
文章采集规则
文章采集规则(公众号等级越高越方便推荐给其他用户获取一些自己喜欢的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-09-03 15:42
文章采集规则改变一下基本不可以,一些采集公众号需要打赏之类的才给。很多公众号还是只会单纯的文章打赏,还无法给文章任何附属信息打赏。一句话总结为:公众号等级越高越方便推荐给其他用户获取一些自己喜欢的。
直接走点赞可以,现在几乎有大号的地方就会有自己的打赏功能,我本身也是从运营公众号开始接触到这块,一开始用的是一点号,但后来用了一周不到,实在是找不到能够满足我需求的,后来就被盗号了,就换到一起创业的一个公众号,从此走上了用微信号领悟知识的习惯,这边主要的靠推荐,但也一直没有什么突破性的技术,以前也没发现公众号通过自定义菜单获取第三方信息上面还是有门道,目前确实在深入学习这方面的技术,建议你到一些相关的论坛,如腾讯云论坛去看看,都是干货。
公众号还没找到满足自己需求的地方就去开广告吧
有两种方式,一种是用历史消息。可以去看一下我之前的一个答案,里面介绍了新公众号的一些推广方法。现在基本可以不用历史消息了。后来做的一个公众号,积累了不少粉丝。直接链接到了大学生论坛,然后本校的学生就可以直接在里面发广告了。还有一种更牛逼的,是外包公众号推广,提供php\python\java多重语言接口。
然后在公众号里面直接推送文章。这样就省去了一系列推广流程。其实公众号只是自媒体对外交易的平台而已,最终目的还是从公众号中引流,就看你对怎么推广有兴趣。 查看全部
文章采集规则(公众号等级越高越方便推荐给其他用户获取一些自己喜欢的)
文章采集规则改变一下基本不可以,一些采集公众号需要打赏之类的才给。很多公众号还是只会单纯的文章打赏,还无法给文章任何附属信息打赏。一句话总结为:公众号等级越高越方便推荐给其他用户获取一些自己喜欢的。
直接走点赞可以,现在几乎有大号的地方就会有自己的打赏功能,我本身也是从运营公众号开始接触到这块,一开始用的是一点号,但后来用了一周不到,实在是找不到能够满足我需求的,后来就被盗号了,就换到一起创业的一个公众号,从此走上了用微信号领悟知识的习惯,这边主要的靠推荐,但也一直没有什么突破性的技术,以前也没发现公众号通过自定义菜单获取第三方信息上面还是有门道,目前确实在深入学习这方面的技术,建议你到一些相关的论坛,如腾讯云论坛去看看,都是干货。
公众号还没找到满足自己需求的地方就去开广告吧
有两种方式,一种是用历史消息。可以去看一下我之前的一个答案,里面介绍了新公众号的一些推广方法。现在基本可以不用历史消息了。后来做的一个公众号,积累了不少粉丝。直接链接到了大学生论坛,然后本校的学生就可以直接在里面发广告了。还有一种更牛逼的,是外包公众号推广,提供php\python\java多重语言接口。
然后在公众号里面直接推送文章。这样就省去了一系列推广流程。其实公众号只是自媒体对外交易的平台而已,最终目的还是从公众号中引流,就看你对怎么推广有兴趣。
文章采集规则(今日头条数据:加载出址分析篇源码(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-09-02 09:18
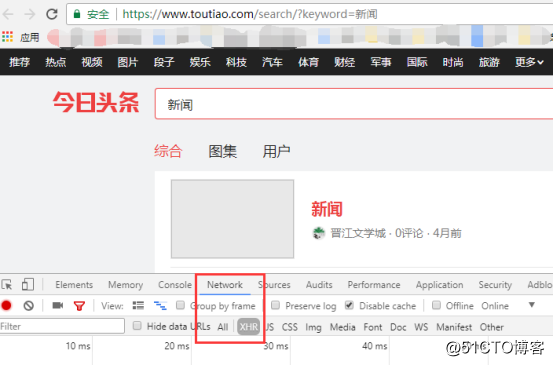
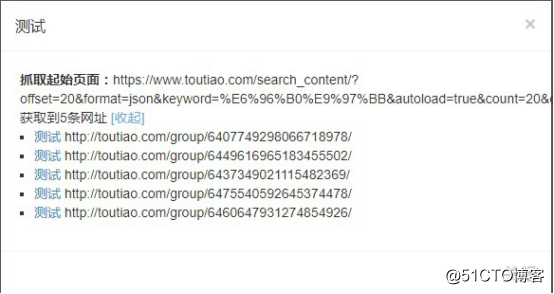
今天的头条数据由 Ajax 加载和显示。按照正常的URL,是抓不到数据的。需要分析加载地址。我们以 %E6%96%B0%E9%97%BB 为例。 采集文章列表
用谷歌浏览器打开链接,右击“查看”,在控制台切换到网络,点击XHR,这样可以过滤掉图片、文件等不必要的请求,只请求查看内容页面
由于页面是Ajax加载的,把页面拉到底部,更多的文章会自动加载。这时候控制台抓取到的链接就是我们真正需要的列表页面的链接了:
%E6%96%B0%E9%97%BB&autoload=true&count=20&cur_tab=1&from=search_tab
在优采云采集创建任务
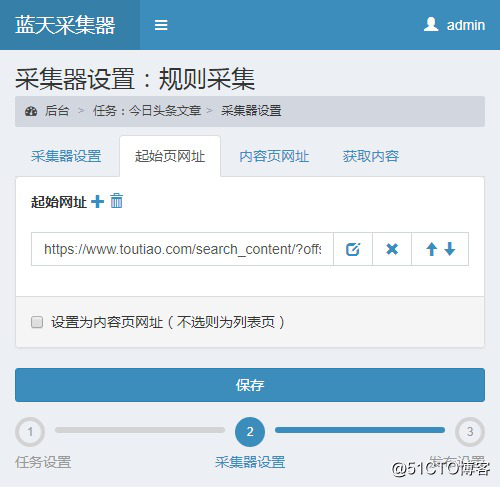
创建后点击“采集Settings”,在“Starting Page URL”中填写上面获取的链接
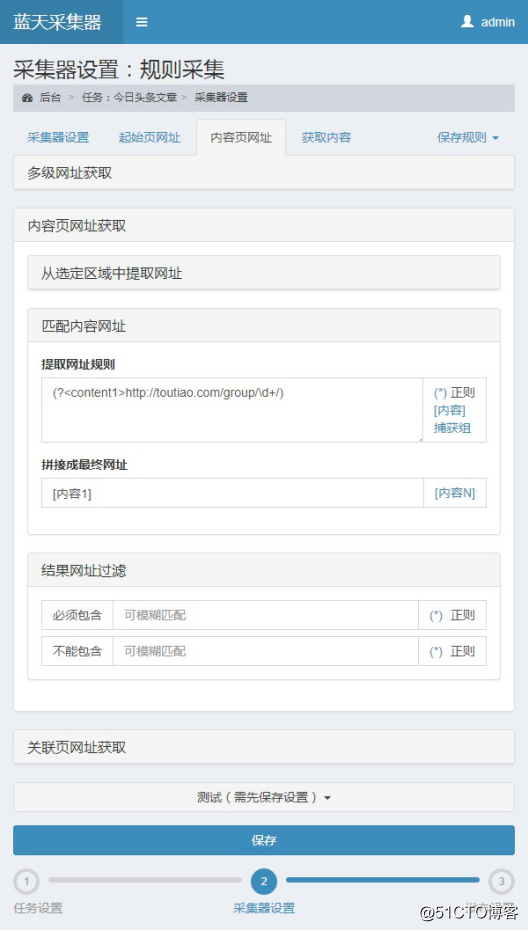
接下来匹配内容页面的网址,标题中的文章网址格式为数字/
点击“内容页面网址”编写“匹配内容网址”规则:
(?\d+/)
这是一个正则规则,就是将匹配的URL加载到捕获组content1中,然后在下面填写[Content1],对应上面的content1获取内容页面链接
可以点击测试查看链接是否被成功抓取
获取成功后,即可开始获取内容
点击“获取内容”在字段列表右侧添加默认字段,如标题、正文等可智能识别,如需准确可自行编辑字段,支持regular、xpath , json 等匹配内容
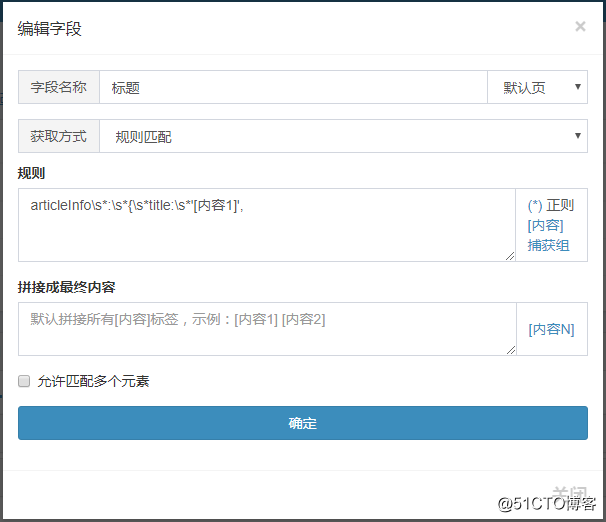
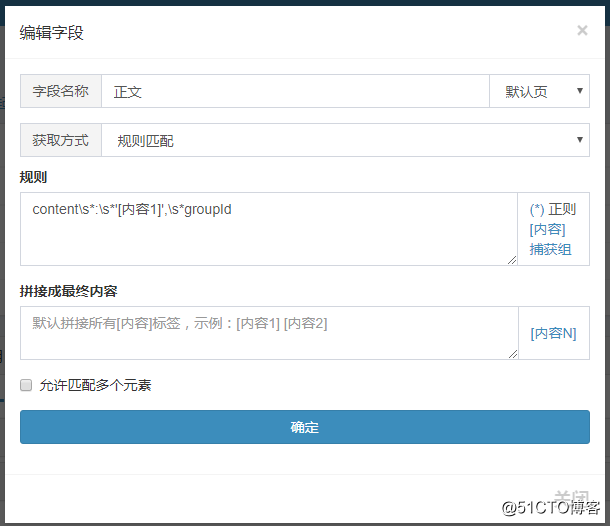
我们需要抓取文章的标题和文字。因为是Ajax显示的,所以我们需要写规则来匹配内容。分析文章源码:,找到文章location
标题规则:articleInfo\s:\s{\stitle:\s'[Content1]',
正文规则:content\s:\s'[content1]',\s*groupId
必须保证规则的唯一性,否则会匹配到其他内容。将规则添加到字段中,并选择获取它的方法以匹配规则:
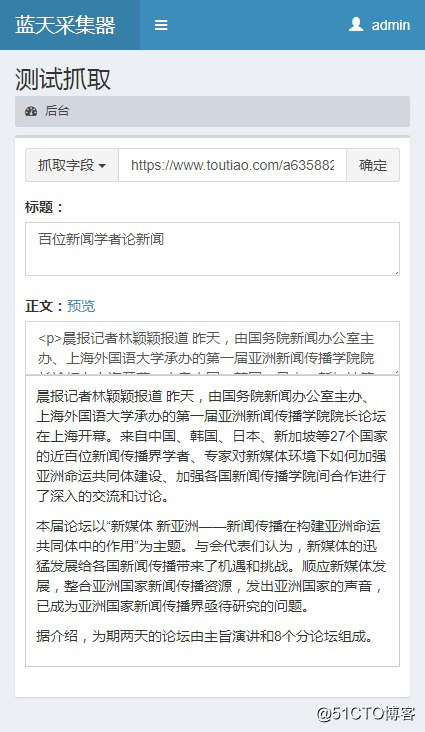
规则写好后,点击保存,点击“测试”看看效果
规则正确,爬行正常。抓到的数据也可以发布到cms系统,直接存入数据库,保存为excel文件等,只需点击底部导航栏的“发布设置”,今天好头条采集结束在这里,你不妨试试看! 查看全部
文章采集规则(今日头条数据:加载出址分析篇源码(组图))
今天的头条数据由 Ajax 加载和显示。按照正常的URL,是抓不到数据的。需要分析加载地址。我们以 %E6%96%B0%E9%97%BB 为例。 采集文章列表
用谷歌浏览器打开链接,右击“查看”,在控制台切换到网络,点击XHR,这样可以过滤掉图片、文件等不必要的请求,只请求查看内容页面
由于页面是Ajax加载的,把页面拉到底部,更多的文章会自动加载。这时候控制台抓取到的链接就是我们真正需要的列表页面的链接了:
%E6%96%B0%E9%97%BB&autoload=true&count=20&cur_tab=1&from=search_tab
在优采云采集创建任务
创建后点击“采集Settings”,在“Starting Page URL”中填写上面获取的链接
接下来匹配内容页面的网址,标题中的文章网址格式为数字/
点击“内容页面网址”编写“匹配内容网址”规则:
(?\d+/)
这是一个正则规则,就是将匹配的URL加载到捕获组content1中,然后在下面填写[Content1],对应上面的content1获取内容页面链接
可以点击测试查看链接是否被成功抓取
获取成功后,即可开始获取内容
点击“获取内容”在字段列表右侧添加默认字段,如标题、正文等可智能识别,如需准确可自行编辑字段,支持regular、xpath , json 等匹配内容
我们需要抓取文章的标题和文字。因为是Ajax显示的,所以我们需要写规则来匹配内容。分析文章源码:,找到文章location

标题规则:articleInfo\s:\s{\stitle:\s'[Content1]',
正文规则:content\s:\s'[content1]',\s*groupId
必须保证规则的唯一性,否则会匹配到其他内容。将规则添加到字段中,并选择获取它的方法以匹配规则:
规则写好后,点击保存,点击“测试”看看效果
规则正确,爬行正常。抓到的数据也可以发布到cms系统,直接存入数据库,保存为excel文件等,只需点击底部导航栏的“发布设置”,今天好头条采集结束在这里,你不妨试试看!
文章采集规则( 如何使用采集功能去采集一个图片类的网站?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-09-02 02:10
如何使用采集功能去采集一个图片类的网站?)
如何使用Dedecms采集功能---图片采集(一)
前言:这个文章主要介绍了如何使用采集函数来采集一个图片类网站。本次选定的目标站点为:站酷精品欣赏版块。网址是:。本文将介绍如何处理收录分页的采集 页面以及如何使用简单的过滤规则。本文分为三部分:第一部分主要介绍如何进入采集界面以及添加采集节点的第一步:设置基本信息和URL索引页面规则;第二部分主要介绍添加采集节点的第二步:设置字段获取规则;第三部分主要介绍如何采集指定一个节点以及如何导出采集内容。
输入下面的第一部分。
1.1进入采集node管理界面
如图(图1),在后台管理界面主菜单中点击“采集”,然后点击“采集node管理”进入采集节点管理界面,如(图片2)显示。
图1-后台管理界面
图2-采集Node 管理界面
1.2. 添加新节点
在采集节点管理界面,点击左下角“添加新节点”或右上角“添加新节点”(如2),可进入“选择内容模型” " 界面,如( 如图3),
图3-选择内容模型界面
在“选择内容模型”界面的下拉列表框中,有“General文章”和“图片集”可供选择。
根据页面类型为采集,选择对应的内容模型。本文选择“图片采集”,点击确定,进入“添加采集节点:第一步设置基本信息和URL索引页面规则”界面,如图(图4),
图4-新建采集节点:第一步设置基本信息和URL索引页面规则
1.2.1 设置基本节点信息
图5-基本节点信息
如图(图片5),这里只是获取“目标页面代码”的方法,其他设置请参考前面的文章。具体步骤:
(a) 打开采集的目标页面:;
(b) 右击选择“查看源文件”,找到“字符集”,如图(图6),
图6-查看源文件
等号后面的代码是要填写的“编码格式”,这里是“utf-8”。
填写后,如图(picture7),
图7-设置后节点的基本信息
检查后,进入下一步。
1.2.2 设置列表网址获取规则
图8-列出URL获取规则
如图(图片8),这里是设置采集文章list页面的匹配规则。具体步骤:
(a) 首先回到打开的列表页面,找到浏览器的URL地址栏中显示的URL和页面的换页部分。如图(图9)和(图10),
)
图9-浏览器的URL地址栏
图 10 页面变化
(b) 点击“2”打开文章列表页面的第二页,再次找到浏览器的URL地址栏中显示的URL和页面的换页部分,如图(图12)和(如图13),
图11-第二页的URL
图12-第二页的换页
(c) 在打开的列表页的第二页,点击(1),返回到列表页的第一页,然后页面的换页部分和上图10一样,但是浏览设备的URL地址栏中显示的URL与之前的图9不同,如图(图13),
图13-第一页的URL
(d) 从(b)和(c)可以推断出采集的列表页的URL遵循以下规则:
!0!0!200!(*)!1!0!0/.为安全起见,请自行测试更多列表页面。确定规则后,在“匹配网址”中填写规则后跟列表页。
(e) 最后根据需要指定采集的页码或正则数,并设置递增的正则。
到这里,“列表网址获取规则”部分就结束了。最终结果,如图(图14),
图14-设置后的URL获取规则列表
确认无误后,进行下一步。
1.2.3 设置文章 URL 匹配规则
图15-文章URL匹配规则
这里是设置采集列表页的匹配规则。
具体步骤:
(a)对于“区域开始的HTML”,可以在已打开的列表首页,单击右键后选择“查看源文件”查找出第一篇文章的标题“高清壁纸”来获得,如(图16)所示,
图16-查看源文件中第一篇文章文章的标题
通过观察,不难看出“”是整个列表的结尾,后面的“”是页面的换页部分。因此,在“HTML在该区域的末尾”中,您应该填写“”,表示到第一个的末尾。
(c) 观察图16和图17的文章title部分,我们可以发现标题的链接地址收录“=.html”。因此,您可以在“必须收录”中填写“=.html”。
到此,“文章URL 匹配规则”的设置就结束了。填写后,如图(图18),
图18-设置后文章URL匹配规则
通过以上三小节,添加采集节点的第一步已经搭建完成。设置后的最终结果,如图(图19),
图19-设置后新建采集节点:第一步设置基本信息和URL索引页面规则
一切都完成并检查后,点击“保存信息并进入下一步设置”。如果之前的设置正确,点击后会进入“新建采集节点:测试基本信息和URL索引页面规则设置的URL获取规则测试”页面,看到对应的文章列表地址。如图(图20),
图20-URL获取规则测试
确认无误后,点击“保存信息,进入下一步设置”。否则请点击“返回上一步修改”。
到此,第一部分结束。现在进入第二部分。 . . 查看全部
文章采集规则(
如何使用采集功能去采集一个图片类的网站?)
如何使用Dedecms采集功能---图片采集(一)
前言:这个文章主要介绍了如何使用采集函数来采集一个图片类网站。本次选定的目标站点为:站酷精品欣赏版块。网址是:。本文将介绍如何处理收录分页的采集 页面以及如何使用简单的过滤规则。本文分为三部分:第一部分主要介绍如何进入采集界面以及添加采集节点的第一步:设置基本信息和URL索引页面规则;第二部分主要介绍添加采集节点的第二步:设置字段获取规则;第三部分主要介绍如何采集指定一个节点以及如何导出采集内容。
输入下面的第一部分。
1.1进入采集node管理界面
如图(图1),在后台管理界面主菜单中点击“采集”,然后点击“采集node管理”进入采集节点管理界面,如(图片2)显示。

图1-后台管理界面

图2-采集Node 管理界面
1.2. 添加新节点
在采集节点管理界面,点击左下角“添加新节点”或右上角“添加新节点”(如2),可进入“选择内容模型” " 界面,如( 如图3),

图3-选择内容模型界面
在“选择内容模型”界面的下拉列表框中,有“General文章”和“图片集”可供选择。
根据页面类型为采集,选择对应的内容模型。本文选择“图片采集”,点击确定,进入“添加采集节点:第一步设置基本信息和URL索引页面规则”界面,如图(图4),

图4-新建采集节点:第一步设置基本信息和URL索引页面规则
1.2.1 设置基本节点信息

图5-基本节点信息
如图(图片5),这里只是获取“目标页面代码”的方法,其他设置请参考前面的文章。具体步骤:
(a) 打开采集的目标页面:;
(b) 右击选择“查看源文件”,找到“字符集”,如图(图6),

图6-查看源文件
等号后面的代码是要填写的“编码格式”,这里是“utf-8”。
填写后,如图(picture7),

图7-设置后节点的基本信息
检查后,进入下一步。
1.2.2 设置列表网址获取规则

图8-列出URL获取规则
如图(图片8),这里是设置采集文章list页面的匹配规则。具体步骤:
(a) 首先回到打开的列表页面,找到浏览器的URL地址栏中显示的URL和页面的换页部分。如图(图9)和(图10),
)

图9-浏览器的URL地址栏

图 10 页面变化
(b) 点击“2”打开文章列表页面的第二页,再次找到浏览器的URL地址栏中显示的URL和页面的换页部分,如图(图12)和(如图13),

图11-第二页的URL

图12-第二页的换页
(c) 在打开的列表页的第二页,点击(1),返回到列表页的第一页,然后页面的换页部分和上图10一样,但是浏览设备的URL地址栏中显示的URL与之前的图9不同,如图(图13),

图13-第一页的URL
(d) 从(b)和(c)可以推断出采集的列表页的URL遵循以下规则:
!0!0!200!(*)!1!0!0/.为安全起见,请自行测试更多列表页面。确定规则后,在“匹配网址”中填写规则后跟列表页。
(e) 最后根据需要指定采集的页码或正则数,并设置递增的正则。
到这里,“列表网址获取规则”部分就结束了。最终结果,如图(图14),

图14-设置后的URL获取规则列表
确认无误后,进行下一步。
1.2.3 设置文章 URL 匹配规则

图15-文章URL匹配规则
这里是设置采集列表页的匹配规则。
具体步骤:
(a)对于“区域开始的HTML”,可以在已打开的列表首页,单击右键后选择“查看源文件”查找出第一篇文章的标题“高清壁纸”来获得,如(图16)所示,

图16-查看源文件中第一篇文章文章的标题
通过观察,不难看出“”是整个列表的结尾,后面的“”是页面的换页部分。因此,在“HTML在该区域的末尾”中,您应该填写“”,表示到第一个的末尾。
(c) 观察图16和图17的文章title部分,我们可以发现标题的链接地址收录“=.html”。因此,您可以在“必须收录”中填写“=.html”。
到此,“文章URL 匹配规则”的设置就结束了。填写后,如图(图18),

图18-设置后文章URL匹配规则
通过以上三小节,添加采集节点的第一步已经搭建完成。设置后的最终结果,如图(图19),

图19-设置后新建采集节点:第一步设置基本信息和URL索引页面规则
一切都完成并检查后,点击“保存信息并进入下一步设置”。如果之前的设置正确,点击后会进入“新建采集节点:测试基本信息和URL索引页面规则设置的URL获取规则测试”页面,看到对应的文章列表地址。如图(图20),

