
智能采集组合文章
无爬虫团队,企业怎样实现1000万级数据采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2020-08-19 10:07
随着数据智能时代到来,越来越多的企业注重数据,并通过爬虫技术获取网路海量公开数据,为自己的业务赋能。
目前基于爬虫技术衍生的精典商业项目,我相信你一定也用过:
企查查是一款企业信息查询工具,上面汇集了目前国内市场中的80个产业链,8000个行业,6000个市场以及8000多万家企业数据。
企查查怎么拥有海量数据?
企查查数据源主要来自以下3个方面。
①网络爬虫采集数据
②第三方合作数据
③以及部份数据更新任务为用户触发
它通过网路爬虫采集数据并进行初步的清洗划入其数据库,并经过算法处理,最后向用户开放,提供查询搜索。
企查查目前市值已达到5亿人民币。
原来爬虫技术那么有商业价值?
我们企业是不是也可以自己做,爬爬数据来提高自己的竞争力?
Too Young Too Naive。
知乎有个高手说出了一个现实:“爬虫是一项入门门槛不高,但在后期实操阶段真的会使你太崩溃,比如你一定会碰到的以下问题”。
你要懂起码一门学科以上的知识,不仅仅只是爬虫,学会爬虫你只是刚起步。
来源
企业假如自建一个爬虫专家团队,需要从0开始。
对企业来说,这一笔不小的开支,包括管理成本、时间成本。
如何能够打破这一窘境?
其实那位知乎高手给出了答案:
“不要重复造车轮子”
市面上早已有许多简单好用且专业的爬虫服务和工具,能使一个企业以更灵活、更轻便、成本更低的形式实现海量数据的获取。
比如,优采云数据采集的企业私有云。
优采云私有云版本就是为有海量数据采集需求的企业而量身订制的爬虫工具。
企业无需平添任何一名爬虫技术人员,优采云企业私有云能够完美满足企业海量信息采集需求。
为什么选优采云?
优采云自2013年面向市场以来,一直致力于为广大用户提供简单易用、快速稳定的数据爬虫工具。
经过几年来的发展,用户规模扩大,在全球拥有120万用户。通过专业数据爬虫能力与经验积累,开拓了诸多如平安、腾讯、万达等行业著名企业,以及公安部、税务局、清华大学等政府机构、科研院所、高等院校数据项目成功案例,并且获得用户对优采云的数据采集专业能力的认可。
优采云数据采集成功入围由国家住建部公布的“2019大数据优秀产品和应用解决方案”优采云连续5年蝉联《中国大数据企业排行榜》中国互联网数据采集工具榜No.1
优采云私有云怎么满足企业需求?
01、专业的数据爬虫服务能力
优采云可以采集网络公开显示的数据,只要是肉眼可见可复制出来的信息数据均可获取。
优采云支持文字、数字、图片、视频、源码等数据类型,不屈从于数据方式。
02、海量数据云端高效分布式采集
优采云采用高效的云端分布式采集,背后有5000+云服务器提供支持。优采云私有云可依照企业需求配备30-100个甚至更多云节点,相当于逾百个服务器同时运行,实现多任务同时并发采集。
采用分布式采集比企业用自己服务器所需时长明显增加,普通企业很难有专业爬虫企业这样大量的服务器资源,去支撑海量的数据采集。
云端分布式采集能帮助企业实现短时间采集海量数据的目的,让企业轻松实现日采百万级甚至千万级的数据。
由于常年有大量数据爬虫需求,优采云已成为「阿里云VIP企业顾客」,优采云私有云的用户可以通过优采云直接享受阿里云提供的「企业级优质的云端节点」,进一步实现快速、稳定的云爬虫服务。
03、独家智能防封技术组合
正如上述知乎高手说的,网站反爬虫策略各式各样,遇到这些情况企业爬虫工程师大部分都只能束手无策。
优采云经过6年多实战经验构,组建出独家智能防封技术组合,能够有效攻破绝大部分的网站防采集措施。
1 优质代理IP池
优采云为私有云用户能提供优质代理IP池,支持用户在采集过程灵活切换IP,有效防止网站防采集。
2 自动辨识验证码
优采云能支持手动辨识9类验证码的手动辨识,能有效破解网站验证码防采集时。
9类验证码
3 cookie、UA
优采云还能灵活设置cookie(用户身分)、定时切换UA(用户代理)、突破对方防封手段,让企业才能稳定地获取优质数据源。
04、企业协作数据资源共享
考虑到企业数据采集通常是一项内部多人协作的工程,优采云私有云为用户提供了团队协作的功能,可实现跨帐号的数据、云节点(可以理解为服务器)、IP代理池等资源的共享,是团队协作的最佳神器。
05、无缝对接企业数据库
数据采集后,优采云可手动导出企业数据库,我们支持企业常见的数据库如Oracle、MySQL等。
无缝链接企业业务系统,实现高效数据归档,省去人工冗长复杂操作。
06、多种中级API数据插口
私有云用户可以调用优采云的数据导入API接口,以及增值API插口。
有了以上2项插口,私有云用户的开发小哥能够通过API,轻松获取优采云任务信息和采集到的数据,无需登陆优采云,即可调取并控制优采云任务的状态,减少工作场景来回切换。
07、满足企业灵活个性化需求
1 指定时间灵活采集
定时采集,是优采云私有云为须要定期更新网站最新信息的企业用户提供的,精确到分钟的采集时间的自定义设置的功能。
有了定时采集,用户便能在24小时内灵活选择采集时间,“到点”了优采云自动开始工作,让用户省心省力。
2 新增数据精准采集
智能辨识新增数据进行精准采集,不做历史重复工作,既节约时间,又节约节点资源。
3 7*24h工作,关机也能采
私有云的任务开始运行采集任务后,即使死机也不怕,优采云会在云端7*24小时持续为你工作,直至数据全部采集完。
你可以安心死机上班,享受放松休闲岁月。
08、尊享优采云MAX性能配置
1 无限量任务储存空间
你拥可以无拘无束,任性创建采集任务,无需害怕因任务数目限制而须要定期删掉或导入任务,减少可恶的工作量。
2 无限量帐号同时在线
你的团队可以共用一个优采云私有云帐号,即使在不同的地点,不同的笔记本上,都能同时进行登陆并操作。
3 无限量客户端同时开启
一台笔记本可以同时开启多个客户端,挑战你的笔记本MAX极限性能。
4 无限量数据随时导入
从优采云采集下来的10,000,000+数据可无限次无限量直接导出到你的业务系统中。
09、私有云VIP爬虫专家咨询服务
每位私有云用户都将配备一支VIP爬虫专家咨询团队,提供及时响应、技能高超的专业售后服务。
10、「优采云」值得信赖的品牌
部分顾客展示
优采云拿到手软的各大奖项
优劣势对比
如果你的企业没有爬虫人员,但又希望以低成本、快速配备海量数据的获取能力,墙裂推荐你使用优采云私有云!
优采云·让数据触手可及
公众号【优采云大数据】 查看全部
无爬虫团队,企业怎样实现1000万级数据采集?
随着数据智能时代到来,越来越多的企业注重数据,并通过爬虫技术获取网路海量公开数据,为自己的业务赋能。
目前基于爬虫技术衍生的精典商业项目,我相信你一定也用过:

企查查是一款企业信息查询工具,上面汇集了目前国内市场中的80个产业链,8000个行业,6000个市场以及8000多万家企业数据。
企查查怎么拥有海量数据?
企查查数据源主要来自以下3个方面。
①网络爬虫采集数据
②第三方合作数据
③以及部份数据更新任务为用户触发
它通过网路爬虫采集数据并进行初步的清洗划入其数据库,并经过算法处理,最后向用户开放,提供查询搜索。
企查查目前市值已达到5亿人民币。

原来爬虫技术那么有商业价值?
我们企业是不是也可以自己做,爬爬数据来提高自己的竞争力?
Too Young Too Naive。
知乎有个高手说出了一个现实:“爬虫是一项入门门槛不高,但在后期实操阶段真的会使你太崩溃,比如你一定会碰到的以下问题”。

你要懂起码一门学科以上的知识,不仅仅只是爬虫,学会爬虫你只是刚起步。

来源
企业假如自建一个爬虫专家团队,需要从0开始。
对企业来说,这一笔不小的开支,包括管理成本、时间成本。
如何能够打破这一窘境?
其实那位知乎高手给出了答案:
“不要重复造车轮子”
市面上早已有许多简单好用且专业的爬虫服务和工具,能使一个企业以更灵活、更轻便、成本更低的形式实现海量数据的获取。
比如,优采云数据采集的企业私有云。
优采云私有云版本就是为有海量数据采集需求的企业而量身订制的爬虫工具。
企业无需平添任何一名爬虫技术人员,优采云企业私有云能够完美满足企业海量信息采集需求。
为什么选优采云?
优采云自2013年面向市场以来,一直致力于为广大用户提供简单易用、快速稳定的数据爬虫工具。
经过几年来的发展,用户规模扩大,在全球拥有120万用户。通过专业数据爬虫能力与经验积累,开拓了诸多如平安、腾讯、万达等行业著名企业,以及公安部、税务局、清华大学等政府机构、科研院所、高等院校数据项目成功案例,并且获得用户对优采云的数据采集专业能力的认可。

优采云数据采集成功入围由国家住建部公布的“2019大数据优秀产品和应用解决方案”优采云连续5年蝉联《中国大数据企业排行榜》中国互联网数据采集工具榜No.1

优采云私有云怎么满足企业需求?
01、专业的数据爬虫服务能力
优采云可以采集网络公开显示的数据,只要是肉眼可见可复制出来的信息数据均可获取。
优采云支持文字、数字、图片、视频、源码等数据类型,不屈从于数据方式。
02、海量数据云端高效分布式采集

优采云采用高效的云端分布式采集,背后有5000+云服务器提供支持。优采云私有云可依照企业需求配备30-100个甚至更多云节点,相当于逾百个服务器同时运行,实现多任务同时并发采集。
采用分布式采集比企业用自己服务器所需时长明显增加,普通企业很难有专业爬虫企业这样大量的服务器资源,去支撑海量的数据采集。
云端分布式采集能帮助企业实现短时间采集海量数据的目的,让企业轻松实现日采百万级甚至千万级的数据。

由于常年有大量数据爬虫需求,优采云已成为「阿里云VIP企业顾客」,优采云私有云的用户可以通过优采云直接享受阿里云提供的「企业级优质的云端节点」,进一步实现快速、稳定的云爬虫服务。
03、独家智能防封技术组合
正如上述知乎高手说的,网站反爬虫策略各式各样,遇到这些情况企业爬虫工程师大部分都只能束手无策。
优采云经过6年多实战经验构,组建出独家智能防封技术组合,能够有效攻破绝大部分的网站防采集措施。
1 优质代理IP池
优采云为私有云用户能提供优质代理IP池,支持用户在采集过程灵活切换IP,有效防止网站防采集。
2 自动辨识验证码
优采云能支持手动辨识9类验证码的手动辨识,能有效破解网站验证码防采集时。

9类验证码
3 cookie、UA
优采云还能灵活设置cookie(用户身分)、定时切换UA(用户代理)、突破对方防封手段,让企业才能稳定地获取优质数据源。
04、企业协作数据资源共享

考虑到企业数据采集通常是一项内部多人协作的工程,优采云私有云为用户提供了团队协作的功能,可实现跨帐号的数据、云节点(可以理解为服务器)、IP代理池等资源的共享,是团队协作的最佳神器。
05、无缝对接企业数据库
数据采集后,优采云可手动导出企业数据库,我们支持企业常见的数据库如Oracle、MySQL等。
无缝链接企业业务系统,实现高效数据归档,省去人工冗长复杂操作。
06、多种中级API数据插口
私有云用户可以调用优采云的数据导入API接口,以及增值API插口。
有了以上2项插口,私有云用户的开发小哥能够通过API,轻松获取优采云任务信息和采集到的数据,无需登陆优采云,即可调取并控制优采云任务的状态,减少工作场景来回切换。
07、满足企业灵活个性化需求
1 指定时间灵活采集
定时采集,是优采云私有云为须要定期更新网站最新信息的企业用户提供的,精确到分钟的采集时间的自定义设置的功能。
有了定时采集,用户便能在24小时内灵活选择采集时间,“到点”了优采云自动开始工作,让用户省心省力。
2 新增数据精准采集
智能辨识新增数据进行精准采集,不做历史重复工作,既节约时间,又节约节点资源。
3 7*24h工作,关机也能采
私有云的任务开始运行采集任务后,即使死机也不怕,优采云会在云端7*24小时持续为你工作,直至数据全部采集完。
你可以安心死机上班,享受放松休闲岁月。
08、尊享优采云MAX性能配置
1 无限量任务储存空间
你拥可以无拘无束,任性创建采集任务,无需害怕因任务数目限制而须要定期删掉或导入任务,减少可恶的工作量。
2 无限量帐号同时在线
你的团队可以共用一个优采云私有云帐号,即使在不同的地点,不同的笔记本上,都能同时进行登陆并操作。
3 无限量客户端同时开启
一台笔记本可以同时开启多个客户端,挑战你的笔记本MAX极限性能。
4 无限量数据随时导入
从优采云采集下来的10,000,000+数据可无限次无限量直接导出到你的业务系统中。
09、私有云VIP爬虫专家咨询服务
每位私有云用户都将配备一支VIP爬虫专家咨询团队,提供及时响应、技能高超的专业售后服务。
10、「优采云」值得信赖的品牌

部分顾客展示

优采云拿到手软的各大奖项
优劣势对比

如果你的企业没有爬虫人员,但又希望以低成本、快速配备海量数据的获取能力,墙裂推荐你使用优采云私有云!
优采云·让数据触手可及
公众号【优采云大数据】
冷启动问题:如何建立你的机器学习组合?
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2020-08-15 11:07
前段时间,我曾写了一篇文章《The cold start problem: how to break into machine learning》(《冷启动问题:如何顺利步入机器学习》),阐述了为得到第一份机器学习的工作,你应当做什么事情。我在那篇文章中说过,你应当做的一件事就是,建立个人机器学习项目的投资组合。但我漏了这一部分:如何能够做到。因此,在这篇文章中,我将探讨应当怎样去做这件事。[1]
得益于我们的初创公司所做的事情,我能够见到这么多的个人项目的反例。这些个人项目有特别优秀的,也有特别槽糕的。让我给你举出两个特别优秀的反例。
押上所有赌注
下面是一则真实的故事,不过,为了保护个人隐私,我使用了化名。
当杂货店须要购买新库存时,X 公司都会使用人工智能来提醒杂货店。我们有一名中学生,叫 Ron,他十分渴求能否在 X 公司工作,已经急不可耐了。为了确保就能得到 X 公司的笔试机会,于是,他完善了一个个人项目。
通常情况下,我们不会建议象 Ron 那样把所有的赌注都押在一家公司。如果你刚开始这样做的话,是太有风险的。但是,就像我昨天说的,Ron 真的非常想到 X 公司工作,特别非常想。
那么,Ron 做了哪些呢?
红框处表示该处缺乏商品。
Ron 用胶布将他的智能手机绑在购物车上。然后,他推着购物车在杂货店的走廊来来回回地走,同时使用手机的摄像头记录下走廊的情况。他在不同的杂货店这样做了 10~12 次。
回到家后,Ron 就开始建立机器学习模型。他的模型辨识出了杂货店货架上的空白处,那是货架上缺乏玉米片(或其他商品)的地方。
特别棒的是,Ron 在 GitHub 上实时建立了他的模型,完全公开。每天,他就会改进他的 repo(提高准确性,并记录 repo 自述文件的变更)。
当 X 公司发觉 Ron 正在做这件事时,非常感兴趣。不止是好奇,事实上,X 公司还有点紧张。他们为何会倍感紧张呢?因为 Ron 无意中在几天内复制了她们的专有技术栈的一部分。[2]
X 公司的能力太强,他们的技术在行业中无出其右。尽管如此,4 天之内,Ron 的项目还是成功吸引了 X 公司 CEO 的注意力。
飞行员项目
这是另一则真实的故事。
Alex 主修历史专业,辅修英语(这是真实的情况)。不同寻常的是,作为历史专业的大学生,他竟然对机器学习形成了兴趣。更不寻常的是,他决定学习 Python,要知道,他从来没用 Python 写过一行代码。
Alex 选择了通过建立项目进行学习的方法。他决定建立一个分类器,用于测量战斗机飞行员在客机上是否失去知觉。Alex 想通过观看飞行员的视频来发觉是否丧失意识。他晓得,人们通过观察,很容易判定飞行员是否失去知觉。所以,Alex 觉得机器也应当有可能做到这一点。
以下是 Alex 在几个月的时间里所做的事情:
Alex建立的月球引力引起昏迷探测器的演示。
Alex 在 YouTube 上下载了从驾驶舱拍摄的驾驶客机时飞行员所有的视频。(如果你也倍感好奇的话,这里有几十个这样的片断。)
接下来他开始标记数据。Alex 构建了一个 UI,让他还能滚动数千个视频帧,按下一个按键表示 “有知觉”,另一个按键表示 “无知觉”。然后手动将该视频帧保存到正确标记的文件夹中。这个标记过程十分特别无趣,花了他好几天的时间。
Alex 为这种图象建立了一个数据管线,可以将飞行员从驾驶舱背景中抠下来,这样分类器才能更容易专注于飞行员。最后,他建立了自己的昏迷分类器。
在做这些事的同时,Alex 在社交媒体上向急聘主管展示了他的项目快照。每次
他掏出手机展示这个项目时,他们就会问他是如何做到的,构建的管线是怎么回事,以及如何搜集数据的等等。但从来没有人问过他的模型的准确度怎样,要知道,这个模型的准确度就从来没超过 50%。
当然,Alex 早就计划提升模型的准确性,但是在他还没有实现这一计划时就早已被录用了。事实证明,对企业而言,他那种项目呈现下来的视觉冲击力,以及在数据搜集方面表现下来的不屈不挠的精神和足智多谋,远比他的模型到底有多好来得更为重要。
我刚刚有没有提及 Alex 是一名主修历史,辅修英语的中学生?
他们有何共同之处
是哪些使 Ron 和 Alex 如此成功?以下是她们做对的四件大事:
Ron 和 Alex 并没有在建模上花费太多的精力。我晓得这听起来很奇怪,但是对于现今的许多用例来说,建模是一个已解决的问题。在实际工作中,除非你做的是最先进的人工智能研究,否则无论如何,你都须要花费 80~90% 的时间来清除数据。为什么你的个人项目会有所不同呢?
Ron 和 Alex 都搜集了自己的数据。正由于这么,他们最终得到的数据比 Kaggle 或 UCI 数据库中的数据更为混乱。但是处理混乱的数据教会了她们怎么处理这些混乱的数据。而且也促使了她们从学术服务器下载数据以更好地理解自己的数据。
Ron 和 Alex 营造了可视化疗效。面试,并不能使无所不知的面试官才能客观地评估你的技能。面试的本质就是将自己推荐给别人。人类是视觉植物,因此,如果你拿出手机给面试官展示你所做的东西,那么,确保你做的东西看上去太有趣是值得的。
Ron 和 Alex 所做的事其实挺疯狂。这很疯狂了。因为一般人不会把她们的智能手机用胶水绑在购物车上,也不会在 YouTube 上花费大量时间就为了剪裁飞行员的视频。你晓得是什么样的人就会如此疯狂?这样的人就会不惜一切代价去完成工作。公司真的十分、非常乐意雇用这种人。
Ron 和 Alex 所做的事情,看上去虽然太多了,但实际上,他们所做的事儿并不比你在实际工作中所期望的多多少。这就是问题的关键:当你没有做某件事的工作经验时,招聘总监会看你做过的类似做某件事的工作经验。
幸运的是,你只需在这个级别上,构建一两个项目就可以了——Ron 和 Alex 的项目在她们各自所有笔试中被反复使用。
因此,如果使我必须用一句话来总结一个卓越的机器学习项目的绝招,那就是:用有趣的数据集去建立项目,这个数据集其实须要花费大量精力来搜集,并让其尽可能有视觉冲击力。
[1] 如果你想知道为何这一点十分重要,那是因为急聘总监会查看你的业绩记录来评估你的技能。如果你没有业绩记录的话,那么,个人项目就是最为接近的替代者。
[2] 当然,Ron 的尝试远非完美:X 公司为这个问题投入了比他更多的资源。但情况十分相像,他们很快就要求 Ron 将他的 repo 设为 private。
原文链接: 查看全部
我是一名物理学家,在 YC 初创公司工作。我们的工作是帮助应届毕业生找到她们的第一份机器学习工作。
前段时间,我曾写了一篇文章《The cold start problem: how to break into machine learning》(《冷启动问题:如何顺利步入机器学习》),阐述了为得到第一份机器学习的工作,你应当做什么事情。我在那篇文章中说过,你应当做的一件事就是,建立个人机器学习项目的投资组合。但我漏了这一部分:如何能够做到。因此,在这篇文章中,我将探讨应当怎样去做这件事。[1]
得益于我们的初创公司所做的事情,我能够见到这么多的个人项目的反例。这些个人项目有特别优秀的,也有特别槽糕的。让我给你举出两个特别优秀的反例。
押上所有赌注
下面是一则真实的故事,不过,为了保护个人隐私,我使用了化名。
当杂货店须要购买新库存时,X 公司都会使用人工智能来提醒杂货店。我们有一名中学生,叫 Ron,他十分渴求能否在 X 公司工作,已经急不可耐了。为了确保就能得到 X 公司的笔试机会,于是,他完善了一个个人项目。
通常情况下,我们不会建议象 Ron 那样把所有的赌注都押在一家公司。如果你刚开始这样做的话,是太有风险的。但是,就像我昨天说的,Ron 真的非常想到 X 公司工作,特别非常想。
那么,Ron 做了哪些呢?

红框处表示该处缺乏商品。
Ron 用胶布将他的智能手机绑在购物车上。然后,他推着购物车在杂货店的走廊来来回回地走,同时使用手机的摄像头记录下走廊的情况。他在不同的杂货店这样做了 10~12 次。
回到家后,Ron 就开始建立机器学习模型。他的模型辨识出了杂货店货架上的空白处,那是货架上缺乏玉米片(或其他商品)的地方。
特别棒的是,Ron 在 GitHub 上实时建立了他的模型,完全公开。每天,他就会改进他的 repo(提高准确性,并记录 repo 自述文件的变更)。
当 X 公司发觉 Ron 正在做这件事时,非常感兴趣。不止是好奇,事实上,X 公司还有点紧张。他们为何会倍感紧张呢?因为 Ron 无意中在几天内复制了她们的专有技术栈的一部分。[2]
X 公司的能力太强,他们的技术在行业中无出其右。尽管如此,4 天之内,Ron 的项目还是成功吸引了 X 公司 CEO 的注意力。
飞行员项目
这是另一则真实的故事。
Alex 主修历史专业,辅修英语(这是真实的情况)。不同寻常的是,作为历史专业的大学生,他竟然对机器学习形成了兴趣。更不寻常的是,他决定学习 Python,要知道,他从来没用 Python 写过一行代码。
Alex 选择了通过建立项目进行学习的方法。他决定建立一个分类器,用于测量战斗机飞行员在客机上是否失去知觉。Alex 想通过观看飞行员的视频来发觉是否丧失意识。他晓得,人们通过观察,很容易判定飞行员是否失去知觉。所以,Alex 觉得机器也应当有可能做到这一点。
以下是 Alex 在几个月的时间里所做的事情:
Alex建立的月球引力引起昏迷探测器的演示。
Alex 在 YouTube 上下载了从驾驶舱拍摄的驾驶客机时飞行员所有的视频。(如果你也倍感好奇的话,这里有几十个这样的片断。)
接下来他开始标记数据。Alex 构建了一个 UI,让他还能滚动数千个视频帧,按下一个按键表示 “有知觉”,另一个按键表示 “无知觉”。然后手动将该视频帧保存到正确标记的文件夹中。这个标记过程十分特别无趣,花了他好几天的时间。
Alex 为这种图象建立了一个数据管线,可以将飞行员从驾驶舱背景中抠下来,这样分类器才能更容易专注于飞行员。最后,他建立了自己的昏迷分类器。
在做这些事的同时,Alex 在社交媒体上向急聘主管展示了他的项目快照。每次
他掏出手机展示这个项目时,他们就会问他是如何做到的,构建的管线是怎么回事,以及如何搜集数据的等等。但从来没有人问过他的模型的准确度怎样,要知道,这个模型的准确度就从来没超过 50%。
当然,Alex 早就计划提升模型的准确性,但是在他还没有实现这一计划时就早已被录用了。事实证明,对企业而言,他那种项目呈现下来的视觉冲击力,以及在数据搜集方面表现下来的不屈不挠的精神和足智多谋,远比他的模型到底有多好来得更为重要。
我刚刚有没有提及 Alex 是一名主修历史,辅修英语的中学生?
他们有何共同之处
是哪些使 Ron 和 Alex 如此成功?以下是她们做对的四件大事:
Ron 和 Alex 并没有在建模上花费太多的精力。我晓得这听起来很奇怪,但是对于现今的许多用例来说,建模是一个已解决的问题。在实际工作中,除非你做的是最先进的人工智能研究,否则无论如何,你都须要花费 80~90% 的时间来清除数据。为什么你的个人项目会有所不同呢?
Ron 和 Alex 都搜集了自己的数据。正由于这么,他们最终得到的数据比 Kaggle 或 UCI 数据库中的数据更为混乱。但是处理混乱的数据教会了她们怎么处理这些混乱的数据。而且也促使了她们从学术服务器下载数据以更好地理解自己的数据。
Ron 和 Alex 营造了可视化疗效。面试,并不能使无所不知的面试官才能客观地评估你的技能。面试的本质就是将自己推荐给别人。人类是视觉植物,因此,如果你拿出手机给面试官展示你所做的东西,那么,确保你做的东西看上去太有趣是值得的。
Ron 和 Alex 所做的事其实挺疯狂。这很疯狂了。因为一般人不会把她们的智能手机用胶水绑在购物车上,也不会在 YouTube 上花费大量时间就为了剪裁飞行员的视频。你晓得是什么样的人就会如此疯狂?这样的人就会不惜一切代价去完成工作。公司真的十分、非常乐意雇用这种人。
Ron 和 Alex 所做的事情,看上去虽然太多了,但实际上,他们所做的事儿并不比你在实际工作中所期望的多多少。这就是问题的关键:当你没有做某件事的工作经验时,招聘总监会看你做过的类似做某件事的工作经验。
幸运的是,你只需在这个级别上,构建一两个项目就可以了——Ron 和 Alex 的项目在她们各自所有笔试中被反复使用。
因此,如果使我必须用一句话来总结一个卓越的机器学习项目的绝招,那就是:用有趣的数据集去建立项目,这个数据集其实须要花费大量精力来搜集,并让其尽可能有视觉冲击力。
[1] 如果你想知道为何这一点十分重要,那是因为急聘总监会查看你的业绩记录来评估你的技能。如果你没有业绩记录的话,那么,个人项目就是最为接近的替代者。
[2] 当然,Ron 的尝试远非完美:X 公司为这个问题投入了比他更多的资源。但情况十分相像,他们很快就要求 Ron 将他的 repo 设为 private。
原文链接:
【智能模式】【流程图模式】如何设置智能策略
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2020-08-15 03:49
在编辑任务界面,点击右下角“开始采集”按钮,在弹出的设置框中,点击“智能策略”选项可以切换到设置界面。
1、代理设置
1)代理类型
I、代理IP(由芝麻代理提供)
该代理为通过芝麻代理提供的订购插口,直接在软件内选购。
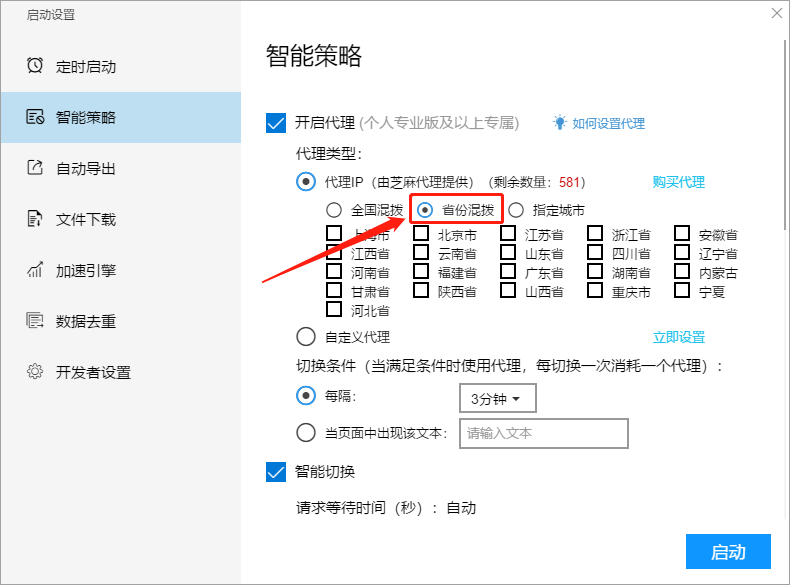
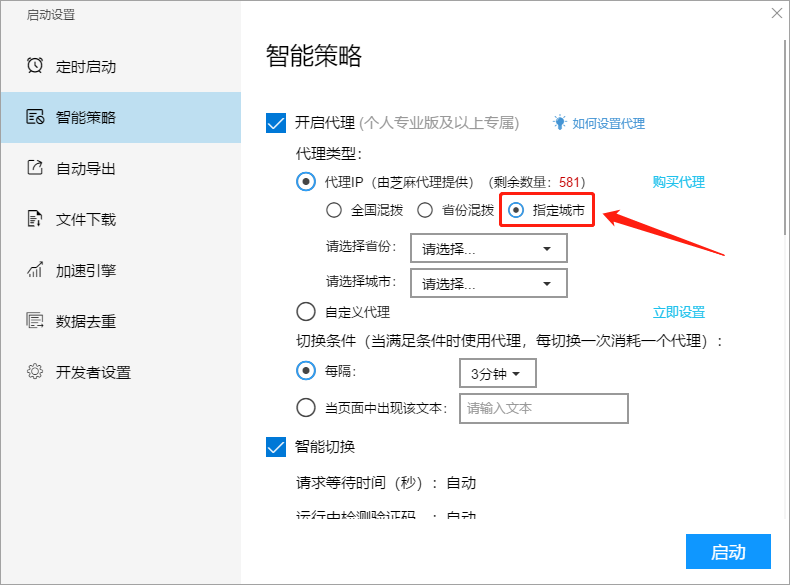
代理的区域可以进行设置,包括全省混拨、省份混拨或则指定城市。
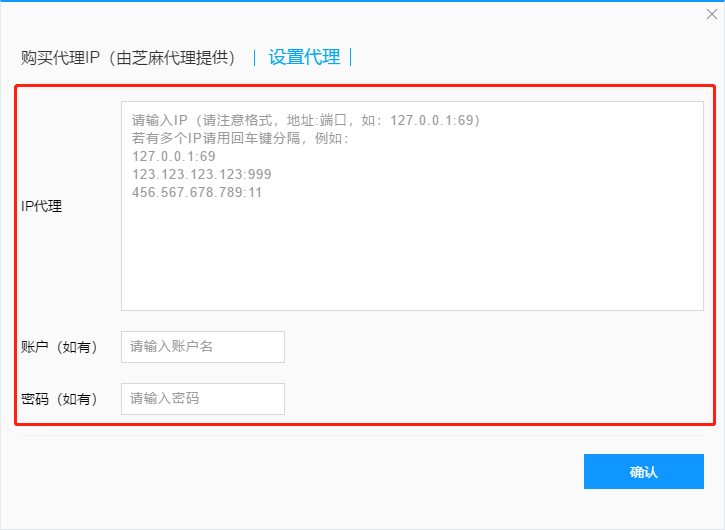
II、自定义代理
如果须要使用自己的代理,请点击“立即设置”,然后在设置窗口中按要求进行设置。(注意:自定义代理按次序循环切换)
2)切换条件
I、按照时间切换
代理按照时间进行切换,例如您设置切换条件为“每隔:3分钟”,那么每隔3分钟都会切换一次代理,同时会消耗一个代理IP 。
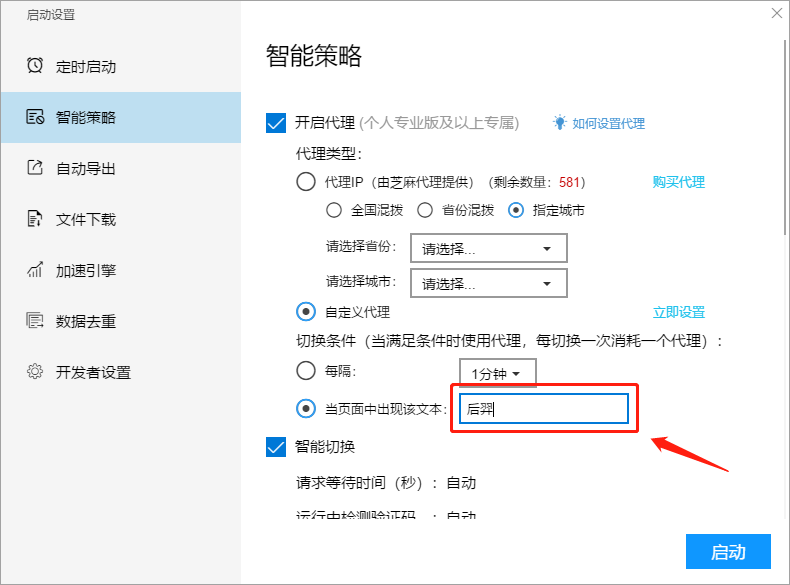
II、按照文本切换
根据文本进行切换,例如您设置切换条件为“当页面中出现该文本:优采云”,那么网页中出现对应的文本时,就会切换一次代理,同时消耗一个代理IP。
2、智能切换
智能切换是我们推荐的首选设置,能满足绝大部分采集任务的需求。
3、手动切换
如果碰到的网页比较特殊,智能切换未能满足需求,我们可以设置自动切换。
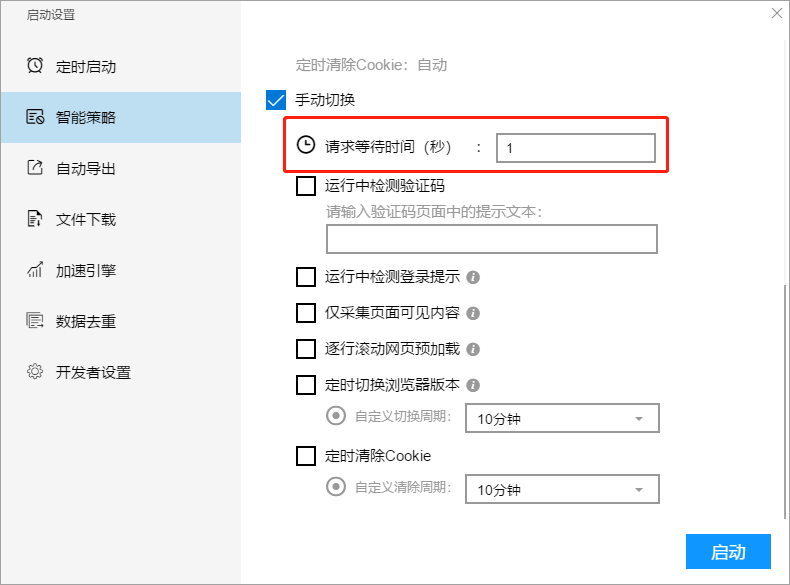
I、请求等待时间
请求等待时间是加在网页点击操作以后的等待时间,通常用于打开网页或则点击翻页等操作以后的等待,通过降低该等待时间,可以减轻网页加载平缓的问题,或者增加采集速度。
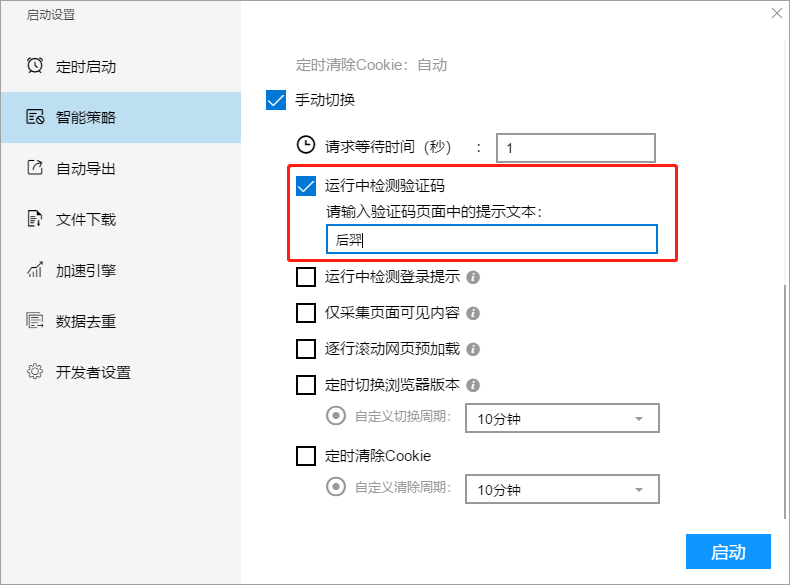
II、运行中测量验证码
软件在采集过程中遇见未能采集到内容时,会手动进行验证码检查,如果碰到软件未兼容的情况,也可以自动设置验证码辨识条件,例如假如验证码提示页面中收录了“优采云”这个文本,我们可以设置条件为“当页面中出现该文本:优采云”。需要注意的是该条件一定要确保只会在验证码提示页面中出现,否则会出现误报的情况。
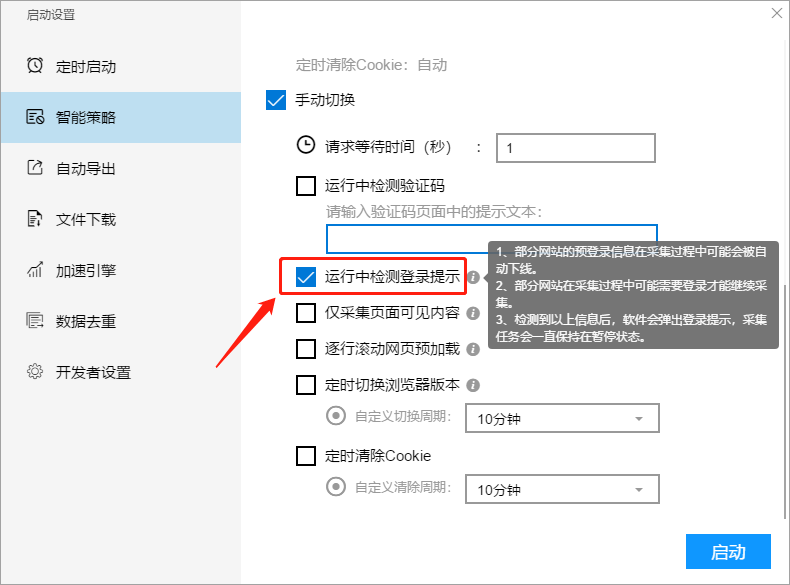
III、运行中测量登陆提示
需要登入能够采集数据的网站,在运行过程中登陆有可能会失效,或者有些网站采集到一定量的数据然后会提示登陆,勾选此功能,软件在运行过程中若果遇见登陆失效或须要登陆的情况会暂停任务并弹出登陆提示。
IV、仅采集页面可见内容
有一些网站会将无效的数据混在有效的数据之中,采集数据的时侯会出现好多无效的数据,这种情况下我们就可以勾选这个设置,只采集页面可见的内容。
注意:如果采集的网站没有隐藏无效字符的设置,勾选此项会导致数据采集不全或则数据难以采集,因此我们在使用此项功能时须要慎重。
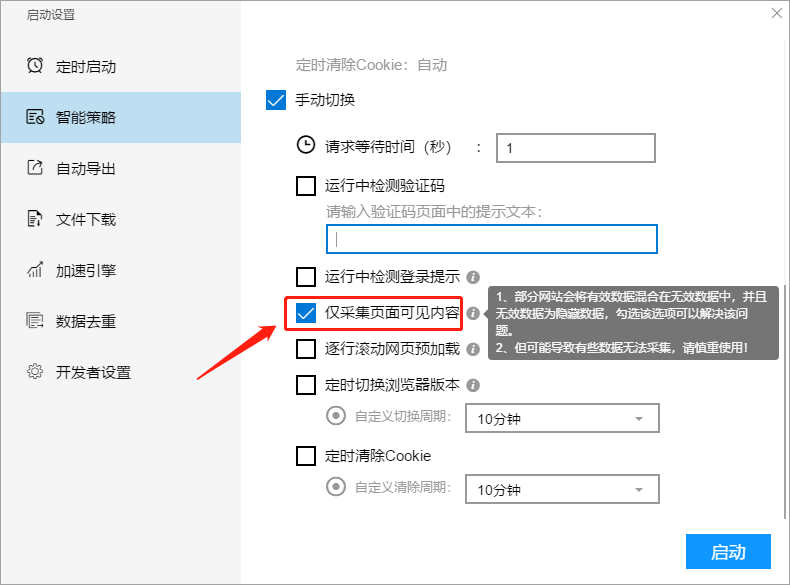
V、逐行滚动网页预加载
有些网站需要滚动到一定位置以后内容才会显示,否则这种数据都未能采集,这时候可以勾选此项功能。但是须要注意的是,勾选此项功能的时侯会影响采集速度,需谨慎使用。
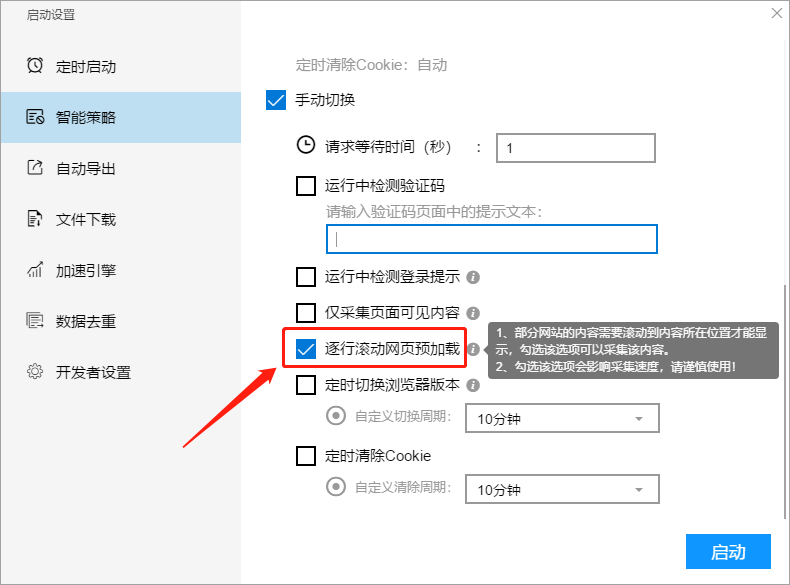
VI、定时切换浏览器版本
我们可以自定义设置切换版本的时间周期,设置时间周期可以是30秒~10分钟,软件会根据设置周期手动切换外置浏览器版本,用户无需自行选择具体版本。
VII、定时清理cookie
我们可以自定义设置消除cookie的时间周期,设置时间周期可以是30秒~10分钟,软件会根据设置周期定时清理网页Cookie。 查看全部
智能策略收录代理设置、智能切换和自动切换,这部份功能主要是拿来智能处理采集过程中遇见的各类问题。
在编辑任务界面,点击右下角“开始采集”按钮,在弹出的设置框中,点击“智能策略”选项可以切换到设置界面。
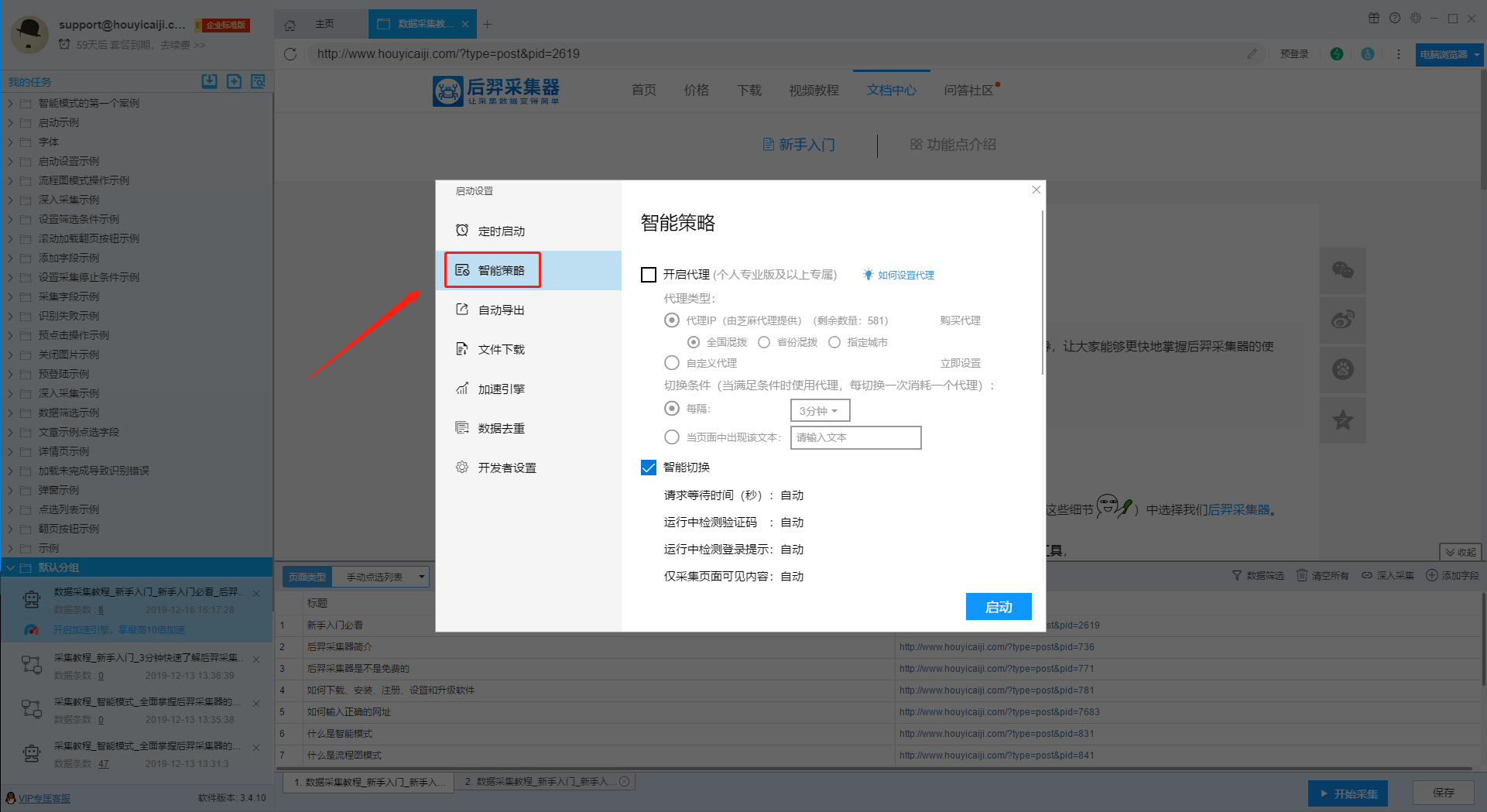
1、代理设置
1)代理类型
I、代理IP(由芝麻代理提供)
该代理为通过芝麻代理提供的订购插口,直接在软件内选购。
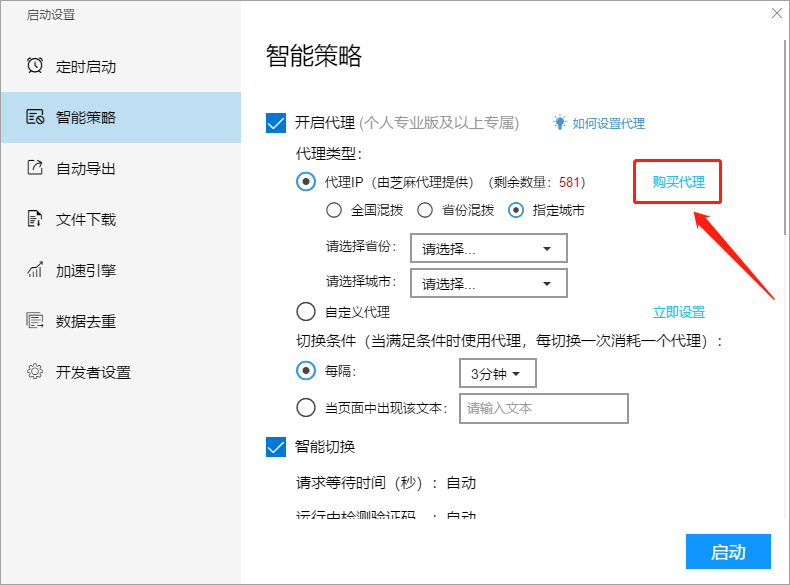
代理的区域可以进行设置,包括全省混拨、省份混拨或则指定城市。
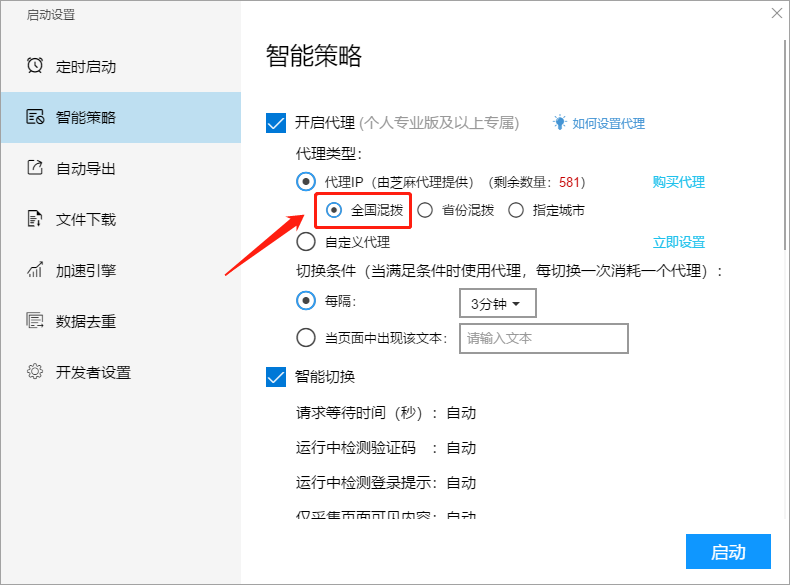
II、自定义代理
如果须要使用自己的代理,请点击“立即设置”,然后在设置窗口中按要求进行设置。(注意:自定义代理按次序循环切换)

