文章采集规则(集搜客GooSeeker爬虫术语“主题”统一改为“任务” )
优采云 发布时间: 2022-03-21 09:09文章采集规则(集搜客GooSeeker爬虫术语“主题”统一改为“任务”
)
注意:从Jisouke GooSeeker爬虫V9.0.2版本开始,爬虫术语“主题”已更改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则。然后登录Jisoke官网会员中心的“任务管理”,可以查看采集任务的执行情况,管理线索的URL,进行调度设置。
一、操作步骤
今天教大家如何抓取搜狐新闻文章,重点是如何抓取全文内容,如何批量抓取更多新闻。方法通用,可以应用到其他新闻网站整体操作步骤如下:
二、案例+操作步骤
第一步,打开网页
1.1、打开Jisouke软件,输入网址回车,等待页面加载完毕,然后点击右上角的“定义规则”按钮,可以看到一个浮动窗口显示出来,这是一个工作台,下面定义的规则会在上面输出。
1.2,在工作台上输入主题名称,然后点击检查重复项。如果提示被占用,请更改名称以确保主题名称是唯一的。
第二步:标签信息
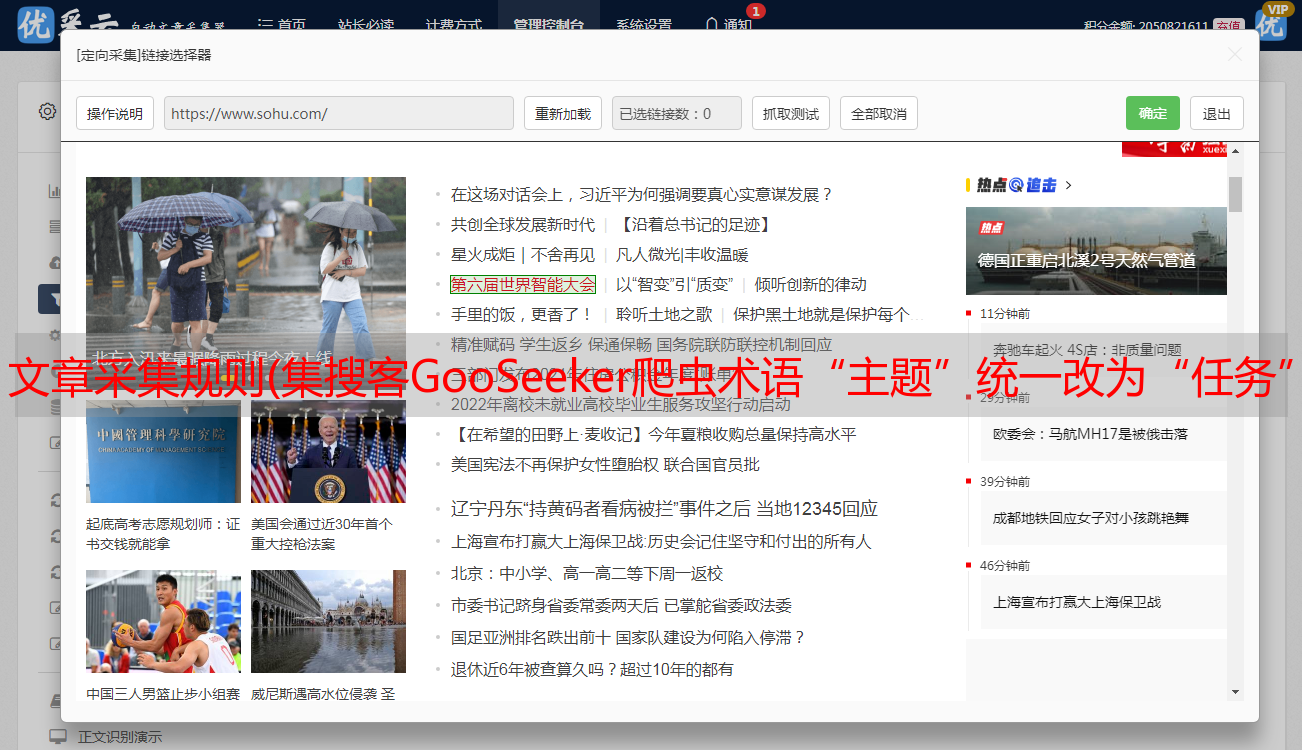
2.1、在浏览器窗口中用鼠标点击你要抓取的内容,这里是选中的新闻标题,然后你会看到整个标题变成了黄底红框闪烁框出这个范围,根据*敏*感*词*范围检查是否有正确的信息。如果没有问题,再次点击弹出标签窗口。输入标签名称后,点击打勾保存或按回车键保存。需要输入规则中的第一个标签。整理出框的名称,确认后可以在右上角的工作台中看到输出数据结构;
2.2、按照前面的操作,也在网页上标注作者和发布时间;
2.3、下一步是标记文本。如果单击文本的某个段落,则只会选择该段落的范围。如果要抓取所有文本,则需要单击文本的部分。在空白处,你会看到文字全部被选中,再次点击进行标注映射;
PS:如果是其他网页,不需要点击空白处全选,可以点击其他位置,直到选中你想要的内容范围;

2.4、如果不能点击整个范围可以选择的位置,可以点击目标信息的一部分,底部的dom窗口会定位到对应的网页节点到该信息,然后点击收录该信息的节点 的每个上层节点,直到可以看到网页上所有范围都被选中;

2.5、然后右击节点,在快捷菜单中选择Content Mapping -> New Grab Content -> 输入标签名,此操作结果与上一步相同2.3 ;
第三步,保存规则,抓取数据
3.1、点击右侧测试按钮预览输出信息是否完整,如果没有问题点击右上角的保存按钮,然后点击“抓取数据”,将弹出一个 DS 计数器窗口,并开始捕获获取数据;

3.2、之前只抓到了一个网页新闻,很多人会问如何获取更多的新闻?很简单,只要网页结构和示例页面一样,就可以用这条规则来爬取信息。因此,我们可以将与该页面结构相同的其他搜狐新闻网站整理出来,然后添加到规则中。操作在柜台上右键规则,点击“Manage Leads”然后选择“Add”,将URL复制进去保存,然后点击规则旁边的“Single Search”,启动采集逐个。另外,还可以使用分层采集的方法来实现URL的自动导入。有关详细信息,请参阅“使用层次结构的 URL采集”。
第四步,转换成Excel表格
4.1,采集成功的数据会以xml文件的形式保存在电脑的DataScraperWorks文件夹中。点击左上角的文件菜单->存储路径找到文件夹的位置。
4.2、然后我们可以将采集中的xml文件压缩成一个zip压缩包,进入会员中心的规则管理,选择对应的规则,然后点击导入数据,选择压缩将一个好的 zip 存档导入其中。导入成功后,点击导出数据,即可下载下载的Excel文件。