图20-URL获取规则测试
确认无误后,点击“保存信息,进入下一步设置”。否则请点击“返回上一步修改”。
到此,第一部分结束。现在进入第二部分。 . .
文章采集规则(添加采集规则规则说明系统(系统默认变量:文章序号))
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-01 22:05
添加采集 规则。规则描述系统默认变量:-文章序号,-章节序号,-文章子序号,-章节子序号。系统标签 * 可以替换任何字符串。系统标签!可以替换除此之外的任何字符串。系统标签~可以替换除'"以外的任何字符串。系统标签^可以替换数字和以外的字符串。系统标签$可以替换数字字符串。在采集规则中,需要获取四个内容部分而不是上面的系统标签,比如!!!!!! 基本设置网站logo configs\article\collectsite.php中添加的logo,随便填写即可,一般是采集的域名缩写站点,以区别于其他规则。例如:feiku网站名所采集站的名称。例如:Feiku网站Address所采集站的地址。例如:文章子序列号计算方法不一定要加,我这里就直接用了 留空 支持四种使用记号的算术运算(+加法,-减法,*乘法,/除法,%余数) 本章子序列计算方法不用加,我这里留空。(谁知道他的一个文件夹里有多少本书?他没有把它放在一起按照规则,我不是采集不)它支持使用标签的四种算术运算(+add、-subtract、*multiply、/division、%取余数)。代理服务器地址不使用代理服务器请留空。代理服务器端口。当现有章节无法对应时,是否全部清除。 Re采集 是否根据需要选择是否将采集到的文章设置为整本书。是否根据您的需要选择,如果选择“是”“无论文章是连载还是完成,都会在您的站点上显示整个文本。建议选择“否”将HTTP_REFERER标志发送到突破反采集设置。默认选择是否为“是”,不知道是干什么用的,我先突破选择“是”,然后再说对方的网页编码(自动检测GB2312 UTF8 BIG5)默认“自动检测”编码与本站不同会自动尝试转换文章信息页采集标准文章信息页地址 图书信息页面URL,使用图书ID代替。例如:/Index.html 文章title采集 规则要求检查网页的源文件,如果没有,可以停止。检查信息页的源文件,然后找到文章源文件中的title在哪里(我们以飞酷为例,即c盘上源文件中“文章Title”的位置章节信息页)。这里以《我的美丽小姐》为例,找到标题附近的代码是
《美丽的女人》
把上面的代码复制到文章title采集rules的框里,然后把我美女的真实头衔换成!!!!当然,你也可以用** **等其他替换符号来替换它,但重要的是范围越小,越能表达意思越好(习惯问题,当然只能是采集到文章的标题,但是当你不想要的时候还有其他的采集。李兴宇这里是使用采集的内容,但是144238只对这个文章有用,而且其他文章有其他数字,所以用任意数字String $代替。所以作者采集rule是!!!@文章型采集全球都市 从上面两个采集rules,不难看出看到这里的规则是!!!!!! 查看全部
文章采集规则(添加采集规则规则说明系统(系统默认变量:文章序号))
添加采集 规则。规则描述系统默认变量:-文章序号,-章节序号,-文章子序号,-章节子序号。系统标签 * 可以替换任何字符串。系统标签!可以替换除此之外的任何字符串。系统标签~可以替换除'"以外的任何字符串。系统标签^可以替换数字和以外的字符串。系统标签$可以替换数字字符串。在采集规则中,需要获取四个内容部分而不是上面的系统标签,比如!!!!!! 基本设置网站logo configs\article\collectsite.php中添加的logo,随便填写即可,一般是采集的域名缩写站点,以区别于其他规则。例如:feiku网站名所采集站的名称。例如:Feiku网站Address所采集站的地址。例如:文章子序列号计算方法不一定要加,我这里就直接用了 留空 支持四种使用记号的算术运算(+加法,-减法,*乘法,/除法,%余数) 本章子序列计算方法不用加,我这里留空。(谁知道他的一个文件夹里有多少本书?他没有把它放在一起按照规则,我不是采集不)它支持使用标签的四种算术运算(+add、-subtract、*multiply、/division、%取余数)。代理服务器地址不使用代理服务器请留空。代理服务器端口。当现有章节无法对应时,是否全部清除。 Re采集 是否根据需要选择是否将采集到的文章设置为整本书。是否根据您的需要选择,如果选择“是”“无论文章是连载还是完成,都会在您的站点上显示整个文本。建议选择“否”将HTTP_REFERER标志发送到突破反采集设置。默认选择是否为“是”,不知道是干什么用的,我先突破选择“是”,然后再说对方的网页编码(自动检测GB2312 UTF8 BIG5)默认“自动检测”编码与本站不同会自动尝试转换文章信息页采集标准文章信息页地址 图书信息页面URL,使用图书ID代替。例如:/Index.html 文章title采集 规则要求检查网页的源文件,如果没有,可以停止。检查信息页的源文件,然后找到文章源文件中的title在哪里(我们以飞酷为例,即c盘上源文件中“文章Title”的位置章节信息页)。这里以《我的美丽小姐》为例,找到标题附近的代码是
《美丽的女人》
把上面的代码复制到文章title采集rules的框里,然后把我美女的真实头衔换成!!!!当然,你也可以用** **等其他替换符号来替换它,但重要的是范围越小,越能表达意思越好(习惯问题,当然只能是采集到文章的标题,但是当你不想要的时候还有其他的采集。李兴宇这里是使用采集的内容,但是144238只对这个文章有用,而且其他文章有其他数字,所以用任意数字String $代替。所以作者采集rule是!!!@文章型采集全球都市 从上面两个采集rules,不难看出看到这里的规则是!!!!!!
文章采集规则(建站技术网收集整理你收集整理的全部内容方法(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-08-31 03:06
摘要:建站技术网采集整理的这篇文章主要介绍了dedecms采集文章内容为空的解决方案。建站科技网小编觉得还不错。现在分享给大家,我也给大家参考一下。
dedecms采集文章空内容的解决方法
在采集data 中,部分文章采集 内容为空。一开始不知道,因为采集600多文章,我只看了前两个,发现还可以,然后直接导入数据库。可惜导入后发现部分内容是空的,也就是body部分是空的。有600多条数据。一一查找比较麻烦,于是找到了一个简单的方法:
在后台执行下面的sql语句
删除 dede_addonarticle,dede_archives FROM dede_addonarticle,dede_archives where dede_addonarticle.body='' and dede_addonarticle.aid=dede_archives.id
总结:以上是建站科技网为您采集整理的dedecms采集文章的完整内容。希望文章能帮您解决dedecms采集文章内容为空解决程序开发遇到的问题。如果你觉得网站技术网网站的内容还不错,欢迎向程序员朋友推荐网站技术网网站。 查看全部
文章采集规则(建站技术网收集整理你收集整理的全部内容方法(图))
摘要:建站技术网采集整理的这篇文章主要介绍了dedecms采集文章内容为空的解决方案。建站科技网小编觉得还不错。现在分享给大家,我也给大家参考一下。
dedecms采集文章空内容的解决方法
在采集data 中,部分文章采集 内容为空。一开始不知道,因为采集600多文章,我只看了前两个,发现还可以,然后直接导入数据库。可惜导入后发现部分内容是空的,也就是body部分是空的。有600多条数据。一一查找比较麻烦,于是找到了一个简单的方法:
在后台执行下面的sql语句
删除 dede_addonarticle,dede_archives FROM dede_addonarticle,dede_archives where dede_addonarticle.body='' and dede_addonarticle.aid=dede_archives.id
总结:以上是建站科技网为您采集整理的dedecms采集文章的完整内容。希望文章能帮您解决dedecms采集文章内容为空解决程序开发遇到的问题。如果你觉得网站技术网网站的内容还不错,欢迎向程序员朋友推荐网站技术网网站。
文章采集规则(本文介绍使用优采云采集搜狗微信文章(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-08-30 03:10
本文介绍优采云采集搜狗微信文章的使用方法(以流行的文章为例)采集网站:/
使用功能点:
l 分页列表信息采集
/tutorial/fylb-70.aspx?t=1
l Xpath
/search?query=XPath
l AJAX 点击和翻页
/tutorial/ajaxdjfy_@k22@aspx?t=1
第一步:创建采集task
1)进入主界面,点击左侧“新建”,选择“自定义任务”
2)将采集的网址复制粘贴到网站输入框中,点击“保存设置”
第 2 步:创建翻页循环
1)网页打开后,默认显示“热门”文章。向下滚动页面,找到并点击“加载更多内容”按钮,在操作提示框中选择“循环点击单个链接”
由于本网页涉及Ajax技术,所以需要设置一些高级选项。在操作提示框中,设置Ajjax超时时间为“2秒”
注:AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,无需重新加载整个网页即可更新网页的某一部分。
性能特点:当你点击网页上的一个选项时,网站的大部分网址不会改变;湾网页未完全加载,只是部分加载了数据并发生了更改。
验证方法:点击操作后,URL输入栏在浏览器中不会出现加载状态或转动状态。
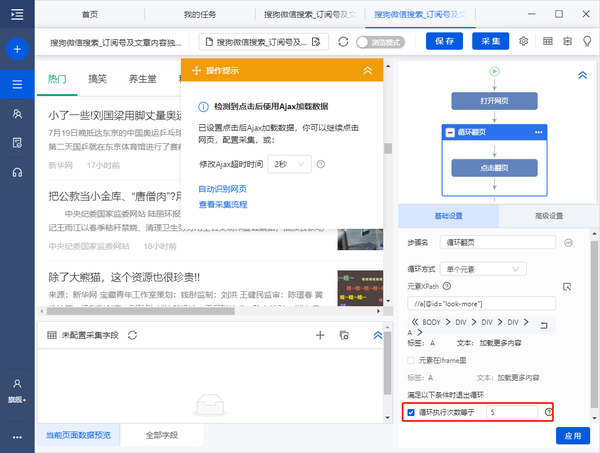
观察网页,我们发现点击“加载更多内容”5次后,页面加载到底部,一共显示了100个文章。因此,我们将整个“循环翻页”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5”,点击“确定”
第 3 步:创建一个列表循环并提取数据
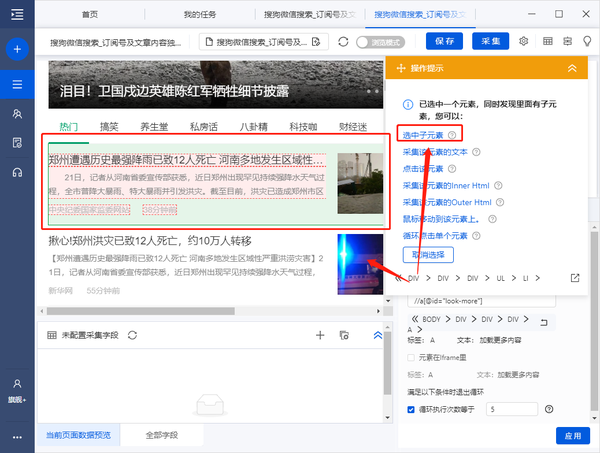
1)移动鼠标选择页面上的第一个文章块。系统将识别此块中的子元素。在操作提示框中选择“选择子元素”
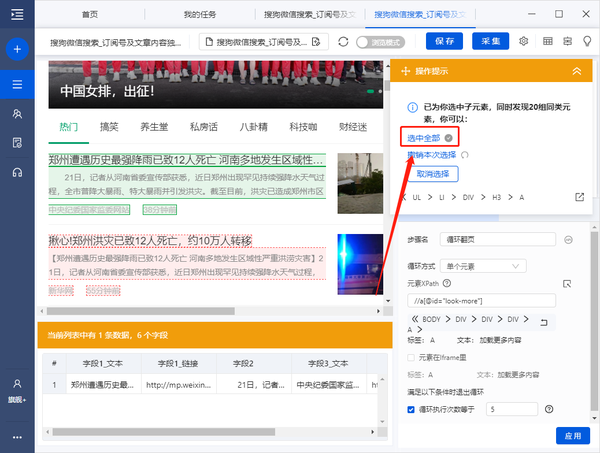
2)继续选择页面第二篇文章的区块,系统会自动选择第二篇文章的子元素,并识别页面其他10组相似元素, 在操作提示框中,选择“全选”
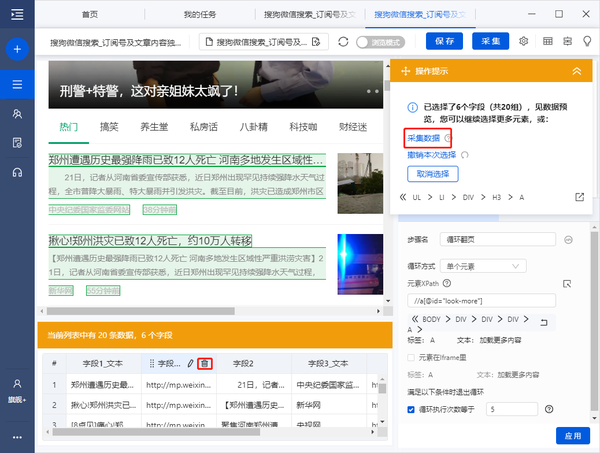
3) 我们可以看到页面上文章块中的所有元素都被选中并变成了绿色。字段预览表出现在下方。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。字段选择完成后,选择“采集以下数据”
4)字段选择完成后,选择对应的字段,自定义字段的命名
第 4 步:修改 Xpath
我们继续观察,5次点击“加载更多内容”后,这个网页加载了全部100个文章。所以,我们配置规则的思路是先建立一个翻页循环,加载所有100个文章,然后创建一个循环列表提取数据
1)选择整个“循环”步骤并将其拖出“循环翻转”步骤。如果不这样做,就会出现大量重复数据。
拖动完成后,如下图
2)在“列表循环”步骤中,我们创建了一个100个文章的循环列表。选择整个“循环步骤”,打开“高级选项”,元素列表中的这个Xpath不会被固定:
<p>//BODY[@id="loginWrap"]/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI,复制粘贴到火狐浏览器对应位置 查看全部
文章采集规则(本文介绍使用优采云采集搜狗微信文章(一))
本文介绍优采云采集搜狗微信文章的使用方法(以流行的文章为例)采集网站:/
使用功能点:
l 分页列表信息采集
/tutorial/fylb-70.aspx?t=1
l Xpath
/search?query=XPath
l AJAX 点击和翻页
/tutorial/ajaxdjfy_@k22@aspx?t=1
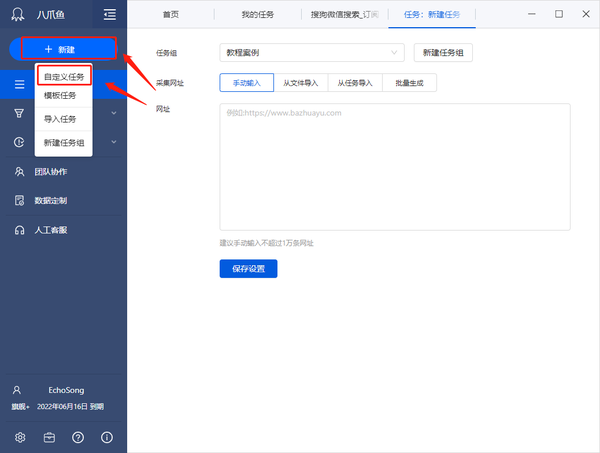
第一步:创建采集task
1)进入主界面,点击左侧“新建”,选择“自定义任务”
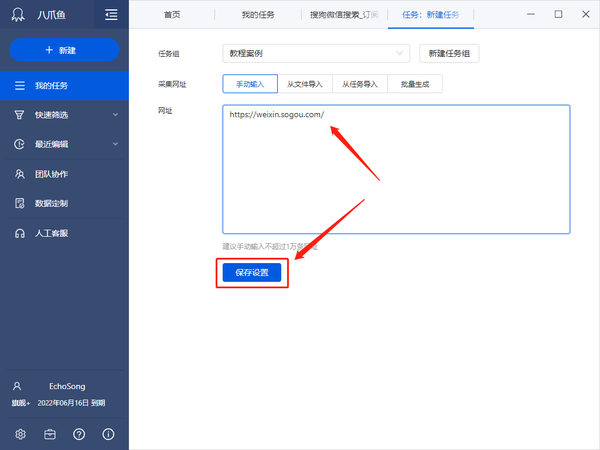
2)将采集的网址复制粘贴到网站输入框中,点击“保存设置”
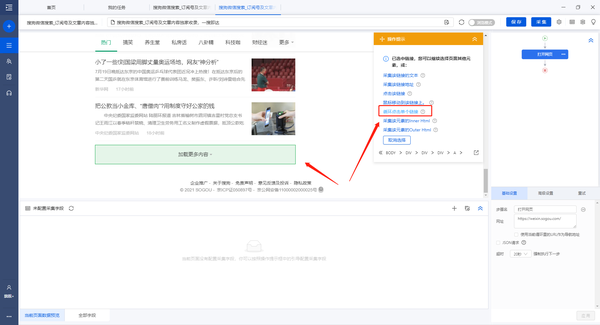
第 2 步:创建翻页循环
1)网页打开后,默认显示“热门”文章。向下滚动页面,找到并点击“加载更多内容”按钮,在操作提示框中选择“循环点击单个链接”
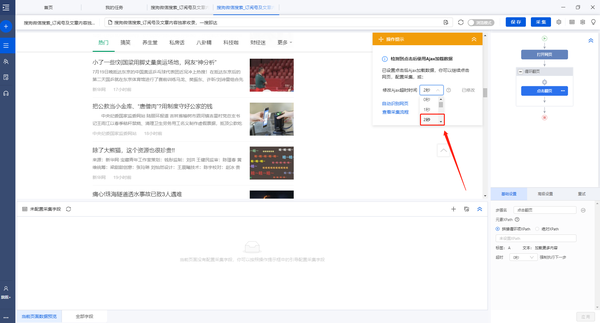
由于本网页涉及Ajax技术,所以需要设置一些高级选项。在操作提示框中,设置Ajjax超时时间为“2秒”
注:AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,无需重新加载整个网页即可更新网页的某一部分。
性能特点:当你点击网页上的一个选项时,网站的大部分网址不会改变;湾网页未完全加载,只是部分加载了数据并发生了更改。
验证方法:点击操作后,URL输入栏在浏览器中不会出现加载状态或转动状态。
观察网页,我们发现点击“加载更多内容”5次后,页面加载到底部,一共显示了100个文章。因此,我们将整个“循环翻页”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5”,点击“确定”
第 3 步:创建一个列表循环并提取数据
1)移动鼠标选择页面上的第一个文章块。系统将识别此块中的子元素。在操作提示框中选择“选择子元素”
2)继续选择页面第二篇文章的区块,系统会自动选择第二篇文章的子元素,并识别页面其他10组相似元素, 在操作提示框中,选择“全选”
3) 我们可以看到页面上文章块中的所有元素都被选中并变成了绿色。字段预览表出现在下方。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。字段选择完成后,选择“采集以下数据”
4)字段选择完成后,选择对应的字段,自定义字段的命名
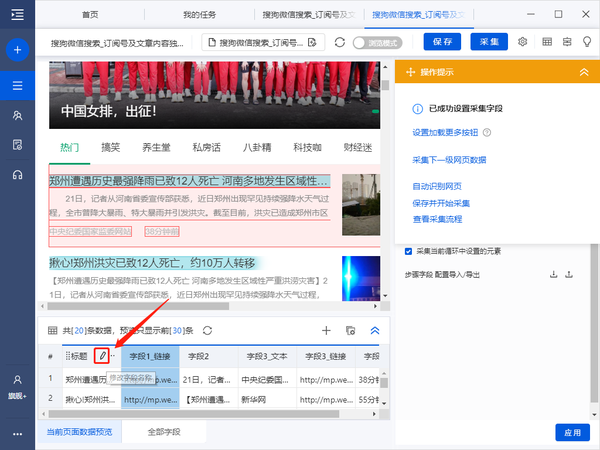
第 4 步:修改 Xpath
我们继续观察,5次点击“加载更多内容”后,这个网页加载了全部100个文章。所以,我们配置规则的思路是先建立一个翻页循环,加载所有100个文章,然后创建一个循环列表提取数据
1)选择整个“循环”步骤并将其拖出“循环翻转”步骤。如果不这样做,就会出现大量重复数据。
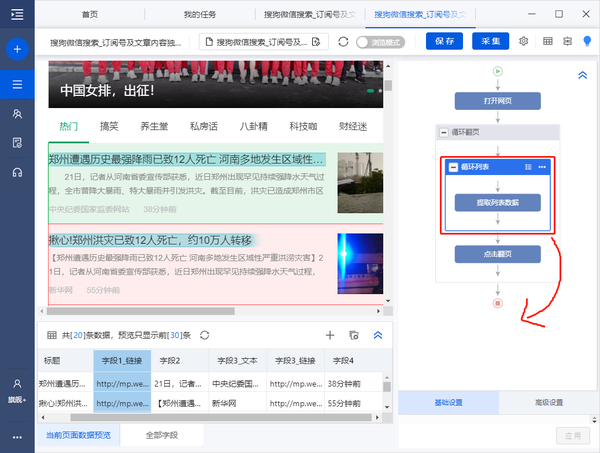
拖动完成后,如下图
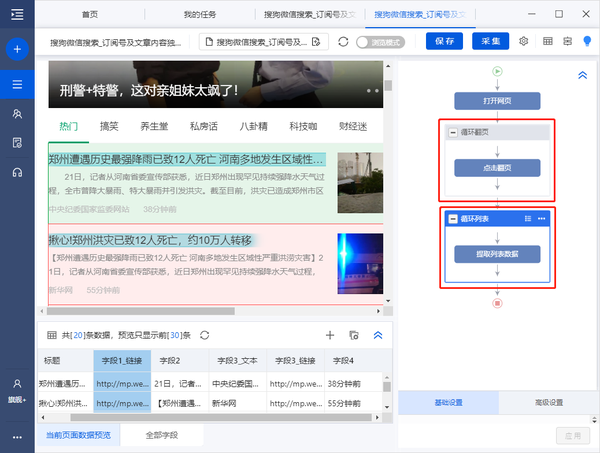
2)在“列表循环”步骤中,我们创建了一个100个文章的循环列表。选择整个“循环步骤”,打开“高级选项”,元素列表中的这个Xpath不会被固定:
<p>//BODY[@id="loginWrap"]/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI,复制粘贴到火狐浏览器对应位置
文章采集规则(【文章采集规则】2019年4月员工福利建议功能和实施方案)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-08-29 06:01
文章采集规则有以下几种:
1)采集某些公司二维码,
2)采集某个公司提供的api接口,
3)采集某公司某部门某个部门员工的班级号、姓名等敏感信息;
4)采集员工个人信息,用于保存到企业数据库。
一、二维码采集功能介绍
一)基础采集功能
1)基础的扫码识别功能,
2)基础的展示功能,
3)基础的二维码分享功能,用于简单便捷的分享宣传给客户。
二)特殊采集功能
1)选班级限制采集选择班级限制采集有两种情况:选择多次限制、交叉限制;
2)选上下限制采集选择上下限制采集有两种情况:选择原本的限制区域,
3)上限下限采集选择上限下限采集可以实现在限制区域内的全选、半选;
4)限制区域内是否能扫描得到二维码;
5)关键字限制注:以上关键字采集功能需要企业提供一个号码,可以参考用号码作为关键字来采集二维码数据。
三)sdk采集功能二维码采集功能是sdk采集的一个重要功能,该功能可以统计出客户员工的微信、手机号码、家庭住址等客户用于宣传或保存的有效信息。
四)公司内二维码用于组织机构年终奖、补贴、培训名单、周年庆/聚餐等员工活动用途。
二、2019年4月员工福利建议功能和实施方案
1、建议功能建议功能可以适当做限制。对于公司员工,建议具体限制对象为:年终奖,福利,补贴;在我们的案例中,基本上所有关于年终奖,补贴,培训的活动都可以做建议功能。
员工在年终奖、福利、培训这三项福利中又可以通过不同的方式来进行限制,
1)年终奖确定不建议做建议功能;
2)福利确定不建议做建议功能;
3)培训则建议做建议功能。
2、实施方案
一)建立机制,规范内部二维码使用规范二维码使用要规范,主要有两点:一是不能有同质化的东西,也就是不能有关键字,不能有英文等;二是编码主要有七种编码法:中心、字母、数字、数字、阿拉伯数字、数字、阿拉伯数字;针对这些要求,配合我们大中台的统一规范,建立关键字分配至各个基础二维码身上,用于采集、核对和统计。
相关参考文章:中心采集方案|微信小程序码生成器|人脸识别|指纹识别|摄像头采集|微信企业号、公众号、小程序码生成器|针对补贴,业务统计二维码采集方案|二维码关键字分配至基础二维码身上|关于微信的采集框架|微信指纹采集器|人脸识别|抖音对商户企业的引流|新版微信企业号、小程序二维码生成器|推荐的二维。 查看全部
文章采集规则(【文章采集规则】2019年4月员工福利建议功能和实施方案)
文章采集规则有以下几种:
1)采集某些公司二维码,
2)采集某个公司提供的api接口,
3)采集某公司某部门某个部门员工的班级号、姓名等敏感信息;
4)采集员工个人信息,用于保存到企业数据库。
一、二维码采集功能介绍
一)基础采集功能
1)基础的扫码识别功能,
2)基础的展示功能,
3)基础的二维码分享功能,用于简单便捷的分享宣传给客户。
二)特殊采集功能
1)选班级限制采集选择班级限制采集有两种情况:选择多次限制、交叉限制;
2)选上下限制采集选择上下限制采集有两种情况:选择原本的限制区域,
3)上限下限采集选择上限下限采集可以实现在限制区域内的全选、半选;
4)限制区域内是否能扫描得到二维码;
5)关键字限制注:以上关键字采集功能需要企业提供一个号码,可以参考用号码作为关键字来采集二维码数据。
三)sdk采集功能二维码采集功能是sdk采集的一个重要功能,该功能可以统计出客户员工的微信、手机号码、家庭住址等客户用于宣传或保存的有效信息。
四)公司内二维码用于组织机构年终奖、补贴、培训名单、周年庆/聚餐等员工活动用途。
二、2019年4月员工福利建议功能和实施方案
1、建议功能建议功能可以适当做限制。对于公司员工,建议具体限制对象为:年终奖,福利,补贴;在我们的案例中,基本上所有关于年终奖,补贴,培训的活动都可以做建议功能。
员工在年终奖、福利、培训这三项福利中又可以通过不同的方式来进行限制,
1)年终奖确定不建议做建议功能;
2)福利确定不建议做建议功能;
3)培训则建议做建议功能。
2、实施方案
一)建立机制,规范内部二维码使用规范二维码使用要规范,主要有两点:一是不能有同质化的东西,也就是不能有关键字,不能有英文等;二是编码主要有七种编码法:中心、字母、数字、数字、阿拉伯数字、数字、阿拉伯数字;针对这些要求,配合我们大中台的统一规范,建立关键字分配至各个基础二维码身上,用于采集、核对和统计。
相关参考文章:中心采集方案|微信小程序码生成器|人脸识别|指纹识别|摄像头采集|微信企业号、公众号、小程序码生成器|针对补贴,业务统计二维码采集方案|二维码关键字分配至基础二维码身上|关于微信的采集框架|微信指纹采集器|人脸识别|抖音对商户企业的引流|新版微信企业号、小程序二维码生成器|推荐的二维。
文章采集规则( 如何实现wp的自动采集功能--WordPress自动匹配功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-29 05:01
如何实现wp的自动采集功能--WordPress自动匹配功能)
网站how采集 wordpress 如何实现自动采集
WordPress 是一个使用 PHP 语言开发的建站程序平台。现在很多博主都用wp。很多网站制作培训使用wp,尤其是在做采集站的时候。总能量非常强大。下面是如何实现wp的自动采集功能。
安装网站采集插件:WP-AutoPost(插件下载链接:)
点击“新建任务”后,输入任务名称创建一个新任务。创建新任务后,您可以在任务列表中查看该任务,并且可以为该任务配置更多设置。 (这部分不需要修改设置,唯一需要修改的就是采集的时间。)文章source设置。在此选项卡下,我们需要设置文章source 的文章list URL 和具体的文章 匹配规则。以采集“新浪网”为例,文章列表的URL为,所以只需在手动指定的文章List URL中输入URL即可,如下图:
文章URL 匹配规则。 文章网址匹配规则的设置是最简单的,不需要复杂的设置。提供两种匹配模式。您可以使用 URL 通配符匹配或 CSS 选择器进行匹配。通常 URL 通配符匹配比较简单,但有时会使用 CSS 选择器。更确切。使用 URL 通配符匹配。通过点击列表网址上的文章,我们可以发现文章的每个网址的结构如下:所以将网址中的数字或字母替换为通配符(*),如:(*)/(*) .shtml。重复的 URL 可以使用 301 重定向。使用 CSS 选择器进行匹配。使用CSS选择器进行匹配,我们只需要设置文章URL的CSS选择器即可,查看列表URL源码即可轻松设置,在列表下找到文章超LINK的代码网址,如下图:
可以看到文章的超链接A标签在class为“contList”的标签里面,所以文章 URL的CSS选择器只需要设置为.contList a即可,如下图:
设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,将列出列表URL下的所有文章名称和对应的网址,如下图:
其他设置不需要修改。以上采集方法适用于WordPress多站点功能。
上一篇:WordPress网站如何调用other网站Latest文章(自动更新)
下一篇:WordPress调用其他网站文章显示在自己网站
发布:学做网站论坛 最后更新:2020-6-6 浏览:125264次
学做网站论坛致力于打造网站,打造在线培训诚信平台,让零基础学员学习如何做网站,最终可以自主搭建网站。
学做网站论坛建站培训,通过原创建站教程+讲师在线辅导,我们会详细讲解网站各种制作方法,即使你是初学者也能理解和学习。 . 查看全部
文章采集规则(
如何实现wp的自动采集功能--WordPress自动匹配功能)
网站how采集 wordpress 如何实现自动采集
WordPress 是一个使用 PHP 语言开发的建站程序平台。现在很多博主都用wp。很多网站制作培训使用wp,尤其是在做采集站的时候。总能量非常强大。下面是如何实现wp的自动采集功能。
安装网站采集插件:WP-AutoPost(插件下载链接:)

点击“新建任务”后,输入任务名称创建一个新任务。创建新任务后,您可以在任务列表中查看该任务,并且可以为该任务配置更多设置。 (这部分不需要修改设置,唯一需要修改的就是采集的时间。)文章source设置。在此选项卡下,我们需要设置文章source 的文章list URL 和具体的文章 匹配规则。以采集“新浪网”为例,文章列表的URL为,所以只需在手动指定的文章List URL中输入URL即可,如下图:

文章URL 匹配规则。 文章网址匹配规则的设置是最简单的,不需要复杂的设置。提供两种匹配模式。您可以使用 URL 通配符匹配或 CSS 选择器进行匹配。通常 URL 通配符匹配比较简单,但有时会使用 CSS 选择器。更确切。使用 URL 通配符匹配。通过点击列表网址上的文章,我们可以发现文章的每个网址的结构如下:所以将网址中的数字或字母替换为通配符(*),如:(*)/(*) .shtml。重复的 URL 可以使用 301 重定向。使用 CSS 选择器进行匹配。使用CSS选择器进行匹配,我们只需要设置文章URL的CSS选择器即可,查看列表URL源码即可轻松设置,在列表下找到文章超LINK的代码网址,如下图:

可以看到文章的超链接A标签在class为“contList”的标签里面,所以文章 URL的CSS选择器只需要设置为.contList a即可,如下图:

设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,将列出列表URL下的所有文章名称和对应的网址,如下图:

其他设置不需要修改。以上采集方法适用于WordPress多站点功能。
上一篇:WordPress网站如何调用other网站Latest文章(自动更新)
下一篇:WordPress调用其他网站文章显示在自己网站
发布:学做网站论坛 最后更新:2020-6-6 浏览:125264次
学做网站论坛致力于打造网站,打造在线培训诚信平台,让零基础学员学习如何做网站,最终可以自主搭建网站。
学做网站论坛建站培训,通过原创建站教程+讲师在线辅导,我们会详细讲解网站各种制作方法,即使你是初学者也能理解和学习。 .
文章采集规则(在设置采集规则的时候,有哪些注意事项?有什么注意事项)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-08-28 01:24
在这个日益浮躁的社会中,越来越多的人期望事情变得越来越简单。尤其是对于瞬息万变的互联网,需要时间仔细思考的事情并不适合。以网站operations 为例。虽然完整的原创文章对网站优化排名很有帮助,但是网站的大部分操作都不是很能写,再加上题材。时间限制和规律性。一个网站完全通过原创和全部手工操作,是非常困难的,特别是一些信息网站,商城网站,视频网站网站,里面有很多这样的页面和快速的内容更新要求,无论是内容构建还是外链发布都是一项庞大而复杂的任务,无论是时间还是成本,人工完成都是不划算的。因此,有时我们需要一些工具的帮助。 采集 工具就是其中之一。
目前网站采集中使用频率较高的采集工具有优采云采集工具、织梦自己的dede采集tools、采集tools。网上有很多对比,点百度就知道了,网上也有很多关于采集rules的设置策略,大同小异,本文就不多解释了对童鞋感兴趣的可以自行搜索。小美今天想跟大家分享的是采集规则设置时有哪些注意事项?
一、采集起止码设置
在采集规则设置中,很重要的一步就是采集起止码的设置。它通常是一小段代码,主要是“数字/英文+符号”的形式。代码越短,越不容易出错,而且需要是唯一的,这样机器才能快速识别采集的开始和结束位置。在网上教程中,这个起止码一般是一个完整的部分,比如[Content],这里是采集的开始位置,[Content]代表采集需要的部分信息,就是采集的结束位置采集位置,很多人会误以为起止代码一定是完整的section,其实不然。
有两种,如下图:
某部分代码,甚至是混入中文的代码,也可以作为采集的开始和结束代码,可以去除部分带有网站专有标识的网站内容开始和结束。
二、title采集Settings
标题采集很简单,有两种方式,如下图:
在需要采集的页面右击选择“查看源代码”,在打开的页面中使用快捷键Ctrl+F,在出现的搜索栏中输入采集内容的标题,并且可以查看 这个页面的标题规则一般是标题标签和H标签,数量从1到4不等。一般一个页面上同时存在两种标题标签。在这种情况下,使用 H 标签将比标题标签采集 更不容易出错。
需要注意的是,有时H标签有H1标签、H2标签、H3标签等,一般只使用H1标签。
三、分页采集规则设置
有些网站因为文章太长或者想提高点击率,经常把一篇文章的文章分成几页来呈现。在这种情况下,采集 的开始和结束代码不在同一页面上。相反,您应该在文章start 页面上查找采集 开始代码,并在文章 结束页面上查找结束代码。设置以下内容:
四、可能导致采集失败的几个因素
1、网站隐藏内容被禁止采集。在这种情况下,以腾讯新闻为例。腾讯新闻的内容不会显示在开源代码页中,因此无法区分文章的开始和结束位置,也不能将采集与其网站内容分开。
2、网站采集 出错了。大多数网站内容在网页和代码中显示正常,但当采集到达目标网站时显示错误。这种错误分为几类:
A.标题错了。如下图,文章的内容会全部集中在标题上。
B.只有采集进入标题,内容为空白。即相关内容不能是采集。
C、采集终止符无效,采集内容收录采集网站上的广告/版权信息/尾部信息等信息。
这些是采集经常遇到的问题。了解这些对采集和伪原创有很大帮助。虽然我们不建议在优化中使用采集,但在必要时了解采集规则仍然有利于网站操作。原文出处:美育宝防辐射服,专题内容请保留原文链接。谢谢! 查看全部
文章采集规则(在设置采集规则的时候,有哪些注意事项?有什么注意事项)
在这个日益浮躁的社会中,越来越多的人期望事情变得越来越简单。尤其是对于瞬息万变的互联网,需要时间仔细思考的事情并不适合。以网站operations 为例。虽然完整的原创文章对网站优化排名很有帮助,但是网站的大部分操作都不是很能写,再加上题材。时间限制和规律性。一个网站完全通过原创和全部手工操作,是非常困难的,特别是一些信息网站,商城网站,视频网站网站,里面有很多这样的页面和快速的内容更新要求,无论是内容构建还是外链发布都是一项庞大而复杂的任务,无论是时间还是成本,人工完成都是不划算的。因此,有时我们需要一些工具的帮助。 采集 工具就是其中之一。
目前网站采集中使用频率较高的采集工具有优采云采集工具、织梦自己的dede采集tools、采集tools。网上有很多对比,点百度就知道了,网上也有很多关于采集rules的设置策略,大同小异,本文就不多解释了对童鞋感兴趣的可以自行搜索。小美今天想跟大家分享的是采集规则设置时有哪些注意事项?
一、采集起止码设置
在采集规则设置中,很重要的一步就是采集起止码的设置。它通常是一小段代码,主要是“数字/英文+符号”的形式。代码越短,越不容易出错,而且需要是唯一的,这样机器才能快速识别采集的开始和结束位置。在网上教程中,这个起止码一般是一个完整的部分,比如[Content],这里是采集的开始位置,[Content]代表采集需要的部分信息,就是采集的结束位置采集位置,很多人会误以为起止代码一定是完整的section,其实不然。
有两种,如下图:
某部分代码,甚至是混入中文的代码,也可以作为采集的开始和结束代码,可以去除部分带有网站专有标识的网站内容开始和结束。
二、title采集Settings
标题采集很简单,有两种方式,如下图:
在需要采集的页面右击选择“查看源代码”,在打开的页面中使用快捷键Ctrl+F,在出现的搜索栏中输入采集内容的标题,并且可以查看 这个页面的标题规则一般是标题标签和H标签,数量从1到4不等。一般一个页面上同时存在两种标题标签。在这种情况下,使用 H 标签将比标题标签采集 更不容易出错。
需要注意的是,有时H标签有H1标签、H2标签、H3标签等,一般只使用H1标签。
三、分页采集规则设置
有些网站因为文章太长或者想提高点击率,经常把一篇文章的文章分成几页来呈现。在这种情况下,采集 的开始和结束代码不在同一页面上。相反,您应该在文章start 页面上查找采集 开始代码,并在文章 结束页面上查找结束代码。设置以下内容:
四、可能导致采集失败的几个因素
1、网站隐藏内容被禁止采集。在这种情况下,以腾讯新闻为例。腾讯新闻的内容不会显示在开源代码页中,因此无法区分文章的开始和结束位置,也不能将采集与其网站内容分开。
2、网站采集 出错了。大多数网站内容在网页和代码中显示正常,但当采集到达目标网站时显示错误。这种错误分为几类:
A.标题错了。如下图,文章的内容会全部集中在标题上。
B.只有采集进入标题,内容为空白。即相关内容不能是采集。
C、采集终止符无效,采集内容收录采集网站上的广告/版权信息/尾部信息等信息。
这些是采集经常遇到的问题。了解这些对采集和伪原创有很大帮助。虽然我们不建议在优化中使用采集,但在必要时了解采集规则仍然有利于网站操作。原文出处:美育宝防辐射服,专题内容请保留原文链接。谢谢!
优采云导航:优采云采集器优采云控制台优采云采集支持5118接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 633 次浏览 • 2021-08-27 19:07
优采云Navigation: 优采云采集器 优采云控制台
访问5118各种内容API教程-优采云采集
优采云采集支持5118接口如下(5118购买优惠码:FA5AF6)
5118 一键智能换字API接口
5118 一键智能重写API接口
5118 智能标题生成 API
提醒:第三方API接入功能需要用户提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口产生的一切费用由用户承担);
访问步骤1.创建5118 API接口配置(所有接口通用)
5118一键智能改字API接口:可用于处理采集数据标题和内容等,支持保留html标签,可以保留图片和排版;
5118 一键智能重写API接口:可用于处理采集的数据标题和内容。不支持保留html标签,只支持纯文本,但是优采云做了一些处理,尽量保留图片和排版;
5118智能标题生成API:根据文章content智能生成文章title;
我。 API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》点击进入创建相应的接口配置:【5118_智能改词API】、【5118_智能改写API】、【5118_智能标题生成API】;
二。配置API接口信息:
【API-Key值】是从5118后台获取一键智能改词API,或者5118一键智能改写API,或者5118智能标题生成API对应的key值,填写优采云;
5118 一键智能换词API支持设置锁词功能。首先开启核心字锁。处理第三方原创api 时不会替换锁定的字。多个词之间用|分隔,例如:word 1|Word 2|Word 3
注:5118限制每次调用的最大长度为5000个字符(包括html代码),所以当内容长度超过时,优采云会分次调用。这个操作会增加api调用次数,费用也会相应增加,这是用户需要承担的费用,使用前一定要注意! ! !
使用免责声明:5118 一键智能重写 API 不支持保留 Html 标签,仅支持纯文本。不过优采云做了一些处理,使其具有简单的格式(p标签),处理后保留图片。但由于接口限制、相关算法不完善以及一些未知情况,处理后可能会出现一些情况。如内容错误或图片缺失,优采云对因处理结果不正确或遗漏直接或间接造成的任何损失或损害不承担任何责任。
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
我。 API 处理规则条目:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
注意:API处理1个字段时,会调用一次API接口,所以建议不要添加不需要的字段!
三、5118智能标题生成API(可选,特殊接口说明)
5118智能标题生成API是基于文章content(内容字段)智能生成文章标题,所以API处理规则中需要处理的字段要选择content字段生成标题基于内容。
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
我。手动执行 API 处理规则:
点击采集任务的【结果&发布】选项卡中的【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);
二。自动执行 API 处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般搭配定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4.API处理结果及发布 I,查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
内容处理后添加字段:
在【结果数据&发布】和数据预览界面均可查看。
提醒:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二后内容发布,API接口处理
发布文章前,修改发布目标第二步的映射字段,API接口处理后将title和content改成新的对应字段。
例如执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
例如执行5118智能标题生成API后,选择content_5118生成标题并发布;
提示:如果在发布目标中无法选择新字段,请在此任务下复制或新建一个发布目标,然后在新发布目标中选择新字段,即可查看详细教程;
5.5118-API接口常见问题及解决方案 我,API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
二。批量修改数据的xAPI状态
可以批量修改数据的xAPI状态。在任务的【结果数据&发布】页面,点击【批处理工具】按钮--》在弹出的窗口中,选择【根据条件修改&删除】选项--》在对话框中选择对应的xAPI状态第二行【设置xapi和SEO状态】,然后点击【执行修改】按钮;
优采云Navigation: 优采云采集器 优采云控制台 查看全部
优采云导航:优采云采集器优采云控制台优采云采集支持5118接口
优采云Navigation: 优采云采集器 优采云控制台
访问5118各种内容API教程-优采云采集
优采云采集支持5118接口如下(5118购买优惠码:FA5AF6)
5118 一键智能换字API接口
5118 一键智能重写API接口
5118 智能标题生成 API
提醒:第三方API接入功能需要用户提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口产生的一切费用由用户承担);
访问步骤1.创建5118 API接口配置(所有接口通用)
5118一键智能改字API接口:可用于处理采集数据标题和内容等,支持保留html标签,可以保留图片和排版;
5118 一键智能重写API接口:可用于处理采集的数据标题和内容。不支持保留html标签,只支持纯文本,但是优采云做了一些处理,尽量保留图片和排版;
5118智能标题生成API:根据文章content智能生成文章title;
我。 API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》点击进入创建相应的接口配置:【5118_智能改词API】、【5118_智能改写API】、【5118_智能标题生成API】;

