理查德·劳森(Richard Lawson)
译者:李斌

为 Python 3.6 版本编写。
提供示例完整源代码和示例网站构建源代码,确保用户在本地成功重现爬取网站环境,并保证网站的稳定性和可靠性以及代码运行结果的可复现性。
互联网收录大量有用的数据,其中大部分是免费且可公开访问的。然而,这些数据并不容易使用。它们嵌入在网站的结构和样式中,提取时需要小心。作为一种采集和了解 Internet 上信息量的方法,网络抓取技术正变得越来越有用。
本书是使用Python3.6的新特性爬取网络数据的入门指南。本书解释了如何从静态网站中提取数据,以及如何使用数据库和文件缓存技术来节省时间和管理服务器负载,然后介绍如何使用浏览器、爬虫和并发爬虫来开发更复杂的爬虫。
借助 PyQt 和 Selenium,您可以决定何时以及如何从依赖 JavaScript 的 网站 抓取数据,并更好地了解如何在受 CAPTCHA 保护的复杂 网站 上提交表单。书中还讲解了如何使用Python包(如mechanize)进行自动化处理,如何使用Scrapy库创建基于类的爬虫,以及如何实现在真实网站上学到的爬虫技巧。
在本书的最后,它还涵盖了使用爬虫测试网站、远程爬虫技术、图像处理和其他相关主题。
访客爬取:解密网站获取访问者手机号的方法和原理
网站优化 • 优采云 发表了文章 • 0 个评论 • 550 次浏览 • 2021-07-06 22:41
网站访问者,可以安装在线客服系统,如商桥、53客服等,以前有网站类型的安装码,但为了保护用户隐私,现在当前不可用。也可以用一品的大数据分析来获取用户,但这仅限于手机。前提是你的网站必须有流量,不然没人访问,软件再好也没用。
网站访问者手机号的抓取效果好吗?
部分客户安装后立即使用手机进行测试,发现无法获取手机号码。这是不科学的。有一定几率抢到,数量大才能看到效果。比如一百个访客能抢到30个号和50个号是正常的。记住,如果几个人访问它们,它们就无法被抓取,这意味着该软件没有效果。
通过测试我们的软件爬行率超过 60%,它实际上可以帮助中小企业建立潜在客户群并为公司带来真正的交易量。
访客爬取:解密网站获取访客手机号的方法和原理
近日,网上出现了一个手机号码。访问者访问您的网站时可以获得他们的手机号码。许多公司将其用于盈利,有些公司出售一套程序。
经过几天的分析和研究,只开发了一个极其简单的方法。还有其他方法没找到。
目前在网上获取网站visitor手机号的方式有很多种。简而言之:抢到指定的网站visitor 手机号。
1、分析手机号控制,然后跨域获取手机号,难度较大; 网站visitor 手机号抓取软件。
2、使用PHP
file_get_contents 获取腾讯某个页面的内容,截取手机号。此方法11月前有效,已失效;
3、 这个方法比较简单,估计腾讯很快就屏蔽了。这也是我这几天练出来的方法,和大家分享一下。
代码如下:获取peer网站visitor手机号。
就是这么简单的一段JS,就可以拿到访问者的手机号了。 网站客人手机号抢。
注意:更多精彩教程请关注三联网页设计教程。
抢客:我可以抢网站visitor 电话号码吗?
你需要在你的网站上嵌入一段代码,然后你就可以统计你的网站访问者的手机号码。关键字来源、页面访问、ip等都可以统计。
号码打印机访客手机号码统计可以实现这些功能,大家可以免费试用。希望对您的问题有所帮助!
满意,请采纳。
网站访客如何抓取手机号码?
修改程序
如何获取访问者的手机号码。大数据抓取应用访问者手机号。
获取访问者手机号的方式一般有以下三种:
**类型是:获取自己的网站visitor 电话号码
第二种是:获取peer网站customer的电话
第三种是获取应用注册和下载信息,防止网站访问者被抓。
火客_
这三个是比较快速有效的方法
访客抓取:现在有抓取网站visitor手机号的功能吗?在某些情况下,爬行可以达到百分之几
一般情况下,移动终端的爬虫率不高。 查看全部
访客爬取:解密网站获取访问者手机号的方法和原理
网站访问者,可以安装在线客服系统,如商桥、53客服等,以前有网站类型的安装码,但为了保护用户隐私,现在当前不可用。也可以用一品的大数据分析来获取用户,但这仅限于手机。前提是你的网站必须有流量,不然没人访问,软件再好也没用。
网站访问者手机号的抓取效果好吗?
部分客户安装后立即使用手机进行测试,发现无法获取手机号码。这是不科学的。有一定几率抢到,数量大才能看到效果。比如一百个访客能抢到30个号和50个号是正常的。记住,如果几个人访问它们,它们就无法被抓取,这意味着该软件没有效果。
通过测试我们的软件爬行率超过 60%,它实际上可以帮助中小企业建立潜在客户群并为公司带来真正的交易量。
访客爬取:解密网站获取访客手机号的方法和原理
近日,网上出现了一个手机号码。访问者访问您的网站时可以获得他们的手机号码。许多公司将其用于盈利,有些公司出售一套程序。
经过几天的分析和研究,只开发了一个极其简单的方法。还有其他方法没找到。
目前在网上获取网站visitor手机号的方式有很多种。简而言之:抢到指定的网站visitor 手机号。
1、分析手机号控制,然后跨域获取手机号,难度较大; 网站visitor 手机号抓取软件。
2、使用PHP
file_get_contents 获取腾讯某个页面的内容,截取手机号。此方法11月前有效,已失效;
3、 这个方法比较简单,估计腾讯很快就屏蔽了。这也是我这几天练出来的方法,和大家分享一下。
代码如下:获取peer网站visitor手机号。
就是这么简单的一段JS,就可以拿到访问者的手机号了。 网站客人手机号抢。
注意:更多精彩教程请关注三联网页设计教程。
抢客:我可以抢网站visitor 电话号码吗?
你需要在你的网站上嵌入一段代码,然后你就可以统计你的网站访问者的手机号码。关键字来源、页面访问、ip等都可以统计。
号码打印机访客手机号码统计可以实现这些功能,大家可以免费试用。希望对您的问题有所帮助!
满意,请采纳。
网站访客如何抓取手机号码?
修改程序
如何获取访问者的手机号码。大数据抓取应用访问者手机号。
获取访问者手机号的方式一般有以下三种:
**类型是:获取自己的网站visitor 电话号码
第二种是:获取peer网站customer的电话
第三种是获取应用注册和下载信息,防止网站访问者被抓。
火客_
这三个是比较快速有效的方法
访客抓取:现在有抓取网站visitor手机号的功能吗?在某些情况下,爬行可以达到百分之几
一般情况下,移动终端的爬虫率不高。
一天就能上线一个微信小程序的云开发功能
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-07-06 01:23
最近在研究微信小程序的云开发功能。云开发最大的好处是不需要在前端搭建服务器,可以利用云的能力编写一个可以从头启动的微信小程序,避免购买服务器的成本,而且对于个人尝试从前端到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就能上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代同时,这种能力与开发者使用的云服务是相互兼容的,而不是相互排斥的。
云开发目前提供三个基本能力:
云功能:代码运行在云端,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码数据库:可在小程序前端操作,可读写的JSON数据库云功能存储:在小程序前端直接上传/下载云文件,在云开发控制台中可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。网上搜了一下,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。把我之前学过的节点拿起来就行了。
所需工具:Cheerio。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。 Node 的 fs 模块。这是node自带的模块,用于读写文件。这用于将解析后的数据写入 json 文件。 Axios(非必需)。用于抓取网站 HTML 页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。没办法,只好复制自己想要的内容,另存为字符串,解析字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是使用cheerio实现了类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后使用fs.writeFile将数据保存到json文件中,大功告成。
具体代码如下:
让 axios = require(axios);
让cheerio = require(cheerio);
让 fs = require(fs);
//我的html结构大致如下,数据很多
const 问题 = `
`;
const $ =cheerio.load(questions);
var arr = [];
for (var i = 0; i
var obj = {};
obj.quesitons = $(#q + i).find(.question).text();
obj.A = $($(#q + i).find(.answer)[0]).text();
obj.B = $($(#q + i).find(.answer)[1]).text();
obj.C = $($(#q + i).find(.answer)[2]).text();
obj.D = $($(#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer =
$($(#q + i).find(.answer)[0]).attr(value) == 1
: $($(#q + i).find(.answer)[1]).attr(value) == 1
: $($(#q + i).find(.answer)[2]).attr(value) == 1
: D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
if (err) 抛出错误;
console.log(json文件已经成功保存!);
});
保存为json后的文件格式如下,方便通过json文件上传到云服务器。
注意事项
微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前也提示过格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象之间使用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。 查看全部
一天就能上线一个微信小程序的云开发功能
最近在研究微信小程序的云开发功能。云开发最大的好处是不需要在前端搭建服务器,可以利用云的能力编写一个可以从头启动的微信小程序,避免购买服务器的成本,而且对于个人尝试从前端到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就能上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代同时,这种能力与开发者使用的云服务是相互兼容的,而不是相互排斥的。
云开发目前提供三个基本能力:
云功能:代码运行在云端,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码数据库:可在小程序前端操作,可读写的JSON数据库云功能存储:在小程序前端直接上传/下载云文件,在云开发控制台中可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。网上搜了一下,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。把我之前学过的节点拿起来就行了。
所需工具:Cheerio。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。 Node 的 fs 模块。这是node自带的模块,用于读写文件。这用于将解析后的数据写入 json 文件。 Axios(非必需)。用于抓取网站 HTML 页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。没办法,只好复制自己想要的内容,另存为字符串,解析字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是使用cheerio实现了类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后使用fs.writeFile将数据保存到json文件中,大功告成。
具体代码如下:
让 axios = require(axios);
让cheerio = require(cheerio);
让 fs = require(fs);
//我的html结构大致如下,数据很多
const 问题 = `
`;
const $ =cheerio.load(questions);
var arr = [];
for (var i = 0; i
var obj = {};
obj.quesitons = $(#q + i).find(.question).text();
obj.A = $($(#q + i).find(.answer)[0]).text();
obj.B = $($(#q + i).find(.answer)[1]).text();
obj.C = $($(#q + i).find(.answer)[2]).text();
obj.D = $($(#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer =
$($(#q + i).find(.answer)[0]).attr(value) == 1
: $($(#q + i).find(.answer)[1]).attr(value) == 1
: $($(#q + i).find(.answer)[2]).attr(value) == 1
: D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
if (err) 抛出错误;
console.log(json文件已经成功保存!);
});
保存为json后的文件格式如下,方便通过json文件上传到云服务器。
注意事项
微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前也提示过格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象之间使用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。
网页数据爬取图文教程-爬虫入门教程(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-07-06 01:23
网页数据爬取图文教程-爬虫入门教程
本页提供最新的网页数据爬取图文教程和爬虫入门教程。
网络数据抓取实用教程
优采云网站Grabber Tools 热门网站采集类主要介绍各大电商、新闻媒体、生活服务、金融信用、企业信息等网站数据爬取教程,让你轻松掌握各种网站技能。
如何实时抓取动态网页数据?
使用网页抓取工具,操作员无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。 (2)适用于各种网站不同的网站有不同的结构,所以即使是有经验的程序员也需要...
网页数据爬取方法详解
你有没有想过从网站获取具体的数据,但是当你触发链接或者将鼠标悬停在某处时,内容就会出现?比如下图中的网站,需要鼠标移动到选区,才能显示在抽奖上的分类。对于这种类型,您可以设置“鼠标指向此链...
网络数据爬取的两种方法(2019年最新)
模板的数量还在增加。 【使用模板采集数据】,只需输入几个参数(URL、关键词、页数等),几分钟内即可快速获取目标网站数据。 (类似PPT模板,直接修改关键信息即可使用,无需自己...
模拟登录抓拍网站data_video教程
本文主要介绍如何使用优采云simulation login采集网站需要登录的数据,包括点击登录、文字输入等操作方式。
如何设置网络爬虫来抓取数据
· 内置的正则表达式工具可以提取任何数据。 · 抓取 AJAX 加载的内容。 · 使用云采集支持大规模采集等。想了解更多这款爬虫软件,可以查看下面的初学者教程,了解如何开始使用八... 查看全部
网页数据爬取图文教程-爬虫入门教程(组图)
网页数据爬取图文教程-爬虫入门教程
本页提供最新的网页数据爬取图文教程和爬虫入门教程。
网络数据抓取实用教程
优采云网站Grabber Tools 热门网站采集类主要介绍各大电商、新闻媒体、生活服务、金融信用、企业信息等网站数据爬取教程,让你轻松掌握各种网站技能。
如何实时抓取动态网页数据?
使用网页抓取工具,操作员无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。 (2)适用于各种网站不同的网站有不同的结构,所以即使是有经验的程序员也需要...
网页数据爬取方法详解
你有没有想过从网站获取具体的数据,但是当你触发链接或者将鼠标悬停在某处时,内容就会出现?比如下图中的网站,需要鼠标移动到选区,才能显示在抽奖上的分类。对于这种类型,您可以设置“鼠标指向此链...
网络数据爬取的两种方法(2019年最新)
模板的数量还在增加。 【使用模板采集数据】,只需输入几个参数(URL、关键词、页数等),几分钟内即可快速获取目标网站数据。 (类似PPT模板,直接修改关键信息即可使用,无需自己...
模拟登录抓拍网站data_video教程
本文主要介绍如何使用优采云simulation login采集网站需要登录的数据,包括点击登录、文字输入等操作方式。
如何设置网络爬虫来抓取数据
· 内置的正则表达式工具可以提取任何数据。 · 抓取 AJAX 加载的内容。 · 使用云采集支持大规模采集等。想了解更多这款爬虫软件,可以查看下面的初学者教程,了解如何开始使用八...
怎样才能吸引搜索引擎蜘蛛来抓取网站,怎样被收录
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-07-06 01:22
对于网站 运营商来说,网站 的流量很大程度上依赖于搜索引擎。怎样才能找到我们的网站,怎样才能吸引搜索引擎蜘蛛去抢网站,怎样才能被收录搜索到呢?让我们谈谈。
当我们做搜索引擎优化工作时,我们都明白网站要在搜索引擎中获得良好的排名,它必须被蜘蛛抓取以收录我们的页面。搜索引擎蜘蛛把爬取到的代码放到自己的数据库中,这样我们就可以在搜索引擎上搜索到我们的网站了。
我们的网站搜索引擎优化步骤是将蜘蛛吸引到我们的网站。搜索引擎蜘蛛会爬到我们的网站,会有踪迹,也会有自己的代理名称。每个网站administrator 都可以区分日志文件中的搜索引擎蜘蛛。
常见的搜索引擎蜘蛛有:
如果网站管理员想要吸引蜘蛛爬我们的搜索引擎优化网站,他们必须做一些工作,因为蜘蛛无法爬取互联网上所有的网站。事实上,好的搜索引擎只会抓取互联网的一小部分。
如果搜索引擎优化者希望他们的网站更多地被搜索引擎收录,他们必须尝试吸引蜘蛛来获取。搜索引擎通常会抓取重要页面。为了满足蜘蛛爬行的重要性规则,我们需要满足以下条件:
1、网站weight 问题,网站蜘蛛的权重越高爬得越深,几乎每个页面都会爬,更多的内部页面会被收录。
2、import 链接分为外部链接和内部链接。如果蜘蛛正在抓取页面,页面必须有导入链接,否则蜘蛛根本不知道页面的存在,所以高质量的导入链接可以引导蜘蛛抓取我们的页面。
3、网站 更新频率。蜘蛛每次爬取的网站都会保存起来,方便二次浏览。如果蜘蛛第二次爬到优化后的网站,发现页面已经更新,就会爬到新的内容。如果每天更新,蜘蛛就会习惯每天定期爬到你的网站。
4、 对于质量和可读性高的页面,搜索引擎更容易捕获它们,因此收录它们后,页面的权重会增加。下次我们会继续爬取我们的网站,因为搜索引擎喜欢有价值的页面、可读的页面和逻辑页面。
5、 网页在主页上有一个链接。一般来说,我们会在网站 上更新。更新后的链接应该尽可能多地出现在首页,因为首页权重较高,被很多蜘蛛访问。我们的主页是最常见的。如果主页上有更新链接,蜘蛛可以更快更好地爬到我们更新的页面,以便更好地收录我们的页面。
这五点都和你的网站和收录优化有关,直接影响你的网站seo优化效果。所以建议大家做好网站seo的培训。另外,一些网站administrators 也说在日志文件中发现了蜘蛛,但没有收录网页。这样做的原因是简单的。如果蜘蛛发现你的网站之前抓取的内容过于相似,就会认为你的网站抄袭或者抄袭了别人的内容,很可能不会继续抓取你的网站,从而创建蜘蛛,而不是你的页面。
要做好搜索引擎优化,必须掌握搜索引擎机器人访问的时间和规则。我们站长要做的,就是等待搜索引擎机器人的访问,做出更好的网站。未来,优化固然重要,但网站自身的内容建设是网站可持续发展的生命线。 查看全部
怎样才能吸引搜索引擎蜘蛛来抓取网站,怎样被收录
对于网站 运营商来说,网站 的流量很大程度上依赖于搜索引擎。怎样才能找到我们的网站,怎样才能吸引搜索引擎蜘蛛去抢网站,怎样才能被收录搜索到呢?让我们谈谈。
当我们做搜索引擎优化工作时,我们都明白网站要在搜索引擎中获得良好的排名,它必须被蜘蛛抓取以收录我们的页面。搜索引擎蜘蛛把爬取到的代码放到自己的数据库中,这样我们就可以在搜索引擎上搜索到我们的网站了。
我们的网站搜索引擎优化步骤是将蜘蛛吸引到我们的网站。搜索引擎蜘蛛会爬到我们的网站,会有踪迹,也会有自己的代理名称。每个网站administrator 都可以区分日志文件中的搜索引擎蜘蛛。

常见的搜索引擎蜘蛛有:
如果网站管理员想要吸引蜘蛛爬我们的搜索引擎优化网站,他们必须做一些工作,因为蜘蛛无法爬取互联网上所有的网站。事实上,好的搜索引擎只会抓取互联网的一小部分。
如果搜索引擎优化者希望他们的网站更多地被搜索引擎收录,他们必须尝试吸引蜘蛛来获取。搜索引擎通常会抓取重要页面。为了满足蜘蛛爬行的重要性规则,我们需要满足以下条件:
1、网站weight 问题,网站蜘蛛的权重越高爬得越深,几乎每个页面都会爬,更多的内部页面会被收录。
2、import 链接分为外部链接和内部链接。如果蜘蛛正在抓取页面,页面必须有导入链接,否则蜘蛛根本不知道页面的存在,所以高质量的导入链接可以引导蜘蛛抓取我们的页面。
3、网站 更新频率。蜘蛛每次爬取的网站都会保存起来,方便二次浏览。如果蜘蛛第二次爬到优化后的网站,发现页面已经更新,就会爬到新的内容。如果每天更新,蜘蛛就会习惯每天定期爬到你的网站。
4、 对于质量和可读性高的页面,搜索引擎更容易捕获它们,因此收录它们后,页面的权重会增加。下次我们会继续爬取我们的网站,因为搜索引擎喜欢有价值的页面、可读的页面和逻辑页面。
5、 网页在主页上有一个链接。一般来说,我们会在网站 上更新。更新后的链接应该尽可能多地出现在首页,因为首页权重较高,被很多蜘蛛访问。我们的主页是最常见的。如果主页上有更新链接,蜘蛛可以更快更好地爬到我们更新的页面,以便更好地收录我们的页面。
这五点都和你的网站和收录优化有关,直接影响你的网站seo优化效果。所以建议大家做好网站seo的培训。另外,一些网站administrators 也说在日志文件中发现了蜘蛛,但没有收录网页。这样做的原因是简单的。如果蜘蛛发现你的网站之前抓取的内容过于相似,就会认为你的网站抄袭或者抄袭了别人的内容,很可能不会继续抓取你的网站,从而创建蜘蛛,而不是你的页面。
要做好搜索引擎优化,必须掌握搜索引擎机器人访问的时间和规则。我们站长要做的,就是等待搜索引擎机器人的访问,做出更好的网站。未来,优化固然重要,但网站自身的内容建设是网站可持续发展的生命线。
企业需要了解爬虫喜欢怎样的网站,如何吸引爬虫抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-07-05 18:42
一个好的网站不仅可以提升公司的知名度,还可以为公司吸引更多的意向客户。而网站需要在搜索引擎上有好的排名,才能被更多的人看到。搜索引擎中的排名大多不稳定,上升缓慢,下降迅速。做一个能吸引爬虫爬的网站,那么就必须在各方面都符合它的爬取原则。公司需要了解什么样的网站爬虫喜欢什么样的网站他们不喜欢什么样的。排名最重要的是允许爬虫爬取网站上的内容。 收录的内容越多,客户搜索起来就越容易。那么网站怎么才能吸引网络爬虫来爬呢?
