
文章采集链接
文章采集链接(新闻数据爬取框架+js脚本采集(.md5版))
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-10-06 02:01
文章采集链接:新闻数据爬取框架+js脚本采集(.md5版)项目说明工欲善其事必先利其器,要想高效地用excel把一份新闻数据采集到本地,第一步是要找到正确的爬取方法,本篇文章将会介绍一种基于javascript脚本实现新闻数据采集工具——js采集,它相对比较简单,适合爬取我们常见的新闻数据或者网页上已经有新闻数据的网站,甚至爬取一些自动采集代码也可以,它们都可以用js实现,例如我们可以做出下面这样的一个js采集框架:爬取网站只需用到navicat提供的javascript库,或者通过python的node.js库,lxml提供的反向工程js库等。
到目前为止,我们已经可以直接从源代码的javascript库写出一份新闻数据采集的工具代码,但是具体的爬取流程还是可以通过源代码写入的工具代码来实现,本文在最后主要讲一下我们应该如何用源代码写新闻数据采集工具代码。url爬取源代码写新闻数据采集工具的url地址为:;sourceid=c42324&_url=jsformodernedition-gui和javascript库地址,web解析地址javascript解析库用javascript解析工具写出来的代码主要如下:%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%。 查看全部
文章采集链接(新闻数据爬取框架+js脚本采集(.md5版))
文章采集链接:新闻数据爬取框架+js脚本采集(.md5版)项目说明工欲善其事必先利其器,要想高效地用excel把一份新闻数据采集到本地,第一步是要找到正确的爬取方法,本篇文章将会介绍一种基于javascript脚本实现新闻数据采集工具——js采集,它相对比较简单,适合爬取我们常见的新闻数据或者网页上已经有新闻数据的网站,甚至爬取一些自动采集代码也可以,它们都可以用js实现,例如我们可以做出下面这样的一个js采集框架:爬取网站只需用到navicat提供的javascript库,或者通过python的node.js库,lxml提供的反向工程js库等。
到目前为止,我们已经可以直接从源代码的javascript库写出一份新闻数据采集的工具代码,但是具体的爬取流程还是可以通过源代码写入的工具代码来实现,本文在最后主要讲一下我们应该如何用源代码写新闻数据采集工具代码。url爬取源代码写新闻数据采集工具的url地址为:;sourceid=c42324&_url=jsformodernedition-gui和javascript库地址,web解析地址javascript解析库用javascript解析工具写出来的代码主要如下:%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%。
文章采集链接(网页文本采集大师就是更简单、高效、省力的办法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 319 次浏览 • 2021-09-29 23:38
)
在网络信息时代,你每天上网时,经常会遇到喜欢的文章,或者小说等,从一两页到几十页,甚至数百、数千页不等。需要这么多字。复制下载非常麻烦。在记事本和网络浏览器之间频繁切换已经够难过了。现在我面临着需要同时进行数十次或数百次这种无聊的机械动作的需求。问题是,有没有更简单、更高效、更省力的方法?
哈哈,你找对地方了。我们开发的“Web Text 采集Master”就是这样一款专门为您准备的工具软件。
点击下载:
软件已升级到3.2版本。新版界面截图如下,功能更强大,无论是静态的还是动态的网站,禁止复制的文章,还是带有随机干扰码的任意文章可以是采集,我一拿就给你发最新版。成为第一个使用它并体验它的人!
网页文字采集大师是专门用于批量采集,复制或下载文章或网上小说,甚至整个网站文字内容的工具,无论是一个静态的网站或者一个动态的网站,只要有文字就可以获取,只要输入几条简单的信息,就可以自动为你下载复制网络批量文章 现在,可以说是快捷方便了。
除了抓取网上的文章,还可以用来抓取一些特殊的信息,比如抓取百度词典上的信息,也可以用来抓取一些网页上的链接地址。
此外,这款软件还有很多其他功能,比如文本段落重排、文本合并、文件批量重命名等功能,非常实用。您需要知道时间就是您可以让计算机为您做的事情。你不能自己做。赶快下载使用吧,希望你会喜欢她。
网页正文采集 主软件使用简要说明
下例介绍的新浪小说网站,因新浪小说频道重组,目前已关闭。可以到软件官网论坛查看更多示例和视频教程:
以下教程,因新浪网已关闭相应页面,不再提供测试!
假设我们要从新浪在线抓取小说《孩子,爸爸其实不想和妈妈离婚》,这意味着以下网址不再有效。以下只是一个例子:
为 采集 寻找 web 目录的第一个端口
在这里,我们将在新浪网找到该小说的目录页。目录地址如下:
/book/index_66681.html
第二个端口输入文章目录页地址
将上述地址复制到软件文章目录页面的输入框,然后回车打开带有软件的网页。
第三端口搜索链接关键字
找到第一章第一节的链接地址,查看其格式为:
/book/chapter_66681_47253.html
然后查找以下地址。请注意,VIP 会员网页只能由 VIP 会员阅读。如果你要下载这种文章,你必须是VIP会员,所以我们找一些以前的,这里是第11章和第11节作为我们要抓取的最后一章。链接地址是:
/book/chapter_66681_49404.html
现在我们比较上面两个链接地址,找出它们的共同点:
/书/chapter_66681_4
然后将其输入到链接关键字输入框中。
获取第四个端口采集文章的列表
这一步非常简单。只需单击“获取列表”按钮。点击后,您会在软件左侧的网址列表框中看到很多网址。
在第五个端口输入文本的开始和结束关键字
在软件左侧的URL中,选择第一个,点击打开软件右侧的网页,删除软件正文开始关键字和结束关键字输入框中的文字,直接点击获取文章,勾选获取整个网页的文本,找出官方的起止关键词。在这里我们可以看到,小说的每一节都以“爸爸其实不想和妈妈离婚>”这样的文字开头。并且以“上一章”的3个字符结尾,因此,我们将刚刚在软件的文本起始关键字和结束关键字输入框中找到的两个关键字(词)对应复制。,然后再次点击得到文章,看看是不是你想要的结果。
确认第六个端口采集文章保存目录
这一步比较简单。您只需要在软件左下角找到您要保存的目录,或者点击目录浏览框的右键菜单,新建一个目录即可。
第七个端口决定了文章的标题的开始和结束关键字
这一步其实就是确定每个文件名的风格。我们看到刚才得到的文章。第一行是“第一章离婚第一节”。事实上,第一行可以作为文件的标题。所以在这里,我们不需要输入标题采集关键字,程序会自动识别,您可以点击保存文章试试效果。
第八端口开始批量抓包
OK,以上步骤都准备好了,现在我们可以开始采集,当采集时,还可以选择是否自动刷新采集的文章,如果你选择,以后阅读会更容易。好,我们现在泡一杯茶,等待结果。
购买网页文字大师采集后,点赞后赠送智能网页文字提取器:
特别声明:网络世界中,网站数不胜数,每个网站的结构千差万别。不可能一个有价格(咨询特价)的软件包罗万象,让你可以网站的所有文章,或者文章的网站采集 可以过滤掉所有你不想要的信息。如果你购买了这个软件,因为一个网站 采集 如果不顺利,你必须申请退款。那么请绕道而行。我们不想在像你这样的人身上浪费时间。一旦为虚拟产品发布了注册码,即使您现在卸载该软件,将来也会再次安装。还是可以用的,想象一下,你能完全回收溢出的水吗?鄙视收到注册码申请退款的,(咨询特价)不划算!
查看全部
文章采集链接(网页文本采集大师就是更简单、高效、省力的办法
)
在网络信息时代,你每天上网时,经常会遇到喜欢的文章,或者小说等,从一两页到几十页,甚至数百、数千页不等。需要这么多字。复制下载非常麻烦。在记事本和网络浏览器之间频繁切换已经够难过了。现在我面临着需要同时进行数十次或数百次这种无聊的机械动作的需求。问题是,有没有更简单、更高效、更省力的方法?
哈哈,你找对地方了。我们开发的“Web Text 采集Master”就是这样一款专门为您准备的工具软件。
点击下载:
软件已升级到3.2版本。新版界面截图如下,功能更强大,无论是静态的还是动态的网站,禁止复制的文章,还是带有随机干扰码的任意文章可以是采集,我一拿就给你发最新版。成为第一个使用它并体验它的人!
网页文字采集大师是专门用于批量采集,复制或下载文章或网上小说,甚至整个网站文字内容的工具,无论是一个静态的网站或者一个动态的网站,只要有文字就可以获取,只要输入几条简单的信息,就可以自动为你下载复制网络批量文章 现在,可以说是快捷方便了。
除了抓取网上的文章,还可以用来抓取一些特殊的信息,比如抓取百度词典上的信息,也可以用来抓取一些网页上的链接地址。
此外,这款软件还有很多其他功能,比如文本段落重排、文本合并、文件批量重命名等功能,非常实用。您需要知道时间就是您可以让计算机为您做的事情。你不能自己做。赶快下载使用吧,希望你会喜欢她。

网页正文采集 主软件使用简要说明
下例介绍的新浪小说网站,因新浪小说频道重组,目前已关闭。可以到软件官网论坛查看更多示例和视频教程:
以下教程,因新浪网已关闭相应页面,不再提供测试!
假设我们要从新浪在线抓取小说《孩子,爸爸其实不想和妈妈离婚》,这意味着以下网址不再有效。以下只是一个例子:
为 采集 寻找 web 目录的第一个端口
在这里,我们将在新浪网找到该小说的目录页。目录地址如下:
/book/index_66681.html
第二个端口输入文章目录页地址
将上述地址复制到软件文章目录页面的输入框,然后回车打开带有软件的网页。
第三端口搜索链接关键字
找到第一章第一节的链接地址,查看其格式为:
/book/chapter_66681_47253.html
然后查找以下地址。请注意,VIP 会员网页只能由 VIP 会员阅读。如果你要下载这种文章,你必须是VIP会员,所以我们找一些以前的,这里是第11章和第11节作为我们要抓取的最后一章。链接地址是:
/book/chapter_66681_49404.html
现在我们比较上面两个链接地址,找出它们的共同点:
/书/chapter_66681_4
然后将其输入到链接关键字输入框中。
获取第四个端口采集文章的列表
这一步非常简单。只需单击“获取列表”按钮。点击后,您会在软件左侧的网址列表框中看到很多网址。
在第五个端口输入文本的开始和结束关键字
在软件左侧的URL中,选择第一个,点击打开软件右侧的网页,删除软件正文开始关键字和结束关键字输入框中的文字,直接点击获取文章,勾选获取整个网页的文本,找出官方的起止关键词。在这里我们可以看到,小说的每一节都以“爸爸其实不想和妈妈离婚>”这样的文字开头。并且以“上一章”的3个字符结尾,因此,我们将刚刚在软件的文本起始关键字和结束关键字输入框中找到的两个关键字(词)对应复制。,然后再次点击得到文章,看看是不是你想要的结果。
确认第六个端口采集文章保存目录
这一步比较简单。您只需要在软件左下角找到您要保存的目录,或者点击目录浏览框的右键菜单,新建一个目录即可。
第七个端口决定了文章的标题的开始和结束关键字
这一步其实就是确定每个文件名的风格。我们看到刚才得到的文章。第一行是“第一章离婚第一节”。事实上,第一行可以作为文件的标题。所以在这里,我们不需要输入标题采集关键字,程序会自动识别,您可以点击保存文章试试效果。
第八端口开始批量抓包
OK,以上步骤都准备好了,现在我们可以开始采集,当采集时,还可以选择是否自动刷新采集的文章,如果你选择,以后阅读会更容易。好,我们现在泡一杯茶,等待结果。
购买网页文字大师采集后,点赞后赠送智能网页文字提取器:

特别声明:网络世界中,网站数不胜数,每个网站的结构千差万别。不可能一个有价格(咨询特价)的软件包罗万象,让你可以网站的所有文章,或者文章的网站采集 可以过滤掉所有你不想要的信息。如果你购买了这个软件,因为一个网站 采集 如果不顺利,你必须申请退款。那么请绕道而行。我们不想在像你这样的人身上浪费时间。一旦为虚拟产品发布了注册码,即使您现在卸载该软件,将来也会再次安装。还是可以用的,想象一下,你能完全回收溢出的水吗?鄙视收到注册码申请退款的,(咨询特价)不划算!

文章采集链接( BeeCollector(小蜜蜂采集器)文章采集系统,完善Flash采集模块对目标字符集UTF8的支持)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-09-29 23:37
BeeCollector(小蜜蜂采集器)文章采集系统,完善Flash采集模块对目标字符集UTF8的支持)
BeeCollector(Little Bee采集器)文章采集系统,改进Flash采集对目标字符集UTF8的支持。
特征:
1、支持文章内容分页采集;
2、支持论坛采集;
3、支持UTF-8转GB2312,但采集内容字符格式是UTF-8的目标;
4、 支持将文章的内容保存到本地;
5、支持站点+栏目管理模式,让采集管理一目了然;
6、支持链接替换,分页链接替换,破解一些JS/后台程序设置的反扒功能;
7、支持采集器设置无限过滤功能;
8、支持图片采集保存到本地,自动替换文件名避免重复;
9、支持FLASH文件采集保存到本地,自动替换文件名避免重复;
10、 支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
11、 支持手动过滤采集结果,并提供“空标题空内容”的快速过滤和删除;
12、支持Flash专业站点采集,特色采集flash小游戏,可完美采集缩略图,游戏介绍;
13、 支持全站配置规则的导入导出;
14、 支持列配置规则的导入导出,并提供规则复制功能,简化设置;
15、 提供引导库规则导入导出;
16、支持自定义采集间隔时间,避免被误认为DDOS攻击而拒绝响应,可以设置采集防止DDOS攻击网站;
17、 支持自定义存储间隔时间,避免虚拟主机并发限制;
18、支持自定义内容写入,用户可以设置任意内容(如自己的链接、广告代码),写入采集的内容:第一个、最后一个或随机写入;需要写入的内容在浏览库时自动带在身边,无需修改WEB系统模板。
19、支持采集内容替换功能,用户可以设置替换规则随意替换;
20、支持html标签过滤,让采集接收到的内容只保留必要的html标签,甚至是纯文本,不带任何html标签;
21、支持多种cms向导库包收录PHPcms V2/V3、Dedecms(织梦) V2/V 3、PHP168 cms、mephpcms、Mambo cms、Joomla cms系统指南库规则及操作说明;
22、支持PHPWIND、Discuz论坛指南库,程序包中收录2个论坛指南库规则和操作说明;
23、自带数据库优化工具,减少频繁采集过多的数据碎片降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、 支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;
2、 支持自动比较过滤功能,不会在采集的链接系统中重复采集和存储;以上两个功能可以大大减少采集时间,减少系统负载。
3、 支持系统每天自动创建图片存储目录,方便管理;
4、 支持采集/guidance间隔设置,避免被目标站识别为流量攻击而拒绝响应;
5、支持自定义内容写入,实现简单的反采集功能;
6、支持html标签过滤,几乎完美展现你想要的采集效果;
7、完美的内容存储解决方案,不受目标编程语言和数据库类别的限制。
以上众多强大功能免费供您使用,您可以轻松高效地安装使用体验资料采集。 查看全部
文章采集链接(
BeeCollector(小蜜蜂采集器)文章采集系统,完善Flash采集模块对目标字符集UTF8的支持)

BeeCollector(Little Bee采集器)文章采集系统,改进Flash采集对目标字符集UTF8的支持。
特征:
1、支持文章内容分页采集;
2、支持论坛采集;
3、支持UTF-8转GB2312,但采集内容字符格式是UTF-8的目标;
4、 支持将文章的内容保存到本地;
5、支持站点+栏目管理模式,让采集管理一目了然;
6、支持链接替换,分页链接替换,破解一些JS/后台程序设置的反扒功能;
7、支持采集器设置无限过滤功能;
8、支持图片采集保存到本地,自动替换文件名避免重复;
9、支持FLASH文件采集保存到本地,自动替换文件名避免重复;
10、 支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
11、 支持手动过滤采集结果,并提供“空标题空内容”的快速过滤和删除;
12、支持Flash专业站点采集,特色采集flash小游戏,可完美采集缩略图,游戏介绍;
13、 支持全站配置规则的导入导出;
14、 支持列配置规则的导入导出,并提供规则复制功能,简化设置;
15、 提供引导库规则导入导出;
16、支持自定义采集间隔时间,避免被误认为DDOS攻击而拒绝响应,可以设置采集防止DDOS攻击网站;
17、 支持自定义存储间隔时间,避免虚拟主机并发限制;
18、支持自定义内容写入,用户可以设置任意内容(如自己的链接、广告代码),写入采集的内容:第一个、最后一个或随机写入;需要写入的内容在浏览库时自动带在身边,无需修改WEB系统模板。
19、支持采集内容替换功能,用户可以设置替换规则随意替换;
20、支持html标签过滤,让采集接收到的内容只保留必要的html标签,甚至是纯文本,不带任何html标签;
21、支持多种cms向导库包收录PHPcms V2/V3、Dedecms(织梦) V2/V 3、PHP168 cms、mephpcms、Mambo cms、Joomla cms系统指南库规则及操作说明;
22、支持PHPWIND、Discuz论坛指南库,程序包中收录2个论坛指南库规则和操作说明;
23、自带数据库优化工具,减少频繁采集过多的数据碎片降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、 支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;
2、 支持自动比较过滤功能,不会在采集的链接系统中重复采集和存储;以上两个功能可以大大减少采集时间,减少系统负载。
3、 支持系统每天自动创建图片存储目录,方便管理;
4、 支持采集/guidance间隔设置,避免被目标站识别为流量攻击而拒绝响应;
5、支持自定义内容写入,实现简单的反采集功能;
6、支持html标签过滤,几乎完美展现你想要的采集效果;
7、完美的内容存储解决方案,不受目标编程语言和数据库类别的限制。
以上众多强大功能免费供您使用,您可以轻松高效地安装使用体验资料采集。
文章采集链接(网上看了一部小说,换个名字,居然要付费了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 573 次浏览 • 2021-09-29 22:25
今天在网上看了一本小说。明明是很久以前的小说。我改了名字,我不得不付钱。我很不高兴。通过强大的百度,找到了原版。我很高兴,但我无法下载它。这很难。本来打算把它读下来,然后在我的手机上阅读。我别无选择,只能自己做采集,然后我就下来了;
导入 urllib.requestimport re
话不多说,先列出你需要的包。我们的命名要尽量规范,这样才能养成一个好习惯,也容易别人理解;这个东西在行业里叫做驼峰命名法。
第一步,我们需要获取主页的源代码:
def getNoverContent():
这里我定义getNoverCotent的变量作为代码的核心部分,然后定义html变量
html = urllib.request.urlopen('目录地址').read()html = html.decode('gbk')
拿到html内容后,我们先打印出来看看是否检索成功
打印(html)
成功了可以把这行代码删掉或者注释掉,养成一个习惯,一步一步来,不容易出错:print(html)
第二部分是获取我们需要的那部分网页代码:
我们在网页上调出刚才页面的源码,找到你想要的部分的div采集。这里使用了正则表达式。不明白的可以自学,也可以找个时间写一篇常规文章的介绍;
请求 = r'
(.*?)'
他们之中。*? 这是一个通配符,匹配所有的内容,我们要的是在通配符外面加一个()
我们这里得到的是目录页的超链接和目录的内容
req = 桩(req)urls = re.findall(req,html)
urls变量的内容就是我们想要的超链接和目录内容,打出来看看?
打印(网址)
用完记得注释掉
第三部分,获取章节源码:
我们用一个for循环来完成这个功能
对于网址中的网址:
让我们打印出 url[0] 看看我们是否需要超链接
#打印(网址[0])
确认无误后,设置变量novel_urlnovel_url ='如果是部分超链接,在此处添加链接前端' + url[0]novel_title = url[1] chapt = urllib.request.urlopen(novel_url).read ()
设置编码,在哪里看编码?
这部分网页源码,可以看看是utf-8还是gbk
chapt_html = chapt.decode('gbk') #获取文章内容 req = r'
(.*?)
'#re.S 多行匹配
毕竟文章的内容还有很多行,这部分不能省了 req = pie(req,re.S) chapt_content = re.findall(req,chapt_html)
全部 采集 好的,输入并尝试一下?
打印(章节内容)
章节内容
没问题,我们继续第三部分
第三步,另存为txt并导出:
with open("fiction name.txt", mode='a+',encoding='utf-8') as f:f.write(novel_title) f.write(chapt_content) f.write("\n")
最后记得加一行启动代码
如果 __name__ =='__main__':getNoverContent()
大功告成,可以把采集全部上传到手机上慢慢欣赏!
大部分代码显示 查看全部
文章采集链接(网上看了一部小说,换个名字,居然要付费了)
今天在网上看了一本小说。明明是很久以前的小说。我改了名字,我不得不付钱。我很不高兴。通过强大的百度,找到了原版。我很高兴,但我无法下载它。这很难。本来打算把它读下来,然后在我的手机上阅读。我别无选择,只能自己做采集,然后我就下来了;
导入 urllib.requestimport re
话不多说,先列出你需要的包。我们的命名要尽量规范,这样才能养成一个好习惯,也容易别人理解;这个东西在行业里叫做驼峰命名法。
第一步,我们需要获取主页的源代码:
def getNoverContent():
这里我定义getNoverCotent的变量作为代码的核心部分,然后定义html变量
html = urllib.request.urlopen('目录地址').read()html = html.decode('gbk')
拿到html内容后,我们先打印出来看看是否检索成功
打印(html)
成功了可以把这行代码删掉或者注释掉,养成一个习惯,一步一步来,不容易出错:print(html)
第二部分是获取我们需要的那部分网页代码:
我们在网页上调出刚才页面的源码,找到你想要的部分的div采集。这里使用了正则表达式。不明白的可以自学,也可以找个时间写一篇常规文章的介绍;
请求 = r'
(.*?)'
他们之中。*? 这是一个通配符,匹配所有的内容,我们要的是在通配符外面加一个()
我们这里得到的是目录页的超链接和目录的内容
req = 桩(req)urls = re.findall(req,html)
urls变量的内容就是我们想要的超链接和目录内容,打出来看看?
打印(网址)
用完记得注释掉
第三部分,获取章节源码:
我们用一个for循环来完成这个功能
对于网址中的网址:
让我们打印出 url[0] 看看我们是否需要超链接
#打印(网址[0])
确认无误后,设置变量novel_urlnovel_url ='如果是部分超链接,在此处添加链接前端' + url[0]novel_title = url[1] chapt = urllib.request.urlopen(novel_url).read ()
设置编码,在哪里看编码?

这部分网页源码,可以看看是utf-8还是gbk
chapt_html = chapt.decode('gbk') #获取文章内容 req = r'
(.*?)
'#re.S 多行匹配
毕竟文章的内容还有很多行,这部分不能省了 req = pie(req,re.S) chapt_content = re.findall(req,chapt_html)
全部 采集 好的,输入并尝试一下?
打印(章节内容)
章节内容
没问题,我们继续第三部分
第三步,另存为txt并导出:
with open("fiction name.txt", mode='a+',encoding='utf-8') as f:f.write(novel_title) f.write(chapt_content) f.write("\n")
最后记得加一行启动代码
如果 __name__ =='__main__':getNoverContent()
大功告成,可以把采集全部上传到手机上慢慢欣赏!

