
文章采集规则
文章采集规则(论坛采集核心技术是模式定义和模式匹配的经验的抽象和升华)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-06 19:09
论坛采集是论坛站长的辅助工具。论坛建设初期,需要内容较多,人工发送费时费力,难以形成论坛互动。论坛采集器主要是帮助论坛站长采集,将大量发帖内容发送到指定版块,论坛采集的辅助功能是模拟千人上线,看帖、发帖、回帖、点赞,形成一定的互动效果,提高人气,吸引新用户,留住老用户。
论坛采集核心技术是模式定义和模式匹配。模式属于人工智能的术语,意为对物体前身所积累的经验的抽象和升华。简单来说,论坛采集就是从反复出现的事件中发现和抽象出来的规则,是解决问题的经验总结。只要是一遍又一遍地重复的东西,就可能有规律。
因此,要使论坛 采集 起作用,目标论坛必须具有重复出现的特征。大多数论坛是动态生成的,因此相同模板的页面收录相同的内容,论坛 采集 使用这些内容来定位 采集 数据。
论坛采集中的大部分模式都不是程序自动发现的,论坛采集几乎所有的功能都需要手动定义。但是论坛采集模式本身就是一个非常复杂抽象的内容,所以开发者的全部精力都花在了如何让模式定义更简单更准确上,这也是论坛竞争力的标杆采集 。论坛采集技术主要有两种方式:正则表达式定义和文档结构定义。
论坛采集可以定时抓取、同步关注、下载附件、打通防盗链等。系统内置操作向导。论坛采集很好的支持Discuz、PHPWind、Dvbbs等论坛采集。论坛采集实现所见即所得,用户在可视化页面视图上点击想要的采集内容,预览采集的结果。网站监控,定期监控目标网站的数据更新,并自动采集更新数据。
Forum采集的智能抽取系统对半结构化数据进行语义分析,根据语义规则智能抽取复杂多变的数据。网站全站下载,论坛采集无限深度,无限分页数据采集,可以跨页发布数据。论坛采集的万维网WEB技术,采用WEB技术,站长无需安装即可使用论坛采集。论坛采集特征列表功能,区域预览和特征列表展示,让规则定义准确又轻松。多线程采集,论坛采集多任务并发,多线程采集。支持线程并发控制和状态监控。插件支持,论坛采集有丰富的插件功能,支持采集
论坛采集文章各类cms,新闻等资料采集。论坛采集可以为织梦的采集、东夷、帝国等cms添加插件。站长可以自定义自己的采集模块,采集各种新闻,文章到自己的博客来吸引流量。论坛采集根据站长自定义的任务配置,批量准确提取目标论坛栏目中的主题帖和回复帖的作者、标题、发布时间、内容、栏目等,并进行转换成结构化记录,存储在本地数据库中。 查看全部
文章采集规则(论坛采集核心技术是模式定义和模式匹配的经验的抽象和升华)
论坛采集是论坛站长的辅助工具。论坛建设初期,需要内容较多,人工发送费时费力,难以形成论坛互动。论坛采集器主要是帮助论坛站长采集,将大量发帖内容发送到指定版块,论坛采集的辅助功能是模拟千人上线,看帖、发帖、回帖、点赞,形成一定的互动效果,提高人气,吸引新用户,留住老用户。

论坛采集核心技术是模式定义和模式匹配。模式属于人工智能的术语,意为对物体前身所积累的经验的抽象和升华。简单来说,论坛采集就是从反复出现的事件中发现和抽象出来的规则,是解决问题的经验总结。只要是一遍又一遍地重复的东西,就可能有规律。

因此,要使论坛 采集 起作用,目标论坛必须具有重复出现的特征。大多数论坛是动态生成的,因此相同模板的页面收录相同的内容,论坛 采集 使用这些内容来定位 采集 数据。

论坛采集中的大部分模式都不是程序自动发现的,论坛采集几乎所有的功能都需要手动定义。但是论坛采集模式本身就是一个非常复杂抽象的内容,所以开发者的全部精力都花在了如何让模式定义更简单更准确上,这也是论坛竞争力的标杆采集 。论坛采集技术主要有两种方式:正则表达式定义和文档结构定义。

论坛采集可以定时抓取、同步关注、下载附件、打通防盗链等。系统内置操作向导。论坛采集很好的支持Discuz、PHPWind、Dvbbs等论坛采集。论坛采集实现所见即所得,用户在可视化页面视图上点击想要的采集内容,预览采集的结果。网站监控,定期监控目标网站的数据更新,并自动采集更新数据。


Forum采集的智能抽取系统对半结构化数据进行语义分析,根据语义规则智能抽取复杂多变的数据。网站全站下载,论坛采集无限深度,无限分页数据采集,可以跨页发布数据。论坛采集的万维网WEB技术,采用WEB技术,站长无需安装即可使用论坛采集。论坛采集特征列表功能,区域预览和特征列表展示,让规则定义准确又轻松。多线程采集,论坛采集多任务并发,多线程采集。支持线程并发控制和状态监控。插件支持,论坛采集有丰富的插件功能,支持采集

论坛采集文章各类cms,新闻等资料采集。论坛采集可以为织梦的采集、东夷、帝国等cms添加插件。站长可以自定义自己的采集模块,采集各种新闻,文章到自己的博客来吸引流量。论坛采集根据站长自定义的任务配置,批量准确提取目标论坛栏目中的主题帖和回复帖的作者、标题、发布时间、内容、栏目等,并进行转换成结构化记录,存储在本地数据库中。
文章采集规则(多文写手2020年破解版解决方案介绍及使用说明书)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-05 06:11
详细介绍
Multi-Writing Writer是一个伪原创文章生成器,可以应用于原创文章制作作品集,非常方便实用。使用多语言编写器可以快速大量生成可读性强的收录good原创文章,对搜索引擎更有利收录。由于网络文化的严格管理,现在大多数搜索引擎对收录敏感词或根本不收录收录的网页进行不同程度的降级。所以过滤文章敏感词尤为重要。多文本编写器内置了材质敏感词过滤,可以快速过滤掉一些不好的关键词,让文章的质量更高,对收录@更有利>。这是一个营销版本,网站 日常维护和更新所需的软件。还支持所有前景和背景数据。支持通过脚本在所有网站上发布文章。
这次推荐多文写作2020 vip破解版。此版本已破解vip,可免费使用软件所有功能。欢迎下载体验!
软件功能1、自动伪原创;
2、自动组合问候语;
3、自动采集图片;
4、图片自动加水印;
5、自动过滤敏感词;
6、Script Universal Publishing 支持所有后端。软件功能1、自动过滤敏感词
自动过滤敏感词,使文章内容更安全,对收录更有利。
2、自动伪原创材料
在材料导入过程中,材料自动进行伪原创处理,对收录更有利。
3、一键图片采集
根据关键词一键采集相关图片,速度快,效率高,图片更容易匹配。
4、图片采集重新压缩
独有的图片伪原创技术可以批量随机调整图片分辨率。
5、材料采集多式联运
支持爬虫采集、规则采集、关键词采集多种素材获取方式。
6、自动脚本发布
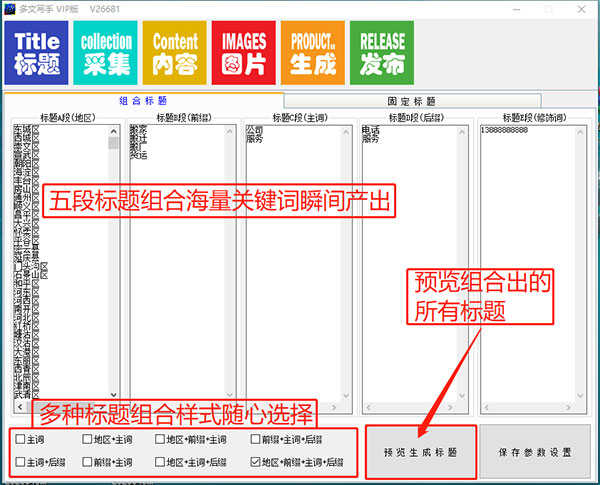
通用脚本发布支持所有网站后台/前端发布,实现文章生成与发布一体化解决方案。使用说明一、多文本编写器有两种文章生成模式:组合标题和固定标题。
1、组合标题分为五段来指定组合。每段100字,可以组合不同的标题
标题数量:100×100×100×100×100=
2、固定标题模式,使用自己设置的固定标题生成文章。您可以根据需要生成任意数量。
3、标题设置支持5个标题段,最多可组合1亿级。
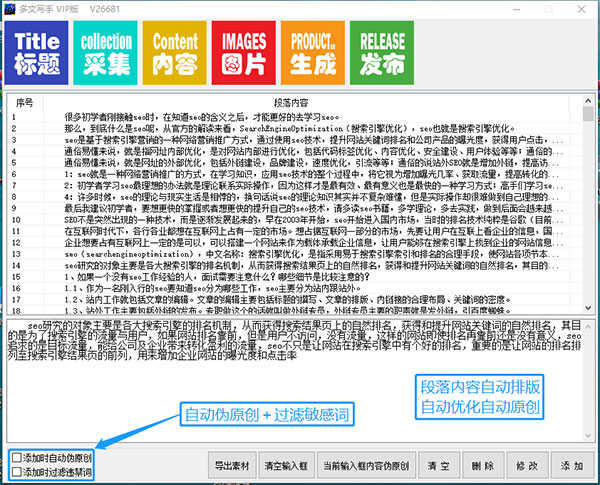
二、由于对网络文化的严格管理,现在大部分搜索引擎对收录敏感词的网页进行不同程度的降级或不直接收录。所以过滤文章敏感词尤为重要。多文本编写器内置了材质敏感词过滤,可以快速过滤掉一些不好的关键词,让文章的质量更高,对收录@更有利>。
三、伪原创处理,添加素材时自动伪原创处理素材内容。从分词技术让文章原创更好。
四、内容采集
选择关键词采集材质,填写材质为采集关键词,启动采集。内容采集功能多文本书写器内容采集功能显示及说明:
一、规则采集:
对于更具体的 文章,您可以为内容 采集 手动编写 采集 规则。
二、单个站点采集:
如果不知道采集规则怎么写,也可以做单站采集,内置爬虫spider可以直接设置采集深度一键< @采集目标网站所有内容。
三、关键词采集:
通过设置指定与此关键词 关联的关键词一键式采集 材质。注册账号1、新用户下载软件后点击注册续订按钮,自动跳转到注册页面。
2、注册时填写账号密码和网购激活码。
3、点击用户注册完成注册。 查看全部
文章采集规则(多文写手2020年破解版解决方案介绍及使用说明书)
详细介绍
Multi-Writing Writer是一个伪原创文章生成器,可以应用于原创文章制作作品集,非常方便实用。使用多语言编写器可以快速大量生成可读性强的收录good原创文章,对搜索引擎更有利收录。由于网络文化的严格管理,现在大多数搜索引擎对收录敏感词或根本不收录收录的网页进行不同程度的降级。所以过滤文章敏感词尤为重要。多文本编写器内置了材质敏感词过滤,可以快速过滤掉一些不好的关键词,让文章的质量更高,对收录@更有利>。这是一个营销版本,网站 日常维护和更新所需的软件。还支持所有前景和背景数据。支持通过脚本在所有网站上发布文章。
这次推荐多文写作2020 vip破解版。此版本已破解vip,可免费使用软件所有功能。欢迎下载体验!
软件功能1、自动伪原创;
2、自动组合问候语;
3、自动采集图片;
4、图片自动加水印;
5、自动过滤敏感词;
6、Script Universal Publishing 支持所有后端。软件功能1、自动过滤敏感词
自动过滤敏感词,使文章内容更安全,对收录更有利。
2、自动伪原创材料
在材料导入过程中,材料自动进行伪原创处理,对收录更有利。
3、一键图片采集
根据关键词一键采集相关图片,速度快,效率高,图片更容易匹配。
4、图片采集重新压缩
独有的图片伪原创技术可以批量随机调整图片分辨率。
5、材料采集多式联运
支持爬虫采集、规则采集、关键词采集多种素材获取方式。
6、自动脚本发布
通用脚本发布支持所有网站后台/前端发布,实现文章生成与发布一体化解决方案。使用说明一、多文本编写器有两种文章生成模式:组合标题和固定标题。
1、组合标题分为五段来指定组合。每段100字,可以组合不同的标题
标题数量:100×100×100×100×100=
2、固定标题模式,使用自己设置的固定标题生成文章。您可以根据需要生成任意数量。
3、标题设置支持5个标题段,最多可组合1亿级。
二、由于对网络文化的严格管理,现在大部分搜索引擎对收录敏感词的网页进行不同程度的降级或不直接收录。所以过滤文章敏感词尤为重要。多文本编写器内置了材质敏感词过滤,可以快速过滤掉一些不好的关键词,让文章的质量更高,对收录@更有利>。
三、伪原创处理,添加素材时自动伪原创处理素材内容。从分词技术让文章原创更好。
四、内容采集
选择关键词采集材质,填写材质为采集关键词,启动采集。内容采集功能多文本书写器内容采集功能显示及说明:
一、规则采集:
对于更具体的 文章,您可以为内容 采集 手动编写 采集 规则。
二、单个站点采集:
如果不知道采集规则怎么写,也可以做单站采集,内置爬虫spider可以直接设置采集深度一键< @采集目标网站所有内容。
三、关键词采集:
通过设置指定与此关键词 关联的关键词一键式采集 材质。注册账号1、新用户下载软件后点击注册续订按钮,自动跳转到注册页面。
2、注册时填写账号密码和网购激活码。
3、点击用户注册完成注册。
文章采集规则(计算机和互联网基础知识作业()计算机作业开始时间)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-04-05 03:19
计算机与互联网基础功课,计算机功课1带Answers.doc_weixin_39788131的博客-程序员的秘密
计算机作业 1Basic Knowledge with Answers.doc 跳至主要内容在线课程学院主页电子学习实验室联系我们FormTopFormBottomPage PathHome/我的课程/计算机应用基础知识 2299/主题 2/第一次作业计算机基础知识开始于 2015 年 10 月 1 日星期四 1301 完成于 2015 年 10 月 1 日星期四 1435 用时 1 小时34 分钟 分数 37.00/40.00Grades 92.50/...
FPGA控制TDC7200时间间隔测量(一)_*临时博客-程序员的秘密_tdc芯片
简介 TDC7200是TI推出的时间间隔测量芯片,分辨率低至55ps,标准差35ps,低功耗模式,最多可计数5个停止脉冲,最小工作负40度摄氏度。芯片介绍 引脚说明 我们将结合官方手册说明介绍其引脚(1)ENABLE使能引脚,根据手册,该引脚为高电平时芯片使能。(2)TRIGG触发引脚) ,按照说明书,芯片上电使能后,会一直保持低电平,当我们初始化后进入测试环节时,该引脚会被拉低,芯片接收到START脉冲后,该引脚被拉低低。(3、4)STA
wpf结合java_如何使用WPF绑定RelativeSource?_ 风神理性博客-程序员的秘密
当我们试图将一个对象的一个属性绑定到该对象本身的另一个属性时,RelativeSource 是一个标记扩展,当我们试图将一个对象的一个属性绑定到其相对父级的另一个属性时,在特定的绑定情况下使用自定义控件开发时绑定一个依赖属性值到一段XAML,最后在绑定数据使用一系列差异的情况下。所有这些情况都表示为相对源模式。我将一一揭露所有这些案例。模式自我:想象一下这种情况,我们想要一个高度总是等于宽度的矩形......
@Data_Max_Tsui 博客的使用 - 程序员的秘密
这里写一个自定义的目录标题@Data使用新的更改功能快捷键创建一个合理的标题,有助于目录的生成如何更改文本的样式插入链接和图片如何插入漂亮的代码片段生成一个列表适合你创建表格设置内容居中、左、右 SmartyPants 创建自定义列表 如何创建脚注注释也是 KaTeX 数学公式必不可少的新甘特图功能,丰富您的 文章UML 图 FLowchart 流程图 导出和 Import Export Import Import @Data 使用 @d...
TCP 和 UDP_caiyec 的博客 - 程序员的秘密
提示:文章写好后可以自动生成目录,如何生成可以参考右边的帮助文档TCP和UDP前言一、什么是UDP?二、什么是 TCP?1.库介绍2.TCP和UDP的区别总结介绍目前我们常用的计算机网络架构是TCP/IP五层网络结构自上而下为应用层,传输层,网络层,数据链路层,物理层,今天介绍的TCP和UDP是传输层的两个协议。传输层负责端到端的数据传输,传输层由操作系统内核实现。一、什么是UDP?首先,UDP是传输层的协议。
线程安全——从StringBuffer和StringBuilder的区别看 - 程序员大本营
面试的时候,面试官问了线程安全问题,感觉回答不太满意。那个时候,我没有好好回答。我问面试官如何理解它。他说:可以参考StringBuffer和StringBuilder。所以赶紧回来自己弥补。这是学渣的苦果/(ㄒoㄒ)/~~线程安全概念线程安全:多线程访问时,使用了锁机制。当一个线程访问这个类的某个数据时,它是受保护的。在线程读完之前,其他线程无法访问它,其他线程也无法使用它。没有出现 查看全部
文章采集规则(计算机和互联网基础知识作业()计算机作业开始时间)
计算机与互联网基础功课,计算机功课1带Answers.doc_weixin_39788131的博客-程序员的秘密
计算机作业 1Basic Knowledge with Answers.doc 跳至主要内容在线课程学院主页电子学习实验室联系我们FormTopFormBottomPage PathHome/我的课程/计算机应用基础知识 2299/主题 2/第一次作业计算机基础知识开始于 2015 年 10 月 1 日星期四 1301 完成于 2015 年 10 月 1 日星期四 1435 用时 1 小时34 分钟 分数 37.00/40.00Grades 92.50/...
FPGA控制TDC7200时间间隔测量(一)_*临时博客-程序员的秘密_tdc芯片
简介 TDC7200是TI推出的时间间隔测量芯片,分辨率低至55ps,标准差35ps,低功耗模式,最多可计数5个停止脉冲,最小工作负40度摄氏度。芯片介绍 引脚说明 我们将结合官方手册说明介绍其引脚(1)ENABLE使能引脚,根据手册,该引脚为高电平时芯片使能。(2)TRIGG触发引脚) ,按照说明书,芯片上电使能后,会一直保持低电平,当我们初始化后进入测试环节时,该引脚会被拉低,芯片接收到START脉冲后,该引脚被拉低低。(3、4)STA
wpf结合java_如何使用WPF绑定RelativeSource?_ 风神理性博客-程序员的秘密
当我们试图将一个对象的一个属性绑定到该对象本身的另一个属性时,RelativeSource 是一个标记扩展,当我们试图将一个对象的一个属性绑定到其相对父级的另一个属性时,在特定的绑定情况下使用自定义控件开发时绑定一个依赖属性值到一段XAML,最后在绑定数据使用一系列差异的情况下。所有这些情况都表示为相对源模式。我将一一揭露所有这些案例。模式自我:想象一下这种情况,我们想要一个高度总是等于宽度的矩形......
@Data_Max_Tsui 博客的使用 - 程序员的秘密
这里写一个自定义的目录标题@Data使用新的更改功能快捷键创建一个合理的标题,有助于目录的生成如何更改文本的样式插入链接和图片如何插入漂亮的代码片段生成一个列表适合你创建表格设置内容居中、左、右 SmartyPants 创建自定义列表 如何创建脚注注释也是 KaTeX 数学公式必不可少的新甘特图功能,丰富您的 文章UML 图 FLowchart 流程图 导出和 Import Export Import Import @Data 使用 @d...
TCP 和 UDP_caiyec 的博客 - 程序员的秘密
提示:文章写好后可以自动生成目录,如何生成可以参考右边的帮助文档TCP和UDP前言一、什么是UDP?二、什么是 TCP?1.库介绍2.TCP和UDP的区别总结介绍目前我们常用的计算机网络架构是TCP/IP五层网络结构自上而下为应用层,传输层,网络层,数据链路层,物理层,今天介绍的TCP和UDP是传输层的两个协议。传输层负责端到端的数据传输,传输层由操作系统内核实现。一、什么是UDP?首先,UDP是传输层的协议。
线程安全——从StringBuffer和StringBuilder的区别看 - 程序员大本营
面试的时候,面试官问了线程安全问题,感觉回答不太满意。那个时候,我没有好好回答。我问面试官如何理解它。他说:可以参考StringBuffer和StringBuilder。所以赶紧回来自己弥补。这是学渣的苦果/(ㄒoㄒ)/~~线程安全概念线程安全:多线程访问时,使用了锁机制。当一个线程访问这个类的某个数据时,它是受保护的。在线程读完之前,其他线程无法访问它,其他线程也无法使用它。没有出现
文章采集规则(在设置织梦采集规则的时候,有哪些注意事项?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-03 18:07
在这个日益浮躁的社会中,越来越多的人期望事情变得越来越容易。尤其是在瞬息万变的互联网时代,需要时间去思考的东西是不适合的。以网站操作为例,虽然完整的原创文章对网站优化排名很有帮助,但是网站操作的写法大部分能力是不高,加上题材的限制和时间的规律性,完全通过原创和人工操作和优化一个网站是非常困难的,尤其是对于一些信息类型网站、商城类型网站、视频类型网站等此类页面类型网站,内容更新要求快,无论是内容建设,还是外链发布,都是一项庞大而复杂的任务,无论是从时间上还是从成本上,手工去做都不划算。因此,有时我们需要借助一些工具。采集工具就是其中之一。
目前网站采集中最常用的采集工具是优采云采集工具和织梦自己的dede采集工具,采集网上有很多工具的优劣对比,百度一下就知道了,网上也有很多织梦采集规则设置的攻略,都差不多,所以本文就不多解释了,有兴趣的童鞋可以自行搜索看看。今天要和大家分享的是,设置织梦采集规则有哪些注意事项?
一、采集开始和结束代码设置
在织梦采集规则设置中,很重要的一步就是采集开始码和结束码的设置。一般是一小段代码,主要是“数字/英文+符号”的形式。代码越短,越不容易出错,并且需要唯一性,以便机器能够快速识别采集的开始和结束位置。在线教程中,这个起停代码一般是一个完整的段落,比如[content],这里是开始采集的位置,[content]代表需要采集的部分信息,是end采集 位置,很多人会误以为起止代码一定是一个完整的段落,其实不然。
如下图二:
代码的某一部分,甚至是混有中文的代码,也可以作为采集的起止码,可以去掉一些网站内容,上面带有网站特殊标识开始和结束。
二、标题采集设置
标题采集很简单,有两种方式,如下图所示:
在需要采集的页面右击选择“查看源代码”,在打开的页面中使用快捷键Ctrl+F,在搜索中输入采集的内容标题显示查看它的栏。页面的标题规则一般是标题标签和H标签,数量从1到4不等。一般页面上两种标题标签并存。在这种情况下,使用 H 标记比标题标记 采集 更不容易出错。
需要注意的是,有时H标签有H1标签、H2标签、H3标签等,一般只使用H1标签。
三、分页织梦采集规则设置
有的网站经常因为文章篇幅过长或者想提高点击率,把一篇文章文章分成几页呈现。在这种情况下,采集的起始码和结束码不在同一个页面,但是采集起始码应该在文章起始页上找到,结束码应该是在 文章 end page 找到,设置如下:
四、可能导致 采集 失败的几个因素
1、网站禁止隐藏内容采集。以腾讯新闻为例,腾讯新闻的内容不会在开源代码页展示,所以无法确定文章的起止位置,也无法确定采集对其< @网站 内容。
2、网站采集错误。网站 的大部分内容在页面和代码中看起来都很好,但是当 采集 转到目标网站 时会显示错误。此类错误分为几类:
A. 标题错误。如下图所示,文章的内容会集中在标题上。
B、只有采集去标题,内容为空。也就是说,无法采集到相关内容。
C、采集的终止符无效,采集的内容包括采集网站上张贴的广告/版权信息/页脚信息等信息。
这些都是采集中经常遇到的问题,理解它们对采集和伪原创会有很大帮助。虽然我们不推荐使用 采集 方法进行优化,但如有必要,了解 织梦采集 规则将有利于 网站 操作。. 查看全部
文章采集规则(在设置织梦采集规则的时候,有哪些注意事项?)
在这个日益浮躁的社会中,越来越多的人期望事情变得越来越容易。尤其是在瞬息万变的互联网时代,需要时间去思考的东西是不适合的。以网站操作为例,虽然完整的原创文章对网站优化排名很有帮助,但是网站操作的写法大部分能力是不高,加上题材的限制和时间的规律性,完全通过原创和人工操作和优化一个网站是非常困难的,尤其是对于一些信息类型网站、商城类型网站、视频类型网站等此类页面类型网站,内容更新要求快,无论是内容建设,还是外链发布,都是一项庞大而复杂的任务,无论是从时间上还是从成本上,手工去做都不划算。因此,有时我们需要借助一些工具。采集工具就是其中之一。
目前网站采集中最常用的采集工具是优采云采集工具和织梦自己的dede采集工具,采集网上有很多工具的优劣对比,百度一下就知道了,网上也有很多织梦采集规则设置的攻略,都差不多,所以本文就不多解释了,有兴趣的童鞋可以自行搜索看看。今天要和大家分享的是,设置织梦采集规则有哪些注意事项?
一、采集开始和结束代码设置
在织梦采集规则设置中,很重要的一步就是采集开始码和结束码的设置。一般是一小段代码,主要是“数字/英文+符号”的形式。代码越短,越不容易出错,并且需要唯一性,以便机器能够快速识别采集的开始和结束位置。在线教程中,这个起停代码一般是一个完整的段落,比如[content],这里是开始采集的位置,[content]代表需要采集的部分信息,是end采集 位置,很多人会误以为起止代码一定是一个完整的段落,其实不然。
如下图二:


代码的某一部分,甚至是混有中文的代码,也可以作为采集的起止码,可以去掉一些网站内容,上面带有网站特殊标识开始和结束。
二、标题采集设置
标题采集很简单,有两种方式,如下图所示:

在需要采集的页面右击选择“查看源代码”,在打开的页面中使用快捷键Ctrl+F,在搜索中输入采集的内容标题显示查看它的栏。页面的标题规则一般是标题标签和H标签,数量从1到4不等。一般页面上两种标题标签并存。在这种情况下,使用 H 标记比标题标记 采集 更不容易出错。
需要注意的是,有时H标签有H1标签、H2标签、H3标签等,一般只使用H1标签。
三、分页织梦采集规则设置
有的网站经常因为文章篇幅过长或者想提高点击率,把一篇文章文章分成几页呈现。在这种情况下,采集的起始码和结束码不在同一个页面,但是采集起始码应该在文章起始页上找到,结束码应该是在 文章 end page 找到,设置如下:

四、可能导致 采集 失败的几个因素
1、网站禁止隐藏内容采集。以腾讯新闻为例,腾讯新闻的内容不会在开源代码页展示,所以无法确定文章的起止位置,也无法确定采集对其< @网站 内容。
2、网站采集错误。网站 的大部分内容在页面和代码中看起来都很好,但是当 采集 转到目标网站 时会显示错误。此类错误分为几类:
A. 标题错误。如下图所示,文章的内容会集中在标题上。

B、只有采集去标题,内容为空。也就是说,无法采集到相关内容。
C、采集的终止符无效,采集的内容包括采集网站上张贴的广告/版权信息/页脚信息等信息。

这些都是采集中经常遇到的问题,理解它们对采集和伪原创会有很大帮助。虽然我们不推荐使用 采集 方法进行优化,但如有必要,了解 织梦采集 规则将有利于 网站 操作。.
文章采集规则( 优采云运营2个月最高IP一天达到6000+,可见源码模板优化非常好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-04-03 00:23
优采云运营2个月最高IP一天达到6000+,可见源码模板优化非常好)
也想来这里吗?点击联系我~
源码介绍:作者亲自操作小说系统2个月,每天最高IP达到6000+。可以看出源码模板优化的非常好,适合优采云操作,因为完全没有管理,就买了一些朋友链。
盈利方式:变现的方式也很简单,就是做广告,如果你有几千个IP就可以做广告,申请谷歌+百度+搜狗等联盟广告,每月几千元,做不来很多钱,但赚一点钱就可以了。
服务器系统:Linux+Centos7.0以上+宝塔
PHP扩展:宝塔上直接安装扩展【fileinfo + memcache】安装好后重载+重启PHP即可
亲测环境:Nginx1.16.1+PHP5.6+Mysql5.5
有安装程序配置好环境直接访问域名即可
Nginx伪静态
location / {
if (!-e $request_filename){
rewrite ^(.*)$ /index.php?s=$1 last; break;
}
}
注意:打开后台如果报404,需打开网站根目录的index.php,在倒数第2行添加:
define('APP_DEBUG',true);
并在正常访问后,将这段代码删除。
如果要更多采集规则 百度搜索:PTCMS采集规则
资源下载 本资源仅供注册用户下载,请先登录 查看全部
文章采集规则(
优采云运营2个月最高IP一天达到6000+,可见源码模板优化非常好)