如何做网站吸引网络爬虫爬取
一、优质内容
企业与网站上线后,即开始运营。如果它想一直活跃,就必须每天进行更新,上传文章是一种常见的更新方式。公司上传新内容到网站,但不代表可以快速抓取。关键是看内容的质量是否通过测试。一篇优质文章的质量在于原创有价值,满足客户的阅读需求。企业不应该只为了数量去网络采集文章。就算上传到自己的网站,爬虫也能认出来。这会降低爬虫对网站的友好度,也会影响网站整体的内容质量。客户和爬虫都喜欢新颖的内容,从而被吸引到网站浏览。重复太多只会让人恶心。
二、做好反链和外链
一般来说,网站设置反链比较多,这也是吸引爬虫的必要手段。设置反链不仅可以帮助提升网站的权重值,还可以提升排名。在保证逆序的情况下,反链越多,越能吸引爬虫,排名会更好。接下来是外链,主要是在各大平台发布信息,然后被吸引过来的爬虫会跳转到企业网站继续爬取信息中的链接。可以加快网站快照的更新速度,也可以通过收录让网站内容更快。与反链相比,外链重质不重,选择优质平台可以更好的增加权重和收录。
三、clear 导航
要做网站,你需要有清晰的导航。这也是企业在设计时需要注意的部分。这对网站的信息构成和客户体验有影响。从客户的角度来看,导航是为了解决客户可能面临的问题。一个可以让客户知道他们目前在哪里,另一个要求客户知道他们下一步要去哪里。很多时候从搜索引擎跳转到网站,不知道怎么在随机点击下返回上一页。那么网站Navigation 这个时候就起到了作用,可以帮助客户了解你所在的车站内的区域。如果网站导航像原创森林一样错综复杂,爬虫就不会来了。从另一个角度来说,清晰的导航有利于爬取,可以快速找到新的内容进行爬取,收录速度更快。 查看全部
企业需要了解爬虫喜欢怎样的网站,如何吸引爬虫抓取
一个好的网站不仅可以提升公司的知名度,还可以为公司吸引更多的意向客户。而网站需要在搜索引擎上有好的排名,才能被更多的人看到。搜索引擎中的排名大多不稳定,上升缓慢,下降迅速。做一个能吸引爬虫爬的网站,那么就必须在各方面都符合它的爬取原则。公司需要了解什么样的网站爬虫喜欢什么样的网站他们不喜欢什么样的。排名最重要的是允许爬虫爬取网站上的内容。 收录的内容越多,客户搜索起来就越容易。那么网站怎么才能吸引网络爬虫来爬呢?

如何做网站吸引网络爬虫爬取
一、优质内容
企业与网站上线后,即开始运营。如果它想一直活跃,就必须每天进行更新,上传文章是一种常见的更新方式。公司上传新内容到网站,但不代表可以快速抓取。关键是看内容的质量是否通过测试。一篇优质文章的质量在于原创有价值,满足客户的阅读需求。企业不应该只为了数量去网络采集文章。就算上传到自己的网站,爬虫也能认出来。这会降低爬虫对网站的友好度,也会影响网站整体的内容质量。客户和爬虫都喜欢新颖的内容,从而被吸引到网站浏览。重复太多只会让人恶心。
二、做好反链和外链
一般来说,网站设置反链比较多,这也是吸引爬虫的必要手段。设置反链不仅可以帮助提升网站的权重值,还可以提升排名。在保证逆序的情况下,反链越多,越能吸引爬虫,排名会更好。接下来是外链,主要是在各大平台发布信息,然后被吸引过来的爬虫会跳转到企业网站继续爬取信息中的链接。可以加快网站快照的更新速度,也可以通过收录让网站内容更快。与反链相比,外链重质不重,选择优质平台可以更好的增加权重和收录。
三、clear 导航
要做网站,你需要有清晰的导航。这也是企业在设计时需要注意的部分。这对网站的信息构成和客户体验有影响。从客户的角度来看,导航是为了解决客户可能面临的问题。一个可以让客户知道他们目前在哪里,另一个要求客户知道他们下一步要去哪里。很多时候从搜索引擎跳转到网站,不知道怎么在随机点击下返回上一页。那么网站Navigation 这个时候就起到了作用,可以帮助客户了解你所在的车站内的区域。如果网站导航像原创森林一样错综复杂,爬虫就不会来了。从另一个角度来说,清晰的导航有利于爬取,可以快速找到新的内容进行爬取,收录速度更快。
知乎app榜单里看啊答案中的排名情况要是让老板看到了你对产品设计理念的思考
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-07-04 04:01
网站内容抓取相比文章抓取来说,更难提取有效的信息,抓取网站内容不可避免会涉及爬虫,爬虫实际上在做商业交易,收钱劳动力。爬虫要么都是固定ip不用cookie,要么只能用selenium库来实现。如果每一篇内容都需要手动去加载对于开发人员来说是非常费力的。如果大家经常了解我在做什么,可以举一反三的去举一反三,这里再次重申,这只是一个学习笔记。文章来源:商品推荐。
知乎
注册商店
大家一起来补充知乎app榜单里看啊答案中的排名情况要是让老板看到了你对产品设计理念的思考是世界上最美妙的事情
如果要说,我想到了一个im产品。在这个产品里的『把』会带来额外的额外的价值。
资源宝库-读书.社区.游戏.电商.绘画.文库.论坛.找工作.求婚.刷单.学习.写作.生活.车站.喜马拉雅.分答.在行.万库。
12306买一张优采云票的价钱折合成现在的rmb可以买几十几百本相关的书籍
模拟登录和注册哪个更难?
文字版:office,flash邮件服务器,图片版:电影,游戏,视频。
音乐搜索,
自从升级到ipad以后,我自己装了各种各样的正版软件,通过itunes备份然后从itunesstore里卖钱了,对我来说是不可多得的体验。
优酷,但网速真不是优势。 查看全部
知乎app榜单里看啊答案中的排名情况要是让老板看到了你对产品设计理念的思考
网站内容抓取相比文章抓取来说,更难提取有效的信息,抓取网站内容不可避免会涉及爬虫,爬虫实际上在做商业交易,收钱劳动力。爬虫要么都是固定ip不用cookie,要么只能用selenium库来实现。如果每一篇内容都需要手动去加载对于开发人员来说是非常费力的。如果大家经常了解我在做什么,可以举一反三的去举一反三,这里再次重申,这只是一个学习笔记。文章来源:商品推荐。
知乎
注册商店
大家一起来补充知乎app榜单里看啊答案中的排名情况要是让老板看到了你对产品设计理念的思考是世界上最美妙的事情
如果要说,我想到了一个im产品。在这个产品里的『把』会带来额外的额外的价值。
资源宝库-读书.社区.游戏.电商.绘画.文库.论坛.找工作.求婚.刷单.学习.写作.生活.车站.喜马拉雅.分答.在行.万库。
12306买一张优采云票的价钱折合成现在的rmb可以买几十几百本相关的书籍
模拟登录和注册哪个更难?
文字版:office,flash邮件服务器,图片版:电影,游戏,视频。
音乐搜索,
自从升级到ipad以后,我自己装了各种各样的正版软件,通过itunes备份然后从itunesstore里卖钱了,对我来说是不可多得的体验。
优酷,但网速真不是优势。
如何让蜘蛛爱上你的网站的方法优帮云
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-07-03 20:06
在SEO排名规则中,收录意味着可能有排名,但不收录则不可能有排名。在线解决的一个问题是包容性问题。充分理解蜘蛛程序,正确开药,是实现网站二次收益的基础工作。那么蜘蛛程序的原理是什么呢?如何让蜘蛛爱上我们的网站并快速融入我们的网站?下面将给出简要说明。
百度蜘蛛编程原理
从人类的角度来看,蜘蛛程序其实和我们是一样的。打开网站-抓取页面-放入数据库-符合标准-建立索引-分类,按质量排名显示用户,不符合标准直接丢弃。然而,它是一个智能机器人。蜘蛛程序需要对我们网站的内容进行评估和审核。内容属于优质网站进行收录,而低素质网站已进入观察期,只有合格后方可收录。
蜘蛛是怎么找到网站的?
(1)网站submit; (2)external link (anchor text, hyperlink is yes); and (3)browser cookie data (浏览器已开启网站); 这是百度蜘蛛了解网站存在的三种方式,但需要注意的是百度蜘蛛程序发送的爬取网站content蜘蛛都是文字内容蜘蛛,其他的东西他们不懂,所以新手要注意建网站,那些凉挂的爆炸效果,蜘蛛不喜欢。
四种网站让百度蜘蛛爱上你的方法
深入了解百度蜘蛛程序的原理后,可以提取一些知识点。蜘蛛程序的内容是什么?蜘蛛抓取网页的特点是什么?如何评估一个网页的质量并最终显示排名?掌握了这些内容后,只需要4招就能让蜘蛛爱上我们的网站并提升它的排名。
1、高质量原创内容,满足用户需求。
原创性+解决用户需求+解决潜在用户需求,可以称得上是满足用户需求的优质原创内容。思路很简单,通过数据就能满足一般用户的需求。解决用户的潜在需求需要深入思考。例如:从上海到哈尔滨需要多长时间?用户需求是显而易见的,但隐藏的需求是“从上海到哈尔滨的路”。如何节省时间,提升旅途的舒适体验,需要充分考虑,符合蜘蛛程序的内容标准。
2、更快的页面打开速度。
这是一个难以配置的站点。当蜘蛛来到你的网站时,它不稳定,摇摆不定,然后一下子打开,一个网站被丢弃。喜欢一个网站是不可能的。所以在选择空间的时候要注意配置,注意页面图片不要太大,这样更有利于蜘蛛程序的体验。
3、合理搭建内链。
蜘蛛程序喜欢超链接,尤其是锚链接。这时候,页面的内部链接就显得尤为重要。推荐相关内容和插入有利于用户体验的锚链接都是促进蜘蛛程序快速抓取页面内容并提高包容性的有效手段。
4、添加 XML 站点地图。
蜘蛛可能对道路很着迷。没有路标,很容易迷路,和编辑一样迷路。除了网站的内部链接,做一个XML映射还可以让蜘蛛程序合理有序的抓取整个网站页面的内容。生成 XML 映射后,在 robots.txt 文件中添加指向映射的链接。你知道蜘蛛程序访问网站这个文件夹。我们需要帮助蜘蛛提高他们的工作效率。我更喜欢我们的网站。
总结:以上就是蜘蛛程序的原理以及如何让百度蜘蛛爱上网站四点。因材施教、剪衣服是满足蜘蛛喜好的基本任务。只有优化基础,后续高层思维才能发挥应有的作用。 查看全部
如何让蜘蛛爱上你的网站的方法优帮云
在SEO排名规则中,收录意味着可能有排名,但不收录则不可能有排名。在线解决的一个问题是包容性问题。充分理解蜘蛛程序,正确开药,是实现网站二次收益的基础工作。那么蜘蛛程序的原理是什么呢?如何让蜘蛛爱上我们的网站并快速融入我们的网站?下面将给出简要说明。
百度蜘蛛编程原理
从人类的角度来看,蜘蛛程序其实和我们是一样的。打开网站-抓取页面-放入数据库-符合标准-建立索引-分类,按质量排名显示用户,不符合标准直接丢弃。然而,它是一个智能机器人。蜘蛛程序需要对我们网站的内容进行评估和审核。内容属于优质网站进行收录,而低素质网站已进入观察期,只有合格后方可收录。
蜘蛛是怎么找到网站的?
(1)网站submit; (2)external link (anchor text, hyperlink is yes); and (3)browser cookie data (浏览器已开启网站); 这是百度蜘蛛了解网站存在的三种方式,但需要注意的是百度蜘蛛程序发送的爬取网站content蜘蛛都是文字内容蜘蛛,其他的东西他们不懂,所以新手要注意建网站,那些凉挂的爆炸效果,蜘蛛不喜欢。

四种网站让百度蜘蛛爱上你的方法
深入了解百度蜘蛛程序的原理后,可以提取一些知识点。蜘蛛程序的内容是什么?蜘蛛抓取网页的特点是什么?如何评估一个网页的质量并最终显示排名?掌握了这些内容后,只需要4招就能让蜘蛛爱上我们的网站并提升它的排名。
1、高质量原创内容,满足用户需求。
原创性+解决用户需求+解决潜在用户需求,可以称得上是满足用户需求的优质原创内容。思路很简单,通过数据就能满足一般用户的需求。解决用户的潜在需求需要深入思考。例如:从上海到哈尔滨需要多长时间?用户需求是显而易见的,但隐藏的需求是“从上海到哈尔滨的路”。如何节省时间,提升旅途的舒适体验,需要充分考虑,符合蜘蛛程序的内容标准。
2、更快的页面打开速度。
这是一个难以配置的站点。当蜘蛛来到你的网站时,它不稳定,摇摆不定,然后一下子打开,一个网站被丢弃。喜欢一个网站是不可能的。所以在选择空间的时候要注意配置,注意页面图片不要太大,这样更有利于蜘蛛程序的体验。
3、合理搭建内链。
蜘蛛程序喜欢超链接,尤其是锚链接。这时候,页面的内部链接就显得尤为重要。推荐相关内容和插入有利于用户体验的锚链接都是促进蜘蛛程序快速抓取页面内容并提高包容性的有效手段。
4、添加 XML 站点地图。
蜘蛛可能对道路很着迷。没有路标,很容易迷路,和编辑一样迷路。除了网站的内部链接,做一个XML映射还可以让蜘蛛程序合理有序的抓取整个网站页面的内容。生成 XML 映射后,在 robots.txt 文件中添加指向映射的链接。你知道蜘蛛程序访问网站这个文件夹。我们需要帮助蜘蛛提高他们的工作效率。我更喜欢我们的网站。
总结:以上就是蜘蛛程序的原理以及如何让百度蜘蛛爱上网站四点。因材施教、剪衣服是满足蜘蛛喜好的基本任务。只有优化基础,后续高层思维才能发挥应有的作用。
使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-07-16 21:33
爬虫是 Python 的一个重要应用。使用 Python 爬虫,我们可以轻松地从互联网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍 Python爬虫的基本流程。如果您还处于初始爬虫阶段或不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第一步:尝试请求
首先进入b站首页,点击排行榜复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第 2 步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换为Web页面结构化数据,因此您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用时需要开发一个解析器,这里使用的是html.parser。
然后您可以获得结构化元素之一及其属性。例如,您可以使用soup.title.text 来获取页面标题。你也可以使用soup.body、soup.p等来获取任何需要的元素。
第 3 步:提取内容
在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
现在我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码就可以这样写了
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取字段信息我们想要的是以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码。
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到此我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
虽然看起来很简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有各种形式的反爬、加密,以及后续的数据分析、提取甚至存储。许多需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据
爬虫是 Python 的一个重要应用。使用 Python 爬虫,我们可以轻松地从互联网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍 Python爬虫的基本流程。如果您还处于初始爬虫阶段或不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第一步:尝试请求
首先进入b站首页,点击排行榜复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第 2 步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换为Web页面结构化数据,因此您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用时需要开发一个解析器,这里使用的是html.parser。
然后您可以获得结构化元素之一及其属性。例如,您可以使用soup.title.text 来获取页面标题。你也可以使用soup.body、soup.p等来获取任何需要的元素。
第 3 步:提取内容
在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
现在我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码就可以这样写了
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取字段信息我们想要的是以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码。
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到此我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
虽然看起来很简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有各种形式的反爬、加密,以及后续的数据分析、提取甚至存储。许多需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
Python可以运用selenium+scrapy来进行爬取拉勾网的信息
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-07-16 21:29
作为数据分析的强大工具,R语言也有很多方便的封装示例Rcurl和rvest,用于数据采集,满足基本需求。 知乎上已经有很多文章来介绍他们的用途了。
但是,当我尝试爬取拉勾网的数据时,发现没有抓取到信息,而且源代码没有对应右键review元素,这让我很困扰。在网上搜索了相关问题,发现这是一个基于AJAX的动态网页,不同于静态网页。
AJAX AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
简单来说,网页通过异步传输获取页面信息。以拉勾网为例:
点击右下角下一页后,页面内容发生了变化,但网址没有变化。对爬虫的影响是无法简单地使用Rcurl获取想要的信息。
查找相关资料,了解到Python可以使用selenium+scrapy来抓取动态网页。
Selenium(浏览器自动化测试框架)Selenium 是一种用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真实用户操作一样。
无独有偶,作为开源语言,R语言也为类似的操作开发了相应的Rwebdriver包。
本文基于Rwebdriver包抓取拉勾网信息。
前期准备
先下载selenium.3.4。 (下载链接)
要运行selenium,需要java并配置环境变量。 (不明白的请戳传送门)
那么如果你的浏览器和我一样是chorme,你需要下载对应版本的浏览器驱动chormedriver。
(下载地址比如我是V59,对应的下载就近2.31)
Chromedriver可以放在chorme的安装根目录下,路径也设置为系统路径。
(比如我把chromedriver放在"C:\Program Files (x86)\Google\Chrome\Application\",所以我也把path设置为path)
最后在selenium所在根目录打开cmd,输入“java -jar selenium-server-standalone-3.4.0.jar”启动服务。
(每次开启selenium服务都需要,所以可以写个bat)
当出现“Selenium Server is up and running”时,表示它开始运行了。
R 语言代码部分
需要加载的包
library(RCurl)# 抓取数据
library(XML)# 解析网页
library(stringr)# 字符串处理
library(dplyr)# 调用%>%管道
library(Rwebdriver)# 爬取动态网页
Rwebdriver包需要通过调用devtools从github下载:
devtools::install_github(repo = "Rwebdriver", username = "crubba")
提供主要的浏览器操作功能:
start_session(root = NULL, browser = "firefox",
javascriptEnabled = TRUE, takesScreenshot = TRUE,
handlesAlerts = TRUE, databaseEnabled = TRUE,
cssSelectorsEnabled = TRUE) # 打开浏览器
post.url(url = NULL) # 打开网页
page_refresh() # 刷新网页
page_back() # 网页后退
page_forward() # 网页前进
page_source() # 获得当前页面信息
element_xpath_find() #通过XPATH找到所要部分
element_css_find() #通过CSS找到所要部分
element_click(ID = ID, times = 1, button = "left")# ID为所要点击的地方,times为点击次数,button="left"为左键点击
keys()#输入内容
element_clear()#清除内容
以下为爬行拉钩网示例,可根据需要修改:
<p>start_session(root = 'http://localhost:4444/wd/hub/',browser ="chrome")# 默认端口是4444,我的浏览器是chorme,如果使用火狐改成firefox
list_url 查看全部
Python可以运用selenium+scrapy来进行爬取拉勾网的信息
作为数据分析的强大工具,R语言也有很多方便的封装示例Rcurl和rvest,用于数据采集,满足基本需求。 知乎上已经有很多文章来介绍他们的用途了。
但是,当我尝试爬取拉勾网的数据时,发现没有抓取到信息,而且源代码没有对应右键review元素,这让我很困扰。在网上搜索了相关问题,发现这是一个基于AJAX的动态网页,不同于静态网页。
AJAX AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
简单来说,网页通过异步传输获取页面信息。以拉勾网为例:
点击右下角下一页后,页面内容发生了变化,但网址没有变化。对爬虫的影响是无法简单地使用Rcurl获取想要的信息。
查找相关资料,了解到Python可以使用selenium+scrapy来抓取动态网页。
Selenium(浏览器自动化测试框架)Selenium 是一种用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真实用户操作一样。
无独有偶,作为开源语言,R语言也为类似的操作开发了相应的Rwebdriver包。
本文基于Rwebdriver包抓取拉勾网信息。
前期准备
先下载selenium.3.4。 (下载链接)
要运行selenium,需要java并配置环境变量。 (不明白的请戳传送门)
那么如果你的浏览器和我一样是chorme,你需要下载对应版本的浏览器驱动chormedriver。
(下载地址比如我是V59,对应的下载就近2.31)
Chromedriver可以放在chorme的安装根目录下,路径也设置为系统路径。
(比如我把chromedriver放在"C:\Program Files (x86)\Google\Chrome\Application\",所以我也把path设置为path)
最后在selenium所在根目录打开cmd,输入“java -jar selenium-server-standalone-3.4.0.jar”启动服务。
(每次开启selenium服务都需要,所以可以写个bat)
当出现“Selenium Server is up and running”时,表示它开始运行了。
R 语言代码部分
需要加载的包
library(RCurl)# 抓取数据
library(XML)# 解析网页
library(stringr)# 字符串处理
library(dplyr)# 调用%>%管道
library(Rwebdriver)# 爬取动态网页
Rwebdriver包需要通过调用devtools从github下载:
devtools::install_github(repo = "Rwebdriver", username = "crubba")
提供主要的浏览器操作功能:
start_session(root = NULL, browser = "firefox",
javascriptEnabled = TRUE, takesScreenshot = TRUE,
handlesAlerts = TRUE, databaseEnabled = TRUE,
cssSelectorsEnabled = TRUE) # 打开浏览器
post.url(url = NULL) # 打开网页
page_refresh() # 刷新网页
page_back() # 网页后退
page_forward() # 网页前进
page_source() # 获得当前页面信息
element_xpath_find() #通过XPATH找到所要部分
element_css_find() #通过CSS找到所要部分
element_click(ID = ID, times = 1, button = "left")# ID为所要点击的地方,times为点击次数,button="left"为左键点击
keys()#输入内容
element_clear()#清除内容
以下为爬行拉钩网示例,可根据需要修改:
<p>start_session(root = 'http://localhost:4444/wd/hub/',browser ="chrome")# 默认端口是4444,我的浏览器是chorme,如果使用火狐改成firefox
list_url
沉迷于实时数据将您的业务提升到一个新水平
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-07-16 20:51
现代世界都是关于技术以及我们如何充分利用它;实时捕获数据只是这个技术驱动世界的革命性方面之一。我们将向您展示如何通过捕获实时数据将您的业务提升到一个新的水平。在线可用的数据量巨大且不断变化;因此,如果您想在这个竞争激烈的世界中保持相关性,跟上这些变化至关重要。信息不足或不正确不应成为您失败的原因,我们会告诉您如何捕获实时数据并提高准确性。
许多新的或小型企业主询问什么是实时数据抓取以及它如何使他们受益。让我们回答这些基本常见问题解答以消除混淆。
网页抓取是一个自动化过程,它倾向于从网站 采集信息并将其传输到各种电子表格和数据库。它是处理网络信息最快的数据提取方法,最适用于不断变化的数据,例如股票价格、冠状病毒病例、天气预报等。实时网络爬虫可以很容易地跟上这些变化和在现代世界中获得了极大的欢迎。一个悬而未决的问题是如何捕获实时数据?有什么要求以及如何去做?
