
算法 自动采集列表
分页列表详细信息采集 | 2个月精通优采云第1课
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-05-15 16:50
在之前的教程中,我们以赶集网商铺数据采集、携程网旅游数据采集为例,感受了一波优采云嗖嗖嗖采集数据的常(li)规(hai)操作。
咦?这两个实战案例,规则配置长相似,采集流程有点像?
来吧,是时候溯本求源,透过现象看本质了。
网页内容由相似的区块组成,需要点击“下一页”进行翻页,再点击每个链接进入详情页采集数据,没错就是——分页列表详细信息采集。
本文中示例网站地址为:
在开始采集之前,需观察网页结构、明确采集内容。以示例网址为例,内容共有4页,每页有3个电影链接。我们需要点击每一部电影的链接,进入电影详情页,采集电影的剧情、上映时间等字段。
优采云基于 Firefox 内核浏览器,通过模拟人的思维操作方式,对网页内容进行全自动提取。以示例网址为例,在优采云里打开后,需先建立一个点击“下一页”的翻页循环,自动点击“下一页”翻页。再建立一个电影链接列表循环,以打开每个电影的链接,进入电影详情页。然后再采集电影详情页的数据。
1打开网页
1)登陆优采云7.0采集器,点击新建任务,选择“自定义采集”。进入到任务配置页面
2)输入要采集的网址,点击“保存网址”。系统会进入到流程设计页面,并自动打开前面输入的网址
2建立翻页循环
1)用鼠标点击“下一页”按钮,在弹出的操作提示框中,选择“循环点击下一页”。这个步骤会模拟人工,自动点击翻页
3建立循环列表
1)点击下图中第一个电影“教父:第二部”的链接,链接将被选中,用绿色框标注出来
2)优采云的智能算法,会自动检测出其他相似元素(本例中为其他两个电影标题链接)。在操作提示框中,选择“选中全部”,优采云自动选中全部电影链接
3)选择“循环点击每个链接”,优采云会自动逐个点击每个电影链接,进入电影详情页
4提取数据
1)点击页面中要提取的电影标题字段,标题字段即被选中,选中后以红色框标注出来
2)在弹出的提示框中,选择“采集该元素的文本”,表明要采集的是页面中的文本数据
3)以同样的方式,点击要采集的其他段,再选择“采集该元素的文本”
5修改字段名称
1)点击“流程”按钮,以显示“流程设计器”和“定制当前操作”两个板块。(在配置规则过程中,“流程”随时可打开)
2)在如下界面中,修改字段名称。这里的字段名称相当于表头,便于采集时区分每个字段类别。 修改完成后,点击“确定”保存
6启动采集
1)点击“保存并启动”,在弹出的对话框中选择“启动本地采集”。系统会在本地电脑上,开启一个采集任务并采集数据
2)任务采集完毕之后,会弹出一个采集结束的提示, 接下来选择导出数据,这里以选择导出excel2007为例,然后点击确定
3)选择文件存放路径,再点保存即可
然后,我们分分钟就得到了这样的数据
动图模式有木有学得更爽?
有任何建议或问题,请biubiubiu砸向我!
建议各位小可爱
学了分页列表详细信息采集
趁热打铁 实战一波
更多实战教程 查看全部
分页列表详细信息采集 | 2个月精通优采云第1课
在之前的教程中,我们以赶集网商铺数据采集、携程网旅游数据采集为例,感受了一波优采云嗖嗖嗖采集数据的常(li)规(hai)操作。
咦?这两个实战案例,规则配置长相似,采集流程有点像?
来吧,是时候溯本求源,透过现象看本质了。
网页内容由相似的区块组成,需要点击“下一页”进行翻页,再点击每个链接进入详情页采集数据,没错就是——分页列表详细信息采集。
本文中示例网站地址为:
在开始采集之前,需观察网页结构、明确采集内容。以示例网址为例,内容共有4页,每页有3个电影链接。我们需要点击每一部电影的链接,进入电影详情页,采集电影的剧情、上映时间等字段。
优采云基于 Firefox 内核浏览器,通过模拟人的思维操作方式,对网页内容进行全自动提取。以示例网址为例,在优采云里打开后,需先建立一个点击“下一页”的翻页循环,自动点击“下一页”翻页。再建立一个电影链接列表循环,以打开每个电影的链接,进入电影详情页。然后再采集电影详情页的数据。
1打开网页
1)登陆优采云7.0采集器,点击新建任务,选择“自定义采集”。进入到任务配置页面
2)输入要采集的网址,点击“保存网址”。系统会进入到流程设计页面,并自动打开前面输入的网址
2建立翻页循环
1)用鼠标点击“下一页”按钮,在弹出的操作提示框中,选择“循环点击下一页”。这个步骤会模拟人工,自动点击翻页
3建立循环列表
1)点击下图中第一个电影“教父:第二部”的链接,链接将被选中,用绿色框标注出来
2)优采云的智能算法,会自动检测出其他相似元素(本例中为其他两个电影标题链接)。在操作提示框中,选择“选中全部”,优采云自动选中全部电影链接
3)选择“循环点击每个链接”,优采云会自动逐个点击每个电影链接,进入电影详情页
4提取数据
1)点击页面中要提取的电影标题字段,标题字段即被选中,选中后以红色框标注出来
2)在弹出的提示框中,选择“采集该元素的文本”,表明要采集的是页面中的文本数据
3)以同样的方式,点击要采集的其他段,再选择“采集该元素的文本”
5修改字段名称
1)点击“流程”按钮,以显示“流程设计器”和“定制当前操作”两个板块。(在配置规则过程中,“流程”随时可打开)
2)在如下界面中,修改字段名称。这里的字段名称相当于表头,便于采集时区分每个字段类别。 修改完成后,点击“确定”保存
6启动采集
1)点击“保存并启动”,在弹出的对话框中选择“启动本地采集”。系统会在本地电脑上,开启一个采集任务并采集数据
2)任务采集完毕之后,会弹出一个采集结束的提示, 接下来选择导出数据,这里以选择导出excel2007为例,然后点击确定
3)选择文件存放路径,再点保存即可
然后,我们分分钟就得到了这样的数据
动图模式有木有学得更爽?
有任何建议或问题,请biubiubiu砸向我!
建议各位小可爱
学了分页列表详细信息采集
趁热打铁 实战一波
更多实战教程
发布一个智能解析算法库
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-05-12 07:23
之前我写过几篇文章介绍过有关爬虫的智能解析算法,包括商业化应用 Diffbot、Readability、Newspaper 这些库,另外我有一位朋友之前还专门针对新闻正文的提取算法 GeneralNewsExtractor,这段时间我也参考和研究了一下这些库的算法,同时参考一些论文,也写了一个智能解析库,在这里就做一个非正式的介绍。
引入
那首先说说我想做的是什么。
比如这里有一个网站,网易新闻,,这里有个新闻列表,预览图如下:
任意点开一篇新闻,看到的结果如下:
我现在需要做到的是在不编写任何 XPath、Selector 的情况下实现下面信息的提取:
对于列表页来说,我要提取新闻的所有标题列表和对应的链接,它们就是图中的红色区域:
这里红色区域分了多个区块,比如这里一共就是 40 个链接,我都需要提取出来,包括标题的名称,标题的 URL。
我们看到页面里面还有很多无用的链接,如上图绿色区域,包括分类、内部导航等,这些需要排除掉。
对于详情页,我主要关心的内容有标题、发布时间、正文内容,它们就是图中红色区域:
其中这里也带有一些干扰项,比如绿色区域的侧边栏的内容,无用的分享链接等。
总之,我想实现某种算法,实现如上两大部分的智能化提取。
框架
之前我开发了一个叫做 Gerapy 的框架,是一个基于 Scrapy、Scrapyd 的分布式爬虫管理框架,属 1.x 版本。现在正在开发 Gerapy 2.x 版本,其定位转向了 Scrapy 的可视化配置和调试、智能化解析方向,放弃支持 Scraypd,转而支持 Docker、Kubernetes 的部署和监控。
对于智能解析来说,就像刚才说的,我期望的就是上述的功能,在不编写任何 XPath 和 Selector 的情况下实现页面关键内容的提取。
框架现在发布了第一个初步版本,名称叫做 Gerapy Auto Extractor,名字 Gerapy 相关,也会作为 Gerapy 的其中一个模块。
GitHub 链接:
现在已经发布了 PyPi,,可以使用 pip3 来安装,安装方式如下:
pip3 install gerapy-auto-extractor
安装完了之后我们就可以导入使用了。
功能
下面简单介绍下它的功能,它能够做到列表页和详情页的解析。
列表页:
•标题内容•标题链接
详情页:
•标题•正文•发布时间
先暂时实现了如上内容的提取,其他字段的提取暂时还未实现。
使用
要使用 Gerapy Auto Extractor,前提我们必须要先获得 HTML 代码,注意这个 HTML 代码是我们在浏览器里面看到的内容,是整个页面渲染完成之后的代码。在某些情况下如果我们简单用「查看源代码」或 requests 请求获取到的源码并不是真正渲染完成后的 HTML 代码。
要获取完整 HTML 代码可以在浏览器开发者工具,打开 Elements 选项卡,然后复制你所看到的 HTML 内容即可。
先测试下列表页,比如我把 这个保存为 list.html,
然后编写提取代码如下:
import jsonfrom gerapy_auto_extractor.extractors.list import extract_list<br />html = open('list.html', encoding='utf-8').read()print(json.dumps(extract_list(html), indent=2, ensure_ascii=False, default=str))
就是这么简单,核心代码就一行,就是调用了一个 extract_list 方法。
运行结果如下:
[ { "title": "1家6口5年\"结离婚\"10次:儿媳\"嫁\"公公岳", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "\"港独\"议员泼水阻碍教科书议题林郑月娥深夜斥责", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "感动中国致敬留德女学生:街头怒怼\"港独\"有理有", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "香港名医讽刺港警流血少过月经受访时辩称遭盗号", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "李晨独居北京复式豪宅没想到肌肉男喜欢小花椅子", "url": "https://home.163.com/20/0705/0 ... ot%3B }, { "title": "不战东京!林丹官宣退役正式结束20年职业生涯", "url": "https://sports.163.com/20/0704 ... ot%3B }, { "title": "香港美女搬运工月薪1.6万每月花6千租5平出租", "url": "https://home.163.com/20/0705/0 ... ot%3B }, { "title": "杭州第一大P2P\"凉了\":近百亿未还!被警方立案", "url": "https://money.163.com/20/0705/ ... ot%3B }, ...]
可以看到想要的内容就提取出来了,结果是一个列表,包含标题内容和标题链接两个字段,由于内容过长,这里就省略了一部分。
接着我们再测试下正文的提取,随便打开一篇文章,比如 ,保存下 HTML,命名为 detail.html。
编写测试代码如下:
import jsonfrom gerapy_auto_extractor.extractors import extract_detailhtml = open('detail.html', encoding='utf-8').read()print(json.dumps(extract_detail(html), indent=2, ensure_ascii=False, default=str))
运行结果如下:
{ "title": "内蒙古巴彦淖尔发布鼠疫疫情Ⅲ级预警", "datetime": "2020-07-05 18:54:15", "content": "2020年7月4日,乌拉特中旗人民医院报告了1例疑似腺鼠疫病例,根据《内蒙古自治区鼠疫疫情预警实施方案》(内鼠防应急发﹝2020﹞7号)和《自治区鼠疫控制应急预案(2020年版)》(内政办发﹝2020﹞17号)的要求,经研究决定,于7月5日发布鼠疫防控Ⅲ级预警信息如下:\n一、预警级别及起始时间\n预警级别:Ⅲ级。\n2020年7月5日起进入预警期,预警时间从本预警通告发布之日持续到2020年底。\n二、注意事项\n当前我市存在人间鼠疫疫情传播的风险,请广大公众严格按照鼠疫防控“三不三报”的要求,切实做好个人防护,提高自我防护意识和能力。不私自捕猎疫源动物、不剥食疫源动物、不私自携带疫源动物及其产品出疫区;发现病(死)旱獭及其他动物要报告、发现疑似鼠疫病人要报告、发现不明原因的高热病人和急死病人要报告。要谨慎进入鼠疫疫源地,如有鼠疫疫源地的旅居史,出现发热等不适症状时及时赴定点医院就诊。\n按照国家、自治区鼠疫控制应急预案的要求,市卫生健康委将根据鼠疫疫情预警的分级,及时发布和调整预警信息。\n巴彦淖尔市卫生健康委员会\n2020年7月5日\n来源:巴彦淖尔市卫生健康委员会"}
成功输出了标题、正文、发布时间等内容。
这里就演示了基本的列表页、详情页的提取操作。
算法
整个算法的实现比较杂,我看了几篇论文和几个项目的源码,然后经过一些修改实现的。
其中列表页解析的参考论文:
•面向不规则列表的网页数据抽取技术的研究[1]•基于块密度加权标签路径特征的Web新闻在线抽取[2]
详情页解析的参考论文和项目:
•基于文本及符号密度的网页正文提取方法[3]•GeneralNewsExtractor[4]
这些都是不完全参考,然后加上自己的一些修改最终才形成了现在的结果。
算法在这里就几句话描述一下思路,暂时先不展开讲了。
列表页解析:
•找到具有公共父节点的连续相邻子节点,父节点作为候选节点。•根据节点特征进行聚类融合,将符合条件的父节点融合在一起。•根据节点的特征、文本密度、视觉信息(尚未实现)挑选最优父节点。•从最优父节点内根据标题特征提取标题。
详情页解析:
•标题根据 meta、title、h 节点综合提取•时间根据 meta、正则信息综合提取•正文根据文本密度、符号密度、视觉信息(尚未实现)综合提取。
后面等完善了之后再详细介绍算法的具体实现,现在如感兴趣可以去看源码。
说明
本框架仅仅发布了最初测试版本,测试覆盖度比较少,目前仅仅测试了有限的几个网站,尚未大规模测试和添加对比实验,因此准确率现在还没有标准的保证。
参考:关于详情页正文的提取我主要参考了GeneralNewsExtractor[5]这个项目,原项目据测试可以达到 90% 以上的准确率。
列表页我测试了腾讯、网易、知乎等都是可以顺利提取的,如:
后面会有大规模测试和修正。
项目初版,肯定存在很多不足,希望大家可以多发 Issue 和提 PR。
另外这里建立了一个 Gerapy 开发交流群,之前在 群的也欢迎加入,以后交流就在微信群了,大家在使用过程遇到关于 Gerapy、Gerapy Auto Extractor 的问题欢迎交流。
这里放一个临时二维码,后期可能会失效,失效后大家可以到公众号「进击的Coder」或 「崔庆才丨静觅」获取加群方式,欢迎大家加入哈。
交流群
待开发功能
•视觉信息的融合•文本相似度的融合•分类模型的融合•下一页翻页的信息提取•正文图片、视频的提取•对接 Gerapy
最后感谢大家的支持!
References
[1]面向不规则列表的网页数据抽取技术的研究:
[2]基于块密度加权标签路径特征的Web新闻在线抽取:
[3]基于文本及符号密度的网页正文提取方法:
[4]GeneralNewsExtractor:
[5]GeneralNewsExtractor:
精选文章
语法最简单的微博通用爬虫weibo_crawler<br />hiResearch 定义自己的科研首页<br />大邓github汇总, 觉得有用记得starmultistop ~ 多语言停用词库Jaal 库 轻松绘制动态社交网络关系图<br />addressparser中文地址提取工具<br />来自kaggle最佳数据分析实践<br />B站视频 | Python自动化办公<br />SciencePlots | 科研样式绘图库使用streamlit上线中文文本分析网站<br />bsite库 | 采集B站视频信息、评论数据<br />texthero包 | 支持dataframe的文本分析包爬虫实战 | 采集&可视化知乎问题的回答reticulate包 | 在Rmarkdown中调用Python代码plydata库 | 数据操作管道操作符>>plotnine: Python版的ggplot2作图库读完本文你就了解什么是文本分析<br />文本分析在经管领域中的应用概述 综述:文本分析在市场营销研究中的应用<br />plotnine: Python版的ggplot2作图库Wow~70G上市公司定期报告数据集<br />漂亮~pandas可以无缝衔接Bokeh YelpDaset: 酒店管理类数据集10+G
好文和朋友一起看~ 查看全部
发布一个智能解析算法库
之前我写过几篇文章介绍过有关爬虫的智能解析算法,包括商业化应用 Diffbot、Readability、Newspaper 这些库,另外我有一位朋友之前还专门针对新闻正文的提取算法 GeneralNewsExtractor,这段时间我也参考和研究了一下这些库的算法,同时参考一些论文,也写了一个智能解析库,在这里就做一个非正式的介绍。
引入
那首先说说我想做的是什么。
比如这里有一个网站,网易新闻,,这里有个新闻列表,预览图如下:
任意点开一篇新闻,看到的结果如下:
我现在需要做到的是在不编写任何 XPath、Selector 的情况下实现下面信息的提取:
对于列表页来说,我要提取新闻的所有标题列表和对应的链接,它们就是图中的红色区域:
这里红色区域分了多个区块,比如这里一共就是 40 个链接,我都需要提取出来,包括标题的名称,标题的 URL。
我们看到页面里面还有很多无用的链接,如上图绿色区域,包括分类、内部导航等,这些需要排除掉。
对于详情页,我主要关心的内容有标题、发布时间、正文内容,它们就是图中红色区域:
其中这里也带有一些干扰项,比如绿色区域的侧边栏的内容,无用的分享链接等。
总之,我想实现某种算法,实现如上两大部分的智能化提取。
框架
之前我开发了一个叫做 Gerapy 的框架,是一个基于 Scrapy、Scrapyd 的分布式爬虫管理框架,属 1.x 版本。现在正在开发 Gerapy 2.x 版本,其定位转向了 Scrapy 的可视化配置和调试、智能化解析方向,放弃支持 Scraypd,转而支持 Docker、Kubernetes 的部署和监控。
对于智能解析来说,就像刚才说的,我期望的就是上述的功能,在不编写任何 XPath 和 Selector 的情况下实现页面关键内容的提取。
框架现在发布了第一个初步版本,名称叫做 Gerapy Auto Extractor,名字 Gerapy 相关,也会作为 Gerapy 的其中一个模块。
GitHub 链接:
现在已经发布了 PyPi,,可以使用 pip3 来安装,安装方式如下:
pip3 install gerapy-auto-extractor
安装完了之后我们就可以导入使用了。
功能
下面简单介绍下它的功能,它能够做到列表页和详情页的解析。
列表页:
•标题内容•标题链接
详情页:
•标题•正文•发布时间
先暂时实现了如上内容的提取,其他字段的提取暂时还未实现。
使用
要使用 Gerapy Auto Extractor,前提我们必须要先获得 HTML 代码,注意这个 HTML 代码是我们在浏览器里面看到的内容,是整个页面渲染完成之后的代码。在某些情况下如果我们简单用「查看源代码」或 requests 请求获取到的源码并不是真正渲染完成后的 HTML 代码。
要获取完整 HTML 代码可以在浏览器开发者工具,打开 Elements 选项卡,然后复制你所看到的 HTML 内容即可。
先测试下列表页,比如我把 这个保存为 list.html,
然后编写提取代码如下:
import jsonfrom gerapy_auto_extractor.extractors.list import extract_list<br />html = open('list.html', encoding='utf-8').read()print(json.dumps(extract_list(html), indent=2, ensure_ascii=False, default=str))
就是这么简单,核心代码就一行,就是调用了一个 extract_list 方法。
运行结果如下:
[ { "title": "1家6口5年\"结离婚\"10次:儿媳\"嫁\"公公岳", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "\"港独\"议员泼水阻碍教科书议题林郑月娥深夜斥责", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "感动中国致敬留德女学生:街头怒怼\"港独\"有理有", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "香港名医讽刺港警流血少过月经受访时辩称遭盗号", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "李晨独居北京复式豪宅没想到肌肉男喜欢小花椅子", "url": "https://home.163.com/20/0705/0 ... ot%3B }, { "title": "不战东京!林丹官宣退役正式结束20年职业生涯", "url": "https://sports.163.com/20/0704 ... ot%3B }, { "title": "香港美女搬运工月薪1.6万每月花6千租5平出租", "url": "https://home.163.com/20/0705/0 ... ot%3B }, { "title": "杭州第一大P2P\"凉了\":近百亿未还!被警方立案", "url": "https://money.163.com/20/0705/ ... ot%3B }, ...]
可以看到想要的内容就提取出来了,结果是一个列表,包含标题内容和标题链接两个字段,由于内容过长,这里就省略了一部分。
接着我们再测试下正文的提取,随便打开一篇文章,比如 ,保存下 HTML,命名为 detail.html。
编写测试代码如下:
import jsonfrom gerapy_auto_extractor.extractors import extract_detailhtml = open('detail.html', encoding='utf-8').read()print(json.dumps(extract_detail(html), indent=2, ensure_ascii=False, default=str))
运行结果如下:
{ "title": "内蒙古巴彦淖尔发布鼠疫疫情Ⅲ级预警", "datetime": "2020-07-05 18:54:15", "content": "2020年7月4日,乌拉特中旗人民医院报告了1例疑似腺鼠疫病例,根据《内蒙古自治区鼠疫疫情预警实施方案》(内鼠防应急发﹝2020﹞7号)和《自治区鼠疫控制应急预案(2020年版)》(内政办发﹝2020﹞17号)的要求,经研究决定,于7月5日发布鼠疫防控Ⅲ级预警信息如下:\n一、预警级别及起始时间\n预警级别:Ⅲ级。\n2020年7月5日起进入预警期,预警时间从本预警通告发布之日持续到2020年底。\n二、注意事项\n当前我市存在人间鼠疫疫情传播的风险,请广大公众严格按照鼠疫防控“三不三报”的要求,切实做好个人防护,提高自我防护意识和能力。不私自捕猎疫源动物、不剥食疫源动物、不私自携带疫源动物及其产品出疫区;发现病(死)旱獭及其他动物要报告、发现疑似鼠疫病人要报告、发现不明原因的高热病人和急死病人要报告。要谨慎进入鼠疫疫源地,如有鼠疫疫源地的旅居史,出现发热等不适症状时及时赴定点医院就诊。\n按照国家、自治区鼠疫控制应急预案的要求,市卫生健康委将根据鼠疫疫情预警的分级,及时发布和调整预警信息。\n巴彦淖尔市卫生健康委员会\n2020年7月5日\n来源:巴彦淖尔市卫生健康委员会"}
成功输出了标题、正文、发布时间等内容。
这里就演示了基本的列表页、详情页的提取操作。
算法
整个算法的实现比较杂,我看了几篇论文和几个项目的源码,然后经过一些修改实现的。
其中列表页解析的参考论文:
•面向不规则列表的网页数据抽取技术的研究[1]•基于块密度加权标签路径特征的Web新闻在线抽取[2]
详情页解析的参考论文和项目:
•基于文本及符号密度的网页正文提取方法[3]•GeneralNewsExtractor[4]
这些都是不完全参考,然后加上自己的一些修改最终才形成了现在的结果。
算法在这里就几句话描述一下思路,暂时先不展开讲了。
列表页解析:
•找到具有公共父节点的连续相邻子节点,父节点作为候选节点。•根据节点特征进行聚类融合,将符合条件的父节点融合在一起。•根据节点的特征、文本密度、视觉信息(尚未实现)挑选最优父节点。•从最优父节点内根据标题特征提取标题。
详情页解析:
•标题根据 meta、title、h 节点综合提取•时间根据 meta、正则信息综合提取•正文根据文本密度、符号密度、视觉信息(尚未实现)综合提取。
后面等完善了之后再详细介绍算法的具体实现,现在如感兴趣可以去看源码。
说明
本框架仅仅发布了最初测试版本,测试覆盖度比较少,目前仅仅测试了有限的几个网站,尚未大规模测试和添加对比实验,因此准确率现在还没有标准的保证。
参考:关于详情页正文的提取我主要参考了GeneralNewsExtractor[5]这个项目,原项目据测试可以达到 90% 以上的准确率。
列表页我测试了腾讯、网易、知乎等都是可以顺利提取的,如:
后面会有大规模测试和修正。
项目初版,肯定存在很多不足,希望大家可以多发 Issue 和提 PR。
另外这里建立了一个 Gerapy 开发交流群,之前在 群的也欢迎加入,以后交流就在微信群了,大家在使用过程遇到关于 Gerapy、Gerapy Auto Extractor 的问题欢迎交流。
这里放一个临时二维码,后期可能会失效,失效后大家可以到公众号「进击的Coder」或 「崔庆才丨静觅」获取加群方式,欢迎大家加入哈。
交流群
待开发功能
•视觉信息的融合•文本相似度的融合•分类模型的融合•下一页翻页的信息提取•正文图片、视频的提取•对接 Gerapy
最后感谢大家的支持!
References
[1]面向不规则列表的网页数据抽取技术的研究:
[2]基于块密度加权标签路径特征的Web新闻在线抽取:
[3]基于文本及符号密度的网页正文提取方法:
[4]GeneralNewsExtractor:
[5]GeneralNewsExtractor:
精选文章
语法最简单的微博通用爬虫weibo_crawler<br />hiResearch 定义自己的科研首页<br />大邓github汇总, 觉得有用记得starmultistop ~ 多语言停用词库Jaal 库 轻松绘制动态社交网络关系图<br />addressparser中文地址提取工具<br />来自kaggle最佳数据分析实践<br />B站视频 | Python自动化办公<br />SciencePlots | 科研样式绘图库使用streamlit上线中文文本分析网站<br />bsite库 | 采集B站视频信息、评论数据<br />texthero包 | 支持dataframe的文本分析包爬虫实战 | 采集&可视化知乎问题的回答reticulate包 | 在Rmarkdown中调用Python代码plydata库 | 数据操作管道操作符>>plotnine: Python版的ggplot2作图库读完本文你就了解什么是文本分析<br />文本分析在经管领域中的应用概述 综述:文本分析在市场营销研究中的应用<br />plotnine: Python版的ggplot2作图库Wow~70G上市公司定期报告数据集<br />漂亮~pandas可以无缝衔接Bokeh YelpDaset: 酒店管理类数据集10+G
好文和朋友一起看~
算法自动采集列表页简介页推荐页和最近页的爬虫python
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-05-09 00:01
算法自动采集列表页简介页推荐页和最近页的爬虫python实现,第二天使用selenium实现效果1。爬虫:爬取24万条微信好友聊天记录-python-伯乐在线2。分析:列表页是通过人脸识别技术做的识别2-1。提取人脸,2-2。提取微信昵称、微信地区、分组信息2-3。提取人脸2-4。提取人脸识别-selenium小工具课程_伯乐在线3。
实现目标3。1。爬取24万条微信好友聊天记录3。2。分析及合并微信昵称、微信地区、分组信息3。3。爬取每个用户自带的群2。提取人脸3。1。抓取好友姓名,爬取昵称,分组信息3。2。提取人脸3。3。分析及合并,爬取每个用户自带的群2。1。抓取好友姓名,爬取昵称,分组信息3。2。提取人脸3。3。抓取地区信息2。
提取昵称、分组信息3。1。提取好友地区信息4。代码分析4。1。抓取昵称4。2。提取昵称和微信昵称4。3。提取微信昵称4。4。分组信息4。5。抓取每个用户自带的群2。提取昵称、分组信息5。学习笔记2。1。抓取昵称抓取昵称后代码:#-*-coding:utf-8-*-importrequests#爬取24万条微信好友聊天记录#给好友打标签#一共爬取25万个男用户的聊天记录#好友类型ex1=requests。
get('thread',headers=headers)#用户简介ex2=requests。get('thread',headers=headers)#关键字,男/女#抓取人脸ex3=requests。get('thread',headers=headers)#发送消息和发送长文件ex4=requests。
get('thread',headers=headers)#人脸识别t=requests。get('thread',headers=headers)#获取对方接收的session#获取每个用户自带的群#加入的群越多越好#运行python爬虫的环境:python3。6pip3installseleniumpip3installmultiprocessingfrompilimportimage#特殊js特性:'''(不再看)'''html=python3。
6imgurl=';uid=35853&name=jullin'#手机微信号以及昵称ex3=python3。6img_format='png'#获取共计24万条微信聊天记录名字"""抓取好友的昵称"""#发送自定义短信,获取昵称#。
1、注册爬虫抓取28万条微信好友的通讯录#
2、爬取微信通讯录爬取好友的昵称#
3、爬取微信好友的发送的自定义短信#第一种,
4)applewebkit/537.36(khtml,likegecko)chrome 查看全部
算法自动采集列表页简介页推荐页和最近页的爬虫python
算法自动采集列表页简介页推荐页和最近页的爬虫python实现,第二天使用selenium实现效果1。爬虫:爬取24万条微信好友聊天记录-python-伯乐在线2。分析:列表页是通过人脸识别技术做的识别2-1。提取人脸,2-2。提取微信昵称、微信地区、分组信息2-3。提取人脸2-4。提取人脸识别-selenium小工具课程_伯乐在线3。
实现目标3。1。爬取24万条微信好友聊天记录3。2。分析及合并微信昵称、微信地区、分组信息3。3。爬取每个用户自带的群2。提取人脸3。1。抓取好友姓名,爬取昵称,分组信息3。2。提取人脸3。3。分析及合并,爬取每个用户自带的群2。1。抓取好友姓名,爬取昵称,分组信息3。2。提取人脸3。3。抓取地区信息2。
提取昵称、分组信息3。1。提取好友地区信息4。代码分析4。1。抓取昵称4。2。提取昵称和微信昵称4。3。提取微信昵称4。4。分组信息4。5。抓取每个用户自带的群2。提取昵称、分组信息5。学习笔记2。1。抓取昵称抓取昵称后代码:#-*-coding:utf-8-*-importrequests#爬取24万条微信好友聊天记录#给好友打标签#一共爬取25万个男用户的聊天记录#好友类型ex1=requests。
get('thread',headers=headers)#用户简介ex2=requests。get('thread',headers=headers)#关键字,男/女#抓取人脸ex3=requests。get('thread',headers=headers)#发送消息和发送长文件ex4=requests。
get('thread',headers=headers)#人脸识别t=requests。get('thread',headers=headers)#获取对方接收的session#获取每个用户自带的群#加入的群越多越好#运行python爬虫的环境:python3。6pip3installseleniumpip3installmultiprocessingfrompilimportimage#特殊js特性:'''(不再看)'''html=python3。
6imgurl=';uid=35853&name=jullin'#手机微信号以及昵称ex3=python3。6img_format='png'#获取共计24万条微信聊天记录名字"""抓取好友的昵称"""#发送自定义短信,获取昵称#。
1、注册爬虫抓取28万条微信好友的通讯录#
2、爬取微信通讯录爬取好友的昵称#
3、爬取微信好友的发送的自定义短信#第一种,
4)applewebkit/537.36(khtml,likegecko)chrome
DBA要失业了?看ML如何自动优化数据库
采集交流 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-05-05 10:08
译者注:看到标题的时候,确实被吓了一大跳。看的过程,心里其实一直在降低警惕。但完整看完这篇文章的时候,情绪又回落到刚看到标题的状态了。虽然DBA的工作不会那么快被AI替代,文章所说的也主要是开关(参数),但显然数据库的管理只会越来越智能,不是由厂家自己(比如Oracle,这些年从PGA自动管理,SGA自动管理到整个内存自动管理,从Perfstat到AWR到ADDM,正在一步步把DBA“傻瓜化”),就是由第三方公司或者研究机构(比如本文的卡耐基大学数据库研究团队),作为DBA来说,必须要不断尝试,站在一个更高层面来看待数据库,看待运维,看待IT,否则就会成为被机器人替代的炮灰。
数据库管理系统(DBMSs,DatabaseManagement Systems)是任何数据密集型应用最重要的组成部分。他们可以处理大规模数据和复杂的负载形态,但它们很难管理,因为它们有成百上千个配置“开关”,用来控制诸如将多少内存用作缓存、怎样将数据写到存储等等这些事情。企业或组织经常雇佣技术专家来帮忙做系统优化,但专家对许多公司来说还是非常昂贵的。
卡耐基梅隆大学数据库组的研究员和学生们研发了一款新工具,叫做OtterTune。OtterTune可以从数据库成百上千个配置开关中自动发现最佳设置。它的目标是让随便一个工程师都可以更容易去部署一套关系型数据库,即使他们在数据库管理方面没有任何专业知识也行。
OtterTune与其他的数据库配置工具不一样,因为它利用调优先前的数据库配置知识去调优新的数据库配置。这可以显著地降低调优一个新的数据库部署所需时间及相关的资源。为了做到这一点,OtterTune维持着一个资料库,其中存放了从先前调优环境中采集回来的调优数据。OtterTune使用这些调优模型来指导新应用程序的实验,推荐能够改进目标对象(比如降低延时或者提升吞吐量)的设置。
在这篇文章中,我们讨论OtterTune工具 ML pipeline(机器学习的工作流API库)的每个组件,并展示他们之间怎样互相协作去调优一个数据库配置。我们在MySQL和Postgre上评估OtterTune的调优能力,通过将OtterTune最佳配置的性能与DBA选择的配置及其他自动调优工具的配置得出的性能做比较。
OtterTune是一个开源工具,由卡耐基梅隆大学数据库研究组的研究员和学生们研发。所有的工具代码都放在GitHub上,遵从Apache License 2.0协议授权。
Otter Tune怎样工作?
在一个新的调优场景,首先,用户告诉OtterTune要通过调优来满足哪个目标对象(比如,延迟或者吞吐量)。客户端的控制器(controller)连接到目标数据库,搜集它的Amazon EC2实例类型和当前配置。
然后控制器开始它的第一个探测周期,在这个期间内,它监控数据库,并记录目标对象。探测周期结束的时候,控制器从数据库中采集好内部指标,比如MySQL中从磁盘读取的页面和写到磁盘的页面(pages)的计数器。控制器会将目标对象和内部指标信息都传递给调优管理器(tuning manager)。
当OtterTune调优管理器收到这些指标后,把它们存放在资料库当中。OtterTune使用这些结果,计算下一个要部署的目标数据库的配置。调优管理器将这一配置信息传输给控制器,并告诉控制器,采纳这一配置后可能会获得的性能提升。用户可以决定是继续调优,还是结束这次优化工作。
注意
OtterTune为它支持的每个数据库版本维护着一个配置开关的黑名单。黑名单包括那些调整了不会产生效果的配置开关(比如,数据库中存放文件的路径名),或者这些开关会有严重的或者潜在不良后果(比如,可能会导致数据库丢失数据)。每场调优开始的时候,OtterTune都会给用户提供一个黑名单,所以他/她可以增加其他开关进去,如果他们希望OtterTune不要去调优这部分的话。
OtterTune作了一些假设限制,可能会限制了一些用户的可用性。比如,它假定用户有允许控制器更改数据库配置的管理权限。如果用户没有这个权限,那他或者她可以在其他硬件上部署一个数据库镜像,用于OtterTune调优实验。这就需要用户去重演(replay)一个工作负载跟踪,或者在生产数据库中转发查询。关于假定和限制的完整讨论,详见我们的论文(读者可以点击文末的“阅读原文”进行阅读)。
ML pipeline
下面的图中展示了通过OtterTune的ML pipeline,数据在移动过程中是如何处理的。所有探查数据都存放在OtterTune资料库中。
OtterTune首先将探测数据传给“工作负载表征”(Workload Characterization)组件。该组件识别一组较小的数据库指标度量,可以最佳地捕获性能上的差异性,以及不同工作负载的区别特征。
接着,开关识别组件(Knob Identification)生成一个开关的排名列表,以对数据库性能的影响度大小排序。OtterTune将所有这些信息提供给自动调优器(Automatic Tuner)组件。该组件在它的数据资料库中为目标数据库负载匹配(map)最相似的负载,并用这个负载数据生成最佳配置。
让我们把ML pipeline中的每个组件再详细说说。
工作负载表征(Workload Characterization)组件:OtterTune使用数据库内部运行时的度量指标来表征(或识别)工作负载的行为。这些度量指标提供了负载的准确表现,因为它们捕获了运行时行为的许多因素。可是,很多度量指标是冗余的,一些是相同的度量记录只是单位不同,其他的则是表现数据库不同组件,它们的值高度相关。所以裁剪冗余度量就很重要,这可以降低ML模型使用它们的时候的复杂性。为此,我们根据其相关性模型对数据库的度量指标进行了聚类。然后,我们从每个聚类中选择一个作为代表度量,就是最靠近聚类中心的那个度量。ML pipeline的后续组件直接使用这些度量。
开关识别组件(Knob Identification):数据库中可能有几百个开关,但只有一小部分会影响数据库的性能。OtterTune使用一个叫做Lasso的流行特征选择(feature-selection)技术,来确定哪些开关会很大程度上影响系统的整体性能。通过使用这一技术于资料库中的数据,OtterTune就可以列出数据库中这些开关的重要性顺序。
然后,OtterTune必须决定,做配置推荐的时候用多少个开关。使用太多必然会显著增加OtterTune的调优时间。用得太少又会妨碍OtterTune去找到最佳配置。OtterTune使用渐进化的方式自动化这一过程,在调优时它会逐渐增加开关的个数。这个方式让OtterTune在扩展到更多开关之前,探寻和优化一组最重要的开关配置。
自动调优(Automatic Tuner)组件:自动调优组件通过在每个观察周期之后执行“两步分析”(two-step analysis)来确定OtterTune应推荐的配置。
首先,系统使用工作负载表征组件中标识的度量性能数据,识别来自先前调优场景的最能匹配目标数据库负载的负载。它将当前场景的度量指标与先前场景的度量指标进行比较,以确定哪些指标与不同的开关设置类似。
然后,OtterTune会选择另一个开关设置去尝试。它适用一个统计模型,搜集数据,与资料库中最相近负载的数据一样。这个模型让OtterTune可以预测实施每个可能的配置后,数据库性能会怎样。OtterTune优化下一个配置,采用探索的方式(搜集信息以改进模型)而不是剥削的方式(试图只在目标度量上就贪婪地做好)。
实现
OtterTune用Python编写。
对工作负载表征和开关识别组件来说,运行时的性能并不特别需要考虑,因此我们用scikit-learn来实现相应的机器学习算法。这些算法以后台进程的形式运行,并使用OtterTune资料库中的新数据。
对自动优化组件来说,机器学习算法在关键路径上。他们在每一个观察周期后运行,获取新数据以便OtterTune能取得一个开关配置进行下一次尝试。因为它的性能是要特别考虑的,我们用TensorFlow来实现其算法。
搜集关于数据库硬件的数据、开关配置以及运行时的性能度量指标,我们将OLTP-Bench测评框架集成到OtterTune的控制器中。
实验设计
为了评估效果,我们使用OtterTune选择的最佳配置来比较MySQL和Postgre的性能:
我们所有的实验都是在Amazon EC2 Spot Instance上完成的。每一个实验都用了2个实例:一个作为OtterTune控制器,一个作为目标数据库部署用。我们分别使用m4.large和m3.xlarge实例类型。我们将OtterTune调优管理器和资料库部署在本地服务器上,配置是20核CPU、128G内存。我们用TPC-C负载模型,这是评估OLTP系统性能的工业标准。
评估
对实验中我们用到的每一种数据库,MySQL及Postgre,我们评估延迟和性能。下面的图展示了评估结果。第一个图表展示了第99百分位数指标的延迟数量,代表完成交易所需的“最坏情况”时间长度。第二个图展示吞吐量的结果,评估的是每秒完成的平均事务数。
MySQL评估结果:
比较由OtterTune生成的最佳配置与其他工具的“优化脚本”、RDS生成的配置,OtterTune推荐的配置对MySQL数据库大约降低了60%的延迟,提升了22%到35%的吞吐量。OtterTune生成的配置几乎与DBA做的选择一样好。
只有一些MySQL的开关会显著影响TPC-C负载的性能。由OtterTune生成的配置和DBA为每个开关提供了很好的设置。RDS干的稍微要差点,因为它为一个开关提供了不是最优的设置。“优化脚本”的配置表现最差,因为它只改了一个开关。
Postgre评估结果:
对延迟来说,OtterTUne生成的配置,与“优化脚本”、DBA、RDS差不多,相对Postgre的默认设置都获得了不少的提升。我们可以将其归因于OTLP测评工具客户端和数据库之间的网络开销。对于吞吐量,OtterTune设置相对DBA和“优化脚本”的设置得到了12%的提升,相对RDS,得到了32%的提升。
跟MySQL相似,只要少数开关显著影响Postgre的性能。OtterTune、DBA、“优化脚本”以及RDS都调整了所有这些开关,大多都提供了合理的设置。
结论
OtterTune为关系型数据库的配置开关自动化发现最佳设置,用于调优新的数据库部署,重用从先前调优场景获取的训练数据。因为OtterTune不需要为训练ML模型生成厨师数据集,所需调优时间大大减少。
译后记
OtterTune为关系型数据库的配置开关自动化发现最佳设置,用于调优。
不客气地说,OtterTune目前也只是支持MySQL和Postgre两种数据库,而且只是在开关设置层面,相比Oracle数据库在自动化管理方面的强大功力,OtterTune只能算是一个玩具。我突然想到,2004年的时候,我去贵州给某个运营商做Oracle数据库优化,只是把SGA从100M调大到1GB,客户的核心业务整体性能就得到了飞速提升。放到今天来说是个不可思议的事情,今天随便一个省级运营商的核心系统标配可能都是一个TB的内存,缺省安装的时候,工程师就会把SGA缺省配到700G,其他相关参数也会按所谓的最佳实践进行。
但是,没有开关的问题,不代表就没有数据库的性能问题。
时至今日,Oracle数据库的性能问题依然层出不穷(不是因为Oracle不行,其他数据库还在后面远远的跟着Oracle在前进呢),参数开关层面基本已经不太可能有遗漏。性能问题更多的层面来自于开发,开发部门数据模型设计得不合理,开发人员SQL写得不合理,往往导致了90%的性能问题。前两天朋友谈及的一个案例,某银行的信用卡业务查询,每天一次,表当然有几亿条记录,查询一次要花费小时计的时间,通过一个简单的rownum查询时间降低到秒级。单纯的开发人员搞不定,普通的DBA也想不到,机器学习能做这种优化么?现在不好判断。
有远虑,不是坏事。但也无需太执着于远虑,还是要把当前的事情先做好。
如果你们的开发团队老是出一些表结构设计问题、索引问题、劣质SQL问题,不妨推荐他们先来上上D+学院先开设的精品SQL优化课程。Oracle和MySQL都有,只要一天时间,可以跟业界一线DBA大师学习怎样做SQL优化,省时、省力、利人、利己。
当然,如果你连1天完整时间都抽不出来,也不用气馁,DBAplus仍然不定期将各类优化妙文推送出来,给需要精进的你。 查看全部
DBA要失业了?看ML如何自动优化数据库
译者注:看到标题的时候,确实被吓了一大跳。看的过程,心里其实一直在降低警惕。但完整看完这篇文章的时候,情绪又回落到刚看到标题的状态了。虽然DBA的工作不会那么快被AI替代,文章所说的也主要是开关(参数),但显然数据库的管理只会越来越智能,不是由厂家自己(比如Oracle,这些年从PGA自动管理,SGA自动管理到整个内存自动管理,从Perfstat到AWR到ADDM,正在一步步把DBA“傻瓜化”),就是由第三方公司或者研究机构(比如本文的卡耐基大学数据库研究团队),作为DBA来说,必须要不断尝试,站在一个更高层面来看待数据库,看待运维,看待IT,否则就会成为被机器人替代的炮灰。
数据库管理系统(DBMSs,DatabaseManagement Systems)是任何数据密集型应用最重要的组成部分。他们可以处理大规模数据和复杂的负载形态,但它们很难管理,因为它们有成百上千个配置“开关”,用来控制诸如将多少内存用作缓存、怎样将数据写到存储等等这些事情。企业或组织经常雇佣技术专家来帮忙做系统优化,但专家对许多公司来说还是非常昂贵的。
卡耐基梅隆大学数据库组的研究员和学生们研发了一款新工具,叫做OtterTune。OtterTune可以从数据库成百上千个配置开关中自动发现最佳设置。它的目标是让随便一个工程师都可以更容易去部署一套关系型数据库,即使他们在数据库管理方面没有任何专业知识也行。
OtterTune与其他的数据库配置工具不一样,因为它利用调优先前的数据库配置知识去调优新的数据库配置。这可以显著地降低调优一个新的数据库部署所需时间及相关的资源。为了做到这一点,OtterTune维持着一个资料库,其中存放了从先前调优环境中采集回来的调优数据。OtterTune使用这些调优模型来指导新应用程序的实验,推荐能够改进目标对象(比如降低延时或者提升吞吐量)的设置。
在这篇文章中,我们讨论OtterTune工具 ML pipeline(机器学习的工作流API库)的每个组件,并展示他们之间怎样互相协作去调优一个数据库配置。我们在MySQL和Postgre上评估OtterTune的调优能力,通过将OtterTune最佳配置的性能与DBA选择的配置及其他自动调优工具的配置得出的性能做比较。
OtterTune是一个开源工具,由卡耐基梅隆大学数据库研究组的研究员和学生们研发。所有的工具代码都放在GitHub上,遵从Apache License 2.0协议授权。
Otter Tune怎样工作?
在一个新的调优场景,首先,用户告诉OtterTune要通过调优来满足哪个目标对象(比如,延迟或者吞吐量)。客户端的控制器(controller)连接到目标数据库,搜集它的Amazon EC2实例类型和当前配置。
然后控制器开始它的第一个探测周期,在这个期间内,它监控数据库,并记录目标对象。探测周期结束的时候,控制器从数据库中采集好内部指标,比如MySQL中从磁盘读取的页面和写到磁盘的页面(pages)的计数器。控制器会将目标对象和内部指标信息都传递给调优管理器(tuning manager)。
当OtterTune调优管理器收到这些指标后,把它们存放在资料库当中。OtterTune使用这些结果,计算下一个要部署的目标数据库的配置。调优管理器将这一配置信息传输给控制器,并告诉控制器,采纳这一配置后可能会获得的性能提升。用户可以决定是继续调优,还是结束这次优化工作。
注意
OtterTune为它支持的每个数据库版本维护着一个配置开关的黑名单。黑名单包括那些调整了不会产生效果的配置开关(比如,数据库中存放文件的路径名),或者这些开关会有严重的或者潜在不良后果(比如,可能会导致数据库丢失数据)。每场调优开始的时候,OtterTune都会给用户提供一个黑名单,所以他/她可以增加其他开关进去,如果他们希望OtterTune不要去调优这部分的话。
OtterTune作了一些假设限制,可能会限制了一些用户的可用性。比如,它假定用户有允许控制器更改数据库配置的管理权限。如果用户没有这个权限,那他或者她可以在其他硬件上部署一个数据库镜像,用于OtterTune调优实验。这就需要用户去重演(replay)一个工作负载跟踪,或者在生产数据库中转发查询。关于假定和限制的完整讨论,详见我们的论文(读者可以点击文末的“阅读原文”进行阅读)。
ML pipeline
下面的图中展示了通过OtterTune的ML pipeline,数据在移动过程中是如何处理的。所有探查数据都存放在OtterTune资料库中。
OtterTune首先将探测数据传给“工作负载表征”(Workload Characterization)组件。该组件识别一组较小的数据库指标度量,可以最佳地捕获性能上的差异性,以及不同工作负载的区别特征。
接着,开关识别组件(Knob Identification)生成一个开关的排名列表,以对数据库性能的影响度大小排序。OtterTune将所有这些信息提供给自动调优器(Automatic Tuner)组件。该组件在它的数据资料库中为目标数据库负载匹配(map)最相似的负载,并用这个负载数据生成最佳配置。
让我们把ML pipeline中的每个组件再详细说说。
工作负载表征(Workload Characterization)组件:OtterTune使用数据库内部运行时的度量指标来表征(或识别)工作负载的行为。这些度量指标提供了负载的准确表现,因为它们捕获了运行时行为的许多因素。可是,很多度量指标是冗余的,一些是相同的度量记录只是单位不同,其他的则是表现数据库不同组件,它们的值高度相关。所以裁剪冗余度量就很重要,这可以降低ML模型使用它们的时候的复杂性。为此,我们根据其相关性模型对数据库的度量指标进行了聚类。然后,我们从每个聚类中选择一个作为代表度量,就是最靠近聚类中心的那个度量。ML pipeline的后续组件直接使用这些度量。
开关识别组件(Knob Identification):数据库中可能有几百个开关,但只有一小部分会影响数据库的性能。OtterTune使用一个叫做Lasso的流行特征选择(feature-selection)技术,来确定哪些开关会很大程度上影响系统的整体性能。通过使用这一技术于资料库中的数据,OtterTune就可以列出数据库中这些开关的重要性顺序。
然后,OtterTune必须决定,做配置推荐的时候用多少个开关。使用太多必然会显著增加OtterTune的调优时间。用得太少又会妨碍OtterTune去找到最佳配置。OtterTune使用渐进化的方式自动化这一过程,在调优时它会逐渐增加开关的个数。这个方式让OtterTune在扩展到更多开关之前,探寻和优化一组最重要的开关配置。
自动调优(Automatic Tuner)组件:自动调优组件通过在每个观察周期之后执行“两步分析”(two-step analysis)来确定OtterTune应推荐的配置。
首先,系统使用工作负载表征组件中标识的度量性能数据,识别来自先前调优场景的最能匹配目标数据库负载的负载。它将当前场景的度量指标与先前场景的度量指标进行比较,以确定哪些指标与不同的开关设置类似。
然后,OtterTune会选择另一个开关设置去尝试。它适用一个统计模型,搜集数据,与资料库中最相近负载的数据一样。这个模型让OtterTune可以预测实施每个可能的配置后,数据库性能会怎样。OtterTune优化下一个配置,采用探索的方式(搜集信息以改进模型)而不是剥削的方式(试图只在目标度量上就贪婪地做好)。
实现
OtterTune用Python编写。
对工作负载表征和开关识别组件来说,运行时的性能并不特别需要考虑,因此我们用scikit-learn来实现相应的机器学习算法。这些算法以后台进程的形式运行,并使用OtterTune资料库中的新数据。
对自动优化组件来说,机器学习算法在关键路径上。他们在每一个观察周期后运行,获取新数据以便OtterTune能取得一个开关配置进行下一次尝试。因为它的性能是要特别考虑的,我们用TensorFlow来实现其算法。
搜集关于数据库硬件的数据、开关配置以及运行时的性能度量指标,我们将OLTP-Bench测评框架集成到OtterTune的控制器中。
实验设计
为了评估效果,我们使用OtterTune选择的最佳配置来比较MySQL和Postgre的性能:
我们所有的实验都是在Amazon EC2 Spot Instance上完成的。每一个实验都用了2个实例:一个作为OtterTune控制器,一个作为目标数据库部署用。我们分别使用m4.large和m3.xlarge实例类型。我们将OtterTune调优管理器和资料库部署在本地服务器上,配置是20核CPU、128G内存。我们用TPC-C负载模型,这是评估OLTP系统性能的工业标准。
评估
对实验中我们用到的每一种数据库,MySQL及Postgre,我们评估延迟和性能。下面的图展示了评估结果。第一个图表展示了第99百分位数指标的延迟数量,代表完成交易所需的“最坏情况”时间长度。第二个图展示吞吐量的结果,评估的是每秒完成的平均事务数。
MySQL评估结果:
比较由OtterTune生成的最佳配置与其他工具的“优化脚本”、RDS生成的配置,OtterTune推荐的配置对MySQL数据库大约降低了60%的延迟,提升了22%到35%的吞吐量。OtterTune生成的配置几乎与DBA做的选择一样好。
只有一些MySQL的开关会显著影响TPC-C负载的性能。由OtterTune生成的配置和DBA为每个开关提供了很好的设置。RDS干的稍微要差点,因为它为一个开关提供了不是最优的设置。“优化脚本”的配置表现最差,因为它只改了一个开关。
Postgre评估结果:
对延迟来说,OtterTUne生成的配置,与“优化脚本”、DBA、RDS差不多,相对Postgre的默认设置都获得了不少的提升。我们可以将其归因于OTLP测评工具客户端和数据库之间的网络开销。对于吞吐量,OtterTune设置相对DBA和“优化脚本”的设置得到了12%的提升,相对RDS,得到了32%的提升。
跟MySQL相似,只要少数开关显著影响Postgre的性能。OtterTune、DBA、“优化脚本”以及RDS都调整了所有这些开关,大多都提供了合理的设置。
结论
OtterTune为关系型数据库的配置开关自动化发现最佳设置,用于调优新的数据库部署,重用从先前调优场景获取的训练数据。因为OtterTune不需要为训练ML模型生成厨师数据集,所需调优时间大大减少。
译后记
OtterTune为关系型数据库的配置开关自动化发现最佳设置,用于调优。
不客气地说,OtterTune目前也只是支持MySQL和Postgre两种数据库,而且只是在开关设置层面,相比Oracle数据库在自动化管理方面的强大功力,OtterTune只能算是一个玩具。我突然想到,2004年的时候,我去贵州给某个运营商做Oracle数据库优化,只是把SGA从100M调大到1GB,客户的核心业务整体性能就得到了飞速提升。放到今天来说是个不可思议的事情,今天随便一个省级运营商的核心系统标配可能都是一个TB的内存,缺省安装的时候,工程师就会把SGA缺省配到700G,其他相关参数也会按所谓的最佳实践进行。
但是,没有开关的问题,不代表就没有数据库的性能问题。
时至今日,Oracle数据库的性能问题依然层出不穷(不是因为Oracle不行,其他数据库还在后面远远的跟着Oracle在前进呢),参数开关层面基本已经不太可能有遗漏。性能问题更多的层面来自于开发,开发部门数据模型设计得不合理,开发人员SQL写得不合理,往往导致了90%的性能问题。前两天朋友谈及的一个案例,某银行的信用卡业务查询,每天一次,表当然有几亿条记录,查询一次要花费小时计的时间,通过一个简单的rownum查询时间降低到秒级。单纯的开发人员搞不定,普通的DBA也想不到,机器学习能做这种优化么?现在不好判断。
有远虑,不是坏事。但也无需太执着于远虑,还是要把当前的事情先做好。
如果你们的开发团队老是出一些表结构设计问题、索引问题、劣质SQL问题,不妨推荐他们先来上上D+学院先开设的精品SQL优化课程。Oracle和MySQL都有,只要一天时间,可以跟业界一线DBA大师学习怎样做SQL优化,省时、省力、利人、利己。
当然,如果你连1天完整时间都抽不出来,也不用气馁,DBAplus仍然不定期将各类优化妙文推送出来,给需要精进的你。
算法 自动采集列表( 【干货】自动驾驶中的视觉感知模块(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-15 10:18
【干货】自动驾驶中的视觉感知模块(一))
1 简介
自动驾驶中的视觉感知模块通过图像或视频数据了解车辆周围环境,具体任务包括物体检测与跟踪(2D或3D物体)、语义分割(2D或3D场景)、深度估计、光流估计, ETC。
在这个文章中,我们首先介绍基于图像或视频的2D对象检测和跟踪,以及2D场景的语义分割。这些任务在自动驾驶中被广泛使用,已经有很多各种各样的评论文章,所以这里我只选择介绍一些经典算法,重点介绍上下文和方向。
自从2012年深度学习在图像分类任务上取得突破,迅速占领了图像感知的各个领域,所以下面的介绍也是基于深度学习算法。
2 目标检测2.1 两阶段检测
传统的图像目标检测算法大多是滑动窗口、特征提取和分类器的结合,如Haar特征+AdaBoost分类器、HOG特征+SVM分类器。这种方法的一个主要问题是需要为不同的目标检测任务手动设计不同的特征。因此,在深度学习兴起之前,特征设计是目标检测领域的主要增长点。
R-CNN[1]作为深度学习在目标检测领域的开创性工作,仍然有很多传统方法的影子。首先,Selective Search 替代了滑动窗口以减少窗口数量。第二个也是最重要的变化是使用卷积神经网络 (CNN) 来提取每个窗口的图像特征,而不是手工制作的特征设计。这里的CNN是在ImageNet上预训练的,对于一般图像特征的提取非常有效。最后利用SVM对每个窗口的特征进行分类,完成目标检测任务。
R-CNN的主要问题之一是选择性搜索得到的窗口数量重叠过多,导致特征提取部分有大量冗余操作,严重影响算法的运行效率(约2000个候选图片中的框,在 GPU 上运行时间也超过 10 秒)。
卷积神经网络
为了复用不同位置的特征,Fast R-CNN[2]提出先通过CNN提取图像特征,然后对选择性搜索得到的候选帧进行ROI Pooling,得到相同长度的特征向量。最后,使用全连接网络进行候选框分类和边界框回归。这样就避免了重叠候选框的冗余操作,大大提高了特征提取的效率。
与 R-CNN 相比,Fast R-CNN 在 VOC07 数据集上的 mAP 从 58.5% 提高到 70.0%,检测速度提高了约 200 倍。但是,Fast R-CNN 仍然使用选择性搜索来获取候选区域。这个过程还是比较慢的。处理一张图片大约需要2秒左右,对于实时性要求高的应用来说,这远远不够。
快速 R-CNN
既然选择性搜索是算法速度的瓶颈,那么自然而然会想到用神经网络来完成这一步是可能的吗?这个问题的答案是 Faster R-CNN [3]。它利用区域候选网络(RPN)根据特征图生成候选框。接下来的步骤和 Fast R-CNN 类似,都是 ROI Pooling 生成候选框的特征,然后使用全连接层进行分类和回归。
Faster RCNN中出现了一个重要的概念,即Anchor。特征图的每个位置都会生成不同大小和不同纵横比的anchors,作为object frame回归的参考。Anchor 的引入使得回归任务只需要处理相对较小的变化,因此网络的学习会更容易。
Faster RCNN是第一个端到端的物体检测网络,VOC07上的mAP达到73.2%,速度也达到了17FPS,接近实时。
更快的 R-CNN
随后的FPN[4](Feature Pyramid Network)在特征提取阶段进行了优化,使用类似于U-Shape网络的特征金字塔结构来提取多尺度信息,以适应不同大小的物体检测。
FPN2.2 单级检测
两阶段检测器需要处理大量的物体候选框,每个候选框通过ROI Pooling生成长度一致的特征。这个过程比较耗时,从而影响算法的整体速度。单级检测器的主要思想是使用全卷积网络在特征图的每个位置进行物体分类和边界框回归。这实际上相当于在每个位置生成一个候选框,但是由于省略了耗时的 ROI Pooling,只使用了标准的卷积操作,提高了算法的运行速度。
SSD[5]采用上述全卷积网络的思想,对多种分辨率的特征图进行物体检测,提高对物体尺度变化的适应能力。同时在特征图的每个位置使用不同尺度和纵横比的anchors进行边界回归。
在特征图的每个位置执行密集对象检测。虽然省略了ROI Pooling,但是会带来一个新的问题,就是正负样本的不平衡。密集采样导致负样本(非对象)的数量远大于正样本(对象)的数量。在训练中,大量易于分类的负样本产生的Loss占主导地位,而获得真正有价值的难分类样本。不如好好学习。
固态硬盘
为了解决这个问题,RetinaNet[6]提出了Focal Loss,它根据Loss的大小自动调整权重,而不是标准的Cross Entropy,让训练过程更加关注困难样本。在特征提取方面,RetinaNet也采用了FPN的结构。
焦点损失与交叉熵
最后不得不说一下YOLO[7]系列的检测器,这也是业界使用最广泛的算法,甚至是其中之一。YOLOv1采用卷积和Pooling相结合的方式提取特征,最终的特征图空间大小为7*7。与 SSD 和 RetinaNet 不同的是,YOLOv1 使用全连接层直接输出每个 7*7 位置的物体类别和帧,无需 Anchor 的辅助。在每个位置输出两个对象,并选择一个更有信心的对象。当场景中有很多小物体时,可能会丢失位置相似的物体,这也是YOLOv1的一大问题。
之后,YOLO 推出了四个改进版本(v2-v5),增强了特征提取网络,采用了多尺度特征图,使用 Anchor 和 IOU Loss 辅助帧回归,以及许多其他的 Tricks物体检测)。,大大提高了检测的准确率,在运行速度和部署灵活性方面依然保持了YOLO的一贯优势。
YOLO2.3 无 Anchor 检测
之前介绍的大部分方法都是使用Anchor来辅助对象框的回归。Anchor的参数需要手动设计。通常需要根据不同的检测任务设计不同的Anchor,影响算法的通用性。另外,为了覆盖任务中的所有对象,Anchor的数量会比较大,这也会对算法的速度产生一定的影响。
因此,如何避免使用 Anchor 或让网络自动学习 Anchor 参数受到越来越多的关注。此类方法一般将物体表示为一些关键点,CNN用于回归这些关键点的位置。关键点可以是对象框的中心点(CenterNet)、角点(CornerNet)或代表点(RepPoints)。
CenterNet [8] 使用多层卷积神经网络对输入图像进行处理,并将其转换为物体类别的 Heatmap,其上的 Peak 位置对应于物体的中心。中心点的特征用于边界框回归。整个网络可以完全通过卷积操作来实现,非常简洁。
作为中心点的对象
仅使用对象中心点的特征返回对象框有一定的局限性,因为中心点的特征有时不能很好地描述对象,尤其是当对象比较大的时候。CornerNet[9]通过卷积神经网络和Corner Pooling操作预测物体框的左上角和右下角,输出每个角点的特征向量,用于匹配属于同一物体的角点。
角网
无论是中心点还是角点,对象都表示为矩形框。这种表示方式虽然有利于计算,但没有考虑到物体的形状变化,而且矩形框还收录很多来自背景的特征,影响了物体识别的准确性。RepPoints [10] 提出将物体表示为一个代表点集,并通过可变形卷积适应物体的形状变化。点集最终转化为对象框,用于计算与人工标注的差异。
最后,目标检测领域的最新趋势是采用在自然语言处理(NLP)中取得巨大成功的Transformer结构。Transformer 是一个完全基于自注意力机制的深度学习网络,在大数据和预训练模型的帮助下,其性能超过了经典的递归神经网络方法。从 2020 年开始,Transformer 已应用于各种视觉任务,并取得了不错的效果。Transformer 可以提取 NLP 任务中单词的长期依赖关系(或上下文信息),这对应于图像中提取的像素的长期依赖关系(或扩展的感受野)。
DETR[11]是Transformer在目标检测领域的代表作。上面介绍的所有目标检测网络,无论是两阶段还是单段,无论是否使用 Anchor,都在图像空间进行密集检测。另一方面,DETR 将目标检测视为一个集合预测问题,直接输出稀疏目标检测结果。具体过程是先用CNN提取图像特征,再用Transformer对全局空间关系进行建模。最终输出通过二分图匹配算法与人工标注相匹配。DETR 通常需要更长的训练收敛时间。由于感受野的扩大,对大物体的检测效果更好,而对小物体的检测效果相对较差。
DETR2.4 性能对比
让我们比较一下上面描述的一些算法。准确率是通过 MS COCO 数据库上的 mAP 来衡量的,速度是通过 FPS 来衡量的。从下表的对比可以看出,YOLOv4无论是准确率还是速度都表现不错,是目前业界使用最广泛的模型。最新的DETR模型也有很好的准确率,未来应该会有更多的改进工作。这里需要说的是,由于在网络的结构设计上有很多不同的选择(比如不同的输入大小,不同的Backbone网络等),所以每种算法实现的硬件平台也不同,所以精度和速度不完全可比。,这里只列出一个粗略的结果供大家参考。
3 对象跟踪
在自动驾驶应用中,输入是视频数据,需要注意的物体很多,比如车辆、行人、自行车等。因此,这是一个典型的多目标跟踪任务(MOT)。对于MOT任务,目前最流行的框架是Tracking-by-Detection,其流程如下:
对象检测器在单帧图像上获得对象帧输出。
提取每个检测到的对象的特征,通常包括视觉特征和运动特征。
根据特征计算来自相邻帧的目标检测之间的相似度,以判断它们来自同一目标的概率。
来自相邻帧的对象检测被匹配,来自同一目标的对象被分配相同的 ID。
Tracking-by-Detection方法流程[12]
深度学习应用于上述所有四个步骤,但前两个步骤占主导地位。
第一步,深度学习的应用主要在于提供高质量的物体检测器。理论上,所有的物体检测器都可以用来提供检测框,但是由于检测的质量对于Tracking-by-Detection方法来说非常重要,所以一般会选择精度更高的方法,比如Faster R-CNN。SORT[13] 是这个方向的早期作品之一。作者使用 Faster R-CNN 代替 ACF 目标检测器,在 MOT15 数据库上将目标跟踪准确率指标(MOTA)的绝对值提高了 18.9%。SORT使用卡尔曼滤波来预测物体的运动(得到运动特征),使用匈牙利算法计算物体匹配。
第二步,深度学习的应用主要在于使用CNN提取物体的视觉特征。SORT 算法随后使用 CNN 进行特征提取,这种扩展算法称为 DeepSORT [14]。
DeepSORT 中的视觉特征提取网络
深度学习在第 3 步和第 4 步中使用较少。比较典型的方法之一是 Milan 等人提出的端到端对象跟踪算法。[15]。该算法采用RNN网络模拟贝叶斯滤波器完成主要检测工作,包括运动预测模块、状态更新模块和轨迹管理模块。状态更新模块可以完成对象匹配(Association)的工作,关联向量由一个LSTM提供。这种方法的跟踪效果不是很好,但是由于特征简单,速度可以达到165FPS(不包括物体检测模块)。
Milan等人提出的端到端目标跟踪网络。
除了Tracking-by-Detection,还有一个框架叫做Simultaneous Detection and Tracking,就是同时检测和跟踪。CenterTrack [16] 是该方向的代表性方法之一。CenterTrack 源自前面介绍的单段 Anchor-free 目标检测算法 CenterNet。与CenterNet相比,CenterTrack增加了前一帧的RGB图像和物体中心Heatmap作为附加输入,并为前一帧的Association增加了一个Offset分支。与之前介绍的多阶段 Tracking-by-Detection 策略相比,CenterTrack 以单个网络实现检测和匹配阶段,提高了 MOT 系统的速度。
CenterTrack4 语义分割
深度学习最早在语义分割中的应用比较简单,即对固定大小的图像块进行语义分类。这里对图像块进行分类的网络实际上是一些全连接层,所以块的大小需要固定。显然,这种简单粗暴的方式并不是最优的,尤其是不能有效利用空间上下文信息,这对于语义分割非常重要。
为了更好地提取上下文信息,神经网络需要更大的感受野。全卷积网络(FCN)[17]通过堆叠多个卷积层和下采样层不断扩展感受野并提取高层空间上下文特征,最终的特征图在反卷积上采样后恢复到原创图像每个位置的分辨率对应位置的语义分类。虽然下采样操作有利于上下文特征提取,减少计算量,但也存在一个问题,即空间细节信息的丢失,会影响最终语义分割结果在位置上的分辨率和正确性.
FCN
U-Net [18] 采用了类似的编码器-解码器结构,但在相同分辨率的特征图之间增加了 Skip 连接。这样做的好处是可以同时保留高级上下文特征和低级详细特征,让网络通过学习自动平衡上下文和详细信息的权重。
网络
在语义分割中,上下文信息和细节信息都很重要。FCN 只关注上下文信息,而 U-Net 通过层间的 Skip 连接保留了这两种信息。语义分割领域的大部分后续工作都致力于更好地保留这两种信息。
Dilated/Atrous Convolution 修改标准卷积操作的卷积核以覆盖更大的空间位置。Atrous 卷积可以用来代替下采样。一方面可以保持空间分辨率,另一方面可以在不增加计算量的情况下扩大感受野,从而更好地提取空间上下文信息。
扩张卷积
DeepLab [18] 系列方法使用扩张卷积和 ASPP(Atrous Spatial Pyramid Pooling)结构对输入图像进行多尺度缩放。最后,利用传统语义分割方法中常用的条件随机场(CRF)对分割结果进行优化。CRF 作为后处理步骤单独训练。
深度实验室
最后介绍的方法是使用大卷积核。这是增加感受野的一种自然方式,如果步幅不变,卷积结果的空间分辨率不会受到影响。但是,大的卷积核会显着增加计算量,这就是为什么要使用 atrous 卷积。Large Kernel Matters[19] 这个文章提出将二维大卷积核(KxK)分解成两个一维卷积核(1xK和Kx1),二维卷积核的结果被建模为两个 1D 卷积结果的总和。这样做将计算量从 O(KxK) 减少到 O(K)。
一个 2D 卷积被分解为两个 1D 卷积
参考文献 [1] Girshick et al., Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation, 2014.
[2] Girshick,快速 R-CNN,2015.
[3] Ren 等人,Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks,2016.
[4] Lin 等人,用于对象检测的特征金字塔网络,2017.
[5] Liu 等人,SSD:Single Shot MultiBox Detector,2015.
[6] Lin et al., Focal Loss for Dense Object Detection, 2017.
[7] Redmon 等人,你只看一次:统一的实时对象检测,2015.
[8] Zhou et al., Objects as Points, 2019.
[9] Law 和 Deng,CornerNet:将对象检测为配对关键点,2019.
[10] Yang et al., RepPoints: Point Set Representation for Object Detection, 2019.
[11] Carion et al., End-to-End Object Detection with Transformers, 2020.
[12] Ciaparrone 等人,视频多对象跟踪中的深度学习:调查,2019.
[13] Bewley 等人,简单的在线和实时跟踪,2016.
[14] Wojke et al., Simple Online and Realtime Tracking with A Deep Association Metric, 2017.
[15] Milan et al., Online Multi-Target Tracking using Recurrent Neural Networks, 2017.
[16] Zhou et al., Tracking Objects as Points, 2020.
[17] Long 等人,用于语义分割的全卷积网络,2014.
[18] Chen et al., DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, andfully Connected CRFs, 2017.
[19] Peng et al.,Large Kernel Matters ——通过全局卷积网络改进语义分割,2017. 查看全部
算法 自动采集列表(
【干货】自动驾驶中的视觉感知模块(一))