2)切换条件
I、按照时间切换
代理按照时间进行切换,例如您设置切换条件为“每隔:3分钟”,那么每隔3分钟都会切换一次代理,同时会消耗一个代理IP 。

II、按照文本切换
根据文本进行切换,例如您设置切换条件为“当页面中出现该文本:优采云”,那么网页中出现对应的文本时,就会切换一次代理,同时消耗一个代理IP。
2、智能切换
智能切换是我们推荐的首选设置,能满足绝大部分采集任务的需求。
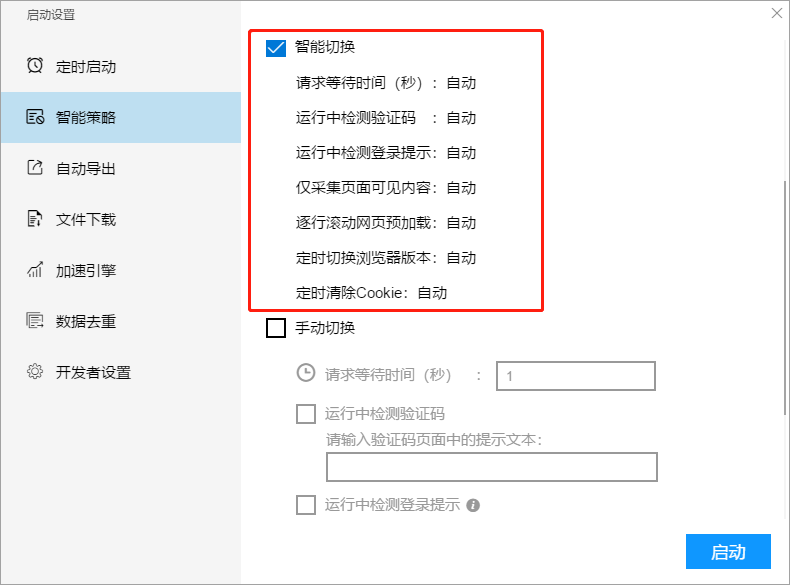
3、手动切换
如果碰到的网页比较特殊,智能切换未能满足需求,我们可以设置自动切换。
I、请求等待时间
请求等待时间是加在网页点击操作以后的等待时间,通常用于打开网页或则点击翻页等操作以后的等待,通过降低该等待时间,可以减轻网页加载平缓的问题,或者增加采集速度。
II、运行中测量验证码
软件在采集过程中遇见未能采集到内容时,会手动进行验证码检查,如果碰到软件未兼容的情况,也可以自动设置验证码辨识条件,例如假如验证码提示页面中收录了“优采云”这个文本,我们可以设置条件为“当页面中出现该文本:优采云”。需要注意的是该条件一定要确保只会在验证码提示页面中出现,否则会出现误报的情况。
III、运行中测量登陆提示
需要登入能够采集数据的网站,在运行过程中登陆有可能会失效,或者有些网站采集到一定量的数据然后会提示登陆,勾选此功能,软件在运行过程中若果遇见登陆失效或须要登陆的情况会暂停任务并弹出登陆提示。
IV、仅采集页面可见内容
有一些网站会将无效的数据混在有效的数据之中,采集数据的时侯会出现好多无效的数据,这种情况下我们就可以勾选这个设置,只采集页面可见的内容。
注意:如果采集的网站没有隐藏无效字符的设置,勾选此项会导致数据采集不全或则数据难以采集,因此我们在使用此项功能时须要慎重。
V、逐行滚动网页预加载
有些网站需要滚动到一定位置以后内容才会显示,否则这种数据都未能采集,这时候可以勾选此项功能。但是须要注意的是,勾选此项功能的时侯会影响采集速度,需谨慎使用。
VI、定时切换浏览器版本
我们可以自定义设置切换版本的时间周期,设置时间周期可以是30秒~10分钟,软件会根据设置周期手动切换外置浏览器版本,用户无需自行选择具体版本。
VII、定时清理cookie
我们可以自定义设置消除cookie的时间周期,设置时间周期可以是30秒~10分钟,软件会根据设置周期定时清理网页Cookie。
采集 | 数据智能与计算机图形学领域2019推荐论文列表(附链接)
采集交流 • 优采云 发表了文章 • 0 个评论 • 449 次浏览 • 2020-08-14 15:29
2019年度数据智能与估算及图形学领域论文推荐。
数据智能
1. Data-anonymous Encoding for Text-to-SQL Generation
论文链接:
在跨领域 Text-to-SQL 研究中一个重要的问题是辨识自然语言句子中提及的列名、表格、及单元格的值。本文中提出了一种基于中间变量和多任务学习的框架,尝试同时解决表格实体辨识和语义解析问题,取得了良好的疗效。论文在 EMNLP 2019 会议发表。
2. Towards Complex Text-to-SQL in Cross-domain Database
论文链接:
计算机的可执行语言(例如 SQL 语句与储存结构紧密相关)与自然语言存在不匹配问题,给复杂问题的语义解析带来了困难。为了解决这个问题,论文中设计了一种中间语言。先将自然语言转换成中间语言,再将中间语言转换成 SQL,可以提升语义解析的准确率。该论文已在 ACL 2019 会议发表。
3. Leveraging Adjective-Noun Phrasing Knowledge for Comparison Relation Prediction in Text-to-SQL
论文链接:
在自然语言理解中,知识的运用极其重要。本文以 Adjective-Noun Phrasing Knowledge 为切入点尝试在 Text-to-SQL 中运用语言相关知识来提升语言理解的准确率。论文在 EMNLP 2019 会议发表。
4. FANDA: A Novel Approach to Perform Follow-up Query Analysis
论文链接:
在多履带对话中,对话句子中常常存在省略或指代,需要依据上下文来理解当前词句。本文剖析总结了在对话式数据剖析中普遍出现的省略或指代现象,并提出了将当前句子补充完整的方式。论文发表在 AAAI 2019。
5. A Split-and-Recombine Approach for Follow-up Query Analysis
论文链接:
本文中提出了一个处理上下文的 split-recombine 框架,能够拿来有效处理对话句子中常常存在上下文省略或指代问题。这个框架既可以用于将当前句子补充完整(restate),也可以直接生成 logic form(例如SQL)。论文发表在 EMNLP 2019。
6. QuickInsights: Quick and Automatic Discovery of Insights from Multi-Dimensional Data
论文链接:
该论文创新性地提出了多维数据中洞察 (insights) 的一种普遍适用的具象定义,并系统化地提出了面向大规模多维数据的有效的洞察挖掘算法。文章发表在 SIGMOD 2019。相应技术从2015年起转化到谷歌 Power BI,Office 365 等产品中。
7. TableSense: Spreadsheet Table Detection with Convolutional Neural Networks
论文链接:
文章提出的基于深度学习模型的 TableSense 技术,可对电子表格进行区域监测和表格结构理解,并将其转换为结构化的多维数据进行手动剖析。这项技术已转化到谷歌的 Office 365 产品中,随 Ideas in Excel 功能全面上线。文章发表在 AAAI 2019。
8. Text-to-Viz: Automatic Generation of Infographics from Proportion-Related Natural language Statements
论文链接:
该论文发表在 IEEE VIS 2019,首创了由自然语言手动生成数据信息图(Infographics)的技术。该技术让人们就能十分容易的获得大量数据信息图的设计,用于强化数据故事的抒发。
9. DataShot: Automatic Generation of Fact Sheets from Tabular Data
论文链接:
该论文发表在 IEEE VIS 2019,提出了一种从数据表格出发手动生成由多个数据信息图组合而成的数据海报的技术。
10. Towards Automated Infographic Design: Deep Learning-based Auto-Extraction of Extensible Timeline
论文链接:
该论文提出了一种手动从图片中抽取数据信息图模板的技术。利用计算机视觉技术,将时间轴的设计图片分解成多个视觉元素并重新组合,使可视化时间轴设计图片的重用成为了可能。该论文发表在 IEEE VIS 2019。
11. Visualization Assessment: A Machine Learning Approach
论文链接:
该论文发表在 IEEE VIS 2019,探索了手动评估可视化图片特点的方式,比如记忆度、美观度,让机器学习的算法在可视化的生成、推荐中发挥作用。
12. Supporting Story Synthesis: Bridging the Gap between Visual Analytics and Storytelling
论文链接:
该论文定义了一个新的故事生成框架,将数据剖析到结果展示的过程具象成普遍的故事生成流程。该框架支持交互式地从复杂的可视剖析结果中生成可以使普通读者理解的故事。论文发表在 TVCG 2019。
13. Cross-dataset Time Series Anomaly Detection for Cloud Systems
论文链接:
文章提出了基于迁移学习和主动学习的跨数据集异常检查框架,可以有效地在不同时间序列数据集之间进行迁移,只须要1%-5% 的标明样本量即可达到高精度检查。文章发表在系统领域顶尖大会 USENIX ATC 2019 上。
14. Robust Log-based Anomaly Detection on Unstable Log Data
论文链接:
文章提出了基于深度学习技术的模型 LogRobust,可有效克服日志不稳定问题,在快速迭代的实际工业数据中取得了出色的疗效,该研究发表在了软件工程领域顶尖大会 FSE 2019。
15. An Intelligent, End-To-End Analytics Service for Safe Deployment in Large-Scale Cloud Infrastructure
论文链接:
该文章提出了时空相关性模型,在时间和空间的双重维度上对比故障前后的系统状态,为故障确诊提供线索,该模型在安全布署中取得了很高的准确率,研究成果将发表在系统领域顶尖大会 NSDI 2020上。
16. Outage Prediction and Diagnosis for Cloud Service Systems
论文链接:
该文章提出了一种智能的大规模中断预警机制 AirAlert,AirAlert 采集整个云系统中的所有系统监控讯号,采用鲁棒梯度提高树算法做预测,并借助贝叶斯网络进行确诊剖析。相关研究短文发表在 WWW 2019。
17. Prediction-Guided Design for Software Systems
论文链接:
文章提出了智能缓冲区管理方式,基于预测导向(Prediction-Guided)框架,以机器学习预测引擎为核心,可监控集群已布署的工作负载与平台操作,对这种负载在发生故障的机率和新的容量下降需求进行预测,动态调整预留缓冲区。该方式已成功集成到谷歌 Azure 中,提高了容量配置的稳健性,减少了巨大的成本开支。相关研究将在 AAAI 2020 Workshop 发布。
18. An Empirical Investigation of Incident Triage for Online Service Systems
论文链接:
该文章基于谷歌 20 个小型在线服务系统展开实例研究,发现错误的故障分派会导致额外的时间开支,进而验证了已有软件 Bug 分派算法在故障分派场景下的疗效。这是首次研究故障分派在工业小型在线服务系统中的实践,相关研究发表在 ICSE SEIP 2019。
19. Continuous Incident Triage for Large-Scale Online Service Systems
论文链接:
该文章提出一种基于深度学习的自动化连续故障分派算法 DeepCT。DeepCT 结合了一个新的基于注意力机制的屏蔽策略、门控循环单元模型和改进后的损失函数,可以从工程师对问题的讨论中逐渐积累知识并优化分派结果。相关成果发表在 ASE 2019。
20. Neural Feature Search: A Neural Architecture for Automated Feature Engineering
论文链接:
文章提出了神经特点搜索(Neural Feature Search,NFS),基于递归神经网络(Recurrent Neural Network,RNN)的控制器,通过最有潜力的变换规则变换每位原创特点,取得了优于现有手动特点工程方式的性能。该成果已在在数据挖掘领域大会 ICDM 2019 发表,在手动特点工程研究领域确立了新的技术水平。
图形学
21. Repairing Man-Made Meshes via Visual Driven Global Optimization with Minimum Intrusion
论文链接:
文章提出的方式修补了 ShapeNet、ModelNet 等小型 3D 数据集中的模型缺陷。该文章发表在 SIGGRAPH Asia 2019。
22. Learning Adaptive Hierarchical Cuboid Abstractions of 3D Shape 采集s
论文链接:
人造物体如衣柜一般具有结构化特点,人类可以容易地将那些物体抽象化为简单的几何形状的组合,如长方体,便于物体理解和剖析。该论文通过在同类物体上进行无监督学习,生成具有自适应并层次化的长方体具象抒发。文章发表在 SIGGRAPH Asia 2019。
23. A Scalable Galerkin Multigrid Method for Real-time Simulation of Deformable Objects
论文链接:
一种在无结构网格上的 Galerkin 多重网格法,其极大加速了现有柔性体仿真技术的性能。该方式可实时仿真含近百万有限元的柔性体模型,将人们在虚拟世界中可交互的模型复杂度提高了一到两个量级。该论文发表在 SIGGRAPH Asia 2019。
24. Deep Inverse Rendering for High-resolution SVBRDF Estimation from an Arbitrary Number of Images
论文链接:
该论文提出了一种在纹理材质本征空间进行优化的方式,实现了针对任意数目输入图片的纹理材质建模。在给定图象数目较少时给出视觉上合理的结果,而随着输入数目的增多,逐渐得到更为精确的重建结果。该论文发表在 SIGGRAPH 2019。
25. Synthesizing 3D Shapes from Silhouette Image 采集s using Multi-Projection Generative Adversarial Networks
论文链接:
利用二维轮廓图象学习三维形体生成。该方式仅须要对于某一类物体的大量二维轮廓图象,并不需要任何对应关系,它通过该类别物体在不同方向上的轮廓所具有的特点分布,学习并生成满足这种训练数据分布的三维形体。该论文发表在 CVPR 2019。 查看全部
本文约3600字,建议阅读10分钟。
2019年度数据智能与估算及图形学领域论文推荐。
数据智能
1. Data-anonymous Encoding for Text-to-SQL Generation
论文链接:
在跨领域 Text-to-SQL 研究中一个重要的问题是辨识自然语言句子中提及的列名、表格、及单元格的值。本文中提出了一种基于中间变量和多任务学习的框架,尝试同时解决表格实体辨识和语义解析问题,取得了良好的疗效。论文在 EMNLP 2019 会议发表。
2. Towards Complex Text-to-SQL in Cross-domain Database
论文链接:
计算机的可执行语言(例如 SQL 语句与储存结构紧密相关)与自然语言存在不匹配问题,给复杂问题的语义解析带来了困难。为了解决这个问题,论文中设计了一种中间语言。先将自然语言转换成中间语言,再将中间语言转换成 SQL,可以提升语义解析的准确率。该论文已在 ACL 2019 会议发表。
3. Leveraging Adjective-Noun Phrasing Knowledge for Comparison Relation Prediction in Text-to-SQL
论文链接:
在自然语言理解中,知识的运用极其重要。本文以 Adjective-Noun Phrasing Knowledge 为切入点尝试在 Text-to-SQL 中运用语言相关知识来提升语言理解的准确率。论文在 EMNLP 2019 会议发表。
4. FANDA: A Novel Approach to Perform Follow-up Query Analysis
论文链接:
在多履带对话中,对话句子中常常存在省略或指代,需要依据上下文来理解当前词句。本文剖析总结了在对话式数据剖析中普遍出现的省略或指代现象,并提出了将当前句子补充完整的方式。论文发表在 AAAI 2019。
5. A Split-and-Recombine Approach for Follow-up Query Analysis
论文链接:
本文中提出了一个处理上下文的 split-recombine 框架,能够拿来有效处理对话句子中常常存在上下文省略或指代问题。这个框架既可以用于将当前句子补充完整(restate),也可以直接生成 logic form(例如SQL)。论文发表在 EMNLP 2019。
6. QuickInsights: Quick and Automatic Discovery of Insights from Multi-Dimensional Data
论文链接:
该论文创新性地提出了多维数据中洞察 (insights) 的一种普遍适用的具象定义,并系统化地提出了面向大规模多维数据的有效的洞察挖掘算法。文章发表在 SIGMOD 2019。相应技术从2015年起转化到谷歌 Power BI,Office 365 等产品中。
7. TableSense: Spreadsheet Table Detection with Convolutional Neural Networks
论文链接:
文章提出的基于深度学习模型的 TableSense 技术,可对电子表格进行区域监测和表格结构理解,并将其转换为结构化的多维数据进行手动剖析。这项技术已转化到谷歌的 Office 365 产品中,随 Ideas in Excel 功能全面上线。文章发表在 AAAI 2019。
8. Text-to-Viz: Automatic Generation of Infographics from Proportion-Related Natural language Statements
论文链接:
该论文发表在 IEEE VIS 2019,首创了由自然语言手动生成数据信息图(Infographics)的技术。该技术让人们就能十分容易的获得大量数据信息图的设计,用于强化数据故事的抒发。
9. DataShot: Automatic Generation of Fact Sheets from Tabular Data
论文链接:
该论文发表在 IEEE VIS 2019,提出了一种从数据表格出发手动生成由多个数据信息图组合而成的数据海报的技术。
10. Towards Automated Infographic Design: Deep Learning-based Auto-Extraction of Extensible Timeline
论文链接:
该论文提出了一种手动从图片中抽取数据信息图模板的技术。利用计算机视觉技术,将时间轴的设计图片分解成多个视觉元素并重新组合,使可视化时间轴设计图片的重用成为了可能。该论文发表在 IEEE VIS 2019。
11. Visualization Assessment: A Machine Learning Approach
论文链接:
该论文发表在 IEEE VIS 2019,探索了手动评估可视化图片特点的方式,比如记忆度、美观度,让机器学习的算法在可视化的生成、推荐中发挥作用。
12. Supporting Story Synthesis: Bridging the Gap between Visual Analytics and Storytelling
论文链接:
该论文定义了一个新的故事生成框架,将数据剖析到结果展示的过程具象成普遍的故事生成流程。该框架支持交互式地从复杂的可视剖析结果中生成可以使普通读者理解的故事。论文发表在 TVCG 2019。
13. Cross-dataset Time Series Anomaly Detection for Cloud Systems
论文链接:
文章提出了基于迁移学习和主动学习的跨数据集异常检查框架,可以有效地在不同时间序列数据集之间进行迁移,只须要1%-5% 的标明样本量即可达到高精度检查。文章发表在系统领域顶尖大会 USENIX ATC 2019 上。
14. Robust Log-based Anomaly Detection on Unstable Log Data
论文链接:
文章提出了基于深度学习技术的模型 LogRobust,可有效克服日志不稳定问题,在快速迭代的实际工业数据中取得了出色的疗效,该研究发表在了软件工程领域顶尖大会 FSE 2019。
15. An Intelligent, End-To-End Analytics Service for Safe Deployment in Large-Scale Cloud Infrastructure
论文链接:
该文章提出了时空相关性模型,在时间和空间的双重维度上对比故障前后的系统状态,为故障确诊提供线索,该模型在安全布署中取得了很高的准确率,研究成果将发表在系统领域顶尖大会 NSDI 2020上。
16. Outage Prediction and Diagnosis for Cloud Service Systems
论文链接:
该文章提出了一种智能的大规模中断预警机制 AirAlert,AirAlert 采集整个云系统中的所有系统监控讯号,采用鲁棒梯度提高树算法做预测,并借助贝叶斯网络进行确诊剖析。相关研究短文发表在 WWW 2019。
17. Prediction-Guided Design for Software Systems
论文链接:
文章提出了智能缓冲区管理方式,基于预测导向(Prediction-Guided)框架,以机器学习预测引擎为核心,可监控集群已布署的工作负载与平台操作,对这种负载在发生故障的机率和新的容量下降需求进行预测,动态调整预留缓冲区。该方式已成功集成到谷歌 Azure 中,提高了容量配置的稳健性,减少了巨大的成本开支。相关研究将在 AAAI 2020 Workshop 发布。
18. An Empirical Investigation of Incident Triage for Online Service Systems
论文链接:
该文章基于谷歌 20 个小型在线服务系统展开实例研究,发现错误的故障分派会导致额外的时间开支,进而验证了已有软件 Bug 分派算法在故障分派场景下的疗效。这是首次研究故障分派在工业小型在线服务系统中的实践,相关研究发表在 ICSE SEIP 2019。
19. Continuous Incident Triage for Large-Scale Online Service Systems
论文链接:
该文章提出一种基于深度学习的自动化连续故障分派算法 DeepCT。DeepCT 结合了一个新的基于注意力机制的屏蔽策略、门控循环单元模型和改进后的损失函数,可以从工程师对问题的讨论中逐渐积累知识并优化分派结果。相关成果发表在 ASE 2019。
20. Neural Feature Search: A Neural Architecture for Automated Feature Engineering
论文链接:
文章提出了神经特点搜索(Neural Feature Search,NFS),基于递归神经网络(Recurrent Neural Network,RNN)的控制器,通过最有潜力的变换规则变换每位原创特点,取得了优于现有手动特点工程方式的性能。该成果已在在数据挖掘领域大会 ICDM 2019 发表,在手动特点工程研究领域确立了新的技术水平。
图形学
21. Repairing Man-Made Meshes via Visual Driven Global Optimization with Minimum Intrusion
论文链接:
文章提出的方式修补了 ShapeNet、ModelNet 等小型 3D 数据集中的模型缺陷。该文章发表在 SIGGRAPH Asia 2019。
22. Learning Adaptive Hierarchical Cuboid Abstractions of 3D Shape 采集s
论文链接:
人造物体如衣柜一般具有结构化特点,人类可以容易地将那些物体抽象化为简单的几何形状的组合,如长方体,便于物体理解和剖析。该论文通过在同类物体上进行无监督学习,生成具有自适应并层次化的长方体具象抒发。文章发表在 SIGGRAPH Asia 2019。
23. A Scalable Galerkin Multigrid Method for Real-time Simulation of Deformable Objects
论文链接:
一种在无结构网格上的 Galerkin 多重网格法,其极大加速了现有柔性体仿真技术的性能。该方式可实时仿真含近百万有限元的柔性体模型,将人们在虚拟世界中可交互的模型复杂度提高了一到两个量级。该论文发表在 SIGGRAPH Asia 2019。
24. Deep Inverse Rendering for High-resolution SVBRDF Estimation from an Arbitrary Number of Images
论文链接:
该论文提出了一种在纹理材质本征空间进行优化的方式,实现了针对任意数目输入图片的纹理材质建模。在给定图象数目较少时给出视觉上合理的结果,而随着输入数目的增多,逐渐得到更为精确的重建结果。该论文发表在 SIGGRAPH 2019。
25. Synthesizing 3D Shapes from Silhouette Image 采集s using Multi-Projection Generative Adversarial Networks
论文链接:
利用二维轮廓图象学习三维形体生成。该方式仅须要对于某一类物体的大量二维轮廓图象,并不需要任何对应关系,它通过该类别物体在不同方向上的轮廓所具有的特点分布,学习并生成满足这种训练数据分布的三维形体。该论文发表在 CVPR 2019。
Python+fiddler:爬取微信公众号的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 437 次浏览 • 2020-08-13 00:35
图1:流程
其实我们看见,这里并没有想像中的“智能”——依然须要自动刷公众号文章,然后就能够搜集到信息。(误:更新的第9部份是愈发智能的操作,减少手刷)
1. 电脑下载fiddler
图2:下载fiddler2. 安装以后,点开第一眼听到的是这样
图3:fiddler第一次点开以后
这里附上fiddler的介绍。
3. 设置
图4:设置Tools-Options-HTTPS
然后设置Actions:点击Actions,选择Trust root certificate以及export root certificate to desktop(弹下来的提示都选Yes)。
图5:设置Actions
图6:设置Tools-Options-Connections4. 手机设置(我使用小米手机,其他手机大致一样)
图7:设置手机WiFi代理(proxy)
图8:手机步入网址192.168.124.14:8888
图9:点击FiddlerRoot Certificate
图10:下载以后安装它,随意命名,我命名为“Fiddler2”
5. 重启笔记本的Fiddler,手机点开公众号文章,电脑Fiddler搜集信息
图11:记录
图12:具体剖析
图13:复制Fiddler记录的链接,在浏览器中点开
图14:过滤
图15:过滤以后的信息
可以看见,序号存在着跳跃,因为过滤起到了作用。
6. 将所有信息导入
图16:导出手机浏览记录
图17:txt信息7. Python抽取公众号信息
import numpy as np
data = []
with open(r'...\1_Full.txt', 'r', encoding='utf-8') as fp:
for line in fp:
if 'Referer: https://mp.weixin.qq.com/' in line: //将含有重要信息的链接保留到data中
data.append(line[9:])
// 去重
data = np.unique(data)
8. 通过笔记本陌陌客户端抓取公众号的信息
在一遍一遍刷手机以后,本人勿必厌恶。。如果还能通过键盘点击笔记本为内心客户端,然后通过fiddler搜集信息,那么就不用刷手机了。。注意,在调整fiddler的时侯,anaconda的jupyter关掉(可以使用spyder),否则fiddler会出问题。
操作差不多。
首先,将fiddler-Tools-Options-HTTPS,将Decrypt HTTPS traffic更改为“from all processes”.
图18:电脑搜集微信公众号的操作
然后,同样在自己的浏览器中,输入IP地址+8888,下载证书。
图19:下载FiddlerRoot证书
下载以后进行安装。
图20:安装证书
其他设置filter和前面手机设置一样,都是把关于wp.weixin的内容筛选下来。
然后,刷笔记本端微信公众号,那么filter才能够记录下所有的公众号文章。注意,一旦打开fiddler,那么笔记本难以访问其他网页,因为百度等防爬机制太严格,会检查到fiddler早已启动。
9. 更加手动和智能的操作
无论是刷手机搜集信息,还是通过笔记本端刷公众号,依然是须要人点击信息,不够智能。这里在参考了新的案例以后,能够进行颠覆性的改进。
首先,本文后面的模块仍然须要了解。当早已才能在笔记本端刷微信公众号的文章、同时fiddler才能搜集https的信息,那么继续往下。以“首都之窗”微信公众号为例。
(1)电脑陌陌端的操作
打开fiddler。
点击设置-通用设置-使用系统默认浏览器打开网页。
图21:电脑陌陌端设置
然后,随意点击“首都之窗”的任意一篇文章,会在浏览器中弹下来。放在哪里,不用理会。顺便把fiddler中记录的这个文章信息删了。留着fiddler空白,记录第25图的重点内容!
这一步的目的是为了才能顺利在浏览器中打开公众号的历史消息但是刷新。
图22:先点一篇文章
图23:该文章在浏览器弹下来
图24:完整操作
接着,进入“首都之窗”公众号,点击查看历史消息。
图25:查看历史消息
同样,“历史消息”在浏览器(绝不能在陌陌客户端下拉、因为fiddler收不到信息)中弹下来,然后往下开始刷几下,需要听到有新的内容弹下来,同时见到fiddler正在记录更新的信息。fiddler更新的消息就是最重要的内容。
图26:在浏览器中下拉几次“历史消息”
(2)fiddler信息剖析
刚刚通过在浏览器下拉公众号历史消息,fiddler采集到了更新的信息。我们开始剖析。
图27:分析由于下拉历史消息而搜集到的某一条记录
选择第8条记录(该记录来自浏览器中下拉历史记录而搜集到的消息),重点部份早已在headers中圈下来了。
(3)链接分析(看不下去的话,直接看代码如何拼出链接)
首先,在Request headers中,该链接简拼是 /mp/profile_ext?action=getmsg&__biz=MzA5NDY5MzUzMQ==&f=json&offset=20&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxtoken=&appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~&x5=0&f=json HTTP/1.1
分析这个链接。可以看见,它是由几个部份组成。
①/mp/profile_ext?②action=getmsg ③&__biz=MzA5NDY5MzUzMQ== ④&f=json⑤&offset=20 ⑥&count=10 ⑦&is_ok=1 ⑧&scene=124 ⑨&uin=777 ⑩&key=777 &pass_ticket= &wxtoken= &appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~ &x5=0&f=json HTTP/1.1
那么我们须要关注的信息是:
③__biz:公众号的id(公众号的biz惟一),⑤offset:翻页标志,appmsg_token:某个有时效性的token(隔一段时间会变化)
我们再看下边几个链接
GET /mp/profile_ext?action=getmsg&__biz=MzA5NDY5MzUzMQ==&f=json&offset=40&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxtoken=&appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~&x5=0&f=json HTTP/1.1
GET /mp/profile_ext?action=getmsg&__biz=MzA5NDY5MzUzMQ==&f=json&offset=60&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxtoken=&appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~&x5=0&f=json HTTP/1.1
biz和appmsg_token一致,offset改变,即为新的一页。因此,第一步,我们早已找到了翻页的规律。链接中只有这三个在变化,其他没有变动。因此,链接在python中才能写成:
api = 'https://mp.weixin.qq.com/mp/pr ... iz%3D{0}&f=json&offset={1}&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxton=&appmsg_token={2}&x5=0&f=json HTTP/1.1'.format(
__biz, offset, appmsg_token)
(4)cookie和headers
cookie保存的是陌陌登陆的信息,在爬虫的时侯须要填进去。我们只要关注wsp_sid2的cookies信息。
cookies同样来自图27。找到wap_sid2=CK6vyK4CElxLdmda............
headers同样来自图27。找到 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
(5)爬取
好的,以上找到了好多信息。初步的python如下:
import requests
import json
# 链接拼接三个信息
__biz = "MzA5NDY5MzUzMQ=="
appmsg_token = "1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~"
offset = 20
# cookies和headers
cookies = "wap_sid2=CK6vyK4CElxLdmda......."
headers = {'Cookie':cookies,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
}
# api拼出来
api = 'https://mp.weixin.qq.com/mp/pr ... iz%3D{0}&f=json&offset={1}&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxton=&appmsg_token={2}&x5=0&f=json HTTP/1.1'.format(
__biz, offset, appmsg_token)
# 抓取并且json化
resp = requests.get(api, headers = headers, verify=False).json()
为什么须要把resp进行json化?我们可以尝试着打开9(3)一开始的链接的网页,
图28:拼下来的api打开的网页长这样
很明显这是个json信息。因此须要json化。复制该网页的全部文本,放在网页中,可以看见完整的json结构。这就是resp的网页结果。
图29:把图28的文本信息复制置于中的结果
那么resp在python中被json化以后的结果如下
图30:resp在python中的结构
(6)网页解析
接下来,关注该resp的结构以及一层一层剖析。图30中resp中errmsg=ok和ret=0,均表示网页可以正常打开(如果报错的话,ret=-3)。next_offset是下一次翻页的标志,需要保存上去。
next_offset = resp.get('next_offset')
general_msg_list = resp.get('general_msg_list')
# 将general_msg_list转为json格式
msg_list = json.loads(general_msg_list)['list']
general_msg_list 是 重要的内容。点击general_msg_list,这仍然是一个json结构。
图31:general_msg_list仍然是json结构。
复制上面的文本,放到中瞧瞧是哪些。
图32:general_msg_list放在中的结果
因此被json化以后的msg_list,在python中长这样
图33:把general_msg_list进行json化在python中的样子
可以看见,msg_list中富含10个记录。我们抽出一个记录,进行具体剖析。在剖析之前,我们要明晰一个东西。msg_list中收录了10个记录,不是指10篇文章,而是10次推送。某一次公众号推送消息,可能同时发布好几条文章,也有可能是一篇文章。因此,要明白,单个msg记录,是指一个推送(and可能一次性发布了好几篇文章)。
图34:某一次推送,一起发布了3篇文章
msg = msg_list[0]
图35:某一个具体的msg
该msg上面收录了“app_msg_ext_info”和“comm_msg_info”两个内容。在中,这两个内容分别长这样子。
图36:某一个msg具体的两部份---app_msg_ext_info和comm_msg_info
那么comm_msg_info收录了该推送的基本信息:推送ID,时间等。
app_msg_ext_info是哪些?且听我渐渐剖析。首先,title,digest仍然到is_multi,都是该次推送的打头文章(就是图34中带图片的那种文章的信息)。例如title标题/digest关键词/content_url链接/source_url原链接等。
is_multi是判定该次推送是不是有读篇文章;=1表示yes,=0表示no。那么这儿等于1,说明该次推送还有其他文章,存在于multi_app_msg_item_list中。
把multi_app_msg_item_list取下来。
multi_app_msg_item_list = app_msg_ext_info.get('multi_app_msg_item_list')
图37:该推送剩下的两篇文章藏在multi_app_msg_item_list中
到目前为止,我们早已剖析完了整体的流程。
总结
图38:总结怎样走出第一步
图39:具体剖析结构
(7)具体代码如下
<p>import requests
import json
from datetime import datetime
import pandas as pd
import time
class WxMps:
def __init__(self, biz, appmsg_token, cookies, offset, city):
self.biz = biz
self.msg_token = appmsg_token
self.offset = offset
self.headers = {'Cookie':cookies, 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
self.city = city
def parse1(self, resp):
# 控制下一个抓取的offset
offset = resp.get('next_offset')
# 将包含主要内容的list转为json格式
general_msg_list = resp.get('general_msg_list')
# 一个msg_list中含有10个msg
msg_list = json.loads(general_msg_list)['list']
df1 = pd.DataFrame(columns = ['msg_id', 'post_time', 'msg_type', 'title', 'cover', 'author', 'digest', 'source_url', 'content_url'])
# 循环message列表
for msg in msg_list:
# msg是该推送的信息,包含了comm_msg_info以及app_msg_ext_info两个信息,注意某一个推送中可能含有多个文章。
comm_msg_info = msg.get('comm_msg_info')
app_msg_ext_info = msg.get('app_msg_ext_info')
# 该推送的id
msg_id = comm_msg_info.get('id')
# 该推送的发布时间,例如1579965567需要转化为datetime,datetime.fromtimestamp(1579965567)
post_time = datetime.fromtimestamp(comm_msg_info['datetime'])
# 该推送的类型
msg_type = comm_msg_info.get('type')
if app_msg_ext_info:
# 推送的第一篇文章
title, cover, author, digest, source_url, content_url = self.parse2(app_msg_ext_info)
df2 = self.df_process(msg_id, post_time, msg_type, title, cover, author, digest, source_url, content_url)
df1 = pd.concat([df1, df2])
# 判断是不是多篇文章
is_multi = app_msg_ext_info.get("is_multi")
# 如果是1,继续爬取;如果是0,单条推送=只有一篇文章
if is_multi:
multi_app_msg_item_list = app_msg_ext_info.get('multi_app_msg_item_list')
for information in multi_app_msg_item_list:
(title, cover, author, digest, source_url, content_url) = self.parse2(information)
df2 = self.df_process(msg_id, post_time, msg_type, title, cover, author, digest, source_url, content_url)
df1 = pd.concat([df1, df2])
return df1, offset
def start(self):
offset = self.offset
df1 = pd.DataFrame(columns = ['msg_id', 'post_time', 'msg_type', 'title', 'cover', 'author', 'digest', 'source_url', 'content_url'])
while offset 查看全部
这几天师傅有个小项目,挺有意思,如何使用python爬微信公众号中的新闻信息。大体流程如下。
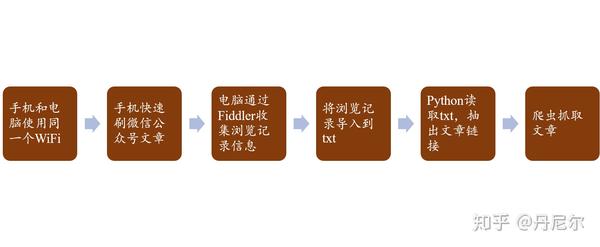
图1:流程
其实我们看见,这里并没有想像中的“智能”——依然须要自动刷公众号文章,然后就能够搜集到信息。(误:更新的第9部份是愈发智能的操作,减少手刷)
1. 电脑下载fiddler
图2:下载fiddler2. 安装以后,点开第一眼听到的是这样