现在,让我来回答这个问题。程序员和非程序员都可以轻松提取实时数据。程序员可以通过编写自己的爬虫/爬虫来抓取实时数据,了解具体的内容需求、语言等。 这里的另一个问题是,你刚开发的爬虫可能一周内都无法工作,所以需要不断修复错误,这可能很贵。让我们变得真实;为新的或小型企业招聘程序员并不完全可行,因为它很昂贵。那么,这些小企业如何应对这个庞大且不断变化的数据池呢?最好的方法是使用现有的和预制的实时数据捕获工具和软件。预制网络爬虫允许您提取相关数据并下载特定网页。这可以包括可用产品及其价格、可用性和其他重要信息的列表。它们的自动化功能通常给它们带来巨大的优势,因为它们可以轻松检测 Web 结构、获取数据、解析 HTML 并将所有这些都集成到您的数据库中。随着时间的推移,它们变得非常流行,为什么不呢,因为它们便于携带,而且往往可以节省大量时间。
我们现在已经确定了网页抓取的重要性以及使用数据提取工具的好处。接下来,我们需要决定必须使用哪种数据提取工具,因为这些工具和软件正在充斥市场。为您选择合适的唯一方法是了解您的需求。使用web扩展可以提取实时数据,它是浏览器的一个小插件,但功能有限,安全性不确定。数据提取软件是您的另一个选择。它必须安装在系统中,并且由于其现代和先进的功能,非常适合处理敏感数据。
数据抓取软件有很多,比如ScrapingBee、ScrapingBot、Scraper AP I等,但是我给大家介绍一下我们最喜欢的网页抓取软件——Octoparse。
我相信所有其他软件都很好,但 Octoparse 有一些特殊的品质,使其比其他软件更具优势。这对于从多个网络源进行大规模实时数据捕获非常有用。我们可以保证每个小企业都会从其独特的功能中受益,因为它不是您普通的刮板。它凭借其广泛的工具超越了大多数工具。
预设提取模块不受任何复杂配置的约束,倾向于立即读取结果。它涵盖了所有重要的网站,无论是社交媒体、电子商务等。它适合所有人,因为它具有三种不同的模式,迎合初学者、季节专业人士和自定义爬虫,快速、即时地获取数据和信息他们需要。它拥有丰富而无所不包的功能,如RegEx编辑、任务调度、JSON抓取等,将您的实时抓取提升到一个新的高度。
使用 Octoparse,您甚至可以从 Ad-heavy 页面中提取数据,因为其出色的 Ad-block 功能可以解决这个问题。它倾向于模仿人类,同时从各种网站 抓取数据,并允许我们在您的系统或云上运行提取的信息。 Octoparse 的另一个前沿特性是它可以导出各种捕获的数据,包括 CSV、TXT、HTML,甚至 Excel 格式。 Octoparse 中的所有模板都非常人性化,因此不需要专业程序员;只需点击几下鼠标即可轻松获取数据,而无需花费一分钱。
归根结底,这是您考虑什么最有利于您的业务及其增长和繁荣的决定。因此,您可以探索所有可用的不同软件来帮助您实时抓取数据,但在结束本文之前,让我们给您一个建议。去下载 Octoparse,探索它的功能,了解为什么我们认为它是最好的网络抓取软件,然后自己决定。它是免费的,可在线获得,所以准备好被震撼吧! 查看全部
沉迷于实时数据将您的业务提升到一个新水平
现代世界都是关于技术以及我们如何充分利用它;实时捕获数据只是这个技术驱动世界的革命性方面之一。我们将向您展示如何通过捕获实时数据将您的业务提升到一个新的水平。在线可用的数据量巨大且不断变化;因此,如果您想在这个竞争激烈的世界中保持相关性,跟上这些变化至关重要。信息不足或不正确不应成为您失败的原因,我们会告诉您如何捕获实时数据并提高准确性。
许多新的或小型企业主询问什么是实时数据抓取以及它如何使他们受益。让我们回答这些基本常见问题解答以消除混淆。
网页抓取是一个自动化过程,它倾向于从网站 采集信息并将其传输到各种电子表格和数据库。它是处理网络信息最快的数据提取方法,最适用于不断变化的数据,例如股票价格、冠状病毒病例、天气预报等。实时网络爬虫可以很容易地跟上这些变化和在现代世界中获得了极大的欢迎。一个悬而未决的问题是如何捕获实时数据?有什么要求以及如何去做?
现在,让我来回答这个问题。程序员和非程序员都可以轻松提取实时数据。程序员可以通过编写自己的爬虫/爬虫来抓取实时数据,了解具体的内容需求、语言等。 这里的另一个问题是,你刚开发的爬虫可能一周内都无法工作,所以需要不断修复错误,这可能很贵。让我们变得真实;为新的或小型企业招聘程序员并不完全可行,因为它很昂贵。那么,这些小企业如何应对这个庞大且不断变化的数据池呢?最好的方法是使用现有的和预制的实时数据捕获工具和软件。预制网络爬虫允许您提取相关数据并下载特定网页。这可以包括可用产品及其价格、可用性和其他重要信息的列表。它们的自动化功能通常给它们带来巨大的优势,因为它们可以轻松检测 Web 结构、获取数据、解析 HTML 并将所有这些都集成到您的数据库中。随着时间的推移,它们变得非常流行,为什么不呢,因为它们便于携带,而且往往可以节省大量时间。
我们现在已经确定了网页抓取的重要性以及使用数据提取工具的好处。接下来,我们需要决定必须使用哪种数据提取工具,因为这些工具和软件正在充斥市场。为您选择合适的唯一方法是了解您的需求。使用web扩展可以提取实时数据,它是浏览器的一个小插件,但功能有限,安全性不确定。数据提取软件是您的另一个选择。它必须安装在系统中,并且由于其现代和先进的功能,非常适合处理敏感数据。
数据抓取软件有很多,比如ScrapingBee、ScrapingBot、Scraper AP I等,但是我给大家介绍一下我们最喜欢的网页抓取软件——Octoparse。
我相信所有其他软件都很好,但 Octoparse 有一些特殊的品质,使其比其他软件更具优势。这对于从多个网络源进行大规模实时数据捕获非常有用。我们可以保证每个小企业都会从其独特的功能中受益,因为它不是您普通的刮板。它凭借其广泛的工具超越了大多数工具。
预设提取模块不受任何复杂配置的约束,倾向于立即读取结果。它涵盖了所有重要的网站,无论是社交媒体、电子商务等。它适合所有人,因为它具有三种不同的模式,迎合初学者、季节专业人士和自定义爬虫,快速、即时地获取数据和信息他们需要。它拥有丰富而无所不包的功能,如RegEx编辑、任务调度、JSON抓取等,将您的实时抓取提升到一个新的高度。
使用 Octoparse,您甚至可以从 Ad-heavy 页面中提取数据,因为其出色的 Ad-block 功能可以解决这个问题。它倾向于模仿人类,同时从各种网站 抓取数据,并允许我们在您的系统或云上运行提取的信息。 Octoparse 的另一个前沿特性是它可以导出各种捕获的数据,包括 CSV、TXT、HTML,甚至 Excel 格式。 Octoparse 中的所有模板都非常人性化,因此不需要专业程序员;只需点击几下鼠标即可轻松获取数据,而无需花费一分钱。
归根结底,这是您考虑什么最有利于您的业务及其增长和繁荣的决定。因此,您可以探索所有可用的不同软件来帮助您实时抓取数据,但在结束本文之前,让我们给您一个建议。去下载 Octoparse,探索它的功能,了解为什么我们认为它是最好的网络抓取软件,然后自己决定。它是免费的,可在线获得,所以准备好被震撼吧!
怎样让网站的文章能够能够快速收录?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-07-16 20:48
指导:网站的文章怎么能快速收录?最近有很多客户在问这个问题,说一直在更新原创文章。现在已经一两个月了,周期基本都是更新的文章还没有被搜索引擎收录搜索到,很头疼。新站收录慢情情有可原,但网站上线三个多月了,文章收录还是那么慢,严重的不是收录,为什么会这样?所以作为深度网络的编辑,我采集了最近的收录bad 网站并进行了分析。总结如下:
一、没有使用链接提交功能。
每个搜索引擎都有一个站长平台,站长平台有链接提交功能。以百度为例。百度有百度站长,有链接提交功能。链接提交分为2种,1、自动提交:主动推送、自动推送、站点地图提交; 2、手动提交;各位站长一定要记得在网站上线时添加这三种自动提交功能,第一时间将更新的内容推送到百度,有助于加速收录,保护原创。使用此功能前请务必先验证百度站长。具体验证方法请参考“百度站长验证方法”。
二、内容不是原创,没有价值。
很多站长更新文章不是在做原创内容,都是在做伪原创,在做伪原创又没用伪原创技能,抱着文章改下同行业为标题,改首段,改尾,其余不变,只更新网站。这种做法和采集文章没有太大区别,除非你网站权重特别高,对搜索引擎有很强的信任感,比如腾讯、新浪、搜狐。否则不利于网站收录。
现在搜索引擎正在增加对文章 的评论。这样,很容易被识别。如果经常更新,会让搜索引擎认为网站一文不值,以后就不会去收录你了。 网站,所以大家一定要做好原创和有价值的文章,当网站稳定后,可以用原创文章和伪原创文章更新,可以写@ k17前期@,一定要多更新原创文章。
三、文章 不定期更新。
文章Update 一定要选择一个时间点,然后每天这个时间点继续更新,让搜索引擎蜘蛛养成每天这个时间爬的好习惯,每次来网站有新的内容爬取,久而久之会增加你对网站的好感,自然会加快你网站内容的收录。为了能够掌握蜘蛛来到网站的时间,可以查看网站日志,查看蜘蛛抓取网站内容的时间,然后在这个时候更新。记得更新原创内容,以吸引蜘蛛频繁爬取。
四、没有做过高质量的外链指导。
百度减少了外链掉链对网站优化的影响,但引导蜘蛛蜘蛛抓取网站的内容价值还在,站长一定要注意优质外链的建设。寻找相关的B2B平台、分类信息平台、论坛平台、自媒体平台、问答平台、新闻源平台等,发布原创内容,带网站链接,不要只带首页链接,带一些新闻栏目页面的内部页面或者产品栏目页面的链接,通过外部链接引导搜索引擎抓取这些页面的内容。
刚好是网站的更新内容也会显示在这些页面上。发送这些页面的链接,有助于蜘蛛第一时间抓取最新内容,尽快收录网站页面。外链的发布也需要定期、定量的发布,切记不要使用大量分发软件,以免造成搜索引擎掉电和K站。
五、 没有交换高质量的友情链接。
友联是优质外链。在每个网站主页的底部,都有一个专门的友情链展示区。这个函数主要是从优化的角度考虑的。一条优质的友情链,有利于带动网站收录,传递权重,提升关键词的排名,也给网站带来一点流量。很多公司的朋友链都是单向链接。只有你链接到其他人。其他人的网站 没有你的链接。一些公司交换他们的朋友链。另一方无人维护。它纯粹是一个僵尸网站。你的网站没有帮助,你必须换一个高质量的朋友链,有人维护,稳定的网站。
总结,除了以上5点之外,影响网站的文章能收录的原因还有很多,比如网站结构问题,网站空间问题等等,具体具体问题分析,以上5点是新手站长常犯的错误,也是常犯的错误。新手站长在做网站优化时一定要注意这几点,才能帮助网页提速收录。 查看全部
怎样让网站的文章能够能够快速收录?(图)
指导:网站的文章怎么能快速收录?最近有很多客户在问这个问题,说一直在更新原创文章。现在已经一两个月了,周期基本都是更新的文章还没有被搜索引擎收录搜索到,很头疼。新站收录慢情情有可原,但网站上线三个多月了,文章收录还是那么慢,严重的不是收录,为什么会这样?所以作为深度网络的编辑,我采集了最近的收录bad 网站并进行了分析。总结如下:
一、没有使用链接提交功能。
每个搜索引擎都有一个站长平台,站长平台有链接提交功能。以百度为例。百度有百度站长,有链接提交功能。链接提交分为2种,1、自动提交:主动推送、自动推送、站点地图提交; 2、手动提交;各位站长一定要记得在网站上线时添加这三种自动提交功能,第一时间将更新的内容推送到百度,有助于加速收录,保护原创。使用此功能前请务必先验证百度站长。具体验证方法请参考“百度站长验证方法”。
二、内容不是原创,没有价值。
很多站长更新文章不是在做原创内容,都是在做伪原创,在做伪原创又没用伪原创技能,抱着文章改下同行业为标题,改首段,改尾,其余不变,只更新网站。这种做法和采集文章没有太大区别,除非你网站权重特别高,对搜索引擎有很强的信任感,比如腾讯、新浪、搜狐。否则不利于网站收录。
现在搜索引擎正在增加对文章 的评论。这样,很容易被识别。如果经常更新,会让搜索引擎认为网站一文不值,以后就不会去收录你了。 网站,所以大家一定要做好原创和有价值的文章,当网站稳定后,可以用原创文章和伪原创文章更新,可以写@ k17前期@,一定要多更新原创文章。
三、文章 不定期更新。
文章Update 一定要选择一个时间点,然后每天这个时间点继续更新,让搜索引擎蜘蛛养成每天这个时间爬的好习惯,每次来网站有新的内容爬取,久而久之会增加你对网站的好感,自然会加快你网站内容的收录。为了能够掌握蜘蛛来到网站的时间,可以查看网站日志,查看蜘蛛抓取网站内容的时间,然后在这个时候更新。记得更新原创内容,以吸引蜘蛛频繁爬取。
四、没有做过高质量的外链指导。
百度减少了外链掉链对网站优化的影响,但引导蜘蛛蜘蛛抓取网站的内容价值还在,站长一定要注意优质外链的建设。寻找相关的B2B平台、分类信息平台、论坛平台、自媒体平台、问答平台、新闻源平台等,发布原创内容,带网站链接,不要只带首页链接,带一些新闻栏目页面的内部页面或者产品栏目页面的链接,通过外部链接引导搜索引擎抓取这些页面的内容。
刚好是网站的更新内容也会显示在这些页面上。发送这些页面的链接,有助于蜘蛛第一时间抓取最新内容,尽快收录网站页面。外链的发布也需要定期、定量的发布,切记不要使用大量分发软件,以免造成搜索引擎掉电和K站。
五、 没有交换高质量的友情链接。
友联是优质外链。在每个网站主页的底部,都有一个专门的友情链展示区。这个函数主要是从优化的角度考虑的。一条优质的友情链,有利于带动网站收录,传递权重,提升关键词的排名,也给网站带来一点流量。很多公司的朋友链都是单向链接。只有你链接到其他人。其他人的网站 没有你的链接。一些公司交换他们的朋友链。另一方无人维护。它纯粹是一个僵尸网站。你的网站没有帮助,你必须换一个高质量的朋友链,有人维护,稳定的网站。
总结,除了以上5点之外,影响网站的文章能收录的原因还有很多,比如网站结构问题,网站空间问题等等,具体具体问题分析,以上5点是新手站长常犯的错误,也是常犯的错误。新手站长在做网站优化时一定要注意这几点,才能帮助网页提速收录。
代理爬虫的四步爬取器是不是越多越好?