1 简介
自动驾驶中的视觉感知模块通过图像或视频数据了解车辆周围环境,具体任务包括物体检测与跟踪(2D或3D物体)、语义分割(2D或3D场景)、深度估计、光流估计, ETC。
在这个文章中,我们首先介绍基于图像或视频的2D对象检测和跟踪,以及2D场景的语义分割。这些任务在自动驾驶中被广泛使用,已经有很多各种各样的评论文章,所以这里我只选择介绍一些经典算法,重点介绍上下文和方向。
自从2012年深度学习在图像分类任务上取得突破,迅速占领了图像感知的各个领域,所以下面的介绍也是基于深度学习算法。
2 目标检测2.1 两阶段检测
传统的图像目标检测算法大多是滑动窗口、特征提取和分类器的结合,如Haar特征+AdaBoost分类器、HOG特征+SVM分类器。这种方法的一个主要问题是需要为不同的目标检测任务手动设计不同的特征。因此,在深度学习兴起之前,特征设计是目标检测领域的主要增长点。
R-CNN[1]作为深度学习在目标检测领域的开创性工作,仍然有很多传统方法的影子。首先,Selective Search 替代了滑动窗口以减少窗口数量。第二个也是最重要的变化是使用卷积神经网络 (CNN) 来提取每个窗口的图像特征,而不是手工制作的特征设计。这里的CNN是在ImageNet上预训练的,对于一般图像特征的提取非常有效。最后利用SVM对每个窗口的特征进行分类,完成目标检测任务。
R-CNN的主要问题之一是选择性搜索得到的窗口数量重叠过多,导致特征提取部分有大量冗余操作,严重影响算法的运行效率(约2000个候选图片中的框,在 GPU 上运行时间也超过 10 秒)。

卷积神经网络
为了复用不同位置的特征,Fast R-CNN[2]提出先通过CNN提取图像特征,然后对选择性搜索得到的候选帧进行ROI Pooling,得到相同长度的特征向量。最后,使用全连接网络进行候选框分类和边界框回归。这样就避免了重叠候选框的冗余操作,大大提高了特征提取的效率。
与 R-CNN 相比,Fast R-CNN 在 VOC07 数据集上的 mAP 从 58.5% 提高到 70.0%,检测速度提高了约 200 倍。但是,Fast R-CNN 仍然使用选择性搜索来获取候选区域。这个过程还是比较慢的。处理一张图片大约需要2秒左右,对于实时性要求高的应用来说,这远远不够。

快速 R-CNN
既然选择性搜索是算法速度的瓶颈,那么自然而然会想到用神经网络来完成这一步是可能的吗?这个问题的答案是 Faster R-CNN [3]。它利用区域候选网络(RPN)根据特征图生成候选框。接下来的步骤和 Fast R-CNN 类似,都是 ROI Pooling 生成候选框的特征,然后使用全连接层进行分类和回归。
Faster RCNN中出现了一个重要的概念,即Anchor。特征图的每个位置都会生成不同大小和不同纵横比的anchors,作为object frame回归的参考。Anchor 的引入使得回归任务只需要处理相对较小的变化,因此网络的学习会更容易。
Faster RCNN是第一个端到端的物体检测网络,VOC07上的mAP达到73.2%,速度也达到了17FPS,接近实时。

更快的 R-CNN
随后的FPN[4](Feature Pyramid Network)在特征提取阶段进行了优化,使用类似于U-Shape网络的特征金字塔结构来提取多尺度信息,以适应不同大小的物体检测。

FPN2.2 单级检测
两阶段检测器需要处理大量的物体候选框,每个候选框通过ROI Pooling生成长度一致的特征。这个过程比较耗时,从而影响算法的整体速度。单级检测器的主要思想是使用全卷积网络在特征图的每个位置进行物体分类和边界框回归。这实际上相当于在每个位置生成一个候选框,但是由于省略了耗时的 ROI Pooling,只使用了标准的卷积操作,提高了算法的运行速度。
SSD[5]采用上述全卷积网络的思想,对多种分辨率的特征图进行物体检测,提高对物体尺度变化的适应能力。同时在特征图的每个位置使用不同尺度和纵横比的anchors进行边界回归。
在特征图的每个位置执行密集对象检测。虽然省略了ROI Pooling,但是会带来一个新的问题,就是正负样本的不平衡。密集采样导致负样本(非对象)的数量远大于正样本(对象)的数量。在训练中,大量易于分类的负样本产生的Loss占主导地位,而获得真正有价值的难分类样本。不如好好学习。

固态硬盘
为了解决这个问题,RetinaNet[6]提出了Focal Loss,它根据Loss的大小自动调整权重,而不是标准的Cross Entropy,让训练过程更加关注困难样本。在特征提取方面,RetinaNet也采用了FPN的结构。

焦点损失与交叉熵
最后不得不说一下YOLO[7]系列的检测器,这也是业界使用最广泛的算法,甚至是其中之一。YOLOv1采用卷积和Pooling相结合的方式提取特征,最终的特征图空间大小为7*7。与 SSD 和 RetinaNet 不同的是,YOLOv1 使用全连接层直接输出每个 7*7 位置的物体类别和帧,无需 Anchor 的辅助。在每个位置输出两个对象,并选择一个更有信心的对象。当场景中有很多小物体时,可能会丢失位置相似的物体,这也是YOLOv1的一大问题。
之后,YOLO 推出了四个改进版本(v2-v5),增强了特征提取网络,采用了多尺度特征图,使用 Anchor 和 IOU Loss 辅助帧回归,以及许多其他的 Tricks物体检测)。,大大提高了检测的准确率,在运行速度和部署灵活性方面依然保持了YOLO的一贯优势。

YOLO2.3 无 Anchor 检测
之前介绍的大部分方法都是使用Anchor来辅助对象框的回归。Anchor的参数需要手动设计。通常需要根据不同的检测任务设计不同的Anchor,影响算法的通用性。另外,为了覆盖任务中的所有对象,Anchor的数量会比较大,这也会对算法的速度产生一定的影响。
因此,如何避免使用 Anchor 或让网络自动学习 Anchor 参数受到越来越多的关注。此类方法一般将物体表示为一些关键点,CNN用于回归这些关键点的位置。关键点可以是对象框的中心点(CenterNet)、角点(CornerNet)或代表点(RepPoints)。
CenterNet [8] 使用多层卷积神经网络对输入图像进行处理,并将其转换为物体类别的 Heatmap,其上的 Peak 位置对应于物体的中心。中心点的特征用于边界框回归。整个网络可以完全通过卷积操作来实现,非常简洁。

作为中心点的对象
仅使用对象中心点的特征返回对象框有一定的局限性,因为中心点的特征有时不能很好地描述对象,尤其是当对象比较大的时候。CornerNet[9]通过卷积神经网络和Corner Pooling操作预测物体框的左上角和右下角,输出每个角点的特征向量,用于匹配属于同一物体的角点。

角网
无论是中心点还是角点,对象都表示为矩形框。这种表示方式虽然有利于计算,但没有考虑到物体的形状变化,而且矩形框还收录很多来自背景的特征,影响了物体识别的准确性。RepPoints [10] 提出将物体表示为一个代表点集,并通过可变形卷积适应物体的形状变化。点集最终转化为对象框,用于计算与人工标注的差异。

最后,目标检测领域的最新趋势是采用在自然语言处理(NLP)中取得巨大成功的Transformer结构。Transformer 是一个完全基于自注意力机制的深度学习网络,在大数据和预训练模型的帮助下,其性能超过了经典的递归神经网络方法。从 2020 年开始,Transformer 已应用于各种视觉任务,并取得了不错的效果。Transformer 可以提取 NLP 任务中单词的长期依赖关系(或上下文信息),这对应于图像中提取的像素的长期依赖关系(或扩展的感受野)。
DETR[11]是Transformer在目标检测领域的代表作。上面介绍的所有目标检测网络,无论是两阶段还是单段,无论是否使用 Anchor,都在图像空间进行密集检测。另一方面,DETR 将目标检测视为一个集合预测问题,直接输出稀疏目标检测结果。具体过程是先用CNN提取图像特征,再用Transformer对全局空间关系进行建模。最终输出通过二分图匹配算法与人工标注相匹配。DETR 通常需要更长的训练收敛时间。由于感受野的扩大,对大物体的检测效果更好,而对小物体的检测效果相对较差。

DETR2.4 性能对比
让我们比较一下上面描述的一些算法。准确率是通过 MS COCO 数据库上的 mAP 来衡量的,速度是通过 FPS 来衡量的。从下表的对比可以看出,YOLOv4无论是准确率还是速度都表现不错,是目前业界使用最广泛的模型。最新的DETR模型也有很好的准确率,未来应该会有更多的改进工作。这里需要说的是,由于在网络的结构设计上有很多不同的选择(比如不同的输入大小,不同的Backbone网络等),所以每种算法实现的硬件平台也不同,所以精度和速度不完全可比。,这里只列出一个粗略的结果供大家参考。

3 对象跟踪
在自动驾驶应用中,输入是视频数据,需要注意的物体很多,比如车辆、行人、自行车等。因此,这是一个典型的多目标跟踪任务(MOT)。对于MOT任务,目前最流行的框架是Tracking-by-Detection,其流程如下:
对象检测器在单帧图像上获得对象帧输出。
提取每个检测到的对象的特征,通常包括视觉特征和运动特征。
根据特征计算来自相邻帧的目标检测之间的相似度,以判断它们来自同一目标的概率。
来自相邻帧的对象检测被匹配,来自同一目标的对象被分配相同的 ID。

Tracking-by-Detection方法流程[12]
深度学习应用于上述所有四个步骤,但前两个步骤占主导地位。
第一步,深度学习的应用主要在于提供高质量的物体检测器。理论上,所有的物体检测器都可以用来提供检测框,但是由于检测的质量对于Tracking-by-Detection方法来说非常重要,所以一般会选择精度更高的方法,比如Faster R-CNN。SORT[13] 是这个方向的早期作品之一。作者使用 Faster R-CNN 代替 ACF 目标检测器,在 MOT15 数据库上将目标跟踪准确率指标(MOTA)的绝对值提高了 18.9%。SORT使用卡尔曼滤波来预测物体的运动(得到运动特征),使用匈牙利算法计算物体匹配。
第二步,深度学习的应用主要在于使用CNN提取物体的视觉特征。SORT 算法随后使用 CNN 进行特征提取,这种扩展算法称为 DeepSORT [14]。

DeepSORT 中的视觉特征提取网络
深度学习在第 3 步和第 4 步中使用较少。比较典型的方法之一是 Milan 等人提出的端到端对象跟踪算法。[15]。该算法采用RNN网络模拟贝叶斯滤波器完成主要检测工作,包括运动预测模块、状态更新模块和轨迹管理模块。状态更新模块可以完成对象匹配(Association)的工作,关联向量由一个LSTM提供。这种方法的跟踪效果不是很好,但是由于特征简单,速度可以达到165FPS(不包括物体检测模块)。

Milan等人提出的端到端目标跟踪网络。
除了Tracking-by-Detection,还有一个框架叫做Simultaneous Detection and Tracking,就是同时检测和跟踪。CenterTrack [16] 是该方向的代表性方法之一。CenterTrack 源自前面介绍的单段 Anchor-free 目标检测算法 CenterNet。与CenterNet相比,CenterTrack增加了前一帧的RGB图像和物体中心Heatmap作为附加输入,并为前一帧的Association增加了一个Offset分支。与之前介绍的多阶段 Tracking-by-Detection 策略相比,CenterTrack 以单个网络实现检测和匹配阶段,提高了 MOT 系统的速度。

CenterTrack4 语义分割
深度学习最早在语义分割中的应用比较简单,即对固定大小的图像块进行语义分类。这里对图像块进行分类的网络实际上是一些全连接层,所以块的大小需要固定。显然,这种简单粗暴的方式并不是最优的,尤其是不能有效利用空间上下文信息,这对于语义分割非常重要。
为了更好地提取上下文信息,神经网络需要更大的感受野。全卷积网络(FCN)[17]通过堆叠多个卷积层和下采样层不断扩展感受野并提取高层空间上下文特征,最终的特征图在反卷积上采样后恢复到原创图像每个位置的分辨率对应位置的语义分类。虽然下采样操作有利于上下文特征提取,减少计算量,但也存在一个问题,即空间细节信息的丢失,会影响最终语义分割结果在位置上的分辨率和正确性.

FCN
U-Net [18] 采用了类似的编码器-解码器结构,但在相同分辨率的特征图之间增加了 Skip 连接。这样做的好处是可以同时保留高级上下文特征和低级详细特征,让网络通过学习自动平衡上下文和详细信息的权重。

网络
在语义分割中,上下文信息和细节信息都很重要。FCN 只关注上下文信息,而 U-Net 通过层间的 Skip 连接保留了这两种信息。语义分割领域的大部分后续工作都致力于更好地保留这两种信息。
Dilated/Atrous Convolution 修改标准卷积操作的卷积核以覆盖更大的空间位置。Atrous 卷积可以用来代替下采样。一方面可以保持空间分辨率,另一方面可以在不增加计算量的情况下扩大感受野,从而更好地提取空间上下文信息。

扩张卷积
DeepLab [18] 系列方法使用扩张卷积和 ASPP(Atrous Spatial Pyramid Pooling)结构对输入图像进行多尺度缩放。最后,利用传统语义分割方法中常用的条件随机场(CRF)对分割结果进行优化。CRF 作为后处理步骤单独训练。

深度实验室
最后介绍的方法是使用大卷积核。这是增加感受野的一种自然方式,如果步幅不变,卷积结果的空间分辨率不会受到影响。但是,大的卷积核会显着增加计算量,这就是为什么要使用 atrous 卷积。Large Kernel Matters[19] 这个文章提出将二维大卷积核(KxK)分解成两个一维卷积核(1xK和Kx1),二维卷积核的结果被建模为两个 1D 卷积结果的总和。这样做将计算量从 O(KxK) 减少到 O(K)。

一个 2D 卷积被分解为两个 1D 卷积
参考文献 [1] Girshick et al., Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation, 2014.
[2] Girshick,快速 R-CNN,2015.
[3] Ren 等人,Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks,2016.
[4] Lin 等人,用于对象检测的特征金字塔网络,2017.
[5] Liu 等人,SSD:Single Shot MultiBox Detector,2015.
[6] Lin et al., Focal Loss for Dense Object Detection, 2017.
[7] Redmon 等人,你只看一次:统一的实时对象检测,2015.
[8] Zhou et al., Objects as Points, 2019.
[9] Law 和 Deng,CornerNet:将对象检测为配对关键点,2019.
[10] Yang et al., RepPoints: Point Set Representation for Object Detection, 2019.
[11] Carion et al., End-to-End Object Detection with Transformers, 2020.
[12] Ciaparrone 等人,视频多对象跟踪中的深度学习:调查,2019.
[13] Bewley 等人,简单的在线和实时跟踪,2016.
[14] Wojke et al., Simple Online and Realtime Tracking with A Deep Association Metric, 2017.
[15] Milan et al., Online Multi-Target Tracking using Recurrent Neural Networks, 2017.
[16] Zhou et al., Tracking Objects as Points, 2020.
[17] Long 等人,用于语义分割的全卷积网络,2014.
[18] Chen et al., DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, andfully Connected CRFs, 2017.
[19] Peng et al.,Large Kernel Matters ——通过全局卷积网络改进语义分割,2017.
算法 自动采集列表(网站发布飓风算法的类型有哪些?如何正确使用?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-14 05:10
概括
飓风算法是百度搜索推出的以不良采集为主要内容来源的网站的搜索引擎算法。类型3:采集痕迹明显,详细描述:本站有大量从其他网站或公众号转来的内容采集,信息不整合,布局杂乱,部分功能缺失或文章可读性差,有明显采集标记,用户阅读体验很差。建议:网站发布的内容,要注意文章的排版和排版,不能有与文章主题无关的信息或无法使用的功能@>,可能会干扰用户的浏览。不出现字体大小,
飓风算法是百度搜索推出的以不良采集为主要内容来源的网站的搜索引擎算法。
类型 3:采集清除标记
详细描述:本站有大量从其他网站或公众号采集转来的内容,信息未整合,版面混乱,部分功能缺失或文章可读性差,有有明显的采集痕迹,用户的阅读体验很差。
建议:网站发布的内容,要注意文章的排版和排版,不能有与文章主题无关的信息或无法使用的功能@>,可能会干扰用户的浏览。不要有不同的字号和字号,注意标点符号的大小写,以及文章的段落分类和强调。百度会对可以自产原创内容的网站更加友好,可以加快网站的排名。
类型 4:黑帽 SEO
详细说明:一些灰色地带的黑帽SEO也利用一些工具,自动生成乱七八糟的文章,并在里面插入关键词,从而欺骗搜索引擎,达到快速排序的目的。
建议:停止使用黑帽SEO,写文章,好好优化网站SEO。做 网站 不是一天的工作。快速赚钱的方式永远不会那么稳定。要想把网站做好,还是需要使用形式化的优化方法。
类型五:内容拼接
详细说明:采集不同文章的多篇文章拼接在一起,整体内容没有形成完整的逻辑,存在看不懂、文章不连贯等问题。 ,不能满足用户的需求。
建议:内容拼接是采集内容的高级版,一般由人工操作,但百度官方反对使用采集编辑器等工具随意制作拼接采集@ > 内容行为,请网站制作大量对用户有价值的原创内容。
我们在使用内容拼接的时候,不要随意拼装,更要注意质量。网站内容的价值在于用户能否阅读网站中的内容来解决自己的问题。如果用户搜索与标题不匹配的问题,那么这样的网站排名不会很好。, 很可能会被算法击中。网站不要弄乱布局。如果影响了用户的阅读体验,对搜索引擎是不友好的。
飓风算法旨在保障搜索用户的浏览体验,保障搜索生态的健康发展。对于违规网站,百度搜索将根据问题的严重程度限制对搜索呈现的处理。
如果你的网站内容做好了,我想不管“飓风算法”怎么升级,对你都没有影响。
首次违规的网站,改正后解除限制的期限为1个月;
我们不会发布第二次犯罪的网站。
请各位站长尽快按照上述说明进行自查整改,清理所有非法采集内容。 查看全部
算法 自动采集列表(网站发布飓风算法的类型有哪些?如何正确使用?)
概括
飓风算法是百度搜索推出的以不良采集为主要内容来源的网站的搜索引擎算法。类型3:采集痕迹明显,详细描述:本站有大量从其他网站或公众号转来的内容采集,信息不整合,布局杂乱,部分功能缺失或文章可读性差,有明显采集标记,用户阅读体验很差。建议:网站发布的内容,要注意文章的排版和排版,不能有与文章主题无关的信息或无法使用的功能@>,可能会干扰用户的浏览。不出现字体大小,
飓风算法是百度搜索推出的以不良采集为主要内容来源的网站的搜索引擎算法。
类型 3:采集清除标记
详细描述:本站有大量从其他网站或公众号采集转来的内容,信息未整合,版面混乱,部分功能缺失或文章可读性差,有有明显的采集痕迹,用户的阅读体验很差。
建议:网站发布的内容,要注意文章的排版和排版,不能有与文章主题无关的信息或无法使用的功能@>,可能会干扰用户的浏览。不要有不同的字号和字号,注意标点符号的大小写,以及文章的段落分类和强调。百度会对可以自产原创内容的网站更加友好,可以加快网站的排名。
类型 4:黑帽 SEO
详细说明:一些灰色地带的黑帽SEO也利用一些工具,自动生成乱七八糟的文章,并在里面插入关键词,从而欺骗搜索引擎,达到快速排序的目的。
建议:停止使用黑帽SEO,写文章,好好优化网站SEO。做 网站 不是一天的工作。快速赚钱的方式永远不会那么稳定。要想把网站做好,还是需要使用形式化的优化方法。
类型五:内容拼接
详细说明:采集不同文章的多篇文章拼接在一起,整体内容没有形成完整的逻辑,存在看不懂、文章不连贯等问题。 ,不能满足用户的需求。
建议:内容拼接是采集内容的高级版,一般由人工操作,但百度官方反对使用采集编辑器等工具随意制作拼接采集@ > 内容行为,请网站制作大量对用户有价值的原创内容。
我们在使用内容拼接的时候,不要随意拼装,更要注意质量。网站内容的价值在于用户能否阅读网站中的内容来解决自己的问题。如果用户搜索与标题不匹配的问题,那么这样的网站排名不会很好。, 很可能会被算法击中。网站不要弄乱布局。如果影响了用户的阅读体验,对搜索引擎是不友好的。
飓风算法旨在保障搜索用户的浏览体验,保障搜索生态的健康发展。对于违规网站,百度搜索将根据问题的严重程度限制对搜索呈现的处理。
如果你的网站内容做好了,我想不管“飓风算法”怎么升级,对你都没有影响。
首次违规的网站,改正后解除限制的期限为1个月;
我们不会发布第二次犯罪的网站。
请各位站长尽快按照上述说明进行自查整改,清理所有非法采集内容。
算法 自动采集列表(网站内容对SEO优化的影响及优化方法有哪些? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-07 08:28
)
通过 Pbootcms采集 填充内容,根据 关键词采集文章。(Pbootcms采集 插件也配置了关键词采集 功能和无关词阻塞功能)。网站内容对SEO优化和优化方法的影响。如果您的 网站 内容是正确的,那么您就为您的 网站SEO 打下了坚实的基础。pbootcms采集直接监听released,pending release,是否是伪原创,发布状态,URL,程序,发布时间等,正确的内容是什么?在搜索引擎眼中,好的网页内容应该符合五个方面的标准:1、内容质量;2、内容研究(关键词研究);3、文本/关键词在内容; 4、 内容的吸引力;5、内容的新鲜度;让我们看看这 5 个因素具体指的是什么。
网站内容质量 内容的质量。在制作任何内容之前要问自己的第一个问题是:我的内容质量好吗?例如,我的网络内容是否优于业内其他人的内容?还是只是重复别人的东西?
pbootcms采集 设置批量发布数量(可以设置发布间隔/每天发布的总数)。您是否让访问者有理由希望多停留几秒钟来浏览您的网页内容?您是否为访问者提供了他们认为独特且与众不同、有用且在其他任何地方都找不到的真正价值?
pbootcms采集内容与标题一致(使内容与标题一致)。如果好的内容是您的 SEO 策略中最重要的部分,那么 Pbootcms采集 提供优质内容,尤其是关键字研究,可能是第二重要的部分。因为关键字研究可以帮助您发现访问者通过搜索引擎找到您的内容的各种途径。pbootcms采集批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, Pbootcms、云游cms、人人展cms、小旋风、站群、PB、Apple、搜外等各大cms,可以批量的工具同时管理和发布)。
进行关键字研究后,您可以根据相关关键字(访问者在引擎中搜索的字词)定制内容。通过关键字研究产生的内容更容易被搜索引擎找到,针对性强,并有效地为访问者提供他们需要的信息。
pbootcms采集支持几十万种不同的cms网站实现统一管理。一个人维护数百个 网站文章 更新也不是问题。例如,如果有人搜索“如何治疗脂肪肝”,而您的内容标题是“如何治疗 NAFLD”。pbootcms采集随机插入图片(文章没有图片可以随机插入相关图片)。
那么搜索引擎引擎可能会认为您的内容与该搜索引擎关键字无关并跳过它,因此您的内容排名不会很好。
pbootcms采集可以通过软件直接查看每日蜘蛛、收录、网站权重。因此,关键字研究可以确保您的内容与普通人正在搜索的内容相关。这可以大大提高您的网页排名。
pbootcms采集随机点赞-随机阅读-随机作者(提高页面度数原创)。关键字研究内容的文本/关键字用法。完成关键字研究后,您可以将相关文本/关键字适当地应用于您的内容。而如果你已经做了很多高质量的内容,但是还没有做关键词研究,那没关系,你现在就可以做,然后在你现有的内容中添加相关的关键词。
这个Pbootcms采集插件还配备了很多SEO功能,不仅可以通过WordPress插件实现采集伪原创发布,还有很多SEO功能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。进行关键字研究的主要目的是使您的网络内容更容易找到。因此,最好在您的文案内容中收录具有一定搜索引擎量的关键字。
pbootcms采集搜索引擎推送(文章发布成功后主动向搜索引擎推送文章,保证新链接能被搜索引擎及时发布收录@ >) 。至于关键字应该在文章的内容中出现多少次,并没有绝对的准则。最好的方式是运用你的常识,选择你认为最符合文章内容的关键词,用最自然的方式呈现出来,让搜索引擎理解,让读者感受光滑的。
pbootcms采集自动过滤其他网站促销信息/支持其他网站信息替换。内容吸引力。如果你的内容足够好,读者自然会被吸引并与之互动。如何判断内容的吸引力?搜索引擎有自己的一套方法。
pbootcms采集标题前缀和后缀设置(标题区分更好收录)。例如,有人在 Internet 上搜索某个关键字,然后找到您的网页。点击后“弹出”,返回原来的搜索引擎结果页面。pbootcms采集 自动内链(在执行发布任务时自动在文章的内容中生成内链,有助于引导页面蜘蛛抓取,提高页面权重)。然后尝试另一个页面。这种立即的“弹出”动作是向搜索引擎发出的信号,表明您的内容可能不够吸引人。这也是搜索引擎考虑的一项措施。
如果访问者没有立即“弹出”,他们是否会在您的 网站 上停留相对较长的时间?这个“网站停留时间”是搜索引擎可以衡量的另一个指标。pbootcms采集定时发布(定时发布网站内容可以让搜索引擎养成定时爬取网页的习惯,从而提高网站的收录) . 除此之外,在 Facebook 等社区 网站 上收到的“点赞”数量是衡量吸引力的另一个指标。我们将在本指南的“社区因素”部分详细介绍。
Pbootcms采集 支持其他平台的图像本地化或存储。事实上,搜索引擎公司对于他们是否真的使用“内容吸引力”指标非常模糊,更不用说那些指标了;pbootcms采集自动批处理挂机后采集伪原创会自动发布推送到搜索引擎。但 SEO 专家普遍认为,内容的吸引力确实是以不同方式衡量的因素之一。但无论如何,SEO的成功与内容的质量高度相关。
pbootcms采集支持多种采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容) . 内容新鲜并不意味着您每天都向 网站 添加新的 文章 或 Web 内容。对于搜索引擎来说,“新鲜度”是指你有没有内容,与某个关键词的搜索量激增有关。pbootcms采集content关键词插入(合理增加关键词的密度)。在这种情况下,搜索引擎会查询与主题相关的内容,然后将相关页面推送到排名靠前的位置。
pbootcms采集不同关键词文章可以设置发布不同的列。如果您的网站与电子产品有关,明天苹果将推出最新产品时,您在这个时候PO了相关的文章报告,那么您的这个网页很可能排名很好。pbootcms采集伪原创保留字(文章原创时伪原创不设置核心字)。您的页面可能会在接下来的一两周内获得高排名,然后随着新鲜度的消逝而消失。今天关于PBootcms采集的讲解就到这里,下期会分享更多SEO相关知识。下次见。
查看全部
算法 自动采集列表(网站内容对SEO优化的影响及优化方法有哪些?
)
通过 Pbootcms采集 填充内容,根据 关键词采集文章。(Pbootcms采集 插件也配置了关键词采集 功能和无关词阻塞功能)。网站内容对SEO优化和优化方法的影响。如果您的 网站 内容是正确的,那么您就为您的 网站SEO 打下了坚实的基础。pbootcms采集直接监听released,pending release,是否是伪原创,发布状态,URL,程序,发布时间等,正确的内容是什么?在搜索引擎眼中,好的网页内容应该符合五个方面的标准:1、内容质量;2、内容研究(关键词研究);3、文本/关键词在内容; 4、 内容的吸引力;5、内容的新鲜度;让我们看看这 5 个因素具体指的是什么。

网站内容质量 内容的质量。在制作任何内容之前要问自己的第一个问题是:我的内容质量好吗?例如,我的网络内容是否优于业内其他人的内容?还是只是重复别人的东西?
pbootcms采集 设置批量发布数量(可以设置发布间隔/每天发布的总数)。您是否让访问者有理由希望多停留几秒钟来浏览您的网页内容?您是否为访问者提供了他们认为独特且与众不同、有用且在其他任何地方都找不到的真正价值?
pbootcms采集内容与标题一致(使内容与标题一致)。如果好的内容是您的 SEO 策略中最重要的部分,那么 Pbootcms采集 提供优质内容,尤其是关键字研究,可能是第二重要的部分。因为关键字研究可以帮助您发现访问者通过搜索引擎找到您的内容的各种途径。pbootcms采集批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, Pbootcms、云游cms、人人展cms、小旋风、站群、PB、Apple、搜外等各大cms,可以批量的工具同时管理和发布)。
进行关键字研究后,您可以根据相关关键字(访问者在引擎中搜索的字词)定制内容。通过关键字研究产生的内容更容易被搜索引擎找到,针对性强,并有效地为访问者提供他们需要的信息。
pbootcms采集支持几十万种不同的cms网站实现统一管理。一个人维护数百个 网站文章 更新也不是问题。例如,如果有人搜索“如何治疗脂肪肝”,而您的内容标题是“如何治疗 NAFLD”。pbootcms采集随机插入图片(文章没有图片可以随机插入相关图片)。
那么搜索引擎引擎可能会认为您的内容与该搜索引擎关键字无关并跳过它,因此您的内容排名不会很好。
pbootcms采集可以通过软件直接查看每日蜘蛛、收录、网站权重。因此,关键字研究可以确保您的内容与普通人正在搜索的内容相关。这可以大大提高您的网页排名。
pbootcms采集随机点赞-随机阅读-随机作者(提高页面度数原创)。关键字研究内容的文本/关键字用法。完成关键字研究后,您可以将相关文本/关键字适当地应用于您的内容。而如果你已经做了很多高质量的内容,但是还没有做关键词研究,那没关系,你现在就可以做,然后在你现有的内容中添加相关的关键词。
这个Pbootcms采集插件还配备了很多SEO功能,不仅可以通过WordPress插件实现采集伪原创发布,还有很多SEO功能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。进行关键字研究的主要目的是使您的网络内容更容易找到。因此,最好在您的文案内容中收录具有一定搜索引擎量的关键字。
pbootcms采集搜索引擎推送(文章发布成功后主动向搜索引擎推送文章,保证新链接能被搜索引擎及时发布收录@ >) 。至于关键字应该在文章的内容中出现多少次,并没有绝对的准则。最好的方式是运用你的常识,选择你认为最符合文章内容的关键词,用最自然的方式呈现出来,让搜索引擎理解,让读者感受光滑的。

pbootcms采集自动过滤其他网站促销信息/支持其他网站信息替换。内容吸引力。如果你的内容足够好,读者自然会被吸引并与之互动。如何判断内容的吸引力?搜索引擎有自己的一套方法。
pbootcms采集标题前缀和后缀设置(标题区分更好收录)。例如,有人在 Internet 上搜索某个关键字,然后找到您的网页。点击后“弹出”,返回原来的搜索引擎结果页面。pbootcms采集 自动内链(在执行发布任务时自动在文章的内容中生成内链,有助于引导页面蜘蛛抓取,提高页面权重)。然后尝试另一个页面。这种立即的“弹出”动作是向搜索引擎发出的信号,表明您的内容可能不够吸引人。这也是搜索引擎考虑的一项措施。
如果访问者没有立即“弹出”,他们是否会在您的 网站 上停留相对较长的时间?这个“网站停留时间”是搜索引擎可以衡量的另一个指标。pbootcms采集定时发布(定时发布网站内容可以让搜索引擎养成定时爬取网页的习惯,从而提高网站的收录) . 除此之外,在 Facebook 等社区 网站 上收到的“点赞”数量是衡量吸引力的另一个指标。我们将在本指南的“社区因素”部分详细介绍。

Pbootcms采集 支持其他平台的图像本地化或存储。事实上,搜索引擎公司对于他们是否真的使用“内容吸引力”指标非常模糊,更不用说那些指标了;pbootcms采集自动批处理挂机后采集伪原创会自动发布推送到搜索引擎。但 SEO 专家普遍认为,内容的吸引力确实是以不同方式衡量的因素之一。但无论如何,SEO的成功与内容的质量高度相关。
pbootcms采集支持多种采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容) . 内容新鲜并不意味着您每天都向 网站 添加新的 文章 或 Web 内容。对于搜索引擎来说,“新鲜度”是指你有没有内容,与某个关键词的搜索量激增有关。pbootcms采集content关键词插入(合理增加关键词的密度)。在这种情况下,搜索引擎会查询与主题相关的内容,然后将相关页面推送到排名靠前的位置。
pbootcms采集不同关键词文章可以设置发布不同的列。如果您的网站与电子产品有关,明天苹果将推出最新产品时,您在这个时候PO了相关的文章报告,那么您的这个网页很可能排名很好。pbootcms采集伪原创保留字(文章原创时伪原创不设置核心字)。您的页面可能会在接下来的一两周内获得高排名,然后随着新鲜度的消逝而消失。今天关于PBootcms采集的讲解就到这里,下期会分享更多SEO相关知识。下次见。

算法 自动采集列表(优采云采集器(www.ucaiyun.com)专业采集软件解密各大网站登录算法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-04-05 18:15
)
优采云采集器()作为采集行业老手采集器是一款功能强大但不易上手的专业采集软件, 优采云采集器捕获数据的过程取决于用户编写的规则。用户必须分析来自目标站的 html 代码中的唯一代码标识符并遵守 优采云 规则,发布模块是向服务器提交 采集 数据,服务器程序自动写入数据正确地存入数据库。这里的服务端程序可以是网站程序,也可以是自己编写的接口,只要数据能正确写入数据库即可。这里提交数据需要大家具备post抓包的基础技术。简单说一下post数据传输的过程。通过HTTP传输数据的方式主要有两种,一种是get,一种是post。 get 一般用于获取数据,可以携带少量参数数据。在此基础上,post 可以承载大量的数据。 采集的发布规则是模拟向网站程序提交post请求,让网站程序认为我们是人。如果您没有权限,主要的 网站 程序不会让您发布 文章,所以!我们只能解密各大网站s的登录算法,只有获得用户登录凭证后才能正常发布文章。明白了原理就可以开始写接口了!
对于小白和基础程序员来说,一定是一头雾水。完全掌握优采云采集器大约需要一个月的时间。涉及的东西更多,知识面更广!
你是否面临着用优采云采集不发表的窘境,花费大量时间却得不到结果!还在为缺少 网站 内容而苦恼,不知道怎么办?如何使用采集三分钟发帖?
1.打开软件输入关键词即可实现全自动采集,多站点采集发布,自动过滤采集文章,与行业无关文章,保证内容100%相关性,全自动批量挂机采集,无缝对接各大cms出版商,后采集 自动发布推送到搜索引擎!
2.全平台cms发行商是目前市面上唯一支持Empire, Yiyou, ZBLOG, 织梦, WP, PB, Apple, 搜外等大cms,一个不需要编写发布模块,可以同时管理和批量发布的工具,可以发布不同类型的文章对应不同的栏目列表,只需要简单的配置,还有很多SEO功能让你网站快速收录!
3. SEO功能:标题前缀和后缀设置、内容关键词插入、随机图片插入、搜索引擎推送、随机点赞-随机阅读-随机作者、内容与标题一致、自动内链,定期发布。
再也不用担心网站没有内容,网站收录低。使用以上软件可以自动采集最新优质内容,并配置多种数据处理选项,标签、链接、邮箱等格式处理,让网站内容独一无二,快速增加网站 流量!高性能产品,全自动运行!另外,要免费找到一位尽职尽责的作者非常困难。看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友同事!
查看全部
算法 自动采集列表(优采云采集器(www.ucaiyun.com)专业采集软件解密各大网站登录算法
)
优采云采集器()作为采集行业老手采集器是一款功能强大但不易上手的专业采集软件, 优采云采集器捕获数据的过程取决于用户编写的规则。用户必须分析来自目标站的 html 代码中的唯一代码标识符并遵守 优采云 规则,发布模块是向服务器提交 采集 数据,服务器程序自动写入数据正确地存入数据库。这里的服务端程序可以是网站程序,也可以是自己编写的接口,只要数据能正确写入数据库即可。这里提交数据需要大家具备post抓包的基础技术。简单说一下post数据传输的过程。通过HTTP传输数据的方式主要有两种,一种是get,一种是post。 get 一般用于获取数据,可以携带少量参数数据。在此基础上,post 可以承载大量的数据。 采集的发布规则是模拟向网站程序提交post请求,让网站程序认为我们是人。如果您没有权限,主要的 网站 程序不会让您发布 文章,所以!我们只能解密各大网站s的登录算法,只有获得用户登录凭证后才能正常发布文章。明白了原理就可以开始写接口了!

对于小白和基础程序员来说,一定是一头雾水。完全掌握优采云采集器大约需要一个月的时间。涉及的东西更多,知识面更广!
你是否面临着用优采云采集不发表的窘境,花费大量时间却得不到结果!还在为缺少 网站 内容而苦恼,不知道怎么办?如何使用采集三分钟发帖?
1.打开软件输入关键词即可实现全自动采集,多站点采集发布,自动过滤采集文章,与行业无关文章,保证内容100%相关性,全自动批量挂机采集,无缝对接各大cms出版商,后采集 自动发布推送到搜索引擎!
2.全平台cms发行商是目前市面上唯一支持Empire, Yiyou, ZBLOG, 织梦, WP, PB, Apple, 搜外等大cms,一个不需要编写发布模块,可以同时管理和批量发布的工具,可以发布不同类型的文章对应不同的栏目列表,只需要简单的配置,还有很多SEO功能让你网站快速收录!
3. SEO功能:标题前缀和后缀设置、内容关键词插入、随机图片插入、搜索引擎推送、随机点赞-随机阅读-随机作者、内容与标题一致、自动内链,定期发布。
再也不用担心网站没有内容,网站收录低。使用以上软件可以自动采集最新优质内容,并配置多种数据处理选项,标签、链接、邮箱等格式处理,让网站内容独一无二,快速增加网站 流量!高性能产品,全自动运行!另外,要免费找到一位尽职尽责的作者非常困难。看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友同事!

算法 自动采集列表(什么是全链路数据血缘(DataLineage)(AST))
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-04-05 11:07
1 什么是全链路数据沿袭
根据维基百科,数据沿袭也称为数据来源或数据谱系。它通常被定义为一个生命周期,主要包括数据来自哪里以及随着时间的推移而移动到哪里。
数据血脉是数据资产的重要组成部分。用于分析表和字段从数据源到当前表的血统路径,血统字段之间的关系是否满足,注意数据的一致性和合理的表设计。它描述了数据从采集、生产到服务全链路的变化和存在形式。
全链路数据血统是指在数据的整个生命周期中,数据与数据之间形成的各种关系,贯穿整个数据链路,如图1所示。
图1 全链路数据沿袭
2 血缘关系建设方案研究2.1 血缘关系分析
目前,数据沿袭主要是通过解析SQL语句来发现上下游调用栈等信息。主流解决方案可以分为两种:
• 运行时解析,即在任务运行时通过钩子接口或监听器接口解析SQL生成的逻辑技术树(AST)。
• 先采集再解析,即通过采集程序将各个计算引擎的SQL统一到采集到mq中进行血液分析。
上述两类方案各有优缺点,对比见表1。
表1 数据沿袭分析方案
方案名称
优势
缺点
运行时解析
解析出来的血脉信息准确,语法错误的SQL和任务不会被解析。
每个计算引擎都需要开发一套血缘关系分析模块,成本高,可能影响任务。
先采集再解析
对于不同的 SQL 方言,可以使用同一套词法/句法解析器进行解析和沿袭解析。
较长的链接可能会导致不准确的血统结果。
2.2 血脉储藏室
与传统的关系型数据库和 ES 工具相比,图数据库在血统信息的查询和分析方面具有以下优势:
1、更好地存储和分析复杂关系
数据沿袭描绘了数据的完整生命周期,具有数据链路长的特点。传统的关系型数据库和ES等,往往只反映当前状态或短路径中的状态,在长链接血缘关系的检索上存在明显劣势。图数据库有效组织复杂关系,通过点-边结构将血脉上下游完美连接,从而实现更长链路血脉的存储、检索和分析。
2、可以有效利用数据之间的相关性,实现更准确可靠的决策
图结构的特点对业务具有重要的指导意义。例如,图的密度可以反映业务数据关联的紧密程度,有助于识别高I/O或高吞吐的服务,识别链路瓶颈;图数据之间的共现可以反映血缘关系中的共生关系,辅助血缘关系重要性的划分;图形可视化帮助业务人员更清晰地了解血缘动态。
与开源图数据库 Neo4j 和 Nebula Graph 相比,华为云 GES 具有以下优势:
• 基于分布式内存计算,性能更高、速度更快、响应时间更短
• 集成 30+ 种高性能算法,增强图形分析能力
• 对接华为云大数据和AI服务,周边支持更全面,服务对接更便捷
• 基于实践自主研发的查询算子Path-Query,支持复杂的过滤查询条件,具有更好的查询性能
华为云GES的基准数据如表2所示。
表2 华为云GES基准测试数据
增加
新节点
15000 TPS
添加边缘
10000 TPS
查询
查询节点详情
20000 TPS
查询边详细信息
10000 TPS
进口
批量导入数据速率
600,000 边/秒
从备份恢复数据速率
600 万边/秒
遍历
1-hop 查询响应时间
第二
2-hop 查询响应时间
第二
三跳查询响应时间
1~3秒
6 跳查询响应时间
5秒
算法
页面排名算法
每次迭代 4 秒
WCC算法
20 秒
SSSP算法
20 秒
3 满帮数据血脉的实践3.1 满帮数据血脉的特点
满帮数据血脉具有以下特点:
• 采集 广泛的覆盖范围。目前已经覆盖了大部分离线和实时场景,涉及的组件包括hive、spark、impala、flink、doris、kafka、clickhouse等。
• 多层次的亲属关系。根据血缘关系模型和血缘关系数据,形成域与域、域与表、表与表、库与库、任务与任务等血缘关系,应用于不同场景。
• 丰富的应用场景。已应用于数据治理、数据质量、数据安全、应用告警等多种场景。
• 开放血统界面。目前,基于血缘关系服务平台,对外提供了丰富的血缘关系接口,包括基本血缘关系信息查询和基于各种算法的血缘关系路径查询。
3.2 数据沿袭模型
定义丰富的血缘关系模型有助于更真实有效地展示血缘关系。满族血统模型主要包括实体和关系,其中实体主要涵盖任务、库、表、视图、字段、函数等实体。实体和关系的组合显示了从一个表/列到其他表/列的沿袭,包括表 INSERT INTO\CTAS 之间的依赖关系,字段 PROJECTION\PREDICATE 之间的依赖关系。
使用完整的数据血缘关系模型可以展示血缘关系的全貌,但存在以下问题:一是完整的血缘关系模型往往收录数千个实体血缘关系,在前端难以展示;其次,过多的冗余信息可能导致问题实体定位困难。为了解决以上问题,满帮在数据血缘模型的基础上,开发了多层次血缘关系模型,主要包括完整血缘关系模型和高层次血缘关系模型。完整数据沿袭模型是所有其他高级沿袭模型的基础,高级沿袭模型通过省略或聚合模型中的某些关系和实体来扩展完整沿袭。在实际业务中,
3.3 整体架构方案
满帮全链路数据血脉实现了血脉数据数据采集从开始到最终数据服务的全链路,有助于高效定位问题,快速评估影响。全链路血脉架构如图2所示,主要包括5层:
• 血脉采集层:负责采集满帮大数据平台各组件的任务血脉信息,将血脉解析成统一格式;
• 血脉处理层:通过消息队列Kafka,通过实时任务将血脉信息统一处理写入GES和Hive,提供血脉存储接口和血脉管理功能;
• 血缘存储层:分别通过GES和Hive提供血缘信息存储和血缘分析统计功能;
• 血统接口层:提供血统信息功能接口,连接血统应用服务;
• 血脉应用层:提供血脉服务,包括数据资产、数据治理、数据安全等。
图2 满帮全链路血脉架构
3.3.1层血脉采集层
满帮血脉采集层目前涵盖满帮内部数据、离线调度、实时计算等平台上的SQL任务和Spark\Flink任务。血缘关系包括系统血缘关系、职务血缘关系、图书馆血缘关系、表级血缘关系、字段血缘关系,指向数据的上游源头,溯源上游。通过血缘关系,清晰展现数据处理的逻辑脉络,快速定位异常数据域的影响范围,准确勾画数据回溯的最小范围,降低理解数据和解决数据问题的成本. 具体来说:
• Hive SQL lineage 解析主要是指通过Hive hook 函数解析org.apache.hadoop.hive.ql.hooks.LineageLogger。
• Spark SQL通过QueryExecutionListener的onSuccess方法获取逻辑计划的Output,通过Output解析字段血缘关系。
• Flink SQL 通过 Cava cc 获取 SQL 逻辑计划树(AST),通过遍历 AST 获取并执行 Input\Output,从而分析表和字段之间的关系。
• Spark\Flink 任务通过分析DAG 中的关系,找到Input\Output,构建虚拟输入输出表,构建血缘关系。
• Impala 目前使用filebeat采集 血脉日志将血脉信息异步发送到Kafka。
为了方便采集和数据血统的处理,统一了各个组件的血统格式,主要包括输入输出表、字段等信息。
序列号
字段名称
字段类型
描述
1
数据库
细绳
当前数据库
2
期间
长
血统分析时间
3
引擎名称
细绳
执行引擎名称
4
执行平台
细绳
执行的平台名称
5
哈希
细绳
执行 SQL MD5 值
6
工作 ID
细绳
执行Job的Id进行拼接
7
职位名称
细绳
任务名称
8
傲慢的
细绳
任务执行OA用户
9
查询文本
细绳
执行 SQL 语句
10
更新时间
长
血脉更新时间
11
用户
细绳
任务执行账户
12
版本
细绳
血统分析版
13
表血统
JSON 对象
表级血统信息
14
列沿袭
JSON 对象
场级血统信息
3.3.2 血脉处理层
血缘处理层主要由血缘实时处理模块、血缘存储接口模块、血缘管理模块组成。
为了满足近实时血脉查询的需求,满帮采用Flink作为血脉实时处理模块的核心组件。通过对从上游采集接收到的血脉信息进行实时分析处理,快速写入图数据库和Hive。该模块支持批量删除\查询\更新和模糊删除\查询\更新功能。
血脉存储接口模块主要开发快速编写图数据库和Hive的相关接口。
血缘管理模块主要用于血缘信息的维护管理和统计分析。
3.3.3血脉储存层
血脉存储层使用华为云图引擎GES服务作为存储引擎。GES采用华为自研EYWA内核,是一种基于“关系”的“图”结构化数据查询分析服务。GES 目前提供多种原生接口,包括批量读写点、边,以及各种路径查询算法。
全链路全链路数据沿袭场景下,图数据操作主要包括读写操作。写入操作主要是将解析和格式化后的血线数据实时写入图数据库。另一种写操作主要是向应用端提供写请求,如表\字段安全级别标记。读取操作主要来自自满帮内部的各种应用场景,主要涵盖短距离、CRM、客服、金融等。
3.3.4 血脉接口层和血脉应用层
血缘接口层主要连接血缘应用层的各种服务,通过开放血缘RPC接口,为各个应用服务提供丰富的接口选项。
目前,满族血脉信息主要应用于数据资产、数据治理、数据安全、数据质量等各种场景。
1、数据资产
满帮数据资产管理平台提供资产全景、数据地图、数据质量、数据安全等功能,如图4所示。数据地图支持以扇形图的形式直观展示各类数据资产的占比,图表,并通过不同层次的图形进行精细化控制,满足业务中不同应用场景的数据查询和辅助分析需求。
图 4 满帮数据资产管理平台
数据图还支持显示血统信息,分析任务之间的数据流向,如图5所示。目前数据图支持显示任务、库、表、字段级血缘关系。
图5 满帮资料图
2、数据治理
数据治理是指在数据的整个生命周期内管理数据的原则性方法,其目标是确保数据安全、及时、准确、可用和易于使用。满帮数据治理主要围绕“指标明确、质量规范”和“资源合理、节约严格”的原则进行。
如图6所示,满帮数据治理任务对库、表、字段的血脉信息进行分析,从价值密度、访问频率、使用方式、时效度等维度进行评价,从而对数据的流行度进行评分,热数据和热数据。,冷数据和冰数据。通过血缘信息查看离线数仓中某个任务链路的上下游任务依赖,同时分析链路上表的冷热使用情况,对ods和dwd的相关任务和SQL进行优化,trim和merge低价值表,缩短数据流ETL环节,从而降低维护成本,提高数据价值。
图 6 满帮数据治理
3、数据质量
数据质量旨在高效监控各类作业的运行状态,洞察关键信息,形成事前判断、事中监控、事后跟踪的闭环质量管理流程。在满帮数据质量监管平台建设中,面临以下问题:
• 离线实时监控系统不完善,监控存在盲点
• 整个链路的数据质量难以保证,数据不可信
• 数据依赖复杂,链接深,数据输出容易延迟
针对以上问题,满帮基于全链路数据血统,从以下几个方面提升数据全生命周期的数据质量:
• 主动通知交通数据所有者。根据血缘关系,通知依赖调度的任务,并提供多层通知选项,避免过渡干扰。
• 离线ETL链接,如果ods\dwd层的某个表的key字段被修改,将通过血脉信息自动向下游依赖表和任务负责人发送告警
• 对于实时的 Flink 任务,如果源端的 Kafka 字段结构发生变化,会根据血缘关系自动通知下游的依赖表和任务负责人
4、数据安全
随着国家在数据流通过程中对数据安全的重视程度越来越高,如果不能有效识别安全级别高的数据,可能会出现安全合规风险。为此,满帮推出了资产安全打标平台,支持通过“自动+人工”打标实现资产安全分级打标,但存在打标覆盖率低、准确率低等问题。
基于全链路的血缘关系,根据不同的数据安全等级,先用血缘关系标注接口标注不同的表字段,然后识别标注字段的上下游血缘关系,然后自动标注安全等级。如图7所示,city_name字段通过血统标记平台安全标记,等级为L3。根据血脉关系,对下游血脉链路的字段进行自动染色和标记,实现自动“染色”。
图 7 数据安全
4 未来展望
经过探索和实践,满帮已经基本实现了基于图数据库相关技术的全链路数据血统的构建,并取得了一定的成果。未来,我们将在以下几个方面进行更深入的探索,进一步完善我们的业务:
1、目前bloodline采集主要通过SQL、自动任务解析、人工排序等方式来提高bloodline覆盖率。目前覆盖率已达到95%以上。未来将探索人工智能相关的方法,根据数据集之间的依赖关系计算数据相似度,以提高覆盖率。
2、Impala bloodline采集 方法链接长,依赖Filebeat。未来我们会逐步对接使用SQL语法解析AST的方案,实现解析规范化。
3、目前血缘维度不支持功能层。
4、开发全链路血脉开放平台,快速对接应用方,为应用方提供血脉服务。
5 参考文献
[1]
[2]
[3] 查看全部
算法 自动采集列表(什么是全链路数据血缘(DataLineage)(AST))
1 什么是全链路数据沿袭
根据维基百科,数据沿袭也称为数据来源或数据谱系。它通常被定义为一个生命周期,主要包括数据来自哪里以及随着时间的推移而移动到哪里。
数据血脉是数据资产的重要组成部分。用于分析表和字段从数据源到当前表的血统路径,血统字段之间的关系是否满足,注意数据的一致性和合理的表设计。它描述了数据从采集、生产到服务全链路的变化和存在形式。
全链路数据血统是指在数据的整个生命周期中,数据与数据之间形成的各种关系,贯穿整个数据链路,如图1所示。
.png)
图1 全链路数据沿袭
2 血缘关系建设方案研究2.1 血缘关系分析
目前,数据沿袭主要是通过解析SQL语句来发现上下游调用栈等信息。主流解决方案可以分为两种:
• 运行时解析,即在任务运行时通过钩子接口或监听器接口解析SQL生成的逻辑技术树(AST)。
• 先采集再解析,即通过采集程序将各个计算引擎的SQL统一到采集到mq中进行血液分析。
上述两类方案各有优缺点,对比见表1。
表1 数据沿袭分析方案
方案名称
优势
缺点
运行时解析
解析出来的血脉信息准确,语法错误的SQL和任务不会被解析。
每个计算引擎都需要开发一套血缘关系分析模块,成本高,可能影响任务。
先采集再解析
对于不同的 SQL 方言,可以使用同一套词法/句法解析器进行解析和沿袭解析。
较长的链接可能会导致不准确的血统结果。
2.2 血脉储藏室
与传统的关系型数据库和 ES 工具相比,图数据库在血统信息的查询和分析方面具有以下优势:
1、更好地存储和分析复杂关系
数据沿袭描绘了数据的完整生命周期,具有数据链路长的特点。传统的关系型数据库和ES等,往往只反映当前状态或短路径中的状态,在长链接血缘关系的检索上存在明显劣势。图数据库有效组织复杂关系,通过点-边结构将血脉上下游完美连接,从而实现更长链路血脉的存储、检索和分析。
2、可以有效利用数据之间的相关性,实现更准确可靠的决策
图结构的特点对业务具有重要的指导意义。例如,图的密度可以反映业务数据关联的紧密程度,有助于识别高I/O或高吞吐的服务,识别链路瓶颈;图数据之间的共现可以反映血缘关系中的共生关系,辅助血缘关系重要性的划分;图形可视化帮助业务人员更清晰地了解血缘动态。
与开源图数据库 Neo4j 和 Nebula Graph 相比,华为云 GES 具有以下优势:
• 基于分布式内存计算,性能更高、速度更快、响应时间更短
• 集成 30+ 种高性能算法,增强图形分析能力
• 对接华为云大数据和AI服务,周边支持更全面,服务对接更便捷
• 基于实践自主研发的查询算子Path-Query,支持复杂的过滤查询条件,具有更好的查询性能
华为云GES的基准数据如表2所示。
表2 华为云GES基准测试数据
增加
新节点
15000 TPS
添加边缘
10000 TPS
查询
查询节点详情
20000 TPS
查询边详细信息
10000 TPS
进口
批量导入数据速率
600,000 边/秒
从备份恢复数据速率
600 万边/秒
遍历
1-hop 查询响应时间
第二
2-hop 查询响应时间
第二
三跳查询响应时间
1~3秒
6 跳查询响应时间
5秒
算法
页面排名算法
每次迭代 4 秒
WCC算法
20 秒
SSSP算法
20 秒
3 满帮数据血脉的实践3.1 满帮数据血脉的特点
满帮数据血脉具有以下特点:
• 采集 广泛的覆盖范围。目前已经覆盖了大部分离线和实时场景,涉及的组件包括hive、spark、impala、flink、doris、kafka、clickhouse等。
• 多层次的亲属关系。根据血缘关系模型和血缘关系数据,形成域与域、域与表、表与表、库与库、任务与任务等血缘关系,应用于不同场景。
• 丰富的应用场景。已应用于数据治理、数据质量、数据安全、应用告警等多种场景。
• 开放血统界面。目前,基于血缘关系服务平台,对外提供了丰富的血缘关系接口,包括基本血缘关系信息查询和基于各种算法的血缘关系路径查询。
3.2 数据沿袭模型
定义丰富的血缘关系模型有助于更真实有效地展示血缘关系。满族血统模型主要包括实体和关系,其中实体主要涵盖任务、库、表、视图、字段、函数等实体。实体和关系的组合显示了从一个表/列到其他表/列的沿袭,包括表 INSERT INTO\CTAS 之间的依赖关系,字段 PROJECTION\PREDICATE 之间的依赖关系。
使用完整的数据血缘关系模型可以展示血缘关系的全貌,但存在以下问题:一是完整的血缘关系模型往往收录数千个实体血缘关系,在前端难以展示;其次,过多的冗余信息可能导致问题实体定位困难。为了解决以上问题,满帮在数据血缘模型的基础上,开发了多层次血缘关系模型,主要包括完整血缘关系模型和高层次血缘关系模型。完整数据沿袭模型是所有其他高级沿袭模型的基础,高级沿袭模型通过省略或聚合模型中的某些关系和实体来扩展完整沿袭。在实际业务中,
3.3 整体架构方案
满帮全链路数据血脉实现了血脉数据数据采集从开始到最终数据服务的全链路,有助于高效定位问题,快速评估影响。全链路血脉架构如图2所示,主要包括5层:
• 血脉采集层:负责采集满帮大数据平台各组件的任务血脉信息,将血脉解析成统一格式;
• 血脉处理层:通过消息队列Kafka,通过实时任务将血脉信息统一处理写入GES和Hive,提供血脉存储接口和血脉管理功能;
• 血缘存储层:分别通过GES和Hive提供血缘信息存储和血缘分析统计功能;
• 血统接口层:提供血统信息功能接口,连接血统应用服务;
• 血脉应用层:提供血脉服务,包括数据资产、数据治理、数据安全等。
.png)
图2 满帮全链路血脉架构
3.3.1层血脉采集层
满帮血脉采集层目前涵盖满帮内部数据、离线调度、实时计算等平台上的SQL任务和Spark\Flink任务。血缘关系包括系统血缘关系、职务血缘关系、图书馆血缘关系、表级血缘关系、字段血缘关系,指向数据的上游源头,溯源上游。通过血缘关系,清晰展现数据处理的逻辑脉络,快速定位异常数据域的影响范围,准确勾画数据回溯的最小范围,降低理解数据和解决数据问题的成本. 具体来说:
• Hive SQL lineage 解析主要是指通过Hive hook 函数解析org.apache.hadoop.hive.ql.hooks.LineageLogger。
• Spark SQL通过QueryExecutionListener的onSuccess方法获取逻辑计划的Output,通过Output解析字段血缘关系。
• Flink SQL 通过 Cava cc 获取 SQL 逻辑计划树(AST),通过遍历 AST 获取并执行 Input\Output,从而分析表和字段之间的关系。
• Spark\Flink 任务通过分析DAG 中的关系,找到Input\Output,构建虚拟输入输出表,构建血缘关系。
• Impala 目前使用filebeat采集 血脉日志将血脉信息异步发送到Kafka。
为了方便采集和数据血统的处理,统一了各个组件的血统格式,主要包括输入输出表、字段等信息。
序列号
字段名称
字段类型
描述
1
数据库
细绳
当前数据库
2
期间
长
血统分析时间
3
引擎名称
细绳
执行引擎名称
4
执行平台
细绳
执行的平台名称
5
哈希
细绳
执行 SQL MD5 值
6
工作 ID
细绳
执行Job的Id进行拼接
7
职位名称
细绳
任务名称
8
傲慢的
细绳
任务执行OA用户
9
查询文本
细绳
执行 SQL 语句
10
更新时间
长
血脉更新时间
11
用户
细绳
任务执行账户
12
版本
细绳
血统分析版
13
表血统
JSON 对象
表级血统信息
14
列沿袭
JSON 对象
场级血统信息
3.3.2 血脉处理层
血缘处理层主要由血缘实时处理模块、血缘存储接口模块、血缘管理模块组成。
为了满足近实时血脉查询的需求,满帮采用Flink作为血脉实时处理模块的核心组件。通过对从上游采集接收到的血脉信息进行实时分析处理,快速写入图数据库和Hive。该模块支持批量删除\查询\更新和模糊删除\查询\更新功能。
血脉存储接口模块主要开发快速编写图数据库和Hive的相关接口。
血缘管理模块主要用于血缘信息的维护管理和统计分析。
3.3.3血脉储存层
血脉存储层使用华为云图引擎GES服务作为存储引擎。GES采用华为自研EYWA内核,是一种基于“关系”的“图”结构化数据查询分析服务。GES 目前提供多种原生接口,包括批量读写点、边,以及各种路径查询算法。
全链路全链路数据沿袭场景下,图数据操作主要包括读写操作。写入操作主要是将解析和格式化后的血线数据实时写入图数据库。另一种写操作主要是向应用端提供写请求,如表\字段安全级别标记。读取操作主要来自自满帮内部的各种应用场景,主要涵盖短距离、CRM、客服、金融等。
3.3.4 血脉接口层和血脉应用层
血缘接口层主要连接血缘应用层的各种服务,通过开放血缘RPC接口,为各个应用服务提供丰富的接口选项。
目前,满族血脉信息主要应用于数据资产、数据治理、数据安全、数据质量等各种场景。
1、数据资产
满帮数据资产管理平台提供资产全景、数据地图、数据质量、数据安全等功能,如图4所示。数据地图支持以扇形图的形式直观展示各类数据资产的占比,图表,并通过不同层次的图形进行精细化控制,满足业务中不同应用场景的数据查询和辅助分析需求。
.png)
图 4 满帮数据资产管理平台
数据图还支持显示血统信息,分析任务之间的数据流向,如图5所示。目前数据图支持显示任务、库、表、字段级血缘关系。
.png)
图5 满帮资料图
2、数据治理
数据治理是指在数据的整个生命周期内管理数据的原则性方法,其目标是确保数据安全、及时、准确、可用和易于使用。满帮数据治理主要围绕“指标明确、质量规范”和“资源合理、节约严格”的原则进行。
如图6所示,满帮数据治理任务对库、表、字段的血脉信息进行分析,从价值密度、访问频率、使用方式、时效度等维度进行评价,从而对数据的流行度进行评分,热数据和热数据。,冷数据和冰数据。通过血缘信息查看离线数仓中某个任务链路的上下游任务依赖,同时分析链路上表的冷热使用情况,对ods和dwd的相关任务和SQL进行优化,trim和merge低价值表,缩短数据流ETL环节,从而降低维护成本,提高数据价值。
.png)
图 6 满帮数据治理
3、数据质量
数据质量旨在高效监控各类作业的运行状态,洞察关键信息,形成事前判断、事中监控、事后跟踪的闭环质量管理流程。在满帮数据质量监管平台建设中,面临以下问题:
• 离线实时监控系统不完善,监控存在盲点
• 整个链路的数据质量难以保证,数据不可信
• 数据依赖复杂,链接深,数据输出容易延迟
针对以上问题,满帮基于全链路数据血统,从以下几个方面提升数据全生命周期的数据质量:
• 主动通知交通数据所有者。根据血缘关系,通知依赖调度的任务,并提供多层通知选项,避免过渡干扰。
• 离线ETL链接,如果ods\dwd层的某个表的key字段被修改,将通过血脉信息自动向下游依赖表和任务负责人发送告警
• 对于实时的 Flink 任务,如果源端的 Kafka 字段结构发生变化,会根据血缘关系自动通知下游的依赖表和任务负责人
4、数据安全
随着国家在数据流通过程中对数据安全的重视程度越来越高,如果不能有效识别安全级别高的数据,可能会出现安全合规风险。为此,满帮推出了资产安全打标平台,支持通过“自动+人工”打标实现资产安全分级打标,但存在打标覆盖率低、准确率低等问题。
基于全链路的血缘关系,根据不同的数据安全等级,先用血缘关系标注接口标注不同的表字段,然后识别标注字段的上下游血缘关系,然后自动标注安全等级。如图7所示,city_name字段通过血统标记平台安全标记,等级为L3。根据血脉关系,对下游血脉链路的字段进行自动染色和标记,实现自动“染色”。
.png)
图 7 数据安全
4 未来展望
经过探索和实践,满帮已经基本实现了基于图数据库相关技术的全链路数据血统的构建,并取得了一定的成果。未来,我们将在以下几个方面进行更深入的探索,进一步完善我们的业务:
1、目前bloodline采集主要通过SQL、自动任务解析、人工排序等方式来提高bloodline覆盖率。目前覆盖率已达到95%以上。未来将探索人工智能相关的方法,根据数据集之间的依赖关系计算数据相似度,以提高覆盖率。
2、Impala bloodline采集 方法链接长,依赖Filebeat。未来我们会逐步对接使用SQL语法解析AST的方案,实现解析规范化。
3、目前血缘维度不支持功能层。
4、开发全链路血脉开放平台,快速对接应用方,为应用方提供血脉服务。
5 参考文献
[1]
[2]
[3]
算法 自动采集列表(Dede采集插件可轻松无缝地把文章内容或者数据发布(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-04-04 04:06
Dede采集 插件可以轻松无缝地将 文章 内容或数据发布到 织梦DEDE网站。 Dede采集插件是一套php+mysql采集程序,适用于企业网站建设和个人网站建设。当您看到这个 文章 时,您正在寻找与 Dede采集 插件相关的工具或信息。本文的重点都在文章图片上,只看图片,文章内容无视。 【重点1来了,Dede采集插件,强大丰富】
基于php的采集插件的性能、功能和稳定性都不是很好,所以Dede采集插件更强大更方便支持采集插件-ins 更合适。稳定采集,定期发布。发布规则超级简单,可以使用任意模型和自定义字段自动下载图片并提取第一张缩略图。 Dede采集插件不需要任何编程基础,它会查看源代码,复制粘贴。 采集规则不用写,输入关键词开始采集即可。 [重点2来了,Dede采集插件,你可以永久免费使用]
Dede采集插件采集文章的一些原理代码:
修复方法,找到:application采集event采集.php
$rules = [
'url' => [$this->_config['url_rule1'], $this->_config['url_rule2'], $this->_config['url_rule3']],
'title' => [$this->_config['url_rule1'], 'html', $this->_config['url_rule3']],
替换为【关键点3来了,Dede采集插件,高效处理,操作简单】
'url' => ['',$this->_config['url_rule2'],$this->_config['url_rule3']
'title' => ['','text',$this->_config['url_rule3']]
Dede采集插件可以每天自动更新。最新最热资讯采集每天自动更新。输入关键词,采集与此关键词相关的最新内容。输入 URL,采集这个 URL 的内容。可用于云通用 伪原创 和本地 伪原创。本地伪原创词库可以在插件设置中自定义。图片可一键本地存储,图片永不丢失。 【重点4来了,Dede采集插件,一键自动设置采集】
Dede采集插件自动采集存储和自动发布文章插件,可以自动通过织梦cms后端采集模块< @采集rules采集文章,并自动存储在对应的栏目中,并自动更新生成内容页的html、栏目页的html、首页的html存储后,实现织梦cms自动更新内容,可以解决很多需要手动采集、手动存储、手动批量更新的问题,提高更新速度网站@ >.
Dede采集插件可以搭配适当的采集内容,但也需要整合采集内容。对于新的网站,搜索引擎会更加注重质量审核,所以我不建议所有的内容都是采集,至少伪原创要处理。这里的伪原创文章一定要注意质量。不能是 文章 的类型只改变头部和尾部。注意改头尾不视为伪原创文章,建议阅读伪原创的概念和伪原创文章的编辑技巧如果采集的文章用高质量的伪原创处理,那么基本没有问题。
Dede采集采集网站的插件要避开搜索引擎算法,必须对内容进行排版,不要刻意拼接,减少网站页面的重复,不要交叉domain采集,对采集的内容做二次处理,当采集站避开这些点时,不会命中搜索引擎算法。
文章的
dede采集插件就写到这里了,希望对各位站长和SEOer有所帮助,如果对文章的内容看不懂,可以直接看文章图片,简单易懂。 查看全部
算法 自动采集列表(Dede采集插件可轻松无缝地把文章内容或者数据发布(图))
Dede采集 插件可以轻松无缝地将 文章 内容或数据发布到 织梦DEDE网站。 Dede采集插件是一套php+mysql采集程序,适用于企业网站建设和个人网站建设。当您看到这个 文章 时,您正在寻找与 Dede采集 插件相关的工具或信息。本文的重点都在文章图片上,只看图片,文章内容无视。 【重点1来了,Dede采集插件,强大丰富】