也想来这里吗?点击联系我~
源码介绍:作者亲自操作小说系统2个月,每天最高IP达到6000+。可以看出源码模板优化的非常好,适合优采云操作,因为完全没有管理,就买了一些朋友链。
盈利方式:变现的方式也很简单,就是做广告,如果你有几千个IP就可以做广告,申请谷歌+百度+搜狗等联盟广告,每月几千元,做不来很多钱,但赚一点钱就可以了。
服务器系统:Linux+Centos7.0以上+宝塔
PHP扩展:宝塔上直接安装扩展【fileinfo + memcache】安装好后重载+重启PHP即可
亲测环境:Nginx1.16.1+PHP5.6+Mysql5.5
有安装程序配置好环境直接访问域名即可
Nginx伪静态
location / {
if (!-e $request_filename){
rewrite ^(.*)$ /index.php?s=$1 last; break;
}
}
注意:打开后台如果报404,需打开网站根目录的index.php,在倒数第2行添加:
define('APP_DEBUG',true);
并在正常访问后,将这段代码删除。
如果要更多采集规则 百度搜索:PTCMS采集规则
资源下载 本资源仅供注册用户下载,请先登录
文章采集规则(带你认识9个营销工具系列教程的第三篇)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-02 12:05
文章采集规则的设计目的在于进行差异化采集,可以为后期的高效精准获取内容做铺垫。但是对于初学者或者是跨行业行业工作人员,肯定不清楚今天的规则是否正确。本文为我们初次推出的“带你认识9个营销工具”系列教程的第三篇。很多企业都在用移动应用举办市场活动。由于大部分移动应用每天都会推送超过80亿条内容信息。很多内容被采集目的都是展示。
这就需要转化为商业价值。也就是说要先做清楚的实际需求是什么。经常被互联网企业所忽略的内容采集工具1.印象笔记·印象笔记拥有强大的语义整理能力,优化了他的用户体验,即便你没有使用过印象笔记,印象笔记同步所有内容依然是非常容易的。而且该系统会收集每一条使用过的笔记。有人说印象笔记不是一个内容采集工具,但是它也是一个内容整理工具。
我所说的内容并不是单纯意义上的来源于网络。更多的是报纸杂志。或者正规媒体。对于其他材料也许是采集的通路。但是对于知识,你可以通过整理笔记来获取知识并且将其实践。虽然过程长,但是知识的价值更高。2.quora·和印象笔记一样,这是全球领先的网络问答社区。作为内容的收集中心,quora会定期从媒体中抓取信息并聚集在一起。
你每一次创建quora帐户都将会收集一定数量的信息,你可以通过查看第一条回答获取所有内容,当你对某一领域产生兴趣时还可以将热门话题从全世界中挖掘出来。这可以帮助你及时了解其他领域的内容,便于你拓展你的知识库。当然了你也可以将原有用户关注的问题、在quora上有赞同的答案、链接等内容放在你的笔记本中,提升内容发掘和内容聚合的能力。
3.美图秀秀·互联网人绝对不陌生美图秀秀,它将每一个摄影师想要保存的原始图片都浓缩在一个软件里。并且一键保存到指定的服务器。自从美图秀秀将内容采集工具发布以来就一直被各种文章的撰稿人使用。这在一定程度上减轻了编辑的工作。只要输入你想要的图片,就可以很方便的获取到你需要的原始图片。特别对于新手而言是非常容易。
在输入图片时,只需要按照顺序组织好文字,图片和一些注释。这些图片就会自动生成。为美图秀秀提供超过300万名供稿人,他们分布在广告投放、图片制作和传播,插画设计,美术教学、在线课程、策划制作等领域。即便你不喜欢美图秀秀,你也可以拿着这样一份美图秀秀的笔记去寻找自己喜欢的文章。美图秀秀通过大量的千万级别用户提供内容。
比如最近的日本花火大会。8月的北京啤酒厂——久保佳一的作品。以及4月的第二届釜山电影节——宝树的作品。已经有超过4000名作者关注图片或者是美化作品, 查看全部
文章采集规则(带你认识9个营销工具系列教程的第三篇)
文章采集规则的设计目的在于进行差异化采集,可以为后期的高效精准获取内容做铺垫。但是对于初学者或者是跨行业行业工作人员,肯定不清楚今天的规则是否正确。本文为我们初次推出的“带你认识9个营销工具”系列教程的第三篇。很多企业都在用移动应用举办市场活动。由于大部分移动应用每天都会推送超过80亿条内容信息。很多内容被采集目的都是展示。
这就需要转化为商业价值。也就是说要先做清楚的实际需求是什么。经常被互联网企业所忽略的内容采集工具1.印象笔记·印象笔记拥有强大的语义整理能力,优化了他的用户体验,即便你没有使用过印象笔记,印象笔记同步所有内容依然是非常容易的。而且该系统会收集每一条使用过的笔记。有人说印象笔记不是一个内容采集工具,但是它也是一个内容整理工具。
我所说的内容并不是单纯意义上的来源于网络。更多的是报纸杂志。或者正规媒体。对于其他材料也许是采集的通路。但是对于知识,你可以通过整理笔记来获取知识并且将其实践。虽然过程长,但是知识的价值更高。2.quora·和印象笔记一样,这是全球领先的网络问答社区。作为内容的收集中心,quora会定期从媒体中抓取信息并聚集在一起。
你每一次创建quora帐户都将会收集一定数量的信息,你可以通过查看第一条回答获取所有内容,当你对某一领域产生兴趣时还可以将热门话题从全世界中挖掘出来。这可以帮助你及时了解其他领域的内容,便于你拓展你的知识库。当然了你也可以将原有用户关注的问题、在quora上有赞同的答案、链接等内容放在你的笔记本中,提升内容发掘和内容聚合的能力。
3.美图秀秀·互联网人绝对不陌生美图秀秀,它将每一个摄影师想要保存的原始图片都浓缩在一个软件里。并且一键保存到指定的服务器。自从美图秀秀将内容采集工具发布以来就一直被各种文章的撰稿人使用。这在一定程度上减轻了编辑的工作。只要输入你想要的图片,就可以很方便的获取到你需要的原始图片。特别对于新手而言是非常容易。
在输入图片时,只需要按照顺序组织好文字,图片和一些注释。这些图片就会自动生成。为美图秀秀提供超过300万名供稿人,他们分布在广告投放、图片制作和传播,插画设计,美术教学、在线课程、策划制作等领域。即便你不喜欢美图秀秀,你也可以拿着这样一份美图秀秀的笔记去寻找自己喜欢的文章。美图秀秀通过大量的千万级别用户提供内容。
比如最近的日本花火大会。8月的北京啤酒厂——久保佳一的作品。以及4月的第二届釜山电影节——宝树的作品。已经有超过4000名作者关注图片或者是美化作品,
文章采集规则(文章采集规则有些第三方抓取平台规则会相对比较多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-04-02 11:04
文章采集规则有些第三方抓取平台规则会相对比较多,如何将其进行有效筛选是第一要务。至于seo流量,呵呵,那是多年积累的roi和带来的用户,到时候公司财大气粗了一场活动或者运营策略定好了,百度有钱任性就必须给好处了。你懂的,如何解决?自己先做一个。
既然出钱,一般还会考虑使用售后服务,这里的售后服务有2个层面:1、每天登录量的上升,可能是用户从来不登录,这个是关键指标,估计如果只是单纯引流,用户的转化率不会太好,如果是seo引流,质量可能会比较高,这样能保证长期的增长,加速产品的推广,保证口碑和积累用户;2、转化率,这个需要整合资源,购买一些服务和工具,还有数据分析等,例如通过百度等搜索引擎引流的时候,自己能以行业数据或产品作为分析依据,分析哪些用户是对产品感兴趣的,有利于整合资源,实现用户转化。希望对你有帮助。
seo的目的是为了提高搜索引擎排名,所以搜索引擎的排名是最核心的指标。我们搜索引擎的数据越多越好,所以做seo前必须需要使用seo的工具进行数据分析,然后再根据数据得出我们需要优化的地方,并提升推广数据,
要说seo目的,我认为最核心的应该就是seo能够带来订单量,大于seo的成本(这个成本跟你的平台粘性也有关系)或者是拉低平台的广告收入,毕竟广告是在中国是不挣钱的,而且基本上是非法的。在这个前提下进行seo排名能够看出网站主体受众数和质量,毕竟,seo排名靠前的,都是有共性的网站(好吧,这句不是我说的,但是不可避免要用到),且公司都会将自己的网站优化到全网民都习惯的位置。
但是,我相信聪明的你应该已经懂了,现在同行竞争挺激烈的,所以要想做好seo必须降低转化率跟投入产出比,而如何降低转化率与降低投入产出比才是核心问题。(seo降低转化率的话可以找到精准客户群体,即便是刚入行的seo,我们也不能将排名第一放在第一页,否则会分散网站主体的流量)基于这个问题,我有一个思路,既然要做seo,就要做出点差异化的优势,相比于别人的优势,关键词能够做到top20之类的。好吧,希望能帮到你。 查看全部
文章采集规则(文章采集规则有些第三方抓取平台规则会相对比较多)
文章采集规则有些第三方抓取平台规则会相对比较多,如何将其进行有效筛选是第一要务。至于seo流量,呵呵,那是多年积累的roi和带来的用户,到时候公司财大气粗了一场活动或者运营策略定好了,百度有钱任性就必须给好处了。你懂的,如何解决?自己先做一个。
既然出钱,一般还会考虑使用售后服务,这里的售后服务有2个层面:1、每天登录量的上升,可能是用户从来不登录,这个是关键指标,估计如果只是单纯引流,用户的转化率不会太好,如果是seo引流,质量可能会比较高,这样能保证长期的增长,加速产品的推广,保证口碑和积累用户;2、转化率,这个需要整合资源,购买一些服务和工具,还有数据分析等,例如通过百度等搜索引擎引流的时候,自己能以行业数据或产品作为分析依据,分析哪些用户是对产品感兴趣的,有利于整合资源,实现用户转化。希望对你有帮助。
seo的目的是为了提高搜索引擎排名,所以搜索引擎的排名是最核心的指标。我们搜索引擎的数据越多越好,所以做seo前必须需要使用seo的工具进行数据分析,然后再根据数据得出我们需要优化的地方,并提升推广数据,
要说seo目的,我认为最核心的应该就是seo能够带来订单量,大于seo的成本(这个成本跟你的平台粘性也有关系)或者是拉低平台的广告收入,毕竟广告是在中国是不挣钱的,而且基本上是非法的。在这个前提下进行seo排名能够看出网站主体受众数和质量,毕竟,seo排名靠前的,都是有共性的网站(好吧,这句不是我说的,但是不可避免要用到),且公司都会将自己的网站优化到全网民都习惯的位置。
但是,我相信聪明的你应该已经懂了,现在同行竞争挺激烈的,所以要想做好seo必须降低转化率跟投入产出比,而如何降低转化率与降低投入产出比才是核心问题。(seo降低转化率的话可以找到精准客户群体,即便是刚入行的seo,我们也不能将排名第一放在第一页,否则会分散网站主体的流量)基于这个问题,我有一个思路,既然要做seo,就要做出点差异化的优势,相比于别人的优势,关键词能够做到top20之类的。好吧,希望能帮到你。
文章采集规则(公众号文章数据采集与处理的优化应对与应对)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-01 19:06
公众号文章资料采集和处理无处不在。并且数量庞大。我们目前处于数据爆炸的时代,数据采集和处理一直伴随着我们。无论是网站论坛、公众号文章还是朋友圈,每天都会产生数亿条数据、文章、内容等。
通过数据采集和处理工具,我们可以采集到我们需要采集的公众号文章的数据。将其保存在本地以进行数据分析或二次创建。
数据采集及处理工具操作简单,页面简洁方便。我们只需要鼠标点击即可完成采集的配置,然后启动目标网站采集。支持采集资源标签保留(更好的保存格式)、过滤原文中敏感词(去除电话号码、地址等)、去除原图水印等
有时网页抓取还不够;通常需要更深入地挖掘和分析数据,以揭示数据背后的真正含义并发现有价值的见解。数据和内容的分析利用可以说与我们的工作生活息息相关。
以网站SEO为例,通过数据分析,我们可以统计出网站每天的流量变化和页面跳出率,得出我们在某些环节的网站不足之处。数据还可以用于采集分析竞争对手排名关键词与我们之间的差距,以便我们及时调整,做出更好的优化响应。
当然,如果你不喜欢使用工具,我们也可以自己打代码来完成这部分工作:
第一步是通过创建蜘蛛从目标中抓取内容:
为了保存数据,以 Facebook 为例,我们将定义一个收录三个字段的项目:“title”、“content”和“stars”:
importscrapy
classFacebookSentimentItem(scrapy.Item):
title=scrapy.Field()
content=scrapy.Field()
stars=scrapy.Field()
我们还创建了一个蜘蛛来填充这些项目。我们为页面提供的起始 URL。
importscrapy
来自Facebook_sentiment.itemsimportFacebookSentimentItem
类目标蜘蛛(scrapy.Spider):
name="目标"
start_urls=[域名]
然后我们定义一个函数来解析单个内容并保存其数据:
defparse_review(self,response):
item=FacebookSentimentItem()
item['title']=response.xpath('//div[@class="quote"]/text()').extract()[0][1:-1]#stripthequotes(firstandlastchar)
item['content']=response.xpath('//div[@class="entry"]/p/text()').extract()[0]
item['stars']=response.xpath('//span[@class="ratesprite-rating_srating_s"]/img/@alt').extract()[0]
退货
之后,我们定义一个函数来解析内容页面,然后传递页面。我们会注意到,在内容页面上,我们看不到整个内容,而只是开始。我们将通过单击指向完整内容的链接并使用 parse_review 从该页面抓取数据来解决此问题:
defparse_Facebook(self,response):
forhrefinresponse.xpath('//div[@class="quote"]/a/@href'):
url=response.urljoin(href.extract())
yieldscrapy.Request(url,callback=self.parse_review)
next_page=response.xpath('//div[@class="unifiedpagination"]/child::*[2][self::a]/@href')
ifnext_page:
url=response.urljoin(next_page[0].extract())
yieldscrapy.Request(url,self.parse_Facebook)
最后,我们定义主解析函数,它会从主页面开始,解析其所有内容:
defparse(self,response):
forhrefinresponse.xpath('//div[@class="listing_title"]/a/@href'):
url=response.urljoin(href.extract())
yieldscrapy.Request(url,callback=self.parse_Facebook)
next_page=response.xpath('//div[@class="unifiedpaginationstandard_pagination"]/child::*[2][self::a]/@href')
ifnext_page:
url=response.urljoin(next_page[0].extract())
yieldscrapy.Request(url,self.parse)
所以,对于内容:我们告诉蜘蛛从主页开始,点击每条内容的链接,然后抓取数据。完成每一页后,它会得到下一页,所以它可以抓取我们需要的尽可能多的内容。
可见,通过代码处理我们的数据采集不仅复杂,还需要更多的专业知识。在网站优化方面,还是要坚持最优解。数据采集的共享和处理到此结束。如有不同意见,请留言讨论。 查看全部
文章采集规则(公众号文章数据采集与处理的优化应对与应对)
公众号文章资料采集和处理无处不在。并且数量庞大。我们目前处于数据爆炸的时代,数据采集和处理一直伴随着我们。无论是网站论坛、公众号文章还是朋友圈,每天都会产生数亿条数据、文章、内容等。

通过数据采集和处理工具,我们可以采集到我们需要采集的公众号文章的数据。将其保存在本地以进行数据分析或二次创建。

数据采集及处理工具操作简单,页面简洁方便。我们只需要鼠标点击即可完成采集的配置,然后启动目标网站采集。支持采集资源标签保留(更好的保存格式)、过滤原文中敏感词(去除电话号码、地址等)、去除原图水印等

有时网页抓取还不够;通常需要更深入地挖掘和分析数据,以揭示数据背后的真正含义并发现有价值的见解。数据和内容的分析利用可以说与我们的工作生活息息相关。

以网站SEO为例,通过数据分析,我们可以统计出网站每天的流量变化和页面跳出率,得出我们在某些环节的网站不足之处。数据还可以用于采集分析竞争对手排名关键词与我们之间的差距,以便我们及时调整,做出更好的优化响应。

当然,如果你不喜欢使用工具,我们也可以自己打代码来完成这部分工作:
第一步是通过创建蜘蛛从目标中抓取内容:
为了保存数据,以 Facebook 为例,我们将定义一个收录三个字段的项目:“title”、“content”和“stars”:
importscrapy
classFacebookSentimentItem(scrapy.Item):
title=scrapy.Field()
content=scrapy.Field()
stars=scrapy.Field()

我们还创建了一个蜘蛛来填充这些项目。我们为页面提供的起始 URL。
importscrapy
来自Facebook_sentiment.itemsimportFacebookSentimentItem
类目标蜘蛛(scrapy.Spider):
name="目标"
start_urls=[域名]

然后我们定义一个函数来解析单个内容并保存其数据:
defparse_review(self,response):
item=FacebookSentimentItem()
item['title']=response.xpath('//div[@class="quote"]/text()').extract()[0][1:-1]#stripthequotes(firstandlastchar)
item['content']=response.xpath('//div[@class="entry"]/p/text()').extract()[0]
item['stars']=response.xpath('//span[@class="ratesprite-rating_srating_s"]/img/@alt').extract()[0]
退货

之后,我们定义一个函数来解析内容页面,然后传递页面。我们会注意到,在内容页面上,我们看不到整个内容,而只是开始。我们将通过单击指向完整内容的链接并使用 parse_review 从该页面抓取数据来解决此问题:
defparse_Facebook(self,response):
forhrefinresponse.xpath('//div[@class="quote"]/a/@href'):
url=response.urljoin(href.extract())
yieldscrapy.Request(url,callback=self.parse_review)
next_page=response.xpath('//div[@class="unifiedpagination"]/child::*[2][self::a]/@href')
ifnext_page:
url=response.urljoin(next_page[0].extract())
yieldscrapy.Request(url,self.parse_Facebook)

最后,我们定义主解析函数,它会从主页面开始,解析其所有内容:
defparse(self,response):
forhrefinresponse.xpath('//div[@class="listing_title"]/a/@href'):
url=response.urljoin(href.extract())
yieldscrapy.Request(url,callback=self.parse_Facebook)
next_page=response.xpath('//div[@class="unifiedpaginationstandard_pagination"]/child::*[2][self::a]/@href')
ifnext_page:
url=response.urljoin(next_page[0].extract())
yieldscrapy.Request(url,self.parse)
所以,对于内容:我们告诉蜘蛛从主页开始,点击每条内容的链接,然后抓取数据。完成每一页后,它会得到下一页,所以它可以抓取我们需要的尽可能多的内容。

可见,通过代码处理我们的数据采集不仅复杂,还需要更多的专业知识。在网站优化方面,还是要坚持最优解。数据采集的共享和处理到此结束。如有不同意见,请留言讨论。
文章采集规则(为什么要采集公众号的文章?免费!效果如何一试!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-31 18:09
首先,为什么要采集公众号的文章?
想必大家在生活中也经常关注公众号,所以公众号的内容丰富多彩。作为曾经是公众号的运营商,文章公众号的质量无论如何都特别优质。素材、文章整体框架、文章内容均精准垂直,公众号原创大于80%。大多数作家都有自己的经验和技能。
如何采集公众号文章?
对于不懂代码的小白来说,采集公众号的文章最简单的方法是复制粘贴,使用其他采集工具,编辑规则,所以对于小白来说很不友好,有没有傻瓜式的采集软件?直接进入关键词采集公众号文章。
所以这次我要介绍的是傻瓜式采集软件,你只需要输入关键词就可以实现采集。方便快捷。
公众号采集流程
1、输入关键词(例如:装修),可以采集到今日头条、公众号文章、百度网页、百度新闻、搜狗网页、搜狗新闻、批量< @关键词全自动采集。
2、智能采集 无需编写复杂规则。
3、采集优质内容
4、最简单最聪明的文章采集器,关键是它是免费的!自由!自由!试一试,看看它是如何工作的!
5、文章采集器不用写规则,大家都可以用采集软件
现在大家都知道“内容为王”。为了优化网站,大家疯狂写文章,但是每天的输出量却很少。一些优化器认为 原创文章 不是那么重要。为了使网站的文章更新频率快,将采用文章采集的方法。很多人的采集 内容太垃圾了。搜索引擎能识别出质量太差,文章的权重比例自然无法提高,也会面临各种处罚。所以采集来源很重要!! 查看全部
文章采集规则(为什么要采集公众号的文章?免费!效果如何一试!)
首先,为什么要采集公众号的文章?
想必大家在生活中也经常关注公众号,所以公众号的内容丰富多彩。作为曾经是公众号的运营商,文章公众号的质量无论如何都特别优质。素材、文章整体框架、文章内容均精准垂直,公众号原创大于80%。大多数作家都有自己的经验和技能。
如何采集公众号文章?
对于不懂代码的小白来说,采集公众号的文章最简单的方法是复制粘贴,使用其他采集工具,编辑规则,所以对于小白来说很不友好,有没有傻瓜式的采集软件?直接进入关键词采集公众号文章。
所以这次我要介绍的是傻瓜式采集软件,你只需要输入关键词就可以实现采集。方便快捷。
公众号采集流程
1、输入关键词(例如:装修),可以采集到今日头条、公众号文章、百度网页、百度新闻、搜狗网页、搜狗新闻、批量< @关键词全自动采集。
2、智能采集 无需编写复杂规则。
3、采集优质内容
4、最简单最聪明的文章采集器,关键是它是免费的!自由!自由!试一试,看看它是如何工作的!
5、文章采集器不用写规则,大家都可以用采集软件
现在大家都知道“内容为王”。为了优化网站,大家疯狂写文章,但是每天的输出量却很少。一些优化器认为 原创文章 不是那么重要。为了使网站的文章更新频率快,将采用文章采集的方法。很多人的采集 内容太垃圾了。搜索引擎能识别出质量太差,文章的权重比例自然无法提高,也会面临各种处罚。所以采集来源很重要!!
文章采集规则(一个批量采集知乎文章的方法有哪些?聚沙计划第二节)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-03-30 16:06
在互联网上创造内容就是创造流量,但是我们很多人知识储备非常有限,写不出更好的文章,很多人认为原创文章很费力,所以不要长时间强迫自己。
此时我们只需要做两件事。
采集——改编……
当今互联网上拥有更多优质内容的几个平台是知乎、公众号和头条。
尤其是知乎文章上有很多高质量的答案。这时候如果我们想把其中的一些文章整理出来,一一复制,那就太费力了。
所以,在巨鲨项目的第二部分,我会告诉你一个采集知乎文章的批处理方法。按照这个方法,可以采集组织知乎大量高质量的文章。
这些文章无论是发布流量还是适配网站,效果都很好。
当你把很多优质内容组织起来,改编和内化,这些文章就属于你的知识了,以后就是你的流量子弹。
网盘里有详细的视频教程以及采集工具和采集规则,可以直接手动使用,跟着教程走。在后续的项目教程中,可以使用这些工具的知识。有兴趣的直接去会员网站下载观看吧!
付费隐藏内容
这里的内容需要权限才能查看
观看价格:¥398 / 永久VIP会员免费
付费查看免费打开VIP视图
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。
知乎采集教程采集规则 查看全部
文章采集规则(一个批量采集知乎文章的方法有哪些?聚沙计划第二节)
在互联网上创造内容就是创造流量,但是我们很多人知识储备非常有限,写不出更好的文章,很多人认为原创文章很费力,所以不要长时间强迫自己。
此时我们只需要做两件事。
采集——改编……

