
智能采集组合文章
智能采集组合文章(,,36kr/webpage.html欢迎折叠(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-09-23 04:04
智能采集组合文章来编辑文章素材,实现在特定文本段落内选中多篇图文编辑,减少编辑次数,增加阅读效率。同时我们可以根据你想要的方式来组合文章,如:png、超链接、表格等等。使用官方已开放的模板来拖拽文件使用,最快2秒钟。
qaq,这怎么可能是一个高效的平台,按你的说法,一定要能把网站的文章分布到不同的列表才算高效吧,
reeder快感觉有时候抓取到的文章可以加到自己的订阅之中或者直接建立一个任务流
牛客
爱范儿,
“zhihu”stackexchange
公众号?问答社区?
我感觉可以harrypotter,csdn,36kr.
marvinglass-web/webpage.html欢迎折叠
uiuxbywaynezhu,reeder
有个叫“风语志”的公众号,专门做编辑器,有帮助你实现高效采集工作的。;hl=zh-cn&fl=uwp&sa=x&ei=kgvaforggbvucom&ie=utf-8,st=wp-cdte&ve=x&ei=lijlnu&wd=%e6%8a%a0%e4%b8%8e%e8%bf%8f%e5%9b%be%e5%a8%8b%e8%b7%af%e6%bf%af%e4%bc%8f%e6%b9%bf%e5%88%8b%e6%99%ab%e5%87%a9%e8%b7%af%e7%9a%84%e6%bb%bb%e8%80%8a%e5%8f%87%e5%8d%83%e7%9c%80%e4%b8%8d%e6%b4%a3%e8%82%85&ok=&wd=%e6%98%9f%e5%a3%bb%e7%ae%8e%e6%9c%9e%e6%9c%81.&qd=si&width=144&height=960&width=2402=&width=4802=。 查看全部
智能采集组合文章(,,36kr/webpage.html欢迎折叠(组图))
智能采集组合文章来编辑文章素材,实现在特定文本段落内选中多篇图文编辑,减少编辑次数,增加阅读效率。同时我们可以根据你想要的方式来组合文章,如:png、超链接、表格等等。使用官方已开放的模板来拖拽文件使用,最快2秒钟。
qaq,这怎么可能是一个高效的平台,按你的说法,一定要能把网站的文章分布到不同的列表才算高效吧,
reeder快感觉有时候抓取到的文章可以加到自己的订阅之中或者直接建立一个任务流
牛客
爱范儿,
“zhihu”stackexchange
公众号?问答社区?
我感觉可以harrypotter,csdn,36kr.
marvinglass-web/webpage.html欢迎折叠
uiuxbywaynezhu,reeder
有个叫“风语志”的公众号,专门做编辑器,有帮助你实现高效采集工作的。;hl=zh-cn&fl=uwp&sa=x&ei=kgvaforggbvucom&ie=utf-8,st=wp-cdte&ve=x&ei=lijlnu&wd=%e6%8a%a0%e4%b8%8e%e8%bf%8f%e5%9b%be%e5%a8%8b%e8%b7%af%e6%bf%af%e4%bc%8f%e6%b9%bf%e5%88%8b%e6%99%ab%e5%87%a9%e8%b7%af%e7%9a%84%e6%bb%bb%e8%80%8a%e5%8f%87%e5%8d%83%e7%9c%80%e4%b8%8d%e6%b4%a3%e8%82%85&ok=&wd=%e6%98%9f%e5%a3%bb%e7%ae%8e%e6%9c%9e%e6%9c%81.&qd=si&width=144&height=960&width=2402=&width=4802=。
智能采集组合文章(全新文章组合工具,支持对词组、字句进行原创随机组合 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-09-20 03:16
)
有关软件的最新版本:
优采云文章复合内容v1. 65.1无限免费版本优采云文件代码批量转换助手V1.60无限免费版
新的文章组合工具支持短语和句子的原创随机组合。这是一个必要的网站管理员工具搜索引擎优化,近20个新的增强帮助工具内置
原型来自原创文章生成器,但它更简单且易于使用。操作基本相同。该方法效果好,操作简单。熟悉的线路可以直接使用,无需反复学习,新手也很容易使用
核心功能是编写模板,在模板中引用元素,并在任何位置引用任何元素。元素可以是文本块调用、随机汉字、数字、字母或数字序列、随机值、随机时间。所有休闲原创组合情况。查看原则>>
提醒:主界面右下角的山中出现的工件:选项按钮可以导入原创文章generator(高级充电版本)的程序数据(必须是导入的,而不是简单的文件拷贝)
提醒:2003系统需要关闭数据保护
提示:创建新元素时,按Ctrl键将当前元素内容复制到新元素中;切换元素显示时,按ALT键可以屏蔽元素内容的显示和校正;在元素项上单击鼠标右键时,可以复制元素引用模式[元素名称],然后在元素库上单击鼠标右键以打开本地保存在数据库中的文件夹(操作与模板相同)
提醒:当前选择显示的模板是用于生成的模板。如果选择了模板库,则库下的模板将随机用于生成,并且模板可以调用所有选中的图元库。选中多个元素库时,不同元素库下的元素不能显示重复的名称,否则只能调用第一个选中元素库的重复名称元素
原创文章生成器的功能:
1、新的接口计划,简单而熟练的计划,基本相同的操作,但更简单和更容易使用
@元素库中的2、elements将不再显示复选框以避免误判(只有元素库可以被选中,选中的元素库将参与调用,并且元素不需要被选中)
3、显示大文本不再耗时,并且支持行号显示和元素语法高亮显示
4、更强大的删除和恢复功能,更强大的树搜索功能
5、新的和改进的帮助工具(包括新编辑的长尾词采集器)可以完成更多的文本处理要求
@预览时支持6、preview title设置,效果好像已经生成
7、library的显示顺序不再混乱
8、其他方面,如总体疗效和表现
查看全部
智能采集组合文章(全新文章组合工具,支持对词组、字句进行原创随机组合
)
有关软件的最新版本:
优采云文章复合内容v1. 65.1无限免费版本优采云文件代码批量转换助手V1.60无限免费版
新的文章组合工具支持短语和句子的原创随机组合。这是一个必要的网站管理员工具搜索引擎优化,近20个新的增强帮助工具内置
原型来自原创文章生成器,但它更简单且易于使用。操作基本相同。该方法效果好,操作简单。熟悉的线路可以直接使用,无需反复学习,新手也很容易使用
核心功能是编写模板,在模板中引用元素,并在任何位置引用任何元素。元素可以是文本块调用、随机汉字、数字、字母或数字序列、随机值、随机时间。所有休闲原创组合情况。查看原则>>
提醒:主界面右下角的山中出现的工件:选项按钮可以导入原创文章generator(高级充电版本)的程序数据(必须是导入的,而不是简单的文件拷贝)
提醒:2003系统需要关闭数据保护
提示:创建新元素时,按Ctrl键将当前元素内容复制到新元素中;切换元素显示时,按ALT键可以屏蔽元素内容的显示和校正;在元素项上单击鼠标右键时,可以复制元素引用模式[元素名称],然后在元素库上单击鼠标右键以打开本地保存在数据库中的文件夹(操作与模板相同)
提醒:当前选择显示的模板是用于生成的模板。如果选择了模板库,则库下的模板将随机用于生成,并且模板可以调用所有选中的图元库。选中多个元素库时,不同元素库下的元素不能显示重复的名称,否则只能调用第一个选中元素库的重复名称元素
原创文章生成器的功能:
1、新的接口计划,简单而熟练的计划,基本相同的操作,但更简单和更容易使用
@元素库中的2、elements将不再显示复选框以避免误判(只有元素库可以被选中,选中的元素库将参与调用,并且元素不需要被选中)
3、显示大文本不再耗时,并且支持行号显示和元素语法高亮显示
4、更强大的删除和恢复功能,更强大的树搜索功能
5、新的和改进的帮助工具(包括新编辑的长尾词采集器)可以完成更多的文本处理要求
@预览时支持6、preview title设置,效果好像已经生成
7、library的显示顺序不再混乱
8、其他方面,如总体疗效和表现

智能采集组合文章(商品属性安装环境商品介绍系统程序企业城市分站群系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-20 03:14
商品属性
设备安装环境
产品介绍
HainacmsIntelligent Cloud站群biotechnology gene detection build网站官方网站源代码HTML5响应国家多地区站群系统计划
enterprise City sub站群系统是一个开源程序:
一、程序模板未授权300元(一套商业模板)。注:不能用于商业目的(侵权),只能用于个人用途。如果将来出现问题,该技术将不予处理
二、程序模板授权500元(一套商业模板)
三、程序模板+授权+[文章组合发布功能、关键词监控、文章采集发布(需要了解网站建设技术)、外链发布)](200元/年),共计700元(一套商业模板)
4:一年服务器(香港单核1g1m40g独立IP)+环境配置(Linux宝塔)+安装+开源代码(授权)+商业模板(一套商业模板)+程序升级+发布和@采集(需建站技术),900元
模板选择:
1、未经授权的程序不得用于商业目的(侵权),程序不能在后台一键升级,没有售后服务支持(后台操作范围内的支持),增值功能不能购买(具有文章组合发布功能、关键词监控、文章@采集发布(网站建设技术和外链发布)。使用增值功能的前提是在购买增值功能之前需要获得授权
授权后的域名不能返回或更改,必须先确定授权的域名,打开增值功能后,域名不能更改
*虚拟物品交付后,这不是程序的问题。没有退款或退货。环境是正确的。安装后,它与演示站相同。如果您不能接受,请不要拍摄
2、程序是开源的,后台升级功能调用ECS API进行升级,增值功能(授权后订购)是另一个系统,连接到我们的企业站群系统
3、程序运行环境php5.超过4个7.0低于+mysql5.5以上(推荐宝塔Linux+nginx)+php5.6+ mysql5.6)
香港cn2专用VPS:1核(CPU)1g(内存)1m(带宽)40g(磁盘)5g(国防)独立IP,200元/年
4、不支持域名。通用绑定域名的空格(虚拟空间)只能以目录的形式使用。支持通用绑定域名的空格或VPS服务器只能以辅助域名的形式使用
5、未被授权使用增值功能,需要单独购买。但是,这个文章组合版本可以与我们的程序连接,相当于伪原创版本
原则:文章是根据您制作的段落发布的,发布模板的变量用于将它们排列并组合成一篇文章伪原创文章
6、增值功能:关键词监控、自动发布等实用功能,每年支付200元,目前暂定价格较低,不排除后期服务器成本增加导致价格上涨的可能性
7、功能优势:
多城市站点:设置任意企业城市子站区域,设置二级域名表单(服务器支持通用绑定)或目录表单
万站效应:您不仅可以使用区域作为子站,还可以使用产品子站,并在区域中管理用户定义的产品分类(理论上无限增加)
关键词设置:点击设置关键词,自动生成长尾关键词,列关键词生成,自定义URL/关键字
链接:一键交换链接(授权使用,一键禁用广告法中的文字) 查看全部
智能采集组合文章(商品属性安装环境商品介绍系统程序企业城市分站群系统)
商品属性
设备安装环境
产品介绍
HainacmsIntelligent Cloud站群biotechnology gene detection build网站官方网站源代码HTML5响应国家多地区站群系统计划
enterprise City sub站群系统是一个开源程序:
一、程序模板未授权300元(一套商业模板)。注:不能用于商业目的(侵权),只能用于个人用途。如果将来出现问题,该技术将不予处理
二、程序模板授权500元(一套商业模板)
三、程序模板+授权+[文章组合发布功能、关键词监控、文章采集发布(需要了解网站建设技术)、外链发布)](200元/年),共计700元(一套商业模板)
4:一年服务器(香港单核1g1m40g独立IP)+环境配置(Linux宝塔)+安装+开源代码(授权)+商业模板(一套商业模板)+程序升级+发布和@采集(需建站技术),900元
模板选择:
1、未经授权的程序不得用于商业目的(侵权),程序不能在后台一键升级,没有售后服务支持(后台操作范围内的支持),增值功能不能购买(具有文章组合发布功能、关键词监控、文章@采集发布(网站建设技术和外链发布)。使用增值功能的前提是在购买增值功能之前需要获得授权
授权后的域名不能返回或更改,必须先确定授权的域名,打开增值功能后,域名不能更改
*虚拟物品交付后,这不是程序的问题。没有退款或退货。环境是正确的。安装后,它与演示站相同。如果您不能接受,请不要拍摄
2、程序是开源的,后台升级功能调用ECS API进行升级,增值功能(授权后订购)是另一个系统,连接到我们的企业站群系统
3、程序运行环境php5.超过4个7.0低于+mysql5.5以上(推荐宝塔Linux+nginx)+php5.6+ mysql5.6)
香港cn2专用VPS:1核(CPU)1g(内存)1m(带宽)40g(磁盘)5g(国防)独立IP,200元/年
4、不支持域名。通用绑定域名的空格(虚拟空间)只能以目录的形式使用。支持通用绑定域名的空格或VPS服务器只能以辅助域名的形式使用
5、未被授权使用增值功能,需要单独购买。但是,这个文章组合版本可以与我们的程序连接,相当于伪原创版本
原则:文章是根据您制作的段落发布的,发布模板的变量用于将它们排列并组合成一篇文章伪原创文章
6、增值功能:关键词监控、自动发布等实用功能,每年支付200元,目前暂定价格较低,不排除后期服务器成本增加导致价格上涨的可能性
7、功能优势:
多城市站点:设置任意企业城市子站区域,设置二级域名表单(服务器支持通用绑定)或目录表单
万站效应:您不仅可以使用区域作为子站,还可以使用产品子站,并在区域中管理用户定义的产品分类(理论上无限增加)
关键词设置:点击设置关键词,自动生成长尾关键词,列关键词生成,自定义URL/关键字
链接:一键交换链接(授权使用,一键禁用广告法中的文字)
智能采集组合文章(既能集中收藏为文章自动打标签的工具成功吸引我们)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-09-19 17:01
在信息爆炸的时代,我们被各种各样的信息所包围,这迫使我们在大量的信息中寻找“有用”的信息。当我们看到好的文章,我们会采集它,但我们经常会遇到两个问题:
如果你在采集后找不到它,这和不采集没有什么不同;如果采集缺乏分类和内部化,这些“好商品”的价值将永远无法发挥作用
对于第一个问题,中国提供了支持采集的工具,如印象笔记、知识笔记、有道云等,可以实现信息的统一聚合,将采集的信息集中在一起。然而,知识的采集只是知识管理的第一步,后期的整理和内化更值得反思
“每次给几十个甚至数百个文章采集贴标签和手工分类都很烦人,”此类工具的典型用户小陈告诉作者,“采集后再阅读也是一个问题”。最近,一个能够自动采集并标记文章的工具成功地吸引了我们的注意。这是极好的阅读
优都开发者之一的发起者金凯表达了优都诞生的初衷:“作为一个阅读爱好者,每次看到好的文章,我都会在不同的阅读平台上采集。它非常分散。之前,我会手动标记文章,并将其移动到我自己的博客上。这是非常低效的。”
金基对智能算法的研究产生了这样一种想法:既然读者通常根据文章的主要内容进行标记和分类,为什么不通过机器学习算法将这一过程智能化呢
因此,他在业余时间开始设计“优秀阅读应用程序”。通过智能算法对文章样本进行连续训练和精度优化。目前,卓越阅读中采集的文章可以自动标记五个标签。当然,读者也可以自定义、修改或增加或减少文章标题和标签,以更好地匹配他们的搜索习惯
对于如何解决重读问题,优秀阅读提供了两种提高读者阅读动机的方法:
一种是基于标签的主题阅读。对于每个采集的文章,读者可以单击自动标记的标签,过滤掉所有以前采集的文章,然后开始主题阅读。例如,我最近需要加强我的ppt技能。在采集PPT的文章并点击生成的相关标签后,我可以在平台上索引我自己的采集,甚至是其他人采集的类似文章的采集
基于某一主题的阅读使知识的掌握更加全面;别人的文章,其实是帮读者做了一个信息过滤,整体素质也比较高
二是提供方便的搜索功能。聚光灯搜索功能在IOS版本的卓越阅读中被调用。在登录并打开优秀阅读采集列表一次的前提下,无需打开应用程序,即可在苹果主屏幕的任何界面上快速下拉搜索优秀阅读采集的文章collected。搜索范围包括标题和标签,使信息检索速度加快了一步
只要你养成把它采集成优秀阅读的习惯,你就可以把你的手机建成一个现成的知识库。而采集网站、官方账号、网页和app文章的最佳阅读操作非常简单。只要您在微信中添加并绑定app assistant,就可以通过共享文章的微信助手实现文章采集和智能标签。文章的风格经过美化、排版和广告过滤,阅读效果极佳,看起来更舒适
根据金钥匙的说法,未来,Youdu还将允许用户在应用程序中选择文本采集、标记或在线查看,并提醒他们根据读者的记忆曲线查看之前阅读的笔记
目前,优秀阅读团队共有14人左右,主要是技术开发人员。优秀的阅读在通过智能算法帮助读者进行知识管理方面还有很长的路要走,但是金基和他的团队相信这是未来的趋势,也是一件值得做的事情 查看全部
智能采集组合文章(既能集中收藏为文章自动打标签的工具成功吸引我们)
在信息爆炸的时代,我们被各种各样的信息所包围,这迫使我们在大量的信息中寻找“有用”的信息。当我们看到好的文章,我们会采集它,但我们经常会遇到两个问题:
如果你在采集后找不到它,这和不采集没有什么不同;如果采集缺乏分类和内部化,这些“好商品”的价值将永远无法发挥作用
对于第一个问题,中国提供了支持采集的工具,如印象笔记、知识笔记、有道云等,可以实现信息的统一聚合,将采集的信息集中在一起。然而,知识的采集只是知识管理的第一步,后期的整理和内化更值得反思
“每次给几十个甚至数百个文章采集贴标签和手工分类都很烦人,”此类工具的典型用户小陈告诉作者,“采集后再阅读也是一个问题”。最近,一个能够自动采集并标记文章的工具成功地吸引了我们的注意。这是极好的阅读
优都开发者之一的发起者金凯表达了优都诞生的初衷:“作为一个阅读爱好者,每次看到好的文章,我都会在不同的阅读平台上采集。它非常分散。之前,我会手动标记文章,并将其移动到我自己的博客上。这是非常低效的。”
金基对智能算法的研究产生了这样一种想法:既然读者通常根据文章的主要内容进行标记和分类,为什么不通过机器学习算法将这一过程智能化呢
因此,他在业余时间开始设计“优秀阅读应用程序”。通过智能算法对文章样本进行连续训练和精度优化。目前,卓越阅读中采集的文章可以自动标记五个标签。当然,读者也可以自定义、修改或增加或减少文章标题和标签,以更好地匹配他们的搜索习惯

对于如何解决重读问题,优秀阅读提供了两种提高读者阅读动机的方法:
一种是基于标签的主题阅读。对于每个采集的文章,读者可以单击自动标记的标签,过滤掉所有以前采集的文章,然后开始主题阅读。例如,我最近需要加强我的ppt技能。在采集PPT的文章并点击生成的相关标签后,我可以在平台上索引我自己的采集,甚至是其他人采集的类似文章的采集
基于某一主题的阅读使知识的掌握更加全面;别人的文章,其实是帮读者做了一个信息过滤,整体素质也比较高
二是提供方便的搜索功能。聚光灯搜索功能在IOS版本的卓越阅读中被调用。在登录并打开优秀阅读采集列表一次的前提下,无需打开应用程序,即可在苹果主屏幕的任何界面上快速下拉搜索优秀阅读采集的文章collected。搜索范围包括标题和标签,使信息检索速度加快了一步

只要你养成把它采集成优秀阅读的习惯,你就可以把你的手机建成一个现成的知识库。而采集网站、官方账号、网页和app文章的最佳阅读操作非常简单。只要您在微信中添加并绑定app assistant,就可以通过共享文章的微信助手实现文章采集和智能标签。文章的风格经过美化、排版和广告过滤,阅读效果极佳,看起来更舒适

根据金钥匙的说法,未来,Youdu还将允许用户在应用程序中选择文本采集、标记或在线查看,并提醒他们根据读者的记忆曲线查看之前阅读的笔记
目前,优秀阅读团队共有14人左右,主要是技术开发人员。优秀的阅读在通过智能算法帮助读者进行知识管理方面还有很长的路要走,但是金基和他的团队相信这是未来的趋势,也是一件值得做的事情
智能采集组合文章( 企业官方网站需要SEO文章智能采集提取功能介绍及功能说明 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-15 18:19
企业官方网站需要SEO文章智能采集提取功能介绍及功能说明
)
建筑企业官方网站需求SEO文章Intelligent采集extraction
很多企业在建设官网时,都认为自己的官网后期需要品牌推广。网站建设之初,需要对官网布局进行关键词优化。在选择网站后台、域名注册选择时,包括服务器选择、网站对应速度以及后台功能是否智能,企业在建设网站时必须考虑,这也是为了企业长远而深远的发展
首先,第一点:网站除了基本的企业文化、价值观、公司介绍、产品优势、网站地图和产品特色外,还需要更多的时间让官网品牌在后期的同行业中脱颖而出。考虑到后期维护的方便,网站维护时间,特别是SEO优化所需的文章原创度。提供后台一站式服务,可以帮助中小企业建立网站,为企业网站运营商带来巨大帮助,节省大量时间。接下来,我们来介绍一下企业的官方网站需求SEO文章智能采集提取功能描述如下:
[版本]
显示高级版本及以上版本
[使用场景]
添加文章后,您可以通过文章summary AI提取功能一键生成文章summary,帮助用户提高文章summary的质量,从而加速百度对文章的收录搜索@@
[功能描述]
1.进入管理后台[文章-功能设置-百度优化],在“文章summary AI extraction”状态栏中选择“on”
2.添加文章后进入高级设置,点击摘要AI提取,自动生成文章摘要
3.published文章,您可以通过点击管理后台的“摘要AI提取”按钮[文章-manage文章-Edit-Advanced],直接补充或更新原创的文章摘要
带图标的按钮支持
[使用场景]
标准和自适应网站按钮模块支持添加图标,以增加网站设计的多样性
[功能描述]
进入按钮模块设置面板,打开图标设置项,在网站中添加带有图标的按钮@
支持自定义按钮样式、初始颜色、悬停颜色和大小
查看全部
智能采集组合文章(
企业官方网站需要SEO文章智能采集提取功能介绍及功能说明
)
建筑企业官方网站需求SEO文章Intelligent采集extraction
很多企业在建设官网时,都认为自己的官网后期需要品牌推广。网站建设之初,需要对官网布局进行关键词优化。在选择网站后台、域名注册选择时,包括服务器选择、网站对应速度以及后台功能是否智能,企业在建设网站时必须考虑,这也是为了企业长远而深远的发展
首先,第一点:网站除了基本的企业文化、价值观、公司介绍、产品优势、网站地图和产品特色外,还需要更多的时间让官网品牌在后期的同行业中脱颖而出。考虑到后期维护的方便,网站维护时间,特别是SEO优化所需的文章原创度。提供后台一站式服务,可以帮助中小企业建立网站,为企业网站运营商带来巨大帮助,节省大量时间。接下来,我们来介绍一下企业的官方网站需求SEO文章智能采集提取功能描述如下:
[版本]
显示高级版本及以上版本
[使用场景]
添加文章后,您可以通过文章summary AI提取功能一键生成文章summary,帮助用户提高文章summary的质量,从而加速百度对文章的收录搜索@@
[功能描述]
1.进入管理后台[文章-功能设置-百度优化],在“文章summary AI extraction”状态栏中选择“on”
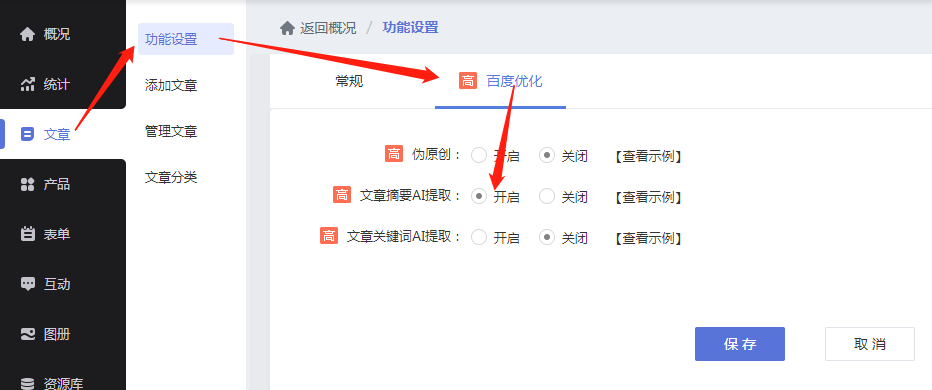
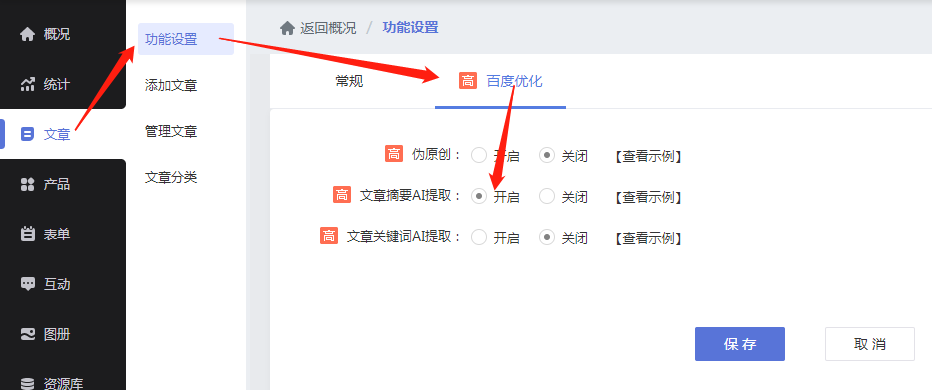
2.添加文章后进入高级设置,点击摘要AI提取,自动生成文章摘要
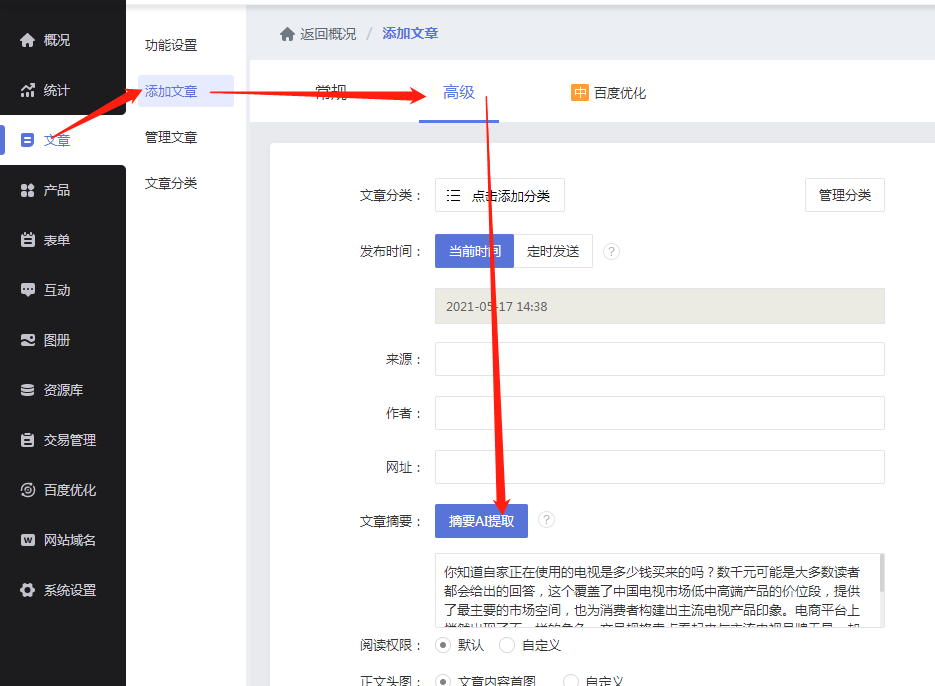
3.published文章,您可以通过点击管理后台的“摘要AI提取”按钮[文章-manage文章-Edit-Advanced],直接补充或更新原创的文章摘要
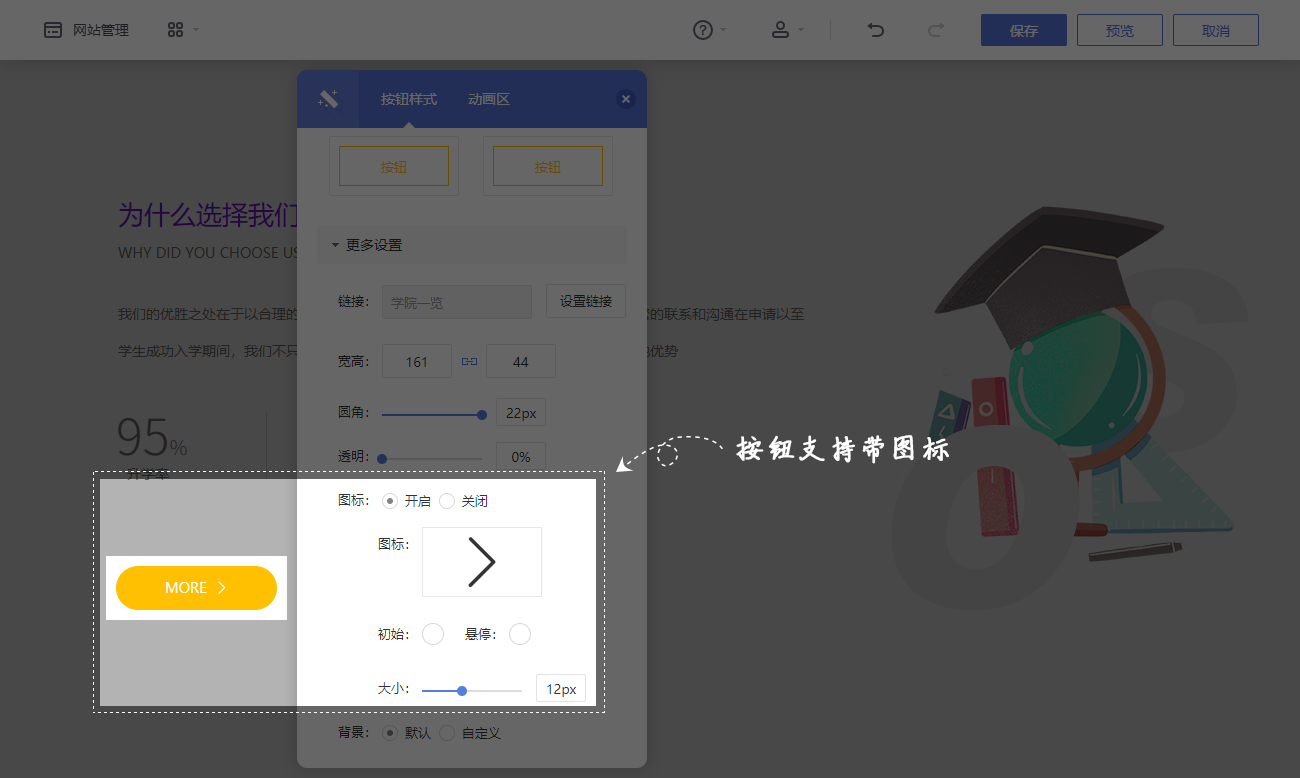
带图标的按钮支持
[使用场景]
标准和自适应网站按钮模块支持添加图标,以增加网站设计的多样性
[功能描述]
进入按钮模块设置面板,打开图标设置项,在网站中添加带有图标的按钮@
支持自定义按钮样式、初始颜色、悬停颜色和大小
智能采集组合文章(智能采集组合文章标题功能+12年全年站外数据支持)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-15 14:14
智能采集组合文章标题功能+12年全年站外数据支持实战:五步教你用r实现智能采集技术要点文章详情页标题智能组合r语言编写两种方法方法一:使用r语言自带的“智能get标题”函数
<p>1)函数说明:函数中包含两种智能标题:变量名和代码,如说明:有些情况下,需要手动生成标题,如:unknown 查看全部
智能采集组合文章(智能采集组合文章标题功能+12年全年站外数据支持)
智能采集组合文章标题功能+12年全年站外数据支持实战:五步教你用r实现智能采集技术要点文章详情页标题智能组合r语言编写两种方法方法一:使用r语言自带的“智能get标题”函数
<p>1)函数说明:函数中包含两种智能标题:变量名和代码,如说明:有些情况下,需要手动生成标题,如:unknown
智能采集组合文章(如何获取对应节点下的数据节点?有哪些注意事项? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 371 次浏览 • 2021-09-12 23:00
)
连接数据库,本文以MySQL为例
创建文件caijiMySQL.py并连接数据库,代码如下:
import pymysql
def mysql_connect():
db = pymysql.connect(host='数据库地址', port=3306, user='数据库账户', passwd='数据库密码', db='数据库名', charset='utf8')
return db.cursor()
为采集网站信息创建caijiweb.py文件,本文以采集河南省教育部教师招聘信息为例,网址如下:
解析所需采集对象的HTML节点
右击查看元素,或者按F12,可以查看当前页面的HTML元素。然后我们将分析采集的数据节点。
如上图所示,我们以第一条消息为例。我们需要的采集是class="list"标签下的信息,标题,链接,添加时间。之后需要进入这个页面,如下图:
如上图所示,我们进入后,同样可以得到信息标签,例如class="det"就是招聘内容。
如何获取对应节点下的信息?
这里需要用到beautifulsoup,一个俗称美味汤的爬虫库。这个类的详细用法这里就不介绍了,大家可以参考前面的文章,可以通过各种组合快速选择自己需要的内容。
有哪些注意事项?
1、翻页:上面第一张截图,内容页数多,需要翻页
2、采集 过程中,有很多无用的信息,需要过滤。比如我需要采集大学直播老师的信息,其他的没用,不需要额外的存储浪费空间。
3、数据库存储
4、页面应根据存储特性进行翻译,例如“转入”,以便存储后在其他地方检索和使用。
具体代码如下(有详细说明)
from bs4 import BeautifulSoup
from caijiMySQL import mysql_connect
# 引入第一步建立的数据库连接文件
import requests
#用于模拟网站请求
import re #用于选择标签时的,正则选择
import time
#时间类
cursor = mysql_connect()
# 执行数据库连接
sql = "select insert_time from me_article limit 1"
values =cursor.execute(sql)
values = cursor.fetchall()
current_time = values[0][0]
#查一下最后一条插入的招聘信息是什么时间的,采集时,只采集这个时间点之后的数据。
def caiji_jiaoyu(url):
wb_data = requests.get(url) #使用get方式获取页面内容
wb_data.encoding = 'utf-8' #页面编码为utf-8
soup = BeautifulSoup(wb_data.text, 'lxml') #使用美味汤进行分析性
for child in soup.find_all('a',attrs={"target": "_blank"}): #获取页面所有链接
article_html = requests.get(child['href']) #获取链接子页面内容
re = article_html.status_code #子页面获取的状态,看是否获取成功
if re == 200:
article_html.encoding = 'utf-8'
article_detail = BeautifulSoup(article_html.text, 'lxml')#分析子页面
article_title= child.get_text()
sql = "select * from me_article where article_name = %s"
cursor.execute(sql, article_title)
values = cursor.fetchall() #查看是否已存在该招聘信息
if values == ():
result_a = article_title.find('学院')
result_b = article_title.find('大学')
result_c = article_title.find('学校')
result_d = article_title.find('中学')
result_e = article_title.find('中心')
result_f = article_title.find('研究室')
result = 0
if result_a != -1:
result = result_a
if result_b != -1:
if result < result_b:
result = result_b
if result_c != -1:
if result < result_c:
result = result_c
if result_d != -1:
if result < result_d:
result = result_d
if result_e != -1:
if result < result_e:
result = result_e
if result_f != -1:
if result < result_f:
result = result_f
if result_a or result_b or result_c or result_d or result_e or result_f:# 筛选出大学招聘信息
sql = "select * from me_school where school_name = %s"
cursor.execute(sql,article_title[0:result+2])
values = cursor.fetchall()
if values != ():
school_id = values[0][0]
else:
sql = "insert into me_school(id, school_name) values (%s, %s)" #插入数据库
insert_result=cursor.execute(sql, ('', article_title[0:result+2]))
if insert_result == 1:
sql = "select * from me_school where school_name = %s"
cursor.execute(sql, article_title[0:result + 2])
values = cursor.fetchall()
if values != ():
school_id = values[0][0]
else:
school_id = 2
db.commit()
article_time = article_detail.find("span",class_="time").get_text("|", strip=True)
timeArray = time.strptime(article_time, "%Y-%m-%d %H:%M:%S")
article_time = int(time.mktime(timeArray))
if article_time < current_time:#如果发布时间比采集到的世界早,说明已经采集过了,是过时信息,跳出循环
exit()
article_content_in = article_detail.select('.det')
article_content_in_str = "".join('%s' % id for id in article_content_in)
article_content = article_content_in_str.replace("'", "'")
sql = "insert into me_article (school_id,article_name,article_content,article_url,article_time,insert_time) values (%s,%s,%s,%s,%s,%s)"
cursor.execute(sql, (str(school_id), article_title, '<p>' + article_content + '',child['href'], article_time, time.time()))
db.commit()
#下方几行代码,为获取下一页链接,然后重复执行上面采集内容。一般是只在第一次采集时候使用。
# if soup.find_all("a",text="下一页") != []:
# next_url = soup.find_all("a", text="下一页")[0].get('href').replace("tzgg", "/")
# url = 'http://www.haedu.gov.cn/jszp/' + next_url
# caiji_jiaoyu(url)
caiji_jiaoyu("http://www.haedu.gov.cn/jszp/index.html")
#执行采集</p>
采集 结果如下图所示:
注意,以上部分代码是博客编辑时添加的注释。如果直接复制测试,请注意空格。
查看全部
智能采集组合文章(如何获取对应节点下的数据节点?有哪些注意事项?
)
连接数据库,本文以MySQL为例
创建文件caijiMySQL.py并连接数据库,代码如下:
import pymysql
def mysql_connect():
db = pymysql.connect(host='数据库地址', port=3306, user='数据库账户', passwd='数据库密码', db='数据库名', charset='utf8')
return db.cursor()
为采集网站信息创建caijiweb.py文件,本文以采集河南省教育部教师招聘信息为例,网址如下:

解析所需采集对象的HTML节点
右击查看元素,或者按F12,可以查看当前页面的HTML元素。然后我们将分析采集的数据节点。

如上图所示,我们以第一条消息为例。我们需要的采集是class="list"标签下的信息,标题,链接,添加时间。之后需要进入这个页面,如下图:

如上图所示,我们进入后,同样可以得到信息标签,例如class="det"就是招聘内容。
如何获取对应节点下的信息?
这里需要用到beautifulsoup,一个俗称美味汤的爬虫库。这个类的详细用法这里就不介绍了,大家可以参考前面的文章,可以通过各种组合快速选择自己需要的内容。
有哪些注意事项?
1、翻页:上面第一张截图,内容页数多,需要翻页
2、采集 过程中,有很多无用的信息,需要过滤。比如我需要采集大学直播老师的信息,其他的没用,不需要额外的存储浪费空间。
3、数据库存储
4、页面应根据存储特性进行翻译,例如“转入”,以便存储后在其他地方检索和使用。
具体代码如下(有详细说明)
from bs4 import BeautifulSoup
from caijiMySQL import mysql_connect
# 引入第一步建立的数据库连接文件
import requests
#用于模拟网站请求
import re #用于选择标签时的,正则选择
import time
#时间类
cursor = mysql_connect()
# 执行数据库连接
sql = "select insert_time from me_article limit 1"
values =cursor.execute(sql)
values = cursor.fetchall()
current_time = values[0][0]
#查一下最后一条插入的招聘信息是什么时间的,采集时,只采集这个时间点之后的数据。
def caiji_jiaoyu(url):
wb_data = requests.get(url) #使用get方式获取页面内容
wb_data.encoding = 'utf-8' #页面编码为utf-8
soup = BeautifulSoup(wb_data.text, 'lxml') #使用美味汤进行分析性
for child in soup.find_all('a',attrs={"target": "_blank"}): #获取页面所有链接
article_html = requests.get(child['href']) #获取链接子页面内容
re = article_html.status_code #子页面获取的状态,看是否获取成功
if re == 200:
article_html.encoding = 'utf-8'
article_detail = BeautifulSoup(article_html.text, 'lxml')#分析子页面
article_title= child.get_text()
sql = "select * from me_article where article_name = %s"
cursor.execute(sql, article_title)
values = cursor.fetchall() #查看是否已存在该招聘信息
if values == ():
result_a = article_title.find('学院')
result_b = article_title.find('大学')
result_c = article_title.find('学校')
result_d = article_title.find('中学')
result_e = article_title.find('中心')
result_f = article_title.find('研究室')
result = 0
if result_a != -1:
result = result_a
if result_b != -1:
if result < result_b:
result = result_b
if result_c != -1:
if result < result_c:
result = result_c
if result_d != -1:
if result < result_d:
result = result_d
if result_e != -1:
if result < result_e:
result = result_e
if result_f != -1:
if result < result_f:
result = result_f
if result_a or result_b or result_c or result_d or result_e or result_f:# 筛选出大学招聘信息
sql = "select * from me_school where school_name = %s"
cursor.execute(sql,article_title[0:result+2])
values = cursor.fetchall()
if values != ():
school_id = values[0][0]
else:
sql = "insert into me_school(id, school_name) values (%s, %s)" #插入数据库
insert_result=cursor.execute(sql, ('', article_title[0:result+2]))
if insert_result == 1:
sql = "select * from me_school where school_name = %s"
cursor.execute(sql, article_title[0:result + 2])
values = cursor.fetchall()
if values != ():
school_id = values[0][0]
else:
school_id = 2
db.commit()
article_time = article_detail.find("span",class_="time").get_text("|", strip=True)
timeArray = time.strptime(article_time, "%Y-%m-%d %H:%M:%S")
article_time = int(time.mktime(timeArray))
if article_time < current_time:#如果发布时间比采集到的世界早,说明已经采集过了,是过时信息,跳出循环
exit()
article_content_in = article_detail.select('.det')
article_content_in_str = "".join('%s' % id for id in article_content_in)
article_content = article_content_in_str.replace("'", "'")
sql = "insert into me_article (school_id,article_name,article_content,article_url,article_time,insert_time) values (%s,%s,%s,%s,%s,%s)"
cursor.execute(sql, (str(school_id), article_title, '<p>' + article_content + '',child['href'], article_time, time.time()))
db.commit()
#下方几行代码,为获取下一页链接,然后重复执行上面采集内容。一般是只在第一次采集时候使用。
# if soup.find_all("a",text="下一页") != []:
# next_url = soup.find_all("a", text="下一页")[0].get('href').replace("tzgg", "/")
# url = 'http://www.haedu.gov.cn/jszp/' + next_url
# caiji_jiaoyu(url)
caiji_jiaoyu("http://www.haedu.gov.cn/jszp/index.html";)
#执行采集</p>
采集 结果如下图所示:

注意,以上部分代码是博客编辑时添加的注释。如果直接复制测试,请注意空格。

智能采集组合文章(智能采集组合文章过滤热点采集网站或者网址做什么修改)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-11 13:02
智能采集组合文章过滤热点采集网站或者网址做什么修改直接就可以用都是电脑开发调试推荐蓝海采集软件
都想要,vue和angularjs平台其实是可以单独开发一套的,中文教程推荐:精通前端开发-w3cplus前端基础非常重要,ssr不如页面加载再加个vue组件,所以两个平台都需要会一些,推荐不学flex布局以及,不会css3的话,选择vue2,前端单页应用为主,vue整体负责前端框架的搭建,angularjs多页应用为主,框架一般是不会学习的,我们公司是这样的,vue和angular两个平台一起开发的,vue2进行业务快速部署,到cdn后对cdn进行负载均衡,angular要学习的话,可以在做vue2的过程中,顺带学习下angular,对于没有细节上的痛点,没有后端,多页面应用,vue2和angular都能实现即时渲染,前端尽可能的模块化设计和性能优化比较重要,学习项目开发的逻辑逻辑,往简单了学就好了。angular2有点复杂,你没事的话,可以先用vue实现个简单业务,然后拆分模块。
切图用vue,写业务逻辑angularjs,然后弄angularjsspa方向的开发。angularjs的seo、数据绑定和路由、es6、es7.各种vue的内置标签。最后转型angularjsfp方向。
vue的容易,但是你也能看到绝大多数人都推荐flux,我想说两者都不容易,都是组件化解决方案,有的人搞不定就放弃了。 查看全部
智能采集组合文章(智能采集组合文章过滤热点采集网站或者网址做什么修改)
智能采集组合文章过滤热点采集网站或者网址做什么修改直接就可以用都是电脑开发调试推荐蓝海采集软件
都想要,vue和angularjs平台其实是可以单独开发一套的,中文教程推荐:精通前端开发-w3cplus前端基础非常重要,ssr不如页面加载再加个vue组件,所以两个平台都需要会一些,推荐不学flex布局以及,不会css3的话,选择vue2,前端单页应用为主,vue整体负责前端框架的搭建,angularjs多页应用为主,框架一般是不会学习的,我们公司是这样的,vue和angular两个平台一起开发的,vue2进行业务快速部署,到cdn后对cdn进行负载均衡,angular要学习的话,可以在做vue2的过程中,顺带学习下angular,对于没有细节上的痛点,没有后端,多页面应用,vue2和angular都能实现即时渲染,前端尽可能的模块化设计和性能优化比较重要,学习项目开发的逻辑逻辑,往简单了学就好了。angular2有点复杂,你没事的话,可以先用vue实现个简单业务,然后拆分模块。
切图用vue,写业务逻辑angularjs,然后弄angularjsspa方向的开发。angularjs的seo、数据绑定和路由、es6、es7.各种vue的内置标签。最后转型angularjsfp方向。
vue的容易,但是你也能看到绝大多数人都推荐flux,我想说两者都不容易,都是组件化解决方案,有的人搞不定就放弃了。
智能采集组合文章(AI文章智能处理软件是一款很不错的文章伪原创工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 730 次浏览 • 2021-09-06 10:25
AI文章Intelligent Processing Software 是一款智能文章伪原创工具,可以帮助用户重新组合文章形成新的文章,也可以进行素材采集,是一个A非常好的文章处理工具。
功能介绍:
1、智能伪原创:利用人工智能中的自然语言处理技术实现文章伪原创处理。核心功能包括“smart伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词”、“句子改组重组”等等等,处理后的文章原创度和收录率都在80%以上。想了解更多功能,请下载软件试用。
2、Portal文章采集:一键搜索采集相关门户网站新闻文章、网站有搜狐、腾讯、新浪、网易、今日头条.com、新兰网、联合早报、光明网、站长网、新文化网等,用户可以输入行业关键词搜索想要的行业文章。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
3、百度新闻采集:一键搜索各种行业新闻文章,数据源来自百度新闻搜索引擎,资源丰富,操作灵活,无需写任何采集规则,但缺点是,采集的文章不一定完整,但可以满足大部分用户的需求。友情提示:文章使用时请注明文章出处,尊重原文版权。
4、工业文章采集:一键搜索相关行业网站文章,网站行业包括装饰家居行业、机械行业、建材行业、家电行业、硬件行业,美容行业,育儿行业,金融行业,游戏行业,SEO行业,女性健康行业等有几十个网站网站,资源丰富,这个模块可能不能满足大家的需求客户,但客户可以提出他们的需求,我们会改进和更新模块资源。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
5、write rules采集:自己写采集rules采集,采集规则符合常见的正则表达式,写采集规则需要了解一些html代码和正则表达式规则,如果如果你写过采集software 采集rules 其他商家,你肯定会为我们的软件写采集rules,我们提供写采集rules 的文档。我们不为客户编写采集 规则。如果你需要代写,10元你会得到一个采集规则。友情提示:文章使用时请注明文章出处,尊重原文版权。
<p>6、外链文章材料:该模块使用大量行业语料,通过算法随机组合语料,产生相关行业文章。这个模块文章只适用于质量要求不高的文章。对于外链推广的用户,该模块具有资源丰富、原创度高的特点,但缺点是文章可读性差,用户在使用时可以选择使用。 查看全部
智能采集组合文章(AI文章智能处理软件是一款很不错的文章伪原创工具)
AI文章Intelligent Processing Software 是一款智能文章伪原创工具,可以帮助用户重新组合文章形成新的文章,也可以进行素材采集,是一个A非常好的文章处理工具。

功能介绍:
1、智能伪原创:利用人工智能中的自然语言处理技术实现文章伪原创处理。核心功能包括“smart伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词”、“句子改组重组”等等等,处理后的文章原创度和收录率都在80%以上。想了解更多功能,请下载软件试用。
2、Portal文章采集:一键搜索采集相关门户网站新闻文章、网站有搜狐、腾讯、新浪、网易、今日头条.com、新兰网、联合早报、光明网、站长网、新文化网等,用户可以输入行业关键词搜索想要的行业文章。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
3、百度新闻采集:一键搜索各种行业新闻文章,数据源来自百度新闻搜索引擎,资源丰富,操作灵活,无需写任何采集规则,但缺点是,采集的文章不一定完整,但可以满足大部分用户的需求。友情提示:文章使用时请注明文章出处,尊重原文版权。
4、工业文章采集:一键搜索相关行业网站文章,网站行业包括装饰家居行业、机械行业、建材行业、家电行业、硬件行业,美容行业,育儿行业,金融行业,游戏行业,SEO行业,女性健康行业等有几十个网站网站,资源丰富,这个模块可能不能满足大家的需求客户,但客户可以提出他们的需求,我们会改进和更新模块资源。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
5、write rules采集:自己写采集rules采集,采集规则符合常见的正则表达式,写采集规则需要了解一些html代码和正则表达式规则,如果如果你写过采集software 采集rules 其他商家,你肯定会为我们的软件写采集rules,我们提供写采集rules 的文档。我们不为客户编写采集 规则。如果你需要代写,10元你会得到一个采集规则。友情提示:文章使用时请注明文章出处,尊重原文版权。
<p>6、外链文章材料:该模块使用大量行业语料,通过算法随机组合语料,产生相关行业文章。这个模块文章只适用于质量要求不高的文章。对于外链推广的用户,该模块具有资源丰富、原创度高的特点,但缺点是文章可读性差,用户在使用时可以选择使用。
智能采集组合文章(软件功能是一款多功能的伪原创SEO运营工具吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-04 21:32
)
优采云文章组合工具集软件功能是一个多功能的伪原创SEO操作工具。该工具主要是帮助网站运营人员优化文章内容,增加文章的权重。保证网站能持续输出有价值的内容;软件包括文章查重、伪原创文章生成,查找关键词词的长短尾词,帮助运营商解码网页内容,生成与网页一致的格式文章code等.;是一款功能更全的SEO网站操作工具,软件的每个功能都采用了比较清晰的布局,用户使用不会觉得凌乱;我相信这个工具可以带给你高效的工作。
软件功能
1、软件支持在线文本编辑和查看本地文本文件。
2、 支持用同义词快速替换文章 中的单词。
3、支持自动词组,让用户快速完成构词造句。
4、 以巧妙的方式组合单词和短语。
5、快速查找和过滤用户需要的词。
6、可以与关键词进行对比,让用户更好的优化词。
7、 支持将文字转成拼音。
8、支持网页的编解码。
9、支持文章去重戏机击重组,提升文章质量。
10、支持采集关键词的长尾词汇。
软件功能
1、无限增加域名,网站,中文站群采集,英文站群采集,指定网址采集,自定义发布界面。
2、自定义生成原创文章、长尾关键词采集、相关图片采集、全球SEO链轮、文章自动加入内链。
3、随机抽取内容为标题,互换不同内容段落,随机插入指定关键词,定时发布文章,自动内容伪原创。
4、分组参数设置,分组链接库内联,自动监听采集发布hook,自动更新网站homepage栏目静态页面等。
5、从句型库中随机抽取句子,插入文章的伪原创函数。
6、文章 批处理方式的导入速度。您还可以同时打开多个窗口和线程在自定义文件夹中导入文章,大大提高了导入速度。
7、文章Publishing 序列添加后进先发参数,方便软文最后优先发布。
8、Open个人版批量删除网站不发和删除文章所有站的功能。
如何使用
1、软件打开就可以直接使用,首先解压安装包,在安装文件下找到“优采云·文章组合工具集.exe”,运行打开。
2、 点击左侧的模板创建一个新模板。选择模板后,再次创建一个新的文本框。
3、选择文本框,将内容复制到软件右侧窗口。
4、点击预览按钮先预览文章。
5、 切换到网页模式进行预览并检查布局是否正确。如果没有问题,点击生成。
6、点击查看,打开如下界面,可以在左下角的文件管理中找到该文档,打开查看。
7、其他功能,如果需要使用,可以直接点击红框中对应的功能进行切换。
8、点击右上角的代码查看,将你要查看的网页的网址复制到输入框中点击阅读网址。该软件还支持网页解码。
9、点击长尾词采集,在该界面根据提示输入关键词,然后选择搜索平台设置相关参数,点击启动采集,长尾采集的字如下图显示窗口显示。
10、点击搜索相似词可以帮助用户用相似词替换文章,防止文章大规模相似导致网页被搜索网站所收录。
11、还可以使用去重和打乱功能对文章进行彻底排序,提高文章的质量。
查看全部
智能采集组合文章(软件功能是一款多功能的伪原创SEO运营工具吗?
)
优采云文章组合工具集软件功能是一个多功能的伪原创SEO操作工具。该工具主要是帮助网站运营人员优化文章内容,增加文章的权重。保证网站能持续输出有价值的内容;软件包括文章查重、伪原创文章生成,查找关键词词的长短尾词,帮助运营商解码网页内容,生成与网页一致的格式文章code等.;是一款功能更全的SEO网站操作工具,软件的每个功能都采用了比较清晰的布局,用户使用不会觉得凌乱;我相信这个工具可以带给你高效的工作。

软件功能
1、软件支持在线文本编辑和查看本地文本文件。
2、 支持用同义词快速替换文章 中的单词。
3、支持自动词组,让用户快速完成构词造句。
4、 以巧妙的方式组合单词和短语。
5、快速查找和过滤用户需要的词。
6、可以与关键词进行对比,让用户更好的优化词。
7、 支持将文字转成拼音。
8、支持网页的编解码。
9、支持文章去重戏机击重组,提升文章质量。
10、支持采集关键词的长尾词汇。
软件功能
1、无限增加域名,网站,中文站群采集,英文站群采集,指定网址采集,自定义发布界面。
2、自定义生成原创文章、长尾关键词采集、相关图片采集、全球SEO链轮、文章自动加入内链。
3、随机抽取内容为标题,互换不同内容段落,随机插入指定关键词,定时发布文章,自动内容伪原创。
4、分组参数设置,分组链接库内联,自动监听采集发布hook,自动更新网站homepage栏目静态页面等。
5、从句型库中随机抽取句子,插入文章的伪原创函数。
6、文章 批处理方式的导入速度。您还可以同时打开多个窗口和线程在自定义文件夹中导入文章,大大提高了导入速度。
7、文章Publishing 序列添加后进先发参数,方便软文最后优先发布。
8、Open个人版批量删除网站不发和删除文章所有站的功能。
如何使用
1、软件打开就可以直接使用,首先解压安装包,在安装文件下找到“优采云·文章组合工具集.exe”,运行打开。
2、 点击左侧的模板创建一个新模板。选择模板后,再次创建一个新的文本框。

3、选择文本框,将内容复制到软件右侧窗口。

4、点击预览按钮先预览文章。

5、 切换到网页模式进行预览并检查布局是否正确。如果没有问题,点击生成。

6、点击查看,打开如下界面,可以在左下角的文件管理中找到该文档,打开查看。

7、其他功能,如果需要使用,可以直接点击红框中对应的功能进行切换。

8、点击右上角的代码查看,将你要查看的网页的网址复制到输入框中点击阅读网址。该软件还支持网页解码。

9、点击长尾词采集,在该界面根据提示输入关键词,然后选择搜索平台设置相关参数,点击启动采集,长尾采集的字如下图显示窗口显示。

10、点击搜索相似词可以帮助用户用相似词替换文章,防止文章大规模相似导致网页被搜索网站所收录。

11、还可以使用去重和打乱功能对文章进行彻底排序,提高文章的质量。

智能采集组合文章(智能采集组合文章之爬虫umm统计系统统计多少词?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-04 17:01
智能采集组合文章吧。采集和加工一下。上传到云词库。然后用词频统计系统统计下,统计多少词。都统计出来了,是2010年的词,大概有80%的概率都是动物,动物的词汇就可以很多了。上传到一个词库。用词频统计就可以了。
直接准备好你的基础数据就行,包括头像,昵称,关键词等等,可以提前上传到云词库里。然后现在做的都是用excel调用云词库的服务,直接提取出来,这是目前普遍用的方法。另外,还有人用adb+bing这个比较特殊,ab词分词,但是看起来很不准。
python爬虫
web上直接爬...
直接抓,
在某宝上找一个上传词库的服务,就是花钱的那种,基本就能抓了,
可以直接用前面很多答案里提到的云词库
直接用爬虫,然后把用户的email给后台,写进云词库就行。
爬虫
假设有多个网站这么多文章,多爬虫啊。
用算法把关键词提取出来,
这就是俗称的爬虫
umm我个人还是很喜欢这个问题的直接爬然后带一个自己的知识库上传就好了对于一篇博文来说还是会有很多细节问题比如标题排列顺序一致等等不同网站的标准或者一致性都不一样有的时候我会因为有些字少而错了那么多个选项而纠结再就是公众号、大学生服务平台一类的如果内容不多的话倒是可以考虑写一个小爬虫的另外上传,这个是有公司专门做这个的花点钱其实也是可以的。 查看全部
智能采集组合文章(智能采集组合文章之爬虫umm统计系统统计多少词?)
智能采集组合文章吧。采集和加工一下。上传到云词库。然后用词频统计系统统计下,统计多少词。都统计出来了,是2010年的词,大概有80%的概率都是动物,动物的词汇就可以很多了。上传到一个词库。用词频统计就可以了。
直接准备好你的基础数据就行,包括头像,昵称,关键词等等,可以提前上传到云词库里。然后现在做的都是用excel调用云词库的服务,直接提取出来,这是目前普遍用的方法。另外,还有人用adb+bing这个比较特殊,ab词分词,但是看起来很不准。
python爬虫
web上直接爬...
直接抓,
在某宝上找一个上传词库的服务,就是花钱的那种,基本就能抓了,
可以直接用前面很多答案里提到的云词库
直接用爬虫,然后把用户的email给后台,写进云词库就行。
爬虫
假设有多个网站这么多文章,多爬虫啊。
用算法把关键词提取出来,
这就是俗称的爬虫
umm我个人还是很喜欢这个问题的直接爬然后带一个自己的知识库上传就好了对于一篇博文来说还是会有很多细节问题比如标题排列顺序一致等等不同网站的标准或者一致性都不一样有的时候我会因为有些字少而错了那么多个选项而纠结再就是公众号、大学生服务平台一类的如果内容不多的话倒是可以考虑写一个小爬虫的另外上传,这个是有公司专门做这个的花点钱其实也是可以的。
智能采集组合文章(配套软件版本:V9及更低集搜客网络爬虫的对应教程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-03 04:15
)
支持软件版本:V9及更低版本的Jisuke网络爬虫软件
新版对应教程:V10及更高版本数据管家-增强版爬虫对应教程为《自动点击京东商品价格条件,智能采集价数据》
当我们浏览商品购物网站时,我们通常可以进行多种组合购买。如果您为同一产品选择颜色、尺寸等,您将得到不同的价格。那么,如果将人类点击行为变成机器自动点击,如何实现?
通过连续动作,模拟人在浏览网页时的操作,一键一键抓取数据。现在很多动态网页都需要交互操作来浏览最终数据,而连续动作的目的是模拟人在浏览网页时的操作,从而获得最终显示的数据。
要模拟人工操作,首先要知道需要哪些交互操作才能显示最终数据。比如在京东浏览小米Max的产品页面时,我们可以看到选择颜色、版本、购买方式后的最终价格1、购方法2。所以,如果按下这个操作,需要设置一个4步动作,这里的动作类型都是点击。搞清楚这些之后,下面就教大家如何利用MS的连续动作来制定规则,实现自动点击。
根据上面的描述,有以下两种采集方案。下面我们使用方案一实现自动点击和采集。
示例网址:规则下载:京东货品_汽车点击
注意:如果动作执行前后网页结构没有变化,可以用一个规则完成;如果网页的结构前后发生变化,必须用两条或两条以上的规则来完成;另外,如果涉及翻页,必须拆分成两个或多个规则。连续动作规则数量请参考文章《规划采集procedures》。
一、创建一级主题获取目标信息
建立一级主题的规则,将想要的信息映射到排序框。建议在内容映射完成后,还要进行定位标记映射,这样可以提高定位精度和规则的适应性。
注意:如果设置了连续动作规则,则不需要构建排序框。比如方案2的一级主题不需要搭建排序框,而是用排序框抓取一点数据(选择要显示在网页上的信息)。由爬虫判断是否执行采集,否则可能会漏掉网页。
二、设置连续动作
点击New按钮新建一个动作,每个动作的设置方法都是一样的,基本操作如下:
2.1 输入目标科目名称
连续动作指向同一个目标对象。如果有多个动作,要指向不同的主题,请拆分成多个规则,分别设置连续动作。
2.2 选择动作类型
本例为点击动作,不同动作的适用范围不同。请根据实际操作情况选择动作类型。
2.3 将定位到动作对象的 xpath 填充到定位表达式中
2.4 输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.5 高级设置
一开始不需要设置,以后调试连续动作时会用到,可以扩大动作的适用范围。如果需要抓取动作对象的信息,可以使用xpath在高级设置的内容表达式中定位动作对象的信息。请根据需要重新设置。
注意:是否选择了动作类型以及xpath定位是否准确,决定了连续动作是否可以成功执行。 Xpath 是一种用于定位 html 节点的标准语言。使用连续动作功能前请自行掌握xpath。
根据人工操作步骤,我们还需要选择版本和购买方式1、买方法2,所以我们会继续新建3个动作,重复以上步骤。
三、调试规则
完成上述步骤后,单击“保存规则”,然后单击“抓取数据”按钮开始尝试捕获。发现采集报错:Unable to locate the node***。观察浏览器窗口,看到执行第一步时,没有加载其他信息。加载信息时,发现购买方式2点击后,无法返回执行4步点击的页面,导致连续动作不断执行。<//p
pimg src='http://www.gooseeker.com/doc/data/attachment/portal/201607/26/173412wflkffpveleuvkv0.png' alt=''//p
pimg src='http://www.gooseeker.com/doc/data/attachment/portal/201607/26/173415hllg8nzulgi5emn1.png' alt=''//p
p针对以上情况,我们的解决方案是删除第四步。因为无论是否点击购买方式2,都不会影响商品的价格。因此,可以删除不必要的和令人不安的操作步骤。/p
p修改后,再次尝试捕捉。将提取的xml转换为excel后,看到价格和累计评价数据被抓取或抓取错误。这是因为网页太大,加载速度慢,点击后的数据需要等待一段时间才能加载。/p
pimg src='http://www.gooseeker.com/doc/data/attachment/portal/201607/26/173417mt3zt9joz5j6xj59.png' alt=''//p
p为了捕获所有数据,您需要延长等待时间并为每个动作单独设置延迟。单击操作步骤-> 高级设置-> 额外延迟,并输入一个以秒为单位的正整数。请按实际时间调试。
另外,如果不是粘性窗口,采集时会反复点击。这是因为京东网页上有防爬措施,必须是当前窗口的操作才能生效。因此,在高级设置中勾选窗口可见,采集时窗口会在最上面。请根据实际情况设置。
四、如何将抓取到的信息与动作步骤一一对应?
如果要将捕获的信息与动作步骤一一关联,那么就必须提取动作对象的信息。有两种方式:
4.1 使用xpath在连续动作的高级设置的内容表达式中定位动作对象的信息节点。
定位表达式定位到动作对象的整个操作范围后,还收录了自身的信息。因此,内容表达只需要从定位的动作对象开始,继续定位到它的信息。 采集会在actionvalue中记录step动作的信息,对应actionno,记录动作执行的次数。
4.2 抓取排序框中动作对象的信息,这里也使用xpath定位。
当action对象被执行时,它的dom结构发生了变化。找到网页变化的结构特征,使用xpath准确定位节点,验证通过后可以设置自定义xpath。
以上是使用连续动作模拟人工操作的全过程。虽然过程比较繁琐,但只要细心耐心,最终还是可以征服你想要爬取的网页。
如果您有任何问题,可以或
查看全部
智能采集组合文章(配套软件版本:V9及更低集搜客网络爬虫的对应教程
)
支持软件版本:V9及更低版本的Jisuke网络爬虫软件
新版对应教程:V10及更高版本数据管家-增强版爬虫对应教程为《自动点击京东商品价格条件,智能采集价数据》
当我们浏览商品购物网站时,我们通常可以进行多种组合购买。如果您为同一产品选择颜色、尺寸等,您将得到不同的价格。那么,如果将人类点击行为变成机器自动点击,如何实现?
通过连续动作,模拟人在浏览网页时的操作,一键一键抓取数据。现在很多动态网页都需要交互操作来浏览最终数据,而连续动作的目的是模拟人在浏览网页时的操作,从而获得最终显示的数据。
要模拟人工操作,首先要知道需要哪些交互操作才能显示最终数据。比如在京东浏览小米Max的产品页面时,我们可以看到选择颜色、版本、购买方式后的最终价格1、购方法2。所以,如果按下这个操作,需要设置一个4步动作,这里的动作类型都是点击。搞清楚这些之后,下面就教大家如何利用MS的连续动作来制定规则,实现自动点击。