大部分代码显示
文章采集链接(讲解一下如何把一个网站的文章采集到自己的网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-09-29 18:04
以飘柔博客网站()为例,讲解如何把网站的文章采集放到自己的网站中,下载链接到同时网盘地址也是你自己的(文件批量传输到你自己的网盘)。
其实采集和发布文章很简单。难点是如何批量转储或下载对方的文件到自己的网站/网盘,可以对应文章和网盘下载链接。
需要准备:
飘柔博客VIP账号网站优采云采集规则,发布模块批量转储工具,城市通网盘VIP账号(对方使用的城市通网盘存储文件网站,如果要转,只能转到城通网盘,其他网盘不能直接转)
目前本站所有中文电子书的文件都在800G左右。不买城市通行证VIP就下载这么多文件到本地是不现实的。我的城市通行证VIP大概一千元,我已经从下载中赚回来了(每次下载2到5美分,超过100M的文件1美分)。
看到这个,有的同学可以关掉网页离开。
第一步:
将所有文件传输到自己的网盘,50000多个文件,当然不是手动工作。所以我写了一个转储工具,可以批量转储并重命名城市通行证文件。
那么问题来了,为什么要重命名?重命名是一个非常重要的步骤,因为它可以:
为防止下载链接因名称问题被统一失效,发布时可以链接到网盘文件下载链接文章
传输文件时,将文件重命名为目标ID网站文章。例如,将本文章中的电子书转移到自己的网盘后,文件名应该是96233.epub。为什么?看第二步。
33%
第二步:
批量转储文件并重命名后,使用优采云下载采集诚通网盘中所有文件的链接和文件名,生成html文件。html 文件以文件名命名。比如前面提到的96233.epub,采集生成96233.html,文件中收录从城通网盘下载文件的链接。
你可以在你的网站文章中直接链接到这个html,用户可以在html页面点击网盘链接下载文件,或者在后面的第三步,使用采集规则采集该页面的网盘地址,用户会直接打开网盘页面下载;链接html的好处是可以展示广告位获取收益,看下面的demo(顺便点一下广告有惊喜):
html文件演示:
此方法适用于免费下载资源。如果收费,当然应该直接采集到网盘地址,避免别人根据html文件名获取其他文件下载地址。
66%
第三步:
<p>现在你有了所有的网盘文件下载链接,并且html文件名对应目标站的文件名,你只需要把生成的html上传到网站空间,就可以使用 查看全部
文章采集链接(讲解一下如何把一个网站的文章采集到自己的网站)
以飘柔博客网站()为例,讲解如何把网站的文章采集放到自己的网站中,下载链接到同时网盘地址也是你自己的(文件批量传输到你自己的网盘)。
其实采集和发布文章很简单。难点是如何批量转储或下载对方的文件到自己的网站/网盘,可以对应文章和网盘下载链接。
需要准备:
飘柔博客VIP账号网站优采云采集规则,发布模块批量转储工具,城市通网盘VIP账号(对方使用的城市通网盘存储文件网站,如果要转,只能转到城通网盘,其他网盘不能直接转)
目前本站所有中文电子书的文件都在800G左右。不买城市通行证VIP就下载这么多文件到本地是不现实的。我的城市通行证VIP大概一千元,我已经从下载中赚回来了(每次下载2到5美分,超过100M的文件1美分)。
看到这个,有的同学可以关掉网页离开。
第一步:
将所有文件传输到自己的网盘,50000多个文件,当然不是手动工作。所以我写了一个转储工具,可以批量转储并重命名城市通行证文件。
那么问题来了,为什么要重命名?重命名是一个非常重要的步骤,因为它可以:
为防止下载链接因名称问题被统一失效,发布时可以链接到网盘文件下载链接文章
传输文件时,将文件重命名为目标ID网站文章。例如,将本文章中的电子书转移到自己的网盘后,文件名应该是96233.epub。为什么?看第二步。
33%
第二步:
批量转储文件并重命名后,使用优采云下载采集诚通网盘中所有文件的链接和文件名,生成html文件。html 文件以文件名命名。比如前面提到的96233.epub,采集生成96233.html,文件中收录从城通网盘下载文件的链接。
你可以在你的网站文章中直接链接到这个html,用户可以在html页面点击网盘链接下载文件,或者在后面的第三步,使用采集规则采集该页面的网盘地址,用户会直接打开网盘页面下载;链接html的好处是可以展示广告位获取收益,看下面的demo(顺便点一下广告有惊喜):
html文件演示:
此方法适用于免费下载资源。如果收费,当然应该直接采集到网盘地址,避免别人根据html文件名获取其他文件下载地址。
66%
第三步:
<p>现在你有了所有的网盘文件下载链接,并且html文件名对应目标站的文件名,你只需要把生成的html上传到网站空间,就可以使用
文章采集链接(优采云采集器V9的数据导入为例讲解数据库发布配置如何制作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-23 16:11
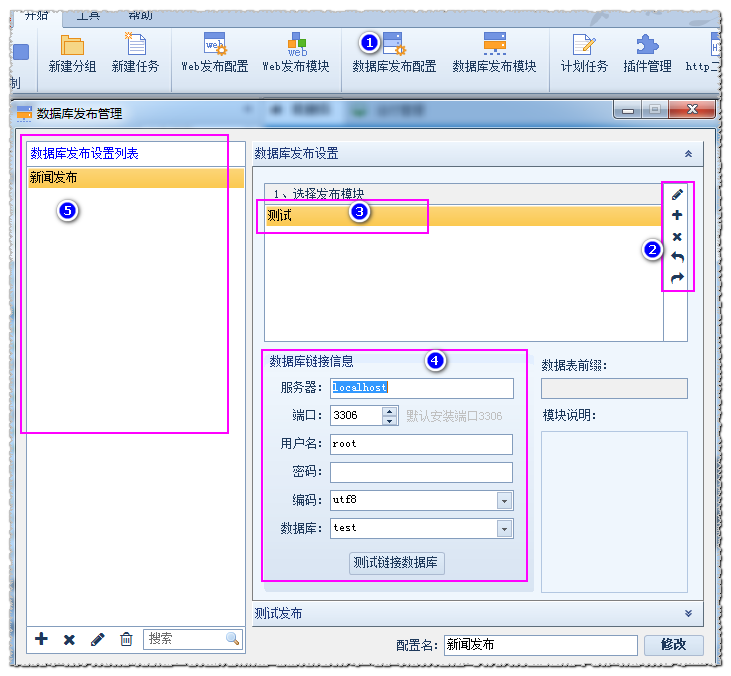
我们正在使用采集文章,有时它将在线发布到网站 column,有时导入自己的数据库或保存为本地文件,这里优采云采集器 v9数据导入举例如何制作数据库发布配置。
@ @采集器 v9支持发布mysql,sqlserver,oracle,访问类型数据库,拍摄mysql数据库作为一个例子,我们打开开始菜单 - 数据库发布配置,如图所示:
1打开数据库发布配置2您可以执行“编辑,新,删除,导入,导出,导出”数据库3数据库链接信息配置5数据库发布配置列表
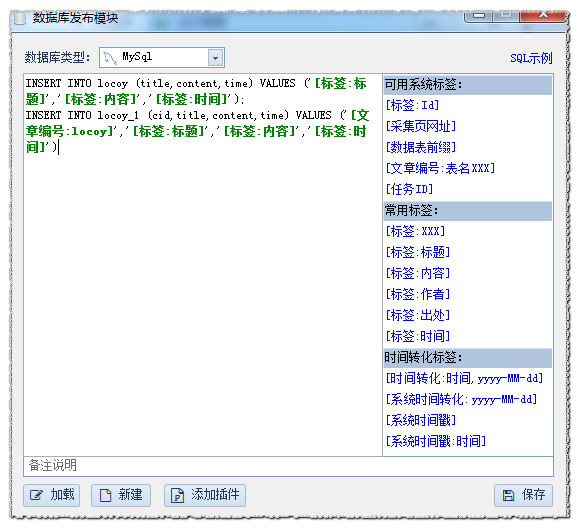
我们首先创建一个释放模块,选择数据库类型,写一个仓库语句,如图所示:
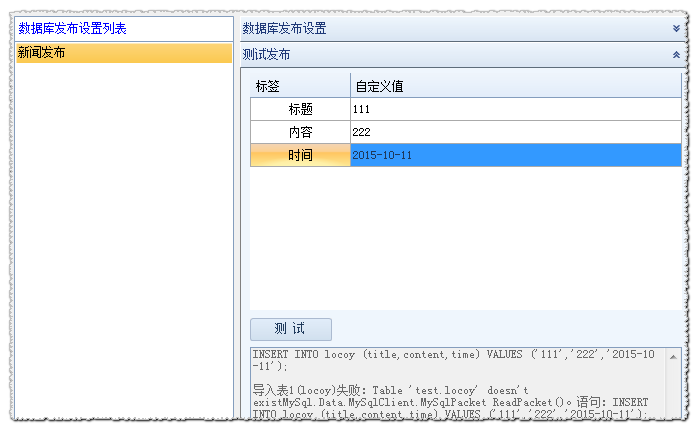
1. @是表表表表;;;;;;;;;;;;;;;表;与上一张表的自增量ID相关,表表表表表表表表表表表表表表表3.自集成ID字段和值需要删除,不需要将其写入SQL语句。存储模块完成后,保存它。然后在数据库发布管理界面中设置链接信息,测试链接数据库,并成功。
可以保存配置并释放测试。如下所示(填写自定义值,单击测试):
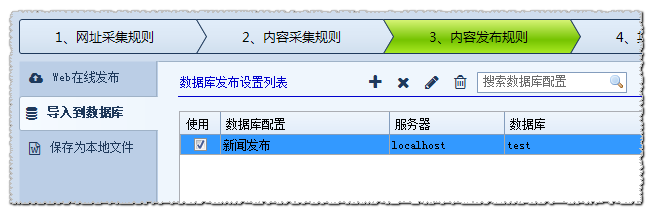
内容发布规则 - 导入数据库对应于数据库设置的输入。
这文章采集器优采云采集器 V9数据导入完成,这也与其他类型的数据库,如果是网上发布,您需要编辑发布模块,具体操作可以看一下官方网站。返回Sohu,查看更多 查看全部
文章采集链接(优采云采集器V9的数据导入为例讲解数据库发布配置如何制作)
我们正在使用采集文章,有时它将在线发布到网站 column,有时导入自己的数据库或保存为本地文件,这里优采云采集器 v9数据导入举例如何制作数据库发布配置。
@ @采集器 v9支持发布mysql,sqlserver,oracle,访问类型数据库,拍摄mysql数据库作为一个例子,我们打开开始菜单 - 数据库发布配置,如图所示:
1打开数据库发布配置2您可以执行“编辑,新,删除,导入,导出,导出”数据库3数据库链接信息配置5数据库发布配置列表
我们首先创建一个释放模块,选择数据库类型,写一个仓库语句,如图所示:
1. @是表表表表;;;;;;;;;;;;;;;表;与上一张表的自增量ID相关,表表表表表表表表表表表表表表表3.自集成ID字段和值需要删除,不需要将其写入SQL语句。存储模块完成后,保存它。然后在数据库发布管理界面中设置链接信息,测试链接数据库,并成功。
可以保存配置并释放测试。如下所示(填写自定义值,单击测试):
内容发布规则 - 导入数据库对应于数据库设置的输入。
这文章采集器优采云采集器 V9数据导入完成,这也与其他类型的数据库,如果是网上发布,您需要编辑发布模块,具体操作可以看一下官方网站。返回Sohu,查看更多
文章采集链接(【赛事日历】瑞典丨选手计算机实时赛前状态_djqdk_新浪博客)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-21 12:08
文章采集链接:-meet-you/文章推荐阅读:数据冰山-知乎专栏【赛事日历】瑞典丨选手计算机实时赛前状态_djqdk_新浪博客【赛事】美国丨nfc联赛#72战队(c9-top)_miscmoni_新浪博客【赛事】#78战队(c5-peak)#76战队(a3-lots)_【赛事】欧洲丨nintendocms#50(cashmajor)-emm_新浪博客【赛事】荷兰丨am#145(apachelpmaster)_thereforerennogon_新浪博客【赛事】日本丨(gen)-looverglobal,#300【赛事】加拿大丨flyportleague-fort-pace【赛事】韩国丨school-stream,#456。
cs:go太小众太多大佬可以去加油,shroud的twitch直播是有粉丝限制的,一般人一天不一定能看到,当然,如果你想看直播可以去马老师的twitch或者youtube,都是能看到粉丝喷的网站。
游戏日报app上各项最近上了比赛日程以下是一些好玩的大大的开挂群(最近很多):425217725shroud两次创造wsc世界纪录第一视角:能打出这种操作的人twitch直播频道:46357240你听不听就打ps:我才是真爱粉,
wacai和faker已经举办过多次有深度的比赛了, 查看全部
文章采集链接(【赛事日历】瑞典丨选手计算机实时赛前状态_djqdk_新浪博客)
文章采集链接:-meet-you/文章推荐阅读:数据冰山-知乎专栏【赛事日历】瑞典丨选手计算机实时赛前状态_djqdk_新浪博客【赛事】美国丨nfc联赛#72战队(c9-top)_miscmoni_新浪博客【赛事】#78战队(c5-peak)#76战队(a3-lots)_【赛事】欧洲丨nintendocms#50(cashmajor)-emm_新浪博客【赛事】荷兰丨am#145(apachelpmaster)_thereforerennogon_新浪博客【赛事】日本丨(gen)-looverglobal,#300【赛事】加拿大丨flyportleague-fort-pace【赛事】韩国丨school-stream,#456。
cs:go太小众太多大佬可以去加油,shroud的twitch直播是有粉丝限制的,一般人一天不一定能看到,当然,如果你想看直播可以去马老师的twitch或者youtube,都是能看到粉丝喷的网站。
游戏日报app上各项最近上了比赛日程以下是一些好玩的大大的开挂群(最近很多):425217725shroud两次创造wsc世界纪录第一视角:能打出这种操作的人twitch直播频道:46357240你听不听就打ps:我才是真爱粉,
wacai和faker已经举办过多次有深度的比赛了,
文章采集链接( 本文介绍使用优采云采集(以BBC的AsiaNews为例))
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-20 22:08
本文介绍使用优采云采集(以BBC的AsiaNews为例))
英语文章采集方法
本文介绍了使用优采云采集(以BBC亚洲新闻为例)采集网站的方法:/
采集的内容包括:文章title、文章body
使用功能点:
分页列表和详细信息提取
步骤1:创建BBC英语文章采集task
1)进入主界面,选择“自定义模式”
2)将采集的URL复制粘贴到网站输入框中,然后单击“保存URL”
步骤2:创建一个列表循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”。选择页面中的第一张图片,系统将自动识别页面中的类似链接并选择“全选”
2)选择“重复单击每个链接”3)设置超时和Ajax滚动
第三步:采集小说内容
1)选择页面中的正文标题为采集(所选内容将变为绿色),然后选择“采集此元素的文本”
二,
)在页面中选择要设置为采集的正文内容(所选内容将变为绿色),然后选择全部
3)
设置合并字段,选择自定义数据字段和自定义数据合并方式
4)
修改字段名
5)选择“本地启动采集”
第四步:BBC英语文章data采集和导出
1)采集完成后,将弹出提示并选择“导出数据”。选择“适当的导出方法”导出采集good BBC English文章数据
2)这里,我们选择excel作为导出格式。数据导出后,见下图
相关采集教程:
爆文采集:
/教程详情-1/baowencj.html
新浪博客文章采集:
/教程详情-1/sinablogcj.html
UC标题文章采集:
/教程详情-1/ucnewscj.html
微信公众号文章采集(文字+图片):
/教程详情-1/wxcjimg.html
网易自媒体文章采集:
/教程详情-1/wyhcj.html
优采云——90万用户在k0选择的网页数据@
1、操作简单,任何人都可以使用:没有技术背景,你可以采集. 完全可视化过程,单击鼠标完成操作,您可以在2分钟内快速开始
2、功能强大,任何网站都可以采用:采集可以简单地设置为网页,点击、登录、翻页、身份验证码、瀑布流和Ajax脚本异步加载数据
3、cloud采集,关机正常。配置采集任务后,可以关闭它们,并在云中执行任务。巨大的云采集集群24*7不间断运行,因此您不必担心IP阻塞和网络中断
4、功能是免费+增值服务,可根据需要选择。免费版具备所有功能,可以满足用户的基本采集需求。同时,一些增值服务(如私有云)被设置为满足高端付费企业用户的需求 查看全部
文章采集链接(
本文介绍使用优采云采集(以BBC的AsiaNews为例))
英语文章采集方法
本文介绍了使用优采云采集(以BBC亚洲新闻为例)采集网站的方法:/
采集的内容包括:文章title、文章body
使用功能点:
分页列表和详细信息提取
步骤1:创建BBC英语文章采集task
1)进入主界面,选择“自定义模式”
2)将采集的URL复制粘贴到网站输入框中,然后单击“保存URL”
步骤2:创建一个列表循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”。选择页面中的第一张图片,系统将自动识别页面中的类似链接并选择“全选”
2)选择“重复单击每个链接”3)设置超时和Ajax滚动
第三步:采集小说内容
1)选择页面中的正文标题为采集(所选内容将变为绿色),然后选择“采集此元素的文本”
二,
)在页面中选择要设置为采集的正文内容(所选内容将变为绿色),然后选择全部
3)
设置合并字段,选择自定义数据字段和自定义数据合并方式
4)
修改字段名
5)选择“本地启动采集”
第四步:BBC英语文章data采集和导出
1)采集完成后,将弹出提示并选择“导出数据”。选择“适当的导出方法”导出采集good BBC English文章数据
2)这里,我们选择excel作为导出格式。数据导出后,见下图
相关采集教程:
爆文采集:
/教程详情-1/baowencj.html
新浪博客文章采集:
/教程详情-1/sinablogcj.html
UC标题文章采集:
/教程详情-1/ucnewscj.html
微信公众号文章采集(文字+图片):
/教程详情-1/wxcjimg.html
网易自媒体文章采集:
/教程详情-1/wyhcj.html
优采云——90万用户在k0选择的网页数据@
1、操作简单,任何人都可以使用:没有技术背景,你可以采集. 完全可视化过程,单击鼠标完成操作,您可以在2分钟内快速开始
2、功能强大,任何网站都可以采用:采集可以简单地设置为网页,点击、登录、翻页、身份验证码、瀑布流和Ajax脚本异步加载数据
3、cloud采集,关机正常。配置采集任务后,可以关闭它们,并在云中执行任务。巨大的云采集集群24*7不间断运行,因此您不必担心IP阻塞和网络中断
4、功能是免费+增值服务,可根据需要选择。免费版具备所有功能,可以满足用户的基本采集需求。同时,一些增值服务(如私有云)被设置为满足高端付费企业用户的需求
文章采集链接(本次采集网站数据的一个重要的步骤,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-09-13 06:10
自从来到Front Sniff,编辑从爬虫成长为采集各种网站各种数据。当然,踩坑在成长过程中绝对是少不了的(很多网站都有防爬措施)。为了让用户更熟练的使用爬虫软件,小编决定定期写一些配置爬虫的经验和技巧,以及遇到坑的解决办法。
本案例使用大众点评网,需提取如下翻页链接。
第一步是看每个页面的链接地址是否有规律。
可以看出,只有每个页面的链接地址的最后一个数字不同,即对应的页码数。我们可以通过拼接得到翻页的所有链接地址。拼接第二页链接地址的脚本如下:
图中的六行代码是提取链接必不可少的部分。这简单的六行是一个完整的链接提取脚本。下面是每一行的解释:
第一行代码:定义一个url类的变量u。
第二行代码:u.urlname 是网页的链接地址,并为其赋值。
第三行代码:u.tmplid是本次链接提取要关联的模板id,这里是翻页,所以关联到自己的模板。
第四行代码:此链接提取对应的频道id。
第五行代码:u.title 是链接标题,被赋值。
第六行代码:将拼接后的链接添加到最终结果中。
上面的代码只得到了第二页的链接,下面给大家展示一下完整的内容:
通过FindClass从源码中获取总页数,然后使用for循环拼接每个页面的链接。只用了12行(包括两行注释)就得到了我想要的链接。
链接提取是大规模采集网站数据的重要步骤。下一期,小编计划在本案例的基础上增加数据提取,使其成为一个完整的爬虫采集模板。 采集数据可以正常。有需要的朋友可以点击上面的公众号,里面一定有你需要的内容。 查看全部
文章采集链接(本次采集网站数据的一个重要的步骤,你知道吗?)
自从来到Front Sniff,编辑从爬虫成长为采集各种网站各种数据。当然,踩坑在成长过程中绝对是少不了的(很多网站都有防爬措施)。为了让用户更熟练的使用爬虫软件,小编决定定期写一些配置爬虫的经验和技巧,以及遇到坑的解决办法。
本案例使用大众点评网,需提取如下翻页链接。
第一步是看每个页面的链接地址是否有规律。
可以看出,只有每个页面的链接地址的最后一个数字不同,即对应的页码数。我们可以通过拼接得到翻页的所有链接地址。拼接第二页链接地址的脚本如下:
图中的六行代码是提取链接必不可少的部分。这简单的六行是一个完整的链接提取脚本。下面是每一行的解释:
第一行代码:定义一个url类的变量u。
第二行代码:u.urlname 是网页的链接地址,并为其赋值。
第三行代码:u.tmplid是本次链接提取要关联的模板id,这里是翻页,所以关联到自己的模板。
第四行代码:此链接提取对应的频道id。
第五行代码:u.title 是链接标题,被赋值。
第六行代码:将拼接后的链接添加到最终结果中。
上面的代码只得到了第二页的链接,下面给大家展示一下完整的内容:
通过FindClass从源码中获取总页数,然后使用for循环拼接每个页面的链接。只用了12行(包括两行注释)就得到了我想要的链接。
链接提取是大规模采集网站数据的重要步骤。下一期,小编计划在本案例的基础上增加数据提取,使其成为一个完整的爬虫采集模板。 采集数据可以正常。有需要的朋友可以点击上面的公众号,里面一定有你需要的内容。
文章采集链接(如何获取公众号文章链接怎么才能将链接下载到本地 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-09-12 21:05
)
如何获取公众号文章链接
如何将公众号文章中的链接下载到本地?很多朋友还不知道用什么方法比较快。他们也使用其他工具导出,但操作步骤比较繁琐。接下来,我来介绍一下这个方便的采集工具的一些步骤。
微信公众号文章采集器
使用孤狼公众号助手时,先注册账号密码,充值后即可登录,打开软件进入,左上角有自定义公众号采集软件功能,打开添加框,可以从搜狗复制公众号文章temporary链接,然后点击获取,添加到软件后,添加框会加载公众号信息,包括永久链接,然后就可以采集Data 出来了!
软件界面功能介绍
1、勾选文章预览(可以预览文章内容)
2、复制文章title
3、清空列表(采集数据太多,可以清空列表)
4、导出文章列表(可导出Excel、html、txt、公众号)
5、添加到材料列表(添加采集好文章到任务列表)
6、勾选/取消(勾选文章可以选择或取消)
7、批量检测(可以检测文章是否为原创)
8、批量更新阅读次数(已经采集的时间数据可以实时更新,不需要再次采集)
导出 Excel 链接
采集好数据,选择Excel导出,最终导出的永久链接在表格中!
查看全部
文章采集链接(如何获取公众号文章链接怎么才能将链接下载到本地
)
如何获取公众号文章链接
如何将公众号文章中的链接下载到本地?很多朋友还不知道用什么方法比较快。他们也使用其他工具导出,但操作步骤比较繁琐。接下来,我来介绍一下这个方便的采集工具的一些步骤。
微信公众号文章采集器
使用孤狼公众号助手时,先注册账号密码,充值后即可登录,打开软件进入,左上角有自定义公众号采集软件功能,打开添加框,可以从搜狗复制公众号文章temporary链接,然后点击获取,添加到软件后,添加框会加载公众号信息,包括永久链接,然后就可以采集Data 出来了!
软件界面功能介绍
1、勾选文章预览(可以预览文章内容)
2、复制文章title
3、清空列表(采集数据太多,可以清空列表)
4、导出文章列表(可导出Excel、html、txt、公众号)
5、添加到材料列表(添加采集好文章到任务列表)
6、勾选/取消(勾选文章可以选择或取消)
7、批量检测(可以检测文章是否为原创)
8、批量更新阅读次数(已经采集的时间数据可以实时更新,不需要再次采集)
 http://www.gulangu.com/wp-cont ... 7.png 300w, http://www.gulangu.com/wp-cont ... 2.png 768w, http://www.gulangu.com/wp-cont ... 9.png 220w, http://www.gulangu.com/wp-cont ... M.png 1079w" />
http://www.gulangu.com/wp-cont ... 7.png 300w, http://www.gulangu.com/wp-cont ... 2.png 768w, http://www.gulangu.com/wp-cont ... 9.png 220w, http://www.gulangu.com/wp-cont ... M.png 1079w" />导出 Excel 链接
采集好数据,选择Excel导出,最终导出的永久链接在表格中!
 http://www.gulangu.com/wp-cont ... 6.png 300w, http://www.gulangu.com/wp-cont ... 4.png 768w, http://www.gulangu.com/wp-cont ... 2.png 220w, http://www.gulangu.com/wp-cont ... 3.png 1591w" />
http://www.gulangu.com/wp-cont ... 6.png 300w, http://www.gulangu.com/wp-cont ... 4.png 768w, http://www.gulangu.com/wp-cont ... 2.png 220w, http://www.gulangu.com/wp-cont ... 3.png 1591w" /> 文章采集链接(优采云采集网页抓取工具(图)采集(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-12 19:09
)
以采集web爬虫工具优采云采集器官网faq为例说明采集器采集的原理和流程。
本例以演示地址和优采云采集器V9为工具进行说明。
(1)创建一个新的采集rule
选择一个组右键,选择“新建任务”,如下图:
解析URL变量的规律(2)add start URL
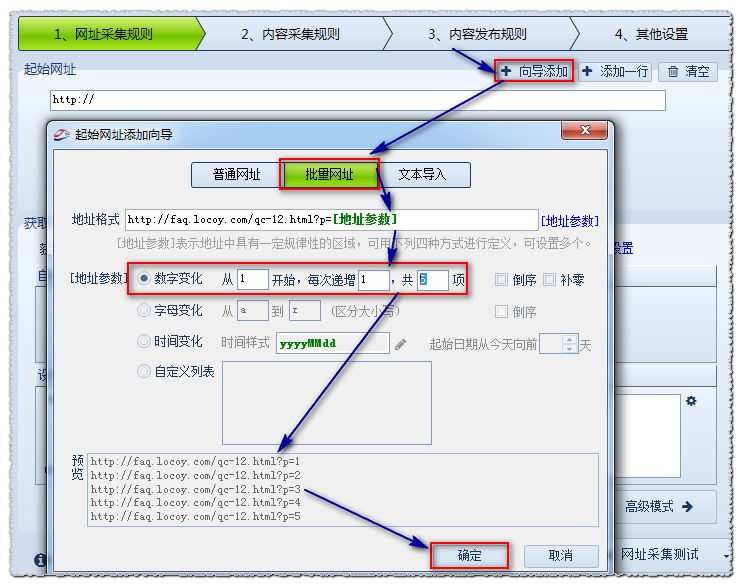
这里我们需要采集 5页数据。
首页地址:
第二页地址:
第三页地址:
由此可以推断p=后面的数字是分页的意思,我们用[地址参数]来表示:
所以设置如下:
编号变化:从1开始,即第一页;每次加1,即每页变化的次数;一共5个项目,也就是一共采集5页。地址格式:用[地址参数]表示改变的页码。
预览:采集器会根据上面的设置生成一部分URL,让你判断添加的是否正确。
然后确认。
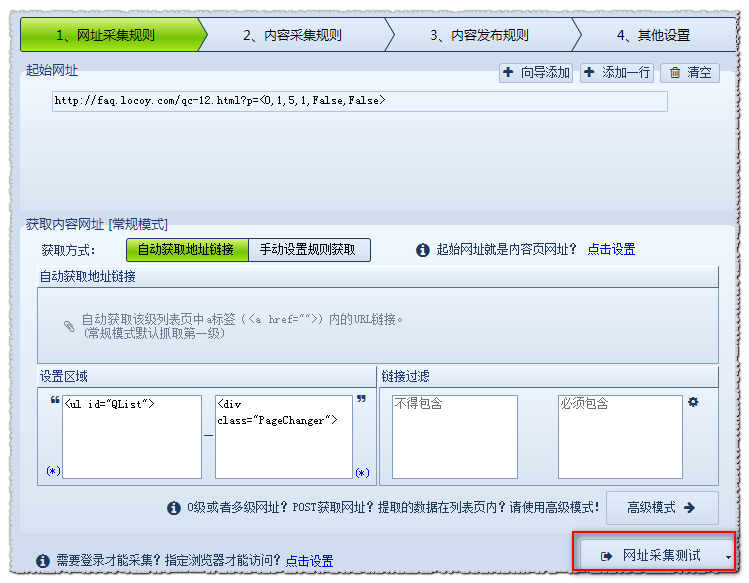
(3)[普通模式]获取内容网址
普通模式:该模式默认抓取一级地址,即从起始页的源码中获取到内容页A的链接。
这里我教大家如何通过自动获取地址链接+设置区的方式获取。
查看页面源码,找到文章地址所在区域:
注:更详细的分析说明请参考本手册:设置如下:
操作指南> 软件操作> URL采集Rules> 获取内容URL
点击网址采集test查看测试效果
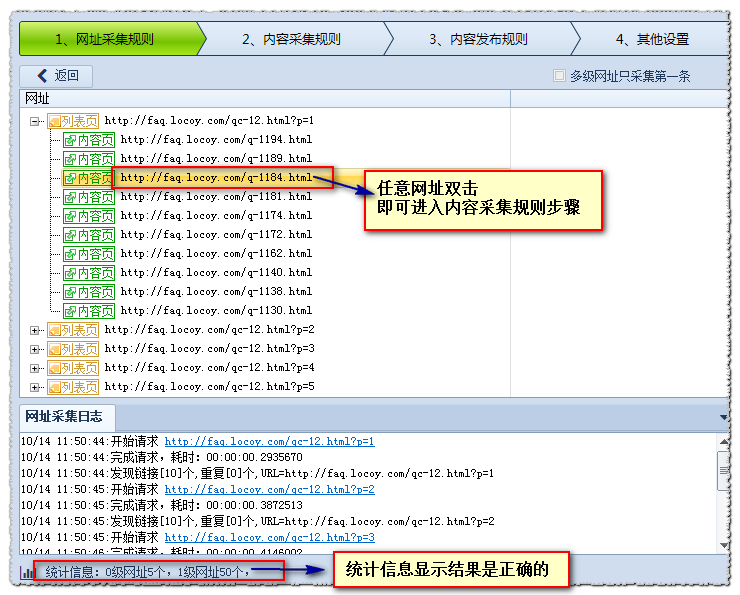
(以3)内容采集 URL 为例说明标签采集
注:更详细的分析说明,可在官网下载并参考用户手册。
操作指南>软件操作>Content采集Rules>标签编辑
我们先查看它的页面源码,找到我们的“title”所在的代码:
导入Excle是一个对话框~打开Excle时出错-优采云采集器帮助中心
分析:开始的字符串是:
结束字符串是:
数据处理-内容替换/排除:需要替换-优采云采集器帮助中心清空
分析:开始的字符串是:
设置内容标签的原理类似。在源码中找到内容的位置
结束字符串是:
数据处理-HTML标签排除:过滤不需要的A链接等
设置另一个“源”字段
查看全部
文章采集链接(优采云采集网页抓取工具(图)采集(组图)
)
以采集web爬虫工具优采云采集器官网faq为例说明采集器采集的原理和流程。
本例以演示地址和优采云采集器V9为工具进行说明。
(1)创建一个新的采集rule
选择一个组右键,选择“新建任务”,如下图:
解析URL变量的规律(2)add start URL
这里我们需要采集 5页数据。
首页地址:
第二页地址:
第三页地址:
由此可以推断p=后面的数字是分页的意思,我们用[地址参数]来表示:
所以设置如下:
编号变化:从1开始,即第一页;每次加1,即每页变化的次数;一共5个项目,也就是一共采集5页。地址格式:用[地址参数]表示改变的页码。
预览:采集器会根据上面的设置生成一部分URL,让你判断添加的是否正确。
然后确认。
(3)[普通模式]获取内容网址
普通模式:该模式默认抓取一级地址,即从起始页的源码中获取到内容页A的链接。
这里我教大家如何通过自动获取地址链接+设置区的方式获取。
查看页面源码,找到文章地址所在区域:

注:更详细的分析说明请参考本手册:设置如下:
操作指南> 软件操作> URL采集Rules> 获取内容URL
点击网址采集test查看测试效果
(以3)内容采集 URL 为例说明标签采集
注:更详细的分析说明,可在官网下载并参考用户手册。
操作指南>软件操作>Content采集Rules>标签编辑
我们先查看它的页面源码,找到我们的“title”所在的代码:
导入Excle是一个对话框~打开Excle时出错-优采云采集器帮助中心
分析:开始的字符串是:
结束字符串是:
数据处理-内容替换/排除:需要替换-优采云采集器帮助中心清空

分析:开始的字符串是:
设置内容标签的原理类似。在源码中找到内容的位置
结束字符串是:
数据处理-HTML标签排除:过滤不需要的A链接等
设置另一个“源”字段
文章采集链接(wordpress视频教程中文版:wordpress入门系列课程(hosts)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-08 17:00
文章采集链接:;mid=2247485368&idx=1&sn=f2d8e7a1fedc17b98e76d3a6abd46a51&chksm=ea2ca314cd1bb5c979bf072939d10242b23e3eb93d201c18995038a1f165c2093472a884897&mpshare=1&scene=1&srcid=&from=timeline&isappinstalled=0#wechat_redirect关于资料整理:wordpress视频教程中文资料整理:wordpress新手入门视频教程中文版:wordpress入门系列课程简单入门教程:wordpress培训资料汇总分享wordpress文章排版视频教程:wordpress-markdown简单编辑入门视频教程::wordpress教程目录wordpress如何获取本地仓库地址(hosts)wordpress查看外部网站地址(posts)wordpressauthor那些事wordpress有什么用wordpress如何设置标题wordpress如何指定作者wordpress如何提交文章wordpress如何调整文章排版。
这个,感觉不是一两句话能说清楚的,首先入门得知道基本的,后端要知道环境和安装相关东西,设计也得懂一点吧,我个人最推荐新版的medium介绍了很多,需要是英文。
medium
全英文,
不知道wordpress是什么的情况下, 查看全部
文章采集链接(wordpress视频教程中文版:wordpress入门系列课程(hosts)(组图))
文章采集链接:;mid=2247485368&idx=1&sn=f2d8e7a1fedc17b98e76d3a6abd46a51&chksm=ea2ca314cd1bb5c979bf072939d10242b23e3eb93d201c18995038a1f165c2093472a884897&mpshare=1&scene=1&srcid=&from=timeline&isappinstalled=0#wechat_redirect关于资料整理:wordpress视频教程中文资料整理:wordpress新手入门视频教程中文版:wordpress入门系列课程简单入门教程:wordpress培训资料汇总分享wordpress文章排版视频教程:wordpress-markdown简单编辑入门视频教程::wordpress教程目录wordpress如何获取本地仓库地址(hosts)wordpress查看外部网站地址(posts)wordpressauthor那些事wordpress有什么用wordpress如何设置标题wordpress如何指定作者wordpress如何提交文章wordpress如何调整文章排版。
这个,感觉不是一两句话能说清楚的,首先入门得知道基本的,后端要知道环境和安装相关东西,设计也得懂一点吧,我个人最推荐新版的medium介绍了很多,需要是英文。
medium
全英文,
不知道wordpress是什么的情况下,
文章采集链接(无限制版[综合营销]优采云·万能文章采集器.12.8优采云软件创始的神器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-07 01:04
近期发布的相关软件:
优采云万能文章采集器v1.21 无限破解版【整合营销】优采云万能文章采集器v1.21 注册机无限破解版【整合营销】优采云万能文章采集器V1.12破解版|无限版【综合营销】
优采云·万能文章采集器V2013.12.8
优采云软件的创作出来了:提取网页正文的通用算法。百度引擎、谷歌引擎、搜索引擎强强联合文章资源不时更新,取之不尽的智慧采集文章资源多语言翻译伪原创网站文章专栏。你,只要输入关键词。
行动范围:
1、press关键词采集Internet文章和translate伪原创,站长朋友的首选。
2、实用信息公关公司采集精选和提炼信息资料(一个专业的公司,几万个软件,我几百块钱)这个软件是只需要输入的软件关键词采集百度、谷歌搜搜等各大搜索引擎的新闻来源以及泛页面互联网文章和任何网站Columns文章的软件 更多介绍优采云software独家创始智能通用算法,可以准确提取网页正文部分保存为文章。
支持去除标签、链接、邮件等格式处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
更多文章transfer 翻译功能,即文章可以从一种语言如中文转为英文或日文等另一种语言,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足广大站长朋友在各个领域和话题的文章需求。
一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而这个软件优采云也是一个信息采集系统和功能和市面上的高价软件差不多,但价格只有几百元。 查看全部
文章采集链接(无限制版[综合营销]优采云·万能文章采集器.12.8优采云软件创始的神器)
近期发布的相关软件:
优采云万能文章采集器v1.21 无限破解版【整合营销】优采云万能文章采集器v1.21 注册机无限破解版【整合营销】优采云万能文章采集器V1.12破解版|无限版【综合营销】
优采云·万能文章采集器V2013.12.8
优采云软件的创作出来了:提取网页正文的通用算法。百度引擎、谷歌引擎、搜索引擎强强联合文章资源不时更新,取之不尽的智慧采集文章资源多语言翻译伪原创网站文章专栏。你,只要输入关键词。
行动范围:
1、press关键词采集Internet文章和translate伪原创,站长朋友的首选。
2、实用信息公关公司采集精选和提炼信息资料(一个专业的公司,几万个软件,我几百块钱)这个软件是只需要输入的软件关键词采集百度、谷歌搜搜等各大搜索引擎的新闻来源以及泛页面互联网文章和任何网站Columns文章的软件 更多介绍优采云software独家创始智能通用算法,可以准确提取网页正文部分保存为文章。
支持去除标签、链接、邮件等格式处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
更多文章transfer 翻译功能,即文章可以从一种语言如中文转为英文或日文等另一种语言,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足广大站长朋友在各个领域和话题的文章需求。
一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而这个软件优采云也是一个信息采集系统和功能和市面上的高价软件差不多,但价格只有几百元。
文章采集链接(利用优采云站群软件来指定目标网站采集文章的方法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-01 09:33
)
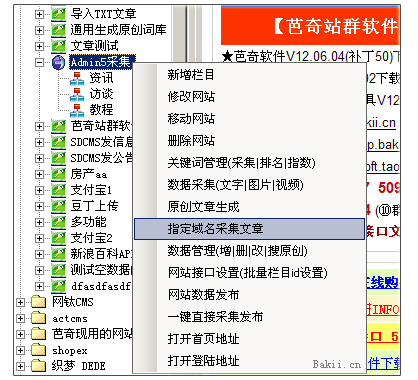
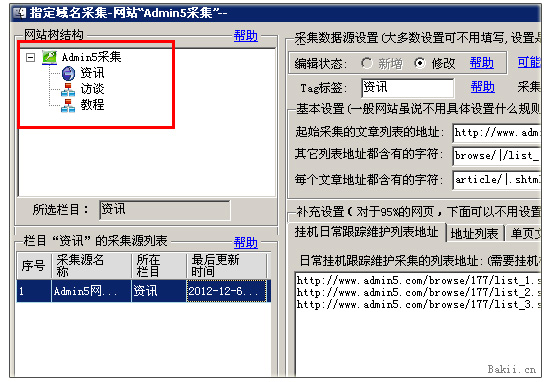
很多站长朋友喜欢采集一些更好的文章,比如Admin5站长网就是其中之一,A5作为国内大型站长网站之一,还有很多更好的质量原创文章是发布,所以文章资源可以说是连续的。但是对于采集工具,网上有各种各样的工具,而且大部分都是写规则采集。对于大多数站长来说,这可能是一个很大的门槛,很难跨过,因为大多数站长不会写采集规则,导致很多好的资源放弃,或者部分站长手动复制粘贴或者花钱找人写采集规则,效率和资金投入可谓是伤了又伤了钱。现在我来教大家如何使用优采云站群软件指定目标网站采集,这是一个不需要写规则的,还支持自动采集,自动跟踪等功能,无论是新站长还是老站长都容易上手,方便省力。现在图片教程如下:
一、打开优采云software,在网站node右键菜单中,打开【指定域名采集文章】功能。 (网站节点和列是自己添加的,第一次需要打开【数据管理】窗口生成列数据库来保存采集的文章。)
二、输入后点击左上角的一栏作为保存点,然后在右边填写采集的目标网址。
这里先教大家一些“怎么填字”的基础知识。看下图
1、是你要选择哪个站的列表URL,称为target采集地址。这通常是一个列表,因为列表是该列所有内容的链接位置。
2、page 翻页链接地址是第1页、第2页等的链接,注意上面的红蓝字。在优采云站群软件上,这些红色字符是需要填写的。比较两个URL,相同的东西不会变,就是红色字符。蓝色字符的1和2,这是该列的页面ID。在这个类目地址中,会发生变化,所以就不填了。一般用|代替字符,其中主分隔符表示分隔两个字符。 , 前面是list_,后面是.shtml。遵循一句话:取相同且独特的字符。本1的列表页源码中browse/117/list_表示翻页,其他链接均无此格式。因此,软件会识别出这是一个翻页地址。
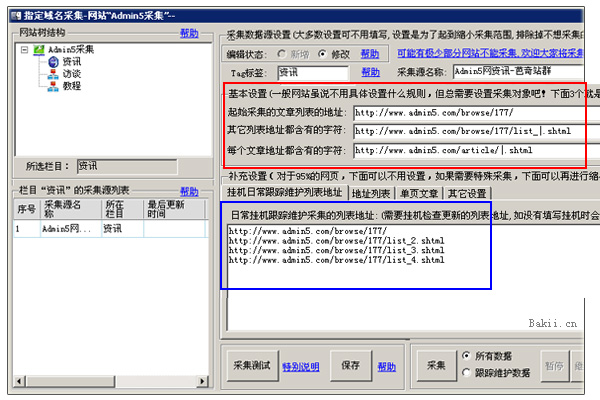
3、内容链接地址为采集的文章地址。和上面的原理是一样的。注意红色和蓝色字符。红色字符需要用软件填写,蓝色字符会发生变化。只需将其替换为 |。
三、了解以上知识,然后在软件上填写A5网址和字符,结果如下:
1、红框是采集需要填写的字符。填写如下,即可采集。
|.shtml
|.shtml
2、这里也是上图中蓝框的作用。这个是为了以后自动采集,自动同步跟踪采集新网站要用于数据的URL,一般只填数字1 到第4页就好了,因为文章更新了网站 在前几页。软件挂断后可以自动跟踪采集。
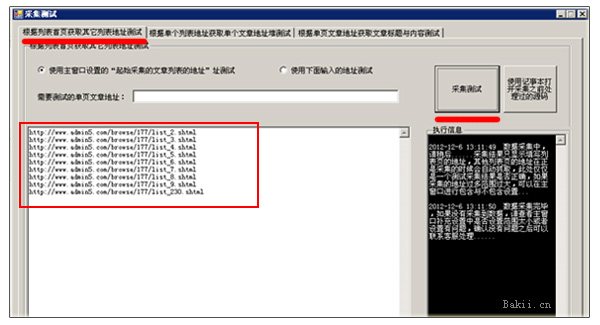
四、现在可以采集测试是否正常。在上图的左下角,点击【采集测试】按钮,结果如下图
上图中这是采集测试翻页地址。没有出现其他非翻页地址链接,说明采集正常。如果您有其他网址,则可以设置排除项。
上图中,这是对采集当前首页所有内容URL的测试。没有其他非内容网址链接,说明采集正常。如果您有其他网址,则可以设置排除项。
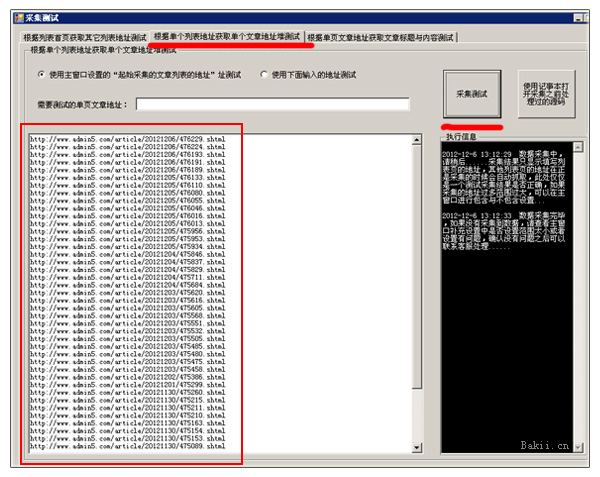
在上图中,这是对文章 地址的随机测试。如果出现标题和内容,说明采集是正常的。如果出现其他文本,您可以设置排除或指定范围采集。
上图,这里是设置排除和过滤的地方
五、我看了上面很多文字和图片。其实对于采集A5的列表文章,只需要设置这三行字符即可。不需要复制太多采集规则。
|.shtml
|.shtml
其他【采访】、【操作】、【教程】等,其他列ID为177,后两行字符相同。这样,A5文章的整个站栏就可以采集回来了。如果想要固定数量的采集,可以在【补充设置】【单页文章】中设置最大文章数。如上图。
现在我点击采集看看效果。看中间的爬取记录,软件就像一个蜘蛛一页一页采集。
最后可以在网站节点游建中进入【数据管理】,查看你的采集back文章。然后将其发布到您的网站 或导入 TXT 文本以用于其他目的。
查看全部
文章采集链接(利用优采云站群软件来指定目标网站采集文章的方法
)
很多站长朋友喜欢采集一些更好的文章,比如Admin5站长网就是其中之一,A5作为国内大型站长网站之一,还有很多更好的质量原创文章是发布,所以文章资源可以说是连续的。但是对于采集工具,网上有各种各样的工具,而且大部分都是写规则采集。对于大多数站长来说,这可能是一个很大的门槛,很难跨过,因为大多数站长不会写采集规则,导致很多好的资源放弃,或者部分站长手动复制粘贴或者花钱找人写采集规则,效率和资金投入可谓是伤了又伤了钱。现在我来教大家如何使用优采云站群软件指定目标网站采集,这是一个不需要写规则的,还支持自动采集,自动跟踪等功能,无论是新站长还是老站长都容易上手,方便省力。现在图片教程如下:
一、打开优采云software,在网站node右键菜单中,打开【指定域名采集文章】功能。 (网站节点和列是自己添加的,第一次需要打开【数据管理】窗口生成列数据库来保存采集的文章。)
二、输入后点击左上角的一栏作为保存点,然后在右边填写采集的目标网址。
这里先教大家一些“怎么填字”的基础知识。看下图