当今互联网上拥有更多优质内容的几个平台是知乎、公众号和头条。
尤其是知乎文章上有很多高质量的答案。这时候如果我们想把其中的一些文章整理出来,一一复制,那就太费力了。
所以,在巨鲨项目的第二部分,我会告诉你一个采集知乎文章的批处理方法。按照这个方法,可以采集组织知乎大量高质量的文章。
这些文章无论是发布流量还是适配网站,效果都很好。
当你把很多优质内容组织起来,改编和内化,这些文章就属于你的知识了,以后就是你的流量子弹。
网盘里有详细的视频教程以及采集工具和采集规则,可以直接手动使用,跟着教程走。在后续的项目教程中,可以使用这些工具的知识。有兴趣的直接去会员网站下载观看吧!
付费隐藏内容
这里的内容需要权限才能查看
观看价格:¥398 / 永久VIP会员免费
付费查看免费打开VIP视图
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。
知乎采集教程采集规则
文章采集规则(买卖易资源网-狂雨小说CMS安装搭建常见问题汇总采集导入方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 564 次浏览 • 2022-03-29 22:00
你好!大家好,这里是资源买卖网站。
今天,TradingEasy 教你如何制作小说网——狂雨小说。
小说下载地址:
施工注意事项:
雨天小说cms安装施工常见问题汇总
采集导入方法,狂鱼小说的采集规则本身并没有导入这个函数,我们只能在mysql中操作。很简单,直接上教程。
1.大部分朋友使用的宝塔面板,以宝塔为例,先进入mysql界面。
2.单击 网站 的数据库 - 单击 SQL
3.复制下载的采集规则——点击执行
4.打开狂雨小说cms背景-资料采集-采集管理-点击采集
5.渲染()
资源下载 本资源下载价格为1易币即买,VIP即刻免费升级
如果下载地址无效,请联系客服。
本资源为虚拟重现,下载后不退不换,感谢您的支持!
我们以专业级共享为基础,实力雄厚。我们欢迎从未离开的朋友。你的出现,会让我更加强大!我们将继续为您提供更好的资源!相信我们,您不会失望的!
下载
下载价格 1 Easy Coin
VIP免费升级VIP
立即购买
如果下载地址无效,请联系客服。
本资源为虚拟重现,下载后不退不换,感谢您的支持!
我们以专业级共享为基础,实力雄厚。我们欢迎从未离开的朋友。你的出现,会让我更加强大!我们将继续为您提供更好的资源!相信我们,您不会失望的! 查看全部
文章采集规则(买卖易资源网-狂雨小说CMS安装搭建常见问题汇总采集导入方法)
你好!大家好,这里是资源买卖网站。
今天,TradingEasy 教你如何制作小说网——狂雨小说。
小说下载地址:
施工注意事项:
雨天小说cms安装施工常见问题汇总
采集导入方法,狂鱼小说的采集规则本身并没有导入这个函数,我们只能在mysql中操作。很简单,直接上教程。
1.大部分朋友使用的宝塔面板,以宝塔为例,先进入mysql界面。
2.单击 网站 的数据库 - 单击 SQL
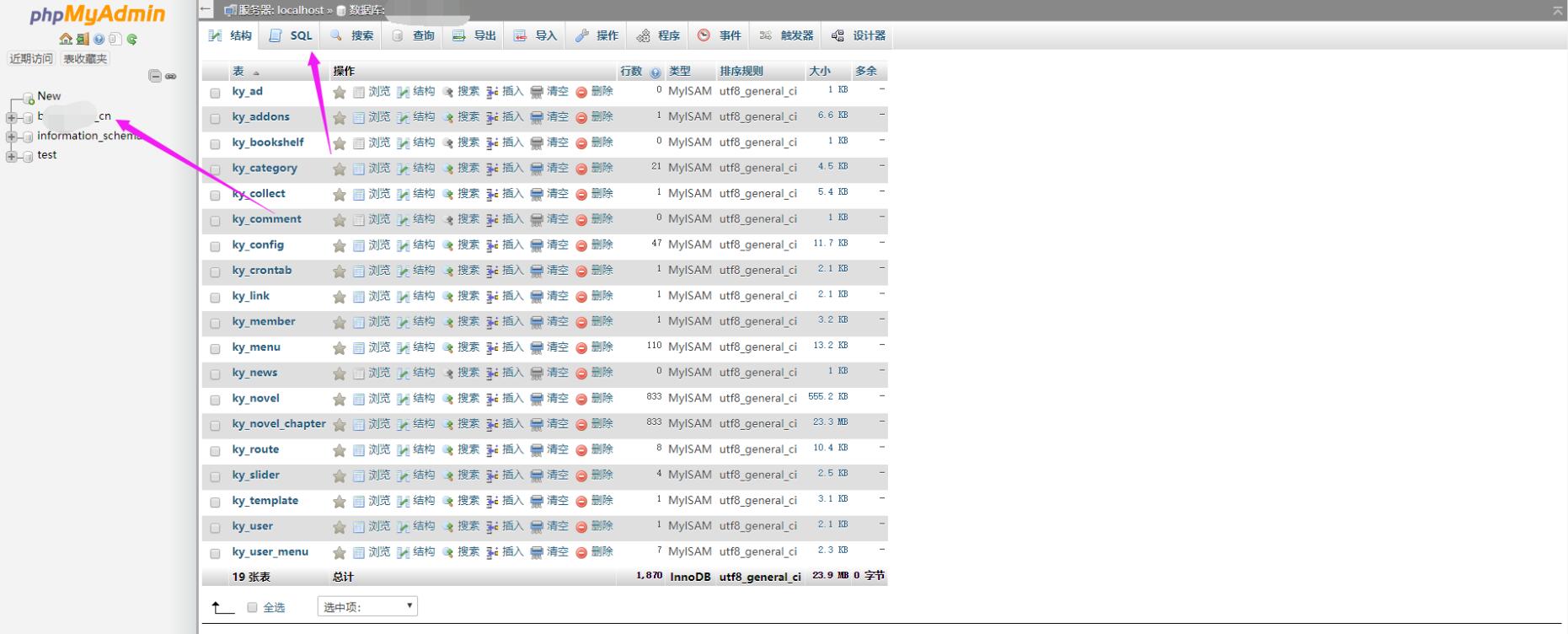
3.复制下载的采集规则——点击执行
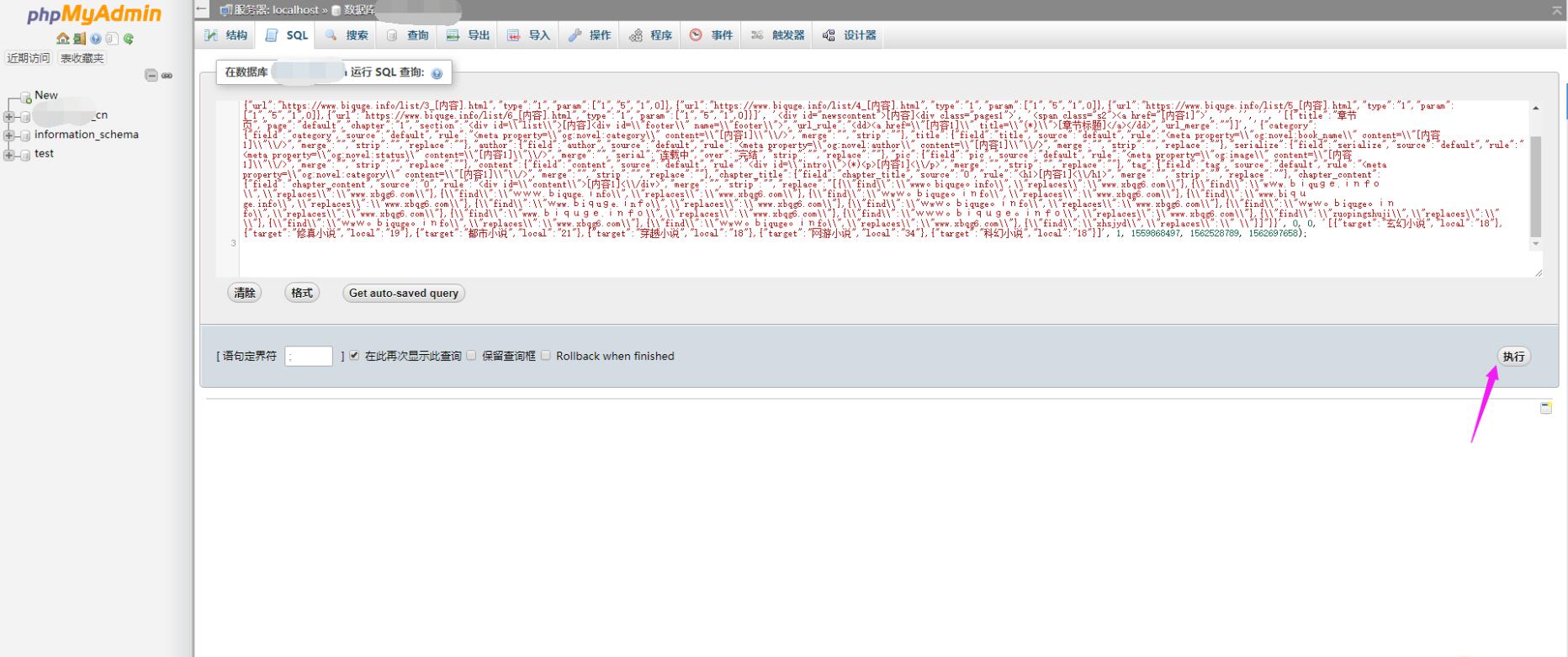
4.打开狂雨小说cms背景-资料采集-采集管理-点击采集
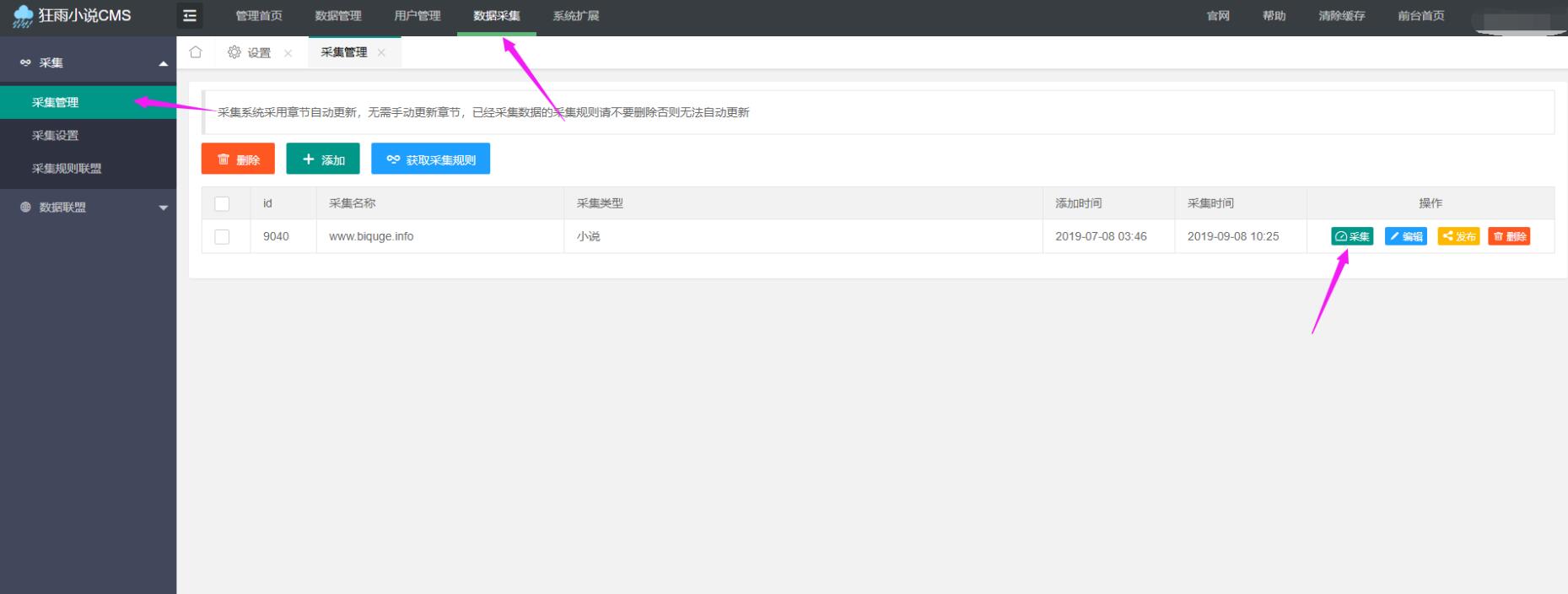
5.渲染()
资源下载 本资源下载价格为1易币即买,VIP即刻免费升级
如果下载地址无效,请联系客服。
本资源为虚拟重现,下载后不退不换,感谢您的支持!
我们以专业级共享为基础,实力雄厚。我们欢迎从未离开的朋友。你的出现,会让我更加强大!我们将继续为您提供更好的资源!相信我们,您不会失望的!
下载
下载价格 1 Easy Coin
VIP免费升级VIP
立即购买
如果下载地址无效,请联系客服。
本资源为虚拟重现,下载后不退不换,感谢您的支持!
我们以专业级共享为基础,实力雄厚。我们欢迎从未离开的朋友。你的出现,会让我更加强大!我们将继续为您提供更好的资源!相信我们,您不会失望的!
文章采集规则(小旋风蜘蛛池如何采集句子及文章添加规则的全套教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2022-03-28 00:01
本文是小旋风蜘蛛池编写后台采集规则的一套完整教程。如果您可以使用 优采云采集器 或 优采云采集器,请跳过本教程。简单易用。
本文仅以X6版小旋风蜘蛛池为例。有任何问题可以在文末留言。
一、小旋风蜘蛛池怎么弄采集标题
题库采集还是很简单的,只需要设置源采集的地址即可。
首先添加 采集 规则,选择 文章 标题。
分页书写:
标记
http://roll.news.sina.com.cn/n ... ndex_{p,1,9,1}.shtml
{p,1,5,1}表示分页,参数:p后面的数字代表开始、结束、递增/递减值,即{p,start,end,递增/递减值}
标记
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
测试规则时可以从 URL 匹配中看到。添加后,测试看看效果:
二、小旋风蜘蛛池怎么样采集句子和文章
添加规则:选择整个内容或句子段落
比如我们要采集新浪新闻,地址是:,只需在列表配置选项的匹配URL中填写上述地址即可。
打开 采集 来源的地址并选择一条新闻。复制其链接地址。
这是地址:
那么,内容匹配规则可以这样写
标记
https://news.sina.com.cn/(w)/(d)-(d)-(d)/(w)-(w).shtml
内容拦截规则:
打开内容地址。右键查看源代码,找到内容区。
那么内容拦截规则可以这样写:
对于像新浪这样的大型网站,它的内容页面有些不同,我们可以写更多的匹配。
保存后,看看效果。
注意:您的 采集 句子和 文章 将自动 采集 链接到图片,所以不用担心您的内容库中没有图片!
本文由网友投稿或由“牛牛源码网”整理自互联网。如需转载,请注明出处:
如果本站发布的内容侵犯了您的权益,请联系zhangqy2022#删除,我们会及时处理! 查看全部
文章采集规则(小旋风蜘蛛池如何采集句子及文章添加规则的全套教程)
本文是小旋风蜘蛛池编写后台采集规则的一套完整教程。如果您可以使用 优采云采集器 或 优采云采集器,请跳过本教程。简单易用。
本文仅以X6版小旋风蜘蛛池为例。有任何问题可以在文末留言。
一、小旋风蜘蛛池怎么弄采集标题
题库采集还是很简单的,只需要设置源采集的地址即可。
首先添加 采集 规则,选择 文章 标题。

分页书写:
标记
http://roll.news.sina.com.cn/n ... ndex_{p,1,9,1}.shtml
{p,1,5,1}表示分页,参数:p后面的数字代表开始、结束、递增/递减值,即{p,start,end,递增/递减值}
标记
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
测试规则时可以从 URL 匹配中看到。添加后,测试看看效果:

二、小旋风蜘蛛池怎么样采集句子和文章
添加规则:选择整个内容或句子段落
比如我们要采集新浪新闻,地址是:,只需在列表配置选项的匹配URL中填写上述地址即可。

打开 采集 来源的地址并选择一条新闻。复制其链接地址。

这是地址:
那么,内容匹配规则可以这样写
标记
https://news.sina.com.cn/(w)/(d)-(d)-(d)/(w)-(w).shtml
内容拦截规则:
打开内容地址。右键查看源代码,找到内容区。

那么内容拦截规则可以这样写:

对于像新浪这样的大型网站,它的内容页面有些不同,我们可以写更多的匹配。
保存后,看看效果。

注意:您的 采集 句子和 文章 将自动 采集 链接到图片,所以不用担心您的内容库中没有图片!
本文由网友投稿或由“牛牛源码网”整理自互联网。如需转载,请注明出处:
如果本站发布的内容侵犯了您的权益,请联系zhangqy2022#删除,我们会及时处理!
文章采集规则( 147SEO2022-03-22文章采集软件,主要功能就是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-03-26 13:01
147SEO2022-03-22文章采集软件,主要功能就是)
文章采集软件,免费文章采集,文章自动采集
147SEO2022-03-22
文章采集软件,它的主要功能是帮助站长采集网站的文章资源在网上发布,然后发布到指定的cms ,获得点击,站长可以自定义采集对象,自由设置采集规则,采集效率也很稳定。文章采集网站站长软件可以自动采集目标站点的文字,提供相似词替换功能,还支持站长自定义关键词@ >替换,有效提升文章伪原创度,让采集的内容质量更高。
文章采集软件不断更新网站的内容,主要反映网站不断发展和完善的基本情况。无论网站面对的是搜索引擎还是用户群,总是需要不断创造或容纳更多的内容,不断扩大网站的体量,才能让网站接收到更多注意力。其中,网站文章更新频率高,但收录量少,成为站长的一大痛点,因为在一定概率下,很多网站有“准死亡”是什么意思?表示网站no收录,快照没有更新,但是网站一直保持更新频率,但是收录 速度慢,没有排名,这种现象一般来说站长都会更换三大标签,更换网站模板。如果没有效果,他们只能放弃。
对于网站,文章采集软件保持一定的文章更新频率,主要体现在增强蜘蛛的活跃度,其作用是促进网站收录,加快网站参与排名的步伐。排名就像一个战场,如果你落后,你就会被打败。而一个更新频率稳定、质量高的文章、良好的布局网站、标准的设置关键词@>的网站对SEO优化有着深远的影响。毕竟对于SEO来说,关键词@>@文章采集软件推广网站主要体现在思维和排名上。当一个站点保持一定的更新频率时,网站或网站的收录情况开始,
文章采集软件页面优化是确保网站上的实际代码和内容得到优化的过程。这包括确保网站管理员的网站具有正确的标题标签、描述标签和独特的内容。正确构造数据以使其易于被搜索引擎读取也很重要。站外优化是建立指向网站的外部链接的过程。最好的办法是让文章采集软件在站长的网站的相关页面上找到实际链接,这是真实的内容,有合适的实际链接到与行业相关的 网站 并在所有主要社交媒体 网站 和目录中列出。
文章采集虽然软件是其他网站的采集或者伪原创文章,但是它是被选中并有效推送的,而不是单纯的采集。文章采集虽然软件是采集,但文章的质量可以让用户满意,归根结底还是擅长采集。
文章采集软件通过自然的方法排名网站并不难,主要是SEO需要花更多的精力充实自己和网站,发送文章@ > 当然可行,主要看你发帖的方式和内容。文章采集软件网站优化,主要是克服网站前期的总困难,大幅提升网站的整体和谐度,长路不恒优化的修复,当然不代表不修复,只是不适合前期不断变化。 查看全部
文章采集规则(
147SEO2022-03-22文章采集软件,主要功能就是)
文章采集软件,免费文章采集,文章自动采集
147SEO2022-03-22
文章采集软件,它的主要功能是帮助站长采集网站的文章资源在网上发布,然后发布到指定的cms ,获得点击,站长可以自定义采集对象,自由设置采集规则,采集效率也很稳定。文章采集网站站长软件可以自动采集目标站点的文字,提供相似词替换功能,还支持站长自定义关键词@ >替换,有效提升文章伪原创度,让采集的内容质量更高。
文章采集软件不断更新网站的内容,主要反映网站不断发展和完善的基本情况。无论网站面对的是搜索引擎还是用户群,总是需要不断创造或容纳更多的内容,不断扩大网站的体量,才能让网站接收到更多注意力。其中,网站文章更新频率高,但收录量少,成为站长的一大痛点,因为在一定概率下,很多网站有“准死亡”是什么意思?表示网站no收录,快照没有更新,但是网站一直保持更新频率,但是收录 速度慢,没有排名,这种现象一般来说站长都会更换三大标签,更换网站模板。如果没有效果,他们只能放弃。
对于网站,文章采集软件保持一定的文章更新频率,主要体现在增强蜘蛛的活跃度,其作用是促进网站收录,加快网站参与排名的步伐。排名就像一个战场,如果你落后,你就会被打败。而一个更新频率稳定、质量高的文章、良好的布局网站、标准的设置关键词@>的网站对SEO优化有着深远的影响。毕竟对于SEO来说,关键词@>@文章采集软件推广网站主要体现在思维和排名上。当一个站点保持一定的更新频率时,网站或网站的收录情况开始,
文章采集软件页面优化是确保网站上的实际代码和内容得到优化的过程。这包括确保网站管理员的网站具有正确的标题标签、描述标签和独特的内容。正确构造数据以使其易于被搜索引擎读取也很重要。站外优化是建立指向网站的外部链接的过程。最好的办法是让文章采集软件在站长的网站的相关页面上找到实际链接,这是真实的内容,有合适的实际链接到与行业相关的 网站 并在所有主要社交媒体 网站 和目录中列出。
文章采集虽然软件是其他网站的采集或者伪原创文章,但是它是被选中并有效推送的,而不是单纯的采集。文章采集虽然软件是采集,但文章的质量可以让用户满意,归根结底还是擅长采集。
文章采集软件通过自然的方法排名网站并不难,主要是SEO需要花更多的精力充实自己和网站,发送文章@ > 当然可行,主要看你发帖的方式和内容。文章采集软件网站优化,主要是克服网站前期的总困难,大幅提升网站的整体和谐度,长路不恒优化的修复,当然不代表不修复,只是不适合前期不断变化。
文章采集规则( 文章类的采集,图片集的另外找个时间来讲,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2022-03-24 01:09
文章类的采集,图片集的另外找个时间来讲,)
dedecms织梦采集规则编写教程文章课堂采集
游戏/数字网络 2017-07-28 22 浏览
织梦系统作为常用的文章系统,操作起来比较简单。在众多功能中,采集系统可能会让一些新手头疼。例如,采集 区域设置不正确。 采集 规则编辑不正确。 采集 为空白。今天我们将详细解释一些比较容易遇到的问题。 (今天主要讲文章类的采集,其他时候图片集会不一样。) 工具/材料自己的网站目标的网站@ > 方法/步骤首先我们登录后台,分别点击采集--采集节点管理,进入采集管理设置界面。这里有两种选择,一种是修改原节点(主要是之前的设置错误导致采集cannot or
织梦系统作为常用的文章系统,操作起来比较简单。在众多功能中,采集系统可能会让一些新手头疼,比如采集区域设置不正确,采集规则编辑不正确,采集空白等问题。今天我们将详细解释一些比较容易遇到的问题。 (今天主要讲文章类的采集,我会另找时间采集图片的,这个不一样)
工具/成分
方法/步骤
首先我们登录后台,点击采集--采集节点管理,进入采集管理设置界面
这里有两个选项,一个是修改原节点(主要是之前的设置错误导致采集失败或者其他设置),另一个是直接添加新节点,大部分主要是新建节点,点击,然后下一步,选择“Normal文章”确认。
然后填写节点名称(推荐为与列相关的名称,避免导入时出错),这个可以根据实际填写。那么第一点:目标页面编码。这是填写目标页面的代码,不是你自己的页面。查看方法:打开目标网站任意页面,在空白处右键-查看源代码(编码一般在前几行)
然后就是填写列表规则。一种是批量生成url,一般适用于规则性强或者需要采集自上而下的情况。例如,我们定位到此列:
首页列表:
第二页列表:.
这个列表规则最重要的就是找到相同点和不同点,把相同的点填上,不同的点用匹配的符号补充,也就是变量。其实通过这个对比我们可以知道,这里的.html也是一样的,所以变量是1.2.3.4.。 所以匹配的网址是:
(*).html.
另一种是列表规则是手动指定列表URL,比较流行。只需填写您需要的所有列表页面采集。 (只适用于采集某些页面或变量较多的页面)
注意:许多网站 栏目主页都以这种形式显示。与上述相比,我们发现缺少以下变量项。所以查找变量项的方法是:点击列表的下一页,如果还是不清楚再点击下一页,对比列表的第二页和第三页,我们也可以找到变量第 4 步中的项目。
这一步是获取列表下文章的所有地址,我们要从列表页面中获取所有文章页面地址。我们以:List 为例。复制列表中第一篇文章文章的标题,然后在列表页空白处右键--查看源码,按ctrl+F搜索,粘贴刚才复制的标题,找到在文本源代码中的位置。事实上,这是一定的规律。然后我们寻找源代码的哪一部分是唯一的,并且可以收录列表中所有的文章地址(注意:开始代码搜索应该从列表中第一个文章的标题开始,然后去向上,并结束代码搜索您应该从列表中第一篇文章的标题开始向下看文章)。从这个源代码可以看出。开始代码: 查看全部
文章采集规则(
文章类的采集,图片集的另外找个时间来讲,)
dedecms织梦采集规则编写教程文章课堂采集
游戏/数字网络 2017-07-28 22 浏览
织梦系统作为常用的文章系统,操作起来比较简单。在众多功能中,采集系统可能会让一些新手头疼。例如,采集 区域设置不正确。 采集 规则编辑不正确。 采集 为空白。今天我们将详细解释一些比较容易遇到的问题。 (今天主要讲文章类的采集,其他时候图片集会不一样。) 工具/材料自己的网站目标的网站@ > 方法/步骤首先我们登录后台,分别点击采集--采集节点管理,进入采集管理设置界面。这里有两种选择,一种是修改原节点(主要是之前的设置错误导致采集cannot or
织梦系统作为常用的文章系统,操作起来比较简单。在众多功能中,采集系统可能会让一些新手头疼,比如采集区域设置不正确,采集规则编辑不正确,采集空白等问题。今天我们将详细解释一些比较容易遇到的问题。 (今天主要讲文章类的采集,我会另找时间采集图片的,这个不一样)
工具/成分
方法/步骤
首先我们登录后台,点击采集--采集节点管理,进入采集管理设置界面

这里有两个选项,一个是修改原节点(主要是之前的设置错误导致采集失败或者其他设置),另一个是直接添加新节点,大部分主要是新建节点,点击,然后下一步,选择“Normal文章”确认。

然后填写节点名称(推荐为与列相关的名称,避免导入时出错),这个可以根据实际填写。那么第一点:目标页面编码。这是填写目标页面的代码,不是你自己的页面。查看方法:打开目标网站任意页面,在空白处右键-查看源代码(编码一般在前几行)

然后就是填写列表规则。一种是批量生成url,一般适用于规则性强或者需要采集自上而下的情况。例如,我们定位到此列:
首页列表:
第二页列表:.
这个列表规则最重要的就是找到相同点和不同点,把相同的点填上,不同的点用匹配的符号补充,也就是变量。其实通过这个对比我们可以知道,这里的.html也是一样的,所以变量是1.2.3.4.。 所以匹配的网址是:
(*).html.

另一种是列表规则是手动指定列表URL,比较流行。只需填写您需要的所有列表页面采集。 (只适用于采集某些页面或变量较多的页面)
注意:许多网站 栏目主页都以这种形式显示。与上述相比,我们发现缺少以下变量项。所以查找变量项的方法是:点击列表的下一页,如果还是不清楚再点击下一页,对比列表的第二页和第三页,我们也可以找到变量第 4 步中的项目。

这一步是获取列表下文章的所有地址,我们要从列表页面中获取所有文章页面地址。我们以:List 为例。复制列表中第一篇文章文章的标题,然后在列表页空白处右键--查看源码,按ctrl+F搜索,粘贴刚才复制的标题,找到在文本源代码中的位置。事实上,这是一定的规律。然后我们寻找源代码的哪一部分是唯一的,并且可以收录列表中所有的文章地址(注意:开始代码搜索应该从列表中第一个文章的标题开始,然后去向上,并结束代码搜索您应该从列表中第一篇文章的标题开始向下看文章)。从这个源代码可以看出。开始代码:
文章采集规则(网站优化是对用户的优化和内容可读性优化的重要性)
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2022-03-23 03:20
SEO是一项庞大而复杂的任务,称他为系统一点也不为过。SEO 过程已经从 网站 规划开始。无论是网站优化、流程优化还是维护优化,每一个环节都是相关的。网站SEO 的质量。
SEO是一项长期无聊的工作。SEOER除了保持对SEO的热情外,还需要学习SEO知识,掌握一些SEO技巧。通过SEO软件辅助我们完成工作是每个SEOER都需要掌握的能力,如图,对于一些重复性高的工作,我们可以用SEO软件来代替。
SEO软件有全网采集,在线翻译和本地伪原创,支持各种cms全平台发布,SEO软件有各种优化功能,无论是原创度或来自 关键词 密度,可配置。SEO软件支持全可视化操作,无需了解配置规则即可完成点击配置。(如图)
SEO的基本思想是通过对网站的功能、结构、布局、内容等关键环节的优化元素进行合理设计,使网站的功能和表达达到良好的效果。基本上包括三个方面:网站结构优化、SEO优化、内容可读性优化。
第一的。网站结构优化
通过网站基本要素的结构优化,真正实现SEO的综合效果。最大化结果不仅仅是获取单个关键词的搜索排名,还要处理页面中的大量问题。相关的关键词可以取得不错的搜索排名。用户搜索行为非常碎片化和庞大,有的用户搜索多个关键词组合,所以仅仅排名几个关键词是不够的,以获得良好的网站推广效果。优化网站的结构可以成为网站的搜索引擎,为网站后期运营推广过程中的优化奠定基础,获得更大的效益。
二、SEO优化部分
SEO专注于网站构建的基本要素的专业设计,使其适合用户获取信息和搜索引擎检索信息。网站优化是对用户的优化,也是对搜索引擎的优化。网站优化是一项系统的、整体的工作,以网络营销为导向,以网站建设理念为指导,对网站的基本要素进行设计,使网站更好的实现向用户传递在线营销信息的目的。
三、内容可读性优化
它不仅可以考虑搜索引擎的排名规则,还可以为用户获取信息和服务提供便利。提高网站内容的可读性是网站优化的一个重要原则。这也是搜索引擎优化。网站优化是一个以网络营销为导向的建设理念网站。网站基础元素的专业设计,是一项系统性、综合性的工作,旨在把网站做得更好更好。不仅要考虑搜索引擎的排名规则,还要为用户获取信息和服务。提供方便和提高网站内容的可读性是网站优化的重要规则。
1、图文结合的单页优化,可以提升网站的浏览体验,增加访问用户的停留时间,让文章的内容更加生动. 但是不代表我们的单页会添加很多图片,因为很多图片会占用网站的流量,拖慢我们页面的打开速度。一般来说,不能打开超过 8 秒的页面,难免会被访问用户关闭。
2.内容更新的单页优化需要一个稳定的周期来更新内容。我们推荐的方法是在每天的固定时间向这个单一页面添加一些内容。需要注意的是,文章的TDK一定不能修改。最好不要轻易修改文章前面的内容,以后继续添加内容就好。
3.网站优化,内外链接。为我们的单页做相关的内外部链接,可以让我们的单页排名更快。例如,如果你被介绍给某人,你肯定会很快成名。因此,在选择外部链接的时候,可以选择一些权重比较好的链接。
网站SEO 是一项需要坚持的工作。通过SEO软件,我们可以减轻部分工作强度,但是如前所述,SEO远不是软件所能涵盖的,只有我们不断学习和改进,在细节上不断优化,才能更好地完成工作搜索引擎优化。返回搜狐,查看更多 查看全部
文章采集规则(网站优化是对用户的优化和内容可读性优化的重要性)
SEO是一项庞大而复杂的任务,称他为系统一点也不为过。SEO 过程已经从 网站 规划开始。无论是网站优化、流程优化还是维护优化,每一个环节都是相关的。网站SEO 的质量。

SEO是一项长期无聊的工作。SEOER除了保持对SEO的热情外,还需要学习SEO知识,掌握一些SEO技巧。通过SEO软件辅助我们完成工作是每个SEOER都需要掌握的能力,如图,对于一些重复性高的工作,我们可以用SEO软件来代替。
SEO软件有全网采集,在线翻译和本地伪原创,支持各种cms全平台发布,SEO软件有各种优化功能,无论是原创度或来自 关键词 密度,可配置。SEO软件支持全可视化操作,无需了解配置规则即可完成点击配置。(如图)
SEO的基本思想是通过对网站的功能、结构、布局、内容等关键环节的优化元素进行合理设计,使网站的功能和表达达到良好的效果。基本上包括三个方面:网站结构优化、SEO优化、内容可读性优化。