基于php的采集插件的性能、功能和稳定性都不是很好,所以Dede采集插件更强大更方便支持采集插件-ins 更合适。稳定采集,定期发布。发布规则超级简单,可以使用任意模型和自定义字段自动下载图片并提取第一张缩略图。 Dede采集插件不需要任何编程基础,它会查看源代码,复制粘贴。 采集规则不用写,输入关键词开始采集即可。 [重点2来了,Dede采集插件,你可以永久免费使用]

Dede采集插件采集文章的一些原理代码:
修复方法,找到:application采集event采集.php
$rules = [
'url' => [$this->_config['url_rule1'], $this->_config['url_rule2'], $this->_config['url_rule3']],
'title' => [$this->_config['url_rule1'], 'html', $this->_config['url_rule3']],
替换为【关键点3来了,Dede采集插件,高效处理,操作简单】

'url' => ['',$this->_config['url_rule2'],$this->_config['url_rule3']
'title' => ['','text',$this->_config['url_rule3']]
Dede采集插件可以每天自动更新。最新最热资讯采集每天自动更新。输入关键词,采集与此关键词相关的最新内容。输入 URL,采集这个 URL 的内容。可用于云通用 伪原创 和本地 伪原创。本地伪原创词库可以在插件设置中自定义。图片可一键本地存储,图片永不丢失。 【重点4来了,Dede采集插件,一键自动设置采集】

Dede采集插件自动采集存储和自动发布文章插件,可以自动通过织梦cms后端采集模块< @采集rules采集文章,并自动存储在对应的栏目中,并自动更新生成内容页的html、栏目页的html、首页的html存储后,实现织梦cms自动更新内容,可以解决很多需要手动采集、手动存储、手动批量更新的问题,提高更新速度网站@ >.
Dede采集插件可以搭配适当的采集内容,但也需要整合采集内容。对于新的网站,搜索引擎会更加注重质量审核,所以我不建议所有的内容都是采集,至少伪原创要处理。这里的伪原创文章一定要注意质量。不能是 文章 的类型只改变头部和尾部。注意改头尾不视为伪原创文章,建议阅读伪原创的概念和伪原创文章的编辑技巧如果采集的文章用高质量的伪原创处理,那么基本没有问题。

Dede采集采集网站的插件要避开搜索引擎算法,必须对内容进行排版,不要刻意拼接,减少网站页面的重复,不要交叉domain采集,对采集的内容做二次处理,当采集站避开这些点时,不会命中搜索引擎算法。
文章的
dede采集插件就写到这里了,希望对各位站长和SEOer有所帮助,如果对文章的内容看不懂,可以直接看文章图片,简单易懂。
算法 自动采集列表(算法自动采集列表页里面的广告页挨个点击才可以)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-30 10:06
算法自动采集列表页列表页里面经常会出现很多的广告等文字。这些文字怎么在图片上显示在数据库中排好顺序,挨个点击才可以呢?最简单的方法是利用一个广告采集程序,它自动连接图片和广告列表页,然后采集图片中的广告页列表,并把不想要的广告页标记为stop。这样就能得到不想要的广告页列表,随后只要只要取出stop中的广告页即可。
这种广告采集效率很低,程序非常麻烦。接下来的办法比较简单,现在以我在旅游度假时会用到的adsense插件来做演示。打开adsense浏览器插件商店,安装adsense。依次输入网站:/,就会看到一个带有广告的广告栏。我们在浏览这个网站时,会点击这些广告,再次刷新该网站,看广告栏中是否有新的广告项目。这时候,在标记广告的小框上,会有两个选项:stop和nomoredirectclicks。
点击stop。接下来点击nomoredirectclicks,然后选择下面我们想要的广告列表页。然后点击进入广告列表页,连续点击这几个广告就能得到想要的广告页列表。这时候,一共有5个广告页:点击stop这两个广告就可以将你的广告页标记stop。接下来的操作比较简单,仅需要让网站更改,并且刷新广告栏即可得到原本的广告页列表。
方法就是通过定时器和cookie相关js,完成获取的过程。有些人可能会问,这种方法太麻烦,要等广告完全显示才能得到。其实并不需要特别久,只需要广告稍微少一点,比如广告栏的广告数量少于10个,基本上。
3、5秒就可以获取到广告页列表,就像原来的广告网站一样。但是,如果广告网站广告有几千个或者更多,通过这种方法就会出现显示广告之后,再也找不到显示广告的地方。这是一个让人头疼的问题。解决方法还是通过定时器和cookie来完成广告的定时采集。首先,需要一个表示表单的cookie。这个cookie可以在我们的浏览器插件商店中找到,也可以在后台自己写js获取。下面我就简单介绍一下从插件商店找到的cookie。我就用最简单的useragent代码来获取。
functionlsj(jsflag){if(jsflag){console.log('cookiefailed');}settimeout(lsj,1,100
0);}else{if(!settimeout){console.log('cookiefailed');}settimeout(lsj,2000,200
0);}如果你是从自己写的脚本中获取,可以借助一些工具来用es6定时采集更多广告,比如我们可以使用javascript实现定时连接服务器获取服务器用户数据。连接后转化为json格式。
functiongetjw(jsflag){lsj(jsflag)}console.log('getjsfailed');settimeout(getjw,100
0) 查看全部
算法 自动采集列表(算法自动采集列表页里面的广告页挨个点击才可以)
算法自动采集列表页列表页里面经常会出现很多的广告等文字。这些文字怎么在图片上显示在数据库中排好顺序,挨个点击才可以呢?最简单的方法是利用一个广告采集程序,它自动连接图片和广告列表页,然后采集图片中的广告页列表,并把不想要的广告页标记为stop。这样就能得到不想要的广告页列表,随后只要只要取出stop中的广告页即可。
这种广告采集效率很低,程序非常麻烦。接下来的办法比较简单,现在以我在旅游度假时会用到的adsense插件来做演示。打开adsense浏览器插件商店,安装adsense。依次输入网站:/,就会看到一个带有广告的广告栏。我们在浏览这个网站时,会点击这些广告,再次刷新该网站,看广告栏中是否有新的广告项目。这时候,在标记广告的小框上,会有两个选项:stop和nomoredirectclicks。
点击stop。接下来点击nomoredirectclicks,然后选择下面我们想要的广告列表页。然后点击进入广告列表页,连续点击这几个广告就能得到想要的广告页列表。这时候,一共有5个广告页:点击stop这两个广告就可以将你的广告页标记stop。接下来的操作比较简单,仅需要让网站更改,并且刷新广告栏即可得到原本的广告页列表。
方法就是通过定时器和cookie相关js,完成获取的过程。有些人可能会问,这种方法太麻烦,要等广告完全显示才能得到。其实并不需要特别久,只需要广告稍微少一点,比如广告栏的广告数量少于10个,基本上。
3、5秒就可以获取到广告页列表,就像原来的广告网站一样。但是,如果广告网站广告有几千个或者更多,通过这种方法就会出现显示广告之后,再也找不到显示广告的地方。这是一个让人头疼的问题。解决方法还是通过定时器和cookie来完成广告的定时采集。首先,需要一个表示表单的cookie。这个cookie可以在我们的浏览器插件商店中找到,也可以在后台自己写js获取。下面我就简单介绍一下从插件商店找到的cookie。我就用最简单的useragent代码来获取。
functionlsj(jsflag){if(jsflag){console.log('cookiefailed');}settimeout(lsj,1,100
0);}else{if(!settimeout){console.log('cookiefailed');}settimeout(lsj,2000,200
0);}如果你是从自己写的脚本中获取,可以借助一些工具来用es6定时采集更多广告,比如我们可以使用javascript实现定时连接服务器获取服务器用户数据。连接后转化为json格式。
functiongetjw(jsflag){lsj(jsflag)}console.log('getjsfailed');settimeout(getjw,100
0)
算法 自动采集列表(《开源精选》之一个、Gitee等开源社区中优质项目)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-03-29 17:16
《开源精选》是我们在Github、Gitee等开源社区分享优质项目的专栏,内容包括技术、学习、实用和各种有趣的内容。本期推荐DrissionPage,一个基于python的开源网络自动化集成工具。
使用请求作为数据采集面对要登录的网站,需要分析数据包,JS源码,构造复杂的请求,经常要处理反爬等方法如验证码、JS混淆、签名参数等,门槛较高。如果数据是JS计算生成的,计算过程必须复现,体验不好,开发效率不高。
使用 selenium,这些坑可以在很大程度上绕过,但 selenium 效率不高。因此,该库将 selenium 和 requests 合二为一,在不同需求时切换相应的模式,并提供一种用户友好的方法来提高开发和运行效率。
这个库除了将两者合并之外,还封装了网页中常用的函数,简化了selenium的操作和语句。用于网页自动化时,减少了对细节的考虑,专注于功能实现,使用起来更方便。一切都很简单,尽量提供简单直接的使用方法,对新手比较友好。
功能亮点功能
结构图
如图,Drission 对象负责创建链接、分享登录状态等,类似于 selenium 中驱动的概念。MixPage 对象负责对获取的页面进行解析和操作。DriverElement 和 SessionElement 是从页面对象中获取的元素对象。负责解析和操作元素。
简单的演示
与硒代码比较
跳转到第一个标签
# 使用 selenium:
driver.switch_to.window(driver.window_handles[0])
# 使用 DrissionPage:
page.to_tab(0)
按文本选择下拉菜单
# 使用 selenium:
from selenium.webdriver.support.select import Select
select_element = Select(element)
select_element.select_by_visible_text('text')
# 使用 DrissionPage:
element.select('text')
拖动一个元素
# 使用 selenium:
ActionChains(driver).drag_and_drop(ele1, ele2).perform()
# 使用 DrissionPage:
ele1.drag_to(ele2)
与请求代码比较
获取元素内容
url = 'https://baike.baidu.com/item/python'
# 使用 requests:
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'}
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
element = html.xpath('//h1')[0]
title = element.text
# 使用 DrissionPage:
page = MixPage('s')
page.get(url)
title = page('tag:h1').text
下载文件
url = 'https://www.baidu.com/img/flex ... 39%3B
save_path = r'C:\download'
# 使用 requests:
r = requests.get(url)
with open(f'{save_path}\\img.png', 'wb') as fd:
for chunk in r.iter_content():
fd.write(chunk)
# 使用 DrissionPage:
page.download(url, save_path, 'img') # 支持重命名,处理文件名冲突,自动创建目标文件夹
爬取新冠排行榜
URL:本例爬取全球新冠疫情排名。网站是一个纯html页面,特别适合s-mode的爬取和解析。
from DrissionPage import MixPage
# 用 s 模式创建页面对象
page = MixPage('s')
# 访问数据网页
page.get('https://www.outbreak.my/zh/world')
# 获取表头元素
thead = page('tag:thead')
# 获取表头列,跳过其中的隐藏的列
title = thead.eles('tag:th@@-style:display: none;')
data = [th.text for th in title]
print(data) # 打印表头
# 获取内容表格元素
tbody = page('tag:tbody')
# 获取表格所有行
rows = tbody.eles('tag:tr')
for row in rows:
# 获取当前行所有列
cols = row.eles('tag:td')
# 生成当前行数据列表(跳过其中没用的几列)
data = [td.text for k, td in enumerate(cols) if k not in (2, 4, 6)]
print(data) # 打印行数据
输出:
['总 (205)', '累积确诊', '死亡', '治愈', '现有确诊', '死亡率', '恢复率']
['美国', '55252823', '845745', '41467660', '12,939,418', '1.53%', '75.05%']
['印度', '34838804', '481080', '34266363', '91,361', '1.38%', '98.36%']
['巴西', '22277239', '619024', '21567845', '90,370', '2.78%', '96.82%']
['英国', '12748050', '148421', '10271706', '2,327,923', '1.16%', '80.57%']
['俄罗斯', '10499982', '308860', '9463919', '727,203', '2.94%', '90.13%']
['法国', '9740600', '123552', '8037752', '1,579,296', '1.27%', '82.52%']
......
登录gitee 网站
URL: ,本例演示使用浏览器控件自动登录gitee 网站。
from DrissionPage import MixPage
# 用 d 模式创建页面对象(默认模式)
page = MixPage()
# 跳转到登录页面
page.get('https://gitee.com/login')
# 定位到账号文本框并输入账号
page.ele('#user_login').input('你的账号')
# 定位到密码文本框并输入密码
page.ele('#user_password').input('你的密码')
# 点击登录按钮
page.ele('@value=登 录').click()
-结尾-
开源许可证:BSD-3-Clause
开源地址: 查看全部
算法 自动采集列表(《开源精选》之一个、Gitee等开源社区中优质项目)
《开源精选》是我们在Github、Gitee等开源社区分享优质项目的专栏,内容包括技术、学习、实用和各种有趣的内容。本期推荐DrissionPage,一个基于python的开源网络自动化集成工具。
使用请求作为数据采集面对要登录的网站,需要分析数据包,JS源码,构造复杂的请求,经常要处理反爬等方法如验证码、JS混淆、签名参数等,门槛较高。如果数据是JS计算生成的,计算过程必须复现,体验不好,开发效率不高。
使用 selenium,这些坑可以在很大程度上绕过,但 selenium 效率不高。因此,该库将 selenium 和 requests 合二为一,在不同需求时切换相应的模式,并提供一种用户友好的方法来提高开发和运行效率。
这个库除了将两者合并之外,还封装了网页中常用的函数,简化了selenium的操作和语句。用于网页自动化时,减少了对细节的考虑,专注于功能实现,使用起来更方便。一切都很简单,尽量提供简单直接的使用方法,对新手比较友好。
功能亮点功能
结构图
如图,Drission 对象负责创建链接、分享登录状态等,类似于 selenium 中驱动的概念。MixPage 对象负责对获取的页面进行解析和操作。DriverElement 和 SessionElement 是从页面对象中获取的元素对象。负责解析和操作元素。
简单的演示
与硒代码比较
跳转到第一个标签
# 使用 selenium:
driver.switch_to.window(driver.window_handles[0])
# 使用 DrissionPage:
page.to_tab(0)
按文本选择下拉菜单
# 使用 selenium:
from selenium.webdriver.support.select import Select
select_element = Select(element)
select_element.select_by_visible_text('text')
# 使用 DrissionPage:
element.select('text')
拖动一个元素
# 使用 selenium:
ActionChains(driver).drag_and_drop(ele1, ele2).perform()
# 使用 DrissionPage:
ele1.drag_to(ele2)
与请求代码比较
获取元素内容
url = 'https://baike.baidu.com/item/python'
# 使用 requests:
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'}
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
element = html.xpath('//h1')[0]
title = element.text
# 使用 DrissionPage:
page = MixPage('s')
page.get(url)
title = page('tag:h1').text
下载文件
url = 'https://www.baidu.com/img/flex ... 39%3B
save_path = r'C:\download'
# 使用 requests:
r = requests.get(url)
with open(f'{save_path}\\img.png', 'wb') as fd:
for chunk in r.iter_content():
fd.write(chunk)
# 使用 DrissionPage:
page.download(url, save_path, 'img') # 支持重命名,处理文件名冲突,自动创建目标文件夹
爬取新冠排行榜
URL:本例爬取全球新冠疫情排名。网站是一个纯html页面,特别适合s-mode的爬取和解析。
from DrissionPage import MixPage
# 用 s 模式创建页面对象
page = MixPage('s')
# 访问数据网页
page.get('https://www.outbreak.my/zh/world')
# 获取表头元素
thead = page('tag:thead')
# 获取表头列,跳过其中的隐藏的列
title = thead.eles('tag:th@@-style:display: none;')
data = [th.text for th in title]
print(data) # 打印表头
# 获取内容表格元素
tbody = page('tag:tbody')
# 获取表格所有行
rows = tbody.eles('tag:tr')
for row in rows:
# 获取当前行所有列
cols = row.eles('tag:td')
# 生成当前行数据列表(跳过其中没用的几列)
data = [td.text for k, td in enumerate(cols) if k not in (2, 4, 6)]
print(data) # 打印行数据
输出:
['总 (205)', '累积确诊', '死亡', '治愈', '现有确诊', '死亡率', '恢复率']
['美国', '55252823', '845745', '41467660', '12,939,418', '1.53%', '75.05%']
['印度', '34838804', '481080', '34266363', '91,361', '1.38%', '98.36%']
['巴西', '22277239', '619024', '21567845', '90,370', '2.78%', '96.82%']
['英国', '12748050', '148421', '10271706', '2,327,923', '1.16%', '80.57%']
['俄罗斯', '10499982', '308860', '9463919', '727,203', '2.94%', '90.13%']
['法国', '9740600', '123552', '8037752', '1,579,296', '1.27%', '82.52%']
......
登录gitee 网站
URL: ,本例演示使用浏览器控件自动登录gitee 网站。
from DrissionPage import MixPage
# 用 d 模式创建页面对象(默认模式)
page = MixPage()
# 跳转到登录页面
page.get('https://gitee.com/login')
# 定位到账号文本框并输入账号
page.ele('#user_login').input('你的账号')
# 定位到密码文本框并输入密码
page.ele('#user_password').input('你的密码')
# 点击登录按钮
page.ele('@value=登 录').click()
-结尾-
开源许可证:BSD-3-Clause
开源地址:
算法 自动采集列表(方法网格搜索随机搜索贝叶斯搜索的实现:系统架构BML自动超参搜索功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-03-29 01:09
方法
网格搜索
随机搜索
贝叶斯搜索
进化算法
优势
实现简单,效果取决于用户设置的网格间隔大小
进行多参数联合搜索时,扩大了各参数的搜索范围,提高了搜索效率。
搜索迭代次数少,效率高,通过贝叶斯算法在已有采样点的帮助下估计最优超参数。
减少每轮迭代的训练时间,将计算资源集中在参数搜索上,通过重用具有良好历史表现的个体的预训练参数来加速收敛
缺点
消耗计算资源
效果不稳定
可能陷入局部最优
因超参数导致模型结构变化等因素无法加载预训练参数时不适用
自动超参数搜索方法的比较
上表总结了这些搜索方法的优缺点。总之,网格搜索和随机搜索实现起来比较简单,不使用先验知识来选择下一组超参数,随机搜索比较高效。贝叶斯搜索和进化算法需要利用上一轮的信息进行迭代搜索,搜索效率显着提高。
BML自动超参数搜索的实现:系统架构
BML自动超参数搜索功能是基于自主研发的自动超参数搜索服务。服务操作流程如下图所示。它依托百度智能云CCE的计算能力,同时支持多个自动搜索任务。为了提供“好用”的自动超参数搜索服务,架构实现侧重于提高并发搜索效率和系统容错能力。
一个超参数搜索任务包括以下过程:
1.业务平台将超参搜索任务的用户配置信息提交给超参搜索服务,会创建一个搜索实验(Experiment)并记录在db中。
2.搜索服务向实验控制器提交任务,实验控制器初始化并创建试验管理模块,负责试验生命周期的管理。
3.Trial 是一个特定的训练实验。一个实验将产生多个试验,以探索不同超参数组合的最终效果。Tuner 是一个超参数生成模块,根据选择的超参数搜索算法推荐下一次 Trial 使用的超参数值。在 Trial 管理模块中,Exp Manager 将负责生成多个 Trial,向 Tuner 请求特定的测试超参数,并将 Trial 任务信息发送给 Trial Scheduler。
4.Trial Scheduler 将与底层资源交互以实际启动 Trial。Trial Scheduler 管理所有试验的生命周期。
5.每次试用完成后,会将指标等信息上报给Exp Manager,用于上报给tuner并记录到db。
BML自动超参数搜索主要有以下特点:
动手实践:如何使用自动超参数搜索
1.先点击
创建一个脚本参数调整项目,如果你已经有项目,可以直接使用!目前,支持超参数搜索的项目类型包括图像分类(单标签和多标签)和对象检测。只需创建相应类型的项目。
2.在工程中新建任务,配置任务的网络、数据、脚本,可以看到“配置超参数”选项。如果这里已经有超参数搜索结果,可以直接勾选“Existing hyperparameter search results”来使用。如果我们不是第一次使用它,只需选择“自动超参数搜索”即可。
3.目前BML支持三种超参数搜索算法,如图,分别是贝叶斯搜索、随机搜索和进化算法。您可以根据需要选择一种进行搜索。具体配置项说明请参考技术文档。
3.1 贝叶斯搜索的参数说明
【初始点数】表示贝叶斯搜索初始化时参数点的个数。该算法根据这些参数信息推断出最优点,并填充在1-20的范围内。
[最大并发] 在贝叶斯搜索中,同时实验的数量。并发越大,搜索效率越高。填写1-20的范围。不过这个并发也受限于页面底部选择的GPU数量,实际并发是两者中较小的一个。
【超参数范围设置】:可以是默认配置,也可以是手动配置。默认情况下,百度的工程师已经帮我们设置了针对不同网络和GPU卡类型的基本可靠的搜索范围,可以直接使用。当然也可以手动配置,可以自定义每个超参数的范围。可以看到物体检测支持以下超参数自定义搜索范围:
【最大搜索次数】:指可以组合并运行测试的最大超参数组数。当然也可能因为提前达到目标而停止,节省成本。
【数据采样率】:使用超参数搜索时,会在训练前对原创数据集进行采样,以加快搜索速度。当数据集不大时,不建议采样,可能会影响最终效果。只有当数据量很大时才需要使用采样。
【Highest mAP/Highest Accuracy Rate】:指每个人都期望模型达到的效果的mAP(物体检测)或准确率(图像分类)的值。当实验中达到这个值时,搜索将停止,以避免将来浪费搜索时间。.
3.2 随机搜索参数说明
随机搜索是最简单的,不需要额外配置算法相关的参数。其他常见选项与贝叶斯搜索具有相同的含义。你可以参考贝叶斯搜索。
3.3 进化算法参数说明
进化算法是一种更好的算法,应用该算法时需要更多的选项。
【迭代轮次】:进化算法运行的迭代次数,范围为5-50。
【扰动区间】:进化算法每隔几个epoch就会随机扰动一次,利用随机因素防止算法结果收敛到局部最优解。
【扰动比】:类似于染色体交叉的形式,在迭代中根据扰动比对种群中最好和最差的个体进行交叉。
【随机初始化概率】:在扰动中,有一定概率初始化各个超参数。
【种群中的个体数】:一个个体代表一个超参数设置,一个种群收录多个个体。
其他选项与贝叶斯搜索含义相同,不再赘述。进化算法的配置需要对算法的原理有一定的了解。不懂算法的就用百度给出的默认值吧!
4.超参数选项设置完成,最后选择GPU卡的类型和数量,以及最大搜索时间,就可以提交任务了!此处的默认搜索时间为 24 小时。毕竟超参数搜索会运行多次测试,需要很长时间,需要耐心。当然,你选择的 GPU 卡越多,并发测试的数量就越高。从提交任务到搜索 完成时间会更短,这是显而易见的
5.任务提交后,一段时间后任务进入“超参搜索”状态,可以看到每个实验的进度,包括每个实验的状态、日志和准确率(mAP)
6.超参数搜索训练完成后,可以在5个结果最好的实验中看到详细的评估结果,也可以用于后续的效果验证和发布。当然,如果在超参数搜索过程中对数据进行了采样,此时可以重新启动训练任务,使用本次搜索结果满意的超参数进行全数据训练,从而获得完整的模型效果数据。
效果是硬道理:超参搜索效果提升高达20%+
我们使用通用脚本参数调整和超参数搜索比较了图像分类、对象检测、实例分割和其他任务的效果。进化算法和使用贝叶斯搜索算法的超参数搜索的效果比较。图中左纵轴是模型的准确率,右纵轴是超参数搜索算法生效的比例。可以看出,在不同数据集上使用超参数搜索的效果有所提升。当默认参数准确率已经超过 85% 时,使用超参数搜索仍然可以提高 5% 左右。在默认参数效果不佳的情况下,超参数搜索的提升效果更为明显,可高达22%。
正常运行下,可用的深度学习自动超参搜索由于需要集群计算资源,往往被认为只有大公司才能配置,普通开发者很难上手。通过使用全功能AI开发平台BML,也有机会在预算有限的情况下使用自动超参数搜索,开发效率瞬间赶上火箭速度,摆脱人类“炼金术”的束缚”。新BML用户现在还提供100小时免费P4显卡算力,羊毛在向你招手,快来咬一口吧! 查看全部
算法 自动采集列表(方法网格搜索随机搜索贝叶斯搜索的实现:系统架构BML自动超参搜索功能)
方法
网格搜索
随机搜索
贝叶斯搜索
进化算法
优势
实现简单,效果取决于用户设置的网格间隔大小
进行多参数联合搜索时,扩大了各参数的搜索范围,提高了搜索效率。
搜索迭代次数少,效率高,通过贝叶斯算法在已有采样点的帮助下估计最优超参数。
减少每轮迭代的训练时间,将计算资源集中在参数搜索上,通过重用具有良好历史表现的个体的预训练参数来加速收敛
缺点
消耗计算资源
效果不稳定
可能陷入局部最优
因超参数导致模型结构变化等因素无法加载预训练参数时不适用
自动超参数搜索方法的比较
上表总结了这些搜索方法的优缺点。总之,网格搜索和随机搜索实现起来比较简单,不使用先验知识来选择下一组超参数,随机搜索比较高效。贝叶斯搜索和进化算法需要利用上一轮的信息进行迭代搜索,搜索效率显着提高。
BML自动超参数搜索的实现:系统架构
BML自动超参数搜索功能是基于自主研发的自动超参数搜索服务。服务操作流程如下图所示。它依托百度智能云CCE的计算能力,同时支持多个自动搜索任务。为了提供“好用”的自动超参数搜索服务,架构实现侧重于提高并发搜索效率和系统容错能力。
一个超参数搜索任务包括以下过程:
1.业务平台将超参搜索任务的用户配置信息提交给超参搜索服务,会创建一个搜索实验(Experiment)并记录在db中。
2.搜索服务向实验控制器提交任务,实验控制器初始化并创建试验管理模块,负责试验生命周期的管理。
3.Trial 是一个特定的训练实验。一个实验将产生多个试验,以探索不同超参数组合的最终效果。Tuner 是一个超参数生成模块,根据选择的超参数搜索算法推荐下一次 Trial 使用的超参数值。在 Trial 管理模块中,Exp Manager 将负责生成多个 Trial,向 Tuner 请求特定的测试超参数,并将 Trial 任务信息发送给 Trial Scheduler。
4.Trial Scheduler 将与底层资源交互以实际启动 Trial。Trial Scheduler 管理所有试验的生命周期。
5.每次试用完成后,会将指标等信息上报给Exp Manager,用于上报给tuner并记录到db。
BML自动超参数搜索主要有以下特点:
动手实践:如何使用自动超参数搜索
1.先点击
创建一个脚本参数调整项目,如果你已经有项目,可以直接使用!目前,支持超参数搜索的项目类型包括图像分类(单标签和多标签)和对象检测。只需创建相应类型的项目。
2.在工程中新建任务,配置任务的网络、数据、脚本,可以看到“配置超参数”选项。如果这里已经有超参数搜索结果,可以直接勾选“Existing hyperparameter search results”来使用。如果我们不是第一次使用它,只需选择“自动超参数搜索”即可。
3.目前BML支持三种超参数搜索算法,如图,分别是贝叶斯搜索、随机搜索和进化算法。您可以根据需要选择一种进行搜索。具体配置项说明请参考技术文档。
3.1 贝叶斯搜索的参数说明
【初始点数】表示贝叶斯搜索初始化时参数点的个数。该算法根据这些参数信息推断出最优点,并填充在1-20的范围内。
[最大并发] 在贝叶斯搜索中,同时实验的数量。并发越大,搜索效率越高。填写1-20的范围。不过这个并发也受限于页面底部选择的GPU数量,实际并发是两者中较小的一个。
【超参数范围设置】:可以是默认配置,也可以是手动配置。默认情况下,百度的工程师已经帮我们设置了针对不同网络和GPU卡类型的基本可靠的搜索范围,可以直接使用。当然也可以手动配置,可以自定义每个超参数的范围。可以看到物体检测支持以下超参数自定义搜索范围:
【最大搜索次数】:指可以组合并运行测试的最大超参数组数。当然也可能因为提前达到目标而停止,节省成本。
【数据采样率】:使用超参数搜索时,会在训练前对原创数据集进行采样,以加快搜索速度。当数据集不大时,不建议采样,可能会影响最终效果。只有当数据量很大时才需要使用采样。
【Highest mAP/Highest Accuracy Rate】:指每个人都期望模型达到的效果的mAP(物体检测)或准确率(图像分类)的值。当实验中达到这个值时,搜索将停止,以避免将来浪费搜索时间。.
3.2 随机搜索参数说明
随机搜索是最简单的,不需要额外配置算法相关的参数。其他常见选项与贝叶斯搜索具有相同的含义。你可以参考贝叶斯搜索。
3.3 进化算法参数说明
进化算法是一种更好的算法,应用该算法时需要更多的选项。
【迭代轮次】:进化算法运行的迭代次数,范围为5-50。
【扰动区间】:进化算法每隔几个epoch就会随机扰动一次,利用随机因素防止算法结果收敛到局部最优解。
【扰动比】:类似于染色体交叉的形式,在迭代中根据扰动比对种群中最好和最差的个体进行交叉。
【随机初始化概率】:在扰动中,有一定概率初始化各个超参数。
【种群中的个体数】:一个个体代表一个超参数设置,一个种群收录多个个体。
其他选项与贝叶斯搜索含义相同,不再赘述。进化算法的配置需要对算法的原理有一定的了解。不懂算法的就用百度给出的默认值吧!
4.超参数选项设置完成,最后选择GPU卡的类型和数量,以及最大搜索时间,就可以提交任务了!此处的默认搜索时间为 24 小时。毕竟超参数搜索会运行多次测试,需要很长时间,需要耐心。当然,你选择的 GPU 卡越多,并发测试的数量就越高。从提交任务到搜索 完成时间会更短,这是显而易见的
5.任务提交后,一段时间后任务进入“超参搜索”状态,可以看到每个实验的进度,包括每个实验的状态、日志和准确率(mAP)
6.超参数搜索训练完成后,可以在5个结果最好的实验中看到详细的评估结果,也可以用于后续的效果验证和发布。当然,如果在超参数搜索过程中对数据进行了采样,此时可以重新启动训练任务,使用本次搜索结果满意的超参数进行全数据训练,从而获得完整的模型效果数据。
效果是硬道理:超参搜索效果提升高达20%+
我们使用通用脚本参数调整和超参数搜索比较了图像分类、对象检测、实例分割和其他任务的效果。进化算法和使用贝叶斯搜索算法的超参数搜索的效果比较。图中左纵轴是模型的准确率,右纵轴是超参数搜索算法生效的比例。可以看出,在不同数据集上使用超参数搜索的效果有所提升。当默认参数准确率已经超过 85% 时,使用超参数搜索仍然可以提高 5% 左右。在默认参数效果不佳的情况下,超参数搜索的提升效果更为明显,可高达22%。
正常运行下,可用的深度学习自动超参搜索由于需要集群计算资源,往往被认为只有大公司才能配置,普通开发者很难上手。通过使用全功能AI开发平台BML,也有机会在预算有限的情况下使用自动超参数搜索,开发效率瞬间赶上火箭速度,摆脱人类“炼金术”的束缚”。新BML用户现在还提供100小时免费P4显卡算力,羊毛在向你招手,快来咬一口吧!
算法 自动采集列表(易企CMS采集的配置及配置集,你值得拥有)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-25 18:16
Easy Enterprisecms采集,当网站上线时,它面临的最大问题是网站内容缺失,或者更新不及时。网站维护需要投入的人力财力越大,长期以来,网站运营商一直在追求最大限度降低成本,获得最高品质的能力网站内容。亿奇cms采集依托高效强大的网络信息采集与整合,与网站对接后,持续为网站提供优质、实时的数据,省去您投入更多人力来四处寻找文章资源的需要。
如果网站位于私网范围内,那么网站就会陷入网络扩容和内容补充的困境,只能依靠人工在网上采集相关信息再复制到内网并将其导入到 网站 上。通过Easy Enterprisecms采集,现在不用那么麻烦了,可以自动采集发布和编辑,让网站管理者可以专注于内容质量审查和审查 网站 上面的整体 SEO。
Easy Enterprisecms采集预设了30多个插件提升网站的排名,通过这些插件优化发布内容的排名,从而提升 的排名。根据网站的行业,它可以自动确定发布到网站的每条内容的“长尾词”,并自动调整发布内容的关键词密度。自动制作发布图片的alt属性,并根据发布的内容自动为内容中的图片生成相应的alt描述。
Easy Enterprisecms采集有4个高效的网络信息采集功能。主题采集,您只需输入关键字即可根据网站的主题设置要求采集符合要求的网络信息,不再需要手动搜索。定位采集,可以与其他同类网站保持同步,只需输入目标网站的地址,即可自动采集同类网站的信息进行筛选。
易奇cms采集随后进行针对性采集,无需在新闻源平台手动采集相关行业的文章。通过目标采集功能,只有目标网站的地址和关键字才行。配置采集,网站可以对信息源进行深度设置为采集,保证采集的数据内容准确完整,满足您的网站要求。
Easy Enterprisecms采集,通过5层网络信息过滤,使网站不会产生垃圾链接。对目标网站的原创信息源的链接的通道和链接类型进行数据过滤。除了标题过滤外,采集的数据源的标题还通过关键字识别和标题重复检查来过滤。内容过滤,通过对采集的数据内容进行HASH算法,保证采集的内容不重复。
结合字段过滤,可以对采集的内容的字段值进行过滤比较,保证采集的各个字段的内容符合要求。组合过滤,通过对采集的内容的多个字段值进行组合比较,确保匹配多个字段组合的内容符合要求。返回搜狐,查看更多 查看全部
算法 自动采集列表(易企CMS采集的配置及配置集,你值得拥有)
Easy Enterprisecms采集,当网站上线时,它面临的最大问题是网站内容缺失,或者更新不及时。网站维护需要投入的人力财力越大,长期以来,网站运营商一直在追求最大限度降低成本,获得最高品质的能力网站内容。亿奇cms采集依托高效强大的网络信息采集与整合,与网站对接后,持续为网站提供优质、实时的数据,省去您投入更多人力来四处寻找文章资源的需要。
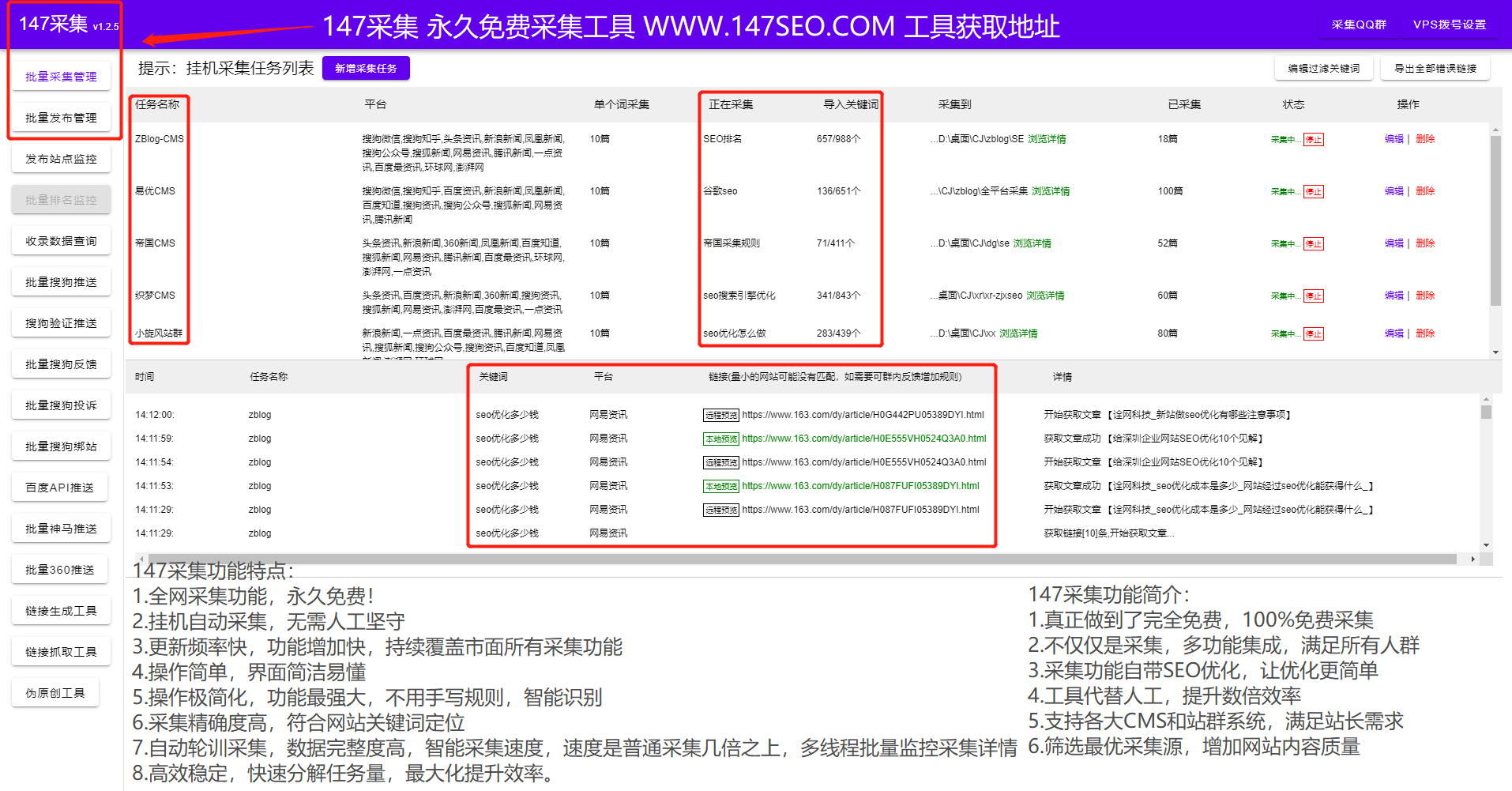
如果网站位于私网范围内,那么网站就会陷入网络扩容和内容补充的困境,只能依靠人工在网上采集相关信息再复制到内网并将其导入到 网站 上。通过Easy Enterprisecms采集,现在不用那么麻烦了,可以自动采集发布和编辑,让网站管理者可以专注于内容质量审查和审查 网站 上面的整体 SEO。
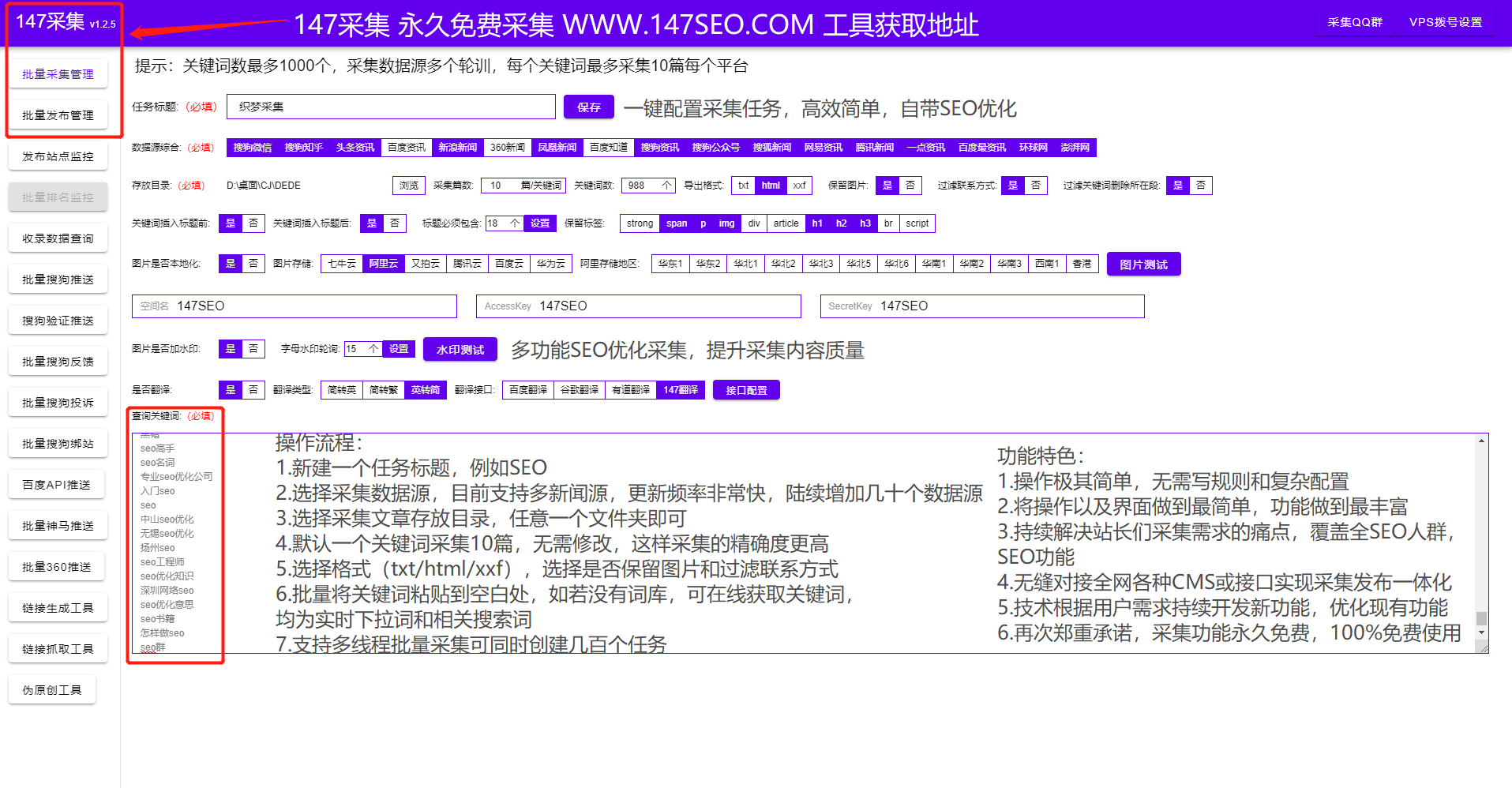
Easy Enterprisecms采集预设了30多个插件提升网站的排名,通过这些插件优化发布内容的排名,从而提升 的排名。根据网站的行业,它可以自动确定发布到网站的每条内容的“长尾词”,并自动调整发布内容的关键词密度。自动制作发布图片的alt属性,并根据发布的内容自动为内容中的图片生成相应的alt描述。
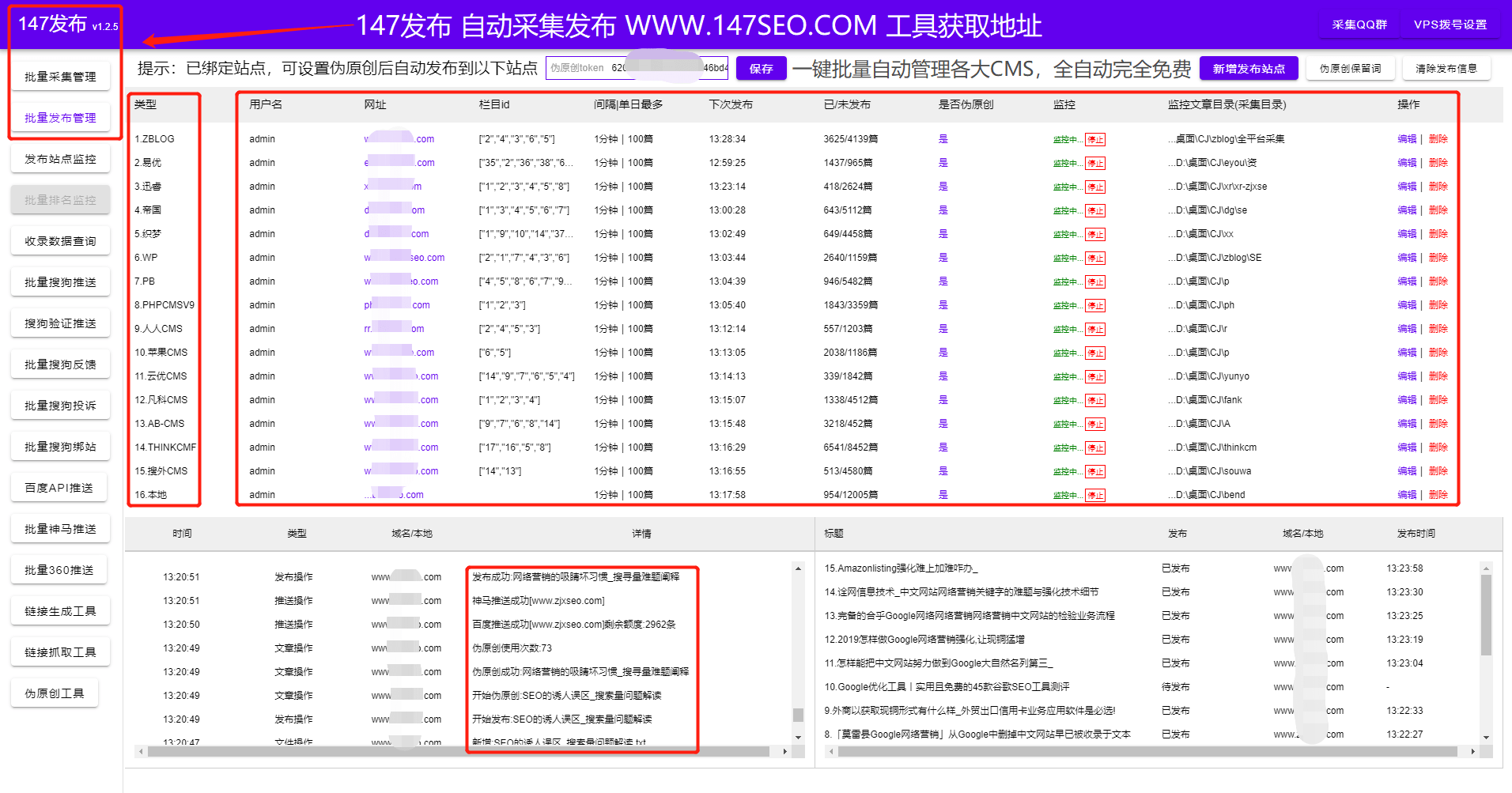
Easy Enterprisecms采集有4个高效的网络信息采集功能。主题采集,您只需输入关键字即可根据网站的主题设置要求采集符合要求的网络信息,不再需要手动搜索。定位采集,可以与其他同类网站保持同步,只需输入目标网站的地址,即可自动采集同类网站的信息进行筛选。
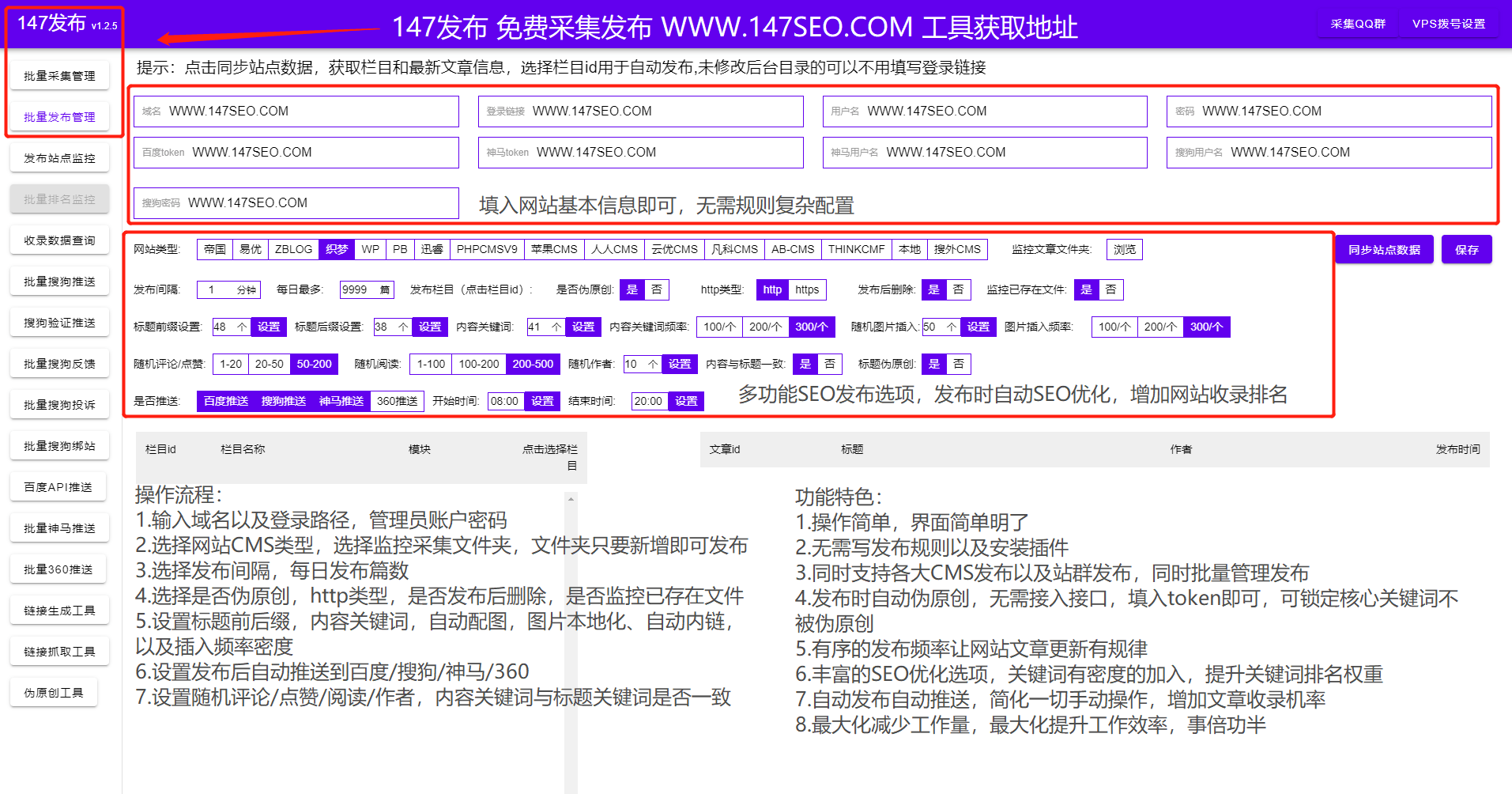
易奇cms采集随后进行针对性采集,无需在新闻源平台手动采集相关行业的文章。通过目标采集功能,只有目标网站的地址和关键字才行。配置采集,网站可以对信息源进行深度设置为采集,保证采集的数据内容准确完整,满足您的网站要求。
Easy Enterprisecms采集,通过5层网络信息过滤,使网站不会产生垃圾链接。对目标网站的原创信息源的链接的通道和链接类型进行数据过滤。除了标题过滤外,采集的数据源的标题还通过关键字识别和标题重复检查来过滤。内容过滤,通过对采集的数据内容进行HASH算法,保证采集的内容不重复。