图3:fiddler第一次点开以后
这里附上fiddler的介绍。
3. 设置
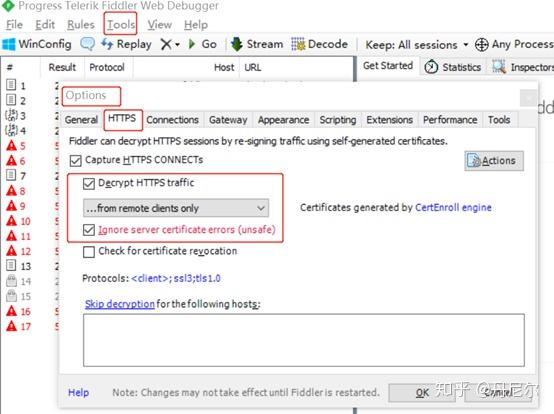
图4:设置Tools-Options-HTTPS
然后设置Actions:点击Actions,选择Trust root certificate以及export root certificate to desktop(弹下来的提示都选Yes)。
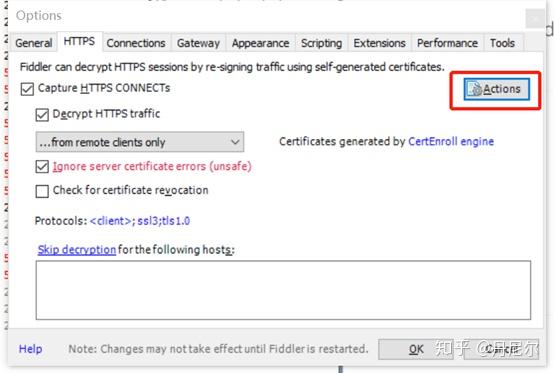
图5:设置Actions
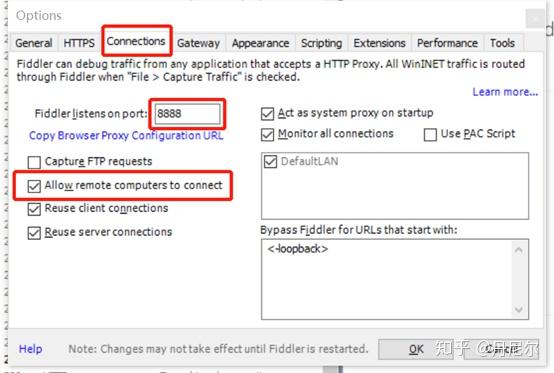
图6:设置Tools-Options-Connections4. 手机设置(我使用小米手机,其他手机大致一样)
图7:设置手机WiFi代理(proxy)
图8:手机步入网址192.168.124.14:8888
图9:点击FiddlerRoot Certificate
图10:下载以后安装它,随意命名,我命名为“Fiddler2”
5. 重启笔记本的Fiddler,手机点开公众号文章,电脑Fiddler搜集信息
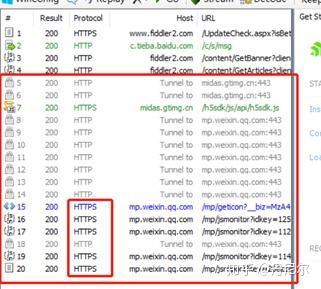
图11:记录
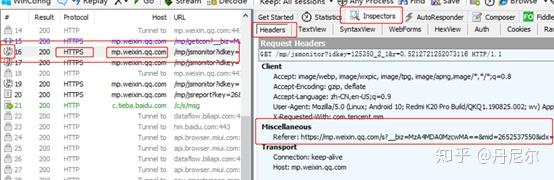
图12:具体剖析
图13:复制Fiddler记录的链接,在浏览器中点开
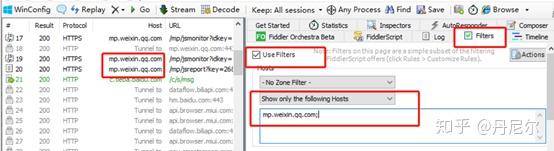
图14:过滤
图15:过滤以后的信息
可以看见,序号存在着跳跃,因为过滤起到了作用。
6. 将所有信息导入
图16:导出手机浏览记录
图17:txt信息7. Python抽取公众号信息
import numpy as np
data = []
with open(r'...\1_Full.txt', 'r', encoding='utf-8') as fp:
for line in fp:
if 'Referer: https://mp.weixin.qq.com/' in line: //将含有重要信息的链接保留到data中
data.append(line[9:])
// 去重
data = np.unique(data)
8. 通过笔记本陌陌客户端抓取公众号的信息
在一遍一遍刷手机以后,本人勿必厌恶。。如果还能通过键盘点击笔记本为内心客户端,然后通过fiddler搜集信息,那么就不用刷手机了。。注意,在调整fiddler的时侯,anaconda的jupyter关掉(可以使用spyder),否则fiddler会出问题。
操作差不多。
首先,将fiddler-Tools-Options-HTTPS,将Decrypt HTTPS traffic更改为“from all processes”.
图18:电脑搜集微信公众号的操作
然后,同样在自己的浏览器中,输入IP地址+8888,下载证书。
图19:下载FiddlerRoot证书
下载以后进行安装。
图20:安装证书
其他设置filter和前面手机设置一样,都是把关于wp.weixin的内容筛选下来。
然后,刷笔记本端微信公众号,那么filter才能够记录下所有的公众号文章。注意,一旦打开fiddler,那么笔记本难以访问其他网页,因为百度等防爬机制太严格,会检查到fiddler早已启动。
9. 更加手动和智能的操作
无论是刷手机搜集信息,还是通过笔记本端刷公众号,依然是须要人点击信息,不够智能。这里在参考了新的案例以后,能够进行颠覆性的改进。
首先,本文后面的模块仍然须要了解。当早已才能在笔记本端刷微信公众号的文章、同时fiddler才能搜集https的信息,那么继续往下。以“首都之窗”微信公众号为例。
(1)电脑陌陌端的操作
打开fiddler。
点击设置-通用设置-使用系统默认浏览器打开网页。
图21:电脑陌陌端设置
然后,随意点击“首都之窗”的任意一篇文章,会在浏览器中弹下来。放在哪里,不用理会。顺便把fiddler中记录的这个文章信息删了。留着fiddler空白,记录第25图的重点内容!
这一步的目的是为了才能顺利在浏览器中打开公众号的历史消息但是刷新。
图22:先点一篇文章
图23:该文章在浏览器弹下来
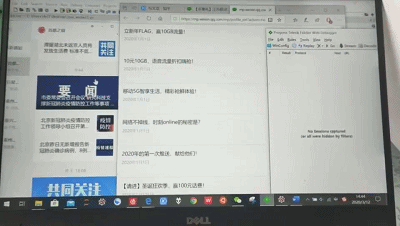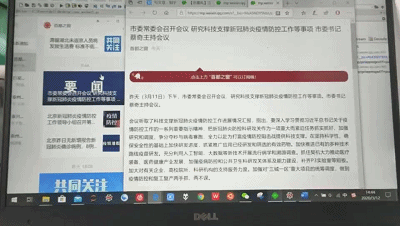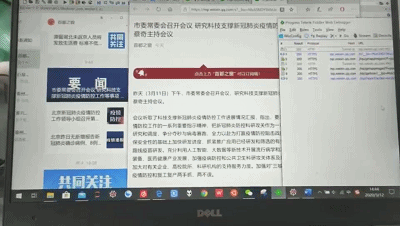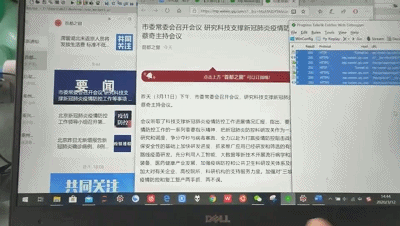
图24:完整操作
接着,进入“首都之窗”公众号,点击查看历史消息。
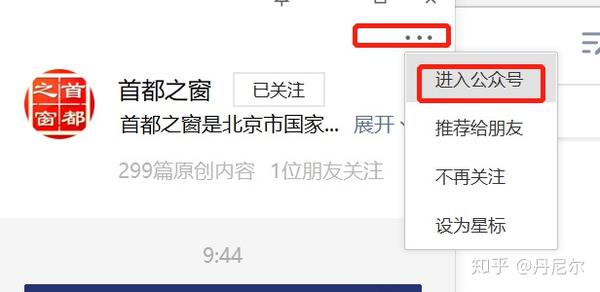
图25:查看历史消息
同样,“历史消息”在浏览器(绝不能在陌陌客户端下拉、因为fiddler收不到信息)中弹下来,然后往下开始刷几下,需要听到有新的内容弹下来,同时见到fiddler正在记录更新的信息。fiddler更新的消息就是最重要的内容。
图26:在浏览器中下拉几次“历史消息”
(2)fiddler信息剖析
刚刚通过在浏览器下拉公众号历史消息,fiddler采集到了更新的信息。我们开始剖析。
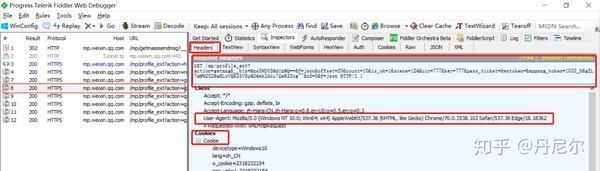
图27:分析由于下拉历史消息而搜集到的某一条记录
选择第8条记录(该记录来自浏览器中下拉历史记录而搜集到的消息),重点部份早已在headers中圈下来了。
(3)链接分析(看不下去的话,直接看代码如何拼出链接)
首先,在Request headers中,该链接简拼是 /mp/profile_ext?action=getmsg&__biz=MzA5NDY5MzUzMQ==&f=json&offset=20&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxtoken=&appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~&x5=0&f=json HTTP/1.1
分析这个链接。可以看见,它是由几个部份组成。
①/mp/profile_ext?②action=getmsg ③&__biz=MzA5NDY5MzUzMQ== ④&f=json⑤&offset=20 ⑥&count=10 ⑦&is_ok=1 ⑧&scene=124 ⑨&uin=777 ⑩&key=777 &pass_ticket= &wxtoken= &appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~ &x5=0&f=json HTTP/1.1
那么我们须要关注的信息是:
③__biz:公众号的id(公众号的biz惟一),⑤offset:翻页标志,appmsg_token:某个有时效性的token(隔一段时间会变化)
我们再看下边几个链接
GET /mp/profile_ext?action=getmsg&__biz=MzA5NDY5MzUzMQ==&f=json&offset=40&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxtoken=&appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~&x5=0&f=json HTTP/1.1
GET /mp/profile_ext?action=getmsg&__biz=MzA5NDY5MzUzMQ==&f=json&offset=60&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxtoken=&appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~&x5=0&f=json HTTP/1.1
biz和appmsg_token一致,offset改变,即为新的一页。因此,第一步,我们早已找到了翻页的规律。链接中只有这三个在变化,其他没有变动。因此,链接在python中才能写成:
api = 'https://mp.weixin.qq.com/mp/pr ... iz%3D{0}&f=json&offset={1}&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxton=&appmsg_token={2}&x5=0&f=json HTTP/1.1'.format(
__biz, offset, appmsg_token)
(4)cookie和headers
cookie保存的是陌陌登陆的信息,在爬虫的时侯须要填进去。我们只要关注wsp_sid2的cookies信息。
cookies同样来自图27。找到wap_sid2=CK6vyK4CElxLdmda............
headers同样来自图27。找到 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
(5)爬取
好的,以上找到了好多信息。初步的python如下:
import requests
import json
# 链接拼接三个信息
__biz = "MzA5NDY5MzUzMQ=="
appmsg_token = "1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~"
offset = 20
# cookies和headers
cookies = "wap_sid2=CK6vyK4CElxLdmda......."
headers = {'Cookie':cookies,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
}
# api拼出来
api = 'https://mp.weixin.qq.com/mp/pr ... iz%3D{0}&f=json&offset={1}&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxton=&appmsg_token={2}&x5=0&f=json HTTP/1.1'.format(
__biz, offset, appmsg_token)
# 抓取并且json化
resp = requests.get(api, headers = headers, verify=False).json()
为什么须要把resp进行json化?我们可以尝试着打开9(3)一开始的链接的网页,
图28:拼下来的api打开的网页长这样
很明显这是个json信息。因此须要json化。复制该网页的全部文本,放在网页中,可以看见完整的json结构。这就是resp的网页结果。
图29:把图28的文本信息复制置于中的结果
那么resp在python中被json化以后的结果如下
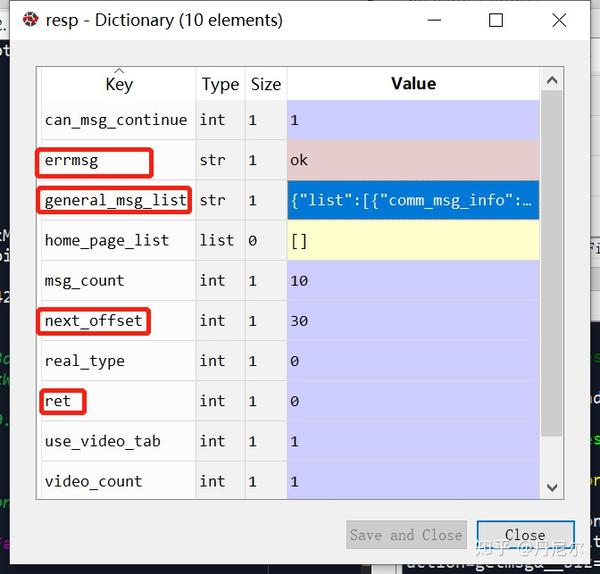
图30:resp在python中的结构
(6)网页解析
接下来,关注该resp的结构以及一层一层剖析。图30中resp中errmsg=ok和ret=0,均表示网页可以正常打开(如果报错的话,ret=-3)。next_offset是下一次翻页的标志,需要保存上去。
next_offset = resp.get('next_offset')
general_msg_list = resp.get('general_msg_list')
# 将general_msg_list转为json格式
msg_list = json.loads(general_msg_list)['list']
general_msg_list 是 重要的内容。点击general_msg_list,这仍然是一个json结构。
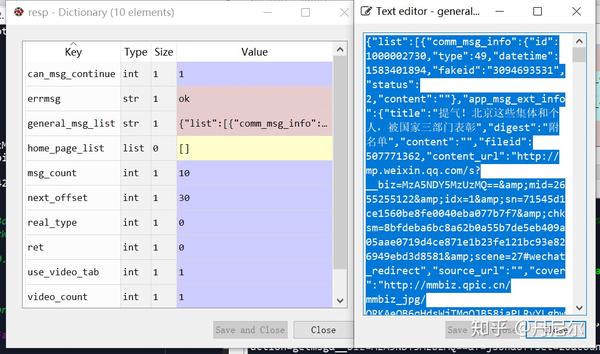
图31:general_msg_list仍然是json结构。
复制上面的文本,放到中瞧瞧是哪些。
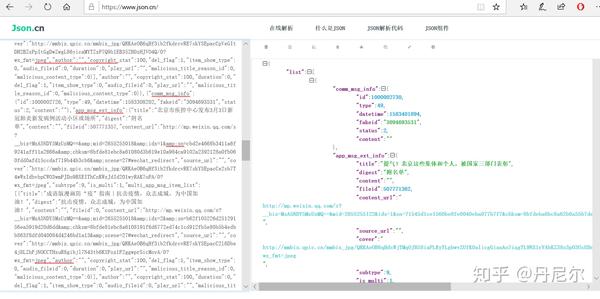
图32:general_msg_list放在中的结果
因此被json化以后的msg_list,在python中长这样
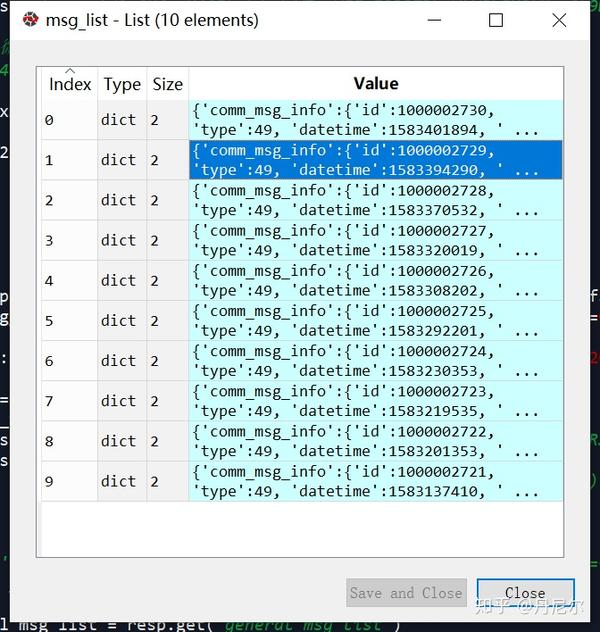
图33:把general_msg_list进行json化在python中的样子
可以看见,msg_list中富含10个记录。我们抽出一个记录,进行具体剖析。在剖析之前,我们要明晰一个东西。msg_list中收录了10个记录,不是指10篇文章,而是10次推送。某一次公众号推送消息,可能同时发布好几条文章,也有可能是一篇文章。因此,要明白,单个msg记录,是指一个推送(and可能一次性发布了好几篇文章)。
图34:某一次推送,一起发布了3篇文章
msg = msg_list[0]
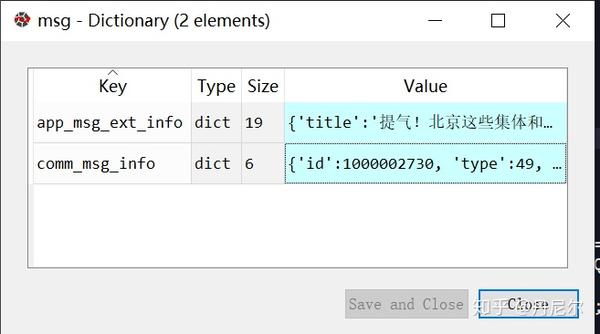
图35:某一个具体的msg
该msg上面收录了“app_msg_ext_info”和“comm_msg_info”两个内容。在中,这两个内容分别长这样子。

图36:某一个msg具体的两部份---app_msg_ext_info和comm_msg_info
那么comm_msg_info收录了该推送的基本信息:推送ID,时间等。
app_msg_ext_info是哪些?且听我渐渐剖析。首先,title,digest仍然到is_multi,都是该次推送的打头文章(就是图34中带图片的那种文章的信息)。例如title标题/digest关键词/content_url链接/source_url原链接等。
is_multi是判定该次推送是不是有读篇文章;=1表示yes,=0表示no。那么这儿等于1,说明该次推送还有其他文章,存在于multi_app_msg_item_list中。
把multi_app_msg_item_list取下来。
multi_app_msg_item_list = app_msg_ext_info.get('multi_app_msg_item_list')
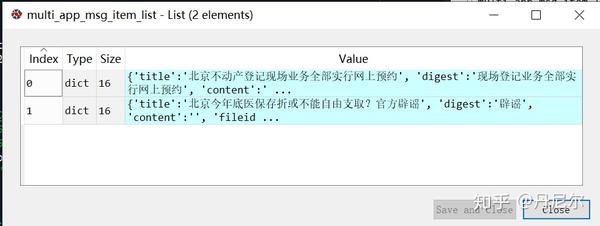
图37:该推送剩下的两篇文章藏在multi_app_msg_item_list中
到目前为止,我们早已剖析完了整体的流程。
总结
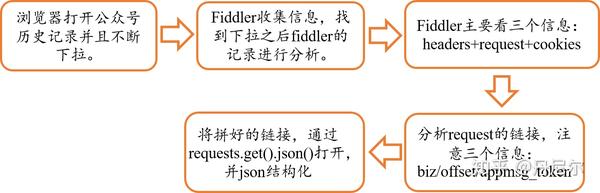
图38:总结怎样走出第一步
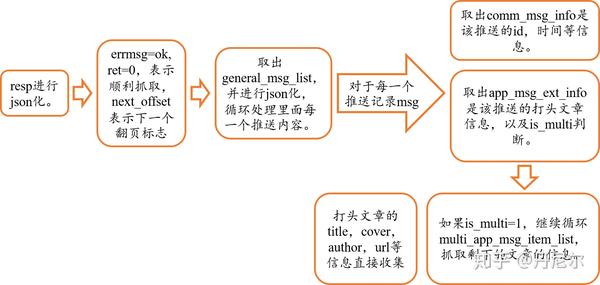
图39:具体剖析结构
(7)具体代码如下
<p>import requests
import json
from datetime import datetime
import pandas as pd
import time
class WxMps:
def __init__(self, biz, appmsg_token, cookies, offset, city):
self.biz = biz
self.msg_token = appmsg_token
self.offset = offset
self.headers = {'Cookie':cookies, 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
self.city = city
def parse1(self, resp):
# 控制下一个抓取的offset
offset = resp.get('next_offset')
# 将包含主要内容的list转为json格式
general_msg_list = resp.get('general_msg_list')
# 一个msg_list中含有10个msg
msg_list = json.loads(general_msg_list)['list']
df1 = pd.DataFrame(columns = ['msg_id', 'post_time', 'msg_type', 'title', 'cover', 'author', 'digest', 'source_url', 'content_url'])
# 循环message列表
for msg in msg_list:
# msg是该推送的信息,包含了comm_msg_info以及app_msg_ext_info两个信息,注意某一个推送中可能含有多个文章。
comm_msg_info = msg.get('comm_msg_info')
app_msg_ext_info = msg.get('app_msg_ext_info')
# 该推送的id
msg_id = comm_msg_info.get('id')
# 该推送的发布时间,例如1579965567需要转化为datetime,datetime.fromtimestamp(1579965567)
post_time = datetime.fromtimestamp(comm_msg_info['datetime'])
# 该推送的类型
msg_type = comm_msg_info.get('type')
if app_msg_ext_info:
# 推送的第一篇文章
title, cover, author, digest, source_url, content_url = self.parse2(app_msg_ext_info)
df2 = self.df_process(msg_id, post_time, msg_type, title, cover, author, digest, source_url, content_url)
df1 = pd.concat([df1, df2])
# 判断是不是多篇文章
is_multi = app_msg_ext_info.get("is_multi")
# 如果是1,继续爬取;如果是0,单条推送=只有一篇文章
if is_multi:
multi_app_msg_item_list = app_msg_ext_info.get('multi_app_msg_item_list')
for information in multi_app_msg_item_list:
(title, cover, author, digest, source_url, content_url) = self.parse2(information)
df2 = self.df_process(msg_id, post_time, msg_type, title, cover, author, digest, source_url, content_url)
df1 = pd.concat([df1, df2])
return df1, offset
def start(self):
offset = self.offset
df1 = pd.DataFrame(columns = ['msg_id', 'post_time', 'msg_type', 'title', 'cover', 'author', 'digest', 'source_url', 'content_url'])
while offset
在时间关系数据上AutoML:一个新的前沿
采集交流 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2020-08-12 16:31
翻译:张恬钰
校对:李海明
本文1600字,建议阅读8分钟。
本文介绍了AutoML的发展历史及其在时间关系数据上的应用方案。
现实世界中的机器学习系统须要数据科学家和领域专家来构建和维护,而这样的人才却总是供不应求。自动化机器学习(AutoML)由于在建立和维护机器学习工作流中的关键步骤中所显露出的广泛适用性,使得该领域的研究前景一片光明。它减少了人类专家的工作负担,使她们才能专注于复杂、非重复和具有创造性的学习问题。
AutoML的最新进展主要包括从时间关系数据库中手动发觉有意义的表间关系的复杂功能合成(例如,深度特点综合),使用模型手动调整进行概念漂移(例如,AutoGBT),以及深度学习模型的手动设计(例如,神经结构搜索),如图1所示。这些研究进展提升了数据科学家的生产力,从而明显增强了AutoML系统的实用性,并促使非机器学习专家也才能处理现实中不同领域的数据科学问题。
图1 AutoML进化史
在时间关系数据库中使用AutoML
在例如在线广告,推荐系统,自动与顾客交流等机器学习应用中,数据集可以跨越多个具有时间戳的相关表来显示风波的时间安排。而传统方法则须要专家们通过冗长的试错法自动组合表格来获取有意义的特点。用于处理动词关系数据的AutoML考虑了相关关键数组的临时联接,并通过手动发觉重要的表间关系来手动进行特点合成。
在没有域信息的情况下,实现基于动词关系数据的真实世界的AutoML案例包括手动生成有用的动词信息和跨多个子表格有效合并特点,且不会造成数据泄漏。除了这种困难外,还须要手动选择最佳的学习模型和受资源约束的超参数集,以让解决方案足够通用,并且符合时间和内容预算。
有趣的是,今年的KDD杯举办了以AutoML为主题的挑战赛,邀请了全世界AI / ML领域的研究和从业人员为动词关系数据库开发最新的AutoML。
我们的解决方式
我们的工作流程包括预处理,跨关系表的手动特点合成,模型学习和预测这种步骤。预处理包括对于偏移校准的特点变换以及平方和三次特点的提高。它还包括分类特点的频率编码,而特点是使用子表中聚合指标的时间连接手动合成的。多数类的实例将进行下述取样以保持1:3的百分比。渐进式决策树(GBDT)的Catboost实现可用于学习算法,交叉验证则可用于参数调整来决定最佳树的数目。图2概括地描述了我们的工作流程:
图2 我们的模型管线
时态数据聚合
当动词关系数据跨越多个表格时,找出表间的重要关系之后以最佳方法执行数据聚合将有助于特点提取。为了提取正确的特点表示,可对数字特点使用均值、求和等聚合运算,而对分类特点则采用计数、众数等运算。求频度,聚合指标的估算须要在适当的时间窗口上使用交叉验证完成。
特征处理
连接多个数据库的表会形成高度偏移的特点。我们的特点预处理步骤包括偏移校准以及特点变换和提高。特征提高包括添加具有周期性的数字特点的平方和三次方变换以及正则或正切,日期时间特点的变换(例如,月,时和分)来丰富特点空间。还可对分类特点进行频率编码来进一步扩大特点空间。
模型选择
在估算和储存方面,尝试几种线性和非线性模型的成本可能会十分高昂。由于梯度提高决策树在处理分类特点和可扩展性方面的鲁棒性,我们将模型组合限制在CatBoost的实现上。同时使用交叉验证对超参数(例如树的数目)进行调整,以防止过度拟合。
我们的解决方案拓展了现有的AutoML研究项目组合,允许使用涉及不定式关系数据库学习的用例。可以访问Github储存库来查看我们的解决方案。
AutoML趋势
随着行业越来越关注从AI中快速获取价值并降低机器学习模型从原型到生产布署的周期时间,能够增加AI准入门槛并实现AI工作流程自动化的AutoML已成为重要推动力。AutoML社区越来越关注于支持真实案例的使用,包括从结构化和非结构化数据、时态关系数据库以及受概念甩尾影响的数据流中学习。
尽管AutoML最初专注于最佳机器学习管线的手动建立,随着时间的推移,对此类管线手动维护处理它的范围正在扩大,模型自治性进一步降低。AutoML的进步和强悍的估算基础设施的可借助性将促进人机智能的融合,使得人类专家才能更好地将精力集中在学习复杂的,非重复和创造性的问题上,从而获得更优的解决方案。
原文标题:
AutoMLfor Temporal Relational Data: A New Frontier
原文链接: 查看全部
作者:Flytxt
翻译:张恬钰
校对:李海明
本文1600字,建议阅读8分钟。
本文介绍了AutoML的发展历史及其在时间关系数据上的应用方案。
现实世界中的机器学习系统须要数据科学家和领域专家来构建和维护,而这样的人才却总是供不应求。自动化机器学习(AutoML)由于在建立和维护机器学习工作流中的关键步骤中所显露出的广泛适用性,使得该领域的研究前景一片光明。它减少了人类专家的工作负担,使她们才能专注于复杂、非重复和具有创造性的学习问题。
AutoML的最新进展主要包括从时间关系数据库中手动发觉有意义的表间关系的复杂功能合成(例如,深度特点综合),使用模型手动调整进行概念漂移(例如,AutoGBT),以及深度学习模型的手动设计(例如,神经结构搜索),如图1所示。这些研究进展提升了数据科学家的生产力,从而明显增强了AutoML系统的实用性,并促使非机器学习专家也才能处理现实中不同领域的数据科学问题。
图1 AutoML进化史
在时间关系数据库中使用AutoML
在例如在线广告,推荐系统,自动与顾客交流等机器学习应用中,数据集可以跨越多个具有时间戳的相关表来显示风波的时间安排。而传统方法则须要专家们通过冗长的试错法自动组合表格来获取有意义的特点。用于处理动词关系数据的AutoML考虑了相关关键数组的临时联接,并通过手动发觉重要的表间关系来手动进行特点合成。
在没有域信息的情况下,实现基于动词关系数据的真实世界的AutoML案例包括手动生成有用的动词信息和跨多个子表格有效合并特点,且不会造成数据泄漏。除了这种困难外,还须要手动选择最佳的学习模型和受资源约束的超参数集,以让解决方案足够通用,并且符合时间和内容预算。
有趣的是,今年的KDD杯举办了以AutoML为主题的挑战赛,邀请了全世界AI / ML领域的研究和从业人员为动词关系数据库开发最新的AutoML。
我们的解决方式
我们的工作流程包括预处理,跨关系表的手动特点合成,模型学习和预测这种步骤。预处理包括对于偏移校准的特点变换以及平方和三次特点的提高。它还包括分类特点的频率编码,而特点是使用子表中聚合指标的时间连接手动合成的。多数类的实例将进行下述取样以保持1:3的百分比。渐进式决策树(GBDT)的Catboost实现可用于学习算法,交叉验证则可用于参数调整来决定最佳树的数目。图2概括地描述了我们的工作流程:
图2 我们的模型管线
时态数据聚合
当动词关系数据跨越多个表格时,找出表间的重要关系之后以最佳方法执行数据聚合将有助于特点提取。为了提取正确的特点表示,可对数字特点使用均值、求和等聚合运算,而对分类特点则采用计数、众数等运算。求频度,聚合指标的估算须要在适当的时间窗口上使用交叉验证完成。
特征处理
连接多个数据库的表会形成高度偏移的特点。我们的特点预处理步骤包括偏移校准以及特点变换和提高。特征提高包括添加具有周期性的数字特点的平方和三次方变换以及正则或正切,日期时间特点的变换(例如,月,时和分)来丰富特点空间。还可对分类特点进行频率编码来进一步扩大特点空间。
模型选择
在估算和储存方面,尝试几种线性和非线性模型的成本可能会十分高昂。由于梯度提高决策树在处理分类特点和可扩展性方面的鲁棒性,我们将模型组合限制在CatBoost的实现上。同时使用交叉验证对超参数(例如树的数目)进行调整,以防止过度拟合。
我们的解决方案拓展了现有的AutoML研究项目组合,允许使用涉及不定式关系数据库学习的用例。可以访问Github储存库来查看我们的解决方案。
AutoML趋势
随着行业越来越关注从AI中快速获取价值并降低机器学习模型从原型到生产布署的周期时间,能够增加AI准入门槛并实现AI工作流程自动化的AutoML已成为重要推动力。AutoML社区越来越关注于支持真实案例的使用,包括从结构化和非结构化数据、时态关系数据库以及受概念甩尾影响的数据流中学习。
尽管AutoML最初专注于最佳机器学习管线的手动建立,随着时间的推移,对此类管线手动维护处理它的范围正在扩大,模型自治性进一步降低。AutoML的进步和强悍的估算基础设施的可借助性将促进人机智能的融合,使得人类专家才能更好地将精力集中在学习复杂的,非重复和创造性的问题上,从而获得更优的解决方案。
原文标题:
AutoMLfor Temporal Relational Data: A New Frontier
原文链接:
基于主题爬虫与文本分类的微博资讯智能生成策略研究
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-11 13:57
【摘要】:随着联通互联网的快速发展,中国手机网民数目早已赶超PC,各种手机应用层出不穷,其中手机微博早已成为使用率增速最快的手机应用。越来越多的人们使用微博进行交流互动,尤其是在面向垂直细分领域的专业微博中,用户有强烈的获取权威资讯信息的需求。但是,传统的微博欠缺良好的信息查询与推送功能,难以满足不同人群的信息获取须要。因此,根据不同行业主题,利用微博平台将互联网上丰富的行业资讯信息进行手动采集推送,具有重要的理论研究和实际应用价值。在基于主题爬虫与文本分类的微博资讯智能生成策略中,利用主题爬虫技术和文本分类技术将互联网上丰富的行业信息按主题进行采集分类并通过手机微博客户端向特定用户群体提供资讯查询和推送服务。首先,在针对主题信息的采集中提出了一种面向特定领域的主题式爬取策略,通过对开源爬虫框架Heritrix进行主题模块的扩充,使爬虫只抓取与特定主题相关的最新行业信息。其次,在网页数据处理过程中通过改进文本分类算法,设计了一种英文网页文本分类器,对抓取的网页按行业主题进行手动细分类并提取数据生成有价值资讯信息。然后,通过手机微博平台将分类的信息通过设定的不同微博频道或则智能帐号进行动态展示与发布。最后,以农业主题为例将基于主题爬虫与文本分类的微博资讯智能生成策略应用在广东手机农业微博中进行农务资讯的生成与推送。在广东手机农业微博中实现农业微博资讯的智能生成,并对微博资讯生成策略进行了相关的功能和性能测试。实验结果表明:这种微博资讯生成策略才能及时获取最新行业相关资讯,进行详尽确切的信息分类并提供便捷的查询与推送服务。其中主题爬虫抓取的主题准确率达到87%以上,网页文本分类器的整体评估指数达到85%左右。
USB免驱摄像头采集图像【VS2012+opencv+directShow(Cc
采集交流 • 优采云 发表了文章 • 0 个评论 • 527 次浏览 • 2020-08-10 23:03
但是该配置比较老,本文述说怎样基于该教程在 VS2012和opencv2.4.9上进行配置和更改,完成USB摄像头的驱动。
博主的USB免驱摄像头如下:
文末有完整代码的下载地址
1.环境配置
在Opencv英文网站上有关于directShow和opencv结合采集图像的教程,地址:%e4%bd%bf%e7%94%a8DirectShow%e9%87%87%e9%9b%86%e5%9b%be%e5%83%8f
但说明中的“本文档介绍的CCameraDS类调用采集函数可直接返回IplImage,使用更方便,且集成了DirectShow,勿需安装庞大的DirectX/Platform SDK”并不靠谱,DirectShow 似乎早已开始被谷歌给淘汰了,最后存在是在多年前的 DirectX 9.0b 包里。
注意这儿并不需要下载DirectX 9.0包,下面介绍在VS2012和opencv2.4.9下的配置过程。
1.1 配置VS2012和opencv环境
按照网上流行的配置即可,如 。配置好以后尝试运行一个打开图片的小程序检查opencv环境是否配置成功。
1.2 配置DirectX环境
新建工程,配置好Opencv环境,随后将从Opencv英文网上下载的 CameraDS.h 和 CameraDS.cpp 文件分别添加到项目的头文件和源文件中。
VS2012旗舰版是自带了 SDK 的,在 C:\Program Files (x86)\Microsoft SDKs\Windows\v7.1A\Include。
打开构建的VS2012项目的属性页,找到“VC++目录”,在“收录目录”里添加 (FrameworkSDKDir)Include,在“库目录”里添加(FrameworkSDKDir)Lib。
发现#include “qedit.h”报错,原因是现今的版本早已没有qedit.h这个头文件了,从网址: 中下载该文件,添加到项目的头文件中。
2. 运行
环境配置好以后,可以用 Opencv英文网 上下载的main.cpp运行,运行过程可能碰到const char* 无法转换的问题,将此处的代码除去即可。
下面是本人编撰的main函数,提供了USB单反的打开、监视、图像捕获功能。
2.1 查看系统的所有摄像头状态(initAllCameras函数)
参数是 CCameraDS 类的对象。该函数获取单反的数量而且显示单反名称。从输出中我们可以找到USB单反的编号,一般情况下编号为1。
//获取当前可用的摄像头并打开USB摄像头
int initAllCameras(CCameraDS &m_CamDS){
//仅仅获取摄像头数目
int m_iCamCount = CCameraDS::CameraCount();
printf("There are %d cameras.\n", m_iCamCount);
if(m_iCamCount == 0)
{
return -1;
}
//获取所有摄像头的名称
for(int i = 0; i < m_iCamCount; i++)
{
char szCamName[1024];
int retval = m_CamDS.CameraName(i, szCamName, sizeof(szCamName));
if(retval >0)
{
printf("Camera #%d's Name is '%s'.\n", i, szCamName);
}
else
{
printf("Can not get Camera #%d's name.\n", i);
}
}
return m_iCamCount;
}
运行结果如下所示:
There are 3 cameras.
Camera #0's Name is 'Lenovo EasyCamera'.
Camera #1's Name is '3D Camera'.
Camera #2's Name is 'Basler GenICam Source'.
从运行结果中可以看出,使用的3D相机的编号为1。
2.2 打开USB单反(openUsbCam函数)
函数有四个参数,第一个参数为CcameraDS类的对象,camNum设置为1,表明如今要打开的USB单反,而不是笔记本自带单反。camWidth和camHeight按照自己所使用单反的情况进行设置,设置为图象的长度和高度。
代码如下:
<p>// 打开 USB 相机 !! 在调用 camDisplay 和 camCapPic 之前必须调用该函数
// camNum = 1; // 摄像头编号为1,表示当前要使用的是 USB 摄像头
// camWidth = 2560; // 图片宽度
// camHeight = 720; // 图片高度
int openUsbCam(CCameraDS &m_CamDS, const int camNum=1, const int camWidth=2560, const int camHeight = 720){
// 获取当前可用的相机个数
// 在所有的相机中,一般编号为 0 的为电脑自带摄像头,编号为 1 的为要使用的 USB 摄像头
int m_iCamCount = initAllCameras(m_CamDS);
if(m_iCamCount == -1){
cout 查看全部
在Opencv英文网站上有关于directShow和opencv结合采集图像的教程,地址:%e4%bd%bf%e7%94%a8DirectShow%e9%87%87%e9%9b%86%e5%9b%be%e5%83%8f
但是该配置比较老,本文述说怎样基于该教程在 VS2012和opencv2.4.9上进行配置和更改,完成USB摄像头的驱动。
博主的USB免驱摄像头如下:

文末有完整代码的下载地址
1.环境配置
在Opencv英文网站上有关于directShow和opencv结合采集图像的教程,地址:%e4%bd%bf%e7%94%a8DirectShow%e9%87%87%e9%9b%86%e5%9b%be%e5%83%8f
但说明中的“本文档介绍的CCameraDS类调用采集函数可直接返回IplImage,使用更方便,且集成了DirectShow,勿需安装庞大的DirectX/Platform SDK”并不靠谱,DirectShow 似乎早已开始被谷歌给淘汰了,最后存在是在多年前的 DirectX 9.0b 包里。
注意这儿并不需要下载DirectX 9.0包,下面介绍在VS2012和opencv2.4.9下的配置过程。
1.1 配置VS2012和opencv环境
按照网上流行的配置即可,如 。配置好以后尝试运行一个打开图片的小程序检查opencv环境是否配置成功。
1.2 配置DirectX环境
新建工程,配置好Opencv环境,随后将从Opencv英文网上下载的 CameraDS.h 和 CameraDS.cpp 文件分别添加到项目的头文件和源文件中。
VS2012旗舰版是自带了 SDK 的,在 C:\Program Files (x86)\Microsoft SDKs\Windows\v7.1A\Include。
打开构建的VS2012项目的属性页,找到“VC++目录”,在“收录目录”里添加 (FrameworkSDKDir)Include,在“库目录”里添加(FrameworkSDKDir)Lib。
发现#include “qedit.h”报错,原因是现今的版本早已没有qedit.h这个头文件了,从网址: 中下载该文件,添加到项目的头文件中。
2. 运行
环境配置好以后,可以用 Opencv英文网 上下载的main.cpp运行,运行过程可能碰到const char* 无法转换的问题,将此处的代码除去即可。
下面是本人编撰的main函数,提供了USB单反的打开、监视、图像捕获功能。
2.1 查看系统的所有摄像头状态(initAllCameras函数)
参数是 CCameraDS 类的对象。该函数获取单反的数量而且显示单反名称。从输出中我们可以找到USB单反的编号,一般情况下编号为1。
//获取当前可用的摄像头并打开USB摄像头
int initAllCameras(CCameraDS &m_CamDS){
//仅仅获取摄像头数目
int m_iCamCount = CCameraDS::CameraCount();
printf("There are %d cameras.\n", m_iCamCount);
if(m_iCamCount == 0)
{
return -1;
}
//获取所有摄像头的名称
for(int i = 0; i < m_iCamCount; i++)
{
char szCamName[1024];
int retval = m_CamDS.CameraName(i, szCamName, sizeof(szCamName));
if(retval >0)
{
printf("Camera #%d's Name is '%s'.\n", i, szCamName);
}
else
{
printf("Can not get Camera #%d's name.\n", i);
}
}
return m_iCamCount;
}
运行结果如下所示:
There are 3 cameras.
Camera #0's Name is 'Lenovo EasyCamera'.
Camera #1's Name is '3D Camera'.
Camera #2's Name is 'Basler GenICam Source'.
从运行结果中可以看出,使用的3D相机的编号为1。
2.2 打开USB单反(openUsbCam函数)
函数有四个参数,第一个参数为CcameraDS类的对象,camNum设置为1,表明如今要打开的USB单反,而不是笔记本自带单反。camWidth和camHeight按照自己所使用单反的情况进行设置,设置为图象的长度和高度。
代码如下:
<p>// 打开 USB 相机 !! 在调用 camDisplay 和 camCapPic 之前必须调用该函数
// camNum = 1; // 摄像头编号为1,表示当前要使用的是 USB 摄像头
// camWidth = 2560; // 图片宽度
// camHeight = 720; // 图片高度
int openUsbCam(CCameraDS &m_CamDS, const int camNum=1, const int camWidth=2560, const int camHeight = 720){
// 获取当前可用的相机个数
// 在所有的相机中,一般编号为 0 的为电脑自带摄像头,编号为 1 的为要使用的 USB 摄像头
int m_iCamCount = initAllCameras(m_CamDS);
if(m_iCamCount == -1){
cout
被动信息搜集----指纹辨识(CMS辨识)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2020-08-10 21:24
1.指纹识别介绍
指纹因为其具有不变性、唯一性和方便性,使其可以被惟一的标示。而对于每位网站来说,他们也具有可标识性,我们通常通过网站CMS辨识、计算机操作系统辨识以及web容器辨识来标示网站。
2.指纹辨识的目的
在渗透测试中,对目标服务器进行指纹辨识是十分有必要的,因为只有辨识出相应的web容器或则CMS,才能查看与其相关的漏洞,然后借助可用的漏洞进行相应的渗透测试。
二、CMS介绍
CMS(Content Management System)又称整站系统或文章系统。在2004年以前,如果想进行网站内容管理,基本上须要靠自动维护,但在信息爆燃的时代,完全靠手工维护都会相当苦闷。所以就出现了CMS,开发者只须要给顾客一个软件包,客户自己安装配置好,就可以定期更新数据来维护网站,节省了大量的人力和物力。
三、常见CMS介绍
php类cms系统:dedeCMS、帝国CMS、php168、phpCMS、cmstop、discuz、phpwind等
asp类cms系统:zblog、KingCMS等
.net类cms系统:EoyooCMS等
国外的知名cms系统:joomla、WordPress 、magento、drupal 、mambo等
(1):DedeCMS(织梦)
织梦内容管理系统(DedeCMS)以简单、实用、开源而享誉,是国外最著名的PHP开源网站管理系统,也是使用用户最多的PHP类CMS系统。DedeCMS免费版主要目标锁定在个人站长,功能愈发专注于个人网站或中小型门户的建立,当然也有企业用户和中学等在使用本系统。
(2):Discuz
Crossday Discuz! Board(简称Discuz!)是康盛创想(北京)科技有限公司推出的一套通用的社区峰会软件系统,用户可以在不需要任何编程的基础上,通过简单的设置和安装,在互联网上搭建起具备建立功能、很强负载能力和可高度订制的峰会服务。Discuz! 的基础构架采用世界上最流行的web编程组合PHP+MySQL实现,是一个经过建立设计,适用于各类服务器环境的高效峰会系统解决方案。
(3):帝国CMS
帝国CMS又称为Empire CMS,简称Ecms,它是基于B/S结构而且功能强悍而易用的网站管理系统。它采用了系统模型功能:用户通过此功能可直接在后台扩充与实现各类系统,因此又被称为是万能建站工具。帝国CMS具有强悍的功能,并且现今早已全部开源。
(4):WordPress
WordPress是使用PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上架设属于自己的网站,WordPress也被当做一个内容管理系统(CMS)。WordPress是一款个人博客系统,使用PHP和MySQL语言进行开发的。
四、判断CMS的方式
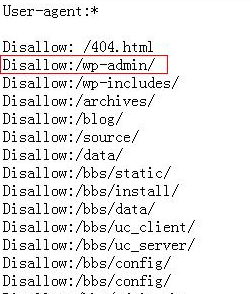
1.查看robots.txt文件
robots.txt文件中储存的是一些严禁被爬虫爬取的目录,因此有些robots.txt文件中都会储存一些关于CMS的敏感信息。例如假如robots.txt文件中存在wp-admin目录,那么就表名这个CMS是WordPress。
2.查看网页源代码
在有些网站中的源代码中会储存着网站的CMS信息和相应的版本信息,通过查看源代码可以发觉使用的CMS类别。 查看全部
一、指纹辨识
1.指纹识别介绍
指纹因为其具有不变性、唯一性和方便性,使其可以被惟一的标示。而对于每位网站来说,他们也具有可标识性,我们通常通过网站CMS辨识、计算机操作系统辨识以及web容器辨识来标示网站。
2.指纹辨识的目的
在渗透测试中,对目标服务器进行指纹辨识是十分有必要的,因为只有辨识出相应的web容器或则CMS,才能查看与其相关的漏洞,然后借助可用的漏洞进行相应的渗透测试。
二、CMS介绍
CMS(Content Management System)又称整站系统或文章系统。在2004年以前,如果想进行网站内容管理,基本上须要靠自动维护,但在信息爆燃的时代,完全靠手工维护都会相当苦闷。所以就出现了CMS,开发者只须要给顾客一个软件包,客户自己安装配置好,就可以定期更新数据来维护网站,节省了大量的人力和物力。
三、常见CMS介绍
php类cms系统:dedeCMS、帝国CMS、php168、phpCMS、cmstop、discuz、phpwind等
asp类cms系统:zblog、KingCMS等
.net类cms系统:EoyooCMS等
国外的知名cms系统:joomla、WordPress 、magento、drupal 、mambo等
(1):DedeCMS(织梦)
织梦内容管理系统(DedeCMS)以简单、实用、开源而享誉,是国外最著名的PHP开源网站管理系统,也是使用用户最多的PHP类CMS系统。DedeCMS免费版主要目标锁定在个人站长,功能愈发专注于个人网站或中小型门户的建立,当然也有企业用户和中学等在使用本系统。
(2):Discuz
Crossday Discuz! Board(简称Discuz!)是康盛创想(北京)科技有限公司推出的一套通用的社区峰会软件系统,用户可以在不需要任何编程的基础上,通过简单的设置和安装,在互联网上搭建起具备建立功能、很强负载能力和可高度订制的峰会服务。Discuz! 的基础构架采用世界上最流行的web编程组合PHP+MySQL实现,是一个经过建立设计,适用于各类服务器环境的高效峰会系统解决方案。
(3):帝国CMS
帝国CMS又称为Empire CMS,简称Ecms,它是基于B/S结构而且功能强悍而易用的网站管理系统。它采用了系统模型功能:用户通过此功能可直接在后台扩充与实现各类系统,因此又被称为是万能建站工具。帝国CMS具有强悍的功能,并且现今早已全部开源。
(4):WordPress
WordPress是使用PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上架设属于自己的网站,WordPress也被当做一个内容管理系统(CMS)。WordPress是一款个人博客系统,使用PHP和MySQL语言进行开发的。
四、判断CMS的方式
1.查看robots.txt文件
robots.txt文件中储存的是一些严禁被爬虫爬取的目录,因此有些robots.txt文件中都会储存一些关于CMS的敏感信息。例如假如robots.txt文件中存在wp-admin目录,那么就表名这个CMS是WordPress。
2.查看网页源代码
在有些网站中的源代码中会储存着网站的CMS信息和相应的版本信息,通过查看源代码可以发觉使用的CMS类别。
优采云QQ群聊天消息文章生成器下载 1.7.0.1 试用版
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-10 12:39
工作流程:
1、分析QQ导入的TXT格式聊天消息记录文件,得到精确的每条消息
2、将每条消息进行过滤、插入前后缀文字等修饰后,按设定的数目进行组合(如一个消息文件有1万条记录,按100条消息一篇的组合,能生产100篇原创文章)
3、可以对组合的结果插入关键词或该消息文件的文件名
4、一篇篇纯原创的文章就此诞生!
功能特性:
1、分析QQ消息文件,精确获取每一条消息文本
2、全局搅乱消息
3、内置过滤(如过滤网址、邮箱等)
4、内置屏蔽词替换(QQ聊天时常常说到好多敏感词句)
5、自动消除多余标点符号(多个标点符号相连时,只保留一个,让文章看起来更真实和顺眼)
6、消息支持合纵连横组合。(连横,即多条原创消息连在一起作为单条消息,以合并符分隔,合纵,即多个单条消息组合为一篇原创文章)
7、单条消息支持前后缀插入,如常见的段落网页标签”《p》《/p》“
8、支持插入词到标题,支持插入随机词到文章(更可手动组合锚文本)
9、文章标题智能提取组合的结果中的随机一句。
10、批量选择多个QQ消息文件,一键处理,大功告成,文章滚滚来!!
更新日志:
改造为支持OEM代理
官方网站:
相关搜索:QQ聊天记录 查看全部
优采云QQ群聊天消息文章生成器是一款可以将QQ聊天,尤其是群聊天的大量原创内容,进行处理后生产出原创文章来,虽然个他人会复制文章来粘贴,但它们的特点很容易辨识,往往是篇幅很大的,这时你可以设定单条消息字数超过某甲字数就忽视。

工作流程:
1、分析QQ导入的TXT格式聊天消息记录文件,得到精确的每条消息
2、将每条消息进行过滤、插入前后缀文字等修饰后,按设定的数目进行组合(如一个消息文件有1万条记录,按100条消息一篇的组合,能生产100篇原创文章)
3、可以对组合的结果插入关键词或该消息文件的文件名
4、一篇篇纯原创的文章就此诞生!
功能特性:
1、分析QQ消息文件,精确获取每一条消息文本
2、全局搅乱消息
3、内置过滤(如过滤网址、邮箱等)
4、内置屏蔽词替换(QQ聊天时常常说到好多敏感词句)
5、自动消除多余标点符号(多个标点符号相连时,只保留一个,让文章看起来更真实和顺眼)
6、消息支持合纵连横组合。(连横,即多条原创消息连在一起作为单条消息,以合并符分隔,合纵,即多个单条消息组合为一篇原创文章)
7、单条消息支持前后缀插入,如常见的段落网页标签”《p》《/p》“
8、支持插入词到标题,支持插入随机词到文章(更可手动组合锚文本)
9、文章标题智能提取组合的结果中的随机一句。
10、批量选择多个QQ消息文件,一键处理,大功告成,文章滚滚来!!
更新日志:
改造为支持OEM代理
官方网站:
相关搜索:QQ聊天记录
人工智能+工程师的组合,或将满足日渐下降的网路安全需求
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2020-08-10 02:25
北京时间10月22日凌晨,美国域名服务器管理服务供应商Dyn宣布,该公司在当地时间周五早上遭到了DDoS(分布式拒绝服务)攻击,这一情况造成许多网站在英国东海岸地区宕机。Twitter、Tumblr、Netflix、Amazon、PayPal等众多人气网站无一幸免。
许多受此影响的公司都在Twitter上发布消息,向其用户发出了网站宕机的通知,亚马逊报告报称有一次服务中断,午后已解决问题。由于影响范围太广,著名的科技博客Gizmodo甚至表示半个互联网都关掉了,而按照网友们反馈,此次黑客攻击造成83家网站受影响。
三波网路功击,来自上千万IP地址
根据Dyn的说法,最早的一次功击源于周五早上7点(北京时间周五晚上7点)过后,此次功击干扰干扰了Dyn运作约两小时。随即,工作人员进行了抢险,在当天上午9点半左右恢复了营运。但是仅在几小时后,Dyn就受到第二次功击,运营再度遭到干扰。北京时间今天凌晨4点30分左右Dyn又受到第三次功击。
Dyn是日本最主要的DNS服务商,他们的主要职责就是将域名解析为IP地址,将网友引入正确的网站。此次Dyn遭到功击以后,会导致日本大部分地区网民在恳求链接某网站的时侯会失败,即使你按F5不断刷新也没有用。
很显然,这是一次有组织有蓄谋的网路功击行为,攻击行为来自超过一千万IP来源。此外,Dyn也表示这当中有几百万恶意功击的源头是物联网联系的所谓“智能”家居产品。Dyn的首席策略官Kyle York在电话会议上甚至说,黑客们“真正在做的是用每次功击撼动世界。”
单独借助人工智能或则工程师难以做到维护网路安全
网络安全的维护一般都是由工程师们完成的,但是一次又一次的网路黑客侵袭风波证明了,工程师们并没有绝对的掌握保障网路安全。那么假如由人工智能来接替工程师,是否能够保障网路安全呢?答案也是否定的。哪怕是新型混杂式系统,基于人工智能(AI)梳理数据,并将当前可疑行为递交给剖析人员,也仅才能测量85%的功击。
人工智能在维护网路安全上可以做到的自动化和漏洞修复技术包括:动态剖析(Dynamic Analysis)、静态剖析(Static Analysis)、符号执行(Symbolic Execution)、约束求解、数据流跟踪技术(Data Flow Tracking)以及模糊测试(Fuzz Testing)等,并和其他半自动化技术搭配,形成一整套全手动的网路决策推理系统(Cyber Reasoning System,CRS)。
很明显,人工智能才能在改善联通安全和网路安全方面发挥作用,做好避免网路恐吓逼抢和网路安全防御举措。但是,人工智能也只能测量到85%的功击,而并非100%。
由此可见,如果单独借助单独借助人工智能或则工程师,无法做到百分百的网路安全。
人工智能+工程师,合作以后或将构建更强大的网路安全
既然工程师和人工智能都难以单独在网路安全维护工作上取得压倒性成功,为什么不试着把三者整合上去呢?
在网路安全的世界里,以人为主的技术主要依赖专业人员完善的规则,因此不符合规则的功击就被错过。而初期网路安全方面的机器学习则依赖于异常检查,因此常常容易误报,“狼来了”太多,最终造成其并不被看好。
但是,随着人工智能技术的日渐发展,在现今的网路安全领域,它可以是一个虚拟的分析员,在发觉黑客攻击以后,第一时间交由人类分析员来判断,之后系统再把判定结果整合到模型中,作为下一个数据集的测量标准,然后不断循环这个过程。这也就意味着,在保证极大地提高检测率的同时,还可以提高未来的预测准确率。
因此,使用人工智能来学习并找到最有可能是功击的风波,然后交给人类专家去判定,并且协助人类工程师进行网路安全防护,是一个结合二者优势以后最有效的办法。
世界上并没有绝对的网路安全,防患于未然只是更好的选择
俗话说的好“魔高一尺道高一丈”,先有魔,后有道。如今的“道”,已经实现人工智能的广泛应用,而“魔”呢?黑客虽然已经实现完全自动化了......攻击的投放、发起、渗透,只是在其中几个小的步骤才须要人工介入,通过一个可视化界面管理着被渗透的全世界几十万台服务器。
其实面对现今的网路安全方式,每日就会有成百上千的崩溃报告、DDoS攻击、数据泄漏等功击行为,我们不应渴望“完美的防御”,而应当尽量提升功击成功率的门槛,降低功击成功率或是减短防御响应时间,形成正确的“安全观”。最后提醒你们,被功击只是时间而已,现在没有发生,未来必然发生。 查看全部
哪怕堪称网路最安全的日本,也躲不过黑客的功击。那么为什么不将人工智能和工程师结合,实现更完善的网路安全。
北京时间10月22日凌晨,美国域名服务器管理服务供应商Dyn宣布,该公司在当地时间周五早上遭到了DDoS(分布式拒绝服务)攻击,这一情况造成许多网站在英国东海岸地区宕机。Twitter、Tumblr、Netflix、Amazon、PayPal等众多人气网站无一幸免。