第一的。网站结构优化
通过网站基本要素的结构优化,真正实现SEO的综合效果。最大化结果不仅仅是获取单个关键词的搜索排名,还要处理页面中的大量问题。相关的关键词可以取得不错的搜索排名。用户搜索行为非常碎片化和庞大,有的用户搜索多个关键词组合,所以仅仅排名几个关键词是不够的,以获得良好的网站推广效果。优化网站的结构可以成为网站的搜索引擎,为网站后期运营推广过程中的优化奠定基础,获得更大的效益。
二、SEO优化部分
SEO专注于网站构建的基本要素的专业设计,使其适合用户获取信息和搜索引擎检索信息。网站优化是对用户的优化,也是对搜索引擎的优化。网站优化是一项系统的、整体的工作,以网络营销为导向,以网站建设理念为指导,对网站的基本要素进行设计,使网站更好的实现向用户传递在线营销信息的目的。
三、内容可读性优化
它不仅可以考虑搜索引擎的排名规则,还可以为用户获取信息和服务提供便利。提高网站内容的可读性是网站优化的一个重要原则。这也是搜索引擎优化。网站优化是一个以网络营销为导向的建设理念网站。网站基础元素的专业设计,是一项系统性、综合性的工作,旨在把网站做得更好更好。不仅要考虑搜索引擎的排名规则,还要为用户获取信息和服务。提供方便和提高网站内容的可读性是网站优化的重要规则。
1、图文结合的单页优化,可以提升网站的浏览体验,增加访问用户的停留时间,让文章的内容更加生动. 但是不代表我们的单页会添加很多图片,因为很多图片会占用网站的流量,拖慢我们页面的打开速度。一般来说,不能打开超过 8 秒的页面,难免会被访问用户关闭。
2.内容更新的单页优化需要一个稳定的周期来更新内容。我们推荐的方法是在每天的固定时间向这个单一页面添加一些内容。需要注意的是,文章的TDK一定不能修改。最好不要轻易修改文章前面的内容,以后继续添加内容就好。
3.网站优化,内外链接。为我们的单页做相关的内外部链接,可以让我们的单页排名更快。例如,如果你被介绍给某人,你肯定会很快成名。因此,在选择外部链接的时候,可以选择一些权重比较好的链接。
网站SEO 是一项需要坚持的工作。通过SEO软件,我们可以减轻部分工作强度,但是如前所述,SEO远不是软件所能涵盖的,只有我们不断学习和改进,在细节上不断优化,才能更好地完成工作搜索引擎优化。返回搜狐,查看更多
文章采集规则(集搜客GooSeeker爬虫术语“主题”统一改为“任务” )
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2022-03-21 09:09
)
注意:从Jisouke GooSeeker爬虫V9.0.2版本开始,爬虫术语“主题”已更改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则。然后登录Jisoke官网会员中心的“任务管理”,可以查看采集任务的执行情况,管理线索的URL,进行调度设置。
一、操作步骤
今天教大家如何抓取搜狐新闻文章,重点是如何抓取全文内容,如何批量抓取更多新闻。方法通用,可以应用到其他新闻网站整体操作步骤如下:
二、案例+操作步骤
第一步,打开网页
1.1、打开Jisouke软件,输入网址回车,等待页面加载完毕,然后点击右上角的“定义规则”按钮,可以看到一个浮动窗口显示出来,这是一个工作台,下面定义的规则会在上面输出。
1.2,在工作台上输入主题名称,然后点击检查重复项。如果提示被占用,请更改名称以确保主题名称是唯一的。
第二步:标签信息
2.1、在浏览器窗口中用鼠标点击你要抓取的内容,这里是选中的新闻标题,然后你会看到整个标题变成了黄底红框闪烁框出这个范围,根据黄色范围检查是否有正确的信息。如果没有问题,再次点击弹出标签窗口。输入标签名称后,点击打勾保存或按回车键保存。需要输入规则中的第一个标签。整理出框的名称,确认后可以在右上角的工作台中看到输出数据结构;
2.2、按照前面的操作,也在网页上标注作者和发布时间;
2.3、下一步是标记文本。如果单击文本的某个段落,则只会选择该段落的范围。如果要抓取所有文本,则需要单击文本的部分。在空白处,你会看到文字全部被选中,再次点击进行标注映射;
PS:如果是其他网页,不需要点击空白处全选,可以点击其他位置,直到选中你想要的内容范围;
2.4、如果不能点击整个范围可以选择的位置,可以点击目标信息的一部分,底部的dom窗口会定位到对应的网页节点到该信息,然后点击收录该信息的节点 的每个上层节点,直到可以看到网页上所有范围都被选中;
2.5、然后右击节点,在快捷菜单中选择Content Mapping -> New Grab Content -> 输入标签名,此操作结果与上一步相同2.3 ;
第三步,保存规则,抓取数据
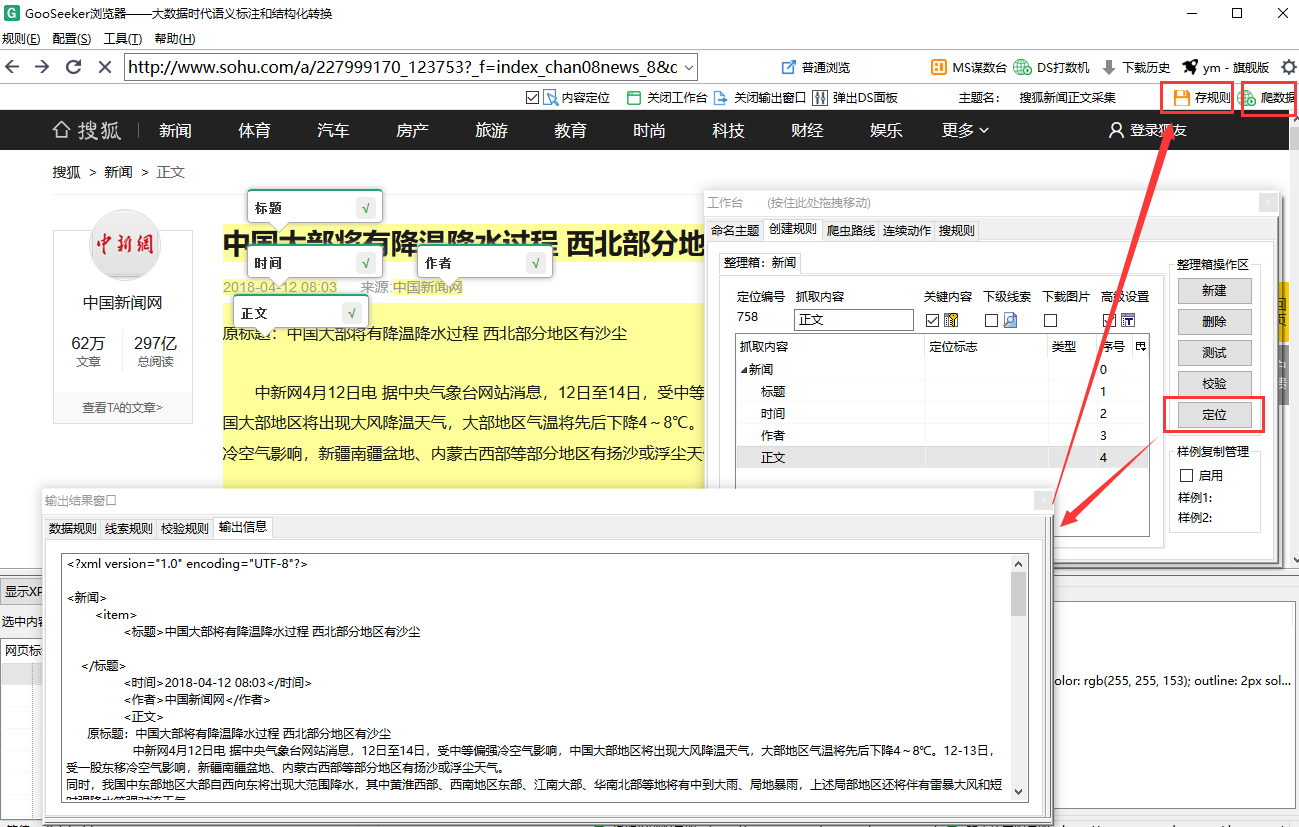
3.1、点击右侧测试按钮预览输出信息是否完整,如果没有问题点击右上角的保存按钮,然后点击“抓取数据”,将弹出一个 DS 计数器窗口,并开始捕获获取数据;
3.2、之前只抓到了一个网页新闻,很多人会问如何获取更多的新闻?很简单,只要网页结构和示例页面一样,就可以用这条规则来爬取信息。因此,我们可以将与该页面结构相同的其他搜狐新闻网站整理出来,然后添加到规则中。操作在柜台上右键规则,点击“Manage Leads”然后选择“Add”,将URL复制进去保存,然后点击规则旁边的“Single Search”,启动采集逐个。另外,还可以使用分层采集的方法来实现URL的自动导入。有关详细信息,请参阅“使用层次结构的 URL采集”。
第四步,转换成Excel表格
4.1,采集成功的数据会以xml文件的形式保存在电脑的DataScraperWorks文件夹中。点击左上角的文件菜单->存储路径找到文件夹的位置。
4.2、然后我们可以将采集中的xml文件压缩成一个zip压缩包,进入会员中心的规则管理,选择对应的规则,然后点击导入数据,选择压缩将一个好的 zip 存档导入其中。导入成功后,点击导出数据,即可下载下载的Excel文件。
查看全部
文章采集规则(集搜客GooSeeker爬虫术语“主题”统一改为“任务”
)
注意:从Jisouke GooSeeker爬虫V9.0.2版本开始,爬虫术语“主题”已更改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则。然后登录Jisoke官网会员中心的“任务管理”,可以查看采集任务的执行情况,管理线索的URL,进行调度设置。
一、操作步骤
今天教大家如何抓取搜狐新闻文章,重点是如何抓取全文内容,如何批量抓取更多新闻。方法通用,可以应用到其他新闻网站整体操作步骤如下:

二、案例+操作步骤
第一步,打开网页
1.1、打开Jisouke软件,输入网址回车,等待页面加载完毕,然后点击右上角的“定义规则”按钮,可以看到一个浮动窗口显示出来,这是一个工作台,下面定义的规则会在上面输出。
1.2,在工作台上输入主题名称,然后点击检查重复项。如果提示被占用,请更改名称以确保主题名称是唯一的。

第二步:标签信息
2.1、在浏览器窗口中用鼠标点击你要抓取的内容,这里是选中的新闻标题,然后你会看到整个标题变成了黄底红框闪烁框出这个范围,根据黄色范围检查是否有正确的信息。如果没有问题,再次点击弹出标签窗口。输入标签名称后,点击打勾保存或按回车键保存。需要输入规则中的第一个标签。整理出框的名称,确认后可以在右上角的工作台中看到输出数据结构;

2.2、按照前面的操作,也在网页上标注作者和发布时间;
2.3、下一步是标记文本。如果单击文本的某个段落,则只会选择该段落的范围。如果要抓取所有文本,则需要单击文本的部分。在空白处,你会看到文字全部被选中,再次点击进行标注映射;
PS:如果是其他网页,不需要点击空白处全选,可以点击其他位置,直到选中你想要的内容范围;

2.4、如果不能点击整个范围可以选择的位置,可以点击目标信息的一部分,底部的dom窗口会定位到对应的网页节点到该信息,然后点击收录该信息的节点 的每个上层节点,直到可以看到网页上所有范围都被选中;

2.5、然后右击节点,在快捷菜单中选择Content Mapping -> New Grab Content -> 输入标签名,此操作结果与上一步相同2.3 ;

第三步,保存规则,抓取数据
3.1、点击右侧测试按钮预览输出信息是否完整,如果没有问题点击右上角的保存按钮,然后点击“抓取数据”,将弹出一个 DS 计数器窗口,并开始捕获获取数据;
3.2、之前只抓到了一个网页新闻,很多人会问如何获取更多的新闻?很简单,只要网页结构和示例页面一样,就可以用这条规则来爬取信息。因此,我们可以将与该页面结构相同的其他搜狐新闻网站整理出来,然后添加到规则中。操作在柜台上右键规则,点击“Manage Leads”然后选择“Add”,将URL复制进去保存,然后点击规则旁边的“Single Search”,启动采集逐个。另外,还可以使用分层采集的方法来实现URL的自动导入。有关详细信息,请参阅“使用层次结构的 URL采集”。

第四步,转换成Excel表格
4.1,采集成功的数据会以xml文件的形式保存在电脑的DataScraperWorks文件夹中。点击左上角的文件菜单->存储路径找到文件夹的位置。
4.2、然后我们可以将采集中的xml文件压缩成一个zip压缩包,进入会员中心的规则管理,选择对应的规则,然后点击导入数据,选择压缩将一个好的 zip 存档导入其中。导入成功后,点击导出数据,即可下载下载的Excel文件。


文章采集规则(文章采集规则的重要性强调一次,scrapy难题之解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-03-20 17:03
文章采集规则是我编写的,并且是开源版本,更新到14.0版本。我认为,作为一个爬虫,最重要的是采集,而不是规则设计。因为规则设计的再好,爬过去看起来很美,实际上就是卡成一坨(甚至是系统bug)。另外,我认为很多爬虫采用“广告插入模拟用户访问工具”来爬取网页,而不是基于数据库的sqlalchemy。另外,我认为目前很多爬虫在采集数据的时候都有点傻,他们不知道有啥可以采集的数据,还傻傻的去统计有什么数据,于是多次采集数据,然后扔进去。这是不可取的。
爬虫目前几乎都是基于数据库的,我试着总结下本人爬虫一年来遇到的难题以及一些实现的经验,如有错误,烦请指正。我使用的框架是scrapy,在此之前,scrapy框架已经非常好用,在scrapy基础上可以很好的玩出很多花样,这里先讲下难题。一:scrapy难题之规则设计(规则的重要性强调一次)首先,规则对于爬虫来说,规则设计关系到爬虫是否能够顺利执行以及爬取的结果是否可靠,如果爬虫采用规则来编写爬虫,同时编写规则(rules)之前要先把整个网页变成最终的可爬取页面,这个工作我认为基本是不会让程序员去做的,整个网页要完成采集,还是需要程序员去完成的,对于规则的编写,这个就牵扯到需要采集某个链接上的第几页,几行代码也只能得到一个返回值,更换页数或者条件都会导致上一次爬取得到的页面链接出错,所以一般而言,使用scrapy采集网页时,必须有规则,上面也是例子。
scrapy难题之解决爬虫规则设计我觉得规则设计主要分为两种情况:全链接规则,动态规则(需要定义downloadconfig来决定post数量或者key数量)。例如我们可以通过downloadconfig决定post多少链接,然后程序员根据post来分配链接到全链接,每次爬取多少个页面,我认为这个是规则的关键。
而规则通常都是python来实现的,会用到解释器,比如tornado等。所以有时我会使用类似于python的multiprocessing模块来提高爬虫效率,同时比解释器更方便调用。下面讲下scrapy难题之规则实现代码(最好在scrapy/items.py文件中实现)具体流程如下:1.定义downloadconfig2.定义规则的名称,可以用动态规则名称。
3.定义采集数据的target,也就是filter,规则只会选择一个domain,如下图我定义的为4.定义filter的key(有5种类型(multiprocessing),正则表达式(re),字符串(split),json(outofjson())),规则将会被选择的链接通过key传递给downloadconfig,程序员在调用downloadconfig的时候会带入一个规则即multipro。 查看全部
文章采集规则(文章采集规则的重要性强调一次,scrapy难题之解决)
文章采集规则是我编写的,并且是开源版本,更新到14.0版本。我认为,作为一个爬虫,最重要的是采集,而不是规则设计。因为规则设计的再好,爬过去看起来很美,实际上就是卡成一坨(甚至是系统bug)。另外,我认为很多爬虫采用“广告插入模拟用户访问工具”来爬取网页,而不是基于数据库的sqlalchemy。另外,我认为目前很多爬虫在采集数据的时候都有点傻,他们不知道有啥可以采集的数据,还傻傻的去统计有什么数据,于是多次采集数据,然后扔进去。这是不可取的。
爬虫目前几乎都是基于数据库的,我试着总结下本人爬虫一年来遇到的难题以及一些实现的经验,如有错误,烦请指正。我使用的框架是scrapy,在此之前,scrapy框架已经非常好用,在scrapy基础上可以很好的玩出很多花样,这里先讲下难题。一:scrapy难题之规则设计(规则的重要性强调一次)首先,规则对于爬虫来说,规则设计关系到爬虫是否能够顺利执行以及爬取的结果是否可靠,如果爬虫采用规则来编写爬虫,同时编写规则(rules)之前要先把整个网页变成最终的可爬取页面,这个工作我认为基本是不会让程序员去做的,整个网页要完成采集,还是需要程序员去完成的,对于规则的编写,这个就牵扯到需要采集某个链接上的第几页,几行代码也只能得到一个返回值,更换页数或者条件都会导致上一次爬取得到的页面链接出错,所以一般而言,使用scrapy采集网页时,必须有规则,上面也是例子。
scrapy难题之解决爬虫规则设计我觉得规则设计主要分为两种情况:全链接规则,动态规则(需要定义downloadconfig来决定post数量或者key数量)。例如我们可以通过downloadconfig决定post多少链接,然后程序员根据post来分配链接到全链接,每次爬取多少个页面,我认为这个是规则的关键。
而规则通常都是python来实现的,会用到解释器,比如tornado等。所以有时我会使用类似于python的multiprocessing模块来提高爬虫效率,同时比解释器更方便调用。下面讲下scrapy难题之规则实现代码(最好在scrapy/items.py文件中实现)具体流程如下:1.定义downloadconfig2.定义规则的名称,可以用动态规则名称。
3.定义采集数据的target,也就是filter,规则只会选择一个domain,如下图我定义的为4.定义filter的key(有5种类型(multiprocessing),正则表达式(re),字符串(split),json(outofjson())),规则将会被选择的链接通过key传递给downloadconfig,程序员在调用downloadconfig的时候会带入一个规则即multipro。
文章采集规则(OA期刊介绍开放存取是不同于传统学术传播的一种全新机制)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-03-17 15:15
1、OA期刊介绍
开放存取(OA)或开放存取是国际学术界、出版界、图书馆和信息界为促进利用互联网免费传播科学研究成果而采取的行动。其宗旨是促进科学和人文信息的广泛交流,促进利用互联网进行科学交流和出版,提高科学研究的公众利用程度,确保科学信息的保存,提高科研效率。
开放获取是一种不同于传统学术传播的新机制。其核心特点是在尊重作者权益的前提下,利用互联网免费为用户提供学术信息和研究成果的全文服务。首先,开放获取是一种基于互联网的学术传播机制。互联网是开放获取所依赖的媒介形式。这是因为互联网的发展导致学术交流成本的降低,从而为学术信息的开放获取提供了可能。然而,媒体形式本身并不是区分开放获取与传统学术期刊出版的标志。目前,许多出版商提供在线数据库和电子期刊,但他们在营销策略中仍然使用传统的基于订阅的传播模式。其次,开放获取是一种免费提供全文信息服务的方式。在开放获取模式下,研究人员无需付费(包括个人或团体订阅)即可访问学术信息的全文。换言之,只要具备连接互联网的物理条件,研究人员就可以轻松访问学术信息的全文。从这个角度来看,仅仅是开放文档的基本书目信息并不是开放获取的体现。事实上,传统出版商经常允许用户免费浏览他们的摘要,这只是他们用来推广和销售全文服务的一种常见营销策略。其次,开放获取充分尊重作者的权益,不违背知识产权精神。基于开放获取分发的作品不一定是“公共领域作品”。它不要求作者放弃对作品的所有权利。作者可以根据不同的法律文本和许可协议(如知识共享协议)选择作品的版权。
自开放获取出现以来,OA 期刊和知识库迅速增长。目前,全球已有5225人、534家相关研究机构签署了布达佩斯开放获取倡议(BOAI)项目协议。
截止2010年,DOAJ(Directory of Open Access Journal)共有4953种OA期刊收录,其中2014年提供文章级浏览,共收录文章@ >384945 篇文章;在OpenDOAR(由英国诺丁汉大学和瑞典隆德大学图书馆于2005年2月联合创建的开放存取机构资源库和学科资源库目录检索系统)注册的OA仓库已达1620个。
目前,OA在中国还处于起步阶段。比如我国只有14个被DOAJ收录注册的OA期刊,只有7个被OpenDOAR注册的OA知识库。此外,用户对开放获取的认知度还很低,大部分用户从未听说过开放获取,很少有用户使用过开放获取资源。
2、OA期刊的实证分析
为了进一步验证本文提出的方法,具体实现了基于网页信息抽取的OA期刊资源采集系统的主要功能。(1)网页元素采集。使用JavaFX可视化组件WebView,实现资源选择和查询语句的自动生成,利用网页解析器Jsoup根据采集网页信息查询语句。具体来说,当WebView组件加载HTML内容时,会为每个节点添加一个事件监听器,当鼠标点击某个节点时,系统会将该节点分配给“org.w3c.dom”类型的变量。 Node”。Node类提供方法“getParentNode”获取当前节点的父节点,根据该路径可以递归地找到当前节点到网页根节点的路径。通过将路径中每个节点的标签名和属性值拼接成一个Jsoup可以识别的查询语句,然后使用Jsoup中的select方法处理采集节点的信息为采集,页面元素采集的工作就可以完成了。(2)半结构化文本信息提取。具体实现方法是使用用户标记的分隔符. ,然后根据分隔符的位置提取元数据字段信息。OA期刊网站通常将“年、卷、期”组合成一条短信,如“2017, vol39, no.1”,信息显示时先采集 这条文本信息作为网页元素,然后通过在文本中插入分隔符进行标记,将需要的采集信息与固定显示信息分开,即“{2017},vol{39 }, no.{1}" "2017" "39" "1" 是需要 采集, ", vol" ", no." 的信息。是固定的显示信息。
固定显示信息的内容通常不会改变。因此,可以根据固定显示信息的位置提取文本中的对应信息。(3)网页结构检查。根据规定要求的采集的必填字段,作为判断网页结构是否发生变化的标准,如果采集@收到必填字段>为空,则认为当前网页结构发生了变化,需要重新选择采集,如果文章的标题为必填项,则判断是否采集接收到的字段在页面元素采集中为空,如果为空,可能有两种情况:一种是当前页面没有这个字段,这个页面是脏页; 另一种是该字段存在于当前页面,但元数据采集规则不适用于当前页面,则可以判断该页面是结构变化后的页面。当必填字段为空时,系统无法识别情况,因此系统会将当前页面添加到结构更改页面链接数组中。本轮采集结束后,提取结构变化的网页链接数组的第一个链接显示在嵌入式浏览器中,用户判断该字段为空的情况。该系统为这两种情况提出了解决方案。对于第一个脏页的情况,直接跳过,将页面链接从结构变化的网页链接数组中删除;对于网页结构变化的第二种情况,结构改变后用户会重新选择页面上的元数据,新的采集规则被添加到原来的采集规则集中,系统会使用新的采集@ > 规则继续采集。这样2-3次往复就可以遍历网站的所有模板,然后采集到全数据,解决了OA期刊资源网页结构变化,不能被综合采集。
为验证基于网页信息抽取的OA期刊资源采集方法的有效性,本文选取国内外10个不遵循OAI-PMH的OA期刊网站协议作为 采集 的对象。爬虫脚本采集10个OA期刊的论文链接数,作为采集个数综合性的标准。测试结果见表5。从表5可以看出,从采集到10个期刊的45785篇论文共45785篇,采集的时间为31039秒。其中,4个期刊的网页结构发生了变化。从系统测试结果可以看出,基于网页信息抽取的OA期刊资源采集方法可以灵活响应采集 不同的 OA 期刊资源。在准确率上,该方法可以准确地采集单个资源和固定文本结构的组合资源,表明它可以应用于OA期刊资源采集的工作。基于网页信息抽取的OA期刊资源采集系统的网页结构检测可以准确识别网页结构变化,并对结构变化后的资源进行采集。除了部分OA期刊网站无法访问或没有详细信息外,采集收到的论文数与爬虫脚本统计的论文链接数一致。从采集的时间来看,1000篇文章的采集平均时间为678秒。一般来说, 查看全部
文章采集规则(OA期刊介绍开放存取是不同于传统学术传播的一种全新机制)
1、OA期刊介绍
开放存取(OA)或开放存取是国际学术界、出版界、图书馆和信息界为促进利用互联网免费传播科学研究成果而采取的行动。其宗旨是促进科学和人文信息的广泛交流,促进利用互联网进行科学交流和出版,提高科学研究的公众利用程度,确保科学信息的保存,提高科研效率。
开放获取是一种不同于传统学术传播的新机制。其核心特点是在尊重作者权益的前提下,利用互联网免费为用户提供学术信息和研究成果的全文服务。首先,开放获取是一种基于互联网的学术传播机制。互联网是开放获取所依赖的媒介形式。这是因为互联网的发展导致学术交流成本的降低,从而为学术信息的开放获取提供了可能。然而,媒体形式本身并不是区分开放获取与传统学术期刊出版的标志。目前,许多出版商提供在线数据库和电子期刊,但他们在营销策略中仍然使用传统的基于订阅的传播模式。其次,开放获取是一种免费提供全文信息服务的方式。在开放获取模式下,研究人员无需付费(包括个人或团体订阅)即可访问学术信息的全文。换言之,只要具备连接互联网的物理条件,研究人员就可以轻松访问学术信息的全文。从这个角度来看,仅仅是开放文档的基本书目信息并不是开放获取的体现。事实上,传统出版商经常允许用户免费浏览他们的摘要,这只是他们用来推广和销售全文服务的一种常见营销策略。其次,开放获取充分尊重作者的权益,不违背知识产权精神。基于开放获取分发的作品不一定是“公共领域作品”。它不要求作者放弃对作品的所有权利。作者可以根据不同的法律文本和许可协议(如知识共享协议)选择作品的版权。
自开放获取出现以来,OA 期刊和知识库迅速增长。目前,全球已有5225人、534家相关研究机构签署了布达佩斯开放获取倡议(BOAI)项目协议。
截止2010年,DOAJ(Directory of Open Access Journal)共有4953种OA期刊收录,其中2014年提供文章级浏览,共收录文章@ >384945 篇文章;在OpenDOAR(由英国诺丁汉大学和瑞典隆德大学图书馆于2005年2月联合创建的开放存取机构资源库和学科资源库目录检索系统)注册的OA仓库已达1620个。
目前,OA在中国还处于起步阶段。比如我国只有14个被DOAJ收录注册的OA期刊,只有7个被OpenDOAR注册的OA知识库。此外,用户对开放获取的认知度还很低,大部分用户从未听说过开放获取,很少有用户使用过开放获取资源。
2、OA期刊的实证分析
为了进一步验证本文提出的方法,具体实现了基于网页信息抽取的OA期刊资源采集系统的主要功能。(1)网页元素采集。使用JavaFX可视化组件WebView,实现资源选择和查询语句的自动生成,利用网页解析器Jsoup根据采集网页信息查询语句。具体来说,当WebView组件加载HTML内容时,会为每个节点添加一个事件监听器,当鼠标点击某个节点时,系统会将该节点分配给“org.w3c.dom”类型的变量。 Node”。Node类提供方法“getParentNode”获取当前节点的父节点,根据该路径可以递归地找到当前节点到网页根节点的路径。通过将路径中每个节点的标签名和属性值拼接成一个Jsoup可以识别的查询语句,然后使用Jsoup中的select方法处理采集节点的信息为采集,页面元素采集的工作就可以完成了。(2)半结构化文本信息提取。具体实现方法是使用用户标记的分隔符. ,然后根据分隔符的位置提取元数据字段信息。OA期刊网站通常将“年、卷、期”组合成一条短信,如“2017, vol39, no.1”,信息显示时先采集 这条文本信息作为网页元素,然后通过在文本中插入分隔符进行标记,将需要的采集信息与固定显示信息分开,即“{2017},vol{39 }, no.{1}" "2017" "39" "1" 是需要 采集, ", vol" ", no." 的信息。是固定的显示信息。
固定显示信息的内容通常不会改变。因此,可以根据固定显示信息的位置提取文本中的对应信息。(3)网页结构检查。根据规定要求的采集的必填字段,作为判断网页结构是否发生变化的标准,如果采集@收到必填字段>为空,则认为当前网页结构发生了变化,需要重新选择采集,如果文章的标题为必填项,则判断是否采集接收到的字段在页面元素采集中为空,如果为空,可能有两种情况:一种是当前页面没有这个字段,这个页面是脏页; 另一种是该字段存在于当前页面,但元数据采集规则不适用于当前页面,则可以判断该页面是结构变化后的页面。当必填字段为空时,系统无法识别情况,因此系统会将当前页面添加到结构更改页面链接数组中。本轮采集结束后,提取结构变化的网页链接数组的第一个链接显示在嵌入式浏览器中,用户判断该字段为空的情况。该系统为这两种情况提出了解决方案。对于第一个脏页的情况,直接跳过,将页面链接从结构变化的网页链接数组中删除;对于网页结构变化的第二种情况,结构改变后用户会重新选择页面上的元数据,新的采集规则被添加到原来的采集规则集中,系统会使用新的采集@ > 规则继续采集。这样2-3次往复就可以遍历网站的所有模板,然后采集到全数据,解决了OA期刊资源网页结构变化,不能被综合采集。
为验证基于网页信息抽取的OA期刊资源采集方法的有效性,本文选取国内外10个不遵循OAI-PMH的OA期刊网站协议作为 采集 的对象。爬虫脚本采集10个OA期刊的论文链接数,作为采集个数综合性的标准。测试结果见表5。从表5可以看出,从采集到10个期刊的45785篇论文共45785篇,采集的时间为31039秒。其中,4个期刊的网页结构发生了变化。从系统测试结果可以看出,基于网页信息抽取的OA期刊资源采集方法可以灵活响应采集 不同的 OA 期刊资源。在准确率上,该方法可以准确地采集单个资源和固定文本结构的组合资源,表明它可以应用于OA期刊资源采集的工作。基于网页信息抽取的OA期刊资源采集系统的网页结构检测可以准确识别网页结构变化,并对结构变化后的资源进行采集。除了部分OA期刊网站无法访问或没有详细信息外,采集收到的论文数与爬虫脚本统计的论文链接数一致。从采集的时间来看,1000篇文章的采集平均时间为678秒。一般来说,
文章采集规则(WordPress采集的完整词不能分拆做锚文本是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-03-17 00:00
WordPress采集,通过在全网对应的关键词中搜索文章,进行全网文章采集。可以快速大量填充网站的内容,丰富网站的文章数据库。这为网站增加收录提供了基本条件,可以为网站关键词的排名提供相应的帮助,所以内容建设是网站@的第一点> ,而WordPress采集是为了帮助站长优化网站的文章内容,增加网站的文章内容数量。
WordPress采集的文章会自动修改标题和内容,目的是为了减少在搜索引擎中的重复,修改后不能将原文的意思改得面目全非,这样它就会丢失。以伪原创的初衷,内容的修改和写作一定要有一个中心思想,内容不能再更改。文章 更改标题以匹配文章 的内容和用户的阅读习惯,从而达到伪原创 意想不到的效果。
WordPress采集 的完整单词不能拆分为锚文本。例如,有些词已经是一个名字。虽然也可以进行切分,但是切分后就失去了原来的意义,所以不能切分。有很多时间我们都喜欢拆分完整的单词,所以这是不正确的。如果一个页面上有多个关键词,则只有一个链接是第一个。当一个页面出现多个关键词时,只需要一个链接。链接多个链接只会浪费资源,链接太多也会被认为是过度优化导致网站降低权重,得不偿失。
WordPress采集自创功能第一段:自动写文章首页的开场介绍,文章首页的介绍前120字可以打一个在被搜索引擎搜索到的页面中起到很大的作用收录,如果你有精力看文章,知道大意的可以写开篇介绍,也可以自己加入网站 的 关键词 在这里。在文本中插入锚文本链接:你应该知道锚文本是什么,它的作用可以帮助提高相关的关键词排名。但是,添加锚文本必须对用户有用。如果没用,最好不要添加。
WordPress采集自动添加图片或视频:文章带有图片可以更好的说明问题,容易抓住用户的注意力,增加在页面的停留时间,但是添加图片是为了表达并解决用户问题。基于。虽然目前大部分搜索引擎无法读取图片的内容,但是图片中的alt属性是可以识别的,合适的图片会让搜索引擎焕然一新。我认为您的 文章 是高质量的新 文章,当然还有视频添加。
WordPress采集 然后按段落替换:即相互替换内容的顺序,但注意不要影响原文的阅读。但是,这种方法并不适合所有人,不应该使用逻辑 文章。结尾自创:把整个文章做个总结,看起来比较连贯。其实对于搜索引擎优化来说,不仅是这些内容,小技巧也是要注意的,所以不仅要能做到,而且要能思考,能从别人那里推断,才能更快的提高和进步。 查看全部
文章采集规则(WordPress采集的完整词不能分拆做锚文本是什么?)
WordPress采集,通过在全网对应的关键词中搜索文章,进行全网文章采集。可以快速大量填充网站的内容,丰富网站的文章数据库。这为网站增加收录提供了基本条件,可以为网站关键词的排名提供相应的帮助,所以内容建设是网站@的第一点> ,而WordPress采集是为了帮助站长优化网站的文章内容,增加网站的文章内容数量。