结合字段过滤,可以对采集的内容的字段值进行过滤比较,保证采集的各个字段的内容符合要求。组合过滤,通过对采集的内容的多个字段值进行组合比较,确保匹配多个字段组合的内容符合要求。返回搜狐,查看更多
算法 自动采集列表(基于目录树的采集算法研究)
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-03-16 10:28
Science technologyresources, Information crawling, Directory tree, Ontology Essentials:本文结合网络技术领域各种资源分类方式和大量数据的特点,提出了一种基于目录树的采集算法. 该算法首先使用领域本体知识库提供的本体。以知识作为评价依据,提取和识别有效目录链接,然后通过改进的链接分析策略获得有效节点链接,最后进行采集操作。考虑到网络技术领域各种资源分类方法和大量数据的特点。该算法首先使用领域本体知识库提供的本体。以知识作为评价依据,提取和识别有效目录链接,然后通过改进的链接分析策略获得有效节点链接,最后进行采集操作。考虑到网络技术领域各种资源分类方法和大量数据的特点。该算法首先使用领域本体知识库提供的本体。以知识作为评价依据,提取和识别有效目录链接,然后通过改进的链接分析策略获得有效节点链接,最后进行采集操作。
该算法不仅对采集的架构进行了深入研究,还注重对最新资源获取速度的优化。实践证明,该算法可以有效提高采集的率。关键词:科技资源、信息采集、目录树、本体介绍 当今互联网发展迅速,科技领域的信息资源极其丰富。充分利用网络,关注科技资源的开发利用,是当前科研人员的一项重要任务。一。网络科技资源的开发利用是科技创新的基础,而科技人员的创新能力在很大程度上取决于对科技信息资源的利用。挖掘网络科技资源,不仅为科技人员研发提供了可靠、丰富的信息,节省了大量的文献查阅时间,也为科研项目的认定、评价、验收提供了客观依据的科技成果。采集 非常重要。通常信息采集主要是借助各种搜索引擎完成的,而采集算法程序是搜索引擎的核心部分。然而,随着网络资源的不断扩展和专业领域对信息检索服务的需求不断增加,通用搜索引擎广泛采用的遍历搜索策略(如广度优先算法)已不再适用。面对网络技术资源分类复杂、数量庞大的特点,传统搜索引擎效率低下,使得网络上的技术信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。一般搜索引擎广泛使用的遍历搜索策略(如广度优先算法)不再适用。面对网络技术资源分类复杂、数量庞大的特点,传统搜索引擎效率低下,使得网络上的技术信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。一般搜索引擎广泛使用的遍历搜索策略(如广度优先算法)不再适用。面对网络技术资源分类复杂、数量庞大的特点,传统搜索引擎效率低下,使得网络上的技术信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。使得网络上的科技信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。使得网络上的科技信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。
每个资源网站都有自己的分类标准,但是单个网站分类目录清晰,层次更清晰,每个分类目录下的资源类别也比较统一。数据量巨大且增长迅速。据不完全统计,整个互联网提供的科技信息总量超过20TB,HTML标记语言正以每年25%以上的速度被激发。用户访问和使用。根据网络技术资源的特点和项目需求,通过采集互联网上的技术资源采集大量技术数据,经过处理后,构建资源目录服务系统,将共享资源呈现给用户. 本文提出的目录树采集算法是基于已建立的资源分类方法网站和本体技术构建分类目录树,具有层次化的采集网络技术根据目录树的结构。资源。基于目录树的采集架构分析,不难发现网上技术资源网站的特点。相同或相似类别的数据资源通常显示在同一子列中。如果把 网站 的主页视为根目录,那么我们可以将 网站 中的每一列称为子目录,该列的链接称为子目录链接。当然,不同的 网站 子目录也可以嵌入Set多个子目录;列下的每个资源条目称为叶节点,指向资源条目的链接称为节点链接,同一列下的节点链接称为兄弟节点链接。
采集,按照从根目录到子目录,再到叶子节点的顺序,分层执行采集工作。图1 是基于本体的目录树采集系统结构 基于目录树的采集系统的系统结构如下: 逐层过滤链接的策略。通过分析网站链接之间的层次关系,构建站点内链接的目录层次结构,并在此基础上采集网络资源链接信息库。保存URL链接之间的相互链接关系,链接周围的URL字符串和锚文本提示信息,以及采集过程中的URL链接状态记录。链接信息库的结构设计如图2所示。在明确某个领域共有的概念以及概念之间的关系的基础上,构建了该领域的概念树,主要包括一个主题词库和一个主题词库。可以根据实际爬取过程中出现的新概念的高频率进行更新和维护。Website 1TABLE1 Website 2TABLE2 Website 3TABLE3 Serial Number Seed Link NFO1 Directory NFO2 Node NFO3 Node Serial Number Link Name Anchor Text Category Status TABLE1 Link Database Structure 在采集的过程中,根据网站地址和参数信息由用户提交,创建根目录,提取首页所有站内链接,然后进行链接分析,确定链接的类别。如果是目录链接,以领域本体知识库提供的本体知识为评价依据,创建目录树,提取页面中的所有链接。对站内链接进行链接分析;如果是节点链接,则对页面进行爬取,保证同目录下所有item链接指向的页面内容存放在同一个目录下。
架构分析4.1 目录链接的提取本文采用W3C提供的LIBWWW库,首先从资源网站的起始页中提取所有站内链接,提取每个对应的锚文本URL 链接同时(链接描述文本)信息,并将所有信息存储在链接信息库中,然后使用以下方法过滤目录链接。目录链接指向的页面是目录页面。我们通过判断链接指向的页面是否为目录页面来判断该链接是否为目录链接。因此,目录页面与网站其他页面的区别特征是我们需要探索的。目录页面是站点中的一个特殊页面,其内容主要是资源列表展示,包括一定数量的节点链接集合。分析发现,页面中的兄弟节点链接在URL表达上具有相似性,包括脚本名称、参数名称、参数个数等。链接对应的锚文本是资源信息内容的摘要。这些链接描述信息通常具有完整的语义,与页面中的其他链接不同。提取思路总结如下: 提取种子页中的所有链接和锚文本信息。如果满足以下条件:一定比例的链接 URL 形式相似,并且所有链接的锚文本信息的平均长度大于设定值,我们将此类链接归类为主题链接。
有效目录链接提取 有效节点链接提取 判断和识别待判断节点的有效目录链接,并非目录链接所指向的页面的所有内容都满足用户的需求。在进行爬取操作之前,需要对目录链接进行分析判断,剔除无效链接,保证爬取的准确性和效率。本文使用预定义的领域本体库作为识别有效目录链接的基础。领域本体库用于识别特定应用领域中的知识,是关于某个主题的知识对象的集合。它对概念层次和概念与属性之间的关系有很好的定义,因此可以很容易地获得一个词的同义词或上下同义词。领域本体知识库中对象的值可以来自数据库或特定应用程序的输出,甚至领域专家也可以手动构建这样的本体库。根据需要,本文以网络技术资源应用集成环境建设项目组构建的科技领域本体为基础,识别有效目录链接。本科技领域本体库中的对象实例如图4所示。 lassific 本文以网络技术资源应用集成环境建设项目组构建的科技领域本体为基础,识别有效目录链接。本科技领域本体库中的对象实例如图4所示。 lassific 本文以网络技术资源应用集成环境建设项目组构建的科技领域本体为基础,识别有效目录链接。本科技领域本体库中的对象实例如图4所示。 lassific 查看全部
算法 自动采集列表(基于目录树的采集算法研究)
Science technologyresources, Information crawling, Directory tree, Ontology Essentials:本文结合网络技术领域各种资源分类方式和大量数据的特点,提出了一种基于目录树的采集算法. 该算法首先使用领域本体知识库提供的本体。以知识作为评价依据,提取和识别有效目录链接,然后通过改进的链接分析策略获得有效节点链接,最后进行采集操作。考虑到网络技术领域各种资源分类方法和大量数据的特点。该算法首先使用领域本体知识库提供的本体。以知识作为评价依据,提取和识别有效目录链接,然后通过改进的链接分析策略获得有效节点链接,最后进行采集操作。考虑到网络技术领域各种资源分类方法和大量数据的特点。该算法首先使用领域本体知识库提供的本体。以知识作为评价依据,提取和识别有效目录链接,然后通过改进的链接分析策略获得有效节点链接,最后进行采集操作。
该算法不仅对采集的架构进行了深入研究,还注重对最新资源获取速度的优化。实践证明,该算法可以有效提高采集的率。关键词:科技资源、信息采集、目录树、本体介绍 当今互联网发展迅速,科技领域的信息资源极其丰富。充分利用网络,关注科技资源的开发利用,是当前科研人员的一项重要任务。一。网络科技资源的开发利用是科技创新的基础,而科技人员的创新能力在很大程度上取决于对科技信息资源的利用。挖掘网络科技资源,不仅为科技人员研发提供了可靠、丰富的信息,节省了大量的文献查阅时间,也为科研项目的认定、评价、验收提供了客观依据的科技成果。采集 非常重要。通常信息采集主要是借助各种搜索引擎完成的,而采集算法程序是搜索引擎的核心部分。然而,随着网络资源的不断扩展和专业领域对信息检索服务的需求不断增加,通用搜索引擎广泛采用的遍历搜索策略(如广度优先算法)已不再适用。面对网络技术资源分类复杂、数量庞大的特点,传统搜索引擎效率低下,使得网络上的技术信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。一般搜索引擎广泛使用的遍历搜索策略(如广度优先算法)不再适用。面对网络技术资源分类复杂、数量庞大的特点,传统搜索引擎效率低下,使得网络上的技术信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。一般搜索引擎广泛使用的遍历搜索策略(如广度优先算法)不再适用。面对网络技术资源分类复杂、数量庞大的特点,传统搜索引擎效率低下,使得网络上的技术信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。使得网络上的科技信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。使得网络上的科技信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。
每个资源网站都有自己的分类标准,但是单个网站分类目录清晰,层次更清晰,每个分类目录下的资源类别也比较统一。数据量巨大且增长迅速。据不完全统计,整个互联网提供的科技信息总量超过20TB,HTML标记语言正以每年25%以上的速度被激发。用户访问和使用。根据网络技术资源的特点和项目需求,通过采集互联网上的技术资源采集大量技术数据,经过处理后,构建资源目录服务系统,将共享资源呈现给用户. 本文提出的目录树采集算法是基于已建立的资源分类方法网站和本体技术构建分类目录树,具有层次化的采集网络技术根据目录树的结构。资源。基于目录树的采集架构分析,不难发现网上技术资源网站的特点。相同或相似类别的数据资源通常显示在同一子列中。如果把 网站 的主页视为根目录,那么我们可以将 网站 中的每一列称为子目录,该列的链接称为子目录链接。当然,不同的 网站 子目录也可以嵌入Set多个子目录;列下的每个资源条目称为叶节点,指向资源条目的链接称为节点链接,同一列下的节点链接称为兄弟节点链接。
采集,按照从根目录到子目录,再到叶子节点的顺序,分层执行采集工作。图1 是基于本体的目录树采集系统结构 基于目录树的采集系统的系统结构如下: 逐层过滤链接的策略。通过分析网站链接之间的层次关系,构建站点内链接的目录层次结构,并在此基础上采集网络资源链接信息库。保存URL链接之间的相互链接关系,链接周围的URL字符串和锚文本提示信息,以及采集过程中的URL链接状态记录。链接信息库的结构设计如图2所示。在明确某个领域共有的概念以及概念之间的关系的基础上,构建了该领域的概念树,主要包括一个主题词库和一个主题词库。可以根据实际爬取过程中出现的新概念的高频率进行更新和维护。Website 1TABLE1 Website 2TABLE2 Website 3TABLE3 Serial Number Seed Link NFO1 Directory NFO2 Node NFO3 Node Serial Number Link Name Anchor Text Category Status TABLE1 Link Database Structure 在采集的过程中,根据网站地址和参数信息由用户提交,创建根目录,提取首页所有站内链接,然后进行链接分析,确定链接的类别。如果是目录链接,以领域本体知识库提供的本体知识为评价依据,创建目录树,提取页面中的所有链接。对站内链接进行链接分析;如果是节点链接,则对页面进行爬取,保证同目录下所有item链接指向的页面内容存放在同一个目录下。
架构分析4.1 目录链接的提取本文采用W3C提供的LIBWWW库,首先从资源网站的起始页中提取所有站内链接,提取每个对应的锚文本URL 链接同时(链接描述文本)信息,并将所有信息存储在链接信息库中,然后使用以下方法过滤目录链接。目录链接指向的页面是目录页面。我们通过判断链接指向的页面是否为目录页面来判断该链接是否为目录链接。因此,目录页面与网站其他页面的区别特征是我们需要探索的。目录页面是站点中的一个特殊页面,其内容主要是资源列表展示,包括一定数量的节点链接集合。分析发现,页面中的兄弟节点链接在URL表达上具有相似性,包括脚本名称、参数名称、参数个数等。链接对应的锚文本是资源信息内容的摘要。这些链接描述信息通常具有完整的语义,与页面中的其他链接不同。提取思路总结如下: 提取种子页中的所有链接和锚文本信息。如果满足以下条件:一定比例的链接 URL 形式相似,并且所有链接的锚文本信息的平均长度大于设定值,我们将此类链接归类为主题链接。
有效目录链接提取 有效节点链接提取 判断和识别待判断节点的有效目录链接,并非目录链接所指向的页面的所有内容都满足用户的需求。在进行爬取操作之前,需要对目录链接进行分析判断,剔除无效链接,保证爬取的准确性和效率。本文使用预定义的领域本体库作为识别有效目录链接的基础。领域本体库用于识别特定应用领域中的知识,是关于某个主题的知识对象的集合。它对概念层次和概念与属性之间的关系有很好的定义,因此可以很容易地获得一个词的同义词或上下同义词。领域本体知识库中对象的值可以来自数据库或特定应用程序的输出,甚至领域专家也可以手动构建这样的本体库。根据需要,本文以网络技术资源应用集成环境建设项目组构建的科技领域本体为基础,识别有效目录链接。本科技领域本体库中的对象实例如图4所示。 lassific 本文以网络技术资源应用集成环境建设项目组构建的科技领域本体为基础,识别有效目录链接。本科技领域本体库中的对象实例如图4所示。 lassific 本文以网络技术资源应用集成环境建设项目组构建的科技领域本体为基础,识别有效目录链接。本科技领域本体库中的对象实例如图4所示。 lassific
算法 自动采集列表(dede采集可以网站主动推送给搜索引擎你网站的链接吗 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-03-13 05:02
)
最近有很多站长问我有没有什么好用的dede采集插件。dedecms自带的采集功能比较简单,很少有SEO相关的优化,比如自动百度、搜狗、360、神马推送。
比如不支持伪原创online伪原创,不支持文章聚合,不支持tag标签聚合。下面我要说的dede采集不仅支持文章聚合,还支持tag标签聚合。Dede采集发布后,可以被百度、搜狗、神马、360自动推送。可以从采集批量伪原创处理文章更方便@>。内容处理充分利用了 SEO。
dede采集
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用dede采集实现自动采集伪原创发布,主动推送给搜索引擎,提高搜索引擎的抓取频率,
本dedecms采集操作简单,无需学习专业技术,简单几步即可轻松采集内容数据,用户只需dedecms< @在采集工具上进行简单设置,工具会根据用户设置的关键词准确采集文章,保证与行业 文章。采集文章 from 采集可以选择将修改后的内容保存到本地,也可以直接选择在软件上发布。
与其他dede采集相比,这个工具使用非常简单,输入关键词即可实现采集,dede采集配备关键词采集 @> 函数。只需设置任务,全程自动挂机!
dede采集无论你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。最重要的是这个dede采集有很多SEO功能,不仅可以提高网站的收录,还可以增加关键词的密度,提高网站 的排名。
dede采集
dede采集可以主动推送网站,让搜索引擎更快发现我们的站点,支持推送到百度、神马、360、搜狗等四大搜索引擎,并主动曝光Giving搜索引擎您的 网站 链接对 SEO 优化非常有益。
dede采集随时随地都可以看到好看的文章,点击浏览器书签即可采集网站的公开内容!dede采集可以自动采集按照设定的时间表(每周、每天、每小时等)发布,dede采集轻松实现内容定时自动更新,无需人工值守。
dede采集
[字段:id runphp='yes'] 全局 $cfg_cms路径;$tags = GetTags(@me); $revalue = ''; $tags = explode(',', $tags); foreach( $tags as $key => $value){ if($value){ $revalue .= ''.$value.' '; } } @me = $revalue; [/字段:id]
dede采集也可以自动匹配图片,dede采集文章没有图片的内容会自动配置相关图片,dede采集设置自动下载图片保存本地或第三方, dede 采集让内容不再有对方的外部链接。
无需编写规则,无需研究网页源代码,可视化界面操作,采集鼠标选择,点击保存,就这么简单!支持:动态或固定段落随机插入(不影响阅读)、标题插入关键词、自动内链、简繁转换、翻译、接入第三方API等。
dede采集
dede采集可以自动链接,dede采集让搜索引擎更深入地抓取你的链接,dede采集可以在内容或标题前后插入段落或关键词,dede< @采集可选标题和插入同一个关键词的标题。只需输入 URL 即可自动识别数据和规则,包括:列表页、翻页和详情页(标题、正文、作者、出版时间、标签等)。
dede采集可以网站内容插入或随机作者、随机阅读等到"height原创"。dede采集可以优化出现关键词的文本的相关性,并自动将文本首段加粗,自动插入title标题,并自动添加当前采集关键词 当描述相关性较低时。文本在随机位置自动插入当前 采集关键词2 次。当当前 采集 的 关键词 出现在文本中时,关键词 将自动加粗。
由 dede 发表
dede采集的数据导出支持多种格式:excel、csv、sql(mysql)。采集在使用数据的时候,只需要输入一个URL(网址),平台会首先使用智能算法提取数据,包括列表页、翻页、详情页。如果智能提取不准确,用户还可以利用在线可视化工具“规则提取器”进行修改,只需鼠标选择并点击即可。
dede采集可以定期发布dede采集文章,让搜索引擎及时抓取你的网站内容。
今天关于织梦采集的解释就到这里了。我希望它可以帮助您在建立您的网站的道路上。下一期我会分享更多与SEO相关的实用干货。
查看全部
算法 自动采集列表(dede采集可以网站主动推送给搜索引擎你网站的链接吗
)
最近有很多站长问我有没有什么好用的dede采集插件。dedecms自带的采集功能比较简单,很少有SEO相关的优化,比如自动百度、搜狗、360、神马推送。
比如不支持伪原创online伪原创,不支持文章聚合,不支持tag标签聚合。下面我要说的dede采集不仅支持文章聚合,还支持tag标签聚合。Dede采集发布后,可以被百度、搜狗、神马、360自动推送。可以从采集批量伪原创处理文章更方便@>。内容处理充分利用了 SEO。

dede采集
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用dede采集实现自动采集伪原创发布,主动推送给搜索引擎,提高搜索引擎的抓取频率,
本dedecms采集操作简单,无需学习专业技术,简单几步即可轻松采集内容数据,用户只需dedecms< @在采集工具上进行简单设置,工具会根据用户设置的关键词准确采集文章,保证与行业 文章。采集文章 from 采集可以选择将修改后的内容保存到本地,也可以直接选择在软件上发布。
与其他dede采集相比,这个工具使用非常简单,输入关键词即可实现采集,dede采集配备关键词采集 @> 函数。只需设置任务,全程自动挂机!
dede采集无论你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。最重要的是这个dede采集有很多SEO功能,不仅可以提高网站的收录,还可以增加关键词的密度,提高网站 的排名。
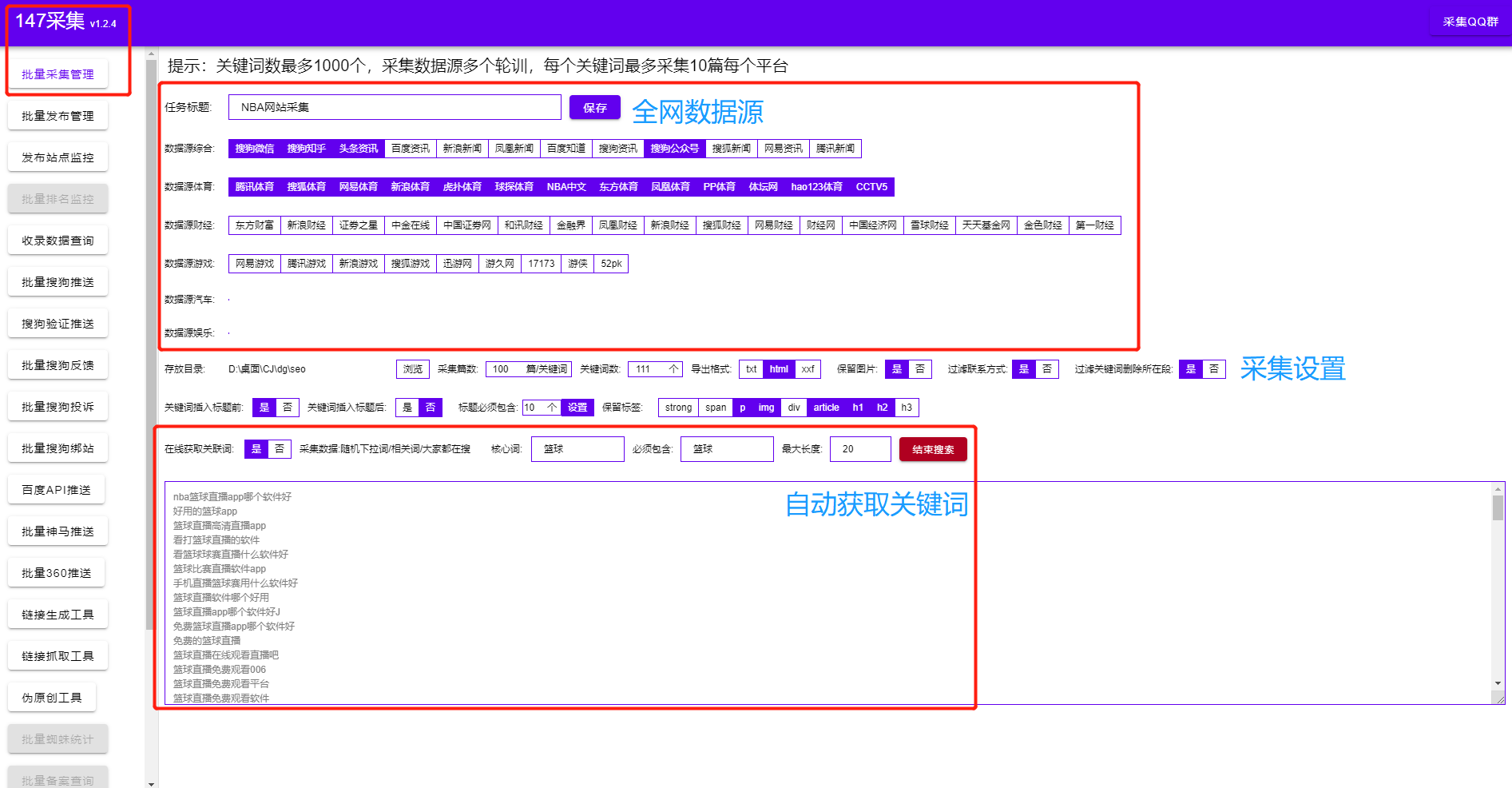
dede采集
dede采集可以主动推送网站,让搜索引擎更快发现我们的站点,支持推送到百度、神马、360、搜狗等四大搜索引擎,并主动曝光Giving搜索引擎您的 网站 链接对 SEO 优化非常有益。
dede采集随时随地都可以看到好看的文章,点击浏览器书签即可采集网站的公开内容!dede采集可以自动采集按照设定的时间表(每周、每天、每小时等)发布,dede采集轻松实现内容定时自动更新,无需人工值守。
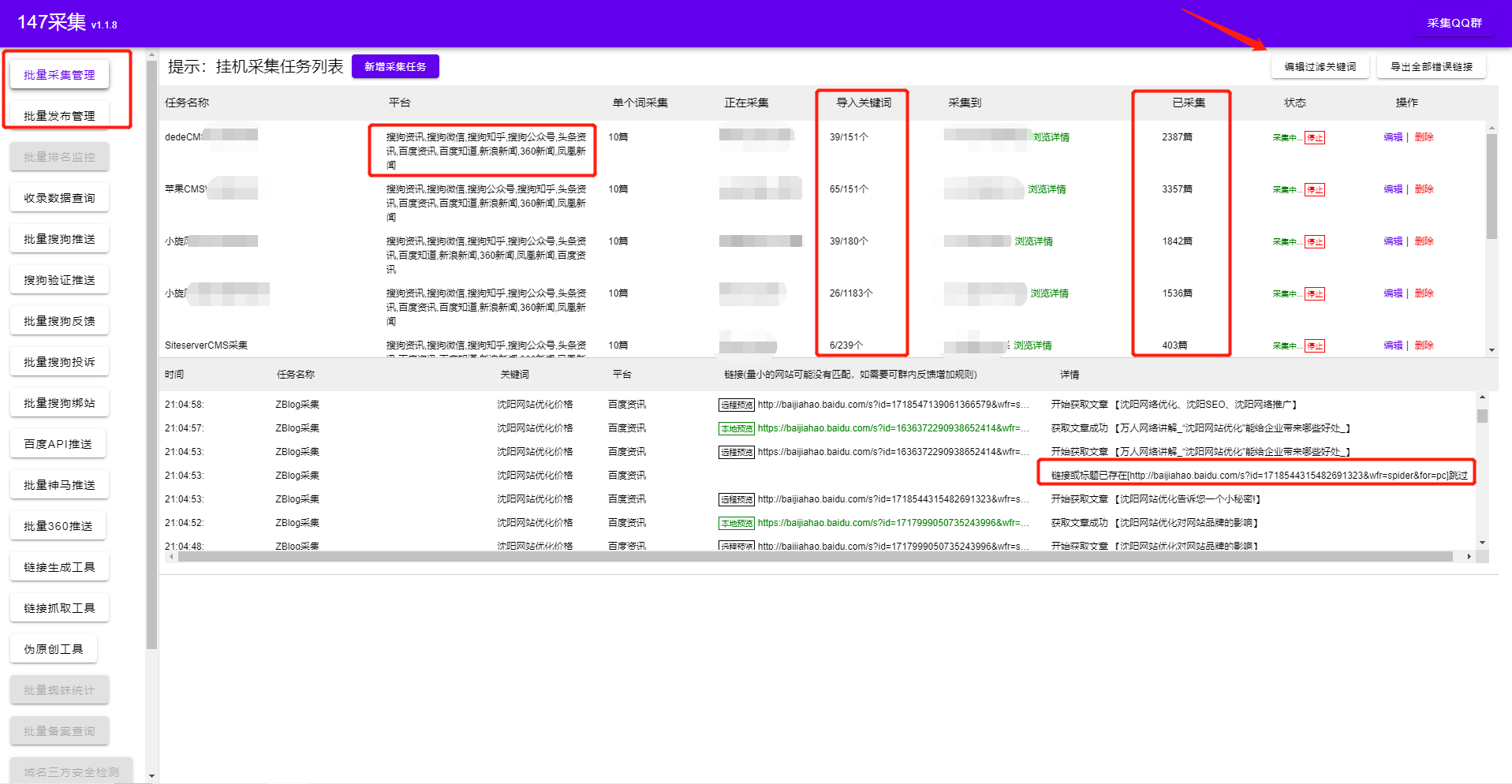
dede采集
[字段:id runphp='yes'] 全局 $cfg_cms路径;$tags = GetTags(@me); $revalue = ''; $tags = explode(',', $tags); foreach( $tags as $key => $value){ if($value){ $revalue .= ''.$value.' '; } } @me = $revalue; [/字段:id]
dede采集也可以自动匹配图片,dede采集文章没有图片的内容会自动配置相关图片,dede采集设置自动下载图片保存本地或第三方, dede 采集让内容不再有对方的外部链接。
无需编写规则,无需研究网页源代码,可视化界面操作,采集鼠标选择,点击保存,就这么简单!支持:动态或固定段落随机插入(不影响阅读)、标题插入关键词、自动内链、简繁转换、翻译、接入第三方API等。
dede采集
dede采集可以自动链接,dede采集让搜索引擎更深入地抓取你的链接,dede采集可以在内容或标题前后插入段落或关键词,dede< @采集可选标题和插入同一个关键词的标题。只需输入 URL 即可自动识别数据和规则,包括:列表页、翻页和详情页(标题、正文、作者、出版时间、标签等)。
dede采集可以网站内容插入或随机作者、随机阅读等到"height原创"。dede采集可以优化出现关键词的文本的相关性,并自动将文本首段加粗,自动插入title标题,并自动添加当前采集关键词 当描述相关性较低时。文本在随机位置自动插入当前 采集关键词2 次。当当前 采集 的 关键词 出现在文本中时,关键词 将自动加粗。
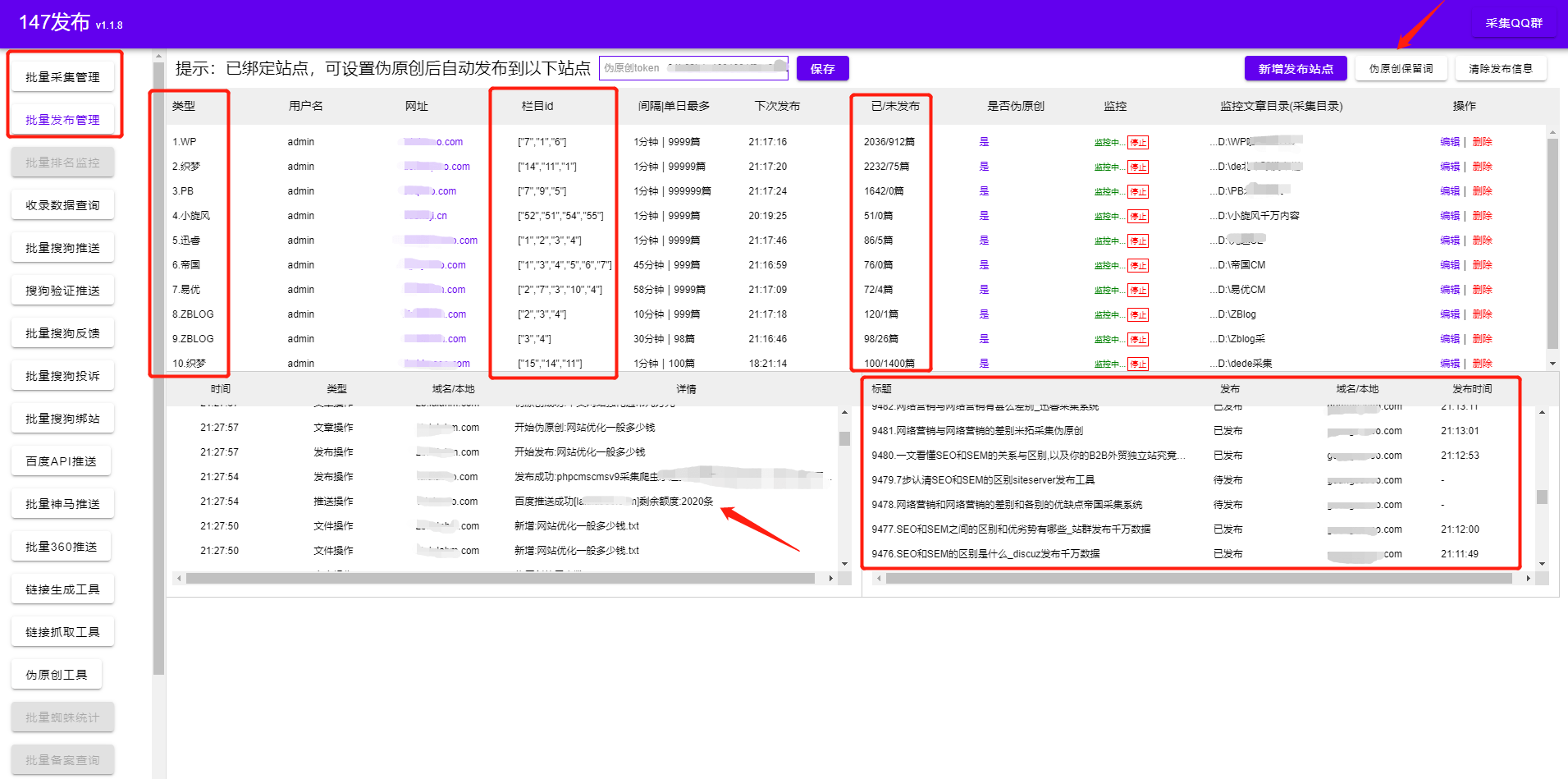
由 dede 发表
dede采集的数据导出支持多种格式:excel、csv、sql(mysql)。采集在使用数据的时候,只需要输入一个URL(网址),平台会首先使用智能算法提取数据,包括列表页、翻页、详情页。如果智能提取不准确,用户还可以利用在线可视化工具“规则提取器”进行修改,只需鼠标选择并点击即可。
dede采集可以定期发布dede采集文章,让搜索引擎及时抓取你的网站内容。
今天关于织梦采集的解释就到这里了。我希望它可以帮助您在建立您的网站的道路上。下一期我会分享更多与SEO相关的实用干货。

算法 自动采集列表(多谢分享GC策略解决了哪些问题?|左潇龙的技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-08 15:11
来源:博客朴左小龙的技术博客--,谢谢分享
GC策略解决了什么问题?
既然要进行自动GC,就必须有相应的策略,这些策略解决了什么问题?粗略地说,主要有以下几点。
1、哪些对象可以回收。
2、这些对象什么时候被回收。
3、如何回收。
GC策略使用什么算法
关于上面提到的三个问题,其实最重要的是第一个,也就是哪些对象可以回收。有一种比较简单直观的方法,效率更高,叫做引用计数。算法,原理是:这个对象有引用,则+1;删除一个引用,然后 -1。仅采集计数为 0 的对象。缺点是:(1)不能处理循环引用的问题。例如:对象A和B分别有字段b和a,让Ab=B和Ba=A,除了这两个对象没有引用,那么实际上这两个对象已经无法访问了,但是引用计数算法却无法回收它们。(2)引用计数方法需要编译器的配合,并且编译器需要为这个对象生成额外的代码。如果赋值函数给这个对象分配一个引用,它需要增加这个对象的引用计数。此外,当引用变量的生命周期结束时,需要更新该对象的引用计数器。引用计数的方法有一个显着的缺点是它并没有被JVM实际使用。想象一下,如果JVM采用这种GC策略,当程序员在编写程序时,应该不会期望再次出现下面的代码。引用计数的方法有一个显着的缺点是它并没有被JVM实际使用。想象一下,如果JVM采用这种GC策略,当程序员在编写程序时,应该不会期望再次出现下面的代码。引用计数的方法有一个显着的缺点是它并没有被JVM实际使用。想象一下,如果JVM采用这种GC策略,当程序员在编写程序时,应该不会期望再次出现下面的代码。
1 public class Object {
2
3 Object field = null;
4
5 public static void main(String[] args) {
6 Thread thread = new Thread(new Runnable() {
7 public void run() {
8 Object objectA = new Object();
9 Object objectB = new Object();//1
10 objectA.field = objectB;
11 objectB.field = objectA;//2
12 //to do something
13 objectA = null;
14 objectB = null;//3
15 }
16 });
17 thread.start();
18 while (true);
19 }
20
21 }
这段代码看似有点刻意,但其实在实际编程过程中,经常会出现,比如两个数据库对象一一对应,各自维护着对另一个的引用,最后的无限循环只是以防止 JVM 运行。退出,没有意义。
对于我们现在使用的GC来说,当线程线程运行完毕后,所有的objectA和objectB都会被视为需要回收的对象,如果我们的GC采用上面提到的引用计数算法,这两个对象永远不会被回收,甚至如果我们在使用后显式地使对象无效,则没有效果。
这是LZ的一般解释。在代码中,LZ标记了三个数字1、2、3。执行第一个语句时,两个对象的引用计数都为1。执行第二个语句时,两个对象的引用计数都变为2。当第三个语句为执行,即两者都归类为null后,两者的引用计数仍为1。根据引用计数算法的回收规则,当引用计数不返回0时,不会被回收。
根搜索算法
由于引用计数算法的缺点,JVM一般采用一种称为根搜索算法的新算法。它的处理方法是设置几个根对象。当任何根对象无法到达某个对象时,该对象就被认为是可回收的。
以上图为例,ObjectD 和 ObjectE 是相互关联的,但是由于这两个对象的 GC 根不可达,所以最终 D 和 E 仍会被视为 GC 对象。如果上图中使用了引用计数的方法,那么 AE 五个对象都不会被回收。说到 GC 根(GC 根),在 JAVA 语言中,可以作为 GC 根的对象有以下几种:
1、虚拟机堆栈中的引用对象。
2、方法区中类静态属性引用的对象。
3、方法区常量引用的对象。
4、本地方法栈中JNI引用的对象。
第一个和第四个是指方法的局部变量表,第二个表达的意思更清楚,第三个主要是声明为final的常量值。
根搜索算法解决了垃圾回收的基本问题,也就是上面提到的第一个问题,也是最关键的问题,就是哪些对象可以被回收,但是垃圾回收显然需要解决最后两个问题,当回收和如何回收,基于寻根算法,在现代虚拟机的实现中,主要有三种垃圾回收算法,分别是mark-sweep算法、copy算法、mark-sort算法,这三种算法已经扩展了root search算法,但它们仍然很好理解。
首先,让我们回忆一下上一章提到的寻根算法。它可以解决我们应该回收哪些对象的问题,但它显然不能承担垃圾采集的重任,因为我们在程序中(程序意味着我们运行在JVM中)。如果要在上面的JAVA程序运行过程中进行垃圾回收),必须让GC线程和程序中的线程相互配合,这样才能顺利回收垃圾而不影响程序的运行。
为了达到这个目的,mark/sweep算法应运而生。它的做法是在堆中可用内存耗尽时停止整个程序(也称为stop the world)。然后完成了两个工作,第一个是标记,第二个是清除。
(1) 标记:标记过程实际上是遍历所有GC Roots,然后将GC Roots 可达的所有对象标记为存活对象。
(2)清除:清除过程会遍历堆中的所有对象,清除所有未标记的对象。
其实这两个步骤并不是特别复杂,也很容易理解。LZ用简单的话来解释mark/sweep算法,就是程序运行的时候,如果可用内存用完,就会触发GC线程,程序会挂起,然后还活着的对象会被再次标记,最后清除堆中所有未标记的对象,然后程序恢复运行。
下面,LZ为大家制作了一组图片来说明上述过程。结合图片,我们直观的看一下流程,首先是第一张图片。
这张图代表了程序执行过程中所有对象的状态,它们的标志位全部为0(即未标记,下面默认0为未标记,1为标记),假设此时有效内存空间已耗尽。,JVM会停止应用程序的运行并启动GC线程,然后开始标记工作。根据寻根算法,标记后对象的状态如下图。
可以看出,根据根搜索算法,所有从根对象可达的对象都被标记为幸存对象,此时第一阶段标记已经完成。接下来,将进行第二阶段的清算。清空后,剩余对象及对象状态如下图所示。
可以看到,没有被标记的对象会被回收并清除,而被标记的对象会被留下,标志位会被清0。不用说,只要唤醒停止的程序线程,让程序继续运行。其实这个过程并不复杂,甚至可以说非常简单。你是对的吗?但是有一点值得一提,那就是为什么一定要停止程序的运行呢?这其实不难理解。LZ举了一个最简单的例子。假设我们的程序和 GC 线程一起运行。想象一下这样的场景。
假设我们刚刚标记了图中最右边的对象,暂时称它为A。结果此时程序中新建了一个对象B,A对象可以到达B对象,但是由于此时A对象已经被标记在末尾,B对象的标记位为这个时候还是0,因为错过了标记阶段,所以下一轮清关的时候,新对象B会被强制清零。这样一来,不难想象GC线程会导致程序无法正常运行的结果。上述结果当然是不可接受的。我们刚刚创建了一个新对象,但是在一次 GC 之后,它突然变成了 null。如何才能做到这一点?
标记/扫描算法的缺点
1、首先它的缺点是它的效率比较低(递归和全堆对象遍历),并且在进行GC时需要停止应用程序,这样会导致用户体验很差,特别是对于交互式应用程序。这简直是不可接受的。试想一下,如果你玩一个网站,这个网站在一小时内挂了五分钟,你还玩吗?
2、第二个主要缺点是这种方式清理出来的空闲内存是不连续的,不难理解。我们的死物立即出现在记忆的各个角落。现在清除它们之后,内存布局自然会乱七八糟。为了解决这个问题,JVM 必须维护一个空闲的内存列表,这是另一个开销。并且在分配数组对象时,要找到连续的内存空间并不容易。
复制算法
我们先来看看复制算法的实践。复制算法将内存分成两个区间。在任何时间点,所有动态分配的对象只能在其中一个区间(称为活动区间)分配,而另一个区间(称为空闲区间)是空闲的。当有效内存空间耗尽时,JVM会暂停程序运行并启动复制算法的GC线程。接下来,GC线程会将活动区中的所有幸存对象复制到空闲区,并严格按照内存地址进行排列。同时,GC线程会更新幸存对象的内存引用地址,指向新的内存地址。至此,空闲区间已与活动区间交换,并且垃圾对象现在都停留在原来的活动区间,也就是当前的空闲区间。事实上,当活动间隔转换为空间间隔时,垃圾对象已经被一次性回收了。LZ给大家画了个图来说明问题,如下图。
其实这张图还是上一章的例子,只不过此时内存被复制算法分成了两部分。我们来看看复制算法的GC线程处理完后这两个区域会是什么样子,如下图。
可以看到,对象1和4都被清空了,而对象2、3、5、6则有规律的排列在刚才的空闲区间,是当前活跃区间之一。里面。至此,左半场就变成了自由区。不难想象,在下一次GC之后,左侧又会成为活跃区。显然,复制算法弥补了标记/扫描算法杂乱的内存布局。但同时,它的缺点也相当明显。
1、浪费了一半的内存,太可怕了。
2、如果对象的存活率很高,我们可以走极端,假设它是100%存活的,那么我们需要复制所有的对象并重置所有的引用地址。当对象存活率达到一定水平时,复制这项工作所需的时间变得不可忽略。
所以从上面的描述不难看出,要想使用复制算法,至少对象的存活率必须很低,最重要的是我们必须克服50%的浪费记忆。
标记/整理算法
mark/sweep 算法与mark/sweep 算法非常相似,也分为两个阶段:mark 和groom。
(1)Marking:它的第一阶段和mark/sweep算法一模一样,遍历GC Roots,对幸存的对象进行标记。
(2)Finishing:移动所有幸存的对象并按照内存地址的顺序排列,然后在结束内存地址之后回收所有内存。因此,第二阶段称为finishing阶段。
GC前后的图和copy算法的图很相似,但是active区间和free区间没有区别,过程和mark/sweep算法很相似。让我们看一下GC之前内存中对象的状态和布局。如下所示。
这张图其实和mark/clear算法一模一样,只是LZ为了方便内存规则的连续排列,增加了一个矩形来表示内存区域。如果此时 GC 线程开始工作,则标记阶段立即开始。该阶段与标记/清除算法的标记阶段相同。我们看看标记阶段之后对象的状态,如下图所示。
没有什么好解释的。接下来应该是排序阶段。我们来看看排序阶段处理后的内存布局是怎样的,如下图所示。
可以看出,被标记的存活对象会按照内存地址的顺序进行排序排列,而未标记的内存会被清理掉。这样,当我们需要为一个新的对象分配内存时,JVM只需要保存一个内存的起始地址,这显然比维护一个空闲列表的开销要小很多。不难看出,标记/排序算法不仅可以弥补标记/清除算法中内存区域分散的缺点,还可以消除复制算法中内存减半的高成本。标记/排序算法唯一的缺点是效率不高,不仅要标记所有幸存的对象,还要对所有幸存对象的引用地址进行排序。标记/整理算法的效率低于复制算法。这里LZ总结了三种算法的共同点以及各自的优缺点。让你比较一下,会更清楚,它们有以下两点共同点。
1、这三种算法都是基于寻根算法来判断一个对象是否应该被回收,而支撑寻根算法正常工作的理论依据是语法中变量作用域的内容。因此,要防止内存泄漏,最根本的方法是掌握变量的作用域,而不是使用上一章内存管理中提到的C/C++风格的内存管理方法。
2、当GC线程启动时,或者当GC进程启动时,它们都停止了世界。
根据以下几点向您展示它们之间的区别。(>表示前者优于后者,=表示两者效果相同)
效率:Copy Algorithm > Mark/Collate Algorithm > Mark/Sweep Algorithm(这里的效率只是时间复杂度的简单比较,实践中不一定如此)。
内存均匀性:复制算法 = 标记/扫描算法 > 标记/扫描算法。
内存利用率:标记/扫描算法 = 标记/扫描算法 > 复制算法。
可以看出mark/clear算法是一种比较落后的算法,但是后两种算法都是建立在这个基础上的。算法的前身。而且,在某些时候,标记/扫描也会派上用场。
至此,我们已经清楚的了解了这三种算法。可以看出,在效率方面,复制算法是当之无愧的leader,但是浪费了太多内存。为了尽可能的兼顾到上面提到的三个指标,mark/排序算法相对来说比较流畅,但是效率还是差强人意。它比复制算法多一个标记阶段,比标记/清除多一个内存排序过程。最后介绍GC算法中的神级算法——分代采集算法。那么分代采集算法是如何处理GC的呢?
对象分类
上一章提到,分代采集算法是根据对象的不同特性,使用合适的算法,并没有实际生成新的算法。分代采集算法与其说是第四种算法,不如说是前三种算法的实际应用。首先,让我们讨论对象的不同特征。接下来,LZ 和你将为这些对象选择 GC 算法。内存中的对象根据其生命周期的长短大致可以分为三种。以下名称均以LZ个人命名。
1、Aborted objects:在不久的将来死亡的对象。通俗地说,它们是活后不久就会死去的物体。示例:方法中的局部变量、循环中的临时变量等。
2、老仙物:这种物一般都活的比较久,到很老的时候依然不会死,但是说到底,老仙物迟早会死的差不多,但是只有差不多。示例:缓存对象、数据库连接对象、单例对象(单例模式)等。
3、坚不可摧的物体:这类物体通常一出生就几乎是不朽的,它们几乎总是不朽的,记住,只是勉强。示例:字符串池中的对象(享元模式)、加载的类信息等。
对象对应的内存区域
还记得我们之前介绍内存管理时 JVM 对内存的划分吗?我们将以上三个对象对应到内存区,即死对象和老不朽对象在JAVA堆中,不朽对象在方法区。上一章我们已经说过,对于JAVA堆,JVM规范要求必须实现GC,所以对于aborted对象和老不死对象来说,死亡几乎是必然的结果,但也只是几乎,难免会有一些将存活到应用程序结束的对象,但 JVM 规范在方法区域中没有 GC。做需求,所以假设一个JVM实现对方法区没有实现GC,那么永生对象就是真正的永生对象。因为不朽物件的生命周期太长,
JAVA堆对象回收(死对象和旧的不死对象)
有了上面的分析,我们来看看分代回收算法是如何处理JAVA堆的内存回收的,也就是aborted对象和old undead对象的回收。Aborted objects:这些对象有生有死,生存时间短。还记得使用复制算法的要求吗?即对象存活率不能太高,所以aborted对象最适合使用复制算法。小问题:如果50%的内存被浪费了怎么办?答:因为被中止的对象的存活率普遍较低,50%的内存不能作为空闲使用。一般两个 10% 的内存用作空闲和活动区,另外 80% 的内存用于为新对象分配内存时,一旦发生 GC,10% 的活动范围和其他 80% 的幸存对象被转移到 10% 的空闲范围,然后之前的 90% 的内存都被释放,以此类推。为了让大家更清楚地看到这个GC过程,LZ给出了下图。
图中标出了每个阶段三个区域的内存情况。相信看图,它的GC过程不难理解。但是,有两点需要提及。第一点,通过这种方式,我们只浪费了10%的内存,这是可以接受的,因为我们获得了内存的整齐排列和GC的速度。第二点,这个策略的前提是每个幸存对象占用的内存不能超过这10%的大小。一旦超过,多余的对象将无法复制。
为了解决上述突发情况,即当幸存对象占用的内存过大时,专家将JAVA堆分成两部分进行处理。以上三个区域是第一部分,称为新生代或年轻代,其余部分,专门用于存储旧的不死对象,称为老年代。这是一个恰当的名字吗?让我们看看如何处理旧的不死物体。不朽的物件:这类物件的成活率非常高,因为大部分是从新生代传下来的,就像人一样,活久了就会长生不老。
通常,当出现以下两种情况时,对象会从年轻代区域转移到老带区域。
1、新生代中的每个对象都会有一个年龄。当这些对象的年龄达到一定程度时(年龄是存活的GC次数,每次GC如果对象存活,加上年龄1),就会转移到老年代,这个转移到老年代的age值一般可以在JVM中设置。
2、当年轻代存活对象占用的内存超过10%时,多余的对象会被放到老年代。此时老一代就是新一代的“后备仓库”。
对于老不朽对象的特性,显然不再适合使用复制算法,因为它的存活率太高了,别忘了,如果老一代使用复制算法,它是没有备份仓库的. 因此,一般来说,对于旧的不死物体,只能使用标记/排序或标记/清除算法。
方法区对象恢复(不朽对象)
以上两种情况解决了GC的大部分问题,因为JAVA堆是GC的主要关注点,而且上面还收录了分代回收算法的全部内容,不朽对象的回收不在分类。采集算法内容的生成。不朽的对象存在于方法区。在我们常用的热点虚拟机(JDK默认的JVM)中,方法区也被亲切地称为永久代,这是一个非常贴切的名字,不是吗?事实上,很久很久以前,没有永久的一代。当时永久代和老年代存储在一起,里面收录了JAVA类的实例信息和类信息。然而,后来发现班级信息的卸载很少发生,所以将两者分开。幸运的是,这确实提高了很多性能,所以永久代被拆分出来了。这部分区域的GC采用与老年代类似的方法。由于没有“备份仓库”,两者都只能使用mark/sweep和mark/sort算法。
回收时机
JVM 在进行 GC 时,并不总是一起回收上述三个内存区域。大多数时候,它指的是新一代。因此,GC根据回收的区域分为两种,一种是普通GC(minor GC),另一种是global GC(major GC或Full GC)。他们针对的领域如下。Normal GC(minor GC):只针对新生代区域进行GC。Global GC(major GC或Full GC):老年代GC,偶尔伴随着新生代GC和永久代GC。因为老年代和永久代的GC效果都比较差,而且两者的内存使用增长速度也比较慢,一般情况下,需要几次普通GC才能触发一次全局GC。 查看全部
算法 自动采集列表(多谢分享GC策略解决了哪些问题?|左潇龙的技术)
来源:博客朴左小龙的技术博客--,谢谢分享
GC策略解决了什么问题?
既然要进行自动GC,就必须有相应的策略,这些策略解决了什么问题?粗略地说,主要有以下几点。
1、哪些对象可以回收。
2、这些对象什么时候被回收。
3、如何回收。
GC策略使用什么算法
关于上面提到的三个问题,其实最重要的是第一个,也就是哪些对象可以回收。有一种比较简单直观的方法,效率更高,叫做引用计数。算法,原理是:这个对象有引用,则+1;删除一个引用,然后 -1。仅采集计数为 0 的对象。缺点是:(1)不能处理循环引用的问题。例如:对象A和B分别有字段b和a,让Ab=B和Ba=A,除了这两个对象没有引用,那么实际上这两个对象已经无法访问了,但是引用计数算法却无法回收它们。(2)引用计数方法需要编译器的配合,并且编译器需要为这个对象生成额外的代码。如果赋值函数给这个对象分配一个引用,它需要增加这个对象的引用计数。此外,当引用变量的生命周期结束时,需要更新该对象的引用计数器。引用计数的方法有一个显着的缺点是它并没有被JVM实际使用。想象一下,如果JVM采用这种GC策略,当程序员在编写程序时,应该不会期望再次出现下面的代码。引用计数的方法有一个显着的缺点是它并没有被JVM实际使用。想象一下,如果JVM采用这种GC策略,当程序员在编写程序时,应该不会期望再次出现下面的代码。引用计数的方法有一个显着的缺点是它并没有被JVM实际使用。想象一下,如果JVM采用这种GC策略,当程序员在编写程序时,应该不会期望再次出现下面的代码。
1 public class Object {
2
3 Object field = null;
4
5 public static void main(String[] args) {
6 Thread thread = new Thread(new Runnable() {
7 public void run() {
8 Object objectA = new Object();
9 Object objectB = new Object();//1
10 objectA.field = objectB;
11 objectB.field = objectA;//2
12 //to do something
13 objectA = null;
14 objectB = null;//3
15 }
16 });
17 thread.start();
18 while (true);
19 }
20
21 }
这段代码看似有点刻意,但其实在实际编程过程中,经常会出现,比如两个数据库对象一一对应,各自维护着对另一个的引用,最后的无限循环只是以防止 JVM 运行。退出,没有意义。
对于我们现在使用的GC来说,当线程线程运行完毕后,所有的objectA和objectB都会被视为需要回收的对象,如果我们的GC采用上面提到的引用计数算法,这两个对象永远不会被回收,甚至如果我们在使用后显式地使对象无效,则没有效果。
这是LZ的一般解释。在代码中,LZ标记了三个数字1、2、3。执行第一个语句时,两个对象的引用计数都为1。执行第二个语句时,两个对象的引用计数都变为2。当第三个语句为执行,即两者都归类为null后,两者的引用计数仍为1。根据引用计数算法的回收规则,当引用计数不返回0时,不会被回收。
根搜索算法
由于引用计数算法的缺点,JVM一般采用一种称为根搜索算法的新算法。它的处理方法是设置几个根对象。当任何根对象无法到达某个对象时,该对象就被认为是可回收的。

以上图为例,ObjectD 和 ObjectE 是相互关联的,但是由于这两个对象的 GC 根不可达,所以最终 D 和 E 仍会被视为 GC 对象。如果上图中使用了引用计数的方法,那么 AE 五个对象都不会被回收。说到 GC 根(GC 根),在 JAVA 语言中,可以作为 GC 根的对象有以下几种:
1、虚拟机堆栈中的引用对象。
2、方法区中类静态属性引用的对象。
3、方法区常量引用的对象。
4、本地方法栈中JNI引用的对象。
第一个和第四个是指方法的局部变量表,第二个表达的意思更清楚,第三个主要是声明为final的常量值。
根搜索算法解决了垃圾回收的基本问题,也就是上面提到的第一个问题,也是最关键的问题,就是哪些对象可以被回收,但是垃圾回收显然需要解决最后两个问题,当回收和如何回收,基于寻根算法,在现代虚拟机的实现中,主要有三种垃圾回收算法,分别是mark-sweep算法、copy算法、mark-sort算法,这三种算法已经扩展了root search算法,但它们仍然很好理解。
首先,让我们回忆一下上一章提到的寻根算法。它可以解决我们应该回收哪些对象的问题,但它显然不能承担垃圾采集的重任,因为我们在程序中(程序意味着我们运行在JVM中)。如果要在上面的JAVA程序运行过程中进行垃圾回收),必须让GC线程和程序中的线程相互配合,这样才能顺利回收垃圾而不影响程序的运行。
为了达到这个目的,mark/sweep算法应运而生。它的做法是在堆中可用内存耗尽时停止整个程序(也称为stop the world)。然后完成了两个工作,第一个是标记,第二个是清除。
(1) 标记:标记过程实际上是遍历所有GC Roots,然后将GC Roots 可达的所有对象标记为存活对象。
(2)清除:清除过程会遍历堆中的所有对象,清除所有未标记的对象。
其实这两个步骤并不是特别复杂,也很容易理解。LZ用简单的话来解释mark/sweep算法,就是程序运行的时候,如果可用内存用完,就会触发GC线程,程序会挂起,然后还活着的对象会被再次标记,最后清除堆中所有未标记的对象,然后程序恢复运行。
下面,LZ为大家制作了一组图片来说明上述过程。结合图片,我们直观的看一下流程,首先是第一张图片。

这张图代表了程序执行过程中所有对象的状态,它们的标志位全部为0(即未标记,下面默认0为未标记,1为标记),假设此时有效内存空间已耗尽。,JVM会停止应用程序的运行并启动GC线程,然后开始标记工作。根据寻根算法,标记后对象的状态如下图。

可以看出,根据根搜索算法,所有从根对象可达的对象都被标记为幸存对象,此时第一阶段标记已经完成。接下来,将进行第二阶段的清算。清空后,剩余对象及对象状态如下图所示。

可以看到,没有被标记的对象会被回收并清除,而被标记的对象会被留下,标志位会被清0。不用说,只要唤醒停止的程序线程,让程序继续运行。其实这个过程并不复杂,甚至可以说非常简单。你是对的吗?但是有一点值得一提,那就是为什么一定要停止程序的运行呢?这其实不难理解。LZ举了一个最简单的例子。假设我们的程序和 GC 线程一起运行。想象一下这样的场景。
假设我们刚刚标记了图中最右边的对象,暂时称它为A。结果此时程序中新建了一个对象B,A对象可以到达B对象,但是由于此时A对象已经被标记在末尾,B对象的标记位为这个时候还是0,因为错过了标记阶段,所以下一轮清关的时候,新对象B会被强制清零。这样一来,不难想象GC线程会导致程序无法正常运行的结果。上述结果当然是不可接受的。我们刚刚创建了一个新对象,但是在一次 GC 之后,它突然变成了 null。如何才能做到这一点?
标记/扫描算法的缺点
1、首先它的缺点是它的效率比较低(递归和全堆对象遍历),并且在进行GC时需要停止应用程序,这样会导致用户体验很差,特别是对于交互式应用程序。这简直是不可接受的。试想一下,如果你玩一个网站,这个网站在一小时内挂了五分钟,你还玩吗?
2、第二个主要缺点是这种方式清理出来的空闲内存是不连续的,不难理解。我们的死物立即出现在记忆的各个角落。现在清除它们之后,内存布局自然会乱七八糟。为了解决这个问题,JVM 必须维护一个空闲的内存列表,这是另一个开销。并且在分配数组对象时,要找到连续的内存空间并不容易。
复制算法
我们先来看看复制算法的实践。复制算法将内存分成两个区间。在任何时间点,所有动态分配的对象只能在其中一个区间(称为活动区间)分配,而另一个区间(称为空闲区间)是空闲的。当有效内存空间耗尽时,JVM会暂停程序运行并启动复制算法的GC线程。接下来,GC线程会将活动区中的所有幸存对象复制到空闲区,并严格按照内存地址进行排列。同时,GC线程会更新幸存对象的内存引用地址,指向新的内存地址。至此,空闲区间已与活动区间交换,并且垃圾对象现在都停留在原来的活动区间,也就是当前的空闲区间。事实上,当活动间隔转换为空间间隔时,垃圾对象已经被一次性回收了。LZ给大家画了个图来说明问题,如下图。

其实这张图还是上一章的例子,只不过此时内存被复制算法分成了两部分。我们来看看复制算法的GC线程处理完后这两个区域会是什么样子,如下图。

可以看到,对象1和4都被清空了,而对象2、3、5、6则有规律的排列在刚才的空闲区间,是当前活跃区间之一。里面。至此,左半场就变成了自由区。不难想象,在下一次GC之后,左侧又会成为活跃区。显然,复制算法弥补了标记/扫描算法杂乱的内存布局。但同时,它的缺点也相当明显。
1、浪费了一半的内存,太可怕了。
2、如果对象的存活率很高,我们可以走极端,假设它是100%存活的,那么我们需要复制所有的对象并重置所有的引用地址。当对象存活率达到一定水平时,复制这项工作所需的时间变得不可忽略。
所以从上面的描述不难看出,要想使用复制算法,至少对象的存活率必须很低,最重要的是我们必须克服50%的浪费记忆。
标记/整理算法
mark/sweep 算法与mark/sweep 算法非常相似,也分为两个阶段:mark 和groom。
(1)Marking:它的第一阶段和mark/sweep算法一模一样,遍历GC Roots,对幸存的对象进行标记。
(2)Finishing:移动所有幸存的对象并按照内存地址的顺序排列,然后在结束内存地址之后回收所有内存。因此,第二阶段称为finishing阶段。
GC前后的图和copy算法的图很相似,但是active区间和free区间没有区别,过程和mark/sweep算法很相似。让我们看一下GC之前内存中对象的状态和布局。如下所示。

这张图其实和mark/clear算法一模一样,只是LZ为了方便内存规则的连续排列,增加了一个矩形来表示内存区域。如果此时 GC 线程开始工作,则标记阶段立即开始。该阶段与标记/清除算法的标记阶段相同。我们看看标记阶段之后对象的状态,如下图所示。

没有什么好解释的。接下来应该是排序阶段。我们来看看排序阶段处理后的内存布局是怎样的,如下图所示。

可以看出,被标记的存活对象会按照内存地址的顺序进行排序排列,而未标记的内存会被清理掉。这样,当我们需要为一个新的对象分配内存时,JVM只需要保存一个内存的起始地址,这显然比维护一个空闲列表的开销要小很多。不难看出,标记/排序算法不仅可以弥补标记/清除算法中内存区域分散的缺点,还可以消除复制算法中内存减半的高成本。标记/排序算法唯一的缺点是效率不高,不仅要标记所有幸存的对象,还要对所有幸存对象的引用地址进行排序。标记/整理算法的效率低于复制算法。这里LZ总结了三种算法的共同点以及各自的优缺点。让你比较一下,会更清楚,它们有以下两点共同点。
1、这三种算法都是基于寻根算法来判断一个对象是否应该被回收,而支撑寻根算法正常工作的理论依据是语法中变量作用域的内容。因此,要防止内存泄漏,最根本的方法是掌握变量的作用域,而不是使用上一章内存管理中提到的C/C++风格的内存管理方法。
2、当GC线程启动时,或者当GC进程启动时,它们都停止了世界。
根据以下几点向您展示它们之间的区别。(>表示前者优于后者,=表示两者效果相同)
效率:Copy Algorithm > Mark/Collate Algorithm > Mark/Sweep Algorithm(这里的效率只是时间复杂度的简单比较,实践中不一定如此)。
内存均匀性:复制算法 = 标记/扫描算法 > 标记/扫描算法。
内存利用率:标记/扫描算法 = 标记/扫描算法 > 复制算法。
可以看出mark/clear算法是一种比较落后的算法,但是后两种算法都是建立在这个基础上的。算法的前身。而且,在某些时候,标记/扫描也会派上用场。
至此,我们已经清楚的了解了这三种算法。可以看出,在效率方面,复制算法是当之无愧的leader,但是浪费了太多内存。为了尽可能的兼顾到上面提到的三个指标,mark/排序算法相对来说比较流畅,但是效率还是差强人意。它比复制算法多一个标记阶段,比标记/清除多一个内存排序过程。最后介绍GC算法中的神级算法——分代采集算法。那么分代采集算法是如何处理GC的呢?
对象分类
上一章提到,分代采集算法是根据对象的不同特性,使用合适的算法,并没有实际生成新的算法。分代采集算法与其说是第四种算法,不如说是前三种算法的实际应用。首先,让我们讨论对象的不同特征。接下来,LZ 和你将为这些对象选择 GC 算法。内存中的对象根据其生命周期的长短大致可以分为三种。以下名称均以LZ个人命名。
1、Aborted objects:在不久的将来死亡的对象。通俗地说,它们是活后不久就会死去的物体。示例:方法中的局部变量、循环中的临时变量等。
2、老仙物:这种物一般都活的比较久,到很老的时候依然不会死,但是说到底,老仙物迟早会死的差不多,但是只有差不多。示例:缓存对象、数据库连接对象、单例对象(单例模式)等。
3、坚不可摧的物体:这类物体通常一出生就几乎是不朽的,它们几乎总是不朽的,记住,只是勉强。示例:字符串池中的对象(享元模式)、加载的类信息等。
对象对应的内存区域
还记得我们之前介绍内存管理时 JVM 对内存的划分吗?我们将以上三个对象对应到内存区,即死对象和老不朽对象在JAVA堆中,不朽对象在方法区。上一章我们已经说过,对于JAVA堆,JVM规范要求必须实现GC,所以对于aborted对象和老不死对象来说,死亡几乎是必然的结果,但也只是几乎,难免会有一些将存活到应用程序结束的对象,但 JVM 规范在方法区域中没有 GC。做需求,所以假设一个JVM实现对方法区没有实现GC,那么永生对象就是真正的永生对象。因为不朽物件的生命周期太长,
JAVA堆对象回收(死对象和旧的不死对象)
有了上面的分析,我们来看看分代回收算法是如何处理JAVA堆的内存回收的,也就是aborted对象和old undead对象的回收。Aborted objects:这些对象有生有死,生存时间短。还记得使用复制算法的要求吗?即对象存活率不能太高,所以aborted对象最适合使用复制算法。小问题:如果50%的内存被浪费了怎么办?答:因为被中止的对象的存活率普遍较低,50%的内存不能作为空闲使用。一般两个 10% 的内存用作空闲和活动区,另外 80% 的内存用于为新对象分配内存时,一旦发生 GC,10% 的活动范围和其他 80% 的幸存对象被转移到 10% 的空闲范围,然后之前的 90% 的内存都被释放,以此类推。为了让大家更清楚地看到这个GC过程,LZ给出了下图。

图中标出了每个阶段三个区域的内存情况。相信看图,它的GC过程不难理解。但是,有两点需要提及。第一点,通过这种方式,我们只浪费了10%的内存,这是可以接受的,因为我们获得了内存的整齐排列和GC的速度。第二点,这个策略的前提是每个幸存对象占用的内存不能超过这10%的大小。一旦超过,多余的对象将无法复制。
为了解决上述突发情况,即当幸存对象占用的内存过大时,专家将JAVA堆分成两部分进行处理。以上三个区域是第一部分,称为新生代或年轻代,其余部分,专门用于存储旧的不死对象,称为老年代。这是一个恰当的名字吗?让我们看看如何处理旧的不死物体。不朽的物件:这类物件的成活率非常高,因为大部分是从新生代传下来的,就像人一样,活久了就会长生不老。
通常,当出现以下两种情况时,对象会从年轻代区域转移到老带区域。
1、新生代中的每个对象都会有一个年龄。当这些对象的年龄达到一定程度时(年龄是存活的GC次数,每次GC如果对象存活,加上年龄1),就会转移到老年代,这个转移到老年代的age值一般可以在JVM中设置。
2、当年轻代存活对象占用的内存超过10%时,多余的对象会被放到老年代。此时老一代就是新一代的“后备仓库”。
对于老不朽对象的特性,显然不再适合使用复制算法,因为它的存活率太高了,别忘了,如果老一代使用复制算法,它是没有备份仓库的. 因此,一般来说,对于旧的不死物体,只能使用标记/排序或标记/清除算法。
方法区对象恢复(不朽对象)
以上两种情况解决了GC的大部分问题,因为JAVA堆是GC的主要关注点,而且上面还收录了分代回收算法的全部内容,不朽对象的回收不在分类。采集算法内容的生成。不朽的对象存在于方法区。在我们常用的热点虚拟机(JDK默认的JVM)中,方法区也被亲切地称为永久代,这是一个非常贴切的名字,不是吗?事实上,很久很久以前,没有永久的一代。当时永久代和老年代存储在一起,里面收录了JAVA类的实例信息和类信息。然而,后来发现班级信息的卸载很少发生,所以将两者分开。幸运的是,这确实提高了很多性能,所以永久代被拆分出来了。这部分区域的GC采用与老年代类似的方法。由于没有“备份仓库”,两者都只能使用mark/sweep和mark/sort算法。
回收时机
JVM 在进行 GC 时,并不总是一起回收上述三个内存区域。大多数时候,它指的是新一代。因此,GC根据回收的区域分为两种,一种是普通GC(minor GC),另一种是global GC(major GC或Full GC)。他们针对的领域如下。Normal GC(minor GC):只针对新生代区域进行GC。Global GC(major GC或Full GC):老年代GC,偶尔伴随着新生代GC和永久代GC。因为老年代和永久代的GC效果都比较差,而且两者的内存使用增长速度也比较慢,一般情况下,需要几次普通GC才能触发一次全局GC。
算法 自动采集列表(优质内容的打造对于没时间来做网站优化的站长来说 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-03-07 00:19
)
罗马不是一天建成的,我们SEO的核心精神也是坚持。网站有自己的关键词,SEO也有自己的核心关键词,那就是坚持。我们不仅需要每天更新网站内容,关键词创建和分析网站数据,还需要关注站点内外的用户体验和优化。
创造高质量的内容
对于没有时间做网站优化的站长,我们也可以通过一些cms采集软件来实现一些SEO技巧,cms采集软件具有强大的功能。只要输入采集规则,就可以完成采集任务,通过软件实现自动采集和释放文章,还可以设置自动下载图片和替换链接(图片本地化),支持的图片存储方式:阿里云、七牛、腾讯云、游拍云等。同时还配备了自动内链,在内容前后插入一定的内容或标题形成“伪原创”。
cms采集软件支持按规则自动插入本地图片文章,提高原创作者的创作效率。
cms采集软件还具有直接监控已发布、即将发布、伪原创、发布状态、URL、节目、发布时间等功能。@收录,以及网站 权重!
在我们的实践过程中,我们需要灵活运用我们的SEO理论知识。cms采集软件和SEO知识是我们从容应对工作中复杂情况的基础。SEO主要侧重于实际操作,这要求我们灵活应用,而不是机械地应用。
考虑用户的搜索习惯和需求
在我们编辑网站的内容之前,不妨想想用户的搜索习惯和需求。一个醒目的标题,总能打动用户的心。为什么其他人可以创建大量内容?学位源于标题的吸引力。我们如何分析用户的搜索习惯和需求,一般通过下拉框、相关搜索、百度索引等工具。同时,内容需要高度相关,关键词的密度要合理,而不是仅仅依靠标题来留住用户。一定要对用户进行细分。
把握市场脉搏
我们需要掌握的是各种搜索引擎的算法及其发展趋势。请注意排名规则的更新,这方面通常有很多需要学习和研究的地方。因为互联网正在飞速发展,要想从竞争对手中脱颖而出,就需要比竞争对手付出更多的努力。我们必须紧跟市场脉搏,紧跟市场发展的潮流。
不断学习和提高
无论搜索引擎有多少排名算法,其核心始终是尽快将最好的质量和最好的用户体验呈现给用户。围绕这个核心,我们不会偏离方向。在学习的过程中,总结很重要。不同的人有不同的理解,我们要在实践中不断总结和形成自己的想法。
查看全部
算法 自动采集列表(优质内容的打造对于没时间来做网站优化的站长来说
)
罗马不是一天建成的,我们SEO的核心精神也是坚持。网站有自己的关键词,SEO也有自己的核心关键词,那就是坚持。我们不仅需要每天更新网站内容,关键词创建和分析网站数据,还需要关注站点内外的用户体验和优化。