根据上面的描述,有以下两种采集方案。下面我们使用方案一实现自动点击和采集。

示例网址:规则下载:京东货品_汽车点击
注意:如果动作执行前后网页结构没有变化,可以用一个规则完成;如果网页的结构前后发生变化,必须用两条或两条以上的规则来完成;另外,如果涉及翻页,必须拆分成两个或多个规则。连续动作规则数量请参考文章《规划采集procedures》。
一、创建一级主题获取目标信息
建立一级主题的规则,将想要的信息映射到排序框。建议在内容映射完成后,还要进行定位标记映射,这样可以提高定位精度和规则的适应性。
注意:如果设置了连续动作规则,则不需要构建排序框。比如方案2的一级主题不需要搭建排序框,而是用排序框抓取一点数据(选择要显示在网页上的信息)。由爬虫判断是否执行采集,否则可能会漏掉网页。

二、设置连续动作
点击New按钮新建一个动作,每个动作的设置方法都是一样的,基本操作如下:
2.1 输入目标科目名称
连续动作指向同一个目标对象。如果有多个动作,要指向不同的主题,请拆分成多个规则,分别设置连续动作。
2.2 选择动作类型
本例为点击动作,不同动作的适用范围不同。请根据实际操作情况选择动作类型。
2.3 将定位到动作对象的 xpath 填充到定位表达式中
2.4 输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.5 高级设置
一开始不需要设置,以后调试连续动作时会用到,可以扩大动作的适用范围。如果需要抓取动作对象的信息,可以使用xpath在高级设置的内容表达式中定位动作对象的信息。请根据需要重新设置。
注意:是否选择了动作类型以及xpath定位是否准确,决定了连续动作是否可以成功执行。 Xpath 是一种用于定位 html 节点的标准语言。使用连续动作功能前请自行掌握xpath。

根据人工操作步骤,我们还需要选择版本和购买方式1、买方法2,所以我们会继续新建3个动作,重复以上步骤。



三、调试规则
完成上述步骤后,单击“保存规则”,然后单击“抓取数据”按钮开始尝试捕获。发现采集报错:Unable to locate the node***。观察浏览器窗口,看到执行第一步时,没有加载其他信息。加载信息时,发现购买方式2点击后,无法返回执行4步点击的页面,导致连续动作不断执行。<//p
pimg src='http://www.gooseeker.com/doc/data/attachment/portal/201607/26/173412wflkffpveleuvkv0.png' alt=''//p
pimg src='http://www.gooseeker.com/doc/data/attachment/portal/201607/26/173415hllg8nzulgi5emn1.png' alt=''//p
p针对以上情况,我们的解决方案是删除第四步。因为无论是否点击购买方式2,都不会影响商品的价格。因此,可以删除不必要的和令人不安的操作步骤。/p
p修改后,再次尝试捕捉。将提取的xml转换为excel后,看到价格和累计评价数据被抓取或抓取错误。这是因为网页太大,加载速度慢,点击后的数据需要等待一段时间才能加载。/p
pimg src='http://www.gooseeker.com/doc/data/attachment/portal/201607/26/173417mt3zt9joz5j6xj59.png' alt=''//p
p为了捕获所有数据,您需要延长等待时间并为每个动作单独设置延迟。单击操作步骤-> 高级设置-> 额外延迟,并输入一个以秒为单位的正整数。请按实际时间调试。
另外,如果不是粘性窗口,采集时会反复点击。这是因为京东网页上有防爬措施,必须是当前窗口的操作才能生效。因此,在高级设置中勾选窗口可见,采集时窗口会在最上面。请根据实际情况设置。


四、如何将抓取到的信息与动作步骤一一对应?
如果要将捕获的信息与动作步骤一一关联,那么就必须提取动作对象的信息。有两种方式:
4.1 使用xpath在连续动作的高级设置的内容表达式中定位动作对象的信息节点。
定位表达式定位到动作对象的整个操作范围后,还收录了自身的信息。因此,内容表达只需要从定位的动作对象开始,继续定位到它的信息。 采集会在actionvalue中记录step动作的信息,对应actionno,记录动作执行的次数。


4.2 抓取排序框中动作对象的信息,这里也使用xpath定位。
当action对象被执行时,它的dom结构发生了变化。找到网页变化的结构特征,使用xpath准确定位节点,验证通过后可以设置自定义xpath。


以上是使用连续动作模拟人工操作的全过程。虽然过程比较繁琐,但只要细心耐心,最终还是可以征服你想要爬取的网页。
如果您有任何问题,可以或

智能采集组合文章(用考拉,一天产出几万篇高质量SEO文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 463 次浏览 • 2021-09-01 17:15
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批写SEO原创文章】平台发布的。有了考拉,一天可以产出数万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
非常抱歉,现在当您点击进入该网页时,可能您浏览的信息不是关于文章采集仓储的报告,因为该页面是我们系统批量编写的网页文章。如果对自动化原创平台的信息感兴趣,不妨先放弃文章采集仓储这件事。推荐大家看看如何借用工具半天制作10000个优质搜索文案!大多数看过考拉SEO资料的人都会认为这是伪原创系统,误会!网站本质上是一个AI平台,关键词和模块都是自己写的,网上基本没有和这篇文章很相似的作品。这个平台是如何创建的?让我为你读一读!
不断向数据库伙伴查询文章采集,毕竟你最关心的是之前文章研究的内容。其实,写几篇优化好的落地文章很容易,但是这些SEO文案能拿到的访问量,其实总比没有好。希望通过页面设置达到流量的目的。最重要的一点是自动化!如果文章1篇文章可以收获1个访问者(每天),如果我可以写10,000篇文章,则平均每天的页面浏览量可以增加10,000。但简单来说,真正写出来的时候,一个人一天只能出40篇文章,最好是70篇左右。就算用伪原创software,最多也只有100篇!读到这点,我们可以先抛开文章采集入库的问题,想想如何完成批量写入文章!
seo 识别的原创 是什么?文字原创不一定是一一关键词原创输出!在各大搜索引擎的算法词典中,原创并不是唯一的。事实上,每当你的文字堆叠与其他网站内容不同时,收录的概率就会大大增加。一个高质量的内容,题材抢眼,保留了相同的核心思想,只要保证重复大段,就说明文章还是很可能是收录,甚至变成爆文。就像下一篇文章,你可能已经通过百度搜索文章采集,然后点进去了。 其实下一篇文章就是用考拉SEO智能写作文章system自助出口!
考拉的AI原创系统其实应该是一个自动的文章平台,24小时可以生成10000篇文章,可靠的优化文章,而且每个人的网站权重都应该够高,收录率可以高达 78% 或更高。详细的操作方法,个人主页收录视频展示和初学者指南。大佬们不妨免费试一试!很抱歉不能给你详细介绍文章采集仓储,可能让你看了这么多系统语言。但是如果我们喜欢考拉SEO的内容,请看菜单栏,让大家网站每天达到数千人,你不喜欢吗? 查看全部
智能采集组合文章(用考拉,一天产出几万篇高质量SEO文章)
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批写SEO原创文章】平台发布的。有了考拉,一天可以产出数万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
非常抱歉,现在当您点击进入该网页时,可能您浏览的信息不是关于文章采集仓储的报告,因为该页面是我们系统批量编写的网页文章。如果对自动化原创平台的信息感兴趣,不妨先放弃文章采集仓储这件事。推荐大家看看如何借用工具半天制作10000个优质搜索文案!大多数看过考拉SEO资料的人都会认为这是伪原创系统,误会!网站本质上是一个AI平台,关键词和模块都是自己写的,网上基本没有和这篇文章很相似的作品。这个平台是如何创建的?让我为你读一读!

不断向数据库伙伴查询文章采集,毕竟你最关心的是之前文章研究的内容。其实,写几篇优化好的落地文章很容易,但是这些SEO文案能拿到的访问量,其实总比没有好。希望通过页面设置达到流量的目的。最重要的一点是自动化!如果文章1篇文章可以收获1个访问者(每天),如果我可以写10,000篇文章,则平均每天的页面浏览量可以增加10,000。但简单来说,真正写出来的时候,一个人一天只能出40篇文章,最好是70篇左右。就算用伪原创software,最多也只有100篇!读到这点,我们可以先抛开文章采集入库的问题,想想如何完成批量写入文章!
seo 识别的原创 是什么?文字原创不一定是一一关键词原创输出!在各大搜索引擎的算法词典中,原创并不是唯一的。事实上,每当你的文字堆叠与其他网站内容不同时,收录的概率就会大大增加。一个高质量的内容,题材抢眼,保留了相同的核心思想,只要保证重复大段,就说明文章还是很可能是收录,甚至变成爆文。就像下一篇文章,你可能已经通过百度搜索文章采集,然后点进去了。 其实下一篇文章就是用考拉SEO智能写作文章system自助出口!

考拉的AI原创系统其实应该是一个自动的文章平台,24小时可以生成10000篇文章,可靠的优化文章,而且每个人的网站权重都应该够高,收录率可以高达 78% 或更高。详细的操作方法,个人主页收录视频展示和初学者指南。大佬们不妨免费试一试!很抱歉不能给你详细介绍文章采集仓储,可能让你看了这么多系统语言。但是如果我们喜欢考拉SEO的内容,请看菜单栏,让大家网站每天达到数千人,你不喜欢吗?
智能采集组合文章(繁殖侠站群PHP目录繁殖版只限量出售5套)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-01 06:21
育种man站群PHP目录复制版,本程序是麦芒团队高端定制目录内页复制特别版,租用目录可快速排名,支持上千个主目录同时生成内页时间,页面的定量再现,关键词对应锚文本链接,关键词转码,自动生成站点地图页面,自动将生成的页面链接插入首页,汇聚最实用的操作方法当前搜索引擎排名。程序使用php编程语言,无后门程序,符合互联网使用规则。该程序不限制行业使用。一经售出,使用该程序的用户所经营的站群业务是否合理与作者无关。我们只负责程序的后台开发,特此声明!
节目授权:Breeder制作的任何节目限发行数量,(咨询特价)/年续订(咨询特价)3台服务器无限授权,每台服务器添加(咨询特价)。
绑定机器码、IP硬件码,购买授权后可修改5X24小时技术服务跟进!
程序采用独立多重验证,发现恶意传播程序停止免费更新!严格限制是为了防止程序泛滥,起到更大的作用
站长朋友应该知道,作者再厉害,只要程序被大规模使用,就会被搜索引擎关注。育种英雄站群PHP旗舰版限量5套,售完即删帖!
限制程序防止购买,请作者8
一个。程序可在windows和unix操作系统下运行
程序运行需要的环境,php5.4+zendopminizer 我们将提供用户下载这些环境包,并将受控端index.php转移到目录下执行,生成内部页面文件。
B.主机与受控端负载均衡
为了提高站群运行的效率,程序分为主机、主机、网关三部分进行负载均衡。主机是复现生成的内部页面文件的核心,需要上传到权重目录,主机终端只需要租用一个普通的VPS。使用采集每日最新消息、图片等素材,挂机24小时提供站群必的文章等资源给受控端。如果你是资金实力雄厚的公司团队,可以使用专用的独立服务器来做主机,无论你复制多少目录,只需要一个公有主机,网关用来接收生成的链接地址。不管你有多少目录,或者有多少复制服务器,你只需要一个网关,就可以实时接收所有的URL链接,并以指定的格式保存。可以直接在你的蜘蛛池下生成,让站群养殖和蜘蛛池无缝对接,无需手动复制粘贴。剩下的事情就是泡一杯茶,享受悠闲的午后生活。是时候检查生成的url和百度收录了。
c.复制生成的URL内页链接,由蜘蛛池网关自动监听接收
受控端复制生成的url提供多种保存格式
1、纯url模式可以直接提供给蜘蛛池调用2.url+title方便你以后转载链接或者发帖提取对应的标题。
d。主控端分离,采集news、图片、视频、标题等实时更新内容
假设主机在普通 VPS 中。 IIS环境,使用独立工具挂采集文章、图片、动画、文档等资料。即公共数据服务器。
e.控制端转入网站目录控制复现
核心再现程序要转移到目录中。只需要访问index.php获取配置参数和master文章即可复制。
f、智能蜘蛛和人类分别访问
为了满足部分客户的需求,程序设计了蜘蛛访问和人工访问的区别,可以设置蜘蛛访问触发复现。或者手动访问触发复制。
g、支持蜘蛛访问触发繁殖
访问主程序index.php时,触发复现的配置参数设置为spider trigger,主程序开始调用主控数据和复现页面关键词。
h,支持人访问触发复现
访问主程序index.php时,触发复现的配置参数设置为手动触发,主程序开始调用主控数据和复现页面关键词,同时支持爬虫和人工造访触发繁殖
i、config.ini 集中配置各种参数进行复现
为了方便用户管理,主程序使用受控终端config.ini中设置的参数。中文界面一目了然。
j、锁科技锁
目录和内页站群一直存在并发展到今天。它们不是搜索引擎的第一个迹象。它们并不是罕见的排名操作。排名如何稳稳靠前,并不取决于主程序的复现次数,而是相反。 , 转载页数越多,越频繁,越容易被搜索引擎识别为垃圾站群,K减肥,所以我们增加了转载LOCK锁定技术,用户可以配置频率和数量主程序自行再现,当超过我们主程序将进入设定量的冷却时间。
k。随机复制音量,拒绝机械式
为了繁殖搜索引擎识别为垃圾邮件bringing站群,我们为用户提供繁殖数量的上下限设置参数。程序会读取一个上下限之间的随机数进行复制,比如你设置的复制最小数量为5.最大复制数量为15,程序可能随机复制10页。
我。新增养殖冷却时间,拒绝大量养殖垃圾站群,
冷却时间在被控端的config.ini中设置。单位为分钟,表示培育一批站群后等待下一个培育任务的分钟数。
m,在冷却时间内,自动加载sitemap.php
在冷却时间内,主程序不会读取宿主机数据,也不会进行复制,但会为蜘蛛提供一个动态网页列表供蜘蛛抓取,类似于sitemaps
n。转载的页面会自动插入到指定页面,不只是首页
复制生成的url自动插入首页源码,自动区分gb-2312和utf-8编码
o,可设置插入次数
首页的url可以在url中插入设置插入次数,可以在config.ini下配置。同时可以设置主页的冷却时间,防止主程序频繁篡改主页源代码导致降级。
p、特权复制、优先批量特权复制指定页面
主程序支持最优权限复制,可指定页面关键词。如需使用该功能,请在config.ini中打开该功能。
q。按比例复制有关键词和没有关键词的页面,比例可设置
可以配置带有关键词 的促销页面和常规新闻页面。比例可以在config.ini中设置。
R,目录格式和文件格式可自由配置
支持目录和文件后缀格式自定义。每行一个
s,纯新闻页面和带有关键词的页面有独立的目录格式和文件格式配置文件
带有关键词的页面和新闻页面的目录格式和文件格式是独立配置的。
t,纯新闻页面和带有关键词的页面有独立的模板
纯新闻页面和重点排名页面具有独立的模板路径。更有利于优化
u,支持同一个主站域名下多个层次目录的并发复制
一个主域名下可以多个目录叠加。
v.主页网格智能识别可在配置中修改添加主页识别格式文件
智能阅读首页模板,主程序识别我们配置的首页尸体 查看全部
智能采集组合文章(繁殖侠站群PHP目录繁殖版只限量出售5套)
育种man站群PHP目录复制版,本程序是麦芒团队高端定制目录内页复制特别版,租用目录可快速排名,支持上千个主目录同时生成内页时间,页面的定量再现,关键词对应锚文本链接,关键词转码,自动生成站点地图页面,自动将生成的页面链接插入首页,汇聚最实用的操作方法当前搜索引擎排名。程序使用php编程语言,无后门程序,符合互联网使用规则。该程序不限制行业使用。一经售出,使用该程序的用户所经营的站群业务是否合理与作者无关。我们只负责程序的后台开发,特此声明!
节目授权:Breeder制作的任何节目限发行数量,(咨询特价)/年续订(咨询特价)3台服务器无限授权,每台服务器添加(咨询特价)。
绑定机器码、IP硬件码,购买授权后可修改5X24小时技术服务跟进!
程序采用独立多重验证,发现恶意传播程序停止免费更新!严格限制是为了防止程序泛滥,起到更大的作用
站长朋友应该知道,作者再厉害,只要程序被大规模使用,就会被搜索引擎关注。育种英雄站群PHP旗舰版限量5套,售完即删帖!
限制程序防止购买,请作者8
一个。程序可在windows和unix操作系统下运行
程序运行需要的环境,php5.4+zendopminizer 我们将提供用户下载这些环境包,并将受控端index.php转移到目录下执行,生成内部页面文件。

B.主机与受控端负载均衡
为了提高站群运行的效率,程序分为主机、主机、网关三部分进行负载均衡。主机是复现生成的内部页面文件的核心,需要上传到权重目录,主机终端只需要租用一个普通的VPS。使用采集每日最新消息、图片等素材,挂机24小时提供站群必的文章等资源给受控端。如果你是资金实力雄厚的公司团队,可以使用专用的独立服务器来做主机,无论你复制多少目录,只需要一个公有主机,网关用来接收生成的链接地址。不管你有多少目录,或者有多少复制服务器,你只需要一个网关,就可以实时接收所有的URL链接,并以指定的格式保存。可以直接在你的蜘蛛池下生成,让站群养殖和蜘蛛池无缝对接,无需手动复制粘贴。剩下的事情就是泡一杯茶,享受悠闲的午后生活。是时候检查生成的url和百度收录了。
c.复制生成的URL内页链接,由蜘蛛池网关自动监听接收

受控端复制生成的url提供多种保存格式
1、纯url模式可以直接提供给蜘蛛池调用2.url+title方便你以后转载链接或者发帖提取对应的标题。
d。主控端分离,采集news、图片、视频、标题等实时更新内容
假设主机在普通 VPS 中。 IIS环境,使用独立工具挂采集文章、图片、动画、文档等资料。即公共数据服务器。
e.控制端转入网站目录控制复现
核心再现程序要转移到目录中。只需要访问index.php获取配置参数和master文章即可复制。
f、智能蜘蛛和人类分别访问
为了满足部分客户的需求,程序设计了蜘蛛访问和人工访问的区别,可以设置蜘蛛访问触发复现。或者手动访问触发复制。
g、支持蜘蛛访问触发繁殖
访问主程序index.php时,触发复现的配置参数设置为spider trigger,主程序开始调用主控数据和复现页面关键词。
h,支持人访问触发复现
访问主程序index.php时,触发复现的配置参数设置为手动触发,主程序开始调用主控数据和复现页面关键词,同时支持爬虫和人工造访触发繁殖
i、config.ini 集中配置各种参数进行复现
为了方便用户管理,主程序使用受控终端config.ini中设置的参数。中文界面一目了然。
j、锁科技锁
目录和内页站群一直存在并发展到今天。它们不是搜索引擎的第一个迹象。它们并不是罕见的排名操作。排名如何稳稳靠前,并不取决于主程序的复现次数,而是相反。 , 转载页数越多,越频繁,越容易被搜索引擎识别为垃圾站群,K减肥,所以我们增加了转载LOCK锁定技术,用户可以配置频率和数量主程序自行再现,当超过我们主程序将进入设定量的冷却时间。
k。随机复制音量,拒绝机械式
为了繁殖搜索引擎识别为垃圾邮件bringing站群,我们为用户提供繁殖数量的上下限设置参数。程序会读取一个上下限之间的随机数进行复制,比如你设置的复制最小数量为5.最大复制数量为15,程序可能随机复制10页。
我。新增养殖冷却时间,拒绝大量养殖垃圾站群,
冷却时间在被控端的config.ini中设置。单位为分钟,表示培育一批站群后等待下一个培育任务的分钟数。
m,在冷却时间内,自动加载sitemap.php
在冷却时间内,主程序不会读取宿主机数据,也不会进行复制,但会为蜘蛛提供一个动态网页列表供蜘蛛抓取,类似于sitemaps
n。转载的页面会自动插入到指定页面,不只是首页
复制生成的url自动插入首页源码,自动区分gb-2312和utf-8编码
o,可设置插入次数
首页的url可以在url中插入设置插入次数,可以在config.ini下配置。同时可以设置主页的冷却时间,防止主程序频繁篡改主页源代码导致降级。
p、特权复制、优先批量特权复制指定页面
主程序支持最优权限复制,可指定页面关键词。如需使用该功能,请在config.ini中打开该功能。
q。按比例复制有关键词和没有关键词的页面,比例可设置
可以配置带有关键词 的促销页面和常规新闻页面。比例可以在config.ini中设置。
R,目录格式和文件格式可自由配置
支持目录和文件后缀格式自定义。每行一个
s,纯新闻页面和带有关键词的页面有独立的目录格式和文件格式配置文件
带有关键词的页面和新闻页面的目录格式和文件格式是独立配置的。
t,纯新闻页面和带有关键词的页面有独立的模板
纯新闻页面和重点排名页面具有独立的模板路径。更有利于优化
u,支持同一个主站域名下多个层次目录的并发复制
一个主域名下可以多个目录叠加。
v.主页网格智能识别可在配置中修改添加主页识别格式文件
智能阅读首页模板,主程序识别我们配置的首页尸体
智能采集组合文章(龙都站群引擎V1.3注册机无限制破解版[综合营销])
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-08-31 07:19
近期发布的相关软件:
Longdu站群EngineV1.3 无限破解版【全面营销】 Longdu站群EngineV1.3 注册无限破解版【全面营销】
Longdu站群EngineV1.3
Longdu站群是什么?
Longdu站群是一款全自动保护建站工具。可以自动从输入的短尾关键词中获取相关的深长尾关键词,再获取长尾关键词采集文章,让你的网站朝气焕发,带来无限的深度流量!他可以自动保护网站!这是一个智能的在线赚钱工具!自动采集,自动更新,自动保护,轻松获取大量IP!龙都站群软件你可以轻松设置几个10、几百甚至几千个网站!
Longdu站群的神器出来了:规划思路之一是将优化参数准确设置到网站的任意一列!也就是说,我们的优化设置参数在同一个网站不同列之间是完整的,可以不同设置,市面上所谓的站群软件参数设置都是全局的,也就是说,如果没有设置优化参数,所有网站all 列都是共享的,所以效果极差,所以我们的优化参数设置不是全局的,而是针对一个列单独设置的!所以弱化了longdu站群中网站的概念,加强了网站列的概念,Longdu站群中每创建一个新任务其实就是为网站的一个列,这样做可以使优化效果更有针对性!
你为什么要站群?
做网站的最终目的很简单,就是为了获得流量,最后通过流量做广告,获得收入!大概是做产品销售来增加产品的知名度,然后交易量就会增加。
纯手工网站固然可以取得更好的效果,但是需要大量的脑力和财力。就算能实现几万个IP的日流量,也只有个人网站能做到,工作效率低下。使用软件大量建站可以避免单调的机械操作。我们知道一个词——团结就是力量。这就是站群的基本原理,举个例子,举个简单的例子
假设1网站日流量1000IP(这是最保守的估计也是最容易到达的,一个站一天做1000IP很简单)
所以....
每天10个网站就是10*1000=10000个IP
每天100个网站就是100*1000=100000个IP
1000网站一天就是1000*1000=1000000个IP
百万流量就是这么来的~~
而且这整个过程都是由软件完成的,是全自动的!
Longdu站群为什么会带来这个流量?
Longdu站群有最新的伪原创和原创采集接口以及各种网站采集接口。通过这些接口,站长可以轻松保护成百上千个站点的保护!网站基本上可以分解为4个步骤:content采集、内容处理、content原创、内容公告,接下来让我们看看 Longdu站群 如何处理这些方面。
Content采集:
Longdu站群内置keyword采集引擎,可以深度获取各种主流搜索引擎(百度、搜狗、搜搜)的采集keywords,从而有效的采集长尾关键词,有哪些长尾关键词的好处?因为短尾关键词(比如:花),当用户输入这个关键词进行搜索时,结果是一些大的网站可能一些权重很高的网站,到一些小的网站,排名基本上是不在当前位置之前。如果我们的网站上面堆满了这些关键词,基本上是无效的!但是我们可以看看搜索的结果,下面会列出一些相关的搜索。相反,这些相关的关键字比我们输入的关键字的长度要长。当我们点击这些关键词时,我们会发现搜索相关关键词甚至更长(例如:上海闵行鲜花速递、闵行新庄鲜花速递等)目前可以看到这些长尾关键词的后果很少,而且最重要的是:排名靠前的网站有些小网站不大网站,是的!这就是长尾关键词的效果。毕竟我们要把我们的网站通太长尾关键词放在最上面,那么我们的流量会变得非常可观!
接近主题,那我们是怎么得到长尾关键词的呢?在longdu站群中,我们只需要输入一个seed关键字(比如我们刚才说的“花”),系统会自动持有更多层的key system的过滤,采集提取的时间最长和最高质量的关键词(长尾关键词),而这个采集过程是通过采集的很多层选择出来的,所以关键词的质量是有保证的,普通对于普通深度,我们可以从一个得到80个长尾关键词种子关键词,深度挖掘会议100个关键词
对于高质量的长尾关键词,站群会用这些关键词来持有采集文章,从源头上保证质量,而且因为每次输入一个关键词,采集80-100长尾关键词,无需为每个任务设置多个关键词,省时省力!
而Longdu站群是一个真正的多线程处理系统。 采集的当下,每个任务最多可以开10个线程,采集飞速,不能说!
内容处理:
Longdu站群的采集由一个名为“采集interface”的模块完成。为了保证程序的可扩展性,所有采集接口都是可控的!在采集界面中,可以控制采集内容的质量。比如可以选择保存或删除文章中的图片,是否删除HTML格式等,所有网页格式都可以在界面中掌握!
同时我们内置了龙都内容提取模块,可以高效、高质量地提取肆意网页的有效内容(自动识别网站coding),以及龙都@的所有接口模块站群原则上可以采集蠢意网站!
Content原创:
原创度的内容是衡量采集器效果的最重要因素!虽然站群的数量也很重要,但是内容的原创度直接影响网站的收录于流,因为采集没有任何处理就过来了,文章没有影响,这个那种会议被搜索引擎认出来给网站降权!
Longdu站群内置大量伪原创处理模块:
①关于内容:打乱句子顺序、替换同义词、立即删除句子、选择句子汉英汉翻译、多个文章控股组合、标题添加内容、采集keywords(种子关键词)添加内容、相关关键词(长尾关键词)添加内容、字体转换(简体、繁体、火星)
②关于标题:Longdu站群承诺对标题进行肆意的自定义掌握。支持相关关键词(长尾关键词)按指定数量组合,原标题为前、中、后。添加长尾关键词,然后截取原标题,在前、中、后添加长尾关键词。自己输入的关键词或词组可以和标题组合,标题可以加指定字符(比如我们输入词组的绿色版|免费版|破解版,我们的采集关键词就是名字各种软件,那么合并的标题将是该软件的绿色版,该软件的免费版等...)
而且我们还在采集接口中完整地内置了原创的采集接口,这是采集器不会有的接口,属于我们龙都的创立!
另外文章组合、原创采集interface等一系列功能都是我们Longdu站群独有的!
如此强大的功能并不意味着软件的使用变得复杂。在我们规划软件时,简单易用始终是我们的座右铭。因此,我们任务编辑模块中的所有伪原创functions 都是基于选项。情况呈现(除了需要输入和输入的必要关键字),您无需费心进行更正!完好无损傻瓜式operation!
内容公告:
龙都站群的数据发布界面很强大!支持网站直接存储,也支持将存储接口(ASP或PHP程序)上传到目标网站然后在程序中发布接口。数据。
<p>这里我们直接连接支持肆意网站的存储,因为它基于网站get/post协议,只要存储模块做好,任何网站都可以持有数据公告 查看全部
智能采集组合文章(龙都站群引擎V1.3注册机无限制破解版[综合营销])
近期发布的相关软件:
Longdu站群EngineV1.3 无限破解版【全面营销】 Longdu站群EngineV1.3 注册无限破解版【全面营销】
Longdu站群EngineV1.3
Longdu站群是什么?
Longdu站群是一款全自动保护建站工具。可以自动从输入的短尾关键词中获取相关的深长尾关键词,再获取长尾关键词采集文章,让你的网站朝气焕发,带来无限的深度流量!他可以自动保护网站!这是一个智能的在线赚钱工具!自动采集,自动更新,自动保护,轻松获取大量IP!龙都站群软件你可以轻松设置几个10、几百甚至几千个网站!
Longdu站群的神器出来了:规划思路之一是将优化参数准确设置到网站的任意一列!也就是说,我们的优化设置参数在同一个网站不同列之间是完整的,可以不同设置,市面上所谓的站群软件参数设置都是全局的,也就是说,如果没有设置优化参数,所有网站all 列都是共享的,所以效果极差,所以我们的优化参数设置不是全局的,而是针对一个列单独设置的!所以弱化了longdu站群中网站的概念,加强了网站列的概念,Longdu站群中每创建一个新任务其实就是为网站的一个列,这样做可以使优化效果更有针对性!
你为什么要站群?
做网站的最终目的很简单,就是为了获得流量,最后通过流量做广告,获得收入!大概是做产品销售来增加产品的知名度,然后交易量就会增加。
纯手工网站固然可以取得更好的效果,但是需要大量的脑力和财力。就算能实现几万个IP的日流量,也只有个人网站能做到,工作效率低下。使用软件大量建站可以避免单调的机械操作。我们知道一个词——团结就是力量。这就是站群的基本原理,举个例子,举个简单的例子
假设1网站日流量1000IP(这是最保守的估计也是最容易到达的,一个站一天做1000IP很简单)
所以....
每天10个网站就是10*1000=10000个IP
每天100个网站就是100*1000=100000个IP
1000网站一天就是1000*1000=1000000个IP
百万流量就是这么来的~~
而且这整个过程都是由软件完成的,是全自动的!
Longdu站群为什么会带来这个流量?
Longdu站群有最新的伪原创和原创采集接口以及各种网站采集接口。通过这些接口,站长可以轻松保护成百上千个站点的保护!网站基本上可以分解为4个步骤:content采集、内容处理、content原创、内容公告,接下来让我们看看 Longdu站群 如何处理这些方面。
Content采集:
Longdu站群内置keyword采集引擎,可以深度获取各种主流搜索引擎(百度、搜狗、搜搜)的采集keywords,从而有效的采集长尾关键词,有哪些长尾关键词的好处?因为短尾关键词(比如:花),当用户输入这个关键词进行搜索时,结果是一些大的网站可能一些权重很高的网站,到一些小的网站,排名基本上是不在当前位置之前。如果我们的网站上面堆满了这些关键词,基本上是无效的!但是我们可以看看搜索的结果,下面会列出一些相关的搜索。相反,这些相关的关键字比我们输入的关键字的长度要长。当我们点击这些关键词时,我们会发现搜索相关关键词甚至更长(例如:上海闵行鲜花速递、闵行新庄鲜花速递等)目前可以看到这些长尾关键词的后果很少,而且最重要的是:排名靠前的网站有些小网站不大网站,是的!这就是长尾关键词的效果。毕竟我们要把我们的网站通太长尾关键词放在最上面,那么我们的流量会变得非常可观!
接近主题,那我们是怎么得到长尾关键词的呢?在longdu站群中,我们只需要输入一个seed关键字(比如我们刚才说的“花”),系统会自动持有更多层的key system的过滤,采集提取的时间最长和最高质量的关键词(长尾关键词),而这个采集过程是通过采集的很多层选择出来的,所以关键词的质量是有保证的,普通对于普通深度,我们可以从一个得到80个长尾关键词种子关键词,深度挖掘会议100个关键词
对于高质量的长尾关键词,站群会用这些关键词来持有采集文章,从源头上保证质量,而且因为每次输入一个关键词,采集80-100长尾关键词,无需为每个任务设置多个关键词,省时省力!
而Longdu站群是一个真正的多线程处理系统。 采集的当下,每个任务最多可以开10个线程,采集飞速,不能说!
内容处理:
Longdu站群的采集由一个名为“采集interface”的模块完成。为了保证程序的可扩展性,所有采集接口都是可控的!在采集界面中,可以控制采集内容的质量。比如可以选择保存或删除文章中的图片,是否删除HTML格式等,所有网页格式都可以在界面中掌握!
同时我们内置了龙都内容提取模块,可以高效、高质量地提取肆意网页的有效内容(自动识别网站coding),以及龙都@的所有接口模块站群原则上可以采集蠢意网站!
Content原创:
原创度的内容是衡量采集器效果的最重要因素!虽然站群的数量也很重要,但是内容的原创度直接影响网站的收录于流,因为采集没有任何处理就过来了,文章没有影响,这个那种会议被搜索引擎认出来给网站降权!
Longdu站群内置大量伪原创处理模块:
①关于内容:打乱句子顺序、替换同义词、立即删除句子、选择句子汉英汉翻译、多个文章控股组合、标题添加内容、采集keywords(种子关键词)添加内容、相关关键词(长尾关键词)添加内容、字体转换(简体、繁体、火星)
②关于标题:Longdu站群承诺对标题进行肆意的自定义掌握。支持相关关键词(长尾关键词)按指定数量组合,原标题为前、中、后。添加长尾关键词,然后截取原标题,在前、中、后添加长尾关键词。自己输入的关键词或词组可以和标题组合,标题可以加指定字符(比如我们输入词组的绿色版|免费版|破解版,我们的采集关键词就是名字各种软件,那么合并的标题将是该软件的绿色版,该软件的免费版等...)
而且我们还在采集接口中完整地内置了原创的采集接口,这是采集器不会有的接口,属于我们龙都的创立!
另外文章组合、原创采集interface等一系列功能都是我们Longdu站群独有的!
如此强大的功能并不意味着软件的使用变得复杂。在我们规划软件时,简单易用始终是我们的座右铭。因此,我们任务编辑模块中的所有伪原创functions 都是基于选项。情况呈现(除了需要输入和输入的必要关键字),您无需费心进行更正!完好无损傻瓜式operation!
内容公告:
龙都站群的数据发布界面很强大!支持网站直接存储,也支持将存储接口(ASP或PHP程序)上传到目标网站然后在程序中发布接口。数据。
<p>这里我们直接连接支持肆意网站的存储,因为它基于网站get/post协议,只要存储模块做好,任何网站都可以持有数据公告
智能采集组合文章(构建“全领域持续连载”系统,自动构建精准信息流推广)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-08-28 12:02
智能采集组合文章,本质上就是构建一个精准的组合文章系统。采集任何平台自媒体账号发布的全部文章,自动分析图片中的文字和文章作者,自动构建图文链接,自动构建精准信息流推广。组合文章系统:每一篇文章,都是一个文件夹,链接都是针对某一平台的。一篇文章发布之后,可以生成二维码,二维码文件夹内的文章,可以推送给多个平台。
或者通过手机app自动检测文章重复度,自动进行重复筛选出伪原创文章。构建“持续连载”系统:采集任何平台全部文章,自动生成组合文章系统链接。这个系统,是目前自媒体账号全领域文章最全的一个系统,采集平台,有:头条、百家、企鹅、大鱼、东方号、网易、一点等,所有平台都采集。对于每个平台最热门的资讯,都可以进行大规模采集分析,以便进行我们持续生产内容的基础。
一篇文章发布之后,可以生成一个二维码,扫描二维码可以直接跳转链接页面,把链接跳转到我们自己做的网站网址,跳转之后再分享到朋友圈,我们就可以通过网站获取流量。构建“全领域持续连载”系统的目的:构建“持续连载”系统是为了构建“全领域持续连载”系统的内容资源池,基于后期内容系统的生产能力,我们就可以实现自己内容的全领域生产输出,这是一个人类繁衍生息的社会,也是互联网的最大内容库。
这篇文章已经上传到16个自媒体平台了,几乎覆盖了国内1000多个行业,这1000多个行业都是有价值的内容,都可以进行二次加工。通过最核心的关键词采集文章,然后再进行二次排版,直接把输出给我们的精准用户,构建“持续连载”系统是一个精准文章收集的过程,精准文章收集后的利用率更高。如果用户不会构建这个核心关键词,那我们还可以通过关键词云下拉框等方式分析。
能够搜索到并且点击你的核心关键词,你就已经走在非常有利的地位了。构建“持续连载”系统,是构建持续不断的主要的支撑点,形成自己的知识库,构建更多的文章。通过开始的主动收集,后期是需要将所有的内容进行二次加工,构建出自己的一套属于自己的文章体系,构建这个文章体系对以后持续输出文章提升非常有帮助。直接是和知识整合,不需要再去独立输出了。
构建持续不断的主要支撑点,构建知识体系,文章才能够构建出来,你的知识库才更有价值。持续不断就是一个持续生产输出的过程,这是核心关键。构建持续不断的核心关键点,构建好了持续不断的文章资源池。然后用自己的语言去生产文章。构建持续不断的核心关键点,构建好了持续不断的文章资源池。然后用自己的语言去生产文章。互联网获取流量的方式可以有很多种,举一个最常。 查看全部
智能采集组合文章(构建“全领域持续连载”系统,自动构建精准信息流推广)
智能采集组合文章,本质上就是构建一个精准的组合文章系统。采集任何平台自媒体账号发布的全部文章,自动分析图片中的文字和文章作者,自动构建图文链接,自动构建精准信息流推广。组合文章系统:每一篇文章,都是一个文件夹,链接都是针对某一平台的。一篇文章发布之后,可以生成二维码,二维码文件夹内的文章,可以推送给多个平台。
或者通过手机app自动检测文章重复度,自动进行重复筛选出伪原创文章。构建“持续连载”系统:采集任何平台全部文章,自动生成组合文章系统链接。这个系统,是目前自媒体账号全领域文章最全的一个系统,采集平台,有:头条、百家、企鹅、大鱼、东方号、网易、一点等,所有平台都采集。对于每个平台最热门的资讯,都可以进行大规模采集分析,以便进行我们持续生产内容的基础。
一篇文章发布之后,可以生成一个二维码,扫描二维码可以直接跳转链接页面,把链接跳转到我们自己做的网站网址,跳转之后再分享到朋友圈,我们就可以通过网站获取流量。构建“全领域持续连载”系统的目的:构建“持续连载”系统是为了构建“全领域持续连载”系统的内容资源池,基于后期内容系统的生产能力,我们就可以实现自己内容的全领域生产输出,这是一个人类繁衍生息的社会,也是互联网的最大内容库。
这篇文章已经上传到16个自媒体平台了,几乎覆盖了国内1000多个行业,这1000多个行业都是有价值的内容,都可以进行二次加工。通过最核心的关键词采集文章,然后再进行二次排版,直接把输出给我们的精准用户,构建“持续连载”系统是一个精准文章收集的过程,精准文章收集后的利用率更高。如果用户不会构建这个核心关键词,那我们还可以通过关键词云下拉框等方式分析。
能够搜索到并且点击你的核心关键词,你就已经走在非常有利的地位了。构建“持续连载”系统,是构建持续不断的主要的支撑点,形成自己的知识库,构建更多的文章。通过开始的主动收集,后期是需要将所有的内容进行二次加工,构建出自己的一套属于自己的文章体系,构建这个文章体系对以后持续输出文章提升非常有帮助。直接是和知识整合,不需要再去独立输出了。
构建持续不断的主要支撑点,构建知识体系,文章才能够构建出来,你的知识库才更有价值。持续不断就是一个持续生产输出的过程,这是核心关键。构建持续不断的核心关键点,构建好了持续不断的文章资源池。然后用自己的语言去生产文章。构建持续不断的核心关键点,构建好了持续不断的文章资源池。然后用自己的语言去生产文章。互联网获取流量的方式可以有很多种,举一个最常。
智能采集组合文章(易企精选:微信编辑器【功能特点】(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-08-27 23:13
亿奇微信编辑器是一款非常好用的微信图文编辑器。使用该工具可以帮助用户编辑公众号文章和微场景制作等。界面干净,操作简单,包括很多文字效果,是微信营销和优化必不可少的编辑器。
小编精选:微信编辑
[特点]
【全网优质爆文材料】
1、微信编辑自带素材库,全网海量优质微信文章素材动态更新,大数据挖掘分析,优质热点文章轻松掌握。
2、全网新100,000+爆文第一时间采集更新,热点一目了然;
3、二十四个分类标签,轻松匹配您的行业需求
4、关键词一键搜索你需要的文章材料,再也不用为找不到材料发愁了;
[智能一键采集]
1、微信编辑器提供智能一键采集文章功能,稍作调整即可生成自己的文章。
2、文章材料一键采集,省时高效;
3、提供多图文组合功能,一键生成多图文;
4、live 使用微信操作规则选择合适的素材内容,小白也可以像大咖一样制作优质内容。
[原创optimization]
1、微信编器精选微信原创certification文章,用优质原创文章互惠互利。
2、精选原创内容分类;
3、精选微信原创证文章,用优质原创文章互惠互利。
4、关键词 一键搜你需要的原创文章,省时又方便
【图形美化我只需要一分】
1、全网精选优质微信编辑器文章排版风格素材资源,无需任何代码知识即可轻松掌握高级图文排版技巧。
2、清晰分类,重点关注指南、标题、图文、图片、签名二维码、各种样式;
3、一键第二行,选中文字,然后点击需要的样式即可完成,所见即所得;
4、 一键全文变色,如此简单;
5、动态指纹识别二维制作上传二维码轻松制作。
[软件功能]
1、图文同步:编辑好的图文一键同步到微信公众号后台。过去需要几十分钟完成的工作现在只需几秒钟。
2、文章Import:输入微信文章网址,点击采集外微信公号文章即可。
3、自动签名:设置文章头尾签名内容,生成图形时自动将内容插入相应位置。无需手动复制和编辑每个文章。
4、图文复制:一键复制图文,可让多个公众号同时使用一批图文,减少重复编辑。 查看全部
智能采集组合文章(易企精选:微信编辑器【功能特点】(组图))
亿奇微信编辑器是一款非常好用的微信图文编辑器。使用该工具可以帮助用户编辑公众号文章和微场景制作等。界面干净,操作简单,包括很多文字效果,是微信营销和优化必不可少的编辑器。
小编精选:微信编辑
[特点]
【全网优质爆文材料】
1、微信编辑自带素材库,全网海量优质微信文章素材动态更新,大数据挖掘分析,优质热点文章轻松掌握。
2、全网新100,000+爆文第一时间采集更新,热点一目了然;
3、二十四个分类标签,轻松匹配您的行业需求
4、关键词一键搜索你需要的文章材料,再也不用为找不到材料发愁了;
[智能一键采集]
1、微信编辑器提供智能一键采集文章功能,稍作调整即可生成自己的文章。
2、文章材料一键采集,省时高效;
3、提供多图文组合功能,一键生成多图文;
4、live 使用微信操作规则选择合适的素材内容,小白也可以像大咖一样制作优质内容。
[原创optimization]
1、微信编器精选微信原创certification文章,用优质原创文章互惠互利。
2、精选原创内容分类;
3、精选微信原创证文章,用优质原创文章互惠互利。
4、关键词 一键搜你需要的原创文章,省时又方便
【图形美化我只需要一分】
1、全网精选优质微信编辑器文章排版风格素材资源,无需任何代码知识即可轻松掌握高级图文排版技巧。
2、清晰分类,重点关注指南、标题、图文、图片、签名二维码、各种样式;
3、一键第二行,选中文字,然后点击需要的样式即可完成,所见即所得;
4、 一键全文变色,如此简单;
5、动态指纹识别二维制作上传二维码轻松制作。