许多受此影响的公司都在Twitter上发布消息,向其用户发出了网站宕机的通知,亚马逊报告报称有一次服务中断,午后已解决问题。由于影响范围太广,著名的科技博客Gizmodo甚至表示半个互联网都关掉了,而按照网友们反馈,此次黑客攻击造成83家网站受影响。
三波网路功击,来自上千万IP地址
根据Dyn的说法,最早的一次功击源于周五早上7点(北京时间周五晚上7点)过后,此次功击干扰干扰了Dyn运作约两小时。随即,工作人员进行了抢险,在当天上午9点半左右恢复了营运。但是仅在几小时后,Dyn就受到第二次功击,运营再度遭到干扰。北京时间今天凌晨4点30分左右Dyn又受到第三次功击。

Dyn是日本最主要的DNS服务商,他们的主要职责就是将域名解析为IP地址,将网友引入正确的网站。此次Dyn遭到功击以后,会导致日本大部分地区网民在恳求链接某网站的时侯会失败,即使你按F5不断刷新也没有用。
很显然,这是一次有组织有蓄谋的网路功击行为,攻击行为来自超过一千万IP来源。此外,Dyn也表示这当中有几百万恶意功击的源头是物联网联系的所谓“智能”家居产品。Dyn的首席策略官Kyle York在电话会议上甚至说,黑客们“真正在做的是用每次功击撼动世界。”
单独借助人工智能或则工程师难以做到维护网路安全
网络安全的维护一般都是由工程师们完成的,但是一次又一次的网路黑客侵袭风波证明了,工程师们并没有绝对的掌握保障网路安全。那么假如由人工智能来接替工程师,是否能够保障网路安全呢?答案也是否定的。哪怕是新型混杂式系统,基于人工智能(AI)梳理数据,并将当前可疑行为递交给剖析人员,也仅才能测量85%的功击。

人工智能在维护网路安全上可以做到的自动化和漏洞修复技术包括:动态剖析(Dynamic Analysis)、静态剖析(Static Analysis)、符号执行(Symbolic Execution)、约束求解、数据流跟踪技术(Data Flow Tracking)以及模糊测试(Fuzz Testing)等,并和其他半自动化技术搭配,形成一整套全手动的网路决策推理系统(Cyber Reasoning System,CRS)。
很明显,人工智能才能在改善联通安全和网路安全方面发挥作用,做好避免网路恐吓逼抢和网路安全防御举措。但是,人工智能也只能测量到85%的功击,而并非100%。
由此可见,如果单独借助单独借助人工智能或则工程师,无法做到百分百的网路安全。
人工智能+工程师,合作以后或将构建更强大的网路安全
既然工程师和人工智能都难以单独在网路安全维护工作上取得压倒性成功,为什么不试着把三者整合上去呢?
在网路安全的世界里,以人为主的技术主要依赖专业人员完善的规则,因此不符合规则的功击就被错过。而初期网路安全方面的机器学习则依赖于异常检查,因此常常容易误报,“狼来了”太多,最终造成其并不被看好。

但是,随着人工智能技术的日渐发展,在现今的网路安全领域,它可以是一个虚拟的分析员,在发觉黑客攻击以后,第一时间交由人类分析员来判断,之后系统再把判定结果整合到模型中,作为下一个数据集的测量标准,然后不断循环这个过程。这也就意味着,在保证极大地提高检测率的同时,还可以提高未来的预测准确率。
因此,使用人工智能来学习并找到最有可能是功击的风波,然后交给人类专家去判定,并且协助人类工程师进行网路安全防护,是一个结合二者优势以后最有效的办法。
世界上并没有绝对的网路安全,防患于未然只是更好的选择
俗话说的好“魔高一尺道高一丈”,先有魔,后有道。如今的“道”,已经实现人工智能的广泛应用,而“魔”呢?黑客虽然已经实现完全自动化了......攻击的投放、发起、渗透,只是在其中几个小的步骤才须要人工介入,通过一个可视化界面管理着被渗透的全世界几十万台服务器。

其实面对现今的网路安全方式,每日就会有成百上千的崩溃报告、DDoS攻击、数据泄漏等功击行为,我们不应渴望“完美的防御”,而应当尽量提升功击成功率的门槛,降低功击成功率或是减短防御响应时间,形成正确的“安全观”。最后提醒你们,被功击只是时间而已,现在没有发生,未来必然发生。
您对昼夜使用的智能推荐系统了解多少? [Aix Smart]
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2020-08-08 20:29
我们知道推荐结果是通过推荐系统所需数据进行计算和处理的结果,并且计算和处理过程使用推荐算法. 如果我们将推荐系统所需的数据视为原材料,则推荐算法是装配线上的工人,根据程序对原材料进行处理和包装,然后将其存储在仓库(缓存层)中. 那么,更广泛使用的推荐算法是什么?
1. 基于神经网络的文本语义推荐算法
CB(基于内容的推荐),即根据用户的历史采集内容(项目),向用户推荐与其历史采集内容相似或相关的内容. 例如,在汽车信息场景中,用户阅读了很多有关“宝马”汽车的文章,然后该列表还将推荐类似于“宝马”汽车的文章. 值得注意的是,基于相似内容的推荐不仅涉及标题,而且还收录所有被认为具有计算价值的文本的相似性
2. 基于协同过滤的推荐算法
基于内容的推荐算法将带来一系列问题. 例如,它将允许用户进入信息茧室而不能执行冷启动(新用户)建议. 因此,在大多数业务场景中,需要将智能推荐应用于基于协作推荐算法(CF),并与CB推荐相结合. (CF)是一种算法,它指的是对哪种类型的数据进行协调,以及完成协作后如何进行过滤. 这些是(CF)算法的关键点.
协作推荐算法(CF)背后的逻辑是,每个人对自己利益的看法都是单方面的,并且是无知的. 即使您还没有看到任何东西,每个人都不知道也不知道他们是否会喜欢. 因此,CF依靠“群体共性”和“群体智慧”来挖掘出用户可能喜欢的那些潜在内容并将其推荐给用户. CF算法也是最早,最经典的推荐算法之一. 可以说CF算法是推荐算法的发起者. 我们的许多后续推荐算法都基于基于CF的协作过滤思想. 基于协作的推荐算法有两种: 基于用户的协作过滤算法和基于项目的协作过滤算法.
3. 基于用户行为的深度学习模型
随着技术的发展,深度学习的应用场景变得越来越广泛,并且已经进行了许多尝试将深度学习应用于行业中的推荐系统. 基于用户行为的深度学习模型首先被应用于中小型计算广告系统. 出于成本考虑,由于庞大的吞吐量和低延迟要求,大型计算广告系统通常使用简单的回归算法.
深度学习模型在推荐系统中有两个主要应用: 一是使用更精确的语义模型来进行项目相似度计算;二是将深度学习模型应用于推荐项目. 另一种是抽象用户行为并提取特征以预测点击概率;
4. 基于关联规则的推荐
在电子商务领域中广泛使用的另一种推荐算法是基于关联规则的推荐. 从本质上讲,它与协作过滤算法相似,不同之处在于它与用户自己的购买记录进行协作. 典型的故事是啤酒和尿布的故事. 尽管故事的来源不再可用,但它是当前最广泛认可的数据带来的好处的案例.
故事的内容是: 经过数据分析,北美的超市运营商发现,啤酒和尿布更有可能以相同的顺序出现. 因此,我进一步研究发现,家庭中购买尿布的大部分事情都是由家庭中的男人完成的,男人在购买尿布时总是会带几罐啤酒. 因此,通过调整货架位置,将尿布和啤酒放在一起,以便更多的男人在购买尿布时可以带一打啤酒. 结果,销售额大大增加了.
这个故事本身不能接受审查. 例如,尿布和啤酒总是总是一起买的,所以你不应该把它们放在一起,而要保持一定距离. 在移动线设计中,让用户浏览两种商品的过程,并放置其他一些男人会随身携带的商品,回报率可能更高. 我们暂时不会讨论这个故事的可信度. 这个故事反映了关联规则推荐背后的最简单逻辑: 我应该需要其他用户经常一起购买哪些产品.
通常,作为一种智能的内容分发平台,其内容分发方法多种多样. 内容平台包括算法分发,编辑(手动)分发,社交分发等,内容平台将根据自身特点选择高分发效率的分发方式. 总体来说,内容平台中存在多种分发方式.
例如,在新闻场景中,可能需要在指定位置显示固定类型的新闻,而其他推荐位置将使用算法进行分发. 例如,微博的热点是算法的分布,而以下各节的算法是纯粹基于订阅的社交分布. 还是在业务场景中,各种分配方法都以权重的形式参与了最终结果的表示. 例如,电子商务搜索部分不仅使用基于语义和用户行为的个性化搜索排名,而且还增加了主要产品,流量产品等的权重,因此这些产品在分发过程. 最上面的一个显示在用户的屏幕上. 当平台内容量大,用户规模达数千万甚至数千万时,信息和用户的有效匹配就显得尤为重要,它将自然通过各种方法提高分发效率.
3. 智能推荐与分类和搜索引擎有什么区别
在当今的互联网时代,我们大致经历了三种获取信息的方式: 目录,搜索引擎和智能推荐. 他们还催生了提供三种类型的信息获取服务的成功公司. 类别包括: Yahoo,Sina;搜索引擎: 谷歌,百度;明智的建议: ByteDance.
类别目录所涵盖的信息量是有限的,并且用户不容易找到不同类别的信息. 搜索引擎覆盖范围广,操作简单,但是用户必须提供准确的关键字. . 在当今的信息爆炸时代,用户依靠上述两种方法来准确地获取所需内容并不容易,尤其是当他们不了解所需内容的具体分类和精确关键字时. 明智的建议是通过计算用户行为数据,将最需要的信息主动推送给用户. 它与目录和搜索引擎之间的区别体现在这里.
推荐系统根据用户的静态属性和用户行为数据来匹配信息. 因为每个用户都有各自的差异,所以每个用户获得的信息都是不同的且个性化的,并且推荐系统传递的信息是主动而非被动的过程.
我们每个人都不能没有的在线购物向我们展示了明智推荐的优势和必要性. 有数千万种产品,搜索词也多种多样. 如果我们不依靠智能推荐系统为我们提供便利,那么我们可能很难找到我们真正想要的产品.
四个. 明智的推荐势在必行
无论它是什么平台,都必须构建一个智能的推荐系统,帮助用户发现内容并克服信息过载. 智能推荐系统正在潜移默化地影响着我们的生活,无论我们是否注意到它,我们都无法离开智能推荐系统. 作为您最了解您的“人”,它正在您和我周围活跃,不仅使该平台有利可图,而且为每个用户提供了更多便利.
这种积极推荐人们喜欢和需要的产品和信息的方式,可以迎合人类固有的惯性. 人们喜欢被动接收而不是主动搜索,特别是当信息是我们感兴趣的信息时. 如今,聪明的建议无处不在. 购物平台上的商品推荐,短视频平台上的视频推荐,娱乐平台上的音乐和电影推荐,新闻信息平台上的信息推荐,甚至社交平台上的朋友卡推荐,都依赖于此. 简而言之,在不同用户手中,每个应用程序可以相同或完全不同. 一切都会根据您的个性和喜好进行定义. 这是智能推荐的本质. 查看全部
(2)推荐算法
我们知道推荐结果是通过推荐系统所需数据进行计算和处理的结果,并且计算和处理过程使用推荐算法. 如果我们将推荐系统所需的数据视为原材料,则推荐算法是装配线上的工人,根据程序对原材料进行处理和包装,然后将其存储在仓库(缓存层)中. 那么,更广泛使用的推荐算法是什么?
1. 基于神经网络的文本语义推荐算法
CB(基于内容的推荐),即根据用户的历史采集内容(项目),向用户推荐与其历史采集内容相似或相关的内容. 例如,在汽车信息场景中,用户阅读了很多有关“宝马”汽车的文章,然后该列表还将推荐类似于“宝马”汽车的文章. 值得注意的是,基于相似内容的推荐不仅涉及标题,而且还收录所有被认为具有计算价值的文本的相似性
2. 基于协同过滤的推荐算法
基于内容的推荐算法将带来一系列问题. 例如,它将允许用户进入信息茧室而不能执行冷启动(新用户)建议. 因此,在大多数业务场景中,需要将智能推荐应用于基于协作推荐算法(CF),并与CB推荐相结合. (CF)是一种算法,它指的是对哪种类型的数据进行协调,以及完成协作后如何进行过滤. 这些是(CF)算法的关键点.
协作推荐算法(CF)背后的逻辑是,每个人对自己利益的看法都是单方面的,并且是无知的. 即使您还没有看到任何东西,每个人都不知道也不知道他们是否会喜欢. 因此,CF依靠“群体共性”和“群体智慧”来挖掘出用户可能喜欢的那些潜在内容并将其推荐给用户. CF算法也是最早,最经典的推荐算法之一. 可以说CF算法是推荐算法的发起者. 我们的许多后续推荐算法都基于基于CF的协作过滤思想. 基于协作的推荐算法有两种: 基于用户的协作过滤算法和基于项目的协作过滤算法.
3. 基于用户行为的深度学习模型
随着技术的发展,深度学习的应用场景变得越来越广泛,并且已经进行了许多尝试将深度学习应用于行业中的推荐系统. 基于用户行为的深度学习模型首先被应用于中小型计算广告系统. 出于成本考虑,由于庞大的吞吐量和低延迟要求,大型计算广告系统通常使用简单的回归算法.
深度学习模型在推荐系统中有两个主要应用: 一是使用更精确的语义模型来进行项目相似度计算;二是将深度学习模型应用于推荐项目. 另一种是抽象用户行为并提取特征以预测点击概率;
4. 基于关联规则的推荐
在电子商务领域中广泛使用的另一种推荐算法是基于关联规则的推荐. 从本质上讲,它与协作过滤算法相似,不同之处在于它与用户自己的购买记录进行协作. 典型的故事是啤酒和尿布的故事. 尽管故事的来源不再可用,但它是当前最广泛认可的数据带来的好处的案例.
故事的内容是: 经过数据分析,北美的超市运营商发现,啤酒和尿布更有可能以相同的顺序出现. 因此,我进一步研究发现,家庭中购买尿布的大部分事情都是由家庭中的男人完成的,男人在购买尿布时总是会带几罐啤酒. 因此,通过调整货架位置,将尿布和啤酒放在一起,以便更多的男人在购买尿布时可以带一打啤酒. 结果,销售额大大增加了.
这个故事本身不能接受审查. 例如,尿布和啤酒总是总是一起买的,所以你不应该把它们放在一起,而要保持一定距离. 在移动线设计中,让用户浏览两种商品的过程,并放置其他一些男人会随身携带的商品,回报率可能更高. 我们暂时不会讨论这个故事的可信度. 这个故事反映了关联规则推荐背后的最简单逻辑: 我应该需要其他用户经常一起购买哪些产品.
通常,作为一种智能的内容分发平台,其内容分发方法多种多样. 内容平台包括算法分发,编辑(手动)分发,社交分发等,内容平台将根据自身特点选择高分发效率的分发方式. 总体来说,内容平台中存在多种分发方式.
例如,在新闻场景中,可能需要在指定位置显示固定类型的新闻,而其他推荐位置将使用算法进行分发. 例如,微博的热点是算法的分布,而以下各节的算法是纯粹基于订阅的社交分布. 还是在业务场景中,各种分配方法都以权重的形式参与了最终结果的表示. 例如,电子商务搜索部分不仅使用基于语义和用户行为的个性化搜索排名,而且还增加了主要产品,流量产品等的权重,因此这些产品在分发过程. 最上面的一个显示在用户的屏幕上. 当平台内容量大,用户规模达数千万甚至数千万时,信息和用户的有效匹配就显得尤为重要,它将自然通过各种方法提高分发效率.
3. 智能推荐与分类和搜索引擎有什么区别
在当今的互联网时代,我们大致经历了三种获取信息的方式: 目录,搜索引擎和智能推荐. 他们还催生了提供三种类型的信息获取服务的成功公司. 类别包括: Yahoo,Sina;搜索引擎: 谷歌,百度;明智的建议: ByteDance.
类别目录所涵盖的信息量是有限的,并且用户不容易找到不同类别的信息. 搜索引擎覆盖范围广,操作简单,但是用户必须提供准确的关键字. . 在当今的信息爆炸时代,用户依靠上述两种方法来准确地获取所需内容并不容易,尤其是当他们不了解所需内容的具体分类和精确关键字时. 明智的建议是通过计算用户行为数据,将最需要的信息主动推送给用户. 它与目录和搜索引擎之间的区别体现在这里.
推荐系统根据用户的静态属性和用户行为数据来匹配信息. 因为每个用户都有各自的差异,所以每个用户获得的信息都是不同的且个性化的,并且推荐系统传递的信息是主动而非被动的过程.
我们每个人都不能没有的在线购物向我们展示了明智推荐的优势和必要性. 有数千万种产品,搜索词也多种多样. 如果我们不依靠智能推荐系统为我们提供便利,那么我们可能很难找到我们真正想要的产品.
四个. 明智的推荐势在必行
无论它是什么平台,都必须构建一个智能的推荐系统,帮助用户发现内容并克服信息过载. 智能推荐系统正在潜移默化地影响着我们的生活,无论我们是否注意到它,我们都无法离开智能推荐系统. 作为您最了解您的“人”,它正在您和我周围活跃,不仅使该平台有利可图,而且为每个用户提供了更多便利.
这种积极推荐人们喜欢和需要的产品和信息的方式,可以迎合人类固有的惯性. 人们喜欢被动接收而不是主动搜索,特别是当信息是我们感兴趣的信息时. 如今,聪明的建议无处不在. 购物平台上的商品推荐,短视频平台上的视频推荐,娱乐平台上的音乐和电影推荐,新闻信息平台上的信息推荐,甚至社交平台上的朋友卡推荐,都依赖于此. 简而言之,在不同用户手中,每个应用程序可以相同或完全不同. 一切都会根据您的个性和喜好进行定义. 这是智能推荐的本质.
Python学习笔记(20)自动点击京东产品的价格状况并智能地采集价格数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 564 次浏览 • 2020-08-07 19:49
1. 建立第一级主题以获取目标信息
建立第一级主题的规则,然后将所需的信息映射到排序框. 建议在完成内容映射后,还应进行定位标记映射,以提高定位精度和规则适应性.
**注意: **如果您设置了连续操作规则,则无需构建排序框. 例如,方案2的第一级主题不需要构建排序框,而是使用排序框来获取一些数据(选择页面一定会显示该信息)供爬虫程序确定是否执行采集,否则可能会错过网页.
二,设置连续动作
单击“新建”按钮创建一个新动作,每个动作的设置方法相同,基本操作如下:
2.1输入目标主题名称
连续动作指向同一目标对象. 如果有多个操作,并且您要指向不同的主题,请将它们分成多个规则并分别设置连续的操作.
2.2选择操作类型
这种情况是单击操作,并且不同操作的应用范围不同. 请根据实际操作情况选择动作类型.
2.3将位于动作对象的xpath填充到定位表达式中
2.4输入动作名称
告诉自己该步骤的用途,以便稍后进行修改.
2.5高级设置
不必先设置它,以后在调试连续动作时将使用它,这可以扩大适用的动作范围. 如果要捕获操作对象的信息,请使用xpath在高级设置的内容表达式中找到操作对象的信息. 请根据需要进行设置.
**注: **是否选择了动作类型以及xpath定位是否正确,请确定连续动作是否可以成功执行. Xpath是用于定位html节点的标准语言. 使用连续动作功能之前,请先掌握xpath.
根据人工步骤,我们还需要选择版本,购买方式1,购买方式2,因此我们将继续创建3个新操作并重复上述步骤.
三,调试规则
完成上述步骤后,单击“保存规则”,然后单击“爬网数据”按钮以开始试用捕获. 采集期间报告了一个错误: 无法找到节点***. 观察浏览器窗口,发现单击第一步后,未加载其他信息. 加载信息后,发现单击购买方法2后,无法返回执行四步单击的页面,从而导致连续执行连续动作.
鉴于上述情况,我们的解决方案是删除第四步. 因为无论您是否单击购买方法2,它都不会影响产品的价格. 因此,可以删除不必要的干扰步骤.
修改后,尝试再次捕获. 将提取的xml转换为excel后,我发现价格和累积评估数据被捕获或捕获不正确. 这是因为网页太大,加载速度太慢,并且单击后的数据将必须等待一段时间才能加载.
为了捕获所有数据,您需要延长等待时间并分别为每个操作设置延迟. 单击操作步骤->高级设置->额外延迟,然后输入以秒为单位的正整数. 请根据实际情况进行调试.
此外,如果不是顶部窗口,则在采集时将反复单击它. 这是因为京东网站上有一些防爬措施,这些措施必须是当前的窗口操作才能生效. 因此,请检查该窗口在高级设置中是否可见,并且在采集过程中该窗口将位于顶部. 请根据实际情况进行设置.
四个. 如何将捕获的信息与操作步骤一一对应?
如果要将捕获的信息与操作步骤一一对应,则必须提取操作对象的信息. 有两种方法:
4.1使用xpath在连续操作的高级设置的内容表达式中找到操作对象的信息节点.
在将定位表达式定位到动作对象的整个操作范围之后,它还收录其自己的信息. 因此,内容表达仅需要从定位的动作对象开始,并继续定位到其信息. 采集时,此步骤的信息将记录在actionvalue中,该值对应于actionno,后者记录该步骤的执行次数.
4.2在整理框中获取动作对象的信息,这里也使用xpath进行定位.
执行动作对象时,其dom结构将更改. 找到网页更改的结构特征,使用xpath精确定位节点,并在通过验证后,可以设置自定义xpath.
查看全部
**注意: **如果在执行操作之前和之后网页结构没有变化,则可以通过一条规则来完成;如果网页结构在前后变化,则必须通过两个或更多规则来完成;另外,如果涉及翻页,则分为两个或更多规则. 有关连续操作的规则数量,请参阅“计划获取过程”一文.
1. 建立第一级主题以获取目标信息
建立第一级主题的规则,然后将所需的信息映射到排序框. 建议在完成内容映射后,还应进行定位标记映射,以提高定位精度和规则适应性.
**注意: **如果您设置了连续操作规则,则无需构建排序框. 例如,方案2的第一级主题不需要构建排序框,而是使用排序框来获取一些数据(选择页面一定会显示该信息)供爬虫程序确定是否执行采集,否则可能会错过网页.
二,设置连续动作
单击“新建”按钮创建一个新动作,每个动作的设置方法相同,基本操作如下:
2.1输入目标主题名称
连续动作指向同一目标对象. 如果有多个操作,并且您要指向不同的主题,请将它们分成多个规则并分别设置连续的操作.
2.2选择操作类型
这种情况是单击操作,并且不同操作的应用范围不同. 请根据实际操作情况选择动作类型.
2.3将位于动作对象的xpath填充到定位表达式中
2.4输入动作名称
告诉自己该步骤的用途,以便稍后进行修改.
2.5高级设置
不必先设置它,以后在调试连续动作时将使用它,这可以扩大适用的动作范围. 如果要捕获操作对象的信息,请使用xpath在高级设置的内容表达式中找到操作对象的信息. 请根据需要进行设置.
**注: **是否选择了动作类型以及xpath定位是否正确,请确定连续动作是否可以成功执行. Xpath是用于定位html节点的标准语言. 使用连续动作功能之前,请先掌握xpath.
根据人工步骤,我们还需要选择版本,购买方式1,购买方式2,因此我们将继续创建3个新操作并重复上述步骤.
三,调试规则
完成上述步骤后,单击“保存规则”,然后单击“爬网数据”按钮以开始试用捕获. 采集期间报告了一个错误: 无法找到节点***. 观察浏览器窗口,发现单击第一步后,未加载其他信息. 加载信息后,发现单击购买方法2后,无法返回执行四步单击的页面,从而导致连续执行连续动作.
鉴于上述情况,我们的解决方案是删除第四步. 因为无论您是否单击购买方法2,它都不会影响产品的价格. 因此,可以删除不必要的干扰步骤.
修改后,尝试再次捕获. 将提取的xml转换为excel后,我发现价格和累积评估数据被捕获或捕获不正确. 这是因为网页太大,加载速度太慢,并且单击后的数据将必须等待一段时间才能加载.
为了捕获所有数据,您需要延长等待时间并分别为每个操作设置延迟. 单击操作步骤->高级设置->额外延迟,然后输入以秒为单位的正整数. 请根据实际情况进行调试.
此外,如果不是顶部窗口,则在采集时将反复单击它. 这是因为京东网站上有一些防爬措施,这些措施必须是当前的窗口操作才能生效. 因此,请检查该窗口在高级设置中是否可见,并且在采集过程中该窗口将位于顶部. 请根据实际情况进行设置.
四个. 如何将捕获的信息与操作步骤一一对应?
如果要将捕获的信息与操作步骤一一对应,则必须提取操作对象的信息. 有两种方法:
4.1使用xpath在连续操作的高级设置的内容表达式中找到操作对象的信息节点.
在将定位表达式定位到动作对象的整个操作范围之后,它还收录其自己的信息. 因此,内容表达仅需要从定位的动作对象开始,并继续定位到其信息. 采集时,此步骤的信息将记录在actionvalue中,该值对应于actionno,后者记录该步骤的执行次数.
4.2在整理框中获取动作对象的信息,这里也使用xpath进行定位.
执行动作对象时,其dom结构将更改. 找到网页更改的结构特征,使用xpath精确定位节点,并在通过验证后,可以设置自定义xpath.
煤矿安全隐患智能采集与智能决策系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 537 次浏览 • 2020-08-06 23:12
[摘要]: 分析和处理煤矿中的隐患对安全有效地生产煤矿非常重要,并受到许多煤矿企业的高度评价. 但是,大多数煤矿企业使用手动方法采集隐患数据并编写安全生产简报. 这种方法存在工作量大,效率低,输入信息混乱,输入信息不准确等问题. 一些煤矿企业还使用计算机软件来辅助数据处理,但是其基本数据存储还不够标准化,并且数据分析能力相对不足. 针对上述问题,本文应用卷积神经网络(CNN)语义映射算法,并对深蚁群算法(ACO)进行了改进,设计了煤矿安全隐患智能采集与智能决策系统. 该系统具有实时数据存储,跟踪和处理,风险管理与控制,分析和预警以及科学决策等功能. 本文首先介绍了煤矿安全隐患智能采集与决策系统的研究背景和意义,以及煤矿相关领域的国内外研究现状,分析了煤矿安全存在的问题. 从多方面,多角度的生产过程,并深入分析煤矿企业的实际情况,对项目的功能要求,建立煤矿安全隐患智能采集与智能决策系统框架进行研究. 根据要求,建立了煤矿安全隐患智能采集与决策系统数据库,并确定了数据表的详细字段. 在此基础上,将改进的CNN技术应用于煤矿隐患的智能采集领域,建立了基于CNN的智能采集模型,并应用ACO改进了隐患的智能检索和决策模型. 在煤矿中,以及从安全风险中使用C#等编程语言的方法七个功能模块,包括数据管理,安全隐患风险管理和控制以及煤矿文件管理,已经开发了智能采集和智能决策煤矿安全隐患系统. 最后,通过多次测试和实际应用,表明隐患智能采集与智能决策系统显着提高了隐患调查的效率和准确性,显着降低了煤矿安全隐患的发生频率,为煤矿安全隐患提供了保障. 煤矿安全生产. 图[61]表[8]参考. [52]
[语音记录]金融云业务网络智能搜集与综合分析实战
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2020-08-06 18:20
▌为什么要谈论虚拟网络采集
云山网络从2008年开始做SDN. 它已经探索了十年. 在云计算和云网络中,我们已经进行了研究和实践. 在此期间,我们看到了两个明显的网络变化. 第一: 网络流量模式的变化. 过去,该网络是具有南北向流量的烟囱架构. 现在,它已成为东西向交通. 据统计,数据中心网络中约80%的流量是东西向流量. 可以看出,东西方交通已成为主要交通方式.
第二个: 网络与企业脱节. 为什么这么说并不是说网络不再能够满足业务需求,而是网络与业务之间的关系越来越远. 那是什么意思?例如,在旧的传统网络中,我们可以从网络中提取流量,然后通过协议可以大致了解应用程序. 但是现在,由于存在一个底层网络和一个覆盖网络,因此我们遵循旧方法,并从提取的流量中看到了VXLAN封装和数据包. 即使解开封装,里面也有重复的IP.
因此,实际上很难发现当今云网络中运行的服务类型,因此该网络逐渐被边缘化. 在这种发展趋势下,日常网络使用以及运维将面临哪些挑战?接下来,我将分享两个典型示例.
每天发生的事件: 业务部门报告业务应用程序响应速度慢,并且网络存在问题,但是网络部门认为网络没有问题. 当然,业务部门不会批准它. 在那之后,有无休止的辩论,但是问题仍然没有解决之道,那么问题出在哪里?
让我们看一下网络的横截面. 对于网络部门来说,他们的视野是在底层网络中. 他们看到了交换机和链接,但是业务专注于虚拟机中的应用程序,因此这里存在一个很大的管理盲点,包括OVS,VGW,VFW和VLB. 这些都是非常重要的网络节点. 如果看不到内部网络状态,如何找到问题根源?或确定报告是否是网络问题. 此事件提醒我们,这是清楚了解虚拟网络中正在发生的事情的关键.
第二个例子发生在一家著名的证券公司. 众所周知,证券行业具有一系列安全要求,例如证券和证券监管. 因此,安全部门对网络部门提出了一个要求: 核心业务系统中关键业务组件的网络流量被导出以进行安全分析,数据审核等.
接下来,为了满足这一需求,网络部门制定了一个计划,通过流表来镜像虚拟网络. 但是,在POC过程中,结果并不理想. 流镜像与流表混合在一起,编排非常复杂. 此外,在迁移虚拟机时,无法自动更新镜像策略,无法实施最终解决方案,需求也就消失了.
后来,发生了更严重的事情. 该公司发生了事故,导致用户信息泄漏. 这种事件可谓是证券业的重大失败. 此时,安全部门必须负责. 同时,网络部门不满意. 安全部门的需求,网络部门和安全部门都负责整个事件.
结合以上两个示例,不难看出在云网络中,业务网络的采集,分析和分发已成为云网络构建的标准配置,如果要采集虚拟网络流量,所有的采集方法和解决方案都必须安全可靠,而且不影响生产.
▌计划和价值
如何解决上述问题,是云山DeepFlow数据中心虚拟网络流量采集分析平台(以下简称DeepFlow)所能做的. 这张照片是最左边的采集部分. 我们知道目前的业务范围非常广泛. 它可能涉及私有云和公共云. 云杉DeepFlow同时涵盖了这些环境. 通过部署DeepFlow,您可以帮助您查看所有业务. 对于所有VPC网络状态,管理员等效于站在高处从多个维度查看云网络的全景,这更便于管理. 同时,您也可以关注业务,例如右上角的图,转到某个VPC网络,观察数据中有多少个网络组件,并根据每个点查看相应的网络信息. 和线.
我们还对采集技术的安全性和可靠性进行了许多优化. 首先,DeepFlow采集器支持500个节点以覆盖大多数数据中心.
第二个是高性能,单个采集点支持10G流量采集. 安全可靠. 特殊阈值用于控制CPU,内存和网络资源的消耗,因此不会影响生产网络. 当发生迁移时,我们的策略也可以及时更新,而不会中断采集到的流量.
简而言之,Spruce DeepFlow采集的虚拟网络流量使我们能够查看虚拟网络上正在发生的事情,涵盖管理盲点. 一旦发生故障,我们可以快速定位,同时,我们可以快速推断出问题的根本原因,并提高操作和维护效率. 其次,采集虚拟网络流量后,您不仅可以自己对其进行分析,还可以将其分发给第三方工具,以帮助数据审核满足安全合规性要求. 第三,从运营商的角度来看整个云网络.
▌应用实践
我想再告诉您两个DeepFlow数据中心虚拟网络流量采集,分析和分发的示例. 首先是故障定位事件. 使用DeepFlow回溯分析功能可以轻松找到问题的根本原因. 怎么做?将事件发生时的虚拟网络流量与正常时间的虚拟网络流量进行比较,结果发现存在明显的异常网络指示,大量网络数据包,非常大的网络延迟等. 导致异常现象的原因是谁?
通过Spruce DeepFlow的细粒度采集功能,发现数据库将大量流量发送到某个IP地址. 看到这种现象后,立即采取回测措施. 回测意味着这种异常现象是过去偶然发生的. 它是经常发生还是定期发生?经过这一系列步骤之后,我们最终得出结论,为什么数据库不断发送数据,实际上是因为最近已安装了新的数据库备份系统,但是当配置了该策略时,时间参数是错误的,通常是一天时间备份,由于时间错误,导致每小时备份一次,因此数据库连续发送出去,数据库信息不断备份,占用了实际的生产资源,最终导致运行缓慢的现象业务.
在其他情况下,我看到了一些有趣的问题. 有时,负载平衡配置不正确,这会导致背面的资源不平衡. 服务器可能有很多虚拟机流量,而其他服务器则是免费的. 或将数据设置为由特定服务器处理,但是由于负载平衡配置错误,固定流量将被散列.
在讨论第二个示例之前,请回顾一下安全部门刚才向网络部门提出的要求,以导出虚拟机的流量以进行安全审核和分析. 实际上,此问题可以在部署DeepFlow之后轻松地采集虚拟网络流量,并将其同时分发到两个后端分析工具资源池. 为什么我们两个?实际上,它可以用作备份,因为数据对于安全,审计和分析部门非常重要.
▌摘要
DeepFlow拥有专利的虚拟流采集技术具有大规模,零干扰,无依赖性,过载保护和预处理的优点. 支持VMware和OpenStack平台,没有版本依赖性. 一个控制器可以管理500个采集点,而无需在生产网络的虚拟交换机上进行其他策略配置. 它支持数据包的重复数据删除,过滤和截断等操作,并支持用户配置采集器的资源使用情况,以确保生产环境的稳定性.
云山网络已经对SDN云网络进行了相应的研究和应用,并在过去十年中得到了资本和客户的认可. 目前,Spruce Network的融资额超过1亿美元,并且有许多成功的财富500强客户案例. 它已部署在金融,电信,电力和教育行业的近100家企业中,其中包括平安科技,工业数字金融,甜橙金融,中国移动,国家电网,苏州国家科学数据中心以及其他基准客户. 成为企业云数据中心网络稳定高效运行的典范.
! !福利! !下载“金融云业务网络的智能采集和集成分析”的语音PPT,可以通过在微信背景中回复“语音PPT”获得.
◆◆◆
相关阅读 查看全部
大家好,让我先自我介绍. 我是云山网络公司的吴玉华. 今天,我想与您分享有关金融云业务网络的采集,分析和分发的实用故事. 在开始讨论之前,我想与您讨论一个问题: 为什么我们需要采集虚拟网络流量.
▌为什么要谈论虚拟网络采集
云山网络从2008年开始做SDN. 它已经探索了十年. 在云计算和云网络中,我们已经进行了研究和实践. 在此期间,我们看到了两个明显的网络变化. 第一: 网络流量模式的变化. 过去,该网络是具有南北向流量的烟囱架构. 现在,它已成为东西向交通. 据统计,数据中心网络中约80%的流量是东西向流量. 可以看出,东西方交通已成为主要交通方式.

第二个: 网络与企业脱节. 为什么这么说并不是说网络不再能够满足业务需求,而是网络与业务之间的关系越来越远. 那是什么意思?例如,在旧的传统网络中,我们可以从网络中提取流量,然后通过协议可以大致了解应用程序. 但是现在,由于存在一个底层网络和一个覆盖网络,因此我们遵循旧方法,并从提取的流量中看到了VXLAN封装和数据包. 即使解开封装,里面也有重复的IP.
因此,实际上很难发现当今云网络中运行的服务类型,因此该网络逐渐被边缘化. 在这种发展趋势下,日常网络使用以及运维将面临哪些挑战?接下来,我将分享两个典型示例.
每天发生的事件: 业务部门报告业务应用程序响应速度慢,并且网络存在问题,但是网络部门认为网络没有问题. 当然,业务部门不会批准它. 在那之后,有无休止的辩论,但是问题仍然没有解决之道,那么问题出在哪里?
让我们看一下网络的横截面. 对于网络部门来说,他们的视野是在底层网络中. 他们看到了交换机和链接,但是业务专注于虚拟机中的应用程序,因此这里存在一个很大的管理盲点,包括OVS,VGW,VFW和VLB. 这些都是非常重要的网络节点. 如果看不到内部网络状态,如何找到问题根源?或确定报告是否是网络问题. 此事件提醒我们,这是清楚了解虚拟网络中正在发生的事情的关键.
第二个例子发生在一家著名的证券公司. 众所周知,证券行业具有一系列安全要求,例如证券和证券监管. 因此,安全部门对网络部门提出了一个要求: 核心业务系统中关键业务组件的网络流量被导出以进行安全分析,数据审核等.
接下来,为了满足这一需求,网络部门制定了一个计划,通过流表来镜像虚拟网络. 但是,在POC过程中,结果并不理想. 流镜像与流表混合在一起,编排非常复杂. 此外,在迁移虚拟机时,无法自动更新镜像策略,无法实施最终解决方案,需求也就消失了.
后来,发生了更严重的事情. 该公司发生了事故,导致用户信息泄漏. 这种事件可谓是证券业的重大失败. 此时,安全部门必须负责. 同时,网络部门不满意. 安全部门的需求,网络部门和安全部门都负责整个事件.

结合以上两个示例,不难看出在云网络中,业务网络的采集,分析和分发已成为云网络构建的标准配置,如果要采集虚拟网络流量,所有的采集方法和解决方案都必须安全可靠,而且不影响生产.
▌计划和价值

如何解决上述问题,是云山DeepFlow数据中心虚拟网络流量采集分析平台(以下简称DeepFlow)所能做的. 这张照片是最左边的采集部分. 我们知道目前的业务范围非常广泛. 它可能涉及私有云和公共云. 云杉DeepFlow同时涵盖了这些环境. 通过部署DeepFlow,您可以帮助您查看所有业务. 对于所有VPC网络状态,管理员等效于站在高处从多个维度查看云网络的全景,这更便于管理. 同时,您也可以关注业务,例如右上角的图,转到某个VPC网络,观察数据中有多少个网络组件,并根据每个点查看相应的网络信息. 和线.
我们还对采集技术的安全性和可靠性进行了许多优化. 首先,DeepFlow采集器支持500个节点以覆盖大多数数据中心.
第二个是高性能,单个采集点支持10G流量采集. 安全可靠. 特殊阈值用于控制CPU,内存和网络资源的消耗,因此不会影响生产网络. 当发生迁移时,我们的策略也可以及时更新,而不会中断采集到的流量.
简而言之,Spruce DeepFlow采集的虚拟网络流量使我们能够查看虚拟网络上正在发生的事情,涵盖管理盲点. 一旦发生故障,我们可以快速定位,同时,我们可以快速推断出问题的根本原因,并提高操作和维护效率. 其次,采集虚拟网络流量后,您不仅可以自己对其进行分析,还可以将其分发给第三方工具,以帮助数据审核满足安全合规性要求. 第三,从运营商的角度来看整个云网络.
▌应用实践
我想再告诉您两个DeepFlow数据中心虚拟网络流量采集,分析和分发的示例. 首先是故障定位事件. 使用DeepFlow回溯分析功能可以轻松找到问题的根本原因. 怎么做?将事件发生时的虚拟网络流量与正常时间的虚拟网络流量进行比较,结果发现存在明显的异常网络指示,大量网络数据包,非常大的网络延迟等. 导致异常现象的原因是谁?

通过Spruce DeepFlow的细粒度采集功能,发现数据库将大量流量发送到某个IP地址. 看到这种现象后,立即采取回测措施. 回测意味着这种异常现象是过去偶然发生的. 它是经常发生还是定期发生?经过这一系列步骤之后,我们最终得出结论,为什么数据库不断发送数据,实际上是因为最近已安装了新的数据库备份系统,但是当配置了该策略时,时间参数是错误的,通常是一天时间备份,由于时间错误,导致每小时备份一次,因此数据库连续发送出去,数据库信息不断备份,占用了实际的生产资源,最终导致运行缓慢的现象业务.
在其他情况下,我看到了一些有趣的问题. 有时,负载平衡配置不正确,这会导致背面的资源不平衡. 服务器可能有很多虚拟机流量,而其他服务器则是免费的. 或将数据设置为由特定服务器处理,但是由于负载平衡配置错误,固定流量将被散列.

在讨论第二个示例之前,请回顾一下安全部门刚才向网络部门提出的要求,以导出虚拟机的流量以进行安全审核和分析. 实际上,此问题可以在部署DeepFlow之后轻松地采集虚拟网络流量,并将其同时分发到两个后端分析工具资源池. 为什么我们两个?实际上,它可以用作备份,因为数据对于安全,审计和分析部门非常重要.
▌摘要

DeepFlow拥有专利的虚拟流采集技术具有大规模,零干扰,无依赖性,过载保护和预处理的优点. 支持VMware和OpenStack平台,没有版本依赖性. 一个控制器可以管理500个采集点,而无需在生产网络的虚拟交换机上进行其他策略配置. 它支持数据包的重复数据删除,过滤和截断等操作,并支持用户配置采集器的资源使用情况,以确保生产环境的稳定性.

云山网络已经对SDN云网络进行了相应的研究和应用,并在过去十年中得到了资本和客户的认可. 目前,Spruce Network的融资额超过1亿美元,并且有许多成功的财富500强客户案例. 它已部署在金融,电信,电力和教育行业的近100家企业中,其中包括平安科技,工业数字金融,甜橙金融,中国移动,国家电网,苏州国家科学数据中心以及其他基准客户. 成为企业云数据中心网络稳定高效运行的典范.

! !福利! !下载“金融云业务网络的智能采集和集成分析”的语音PPT,可以通过在微信背景中回复“语音PPT”获得.
◆◆◆
相关阅读
AI文章智能处理软件版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2020-08-06 09:11
软件功能
1. 人工智能写诗
使用AI技术让机器学习很多诗歌写作技巧,然后根据用户输入的指导句子创建原创诗歌
2,人工智能写散文
允许机器通过AI技术学习很多散文写作技巧,然后根据用户输入的指导句子创建原创散文
3. 文章采集
常规文章采集: 自己编写采集规则,采集指定的文章,采集稳定且不会卡住,支持获取和发布采集,编写规则简单易操作.
4. 一键式采集(无需编写规则即可采集文章)
门户新闻: 支持搜狐新闻,腾讯新闻,新浪新闻,凤凰新闻和网易新闻的一键式采集.
5. 文章组合
材料智能组合: 通过提供不同的文章材料,该软件提取核心内容,然后根据内容将其组合为文章.
6. 原创性优化(用于处理以提高文章的原创性)
批次独创性优化: 批量改进文章独创性操作.
7. 流量点击优化
通过模拟手动搜索和查看流量不同的网站,模拟真实流量以优化网站排名.
软件功能
1. AI文章智能处理软件具有丰富的功能,可帮助用户快速处理其文章
2,您可以在软件中编辑文章,可以在软件中快速修改文章
3. 支持文章比较,检查导入文章是否有差异
4. 支持和比较Internet上的文章,以分析当前文章是否重复
5. 支持网站优化,可以增加您的网站流量
6. 支持文字统计,将文章粘贴到软件中即可立即对字数进行计数
7. 您还可以查看网站排名,还可以查询文章排名
8,您可以快速编辑散文,可以快速编辑诗歌
使用说明
1. 双击aiV2.2.exe进行安装,安装完成后,打开AI文章智能处理软件.exe
2. 提示登录,在软件界面中输入您的帐户登录
3. 显然,我没有该软件的帐户,因此无法登录. 您可以转到官方网站获取帐户
4. 进入官方网站,点击右上角进入注册界面. 编辑者访问时,提示“抱歉,该站点当前禁止新用户注册”
5. 非年度版本将具有一些功能限制,例如“ AI Write Poetry”和“ AI Write Prose”. 非年度版本的用户每天只能生成100篇文章.
6. 如果您可以输入软件,则显示的界面是这样的,您可以在软件中找到所需的功能
7. 收录查询功能,查询您在软件界面中收录的内容
8. 图片下载功能,在软件界面下载所需图片,搜索后下载
9. 源代码查看功能,在软件界面中查看采集的源代码内容,并输入地址以采集源代码
10. 文本统计功能,在软件底部显示当前文本数,您可以检查输入了多少个单词
11. 热门词查看功能,您可以在软件界面中查看百度搜索词并查看360个热门词
12. 文本加密功能,如果需要对编辑的文本进行加密,可以在此处进行操作,输入密码以获取密文
13. 文字转码功能,如果需要转换文字编码,可以在这里操作
14. 支持优化功能,可以在软件界面中优化网站,可以选择优化关键字
15. 在此处显示与优化相关的设置,您可以选择浏览器优化,可以选择搜索引擎优化
16. 也可以在软件界面上查看百度的推送功能,输入地址并单击以开始提交
17. 关键字查看功能,在软件中输入关键字即可立即显示排名
18. 网站排名功能,如果需要了解网站的排名,可以在软件界面中输入
19. 发布功能,您可以在软件界面中设置文章的自动更新方法,并在软件下设置发布时间
20. 发布文章的基本设置功能,在软件中检查网站地址,并在底部检查需要发布的内容
21. 摘要提取功能,将文章复制到软件中以立即对其进行提取,然后软件会自动识别摘要内容
22. 原创检测功能,如果需要分析当前复制的文章是否为原创,可以在软件界面中找到
23. 分析之后,您可以选择导出HTML或TXT
24. 单一文章检测功能,您可以通过在软件界面中输入文章内容立即分析文章内容是否与在线内容重复
25. AI文章智能处理软件具有非常强大的功能. 我不会在这里介绍. 如果需要,请下载! 查看全部
AI文章智能处理软件提供了20多种功能来帮助用户处理文章. 您可以直接在软件界面中修改文章,检测修改后文章的原创性,并可以翻译复制的英语内容和文章内容. Acquisition允许软件自动编辑诗歌和散文. 有许多内置功能. 打开软件,您可以查看所有功能,以便用户在处理文章时可以获得更多操作. 该软件仍然非常易于使用. 多数功能一键即可使用,没有复杂的设置内容,需要注意的是用户需要登录官方注册帐户!