创造高质量的内容
对于没有时间做网站优化的站长,我们也可以通过一些cms采集软件来实现一些SEO技巧,cms采集软件具有强大的功能。只要输入采集规则,就可以完成采集任务,通过软件实现自动采集和释放文章,还可以设置自动下载图片和替换链接(图片本地化),支持的图片存储方式:阿里云、七牛、腾讯云、游拍云等。同时还配备了自动内链,在内容前后插入一定的内容或标题形成“伪原创”。
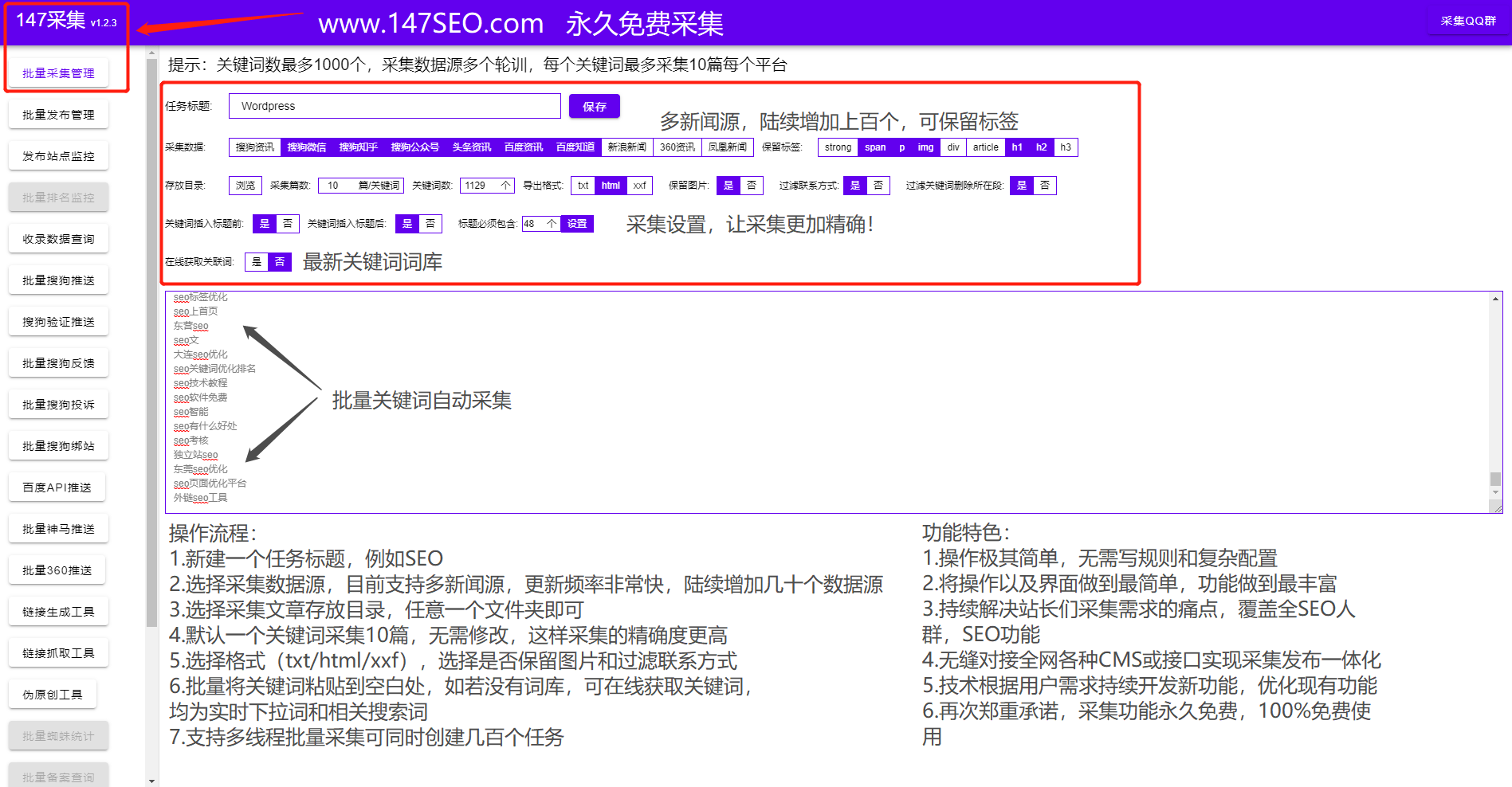
cms采集软件支持按规则自动插入本地图片文章,提高原创作者的创作效率。
cms采集软件还具有直接监控已发布、即将发布、伪原创、发布状态、URL、节目、发布时间等功能。@收录,以及网站 权重!
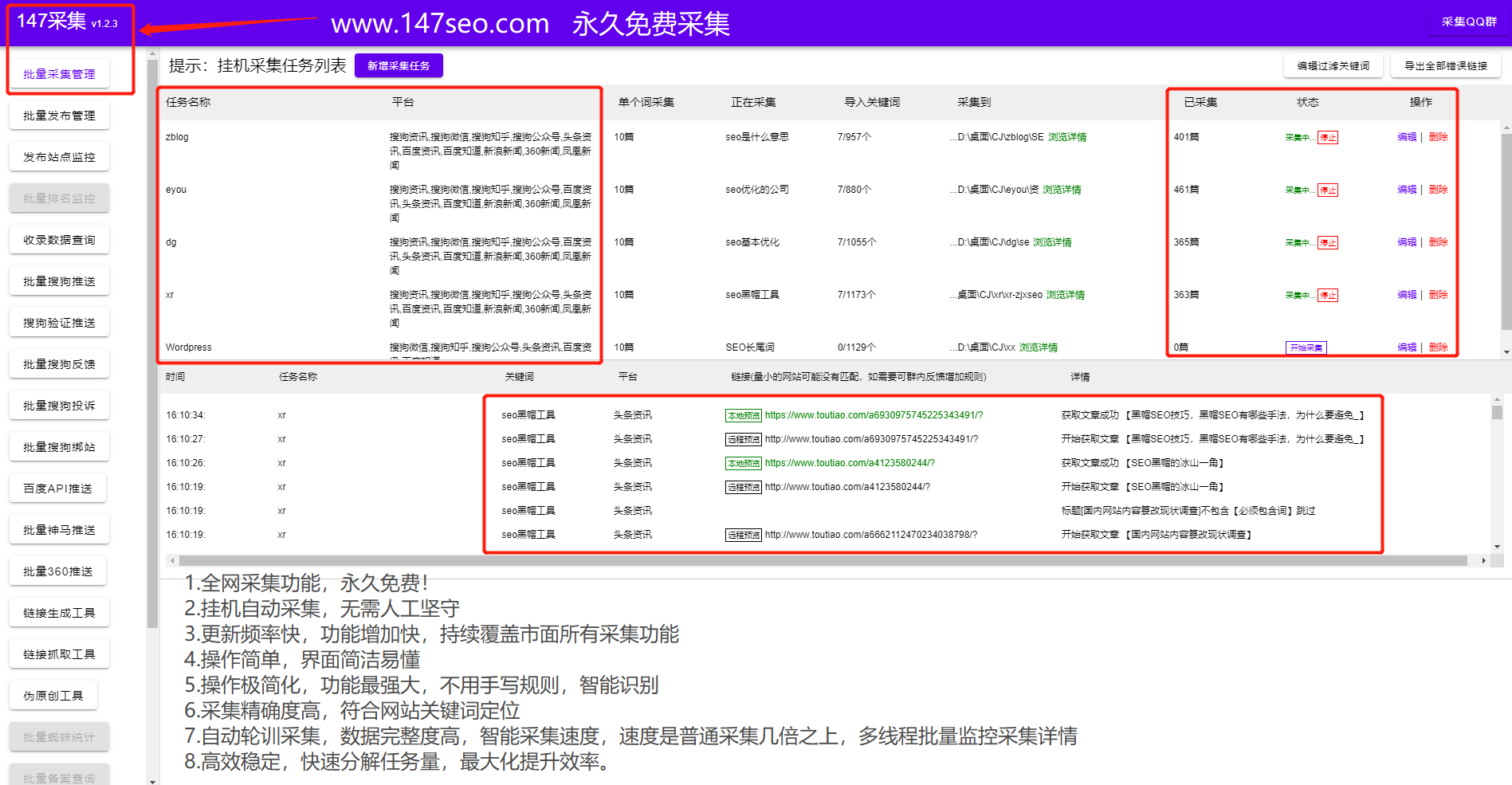
在我们的实践过程中,我们需要灵活运用我们的SEO理论知识。cms采集软件和SEO知识是我们从容应对工作中复杂情况的基础。SEO主要侧重于实际操作,这要求我们灵活应用,而不是机械地应用。
考虑用户的搜索习惯和需求
在我们编辑网站的内容之前,不妨想想用户的搜索习惯和需求。一个醒目的标题,总能打动用户的心。为什么其他人可以创建大量内容?学位源于标题的吸引力。我们如何分析用户的搜索习惯和需求,一般通过下拉框、相关搜索、百度索引等工具。同时,内容需要高度相关,关键词的密度要合理,而不是仅仅依靠标题来留住用户。一定要对用户进行细分。
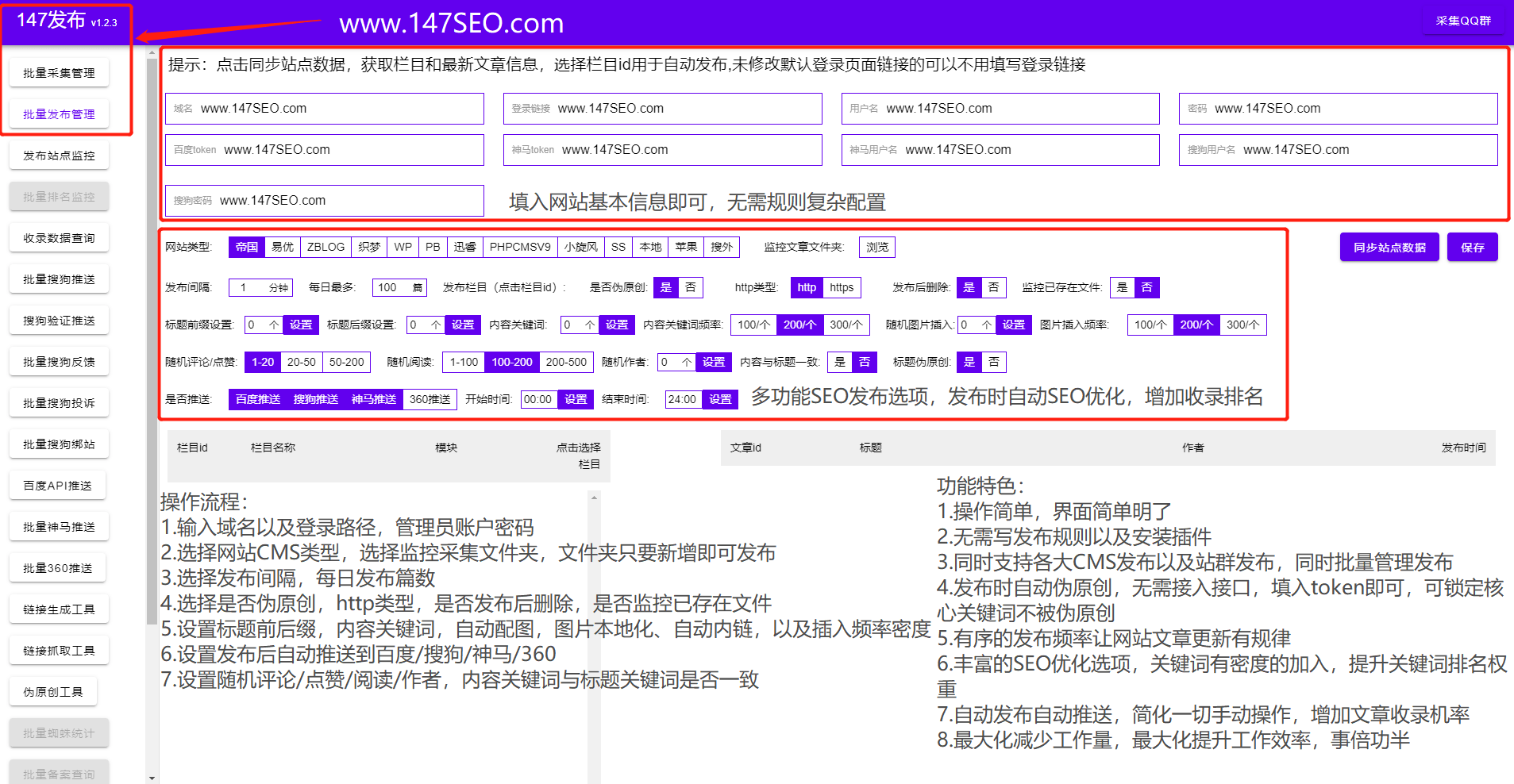
把握市场脉搏
我们需要掌握的是各种搜索引擎的算法及其发展趋势。请注意排名规则的更新,这方面通常有很多需要学习和研究的地方。因为互联网正在飞速发展,要想从竞争对手中脱颖而出,就需要比竞争对手付出更多的努力。我们必须紧跟市场脉搏,紧跟市场发展的潮流。
不断学习和提高
无论搜索引擎有多少排名算法,其核心始终是尽快将最好的质量和最好的用户体验呈现给用户。围绕这个核心,我们不会偏离方向。在学习的过程中,总结很重要。不同的人有不同的理解,我们要在实践中不断总结和形成自己的想法。