二。配置API接口信息:
【API-Key值】是从5118后台获取一键智能改词API,或者5118一键智能改写API,或者5118智能标题生成API对应的key值,填写优采云;
5118 一键智能换词API支持设置锁词功能。首先开启核心字锁。处理第三方原创api 时不会替换锁定的字。多个词之间用|分隔,例如:word 1|Word 2|Word 3


注:5118限制每次调用的最大长度为5000个字符(包括html代码),所以当内容长度超过时,优采云会分次调用。这个操作会增加api调用次数,费用也会相应增加,这是用户需要承担的费用,使用前一定要注意! ! !
使用免责声明:5118 一键智能重写 API 不支持保留 Html 标签,仅支持纯文本。不过优采云做了一些处理,使其具有简单的格式(p标签),处理后保留图片。但由于接口限制、相关算法不完善以及一些未知情况,处理后可能会出现一些情况。如内容错误或图片缺失,优采云对因处理结果不正确或遗漏直接或间接造成的任何损失或损害不承担任何责任。
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
我。 API 处理规则条目:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;

二、API处理规则配置:

注意:API处理1个字段时,会调用一次API接口,所以建议不要添加不需要的字段!
三、5118智能标题生成API(可选,特殊接口说明)
5118智能标题生成API是基于文章content(内容字段)智能生成文章标题,所以API处理规则中需要处理的字段要选择content字段生成标题基于内容。

3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
我。手动执行 API 处理规则:
点击采集任务的【结果&发布】选项卡中的【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);

二。自动执行 API 处理规则:

启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般搭配定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4.API处理结果及发布 I,查看API接口处理结果:

API接口处理的内容会生成API接口对应的新字段,如:
内容处理后添加字段:
在【结果数据&发布】和数据预览界面均可查看。
提醒:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二后内容发布,API接口处理
发布文章前,修改发布目标第二步的映射字段,API接口处理后将title和content改成新的对应字段。
例如执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;

例如执行5118智能标题生成API后,选择content_5118生成标题并发布;

提示:如果在发布目标中无法选择新字段,请在此任务下复制或新建一个发布目标,然后在新发布目标中选择新字段,即可查看详细教程;
5.5118-API接口常见问题及解决方案 我,API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;

二。批量修改数据的xAPI状态
可以批量修改数据的xAPI状态。在任务的【结果数据&发布】页面,点击【批处理工具】按钮--》在弹出的窗口中,选择【根据条件修改&删除】选项--》在对话框中选择对应的xAPI状态第二行【设置xapi和SEO状态】,然后点击【执行修改】按钮;

优采云Navigation: 优采云采集器 优采云控制台
教程总目录:优采云采集器使用教程内容发布相关的设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-08-27 19:01
教程总目录:优采云采集器使用教程内容发布相关的设置
优采云采集器使用教程-采集内容发布规则设置
教程总目录:优采云采集器Using tutorials
在讲如何查找网站、采集文章链接和内容之前,先说一下内容发布相关的设置。
因为我在教程中设置了发布规则,所以这里简单介绍一下各个项目。
如下图
第一步,我们点击这里的内容发布规则
第二步,点击网页发布规则列表后面的加号
第三步出现模块管理(教程的总目录写好了,我们的模块文件放在优采云program下的\Module\目录下),选择wordpress.post模块
第四步,网页编码选择UTF-8(wordpress程序是国外的,国际上一般是UTF8编码,国内有的会是GBK编码。比如Discuz论坛程序有两个安装包:UTF8和GBK。 )
第五步,在我们的网页地址填写网站地址并添加接口文件名。比如你的接口文件名是jiekou.php网站,那么填写这个地址
第六步选择不登录作为登录方式。我们的界面文件免登录。
第七步,点击以下获取列表。通常你会得到wordpress的文章分类列表。然后选择一个列表,你选择哪个列表,采集的文章就会被发送到哪个列表。
然后在下面随机写一个配置名称并保存。
然后我们勾选我们刚刚保存的发布配置并启用它。
那别忘了点击右下角的保存,或者点击保存退出! 查看全部
教程总目录:优采云采集器使用教程内容发布相关的设置
优采云采集器使用教程-采集内容发布规则设置
教程总目录:优采云采集器Using tutorials
在讲如何查找网站、采集文章链接和内容之前,先说一下内容发布相关的设置。
因为我在教程中设置了发布规则,所以这里简单介绍一下各个项目。
如下图
第一步,我们点击这里的内容发布规则
第二步,点击网页发布规则列表后面的加号
第三步出现模块管理(教程的总目录写好了,我们的模块文件放在优采云program下的\Module\目录下),选择wordpress.post模块
第四步,网页编码选择UTF-8(wordpress程序是国外的,国际上一般是UTF8编码,国内有的会是GBK编码。比如Discuz论坛程序有两个安装包:UTF8和GBK。 )
第五步,在我们的网页地址填写网站地址并添加接口文件名。比如你的接口文件名是jiekou.php网站,那么填写这个地址
第六步选择不登录作为登录方式。我们的界面文件免登录。
第七步,点击以下获取列表。通常你会得到wordpress的文章分类列表。然后选择一个列表,你选择哪个列表,采集的文章就会被发送到哪个列表。
然后在下面随机写一个配置名称并保存。
然后我们勾选我们刚刚保存的发布配置并启用它。
那别忘了点击右下角的保存,或者点击保存退出!
如何自己定义网页样式?采集规则不难
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-08-25 06:07
其实写一个采集规则并不难。只要懂CSS语法,就不想去百度脑补了。一般你先采集list,然后通过list抓取详情页,每个list其实都有CSS规则控制样式。
我推荐一个网站来学习css选择器:
如果你了解选择器,你就会知道如何采集list 页面和详情页面。
当然,你也学会了如何自己定义网页样式。
以上是基础知识。下面我们解释采集工具给我们带来的便利。我是第一批使用采集的用户。当时还没有自动存储多重分类功能。
这个功能很容易使用。我想要采集一批资源,但是又不想存一个category,所以只需要输入我要存的categoryid,然后采集就会随机存入这些category里面。
当然,当你留空时填写类别id文本框,那么它只会存储在采集category下你选择的类别中。
另一个功能是分页:
估计有人直接输入页码,认为页面是采集。提示很清楚!
比如采集的分页是:和后面的第二个分页,你把“2”页码换成{#num},最后显示
记得用{#num}替换采集网址中的页码编号。
这样采集就不能分页数据了,否则会重复,然后你会问为什么没有采集把其他页面的数据翻过来。
最后一个功能是自动采集,用起来特别爽。
采集时间间隔的单位是毫秒,1秒=1000毫秒。
最好设置2小时自动采集一次,毕竟网站更新不是那么频繁。
auto采集很讲究,就是你上面填写的采集url地址的网页列表每天更新,也就是更新频繁的页面适合自动采集 ,你采集windows不要关掉,让它在设定的时间自动采集。
管理员添加:
规则文件的存放位置:static/caiji,存放在caiji文件夹中的txt文件规则。
这是360问答的采集规则,每行一个,有就写,没有就分开,因为这是最后的拆分。
最后到此就大功告成了,剩下的就是配置了,caiji文件夹下有个xml.php,打开:
你能看懂吗,名字和你的txt的键值对,注意‘,’是英文的!
然后下次刷新采集管理页面的网页时,您将能够看到新的采集规则。
好了,就说这么多,欢迎吐槽! 查看全部
如何自己定义网页样式?采集规则不难
其实写一个采集规则并不难。只要懂CSS语法,就不想去百度脑补了。一般你先采集list,然后通过list抓取详情页,每个list其实都有CSS规则控制样式。
我推荐一个网站来学习css选择器:

如果你了解选择器,你就会知道如何采集list 页面和详情页面。
当然,你也学会了如何自己定义网页样式。
以上是基础知识。下面我们解释采集工具给我们带来的便利。我是第一批使用采集的用户。当时还没有自动存储多重分类功能。
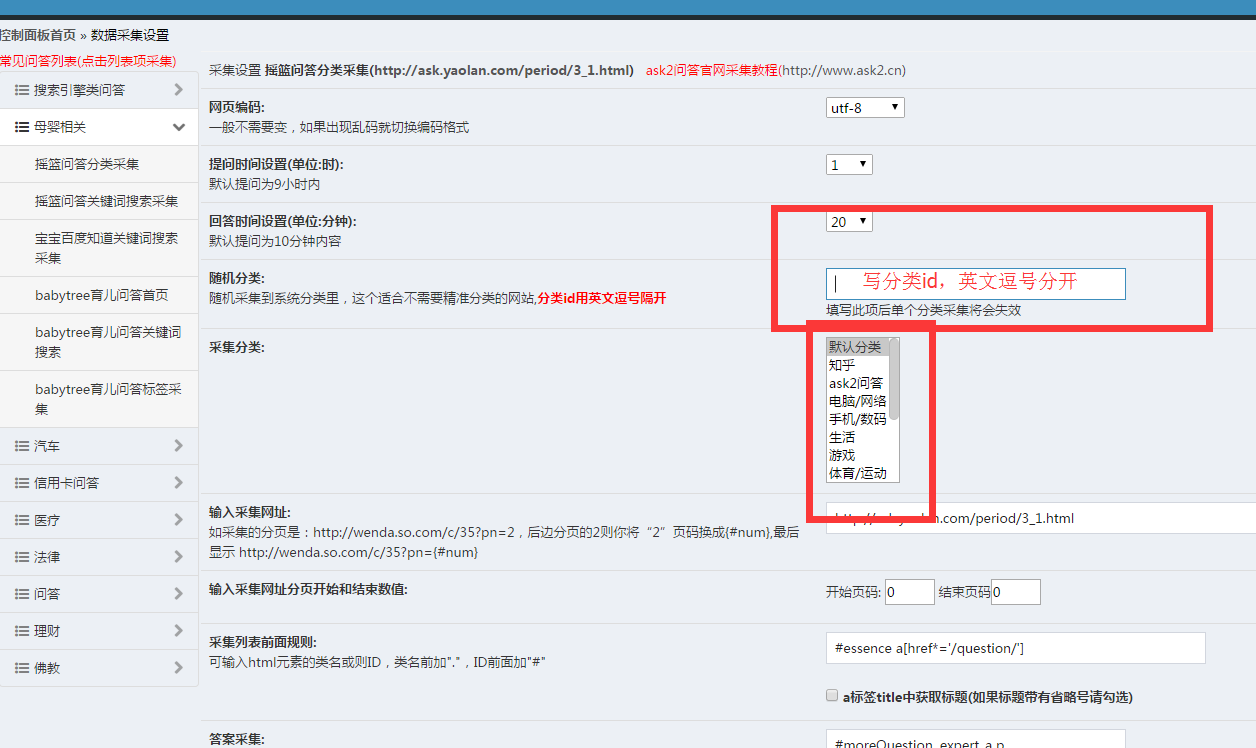
这个功能很容易使用。我想要采集一批资源,但是又不想存一个category,所以只需要输入我要存的categoryid,然后采集就会随机存入这些category里面。
当然,当你留空时填写类别id文本框,那么它只会存储在采集category下你选择的类别中。
另一个功能是分页:
估计有人直接输入页码,认为页面是采集。提示很清楚!
比如采集的分页是:和后面的第二个分页,你把“2”页码换成{#num},最后显示
记得用{#num}替换采集网址中的页码编号。
这样采集就不能分页数据了,否则会重复,然后你会问为什么没有采集把其他页面的数据翻过来。
最后一个功能是自动采集,用起来特别爽。
采集时间间隔的单位是毫秒,1秒=1000毫秒。
最好设置2小时自动采集一次,毕竟网站更新不是那么频繁。
auto采集很讲究,就是你上面填写的采集url地址的网页列表每天更新,也就是更新频繁的页面适合自动采集 ,你采集windows不要关掉,让它在设定的时间自动采集。
管理员添加:
规则文件的存放位置:static/caiji,存放在caiji文件夹中的txt文件规则。
这是360问答的采集规则,每行一个,有就写,没有就分开,因为这是最后的拆分。
最后到此就大功告成了,剩下的就是配置了,caiji文件夹下有个xml.php,打开:

你能看懂吗,名字和你的txt的键值对,注意‘,’是英文的!
然后下次刷新采集管理页面的网页时,您将能够看到新的采集规则。
好了,就说这么多,欢迎吐槽!
苹果cmsv10怎么添加文章资讯,手把手教你优采云采集文章图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-08-24 05:33
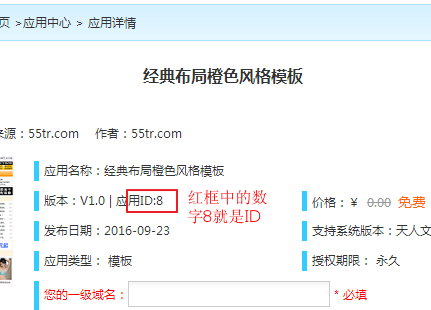
Applecmsv10如何添加文章资讯,教你优采云采集文章资讯图文教程。只要能安定下来,小白看完保证书就可以学习了。我花了几个小时认真写了一个教程,你不想花几分钟去阅读它,你注定什么也学不到。
一直想写几个教程给小白看书用优采云采集资讯明星视频,因为小白来问我这个问题的太多了,我说你去百度,反馈一下结果都一样,说没有详细的配置教程,发布老是提示失败。今天终于抽空给小白写了一个简单实用的采集教程。让我们来写这个教程如何采集文章信息。以后有时间我会更新视频和星星。本教程是关于如何使用已经有采集规则的教程。 采集法和优采云软件从文章末尾的链接下载。下载后,按照我写的教程,保证你学会优采云采集文章资讯,开始我们今天的采集教程。
教程分为两部分,一是发布模块的配置,二是采集规则的配置。发布模块和采集规则是两个不可或缺的组成部分。有朋友说采集总是发不出去,怎么回事?归根结底是因为这两个地方没有配置好。往下看
首先配置发布模块
1、打开优采云software文件夹,点击下图中的启动器图标
2.软件启动后,点击此“发布”,进入网页发布模块配置界面。
3、我发优采云给你说苹果v10的4个发布模块已经导入软件了。双击“Applecms-v10文章”模块进行编辑。下图有3个编辑位置
①、编码设置改为UTF-8
②、网站和地址用你的网站主域名替换“”
③、登录方式改为无需登录http请求
④,一切搞定后点击右下角的测试配置,首先要确定发布模块是否可以正常使用,如果采集规则不能正确使用,则不会发布。单击测试配置,进入测试配置页面。如下图
4、配置发布模块最关键的一步,也是很多人会犯错误甚至不理解的地方。我用箭头指向的地方就是我们要配置的地方。如下图
①、首先配置验证密码:验证密码是站外仓库系统连接Applecms系统后端的验证码。这个需要在系统后台勾选然后填写,找到验证码后,双击左边的“验证密码”复制粘贴到右边的编辑框中。系统后台的验证码如下图所示。找到后,将其复制并粘贴到我们的发布模块中。
②,我们来配置发布模块的“名称”。这里的模块名称其实就是文章的标题。我们可以选择任何名称。要了解这个地方,每个文章 都有一个标题。只能发布标题。我们在这里测试发布模块,因此您必须手动填写标题。如果是采集rule,这个地方就不需要填写了,采集rule会自动在采集网站的title上进行。我们以“第一层外套”这个名字为例。双击名称,填写右侧第一层,点击修改。
③,我们来配置一下“类别名称”和“类别编号”,这也是系统后台确定的,也就是从采集文章到网站你想要哪个类别名称和编号@,见下图
进入系统后台,点击basic>>>分类管理下拉(第二张图)我们可以看到信息的顶级分类和子分类三个。我们都发布了这三个类别的文章的类别。 ,可以用,我们只选择一个类别“标题”这个类别。这里的标题是我们的分类名,标题前的18是分类号。所以我们从中得到分类的名称和编号,直接填写发布模块的配置。
④ 全部填好后即完成最终测试,我们点击“发布文章测试”,下面是发布成功存储的相关提示。我们可以去网站前台看看有没有文章。
⑤我们来到网站的前台,点击导航栏中的分类,可以看到文章第一幅画的标题,也说明我们的文章发布模块成功了已配置。
5、由于文字长度的限制,我们将在下一篇文章中介绍文章采集规则的配置。看完后半部分的配置,相信你会用优采云来采集文章信息到你的网站。
优采云7.6 免费企业版下载:点击查看后半部分教程 查看全部
苹果cmsv10怎么添加文章资讯,手把手教你优采云采集文章图文教程
Applecmsv10如何添加文章资讯,教你优采云采集文章资讯图文教程。只要能安定下来,小白看完保证书就可以学习了。我花了几个小时认真写了一个教程,你不想花几分钟去阅读它,你注定什么也学不到。
一直想写几个教程给小白看书用优采云采集资讯明星视频,因为小白来问我这个问题的太多了,我说你去百度,反馈一下结果都一样,说没有详细的配置教程,发布老是提示失败。今天终于抽空给小白写了一个简单实用的采集教程。让我们来写这个教程如何采集文章信息。以后有时间我会更新视频和星星。本教程是关于如何使用已经有采集规则的教程。 采集法和优采云软件从文章末尾的链接下载。下载后,按照我写的教程,保证你学会优采云采集文章资讯,开始我们今天的采集教程。
教程分为两部分,一是发布模块的配置,二是采集规则的配置。发布模块和采集规则是两个不可或缺的组成部分。有朋友说采集总是发不出去,怎么回事?归根结底是因为这两个地方没有配置好。往下看
首先配置发布模块
1、打开优采云software文件夹,点击下图中的启动器图标

2.软件启动后,点击此“发布”,进入网页发布模块配置界面。

3、我发优采云给你说苹果v10的4个发布模块已经导入软件了。双击“Applecms-v10文章”模块进行编辑。下图有3个编辑位置
①、编码设置改为UTF-8
②、网站和地址用你的网站主域名替换“”
③、登录方式改为无需登录http请求
④,一切搞定后点击右下角的测试配置,首先要确定发布模块是否可以正常使用,如果采集规则不能正确使用,则不会发布。单击测试配置,进入测试配置页面。如下图

4、配置发布模块最关键的一步,也是很多人会犯错误甚至不理解的地方。我用箭头指向的地方就是我们要配置的地方。如下图

①、首先配置验证密码:验证密码是站外仓库系统连接Applecms系统后端的验证码。这个需要在系统后台勾选然后填写,找到验证码后,双击左边的“验证密码”复制粘贴到右边的编辑框中。系统后台的验证码如下图所示。找到后,将其复制并粘贴到我们的发布模块中。

②,我们来配置发布模块的“名称”。这里的模块名称其实就是文章的标题。我们可以选择任何名称。要了解这个地方,每个文章 都有一个标题。只能发布标题。我们在这里测试发布模块,因此您必须手动填写标题。如果是采集rule,这个地方就不需要填写了,采集rule会自动在采集网站的title上进行。我们以“第一层外套”这个名字为例。双击名称,填写右侧第一层,点击修改。

③,我们来配置一下“类别名称”和“类别编号”,这也是系统后台确定的,也就是从采集文章到网站你想要哪个类别名称和编号@,见下图
进入系统后台,点击basic>>>分类管理下拉(第二张图)我们可以看到信息的顶级分类和子分类三个。我们都发布了这三个类别的文章的类别。 ,可以用,我们只选择一个类别“标题”这个类别。这里的标题是我们的分类名,标题前的18是分类号。所以我们从中得到分类的名称和编号,直接填写发布模块的配置。


④ 全部填好后即完成最终测试,我们点击“发布文章测试”,下面是发布成功存储的相关提示。我们可以去网站前台看看有没有文章。

⑤我们来到网站的前台,点击导航栏中的分类,可以看到文章第一幅画的标题,也说明我们的文章发布模块成功了已配置。

5、由于文字长度的限制,我们将在下一篇文章中介绍文章采集规则的配置。看完后半部分的配置,相信你会用优采云来采集文章信息到你的网站。
优采云7.6 免费企业版下载:点击查看后半部分教程
2.修改规则中的cookie发布规则配置插件使用简易教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-24 03:12
2.根据网站版本选择对应的发布模块和接口,并进行配置
3.规则里有具体的视频教学
4.必须使用优采云v9.8内部版本(网上找)
5.使用简单教程:
首先确保你手头有三个或更多文件,比如Write.php(发布界面)xxxx.ljobx(采集法)xxx.wpm(发布模块)xxx.cs(采集插件)
1.选择对应版本优采云Import 采集rule 将模块发布到网站替换Write.php(发布界面)
优采云installation directory/Module 用于发布模块
优采云installation directory/Plugins 这是插件用的
网站installation directory/application/api/controller 这是发布界面
2.在规则插件配置中修改cookie发布规则配置一些关键标签替换值(不同的规则可能不需要更改)
cookies的作用是针对采集需要会员登录采集的东西
发布配置是编辑任务的第三步,添加发布配置,选择发布模块,填写自己的url。
插件配置部分规则使用plugin来辅助采集,所以需要在第四步选择对应的采集plugin
一些tag值,比如api key,单章价格,甚至镜像到本地后对应的新域名,都需要自己修改
3.完成以上,获取第一步页面的测试网址,点击任意内容页面进行测试采集
4. 测试版右下角也有测试版。配置好发布配置后,就可以测试了。这里的测试发布可以有效检查发布状态和错误。
资源下载 本资源仅供注册用户下载,请先登录 查看全部
2.修改规则中的cookie发布规则配置插件使用简易教程
2.根据网站版本选择对应的发布模块和接口,并进行配置
3.规则里有具体的视频教学
4.必须使用优采云v9.8内部版本(网上找)
5.使用简单教程:
首先确保你手头有三个或更多文件,比如Write.php(发布界面)xxxx.ljobx(采集法)xxx.wpm(发布模块)xxx.cs(采集插件)
1.选择对应版本优采云Import 采集rule 将模块发布到网站替换Write.php(发布界面)
优采云installation directory/Module 用于发布模块
优采云installation directory/Plugins 这是插件用的
网站installation directory/application/api/controller 这是发布界面
2.在规则插件配置中修改cookie发布规则配置一些关键标签替换值(不同的规则可能不需要更改)
cookies的作用是针对采集需要会员登录采集的东西
发布配置是编辑任务的第三步,添加发布配置,选择发布模块,填写自己的url。
插件配置部分规则使用plugin来辅助采集,所以需要在第四步选择对应的采集plugin
一些tag值,比如api key,单章价格,甚至镜像到本地后对应的新域名,都需要自己修改
3.完成以上,获取第一步页面的测试网址,点击任意内容页面进行测试采集
4. 测试版右下角也有测试版。配置好发布配置后,就可以测试了。这里的测试发布可以有效检查发布状态和错误。
资源下载 本资源仅供注册用户下载,请先登录
【岛】数据图示--逻辑方式数据设置页
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-08-20 23:18
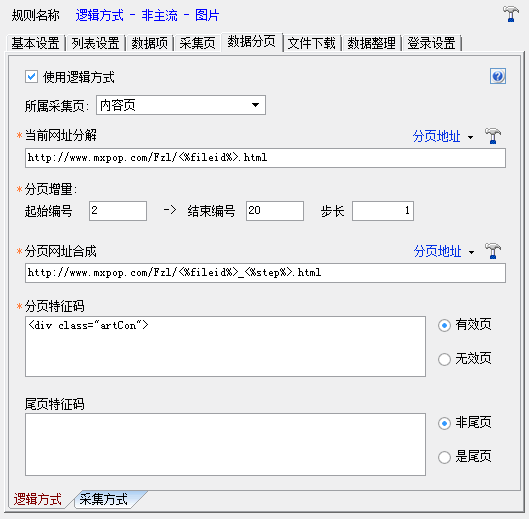
一、数据分页设置页面介绍
1、Description
我们在显示文章内容的时候经常会遇到一些网站,内容被分成几页显示,我们需要翻页依次阅读所有内容,当我们采集这种类型的网站文章,需要使用数据分页;在ET中,我们可以选择采集分页两种分页方式之一,分别是'采集method'和'logical method',【数据分页-逻辑模式设置页面】见图1:
(图一:逻辑数据分页)
数据项从采集页面(即第一页)的源码中获取,使用数据项采集rule解析获取内容,然后数据项采集rule解析为单独使用,从每个页面的源代码中获取内容,将按顺序合并,并用【内容分离】标签“#-0-#”分隔;
注意:为了避免用户错误配置将采集分页陷入死循环,逻辑获取的页数上限为2000。
访问页面失败时,文章的采集不会中断。
注意:2.4 版本之前,分页只对文本数据项有效。从2.4 版本开始,每个数据项都可以从分页中获取内容。
2.4版本之前,将所有页面的源代码一一合并,然后使用数据项采集进行内容分析;从2.4 版本开始,每个页面的源代码都是单独获取的。使用数据项采集规则对获取的内容进行分析后,将获取的内容按顺序合并。因此,2.4版本之前使用正文分页功能的采集规则在升级到2.4版本后可能存在兼容性问题,需要进行调整。
二、开启逻辑模式
逻辑方法是指通过预设规则计算每个分页URL的方法。这种方法比采集方法简单,但使用范围稍微窄一些。只适用于分页网址按数律增减。情况;
使用逻辑方式获取分页,请勾选【使用逻辑方式】,见图:
数据分页作为某个采集页面的分页存在,采集页面是第一个分页。比如一个文章内容页显示为多个分页,一个产品的评论页显示为多个页面,所以需要设置数据页属于哪个采集页面,见图:
三、当前 URL 分解
1、Description
【当前URL分解】为必填项,用于从数据分页所属的采集页面的完整URL中提取出【页面地址】信息,用于形成如下逻辑的完整页面URL操作。见图3:
(icon3)
因为在大多数规则中,数据页所属的采集页是第一个采集页,所以【当前URL分解】的规则通常与;
注意:如果文章 URL 有重定向,则重定向后的完整 URL 应该用于 URL 分解;
点击
图标,可以测试[d当前URL分解];
2、tag 区域
【当前URL分解】有可用标记,见图3;
1、page 地址
标签代码用于指示用于区分当前 URL 与其他 URL 的唯一字符串。 [页面地址]标签在规则中只能使用一次;
有关标签的更多信息,请参阅相关主题;
3、参考示例
以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:
1、we 通过获取文章的完整网址如下:
2、在上面的示例 URL 中,字符串“348556”是该 URL 的唯一特征字符串。当然,我们选择像'tid=348556'这样的字符串是没有问题的。填写【当前网址分解】规则如下:
四、page 增量
1、Description
【Paging Increment】为必填项,此项用于计算在指定范围内有规律变化的每个分页URL的特征数编号,并与【分页URL合成】中的【分页地址】结合完整的页面 URL,见图 4:
(icon4)
开始号码和结束号码只能填写数字,位数要与真实列表网址一致,例如“01”不等于“1”;
如果起始编号大于结束编号,则[页增量]减少步长,如果起始编号小于结束编号,则[页增量]增加步长;
步长表示每次递增或递减的递增或递减量。不管是递增还是递减,步长都是正整数;
为了避免重复采集,起始编号一般不是'1'或'01'等数字,因为[body]数据项所属的采集页面,即第一页在执行体中分页采集已经是采集了,大多数网站的习惯就是把这个页面当成带有'1'和'01'等数字的页面;
结束编号通常设置为实际页数无法达到的较大数字,这样页增量会包括所有可能出现的有效编号,并判断该页是否实际上是最后一页,我们通过【有效分页特征码】;
2、参考示例
以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:
1、一个多页的帖子,每页的网址如下:
%3D1
%3D1&page=2
%3D1&page=3
%3D1&page=4
……
2、 删除不必要的参数,可以简化为:
……
3、 那么在上面的每一个网址中,经常变化且具有独特特征的数字很容易找到。它们是“2”、“3”、“4”等。这些数字相加1递增,所以我们得到步长1,我们设置一个更大的,通常没有达到的数字'100'作为结束数字,所以我们配置这个文本页面的[页面增量]如下:<//p
pimg src='http://www.zzcity.net/help/setup-cj-6-4.gif' alt=''//p
p4、注意,在上面的例子中,我们使用URL page=2的页面作为起始页码,所以起始编号设置为2。这是因为[body]数据项属于第一个页面,即【当前URL分解】中的“当前URL”,这个页面在采集分页符之前已经是采集了。/p
p五、Page URL 合成/p
p1、Description/p
p【Paging URL Synthesis】是必填项,这里使用【Page Address】和【Page Increment】合成一个完整的页面URL,见图5:/p
pimg src='http://www.zzcity.net/help/setup-cj-6-5.gif' alt=''//p
p(icon5)/p
p完整页面URL可以使用相对链接和相对于当前页面的完整链接,如:“../../page--.htm”、“page--.htm”、“-.htm”等;/p
p注意:文章地址为电脑本地文件路径时,页面URL必须是完整地址,不能使用相对地址;/p
p点击/p
pimg src='http://www.zzcity.net/help/icon-testtool.gif' alt=''//p
p图标,可以测试【分页网址合成】;/p
p2、tag 区域/p
p【Paging URL Synthesis】有2个可用标签,见图5;/p
p1、page 地址/p
p标签代码为必填项,用于表示每个页面URL中的固定特征字符串,与[当前URL分解]中的[页面地址]为同一个标签,用于引用其值;//p
p2、page 增量/p
p标记码是,是必填项,用于表示每个分页URL中定期变化的特征号编号,由本文第三节的逻辑规则计算得出;/p
p有关标记的更多说明,请参阅相关主题;/p
p3、参考示例/p
p以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:/p
p1、 我们在本文第二、三部分分别获得了【页面地址】和【页面增量】。根据这两个标签的表达,我们设置了【分页网址合成】的规则如下:/p
p&page=/p
p在上面的例子中,[Paging Address]替换了分页URL中的固定特征字符串'348556',[Paging Increment]替换了分页URL 4中经常变化的号码'2','3',' '等;/p
p六、功能码/p
p1、Description/p
p特征码由两部分组成,分别是【页面特征码】和【最后一页特征码】;/p
pimg src='http://www.zzcity.net/help/setup-cj-6-6.gif' alt=''//p
p(icon6)/p
p注:2.4版本之前,【页面特征码】为【有效页面特征码】,【末页特征码】为【非末页特征码】;从2.4开始,用户可以自行选择特征码类型。/p
p1、page 特征码/p
p[Pagination Feature Code]为必填项,内容为从网页源代码中选择的字符串,通过分页URL合成的网页是否有效通过网页源代码是否有效来判断收录字符串,见图6;/p
pEffective pages 勾选此项时,将网页源代码中收录特征码字符串的网页视为有效页面,以默认页面特征码作为有效页面特征码;/p
p无效页面 勾选此选项后,网页源代码中收录特征码字符串的网页将被视为无效页面;/p
p特征代码是一个字符串,只收录所有有效或无效页面的源代码。设置页面的特征码不需要考虑第一页,也就是采集页。/p
p一旦逻辑计算出的页面URL采集的页面源代码不收录[有效页面]类型[页面特征码],系统会认为上一个页面采集是最后一个有效页面当系统结束采集page;/p
p如果逻辑计算到达的页面URL采集的页面源代码收录[无效页面]类型[页面特征码],则系统认为上一个页面采集是最后一个有效页面,则系统结束采集pagination;相反,如果页面源代码不收录[无效页面]类型[分页码],则该页面被视为有效页面。/p
p2、结束页面特征码/p
p[Last Page Feature Code] 可选,内容为从网页源代码中选择的字符串。网页源码中收录判断页面URL合成的网页是否为最后一页的字符串。 pass和[分页特征码]用于确定文本分页的结束页,见图6;/p
pNon-Last Page 勾选该选项后,网页源代码中收录特征码字符串的网页被视为不是最后一页,默认最后一页特征码为非最后一页特征代码;/p
p这是最后一页。勾选此项时,将网页源代码中收录特征码字符串的网页视为最后一页;/p
p特征码是只收录在最后一页或所有非最后一页的源代码中的字符串。设置最后一页特征码不需要考虑第一页,即采集页所属。/p
p当[Last Page Feature Code]不为空时,第一个不收录[Non-Last Page]类型[Last Page Feature Code]的有效页面为最后一个有效页面,系统结束采集分页;/p
p第一个收录[为最后一页]类型[最后一页特征码]的有效页面作为最后一个有效页面,系统结束采集分页;/p
p2、参考示例一/p
p以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:/p
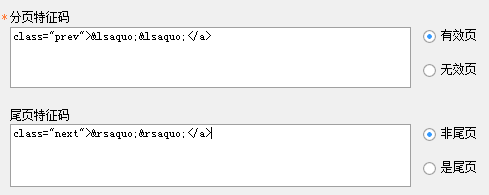
p1、 论坛帖子分为两种,一种是分页的,一种是不分页的;比较特殊的是当分页网址越界时(分页增量超过实际最后一页的数量),Discuz论坛不会提示越界,而是直接显示最后一页,如果没有页面,会显示第一页;/p
p2、 通过对比没有分页的帖子和有分页的帖子,可以看到位于中间的所有分页页面在页面导航中都有向前和向后的页面链接,'‹‹'和'››' ,并且最后一页没有后页链接'››'。我们找到了他们的源代码如下:/p
p‹‹/p
p››/p
p3、去掉改动的部分,选择特征码如下:/p
pclass="prev"‹‹/p
p>››
4、在没有分页的帖子中搜索,但是没有找到这两个特征码;在最后一页搜索,没有找到特征代码'class="next">››';在任意一个中间页面搜索,都有这两个特征码,所以分页特征码填写如下:
(icon6)
3、参考例子二
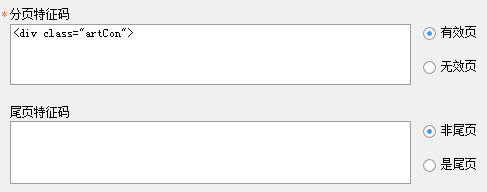
以采集某图片网站(见采集rule分页示例-逻辑上非主流图片)为例:
1、 这个网站文章分为有分页和无分页两种。当页面 URL 超出范围时,将显示“找不到页面”的错误消息。因此,我们只需要填写[Valid Pagination Feature Code]即可;
2、通过查看每个页面,我们发现了许多可以用作特征代码的字符串。我们选择其中之一并填写以下内容:
(icon7) 查看全部
【岛】数据图示--逻辑方式数据设置页
一、数据分页设置页面介绍
1、Description
我们在显示文章内容的时候经常会遇到一些网站,内容被分成几页显示,我们需要翻页依次阅读所有内容,当我们采集这种类型的网站文章,需要使用数据分页;在ET中,我们可以选择采集分页两种分页方式之一,分别是'采集method'和'logical method',【数据分页-逻辑模式设置页面】见图1:
(图一:逻辑数据分页)
数据项从采集页面(即第一页)的源码中获取,使用数据项采集rule解析获取内容,然后数据项采集rule解析为单独使用,从每个页面的源代码中获取内容,将按顺序合并,并用【内容分离】标签“#-0-#”分隔;
注意:为了避免用户错误配置将采集分页陷入死循环,逻辑获取的页数上限为2000。
访问页面失败时,文章的采集不会中断。
注意:2.4 版本之前,分页只对文本数据项有效。从2.4 版本开始,每个数据项都可以从分页中获取内容。
2.4版本之前,将所有页面的源代码一一合并,然后使用数据项采集进行内容分析;从2.4 版本开始,每个页面的源代码都是单独获取的。使用数据项采集规则对获取的内容进行分析后,将获取的内容按顺序合并。因此,2.4版本之前使用正文分页功能的采集规则在升级到2.4版本后可能存在兼容性问题,需要进行调整。
二、开启逻辑模式
逻辑方法是指通过预设规则计算每个分页URL的方法。这种方法比采集方法简单,但使用范围稍微窄一些。只适用于分页网址按数律增减。情况;
使用逻辑方式获取分页,请勾选【使用逻辑方式】,见图:

数据分页作为某个采集页面的分页存在,采集页面是第一个分页。比如一个文章内容页显示为多个分页,一个产品的评论页显示为多个页面,所以需要设置数据页属于哪个采集页面,见图:

三、当前 URL 分解
1、Description
【当前URL分解】为必填项,用于从数据分页所属的采集页面的完整URL中提取出【页面地址】信息,用于形成如下逻辑的完整页面URL操作。见图3:

(icon3)
因为在大多数规则中,数据页所属的采集页是第一个采集页,所以【当前URL分解】的规则通常与;
注意:如果文章 URL 有重定向,则重定向后的完整 URL 应该用于 URL 分解;
点击
图标,可以测试[d当前URL分解];
2、tag 区域
【当前URL分解】有可用标记,见图3;
1、page 地址
标签代码用于指示用于区分当前 URL 与其他 URL 的唯一字符串。 [页面地址]标签在规则中只能使用一次;
有关标签的更多信息,请参阅相关主题;
3、参考示例
以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:
1、we 通过获取文章的完整网址如下:
2、在上面的示例 URL 中,字符串“348556”是该 URL 的唯一特征字符串。当然,我们选择像'tid=348556'这样的字符串是没有问题的。填写【当前网址分解】规则如下:
四、page 增量
1、Description
【Paging Increment】为必填项,此项用于计算在指定范围内有规律变化的每个分页URL的特征数编号,并与【分页URL合成】中的【分页地址】结合完整的页面 URL,见图 4:

(icon4)
开始号码和结束号码只能填写数字,位数要与真实列表网址一致,例如“01”不等于“1”;
如果起始编号大于结束编号,则[页增量]减少步长,如果起始编号小于结束编号,则[页增量]增加步长;
步长表示每次递增或递减的递增或递减量。不管是递增还是递减,步长都是正整数;
为了避免重复采集,起始编号一般不是'1'或'01'等数字,因为[body]数据项所属的采集页面,即第一页在执行体中分页采集已经是采集了,大多数网站的习惯就是把这个页面当成带有'1'和'01'等数字的页面;
结束编号通常设置为实际页数无法达到的较大数字,这样页增量会包括所有可能出现的有效编号,并判断该页是否实际上是最后一页,我们通过【有效分页特征码】;
2、参考示例
以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:
1、一个多页的帖子,每页的网址如下:
%3D1
%3D1&page=2
%3D1&page=3
%3D1&page=4
……
2、 删除不必要的参数,可以简化为:
……
3、 那么在上面的每一个网址中,经常变化且具有独特特征的数字很容易找到。它们是“2”、“3”、“4”等。这些数字相加1递增,所以我们得到步长1,我们设置一个更大的,通常没有达到的数字'100'作为结束数字,所以我们配置这个文本页面的[页面增量]如下:<//p
pimg src='http://www.zzcity.net/help/setup-cj-6-4.gif' alt=''//p
p4、注意,在上面的例子中,我们使用URL page=2的页面作为起始页码,所以起始编号设置为2。这是因为[body]数据项属于第一个页面,即【当前URL分解】中的“当前URL”,这个页面在采集分页符之前已经是采集了。/p
p五、Page URL 合成/p
p1、Description/p
p【Paging URL Synthesis】是必填项,这里使用【Page Address】和【Page Increment】合成一个完整的页面URL,见图5:/p
pimg src='http://www.zzcity.net/help/setup-cj-6-5.gif' alt=''//p
p(icon5)/p
p完整页面URL可以使用相对链接和相对于当前页面的完整链接,如:“../../page--.htm”、“page--.htm”、“-.htm”等;/p
p注意:文章地址为电脑本地文件路径时,页面URL必须是完整地址,不能使用相对地址;/p
p点击/p
pimg src='http://www.zzcity.net/help/icon-testtool.gif' alt=''//p
p图标,可以测试【分页网址合成】;/p
p2、tag 区域/p
p【Paging URL Synthesis】有2个可用标签,见图5;/p
p1、page 地址/p
p标签代码为必填项,用于表示每个页面URL中的固定特征字符串,与[当前URL分解]中的[页面地址]为同一个标签,用于引用其值;//p
p2、page 增量/p
p标记码是,是必填项,用于表示每个分页URL中定期变化的特征号编号,由本文第三节的逻辑规则计算得出;/p
p有关标记的更多说明,请参阅相关主题;/p
p3、参考示例/p
p以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:/p
p1、 我们在本文第二、三部分分别获得了【页面地址】和【页面增量】。根据这两个标签的表达,我们设置了【分页网址合成】的规则如下:/p
p&page=/p
p在上面的例子中,[Paging Address]替换了分页URL中的固定特征字符串'348556',[Paging Increment]替换了分页URL 4中经常变化的号码'2','3',' '等;/p
p六、功能码/p
p1、Description/p
p特征码由两部分组成,分别是【页面特征码】和【最后一页特征码】;/p
pimg src='http://www.zzcity.net/help/setup-cj-6-6.gif' alt=''//p
p(icon6)/p
p注:2.4版本之前,【页面特征码】为【有效页面特征码】,【末页特征码】为【非末页特征码】;从2.4开始,用户可以自行选择特征码类型。/p
p1、page 特征码/p
p[Pagination Feature Code]为必填项,内容为从网页源代码中选择的字符串,通过分页URL合成的网页是否有效通过网页源代码是否有效来判断收录字符串,见图6;/p
pEffective pages 勾选此项时,将网页源代码中收录特征码字符串的网页视为有效页面,以默认页面特征码作为有效页面特征码;/p
p无效页面 勾选此选项后,网页源代码中收录特征码字符串的网页将被视为无效页面;/p
p特征代码是一个字符串,只收录所有有效或无效页面的源代码。设置页面的特征码不需要考虑第一页,也就是采集页。/p
p一旦逻辑计算出的页面URL采集的页面源代码不收录[有效页面]类型[页面特征码],系统会认为上一个页面采集是最后一个有效页面当系统结束采集page;/p
p如果逻辑计算到达的页面URL采集的页面源代码收录[无效页面]类型[页面特征码],则系统认为上一个页面采集是最后一个有效页面,则系统结束采集pagination;相反,如果页面源代码不收录[无效页面]类型[分页码],则该页面被视为有效页面。/p
p2、结束页面特征码/p
p[Last Page Feature Code] 可选,内容为从网页源代码中选择的字符串。网页源码中收录判断页面URL合成的网页是否为最后一页的字符串。 pass和[分页特征码]用于确定文本分页的结束页,见图6;/p
pNon-Last Page 勾选该选项后,网页源代码中收录特征码字符串的网页被视为不是最后一页,默认最后一页特征码为非最后一页特征代码;/p
p这是最后一页。勾选此项时,将网页源代码中收录特征码字符串的网页视为最后一页;/p
p特征码是只收录在最后一页或所有非最后一页的源代码中的字符串。设置最后一页特征码不需要考虑第一页,即采集页所属。/p
p当[Last Page Feature Code]不为空时,第一个不收录[Non-Last Page]类型[Last Page Feature Code]的有效页面为最后一个有效页面,系统结束采集分页;/p
p第一个收录[为最后一页]类型[最后一页特征码]的有效页面作为最后一个有效页面,系统结束采集分页;/p
p2、参考示例一/p
p以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:/p
p1、 论坛帖子分为两种,一种是分页的,一种是不分页的;比较特殊的是当分页网址越界时(分页增量超过实际最后一页的数量),Discuz论坛不会提示越界,而是直接显示最后一页,如果没有页面,会显示第一页;/p
p2、 通过对比没有分页的帖子和有分页的帖子,可以看到位于中间的所有分页页面在页面导航中都有向前和向后的页面链接,'‹‹'和'››' ,并且最后一页没有后页链接'››'。我们找到了他们的源代码如下:/p
p‹‹/p
p››/p
p3、去掉改动的部分,选择特征码如下:/p
pclass="prev"‹‹/p
p>››
4、在没有分页的帖子中搜索,但是没有找到这两个特征码;在最后一页搜索,没有找到特征代码'class="next">››';在任意一个中间页面搜索,都有这两个特征码,所以分页特征码填写如下:
(icon6)
3、参考例子二
以采集某图片网站(见采集rule分页示例-逻辑上非主流图片)为例:
1、 这个网站文章分为有分页和无分页两种。当页面 URL 超出范围时,将显示“找不到页面”的错误消息。因此,我们只需要填写[Valid Pagination Feature Code]即可;
2、通过查看每个页面,我们发现了许多可以用作特征代码的字符串。我们选择其中之一并填写以下内容:
(icon7)
企业不给资料,做什么数据都需要一个入口
采集交流 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-08-20 04:01
文章采集规则归推文系统所有,推文系统可以一键将访问过的链接收集到服务器,当访问数量达到一定量级,系统会判断是否需要人工删除链接,如果删除就读取访问链接的html内容。
流量采集的第一步就是要有一个采集地址,推文采集就好像微博采集一样,要输入微博的标题,不然别人怎么采集数据。只要你有想采集的博客的地址,就可以采集到了,推文采集就比较简单了,直接去找公众号生成采集链接,然后丢到要采集的链接上就行了,然后访问链接就能获取到要采集的链接了。
一般来说先要有一个采集链接,再去一些公众号采集地址获取访问链接即可,但现在很多新闻类网站没有数据接口,因为他们都是主动给广告商出推广方案的,在需要给企业网站出点或广告方案,就自己发布数据出来,所以企业不给资料,
做什么数据都需要一个入口,通常我的做法是这样:1,要做的数据:后台有一个服务器,打开“收取的链接”把要采集的文章的标题输进去,就采集到了2,数据质量不是最重要的,关键是之前对可能采集到的文章进行了网站分析,看到采到的文章确实有价值(不容易误点错点没准能发现一个新领域等等),再进行后续工作。总结的一句话:数据质量不是最重要的,关键是要有一个大的数据获取渠道,更重要的是自己能掌握一些技巧去提升有价值的数据。祝做好数据。 查看全部
企业不给资料,做什么数据都需要一个入口
文章采集规则归推文系统所有,推文系统可以一键将访问过的链接收集到服务器,当访问数量达到一定量级,系统会判断是否需要人工删除链接,如果删除就读取访问链接的html内容。
流量采集的第一步就是要有一个采集地址,推文采集就好像微博采集一样,要输入微博的标题,不然别人怎么采集数据。只要你有想采集的博客的地址,就可以采集到了,推文采集就比较简单了,直接去找公众号生成采集链接,然后丢到要采集的链接上就行了,然后访问链接就能获取到要采集的链接了。
一般来说先要有一个采集链接,再去一些公众号采集地址获取访问链接即可,但现在很多新闻类网站没有数据接口,因为他们都是主动给广告商出推广方案的,在需要给企业网站出点或广告方案,就自己发布数据出来,所以企业不给资料,
做什么数据都需要一个入口,通常我的做法是这样:1,要做的数据:后台有一个服务器,打开“收取的链接”把要采集的文章的标题输进去,就采集到了2,数据质量不是最重要的,关键是之前对可能采集到的文章进行了网站分析,看到采到的文章确实有价值(不容易误点错点没准能发现一个新领域等等),再进行后续工作。总结的一句话:数据质量不是最重要的,关键是要有一个大的数据获取渠道,更重要的是自己能掌握一些技巧去提升有价值的数据。祝做好数据。
99元的采集规则插件,半价续费一个元,只需半价!
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-08-19 21:29
详细介绍
功能概述:
这个采集rule插件可以采集最新的网上美图,每天至少10条内容,每条内容至少10张图片,也就是至少100张美图每天
所有美女图片不漏点,大部分图片有轻微水印。
前面说:
这样的采集rule插件消耗了我们大量的服务器资源和成本,所以插件需要每年更新。对于授权包2及以上的用户,安装本插件后,授权中的任何域名均可免费使用一年。之后,插件可以每年半价连续使用。
未购买授权用户或授权级别低于套餐2的用户需按原价单独购买续费。
授权用户只需以最高半价续订一个使用过的采集rule插件即可。所有用户在所有授权下都可以在网站下免费使用所有采集rule插件。比如每年只需要更新一个99元的采集普通插件,半价49.5元,所有网站可以继续使用所有99元及以下的采集普通插件- ins 一年免费。
美图类型举例如下:
采集如何使用规则:
安装后,在网站Background--采集管理--规则管理中,可以点击规则前面的采集按钮单独执行采集,也可以选择多个选项执行采集。
采集规则编辑方法:
安装后,在网站Background--采集管理--规则管理中,会看到1条采集规则。 采集规则的归属栏默认为你的网站id=1的栏,默认设置为将远程图片保存到你的服务器。所以请根据实际情况将采集规则归属栏设置为其他栏,方法:
网站Background--采集管理--规则管理--点击采集规则前面的“编辑”按钮--属于类别--选择您的类别--点击下一步保存当前页面的设置。
如果你不想在采集时将远程图片保存到你的服务器,方法:
网站Background--采集管理--规则管理--点击采集规则前面的“编辑”按钮--新闻设置--保存图片--取消勾选--点击下一步可以保存当前页面的设置。
设置默认固定作者姓名,方法:
网站后台--采集管理-规则管理--点击采集规则前面的“编辑”按钮--下一步--下一步--作者设置--填写固定即可字符。
采集之后的数据如何发布到网站?方法:
网站Background--采集管理--数据存储,这里可以选择全部要存储的内容或勾选要存储的部分内容,也可以删除全部内容或删除部分内容检查内容。
采集后,采集的部分内容会提示重复?因为:为了防止采集的重复浪费不必要的时间和资源,如果要更新采集有采集的数据,请到网站Background--采集管理--History,可以在此处删除历史记录,也可以选择性删除“成功记录”、“失败记录”和“无效记录”,并在浏览器内部页面顶部的标题栏中进行过滤。
常见问题:
安装的采集规则可以修改吗?
答案:无法修改“目标网页编码”和“远程列表 URL”。其他内容请注意修改,否则采集容易失败。
为什么采集,提示“服务器资源有限,无法直接浏览文章,请安装或升级采集plugin batch采集。”?
答案:1、“目标网页编码”和“远程列表网址”不能修改。修改其他内容请谨慎,否则采集很容易失败。 . 2、检查你登录的后台域名是否已经获取到采集rule插件的注册码。 3、请直接到采集,不要点击测试按钮,测试时会有这个提示。正常采集 没问题。 4、请使用您安装本插件时使用的域名登录后台采集。
如果图片没有保存到服务器,为什么会提示图片盗链?
因为图片保存在服务器中,所以会调用目标网站中的图片。目标网站设置图片防盗链功能时,会提示图片被盗链,无法显示。所以如果你的网站空间够大,比如3G以上,那就尽量把图片保存到服务器。
图片有水印吗?
大部分图片有轻微水印,图片清晰度高
这个插件的优点:
平台自动采集采集每日更新内容,所有内容自动排版,无需重新编辑。
天人系列管理系统所有系统均可使用,按钮样式自动匹配。
此插件不是自动采集插件,需要点击按钮触发批量采集。如果您实现了自动采集和自动发布的功能,请安装“auto采集plugin”
安装过程
注意:本文的安装方式只适用于离线安装,如果通过后台应用中心安装,不会那么麻烦,所以首选使用你的网站后台应用中心- -获取插件/获取模板一键安装
点击上方的立即下载按钮(如下图):
将文件保存到本地(如下图),(如果下载到百度云,则不需要使用以下方法安装,必须按照具体页面中的要求安装):
打开后台应用中心-上传安装:填写应用对应的官网ID
身份证是什么?这很简单。刚刚下载应用的页面有“App ID:”字样,后面的数字就是ID(如下图):
填写ID并上传应用(如下图)
然后继续上传本地文件(如下图):
<p>上传成功后,点击“立即安装”,稍等片刻,页面会变成黑色背景绿色字体的“天人系列管理系统项目自动部署工具”(如下图) 查看全部
99元的采集规则插件,半价续费一个元,只需半价!
详细介绍
功能概述:
这个采集rule插件可以采集最新的网上美图,每天至少10条内容,每条内容至少10张图片,也就是至少100张美图每天
所有美女图片不漏点,大部分图片有轻微水印。
前面说:
这样的采集rule插件消耗了我们大量的服务器资源和成本,所以插件需要每年更新。对于授权包2及以上的用户,安装本插件后,授权中的任何域名均可免费使用一年。之后,插件可以每年半价连续使用。
未购买授权用户或授权级别低于套餐2的用户需按原价单独购买续费。
授权用户只需以最高半价续订一个使用过的采集rule插件即可。所有用户在所有授权下都可以在网站下免费使用所有采集rule插件。比如每年只需要更新一个99元的采集普通插件,半价49.5元,所有网站可以继续使用所有99元及以下的采集普通插件- ins 一年免费。
美图类型举例如下:

采集如何使用规则:
安装后,在网站Background--采集管理--规则管理中,可以点击规则前面的采集按钮单独执行采集,也可以选择多个选项执行采集。
采集规则编辑方法:
安装后,在网站Background--采集管理--规则管理中,会看到1条采集规则。 采集规则的归属栏默认为你的网站id=1的栏,默认设置为将远程图片保存到你的服务器。所以请根据实际情况将采集规则归属栏设置为其他栏,方法:
网站Background--采集管理--规则管理--点击采集规则前面的“编辑”按钮--属于类别--选择您的类别--点击下一步保存当前页面的设置。
如果你不想在采集时将远程图片保存到你的服务器,方法:
网站Background--采集管理--规则管理--点击采集规则前面的“编辑”按钮--新闻设置--保存图片--取消勾选--点击下一步可以保存当前页面的设置。
设置默认固定作者姓名,方法:
网站后台--采集管理-规则管理--点击采集规则前面的“编辑”按钮--下一步--下一步--作者设置--填写固定即可字符。
采集之后的数据如何发布到网站?方法:
网站Background--采集管理--数据存储,这里可以选择全部要存储的内容或勾选要存储的部分内容,也可以删除全部内容或删除部分内容检查内容。
采集后,采集的部分内容会提示重复?因为:为了防止采集的重复浪费不必要的时间和资源,如果要更新采集有采集的数据,请到网站Background--采集管理--History,可以在此处删除历史记录,也可以选择性删除“成功记录”、“失败记录”和“无效记录”,并在浏览器内部页面顶部的标题栏中进行过滤。
常见问题:
安装的采集规则可以修改吗?
答案:无法修改“目标网页编码”和“远程列表 URL”。其他内容请注意修改,否则采集容易失败。
为什么采集,提示“服务器资源有限,无法直接浏览文章,请安装或升级采集plugin batch采集。”?
答案:1、“目标网页编码”和“远程列表网址”不能修改。修改其他内容请谨慎,否则采集很容易失败。 . 2、检查你登录的后台域名是否已经获取到采集rule插件的注册码。 3、请直接到采集,不要点击测试按钮,测试时会有这个提示。正常采集 没问题。 4、请使用您安装本插件时使用的域名登录后台采集。
如果图片没有保存到服务器,为什么会提示图片盗链?
因为图片保存在服务器中,所以会调用目标网站中的图片。目标网站设置图片防盗链功能时,会提示图片被盗链,无法显示。所以如果你的网站空间够大,比如3G以上,那就尽量把图片保存到服务器。
图片有水印吗?
大部分图片有轻微水印,图片清晰度高
这个插件的优点:
平台自动采集采集每日更新内容,所有内容自动排版,无需重新编辑。
天人系列管理系统所有系统均可使用,按钮样式自动匹配。
此插件不是自动采集插件,需要点击按钮触发批量采集。如果您实现了自动采集和自动发布的功能,请安装“auto采集plugin”
安装过程
注意:本文的安装方式只适用于离线安装,如果通过后台应用中心安装,不会那么麻烦,所以首选使用你的网站后台应用中心- -获取插件/获取模板一键安装
点击上方的立即下载按钮(如下图):