软件功能
1. 人工智能写诗
使用AI技术让机器学习很多诗歌写作技巧,然后根据用户输入的指导句子创建原创诗歌
2,人工智能写散文
允许机器通过AI技术学习很多散文写作技巧,然后根据用户输入的指导句子创建原创散文
3. 文章采集
常规文章采集: 自己编写采集规则,采集指定的文章,采集稳定且不会卡住,支持获取和发布采集,编写规则简单易操作.
4. 一键式采集(无需编写规则即可采集文章)
门户新闻: 支持搜狐新闻,腾讯新闻,新浪新闻,凤凰新闻和网易新闻的一键式采集.
5. 文章组合
材料智能组合: 通过提供不同的文章材料,该软件提取核心内容,然后根据内容将其组合为文章.
6. 原创性优化(用于处理以提高文章的原创性)
批次独创性优化: 批量改进文章独创性操作.
7. 流量点击优化
通过模拟手动搜索和查看流量不同的网站,模拟真实流量以优化网站排名.
软件功能
1. AI文章智能处理软件具有丰富的功能,可帮助用户快速处理其文章
2,您可以在软件中编辑文章,可以在软件中快速修改文章
3. 支持文章比较,检查导入文章是否有差异
4. 支持和比较Internet上的文章,以分析当前文章是否重复
5. 支持网站优化,可以增加您的网站流量
6. 支持文字统计,将文章粘贴到软件中即可立即对字数进行计数
7. 您还可以查看网站排名,还可以查询文章排名
8,您可以快速编辑散文,可以快速编辑诗歌
使用说明
1. 双击aiV2.2.exe进行安装,安装完成后,打开AI文章智能处理软件.exe

2. 提示登录,在软件界面中输入您的帐户登录

3. 显然,我没有该软件的帐户,因此无法登录. 您可以转到官方网站获取帐户

4. 进入官方网站,点击右上角进入注册界面. 编辑者访问时,提示“抱歉,该站点当前禁止新用户注册”

5. 非年度版本将具有一些功能限制,例如“ AI Write Poetry”和“ AI Write Prose”. 非年度版本的用户每天只能生成100篇文章.