[软件功能]
1、图文同步:编辑好的图文一键同步到微信公众号后台。过去需要几十分钟完成的工作现在只需几秒钟。
2、文章Import:输入微信文章网址,点击采集外微信公号文章即可。
3、自动签名:设置文章头尾签名内容,生成图形时自动将内容插入相应位置。无需手动复制和编辑每个文章。
4、图文复制:一键复制图文,可让多个公众号同时使用一批图文,减少重复编辑。
连续动作要做多少个规则请文章《规划采集流程》
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-08-27 18:15
注意:如果动作执行前后网页结构没有变化,可以用一个规则完成;如果网页的结构前后发生变化,必须用两条或两条以上的规则来完成;另外,如果涉及翻页,必须拆分成两个或多个规则。连续动作规则数量请参考文章《规划采集procedures》。
一、创建一级topic抓取目标信息
建立一级主题的规则,将想要的信息映射到排序框。建议在内容映射完成后,还要进行定位标记映射,这样可以提高定位精度和规则的适应性。
注意:如果设置了连续动作规则,则不需要构建排序框。比如方案2的一级主题不需要搭建排序框,而是用排序框抓取一点数据(选择网页肯定会显示的信息)。由爬虫判断是否执行采集,否则可能会漏掉网页。
二、设置连续动作点击新建按钮新建一个动作,每个动作的设置方法相同,基本操作如下:
2.1 输入目标科目名称
连续动作指向同一个目标对象。如果有多个动作,要指向不同的主题,请拆分成多个规则,分别设置连续动作。
2.2 选择动作类型
本例为点击动作,不同动作的适用范围不同。请根据实际操作情况选择动作类型。
2.3 将定位到动作对象的 xpath 填充到定位表达式中
2.4 输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.5 高级设置
一开始不需要设置,以后调试连续动作时会用到,可以扩大动作的适用范围。如果需要抓取动作对象的信息,可以使用xpath在高级设置的内容表达式中定位动作对象的信息。请根据需要重新设置。
注意:是否选择了动作类型以及xpath定位是否准确,决定了连续动作是否可以成功执行。 Xpath 是一种用于定位 html 节点的标准语言。使用连续动作功能前请自行掌握xpath。
根据人工步骤,我们还需要选择版本和购买方式1、买方法2,所以我们继续新建3个动作,重复以上步骤。
三、调试规则
完成上述步骤后,单击“保存规则”,然后单击“抓取数据”按钮开始尝试捕获。发现采集报错:Unable to locate the node***。观察浏览器窗口,看到执行第一步时,没有加载其他信息。加载信息的时候,发现我点击了购买方式2之后,无法回到执行4步点击的页面,导致一直执行连续动作。
针对以上情况,我们的解决方案是删除第四步。因为无论是否点击购买方式2,都不会影响商品的价格。因此,可以删除不必要的和令人不安的操作步骤。
修改后,再次尝试捕捉。将提取的xml转换为excel后,看到价格和累计评价数据被抓取或抓取错误。这是因为网页太大,加载速度慢,点击后的数据需要等待一段时间才能加载。
为了捕获所有数据,您需要延长等待时间并为每个动作单独设置延迟。单击操作步骤-> 高级设置-> 额外延迟,并输入一个以秒为单位的正整数。请按实际时间调试。
另外,如果不是粘性窗口,采集时会反复点击。这是因为京东网站上有防爬措施,必须是当前窗口的操作才能生效。因此,在高级设置中勾选窗口可见,采集时窗口会在最上面。请根据实际情况设置。
四、如何将抓取到的信息与动作步骤一一对应?
如果要将捕获的信息与动作步骤一一关联,那么就必须提取动作对象的信息。有两种方式:
4.1 使用xpath在连续动作的高级设置的内容表达式中定位动作对象的信息节点。
定位表达式定位到动作对象的整个操作范围后,还收录了自身的信息。因此,内容表达只需要从定位的动作对象开始,继续定位到它的信息。 采集会在actionvalue中记录step动作的信息,对应actionno,记录动作执行的次数。
4.2 抓取整理框中动作对象的信息,这里也是用xpath定位。
当action对象被执行时,它的dom结构发生了变化。找到网页变化的结构特征,使用xpath准确定位节点,验证通过后可以设置自定义xpath。
以上是使用连续动作模拟人工操作的全过程。虽然过程比较繁琐,但只要细心耐心,最终还是可以征服你想要爬取的网页。 查看全部
连续动作要做多少个规则请文章《规划采集流程》
注意:如果动作执行前后网页结构没有变化,可以用一个规则完成;如果网页的结构前后发生变化,必须用两条或两条以上的规则来完成;另外,如果涉及翻页,必须拆分成两个或多个规则。连续动作规则数量请参考文章《规划采集procedures》。
一、创建一级topic抓取目标信息
建立一级主题的规则,将想要的信息映射到排序框。建议在内容映射完成后,还要进行定位标记映射,这样可以提高定位精度和规则的适应性。
注意:如果设置了连续动作规则,则不需要构建排序框。比如方案2的一级主题不需要搭建排序框,而是用排序框抓取一点数据(选择网页肯定会显示的信息)。由爬虫判断是否执行采集,否则可能会漏掉网页。
二、设置连续动作点击新建按钮新建一个动作,每个动作的设置方法相同,基本操作如下:
2.1 输入目标科目名称
连续动作指向同一个目标对象。如果有多个动作,要指向不同的主题,请拆分成多个规则,分别设置连续动作。
2.2 选择动作类型
本例为点击动作,不同动作的适用范围不同。请根据实际操作情况选择动作类型。
2.3 将定位到动作对象的 xpath 填充到定位表达式中
2.4 输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.5 高级设置
一开始不需要设置,以后调试连续动作时会用到,可以扩大动作的适用范围。如果需要抓取动作对象的信息,可以使用xpath在高级设置的内容表达式中定位动作对象的信息。请根据需要重新设置。
注意:是否选择了动作类型以及xpath定位是否准确,决定了连续动作是否可以成功执行。 Xpath 是一种用于定位 html 节点的标准语言。使用连续动作功能前请自行掌握xpath。
根据人工步骤,我们还需要选择版本和购买方式1、买方法2,所以我们继续新建3个动作,重复以上步骤。
三、调试规则
完成上述步骤后,单击“保存规则”,然后单击“抓取数据”按钮开始尝试捕获。发现采集报错:Unable to locate the node***。观察浏览器窗口,看到执行第一步时,没有加载其他信息。加载信息的时候,发现我点击了购买方式2之后,无法回到执行4步点击的页面,导致一直执行连续动作。
针对以上情况,我们的解决方案是删除第四步。因为无论是否点击购买方式2,都不会影响商品的价格。因此,可以删除不必要的和令人不安的操作步骤。
修改后,再次尝试捕捉。将提取的xml转换为excel后,看到价格和累计评价数据被抓取或抓取错误。这是因为网页太大,加载速度慢,点击后的数据需要等待一段时间才能加载。
为了捕获所有数据,您需要延长等待时间并为每个动作单独设置延迟。单击操作步骤-> 高级设置-> 额外延迟,并输入一个以秒为单位的正整数。请按实际时间调试。
另外,如果不是粘性窗口,采集时会反复点击。这是因为京东网站上有防爬措施,必须是当前窗口的操作才能生效。因此,在高级设置中勾选窗口可见,采集时窗口会在最上面。请根据实际情况设置。
四、如何将抓取到的信息与动作步骤一一对应?
如果要将捕获的信息与动作步骤一一关联,那么就必须提取动作对象的信息。有两种方式:
4.1 使用xpath在连续动作的高级设置的内容表达式中定位动作对象的信息节点。
定位表达式定位到动作对象的整个操作范围后,还收录了自身的信息。因此,内容表达只需要从定位的动作对象开始,继续定位到它的信息。 采集会在actionvalue中记录step动作的信息,对应actionno,记录动作执行的次数。
4.2 抓取整理框中动作对象的信息,这里也是用xpath定位。
当action对象被执行时,它的dom结构发生了变化。找到网页变化的结构特征,使用xpath准确定位节点,验证通过后可以设置自定义xpath。
以上是使用连续动作模拟人工操作的全过程。虽然过程比较繁琐,但只要细心耐心,最终还是可以征服你想要爬取的网页。
智能分析QQ消息,强大组合模式(合纵连横),轻松生成原创文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-08-27 18:13
智能分析QQ消息,强大组合模式(合纵连横),轻松生成原创文章
/smref.php?ref=http://www.baidu.com%26amp%3Bu ... kagwe
优采云·QQ群聊留言文章代器
软件下载
视频教程
软件介绍优采云software 制作导出QQ群消息并生成文章的工具。
智能分析QQ消息,强大的组合模式(纵横组合),轻松生成原创文章!示例
我们都知道QQ聊天,尤其是群聊,每天都有很多原创的内容。我们可以处理这些聊天内容并产生原创文章。可以说是取之不尽。取之不尽。虽然有些人会复制文章来粘贴,但他们的特征很容易识别,而且往往很大。这时候可以设置单条消息超过一定字数时忽略。
现在可以加入各种话题的群,比如写旅游文章,添加旅游团,旅游团等等,然后每天导出一次他们的聊天记录,原创文章你怕不怕没有了? ?
使用提示:本程序处理的聊天记录不是直接从聊天窗口复制的,而是从QQ消息管理器中导出的。 QQ主面板-打开消息管理器,然后切换到“群”,在群列表中选择特定的群,右键群-导出消息记录,选择保存类型为文本文件完成导出,然后在本程序中通过“选择文件”按钮弹出的对话框中选择导出的聊天记录文件进行组合生成文章。软件特点:1.分析QQ消息文件,准确获取每条消息正文
2.全球中断消息
3.内置过滤(如过滤网址、邮件等)
4.内置屏蔽词替换(QQ聊天中经常提到很多敏感词)
5.自动去除多余的标点符号(当连接多个标点符号时,只保留一个,这样文章看起来更真实,更赏心悦目)
6.Message 支持纵横组合。 (横向落地,即多条原创消息连在一起为一条消息,以合并符分隔,纵向落地,即多条单条消息合并为一条原创文章)
7.支持在单条消息中插入后缀和后缀,比如常见的段落网页标签
8.支持在标题中插入单词,支持在文章中插入随机单词(也可以自动组合锚文本)
9.文章Title 智能提取组合结果中的随机句子。
10.批量选择多个QQ消息文件,一键处理,大功告成,文章滚滚来! !
可疑点说明:
文章 数据从何而来?
从QQ消息记录导出,一般是群消息,也有个人消息。导出的是一个txt文件,程序会处理这个文件生成文章。
留言全乱了,能不能发个好的文章?
是的,程序也是按顺序组合的。
无论是私聊还是两个人的群聊,消息都是有顺序的,程序就是这个顺序,每隔几句话(可以设置)组合成一段
每几段(可设置)合并为一个文章。并且您可以在段落前后插入网页段落标签等字符,以更好地适应网页显示。
通常,一条几百页记录的群消息可以从数百到数千文章导出。
文章都是原创吗?
这是肯定的。因为留言记录都是实时真实的交流,独一无二。即使有一些广告方,程序也内置支持智能杀掉他们,让他们在最后的文章中消失。
百度收录okay?
我无法回答这一点。只能说文章是原创,百度收录好不好,高排名受很多因素影响。
我可以试试吗?
可以,可以直接下载软件,选择我先试用,然后就可以使用了。
程序工作流程
1.分析QQ导出的TXT格式聊天消息记录文件,获取每条精准消息
2.对每条消息进行过滤后,插入前缀和后缀等修改,按照设定的编号组合
3.可以在组合结果中插入段落后缀、纯文本关键词或锚文本关键词
4.一篇纯原创的文章诞生了!
添加群提示:搜索群时,注意活跃群和人数较多的群。 (有的群人多但不活跃,最好是活跃且拥挤的),导致每天聊天消息量很大:
/smref.php?ref=http://www.baidu.com%26amp%3Bu ... bawhs
加入群后,建议设置群只显示号码不提示消息,这样消息记录可以累积而不受干扰。
/smref.php?ref=http://www.baidu.com%26amp%3Bu ... 7ygn1
升级记录(2015年5月25日):1.4.0.0:新改版;新增过滤消息条件,只要收录URL、连续数字等,消息将被忽略
1.4.3.0:修复过滤URL时容易过滤掉连接在一起的汉字的问题;调整繁体转简体的执行顺序,避免转繁体后更换失败;添加阻止同义词库文件。
1.5.0.0:软件由“优采云·傻瓜化文章代器”更名为“优采云·QQ群聊留言文章代器”;软件注册方式改变;其他更新
1.5.2.0:修复在进行最小字数过滤时,最后一行消息字数低于此设置,无法正确预览的问题
1.5.3.0:修复由于命名问题启动几分钟后自动退出的问题
1.5.4.0:增加识别网址的能力(新增只识别开头的网址)
1.6.0.0:添加识别消息记录中有2个空格的日期格式
1.6.0.1:转型支持OEM代理
1.6.0.2:完善注册机制,采用硬盘+网卡全识别模式(也兼容旧版注册码),可以解决机器码问题某些情况下因重新安装和更换VPN而引起的变化;其他更新。
1.6.0.3:尝试修复部分电脑获取硬盘码失败的问题。 查看全部
智能分析QQ消息,强大组合模式(合纵连横),轻松生成原创文章
/smref.php?ref=http://www.baidu.com%26amp%3Bu ... kagwe
优采云·QQ群聊留言文章代器
软件下载
视频教程
软件介绍优采云software 制作导出QQ群消息并生成文章的工具。
智能分析QQ消息,强大的组合模式(纵横组合),轻松生成原创文章!示例
我们都知道QQ聊天,尤其是群聊,每天都有很多原创的内容。我们可以处理这些聊天内容并产生原创文章。可以说是取之不尽。取之不尽。虽然有些人会复制文章来粘贴,但他们的特征很容易识别,而且往往很大。这时候可以设置单条消息超过一定字数时忽略。
现在可以加入各种话题的群,比如写旅游文章,添加旅游团,旅游团等等,然后每天导出一次他们的聊天记录,原创文章你怕不怕没有了? ?
使用提示:本程序处理的聊天记录不是直接从聊天窗口复制的,而是从QQ消息管理器中导出的。 QQ主面板-打开消息管理器,然后切换到“群”,在群列表中选择特定的群,右键群-导出消息记录,选择保存类型为文本文件完成导出,然后在本程序中通过“选择文件”按钮弹出的对话框中选择导出的聊天记录文件进行组合生成文章。软件特点:1.分析QQ消息文件,准确获取每条消息正文
2.全球中断消息
3.内置过滤(如过滤网址、邮件等)
4.内置屏蔽词替换(QQ聊天中经常提到很多敏感词)
5.自动去除多余的标点符号(当连接多个标点符号时,只保留一个,这样文章看起来更真实,更赏心悦目)
6.Message 支持纵横组合。 (横向落地,即多条原创消息连在一起为一条消息,以合并符分隔,纵向落地,即多条单条消息合并为一条原创文章)
7.支持在单条消息中插入后缀和后缀,比如常见的段落网页标签
8.支持在标题中插入单词,支持在文章中插入随机单词(也可以自动组合锚文本)
9.文章Title 智能提取组合结果中的随机句子。
10.批量选择多个QQ消息文件,一键处理,大功告成,文章滚滚来! !
可疑点说明:
文章 数据从何而来?
从QQ消息记录导出,一般是群消息,也有个人消息。导出的是一个txt文件,程序会处理这个文件生成文章。
留言全乱了,能不能发个好的文章?
是的,程序也是按顺序组合的。
无论是私聊还是两个人的群聊,消息都是有顺序的,程序就是这个顺序,每隔几句话(可以设置)组合成一段
每几段(可设置)合并为一个文章。并且您可以在段落前后插入网页段落标签等字符,以更好地适应网页显示。
通常,一条几百页记录的群消息可以从数百到数千文章导出。
文章都是原创吗?
这是肯定的。因为留言记录都是实时真实的交流,独一无二。即使有一些广告方,程序也内置支持智能杀掉他们,让他们在最后的文章中消失。
百度收录okay?
我无法回答这一点。只能说文章是原创,百度收录好不好,高排名受很多因素影响。
我可以试试吗?
可以,可以直接下载软件,选择我先试用,然后就可以使用了。
程序工作流程
1.分析QQ导出的TXT格式聊天消息记录文件,获取每条精准消息
2.对每条消息进行过滤后,插入前缀和后缀等修改,按照设定的编号组合
3.可以在组合结果中插入段落后缀、纯文本关键词或锚文本关键词
4.一篇纯原创的文章诞生了!
添加群提示:搜索群时,注意活跃群和人数较多的群。 (有的群人多但不活跃,最好是活跃且拥挤的),导致每天聊天消息量很大:
/smref.php?ref=http://www.baidu.com%26amp%3Bu ... bawhs
加入群后,建议设置群只显示号码不提示消息,这样消息记录可以累积而不受干扰。
/smref.php?ref=http://www.baidu.com%26amp%3Bu ... 7ygn1
升级记录(2015年5月25日):1.4.0.0:新改版;新增过滤消息条件,只要收录URL、连续数字等,消息将被忽略
1.4.3.0:修复过滤URL时容易过滤掉连接在一起的汉字的问题;调整繁体转简体的执行顺序,避免转繁体后更换失败;添加阻止同义词库文件。
1.5.0.0:软件由“优采云·傻瓜化文章代器”更名为“优采云·QQ群聊留言文章代器”;软件注册方式改变;其他更新
1.5.2.0:修复在进行最小字数过滤时,最后一行消息字数低于此设置,无法正确预览的问题
1.5.3.0:修复由于命名问题启动几分钟后自动退出的问题
1.5.4.0:增加识别网址的能力(新增只识别开头的网址)
1.6.0.0:添加识别消息记录中有2个空格的日期格式
1.6.0.1:转型支持OEM代理
1.6.0.2:完善注册机制,采用硬盘+网卡全识别模式(也兼容旧版注册码),可以解决机器码问题某些情况下因重新安装和更换VPN而引起的变化;其他更新。
1.6.0.3:尝试修复部分电脑获取硬盘码失败的问题。
智能采集组合文章类型及就业前景分析-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-08-25 18:08
智能采集组合文章类型:影视片段、明星、综艺、游戏小游戏,校园文章、新闻宣传片、专题工作汇报、背景介绍、创业组合精彩内容类别:情感/婚恋、招聘/求职、新奇/搞笑、安利/电商、青少年/家教、搞笑/电影/动漫组合精彩内容类别:职场/新媒体运营/内容策划/美妆/销售、夜游/私人讲座/户外/公园、经济/文化/国学/意识形态、家庭/亲子/亲子活动、销售/推广/引流/促销组合组合文章类型:情感/婚恋、新奇/搞笑、电影/动漫、职场/新媒体、经济/文化/国学、亲子/亲子活动、引流/推广/促销、健康/养生/电影/动漫组合精彩内容类别:情感/婚恋、新奇/搞笑、电影/动漫、职场/新媒体、经济/文化/国学、亲子/亲子活动、引流/推广/促销、夜游/私人讲座/户外/公园组合精彩内容类别:电影/动漫、职场/新媒体、新奇/搞笑、经济/文化/国学、亲子/亲子活动、引流/推广/促销组合组合图片类型:静态或动态图片、视频或网站广告图片、引爆点、结束语等。
组合文章类型:电影/动漫、职场/新媒体、娱乐明星/恋爱培训、美妆/口红/美发、亲子/亲子活动、青少年/国学/意识形态、孩子/母亲/亲子活动、其他组合视频类型:延时视频、开场剪辑视频、结束视频、片头、片尾等。组合图片类型:教育类视频、视频拍摄/剪辑延时/切割、视频拍摄/切割视频、视频拍摄/截取视频等组合创意图片类型:情景表情包、创意红包、创意投票、互动游戏、发红包、互动游戏、福利展示等。
组合创意花字类型:图片花字、文字花字、二维码花字、视频花字、组合文字等。组合slogan类型:简短的slogan、口号、品牌代言、产品定位等。软文广告类型:。
1、新闻稿类广告
2、软文广告类型
3、音频广告类型
4、视频广告类型
5、软文视频广告类型
6、软文营销推广类型
7、音频软文推广,效果和软文类型的软文类型是一样的。
采集文章的主要模式:
1、每个作者会创建一个作者专属网站,发布他们原创的内容。当他们发布某篇文章时,系统通过本地网站抓取文章所有内容,并加上自己的推荐语和吸引力的标题内容,即可加上你的网站二维码和网站介绍,以便以后互相关注、点击。
2、所有网站把你的内容分享到网上,不加上自己的推荐语和标题,任何作者都可以看到你的文章,在个别一部分网站不用推荐语,自动抓取推荐文章的第一部分,把你的文章放到收录的页面里面。所以大部分网站都是抓取第一部分的。
3、每个作者可以在论坛里面传播他们的文章, 查看全部
智能采集组合文章类型及就业前景分析-乐题库
智能采集组合文章类型:影视片段、明星、综艺、游戏小游戏,校园文章、新闻宣传片、专题工作汇报、背景介绍、创业组合精彩内容类别:情感/婚恋、招聘/求职、新奇/搞笑、安利/电商、青少年/家教、搞笑/电影/动漫组合精彩内容类别:职场/新媒体运营/内容策划/美妆/销售、夜游/私人讲座/户外/公园、经济/文化/国学/意识形态、家庭/亲子/亲子活动、销售/推广/引流/促销组合组合文章类型:情感/婚恋、新奇/搞笑、电影/动漫、职场/新媒体、经济/文化/国学、亲子/亲子活动、引流/推广/促销、健康/养生/电影/动漫组合精彩内容类别:情感/婚恋、新奇/搞笑、电影/动漫、职场/新媒体、经济/文化/国学、亲子/亲子活动、引流/推广/促销、夜游/私人讲座/户外/公园组合精彩内容类别:电影/动漫、职场/新媒体、新奇/搞笑、经济/文化/国学、亲子/亲子活动、引流/推广/促销组合组合图片类型:静态或动态图片、视频或网站广告图片、引爆点、结束语等。
组合文章类型:电影/动漫、职场/新媒体、娱乐明星/恋爱培训、美妆/口红/美发、亲子/亲子活动、青少年/国学/意识形态、孩子/母亲/亲子活动、其他组合视频类型:延时视频、开场剪辑视频、结束视频、片头、片尾等。组合图片类型:教育类视频、视频拍摄/剪辑延时/切割、视频拍摄/切割视频、视频拍摄/截取视频等组合创意图片类型:情景表情包、创意红包、创意投票、互动游戏、发红包、互动游戏、福利展示等。
组合创意花字类型:图片花字、文字花字、二维码花字、视频花字、组合文字等。组合slogan类型:简短的slogan、口号、品牌代言、产品定位等。软文广告类型:。
1、新闻稿类广告
2、软文广告类型
3、音频广告类型
4、视频广告类型
5、软文视频广告类型
6、软文营销推广类型
7、音频软文推广,效果和软文类型的软文类型是一样的。
采集文章的主要模式:
1、每个作者会创建一个作者专属网站,发布他们原创的内容。当他们发布某篇文章时,系统通过本地网站抓取文章所有内容,并加上自己的推荐语和吸引力的标题内容,即可加上你的网站二维码和网站介绍,以便以后互相关注、点击。
2、所有网站把你的内容分享到网上,不加上自己的推荐语和标题,任何作者都可以看到你的文章,在个别一部分网站不用推荐语,自动抓取推荐文章的第一部分,把你的文章放到收录的页面里面。所以大部分网站都是抓取第一部分的。
3、每个作者可以在论坛里面传播他们的文章,
智能采集组合文章(,,36kr/webpage.html欢迎折叠(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-09-23 04:04
智能采集组合文章来编辑文章素材,实现在特定文本段落内选中多篇图文编辑,减少编辑次数,增加阅读效率。同时我们可以根据你想要的方式来组合文章,如:png、超链接、表格等等。使用官方已开放的模板来拖拽文件使用,最快2秒钟。
qaq,这怎么可能是一个高效的平台,按你的说法,一定要能把网站的文章分布到不同的列表才算高效吧,
reeder快感觉有时候抓取到的文章可以加到自己的订阅之中或者直接建立一个任务流
牛客
爱范儿,
“zhihu”stackexchange
公众号?问答社区?
我感觉可以harrypotter,csdn,36kr.
marvinglass-web/webpage.html欢迎折叠
uiuxbywaynezhu,reeder
有个叫“风语志”的公众号,专门做编辑器,有帮助你实现高效采集工作的。;hl=zh-cn&fl=uwp&sa=x&ei=kgvaforggbvucom&ie=utf-8,st=wp-cdte&ve=x&ei=lijlnu&wd=%e6%8a%a0%e4%b8%8e%e8%bf%8f%e5%9b%be%e5%a8%8b%e8%b7%af%e6%bf%af%e4%bc%8f%e6%b9%bf%e5%88%8b%e6%99%ab%e5%87%a9%e8%b7%af%e7%9a%84%e6%bb%bb%e8%80%8a%e5%8f%87%e5%8d%83%e7%9c%80%e4%b8%8d%e6%b4%a3%e8%82%85&ok=&wd=%e6%98%9f%e5%a3%bb%e7%ae%8e%e6%9c%9e%e6%9c%81.&qd=si&width=144&height=960&width=2402=&width=4802=。 查看全部
智能采集组合文章(,,36kr/webpage.html欢迎折叠(组图))
智能采集组合文章来编辑文章素材,实现在特定文本段落内选中多篇图文编辑,减少编辑次数,增加阅读效率。同时我们可以根据你想要的方式来组合文章,如:png、超链接、表格等等。使用官方已开放的模板来拖拽文件使用,最快2秒钟。
qaq,这怎么可能是一个高效的平台,按你的说法,一定要能把网站的文章分布到不同的列表才算高效吧,
reeder快感觉有时候抓取到的文章可以加到自己的订阅之中或者直接建立一个任务流
牛客
爱范儿,
“zhihu”stackexchange
公众号?问答社区?
我感觉可以harrypotter,csdn,36kr.
marvinglass-web/webpage.html欢迎折叠
uiuxbywaynezhu,reeder
有个叫“风语志”的公众号,专门做编辑器,有帮助你实现高效采集工作的。;hl=zh-cn&fl=uwp&sa=x&ei=kgvaforggbvucom&ie=utf-8,st=wp-cdte&ve=x&ei=lijlnu&wd=%e6%8a%a0%e4%b8%8e%e8%bf%8f%e5%9b%be%e5%a8%8b%e8%b7%af%e6%bf%af%e4%bc%8f%e6%b9%bf%e5%88%8b%e6%99%ab%e5%87%a9%e8%b7%af%e7%9a%84%e6%bb%bb%e8%80%8a%e5%8f%87%e5%8d%83%e7%9c%80%e4%b8%8d%e6%b4%a3%e8%82%85&ok=&wd=%e6%98%9f%e5%a3%bb%e7%ae%8e%e6%9c%9e%e6%9c%81.&qd=si&width=144&height=960&width=2402=&width=4802=。
智能采集组合文章(全新文章组合工具,支持对词组、字句进行原创随机组合 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-09-20 03:16
)
有关软件的最新版本:
优采云文章复合内容v1. 65.1无限免费版本优采云文件代码批量转换助手V1.60无限免费版
新的文章组合工具支持短语和句子的原创随机组合。这是一个必要的网站管理员工具搜索引擎优化,近20个新的增强帮助工具内置
原型来自原创文章生成器,但它更简单且易于使用。操作基本相同。该方法效果好,操作简单。熟悉的线路可以直接使用,无需反复学习,新手也很容易使用
核心功能是编写模板,在模板中引用元素,并在任何位置引用任何元素。元素可以是文本块调用、随机汉字、数字、字母或数字序列、随机值、随机时间。所有休闲原创组合情况。查看原则>>
提醒:主界面右下角的山中出现的工件:选项按钮可以导入原创文章generator(高级充电版本)的程序数据(必须是导入的,而不是简单的文件拷贝)
提醒:2003系统需要关闭数据保护
提示:创建新元素时,按Ctrl键将当前元素内容复制到新元素中;切换元素显示时,按ALT键可以屏蔽元素内容的显示和校正;在元素项上单击鼠标右键时,可以复制元素引用模式[元素名称],然后在元素库上单击鼠标右键以打开本地保存在数据库中的文件夹(操作与模板相同)
提醒:当前选择显示的模板是用于生成的模板。如果选择了模板库,则库下的模板将随机用于生成,并且模板可以调用所有选中的图元库。选中多个元素库时,不同元素库下的元素不能显示重复的名称,否则只能调用第一个选中元素库的重复名称元素
原创文章生成器的功能:
1、新的接口计划,简单而熟练的计划,基本相同的操作,但更简单和更容易使用
@元素库中的2、elements将不再显示复选框以避免误判(只有元素库可以被选中,选中的元素库将参与调用,并且元素不需要被选中)
3、显示大文本不再耗时,并且支持行号显示和元素语法高亮显示
4、更强大的删除和恢复功能,更强大的树搜索功能
5、新的和改进的帮助工具(包括新编辑的长尾词采集器)可以完成更多的文本处理要求
@预览时支持6、preview title设置,效果好像已经生成
7、library的显示顺序不再混乱
8、其他方面,如总体疗效和表现
查看全部
智能采集组合文章(全新文章组合工具,支持对词组、字句进行原创随机组合
)
有关软件的最新版本:
优采云文章复合内容v1. 65.1无限免费版本优采云文件代码批量转换助手V1.60无限免费版
新的文章组合工具支持短语和句子的原创随机组合。这是一个必要的网站管理员工具搜索引擎优化,近20个新的增强帮助工具内置
原型来自原创文章生成器,但它更简单且易于使用。操作基本相同。该方法效果好,操作简单。熟悉的线路可以直接使用,无需反复学习,新手也很容易使用
核心功能是编写模板,在模板中引用元素,并在任何位置引用任何元素。元素可以是文本块调用、随机汉字、数字、字母或数字序列、随机值、随机时间。所有休闲原创组合情况。查看原则>>
提醒:主界面右下角的山中出现的工件:选项按钮可以导入原创文章generator(高级充电版本)的程序数据(必须是导入的,而不是简单的文件拷贝)
提醒:2003系统需要关闭数据保护
提示:创建新元素时,按Ctrl键将当前元素内容复制到新元素中;切换元素显示时,按ALT键可以屏蔽元素内容的显示和校正;在元素项上单击鼠标右键时,可以复制元素引用模式[元素名称],然后在元素库上单击鼠标右键以打开本地保存在数据库中的文件夹(操作与模板相同)
提醒:当前选择显示的模板是用于生成的模板。如果选择了模板库,则库下的模板将随机用于生成,并且模板可以调用所有选中的图元库。选中多个元素库时,不同元素库下的元素不能显示重复的名称,否则只能调用第一个选中元素库的重复名称元素
原创文章生成器的功能:
1、新的接口计划,简单而熟练的计划,基本相同的操作,但更简单和更容易使用
@元素库中的2、elements将不再显示复选框以避免误判(只有元素库可以被选中,选中的元素库将参与调用,并且元素不需要被选中)
3、显示大文本不再耗时,并且支持行号显示和元素语法高亮显示
4、更强大的删除和恢复功能,更强大的树搜索功能
5、新的和改进的帮助工具(包括新编辑的长尾词采集器)可以完成更多的文本处理要求
@预览时支持6、preview title设置,效果好像已经生成
7、library的显示顺序不再混乱
8、其他方面,如总体疗效和表现
智能采集组合文章(商品属性安装环境商品介绍系统程序企业城市分站群系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-20 03:14
商品属性
设备安装环境
产品介绍
HainacmsIntelligent Cloud站群biotechnology gene detection build网站官方网站源代码HTML5响应国家多地区站群系统计划