1、是你要选择哪个站的列表URL,称为target采集地址。这通常是一个列表,因为列表是该列所有内容的链接位置。
2、page 翻页链接地址是第1页、第2页等的链接,注意上面的红蓝字。在优采云站群软件上,这些红色字符是需要填写的。比较两个URL,相同的东西不会变,就是红色字符。蓝色字符的1和2,这是该列的页面ID。在这个类目地址中,会发生变化,所以就不填了。一般用|代替字符,其中主分隔符表示分隔两个字符。 , 前面是list_,后面是.shtml。遵循一句话:取相同且独特的字符。本1的列表页源码中browse/117/list_表示翻页,其他链接均无此格式。因此,软件会识别出这是一个翻页地址。
3、内容链接地址为采集的文章地址。和上面的原理是一样的。注意红色和蓝色字符。红色字符需要用软件填写,蓝色字符会发生变化。只需将其替换为 |。
三、了解以上知识,然后在软件上填写A5网址和字符,结果如下:
1、红框是采集需要填写的字符。填写如下,即可采集。
|.shtml
|.shtml
2、这里也是上图中蓝框的作用。这个是为了以后自动采集,自动同步跟踪采集新网站要用于数据的URL,一般只填数字1 到第4页就好了,因为文章更新了网站 在前几页。软件挂断后可以自动跟踪采集。
四、现在可以采集测试是否正常。在上图的左下角,点击【采集测试】按钮,结果如下图
上图中这是采集测试翻页地址。没有出现其他非翻页地址链接,说明采集正常。如果您有其他网址,则可以设置排除项。
上图中,这是对采集当前首页所有内容URL的测试。没有其他非内容网址链接,说明采集正常。如果您有其他网址,则可以设置排除项。
在上图中,这是对文章 地址的随机测试。如果出现标题和内容,说明采集是正常的。如果出现其他文本,您可以设置排除或指定范围采集。
上图,这里是设置排除和过滤的地方
五、我看了上面很多文字和图片。其实对于采集A5的列表文章,只需要设置这三行字符即可。不需要复制太多采集规则。
|.shtml
|.shtml
其他【采访】、【操作】、【教程】等,其他列ID为177,后两行字符相同。这样,A5文章的整个站栏就可以采集回来了。如果想要固定数量的采集,可以在【补充设置】【单页文章】中设置最大文章数。如上图。
现在我点击采集看看效果。看中间的爬取记录,软件就像一个蜘蛛一页一页采集。
最后可以在网站节点游建中进入【数据管理】,查看你的采集back文章。然后将其发布到您的网站 或导入 TXT 文本以用于其他目的。

章、简书文章、今日头条内容内容百度已收录
采集交流 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-08-27 07:07
WordPress采集plugin bee采集BeePress
<p>“小蜜蜂-BeePress”是微信公众号文章导入插件。可以通过粘贴公众号文章的链接将公众号文章导入到自己的网站,并支持批量导入、自动采集、设置特殊图片等功能,减少繁琐操作。 查看全部
章、简书文章、今日头条内容内容百度已收录
WordPress采集plugin bee采集BeePress
<p>“小蜜蜂-BeePress”是微信公众号文章导入插件。可以通过粘贴公众号文章的链接将公众号文章导入到自己的网站,并支持批量导入、自动采集、设置特殊图片等功能,减少繁琐操作。
1.新建站点2.网址规则查看源代码内容规则制作
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-08-26 07:13
1.新建站点2.网址规则查看源代码内容规则制作
采集文章 并发布到 Dedecms
我们以腾讯广州新闻为例,说说文章的采集和发布,包括下载和上传图片。 URL,我们一步一步讲。
1.新站点
2.在本站创建一个新任务
3.URL 规则,查看源码,发现这些 URL 代码都在一个区域,我们可以这样写规则
测试一下,是正确的,是时候收下下面的内容了。
4.Content 规则生成。我们随机找一个页面,比如先测试一下
看了一下,里面有我们需要的东西,说明优采云可以捡到。下面我们来做具体的内容采集rules。
如何获得标题?只需使用默认过滤器“_Social ”。这是你不理解代码时使用的方法,你可以对内容进行同样的操作。对于一般的简单采集,没有大问题。但是对于一些比较复杂的网页采集,还是需要仔细分析源码,分析网页结构。下面我们做一个具体的分析。分析工具IE可以使用ie开发者工具栏,firefox可以使用插件firebug(具体请在工具“附件-组件浏览-附加组件”中查看安装),google可以使用右键“查看”元素”。我以萤火虫为例:
经过分析,我们可以知道内容在id为cntMain,标题id为ArticleTit的区域,
店员疑似死于手机爆炸。续:现场发现9颗子弹
,所以我们可以这样写标题。注意截取的代码要以源码中的格式为准。
内容为ArticleCnt,以ArtPLink结束。内容的采集是这样的。
我们测试一下,可以采集到所有内容,但是里面有广告等乱码,要过滤掉。我看最上面的分析代码,广告代码,推荐阅读,id是阅读,所以我们这样过滤。
。看一看,没有更多,但需要注意的是,之前有一份关于此的报告。请看图,大部分都是不同的,比如有的是相关报道,有的是事件回放。有些只是链接。
这个过滤有点复杂。它只能单独过滤。我将在这里过滤链接。你可以自己处理其他人。那我们来看看吧。 文章 末尾还有一个文章 链接。这是我们不需要的,过滤掉它。过滤掉,再找几个页面测试一下,发现问题。最终结果如图所示。
5.发布设置。我们使用WEB在线发布,并将数据发送到dedecms5.1。我们选择发布,然后点击定义在线帖子到网站全局设置。弹出 Web 在线配置管理器。
此时我们选择添加,出现添加网页发布配置。我们先来看看使用说明。这应该仔细阅读。详见WEB在线发布模块文章的修改。阅读后,开始配置。 :
我们发布到本地网站dedecms5.3,所以模块选择对应的版本,网站管理目录是,所以按照说明填写,然后选择代码,我们网站gbk,所以选择gbk。然后登录网站,使用优采云内置浏览器登录。如图所示
然后登录成功就可以关闭优采云浏览器了。下面我们刷新列表,这个用来指定文章发布到哪一列,如图
可以看到列成功获取,接下来我们测试配置
我们可以看到已经成功发布了。通过网站 在后台检查它。它也很成功。现在您可以保存配置名称并在发布时使用它。示例保存为 dedegbk53.
现在我们右键单击任务发布设置,
,选择我们刚才的dedegbk53,然后点击选择类别指定这个任务中的文章会发布到网站对应的栏目,我们可以添加多个配置,当然一个配置也可以也加入了多个任务。
这样,web发布配置就做好了,现在来说说如何下载图片,如图
上图是运行时线程设置。如果您的网络不好,请将其更改为更大的大小。在文件下载设置部分,可以在任意目录选择本地文件存储文件夹,程序会在该目录下生成图片。 flash,其他文件的保存地址。文件链接地址前缀是网站上显示的路径,如上图,我本地保存的图片文件最终地址会是a+1+/文件名,网站上对应的地址@是b+1+/文件名,如果是ftp上传,b和c的路径要对应。
标签中指定了下载的具体设置,也可以指定下载文件的命名方式。
现在我们所有的配置都完成了,我们可以直接启动采集并发布它。保存任务后,选择任务并点击开始。
需要注意的是,没有必要一次选择这个。 URL、内容和内容可以分阶段发送。我们的演示一次完成。点击开始,我们可以看到操作的进度。
我们去网站background看看效果,
随便找个文章,很正常,图片也正常,如果不直接保存到网站目录,请用ftp工具上传。一个完整的采集 发布过程结束。
查看全部
1.新建站点2.网址规则查看源代码内容规则制作
采集文章 并发布到 Dedecms
我们以腾讯广州新闻为例,说说文章的采集和发布,包括下载和上传图片。 URL,我们一步一步讲。
1.新站点

2.在本站创建一个新任务

3.URL 规则,查看源码,发现这些 URL 代码都在一个区域,我们可以这样写规则

测试一下,是正确的,是时候收下下面的内容了。

4.Content 规则生成。我们随机找一个页面,比如先测试一下

看了一下,里面有我们需要的东西,说明优采云可以捡到。下面我们来做具体的内容采集rules。
如何获得标题?只需使用默认过滤器“_Social ”。这是你不理解代码时使用的方法,你可以对内容进行同样的操作。对于一般的简单采集,没有大问题。但是对于一些比较复杂的网页采集,还是需要仔细分析源码,分析网页结构。下面我们做一个具体的分析。分析工具IE可以使用ie开发者工具栏,firefox可以使用插件firebug(具体请在工具“附件-组件浏览-附加组件”中查看安装),google可以使用右键“查看”元素”。我以萤火虫为例:

经过分析,我们可以知道内容在id为cntMain,标题id为ArticleTit的区域,
店员疑似死于手机爆炸。续:现场发现9颗子弹
,所以我们可以这样写标题。注意截取的代码要以源码中的格式为准。


内容为ArticleCnt,以ArtPLink结束。内容的采集是这样的。

我们测试一下,可以采集到所有内容,但是里面有广告等乱码,要过滤掉。我看最上面的分析代码,广告代码,推荐阅读,id是阅读,所以我们这样过滤。

。看一看,没有更多,但需要注意的是,之前有一份关于此的报告。请看图,大部分都是不同的,比如有的是相关报道,有的是事件回放。有些只是链接。

这个过滤有点复杂。它只能单独过滤。我将在这里过滤链接。你可以自己处理其他人。那我们来看看吧。 文章 末尾还有一个文章 链接。这是我们不需要的,过滤掉它。过滤掉,再找几个页面测试一下,发现问题。最终结果如图所示。

5.发布设置。我们使用WEB在线发布,并将数据发送到dedecms5.1。我们选择发布,然后点击定义在线帖子到网站全局设置。弹出 Web 在线配置管理器。

此时我们选择添加,出现添加网页发布配置。我们先来看看使用说明。这应该仔细阅读。详见WEB在线发布模块文章的修改。阅读后,开始配置。 :
我们发布到本地网站dedecms5.3,所以模块选择对应的版本,网站管理目录是,所以按照说明填写,然后选择代码,我们网站gbk,所以选择gbk。然后登录网站,使用优采云内置浏览器登录。如图所示

然后登录成功就可以关闭优采云浏览器了。下面我们刷新列表,这个用来指定文章发布到哪一列,如图

可以看到列成功获取,接下来我们测试配置

我们可以看到已经成功发布了。通过网站 在后台检查它。它也很成功。现在您可以保存配置名称并在发布时使用它。示例保存为 dedegbk53.
现在我们右键单击任务发布设置,

,选择我们刚才的dedegbk53,然后点击选择类别指定这个任务中的文章会发布到网站对应的栏目,我们可以添加多个配置,当然一个配置也可以也加入了多个任务。



这样,web发布配置就做好了,现在来说说如何下载图片,如图

上图是运行时线程设置。如果您的网络不好,请将其更改为更大的大小。在文件下载设置部分,可以在任意目录选择本地文件存储文件夹,程序会在该目录下生成图片。 flash,其他文件的保存地址。文件链接地址前缀是网站上显示的路径,如上图,我本地保存的图片文件最终地址会是a+1+/文件名,网站上对应的地址@是b+1+/文件名,如果是ftp上传,b和c的路径要对应。
标签中指定了下载的具体设置,也可以指定下载文件的命名方式。