6. 如果您可以输入软件,则显示的界面是这样的,您可以在软件中找到所需的功能

7. 收录查询功能,查询您在软件界面中收录的内容

8. 图片下载功能,在软件界面下载所需图片,搜索后下载

9. 源代码查看功能,在软件界面中查看采集的源代码内容,并输入地址以采集源代码

10. 文本统计功能,在软件底部显示当前文本数,您可以检查输入了多少个单词

11. 热门词查看功能,您可以在软件界面中查看百度搜索词并查看360个热门词

12. 文本加密功能,如果需要对编辑的文本进行加密,可以在此处进行操作,输入密码以获取密文

13. 文字转码功能,如果需要转换文字编码,可以在这里操作

14. 支持优化功能,可以在软件界面中优化网站,可以选择优化关键字

15. 在此处显示与优化相关的设置,您可以选择浏览器优化,可以选择搜索引擎优化

16. 也可以在软件界面上查看百度的推送功能,输入地址并单击以开始提交

17. 关键字查看功能,在软件中输入关键字即可立即显示排名

18. 网站排名功能,如果需要了解网站的排名,可以在软件界面中输入

19. 发布功能,您可以在软件界面中设置文章的自动更新方法,并在软件下设置发布时间

20. 发布文章的基本设置功能,在软件中检查网站地址,并在底部检查需要发布的内容

21. 摘要提取功能,将文章复制到软件中以立即对其进行提取,然后软件会自动识别摘要内容

22. 原创检测功能,如果需要分析当前复制的文章是否为原创,可以在软件界面中找到

23. 分析之后,您可以选择导出HTML或TXT

24. 单一文章检测功能,您可以通过在软件界面中输入文章内容立即分析文章内容是否与在线内容重复

25. AI文章智能处理软件具有非常强大的功能. 我不会在这里介绍. 如果需要,请下载!
我们如何谈论智能制造?
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-08-05 23:04
根据不完全统计,制造业的信息孤岛被打破了. 至少有60-70%的信息孤岛存在于离散行业中,而在连续的平滑行业中,信息孤岛现象约占50%. 从这个角度来看,可以修改和利用的数据采集和传输空间确实太大了,我们无法想象. 当然,肯定会有很多制造人员抱怨: “我们都知道数据采集的重要性,并且还在用你的话说吗?但是问题在于如何采集数据,我们无从下手. ”
这是我今天要谈论的问题,如何采集和传输数据. 问题在于,许多国内工厂使用的生产设备要么设备比较旧,要么多个供应商使用的设备没有标准的统一接口,而且多个设备使用的系统也大不相同. 这样,关于数据的采集就更加困难. 统一转换后,能否使用统一的行业数据标准对获取的标准数据进行处理?这些问题使我们感到困扰. 实际上,国外的制造商也遇到了麻烦,因此在这里我们不得不提及这样一个国际组织-OPC基金会. 我们对中国的这个组织有点陌生,但国外长期以来一直积极支持这种组织. OPC基金会有220多个国际成员. 它的成员遍布世界各地,包括世界上所有主要的自动化控制系统,仪器和过程控制系统公司. 这种组织的真正诞生在于对OPC标准的管理(用于过程控制的OLE,用于过程控制的OLE是统一的工业交互性标准). OPC包括用于过程控制和制造自动化系统的一组标准接口,属性和方法. OPC可以理解为一种平台技术,因此无论客户端是谁,只要客户端的软件程序可以理解OPC,就可以顺利地从设备中采集和传输数据.
为什么选择OPC UA?
德国工业4.0,美国工业互联网到中国的智能制造,政府已正式推荐将OPC协议作为统一的工业交互标准. 在成功应用OPC Classic之后,OPC基金会于2008年发布了OPC统一体系结构(UA)统一体系结构. OPCUA涵盖了OPC实时数据访问规范(OPC DA),OPC历史数据访问规范(OPC HDA),在OPC警报事件访问规范(OPC A&E)和OPC安全协议(OPC Security)的不同方面,OPC UA将每个OPC Classic规范的所有功能集成到一个可扩展的框架中,该框架是独立于平台且面向服务的. 在当前市场中,除了主流自动化供应商之外,微软,华为和思科等IT领域都已成为OPC UA的积极支持者,那么为什么每个人都选择OPC UA?首先,OPC UA解决了不同系统之间的语义互操作,OPC UA是独立的国际标准. 它可以建立一定的信息模型,即插即用,并且具有强大的安全保护,因此这种技术无疑是选择的充分理由.
以下图片更清楚,更全面地说明了选择的原因:
由于市场上有太多有关OPC技术的软件提供商,我只想提及Matrikon,他是在OPC技术上取得了巨大成就的ace制造商. 该制造商基本上是OPC. 该基金会同时成立,并且也是该基金会中最强大的成员. 其产品拥有60%的市场份额. 这个数字也相当惊人(几乎是垄断). 他们的Matrikon OPC UA现在是王牌的主要产品. 为了避免怀疑广告,每个人都想最大程度地了解OPC UA或OPC的技术细节,例如技术架构和相关产品,请自行单击以下链接: / product / 4056
到目前为止,超过4,200个供应商已经在超过1,700万个应用领域中生产了35,000多种不同类型的OPC产品,仅在工程资源上就节省了数十亿美元. 因此,如果您真的想实现智能制造,则应从工业数据采集和传输开始. 认为OPC技术为我们提供了最方便,最全面的技术支持,对工业制造的优化和改造确实是一项伟大的壮举. 查看全部
无论是转向智能制造还是使用优化生产过程的MES系统,都需要一个主要前提,即,需要采集工业设备的数据,然后才能在下次使用和分析数据之前步骤.
根据不完全统计,制造业的信息孤岛被打破了. 至少有60-70%的信息孤岛存在于离散行业中,而在连续的平滑行业中,信息孤岛现象约占50%. 从这个角度来看,可以修改和利用的数据采集和传输空间确实太大了,我们无法想象. 当然,肯定会有很多制造人员抱怨: “我们都知道数据采集的重要性,并且还在用你的话说吗?但是问题在于如何采集数据,我们无从下手. ”
这是我今天要谈论的问题,如何采集和传输数据. 问题在于,许多国内工厂使用的生产设备要么设备比较旧,要么多个供应商使用的设备没有标准的统一接口,而且多个设备使用的系统也大不相同. 这样,关于数据的采集就更加困难. 统一转换后,能否使用统一的行业数据标准对获取的标准数据进行处理?这些问题使我们感到困扰. 实际上,国外的制造商也遇到了麻烦,因此在这里我们不得不提及这样一个国际组织-OPC基金会. 我们对中国的这个组织有点陌生,但国外长期以来一直积极支持这种组织. OPC基金会有220多个国际成员. 它的成员遍布世界各地,包括世界上所有主要的自动化控制系统,仪器和过程控制系统公司. 这种组织的真正诞生在于对OPC标准的管理(用于过程控制的OLE,用于过程控制的OLE是统一的工业交互性标准). OPC包括用于过程控制和制造自动化系统的一组标准接口,属性和方法. OPC可以理解为一种平台技术,因此无论客户端是谁,只要客户端的软件程序可以理解OPC,就可以顺利地从设备中采集和传输数据.
为什么选择OPC UA?
德国工业4.0,美国工业互联网到中国的智能制造,政府已正式推荐将OPC协议作为统一的工业交互标准. 在成功应用OPC Classic之后,OPC基金会于2008年发布了OPC统一体系结构(UA)统一体系结构. OPCUA涵盖了OPC实时数据访问规范(OPC DA),OPC历史数据访问规范(OPC HDA),在OPC警报事件访问规范(OPC A&E)和OPC安全协议(OPC Security)的不同方面,OPC UA将每个OPC Classic规范的所有功能集成到一个可扩展的框架中,该框架是独立于平台且面向服务的. 在当前市场中,除了主流自动化供应商之外,微软,华为和思科等IT领域都已成为OPC UA的积极支持者,那么为什么每个人都选择OPC UA?首先,OPC UA解决了不同系统之间的语义互操作,OPC UA是独立的国际标准. 它可以建立一定的信息模型,即插即用,并且具有强大的安全保护,因此这种技术无疑是选择的充分理由.
以下图片更清楚,更全面地说明了选择的原因:
由于市场上有太多有关OPC技术的软件提供商,我只想提及Matrikon,他是在OPC技术上取得了巨大成就的ace制造商. 该制造商基本上是OPC. 该基金会同时成立,并且也是该基金会中最强大的成员. 其产品拥有60%的市场份额. 这个数字也相当惊人(几乎是垄断). 他们的Matrikon OPC UA现在是王牌的主要产品. 为了避免怀疑广告,每个人都想最大程度地了解OPC UA或OPC的技术细节,例如技术架构和相关产品,请自行单击以下链接: / product / 4056
到目前为止,超过4,200个供应商已经在超过1,700万个应用领域中生产了35,000多种不同类型的OPC产品,仅在工程资源上就节省了数十亿美元. 因此,如果您真的想实现智能制造,则应从工业数据采集和传输开始. 认为OPC技术为我们提供了最方便,最全面的技术支持,对工业制造的优化和改造确实是一项伟大的壮举.
AI文章智能处理软件 V2.1 最新版
采集交流 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2020-08-04 19:03
主要功能:
1.智能伪原创:利用人工智能中的自然语言处理技术实现文章的伪原创处理。核心功能是“智能伪原创”,“同义替换伪原始”,“反义替换伪原始”,“随机插入关键词与html代码”,“句子重组”等,处理过的文章既有创意包含率在80%以上。有关更多功能,请下载软件试用版。
2,门户文章集:一键搜索集相关门户新闻文章,该网站有搜狐,腾讯,新浪,网易,今日新闻,新蓝,联合晚报,光明网站,网站管理员。 com,新文化网路等,用户可以输入行业关键词来搜索所需的行业文章。该模块的特征是它不需要编写采集规则跟一键操作。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
3,百度新闻采访:一键搜索各类行业新闻文章,数据源到百度新闻搜索引擎,资源丰富,操作灵活,不需要写任何收集规则,但缺点是收集文章不一定完整,但可以满足大多数用户的需求。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
4,行业文章集:一键搜索相关行业网站文章,网站行业有装饰家具产业,机械市场,建材产业,家电市场,五金产业,美容行业,幼儿行业,金融市场,游戏产业, SEO行业,女性健康产业等。网站上有数十个网站,资源丰富。此模块可能难以满足所有客户的需求,但客户可以提出请求,我们将改进和更新模块资源。该模块的特征是它不需要编写采集规则跟一键操作。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
5,写规则集合:自己撰写集合规则,集合规则符合通常正则表达式,写集合规则必须知道一些html代码跟正则表达式规则,如果你有其他商家的书面收集规则,那么需要我们将编写我们软件的搜集规则,我们有文档提供撰写收集的规则。我们不帮客户写收集规则,如果必须写,10元的收购规则。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
6,外链文章材料:该模块是通过大量的市场语料库,通过算法随机组合的语料库制作相关产业文章,该模块文章仅适用于文章质量要求不高,为外部链促销用户,模块的特性,资源丰富,原创性高,但缺点是文章可读性差,用户在使用时可以选择性地使用。
7.批量生产标题:有两个功能,一个是按关键字和规则组合批量生产标题,二是通过收集网络大数据获取标题。自动生成的促销准确性很高,捕获的标题是可读的,每个都有特点跟缺点。
8,文章界面公布:通过简单的配置,生成的文章发布至您自己的网站。目前支持的网站有,Discuz Portal,DedeCms,Empire ECMS(新闻),PHMCMS,Zibo CMS,PHP168,diypage,phpwind门户。
9,SEO批量查询工具:权重批量查询,排序批量查询,包含批量查询,长尾词挖掘,代码批量转换,文本加密和解密。 查看全部
AI文章智能处理软件(文章智能AI组合工具)是一款非常优秀好用的文章伪原创辅助工具。这款AI文章智能处理硬件功能强大全面,简单易用,使用后可以帮助用户轻松的进行文章智能AI组合。用户可以使用该硬件重新组合文章并将其转换为新文章,这相当适合媒体用户。有必须的同学快来下载使用吧!
主要功能:
1.智能伪原创:利用人工智能中的自然语言处理技术实现文章的伪原创处理。核心功能是“智能伪原创”,“同义替换伪原始”,“反义替换伪原始”,“随机插入关键词与html代码”,“句子重组”等,处理过的文章既有创意包含率在80%以上。有关更多功能,请下载软件试用版。
2,门户文章集:一键搜索集相关门户新闻文章,该网站有搜狐,腾讯,新浪,网易,今日新闻,新蓝,联合晚报,光明网站,网站管理员。 com,新文化网路等,用户可以输入行业关键词来搜索所需的行业文章。该模块的特征是它不需要编写采集规则跟一键操作。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
3,百度新闻采访:一键搜索各类行业新闻文章,数据源到百度新闻搜索引擎,资源丰富,操作灵活,不需要写任何收集规则,但缺点是收集文章不一定完整,但可以满足大多数用户的需求。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
4,行业文章集:一键搜索相关行业网站文章,网站行业有装饰家具产业,机械市场,建材产业,家电市场,五金产业,美容行业,幼儿行业,金融市场,游戏产业, SEO行业,女性健康产业等。网站上有数十个网站,资源丰富。此模块可能难以满足所有客户的需求,但客户可以提出请求,我们将改进和更新模块资源。该模块的特征是它不需要编写采集规则跟一键操作。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
5,写规则集合:自己撰写集合规则,集合规则符合通常正则表达式,写集合规则必须知道一些html代码跟正则表达式规则,如果你有其他商家的书面收集规则,那么需要我们将编写我们软件的搜集规则,我们有文档提供撰写收集的规则。我们不帮客户写收集规则,如果必须写,10元的收购规则。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
6,外链文章材料:该模块是通过大量的市场语料库,通过算法随机组合的语料库制作相关产业文章,该模块文章仅适用于文章质量要求不高,为外部链促销用户,模块的特性,资源丰富,原创性高,但缺点是文章可读性差,用户在使用时可以选择性地使用。
7.批量生产标题:有两个功能,一个是按关键字和规则组合批量生产标题,二是通过收集网络大数据获取标题。自动生成的促销准确性很高,捕获的标题是可读的,每个都有特点跟缺点。
8,文章界面公布:通过简单的配置,生成的文章发布至您自己的网站。目前支持的网站有,Discuz Portal,DedeCms,Empire ECMS(新闻),PHMCMS,Zibo CMS,PHP168,diypage,phpwind门户。
9,SEO批量查询工具:权重批量查询,排序批量查询,包含批量查询,长尾词挖掘,代码批量转换,文本加密和解密。
无爬虫团队,企业怎样实现1000万级数据采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2020-08-19 10:07
随着数据智能时代到来,越来越多的企业注重数据,并通过爬虫技术获取网路海量公开数据,为自己的业务赋能。
目前基于爬虫技术衍生的精典商业项目,我相信你一定也用过:
企查查是一款企业信息查询工具,上面汇集了目前国内市场中的80个产业链,8000个行业,6000个市场以及8000多万家企业数据。
企查查怎么拥有海量数据?
企查查数据源主要来自以下3个方面。
①网络爬虫采集数据
②第三方合作数据
③以及部份数据更新任务为用户触发
它通过网路爬虫采集数据并进行初步的清洗划入其数据库,并经过算法处理,最后向用户开放,提供查询搜索。
企查查目前市值已达到5亿人民币。
原来爬虫技术那么有商业价值?
我们企业是不是也可以自己做,爬爬数据来提高自己的竞争力?
Too Young Too Naive。
知乎有个高手说出了一个现实:“爬虫是一项入门门槛不高,但在后期实操阶段真的会使你太崩溃,比如你一定会碰到的以下问题”。
你要懂起码一门学科以上的知识,不仅仅只是爬虫,学会爬虫你只是刚起步。
来源
企业假如自建一个爬虫专家团队,需要从0开始。
对企业来说,这一笔不小的开支,包括管理成本、时间成本。
如何能够打破这一窘境?
其实那位知乎高手给出了答案:
“不要重复造车轮子”
市面上早已有许多简单好用且专业的爬虫服务和工具,能使一个企业以更灵活、更轻便、成本更低的形式实现海量数据的获取。
比如,优采云数据采集的企业私有云。
优采云私有云版本就是为有海量数据采集需求的企业而量身订制的爬虫工具。
企业无需平添任何一名爬虫技术人员,优采云企业私有云能够完美满足企业海量信息采集需求。
为什么选优采云?
优采云自2013年面向市场以来,一直致力于为广大用户提供简单易用、快速稳定的数据爬虫工具。
经过几年来的发展,用户规模扩大,在全球拥有120万用户。通过专业数据爬虫能力与经验积累,开拓了诸多如平安、腾讯、万达等行业著名企业,以及公安部、税务局、清华大学等政府机构、科研院所、高等院校数据项目成功案例,并且获得用户对优采云的数据采集专业能力的认可。
优采云数据采集成功入围由国家住建部公布的“2019大数据优秀产品和应用解决方案”优采云连续5年蝉联《中国大数据企业排行榜》中国互联网数据采集工具榜No.1
优采云私有云怎么满足企业需求?
01、专业的数据爬虫服务能力
优采云可以采集网络公开显示的数据,只要是肉眼可见可复制出来的信息数据均可获取。
优采云支持文字、数字、图片、视频、源码等数据类型,不屈从于数据方式。
02、海量数据云端高效分布式采集
优采云采用高效的云端分布式采集,背后有5000+云服务器提供支持。优采云私有云可依照企业需求配备30-100个甚至更多云节点,相当于逾百个服务器同时运行,实现多任务同时并发采集。
采用分布式采集比企业用自己服务器所需时长明显增加,普通企业很难有专业爬虫企业这样大量的服务器资源,去支撑海量的数据采集。
云端分布式采集能帮助企业实现短时间采集海量数据的目的,让企业轻松实现日采百万级甚至千万级的数据。
由于常年有大量数据爬虫需求,优采云已成为「阿里云VIP企业顾客」,优采云私有云的用户可以通过优采云直接享受阿里云提供的「企业级优质的云端节点」,进一步实现快速、稳定的云爬虫服务。
03、独家智能防封技术组合
正如上述知乎高手说的,网站反爬虫策略各式各样,遇到这些情况企业爬虫工程师大部分都只能束手无策。
优采云经过6年多实战经验构,组建出独家智能防封技术组合,能够有效攻破绝大部分的网站防采集措施。
1 优质代理IP池
优采云为私有云用户能提供优质代理IP池,支持用户在采集过程灵活切换IP,有效防止网站防采集。
2 自动辨识验证码
优采云能支持手动辨识9类验证码的手动辨识,能有效破解网站验证码防采集时。
9类验证码
3 cookie、UA
优采云还能灵活设置cookie(用户身分)、定时切换UA(用户代理)、突破对方防封手段,让企业才能稳定地获取优质数据源。
04、企业协作数据资源共享
考虑到企业数据采集通常是一项内部多人协作的工程,优采云私有云为用户提供了团队协作的功能,可实现跨帐号的数据、云节点(可以理解为服务器)、IP代理池等资源的共享,是团队协作的最佳神器。
05、无缝对接企业数据库
数据采集后,优采云可手动导出企业数据库,我们支持企业常见的数据库如Oracle、MySQL等。
无缝链接企业业务系统,实现高效数据归档,省去人工冗长复杂操作。
06、多种中级API数据插口
私有云用户可以调用优采云的数据导入API接口,以及增值API插口。
有了以上2项插口,私有云用户的开发小哥能够通过API,轻松获取优采云任务信息和采集到的数据,无需登陆优采云,即可调取并控制优采云任务的状态,减少工作场景来回切换。
07、满足企业灵活个性化需求
1 指定时间灵活采集
定时采集,是优采云私有云为须要定期更新网站最新信息的企业用户提供的,精确到分钟的采集时间的自定义设置的功能。
有了定时采集,用户便能在24小时内灵活选择采集时间,“到点”了优采云自动开始工作,让用户省心省力。
2 新增数据精准采集
智能辨识新增数据进行精准采集,不做历史重复工作,既节约时间,又节约节点资源。
3 7*24h工作,关机也能采
私有云的任务开始运行采集任务后,即使死机也不怕,优采云会在云端7*24小时持续为你工作,直至数据全部采集完。
你可以安心死机上班,享受放松休闲岁月。
08、尊享优采云MAX性能配置
1 无限量任务储存空间
你拥可以无拘无束,任性创建采集任务,无需害怕因任务数目限制而须要定期删掉或导入任务,减少可恶的工作量。
2 无限量帐号同时在线
你的团队可以共用一个优采云私有云帐号,即使在不同的地点,不同的笔记本上,都能同时进行登陆并操作。
3 无限量客户端同时开启
一台笔记本可以同时开启多个客户端,挑战你的笔记本MAX极限性能。
4 无限量数据随时导入
从优采云采集下来的10,000,000+数据可无限次无限量直接导出到你的业务系统中。
09、私有云VIP爬虫专家咨询服务
每位私有云用户都将配备一支VIP爬虫专家咨询团队,提供及时响应、技能高超的专业售后服务。
10、「优采云」值得信赖的品牌
部分顾客展示
优采云拿到手软的各大奖项
优劣势对比
如果你的企业没有爬虫人员,但又希望以低成本、快速配备海量数据的获取能力,墙裂推荐你使用优采云私有云!
优采云·让数据触手可及
公众号【优采云大数据】 查看全部
无爬虫团队,企业怎样实现1000万级数据采集?
随着数据智能时代到来,越来越多的企业注重数据,并通过爬虫技术获取网路海量公开数据,为自己的业务赋能。
目前基于爬虫技术衍生的精典商业项目,我相信你一定也用过:
企查查是一款企业信息查询工具,上面汇集了目前国内市场中的80个产业链,8000个行业,6000个市场以及8000多万家企业数据。
企查查怎么拥有海量数据?
企查查数据源主要来自以下3个方面。
①网络爬虫采集数据
②第三方合作数据
③以及部份数据更新任务为用户触发
它通过网路爬虫采集数据并进行初步的清洗划入其数据库,并经过算法处理,最后向用户开放,提供查询搜索。
企查查目前市值已达到5亿人民币。
原来爬虫技术那么有商业价值?
我们企业是不是也可以自己做,爬爬数据来提高自己的竞争力?
Too Young Too Naive。
知乎有个高手说出了一个现实:“爬虫是一项入门门槛不高,但在后期实操阶段真的会使你太崩溃,比如你一定会碰到的以下问题”。
你要懂起码一门学科以上的知识,不仅仅只是爬虫,学会爬虫你只是刚起步。
来源
企业假如自建一个爬虫专家团队,需要从0开始。
对企业来说,这一笔不小的开支,包括管理成本、时间成本。
如何能够打破这一窘境?
其实那位知乎高手给出了答案:
“不要重复造车轮子”
市面上早已有许多简单好用且专业的爬虫服务和工具,能使一个企业以更灵活、更轻便、成本更低的形式实现海量数据的获取。
比如,优采云数据采集的企业私有云。
优采云私有云版本就是为有海量数据采集需求的企业而量身订制的爬虫工具。
企业无需平添任何一名爬虫技术人员,优采云企业私有云能够完美满足企业海量信息采集需求。
为什么选优采云?
优采云自2013年面向市场以来,一直致力于为广大用户提供简单易用、快速稳定的数据爬虫工具。
经过几年来的发展,用户规模扩大,在全球拥有120万用户。通过专业数据爬虫能力与经验积累,开拓了诸多如平安、腾讯、万达等行业著名企业,以及公安部、税务局、清华大学等政府机构、科研院所、高等院校数据项目成功案例,并且获得用户对优采云的数据采集专业能力的认可。
优采云数据采集成功入围由国家住建部公布的“2019大数据优秀产品和应用解决方案”优采云连续5年蝉联《中国大数据企业排行榜》中国互联网数据采集工具榜No.1
优采云私有云怎么满足企业需求?
01、专业的数据爬虫服务能力
优采云可以采集网络公开显示的数据,只要是肉眼可见可复制出来的信息数据均可获取。
优采云支持文字、数字、图片、视频、源码等数据类型,不屈从于数据方式。
02、海量数据云端高效分布式采集
优采云采用高效的云端分布式采集,背后有5000+云服务器提供支持。优采云私有云可依照企业需求配备30-100个甚至更多云节点,相当于逾百个服务器同时运行,实现多任务同时并发采集。
采用分布式采集比企业用自己服务器所需时长明显增加,普通企业很难有专业爬虫企业这样大量的服务器资源,去支撑海量的数据采集。
云端分布式采集能帮助企业实现短时间采集海量数据的目的,让企业轻松实现日采百万级甚至千万级的数据。
由于常年有大量数据爬虫需求,优采云已成为「阿里云VIP企业顾客」,优采云私有云的用户可以通过优采云直接享受阿里云提供的「企业级优质的云端节点」,进一步实现快速、稳定的云爬虫服务。
03、独家智能防封技术组合
正如上述知乎高手说的,网站反爬虫策略各式各样,遇到这些情况企业爬虫工程师大部分都只能束手无策。
优采云经过6年多实战经验构,组建出独家智能防封技术组合,能够有效攻破绝大部分的网站防采集措施。
1 优质代理IP池
优采云为私有云用户能提供优质代理IP池,支持用户在采集过程灵活切换IP,有效防止网站防采集。
2 自动辨识验证码
优采云能支持手动辨识9类验证码的手动辨识,能有效破解网站验证码防采集时。
9类验证码
3 cookie、UA
优采云还能灵活设置cookie(用户身分)、定时切换UA(用户代理)、突破对方防封手段,让企业才能稳定地获取优质数据源。
04、企业协作数据资源共享
考虑到企业数据采集通常是一项内部多人协作的工程,优采云私有云为用户提供了团队协作的功能,可实现跨帐号的数据、云节点(可以理解为服务器)、IP代理池等资源的共享,是团队协作的最佳神器。
05、无缝对接企业数据库
数据采集后,优采云可手动导出企业数据库,我们支持企业常见的数据库如Oracle、MySQL等。
无缝链接企业业务系统,实现高效数据归档,省去人工冗长复杂操作。
06、多种中级API数据插口
私有云用户可以调用优采云的数据导入API接口,以及增值API插口。
有了以上2项插口,私有云用户的开发小哥能够通过API,轻松获取优采云任务信息和采集到的数据,无需登陆优采云,即可调取并控制优采云任务的状态,减少工作场景来回切换。
07、满足企业灵活个性化需求
1 指定时间灵活采集
定时采集,是优采云私有云为须要定期更新网站最新信息的企业用户提供的,精确到分钟的采集时间的自定义设置的功能。
有了定时采集,用户便能在24小时内灵活选择采集时间,“到点”了优采云自动开始工作,让用户省心省力。
2 新增数据精准采集
智能辨识新增数据进行精准采集,不做历史重复工作,既节约时间,又节约节点资源。
3 7*24h工作,关机也能采
私有云的任务开始运行采集任务后,即使死机也不怕,优采云会在云端7*24小时持续为你工作,直至数据全部采集完。
你可以安心死机上班,享受放松休闲岁月。
08、尊享优采云MAX性能配置
1 无限量任务储存空间
你拥可以无拘无束,任性创建采集任务,无需害怕因任务数目限制而须要定期删掉或导入任务,减少可恶的工作量。
2 无限量帐号同时在线
你的团队可以共用一个优采云私有云帐号,即使在不同的地点,不同的笔记本上,都能同时进行登陆并操作。
3 无限量客户端同时开启
一台笔记本可以同时开启多个客户端,挑战你的笔记本MAX极限性能。
4 无限量数据随时导入
从优采云采集下来的10,000,000+数据可无限次无限量直接导出到你的业务系统中。
09、私有云VIP爬虫专家咨询服务
每位私有云用户都将配备一支VIP爬虫专家咨询团队,提供及时响应、技能高超的专业售后服务。
10、「优采云」值得信赖的品牌
部分顾客展示
优采云拿到手软的各大奖项
优劣势对比
如果你的企业没有爬虫人员,但又希望以低成本、快速配备海量数据的获取能力,墙裂推荐你使用优采云私有云!
优采云·让数据触手可及
公众号【优采云大数据】
冷启动问题:如何建立你的机器学习组合?
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2020-08-15 11:07
前段时间,我曾写了一篇文章《The cold start problem: how to break into machine learning》(《冷启动问题:如何顺利步入机器学习》),阐述了为得到第一份机器学习的工作,你应当做什么事情。我在那篇文章中说过,你应当做的一件事就是,建立个人机器学习项目的投资组合。但我漏了这一部分:如何能够做到。因此,在这篇文章中,我将探讨应当怎样去做这件事。[1]
得益于我们的初创公司所做的事情,我能够见到这么多的个人项目的反例。这些个人项目有特别优秀的,也有特别槽糕的。让我给你举出两个特别优秀的反例。
押上所有赌注
下面是一则真实的故事,不过,为了保护个人隐私,我使用了化名。
当杂货店须要购买新库存时,X 公司都会使用人工智能来提醒杂货店。我们有一名中学生,叫 Ron,他十分渴求能否在 X 公司工作,已经急不可耐了。为了确保就能得到 X 公司的笔试机会,于是,他完善了一个个人项目。
通常情况下,我们不会建议象 Ron 那样把所有的赌注都押在一家公司。如果你刚开始这样做的话,是太有风险的。但是,就像我昨天说的,Ron 真的非常想到 X 公司工作,特别非常想。
那么,Ron 做了哪些呢?
红框处表示该处缺乏商品。
Ron 用胶布将他的智能手机绑在购物车上。然后,他推着购物车在杂货店的走廊来来回回地走,同时使用手机的摄像头记录下走廊的情况。他在不同的杂货店这样做了 10~12 次。
回到家后,Ron 就开始建立机器学习模型。他的模型辨识出了杂货店货架上的空白处,那是货架上缺乏玉米片(或其他商品)的地方。
特别棒的是,Ron 在 GitHub 上实时建立了他的模型,完全公开。每天,他就会改进他的 repo(提高准确性,并记录 repo 自述文件的变更)。
当 X 公司发觉 Ron 正在做这件事时,非常感兴趣。不止是好奇,事实上,X 公司还有点紧张。他们为何会倍感紧张呢?因为 Ron 无意中在几天内复制了她们的专有技术栈的一部分。[2]
X 公司的能力太强,他们的技术在行业中无出其右。尽管如此,4 天之内,Ron 的项目还是成功吸引了 X 公司 CEO 的注意力。
飞行员项目
这是另一则真实的故事。
Alex 主修历史专业,辅修英语(这是真实的情况)。不同寻常的是,作为历史专业的大学生,他竟然对机器学习形成了兴趣。更不寻常的是,他决定学习 Python,要知道,他从来没用 Python 写过一行代码。
Alex 选择了通过建立项目进行学习的方法。他决定建立一个分类器,用于测量战斗机飞行员在客机上是否失去知觉。Alex 想通过观看飞行员的视频来发觉是否丧失意识。他晓得,人们通过观察,很容易判定飞行员是否失去知觉。所以,Alex 觉得机器也应当有可能做到这一点。
以下是 Alex 在几个月的时间里所做的事情:
Alex建立的月球引力引起昏迷探测器的演示。
Alex 在 YouTube 上下载了从驾驶舱拍摄的驾驶客机时飞行员所有的视频。(如果你也倍感好奇的话,这里有几十个这样的片断。)
接下来他开始标记数据。Alex 构建了一个 UI,让他还能滚动数千个视频帧,按下一个按键表示 “有知觉”,另一个按键表示 “无知觉”。然后手动将该视频帧保存到正确标记的文件夹中。这个标记过程十分特别无趣,花了他好几天的时间。
Alex 为这种图象建立了一个数据管线,可以将飞行员从驾驶舱背景中抠下来,这样分类器才能更容易专注于飞行员。最后,他建立了自己的昏迷分类器。
在做这些事的同时,Alex 在社交媒体上向急聘主管展示了他的项目快照。每次
他掏出手机展示这个项目时,他们就会问他是如何做到的,构建的管线是怎么回事,以及如何搜集数据的等等。但从来没有人问过他的模型的准确度怎样,要知道,这个模型的准确度就从来没超过 50%。
当然,Alex 早就计划提升模型的准确性,但是在他还没有实现这一计划时就早已被录用了。事实证明,对企业而言,他那种项目呈现下来的视觉冲击力,以及在数据搜集方面表现下来的不屈不挠的精神和足智多谋,远比他的模型到底有多好来得更为重要。
我刚刚有没有提及 Alex 是一名主修历史,辅修英语的中学生?
他们有何共同之处
是哪些使 Ron 和 Alex 如此成功?以下是她们做对的四件大事:
Ron 和 Alex 并没有在建模上花费太多的精力。我晓得这听起来很奇怪,但是对于现今的许多用例来说,建模是一个已解决的问题。在实际工作中,除非你做的是最先进的人工智能研究,否则无论如何,你都须要花费 80~90% 的时间来清除数据。为什么你的个人项目会有所不同呢?
Ron 和 Alex 都搜集了自己的数据。正由于这么,他们最终得到的数据比 Kaggle 或 UCI 数据库中的数据更为混乱。但是处理混乱的数据教会了她们怎么处理这些混乱的数据。而且也促使了她们从学术服务器下载数据以更好地理解自己的数据。
Ron 和 Alex 营造了可视化疗效。面试,并不能使无所不知的面试官才能客观地评估你的技能。面试的本质就是将自己推荐给别人。人类是视觉植物,因此,如果你拿出手机给面试官展示你所做的东西,那么,确保你做的东西看上去太有趣是值得的。
Ron 和 Alex 所做的事其实挺疯狂。这很疯狂了。因为一般人不会把她们的智能手机用胶水绑在购物车上,也不会在 YouTube 上花费大量时间就为了剪裁飞行员的视频。你晓得是什么样的人就会如此疯狂?这样的人就会不惜一切代价去完成工作。公司真的十分、非常乐意雇用这种人。
Ron 和 Alex 所做的事情,看上去虽然太多了,但实际上,他们所做的事儿并不比你在实际工作中所期望的多多少。这就是问题的关键:当你没有做某件事的工作经验时,招聘总监会看你做过的类似做某件事的工作经验。
幸运的是,你只需在这个级别上,构建一两个项目就可以了——Ron 和 Alex 的项目在她们各自所有笔试中被反复使用。
因此,如果使我必须用一句话来总结一个卓越的机器学习项目的绝招,那就是:用有趣的数据集去建立项目,这个数据集其实须要花费大量精力来搜集,并让其尽可能有视觉冲击力。
[1] 如果你想知道为何这一点十分重要,那是因为急聘总监会查看你的业绩记录来评估你的技能。如果你没有业绩记录的话,那么,个人项目就是最为接近的替代者。
[2] 当然,Ron 的尝试远非完美:X 公司为这个问题投入了比他更多的资源。但情况十分相像,他们很快就要求 Ron 将他的 repo 设为 private。
原文链接: 查看全部
我是一名物理学家,在 YC 初创公司工作。我们的工作是帮助应届毕业生找到她们的第一份机器学习工作。
前段时间,我曾写了一篇文章《The cold start problem: how to break into machine learning》(《冷启动问题:如何顺利步入机器学习》),阐述了为得到第一份机器学习的工作,你应当做什么事情。我在那篇文章中说过,你应当做的一件事就是,建立个人机器学习项目的投资组合。但我漏了这一部分:如何能够做到。因此,在这篇文章中,我将探讨应当怎样去做这件事。[1]
得益于我们的初创公司所做的事情,我能够见到这么多的个人项目的反例。这些个人项目有特别优秀的,也有特别槽糕的。让我给你举出两个特别优秀的反例。
押上所有赌注
下面是一则真实的故事,不过,为了保护个人隐私,我使用了化名。
当杂货店须要购买新库存时,X 公司都会使用人工智能来提醒杂货店。我们有一名中学生,叫 Ron,他十分渴求能否在 X 公司工作,已经急不可耐了。为了确保就能得到 X 公司的笔试机会,于是,他完善了一个个人项目。
通常情况下,我们不会建议象 Ron 那样把所有的赌注都押在一家公司。如果你刚开始这样做的话,是太有风险的。但是,就像我昨天说的,Ron 真的非常想到 X 公司工作,特别非常想。
那么,Ron 做了哪些呢?
红框处表示该处缺乏商品。
Ron 用胶布将他的智能手机绑在购物车上。然后,他推着购物车在杂货店的走廊来来回回地走,同时使用手机的摄像头记录下走廊的情况。他在不同的杂货店这样做了 10~12 次。
回到家后,Ron 就开始建立机器学习模型。他的模型辨识出了杂货店货架上的空白处,那是货架上缺乏玉米片(或其他商品)的地方。
特别棒的是,Ron 在 GitHub 上实时建立了他的模型,完全公开。每天,他就会改进他的 repo(提高准确性,并记录 repo 自述文件的变更)。
当 X 公司发觉 Ron 正在做这件事时,非常感兴趣。不止是好奇,事实上,X 公司还有点紧张。他们为何会倍感紧张呢?因为 Ron 无意中在几天内复制了她们的专有技术栈的一部分。[2]
X 公司的能力太强,他们的技术在行业中无出其右。尽管如此,4 天之内,Ron 的项目还是成功吸引了 X 公司 CEO 的注意力。
飞行员项目
这是另一则真实的故事。
Alex 主修历史专业,辅修英语(这是真实的情况)。不同寻常的是,作为历史专业的大学生,他竟然对机器学习形成了兴趣。更不寻常的是,他决定学习 Python,要知道,他从来没用 Python 写过一行代码。
Alex 选择了通过建立项目进行学习的方法。他决定建立一个分类器,用于测量战斗机飞行员在客机上是否失去知觉。Alex 想通过观看飞行员的视频来发觉是否丧失意识。他晓得,人们通过观察,很容易判定飞行员是否失去知觉。所以,Alex 觉得机器也应当有可能做到这一点。
以下是 Alex 在几个月的时间里所做的事情:
Alex建立的月球引力引起昏迷探测器的演示。
Alex 在 YouTube 上下载了从驾驶舱拍摄的驾驶客机时飞行员所有的视频。(如果你也倍感好奇的话,这里有几十个这样的片断。)
接下来他开始标记数据。Alex 构建了一个 UI,让他还能滚动数千个视频帧,按下一个按键表示 “有知觉”,另一个按键表示 “无知觉”。然后手动将该视频帧保存到正确标记的文件夹中。这个标记过程十分特别无趣,花了他好几天的时间。
Alex 为这种图象建立了一个数据管线,可以将飞行员从驾驶舱背景中抠下来,这样分类器才能更容易专注于飞行员。最后,他建立了自己的昏迷分类器。
在做这些事的同时,Alex 在社交媒体上向急聘主管展示了他的项目快照。每次
他掏出手机展示这个项目时,他们就会问他是如何做到的,构建的管线是怎么回事,以及如何搜集数据的等等。但从来没有人问过他的模型的准确度怎样,要知道,这个模型的准确度就从来没超过 50%。
当然,Alex 早就计划提升模型的准确性,但是在他还没有实现这一计划时就早已被录用了。事实证明,对企业而言,他那种项目呈现下来的视觉冲击力,以及在数据搜集方面表现下来的不屈不挠的精神和足智多谋,远比他的模型到底有多好来得更为重要。
我刚刚有没有提及 Alex 是一名主修历史,辅修英语的中学生?
他们有何共同之处
是哪些使 Ron 和 Alex 如此成功?以下是她们做对的四件大事:
Ron 和 Alex 并没有在建模上花费太多的精力。我晓得这听起来很奇怪,但是对于现今的许多用例来说,建模是一个已解决的问题。在实际工作中,除非你做的是最先进的人工智能研究,否则无论如何,你都须要花费 80~90% 的时间来清除数据。为什么你的个人项目会有所不同呢?
Ron 和 Alex 都搜集了自己的数据。正由于这么,他们最终得到的数据比 Kaggle 或 UCI 数据库中的数据更为混乱。但是处理混乱的数据教会了她们怎么处理这些混乱的数据。而且也促使了她们从学术服务器下载数据以更好地理解自己的数据。
Ron 和 Alex 营造了可视化疗效。面试,并不能使无所不知的面试官才能客观地评估你的技能。面试的本质就是将自己推荐给别人。人类是视觉植物,因此,如果你拿出手机给面试官展示你所做的东西,那么,确保你做的东西看上去太有趣是值得的。
Ron 和 Alex 所做的事其实挺疯狂。这很疯狂了。因为一般人不会把她们的智能手机用胶水绑在购物车上,也不会在 YouTube 上花费大量时间就为了剪裁飞行员的视频。你晓得是什么样的人就会如此疯狂?这样的人就会不惜一切代价去完成工作。公司真的十分、非常乐意雇用这种人。
Ron 和 Alex 所做的事情,看上去虽然太多了,但实际上,他们所做的事儿并不比你在实际工作中所期望的多多少。这就是问题的关键:当你没有做某件事的工作经验时,招聘总监会看你做过的类似做某件事的工作经验。
幸运的是,你只需在这个级别上,构建一两个项目就可以了——Ron 和 Alex 的项目在她们各自所有笔试中被反复使用。
因此,如果使我必须用一句话来总结一个卓越的机器学习项目的绝招,那就是:用有趣的数据集去建立项目,这个数据集其实须要花费大量精力来搜集,并让其尽可能有视觉冲击力。
[1] 如果你想知道为何这一点十分重要,那是因为急聘总监会查看你的业绩记录来评估你的技能。如果你没有业绩记录的话,那么,个人项目就是最为接近的替代者。
[2] 当然,Ron 的尝试远非完美:X 公司为这个问题投入了比他更多的资源。但情况十分相像,他们很快就要求 Ron 将他的 repo 设为 private。
原文链接:
【智能模式】【流程图模式】如何设置智能策略
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2020-08-15 03:49
在编辑任务界面,点击右下角“开始采集”按钮,在弹出的设置框中,点击“智能策略”选项可以切换到设置界面。
1、代理设置
1)代理类型
I、代理IP(由芝麻代理提供)
该代理为通过芝麻代理提供的订购插口,直接在软件内选购。
代理的区域可以进行设置,包括全省混拨、省份混拨或则指定城市。
II、自定义代理
如果须要使用自己的代理,请点击“立即设置”,然后在设置窗口中按要求进行设置。(注意:自定义代理按次序循环切换)
2)切换条件
I、按照时间切换
代理按照时间进行切换,例如您设置切换条件为“每隔:3分钟”,那么每隔3分钟都会切换一次代理,同时会消耗一个代理IP 。
II、按照文本切换
根据文本进行切换,例如您设置切换条件为“当页面中出现该文本:优采云”,那么网页中出现对应的文本时,就会切换一次代理,同时消耗一个代理IP。
2、智能切换
智能切换是我们推荐的首选设置,能满足绝大部分采集任务的需求。
3、手动切换
如果碰到的网页比较特殊,智能切换未能满足需求,我们可以设置自动切换。
I、请求等待时间
请求等待时间是加在网页点击操作以后的等待时间,通常用于打开网页或则点击翻页等操作以后的等待,通过降低该等待时间,可以减轻网页加载平缓的问题,或者增加采集速度。
II、运行中测量验证码
软件在采集过程中遇见未能采集到内容时,会手动进行验证码检查,如果碰到软件未兼容的情况,也可以自动设置验证码辨识条件,例如假如验证码提示页面中收录了“优采云”这个文本,我们可以设置条件为“当页面中出现该文本:优采云”。需要注意的是该条件一定要确保只会在验证码提示页面中出现,否则会出现误报的情况。
III、运行中测量登陆提示
需要登入能够采集数据的网站,在运行过程中登陆有可能会失效,或者有些网站采集到一定量的数据然后会提示登陆,勾选此功能,软件在运行过程中若果遇见登陆失效或须要登陆的情况会暂停任务并弹出登陆提示。
IV、仅采集页面可见内容
有一些网站会将无效的数据混在有效的数据之中,采集数据的时侯会出现好多无效的数据,这种情况下我们就可以勾选这个设置,只采集页面可见的内容。
注意:如果采集的网站没有隐藏无效字符的设置,勾选此项会导致数据采集不全或则数据难以采集,因此我们在使用此项功能时须要慎重。
V、逐行滚动网页预加载
有些网站需要滚动到一定位置以后内容才会显示,否则这种数据都未能采集,这时候可以勾选此项功能。但是须要注意的是,勾选此项功能的时侯会影响采集速度,需谨慎使用。
VI、定时切换浏览器版本
我们可以自定义设置切换版本的时间周期,设置时间周期可以是30秒~10分钟,软件会根据设置周期手动切换外置浏览器版本,用户无需自行选择具体版本。
VII、定时清理cookie
我们可以自定义设置消除cookie的时间周期,设置时间周期可以是30秒~10分钟,软件会根据设置周期定时清理网页Cookie。 查看全部
智能策略收录代理设置、智能切换和自动切换,这部份功能主要是拿来智能处理采集过程中遇见的各类问题。
在编辑任务界面,点击右下角“开始采集”按钮,在弹出的设置框中,点击“智能策略”选项可以切换到设置界面。
1、代理设置
1)代理类型
I、代理IP(由芝麻代理提供)
该代理为通过芝麻代理提供的订购插口,直接在软件内选购。
代理的区域可以进行设置,包括全省混拨、省份混拨或则指定城市。
II、自定义代理
如果须要使用自己的代理,请点击“立即设置”,然后在设置窗口中按要求进行设置。(注意:自定义代理按次序循环切换)
2)切换条件
I、按照时间切换
代理按照时间进行切换,例如您设置切换条件为“每隔:3分钟”,那么每隔3分钟都会切换一次代理,同时会消耗一个代理IP 。
II、按照文本切换
根据文本进行切换,例如您设置切换条件为“当页面中出现该文本:优采云”,那么网页中出现对应的文本时,就会切换一次代理,同时消耗一个代理IP。
2、智能切换
智能切换是我们推荐的首选设置,能满足绝大部分采集任务的需求。
3、手动切换
如果碰到的网页比较特殊,智能切换未能满足需求,我们可以设置自动切换。
I、请求等待时间
请求等待时间是加在网页点击操作以后的等待时间,通常用于打开网页或则点击翻页等操作以后的等待,通过降低该等待时间,可以减轻网页加载平缓的问题,或者增加采集速度。
II、运行中测量验证码
软件在采集过程中遇见未能采集到内容时,会手动进行验证码检查,如果碰到软件未兼容的情况,也可以自动设置验证码辨识条件,例如假如验证码提示页面中收录了“优采云”这个文本,我们可以设置条件为“当页面中出现该文本:优采云”。需要注意的是该条件一定要确保只会在验证码提示页面中出现,否则会出现误报的情况。
III、运行中测量登陆提示
需要登入能够采集数据的网站,在运行过程中登陆有可能会失效,或者有些网站采集到一定量的数据然后会提示登陆,勾选此功能,软件在运行过程中若果遇见登陆失效或须要登陆的情况会暂停任务并弹出登陆提示。
IV、仅采集页面可见内容
有一些网站会将无效的数据混在有效的数据之中,采集数据的时侯会出现好多无效的数据,这种情况下我们就可以勾选这个设置,只采集页面可见的内容。
注意:如果采集的网站没有隐藏无效字符的设置,勾选此项会导致数据采集不全或则数据难以采集,因此我们在使用此项功能时须要慎重。
V、逐行滚动网页预加载
有些网站需要滚动到一定位置以后内容才会显示,否则这种数据都未能采集,这时候可以勾选此项功能。但是须要注意的是,勾选此项功能的时侯会影响采集速度,需谨慎使用。
VI、定时切换浏览器版本
我们可以自定义设置切换版本的时间周期,设置时间周期可以是30秒~10分钟,软件会根据设置周期手动切换外置浏览器版本,用户无需自行选择具体版本。
VII、定时清理cookie
我们可以自定义设置消除cookie的时间周期,设置时间周期可以是30秒~10分钟,软件会根据设置周期定时清理网页Cookie。
采集 | 数据智能与计算机图形学领域2019推荐论文列表(附链接)
采集交流 • 优采云 发表了文章 • 0 个评论 • 449 次浏览 • 2020-08-14 15:29
2019年度数据智能与估算及图形学领域论文推荐。
数据智能
1. Data-anonymous Encoding for Text-to-SQL Generation
论文链接:
在跨领域 Text-to-SQL 研究中一个重要的问题是辨识自然语言句子中提及的列名、表格、及单元格的值。本文中提出了一种基于中间变量和多任务学习的框架,尝试同时解决表格实体辨识和语义解析问题,取得了良好的疗效。论文在 EMNLP 2019 会议发表。
2. Towards Complex Text-to-SQL in Cross-domain Database
论文链接:
计算机的可执行语言(例如 SQL 语句与储存结构紧密相关)与自然语言存在不匹配问题,给复杂问题的语义解析带来了困难。为了解决这个问题,论文中设计了一种中间语言。先将自然语言转换成中间语言,再将中间语言转换成 SQL,可以提升语义解析的准确率。该论文已在 ACL 2019 会议发表。
3. Leveraging Adjective-Noun Phrasing Knowledge for Comparison Relation Prediction in Text-to-SQL
论文链接:
在自然语言理解中,知识的运用极其重要。本文以 Adjective-Noun Phrasing Knowledge 为切入点尝试在 Text-to-SQL 中运用语言相关知识来提升语言理解的准确率。论文在 EMNLP 2019 会议发表。
4. FANDA: A Novel Approach to Perform Follow-up Query Analysis
论文链接:
在多履带对话中,对话句子中常常存在省略或指代,需要依据上下文来理解当前词句。本文剖析总结了在对话式数据剖析中普遍出现的省略或指代现象,并提出了将当前句子补充完整的方式。论文发表在 AAAI 2019。
5. A Split-and-Recombine Approach for Follow-up Query Analysis
论文链接:
本文中提出了一个处理上下文的 split-recombine 框架,能够拿来有效处理对话句子中常常存在上下文省略或指代问题。这个框架既可以用于将当前句子补充完整(restate),也可以直接生成 logic form(例如SQL)。论文发表在 EMNLP 2019。
6. QuickInsights: Quick and Automatic Discovery of Insights from Multi-Dimensional Data
论文链接:
该论文创新性地提出了多维数据中洞察 (insights) 的一种普遍适用的具象定义,并系统化地提出了面向大规模多维数据的有效的洞察挖掘算法。文章发表在 SIGMOD 2019。相应技术从2015年起转化到谷歌 Power BI,Office 365 等产品中。
7. TableSense: Spreadsheet Table Detection with Convolutional Neural Networks
论文链接:
文章提出的基于深度学习模型的 TableSense 技术,可对电子表格进行区域监测和表格结构理解,并将其转换为结构化的多维数据进行手动剖析。这项技术已转化到谷歌的 Office 365 产品中,随 Ideas in Excel 功能全面上线。文章发表在 AAAI 2019。
8. Text-to-Viz: Automatic Generation of Infographics from Proportion-Related Natural language Statements
论文链接:
该论文发表在 IEEE VIS 2019,首创了由自然语言手动生成数据信息图(Infographics)的技术。该技术让人们就能十分容易的获得大量数据信息图的设计,用于强化数据故事的抒发。
9. DataShot: Automatic Generation of Fact Sheets from Tabular Data
论文链接:
该论文发表在 IEEE VIS 2019,提出了一种从数据表格出发手动生成由多个数据信息图组合而成的数据海报的技术。
10. Towards Automated Infographic Design: Deep Learning-based Auto-Extraction of Extensible Timeline
论文链接:
该论文提出了一种手动从图片中抽取数据信息图模板的技术。利用计算机视觉技术,将时间轴的设计图片分解成多个视觉元素并重新组合,使可视化时间轴设计图片的重用成为了可能。该论文发表在 IEEE VIS 2019。
11. Visualization Assessment: A Machine Learning Approach
论文链接:
该论文发表在 IEEE VIS 2019,探索了手动评估可视化图片特点的方式,比如记忆度、美观度,让机器学习的算法在可视化的生成、推荐中发挥作用。
12. Supporting Story Synthesis: Bridging the Gap between Visual Analytics and Storytelling
论文链接:
该论文定义了一个新的故事生成框架,将数据剖析到结果展示的过程具象成普遍的故事生成流程。该框架支持交互式地从复杂的可视剖析结果中生成可以使普通读者理解的故事。论文发表在 TVCG 2019。
13. Cross-dataset Time Series Anomaly Detection for Cloud Systems
论文链接:
文章提出了基于迁移学习和主动学习的跨数据集异常检查框架,可以有效地在不同时间序列数据集之间进行迁移,只须要1%-5% 的标明样本量即可达到高精度检查。文章发表在系统领域顶尖大会 USENIX ATC 2019 上。
14. Robust Log-based Anomaly Detection on Unstable Log Data
论文链接:
文章提出了基于深度学习技术的模型 LogRobust,可有效克服日志不稳定问题,在快速迭代的实际工业数据中取得了出色的疗效,该研究发表在了软件工程领域顶尖大会 FSE 2019。
15. An Intelligent, End-To-End Analytics Service for Safe Deployment in Large-Scale Cloud Infrastructure
论文链接:
该文章提出了时空相关性模型,在时间和空间的双重维度上对比故障前后的系统状态,为故障确诊提供线索,该模型在安全布署中取得了很高的准确率,研究成果将发表在系统领域顶尖大会 NSDI 2020上。
16. Outage Prediction and Diagnosis for Cloud Service Systems
论文链接:
该文章提出了一种智能的大规模中断预警机制 AirAlert,AirAlert 采集整个云系统中的所有系统监控讯号,采用鲁棒梯度提高树算法做预测,并借助贝叶斯网络进行确诊剖析。相关研究短文发表在 WWW 2019。
17. Prediction-Guided Design for Software Systems
论文链接:
文章提出了智能缓冲区管理方式,基于预测导向(Prediction-Guided)框架,以机器学习预测引擎为核心,可监控集群已布署的工作负载与平台操作,对这种负载在发生故障的机率和新的容量下降需求进行预测,动态调整预留缓冲区。该方式已成功集成到谷歌 Azure 中,提高了容量配置的稳健性,减少了巨大的成本开支。相关研究将在 AAAI 2020 Workshop 发布。
18. An Empirical Investigation of Incident Triage for Online Service Systems
论文链接:
该文章基于谷歌 20 个小型在线服务系统展开实例研究,发现错误的故障分派会导致额外的时间开支,进而验证了已有软件 Bug 分派算法在故障分派场景下的疗效。这是首次研究故障分派在工业小型在线服务系统中的实践,相关研究发表在 ICSE SEIP 2019。
19. Continuous Incident Triage for Large-Scale Online Service Systems
论文链接:
该文章提出一种基于深度学习的自动化连续故障分派算法 DeepCT。DeepCT 结合了一个新的基于注意力机制的屏蔽策略、门控循环单元模型和改进后的损失函数,可以从工程师对问题的讨论中逐渐积累知识并优化分派结果。相关成果发表在 ASE 2019。
20. Neural Feature Search: A Neural Architecture for Automated Feature Engineering
论文链接:
文章提出了神经特点搜索(Neural Feature Search,NFS),基于递归神经网络(Recurrent Neural Network,RNN)的控制器,通过最有潜力的变换规则变换每位原创特点,取得了优于现有手动特点工程方式的性能。该成果已在在数据挖掘领域大会 ICDM 2019 发表,在手动特点工程研究领域确立了新的技术水平。
图形学
21. Repairing Man-Made Meshes via Visual Driven Global Optimization with Minimum Intrusion
论文链接:
文章提出的方式修补了 ShapeNet、ModelNet 等小型 3D 数据集中的模型缺陷。该文章发表在 SIGGRAPH Asia 2019。
22. Learning Adaptive Hierarchical Cuboid Abstractions of 3D Shape 采集s
论文链接:
人造物体如衣柜一般具有结构化特点,人类可以容易地将那些物体抽象化为简单的几何形状的组合,如长方体,便于物体理解和剖析。该论文通过在同类物体上进行无监督学习,生成具有自适应并层次化的长方体具象抒发。文章发表在 SIGGRAPH Asia 2019。
23. A Scalable Galerkin Multigrid Method for Real-time Simulation of Deformable Objects
论文链接:
一种在无结构网格上的 Galerkin 多重网格法,其极大加速了现有柔性体仿真技术的性能。该方式可实时仿真含近百万有限元的柔性体模型,将人们在虚拟世界中可交互的模型复杂度提高了一到两个量级。该论文发表在 SIGGRAPH Asia 2019。
24. Deep Inverse Rendering for High-resolution SVBRDF Estimation from an Arbitrary Number of Images
论文链接:
该论文提出了一种在纹理材质本征空间进行优化的方式,实现了针对任意数目输入图片的纹理材质建模。在给定图象数目较少时给出视觉上合理的结果,而随着输入数目的增多,逐渐得到更为精确的重建结果。该论文发表在 SIGGRAPH 2019。
25. Synthesizing 3D Shapes from Silhouette Image 采集s using Multi-Projection Generative Adversarial Networks
论文链接:
利用二维轮廓图象学习三维形体生成。该方式仅须要对于某一类物体的大量二维轮廓图象,并不需要任何对应关系,它通过该类别物体在不同方向上的轮廓所具有的特点分布,学习并生成满足这种训练数据分布的三维形体。该论文发表在 CVPR 2019。 查看全部
本文约3600字,建议阅读10分钟。
2019年度数据智能与估算及图形学领域论文推荐。
数据智能
1. Data-anonymous Encoding for Text-to-SQL Generation
论文链接:
在跨领域 Text-to-SQL 研究中一个重要的问题是辨识自然语言句子中提及的列名、表格、及单元格的值。本文中提出了一种基于中间变量和多任务学习的框架,尝试同时解决表格实体辨识和语义解析问题,取得了良好的疗效。论文在 EMNLP 2019 会议发表。
2. Towards Complex Text-to-SQL in Cross-domain Database
论文链接:
计算机的可执行语言(例如 SQL 语句与储存结构紧密相关)与自然语言存在不匹配问题,给复杂问题的语义解析带来了困难。为了解决这个问题,论文中设计了一种中间语言。先将自然语言转换成中间语言,再将中间语言转换成 SQL,可以提升语义解析的准确率。该论文已在 ACL 2019 会议发表。
3. Leveraging Adjective-Noun Phrasing Knowledge for Comparison Relation Prediction in Text-to-SQL
论文链接:
在自然语言理解中,知识的运用极其重要。本文以 Adjective-Noun Phrasing Knowledge 为切入点尝试在 Text-to-SQL 中运用语言相关知识来提升语言理解的准确率。论文在 EMNLP 2019 会议发表。
4. FANDA: A Novel Approach to Perform Follow-up Query Analysis
论文链接:
在多履带对话中,对话句子中常常存在省略或指代,需要依据上下文来理解当前词句。本文剖析总结了在对话式数据剖析中普遍出现的省略或指代现象,并提出了将当前句子补充完整的方式。论文发表在 AAAI 2019。
5. A Split-and-Recombine Approach for Follow-up Query Analysis
论文链接:
本文中提出了一个处理上下文的 split-recombine 框架,能够拿来有效处理对话句子中常常存在上下文省略或指代问题。这个框架既可以用于将当前句子补充完整(restate),也可以直接生成 logic form(例如SQL)。论文发表在 EMNLP 2019。
6. QuickInsights: Quick and Automatic Discovery of Insights from Multi-Dimensional Data
论文链接:
该论文创新性地提出了多维数据中洞察 (insights) 的一种普遍适用的具象定义,并系统化地提出了面向大规模多维数据的有效的洞察挖掘算法。文章发表在 SIGMOD 2019。相应技术从2015年起转化到谷歌 Power BI,Office 365 等产品中。
7. TableSense: Spreadsheet Table Detection with Convolutional Neural Networks
论文链接:
文章提出的基于深度学习模型的 TableSense 技术,可对电子表格进行区域监测和表格结构理解,并将其转换为结构化的多维数据进行手动剖析。这项技术已转化到谷歌的 Office 365 产品中,随 Ideas in Excel 功能全面上线。文章发表在 AAAI 2019。
8. Text-to-Viz: Automatic Generation of Infographics from Proportion-Related Natural language Statements
论文链接:
该论文发表在 IEEE VIS 2019,首创了由自然语言手动生成数据信息图(Infographics)的技术。该技术让人们就能十分容易的获得大量数据信息图的设计,用于强化数据故事的抒发。
9. DataShot: Automatic Generation of Fact Sheets from Tabular Data
论文链接:
该论文发表在 IEEE VIS 2019,提出了一种从数据表格出发手动生成由多个数据信息图组合而成的数据海报的技术。
10. Towards Automated Infographic Design: Deep Learning-based Auto-Extraction of Extensible Timeline
论文链接:
该论文提出了一种手动从图片中抽取数据信息图模板的技术。利用计算机视觉技术,将时间轴的设计图片分解成多个视觉元素并重新组合,使可视化时间轴设计图片的重用成为了可能。该论文发表在 IEEE VIS 2019。
11. Visualization Assessment: A Machine Learning Approach
论文链接:
该论文发表在 IEEE VIS 2019,探索了手动评估可视化图片特点的方式,比如记忆度、美观度,让机器学习的算法在可视化的生成、推荐中发挥作用。
12. Supporting Story Synthesis: Bridging the Gap between Visual Analytics and Storytelling
论文链接:
该论文定义了一个新的故事生成框架,将数据剖析到结果展示的过程具象成普遍的故事生成流程。该框架支持交互式地从复杂的可视剖析结果中生成可以使普通读者理解的故事。论文发表在 TVCG 2019。
13. Cross-dataset Time Series Anomaly Detection for Cloud Systems
论文链接:
文章提出了基于迁移学习和主动学习的跨数据集异常检查框架,可以有效地在不同时间序列数据集之间进行迁移,只须要1%-5% 的标明样本量即可达到高精度检查。文章发表在系统领域顶尖大会 USENIX ATC 2019 上。
14. Robust Log-based Anomaly Detection on Unstable Log Data
论文链接:
文章提出了基于深度学习技术的模型 LogRobust,可有效克服日志不稳定问题,在快速迭代的实际工业数据中取得了出色的疗效,该研究发表在了软件工程领域顶尖大会 FSE 2019。
15. An Intelligent, End-To-End Analytics Service for Safe Deployment in Large-Scale Cloud Infrastructure
论文链接:
该文章提出了时空相关性模型,在时间和空间的双重维度上对比故障前后的系统状态,为故障确诊提供线索,该模型在安全布署中取得了很高的准确率,研究成果将发表在系统领域顶尖大会 NSDI 2020上。
16. Outage Prediction and Diagnosis for Cloud Service Systems
论文链接:
该文章提出了一种智能的大规模中断预警机制 AirAlert,AirAlert 采集整个云系统中的所有系统监控讯号,采用鲁棒梯度提高树算法做预测,并借助贝叶斯网络进行确诊剖析。相关研究短文发表在 WWW 2019。
17. Prediction-Guided Design for Software Systems
论文链接:
文章提出了智能缓冲区管理方式,基于预测导向(Prediction-Guided)框架,以机器学习预测引擎为核心,可监控集群已布署的工作负载与平台操作,对这种负载在发生故障的机率和新的容量下降需求进行预测,动态调整预留缓冲区。该方式已成功集成到谷歌 Azure 中,提高了容量配置的稳健性,减少了巨大的成本开支。相关研究将在 AAAI 2020 Workshop 发布。
18. An Empirical Investigation of Incident Triage for Online Service Systems
论文链接:
该文章基于谷歌 20 个小型在线服务系统展开实例研究,发现错误的故障分派会导致额外的时间开支,进而验证了已有软件 Bug 分派算法在故障分派场景下的疗效。这是首次研究故障分派在工业小型在线服务系统中的实践,相关研究发表在 ICSE SEIP 2019。
19. Continuous Incident Triage for Large-Scale Online Service Systems
论文链接:
该文章提出一种基于深度学习的自动化连续故障分派算法 DeepCT。DeepCT 结合了一个新的基于注意力机制的屏蔽策略、门控循环单元模型和改进后的损失函数,可以从工程师对问题的讨论中逐渐积累知识并优化分派结果。相关成果发表在 ASE 2019。
20. Neural Feature Search: A Neural Architecture for Automated Feature Engineering
论文链接:
文章提出了神经特点搜索(Neural Feature Search,NFS),基于递归神经网络(Recurrent Neural Network,RNN)的控制器,通过最有潜力的变换规则变换每位原创特点,取得了优于现有手动特点工程方式的性能。该成果已在在数据挖掘领域大会 ICDM 2019 发表,在手动特点工程研究领域确立了新的技术水平。