将文件保存到本地(如下图),(如果下载到百度云,则不需要使用以下方法安装,必须按照具体页面中的要求安装):
打开后台应用中心-上传安装:填写应用对应的官网ID
身份证是什么?这很简单。刚刚下载应用的页面有“App ID:”字样,后面的数字就是ID(如下图):
填写ID并上传应用(如下图)
然后继续上传本地文件(如下图):
<p>上传成功后,点击“立即安装”,稍等片刻,页面会变成黑色背景绿色字体的“天人系列管理系统项目自动部署工具”(如下图)
网站采集软文信息的统计规则及统计02
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-08-16 21:03
文章采集规则:每一个点击,都对应一个参数,参数名称,参数值,参数个数统计规则:文章-参数数量-参数个数,
1)通过v2ex上面的介绍,可以分析出该网站可能会采集图片的url,判断有多少个图片会采集,
2)观察发现,做好商品的标题等一些标签信息,对应匹配有多少个图片会采集,
3)1a3e79521f88f89074d32e02df2277a你的采集规则是:某个网站已经采集多少个图片以及这些图片用户的点击情况,然后加上50%,10%和50%。举例一个例子,大于50%用户对于某个商品有1000个点击,然后加上50%,然后减去10%和50%,再加上50%=1人点击,然后乘以50%,最后如果总数还是50%的话,即:1a3e79521f88f89074d32e02df2277a然后再加上50%=5%点击的话,就是5%,则pulse:5%,加上50%=1%,则pulse:1%假设这些采集出来的信息按照用户特征来进行匹配。例如用户特征:喜欢打游戏,所以采集了该网站游戏信息;喜欢电影,所以采集了该网站电影信息。
或者1a3e79521f88f89074d32e02df2277a喜欢物流和购物的,就采集物流信息喜欢写软文的,就采集软文信息要是有大量用户合并内容,则进行合并,例如:有10万个用户喜欢写软文,那么就50%用户喜欢写软文,
1)通过这个例子,可以看出,为了达到比较好的人工智能采集效果,我们可以提前分析出来多少用户点击了哪些参数,然后根据点击数目的比例,适当进行百分比的调整就可以了,例如10%用户点击了5个参数,那么我们可以把该比例乘以5%,
2)写程序最好用nginx等,目前来说性能都不错,而且提供rewrite。一般是直接写10%服务器响应1000次,然后根据实际结果调整比例。例如程序比例为1%,那么只有1000次机会达到最佳人工智能效果。
2)一些代码上的语句要自己去理解,不要照搬。
3)各种图片格式使用jquery.extend.img(),必须从url中传入。例如:c.extend('image/jpg',{'data-image':url,'max10,0,0',5})实际效果:一图胜千言,看一下pulse, 查看全部
网站采集软文信息的统计规则及统计02
文章采集规则:每一个点击,都对应一个参数,参数名称,参数值,参数个数统计规则:文章-参数数量-参数个数,
1)通过v2ex上面的介绍,可以分析出该网站可能会采集图片的url,判断有多少个图片会采集,
2)观察发现,做好商品的标题等一些标签信息,对应匹配有多少个图片会采集,
3)1a3e79521f88f89074d32e02df2277a你的采集规则是:某个网站已经采集多少个图片以及这些图片用户的点击情况,然后加上50%,10%和50%。举例一个例子,大于50%用户对于某个商品有1000个点击,然后加上50%,然后减去10%和50%,再加上50%=1人点击,然后乘以50%,最后如果总数还是50%的话,即:1a3e79521f88f89074d32e02df2277a然后再加上50%=5%点击的话,就是5%,则pulse:5%,加上50%=1%,则pulse:1%假设这些采集出来的信息按照用户特征来进行匹配。例如用户特征:喜欢打游戏,所以采集了该网站游戏信息;喜欢电影,所以采集了该网站电影信息。
或者1a3e79521f88f89074d32e02df2277a喜欢物流和购物的,就采集物流信息喜欢写软文的,就采集软文信息要是有大量用户合并内容,则进行合并,例如:有10万个用户喜欢写软文,那么就50%用户喜欢写软文,
1)通过这个例子,可以看出,为了达到比较好的人工智能采集效果,我们可以提前分析出来多少用户点击了哪些参数,然后根据点击数目的比例,适当进行百分比的调整就可以了,例如10%用户点击了5个参数,那么我们可以把该比例乘以5%,
2)写程序最好用nginx等,目前来说性能都不错,而且提供rewrite。一般是直接写10%服务器响应1000次,然后根据实际结果调整比例。例如程序比例为1%,那么只有1000次机会达到最佳人工智能效果。
2)一些代码上的语句要自己去理解,不要照搬。
3)各种图片格式使用jquery.extend.img(),必须从url中传入。例如:c.extend('image/jpg',{'data-image':url,'max10,0,0',5})实际效果:一图胜千言,看一下pulse,
前端http消息格式采集方式获取,post、get方式分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-08-15 01:03
文章采集规则:yii3.x前端http消息格式采集。post、get方式获取。本文不包含什么前端的效果,全部采集网址提供给大家http消息格式采集方式一:无采集规则的路由方式的规则判断,这种方式肯定采用的最多,网址去重,cookie关联,wget提权,去重等等方式。优势非常明显,只需要发送起点标记,不需要定期定向扫描,只需要发送指定关键字即可,如访问/(随便你),如www/id/username即可一次采集成功。
方式二:自己开发一个脚本采集规则。这种方式多用于内容量大的网站,不同的权限要有不同的操作方式,如只提交access.log(),submit()等方式。这种方式的技术难度相对较低,找下现成的开源的。方式三:模拟客户端与服务器交互采集方式,在已有http请求内容的情况下,如登录,注册,注销等交互动作后,采集该动作的相关的数据内容。
如登录时,如提交认证信息,登录后即可获取身份信息,头像,昵称等。如注销,如删除照片,删除昵称。其他如微信互联,官网跳转,支付等等基于同样的采集需求,在网上有很多公司已经提供了很多相关的脚本。具体脚本方法如下:访问,并进入以上元素,同时提交刚才起点内容中的验证码信息。找下这个网址所属的搜索引擎,用sitemesh代理为(sitetoken='')然后将带有scheme:post和scheme:get的scheme代理请求与请求头requestresponse代理请求进行比对。
具体操作如下:访问时,勾选‘access.log('')’选项‘content-type:application/json’选项打开参数表;访问时,如起点没有access.log('')选项时,提示此处有一个未知,继续向下访问,并用.表示,点击‘show’即可得到验证码内容。如果存在access.log('')选项,起点也没有提示该处已有未知,可在这里获取验证码内容,采集时用这一次起点采集的内容,访问地址为’(访问::8000/hqapoui/../../,点击http::8000/hqapoui/../进入)即可实现访问,如下图:但是采集起点后又得返回到主站点,也就是分别返回access.log(''),submit,refresh这几个选项中的某一个,要区分。
还有访问地址时要找到分页权限的参数表,返回参数中的每个url之间都有access.log('')这个选项。在已有的数据中,看一下哪些可以匹配?然后再用requestresponse代理再次进行遍历,直到发现有匹配的参数,即可请求成功。采集相关代码如下:执行的效果如下:网址获取结果:相关拓展:公众号【五营火】,了解更多互联网知识。 查看全部
前端http消息格式采集方式获取,post、get方式分享
文章采集规则:yii3.x前端http消息格式采集。post、get方式获取。本文不包含什么前端的效果,全部采集网址提供给大家http消息格式采集方式一:无采集规则的路由方式的规则判断,这种方式肯定采用的最多,网址去重,cookie关联,wget提权,去重等等方式。优势非常明显,只需要发送起点标记,不需要定期定向扫描,只需要发送指定关键字即可,如访问/(随便你),如www/id/username即可一次采集成功。
方式二:自己开发一个脚本采集规则。这种方式多用于内容量大的网站,不同的权限要有不同的操作方式,如只提交access.log(),submit()等方式。这种方式的技术难度相对较低,找下现成的开源的。方式三:模拟客户端与服务器交互采集方式,在已有http请求内容的情况下,如登录,注册,注销等交互动作后,采集该动作的相关的数据内容。
如登录时,如提交认证信息,登录后即可获取身份信息,头像,昵称等。如注销,如删除照片,删除昵称。其他如微信互联,官网跳转,支付等等基于同样的采集需求,在网上有很多公司已经提供了很多相关的脚本。具体脚本方法如下:访问,并进入以上元素,同时提交刚才起点内容中的验证码信息。找下这个网址所属的搜索引擎,用sitemesh代理为(sitetoken='')然后将带有scheme:post和scheme:get的scheme代理请求与请求头requestresponse代理请求进行比对。
具体操作如下:访问时,勾选‘access.log('')’选项‘content-type:application/json’选项打开参数表;访问时,如起点没有access.log('')选项时,提示此处有一个未知,继续向下访问,并用.表示,点击‘show’即可得到验证码内容。如果存在access.log('')选项,起点也没有提示该处已有未知,可在这里获取验证码内容,采集时用这一次起点采集的内容,访问地址为’(访问::8000/hqapoui/../../,点击http::8000/hqapoui/../进入)即可实现访问,如下图:但是采集起点后又得返回到主站点,也就是分别返回access.log(''),submit,refresh这几个选项中的某一个,要区分。
还有访问地址时要找到分页权限的参数表,返回参数中的每个url之间都有access.log('')这个选项。在已有的数据中,看一下哪些可以匹配?然后再用requestresponse代理再次进行遍历,直到发现有匹配的参数,即可请求成功。采集相关代码如下:执行的效果如下:网址获取结果:相关拓展:公众号【五营火】,了解更多互联网知识。
选取与组织表单的元素设计如何与表单交互介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-08-14 04:10
选取与组织表单的元素设计如何与表单交互介绍
当我第一次接触表单的时候,所有的目光都是在标签是否对齐,输入框的位置是否合理,提示是否足够友好。后面会更深入的研究,思考label的不同对齐方式的区别。 .
但是重点总是离不开表单本身的几个组件,以至于每次表单优化效果总是不尽人意,不知道问题出在哪里。
PS:水平有限,踩过很多前辈的肩膀。请绕道。
似乎说到制作表单,就是要安排一些不同类型的输入框,明确标明必填和非必填字段,并添加解释,说明哪些表单更复杂、更合适。
其实表单设计远不止这些。表格本身也是一个小产品。也需要有需求支撑,也需要嵌套,也需要考虑用户的心智模型;从表单的生成到页面上的表单如何呈现,再到使用表单时与表单的交互,每一步都需要大量的思考来制作表单。
其实做好表格并不难,但是如果把问题往错误的方向思考(产品思维失败),相关的设计知识不够全面,很容易不知道出处遇到问题时开始。
为了不让我凄凉的过去在大家身上重演,也为了总结我的学习心得,特地写了这篇文章;因为想写的比较全面一点,所以构思成一个小系列,一共三篇文章,希望对大家有所帮助!
这个系列文章,从表单的诞生(选择表单)到表单的死亡(提交结束),我将从三个方面给大家全面讲解如何设计出优秀的表单方面。
由于内容较多,本系列文章分为三篇文章来介绍以下三个方面:
如何与组织表单的表单选择和元素设计进行交互
本文介绍第一个方面:表格的选择和组织
一、表单选择与组织
表格的选择和组织是表格生成的第一个过程。任何表单都需要先选择显示的问题,然后将选择的问题合理呈现在页面上;我们将把这个过程分成两个小节来解释:表格的选择,表格的组织。
1.表单选择
表格的选择是指表格中应收录哪些问题。我们需要遵循的原则是:
最好不要采集非必要信息,即用户看到的问题越少越好。必须采集的信息,如果可以延迟,则延迟采集。平衡用户和产品的利益。
1)非必要信息最好不要采集,即用户看到的问题越少越好。
每个用户都必须填写表单,但每个用户都不想填写表单,因为填写表单不是用户的目的。用户填写表单的唯一原因是不填写表单就无法继续。
想象一下,你购物时需要填写收货地址,登录微信前需要注册一个账号,雅思报名时需要填写个人信息,但这些是你的吗?目标?
不,只是因为不填写收货地址没收到货,不注册就不能登录微信,也不能如果您不填写个人信息,则无法完成考试;因此,从需求的角度来看,填表不是用户的需求,而是产品的需求;事实上,填写表单的过程,尤其是长表单,阻碍了用户使用产品的流畅性,降低了用户体验。
所以,在表单的选择阶段,最重要的就是尽可能的简化表单,不问问题就不要问用户。例如:当你要求用户填写雅思报名表时,不需要要求用户填写家庭住址,除非你需要向用户发送纸质成绩单。
多余的问题不仅会增加用户的完成成本,而且往往会引起用户的警觉。
2)必须采集的信息,如果可以延迟采集就会延迟。
如果有些信息是产品需要的,但填表时不是必须的,可以考虑推迟,即:调整采集信息的时间,把原来繁重的填表任务拆分成几个简单的,随时可以执行的小任务;比如电商网站的收货地址在用户注册时不需要填写,但在用户购买商品时需要补充,就是一个很好的例子。
3) 平衡用户和产品的利益。
最后,在形式选择和组织阶段最难处理,但很重要的一点是必须平衡用户和产品的利益。填写表单时,用户需求和产品需求总是矛盾的。
用户希望尽可能少地填写表单,以便尽快进行。产品要采集(比如要把产品寄给用户,必须采集地址信息)或者更长远的战略考虑总是希望采集更多的用户信息,但是采集信息太多损害用户的利益。
没有硬性规定可以参考。只能根据不同的情况做不同的处理。您可以参考以下建议进行相应调整:
试图要求用户承担底线,两个更好的方法是选择真实用户进行可用性测试和数据嵌入。使用其他方法解决产品对用户信息采集的需求,比如大数据分析。采取适当的激励措施,鼓励用户提供更多的信息,如改进信息获取金币、参与抽奖等。好好学习这个由三部分组成的系列文章,用设计来降低用户填写表格的成本。 2.表单组织
表单的组织是指所选问题在页面上的呈现方式以及向用户呈现的方式。
我们需要遵循的原则是:
表单的命名与场景相匹配。考虑对长表格进行分组或分页。排版布局不会中断扫描视线。减少干扰。组织页面时考虑使用 Tab 键跳转。使用情感设计。
1)表单的命名与场景匹配。
表单名称用于告诉用户此次填写的主题。它可以让用户在表单开始时就对要填写的内容建立心理预期,也有助于在填写表单时理解表单的内容。
所以选择一个适合这个表单填写场景的表单名称是非常重要的。 “空头不对马头”的标题容易误导用户或增加用户的疑虑。
例如:
货运司机如果要接单,需要在接单前填写一份个人货运资质信息表。试想一下,点击“接受订单”后进入的页面最上方写着“填写个人信息”后面是“运费哪个更容易理解?
前者容易造成混乱(尤其是对新人而言)。为什么我收到订单时需要填写我的私人信息?会不会导致信息泄露?
相反,后者容易理解:我是做运输交易的,所以自然需要我的运输资质。
2)Long form 考虑分组或分页
当表格过多时,简单的堆叠排列方式让用户感到疲倦而放弃填写表格;这时候我们可以根据表单的类型对表单进行适当的分组,这样可以缓解用户的视觉压力。用户填写表格更容易、更舒适。
当所有表单都与同一主题相关时,使用分组是更好的选择,例如:姓名、身份证号码、性别、种族、政治地位、手机号码、QQ号码、电子邮件地址、家庭住址、雇主。
我们可以将“姓名、身份证号码、性别、种族、政治面貌”分成一组,分别命名为“身份信息”、“手机号码、QQ号码、邮箱地址、家庭住址、工作单位”。将组命名为“联系方式”;虽然分为两组,但都属于用户的基本个人信息,这种情况适合分组。
但如果需要填写的表格涉及不同的主题,可以考虑分页。
如姓名、身份证号码、性别、民族、政治地位、手机号码、QQ号码、邮箱地址、家庭住址、工作单位、驾照类型、货车型号、货龄、事故记录不正确等。
上述信息中,“姓名、身份证号码、性别、民族、政治面貌、手机号码、QQ号码、邮箱、家庭住址、工作单位”为个人基本信息; “驾照类型、货车型号、船龄”、“事故记录不正确”属于资质信息;我们可以将这两类信息拆分成两页展示,让用户逐步完成表格.
3)布局不中断扫描视线
扫描视线是指用户浏览表单时视线的流动。清晰、线性的视线流动有助于用户快速响应问题,用户的思维在不同形式之间切换所需的时间最少。
因此,在布局时,表单应尽可能安排在视线更清晰的流程中。对比下面两种布局方式,很明显右边的布局更容易阅读。
4)减少干扰
用户填写表单的过程是一个任务过程,界面风格越简洁明了,越能提高用户填写的效率。
很多时候为了提升界面的视觉效果,一些设计师喜欢使用一些复杂的样式或者图案或者动画,这对于其他页面的设计来说无疑是有利的;但这种想法不适用于填表页面。过多的视觉干扰很容易打断填表的想法,降低填表的效率。 甚至当用户因为不必要的干扰挡住了填表的想法时,用户也会产生反感而放弃填写表格。
但并不是不能在表单填写页面上使用复杂的样式或一些冷色调。毕竟,我们需要依靠这些来区分和组织形式的不同群体或主题;所以请确保您可以有效区分和组织页面。接下来,尽可能减少更复杂元素的出现。
5)组织页面时考虑Tab键跳转
在PC网页上,用户大多使用键盘与表单进行交互,这涉及到鼠标光标在不同输入框之间切换时常用的Tab键。这是很多人的操作习惯。我们必须注意。
Tab键的影响主要是视线的跳跃。当有两列内容时,当光标定位在第一列的最后一个表格时,切换Tab键后,光标会继续下移或切换到第二列,第一个表格呢?
如果没有好的页面引导,很容易混淆用户(可能用户以为自己切换到了同一列的下一个表单,而在输入时发现内容出现在第二列的第一个表单中)。
另外,当表单过长时,有可能是切换Tab键后,光标已经切换到页面底部的表单了。但是因为一屏不能显示,激活的表单隐藏在页面底部,会导致用户不知道光标去哪里的尴尬。
所以在设计的时候尽量让表格出现在主流分辨率显示器的同屏上。当光标切换到屏幕外的表单时,可以使用锚定位,自动将视线切换到对应的表单位置。
6)使用情感设计
情感化设计是指在页面中使用能够与人类情感产生共鸣的元素,从而增加填写表单的乐趣或减少用户面对大量表单时的焦虑。情感设计可以贯穿整个表单设计。每个阶段。
比如在给表格命名时,可以适当使用图片背景,营造出与表格主题相匹配的氛围;采集地理位置信息时,将“国家”替换为“您来自哪个国家?”
通过这种方式,生硬的表单填写被构建为用户和计算机之间的对话;在分页设计中,适当使用动态效果,增加页面切换时的趣味性等。
二、结语
至此,360°全方位表单设计指南的第一篇文章就结束了。感谢大家花时间阅读这篇文章,希望对大家有所帮助。
下一部分文章我会讲解表单设计的第二个方面:表单的元素设计——表单元素设计中表单设计的核心部分,也是大家付出的部分最关注的,也是学习效果。有兴趣的同学可以立即关注最容易看到的部分!
进阶提问:在情感化设计中,表单的标签名称用疑问句代替。不是增加了标签的复杂度,增加了读取成本吗?
作为一个自认为填了很多表格的“伪老司机”,我将自己的一些理解和体会分享给大家。希望我们作为产品人一起进步,一起成长! 查看全部
选取与组织表单的元素设计如何与表单交互介绍

当我第一次接触表单的时候,所有的目光都是在标签是否对齐,输入框的位置是否合理,提示是否足够友好。后面会更深入的研究,思考label的不同对齐方式的区别。 .
但是重点总是离不开表单本身的几个组件,以至于每次表单优化效果总是不尽人意,不知道问题出在哪里。
PS:水平有限,踩过很多前辈的肩膀。请绕道。
似乎说到制作表单,就是要安排一些不同类型的输入框,明确标明必填和非必填字段,并添加解释,说明哪些表单更复杂、更合适。
其实表单设计远不止这些。表格本身也是一个小产品。也需要有需求支撑,也需要嵌套,也需要考虑用户的心智模型;从表单的生成到页面上的表单如何呈现,再到使用表单时与表单的交互,每一步都需要大量的思考来制作表单。
其实做好表格并不难,但是如果把问题往错误的方向思考(产品思维失败),相关的设计知识不够全面,很容易不知道出处遇到问题时开始。
为了不让我凄凉的过去在大家身上重演,也为了总结我的学习心得,特地写了这篇文章;因为想写的比较全面一点,所以构思成一个小系列,一共三篇文章,希望对大家有所帮助!
这个系列文章,从表单的诞生(选择表单)到表单的死亡(提交结束),我将从三个方面给大家全面讲解如何设计出优秀的表单方面。
由于内容较多,本系列文章分为三篇文章来介绍以下三个方面:
如何与组织表单的表单选择和元素设计进行交互
本文介绍第一个方面:表格的选择和组织
一、表单选择与组织
表格的选择和组织是表格生成的第一个过程。任何表单都需要先选择显示的问题,然后将选择的问题合理呈现在页面上;我们将把这个过程分成两个小节来解释:表格的选择,表格的组织。
1.表单选择
表格的选择是指表格中应收录哪些问题。我们需要遵循的原则是:
最好不要采集非必要信息,即用户看到的问题越少越好。必须采集的信息,如果可以延迟,则延迟采集。平衡用户和产品的利益。
1)非必要信息最好不要采集,即用户看到的问题越少越好。
每个用户都必须填写表单,但每个用户都不想填写表单,因为填写表单不是用户的目的。用户填写表单的唯一原因是不填写表单就无法继续。
想象一下,你购物时需要填写收货地址,登录微信前需要注册一个账号,雅思报名时需要填写个人信息,但这些是你的吗?目标?
不,只是因为不填写收货地址没收到货,不注册就不能登录微信,也不能如果您不填写个人信息,则无法完成考试;因此,从需求的角度来看,填表不是用户的需求,而是产品的需求;事实上,填写表单的过程,尤其是长表单,阻碍了用户使用产品的流畅性,降低了用户体验。
所以,在表单的选择阶段,最重要的就是尽可能的简化表单,不问问题就不要问用户。例如:当你要求用户填写雅思报名表时,不需要要求用户填写家庭住址,除非你需要向用户发送纸质成绩单。
多余的问题不仅会增加用户的完成成本,而且往往会引起用户的警觉。
2)必须采集的信息,如果可以延迟采集就会延迟。
如果有些信息是产品需要的,但填表时不是必须的,可以考虑推迟,即:调整采集信息的时间,把原来繁重的填表任务拆分成几个简单的,随时可以执行的小任务;比如电商网站的收货地址在用户注册时不需要填写,但在用户购买商品时需要补充,就是一个很好的例子。
3) 平衡用户和产品的利益。
最后,在形式选择和组织阶段最难处理,但很重要的一点是必须平衡用户和产品的利益。填写表单时,用户需求和产品需求总是矛盾的。
用户希望尽可能少地填写表单,以便尽快进行。产品要采集(比如要把产品寄给用户,必须采集地址信息)或者更长远的战略考虑总是希望采集更多的用户信息,但是采集信息太多损害用户的利益。
没有硬性规定可以参考。只能根据不同的情况做不同的处理。您可以参考以下建议进行相应调整:
试图要求用户承担底线,两个更好的方法是选择真实用户进行可用性测试和数据嵌入。使用其他方法解决产品对用户信息采集的需求,比如大数据分析。采取适当的激励措施,鼓励用户提供更多的信息,如改进信息获取金币、参与抽奖等。好好学习这个由三部分组成的系列文章,用设计来降低用户填写表格的成本。 2.表单组织
表单的组织是指所选问题在页面上的呈现方式以及向用户呈现的方式。
我们需要遵循的原则是:
表单的命名与场景相匹配。考虑对长表格进行分组或分页。排版布局不会中断扫描视线。减少干扰。组织页面时考虑使用 Tab 键跳转。使用情感设计。
1)表单的命名与场景匹配。
表单名称用于告诉用户此次填写的主题。它可以让用户在表单开始时就对要填写的内容建立心理预期,也有助于在填写表单时理解表单的内容。
所以选择一个适合这个表单填写场景的表单名称是非常重要的。 “空头不对马头”的标题容易误导用户或增加用户的疑虑。
例如:
货运司机如果要接单,需要在接单前填写一份个人货运资质信息表。试想一下,点击“接受订单”后进入的页面最上方写着“填写个人信息”后面是“运费哪个更容易理解?
前者容易造成混乱(尤其是对新人而言)。为什么我收到订单时需要填写我的私人信息?会不会导致信息泄露?
相反,后者容易理解:我是做运输交易的,所以自然需要我的运输资质。
2)Long form 考虑分组或分页
当表格过多时,简单的堆叠排列方式让用户感到疲倦而放弃填写表格;这时候我们可以根据表单的类型对表单进行适当的分组,这样可以缓解用户的视觉压力。用户填写表格更容易、更舒适。
当所有表单都与同一主题相关时,使用分组是更好的选择,例如:姓名、身份证号码、性别、种族、政治地位、手机号码、QQ号码、电子邮件地址、家庭住址、雇主。
我们可以将“姓名、身份证号码、性别、种族、政治面貌”分成一组,分别命名为“身份信息”、“手机号码、QQ号码、邮箱地址、家庭住址、工作单位”。将组命名为“联系方式”;虽然分为两组,但都属于用户的基本个人信息,这种情况适合分组。
但如果需要填写的表格涉及不同的主题,可以考虑分页。
如姓名、身份证号码、性别、民族、政治地位、手机号码、QQ号码、邮箱地址、家庭住址、工作单位、驾照类型、货车型号、货龄、事故记录不正确等。
上述信息中,“姓名、身份证号码、性别、民族、政治面貌、手机号码、QQ号码、邮箱、家庭住址、工作单位”为个人基本信息; “驾照类型、货车型号、船龄”、“事故记录不正确”属于资质信息;我们可以将这两类信息拆分成两页展示,让用户逐步完成表格.

3)布局不中断扫描视线
扫描视线是指用户浏览表单时视线的流动。清晰、线性的视线流动有助于用户快速响应问题,用户的思维在不同形式之间切换所需的时间最少。
因此,在布局时,表单应尽可能安排在视线更清晰的流程中。对比下面两种布局方式,很明显右边的布局更容易阅读。

4)减少干扰
用户填写表单的过程是一个任务过程,界面风格越简洁明了,越能提高用户填写的效率。
很多时候为了提升界面的视觉效果,一些设计师喜欢使用一些复杂的样式或者图案或者动画,这对于其他页面的设计来说无疑是有利的;但这种想法不适用于填表页面。过多的视觉干扰很容易打断填表的想法,降低填表的效率。 甚至当用户因为不必要的干扰挡住了填表的想法时,用户也会产生反感而放弃填写表格。
但并不是不能在表单填写页面上使用复杂的样式或一些冷色调。毕竟,我们需要依靠这些来区分和组织形式的不同群体或主题;所以请确保您可以有效区分和组织页面。接下来,尽可能减少更复杂元素的出现。
5)组织页面时考虑Tab键跳转
在PC网页上,用户大多使用键盘与表单进行交互,这涉及到鼠标光标在不同输入框之间切换时常用的Tab键。这是很多人的操作习惯。我们必须注意。
Tab键的影响主要是视线的跳跃。当有两列内容时,当光标定位在第一列的最后一个表格时,切换Tab键后,光标会继续下移或切换到第二列,第一个表格呢?
如果没有好的页面引导,很容易混淆用户(可能用户以为自己切换到了同一列的下一个表单,而在输入时发现内容出现在第二列的第一个表单中)。

另外,当表单过长时,有可能是切换Tab键后,光标已经切换到页面底部的表单了。但是因为一屏不能显示,激活的表单隐藏在页面底部,会导致用户不知道光标去哪里的尴尬。
所以在设计的时候尽量让表格出现在主流分辨率显示器的同屏上。当光标切换到屏幕外的表单时,可以使用锚定位,自动将视线切换到对应的表单位置。
6)使用情感设计
情感化设计是指在页面中使用能够与人类情感产生共鸣的元素,从而增加填写表单的乐趣或减少用户面对大量表单时的焦虑。情感设计可以贯穿整个表单设计。每个阶段。
比如在给表格命名时,可以适当使用图片背景,营造出与表格主题相匹配的氛围;采集地理位置信息时,将“国家”替换为“您来自哪个国家?”
通过这种方式,生硬的表单填写被构建为用户和计算机之间的对话;在分页设计中,适当使用动态效果,增加页面切换时的趣味性等。