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-07-14 22:01
网站内容抓取是代理站长的核心工作,尤其是大站的代理站点非常多,要获取网站代理抓取的站点,通常需要一个爬虫,实现从几十个网站的代理中自动抓取并去重。今天这篇文章,给大家详细的讲解代理爬虫的四步爬取器。可能大家对爬虫有一定的了解,它不过是根据网页url特征判断找到,但如果一个网站提供了非常多的代理url,我们还需要爬虫去抓取它吗?这个网站不提供代理的情况下还要爬取吗?爬虫是不是越多越好?我们下面进行详细的探讨和验证。
一、什么是代理爬虫的四步爬取器爬虫是我们经常采用的方式来获取并且抓取网站的代理url。根据对应网站提供的代理ip和url识别技术,我们通过一个代理爬虫的爬取器,抓取每个网站的所有代理url,并且在爬取代理url的同时,还将抓取的代理url作为资源,并整理到一个代理池中。看到这里,我们会疑惑,如果网站提供代理ip很多,我们还需要爬虫去抓取并爬取它们吗?通过对网站提供的代理ip进行抓取,我们可以迅速积累非常多的代理ip资源,然后这些代理ip放到一个代理池中,共享给网站对应的爬虫。
而对于那些被淘汰掉的代理ip,就可以放到代理池中不用再用了。总结,代理爬虫的四步爬取器大概包括四步:爬取内容、爬取网站特征(抓取标识、标签列表等)、代理ip池扩充、代理ip池清理。爬虫爬取网站特征的方法其实很简单,就是对爬虫爬取时打包成功率计算。获取ip值的方法也很简单,用python编写一个小程序,为apache及其系列模块中的selector类编写一个初始化和初始化方法,通过代理池获取代理池内所有代理url,并计算获取的几率,只要代理url被爬取到,就返回ip值。
实践经验告诉我们,爬虫最好是用异步加载,因为代理加载后,要等待机器重新给代理ip地址做去重,这个时间因机器的不同而不同,当然还要考虑服务器资源问题。二、爬虫抓取器设计必须考虑的问题爬虫爬取器设计有两个关键字,一个是抓取,一个是去重。首先,爬虫抓取器必须要考虑以下几个问题:最大限度的抽象爬虫爬取策略这是抓取器设计的核心,爬虫抓取器的策略因机器而异,机器越多,处理所用时间越长,往往想要省时间,都是使用apache模块或者python的dirpool方法,并在这里,我们尽量使用selector模块中的模拟类,这样快速且便于理解。
比如爬取百度网站,那么只需要利用它的去重策略去匹配相应的百度搜索页面地址即可,我们可以尝试用上边的方法抓取百度搜索页面,打开apache浏览器,访问这个爬虫程序,假如这里访问了一个url参数返回的是0,即调用我们的爬虫抓取。 查看全部
代理爬虫的四步爬取器是不是越多越好?
网站内容抓取是代理站长的核心工作,尤其是大站的代理站点非常多,要获取网站代理抓取的站点,通常需要一个爬虫,实现从几十个网站的代理中自动抓取并去重。今天这篇文章,给大家详细的讲解代理爬虫的四步爬取器。可能大家对爬虫有一定的了解,它不过是根据网页url特征判断找到,但如果一个网站提供了非常多的代理url,我们还需要爬虫去抓取它吗?这个网站不提供代理的情况下还要爬取吗?爬虫是不是越多越好?我们下面进行详细的探讨和验证。
一、什么是代理爬虫的四步爬取器爬虫是我们经常采用的方式来获取并且抓取网站的代理url。根据对应网站提供的代理ip和url识别技术,我们通过一个代理爬虫的爬取器,抓取每个网站的所有代理url,并且在爬取代理url的同时,还将抓取的代理url作为资源,并整理到一个代理池中。看到这里,我们会疑惑,如果网站提供代理ip很多,我们还需要爬虫去抓取并爬取它们吗?通过对网站提供的代理ip进行抓取,我们可以迅速积累非常多的代理ip资源,然后这些代理ip放到一个代理池中,共享给网站对应的爬虫。
而对于那些被淘汰掉的代理ip,就可以放到代理池中不用再用了。总结,代理爬虫的四步爬取器大概包括四步:爬取内容、爬取网站特征(抓取标识、标签列表等)、代理ip池扩充、代理ip池清理。爬虫爬取网站特征的方法其实很简单,就是对爬虫爬取时打包成功率计算。获取ip值的方法也很简单,用python编写一个小程序,为apache及其系列模块中的selector类编写一个初始化和初始化方法,通过代理池获取代理池内所有代理url,并计算获取的几率,只要代理url被爬取到,就返回ip值。
实践经验告诉我们,爬虫最好是用异步加载,因为代理加载后,要等待机器重新给代理ip地址做去重,这个时间因机器的不同而不同,当然还要考虑服务器资源问题。二、爬虫抓取器设计必须考虑的问题爬虫爬取器设计有两个关键字,一个是抓取,一个是去重。首先,爬虫抓取器必须要考虑以下几个问题:最大限度的抽象爬虫爬取策略这是抓取器设计的核心,爬虫抓取器的策略因机器而异,机器越多,处理所用时间越长,往往想要省时间,都是使用apache模块或者python的dirpool方法,并在这里,我们尽量使用selector模块中的模拟类,这样快速且便于理解。
比如爬取百度网站,那么只需要利用它的去重策略去匹配相应的百度搜索页面地址即可,我们可以尝试用上边的方法抓取百度搜索页面,打开apache浏览器,访问这个爬虫程序,假如这里访问了一个url参数返回的是0,即调用我们的爬虫抓取。
如何实现所谓的动态网页中所需要的信息之Python版和【教程】
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-07-14 20:36
背景
很多时候,很多人需要抓取网页上的某些特定内容。
不过,除了前面的介绍,我还想从一些静态网页中提取具体的内容,比如:
【教程】python版爬取网页并提取网页中需要的信息
和
【教程】C#版抓取网页并提取网页中需要的信息
除了
,有些人会发现自己要爬取的网页的内容不在网页的源代码中。
所以,这个时候,我不知道如何实现它。
在这里,让我们解释一下如何抓取所谓的动态网页中的特定内容。
必备知识
阅读本文前,您需要具备相关的基础知识:
1.Fetch 网页,模拟登录等相关逻辑
不熟悉的请参考:
【整理中】关于爬取网页、分析网页内容、模拟登录网站的逻辑/流程及注意事项
2.学习使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的请参考:
【教程】教你使用工具(IE9的F12)分析模拟登录网站(百度主页)的内部逻辑流程
3.对于普通静态网页,如何提取需要的内容
如果你对此不熟悉,可以参考:
(1)Python 版本:
【教程】python版爬取网页并提取网页中需要的信息
(2)C#Version:
【教程】C#版抓取网页并提取网页中需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指在浏览器中查看网页源码时看到的网页源码中的内容以及网页上显示的内容。
也就是说,当我想在网页上显示某个内容时,可以通过搜索网页的源代码来找到相应的部分。
相反,对于动态网页,如果想获取动态网页中的具体内容,直接查看网页源代码是无法找到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
简而言之,它是通过其他方式生成或获得的。
目前,我学到了几件事:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个URL的过程,你会发现很可能会涉及到,
在网页正常显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些想要抓取的内容,有时这些js脚本是动态执行最后计算出来的。
通过访问另一个 url 地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要爬取的动态内容
其实,关于如何抓取需要的动态内容,简单来说,有一个解决方案:
根据自己通过工具分析的结果,自己找到对应的数据,提取出来;
只是这样,有时可以在分析结果的过程中直接提取这些数据,有时可能会通过js进行计算。
如果要抓取数据,由js脚本生成
虽然最终的一些动态内容是通过js脚本的执行产生的,但是对于你要抓取的数据:
你要抓取的数据是通过访问另一个url获取的
如果对应你要抓取的内容,需要访问另外一个url地址和返回的数据,那么就很简单了,你也需要单独访问这个url,然后获取对应的返回内容,并提取你从它得到你想要的数据。
总结
同一句话,不管你访问的内容是怎么生成的,最后还是可以用工具分析一下对应的内容是怎么从头生成的。
然后用代码模拟这个过程,最后提取出你需要的;
具体的示例演示,请参见:
【教程】以抓取网易博文近期读者信息为例,教你抓取动态网页内容。 查看全部
如何实现所谓的动态网页中所需要的信息之Python版和【教程】
背景
很多时候,很多人需要抓取网页上的某些特定内容。
不过,除了前面的介绍,我还想从一些静态网页中提取具体的内容,比如:
【教程】python版爬取网页并提取网页中需要的信息
和
【教程】C#版抓取网页并提取网页中需要的信息
除了
,有些人会发现自己要爬取的网页的内容不在网页的源代码中。
所以,这个时候,我不知道如何实现它。
在这里,让我们解释一下如何抓取所谓的动态网页中的特定内容。
必备知识
阅读本文前,您需要具备相关的基础知识:
1.Fetch 网页,模拟登录等相关逻辑
不熟悉的请参考:
【整理中】关于爬取网页、分析网页内容、模拟登录网站的逻辑/流程及注意事项
2.学习使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的请参考:
【教程】教你使用工具(IE9的F12)分析模拟登录网站(百度主页)的内部逻辑流程
3.对于普通静态网页,如何提取需要的内容
如果你对此不熟悉,可以参考:
(1)Python 版本:
【教程】python版爬取网页并提取网页中需要的信息
(2)C#Version:
【教程】C#版抓取网页并提取网页中需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指在浏览器中查看网页源码时看到的网页源码中的内容以及网页上显示的内容。
也就是说,当我想在网页上显示某个内容时,可以通过搜索网页的源代码来找到相应的部分。
相反,对于动态网页,如果想获取动态网页中的具体内容,直接查看网页源代码是无法找到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
简而言之,它是通过其他方式生成或获得的。
目前,我学到了几件事:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个URL的过程,你会发现很可能会涉及到,
在网页正常显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些想要抓取的内容,有时这些js脚本是动态执行最后计算出来的。
通过访问另一个 url 地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要爬取的动态内容
其实,关于如何抓取需要的动态内容,简单来说,有一个解决方案:
根据自己通过工具分析的结果,自己找到对应的数据,提取出来;
只是这样,有时可以在分析结果的过程中直接提取这些数据,有时可能会通过js进行计算。
如果要抓取数据,由js脚本生成
虽然最终的一些动态内容是通过js脚本的执行产生的,但是对于你要抓取的数据:
你要抓取的数据是通过访问另一个url获取的
如果对应你要抓取的内容,需要访问另外一个url地址和返回的数据,那么就很简单了,你也需要单独访问这个url,然后获取对应的返回内容,并提取你从它得到你想要的数据。
总结
同一句话,不管你访问的内容是怎么生成的,最后还是可以用工具分析一下对应的内容是怎么从头生成的。
然后用代码模拟这个过程,最后提取出你需要的;
具体的示例演示,请参见:
【教程】以抓取网易博文近期读者信息为例,教你抓取动态网页内容。
SEO让网站快速被爬虫的方法有哪些?怎么做?
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-07-14 20:15
在互联网时代,信息跨时空传播,使得更多的购买依赖于产品,为产品树立了良好的口碑。这些所谓的正面信息维护的声誉的聚集地来自互联网。如何让我们的产品在纷繁复杂的信息中更快、更及时、更准确地出现在搜索者面前,占据绝对优势?是极其重要的。除了付费竞价推广,SEO是大多数人的首选。为什么? SEO优化是一个相对缓慢的过程,但它的长期稳定性决定了时间和精力的成本是值得的。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,其中近70%的搜索者会在搜索结果自然排名的第一页直接找到自己需要的信息。
可见,目前SEO对于企业和产品具有不可替代的意义。那么网站怎么能被爬虫快速抓取呢?
1.关键词是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么? 关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外链也会影响权重
导入链接也是网站优化的一个非常重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
3.如何被爬虫抓取
爬虫是自动提取网页的程序,例如百度的蜘蛛。如果你想让你的网站Morepages 变成收录,你必须先让网页被蜘蛛抓取。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是原创内容。
网站如何快速被蜘蛛抓到:
1.网站 和页面权重
这必须是第一要务。 网站权重高、资历老、权限大的蜘蛛一定要特别对待。这样的网站爬的非常频繁,大家都知道搜索引擎蜘蛛是为了保证高效率。对于网站,并不是所有的页面都会被爬取,网站的权重越高,爬取的深度越高,对应的可爬取的页面也会增加,这样能被@k19的页面@ are 也会变得更多。
2.网站Server
网站server 是网站 的基石。如果网站服务器长时间打不开,那这就相当于闭门谢客了。如果他们愿意,蜘蛛就不能来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都很难爬到,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛的体验如果越来越差,你对网站的评价就会越来越低,自然会影响你对网站的捕获,所以你一定愿意选择一个空间服务器。没有好的地基,再好的房子都会穿越。
3.网站更新频率
蜘蛛每次爬行都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,不需要蜘蛛频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的。不可能蹲在这里等你更新,所以一定要主动把蜘蛛展示给蜘蛛,定期更新文章,让蜘蛛按照你的规则高效爬行,不仅让你更新文章更快地被捕获,同时也不会导致蜘蛛经常白跑。
4.文章的原创性
高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新的东西,所以网站updated 文章不要采集,不要天天转载,我们要给蜘蛛真正有价值的原创内容。蜘蛛如果能得到自己喜欢的东西,自然会对你的网站产生好感,经常来找吃的。
5.平化网站结构
蜘蛛爬行也有自己的线路。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接级别太深,后续页面就很难被蜘蛛抓取。
6.网站程序
在网站程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数实现的。当一个页面对应多个url时,会导致网站content重复,可能导致网站降级,严重影响爬虫的爬取。因此,程序必须确保一个页面只有一个 URL。如果已经产生,尽量通过301重定向、Canonical标签或者robots处理,保证蜘蛛只抓取一个标准网址。
7.外链建筑
大家都知道外链可以为网站吸引蜘蛛,尤其是新站,网站还不是很成熟,蜘蛛访问量少,外链可以增加网站页面在蜘蛛前面的曝光度,防止蜘蛛从无法找到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。我就不多说了,不要好心做坏事。
8.内链建筑
蜘蛛的爬取是跟随链接的,所以合理的优化内链可以要求蜘蛛爬取更多的页面,推广网站的收录。内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐。热门文章,更多赞等栏目,这是很多网站都在使用的,它可以让蜘蛛抓取更广泛的页面。 查看全部
SEO让网站快速被爬虫的方法有哪些?怎么做?
在互联网时代,信息跨时空传播,使得更多的购买依赖于产品,为产品树立了良好的口碑。这些所谓的正面信息维护的声誉的聚集地来自互联网。如何让我们的产品在纷繁复杂的信息中更快、更及时、更准确地出现在搜索者面前,占据绝对优势?是极其重要的。除了付费竞价推广,SEO是大多数人的首选。为什么? SEO优化是一个相对缓慢的过程,但它的长期稳定性决定了时间和精力的成本是值得的。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,其中近70%的搜索者会在搜索结果自然排名的第一页直接找到自己需要的信息。
可见,目前SEO对于企业和产品具有不可替代的意义。那么网站怎么能被爬虫快速抓取呢?
1.关键词是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么? 关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外链也会影响权重
导入链接也是网站优化的一个非常重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
3.如何被爬虫抓取
爬虫是自动提取网页的程序,例如百度的蜘蛛。如果你想让你的网站Morepages 变成收录,你必须先让网页被蜘蛛抓取。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是原创内容。
网站如何快速被蜘蛛抓到:
1.网站 和页面权重
这必须是第一要务。 网站权重高、资历老、权限大的蜘蛛一定要特别对待。这样的网站爬的非常频繁,大家都知道搜索引擎蜘蛛是为了保证高效率。对于网站,并不是所有的页面都会被爬取,网站的权重越高,爬取的深度越高,对应的可爬取的页面也会增加,这样能被@k19的页面@ are 也会变得更多。
2.网站Server
网站server 是网站 的基石。如果网站服务器长时间打不开,那这就相当于闭门谢客了。如果他们愿意,蜘蛛就不能来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都很难爬到,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛的体验如果越来越差,你对网站的评价就会越来越低,自然会影响你对网站的捕获,所以你一定愿意选择一个空间服务器。没有好的地基,再好的房子都会穿越。
3.网站更新频率
蜘蛛每次爬行都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,不需要蜘蛛频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的。不可能蹲在这里等你更新,所以一定要主动把蜘蛛展示给蜘蛛,定期更新文章,让蜘蛛按照你的规则高效爬行,不仅让你更新文章更快地被捕获,同时也不会导致蜘蛛经常白跑。
4.文章的原创性
高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新的东西,所以网站updated 文章不要采集,不要天天转载,我们要给蜘蛛真正有价值的原创内容。蜘蛛如果能得到自己喜欢的东西,自然会对你的网站产生好感,经常来找吃的。
5.平化网站结构
蜘蛛爬行也有自己的线路。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接级别太深,后续页面就很难被蜘蛛抓取。
6.网站程序
在网站程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数实现的。当一个页面对应多个url时,会导致网站content重复,可能导致网站降级,严重影响爬虫的爬取。因此,程序必须确保一个页面只有一个 URL。如果已经产生,尽量通过301重定向、Canonical标签或者robots处理,保证蜘蛛只抓取一个标准网址。
7.外链建筑
大家都知道外链可以为网站吸引蜘蛛,尤其是新站,网站还不是很成熟,蜘蛛访问量少,外链可以增加网站页面在蜘蛛前面的曝光度,防止蜘蛛从无法找到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。我就不多说了,不要好心做坏事。
8.内链建筑
蜘蛛的爬取是跟随链接的,所以合理的优化内链可以要求蜘蛛爬取更多的页面,推广网站的收录。内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐。热门文章,更多赞等栏目,这是很多网站都在使用的,它可以让蜘蛛抓取更广泛的页面。
鉴于技术保密以及网站运营的差异等其他原因有哪些
网站优化 • 优采云 发表了文章 • 0 个评论 • 455 次浏览 • 2021-07-14 01:07
百度认为什么样的网站和收录比较适合爬取?我们简要介绍以下几个方面。鉴于技术保密及网站操作差异等原因,以下内容仅供站长参考。具体收录策略包括但不限于内容。
第一方面:网站创造高质量的内容,可以为用户提供独特的价值。
作为搜索引擎,百度的终极目标是满足用户的搜索需求,所以网站内容首先要满足用户的需求。如今,互联网在也能满足用户需求的前提下,充斥着大量同质化的内容。接下来,如果你网站提供的内容是独一无二的或者具有一定的独特价值,那么百度会更喜欢收录你的网站。
温馨提示:百度希望收录这样网站:
相反,很多网站的内容都是“一般或低质量”,有的网站使用欺骗手段来获得更好的收录或排名。下面是一些常见的情况,虽然无法一一列举。但请不要冒险,百度有全面的技术支持来检测和处理这些行为。
有些网站不是从用户的角度设计的,而是为了从搜索引擎中骗取更多的流量。例如,将一种类型的内容提交给搜索引擎,而将另一种类型的内容显示给用户。这些行为包括但不限于:向网页添加隐藏文本或隐藏链接;添加与网页内容无关的关键词;欺骗性地重定向或重定向;专门为搜索引擎制作桥页;目标搜索引擎利用程序生成的内容。
百度会尽量收录提供不同信息的网页。如果你的网站收录大量重复内容,搜索引擎会减少相同内容的收录,并考虑网站提供的内容价值低。
当然,如果网站上相同的内容以不同的形式展示(比如论坛的短版页面,打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。这也是真的帮助节省带宽。
第二方面:网站提供的内容得到了用户和站长的认可和支持
如果网站上的内容得到用户和站长的认可,对于百度来说,收录也是值得的。百度将通过分析真实用户的搜索行为、访问行为以及网站之间的关系,对网站的认可度进行综合评价。不过值得注意的是,这种认可必须基于网站为用户提供优质内容,并且是真实有效的。下面仅以网站之间的关系为例,说明百度如何看待其他站长对你网站的认可:通常网站之间的链接可以帮助百度爬虫找到你的网站,增加你的网站认出。百度将网页A到网页B的链接解释为网页A到网页B的投票。对一个网页的投票更能体现网页本身的“认可度”权重,有助于提高其他网站的“认可度”页。链接的数量、质量和相关性会影响“接受度”的计算。
但请注意,并非所有链接都可以参与识别计算,只有那些自然链接才有效。 (当其他网站发现您的内容有价值并认为它可能对访问者有帮助时,自然链接是在网络动态生成过程中形成的。)
其他网站 创建与您的网站 相关的链接的最佳方式是创建可以在互联网上流行的独特且相关的内容。您的内容越有用,其他网站管理员就越容易发现您的内容对其用户有价值,因此链接到您的网站 也就越容易。在决定是否添加链接之前,您应该首先考虑:这对我的网站访问者真的有好处吗?