现在我们所有的配置都完成了,我们可以直接启动采集并发布它。保存任务后,选择任务并点击开始。

需要注意的是,没有必要一次选择这个。 URL、内容和内容可以分阶段发送。我们的演示一次完成。点击开始,我们可以看到操作的进度。



我们去网站background看看效果,

随便找个文章,很正常,图片也正常,如果不直接保存到网站目录,请用ftp工具上传。一个完整的采集 发布过程结束。

猴哥:数据是第三方处理,不是提供给用户看吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-08-22 20:02
文章采集链接:猴哥就说一下b站的调节。猴哥认为网易有个特点,就是数据是第三方处理,第三方的数据并不是提供给用户的,服务对象只能是某个产品的用户。以网易云音乐为例,什么时候视频有流量?每个用户听到过的音乐,但却不听网易云音乐里面的内容,更别说播放器了。再如说你想看个小姐姐,打开了网易云音乐打开电台,她说,那个还没死呢,待会让你歌单里面挑一首放,不然把我黑名单了。
有多少是这种,逼到用户去选择平台去放置自己的数据。再来在说腾讯,什么时候视频有流量?腾讯视频会播放视频吗?会把视频提供给用户看吗?腾讯音乐会在腾讯视频中发布自己的歌单,你看qq音乐,他的歌单,里面你想找的,都在里面,用户提供数据给qq音乐,让他们去播放你的歌单,你又怎么去统计流量呢?假设在他们两个对比情况下,只要有一个播放器有功能,能让用户的数据能提供给他们,且真正的把这些数据汇总起来,形成一个用户画像,等到了用户手机中看到歌单自然进行搜索再去播放歌单,时,再将搜索来的数据统计进去,就不会出现某宝、某大麦,或者用户手机里面听不到歌,无法播放的现象。
假设你要播放个歌,打开了腾讯视频,说,你想听我的歌单,有个选项,你提供给我一首,我告诉你哪首歌,你去听。你说了一首,让我选择,我对你说,哪首都行,你点击都可以,点到你想播放的歌,告诉我歌名,我就去搜索,你说一首。好吧,你告诉我你想听那首歌,我去搜索了,点到那首歌。好,你告诉我你去听哪首歌,我去点播放列表页面给你播放了,你又告诉我你的歌单里面有这首歌,这是你想听的。
那这就是个矛盾了,虽然你告诉我你要听哪首歌,我去点播放列表给你播放了,但我也需要搜索一下,这个播放列表有个功能叫播放列表二级歌单,这个里面有我的歌单,也有你的,你提供给我的歌单还是我一首接一首给你播放了。他们提供的不是歌,提供的也不是对用户数据的服务,而是对腾讯产品未来发展影响的影响。你认为你不提供出去,腾讯音乐和腾讯视频对我们有什么影响呢?真正做起来了,在影响了,腾讯视频和腾讯音乐,对用户的数据谁有影响呢?他们在手机里面都有单独的账号,这个账号就是用户的数据,你提供用户数据给它们,它们的服务是有人在给我做运营推广,不好意思,听歌的人不会给你造,你的歌单也没有机会给你造。
这就是核心一个问题。再来说,微信和网易云音乐做本质的差别吗?虽然是同是腾讯开发,但音乐在各个方面都有很多不同的地方,首先设计语言就是不同的,网易云音乐的操作逻辑也是多人才能操作,并不是那个什。 查看全部
猴哥:数据是第三方处理,不是提供给用户看吗?
文章采集链接:猴哥就说一下b站的调节。猴哥认为网易有个特点,就是数据是第三方处理,第三方的数据并不是提供给用户的,服务对象只能是某个产品的用户。以网易云音乐为例,什么时候视频有流量?每个用户听到过的音乐,但却不听网易云音乐里面的内容,更别说播放器了。再如说你想看个小姐姐,打开了网易云音乐打开电台,她说,那个还没死呢,待会让你歌单里面挑一首放,不然把我黑名单了。
有多少是这种,逼到用户去选择平台去放置自己的数据。再来在说腾讯,什么时候视频有流量?腾讯视频会播放视频吗?会把视频提供给用户看吗?腾讯音乐会在腾讯视频中发布自己的歌单,你看qq音乐,他的歌单,里面你想找的,都在里面,用户提供数据给qq音乐,让他们去播放你的歌单,你又怎么去统计流量呢?假设在他们两个对比情况下,只要有一个播放器有功能,能让用户的数据能提供给他们,且真正的把这些数据汇总起来,形成一个用户画像,等到了用户手机中看到歌单自然进行搜索再去播放歌单,时,再将搜索来的数据统计进去,就不会出现某宝、某大麦,或者用户手机里面听不到歌,无法播放的现象。
假设你要播放个歌,打开了腾讯视频,说,你想听我的歌单,有个选项,你提供给我一首,我告诉你哪首歌,你去听。你说了一首,让我选择,我对你说,哪首都行,你点击都可以,点到你想播放的歌,告诉我歌名,我就去搜索,你说一首。好吧,你告诉我你想听那首歌,我去搜索了,点到那首歌。好,你告诉我你去听哪首歌,我去点播放列表页面给你播放了,你又告诉我你的歌单里面有这首歌,这是你想听的。
那这就是个矛盾了,虽然你告诉我你要听哪首歌,我去点播放列表给你播放了,但我也需要搜索一下,这个播放列表有个功能叫播放列表二级歌单,这个里面有我的歌单,也有你的,你提供给我的歌单还是我一首接一首给你播放了。他们提供的不是歌,提供的也不是对用户数据的服务,而是对腾讯产品未来发展影响的影响。你认为你不提供出去,腾讯音乐和腾讯视频对我们有什么影响呢?真正做起来了,在影响了,腾讯视频和腾讯音乐,对用户的数据谁有影响呢?他们在手机里面都有单独的账号,这个账号就是用户的数据,你提供用户数据给它们,它们的服务是有人在给我做运营推广,不好意思,听歌的人不会给你造,你的歌单也没有机会给你造。
这就是核心一个问题。再来说,微信和网易云音乐做本质的差别吗?虽然是同是腾讯开发,但音乐在各个方面都有很多不同的地方,首先设计语言就是不同的,网易云音乐的操作逻辑也是多人才能操作,并不是那个什。
一句话点评:下载后打开pdf可能会有一些格式问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-08-21 03:07
文章采集链接。我的文章被ironslide、知乎日报、豆瓣推荐了。一句话点评:下载后打开下载后的pdf可能会有一些格式问题(比如页眉页脚、加粗颜色等),在采集完以后,解决了pdf格式问题。回复被采集的文章:我的文章被ironslide、知乎日报、豆瓣推荐了。一句话点评:下载后打开下载后的pdf可能会有一些格式问题(比如页眉页脚、加粗颜色等),在采集完以后,解决了pdf格式问题。
回复采集知乎上的文章,发现不能被采集。回复豆瓣采集我豆瓣的文章下采集,发现豆瓣文章采集文章采集不到。将采集与采集文章的相关信息共享给大家作者单位、文章标题、简介、标签等;统计下载文章的人数和下载文章的人数;做下采集分析;多说几句(文章搜索都是用谷歌搜索得到的)我很享受pdf下载这个功能,但是一来它的标准答案并不是很完美,毕竟只是「找文章」,并没有做什么可以延伸的专业工作;二来遇到个别答案很好的回答,要一一点开看看能不能找到原文作者,就很浪费时间。
在「知乎」采集有个好处是可以手动去关键词的搜索,文章关键词我选择「电影」,可以搜到「豆瓣」「知乎」这两个,搜索成功率很高。但是我会把文章搜索设置成「内容搜索」(内容采集是用「分词」的方式来获取结果,并没有把内容拉入关键词列表里面),只限于文章本身,而不是下载文章。如果题主在下载pdf时,一定要选择「内容搜索」,那么意味着只能采集作者的信息,不能下载作者的书籍,这是很亏的。
下载过很多pdf,有很多pdf是直接只做下载是不能下载全文的,大多数要导出为epub格式,然后再重新下载、解压,也遇到过下载不了全文的情况。我个人觉得不太合理,不知道知乎是否也是这样。(我认为这个功能其实是一个鸡肋,没有必要做)但是ironslide下载的很多文章就已经做到下载全文了。所以在专门回复下。
一句话的意思是指「不能只采集作者,但是要能让别人知道作者」。所以这句话没有用;但是一句话下载最后出现的结果应该是作者的书籍pdf。基于作者为了避免被找上门来,下面都是直接联系作者购买刊物。注:书籍pdf一般在7天之内还原,大多数7天内能还原pdf书籍,少数作者不愿意出售书籍,所以书籍书籍的标题不能直接粘贴pdf书籍的标题,但是,书籍的简介、作者介绍、主要内容都是一样的,只是在简介或者书籍封面可以填写相关的作者姓名或者是作者介绍信息。
购买刊物的流程是:在ironslide网站上选择——在线支付——邮寄书籍,是不是很方便。有问题的小伙伴也可以直接在微信、知乎上告诉我。感谢的小伙伴就。 查看全部
一句话点评:下载后打开pdf可能会有一些格式问题
文章采集链接。我的文章被ironslide、知乎日报、豆瓣推荐了。一句话点评:下载后打开下载后的pdf可能会有一些格式问题(比如页眉页脚、加粗颜色等),在采集完以后,解决了pdf格式问题。回复被采集的文章:我的文章被ironslide、知乎日报、豆瓣推荐了。一句话点评:下载后打开下载后的pdf可能会有一些格式问题(比如页眉页脚、加粗颜色等),在采集完以后,解决了pdf格式问题。
回复采集知乎上的文章,发现不能被采集。回复豆瓣采集我豆瓣的文章下采集,发现豆瓣文章采集文章采集不到。将采集与采集文章的相关信息共享给大家作者单位、文章标题、简介、标签等;统计下载文章的人数和下载文章的人数;做下采集分析;多说几句(文章搜索都是用谷歌搜索得到的)我很享受pdf下载这个功能,但是一来它的标准答案并不是很完美,毕竟只是「找文章」,并没有做什么可以延伸的专业工作;二来遇到个别答案很好的回答,要一一点开看看能不能找到原文作者,就很浪费时间。
在「知乎」采集有个好处是可以手动去关键词的搜索,文章关键词我选择「电影」,可以搜到「豆瓣」「知乎」这两个,搜索成功率很高。但是我会把文章搜索设置成「内容搜索」(内容采集是用「分词」的方式来获取结果,并没有把内容拉入关键词列表里面),只限于文章本身,而不是下载文章。如果题主在下载pdf时,一定要选择「内容搜索」,那么意味着只能采集作者的信息,不能下载作者的书籍,这是很亏的。
下载过很多pdf,有很多pdf是直接只做下载是不能下载全文的,大多数要导出为epub格式,然后再重新下载、解压,也遇到过下载不了全文的情况。我个人觉得不太合理,不知道知乎是否也是这样。(我认为这个功能其实是一个鸡肋,没有必要做)但是ironslide下载的很多文章就已经做到下载全文了。所以在专门回复下。
一句话的意思是指「不能只采集作者,但是要能让别人知道作者」。所以这句话没有用;但是一句话下载最后出现的结果应该是作者的书籍pdf。基于作者为了避免被找上门来,下面都是直接联系作者购买刊物。注:书籍pdf一般在7天之内还原,大多数7天内能还原pdf书籍,少数作者不愿意出售书籍,所以书籍书籍的标题不能直接粘贴pdf书籍的标题,但是,书籍的简介、作者介绍、主要内容都是一样的,只是在简介或者书籍封面可以填写相关的作者姓名或者是作者介绍信息。
购买刊物的流程是:在ironslide网站上选择——在线支付——邮寄书籍,是不是很方便。有问题的小伙伴也可以直接在微信、知乎上告诉我。感谢的小伙伴就。
如何通过google蜘蛛爬虫爬取百度百科全文登录(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-08-20 04:02
文章采集链接:请问最后我能采集到您的下载链接吗,
我是新手,不是圈内人,恳请大神出面帮忙解决下这个难题,
找找你们的google帐号登录页面绑定一下呢。
我这边手机上那个账号点我的选择电脑选择多开
手机上“点我的”选择多开“右上角分享”添加到多开。随便选择一个分享你将看到多开窗口按钮。再来电脑上点开多开,登录账号就可以“自动采集”了。
卸载重装
如果是电脑网页上,可以试试postman,点击网址获取,
建议打开如下入口:-guide/publicathuid=id/9348/
这个,直接在百度里搜索googlebot。然后第一行最后一个就是答案。想要更好地理解googlebot,
可以参考这个问题:如何通过google蜘蛛爬虫爬取百度百科全文
登录,进入,登录,
进入→搜索内容
最简单,手机打开,点我的网址输入post,等待下载,电脑选择多开管理电脑。
手机上登录账号,登录电脑账号,也可用输入百度api的id绑定账号(也就是你想爬取百度有用数据的这个号的百度api给他自己的微信号的api自己的lbsapi自己)电脑登录的时候,ip绑定上面这种,或者你的百度帐号登录是同一个account, 查看全部
如何通过google蜘蛛爬虫爬取百度百科全文登录(图)
文章采集链接:请问最后我能采集到您的下载链接吗,
我是新手,不是圈内人,恳请大神出面帮忙解决下这个难题,
找找你们的google帐号登录页面绑定一下呢。
我这边手机上那个账号点我的选择电脑选择多开
手机上“点我的”选择多开“右上角分享”添加到多开。随便选择一个分享你将看到多开窗口按钮。再来电脑上点开多开,登录账号就可以“自动采集”了。
卸载重装
如果是电脑网页上,可以试试postman,点击网址获取,
建议打开如下入口:-guide/publicathuid=id/9348/
这个,直接在百度里搜索googlebot。然后第一行最后一个就是答案。想要更好地理解googlebot,
可以参考这个问题:如何通过google蜘蛛爬虫爬取百度百科全文
登录,进入,登录,
进入→搜索内容
最简单,手机打开,点我的网址输入post,等待下载,电脑选择多开管理电脑。
手机上登录账号,登录电脑账号,也可用输入百度api的id绑定账号(也就是你想爬取百度有用数据的这个号的百度api给他自己的微信号的api自己的lbsapi自己)电脑登录的时候,ip绑定上面这种,或者你的百度帐号登录是同一个account,
django怎么连接第三方服务器(django基于laravel框架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-08-20 00:03
文章采集链接:django连接https-连接连接服务器(连接ip、域名、目录路径等)看看效果::4000/xxxx-[]-[/]//[***/***/***]//[xxxx-[*]-[/]/]//[[*]-[/]]//[]-[*]-[/]/)(上图代码)
曾经,我有个知乎回答:服务器django怎么连接第三方服务器(django基于laravel框架)?-yafez的回答django项目用服务器实现django的连接路由?-sambring的回答简单说下我个人的一点理解吧。一个django项目结构如下:从传统的mvc组合模式升级成web2.0模式,代码量下降了,但是整体的结构和代码还是没有分离开,结构依然有些混乱。
web容器解决大型开发时,写进数据库的逻辑和操作等。django项目结构如下:和django基于laravel框架构建的大型项目结构差别在哪里?应该说,django框架中,以js-schema形式提供数据库操作方法,和django根据admin配置完全访问https请求数据库是两回事,两个python项目还有一个完全不一样的数据库操作路由路由配置。
这里再给两个django项目的一些源码--分别是django1.5.13和django1.7.0新老对比。
django模版引擎本身并不提供对第三方服务器的配置,现在的主流httpserver都提供了对djangoserver的配置接口,比如vuex、vue-loader(在此之前用的是gxjango),但这些只是用来加速管理用户session的,也就是说django在注册session时需要自己配置其他的server,比如googlesearch那样的django框架,这样本身做起来就不顺手,对于django项目来说,最好是再基于mvc框架构建web项目,将数据库管理设计到django框架。 查看全部
django怎么连接第三方服务器(django基于laravel框架)
文章采集链接:django连接https-连接连接服务器(连接ip、域名、目录路径等)看看效果::4000/xxxx-[]-[/]//[***/***/***]//[xxxx-[*]-[/]/]//[[*]-[/]]//[]-[*]-[/]/)(上图代码)
曾经,我有个知乎回答:服务器django怎么连接第三方服务器(django基于laravel框架)?-yafez的回答django项目用服务器实现django的连接路由?-sambring的回答简单说下我个人的一点理解吧。一个django项目结构如下:从传统的mvc组合模式升级成web2.0模式,代码量下降了,但是整体的结构和代码还是没有分离开,结构依然有些混乱。
web容器解决大型开发时,写进数据库的逻辑和操作等。django项目结构如下:和django基于laravel框架构建的大型项目结构差别在哪里?应该说,django框架中,以js-schema形式提供数据库操作方法,和django根据admin配置完全访问https请求数据库是两回事,两个python项目还有一个完全不一样的数据库操作路由路由配置。
这里再给两个django项目的一些源码--分别是django1.5.13和django1.7.0新老对比。
django模版引擎本身并不提供对第三方服务器的配置,现在的主流httpserver都提供了对djangoserver的配置接口,比如vuex、vue-loader(在此之前用的是gxjango),但这些只是用来加速管理用户session的,也就是说django在注册session时需要自己配置其他的server,比如googlesearch那样的django框架,这样本身做起来就不顺手,对于django项目来说,最好是再基于mvc框架构建web项目,将数据库管理设计到django框架。
文章采集链接(新闻数据爬取框架+js脚本采集(.md5版))
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-10-06 02:01
文章采集链接:新闻数据爬取框架+js脚本采集(.md5版)项目说明工欲善其事必先利其器,要想高效地用excel把一份新闻数据采集到本地,第一步是要找到正确的爬取方法,本篇文章将会介绍一种基于javascript脚本实现新闻数据采集工具——js采集,它相对比较简单,适合爬取我们常见的新闻数据或者网页上已经有新闻数据的网站,甚至爬取一些自动采集代码也可以,它们都可以用js实现,例如我们可以做出下面这样的一个js采集框架:爬取网站只需用到navicat提供的javascript库,或者通过python的node.js库,lxml提供的反向工程js库等。
到目前为止,我们已经可以直接从源代码的javascript库写出一份新闻数据采集的工具代码,但是具体的爬取流程还是可以通过源代码写入的工具代码来实现,本文在最后主要讲一下我们应该如何用源代码写新闻数据采集工具代码。url爬取源代码写新闻数据采集工具的url地址为:;sourceid=c42324&_url=jsformodernedition-gui和javascript库地址,web解析地址javascript解析库用javascript解析工具写出来的代码主要如下:%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%。 查看全部
文章采集链接(新闻数据爬取框架+js脚本采集(.md5版))
文章采集链接:新闻数据爬取框架+js脚本采集(.md5版)项目说明工欲善其事必先利其器,要想高效地用excel把一份新闻数据采集到本地,第一步是要找到正确的爬取方法,本篇文章将会介绍一种基于javascript脚本实现新闻数据采集工具——js采集,它相对比较简单,适合爬取我们常见的新闻数据或者网页上已经有新闻数据的网站,甚至爬取一些自动采集代码也可以,它们都可以用js实现,例如我们可以做出下面这样的一个js采集框架:爬取网站只需用到navicat提供的javascript库,或者通过python的node.js库,lxml提供的反向工程js库等。
到目前为止,我们已经可以直接从源代码的javascript库写出一份新闻数据采集的工具代码,但是具体的爬取流程还是可以通过源代码写入的工具代码来实现,本文在最后主要讲一下我们应该如何用源代码写新闻数据采集工具代码。url爬取源代码写新闻数据采集工具的url地址为:;sourceid=c42324&_url=jsformodernedition-gui和javascript库地址,web解析地址javascript解析库用javascript解析工具写出来的代码主要如下:%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%>%。
文章采集链接(网页文本采集大师就是更简单、高效、省力的办法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 319 次浏览 • 2021-09-29 23:38
)
在网络信息时代,你每天上网时,经常会遇到喜欢的文章,或者小说等,从一两页到几十页,甚至数百、数千页不等。需要这么多字。复制下载非常麻烦。在记事本和网络浏览器之间频繁切换已经够难过了。现在我面临着需要同时进行数十次或数百次这种无聊的机械动作的需求。问题是,有没有更简单、更高效、更省力的方法?
哈哈,你找对地方了。我们开发的“Web Text 采集Master”就是这样一款专门为您准备的工具软件。
点击下载:
软件已升级到3.2版本。新版界面截图如下,功能更强大,无论是静态的还是动态的网站,禁止复制的文章,还是带有随机干扰码的任意文章可以是采集,我一拿就给你发最新版。成为第一个使用它并体验它的人!
网页文字采集大师是专门用于批量采集,复制或下载文章或网上小说,甚至整个网站文字内容的工具,无论是一个静态的网站或者一个动态的网站,只要有文字就可以获取,只要输入几条简单的信息,就可以自动为你下载复制网络批量文章 现在,可以说是快捷方便了。
除了抓取网上的文章,还可以用来抓取一些特殊的信息,比如抓取百度词典上的信息,也可以用来抓取一些网页上的链接地址。
此外,这款软件还有很多其他功能,比如文本段落重排、文本合并、文件批量重命名等功能,非常实用。您需要知道时间就是您可以让计算机为您做的事情。你不能自己做。赶快下载使用吧,希望你会喜欢她。
网页正文采集 主软件使用简要说明
下例介绍的新浪小说网站,因新浪小说频道重组,目前已关闭。可以到软件官网论坛查看更多示例和视频教程:
以下教程,因新浪网已关闭相应页面,不再提供测试!
假设我们要从新浪在线抓取小说《孩子,爸爸其实不想和妈妈离婚》,这意味着以下网址不再有效。以下只是一个例子:
为 采集 寻找 web 目录的第一个端口
在这里,我们将在新浪网找到该小说的目录页。目录地址如下:
/book/index_66681.html
第二个端口输入文章目录页地址
将上述地址复制到软件文章目录页面的输入框,然后回车打开带有软件的网页。
第三端口搜索链接关键字
找到第一章第一节的链接地址,查看其格式为:
/book/chapter_66681_47253.html
然后查找以下地址。请注意,VIP 会员网页只能由 VIP 会员阅读。如果你要下载这种文章,你必须是VIP会员,所以我们找一些以前的,这里是第11章和第11节作为我们要抓取的最后一章。链接地址是:
/book/chapter_66681_49404.html
现在我们比较上面两个链接地址,找出它们的共同点:
/书/chapter_66681_4
然后将其输入到链接关键字输入框中。
获取第四个端口采集文章的列表
这一步非常简单。只需单击“获取列表”按钮。点击后,您会在软件左侧的网址列表框中看到很多网址。
在第五个端口输入文本的开始和结束关键字
在软件左侧的URL中,选择第一个,点击打开软件右侧的网页,删除软件正文开始关键字和结束关键字输入框中的文字,直接点击获取文章,勾选获取整个网页的文本,找出官方的起止关键词。在这里我们可以看到,小说的每一节都以“爸爸其实不想和妈妈离婚>”这样的文字开头。并且以“上一章”的3个字符结尾,因此,我们将刚刚在软件的文本起始关键字和结束关键字输入框中找到的两个关键字(词)对应复制。,然后再次点击得到文章,看看是不是你想要的结果。
确认第六个端口采集文章保存目录
这一步比较简单。您只需要在软件左下角找到您要保存的目录,或者点击目录浏览框的右键菜单,新建一个目录即可。
第七个端口决定了文章的标题的开始和结束关键字
这一步其实就是确定每个文件名的风格。我们看到刚才得到的文章。第一行是“第一章离婚第一节”。事实上,第一行可以作为文件的标题。所以在这里,我们不需要输入标题采集关键字,程序会自动识别,您可以点击保存文章试试效果。
第八端口开始批量抓包
OK,以上步骤都准备好了,现在我们可以开始采集,当采集时,还可以选择是否自动刷新采集的文章,如果你选择,以后阅读会更容易。好,我们现在泡一杯茶,等待结果。
购买网页文字大师采集后,点赞后赠送智能网页文字提取器:
特别声明:网络世界中,网站数不胜数,每个网站的结构千差万别。不可能一个有价格(咨询特价)的软件包罗万象,让你可以网站的所有文章,或者文章的网站采集 可以过滤掉所有你不想要的信息。如果你购买了这个软件,因为一个网站 采集 如果不顺利,你必须申请退款。那么请绕道而行。我们不想在像你这样的人身上浪费时间。一旦为虚拟产品发布了注册码,即使您现在卸载该软件,将来也会再次安装。还是可以用的,想象一下,你能完全回收溢出的水吗?鄙视收到注册码申请退款的,(咨询特价)不划算!
查看全部
文章采集链接(网页文本采集大师就是更简单、高效、省力的办法
)
在网络信息时代,你每天上网时,经常会遇到喜欢的文章,或者小说等,从一两页到几十页,甚至数百、数千页不等。需要这么多字。复制下载非常麻烦。在记事本和网络浏览器之间频繁切换已经够难过了。现在我面临着需要同时进行数十次或数百次这种无聊的机械动作的需求。问题是,有没有更简单、更高效、更省力的方法?
哈哈,你找对地方了。我们开发的“Web Text 采集Master”就是这样一款专门为您准备的工具软件。
点击下载:
软件已升级到3.2版本。新版界面截图如下,功能更强大,无论是静态的还是动态的网站,禁止复制的文章,还是带有随机干扰码的任意文章可以是采集,我一拿就给你发最新版。成为第一个使用它并体验它的人!
网页文字采集大师是专门用于批量采集,复制或下载文章或网上小说,甚至整个网站文字内容的工具,无论是一个静态的网站或者一个动态的网站,只要有文字就可以获取,只要输入几条简单的信息,就可以自动为你下载复制网络批量文章 现在,可以说是快捷方便了。
除了抓取网上的文章,还可以用来抓取一些特殊的信息,比如抓取百度词典上的信息,也可以用来抓取一些网页上的链接地址。
此外,这款软件还有很多其他功能,比如文本段落重排、文本合并、文件批量重命名等功能,非常实用。您需要知道时间就是您可以让计算机为您做的事情。你不能自己做。赶快下载使用吧,希望你会喜欢她。
网页正文采集 主软件使用简要说明
下例介绍的新浪小说网站,因新浪小说频道重组,目前已关闭。可以到软件官网论坛查看更多示例和视频教程:
以下教程,因新浪网已关闭相应页面,不再提供测试!
假设我们要从新浪在线抓取小说《孩子,爸爸其实不想和妈妈离婚》,这意味着以下网址不再有效。以下只是一个例子:
为 采集 寻找 web 目录的第一个端口
在这里,我们将在新浪网找到该小说的目录页。目录地址如下:
/book/index_66681.html
第二个端口输入文章目录页地址
将上述地址复制到软件文章目录页面的输入框,然后回车打开带有软件的网页。
第三端口搜索链接关键字
找到第一章第一节的链接地址,查看其格式为:
/book/chapter_66681_47253.html