enterprise City sub站群系统是一个开源程序:
一、程序模板未授权300元(一套商业模板)。注:不能用于商业目的(侵权),只能用于个人用途。如果将来出现问题,该技术将不予处理
二、程序模板授权500元(一套商业模板)
三、程序模板+授权+[文章组合发布功能、关键词监控、文章采集发布(需要了解网站建设技术)、外链发布)](200元/年),共计700元(一套商业模板)
4:一年服务器(香港单核1g1m40g独立IP)+环境配置(Linux宝塔)+安装+开源代码(授权)+商业模板(一套商业模板)+程序升级+发布和@采集(需建站技术),900元
模板选择:
1、未经授权的程序不得用于商业目的(侵权),程序不能在后台一键升级,没有售后服务支持(后台操作范围内的支持),增值功能不能购买(具有文章组合发布功能、关键词监控、文章@采集发布(网站建设技术和外链发布)。使用增值功能的前提是在购买增值功能之前需要获得授权
授权后的域名不能返回或更改,必须先确定授权的域名,打开增值功能后,域名不能更改
*虚拟物品交付后,这不是程序的问题。没有退款或退货。环境是正确的。安装后,它与演示站相同。如果您不能接受,请不要拍摄
2、程序是开源的,后台升级功能调用ECS API进行升级,增值功能(授权后订购)是另一个系统,连接到我们的企业站群系统
3、程序运行环境php5.超过4个7.0低于+mysql5.5以上(推荐宝塔Linux+nginx)+php5.6+ mysql5.6)
香港cn2专用VPS:1核(CPU)1g(内存)1m(带宽)40g(磁盘)5g(国防)独立IP,200元/年
4、不支持域名。通用绑定域名的空格(虚拟空间)只能以目录的形式使用。支持通用绑定域名的空格或VPS服务器只能以辅助域名的形式使用
5、未被授权使用增值功能,需要单独购买。但是,这个文章组合版本可以与我们的程序连接,相当于伪原创版本
原则:文章是根据您制作的段落发布的,发布模板的变量用于将它们排列并组合成一篇文章伪原创文章
6、增值功能:关键词监控、自动发布等实用功能,每年支付200元,目前暂定价格较低,不排除后期服务器成本增加导致价格上涨的可能性
7、功能优势:
多城市站点:设置任意企业城市子站区域,设置二级域名表单(服务器支持通用绑定)或目录表单
万站效应:您不仅可以使用区域作为子站,还可以使用产品子站,并在区域中管理用户定义的产品分类(理论上无限增加)
关键词设置:点击设置关键词,自动生成长尾关键词,列关键词生成,自定义URL/关键字
链接:一键交换链接(授权使用,一键禁用广告法中的文字) 查看全部
智能采集组合文章(商品属性安装环境商品介绍系统程序企业城市分站群系统)
商品属性
设备安装环境
产品介绍
HainacmsIntelligent Cloud站群biotechnology gene detection build网站官方网站源代码HTML5响应国家多地区站群系统计划
enterprise City sub站群系统是一个开源程序:
一、程序模板未授权300元(一套商业模板)。注:不能用于商业目的(侵权),只能用于个人用途。如果将来出现问题,该技术将不予处理
二、程序模板授权500元(一套商业模板)
三、程序模板+授权+[文章组合发布功能、关键词监控、文章采集发布(需要了解网站建设技术)、外链发布)](200元/年),共计700元(一套商业模板)
4:一年服务器(香港单核1g1m40g独立IP)+环境配置(Linux宝塔)+安装+开源代码(授权)+商业模板(一套商业模板)+程序升级+发布和@采集(需建站技术),900元
模板选择:
1、未经授权的程序不得用于商业目的(侵权),程序不能在后台一键升级,没有售后服务支持(后台操作范围内的支持),增值功能不能购买(具有文章组合发布功能、关键词监控、文章@采集发布(网站建设技术和外链发布)。使用增值功能的前提是在购买增值功能之前需要获得授权
授权后的域名不能返回或更改,必须先确定授权的域名,打开增值功能后,域名不能更改
*虚拟物品交付后,这不是程序的问题。没有退款或退货。环境是正确的。安装后,它与演示站相同。如果您不能接受,请不要拍摄
2、程序是开源的,后台升级功能调用ECS API进行升级,增值功能(授权后订购)是另一个系统,连接到我们的企业站群系统
3、程序运行环境php5.超过4个7.0低于+mysql5.5以上(推荐宝塔Linux+nginx)+php5.6+ mysql5.6)
香港cn2专用VPS:1核(CPU)1g(内存)1m(带宽)40g(磁盘)5g(国防)独立IP,200元/年
4、不支持域名。通用绑定域名的空格(虚拟空间)只能以目录的形式使用。支持通用绑定域名的空格或VPS服务器只能以辅助域名的形式使用
5、未被授权使用增值功能,需要单独购买。但是,这个文章组合版本可以与我们的程序连接,相当于伪原创版本
原则:文章是根据您制作的段落发布的,发布模板的变量用于将它们排列并组合成一篇文章伪原创文章
6、增值功能:关键词监控、自动发布等实用功能,每年支付200元,目前暂定价格较低,不排除后期服务器成本增加导致价格上涨的可能性
7、功能优势:
多城市站点:设置任意企业城市子站区域,设置二级域名表单(服务器支持通用绑定)或目录表单
万站效应:您不仅可以使用区域作为子站,还可以使用产品子站,并在区域中管理用户定义的产品分类(理论上无限增加)
关键词设置:点击设置关键词,自动生成长尾关键词,列关键词生成,自定义URL/关键字
链接:一键交换链接(授权使用,一键禁用广告法中的文字)
智能采集组合文章(既能集中收藏为文章自动打标签的工具成功吸引我们)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-09-19 17:01
在信息爆炸的时代,我们被各种各样的信息所包围,这迫使我们在大量的信息中寻找“有用”的信息。当我们看到好的文章,我们会采集它,但我们经常会遇到两个问题:
如果你在采集后找不到它,这和不采集没有什么不同;如果采集缺乏分类和内部化,这些“好商品”的价值将永远无法发挥作用
对于第一个问题,中国提供了支持采集的工具,如印象笔记、知识笔记、有道云等,可以实现信息的统一聚合,将采集的信息集中在一起。然而,知识的采集只是知识管理的第一步,后期的整理和内化更值得反思
“每次给几十个甚至数百个文章采集贴标签和手工分类都很烦人,”此类工具的典型用户小陈告诉作者,“采集后再阅读也是一个问题”。最近,一个能够自动采集并标记文章的工具成功地吸引了我们的注意。这是极好的阅读
优都开发者之一的发起者金凯表达了优都诞生的初衷:“作为一个阅读爱好者,每次看到好的文章,我都会在不同的阅读平台上采集。它非常分散。之前,我会手动标记文章,并将其移动到我自己的博客上。这是非常低效的。”
金基对智能算法的研究产生了这样一种想法:既然读者通常根据文章的主要内容进行标记和分类,为什么不通过机器学习算法将这一过程智能化呢
因此,他在业余时间开始设计“优秀阅读应用程序”。通过智能算法对文章样本进行连续训练和精度优化。目前,卓越阅读中采集的文章可以自动标记五个标签。当然,读者也可以自定义、修改或增加或减少文章标题和标签,以更好地匹配他们的搜索习惯
对于如何解决重读问题,优秀阅读提供了两种提高读者阅读动机的方法:
一种是基于标签的主题阅读。对于每个采集的文章,读者可以单击自动标记的标签,过滤掉所有以前采集的文章,然后开始主题阅读。例如,我最近需要加强我的ppt技能。在采集PPT的文章并点击生成的相关标签后,我可以在平台上索引我自己的采集,甚至是其他人采集的类似文章的采集
基于某一主题的阅读使知识的掌握更加全面;别人的文章,其实是帮读者做了一个信息过滤,整体素质也比较高
二是提供方便的搜索功能。聚光灯搜索功能在IOS版本的卓越阅读中被调用。在登录并打开优秀阅读采集列表一次的前提下,无需打开应用程序,即可在苹果主屏幕的任何界面上快速下拉搜索优秀阅读采集的文章collected。搜索范围包括标题和标签,使信息检索速度加快了一步
只要你养成把它采集成优秀阅读的习惯,你就可以把你的手机建成一个现成的知识库。而采集网站、官方账号、网页和app文章的最佳阅读操作非常简单。只要您在微信中添加并绑定app assistant,就可以通过共享文章的微信助手实现文章采集和智能标签。文章的风格经过美化、排版和广告过滤,阅读效果极佳,看起来更舒适
根据金钥匙的说法,未来,Youdu还将允许用户在应用程序中选择文本采集、标记或在线查看,并提醒他们根据读者的记忆曲线查看之前阅读的笔记
目前,优秀阅读团队共有14人左右,主要是技术开发人员。优秀的阅读在通过智能算法帮助读者进行知识管理方面还有很长的路要走,但是金基和他的团队相信这是未来的趋势,也是一件值得做的事情 查看全部
智能采集组合文章(既能集中收藏为文章自动打标签的工具成功吸引我们)
在信息爆炸的时代,我们被各种各样的信息所包围,这迫使我们在大量的信息中寻找“有用”的信息。当我们看到好的文章,我们会采集它,但我们经常会遇到两个问题:
如果你在采集后找不到它,这和不采集没有什么不同;如果采集缺乏分类和内部化,这些“好商品”的价值将永远无法发挥作用
对于第一个问题,中国提供了支持采集的工具,如印象笔记、知识笔记、有道云等,可以实现信息的统一聚合,将采集的信息集中在一起。然而,知识的采集只是知识管理的第一步,后期的整理和内化更值得反思
“每次给几十个甚至数百个文章采集贴标签和手工分类都很烦人,”此类工具的典型用户小陈告诉作者,“采集后再阅读也是一个问题”。最近,一个能够自动采集并标记文章的工具成功地吸引了我们的注意。这是极好的阅读
优都开发者之一的发起者金凯表达了优都诞生的初衷:“作为一个阅读爱好者,每次看到好的文章,我都会在不同的阅读平台上采集。它非常分散。之前,我会手动标记文章,并将其移动到我自己的博客上。这是非常低效的。”
金基对智能算法的研究产生了这样一种想法:既然读者通常根据文章的主要内容进行标记和分类,为什么不通过机器学习算法将这一过程智能化呢
因此,他在业余时间开始设计“优秀阅读应用程序”。通过智能算法对文章样本进行连续训练和精度优化。目前,卓越阅读中采集的文章可以自动标记五个标签。当然,读者也可以自定义、修改或增加或减少文章标题和标签,以更好地匹配他们的搜索习惯
对于如何解决重读问题,优秀阅读提供了两种提高读者阅读动机的方法:
一种是基于标签的主题阅读。对于每个采集的文章,读者可以单击自动标记的标签,过滤掉所有以前采集的文章,然后开始主题阅读。例如,我最近需要加强我的ppt技能。在采集PPT的文章并点击生成的相关标签后,我可以在平台上索引我自己的采集,甚至是其他人采集的类似文章的采集
基于某一主题的阅读使知识的掌握更加全面;别人的文章,其实是帮读者做了一个信息过滤,整体素质也比较高
二是提供方便的搜索功能。聚光灯搜索功能在IOS版本的卓越阅读中被调用。在登录并打开优秀阅读采集列表一次的前提下,无需打开应用程序,即可在苹果主屏幕的任何界面上快速下拉搜索优秀阅读采集的文章collected。搜索范围包括标题和标签,使信息检索速度加快了一步
只要你养成把它采集成优秀阅读的习惯,你就可以把你的手机建成一个现成的知识库。而采集网站、官方账号、网页和app文章的最佳阅读操作非常简单。只要您在微信中添加并绑定app assistant,就可以通过共享文章的微信助手实现文章采集和智能标签。文章的风格经过美化、排版和广告过滤,阅读效果极佳,看起来更舒适
根据金钥匙的说法,未来,Youdu还将允许用户在应用程序中选择文本采集、标记或在线查看,并提醒他们根据读者的记忆曲线查看之前阅读的笔记
目前,优秀阅读团队共有14人左右,主要是技术开发人员。优秀的阅读在通过智能算法帮助读者进行知识管理方面还有很长的路要走,但是金基和他的团队相信这是未来的趋势,也是一件值得做的事情
智能采集组合文章( 企业官方网站需要SEO文章智能采集提取功能介绍及功能说明 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-15 18:19
企业官方网站需要SEO文章智能采集提取功能介绍及功能说明
)
建筑企业官方网站需求SEO文章Intelligent采集extraction
很多企业在建设官网时,都认为自己的官网后期需要品牌推广。网站建设之初,需要对官网布局进行关键词优化。在选择网站后台、域名注册选择时,包括服务器选择、网站对应速度以及后台功能是否智能,企业在建设网站时必须考虑,这也是为了企业长远而深远的发展
首先,第一点:网站除了基本的企业文化、价值观、公司介绍、产品优势、网站地图和产品特色外,还需要更多的时间让官网品牌在后期的同行业中脱颖而出。考虑到后期维护的方便,网站维护时间,特别是SEO优化所需的文章原创度。提供后台一站式服务,可以帮助中小企业建立网站,为企业网站运营商带来巨大帮助,节省大量时间。接下来,我们来介绍一下企业的官方网站需求SEO文章智能采集提取功能描述如下:
[版本]
显示高级版本及以上版本
[使用场景]
添加文章后,您可以通过文章summary AI提取功能一键生成文章summary,帮助用户提高文章summary的质量,从而加速百度对文章的收录搜索@@
[功能描述]
1.进入管理后台[文章-功能设置-百度优化],在“文章summary AI extraction”状态栏中选择“on”
2.添加文章后进入高级设置,点击摘要AI提取,自动生成文章摘要
3.published文章,您可以通过点击管理后台的“摘要AI提取”按钮[文章-manage文章-Edit-Advanced],直接补充或更新原创的文章摘要
带图标的按钮支持
[使用场景]
标准和自适应网站按钮模块支持添加图标,以增加网站设计的多样性
[功能描述]
进入按钮模块设置面板,打开图标设置项,在网站中添加带有图标的按钮@
支持自定义按钮样式、初始颜色、悬停颜色和大小
查看全部
智能采集组合文章(
企业官方网站需要SEO文章智能采集提取功能介绍及功能说明
)
建筑企业官方网站需求SEO文章Intelligent采集extraction
很多企业在建设官网时,都认为自己的官网后期需要品牌推广。网站建设之初,需要对官网布局进行关键词优化。在选择网站后台、域名注册选择时,包括服务器选择、网站对应速度以及后台功能是否智能,企业在建设网站时必须考虑,这也是为了企业长远而深远的发展
首先,第一点:网站除了基本的企业文化、价值观、公司介绍、产品优势、网站地图和产品特色外,还需要更多的时间让官网品牌在后期的同行业中脱颖而出。考虑到后期维护的方便,网站维护时间,特别是SEO优化所需的文章原创度。提供后台一站式服务,可以帮助中小企业建立网站,为企业网站运营商带来巨大帮助,节省大量时间。接下来,我们来介绍一下企业的官方网站需求SEO文章智能采集提取功能描述如下:
[版本]
显示高级版本及以上版本
[使用场景]
添加文章后,您可以通过文章summary AI提取功能一键生成文章summary,帮助用户提高文章summary的质量,从而加速百度对文章的收录搜索@@
[功能描述]
1.进入管理后台[文章-功能设置-百度优化],在“文章summary AI extraction”状态栏中选择“on”
2.添加文章后进入高级设置,点击摘要AI提取,自动生成文章摘要
3.published文章,您可以通过点击管理后台的“摘要AI提取”按钮[文章-manage文章-Edit-Advanced],直接补充或更新原创的文章摘要
带图标的按钮支持
[使用场景]
标准和自适应网站按钮模块支持添加图标,以增加网站设计的多样性
[功能描述]
进入按钮模块设置面板,打开图标设置项,在网站中添加带有图标的按钮@
支持自定义按钮样式、初始颜色、悬停颜色和大小
智能采集组合文章(智能采集组合文章标题功能+12年全年站外数据支持)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-15 14:14
智能采集组合文章标题功能+12年全年站外数据支持实战:五步教你用r实现智能采集技术要点文章详情页标题智能组合r语言编写两种方法方法一:使用r语言自带的“智能get标题”函数
<p>1)函数说明:函数中包含两种智能标题:变量名和代码,如说明:有些情况下,需要手动生成标题,如:unknown 查看全部
智能采集组合文章(智能采集组合文章标题功能+12年全年站外数据支持)
智能采集组合文章标题功能+12年全年站外数据支持实战:五步教你用r实现智能采集技术要点文章详情页标题智能组合r语言编写两种方法方法一:使用r语言自带的“智能get标题”函数
<p>1)函数说明:函数中包含两种智能标题:变量名和代码,如说明:有些情况下,需要手动生成标题,如:unknown
智能采集组合文章(如何获取对应节点下的数据节点?有哪些注意事项? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 371 次浏览 • 2021-09-12 23:00
)
连接数据库,本文以MySQL为例
创建文件caijiMySQL.py并连接数据库,代码如下:
import pymysql
def mysql_connect():
db = pymysql.connect(host='数据库地址', port=3306, user='数据库账户', passwd='数据库密码', db='数据库名', charset='utf8')
return db.cursor()
为采集网站信息创建caijiweb.py文件,本文以采集河南省教育部教师招聘信息为例,网址如下:
解析所需采集对象的HTML节点
右击查看元素,或者按F12,可以查看当前页面的HTML元素。然后我们将分析采集的数据节点。
如上图所示,我们以第一条消息为例。我们需要的采集是class="list"标签下的信息,标题,链接,添加时间。之后需要进入这个页面,如下图:
如上图所示,我们进入后,同样可以得到信息标签,例如class="det"就是招聘内容。
如何获取对应节点下的信息?
这里需要用到beautifulsoup,一个俗称美味汤的爬虫库。这个类的详细用法这里就不介绍了,大家可以参考前面的文章,可以通过各种组合快速选择自己需要的内容。
有哪些注意事项?
1、翻页:上面第一张截图,内容页数多,需要翻页
2、采集 过程中,有很多无用的信息,需要过滤。比如我需要采集大学直播老师的信息,其他的没用,不需要额外的存储浪费空间。
3、数据库存储
4、页面应根据存储特性进行翻译,例如“转入”,以便存储后在其他地方检索和使用。
具体代码如下(有详细说明)
from bs4 import BeautifulSoup
from caijiMySQL import mysql_connect
# 引入第一步建立的数据库连接文件
import requests
#用于模拟网站请求
import re #用于选择标签时的,正则选择
import time
#时间类
cursor = mysql_connect()
# 执行数据库连接
sql = "select insert_time from me_article limit 1"
values =cursor.execute(sql)
values = cursor.fetchall()
current_time = values[0][0]
#查一下最后一条插入的招聘信息是什么时间的,采集时,只采集这个时间点之后的数据。
def caiji_jiaoyu(url):
wb_data = requests.get(url) #使用get方式获取页面内容
wb_data.encoding = 'utf-8' #页面编码为utf-8
soup = BeautifulSoup(wb_data.text, 'lxml') #使用美味汤进行分析性
for child in soup.find_all('a',attrs={"target": "_blank"}): #获取页面所有链接
article_html = requests.get(child['href']) #获取链接子页面内容
re = article_html.status_code #子页面获取的状态,看是否获取成功
if re == 200:
article_html.encoding = 'utf-8'
article_detail = BeautifulSoup(article_html.text, 'lxml')#分析子页面
article_title= child.get_text()
sql = "select * from me_article where article_name = %s"
cursor.execute(sql, article_title)
values = cursor.fetchall() #查看是否已存在该招聘信息
if values == ():
result_a = article_title.find('学院')
result_b = article_title.find('大学')
result_c = article_title.find('学校')
result_d = article_title.find('中学')
result_e = article_title.find('中心')
result_f = article_title.find('研究室')
result = 0
if result_a != -1:
result = result_a
if result_b != -1:
if result < result_b:
result = result_b
if result_c != -1:
if result < result_c:
result = result_c
if result_d != -1:
if result < result_d:
result = result_d
if result_e != -1:
if result < result_e:
result = result_e
if result_f != -1:
if result < result_f:
result = result_f
if result_a or result_b or result_c or result_d or result_e or result_f:# 筛选出大学招聘信息
sql = "select * from me_school where school_name = %s"
cursor.execute(sql,article_title[0:result+2])
values = cursor.fetchall()
if values != ():
school_id = values[0][0]
else:
sql = "insert into me_school(id, school_name) values (%s, %s)" #插入数据库
insert_result=cursor.execute(sql, ('', article_title[0:result+2]))
if insert_result == 1:
sql = "select * from me_school where school_name = %s"
cursor.execute(sql, article_title[0:result + 2])
values = cursor.fetchall()
if values != ():
school_id = values[0][0]
else:
school_id = 2
db.commit()
article_time = article_detail.find("span",class_="time").get_text("|", strip=True)
timeArray = time.strptime(article_time, "%Y-%m-%d %H:%M:%S")
article_time = int(time.mktime(timeArray))
if article_time < current_time:#如果发布时间比采集到的世界早,说明已经采集过了,是过时信息,跳出循环
exit()
article_content_in = article_detail.select('.det')
article_content_in_str = "".join('%s' % id for id in article_content_in)
article_content = article_content_in_str.replace("'", "'")
sql = "insert into me_article (school_id,article_name,article_content,article_url,article_time,insert_time) values (%s,%s,%s,%s,%s,%s)"
cursor.execute(sql, (str(school_id), article_title, '<p>' + article_content + '',child['href'], article_time, time.time()))
db.commit()
#下方几行代码,为获取下一页链接,然后重复执行上面采集内容。一般是只在第一次采集时候使用。
# if soup.find_all("a",text="下一页") != []:
# next_url = soup.find_all("a", text="下一页")[0].get('href').replace("tzgg", "/")
# url = 'http://www.haedu.gov.cn/jszp/' + next_url
# caiji_jiaoyu(url)
caiji_jiaoyu("http://www.haedu.gov.cn/jszp/index.html")
#执行采集</p>
采集 结果如下图所示:
注意,以上部分代码是博客编辑时添加的注释。如果直接复制测试,请注意空格。
查看全部
智能采集组合文章(如何获取对应节点下的数据节点?有哪些注意事项?
)
连接数据库,本文以MySQL为例
创建文件caijiMySQL.py并连接数据库,代码如下:
import pymysql
def mysql_connect():
db = pymysql.connect(host='数据库地址', port=3306, user='数据库账户', passwd='数据库密码', db='数据库名', charset='utf8')
return db.cursor()
为采集网站信息创建caijiweb.py文件,本文以采集河南省教育部教师招聘信息为例,网址如下:
解析所需采集对象的HTML节点
右击查看元素,或者按F12,可以查看当前页面的HTML元素。然后我们将分析采集的数据节点。
如上图所示,我们以第一条消息为例。我们需要的采集是class="list"标签下的信息,标题,链接,添加时间。之后需要进入这个页面,如下图:
如上图所示,我们进入后,同样可以得到信息标签,例如class="det"就是招聘内容。
如何获取对应节点下的信息?
这里需要用到beautifulsoup,一个俗称美味汤的爬虫库。这个类的详细用法这里就不介绍了,大家可以参考前面的文章,可以通过各种组合快速选择自己需要的内容。
有哪些注意事项?
1、翻页:上面第一张截图,内容页数多,需要翻页
2、采集 过程中,有很多无用的信息,需要过滤。比如我需要采集大学直播老师的信息,其他的没用,不需要额外的存储浪费空间。
3、数据库存储
4、页面应根据存储特性进行翻译,例如“转入”,以便存储后在其他地方检索和使用。
具体代码如下(有详细说明)
from bs4 import BeautifulSoup
from caijiMySQL import mysql_connect
# 引入第一步建立的数据库连接文件
import requests
#用于模拟网站请求
import re #用于选择标签时的,正则选择
import time
#时间类
cursor = mysql_connect()
# 执行数据库连接
sql = "select insert_time from me_article limit 1"
values =cursor.execute(sql)
values = cursor.fetchall()
current_time = values[0][0]
#查一下最后一条插入的招聘信息是什么时间的,采集时,只采集这个时间点之后的数据。
def caiji_jiaoyu(url):
wb_data = requests.get(url) #使用get方式获取页面内容
wb_data.encoding = 'utf-8' #页面编码为utf-8
soup = BeautifulSoup(wb_data.text, 'lxml') #使用美味汤进行分析性
for child in soup.find_all('a',attrs={"target": "_blank"}): #获取页面所有链接
article_html = requests.get(child['href']) #获取链接子页面内容
re = article_html.status_code #子页面获取的状态,看是否获取成功
if re == 200:
article_html.encoding = 'utf-8'
article_detail = BeautifulSoup(article_html.text, 'lxml')#分析子页面
article_title= child.get_text()
sql = "select * from me_article where article_name = %s"
cursor.execute(sql, article_title)
values = cursor.fetchall() #查看是否已存在该招聘信息
if values == ():
result_a = article_title.find('学院')
result_b = article_title.find('大学')
result_c = article_title.find('学校')
result_d = article_title.find('中学')
result_e = article_title.find('中心')
result_f = article_title.find('研究室')
result = 0
if result_a != -1:
result = result_a
if result_b != -1:
if result < result_b:
result = result_b
if result_c != -1:
if result < result_c:
result = result_c
if result_d != -1:
if result < result_d:
result = result_d
if result_e != -1:
if result < result_e:
result = result_e
if result_f != -1:
if result < result_f:
result = result_f