但是,一些网站站长经常不顾链接质量和链接来源,进行链接交换,人为地建立链接关系,仅以识别为目的,这将对他们的网站造成长期影响。
提醒:会对网站产生不利影响的链接包括但不限于:
第三方面:网站具有良好的浏览体验
一个网站有很好的浏览体验,所以对用户非常有利。百度也会认为这样的网站具有更好的收录价值。良好的浏览体验意味着:
为用户提供站点地图和导航,其中收录指向网站 重要部分的链接。让用户可以清晰、简单地浏览网站,快速找到自己需要的信息。
网站速快可以提高用户满意度和网页的整体质量(特别是对于互联网连接速度较慢的用户)。
确保网站的内容在不同浏览器中都能正确显示,防止部分用户正常访问。
广告是网站 的重要收入来源。 网站含有广告是很合理的现象,但是如果广告太多,会影响用户的浏览;或者网站有太多不相关的弹窗和浮动窗口广告可能会冒犯用户。
百度的目标是为用户提供最相关的搜索结果和最佳的用户体验。如果广告对用户体验造成损害,那么百度抓取时需要减少此类网站。
网站的注册权限等权限可以增加网站的注册用户,保证网站的内容质量,但是过多的权限设置可能会让新用户失去耐心,给用户带来不好的体验。从百度的角度来看,它希望减少对用户获取信息过于昂贵的网页的提供。 查看全部
鉴于技术保密以及网站运营的差异等其他原因有哪些
百度认为什么样的网站和收录比较适合爬取?我们简要介绍以下几个方面。鉴于技术保密及网站操作差异等原因,以下内容仅供站长参考。具体收录策略包括但不限于内容。
第一方面:网站创造高质量的内容,可以为用户提供独特的价值。
作为搜索引擎,百度的终极目标是满足用户的搜索需求,所以网站内容首先要满足用户的需求。如今,互联网在也能满足用户需求的前提下,充斥着大量同质化的内容。接下来,如果你网站提供的内容是独一无二的或者具有一定的独特价值,那么百度会更喜欢收录你的网站。
温馨提示:百度希望收录这样网站:
相反,很多网站的内容都是“一般或低质量”,有的网站使用欺骗手段来获得更好的收录或排名。下面是一些常见的情况,虽然无法一一列举。但请不要冒险,百度有全面的技术支持来检测和处理这些行为。
有些网站不是从用户的角度设计的,而是为了从搜索引擎中骗取更多的流量。例如,将一种类型的内容提交给搜索引擎,而将另一种类型的内容显示给用户。这些行为包括但不限于:向网页添加隐藏文本或隐藏链接;添加与网页内容无关的关键词;欺骗性地重定向或重定向;专门为搜索引擎制作桥页;目标搜索引擎利用程序生成的内容。
百度会尽量收录提供不同信息的网页。如果你的网站收录大量重复内容,搜索引擎会减少相同内容的收录,并考虑网站提供的内容价值低。
当然,如果网站上相同的内容以不同的形式展示(比如论坛的短版页面,打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。这也是真的帮助节省带宽。
第二方面:网站提供的内容得到了用户和站长的认可和支持
如果网站上的内容得到用户和站长的认可,对于百度来说,收录也是值得的。百度将通过分析真实用户的搜索行为、访问行为以及网站之间的关系,对网站的认可度进行综合评价。不过值得注意的是,这种认可必须基于网站为用户提供优质内容,并且是真实有效的。下面仅以网站之间的关系为例,说明百度如何看待其他站长对你网站的认可:通常网站之间的链接可以帮助百度爬虫找到你的网站,增加你的网站认出。百度将网页A到网页B的链接解释为网页A到网页B的投票。对一个网页的投票更能体现网页本身的“认可度”权重,有助于提高其他网站的“认可度”页。链接的数量、质量和相关性会影响“接受度”的计算。
但请注意,并非所有链接都可以参与识别计算,只有那些自然链接才有效。 (当其他网站发现您的内容有价值并认为它可能对访问者有帮助时,自然链接是在网络动态生成过程中形成的。)
其他网站 创建与您的网站 相关的链接的最佳方式是创建可以在互联网上流行的独特且相关的内容。您的内容越有用,其他网站管理员就越容易发现您的内容对其用户有价值,因此链接到您的网站 也就越容易。在决定是否添加链接之前,您应该首先考虑:这对我的网站访问者真的有好处吗?
但是,一些网站站长经常不顾链接质量和链接来源,进行链接交换,人为地建立链接关系,仅以识别为目的,这将对他们的网站造成长期影响。
提醒:会对网站产生不利影响的链接包括但不限于:
第三方面:网站具有良好的浏览体验
一个网站有很好的浏览体验,所以对用户非常有利。百度也会认为这样的网站具有更好的收录价值。良好的浏览体验意味着:
为用户提供站点地图和导航,其中收录指向网站 重要部分的链接。让用户可以清晰、简单地浏览网站,快速找到自己需要的信息。
网站速快可以提高用户满意度和网页的整体质量(特别是对于互联网连接速度较慢的用户)。
确保网站的内容在不同浏览器中都能正确显示,防止部分用户正常访问。
广告是网站 的重要收入来源。 网站含有广告是很合理的现象,但是如果广告太多,会影响用户的浏览;或者网站有太多不相关的弹窗和浮动窗口广告可能会冒犯用户。
百度的目标是为用户提供最相关的搜索结果和最佳的用户体验。如果广告对用户体验造成损害,那么百度抓取时需要减少此类网站。
网站的注册权限等权限可以增加网站的注册用户,保证网站的内容质量,但是过多的权限设置可能会让新用户失去耐心,给用户带来不好的体验。从百度的角度来看,它希望减少对用户获取信息过于昂贵的网页的提供。
山西事业单位考试:动态网页抓取(解析真实地址+selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-07-14 01:04
第四章:动态网页爬取(解析真实地址+selenium)
由于网易云线程服务暂停,新写的第4章现更新到这里。请参考文章:
之前抓取的网页都是静态网页,浏览器中显示的此类网页的内容都在HTML源代码中。但是,由于主流的网站使用JavaScript来展示网页内容,与静态网页不同,使用JavaScript时,很多内容不会出现在HTML源代码中,因此抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网络爬虫:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的例子,让读者了解什么是动态抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态捕捉示例
在抓取动态网页之前,我们还需要了解一种异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于通过后台与服务器的少量数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果需要更新传统网页的内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更用户友好。但是AJAX网页的抓取过程比较麻烦。
首先,让我们看一个动态网页的例子。在作者的博客上打开Hello World文章,文章地址:/2018/07/04/hello-world/。网站可能有变动,请到作者官网查找Hello World文章地址。如图4-1所示,页面下方的评论加载了JavaScript,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的源代码。如图4-2所示,放置注释的代码中没有注释数据。只有一段 JavaScript 代码。最后呈现的数据是通过JavaScript提取出来的,加载到源代码中进行呈现。
除了作者的博客,你还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评价”,可以发现上面的URL地址没有变化,整个网页没有重新加载,网页的评论部分有已更新,如图 4-3 所示。显示。
如图4-4所示,我们也可以查看该产品网页的源码。里面没有用户评论,这段内容是空白的。
如果使用 AJAX 加载的动态网页,如何抓取动态加载的内容?有两种方式:
(1)通过浏览器评论元素解析地址。
(2)Selenium 模拟浏览器爬行。
请查看第四章的其他章节
4.2 解析真实地址爬取
4.3 通过 selenium 模拟浏览器爬行 查看全部
山西事业单位考试:动态网页抓取(解析真实地址+selenium)
第四章:动态网页爬取(解析真实地址+selenium)
由于网易云线程服务暂停,新写的第4章现更新到这里。请参考文章:
之前抓取的网页都是静态网页,浏览器中显示的此类网页的内容都在HTML源代码中。但是,由于主流的网站使用JavaScript来展示网页内容,与静态网页不同,使用JavaScript时,很多内容不会出现在HTML源代码中,因此抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网络爬虫:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的例子,让读者了解什么是动态抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态捕捉示例
在抓取动态网页之前,我们还需要了解一种异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于通过后台与服务器的少量数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果需要更新传统网页的内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更用户友好。但是AJAX网页的抓取过程比较麻烦。
首先,让我们看一个动态网页的例子。在作者的博客上打开Hello World文章,文章地址:/2018/07/04/hello-world/。网站可能有变动,请到作者官网查找Hello World文章地址。如图4-1所示,页面下方的评论加载了JavaScript,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的源代码。如图4-2所示,放置注释的代码中没有注释数据。只有一段 JavaScript 代码。最后呈现的数据是通过JavaScript提取出来的,加载到源代码中进行呈现。
除了作者的博客,你还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评价”,可以发现上面的URL地址没有变化,整个网页没有重新加载,网页的评论部分有已更新,如图 4-3 所示。显示。
如图4-4所示,我们也可以查看该产品网页的源码。里面没有用户评论,这段内容是空白的。
如果使用 AJAX 加载的动态网页,如何抓取动态加载的内容?有两种方式:
(1)通过浏览器评论元素解析地址。
(2)Selenium 模拟浏览器爬行。
请查看第四章的其他章节
4.2 解析真实地址爬取
4.3 通过 selenium 模拟浏览器爬行
杭州SEO:搜索引擎优化对企业和产品都具有重要的意义
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-07-12 19:03
在这个互联网时代,很多人在购买新产品之前都会上网查看信息内容,看看哪些品牌的口碑和评价更好。这时候,好的产品就会有好的优势。调查显示,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会在搜索结果自然排名的第一页直接找到自己需要的信息。
因此,可见搜索引擎优化对企业和产品的意义重大。杭州SEO告诉你如何在网站上快速爬取。
我们经常听到关键字,但关键字的具体主要用途是什么? 关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的一个非常重要的过程,它会间接影响网站在搜索引擎中的权重。现阶段我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
crawler 是一个自动提取网页的程序,比如百度的蜘蛛。如果你想收录更多网站的页面,一定要先爬网。
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是最原创的内容。
这一定是第一件事。对权势大、资历大、权威大的蜘蛛,必须采取特殊的处理方法。这种网站的爬取频率非常高。我们都知道,搜索引擎蜘蛛为了保证高效,不会抓取网站的所有页面。 网站的权重越高,爬取深度越高,爬取的页面也就越多。这样,可以收录更多的页面。
网站server 是网站 的基石。如果网站服务器长时间打不开,那么就相当于关机谢客了。如果蜘蛛想来,他就不能来。百度蜘蛛也是这个网站的访客。如果你的服务器不稳定或卡住,蜘蛛每次都很难爬行。有时一个页面只能抓取其中的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的分数也越来越低。自然会影响你的网站爬取,所以选择空间服务器。我们必须放弃。没有好的地基,再好的房子也会过马路。
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次的内容完全一样,说明页面没有更新,蜘蛛不需要经常爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问网页,但蜘蛛不是你自己的,所以不可能蹲在这里等你更新。因此,我们应该主动向蜘蛛展示并及时更新文章,这样蜘蛛就会按照你的规则有效地爬取文章,这样不仅会让你更新的文章更快,不会让蜘蛛白跑。
高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新事物。所以网站更新的文章不能天天采集或者转载。我们需要给蜘蛛提供真正有价值的原创 内容。如果一只蜘蛛能得到它喜欢的东西,它自然会给你的网站留下好印象,它也会经常来觅食。
蜘蛛也有自己的捕食方法。在为他们铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接级别太深,蜘蛛将难以抓取下面的页面。
在网站程序中,有很多程序可以生成大量的重复页面,而这些页面一般都是通过参数来实现的。当一个页面对应大量的URL时,会导致网站内容重复,从而可能导致网站降级,严重影响蜘蛛抓取。因此,程序必须确保页面只有一个 URL(如果它被生成)。尝试通过 301 重定向、规范标签或机器人来处理它,以确保蜘蛛只捕获标准 URL。
大家都知道外链可以把蜘蛛吸引到网站,尤其是在新站里,网站还不是很成熟,蜘蛛的访问量也比较少,外链可以增加网站页面前面的曝光率蜘蛛 防止蜘蛛发现页面。在外链建设过程中,要注意外链的质量。不要为了避免麻烦而做无用的事情。百度现在相信大家都知道外链的管理,就不多说了。善良不做坏事。
蜘蛛沿着链接爬行,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的采集。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这是很多网站 正在使用的,蜘蛛可以抓取更广泛的页面。
首页是蜘蛛访问量最大的页面,也是网站权重好的页面。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛的访问频率,还可以提高对更新页面的抓取和采集。栏目页面也可以这样做。
搜索引擎蜘蛛抓取链接进行搜索。如果链接太多,不仅网页数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。当蜘蛛碰到死链时,它就像一个死胡同。他们不得不回去再回来,这大大降低了蜘蛛爬行网站的效率。所以一定要及时检查网站的死链接,提交给搜索引擎。同时还要做好网站404页面的处理,告知搜索引擎错误的页面。
很多网站有意无意地直接在robots文件中屏蔽了百度或网站的某些页面,但他们一直在寻找蜘蛛整天不爬我的页面的原因。百度会因此受到指责吗?如果你不让别人进来,那百度收录你的页面呢?所以如果有必要,请经常检查网站的robots文件是否正常。
搜索引擎蜘蛛非常喜欢网站map。 网站map 是网站 的所有链接的容器。很多网站都有很深的链接,蜘蛛很难掌握。 网站map 可以方便搜索引擎蜘蛛抓取网站页面。通过爬网,他们可以清楚地掌握网站的结构,所以网站地图的建立不仅可以提高爬网率,还可以很好地获得蜘蛛的感觉。
这也是在每次页面更新后向搜索引擎提交内容的好方法,但不要总是在没有内容的情况下提交。只需提交一次。接受程度取决于搜索引擎。 查看全部
杭州SEO:搜索引擎优化对企业和产品都具有重要的意义
在这个互联网时代,很多人在购买新产品之前都会上网查看信息内容,看看哪些品牌的口碑和评价更好。这时候,好的产品就会有好的优势。调查显示,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会在搜索结果自然排名的第一页直接找到自己需要的信息。
因此,可见搜索引擎优化对企业和产品的意义重大。杭州SEO告诉你如何在网站上快速爬取。
我们经常听到关键字,但关键字的具体主要用途是什么? 关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的一个非常重要的过程,它会间接影响网站在搜索引擎中的权重。现阶段我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
crawler 是一个自动提取网页的程序,比如百度的蜘蛛。如果你想收录更多网站的页面,一定要先爬网。
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是最原创的内容。
这一定是第一件事。对权势大、资历大、权威大的蜘蛛,必须采取特殊的处理方法。这种网站的爬取频率非常高。我们都知道,搜索引擎蜘蛛为了保证高效,不会抓取网站的所有页面。 网站的权重越高,爬取深度越高,爬取的页面也就越多。这样,可以收录更多的页面。
网站server 是网站 的基石。如果网站服务器长时间打不开,那么就相当于关机谢客了。如果蜘蛛想来,他就不能来。百度蜘蛛也是这个网站的访客。如果你的服务器不稳定或卡住,蜘蛛每次都很难爬行。有时一个页面只能抓取其中的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的分数也越来越低。自然会影响你的网站爬取,所以选择空间服务器。我们必须放弃。没有好的地基,再好的房子也会过马路。
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次的内容完全一样,说明页面没有更新,蜘蛛不需要经常爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问网页,但蜘蛛不是你自己的,所以不可能蹲在这里等你更新。因此,我们应该主动向蜘蛛展示并及时更新文章,这样蜘蛛就会按照你的规则有效地爬取文章,这样不仅会让你更新的文章更快,不会让蜘蛛白跑。
高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新事物。所以网站更新的文章不能天天采集或者转载。我们需要给蜘蛛提供真正有价值的原创 内容。如果一只蜘蛛能得到它喜欢的东西,它自然会给你的网站留下好印象,它也会经常来觅食。
蜘蛛也有自己的捕食方法。在为他们铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接级别太深,蜘蛛将难以抓取下面的页面。
在网站程序中,有很多程序可以生成大量的重复页面,而这些页面一般都是通过参数来实现的。当一个页面对应大量的URL时,会导致网站内容重复,从而可能导致网站降级,严重影响蜘蛛抓取。因此,程序必须确保页面只有一个 URL(如果它被生成)。尝试通过 301 重定向、规范标签或机器人来处理它,以确保蜘蛛只捕获标准 URL。
大家都知道外链可以把蜘蛛吸引到网站,尤其是在新站里,网站还不是很成熟,蜘蛛的访问量也比较少,外链可以增加网站页面前面的曝光率蜘蛛 防止蜘蛛发现页面。在外链建设过程中,要注意外链的质量。不要为了避免麻烦而做无用的事情。百度现在相信大家都知道外链的管理,就不多说了。善良不做坏事。
蜘蛛沿着链接爬行,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的采集。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这是很多网站 正在使用的,蜘蛛可以抓取更广泛的页面。
首页是蜘蛛访问量最大的页面,也是网站权重好的页面。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛的访问频率,还可以提高对更新页面的抓取和采集。栏目页面也可以这样做。
搜索引擎蜘蛛抓取链接进行搜索。如果链接太多,不仅网页数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。当蜘蛛碰到死链时,它就像一个死胡同。他们不得不回去再回来,这大大降低了蜘蛛爬行网站的效率。所以一定要及时检查网站的死链接,提交给搜索引擎。同时还要做好网站404页面的处理,告知搜索引擎错误的页面。
很多网站有意无意地直接在robots文件中屏蔽了百度或网站的某些页面,但他们一直在寻找蜘蛛整天不爬我的页面的原因。百度会因此受到指责吗?如果你不让别人进来,那百度收录你的页面呢?所以如果有必要,请经常检查网站的robots文件是否正常。
搜索引擎蜘蛛非常喜欢网站map。 网站map 是网站 的所有链接的容器。很多网站都有很深的链接,蜘蛛很难掌握。 网站map 可以方便搜索引擎蜘蛛抓取网站页面。通过爬网,他们可以清楚地掌握网站的结构,所以网站地图的建立不仅可以提高爬网率,还可以很好地获得蜘蛛的感觉。
这也是在每次页面更新后向搜索引擎提交内容的好方法,但不要总是在没有内容的情况下提交。只需提交一次。接受程度取决于搜索引擎。
3种抓取其中数据的方法,你get到了吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-07-08 23:03
3 种捕获数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1正则表达式
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re
>>> from chp1.advanced_link_crawler import download>>> url = 'http://example.python-scraping.com/view/UnitedKingdom-239'>>> html = download(url)>>> re.findall(r'(.*?)', html)['', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', '<a>EU</a>', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]d{2}[A-Z]{2})|([A-Z]d{3}[A-Z]{2})|([A-Z]{2}d{2} [A-Z]{2})|([A-Z]{2}d{3}[A-Z]{2})|([A-Z]d[A-Z]d[A-Z]{2}) |([A-Z]{2}d[A-Z]d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', '<a>IE </a>']
点击并拖拽以移动
从上面的结果可以看出,多个国家(或地区)属性使用了``标签。如果我们只想捕获国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个计划,但是如果页面发生变化,该计划很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望在未来的某个时间点再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加明确,我们还可以添加其父元素。因为这个元素有一个 ID 属性,所以它应该是唯一的。
>>> re.findall('Area:
(.*?)', html)['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)
['244,820 square kilometres']
这个正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加title 属性,或者为tr 和td` 元素修改其CSS 类或ID。
从这个例子中可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,而且很容易在网页更新后出现问题。幸运的是,还有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签打开和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。下面我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> from pprint import pprint>>> broken_html = 'AreaPopulation'>>> # parse the HTML>>> soup = BeautifulSoup(broken_html, 'html.parser')>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
我们可以看到,使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装 LXML(详见2.2.3 部分),或者使用 html5lib。要安装 html5lib,只需使用 pip。
pip install html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>> soup = BeautifulSoup(broken_html, 'html5lib')
>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
此时使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加&标签使其成为完整的HTML文档。当你使用 lxml 时,你可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country_or_district'})
>>> ul.find('li') # returns just the first matchArea>>> ul.find_all('li') # returns all matches[Area, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.python-scraping.com/places/view/United-Kingdom-239'>>> html = download(url)>>> soup = BeautifulSoup(html)>>> # locate the area row>>> tr = soup.find(attrs={'id':'places_area__row'})>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the data element>>> area = td.text # extract the text from the data element>>> print(area)244,820 square kilometres
虽然这段代码比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的网站 代码中提取数据。
3Lxml
Lxml
它是一个基于 libxml2 构建的 Python 库,一个 XML 解析库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用Anaconda的快速安装会将你的PYTHON_PATH设置为Conda的Python安装位置。
和 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。下面是使用该模块解析同样不完整的 HTML 的示例。
>>> from lxml.html import fromstring, tostring
>>> broken_html = 'AreaPopulation'>>> tree = fromstring(broken_html) # parse the HTML>>> fixed_html = tostring(tree, pretty_print=True)>>> print(fixed_html) Area Population
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验,或者它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip install cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]>>> area = td.text_content()>>> print(area)244,820 square kilometres
通过代码树上的cssselect方法,我们可以使用CSS语法来选择表中id为places_area__row的行元素,然后是w2p_fw类的子表数据标签。由于cssselect返回的是一个列表,所以我们需要获取第一个结果并调用text_content方法遍历所有子元素,并返回每个元素的相关文本。 查看全部
3种抓取其中数据的方法,你get到了吗?