WordPress采集的文章会自动修改标题和内容,目的是为了减少在搜索引擎中的重复,修改后不能将原文的意思改得面目全非,这样它就会丢失。以伪原创的初衷,内容的修改和写作一定要有一个中心思想,内容不能再更改。文章 更改标题以匹配文章 的内容和用户的阅读习惯,从而达到伪原创 意想不到的效果。

WordPress采集 的完整单词不能拆分为锚文本。例如,有些词已经是一个名字。虽然也可以进行切分,但是切分后就失去了原来的意义,所以不能切分。有很多时间我们都喜欢拆分完整的单词,所以这是不正确的。如果一个页面上有多个关键词,则只有一个链接是第一个。当一个页面出现多个关键词时,只需要一个链接。链接多个链接只会浪费资源,链接太多也会被认为是过度优化导致网站降低权重,得不偿失。

WordPress采集自创功能第一段:自动写文章首页的开场介绍,文章首页的介绍前120字可以打一个在被搜索引擎搜索到的页面中起到很大的作用收录,如果你有精力看文章,知道大意的可以写开篇介绍,也可以自己加入网站 的 关键词 在这里。在文本中插入锚文本链接:你应该知道锚文本是什么,它的作用可以帮助提高相关的关键词排名。但是,添加锚文本必须对用户有用。如果没用,最好不要添加。

WordPress采集自动添加图片或视频:文章带有图片可以更好的说明问题,容易抓住用户的注意力,增加在页面的停留时间,但是添加图片是为了表达并解决用户问题。基于。虽然目前大部分搜索引擎无法读取图片的内容,但是图片中的alt属性是可以识别的,合适的图片会让搜索引擎焕然一新。我认为您的 文章 是高质量的新 文章,当然还有视频添加。