if result_a or result_b or result_c or result_d or result_e or result_f:# 筛选出大学招聘信息
sql = "select * from me_school where school_name = %s"
cursor.execute(sql,article_title[0:result+2])
values = cursor.fetchall()
if values != ():
school_id = values[0][0]
else:
sql = "insert into me_school(id, school_name) values (%s, %s)" #插入数据库
insert_result=cursor.execute(sql, ('', article_title[0:result+2]))
if insert_result == 1:
sql = "select * from me_school where school_name = %s"
cursor.execute(sql, article_title[0:result + 2])
values = cursor.fetchall()
if values != ():
school_id = values[0][0]
else:
school_id = 2
db.commit()
article_time = article_detail.find("span",class_="time").get_text("|", strip=True)
timeArray = time.strptime(article_time, "%Y-%m-%d %H:%M:%S")
article_time = int(time.mktime(timeArray))
if article_time < current_time:#如果发布时间比采集到的世界早,说明已经采集过了,是过时信息,跳出循环
exit()
article_content_in = article_detail.select('.det')
article_content_in_str = "".join('%s' % id for id in article_content_in)
article_content = article_content_in_str.replace("'", "'")
sql = "insert into me_article (school_id,article_name,article_content,article_url,article_time,insert_time) values (%s,%s,%s,%s,%s,%s)"
cursor.execute(sql, (str(school_id), article_title, '<p>' + article_content + '',child['href'], article_time, time.time()))
db.commit()
#下方几行代码,为获取下一页链接,然后重复执行上面采集内容。一般是只在第一次采集时候使用。
# if soup.find_all("a",text="下一页") != []:
# next_url = soup.find_all("a", text="下一页")[0].get('href').replace("tzgg", "/")
# url = 'http://www.haedu.gov.cn/jszp/' + next_url
# caiji_jiaoyu(url)
caiji_jiaoyu("http://www.haedu.gov.cn/jszp/index.html";)
#执行采集</p>
采集 结果如下图所示:
注意,以上部分代码是博客编辑时添加的注释。如果直接复制测试,请注意空格。
智能采集组合文章(智能采集组合文章过滤热点采集网站或者网址做什么修改)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-11 13:02
智能采集组合文章过滤热点采集网站或者网址做什么修改直接就可以用都是电脑开发调试推荐蓝海采集软件
都想要,vue和angularjs平台其实是可以单独开发一套的,中文教程推荐:精通前端开发-w3cplus前端基础非常重要,ssr不如页面加载再加个vue组件,所以两个平台都需要会一些,推荐不学flex布局以及,不会css3的话,选择vue2,前端单页应用为主,vue整体负责前端框架的搭建,angularjs多页应用为主,框架一般是不会学习的,我们公司是这样的,vue和angular两个平台一起开发的,vue2进行业务快速部署,到cdn后对cdn进行负载均衡,angular要学习的话,可以在做vue2的过程中,顺带学习下angular,对于没有细节上的痛点,没有后端,多页面应用,vue2和angular都能实现即时渲染,前端尽可能的模块化设计和性能优化比较重要,学习项目开发的逻辑逻辑,往简单了学就好了。angular2有点复杂,你没事的话,可以先用vue实现个简单业务,然后拆分模块。
切图用vue,写业务逻辑angularjs,然后弄angularjsspa方向的开发。angularjs的seo、数据绑定和路由、es6、es7.各种vue的内置标签。最后转型angularjsfp方向。
vue的容易,但是你也能看到绝大多数人都推荐flux,我想说两者都不容易,都是组件化解决方案,有的人搞不定就放弃了。 查看全部
智能采集组合文章(智能采集组合文章过滤热点采集网站或者网址做什么修改)
智能采集组合文章过滤热点采集网站或者网址做什么修改直接就可以用都是电脑开发调试推荐蓝海采集软件
都想要,vue和angularjs平台其实是可以单独开发一套的,中文教程推荐:精通前端开发-w3cplus前端基础非常重要,ssr不如页面加载再加个vue组件,所以两个平台都需要会一些,推荐不学flex布局以及,不会css3的话,选择vue2,前端单页应用为主,vue整体负责前端框架的搭建,angularjs多页应用为主,框架一般是不会学习的,我们公司是这样的,vue和angular两个平台一起开发的,vue2进行业务快速部署,到cdn后对cdn进行负载均衡,angular要学习的话,可以在做vue2的过程中,顺带学习下angular,对于没有细节上的痛点,没有后端,多页面应用,vue2和angular都能实现即时渲染,前端尽可能的模块化设计和性能优化比较重要,学习项目开发的逻辑逻辑,往简单了学就好了。angular2有点复杂,你没事的话,可以先用vue实现个简单业务,然后拆分模块。
切图用vue,写业务逻辑angularjs,然后弄angularjsspa方向的开发。angularjs的seo、数据绑定和路由、es6、es7.各种vue的内置标签。最后转型angularjsfp方向。
vue的容易,但是你也能看到绝大多数人都推荐flux,我想说两者都不容易,都是组件化解决方案,有的人搞不定就放弃了。
智能采集组合文章(AI文章智能处理软件是一款很不错的文章伪原创工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 730 次浏览 • 2021-09-06 10:25
AI文章Intelligent Processing Software 是一款智能文章伪原创工具,可以帮助用户重新组合文章形成新的文章,也可以进行素材采集,是一个A非常好的文章处理工具。
功能介绍:
1、智能伪原创:利用人工智能中的自然语言处理技术实现文章伪原创处理。核心功能包括“smart伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词”、“句子改组重组”等等等,处理后的文章原创度和收录率都在80%以上。想了解更多功能,请下载软件试用。
2、Portal文章采集:一键搜索采集相关门户网站新闻文章、网站有搜狐、腾讯、新浪、网易、今日头条.com、新兰网、联合早报、光明网、站长网、新文化网等,用户可以输入行业关键词搜索想要的行业文章。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
3、百度新闻采集:一键搜索各种行业新闻文章,数据源来自百度新闻搜索引擎,资源丰富,操作灵活,无需写任何采集规则,但缺点是,采集的文章不一定完整,但可以满足大部分用户的需求。友情提示:文章使用时请注明文章出处,尊重原文版权。
4、工业文章采集:一键搜索相关行业网站文章,网站行业包括装饰家居行业、机械行业、建材行业、家电行业、硬件行业,美容行业,育儿行业,金融行业,游戏行业,SEO行业,女性健康行业等有几十个网站网站,资源丰富,这个模块可能不能满足大家的需求客户,但客户可以提出他们的需求,我们会改进和更新模块资源。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
5、write rules采集:自己写采集rules采集,采集规则符合常见的正则表达式,写采集规则需要了解一些html代码和正则表达式规则,如果如果你写过采集software 采集rules 其他商家,你肯定会为我们的软件写采集rules,我们提供写采集rules 的文档。我们不为客户编写采集 规则。如果你需要代写,10元你会得到一个采集规则。友情提示:文章使用时请注明文章出处,尊重原文版权。
<p>6、外链文章材料:该模块使用大量行业语料,通过算法随机组合语料,产生相关行业文章。这个模块文章只适用于质量要求不高的文章。对于外链推广的用户,该模块具有资源丰富、原创度高的特点,但缺点是文章可读性差,用户在使用时可以选择使用。 查看全部
智能采集组合文章(AI文章智能处理软件是一款很不错的文章伪原创工具)
AI文章Intelligent Processing Software 是一款智能文章伪原创工具,可以帮助用户重新组合文章形成新的文章,也可以进行素材采集,是一个A非常好的文章处理工具。
功能介绍:
1、智能伪原创:利用人工智能中的自然语言处理技术实现文章伪原创处理。核心功能包括“smart伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词”、“句子改组重组”等等等,处理后的文章原创度和收录率都在80%以上。想了解更多功能,请下载软件试用。
2、Portal文章采集:一键搜索采集相关门户网站新闻文章、网站有搜狐、腾讯、新浪、网易、今日头条.com、新兰网、联合早报、光明网、站长网、新文化网等,用户可以输入行业关键词搜索想要的行业文章。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
3、百度新闻采集:一键搜索各种行业新闻文章,数据源来自百度新闻搜索引擎,资源丰富,操作灵活,无需写任何采集规则,但缺点是,采集的文章不一定完整,但可以满足大部分用户的需求。友情提示:文章使用时请注明文章出处,尊重原文版权。
4、工业文章采集:一键搜索相关行业网站文章,网站行业包括装饰家居行业、机械行业、建材行业、家电行业、硬件行业,美容行业,育儿行业,金融行业,游戏行业,SEO行业,女性健康行业等有几十个网站网站,资源丰富,这个模块可能不能满足大家的需求客户,但客户可以提出他们的需求,我们会改进和更新模块资源。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
5、write rules采集:自己写采集rules采集,采集规则符合常见的正则表达式,写采集规则需要了解一些html代码和正则表达式规则,如果如果你写过采集software 采集rules 其他商家,你肯定会为我们的软件写采集rules,我们提供写采集rules 的文档。我们不为客户编写采集 规则。如果你需要代写,10元你会得到一个采集规则。友情提示:文章使用时请注明文章出处,尊重原文版权。
<p>6、外链文章材料:该模块使用大量行业语料,通过算法随机组合语料,产生相关行业文章。这个模块文章只适用于质量要求不高的文章。对于外链推广的用户,该模块具有资源丰富、原创度高的特点,但缺点是文章可读性差,用户在使用时可以选择使用。
智能采集组合文章(软件功能是一款多功能的伪原创SEO运营工具吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-04 21:32
)
优采云文章组合工具集软件功能是一个多功能的伪原创SEO操作工具。该工具主要是帮助网站运营人员优化文章内容,增加文章的权重。保证网站能持续输出有价值的内容;软件包括文章查重、伪原创文章生成,查找关键词词的长短尾词,帮助运营商解码网页内容,生成与网页一致的格式文章code等.;是一款功能更全的SEO网站操作工具,软件的每个功能都采用了比较清晰的布局,用户使用不会觉得凌乱;我相信这个工具可以带给你高效的工作。
软件功能
1、软件支持在线文本编辑和查看本地文本文件。
2、 支持用同义词快速替换文章 中的单词。
3、支持自动词组,让用户快速完成构词造句。
4、 以巧妙的方式组合单词和短语。
5、快速查找和过滤用户需要的词。
6、可以与关键词进行对比,让用户更好的优化词。
7、 支持将文字转成拼音。
8、支持网页的编解码。
9、支持文章去重戏机击重组,提升文章质量。
10、支持采集关键词的长尾词汇。
软件功能
1、无限增加域名,网站,中文站群采集,英文站群采集,指定网址采集,自定义发布界面。
2、自定义生成原创文章、长尾关键词采集、相关图片采集、全球SEO链轮、文章自动加入内链。
3、随机抽取内容为标题,互换不同内容段落,随机插入指定关键词,定时发布文章,自动内容伪原创。
4、分组参数设置,分组链接库内联,自动监听采集发布hook,自动更新网站homepage栏目静态页面等。
5、从句型库中随机抽取句子,插入文章的伪原创函数。
6、文章 批处理方式的导入速度。您还可以同时打开多个窗口和线程在自定义文件夹中导入文章,大大提高了导入速度。
7、文章Publishing 序列添加后进先发参数,方便软文最后优先发布。
8、Open个人版批量删除网站不发和删除文章所有站的功能。
如何使用
1、软件打开就可以直接使用,首先解压安装包,在安装文件下找到“优采云·文章组合工具集.exe”,运行打开。
2、 点击左侧的模板创建一个新模板。选择模板后,再次创建一个新的文本框。
3、选择文本框,将内容复制到软件右侧窗口。
4、点击预览按钮先预览文章。
5、 切换到网页模式进行预览并检查布局是否正确。如果没有问题,点击生成。
6、点击查看,打开如下界面,可以在左下角的文件管理中找到该文档,打开查看。
7、其他功能,如果需要使用,可以直接点击红框中对应的功能进行切换。
8、点击右上角的代码查看,将你要查看的网页的网址复制到输入框中点击阅读网址。该软件还支持网页解码。
9、点击长尾词采集,在该界面根据提示输入关键词,然后选择搜索平台设置相关参数,点击启动采集,长尾采集的字如下图显示窗口显示。
10、点击搜索相似词可以帮助用户用相似词替换文章,防止文章大规模相似导致网页被搜索网站所收录。
11、还可以使用去重和打乱功能对文章进行彻底排序,提高文章的质量。
查看全部
智能采集组合文章(软件功能是一款多功能的伪原创SEO运营工具吗?
)
优采云文章组合工具集软件功能是一个多功能的伪原创SEO操作工具。该工具主要是帮助网站运营人员优化文章内容,增加文章的权重。保证网站能持续输出有价值的内容;软件包括文章查重、伪原创文章生成,查找关键词词的长短尾词,帮助运营商解码网页内容,生成与网页一致的格式文章code等.;是一款功能更全的SEO网站操作工具,软件的每个功能都采用了比较清晰的布局,用户使用不会觉得凌乱;我相信这个工具可以带给你高效的工作。
软件功能
1、软件支持在线文本编辑和查看本地文本文件。
2、 支持用同义词快速替换文章 中的单词。
3、支持自动词组,让用户快速完成构词造句。
4、 以巧妙的方式组合单词和短语。
5、快速查找和过滤用户需要的词。
6、可以与关键词进行对比,让用户更好的优化词。
7、 支持将文字转成拼音。
8、支持网页的编解码。
9、支持文章去重戏机击重组,提升文章质量。
10、支持采集关键词的长尾词汇。
软件功能
1、无限增加域名,网站,中文站群采集,英文站群采集,指定网址采集,自定义发布界面。
2、自定义生成原创文章、长尾关键词采集、相关图片采集、全球SEO链轮、文章自动加入内链。
3、随机抽取内容为标题,互换不同内容段落,随机插入指定关键词,定时发布文章,自动内容伪原创。
4、分组参数设置,分组链接库内联,自动监听采集发布hook,自动更新网站homepage栏目静态页面等。
5、从句型库中随机抽取句子,插入文章的伪原创函数。
6、文章 批处理方式的导入速度。您还可以同时打开多个窗口和线程在自定义文件夹中导入文章,大大提高了导入速度。
7、文章Publishing 序列添加后进先发参数,方便软文最后优先发布。
8、Open个人版批量删除网站不发和删除文章所有站的功能。
如何使用
1、软件打开就可以直接使用,首先解压安装包,在安装文件下找到“优采云·文章组合工具集.exe”,运行打开。
2、 点击左侧的模板创建一个新模板。选择模板后,再次创建一个新的文本框。
3、选择文本框,将内容复制到软件右侧窗口。
4、点击预览按钮先预览文章。
5、 切换到网页模式进行预览并检查布局是否正确。如果没有问题,点击生成。
6、点击查看,打开如下界面,可以在左下角的文件管理中找到该文档,打开查看。
7、其他功能,如果需要使用,可以直接点击红框中对应的功能进行切换。
8、点击右上角的代码查看,将你要查看的网页的网址复制到输入框中点击阅读网址。该软件还支持网页解码。
9、点击长尾词采集,在该界面根据提示输入关键词,然后选择搜索平台设置相关参数,点击启动采集,长尾采集的字如下图显示窗口显示。
10、点击搜索相似词可以帮助用户用相似词替换文章,防止文章大规模相似导致网页被搜索网站所收录。
11、还可以使用去重和打乱功能对文章进行彻底排序,提高文章的质量。
智能采集组合文章(智能采集组合文章之爬虫umm统计系统统计多少词?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-04 17:01
智能采集组合文章吧。采集和加工一下。上传到云词库。然后用词频统计系统统计下,统计多少词。都统计出来了,是2010年的词,大概有80%的概率都是动物,动物的词汇就可以很多了。上传到一个词库。用词频统计就可以了。
直接准备好你的基础数据就行,包括头像,昵称,关键词等等,可以提前上传到云词库里。然后现在做的都是用excel调用云词库的服务,直接提取出来,这是目前普遍用的方法。另外,还有人用adb+bing这个比较特殊,ab词分词,但是看起来很不准。
python爬虫
web上直接爬...
直接抓,
在某宝上找一个上传词库的服务,就是花钱的那种,基本就能抓了,
可以直接用前面很多答案里提到的云词库
直接用爬虫,然后把用户的email给后台,写进云词库就行。
爬虫
假设有多个网站这么多文章,多爬虫啊。
用算法把关键词提取出来,
这就是俗称的爬虫
umm我个人还是很喜欢这个问题的直接爬然后带一个自己的知识库上传就好了对于一篇博文来说还是会有很多细节问题比如标题排列顺序一致等等不同网站的标准或者一致性都不一样有的时候我会因为有些字少而错了那么多个选项而纠结再就是公众号、大学生服务平台一类的如果内容不多的话倒是可以考虑写一个小爬虫的另外上传,这个是有公司专门做这个的花点钱其实也是可以的。 查看全部
智能采集组合文章(智能采集组合文章之爬虫umm统计系统统计多少词?)
智能采集组合文章吧。采集和加工一下。上传到云词库。然后用词频统计系统统计下,统计多少词。都统计出来了,是2010年的词,大概有80%的概率都是动物,动物的词汇就可以很多了。上传到一个词库。用词频统计就可以了。
直接准备好你的基础数据就行,包括头像,昵称,关键词等等,可以提前上传到云词库里。然后现在做的都是用excel调用云词库的服务,直接提取出来,这是目前普遍用的方法。另外,还有人用adb+bing这个比较特殊,ab词分词,但是看起来很不准。
python爬虫
web上直接爬...
直接抓,
在某宝上找一个上传词库的服务,就是花钱的那种,基本就能抓了,
可以直接用前面很多答案里提到的云词库
直接用爬虫,然后把用户的email给后台,写进云词库就行。
爬虫
假设有多个网站这么多文章,多爬虫啊。
用算法把关键词提取出来,
这就是俗称的爬虫
umm我个人还是很喜欢这个问题的直接爬然后带一个自己的知识库上传就好了对于一篇博文来说还是会有很多细节问题比如标题排列顺序一致等等不同网站的标准或者一致性都不一样有的时候我会因为有些字少而错了那么多个选项而纠结再就是公众号、大学生服务平台一类的如果内容不多的话倒是可以考虑写一个小爬虫的另外上传,这个是有公司专门做这个的花点钱其实也是可以的。
智能采集组合文章(配套软件版本:V9及更低集搜客网络爬虫的对应教程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-03 04:15
)
支持软件版本:V9及更低版本的Jisuke网络爬虫软件
新版对应教程:V10及更高版本数据管家-增强版爬虫对应教程为《自动点击京东商品价格条件,智能采集价数据》
当我们浏览商品购物网站时,我们通常可以进行多种组合购买。如果您为同一产品选择颜色、尺寸等,您将得到不同的价格。那么,如果将人类点击行为变成机器自动点击,如何实现?
通过连续动作,模拟人在浏览网页时的操作,一键一键抓取数据。现在很多动态网页都需要交互操作来浏览最终数据,而连续动作的目的是模拟人在浏览网页时的操作,从而获得最终显示的数据。
要模拟人工操作,首先要知道需要哪些交互操作才能显示最终数据。比如在京东浏览小米Max的产品页面时,我们可以看到选择颜色、版本、购买方式后的最终价格1、购方法2。所以,如果按下这个操作,需要设置一个4步动作,这里的动作类型都是点击。搞清楚这些之后,下面就教大家如何利用MS的连续动作来制定规则,实现自动点击。
根据上面的描述,有以下两种采集方案。下面我们使用方案一实现自动点击和采集。
示例网址:规则下载:京东货品_汽车点击
注意:如果动作执行前后网页结构没有变化,可以用一个规则完成;如果网页的结构前后发生变化,必须用两条或两条以上的规则来完成;另外,如果涉及翻页,必须拆分成两个或多个规则。连续动作规则数量请参考文章《规划采集procedures》。
一、创建一级主题获取目标信息
建立一级主题的规则,将想要的信息映射到排序框。建议在内容映射完成后,还要进行定位标记映射,这样可以提高定位精度和规则的适应性。
注意:如果设置了连续动作规则,则不需要构建排序框。比如方案2的一级主题不需要搭建排序框,而是用排序框抓取一点数据(选择要显示在网页上的信息)。由爬虫判断是否执行采集,否则可能会漏掉网页。
二、设置连续动作
点击New按钮新建一个动作,每个动作的设置方法都是一样的,基本操作如下:
2.1 输入目标科目名称
连续动作指向同一个目标对象。如果有多个动作,要指向不同的主题,请拆分成多个规则,分别设置连续动作。
2.2 选择动作类型
本例为点击动作,不同动作的适用范围不同。请根据实际操作情况选择动作类型。
2.3 将定位到动作对象的 xpath 填充到定位表达式中
2.4 输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.5 高级设置
一开始不需要设置,以后调试连续动作时会用到,可以扩大动作的适用范围。如果需要抓取动作对象的信息,可以使用xpath在高级设置的内容表达式中定位动作对象的信息。请根据需要重新设置。
注意:是否选择了动作类型以及xpath定位是否准确,决定了连续动作是否可以成功执行。 Xpath 是一种用于定位 html 节点的标准语言。使用连续动作功能前请自行掌握xpath。
根据人工操作步骤,我们还需要选择版本和购买方式1、买方法2,所以我们会继续新建3个动作,重复以上步骤。
三、调试规则
完成上述步骤后,单击“保存规则”,然后单击“抓取数据”按钮开始尝试捕获。发现采集报错:Unable to locate the node***。观察浏览器窗口,看到执行第一步时,没有加载其他信息。加载信息时,发现购买方式2点击后,无法返回执行4步点击的页面,导致连续动作不断执行。<//p
pimg src='http://www.gooseeker.com/doc/data/attachment/portal/201607/26/173412wflkffpveleuvkv0.png' alt=''//p
pimg src='http://www.gooseeker.com/doc/data/attachment/portal/201607/26/173415hllg8nzulgi5emn1.png' alt=''//p
p针对以上情况,我们的解决方案是删除第四步。因为无论是否点击购买方式2,都不会影响商品的价格。因此,可以删除不必要的和令人不安的操作步骤。/p
p修改后,再次尝试捕捉。将提取的xml转换为excel后,看到价格和累计评价数据被抓取或抓取错误。这是因为网页太大,加载速度慢,点击后的数据需要等待一段时间才能加载。/p
pimg src='http://www.gooseeker.com/doc/data/attachment/portal/201607/26/173417mt3zt9joz5j6xj59.png' alt=''//p
p为了捕获所有数据,您需要延长等待时间并为每个动作单独设置延迟。单击操作步骤-> 高级设置-> 额外延迟,并输入一个以秒为单位的正整数。请按实际时间调试。
另外,如果不是粘性窗口,采集时会反复点击。这是因为京东网页上有防爬措施,必须是当前窗口的操作才能生效。因此,在高级设置中勾选窗口可见,采集时窗口会在最上面。请根据实际情况设置。
四、如何将抓取到的信息与动作步骤一一对应?
如果要将捕获的信息与动作步骤一一关联,那么就必须提取动作对象的信息。有两种方式:
4.1 使用xpath在连续动作的高级设置的内容表达式中定位动作对象的信息节点。
定位表达式定位到动作对象的整个操作范围后,还收录了自身的信息。因此,内容表达只需要从定位的动作对象开始,继续定位到它的信息。 采集会在actionvalue中记录step动作的信息,对应actionno,记录动作执行的次数。
4.2 抓取排序框中动作对象的信息,这里也使用xpath定位。
当action对象被执行时,它的dom结构发生了变化。找到网页变化的结构特征,使用xpath准确定位节点,验证通过后可以设置自定义xpath。
以上是使用连续动作模拟人工操作的全过程。虽然过程比较繁琐,但只要细心耐心,最终还是可以征服你想要爬取的网页。
如果您有任何问题,可以或
查看全部
智能采集组合文章(配套软件版本:V9及更低集搜客网络爬虫的对应教程
)
支持软件版本:V9及更低版本的Jisuke网络爬虫软件
新版对应教程:V10及更高版本数据管家-增强版爬虫对应教程为《自动点击京东商品价格条件,智能采集价数据》
当我们浏览商品购物网站时,我们通常可以进行多种组合购买。如果您为同一产品选择颜色、尺寸等,您将得到不同的价格。那么,如果将人类点击行为变成机器自动点击,如何实现?
通过连续动作,模拟人在浏览网页时的操作,一键一键抓取数据。现在很多动态网页都需要交互操作来浏览最终数据,而连续动作的目的是模拟人在浏览网页时的操作,从而获得最终显示的数据。
要模拟人工操作,首先要知道需要哪些交互操作才能显示最终数据。比如在京东浏览小米Max的产品页面时,我们可以看到选择颜色、版本、购买方式后的最终价格1、购方法2。所以,如果按下这个操作,需要设置一个4步动作,这里的动作类型都是点击。搞清楚这些之后,下面就教大家如何利用MS的连续动作来制定规则,实现自动点击。
根据上面的描述,有以下两种采集方案。下面我们使用方案一实现自动点击和采集。
示例网址:规则下载:京东货品_汽车点击
注意:如果动作执行前后网页结构没有变化,可以用一个规则完成;如果网页的结构前后发生变化,必须用两条或两条以上的规则来完成;另外,如果涉及翻页,必须拆分成两个或多个规则。连续动作规则数量请参考文章《规划采集procedures》。
一、创建一级主题获取目标信息
建立一级主题的规则,将想要的信息映射到排序框。建议在内容映射完成后,还要进行定位标记映射,这样可以提高定位精度和规则的适应性。
注意:如果设置了连续动作规则,则不需要构建排序框。比如方案2的一级主题不需要搭建排序框,而是用排序框抓取一点数据(选择要显示在网页上的信息)。由爬虫判断是否执行采集,否则可能会漏掉网页。
二、设置连续动作
点击New按钮新建一个动作,每个动作的设置方法都是一样的,基本操作如下:
2.1 输入目标科目名称
连续动作指向同一个目标对象。如果有多个动作,要指向不同的主题,请拆分成多个规则,分别设置连续动作。
2.2 选择动作类型
本例为点击动作,不同动作的适用范围不同。请根据实际操作情况选择动作类型。
2.3 将定位到动作对象的 xpath 填充到定位表达式中
2.4 输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.5 高级设置
一开始不需要设置,以后调试连续动作时会用到,可以扩大动作的适用范围。如果需要抓取动作对象的信息,可以使用xpath在高级设置的内容表达式中定位动作对象的信息。请根据需要重新设置。
注意:是否选择了动作类型以及xpath定位是否准确,决定了连续动作是否可以成功执行。 Xpath 是一种用于定位 html 节点的标准语言。使用连续动作功能前请自行掌握xpath。
根据人工操作步骤,我们还需要选择版本和购买方式1、买方法2,所以我们会继续新建3个动作,重复以上步骤。
三、调试规则
完成上述步骤后,单击“保存规则”,然后单击“抓取数据”按钮开始尝试捕获。发现采集报错:Unable to locate the node***。观察浏览器窗口,看到执行第一步时,没有加载其他信息。加载信息时,发现购买方式2点击后,无法返回执行4步点击的页面,导致连续动作不断执行。<//p
pimg src='http://www.gooseeker.com/doc/data/attachment/portal/201607/26/173412wflkffpveleuvkv0.png' alt=''//p
pimg src='http://www.gooseeker.com/doc/data/attachment/portal/201607/26/173415hllg8nzulgi5emn1.png' alt=''//p
p针对以上情况,我们的解决方案是删除第四步。因为无论是否点击购买方式2,都不会影响商品的价格。因此,可以删除不必要的和令人不安的操作步骤。/p
p修改后,再次尝试捕捉。将提取的xml转换为excel后,看到价格和累计评价数据被抓取或抓取错误。这是因为网页太大,加载速度慢,点击后的数据需要等待一段时间才能加载。/p
pimg src='http://www.gooseeker.com/doc/data/attachment/portal/201607/26/173417mt3zt9joz5j6xj59.png' alt=''//p
p为了捕获所有数据,您需要延长等待时间并为每个动作单独设置延迟。单击操作步骤-> 高级设置-> 额外延迟,并输入一个以秒为单位的正整数。请按实际时间调试。