3 种捕获数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1正则表达式
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re
>>> from chp1.advanced_link_crawler import download>>> url = 'http://example.python-scraping.com/view/UnitedKingdom-239'>>> html = download(url)>>> re.findall(r'(.*?)', html)['', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', '<a>EU</a>', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]d{2}[A-Z]{2})|([A-Z]d{3}[A-Z]{2})|([A-Z]{2}d{2} [A-Z]{2})|([A-Z]{2}d{3}[A-Z]{2})|([A-Z]d[A-Z]d[A-Z]{2}) |([A-Z]{2}d[A-Z]d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', '<a>IE </a>']
点击并拖拽以移动
从上面的结果可以看出,多个国家(或地区)属性使用了``标签。如果我们只想捕获国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个计划,但是如果页面发生变化,该计划很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望在未来的某个时间点再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加明确,我们还可以添加其父元素。因为这个元素有一个 ID 属性,所以它应该是唯一的。
>>> re.findall('Area:
(.*?)', html)['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)
['244,820 square kilometres']
这个正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加title 属性,或者为tr 和td` 元素修改其CSS 类或ID。
从这个例子中可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,而且很容易在网页更新后出现问题。幸运的是,还有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签打开和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。下面我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> from pprint import pprint>>> broken_html = 'AreaPopulation'>>> # parse the HTML>>> soup = BeautifulSoup(broken_html, 'html.parser')>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
我们可以看到,使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装 LXML(详见2.2.3 部分),或者使用 html5lib。要安装 html5lib,只需使用 pip。
pip install html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>> soup = BeautifulSoup(broken_html, 'html5lib')
>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
此时使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加&标签使其成为完整的HTML文档。当你使用 lxml 时,你可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country_or_district'})
>>> ul.find('li') # returns just the first matchArea>>> ul.find_all('li') # returns all matches[Area, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.python-scraping.com/places/view/United-Kingdom-239'>>> html = download(url)>>> soup = BeautifulSoup(html)>>> # locate the area row>>> tr = soup.find(attrs={'id':'places_area__row'})>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the data element>>> area = td.text # extract the text from the data element>>> print(area)244,820 square kilometres
虽然这段代码比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的网站 代码中提取数据。
3Lxml
Lxml
它是一个基于 libxml2 构建的 Python 库,一个 XML 解析库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用Anaconda的快速安装会将你的PYTHON_PATH设置为Conda的Python安装位置。
和 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。下面是使用该模块解析同样不完整的 HTML 的示例。
>>> from lxml.html import fromstring, tostring
>>> broken_html = 'AreaPopulation'>>> tree = fromstring(broken_html) # parse the HTML>>> fixed_html = tostring(tree, pretty_print=True)>>> print(fixed_html) Area Population
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验,或者它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip install cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]>>> area = td.text_content()>>> print(area)244,820 square kilometres
通过代码树上的cssselect方法,我们可以使用CSS语法来选择表中id为places_area__row的行元素,然后是w2p_fw类的子表数据标签。由于cssselect返回的是一个列表,所以我们需要获取第一个结果并调用text_content方法遍历所有子元素,并返回每个元素的相关文本。
维基百科:Web搜寻器开发的免费开放源代码(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-07-08 22:52
来自维基百科
网络爬虫(有时称为蜘蛛)是互联网机器人,通常系统地浏览网络索引以进行网络索引。
网络爬虫从要访问的 URL 列表(称为种子)开始。当爬虫访问这些 URL 时,它会识别页面中的所有超链接,并将它们添加到要访问的 URL 列表中。如果爬虫正在执行网站的归档,它会复制并保存信息。存档称为存储库,旨在存储和管理网页集合。存储库类似于任何其他存储数据的系统,例如现代数据库。
让我们开始吧! !
Metasploit
这个辅助模块是一个模块化的网络爬虫,可以与wmap(有时)或独立使用。
使用辅助/爬虫/msfcrawler
msf 辅助(msfcrawler)> 设置 rhosts
msf 辅助(msfcrawler)> 漏洞利用
从截图中可以看到截图已经加载了搜索引擎,这样就可以对任何网站准确隐藏文件,比如about.php、jquery联系表单、html等,同时使用浏览器无法准确隐藏网站。为了采集任何网站信息,我们可以使用它。
Httrack
HTTrack 是 Xavier Roche 开发的免费开源网络搜索器和离线浏览器
它可以让你将网上的wanwei网站dots下载到本地目录,递归构建所有目录,从服务器获取HTML、图片等文件到电脑。 HTTrack 整理原站的相对链接结构。
在终端输入以下命令
httrack –O /root/Desktop/file
它将输出保存在给定的目录 /root/Desktop/file 中。
从给定的屏幕截图中,您可以观察到这一点,它使网站 信息包括 html 文件以及 JavaScript 和 jquery 变得愚蠢
黑寡妇
此Web Spider实用程序检测并显示用户选择的网页的详细信息,并提供其他网络工具。
BlackWidow 干净、合乎逻辑的标签式界面足够简单,适合中级用户,但在底部足以满足高级用户的需求。只需输入您选择的 URL,然后按 Go。 BlackWidow 使用多线程快速下载所有文件和测试链接。对于小网站,这个操作只需要几分钟。
您可以从这里下载。
在地址字段中输入您的 URL,然后按 Go。
点击开始按钮开始扫描左边的网址,然后选择一个文件夹来保存输出文件按钮。
从截图中可以看出,我浏览了 C:\Users\RAJ\Desktop\tptl 以便将输出文件存储在其中。
打开目标文件夹tptl,会得到网站图片或内容的完整数据,html文件、php文件和JavaScript都存储在里面。
网站开膛手复印机
Website Ripper Copier (WRC) 是一种通用高速网站downloader 软件,用于保存网站 数据。 WRC 可以将网站 文件下载到本地驱动器进行离线浏览,提取特定大小和类型的网站 文件,例如图像、视频、图片、电影和音乐,并充当具有恢复支持的下载管理器 检索大量的文件和镜像站点。 WRC 还是站点链接验证器、资源管理器和选项卡式反弹网页/离线浏览器。
Website Ripper Copier 是唯一可以从 HTTP、HTTPS 和 FTP 连接恢复中断下载、访问受密码保护的 网站、支持 Web Cookie、分析脚本、更新检索到的 网站 或文件并启动 50 @K14 的下载用于多个检索线程的@downloader 工具
您可以从这里下载。
选择“离线浏览网站(网站)”选项。
输入网站URL 并点击下一步。
提取目录路径保存输出结果,然后点击立即运行。
当你打开选定的文件夹 tp 时,你会在其中看到 CSS、php、html 和 js 文件。
Burp Suite Spider
Burp Spider 是一款自动抓取 Web 应用程序的工具。通常最好手动映射应用程序,但对于非常大的应用程序或时间不足的情况,可以使用 Burp Spider 来部分自动化此过程。
欲了解更多详情,请从这里阅读我们之前的文章。
从给定的截图中,您可以观察到我获得的http请求;现在它在“Operation”标签的帮助下发送给Spider。
Target网站 已添加到站点地图中“目标”选项卡下的位置,作为网络爬行的新范围。从截图中可以看出,它启动了对目标网站 的网络爬虫。在这个网站中,它以php、html和js的形式采集了网站信息。
作者:Aarti Singh 是 Hacking Articles(信息安全顾问、社交媒体爱好者和小工具)的研究员和技术作家。入侵 查看全部
维基百科:Web搜寻器开发的免费开放源代码(图)
来自维基百科
网络爬虫(有时称为蜘蛛)是互联网机器人,通常系统地浏览网络索引以进行网络索引。
网络爬虫从要访问的 URL 列表(称为种子)开始。当爬虫访问这些 URL 时,它会识别页面中的所有超链接,并将它们添加到要访问的 URL 列表中。如果爬虫正在执行网站的归档,它会复制并保存信息。存档称为存储库,旨在存储和管理网页集合。存储库类似于任何其他存储数据的系统,例如现代数据库。
让我们开始吧! !
Metasploit
这个辅助模块是一个模块化的网络爬虫,可以与wmap(有时)或独立使用。
使用辅助/爬虫/msfcrawler
msf 辅助(msfcrawler)> 设置 rhosts
msf 辅助(msfcrawler)> 漏洞利用
从截图中可以看到截图已经加载了搜索引擎,这样就可以对任何网站准确隐藏文件,比如about.php、jquery联系表单、html等,同时使用浏览器无法准确隐藏网站。为了采集任何网站信息,我们可以使用它。
Httrack
HTTrack 是 Xavier Roche 开发的免费开源网络搜索器和离线浏览器
它可以让你将网上的wanwei网站dots下载到本地目录,递归构建所有目录,从服务器获取HTML、图片等文件到电脑。 HTTrack 整理原站的相对链接结构。
在终端输入以下命令
httrack –O /root/Desktop/file
它将输出保存在给定的目录 /root/Desktop/file 中。
从给定的屏幕截图中,您可以观察到这一点,它使网站 信息包括 html 文件以及 JavaScript 和 jquery 变得愚蠢
黑寡妇
此Web Spider实用程序检测并显示用户选择的网页的详细信息,并提供其他网络工具。
BlackWidow 干净、合乎逻辑的标签式界面足够简单,适合中级用户,但在底部足以满足高级用户的需求。只需输入您选择的 URL,然后按 Go。 BlackWidow 使用多线程快速下载所有文件和测试链接。对于小网站,这个操作只需要几分钟。
您可以从这里下载。
在地址字段中输入您的 URL,然后按 Go。
点击开始按钮开始扫描左边的网址,然后选择一个文件夹来保存输出文件按钮。
从截图中可以看出,我浏览了 C:\Users\RAJ\Desktop\tptl 以便将输出文件存储在其中。
打开目标文件夹tptl,会得到网站图片或内容的完整数据,html文件、php文件和JavaScript都存储在里面。
网站开膛手复印机
Website Ripper Copier (WRC) 是一种通用高速网站downloader 软件,用于保存网站 数据。 WRC 可以将网站 文件下载到本地驱动器进行离线浏览,提取特定大小和类型的网站 文件,例如图像、视频、图片、电影和音乐,并充当具有恢复支持的下载管理器 检索大量的文件和镜像站点。 WRC 还是站点链接验证器、资源管理器和选项卡式反弹网页/离线浏览器。
Website Ripper Copier 是唯一可以从 HTTP、HTTPS 和 FTP 连接恢复中断下载、访问受密码保护的 网站、支持 Web Cookie、分析脚本、更新检索到的 网站 或文件并启动 50 @K14 的下载用于多个检索线程的@downloader 工具
您可以从这里下载。
选择“离线浏览网站(网站)”选项。
输入网站URL 并点击下一步。
提取目录路径保存输出结果,然后点击立即运行。
当你打开选定的文件夹 tp 时,你会在其中看到 CSS、php、html 和 js 文件。
Burp Suite Spider
Burp Spider 是一款自动抓取 Web 应用程序的工具。通常最好手动映射应用程序,但对于非常大的应用程序或时间不足的情况,可以使用 Burp Spider 来部分自动化此过程。
欲了解更多详情,请从这里阅读我们之前的文章。
从给定的截图中,您可以观察到我获得的http请求;现在它在“Operation”标签的帮助下发送给Spider。
Target网站 已添加到站点地图中“目标”选项卡下的位置,作为网络爬行的新范围。从截图中可以看出,它启动了对目标网站 的网络爬虫。在这个网站中,它以php、html和js的形式采集了网站信息。
作者:Aarti Singh 是 Hacking Articles(信息安全顾问、社交媒体爱好者和小工具)的研究员和技术作家。入侵
正则表达式国家(或地区)面积数据抓取其中数据的方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-07-08 01:39
3 种捕获数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1正则表达式
如果你不熟悉正则表达式或者需要一些提示,那么你可以查看完整的介绍。即使你用过其他编程语言的正则表达式,我还是建议你一步一步复习Python中正则表达式的编写。
因为每一章都可能构建或使用前几章的内容,所以建议你遵循类似于本书代码库的文件结构。所有代码都可以从代码库的代码目录运行,这样导入才能正常进行。如果要创建不同的结构,请注意其他章节的所有导入操作都需要更改(例如以下代码中的chp1.advanced_link_crawler)。
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re>>> from chp1.advanced_link_crawler import download>>> url ='#39;>>> html = download(url)>>> re.findall(r'(.*? )', html)['
','244,820 平方公里','62,348,447','GB','英国','伦敦','EU','.uk','GBP','英镑','44',' @##@@|@###@@|@@##@@|@@###@@|@#@ #@@|@@#@ #@@|GIR0AA','^(( [AZ]d{2}[AZ]{2})|([AZ]d{3}[AZ]{2})|([AZ]{2}d{2} [AZ]{2})| ([AZ]{2}d{3}[AZ]{2})|([AZ]d[AZ]d[AZ]{2})|([AZ]{2}d[AZ]d[AZ] ]{2})|(GIR0AA))$','en-GB,cy-GB,gd','
浏览器
']
从上面的结果可以看出,多个国家(或地区)属性使用了``标签。如果我们只想捕获国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]'244,820 平方公里'
虽然现在可以使用这个计划,但是如果页面发生变化,该计划很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望能够在未来的某个时刻再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加明确,我们还可以添加其父元素。因为这个元素有一个 ID 属性,所以它应该是唯一的。
>>> re.findall('(.*?)', html)['244,820 平方公里']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)['244,820平方公里']
这个正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加title 属性,或者为tr 和td` 元素修改其CSS 类或ID。
从这个例子中可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,而且很容易在网页更新后出现问题。幸运的是,还有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签打开和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。下面我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup>>> from pprint import pprint>>>broken_html =''>>> # 解析HTML>>>soup = BeautifulSoup(broken_html,'html.parser')>>> fixed_html =soup.prettify()>>> pprint(fixed_html)
我们可以看到,使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装 LXML(详见2.2.3 部分),或者使用 html5lib。要安装 html5lib,只需使用 pip。
pip 安装 html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>>soup = BeautifulSoup(broken_html,'html5lib')>>> fixed_html = soup.prettify()>>> pprint(fixed_html)
此时使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加&标签使其成为完整的HTML文档。当你使用 lxml 时,你可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs=('class':'country_or_district'))>>> ul.find('li') # 只返回第一个匹配区域>>> ul. find_all('li') # 返回所有匹配项[Area, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup>>> url ='#39;>>> html = download(url)>>> soup = BeautifulSoup(html)>>> # 定位区域行>>> tr = soup.find(attrs={'id':'places_area__row'})>>>td = tr.find(attrs={'class':'w2p_fw'}) # 定位数据元素>>> area = td.text # 从数据元素中提取文本>>> print(area)244,820 平方公里
虽然这段代码比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的网站 代码中提取数据。
3Lxml
Lxml
它是一个基于 libxml2 构建的 Python 库,一个 XML 解析库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。您可以参考最新的安装说明。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用Anaconda的快速安装会将你的PYTHON_PATH设置为Conda的Python安装位置。
和 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。下面是使用该模块解析同样不完整的 HTML 的示例。
>>> from lxml.html import fromstring, tostring>>>broken_html =''>>> tree = fromstring(broken_html) # 解析HTML>>>fixed_html = tostring(tree,pretty_print=True)>>>打印(fixed_html)
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验或它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip 安装 cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)>>> td = tree.cssselect('tr#places_area__row> td.w2p_fw')[0]>>> area = td.text_content()>>> print(area )244,820 平方公里
通过在代码树上使用cssselect方法,我们可以使用CSS语法选择表中ID为places_area__row的行元素,然后选择类w2p_fw的子表数据标签。由于cssselect返回的是一个列表,我们需要获取第一个结果并调用text_content方法迭代所有子元素并返回每个元素的相关文本。在这个例子中,虽然我们只有一个元素,但这个特征对于更复杂的提取例子非常有用。
本文摘自:《Writing Web Crawlers in Python (2nd Edition)》
作者:[德国]凯瑟琳·贾穆尔(Katharine Jarmul)、[澳大利亚]理查德·劳森(Richard Lawson)
译者:李斌
为 Python 3.6 版本编写。
提供示例完整源代码和示例网站构建源代码,确保用户在本地成功重现爬取网站环境,并保证网站的稳定性和可靠性以及代码运行结果的可复现性。
互联网收录大量有用的数据,其中大部分是免费且可公开访问的。然而,这些数据并不容易使用。它们嵌入在网站的结构和样式中,提取时需要小心。作为一种采集和了解 Internet 上信息量的方法,网络抓取技术正变得越来越有用。
本书是使用Python3.6的新特性爬取网络数据的入门指南。本书解释了如何从静态网站中提取数据,以及如何使用数据库和文件缓存技术来节省时间和管理服务器负载,然后介绍如何使用浏览器、爬虫和并发爬虫来开发更复杂的爬虫。
借助 PyQt 和 Selenium,您可以决定何时以及如何从依赖 JavaScript 的 网站 抓取数据,并更好地了解如何在受 CAPTCHA 保护的复杂 网站 上提交表单。书中还讲解了如何使用Python包(如mechanize)进行自动化处理,如何使用Scrapy库创建基于类的爬虫,以及如何实现在真实网站上学到的爬虫技巧。
在本书的最后,它还涵盖了使用爬虫测试网站、远程爬虫技术、图像处理和其他相关主题。 查看全部
正则表达式国家(或地区)面积数据抓取其中数据的方法