图形学
21. Repairing Man-Made Meshes via Visual Driven Global Optimization with Minimum Intrusion
论文链接:
文章提出的方式修补了 ShapeNet、ModelNet 等小型 3D 数据集中的模型缺陷。该文章发表在 SIGGRAPH Asia 2019。
22. Learning Adaptive Hierarchical Cuboid Abstractions of 3D Shape 采集s
论文链接:
人造物体如衣柜一般具有结构化特点,人类可以容易地将那些物体抽象化为简单的几何形状的组合,如长方体,便于物体理解和剖析。该论文通过在同类物体上进行无监督学习,生成具有自适应并层次化的长方体具象抒发。文章发表在 SIGGRAPH Asia 2019。
23. A Scalable Galerkin Multigrid Method for Real-time Simulation of Deformable Objects
论文链接:
一种在无结构网格上的 Galerkin 多重网格法,其极大加速了现有柔性体仿真技术的性能。该方式可实时仿真含近百万有限元的柔性体模型,将人们在虚拟世界中可交互的模型复杂度提高了一到两个量级。该论文发表在 SIGGRAPH Asia 2019。
24. Deep Inverse Rendering for High-resolution SVBRDF Estimation from an Arbitrary Number of Images
论文链接:
该论文提出了一种在纹理材质本征空间进行优化的方式,实现了针对任意数目输入图片的纹理材质建模。在给定图象数目较少时给出视觉上合理的结果,而随着输入数目的增多,逐渐得到更为精确的重建结果。该论文发表在 SIGGRAPH 2019。
25. Synthesizing 3D Shapes from Silhouette Image 采集s using Multi-Projection Generative Adversarial Networks
论文链接:
利用二维轮廓图象学习三维形体生成。该方式仅须要对于某一类物体的大量二维轮廓图象,并不需要任何对应关系,它通过该类别物体在不同方向上的轮廓所具有的特点分布,学习并生成满足这种训练数据分布的三维形体。该论文发表在 CVPR 2019。
Python+fiddler:爬取微信公众号的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 437 次浏览 • 2020-08-13 00:35
图1:流程
其实我们看见,这里并没有想像中的“智能”——依然须要自动刷公众号文章,然后就能够搜集到信息。(误:更新的第9部份是愈发智能的操作,减少手刷)
1. 电脑下载fiddler
图2:下载fiddler2. 安装以后,点开第一眼听到的是这样
图3:fiddler第一次点开以后
这里附上fiddler的介绍。
3. 设置
图4:设置Tools-Options-HTTPS
然后设置Actions:点击Actions,选择Trust root certificate以及export root certificate to desktop(弹下来的提示都选Yes)。
图5:设置Actions
图6:设置Tools-Options-Connections4. 手机设置(我使用小米手机,其他手机大致一样)
图7:设置手机WiFi代理(proxy)
图8:手机步入网址192.168.124.14:8888
图9:点击FiddlerRoot Certificate
图10:下载以后安装它,随意命名,我命名为“Fiddler2”
5. 重启笔记本的Fiddler,手机点开公众号文章,电脑Fiddler搜集信息
图11:记录
图12:具体剖析
图13:复制Fiddler记录的链接,在浏览器中点开
图14:过滤
图15:过滤以后的信息
可以看见,序号存在着跳跃,因为过滤起到了作用。
6. 将所有信息导入
图16:导出手机浏览记录
图17:txt信息7. Python抽取公众号信息
import numpy as np
data = []
with open(r'...\1_Full.txt', 'r', encoding='utf-8') as fp:
for line in fp:
if 'Referer: https://mp.weixin.qq.com/' in line: //将含有重要信息的链接保留到data中
data.append(line[9:])
// 去重
data = np.unique(data)
8. 通过笔记本陌陌客户端抓取公众号的信息
在一遍一遍刷手机以后,本人勿必厌恶。。如果还能通过键盘点击笔记本为内心客户端,然后通过fiddler搜集信息,那么就不用刷手机了。。注意,在调整fiddler的时侯,anaconda的jupyter关掉(可以使用spyder),否则fiddler会出问题。
操作差不多。
首先,将fiddler-Tools-Options-HTTPS,将Decrypt HTTPS traffic更改为“from all processes”.
图18:电脑搜集微信公众号的操作
然后,同样在自己的浏览器中,输入IP地址+8888,下载证书。
图19:下载FiddlerRoot证书
下载以后进行安装。
图20:安装证书
其他设置filter和前面手机设置一样,都是把关于wp.weixin的内容筛选下来。
然后,刷笔记本端微信公众号,那么filter才能够记录下所有的公众号文章。注意,一旦打开fiddler,那么笔记本难以访问其他网页,因为百度等防爬机制太严格,会检查到fiddler早已启动。
9. 更加手动和智能的操作
无论是刷手机搜集信息,还是通过笔记本端刷公众号,依然是须要人点击信息,不够智能。这里在参考了新的案例以后,能够进行颠覆性的改进。
首先,本文后面的模块仍然须要了解。当早已才能在笔记本端刷微信公众号的文章、同时fiddler才能搜集https的信息,那么继续往下。以“首都之窗”微信公众号为例。
(1)电脑陌陌端的操作
打开fiddler。
点击设置-通用设置-使用系统默认浏览器打开网页。
图21:电脑陌陌端设置
然后,随意点击“首都之窗”的任意一篇文章,会在浏览器中弹下来。放在哪里,不用理会。顺便把fiddler中记录的这个文章信息删了。留着fiddler空白,记录第25图的重点内容!
这一步的目的是为了才能顺利在浏览器中打开公众号的历史消息但是刷新。
图22:先点一篇文章
图23:该文章在浏览器弹下来
图24:完整操作
接着,进入“首都之窗”公众号,点击查看历史消息。
图25:查看历史消息
同样,“历史消息”在浏览器(绝不能在陌陌客户端下拉、因为fiddler收不到信息)中弹下来,然后往下开始刷几下,需要听到有新的内容弹下来,同时见到fiddler正在记录更新的信息。fiddler更新的消息就是最重要的内容。
图26:在浏览器中下拉几次“历史消息”
(2)fiddler信息剖析
刚刚通过在浏览器下拉公众号历史消息,fiddler采集到了更新的信息。我们开始剖析。
图27:分析由于下拉历史消息而搜集到的某一条记录
选择第8条记录(该记录来自浏览器中下拉历史记录而搜集到的消息),重点部份早已在headers中圈下来了。
(3)链接分析(看不下去的话,直接看代码如何拼出链接)
首先,在Request headers中,该链接简拼是 /mp/profile_ext?action=getmsg&__biz=MzA5NDY5MzUzMQ==&f=json&offset=20&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxtoken=&appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~&x5=0&f=json HTTP/1.1
分析这个链接。可以看见,它是由几个部份组成。
①/mp/profile_ext?②action=getmsg ③&__biz=MzA5NDY5MzUzMQ== ④&f=json⑤&offset=20 ⑥&count=10 ⑦&is_ok=1 ⑧&scene=124 ⑨&uin=777 ⑩&key=777 &pass_ticket= &wxtoken= &appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~ &x5=0&f=json HTTP/1.1
那么我们须要关注的信息是:
③__biz:公众号的id(公众号的biz惟一),⑤offset:翻页标志,appmsg_token:某个有时效性的token(隔一段时间会变化)
我们再看下边几个链接
GET /mp/profile_ext?action=getmsg&__biz=MzA5NDY5MzUzMQ==&f=json&offset=40&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxtoken=&appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~&x5=0&f=json HTTP/1.1
GET /mp/profile_ext?action=getmsg&__biz=MzA5NDY5MzUzMQ==&f=json&offset=60&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxtoken=&appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~&x5=0&f=json HTTP/1.1
biz和appmsg_token一致,offset改变,即为新的一页。因此,第一步,我们早已找到了翻页的规律。链接中只有这三个在变化,其他没有变动。因此,链接在python中才能写成:
api = 'https://mp.weixin.qq.com/mp/pr ... iz%3D{0}&f=json&offset={1}&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxton=&appmsg_token={2}&x5=0&f=json HTTP/1.1'.format(
__biz, offset, appmsg_token)
(4)cookie和headers
cookie保存的是陌陌登陆的信息,在爬虫的时侯须要填进去。我们只要关注wsp_sid2的cookies信息。
cookies同样来自图27。找到wap_sid2=CK6vyK4CElxLdmda............
headers同样来自图27。找到 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
(5)爬取
好的,以上找到了好多信息。初步的python如下:
import requests
import json
# 链接拼接三个信息
__biz = "MzA5NDY5MzUzMQ=="
appmsg_token = "1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~"
offset = 20
# cookies和headers
cookies = "wap_sid2=CK6vyK4CElxLdmda......."
headers = {'Cookie':cookies,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
}
# api拼出来
api = 'https://mp.weixin.qq.com/mp/pr ... iz%3D{0}&f=json&offset={1}&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxton=&appmsg_token={2}&x5=0&f=json HTTP/1.1'.format(
__biz, offset, appmsg_token)
# 抓取并且json化
resp = requests.get(api, headers = headers, verify=False).json()
为什么须要把resp进行json化?我们可以尝试着打开9(3)一开始的链接的网页,
图28:拼下来的api打开的网页长这样
很明显这是个json信息。因此须要json化。复制该网页的全部文本,放在网页中,可以看见完整的json结构。这就是resp的网页结果。
图29:把图28的文本信息复制置于中的结果
那么resp在python中被json化以后的结果如下
图30:resp在python中的结构
(6)网页解析
接下来,关注该resp的结构以及一层一层剖析。图30中resp中errmsg=ok和ret=0,均表示网页可以正常打开(如果报错的话,ret=-3)。next_offset是下一次翻页的标志,需要保存上去。
next_offset = resp.get('next_offset')
general_msg_list = resp.get('general_msg_list')
# 将general_msg_list转为json格式
msg_list = json.loads(general_msg_list)['list']
general_msg_list 是 重要的内容。点击general_msg_list,这仍然是一个json结构。
图31:general_msg_list仍然是json结构。
复制上面的文本,放到中瞧瞧是哪些。
图32:general_msg_list放在中的结果
因此被json化以后的msg_list,在python中长这样
图33:把general_msg_list进行json化在python中的样子
可以看见,msg_list中富含10个记录。我们抽出一个记录,进行具体剖析。在剖析之前,我们要明晰一个东西。msg_list中收录了10个记录,不是指10篇文章,而是10次推送。某一次公众号推送消息,可能同时发布好几条文章,也有可能是一篇文章。因此,要明白,单个msg记录,是指一个推送(and可能一次性发布了好几篇文章)。
图34:某一次推送,一起发布了3篇文章
msg = msg_list[0]
图35:某一个具体的msg
该msg上面收录了“app_msg_ext_info”和“comm_msg_info”两个内容。在中,这两个内容分别长这样子。
图36:某一个msg具体的两部份---app_msg_ext_info和comm_msg_info
那么comm_msg_info收录了该推送的基本信息:推送ID,时间等。
app_msg_ext_info是哪些?且听我渐渐剖析。首先,title,digest仍然到is_multi,都是该次推送的打头文章(就是图34中带图片的那种文章的信息)。例如title标题/digest关键词/content_url链接/source_url原链接等。
is_multi是判定该次推送是不是有读篇文章;=1表示yes,=0表示no。那么这儿等于1,说明该次推送还有其他文章,存在于multi_app_msg_item_list中。
把multi_app_msg_item_list取下来。
multi_app_msg_item_list = app_msg_ext_info.get('multi_app_msg_item_list')
图37:该推送剩下的两篇文章藏在multi_app_msg_item_list中
到目前为止,我们早已剖析完了整体的流程。
总结
图38:总结怎样走出第一步
图39:具体剖析结构
(7)具体代码如下
<p>import requests
import json
from datetime import datetime
import pandas as pd
import time
class WxMps:
def __init__(self, biz, appmsg_token, cookies, offset, city):
self.biz = biz
self.msg_token = appmsg_token
self.offset = offset
self.headers = {'Cookie':cookies, 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
self.city = city
def parse1(self, resp):
# 控制下一个抓取的offset
offset = resp.get('next_offset')
# 将包含主要内容的list转为json格式
general_msg_list = resp.get('general_msg_list')
# 一个msg_list中含有10个msg
msg_list = json.loads(general_msg_list)['list']
df1 = pd.DataFrame(columns = ['msg_id', 'post_time', 'msg_type', 'title', 'cover', 'author', 'digest', 'source_url', 'content_url'])
# 循环message列表
for msg in msg_list:
# msg是该推送的信息,包含了comm_msg_info以及app_msg_ext_info两个信息,注意某一个推送中可能含有多个文章。
comm_msg_info = msg.get('comm_msg_info')
app_msg_ext_info = msg.get('app_msg_ext_info')
# 该推送的id
msg_id = comm_msg_info.get('id')
# 该推送的发布时间,例如1579965567需要转化为datetime,datetime.fromtimestamp(1579965567)
post_time = datetime.fromtimestamp(comm_msg_info['datetime'])
# 该推送的类型
msg_type = comm_msg_info.get('type')
if app_msg_ext_info:
# 推送的第一篇文章
title, cover, author, digest, source_url, content_url = self.parse2(app_msg_ext_info)
df2 = self.df_process(msg_id, post_time, msg_type, title, cover, author, digest, source_url, content_url)
df1 = pd.concat([df1, df2])
# 判断是不是多篇文章
is_multi = app_msg_ext_info.get("is_multi")
# 如果是1,继续爬取;如果是0,单条推送=只有一篇文章
if is_multi:
multi_app_msg_item_list = app_msg_ext_info.get('multi_app_msg_item_list')
for information in multi_app_msg_item_list:
(title, cover, author, digest, source_url, content_url) = self.parse2(information)
df2 = self.df_process(msg_id, post_time, msg_type, title, cover, author, digest, source_url, content_url)
df1 = pd.concat([df1, df2])
return df1, offset
def start(self):
offset = self.offset
df1 = pd.DataFrame(columns = ['msg_id', 'post_time', 'msg_type', 'title', 'cover', 'author', 'digest', 'source_url', 'content_url'])
while offset 查看全部
这几天师傅有个小项目,挺有意思,如何使用python爬微信公众号中的新闻信息。大体流程如下。
图1:流程
其实我们看见,这里并没有想像中的“智能”——依然须要自动刷公众号文章,然后就能够搜集到信息。(误:更新的第9部份是愈发智能的操作,减少手刷)
1. 电脑下载fiddler
图2:下载fiddler2. 安装以后,点开第一眼听到的是这样
图3:fiddler第一次点开以后
这里附上fiddler的介绍。
3. 设置
图4:设置Tools-Options-HTTPS
然后设置Actions:点击Actions,选择Trust root certificate以及export root certificate to desktop(弹下来的提示都选Yes)。
图5:设置Actions
图6:设置Tools-Options-Connections4. 手机设置(我使用小米手机,其他手机大致一样)
图7:设置手机WiFi代理(proxy)
图8:手机步入网址192.168.124.14:8888
图9:点击FiddlerRoot Certificate
图10:下载以后安装它,随意命名,我命名为“Fiddler2”
5. 重启笔记本的Fiddler,手机点开公众号文章,电脑Fiddler搜集信息
图11:记录
图12:具体剖析
图13:复制Fiddler记录的链接,在浏览器中点开
图14:过滤
图15:过滤以后的信息
可以看见,序号存在着跳跃,因为过滤起到了作用。
6. 将所有信息导入
图16:导出手机浏览记录
图17:txt信息7. Python抽取公众号信息
import numpy as np
data = []
with open(r'...\1_Full.txt', 'r', encoding='utf-8') as fp:
for line in fp:
if 'Referer: https://mp.weixin.qq.com/' in line: //将含有重要信息的链接保留到data中
data.append(line[9:])
// 去重
data = np.unique(data)
8. 通过笔记本陌陌客户端抓取公众号的信息
在一遍一遍刷手机以后,本人勿必厌恶。。如果还能通过键盘点击笔记本为内心客户端,然后通过fiddler搜集信息,那么就不用刷手机了。。注意,在调整fiddler的时侯,anaconda的jupyter关掉(可以使用spyder),否则fiddler会出问题。
操作差不多。
首先,将fiddler-Tools-Options-HTTPS,将Decrypt HTTPS traffic更改为“from all processes”.
图18:电脑搜集微信公众号的操作
然后,同样在自己的浏览器中,输入IP地址+8888,下载证书。
图19:下载FiddlerRoot证书
下载以后进行安装。
图20:安装证书
其他设置filter和前面手机设置一样,都是把关于wp.weixin的内容筛选下来。
然后,刷笔记本端微信公众号,那么filter才能够记录下所有的公众号文章。注意,一旦打开fiddler,那么笔记本难以访问其他网页,因为百度等防爬机制太严格,会检查到fiddler早已启动。
9. 更加手动和智能的操作
无论是刷手机搜集信息,还是通过笔记本端刷公众号,依然是须要人点击信息,不够智能。这里在参考了新的案例以后,能够进行颠覆性的改进。
首先,本文后面的模块仍然须要了解。当早已才能在笔记本端刷微信公众号的文章、同时fiddler才能搜集https的信息,那么继续往下。以“首都之窗”微信公众号为例。
(1)电脑陌陌端的操作
打开fiddler。
点击设置-通用设置-使用系统默认浏览器打开网页。
图21:电脑陌陌端设置
然后,随意点击“首都之窗”的任意一篇文章,会在浏览器中弹下来。放在哪里,不用理会。顺便把fiddler中记录的这个文章信息删了。留着fiddler空白,记录第25图的重点内容!
这一步的目的是为了才能顺利在浏览器中打开公众号的历史消息但是刷新。
图22:先点一篇文章
图23:该文章在浏览器弹下来
图24:完整操作
接着,进入“首都之窗”公众号,点击查看历史消息。
图25:查看历史消息
同样,“历史消息”在浏览器(绝不能在陌陌客户端下拉、因为fiddler收不到信息)中弹下来,然后往下开始刷几下,需要听到有新的内容弹下来,同时见到fiddler正在记录更新的信息。fiddler更新的消息就是最重要的内容。
图26:在浏览器中下拉几次“历史消息”
(2)fiddler信息剖析
刚刚通过在浏览器下拉公众号历史消息,fiddler采集到了更新的信息。我们开始剖析。
图27:分析由于下拉历史消息而搜集到的某一条记录
选择第8条记录(该记录来自浏览器中下拉历史记录而搜集到的消息),重点部份早已在headers中圈下来了。
(3)链接分析(看不下去的话,直接看代码如何拼出链接)
首先,在Request headers中,该链接简拼是 /mp/profile_ext?action=getmsg&__biz=MzA5NDY5MzUzMQ==&f=json&offset=20&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxtoken=&appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~&x5=0&f=json HTTP/1.1
分析这个链接。可以看见,它是由几个部份组成。
①/mp/profile_ext?②action=getmsg ③&__biz=MzA5NDY5MzUzMQ== ④&f=json⑤&offset=20 ⑥&count=10 ⑦&is_ok=1 ⑧&scene=124 ⑨&uin=777 ⑩&key=777 &pass_ticket= &wxtoken= &appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~ &x5=0&f=json HTTP/1.1
那么我们须要关注的信息是:
③__biz:公众号的id(公众号的biz惟一),⑤offset:翻页标志,appmsg_token:某个有时效性的token(隔一段时间会变化)
我们再看下边几个链接
GET /mp/profile_ext?action=getmsg&__biz=MzA5NDY5MzUzMQ==&f=json&offset=40&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxtoken=&appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~&x5=0&f=json HTTP/1.1
GET /mp/profile_ext?action=getmsg&__biz=MzA5NDY5MzUzMQ==&f=json&offset=60&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxtoken=&appmsg_token=1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~&x5=0&f=json HTTP/1.1
biz和appmsg_token一致,offset改变,即为新的一页。因此,第一步,我们早已找到了翻页的规律。链接中只有这三个在变化,其他没有变动。因此,链接在python中才能写成:
api = 'https://mp.weixin.qq.com/mp/pr ... iz%3D{0}&f=json&offset={1}&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxton=&appmsg_token={2}&x5=0&f=json HTTP/1.1'.format(
__biz, offset, appmsg_token)
(4)cookie和headers
cookie保存的是陌陌登陆的信息,在爬虫的时侯须要填进去。我们只要关注wsp_sid2的cookies信息。
cookies同样来自图27。找到wap_sid2=CK6vyK4CElxLdmda............
headers同样来自图27。找到 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
(5)爬取
好的,以上找到了好多信息。初步的python如下:
import requests
import json
# 链接拼接三个信息
__biz = "MzA5NDY5MzUzMQ=="
appmsg_token = "1052_D6g2L7mM%252BaKLoVQK33V8q4D4wk3doi7QeR3Zog~~"
offset = 20
# cookies和headers
cookies = "wap_sid2=CK6vyK4CElxLdmda......."
headers = {'Cookie':cookies,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
}
# api拼出来
api = 'https://mp.weixin.qq.com/mp/pr ... iz%3D{0}&f=json&offset={1}&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxton=&appmsg_token={2}&x5=0&f=json HTTP/1.1'.format(
__biz, offset, appmsg_token)
# 抓取并且json化
resp = requests.get(api, headers = headers, verify=False).json()
为什么须要把resp进行json化?我们可以尝试着打开9(3)一开始的链接的网页,
图28:拼下来的api打开的网页长这样
很明显这是个json信息。因此须要json化。复制该网页的全部文本,放在网页中,可以看见完整的json结构。这就是resp的网页结果。
图29:把图28的文本信息复制置于中的结果
那么resp在python中被json化以后的结果如下
图30:resp在python中的结构
(6)网页解析
接下来,关注该resp的结构以及一层一层剖析。图30中resp中errmsg=ok和ret=0,均表示网页可以正常打开(如果报错的话,ret=-3)。next_offset是下一次翻页的标志,需要保存上去。
next_offset = resp.get('next_offset')
general_msg_list = resp.get('general_msg_list')
# 将general_msg_list转为json格式
msg_list = json.loads(general_msg_list)['list']
general_msg_list 是 重要的内容。点击general_msg_list,这仍然是一个json结构。
图31:general_msg_list仍然是json结构。
复制上面的文本,放到中瞧瞧是哪些。
图32:general_msg_list放在中的结果
因此被json化以后的msg_list,在python中长这样
图33:把general_msg_list进行json化在python中的样子
可以看见,msg_list中富含10个记录。我们抽出一个记录,进行具体剖析。在剖析之前,我们要明晰一个东西。msg_list中收录了10个记录,不是指10篇文章,而是10次推送。某一次公众号推送消息,可能同时发布好几条文章,也有可能是一篇文章。因此,要明白,单个msg记录,是指一个推送(and可能一次性发布了好几篇文章)。
图34:某一次推送,一起发布了3篇文章
msg = msg_list[0]
图35:某一个具体的msg
该msg上面收录了“app_msg_ext_info”和“comm_msg_info”两个内容。在中,这两个内容分别长这样子。
图36:某一个msg具体的两部份---app_msg_ext_info和comm_msg_info
那么comm_msg_info收录了该推送的基本信息:推送ID,时间等。
app_msg_ext_info是哪些?且听我渐渐剖析。首先,title,digest仍然到is_multi,都是该次推送的打头文章(就是图34中带图片的那种文章的信息)。例如title标题/digest关键词/content_url链接/source_url原链接等。
is_multi是判定该次推送是不是有读篇文章;=1表示yes,=0表示no。那么这儿等于1,说明该次推送还有其他文章,存在于multi_app_msg_item_list中。
把multi_app_msg_item_list取下来。
multi_app_msg_item_list = app_msg_ext_info.get('multi_app_msg_item_list')
图37:该推送剩下的两篇文章藏在multi_app_msg_item_list中
到目前为止,我们早已剖析完了整体的流程。
总结
图38:总结怎样走出第一步
图39:具体剖析结构
(7)具体代码如下
<p>import requests
import json
from datetime import datetime
import pandas as pd
import time
class WxMps:
def __init__(self, biz, appmsg_token, cookies, offset, city):
self.biz = biz
self.msg_token = appmsg_token
self.offset = offset
self.headers = {'Cookie':cookies, 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
self.city = city
def parse1(self, resp):
# 控制下一个抓取的offset
offset = resp.get('next_offset')
# 将包含主要内容的list转为json格式
general_msg_list = resp.get('general_msg_list')
# 一个msg_list中含有10个msg
msg_list = json.loads(general_msg_list)['list']
df1 = pd.DataFrame(columns = ['msg_id', 'post_time', 'msg_type', 'title', 'cover', 'author', 'digest', 'source_url', 'content_url'])
# 循环message列表
for msg in msg_list:
# msg是该推送的信息,包含了comm_msg_info以及app_msg_ext_info两个信息,注意某一个推送中可能含有多个文章。
comm_msg_info = msg.get('comm_msg_info')
app_msg_ext_info = msg.get('app_msg_ext_info')
# 该推送的id
msg_id = comm_msg_info.get('id')
# 该推送的发布时间,例如1579965567需要转化为datetime,datetime.fromtimestamp(1579965567)
post_time = datetime.fromtimestamp(comm_msg_info['datetime'])
# 该推送的类型
msg_type = comm_msg_info.get('type')
if app_msg_ext_info:
# 推送的第一篇文章
title, cover, author, digest, source_url, content_url = self.parse2(app_msg_ext_info)
df2 = self.df_process(msg_id, post_time, msg_type, title, cover, author, digest, source_url, content_url)
df1 = pd.concat([df1, df2])
# 判断是不是多篇文章
is_multi = app_msg_ext_info.get("is_multi")
# 如果是1,继续爬取;如果是0,单条推送=只有一篇文章
if is_multi:
multi_app_msg_item_list = app_msg_ext_info.get('multi_app_msg_item_list')
for information in multi_app_msg_item_list:
(title, cover, author, digest, source_url, content_url) = self.parse2(information)
df2 = self.df_process(msg_id, post_time, msg_type, title, cover, author, digest, source_url, content_url)
df1 = pd.concat([df1, df2])
return df1, offset
def start(self):
offset = self.offset
df1 = pd.DataFrame(columns = ['msg_id', 'post_time', 'msg_type', 'title', 'cover', 'author', 'digest', 'source_url', 'content_url'])
while offset
在时间关系数据上AutoML:一个新的前沿
采集交流 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2020-08-12 16:31
翻译:张恬钰
校对:李海明
本文1600字,建议阅读8分钟。
本文介绍了AutoML的发展历史及其在时间关系数据上的应用方案。
现实世界中的机器学习系统须要数据科学家和领域专家来构建和维护,而这样的人才却总是供不应求。自动化机器学习(AutoML)由于在建立和维护机器学习工作流中的关键步骤中所显露出的广泛适用性,使得该领域的研究前景一片光明。它减少了人类专家的工作负担,使她们才能专注于复杂、非重复和具有创造性的学习问题。
AutoML的最新进展主要包括从时间关系数据库中手动发觉有意义的表间关系的复杂功能合成(例如,深度特点综合),使用模型手动调整进行概念漂移(例如,AutoGBT),以及深度学习模型的手动设计(例如,神经结构搜索),如图1所示。这些研究进展提升了数据科学家的生产力,从而明显增强了AutoML系统的实用性,并促使非机器学习专家也才能处理现实中不同领域的数据科学问题。
图1 AutoML进化史
在时间关系数据库中使用AutoML
在例如在线广告,推荐系统,自动与顾客交流等机器学习应用中,数据集可以跨越多个具有时间戳的相关表来显示风波的时间安排。而传统方法则须要专家们通过冗长的试错法自动组合表格来获取有意义的特点。用于处理动词关系数据的AutoML考虑了相关关键数组的临时联接,并通过手动发觉重要的表间关系来手动进行特点合成。
在没有域信息的情况下,实现基于动词关系数据的真实世界的AutoML案例包括手动生成有用的动词信息和跨多个子表格有效合并特点,且不会造成数据泄漏。除了这种困难外,还须要手动选择最佳的学习模型和受资源约束的超参数集,以让解决方案足够通用,并且符合时间和内容预算。
有趣的是,今年的KDD杯举办了以AutoML为主题的挑战赛,邀请了全世界AI / ML领域的研究和从业人员为动词关系数据库开发最新的AutoML。
我们的解决方式
我们的工作流程包括预处理,跨关系表的手动特点合成,模型学习和预测这种步骤。预处理包括对于偏移校准的特点变换以及平方和三次特点的提高。它还包括分类特点的频率编码,而特点是使用子表中聚合指标的时间连接手动合成的。多数类的实例将进行下述取样以保持1:3的百分比。渐进式决策树(GBDT)的Catboost实现可用于学习算法,交叉验证则可用于参数调整来决定最佳树的数目。图2概括地描述了我们的工作流程:
图2 我们的模型管线
时态数据聚合
当动词关系数据跨越多个表格时,找出表间的重要关系之后以最佳方法执行数据聚合将有助于特点提取。为了提取正确的特点表示,可对数字特点使用均值、求和等聚合运算,而对分类特点则采用计数、众数等运算。求频度,聚合指标的估算须要在适当的时间窗口上使用交叉验证完成。
特征处理
连接多个数据库的表会形成高度偏移的特点。我们的特点预处理步骤包括偏移校准以及特点变换和提高。特征提高包括添加具有周期性的数字特点的平方和三次方变换以及正则或正切,日期时间特点的变换(例如,月,时和分)来丰富特点空间。还可对分类特点进行频率编码来进一步扩大特点空间。
模型选择
在估算和储存方面,尝试几种线性和非线性模型的成本可能会十分高昂。由于梯度提高决策树在处理分类特点和可扩展性方面的鲁棒性,我们将模型组合限制在CatBoost的实现上。同时使用交叉验证对超参数(例如树的数目)进行调整,以防止过度拟合。
我们的解决方案拓展了现有的AutoML研究项目组合,允许使用涉及不定式关系数据库学习的用例。可以访问Github储存库来查看我们的解决方案。
AutoML趋势
随着行业越来越关注从AI中快速获取价值并降低机器学习模型从原型到生产布署的周期时间,能够增加AI准入门槛并实现AI工作流程自动化的AutoML已成为重要推动力。AutoML社区越来越关注于支持真实案例的使用,包括从结构化和非结构化数据、时态关系数据库以及受概念甩尾影响的数据流中学习。
尽管AutoML最初专注于最佳机器学习管线的手动建立,随着时间的推移,对此类管线手动维护处理它的范围正在扩大,模型自治性进一步降低。AutoML的进步和强悍的估算基础设施的可借助性将促进人机智能的融合,使得人类专家才能更好地将精力集中在学习复杂的,非重复和创造性的问题上,从而获得更优的解决方案。
原文标题:
AutoMLfor Temporal Relational Data: A New Frontier
原文链接: 查看全部
作者:Flytxt
翻译:张恬钰
校对:李海明
本文1600字,建议阅读8分钟。
本文介绍了AutoML的发展历史及其在时间关系数据上的应用方案。
现实世界中的机器学习系统须要数据科学家和领域专家来构建和维护,而这样的人才却总是供不应求。自动化机器学习(AutoML)由于在建立和维护机器学习工作流中的关键步骤中所显露出的广泛适用性,使得该领域的研究前景一片光明。它减少了人类专家的工作负担,使她们才能专注于复杂、非重复和具有创造性的学习问题。
AutoML的最新进展主要包括从时间关系数据库中手动发觉有意义的表间关系的复杂功能合成(例如,深度特点综合),使用模型手动调整进行概念漂移(例如,AutoGBT),以及深度学习模型的手动设计(例如,神经结构搜索),如图1所示。这些研究进展提升了数据科学家的生产力,从而明显增强了AutoML系统的实用性,并促使非机器学习专家也才能处理现实中不同领域的数据科学问题。
图1 AutoML进化史
在时间关系数据库中使用AutoML
在例如在线广告,推荐系统,自动与顾客交流等机器学习应用中,数据集可以跨越多个具有时间戳的相关表来显示风波的时间安排。而传统方法则须要专家们通过冗长的试错法自动组合表格来获取有意义的特点。用于处理动词关系数据的AutoML考虑了相关关键数组的临时联接,并通过手动发觉重要的表间关系来手动进行特点合成。
在没有域信息的情况下,实现基于动词关系数据的真实世界的AutoML案例包括手动生成有用的动词信息和跨多个子表格有效合并特点,且不会造成数据泄漏。除了这种困难外,还须要手动选择最佳的学习模型和受资源约束的超参数集,以让解决方案足够通用,并且符合时间和内容预算。
有趣的是,今年的KDD杯举办了以AutoML为主题的挑战赛,邀请了全世界AI / ML领域的研究和从业人员为动词关系数据库开发最新的AutoML。
我们的解决方式
我们的工作流程包括预处理,跨关系表的手动特点合成,模型学习和预测这种步骤。预处理包括对于偏移校准的特点变换以及平方和三次特点的提高。它还包括分类特点的频率编码,而特点是使用子表中聚合指标的时间连接手动合成的。多数类的实例将进行下述取样以保持1:3的百分比。渐进式决策树(GBDT)的Catboost实现可用于学习算法,交叉验证则可用于参数调整来决定最佳树的数目。图2概括地描述了我们的工作流程:
图2 我们的模型管线
时态数据聚合
当动词关系数据跨越多个表格时,找出表间的重要关系之后以最佳方法执行数据聚合将有助于特点提取。为了提取正确的特点表示,可对数字特点使用均值、求和等聚合运算,而对分类特点则采用计数、众数等运算。求频度,聚合指标的估算须要在适当的时间窗口上使用交叉验证完成。
特征处理
连接多个数据库的表会形成高度偏移的特点。我们的特点预处理步骤包括偏移校准以及特点变换和提高。特征提高包括添加具有周期性的数字特点的平方和三次方变换以及正则或正切,日期时间特点的变换(例如,月,时和分)来丰富特点空间。还可对分类特点进行频率编码来进一步扩大特点空间。
模型选择
在估算和储存方面,尝试几种线性和非线性模型的成本可能会十分高昂。由于梯度提高决策树在处理分类特点和可扩展性方面的鲁棒性,我们将模型组合限制在CatBoost的实现上。同时使用交叉验证对超参数(例如树的数目)进行调整,以防止过度拟合。
我们的解决方案拓展了现有的AutoML研究项目组合,允许使用涉及不定式关系数据库学习的用例。可以访问Github储存库来查看我们的解决方案。
AutoML趋势
随着行业越来越关注从AI中快速获取价值并降低机器学习模型从原型到生产布署的周期时间,能够增加AI准入门槛并实现AI工作流程自动化的AutoML已成为重要推动力。AutoML社区越来越关注于支持真实案例的使用,包括从结构化和非结构化数据、时态关系数据库以及受概念甩尾影响的数据流中学习。
尽管AutoML最初专注于最佳机器学习管线的手动建立,随着时间的推移,对此类管线手动维护处理它的范围正在扩大,模型自治性进一步降低。AutoML的进步和强悍的估算基础设施的可借助性将促进人机智能的融合,使得人类专家才能更好地将精力集中在学习复杂的,非重复和创造性的问题上,从而获得更优的解决方案。
原文标题:
AutoMLfor Temporal Relational Data: A New Frontier
原文链接:
基于主题爬虫与文本分类的微博资讯智能生成策略研究
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-11 13:57
【摘要】:随着联通互联网的快速发展,中国手机网民数目早已赶超PC,各种手机应用层出不穷,其中手机微博早已成为使用率增速最快的手机应用。越来越多的人们使用微博进行交流互动,尤其是在面向垂直细分领域的专业微博中,用户有强烈的获取权威资讯信息的需求。但是,传统的微博欠缺良好的信息查询与推送功能,难以满足不同人群的信息获取须要。因此,根据不同行业主题,利用微博平台将互联网上丰富的行业资讯信息进行手动采集推送,具有重要的理论研究和实际应用价值。在基于主题爬虫与文本分类的微博资讯智能生成策略中,利用主题爬虫技术和文本分类技术将互联网上丰富的行业信息按主题进行采集分类并通过手机微博客户端向特定用户群体提供资讯查询和推送服务。首先,在针对主题信息的采集中提出了一种面向特定领域的主题式爬取策略,通过对开源爬虫框架Heritrix进行主题模块的扩充,使爬虫只抓取与特定主题相关的最新行业信息。其次,在网页数据处理过程中通过改进文本分类算法,设计了一种英文网页文本分类器,对抓取的网页按行业主题进行手动细分类并提取数据生成有价值资讯信息。然后,通过手机微博平台将分类的信息通过设定的不同微博频道或则智能帐号进行动态展示与发布。最后,以农业主题为例将基于主题爬虫与文本分类的微博资讯智能生成策略应用在广东手机农业微博中进行农务资讯的生成与推送。在广东手机农业微博中实现农业微博资讯的智能生成,并对微博资讯生成策略进行了相关的功能和性能测试。实验结果表明:这种微博资讯生成策略才能及时获取最新行业相关资讯,进行详尽确切的信息分类并提供便捷的查询与推送服务。其中主题爬虫抓取的主题准确率达到87%以上,网页文本分类器的整体评估指数达到85%左右。
USB免驱摄像头采集图像【VS2012+opencv+directShow(Cc
采集交流 • 优采云 发表了文章 • 0 个评论 • 527 次浏览 • 2020-08-10 23:03
但是该配置比较老,本文述说怎样基于该教程在 VS2012和opencv2.4.9上进行配置和更改,完成USB摄像头的驱动。
博主的USB免驱摄像头如下:
文末有完整代码的下载地址
1.环境配置
在Opencv英文网站上有关于directShow和opencv结合采集图像的教程,地址:%e4%bd%bf%e7%94%a8DirectShow%e9%87%87%e9%9b%86%e5%9b%be%e5%83%8f
但说明中的“本文档介绍的CCameraDS类调用采集函数可直接返回IplImage,使用更方便,且集成了DirectShow,勿需安装庞大的DirectX/Platform SDK”并不靠谱,DirectShow 似乎早已开始被谷歌给淘汰了,最后存在是在多年前的 DirectX 9.0b 包里。
注意这儿并不需要下载DirectX 9.0包,下面介绍在VS2012和opencv2.4.9下的配置过程。
1.1 配置VS2012和opencv环境
按照网上流行的配置即可,如 。配置好以后尝试运行一个打开图片的小程序检查opencv环境是否配置成功。
1.2 配置DirectX环境
新建工程,配置好Opencv环境,随后将从Opencv英文网上下载的 CameraDS.h 和 CameraDS.cpp 文件分别添加到项目的头文件和源文件中。
VS2012旗舰版是自带了 SDK 的,在 C:\Program Files (x86)\Microsoft SDKs\Windows\v7.1A\Include。
打开构建的VS2012项目的属性页,找到“VC++目录”,在“收录目录”里添加 (FrameworkSDKDir)Include,在“库目录”里添加(FrameworkSDKDir)Lib。
发现#include “qedit.h”报错,原因是现今的版本早已没有qedit.h这个头文件了,从网址: 中下载该文件,添加到项目的头文件中。
2. 运行
环境配置好以后,可以用 Opencv英文网 上下载的main.cpp运行,运行过程可能碰到const char* 无法转换的问题,将此处的代码除去即可。
下面是本人编撰的main函数,提供了USB单反的打开、监视、图像捕获功能。
2.1 查看系统的所有摄像头状态(initAllCameras函数)
参数是 CCameraDS 类的对象。该函数获取单反的数量而且显示单反名称。从输出中我们可以找到USB单反的编号,一般情况下编号为1。
//获取当前可用的摄像头并打开USB摄像头
int initAllCameras(CCameraDS &m_CamDS){
//仅仅获取摄像头数目
int m_iCamCount = CCameraDS::CameraCount();
printf("There are %d cameras.\n", m_iCamCount);
if(m_iCamCount == 0)
{
return -1;
}
//获取所有摄像头的名称
for(int i = 0; i < m_iCamCount; i++)
{
char szCamName[1024];
int retval = m_CamDS.CameraName(i, szCamName, sizeof(szCamName));
if(retval >0)
{
printf("Camera #%d's Name is '%s'.\n", i, szCamName);
}
else
{
printf("Can not get Camera #%d's name.\n", i);
}
}
return m_iCamCount;
}
运行结果如下所示:
There are 3 cameras.
Camera #0's Name is 'Lenovo EasyCamera'.
Camera #1's Name is '3D Camera'.
Camera #2's Name is 'Basler GenICam Source'.
从运行结果中可以看出,使用的3D相机的编号为1。
2.2 打开USB单反(openUsbCam函数)
函数有四个参数,第一个参数为CcameraDS类的对象,camNum设置为1,表明如今要打开的USB单反,而不是笔记本自带单反。camWidth和camHeight按照自己所使用单反的情况进行设置,设置为图象的长度和高度。
代码如下:
<p>// 打开 USB 相机 !! 在调用 camDisplay 和 camCapPic 之前必须调用该函数
// camNum = 1; // 摄像头编号为1,表示当前要使用的是 USB 摄像头
// camWidth = 2560; // 图片宽度
// camHeight = 720; // 图片高度
int openUsbCam(CCameraDS &m_CamDS, const int camNum=1, const int camWidth=2560, const int camHeight = 720){
// 获取当前可用的相机个数
// 在所有的相机中,一般编号为 0 的为电脑自带摄像头,编号为 1 的为要使用的 USB 摄像头
int m_iCamCount = initAllCameras(m_CamDS);
if(m_iCamCount == -1){
cout 查看全部
在Opencv英文网站上有关于directShow和opencv结合采集图像的教程,地址:%e4%bd%bf%e7%94%a8DirectShow%e9%87%87%e9%9b%86%e5%9b%be%e5%83%8f
但是该配置比较老,本文述说怎样基于该教程在 VS2012和opencv2.4.9上进行配置和更改,完成USB摄像头的驱动。
博主的USB免驱摄像头如下:
文末有完整代码的下载地址
1.环境配置
在Opencv英文网站上有关于directShow和opencv结合采集图像的教程,地址:%e4%bd%bf%e7%94%a8DirectShow%e9%87%87%e9%9b%86%e5%9b%be%e5%83%8f
但说明中的“本文档介绍的CCameraDS类调用采集函数可直接返回IplImage,使用更方便,且集成了DirectShow,勿需安装庞大的DirectX/Platform SDK”并不靠谱,DirectShow 似乎早已开始被谷歌给淘汰了,最后存在是在多年前的 DirectX 9.0b 包里。
注意这儿并不需要下载DirectX 9.0包,下面介绍在VS2012和opencv2.4.9下的配置过程。
1.1 配置VS2012和opencv环境
按照网上流行的配置即可,如 。配置好以后尝试运行一个打开图片的小程序检查opencv环境是否配置成功。
1.2 配置DirectX环境
新建工程,配置好Opencv环境,随后将从Opencv英文网上下载的 CameraDS.h 和 CameraDS.cpp 文件分别添加到项目的头文件和源文件中。
VS2012旗舰版是自带了 SDK 的,在 C:\Program Files (x86)\Microsoft SDKs\Windows\v7.1A\Include。
打开构建的VS2012项目的属性页,找到“VC++目录”,在“收录目录”里添加 (FrameworkSDKDir)Include,在“库目录”里添加(FrameworkSDKDir)Lib。
发现#include “qedit.h”报错,原因是现今的版本早已没有qedit.h这个头文件了,从网址: 中下载该文件,添加到项目的头文件中。
2. 运行
环境配置好以后,可以用 Opencv英文网 上下载的main.cpp运行,运行过程可能碰到const char* 无法转换的问题,将此处的代码除去即可。
下面是本人编撰的main函数,提供了USB单反的打开、监视、图像捕获功能。
2.1 查看系统的所有摄像头状态(initAllCameras函数)
参数是 CCameraDS 类的对象。该函数获取单反的数量而且显示单反名称。从输出中我们可以找到USB单反的编号,一般情况下编号为1。
//获取当前可用的摄像头并打开USB摄像头
int initAllCameras(CCameraDS &m_CamDS){
//仅仅获取摄像头数目
int m_iCamCount = CCameraDS::CameraCount();
printf("There are %d cameras.\n", m_iCamCount);
if(m_iCamCount == 0)
{
return -1;
}
//获取所有摄像头的名称
for(int i = 0; i < m_iCamCount; i++)
{
char szCamName[1024];
int retval = m_CamDS.CameraName(i, szCamName, sizeof(szCamName));
if(retval >0)
{
printf("Camera #%d's Name is '%s'.\n", i, szCamName);
}
else
{
printf("Can not get Camera #%d's name.\n", i);
}
}
return m_iCamCount;
}
运行结果如下所示:
There are 3 cameras.
Camera #0's Name is 'Lenovo EasyCamera'.
Camera #1's Name is '3D Camera'.
Camera #2's Name is 'Basler GenICam Source'.
从运行结果中可以看出,使用的3D相机的编号为1。
2.2 打开USB单反(openUsbCam函数)
函数有四个参数,第一个参数为CcameraDS类的对象,camNum设置为1,表明如今要打开的USB单反,而不是笔记本自带单反。camWidth和camHeight按照自己所使用单反的情况进行设置,设置为图象的长度和高度。
代码如下:
<p>// 打开 USB 相机 !! 在调用 camDisplay 和 camCapPic 之前必须调用该函数
// camNum = 1; // 摄像头编号为1,表示当前要使用的是 USB 摄像头
// camWidth = 2560; // 图片宽度
// camHeight = 720; // 图片高度
int openUsbCam(CCameraDS &m_CamDS, const int camNum=1, const int camWidth=2560, const int camHeight = 720){
// 获取当前可用的相机个数
// 在所有的相机中,一般编号为 0 的为电脑自带摄像头,编号为 1 的为要使用的 USB 摄像头
int m_iCamCount = initAllCameras(m_CamDS);
if(m_iCamCount == -1){
cout
被动信息搜集----指纹辨识(CMS辨识)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2020-08-10 21:24
1.指纹识别介绍
指纹因为其具有不变性、唯一性和方便性,使其可以被惟一的标示。而对于每位网站来说,他们也具有可标识性,我们通常通过网站CMS辨识、计算机操作系统辨识以及web容器辨识来标示网站。
2.指纹辨识的目的
在渗透测试中,对目标服务器进行指纹辨识是十分有必要的,因为只有辨识出相应的web容器或则CMS,才能查看与其相关的漏洞,然后借助可用的漏洞进行相应的渗透测试。
二、CMS介绍
CMS(Content Management System)又称整站系统或文章系统。在2004年以前,如果想进行网站内容管理,基本上须要靠自动维护,但在信息爆燃的时代,完全靠手工维护都会相当苦闷。所以就出现了CMS,开发者只须要给顾客一个软件包,客户自己安装配置好,就可以定期更新数据来维护网站,节省了大量的人力和物力。
三、常见CMS介绍
php类cms系统:dedeCMS、帝国CMS、php168、phpCMS、cmstop、discuz、phpwind等
asp类cms系统:zblog、KingCMS等
.net类cms系统:EoyooCMS等
国外的知名cms系统:joomla、WordPress 、magento、drupal 、mambo等
(1):DedeCMS(织梦)
织梦内容管理系统(DedeCMS)以简单、实用、开源而享誉,是国外最著名的PHP开源网站管理系统,也是使用用户最多的PHP类CMS系统。DedeCMS免费版主要目标锁定在个人站长,功能愈发专注于个人网站或中小型门户的建立,当然也有企业用户和中学等在使用本系统。
(2):Discuz
Crossday Discuz! Board(简称Discuz!)是康盛创想(北京)科技有限公司推出的一套通用的社区峰会软件系统,用户可以在不需要任何编程的基础上,通过简单的设置和安装,在互联网上搭建起具备建立功能、很强负载能力和可高度订制的峰会服务。Discuz! 的基础构架采用世界上最流行的web编程组合PHP+MySQL实现,是一个经过建立设计,适用于各类服务器环境的高效峰会系统解决方案。
(3):帝国CMS
帝国CMS又称为Empire CMS,简称Ecms,它是基于B/S结构而且功能强悍而易用的网站管理系统。它采用了系统模型功能:用户通过此功能可直接在后台扩充与实现各类系统,因此又被称为是万能建站工具。帝国CMS具有强悍的功能,并且现今早已全部开源。
(4):WordPress
WordPress是使用PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上架设属于自己的网站,WordPress也被当做一个内容管理系统(CMS)。WordPress是一款个人博客系统,使用PHP和MySQL语言进行开发的。
四、判断CMS的方式
1.查看robots.txt文件
robots.txt文件中储存的是一些严禁被爬虫爬取的目录,因此有些robots.txt文件中都会储存一些关于CMS的敏感信息。例如假如robots.txt文件中存在wp-admin目录,那么就表名这个CMS是WordPress。
2.查看网页源代码
在有些网站中的源代码中会储存着网站的CMS信息和相应的版本信息,通过查看源代码可以发觉使用的CMS类别。 查看全部
一、指纹辨识
1.指纹识别介绍
指纹因为其具有不变性、唯一性和方便性,使其可以被惟一的标示。而对于每位网站来说,他们也具有可标识性,我们通常通过网站CMS辨识、计算机操作系统辨识以及web容器辨识来标示网站。
2.指纹辨识的目的
在渗透测试中,对目标服务器进行指纹辨识是十分有必要的,因为只有辨识出相应的web容器或则CMS,才能查看与其相关的漏洞,然后借助可用的漏洞进行相应的渗透测试。
二、CMS介绍
CMS(Content Management System)又称整站系统或文章系统。在2004年以前,如果想进行网站内容管理,基本上须要靠自动维护,但在信息爆燃的时代,完全靠手工维护都会相当苦闷。所以就出现了CMS,开发者只须要给顾客一个软件包,客户自己安装配置好,就可以定期更新数据来维护网站,节省了大量的人力和物力。
三、常见CMS介绍
php类cms系统:dedeCMS、帝国CMS、php168、phpCMS、cmstop、discuz、phpwind等
asp类cms系统:zblog、KingCMS等
.net类cms系统:EoyooCMS等
国外的知名cms系统:joomla、WordPress 、magento、drupal 、mambo等
(1):DedeCMS(织梦)
织梦内容管理系统(DedeCMS)以简单、实用、开源而享誉,是国外最著名的PHP开源网站管理系统,也是使用用户最多的PHP类CMS系统。DedeCMS免费版主要目标锁定在个人站长,功能愈发专注于个人网站或中小型门户的建立,当然也有企业用户和中学等在使用本系统。
(2):Discuz
Crossday Discuz! Board(简称Discuz!)是康盛创想(北京)科技有限公司推出的一套通用的社区峰会软件系统,用户可以在不需要任何编程的基础上,通过简单的设置和安装,在互联网上搭建起具备建立功能、很强负载能力和可高度订制的峰会服务。Discuz! 的基础构架采用世界上最流行的web编程组合PHP+MySQL实现,是一个经过建立设计,适用于各类服务器环境的高效峰会系统解决方案。
(3):帝国CMS
帝国CMS又称为Empire CMS,简称Ecms,它是基于B/S结构而且功能强悍而易用的网站管理系统。它采用了系统模型功能:用户通过此功能可直接在后台扩充与实现各类系统,因此又被称为是万能建站工具。帝国CMS具有强悍的功能,并且现今早已全部开源。
(4):WordPress
WordPress是使用PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上架设属于自己的网站,WordPress也被当做一个内容管理系统(CMS)。WordPress是一款个人博客系统,使用PHP和MySQL语言进行开发的。
四、判断CMS的方式
1.查看robots.txt文件
robots.txt文件中储存的是一些严禁被爬虫爬取的目录,因此有些robots.txt文件中都会储存一些关于CMS的敏感信息。例如假如robots.txt文件中存在wp-admin目录,那么就表名这个CMS是WordPress。
2.查看网页源代码
在有些网站中的源代码中会储存着网站的CMS信息和相应的版本信息,通过查看源代码可以发觉使用的CMS类别。
优采云QQ群聊天消息文章生成器下载 1.7.0.1 试用版
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-10 12:39
工作流程:
1、分析QQ导入的TXT格式聊天消息记录文件,得到精确的每条消息
2、将每条消息进行过滤、插入前后缀文字等修饰后,按设定的数目进行组合(如一个消息文件有1万条记录,按100条消息一篇的组合,能生产100篇原创文章)
3、可以对组合的结果插入关键词或该消息文件的文件名
4、一篇篇纯原创的文章就此诞生!
功能特性:
1、分析QQ消息文件,精确获取每一条消息文本
2、全局搅乱消息
3、内置过滤(如过滤网址、邮箱等)
4、内置屏蔽词替换(QQ聊天时常常说到好多敏感词句)
5、自动消除多余标点符号(多个标点符号相连时,只保留一个,让文章看起来更真实和顺眼)