另外,如果不是粘性窗口,采集时会反复点击。这是因为京东网页上有防爬措施,必须是当前窗口的操作才能生效。因此,在高级设置中勾选窗口可见,采集时窗口会在最上面。请根据实际情况设置。
四、如何将抓取到的信息与动作步骤一一对应?
如果要将捕获的信息与动作步骤一一关联,那么就必须提取动作对象的信息。有两种方式:
4.1 使用xpath在连续动作的高级设置的内容表达式中定位动作对象的信息节点。
定位表达式定位到动作对象的整个操作范围后,还收录了自身的信息。因此,内容表达只需要从定位的动作对象开始,继续定位到它的信息。 采集会在actionvalue中记录step动作的信息,对应actionno,记录动作执行的次数。
4.2 抓取排序框中动作对象的信息,这里也使用xpath定位。
当action对象被执行时,它的dom结构发生了变化。找到网页变化的结构特征,使用xpath准确定位节点,验证通过后可以设置自定义xpath。
以上是使用连续动作模拟人工操作的全过程。虽然过程比较繁琐,但只要细心耐心,最终还是可以征服你想要爬取的网页。
如果您有任何问题,可以或
智能采集组合文章(用考拉,一天产出几万篇高质量SEO文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 463 次浏览 • 2021-09-01 17:15
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批写SEO原创文章】平台发布的。有了考拉,一天可以产出数万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
非常抱歉,现在当您点击进入该网页时,可能您浏览的信息不是关于文章采集仓储的报告,因为该页面是我们系统批量编写的网页文章。如果对自动化原创平台的信息感兴趣,不妨先放弃文章采集仓储这件事。推荐大家看看如何借用工具半天制作10000个优质搜索文案!大多数看过考拉SEO资料的人都会认为这是伪原创系统,误会!网站本质上是一个AI平台,关键词和模块都是自己写的,网上基本没有和这篇文章很相似的作品。这个平台是如何创建的?让我为你读一读!
不断向数据库伙伴查询文章采集,毕竟你最关心的是之前文章研究的内容。其实,写几篇优化好的落地文章很容易,但是这些SEO文案能拿到的访问量,其实总比没有好。希望通过页面设置达到流量的目的。最重要的一点是自动化!如果文章1篇文章可以收获1个访问者(每天),如果我可以写10,000篇文章,则平均每天的页面浏览量可以增加10,000。但简单来说,真正写出来的时候,一个人一天只能出40篇文章,最好是70篇左右。就算用伪原创software,最多也只有100篇!读到这点,我们可以先抛开文章采集入库的问题,想想如何完成批量写入文章!
seo 识别的原创 是什么?文字原创不一定是一一关键词原创输出!在各大搜索引擎的算法词典中,原创并不是唯一的。事实上,每当你的文字堆叠与其他网站内容不同时,收录的概率就会大大增加。一个高质量的内容,题材抢眼,保留了相同的核心思想,只要保证重复大段,就说明文章还是很可能是收录,甚至变成爆文。就像下一篇文章,你可能已经通过百度搜索文章采集,然后点进去了。 其实下一篇文章就是用考拉SEO智能写作文章system自助出口!
考拉的AI原创系统其实应该是一个自动的文章平台,24小时可以生成10000篇文章,可靠的优化文章,而且每个人的网站权重都应该够高,收录率可以高达 78% 或更高。详细的操作方法,个人主页收录视频展示和初学者指南。大佬们不妨免费试一试!很抱歉不能给你详细介绍文章采集仓储,可能让你看了这么多系统语言。但是如果我们喜欢考拉SEO的内容,请看菜单栏,让大家网站每天达到数千人,你不喜欢吗? 查看全部
智能采集组合文章(用考拉,一天产出几万篇高质量SEO文章)
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批写SEO原创文章】平台发布的。有了考拉,一天可以产出数万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
非常抱歉,现在当您点击进入该网页时,可能您浏览的信息不是关于文章采集仓储的报告,因为该页面是我们系统批量编写的网页文章。如果对自动化原创平台的信息感兴趣,不妨先放弃文章采集仓储这件事。推荐大家看看如何借用工具半天制作10000个优质搜索文案!大多数看过考拉SEO资料的人都会认为这是伪原创系统,误会!网站本质上是一个AI平台,关键词和模块都是自己写的,网上基本没有和这篇文章很相似的作品。这个平台是如何创建的?让我为你读一读!
不断向数据库伙伴查询文章采集,毕竟你最关心的是之前文章研究的内容。其实,写几篇优化好的落地文章很容易,但是这些SEO文案能拿到的访问量,其实总比没有好。希望通过页面设置达到流量的目的。最重要的一点是自动化!如果文章1篇文章可以收获1个访问者(每天),如果我可以写10,000篇文章,则平均每天的页面浏览量可以增加10,000。但简单来说,真正写出来的时候,一个人一天只能出40篇文章,最好是70篇左右。就算用伪原创software,最多也只有100篇!读到这点,我们可以先抛开文章采集入库的问题,想想如何完成批量写入文章!
seo 识别的原创 是什么?文字原创不一定是一一关键词原创输出!在各大搜索引擎的算法词典中,原创并不是唯一的。事实上,每当你的文字堆叠与其他网站内容不同时,收录的概率就会大大增加。一个高质量的内容,题材抢眼,保留了相同的核心思想,只要保证重复大段,就说明文章还是很可能是收录,甚至变成爆文。就像下一篇文章,你可能已经通过百度搜索文章采集,然后点进去了。 其实下一篇文章就是用考拉SEO智能写作文章system自助出口!
考拉的AI原创系统其实应该是一个自动的文章平台,24小时可以生成10000篇文章,可靠的优化文章,而且每个人的网站权重都应该够高,收录率可以高达 78% 或更高。详细的操作方法,个人主页收录视频展示和初学者指南。大佬们不妨免费试一试!很抱歉不能给你详细介绍文章采集仓储,可能让你看了这么多系统语言。但是如果我们喜欢考拉SEO的内容,请看菜单栏,让大家网站每天达到数千人,你不喜欢吗?
智能采集组合文章(繁殖侠站群PHP目录繁殖版只限量出售5套)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-01 06:21
育种man站群PHP目录复制版,本程序是麦芒团队高端定制目录内页复制特别版,租用目录可快速排名,支持上千个主目录同时生成内页时间,页面的定量再现,关键词对应锚文本链接,关键词转码,自动生成站点地图页面,自动将生成的页面链接插入首页,汇聚最实用的操作方法当前搜索引擎排名。程序使用php编程语言,无后门程序,符合互联网使用规则。该程序不限制行业使用。一经售出,使用该程序的用户所经营的站群业务是否合理与作者无关。我们只负责程序的后台开发,特此声明!
节目授权:Breeder制作的任何节目限发行数量,(咨询特价)/年续订(咨询特价)3台服务器无限授权,每台服务器添加(咨询特价)。
绑定机器码、IP硬件码,购买授权后可修改5X24小时技术服务跟进!
程序采用独立多重验证,发现恶意传播程序停止免费更新!严格限制是为了防止程序泛滥,起到更大的作用
站长朋友应该知道,作者再厉害,只要程序被大规模使用,就会被搜索引擎关注。育种英雄站群PHP旗舰版限量5套,售完即删帖!
限制程序防止购买,请作者8
一个。程序可在windows和unix操作系统下运行
程序运行需要的环境,php5.4+zendopminizer 我们将提供用户下载这些环境包,并将受控端index.php转移到目录下执行,生成内部页面文件。
B.主机与受控端负载均衡
为了提高站群运行的效率,程序分为主机、主机、网关三部分进行负载均衡。主机是复现生成的内部页面文件的核心,需要上传到权重目录,主机终端只需要租用一个普通的VPS。使用采集每日最新消息、图片等素材,挂机24小时提供站群必的文章等资源给受控端。如果你是资金实力雄厚的公司团队,可以使用专用的独立服务器来做主机,无论你复制多少目录,只需要一个公有主机,网关用来接收生成的链接地址。不管你有多少目录,或者有多少复制服务器,你只需要一个网关,就可以实时接收所有的URL链接,并以指定的格式保存。可以直接在你的蜘蛛池下生成,让站群养殖和蜘蛛池无缝对接,无需手动复制粘贴。剩下的事情就是泡一杯茶,享受悠闲的午后生活。是时候检查生成的url和百度收录了。
c.复制生成的URL内页链接,由蜘蛛池网关自动监听接收
受控端复制生成的url提供多种保存格式
1、纯url模式可以直接提供给蜘蛛池调用2.url+title方便你以后转载链接或者发帖提取对应的标题。
d。主控端分离,采集news、图片、视频、标题等实时更新内容
假设主机在普通 VPS 中。 IIS环境,使用独立工具挂采集文章、图片、动画、文档等资料。即公共数据服务器。
e.控制端转入网站目录控制复现
核心再现程序要转移到目录中。只需要访问index.php获取配置参数和master文章即可复制。
f、智能蜘蛛和人类分别访问
为了满足部分客户的需求,程序设计了蜘蛛访问和人工访问的区别,可以设置蜘蛛访问触发复现。或者手动访问触发复制。
g、支持蜘蛛访问触发繁殖
访问主程序index.php时,触发复现的配置参数设置为spider trigger,主程序开始调用主控数据和复现页面关键词。
h,支持人访问触发复现
访问主程序index.php时,触发复现的配置参数设置为手动触发,主程序开始调用主控数据和复现页面关键词,同时支持爬虫和人工造访触发繁殖
i、config.ini 集中配置各种参数进行复现
为了方便用户管理,主程序使用受控终端config.ini中设置的参数。中文界面一目了然。
j、锁科技锁
目录和内页站群一直存在并发展到今天。它们不是搜索引擎的第一个迹象。它们并不是罕见的排名操作。排名如何稳稳靠前,并不取决于主程序的复现次数,而是相反。 , 转载页数越多,越频繁,越容易被搜索引擎识别为垃圾站群,K减肥,所以我们增加了转载LOCK锁定技术,用户可以配置频率和数量主程序自行再现,当超过我们主程序将进入设定量的冷却时间。
k。随机复制音量,拒绝机械式
为了繁殖搜索引擎识别为垃圾邮件bringing站群,我们为用户提供繁殖数量的上下限设置参数。程序会读取一个上下限之间的随机数进行复制,比如你设置的复制最小数量为5.最大复制数量为15,程序可能随机复制10页。
我。新增养殖冷却时间,拒绝大量养殖垃圾站群,
冷却时间在被控端的config.ini中设置。单位为分钟,表示培育一批站群后等待下一个培育任务的分钟数。
m,在冷却时间内,自动加载sitemap.php
在冷却时间内,主程序不会读取宿主机数据,也不会进行复制,但会为蜘蛛提供一个动态网页列表供蜘蛛抓取,类似于sitemaps
n。转载的页面会自动插入到指定页面,不只是首页
复制生成的url自动插入首页源码,自动区分gb-2312和utf-8编码
o,可设置插入次数
首页的url可以在url中插入设置插入次数,可以在config.ini下配置。同时可以设置主页的冷却时间,防止主程序频繁篡改主页源代码导致降级。
p、特权复制、优先批量特权复制指定页面
主程序支持最优权限复制,可指定页面关键词。如需使用该功能,请在config.ini中打开该功能。
q。按比例复制有关键词和没有关键词的页面,比例可设置
可以配置带有关键词 的促销页面和常规新闻页面。比例可以在config.ini中设置。
R,目录格式和文件格式可自由配置
支持目录和文件后缀格式自定义。每行一个
s,纯新闻页面和带有关键词的页面有独立的目录格式和文件格式配置文件
带有关键词的页面和新闻页面的目录格式和文件格式是独立配置的。
t,纯新闻页面和带有关键词的页面有独立的模板
纯新闻页面和重点排名页面具有独立的模板路径。更有利于优化
u,支持同一个主站域名下多个层次目录的并发复制
一个主域名下可以多个目录叠加。
v.主页网格智能识别可在配置中修改添加主页识别格式文件
智能阅读首页模板,主程序识别我们配置的首页尸体 查看全部
智能采集组合文章(繁殖侠站群PHP目录繁殖版只限量出售5套)
育种man站群PHP目录复制版,本程序是麦芒团队高端定制目录内页复制特别版,租用目录可快速排名,支持上千个主目录同时生成内页时间,页面的定量再现,关键词对应锚文本链接,关键词转码,自动生成站点地图页面,自动将生成的页面链接插入首页,汇聚最实用的操作方法当前搜索引擎排名。程序使用php编程语言,无后门程序,符合互联网使用规则。该程序不限制行业使用。一经售出,使用该程序的用户所经营的站群业务是否合理与作者无关。我们只负责程序的后台开发,特此声明!
节目授权:Breeder制作的任何节目限发行数量,(咨询特价)/年续订(咨询特价)3台服务器无限授权,每台服务器添加(咨询特价)。
绑定机器码、IP硬件码,购买授权后可修改5X24小时技术服务跟进!
程序采用独立多重验证,发现恶意传播程序停止免费更新!严格限制是为了防止程序泛滥,起到更大的作用
站长朋友应该知道,作者再厉害,只要程序被大规模使用,就会被搜索引擎关注。育种英雄站群PHP旗舰版限量5套,售完即删帖!
限制程序防止购买,请作者8
一个。程序可在windows和unix操作系统下运行
程序运行需要的环境,php5.4+zendopminizer 我们将提供用户下载这些环境包,并将受控端index.php转移到目录下执行,生成内部页面文件。
B.主机与受控端负载均衡
为了提高站群运行的效率,程序分为主机、主机、网关三部分进行负载均衡。主机是复现生成的内部页面文件的核心,需要上传到权重目录,主机终端只需要租用一个普通的VPS。使用采集每日最新消息、图片等素材,挂机24小时提供站群必的文章等资源给受控端。如果你是资金实力雄厚的公司团队,可以使用专用的独立服务器来做主机,无论你复制多少目录,只需要一个公有主机,网关用来接收生成的链接地址。不管你有多少目录,或者有多少复制服务器,你只需要一个网关,就可以实时接收所有的URL链接,并以指定的格式保存。可以直接在你的蜘蛛池下生成,让站群养殖和蜘蛛池无缝对接,无需手动复制粘贴。剩下的事情就是泡一杯茶,享受悠闲的午后生活。是时候检查生成的url和百度收录了。
c.复制生成的URL内页链接,由蜘蛛池网关自动监听接收
受控端复制生成的url提供多种保存格式
1、纯url模式可以直接提供给蜘蛛池调用2.url+title方便你以后转载链接或者发帖提取对应的标题。
d。主控端分离,采集news、图片、视频、标题等实时更新内容
假设主机在普通 VPS 中。 IIS环境,使用独立工具挂采集文章、图片、动画、文档等资料。即公共数据服务器。
e.控制端转入网站目录控制复现
核心再现程序要转移到目录中。只需要访问index.php获取配置参数和master文章即可复制。
f、智能蜘蛛和人类分别访问
为了满足部分客户的需求,程序设计了蜘蛛访问和人工访问的区别,可以设置蜘蛛访问触发复现。或者手动访问触发复制。
g、支持蜘蛛访问触发繁殖
访问主程序index.php时,触发复现的配置参数设置为spider trigger,主程序开始调用主控数据和复现页面关键词。
h,支持人访问触发复现
访问主程序index.php时,触发复现的配置参数设置为手动触发,主程序开始调用主控数据和复现页面关键词,同时支持爬虫和人工造访触发繁殖
i、config.ini 集中配置各种参数进行复现
为了方便用户管理,主程序使用受控终端config.ini中设置的参数。中文界面一目了然。
j、锁科技锁
目录和内页站群一直存在并发展到今天。它们不是搜索引擎的第一个迹象。它们并不是罕见的排名操作。排名如何稳稳靠前,并不取决于主程序的复现次数,而是相反。 , 转载页数越多,越频繁,越容易被搜索引擎识别为垃圾站群,K减肥,所以我们增加了转载LOCK锁定技术,用户可以配置频率和数量主程序自行再现,当超过我们主程序将进入设定量的冷却时间。
k。随机复制音量,拒绝机械式
为了繁殖搜索引擎识别为垃圾邮件bringing站群,我们为用户提供繁殖数量的上下限设置参数。程序会读取一个上下限之间的随机数进行复制,比如你设置的复制最小数量为5.最大复制数量为15,程序可能随机复制10页。
我。新增养殖冷却时间,拒绝大量养殖垃圾站群,
冷却时间在被控端的config.ini中设置。单位为分钟,表示培育一批站群后等待下一个培育任务的分钟数。
m,在冷却时间内,自动加载sitemap.php
在冷却时间内,主程序不会读取宿主机数据,也不会进行复制,但会为蜘蛛提供一个动态网页列表供蜘蛛抓取,类似于sitemaps
n。转载的页面会自动插入到指定页面,不只是首页
复制生成的url自动插入首页源码,自动区分gb-2312和utf-8编码
o,可设置插入次数
首页的url可以在url中插入设置插入次数,可以在config.ini下配置。同时可以设置主页的冷却时间,防止主程序频繁篡改主页源代码导致降级。
p、特权复制、优先批量特权复制指定页面
主程序支持最优权限复制,可指定页面关键词。如需使用该功能,请在config.ini中打开该功能。
q。按比例复制有关键词和没有关键词的页面,比例可设置
可以配置带有关键词 的促销页面和常规新闻页面。比例可以在config.ini中设置。
R,目录格式和文件格式可自由配置
支持目录和文件后缀格式自定义。每行一个
s,纯新闻页面和带有关键词的页面有独立的目录格式和文件格式配置文件
带有关键词的页面和新闻页面的目录格式和文件格式是独立配置的。
t,纯新闻页面和带有关键词的页面有独立的模板
纯新闻页面和重点排名页面具有独立的模板路径。更有利于优化
u,支持同一个主站域名下多个层次目录的并发复制
一个主域名下可以多个目录叠加。
v.主页网格智能识别可在配置中修改添加主页识别格式文件
智能阅读首页模板,主程序识别我们配置的首页尸体
智能采集组合文章(龙都站群引擎V1.3注册机无限制破解版[综合营销])
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-08-31 07:19
近期发布的相关软件:
Longdu站群EngineV1.3 无限破解版【全面营销】 Longdu站群EngineV1.3 注册无限破解版【全面营销】
Longdu站群EngineV1.3
Longdu站群是什么?
Longdu站群是一款全自动保护建站工具。可以自动从输入的短尾关键词中获取相关的深长尾关键词,再获取长尾关键词采集文章,让你的网站朝气焕发,带来无限的深度流量!他可以自动保护网站!这是一个智能的在线赚钱工具!自动采集,自动更新,自动保护,轻松获取大量IP!龙都站群软件你可以轻松设置几个10、几百甚至几千个网站!
Longdu站群的神器出来了:规划思路之一是将优化参数准确设置到网站的任意一列!也就是说,我们的优化设置参数在同一个网站不同列之间是完整的,可以不同设置,市面上所谓的站群软件参数设置都是全局的,也就是说,如果没有设置优化参数,所有网站all 列都是共享的,所以效果极差,所以我们的优化参数设置不是全局的,而是针对一个列单独设置的!所以弱化了longdu站群中网站的概念,加强了网站列的概念,Longdu站群中每创建一个新任务其实就是为网站的一个列,这样做可以使优化效果更有针对性!
你为什么要站群?
做网站的最终目的很简单,就是为了获得流量,最后通过流量做广告,获得收入!大概是做产品销售来增加产品的知名度,然后交易量就会增加。
纯手工网站固然可以取得更好的效果,但是需要大量的脑力和财力。就算能实现几万个IP的日流量,也只有个人网站能做到,工作效率低下。使用软件大量建站可以避免单调的机械操作。我们知道一个词——团结就是力量。这就是站群的基本原理,举个例子,举个简单的例子
假设1网站日流量1000IP(这是最保守的估计也是最容易到达的,一个站一天做1000IP很简单)
所以....
每天10个网站就是10*1000=10000个IP
每天100个网站就是100*1000=100000个IP
1000网站一天就是1000*1000=1000000个IP
百万流量就是这么来的~~
而且这整个过程都是由软件完成的,是全自动的!
Longdu站群为什么会带来这个流量?
Longdu站群有最新的伪原创和原创采集接口以及各种网站采集接口。通过这些接口,站长可以轻松保护成百上千个站点的保护!网站基本上可以分解为4个步骤:content采集、内容处理、content原创、内容公告,接下来让我们看看 Longdu站群 如何处理这些方面。
Content采集:
Longdu站群内置keyword采集引擎,可以深度获取各种主流搜索引擎(百度、搜狗、搜搜)的采集keywords,从而有效的采集长尾关键词,有哪些长尾关键词的好处?因为短尾关键词(比如:花),当用户输入这个关键词进行搜索时,结果是一些大的网站可能一些权重很高的网站,到一些小的网站,排名基本上是不在当前位置之前。如果我们的网站上面堆满了这些关键词,基本上是无效的!但是我们可以看看搜索的结果,下面会列出一些相关的搜索。相反,这些相关的关键字比我们输入的关键字的长度要长。当我们点击这些关键词时,我们会发现搜索相关关键词甚至更长(例如:上海闵行鲜花速递、闵行新庄鲜花速递等)目前可以看到这些长尾关键词的后果很少,而且最重要的是:排名靠前的网站有些小网站不大网站,是的!这就是长尾关键词的效果。毕竟我们要把我们的网站通太长尾关键词放在最上面,那么我们的流量会变得非常可观!
接近主题,那我们是怎么得到长尾关键词的呢?在longdu站群中,我们只需要输入一个seed关键字(比如我们刚才说的“花”),系统会自动持有更多层的key system的过滤,采集提取的时间最长和最高质量的关键词(长尾关键词),而这个采集过程是通过采集的很多层选择出来的,所以关键词的质量是有保证的,普通对于普通深度,我们可以从一个得到80个长尾关键词种子关键词,深度挖掘会议100个关键词
对于高质量的长尾关键词,站群会用这些关键词来持有采集文章,从源头上保证质量,而且因为每次输入一个关键词,采集80-100长尾关键词,无需为每个任务设置多个关键词,省时省力!
而Longdu站群是一个真正的多线程处理系统。 采集的当下,每个任务最多可以开10个线程,采集飞速,不能说!
内容处理:
Longdu站群的采集由一个名为“采集interface”的模块完成。为了保证程序的可扩展性,所有采集接口都是可控的!在采集界面中,可以控制采集内容的质量。比如可以选择保存或删除文章中的图片,是否删除HTML格式等,所有网页格式都可以在界面中掌握!
同时我们内置了龙都内容提取模块,可以高效、高质量地提取肆意网页的有效内容(自动识别网站coding),以及龙都@的所有接口模块站群原则上可以采集蠢意网站!
Content原创:
原创度的内容是衡量采集器效果的最重要因素!虽然站群的数量也很重要,但是内容的原创度直接影响网站的收录于流,因为采集没有任何处理就过来了,文章没有影响,这个那种会议被搜索引擎认出来给网站降权!
Longdu站群内置大量伪原创处理模块:
①关于内容:打乱句子顺序、替换同义词、立即删除句子、选择句子汉英汉翻译、多个文章控股组合、标题添加内容、采集keywords(种子关键词)添加内容、相关关键词(长尾关键词)添加内容、字体转换(简体、繁体、火星)
②关于标题:Longdu站群承诺对标题进行肆意的自定义掌握。支持相关关键词(长尾关键词)按指定数量组合,原标题为前、中、后。添加长尾关键词,然后截取原标题,在前、中、后添加长尾关键词。自己输入的关键词或词组可以和标题组合,标题可以加指定字符(比如我们输入词组的绿色版|免费版|破解版,我们的采集关键词就是名字各种软件,那么合并的标题将是该软件的绿色版,该软件的免费版等...)
而且我们还在采集接口中完整地内置了原创的采集接口,这是采集器不会有的接口,属于我们龙都的创立!
另外文章组合、原创采集interface等一系列功能都是我们Longdu站群独有的!
如此强大的功能并不意味着软件的使用变得复杂。在我们规划软件时,简单易用始终是我们的座右铭。因此,我们任务编辑模块中的所有伪原创functions 都是基于选项。情况呈现(除了需要输入和输入的必要关键字),您无需费心进行更正!完好无损傻瓜式operation!
内容公告:
龙都站群的数据发布界面很强大!支持网站直接存储,也支持将存储接口(ASP或PHP程序)上传到目标网站然后在程序中发布接口。数据。
<p>这里我们直接连接支持肆意网站的存储,因为它基于网站get/post协议,只要存储模块做好,任何网站都可以持有数据公告 查看全部
智能采集组合文章(龙都站群引擎V1.3注册机无限制破解版[综合营销])
近期发布的相关软件:
Longdu站群EngineV1.3 无限破解版【全面营销】 Longdu站群EngineV1.3 注册无限破解版【全面营销】
Longdu站群EngineV1.3
Longdu站群是什么?
Longdu站群是一款全自动保护建站工具。可以自动从输入的短尾关键词中获取相关的深长尾关键词,再获取长尾关键词采集文章,让你的网站朝气焕发,带来无限的深度流量!他可以自动保护网站!这是一个智能的在线赚钱工具!自动采集,自动更新,自动保护,轻松获取大量IP!龙都站群软件你可以轻松设置几个10、几百甚至几千个网站!
Longdu站群的神器出来了:规划思路之一是将优化参数准确设置到网站的任意一列!也就是说,我们的优化设置参数在同一个网站不同列之间是完整的,可以不同设置,市面上所谓的站群软件参数设置都是全局的,也就是说,如果没有设置优化参数,所有网站all 列都是共享的,所以效果极差,所以我们的优化参数设置不是全局的,而是针对一个列单独设置的!所以弱化了longdu站群中网站的概念,加强了网站列的概念,Longdu站群中每创建一个新任务其实就是为网站的一个列,这样做可以使优化效果更有针对性!
你为什么要站群?
做网站的最终目的很简单,就是为了获得流量,最后通过流量做广告,获得收入!大概是做产品销售来增加产品的知名度,然后交易量就会增加。
纯手工网站固然可以取得更好的效果,但是需要大量的脑力和财力。就算能实现几万个IP的日流量,也只有个人网站能做到,工作效率低下。使用软件大量建站可以避免单调的机械操作。我们知道一个词——团结就是力量。这就是站群的基本原理,举个例子,举个简单的例子
假设1网站日流量1000IP(这是最保守的估计也是最容易到达的,一个站一天做1000IP很简单)
所以....
每天10个网站就是10*1000=10000个IP
每天100个网站就是100*1000=100000个IP
1000网站一天就是1000*1000=1000000个IP
百万流量就是这么来的~~
而且这整个过程都是由软件完成的,是全自动的!
Longdu站群为什么会带来这个流量?
Longdu站群有最新的伪原创和原创采集接口以及各种网站采集接口。通过这些接口,站长可以轻松保护成百上千个站点的保护!网站基本上可以分解为4个步骤:content采集、内容处理、content原创、内容公告,接下来让我们看看 Longdu站群 如何处理这些方面。
Content采集:
Longdu站群内置keyword采集引擎,可以深度获取各种主流搜索引擎(百度、搜狗、搜搜)的采集keywords,从而有效的采集长尾关键词,有哪些长尾关键词的好处?因为短尾关键词(比如:花),当用户输入这个关键词进行搜索时,结果是一些大的网站可能一些权重很高的网站,到一些小的网站,排名基本上是不在当前位置之前。如果我们的网站上面堆满了这些关键词,基本上是无效的!但是我们可以看看搜索的结果,下面会列出一些相关的搜索。相反,这些相关的关键字比我们输入的关键字的长度要长。当我们点击这些关键词时,我们会发现搜索相关关键词甚至更长(例如:上海闵行鲜花速递、闵行新庄鲜花速递等)目前可以看到这些长尾关键词的后果很少,而且最重要的是:排名靠前的网站有些小网站不大网站,是的!这就是长尾关键词的效果。毕竟我们要把我们的网站通太长尾关键词放在最上面,那么我们的流量会变得非常可观!
接近主题,那我们是怎么得到长尾关键词的呢?在longdu站群中,我们只需要输入一个seed关键字(比如我们刚才说的“花”),系统会自动持有更多层的key system的过滤,采集提取的时间最长和最高质量的关键词(长尾关键词),而这个采集过程是通过采集的很多层选择出来的,所以关键词的质量是有保证的,普通对于普通深度,我们可以从一个得到80个长尾关键词种子关键词,深度挖掘会议100个关键词
对于高质量的长尾关键词,站群会用这些关键词来持有采集文章,从源头上保证质量,而且因为每次输入一个关键词,采集80-100长尾关键词,无需为每个任务设置多个关键词,省时省力!
而Longdu站群是一个真正的多线程处理系统。 采集的当下,每个任务最多可以开10个线程,采集飞速,不能说!
内容处理:
Longdu站群的采集由一个名为“采集interface”的模块完成。为了保证程序的可扩展性,所有采集接口都是可控的!在采集界面中,可以控制采集内容的质量。比如可以选择保存或删除文章中的图片,是否删除HTML格式等,所有网页格式都可以在界面中掌握!
同时我们内置了龙都内容提取模块,可以高效、高质量地提取肆意网页的有效内容(自动识别网站coding),以及龙都@的所有接口模块站群原则上可以采集蠢意网站!
Content原创:
原创度的内容是衡量采集器效果的最重要因素!虽然站群的数量也很重要,但是内容的原创度直接影响网站的收录于流,因为采集没有任何处理就过来了,文章没有影响,这个那种会议被搜索引擎认出来给网站降权!
Longdu站群内置大量伪原创处理模块:
①关于内容:打乱句子顺序、替换同义词、立即删除句子、选择句子汉英汉翻译、多个文章控股组合、标题添加内容、采集keywords(种子关键词)添加内容、相关关键词(长尾关键词)添加内容、字体转换(简体、繁体、火星)
②关于标题:Longdu站群承诺对标题进行肆意的自定义掌握。支持相关关键词(长尾关键词)按指定数量组合,原标题为前、中、后。添加长尾关键词,然后截取原标题,在前、中、后添加长尾关键词。自己输入的关键词或词组可以和标题组合,标题可以加指定字符(比如我们输入词组的绿色版|免费版|破解版,我们的采集关键词就是名字各种软件,那么合并的标题将是该软件的绿色版,该软件的免费版等...)
而且我们还在采集接口中完整地内置了原创的采集接口,这是采集器不会有的接口,属于我们龙都的创立!
另外文章组合、原创采集interface等一系列功能都是我们Longdu站群独有的!
如此强大的功能并不意味着软件的使用变得复杂。在我们规划软件时,简单易用始终是我们的座右铭。因此,我们任务编辑模块中的所有伪原创functions 都是基于选项。情况呈现(除了需要输入和输入的必要关键字),您无需费心进行更正!完好无损傻瓜式operation!
内容公告:
龙都站群的数据发布界面很强大!支持网站直接存储,也支持将存储接口(ASP或PHP程序)上传到目标网站然后在程序中发布接口。数据。
<p>这里我们直接连接支持肆意网站的存储,因为它基于网站get/post协议,只要存储模块做好,任何网站都可以持有数据公告
智能采集组合文章(构建“全领域持续连载”系统,自动构建精准信息流推广)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-08-28 12:02