WordPress采集 然后按段落替换:即相互替换内容的顺序,但注意不要影响原文的阅读。但是,这种方法并不适合所有人,不应该使用逻辑 文章。结尾自创:把整个文章做个总结,看起来比较连贯。其实对于搜索引擎优化来说,不仅是这些内容,小技巧也是要注意的,所以不仅要能做到,而且要能思考,能从别人那里推断,才能更快的提高和进步。
文章采集规则(台州SEO培训网站优化教程(采集站的日益多见))
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-15 12:10
台州SEO培训网站优化教程。越来越多的采集站使得百度一次次攻击采集站,所以很多权重非常高的采集站倒下了,但采集并没有恶意垃圾邮件采集,只要采集的内容是优质的,网站有一定数量的原创文章,采集不会使 网站 降级正确。今天小小课堂分享的内容是“台州SEO培训网站优化(优采云常用采集规则)”。我希望能有所帮助。
一、网址采集规则
以中国新闻网为例。要想写好URL采集的规则,就需要了解正则表达式。如果这样不好,那就去一个宝藏几十块钱,找专业人士写一个。
二、内容采集规则
在内容采集规则中,我们需要得到两个内容,一个是标题内容,一个是文章主题内容。
1、标题内容
根据页面获取的html和css截取title内容。开始字符串和结束字符串的中间部分是标题。除了标题,我们还要修改标题,一般像你打算自己发布的这个自动采集和文章,你必须修改标题。修改标题的方法一般是插入单词,缩短标题的长度。插入词的方式可以在标题的前面、中间和后面,前后插入不会影响阅读体验。但是会有插曲,但也有很多采集台在标题中选择了插曲。
2、文章主题内容
文章主题内容和标题类似,都是用字符串截取的,但不同的是数据处理需要处理那些没价值的标签,还有我们不想看到的标签,比如一个标签。理论上,关键词也应该插入到主题内容中,但也可能不插入。随意插入关键词可能会导致采集原来的文章中的图片无法正常显示。. 建议在某些标签之前或文本的开头和结尾处插入。
以上是小小课堂分享的内容为《台州SEO培训网站优化(优采云常用采集规则)》。谢谢阅读。
本文最后更新时间:2022 年 2 月 28 日 查看全部
文章采集规则(台州SEO培训网站优化教程(采集站的日益多见))
台州SEO培训网站优化教程。越来越多的采集站使得百度一次次攻击采集站,所以很多权重非常高的采集站倒下了,但采集并没有恶意垃圾邮件采集,只要采集的内容是优质的,网站有一定数量的原创文章,采集不会使 网站 降级正确。今天小小课堂分享的内容是“台州SEO培训网站优化(优采云常用采集规则)”。我希望能有所帮助。
一、网址采集规则
以中国新闻网为例。要想写好URL采集的规则,就需要了解正则表达式。如果这样不好,那就去一个宝藏几十块钱,找专业人士写一个。
 https://xxkt.org.cn/wp-content ... 63285 300w, https://xxkt.org.cn/wp-content ... 63285 768w" />
https://xxkt.org.cn/wp-content ... 63285 300w, https://xxkt.org.cn/wp-content ... 63285 768w" />二、内容采集规则
在内容采集规则中,我们需要得到两个内容,一个是标题内容,一个是文章主题内容。
1、标题内容
根据页面获取的html和css截取title内容。开始字符串和结束字符串的中间部分是标题。除了标题,我们还要修改标题,一般像你打算自己发布的这个自动采集和文章,你必须修改标题。修改标题的方法一般是插入单词,缩短标题的长度。插入词的方式可以在标题的前面、中间和后面,前后插入不会影响阅读体验。但是会有插曲,但也有很多采集台在标题中选择了插曲。
 https://xxkt.org.cn/wp-content ... 63472 300w, https://xxkt.org.cn/wp-content ... 63472 768w" />
https://xxkt.org.cn/wp-content ... 63472 300w, https://xxkt.org.cn/wp-content ... 63472 768w" />2、文章主题内容
文章主题内容和标题类似,都是用字符串截取的,但不同的是数据处理需要处理那些没价值的标签,还有我们不想看到的标签,比如一个标签。理论上,关键词也应该插入到主题内容中,但也可能不插入。随意插入关键词可能会导致采集原来的文章中的图片无法正常显示。. 建议在某些标签之前或文本的开头和结尾处插入。
 https://xxkt.org.cn/wp-content ... 63514 300w, https://xxkt.org.cn/wp-content ... 63514 768w" />
https://xxkt.org.cn/wp-content ... 63514 300w, https://xxkt.org.cn/wp-content ... 63514 768w" />以上是小小课堂分享的内容为《台州SEO培训网站优化(优采云常用采集规则)》。谢谢阅读。
本文最后更新时间:2022 年 2 月 28 日
文章采集规则(论坛采集核心技术是模式定义和模式匹配的经验的抽象和升华)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-06 19:09
论坛采集是论坛站长的辅助工具。论坛建设初期,需要内容较多,人工发送费时费力,难以形成论坛互动。论坛采集器主要是帮助论坛站长采集,将大量发帖内容发送到指定版块,论坛采集的辅助功能是模拟千人上线,看帖、发帖、回帖、点赞,形成一定的互动效果,提高人气,吸引新用户,留住老用户。
论坛采集核心技术是模式定义和模式匹配。模式属于人工智能的术语,意为对物体前身所积累的经验的抽象和升华。简单来说,论坛采集就是从反复出现的事件中发现和抽象出来的规则,是解决问题的经验总结。只要是一遍又一遍地重复的东西,就可能有规律。
因此,要使论坛 采集 起作用,目标论坛必须具有重复出现的特征。大多数论坛是动态生成的,因此相同模板的页面收录相同的内容,论坛 采集 使用这些内容来定位 采集 数据。
论坛采集中的大部分模式都不是程序自动发现的,论坛采集几乎所有的功能都需要手动定义。但是论坛采集模式本身就是一个非常复杂抽象的内容,所以开发者的全部精力都花在了如何让模式定义更简单更准确上,这也是论坛竞争力的标杆采集 。论坛采集技术主要有两种方式:正则表达式定义和文档结构定义。
论坛采集可以定时抓取、同步关注、下载附件、打通防盗链等。系统内置操作向导。论坛采集很好的支持Discuz、PHPWind、Dvbbs等论坛采集。论坛采集实现所见即所得,用户在可视化页面视图上点击想要的采集内容,预览采集的结果。网站监控,定期监控目标网站的数据更新,并自动采集更新数据。
Forum采集的智能抽取系统对半结构化数据进行语义分析,根据语义规则智能抽取复杂多变的数据。网站全站下载,论坛采集无限深度,无限分页数据采集,可以跨页发布数据。论坛采集的万维网WEB技术,采用WEB技术,站长无需安装即可使用论坛采集。论坛采集特征列表功能,区域预览和特征列表展示,让规则定义准确又轻松。多线程采集,论坛采集多任务并发,多线程采集。支持线程并发控制和状态监控。插件支持,论坛采集有丰富的插件功能,支持采集
论坛采集文章各类cms,新闻等资料采集。论坛采集可以为织梦的采集、东夷、帝国等cms添加插件。站长可以自定义自己的采集模块,采集各种新闻,文章到自己的博客来吸引流量。论坛采集根据站长自定义的任务配置,批量准确提取目标论坛栏目中的主题帖和回复帖的作者、标题、发布时间、内容、栏目等,并进行转换成结构化记录,存储在本地数据库中。 查看全部
文章采集规则(论坛采集核心技术是模式定义和模式匹配的经验的抽象和升华)
论坛采集是论坛站长的辅助工具。论坛建设初期,需要内容较多,人工发送费时费力,难以形成论坛互动。论坛采集器主要是帮助论坛站长采集,将大量发帖内容发送到指定版块,论坛采集的辅助功能是模拟千人上线,看帖、发帖、回帖、点赞,形成一定的互动效果,提高人气,吸引新用户,留住老用户。
论坛采集核心技术是模式定义和模式匹配。模式属于人工智能的术语,意为对物体前身所积累的经验的抽象和升华。简单来说,论坛采集就是从反复出现的事件中发现和抽象出来的规则,是解决问题的经验总结。只要是一遍又一遍地重复的东西,就可能有规律。
因此,要使论坛 采集 起作用,目标论坛必须具有重复出现的特征。大多数论坛是动态生成的,因此相同模板的页面收录相同的内容,论坛 采集 使用这些内容来定位 采集 数据。
论坛采集中的大部分模式都不是程序自动发现的,论坛采集几乎所有的功能都需要手动定义。但是论坛采集模式本身就是一个非常复杂抽象的内容,所以开发者的全部精力都花在了如何让模式定义更简单更准确上,这也是论坛竞争力的标杆采集 。论坛采集技术主要有两种方式:正则表达式定义和文档结构定义。
论坛采集可以定时抓取、同步关注、下载附件、打通防盗链等。系统内置操作向导。论坛采集很好的支持Discuz、PHPWind、Dvbbs等论坛采集。论坛采集实现所见即所得,用户在可视化页面视图上点击想要的采集内容,预览采集的结果。网站监控,定期监控目标网站的数据更新,并自动采集更新数据。
Forum采集的智能抽取系统对半结构化数据进行语义分析,根据语义规则智能抽取复杂多变的数据。网站全站下载,论坛采集无限深度,无限分页数据采集,可以跨页发布数据。论坛采集的万维网WEB技术,采用WEB技术,站长无需安装即可使用论坛采集。论坛采集特征列表功能,区域预览和特征列表展示,让规则定义准确又轻松。多线程采集,论坛采集多任务并发,多线程采集。支持线程并发控制和状态监控。插件支持,论坛采集有丰富的插件功能,支持采集
论坛采集文章各类cms,新闻等资料采集。论坛采集可以为织梦的采集、东夷、帝国等cms添加插件。站长可以自定义自己的采集模块,采集各种新闻,文章到自己的博客来吸引流量。论坛采集根据站长自定义的任务配置,批量准确提取目标论坛栏目中的主题帖和回复帖的作者、标题、发布时间、内容、栏目等,并进行转换成结构化记录,存储在本地数据库中。
文章采集规则(多文写手2020年破解版解决方案介绍及使用说明书)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-05 06:11
详细介绍
Multi-Writing Writer是一个伪原创文章生成器,可以应用于原创文章制作作品集,非常方便实用。使用多语言编写器可以快速大量生成可读性强的收录good原创文章,对搜索引擎更有利收录。由于网络文化的严格管理,现在大多数搜索引擎对收录敏感词或根本不收录收录的网页进行不同程度的降级。所以过滤文章敏感词尤为重要。多文本编写器内置了材质敏感词过滤,可以快速过滤掉一些不好的关键词,让文章的质量更高,对收录@更有利>。这是一个营销版本,网站 日常维护和更新所需的软件。还支持所有前景和背景数据。支持通过脚本在所有网站上发布文章。
这次推荐多文写作2020 vip破解版。此版本已破解vip,可免费使用软件所有功能。欢迎下载体验!
软件功能1、自动伪原创;
2、自动组合问候语;
3、自动采集图片;
4、图片自动加水印;
5、自动过滤敏感词;
6、Script Universal Publishing 支持所有后端。软件功能1、自动过滤敏感词
自动过滤敏感词,使文章内容更安全,对收录更有利。
2、自动伪原创材料
在材料导入过程中,材料自动进行伪原创处理,对收录更有利。
3、一键图片采集
根据关键词一键采集相关图片,速度快,效率高,图片更容易匹配。
4、图片采集重新压缩
独有的图片伪原创技术可以批量随机调整图片分辨率。
5、材料采集多式联运
支持爬虫采集、规则采集、关键词采集多种素材获取方式。
6、自动脚本发布
通用脚本发布支持所有网站后台/前端发布,实现文章生成与发布一体化解决方案。使用说明一、多文本编写器有两种文章生成模式:组合标题和固定标题。
1、组合标题分为五段来指定组合。每段100字,可以组合不同的标题
标题数量:100×100×100×100×100=
2、固定标题模式,使用自己设置的固定标题生成文章。您可以根据需要生成任意数量。
3、标题设置支持5个标题段,最多可组合1亿级。
二、由于对网络文化的严格管理,现在大部分搜索引擎对收录敏感词的网页进行不同程度的降级或不直接收录。所以过滤文章敏感词尤为重要。多文本编写器内置了材质敏感词过滤,可以快速过滤掉一些不好的关键词,让文章的质量更高,对收录@更有利>。
三、伪原创处理,添加素材时自动伪原创处理素材内容。从分词技术让文章原创更好。
四、内容采集
选择关键词采集材质,填写材质为采集关键词,启动采集。内容采集功能多文本书写器内容采集功能显示及说明:
一、规则采集:
对于更具体的 文章,您可以为内容 采集 手动编写 采集 规则。
二、单个站点采集:
如果不知道采集规则怎么写,也可以做单站采集,内置爬虫spider可以直接设置采集深度一键< @采集目标网站所有内容。
三、关键词采集:
通过设置指定与此关键词 关联的关键词一键式采集 材质。注册账号1、新用户下载软件后点击注册续订按钮,自动跳转到注册页面。
2、注册时填写账号密码和网购激活码。
3、点击用户注册完成注册。 查看全部
文章采集规则(多文写手2020年破解版解决方案介绍及使用说明书)
详细介绍
Multi-Writing Writer是一个伪原创文章生成器,可以应用于原创文章制作作品集,非常方便实用。使用多语言编写器可以快速大量生成可读性强的收录good原创文章,对搜索引擎更有利收录。由于网络文化的严格管理,现在大多数搜索引擎对收录敏感词或根本不收录收录的网页进行不同程度的降级。所以过滤文章敏感词尤为重要。多文本编写器内置了材质敏感词过滤,可以快速过滤掉一些不好的关键词,让文章的质量更高,对收录@更有利>。这是一个营销版本,网站 日常维护和更新所需的软件。还支持所有前景和背景数据。支持通过脚本在所有网站上发布文章。
这次推荐多文写作2020 vip破解版。此版本已破解vip,可免费使用软件所有功能。欢迎下载体验!
软件功能1、自动伪原创;
2、自动组合问候语;
3、自动采集图片;
4、图片自动加水印;
5、自动过滤敏感词;
6、Script Universal Publishing 支持所有后端。软件功能1、自动过滤敏感词
自动过滤敏感词,使文章内容更安全,对收录更有利。
2、自动伪原创材料
在材料导入过程中,材料自动进行伪原创处理,对收录更有利。
3、一键图片采集
根据关键词一键采集相关图片,速度快,效率高,图片更容易匹配。
4、图片采集重新压缩
独有的图片伪原创技术可以批量随机调整图片分辨率。
5、材料采集多式联运
支持爬虫采集、规则采集、关键词采集多种素材获取方式。
6、自动脚本发布
通用脚本发布支持所有网站后台/前端发布,实现文章生成与发布一体化解决方案。使用说明一、多文本编写器有两种文章生成模式:组合标题和固定标题。
1、组合标题分为五段来指定组合。每段100字,可以组合不同的标题
标题数量:100×100×100×100×100=
2、固定标题模式,使用自己设置的固定标题生成文章。您可以根据需要生成任意数量。
3、标题设置支持5个标题段,最多可组合1亿级。
二、由于对网络文化的严格管理,现在大部分搜索引擎对收录敏感词的网页进行不同程度的降级或不直接收录。所以过滤文章敏感词尤为重要。多文本编写器内置了材质敏感词过滤,可以快速过滤掉一些不好的关键词,让文章的质量更高,对收录@更有利>。
三、伪原创处理,添加素材时自动伪原创处理素材内容。从分词技术让文章原创更好。
四、内容采集
选择关键词采集材质,填写材质为采集关键词,启动采集。内容采集功能多文本书写器内容采集功能显示及说明:
一、规则采集:
对于更具体的 文章,您可以为内容 采集 手动编写 采集 规则。
二、单个站点采集:
如果不知道采集规则怎么写,也可以做单站采集,内置爬虫spider可以直接设置采集深度一键< @采集目标网站所有内容。
三、关键词采集:
通过设置指定与此关键词 关联的关键词一键式采集 材质。注册账号1、新用户下载软件后点击注册续订按钮,自动跳转到注册页面。
2、注册时填写账号密码和网购激活码。
3、点击用户注册完成注册。
文章采集规则(计算机和互联网基础知识作业()计算机作业开始时间)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-04-05 03:19
计算机与互联网基础功课,计算机功课1带Answers.doc_weixin_39788131的博客-程序员的秘密
计算机作业 1Basic Knowledge with Answers.doc 跳至主要内容在线课程学院主页电子学习实验室联系我们FormTopFormBottomPage PathHome/我的课程/计算机应用基础知识 2299/主题 2/第一次作业计算机基础知识开始于 2015 年 10 月 1 日星期四 1301 完成于 2015 年 10 月 1 日星期四 1435 用时 1 小时34 分钟 分数 37.00/40.00Grades 92.50/...
FPGA控制TDC7200时间间隔测量(一)_*临时博客-程序员的秘密_tdc芯片
简介 TDC7200是TI推出的时间间隔测量芯片,分辨率低至55ps,标准差35ps,低功耗模式,最多可计数5个停止脉冲,最小工作负40度摄氏度。芯片介绍 引脚说明 我们将结合官方手册说明介绍其引脚(1)ENABLE使能引脚,根据手册,该引脚为高电平时芯片使能。(2)TRIGG触发引脚) ,按照说明书,芯片上电使能后,会一直保持低电平,当我们初始化后进入测试环节时,该引脚会被拉低,芯片接收到START脉冲后,该引脚被拉低低。(3、4)STA
wpf结合java_如何使用WPF绑定RelativeSource?_ 风神理性博客-程序员的秘密
当我们试图将一个对象的一个属性绑定到该对象本身的另一个属性时,RelativeSource 是一个标记扩展,当我们试图将一个对象的一个属性绑定到其相对父级的另一个属性时,在特定的绑定情况下使用自定义控件开发时绑定一个依赖属性值到一段XAML,最后在绑定数据使用一系列差异的情况下。所有这些情况都表示为相对源模式。我将一一揭露所有这些案例。模式自我:想象一下这种情况,我们想要一个高度总是等于宽度的矩形......
@Data_Max_Tsui 博客的使用 - 程序员的秘密
这里写一个自定义的目录标题@Data使用新的更改功能快捷键创建一个合理的标题,有助于目录的生成如何更改文本的样式插入链接和图片如何插入漂亮的代码片段生成一个列表适合你创建表格设置内容居中、左、右 SmartyPants 创建自定义列表 如何创建脚注注释也是 KaTeX 数学公式必不可少的新甘特图功能,丰富您的 文章UML 图 FLowchart 流程图 导出和 Import Export Import Import @Data 使用 @d...
TCP 和 UDP_caiyec 的博客 - 程序员的秘密
提示:文章写好后可以自动生成目录,如何生成可以参考右边的帮助文档TCP和UDP前言一、什么是UDP?二、什么是 TCP?1.库介绍2.TCP和UDP的区别总结介绍目前我们常用的计算机网络架构是TCP/IP五层网络结构自上而下为应用层,传输层,网络层,数据链路层,物理层,今天介绍的TCP和UDP是传输层的两个协议。传输层负责端到端的数据传输,传输层由操作系统内核实现。一、什么是UDP?首先,UDP是传输层的协议。
线程安全——从StringBuffer和StringBuilder的区别看 - 程序员大本营
面试的时候,面试官问了线程安全问题,感觉回答不太满意。那个时候,我没有好好回答。我问面试官如何理解它。他说:可以参考StringBuffer和StringBuilder。所以赶紧回来自己弥补。这是学渣的苦果/(ㄒoㄒ)/~~线程安全概念线程安全:多线程访问时,使用了锁机制。当一个线程访问这个类的某个数据时,它是受保护的。在线程读完之前,其他线程无法访问它,其他线程也无法使用它。没有出现 查看全部
文章采集规则(计算机和互联网基础知识作业()计算机作业开始时间)
计算机与互联网基础功课,计算机功课1带Answers.doc_weixin_39788131的博客-程序员的秘密
计算机作业 1Basic Knowledge with Answers.doc 跳至主要内容在线课程学院主页电子学习实验室联系我们FormTopFormBottomPage PathHome/我的课程/计算机应用基础知识 2299/主题 2/第一次作业计算机基础知识开始于 2015 年 10 月 1 日星期四 1301 完成于 2015 年 10 月 1 日星期四 1435 用时 1 小时34 分钟 分数 37.00/40.00Grades 92.50/...
FPGA控制TDC7200时间间隔测量(一)_*临时博客-程序员的秘密_tdc芯片
简介 TDC7200是TI推出的时间间隔测量芯片,分辨率低至55ps,标准差35ps,低功耗模式,最多可计数5个停止脉冲,最小工作负40度摄氏度。芯片介绍 引脚说明 我们将结合官方手册说明介绍其引脚(1)ENABLE使能引脚,根据手册,该引脚为高电平时芯片使能。(2)TRIGG触发引脚) ,按照说明书,芯片上电使能后,会一直保持低电平,当我们初始化后进入测试环节时,该引脚会被拉低,芯片接收到START脉冲后,该引脚被拉低低。(3、4)STA
wpf结合java_如何使用WPF绑定RelativeSource?_ 风神理性博客-程序员的秘密
当我们试图将一个对象的一个属性绑定到该对象本身的另一个属性时,RelativeSource 是一个标记扩展,当我们试图将一个对象的一个属性绑定到其相对父级的另一个属性时,在特定的绑定情况下使用自定义控件开发时绑定一个依赖属性值到一段XAML,最后在绑定数据使用一系列差异的情况下。所有这些情况都表示为相对源模式。我将一一揭露所有这些案例。模式自我:想象一下这种情况,我们想要一个高度总是等于宽度的矩形......
@Data_Max_Tsui 博客的使用 - 程序员的秘密
这里写一个自定义的目录标题@Data使用新的更改功能快捷键创建一个合理的标题,有助于目录的生成如何更改文本的样式插入链接和图片如何插入漂亮的代码片段生成一个列表适合你创建表格设置内容居中、左、右 SmartyPants 创建自定义列表 如何创建脚注注释也是 KaTeX 数学公式必不可少的新甘特图功能,丰富您的 文章UML 图 FLowchart 流程图 导出和 Import Export Import Import @Data 使用 @d...
TCP 和 UDP_caiyec 的博客 - 程序员的秘密
提示:文章写好后可以自动生成目录,如何生成可以参考右边的帮助文档TCP和UDP前言一、什么是UDP?二、什么是 TCP?1.库介绍2.TCP和UDP的区别总结介绍目前我们常用的计算机网络架构是TCP/IP五层网络结构自上而下为应用层,传输层,网络层,数据链路层,物理层,今天介绍的TCP和UDP是传输层的两个协议。传输层负责端到端的数据传输,传输层由操作系统内核实现。一、什么是UDP?首先,UDP是传输层的协议。
线程安全——从StringBuffer和StringBuilder的区别看 - 程序员大本营
面试的时候,面试官问了线程安全问题,感觉回答不太满意。那个时候,我没有好好回答。我问面试官如何理解它。他说:可以参考StringBuffer和StringBuilder。所以赶紧回来自己弥补。这是学渣的苦果/(ㄒoㄒ)/~~线程安全概念线程安全:多线程访问时,使用了锁机制。当一个线程访问这个类的某个数据时,它是受保护的。在线程读完之前,其他线程无法访问它,其他线程也无法使用它。没有出现
文章采集规则(在设置织梦采集规则的时候,有哪些注意事项?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-03 18:07
在这个日益浮躁的社会中,越来越多的人期望事情变得越来越容易。尤其是在瞬息万变的互联网时代,需要时间去思考的东西是不适合的。以网站操作为例,虽然完整的原创文章对网站优化排名很有帮助,但是网站操作的写法大部分能力是不高,加上题材的限制和时间的规律性,完全通过原创和人工操作和优化一个网站是非常困难的,尤其是对于一些信息类型网站、商城类型网站、视频类型网站等此类页面类型网站,内容更新要求快,无论是内容建设,还是外链发布,都是一项庞大而复杂的任务,无论是从时间上还是从成本上,手工去做都不划算。因此,有时我们需要借助一些工具。采集工具就是其中之一。
目前网站采集中最常用的采集工具是优采云采集工具和织梦自己的dede采集工具,采集网上有很多工具的优劣对比,百度一下就知道了,网上也有很多织梦采集规则设置的攻略,都差不多,所以本文就不多解释了,有兴趣的童鞋可以自行搜索看看。今天要和大家分享的是,设置织梦采集规则有哪些注意事项?
一、采集开始和结束代码设置
在织梦采集规则设置中,很重要的一步就是采集开始码和结束码的设置。一般是一小段代码,主要是“数字/英文+符号”的形式。代码越短,越不容易出错,并且需要唯一性,以便机器能够快速识别采集的开始和结束位置。在线教程中,这个起停代码一般是一个完整的段落,比如[content],这里是开始采集的位置,[content]代表需要采集的部分信息,是end采集 位置,很多人会误以为起止代码一定是一个完整的段落,其实不然。
如下图二:
代码的某一部分,甚至是混有中文的代码,也可以作为采集的起止码,可以去掉一些网站内容,上面带有网站特殊标识开始和结束。
二、标题采集设置
标题采集很简单,有两种方式,如下图所示:
在需要采集的页面右击选择“查看源代码”,在打开的页面中使用快捷键Ctrl+F,在搜索中输入采集的内容标题显示查看它的栏。页面的标题规则一般是标题标签和H标签,数量从1到4不等。一般页面上两种标题标签并存。在这种情况下,使用 H 标记比标题标记 采集 更不容易出错。
需要注意的是,有时H标签有H1标签、H2标签、H3标签等,一般只使用H1标签。
三、分页织梦采集规则设置
有的网站经常因为文章篇幅过长或者想提高点击率,把一篇文章文章分成几页呈现。在这种情况下,采集的起始码和结束码不在同一个页面,但是采集起始码应该在文章起始页上找到,结束码应该是在 文章 end page 找到,设置如下:
四、可能导致 采集 失败的几个因素
1、网站禁止隐藏内容采集。以腾讯新闻为例,腾讯新闻的内容不会在开源代码页展示,所以无法确定文章的起止位置,也无法确定采集对其< @网站 内容。
2、网站采集错误。网站 的大部分内容在页面和代码中看起来都很好,但是当 采集 转到目标网站 时会显示错误。此类错误分为几类:
A. 标题错误。如下图所示,文章的内容会集中在标题上。
B、只有采集去标题,内容为空。也就是说,无法采集到相关内容。
C、采集的终止符无效,采集的内容包括采集网站上张贴的广告/版权信息/页脚信息等信息。
这些都是采集中经常遇到的问题,理解它们对采集和伪原创会有很大帮助。虽然我们不推荐使用 采集 方法进行优化,但如有必要,了解 织梦采集 规则将有利于 网站 操作。. 查看全部
文章采集规则(在设置织梦采集规则的时候,有哪些注意事项?)
在这个日益浮躁的社会中,越来越多的人期望事情变得越来越容易。尤其是在瞬息万变的互联网时代,需要时间去思考的东西是不适合的。以网站操作为例,虽然完整的原创文章对网站优化排名很有帮助,但是网站操作的写法大部分能力是不高,加上题材的限制和时间的规律性,完全通过原创和人工操作和优化一个网站是非常困难的,尤其是对于一些信息类型网站、商城类型网站、视频类型网站等此类页面类型网站,内容更新要求快,无论是内容建设,还是外链发布,都是一项庞大而复杂的任务,无论是从时间上还是从成本上,手工去做都不划算。因此,有时我们需要借助一些工具。采集工具就是其中之一。
目前网站采集中最常用的采集工具是优采云采集工具和织梦自己的dede采集工具,采集网上有很多工具的优劣对比,百度一下就知道了,网上也有很多织梦采集规则设置的攻略,都差不多,所以本文就不多解释了,有兴趣的童鞋可以自行搜索看看。今天要和大家分享的是,设置织梦采集规则有哪些注意事项?
一、采集开始和结束代码设置
在织梦采集规则设置中,很重要的一步就是采集开始码和结束码的设置。一般是一小段代码,主要是“数字/英文+符号”的形式。代码越短,越不容易出错,并且需要唯一性,以便机器能够快速识别采集的开始和结束位置。在线教程中,这个起停代码一般是一个完整的段落,比如[content],这里是开始采集的位置,[content]代表需要采集的部分信息,是end采集 位置,很多人会误以为起止代码一定是一个完整的段落,其实不然。
如下图二:
代码的某一部分,甚至是混有中文的代码,也可以作为采集的起止码,可以去掉一些网站内容,上面带有网站特殊标识开始和结束。
二、标题采集设置
标题采集很简单,有两种方式,如下图所示:
在需要采集的页面右击选择“查看源代码”,在打开的页面中使用快捷键Ctrl+F,在搜索中输入采集的内容标题显示查看它的栏。页面的标题规则一般是标题标签和H标签,数量从1到4不等。一般页面上两种标题标签并存。在这种情况下,使用 H 标记比标题标记 采集 更不容易出错。
需要注意的是,有时H标签有H1标签、H2标签、H3标签等,一般只使用H1标签。
三、分页织梦采集规则设置
有的网站经常因为文章篇幅过长或者想提高点击率,把一篇文章文章分成几页呈现。在这种情况下,采集的起始码和结束码不在同一个页面,但是采集起始码应该在文章起始页上找到,结束码应该是在 文章 end page 找到,设置如下:
四、可能导致 采集 失败的几个因素
1、网站禁止隐藏内容采集。以腾讯新闻为例,腾讯新闻的内容不会在开源代码页展示,所以无法确定文章的起止位置,也无法确定采集对其< @网站 内容。
2、网站采集错误。网站 的大部分内容在页面和代码中看起来都很好,但是当 采集 转到目标网站 时会显示错误。此类错误分为几类:
A. 标题错误。如下图所示,文章的内容会集中在标题上。
B、只有采集去标题,内容为空。也就是说,无法采集到相关内容。
C、采集的终止符无效,采集的内容包括采集网站上张贴的广告/版权信息/页脚信息等信息。
这些都是采集中经常遇到的问题,理解它们对采集和伪原创会有很大帮助。虽然我们不推荐使用 采集 方法进行优化,但如有必要,了解 织梦采集 规则将有利于 网站 操作。.
文章采集规则( 优采云运营2个月最高IP一天达到6000+,可见源码模板优化非常好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-04-03 00:23
优采云运营2个月最高IP一天达到6000+,可见源码模板优化非常好)
也想来这里吗?点击联系我~
源码介绍:作者亲自操作小说系统2个月,每天最高IP达到6000+。可以看出源码模板优化的非常好,适合优采云操作,因为完全没有管理,就买了一些朋友链。
盈利方式:变现的方式也很简单,就是做广告,如果你有几千个IP就可以做广告,申请谷歌+百度+搜狗等联盟广告,每月几千元,做不来很多钱,但赚一点钱就可以了。
服务器系统:Linux+Centos7.0以上+宝塔
PHP扩展:宝塔上直接安装扩展【fileinfo + memcache】安装好后重载+重启PHP即可
亲测环境:Nginx1.16.1+PHP5.6+Mysql5.5
有安装程序配置好环境直接访问域名即可
Nginx伪静态
location / {
if (!-e $request_filename){
rewrite ^(.*)$ /index.php?s=$1 last; break;
}
}
注意:打开后台如果报404,需打开网站根目录的index.php,在倒数第2行添加:
define('APP_DEBUG',true);
并在正常访问后,将这段代码删除。
如果要更多采集规则 百度搜索:PTCMS采集规则
资源下载 本资源仅供注册用户下载,请先登录 查看全部
文章采集规则(
优采云运营2个月最高IP一天达到6000+,可见源码模板优化非常好)
也想来这里吗?点击联系我~
源码介绍:作者亲自操作小说系统2个月,每天最高IP达到6000+。可以看出源码模板优化的非常好,适合优采云操作,因为完全没有管理,就买了一些朋友链。
盈利方式:变现的方式也很简单,就是做广告,如果你有几千个IP就可以做广告,申请谷歌+百度+搜狗等联盟广告,每月几千元,做不来很多钱,但赚一点钱就可以了。
服务器系统:Linux+Centos7.0以上+宝塔
PHP扩展:宝塔上直接安装扩展【fileinfo + memcache】安装好后重载+重启PHP即可
亲测环境:Nginx1.16.1+PHP5.6+Mysql5.5
有安装程序配置好环境直接访问域名即可
Nginx伪静态
location / {
if (!-e $request_filename){
rewrite ^(.*)$ /index.php?s=$1 last; break;
}
}
注意:打开后台如果报404,需打开网站根目录的index.php,在倒数第2行添加:
define('APP_DEBUG',true);
并在正常访问后,将这段代码删除。
如果要更多采集规则 百度搜索:PTCMS采集规则
资源下载 本资源仅供注册用户下载,请先登录
文章采集规则(带你认识9个营销工具系列教程的第三篇)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-02 12:05
文章采集规则的设计目的在于进行差异化采集,可以为后期的高效精准获取内容做铺垫。但是对于初学者或者是跨行业行业工作人员,肯定不清楚今天的规则是否正确。本文为我们初次推出的“带你认识9个营销工具”系列教程的第三篇。很多企业都在用移动应用举办市场活动。由于大部分移动应用每天都会推送超过80亿条内容信息。很多内容被采集目的都是展示。
这就需要转化为商业价值。也就是说要先做清楚的实际需求是什么。经常被互联网企业所忽略的内容采集工具1.印象笔记·印象笔记拥有强大的语义整理能力,优化了他的用户体验,即便你没有使用过印象笔记,印象笔记同步所有内容依然是非常容易的。而且该系统会收集每一条使用过的笔记。有人说印象笔记不是一个内容采集工具,但是它也是一个内容整理工具。
我所说的内容并不是单纯意义上的来源于网络。更多的是报纸杂志。或者正规媒体。对于其他材料也许是采集的通路。但是对于知识,你可以通过整理笔记来获取知识并且将其实践。虽然过程长,但是知识的价值更高。2.quora·和印象笔记一样,这是全球领先的网络问答社区。作为内容的收集中心,quora会定期从媒体中抓取信息并聚集在一起。
你每一次创建quora帐户都将会收集一定数量的信息,你可以通过查看第一条回答获取所有内容,当你对某一领域产生兴趣时还可以将热门话题从全世界中挖掘出来。这可以帮助你及时了解其他领域的内容,便于你拓展你的知识库。当然了你也可以将原有用户关注的问题、在quora上有赞同的答案、链接等内容放在你的笔记本中,提升内容发掘和内容聚合的能力。
3.美图秀秀·互联网人绝对不陌生美图秀秀,它将每一个摄影师想要保存的原始图片都浓缩在一个软件里。并且一键保存到指定的服务器。自从美图秀秀将内容采集工具发布以来就一直被各种文章的撰稿人使用。这在一定程度上减轻了编辑的工作。只要输入你想要的图片,就可以很方便的获取到你需要的原始图片。特别对于新手而言是非常容易。
在输入图片时,只需要按照顺序组织好文字,图片和一些注释。这些图片就会自动生成。为美图秀秀提供超过300万名供稿人,他们分布在广告投放、图片制作和传播,插画设计,美术教学、在线课程、策划制作等领域。即便你不喜欢美图秀秀,你也可以拿着这样一份美图秀秀的笔记去寻找自己喜欢的文章。美图秀秀通过大量的千万级别用户提供内容。
比如最近的日本花火大会。8月的北京啤酒厂——久保佳一的作品。以及4月的第二届釜山电影节——宝树的作品。已经有超过4000名作者关注图片或者是美化作品, 查看全部
文章采集规则(带你认识9个营销工具系列教程的第三篇)
文章采集规则的设计目的在于进行差异化采集,可以为后期的高效精准获取内容做铺垫。但是对于初学者或者是跨行业行业工作人员,肯定不清楚今天的规则是否正确。本文为我们初次推出的“带你认识9个营销工具”系列教程的第三篇。很多企业都在用移动应用举办市场活动。由于大部分移动应用每天都会推送超过80亿条内容信息。很多内容被采集目的都是展示。
这就需要转化为商业价值。也就是说要先做清楚的实际需求是什么。经常被互联网企业所忽略的内容采集工具1.印象笔记·印象笔记拥有强大的语义整理能力,优化了他的用户体验,即便你没有使用过印象笔记,印象笔记同步所有内容依然是非常容易的。而且该系统会收集每一条使用过的笔记。有人说印象笔记不是一个内容采集工具,但是它也是一个内容整理工具。
我所说的内容并不是单纯意义上的来源于网络。更多的是报纸杂志。或者正规媒体。对于其他材料也许是采集的通路。但是对于知识,你可以通过整理笔记来获取知识并且将其实践。虽然过程长,但是知识的价值更高。2.quora·和印象笔记一样,这是全球领先的网络问答社区。作为内容的收集中心,quora会定期从媒体中抓取信息并聚集在一起。
你每一次创建quora帐户都将会收集一定数量的信息,你可以通过查看第一条回答获取所有内容,当你对某一领域产生兴趣时还可以将热门话题从全世界中挖掘出来。这可以帮助你及时了解其他领域的内容,便于你拓展你的知识库。当然了你也可以将原有用户关注的问题、在quora上有赞同的答案、链接等内容放在你的笔记本中,提升内容发掘和内容聚合的能力。
3.美图秀秀·互联网人绝对不陌生美图秀秀,它将每一个摄影师想要保存的原始图片都浓缩在一个软件里。并且一键保存到指定的服务器。自从美图秀秀将内容采集工具发布以来就一直被各种文章的撰稿人使用。这在一定程度上减轻了编辑的工作。只要输入你想要的图片,就可以很方便的获取到你需要的原始图片。特别对于新手而言是非常容易。
在输入图片时,只需要按照顺序组织好文字,图片和一些注释。这些图片就会自动生成。为美图秀秀提供超过300万名供稿人,他们分布在广告投放、图片制作和传播,插画设计,美术教学、在线课程、策划制作等领域。即便你不喜欢美图秀秀,你也可以拿着这样一份美图秀秀的笔记去寻找自己喜欢的文章。美图秀秀通过大量的千万级别用户提供内容。
比如最近的日本花火大会。8月的北京啤酒厂——久保佳一的作品。以及4月的第二届釜山电影节——宝树的作品。已经有超过4000名作者关注图片或者是美化作品,
文章采集规则(文章采集规则有些第三方抓取平台规则会相对比较多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-04-02 11:04
文章采集规则有些第三方抓取平台规则会相对比较多,如何将其进行有效筛选是第一要务。至于seo流量,呵呵,那是多年积累的roi和带来的用户,到时候公司财大气粗了一场活动或者运营策略定好了,百度有钱任性就必须给好处了。你懂的,如何解决?自己先做一个。
既然出钱,一般还会考虑使用售后服务,这里的售后服务有2个层面:1、每天登录量的上升,可能是用户从来不登录,这个是关键指标,估计如果只是单纯引流,用户的转化率不会太好,如果是seo引流,质量可能会比较高,这样能保证长期的增长,加速产品的推广,保证口碑和积累用户;2、转化率,这个需要整合资源,购买一些服务和工具,还有数据分析等,例如通过百度等搜索引擎引流的时候,自己能以行业数据或产品作为分析依据,分析哪些用户是对产品感兴趣的,有利于整合资源,实现用户转化。希望对你有帮助。