6、消息支持合纵连横组合。(连横,即多条原创消息连在一起作为单条消息,以合并符分隔,合纵,即多个单条消息组合为一篇原创文章)
7、单条消息支持前后缀插入,如常见的段落网页标签”《p》《/p》“
8、支持插入词到标题,支持插入随机词到文章(更可手动组合锚文本)
9、文章标题智能提取组合的结果中的随机一句。
10、批量选择多个QQ消息文件,一键处理,大功告成,文章滚滚来!!
更新日志:
改造为支持OEM代理
官方网站:
相关搜索:QQ聊天记录 查看全部
优采云QQ群聊天消息文章生成器是一款可以将QQ聊天,尤其是群聊天的大量原创内容,进行处理后生产出原创文章来,虽然个他人会复制文章来粘贴,但它们的特点很容易辨识,往往是篇幅很大的,这时你可以设定单条消息字数超过某甲字数就忽视。
工作流程:
1、分析QQ导入的TXT格式聊天消息记录文件,得到精确的每条消息
2、将每条消息进行过滤、插入前后缀文字等修饰后,按设定的数目进行组合(如一个消息文件有1万条记录,按100条消息一篇的组合,能生产100篇原创文章)
3、可以对组合的结果插入关键词或该消息文件的文件名
4、一篇篇纯原创的文章就此诞生!
功能特性:
1、分析QQ消息文件,精确获取每一条消息文本
2、全局搅乱消息
3、内置过滤(如过滤网址、邮箱等)
4、内置屏蔽词替换(QQ聊天时常常说到好多敏感词句)
5、自动消除多余标点符号(多个标点符号相连时,只保留一个,让文章看起来更真实和顺眼)
6、消息支持合纵连横组合。(连横,即多条原创消息连在一起作为单条消息,以合并符分隔,合纵,即多个单条消息组合为一篇原创文章)
7、单条消息支持前后缀插入,如常见的段落网页标签”《p》《/p》“
8、支持插入词到标题,支持插入随机词到文章(更可手动组合锚文本)
9、文章标题智能提取组合的结果中的随机一句。
10、批量选择多个QQ消息文件,一键处理,大功告成,文章滚滚来!!
更新日志:
改造为支持OEM代理
官方网站:
相关搜索:QQ聊天记录
人工智能+工程师的组合,或将满足日渐下降的网路安全需求
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2020-08-10 02:25
北京时间10月22日凌晨,美国域名服务器管理服务供应商Dyn宣布,该公司在当地时间周五早上遭到了DDoS(分布式拒绝服务)攻击,这一情况造成许多网站在英国东海岸地区宕机。Twitter、Tumblr、Netflix、Amazon、PayPal等众多人气网站无一幸免。
许多受此影响的公司都在Twitter上发布消息,向其用户发出了网站宕机的通知,亚马逊报告报称有一次服务中断,午后已解决问题。由于影响范围太广,著名的科技博客Gizmodo甚至表示半个互联网都关掉了,而按照网友们反馈,此次黑客攻击造成83家网站受影响。
三波网路功击,来自上千万IP地址
根据Dyn的说法,最早的一次功击源于周五早上7点(北京时间周五晚上7点)过后,此次功击干扰干扰了Dyn运作约两小时。随即,工作人员进行了抢险,在当天上午9点半左右恢复了营运。但是仅在几小时后,Dyn就受到第二次功击,运营再度遭到干扰。北京时间今天凌晨4点30分左右Dyn又受到第三次功击。
Dyn是日本最主要的DNS服务商,他们的主要职责就是将域名解析为IP地址,将网友引入正确的网站。此次Dyn遭到功击以后,会导致日本大部分地区网民在恳求链接某网站的时侯会失败,即使你按F5不断刷新也没有用。
很显然,这是一次有组织有蓄谋的网路功击行为,攻击行为来自超过一千万IP来源。此外,Dyn也表示这当中有几百万恶意功击的源头是物联网联系的所谓“智能”家居产品。Dyn的首席策略官Kyle York在电话会议上甚至说,黑客们“真正在做的是用每次功击撼动世界。”
单独借助人工智能或则工程师难以做到维护网路安全
网络安全的维护一般都是由工程师们完成的,但是一次又一次的网路黑客侵袭风波证明了,工程师们并没有绝对的掌握保障网路安全。那么假如由人工智能来接替工程师,是否能够保障网路安全呢?答案也是否定的。哪怕是新型混杂式系统,基于人工智能(AI)梳理数据,并将当前可疑行为递交给剖析人员,也仅才能测量85%的功击。
人工智能在维护网路安全上可以做到的自动化和漏洞修复技术包括:动态剖析(Dynamic Analysis)、静态剖析(Static Analysis)、符号执行(Symbolic Execution)、约束求解、数据流跟踪技术(Data Flow Tracking)以及模糊测试(Fuzz Testing)等,并和其他半自动化技术搭配,形成一整套全手动的网路决策推理系统(Cyber Reasoning System,CRS)。
很明显,人工智能才能在改善联通安全和网路安全方面发挥作用,做好避免网路恐吓逼抢和网路安全防御举措。但是,人工智能也只能测量到85%的功击,而并非100%。
由此可见,如果单独借助单独借助人工智能或则工程师,无法做到百分百的网路安全。
人工智能+工程师,合作以后或将构建更强大的网路安全
既然工程师和人工智能都难以单独在网路安全维护工作上取得压倒性成功,为什么不试着把三者整合上去呢?
在网路安全的世界里,以人为主的技术主要依赖专业人员完善的规则,因此不符合规则的功击就被错过。而初期网路安全方面的机器学习则依赖于异常检查,因此常常容易误报,“狼来了”太多,最终造成其并不被看好。
但是,随着人工智能技术的日渐发展,在现今的网路安全领域,它可以是一个虚拟的分析员,在发觉黑客攻击以后,第一时间交由人类分析员来判断,之后系统再把判定结果整合到模型中,作为下一个数据集的测量标准,然后不断循环这个过程。这也就意味着,在保证极大地提高检测率的同时,还可以提高未来的预测准确率。
因此,使用人工智能来学习并找到最有可能是功击的风波,然后交给人类专家去判定,并且协助人类工程师进行网路安全防护,是一个结合二者优势以后最有效的办法。
世界上并没有绝对的网路安全,防患于未然只是更好的选择
俗话说的好“魔高一尺道高一丈”,先有魔,后有道。如今的“道”,已经实现人工智能的广泛应用,而“魔”呢?黑客虽然已经实现完全自动化了......攻击的投放、发起、渗透,只是在其中几个小的步骤才须要人工介入,通过一个可视化界面管理着被渗透的全世界几十万台服务器。
其实面对现今的网路安全方式,每日就会有成百上千的崩溃报告、DDoS攻击、数据泄漏等功击行为,我们不应渴望“完美的防御”,而应当尽量提升功击成功率的门槛,降低功击成功率或是减短防御响应时间,形成正确的“安全观”。最后提醒你们,被功击只是时间而已,现在没有发生,未来必然发生。 查看全部
哪怕堪称网路最安全的日本,也躲不过黑客的功击。那么为什么不将人工智能和工程师结合,实现更完善的网路安全。
北京时间10月22日凌晨,美国域名服务器管理服务供应商Dyn宣布,该公司在当地时间周五早上遭到了DDoS(分布式拒绝服务)攻击,这一情况造成许多网站在英国东海岸地区宕机。Twitter、Tumblr、Netflix、Amazon、PayPal等众多人气网站无一幸免。
许多受此影响的公司都在Twitter上发布消息,向其用户发出了网站宕机的通知,亚马逊报告报称有一次服务中断,午后已解决问题。由于影响范围太广,著名的科技博客Gizmodo甚至表示半个互联网都关掉了,而按照网友们反馈,此次黑客攻击造成83家网站受影响。
三波网路功击,来自上千万IP地址
根据Dyn的说法,最早的一次功击源于周五早上7点(北京时间周五晚上7点)过后,此次功击干扰干扰了Dyn运作约两小时。随即,工作人员进行了抢险,在当天上午9点半左右恢复了营运。但是仅在几小时后,Dyn就受到第二次功击,运营再度遭到干扰。北京时间今天凌晨4点30分左右Dyn又受到第三次功击。
Dyn是日本最主要的DNS服务商,他们的主要职责就是将域名解析为IP地址,将网友引入正确的网站。此次Dyn遭到功击以后,会导致日本大部分地区网民在恳求链接某网站的时侯会失败,即使你按F5不断刷新也没有用。
很显然,这是一次有组织有蓄谋的网路功击行为,攻击行为来自超过一千万IP来源。此外,Dyn也表示这当中有几百万恶意功击的源头是物联网联系的所谓“智能”家居产品。Dyn的首席策略官Kyle York在电话会议上甚至说,黑客们“真正在做的是用每次功击撼动世界。”
单独借助人工智能或则工程师难以做到维护网路安全
网络安全的维护一般都是由工程师们完成的,但是一次又一次的网路黑客侵袭风波证明了,工程师们并没有绝对的掌握保障网路安全。那么假如由人工智能来接替工程师,是否能够保障网路安全呢?答案也是否定的。哪怕是新型混杂式系统,基于人工智能(AI)梳理数据,并将当前可疑行为递交给剖析人员,也仅才能测量85%的功击。
人工智能在维护网路安全上可以做到的自动化和漏洞修复技术包括:动态剖析(Dynamic Analysis)、静态剖析(Static Analysis)、符号执行(Symbolic Execution)、约束求解、数据流跟踪技术(Data Flow Tracking)以及模糊测试(Fuzz Testing)等,并和其他半自动化技术搭配,形成一整套全手动的网路决策推理系统(Cyber Reasoning System,CRS)。
很明显,人工智能才能在改善联通安全和网路安全方面发挥作用,做好避免网路恐吓逼抢和网路安全防御举措。但是,人工智能也只能测量到85%的功击,而并非100%。
由此可见,如果单独借助单独借助人工智能或则工程师,无法做到百分百的网路安全。
人工智能+工程师,合作以后或将构建更强大的网路安全
既然工程师和人工智能都难以单独在网路安全维护工作上取得压倒性成功,为什么不试着把三者整合上去呢?
在网路安全的世界里,以人为主的技术主要依赖专业人员完善的规则,因此不符合规则的功击就被错过。而初期网路安全方面的机器学习则依赖于异常检查,因此常常容易误报,“狼来了”太多,最终造成其并不被看好。
但是,随着人工智能技术的日渐发展,在现今的网路安全领域,它可以是一个虚拟的分析员,在发觉黑客攻击以后,第一时间交由人类分析员来判断,之后系统再把判定结果整合到模型中,作为下一个数据集的测量标准,然后不断循环这个过程。这也就意味着,在保证极大地提高检测率的同时,还可以提高未来的预测准确率。
因此,使用人工智能来学习并找到最有可能是功击的风波,然后交给人类专家去判定,并且协助人类工程师进行网路安全防护,是一个结合二者优势以后最有效的办法。
世界上并没有绝对的网路安全,防患于未然只是更好的选择
俗话说的好“魔高一尺道高一丈”,先有魔,后有道。如今的“道”,已经实现人工智能的广泛应用,而“魔”呢?黑客虽然已经实现完全自动化了......攻击的投放、发起、渗透,只是在其中几个小的步骤才须要人工介入,通过一个可视化界面管理着被渗透的全世界几十万台服务器。
其实面对现今的网路安全方式,每日就会有成百上千的崩溃报告、DDoS攻击、数据泄漏等功击行为,我们不应渴望“完美的防御”,而应当尽量提升功击成功率的门槛,降低功击成功率或是减短防御响应时间,形成正确的“安全观”。最后提醒你们,被功击只是时间而已,现在没有发生,未来必然发生。
您对昼夜使用的智能推荐系统了解多少? [Aix Smart]
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2020-08-08 20:29
我们知道推荐结果是通过推荐系统所需数据进行计算和处理的结果,并且计算和处理过程使用推荐算法. 如果我们将推荐系统所需的数据视为原材料,则推荐算法是装配线上的工人,根据程序对原材料进行处理和包装,然后将其存储在仓库(缓存层)中. 那么,更广泛使用的推荐算法是什么?
1. 基于神经网络的文本语义推荐算法
CB(基于内容的推荐),即根据用户的历史采集内容(项目),向用户推荐与其历史采集内容相似或相关的内容. 例如,在汽车信息场景中,用户阅读了很多有关“宝马”汽车的文章,然后该列表还将推荐类似于“宝马”汽车的文章. 值得注意的是,基于相似内容的推荐不仅涉及标题,而且还收录所有被认为具有计算价值的文本的相似性
2. 基于协同过滤的推荐算法
基于内容的推荐算法将带来一系列问题. 例如,它将允许用户进入信息茧室而不能执行冷启动(新用户)建议. 因此,在大多数业务场景中,需要将智能推荐应用于基于协作推荐算法(CF),并与CB推荐相结合. (CF)是一种算法,它指的是对哪种类型的数据进行协调,以及完成协作后如何进行过滤. 这些是(CF)算法的关键点.
协作推荐算法(CF)背后的逻辑是,每个人对自己利益的看法都是单方面的,并且是无知的. 即使您还没有看到任何东西,每个人都不知道也不知道他们是否会喜欢. 因此,CF依靠“群体共性”和“群体智慧”来挖掘出用户可能喜欢的那些潜在内容并将其推荐给用户. CF算法也是最早,最经典的推荐算法之一. 可以说CF算法是推荐算法的发起者. 我们的许多后续推荐算法都基于基于CF的协作过滤思想. 基于协作的推荐算法有两种: 基于用户的协作过滤算法和基于项目的协作过滤算法.
3. 基于用户行为的深度学习模型
随着技术的发展,深度学习的应用场景变得越来越广泛,并且已经进行了许多尝试将深度学习应用于行业中的推荐系统. 基于用户行为的深度学习模型首先被应用于中小型计算广告系统. 出于成本考虑,由于庞大的吞吐量和低延迟要求,大型计算广告系统通常使用简单的回归算法.
深度学习模型在推荐系统中有两个主要应用: 一是使用更精确的语义模型来进行项目相似度计算;二是将深度学习模型应用于推荐项目. 另一种是抽象用户行为并提取特征以预测点击概率;
4. 基于关联规则的推荐
在电子商务领域中广泛使用的另一种推荐算法是基于关联规则的推荐. 从本质上讲,它与协作过滤算法相似,不同之处在于它与用户自己的购买记录进行协作. 典型的故事是啤酒和尿布的故事. 尽管故事的来源不再可用,但它是当前最广泛认可的数据带来的好处的案例.
故事的内容是: 经过数据分析,北美的超市运营商发现,啤酒和尿布更有可能以相同的顺序出现. 因此,我进一步研究发现,家庭中购买尿布的大部分事情都是由家庭中的男人完成的,男人在购买尿布时总是会带几罐啤酒. 因此,通过调整货架位置,将尿布和啤酒放在一起,以便更多的男人在购买尿布时可以带一打啤酒. 结果,销售额大大增加了.
这个故事本身不能接受审查. 例如,尿布和啤酒总是总是一起买的,所以你不应该把它们放在一起,而要保持一定距离. 在移动线设计中,让用户浏览两种商品的过程,并放置其他一些男人会随身携带的商品,回报率可能更高. 我们暂时不会讨论这个故事的可信度. 这个故事反映了关联规则推荐背后的最简单逻辑: 我应该需要其他用户经常一起购买哪些产品.
通常,作为一种智能的内容分发平台,其内容分发方法多种多样. 内容平台包括算法分发,编辑(手动)分发,社交分发等,内容平台将根据自身特点选择高分发效率的分发方式. 总体来说,内容平台中存在多种分发方式.
例如,在新闻场景中,可能需要在指定位置显示固定类型的新闻,而其他推荐位置将使用算法进行分发. 例如,微博的热点是算法的分布,而以下各节的算法是纯粹基于订阅的社交分布. 还是在业务场景中,各种分配方法都以权重的形式参与了最终结果的表示. 例如,电子商务搜索部分不仅使用基于语义和用户行为的个性化搜索排名,而且还增加了主要产品,流量产品等的权重,因此这些产品在分发过程. 最上面的一个显示在用户的屏幕上. 当平台内容量大,用户规模达数千万甚至数千万时,信息和用户的有效匹配就显得尤为重要,它将自然通过各种方法提高分发效率.
3. 智能推荐与分类和搜索引擎有什么区别
在当今的互联网时代,我们大致经历了三种获取信息的方式: 目录,搜索引擎和智能推荐. 他们还催生了提供三种类型的信息获取服务的成功公司. 类别包括: Yahoo,Sina;搜索引擎: 谷歌,百度;明智的建议: ByteDance.
类别目录所涵盖的信息量是有限的,并且用户不容易找到不同类别的信息. 搜索引擎覆盖范围广,操作简单,但是用户必须提供准确的关键字. . 在当今的信息爆炸时代,用户依靠上述两种方法来准确地获取所需内容并不容易,尤其是当他们不了解所需内容的具体分类和精确关键字时. 明智的建议是通过计算用户行为数据,将最需要的信息主动推送给用户. 它与目录和搜索引擎之间的区别体现在这里.
推荐系统根据用户的静态属性和用户行为数据来匹配信息. 因为每个用户都有各自的差异,所以每个用户获得的信息都是不同的且个性化的,并且推荐系统传递的信息是主动而非被动的过程.
我们每个人都不能没有的在线购物向我们展示了明智推荐的优势和必要性. 有数千万种产品,搜索词也多种多样. 如果我们不依靠智能推荐系统为我们提供便利,那么我们可能很难找到我们真正想要的产品.
四个. 明智的推荐势在必行
无论它是什么平台,都必须构建一个智能的推荐系统,帮助用户发现内容并克服信息过载. 智能推荐系统正在潜移默化地影响着我们的生活,无论我们是否注意到它,我们都无法离开智能推荐系统. 作为您最了解您的“人”,它正在您和我周围活跃,不仅使该平台有利可图,而且为每个用户提供了更多便利.
这种积极推荐人们喜欢和需要的产品和信息的方式,可以迎合人类固有的惯性. 人们喜欢被动接收而不是主动搜索,特别是当信息是我们感兴趣的信息时. 如今,聪明的建议无处不在. 购物平台上的商品推荐,短视频平台上的视频推荐,娱乐平台上的音乐和电影推荐,新闻信息平台上的信息推荐,甚至社交平台上的朋友卡推荐,都依赖于此. 简而言之,在不同用户手中,每个应用程序可以相同或完全不同. 一切都会根据您的个性和喜好进行定义. 这是智能推荐的本质. 查看全部
(2)推荐算法
我们知道推荐结果是通过推荐系统所需数据进行计算和处理的结果,并且计算和处理过程使用推荐算法. 如果我们将推荐系统所需的数据视为原材料,则推荐算法是装配线上的工人,根据程序对原材料进行处理和包装,然后将其存储在仓库(缓存层)中. 那么,更广泛使用的推荐算法是什么?
1. 基于神经网络的文本语义推荐算法
CB(基于内容的推荐),即根据用户的历史采集内容(项目),向用户推荐与其历史采集内容相似或相关的内容. 例如,在汽车信息场景中,用户阅读了很多有关“宝马”汽车的文章,然后该列表还将推荐类似于“宝马”汽车的文章. 值得注意的是,基于相似内容的推荐不仅涉及标题,而且还收录所有被认为具有计算价值的文本的相似性
2. 基于协同过滤的推荐算法
基于内容的推荐算法将带来一系列问题. 例如,它将允许用户进入信息茧室而不能执行冷启动(新用户)建议. 因此,在大多数业务场景中,需要将智能推荐应用于基于协作推荐算法(CF),并与CB推荐相结合. (CF)是一种算法,它指的是对哪种类型的数据进行协调,以及完成协作后如何进行过滤. 这些是(CF)算法的关键点.
协作推荐算法(CF)背后的逻辑是,每个人对自己利益的看法都是单方面的,并且是无知的. 即使您还没有看到任何东西,每个人都不知道也不知道他们是否会喜欢. 因此,CF依靠“群体共性”和“群体智慧”来挖掘出用户可能喜欢的那些潜在内容并将其推荐给用户. CF算法也是最早,最经典的推荐算法之一. 可以说CF算法是推荐算法的发起者. 我们的许多后续推荐算法都基于基于CF的协作过滤思想. 基于协作的推荐算法有两种: 基于用户的协作过滤算法和基于项目的协作过滤算法.
3. 基于用户行为的深度学习模型
随着技术的发展,深度学习的应用场景变得越来越广泛,并且已经进行了许多尝试将深度学习应用于行业中的推荐系统. 基于用户行为的深度学习模型首先被应用于中小型计算广告系统. 出于成本考虑,由于庞大的吞吐量和低延迟要求,大型计算广告系统通常使用简单的回归算法.
深度学习模型在推荐系统中有两个主要应用: 一是使用更精确的语义模型来进行项目相似度计算;二是将深度学习模型应用于推荐项目. 另一种是抽象用户行为并提取特征以预测点击概率;
4. 基于关联规则的推荐
在电子商务领域中广泛使用的另一种推荐算法是基于关联规则的推荐. 从本质上讲,它与协作过滤算法相似,不同之处在于它与用户自己的购买记录进行协作. 典型的故事是啤酒和尿布的故事. 尽管故事的来源不再可用,但它是当前最广泛认可的数据带来的好处的案例.
故事的内容是: 经过数据分析,北美的超市运营商发现,啤酒和尿布更有可能以相同的顺序出现. 因此,我进一步研究发现,家庭中购买尿布的大部分事情都是由家庭中的男人完成的,男人在购买尿布时总是会带几罐啤酒. 因此,通过调整货架位置,将尿布和啤酒放在一起,以便更多的男人在购买尿布时可以带一打啤酒. 结果,销售额大大增加了.
这个故事本身不能接受审查. 例如,尿布和啤酒总是总是一起买的,所以你不应该把它们放在一起,而要保持一定距离. 在移动线设计中,让用户浏览两种商品的过程,并放置其他一些男人会随身携带的商品,回报率可能更高. 我们暂时不会讨论这个故事的可信度. 这个故事反映了关联规则推荐背后的最简单逻辑: 我应该需要其他用户经常一起购买哪些产品.
通常,作为一种智能的内容分发平台,其内容分发方法多种多样. 内容平台包括算法分发,编辑(手动)分发,社交分发等,内容平台将根据自身特点选择高分发效率的分发方式. 总体来说,内容平台中存在多种分发方式.
例如,在新闻场景中,可能需要在指定位置显示固定类型的新闻,而其他推荐位置将使用算法进行分发. 例如,微博的热点是算法的分布,而以下各节的算法是纯粹基于订阅的社交分布. 还是在业务场景中,各种分配方法都以权重的形式参与了最终结果的表示. 例如,电子商务搜索部分不仅使用基于语义和用户行为的个性化搜索排名,而且还增加了主要产品,流量产品等的权重,因此这些产品在分发过程. 最上面的一个显示在用户的屏幕上. 当平台内容量大,用户规模达数千万甚至数千万时,信息和用户的有效匹配就显得尤为重要,它将自然通过各种方法提高分发效率.
3. 智能推荐与分类和搜索引擎有什么区别
在当今的互联网时代,我们大致经历了三种获取信息的方式: 目录,搜索引擎和智能推荐. 他们还催生了提供三种类型的信息获取服务的成功公司. 类别包括: Yahoo,Sina;搜索引擎: 谷歌,百度;明智的建议: ByteDance.
类别目录所涵盖的信息量是有限的,并且用户不容易找到不同类别的信息. 搜索引擎覆盖范围广,操作简单,但是用户必须提供准确的关键字. . 在当今的信息爆炸时代,用户依靠上述两种方法来准确地获取所需内容并不容易,尤其是当他们不了解所需内容的具体分类和精确关键字时. 明智的建议是通过计算用户行为数据,将最需要的信息主动推送给用户. 它与目录和搜索引擎之间的区别体现在这里.
推荐系统根据用户的静态属性和用户行为数据来匹配信息. 因为每个用户都有各自的差异,所以每个用户获得的信息都是不同的且个性化的,并且推荐系统传递的信息是主动而非被动的过程.
我们每个人都不能没有的在线购物向我们展示了明智推荐的优势和必要性. 有数千万种产品,搜索词也多种多样. 如果我们不依靠智能推荐系统为我们提供便利,那么我们可能很难找到我们真正想要的产品.
四个. 明智的推荐势在必行
无论它是什么平台,都必须构建一个智能的推荐系统,帮助用户发现内容并克服信息过载. 智能推荐系统正在潜移默化地影响着我们的生活,无论我们是否注意到它,我们都无法离开智能推荐系统. 作为您最了解您的“人”,它正在您和我周围活跃,不仅使该平台有利可图,而且为每个用户提供了更多便利.
这种积极推荐人们喜欢和需要的产品和信息的方式,可以迎合人类固有的惯性. 人们喜欢被动接收而不是主动搜索,特别是当信息是我们感兴趣的信息时. 如今,聪明的建议无处不在. 购物平台上的商品推荐,短视频平台上的视频推荐,娱乐平台上的音乐和电影推荐,新闻信息平台上的信息推荐,甚至社交平台上的朋友卡推荐,都依赖于此. 简而言之,在不同用户手中,每个应用程序可以相同或完全不同. 一切都会根据您的个性和喜好进行定义. 这是智能推荐的本质.
Python学习笔记(20)自动点击京东产品的价格状况并智能地采集价格数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 564 次浏览 • 2020-08-07 19:49
1. 建立第一级主题以获取目标信息
建立第一级主题的规则,然后将所需的信息映射到排序框. 建议在完成内容映射后,还应进行定位标记映射,以提高定位精度和规则适应性.
**注意: **如果您设置了连续操作规则,则无需构建排序框. 例如,方案2的第一级主题不需要构建排序框,而是使用排序框来获取一些数据(选择页面一定会显示该信息)供爬虫程序确定是否执行采集,否则可能会错过网页.
二,设置连续动作
单击“新建”按钮创建一个新动作,每个动作的设置方法相同,基本操作如下:
2.1输入目标主题名称
连续动作指向同一目标对象. 如果有多个操作,并且您要指向不同的主题,请将它们分成多个规则并分别设置连续的操作.
2.2选择操作类型
这种情况是单击操作,并且不同操作的应用范围不同. 请根据实际操作情况选择动作类型.
2.3将位于动作对象的xpath填充到定位表达式中
2.4输入动作名称
告诉自己该步骤的用途,以便稍后进行修改.
2.5高级设置
不必先设置它,以后在调试连续动作时将使用它,这可以扩大适用的动作范围. 如果要捕获操作对象的信息,请使用xpath在高级设置的内容表达式中找到操作对象的信息. 请根据需要进行设置.
**注: **是否选择了动作类型以及xpath定位是否正确,请确定连续动作是否可以成功执行. Xpath是用于定位html节点的标准语言. 使用连续动作功能之前,请先掌握xpath.
根据人工步骤,我们还需要选择版本,购买方式1,购买方式2,因此我们将继续创建3个新操作并重复上述步骤.
三,调试规则
完成上述步骤后,单击“保存规则”,然后单击“爬网数据”按钮以开始试用捕获. 采集期间报告了一个错误: 无法找到节点***. 观察浏览器窗口,发现单击第一步后,未加载其他信息. 加载信息后,发现单击购买方法2后,无法返回执行四步单击的页面,从而导致连续执行连续动作.
鉴于上述情况,我们的解决方案是删除第四步. 因为无论您是否单击购买方法2,它都不会影响产品的价格. 因此,可以删除不必要的干扰步骤.
修改后,尝试再次捕获. 将提取的xml转换为excel后,我发现价格和累积评估数据被捕获或捕获不正确. 这是因为网页太大,加载速度太慢,并且单击后的数据将必须等待一段时间才能加载.
为了捕获所有数据,您需要延长等待时间并分别为每个操作设置延迟. 单击操作步骤->高级设置->额外延迟,然后输入以秒为单位的正整数. 请根据实际情况进行调试.
此外,如果不是顶部窗口,则在采集时将反复单击它. 这是因为京东网站上有一些防爬措施,这些措施必须是当前的窗口操作才能生效. 因此,请检查该窗口在高级设置中是否可见,并且在采集过程中该窗口将位于顶部. 请根据实际情况进行设置.
四个. 如何将捕获的信息与操作步骤一一对应?
如果要将捕获的信息与操作步骤一一对应,则必须提取操作对象的信息. 有两种方法:
4.1使用xpath在连续操作的高级设置的内容表达式中找到操作对象的信息节点.
在将定位表达式定位到动作对象的整个操作范围之后,它还收录其自己的信息. 因此,内容表达仅需要从定位的动作对象开始,并继续定位到其信息. 采集时,此步骤的信息将记录在actionvalue中,该值对应于actionno,后者记录该步骤的执行次数.
4.2在整理框中获取动作对象的信息,这里也使用xpath进行定位.
执行动作对象时,其dom结构将更改. 找到网页更改的结构特征,使用xpath精确定位节点,并在通过验证后,可以设置自定义xpath.
查看全部
**注意: **如果在执行操作之前和之后网页结构没有变化,则可以通过一条规则来完成;如果网页结构在前后变化,则必须通过两个或更多规则来完成;另外,如果涉及翻页,则分为两个或更多规则. 有关连续操作的规则数量,请参阅“计划获取过程”一文.
1. 建立第一级主题以获取目标信息
建立第一级主题的规则,然后将所需的信息映射到排序框. 建议在完成内容映射后,还应进行定位标记映射,以提高定位精度和规则适应性.
**注意: **如果您设置了连续操作规则,则无需构建排序框. 例如,方案2的第一级主题不需要构建排序框,而是使用排序框来获取一些数据(选择页面一定会显示该信息)供爬虫程序确定是否执行采集,否则可能会错过网页.
二,设置连续动作
单击“新建”按钮创建一个新动作,每个动作的设置方法相同,基本操作如下:
2.1输入目标主题名称
连续动作指向同一目标对象. 如果有多个操作,并且您要指向不同的主题,请将它们分成多个规则并分别设置连续的操作.
2.2选择操作类型
这种情况是单击操作,并且不同操作的应用范围不同. 请根据实际操作情况选择动作类型.
2.3将位于动作对象的xpath填充到定位表达式中
2.4输入动作名称
告诉自己该步骤的用途,以便稍后进行修改.
2.5高级设置
不必先设置它,以后在调试连续动作时将使用它,这可以扩大适用的动作范围. 如果要捕获操作对象的信息,请使用xpath在高级设置的内容表达式中找到操作对象的信息. 请根据需要进行设置.
**注: **是否选择了动作类型以及xpath定位是否正确,请确定连续动作是否可以成功执行. Xpath是用于定位html节点的标准语言. 使用连续动作功能之前,请先掌握xpath.
根据人工步骤,我们还需要选择版本,购买方式1,购买方式2,因此我们将继续创建3个新操作并重复上述步骤.
三,调试规则
完成上述步骤后,单击“保存规则”,然后单击“爬网数据”按钮以开始试用捕获. 采集期间报告了一个错误: 无法找到节点***. 观察浏览器窗口,发现单击第一步后,未加载其他信息. 加载信息后,发现单击购买方法2后,无法返回执行四步单击的页面,从而导致连续执行连续动作.
鉴于上述情况,我们的解决方案是删除第四步. 因为无论您是否单击购买方法2,它都不会影响产品的价格. 因此,可以删除不必要的干扰步骤.
修改后,尝试再次捕获. 将提取的xml转换为excel后,我发现价格和累积评估数据被捕获或捕获不正确. 这是因为网页太大,加载速度太慢,并且单击后的数据将必须等待一段时间才能加载.
为了捕获所有数据,您需要延长等待时间并分别为每个操作设置延迟. 单击操作步骤->高级设置->额外延迟,然后输入以秒为单位的正整数. 请根据实际情况进行调试.
此外,如果不是顶部窗口,则在采集时将反复单击它. 这是因为京东网站上有一些防爬措施,这些措施必须是当前的窗口操作才能生效. 因此,请检查该窗口在高级设置中是否可见,并且在采集过程中该窗口将位于顶部. 请根据实际情况进行设置.
四个. 如何将捕获的信息与操作步骤一一对应?
如果要将捕获的信息与操作步骤一一对应,则必须提取操作对象的信息. 有两种方法:
4.1使用xpath在连续操作的高级设置的内容表达式中找到操作对象的信息节点.
在将定位表达式定位到动作对象的整个操作范围之后,它还收录其自己的信息. 因此,内容表达仅需要从定位的动作对象开始,并继续定位到其信息. 采集时,此步骤的信息将记录在actionvalue中,该值对应于actionno,后者记录该步骤的执行次数.
4.2在整理框中获取动作对象的信息,这里也使用xpath进行定位.
执行动作对象时,其dom结构将更改. 找到网页更改的结构特征,使用xpath精确定位节点,并在通过验证后,可以设置自定义xpath.
煤矿安全隐患智能采集与智能决策系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 537 次浏览 • 2020-08-06 23:12
[摘要]: 分析和处理煤矿中的隐患对安全有效地生产煤矿非常重要,并受到许多煤矿企业的高度评价. 但是,大多数煤矿企业使用手动方法采集隐患数据并编写安全生产简报. 这种方法存在工作量大,效率低,输入信息混乱,输入信息不准确等问题. 一些煤矿企业还使用计算机软件来辅助数据处理,但是其基本数据存储还不够标准化,并且数据分析能力相对不足. 针对上述问题,本文应用卷积神经网络(CNN)语义映射算法,并对深蚁群算法(ACO)进行了改进,设计了煤矿安全隐患智能采集与智能决策系统. 该系统具有实时数据存储,跟踪和处理,风险管理与控制,分析和预警以及科学决策等功能. 本文首先介绍了煤矿安全隐患智能采集与决策系统的研究背景和意义,以及煤矿相关领域的国内外研究现状,分析了煤矿安全存在的问题. 从多方面,多角度的生产过程,并深入分析煤矿企业的实际情况,对项目的功能要求,建立煤矿安全隐患智能采集与智能决策系统框架进行研究. 根据要求,建立了煤矿安全隐患智能采集与决策系统数据库,并确定了数据表的详细字段. 在此基础上,将改进的CNN技术应用于煤矿隐患的智能采集领域,建立了基于CNN的智能采集模型,并应用ACO改进了隐患的智能检索和决策模型. 在煤矿中,以及从安全风险中使用C#等编程语言的方法七个功能模块,包括数据管理,安全隐患风险管理和控制以及煤矿文件管理,已经开发了智能采集和智能决策煤矿安全隐患系统. 最后,通过多次测试和实际应用,表明隐患智能采集与智能决策系统显着提高了隐患调查的效率和准确性,显着降低了煤矿安全隐患的发生频率,为煤矿安全隐患提供了保障. 煤矿安全生产. 图[61]表[8]参考. [52]
[语音记录]金融云业务网络智能搜集与综合分析实战
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2020-08-06 18:20
▌为什么要谈论虚拟网络采集
云山网络从2008年开始做SDN. 它已经探索了十年. 在云计算和云网络中,我们已经进行了研究和实践. 在此期间,我们看到了两个明显的网络变化. 第一: 网络流量模式的变化. 过去,该网络是具有南北向流量的烟囱架构. 现在,它已成为东西向交通. 据统计,数据中心网络中约80%的流量是东西向流量. 可以看出,东西方交通已成为主要交通方式.
第二个: 网络与企业脱节. 为什么这么说并不是说网络不再能够满足业务需求,而是网络与业务之间的关系越来越远. 那是什么意思?例如,在旧的传统网络中,我们可以从网络中提取流量,然后通过协议可以大致了解应用程序. 但是现在,由于存在一个底层网络和一个覆盖网络,因此我们遵循旧方法,并从提取的流量中看到了VXLAN封装和数据包. 即使解开封装,里面也有重复的IP.
因此,实际上很难发现当今云网络中运行的服务类型,因此该网络逐渐被边缘化. 在这种发展趋势下,日常网络使用以及运维将面临哪些挑战?接下来,我将分享两个典型示例.
每天发生的事件: 业务部门报告业务应用程序响应速度慢,并且网络存在问题,但是网络部门认为网络没有问题. 当然,业务部门不会批准它. 在那之后,有无休止的辩论,但是问题仍然没有解决之道,那么问题出在哪里?
让我们看一下网络的横截面. 对于网络部门来说,他们的视野是在底层网络中. 他们看到了交换机和链接,但是业务专注于虚拟机中的应用程序,因此这里存在一个很大的管理盲点,包括OVS,VGW,VFW和VLB. 这些都是非常重要的网络节点. 如果看不到内部网络状态,如何找到问题根源?或确定报告是否是网络问题. 此事件提醒我们,这是清楚了解虚拟网络中正在发生的事情的关键.
第二个例子发生在一家著名的证券公司. 众所周知,证券行业具有一系列安全要求,例如证券和证券监管. 因此,安全部门对网络部门提出了一个要求: 核心业务系统中关键业务组件的网络流量被导出以进行安全分析,数据审核等.
接下来,为了满足这一需求,网络部门制定了一个计划,通过流表来镜像虚拟网络. 但是,在POC过程中,结果并不理想. 流镜像与流表混合在一起,编排非常复杂. 此外,在迁移虚拟机时,无法自动更新镜像策略,无法实施最终解决方案,需求也就消失了.
后来,发生了更严重的事情. 该公司发生了事故,导致用户信息泄漏. 这种事件可谓是证券业的重大失败. 此时,安全部门必须负责. 同时,网络部门不满意. 安全部门的需求,网络部门和安全部门都负责整个事件.
结合以上两个示例,不难看出在云网络中,业务网络的采集,分析和分发已成为云网络构建的标准配置,如果要采集虚拟网络流量,所有的采集方法和解决方案都必须安全可靠,而且不影响生产.
▌计划和价值
如何解决上述问题,是云山DeepFlow数据中心虚拟网络流量采集分析平台(以下简称DeepFlow)所能做的. 这张照片是最左边的采集部分. 我们知道目前的业务范围非常广泛. 它可能涉及私有云和公共云. 云杉DeepFlow同时涵盖了这些环境. 通过部署DeepFlow,您可以帮助您查看所有业务. 对于所有VPC网络状态,管理员等效于站在高处从多个维度查看云网络的全景,这更便于管理. 同时,您也可以关注业务,例如右上角的图,转到某个VPC网络,观察数据中有多少个网络组件,并根据每个点查看相应的网络信息. 和线.
我们还对采集技术的安全性和可靠性进行了许多优化. 首先,DeepFlow采集器支持500个节点以覆盖大多数数据中心.
第二个是高性能,单个采集点支持10G流量采集. 安全可靠. 特殊阈值用于控制CPU,内存和网络资源的消耗,因此不会影响生产网络. 当发生迁移时,我们的策略也可以及时更新,而不会中断采集到的流量.
简而言之,Spruce DeepFlow采集的虚拟网络流量使我们能够查看虚拟网络上正在发生的事情,涵盖管理盲点. 一旦发生故障,我们可以快速定位,同时,我们可以快速推断出问题的根本原因,并提高操作和维护效率. 其次,采集虚拟网络流量后,您不仅可以自己对其进行分析,还可以将其分发给第三方工具,以帮助数据审核满足安全合规性要求. 第三,从运营商的角度来看整个云网络.
▌应用实践
我想再告诉您两个DeepFlow数据中心虚拟网络流量采集,分析和分发的示例. 首先是故障定位事件. 使用DeepFlow回溯分析功能可以轻松找到问题的根本原因. 怎么做?将事件发生时的虚拟网络流量与正常时间的虚拟网络流量进行比较,结果发现存在明显的异常网络指示,大量网络数据包,非常大的网络延迟等. 导致异常现象的原因是谁?
通过Spruce DeepFlow的细粒度采集功能,发现数据库将大量流量发送到某个IP地址. 看到这种现象后,立即采取回测措施. 回测意味着这种异常现象是过去偶然发生的. 它是经常发生还是定期发生?经过这一系列步骤之后,我们最终得出结论,为什么数据库不断发送数据,实际上是因为最近已安装了新的数据库备份系统,但是当配置了该策略时,时间参数是错误的,通常是一天时间备份,由于时间错误,导致每小时备份一次,因此数据库连续发送出去,数据库信息不断备份,占用了实际的生产资源,最终导致运行缓慢的现象业务.
在其他情况下,我看到了一些有趣的问题. 有时,负载平衡配置不正确,这会导致背面的资源不平衡. 服务器可能有很多虚拟机流量,而其他服务器则是免费的. 或将数据设置为由特定服务器处理,但是由于负载平衡配置错误,固定流量将被散列.
在讨论第二个示例之前,请回顾一下安全部门刚才向网络部门提出的要求,以导出虚拟机的流量以进行安全审核和分析. 实际上,此问题可以在部署DeepFlow之后轻松地采集虚拟网络流量,并将其同时分发到两个后端分析工具资源池. 为什么我们两个?实际上,它可以用作备份,因为数据对于安全,审计和分析部门非常重要.
▌摘要
DeepFlow拥有专利的虚拟流采集技术具有大规模,零干扰,无依赖性,过载保护和预处理的优点. 支持VMware和OpenStack平台,没有版本依赖性. 一个控制器可以管理500个采集点,而无需在生产网络的虚拟交换机上进行其他策略配置. 它支持数据包的重复数据删除,过滤和截断等操作,并支持用户配置采集器的资源使用情况,以确保生产环境的稳定性.
云山网络已经对SDN云网络进行了相应的研究和应用,并在过去十年中得到了资本和客户的认可. 目前,Spruce Network的融资额超过1亿美元,并且有许多成功的财富500强客户案例. 它已部署在金融,电信,电力和教育行业的近100家企业中,其中包括平安科技,工业数字金融,甜橙金融,中国移动,国家电网,苏州国家科学数据中心以及其他基准客户. 成为企业云数据中心网络稳定高效运行的典范.
! !福利! !下载“金融云业务网络的智能采集和集成分析”的语音PPT,可以通过在微信背景中回复“语音PPT”获得.
◆◆◆
相关阅读 查看全部
大家好,让我先自我介绍. 我是云山网络公司的吴玉华. 今天,我想与您分享有关金融云业务网络的采集,分析和分发的实用故事. 在开始讨论之前,我想与您讨论一个问题: 为什么我们需要采集虚拟网络流量.
▌为什么要谈论虚拟网络采集
云山网络从2008年开始做SDN. 它已经探索了十年. 在云计算和云网络中,我们已经进行了研究和实践. 在此期间,我们看到了两个明显的网络变化. 第一: 网络流量模式的变化. 过去,该网络是具有南北向流量的烟囱架构. 现在,它已成为东西向交通. 据统计,数据中心网络中约80%的流量是东西向流量. 可以看出,东西方交通已成为主要交通方式.
第二个: 网络与企业脱节. 为什么这么说并不是说网络不再能够满足业务需求,而是网络与业务之间的关系越来越远. 那是什么意思?例如,在旧的传统网络中,我们可以从网络中提取流量,然后通过协议可以大致了解应用程序. 但是现在,由于存在一个底层网络和一个覆盖网络,因此我们遵循旧方法,并从提取的流量中看到了VXLAN封装和数据包. 即使解开封装,里面也有重复的IP.
因此,实际上很难发现当今云网络中运行的服务类型,因此该网络逐渐被边缘化. 在这种发展趋势下,日常网络使用以及运维将面临哪些挑战?接下来,我将分享两个典型示例.
每天发生的事件: 业务部门报告业务应用程序响应速度慢,并且网络存在问题,但是网络部门认为网络没有问题. 当然,业务部门不会批准它. 在那之后,有无休止的辩论,但是问题仍然没有解决之道,那么问题出在哪里?
让我们看一下网络的横截面. 对于网络部门来说,他们的视野是在底层网络中. 他们看到了交换机和链接,但是业务专注于虚拟机中的应用程序,因此这里存在一个很大的管理盲点,包括OVS,VGW,VFW和VLB. 这些都是非常重要的网络节点. 如果看不到内部网络状态,如何找到问题根源?或确定报告是否是网络问题. 此事件提醒我们,这是清楚了解虚拟网络中正在发生的事情的关键.
第二个例子发生在一家著名的证券公司. 众所周知,证券行业具有一系列安全要求,例如证券和证券监管. 因此,安全部门对网络部门提出了一个要求: 核心业务系统中关键业务组件的网络流量被导出以进行安全分析,数据审核等.
接下来,为了满足这一需求,网络部门制定了一个计划,通过流表来镜像虚拟网络. 但是,在POC过程中,结果并不理想. 流镜像与流表混合在一起,编排非常复杂. 此外,在迁移虚拟机时,无法自动更新镜像策略,无法实施最终解决方案,需求也就消失了.
后来,发生了更严重的事情. 该公司发生了事故,导致用户信息泄漏. 这种事件可谓是证券业的重大失败. 此时,安全部门必须负责. 同时,网络部门不满意. 安全部门的需求,网络部门和安全部门都负责整个事件.
结合以上两个示例,不难看出在云网络中,业务网络的采集,分析和分发已成为云网络构建的标准配置,如果要采集虚拟网络流量,所有的采集方法和解决方案都必须安全可靠,而且不影响生产.
▌计划和价值
如何解决上述问题,是云山DeepFlow数据中心虚拟网络流量采集分析平台(以下简称DeepFlow)所能做的. 这张照片是最左边的采集部分. 我们知道目前的业务范围非常广泛. 它可能涉及私有云和公共云. 云杉DeepFlow同时涵盖了这些环境. 通过部署DeepFlow,您可以帮助您查看所有业务. 对于所有VPC网络状态,管理员等效于站在高处从多个维度查看云网络的全景,这更便于管理. 同时,您也可以关注业务,例如右上角的图,转到某个VPC网络,观察数据中有多少个网络组件,并根据每个点查看相应的网络信息. 和线.
我们还对采集技术的安全性和可靠性进行了许多优化. 首先,DeepFlow采集器支持500个节点以覆盖大多数数据中心.
第二个是高性能,单个采集点支持10G流量采集. 安全可靠. 特殊阈值用于控制CPU,内存和网络资源的消耗,因此不会影响生产网络. 当发生迁移时,我们的策略也可以及时更新,而不会中断采集到的流量.
简而言之,Spruce DeepFlow采集的虚拟网络流量使我们能够查看虚拟网络上正在发生的事情,涵盖管理盲点. 一旦发生故障,我们可以快速定位,同时,我们可以快速推断出问题的根本原因,并提高操作和维护效率. 其次,采集虚拟网络流量后,您不仅可以自己对其进行分析,还可以将其分发给第三方工具,以帮助数据审核满足安全合规性要求. 第三,从运营商的角度来看整个云网络.
▌应用实践
我想再告诉您两个DeepFlow数据中心虚拟网络流量采集,分析和分发的示例. 首先是故障定位事件. 使用DeepFlow回溯分析功能可以轻松找到问题的根本原因. 怎么做?将事件发生时的虚拟网络流量与正常时间的虚拟网络流量进行比较,结果发现存在明显的异常网络指示,大量网络数据包,非常大的网络延迟等. 导致异常现象的原因是谁?
通过Spruce DeepFlow的细粒度采集功能,发现数据库将大量流量发送到某个IP地址. 看到这种现象后,立即采取回测措施. 回测意味着这种异常现象是过去偶然发生的. 它是经常发生还是定期发生?经过这一系列步骤之后,我们最终得出结论,为什么数据库不断发送数据,实际上是因为最近已安装了新的数据库备份系统,但是当配置了该策略时,时间参数是错误的,通常是一天时间备份,由于时间错误,导致每小时备份一次,因此数据库连续发送出去,数据库信息不断备份,占用了实际的生产资源,最终导致运行缓慢的现象业务.
在其他情况下,我看到了一些有趣的问题. 有时,负载平衡配置不正确,这会导致背面的资源不平衡. 服务器可能有很多虚拟机流量,而其他服务器则是免费的. 或将数据设置为由特定服务器处理,但是由于负载平衡配置错误,固定流量将被散列.
在讨论第二个示例之前,请回顾一下安全部门刚才向网络部门提出的要求,以导出虚拟机的流量以进行安全审核和分析. 实际上,此问题可以在部署DeepFlow之后轻松地采集虚拟网络流量,并将其同时分发到两个后端分析工具资源池. 为什么我们两个?实际上,它可以用作备份,因为数据对于安全,审计和分析部门非常重要.
▌摘要
DeepFlow拥有专利的虚拟流采集技术具有大规模,零干扰,无依赖性,过载保护和预处理的优点. 支持VMware和OpenStack平台,没有版本依赖性. 一个控制器可以管理500个采集点,而无需在生产网络的虚拟交换机上进行其他策略配置. 它支持数据包的重复数据删除,过滤和截断等操作,并支持用户配置采集器的资源使用情况,以确保生产环境的稳定性.
云山网络已经对SDN云网络进行了相应的研究和应用,并在过去十年中得到了资本和客户的认可. 目前,Spruce Network的融资额超过1亿美元,并且有许多成功的财富500强客户案例. 它已部署在金融,电信,电力和教育行业的近100家企业中,其中包括平安科技,工业数字金融,甜橙金融,中国移动,国家电网,苏州国家科学数据中心以及其他基准客户. 成为企业云数据中心网络稳定高效运行的典范.
! !福利! !下载“金融云业务网络的智能采集和集成分析”的语音PPT,可以通过在微信背景中回复“语音PPT”获得.
◆◆◆
相关阅读
AI文章智能处理软件版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2020-08-06 09:11
软件功能
1. 人工智能写诗
使用AI技术让机器学习很多诗歌写作技巧,然后根据用户输入的指导句子创建原创诗歌
2,人工智能写散文
允许机器通过AI技术学习很多散文写作技巧,然后根据用户输入的指导句子创建原创散文
3. 文章采集
常规文章采集: 自己编写采集规则,采集指定的文章,采集稳定且不会卡住,支持获取和发布采集,编写规则简单易操作.
4. 一键式采集(无需编写规则即可采集文章)
门户新闻: 支持搜狐新闻,腾讯新闻,新浪新闻,凤凰新闻和网易新闻的一键式采集.
5. 文章组合
材料智能组合: 通过提供不同的文章材料,该软件提取核心内容,然后根据内容将其组合为文章.
6. 原创性优化(用于处理以提高文章的原创性)
批次独创性优化: 批量改进文章独创性操作.
7. 流量点击优化
通过模拟手动搜索和查看流量不同的网站,模拟真实流量以优化网站排名.
软件功能
1. AI文章智能处理软件具有丰富的功能,可帮助用户快速处理其文章
2,您可以在软件中编辑文章,可以在软件中快速修改文章
3. 支持文章比较,检查导入文章是否有差异
4. 支持和比较Internet上的文章,以分析当前文章是否重复
5. 支持网站优化,可以增加您的网站流量
6. 支持文字统计,将文章粘贴到软件中即可立即对字数进行计数
7. 您还可以查看网站排名,还可以查询文章排名
8,您可以快速编辑散文,可以快速编辑诗歌
使用说明
1. 双击aiV2.2.exe进行安装,安装完成后,打开AI文章智能处理软件.exe
2. 提示登录,在软件界面中输入您的帐户登录
3. 显然,我没有该软件的帐户,因此无法登录. 您可以转到官方网站获取帐户
4. 进入官方网站,点击右上角进入注册界面. 编辑者访问时,提示“抱歉,该站点当前禁止新用户注册”
5. 非年度版本将具有一些功能限制,例如“ AI Write Poetry”和“ AI Write Prose”. 非年度版本的用户每天只能生成100篇文章.
6. 如果您可以输入软件,则显示的界面是这样的,您可以在软件中找到所需的功能
7. 收录查询功能,查询您在软件界面中收录的内容
8. 图片下载功能,在软件界面下载所需图片,搜索后下载
9. 源代码查看功能,在软件界面中查看采集的源代码内容,并输入地址以采集源代码
10. 文本统计功能,在软件底部显示当前文本数,您可以检查输入了多少个单词
11. 热门词查看功能,您可以在软件界面中查看百度搜索词并查看360个热门词
12. 文本加密功能,如果需要对编辑的文本进行加密,可以在此处进行操作,输入密码以获取密文
13. 文字转码功能,如果需要转换文字编码,可以在这里操作
14. 支持优化功能,可以在软件界面中优化网站,可以选择优化关键字
15. 在此处显示与优化相关的设置,您可以选择浏览器优化,可以选择搜索引擎优化
16. 也可以在软件界面上查看百度的推送功能,输入地址并单击以开始提交
17. 关键字查看功能,在软件中输入关键字即可立即显示排名
18. 网站排名功能,如果需要了解网站的排名,可以在软件界面中输入
19. 发布功能,您可以在软件界面中设置文章的自动更新方法,并在软件下设置发布时间
20. 发布文章的基本设置功能,在软件中检查网站地址,并在底部检查需要发布的内容
21. 摘要提取功能,将文章复制到软件中以立即对其进行提取,然后软件会自动识别摘要内容
22. 原创检测功能,如果需要分析当前复制的文章是否为原创,可以在软件界面中找到
23. 分析之后,您可以选择导出HTML或TXT
24. 单一文章检测功能,您可以通过在软件界面中输入文章内容立即分析文章内容是否与在线内容重复
25. AI文章智能处理软件具有非常强大的功能. 我不会在这里介绍. 如果需要,请下载! 查看全部
AI文章智能处理软件提供了20多种功能来帮助用户处理文章. 您可以直接在软件界面中修改文章,检测修改后文章的原创性,并可以翻译复制的英语内容和文章内容. Acquisition允许软件自动编辑诗歌和散文. 有许多内置功能. 打开软件,您可以查看所有功能,以便用户在处理文章时可以获得更多操作. 该软件仍然非常易于使用. 多数功能一键即可使用,没有复杂的设置内容,需要注意的是用户需要登录官方注册帐户!
软件功能
1. 人工智能写诗
使用AI技术让机器学习很多诗歌写作技巧,然后根据用户输入的指导句子创建原创诗歌
2,人工智能写散文
允许机器通过AI技术学习很多散文写作技巧,然后根据用户输入的指导句子创建原创散文
3. 文章采集
常规文章采集: 自己编写采集规则,采集指定的文章,采集稳定且不会卡住,支持获取和发布采集,编写规则简单易操作.
4. 一键式采集(无需编写规则即可采集文章)
门户新闻: 支持搜狐新闻,腾讯新闻,新浪新闻,凤凰新闻和网易新闻的一键式采集.
5. 文章组合
材料智能组合: 通过提供不同的文章材料,该软件提取核心内容,然后根据内容将其组合为文章.
6. 原创性优化(用于处理以提高文章的原创性)
批次独创性优化: 批量改进文章独创性操作.
7. 流量点击优化
通过模拟手动搜索和查看流量不同的网站,模拟真实流量以优化网站排名.
软件功能
1. AI文章智能处理软件具有丰富的功能,可帮助用户快速处理其文章
2,您可以在软件中编辑文章,可以在软件中快速修改文章
3. 支持文章比较,检查导入文章是否有差异
4. 支持和比较Internet上的文章,以分析当前文章是否重复
5. 支持网站优化,可以增加您的网站流量
6. 支持文字统计,将文章粘贴到软件中即可立即对字数进行计数
7. 您还可以查看网站排名,还可以查询文章排名
8,您可以快速编辑散文,可以快速编辑诗歌
使用说明
1. 双击aiV2.2.exe进行安装,安装完成后,打开AI文章智能处理软件.exe
2. 提示登录,在软件界面中输入您的帐户登录
3. 显然,我没有该软件的帐户,因此无法登录. 您可以转到官方网站获取帐户
4. 进入官方网站,点击右上角进入注册界面. 编辑者访问时,提示“抱歉,该站点当前禁止新用户注册”
5. 非年度版本将具有一些功能限制,例如“ AI Write Poetry”和“ AI Write Prose”. 非年度版本的用户每天只能生成100篇文章.
6. 如果您可以输入软件,则显示的界面是这样的,您可以在软件中找到所需的功能
7. 收录查询功能,查询您在软件界面中收录的内容
8. 图片下载功能,在软件界面下载所需图片,搜索后下载
9. 源代码查看功能,在软件界面中查看采集的源代码内容,并输入地址以采集源代码
10. 文本统计功能,在软件底部显示当前文本数,您可以检查输入了多少个单词
11. 热门词查看功能,您可以在软件界面中查看百度搜索词并查看360个热门词
12. 文本加密功能,如果需要对编辑的文本进行加密,可以在此处进行操作,输入密码以获取密文
13. 文字转码功能,如果需要转换文字编码,可以在这里操作
14. 支持优化功能,可以在软件界面中优化网站,可以选择优化关键字
15. 在此处显示与优化相关的设置,您可以选择浏览器优化,可以选择搜索引擎优化
16. 也可以在软件界面上查看百度的推送功能,输入地址并单击以开始提交
17. 关键字查看功能,在软件中输入关键字即可立即显示排名
18. 网站排名功能,如果需要了解网站的排名,可以在软件界面中输入
19. 发布功能,您可以在软件界面中设置文章的自动更新方法,并在软件下设置发布时间
20. 发布文章的基本设置功能,在软件中检查网站地址,并在底部检查需要发布的内容
21. 摘要提取功能,将文章复制到软件中以立即对其进行提取,然后软件会自动识别摘要内容
22. 原创检测功能,如果需要分析当前复制的文章是否为原创,可以在软件界面中找到
23. 分析之后,您可以选择导出HTML或TXT
24. 单一文章检测功能,您可以通过在软件界面中输入文章内容立即分析文章内容是否与在线内容重复
25. AI文章智能处理软件具有非常强大的功能. 我不会在这里介绍. 如果需要,请下载!
我们如何谈论智能制造?
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-08-05 23:04
根据不完全统计,制造业的信息孤岛被打破了. 至少有60-70%的信息孤岛存在于离散行业中,而在连续的平滑行业中,信息孤岛现象约占50%. 从这个角度来看,可以修改和利用的数据采集和传输空间确实太大了,我们无法想象. 当然,肯定会有很多制造人员抱怨: “我们都知道数据采集的重要性,并且还在用你的话说吗?但是问题在于如何采集数据,我们无从下手. ”
这是我今天要谈论的问题,如何采集和传输数据. 问题在于,许多国内工厂使用的生产设备要么设备比较旧,要么多个供应商使用的设备没有标准的统一接口,而且多个设备使用的系统也大不相同. 这样,关于数据的采集就更加困难. 统一转换后,能否使用统一的行业数据标准对获取的标准数据进行处理?这些问题使我们感到困扰. 实际上,国外的制造商也遇到了麻烦,因此在这里我们不得不提及这样一个国际组织-OPC基金会. 我们对中国的这个组织有点陌生,但国外长期以来一直积极支持这种组织. OPC基金会有220多个国际成员. 它的成员遍布世界各地,包括世界上所有主要的自动化控制系统,仪器和过程控制系统公司. 这种组织的真正诞生在于对OPC标准的管理(用于过程控制的OLE,用于过程控制的OLE是统一的工业交互性标准). OPC包括用于过程控制和制造自动化系统的一组标准接口,属性和方法. OPC可以理解为一种平台技术,因此无论客户端是谁,只要客户端的软件程序可以理解OPC,就可以顺利地从设备中采集和传输数据.
为什么选择OPC UA?
德国工业4.0,美国工业互联网到中国的智能制造,政府已正式推荐将OPC协议作为统一的工业交互标准. 在成功应用OPC Classic之后,OPC基金会于2008年发布了OPC统一体系结构(UA)统一体系结构. OPCUA涵盖了OPC实时数据访问规范(OPC DA),OPC历史数据访问规范(OPC HDA),在OPC警报事件访问规范(OPC A&E)和OPC安全协议(OPC Security)的不同方面,OPC UA将每个OPC Classic规范的所有功能集成到一个可扩展的框架中,该框架是独立于平台且面向服务的. 在当前市场中,除了主流自动化供应商之外,微软,华为和思科等IT领域都已成为OPC UA的积极支持者,那么为什么每个人都选择OPC UA?首先,OPC UA解决了不同系统之间的语义互操作,OPC UA是独立的国际标准. 它可以建立一定的信息模型,即插即用,并且具有强大的安全保护,因此这种技术无疑是选择的充分理由.
以下图片更清楚,更全面地说明了选择的原因:
由于市场上有太多有关OPC技术的软件提供商,我只想提及Matrikon,他是在OPC技术上取得了巨大成就的ace制造商. 该制造商基本上是OPC. 该基金会同时成立,并且也是该基金会中最强大的成员. 其产品拥有60%的市场份额. 这个数字也相当惊人(几乎是垄断). 他们的Matrikon OPC UA现在是王牌的主要产品. 为了避免怀疑广告,每个人都想最大程度地了解OPC UA或OPC的技术细节,例如技术架构和相关产品,请自行单击以下链接: / product / 4056
到目前为止,超过4,200个供应商已经在超过1,700万个应用领域中生产了35,000多种不同类型的OPC产品,仅在工程资源上就节省了数十亿美元. 因此,如果您真的想实现智能制造,则应从工业数据采集和传输开始. 认为OPC技术为我们提供了最方便,最全面的技术支持,对工业制造的优化和改造确实是一项伟大的壮举. 查看全部
无论是转向智能制造还是使用优化生产过程的MES系统,都需要一个主要前提,即,需要采集工业设备的数据,然后才能在下次使用和分析数据之前步骤.
根据不完全统计,制造业的信息孤岛被打破了. 至少有60-70%的信息孤岛存在于离散行业中,而在连续的平滑行业中,信息孤岛现象约占50%. 从这个角度来看,可以修改和利用的数据采集和传输空间确实太大了,我们无法想象. 当然,肯定会有很多制造人员抱怨: “我们都知道数据采集的重要性,并且还在用你的话说吗?但是问题在于如何采集数据,我们无从下手. ”
这是我今天要谈论的问题,如何采集和传输数据. 问题在于,许多国内工厂使用的生产设备要么设备比较旧,要么多个供应商使用的设备没有标准的统一接口,而且多个设备使用的系统也大不相同. 这样,关于数据的采集就更加困难. 统一转换后,能否使用统一的行业数据标准对获取的标准数据进行处理?这些问题使我们感到困扰. 实际上,国外的制造商也遇到了麻烦,因此在这里我们不得不提及这样一个国际组织-OPC基金会. 我们对中国的这个组织有点陌生,但国外长期以来一直积极支持这种组织. OPC基金会有220多个国际成员. 它的成员遍布世界各地,包括世界上所有主要的自动化控制系统,仪器和过程控制系统公司. 这种组织的真正诞生在于对OPC标准的管理(用于过程控制的OLE,用于过程控制的OLE是统一的工业交互性标准). OPC包括用于过程控制和制造自动化系统的一组标准接口,属性和方法. OPC可以理解为一种平台技术,因此无论客户端是谁,只要客户端的软件程序可以理解OPC,就可以顺利地从设备中采集和传输数据.
为什么选择OPC UA?
德国工业4.0,美国工业互联网到中国的智能制造,政府已正式推荐将OPC协议作为统一的工业交互标准. 在成功应用OPC Classic之后,OPC基金会于2008年发布了OPC统一体系结构(UA)统一体系结构. OPCUA涵盖了OPC实时数据访问规范(OPC DA),OPC历史数据访问规范(OPC HDA),在OPC警报事件访问规范(OPC A&E)和OPC安全协议(OPC Security)的不同方面,OPC UA将每个OPC Classic规范的所有功能集成到一个可扩展的框架中,该框架是独立于平台且面向服务的. 在当前市场中,除了主流自动化供应商之外,微软,华为和思科等IT领域都已成为OPC UA的积极支持者,那么为什么每个人都选择OPC UA?首先,OPC UA解决了不同系统之间的语义互操作,OPC UA是独立的国际标准. 它可以建立一定的信息模型,即插即用,并且具有强大的安全保护,因此这种技术无疑是选择的充分理由.
以下图片更清楚,更全面地说明了选择的原因:
由于市场上有太多有关OPC技术的软件提供商,我只想提及Matrikon,他是在OPC技术上取得了巨大成就的ace制造商. 该制造商基本上是OPC. 该基金会同时成立,并且也是该基金会中最强大的成员. 其产品拥有60%的市场份额. 这个数字也相当惊人(几乎是垄断). 他们的Matrikon OPC UA现在是王牌的主要产品. 为了避免怀疑广告,每个人都想最大程度地了解OPC UA或OPC的技术细节,例如技术架构和相关产品,请自行单击以下链接: / product / 4056
到目前为止,超过4,200个供应商已经在超过1,700万个应用领域中生产了35,000多种不同类型的OPC产品,仅在工程资源上就节省了数十亿美元. 因此,如果您真的想实现智能制造,则应从工业数据采集和传输开始. 认为OPC技术为我们提供了最方便,最全面的技术支持,对工业制造的优化和改造确实是一项伟大的壮举.
AI文章智能处理软件 V2.1 最新版
采集交流 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2020-08-04 19:03
主要功能:
1.智能伪原创:利用人工智能中的自然语言处理技术实现文章的伪原创处理。核心功能是“智能伪原创”,“同义替换伪原始”,“反义替换伪原始”,“随机插入关键词与html代码”,“句子重组”等,处理过的文章既有创意包含率在80%以上。有关更多功能,请下载软件试用版。
2,门户文章集:一键搜索集相关门户新闻文章,该网站有搜狐,腾讯,新浪,网易,今日新闻,新蓝,联合晚报,光明网站,网站管理员。 com,新文化网路等,用户可以输入行业关键词来搜索所需的行业文章。该模块的特征是它不需要编写采集规则跟一键操作。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
3,百度新闻采访:一键搜索各类行业新闻文章,数据源到百度新闻搜索引擎,资源丰富,操作灵活,不需要写任何收集规则,但缺点是收集文章不一定完整,但可以满足大多数用户的需求。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
4,行业文章集:一键搜索相关行业网站文章,网站行业有装饰家具产业,机械市场,建材产业,家电市场,五金产业,美容行业,幼儿行业,金融市场,游戏产业, SEO行业,女性健康产业等。网站上有数十个网站,资源丰富。此模块可能难以满足所有客户的需求,但客户可以提出请求,我们将改进和更新模块资源。该模块的特征是它不需要编写采集规则跟一键操作。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
5,写规则集合:自己撰写集合规则,集合规则符合通常正则表达式,写集合规则必须知道一些html代码跟正则表达式规则,如果你有其他商家的书面收集规则,那么需要我们将编写我们软件的搜集规则,我们有文档提供撰写收集的规则。我们不帮客户写收集规则,如果必须写,10元的收购规则。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
6,外链文章材料:该模块是通过大量的市场语料库,通过算法随机组合的语料库制作相关产业文章,该模块文章仅适用于文章质量要求不高,为外部链促销用户,模块的特性,资源丰富,原创性高,但缺点是文章可读性差,用户在使用时可以选择性地使用。
7.批量生产标题:有两个功能,一个是按关键字和规则组合批量生产标题,二是通过收集网络大数据获取标题。自动生成的促销准确性很高,捕获的标题是可读的,每个都有特点跟缺点。
8,文章界面公布:通过简单的配置,生成的文章发布至您自己的网站。目前支持的网站有,Discuz Portal,DedeCms,Empire ECMS(新闻),PHMCMS,Zibo CMS,PHP168,diypage,phpwind门户。
9,SEO批量查询工具:权重批量查询,排序批量查询,包含批量查询,长尾词挖掘,代码批量转换,文本加密和解密。 查看全部
AI文章智能处理软件(文章智能AI组合工具)是一款非常优秀好用的文章伪原创辅助工具。这款AI文章智能处理硬件功能强大全面,简单易用,使用后可以帮助用户轻松的进行文章智能AI组合。用户可以使用该硬件重新组合文章并将其转换为新文章,这相当适合媒体用户。有必须的同学快来下载使用吧!
主要功能:
1.智能伪原创:利用人工智能中的自然语言处理技术实现文章的伪原创处理。核心功能是“智能伪原创”,“同义替换伪原始”,“反义替换伪原始”,“随机插入关键词与html代码”,“句子重组”等,处理过的文章既有创意包含率在80%以上。有关更多功能,请下载软件试用版。
2,门户文章集:一键搜索集相关门户新闻文章,该网站有搜狐,腾讯,新浪,网易,今日新闻,新蓝,联合晚报,光明网站,网站管理员。 com,新文化网路等,用户可以输入行业关键词来搜索所需的行业文章。该模块的特征是它不需要编写采集规则跟一键操作。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
3,百度新闻采访:一键搜索各类行业新闻文章,数据源到百度新闻搜索引擎,资源丰富,操作灵活,不需要写任何收集规则,但缺点是收集文章不一定完整,但可以满足大多数用户的需求。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
4,行业文章集:一键搜索相关行业网站文章,网站行业有装饰家具产业,机械市场,建材产业,家电市场,五金产业,美容行业,幼儿行业,金融市场,游戏产业, SEO行业,女性健康产业等。网站上有数十个网站,资源丰富。此模块可能难以满足所有客户的需求,但客户可以提出请求,我们将改进和更新模块资源。该模块的特征是它不需要编写采集规则跟一键操作。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
5,写规则集合:自己撰写集合规则,集合规则符合通常正则表达式,写集合规则必须知道一些html代码跟正则表达式规则,如果你有其他商家的书面收集规则,那么需要我们将编写我们软件的搜集规则,我们有文档提供撰写收集的规则。我们不帮客户写收集规则,如果必须写,10元的收购规则。友情提示:请在使用本文时注明文章的来源并尊重原始版权。
6,外链文章材料:该模块是通过大量的市场语料库,通过算法随机组合的语料库制作相关产业文章,该模块文章仅适用于文章质量要求不高,为外部链促销用户,模块的特性,资源丰富,原创性高,但缺点是文章可读性差,用户在使用时可以选择性地使用。
7.批量生产标题:有两个功能,一个是按关键字和规则组合批量生产标题,二是通过收集网络大数据获取标题。自动生成的促销准确性很高,捕获的标题是可读的,每个都有特点跟缺点。
8,文章界面公布:通过简单的配置,生成的文章发布至您自己的网站。目前支持的网站有,Discuz Portal,DedeCms,Empire ECMS(新闻),PHMCMS,Zibo CMS,PHP168,diypage,phpwind门户。
9,SEO批量查询工具:权重批量查询,排序批量查询,包含批量查询,长尾词挖掘,代码批量转换,文本加密和解密。