二、结语
至此,360°全方位表单设计指南的第一篇文章就结束了。感谢大家花时间阅读这篇文章,希望对大家有所帮助。
下一部分文章我会讲解表单设计的第二个方面:表单的元素设计——表单元素设计中表单设计的核心部分,也是大家付出的部分最关注的,也是学习效果。有兴趣的同学可以立即关注最容易看到的部分!
进阶提问:在情感化设计中,表单的标签名称用疑问句代替。不是增加了标签的复杂度,增加了读取成本吗?
作为一个自认为填了很多表格的“伪老司机”,我将自己的一些理解和体会分享给大家。希望我们作为产品人一起进步,一起成长!
文章采集规则(公众号等级越高越方便推荐给其他用户获取一些自己喜欢的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-09-03 15:42
文章采集规则改变一下基本不可以,一些采集公众号需要打赏之类的才给。很多公众号还是只会单纯的文章打赏,还无法给文章任何附属信息打赏。一句话总结为:公众号等级越高越方便推荐给其他用户获取一些自己喜欢的。
直接走点赞可以,现在几乎有大号的地方就会有自己的打赏功能,我本身也是从运营公众号开始接触到这块,一开始用的是一点号,但后来用了一周不到,实在是找不到能够满足我需求的,后来就被盗号了,就换到一起创业的一个公众号,从此走上了用微信号领悟知识的习惯,这边主要的靠推荐,但也一直没有什么突破性的技术,以前也没发现公众号通过自定义菜单获取第三方信息上面还是有门道,目前确实在深入学习这方面的技术,建议你到一些相关的论坛,如腾讯云论坛去看看,都是干货。
公众号还没找到满足自己需求的地方就去开广告吧
有两种方式,一种是用历史消息。可以去看一下我之前的一个答案,里面介绍了新公众号的一些推广方法。现在基本可以不用历史消息了。后来做的一个公众号,积累了不少粉丝。直接链接到了大学生论坛,然后本校的学生就可以直接在里面发广告了。还有一种更牛逼的,是外包公众号推广,提供php\python\java多重语言接口。
然后在公众号里面直接推送文章。这样就省去了一系列推广流程。其实公众号只是自媒体对外交易的平台而已,最终目的还是从公众号中引流,就看你对怎么推广有兴趣。 查看全部
文章采集规则(公众号等级越高越方便推荐给其他用户获取一些自己喜欢的)
文章采集规则改变一下基本不可以,一些采集公众号需要打赏之类的才给。很多公众号还是只会单纯的文章打赏,还无法给文章任何附属信息打赏。一句话总结为:公众号等级越高越方便推荐给其他用户获取一些自己喜欢的。
直接走点赞可以,现在几乎有大号的地方就会有自己的打赏功能,我本身也是从运营公众号开始接触到这块,一开始用的是一点号,但后来用了一周不到,实在是找不到能够满足我需求的,后来就被盗号了,就换到一起创业的一个公众号,从此走上了用微信号领悟知识的习惯,这边主要的靠推荐,但也一直没有什么突破性的技术,以前也没发现公众号通过自定义菜单获取第三方信息上面还是有门道,目前确实在深入学习这方面的技术,建议你到一些相关的论坛,如腾讯云论坛去看看,都是干货。
公众号还没找到满足自己需求的地方就去开广告吧
有两种方式,一种是用历史消息。可以去看一下我之前的一个答案,里面介绍了新公众号的一些推广方法。现在基本可以不用历史消息了。后来做的一个公众号,积累了不少粉丝。直接链接到了大学生论坛,然后本校的学生就可以直接在里面发广告了。还有一种更牛逼的,是外包公众号推广,提供php\python\java多重语言接口。
然后在公众号里面直接推送文章。这样就省去了一系列推广流程。其实公众号只是自媒体对外交易的平台而已,最终目的还是从公众号中引流,就看你对怎么推广有兴趣。
文章采集规则(今日头条数据:加载出址分析篇源码(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-09-02 09:18
今天的头条数据由 Ajax 加载和显示。按照正常的URL,是抓不到数据的。需要分析加载地址。我们以 %E6%96%B0%E9%97%BB 为例。 采集文章列表
用谷歌浏览器打开链接,右击“查看”,在控制台切换到网络,点击XHR,这样可以过滤掉图片、文件等不必要的请求,只请求查看内容页面
由于页面是Ajax加载的,把页面拉到底部,更多的文章会自动加载。这时候控制台抓取到的链接就是我们真正需要的列表页面的链接了:
%E6%96%B0%E9%97%BB&autoload=true&count=20&cur_tab=1&from=search_tab
在优采云采集创建任务
创建后点击“采集Settings”,在“Starting Page URL”中填写上面获取的链接
接下来匹配内容页面的网址,标题中的文章网址格式为数字/
点击“内容页面网址”编写“匹配内容网址”规则:
(?\d+/)
这是一个正则规则,就是将匹配的URL加载到捕获组content1中,然后在下面填写[Content1],对应上面的content1获取内容页面链接
可以点击测试查看链接是否被成功抓取
获取成功后,即可开始获取内容
点击“获取内容”在字段列表右侧添加默认字段,如标题、正文等可智能识别,如需准确可自行编辑字段,支持regular、xpath , json 等匹配内容
我们需要抓取文章的标题和文字。因为是Ajax显示的,所以我们需要写规则来匹配内容。分析文章源码:,找到文章location
标题规则:articleInfo\s:\s{\stitle:\s'[Content1]',
正文规则:content\s:\s'[content1]',\s*groupId
必须保证规则的唯一性,否则会匹配到其他内容。将规则添加到字段中,并选择获取它的方法以匹配规则:
规则写好后,点击保存,点击“测试”看看效果
规则正确,爬行正常。抓到的数据也可以发布到cms系统,直接存入数据库,保存为excel文件等,只需点击底部导航栏的“发布设置”,今天好头条采集结束在这里,你不妨试试看! 查看全部
文章采集规则(今日头条数据:加载出址分析篇源码(组图))
今天的头条数据由 Ajax 加载和显示。按照正常的URL,是抓不到数据的。需要分析加载地址。我们以 %E6%96%B0%E9%97%BB 为例。 采集文章列表
用谷歌浏览器打开链接,右击“查看”,在控制台切换到网络,点击XHR,这样可以过滤掉图片、文件等不必要的请求,只请求查看内容页面
由于页面是Ajax加载的,把页面拉到底部,更多的文章会自动加载。这时候控制台抓取到的链接就是我们真正需要的列表页面的链接了:
%E6%96%B0%E9%97%BB&autoload=true&count=20&cur_tab=1&from=search_tab
在优采云采集创建任务
创建后点击“采集Settings”,在“Starting Page URL”中填写上面获取的链接
接下来匹配内容页面的网址,标题中的文章网址格式为数字/
点击“内容页面网址”编写“匹配内容网址”规则:
(?\d+/)
这是一个正则规则,就是将匹配的URL加载到捕获组content1中,然后在下面填写[Content1],对应上面的content1获取内容页面链接
可以点击测试查看链接是否被成功抓取
获取成功后,即可开始获取内容
点击“获取内容”在字段列表右侧添加默认字段,如标题、正文等可智能识别,如需准确可自行编辑字段,支持regular、xpath , json 等匹配内容
我们需要抓取文章的标题和文字。因为是Ajax显示的,所以我们需要写规则来匹配内容。分析文章源码:,找到文章location
标题规则:articleInfo\s:\s{\stitle:\s'[Content1]',
正文规则:content\s:\s'[content1]',\s*groupId
必须保证规则的唯一性,否则会匹配到其他内容。将规则添加到字段中,并选择获取它的方法以匹配规则:
规则写好后,点击保存,点击“测试”看看效果
规则正确,爬行正常。抓到的数据也可以发布到cms系统,直接存入数据库,保存为excel文件等,只需点击底部导航栏的“发布设置”,今天好头条采集结束在这里,你不妨试试看!
文章采集规则( 如何使用采集功能去采集一个图片类的网站?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-09-02 02:10
如何使用采集功能去采集一个图片类的网站?)
如何使用Dedecms采集功能---图片采集(一)
前言:这个文章主要介绍了如何使用采集函数来采集一个图片类网站。本次选定的目标站点为:站酷精品欣赏版块。网址是:。本文将介绍如何处理收录分页的采集 页面以及如何使用简单的过滤规则。本文分为三部分:第一部分主要介绍如何进入采集界面以及添加采集节点的第一步:设置基本信息和URL索引页面规则;第二部分主要介绍添加采集节点的第二步:设置字段获取规则;第三部分主要介绍如何采集指定一个节点以及如何导出采集内容。
输入下面的第一部分。
1.1进入采集node管理界面
如图(图1),在后台管理界面主菜单中点击“采集”,然后点击“采集node管理”进入采集节点管理界面,如(图片2)显示。
图1-后台管理界面
图2-采集Node 管理界面
1.2. 添加新节点
在采集节点管理界面,点击左下角“添加新节点”或右上角“添加新节点”(如2),可进入“选择内容模型” " 界面,如( 如图3),
图3-选择内容模型界面
在“选择内容模型”界面的下拉列表框中,有“General文章”和“图片集”可供选择。
根据页面类型为采集,选择对应的内容模型。本文选择“图片采集”,点击确定,进入“添加采集节点:第一步设置基本信息和URL索引页面规则”界面,如图(图4),
图4-新建采集节点:第一步设置基本信息和URL索引页面规则
1.2.1 设置基本节点信息
图5-基本节点信息
如图(图片5),这里只是获取“目标页面代码”的方法,其他设置请参考前面的文章。具体步骤:
(a) 打开采集的目标页面:;
(b) 右击选择“查看源文件”,找到“字符集”,如图(图6),
图6-查看源文件
等号后面的代码是要填写的“编码格式”,这里是“utf-8”。
填写后,如图(picture7),
图7-设置后节点的基本信息
检查后,进入下一步。
1.2.2 设置列表网址获取规则
图8-列出URL获取规则
如图(图片8),这里是设置采集文章list页面的匹配规则。具体步骤:
(a) 首先回到打开的列表页面,找到浏览器的URL地址栏中显示的URL和页面的换页部分。如图(图9)和(图10),
)
图9-浏览器的URL地址栏
图 10 页面变化
(b) 点击“2”打开文章列表页面的第二页,再次找到浏览器的URL地址栏中显示的URL和页面的换页部分,如图(图12)和(如图13),
图11-第二页的URL
图12-第二页的换页
(c) 在打开的列表页的第二页,点击(1),返回到列表页的第一页,然后页面的换页部分和上图10一样,但是浏览设备的URL地址栏中显示的URL与之前的图9不同,如图(图13),
图13-第一页的URL
(d) 从(b)和(c)可以推断出采集的列表页的URL遵循以下规则:
!0!0!200!(*)!1!0!0/.为安全起见,请自行测试更多列表页面。确定规则后,在“匹配网址”中填写规则后跟列表页。
(e) 最后根据需要指定采集的页码或正则数,并设置递增的正则。
到这里,“列表网址获取规则”部分就结束了。最终结果,如图(图14),
图14-设置后的URL获取规则列表
确认无误后,进行下一步。
1.2.3 设置文章 URL 匹配规则
图15-文章URL匹配规则
这里是设置采集列表页的匹配规则。
具体步骤:
(a)对于“区域开始的HTML”,可以在已打开的列表首页,单击右键后选择“查看源文件”查找出第一篇文章的标题“高清壁纸”来获得,如(图16)所示,
图16-查看源文件中第一篇文章文章的标题
通过观察,不难看出“”是整个列表的结尾,后面的“”是页面的换页部分。因此,在“HTML在该区域的末尾”中,您应该填写“”,表示到第一个的末尾。
(c) 观察图16和图17的文章title部分,我们可以发现标题的链接地址收录“=.html”。因此,您可以在“必须收录”中填写“=.html”。
到此,“文章URL 匹配规则”的设置就结束了。填写后,如图(图18),
图18-设置后文章URL匹配规则
通过以上三小节,添加采集节点的第一步已经搭建完成。设置后的最终结果,如图(图19),
图19-设置后新建采集节点:第一步设置基本信息和URL索引页面规则
一切都完成并检查后,点击“保存信息并进入下一步设置”。如果之前的设置正确,点击后会进入“新建采集节点:测试基本信息和URL索引页面规则设置的URL获取规则测试”页面,看到对应的文章列表地址。如图(图20),
图20-URL获取规则测试
确认无误后,点击“保存信息,进入下一步设置”。否则请点击“返回上一步修改”。
到此,第一部分结束。现在进入第二部分。 . . 查看全部
文章采集规则(
如何使用采集功能去采集一个图片类的网站?)
如何使用Dedecms采集功能---图片采集(一)
前言:这个文章主要介绍了如何使用采集函数来采集一个图片类网站。本次选定的目标站点为:站酷精品欣赏版块。网址是:。本文将介绍如何处理收录分页的采集 页面以及如何使用简单的过滤规则。本文分为三部分:第一部分主要介绍如何进入采集界面以及添加采集节点的第一步:设置基本信息和URL索引页面规则;第二部分主要介绍添加采集节点的第二步:设置字段获取规则;第三部分主要介绍如何采集指定一个节点以及如何导出采集内容。
输入下面的第一部分。
1.1进入采集node管理界面
如图(图1),在后台管理界面主菜单中点击“采集”,然后点击“采集node管理”进入采集节点管理界面,如(图片2)显示。
图1-后台管理界面
图2-采集Node 管理界面
1.2. 添加新节点
在采集节点管理界面,点击左下角“添加新节点”或右上角“添加新节点”(如2),可进入“选择内容模型” " 界面,如( 如图3),
图3-选择内容模型界面
在“选择内容模型”界面的下拉列表框中,有“General文章”和“图片集”可供选择。
根据页面类型为采集,选择对应的内容模型。本文选择“图片采集”,点击确定,进入“添加采集节点:第一步设置基本信息和URL索引页面规则”界面,如图(图4),
图4-新建采集节点:第一步设置基本信息和URL索引页面规则
1.2.1 设置基本节点信息
图5-基本节点信息
如图(图片5),这里只是获取“目标页面代码”的方法,其他设置请参考前面的文章。具体步骤:
(a) 打开采集的目标页面:;
(b) 右击选择“查看源文件”,找到“字符集”,如图(图6),
图6-查看源文件
等号后面的代码是要填写的“编码格式”,这里是“utf-8”。
填写后,如图(picture7),
图7-设置后节点的基本信息
检查后,进入下一步。
1.2.2 设置列表网址获取规则
图8-列出URL获取规则
如图(图片8),这里是设置采集文章list页面的匹配规则。具体步骤:
(a) 首先回到打开的列表页面,找到浏览器的URL地址栏中显示的URL和页面的换页部分。如图(图9)和(图10),
)
图9-浏览器的URL地址栏
图 10 页面变化
(b) 点击“2”打开文章列表页面的第二页,再次找到浏览器的URL地址栏中显示的URL和页面的换页部分,如图(图12)和(如图13),
图11-第二页的URL
图12-第二页的换页
(c) 在打开的列表页的第二页,点击(1),返回到列表页的第一页,然后页面的换页部分和上图10一样,但是浏览设备的URL地址栏中显示的URL与之前的图9不同,如图(图13),
图13-第一页的URL
(d) 从(b)和(c)可以推断出采集的列表页的URL遵循以下规则:
!0!0!200!(*)!1!0!0/.为安全起见,请自行测试更多列表页面。确定规则后,在“匹配网址”中填写规则后跟列表页。
(e) 最后根据需要指定采集的页码或正则数,并设置递增的正则。
到这里,“列表网址获取规则”部分就结束了。最终结果,如图(图14),
图14-设置后的URL获取规则列表
确认无误后,进行下一步。
1.2.3 设置文章 URL 匹配规则
图15-文章URL匹配规则
这里是设置采集列表页的匹配规则。
具体步骤:
(a)对于“区域开始的HTML”,可以在已打开的列表首页,单击右键后选择“查看源文件”查找出第一篇文章的标题“高清壁纸”来获得,如(图16)所示,
图16-查看源文件中第一篇文章文章的标题
通过观察,不难看出“”是整个列表的结尾,后面的“”是页面的换页部分。因此,在“HTML在该区域的末尾”中,您应该填写“”,表示到第一个的末尾。
(c) 观察图16和图17的文章title部分,我们可以发现标题的链接地址收录“=.html”。因此,您可以在“必须收录”中填写“=.html”。
到此,“文章URL 匹配规则”的设置就结束了。填写后,如图(图18),
图18-设置后文章URL匹配规则
通过以上三小节,添加采集节点的第一步已经搭建完成。设置后的最终结果,如图(图19),
图19-设置后新建采集节点:第一步设置基本信息和URL索引页面规则
一切都完成并检查后,点击“保存信息并进入下一步设置”。如果之前的设置正确,点击后会进入“新建采集节点:测试基本信息和URL索引页面规则设置的URL获取规则测试”页面,看到对应的文章列表地址。如图(图20),
图20-URL获取规则测试
确认无误后,点击“保存信息,进入下一步设置”。否则请点击“返回上一步修改”。
到此,第一部分结束。现在进入第二部分。 . .
文章采集规则(添加采集规则规则说明系统(系统默认变量:文章序号))
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-01 22:05
添加采集 规则。规则描述系统默认变量:-文章序号,-章节序号,-文章子序号,-章节子序号。系统标签 * 可以替换任何字符串。系统标签!可以替换除此之外的任何字符串。系统标签~可以替换除'"以外的任何字符串。系统标签^可以替换数字和以外的字符串。系统标签$可以替换数字字符串。在采集规则中,需要获取四个内容部分而不是上面的系统标签,比如!!!!!! 基本设置网站logo configs\article\collectsite.php中添加的logo,随便填写即可,一般是采集的域名缩写站点,以区别于其他规则。例如:feiku网站名所采集站的名称。例如:Feiku网站Address所采集站的地址。例如:文章子序列号计算方法不一定要加,我这里就直接用了 留空 支持四种使用记号的算术运算(+加法,-减法,*乘法,/除法,%余数) 本章子序列计算方法不用加,我这里留空。(谁知道他的一个文件夹里有多少本书?他没有把它放在一起按照规则,我不是采集不)它支持使用标签的四种算术运算(+add、-subtract、*multiply、/division、%取余数)。代理服务器地址不使用代理服务器请留空。代理服务器端口。当现有章节无法对应时,是否全部清除。 Re采集 是否根据需要选择是否将采集到的文章设置为整本书。是否根据您的需要选择,如果选择“是”“无论文章是连载还是完成,都会在您的站点上显示整个文本。建议选择“否”将HTTP_REFERER标志发送到突破反采集设置。默认选择是否为“是”,不知道是干什么用的,我先突破选择“是”,然后再说对方的网页编码(自动检测GB2312 UTF8 BIG5)默认“自动检测”编码与本站不同会自动尝试转换文章信息页采集标准文章信息页地址 图书信息页面URL,使用图书ID代替。例如:/Index.html 文章title采集 规则要求检查网页的源文件,如果没有,可以停止。检查信息页的源文件,然后找到文章源文件中的title在哪里(我们以飞酷为例,即c盘上源文件中“文章Title”的位置章节信息页)。这里以《我的美丽小姐》为例,找到标题附近的代码是
《美丽的女人》
把上面的代码复制到文章title采集rules的框里,然后把我美女的真实头衔换成!!!!当然,你也可以用** **等其他替换符号来替换它,但重要的是范围越小,越能表达意思越好(习惯问题,当然只能是采集到文章的标题,但是当你不想要的时候还有其他的采集。李兴宇这里是使用采集的内容,但是144238只对这个文章有用,而且其他文章有其他数字,所以用任意数字String $代替。所以作者采集rule是!!!@文章型采集全球都市 从上面两个采集rules,不难看出看到这里的规则是!!!!!! 查看全部
文章采集规则(添加采集规则规则说明系统(系统默认变量:文章序号))
添加采集 规则。规则描述系统默认变量:-文章序号,-章节序号,-文章子序号,-章节子序号。系统标签 * 可以替换任何字符串。系统标签!可以替换除此之外的任何字符串。系统标签~可以替换除'"以外的任何字符串。系统标签^可以替换数字和以外的字符串。系统标签$可以替换数字字符串。在采集规则中,需要获取四个内容部分而不是上面的系统标签,比如!!!!!! 基本设置网站logo configs\article\collectsite.php中添加的logo,随便填写即可,一般是采集的域名缩写站点,以区别于其他规则。例如:feiku网站名所采集站的名称。例如:Feiku网站Address所采集站的地址。例如:文章子序列号计算方法不一定要加,我这里就直接用了 留空 支持四种使用记号的算术运算(+加法,-减法,*乘法,/除法,%余数) 本章子序列计算方法不用加,我这里留空。(谁知道他的一个文件夹里有多少本书?他没有把它放在一起按照规则,我不是采集不)它支持使用标签的四种算术运算(+add、-subtract、*multiply、/division、%取余数)。代理服务器地址不使用代理服务器请留空。代理服务器端口。当现有章节无法对应时,是否全部清除。 Re采集 是否根据需要选择是否将采集到的文章设置为整本书。是否根据您的需要选择,如果选择“是”“无论文章是连载还是完成,都会在您的站点上显示整个文本。建议选择“否”将HTTP_REFERER标志发送到突破反采集设置。默认选择是否为“是”,不知道是干什么用的,我先突破选择“是”,然后再说对方的网页编码(自动检测GB2312 UTF8 BIG5)默认“自动检测”编码与本站不同会自动尝试转换文章信息页采集标准文章信息页地址 图书信息页面URL,使用图书ID代替。例如:/Index.html 文章title采集 规则要求检查网页的源文件,如果没有,可以停止。检查信息页的源文件,然后找到文章源文件中的title在哪里(我们以飞酷为例,即c盘上源文件中“文章Title”的位置章节信息页)。这里以《我的美丽小姐》为例,找到标题附近的代码是
《美丽的女人》
把上面的代码复制到文章title采集rules的框里,然后把我美女的真实头衔换成!!!!当然,你也可以用** **等其他替换符号来替换它,但重要的是范围越小,越能表达意思越好(习惯问题,当然只能是采集到文章的标题,但是当你不想要的时候还有其他的采集。李兴宇这里是使用采集的内容,但是144238只对这个文章有用,而且其他文章有其他数字,所以用任意数字String $代替。所以作者采集rule是!!!@文章型采集全球都市 从上面两个采集rules,不难看出看到这里的规则是!!!!!!
文章采集规则(建站技术网收集整理你收集整理的全部内容方法(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-08-31 03:06
摘要:建站技术网采集整理的这篇文章主要介绍了dedecms采集文章内容为空的解决方案。建站科技网小编觉得还不错。现在分享给大家,我也给大家参考一下。
dedecms采集文章空内容的解决方法
在采集data 中,部分文章采集 内容为空。一开始不知道,因为采集600多文章,我只看了前两个,发现还可以,然后直接导入数据库。可惜导入后发现部分内容是空的,也就是body部分是空的。有600多条数据。一一查找比较麻烦,于是找到了一个简单的方法:
在后台执行下面的sql语句
删除 dede_addonarticle,dede_archives FROM dede_addonarticle,dede_archives where dede_addonarticle.body='' and dede_addonarticle.aid=dede_archives.id
总结:以上是建站科技网为您采集整理的dedecms采集文章的完整内容。希望文章能帮您解决dedecms采集文章内容为空解决程序开发遇到的问题。如果你觉得网站技术网网站的内容还不错,欢迎向程序员朋友推荐网站技术网网站。 查看全部
文章采集规则(建站技术网收集整理你收集整理的全部内容方法(图))
摘要:建站技术网采集整理的这篇文章主要介绍了dedecms采集文章内容为空的解决方案。建站科技网小编觉得还不错。现在分享给大家,我也给大家参考一下。
dedecms采集文章空内容的解决方法
在采集data 中,部分文章采集 内容为空。一开始不知道,因为采集600多文章,我只看了前两个,发现还可以,然后直接导入数据库。可惜导入后发现部分内容是空的,也就是body部分是空的。有600多条数据。一一查找比较麻烦,于是找到了一个简单的方法:
在后台执行下面的sql语句
删除 dede_addonarticle,dede_archives FROM dede_addonarticle,dede_archives where dede_addonarticle.body='' and dede_addonarticle.aid=dede_archives.id
总结:以上是建站科技网为您采集整理的dedecms采集文章的完整内容。希望文章能帮您解决dedecms采集文章内容为空解决程序开发遇到的问题。如果你觉得网站技术网网站的内容还不错,欢迎向程序员朋友推荐网站技术网网站。
文章采集规则(本文介绍使用优采云采集搜狗微信文章(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-08-30 03:10
本文介绍优采云采集搜狗微信文章的使用方法(以流行的文章为例)采集网站:/
使用功能点:
l 分页列表信息采集
/tutorial/fylb-70.aspx?t=1
l Xpath
/search?query=XPath
l AJAX 点击和翻页
/tutorial/ajaxdjfy_@k22@aspx?t=1
第一步:创建采集task
1)进入主界面,点击左侧“新建”,选择“自定义任务”
2)将采集的网址复制粘贴到网站输入框中,点击“保存设置”
第 2 步:创建翻页循环
1)网页打开后,默认显示“热门”文章。向下滚动页面,找到并点击“加载更多内容”按钮,在操作提示框中选择“循环点击单个链接”
由于本网页涉及Ajax技术,所以需要设置一些高级选项。在操作提示框中,设置Ajjax超时时间为“2秒”
注:AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,无需重新加载整个网页即可更新网页的某一部分。
性能特点:当你点击网页上的一个选项时,网站的大部分网址不会改变;湾网页未完全加载,只是部分加载了数据并发生了更改。
验证方法:点击操作后,URL输入栏在浏览器中不会出现加载状态或转动状态。
观察网页,我们发现点击“加载更多内容”5次后,页面加载到底部,一共显示了100个文章。因此,我们将整个“循环翻页”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5”,点击“确定”
第 3 步:创建一个列表循环并提取数据
1)移动鼠标选择页面上的第一个文章块。系统将识别此块中的子元素。在操作提示框中选择“选择子元素”
2)继续选择页面第二篇文章的区块,系统会自动选择第二篇文章的子元素,并识别页面其他10组相似元素, 在操作提示框中,选择“全选”
3) 我们可以看到页面上文章块中的所有元素都被选中并变成了绿色。字段预览表出现在下方。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。字段选择完成后,选择“采集以下数据”
4)字段选择完成后,选择对应的字段,自定义字段的命名
第 4 步:修改 Xpath
我们继续观察,5次点击“加载更多内容”后,这个网页加载了全部100个文章。所以,我们配置规则的思路是先建立一个翻页循环,加载所有100个文章,然后创建一个循环列表提取数据
1)选择整个“循环”步骤并将其拖出“循环翻转”步骤。如果不这样做,就会出现大量重复数据。
拖动完成后,如下图
2)在“列表循环”步骤中,我们创建了一个100个文章的循环列表。选择整个“循环步骤”,打开“高级选项”,元素列表中的这个Xpath不会被固定:
<p>//BODY[@id="loginWrap"]/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI,复制粘贴到火狐浏览器对应位置 查看全部
文章采集规则(本文介绍使用优采云采集搜狗微信文章(一))
本文介绍优采云采集搜狗微信文章的使用方法(以流行的文章为例)采集网站:/
使用功能点:
l 分页列表信息采集
/tutorial/fylb-70.aspx?t=1
l Xpath
/search?query=XPath
l AJAX 点击和翻页
/tutorial/ajaxdjfy_@k22@aspx?t=1
第一步:创建采集task
1)进入主界面,点击左侧“新建”,选择“自定义任务”
2)将采集的网址复制粘贴到网站输入框中,点击“保存设置”
第 2 步:创建翻页循环
1)网页打开后,默认显示“热门”文章。向下滚动页面,找到并点击“加载更多内容”按钮,在操作提示框中选择“循环点击单个链接”
由于本网页涉及Ajax技术,所以需要设置一些高级选项。在操作提示框中,设置Ajjax超时时间为“2秒”
注:AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,无需重新加载整个网页即可更新网页的某一部分。
性能特点:当你点击网页上的一个选项时,网站的大部分网址不会改变;湾网页未完全加载,只是部分加载了数据并发生了更改。
验证方法:点击操作后,URL输入栏在浏览器中不会出现加载状态或转动状态。
观察网页,我们发现点击“加载更多内容”5次后,页面加载到底部,一共显示了100个文章。因此,我们将整个“循环翻页”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5”,点击“确定”
第 3 步:创建一个列表循环并提取数据
1)移动鼠标选择页面上的第一个文章块。系统将识别此块中的子元素。在操作提示框中选择“选择子元素”
2)继续选择页面第二篇文章的区块,系统会自动选择第二篇文章的子元素,并识别页面其他10组相似元素, 在操作提示框中,选择“全选”
3) 我们可以看到页面上文章块中的所有元素都被选中并变成了绿色。字段预览表出现在下方。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。字段选择完成后,选择“采集以下数据”
4)字段选择完成后,选择对应的字段,自定义字段的命名
第 4 步:修改 Xpath
我们继续观察,5次点击“加载更多内容”后,这个网页加载了全部100个文章。所以,我们配置规则的思路是先建立一个翻页循环,加载所有100个文章,然后创建一个循环列表提取数据
1)选择整个“循环”步骤并将其拖出“循环翻转”步骤。如果不这样做,就会出现大量重复数据。
拖动完成后,如下图
2)在“列表循环”步骤中,我们创建了一个100个文章的循环列表。选择整个“循环步骤”,打开“高级选项”,元素列表中的这个Xpath不会被固定:
<p>//BODY[@id="loginWrap"]/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI,复制粘贴到火狐浏览器对应位置
文章采集规则(【文章采集规则】2019年4月员工福利建议功能和实施方案)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-08-29 06:01
文章采集规则有以下几种:
1)采集某些公司二维码,
2)采集某个公司提供的api接口,
3)采集某公司某部门某个部门员工的班级号、姓名等敏感信息;
4)采集员工个人信息,用于保存到企业数据库。
一、二维码采集功能介绍
一)基础采集功能
1)基础的扫码识别功能,
2)基础的展示功能,
3)基础的二维码分享功能,用于简单便捷的分享宣传给客户。
二)特殊采集功能
1)选班级限制采集选择班级限制采集有两种情况:选择多次限制、交叉限制;
2)选上下限制采集选择上下限制采集有两种情况:选择原本的限制区域,
3)上限下限采集选择上限下限采集可以实现在限制区域内的全选、半选;
4)限制区域内是否能扫描得到二维码;
5)关键字限制注:以上关键字采集功能需要企业提供一个号码,可以参考用号码作为关键字来采集二维码数据。
三)sdk采集功能二维码采集功能是sdk采集的一个重要功能,该功能可以统计出客户员工的微信、手机号码、家庭住址等客户用于宣传或保存的有效信息。
四)公司内二维码用于组织机构年终奖、补贴、培训名单、周年庆/聚餐等员工活动用途。
二、2019年4月员工福利建议功能和实施方案
1、建议功能建议功能可以适当做限制。对于公司员工,建议具体限制对象为:年终奖,福利,补贴;在我们的案例中,基本上所有关于年终奖,补贴,培训的活动都可以做建议功能。
员工在年终奖、福利、培训这三项福利中又可以通过不同的方式来进行限制,
1)年终奖确定不建议做建议功能;
2)福利确定不建议做建议功能;
3)培训则建议做建议功能。
2、实施方案
一)建立机制,规范内部二维码使用规范二维码使用要规范,主要有两点:一是不能有同质化的东西,也就是不能有关键字,不能有英文等;二是编码主要有七种编码法:中心、字母、数字、数字、阿拉伯数字、数字、阿拉伯数字;针对这些要求,配合我们大中台的统一规范,建立关键字分配至各个基础二维码身上,用于采集、核对和统计。
相关参考文章:中心采集方案|微信小程序码生成器|人脸识别|指纹识别|摄像头采集|微信企业号、公众号、小程序码生成器|针对补贴,业务统计二维码采集方案|二维码关键字分配至基础二维码身上|关于微信的采集框架|微信指纹采集器|人脸识别|抖音对商户企业的引流|新版微信企业号、小程序二维码生成器|推荐的二维。 查看全部
文章采集规则(【文章采集规则】2019年4月员工福利建议功能和实施方案)
文章采集规则有以下几种:
1)采集某些公司二维码,
2)采集某个公司提供的api接口,
3)采集某公司某部门某个部门员工的班级号、姓名等敏感信息;
4)采集员工个人信息,用于保存到企业数据库。
一、二维码采集功能介绍
一)基础采集功能
1)基础的扫码识别功能,
2)基础的展示功能,
3)基础的二维码分享功能,用于简单便捷的分享宣传给客户。
二)特殊采集功能
1)选班级限制采集选择班级限制采集有两种情况:选择多次限制、交叉限制;
2)选上下限制采集选择上下限制采集有两种情况:选择原本的限制区域,
3)上限下限采集选择上限下限采集可以实现在限制区域内的全选、半选;
4)限制区域内是否能扫描得到二维码;
5)关键字限制注:以上关键字采集功能需要企业提供一个号码,可以参考用号码作为关键字来采集二维码数据。
三)sdk采集功能二维码采集功能是sdk采集的一个重要功能,该功能可以统计出客户员工的微信、手机号码、家庭住址等客户用于宣传或保存的有效信息。
四)公司内二维码用于组织机构年终奖、补贴、培训名单、周年庆/聚餐等员工活动用途。
二、2019年4月员工福利建议功能和实施方案
1、建议功能建议功能可以适当做限制。对于公司员工,建议具体限制对象为:年终奖,福利,补贴;在我们的案例中,基本上所有关于年终奖,补贴,培训的活动都可以做建议功能。
员工在年终奖、福利、培训这三项福利中又可以通过不同的方式来进行限制,
1)年终奖确定不建议做建议功能;
2)福利确定不建议做建议功能;
3)培训则建议做建议功能。
2、实施方案
一)建立机制,规范内部二维码使用规范二维码使用要规范,主要有两点:一是不能有同质化的东西,也就是不能有关键字,不能有英文等;二是编码主要有七种编码法:中心、字母、数字、数字、阿拉伯数字、数字、阿拉伯数字;针对这些要求,配合我们大中台的统一规范,建立关键字分配至各个基础二维码身上,用于采集、核对和统计。
相关参考文章:中心采集方案|微信小程序码生成器|人脸识别|指纹识别|摄像头采集|微信企业号、公众号、小程序码生成器|针对补贴,业务统计二维码采集方案|二维码关键字分配至基础二维码身上|关于微信的采集框架|微信指纹采集器|人脸识别|抖音对商户企业的引流|新版微信企业号、小程序二维码生成器|推荐的二维。
文章采集规则( 如何实现wp的自动采集功能--WordPress自动匹配功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-29 05:01
如何实现wp的自动采集功能--WordPress自动匹配功能)