算法 自动采集列表(易企CMS采集的网络信息搜集与整合,你了解多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-07 00:16
E-Enterprisecms采集,网站发布后,面临的最大问题是网站内容缺失,或者更新不及时。 网站维护需要投入的人力财力越大,长期以来,网站运营商一直在追求最大限度降低成本,获得最高品质的能力网站内容。亿奇cms采集依托高效强大的网络信息采集与整合,与网站对接后,持续为网站提供优质、实时的数据,省去您投入更多人力来寻找文章无处不在的资源的需要。
如果网站位于私网范围内,那么网站就会陷入网络扩容和内容补充的困境,只能依靠人工采集网上相关信息再复制到内网并导入到私网。在 网站 上。通过Easy Enterprisecms采集,现在不用那么麻烦了,可以自动采集发布和编辑,让网站管理者可以专注于内容质量审查和审查 网站以上整体 SEO。
E-Enterprisecms采集预设了30多个插件来提升网站的排名,通过这些插件来优化发布内容的排名,使其能够提升在很长的时间。 网站 的排名。根据网站的行业,它可以自动确定发布到网站的每条内容的“长尾词”,并自动调整发布内容的关键词密度。自动制作已发布图片的alt属性,并根据已发布内容自动为内容中的图片生成相应的alt描述。
E-Enterprisecms采集有4个高效的网络信息采集功能。主题采集,您只需输入关键字即可根据网站的主题设置要求采集符合要求的网络信息,不再需要手动搜索。定位采集,可以与其他同类网站保持同步,只需输入目标网站的地址,即可自动采集同类网站的信息进行筛选。 查看全部
算法 自动采集列表(易企CMS采集的网络信息搜集与整合,你了解多少?)
E-Enterprisecms采集,网站发布后,面临的最大问题是网站内容缺失,或者更新不及时。 网站维护需要投入的人力财力越大,长期以来,网站运营商一直在追求最大限度降低成本,获得最高品质的能力网站内容。亿奇cms采集依托高效强大的网络信息采集与整合,与网站对接后,持续为网站提供优质、实时的数据,省去您投入更多人力来寻找文章无处不在的资源的需要。
如果网站位于私网范围内,那么网站就会陷入网络扩容和内容补充的困境,只能依靠人工采集网上相关信息再复制到内网并导入到私网。在 网站 上。通过Easy Enterprisecms采集,现在不用那么麻烦了,可以自动采集发布和编辑,让网站管理者可以专注于内容质量审查和审查 网站以上整体 SEO。
E-Enterprisecms采集预设了30多个插件来提升网站的排名,通过这些插件来优化发布内容的排名,使其能够提升在很长的时间。 网站 的排名。根据网站的行业,它可以自动确定发布到网站的每条内容的“长尾词”,并自动调整发布内容的关键词密度。自动制作已发布图片的alt属性,并根据已发布内容自动为内容中的图片生成相应的alt描述。
E-Enterprisecms采集有4个高效的网络信息采集功能。主题采集,您只需输入关键字即可根据网站的主题设置要求采集符合要求的网络信息,不再需要手动搜索。定位采集,可以与其他同类网站保持同步,只需输入目标网站的地址,即可自动采集同类网站的信息进行筛选。
算法 自动采集列表(算法自动采集列表的加分,你知道吗?(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-27 19:07
算法自动采集列表的加分1.基于内容的自动采集(top20页的所有内容).2.基于友情链接的自动采集(都找到了链接,跟帖子人工带上)3.基于匹配用户行为的自动采集(对一个人的带上,同时带上另一个人的,都采集到)4.自动识别关键词自动采集(关键词自动识别后,自动采集)5.页面定向规则自动采集(类似谷歌,上下页定向规则自动采集)6.百度统计抓取整站,分析引流效果7.条件自动采集(通过公共场景分析,猜你喜欢等各大产品的使用习惯,达到自动抓取的目的)8.api自动采集(其实只抓取了一小部分)api上每个产品都可以抓取到上千条内容,基本已经能满足需求,更多信息请关注我们qq号:214417614,欢迎大家来聊交流。
想必每个up主在投稿过程中都会收到无法抓取这样的提示邮件,当我们以为自己收到的是某个专门的抓取工具,下载下来后,也没有发现有抓取历史。为什么是抓取历史?这些历史到底是从哪里来的呢?如果这个抓取工具并不能抓取我们所发布的视频或文章,那它就是毫无意义的。现在很多视频网站是没有直接抓取历史这一板块的,都是需要我们人工智能抓取。
其实早在以前就有人想过直接抓取用户的帖子,但是都被这样的人抓走了。所以如果我们并不想通过人工抓取的方式在发布内容时留下自己的内容的历史纪录,还有另一种解决方式。这里介绍一下freebirded这个脚本,可以自动抓取你上传的内容,前提是你得先找到他,不然他用什么去抓取你的内容呢?当然我们可以把网址复制进去,然后就可以自动抓取。
这里是随便找了个视频网站比如:站酷网我们直接找一条新闻内容,抓取下来之后就是这样子的。因为这个内容只是存在于你的网站所以我们并不需要做任何处理,当然你要是愿意多弄几个网站也是可以的。 查看全部
算法 自动采集列表(算法自动采集列表的加分,你知道吗?(上))
算法自动采集列表的加分1.基于内容的自动采集(top20页的所有内容).2.基于友情链接的自动采集(都找到了链接,跟帖子人工带上)3.基于匹配用户行为的自动采集(对一个人的带上,同时带上另一个人的,都采集到)4.自动识别关键词自动采集(关键词自动识别后,自动采集)5.页面定向规则自动采集(类似谷歌,上下页定向规则自动采集)6.百度统计抓取整站,分析引流效果7.条件自动采集(通过公共场景分析,猜你喜欢等各大产品的使用习惯,达到自动抓取的目的)8.api自动采集(其实只抓取了一小部分)api上每个产品都可以抓取到上千条内容,基本已经能满足需求,更多信息请关注我们qq号:214417614,欢迎大家来聊交流。
想必每个up主在投稿过程中都会收到无法抓取这样的提示邮件,当我们以为自己收到的是某个专门的抓取工具,下载下来后,也没有发现有抓取历史。为什么是抓取历史?这些历史到底是从哪里来的呢?如果这个抓取工具并不能抓取我们所发布的视频或文章,那它就是毫无意义的。现在很多视频网站是没有直接抓取历史这一板块的,都是需要我们人工智能抓取。
其实早在以前就有人想过直接抓取用户的帖子,但是都被这样的人抓走了。所以如果我们并不想通过人工抓取的方式在发布内容时留下自己的内容的历史纪录,还有另一种解决方式。这里介绍一下freebirded这个脚本,可以自动抓取你上传的内容,前提是你得先找到他,不然他用什么去抓取你的内容呢?当然我们可以把网址复制进去,然后就可以自动抓取。
这里是随便找了个视频网站比如:站酷网我们直接找一条新闻内容,抓取下来之后就是这样子的。因为这个内容只是存在于你的网站所以我们并不需要做任何处理,当然你要是愿意多弄几个网站也是可以的。
分页列表详细信息采集 | 2个月精通优采云第1课
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-05-15 16:50
在之前的教程中,我们以赶集网商铺数据采集、携程网旅游数据采集为例,感受了一波优采云嗖嗖嗖采集数据的常(li)规(hai)操作。
咦?这两个实战案例,规则配置长相似,采集流程有点像?
来吧,是时候溯本求源,透过现象看本质了。
网页内容由相似的区块组成,需要点击“下一页”进行翻页,再点击每个链接进入详情页采集数据,没错就是——分页列表详细信息采集。
本文中示例网站地址为:
在开始采集之前,需观察网页结构、明确采集内容。以示例网址为例,内容共有4页,每页有3个电影链接。我们需要点击每一部电影的链接,进入电影详情页,采集电影的剧情、上映时间等字段。
优采云基于 Firefox 内核浏览器,通过模拟人的思维操作方式,对网页内容进行全自动提取。以示例网址为例,在优采云里打开后,需先建立一个点击“下一页”的翻页循环,自动点击“下一页”翻页。再建立一个电影链接列表循环,以打开每个电影的链接,进入电影详情页。然后再采集电影详情页的数据。
1打开网页
1)登陆优采云7.0采集器,点击新建任务,选择“自定义采集”。进入到任务配置页面
2)输入要采集的网址,点击“保存网址”。系统会进入到流程设计页面,并自动打开前面输入的网址
2建立翻页循环
1)用鼠标点击“下一页”按钮,在弹出的操作提示框中,选择“循环点击下一页”。这个步骤会模拟人工,自动点击翻页
3建立循环列表
1)点击下图中第一个电影“教父:第二部”的链接,链接将被选中,用绿色框标注出来
2)优采云的智能算法,会自动检测出其他相似元素(本例中为其他两个电影标题链接)。在操作提示框中,选择“选中全部”,优采云自动选中全部电影链接
3)选择“循环点击每个链接”,优采云会自动逐个点击每个电影链接,进入电影详情页
4提取数据
1)点击页面中要提取的电影标题字段,标题字段即被选中,选中后以红色框标注出来
2)在弹出的提示框中,选择“采集该元素的文本”,表明要采集的是页面中的文本数据
3)以同样的方式,点击要采集的其他段,再选择“采集该元素的文本”
5修改字段名称
1)点击“流程”按钮,以显示“流程设计器”和“定制当前操作”两个板块。(在配置规则过程中,“流程”随时可打开)
2)在如下界面中,修改字段名称。这里的字段名称相当于表头,便于采集时区分每个字段类别。 修改完成后,点击“确定”保存
6启动采集
1)点击“保存并启动”,在弹出的对话框中选择“启动本地采集”。系统会在本地电脑上,开启一个采集任务并采集数据
2)任务采集完毕之后,会弹出一个采集结束的提示, 接下来选择导出数据,这里以选择导出excel2007为例,然后点击确定
3)选择文件存放路径,再点保存即可
然后,我们分分钟就得到了这样的数据
动图模式有木有学得更爽?
有任何建议或问题,请biubiubiu砸向我!
建议各位小可爱
学了分页列表详细信息采集
趁热打铁 实战一波
更多实战教程 查看全部
分页列表详细信息采集 | 2个月精通优采云第1课
在之前的教程中,我们以赶集网商铺数据采集、携程网旅游数据采集为例,感受了一波优采云嗖嗖嗖采集数据的常(li)规(hai)操作。
咦?这两个实战案例,规则配置长相似,采集流程有点像?
来吧,是时候溯本求源,透过现象看本质了。
网页内容由相似的区块组成,需要点击“下一页”进行翻页,再点击每个链接进入详情页采集数据,没错就是——分页列表详细信息采集。
本文中示例网站地址为:
在开始采集之前,需观察网页结构、明确采集内容。以示例网址为例,内容共有4页,每页有3个电影链接。我们需要点击每一部电影的链接,进入电影详情页,采集电影的剧情、上映时间等字段。
优采云基于 Firefox 内核浏览器,通过模拟人的思维操作方式,对网页内容进行全自动提取。以示例网址为例,在优采云里打开后,需先建立一个点击“下一页”的翻页循环,自动点击“下一页”翻页。再建立一个电影链接列表循环,以打开每个电影的链接,进入电影详情页。然后再采集电影详情页的数据。
1打开网页
1)登陆优采云7.0采集器,点击新建任务,选择“自定义采集”。进入到任务配置页面
2)输入要采集的网址,点击“保存网址”。系统会进入到流程设计页面,并自动打开前面输入的网址
2建立翻页循环
1)用鼠标点击“下一页”按钮,在弹出的操作提示框中,选择“循环点击下一页”。这个步骤会模拟人工,自动点击翻页
3建立循环列表
1)点击下图中第一个电影“教父:第二部”的链接,链接将被选中,用绿色框标注出来
2)优采云的智能算法,会自动检测出其他相似元素(本例中为其他两个电影标题链接)。在操作提示框中,选择“选中全部”,优采云自动选中全部电影链接
3)选择“循环点击每个链接”,优采云会自动逐个点击每个电影链接,进入电影详情页
4提取数据
1)点击页面中要提取的电影标题字段,标题字段即被选中,选中后以红色框标注出来
2)在弹出的提示框中,选择“采集该元素的文本”,表明要采集的是页面中的文本数据
3)以同样的方式,点击要采集的其他段,再选择“采集该元素的文本”
5修改字段名称
1)点击“流程”按钮,以显示“流程设计器”和“定制当前操作”两个板块。(在配置规则过程中,“流程”随时可打开)
2)在如下界面中,修改字段名称。这里的字段名称相当于表头,便于采集时区分每个字段类别。 修改完成后,点击“确定”保存
6启动采集
1)点击“保存并启动”,在弹出的对话框中选择“启动本地采集”。系统会在本地电脑上,开启一个采集任务并采集数据
2)任务采集完毕之后,会弹出一个采集结束的提示, 接下来选择导出数据,这里以选择导出excel2007为例,然后点击确定
3)选择文件存放路径,再点保存即可
然后,我们分分钟就得到了这样的数据
动图模式有木有学得更爽?
有任何建议或问题,请biubiubiu砸向我!
建议各位小可爱
学了分页列表详细信息采集
趁热打铁 实战一波
更多实战教程
发布一个智能解析算法库
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-05-12 07:23
之前我写过几篇文章介绍过有关爬虫的智能解析算法,包括商业化应用 Diffbot、Readability、Newspaper 这些库,另外我有一位朋友之前还专门针对新闻正文的提取算法 GeneralNewsExtractor,这段时间我也参考和研究了一下这些库的算法,同时参考一些论文,也写了一个智能解析库,在这里就做一个非正式的介绍。
引入
那首先说说我想做的是什么。
比如这里有一个网站,网易新闻,,这里有个新闻列表,预览图如下:
任意点开一篇新闻,看到的结果如下:
我现在需要做到的是在不编写任何 XPath、Selector 的情况下实现下面信息的提取:
对于列表页来说,我要提取新闻的所有标题列表和对应的链接,它们就是图中的红色区域:
这里红色区域分了多个区块,比如这里一共就是 40 个链接,我都需要提取出来,包括标题的名称,标题的 URL。
我们看到页面里面还有很多无用的链接,如上图绿色区域,包括分类、内部导航等,这些需要排除掉。
对于详情页,我主要关心的内容有标题、发布时间、正文内容,它们就是图中红色区域:
其中这里也带有一些干扰项,比如绿色区域的侧边栏的内容,无用的分享链接等。
总之,我想实现某种算法,实现如上两大部分的智能化提取。
框架
之前我开发了一个叫做 Gerapy 的框架,是一个基于 Scrapy、Scrapyd 的分布式爬虫管理框架,属 1.x 版本。现在正在开发 Gerapy 2.x 版本,其定位转向了 Scrapy 的可视化配置和调试、智能化解析方向,放弃支持 Scraypd,转而支持 Docker、Kubernetes 的部署和监控。
对于智能解析来说,就像刚才说的,我期望的就是上述的功能,在不编写任何 XPath 和 Selector 的情况下实现页面关键内容的提取。
框架现在发布了第一个初步版本,名称叫做 Gerapy Auto Extractor,名字 Gerapy 相关,也会作为 Gerapy 的其中一个模块。
GitHub 链接:
现在已经发布了 PyPi,,可以使用 pip3 来安装,安装方式如下:
pip3 install gerapy-auto-extractor
安装完了之后我们就可以导入使用了。
功能
下面简单介绍下它的功能,它能够做到列表页和详情页的解析。
列表页:
•标题内容•标题链接
详情页:
•标题•正文•发布时间
先暂时实现了如上内容的提取,其他字段的提取暂时还未实现。
使用
要使用 Gerapy Auto Extractor,前提我们必须要先获得 HTML 代码,注意这个 HTML 代码是我们在浏览器里面看到的内容,是整个页面渲染完成之后的代码。在某些情况下如果我们简单用「查看源代码」或 requests 请求获取到的源码并不是真正渲染完成后的 HTML 代码。
要获取完整 HTML 代码可以在浏览器开发者工具,打开 Elements 选项卡,然后复制你所看到的 HTML 内容即可。
先测试下列表页,比如我把 这个保存为 list.html,
然后编写提取代码如下:
import jsonfrom gerapy_auto_extractor.extractors.list import extract_list<br />html = open('list.html', encoding='utf-8').read()print(json.dumps(extract_list(html), indent=2, ensure_ascii=False, default=str))
就是这么简单,核心代码就一行,就是调用了一个 extract_list 方法。
运行结果如下:
[ { "title": "1家6口5年\"结离婚\"10次:儿媳\"嫁\"公公岳", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "\"港独\"议员泼水阻碍教科书议题林郑月娥深夜斥责", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "感动中国致敬留德女学生:街头怒怼\"港独\"有理有", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "香港名医讽刺港警流血少过月经受访时辩称遭盗号", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "李晨独居北京复式豪宅没想到肌肉男喜欢小花椅子", "url": "https://home.163.com/20/0705/0 ... ot%3B }, { "title": "不战东京!林丹官宣退役正式结束20年职业生涯", "url": "https://sports.163.com/20/0704 ... ot%3B }, { "title": "香港美女搬运工月薪1.6万每月花6千租5平出租", "url": "https://home.163.com/20/0705/0 ... ot%3B }, { "title": "杭州第一大P2P\"凉了\":近百亿未还!被警方立案", "url": "https://money.163.com/20/0705/ ... ot%3B }, ...]
可以看到想要的内容就提取出来了,结果是一个列表,包含标题内容和标题链接两个字段,由于内容过长,这里就省略了一部分。
接着我们再测试下正文的提取,随便打开一篇文章,比如 ,保存下 HTML,命名为 detail.html。
编写测试代码如下:
import jsonfrom gerapy_auto_extractor.extractors import extract_detailhtml = open('detail.html', encoding='utf-8').read()print(json.dumps(extract_detail(html), indent=2, ensure_ascii=False, default=str))
运行结果如下:
{ "title": "内蒙古巴彦淖尔发布鼠疫疫情Ⅲ级预警", "datetime": "2020-07-05 18:54:15", "content": "2020年7月4日,乌拉特中旗人民医院报告了1例疑似腺鼠疫病例,根据《内蒙古自治区鼠疫疫情预警实施方案》(内鼠防应急发﹝2020﹞7号)和《自治区鼠疫控制应急预案(2020年版)》(内政办发﹝2020﹞17号)的要求,经研究决定,于7月5日发布鼠疫防控Ⅲ级预警信息如下:\n一、预警级别及起始时间\n预警级别:Ⅲ级。\n2020年7月5日起进入预警期,预警时间从本预警通告发布之日持续到2020年底。\n二、注意事项\n当前我市存在人间鼠疫疫情传播的风险,请广大公众严格按照鼠疫防控“三不三报”的要求,切实做好个人防护,提高自我防护意识和能力。不私自捕猎疫源动物、不剥食疫源动物、不私自携带疫源动物及其产品出疫区;发现病(死)旱獭及其他动物要报告、发现疑似鼠疫病人要报告、发现不明原因的高热病人和急死病人要报告。要谨慎进入鼠疫疫源地,如有鼠疫疫源地的旅居史,出现发热等不适症状时及时赴定点医院就诊。\n按照国家、自治区鼠疫控制应急预案的要求,市卫生健康委将根据鼠疫疫情预警的分级,及时发布和调整预警信息。\n巴彦淖尔市卫生健康委员会\n2020年7月5日\n来源:巴彦淖尔市卫生健康委员会"}
成功输出了标题、正文、发布时间等内容。
这里就演示了基本的列表页、详情页的提取操作。
算法
整个算法的实现比较杂,我看了几篇论文和几个项目的源码,然后经过一些修改实现的。
其中列表页解析的参考论文:
•面向不规则列表的网页数据抽取技术的研究[1]•基于块密度加权标签路径特征的Web新闻在线抽取[2]
详情页解析的参考论文和项目:
•基于文本及符号密度的网页正文提取方法[3]•GeneralNewsExtractor[4]
这些都是不完全参考,然后加上自己的一些修改最终才形成了现在的结果。
算法在这里就几句话描述一下思路,暂时先不展开讲了。
列表页解析:
•找到具有公共父节点的连续相邻子节点,父节点作为候选节点。•根据节点特征进行聚类融合,将符合条件的父节点融合在一起。•根据节点的特征、文本密度、视觉信息(尚未实现)挑选最优父节点。•从最优父节点内根据标题特征提取标题。
详情页解析:
•标题根据 meta、title、h 节点综合提取•时间根据 meta、正则信息综合提取•正文根据文本密度、符号密度、视觉信息(尚未实现)综合提取。
后面等完善了之后再详细介绍算法的具体实现,现在如感兴趣可以去看源码。
说明
本框架仅仅发布了最初测试版本,测试覆盖度比较少,目前仅仅测试了有限的几个网站,尚未大规模测试和添加对比实验,因此准确率现在还没有标准的保证。
参考:关于详情页正文的提取我主要参考了GeneralNewsExtractor[5]这个项目,原项目据测试可以达到 90% 以上的准确率。
列表页我测试了腾讯、网易、知乎等都是可以顺利提取的,如:
后面会有大规模测试和修正。
项目初版,肯定存在很多不足,希望大家可以多发 Issue 和提 PR。
另外这里建立了一个 Gerapy 开发交流群,之前在 群的也欢迎加入,以后交流就在微信群了,大家在使用过程遇到关于 Gerapy、Gerapy Auto Extractor 的问题欢迎交流。
这里放一个临时二维码,后期可能会失效,失效后大家可以到公众号「进击的Coder」或 「崔庆才丨静觅」获取加群方式,欢迎大家加入哈。
交流群
待开发功能
•视觉信息的融合•文本相似度的融合•分类模型的融合•下一页翻页的信息提取•正文图片、视频的提取•对接 Gerapy
最后感谢大家的支持!
References
[1]面向不规则列表的网页数据抽取技术的研究:
[2]基于块密度加权标签路径特征的Web新闻在线抽取:
[3]基于文本及符号密度的网页正文提取方法:
[4]GeneralNewsExtractor:
[5]GeneralNewsExtractor:
精选文章
语法最简单的微博通用爬虫weibo_crawler<br />hiResearch 定义自己的科研首页<br />大邓github汇总, 觉得有用记得starmultistop ~ 多语言停用词库Jaal 库 轻松绘制动态社交网络关系图<br />addressparser中文地址提取工具<br />来自kaggle最佳数据分析实践<br />B站视频 | Python自动化办公<br />SciencePlots | 科研样式绘图库使用streamlit上线中文文本分析网站<br />bsite库 | 采集B站视频信息、评论数据<br />texthero包 | 支持dataframe的文本分析包爬虫实战 | 采集&可视化知乎问题的回答reticulate包 | 在Rmarkdown中调用Python代码plydata库 | 数据操作管道操作符>>plotnine: Python版的ggplot2作图库读完本文你就了解什么是文本分析<br />文本分析在经管领域中的应用概述 综述:文本分析在市场营销研究中的应用<br />plotnine: Python版的ggplot2作图库Wow~70G上市公司定期报告数据集<br />漂亮~pandas可以无缝衔接Bokeh YelpDaset: 酒店管理类数据集10+G
好文和朋友一起看~ 查看全部
发布一个智能解析算法库
之前我写过几篇文章介绍过有关爬虫的智能解析算法,包括商业化应用 Diffbot、Readability、Newspaper 这些库,另外我有一位朋友之前还专门针对新闻正文的提取算法 GeneralNewsExtractor,这段时间我也参考和研究了一下这些库的算法,同时参考一些论文,也写了一个智能解析库,在这里就做一个非正式的介绍。
引入
那首先说说我想做的是什么。
比如这里有一个网站,网易新闻,,这里有个新闻列表,预览图如下:
任意点开一篇新闻,看到的结果如下:
我现在需要做到的是在不编写任何 XPath、Selector 的情况下实现下面信息的提取:
对于列表页来说,我要提取新闻的所有标题列表和对应的链接,它们就是图中的红色区域:
这里红色区域分了多个区块,比如这里一共就是 40 个链接,我都需要提取出来,包括标题的名称,标题的 URL。
我们看到页面里面还有很多无用的链接,如上图绿色区域,包括分类、内部导航等,这些需要排除掉。
对于详情页,我主要关心的内容有标题、发布时间、正文内容,它们就是图中红色区域:
其中这里也带有一些干扰项,比如绿色区域的侧边栏的内容,无用的分享链接等。
总之,我想实现某种算法,实现如上两大部分的智能化提取。
框架
之前我开发了一个叫做 Gerapy 的框架,是一个基于 Scrapy、Scrapyd 的分布式爬虫管理框架,属 1.x 版本。现在正在开发 Gerapy 2.x 版本,其定位转向了 Scrapy 的可视化配置和调试、智能化解析方向,放弃支持 Scraypd,转而支持 Docker、Kubernetes 的部署和监控。
对于智能解析来说,就像刚才说的,我期望的就是上述的功能,在不编写任何 XPath 和 Selector 的情况下实现页面关键内容的提取。
框架现在发布了第一个初步版本,名称叫做 Gerapy Auto Extractor,名字 Gerapy 相关,也会作为 Gerapy 的其中一个模块。
GitHub 链接:
现在已经发布了 PyPi,,可以使用 pip3 来安装,安装方式如下:
pip3 install gerapy-auto-extractor
安装完了之后我们就可以导入使用了。
功能
下面简单介绍下它的功能,它能够做到列表页和详情页的解析。
列表页:
•标题内容•标题链接
详情页:
•标题•正文•发布时间
先暂时实现了如上内容的提取,其他字段的提取暂时还未实现。
使用
要使用 Gerapy Auto Extractor,前提我们必须要先获得 HTML 代码,注意这个 HTML 代码是我们在浏览器里面看到的内容,是整个页面渲染完成之后的代码。在某些情况下如果我们简单用「查看源代码」或 requests 请求获取到的源码并不是真正渲染完成后的 HTML 代码。
要获取完整 HTML 代码可以在浏览器开发者工具,打开 Elements 选项卡,然后复制你所看到的 HTML 内容即可。
先测试下列表页,比如我把 这个保存为 list.html,
然后编写提取代码如下:
import jsonfrom gerapy_auto_extractor.extractors.list import extract_list<br />html = open('list.html', encoding='utf-8').read()print(json.dumps(extract_list(html), indent=2, ensure_ascii=False, default=str))
就是这么简单,核心代码就一行,就是调用了一个 extract_list 方法。
运行结果如下:
[ { "title": "1家6口5年\"结离婚\"10次:儿媳\"嫁\"公公岳", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "\"港独\"议员泼水阻碍教科书议题林郑月娥深夜斥责", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "感动中国致敬留德女学生:街头怒怼\"港独\"有理有", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "香港名医讽刺港警流血少过月经受访时辩称遭盗号", "url": "https://news.163.com/20/0705/0 ... ot%3B }, { "title": "李晨独居北京复式豪宅没想到肌肉男喜欢小花椅子", "url": "https://home.163.com/20/0705/0 ... ot%3B }, { "title": "不战东京!林丹官宣退役正式结束20年职业生涯", "url": "https://sports.163.com/20/0704 ... ot%3B }, { "title": "香港美女搬运工月薪1.6万每月花6千租5平出租", "url": "https://home.163.com/20/0705/0 ... ot%3B }, { "title": "杭州第一大P2P\"凉了\":近百亿未还!被警方立案", "url": "https://money.163.com/20/0705/ ... ot%3B }, ...]
可以看到想要的内容就提取出来了,结果是一个列表,包含标题内容和标题链接两个字段,由于内容过长,这里就省略了一部分。
接着我们再测试下正文的提取,随便打开一篇文章,比如 ,保存下 HTML,命名为 detail.html。
编写测试代码如下:
import jsonfrom gerapy_auto_extractor.extractors import extract_detailhtml = open('detail.html', encoding='utf-8').read()print(json.dumps(extract_detail(html), indent=2, ensure_ascii=False, default=str))
运行结果如下:
{ "title": "内蒙古巴彦淖尔发布鼠疫疫情Ⅲ级预警", "datetime": "2020-07-05 18:54:15", "content": "2020年7月4日,乌拉特中旗人民医院报告了1例疑似腺鼠疫病例,根据《内蒙古自治区鼠疫疫情预警实施方案》(内鼠防应急发﹝2020﹞7号)和《自治区鼠疫控制应急预案(2020年版)》(内政办发﹝2020﹞17号)的要求,经研究决定,于7月5日发布鼠疫防控Ⅲ级预警信息如下:\n一、预警级别及起始时间\n预警级别:Ⅲ级。\n2020年7月5日起进入预警期,预警时间从本预警通告发布之日持续到2020年底。\n二、注意事项\n当前我市存在人间鼠疫疫情传播的风险,请广大公众严格按照鼠疫防控“三不三报”的要求,切实做好个人防护,提高自我防护意识和能力。不私自捕猎疫源动物、不剥食疫源动物、不私自携带疫源动物及其产品出疫区;发现病(死)旱獭及其他动物要报告、发现疑似鼠疫病人要报告、发现不明原因的高热病人和急死病人要报告。要谨慎进入鼠疫疫源地,如有鼠疫疫源地的旅居史,出现发热等不适症状时及时赴定点医院就诊。\n按照国家、自治区鼠疫控制应急预案的要求,市卫生健康委将根据鼠疫疫情预警的分级,及时发布和调整预警信息。\n巴彦淖尔市卫生健康委员会\n2020年7月5日\n来源:巴彦淖尔市卫生健康委员会"}
成功输出了标题、正文、发布时间等内容。
这里就演示了基本的列表页、详情页的提取操作。
算法
整个算法的实现比较杂,我看了几篇论文和几个项目的源码,然后经过一些修改实现的。
其中列表页解析的参考论文:
•面向不规则列表的网页数据抽取技术的研究[1]•基于块密度加权标签路径特征的Web新闻在线抽取[2]
详情页解析的参考论文和项目:
•基于文本及符号密度的网页正文提取方法[3]•GeneralNewsExtractor[4]
这些都是不完全参考,然后加上自己的一些修改最终才形成了现在的结果。
算法在这里就几句话描述一下思路,暂时先不展开讲了。
列表页解析:
•找到具有公共父节点的连续相邻子节点,父节点作为候选节点。•根据节点特征进行聚类融合,将符合条件的父节点融合在一起。•根据节点的特征、文本密度、视觉信息(尚未实现)挑选最优父节点。•从最优父节点内根据标题特征提取标题。
详情页解析:
•标题根据 meta、title、h 节点综合提取•时间根据 meta、正则信息综合提取•正文根据文本密度、符号密度、视觉信息(尚未实现)综合提取。
后面等完善了之后再详细介绍算法的具体实现,现在如感兴趣可以去看源码。
说明
本框架仅仅发布了最初测试版本,测试覆盖度比较少,目前仅仅测试了有限的几个网站,尚未大规模测试和添加对比实验,因此准确率现在还没有标准的保证。
参考:关于详情页正文的提取我主要参考了GeneralNewsExtractor[5]这个项目,原项目据测试可以达到 90% 以上的准确率。
列表页我测试了腾讯、网易、知乎等都是可以顺利提取的,如:
后面会有大规模测试和修正。
项目初版,肯定存在很多不足,希望大家可以多发 Issue 和提 PR。
另外这里建立了一个 Gerapy 开发交流群,之前在 群的也欢迎加入,以后交流就在微信群了,大家在使用过程遇到关于 Gerapy、Gerapy Auto Extractor 的问题欢迎交流。
这里放一个临时二维码,后期可能会失效,失效后大家可以到公众号「进击的Coder」或 「崔庆才丨静觅」获取加群方式,欢迎大家加入哈。
交流群
待开发功能
•视觉信息的融合•文本相似度的融合•分类模型的融合•下一页翻页的信息提取•正文图片、视频的提取•对接 Gerapy
最后感谢大家的支持!
References
[1]面向不规则列表的网页数据抽取技术的研究:
[2]基于块密度加权标签路径特征的Web新闻在线抽取:
[3]基于文本及符号密度的网页正文提取方法:
[4]GeneralNewsExtractor:
[5]GeneralNewsExtractor:
精选文章
语法最简单的微博通用爬虫weibo_crawler<br />hiResearch 定义自己的科研首页<br />大邓github汇总, 觉得有用记得starmultistop ~ 多语言停用词库Jaal 库 轻松绘制动态社交网络关系图<br />addressparser中文地址提取工具<br />来自kaggle最佳数据分析实践<br />B站视频 | Python自动化办公<br />SciencePlots | 科研样式绘图库使用streamlit上线中文文本分析网站<br />bsite库 | 采集B站视频信息、评论数据<br />texthero包 | 支持dataframe的文本分析包爬虫实战 | 采集&可视化知乎问题的回答reticulate包 | 在Rmarkdown中调用Python代码plydata库 | 数据操作管道操作符>>plotnine: Python版的ggplot2作图库读完本文你就了解什么是文本分析<br />文本分析在经管领域中的应用概述 综述:文本分析在市场营销研究中的应用<br />plotnine: Python版的ggplot2作图库Wow~70G上市公司定期报告数据集<br />漂亮~pandas可以无缝衔接Bokeh YelpDaset: 酒店管理类数据集10+G
好文和朋友一起看~
算法自动采集列表页简介页推荐页和最近页的爬虫python
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-05-09 00:01
算法自动采集列表页简介页推荐页和最近页的爬虫python实现,第二天使用selenium实现效果1。爬虫:爬取24万条微信好友聊天记录-python-伯乐在线2。分析:列表页是通过人脸识别技术做的识别2-1。提取人脸,2-2。提取微信昵称、微信地区、分组信息2-3。提取人脸2-4。提取人脸识别-selenium小工具课程_伯乐在线3。
实现目标3。1。爬取24万条微信好友聊天记录3。2。分析及合并微信昵称、微信地区、分组信息3。3。爬取每个用户自带的群2。提取人脸3。1。抓取好友姓名,爬取昵称,分组信息3。2。提取人脸3。3。分析及合并,爬取每个用户自带的群2。1。抓取好友姓名,爬取昵称,分组信息3。2。提取人脸3。3。抓取地区信息2。
提取昵称、分组信息3。1。提取好友地区信息4。代码分析4。1。抓取昵称4。2。提取昵称和微信昵称4。3。提取微信昵称4。4。分组信息4。5。抓取每个用户自带的群2。提取昵称、分组信息5。学习笔记2。1。抓取昵称抓取昵称后代码:#-*-coding:utf-8-*-importrequests#爬取24万条微信好友聊天记录#给好友打标签#一共爬取25万个男用户的聊天记录#好友类型ex1=requests。
get('thread',headers=headers)#用户简介ex2=requests。get('thread',headers=headers)#关键字,男/女#抓取人脸ex3=requests。get('thread',headers=headers)#发送消息和发送长文件ex4=requests。
get('thread',headers=headers)#人脸识别t=requests。get('thread',headers=headers)#获取对方接收的session#获取每个用户自带的群#加入的群越多越好#运行python爬虫的环境:python3。6pip3installseleniumpip3installmultiprocessingfrompilimportimage#特殊js特性:'''(不再看)'''html=python3。
6imgurl=';uid=35853&name=jullin'#手机微信号以及昵称ex3=python3。6img_format='png'#获取共计24万条微信聊天记录名字"""抓取好友的昵称"""#发送自定义短信,获取昵称#。
1、注册爬虫抓取28万条微信好友的通讯录#
2、爬取微信通讯录爬取好友的昵称#
3、爬取微信好友的发送的自定义短信#第一种,
4)applewebkit/537.36(khtml,likegecko)chrome 查看全部
算法自动采集列表页简介页推荐页和最近页的爬虫python
算法自动采集列表页简介页推荐页和最近页的爬虫python实现,第二天使用selenium实现效果1。爬虫:爬取24万条微信好友聊天记录-python-伯乐在线2。分析:列表页是通过人脸识别技术做的识别2-1。提取人脸,2-2。提取微信昵称、微信地区、分组信息2-3。提取人脸2-4。提取人脸识别-selenium小工具课程_伯乐在线3。
实现目标3。1。爬取24万条微信好友聊天记录3。2。分析及合并微信昵称、微信地区、分组信息3。3。爬取每个用户自带的群2。提取人脸3。1。抓取好友姓名,爬取昵称,分组信息3。2。提取人脸3。3。分析及合并,爬取每个用户自带的群2。1。抓取好友姓名,爬取昵称,分组信息3。2。提取人脸3。3。抓取地区信息2。
提取昵称、分组信息3。1。提取好友地区信息4。代码分析4。1。抓取昵称4。2。提取昵称和微信昵称4。3。提取微信昵称4。4。分组信息4。5。抓取每个用户自带的群2。提取昵称、分组信息5。学习笔记2。1。抓取昵称抓取昵称后代码:#-*-coding:utf-8-*-importrequests#爬取24万条微信好友聊天记录#给好友打标签#一共爬取25万个男用户的聊天记录#好友类型ex1=requests。
get('thread',headers=headers)#用户简介ex2=requests。get('thread',headers=headers)#关键字,男/女#抓取人脸ex3=requests。get('thread',headers=headers)#发送消息和发送长文件ex4=requests。
get('thread',headers=headers)#人脸识别t=requests。get('thread',headers=headers)#获取对方接收的session#获取每个用户自带的群#加入的群越多越好#运行python爬虫的环境:python3。6pip3installseleniumpip3installmultiprocessingfrompilimportimage#特殊js特性:'''(不再看)'''html=python3。
6imgurl=';uid=35853&name=jullin'#手机微信号以及昵称ex3=python3。6img_format='png'#获取共计24万条微信聊天记录名字"""抓取好友的昵称"""#发送自定义短信,获取昵称#。
1、注册爬虫抓取28万条微信好友的通讯录#
2、爬取微信通讯录爬取好友的昵称#
3、爬取微信好友的发送的自定义短信#第一种,
4)applewebkit/537.36(khtml,likegecko)chrome
DBA要失业了?看ML如何自动优化数据库
采集交流 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-05-05 10:08
译者注:看到标题的时候,确实被吓了一大跳。看的过程,心里其实一直在降低警惕。但完整看完这篇文章的时候,情绪又回落到刚看到标题的状态了。虽然DBA的工作不会那么快被AI替代,文章所说的也主要是开关(参数),但显然数据库的管理只会越来越智能,不是由厂家自己(比如Oracle,这些年从PGA自动管理,SGA自动管理到整个内存自动管理,从Perfstat到AWR到ADDM,正在一步步把DBA“傻瓜化”),就是由第三方公司或者研究机构(比如本文的卡耐基大学数据库研究团队),作为DBA来说,必须要不断尝试,站在一个更高层面来看待数据库,看待运维,看待IT,否则就会成为被机器人替代的炮灰。
数据库管理系统(DBMSs,DatabaseManagement Systems)是任何数据密集型应用最重要的组成部分。他们可以处理大规模数据和复杂的负载形态,但它们很难管理,因为它们有成百上千个配置“开关”,用来控制诸如将多少内存用作缓存、怎样将数据写到存储等等这些事情。企业或组织经常雇佣技术专家来帮忙做系统优化,但专家对许多公司来说还是非常昂贵的。
卡耐基梅隆大学数据库组的研究员和学生们研发了一款新工具,叫做OtterTune。OtterTune可以从数据库成百上千个配置开关中自动发现最佳设置。它的目标是让随便一个工程师都可以更容易去部署一套关系型数据库,即使他们在数据库管理方面没有任何专业知识也行。
OtterTune与其他的数据库配置工具不一样,因为它利用调优先前的数据库配置知识去调优新的数据库配置。这可以显著地降低调优一个新的数据库部署所需时间及相关的资源。为了做到这一点,OtterTune维持着一个资料库,其中存放了从先前调优环境中采集回来的调优数据。OtterTune使用这些调优模型来指导新应用程序的实验,推荐能够改进目标对象(比如降低延时或者提升吞吐量)的设置。
在这篇文章中,我们讨论OtterTune工具 ML pipeline(机器学习的工作流API库)的每个组件,并展示他们之间怎样互相协作去调优一个数据库配置。我们在MySQL和Postgre上评估OtterTune的调优能力,通过将OtterTune最佳配置的性能与DBA选择的配置及其他自动调优工具的配置得出的性能做比较。
OtterTune是一个开源工具,由卡耐基梅隆大学数据库研究组的研究员和学生们研发。所有的工具代码都放在GitHub上,遵从Apache License 2.0协议授权。
Otter Tune怎样工作?
在一个新的调优场景,首先,用户告诉OtterTune要通过调优来满足哪个目标对象(比如,延迟或者吞吐量)。客户端的控制器(controller)连接到目标数据库,搜集它的Amazon EC2实例类型和当前配置。
然后控制器开始它的第一个探测周期,在这个期间内,它监控数据库,并记录目标对象。探测周期结束的时候,控制器从数据库中采集好内部指标,比如MySQL中从磁盘读取的页面和写到磁盘的页面(pages)的计数器。控制器会将目标对象和内部指标信息都传递给调优管理器(tuning manager)。
当OtterTune调优管理器收到这些指标后,把它们存放在资料库当中。OtterTune使用这些结果,计算下一个要部署的目标数据库的配置。调优管理器将这一配置信息传输给控制器,并告诉控制器,采纳这一配置后可能会获得的性能提升。用户可以决定是继续调优,还是结束这次优化工作。
注意
OtterTune为它支持的每个数据库版本维护着一个配置开关的黑名单。黑名单包括那些调整了不会产生效果的配置开关(比如,数据库中存放文件的路径名),或者这些开关会有严重的或者潜在不良后果(比如,可能会导致数据库丢失数据)。每场调优开始的时候,OtterTune都会给用户提供一个黑名单,所以他/她可以增加其他开关进去,如果他们希望OtterTune不要去调优这部分的话。
OtterTune作了一些假设限制,可能会限制了一些用户的可用性。比如,它假定用户有允许控制器更改数据库配置的管理权限。如果用户没有这个权限,那他或者她可以在其他硬件上部署一个数据库镜像,用于OtterTune调优实验。这就需要用户去重演(replay)一个工作负载跟踪,或者在生产数据库中转发查询。关于假定和限制的完整讨论,详见我们的论文(读者可以点击文末的“阅读原文”进行阅读)。
ML pipeline
下面的图中展示了通过OtterTune的ML pipeline,数据在移动过程中是如何处理的。所有探查数据都存放在OtterTune资料库中。
OtterTune首先将探测数据传给“工作负载表征”(Workload Characterization)组件。该组件识别一组较小的数据库指标度量,可以最佳地捕获性能上的差异性,以及不同工作负载的区别特征。
接着,开关识别组件(Knob Identification)生成一个开关的排名列表,以对数据库性能的影响度大小排序。OtterTune将所有这些信息提供给自动调优器(Automatic Tuner)组件。该组件在它的数据资料库中为目标数据库负载匹配(map)最相似的负载,并用这个负载数据生成最佳配置。
让我们把ML pipeline中的每个组件再详细说说。
工作负载表征(Workload Characterization)组件:OtterTune使用数据库内部运行时的度量指标来表征(或识别)工作负载的行为。这些度量指标提供了负载的准确表现,因为它们捕获了运行时行为的许多因素。可是,很多度量指标是冗余的,一些是相同的度量记录只是单位不同,其他的则是表现数据库不同组件,它们的值高度相关。所以裁剪冗余度量就很重要,这可以降低ML模型使用它们的时候的复杂性。为此,我们根据其相关性模型对数据库的度量指标进行了聚类。然后,我们从每个聚类中选择一个作为代表度量,就是最靠近聚类中心的那个度量。ML pipeline的后续组件直接使用这些度量。
开关识别组件(Knob Identification):数据库中可能有几百个开关,但只有一小部分会影响数据库的性能。OtterTune使用一个叫做Lasso的流行特征选择(feature-selection)技术,来确定哪些开关会很大程度上影响系统的整体性能。通过使用这一技术于资料库中的数据,OtterTune就可以列出数据库中这些开关的重要性顺序。
然后,OtterTune必须决定,做配置推荐的时候用多少个开关。使用太多必然会显著增加OtterTune的调优时间。用得太少又会妨碍OtterTune去找到最佳配置。OtterTune使用渐进化的方式自动化这一过程,在调优时它会逐渐增加开关的个数。这个方式让OtterTune在扩展到更多开关之前,探寻和优化一组最重要的开关配置。
自动调优(Automatic Tuner)组件:自动调优组件通过在每个观察周期之后执行“两步分析”(two-step analysis)来确定OtterTune应推荐的配置。
首先,系统使用工作负载表征组件中标识的度量性能数据,识别来自先前调优场景的最能匹配目标数据库负载的负载。它将当前场景的度量指标与先前场景的度量指标进行比较,以确定哪些指标与不同的开关设置类似。
然后,OtterTune会选择另一个开关设置去尝试。它适用一个统计模型,搜集数据,与资料库中最相近负载的数据一样。这个模型让OtterTune可以预测实施每个可能的配置后,数据库性能会怎样。OtterTune优化下一个配置,采用探索的方式(搜集信息以改进模型)而不是剥削的方式(试图只在目标度量上就贪婪地做好)。
实现
OtterTune用Python编写。
对工作负载表征和开关识别组件来说,运行时的性能并不特别需要考虑,因此我们用scikit-learn来实现相应的机器学习算法。这些算法以后台进程的形式运行,并使用OtterTune资料库中的新数据。
对自动优化组件来说,机器学习算法在关键路径上。他们在每一个观察周期后运行,获取新数据以便OtterTune能取得一个开关配置进行下一次尝试。因为它的性能是要特别考虑的,我们用TensorFlow来实现其算法。
搜集关于数据库硬件的数据、开关配置以及运行时的性能度量指标,我们将OLTP-Bench测评框架集成到OtterTune的控制器中。
实验设计
为了评估效果,我们使用OtterTune选择的最佳配置来比较MySQL和Postgre的性能:
我们所有的实验都是在Amazon EC2 Spot Instance上完成的。每一个实验都用了2个实例:一个作为OtterTune控制器,一个作为目标数据库部署用。我们分别使用m4.large和m3.xlarge实例类型。我们将OtterTune调优管理器和资料库部署在本地服务器上,配置是20核CPU、128G内存。我们用TPC-C负载模型,这是评估OLTP系统性能的工业标准。
评估
对实验中我们用到的每一种数据库,MySQL及Postgre,我们评估延迟和性能。下面的图展示了评估结果。第一个图表展示了第99百分位数指标的延迟数量,代表完成交易所需的“最坏情况”时间长度。第二个图展示吞吐量的结果,评估的是每秒完成的平均事务数。
MySQL评估结果:
比较由OtterTune生成的最佳配置与其他工具的“优化脚本”、RDS生成的配置,OtterTune推荐的配置对MySQL数据库大约降低了60%的延迟,提升了22%到35%的吞吐量。OtterTune生成的配置几乎与DBA做的选择一样好。
只有一些MySQL的开关会显著影响TPC-C负载的性能。由OtterTune生成的配置和DBA为每个开关提供了很好的设置。RDS干的稍微要差点,因为它为一个开关提供了不是最优的设置。“优化脚本”的配置表现最差,因为它只改了一个开关。
Postgre评估结果:
对延迟来说,OtterTUne生成的配置,与“优化脚本”、DBA、RDS差不多,相对Postgre的默认设置都获得了不少的提升。我们可以将其归因于OTLP测评工具客户端和数据库之间的网络开销。对于吞吐量,OtterTune设置相对DBA和“优化脚本”的设置得到了12%的提升,相对RDS,得到了32%的提升。
跟MySQL相似,只要少数开关显著影响Postgre的性能。OtterTune、DBA、“优化脚本”以及RDS都调整了所有这些开关,大多都提供了合理的设置。
结论
OtterTune为关系型数据库的配置开关自动化发现最佳设置,用于调优新的数据库部署,重用从先前调优场景获取的训练数据。因为OtterTune不需要为训练ML模型生成厨师数据集,所需调优时间大大减少。
译后记
OtterTune为关系型数据库的配置开关自动化发现最佳设置,用于调优。
不客气地说,OtterTune目前也只是支持MySQL和Postgre两种数据库,而且只是在开关设置层面,相比Oracle数据库在自动化管理方面的强大功力,OtterTune只能算是一个玩具。我突然想到,2004年的时候,我去贵州给某个运营商做Oracle数据库优化,只是把SGA从100M调大到1GB,客户的核心业务整体性能就得到了飞速提升。放到今天来说是个不可思议的事情,今天随便一个省级运营商的核心系统标配可能都是一个TB的内存,缺省安装的时候,工程师就会把SGA缺省配到700G,其他相关参数也会按所谓的最佳实践进行。
但是,没有开关的问题,不代表就没有数据库的性能问题。
时至今日,Oracle数据库的性能问题依然层出不穷(不是因为Oracle不行,其他数据库还在后面远远的跟着Oracle在前进呢),参数开关层面基本已经不太可能有遗漏。性能问题更多的层面来自于开发,开发部门数据模型设计得不合理,开发人员SQL写得不合理,往往导致了90%的性能问题。前两天朋友谈及的一个案例,某银行的信用卡业务查询,每天一次,表当然有几亿条记录,查询一次要花费小时计的时间,通过一个简单的rownum查询时间降低到秒级。单纯的开发人员搞不定,普通的DBA也想不到,机器学习能做这种优化么?现在不好判断。
有远虑,不是坏事。但也无需太执着于远虑,还是要把当前的事情先做好。
如果你们的开发团队老是出一些表结构设计问题、索引问题、劣质SQL问题,不妨推荐他们先来上上D+学院先开设的精品SQL优化课程。Oracle和MySQL都有,只要一天时间,可以跟业界一线DBA大师学习怎样做SQL优化,省时、省力、利人、利己。
当然,如果你连1天完整时间都抽不出来,也不用气馁,DBAplus仍然不定期将各类优化妙文推送出来,给需要精进的你。 查看全部
DBA要失业了?看ML如何自动优化数据库
译者注:看到标题的时候,确实被吓了一大跳。看的过程,心里其实一直在降低警惕。但完整看完这篇文章的时候,情绪又回落到刚看到标题的状态了。虽然DBA的工作不会那么快被AI替代,文章所说的也主要是开关(参数),但显然数据库的管理只会越来越智能,不是由厂家自己(比如Oracle,这些年从PGA自动管理,SGA自动管理到整个内存自动管理,从Perfstat到AWR到ADDM,正在一步步把DBA“傻瓜化”),就是由第三方公司或者研究机构(比如本文的卡耐基大学数据库研究团队),作为DBA来说,必须要不断尝试,站在一个更高层面来看待数据库,看待运维,看待IT,否则就会成为被机器人替代的炮灰。
数据库管理系统(DBMSs,DatabaseManagement Systems)是任何数据密集型应用最重要的组成部分。他们可以处理大规模数据和复杂的负载形态,但它们很难管理,因为它们有成百上千个配置“开关”,用来控制诸如将多少内存用作缓存、怎样将数据写到存储等等这些事情。企业或组织经常雇佣技术专家来帮忙做系统优化,但专家对许多公司来说还是非常昂贵的。
卡耐基梅隆大学数据库组的研究员和学生们研发了一款新工具,叫做OtterTune。OtterTune可以从数据库成百上千个配置开关中自动发现最佳设置。它的目标是让随便一个工程师都可以更容易去部署一套关系型数据库,即使他们在数据库管理方面没有任何专业知识也行。
OtterTune与其他的数据库配置工具不一样,因为它利用调优先前的数据库配置知识去调优新的数据库配置。这可以显著地降低调优一个新的数据库部署所需时间及相关的资源。为了做到这一点,OtterTune维持着一个资料库,其中存放了从先前调优环境中采集回来的调优数据。OtterTune使用这些调优模型来指导新应用程序的实验,推荐能够改进目标对象(比如降低延时或者提升吞吐量)的设置。
在这篇文章中,我们讨论OtterTune工具 ML pipeline(机器学习的工作流API库)的每个组件,并展示他们之间怎样互相协作去调优一个数据库配置。我们在MySQL和Postgre上评估OtterTune的调优能力,通过将OtterTune最佳配置的性能与DBA选择的配置及其他自动调优工具的配置得出的性能做比较。
OtterTune是一个开源工具,由卡耐基梅隆大学数据库研究组的研究员和学生们研发。所有的工具代码都放在GitHub上,遵从Apache License 2.0协议授权。
Otter Tune怎样工作?
在一个新的调优场景,首先,用户告诉OtterTune要通过调优来满足哪个目标对象(比如,延迟或者吞吐量)。客户端的控制器(controller)连接到目标数据库,搜集它的Amazon EC2实例类型和当前配置。
然后控制器开始它的第一个探测周期,在这个期间内,它监控数据库,并记录目标对象。探测周期结束的时候,控制器从数据库中采集好内部指标,比如MySQL中从磁盘读取的页面和写到磁盘的页面(pages)的计数器。控制器会将目标对象和内部指标信息都传递给调优管理器(tuning manager)。
当OtterTune调优管理器收到这些指标后,把它们存放在资料库当中。OtterTune使用这些结果,计算下一个要部署的目标数据库的配置。调优管理器将这一配置信息传输给控制器,并告诉控制器,采纳这一配置后可能会获得的性能提升。用户可以决定是继续调优,还是结束这次优化工作。
注意
OtterTune为它支持的每个数据库版本维护着一个配置开关的黑名单。黑名单包括那些调整了不会产生效果的配置开关(比如,数据库中存放文件的路径名),或者这些开关会有严重的或者潜在不良后果(比如,可能会导致数据库丢失数据)。每场调优开始的时候,OtterTune都会给用户提供一个黑名单,所以他/她可以增加其他开关进去,如果他们希望OtterTune不要去调优这部分的话。
OtterTune作了一些假设限制,可能会限制了一些用户的可用性。比如,它假定用户有允许控制器更改数据库配置的管理权限。如果用户没有这个权限,那他或者她可以在其他硬件上部署一个数据库镜像,用于OtterTune调优实验。这就需要用户去重演(replay)一个工作负载跟踪,或者在生产数据库中转发查询。关于假定和限制的完整讨论,详见我们的论文(读者可以点击文末的“阅读原文”进行阅读)。
ML pipeline
下面的图中展示了通过OtterTune的ML pipeline,数据在移动过程中是如何处理的。所有探查数据都存放在OtterTune资料库中。
OtterTune首先将探测数据传给“工作负载表征”(Workload Characterization)组件。该组件识别一组较小的数据库指标度量,可以最佳地捕获性能上的差异性,以及不同工作负载的区别特征。
接着,开关识别组件(Knob Identification)生成一个开关的排名列表,以对数据库性能的影响度大小排序。OtterTune将所有这些信息提供给自动调优器(Automatic Tuner)组件。该组件在它的数据资料库中为目标数据库负载匹配(map)最相似的负载,并用这个负载数据生成最佳配置。
让我们把ML pipeline中的每个组件再详细说说。
工作负载表征(Workload Characterization)组件:OtterTune使用数据库内部运行时的度量指标来表征(或识别)工作负载的行为。这些度量指标提供了负载的准确表现,因为它们捕获了运行时行为的许多因素。可是,很多度量指标是冗余的,一些是相同的度量记录只是单位不同,其他的则是表现数据库不同组件,它们的值高度相关。所以裁剪冗余度量就很重要,这可以降低ML模型使用它们的时候的复杂性。为此,我们根据其相关性模型对数据库的度量指标进行了聚类。然后,我们从每个聚类中选择一个作为代表度量,就是最靠近聚类中心的那个度量。ML pipeline的后续组件直接使用这些度量。
开关识别组件(Knob Identification):数据库中可能有几百个开关,但只有一小部分会影响数据库的性能。OtterTune使用一个叫做Lasso的流行特征选择(feature-selection)技术,来确定哪些开关会很大程度上影响系统的整体性能。通过使用这一技术于资料库中的数据,OtterTune就可以列出数据库中这些开关的重要性顺序。
然后,OtterTune必须决定,做配置推荐的时候用多少个开关。使用太多必然会显著增加OtterTune的调优时间。用得太少又会妨碍OtterTune去找到最佳配置。OtterTune使用渐进化的方式自动化这一过程,在调优时它会逐渐增加开关的个数。这个方式让OtterTune在扩展到更多开关之前,探寻和优化一组最重要的开关配置。
自动调优(Automatic Tuner)组件:自动调优组件通过在每个观察周期之后执行“两步分析”(two-step analysis)来确定OtterTune应推荐的配置。
首先,系统使用工作负载表征组件中标识的度量性能数据,识别来自先前调优场景的最能匹配目标数据库负载的负载。它将当前场景的度量指标与先前场景的度量指标进行比较,以确定哪些指标与不同的开关设置类似。
然后,OtterTune会选择另一个开关设置去尝试。它适用一个统计模型,搜集数据,与资料库中最相近负载的数据一样。这个模型让OtterTune可以预测实施每个可能的配置后,数据库性能会怎样。OtterTune优化下一个配置,采用探索的方式(搜集信息以改进模型)而不是剥削的方式(试图只在目标度量上就贪婪地做好)。
实现
OtterTune用Python编写。
对工作负载表征和开关识别组件来说,运行时的性能并不特别需要考虑,因此我们用scikit-learn来实现相应的机器学习算法。这些算法以后台进程的形式运行,并使用OtterTune资料库中的新数据。
对自动优化组件来说,机器学习算法在关键路径上。他们在每一个观察周期后运行,获取新数据以便OtterTune能取得一个开关配置进行下一次尝试。因为它的性能是要特别考虑的,我们用TensorFlow来实现其算法。
搜集关于数据库硬件的数据、开关配置以及运行时的性能度量指标,我们将OLTP-Bench测评框架集成到OtterTune的控制器中。
实验设计
为了评估效果,我们使用OtterTune选择的最佳配置来比较MySQL和Postgre的性能:
我们所有的实验都是在Amazon EC2 Spot Instance上完成的。每一个实验都用了2个实例:一个作为OtterTune控制器,一个作为目标数据库部署用。我们分别使用m4.large和m3.xlarge实例类型。我们将OtterTune调优管理器和资料库部署在本地服务器上,配置是20核CPU、128G内存。我们用TPC-C负载模型,这是评估OLTP系统性能的工业标准。
评估
对实验中我们用到的每一种数据库,MySQL及Postgre,我们评估延迟和性能。下面的图展示了评估结果。第一个图表展示了第99百分位数指标的延迟数量,代表完成交易所需的“最坏情况”时间长度。第二个图展示吞吐量的结果,评估的是每秒完成的平均事务数。
MySQL评估结果:
比较由OtterTune生成的最佳配置与其他工具的“优化脚本”、RDS生成的配置,OtterTune推荐的配置对MySQL数据库大约降低了60%的延迟,提升了22%到35%的吞吐量。OtterTune生成的配置几乎与DBA做的选择一样好。
只有一些MySQL的开关会显著影响TPC-C负载的性能。由OtterTune生成的配置和DBA为每个开关提供了很好的设置。RDS干的稍微要差点,因为它为一个开关提供了不是最优的设置。“优化脚本”的配置表现最差,因为它只改了一个开关。
Postgre评估结果:
对延迟来说,OtterTUne生成的配置,与“优化脚本”、DBA、RDS差不多,相对Postgre的默认设置都获得了不少的提升。我们可以将其归因于OTLP测评工具客户端和数据库之间的网络开销。对于吞吐量,OtterTune设置相对DBA和“优化脚本”的设置得到了12%的提升,相对RDS,得到了32%的提升。
跟MySQL相似,只要少数开关显著影响Postgre的性能。OtterTune、DBA、“优化脚本”以及RDS都调整了所有这些开关,大多都提供了合理的设置。
结论
OtterTune为关系型数据库的配置开关自动化发现最佳设置,用于调优新的数据库部署,重用从先前调优场景获取的训练数据。因为OtterTune不需要为训练ML模型生成厨师数据集,所需调优时间大大减少。
译后记
OtterTune为关系型数据库的配置开关自动化发现最佳设置,用于调优。
不客气地说,OtterTune目前也只是支持MySQL和Postgre两种数据库,而且只是在开关设置层面,相比Oracle数据库在自动化管理方面的强大功力,OtterTune只能算是一个玩具。我突然想到,2004年的时候,我去贵州给某个运营商做Oracle数据库优化,只是把SGA从100M调大到1GB,客户的核心业务整体性能就得到了飞速提升。放到今天来说是个不可思议的事情,今天随便一个省级运营商的核心系统标配可能都是一个TB的内存,缺省安装的时候,工程师就会把SGA缺省配到700G,其他相关参数也会按所谓的最佳实践进行。
但是,没有开关的问题,不代表就没有数据库的性能问题。
时至今日,Oracle数据库的性能问题依然层出不穷(不是因为Oracle不行,其他数据库还在后面远远的跟着Oracle在前进呢),参数开关层面基本已经不太可能有遗漏。性能问题更多的层面来自于开发,开发部门数据模型设计得不合理,开发人员SQL写得不合理,往往导致了90%的性能问题。前两天朋友谈及的一个案例,某银行的信用卡业务查询,每天一次,表当然有几亿条记录,查询一次要花费小时计的时间,通过一个简单的rownum查询时间降低到秒级。单纯的开发人员搞不定,普通的DBA也想不到,机器学习能做这种优化么?现在不好判断。
有远虑,不是坏事。但也无需太执着于远虑,还是要把当前的事情先做好。
如果你们的开发团队老是出一些表结构设计问题、索引问题、劣质SQL问题,不妨推荐他们先来上上D+学院先开设的精品SQL优化课程。Oracle和MySQL都有,只要一天时间,可以跟业界一线DBA大师学习怎样做SQL优化,省时、省力、利人、利己。
当然,如果你连1天完整时间都抽不出来,也不用气馁,DBAplus仍然不定期将各类优化妙文推送出来,给需要精进的你。
算法 自动采集列表( 【干货】自动驾驶中的视觉感知模块(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-15 10:18
【干货】自动驾驶中的视觉感知模块(一))
1 简介
自动驾驶中的视觉感知模块通过图像或视频数据了解车辆周围环境,具体任务包括物体检测与跟踪(2D或3D物体)、语义分割(2D或3D场景)、深度估计、光流估计, ETC。
在这个文章中,我们首先介绍基于图像或视频的2D对象检测和跟踪,以及2D场景的语义分割。这些任务在自动驾驶中被广泛使用,已经有很多各种各样的评论文章,所以这里我只选择介绍一些经典算法,重点介绍上下文和方向。
自从2012年深度学习在图像分类任务上取得突破,迅速占领了图像感知的各个领域,所以下面的介绍也是基于深度学习算法。
2 目标检测2.1 两阶段检测
传统的图像目标检测算法大多是滑动窗口、特征提取和分类器的结合,如Haar特征+AdaBoost分类器、HOG特征+SVM分类器。这种方法的一个主要问题是需要为不同的目标检测任务手动设计不同的特征。因此,在深度学习兴起之前,特征设计是目标检测领域的主要增长点。
R-CNN[1]作为深度学习在目标检测领域的开创性工作,仍然有很多传统方法的影子。首先,Selective Search 替代了滑动窗口以减少窗口数量。第二个也是最重要的变化是使用卷积神经网络 (CNN) 来提取每个窗口的图像特征,而不是手工制作的特征设计。这里的CNN是在ImageNet上预训练的,对于一般图像特征的提取非常有效。最后利用SVM对每个窗口的特征进行分类,完成目标检测任务。
R-CNN的主要问题之一是选择性搜索得到的窗口数量重叠过多,导致特征提取部分有大量冗余操作,严重影响算法的运行效率(约2000个候选图片中的框,在 GPU 上运行时间也超过 10 秒)。
卷积神经网络
为了复用不同位置的特征,Fast R-CNN[2]提出先通过CNN提取图像特征,然后对选择性搜索得到的候选帧进行ROI Pooling,得到相同长度的特征向量。最后,使用全连接网络进行候选框分类和边界框回归。这样就避免了重叠候选框的冗余操作,大大提高了特征提取的效率。
与 R-CNN 相比,Fast R-CNN 在 VOC07 数据集上的 mAP 从 58.5% 提高到 70.0%,检测速度提高了约 200 倍。但是,Fast R-CNN 仍然使用选择性搜索来获取候选区域。这个过程还是比较慢的。处理一张图片大约需要2秒左右,对于实时性要求高的应用来说,这远远不够。
快速 R-CNN
既然选择性搜索是算法速度的瓶颈,那么自然而然会想到用神经网络来完成这一步是可能的吗?这个问题的答案是 Faster R-CNN [3]。它利用区域候选网络(RPN)根据特征图生成候选框。接下来的步骤和 Fast R-CNN 类似,都是 ROI Pooling 生成候选框的特征,然后使用全连接层进行分类和回归。
Faster RCNN中出现了一个重要的概念,即Anchor。特征图的每个位置都会生成不同大小和不同纵横比的anchors,作为object frame回归的参考。Anchor 的引入使得回归任务只需要处理相对较小的变化,因此网络的学习会更容易。
Faster RCNN是第一个端到端的物体检测网络,VOC07上的mAP达到73.2%,速度也达到了17FPS,接近实时。
更快的 R-CNN
随后的FPN[4](Feature Pyramid Network)在特征提取阶段进行了优化,使用类似于U-Shape网络的特征金字塔结构来提取多尺度信息,以适应不同大小的物体检测。
FPN2.2 单级检测
两阶段检测器需要处理大量的物体候选框,每个候选框通过ROI Pooling生成长度一致的特征。这个过程比较耗时,从而影响算法的整体速度。单级检测器的主要思想是使用全卷积网络在特征图的每个位置进行物体分类和边界框回归。这实际上相当于在每个位置生成一个候选框,但是由于省略了耗时的 ROI Pooling,只使用了标准的卷积操作,提高了算法的运行速度。
SSD[5]采用上述全卷积网络的思想,对多种分辨率的特征图进行物体检测,提高对物体尺度变化的适应能力。同时在特征图的每个位置使用不同尺度和纵横比的anchors进行边界回归。
在特征图的每个位置执行密集对象检测。虽然省略了ROI Pooling,但是会带来一个新的问题,就是正负样本的不平衡。密集采样导致负样本(非对象)的数量远大于正样本(对象)的数量。在训练中,大量易于分类的负样本产生的Loss占主导地位,而获得真正有价值的难分类样本。不如好好学习。
固态硬盘
为了解决这个问题,RetinaNet[6]提出了Focal Loss,它根据Loss的大小自动调整权重,而不是标准的Cross Entropy,让训练过程更加关注困难样本。在特征提取方面,RetinaNet也采用了FPN的结构。
焦点损失与交叉熵
最后不得不说一下YOLO[7]系列的检测器,这也是业界使用最广泛的算法,甚至是其中之一。YOLOv1采用卷积和Pooling相结合的方式提取特征,最终的特征图空间大小为7*7。与 SSD 和 RetinaNet 不同的是,YOLOv1 使用全连接层直接输出每个 7*7 位置的物体类别和帧,无需 Anchor 的辅助。在每个位置输出两个对象,并选择一个更有信心的对象。当场景中有很多小物体时,可能会丢失位置相似的物体,这也是YOLOv1的一大问题。
之后,YOLO 推出了四个改进版本(v2-v5),增强了特征提取网络,采用了多尺度特征图,使用 Anchor 和 IOU Loss 辅助帧回归,以及许多其他的 Tricks物体检测)。,大大提高了检测的准确率,在运行速度和部署灵活性方面依然保持了YOLO的一贯优势。
YOLO2.3 无 Anchor 检测
之前介绍的大部分方法都是使用Anchor来辅助对象框的回归。Anchor的参数需要手动设计。通常需要根据不同的检测任务设计不同的Anchor,影响算法的通用性。另外,为了覆盖任务中的所有对象,Anchor的数量会比较大,这也会对算法的速度产生一定的影响。
因此,如何避免使用 Anchor 或让网络自动学习 Anchor 参数受到越来越多的关注。此类方法一般将物体表示为一些关键点,CNN用于回归这些关键点的位置。关键点可以是对象框的中心点(CenterNet)、角点(CornerNet)或代表点(RepPoints)。
CenterNet [8] 使用多层卷积神经网络对输入图像进行处理,并将其转换为物体类别的 Heatmap,其上的 Peak 位置对应于物体的中心。中心点的特征用于边界框回归。整个网络可以完全通过卷积操作来实现,非常简洁。
作为中心点的对象
仅使用对象中心点的特征返回对象框有一定的局限性,因为中心点的特征有时不能很好地描述对象,尤其是当对象比较大的时候。CornerNet[9]通过卷积神经网络和Corner Pooling操作预测物体框的左上角和右下角,输出每个角点的特征向量,用于匹配属于同一物体的角点。
角网
无论是中心点还是角点,对象都表示为矩形框。这种表示方式虽然有利于计算,但没有考虑到物体的形状变化,而且矩形框还收录很多来自背景的特征,影响了物体识别的准确性。RepPoints [10] 提出将物体表示为一个代表点集,并通过可变形卷积适应物体的形状变化。点集最终转化为对象框,用于计算与人工标注的差异。
最后,目标检测领域的最新趋势是采用在自然语言处理(NLP)中取得巨大成功的Transformer结构。Transformer 是一个完全基于自注意力机制的深度学习网络,在大数据和预训练模型的帮助下,其性能超过了经典的递归神经网络方法。从 2020 年开始,Transformer 已应用于各种视觉任务,并取得了不错的效果。Transformer 可以提取 NLP 任务中单词的长期依赖关系(或上下文信息),这对应于图像中提取的像素的长期依赖关系(或扩展的感受野)。
DETR[11]是Transformer在目标检测领域的代表作。上面介绍的所有目标检测网络,无论是两阶段还是单段,无论是否使用 Anchor,都在图像空间进行密集检测。另一方面,DETR 将目标检测视为一个集合预测问题,直接输出稀疏目标检测结果。具体过程是先用CNN提取图像特征,再用Transformer对全局空间关系进行建模。最终输出通过二分图匹配算法与人工标注相匹配。DETR 通常需要更长的训练收敛时间。由于感受野的扩大,对大物体的检测效果更好,而对小物体的检测效果相对较差。
DETR2.4 性能对比
让我们比较一下上面描述的一些算法。准确率是通过 MS COCO 数据库上的 mAP 来衡量的,速度是通过 FPS 来衡量的。从下表的对比可以看出,YOLOv4无论是准确率还是速度都表现不错,是目前业界使用最广泛的模型。最新的DETR模型也有很好的准确率,未来应该会有更多的改进工作。这里需要说的是,由于在网络的结构设计上有很多不同的选择(比如不同的输入大小,不同的Backbone网络等),所以每种算法实现的硬件平台也不同,所以精度和速度不完全可比。,这里只列出一个粗略的结果供大家参考。
3 对象跟踪
在自动驾驶应用中,输入是视频数据,需要注意的物体很多,比如车辆、行人、自行车等。因此,这是一个典型的多目标跟踪任务(MOT)。对于MOT任务,目前最流行的框架是Tracking-by-Detection,其流程如下:
对象检测器在单帧图像上获得对象帧输出。
提取每个检测到的对象的特征,通常包括视觉特征和运动特征。
根据特征计算来自相邻帧的目标检测之间的相似度,以判断它们来自同一目标的概率。
来自相邻帧的对象检测被匹配,来自同一目标的对象被分配相同的 ID。
Tracking-by-Detection方法流程[12]
深度学习应用于上述所有四个步骤,但前两个步骤占主导地位。
第一步,深度学习的应用主要在于提供高质量的物体检测器。理论上,所有的物体检测器都可以用来提供检测框,但是由于检测的质量对于Tracking-by-Detection方法来说非常重要,所以一般会选择精度更高的方法,比如Faster R-CNN。SORT[13] 是这个方向的早期作品之一。作者使用 Faster R-CNN 代替 ACF 目标检测器,在 MOT15 数据库上将目标跟踪准确率指标(MOTA)的绝对值提高了 18.9%。SORT使用卡尔曼滤波来预测物体的运动(得到运动特征),使用匈牙利算法计算物体匹配。
第二步,深度学习的应用主要在于使用CNN提取物体的视觉特征。SORT 算法随后使用 CNN 进行特征提取,这种扩展算法称为 DeepSORT [14]。
DeepSORT 中的视觉特征提取网络
深度学习在第 3 步和第 4 步中使用较少。比较典型的方法之一是 Milan 等人提出的端到端对象跟踪算法。[15]。该算法采用RNN网络模拟贝叶斯滤波器完成主要检测工作,包括运动预测模块、状态更新模块和轨迹管理模块。状态更新模块可以完成对象匹配(Association)的工作,关联向量由一个LSTM提供。这种方法的跟踪效果不是很好,但是由于特征简单,速度可以达到165FPS(不包括物体检测模块)。
Milan等人提出的端到端目标跟踪网络。
除了Tracking-by-Detection,还有一个框架叫做Simultaneous Detection and Tracking,就是同时检测和跟踪。CenterTrack [16] 是该方向的代表性方法之一。CenterTrack 源自前面介绍的单段 Anchor-free 目标检测算法 CenterNet。与CenterNet相比,CenterTrack增加了前一帧的RGB图像和物体中心Heatmap作为附加输入,并为前一帧的Association增加了一个Offset分支。与之前介绍的多阶段 Tracking-by-Detection 策略相比,CenterTrack 以单个网络实现检测和匹配阶段,提高了 MOT 系统的速度。
CenterTrack4 语义分割
深度学习最早在语义分割中的应用比较简单,即对固定大小的图像块进行语义分类。这里对图像块进行分类的网络实际上是一些全连接层,所以块的大小需要固定。显然,这种简单粗暴的方式并不是最优的,尤其是不能有效利用空间上下文信息,这对于语义分割非常重要。
为了更好地提取上下文信息,神经网络需要更大的感受野。全卷积网络(FCN)[17]通过堆叠多个卷积层和下采样层不断扩展感受野并提取高层空间上下文特征,最终的特征图在反卷积上采样后恢复到原创图像每个位置的分辨率对应位置的语义分类。虽然下采样操作有利于上下文特征提取,减少计算量,但也存在一个问题,即空间细节信息的丢失,会影响最终语义分割结果在位置上的分辨率和正确性.
FCN
U-Net [18] 采用了类似的编码器-解码器结构,但在相同分辨率的特征图之间增加了 Skip 连接。这样做的好处是可以同时保留高级上下文特征和低级详细特征,让网络通过学习自动平衡上下文和详细信息的权重。
网络
在语义分割中,上下文信息和细节信息都很重要。FCN 只关注上下文信息,而 U-Net 通过层间的 Skip 连接保留了这两种信息。语义分割领域的大部分后续工作都致力于更好地保留这两种信息。
Dilated/Atrous Convolution 修改标准卷积操作的卷积核以覆盖更大的空间位置。Atrous 卷积可以用来代替下采样。一方面可以保持空间分辨率,另一方面可以在不增加计算量的情况下扩大感受野,从而更好地提取空间上下文信息。
扩张卷积
DeepLab [18] 系列方法使用扩张卷积和 ASPP(Atrous Spatial Pyramid Pooling)结构对输入图像进行多尺度缩放。最后,利用传统语义分割方法中常用的条件随机场(CRF)对分割结果进行优化。CRF 作为后处理步骤单独训练。
深度实验室
最后介绍的方法是使用大卷积核。这是增加感受野的一种自然方式,如果步幅不变,卷积结果的空间分辨率不会受到影响。但是,大的卷积核会显着增加计算量,这就是为什么要使用 atrous 卷积。Large Kernel Matters[19] 这个文章提出将二维大卷积核(KxK)分解成两个一维卷积核(1xK和Kx1),二维卷积核的结果被建模为两个 1D 卷积结果的总和。这样做将计算量从 O(KxK) 减少到 O(K)。
一个 2D 卷积被分解为两个 1D 卷积
参考文献 [1] Girshick et al., Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation, 2014.
[2] Girshick,快速 R-CNN,2015.
[3] Ren 等人,Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks,2016.
[4] Lin 等人,用于对象检测的特征金字塔网络,2017.
[5] Liu 等人,SSD:Single Shot MultiBox Detector,2015.
[6] Lin et al., Focal Loss for Dense Object Detection, 2017.
[7] Redmon 等人,你只看一次:统一的实时对象检测,2015.
[8] Zhou et al., Objects as Points, 2019.
[9] Law 和 Deng,CornerNet:将对象检测为配对关键点,2019.
[10] Yang et al., RepPoints: Point Set Representation for Object Detection, 2019.
[11] Carion et al., End-to-End Object Detection with Transformers, 2020.
[12] Ciaparrone 等人,视频多对象跟踪中的深度学习:调查,2019.
[13] Bewley 等人,简单的在线和实时跟踪,2016.
[14] Wojke et al., Simple Online and Realtime Tracking with A Deep Association Metric, 2017.
[15] Milan et al., Online Multi-Target Tracking using Recurrent Neural Networks, 2017.
[16] Zhou et al., Tracking Objects as Points, 2020.
[17] Long 等人,用于语义分割的全卷积网络,2014.
[18] Chen et al., DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, andfully Connected CRFs, 2017.
[19] Peng et al.,Large Kernel Matters ——通过全局卷积网络改进语义分割,2017. 查看全部
算法 自动采集列表(
【干货】自动驾驶中的视觉感知模块(一))
1 简介
自动驾驶中的视觉感知模块通过图像或视频数据了解车辆周围环境,具体任务包括物体检测与跟踪(2D或3D物体)、语义分割(2D或3D场景)、深度估计、光流估计, ETC。
在这个文章中,我们首先介绍基于图像或视频的2D对象检测和跟踪,以及2D场景的语义分割。这些任务在自动驾驶中被广泛使用,已经有很多各种各样的评论文章,所以这里我只选择介绍一些经典算法,重点介绍上下文和方向。
自从2012年深度学习在图像分类任务上取得突破,迅速占领了图像感知的各个领域,所以下面的介绍也是基于深度学习算法。
2 目标检测2.1 两阶段检测
传统的图像目标检测算法大多是滑动窗口、特征提取和分类器的结合,如Haar特征+AdaBoost分类器、HOG特征+SVM分类器。这种方法的一个主要问题是需要为不同的目标检测任务手动设计不同的特征。因此,在深度学习兴起之前,特征设计是目标检测领域的主要增长点。
R-CNN[1]作为深度学习在目标检测领域的开创性工作,仍然有很多传统方法的影子。首先,Selective Search 替代了滑动窗口以减少窗口数量。第二个也是最重要的变化是使用卷积神经网络 (CNN) 来提取每个窗口的图像特征,而不是手工制作的特征设计。这里的CNN是在ImageNet上预训练的,对于一般图像特征的提取非常有效。最后利用SVM对每个窗口的特征进行分类,完成目标检测任务。
R-CNN的主要问题之一是选择性搜索得到的窗口数量重叠过多,导致特征提取部分有大量冗余操作,严重影响算法的运行效率(约2000个候选图片中的框,在 GPU 上运行时间也超过 10 秒)。
卷积神经网络
为了复用不同位置的特征,Fast R-CNN[2]提出先通过CNN提取图像特征,然后对选择性搜索得到的候选帧进行ROI Pooling,得到相同长度的特征向量。最后,使用全连接网络进行候选框分类和边界框回归。这样就避免了重叠候选框的冗余操作,大大提高了特征提取的效率。
与 R-CNN 相比,Fast R-CNN 在 VOC07 数据集上的 mAP 从 58.5% 提高到 70.0%,检测速度提高了约 200 倍。但是,Fast R-CNN 仍然使用选择性搜索来获取候选区域。这个过程还是比较慢的。处理一张图片大约需要2秒左右,对于实时性要求高的应用来说,这远远不够。
快速 R-CNN
既然选择性搜索是算法速度的瓶颈,那么自然而然会想到用神经网络来完成这一步是可能的吗?这个问题的答案是 Faster R-CNN [3]。它利用区域候选网络(RPN)根据特征图生成候选框。接下来的步骤和 Fast R-CNN 类似,都是 ROI Pooling 生成候选框的特征,然后使用全连接层进行分类和回归。
Faster RCNN中出现了一个重要的概念,即Anchor。特征图的每个位置都会生成不同大小和不同纵横比的anchors,作为object frame回归的参考。Anchor 的引入使得回归任务只需要处理相对较小的变化,因此网络的学习会更容易。
Faster RCNN是第一个端到端的物体检测网络,VOC07上的mAP达到73.2%,速度也达到了17FPS,接近实时。
更快的 R-CNN
随后的FPN[4](Feature Pyramid Network)在特征提取阶段进行了优化,使用类似于U-Shape网络的特征金字塔结构来提取多尺度信息,以适应不同大小的物体检测。
FPN2.2 单级检测
两阶段检测器需要处理大量的物体候选框,每个候选框通过ROI Pooling生成长度一致的特征。这个过程比较耗时,从而影响算法的整体速度。单级检测器的主要思想是使用全卷积网络在特征图的每个位置进行物体分类和边界框回归。这实际上相当于在每个位置生成一个候选框,但是由于省略了耗时的 ROI Pooling,只使用了标准的卷积操作,提高了算法的运行速度。
SSD[5]采用上述全卷积网络的思想,对多种分辨率的特征图进行物体检测,提高对物体尺度变化的适应能力。同时在特征图的每个位置使用不同尺度和纵横比的anchors进行边界回归。
在特征图的每个位置执行密集对象检测。虽然省略了ROI Pooling,但是会带来一个新的问题,就是正负样本的不平衡。密集采样导致负样本(非对象)的数量远大于正样本(对象)的数量。在训练中,大量易于分类的负样本产生的Loss占主导地位,而获得真正有价值的难分类样本。不如好好学习。
固态硬盘
为了解决这个问题,RetinaNet[6]提出了Focal Loss,它根据Loss的大小自动调整权重,而不是标准的Cross Entropy,让训练过程更加关注困难样本。在特征提取方面,RetinaNet也采用了FPN的结构。
焦点损失与交叉熵
最后不得不说一下YOLO[7]系列的检测器,这也是业界使用最广泛的算法,甚至是其中之一。YOLOv1采用卷积和Pooling相结合的方式提取特征,最终的特征图空间大小为7*7。与 SSD 和 RetinaNet 不同的是,YOLOv1 使用全连接层直接输出每个 7*7 位置的物体类别和帧,无需 Anchor 的辅助。在每个位置输出两个对象,并选择一个更有信心的对象。当场景中有很多小物体时,可能会丢失位置相似的物体,这也是YOLOv1的一大问题。