智能采集组合文章,本质上就是构建一个精准的组合文章系统。采集任何平台自媒体账号发布的全部文章,自动分析图片中的文字和文章作者,自动构建图文链接,自动构建精准信息流推广。组合文章系统:每一篇文章,都是一个文件夹,链接都是针对某一平台的。一篇文章发布之后,可以生成二维码,二维码文件夹内的文章,可以推送给多个平台。
或者通过手机app自动检测文章重复度,自动进行重复筛选出伪原创文章。构建“持续连载”系统:采集任何平台全部文章,自动生成组合文章系统链接。这个系统,是目前自媒体账号全领域文章最全的一个系统,采集平台,有:头条、百家、企鹅、大鱼、东方号、网易、一点等,所有平台都采集。对于每个平台最热门的资讯,都可以进行大规模采集分析,以便进行我们持续生产内容的基础。
一篇文章发布之后,可以生成一个二维码,扫描二维码可以直接跳转链接页面,把链接跳转到我们自己做的网站网址,跳转之后再分享到朋友圈,我们就可以通过网站获取流量。构建“全领域持续连载”系统的目的:构建“持续连载”系统是为了构建“全领域持续连载”系统的内容资源池,基于后期内容系统的生产能力,我们就可以实现自己内容的全领域生产输出,这是一个人类繁衍生息的社会,也是互联网的最大内容库。
这篇文章已经上传到16个自媒体平台了,几乎覆盖了国内1000多个行业,这1000多个行业都是有价值的内容,都可以进行二次加工。通过最核心的关键词采集文章,然后再进行二次排版,直接把输出给我们的精准用户,构建“持续连载”系统是一个精准文章收集的过程,精准文章收集后的利用率更高。如果用户不会构建这个核心关键词,那我们还可以通过关键词云下拉框等方式分析。
能够搜索到并且点击你的核心关键词,你就已经走在非常有利的地位了。构建“持续连载”系统,是构建持续不断的主要的支撑点,形成自己的知识库,构建更多的文章。通过开始的主动收集,后期是需要将所有的内容进行二次加工,构建出自己的一套属于自己的文章体系,构建这个文章体系对以后持续输出文章提升非常有帮助。直接是和知识整合,不需要再去独立输出了。
构建持续不断的主要支撑点,构建知识体系,文章才能够构建出来,你的知识库才更有价值。持续不断就是一个持续生产输出的过程,这是核心关键。构建持续不断的核心关键点,构建好了持续不断的文章资源池。然后用自己的语言去生产文章。构建持续不断的核心关键点,构建好了持续不断的文章资源池。然后用自己的语言去生产文章。互联网获取流量的方式可以有很多种,举一个最常。 查看全部
智能采集组合文章(构建“全领域持续连载”系统,自动构建精准信息流推广)
智能采集组合文章,本质上就是构建一个精准的组合文章系统。采集任何平台自媒体账号发布的全部文章,自动分析图片中的文字和文章作者,自动构建图文链接,自动构建精准信息流推广。组合文章系统:每一篇文章,都是一个文件夹,链接都是针对某一平台的。一篇文章发布之后,可以生成二维码,二维码文件夹内的文章,可以推送给多个平台。
或者通过手机app自动检测文章重复度,自动进行重复筛选出伪原创文章。构建“持续连载”系统:采集任何平台全部文章,自动生成组合文章系统链接。这个系统,是目前自媒体账号全领域文章最全的一个系统,采集平台,有:头条、百家、企鹅、大鱼、东方号、网易、一点等,所有平台都采集。对于每个平台最热门的资讯,都可以进行大规模采集分析,以便进行我们持续生产内容的基础。
一篇文章发布之后,可以生成一个二维码,扫描二维码可以直接跳转链接页面,把链接跳转到我们自己做的网站网址,跳转之后再分享到朋友圈,我们就可以通过网站获取流量。构建“全领域持续连载”系统的目的:构建“持续连载”系统是为了构建“全领域持续连载”系统的内容资源池,基于后期内容系统的生产能力,我们就可以实现自己内容的全领域生产输出,这是一个人类繁衍生息的社会,也是互联网的最大内容库。
这篇文章已经上传到16个自媒体平台了,几乎覆盖了国内1000多个行业,这1000多个行业都是有价值的内容,都可以进行二次加工。通过最核心的关键词采集文章,然后再进行二次排版,直接把输出给我们的精准用户,构建“持续连载”系统是一个精准文章收集的过程,精准文章收集后的利用率更高。如果用户不会构建这个核心关键词,那我们还可以通过关键词云下拉框等方式分析。
能够搜索到并且点击你的核心关键词,你就已经走在非常有利的地位了。构建“持续连载”系统,是构建持续不断的主要的支撑点,形成自己的知识库,构建更多的文章。通过开始的主动收集,后期是需要将所有的内容进行二次加工,构建出自己的一套属于自己的文章体系,构建这个文章体系对以后持续输出文章提升非常有帮助。直接是和知识整合,不需要再去独立输出了。
构建持续不断的主要支撑点,构建知识体系,文章才能够构建出来,你的知识库才更有价值。持续不断就是一个持续生产输出的过程,这是核心关键。构建持续不断的核心关键点,构建好了持续不断的文章资源池。然后用自己的语言去生产文章。构建持续不断的核心关键点,构建好了持续不断的文章资源池。然后用自己的语言去生产文章。互联网获取流量的方式可以有很多种,举一个最常。
智能采集组合文章(易企精选:微信编辑器【功能特点】(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-08-27 23:13
亿奇微信编辑器是一款非常好用的微信图文编辑器。使用该工具可以帮助用户编辑公众号文章和微场景制作等。界面干净,操作简单,包括很多文字效果,是微信营销和优化必不可少的编辑器。
小编精选:微信编辑
[特点]
【全网优质爆文材料】
1、微信编辑自带素材库,全网海量优质微信文章素材动态更新,大数据挖掘分析,优质热点文章轻松掌握。
2、全网新100,000+爆文第一时间采集更新,热点一目了然;
3、二十四个分类标签,轻松匹配您的行业需求
4、关键词一键搜索你需要的文章材料,再也不用为找不到材料发愁了;
[智能一键采集]
1、微信编辑器提供智能一键采集文章功能,稍作调整即可生成自己的文章。
2、文章材料一键采集,省时高效;
3、提供多图文组合功能,一键生成多图文;
4、live 使用微信操作规则选择合适的素材内容,小白也可以像大咖一样制作优质内容。
[原创optimization]
1、微信编器精选微信原创certification文章,用优质原创文章互惠互利。
2、精选原创内容分类;
3、精选微信原创证文章,用优质原创文章互惠互利。
4、关键词 一键搜你需要的原创文章,省时又方便
【图形美化我只需要一分】
1、全网精选优质微信编辑器文章排版风格素材资源,无需任何代码知识即可轻松掌握高级图文排版技巧。
2、清晰分类,重点关注指南、标题、图文、图片、签名二维码、各种样式;
3、一键第二行,选中文字,然后点击需要的样式即可完成,所见即所得;
4、 一键全文变色,如此简单;
5、动态指纹识别二维制作上传二维码轻松制作。
[软件功能]
1、图文同步:编辑好的图文一键同步到微信公众号后台。过去需要几十分钟完成的工作现在只需几秒钟。
2、文章Import:输入微信文章网址,点击采集外微信公号文章即可。
3、自动签名:设置文章头尾签名内容,生成图形时自动将内容插入相应位置。无需手动复制和编辑每个文章。
4、图文复制:一键复制图文,可让多个公众号同时使用一批图文,减少重复编辑。 查看全部
智能采集组合文章(易企精选:微信编辑器【功能特点】(组图))
亿奇微信编辑器是一款非常好用的微信图文编辑器。使用该工具可以帮助用户编辑公众号文章和微场景制作等。界面干净,操作简单,包括很多文字效果,是微信营销和优化必不可少的编辑器。
小编精选:微信编辑
[特点]
【全网优质爆文材料】
1、微信编辑自带素材库,全网海量优质微信文章素材动态更新,大数据挖掘分析,优质热点文章轻松掌握。
2、全网新100,000+爆文第一时间采集更新,热点一目了然;
3、二十四个分类标签,轻松匹配您的行业需求
4、关键词一键搜索你需要的文章材料,再也不用为找不到材料发愁了;
[智能一键采集]
1、微信编辑器提供智能一键采集文章功能,稍作调整即可生成自己的文章。
2、文章材料一键采集,省时高效;
3、提供多图文组合功能,一键生成多图文;
4、live 使用微信操作规则选择合适的素材内容,小白也可以像大咖一样制作优质内容。
[原创optimization]
1、微信编器精选微信原创certification文章,用优质原创文章互惠互利。
2、精选原创内容分类;
3、精选微信原创证文章,用优质原创文章互惠互利。
4、关键词 一键搜你需要的原创文章,省时又方便
【图形美化我只需要一分】
1、全网精选优质微信编辑器文章排版风格素材资源,无需任何代码知识即可轻松掌握高级图文排版技巧。
2、清晰分类,重点关注指南、标题、图文、图片、签名二维码、各种样式;
3、一键第二行,选中文字,然后点击需要的样式即可完成,所见即所得;
4、 一键全文变色,如此简单;
5、动态指纹识别二维制作上传二维码轻松制作。
[软件功能]
1、图文同步:编辑好的图文一键同步到微信公众号后台。过去需要几十分钟完成的工作现在只需几秒钟。
2、文章Import:输入微信文章网址,点击采集外微信公号文章即可。
3、自动签名:设置文章头尾签名内容,生成图形时自动将内容插入相应位置。无需手动复制和编辑每个文章。
4、图文复制:一键复制图文,可让多个公众号同时使用一批图文,减少重复编辑。
连续动作要做多少个规则请文章《规划采集流程》
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-08-27 18:15
注意:如果动作执行前后网页结构没有变化,可以用一个规则完成;如果网页的结构前后发生变化,必须用两条或两条以上的规则来完成;另外,如果涉及翻页,必须拆分成两个或多个规则。连续动作规则数量请参考文章《规划采集procedures》。
一、创建一级topic抓取目标信息
建立一级主题的规则,将想要的信息映射到排序框。建议在内容映射完成后,还要进行定位标记映射,这样可以提高定位精度和规则的适应性。
注意:如果设置了连续动作规则,则不需要构建排序框。比如方案2的一级主题不需要搭建排序框,而是用排序框抓取一点数据(选择网页肯定会显示的信息)。由爬虫判断是否执行采集,否则可能会漏掉网页。
二、设置连续动作点击新建按钮新建一个动作,每个动作的设置方法相同,基本操作如下:
2.1 输入目标科目名称
连续动作指向同一个目标对象。如果有多个动作,要指向不同的主题,请拆分成多个规则,分别设置连续动作。
2.2 选择动作类型
本例为点击动作,不同动作的适用范围不同。请根据实际操作情况选择动作类型。
2.3 将定位到动作对象的 xpath 填充到定位表达式中
2.4 输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.5 高级设置
一开始不需要设置,以后调试连续动作时会用到,可以扩大动作的适用范围。如果需要抓取动作对象的信息,可以使用xpath在高级设置的内容表达式中定位动作对象的信息。请根据需要重新设置。
注意:是否选择了动作类型以及xpath定位是否准确,决定了连续动作是否可以成功执行。 Xpath 是一种用于定位 html 节点的标准语言。使用连续动作功能前请自行掌握xpath。
根据人工步骤,我们还需要选择版本和购买方式1、买方法2,所以我们继续新建3个动作,重复以上步骤。
三、调试规则
完成上述步骤后,单击“保存规则”,然后单击“抓取数据”按钮开始尝试捕获。发现采集报错:Unable to locate the node***。观察浏览器窗口,看到执行第一步时,没有加载其他信息。加载信息的时候,发现我点击了购买方式2之后,无法回到执行4步点击的页面,导致一直执行连续动作。
针对以上情况,我们的解决方案是删除第四步。因为无论是否点击购买方式2,都不会影响商品的价格。因此,可以删除不必要的和令人不安的操作步骤。
修改后,再次尝试捕捉。将提取的xml转换为excel后,看到价格和累计评价数据被抓取或抓取错误。这是因为网页太大,加载速度慢,点击后的数据需要等待一段时间才能加载。
为了捕获所有数据,您需要延长等待时间并为每个动作单独设置延迟。单击操作步骤-> 高级设置-> 额外延迟,并输入一个以秒为单位的正整数。请按实际时间调试。
另外,如果不是粘性窗口,采集时会反复点击。这是因为京东网站上有防爬措施,必须是当前窗口的操作才能生效。因此,在高级设置中勾选窗口可见,采集时窗口会在最上面。请根据实际情况设置。
四、如何将抓取到的信息与动作步骤一一对应?
如果要将捕获的信息与动作步骤一一关联,那么就必须提取动作对象的信息。有两种方式:
4.1 使用xpath在连续动作的高级设置的内容表达式中定位动作对象的信息节点。
定位表达式定位到动作对象的整个操作范围后,还收录了自身的信息。因此,内容表达只需要从定位的动作对象开始,继续定位到它的信息。 采集会在actionvalue中记录step动作的信息,对应actionno,记录动作执行的次数。
4.2 抓取整理框中动作对象的信息,这里也是用xpath定位。
当action对象被执行时,它的dom结构发生了变化。找到网页变化的结构特征,使用xpath准确定位节点,验证通过后可以设置自定义xpath。
以上是使用连续动作模拟人工操作的全过程。虽然过程比较繁琐,但只要细心耐心,最终还是可以征服你想要爬取的网页。 查看全部
连续动作要做多少个规则请文章《规划采集流程》
注意:如果动作执行前后网页结构没有变化,可以用一个规则完成;如果网页的结构前后发生变化,必须用两条或两条以上的规则来完成;另外,如果涉及翻页,必须拆分成两个或多个规则。连续动作规则数量请参考文章《规划采集procedures》。
一、创建一级topic抓取目标信息
建立一级主题的规则,将想要的信息映射到排序框。建议在内容映射完成后,还要进行定位标记映射,这样可以提高定位精度和规则的适应性。
注意:如果设置了连续动作规则,则不需要构建排序框。比如方案2的一级主题不需要搭建排序框,而是用排序框抓取一点数据(选择网页肯定会显示的信息)。由爬虫判断是否执行采集,否则可能会漏掉网页。
二、设置连续动作点击新建按钮新建一个动作,每个动作的设置方法相同,基本操作如下:
2.1 输入目标科目名称
连续动作指向同一个目标对象。如果有多个动作,要指向不同的主题,请拆分成多个规则,分别设置连续动作。
2.2 选择动作类型
本例为点击动作,不同动作的适用范围不同。请根据实际操作情况选择动作类型。
2.3 将定位到动作对象的 xpath 填充到定位表达式中
2.4 输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.5 高级设置
一开始不需要设置,以后调试连续动作时会用到,可以扩大动作的适用范围。如果需要抓取动作对象的信息,可以使用xpath在高级设置的内容表达式中定位动作对象的信息。请根据需要重新设置。
注意:是否选择了动作类型以及xpath定位是否准确,决定了连续动作是否可以成功执行。 Xpath 是一种用于定位 html 节点的标准语言。使用连续动作功能前请自行掌握xpath。
根据人工步骤,我们还需要选择版本和购买方式1、买方法2,所以我们继续新建3个动作,重复以上步骤。
三、调试规则
完成上述步骤后,单击“保存规则”,然后单击“抓取数据”按钮开始尝试捕获。发现采集报错:Unable to locate the node***。观察浏览器窗口,看到执行第一步时,没有加载其他信息。加载信息的时候,发现我点击了购买方式2之后,无法回到执行4步点击的页面,导致一直执行连续动作。
针对以上情况,我们的解决方案是删除第四步。因为无论是否点击购买方式2,都不会影响商品的价格。因此,可以删除不必要的和令人不安的操作步骤。
修改后,再次尝试捕捉。将提取的xml转换为excel后,看到价格和累计评价数据被抓取或抓取错误。这是因为网页太大,加载速度慢,点击后的数据需要等待一段时间才能加载。
为了捕获所有数据,您需要延长等待时间并为每个动作单独设置延迟。单击操作步骤-> 高级设置-> 额外延迟,并输入一个以秒为单位的正整数。请按实际时间调试。
另外,如果不是粘性窗口,采集时会反复点击。这是因为京东网站上有防爬措施,必须是当前窗口的操作才能生效。因此,在高级设置中勾选窗口可见,采集时窗口会在最上面。请根据实际情况设置。
四、如何将抓取到的信息与动作步骤一一对应?
如果要将捕获的信息与动作步骤一一关联,那么就必须提取动作对象的信息。有两种方式:
4.1 使用xpath在连续动作的高级设置的内容表达式中定位动作对象的信息节点。
定位表达式定位到动作对象的整个操作范围后,还收录了自身的信息。因此,内容表达只需要从定位的动作对象开始,继续定位到它的信息。 采集会在actionvalue中记录step动作的信息,对应actionno,记录动作执行的次数。
4.2 抓取整理框中动作对象的信息,这里也是用xpath定位。
当action对象被执行时,它的dom结构发生了变化。找到网页变化的结构特征,使用xpath准确定位节点,验证通过后可以设置自定义xpath。
以上是使用连续动作模拟人工操作的全过程。虽然过程比较繁琐,但只要细心耐心,最终还是可以征服你想要爬取的网页。
智能分析QQ消息,强大组合模式(合纵连横),轻松生成原创文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-08-27 18:13
智能分析QQ消息,强大组合模式(合纵连横),轻松生成原创文章
/smref.php?ref=http://www.baidu.com%26amp%3Bu ... kagwe
优采云·QQ群聊留言文章代器
软件下载
视频教程
软件介绍优采云software 制作导出QQ群消息并生成文章的工具。
智能分析QQ消息,强大的组合模式(纵横组合),轻松生成原创文章!示例
我们都知道QQ聊天,尤其是群聊,每天都有很多原创的内容。我们可以处理这些聊天内容并产生原创文章。可以说是取之不尽。取之不尽。虽然有些人会复制文章来粘贴,但他们的特征很容易识别,而且往往很大。这时候可以设置单条消息超过一定字数时忽略。
现在可以加入各种话题的群,比如写旅游文章,添加旅游团,旅游团等等,然后每天导出一次他们的聊天记录,原创文章你怕不怕没有了? ?
使用提示:本程序处理的聊天记录不是直接从聊天窗口复制的,而是从QQ消息管理器中导出的。 QQ主面板-打开消息管理器,然后切换到“群”,在群列表中选择特定的群,右键群-导出消息记录,选择保存类型为文本文件完成导出,然后在本程序中通过“选择文件”按钮弹出的对话框中选择导出的聊天记录文件进行组合生成文章。软件特点:1.分析QQ消息文件,准确获取每条消息正文
2.全球中断消息
3.内置过滤(如过滤网址、邮件等)
4.内置屏蔽词替换(QQ聊天中经常提到很多敏感词)
5.自动去除多余的标点符号(当连接多个标点符号时,只保留一个,这样文章看起来更真实,更赏心悦目)
6.Message 支持纵横组合。 (横向落地,即多条原创消息连在一起为一条消息,以合并符分隔,纵向落地,即多条单条消息合并为一条原创文章)
7.支持在单条消息中插入后缀和后缀,比如常见的段落网页标签
8.支持在标题中插入单词,支持在文章中插入随机单词(也可以自动组合锚文本)
9.文章Title 智能提取组合结果中的随机句子。
10.批量选择多个QQ消息文件,一键处理,大功告成,文章滚滚来! !
可疑点说明:
文章 数据从何而来?
从QQ消息记录导出,一般是群消息,也有个人消息。导出的是一个txt文件,程序会处理这个文件生成文章。
留言全乱了,能不能发个好的文章?
是的,程序也是按顺序组合的。
无论是私聊还是两个人的群聊,消息都是有顺序的,程序就是这个顺序,每隔几句话(可以设置)组合成一段
每几段(可设置)合并为一个文章。并且您可以在段落前后插入网页段落标签等字符,以更好地适应网页显示。
通常,一条几百页记录的群消息可以从数百到数千文章导出。
文章都是原创吗?
这是肯定的。因为留言记录都是实时真实的交流,独一无二。即使有一些广告方,程序也内置支持智能杀掉他们,让他们在最后的文章中消失。
百度收录okay?
我无法回答这一点。只能说文章是原创,百度收录好不好,高排名受很多因素影响。
我可以试试吗?
可以,可以直接下载软件,选择我先试用,然后就可以使用了。
程序工作流程
1.分析QQ导出的TXT格式聊天消息记录文件,获取每条精准消息
2.对每条消息进行过滤后,插入前缀和后缀等修改,按照设定的编号组合
3.可以在组合结果中插入段落后缀、纯文本关键词或锚文本关键词
4.一篇纯原创的文章诞生了!
添加群提示:搜索群时,注意活跃群和人数较多的群。 (有的群人多但不活跃,最好是活跃且拥挤的),导致每天聊天消息量很大:
/smref.php?ref=http://www.baidu.com%26amp%3Bu ... bawhs
加入群后,建议设置群只显示号码不提示消息,这样消息记录可以累积而不受干扰。
/smref.php?ref=http://www.baidu.com%26amp%3Bu ... 7ygn1
升级记录(2015年5月25日):1.4.0.0:新改版;新增过滤消息条件,只要收录URL、连续数字等,消息将被忽略
1.4.3.0:修复过滤URL时容易过滤掉连接在一起的汉字的问题;调整繁体转简体的执行顺序,避免转繁体后更换失败;添加阻止同义词库文件。
1.5.0.0:软件由“优采云·傻瓜化文章代器”更名为“优采云·QQ群聊留言文章代器”;软件注册方式改变;其他更新
1.5.2.0:修复在进行最小字数过滤时,最后一行消息字数低于此设置,无法正确预览的问题
1.5.3.0:修复由于命名问题启动几分钟后自动退出的问题
1.5.4.0:增加识别网址的能力(新增只识别开头的网址)
1.6.0.0:添加识别消息记录中有2个空格的日期格式
1.6.0.1:转型支持OEM代理
1.6.0.2:完善注册机制,采用硬盘+网卡全识别模式(也兼容旧版注册码),可以解决机器码问题某些情况下因重新安装和更换VPN而引起的变化;其他更新。
1.6.0.3:尝试修复部分电脑获取硬盘码失败的问题。 查看全部
智能分析QQ消息,强大组合模式(合纵连横),轻松生成原创文章
/smref.php?ref=http://www.baidu.com%26amp%3Bu ... kagwe
优采云·QQ群聊留言文章代器
软件下载
视频教程
软件介绍优采云software 制作导出QQ群消息并生成文章的工具。
智能分析QQ消息,强大的组合模式(纵横组合),轻松生成原创文章!示例
我们都知道QQ聊天,尤其是群聊,每天都有很多原创的内容。我们可以处理这些聊天内容并产生原创文章。可以说是取之不尽。取之不尽。虽然有些人会复制文章来粘贴,但他们的特征很容易识别,而且往往很大。这时候可以设置单条消息超过一定字数时忽略。
现在可以加入各种话题的群,比如写旅游文章,添加旅游团,旅游团等等,然后每天导出一次他们的聊天记录,原创文章你怕不怕没有了? ?
使用提示:本程序处理的聊天记录不是直接从聊天窗口复制的,而是从QQ消息管理器中导出的。 QQ主面板-打开消息管理器,然后切换到“群”,在群列表中选择特定的群,右键群-导出消息记录,选择保存类型为文本文件完成导出,然后在本程序中通过“选择文件”按钮弹出的对话框中选择导出的聊天记录文件进行组合生成文章。软件特点:1.分析QQ消息文件,准确获取每条消息正文
2.全球中断消息
3.内置过滤(如过滤网址、邮件等)
4.内置屏蔽词替换(QQ聊天中经常提到很多敏感词)
5.自动去除多余的标点符号(当连接多个标点符号时,只保留一个,这样文章看起来更真实,更赏心悦目)
6.Message 支持纵横组合。 (横向落地,即多条原创消息连在一起为一条消息,以合并符分隔,纵向落地,即多条单条消息合并为一条原创文章)
7.支持在单条消息中插入后缀和后缀,比如常见的段落网页标签
8.支持在标题中插入单词,支持在文章中插入随机单词(也可以自动组合锚文本)
9.文章Title 智能提取组合结果中的随机句子。
10.批量选择多个QQ消息文件,一键处理,大功告成,文章滚滚来! !
可疑点说明:
文章 数据从何而来?
从QQ消息记录导出,一般是群消息,也有个人消息。导出的是一个txt文件,程序会处理这个文件生成文章。
留言全乱了,能不能发个好的文章?
是的,程序也是按顺序组合的。
无论是私聊还是两个人的群聊,消息都是有顺序的,程序就是这个顺序,每隔几句话(可以设置)组合成一段
每几段(可设置)合并为一个文章。并且您可以在段落前后插入网页段落标签等字符,以更好地适应网页显示。
通常,一条几百页记录的群消息可以从数百到数千文章导出。
文章都是原创吗?
这是肯定的。因为留言记录都是实时真实的交流,独一无二。即使有一些广告方,程序也内置支持智能杀掉他们,让他们在最后的文章中消失。
百度收录okay?
我无法回答这一点。只能说文章是原创,百度收录好不好,高排名受很多因素影响。
我可以试试吗?
可以,可以直接下载软件,选择我先试用,然后就可以使用了。
程序工作流程
1.分析QQ导出的TXT格式聊天消息记录文件,获取每条精准消息
2.对每条消息进行过滤后,插入前缀和后缀等修改,按照设定的编号组合
3.可以在组合结果中插入段落后缀、纯文本关键词或锚文本关键词
4.一篇纯原创的文章诞生了!
添加群提示:搜索群时,注意活跃群和人数较多的群。 (有的群人多但不活跃,最好是活跃且拥挤的),导致每天聊天消息量很大:
/smref.php?ref=http://www.baidu.com%26amp%3Bu ... bawhs
加入群后,建议设置群只显示号码不提示消息,这样消息记录可以累积而不受干扰。
/smref.php?ref=http://www.baidu.com%26amp%3Bu ... 7ygn1
升级记录(2015年5月25日):1.4.0.0:新改版;新增过滤消息条件,只要收录URL、连续数字等,消息将被忽略
1.4.3.0:修复过滤URL时容易过滤掉连接在一起的汉字的问题;调整繁体转简体的执行顺序,避免转繁体后更换失败;添加阻止同义词库文件。
1.5.0.0:软件由“优采云·傻瓜化文章代器”更名为“优采云·QQ群聊留言文章代器”;软件注册方式改变;其他更新
1.5.2.0:修复在进行最小字数过滤时,最后一行消息字数低于此设置,无法正确预览的问题
1.5.3.0:修复由于命名问题启动几分钟后自动退出的问题
1.5.4.0:增加识别网址的能力(新增只识别开头的网址)
1.6.0.0:添加识别消息记录中有2个空格的日期格式
1.6.0.1:转型支持OEM代理
1.6.0.2:完善注册机制,采用硬盘+网卡全识别模式(也兼容旧版注册码),可以解决机器码问题某些情况下因重新安装和更换VPN而引起的变化;其他更新。
1.6.0.3:尝试修复部分电脑获取硬盘码失败的问题。
智能采集组合文章类型及就业前景分析-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-08-25 18:08
智能采集组合文章类型:影视片段、明星、综艺、游戏小游戏,校园文章、新闻宣传片、专题工作汇报、背景介绍、创业组合精彩内容类别:情感/婚恋、招聘/求职、新奇/搞笑、安利/电商、青少年/家教、搞笑/电影/动漫组合精彩内容类别:职场/新媒体运营/内容策划/美妆/销售、夜游/私人讲座/户外/公园、经济/文化/国学/意识形态、家庭/亲子/亲子活动、销售/推广/引流/促销组合组合文章类型:情感/婚恋、新奇/搞笑、电影/动漫、职场/新媒体、经济/文化/国学、亲子/亲子活动、引流/推广/促销、健康/养生/电影/动漫组合精彩内容类别:情感/婚恋、新奇/搞笑、电影/动漫、职场/新媒体、经济/文化/国学、亲子/亲子活动、引流/推广/促销、夜游/私人讲座/户外/公园组合精彩内容类别:电影/动漫、职场/新媒体、新奇/搞笑、经济/文化/国学、亲子/亲子活动、引流/推广/促销组合组合图片类型:静态或动态图片、视频或网站广告图片、引爆点、结束语等。
组合文章类型:电影/动漫、职场/新媒体、娱乐明星/恋爱培训、美妆/口红/美发、亲子/亲子活动、青少年/国学/意识形态、孩子/母亲/亲子活动、其他组合视频类型:延时视频、开场剪辑视频、结束视频、片头、片尾等。组合图片类型:教育类视频、视频拍摄/剪辑延时/切割、视频拍摄/切割视频、视频拍摄/截取视频等组合创意图片类型:情景表情包、创意红包、创意投票、互动游戏、发红包、互动游戏、福利展示等。
组合创意花字类型:图片花字、文字花字、二维码花字、视频花字、组合文字等。组合slogan类型:简短的slogan、口号、品牌代言、产品定位等。软文广告类型:。
1、新闻稿类广告
2、软文广告类型
3、音频广告类型
4、视频广告类型
5、软文视频广告类型
6、软文营销推广类型
7、音频软文推广,效果和软文类型的软文类型是一样的。
采集文章的主要模式:
1、每个作者会创建一个作者专属网站,发布他们原创的内容。当他们发布某篇文章时,系统通过本地网站抓取文章所有内容,并加上自己的推荐语和吸引力的标题内容,即可加上你的网站二维码和网站介绍,以便以后互相关注、点击。
2、所有网站把你的内容分享到网上,不加上自己的推荐语和标题,任何作者都可以看到你的文章,在个别一部分网站不用推荐语,自动抓取推荐文章的第一部分,把你的文章放到收录的页面里面。所以大部分网站都是抓取第一部分的。
3、每个作者可以在论坛里面传播他们的文章, 查看全部
智能采集组合文章类型及就业前景分析-乐题库
智能采集组合文章类型:影视片段、明星、综艺、游戏小游戏,校园文章、新闻宣传片、专题工作汇报、背景介绍、创业组合精彩内容类别:情感/婚恋、招聘/求职、新奇/搞笑、安利/电商、青少年/家教、搞笑/电影/动漫组合精彩内容类别:职场/新媒体运营/内容策划/美妆/销售、夜游/私人讲座/户外/公园、经济/文化/国学/意识形态、家庭/亲子/亲子活动、销售/推广/引流/促销组合组合文章类型:情感/婚恋、新奇/搞笑、电影/动漫、职场/新媒体、经济/文化/国学、亲子/亲子活动、引流/推广/促销、健康/养生/电影/动漫组合精彩内容类别:情感/婚恋、新奇/搞笑、电影/动漫、职场/新媒体、经济/文化/国学、亲子/亲子活动、引流/推广/促销、夜游/私人讲座/户外/公园组合精彩内容类别:电影/动漫、职场/新媒体、新奇/搞笑、经济/文化/国学、亲子/亲子活动、引流/推广/促销组合组合图片类型:静态或动态图片、视频或网站广告图片、引爆点、结束语等。
组合文章类型:电影/动漫、职场/新媒体、娱乐明星/恋爱培训、美妆/口红/美发、亲子/亲子活动、青少年/国学/意识形态、孩子/母亲/亲子活动、其他组合视频类型:延时视频、开场剪辑视频、结束视频、片头、片尾等。组合图片类型:教育类视频、视频拍摄/剪辑延时/切割、视频拍摄/切割视频、视频拍摄/截取视频等组合创意图片类型:情景表情包、创意红包、创意投票、互动游戏、发红包、互动游戏、福利展示等。
组合创意花字类型:图片花字、文字花字、二维码花字、视频花字、组合文字等。组合slogan类型:简短的slogan、口号、品牌代言、产品定位等。软文广告类型:。
1、新闻稿类广告
2、软文广告类型
3、音频广告类型
4、视频广告类型
5、软文视频广告类型
6、软文营销推广类型
7、音频软文推广,效果和软文类型的软文类型是一样的。
采集文章的主要模式:
1、每个作者会创建一个作者专属网站,发布他们原创的内容。当他们发布某篇文章时,系统通过本地网站抓取文章所有内容,并加上自己的推荐语和吸引力的标题内容,即可加上你的网站二维码和网站介绍,以便以后互相关注、点击。
2、所有网站把你的内容分享到网上,不加上自己的推荐语和标题,任何作者都可以看到你的文章,在个别一部分网站不用推荐语,自动抓取推荐文章的第一部分,把你的文章放到收录的页面里面。所以大部分网站都是抓取第一部分的。
3、每个作者可以在论坛里面传播他们的文章,