然后查找以下地址。请注意,VIP 会员网页只能由 VIP 会员阅读。如果你要下载这种文章,你必须是VIP会员,所以我们找一些以前的,这里是第11章和第11节作为我们要抓取的最后一章。链接地址是:
/book/chapter_66681_49404.html
现在我们比较上面两个链接地址,找出它们的共同点:
/书/chapter_66681_4
然后将其输入到链接关键字输入框中。
获取第四个端口采集文章的列表
这一步非常简单。只需单击“获取列表”按钮。点击后,您会在软件左侧的网址列表框中看到很多网址。
在第五个端口输入文本的开始和结束关键字
在软件左侧的URL中,选择第一个,点击打开软件右侧的网页,删除软件正文开始关键字和结束关键字输入框中的文字,直接点击获取文章,勾选获取整个网页的文本,找出官方的起止关键词。在这里我们可以看到,小说的每一节都以“爸爸其实不想和妈妈离婚>”这样的文字开头。并且以“上一章”的3个字符结尾,因此,我们将刚刚在软件的文本起始关键字和结束关键字输入框中找到的两个关键字(词)对应复制。,然后再次点击得到文章,看看是不是你想要的结果。
确认第六个端口采集文章保存目录
这一步比较简单。您只需要在软件左下角找到您要保存的目录,或者点击目录浏览框的右键菜单,新建一个目录即可。
第七个端口决定了文章的标题的开始和结束关键字
这一步其实就是确定每个文件名的风格。我们看到刚才得到的文章。第一行是“第一章离婚第一节”。事实上,第一行可以作为文件的标题。所以在这里,我们不需要输入标题采集关键字,程序会自动识别,您可以点击保存文章试试效果。
第八端口开始批量抓包
OK,以上步骤都准备好了,现在我们可以开始采集,当采集时,还可以选择是否自动刷新采集的文章,如果你选择,以后阅读会更容易。好,我们现在泡一杯茶,等待结果。
购买网页文字大师采集后,点赞后赠送智能网页文字提取器:
特别声明:网络世界中,网站数不胜数,每个网站的结构千差万别。不可能一个有价格(咨询特价)的软件包罗万象,让你可以网站的所有文章,或者文章的网站采集 可以过滤掉所有你不想要的信息。如果你购买了这个软件,因为一个网站 采集 如果不顺利,你必须申请退款。那么请绕道而行。我们不想在像你这样的人身上浪费时间。一旦为虚拟产品发布了注册码,即使您现在卸载该软件,将来也会再次安装。还是可以用的,想象一下,你能完全回收溢出的水吗?鄙视收到注册码申请退款的,(咨询特价)不划算!
文章采集链接( BeeCollector(小蜜蜂采集器)文章采集系统,完善Flash采集模块对目标字符集UTF8的支持)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-09-29 23:37
BeeCollector(小蜜蜂采集器)文章采集系统,完善Flash采集模块对目标字符集UTF8的支持)
BeeCollector(Little Bee采集器)文章采集系统,改进Flash采集对目标字符集UTF8的支持。
特征:
1、支持文章内容分页采集;
2、支持论坛采集;
3、支持UTF-8转GB2312,但采集内容字符格式是UTF-8的目标;
4、 支持将文章的内容保存到本地;
5、支持站点+栏目管理模式,让采集管理一目了然;
6、支持链接替换,分页链接替换,破解一些JS/后台程序设置的反扒功能;
7、支持采集器设置无限过滤功能;
8、支持图片采集保存到本地,自动替换文件名避免重复;
9、支持FLASH文件采集保存到本地,自动替换文件名避免重复;
10、 支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
11、 支持手动过滤采集结果,并提供“空标题空内容”的快速过滤和删除;
12、支持Flash专业站点采集,特色采集flash小游戏,可完美采集缩略图,游戏介绍;
13、 支持全站配置规则的导入导出;
14、 支持列配置规则的导入导出,并提供规则复制功能,简化设置;
15、 提供引导库规则导入导出;
16、支持自定义采集间隔时间,避免被误认为DDOS攻击而拒绝响应,可以设置采集防止DDOS攻击网站;
17、 支持自定义存储间隔时间,避免虚拟主机并发限制;
18、支持自定义内容写入,用户可以设置任意内容(如自己的链接、广告代码),写入采集的内容:第一个、最后一个或随机写入;需要写入的内容在浏览库时自动带在身边,无需修改WEB系统模板。
19、支持采集内容替换功能,用户可以设置替换规则随意替换;
20、支持html标签过滤,让采集接收到的内容只保留必要的html标签,甚至是纯文本,不带任何html标签;
21、支持多种cms向导库包收录PHPcms V2/V3、Dedecms(织梦) V2/V 3、PHP168 cms、mephpcms、Mambo cms、Joomla cms系统指南库规则及操作说明;
22、支持PHPWIND、Discuz论坛指南库,程序包中收录2个论坛指南库规则和操作说明;
23、自带数据库优化工具,减少频繁采集过多的数据碎片降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、 支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;
2、 支持自动比较过滤功能,不会在采集的链接系统中重复采集和存储;以上两个功能可以大大减少采集时间,减少系统负载。
3、 支持系统每天自动创建图片存储目录,方便管理;
4、 支持采集/guidance间隔设置,避免被目标站识别为流量攻击而拒绝响应;
5、支持自定义内容写入,实现简单的反采集功能;
6、支持html标签过滤,几乎完美展现你想要的采集效果;
7、完美的内容存储解决方案,不受目标编程语言和数据库类别的限制。
以上众多强大功能免费供您使用,您可以轻松高效地安装使用体验资料采集。 查看全部
文章采集链接(
BeeCollector(小蜜蜂采集器)文章采集系统,完善Flash采集模块对目标字符集UTF8的支持)
BeeCollector(Little Bee采集器)文章采集系统,改进Flash采集对目标字符集UTF8的支持。
特征:
1、支持文章内容分页采集;
2、支持论坛采集;
3、支持UTF-8转GB2312,但采集内容字符格式是UTF-8的目标;
4、 支持将文章的内容保存到本地;
5、支持站点+栏目管理模式,让采集管理一目了然;
6、支持链接替换,分页链接替换,破解一些JS/后台程序设置的反扒功能;
7、支持采集器设置无限过滤功能;
8、支持图片采集保存到本地,自动替换文件名避免重复;
9、支持FLASH文件采集保存到本地,自动替换文件名避免重复;
10、 支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
11、 支持手动过滤采集结果,并提供“空标题空内容”的快速过滤和删除;
12、支持Flash专业站点采集,特色采集flash小游戏,可完美采集缩略图,游戏介绍;
13、 支持全站配置规则的导入导出;
14、 支持列配置规则的导入导出,并提供规则复制功能,简化设置;
15、 提供引导库规则导入导出;
16、支持自定义采集间隔时间,避免被误认为DDOS攻击而拒绝响应,可以设置采集防止DDOS攻击网站;
17、 支持自定义存储间隔时间,避免虚拟主机并发限制;
18、支持自定义内容写入,用户可以设置任意内容(如自己的链接、广告代码),写入采集的内容:第一个、最后一个或随机写入;需要写入的内容在浏览库时自动带在身边,无需修改WEB系统模板。
19、支持采集内容替换功能,用户可以设置替换规则随意替换;
20、支持html标签过滤,让采集接收到的内容只保留必要的html标签,甚至是纯文本,不带任何html标签;
21、支持多种cms向导库包收录PHPcms V2/V3、Dedecms(织梦) V2/V 3、PHP168 cms、mephpcms、Mambo cms、Joomla cms系统指南库规则及操作说明;
22、支持PHPWIND、Discuz论坛指南库,程序包中收录2个论坛指南库规则和操作说明;
23、自带数据库优化工具,减少频繁采集过多的数据碎片降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、 支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;
2、 支持自动比较过滤功能,不会在采集的链接系统中重复采集和存储;以上两个功能可以大大减少采集时间,减少系统负载。
3、 支持系统每天自动创建图片存储目录,方便管理;
4、 支持采集/guidance间隔设置,避免被目标站识别为流量攻击而拒绝响应;
5、支持自定义内容写入,实现简单的反采集功能;
6、支持html标签过滤,几乎完美展现你想要的采集效果;
7、完美的内容存储解决方案,不受目标编程语言和数据库类别的限制。
以上众多强大功能免费供您使用,您可以轻松高效地安装使用体验资料采集。
文章采集链接(网上看了一部小说,换个名字,居然要付费了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 573 次浏览 • 2021-09-29 22:25
今天在网上看了一本小说。明明是很久以前的小说。我改了名字,我不得不付钱。我很不高兴。通过强大的百度,找到了原版。我很高兴,但我无法下载它。这很难。本来打算把它读下来,然后在我的手机上阅读。我别无选择,只能自己做采集,然后我就下来了;
导入 urllib.requestimport re
话不多说,先列出你需要的包。我们的命名要尽量规范,这样才能养成一个好习惯,也容易别人理解;这个东西在行业里叫做驼峰命名法。
第一步,我们需要获取主页的源代码:
def getNoverContent():
这里我定义getNoverCotent的变量作为代码的核心部分,然后定义html变量
html = urllib.request.urlopen('目录地址').read()html = html.decode('gbk')
拿到html内容后,我们先打印出来看看是否检索成功
打印(html)
成功了可以把这行代码删掉或者注释掉,养成一个习惯,一步一步来,不容易出错:print(html)
第二部分是获取我们需要的那部分网页代码:
我们在网页上调出刚才页面的源码,找到你想要的部分的div采集。这里使用了正则表达式。不明白的可以自学,也可以找个时间写一篇常规文章的介绍;
请求 = r'
(.*?)'
他们之中。*? 这是一个通配符,匹配所有的内容,我们要的是在通配符外面加一个()
我们这里得到的是目录页的超链接和目录的内容
req = 桩(req)urls = re.findall(req,html)
urls变量的内容就是我们想要的超链接和目录内容,打出来看看?
打印(网址)
用完记得注释掉
第三部分,获取章节源码:
我们用一个for循环来完成这个功能
对于网址中的网址:
让我们打印出 url[0] 看看我们是否需要超链接
#打印(网址[0])
确认无误后,设置变量novel_urlnovel_url ='如果是部分超链接,在此处添加链接前端' + url[0]novel_title = url[1] chapt = urllib.request.urlopen(novel_url).read ()
设置编码,在哪里看编码?
这部分网页源码,可以看看是utf-8还是gbk
chapt_html = chapt.decode('gbk') #获取文章内容 req = r'
(.*?)
'#re.S 多行匹配
毕竟文章的内容还有很多行,这部分不能省了 req = pie(req,re.S) chapt_content = re.findall(req,chapt_html)
全部 采集 好的,输入并尝试一下?
打印(章节内容)
章节内容
没问题,我们继续第三部分
第三步,另存为txt并导出:
with open("fiction name.txt", mode='a+',encoding='utf-8') as f:f.write(novel_title) f.write(chapt_content) f.write("\n")
最后记得加一行启动代码
如果 __name__ =='__main__':getNoverContent()
大功告成,可以把采集全部上传到手机上慢慢欣赏!
大部分代码显示 查看全部
文章采集链接(网上看了一部小说,换个名字,居然要付费了)
今天在网上看了一本小说。明明是很久以前的小说。我改了名字,我不得不付钱。我很不高兴。通过强大的百度,找到了原版。我很高兴,但我无法下载它。这很难。本来打算把它读下来,然后在我的手机上阅读。我别无选择,只能自己做采集,然后我就下来了;
导入 urllib.requestimport re
话不多说,先列出你需要的包。我们的命名要尽量规范,这样才能养成一个好习惯,也容易别人理解;这个东西在行业里叫做驼峰命名法。
第一步,我们需要获取主页的源代码:
def getNoverContent():
这里我定义getNoverCotent的变量作为代码的核心部分,然后定义html变量
html = urllib.request.urlopen('目录地址').read()html = html.decode('gbk')
拿到html内容后,我们先打印出来看看是否检索成功
打印(html)
成功了可以把这行代码删掉或者注释掉,养成一个习惯,一步一步来,不容易出错:print(html)
第二部分是获取我们需要的那部分网页代码:
我们在网页上调出刚才页面的源码,找到你想要的部分的div采集。这里使用了正则表达式。不明白的可以自学,也可以找个时间写一篇常规文章的介绍;
请求 = r'
(.*?)'
他们之中。*? 这是一个通配符,匹配所有的内容,我们要的是在通配符外面加一个()
我们这里得到的是目录页的超链接和目录的内容
req = 桩(req)urls = re.findall(req,html)
urls变量的内容就是我们想要的超链接和目录内容,打出来看看?
打印(网址)
用完记得注释掉
第三部分,获取章节源码:
我们用一个for循环来完成这个功能
对于网址中的网址:
让我们打印出 url[0] 看看我们是否需要超链接
#打印(网址[0])
确认无误后,设置变量novel_urlnovel_url ='如果是部分超链接,在此处添加链接前端' + url[0]novel_title = url[1] chapt = urllib.request.urlopen(novel_url).read ()
设置编码,在哪里看编码?
这部分网页源码,可以看看是utf-8还是gbk
chapt_html = chapt.decode('gbk') #获取文章内容 req = r'
(.*?)
'#re.S 多行匹配
毕竟文章的内容还有很多行,这部分不能省了 req = pie(req,re.S) chapt_content = re.findall(req,chapt_html)
全部 采集 好的,输入并尝试一下?
打印(章节内容)
章节内容
没问题,我们继续第三部分
第三步,另存为txt并导出:
with open("fiction name.txt", mode='a+',encoding='utf-8') as f:f.write(novel_title) f.write(chapt_content) f.write("\n")
最后记得加一行启动代码
如果 __name__ =='__main__':getNoverContent()
大功告成,可以把采集全部上传到手机上慢慢欣赏!
大部分代码显示
文章采集链接(讲解一下如何把一个网站的文章采集到自己的网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-09-29 18:04
以飘柔博客网站()为例,讲解如何把网站的文章采集放到自己的网站中,下载链接到同时网盘地址也是你自己的(文件批量传输到你自己的网盘)。
其实采集和发布文章很简单。难点是如何批量转储或下载对方的文件到自己的网站/网盘,可以对应文章和网盘下载链接。
需要准备:
飘柔博客VIP账号网站优采云采集规则,发布模块批量转储工具,城市通网盘VIP账号(对方使用的城市通网盘存储文件网站,如果要转,只能转到城通网盘,其他网盘不能直接转)
目前本站所有中文电子书的文件都在800G左右。不买城市通行证VIP就下载这么多文件到本地是不现实的。我的城市通行证VIP大概一千元,我已经从下载中赚回来了(每次下载2到5美分,超过100M的文件1美分)。
看到这个,有的同学可以关掉网页离开。
第一步:
将所有文件传输到自己的网盘,50000多个文件,当然不是手动工作。所以我写了一个转储工具,可以批量转储并重命名城市通行证文件。
那么问题来了,为什么要重命名?重命名是一个非常重要的步骤,因为它可以:
为防止下载链接因名称问题被统一失效,发布时可以链接到网盘文件下载链接文章
传输文件时,将文件重命名为目标ID网站文章。例如,将本文章中的电子书转移到自己的网盘后,文件名应该是96233.epub。为什么?看第二步。
33%
第二步:
批量转储文件并重命名后,使用优采云下载采集诚通网盘中所有文件的链接和文件名,生成html文件。html 文件以文件名命名。比如前面提到的96233.epub,采集生成96233.html,文件中收录从城通网盘下载文件的链接。
你可以在你的网站文章中直接链接到这个html,用户可以在html页面点击网盘链接下载文件,或者在后面的第三步,使用采集规则采集该页面的网盘地址,用户会直接打开网盘页面下载;链接html的好处是可以展示广告位获取收益,看下面的demo(顺便点一下广告有惊喜):
html文件演示:
此方法适用于免费下载资源。如果收费,当然应该直接采集到网盘地址,避免别人根据html文件名获取其他文件下载地址。
66%
第三步:
<p>现在你有了所有的网盘文件下载链接,并且html文件名对应目标站的文件名,你只需要把生成的html上传到网站空间,就可以使用 查看全部
文章采集链接(讲解一下如何把一个网站的文章采集到自己的网站)
以飘柔博客网站()为例,讲解如何把网站的文章采集放到自己的网站中,下载链接到同时网盘地址也是你自己的(文件批量传输到你自己的网盘)。
其实采集和发布文章很简单。难点是如何批量转储或下载对方的文件到自己的网站/网盘,可以对应文章和网盘下载链接。
需要准备:
飘柔博客VIP账号网站优采云采集规则,发布模块批量转储工具,城市通网盘VIP账号(对方使用的城市通网盘存储文件网站,如果要转,只能转到城通网盘,其他网盘不能直接转)
目前本站所有中文电子书的文件都在800G左右。不买城市通行证VIP就下载这么多文件到本地是不现实的。我的城市通行证VIP大概一千元,我已经从下载中赚回来了(每次下载2到5美分,超过100M的文件1美分)。
看到这个,有的同学可以关掉网页离开。
第一步:
将所有文件传输到自己的网盘,50000多个文件,当然不是手动工作。所以我写了一个转储工具,可以批量转储并重命名城市通行证文件。
那么问题来了,为什么要重命名?重命名是一个非常重要的步骤,因为它可以:
为防止下载链接因名称问题被统一失效,发布时可以链接到网盘文件下载链接文章
传输文件时,将文件重命名为目标ID网站文章。例如,将本文章中的电子书转移到自己的网盘后,文件名应该是96233.epub。为什么?看第二步。
33%
第二步:
批量转储文件并重命名后,使用优采云下载采集诚通网盘中所有文件的链接和文件名,生成html文件。html 文件以文件名命名。比如前面提到的96233.epub,采集生成96233.html,文件中收录从城通网盘下载文件的链接。
你可以在你的网站文章中直接链接到这个html,用户可以在html页面点击网盘链接下载文件,或者在后面的第三步,使用采集规则采集该页面的网盘地址,用户会直接打开网盘页面下载;链接html的好处是可以展示广告位获取收益,看下面的demo(顺便点一下广告有惊喜):
html文件演示:
此方法适用于免费下载资源。如果收费,当然应该直接采集到网盘地址,避免别人根据html文件名获取其他文件下载地址。
66%
第三步:
<p>现在你有了所有的网盘文件下载链接,并且html文件名对应目标站的文件名,你只需要把生成的html上传到网站空间,就可以使用
文章采集链接(优采云采集器V9的数据导入为例讲解数据库发布配置如何制作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-23 16:11
我们正在使用采集文章,有时它将在线发布到网站 column,有时导入自己的数据库或保存为本地文件,这里优采云采集器 v9数据导入举例如何制作数据库发布配置。
@ @采集器 v9支持发布mysql,sqlserver,oracle,访问类型数据库,拍摄mysql数据库作为一个例子,我们打开开始菜单 - 数据库发布配置,如图所示:
1打开数据库发布配置2您可以执行“编辑,新,删除,导入,导出,导出”数据库3数据库链接信息配置5数据库发布配置列表
我们首先创建一个释放模块,选择数据库类型,写一个仓库语句,如图所示:
1. @是表表表表;;;;;;;;;;;;;;;表;与上一张表的自增量ID相关,表表表表表表表表表表表表表表表3.自集成ID字段和值需要删除,不需要将其写入SQL语句。存储模块完成后,保存它。然后在数据库发布管理界面中设置链接信息,测试链接数据库,并成功。
可以保存配置并释放测试。如下所示(填写自定义值,单击测试):
内容发布规则 - 导入数据库对应于数据库设置的输入。
这文章采集器优采云采集器 V9数据导入完成,这也与其他类型的数据库,如果是网上发布,您需要编辑发布模块,具体操作可以看一下官方网站。返回Sohu,查看更多 查看全部
文章采集链接(优采云采集器V9的数据导入为例讲解数据库发布配置如何制作)
我们正在使用采集文章,有时它将在线发布到网站 column,有时导入自己的数据库或保存为本地文件,这里优采云采集器 v9数据导入举例如何制作数据库发布配置。
@ @采集器 v9支持发布mysql,sqlserver,oracle,访问类型数据库,拍摄mysql数据库作为一个例子,我们打开开始菜单 - 数据库发布配置,如图所示:
1打开数据库发布配置2您可以执行“编辑,新,删除,导入,导出,导出”数据库3数据库链接信息配置5数据库发布配置列表
我们首先创建一个释放模块,选择数据库类型,写一个仓库语句,如图所示:
1. @是表表表表;;;;;;;;;;;;;;;表;与上一张表的自增量ID相关,表表表表表表表表表表表表表表表3.自集成ID字段和值需要删除,不需要将其写入SQL语句。存储模块完成后,保存它。然后在数据库发布管理界面中设置链接信息,测试链接数据库,并成功。
可以保存配置并释放测试。如下所示(填写自定义值,单击测试):
内容发布规则 - 导入数据库对应于数据库设置的输入。
这文章采集器优采云采集器 V9数据导入完成,这也与其他类型的数据库,如果是网上发布,您需要编辑发布模块,具体操作可以看一下官方网站。返回Sohu,查看更多
文章采集链接(【赛事日历】瑞典丨选手计算机实时赛前状态_djqdk_新浪博客)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-21 12:08
文章采集链接:-meet-you/文章推荐阅读:数据冰山-知乎专栏【赛事日历】瑞典丨选手计算机实时赛前状态_djqdk_新浪博客【赛事】美国丨nfc联赛#72战队(c9-top)_miscmoni_新浪博客【赛事】#78战队(c5-peak)#76战队(a3-lots)_【赛事】欧洲丨nintendocms#50(cashmajor)-emm_新浪博客【赛事】荷兰丨am#145(apachelpmaster)_thereforerennogon_新浪博客【赛事】日本丨(gen)-looverglobal,#300【赛事】加拿大丨flyportleague-fort-pace【赛事】韩国丨school-stream,#456。
cs:go太小众太多大佬可以去加油,shroud的twitch直播是有粉丝限制的,一般人一天不一定能看到,当然,如果你想看直播可以去马老师的twitch或者youtube,都是能看到粉丝喷的网站。
游戏日报app上各项最近上了比赛日程以下是一些好玩的大大的开挂群(最近很多):425217725shroud两次创造wsc世界纪录第一视角:能打出这种操作的人twitch直播频道:46357240你听不听就打ps:我才是真爱粉,
wacai和faker已经举办过多次有深度的比赛了, 查看全部
文章采集链接(【赛事日历】瑞典丨选手计算机实时赛前状态_djqdk_新浪博客)
文章采集链接:-meet-you/文章推荐阅读:数据冰山-知乎专栏【赛事日历】瑞典丨选手计算机实时赛前状态_djqdk_新浪博客【赛事】美国丨nfc联赛#72战队(c9-top)_miscmoni_新浪博客【赛事】#78战队(c5-peak)#76战队(a3-lots)_【赛事】欧洲丨nintendocms#50(cashmajor)-emm_新浪博客【赛事】荷兰丨am#145(apachelpmaster)_thereforerennogon_新浪博客【赛事】日本丨(gen)-looverglobal,#300【赛事】加拿大丨flyportleague-fort-pace【赛事】韩国丨school-stream,#456。
cs:go太小众太多大佬可以去加油,shroud的twitch直播是有粉丝限制的,一般人一天不一定能看到,当然,如果你想看直播可以去马老师的twitch或者youtube,都是能看到粉丝喷的网站。
游戏日报app上各项最近上了比赛日程以下是一些好玩的大大的开挂群(最近很多):425217725shroud两次创造wsc世界纪录第一视角:能打出这种操作的人twitch直播频道:46357240你听不听就打ps:我才是真爱粉,
wacai和faker已经举办过多次有深度的比赛了,
文章采集链接( 本文介绍使用优采云采集(以BBC的AsiaNews为例))
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-20 22:08
本文介绍使用优采云采集(以BBC的AsiaNews为例))
英语文章采集方法
本文介绍了使用优采云采集(以BBC亚洲新闻为例)采集网站的方法:/
采集的内容包括:文章title、文章body
使用功能点:
分页列表和详细信息提取
步骤1:创建BBC英语文章采集task
1)进入主界面,选择“自定义模式”
2)将采集的URL复制粘贴到网站输入框中,然后单击“保存URL”
步骤2:创建一个列表循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”。选择页面中的第一张图片,系统将自动识别页面中的类似链接并选择“全选”
2)选择“重复单击每个链接”3)设置超时和Ajax滚动
第三步:采集小说内容
1)选择页面中的正文标题为采集(所选内容将变为绿色),然后选择“采集此元素的文本”
二,
)在页面中选择要设置为采集的正文内容(所选内容将变为绿色),然后选择全部
3)
设置合并字段,选择自定义数据字段和自定义数据合并方式
4)
修改字段名
5)选择“本地启动采集”