seo的目的是为了提高搜索引擎排名,所以搜索引擎的排名是最核心的指标。我们搜索引擎的数据越多越好,所以做seo前必须需要使用seo的工具进行数据分析,然后再根据数据得出我们需要优化的地方,并提升推广数据,
要说seo目的,我认为最核心的应该就是seo能够带来订单量,大于seo的成本(这个成本跟你的平台粘性也有关系)或者是拉低平台的广告收入,毕竟广告是在中国是不挣钱的,而且基本上是非法的。在这个前提下进行seo排名能够看出网站主体受众数和质量,毕竟,seo排名靠前的,都是有共性的网站(好吧,这句不是我说的,但是不可避免要用到),且公司都会将自己的网站优化到全网民都习惯的位置。
但是,我相信聪明的你应该已经懂了,现在同行竞争挺激烈的,所以要想做好seo必须降低转化率跟投入产出比,而如何降低转化率与降低投入产出比才是核心问题。(seo降低转化率的话可以找到精准客户群体,即便是刚入行的seo,我们也不能将排名第一放在第一页,否则会分散网站主体的流量)基于这个问题,我有一个思路,既然要做seo,就要做出点差异化的优势,相比于别人的优势,关键词能够做到top20之类的。好吧,希望能帮到你。 查看全部
文章采集规则(文章采集规则有些第三方抓取平台规则会相对比较多)
文章采集规则有些第三方抓取平台规则会相对比较多,如何将其进行有效筛选是第一要务。至于seo流量,呵呵,那是多年积累的roi和带来的用户,到时候公司财大气粗了一场活动或者运营策略定好了,百度有钱任性就必须给好处了。你懂的,如何解决?自己先做一个。
既然出钱,一般还会考虑使用售后服务,这里的售后服务有2个层面:1、每天登录量的上升,可能是用户从来不登录,这个是关键指标,估计如果只是单纯引流,用户的转化率不会太好,如果是seo引流,质量可能会比较高,这样能保证长期的增长,加速产品的推广,保证口碑和积累用户;2、转化率,这个需要整合资源,购买一些服务和工具,还有数据分析等,例如通过百度等搜索引擎引流的时候,自己能以行业数据或产品作为分析依据,分析哪些用户是对产品感兴趣的,有利于整合资源,实现用户转化。希望对你有帮助。
seo的目的是为了提高搜索引擎排名,所以搜索引擎的排名是最核心的指标。我们搜索引擎的数据越多越好,所以做seo前必须需要使用seo的工具进行数据分析,然后再根据数据得出我们需要优化的地方,并提升推广数据,
要说seo目的,我认为最核心的应该就是seo能够带来订单量,大于seo的成本(这个成本跟你的平台粘性也有关系)或者是拉低平台的广告收入,毕竟广告是在中国是不挣钱的,而且基本上是非法的。在这个前提下进行seo排名能够看出网站主体受众数和质量,毕竟,seo排名靠前的,都是有共性的网站(好吧,这句不是我说的,但是不可避免要用到),且公司都会将自己的网站优化到全网民都习惯的位置。
但是,我相信聪明的你应该已经懂了,现在同行竞争挺激烈的,所以要想做好seo必须降低转化率跟投入产出比,而如何降低转化率与降低投入产出比才是核心问题。(seo降低转化率的话可以找到精准客户群体,即便是刚入行的seo,我们也不能将排名第一放在第一页,否则会分散网站主体的流量)基于这个问题,我有一个思路,既然要做seo,就要做出点差异化的优势,相比于别人的优势,关键词能够做到top20之类的。好吧,希望能帮到你。
文章采集规则(公众号文章数据采集与处理的优化应对与应对)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-01 19:06
公众号文章资料采集和处理无处不在。并且数量庞大。我们目前处于数据爆炸的时代,数据采集和处理一直伴随着我们。无论是网站论坛、公众号文章还是朋友圈,每天都会产生数亿条数据、文章、内容等。
通过数据采集和处理工具,我们可以采集到我们需要采集的公众号文章的数据。将其保存在本地以进行数据分析或二次创建。
数据采集及处理工具操作简单,页面简洁方便。我们只需要鼠标点击即可完成采集的配置,然后启动目标网站采集。支持采集资源标签保留(更好的保存格式)、过滤原文中敏感词(去除电话号码、地址等)、去除原图水印等
有时网页抓取还不够;通常需要更深入地挖掘和分析数据,以揭示数据背后的真正含义并发现有价值的见解。数据和内容的分析利用可以说与我们的工作生活息息相关。
以网站SEO为例,通过数据分析,我们可以统计出网站每天的流量变化和页面跳出率,得出我们在某些环节的网站不足之处。数据还可以用于采集分析竞争对手排名关键词与我们之间的差距,以便我们及时调整,做出更好的优化响应。
当然,如果你不喜欢使用工具,我们也可以自己打代码来完成这部分工作:
第一步是通过创建蜘蛛从目标中抓取内容:
为了保存数据,以 Facebook 为例,我们将定义一个收录三个字段的项目:“title”、“content”和“stars”:
importscrapy
classFacebookSentimentItem(scrapy.Item):
title=scrapy.Field()
content=scrapy.Field()
stars=scrapy.Field()
我们还创建了一个蜘蛛来填充这些项目。我们为页面提供的起始 URL。
importscrapy
来自Facebook_sentiment.itemsimportFacebookSentimentItem
类目标蜘蛛(scrapy.Spider):
name="目标"
start_urls=[域名]
然后我们定义一个函数来解析单个内容并保存其数据:
defparse_review(self,response):
item=FacebookSentimentItem()
item['title']=response.xpath('//div[@class="quote"]/text()').extract()[0][1:-1]#stripthequotes(firstandlastchar)
item['content']=response.xpath('//div[@class="entry"]/p/text()').extract()[0]
item['stars']=response.xpath('//span[@class="ratesprite-rating_srating_s"]/img/@alt').extract()[0]
退货
之后,我们定义一个函数来解析内容页面,然后传递页面。我们会注意到,在内容页面上,我们看不到整个内容,而只是开始。我们将通过单击指向完整内容的链接并使用 parse_review 从该页面抓取数据来解决此问题:
defparse_Facebook(self,response):
forhrefinresponse.xpath('//div[@class="quote"]/a/@href'):
url=response.urljoin(href.extract())
yieldscrapy.Request(url,callback=self.parse_review)
next_page=response.xpath('//div[@class="unifiedpagination"]/child::*[2][self::a]/@href')
ifnext_page:
url=response.urljoin(next_page[0].extract())
yieldscrapy.Request(url,self.parse_Facebook)
最后,我们定义主解析函数,它会从主页面开始,解析其所有内容:
defparse(self,response):
forhrefinresponse.xpath('//div[@class="listing_title"]/a/@href'):
url=response.urljoin(href.extract())
yieldscrapy.Request(url,callback=self.parse_Facebook)
next_page=response.xpath('//div[@class="unifiedpaginationstandard_pagination"]/child::*[2][self::a]/@href')
ifnext_page:
url=response.urljoin(next_page[0].extract())
yieldscrapy.Request(url,self.parse)
所以,对于内容:我们告诉蜘蛛从主页开始,点击每条内容的链接,然后抓取数据。完成每一页后,它会得到下一页,所以它可以抓取我们需要的尽可能多的内容。
可见,通过代码处理我们的数据采集不仅复杂,还需要更多的专业知识。在网站优化方面,还是要坚持最优解。数据采集的共享和处理到此结束。如有不同意见,请留言讨论。 查看全部
文章采集规则(公众号文章数据采集与处理的优化应对与应对)
公众号文章资料采集和处理无处不在。并且数量庞大。我们目前处于数据爆炸的时代,数据采集和处理一直伴随着我们。无论是网站论坛、公众号文章还是朋友圈,每天都会产生数亿条数据、文章、内容等。
通过数据采集和处理工具,我们可以采集到我们需要采集的公众号文章的数据。将其保存在本地以进行数据分析或二次创建。
数据采集及处理工具操作简单,页面简洁方便。我们只需要鼠标点击即可完成采集的配置,然后启动目标网站采集。支持采集资源标签保留(更好的保存格式)、过滤原文中敏感词(去除电话号码、地址等)、去除原图水印等
有时网页抓取还不够;通常需要更深入地挖掘和分析数据,以揭示数据背后的真正含义并发现有价值的见解。数据和内容的分析利用可以说与我们的工作生活息息相关。
以网站SEO为例,通过数据分析,我们可以统计出网站每天的流量变化和页面跳出率,得出我们在某些环节的网站不足之处。数据还可以用于采集分析竞争对手排名关键词与我们之间的差距,以便我们及时调整,做出更好的优化响应。
当然,如果你不喜欢使用工具,我们也可以自己打代码来完成这部分工作:
第一步是通过创建蜘蛛从目标中抓取内容:
为了保存数据,以 Facebook 为例,我们将定义一个收录三个字段的项目:“title”、“content”和“stars”:
importscrapy
classFacebookSentimentItem(scrapy.Item):
title=scrapy.Field()
content=scrapy.Field()
stars=scrapy.Field()
我们还创建了一个蜘蛛来填充这些项目。我们为页面提供的起始 URL。
importscrapy
来自Facebook_sentiment.itemsimportFacebookSentimentItem
类目标蜘蛛(scrapy.Spider):
name="目标"
start_urls=[域名]
然后我们定义一个函数来解析单个内容并保存其数据:
defparse_review(self,response):
item=FacebookSentimentItem()
item['title']=response.xpath('//div[@class="quote"]/text()').extract()[0][1:-1]#stripthequotes(firstandlastchar)
item['content']=response.xpath('//div[@class="entry"]/p/text()').extract()[0]
item['stars']=response.xpath('//span[@class="ratesprite-rating_srating_s"]/img/@alt').extract()[0]
退货
之后,我们定义一个函数来解析内容页面,然后传递页面。我们会注意到,在内容页面上,我们看不到整个内容,而只是开始。我们将通过单击指向完整内容的链接并使用 parse_review 从该页面抓取数据来解决此问题:
defparse_Facebook(self,response):
forhrefinresponse.xpath('//div[@class="quote"]/a/@href'):
url=response.urljoin(href.extract())
yieldscrapy.Request(url,callback=self.parse_review)
next_page=response.xpath('//div[@class="unifiedpagination"]/child::*[2][self::a]/@href')
ifnext_page:
url=response.urljoin(next_page[0].extract())
yieldscrapy.Request(url,self.parse_Facebook)
最后,我们定义主解析函数,它会从主页面开始,解析其所有内容:
defparse(self,response):
forhrefinresponse.xpath('//div[@class="listing_title"]/a/@href'):
url=response.urljoin(href.extract())
yieldscrapy.Request(url,callback=self.parse_Facebook)
next_page=response.xpath('//div[@class="unifiedpaginationstandard_pagination"]/child::*[2][self::a]/@href')
ifnext_page:
url=response.urljoin(next_page[0].extract())
yieldscrapy.Request(url,self.parse)
所以,对于内容:我们告诉蜘蛛从主页开始,点击每条内容的链接,然后抓取数据。完成每一页后,它会得到下一页,所以它可以抓取我们需要的尽可能多的内容。
可见,通过代码处理我们的数据采集不仅复杂,还需要更多的专业知识。在网站优化方面,还是要坚持最优解。数据采集的共享和处理到此结束。如有不同意见,请留言讨论。
文章采集规则(为什么要采集公众号的文章?免费!效果如何一试!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-31 18:09
首先,为什么要采集公众号的文章?
想必大家在生活中也经常关注公众号,所以公众号的内容丰富多彩。作为曾经是公众号的运营商,文章公众号的质量无论如何都特别优质。素材、文章整体框架、文章内容均精准垂直,公众号原创大于80%。大多数作家都有自己的经验和技能。
如何采集公众号文章?
对于不懂代码的小白来说,采集公众号的文章最简单的方法是复制粘贴,使用其他采集工具,编辑规则,所以对于小白来说很不友好,有没有傻瓜式的采集软件?直接进入关键词采集公众号文章。
所以这次我要介绍的是傻瓜式采集软件,你只需要输入关键词就可以实现采集。方便快捷。
公众号采集流程
1、输入关键词(例如:装修),可以采集到今日头条、公众号文章、百度网页、百度新闻、搜狗网页、搜狗新闻、批量< @关键词全自动采集。
2、智能采集 无需编写复杂规则。
3、采集优质内容
4、最简单最聪明的文章采集器,关键是它是免费的!自由!自由!试一试,看看它是如何工作的!
5、文章采集器不用写规则,大家都可以用采集软件
现在大家都知道“内容为王”。为了优化网站,大家疯狂写文章,但是每天的输出量却很少。一些优化器认为 原创文章 不是那么重要。为了使网站的文章更新频率快,将采用文章采集的方法。很多人的采集 内容太垃圾了。搜索引擎能识别出质量太差,文章的权重比例自然无法提高,也会面临各种处罚。所以采集来源很重要!! 查看全部
文章采集规则(为什么要采集公众号的文章?免费!效果如何一试!)
首先,为什么要采集公众号的文章?
想必大家在生活中也经常关注公众号,所以公众号的内容丰富多彩。作为曾经是公众号的运营商,文章公众号的质量无论如何都特别优质。素材、文章整体框架、文章内容均精准垂直,公众号原创大于80%。大多数作家都有自己的经验和技能。
如何采集公众号文章?
对于不懂代码的小白来说,采集公众号的文章最简单的方法是复制粘贴,使用其他采集工具,编辑规则,所以对于小白来说很不友好,有没有傻瓜式的采集软件?直接进入关键词采集公众号文章。
所以这次我要介绍的是傻瓜式采集软件,你只需要输入关键词就可以实现采集。方便快捷。
公众号采集流程
1、输入关键词(例如:装修),可以采集到今日头条、公众号文章、百度网页、百度新闻、搜狗网页、搜狗新闻、批量< @关键词全自动采集。
2、智能采集 无需编写复杂规则。
3、采集优质内容
4、最简单最聪明的文章采集器,关键是它是免费的!自由!自由!试一试,看看它是如何工作的!
5、文章采集器不用写规则,大家都可以用采集软件
现在大家都知道“内容为王”。为了优化网站,大家疯狂写文章,但是每天的输出量却很少。一些优化器认为 原创文章 不是那么重要。为了使网站的文章更新频率快,将采用文章采集的方法。很多人的采集 内容太垃圾了。搜索引擎能识别出质量太差,文章的权重比例自然无法提高,也会面临各种处罚。所以采集来源很重要!!
文章采集规则(一个批量采集知乎文章的方法有哪些?聚沙计划第二节)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-03-30 16:06
在互联网上创造内容就是创造流量,但是我们很多人知识储备非常有限,写不出更好的文章,很多人认为原创文章很费力,所以不要长时间强迫自己。
此时我们只需要做两件事。
采集——改编……
当今互联网上拥有更多优质内容的几个平台是知乎、公众号和头条。
尤其是知乎文章上有很多高质量的答案。这时候如果我们想把其中的一些文章整理出来,一一复制,那就太费力了。
所以,在巨鲨项目的第二部分,我会告诉你一个采集知乎文章的批处理方法。按照这个方法,可以采集组织知乎大量高质量的文章。
这些文章无论是发布流量还是适配网站,效果都很好。
当你把很多优质内容组织起来,改编和内化,这些文章就属于你的知识了,以后就是你的流量子弹。
网盘里有详细的视频教程以及采集工具和采集规则,可以直接手动使用,跟着教程走。在后续的项目教程中,可以使用这些工具的知识。有兴趣的直接去会员网站下载观看吧!
付费隐藏内容
这里的内容需要权限才能查看
观看价格:¥398 / 永久VIP会员免费
付费查看免费打开VIP视图
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。
知乎采集教程采集规则 查看全部
文章采集规则(一个批量采集知乎文章的方法有哪些?聚沙计划第二节)
在互联网上创造内容就是创造流量,但是我们很多人知识储备非常有限,写不出更好的文章,很多人认为原创文章很费力,所以不要长时间强迫自己。
此时我们只需要做两件事。
采集——改编……
当今互联网上拥有更多优质内容的几个平台是知乎、公众号和头条。
尤其是知乎文章上有很多高质量的答案。这时候如果我们想把其中的一些文章整理出来,一一复制,那就太费力了。
所以,在巨鲨项目的第二部分,我会告诉你一个采集知乎文章的批处理方法。按照这个方法,可以采集组织知乎大量高质量的文章。
这些文章无论是发布流量还是适配网站,效果都很好。
当你把很多优质内容组织起来,改编和内化,这些文章就属于你的知识了,以后就是你的流量子弹。
网盘里有详细的视频教程以及采集工具和采集规则,可以直接手动使用,跟着教程走。在后续的项目教程中,可以使用这些工具的知识。有兴趣的直接去会员网站下载观看吧!
付费隐藏内容
这里的内容需要权限才能查看
观看价格:¥398 / 永久VIP会员免费
付费查看免费打开VIP视图
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。
知乎采集教程采集规则
文章采集规则(买卖易资源网-狂雨小说CMS安装搭建常见问题汇总采集导入方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 564 次浏览 • 2022-03-29 22:00
你好!大家好,这里是资源买卖网站。
今天,TradingEasy 教你如何制作小说网——狂雨小说。
小说下载地址:
施工注意事项:
雨天小说cms安装施工常见问题汇总
采集导入方法,狂鱼小说的采集规则本身并没有导入这个函数,我们只能在mysql中操作。很简单,直接上教程。
1.大部分朋友使用的宝塔面板,以宝塔为例,先进入mysql界面。
2.单击 网站 的数据库 - 单击 SQL
3.复制下载的采集规则——点击执行
4.打开狂雨小说cms背景-资料采集-采集管理-点击采集
5.渲染()
资源下载 本资源下载价格为1易币即买,VIP即刻免费升级
如果下载地址无效,请联系客服。
本资源为虚拟重现,下载后不退不换,感谢您的支持!
我们以专业级共享为基础,实力雄厚。我们欢迎从未离开的朋友。你的出现,会让我更加强大!我们将继续为您提供更好的资源!相信我们,您不会失望的!
下载
下载价格 1 Easy Coin
VIP免费升级VIP
立即购买
如果下载地址无效,请联系客服。
本资源为虚拟重现,下载后不退不换,感谢您的支持!
我们以专业级共享为基础,实力雄厚。我们欢迎从未离开的朋友。你的出现,会让我更加强大!我们将继续为您提供更好的资源!相信我们,您不会失望的! 查看全部
文章采集规则(买卖易资源网-狂雨小说CMS安装搭建常见问题汇总采集导入方法)
你好!大家好,这里是资源买卖网站。
今天,TradingEasy 教你如何制作小说网——狂雨小说。
小说下载地址:
施工注意事项:
雨天小说cms安装施工常见问题汇总
采集导入方法,狂鱼小说的采集规则本身并没有导入这个函数,我们只能在mysql中操作。很简单,直接上教程。
1.大部分朋友使用的宝塔面板,以宝塔为例,先进入mysql界面。
2.单击 网站 的数据库 - 单击 SQL
3.复制下载的采集规则——点击执行
4.打开狂雨小说cms背景-资料采集-采集管理-点击采集
5.渲染()
资源下载 本资源下载价格为1易币即买,VIP即刻免费升级
如果下载地址无效,请联系客服。
本资源为虚拟重现,下载后不退不换,感谢您的支持!
我们以专业级共享为基础,实力雄厚。我们欢迎从未离开的朋友。你的出现,会让我更加强大!我们将继续为您提供更好的资源!相信我们,您不会失望的!
下载
下载价格 1 Easy Coin
VIP免费升级VIP
立即购买
如果下载地址无效,请联系客服。
本资源为虚拟重现,下载后不退不换,感谢您的支持!
我们以专业级共享为基础,实力雄厚。我们欢迎从未离开的朋友。你的出现,会让我更加强大!我们将继续为您提供更好的资源!相信我们,您不会失望的!
文章采集规则(小旋风蜘蛛池如何采集句子及文章添加规则的全套教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2022-03-28 00:01
本文是小旋风蜘蛛池编写后台采集规则的一套完整教程。如果您可以使用 优采云采集器 或 优采云采集器,请跳过本教程。简单易用。
本文仅以X6版小旋风蜘蛛池为例。有任何问题可以在文末留言。
一、小旋风蜘蛛池怎么弄采集标题
题库采集还是很简单的,只需要设置源采集的地址即可。
首先添加 采集 规则,选择 文章 标题。
分页书写:
标记
http://roll.news.sina.com.cn/n ... ndex_{p,1,9,1}.shtml
{p,1,5,1}表示分页,参数:p后面的数字代表开始、结束、递增/递减值,即{p,start,end,递增/递减值}
标记
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
测试规则时可以从 URL 匹配中看到。添加后,测试看看效果:
二、小旋风蜘蛛池怎么样采集句子和文章
添加规则:选择整个内容或句子段落
比如我们要采集新浪新闻,地址是:,只需在列表配置选项的匹配URL中填写上述地址即可。
打开 采集 来源的地址并选择一条新闻。复制其链接地址。
这是地址:
那么,内容匹配规则可以这样写
标记
https://news.sina.com.cn/(w)/(d)-(d)-(d)/(w)-(w).shtml
内容拦截规则:
打开内容地址。右键查看源代码,找到内容区。
那么内容拦截规则可以这样写:
对于像新浪这样的大型网站,它的内容页面有些不同,我们可以写更多的匹配。
保存后,看看效果。
注意:您的 采集 句子和 文章 将自动 采集 链接到图片,所以不用担心您的内容库中没有图片!
本文由网友投稿或由“牛牛源码网”整理自互联网。如需转载,请注明出处:
如果本站发布的内容侵犯了您的权益,请联系zhangqy2022#删除,我们会及时处理! 查看全部
文章采集规则(小旋风蜘蛛池如何采集句子及文章添加规则的全套教程)
本文是小旋风蜘蛛池编写后台采集规则的一套完整教程。如果您可以使用 优采云采集器 或 优采云采集器,请跳过本教程。简单易用。
本文仅以X6版小旋风蜘蛛池为例。有任何问题可以在文末留言。
一、小旋风蜘蛛池怎么弄采集标题
题库采集还是很简单的,只需要设置源采集的地址即可。
首先添加 采集 规则,选择 文章 标题。
分页书写:
标记
http://roll.news.sina.com.cn/n ... ndex_{p,1,9,1}.shtml
{p,1,5,1}表示分页,参数:p后面的数字代表开始、结束、递增/递减值,即{p,start,end,递增/递减值}
标记
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
http://roll.news.sina.com.cn/n ... shtml
测试规则时可以从 URL 匹配中看到。添加后,测试看看效果:
二、小旋风蜘蛛池怎么样采集句子和文章
添加规则:选择整个内容或句子段落
比如我们要采集新浪新闻,地址是:,只需在列表配置选项的匹配URL中填写上述地址即可。
打开 采集 来源的地址并选择一条新闻。复制其链接地址。
这是地址:
那么,内容匹配规则可以这样写
标记
https://news.sina.com.cn/(w)/(d)-(d)-(d)/(w)-(w).shtml
内容拦截规则:
打开内容地址。右键查看源代码,找到内容区。
那么内容拦截规则可以这样写:
对于像新浪这样的大型网站,它的内容页面有些不同,我们可以写更多的匹配。
保存后,看看效果。
注意:您的 采集 句子和 文章 将自动 采集 链接到图片,所以不用担心您的内容库中没有图片!
本文由网友投稿或由“牛牛源码网”整理自互联网。如需转载,请注明出处:
如果本站发布的内容侵犯了您的权益,请联系zhangqy2022#删除,我们会及时处理!
文章采集规则( 147SEO2022-03-22文章采集软件,主要功能就是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-03-26 13:01
147SEO2022-03-22文章采集软件,主要功能就是)
文章采集软件,免费文章采集,文章自动采集
147SEO2022-03-22
文章采集软件,它的主要功能是帮助站长采集网站的文章资源在网上发布,然后发布到指定的cms ,获得点击,站长可以自定义采集对象,自由设置采集规则,采集效率也很稳定。文章采集网站站长软件可以自动采集目标站点的文字,提供相似词替换功能,还支持站长自定义关键词@ >替换,有效提升文章伪原创度,让采集的内容质量更高。
文章采集软件不断更新网站的内容,主要反映网站不断发展和完善的基本情况。无论网站面对的是搜索引擎还是用户群,总是需要不断创造或容纳更多的内容,不断扩大网站的体量,才能让网站接收到更多注意力。其中,网站文章更新频率高,但收录量少,成为站长的一大痛点,因为在一定概率下,很多网站有“准死亡”是什么意思?表示网站no收录,快照没有更新,但是网站一直保持更新频率,但是收录 速度慢,没有排名,这种现象一般来说站长都会更换三大标签,更换网站模板。如果没有效果,他们只能放弃。
对于网站,文章采集软件保持一定的文章更新频率,主要体现在增强蜘蛛的活跃度,其作用是促进网站收录,加快网站参与排名的步伐。排名就像一个战场,如果你落后,你就会被打败。而一个更新频率稳定、质量高的文章、良好的布局网站、标准的设置关键词@>的网站对SEO优化有着深远的影响。毕竟对于SEO来说,关键词@>@文章采集软件推广网站主要体现在思维和排名上。当一个站点保持一定的更新频率时,网站或网站的收录情况开始,
文章采集软件页面优化是确保网站上的实际代码和内容得到优化的过程。这包括确保网站管理员的网站具有正确的标题标签、描述标签和独特的内容。正确构造数据以使其易于被搜索引擎读取也很重要。站外优化是建立指向网站的外部链接的过程。最好的办法是让文章采集软件在站长的网站的相关页面上找到实际链接,这是真实的内容,有合适的实际链接到与行业相关的 网站 并在所有主要社交媒体 网站 和目录中列出。
文章采集虽然软件是其他网站的采集或者伪原创文章,但是它是被选中并有效推送的,而不是单纯的采集。文章采集虽然软件是采集,但文章的质量可以让用户满意,归根结底还是擅长采集。
文章采集软件通过自然的方法排名网站并不难,主要是SEO需要花更多的精力充实自己和网站,发送文章@ > 当然可行,主要看你发帖的方式和内容。文章采集软件网站优化,主要是克服网站前期的总困难,大幅提升网站的整体和谐度,长路不恒优化的修复,当然不代表不修复,只是不适合前期不断变化。 查看全部
文章采集规则(
147SEO2022-03-22文章采集软件,主要功能就是)
文章采集软件,免费文章采集,文章自动采集
147SEO2022-03-22
文章采集软件,它的主要功能是帮助站长采集网站的文章资源在网上发布,然后发布到指定的cms ,获得点击,站长可以自定义采集对象,自由设置采集规则,采集效率也很稳定。文章采集网站站长软件可以自动采集目标站点的文字,提供相似词替换功能,还支持站长自定义关键词@ >替换,有效提升文章伪原创度,让采集的内容质量更高。
文章采集软件不断更新网站的内容,主要反映网站不断发展和完善的基本情况。无论网站面对的是搜索引擎还是用户群,总是需要不断创造或容纳更多的内容,不断扩大网站的体量,才能让网站接收到更多注意力。其中,网站文章更新频率高,但收录量少,成为站长的一大痛点,因为在一定概率下,很多网站有“准死亡”是什么意思?表示网站no收录,快照没有更新,但是网站一直保持更新频率,但是收录 速度慢,没有排名,这种现象一般来说站长都会更换三大标签,更换网站模板。如果没有效果,他们只能放弃。
对于网站,文章采集软件保持一定的文章更新频率,主要体现在增强蜘蛛的活跃度,其作用是促进网站收录,加快网站参与排名的步伐。排名就像一个战场,如果你落后,你就会被打败。而一个更新频率稳定、质量高的文章、良好的布局网站、标准的设置关键词@>的网站对SEO优化有着深远的影响。毕竟对于SEO来说,关键词@>@文章采集软件推广网站主要体现在思维和排名上。当一个站点保持一定的更新频率时,网站或网站的收录情况开始,
文章采集软件页面优化是确保网站上的实际代码和内容得到优化的过程。这包括确保网站管理员的网站具有正确的标题标签、描述标签和独特的内容。正确构造数据以使其易于被搜索引擎读取也很重要。站外优化是建立指向网站的外部链接的过程。最好的办法是让文章采集软件在站长的网站的相关页面上找到实际链接,这是真实的内容,有合适的实际链接到与行业相关的 网站 并在所有主要社交媒体 网站 和目录中列出。
文章采集虽然软件是其他网站的采集或者伪原创文章,但是它是被选中并有效推送的,而不是单纯的采集。文章采集虽然软件是采集,但文章的质量可以让用户满意,归根结底还是擅长采集。
文章采集软件通过自然的方法排名网站并不难,主要是SEO需要花更多的精力充实自己和网站,发送文章@ > 当然可行,主要看你发帖的方式和内容。文章采集软件网站优化,主要是克服网站前期的总困难,大幅提升网站的整体和谐度,长路不恒优化的修复,当然不代表不修复,只是不适合前期不断变化。
文章采集规则( 文章类的采集,图片集的另外找个时间来讲,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2022-03-24 01:09
文章类的采集,图片集的另外找个时间来讲,)
dedecms织梦采集规则编写教程文章课堂采集
游戏/数字网络 2017-07-28 22 浏览
织梦系统作为常用的文章系统,操作起来比较简单。在众多功能中,采集系统可能会让一些新手头疼。例如,采集 区域设置不正确。 采集 规则编辑不正确。 采集 为空白。今天我们将详细解释一些比较容易遇到的问题。 (今天主要讲文章类的采集,其他时候图片集会不一样。) 工具/材料自己的网站目标的网站@ > 方法/步骤首先我们登录后台,分别点击采集--采集节点管理,进入采集管理设置界面。这里有两种选择,一种是修改原节点(主要是之前的设置错误导致采集cannot or
织梦系统作为常用的文章系统,操作起来比较简单。在众多功能中,采集系统可能会让一些新手头疼,比如采集区域设置不正确,采集规则编辑不正确,采集空白等问题。今天我们将详细解释一些比较容易遇到的问题。 (今天主要讲文章类的采集,我会另找时间采集图片的,这个不一样)
工具/成分
方法/步骤
首先我们登录后台,点击采集--采集节点管理,进入采集管理设置界面
这里有两个选项,一个是修改原节点(主要是之前的设置错误导致采集失败或者其他设置),另一个是直接添加新节点,大部分主要是新建节点,点击,然后下一步,选择“Normal文章”确认。
然后填写节点名称(推荐为与列相关的名称,避免导入时出错),这个可以根据实际填写。那么第一点:目标页面编码。这是填写目标页面的代码,不是你自己的页面。查看方法:打开目标网站任意页面,在空白处右键-查看源代码(编码一般在前几行)
然后就是填写列表规则。一种是批量生成url,一般适用于规则性强或者需要采集自上而下的情况。例如,我们定位到此列:
首页列表:
第二页列表:.
这个列表规则最重要的就是找到相同点和不同点,把相同的点填上,不同的点用匹配的符号补充,也就是变量。其实通过这个对比我们可以知道,这里的.html也是一样的,所以变量是1.2.3.4.。 所以匹配的网址是:
(*).html.
另一种是列表规则是手动指定列表URL,比较流行。只需填写您需要的所有列表页面采集。 (只适用于采集某些页面或变量较多的页面)
注意:许多网站 栏目主页都以这种形式显示。与上述相比,我们发现缺少以下变量项。所以查找变量项的方法是:点击列表的下一页,如果还是不清楚再点击下一页,对比列表的第二页和第三页,我们也可以找到变量第 4 步中的项目。
这一步是获取列表下文章的所有地址,我们要从列表页面中获取所有文章页面地址。我们以:List 为例。复制列表中第一篇文章文章的标题,然后在列表页空白处右键--查看源码,按ctrl+F搜索,粘贴刚才复制的标题,找到在文本源代码中的位置。事实上,这是一定的规律。然后我们寻找源代码的哪一部分是唯一的,并且可以收录列表中所有的文章地址(注意:开始代码搜索应该从列表中第一个文章的标题开始,然后去向上,并结束代码搜索您应该从列表中第一篇文章的标题开始向下看文章)。从这个源代码可以看出。开始代码: 查看全部
文章采集规则(
文章类的采集,图片集的另外找个时间来讲,)
dedecms织梦采集规则编写教程文章课堂采集
游戏/数字网络 2017-07-28 22 浏览
织梦系统作为常用的文章系统,操作起来比较简单。在众多功能中,采集系统可能会让一些新手头疼。例如,采集 区域设置不正确。 采集 规则编辑不正确。 采集 为空白。今天我们将详细解释一些比较容易遇到的问题。 (今天主要讲文章类的采集,其他时候图片集会不一样。) 工具/材料自己的网站目标的网站@ > 方法/步骤首先我们登录后台,分别点击采集--采集节点管理,进入采集管理设置界面。这里有两种选择,一种是修改原节点(主要是之前的设置错误导致采集cannot or
织梦系统作为常用的文章系统,操作起来比较简单。在众多功能中,采集系统可能会让一些新手头疼,比如采集区域设置不正确,采集规则编辑不正确,采集空白等问题。今天我们将详细解释一些比较容易遇到的问题。 (今天主要讲文章类的采集,我会另找时间采集图片的,这个不一样)
工具/成分
方法/步骤
首先我们登录后台,点击采集--采集节点管理,进入采集管理设置界面
这里有两个选项,一个是修改原节点(主要是之前的设置错误导致采集失败或者其他设置),另一个是直接添加新节点,大部分主要是新建节点,点击,然后下一步,选择“Normal文章”确认。
然后填写节点名称(推荐为与列相关的名称,避免导入时出错),这个可以根据实际填写。那么第一点:目标页面编码。这是填写目标页面的代码,不是你自己的页面。查看方法:打开目标网站任意页面,在空白处右键-查看源代码(编码一般在前几行)
然后就是填写列表规则。一种是批量生成url,一般适用于规则性强或者需要采集自上而下的情况。例如,我们定位到此列:
首页列表:
第二页列表:.
这个列表规则最重要的就是找到相同点和不同点,把相同的点填上,不同的点用匹配的符号补充,也就是变量。其实通过这个对比我们可以知道,这里的.html也是一样的,所以变量是1.2.3.4.。 所以匹配的网址是:
(*).html.
另一种是列表规则是手动指定列表URL,比较流行。只需填写您需要的所有列表页面采集。 (只适用于采集某些页面或变量较多的页面)
注意:许多网站 栏目主页都以这种形式显示。与上述相比,我们发现缺少以下变量项。所以查找变量项的方法是:点击列表的下一页,如果还是不清楚再点击下一页,对比列表的第二页和第三页,我们也可以找到变量第 4 步中的项目。
这一步是获取列表下文章的所有地址,我们要从列表页面中获取所有文章页面地址。我们以:List 为例。复制列表中第一篇文章文章的标题,然后在列表页空白处右键--查看源码,按ctrl+F搜索,粘贴刚才复制的标题,找到在文本源代码中的位置。事实上,这是一定的规律。然后我们寻找源代码的哪一部分是唯一的,并且可以收录列表中所有的文章地址(注意:开始代码搜索应该从列表中第一个文章的标题开始,然后去向上,并结束代码搜索您应该从列表中第一篇文章的标题开始向下看文章)。从这个源代码可以看出。开始代码:
文章采集规则(网站优化是对用户的优化和内容可读性优化的重要性)
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2022-03-23 03:20
SEO是一项庞大而复杂的任务,称他为系统一点也不为过。SEO 过程已经从 网站 规划开始。无论是网站优化、流程优化还是维护优化,每一个环节都是相关的。网站SEO 的质量。
SEO是一项长期无聊的工作。SEOER除了保持对SEO的热情外,还需要学习SEO知识,掌握一些SEO技巧。通过SEO软件辅助我们完成工作是每个SEOER都需要掌握的能力,如图,对于一些重复性高的工作,我们可以用SEO软件来代替。
SEO软件有全网采集,在线翻译和本地伪原创,支持各种cms全平台发布,SEO软件有各种优化功能,无论是原创度或来自 关键词 密度,可配置。SEO软件支持全可视化操作,无需了解配置规则即可完成点击配置。(如图)
SEO的基本思想是通过对网站的功能、结构、布局、内容等关键环节的优化元素进行合理设计,使网站的功能和表达达到良好的效果。基本上包括三个方面:网站结构优化、SEO优化、内容可读性优化。
第一的。网站结构优化