3 种捕获数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1正则表达式
如果你不熟悉正则表达式或者需要一些提示,那么你可以查看完整的介绍。即使你用过其他编程语言的正则表达式,我还是建议你一步一步复习Python中正则表达式的编写。
因为每一章都可能构建或使用前几章的内容,所以建议你遵循类似于本书代码库的文件结构。所有代码都可以从代码库的代码目录运行,这样导入才能正常进行。如果要创建不同的结构,请注意其他章节的所有导入操作都需要更改(例如以下代码中的chp1.advanced_link_crawler)。
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re>>> from chp1.advanced_link_crawler import download>>> url ='#39;>>> html = download(url)>>> re.findall(r'(.*? )', html)['
','244,820 平方公里','62,348,447','GB','英国','伦敦','EU','.uk','GBP','英镑','44',' @##@@|@###@@|@@##@@|@@###@@|@#@ #@@|@@#@ #@@|GIR0AA','^(( [AZ]d{2}[AZ]{2})|([AZ]d{3}[AZ]{2})|([AZ]{2}d{2} [AZ]{2})| ([AZ]{2}d{3}[AZ]{2})|([AZ]d[AZ]d[AZ]{2})|([AZ]{2}d[AZ]d[AZ] ]{2})|(GIR0AA))$','en-GB,cy-GB,gd','
浏览器
']
从上面的结果可以看出,多个国家(或地区)属性使用了``标签。如果我们只想捕获国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]'244,820 平方公里'
虽然现在可以使用这个计划,但是如果页面发生变化,该计划很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望能够在未来的某个时刻再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加明确,我们还可以添加其父元素。因为这个元素有一个 ID 属性,所以它应该是唯一的。
>>> re.findall('(.*?)', html)['244,820 平方公里']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)['244,820平方公里']
这个正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加title 属性,或者为tr 和td` 元素修改其CSS 类或ID。
从这个例子中可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,而且很容易在网页更新后出现问题。幸运的是,还有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签打开和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。下面我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup>>> from pprint import pprint>>>broken_html =''>>> # 解析HTML>>>soup = BeautifulSoup(broken_html,'html.parser')>>> fixed_html =soup.prettify()>>> pprint(fixed_html)
我们可以看到,使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装 LXML(详见2.2.3 部分),或者使用 html5lib。要安装 html5lib,只需使用 pip。
pip 安装 html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>>soup = BeautifulSoup(broken_html,'html5lib')>>> fixed_html = soup.prettify()>>> pprint(fixed_html)
此时使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加&标签使其成为完整的HTML文档。当你使用 lxml 时,你可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs=('class':'country_or_district'))>>> ul.find('li') # 只返回第一个匹配区域>>> ul. find_all('li') # 返回所有匹配项[Area, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup>>> url ='#39;>>> html = download(url)>>> soup = BeautifulSoup(html)>>> # 定位区域行>>> tr = soup.find(attrs={'id':'places_area__row'})>>>td = tr.find(attrs={'class':'w2p_fw'}) # 定位数据元素>>> area = td.text # 从数据元素中提取文本>>> print(area)244,820 平方公里
虽然这段代码比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的网站 代码中提取数据。
3Lxml
Lxml
它是一个基于 libxml2 构建的 Python 库,一个 XML 解析库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。您可以参考最新的安装说明。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用Anaconda的快速安装会将你的PYTHON_PATH设置为Conda的Python安装位置。
和 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。下面是使用该模块解析同样不完整的 HTML 的示例。
>>> from lxml.html import fromstring, tostring>>>broken_html =''>>> tree = fromstring(broken_html) # 解析HTML>>>fixed_html = tostring(tree,pretty_print=True)>>>打印(fixed_html)
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验或它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip 安装 cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)>>> td = tree.cssselect('tr#places_area__row> td.w2p_fw')[0]>>> area = td.text_content()>>> print(area )244,820 平方公里
通过在代码树上使用cssselect方法,我们可以使用CSS语法选择表中ID为places_area__row的行元素,然后选择类w2p_fw的子表数据标签。由于cssselect返回的是一个列表,我们需要获取第一个结果并调用text_content方法迭代所有子元素并返回每个元素的相关文本。在这个例子中,虽然我们只有一个元素,但这个特征对于更复杂的提取例子非常有用。
本文摘自:《Writing Web Crawlers in Python (2nd Edition)》
作者:[德国]凯瑟琳·贾穆尔(Katharine Jarmul)、[澳大利亚]理查德·劳森(Richard Lawson)
译者:李斌
为 Python 3.6 版本编写。
提供示例完整源代码和示例网站构建源代码,确保用户在本地成功重现爬取网站环境,并保证网站的稳定性和可靠性以及代码运行结果的可复现性。
互联网收录大量有用的数据,其中大部分是免费且可公开访问的。然而,这些数据并不容易使用。它们嵌入在网站的结构和样式中,提取时需要小心。作为一种采集和了解 Internet 上信息量的方法,网络抓取技术正变得越来越有用。
本书是使用Python3.6的新特性爬取网络数据的入门指南。本书解释了如何从静态网站中提取数据,以及如何使用数据库和文件缓存技术来节省时间和管理服务器负载,然后介绍如何使用浏览器、爬虫和并发爬虫来开发更复杂的爬虫。
借助 PyQt 和 Selenium,您可以决定何时以及如何从依赖 JavaScript 的 网站 抓取数据,并更好地了解如何在受 CAPTCHA 保护的复杂 网站 上提交表单。书中还讲解了如何使用Python包(如mechanize)进行自动化处理,如何使用Scrapy库创建基于类的爬虫,以及如何实现在真实网站上学到的爬虫技巧。
在本书的最后,它还涵盖了使用爬虫测试网站、远程爬虫技术、图像处理和其他相关主题。
访客爬取:解密网站获取访问者手机号的方法和原理
网站优化 • 优采云 发表了文章 • 0 个评论 • 550 次浏览 • 2021-07-06 22:41
网站访问者,可以安装在线客服系统,如商桥、53客服等,以前有网站类型的安装码,但为了保护用户隐私,现在当前不可用。也可以用一品的大数据分析来获取用户,但这仅限于手机。前提是你的网站必须有流量,不然没人访问,软件再好也没用。
网站访问者手机号的抓取效果好吗?
部分客户安装后立即使用手机进行测试,发现无法获取手机号码。这是不科学的。有一定几率抢到,数量大才能看到效果。比如一百个访客能抢到30个号和50个号是正常的。记住,如果几个人访问它们,它们就无法被抓取,这意味着该软件没有效果。
通过测试我们的软件爬行率超过 60%,它实际上可以帮助中小企业建立潜在客户群并为公司带来真正的交易量。
访客爬取:解密网站获取访客手机号的方法和原理
近日,网上出现了一个手机号码。访问者访问您的网站时可以获得他们的手机号码。许多公司将其用于盈利,有些公司出售一套程序。
经过几天的分析和研究,只开发了一个极其简单的方法。还有其他方法没找到。
目前在网上获取网站visitor手机号的方式有很多种。简而言之:抢到指定的网站visitor 手机号。
1、分析手机号控制,然后跨域获取手机号,难度较大; 网站visitor 手机号抓取软件。
2、使用PHP
file_get_contents 获取腾讯某个页面的内容,截取手机号。此方法11月前有效,已失效;
3、 这个方法比较简单,估计腾讯很快就屏蔽了。这也是我这几天练出来的方法,和大家分享一下。
代码如下:获取peer网站visitor手机号。
就是这么简单的一段JS,就可以拿到访问者的手机号了。 网站客人手机号抢。
注意:更多精彩教程请关注三联网页设计教程。
抢客:我可以抢网站visitor 电话号码吗?
你需要在你的网站上嵌入一段代码,然后你就可以统计你的网站访问者的手机号码。关键字来源、页面访问、ip等都可以统计。
号码打印机访客手机号码统计可以实现这些功能,大家可以免费试用。希望对您的问题有所帮助!
满意,请采纳。
网站访客如何抓取手机号码?
修改程序
如何获取访问者的手机号码。大数据抓取应用访问者手机号。
获取访问者手机号的方式一般有以下三种:
**类型是:获取自己的网站visitor 电话号码
第二种是:获取peer网站customer的电话
第三种是获取应用注册和下载信息,防止网站访问者被抓。
火客_
这三个是比较快速有效的方法
访客抓取:现在有抓取网站visitor手机号的功能吗?在某些情况下,爬行可以达到百分之几
一般情况下,移动终端的爬虫率不高。 查看全部
访客爬取:解密网站获取访问者手机号的方法和原理
网站访问者,可以安装在线客服系统,如商桥、53客服等,以前有网站类型的安装码,但为了保护用户隐私,现在当前不可用。也可以用一品的大数据分析来获取用户,但这仅限于手机。前提是你的网站必须有流量,不然没人访问,软件再好也没用。
网站访问者手机号的抓取效果好吗?
部分客户安装后立即使用手机进行测试,发现无法获取手机号码。这是不科学的。有一定几率抢到,数量大才能看到效果。比如一百个访客能抢到30个号和50个号是正常的。记住,如果几个人访问它们,它们就无法被抓取,这意味着该软件没有效果。
通过测试我们的软件爬行率超过 60%,它实际上可以帮助中小企业建立潜在客户群并为公司带来真正的交易量。
访客爬取:解密网站获取访客手机号的方法和原理
近日,网上出现了一个手机号码。访问者访问您的网站时可以获得他们的手机号码。许多公司将其用于盈利,有些公司出售一套程序。
经过几天的分析和研究,只开发了一个极其简单的方法。还有其他方法没找到。
目前在网上获取网站visitor手机号的方式有很多种。简而言之:抢到指定的网站visitor 手机号。
1、分析手机号控制,然后跨域获取手机号,难度较大; 网站visitor 手机号抓取软件。
2、使用PHP
file_get_contents 获取腾讯某个页面的内容,截取手机号。此方法11月前有效,已失效;
3、 这个方法比较简单,估计腾讯很快就屏蔽了。这也是我这几天练出来的方法,和大家分享一下。
代码如下:获取peer网站visitor手机号。
就是这么简单的一段JS,就可以拿到访问者的手机号了。 网站客人手机号抢。
注意:更多精彩教程请关注三联网页设计教程。
抢客:我可以抢网站visitor 电话号码吗?
你需要在你的网站上嵌入一段代码,然后你就可以统计你的网站访问者的手机号码。关键字来源、页面访问、ip等都可以统计。
号码打印机访客手机号码统计可以实现这些功能,大家可以免费试用。希望对您的问题有所帮助!
满意,请采纳。
网站访客如何抓取手机号码?
修改程序
如何获取访问者的手机号码。大数据抓取应用访问者手机号。
获取访问者手机号的方式一般有以下三种:
**类型是:获取自己的网站visitor 电话号码
第二种是:获取peer网站customer的电话
第三种是获取应用注册和下载信息,防止网站访问者被抓。
火客_
这三个是比较快速有效的方法
访客抓取:现在有抓取网站visitor手机号的功能吗?在某些情况下,爬行可以达到百分之几
一般情况下,移动终端的爬虫率不高。
一天就能上线一个微信小程序的云开发功能
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-07-06 01:23
最近在研究微信小程序的云开发功能。云开发最大的好处是不需要在前端搭建服务器,可以利用云的能力编写一个可以从头启动的微信小程序,避免购买服务器的成本,而且对于个人尝试从前端到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就能上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代同时,这种能力与开发者使用的云服务是相互兼容的,而不是相互排斥的。
云开发目前提供三个基本能力:
云功能:代码运行在云端,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码数据库:可在小程序前端操作,可读写的JSON数据库云功能存储:在小程序前端直接上传/下载云文件,在云开发控制台中可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。网上搜了一下,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。把我之前学过的节点拿起来就行了。
所需工具:Cheerio。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。 Node 的 fs 模块。这是node自带的模块,用于读写文件。这用于将解析后的数据写入 json 文件。 Axios(非必需)。用于抓取网站 HTML 页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。没办法,只好复制自己想要的内容,另存为字符串,解析字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是使用cheerio实现了类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后使用fs.writeFile将数据保存到json文件中,大功告成。
具体代码如下:
让 axios = require(axios);
让cheerio = require(cheerio);
让 fs = require(fs);
//我的html结构大致如下,数据很多
const 问题 = `
`;
const $ =cheerio.load(questions);
var arr = [];
for (var i = 0; i
var obj = {};
obj.quesitons = $(#q + i).find(.question).text();
obj.A = $($(#q + i).find(.answer)[0]).text();
obj.B = $($(#q + i).find(.answer)[1]).text();
obj.C = $($(#q + i).find(.answer)[2]).text();
obj.D = $($(#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer =
$($(#q + i).find(.answer)[0]).attr(value) == 1
: $($(#q + i).find(.answer)[1]).attr(value) == 1
: $($(#q + i).find(.answer)[2]).attr(value) == 1
: D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
if (err) 抛出错误;
console.log(json文件已经成功保存!);
});
保存为json后的文件格式如下,方便通过json文件上传到云服务器。
注意事项
微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前也提示过格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象之间使用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。 查看全部
一天就能上线一个微信小程序的云开发功能
最近在研究微信小程序的云开发功能。云开发最大的好处是不需要在前端搭建服务器,可以利用云的能力编写一个可以从头启动的微信小程序,避免购买服务器的成本,而且对于个人尝试从前端到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就能上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代同时,这种能力与开发者使用的云服务是相互兼容的,而不是相互排斥的。
云开发目前提供三个基本能力:
云功能:代码运行在云端,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码数据库:可在小程序前端操作,可读写的JSON数据库云功能存储:在小程序前端直接上传/下载云文件,在云开发控制台中可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。网上搜了一下,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。把我之前学过的节点拿起来就行了。
所需工具:Cheerio。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。 Node 的 fs 模块。这是node自带的模块,用于读写文件。这用于将解析后的数据写入 json 文件。 Axios(非必需)。用于抓取网站 HTML 页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。没办法,只好复制自己想要的内容,另存为字符串,解析字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是使用cheerio实现了类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后使用fs.writeFile将数据保存到json文件中,大功告成。
具体代码如下:
让 axios = require(axios);
让cheerio = require(cheerio);
让 fs = require(fs);
//我的html结构大致如下,数据很多
const 问题 = `
`;
const $ =cheerio.load(questions);
var arr = [];
for (var i = 0; i
var obj = {};
obj.quesitons = $(#q + i).find(.question).text();
obj.A = $($(#q + i).find(.answer)[0]).text();
obj.B = $($(#q + i).find(.answer)[1]).text();
obj.C = $($(#q + i).find(.answer)[2]).text();
obj.D = $($(#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer =
$($(#q + i).find(.answer)[0]).attr(value) == 1
: $($(#q + i).find(.answer)[1]).attr(value) == 1
: $($(#q + i).find(.answer)[2]).attr(value) == 1
: D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
if (err) 抛出错误;
console.log(json文件已经成功保存!);
});
保存为json后的文件格式如下,方便通过json文件上传到云服务器。
注意事项
微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前也提示过格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象之间使用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。
网页数据爬取图文教程-爬虫入门教程(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-07-06 01:23
网页数据爬取图文教程-爬虫入门教程
本页提供最新的网页数据爬取图文教程和爬虫入门教程。
网络数据抓取实用教程
优采云网站Grabber Tools 热门网站采集类主要介绍各大电商、新闻媒体、生活服务、金融信用、企业信息等网站数据爬取教程,让你轻松掌握各种网站技能。
如何实时抓取动态网页数据?
使用网页抓取工具,操作员无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。 (2)适用于各种网站不同的网站有不同的结构,所以即使是有经验的程序员也需要...
网页数据爬取方法详解
你有没有想过从网站获取具体的数据,但是当你触发链接或者将鼠标悬停在某处时,内容就会出现?比如下图中的网站,需要鼠标移动到选区,才能显示在抽奖上的分类。对于这种类型,您可以设置“鼠标指向此链...
网络数据爬取的两种方法(2019年最新)
模板的数量还在增加。 【使用模板采集数据】,只需输入几个参数(URL、关键词、页数等),几分钟内即可快速获取目标网站数据。 (类似PPT模板,直接修改关键信息即可使用,无需自己...
模拟登录抓拍网站data_video教程
本文主要介绍如何使用优采云simulation login采集网站需要登录的数据,包括点击登录、文字输入等操作方式。
如何设置网络爬虫来抓取数据
· 内置的正则表达式工具可以提取任何数据。 · 抓取 AJAX 加载的内容。 · 使用云采集支持大规模采集等。想了解更多这款爬虫软件,可以查看下面的初学者教程,了解如何开始使用八... 查看全部
网页数据爬取图文教程-爬虫入门教程(组图)
网页数据爬取图文教程-爬虫入门教程
本页提供最新的网页数据爬取图文教程和爬虫入门教程。
网络数据抓取实用教程
优采云网站Grabber Tools 热门网站采集类主要介绍各大电商、新闻媒体、生活服务、金融信用、企业信息等网站数据爬取教程,让你轻松掌握各种网站技能。
如何实时抓取动态网页数据?
使用网页抓取工具,操作员无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。 (2)适用于各种网站不同的网站有不同的结构,所以即使是有经验的程序员也需要...
网页数据爬取方法详解
你有没有想过从网站获取具体的数据,但是当你触发链接或者将鼠标悬停在某处时,内容就会出现?比如下图中的网站,需要鼠标移动到选区,才能显示在抽奖上的分类。对于这种类型,您可以设置“鼠标指向此链...
网络数据爬取的两种方法(2019年最新)
模板的数量还在增加。 【使用模板采集数据】,只需输入几个参数(URL、关键词、页数等),几分钟内即可快速获取目标网站数据。 (类似PPT模板,直接修改关键信息即可使用,无需自己...
模拟登录抓拍网站data_video教程
本文主要介绍如何使用优采云simulation login采集网站需要登录的数据,包括点击登录、文字输入等操作方式。
如何设置网络爬虫来抓取数据
· 内置的正则表达式工具可以提取任何数据。 · 抓取 AJAX 加载的内容。 · 使用云采集支持大规模采集等。想了解更多这款爬虫软件,可以查看下面的初学者教程,了解如何开始使用八...