第四步:BBC英语文章data采集和导出
1)采集完成后,将弹出提示并选择“导出数据”。选择“适当的导出方法”导出采集good BBC English文章数据
2)这里,我们选择excel作为导出格式。数据导出后,见下图
相关采集教程:
爆文采集:
/教程详情-1/baowencj.html
新浪博客文章采集:
/教程详情-1/sinablogcj.html
UC标题文章采集:
/教程详情-1/ucnewscj.html
微信公众号文章采集(文字+图片):
/教程详情-1/wxcjimg.html
网易自媒体文章采集:
/教程详情-1/wyhcj.html
优采云——90万用户在k0选择的网页数据@
1、操作简单,任何人都可以使用:没有技术背景,你可以采集. 完全可视化过程,单击鼠标完成操作,您可以在2分钟内快速开始
2、功能强大,任何网站都可以采用:采集可以简单地设置为网页,点击、登录、翻页、身份验证码、瀑布流和Ajax脚本异步加载数据
3、cloud采集,关机正常。配置采集任务后,可以关闭它们,并在云中执行任务。巨大的云采集集群24*7不间断运行,因此您不必担心IP阻塞和网络中断
4、功能是免费+增值服务,可根据需要选择。免费版具备所有功能,可以满足用户的基本采集需求。同时,一些增值服务(如私有云)被设置为满足高端付费企业用户的需求 查看全部
文章采集链接(
本文介绍使用优采云采集(以BBC的AsiaNews为例))
英语文章采集方法
本文介绍了使用优采云采集(以BBC亚洲新闻为例)采集网站的方法:/
采集的内容包括:文章title、文章body
使用功能点:
分页列表和详细信息提取
步骤1:创建BBC英语文章采集task
1)进入主界面,选择“自定义模式”
2)将采集的URL复制粘贴到网站输入框中,然后单击“保存URL”
步骤2:创建一个列表循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”。选择页面中的第一张图片,系统将自动识别页面中的类似链接并选择“全选”
2)选择“重复单击每个链接”3)设置超时和Ajax滚动
第三步:采集小说内容
1)选择页面中的正文标题为采集(所选内容将变为绿色),然后选择“采集此元素的文本”
二,
)在页面中选择要设置为采集的正文内容(所选内容将变为绿色),然后选择全部
3)
设置合并字段,选择自定义数据字段和自定义数据合并方式
4)
修改字段名
5)选择“本地启动采集”
第四步:BBC英语文章data采集和导出
1)采集完成后,将弹出提示并选择“导出数据”。选择“适当的导出方法”导出采集good BBC English文章数据
2)这里,我们选择excel作为导出格式。数据导出后,见下图
相关采集教程:
爆文采集:
/教程详情-1/baowencj.html
新浪博客文章采集:
/教程详情-1/sinablogcj.html
UC标题文章采集:
/教程详情-1/ucnewscj.html
微信公众号文章采集(文字+图片):
/教程详情-1/wxcjimg.html
网易自媒体文章采集:
/教程详情-1/wyhcj.html
优采云——90万用户在k0选择的网页数据@
1、操作简单,任何人都可以使用:没有技术背景,你可以采集. 完全可视化过程,单击鼠标完成操作,您可以在2分钟内快速开始
2、功能强大,任何网站都可以采用:采集可以简单地设置为网页,点击、登录、翻页、身份验证码、瀑布流和Ajax脚本异步加载数据
3、cloud采集,关机正常。配置采集任务后,可以关闭它们,并在云中执行任务。巨大的云采集集群24*7不间断运行,因此您不必担心IP阻塞和网络中断
4、功能是免费+增值服务,可根据需要选择。免费版具备所有功能,可以满足用户的基本采集需求。同时,一些增值服务(如私有云)被设置为满足高端付费企业用户的需求
文章采集链接(本次采集网站数据的一个重要的步骤,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-09-13 06:10
自从来到Front Sniff,编辑从爬虫成长为采集各种网站各种数据。当然,踩坑在成长过程中绝对是少不了的(很多网站都有防爬措施)。为了让用户更熟练的使用爬虫软件,小编决定定期写一些配置爬虫的经验和技巧,以及遇到坑的解决办法。
本案例使用大众点评网,需提取如下翻页链接。
第一步是看每个页面的链接地址是否有规律。
可以看出,只有每个页面的链接地址的最后一个数字不同,即对应的页码数。我们可以通过拼接得到翻页的所有链接地址。拼接第二页链接地址的脚本如下:
图中的六行代码是提取链接必不可少的部分。这简单的六行是一个完整的链接提取脚本。下面是每一行的解释:
第一行代码:定义一个url类的变量u。
第二行代码:u.urlname 是网页的链接地址,并为其赋值。
第三行代码:u.tmplid是本次链接提取要关联的模板id,这里是翻页,所以关联到自己的模板。
第四行代码:此链接提取对应的频道id。
第五行代码:u.title 是链接标题,被赋值。
第六行代码:将拼接后的链接添加到最终结果中。
上面的代码只得到了第二页的链接,下面给大家展示一下完整的内容:
通过FindClass从源码中获取总页数,然后使用for循环拼接每个页面的链接。只用了12行(包括两行注释)就得到了我想要的链接。
链接提取是大规模采集网站数据的重要步骤。下一期,小编计划在本案例的基础上增加数据提取,使其成为一个完整的爬虫采集模板。 采集数据可以正常。有需要的朋友可以点击上面的公众号,里面一定有你需要的内容。 查看全部
文章采集链接(本次采集网站数据的一个重要的步骤,你知道吗?)
自从来到Front Sniff,编辑从爬虫成长为采集各种网站各种数据。当然,踩坑在成长过程中绝对是少不了的(很多网站都有防爬措施)。为了让用户更熟练的使用爬虫软件,小编决定定期写一些配置爬虫的经验和技巧,以及遇到坑的解决办法。
本案例使用大众点评网,需提取如下翻页链接。
第一步是看每个页面的链接地址是否有规律。
可以看出,只有每个页面的链接地址的最后一个数字不同,即对应的页码数。我们可以通过拼接得到翻页的所有链接地址。拼接第二页链接地址的脚本如下:
图中的六行代码是提取链接必不可少的部分。这简单的六行是一个完整的链接提取脚本。下面是每一行的解释:
第一行代码:定义一个url类的变量u。
第二行代码:u.urlname 是网页的链接地址,并为其赋值。
第三行代码:u.tmplid是本次链接提取要关联的模板id,这里是翻页,所以关联到自己的模板。
第四行代码:此链接提取对应的频道id。
第五行代码:u.title 是链接标题,被赋值。
第六行代码:将拼接后的链接添加到最终结果中。
上面的代码只得到了第二页的链接,下面给大家展示一下完整的内容:
通过FindClass从源码中获取总页数,然后使用for循环拼接每个页面的链接。只用了12行(包括两行注释)就得到了我想要的链接。
链接提取是大规模采集网站数据的重要步骤。下一期,小编计划在本案例的基础上增加数据提取,使其成为一个完整的爬虫采集模板。 采集数据可以正常。有需要的朋友可以点击上面的公众号,里面一定有你需要的内容。
文章采集链接(如何获取公众号文章链接怎么才能将链接下载到本地 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-09-12 21:05
)
如何获取公众号文章链接
如何将公众号文章中的链接下载到本地?很多朋友还不知道用什么方法比较快。他们也使用其他工具导出,但操作步骤比较繁琐。接下来,我来介绍一下这个方便的采集工具的一些步骤。
微信公众号文章采集器
使用孤狼公众号助手时,先注册账号密码,充值后即可登录,打开软件进入,左上角有自定义公众号采集软件功能,打开添加框,可以从搜狗复制公众号文章temporary链接,然后点击获取,添加到软件后,添加框会加载公众号信息,包括永久链接,然后就可以采集Data 出来了!
软件界面功能介绍
1、勾选文章预览(可以预览文章内容)
2、复制文章title
3、清空列表(采集数据太多,可以清空列表)
4、导出文章列表(可导出Excel、html、txt、公众号)
5、添加到材料列表(添加采集好文章到任务列表)
6、勾选/取消(勾选文章可以选择或取消)
7、批量检测(可以检测文章是否为原创)
8、批量更新阅读次数(已经采集的时间数据可以实时更新,不需要再次采集)
导出 Excel 链接
采集好数据,选择Excel导出,最终导出的永久链接在表格中!
查看全部
文章采集链接(如何获取公众号文章链接怎么才能将链接下载到本地
)
如何获取公众号文章链接
如何将公众号文章中的链接下载到本地?很多朋友还不知道用什么方法比较快。他们也使用其他工具导出,但操作步骤比较繁琐。接下来,我来介绍一下这个方便的采集工具的一些步骤。
微信公众号文章采集器
使用孤狼公众号助手时,先注册账号密码,充值后即可登录,打开软件进入,左上角有自定义公众号采集软件功能,打开添加框,可以从搜狗复制公众号文章temporary链接,然后点击获取,添加到软件后,添加框会加载公众号信息,包括永久链接,然后就可以采集Data 出来了!
软件界面功能介绍
1、勾选文章预览(可以预览文章内容)
2、复制文章title
3、清空列表(采集数据太多,可以清空列表)
4、导出文章列表(可导出Excel、html、txt、公众号)
5、添加到材料列表(添加采集好文章到任务列表)
6、勾选/取消(勾选文章可以选择或取消)
7、批量检测(可以检测文章是否为原创)
8、批量更新阅读次数(已经采集的时间数据可以实时更新,不需要再次采集)
http://www.gulangu.com/wp-cont ... 7.png 300w, http://www.gulangu.com/wp-cont ... 2.png 768w, http://www.gulangu.com/wp-cont ... 9.png 220w, http://www.gulangu.com/wp-cont ... M.png 1079w" />导出 Excel 链接
采集好数据,选择Excel导出,最终导出的永久链接在表格中!
http://www.gulangu.com/wp-cont ... 6.png 300w, http://www.gulangu.com/wp-cont ... 4.png 768w, http://www.gulangu.com/wp-cont ... 2.png 220w, http://www.gulangu.com/wp-cont ... 3.png 1591w" /> 文章采集链接(优采云采集网页抓取工具(图)采集(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-12 19:09
)
以采集web爬虫工具优采云采集器官网faq为例说明采集器采集的原理和流程。
本例以演示地址和优采云采集器V9为工具进行说明。
(1)创建一个新的采集rule
选择一个组右键,选择“新建任务”,如下图:
解析URL变量的规律(2)add start URL
这里我们需要采集 5页数据。
首页地址:
第二页地址:
第三页地址:
由此可以推断p=后面的数字是分页的意思,我们用[地址参数]来表示:
所以设置如下:
编号变化:从1开始,即第一页;每次加1,即每页变化的次数;一共5个项目,也就是一共采集5页。地址格式:用[地址参数]表示改变的页码。
预览:采集器会根据上面的设置生成一部分URL,让你判断添加的是否正确。
然后确认。
(3)[普通模式]获取内容网址
普通模式:该模式默认抓取一级地址,即从起始页的源码中获取到内容页A的链接。
这里我教大家如何通过自动获取地址链接+设置区的方式获取。
查看页面源码,找到文章地址所在区域:
注:更详细的分析说明请参考本手册:设置如下:
操作指南> 软件操作> URL采集Rules> 获取内容URL
点击网址采集test查看测试效果
(以3)内容采集 URL 为例说明标签采集
注:更详细的分析说明,可在官网下载并参考用户手册。
操作指南>软件操作>Content采集Rules>标签编辑
我们先查看它的页面源码,找到我们的“title”所在的代码:
导入Excle是一个对话框~打开Excle时出错-优采云采集器帮助中心
分析:开始的字符串是:
结束字符串是:
数据处理-内容替换/排除:需要替换-优采云采集器帮助中心清空
分析:开始的字符串是:
设置内容标签的原理类似。在源码中找到内容的位置
结束字符串是:
数据处理-HTML标签排除:过滤不需要的A链接等
设置另一个“源”字段
查看全部
文章采集链接(优采云采集网页抓取工具(图)采集(组图)
)
以采集web爬虫工具优采云采集器官网faq为例说明采集器采集的原理和流程。
本例以演示地址和优采云采集器V9为工具进行说明。
(1)创建一个新的采集rule
选择一个组右键,选择“新建任务”,如下图:
解析URL变量的规律(2)add start URL
这里我们需要采集 5页数据。
首页地址:
第二页地址:
第三页地址:
由此可以推断p=后面的数字是分页的意思,我们用[地址参数]来表示:
所以设置如下:
编号变化:从1开始,即第一页;每次加1,即每页变化的次数;一共5个项目,也就是一共采集5页。地址格式:用[地址参数]表示改变的页码。
预览:采集器会根据上面的设置生成一部分URL,让你判断添加的是否正确。
然后确认。
(3)[普通模式]获取内容网址
普通模式:该模式默认抓取一级地址,即从起始页的源码中获取到内容页A的链接。
这里我教大家如何通过自动获取地址链接+设置区的方式获取。
查看页面源码,找到文章地址所在区域:
注:更详细的分析说明请参考本手册:设置如下:
操作指南> 软件操作> URL采集Rules> 获取内容URL
点击网址采集test查看测试效果
(以3)内容采集 URL 为例说明标签采集
注:更详细的分析说明,可在官网下载并参考用户手册。
操作指南>软件操作>Content采集Rules>标签编辑
我们先查看它的页面源码,找到我们的“title”所在的代码:
导入Excle是一个对话框~打开Excle时出错-优采云采集器帮助中心
分析:开始的字符串是:
结束字符串是:
数据处理-内容替换/排除:需要替换-优采云采集器帮助中心清空
分析:开始的字符串是:
设置内容标签的原理类似。在源码中找到内容的位置
结束字符串是:
数据处理-HTML标签排除:过滤不需要的A链接等
设置另一个“源”字段
文章采集链接(wordpress视频教程中文版:wordpress入门系列课程(hosts)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-08 17:00
文章采集链接:;mid=2247485368&idx=1&sn=f2d8e7a1fedc17b98e76d3a6abd46a51&chksm=ea2ca314cd1bb5c979bf072939d10242b23e3eb93d201c18995038a1f165c2093472a884897&mpshare=1&scene=1&srcid=&from=timeline&isappinstalled=0#wechat_redirect关于资料整理:wordpress视频教程中文资料整理:wordpress新手入门视频教程中文版:wordpress入门系列课程简单入门教程:wordpress培训资料汇总分享wordpress文章排版视频教程:wordpress-markdown简单编辑入门视频教程::wordpress教程目录wordpress如何获取本地仓库地址(hosts)wordpress查看外部网站地址(posts)wordpressauthor那些事wordpress有什么用wordpress如何设置标题wordpress如何指定作者wordpress如何提交文章wordpress如何调整文章排版。
这个,感觉不是一两句话能说清楚的,首先入门得知道基本的,后端要知道环境和安装相关东西,设计也得懂一点吧,我个人最推荐新版的medium介绍了很多,需要是英文。
medium
全英文,
不知道wordpress是什么的情况下, 查看全部
文章采集链接(wordpress视频教程中文版:wordpress入门系列课程(hosts)(组图))
文章采集链接:;mid=2247485368&idx=1&sn=f2d8e7a1fedc17b98e76d3a6abd46a51&chksm=ea2ca314cd1bb5c979bf072939d10242b23e3eb93d201c18995038a1f165c2093472a884897&mpshare=1&scene=1&srcid=&from=timeline&isappinstalled=0#wechat_redirect关于资料整理:wordpress视频教程中文资料整理:wordpress新手入门视频教程中文版:wordpress入门系列课程简单入门教程:wordpress培训资料汇总分享wordpress文章排版视频教程:wordpress-markdown简单编辑入门视频教程::wordpress教程目录wordpress如何获取本地仓库地址(hosts)wordpress查看外部网站地址(posts)wordpressauthor那些事wordpress有什么用wordpress如何设置标题wordpress如何指定作者wordpress如何提交文章wordpress如何调整文章排版。
这个,感觉不是一两句话能说清楚的,首先入门得知道基本的,后端要知道环境和安装相关东西,设计也得懂一点吧,我个人最推荐新版的medium介绍了很多,需要是英文。
medium
全英文,
不知道wordpress是什么的情况下,
文章采集链接(无限制版[综合营销]优采云·万能文章采集器.12.8优采云软件创始的神器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-07 01:04
近期发布的相关软件:
优采云万能文章采集器v1.21 无限破解版【整合营销】优采云万能文章采集器v1.21 注册机无限破解版【整合营销】优采云万能文章采集器V1.12破解版|无限版【综合营销】
优采云·万能文章采集器V2013.12.8
优采云软件的创作出来了:提取网页正文的通用算法。百度引擎、谷歌引擎、搜索引擎强强联合文章资源不时更新,取之不尽的智慧采集文章资源多语言翻译伪原创网站文章专栏。你,只要输入关键词。
行动范围:
1、press关键词采集Internet文章和translate伪原创,站长朋友的首选。
2、实用信息公关公司采集精选和提炼信息资料(一个专业的公司,几万个软件,我几百块钱)这个软件是只需要输入的软件关键词采集百度、谷歌搜搜等各大搜索引擎的新闻来源以及泛页面互联网文章和任何网站Columns文章的软件 更多介绍优采云software独家创始智能通用算法,可以准确提取网页正文部分保存为文章。
支持去除标签、链接、邮件等格式处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
更多文章transfer 翻译功能,即文章可以从一种语言如中文转为英文或日文等另一种语言,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足广大站长朋友在各个领域和话题的文章需求。
一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而这个软件优采云也是一个信息采集系统和功能和市面上的高价软件差不多,但价格只有几百元。 查看全部
文章采集链接(无限制版[综合营销]优采云·万能文章采集器.12.8优采云软件创始的神器)
近期发布的相关软件:
优采云万能文章采集器v1.21 无限破解版【整合营销】优采云万能文章采集器v1.21 注册机无限破解版【整合营销】优采云万能文章采集器V1.12破解版|无限版【综合营销】
优采云·万能文章采集器V2013.12.8
优采云软件的创作出来了:提取网页正文的通用算法。百度引擎、谷歌引擎、搜索引擎强强联合文章资源不时更新,取之不尽的智慧采集文章资源多语言翻译伪原创网站文章专栏。你,只要输入关键词。
行动范围:
1、press关键词采集Internet文章和translate伪原创,站长朋友的首选。
2、实用信息公关公司采集精选和提炼信息资料(一个专业的公司,几万个软件,我几百块钱)这个软件是只需要输入的软件关键词采集百度、谷歌搜搜等各大搜索引擎的新闻来源以及泛页面互联网文章和任何网站Columns文章的软件 更多介绍优采云software独家创始智能通用算法,可以准确提取网页正文部分保存为文章。
支持去除标签、链接、邮件等格式处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
更多文章transfer 翻译功能,即文章可以从一种语言如中文转为英文或日文等另一种语言,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足广大站长朋友在各个领域和话题的文章需求。
一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而这个软件优采云也是一个信息采集系统和功能和市面上的高价软件差不多,但价格只有几百元。
文章采集链接(利用优采云站群软件来指定目标网站采集文章的方法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-01 09:33
)
很多站长朋友喜欢采集一些更好的文章,比如Admin5站长网就是其中之一,A5作为国内大型站长网站之一,还有很多更好的质量原创文章是发布,所以文章资源可以说是连续的。但是对于采集工具,网上有各种各样的工具,而且大部分都是写规则采集。对于大多数站长来说,这可能是一个很大的门槛,很难跨过,因为大多数站长不会写采集规则,导致很多好的资源放弃,或者部分站长手动复制粘贴或者花钱找人写采集规则,效率和资金投入可谓是伤了又伤了钱。现在我来教大家如何使用优采云站群软件指定目标网站采集,这是一个不需要写规则的,还支持自动采集,自动跟踪等功能,无论是新站长还是老站长都容易上手,方便省力。现在图片教程如下:
一、打开优采云software,在网站node右键菜单中,打开【指定域名采集文章】功能。 (网站节点和列是自己添加的,第一次需要打开【数据管理】窗口生成列数据库来保存采集的文章。)
二、输入后点击左上角的一栏作为保存点,然后在右边填写采集的目标网址。
这里先教大家一些“怎么填字”的基础知识。看下图
1、是你要选择哪个站的列表URL,称为target采集地址。这通常是一个列表,因为列表是该列所有内容的链接位置。
2、page 翻页链接地址是第1页、第2页等的链接,注意上面的红蓝字。在优采云站群软件上,这些红色字符是需要填写的。比较两个URL,相同的东西不会变,就是红色字符。蓝色字符的1和2,这是该列的页面ID。在这个类目地址中,会发生变化,所以就不填了。一般用|代替字符,其中主分隔符表示分隔两个字符。 , 前面是list_,后面是.shtml。遵循一句话:取相同且独特的字符。本1的列表页源码中browse/117/list_表示翻页,其他链接均无此格式。因此,软件会识别出这是一个翻页地址。
3、内容链接地址为采集的文章地址。和上面的原理是一样的。注意红色和蓝色字符。红色字符需要用软件填写,蓝色字符会发生变化。只需将其替换为 |。
三、了解以上知识,然后在软件上填写A5网址和字符,结果如下:
1、红框是采集需要填写的字符。填写如下,即可采集。
|.shtml
|.shtml
2、这里也是上图中蓝框的作用。这个是为了以后自动采集,自动同步跟踪采集新网站要用于数据的URL,一般只填数字1 到第4页就好了,因为文章更新了网站 在前几页。软件挂断后可以自动跟踪采集。
四、现在可以采集测试是否正常。在上图的左下角,点击【采集测试】按钮,结果如下图
上图中这是采集测试翻页地址。没有出现其他非翻页地址链接,说明采集正常。如果您有其他网址,则可以设置排除项。
上图中,这是对采集当前首页所有内容URL的测试。没有其他非内容网址链接,说明采集正常。如果您有其他网址,则可以设置排除项。
在上图中,这是对文章 地址的随机测试。如果出现标题和内容,说明采集是正常的。如果出现其他文本,您可以设置排除或指定范围采集。
上图,这里是设置排除和过滤的地方
五、我看了上面很多文字和图片。其实对于采集A5的列表文章,只需要设置这三行字符即可。不需要复制太多采集规则。
|.shtml
|.shtml
其他【采访】、【操作】、【教程】等,其他列ID为177,后两行字符相同。这样,A5文章的整个站栏就可以采集回来了。如果想要固定数量的采集,可以在【补充设置】【单页文章】中设置最大文章数。如上图。
现在我点击采集看看效果。看中间的爬取记录,软件就像一个蜘蛛一页一页采集。
最后可以在网站节点游建中进入【数据管理】,查看你的采集back文章。然后将其发布到您的网站 或导入 TXT 文本以用于其他目的。
查看全部
文章采集链接(利用优采云站群软件来指定目标网站采集文章的方法
)
很多站长朋友喜欢采集一些更好的文章,比如Admin5站长网就是其中之一,A5作为国内大型站长网站之一,还有很多更好的质量原创文章是发布,所以文章资源可以说是连续的。但是对于采集工具,网上有各种各样的工具,而且大部分都是写规则采集。对于大多数站长来说,这可能是一个很大的门槛,很难跨过,因为大多数站长不会写采集规则,导致很多好的资源放弃,或者部分站长手动复制粘贴或者花钱找人写采集规则,效率和资金投入可谓是伤了又伤了钱。现在我来教大家如何使用优采云站群软件指定目标网站采集,这是一个不需要写规则的,还支持自动采集,自动跟踪等功能,无论是新站长还是老站长都容易上手,方便省力。现在图片教程如下:
一、打开优采云software,在网站node右键菜单中,打开【指定域名采集文章】功能。 (网站节点和列是自己添加的,第一次需要打开【数据管理】窗口生成列数据库来保存采集的文章。)
二、输入后点击左上角的一栏作为保存点,然后在右边填写采集的目标网址。
这里先教大家一些“怎么填字”的基础知识。看下图
1、是你要选择哪个站的列表URL,称为target采集地址。这通常是一个列表,因为列表是该列所有内容的链接位置。
2、page 翻页链接地址是第1页、第2页等的链接,注意上面的红蓝字。在优采云站群软件上,这些红色字符是需要填写的。比较两个URL,相同的东西不会变,就是红色字符。蓝色字符的1和2,这是该列的页面ID。在这个类目地址中,会发生变化,所以就不填了。一般用|代替字符,其中主分隔符表示分隔两个字符。 , 前面是list_,后面是.shtml。遵循一句话:取相同且独特的字符。本1的列表页源码中browse/117/list_表示翻页,其他链接均无此格式。因此,软件会识别出这是一个翻页地址。
3、内容链接地址为采集的文章地址。和上面的原理是一样的。注意红色和蓝色字符。红色字符需要用软件填写,蓝色字符会发生变化。只需将其替换为 |。
三、了解以上知识,然后在软件上填写A5网址和字符,结果如下:
1、红框是采集需要填写的字符。填写如下,即可采集。
|.shtml
|.shtml
2、这里也是上图中蓝框的作用。这个是为了以后自动采集,自动同步跟踪采集新网站要用于数据的URL,一般只填数字1 到第4页就好了,因为文章更新了网站 在前几页。软件挂断后可以自动跟踪采集。