之后,YOLO 推出了四个改进版本(v2-v5),增强了特征提取网络,采用了多尺度特征图,使用 Anchor 和 IOU Loss 辅助帧回归,以及许多其他的 Tricks物体检测)。,大大提高了检测的准确率,在运行速度和部署灵活性方面依然保持了YOLO的一贯优势。
YOLO2.3 无 Anchor 检测
之前介绍的大部分方法都是使用Anchor来辅助对象框的回归。Anchor的参数需要手动设计。通常需要根据不同的检测任务设计不同的Anchor,影响算法的通用性。另外,为了覆盖任务中的所有对象,Anchor的数量会比较大,这也会对算法的速度产生一定的影响。
因此,如何避免使用 Anchor 或让网络自动学习 Anchor 参数受到越来越多的关注。此类方法一般将物体表示为一些关键点,CNN用于回归这些关键点的位置。关键点可以是对象框的中心点(CenterNet)、角点(CornerNet)或代表点(RepPoints)。
CenterNet [8] 使用多层卷积神经网络对输入图像进行处理,并将其转换为物体类别的 Heatmap,其上的 Peak 位置对应于物体的中心。中心点的特征用于边界框回归。整个网络可以完全通过卷积操作来实现,非常简洁。
作为中心点的对象
仅使用对象中心点的特征返回对象框有一定的局限性,因为中心点的特征有时不能很好地描述对象,尤其是当对象比较大的时候。CornerNet[9]通过卷积神经网络和Corner Pooling操作预测物体框的左上角和右下角,输出每个角点的特征向量,用于匹配属于同一物体的角点。
角网
无论是中心点还是角点,对象都表示为矩形框。这种表示方式虽然有利于计算,但没有考虑到物体的形状变化,而且矩形框还收录很多来自背景的特征,影响了物体识别的准确性。RepPoints [10] 提出将物体表示为一个代表点集,并通过可变形卷积适应物体的形状变化。点集最终转化为对象框,用于计算与人工标注的差异。
最后,目标检测领域的最新趋势是采用在自然语言处理(NLP)中取得巨大成功的Transformer结构。Transformer 是一个完全基于自注意力机制的深度学习网络,在大数据和预训练模型的帮助下,其性能超过了经典的递归神经网络方法。从 2020 年开始,Transformer 已应用于各种视觉任务,并取得了不错的效果。Transformer 可以提取 NLP 任务中单词的长期依赖关系(或上下文信息),这对应于图像中提取的像素的长期依赖关系(或扩展的感受野)。
DETR[11]是Transformer在目标检测领域的代表作。上面介绍的所有目标检测网络,无论是两阶段还是单段,无论是否使用 Anchor,都在图像空间进行密集检测。另一方面,DETR 将目标检测视为一个集合预测问题,直接输出稀疏目标检测结果。具体过程是先用CNN提取图像特征,再用Transformer对全局空间关系进行建模。最终输出通过二分图匹配算法与人工标注相匹配。DETR 通常需要更长的训练收敛时间。由于感受野的扩大,对大物体的检测效果更好,而对小物体的检测效果相对较差。
DETR2.4 性能对比
让我们比较一下上面描述的一些算法。准确率是通过 MS COCO 数据库上的 mAP 来衡量的,速度是通过 FPS 来衡量的。从下表的对比可以看出,YOLOv4无论是准确率还是速度都表现不错,是目前业界使用最广泛的模型。最新的DETR模型也有很好的准确率,未来应该会有更多的改进工作。这里需要说的是,由于在网络的结构设计上有很多不同的选择(比如不同的输入大小,不同的Backbone网络等),所以每种算法实现的硬件平台也不同,所以精度和速度不完全可比。,这里只列出一个粗略的结果供大家参考。
3 对象跟踪
在自动驾驶应用中,输入是视频数据,需要注意的物体很多,比如车辆、行人、自行车等。因此,这是一个典型的多目标跟踪任务(MOT)。对于MOT任务,目前最流行的框架是Tracking-by-Detection,其流程如下:
对象检测器在单帧图像上获得对象帧输出。
提取每个检测到的对象的特征,通常包括视觉特征和运动特征。
根据特征计算来自相邻帧的目标检测之间的相似度,以判断它们来自同一目标的概率。
来自相邻帧的对象检测被匹配,来自同一目标的对象被分配相同的 ID。
Tracking-by-Detection方法流程[12]
深度学习应用于上述所有四个步骤,但前两个步骤占主导地位。
第一步,深度学习的应用主要在于提供高质量的物体检测器。理论上,所有的物体检测器都可以用来提供检测框,但是由于检测的质量对于Tracking-by-Detection方法来说非常重要,所以一般会选择精度更高的方法,比如Faster R-CNN。SORT[13] 是这个方向的早期作品之一。作者使用 Faster R-CNN 代替 ACF 目标检测器,在 MOT15 数据库上将目标跟踪准确率指标(MOTA)的绝对值提高了 18.9%。SORT使用卡尔曼滤波来预测物体的运动(得到运动特征),使用匈牙利算法计算物体匹配。
第二步,深度学习的应用主要在于使用CNN提取物体的视觉特征。SORT 算法随后使用 CNN 进行特征提取,这种扩展算法称为 DeepSORT [14]。
DeepSORT 中的视觉特征提取网络
深度学习在第 3 步和第 4 步中使用较少。比较典型的方法之一是 Milan 等人提出的端到端对象跟踪算法。[15]。该算法采用RNN网络模拟贝叶斯滤波器完成主要检测工作,包括运动预测模块、状态更新模块和轨迹管理模块。状态更新模块可以完成对象匹配(Association)的工作,关联向量由一个LSTM提供。这种方法的跟踪效果不是很好,但是由于特征简单,速度可以达到165FPS(不包括物体检测模块)。
Milan等人提出的端到端目标跟踪网络。
除了Tracking-by-Detection,还有一个框架叫做Simultaneous Detection and Tracking,就是同时检测和跟踪。CenterTrack [16] 是该方向的代表性方法之一。CenterTrack 源自前面介绍的单段 Anchor-free 目标检测算法 CenterNet。与CenterNet相比,CenterTrack增加了前一帧的RGB图像和物体中心Heatmap作为附加输入,并为前一帧的Association增加了一个Offset分支。与之前介绍的多阶段 Tracking-by-Detection 策略相比,CenterTrack 以单个网络实现检测和匹配阶段,提高了 MOT 系统的速度。
CenterTrack4 语义分割
深度学习最早在语义分割中的应用比较简单,即对固定大小的图像块进行语义分类。这里对图像块进行分类的网络实际上是一些全连接层,所以块的大小需要固定。显然,这种简单粗暴的方式并不是最优的,尤其是不能有效利用空间上下文信息,这对于语义分割非常重要。
为了更好地提取上下文信息,神经网络需要更大的感受野。全卷积网络(FCN)[17]通过堆叠多个卷积层和下采样层不断扩展感受野并提取高层空间上下文特征,最终的特征图在反卷积上采样后恢复到原创图像每个位置的分辨率对应位置的语义分类。虽然下采样操作有利于上下文特征提取,减少计算量,但也存在一个问题,即空间细节信息的丢失,会影响最终语义分割结果在位置上的分辨率和正确性.
FCN
U-Net [18] 采用了类似的编码器-解码器结构,但在相同分辨率的特征图之间增加了 Skip 连接。这样做的好处是可以同时保留高级上下文特征和低级详细特征,让网络通过学习自动平衡上下文和详细信息的权重。
网络
在语义分割中,上下文信息和细节信息都很重要。FCN 只关注上下文信息,而 U-Net 通过层间的 Skip 连接保留了这两种信息。语义分割领域的大部分后续工作都致力于更好地保留这两种信息。
Dilated/Atrous Convolution 修改标准卷积操作的卷积核以覆盖更大的空间位置。Atrous 卷积可以用来代替下采样。一方面可以保持空间分辨率,另一方面可以在不增加计算量的情况下扩大感受野,从而更好地提取空间上下文信息。
扩张卷积
DeepLab [18] 系列方法使用扩张卷积和 ASPP(Atrous Spatial Pyramid Pooling)结构对输入图像进行多尺度缩放。最后,利用传统语义分割方法中常用的条件随机场(CRF)对分割结果进行优化。CRF 作为后处理步骤单独训练。
深度实验室
最后介绍的方法是使用大卷积核。这是增加感受野的一种自然方式,如果步幅不变,卷积结果的空间分辨率不会受到影响。但是,大的卷积核会显着增加计算量,这就是为什么要使用 atrous 卷积。Large Kernel Matters[19] 这个文章提出将二维大卷积核(KxK)分解成两个一维卷积核(1xK和Kx1),二维卷积核的结果被建模为两个 1D 卷积结果的总和。这样做将计算量从 O(KxK) 减少到 O(K)。
一个 2D 卷积被分解为两个 1D 卷积
参考文献 [1] Girshick et al., Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation, 2014.
[2] Girshick,快速 R-CNN,2015.
[3] Ren 等人,Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks,2016.
[4] Lin 等人,用于对象检测的特征金字塔网络,2017.
[5] Liu 等人,SSD:Single Shot MultiBox Detector,2015.
[6] Lin et al., Focal Loss for Dense Object Detection, 2017.
[7] Redmon 等人,你只看一次:统一的实时对象检测,2015.
[8] Zhou et al., Objects as Points, 2019.
[9] Law 和 Deng,CornerNet:将对象检测为配对关键点,2019.
[10] Yang et al., RepPoints: Point Set Representation for Object Detection, 2019.
[11] Carion et al., End-to-End Object Detection with Transformers, 2020.
[12] Ciaparrone 等人,视频多对象跟踪中的深度学习:调查,2019.
[13] Bewley 等人,简单的在线和实时跟踪,2016.
[14] Wojke et al., Simple Online and Realtime Tracking with A Deep Association Metric, 2017.
[15] Milan et al., Online Multi-Target Tracking using Recurrent Neural Networks, 2017.
[16] Zhou et al., Tracking Objects as Points, 2020.
[17] Long 等人,用于语义分割的全卷积网络,2014.
[18] Chen et al., DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, andfully Connected CRFs, 2017.
[19] Peng et al.,Large Kernel Matters ——通过全局卷积网络改进语义分割,2017.
算法 自动采集列表(网站发布飓风算法的类型有哪些?如何正确使用?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-14 05:10
概括
飓风算法是百度搜索推出的以不良采集为主要内容来源的网站的搜索引擎算法。类型3:采集痕迹明显,详细描述:本站有大量从其他网站或公众号转来的内容采集,信息不整合,布局杂乱,部分功能缺失或文章可读性差,有明显采集标记,用户阅读体验很差。建议:网站发布的内容,要注意文章的排版和排版,不能有与文章主题无关的信息或无法使用的功能@>,可能会干扰用户的浏览。不出现字体大小,
飓风算法是百度搜索推出的以不良采集为主要内容来源的网站的搜索引擎算法。
类型 3:采集清除标记
详细描述:本站有大量从其他网站或公众号采集转来的内容,信息未整合,版面混乱,部分功能缺失或文章可读性差,有有明显的采集痕迹,用户的阅读体验很差。
建议:网站发布的内容,要注意文章的排版和排版,不能有与文章主题无关的信息或无法使用的功能@>,可能会干扰用户的浏览。不要有不同的字号和字号,注意标点符号的大小写,以及文章的段落分类和强调。百度会对可以自产原创内容的网站更加友好,可以加快网站的排名。
类型 4:黑帽 SEO
详细说明:一些灰色地带的黑帽SEO也利用一些工具,自动生成乱七八糟的文章,并在里面插入关键词,从而欺骗搜索引擎,达到快速排序的目的。
建议:停止使用黑帽SEO,写文章,好好优化网站SEO。做 网站 不是一天的工作。快速赚钱的方式永远不会那么稳定。要想把网站做好,还是需要使用形式化的优化方法。
类型五:内容拼接
详细说明:采集不同文章的多篇文章拼接在一起,整体内容没有形成完整的逻辑,存在看不懂、文章不连贯等问题。 ,不能满足用户的需求。
建议:内容拼接是采集内容的高级版,一般由人工操作,但百度官方反对使用采集编辑器等工具随意制作拼接采集@ > 内容行为,请网站制作大量对用户有价值的原创内容。
我们在使用内容拼接的时候,不要随意拼装,更要注意质量。网站内容的价值在于用户能否阅读网站中的内容来解决自己的问题。如果用户搜索与标题不匹配的问题,那么这样的网站排名不会很好。, 很可能会被算法击中。网站不要弄乱布局。如果影响了用户的阅读体验,对搜索引擎是不友好的。
飓风算法旨在保障搜索用户的浏览体验,保障搜索生态的健康发展。对于违规网站,百度搜索将根据问题的严重程度限制对搜索呈现的处理。
如果你的网站内容做好了,我想不管“飓风算法”怎么升级,对你都没有影响。
首次违规的网站,改正后解除限制的期限为1个月;
我们不会发布第二次犯罪的网站。
请各位站长尽快按照上述说明进行自查整改,清理所有非法采集内容。 查看全部
算法 自动采集列表(网站发布飓风算法的类型有哪些?如何正确使用?)
概括
飓风算法是百度搜索推出的以不良采集为主要内容来源的网站的搜索引擎算法。类型3:采集痕迹明显,详细描述:本站有大量从其他网站或公众号转来的内容采集,信息不整合,布局杂乱,部分功能缺失或文章可读性差,有明显采集标记,用户阅读体验很差。建议:网站发布的内容,要注意文章的排版和排版,不能有与文章主题无关的信息或无法使用的功能@>,可能会干扰用户的浏览。不出现字体大小,
飓风算法是百度搜索推出的以不良采集为主要内容来源的网站的搜索引擎算法。
类型 3:采集清除标记
详细描述:本站有大量从其他网站或公众号采集转来的内容,信息未整合,版面混乱,部分功能缺失或文章可读性差,有有明显的采集痕迹,用户的阅读体验很差。
建议:网站发布的内容,要注意文章的排版和排版,不能有与文章主题无关的信息或无法使用的功能@>,可能会干扰用户的浏览。不要有不同的字号和字号,注意标点符号的大小写,以及文章的段落分类和强调。百度会对可以自产原创内容的网站更加友好,可以加快网站的排名。
类型 4:黑帽 SEO
详细说明:一些灰色地带的黑帽SEO也利用一些工具,自动生成乱七八糟的文章,并在里面插入关键词,从而欺骗搜索引擎,达到快速排序的目的。
建议:停止使用黑帽SEO,写文章,好好优化网站SEO。做 网站 不是一天的工作。快速赚钱的方式永远不会那么稳定。要想把网站做好,还是需要使用形式化的优化方法。
类型五:内容拼接
详细说明:采集不同文章的多篇文章拼接在一起,整体内容没有形成完整的逻辑,存在看不懂、文章不连贯等问题。 ,不能满足用户的需求。
建议:内容拼接是采集内容的高级版,一般由人工操作,但百度官方反对使用采集编辑器等工具随意制作拼接采集@ > 内容行为,请网站制作大量对用户有价值的原创内容。
我们在使用内容拼接的时候,不要随意拼装,更要注意质量。网站内容的价值在于用户能否阅读网站中的内容来解决自己的问题。如果用户搜索与标题不匹配的问题,那么这样的网站排名不会很好。, 很可能会被算法击中。网站不要弄乱布局。如果影响了用户的阅读体验,对搜索引擎是不友好的。
飓风算法旨在保障搜索用户的浏览体验,保障搜索生态的健康发展。对于违规网站,百度搜索将根据问题的严重程度限制对搜索呈现的处理。
如果你的网站内容做好了,我想不管“飓风算法”怎么升级,对你都没有影响。
首次违规的网站,改正后解除限制的期限为1个月;
我们不会发布第二次犯罪的网站。
请各位站长尽快按照上述说明进行自查整改,清理所有非法采集内容。
算法 自动采集列表(网站内容对SEO优化的影响及优化方法有哪些? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-07 08:28
)
通过 Pbootcms采集 填充内容,根据 关键词采集文章。(Pbootcms采集 插件也配置了关键词采集 功能和无关词阻塞功能)。网站内容对SEO优化和优化方法的影响。如果您的 网站 内容是正确的,那么您就为您的 网站SEO 打下了坚实的基础。pbootcms采集直接监听released,pending release,是否是伪原创,发布状态,URL,程序,发布时间等,正确的内容是什么?在搜索引擎眼中,好的网页内容应该符合五个方面的标准:1、内容质量;2、内容研究(关键词研究);3、文本/关键词在内容; 4、 内容的吸引力;5、内容的新鲜度;让我们看看这 5 个因素具体指的是什么。
网站内容质量 内容的质量。在制作任何内容之前要问自己的第一个问题是:我的内容质量好吗?例如,我的网络内容是否优于业内其他人的内容?还是只是重复别人的东西?
pbootcms采集 设置批量发布数量(可以设置发布间隔/每天发布的总数)。您是否让访问者有理由希望多停留几秒钟来浏览您的网页内容?您是否为访问者提供了他们认为独特且与众不同、有用且在其他任何地方都找不到的真正价值?
pbootcms采集内容与标题一致(使内容与标题一致)。如果好的内容是您的 SEO 策略中最重要的部分,那么 Pbootcms采集 提供优质内容,尤其是关键字研究,可能是第二重要的部分。因为关键字研究可以帮助您发现访问者通过搜索引擎找到您的内容的各种途径。pbootcms采集批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, Pbootcms、云游cms、人人展cms、小旋风、站群、PB、Apple、搜外等各大cms,可以批量的工具同时管理和发布)。
进行关键字研究后,您可以根据相关关键字(访问者在引擎中搜索的字词)定制内容。通过关键字研究产生的内容更容易被搜索引擎找到,针对性强,并有效地为访问者提供他们需要的信息。
pbootcms采集支持几十万种不同的cms网站实现统一管理。一个人维护数百个 网站文章 更新也不是问题。例如,如果有人搜索“如何治疗脂肪肝”,而您的内容标题是“如何治疗 NAFLD”。pbootcms采集随机插入图片(文章没有图片可以随机插入相关图片)。
那么搜索引擎引擎可能会认为您的内容与该搜索引擎关键字无关并跳过它,因此您的内容排名不会很好。
pbootcms采集可以通过软件直接查看每日蜘蛛、收录、网站权重。因此,关键字研究可以确保您的内容与普通人正在搜索的内容相关。这可以大大提高您的网页排名。
pbootcms采集随机点赞-随机阅读-随机作者(提高页面度数原创)。关键字研究内容的文本/关键字用法。完成关键字研究后,您可以将相关文本/关键字适当地应用于您的内容。而如果你已经做了很多高质量的内容,但是还没有做关键词研究,那没关系,你现在就可以做,然后在你现有的内容中添加相关的关键词。
这个Pbootcms采集插件还配备了很多SEO功能,不仅可以通过WordPress插件实现采集伪原创发布,还有很多SEO功能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。进行关键字研究的主要目的是使您的网络内容更容易找到。因此,最好在您的文案内容中收录具有一定搜索引擎量的关键字。
pbootcms采集搜索引擎推送(文章发布成功后主动向搜索引擎推送文章,保证新链接能被搜索引擎及时发布收录@ >) 。至于关键字应该在文章的内容中出现多少次,并没有绝对的准则。最好的方式是运用你的常识,选择你认为最符合文章内容的关键词,用最自然的方式呈现出来,让搜索引擎理解,让读者感受光滑的。
pbootcms采集自动过滤其他网站促销信息/支持其他网站信息替换。内容吸引力。如果你的内容足够好,读者自然会被吸引并与之互动。如何判断内容的吸引力?搜索引擎有自己的一套方法。
pbootcms采集标题前缀和后缀设置(标题区分更好收录)。例如,有人在 Internet 上搜索某个关键字,然后找到您的网页。点击后“弹出”,返回原来的搜索引擎结果页面。pbootcms采集 自动内链(在执行发布任务时自动在文章的内容中生成内链,有助于引导页面蜘蛛抓取,提高页面权重)。然后尝试另一个页面。这种立即的“弹出”动作是向搜索引擎发出的信号,表明您的内容可能不够吸引人。这也是搜索引擎考虑的一项措施。
如果访问者没有立即“弹出”,他们是否会在您的 网站 上停留相对较长的时间?这个“网站停留时间”是搜索引擎可以衡量的另一个指标。pbootcms采集定时发布(定时发布网站内容可以让搜索引擎养成定时爬取网页的习惯,从而提高网站的收录) . 除此之外,在 Facebook 等社区 网站 上收到的“点赞”数量是衡量吸引力的另一个指标。我们将在本指南的“社区因素”部分详细介绍。
Pbootcms采集 支持其他平台的图像本地化或存储。事实上,搜索引擎公司对于他们是否真的使用“内容吸引力”指标非常模糊,更不用说那些指标了;pbootcms采集自动批处理挂机后采集伪原创会自动发布推送到搜索引擎。但 SEO 专家普遍认为,内容的吸引力确实是以不同方式衡量的因素之一。但无论如何,SEO的成功与内容的质量高度相关。
pbootcms采集支持多种采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容) . 内容新鲜并不意味着您每天都向 网站 添加新的 文章 或 Web 内容。对于搜索引擎来说,“新鲜度”是指你有没有内容,与某个关键词的搜索量激增有关。pbootcms采集content关键词插入(合理增加关键词的密度)。在这种情况下,搜索引擎会查询与主题相关的内容,然后将相关页面推送到排名靠前的位置。
pbootcms采集不同关键词文章可以设置发布不同的列。如果您的网站与电子产品有关,明天苹果将推出最新产品时,您在这个时候PO了相关的文章报告,那么您的这个网页很可能排名很好。pbootcms采集伪原创保留字(文章原创时伪原创不设置核心字)。您的页面可能会在接下来的一两周内获得高排名,然后随着新鲜度的消逝而消失。今天关于PBootcms采集的讲解就到这里,下期会分享更多SEO相关知识。下次见。
查看全部
算法 自动采集列表(网站内容对SEO优化的影响及优化方法有哪些?
)
通过 Pbootcms采集 填充内容,根据 关键词采集文章。(Pbootcms采集 插件也配置了关键词采集 功能和无关词阻塞功能)。网站内容对SEO优化和优化方法的影响。如果您的 网站 内容是正确的,那么您就为您的 网站SEO 打下了坚实的基础。pbootcms采集直接监听released,pending release,是否是伪原创,发布状态,URL,程序,发布时间等,正确的内容是什么?在搜索引擎眼中,好的网页内容应该符合五个方面的标准:1、内容质量;2、内容研究(关键词研究);3、文本/关键词在内容; 4、 内容的吸引力;5、内容的新鲜度;让我们看看这 5 个因素具体指的是什么。
网站内容质量 内容的质量。在制作任何内容之前要问自己的第一个问题是:我的内容质量好吗?例如,我的网络内容是否优于业内其他人的内容?还是只是重复别人的东西?
pbootcms采集 设置批量发布数量(可以设置发布间隔/每天发布的总数)。您是否让访问者有理由希望多停留几秒钟来浏览您的网页内容?您是否为访问者提供了他们认为独特且与众不同、有用且在其他任何地方都找不到的真正价值?
pbootcms采集内容与标题一致(使内容与标题一致)。如果好的内容是您的 SEO 策略中最重要的部分,那么 Pbootcms采集 提供优质内容,尤其是关键字研究,可能是第二重要的部分。因为关键字研究可以帮助您发现访问者通过搜索引擎找到您的内容的各种途径。pbootcms采集批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, Pbootcms、云游cms、人人展cms、小旋风、站群、PB、Apple、搜外等各大cms,可以批量的工具同时管理和发布)。
进行关键字研究后,您可以根据相关关键字(访问者在引擎中搜索的字词)定制内容。通过关键字研究产生的内容更容易被搜索引擎找到,针对性强,并有效地为访问者提供他们需要的信息。
pbootcms采集支持几十万种不同的cms网站实现统一管理。一个人维护数百个 网站文章 更新也不是问题。例如,如果有人搜索“如何治疗脂肪肝”,而您的内容标题是“如何治疗 NAFLD”。pbootcms采集随机插入图片(文章没有图片可以随机插入相关图片)。
那么搜索引擎引擎可能会认为您的内容与该搜索引擎关键字无关并跳过它,因此您的内容排名不会很好。
pbootcms采集可以通过软件直接查看每日蜘蛛、收录、网站权重。因此,关键字研究可以确保您的内容与普通人正在搜索的内容相关。这可以大大提高您的网页排名。
pbootcms采集随机点赞-随机阅读-随机作者(提高页面度数原创)。关键字研究内容的文本/关键字用法。完成关键字研究后,您可以将相关文本/关键字适当地应用于您的内容。而如果你已经做了很多高质量的内容,但是还没有做关键词研究,那没关系,你现在就可以做,然后在你现有的内容中添加相关的关键词。
这个Pbootcms采集插件还配备了很多SEO功能,不仅可以通过WordPress插件实现采集伪原创发布,还有很多SEO功能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。进行关键字研究的主要目的是使您的网络内容更容易找到。因此,最好在您的文案内容中收录具有一定搜索引擎量的关键字。
pbootcms采集搜索引擎推送(文章发布成功后主动向搜索引擎推送文章,保证新链接能被搜索引擎及时发布收录@ >) 。至于关键字应该在文章的内容中出现多少次,并没有绝对的准则。最好的方式是运用你的常识,选择你认为最符合文章内容的关键词,用最自然的方式呈现出来,让搜索引擎理解,让读者感受光滑的。
pbootcms采集自动过滤其他网站促销信息/支持其他网站信息替换。内容吸引力。如果你的内容足够好,读者自然会被吸引并与之互动。如何判断内容的吸引力?搜索引擎有自己的一套方法。
pbootcms采集标题前缀和后缀设置(标题区分更好收录)。例如,有人在 Internet 上搜索某个关键字,然后找到您的网页。点击后“弹出”,返回原来的搜索引擎结果页面。pbootcms采集 自动内链(在执行发布任务时自动在文章的内容中生成内链,有助于引导页面蜘蛛抓取,提高页面权重)。然后尝试另一个页面。这种立即的“弹出”动作是向搜索引擎发出的信号,表明您的内容可能不够吸引人。这也是搜索引擎考虑的一项措施。
如果访问者没有立即“弹出”,他们是否会在您的 网站 上停留相对较长的时间?这个“网站停留时间”是搜索引擎可以衡量的另一个指标。pbootcms采集定时发布(定时发布网站内容可以让搜索引擎养成定时爬取网页的习惯,从而提高网站的收录) . 除此之外,在 Facebook 等社区 网站 上收到的“点赞”数量是衡量吸引力的另一个指标。我们将在本指南的“社区因素”部分详细介绍。
Pbootcms采集 支持其他平台的图像本地化或存储。事实上,搜索引擎公司对于他们是否真的使用“内容吸引力”指标非常模糊,更不用说那些指标了;pbootcms采集自动批处理挂机后采集伪原创会自动发布推送到搜索引擎。但 SEO 专家普遍认为,内容的吸引力确实是以不同方式衡量的因素之一。但无论如何,SEO的成功与内容的质量高度相关。
pbootcms采集支持多种采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容) . 内容新鲜并不意味着您每天都向 网站 添加新的 文章 或 Web 内容。对于搜索引擎来说,“新鲜度”是指你有没有内容,与某个关键词的搜索量激增有关。pbootcms采集content关键词插入(合理增加关键词的密度)。在这种情况下,搜索引擎会查询与主题相关的内容,然后将相关页面推送到排名靠前的位置。
pbootcms采集不同关键词文章可以设置发布不同的列。如果您的网站与电子产品有关,明天苹果将推出最新产品时,您在这个时候PO了相关的文章报告,那么您的这个网页很可能排名很好。pbootcms采集伪原创保留字(文章原创时伪原创不设置核心字)。您的页面可能会在接下来的一两周内获得高排名,然后随着新鲜度的消逝而消失。今天关于PBootcms采集的讲解就到这里,下期会分享更多SEO相关知识。下次见。
算法 自动采集列表(优采云采集器(www.ucaiyun.com)专业采集软件解密各大网站登录算法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-04-05 18:15
)
优采云采集器()作为采集行业老手采集器是一款功能强大但不易上手的专业采集软件, 优采云采集器捕获数据的过程取决于用户编写的规则。用户必须分析来自目标站的 html 代码中的唯一代码标识符并遵守 优采云 规则,发布模块是向服务器提交 采集 数据,服务器程序自动写入数据正确地存入数据库。这里的服务端程序可以是网站程序,也可以是自己编写的接口,只要数据能正确写入数据库即可。这里提交数据需要大家具备post抓包的基础技术。简单说一下post数据传输的过程。通过HTTP传输数据的方式主要有两种,一种是get,一种是post。 get 一般用于获取数据,可以携带少量参数数据。在此基础上,post 可以承载大量的数据。 采集的发布规则是模拟向网站程序提交post请求,让网站程序认为我们是人。如果您没有权限,主要的 网站 程序不会让您发布 文章,所以!我们只能解密各大网站s的登录算法,只有获得用户登录凭证后才能正常发布文章。明白了原理就可以开始写接口了!
对于小白和基础程序员来说,一定是一头雾水。完全掌握优采云采集器大约需要一个月的时间。涉及的东西更多,知识面更广!
你是否面临着用优采云采集不发表的窘境,花费大量时间却得不到结果!还在为缺少 网站 内容而苦恼,不知道怎么办?如何使用采集三分钟发帖?
1.打开软件输入关键词即可实现全自动采集,多站点采集发布,自动过滤采集文章,与行业无关文章,保证内容100%相关性,全自动批量挂机采集,无缝对接各大cms出版商,后采集 自动发布推送到搜索引擎!
2.全平台cms发行商是目前市面上唯一支持Empire, Yiyou, ZBLOG, 织梦, WP, PB, Apple, 搜外等大cms,一个不需要编写发布模块,可以同时管理和批量发布的工具,可以发布不同类型的文章对应不同的栏目列表,只需要简单的配置,还有很多SEO功能让你网站快速收录!
3. SEO功能:标题前缀和后缀设置、内容关键词插入、随机图片插入、搜索引擎推送、随机点赞-随机阅读-随机作者、内容与标题一致、自动内链,定期发布。
再也不用担心网站没有内容,网站收录低。使用以上软件可以自动采集最新优质内容,并配置多种数据处理选项,标签、链接、邮箱等格式处理,让网站内容独一无二,快速增加网站 流量!高性能产品,全自动运行!另外,要免费找到一位尽职尽责的作者非常困难。看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友同事!
查看全部
算法 自动采集列表(优采云采集器(www.ucaiyun.com)专业采集软件解密各大网站登录算法
)
优采云采集器()作为采集行业老手采集器是一款功能强大但不易上手的专业采集软件, 优采云采集器捕获数据的过程取决于用户编写的规则。用户必须分析来自目标站的 html 代码中的唯一代码标识符并遵守 优采云 规则,发布模块是向服务器提交 采集 数据,服务器程序自动写入数据正确地存入数据库。这里的服务端程序可以是网站程序,也可以是自己编写的接口,只要数据能正确写入数据库即可。这里提交数据需要大家具备post抓包的基础技术。简单说一下post数据传输的过程。通过HTTP传输数据的方式主要有两种,一种是get,一种是post。 get 一般用于获取数据,可以携带少量参数数据。在此基础上,post 可以承载大量的数据。 采集的发布规则是模拟向网站程序提交post请求,让网站程序认为我们是人。如果您没有权限,主要的 网站 程序不会让您发布 文章,所以!我们只能解密各大网站s的登录算法,只有获得用户登录凭证后才能正常发布文章。明白了原理就可以开始写接口了!
对于小白和基础程序员来说,一定是一头雾水。完全掌握优采云采集器大约需要一个月的时间。涉及的东西更多,知识面更广!
你是否面临着用优采云采集不发表的窘境,花费大量时间却得不到结果!还在为缺少 网站 内容而苦恼,不知道怎么办?如何使用采集三分钟发帖?
1.打开软件输入关键词即可实现全自动采集,多站点采集发布,自动过滤采集文章,与行业无关文章,保证内容100%相关性,全自动批量挂机采集,无缝对接各大cms出版商,后采集 自动发布推送到搜索引擎!
2.全平台cms发行商是目前市面上唯一支持Empire, Yiyou, ZBLOG, 织梦, WP, PB, Apple, 搜外等大cms,一个不需要编写发布模块,可以同时管理和批量发布的工具,可以发布不同类型的文章对应不同的栏目列表,只需要简单的配置,还有很多SEO功能让你网站快速收录!
3. SEO功能:标题前缀和后缀设置、内容关键词插入、随机图片插入、搜索引擎推送、随机点赞-随机阅读-随机作者、内容与标题一致、自动内链,定期发布。
再也不用担心网站没有内容,网站收录低。使用以上软件可以自动采集最新优质内容,并配置多种数据处理选项,标签、链接、邮箱等格式处理,让网站内容独一无二,快速增加网站 流量!高性能产品,全自动运行!另外,要免费找到一位尽职尽责的作者非常困难。看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友同事!
算法 自动采集列表(什么是全链路数据血缘(DataLineage)(AST))
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-04-05 11:07
1 什么是全链路数据沿袭
根据维基百科,数据沿袭也称为数据来源或数据谱系。它通常被定义为一个生命周期,主要包括数据来自哪里以及随着时间的推移而移动到哪里。
数据血脉是数据资产的重要组成部分。用于分析表和字段从数据源到当前表的血统路径,血统字段之间的关系是否满足,注意数据的一致性和合理的表设计。它描述了数据从采集、生产到服务全链路的变化和存在形式。
全链路数据血统是指在数据的整个生命周期中,数据与数据之间形成的各种关系,贯穿整个数据链路,如图1所示。
图1 全链路数据沿袭
2 血缘关系建设方案研究2.1 血缘关系分析
目前,数据沿袭主要是通过解析SQL语句来发现上下游调用栈等信息。主流解决方案可以分为两种:
• 运行时解析,即在任务运行时通过钩子接口或监听器接口解析SQL生成的逻辑技术树(AST)。
• 先采集再解析,即通过采集程序将各个计算引擎的SQL统一到采集到mq中进行血液分析。
上述两类方案各有优缺点,对比见表1。
表1 数据沿袭分析方案
方案名称
优势
缺点
运行时解析
解析出来的血脉信息准确,语法错误的SQL和任务不会被解析。
每个计算引擎都需要开发一套血缘关系分析模块,成本高,可能影响任务。
先采集再解析
对于不同的 SQL 方言,可以使用同一套词法/句法解析器进行解析和沿袭解析。
较长的链接可能会导致不准确的血统结果。
2.2 血脉储藏室
与传统的关系型数据库和 ES 工具相比,图数据库在血统信息的查询和分析方面具有以下优势:
1、更好地存储和分析复杂关系
数据沿袭描绘了数据的完整生命周期,具有数据链路长的特点。传统的关系型数据库和ES等,往往只反映当前状态或短路径中的状态,在长链接血缘关系的检索上存在明显劣势。图数据库有效组织复杂关系,通过点-边结构将血脉上下游完美连接,从而实现更长链路血脉的存储、检索和分析。
2、可以有效利用数据之间的相关性,实现更准确可靠的决策
图结构的特点对业务具有重要的指导意义。例如,图的密度可以反映业务数据关联的紧密程度,有助于识别高I/O或高吞吐的服务,识别链路瓶颈;图数据之间的共现可以反映血缘关系中的共生关系,辅助血缘关系重要性的划分;图形可视化帮助业务人员更清晰地了解血缘动态。
与开源图数据库 Neo4j 和 Nebula Graph 相比,华为云 GES 具有以下优势:
• 基于分布式内存计算,性能更高、速度更快、响应时间更短
• 集成 30+ 种高性能算法,增强图形分析能力
• 对接华为云大数据和AI服务,周边支持更全面,服务对接更便捷
• 基于实践自主研发的查询算子Path-Query,支持复杂的过滤查询条件,具有更好的查询性能
华为云GES的基准数据如表2所示。
表2 华为云GES基准测试数据
增加
新节点
15000 TPS
添加边缘
10000 TPS
查询
查询节点详情
20000 TPS
查询边详细信息
10000 TPS
进口
批量导入数据速率
600,000 边/秒
从备份恢复数据速率
600 万边/秒
遍历
1-hop 查询响应时间
第二
2-hop 查询响应时间
第二
三跳查询响应时间
1~3秒
6 跳查询响应时间
5秒
算法
页面排名算法
每次迭代 4 秒
WCC算法
20 秒
SSSP算法
20 秒
3 满帮数据血脉的实践3.1 满帮数据血脉的特点
满帮数据血脉具有以下特点:
• 采集 广泛的覆盖范围。目前已经覆盖了大部分离线和实时场景,涉及的组件包括hive、spark、impala、flink、doris、kafka、clickhouse等。
• 多层次的亲属关系。根据血缘关系模型和血缘关系数据,形成域与域、域与表、表与表、库与库、任务与任务等血缘关系,应用于不同场景。
• 丰富的应用场景。已应用于数据治理、数据质量、数据安全、应用告警等多种场景。
• 开放血统界面。目前,基于血缘关系服务平台,对外提供了丰富的血缘关系接口,包括基本血缘关系信息查询和基于各种算法的血缘关系路径查询。
3.2 数据沿袭模型
定义丰富的血缘关系模型有助于更真实有效地展示血缘关系。满族血统模型主要包括实体和关系,其中实体主要涵盖任务、库、表、视图、字段、函数等实体。实体和关系的组合显示了从一个表/列到其他表/列的沿袭,包括表 INSERT INTO\CTAS 之间的依赖关系,字段 PROJECTION\PREDICATE 之间的依赖关系。
使用完整的数据血缘关系模型可以展示血缘关系的全貌,但存在以下问题:一是完整的血缘关系模型往往收录数千个实体血缘关系,在前端难以展示;其次,过多的冗余信息可能导致问题实体定位困难。为了解决以上问题,满帮在数据血缘模型的基础上,开发了多层次血缘关系模型,主要包括完整血缘关系模型和高层次血缘关系模型。完整数据沿袭模型是所有其他高级沿袭模型的基础,高级沿袭模型通过省略或聚合模型中的某些关系和实体来扩展完整沿袭。在实际业务中,
3.3 整体架构方案
满帮全链路数据血脉实现了血脉数据数据采集从开始到最终数据服务的全链路,有助于高效定位问题,快速评估影响。全链路血脉架构如图2所示,主要包括5层:
• 血脉采集层:负责采集满帮大数据平台各组件的任务血脉信息,将血脉解析成统一格式;
• 血脉处理层:通过消息队列Kafka,通过实时任务将血脉信息统一处理写入GES和Hive,提供血脉存储接口和血脉管理功能;
• 血缘存储层:分别通过GES和Hive提供血缘信息存储和血缘分析统计功能;
• 血统接口层:提供血统信息功能接口,连接血统应用服务;
• 血脉应用层:提供血脉服务,包括数据资产、数据治理、数据安全等。
图2 满帮全链路血脉架构
3.3.1层血脉采集层
满帮血脉采集层目前涵盖满帮内部数据、离线调度、实时计算等平台上的SQL任务和Spark\Flink任务。血缘关系包括系统血缘关系、职务血缘关系、图书馆血缘关系、表级血缘关系、字段血缘关系,指向数据的上游源头,溯源上游。通过血缘关系,清晰展现数据处理的逻辑脉络,快速定位异常数据域的影响范围,准确勾画数据回溯的最小范围,降低理解数据和解决数据问题的成本. 具体来说:
• Hive SQL lineage 解析主要是指通过Hive hook 函数解析org.apache.hadoop.hive.ql.hooks.LineageLogger。
• Spark SQL通过QueryExecutionListener的onSuccess方法获取逻辑计划的Output,通过Output解析字段血缘关系。
• Flink SQL 通过 Cava cc 获取 SQL 逻辑计划树(AST),通过遍历 AST 获取并执行 Input\Output,从而分析表和字段之间的关系。
• Spark\Flink 任务通过分析DAG 中的关系,找到Input\Output,构建虚拟输入输出表,构建血缘关系。
• Impala 目前使用filebeat采集 血脉日志将血脉信息异步发送到Kafka。
为了方便采集和数据血统的处理,统一了各个组件的血统格式,主要包括输入输出表、字段等信息。
序列号
字段名称
字段类型
描述
1
数据库
细绳
当前数据库
2
期间
长
血统分析时间
3
引擎名称
细绳
执行引擎名称
4
执行平台
细绳
执行的平台名称
5
哈希
细绳
执行 SQL MD5 值
6
工作 ID
细绳
执行Job的Id进行拼接
7
职位名称
细绳
任务名称
8
傲慢的
细绳
任务执行OA用户
9
查询文本
细绳
执行 SQL 语句
10
更新时间
长
血脉更新时间
11
用户
细绳
任务执行账户
12
版本
细绳
血统分析版
13
表血统
JSON 对象
表级血统信息
14
列沿袭
JSON 对象
场级血统信息
3.3.2 血脉处理层
血缘处理层主要由血缘实时处理模块、血缘存储接口模块、血缘管理模块组成。
为了满足近实时血脉查询的需求,满帮采用Flink作为血脉实时处理模块的核心组件。通过对从上游采集接收到的血脉信息进行实时分析处理,快速写入图数据库和Hive。该模块支持批量删除\查询\更新和模糊删除\查询\更新功能。
血脉存储接口模块主要开发快速编写图数据库和Hive的相关接口。
血缘管理模块主要用于血缘信息的维护管理和统计分析。
3.3.3血脉储存层
血脉存储层使用华为云图引擎GES服务作为存储引擎。GES采用华为自研EYWA内核,是一种基于“关系”的“图”结构化数据查询分析服务。GES 目前提供多种原生接口,包括批量读写点、边,以及各种路径查询算法。
全链路全链路数据沿袭场景下,图数据操作主要包括读写操作。写入操作主要是将解析和格式化后的血线数据实时写入图数据库。另一种写操作主要是向应用端提供写请求,如表\字段安全级别标记。读取操作主要来自自满帮内部的各种应用场景,主要涵盖短距离、CRM、客服、金融等。
3.3.4 血脉接口层和血脉应用层
血缘接口层主要连接血缘应用层的各种服务,通过开放血缘RPC接口,为各个应用服务提供丰富的接口选项。
目前,满族血脉信息主要应用于数据资产、数据治理、数据安全、数据质量等各种场景。
1、数据资产
满帮数据资产管理平台提供资产全景、数据地图、数据质量、数据安全等功能,如图4所示。数据地图支持以扇形图的形式直观展示各类数据资产的占比,图表,并通过不同层次的图形进行精细化控制,满足业务中不同应用场景的数据查询和辅助分析需求。
图 4 满帮数据资产管理平台
数据图还支持显示血统信息,分析任务之间的数据流向,如图5所示。目前数据图支持显示任务、库、表、字段级血缘关系。
图5 满帮资料图
2、数据治理
数据治理是指在数据的整个生命周期内管理数据的原则性方法,其目标是确保数据安全、及时、准确、可用和易于使用。满帮数据治理主要围绕“指标明确、质量规范”和“资源合理、节约严格”的原则进行。
如图6所示,满帮数据治理任务对库、表、字段的血脉信息进行分析,从价值密度、访问频率、使用方式、时效度等维度进行评价,从而对数据的流行度进行评分,热数据和热数据。,冷数据和冰数据。通过血缘信息查看离线数仓中某个任务链路的上下游任务依赖,同时分析链路上表的冷热使用情况,对ods和dwd的相关任务和SQL进行优化,trim和merge低价值表,缩短数据流ETL环节,从而降低维护成本,提高数据价值。
图 6 满帮数据治理
3、数据质量
数据质量旨在高效监控各类作业的运行状态,洞察关键信息,形成事前判断、事中监控、事后跟踪的闭环质量管理流程。在满帮数据质量监管平台建设中,面临以下问题:
• 离线实时监控系统不完善,监控存在盲点
• 整个链路的数据质量难以保证,数据不可信
• 数据依赖复杂,链接深,数据输出容易延迟
针对以上问题,满帮基于全链路数据血统,从以下几个方面提升数据全生命周期的数据质量:
• 主动通知交通数据所有者。根据血缘关系,通知依赖调度的任务,并提供多层通知选项,避免过渡干扰。
• 离线ETL链接,如果ods\dwd层的某个表的key字段被修改,将通过血脉信息自动向下游依赖表和任务负责人发送告警
• 对于实时的 Flink 任务,如果源端的 Kafka 字段结构发生变化,会根据血缘关系自动通知下游的依赖表和任务负责人
4、数据安全
随着国家在数据流通过程中对数据安全的重视程度越来越高,如果不能有效识别安全级别高的数据,可能会出现安全合规风险。为此,满帮推出了资产安全打标平台,支持通过“自动+人工”打标实现资产安全分级打标,但存在打标覆盖率低、准确率低等问题。
基于全链路的血缘关系,根据不同的数据安全等级,先用血缘关系标注接口标注不同的表字段,然后识别标注字段的上下游血缘关系,然后自动标注安全等级。如图7所示,city_name字段通过血统标记平台安全标记,等级为L3。根据血脉关系,对下游血脉链路的字段进行自动染色和标记,实现自动“染色”。
图 7 数据安全
4 未来展望
经过探索和实践,满帮已经基本实现了基于图数据库相关技术的全链路数据血统的构建,并取得了一定的成果。未来,我们将在以下几个方面进行更深入的探索,进一步完善我们的业务:
1、目前bloodline采集主要通过SQL、自动任务解析、人工排序等方式来提高bloodline覆盖率。目前覆盖率已达到95%以上。未来将探索人工智能相关的方法,根据数据集之间的依赖关系计算数据相似度,以提高覆盖率。
2、Impala bloodline采集 方法链接长,依赖Filebeat。未来我们会逐步对接使用SQL语法解析AST的方案,实现解析规范化。
3、目前血缘维度不支持功能层。
4、开发全链路血脉开放平台,快速对接应用方,为应用方提供血脉服务。
5 参考文献
[1]
[2]
[3] 查看全部
算法 自动采集列表(什么是全链路数据血缘(DataLineage)(AST))
1 什么是全链路数据沿袭
根据维基百科,数据沿袭也称为数据来源或数据谱系。它通常被定义为一个生命周期,主要包括数据来自哪里以及随着时间的推移而移动到哪里。
数据血脉是数据资产的重要组成部分。用于分析表和字段从数据源到当前表的血统路径,血统字段之间的关系是否满足,注意数据的一致性和合理的表设计。它描述了数据从采集、生产到服务全链路的变化和存在形式。
全链路数据血统是指在数据的整个生命周期中,数据与数据之间形成的各种关系,贯穿整个数据链路,如图1所示。
图1 全链路数据沿袭
2 血缘关系建设方案研究2.1 血缘关系分析
目前,数据沿袭主要是通过解析SQL语句来发现上下游调用栈等信息。主流解决方案可以分为两种:
• 运行时解析,即在任务运行时通过钩子接口或监听器接口解析SQL生成的逻辑技术树(AST)。
• 先采集再解析,即通过采集程序将各个计算引擎的SQL统一到采集到mq中进行血液分析。
上述两类方案各有优缺点,对比见表1。
表1 数据沿袭分析方案
方案名称
优势
缺点
运行时解析
解析出来的血脉信息准确,语法错误的SQL和任务不会被解析。
每个计算引擎都需要开发一套血缘关系分析模块,成本高,可能影响任务。
先采集再解析
对于不同的 SQL 方言,可以使用同一套词法/句法解析器进行解析和沿袭解析。
较长的链接可能会导致不准确的血统结果。
2.2 血脉储藏室
与传统的关系型数据库和 ES 工具相比,图数据库在血统信息的查询和分析方面具有以下优势:
1、更好地存储和分析复杂关系
数据沿袭描绘了数据的完整生命周期,具有数据链路长的特点。传统的关系型数据库和ES等,往往只反映当前状态或短路径中的状态,在长链接血缘关系的检索上存在明显劣势。图数据库有效组织复杂关系,通过点-边结构将血脉上下游完美连接,从而实现更长链路血脉的存储、检索和分析。
2、可以有效利用数据之间的相关性,实现更准确可靠的决策
图结构的特点对业务具有重要的指导意义。例如,图的密度可以反映业务数据关联的紧密程度,有助于识别高I/O或高吞吐的服务,识别链路瓶颈;图数据之间的共现可以反映血缘关系中的共生关系,辅助血缘关系重要性的划分;图形可视化帮助业务人员更清晰地了解血缘动态。
与开源图数据库 Neo4j 和 Nebula Graph 相比,华为云 GES 具有以下优势:
• 基于分布式内存计算,性能更高、速度更快、响应时间更短
• 集成 30+ 种高性能算法,增强图形分析能力
• 对接华为云大数据和AI服务,周边支持更全面,服务对接更便捷
• 基于实践自主研发的查询算子Path-Query,支持复杂的过滤查询条件,具有更好的查询性能
华为云GES的基准数据如表2所示。
表2 华为云GES基准测试数据
增加
新节点
15000 TPS
添加边缘
10000 TPS
查询
查询节点详情
20000 TPS
查询边详细信息
10000 TPS
进口
批量导入数据速率
600,000 边/秒
从备份恢复数据速率
600 万边/秒
遍历
1-hop 查询响应时间
第二
2-hop 查询响应时间
第二
三跳查询响应时间
1~3秒
6 跳查询响应时间
5秒
算法
页面排名算法
每次迭代 4 秒
WCC算法
20 秒
SSSP算法
20 秒
3 满帮数据血脉的实践3.1 满帮数据血脉的特点
满帮数据血脉具有以下特点:
• 采集 广泛的覆盖范围。目前已经覆盖了大部分离线和实时场景,涉及的组件包括hive、spark、impala、flink、doris、kafka、clickhouse等。
• 多层次的亲属关系。根据血缘关系模型和血缘关系数据,形成域与域、域与表、表与表、库与库、任务与任务等血缘关系,应用于不同场景。
• 丰富的应用场景。已应用于数据治理、数据质量、数据安全、应用告警等多种场景。
• 开放血统界面。目前,基于血缘关系服务平台,对外提供了丰富的血缘关系接口,包括基本血缘关系信息查询和基于各种算法的血缘关系路径查询。
3.2 数据沿袭模型
定义丰富的血缘关系模型有助于更真实有效地展示血缘关系。满族血统模型主要包括实体和关系,其中实体主要涵盖任务、库、表、视图、字段、函数等实体。实体和关系的组合显示了从一个表/列到其他表/列的沿袭,包括表 INSERT INTO\CTAS 之间的依赖关系,字段 PROJECTION\PREDICATE 之间的依赖关系。
使用完整的数据血缘关系模型可以展示血缘关系的全貌,但存在以下问题:一是完整的血缘关系模型往往收录数千个实体血缘关系,在前端难以展示;其次,过多的冗余信息可能导致问题实体定位困难。为了解决以上问题,满帮在数据血缘模型的基础上,开发了多层次血缘关系模型,主要包括完整血缘关系模型和高层次血缘关系模型。完整数据沿袭模型是所有其他高级沿袭模型的基础,高级沿袭模型通过省略或聚合模型中的某些关系和实体来扩展完整沿袭。在实际业务中,
3.3 整体架构方案
满帮全链路数据血脉实现了血脉数据数据采集从开始到最终数据服务的全链路,有助于高效定位问题,快速评估影响。全链路血脉架构如图2所示,主要包括5层:
• 血脉采集层:负责采集满帮大数据平台各组件的任务血脉信息,将血脉解析成统一格式;
• 血脉处理层:通过消息队列Kafka,通过实时任务将血脉信息统一处理写入GES和Hive,提供血脉存储接口和血脉管理功能;
• 血缘存储层:分别通过GES和Hive提供血缘信息存储和血缘分析统计功能;
• 血统接口层:提供血统信息功能接口,连接血统应用服务;
• 血脉应用层:提供血脉服务,包括数据资产、数据治理、数据安全等。
图2 满帮全链路血脉架构
3.3.1层血脉采集层
满帮血脉采集层目前涵盖满帮内部数据、离线调度、实时计算等平台上的SQL任务和Spark\Flink任务。血缘关系包括系统血缘关系、职务血缘关系、图书馆血缘关系、表级血缘关系、字段血缘关系,指向数据的上游源头,溯源上游。通过血缘关系,清晰展现数据处理的逻辑脉络,快速定位异常数据域的影响范围,准确勾画数据回溯的最小范围,降低理解数据和解决数据问题的成本. 具体来说:
• Hive SQL lineage 解析主要是指通过Hive hook 函数解析org.apache.hadoop.hive.ql.hooks.LineageLogger。
• Spark SQL通过QueryExecutionListener的onSuccess方法获取逻辑计划的Output,通过Output解析字段血缘关系。
• Flink SQL 通过 Cava cc 获取 SQL 逻辑计划树(AST),通过遍历 AST 获取并执行 Input\Output,从而分析表和字段之间的关系。
• Spark\Flink 任务通过分析DAG 中的关系,找到Input\Output,构建虚拟输入输出表,构建血缘关系。
• Impala 目前使用filebeat采集 血脉日志将血脉信息异步发送到Kafka。
为了方便采集和数据血统的处理,统一了各个组件的血统格式,主要包括输入输出表、字段等信息。
序列号
字段名称
字段类型
描述
1
数据库
细绳
当前数据库
2
期间
长
血统分析时间
3
引擎名称
细绳
执行引擎名称
4
执行平台
细绳
执行的平台名称
5
哈希
细绳
执行 SQL MD5 值
6
工作 ID
细绳
执行Job的Id进行拼接
7
职位名称
细绳
任务名称
8
傲慢的
细绳
任务执行OA用户
9
查询文本
细绳
执行 SQL 语句
10
更新时间
长
血脉更新时间
11
用户
细绳
任务执行账户
12
版本
细绳
血统分析版
13
表血统
JSON 对象
表级血统信息
14
列沿袭
JSON 对象
场级血统信息
3.3.2 血脉处理层
血缘处理层主要由血缘实时处理模块、血缘存储接口模块、血缘管理模块组成。
为了满足近实时血脉查询的需求,满帮采用Flink作为血脉实时处理模块的核心组件。通过对从上游采集接收到的血脉信息进行实时分析处理,快速写入图数据库和Hive。该模块支持批量删除\查询\更新和模糊删除\查询\更新功能。
血脉存储接口模块主要开发快速编写图数据库和Hive的相关接口。
血缘管理模块主要用于血缘信息的维护管理和统计分析。
3.3.3血脉储存层
血脉存储层使用华为云图引擎GES服务作为存储引擎。GES采用华为自研EYWA内核,是一种基于“关系”的“图”结构化数据查询分析服务。GES 目前提供多种原生接口,包括批量读写点、边,以及各种路径查询算法。
全链路全链路数据沿袭场景下,图数据操作主要包括读写操作。写入操作主要是将解析和格式化后的血线数据实时写入图数据库。另一种写操作主要是向应用端提供写请求,如表\字段安全级别标记。读取操作主要来自自满帮内部的各种应用场景,主要涵盖短距离、CRM、客服、金融等。
3.3.4 血脉接口层和血脉应用层
血缘接口层主要连接血缘应用层的各种服务,通过开放血缘RPC接口,为各个应用服务提供丰富的接口选项。
目前,满族血脉信息主要应用于数据资产、数据治理、数据安全、数据质量等各种场景。
1、数据资产
满帮数据资产管理平台提供资产全景、数据地图、数据质量、数据安全等功能,如图4所示。数据地图支持以扇形图的形式直观展示各类数据资产的占比,图表,并通过不同层次的图形进行精细化控制,满足业务中不同应用场景的数据查询和辅助分析需求。
图 4 满帮数据资产管理平台
数据图还支持显示血统信息,分析任务之间的数据流向,如图5所示。目前数据图支持显示任务、库、表、字段级血缘关系。
图5 满帮资料图
2、数据治理
数据治理是指在数据的整个生命周期内管理数据的原则性方法,其目标是确保数据安全、及时、准确、可用和易于使用。满帮数据治理主要围绕“指标明确、质量规范”和“资源合理、节约严格”的原则进行。
如图6所示,满帮数据治理任务对库、表、字段的血脉信息进行分析,从价值密度、访问频率、使用方式、时效度等维度进行评价,从而对数据的流行度进行评分,热数据和热数据。,冷数据和冰数据。通过血缘信息查看离线数仓中某个任务链路的上下游任务依赖,同时分析链路上表的冷热使用情况,对ods和dwd的相关任务和SQL进行优化,trim和merge低价值表,缩短数据流ETL环节,从而降低维护成本,提高数据价值。
图 6 满帮数据治理
3、数据质量
数据质量旨在高效监控各类作业的运行状态,洞察关键信息,形成事前判断、事中监控、事后跟踪的闭环质量管理流程。在满帮数据质量监管平台建设中,面临以下问题:
• 离线实时监控系统不完善,监控存在盲点
• 整个链路的数据质量难以保证,数据不可信
• 数据依赖复杂,链接深,数据输出容易延迟
针对以上问题,满帮基于全链路数据血统,从以下几个方面提升数据全生命周期的数据质量:
• 主动通知交通数据所有者。根据血缘关系,通知依赖调度的任务,并提供多层通知选项,避免过渡干扰。
• 离线ETL链接,如果ods\dwd层的某个表的key字段被修改,将通过血脉信息自动向下游依赖表和任务负责人发送告警
• 对于实时的 Flink 任务,如果源端的 Kafka 字段结构发生变化,会根据血缘关系自动通知下游的依赖表和任务负责人
4、数据安全
随着国家在数据流通过程中对数据安全的重视程度越来越高,如果不能有效识别安全级别高的数据,可能会出现安全合规风险。为此,满帮推出了资产安全打标平台,支持通过“自动+人工”打标实现资产安全分级打标,但存在打标覆盖率低、准确率低等问题。
基于全链路的血缘关系,根据不同的数据安全等级,先用血缘关系标注接口标注不同的表字段,然后识别标注字段的上下游血缘关系,然后自动标注安全等级。如图7所示,city_name字段通过血统标记平台安全标记,等级为L3。根据血脉关系,对下游血脉链路的字段进行自动染色和标记,实现自动“染色”。
图 7 数据安全
4 未来展望
经过探索和实践,满帮已经基本实现了基于图数据库相关技术的全链路数据血统的构建,并取得了一定的成果。未来,我们将在以下几个方面进行更深入的探索,进一步完善我们的业务:
1、目前bloodline采集主要通过SQL、自动任务解析、人工排序等方式来提高bloodline覆盖率。目前覆盖率已达到95%以上。未来将探索人工智能相关的方法,根据数据集之间的依赖关系计算数据相似度,以提高覆盖率。
2、Impala bloodline采集 方法链接长,依赖Filebeat。未来我们会逐步对接使用SQL语法解析AST的方案,实现解析规范化。
3、目前血缘维度不支持功能层。
4、开发全链路血脉开放平台,快速对接应用方,为应用方提供血脉服务。
5 参考文献
[1]
[2]
[3]
算法 自动采集列表(Dede采集插件可轻松无缝地把文章内容或者数据发布(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-04-04 04:06
Dede采集 插件可以轻松无缝地将 文章 内容或数据发布到 织梦DEDE网站。 Dede采集插件是一套php+mysql采集程序,适用于企业网站建设和个人网站建设。当您看到这个 文章 时,您正在寻找与 Dede采集 插件相关的工具或信息。本文的重点都在文章图片上,只看图片,文章内容无视。 【重点1来了,Dede采集插件,强大丰富】
基于php的采集插件的性能、功能和稳定性都不是很好,所以Dede采集插件更强大更方便支持采集插件-ins 更合适。稳定采集,定期发布。发布规则超级简单,可以使用任意模型和自定义字段自动下载图片并提取第一张缩略图。 Dede采集插件不需要任何编程基础,它会查看源代码,复制粘贴。 采集规则不用写,输入关键词开始采集即可。 [重点2来了,Dede采集插件,你可以永久免费使用]
Dede采集插件采集文章的一些原理代码:
修复方法,找到:application采集event采集.php
$rules = [
'url' => [$this->_config['url_rule1'], $this->_config['url_rule2'], $this->_config['url_rule3']],
'title' => [$this->_config['url_rule1'], 'html', $this->_config['url_rule3']],
替换为【关键点3来了,Dede采集插件,高效处理,操作简单】
'url' => ['',$this->_config['url_rule2'],$this->_config['url_rule3']
'title' => ['','text',$this->_config['url_rule3']]
Dede采集插件可以每天自动更新。最新最热资讯采集每天自动更新。输入关键词,采集与此关键词相关的最新内容。输入 URL,采集这个 URL 的内容。可用于云通用 伪原创 和本地 伪原创。本地伪原创词库可以在插件设置中自定义。图片可一键本地存储,图片永不丢失。 【重点4来了,Dede采集插件,一键自动设置采集】
Dede采集插件自动采集存储和自动发布文章插件,可以自动通过织梦cms后端采集模块< @采集rules采集文章,并自动存储在对应的栏目中,并自动更新生成内容页的html、栏目页的html、首页的html存储后,实现织梦cms自动更新内容,可以解决很多需要手动采集、手动存储、手动批量更新的问题,提高更新速度网站@ >.
Dede采集插件可以搭配适当的采集内容,但也需要整合采集内容。对于新的网站,搜索引擎会更加注重质量审核,所以我不建议所有的内容都是采集,至少伪原创要处理。这里的伪原创文章一定要注意质量。不能是 文章 的类型只改变头部和尾部。注意改头尾不视为伪原创文章,建议阅读伪原创的概念和伪原创文章的编辑技巧如果采集的文章用高质量的伪原创处理,那么基本没有问题。
Dede采集采集网站的插件要避开搜索引擎算法,必须对内容进行排版,不要刻意拼接,减少网站页面的重复,不要交叉domain采集,对采集的内容做二次处理,当采集站避开这些点时,不会命中搜索引擎算法。
文章的
dede采集插件就写到这里了,希望对各位站长和SEOer有所帮助,如果对文章的内容看不懂,可以直接看文章图片,简单易懂。 查看全部
算法 自动采集列表(Dede采集插件可轻松无缝地把文章内容或者数据发布(图))
Dede采集 插件可以轻松无缝地将 文章 内容或数据发布到 织梦DEDE网站。 Dede采集插件是一套php+mysql采集程序,适用于企业网站建设和个人网站建设。当您看到这个 文章 时,您正在寻找与 Dede采集 插件相关的工具或信息。本文的重点都在文章图片上,只看图片,文章内容无视。 【重点1来了,Dede采集插件,强大丰富】
基于php的采集插件的性能、功能和稳定性都不是很好,所以Dede采集插件更强大更方便支持采集插件-ins 更合适。稳定采集,定期发布。发布规则超级简单,可以使用任意模型和自定义字段自动下载图片并提取第一张缩略图。 Dede采集插件不需要任何编程基础,它会查看源代码,复制粘贴。 采集规则不用写,输入关键词开始采集即可。 [重点2来了,Dede采集插件,你可以永久免费使用]
Dede采集插件采集文章的一些原理代码:
修复方法,找到:application采集event采集.php
$rules = [
'url' => [$this->_config['url_rule1'], $this->_config['url_rule2'], $this->_config['url_rule3']],
'title' => [$this->_config['url_rule1'], 'html', $this->_config['url_rule3']],
替换为【关键点3来了,Dede采集插件,高效处理,操作简单】
'url' => ['',$this->_config['url_rule2'],$this->_config['url_rule3']
'title' => ['','text',$this->_config['url_rule3']]
Dede采集插件可以每天自动更新。最新最热资讯采集每天自动更新。输入关键词,采集与此关键词相关的最新内容。输入 URL,采集这个 URL 的内容。可用于云通用 伪原创 和本地 伪原创。本地伪原创词库可以在插件设置中自定义。图片可一键本地存储,图片永不丢失。 【重点4来了,Dede采集插件,一键自动设置采集】
Dede采集插件自动采集存储和自动发布文章插件,可以自动通过织梦cms后端采集模块< @采集rules采集文章,并自动存储在对应的栏目中,并自动更新生成内容页的html、栏目页的html、首页的html存储后,实现织梦cms自动更新内容,可以解决很多需要手动采集、手动存储、手动批量更新的问题,提高更新速度网站@ >.
Dede采集插件可以搭配适当的采集内容,但也需要整合采集内容。对于新的网站,搜索引擎会更加注重质量审核,所以我不建议所有的内容都是采集,至少伪原创要处理。这里的伪原创文章一定要注意质量。不能是 文章 的类型只改变头部和尾部。注意改头尾不视为伪原创文章,建议阅读伪原创的概念和伪原创文章的编辑技巧如果采集的文章用高质量的伪原创处理,那么基本没有问题。
Dede采集采集网站的插件要避开搜索引擎算法,必须对内容进行排版,不要刻意拼接,减少网站页面的重复,不要交叉domain采集,对采集的内容做二次处理,当采集站避开这些点时,不会命中搜索引擎算法。
文章的
dede采集插件就写到这里了,希望对各位站长和SEOer有所帮助,如果对文章的内容看不懂,可以直接看文章图片,简单易懂。
算法 自动采集列表(算法自动采集列表页里面的广告页挨个点击才可以)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-30 10:06
算法自动采集列表页列表页里面经常会出现很多的广告等文字。这些文字怎么在图片上显示在数据库中排好顺序,挨个点击才可以呢?最简单的方法是利用一个广告采集程序,它自动连接图片和广告列表页,然后采集图片中的广告页列表,并把不想要的广告页标记为stop。这样就能得到不想要的广告页列表,随后只要只要取出stop中的广告页即可。
这种广告采集效率很低,程序非常麻烦。接下来的办法比较简单,现在以我在旅游度假时会用到的adsense插件来做演示。打开adsense浏览器插件商店,安装adsense。依次输入网站:/,就会看到一个带有广告的广告栏。我们在浏览这个网站时,会点击这些广告,再次刷新该网站,看广告栏中是否有新的广告项目。这时候,在标记广告的小框上,会有两个选项:stop和nomoredirectclicks。
点击stop。接下来点击nomoredirectclicks,然后选择下面我们想要的广告列表页。然后点击进入广告列表页,连续点击这几个广告就能得到想要的广告页列表。这时候,一共有5个广告页:点击stop这两个广告就可以将你的广告页标记stop。接下来的操作比较简单,仅需要让网站更改,并且刷新广告栏即可得到原本的广告页列表。
方法就是通过定时器和cookie相关js,完成获取的过程。有些人可能会问,这种方法太麻烦,要等广告完全显示才能得到。其实并不需要特别久,只需要广告稍微少一点,比如广告栏的广告数量少于10个,基本上。
3、5秒就可以获取到广告页列表,就像原来的广告网站一样。但是,如果广告网站广告有几千个或者更多,通过这种方法就会出现显示广告之后,再也找不到显示广告的地方。这是一个让人头疼的问题。解决方法还是通过定时器和cookie来完成广告的定时采集。首先,需要一个表示表单的cookie。这个cookie可以在我们的浏览器插件商店中找到,也可以在后台自己写js获取。下面我就简单介绍一下从插件商店找到的cookie。我就用最简单的useragent代码来获取。
functionlsj(jsflag){if(jsflag){console.log('cookiefailed');}settimeout(lsj,1,100
0);}else{if(!settimeout){console.log('cookiefailed');}settimeout(lsj,2000,200
0);}如果你是从自己写的脚本中获取,可以借助一些工具来用es6定时采集更多广告,比如我们可以使用javascript实现定时连接服务器获取服务器用户数据。连接后转化为json格式。
functiongetjw(jsflag){lsj(jsflag)}console.log('getjsfailed');settimeout(getjw,100
0) 查看全部
算法 自动采集列表(算法自动采集列表页里面的广告页挨个点击才可以)
算法自动采集列表页列表页里面经常会出现很多的广告等文字。这些文字怎么在图片上显示在数据库中排好顺序,挨个点击才可以呢?最简单的方法是利用一个广告采集程序,它自动连接图片和广告列表页,然后采集图片中的广告页列表,并把不想要的广告页标记为stop。这样就能得到不想要的广告页列表,随后只要只要取出stop中的广告页即可。
这种广告采集效率很低,程序非常麻烦。接下来的办法比较简单,现在以我在旅游度假时会用到的adsense插件来做演示。打开adsense浏览器插件商店,安装adsense。依次输入网站:/,就会看到一个带有广告的广告栏。我们在浏览这个网站时,会点击这些广告,再次刷新该网站,看广告栏中是否有新的广告项目。这时候,在标记广告的小框上,会有两个选项:stop和nomoredirectclicks。
点击stop。接下来点击nomoredirectclicks,然后选择下面我们想要的广告列表页。然后点击进入广告列表页,连续点击这几个广告就能得到想要的广告页列表。这时候,一共有5个广告页:点击stop这两个广告就可以将你的广告页标记stop。接下来的操作比较简单,仅需要让网站更改,并且刷新广告栏即可得到原本的广告页列表。
方法就是通过定时器和cookie相关js,完成获取的过程。有些人可能会问,这种方法太麻烦,要等广告完全显示才能得到。其实并不需要特别久,只需要广告稍微少一点,比如广告栏的广告数量少于10个,基本上。
3、5秒就可以获取到广告页列表,就像原来的广告网站一样。但是,如果广告网站广告有几千个或者更多,通过这种方法就会出现显示广告之后,再也找不到显示广告的地方。这是一个让人头疼的问题。解决方法还是通过定时器和cookie来完成广告的定时采集。首先,需要一个表示表单的cookie。这个cookie可以在我们的浏览器插件商店中找到,也可以在后台自己写js获取。下面我就简单介绍一下从插件商店找到的cookie。我就用最简单的useragent代码来获取。
functionlsj(jsflag){if(jsflag){console.log('cookiefailed');}settimeout(lsj,1,100
0);}else{if(!settimeout){console.log('cookiefailed');}settimeout(lsj,2000,200
0);}如果你是从自己写的脚本中获取,可以借助一些工具来用es6定时采集更多广告,比如我们可以使用javascript实现定时连接服务器获取服务器用户数据。连接后转化为json格式。
functiongetjw(jsflag){lsj(jsflag)}console.log('getjsfailed');settimeout(getjw,100
0)
算法 自动采集列表(《开源精选》之一个、Gitee等开源社区中优质项目)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-03-29 17:16
《开源精选》是我们在Github、Gitee等开源社区分享优质项目的专栏,内容包括技术、学习、实用和各种有趣的内容。本期推荐DrissionPage,一个基于python的开源网络自动化集成工具。
使用请求作为数据采集面对要登录的网站,需要分析数据包,JS源码,构造复杂的请求,经常要处理反爬等方法如验证码、JS混淆、签名参数等,门槛较高。如果数据是JS计算生成的,计算过程必须复现,体验不好,开发效率不高。
使用 selenium,这些坑可以在很大程度上绕过,但 selenium 效率不高。因此,该库将 selenium 和 requests 合二为一,在不同需求时切换相应的模式,并提供一种用户友好的方法来提高开发和运行效率。
这个库除了将两者合并之外,还封装了网页中常用的函数,简化了selenium的操作和语句。用于网页自动化时,减少了对细节的考虑,专注于功能实现,使用起来更方便。一切都很简单,尽量提供简单直接的使用方法,对新手比较友好。
功能亮点功能
结构图
如图,Drission 对象负责创建链接、分享登录状态等,类似于 selenium 中驱动的概念。MixPage 对象负责对获取的页面进行解析和操作。DriverElement 和 SessionElement 是从页面对象中获取的元素对象。负责解析和操作元素。
简单的演示
与硒代码比较
跳转到第一个标签
# 使用 selenium:
driver.switch_to.window(driver.window_handles[0])
# 使用 DrissionPage:
page.to_tab(0)
按文本选择下拉菜单
# 使用 selenium:
from selenium.webdriver.support.select import Select
select_element = Select(element)
select_element.select_by_visible_text('text')
# 使用 DrissionPage:
element.select('text')
拖动一个元素
# 使用 selenium:
ActionChains(driver).drag_and_drop(ele1, ele2).perform()
# 使用 DrissionPage:
ele1.drag_to(ele2)
与请求代码比较
获取元素内容
url = 'https://baike.baidu.com/item/python'
# 使用 requests:
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'}
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
element = html.xpath('//h1')[0]
title = element.text
# 使用 DrissionPage:
page = MixPage('s')
page.get(url)
title = page('tag:h1').text
下载文件
url = 'https://www.baidu.com/img/flex ... 39%3B
save_path = r'C:\download'
# 使用 requests:
r = requests.get(url)
with open(f'{save_path}\\img.png', 'wb') as fd:
for chunk in r.iter_content():
fd.write(chunk)
# 使用 DrissionPage:
page.download(url, save_path, 'img') # 支持重命名,处理文件名冲突,自动创建目标文件夹
爬取新冠排行榜
URL:本例爬取全球新冠疫情排名。网站是一个纯html页面,特别适合s-mode的爬取和解析。
from DrissionPage import MixPage
# 用 s 模式创建页面对象
page = MixPage('s')
# 访问数据网页
page.get('https://www.outbreak.my/zh/world')
# 获取表头元素
thead = page('tag:thead')
# 获取表头列,跳过其中的隐藏的列
title = thead.eles('tag:th@@-style:display: none;')
data = [th.text for th in title]
print(data) # 打印表头
# 获取内容表格元素
tbody = page('tag:tbody')
# 获取表格所有行
rows = tbody.eles('tag:tr')
for row in rows:
# 获取当前行所有列
cols = row.eles('tag:td')
# 生成当前行数据列表(跳过其中没用的几列)
data = [td.text for k, td in enumerate(cols) if k not in (2, 4, 6)]
print(data) # 打印行数据
输出:
['总 (205)', '累积确诊', '死亡', '治愈', '现有确诊', '死亡率', '恢复率']
['美国', '55252823', '845745', '41467660', '12,939,418', '1.53%', '75.05%']
['印度', '34838804', '481080', '34266363', '91,361', '1.38%', '98.36%']
['巴西', '22277239', '619024', '21567845', '90,370', '2.78%', '96.82%']
['英国', '12748050', '148421', '10271706', '2,327,923', '1.16%', '80.57%']
['俄罗斯', '10499982', '308860', '9463919', '727,203', '2.94%', '90.13%']
['法国', '9740600', '123552', '8037752', '1,579,296', '1.27%', '82.52%']
......
登录gitee 网站
URL: ,本例演示使用浏览器控件自动登录gitee 网站。
from DrissionPage import MixPage
# 用 d 模式创建页面对象(默认模式)
page = MixPage()
# 跳转到登录页面
page.get('https://gitee.com/login')
# 定位到账号文本框并输入账号
page.ele('#user_login').input('你的账号')
# 定位到密码文本框并输入密码
page.ele('#user_password').input('你的密码')
# 点击登录按钮
page.ele('@value=登 录').click()
-结尾-
开源许可证:BSD-3-Clause
开源地址: 查看全部
算法 自动采集列表(《开源精选》之一个、Gitee等开源社区中优质项目)
《开源精选》是我们在Github、Gitee等开源社区分享优质项目的专栏,内容包括技术、学习、实用和各种有趣的内容。本期推荐DrissionPage,一个基于python的开源网络自动化集成工具。
使用请求作为数据采集面对要登录的网站,需要分析数据包,JS源码,构造复杂的请求,经常要处理反爬等方法如验证码、JS混淆、签名参数等,门槛较高。如果数据是JS计算生成的,计算过程必须复现,体验不好,开发效率不高。
使用 selenium,这些坑可以在很大程度上绕过,但 selenium 效率不高。因此,该库将 selenium 和 requests 合二为一,在不同需求时切换相应的模式,并提供一种用户友好的方法来提高开发和运行效率。
这个库除了将两者合并之外,还封装了网页中常用的函数,简化了selenium的操作和语句。用于网页自动化时,减少了对细节的考虑,专注于功能实现,使用起来更方便。一切都很简单,尽量提供简单直接的使用方法,对新手比较友好。
功能亮点功能
结构图
如图,Drission 对象负责创建链接、分享登录状态等,类似于 selenium 中驱动的概念。MixPage 对象负责对获取的页面进行解析和操作。DriverElement 和 SessionElement 是从页面对象中获取的元素对象。负责解析和操作元素。
简单的演示
与硒代码比较
跳转到第一个标签
# 使用 selenium:
driver.switch_to.window(driver.window_handles[0])
# 使用 DrissionPage:
page.to_tab(0)
按文本选择下拉菜单
# 使用 selenium:
from selenium.webdriver.support.select import Select
select_element = Select(element)
select_element.select_by_visible_text('text')
# 使用 DrissionPage:
element.select('text')
拖动一个元素
# 使用 selenium:
ActionChains(driver).drag_and_drop(ele1, ele2).perform()
# 使用 DrissionPage:
ele1.drag_to(ele2)
与请求代码比较
获取元素内容
url = 'https://baike.baidu.com/item/python'
# 使用 requests:
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'}
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
element = html.xpath('//h1')[0]
title = element.text
# 使用 DrissionPage:
page = MixPage('s')
page.get(url)
title = page('tag:h1').text
下载文件
url = 'https://www.baidu.com/img/flex ... 39%3B
save_path = r'C:\download'
# 使用 requests:
r = requests.get(url)
with open(f'{save_path}\\img.png', 'wb') as fd:
for chunk in r.iter_content():
fd.write(chunk)
# 使用 DrissionPage:
page.download(url, save_path, 'img') # 支持重命名,处理文件名冲突,自动创建目标文件夹
爬取新冠排行榜
URL:本例爬取全球新冠疫情排名。网站是一个纯html页面,特别适合s-mode的爬取和解析。
from DrissionPage import MixPage
# 用 s 模式创建页面对象
page = MixPage('s')
# 访问数据网页
page.get('https://www.outbreak.my/zh/world')
# 获取表头元素
thead = page('tag:thead')
# 获取表头列,跳过其中的隐藏的列
title = thead.eles('tag:th@@-style:display: none;')
data = [th.text for th in title]
print(data) # 打印表头
# 获取内容表格元素
tbody = page('tag:tbody')
# 获取表格所有行
rows = tbody.eles('tag:tr')
for row in rows:
# 获取当前行所有列
cols = row.eles('tag:td')
# 生成当前行数据列表(跳过其中没用的几列)
data = [td.text for k, td in enumerate(cols) if k not in (2, 4, 6)]
print(data) # 打印行数据
输出:
['总 (205)', '累积确诊', '死亡', '治愈', '现有确诊', '死亡率', '恢复率']
['美国', '55252823', '845745', '41467660', '12,939,418', '1.53%', '75.05%']
['印度', '34838804', '481080', '34266363', '91,361', '1.38%', '98.36%']
['巴西', '22277239', '619024', '21567845', '90,370', '2.78%', '96.82%']
['英国', '12748050', '148421', '10271706', '2,327,923', '1.16%', '80.57%']
['俄罗斯', '10499982', '308860', '9463919', '727,203', '2.94%', '90.13%']
['法国', '9740600', '123552', '8037752', '1,579,296', '1.27%', '82.52%']
......
登录gitee 网站
URL: ,本例演示使用浏览器控件自动登录gitee 网站。
from DrissionPage import MixPage
# 用 d 模式创建页面对象(默认模式)
page = MixPage()
# 跳转到登录页面
page.get('https://gitee.com/login')
# 定位到账号文本框并输入账号
page.ele('#user_login').input('你的账号')
# 定位到密码文本框并输入密码
page.ele('#user_password').input('你的密码')
# 点击登录按钮
page.ele('@value=登 录').click()
-结尾-
开源许可证:BSD-3-Clause
开源地址:
算法 自动采集列表(方法网格搜索随机搜索贝叶斯搜索的实现:系统架构BML自动超参搜索功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-03-29 01:09
方法
网格搜索
随机搜索
贝叶斯搜索
进化算法
优势
实现简单,效果取决于用户设置的网格间隔大小
进行多参数联合搜索时,扩大了各参数的搜索范围,提高了搜索效率。
搜索迭代次数少,效率高,通过贝叶斯算法在已有采样点的帮助下估计最优超参数。
减少每轮迭代的训练时间,将计算资源集中在参数搜索上,通过重用具有良好历史表现的个体的预训练参数来加速收敛
缺点
消耗计算资源
效果不稳定
可能陷入局部最优
因超参数导致模型结构变化等因素无法加载预训练参数时不适用
自动超参数搜索方法的比较
上表总结了这些搜索方法的优缺点。总之,网格搜索和随机搜索实现起来比较简单,不使用先验知识来选择下一组超参数,随机搜索比较高效。贝叶斯搜索和进化算法需要利用上一轮的信息进行迭代搜索,搜索效率显着提高。
BML自动超参数搜索的实现:系统架构