通过网站基本要素的结构优化,真正实现SEO的综合效果。最大化结果不仅仅是获取单个关键词的搜索排名,还要处理页面中的大量问题。相关的关键词可以取得不错的搜索排名。用户搜索行为非常碎片化和庞大,有的用户搜索多个关键词组合,所以仅仅排名几个关键词是不够的,以获得良好的网站推广效果。优化网站的结构可以成为网站的搜索引擎,为网站后期运营推广过程中的优化奠定基础,获得更大的效益。
二、SEO优化部分
SEO专注于网站构建的基本要素的专业设计,使其适合用户获取信息和搜索引擎检索信息。网站优化是对用户的优化,也是对搜索引擎的优化。网站优化是一项系统的、整体的工作,以网络营销为导向,以网站建设理念为指导,对网站的基本要素进行设计,使网站更好的实现向用户传递在线营销信息的目的。
三、内容可读性优化
它不仅可以考虑搜索引擎的排名规则,还可以为用户获取信息和服务提供便利。提高网站内容的可读性是网站优化的一个重要原则。这也是搜索引擎优化。网站优化是一个以网络营销为导向的建设理念网站。网站基础元素的专业设计,是一项系统性、综合性的工作,旨在把网站做得更好更好。不仅要考虑搜索引擎的排名规则,还要为用户获取信息和服务。提供方便和提高网站内容的可读性是网站优化的重要规则。
1、图文结合的单页优化,可以提升网站的浏览体验,增加访问用户的停留时间,让文章的内容更加生动. 但是不代表我们的单页会添加很多图片,因为很多图片会占用网站的流量,拖慢我们页面的打开速度。一般来说,不能打开超过 8 秒的页面,难免会被访问用户关闭。
2.内容更新的单页优化需要一个稳定的周期来更新内容。我们推荐的方法是在每天的固定时间向这个单一页面添加一些内容。需要注意的是,文章的TDK一定不能修改。最好不要轻易修改文章前面的内容,以后继续添加内容就好。
3.网站优化,内外链接。为我们的单页做相关的内外部链接,可以让我们的单页排名更快。例如,如果你被介绍给某人,你肯定会很快成名。因此,在选择外部链接的时候,可以选择一些权重比较好的链接。
网站SEO 是一项需要坚持的工作。通过SEO软件,我们可以减轻部分工作强度,但是如前所述,SEO远不是软件所能涵盖的,只有我们不断学习和改进,在细节上不断优化,才能更好地完成工作搜索引擎优化。返回搜狐,查看更多 查看全部
文章采集规则(网站优化是对用户的优化和内容可读性优化的重要性)
SEO是一项庞大而复杂的任务,称他为系统一点也不为过。SEO 过程已经从 网站 规划开始。无论是网站优化、流程优化还是维护优化,每一个环节都是相关的。网站SEO 的质量。
SEO是一项长期无聊的工作。SEOER除了保持对SEO的热情外,还需要学习SEO知识,掌握一些SEO技巧。通过SEO软件辅助我们完成工作是每个SEOER都需要掌握的能力,如图,对于一些重复性高的工作,我们可以用SEO软件来代替。
SEO软件有全网采集,在线翻译和本地伪原创,支持各种cms全平台发布,SEO软件有各种优化功能,无论是原创度或来自 关键词 密度,可配置。SEO软件支持全可视化操作,无需了解配置规则即可完成点击配置。(如图)
SEO的基本思想是通过对网站的功能、结构、布局、内容等关键环节的优化元素进行合理设计,使网站的功能和表达达到良好的效果。基本上包括三个方面:网站结构优化、SEO优化、内容可读性优化。
第一的。网站结构优化
通过网站基本要素的结构优化,真正实现SEO的综合效果。最大化结果不仅仅是获取单个关键词的搜索排名,还要处理页面中的大量问题。相关的关键词可以取得不错的搜索排名。用户搜索行为非常碎片化和庞大,有的用户搜索多个关键词组合,所以仅仅排名几个关键词是不够的,以获得良好的网站推广效果。优化网站的结构可以成为网站的搜索引擎,为网站后期运营推广过程中的优化奠定基础,获得更大的效益。
二、SEO优化部分
SEO专注于网站构建的基本要素的专业设计,使其适合用户获取信息和搜索引擎检索信息。网站优化是对用户的优化,也是对搜索引擎的优化。网站优化是一项系统的、整体的工作,以网络营销为导向,以网站建设理念为指导,对网站的基本要素进行设计,使网站更好的实现向用户传递在线营销信息的目的。
三、内容可读性优化
它不仅可以考虑搜索引擎的排名规则,还可以为用户获取信息和服务提供便利。提高网站内容的可读性是网站优化的一个重要原则。这也是搜索引擎优化。网站优化是一个以网络营销为导向的建设理念网站。网站基础元素的专业设计,是一项系统性、综合性的工作,旨在把网站做得更好更好。不仅要考虑搜索引擎的排名规则,还要为用户获取信息和服务。提供方便和提高网站内容的可读性是网站优化的重要规则。
1、图文结合的单页优化,可以提升网站的浏览体验,增加访问用户的停留时间,让文章的内容更加生动. 但是不代表我们的单页会添加很多图片,因为很多图片会占用网站的流量,拖慢我们页面的打开速度。一般来说,不能打开超过 8 秒的页面,难免会被访问用户关闭。
2.内容更新的单页优化需要一个稳定的周期来更新内容。我们推荐的方法是在每天的固定时间向这个单一页面添加一些内容。需要注意的是,文章的TDK一定不能修改。最好不要轻易修改文章前面的内容,以后继续添加内容就好。
3.网站优化,内外链接。为我们的单页做相关的内外部链接,可以让我们的单页排名更快。例如,如果你被介绍给某人,你肯定会很快成名。因此,在选择外部链接的时候,可以选择一些权重比较好的链接。
网站SEO 是一项需要坚持的工作。通过SEO软件,我们可以减轻部分工作强度,但是如前所述,SEO远不是软件所能涵盖的,只有我们不断学习和改进,在细节上不断优化,才能更好地完成工作搜索引擎优化。返回搜狐,查看更多
文章采集规则(集搜客GooSeeker爬虫术语“主题”统一改为“任务” )
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2022-03-21 09:09
)
注意:从Jisouke GooSeeker爬虫V9.0.2版本开始,爬虫术语“主题”已更改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则。然后登录Jisoke官网会员中心的“任务管理”,可以查看采集任务的执行情况,管理线索的URL,进行调度设置。
一、操作步骤
今天教大家如何抓取搜狐新闻文章,重点是如何抓取全文内容,如何批量抓取更多新闻。方法通用,可以应用到其他新闻网站整体操作步骤如下:
二、案例+操作步骤
第一步,打开网页
1.1、打开Jisouke软件,输入网址回车,等待页面加载完毕,然后点击右上角的“定义规则”按钮,可以看到一个浮动窗口显示出来,这是一个工作台,下面定义的规则会在上面输出。
1.2,在工作台上输入主题名称,然后点击检查重复项。如果提示被占用,请更改名称以确保主题名称是唯一的。
第二步:标签信息
2.1、在浏览器窗口中用鼠标点击你要抓取的内容,这里是选中的新闻标题,然后你会看到整个标题变成了黄底红框闪烁框出这个范围,根据黄色范围检查是否有正确的信息。如果没有问题,再次点击弹出标签窗口。输入标签名称后,点击打勾保存或按回车键保存。需要输入规则中的第一个标签。整理出框的名称,确认后可以在右上角的工作台中看到输出数据结构;
2.2、按照前面的操作,也在网页上标注作者和发布时间;
2.3、下一步是标记文本。如果单击文本的某个段落,则只会选择该段落的范围。如果要抓取所有文本,则需要单击文本的部分。在空白处,你会看到文字全部被选中,再次点击进行标注映射;
PS:如果是其他网页,不需要点击空白处全选,可以点击其他位置,直到选中你想要的内容范围;
2.4、如果不能点击整个范围可以选择的位置,可以点击目标信息的一部分,底部的dom窗口会定位到对应的网页节点到该信息,然后点击收录该信息的节点 的每个上层节点,直到可以看到网页上所有范围都被选中;
2.5、然后右击节点,在快捷菜单中选择Content Mapping -> New Grab Content -> 输入标签名,此操作结果与上一步相同2.3 ;
第三步,保存规则,抓取数据
3.1、点击右侧测试按钮预览输出信息是否完整,如果没有问题点击右上角的保存按钮,然后点击“抓取数据”,将弹出一个 DS 计数器窗口,并开始捕获获取数据;
3.2、之前只抓到了一个网页新闻,很多人会问如何获取更多的新闻?很简单,只要网页结构和示例页面一样,就可以用这条规则来爬取信息。因此,我们可以将与该页面结构相同的其他搜狐新闻网站整理出来,然后添加到规则中。操作在柜台上右键规则,点击“Manage Leads”然后选择“Add”,将URL复制进去保存,然后点击规则旁边的“Single Search”,启动采集逐个。另外,还可以使用分层采集的方法来实现URL的自动导入。有关详细信息,请参阅“使用层次结构的 URL采集”。
第四步,转换成Excel表格
4.1,采集成功的数据会以xml文件的形式保存在电脑的DataScraperWorks文件夹中。点击左上角的文件菜单->存储路径找到文件夹的位置。
4.2、然后我们可以将采集中的xml文件压缩成一个zip压缩包,进入会员中心的规则管理,选择对应的规则,然后点击导入数据,选择压缩将一个好的 zip 存档导入其中。导入成功后,点击导出数据,即可下载下载的Excel文件。
查看全部
文章采集规则(集搜客GooSeeker爬虫术语“主题”统一改为“任务”
)
注意:从Jisouke GooSeeker爬虫V9.0.2版本开始,爬虫术语“主题”已更改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则。然后登录Jisoke官网会员中心的“任务管理”,可以查看采集任务的执行情况,管理线索的URL,进行调度设置。
一、操作步骤
今天教大家如何抓取搜狐新闻文章,重点是如何抓取全文内容,如何批量抓取更多新闻。方法通用,可以应用到其他新闻网站整体操作步骤如下:
二、案例+操作步骤
第一步,打开网页
1.1、打开Jisouke软件,输入网址回车,等待页面加载完毕,然后点击右上角的“定义规则”按钮,可以看到一个浮动窗口显示出来,这是一个工作台,下面定义的规则会在上面输出。
1.2,在工作台上输入主题名称,然后点击检查重复项。如果提示被占用,请更改名称以确保主题名称是唯一的。
第二步:标签信息
2.1、在浏览器窗口中用鼠标点击你要抓取的内容,这里是选中的新闻标题,然后你会看到整个标题变成了黄底红框闪烁框出这个范围,根据黄色范围检查是否有正确的信息。如果没有问题,再次点击弹出标签窗口。输入标签名称后,点击打勾保存或按回车键保存。需要输入规则中的第一个标签。整理出框的名称,确认后可以在右上角的工作台中看到输出数据结构;
2.2、按照前面的操作,也在网页上标注作者和发布时间;
2.3、下一步是标记文本。如果单击文本的某个段落,则只会选择该段落的范围。如果要抓取所有文本,则需要单击文本的部分。在空白处,你会看到文字全部被选中,再次点击进行标注映射;
PS:如果是其他网页,不需要点击空白处全选,可以点击其他位置,直到选中你想要的内容范围;
2.4、如果不能点击整个范围可以选择的位置,可以点击目标信息的一部分,底部的dom窗口会定位到对应的网页节点到该信息,然后点击收录该信息的节点 的每个上层节点,直到可以看到网页上所有范围都被选中;
2.5、然后右击节点,在快捷菜单中选择Content Mapping -> New Grab Content -> 输入标签名,此操作结果与上一步相同2.3 ;
第三步,保存规则,抓取数据
3.1、点击右侧测试按钮预览输出信息是否完整,如果没有问题点击右上角的保存按钮,然后点击“抓取数据”,将弹出一个 DS 计数器窗口,并开始捕获获取数据;
3.2、之前只抓到了一个网页新闻,很多人会问如何获取更多的新闻?很简单,只要网页结构和示例页面一样,就可以用这条规则来爬取信息。因此,我们可以将与该页面结构相同的其他搜狐新闻网站整理出来,然后添加到规则中。操作在柜台上右键规则,点击“Manage Leads”然后选择“Add”,将URL复制进去保存,然后点击规则旁边的“Single Search”,启动采集逐个。另外,还可以使用分层采集的方法来实现URL的自动导入。有关详细信息,请参阅“使用层次结构的 URL采集”。
第四步,转换成Excel表格
4.1,采集成功的数据会以xml文件的形式保存在电脑的DataScraperWorks文件夹中。点击左上角的文件菜单->存储路径找到文件夹的位置。
4.2、然后我们可以将采集中的xml文件压缩成一个zip压缩包,进入会员中心的规则管理,选择对应的规则,然后点击导入数据,选择压缩将一个好的 zip 存档导入其中。导入成功后,点击导出数据,即可下载下载的Excel文件。
文章采集规则(文章采集规则的重要性强调一次,scrapy难题之解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-03-20 17:03
文章采集规则是我编写的,并且是开源版本,更新到14.0版本。我认为,作为一个爬虫,最重要的是采集,而不是规则设计。因为规则设计的再好,爬过去看起来很美,实际上就是卡成一坨(甚至是系统bug)。另外,我认为很多爬虫采用“广告插入模拟用户访问工具”来爬取网页,而不是基于数据库的sqlalchemy。另外,我认为目前很多爬虫在采集数据的时候都有点傻,他们不知道有啥可以采集的数据,还傻傻的去统计有什么数据,于是多次采集数据,然后扔进去。这是不可取的。
爬虫目前几乎都是基于数据库的,我试着总结下本人爬虫一年来遇到的难题以及一些实现的经验,如有错误,烦请指正。我使用的框架是scrapy,在此之前,scrapy框架已经非常好用,在scrapy基础上可以很好的玩出很多花样,这里先讲下难题。一:scrapy难题之规则设计(规则的重要性强调一次)首先,规则对于爬虫来说,规则设计关系到爬虫是否能够顺利执行以及爬取的结果是否可靠,如果爬虫采用规则来编写爬虫,同时编写规则(rules)之前要先把整个网页变成最终的可爬取页面,这个工作我认为基本是不会让程序员去做的,整个网页要完成采集,还是需要程序员去完成的,对于规则的编写,这个就牵扯到需要采集某个链接上的第几页,几行代码也只能得到一个返回值,更换页数或者条件都会导致上一次爬取得到的页面链接出错,所以一般而言,使用scrapy采集网页时,必须有规则,上面也是例子。
scrapy难题之解决爬虫规则设计我觉得规则设计主要分为两种情况:全链接规则,动态规则(需要定义downloadconfig来决定post数量或者key数量)。例如我们可以通过downloadconfig决定post多少链接,然后程序员根据post来分配链接到全链接,每次爬取多少个页面,我认为这个是规则的关键。
而规则通常都是python来实现的,会用到解释器,比如tornado等。所以有时我会使用类似于python的multiprocessing模块来提高爬虫效率,同时比解释器更方便调用。下面讲下scrapy难题之规则实现代码(最好在scrapy/items.py文件中实现)具体流程如下:1.定义downloadconfig2.定义规则的名称,可以用动态规则名称。
3.定义采集数据的target,也就是filter,规则只会选择一个domain,如下图我定义的为4.定义filter的key(有5种类型(multiprocessing),正则表达式(re),字符串(split),json(outofjson())),规则将会被选择的链接通过key传递给downloadconfig,程序员在调用downloadconfig的时候会带入一个规则即multipro。 查看全部
文章采集规则(文章采集规则的重要性强调一次,scrapy难题之解决)
文章采集规则是我编写的,并且是开源版本,更新到14.0版本。我认为,作为一个爬虫,最重要的是采集,而不是规则设计。因为规则设计的再好,爬过去看起来很美,实际上就是卡成一坨(甚至是系统bug)。另外,我认为很多爬虫采用“广告插入模拟用户访问工具”来爬取网页,而不是基于数据库的sqlalchemy。另外,我认为目前很多爬虫在采集数据的时候都有点傻,他们不知道有啥可以采集的数据,还傻傻的去统计有什么数据,于是多次采集数据,然后扔进去。这是不可取的。
爬虫目前几乎都是基于数据库的,我试着总结下本人爬虫一年来遇到的难题以及一些实现的经验,如有错误,烦请指正。我使用的框架是scrapy,在此之前,scrapy框架已经非常好用,在scrapy基础上可以很好的玩出很多花样,这里先讲下难题。一:scrapy难题之规则设计(规则的重要性强调一次)首先,规则对于爬虫来说,规则设计关系到爬虫是否能够顺利执行以及爬取的结果是否可靠,如果爬虫采用规则来编写爬虫,同时编写规则(rules)之前要先把整个网页变成最终的可爬取页面,这个工作我认为基本是不会让程序员去做的,整个网页要完成采集,还是需要程序员去完成的,对于规则的编写,这个就牵扯到需要采集某个链接上的第几页,几行代码也只能得到一个返回值,更换页数或者条件都会导致上一次爬取得到的页面链接出错,所以一般而言,使用scrapy采集网页时,必须有规则,上面也是例子。
scrapy难题之解决爬虫规则设计我觉得规则设计主要分为两种情况:全链接规则,动态规则(需要定义downloadconfig来决定post数量或者key数量)。例如我们可以通过downloadconfig决定post多少链接,然后程序员根据post来分配链接到全链接,每次爬取多少个页面,我认为这个是规则的关键。
而规则通常都是python来实现的,会用到解释器,比如tornado等。所以有时我会使用类似于python的multiprocessing模块来提高爬虫效率,同时比解释器更方便调用。下面讲下scrapy难题之规则实现代码(最好在scrapy/items.py文件中实现)具体流程如下:1.定义downloadconfig2.定义规则的名称,可以用动态规则名称。
3.定义采集数据的target,也就是filter,规则只会选择一个domain,如下图我定义的为4.定义filter的key(有5种类型(multiprocessing),正则表达式(re),字符串(split),json(outofjson())),规则将会被选择的链接通过key传递给downloadconfig,程序员在调用downloadconfig的时候会带入一个规则即multipro。
文章采集规则(OA期刊介绍开放存取是不同于传统学术传播的一种全新机制)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-03-17 15:15
1、OA期刊介绍
开放存取(OA)或开放存取是国际学术界、出版界、图书馆和信息界为促进利用互联网免费传播科学研究成果而采取的行动。其宗旨是促进科学和人文信息的广泛交流,促进利用互联网进行科学交流和出版,提高科学研究的公众利用程度,确保科学信息的保存,提高科研效率。
开放获取是一种不同于传统学术传播的新机制。其核心特点是在尊重作者权益的前提下,利用互联网免费为用户提供学术信息和研究成果的全文服务。首先,开放获取是一种基于互联网的学术传播机制。互联网是开放获取所依赖的媒介形式。这是因为互联网的发展导致学术交流成本的降低,从而为学术信息的开放获取提供了可能。然而,媒体形式本身并不是区分开放获取与传统学术期刊出版的标志。目前,许多出版商提供在线数据库和电子期刊,但他们在营销策略中仍然使用传统的基于订阅的传播模式。其次,开放获取是一种免费提供全文信息服务的方式。在开放获取模式下,研究人员无需付费(包括个人或团体订阅)即可访问学术信息的全文。换言之,只要具备连接互联网的物理条件,研究人员就可以轻松访问学术信息的全文。从这个角度来看,仅仅是开放文档的基本书目信息并不是开放获取的体现。事实上,传统出版商经常允许用户免费浏览他们的摘要,这只是他们用来推广和销售全文服务的一种常见营销策略。其次,开放获取充分尊重作者的权益,不违背知识产权精神。基于开放获取分发的作品不一定是“公共领域作品”。它不要求作者放弃对作品的所有权利。作者可以根据不同的法律文本和许可协议(如知识共享协议)选择作品的版权。
自开放获取出现以来,OA 期刊和知识库迅速增长。目前,全球已有5225人、534家相关研究机构签署了布达佩斯开放获取倡议(BOAI)项目协议。
截止2010年,DOAJ(Directory of Open Access Journal)共有4953种OA期刊收录,其中2014年提供文章级浏览,共收录文章@ >384945 篇文章;在OpenDOAR(由英国诺丁汉大学和瑞典隆德大学图书馆于2005年2月联合创建的开放存取机构资源库和学科资源库目录检索系统)注册的OA仓库已达1620个。
目前,OA在中国还处于起步阶段。比如我国只有14个被DOAJ收录注册的OA期刊,只有7个被OpenDOAR注册的OA知识库。此外,用户对开放获取的认知度还很低,大部分用户从未听说过开放获取,很少有用户使用过开放获取资源。
2、OA期刊的实证分析
为了进一步验证本文提出的方法,具体实现了基于网页信息抽取的OA期刊资源采集系统的主要功能。(1)网页元素采集。使用JavaFX可视化组件WebView,实现资源选择和查询语句的自动生成,利用网页解析器Jsoup根据采集网页信息查询语句。具体来说,当WebView组件加载HTML内容时,会为每个节点添加一个事件监听器,当鼠标点击某个节点时,系统会将该节点分配给“org.w3c.dom”类型的变量。 Node”。Node类提供方法“getParentNode”获取当前节点的父节点,根据该路径可以递归地找到当前节点到网页根节点的路径。通过将路径中每个节点的标签名和属性值拼接成一个Jsoup可以识别的查询语句,然后使用Jsoup中的select方法处理采集节点的信息为采集,页面元素采集的工作就可以完成了。(2)半结构化文本信息提取。具体实现方法是使用用户标记的分隔符. ,然后根据分隔符的位置提取元数据字段信息。OA期刊网站通常将“年、卷、期”组合成一条短信,如“2017, vol39, no.1”,信息显示时先采集 这条文本信息作为网页元素,然后通过在文本中插入分隔符进行标记,将需要的采集信息与固定显示信息分开,即“{2017},vol{39 }, no.{1}" "2017" "39" "1" 是需要 采集, ", vol" ", no." 的信息。是固定的显示信息。
固定显示信息的内容通常不会改变。因此,可以根据固定显示信息的位置提取文本中的对应信息。(3)网页结构检查。根据规定要求的采集的必填字段,作为判断网页结构是否发生变化的标准,如果采集@收到必填字段>为空,则认为当前网页结构发生了变化,需要重新选择采集,如果文章的标题为必填项,则判断是否采集接收到的字段在页面元素采集中为空,如果为空,可能有两种情况:一种是当前页面没有这个字段,这个页面是脏页; 另一种是该字段存在于当前页面,但元数据采集规则不适用于当前页面,则可以判断该页面是结构变化后的页面。当必填字段为空时,系统无法识别情况,因此系统会将当前页面添加到结构更改页面链接数组中。本轮采集结束后,提取结构变化的网页链接数组的第一个链接显示在嵌入式浏览器中,用户判断该字段为空的情况。该系统为这两种情况提出了解决方案。对于第一个脏页的情况,直接跳过,将页面链接从结构变化的网页链接数组中删除;对于网页结构变化的第二种情况,结构改变后用户会重新选择页面上的元数据,新的采集规则被添加到原来的采集规则集中,系统会使用新的采集@ > 规则继续采集。这样2-3次往复就可以遍历网站的所有模板,然后采集到全数据,解决了OA期刊资源网页结构变化,不能被综合采集。
为验证基于网页信息抽取的OA期刊资源采集方法的有效性,本文选取国内外10个不遵循OAI-PMH的OA期刊网站协议作为 采集 的对象。爬虫脚本采集10个OA期刊的论文链接数,作为采集个数综合性的标准。测试结果见表5。从表5可以看出,从采集到10个期刊的45785篇论文共45785篇,采集的时间为31039秒。其中,4个期刊的网页结构发生了变化。从系统测试结果可以看出,基于网页信息抽取的OA期刊资源采集方法可以灵活响应采集 不同的 OA 期刊资源。在准确率上,该方法可以准确地采集单个资源和固定文本结构的组合资源,表明它可以应用于OA期刊资源采集的工作。基于网页信息抽取的OA期刊资源采集系统的网页结构检测可以准确识别网页结构变化,并对结构变化后的资源进行采集。除了部分OA期刊网站无法访问或没有详细信息外,采集收到的论文数与爬虫脚本统计的论文链接数一致。从采集的时间来看,1000篇文章的采集平均时间为678秒。一般来说, 查看全部
文章采集规则(OA期刊介绍开放存取是不同于传统学术传播的一种全新机制)
1、OA期刊介绍
开放存取(OA)或开放存取是国际学术界、出版界、图书馆和信息界为促进利用互联网免费传播科学研究成果而采取的行动。其宗旨是促进科学和人文信息的广泛交流,促进利用互联网进行科学交流和出版,提高科学研究的公众利用程度,确保科学信息的保存,提高科研效率。
开放获取是一种不同于传统学术传播的新机制。其核心特点是在尊重作者权益的前提下,利用互联网免费为用户提供学术信息和研究成果的全文服务。首先,开放获取是一种基于互联网的学术传播机制。互联网是开放获取所依赖的媒介形式。这是因为互联网的发展导致学术交流成本的降低,从而为学术信息的开放获取提供了可能。然而,媒体形式本身并不是区分开放获取与传统学术期刊出版的标志。目前,许多出版商提供在线数据库和电子期刊,但他们在营销策略中仍然使用传统的基于订阅的传播模式。其次,开放获取是一种免费提供全文信息服务的方式。在开放获取模式下,研究人员无需付费(包括个人或团体订阅)即可访问学术信息的全文。换言之,只要具备连接互联网的物理条件,研究人员就可以轻松访问学术信息的全文。从这个角度来看,仅仅是开放文档的基本书目信息并不是开放获取的体现。事实上,传统出版商经常允许用户免费浏览他们的摘要,这只是他们用来推广和销售全文服务的一种常见营销策略。其次,开放获取充分尊重作者的权益,不违背知识产权精神。基于开放获取分发的作品不一定是“公共领域作品”。它不要求作者放弃对作品的所有权利。作者可以根据不同的法律文本和许可协议(如知识共享协议)选择作品的版权。
自开放获取出现以来,OA 期刊和知识库迅速增长。目前,全球已有5225人、534家相关研究机构签署了布达佩斯开放获取倡议(BOAI)项目协议。
截止2010年,DOAJ(Directory of Open Access Journal)共有4953种OA期刊收录,其中2014年提供文章级浏览,共收录文章@ >384945 篇文章;在OpenDOAR(由英国诺丁汉大学和瑞典隆德大学图书馆于2005年2月联合创建的开放存取机构资源库和学科资源库目录检索系统)注册的OA仓库已达1620个。
目前,OA在中国还处于起步阶段。比如我国只有14个被DOAJ收录注册的OA期刊,只有7个被OpenDOAR注册的OA知识库。此外,用户对开放获取的认知度还很低,大部分用户从未听说过开放获取,很少有用户使用过开放获取资源。
2、OA期刊的实证分析
为了进一步验证本文提出的方法,具体实现了基于网页信息抽取的OA期刊资源采集系统的主要功能。(1)网页元素采集。使用JavaFX可视化组件WebView,实现资源选择和查询语句的自动生成,利用网页解析器Jsoup根据采集网页信息查询语句。具体来说,当WebView组件加载HTML内容时,会为每个节点添加一个事件监听器,当鼠标点击某个节点时,系统会将该节点分配给“org.w3c.dom”类型的变量。 Node”。Node类提供方法“getParentNode”获取当前节点的父节点,根据该路径可以递归地找到当前节点到网页根节点的路径。通过将路径中每个节点的标签名和属性值拼接成一个Jsoup可以识别的查询语句,然后使用Jsoup中的select方法处理采集节点的信息为采集,页面元素采集的工作就可以完成了。(2)半结构化文本信息提取。具体实现方法是使用用户标记的分隔符. ,然后根据分隔符的位置提取元数据字段信息。OA期刊网站通常将“年、卷、期”组合成一条短信,如“2017, vol39, no.1”,信息显示时先采集 这条文本信息作为网页元素,然后通过在文本中插入分隔符进行标记,将需要的采集信息与固定显示信息分开,即“{2017},vol{39 }, no.{1}" "2017" "39" "1" 是需要 采集, ", vol" ", no." 的信息。是固定的显示信息。
固定显示信息的内容通常不会改变。因此,可以根据固定显示信息的位置提取文本中的对应信息。(3)网页结构检查。根据规定要求的采集的必填字段,作为判断网页结构是否发生变化的标准,如果采集@收到必填字段>为空,则认为当前网页结构发生了变化,需要重新选择采集,如果文章的标题为必填项,则判断是否采集接收到的字段在页面元素采集中为空,如果为空,可能有两种情况:一种是当前页面没有这个字段,这个页面是脏页; 另一种是该字段存在于当前页面,但元数据采集规则不适用于当前页面,则可以判断该页面是结构变化后的页面。当必填字段为空时,系统无法识别情况,因此系统会将当前页面添加到结构更改页面链接数组中。本轮采集结束后,提取结构变化的网页链接数组的第一个链接显示在嵌入式浏览器中,用户判断该字段为空的情况。该系统为这两种情况提出了解决方案。对于第一个脏页的情况,直接跳过,将页面链接从结构变化的网页链接数组中删除;对于网页结构变化的第二种情况,结构改变后用户会重新选择页面上的元数据,新的采集规则被添加到原来的采集规则集中,系统会使用新的采集@ > 规则继续采集。这样2-3次往复就可以遍历网站的所有模板,然后采集到全数据,解决了OA期刊资源网页结构变化,不能被综合采集。
为验证基于网页信息抽取的OA期刊资源采集方法的有效性,本文选取国内外10个不遵循OAI-PMH的OA期刊网站协议作为 采集 的对象。爬虫脚本采集10个OA期刊的论文链接数,作为采集个数综合性的标准。测试结果见表5。从表5可以看出,从采集到10个期刊的45785篇论文共45785篇,采集的时间为31039秒。其中,4个期刊的网页结构发生了变化。从系统测试结果可以看出,基于网页信息抽取的OA期刊资源采集方法可以灵活响应采集 不同的 OA 期刊资源。在准确率上,该方法可以准确地采集单个资源和固定文本结构的组合资源,表明它可以应用于OA期刊资源采集的工作。基于网页信息抽取的OA期刊资源采集系统的网页结构检测可以准确识别网页结构变化,并对结构变化后的资源进行采集。除了部分OA期刊网站无法访问或没有详细信息外,采集收到的论文数与爬虫脚本统计的论文链接数一致。从采集的时间来看,1000篇文章的采集平均时间为678秒。一般来说,
文章采集规则(WordPress采集的完整词不能分拆做锚文本是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-03-17 00:00
WordPress采集,通过在全网对应的关键词中搜索文章,进行全网文章采集。可以快速大量填充网站的内容,丰富网站的文章数据库。这为网站增加收录提供了基本条件,可以为网站关键词的排名提供相应的帮助,所以内容建设是网站@的第一点> ,而WordPress采集是为了帮助站长优化网站的文章内容,增加网站的文章内容数量。
WordPress采集的文章会自动修改标题和内容,目的是为了减少在搜索引擎中的重复,修改后不能将原文的意思改得面目全非,这样它就会丢失。以伪原创的初衷,内容的修改和写作一定要有一个中心思想,内容不能再更改。文章 更改标题以匹配文章 的内容和用户的阅读习惯,从而达到伪原创 意想不到的效果。
WordPress采集 的完整单词不能拆分为锚文本。例如,有些词已经是一个名字。虽然也可以进行切分,但是切分后就失去了原来的意义,所以不能切分。有很多时间我们都喜欢拆分完整的单词,所以这是不正确的。如果一个页面上有多个关键词,则只有一个链接是第一个。当一个页面出现多个关键词时,只需要一个链接。链接多个链接只会浪费资源,链接太多也会被认为是过度优化导致网站降低权重,得不偿失。
WordPress采集自创功能第一段:自动写文章首页的开场介绍,文章首页的介绍前120字可以打一个在被搜索引擎搜索到的页面中起到很大的作用收录,如果你有精力看文章,知道大意的可以写开篇介绍,也可以自己加入网站 的 关键词 在这里。在文本中插入锚文本链接:你应该知道锚文本是什么,它的作用可以帮助提高相关的关键词排名。但是,添加锚文本必须对用户有用。如果没用,最好不要添加。
WordPress采集自动添加图片或视频:文章带有图片可以更好的说明问题,容易抓住用户的注意力,增加在页面的停留时间,但是添加图片是为了表达并解决用户问题。基于。虽然目前大部分搜索引擎无法读取图片的内容,但是图片中的alt属性是可以识别的,合适的图片会让搜索引擎焕然一新。我认为您的 文章 是高质量的新 文章,当然还有视频添加。
WordPress采集 然后按段落替换:即相互替换内容的顺序,但注意不要影响原文的阅读。但是,这种方法并不适合所有人,不应该使用逻辑 文章。结尾自创:把整个文章做个总结,看起来比较连贯。其实对于搜索引擎优化来说,不仅是这些内容,小技巧也是要注意的,所以不仅要能做到,而且要能思考,能从别人那里推断,才能更快的提高和进步。 查看全部
文章采集规则(WordPress采集的完整词不能分拆做锚文本是什么?)
WordPress采集,通过在全网对应的关键词中搜索文章,进行全网文章采集。可以快速大量填充网站的内容,丰富网站的文章数据库。这为网站增加收录提供了基本条件,可以为网站关键词的排名提供相应的帮助,所以内容建设是网站@的第一点> ,而WordPress采集是为了帮助站长优化网站的文章内容,增加网站的文章内容数量。
WordPress采集的文章会自动修改标题和内容,目的是为了减少在搜索引擎中的重复,修改后不能将原文的意思改得面目全非,这样它就会丢失。以伪原创的初衷,内容的修改和写作一定要有一个中心思想,内容不能再更改。文章 更改标题以匹配文章 的内容和用户的阅读习惯,从而达到伪原创 意想不到的效果。
WordPress采集 的完整单词不能拆分为锚文本。例如,有些词已经是一个名字。虽然也可以进行切分,但是切分后就失去了原来的意义,所以不能切分。有很多时间我们都喜欢拆分完整的单词,所以这是不正确的。如果一个页面上有多个关键词,则只有一个链接是第一个。当一个页面出现多个关键词时,只需要一个链接。链接多个链接只会浪费资源,链接太多也会被认为是过度优化导致网站降低权重,得不偿失。
WordPress采集自创功能第一段:自动写文章首页的开场介绍,文章首页的介绍前120字可以打一个在被搜索引擎搜索到的页面中起到很大的作用收录,如果你有精力看文章,知道大意的可以写开篇介绍,也可以自己加入网站 的 关键词 在这里。在文本中插入锚文本链接:你应该知道锚文本是什么,它的作用可以帮助提高相关的关键词排名。但是,添加锚文本必须对用户有用。如果没用,最好不要添加。
WordPress采集自动添加图片或视频:文章带有图片可以更好的说明问题,容易抓住用户的注意力,增加在页面的停留时间,但是添加图片是为了表达并解决用户问题。基于。虽然目前大部分搜索引擎无法读取图片的内容,但是图片中的alt属性是可以识别的,合适的图片会让搜索引擎焕然一新。我认为您的 文章 是高质量的新 文章,当然还有视频添加。
WordPress采集 然后按段落替换:即相互替换内容的顺序,但注意不要影响原文的阅读。但是,这种方法并不适合所有人,不应该使用逻辑 文章。结尾自创:把整个文章做个总结,看起来比较连贯。其实对于搜索引擎优化来说,不仅是这些内容,小技巧也是要注意的,所以不仅要能做到,而且要能思考,能从别人那里推断,才能更快的提高和进步。
文章采集规则(台州SEO培训网站优化教程(采集站的日益多见))
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-15 12:10
台州SEO培训网站优化教程。越来越多的采集站使得百度一次次攻击采集站,所以很多权重非常高的采集站倒下了,但采集并没有恶意垃圾邮件采集,只要采集的内容是优质的,网站有一定数量的原创文章,采集不会使 网站 降级正确。今天小小课堂分享的内容是“台州SEO培训网站优化(优采云常用采集规则)”。我希望能有所帮助。
一、网址采集规则
以中国新闻网为例。要想写好URL采集的规则,就需要了解正则表达式。如果这样不好,那就去一个宝藏几十块钱,找专业人士写一个。
二、内容采集规则
在内容采集规则中,我们需要得到两个内容,一个是标题内容,一个是文章主题内容。
1、标题内容
根据页面获取的html和css截取title内容。开始字符串和结束字符串的中间部分是标题。除了标题,我们还要修改标题,一般像你打算自己发布的这个自动采集和文章,你必须修改标题。修改标题的方法一般是插入单词,缩短标题的长度。插入词的方式可以在标题的前面、中间和后面,前后插入不会影响阅读体验。但是会有插曲,但也有很多采集台在标题中选择了插曲。
2、文章主题内容
文章主题内容和标题类似,都是用字符串截取的,但不同的是数据处理需要处理那些没价值的标签,还有我们不想看到的标签,比如一个标签。理论上,关键词也应该插入到主题内容中,但也可能不插入。随意插入关键词可能会导致采集原来的文章中的图片无法正常显示。. 建议在某些标签之前或文本的开头和结尾处插入。
以上是小小课堂分享的内容为《台州SEO培训网站优化(优采云常用采集规则)》。谢谢阅读。
本文最后更新时间:2022 年 2 月 28 日 查看全部
文章采集规则(台州SEO培训网站优化教程(采集站的日益多见))
台州SEO培训网站优化教程。越来越多的采集站使得百度一次次攻击采集站,所以很多权重非常高的采集站倒下了,但采集并没有恶意垃圾邮件采集,只要采集的内容是优质的,网站有一定数量的原创文章,采集不会使 网站 降级正确。今天小小课堂分享的内容是“台州SEO培训网站优化(优采云常用采集规则)”。我希望能有所帮助。
一、网址采集规则
以中国新闻网为例。要想写好URL采集的规则,就需要了解正则表达式。如果这样不好,那就去一个宝藏几十块钱,找专业人士写一个。
https://xxkt.org.cn/wp-content ... 63285 300w, https://xxkt.org.cn/wp-content ... 63285 768w" />二、内容采集规则
在内容采集规则中,我们需要得到两个内容,一个是标题内容,一个是文章主题内容。
1、标题内容
根据页面获取的html和css截取title内容。开始字符串和结束字符串的中间部分是标题。除了标题,我们还要修改标题,一般像你打算自己发布的这个自动采集和文章,你必须修改标题。修改标题的方法一般是插入单词,缩短标题的长度。插入词的方式可以在标题的前面、中间和后面,前后插入不会影响阅读体验。但是会有插曲,但也有很多采集台在标题中选择了插曲。
https://xxkt.org.cn/wp-content ... 63472 300w, https://xxkt.org.cn/wp-content ... 63472 768w" />2、文章主题内容
文章主题内容和标题类似,都是用字符串截取的,但不同的是数据处理需要处理那些没价值的标签,还有我们不想看到的标签,比如一个标签。理论上,关键词也应该插入到主题内容中,但也可能不插入。随意插入关键词可能会导致采集原来的文章中的图片无法正常显示。. 建议在某些标签之前或文本的开头和结尾处插入。
https://xxkt.org.cn/wp-content ... 63514 300w, https://xxkt.org.cn/wp-content ... 63514 768w" />以上是小小课堂分享的内容为《台州SEO培训网站优化(优采云常用采集规则)》。谢谢阅读。
本文最后更新时间:2022 年 2 月 28 日