四、现在可以采集测试是否正常。在上图的左下角,点击【采集测试】按钮,结果如下图
上图中这是采集测试翻页地址。没有出现其他非翻页地址链接,说明采集正常。如果您有其他网址,则可以设置排除项。
上图中,这是对采集当前首页所有内容URL的测试。没有其他非内容网址链接,说明采集正常。如果您有其他网址,则可以设置排除项。
在上图中,这是对文章 地址的随机测试。如果出现标题和内容,说明采集是正常的。如果出现其他文本,您可以设置排除或指定范围采集。
上图,这里是设置排除和过滤的地方
五、我看了上面很多文字和图片。其实对于采集A5的列表文章,只需要设置这三行字符即可。不需要复制太多采集规则。
|.shtml
|.shtml
其他【采访】、【操作】、【教程】等,其他列ID为177,后两行字符相同。这样,A5文章的整个站栏就可以采集回来了。如果想要固定数量的采集,可以在【补充设置】【单页文章】中设置最大文章数。如上图。
现在我点击采集看看效果。看中间的爬取记录,软件就像一个蜘蛛一页一页采集。
最后可以在网站节点游建中进入【数据管理】,查看你的采集back文章。然后将其发布到您的网站 或导入 TXT 文本以用于其他目的。
章、简书文章、今日头条内容内容百度已收录
采集交流 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-08-27 07:07
WordPress采集plugin bee采集BeePress
<p>“小蜜蜂-BeePress”是微信公众号文章导入插件。可以通过粘贴公众号文章的链接将公众号文章导入到自己的网站,并支持批量导入、自动采集、设置特殊图片等功能,减少繁琐操作。 查看全部
章、简书文章、今日头条内容内容百度已收录
WordPress采集plugin bee采集BeePress
<p>“小蜜蜂-BeePress”是微信公众号文章导入插件。可以通过粘贴公众号文章的链接将公众号文章导入到自己的网站,并支持批量导入、自动采集、设置特殊图片等功能,减少繁琐操作。
1.新建站点2.网址规则查看源代码内容规则制作
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-08-26 07:13
1.新建站点2.网址规则查看源代码内容规则制作
采集文章 并发布到 Dedecms
我们以腾讯广州新闻为例,说说文章的采集和发布,包括下载和上传图片。 URL,我们一步一步讲。
1.新站点
2.在本站创建一个新任务
3.URL 规则,查看源码,发现这些 URL 代码都在一个区域,我们可以这样写规则
测试一下,是正确的,是时候收下下面的内容了。
4.Content 规则生成。我们随机找一个页面,比如先测试一下
看了一下,里面有我们需要的东西,说明优采云可以捡到。下面我们来做具体的内容采集rules。
如何获得标题?只需使用默认过滤器“_Social ”。这是你不理解代码时使用的方法,你可以对内容进行同样的操作。对于一般的简单采集,没有大问题。但是对于一些比较复杂的网页采集,还是需要仔细分析源码,分析网页结构。下面我们做一个具体的分析。分析工具IE可以使用ie开发者工具栏,firefox可以使用插件firebug(具体请在工具“附件-组件浏览-附加组件”中查看安装),google可以使用右键“查看”元素”。我以萤火虫为例:
经过分析,我们可以知道内容在id为cntMain,标题id为ArticleTit的区域,
店员疑似死于手机爆炸。续:现场发现9颗子弹
,所以我们可以这样写标题。注意截取的代码要以源码中的格式为准。
内容为ArticleCnt,以ArtPLink结束。内容的采集是这样的。
我们测试一下,可以采集到所有内容,但是里面有广告等乱码,要过滤掉。我看最上面的分析代码,广告代码,推荐阅读,id是阅读,所以我们这样过滤。
。看一看,没有更多,但需要注意的是,之前有一份关于此的报告。请看图,大部分都是不同的,比如有的是相关报道,有的是事件回放。有些只是链接。
这个过滤有点复杂。它只能单独过滤。我将在这里过滤链接。你可以自己处理其他人。那我们来看看吧。 文章 末尾还有一个文章 链接。这是我们不需要的,过滤掉它。过滤掉,再找几个页面测试一下,发现问题。最终结果如图所示。
5.发布设置。我们使用WEB在线发布,并将数据发送到dedecms5.1。我们选择发布,然后点击定义在线帖子到网站全局设置。弹出 Web 在线配置管理器。
此时我们选择添加,出现添加网页发布配置。我们先来看看使用说明。这应该仔细阅读。详见WEB在线发布模块文章的修改。阅读后,开始配置。 :
我们发布到本地网站dedecms5.3,所以模块选择对应的版本,网站管理目录是,所以按照说明填写,然后选择代码,我们网站gbk,所以选择gbk。然后登录网站,使用优采云内置浏览器登录。如图所示
然后登录成功就可以关闭优采云浏览器了。下面我们刷新列表,这个用来指定文章发布到哪一列,如图
可以看到列成功获取,接下来我们测试配置
我们可以看到已经成功发布了。通过网站 在后台检查它。它也很成功。现在您可以保存配置名称并在发布时使用它。示例保存为 dedegbk53.
现在我们右键单击任务发布设置,
,选择我们刚才的dedegbk53,然后点击选择类别指定这个任务中的文章会发布到网站对应的栏目,我们可以添加多个配置,当然一个配置也可以也加入了多个任务。
这样,web发布配置就做好了,现在来说说如何下载图片,如图
上图是运行时线程设置。如果您的网络不好,请将其更改为更大的大小。在文件下载设置部分,可以在任意目录选择本地文件存储文件夹,程序会在该目录下生成图片。 flash,其他文件的保存地址。文件链接地址前缀是网站上显示的路径,如上图,我本地保存的图片文件最终地址会是a+1+/文件名,网站上对应的地址@是b+1+/文件名,如果是ftp上传,b和c的路径要对应。
标签中指定了下载的具体设置,也可以指定下载文件的命名方式。
现在我们所有的配置都完成了,我们可以直接启动采集并发布它。保存任务后,选择任务并点击开始。
需要注意的是,没有必要一次选择这个。 URL、内容和内容可以分阶段发送。我们的演示一次完成。点击开始,我们可以看到操作的进度。
我们去网站background看看效果,
随便找个文章,很正常,图片也正常,如果不直接保存到网站目录,请用ftp工具上传。一个完整的采集 发布过程结束。
查看全部
1.新建站点2.网址规则查看源代码内容规则制作
采集文章 并发布到 Dedecms
我们以腾讯广州新闻为例,说说文章的采集和发布,包括下载和上传图片。 URL,我们一步一步讲。
1.新站点
2.在本站创建一个新任务
3.URL 规则,查看源码,发现这些 URL 代码都在一个区域,我们可以这样写规则
测试一下,是正确的,是时候收下下面的内容了。
4.Content 规则生成。我们随机找一个页面,比如先测试一下
看了一下,里面有我们需要的东西,说明优采云可以捡到。下面我们来做具体的内容采集rules。
如何获得标题?只需使用默认过滤器“_Social ”。这是你不理解代码时使用的方法,你可以对内容进行同样的操作。对于一般的简单采集,没有大问题。但是对于一些比较复杂的网页采集,还是需要仔细分析源码,分析网页结构。下面我们做一个具体的分析。分析工具IE可以使用ie开发者工具栏,firefox可以使用插件firebug(具体请在工具“附件-组件浏览-附加组件”中查看安装),google可以使用右键“查看”元素”。我以萤火虫为例:
经过分析,我们可以知道内容在id为cntMain,标题id为ArticleTit的区域,
店员疑似死于手机爆炸。续:现场发现9颗子弹
,所以我们可以这样写标题。注意截取的代码要以源码中的格式为准。
内容为ArticleCnt,以ArtPLink结束。内容的采集是这样的。
我们测试一下,可以采集到所有内容,但是里面有广告等乱码,要过滤掉。我看最上面的分析代码,广告代码,推荐阅读,id是阅读,所以我们这样过滤。
。看一看,没有更多,但需要注意的是,之前有一份关于此的报告。请看图,大部分都是不同的,比如有的是相关报道,有的是事件回放。有些只是链接。
这个过滤有点复杂。它只能单独过滤。我将在这里过滤链接。你可以自己处理其他人。那我们来看看吧。 文章 末尾还有一个文章 链接。这是我们不需要的,过滤掉它。过滤掉,再找几个页面测试一下,发现问题。最终结果如图所示。
5.发布设置。我们使用WEB在线发布,并将数据发送到dedecms5.1。我们选择发布,然后点击定义在线帖子到网站全局设置。弹出 Web 在线配置管理器。
此时我们选择添加,出现添加网页发布配置。我们先来看看使用说明。这应该仔细阅读。详见WEB在线发布模块文章的修改。阅读后,开始配置。 :
我们发布到本地网站dedecms5.3,所以模块选择对应的版本,网站管理目录是,所以按照说明填写,然后选择代码,我们网站gbk,所以选择gbk。然后登录网站,使用优采云内置浏览器登录。如图所示
然后登录成功就可以关闭优采云浏览器了。下面我们刷新列表,这个用来指定文章发布到哪一列,如图
可以看到列成功获取,接下来我们测试配置
我们可以看到已经成功发布了。通过网站 在后台检查它。它也很成功。现在您可以保存配置名称并在发布时使用它。示例保存为 dedegbk53.
现在我们右键单击任务发布设置,
,选择我们刚才的dedegbk53,然后点击选择类别指定这个任务中的文章会发布到网站对应的栏目,我们可以添加多个配置,当然一个配置也可以也加入了多个任务。
这样,web发布配置就做好了,现在来说说如何下载图片,如图
上图是运行时线程设置。如果您的网络不好,请将其更改为更大的大小。在文件下载设置部分,可以在任意目录选择本地文件存储文件夹,程序会在该目录下生成图片。 flash,其他文件的保存地址。文件链接地址前缀是网站上显示的路径,如上图,我本地保存的图片文件最终地址会是a+1+/文件名,网站上对应的地址@是b+1+/文件名,如果是ftp上传,b和c的路径要对应。
标签中指定了下载的具体设置,也可以指定下载文件的命名方式。
现在我们所有的配置都完成了,我们可以直接启动采集并发布它。保存任务后,选择任务并点击开始。
需要注意的是,没有必要一次选择这个。 URL、内容和内容可以分阶段发送。我们的演示一次完成。点击开始,我们可以看到操作的进度。
我们去网站background看看效果,
随便找个文章,很正常,图片也正常,如果不直接保存到网站目录,请用ftp工具上传。一个完整的采集 发布过程结束。
猴哥:数据是第三方处理,不是提供给用户看吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-08-22 20:02
文章采集链接:猴哥就说一下b站的调节。猴哥认为网易有个特点,就是数据是第三方处理,第三方的数据并不是提供给用户的,服务对象只能是某个产品的用户。以网易云音乐为例,什么时候视频有流量?每个用户听到过的音乐,但却不听网易云音乐里面的内容,更别说播放器了。再如说你想看个小姐姐,打开了网易云音乐打开电台,她说,那个还没死呢,待会让你歌单里面挑一首放,不然把我黑名单了。
有多少是这种,逼到用户去选择平台去放置自己的数据。再来在说腾讯,什么时候视频有流量?腾讯视频会播放视频吗?会把视频提供给用户看吗?腾讯音乐会在腾讯视频中发布自己的歌单,你看qq音乐,他的歌单,里面你想找的,都在里面,用户提供数据给qq音乐,让他们去播放你的歌单,你又怎么去统计流量呢?假设在他们两个对比情况下,只要有一个播放器有功能,能让用户的数据能提供给他们,且真正的把这些数据汇总起来,形成一个用户画像,等到了用户手机中看到歌单自然进行搜索再去播放歌单,时,再将搜索来的数据统计进去,就不会出现某宝、某大麦,或者用户手机里面听不到歌,无法播放的现象。
假设你要播放个歌,打开了腾讯视频,说,你想听我的歌单,有个选项,你提供给我一首,我告诉你哪首歌,你去听。你说了一首,让我选择,我对你说,哪首都行,你点击都可以,点到你想播放的歌,告诉我歌名,我就去搜索,你说一首。好吧,你告诉我你想听那首歌,我去搜索了,点到那首歌。好,你告诉我你去听哪首歌,我去点播放列表页面给你播放了,你又告诉我你的歌单里面有这首歌,这是你想听的。
那这就是个矛盾了,虽然你告诉我你要听哪首歌,我去点播放列表给你播放了,但我也需要搜索一下,这个播放列表有个功能叫播放列表二级歌单,这个里面有我的歌单,也有你的,你提供给我的歌单还是我一首接一首给你播放了。他们提供的不是歌,提供的也不是对用户数据的服务,而是对腾讯产品未来发展影响的影响。你认为你不提供出去,腾讯音乐和腾讯视频对我们有什么影响呢?真正做起来了,在影响了,腾讯视频和腾讯音乐,对用户的数据谁有影响呢?他们在手机里面都有单独的账号,这个账号就是用户的数据,你提供用户数据给它们,它们的服务是有人在给我做运营推广,不好意思,听歌的人不会给你造,你的歌单也没有机会给你造。
这就是核心一个问题。再来说,微信和网易云音乐做本质的差别吗?虽然是同是腾讯开发,但音乐在各个方面都有很多不同的地方,首先设计语言就是不同的,网易云音乐的操作逻辑也是多人才能操作,并不是那个什。 查看全部
猴哥:数据是第三方处理,不是提供给用户看吗?
文章采集链接:猴哥就说一下b站的调节。猴哥认为网易有个特点,就是数据是第三方处理,第三方的数据并不是提供给用户的,服务对象只能是某个产品的用户。以网易云音乐为例,什么时候视频有流量?每个用户听到过的音乐,但却不听网易云音乐里面的内容,更别说播放器了。再如说你想看个小姐姐,打开了网易云音乐打开电台,她说,那个还没死呢,待会让你歌单里面挑一首放,不然把我黑名单了。
有多少是这种,逼到用户去选择平台去放置自己的数据。再来在说腾讯,什么时候视频有流量?腾讯视频会播放视频吗?会把视频提供给用户看吗?腾讯音乐会在腾讯视频中发布自己的歌单,你看qq音乐,他的歌单,里面你想找的,都在里面,用户提供数据给qq音乐,让他们去播放你的歌单,你又怎么去统计流量呢?假设在他们两个对比情况下,只要有一个播放器有功能,能让用户的数据能提供给他们,且真正的把这些数据汇总起来,形成一个用户画像,等到了用户手机中看到歌单自然进行搜索再去播放歌单,时,再将搜索来的数据统计进去,就不会出现某宝、某大麦,或者用户手机里面听不到歌,无法播放的现象。
假设你要播放个歌,打开了腾讯视频,说,你想听我的歌单,有个选项,你提供给我一首,我告诉你哪首歌,你去听。你说了一首,让我选择,我对你说,哪首都行,你点击都可以,点到你想播放的歌,告诉我歌名,我就去搜索,你说一首。好吧,你告诉我你想听那首歌,我去搜索了,点到那首歌。好,你告诉我你去听哪首歌,我去点播放列表页面给你播放了,你又告诉我你的歌单里面有这首歌,这是你想听的。
那这就是个矛盾了,虽然你告诉我你要听哪首歌,我去点播放列表给你播放了,但我也需要搜索一下,这个播放列表有个功能叫播放列表二级歌单,这个里面有我的歌单,也有你的,你提供给我的歌单还是我一首接一首给你播放了。他们提供的不是歌,提供的也不是对用户数据的服务,而是对腾讯产品未来发展影响的影响。你认为你不提供出去,腾讯音乐和腾讯视频对我们有什么影响呢?真正做起来了,在影响了,腾讯视频和腾讯音乐,对用户的数据谁有影响呢?他们在手机里面都有单独的账号,这个账号就是用户的数据,你提供用户数据给它们,它们的服务是有人在给我做运营推广,不好意思,听歌的人不会给你造,你的歌单也没有机会给你造。
这就是核心一个问题。再来说,微信和网易云音乐做本质的差别吗?虽然是同是腾讯开发,但音乐在各个方面都有很多不同的地方,首先设计语言就是不同的,网易云音乐的操作逻辑也是多人才能操作,并不是那个什。
一句话点评:下载后打开pdf可能会有一些格式问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-08-21 03:07
文章采集链接。我的文章被ironslide、知乎日报、豆瓣推荐了。一句话点评:下载后打开下载后的pdf可能会有一些格式问题(比如页眉页脚、加粗颜色等),在采集完以后,解决了pdf格式问题。回复被采集的文章:我的文章被ironslide、知乎日报、豆瓣推荐了。一句话点评:下载后打开下载后的pdf可能会有一些格式问题(比如页眉页脚、加粗颜色等),在采集完以后,解决了pdf格式问题。
回复采集知乎上的文章,发现不能被采集。回复豆瓣采集我豆瓣的文章下采集,发现豆瓣文章采集文章采集不到。将采集与采集文章的相关信息共享给大家作者单位、文章标题、简介、标签等;统计下载文章的人数和下载文章的人数;做下采集分析;多说几句(文章搜索都是用谷歌搜索得到的)我很享受pdf下载这个功能,但是一来它的标准答案并不是很完美,毕竟只是「找文章」,并没有做什么可以延伸的专业工作;二来遇到个别答案很好的回答,要一一点开看看能不能找到原文作者,就很浪费时间。
在「知乎」采集有个好处是可以手动去关键词的搜索,文章关键词我选择「电影」,可以搜到「豆瓣」「知乎」这两个,搜索成功率很高。但是我会把文章搜索设置成「内容搜索」(内容采集是用「分词」的方式来获取结果,并没有把内容拉入关键词列表里面),只限于文章本身,而不是下载文章。如果题主在下载pdf时,一定要选择「内容搜索」,那么意味着只能采集作者的信息,不能下载作者的书籍,这是很亏的。
下载过很多pdf,有很多pdf是直接只做下载是不能下载全文的,大多数要导出为epub格式,然后再重新下载、解压,也遇到过下载不了全文的情况。我个人觉得不太合理,不知道知乎是否也是这样。(我认为这个功能其实是一个鸡肋,没有必要做)但是ironslide下载的很多文章就已经做到下载全文了。所以在专门回复下。
一句话的意思是指「不能只采集作者,但是要能让别人知道作者」。所以这句话没有用;但是一句话下载最后出现的结果应该是作者的书籍pdf。基于作者为了避免被找上门来,下面都是直接联系作者购买刊物。注:书籍pdf一般在7天之内还原,大多数7天内能还原pdf书籍,少数作者不愿意出售书籍,所以书籍书籍的标题不能直接粘贴pdf书籍的标题,但是,书籍的简介、作者介绍、主要内容都是一样的,只是在简介或者书籍封面可以填写相关的作者姓名或者是作者介绍信息。
购买刊物的流程是:在ironslide网站上选择——在线支付——邮寄书籍,是不是很方便。有问题的小伙伴也可以直接在微信、知乎上告诉我。感谢的小伙伴就。 查看全部
一句话点评:下载后打开pdf可能会有一些格式问题
文章采集链接。我的文章被ironslide、知乎日报、豆瓣推荐了。一句话点评:下载后打开下载后的pdf可能会有一些格式问题(比如页眉页脚、加粗颜色等),在采集完以后,解决了pdf格式问题。回复被采集的文章:我的文章被ironslide、知乎日报、豆瓣推荐了。一句话点评:下载后打开下载后的pdf可能会有一些格式问题(比如页眉页脚、加粗颜色等),在采集完以后,解决了pdf格式问题。
回复采集知乎上的文章,发现不能被采集。回复豆瓣采集我豆瓣的文章下采集,发现豆瓣文章采集文章采集不到。将采集与采集文章的相关信息共享给大家作者单位、文章标题、简介、标签等;统计下载文章的人数和下载文章的人数;做下采集分析;多说几句(文章搜索都是用谷歌搜索得到的)我很享受pdf下载这个功能,但是一来它的标准答案并不是很完美,毕竟只是「找文章」,并没有做什么可以延伸的专业工作;二来遇到个别答案很好的回答,要一一点开看看能不能找到原文作者,就很浪费时间。
在「知乎」采集有个好处是可以手动去关键词的搜索,文章关键词我选择「电影」,可以搜到「豆瓣」「知乎」这两个,搜索成功率很高。但是我会把文章搜索设置成「内容搜索」(内容采集是用「分词」的方式来获取结果,并没有把内容拉入关键词列表里面),只限于文章本身,而不是下载文章。如果题主在下载pdf时,一定要选择「内容搜索」,那么意味着只能采集作者的信息,不能下载作者的书籍,这是很亏的。
下载过很多pdf,有很多pdf是直接只做下载是不能下载全文的,大多数要导出为epub格式,然后再重新下载、解压,也遇到过下载不了全文的情况。我个人觉得不太合理,不知道知乎是否也是这样。(我认为这个功能其实是一个鸡肋,没有必要做)但是ironslide下载的很多文章就已经做到下载全文了。所以在专门回复下。
一句话的意思是指「不能只采集作者,但是要能让别人知道作者」。所以这句话没有用;但是一句话下载最后出现的结果应该是作者的书籍pdf。基于作者为了避免被找上门来,下面都是直接联系作者购买刊物。注:书籍pdf一般在7天之内还原,大多数7天内能还原pdf书籍,少数作者不愿意出售书籍,所以书籍书籍的标题不能直接粘贴pdf书籍的标题,但是,书籍的简介、作者介绍、主要内容都是一样的,只是在简介或者书籍封面可以填写相关的作者姓名或者是作者介绍信息。
购买刊物的流程是:在ironslide网站上选择——在线支付——邮寄书籍,是不是很方便。有问题的小伙伴也可以直接在微信、知乎上告诉我。感谢的小伙伴就。
如何通过google蜘蛛爬虫爬取百度百科全文登录(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-08-20 04:02
文章采集链接:请问最后我能采集到您的下载链接吗,
我是新手,不是圈内人,恳请大神出面帮忙解决下这个难题,
找找你们的google帐号登录页面绑定一下呢。
我这边手机上那个账号点我的选择电脑选择多开
手机上“点我的”选择多开“右上角分享”添加到多开。随便选择一个分享你将看到多开窗口按钮。再来电脑上点开多开,登录账号就可以“自动采集”了。
卸载重装
如果是电脑网页上,可以试试postman,点击网址获取,
建议打开如下入口:-guide/publicathuid=id/9348/
这个,直接在百度里搜索googlebot。然后第一行最后一个就是答案。想要更好地理解googlebot,
可以参考这个问题:如何通过google蜘蛛爬虫爬取百度百科全文
登录,进入,登录,
进入→搜索内容
最简单,手机打开,点我的网址输入post,等待下载,电脑选择多开管理电脑。
手机上登录账号,登录电脑账号,也可用输入百度api的id绑定账号(也就是你想爬取百度有用数据的这个号的百度api给他自己的微信号的api自己的lbsapi自己)电脑登录的时候,ip绑定上面这种,或者你的百度帐号登录是同一个account, 查看全部
如何通过google蜘蛛爬虫爬取百度百科全文登录(图)
文章采集链接:请问最后我能采集到您的下载链接吗,
我是新手,不是圈内人,恳请大神出面帮忙解决下这个难题,
找找你们的google帐号登录页面绑定一下呢。
我这边手机上那个账号点我的选择电脑选择多开
手机上“点我的”选择多开“右上角分享”添加到多开。随便选择一个分享你将看到多开窗口按钮。再来电脑上点开多开,登录账号就可以“自动采集”了。
卸载重装
如果是电脑网页上,可以试试postman,点击网址获取,
建议打开如下入口:-guide/publicathuid=id/9348/
这个,直接在百度里搜索googlebot。然后第一行最后一个就是答案。想要更好地理解googlebot,
可以参考这个问题:如何通过google蜘蛛爬虫爬取百度百科全文
登录,进入,登录,
进入→搜索内容
最简单,手机打开,点我的网址输入post,等待下载,电脑选择多开管理电脑。
手机上登录账号,登录电脑账号,也可用输入百度api的id绑定账号(也就是你想爬取百度有用数据的这个号的百度api给他自己的微信号的api自己的lbsapi自己)电脑登录的时候,ip绑定上面这种,或者你的百度帐号登录是同一个account,
django怎么连接第三方服务器(django基于laravel框架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-08-20 00:03
文章采集链接:django连接https-连接连接服务器(连接ip、域名、目录路径等)看看效果::4000/xxxx-[]-[/]//[***/***/***]//[xxxx-[*]-[/]/]//[[*]-[/]]//[]-[*]-[/]/)(上图代码)
曾经,我有个知乎回答:服务器django怎么连接第三方服务器(django基于laravel框架)?-yafez的回答django项目用服务器实现django的连接路由?-sambring的回答简单说下我个人的一点理解吧。一个django项目结构如下:从传统的mvc组合模式升级成web2.0模式,代码量下降了,但是整体的结构和代码还是没有分离开,结构依然有些混乱。
web容器解决大型开发时,写进数据库的逻辑和操作等。django项目结构如下:和django基于laravel框架构建的大型项目结构差别在哪里?应该说,django框架中,以js-schema形式提供数据库操作方法,和django根据admin配置完全访问https请求数据库是两回事,两个python项目还有一个完全不一样的数据库操作路由路由配置。
这里再给两个django项目的一些源码--分别是django1.5.13和django1.7.0新老对比。
django模版引擎本身并不提供对第三方服务器的配置,现在的主流httpserver都提供了对djangoserver的配置接口,比如vuex、vue-loader(在此之前用的是gxjango),但这些只是用来加速管理用户session的,也就是说django在注册session时需要自己配置其他的server,比如googlesearch那样的django框架,这样本身做起来就不顺手,对于django项目来说,最好是再基于mvc框架构建web项目,将数据库管理设计到django框架。 查看全部
django怎么连接第三方服务器(django基于laravel框架)
文章采集链接:django连接https-连接连接服务器(连接ip、域名、目录路径等)看看效果::4000/xxxx-[]-[/]//[***/***/***]//[xxxx-[*]-[/]/]//[[*]-[/]]//[]-[*]-[/]/)(上图代码)
曾经,我有个知乎回答:服务器django怎么连接第三方服务器(django基于laravel框架)?-yafez的回答django项目用服务器实现django的连接路由?-sambring的回答简单说下我个人的一点理解吧。一个django项目结构如下:从传统的mvc组合模式升级成web2.0模式,代码量下降了,但是整体的结构和代码还是没有分离开,结构依然有些混乱。
web容器解决大型开发时,写进数据库的逻辑和操作等。django项目结构如下:和django基于laravel框架构建的大型项目结构差别在哪里?应该说,django框架中,以js-schema形式提供数据库操作方法,和django根据admin配置完全访问https请求数据库是两回事,两个python项目还有一个完全不一样的数据库操作路由路由配置。
这里再给两个django项目的一些源码--分别是django1.5.13和django1.7.0新老对比。
django模版引擎本身并不提供对第三方服务器的配置,现在的主流httpserver都提供了对djangoserver的配置接口,比如vuex、vue-loader(在此之前用的是gxjango),但这些只是用来加速管理用户session的,也就是说django在注册session时需要自己配置其他的server,比如googlesearch那样的django框架,这样本身做起来就不顺手,对于django项目来说,最好是再基于mvc框架构建web项目,将数据库管理设计到django框架。