BML自动超参数搜索功能是基于自主研发的自动超参数搜索服务。服务操作流程如下图所示。它依托百度智能云CCE的计算能力,同时支持多个自动搜索任务。为了提供“好用”的自动超参数搜索服务,架构实现侧重于提高并发搜索效率和系统容错能力。
一个超参数搜索任务包括以下过程:
1.业务平台将超参搜索任务的用户配置信息提交给超参搜索服务,会创建一个搜索实验(Experiment)并记录在db中。
2.搜索服务向实验控制器提交任务,实验控制器初始化并创建试验管理模块,负责试验生命周期的管理。
3.Trial 是一个特定的训练实验。一个实验将产生多个试验,以探索不同超参数组合的最终效果。Tuner 是一个超参数生成模块,根据选择的超参数搜索算法推荐下一次 Trial 使用的超参数值。在 Trial 管理模块中,Exp Manager 将负责生成多个 Trial,向 Tuner 请求特定的测试超参数,并将 Trial 任务信息发送给 Trial Scheduler。
4.Trial Scheduler 将与底层资源交互以实际启动 Trial。Trial Scheduler 管理所有试验的生命周期。
5.每次试用完成后,会将指标等信息上报给Exp Manager,用于上报给tuner并记录到db。
BML自动超参数搜索主要有以下特点:
动手实践:如何使用自动超参数搜索
1.先点击
创建一个脚本参数调整项目,如果你已经有项目,可以直接使用!目前,支持超参数搜索的项目类型包括图像分类(单标签和多标签)和对象检测。只需创建相应类型的项目。
2.在工程中新建任务,配置任务的网络、数据、脚本,可以看到“配置超参数”选项。如果这里已经有超参数搜索结果,可以直接勾选“Existing hyperparameter search results”来使用。如果我们不是第一次使用它,只需选择“自动超参数搜索”即可。
3.目前BML支持三种超参数搜索算法,如图,分别是贝叶斯搜索、随机搜索和进化算法。您可以根据需要选择一种进行搜索。具体配置项说明请参考技术文档。
3.1 贝叶斯搜索的参数说明
【初始点数】表示贝叶斯搜索初始化时参数点的个数。该算法根据这些参数信息推断出最优点,并填充在1-20的范围内。
[最大并发] 在贝叶斯搜索中,同时实验的数量。并发越大,搜索效率越高。填写1-20的范围。不过这个并发也受限于页面底部选择的GPU数量,实际并发是两者中较小的一个。
【超参数范围设置】:可以是默认配置,也可以是手动配置。默认情况下,百度的工程师已经帮我们设置了针对不同网络和GPU卡类型的基本可靠的搜索范围,可以直接使用。当然也可以手动配置,可以自定义每个超参数的范围。可以看到物体检测支持以下超参数自定义搜索范围:
【最大搜索次数】:指可以组合并运行测试的最大超参数组数。当然也可能因为提前达到目标而停止,节省成本。
【数据采样率】:使用超参数搜索时,会在训练前对原创数据集进行采样,以加快搜索速度。当数据集不大时,不建议采样,可能会影响最终效果。只有当数据量很大时才需要使用采样。
【Highest mAP/Highest Accuracy Rate】:指每个人都期望模型达到的效果的mAP(物体检测)或准确率(图像分类)的值。当实验中达到这个值时,搜索将停止,以避免将来浪费搜索时间。.
3.2 随机搜索参数说明
随机搜索是最简单的,不需要额外配置算法相关的参数。其他常见选项与贝叶斯搜索具有相同的含义。你可以参考贝叶斯搜索。
3.3 进化算法参数说明
进化算法是一种更好的算法,应用该算法时需要更多的选项。
【迭代轮次】:进化算法运行的迭代次数,范围为5-50。
【扰动区间】:进化算法每隔几个epoch就会随机扰动一次,利用随机因素防止算法结果收敛到局部最优解。
【扰动比】:类似于染色体交叉的形式,在迭代中根据扰动比对种群中最好和最差的个体进行交叉。
【随机初始化概率】:在扰动中,有一定概率初始化各个超参数。
【种群中的个体数】:一个个体代表一个超参数设置,一个种群收录多个个体。
其他选项与贝叶斯搜索含义相同,不再赘述。进化算法的配置需要对算法的原理有一定的了解。不懂算法的就用百度给出的默认值吧!
4.超参数选项设置完成,最后选择GPU卡的类型和数量,以及最大搜索时间,就可以提交任务了!此处的默认搜索时间为 24 小时。毕竟超参数搜索会运行多次测试,需要很长时间,需要耐心。当然,你选择的 GPU 卡越多,并发测试的数量就越高。从提交任务到搜索 完成时间会更短,这是显而易见的
5.任务提交后,一段时间后任务进入“超参搜索”状态,可以看到每个实验的进度,包括每个实验的状态、日志和准确率(mAP)
6.超参数搜索训练完成后,可以在5个结果最好的实验中看到详细的评估结果,也可以用于后续的效果验证和发布。当然,如果在超参数搜索过程中对数据进行了采样,此时可以重新启动训练任务,使用本次搜索结果满意的超参数进行全数据训练,从而获得完整的模型效果数据。
效果是硬道理:超参搜索效果提升高达20%+
我们使用通用脚本参数调整和超参数搜索比较了图像分类、对象检测、实例分割和其他任务的效果。进化算法和使用贝叶斯搜索算法的超参数搜索的效果比较。图中左纵轴是模型的准确率,右纵轴是超参数搜索算法生效的比例。可以看出,在不同数据集上使用超参数搜索的效果有所提升。当默认参数准确率已经超过 85% 时,使用超参数搜索仍然可以提高 5% 左右。在默认参数效果不佳的情况下,超参数搜索的提升效果更为明显,可高达22%。
正常运行下,可用的深度学习自动超参搜索由于需要集群计算资源,往往被认为只有大公司才能配置,普通开发者很难上手。通过使用全功能AI开发平台BML,也有机会在预算有限的情况下使用自动超参数搜索,开发效率瞬间赶上火箭速度,摆脱人类“炼金术”的束缚”。新BML用户现在还提供100小时免费P4显卡算力,羊毛在向你招手,快来咬一口吧! 查看全部
算法 自动采集列表(方法网格搜索随机搜索贝叶斯搜索的实现:系统架构BML自动超参搜索功能)
方法
网格搜索
随机搜索
贝叶斯搜索
进化算法
优势
实现简单,效果取决于用户设置的网格间隔大小
进行多参数联合搜索时,扩大了各参数的搜索范围,提高了搜索效率。
搜索迭代次数少,效率高,通过贝叶斯算法在已有采样点的帮助下估计最优超参数。
减少每轮迭代的训练时间,将计算资源集中在参数搜索上,通过重用具有良好历史表现的个体的预训练参数来加速收敛
缺点
消耗计算资源
效果不稳定
可能陷入局部最优
因超参数导致模型结构变化等因素无法加载预训练参数时不适用
自动超参数搜索方法的比较
上表总结了这些搜索方法的优缺点。总之,网格搜索和随机搜索实现起来比较简单,不使用先验知识来选择下一组超参数,随机搜索比较高效。贝叶斯搜索和进化算法需要利用上一轮的信息进行迭代搜索,搜索效率显着提高。
BML自动超参数搜索的实现:系统架构
BML自动超参数搜索功能是基于自主研发的自动超参数搜索服务。服务操作流程如下图所示。它依托百度智能云CCE的计算能力,同时支持多个自动搜索任务。为了提供“好用”的自动超参数搜索服务,架构实现侧重于提高并发搜索效率和系统容错能力。
一个超参数搜索任务包括以下过程:
1.业务平台将超参搜索任务的用户配置信息提交给超参搜索服务,会创建一个搜索实验(Experiment)并记录在db中。
2.搜索服务向实验控制器提交任务,实验控制器初始化并创建试验管理模块,负责试验生命周期的管理。
3.Trial 是一个特定的训练实验。一个实验将产生多个试验,以探索不同超参数组合的最终效果。Tuner 是一个超参数生成模块,根据选择的超参数搜索算法推荐下一次 Trial 使用的超参数值。在 Trial 管理模块中,Exp Manager 将负责生成多个 Trial,向 Tuner 请求特定的测试超参数,并将 Trial 任务信息发送给 Trial Scheduler。
4.Trial Scheduler 将与底层资源交互以实际启动 Trial。Trial Scheduler 管理所有试验的生命周期。
5.每次试用完成后,会将指标等信息上报给Exp Manager,用于上报给tuner并记录到db。
BML自动超参数搜索主要有以下特点:
动手实践:如何使用自动超参数搜索
1.先点击
创建一个脚本参数调整项目,如果你已经有项目,可以直接使用!目前,支持超参数搜索的项目类型包括图像分类(单标签和多标签)和对象检测。只需创建相应类型的项目。
2.在工程中新建任务,配置任务的网络、数据、脚本,可以看到“配置超参数”选项。如果这里已经有超参数搜索结果,可以直接勾选“Existing hyperparameter search results”来使用。如果我们不是第一次使用它,只需选择“自动超参数搜索”即可。
3.目前BML支持三种超参数搜索算法,如图,分别是贝叶斯搜索、随机搜索和进化算法。您可以根据需要选择一种进行搜索。具体配置项说明请参考技术文档。
3.1 贝叶斯搜索的参数说明
【初始点数】表示贝叶斯搜索初始化时参数点的个数。该算法根据这些参数信息推断出最优点,并填充在1-20的范围内。
[最大并发] 在贝叶斯搜索中,同时实验的数量。并发越大,搜索效率越高。填写1-20的范围。不过这个并发也受限于页面底部选择的GPU数量,实际并发是两者中较小的一个。
【超参数范围设置】:可以是默认配置,也可以是手动配置。默认情况下,百度的工程师已经帮我们设置了针对不同网络和GPU卡类型的基本可靠的搜索范围,可以直接使用。当然也可以手动配置,可以自定义每个超参数的范围。可以看到物体检测支持以下超参数自定义搜索范围:
【最大搜索次数】:指可以组合并运行测试的最大超参数组数。当然也可能因为提前达到目标而停止,节省成本。
【数据采样率】:使用超参数搜索时,会在训练前对原创数据集进行采样,以加快搜索速度。当数据集不大时,不建议采样,可能会影响最终效果。只有当数据量很大时才需要使用采样。
【Highest mAP/Highest Accuracy Rate】:指每个人都期望模型达到的效果的mAP(物体检测)或准确率(图像分类)的值。当实验中达到这个值时,搜索将停止,以避免将来浪费搜索时间。.
3.2 随机搜索参数说明
随机搜索是最简单的,不需要额外配置算法相关的参数。其他常见选项与贝叶斯搜索具有相同的含义。你可以参考贝叶斯搜索。
3.3 进化算法参数说明
进化算法是一种更好的算法,应用该算法时需要更多的选项。
【迭代轮次】:进化算法运行的迭代次数,范围为5-50。
【扰动区间】:进化算法每隔几个epoch就会随机扰动一次,利用随机因素防止算法结果收敛到局部最优解。
【扰动比】:类似于染色体交叉的形式,在迭代中根据扰动比对种群中最好和最差的个体进行交叉。
【随机初始化概率】:在扰动中,有一定概率初始化各个超参数。
【种群中的个体数】:一个个体代表一个超参数设置,一个种群收录多个个体。
其他选项与贝叶斯搜索含义相同,不再赘述。进化算法的配置需要对算法的原理有一定的了解。不懂算法的就用百度给出的默认值吧!
4.超参数选项设置完成,最后选择GPU卡的类型和数量,以及最大搜索时间,就可以提交任务了!此处的默认搜索时间为 24 小时。毕竟超参数搜索会运行多次测试,需要很长时间,需要耐心。当然,你选择的 GPU 卡越多,并发测试的数量就越高。从提交任务到搜索 完成时间会更短,这是显而易见的
5.任务提交后,一段时间后任务进入“超参搜索”状态,可以看到每个实验的进度,包括每个实验的状态、日志和准确率(mAP)
6.超参数搜索训练完成后,可以在5个结果最好的实验中看到详细的评估结果,也可以用于后续的效果验证和发布。当然,如果在超参数搜索过程中对数据进行了采样,此时可以重新启动训练任务,使用本次搜索结果满意的超参数进行全数据训练,从而获得完整的模型效果数据。
效果是硬道理:超参搜索效果提升高达20%+
我们使用通用脚本参数调整和超参数搜索比较了图像分类、对象检测、实例分割和其他任务的效果。进化算法和使用贝叶斯搜索算法的超参数搜索的效果比较。图中左纵轴是模型的准确率,右纵轴是超参数搜索算法生效的比例。可以看出,在不同数据集上使用超参数搜索的效果有所提升。当默认参数准确率已经超过 85% 时,使用超参数搜索仍然可以提高 5% 左右。在默认参数效果不佳的情况下,超参数搜索的提升效果更为明显,可高达22%。
正常运行下,可用的深度学习自动超参搜索由于需要集群计算资源,往往被认为只有大公司才能配置,普通开发者很难上手。通过使用全功能AI开发平台BML,也有机会在预算有限的情况下使用自动超参数搜索,开发效率瞬间赶上火箭速度,摆脱人类“炼金术”的束缚”。新BML用户现在还提供100小时免费P4显卡算力,羊毛在向你招手,快来咬一口吧!
算法 自动采集列表(易企CMS采集的配置及配置集,你值得拥有)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-25 18:16
Easy Enterprisecms采集,当网站上线时,它面临的最大问题是网站内容缺失,或者更新不及时。网站维护需要投入的人力财力越大,长期以来,网站运营商一直在追求最大限度降低成本,获得最高品质的能力网站内容。亿奇cms采集依托高效强大的网络信息采集与整合,与网站对接后,持续为网站提供优质、实时的数据,省去您投入更多人力来四处寻找文章资源的需要。
如果网站位于私网范围内,那么网站就会陷入网络扩容和内容补充的困境,只能依靠人工在网上采集相关信息再复制到内网并将其导入到 网站 上。通过Easy Enterprisecms采集,现在不用那么麻烦了,可以自动采集发布和编辑,让网站管理者可以专注于内容质量审查和审查 网站 上面的整体 SEO。
Easy Enterprisecms采集预设了30多个插件提升网站的排名,通过这些插件优化发布内容的排名,从而提升 的排名。根据网站的行业,它可以自动确定发布到网站的每条内容的“长尾词”,并自动调整发布内容的关键词密度。自动制作发布图片的alt属性,并根据发布的内容自动为内容中的图片生成相应的alt描述。
Easy Enterprisecms采集有4个高效的网络信息采集功能。主题采集,您只需输入关键字即可根据网站的主题设置要求采集符合要求的网络信息,不再需要手动搜索。定位采集,可以与其他同类网站保持同步,只需输入目标网站的地址,即可自动采集同类网站的信息进行筛选。
易奇cms采集随后进行针对性采集,无需在新闻源平台手动采集相关行业的文章。通过目标采集功能,只有目标网站的地址和关键字才行。配置采集,网站可以对信息源进行深度设置为采集,保证采集的数据内容准确完整,满足您的网站要求。
Easy Enterprisecms采集,通过5层网络信息过滤,使网站不会产生垃圾链接。对目标网站的原创信息源的链接的通道和链接类型进行数据过滤。除了标题过滤外,采集的数据源的标题还通过关键字识别和标题重复检查来过滤。内容过滤,通过对采集的数据内容进行HASH算法,保证采集的内容不重复。
结合字段过滤,可以对采集的内容的字段值进行过滤比较,保证采集的各个字段的内容符合要求。组合过滤,通过对采集的内容的多个字段值进行组合比较,确保匹配多个字段组合的内容符合要求。返回搜狐,查看更多 查看全部
算法 自动采集列表(易企CMS采集的配置及配置集,你值得拥有)
Easy Enterprisecms采集,当网站上线时,它面临的最大问题是网站内容缺失,或者更新不及时。网站维护需要投入的人力财力越大,长期以来,网站运营商一直在追求最大限度降低成本,获得最高品质的能力网站内容。亿奇cms采集依托高效强大的网络信息采集与整合,与网站对接后,持续为网站提供优质、实时的数据,省去您投入更多人力来四处寻找文章资源的需要。
如果网站位于私网范围内,那么网站就会陷入网络扩容和内容补充的困境,只能依靠人工在网上采集相关信息再复制到内网并将其导入到 网站 上。通过Easy Enterprisecms采集,现在不用那么麻烦了,可以自动采集发布和编辑,让网站管理者可以专注于内容质量审查和审查 网站 上面的整体 SEO。
Easy Enterprisecms采集预设了30多个插件提升网站的排名,通过这些插件优化发布内容的排名,从而提升 的排名。根据网站的行业,它可以自动确定发布到网站的每条内容的“长尾词”,并自动调整发布内容的关键词密度。自动制作发布图片的alt属性,并根据发布的内容自动为内容中的图片生成相应的alt描述。
Easy Enterprisecms采集有4个高效的网络信息采集功能。主题采集,您只需输入关键字即可根据网站的主题设置要求采集符合要求的网络信息,不再需要手动搜索。定位采集,可以与其他同类网站保持同步,只需输入目标网站的地址,即可自动采集同类网站的信息进行筛选。
易奇cms采集随后进行针对性采集,无需在新闻源平台手动采集相关行业的文章。通过目标采集功能,只有目标网站的地址和关键字才行。配置采集,网站可以对信息源进行深度设置为采集,保证采集的数据内容准确完整,满足您的网站要求。
Easy Enterprisecms采集,通过5层网络信息过滤,使网站不会产生垃圾链接。对目标网站的原创信息源的链接的通道和链接类型进行数据过滤。除了标题过滤外,采集的数据源的标题还通过关键字识别和标题重复检查来过滤。内容过滤,通过对采集的数据内容进行HASH算法,保证采集的内容不重复。
结合字段过滤,可以对采集的内容的字段值进行过滤比较,保证采集的各个字段的内容符合要求。组合过滤,通过对采集的内容的多个字段值进行组合比较,确保匹配多个字段组合的内容符合要求。返回搜狐,查看更多
算法 自动采集列表(基于目录树的采集算法研究)
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-03-16 10:28
Science technologyresources, Information crawling, Directory tree, Ontology Essentials:本文结合网络技术领域各种资源分类方式和大量数据的特点,提出了一种基于目录树的采集算法. 该算法首先使用领域本体知识库提供的本体。以知识作为评价依据,提取和识别有效目录链接,然后通过改进的链接分析策略获得有效节点链接,最后进行采集操作。考虑到网络技术领域各种资源分类方法和大量数据的特点。该算法首先使用领域本体知识库提供的本体。以知识作为评价依据,提取和识别有效目录链接,然后通过改进的链接分析策略获得有效节点链接,最后进行采集操作。考虑到网络技术领域各种资源分类方法和大量数据的特点。该算法首先使用领域本体知识库提供的本体。以知识作为评价依据,提取和识别有效目录链接,然后通过改进的链接分析策略获得有效节点链接,最后进行采集操作。
该算法不仅对采集的架构进行了深入研究,还注重对最新资源获取速度的优化。实践证明,该算法可以有效提高采集的率。关键词:科技资源、信息采集、目录树、本体介绍 当今互联网发展迅速,科技领域的信息资源极其丰富。充分利用网络,关注科技资源的开发利用,是当前科研人员的一项重要任务。一。网络科技资源的开发利用是科技创新的基础,而科技人员的创新能力在很大程度上取决于对科技信息资源的利用。挖掘网络科技资源,不仅为科技人员研发提供了可靠、丰富的信息,节省了大量的文献查阅时间,也为科研项目的认定、评价、验收提供了客观依据的科技成果。采集 非常重要。通常信息采集主要是借助各种搜索引擎完成的,而采集算法程序是搜索引擎的核心部分。然而,随着网络资源的不断扩展和专业领域对信息检索服务的需求不断增加,通用搜索引擎广泛采用的遍历搜索策略(如广度优先算法)已不再适用。面对网络技术资源分类复杂、数量庞大的特点,传统搜索引擎效率低下,使得网络上的技术信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。一般搜索引擎广泛使用的遍历搜索策略(如广度优先算法)不再适用。面对网络技术资源分类复杂、数量庞大的特点,传统搜索引擎效率低下,使得网络上的技术信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。一般搜索引擎广泛使用的遍历搜索策略(如广度优先算法)不再适用。面对网络技术资源分类复杂、数量庞大的特点,传统搜索引擎效率低下,使得网络上的技术信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。使得网络上的科技信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。使得网络上的科技信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。
每个资源网站都有自己的分类标准,但是单个网站分类目录清晰,层次更清晰,每个分类目录下的资源类别也比较统一。数据量巨大且增长迅速。据不完全统计,整个互联网提供的科技信息总量超过20TB,HTML标记语言正以每年25%以上的速度被激发。用户访问和使用。根据网络技术资源的特点和项目需求,通过采集互联网上的技术资源采集大量技术数据,经过处理后,构建资源目录服务系统,将共享资源呈现给用户. 本文提出的目录树采集算法是基于已建立的资源分类方法网站和本体技术构建分类目录树,具有层次化的采集网络技术根据目录树的结构。资源。基于目录树的采集架构分析,不难发现网上技术资源网站的特点。相同或相似类别的数据资源通常显示在同一子列中。如果把 网站 的主页视为根目录,那么我们可以将 网站 中的每一列称为子目录,该列的链接称为子目录链接。当然,不同的 网站 子目录也可以嵌入Set多个子目录;列下的每个资源条目称为叶节点,指向资源条目的链接称为节点链接,同一列下的节点链接称为兄弟节点链接。
采集,按照从根目录到子目录,再到叶子节点的顺序,分层执行采集工作。图1 是基于本体的目录树采集系统结构 基于目录树的采集系统的系统结构如下: 逐层过滤链接的策略。通过分析网站链接之间的层次关系,构建站点内链接的目录层次结构,并在此基础上采集网络资源链接信息库。保存URL链接之间的相互链接关系,链接周围的URL字符串和锚文本提示信息,以及采集过程中的URL链接状态记录。链接信息库的结构设计如图2所示。在明确某个领域共有的概念以及概念之间的关系的基础上,构建了该领域的概念树,主要包括一个主题词库和一个主题词库。可以根据实际爬取过程中出现的新概念的高频率进行更新和维护。Website 1TABLE1 Website 2TABLE2 Website 3TABLE3 Serial Number Seed Link NFO1 Directory NFO2 Node NFO3 Node Serial Number Link Name Anchor Text Category Status TABLE1 Link Database Structure 在采集的过程中,根据网站地址和参数信息由用户提交,创建根目录,提取首页所有站内链接,然后进行链接分析,确定链接的类别。如果是目录链接,以领域本体知识库提供的本体知识为评价依据,创建目录树,提取页面中的所有链接。对站内链接进行链接分析;如果是节点链接,则对页面进行爬取,保证同目录下所有item链接指向的页面内容存放在同一个目录下。
架构分析4.1 目录链接的提取本文采用W3C提供的LIBWWW库,首先从资源网站的起始页中提取所有站内链接,提取每个对应的锚文本URL 链接同时(链接描述文本)信息,并将所有信息存储在链接信息库中,然后使用以下方法过滤目录链接。目录链接指向的页面是目录页面。我们通过判断链接指向的页面是否为目录页面来判断该链接是否为目录链接。因此,目录页面与网站其他页面的区别特征是我们需要探索的。目录页面是站点中的一个特殊页面,其内容主要是资源列表展示,包括一定数量的节点链接集合。分析发现,页面中的兄弟节点链接在URL表达上具有相似性,包括脚本名称、参数名称、参数个数等。链接对应的锚文本是资源信息内容的摘要。这些链接描述信息通常具有完整的语义,与页面中的其他链接不同。提取思路总结如下: 提取种子页中的所有链接和锚文本信息。如果满足以下条件:一定比例的链接 URL 形式相似,并且所有链接的锚文本信息的平均长度大于设定值,我们将此类链接归类为主题链接。
有效目录链接提取 有效节点链接提取 判断和识别待判断节点的有效目录链接,并非目录链接所指向的页面的所有内容都满足用户的需求。在进行爬取操作之前,需要对目录链接进行分析判断,剔除无效链接,保证爬取的准确性和效率。本文使用预定义的领域本体库作为识别有效目录链接的基础。领域本体库用于识别特定应用领域中的知识,是关于某个主题的知识对象的集合。它对概念层次和概念与属性之间的关系有很好的定义,因此可以很容易地获得一个词的同义词或上下同义词。领域本体知识库中对象的值可以来自数据库或特定应用程序的输出,甚至领域专家也可以手动构建这样的本体库。根据需要,本文以网络技术资源应用集成环境建设项目组构建的科技领域本体为基础,识别有效目录链接。本科技领域本体库中的对象实例如图4所示。 lassific 本文以网络技术资源应用集成环境建设项目组构建的科技领域本体为基础,识别有效目录链接。本科技领域本体库中的对象实例如图4所示。 lassific 本文以网络技术资源应用集成环境建设项目组构建的科技领域本体为基础,识别有效目录链接。本科技领域本体库中的对象实例如图4所示。 lassific 查看全部
算法 自动采集列表(基于目录树的采集算法研究)
Science technologyresources, Information crawling, Directory tree, Ontology Essentials:本文结合网络技术领域各种资源分类方式和大量数据的特点,提出了一种基于目录树的采集算法. 该算法首先使用领域本体知识库提供的本体。以知识作为评价依据,提取和识别有效目录链接,然后通过改进的链接分析策略获得有效节点链接,最后进行采集操作。考虑到网络技术领域各种资源分类方法和大量数据的特点。该算法首先使用领域本体知识库提供的本体。以知识作为评价依据,提取和识别有效目录链接,然后通过改进的链接分析策略获得有效节点链接,最后进行采集操作。考虑到网络技术领域各种资源分类方法和大量数据的特点。该算法首先使用领域本体知识库提供的本体。以知识作为评价依据,提取和识别有效目录链接,然后通过改进的链接分析策略获得有效节点链接,最后进行采集操作。
该算法不仅对采集的架构进行了深入研究,还注重对最新资源获取速度的优化。实践证明,该算法可以有效提高采集的率。关键词:科技资源、信息采集、目录树、本体介绍 当今互联网发展迅速,科技领域的信息资源极其丰富。充分利用网络,关注科技资源的开发利用,是当前科研人员的一项重要任务。一。网络科技资源的开发利用是科技创新的基础,而科技人员的创新能力在很大程度上取决于对科技信息资源的利用。挖掘网络科技资源,不仅为科技人员研发提供了可靠、丰富的信息,节省了大量的文献查阅时间,也为科研项目的认定、评价、验收提供了客观依据的科技成果。采集 非常重要。通常信息采集主要是借助各种搜索引擎完成的,而采集算法程序是搜索引擎的核心部分。然而,随着网络资源的不断扩展和专业领域对信息检索服务的需求不断增加,通用搜索引擎广泛采用的遍历搜索策略(如广度优先算法)已不再适用。面对网络技术资源分类复杂、数量庞大的特点,传统搜索引擎效率低下,使得网络上的技术信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。一般搜索引擎广泛使用的遍历搜索策略(如广度优先算法)不再适用。面对网络技术资源分类复杂、数量庞大的特点,传统搜索引擎效率低下,使得网络上的技术信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。一般搜索引擎广泛使用的遍历搜索策略(如广度优先算法)不再适用。面对网络技术资源分类复杂、数量庞大的特点,传统搜索引擎效率低下,使得网络上的技术信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。使得网络上的科技信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。使得网络上的科技信息资源没有得到充分利用。网络科技资源的特点及目录树采集算法的提出网络科技资源的特点主要包括: 分类方法多样化。
每个资源网站都有自己的分类标准,但是单个网站分类目录清晰,层次更清晰,每个分类目录下的资源类别也比较统一。数据量巨大且增长迅速。据不完全统计,整个互联网提供的科技信息总量超过20TB,HTML标记语言正以每年25%以上的速度被激发。用户访问和使用。根据网络技术资源的特点和项目需求,通过采集互联网上的技术资源采集大量技术数据,经过处理后,构建资源目录服务系统,将共享资源呈现给用户. 本文提出的目录树采集算法是基于已建立的资源分类方法网站和本体技术构建分类目录树,具有层次化的采集网络技术根据目录树的结构。资源。基于目录树的采集架构分析,不难发现网上技术资源网站的特点。相同或相似类别的数据资源通常显示在同一子列中。如果把 网站 的主页视为根目录,那么我们可以将 网站 中的每一列称为子目录,该列的链接称为子目录链接。当然,不同的 网站 子目录也可以嵌入Set多个子目录;列下的每个资源条目称为叶节点,指向资源条目的链接称为节点链接,同一列下的节点链接称为兄弟节点链接。
采集,按照从根目录到子目录,再到叶子节点的顺序,分层执行采集工作。图1 是基于本体的目录树采集系统结构 基于目录树的采集系统的系统结构如下: 逐层过滤链接的策略。通过分析网站链接之间的层次关系,构建站点内链接的目录层次结构,并在此基础上采集网络资源链接信息库。保存URL链接之间的相互链接关系,链接周围的URL字符串和锚文本提示信息,以及采集过程中的URL链接状态记录。链接信息库的结构设计如图2所示。在明确某个领域共有的概念以及概念之间的关系的基础上,构建了该领域的概念树,主要包括一个主题词库和一个主题词库。可以根据实际爬取过程中出现的新概念的高频率进行更新和维护。Website 1TABLE1 Website 2TABLE2 Website 3TABLE3 Serial Number Seed Link NFO1 Directory NFO2 Node NFO3 Node Serial Number Link Name Anchor Text Category Status TABLE1 Link Database Structure 在采集的过程中,根据网站地址和参数信息由用户提交,创建根目录,提取首页所有站内链接,然后进行链接分析,确定链接的类别。如果是目录链接,以领域本体知识库提供的本体知识为评价依据,创建目录树,提取页面中的所有链接。对站内链接进行链接分析;如果是节点链接,则对页面进行爬取,保证同目录下所有item链接指向的页面内容存放在同一个目录下。
架构分析4.1 目录链接的提取本文采用W3C提供的LIBWWW库,首先从资源网站的起始页中提取所有站内链接,提取每个对应的锚文本URL 链接同时(链接描述文本)信息,并将所有信息存储在链接信息库中,然后使用以下方法过滤目录链接。目录链接指向的页面是目录页面。我们通过判断链接指向的页面是否为目录页面来判断该链接是否为目录链接。因此,目录页面与网站其他页面的区别特征是我们需要探索的。目录页面是站点中的一个特殊页面,其内容主要是资源列表展示,包括一定数量的节点链接集合。分析发现,页面中的兄弟节点链接在URL表达上具有相似性,包括脚本名称、参数名称、参数个数等。链接对应的锚文本是资源信息内容的摘要。这些链接描述信息通常具有完整的语义,与页面中的其他链接不同。提取思路总结如下: 提取种子页中的所有链接和锚文本信息。如果满足以下条件:一定比例的链接 URL 形式相似,并且所有链接的锚文本信息的平均长度大于设定值,我们将此类链接归类为主题链接。
有效目录链接提取 有效节点链接提取 判断和识别待判断节点的有效目录链接,并非目录链接所指向的页面的所有内容都满足用户的需求。在进行爬取操作之前,需要对目录链接进行分析判断,剔除无效链接,保证爬取的准确性和效率。本文使用预定义的领域本体库作为识别有效目录链接的基础。领域本体库用于识别特定应用领域中的知识,是关于某个主题的知识对象的集合。它对概念层次和概念与属性之间的关系有很好的定义,因此可以很容易地获得一个词的同义词或上下同义词。领域本体知识库中对象的值可以来自数据库或特定应用程序的输出,甚至领域专家也可以手动构建这样的本体库。根据需要,本文以网络技术资源应用集成环境建设项目组构建的科技领域本体为基础,识别有效目录链接。本科技领域本体库中的对象实例如图4所示。 lassific 本文以网络技术资源应用集成环境建设项目组构建的科技领域本体为基础,识别有效目录链接。本科技领域本体库中的对象实例如图4所示。 lassific 本文以网络技术资源应用集成环境建设项目组构建的科技领域本体为基础,识别有效目录链接。本科技领域本体库中的对象实例如图4所示。 lassific
算法 自动采集列表(dede采集可以网站主动推送给搜索引擎你网站的链接吗 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-03-13 05:02
)
最近有很多站长问我有没有什么好用的dede采集插件。dedecms自带的采集功能比较简单,很少有SEO相关的优化,比如自动百度、搜狗、360、神马推送。
比如不支持伪原创online伪原创,不支持文章聚合,不支持tag标签聚合。下面我要说的dede采集不仅支持文章聚合,还支持tag标签聚合。Dede采集发布后,可以被百度、搜狗、神马、360自动推送。可以从采集批量伪原创处理文章更方便@>。内容处理充分利用了 SEO。
dede采集
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用dede采集实现自动采集伪原创发布,主动推送给搜索引擎,提高搜索引擎的抓取频率,
本dedecms采集操作简单,无需学习专业技术,简单几步即可轻松采集内容数据,用户只需dedecms< @在采集工具上进行简单设置,工具会根据用户设置的关键词准确采集文章,保证与行业 文章。采集文章 from 采集可以选择将修改后的内容保存到本地,也可以直接选择在软件上发布。
与其他dede采集相比,这个工具使用非常简单,输入关键词即可实现采集,dede采集配备关键词采集 @> 函数。只需设置任务,全程自动挂机!
dede采集无论你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。最重要的是这个dede采集有很多SEO功能,不仅可以提高网站的收录,还可以增加关键词的密度,提高网站 的排名。
dede采集
dede采集可以主动推送网站,让搜索引擎更快发现我们的站点,支持推送到百度、神马、360、搜狗等四大搜索引擎,并主动曝光Giving搜索引擎您的 网站 链接对 SEO 优化非常有益。
dede采集随时随地都可以看到好看的文章,点击浏览器书签即可采集网站的公开内容!dede采集可以自动采集按照设定的时间表(每周、每天、每小时等)发布,dede采集轻松实现内容定时自动更新,无需人工值守。
dede采集
[字段:id runphp='yes'] 全局 $cfg_cms路径;$tags = GetTags(@me); $revalue = ''; $tags = explode(',', $tags); foreach( $tags as $key => $value){ if($value){ $revalue .= ''.$value.' '; } } @me = $revalue; [/字段:id]
dede采集也可以自动匹配图片,dede采集文章没有图片的内容会自动配置相关图片,dede采集设置自动下载图片保存本地或第三方, dede 采集让内容不再有对方的外部链接。
无需编写规则,无需研究网页源代码,可视化界面操作,采集鼠标选择,点击保存,就这么简单!支持:动态或固定段落随机插入(不影响阅读)、标题插入关键词、自动内链、简繁转换、翻译、接入第三方API等。
dede采集
dede采集可以自动链接,dede采集让搜索引擎更深入地抓取你的链接,dede采集可以在内容或标题前后插入段落或关键词,dede< @采集可选标题和插入同一个关键词的标题。只需输入 URL 即可自动识别数据和规则,包括:列表页、翻页和详情页(标题、正文、作者、出版时间、标签等)。
dede采集可以网站内容插入或随机作者、随机阅读等到"height原创"。dede采集可以优化出现关键词的文本的相关性,并自动将文本首段加粗,自动插入title标题,并自动添加当前采集关键词 当描述相关性较低时。文本在随机位置自动插入当前 采集关键词2 次。当当前 采集 的 关键词 出现在文本中时,关键词 将自动加粗。
由 dede 发表
dede采集的数据导出支持多种格式:excel、csv、sql(mysql)。采集在使用数据的时候,只需要输入一个URL(网址),平台会首先使用智能算法提取数据,包括列表页、翻页、详情页。如果智能提取不准确,用户还可以利用在线可视化工具“规则提取器”进行修改,只需鼠标选择并点击即可。
dede采集可以定期发布dede采集文章,让搜索引擎及时抓取你的网站内容。
今天关于织梦采集的解释就到这里了。我希望它可以帮助您在建立您的网站的道路上。下一期我会分享更多与SEO相关的实用干货。
查看全部
算法 自动采集列表(dede采集可以网站主动推送给搜索引擎你网站的链接吗
)
最近有很多站长问我有没有什么好用的dede采集插件。dedecms自带的采集功能比较简单,很少有SEO相关的优化,比如自动百度、搜狗、360、神马推送。
比如不支持伪原创online伪原创,不支持文章聚合,不支持tag标签聚合。下面我要说的dede采集不仅支持文章聚合,还支持tag标签聚合。Dede采集发布后,可以被百度、搜狗、神马、360自动推送。可以从采集批量伪原创处理文章更方便@>。内容处理充分利用了 SEO。
dede采集
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用dede采集实现自动采集伪原创发布,主动推送给搜索引擎,提高搜索引擎的抓取频率,
本dedecms采集操作简单,无需学习专业技术,简单几步即可轻松采集内容数据,用户只需dedecms< @在采集工具上进行简单设置,工具会根据用户设置的关键词准确采集文章,保证与行业 文章。采集文章 from 采集可以选择将修改后的内容保存到本地,也可以直接选择在软件上发布。
与其他dede采集相比,这个工具使用非常简单,输入关键词即可实现采集,dede采集配备关键词采集 @> 函数。只需设置任务,全程自动挂机!
dede采集无论你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。最重要的是这个dede采集有很多SEO功能,不仅可以提高网站的收录,还可以增加关键词的密度,提高网站 的排名。
dede采集
dede采集可以主动推送网站,让搜索引擎更快发现我们的站点,支持推送到百度、神马、360、搜狗等四大搜索引擎,并主动曝光Giving搜索引擎您的 网站 链接对 SEO 优化非常有益。
dede采集随时随地都可以看到好看的文章,点击浏览器书签即可采集网站的公开内容!dede采集可以自动采集按照设定的时间表(每周、每天、每小时等)发布,dede采集轻松实现内容定时自动更新,无需人工值守。
dede采集
[字段:id runphp='yes'] 全局 $cfg_cms路径;$tags = GetTags(@me); $revalue = ''; $tags = explode(',', $tags); foreach( $tags as $key => $value){ if($value){ $revalue .= ''.$value.' '; } } @me = $revalue; [/字段:id]
dede采集也可以自动匹配图片,dede采集文章没有图片的内容会自动配置相关图片,dede采集设置自动下载图片保存本地或第三方, dede 采集让内容不再有对方的外部链接。
无需编写规则,无需研究网页源代码,可视化界面操作,采集鼠标选择,点击保存,就这么简单!支持:动态或固定段落随机插入(不影响阅读)、标题插入关键词、自动内链、简繁转换、翻译、接入第三方API等。
dede采集
dede采集可以自动链接,dede采集让搜索引擎更深入地抓取你的链接,dede采集可以在内容或标题前后插入段落或关键词,dede< @采集可选标题和插入同一个关键词的标题。只需输入 URL 即可自动识别数据和规则,包括:列表页、翻页和详情页(标题、正文、作者、出版时间、标签等)。
dede采集可以网站内容插入或随机作者、随机阅读等到"height原创"。dede采集可以优化出现关键词的文本的相关性,并自动将文本首段加粗,自动插入title标题,并自动添加当前采集关键词 当描述相关性较低时。文本在随机位置自动插入当前 采集关键词2 次。当当前 采集 的 关键词 出现在文本中时,关键词 将自动加粗。
由 dede 发表
dede采集的数据导出支持多种格式:excel、csv、sql(mysql)。采集在使用数据的时候,只需要输入一个URL(网址),平台会首先使用智能算法提取数据,包括列表页、翻页、详情页。如果智能提取不准确,用户还可以利用在线可视化工具“规则提取器”进行修改,只需鼠标选择并点击即可。
dede采集可以定期发布dede采集文章,让搜索引擎及时抓取你的网站内容。
今天关于织梦采集的解释就到这里了。我希望它可以帮助您在建立您的网站的道路上。下一期我会分享更多与SEO相关的实用干货。
算法 自动采集列表(多谢分享GC策略解决了哪些问题?|左潇龙的技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-08 15:11
来源:博客朴左小龙的技术博客--,谢谢分享
GC策略解决了什么问题?
既然要进行自动GC,就必须有相应的策略,这些策略解决了什么问题?粗略地说,主要有以下几点。
1、哪些对象可以回收。
2、这些对象什么时候被回收。
3、如何回收。
GC策略使用什么算法
关于上面提到的三个问题,其实最重要的是第一个,也就是哪些对象可以回收。有一种比较简单直观的方法,效率更高,叫做引用计数。算法,原理是:这个对象有引用,则+1;删除一个引用,然后 -1。仅采集计数为 0 的对象。缺点是:(1)不能处理循环引用的问题。例如:对象A和B分别有字段b和a,让Ab=B和Ba=A,除了这两个对象没有引用,那么实际上这两个对象已经无法访问了,但是引用计数算法却无法回收它们。(2)引用计数方法需要编译器的配合,并且编译器需要为这个对象生成额外的代码。如果赋值函数给这个对象分配一个引用,它需要增加这个对象的引用计数。此外,当引用变量的生命周期结束时,需要更新该对象的引用计数器。引用计数的方法有一个显着的缺点是它并没有被JVM实际使用。想象一下,如果JVM采用这种GC策略,当程序员在编写程序时,应该不会期望再次出现下面的代码。引用计数的方法有一个显着的缺点是它并没有被JVM实际使用。想象一下,如果JVM采用这种GC策略,当程序员在编写程序时,应该不会期望再次出现下面的代码。引用计数的方法有一个显着的缺点是它并没有被JVM实际使用。想象一下,如果JVM采用这种GC策略,当程序员在编写程序时,应该不会期望再次出现下面的代码。
1 public class Object {
2
3 Object field = null;
4
5 public static void main(String[] args) {
6 Thread thread = new Thread(new Runnable() {
7 public void run() {
8 Object objectA = new Object();
9 Object objectB = new Object();//1
10 objectA.field = objectB;
11 objectB.field = objectA;//2
12 //to do something
13 objectA = null;
14 objectB = null;//3
15 }
16 });
17 thread.start();
18 while (true);
19 }
20
21 }
这段代码看似有点刻意,但其实在实际编程过程中,经常会出现,比如两个数据库对象一一对应,各自维护着对另一个的引用,最后的无限循环只是以防止 JVM 运行。退出,没有意义。
对于我们现在使用的GC来说,当线程线程运行完毕后,所有的objectA和objectB都会被视为需要回收的对象,如果我们的GC采用上面提到的引用计数算法,这两个对象永远不会被回收,甚至如果我们在使用后显式地使对象无效,则没有效果。
这是LZ的一般解释。在代码中,LZ标记了三个数字1、2、3。执行第一个语句时,两个对象的引用计数都为1。执行第二个语句时,两个对象的引用计数都变为2。当第三个语句为执行,即两者都归类为null后,两者的引用计数仍为1。根据引用计数算法的回收规则,当引用计数不返回0时,不会被回收。
根搜索算法
由于引用计数算法的缺点,JVM一般采用一种称为根搜索算法的新算法。它的处理方法是设置几个根对象。当任何根对象无法到达某个对象时,该对象就被认为是可回收的。
以上图为例,ObjectD 和 ObjectE 是相互关联的,但是由于这两个对象的 GC 根不可达,所以最终 D 和 E 仍会被视为 GC 对象。如果上图中使用了引用计数的方法,那么 AE 五个对象都不会被回收。说到 GC 根(GC 根),在 JAVA 语言中,可以作为 GC 根的对象有以下几种:
1、虚拟机堆栈中的引用对象。
2、方法区中类静态属性引用的对象。
3、方法区常量引用的对象。
4、本地方法栈中JNI引用的对象。
第一个和第四个是指方法的局部变量表,第二个表达的意思更清楚,第三个主要是声明为final的常量值。
根搜索算法解决了垃圾回收的基本问题,也就是上面提到的第一个问题,也是最关键的问题,就是哪些对象可以被回收,但是垃圾回收显然需要解决最后两个问题,当回收和如何回收,基于寻根算法,在现代虚拟机的实现中,主要有三种垃圾回收算法,分别是mark-sweep算法、copy算法、mark-sort算法,这三种算法已经扩展了root search算法,但它们仍然很好理解。
首先,让我们回忆一下上一章提到的寻根算法。它可以解决我们应该回收哪些对象的问题,但它显然不能承担垃圾采集的重任,因为我们在程序中(程序意味着我们运行在JVM中)。如果要在上面的JAVA程序运行过程中进行垃圾回收),必须让GC线程和程序中的线程相互配合,这样才能顺利回收垃圾而不影响程序的运行。
为了达到这个目的,mark/sweep算法应运而生。它的做法是在堆中可用内存耗尽时停止整个程序(也称为stop the world)。然后完成了两个工作,第一个是标记,第二个是清除。
(1) 标记:标记过程实际上是遍历所有GC Roots,然后将GC Roots 可达的所有对象标记为存活对象。
(2)清除:清除过程会遍历堆中的所有对象,清除所有未标记的对象。
其实这两个步骤并不是特别复杂,也很容易理解。LZ用简单的话来解释mark/sweep算法,就是程序运行的时候,如果可用内存用完,就会触发GC线程,程序会挂起,然后还活着的对象会被再次标记,最后清除堆中所有未标记的对象,然后程序恢复运行。
下面,LZ为大家制作了一组图片来说明上述过程。结合图片,我们直观的看一下流程,首先是第一张图片。
这张图代表了程序执行过程中所有对象的状态,它们的标志位全部为0(即未标记,下面默认0为未标记,1为标记),假设此时有效内存空间已耗尽。,JVM会停止应用程序的运行并启动GC线程,然后开始标记工作。根据寻根算法,标记后对象的状态如下图。
可以看出,根据根搜索算法,所有从根对象可达的对象都被标记为幸存对象,此时第一阶段标记已经完成。接下来,将进行第二阶段的清算。清空后,剩余对象及对象状态如下图所示。
可以看到,没有被标记的对象会被回收并清除,而被标记的对象会被留下,标志位会被清0。不用说,只要唤醒停止的程序线程,让程序继续运行。其实这个过程并不复杂,甚至可以说非常简单。你是对的吗?但是有一点值得一提,那就是为什么一定要停止程序的运行呢?这其实不难理解。LZ举了一个最简单的例子。假设我们的程序和 GC 线程一起运行。想象一下这样的场景。
假设我们刚刚标记了图中最右边的对象,暂时称它为A。结果此时程序中新建了一个对象B,A对象可以到达B对象,但是由于此时A对象已经被标记在末尾,B对象的标记位为这个时候还是0,因为错过了标记阶段,所以下一轮清关的时候,新对象B会被强制清零。这样一来,不难想象GC线程会导致程序无法正常运行的结果。上述结果当然是不可接受的。我们刚刚创建了一个新对象,但是在一次 GC 之后,它突然变成了 null。如何才能做到这一点?
标记/扫描算法的缺点
1、首先它的缺点是它的效率比较低(递归和全堆对象遍历),并且在进行GC时需要停止应用程序,这样会导致用户体验很差,特别是对于交互式应用程序。这简直是不可接受的。试想一下,如果你玩一个网站,这个网站在一小时内挂了五分钟,你还玩吗?
2、第二个主要缺点是这种方式清理出来的空闲内存是不连续的,不难理解。我们的死物立即出现在记忆的各个角落。现在清除它们之后,内存布局自然会乱七八糟。为了解决这个问题,JVM 必须维护一个空闲的内存列表,这是另一个开销。并且在分配数组对象时,要找到连续的内存空间并不容易。
复制算法
我们先来看看复制算法的实践。复制算法将内存分成两个区间。在任何时间点,所有动态分配的对象只能在其中一个区间(称为活动区间)分配,而另一个区间(称为空闲区间)是空闲的。当有效内存空间耗尽时,JVM会暂停程序运行并启动复制算法的GC线程。接下来,GC线程会将活动区中的所有幸存对象复制到空闲区,并严格按照内存地址进行排列。同时,GC线程会更新幸存对象的内存引用地址,指向新的内存地址。至此,空闲区间已与活动区间交换,并且垃圾对象现在都停留在原来的活动区间,也就是当前的空闲区间。事实上,当活动间隔转换为空间间隔时,垃圾对象已经被一次性回收了。LZ给大家画了个图来说明问题,如下图。
其实这张图还是上一章的例子,只不过此时内存被复制算法分成了两部分。我们来看看复制算法的GC线程处理完后这两个区域会是什么样子,如下图。
可以看到,对象1和4都被清空了,而对象2、3、5、6则有规律的排列在刚才的空闲区间,是当前活跃区间之一。里面。至此,左半场就变成了自由区。不难想象,在下一次GC之后,左侧又会成为活跃区。显然,复制算法弥补了标记/扫描算法杂乱的内存布局。但同时,它的缺点也相当明显。
1、浪费了一半的内存,太可怕了。
2、如果对象的存活率很高,我们可以走极端,假设它是100%存活的,那么我们需要复制所有的对象并重置所有的引用地址。当对象存活率达到一定水平时,复制这项工作所需的时间变得不可忽略。
所以从上面的描述不难看出,要想使用复制算法,至少对象的存活率必须很低,最重要的是我们必须克服50%的浪费记忆。
标记/整理算法
mark/sweep 算法与mark/sweep 算法非常相似,也分为两个阶段:mark 和groom。
(1)Marking:它的第一阶段和mark/sweep算法一模一样,遍历GC Roots,对幸存的对象进行标记。
(2)Finishing:移动所有幸存的对象并按照内存地址的顺序排列,然后在结束内存地址之后回收所有内存。因此,第二阶段称为finishing阶段。
GC前后的图和copy算法的图很相似,但是active区间和free区间没有区别,过程和mark/sweep算法很相似。让我们看一下GC之前内存中对象的状态和布局。如下所示。
这张图其实和mark/clear算法一模一样,只是LZ为了方便内存规则的连续排列,增加了一个矩形来表示内存区域。如果此时 GC 线程开始工作,则标记阶段立即开始。该阶段与标记/清除算法的标记阶段相同。我们看看标记阶段之后对象的状态,如下图所示。
没有什么好解释的。接下来应该是排序阶段。我们来看看排序阶段处理后的内存布局是怎样的,如下图所示。
可以看出,被标记的存活对象会按照内存地址的顺序进行排序排列,而未标记的内存会被清理掉。这样,当我们需要为一个新的对象分配内存时,JVM只需要保存一个内存的起始地址,这显然比维护一个空闲列表的开销要小很多。不难看出,标记/排序算法不仅可以弥补标记/清除算法中内存区域分散的缺点,还可以消除复制算法中内存减半的高成本。标记/排序算法唯一的缺点是效率不高,不仅要标记所有幸存的对象,还要对所有幸存对象的引用地址进行排序。标记/整理算法的效率低于复制算法。这里LZ总结了三种算法的共同点以及各自的优缺点。让你比较一下,会更清楚,它们有以下两点共同点。
1、这三种算法都是基于寻根算法来判断一个对象是否应该被回收,而支撑寻根算法正常工作的理论依据是语法中变量作用域的内容。因此,要防止内存泄漏,最根本的方法是掌握变量的作用域,而不是使用上一章内存管理中提到的C/C++风格的内存管理方法。
2、当GC线程启动时,或者当GC进程启动时,它们都停止了世界。
根据以下几点向您展示它们之间的区别。(>表示前者优于后者,=表示两者效果相同)
效率:Copy Algorithm > Mark/Collate Algorithm > Mark/Sweep Algorithm(这里的效率只是时间复杂度的简单比较,实践中不一定如此)。
内存均匀性:复制算法 = 标记/扫描算法 > 标记/扫描算法。
内存利用率:标记/扫描算法 = 标记/扫描算法 > 复制算法。
可以看出mark/clear算法是一种比较落后的算法,但是后两种算法都是建立在这个基础上的。算法的前身。而且,在某些时候,标记/扫描也会派上用场。
至此,我们已经清楚的了解了这三种算法。可以看出,在效率方面,复制算法是当之无愧的leader,但是浪费了太多内存。为了尽可能的兼顾到上面提到的三个指标,mark/排序算法相对来说比较流畅,但是效率还是差强人意。它比复制算法多一个标记阶段,比标记/清除多一个内存排序过程。最后介绍GC算法中的神级算法——分代采集算法。那么分代采集算法是如何处理GC的呢?
对象分类
上一章提到,分代采集算法是根据对象的不同特性,使用合适的算法,并没有实际生成新的算法。分代采集算法与其说是第四种算法,不如说是前三种算法的实际应用。首先,让我们讨论对象的不同特征。接下来,LZ 和你将为这些对象选择 GC 算法。内存中的对象根据其生命周期的长短大致可以分为三种。以下名称均以LZ个人命名。
1、Aborted objects:在不久的将来死亡的对象。通俗地说,它们是活后不久就会死去的物体。示例:方法中的局部变量、循环中的临时变量等。
2、老仙物:这种物一般都活的比较久,到很老的时候依然不会死,但是说到底,老仙物迟早会死的差不多,但是只有差不多。示例:缓存对象、数据库连接对象、单例对象(单例模式)等。
3、坚不可摧的物体:这类物体通常一出生就几乎是不朽的,它们几乎总是不朽的,记住,只是勉强。示例:字符串池中的对象(享元模式)、加载的类信息等。
对象对应的内存区域
还记得我们之前介绍内存管理时 JVM 对内存的划分吗?我们将以上三个对象对应到内存区,即死对象和老不朽对象在JAVA堆中,不朽对象在方法区。上一章我们已经说过,对于JAVA堆,JVM规范要求必须实现GC,所以对于aborted对象和老不死对象来说,死亡几乎是必然的结果,但也只是几乎,难免会有一些将存活到应用程序结束的对象,但 JVM 规范在方法区域中没有 GC。做需求,所以假设一个JVM实现对方法区没有实现GC,那么永生对象就是真正的永生对象。因为不朽物件的生命周期太长,
JAVA堆对象回收(死对象和旧的不死对象)
有了上面的分析,我们来看看分代回收算法是如何处理JAVA堆的内存回收的,也就是aborted对象和old undead对象的回收。Aborted objects:这些对象有生有死,生存时间短。还记得使用复制算法的要求吗?即对象存活率不能太高,所以aborted对象最适合使用复制算法。小问题:如果50%的内存被浪费了怎么办?答:因为被中止的对象的存活率普遍较低,50%的内存不能作为空闲使用。一般两个 10% 的内存用作空闲和活动区,另外 80% 的内存用于为新对象分配内存时,一旦发生 GC,10% 的活动范围和其他 80% 的幸存对象被转移到 10% 的空闲范围,然后之前的 90% 的内存都被释放,以此类推。为了让大家更清楚地看到这个GC过程,LZ给出了下图。
图中标出了每个阶段三个区域的内存情况。相信看图,它的GC过程不难理解。但是,有两点需要提及。第一点,通过这种方式,我们只浪费了10%的内存,这是可以接受的,因为我们获得了内存的整齐排列和GC的速度。第二点,这个策略的前提是每个幸存对象占用的内存不能超过这10%的大小。一旦超过,多余的对象将无法复制。
为了解决上述突发情况,即当幸存对象占用的内存过大时,专家将JAVA堆分成两部分进行处理。以上三个区域是第一部分,称为新生代或年轻代,其余部分,专门用于存储旧的不死对象,称为老年代。这是一个恰当的名字吗?让我们看看如何处理旧的不死物体。不朽的物件:这类物件的成活率非常高,因为大部分是从新生代传下来的,就像人一样,活久了就会长生不老。
通常,当出现以下两种情况时,对象会从年轻代区域转移到老带区域。
1、新生代中的每个对象都会有一个年龄。当这些对象的年龄达到一定程度时(年龄是存活的GC次数,每次GC如果对象存活,加上年龄1),就会转移到老年代,这个转移到老年代的age值一般可以在JVM中设置。
2、当年轻代存活对象占用的内存超过10%时,多余的对象会被放到老年代。此时老一代就是新一代的“后备仓库”。
对于老不朽对象的特性,显然不再适合使用复制算法,因为它的存活率太高了,别忘了,如果老一代使用复制算法,它是没有备份仓库的. 因此,一般来说,对于旧的不死物体,只能使用标记/排序或标记/清除算法。
方法区对象恢复(不朽对象)
以上两种情况解决了GC的大部分问题,因为JAVA堆是GC的主要关注点,而且上面还收录了分代回收算法的全部内容,不朽对象的回收不在分类。采集算法内容的生成。不朽的对象存在于方法区。在我们常用的热点虚拟机(JDK默认的JVM)中,方法区也被亲切地称为永久代,这是一个非常贴切的名字,不是吗?事实上,很久很久以前,没有永久的一代。当时永久代和老年代存储在一起,里面收录了JAVA类的实例信息和类信息。然而,后来发现班级信息的卸载很少发生,所以将两者分开。幸运的是,这确实提高了很多性能,所以永久代被拆分出来了。这部分区域的GC采用与老年代类似的方法。由于没有“备份仓库”,两者都只能使用mark/sweep和mark/sort算法。
回收时机
JVM 在进行 GC 时,并不总是一起回收上述三个内存区域。大多数时候,它指的是新一代。因此,GC根据回收的区域分为两种,一种是普通GC(minor GC),另一种是global GC(major GC或Full GC)。他们针对的领域如下。Normal GC(minor GC):只针对新生代区域进行GC。Global GC(major GC或Full GC):老年代GC,偶尔伴随着新生代GC和永久代GC。因为老年代和永久代的GC效果都比较差,而且两者的内存使用增长速度也比较慢,一般情况下,需要几次普通GC才能触发一次全局GC。 查看全部
算法 自动采集列表(多谢分享GC策略解决了哪些问题?|左潇龙的技术)
来源:博客朴左小龙的技术博客--,谢谢分享
GC策略解决了什么问题?
既然要进行自动GC,就必须有相应的策略,这些策略解决了什么问题?粗略地说,主要有以下几点。
1、哪些对象可以回收。
2、这些对象什么时候被回收。
3、如何回收。
GC策略使用什么算法
关于上面提到的三个问题,其实最重要的是第一个,也就是哪些对象可以回收。有一种比较简单直观的方法,效率更高,叫做引用计数。算法,原理是:这个对象有引用,则+1;删除一个引用,然后 -1。仅采集计数为 0 的对象。缺点是:(1)不能处理循环引用的问题。例如:对象A和B分别有字段b和a,让Ab=B和Ba=A,除了这两个对象没有引用,那么实际上这两个对象已经无法访问了,但是引用计数算法却无法回收它们。(2)引用计数方法需要编译器的配合,并且编译器需要为这个对象生成额外的代码。如果赋值函数给这个对象分配一个引用,它需要增加这个对象的引用计数。此外,当引用变量的生命周期结束时,需要更新该对象的引用计数器。引用计数的方法有一个显着的缺点是它并没有被JVM实际使用。想象一下,如果JVM采用这种GC策略,当程序员在编写程序时,应该不会期望再次出现下面的代码。引用计数的方法有一个显着的缺点是它并没有被JVM实际使用。想象一下,如果JVM采用这种GC策略,当程序员在编写程序时,应该不会期望再次出现下面的代码。引用计数的方法有一个显着的缺点是它并没有被JVM实际使用。想象一下,如果JVM采用这种GC策略,当程序员在编写程序时,应该不会期望再次出现下面的代码。
1 public class Object {
2
3 Object field = null;
4
5 public static void main(String[] args) {
6 Thread thread = new Thread(new Runnable() {
7 public void run() {
8 Object objectA = new Object();
9 Object objectB = new Object();//1
10 objectA.field = objectB;
11 objectB.field = objectA;//2
12 //to do something
13 objectA = null;
14 objectB = null;//3
15 }
16 });
17 thread.start();
18 while (true);
19 }
20
21 }
这段代码看似有点刻意,但其实在实际编程过程中,经常会出现,比如两个数据库对象一一对应,各自维护着对另一个的引用,最后的无限循环只是以防止 JVM 运行。退出,没有意义。
对于我们现在使用的GC来说,当线程线程运行完毕后,所有的objectA和objectB都会被视为需要回收的对象,如果我们的GC采用上面提到的引用计数算法,这两个对象永远不会被回收,甚至如果我们在使用后显式地使对象无效,则没有效果。
这是LZ的一般解释。在代码中,LZ标记了三个数字1、2、3。执行第一个语句时,两个对象的引用计数都为1。执行第二个语句时,两个对象的引用计数都变为2。当第三个语句为执行,即两者都归类为null后,两者的引用计数仍为1。根据引用计数算法的回收规则,当引用计数不返回0时,不会被回收。
根搜索算法
由于引用计数算法的缺点,JVM一般采用一种称为根搜索算法的新算法。它的处理方法是设置几个根对象。当任何根对象无法到达某个对象时,该对象就被认为是可回收的。
以上图为例,ObjectD 和 ObjectE 是相互关联的,但是由于这两个对象的 GC 根不可达,所以最终 D 和 E 仍会被视为 GC 对象。如果上图中使用了引用计数的方法,那么 AE 五个对象都不会被回收。说到 GC 根(GC 根),在 JAVA 语言中,可以作为 GC 根的对象有以下几种:
1、虚拟机堆栈中的引用对象。
2、方法区中类静态属性引用的对象。
3、方法区常量引用的对象。
4、本地方法栈中JNI引用的对象。
第一个和第四个是指方法的局部变量表,第二个表达的意思更清楚,第三个主要是声明为final的常量值。
根搜索算法解决了垃圾回收的基本问题,也就是上面提到的第一个问题,也是最关键的问题,就是哪些对象可以被回收,但是垃圾回收显然需要解决最后两个问题,当回收和如何回收,基于寻根算法,在现代虚拟机的实现中,主要有三种垃圾回收算法,分别是mark-sweep算法、copy算法、mark-sort算法,这三种算法已经扩展了root search算法,但它们仍然很好理解。
首先,让我们回忆一下上一章提到的寻根算法。它可以解决我们应该回收哪些对象的问题,但它显然不能承担垃圾采集的重任,因为我们在程序中(程序意味着我们运行在JVM中)。如果要在上面的JAVA程序运行过程中进行垃圾回收),必须让GC线程和程序中的线程相互配合,这样才能顺利回收垃圾而不影响程序的运行。
为了达到这个目的,mark/sweep算法应运而生。它的做法是在堆中可用内存耗尽时停止整个程序(也称为stop the world)。然后完成了两个工作,第一个是标记,第二个是清除。
(1) 标记:标记过程实际上是遍历所有GC Roots,然后将GC Roots 可达的所有对象标记为存活对象。
(2)清除:清除过程会遍历堆中的所有对象,清除所有未标记的对象。
其实这两个步骤并不是特别复杂,也很容易理解。LZ用简单的话来解释mark/sweep算法,就是程序运行的时候,如果可用内存用完,就会触发GC线程,程序会挂起,然后还活着的对象会被再次标记,最后清除堆中所有未标记的对象,然后程序恢复运行。
下面,LZ为大家制作了一组图片来说明上述过程。结合图片,我们直观的看一下流程,首先是第一张图片。
这张图代表了程序执行过程中所有对象的状态,它们的标志位全部为0(即未标记,下面默认0为未标记,1为标记),假设此时有效内存空间已耗尽。,JVM会停止应用程序的运行并启动GC线程,然后开始标记工作。根据寻根算法,标记后对象的状态如下图。
可以看出,根据根搜索算法,所有从根对象可达的对象都被标记为幸存对象,此时第一阶段标记已经完成。接下来,将进行第二阶段的清算。清空后,剩余对象及对象状态如下图所示。
可以看到,没有被标记的对象会被回收并清除,而被标记的对象会被留下,标志位会被清0。不用说,只要唤醒停止的程序线程,让程序继续运行。其实这个过程并不复杂,甚至可以说非常简单。你是对的吗?但是有一点值得一提,那就是为什么一定要停止程序的运行呢?这其实不难理解。LZ举了一个最简单的例子。假设我们的程序和 GC 线程一起运行。想象一下这样的场景。
假设我们刚刚标记了图中最右边的对象,暂时称它为A。结果此时程序中新建了一个对象B,A对象可以到达B对象,但是由于此时A对象已经被标记在末尾,B对象的标记位为这个时候还是0,因为错过了标记阶段,所以下一轮清关的时候,新对象B会被强制清零。这样一来,不难想象GC线程会导致程序无法正常运行的结果。上述结果当然是不可接受的。我们刚刚创建了一个新对象,但是在一次 GC 之后,它突然变成了 null。如何才能做到这一点?
标记/扫描算法的缺点
1、首先它的缺点是它的效率比较低(递归和全堆对象遍历),并且在进行GC时需要停止应用程序,这样会导致用户体验很差,特别是对于交互式应用程序。这简直是不可接受的。试想一下,如果你玩一个网站,这个网站在一小时内挂了五分钟,你还玩吗?
2、第二个主要缺点是这种方式清理出来的空闲内存是不连续的,不难理解。我们的死物立即出现在记忆的各个角落。现在清除它们之后,内存布局自然会乱七八糟。为了解决这个问题,JVM 必须维护一个空闲的内存列表,这是另一个开销。并且在分配数组对象时,要找到连续的内存空间并不容易。
复制算法
我们先来看看复制算法的实践。复制算法将内存分成两个区间。在任何时间点,所有动态分配的对象只能在其中一个区间(称为活动区间)分配,而另一个区间(称为空闲区间)是空闲的。当有效内存空间耗尽时,JVM会暂停程序运行并启动复制算法的GC线程。接下来,GC线程会将活动区中的所有幸存对象复制到空闲区,并严格按照内存地址进行排列。同时,GC线程会更新幸存对象的内存引用地址,指向新的内存地址。至此,空闲区间已与活动区间交换,并且垃圾对象现在都停留在原来的活动区间,也就是当前的空闲区间。事实上,当活动间隔转换为空间间隔时,垃圾对象已经被一次性回收了。LZ给大家画了个图来说明问题,如下图。
其实这张图还是上一章的例子,只不过此时内存被复制算法分成了两部分。我们来看看复制算法的GC线程处理完后这两个区域会是什么样子,如下图。
可以看到,对象1和4都被清空了,而对象2、3、5、6则有规律的排列在刚才的空闲区间,是当前活跃区间之一。里面。至此,左半场就变成了自由区。不难想象,在下一次GC之后,左侧又会成为活跃区。显然,复制算法弥补了标记/扫描算法杂乱的内存布局。但同时,它的缺点也相当明显。
1、浪费了一半的内存,太可怕了。
2、如果对象的存活率很高,我们可以走极端,假设它是100%存活的,那么我们需要复制所有的对象并重置所有的引用地址。当对象存活率达到一定水平时,复制这项工作所需的时间变得不可忽略。
所以从上面的描述不难看出,要想使用复制算法,至少对象的存活率必须很低,最重要的是我们必须克服50%的浪费记忆。
标记/整理算法
mark/sweep 算法与mark/sweep 算法非常相似,也分为两个阶段:mark 和groom。
(1)Marking:它的第一阶段和mark/sweep算法一模一样,遍历GC Roots,对幸存的对象进行标记。
(2)Finishing:移动所有幸存的对象并按照内存地址的顺序排列,然后在结束内存地址之后回收所有内存。因此,第二阶段称为finishing阶段。
GC前后的图和copy算法的图很相似,但是active区间和free区间没有区别,过程和mark/sweep算法很相似。让我们看一下GC之前内存中对象的状态和布局。如下所示。
这张图其实和mark/clear算法一模一样,只是LZ为了方便内存规则的连续排列,增加了一个矩形来表示内存区域。如果此时 GC 线程开始工作,则标记阶段立即开始。该阶段与标记/清除算法的标记阶段相同。我们看看标记阶段之后对象的状态,如下图所示。
没有什么好解释的。接下来应该是排序阶段。我们来看看排序阶段处理后的内存布局是怎样的,如下图所示。
可以看出,被标记的存活对象会按照内存地址的顺序进行排序排列,而未标记的内存会被清理掉。这样,当我们需要为一个新的对象分配内存时,JVM只需要保存一个内存的起始地址,这显然比维护一个空闲列表的开销要小很多。不难看出,标记/排序算法不仅可以弥补标记/清除算法中内存区域分散的缺点,还可以消除复制算法中内存减半的高成本。标记/排序算法唯一的缺点是效率不高,不仅要标记所有幸存的对象,还要对所有幸存对象的引用地址进行排序。标记/整理算法的效率低于复制算法。这里LZ总结了三种算法的共同点以及各自的优缺点。让你比较一下,会更清楚,它们有以下两点共同点。
1、这三种算法都是基于寻根算法来判断一个对象是否应该被回收,而支撑寻根算法正常工作的理论依据是语法中变量作用域的内容。因此,要防止内存泄漏,最根本的方法是掌握变量的作用域,而不是使用上一章内存管理中提到的C/C++风格的内存管理方法。
2、当GC线程启动时,或者当GC进程启动时,它们都停止了世界。
根据以下几点向您展示它们之间的区别。(>表示前者优于后者,=表示两者效果相同)
效率:Copy Algorithm > Mark/Collate Algorithm > Mark/Sweep Algorithm(这里的效率只是时间复杂度的简单比较,实践中不一定如此)。
内存均匀性:复制算法 = 标记/扫描算法 > 标记/扫描算法。
内存利用率:标记/扫描算法 = 标记/扫描算法 > 复制算法。
可以看出mark/clear算法是一种比较落后的算法,但是后两种算法都是建立在这个基础上的。算法的前身。而且,在某些时候,标记/扫描也会派上用场。
至此,我们已经清楚的了解了这三种算法。可以看出,在效率方面,复制算法是当之无愧的leader,但是浪费了太多内存。为了尽可能的兼顾到上面提到的三个指标,mark/排序算法相对来说比较流畅,但是效率还是差强人意。它比复制算法多一个标记阶段,比标记/清除多一个内存排序过程。最后介绍GC算法中的神级算法——分代采集算法。那么分代采集算法是如何处理GC的呢?
对象分类
上一章提到,分代采集算法是根据对象的不同特性,使用合适的算法,并没有实际生成新的算法。分代采集算法与其说是第四种算法,不如说是前三种算法的实际应用。首先,让我们讨论对象的不同特征。接下来,LZ 和你将为这些对象选择 GC 算法。内存中的对象根据其生命周期的长短大致可以分为三种。以下名称均以LZ个人命名。
1、Aborted objects:在不久的将来死亡的对象。通俗地说,它们是活后不久就会死去的物体。示例:方法中的局部变量、循环中的临时变量等。
2、老仙物:这种物一般都活的比较久,到很老的时候依然不会死,但是说到底,老仙物迟早会死的差不多,但是只有差不多。示例:缓存对象、数据库连接对象、单例对象(单例模式)等。
3、坚不可摧的物体:这类物体通常一出生就几乎是不朽的,它们几乎总是不朽的,记住,只是勉强。示例:字符串池中的对象(享元模式)、加载的类信息等。
对象对应的内存区域
还记得我们之前介绍内存管理时 JVM 对内存的划分吗?我们将以上三个对象对应到内存区,即死对象和老不朽对象在JAVA堆中,不朽对象在方法区。上一章我们已经说过,对于JAVA堆,JVM规范要求必须实现GC,所以对于aborted对象和老不死对象来说,死亡几乎是必然的结果,但也只是几乎,难免会有一些将存活到应用程序结束的对象,但 JVM 规范在方法区域中没有 GC。做需求,所以假设一个JVM实现对方法区没有实现GC,那么永生对象就是真正的永生对象。因为不朽物件的生命周期太长,
JAVA堆对象回收(死对象和旧的不死对象)
有了上面的分析,我们来看看分代回收算法是如何处理JAVA堆的内存回收的,也就是aborted对象和old undead对象的回收。Aborted objects:这些对象有生有死,生存时间短。还记得使用复制算法的要求吗?即对象存活率不能太高,所以aborted对象最适合使用复制算法。小问题:如果50%的内存被浪费了怎么办?答:因为被中止的对象的存活率普遍较低,50%的内存不能作为空闲使用。一般两个 10% 的内存用作空闲和活动区,另外 80% 的内存用于为新对象分配内存时,一旦发生 GC,10% 的活动范围和其他 80% 的幸存对象被转移到 10% 的空闲范围,然后之前的 90% 的内存都被释放,以此类推。为了让大家更清楚地看到这个GC过程,LZ给出了下图。
图中标出了每个阶段三个区域的内存情况。相信看图,它的GC过程不难理解。但是,有两点需要提及。第一点,通过这种方式,我们只浪费了10%的内存,这是可以接受的,因为我们获得了内存的整齐排列和GC的速度。第二点,这个策略的前提是每个幸存对象占用的内存不能超过这10%的大小。一旦超过,多余的对象将无法复制。
为了解决上述突发情况,即当幸存对象占用的内存过大时,专家将JAVA堆分成两部分进行处理。以上三个区域是第一部分,称为新生代或年轻代,其余部分,专门用于存储旧的不死对象,称为老年代。这是一个恰当的名字吗?让我们看看如何处理旧的不死物体。不朽的物件:这类物件的成活率非常高,因为大部分是从新生代传下来的,就像人一样,活久了就会长生不老。
通常,当出现以下两种情况时,对象会从年轻代区域转移到老带区域。
1、新生代中的每个对象都会有一个年龄。当这些对象的年龄达到一定程度时(年龄是存活的GC次数,每次GC如果对象存活,加上年龄1),就会转移到老年代,这个转移到老年代的age值一般可以在JVM中设置。
2、当年轻代存活对象占用的内存超过10%时,多余的对象会被放到老年代。此时老一代就是新一代的“后备仓库”。
对于老不朽对象的特性,显然不再适合使用复制算法,因为它的存活率太高了,别忘了,如果老一代使用复制算法,它是没有备份仓库的. 因此,一般来说,对于旧的不死物体,只能使用标记/排序或标记/清除算法。
方法区对象恢复(不朽对象)
以上两种情况解决了GC的大部分问题,因为JAVA堆是GC的主要关注点,而且上面还收录了分代回收算法的全部内容,不朽对象的回收不在分类。采集算法内容的生成。不朽的对象存在于方法区。在我们常用的热点虚拟机(JDK默认的JVM)中,方法区也被亲切地称为永久代,这是一个非常贴切的名字,不是吗?事实上,很久很久以前,没有永久的一代。当时永久代和老年代存储在一起,里面收录了JAVA类的实例信息和类信息。然而,后来发现班级信息的卸载很少发生,所以将两者分开。幸运的是,这确实提高了很多性能,所以永久代被拆分出来了。这部分区域的GC采用与老年代类似的方法。由于没有“备份仓库”,两者都只能使用mark/sweep和mark/sort算法。
回收时机
JVM 在进行 GC 时,并不总是一起回收上述三个内存区域。大多数时候,它指的是新一代。因此,GC根据回收的区域分为两种,一种是普通GC(minor GC),另一种是global GC(major GC或Full GC)。他们针对的领域如下。Normal GC(minor GC):只针对新生代区域进行GC。Global GC(major GC或Full GC):老年代GC,偶尔伴随着新生代GC和永久代GC。因为老年代和永久代的GC效果都比较差,而且两者的内存使用增长速度也比较慢,一般情况下,需要几次普通GC才能触发一次全局GC。
算法 自动采集列表(优质内容的打造对于没时间来做网站优化的站长来说 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-03-07 00:19
)
罗马不是一天建成的,我们SEO的核心精神也是坚持。网站有自己的关键词,SEO也有自己的核心关键词,那就是坚持。我们不仅需要每天更新网站内容,关键词创建和分析网站数据,还需要关注站点内外的用户体验和优化。
创造高质量的内容
对于没有时间做网站优化的站长,我们也可以通过一些cms采集软件来实现一些SEO技巧,cms采集软件具有强大的功能。只要输入采集规则,就可以完成采集任务,通过软件实现自动采集和释放文章,还可以设置自动下载图片和替换链接(图片本地化),支持的图片存储方式:阿里云、七牛、腾讯云、游拍云等。同时还配备了自动内链,在内容前后插入一定的内容或标题形成“伪原创”。
cms采集软件支持按规则自动插入本地图片文章,提高原创作者的创作效率。
cms采集软件还具有直接监控已发布、即将发布、伪原创、发布状态、URL、节目、发布时间等功能。@收录,以及网站 权重!
在我们的实践过程中,我们需要灵活运用我们的SEO理论知识。cms采集软件和SEO知识是我们从容应对工作中复杂情况的基础。SEO主要侧重于实际操作,这要求我们灵活应用,而不是机械地应用。
考虑用户的搜索习惯和需求
在我们编辑网站的内容之前,不妨想想用户的搜索习惯和需求。一个醒目的标题,总能打动用户的心。为什么其他人可以创建大量内容?学位源于标题的吸引力。我们如何分析用户的搜索习惯和需求,一般通过下拉框、相关搜索、百度索引等工具。同时,内容需要高度相关,关键词的密度要合理,而不是仅仅依靠标题来留住用户。一定要对用户进行细分。
把握市场脉搏
我们需要掌握的是各种搜索引擎的算法及其发展趋势。请注意排名规则的更新,这方面通常有很多需要学习和研究的地方。因为互联网正在飞速发展,要想从竞争对手中脱颖而出,就需要比竞争对手付出更多的努力。我们必须紧跟市场脉搏,紧跟市场发展的潮流。
不断学习和提高
无论搜索引擎有多少排名算法,其核心始终是尽快将最好的质量和最好的用户体验呈现给用户。围绕这个核心,我们不会偏离方向。在学习的过程中,总结很重要。不同的人有不同的理解,我们要在实践中不断总结和形成自己的想法。
查看全部
算法 自动采集列表(优质内容的打造对于没时间来做网站优化的站长来说
)
罗马不是一天建成的,我们SEO的核心精神也是坚持。网站有自己的关键词,SEO也有自己的核心关键词,那就是坚持。我们不仅需要每天更新网站内容,关键词创建和分析网站数据,还需要关注站点内外的用户体验和优化。
创造高质量的内容
对于没有时间做网站优化的站长,我们也可以通过一些cms采集软件来实现一些SEO技巧,cms采集软件具有强大的功能。只要输入采集规则,就可以完成采集任务,通过软件实现自动采集和释放文章,还可以设置自动下载图片和替换链接(图片本地化),支持的图片存储方式:阿里云、七牛、腾讯云、游拍云等。同时还配备了自动内链,在内容前后插入一定的内容或标题形成“伪原创”。
cms采集软件支持按规则自动插入本地图片文章,提高原创作者的创作效率。
cms采集软件还具有直接监控已发布、即将发布、伪原创、发布状态、URL、节目、发布时间等功能。@收录,以及网站 权重!
在我们的实践过程中,我们需要灵活运用我们的SEO理论知识。cms采集软件和SEO知识是我们从容应对工作中复杂情况的基础。SEO主要侧重于实际操作,这要求我们灵活应用,而不是机械地应用。
考虑用户的搜索习惯和需求
在我们编辑网站的内容之前,不妨想想用户的搜索习惯和需求。一个醒目的标题,总能打动用户的心。为什么其他人可以创建大量内容?学位源于标题的吸引力。我们如何分析用户的搜索习惯和需求,一般通过下拉框、相关搜索、百度索引等工具。同时,内容需要高度相关,关键词的密度要合理,而不是仅仅依靠标题来留住用户。一定要对用户进行细分。
把握市场脉搏
我们需要掌握的是各种搜索引擎的算法及其发展趋势。请注意排名规则的更新,这方面通常有很多需要学习和研究的地方。因为互联网正在飞速发展,要想从竞争对手中脱颖而出,就需要比竞争对手付出更多的努力。我们必须紧跟市场脉搏,紧跟市场发展的潮流。
不断学习和提高
无论搜索引擎有多少排名算法,其核心始终是尽快将最好的质量和最好的用户体验呈现给用户。围绕这个核心,我们不会偏离方向。在学习的过程中,总结很重要。不同的人有不同的理解,我们要在实践中不断总结和形成自己的想法。
算法 自动采集列表(易企CMS采集的网络信息搜集与整合,你了解多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-07 00:16
E-Enterprisecms采集,网站发布后,面临的最大问题是网站内容缺失,或者更新不及时。 网站维护需要投入的人力财力越大,长期以来,网站运营商一直在追求最大限度降低成本,获得最高品质的能力网站内容。亿奇cms采集依托高效强大的网络信息采集与整合,与网站对接后,持续为网站提供优质、实时的数据,省去您投入更多人力来寻找文章无处不在的资源的需要。
如果网站位于私网范围内,那么网站就会陷入网络扩容和内容补充的困境,只能依靠人工采集网上相关信息再复制到内网并导入到私网。在 网站 上。通过Easy Enterprisecms采集,现在不用那么麻烦了,可以自动采集发布和编辑,让网站管理者可以专注于内容质量审查和审查 网站以上整体 SEO。
E-Enterprisecms采集预设了30多个插件来提升网站的排名,通过这些插件来优化发布内容的排名,使其能够提升在很长的时间。 网站 的排名。根据网站的行业,它可以自动确定发布到网站的每条内容的“长尾词”,并自动调整发布内容的关键词密度。自动制作已发布图片的alt属性,并根据已发布内容自动为内容中的图片生成相应的alt描述。
E-Enterprisecms采集有4个高效的网络信息采集功能。主题采集,您只需输入关键字即可根据网站的主题设置要求采集符合要求的网络信息,不再需要手动搜索。定位采集,可以与其他同类网站保持同步,只需输入目标网站的地址,即可自动采集同类网站的信息进行筛选。 查看全部
算法 自动采集列表(易企CMS采集的网络信息搜集与整合,你了解多少?)
E-Enterprisecms采集,网站发布后,面临的最大问题是网站内容缺失,或者更新不及时。 网站维护需要投入的人力财力越大,长期以来,网站运营商一直在追求最大限度降低成本,获得最高品质的能力网站内容。亿奇cms采集依托高效强大的网络信息采集与整合,与网站对接后,持续为网站提供优质、实时的数据,省去您投入更多人力来寻找文章无处不在的资源的需要。
如果网站位于私网范围内,那么网站就会陷入网络扩容和内容补充的困境,只能依靠人工采集网上相关信息再复制到内网并导入到私网。在 网站 上。通过Easy Enterprisecms采集,现在不用那么麻烦了,可以自动采集发布和编辑,让网站管理者可以专注于内容质量审查和审查 网站以上整体 SEO。
E-Enterprisecms采集预设了30多个插件来提升网站的排名,通过这些插件来优化发布内容的排名,使其能够提升在很长的时间。 网站 的排名。根据网站的行业,它可以自动确定发布到网站的每条内容的“长尾词”,并自动调整发布内容的关键词密度。自动制作已发布图片的alt属性,并根据已发布内容自动为内容中的图片生成相应的alt描述。
E-Enterprisecms采集有4个高效的网络信息采集功能。主题采集,您只需输入关键字即可根据网站的主题设置要求采集符合要求的网络信息,不再需要手动搜索。定位采集,可以与其他同类网站保持同步,只需输入目标网站的地址,即可自动采集同类网站的信息进行筛选。
算法 自动采集列表(算法自动采集列表的加分,你知道吗?(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-27 19:07
算法自动采集列表的加分1.基于内容的自动采集(top20页的所有内容).2.基于友情链接的自动采集(都找到了链接,跟帖子人工带上)3.基于匹配用户行为的自动采集(对一个人的带上,同时带上另一个人的,都采集到)4.自动识别关键词自动采集(关键词自动识别后,自动采集)5.页面定向规则自动采集(类似谷歌,上下页定向规则自动采集)6.百度统计抓取整站,分析引流效果7.条件自动采集(通过公共场景分析,猜你喜欢等各大产品的使用习惯,达到自动抓取的目的)8.api自动采集(其实只抓取了一小部分)api上每个产品都可以抓取到上千条内容,基本已经能满足需求,更多信息请关注我们qq号:214417614,欢迎大家来聊交流。
想必每个up主在投稿过程中都会收到无法抓取这样的提示邮件,当我们以为自己收到的是某个专门的抓取工具,下载下来后,也没有发现有抓取历史。为什么是抓取历史?这些历史到底是从哪里来的呢?如果这个抓取工具并不能抓取我们所发布的视频或文章,那它就是毫无意义的。现在很多视频网站是没有直接抓取历史这一板块的,都是需要我们人工智能抓取。
其实早在以前就有人想过直接抓取用户的帖子,但是都被这样的人抓走了。所以如果我们并不想通过人工抓取的方式在发布内容时留下自己的内容的历史纪录,还有另一种解决方式。这里介绍一下freebirded这个脚本,可以自动抓取你上传的内容,前提是你得先找到他,不然他用什么去抓取你的内容呢?当然我们可以把网址复制进去,然后就可以自动抓取。
这里是随便找了个视频网站比如:站酷网我们直接找一条新闻内容,抓取下来之后就是这样子的。因为这个内容只是存在于你的网站所以我们并不需要做任何处理,当然你要是愿意多弄几个网站也是可以的。 查看全部
算法 自动采集列表(算法自动采集列表的加分,你知道吗?(上))
算法自动采集列表的加分1.基于内容的自动采集(top20页的所有内容).2.基于友情链接的自动采集(都找到了链接,跟帖子人工带上)3.基于匹配用户行为的自动采集(对一个人的带上,同时带上另一个人的,都采集到)4.自动识别关键词自动采集(关键词自动识别后,自动采集)5.页面定向规则自动采集(类似谷歌,上下页定向规则自动采集)6.百度统计抓取整站,分析引流效果7.条件自动采集(通过公共场景分析,猜你喜欢等各大产品的使用习惯,达到自动抓取的目的)8.api自动采集(其实只抓取了一小部分)api上每个产品都可以抓取到上千条内容,基本已经能满足需求,更多信息请关注我们qq号:214417614,欢迎大家来聊交流。
想必每个up主在投稿过程中都会收到无法抓取这样的提示邮件,当我们以为自己收到的是某个专门的抓取工具,下载下来后,也没有发现有抓取历史。为什么是抓取历史?这些历史到底是从哪里来的呢?如果这个抓取工具并不能抓取我们所发布的视频或文章,那它就是毫无意义的。现在很多视频网站是没有直接抓取历史这一板块的,都是需要我们人工智能抓取。
其实早在以前就有人想过直接抓取用户的帖子,但是都被这样的人抓走了。所以如果我们并不想通过人工抓取的方式在发布内容时留下自己的内容的历史纪录,还有另一种解决方式。这里介绍一下freebirded这个脚本,可以自动抓取你上传的内容,前提是你得先找到他,不然他用什么去抓取你的内容呢?当然我们可以把网址复制进去,然后就可以自动抓取。
这里是随便找了个视频网站比如:站酷网我们直接找一条新闻内容,抓取下来之后就是这样子的。因为这个内容只是存在于你的网站所以我们并不需要做任何处理,当然你要是愿意多弄几个网站也是可以的。