怎样才能吸引搜索引擎蜘蛛来抓取网站,怎样被收录
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-07-06 01:22
对于网站 运营商来说,网站 的流量很大程度上依赖于搜索引擎。怎样才能找到我们的网站,怎样才能吸引搜索引擎蜘蛛去抢网站,怎样才能被收录搜索到呢?让我们谈谈。
当我们做搜索引擎优化工作时,我们都明白网站要在搜索引擎中获得良好的排名,它必须被蜘蛛抓取以收录我们的页面。搜索引擎蜘蛛把爬取到的代码放到自己的数据库中,这样我们就可以在搜索引擎上搜索到我们的网站了。
我们的网站搜索引擎优化步骤是将蜘蛛吸引到我们的网站。搜索引擎蜘蛛会爬到我们的网站,会有踪迹,也会有自己的代理名称。每个网站administrator 都可以区分日志文件中的搜索引擎蜘蛛。
常见的搜索引擎蜘蛛有:
如果网站管理员想要吸引蜘蛛爬我们的搜索引擎优化网站,他们必须做一些工作,因为蜘蛛无法爬取互联网上所有的网站。事实上,好的搜索引擎只会抓取互联网的一小部分。
如果搜索引擎优化者希望他们的网站更多地被搜索引擎收录,他们必须尝试吸引蜘蛛来获取。搜索引擎通常会抓取重要页面。为了满足蜘蛛爬行的重要性规则,我们需要满足以下条件:
1、网站weight 问题,网站蜘蛛的权重越高爬得越深,几乎每个页面都会爬,更多的内部页面会被收录。
2、import 链接分为外部链接和内部链接。如果蜘蛛正在抓取页面,页面必须有导入链接,否则蜘蛛根本不知道页面的存在,所以高质量的导入链接可以引导蜘蛛抓取我们的页面。
3、网站 更新频率。蜘蛛每次爬取的网站都会保存起来,方便二次浏览。如果蜘蛛第二次爬到优化后的网站,发现页面已经更新,就会爬到新的内容。如果每天更新,蜘蛛就会习惯每天定期爬到你的网站。
4、 对于质量和可读性高的页面,搜索引擎更容易捕获它们,因此收录它们后,页面的权重会增加。下次我们会继续爬取我们的网站,因为搜索引擎喜欢有价值的页面、可读的页面和逻辑页面。
5、 网页在主页上有一个链接。一般来说,我们会在网站 上更新。更新后的链接应该尽可能多地出现在首页,因为首页权重较高,被很多蜘蛛访问。我们的主页是最常见的。如果主页上有更新链接,蜘蛛可以更快更好地爬到我们更新的页面,以便更好地收录我们的页面。
这五点都和你的网站和收录优化有关,直接影响你的网站seo优化效果。所以建议大家做好网站seo的培训。另外,一些网站administrators 也说在日志文件中发现了蜘蛛,但没有收录网页。这样做的原因是简单的。如果蜘蛛发现你的网站之前抓取的内容过于相似,就会认为你的网站抄袭或者抄袭了别人的内容,很可能不会继续抓取你的网站,从而创建蜘蛛,而不是你的页面。
要做好搜索引擎优化,必须掌握搜索引擎机器人访问的时间和规则。我们站长要做的,就是等待搜索引擎机器人的访问,做出更好的网站。未来,优化固然重要,但网站自身的内容建设是网站可持续发展的生命线。 查看全部
怎样才能吸引搜索引擎蜘蛛来抓取网站,怎样被收录
对于网站 运营商来说,网站 的流量很大程度上依赖于搜索引擎。怎样才能找到我们的网站,怎样才能吸引搜索引擎蜘蛛去抢网站,怎样才能被收录搜索到呢?让我们谈谈。
当我们做搜索引擎优化工作时,我们都明白网站要在搜索引擎中获得良好的排名,它必须被蜘蛛抓取以收录我们的页面。搜索引擎蜘蛛把爬取到的代码放到自己的数据库中,这样我们就可以在搜索引擎上搜索到我们的网站了。
我们的网站搜索引擎优化步骤是将蜘蛛吸引到我们的网站。搜索引擎蜘蛛会爬到我们的网站,会有踪迹,也会有自己的代理名称。每个网站administrator 都可以区分日志文件中的搜索引擎蜘蛛。
常见的搜索引擎蜘蛛有:
如果网站管理员想要吸引蜘蛛爬我们的搜索引擎优化网站,他们必须做一些工作,因为蜘蛛无法爬取互联网上所有的网站。事实上,好的搜索引擎只会抓取互联网的一小部分。
如果搜索引擎优化者希望他们的网站更多地被搜索引擎收录,他们必须尝试吸引蜘蛛来获取。搜索引擎通常会抓取重要页面。为了满足蜘蛛爬行的重要性规则,我们需要满足以下条件:
1、网站weight 问题,网站蜘蛛的权重越高爬得越深,几乎每个页面都会爬,更多的内部页面会被收录。
2、import 链接分为外部链接和内部链接。如果蜘蛛正在抓取页面,页面必须有导入链接,否则蜘蛛根本不知道页面的存在,所以高质量的导入链接可以引导蜘蛛抓取我们的页面。
3、网站 更新频率。蜘蛛每次爬取的网站都会保存起来,方便二次浏览。如果蜘蛛第二次爬到优化后的网站,发现页面已经更新,就会爬到新的内容。如果每天更新,蜘蛛就会习惯每天定期爬到你的网站。
4、 对于质量和可读性高的页面,搜索引擎更容易捕获它们,因此收录它们后,页面的权重会增加。下次我们会继续爬取我们的网站,因为搜索引擎喜欢有价值的页面、可读的页面和逻辑页面。
5、 网页在主页上有一个链接。一般来说,我们会在网站 上更新。更新后的链接应该尽可能多地出现在首页,因为首页权重较高,被很多蜘蛛访问。我们的主页是最常见的。如果主页上有更新链接,蜘蛛可以更快更好地爬到我们更新的页面,以便更好地收录我们的页面。
这五点都和你的网站和收录优化有关,直接影响你的网站seo优化效果。所以建议大家做好网站seo的培训。另外,一些网站administrators 也说在日志文件中发现了蜘蛛,但没有收录网页。这样做的原因是简单的。如果蜘蛛发现你的网站之前抓取的内容过于相似,就会认为你的网站抄袭或者抄袭了别人的内容,很可能不会继续抓取你的网站,从而创建蜘蛛,而不是你的页面。
要做好搜索引擎优化,必须掌握搜索引擎机器人访问的时间和规则。我们站长要做的,就是等待搜索引擎机器人的访问,做出更好的网站。未来,优化固然重要,但网站自身的内容建设是网站可持续发展的生命线。
企业需要了解爬虫喜欢怎样的网站,如何吸引爬虫抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-07-05 18:42
一个好的网站不仅可以提升公司的知名度,还可以为公司吸引更多的意向客户。而网站需要在搜索引擎上有好的排名,才能被更多的人看到。搜索引擎中的排名大多不稳定,上升缓慢,下降迅速。做一个能吸引爬虫爬的网站,那么就必须在各方面都符合它的爬取原则。公司需要了解什么样的网站爬虫喜欢什么样的网站他们不喜欢什么样的。排名最重要的是允许爬虫爬取网站上的内容。 收录的内容越多,客户搜索起来就越容易。那么网站怎么才能吸引网络爬虫来爬呢?
如何做网站吸引网络爬虫爬取
一、优质内容
企业与网站上线后,即开始运营。如果它想一直活跃,就必须每天进行更新,上传文章是一种常见的更新方式。公司上传新内容到网站,但不代表可以快速抓取。关键是看内容的质量是否通过测试。一篇优质文章的质量在于原创有价值,满足客户的阅读需求。企业不应该只为了数量去网络采集文章。就算上传到自己的网站,爬虫也能认出来。这会降低爬虫对网站的友好度,也会影响网站整体的内容质量。客户和爬虫都喜欢新颖的内容,从而被吸引到网站浏览。重复太多只会让人恶心。
二、做好反链和外链
一般来说,网站设置反链比较多,这也是吸引爬虫的必要手段。设置反链不仅可以帮助提升网站的权重值,还可以提升排名。在保证逆序的情况下,反链越多,越能吸引爬虫,排名会更好。接下来是外链,主要是在各大平台发布信息,然后被吸引过来的爬虫会跳转到企业网站继续爬取信息中的链接。可以加快网站快照的更新速度,也可以通过收录让网站内容更快。与反链相比,外链重质不重,选择优质平台可以更好的增加权重和收录。
三、clear 导航
要做网站,你需要有清晰的导航。这也是企业在设计时需要注意的部分。这对网站的信息构成和客户体验有影响。从客户的角度来看,导航是为了解决客户可能面临的问题。一个可以让客户知道他们目前在哪里,另一个要求客户知道他们下一步要去哪里。很多时候从搜索引擎跳转到网站,不知道怎么在随机点击下返回上一页。那么网站Navigation 这个时候就起到了作用,可以帮助客户了解你所在的车站内的区域。如果网站导航像原创森林一样错综复杂,爬虫就不会来了。从另一个角度来说,清晰的导航有利于爬取,可以快速找到新的内容进行爬取,收录速度更快。 查看全部
企业需要了解爬虫喜欢怎样的网站,如何吸引爬虫抓取
一个好的网站不仅可以提升公司的知名度,还可以为公司吸引更多的意向客户。而网站需要在搜索引擎上有好的排名,才能被更多的人看到。搜索引擎中的排名大多不稳定,上升缓慢,下降迅速。做一个能吸引爬虫爬的网站,那么就必须在各方面都符合它的爬取原则。公司需要了解什么样的网站爬虫喜欢什么样的网站他们不喜欢什么样的。排名最重要的是允许爬虫爬取网站上的内容。 收录的内容越多,客户搜索起来就越容易。那么网站怎么才能吸引网络爬虫来爬呢?
如何做网站吸引网络爬虫爬取
一、优质内容
企业与网站上线后,即开始运营。如果它想一直活跃,就必须每天进行更新,上传文章是一种常见的更新方式。公司上传新内容到网站,但不代表可以快速抓取。关键是看内容的质量是否通过测试。一篇优质文章的质量在于原创有价值,满足客户的阅读需求。企业不应该只为了数量去网络采集文章。就算上传到自己的网站,爬虫也能认出来。这会降低爬虫对网站的友好度,也会影响网站整体的内容质量。客户和爬虫都喜欢新颖的内容,从而被吸引到网站浏览。重复太多只会让人恶心。
二、做好反链和外链
一般来说,网站设置反链比较多,这也是吸引爬虫的必要手段。设置反链不仅可以帮助提升网站的权重值,还可以提升排名。在保证逆序的情况下,反链越多,越能吸引爬虫,排名会更好。接下来是外链,主要是在各大平台发布信息,然后被吸引过来的爬虫会跳转到企业网站继续爬取信息中的链接。可以加快网站快照的更新速度,也可以通过收录让网站内容更快。与反链相比,外链重质不重,选择优质平台可以更好的增加权重和收录。
三、clear 导航
要做网站,你需要有清晰的导航。这也是企业在设计时需要注意的部分。这对网站的信息构成和客户体验有影响。从客户的角度来看,导航是为了解决客户可能面临的问题。一个可以让客户知道他们目前在哪里,另一个要求客户知道他们下一步要去哪里。很多时候从搜索引擎跳转到网站,不知道怎么在随机点击下返回上一页。那么网站Navigation 这个时候就起到了作用,可以帮助客户了解你所在的车站内的区域。如果网站导航像原创森林一样错综复杂,爬虫就不会来了。从另一个角度来说,清晰的导航有利于爬取,可以快速找到新的内容进行爬取,收录速度更快。
知乎app榜单里看啊答案中的排名情况要是让老板看到了你对产品设计理念的思考
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-07-04 04:01
网站内容抓取相比文章抓取来说,更难提取有效的信息,抓取网站内容不可避免会涉及爬虫,爬虫实际上在做商业交易,收钱劳动力。爬虫要么都是固定ip不用cookie,要么只能用selenium库来实现。如果每一篇内容都需要手动去加载对于开发人员来说是非常费力的。如果大家经常了解我在做什么,可以举一反三的去举一反三,这里再次重申,这只是一个学习笔记。文章来源:商品推荐。
知乎
注册商店
大家一起来补充知乎app榜单里看啊答案中的排名情况要是让老板看到了你对产品设计理念的思考是世界上最美妙的事情
如果要说,我想到了一个im产品。在这个产品里的『把』会带来额外的额外的价值。
资源宝库-读书.社区.游戏.电商.绘画.文库.论坛.找工作.求婚.刷单.学习.写作.生活.车站.喜马拉雅.分答.在行.万库。
12306买一张优采云票的价钱折合成现在的rmb可以买几十几百本相关的书籍
模拟登录和注册哪个更难?
文字版:office,flash邮件服务器,图片版:电影,游戏,视频。
音乐搜索,
自从升级到ipad以后,我自己装了各种各样的正版软件,通过itunes备份然后从itunesstore里卖钱了,对我来说是不可多得的体验。
优酷,但网速真不是优势。 查看全部
知乎app榜单里看啊答案中的排名情况要是让老板看到了你对产品设计理念的思考
网站内容抓取相比文章抓取来说,更难提取有效的信息,抓取网站内容不可避免会涉及爬虫,爬虫实际上在做商业交易,收钱劳动力。爬虫要么都是固定ip不用cookie,要么只能用selenium库来实现。如果每一篇内容都需要手动去加载对于开发人员来说是非常费力的。如果大家经常了解我在做什么,可以举一反三的去举一反三,这里再次重申,这只是一个学习笔记。文章来源:商品推荐。
知乎
注册商店
大家一起来补充知乎app榜单里看啊答案中的排名情况要是让老板看到了你对产品设计理念的思考是世界上最美妙的事情
如果要说,我想到了一个im产品。在这个产品里的『把』会带来额外的额外的价值。
资源宝库-读书.社区.游戏.电商.绘画.文库.论坛.找工作.求婚.刷单.学习.写作.生活.车站.喜马拉雅.分答.在行.万库。
12306买一张优采云票的价钱折合成现在的rmb可以买几十几百本相关的书籍
模拟登录和注册哪个更难?
文字版:office,flash邮件服务器,图片版:电影,游戏,视频。
音乐搜索,
自从升级到ipad以后,我自己装了各种各样的正版软件,通过itunes备份然后从itunesstore里卖钱了,对我来说是不可多得的体验。
优酷,但网速真不是优势。
如何让蜘蛛爱上你的网站的方法优帮云
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-07-03 20:06
在SEO排名规则中,收录意味着可能有排名,但不收录则不可能有排名。在线解决的一个问题是包容性问题。充分理解蜘蛛程序,正确开药,是实现网站二次收益的基础工作。那么蜘蛛程序的原理是什么呢?如何让蜘蛛爱上我们的网站并快速融入我们的网站?下面将给出简要说明。
百度蜘蛛编程原理
从人类的角度来看,蜘蛛程序其实和我们是一样的。打开网站-抓取页面-放入数据库-符合标准-建立索引-分类,按质量排名显示用户,不符合标准直接丢弃。然而,它是一个智能机器人。蜘蛛程序需要对我们网站的内容进行评估和审核。内容属于优质网站进行收录,而低素质网站已进入观察期,只有合格后方可收录。
蜘蛛是怎么找到网站的?
(1)网站submit; (2)external link (anchor text, hyperlink is yes); and (3)browser cookie data (浏览器已开启网站); 这是百度蜘蛛了解网站存在的三种方式,但需要注意的是百度蜘蛛程序发送的爬取网站content蜘蛛都是文字内容蜘蛛,其他的东西他们不懂,所以新手要注意建网站,那些凉挂的爆炸效果,蜘蛛不喜欢。
四种网站让百度蜘蛛爱上你的方法
深入了解百度蜘蛛程序的原理后,可以提取一些知识点。蜘蛛程序的内容是什么?蜘蛛抓取网页的特点是什么?如何评估一个网页的质量并最终显示排名?掌握了这些内容后,只需要4招就能让蜘蛛爱上我们的网站并提升它的排名。
1、高质量原创内容,满足用户需求。
原创性+解决用户需求+解决潜在用户需求,可以称得上是满足用户需求的优质原创内容。思路很简单,通过数据就能满足一般用户的需求。解决用户的潜在需求需要深入思考。例如:从上海到哈尔滨需要多长时间?用户需求是显而易见的,但隐藏的需求是“从上海到哈尔滨的路”。如何节省时间,提升旅途的舒适体验,需要充分考虑,符合蜘蛛程序的内容标准。
2、更快的页面打开速度。
这是一个难以配置的站点。当蜘蛛来到你的网站时,它不稳定,摇摆不定,然后一下子打开,一个网站被丢弃。喜欢一个网站是不可能的。所以在选择空间的时候要注意配置,注意页面图片不要太大,这样更有利于蜘蛛程序的体验。
3、合理搭建内链。
蜘蛛程序喜欢超链接,尤其是锚链接。这时候,页面的内部链接就显得尤为重要。推荐相关内容和插入有利于用户体验的锚链接都是促进蜘蛛程序快速抓取页面内容并提高包容性的有效手段。
4、添加 XML 站点地图。
蜘蛛可能对道路很着迷。没有路标,很容易迷路,和编辑一样迷路。除了网站的内部链接,做一个XML映射还可以让蜘蛛程序合理有序的抓取整个网站页面的内容。生成 XML 映射后,在 robots.txt 文件中添加指向映射的链接。你知道蜘蛛程序访问网站这个文件夹。我们需要帮助蜘蛛提高他们的工作效率。我更喜欢我们的网站。
总结:以上就是蜘蛛程序的原理以及如何让百度蜘蛛爱上网站四点。因材施教、剪衣服是满足蜘蛛喜好的基本任务。只有优化基础,后续高层思维才能发挥应有的作用。 查看全部
如何让蜘蛛爱上你的网站的方法优帮云
在SEO排名规则中,收录意味着可能有排名,但不收录则不可能有排名。在线解决的一个问题是包容性问题。充分理解蜘蛛程序,正确开药,是实现网站二次收益的基础工作。那么蜘蛛程序的原理是什么呢?如何让蜘蛛爱上我们的网站并快速融入我们的网站?下面将给出简要说明。
百度蜘蛛编程原理
从人类的角度来看,蜘蛛程序其实和我们是一样的。打开网站-抓取页面-放入数据库-符合标准-建立索引-分类,按质量排名显示用户,不符合标准直接丢弃。然而,它是一个智能机器人。蜘蛛程序需要对我们网站的内容进行评估和审核。内容属于优质网站进行收录,而低素质网站已进入观察期,只有合格后方可收录。
蜘蛛是怎么找到网站的?
(1)网站submit; (2)external link (anchor text, hyperlink is yes); and (3)browser cookie data (浏览器已开启网站); 这是百度蜘蛛了解网站存在的三种方式,但需要注意的是百度蜘蛛程序发送的爬取网站content蜘蛛都是文字内容蜘蛛,其他的东西他们不懂,所以新手要注意建网站,那些凉挂的爆炸效果,蜘蛛不喜欢。
四种网站让百度蜘蛛爱上你的方法
深入了解百度蜘蛛程序的原理后,可以提取一些知识点。蜘蛛程序的内容是什么?蜘蛛抓取网页的特点是什么?如何评估一个网页的质量并最终显示排名?掌握了这些内容后,只需要4招就能让蜘蛛爱上我们的网站并提升它的排名。
1、高质量原创内容,满足用户需求。
原创性+解决用户需求+解决潜在用户需求,可以称得上是满足用户需求的优质原创内容。思路很简单,通过数据就能满足一般用户的需求。解决用户的潜在需求需要深入思考。例如:从上海到哈尔滨需要多长时间?用户需求是显而易见的,但隐藏的需求是“从上海到哈尔滨的路”。如何节省时间,提升旅途的舒适体验,需要充分考虑,符合蜘蛛程序的内容标准。
2、更快的页面打开速度。
这是一个难以配置的站点。当蜘蛛来到你的网站时,它不稳定,摇摆不定,然后一下子打开,一个网站被丢弃。喜欢一个网站是不可能的。所以在选择空间的时候要注意配置,注意页面图片不要太大,这样更有利于蜘蛛程序的体验。
3、合理搭建内链。
蜘蛛程序喜欢超链接,尤其是锚链接。这时候,页面的内部链接就显得尤为重要。推荐相关内容和插入有利于用户体验的锚链接都是促进蜘蛛程序快速抓取页面内容并提高包容性的有效手段。
4、添加 XML 站点地图。
蜘蛛可能对道路很着迷。没有路标,很容易迷路,和编辑一样迷路。除了网站的内部链接,做一个XML映射还可以让蜘蛛程序合理有序的抓取整个网站页面的内容。生成 XML 映射后,在 robots.txt 文件中添加指向映射的链接。你知道蜘蛛程序访问网站这个文件夹。我们需要帮助蜘蛛提高他们的工作效率。我更喜欢我们的网站。
总结:以上就是蜘蛛程序的原理以及如何让百度蜘蛛爱上网站四点。因材施教、剪衣服是满足蜘蛛喜好的基本任务。只有优化基础,后续高层思维才能发挥应有的作用。