网站how采集 wordpress 如何实现自动采集
WordPress 是一个使用 PHP 语言开发的建站程序平台。现在很多博主都用wp。很多网站制作培训使用wp,尤其是在做采集站的时候。总能量非常强大。下面是如何实现wp的自动采集功能。
安装网站采集插件:WP-AutoPost(插件下载链接:)
点击“新建任务”后,输入任务名称创建一个新任务。创建新任务后,您可以在任务列表中查看该任务,并且可以为该任务配置更多设置。 (这部分不需要修改设置,唯一需要修改的就是采集的时间。)文章source设置。在此选项卡下,我们需要设置文章source 的文章list URL 和具体的文章 匹配规则。以采集“新浪网”为例,文章列表的URL为,所以只需在手动指定的文章List URL中输入URL即可,如下图:
文章URL 匹配规则。 文章网址匹配规则的设置是最简单的,不需要复杂的设置。提供两种匹配模式。您可以使用 URL 通配符匹配或 CSS 选择器进行匹配。通常 URL 通配符匹配比较简单,但有时会使用 CSS 选择器。更确切。使用 URL 通配符匹配。通过点击列表网址上的文章,我们可以发现文章的每个网址的结构如下:所以将网址中的数字或字母替换为通配符(*),如:(*)/(*) .shtml。重复的 URL 可以使用 301 重定向。使用 CSS 选择器进行匹配。使用CSS选择器进行匹配,我们只需要设置文章URL的CSS选择器即可,查看列表URL源码即可轻松设置,在列表下找到文章超LINK的代码网址,如下图:
可以看到文章的超链接A标签在class为“contList”的标签里面,所以文章 URL的CSS选择器只需要设置为.contList a即可,如下图:
设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,将列出列表URL下的所有文章名称和对应的网址,如下图:
其他设置不需要修改。以上采集方法适用于WordPress多站点功能。
上一篇:WordPress网站如何调用other网站Latest文章(自动更新)
下一篇:WordPress调用其他网站文章显示在自己网站
发布:学做网站论坛 最后更新:2020-6-6 浏览:125264次
学做网站论坛致力于打造网站,打造在线培训诚信平台,让零基础学员学习如何做网站,最终可以自主搭建网站。
学做网站论坛建站培训,通过原创建站教程+讲师在线辅导,我们会详细讲解网站各种制作方法,即使你是初学者也能理解和学习。 . 查看全部
文章采集规则(
如何实现wp的自动采集功能--WordPress自动匹配功能)
网站how采集 wordpress 如何实现自动采集
WordPress 是一个使用 PHP 语言开发的建站程序平台。现在很多博主都用wp。很多网站制作培训使用wp,尤其是在做采集站的时候。总能量非常强大。下面是如何实现wp的自动采集功能。
安装网站采集插件:WP-AutoPost(插件下载链接:)
点击“新建任务”后,输入任务名称创建一个新任务。创建新任务后,您可以在任务列表中查看该任务,并且可以为该任务配置更多设置。 (这部分不需要修改设置,唯一需要修改的就是采集的时间。)文章source设置。在此选项卡下,我们需要设置文章source 的文章list URL 和具体的文章 匹配规则。以采集“新浪网”为例,文章列表的URL为,所以只需在手动指定的文章List URL中输入URL即可,如下图:
文章URL 匹配规则。 文章网址匹配规则的设置是最简单的,不需要复杂的设置。提供两种匹配模式。您可以使用 URL 通配符匹配或 CSS 选择器进行匹配。通常 URL 通配符匹配比较简单,但有时会使用 CSS 选择器。更确切。使用 URL 通配符匹配。通过点击列表网址上的文章,我们可以发现文章的每个网址的结构如下:所以将网址中的数字或字母替换为通配符(*),如:(*)/(*) .shtml。重复的 URL 可以使用 301 重定向。使用 CSS 选择器进行匹配。使用CSS选择器进行匹配,我们只需要设置文章URL的CSS选择器即可,查看列表URL源码即可轻松设置,在列表下找到文章超LINK的代码网址,如下图:
可以看到文章的超链接A标签在class为“contList”的标签里面,所以文章 URL的CSS选择器只需要设置为.contList a即可,如下图:
设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,将列出列表URL下的所有文章名称和对应的网址,如下图:
其他设置不需要修改。以上采集方法适用于WordPress多站点功能。
上一篇:WordPress网站如何调用other网站Latest文章(自动更新)
下一篇:WordPress调用其他网站文章显示在自己网站
发布:学做网站论坛 最后更新:2020-6-6 浏览:125264次
学做网站论坛致力于打造网站,打造在线培训诚信平台,让零基础学员学习如何做网站,最终可以自主搭建网站。
学做网站论坛建站培训,通过原创建站教程+讲师在线辅导,我们会详细讲解网站各种制作方法,即使你是初学者也能理解和学习。 .
文章采集规则(在设置采集规则的时候,有哪些注意事项?有什么注意事项)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-08-28 01:24
在这个日益浮躁的社会中,越来越多的人期望事情变得越来越简单。尤其是对于瞬息万变的互联网,需要时间仔细思考的事情并不适合。以网站operations 为例。虽然完整的原创文章对网站优化排名很有帮助,但是网站的大部分操作都不是很能写,再加上题材。时间限制和规律性。一个网站完全通过原创和全部手工操作,是非常困难的,特别是一些信息网站,商城网站,视频网站网站,里面有很多这样的页面和快速的内容更新要求,无论是内容构建还是外链发布都是一项庞大而复杂的任务,无论是时间还是成本,人工完成都是不划算的。因此,有时我们需要一些工具的帮助。 采集 工具就是其中之一。
目前网站采集中使用频率较高的采集工具有优采云采集工具、织梦自己的dede采集tools、采集tools。网上有很多对比,点百度就知道了,网上也有很多关于采集rules的设置策略,大同小异,本文就不多解释了对童鞋感兴趣的可以自行搜索。小美今天想跟大家分享的是采集规则设置时有哪些注意事项?
一、采集起止码设置
在采集规则设置中,很重要的一步就是采集起止码的设置。它通常是一小段代码,主要是“数字/英文+符号”的形式。代码越短,越不容易出错,而且需要是唯一的,这样机器才能快速识别采集的开始和结束位置。在网上教程中,这个起止码一般是一个完整的部分,比如[Content],这里是采集的开始位置,[Content]代表采集需要的部分信息,就是采集的结束位置采集位置,很多人会误以为起止代码一定是完整的section,其实不然。
有两种,如下图:
某部分代码,甚至是混入中文的代码,也可以作为采集的开始和结束代码,可以去除部分带有网站专有标识的网站内容开始和结束。
二、title采集Settings
标题采集很简单,有两种方式,如下图:
在需要采集的页面右击选择“查看源代码”,在打开的页面中使用快捷键Ctrl+F,在出现的搜索栏中输入采集内容的标题,并且可以查看 这个页面的标题规则一般是标题标签和H标签,数量从1到4不等。一般一个页面上同时存在两种标题标签。在这种情况下,使用 H 标签将比标题标签采集 更不容易出错。
需要注意的是,有时H标签有H1标签、H2标签、H3标签等,一般只使用H1标签。
三、分页采集规则设置
有些网站因为文章太长或者想提高点击率,经常把一篇文章的文章分成几页来呈现。在这种情况下,采集 的开始和结束代码不在同一页面上。相反,您应该在文章start 页面上查找采集 开始代码,并在文章 结束页面上查找结束代码。设置以下内容:
四、可能导致采集失败的几个因素
1、网站隐藏内容被禁止采集。在这种情况下,以腾讯新闻为例。腾讯新闻的内容不会显示在开源代码页中,因此无法区分文章的开始和结束位置,也不能将采集与其网站内容分开。
2、网站采集 出错了。大多数网站内容在网页和代码中显示正常,但当采集到达目标网站时显示错误。这种错误分为几类:
A.标题错了。如下图,文章的内容会全部集中在标题上。
B.只有采集进入标题,内容为空白。即相关内容不能是采集。
C、采集终止符无效,采集内容收录采集网站上的广告/版权信息/尾部信息等信息。
这些是采集经常遇到的问题。了解这些对采集和伪原创有很大帮助。虽然我们不建议在优化中使用采集,但在必要时了解采集规则仍然有利于网站操作。原文出处:美育宝防辐射服,专题内容请保留原文链接。谢谢! 查看全部
文章采集规则(在设置采集规则的时候,有哪些注意事项?有什么注意事项)
在这个日益浮躁的社会中,越来越多的人期望事情变得越来越简单。尤其是对于瞬息万变的互联网,需要时间仔细思考的事情并不适合。以网站operations 为例。虽然完整的原创文章对网站优化排名很有帮助,但是网站的大部分操作都不是很能写,再加上题材。时间限制和规律性。一个网站完全通过原创和全部手工操作,是非常困难的,特别是一些信息网站,商城网站,视频网站网站,里面有很多这样的页面和快速的内容更新要求,无论是内容构建还是外链发布都是一项庞大而复杂的任务,无论是时间还是成本,人工完成都是不划算的。因此,有时我们需要一些工具的帮助。 采集 工具就是其中之一。
目前网站采集中使用频率较高的采集工具有优采云采集工具、织梦自己的dede采集tools、采集tools。网上有很多对比,点百度就知道了,网上也有很多关于采集rules的设置策略,大同小异,本文就不多解释了对童鞋感兴趣的可以自行搜索。小美今天想跟大家分享的是采集规则设置时有哪些注意事项?
一、采集起止码设置
在采集规则设置中,很重要的一步就是采集起止码的设置。它通常是一小段代码,主要是“数字/英文+符号”的形式。代码越短,越不容易出错,而且需要是唯一的,这样机器才能快速识别采集的开始和结束位置。在网上教程中,这个起止码一般是一个完整的部分,比如[Content],这里是采集的开始位置,[Content]代表采集需要的部分信息,就是采集的结束位置采集位置,很多人会误以为起止代码一定是完整的section,其实不然。
有两种,如下图:
某部分代码,甚至是混入中文的代码,也可以作为采集的开始和结束代码,可以去除部分带有网站专有标识的网站内容开始和结束。
二、title采集Settings
标题采集很简单,有两种方式,如下图:
在需要采集的页面右击选择“查看源代码”,在打开的页面中使用快捷键Ctrl+F,在出现的搜索栏中输入采集内容的标题,并且可以查看 这个页面的标题规则一般是标题标签和H标签,数量从1到4不等。一般一个页面上同时存在两种标题标签。在这种情况下,使用 H 标签将比标题标签采集 更不容易出错。
需要注意的是,有时H标签有H1标签、H2标签、H3标签等,一般只使用H1标签。
三、分页采集规则设置
有些网站因为文章太长或者想提高点击率,经常把一篇文章的文章分成几页来呈现。在这种情况下,采集 的开始和结束代码不在同一页面上。相反,您应该在文章start 页面上查找采集 开始代码,并在文章 结束页面上查找结束代码。设置以下内容:
四、可能导致采集失败的几个因素
1、网站隐藏内容被禁止采集。在这种情况下,以腾讯新闻为例。腾讯新闻的内容不会显示在开源代码页中,因此无法区分文章的开始和结束位置,也不能将采集与其网站内容分开。
2、网站采集 出错了。大多数网站内容在网页和代码中显示正常,但当采集到达目标网站时显示错误。这种错误分为几类:
A.标题错了。如下图,文章的内容会全部集中在标题上。
B.只有采集进入标题,内容为空白。即相关内容不能是采集。
C、采集终止符无效,采集内容收录采集网站上的广告/版权信息/尾部信息等信息。
这些是采集经常遇到的问题。了解这些对采集和伪原创有很大帮助。虽然我们不建议在优化中使用采集,但在必要时了解采集规则仍然有利于网站操作。原文出处:美育宝防辐射服,专题内容请保留原文链接。谢谢!
优采云导航:优采云采集器优采云控制台优采云采集支持5118接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 633 次浏览 • 2021-08-27 19:07
优采云Navigation: 优采云采集器 优采云控制台
访问5118各种内容API教程-优采云采集
优采云采集支持5118接口如下(5118购买优惠码:FA5AF6)
5118 一键智能换字API接口
5118 一键智能重写API接口
5118 智能标题生成 API
提醒:第三方API接入功能需要用户提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口产生的一切费用由用户承担);
访问步骤1.创建5118 API接口配置(所有接口通用)
5118一键智能改字API接口:可用于处理采集数据标题和内容等,支持保留html标签,可以保留图片和排版;
5118 一键智能重写API接口:可用于处理采集的数据标题和内容。不支持保留html标签,只支持纯文本,但是优采云做了一些处理,尽量保留图片和排版;
5118智能标题生成API:根据文章content智能生成文章title;
我。 API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》点击进入创建相应的接口配置:【5118_智能改词API】、【5118_智能改写API】、【5118_智能标题生成API】;
二。配置API接口信息:
【API-Key值】是从5118后台获取一键智能改词API,或者5118一键智能改写API,或者5118智能标题生成API对应的key值,填写优采云;
5118 一键智能换词API支持设置锁词功能。首先开启核心字锁。处理第三方原创api 时不会替换锁定的字。多个词之间用|分隔,例如:word 1|Word 2|Word 3
注:5118限制每次调用的最大长度为5000个字符(包括html代码),所以当内容长度超过时,优采云会分次调用。这个操作会增加api调用次数,费用也会相应增加,这是用户需要承担的费用,使用前一定要注意! ! !
使用免责声明:5118 一键智能重写 API 不支持保留 Html 标签,仅支持纯文本。不过优采云做了一些处理,使其具有简单的格式(p标签),处理后保留图片。但由于接口限制、相关算法不完善以及一些未知情况,处理后可能会出现一些情况。如内容错误或图片缺失,优采云对因处理结果不正确或遗漏直接或间接造成的任何损失或损害不承担任何责任。
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
我。 API 处理规则条目:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
注意:API处理1个字段时,会调用一次API接口,所以建议不要添加不需要的字段!
三、5118智能标题生成API(可选,特殊接口说明)
5118智能标题生成API是基于文章content(内容字段)智能生成文章标题,所以API处理规则中需要处理的字段要选择content字段生成标题基于内容。
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
我。手动执行 API 处理规则:
点击采集任务的【结果&发布】选项卡中的【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);
二。自动执行 API 处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般搭配定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4.API处理结果及发布 I,查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
内容处理后添加字段:
在【结果数据&发布】和数据预览界面均可查看。
提醒:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二后内容发布,API接口处理
发布文章前,修改发布目标第二步的映射字段,API接口处理后将title和content改成新的对应字段。
例如执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
例如执行5118智能标题生成API后,选择content_5118生成标题并发布;
提示:如果在发布目标中无法选择新字段,请在此任务下复制或新建一个发布目标,然后在新发布目标中选择新字段,即可查看详细教程;
5.5118-API接口常见问题及解决方案 我,API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
二。批量修改数据的xAPI状态
可以批量修改数据的xAPI状态。在任务的【结果数据&发布】页面,点击【批处理工具】按钮--》在弹出的窗口中,选择【根据条件修改&删除】选项--》在对话框中选择对应的xAPI状态第二行【设置xapi和SEO状态】,然后点击【执行修改】按钮;
优采云Navigation: 优采云采集器 优采云控制台 查看全部
优采云导航:优采云采集器优采云控制台优采云采集支持5118接口
优采云Navigation: 优采云采集器 优采云控制台
访问5118各种内容API教程-优采云采集
优采云采集支持5118接口如下(5118购买优惠码:FA5AF6)
5118 一键智能换字API接口
5118 一键智能重写API接口
5118 智能标题生成 API
提醒:第三方API接入功能需要用户提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口产生的一切费用由用户承担);
访问步骤1.创建5118 API接口配置(所有接口通用)
5118一键智能改字API接口:可用于处理采集数据标题和内容等,支持保留html标签,可以保留图片和排版;
5118 一键智能重写API接口:可用于处理采集的数据标题和内容。不支持保留html标签,只支持纯文本,但是优采云做了一些处理,尽量保留图片和排版;
5118智能标题生成API:根据文章content智能生成文章title;
我。 API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》点击进入创建相应的接口配置:【5118_智能改词API】、【5118_智能改写API】、【5118_智能标题生成API】;
二。配置API接口信息:
【API-Key值】是从5118后台获取一键智能改词API,或者5118一键智能改写API,或者5118智能标题生成API对应的key值,填写优采云;
5118 一键智能换词API支持设置锁词功能。首先开启核心字锁。处理第三方原创api 时不会替换锁定的字。多个词之间用|分隔,例如:word 1|Word 2|Word 3
注:5118限制每次调用的最大长度为5000个字符(包括html代码),所以当内容长度超过时,优采云会分次调用。这个操作会增加api调用次数,费用也会相应增加,这是用户需要承担的费用,使用前一定要注意! ! !
使用免责声明:5118 一键智能重写 API 不支持保留 Html 标签,仅支持纯文本。不过优采云做了一些处理,使其具有简单的格式(p标签),处理后保留图片。但由于接口限制、相关算法不完善以及一些未知情况,处理后可能会出现一些情况。如内容错误或图片缺失,优采云对因处理结果不正确或遗漏直接或间接造成的任何损失或损害不承担任何责任。
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
我。 API 处理规则条目:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
注意:API处理1个字段时,会调用一次API接口,所以建议不要添加不需要的字段!
三、5118智能标题生成API(可选,特殊接口说明)
5118智能标题生成API是基于文章content(内容字段)智能生成文章标题,所以API处理规则中需要处理的字段要选择content字段生成标题基于内容。
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
我。手动执行 API 处理规则:
点击采集任务的【结果&发布】选项卡中的【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);
二。自动执行 API 处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般搭配定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4.API处理结果及发布 I,查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
内容处理后添加字段:
在【结果数据&发布】和数据预览界面均可查看。
提醒:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二后内容发布,API接口处理
发布文章前,修改发布目标第二步的映射字段,API接口处理后将title和content改成新的对应字段。
例如执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
例如执行5118智能标题生成API后,选择content_5118生成标题并发布;
提示:如果在发布目标中无法选择新字段,请在此任务下复制或新建一个发布目标,然后在新发布目标中选择新字段,即可查看详细教程;
5.5118-API接口常见问题及解决方案 我,API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
二。批量修改数据的xAPI状态
可以批量修改数据的xAPI状态。在任务的【结果数据&发布】页面,点击【批处理工具】按钮--》在弹出的窗口中,选择【根据条件修改&删除】选项--》在对话框中选择对应的xAPI状态第二行【设置xapi和SEO状态】,然后点击【执行修改】按钮;
优采云Navigation: 优采云采集器 优采云控制台
教程总目录:优采云采集器使用教程内容发布相关的设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-08-27 19:01
教程总目录:优采云采集器使用教程内容发布相关的设置
优采云采集器使用教程-采集内容发布规则设置
教程总目录:优采云采集器Using tutorials
在讲如何查找网站、采集文章链接和内容之前,先说一下内容发布相关的设置。
因为我在教程中设置了发布规则,所以这里简单介绍一下各个项目。
如下图
第一步,我们点击这里的内容发布规则
第二步,点击网页发布规则列表后面的加号
第三步出现模块管理(教程的总目录写好了,我们的模块文件放在优采云program下的\Module\目录下),选择wordpress.post模块
第四步,网页编码选择UTF-8(wordpress程序是国外的,国际上一般是UTF8编码,国内有的会是GBK编码。比如Discuz论坛程序有两个安装包:UTF8和GBK。 )
第五步,在我们的网页地址填写网站地址并添加接口文件名。比如你的接口文件名是jiekou.php网站,那么填写这个地址
第六步选择不登录作为登录方式。我们的界面文件免登录。
第七步,点击以下获取列表。通常你会得到wordpress的文章分类列表。然后选择一个列表,你选择哪个列表,采集的文章就会被发送到哪个列表。
然后在下面随机写一个配置名称并保存。
然后我们勾选我们刚刚保存的发布配置并启用它。
那别忘了点击右下角的保存,或者点击保存退出! 查看全部
教程总目录:优采云采集器使用教程内容发布相关的设置
优采云采集器使用教程-采集内容发布规则设置
教程总目录:优采云采集器Using tutorials
在讲如何查找网站、采集文章链接和内容之前,先说一下内容发布相关的设置。
因为我在教程中设置了发布规则,所以这里简单介绍一下各个项目。
如下图
第一步,我们点击这里的内容发布规则
第二步,点击网页发布规则列表后面的加号
第三步出现模块管理(教程的总目录写好了,我们的模块文件放在优采云program下的\Module\目录下),选择wordpress.post模块
第四步,网页编码选择UTF-8(wordpress程序是国外的,国际上一般是UTF8编码,国内有的会是GBK编码。比如Discuz论坛程序有两个安装包:UTF8和GBK。 )
第五步,在我们的网页地址填写网站地址并添加接口文件名。比如你的接口文件名是jiekou.php网站,那么填写这个地址
第六步选择不登录作为登录方式。我们的界面文件免登录。
第七步,点击以下获取列表。通常你会得到wordpress的文章分类列表。然后选择一个列表,你选择哪个列表,采集的文章就会被发送到哪个列表。
然后在下面随机写一个配置名称并保存。
然后我们勾选我们刚刚保存的发布配置并启用它。
那别忘了点击右下角的保存,或者点击保存退出!
如何自己定义网页样式?采集规则不难
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-08-25 06:07
其实写一个采集规则并不难。只要懂CSS语法,就不想去百度脑补了。一般你先采集list,然后通过list抓取详情页,每个list其实都有CSS规则控制样式。
我推荐一个网站来学习css选择器:
如果你了解选择器,你就会知道如何采集list 页面和详情页面。
当然,你也学会了如何自己定义网页样式。
以上是基础知识。下面我们解释采集工具给我们带来的便利。我是第一批使用采集的用户。当时还没有自动存储多重分类功能。
这个功能很容易使用。我想要采集一批资源,但是又不想存一个category,所以只需要输入我要存的categoryid,然后采集就会随机存入这些category里面。
当然,当你留空时填写类别id文本框,那么它只会存储在采集category下你选择的类别中。
另一个功能是分页:
估计有人直接输入页码,认为页面是采集。提示很清楚!
比如采集的分页是:和后面的第二个分页,你把“2”页码换成{#num},最后显示
记得用{#num}替换采集网址中的页码编号。
这样采集就不能分页数据了,否则会重复,然后你会问为什么没有采集把其他页面的数据翻过来。
最后一个功能是自动采集,用起来特别爽。
采集时间间隔的单位是毫秒,1秒=1000毫秒。
最好设置2小时自动采集一次,毕竟网站更新不是那么频繁。
auto采集很讲究,就是你上面填写的采集url地址的网页列表每天更新,也就是更新频繁的页面适合自动采集 ,你采集windows不要关掉,让它在设定的时间自动采集。
管理员添加:
规则文件的存放位置:static/caiji,存放在caiji文件夹中的txt文件规则。
这是360问答的采集规则,每行一个,有就写,没有就分开,因为这是最后的拆分。
最后到此就大功告成了,剩下的就是配置了,caiji文件夹下有个xml.php,打开:
你能看懂吗,名字和你的txt的键值对,注意‘,’是英文的!
然后下次刷新采集管理页面的网页时,您将能够看到新的采集规则。
好了,就说这么多,欢迎吐槽! 查看全部
如何自己定义网页样式?采集规则不难
其实写一个采集规则并不难。只要懂CSS语法,就不想去百度脑补了。一般你先采集list,然后通过list抓取详情页,每个list其实都有CSS规则控制样式。
我推荐一个网站来学习css选择器:
如果你了解选择器,你就会知道如何采集list 页面和详情页面。
当然,你也学会了如何自己定义网页样式。
以上是基础知识。下面我们解释采集工具给我们带来的便利。我是第一批使用采集的用户。当时还没有自动存储多重分类功能。
这个功能很容易使用。我想要采集一批资源,但是又不想存一个category,所以只需要输入我要存的categoryid,然后采集就会随机存入这些category里面。
当然,当你留空时填写类别id文本框,那么它只会存储在采集category下你选择的类别中。
另一个功能是分页:
估计有人直接输入页码,认为页面是采集。提示很清楚!
比如采集的分页是:和后面的第二个分页,你把“2”页码换成{#num},最后显示
记得用{#num}替换采集网址中的页码编号。
这样采集就不能分页数据了,否则会重复,然后你会问为什么没有采集把其他页面的数据翻过来。
最后一个功能是自动采集,用起来特别爽。
采集时间间隔的单位是毫秒,1秒=1000毫秒。
最好设置2小时自动采集一次,毕竟网站更新不是那么频繁。
auto采集很讲究,就是你上面填写的采集url地址的网页列表每天更新,也就是更新频繁的页面适合自动采集 ,你采集windows不要关掉,让它在设定的时间自动采集。
管理员添加:
规则文件的存放位置:static/caiji,存放在caiji文件夹中的txt文件规则。
这是360问答的采集规则,每行一个,有就写,没有就分开,因为这是最后的拆分。
最后到此就大功告成了,剩下的就是配置了,caiji文件夹下有个xml.php,打开:
你能看懂吗,名字和你的txt的键值对,注意‘,’是英文的!
然后下次刷新采集管理页面的网页时,您将能够看到新的采集规则。
好了,就说这么多,欢迎吐槽!
苹果cmsv10怎么添加文章资讯,手把手教你优采云采集文章图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-08-24 05:33
Applecmsv10如何添加文章资讯,教你优采云采集文章资讯图文教程。只要能安定下来,小白看完保证书就可以学习了。我花了几个小时认真写了一个教程,你不想花几分钟去阅读它,你注定什么也学不到。
一直想写几个教程给小白看书用优采云采集资讯明星视频,因为小白来问我这个问题的太多了,我说你去百度,反馈一下结果都一样,说没有详细的配置教程,发布老是提示失败。今天终于抽空给小白写了一个简单实用的采集教程。让我们来写这个教程如何采集文章信息。以后有时间我会更新视频和星星。本教程是关于如何使用已经有采集规则的教程。 采集法和优采云软件从文章末尾的链接下载。下载后,按照我写的教程,保证你学会优采云采集文章资讯,开始我们今天的采集教程。
教程分为两部分,一是发布模块的配置,二是采集规则的配置。发布模块和采集规则是两个不可或缺的组成部分。有朋友说采集总是发不出去,怎么回事?归根结底是因为这两个地方没有配置好。往下看
首先配置发布模块
1、打开优采云software文件夹,点击下图中的启动器图标
2.软件启动后,点击此“发布”,进入网页发布模块配置界面。
3、我发优采云给你说苹果v10的4个发布模块已经导入软件了。双击“Applecms-v10文章”模块进行编辑。下图有3个编辑位置
①、编码设置改为UTF-8
②、网站和地址用你的网站主域名替换“”
③、登录方式改为无需登录http请求
④,一切搞定后点击右下角的测试配置,首先要确定发布模块是否可以正常使用,如果采集规则不能正确使用,则不会发布。单击测试配置,进入测试配置页面。如下图
4、配置发布模块最关键的一步,也是很多人会犯错误甚至不理解的地方。我用箭头指向的地方就是我们要配置的地方。如下图
①、首先配置验证密码:验证密码是站外仓库系统连接Applecms系统后端的验证码。这个需要在系统后台勾选然后填写,找到验证码后,双击左边的“验证密码”复制粘贴到右边的编辑框中。系统后台的验证码如下图所示。找到后,将其复制并粘贴到我们的发布模块中。
②,我们来配置发布模块的“名称”。这里的模块名称其实就是文章的标题。我们可以选择任何名称。要了解这个地方,每个文章 都有一个标题。只能发布标题。我们在这里测试发布模块,因此您必须手动填写标题。如果是采集rule,这个地方就不需要填写了,采集rule会自动在采集网站的title上进行。我们以“第一层外套”这个名字为例。双击名称,填写右侧第一层,点击修改。
③,我们来配置一下“类别名称”和“类别编号”,这也是系统后台确定的,也就是从采集文章到网站你想要哪个类别名称和编号@,见下图
进入系统后台,点击basic>>>分类管理下拉(第二张图)我们可以看到信息的顶级分类和子分类三个。我们都发布了这三个类别的文章的类别。 ,可以用,我们只选择一个类别“标题”这个类别。这里的标题是我们的分类名,标题前的18是分类号。所以我们从中得到分类的名称和编号,直接填写发布模块的配置。
④ 全部填好后即完成最终测试,我们点击“发布文章测试”,下面是发布成功存储的相关提示。我们可以去网站前台看看有没有文章。
⑤我们来到网站的前台,点击导航栏中的分类,可以看到文章第一幅画的标题,也说明我们的文章发布模块成功了已配置。
5、由于文字长度的限制,我们将在下一篇文章中介绍文章采集规则的配置。看完后半部分的配置,相信你会用优采云来采集文章信息到你的网站。
优采云7.6 免费企业版下载:点击查看后半部分教程 查看全部
苹果cmsv10怎么添加文章资讯,手把手教你优采云采集文章图文教程
Applecmsv10如何添加文章资讯,教你优采云采集文章资讯图文教程。只要能安定下来,小白看完保证书就可以学习了。我花了几个小时认真写了一个教程,你不想花几分钟去阅读它,你注定什么也学不到。
一直想写几个教程给小白看书用优采云采集资讯明星视频,因为小白来问我这个问题的太多了,我说你去百度,反馈一下结果都一样,说没有详细的配置教程,发布老是提示失败。今天终于抽空给小白写了一个简单实用的采集教程。让我们来写这个教程如何采集文章信息。以后有时间我会更新视频和星星。本教程是关于如何使用已经有采集规则的教程。 采集法和优采云软件从文章末尾的链接下载。下载后,按照我写的教程,保证你学会优采云采集文章资讯,开始我们今天的采集教程。
教程分为两部分,一是发布模块的配置,二是采集规则的配置。发布模块和采集规则是两个不可或缺的组成部分。有朋友说采集总是发不出去,怎么回事?归根结底是因为这两个地方没有配置好。往下看
首先配置发布模块
1、打开优采云software文件夹,点击下图中的启动器图标
2.软件启动后,点击此“发布”,进入网页发布模块配置界面。
3、我发优采云给你说苹果v10的4个发布模块已经导入软件了。双击“Applecms-v10文章”模块进行编辑。下图有3个编辑位置
①、编码设置改为UTF-8
②、网站和地址用你的网站主域名替换“”
③、登录方式改为无需登录http请求
④,一切搞定后点击右下角的测试配置,首先要确定发布模块是否可以正常使用,如果采集规则不能正确使用,则不会发布。单击测试配置,进入测试配置页面。如下图
4、配置发布模块最关键的一步,也是很多人会犯错误甚至不理解的地方。我用箭头指向的地方就是我们要配置的地方。如下图
①、首先配置验证密码:验证密码是站外仓库系统连接Applecms系统后端的验证码。这个需要在系统后台勾选然后填写,找到验证码后,双击左边的“验证密码”复制粘贴到右边的编辑框中。系统后台的验证码如下图所示。找到后,将其复制并粘贴到我们的发布模块中。
②,我们来配置发布模块的“名称”。这里的模块名称其实就是文章的标题。我们可以选择任何名称。要了解这个地方,每个文章 都有一个标题。只能发布标题。我们在这里测试发布模块,因此您必须手动填写标题。如果是采集rule,这个地方就不需要填写了,采集rule会自动在采集网站的title上进行。我们以“第一层外套”这个名字为例。双击名称,填写右侧第一层,点击修改。
③,我们来配置一下“类别名称”和“类别编号”,这也是系统后台确定的,也就是从采集文章到网站你想要哪个类别名称和编号@,见下图
进入系统后台,点击basic>>>分类管理下拉(第二张图)我们可以看到信息的顶级分类和子分类三个。我们都发布了这三个类别的文章的类别。 ,可以用,我们只选择一个类别“标题”这个类别。这里的标题是我们的分类名,标题前的18是分类号。所以我们从中得到分类的名称和编号,直接填写发布模块的配置。
④ 全部填好后即完成最终测试,我们点击“发布文章测试”,下面是发布成功存储的相关提示。我们可以去网站前台看看有没有文章。
⑤我们来到网站的前台,点击导航栏中的分类,可以看到文章第一幅画的标题,也说明我们的文章发布模块成功了已配置。
5、由于文字长度的限制,我们将在下一篇文章中介绍文章采集规则的配置。看完后半部分的配置,相信你会用优采云来采集文章信息到你的网站。
优采云7.6 免费企业版下载:点击查看后半部分教程
2.修改规则中的cookie发布规则配置插件使用简易教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-24 03:12
2.根据网站版本选择对应的发布模块和接口,并进行配置
3.规则里有具体的视频教学
4.必须使用优采云v9.8内部版本(网上找)
5.使用简单教程:
首先确保你手头有三个或更多文件,比如Write.php(发布界面)xxxx.ljobx(采集法)xxx.wpm(发布模块)xxx.cs(采集插件)
1.选择对应版本优采云Import 采集rule 将模块发布到网站替换Write.php(发布界面)
优采云installation directory/Module 用于发布模块
优采云installation directory/Plugins 这是插件用的
网站installation directory/application/api/controller 这是发布界面
2.在规则插件配置中修改cookie发布规则配置一些关键标签替换值(不同的规则可能不需要更改)
cookies的作用是针对采集需要会员登录采集的东西
发布配置是编辑任务的第三步,添加发布配置,选择发布模块,填写自己的url。
插件配置部分规则使用plugin来辅助采集,所以需要在第四步选择对应的采集plugin
一些tag值,比如api key,单章价格,甚至镜像到本地后对应的新域名,都需要自己修改
3.完成以上,获取第一步页面的测试网址,点击任意内容页面进行测试采集
4. 测试版右下角也有测试版。配置好发布配置后,就可以测试了。这里的测试发布可以有效检查发布状态和错误。
资源下载 本资源仅供注册用户下载,请先登录 查看全部
2.修改规则中的cookie发布规则配置插件使用简易教程
2.根据网站版本选择对应的发布模块和接口,并进行配置
3.规则里有具体的视频教学
4.必须使用优采云v9.8内部版本(网上找)
5.使用简单教程:
首先确保你手头有三个或更多文件,比如Write.php(发布界面)xxxx.ljobx(采集法)xxx.wpm(发布模块)xxx.cs(采集插件)
1.选择对应版本优采云Import 采集rule 将模块发布到网站替换Write.php(发布界面)
优采云installation directory/Module 用于发布模块
优采云installation directory/Plugins 这是插件用的
网站installation directory/application/api/controller 这是发布界面
2.在规则插件配置中修改cookie发布规则配置一些关键标签替换值(不同的规则可能不需要更改)
cookies的作用是针对采集需要会员登录采集的东西
发布配置是编辑任务的第三步,添加发布配置,选择发布模块,填写自己的url。
插件配置部分规则使用plugin来辅助采集,所以需要在第四步选择对应的采集plugin
一些tag值,比如api key,单章价格,甚至镜像到本地后对应的新域名,都需要自己修改
3.完成以上,获取第一步页面的测试网址,点击任意内容页面进行测试采集
4. 测试版右下角也有测试版。配置好发布配置后,就可以测试了。这里的测试发布可以有效检查发布状态和错误。
资源下载 本资源仅供注册用户下载,请先登录
【岛】数据图示--逻辑方式数据设置页
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-08-20 23:18
一、数据分页设置页面介绍
1、Description
我们在显示文章内容的时候经常会遇到一些网站,内容被分成几页显示,我们需要翻页依次阅读所有内容,当我们采集这种类型的网站文章,需要使用数据分页;在ET中,我们可以选择采集分页两种分页方式之一,分别是'采集method'和'logical method',【数据分页-逻辑模式设置页面】见图1:
(图一:逻辑数据分页)
数据项从采集页面(即第一页)的源码中获取,使用数据项采集rule解析获取内容,然后数据项采集rule解析为单独使用,从每个页面的源代码中获取内容,将按顺序合并,并用【内容分离】标签“#-0-#”分隔;
注意:为了避免用户错误配置将采集分页陷入死循环,逻辑获取的页数上限为2000。
访问页面失败时,文章的采集不会中断。
注意:2.4 版本之前,分页只对文本数据项有效。从2.4 版本开始,每个数据项都可以从分页中获取内容。
2.4版本之前,将所有页面的源代码一一合并,然后使用数据项采集进行内容分析;从2.4 版本开始,每个页面的源代码都是单独获取的。使用数据项采集规则对获取的内容进行分析后,将获取的内容按顺序合并。因此,2.4版本之前使用正文分页功能的采集规则在升级到2.4版本后可能存在兼容性问题,需要进行调整。
二、开启逻辑模式
逻辑方法是指通过预设规则计算每个分页URL的方法。这种方法比采集方法简单,但使用范围稍微窄一些。只适用于分页网址按数律增减。情况;
使用逻辑方式获取分页,请勾选【使用逻辑方式】,见图:
数据分页作为某个采集页面的分页存在,采集页面是第一个分页。比如一个文章内容页显示为多个分页,一个产品的评论页显示为多个页面,所以需要设置数据页属于哪个采集页面,见图:
三、当前 URL 分解
1、Description
【当前URL分解】为必填项,用于从数据分页所属的采集页面的完整URL中提取出【页面地址】信息,用于形成如下逻辑的完整页面URL操作。见图3:
(icon3)
因为在大多数规则中,数据页所属的采集页是第一个采集页,所以【当前URL分解】的规则通常与;
注意:如果文章 URL 有重定向,则重定向后的完整 URL 应该用于 URL 分解;
点击
图标,可以测试[d当前URL分解];
2、tag 区域
【当前URL分解】有可用标记,见图3;
1、page 地址
标签代码用于指示用于区分当前 URL 与其他 URL 的唯一字符串。 [页面地址]标签在规则中只能使用一次;
有关标签的更多信息,请参阅相关主题;
3、参考示例
以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:
1、we 通过获取文章的完整网址如下:
2、在上面的示例 URL 中,字符串“348556”是该 URL 的唯一特征字符串。当然,我们选择像'tid=348556'这样的字符串是没有问题的。填写【当前网址分解】规则如下:
四、page 增量
1、Description
【Paging Increment】为必填项,此项用于计算在指定范围内有规律变化的每个分页URL的特征数编号,并与【分页URL合成】中的【分页地址】结合完整的页面 URL,见图 4:
(icon4)
开始号码和结束号码只能填写数字,位数要与真实列表网址一致,例如“01”不等于“1”;
如果起始编号大于结束编号,则[页增量]减少步长,如果起始编号小于结束编号,则[页增量]增加步长;
步长表示每次递增或递减的递增或递减量。不管是递增还是递减,步长都是正整数;
为了避免重复采集,起始编号一般不是'1'或'01'等数字,因为[body]数据项所属的采集页面,即第一页在执行体中分页采集已经是采集了,大多数网站的习惯就是把这个页面当成带有'1'和'01'等数字的页面;
结束编号通常设置为实际页数无法达到的较大数字,这样页增量会包括所有可能出现的有效编号,并判断该页是否实际上是最后一页,我们通过【有效分页特征码】;
2、参考示例
以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:
1、一个多页的帖子,每页的网址如下:
%3D1
%3D1&page=2
%3D1&page=3
%3D1&page=4
……
2、 删除不必要的参数,可以简化为:
……
3、 那么在上面的每一个网址中,经常变化且具有独特特征的数字很容易找到。它们是“2”、“3”、“4”等。这些数字相加1递增,所以我们得到步长1,我们设置一个更大的,通常没有达到的数字'100'作为结束数字,所以我们配置这个文本页面的[页面增量]如下:<//p
pimg src='http://www.zzcity.net/help/setup-cj-6-4.gif' alt=''//p
p4、注意,在上面的例子中,我们使用URL page=2的页面作为起始页码,所以起始编号设置为2。这是因为[body]数据项属于第一个页面,即【当前URL分解】中的“当前URL”,这个页面在采集分页符之前已经是采集了。/p
p五、Page URL 合成/p
p1、Description/p
p【Paging URL Synthesis】是必填项,这里使用【Page Address】和【Page Increment】合成一个完整的页面URL,见图5:/p
pimg src='http://www.zzcity.net/help/setup-cj-6-5.gif' alt=''//p
p(icon5)/p
p完整页面URL可以使用相对链接和相对于当前页面的完整链接,如:“../../page--.htm”、“page--.htm”、“-.htm”等;/p
p注意:文章地址为电脑本地文件路径时,页面URL必须是完整地址,不能使用相对地址;/p
p点击/p
pimg src='http://www.zzcity.net/help/icon-testtool.gif' alt=''//p
p图标,可以测试【分页网址合成】;/p
p2、tag 区域/p
p【Paging URL Synthesis】有2个可用标签,见图5;/p
p1、page 地址/p
p标签代码为必填项,用于表示每个页面URL中的固定特征字符串,与[当前URL分解]中的[页面地址]为同一个标签,用于引用其值;//p
p2、page 增量/p
p标记码是,是必填项,用于表示每个分页URL中定期变化的特征号编号,由本文第三节的逻辑规则计算得出;/p
p有关标记的更多说明,请参阅相关主题;/p
p3、参考示例/p
p以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:/p
p1、 我们在本文第二、三部分分别获得了【页面地址】和【页面增量】。根据这两个标签的表达,我们设置了【分页网址合成】的规则如下:/p
p&page=/p
p在上面的例子中,[Paging Address]替换了分页URL中的固定特征字符串'348556',[Paging Increment]替换了分页URL 4中经常变化的号码'2','3',' '等;/p
p六、功能码/p
p1、Description/p
p特征码由两部分组成,分别是【页面特征码】和【最后一页特征码】;/p
pimg src='http://www.zzcity.net/help/setup-cj-6-6.gif' alt=''//p
p(icon6)/p
p注:2.4版本之前,【页面特征码】为【有效页面特征码】,【末页特征码】为【非末页特征码】;从2.4开始,用户可以自行选择特征码类型。/p
p1、page 特征码/p
p[Pagination Feature Code]为必填项,内容为从网页源代码中选择的字符串,通过分页URL合成的网页是否有效通过网页源代码是否有效来判断收录字符串,见图6;/p
pEffective pages 勾选此项时,将网页源代码中收录特征码字符串的网页视为有效页面,以默认页面特征码作为有效页面特征码;/p
p无效页面 勾选此选项后,网页源代码中收录特征码字符串的网页将被视为无效页面;/p
p特征代码是一个字符串,只收录所有有效或无效页面的源代码。设置页面的特征码不需要考虑第一页,也就是采集页。/p
p一旦逻辑计算出的页面URL采集的页面源代码不收录[有效页面]类型[页面特征码],系统会认为上一个页面采集是最后一个有效页面当系统结束采集page;/p
p如果逻辑计算到达的页面URL采集的页面源代码收录[无效页面]类型[页面特征码],则系统认为上一个页面采集是最后一个有效页面,则系统结束采集pagination;相反,如果页面源代码不收录[无效页面]类型[分页码],则该页面被视为有效页面。/p
p2、结束页面特征码/p
p[Last Page Feature Code] 可选,内容为从网页源代码中选择的字符串。网页源码中收录判断页面URL合成的网页是否为最后一页的字符串。 pass和[分页特征码]用于确定文本分页的结束页,见图6;/p
pNon-Last Page 勾选该选项后,网页源代码中收录特征码字符串的网页被视为不是最后一页,默认最后一页特征码为非最后一页特征代码;/p
p这是最后一页。勾选此项时,将网页源代码中收录特征码字符串的网页视为最后一页;/p
p特征码是只收录在最后一页或所有非最后一页的源代码中的字符串。设置最后一页特征码不需要考虑第一页,即采集页所属。/p
p当[Last Page Feature Code]不为空时,第一个不收录[Non-Last Page]类型[Last Page Feature Code]的有效页面为最后一个有效页面,系统结束采集分页;/p
p第一个收录[为最后一页]类型[最后一页特征码]的有效页面作为最后一个有效页面,系统结束采集分页;/p
p2、参考示例一/p
p以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:/p
p1、 论坛帖子分为两种,一种是分页的,一种是不分页的;比较特殊的是当分页网址越界时(分页增量超过实际最后一页的数量),Discuz论坛不会提示越界,而是直接显示最后一页,如果没有页面,会显示第一页;/p
p2、 通过对比没有分页的帖子和有分页的帖子,可以看到位于中间的所有分页页面在页面导航中都有向前和向后的页面链接,'‹‹'和'››' ,并且最后一页没有后页链接'››'。我们找到了他们的源代码如下:/p
p‹‹/p
p››/p
p3、去掉改动的部分,选择特征码如下:/p
pclass="prev"‹‹/p
p>››
4、在没有分页的帖子中搜索,但是没有找到这两个特征码;在最后一页搜索,没有找到特征代码'class="next">››';在任意一个中间页面搜索,都有这两个特征码,所以分页特征码填写如下:
(icon6)
3、参考例子二
以采集某图片网站(见采集rule分页示例-逻辑上非主流图片)为例:
1、 这个网站文章分为有分页和无分页两种。当页面 URL 超出范围时,将显示“找不到页面”的错误消息。因此,我们只需要填写[Valid Pagination Feature Code]即可;
2、通过查看每个页面,我们发现了许多可以用作特征代码的字符串。我们选择其中之一并填写以下内容:
(icon7) 查看全部
【岛】数据图示--逻辑方式数据设置页
一、数据分页设置页面介绍
1、Description
我们在显示文章内容的时候经常会遇到一些网站,内容被分成几页显示,我们需要翻页依次阅读所有内容,当我们采集这种类型的网站文章,需要使用数据分页;在ET中,我们可以选择采集分页两种分页方式之一,分别是'采集method'和'logical method',【数据分页-逻辑模式设置页面】见图1:
(图一:逻辑数据分页)
数据项从采集页面(即第一页)的源码中获取,使用数据项采集rule解析获取内容,然后数据项采集rule解析为单独使用,从每个页面的源代码中获取内容,将按顺序合并,并用【内容分离】标签“#-0-#”分隔;
注意:为了避免用户错误配置将采集分页陷入死循环,逻辑获取的页数上限为2000。
访问页面失败时,文章的采集不会中断。
注意:2.4 版本之前,分页只对文本数据项有效。从2.4 版本开始,每个数据项都可以从分页中获取内容。
2.4版本之前,将所有页面的源代码一一合并,然后使用数据项采集进行内容分析;从2.4 版本开始,每个页面的源代码都是单独获取的。使用数据项采集规则对获取的内容进行分析后,将获取的内容按顺序合并。因此,2.4版本之前使用正文分页功能的采集规则在升级到2.4版本后可能存在兼容性问题,需要进行调整。
二、开启逻辑模式
逻辑方法是指通过预设规则计算每个分页URL的方法。这种方法比采集方法简单,但使用范围稍微窄一些。只适用于分页网址按数律增减。情况;
使用逻辑方式获取分页,请勾选【使用逻辑方式】,见图:
数据分页作为某个采集页面的分页存在,采集页面是第一个分页。比如一个文章内容页显示为多个分页,一个产品的评论页显示为多个页面,所以需要设置数据页属于哪个采集页面,见图:
三、当前 URL 分解
1、Description
【当前URL分解】为必填项,用于从数据分页所属的采集页面的完整URL中提取出【页面地址】信息,用于形成如下逻辑的完整页面URL操作。见图3:
(icon3)
因为在大多数规则中,数据页所属的采集页是第一个采集页,所以【当前URL分解】的规则通常与;
注意:如果文章 URL 有重定向,则重定向后的完整 URL 应该用于 URL 分解;
点击
图标,可以测试[d当前URL分解];
2、tag 区域
【当前URL分解】有可用标记,见图3;
1、page 地址
标签代码用于指示用于区分当前 URL 与其他 URL 的唯一字符串。 [页面地址]标签在规则中只能使用一次;
有关标签的更多信息,请参阅相关主题;
3、参考示例
以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:
1、we 通过获取文章的完整网址如下:
2、在上面的示例 URL 中,字符串“348556”是该 URL 的唯一特征字符串。当然,我们选择像'tid=348556'这样的字符串是没有问题的。填写【当前网址分解】规则如下:
四、page 增量
1、Description
【Paging Increment】为必填项,此项用于计算在指定范围内有规律变化的每个分页URL的特征数编号,并与【分页URL合成】中的【分页地址】结合完整的页面 URL,见图 4:
(icon4)
开始号码和结束号码只能填写数字,位数要与真实列表网址一致,例如“01”不等于“1”;
如果起始编号大于结束编号,则[页增量]减少步长,如果起始编号小于结束编号,则[页增量]增加步长;
步长表示每次递增或递减的递增或递减量。不管是递增还是递减,步长都是正整数;
为了避免重复采集,起始编号一般不是'1'或'01'等数字,因为[body]数据项所属的采集页面,即第一页在执行体中分页采集已经是采集了,大多数网站的习惯就是把这个页面当成带有'1'和'01'等数字的页面;
结束编号通常设置为实际页数无法达到的较大数字,这样页增量会包括所有可能出现的有效编号,并判断该页是否实际上是最后一页,我们通过【有效分页特征码】;
2、参考示例
以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:
1、一个多页的帖子,每页的网址如下:
%3D1
%3D1&page=2
%3D1&page=3
%3D1&page=4
……
2、 删除不必要的参数,可以简化为:
……
3、 那么在上面的每一个网址中,经常变化且具有独特特征的数字很容易找到。它们是“2”、“3”、“4”等。这些数字相加1递增,所以我们得到步长1,我们设置一个更大的,通常没有达到的数字'100'作为结束数字,所以我们配置这个文本页面的[页面增量]如下:<//p
pimg src='http://www.zzcity.net/help/setup-cj-6-4.gif' alt=''//p
p4、注意,在上面的例子中,我们使用URL page=2的页面作为起始页码,所以起始编号设置为2。这是因为[body]数据项属于第一个页面,即【当前URL分解】中的“当前URL”,这个页面在采集分页符之前已经是采集了。/p
p五、Page URL 合成/p
p1、Description/p
p【Paging URL Synthesis】是必填项,这里使用【Page Address】和【Page Increment】合成一个完整的页面URL,见图5:/p
pimg src='http://www.zzcity.net/help/setup-cj-6-5.gif' alt=''//p
p(icon5)/p
p完整页面URL可以使用相对链接和相对于当前页面的完整链接,如:“../../page--.htm”、“page--.htm”、“-.htm”等;/p
p注意:文章地址为电脑本地文件路径时,页面URL必须是完整地址,不能使用相对地址;/p
p点击/p
pimg src='http://www.zzcity.net/help/icon-testtool.gif' alt=''//p
p图标,可以测试【分页网址合成】;/p
p2、tag 区域/p
p【Paging URL Synthesis】有2个可用标签,见图5;/p
p1、page 地址/p
p标签代码为必填项,用于表示每个页面URL中的固定特征字符串,与[当前URL分解]中的[页面地址]为同一个标签,用于引用其值;//p
p2、page 增量/p
p标记码是,是必填项,用于表示每个分页URL中定期变化的特征号编号,由本文第三节的逻辑规则计算得出;/p
p有关标记的更多说明,请参阅相关主题;/p
p3、参考示例/p
p以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:/p
p1、 我们在本文第二、三部分分别获得了【页面地址】和【页面增量】。根据这两个标签的表达,我们设置了【分页网址合成】的规则如下:/p
p&page=/p
p在上面的例子中,[Paging Address]替换了分页URL中的固定特征字符串'348556',[Paging Increment]替换了分页URL 4中经常变化的号码'2','3',' '等;/p
p六、功能码/p
p1、Description/p
p特征码由两部分组成,分别是【页面特征码】和【最后一页特征码】;/p
pimg src='http://www.zzcity.net/help/setup-cj-6-6.gif' alt=''//p
p(icon6)/p
p注:2.4版本之前,【页面特征码】为【有效页面特征码】,【末页特征码】为【非末页特征码】;从2.4开始,用户可以自行选择特征码类型。/p
p1、page 特征码/p
p[Pagination Feature Code]为必填项,内容为从网页源代码中选择的字符串,通过分页URL合成的网页是否有效通过网页源代码是否有效来判断收录字符串,见图6;/p
pEffective pages 勾选此项时,将网页源代码中收录特征码字符串的网页视为有效页面,以默认页面特征码作为有效页面特征码;/p
p无效页面 勾选此选项后,网页源代码中收录特征码字符串的网页将被视为无效页面;/p
p特征代码是一个字符串,只收录所有有效或无效页面的源代码。设置页面的特征码不需要考虑第一页,也就是采集页。/p
p一旦逻辑计算出的页面URL采集的页面源代码不收录[有效页面]类型[页面特征码],系统会认为上一个页面采集是最后一个有效页面当系统结束采集page;/p
p如果逻辑计算到达的页面URL采集的页面源代码收录[无效页面]类型[页面特征码],则系统认为上一个页面采集是最后一个有效页面,则系统结束采集pagination;相反,如果页面源代码不收录[无效页面]类型[分页码],则该页面被视为有效页面。/p
p2、结束页面特征码/p
p[Last Page Feature Code] 可选,内容为从网页源代码中选择的字符串。网页源码中收录判断页面URL合成的网页是否为最后一页的字符串。 pass和[分页特征码]用于确定文本分页的结束页,见图6;/p
pNon-Last Page 勾选该选项后,网页源代码中收录特征码字符串的网页被视为不是最后一页,默认最后一页特征码为非最后一页特征代码;/p
p这是最后一页。勾选此项时,将网页源代码中收录特征码字符串的网页视为最后一页;/p
p特征码是只收录在最后一页或所有非最后一页的源代码中的字符串。设置最后一页特征码不需要考虑第一页,即采集页所属。/p
p当[Last Page Feature Code]不为空时,第一个不收录[Non-Last Page]类型[Last Page Feature Code]的有效页面为最后一个有效页面,系统结束采集分页;/p
p第一个收录[为最后一页]类型[最后一页特征码]的有效页面作为最后一个有效页面,系统结束采集分页;/p
p2、参考示例一/p
p以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:/p
p1、 论坛帖子分为两种,一种是分页的,一种是不分页的;比较特殊的是当分页网址越界时(分页增量超过实际最后一页的数量),Discuz论坛不会提示越界,而是直接显示最后一页,如果没有页面,会显示第一页;/p
p2、 通过对比没有分页的帖子和有分页的帖子,可以看到位于中间的所有分页页面在页面导航中都有向前和向后的页面链接,'‹‹'和'››' ,并且最后一页没有后页链接'››'。我们找到了他们的源代码如下:/p
p‹‹/p
p››/p
p3、去掉改动的部分,选择特征码如下:/p
pclass="prev"‹‹/p
p>››
4、在没有分页的帖子中搜索,但是没有找到这两个特征码;在最后一页搜索,没有找到特征代码'class="next">››';在任意一个中间页面搜索,都有这两个特征码,所以分页特征码填写如下:
(icon6)
3、参考例子二
以采集某图片网站(见采集rule分页示例-逻辑上非主流图片)为例:
1、 这个网站文章分为有分页和无分页两种。当页面 URL 超出范围时,将显示“找不到页面”的错误消息。因此,我们只需要填写[Valid Pagination Feature Code]即可;
2、通过查看每个页面,我们发现了许多可以用作特征代码的字符串。我们选择其中之一并填写以下内容:
(icon7)
企业不给资料,做什么数据都需要一个入口
采集交流 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-08-20 04:01
文章采集规则归推文系统所有,推文系统可以一键将访问过的链接收集到服务器,当访问数量达到一定量级,系统会判断是否需要人工删除链接,如果删除就读取访问链接的html内容。
流量采集的第一步就是要有一个采集地址,推文采集就好像微博采集一样,要输入微博的标题,不然别人怎么采集数据。只要你有想采集的博客的地址,就可以采集到了,推文采集就比较简单了,直接去找公众号生成采集链接,然后丢到要采集的链接上就行了,然后访问链接就能获取到要采集的链接了。
一般来说先要有一个采集链接,再去一些公众号采集地址获取访问链接即可,但现在很多新闻类网站没有数据接口,因为他们都是主动给广告商出推广方案的,在需要给企业网站出点或广告方案,就自己发布数据出来,所以企业不给资料,
做什么数据都需要一个入口,通常我的做法是这样:1,要做的数据:后台有一个服务器,打开“收取的链接”把要采集的文章的标题输进去,就采集到了2,数据质量不是最重要的,关键是之前对可能采集到的文章进行了网站分析,看到采到的文章确实有价值(不容易误点错点没准能发现一个新领域等等),再进行后续工作。总结的一句话:数据质量不是最重要的,关键是要有一个大的数据获取渠道,更重要的是自己能掌握一些技巧去提升有价值的数据。祝做好数据。 查看全部
企业不给资料,做什么数据都需要一个入口
文章采集规则归推文系统所有,推文系统可以一键将访问过的链接收集到服务器,当访问数量达到一定量级,系统会判断是否需要人工删除链接,如果删除就读取访问链接的html内容。
流量采集的第一步就是要有一个采集地址,推文采集就好像微博采集一样,要输入微博的标题,不然别人怎么采集数据。只要你有想采集的博客的地址,就可以采集到了,推文采集就比较简单了,直接去找公众号生成采集链接,然后丢到要采集的链接上就行了,然后访问链接就能获取到要采集的链接了。
一般来说先要有一个采集链接,再去一些公众号采集地址获取访问链接即可,但现在很多新闻类网站没有数据接口,因为他们都是主动给广告商出推广方案的,在需要给企业网站出点或广告方案,就自己发布数据出来,所以企业不给资料,
做什么数据都需要一个入口,通常我的做法是这样:1,要做的数据:后台有一个服务器,打开“收取的链接”把要采集的文章的标题输进去,就采集到了2,数据质量不是最重要的,关键是之前对可能采集到的文章进行了网站分析,看到采到的文章确实有价值(不容易误点错点没准能发现一个新领域等等),再进行后续工作。总结的一句话:数据质量不是最重要的,关键是要有一个大的数据获取渠道,更重要的是自己能掌握一些技巧去提升有价值的数据。祝做好数据。
99元的采集规则插件,半价续费一个元,只需半价!
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-08-19 21:29
详细介绍
功能概述:
这个采集rule插件可以采集最新的网上美图,每天至少10条内容,每条内容至少10张图片,也就是至少100张美图每天
所有美女图片不漏点,大部分图片有轻微水印。
前面说:
这样的采集rule插件消耗了我们大量的服务器资源和成本,所以插件需要每年更新。对于授权包2及以上的用户,安装本插件后,授权中的任何域名均可免费使用一年。之后,插件可以每年半价连续使用。
未购买授权用户或授权级别低于套餐2的用户需按原价单独购买续费。
授权用户只需以最高半价续订一个使用过的采集rule插件即可。所有用户在所有授权下都可以在网站下免费使用所有采集rule插件。比如每年只需要更新一个99元的采集普通插件,半价49.5元,所有网站可以继续使用所有99元及以下的采集普通插件- ins 一年免费。
美图类型举例如下:
采集如何使用规则:
安装后,在网站Background--采集管理--规则管理中,可以点击规则前面的采集按钮单独执行采集,也可以选择多个选项执行采集。
采集规则编辑方法:
安装后,在网站Background--采集管理--规则管理中,会看到1条采集规则。 采集规则的归属栏默认为你的网站id=1的栏,默认设置为将远程图片保存到你的服务器。所以请根据实际情况将采集规则归属栏设置为其他栏,方法:
网站Background--采集管理--规则管理--点击采集规则前面的“编辑”按钮--属于类别--选择您的类别--点击下一步保存当前页面的设置。
如果你不想在采集时将远程图片保存到你的服务器,方法:
网站Background--采集管理--规则管理--点击采集规则前面的“编辑”按钮--新闻设置--保存图片--取消勾选--点击下一步可以保存当前页面的设置。
设置默认固定作者姓名,方法:
网站后台--采集管理-规则管理--点击采集规则前面的“编辑”按钮--下一步--下一步--作者设置--填写固定即可字符。
采集之后的数据如何发布到网站?方法:
网站Background--采集管理--数据存储,这里可以选择全部要存储的内容或勾选要存储的部分内容,也可以删除全部内容或删除部分内容检查内容。
采集后,采集的部分内容会提示重复?因为:为了防止采集的重复浪费不必要的时间和资源,如果要更新采集有采集的数据,请到网站Background--采集管理--History,可以在此处删除历史记录,也可以选择性删除“成功记录”、“失败记录”和“无效记录”,并在浏览器内部页面顶部的标题栏中进行过滤。
常见问题:
安装的采集规则可以修改吗?
答案:无法修改“目标网页编码”和“远程列表 URL”。其他内容请注意修改,否则采集容易失败。
为什么采集,提示“服务器资源有限,无法直接浏览文章,请安装或升级采集plugin batch采集。”?
答案:1、“目标网页编码”和“远程列表网址”不能修改。修改其他内容请谨慎,否则采集很容易失败。 . 2、检查你登录的后台域名是否已经获取到采集rule插件的注册码。 3、请直接到采集,不要点击测试按钮,测试时会有这个提示。正常采集 没问题。 4、请使用您安装本插件时使用的域名登录后台采集。
如果图片没有保存到服务器,为什么会提示图片盗链?
因为图片保存在服务器中,所以会调用目标网站中的图片。目标网站设置图片防盗链功能时,会提示图片被盗链,无法显示。所以如果你的网站空间够大,比如3G以上,那就尽量把图片保存到服务器。
图片有水印吗?
大部分图片有轻微水印,图片清晰度高
这个插件的优点:
平台自动采集采集每日更新内容,所有内容自动排版,无需重新编辑。
天人系列管理系统所有系统均可使用,按钮样式自动匹配。
此插件不是自动采集插件,需要点击按钮触发批量采集。如果您实现了自动采集和自动发布的功能,请安装“auto采集plugin”
安装过程
注意:本文的安装方式只适用于离线安装,如果通过后台应用中心安装,不会那么麻烦,所以首选使用你的网站后台应用中心- -获取插件/获取模板一键安装
点击上方的立即下载按钮(如下图):
将文件保存到本地(如下图),(如果下载到百度云,则不需要使用以下方法安装,必须按照具体页面中的要求安装):
打开后台应用中心-上传安装:填写应用对应的官网ID
身份证是什么?这很简单。刚刚下载应用的页面有“App ID:”字样,后面的数字就是ID(如下图):
填写ID并上传应用(如下图)
然后继续上传本地文件(如下图):
<p>上传成功后,点击“立即安装”,稍等片刻,页面会变成黑色背景绿色字体的“天人系列管理系统项目自动部署工具”(如下图) 查看全部
99元的采集规则插件,半价续费一个元,只需半价!
详细介绍
功能概述:
这个采集rule插件可以采集最新的网上美图,每天至少10条内容,每条内容至少10张图片,也就是至少100张美图每天
所有美女图片不漏点,大部分图片有轻微水印。
前面说:
这样的采集rule插件消耗了我们大量的服务器资源和成本,所以插件需要每年更新。对于授权包2及以上的用户,安装本插件后,授权中的任何域名均可免费使用一年。之后,插件可以每年半价连续使用。
未购买授权用户或授权级别低于套餐2的用户需按原价单独购买续费。
授权用户只需以最高半价续订一个使用过的采集rule插件即可。所有用户在所有授权下都可以在网站下免费使用所有采集rule插件。比如每年只需要更新一个99元的采集普通插件,半价49.5元,所有网站可以继续使用所有99元及以下的采集普通插件- ins 一年免费。
美图类型举例如下:
采集如何使用规则:
安装后,在网站Background--采集管理--规则管理中,可以点击规则前面的采集按钮单独执行采集,也可以选择多个选项执行采集。
采集规则编辑方法:
安装后,在网站Background--采集管理--规则管理中,会看到1条采集规则。 采集规则的归属栏默认为你的网站id=1的栏,默认设置为将远程图片保存到你的服务器。所以请根据实际情况将采集规则归属栏设置为其他栏,方法:
网站Background--采集管理--规则管理--点击采集规则前面的“编辑”按钮--属于类别--选择您的类别--点击下一步保存当前页面的设置。
如果你不想在采集时将远程图片保存到你的服务器,方法:
网站Background--采集管理--规则管理--点击采集规则前面的“编辑”按钮--新闻设置--保存图片--取消勾选--点击下一步可以保存当前页面的设置。
设置默认固定作者姓名,方法:
网站后台--采集管理-规则管理--点击采集规则前面的“编辑”按钮--下一步--下一步--作者设置--填写固定即可字符。
采集之后的数据如何发布到网站?方法:
网站Background--采集管理--数据存储,这里可以选择全部要存储的内容或勾选要存储的部分内容,也可以删除全部内容或删除部分内容检查内容。
采集后,采集的部分内容会提示重复?因为:为了防止采集的重复浪费不必要的时间和资源,如果要更新采集有采集的数据,请到网站Background--采集管理--History,可以在此处删除历史记录,也可以选择性删除“成功记录”、“失败记录”和“无效记录”,并在浏览器内部页面顶部的标题栏中进行过滤。
常见问题:
安装的采集规则可以修改吗?
答案:无法修改“目标网页编码”和“远程列表 URL”。其他内容请注意修改,否则采集容易失败。
为什么采集,提示“服务器资源有限,无法直接浏览文章,请安装或升级采集plugin batch采集。”?
答案:1、“目标网页编码”和“远程列表网址”不能修改。修改其他内容请谨慎,否则采集很容易失败。 . 2、检查你登录的后台域名是否已经获取到采集rule插件的注册码。 3、请直接到采集,不要点击测试按钮,测试时会有这个提示。正常采集 没问题。 4、请使用您安装本插件时使用的域名登录后台采集。
如果图片没有保存到服务器,为什么会提示图片盗链?
因为图片保存在服务器中,所以会调用目标网站中的图片。目标网站设置图片防盗链功能时,会提示图片被盗链,无法显示。所以如果你的网站空间够大,比如3G以上,那就尽量把图片保存到服务器。
图片有水印吗?
大部分图片有轻微水印,图片清晰度高
这个插件的优点:
平台自动采集采集每日更新内容,所有内容自动排版,无需重新编辑。
天人系列管理系统所有系统均可使用,按钮样式自动匹配。
此插件不是自动采集插件,需要点击按钮触发批量采集。如果您实现了自动采集和自动发布的功能,请安装“auto采集plugin”
安装过程
注意:本文的安装方式只适用于离线安装,如果通过后台应用中心安装,不会那么麻烦,所以首选使用你的网站后台应用中心- -获取插件/获取模板一键安装
点击上方的立即下载按钮(如下图):
将文件保存到本地(如下图),(如果下载到百度云,则不需要使用以下方法安装,必须按照具体页面中的要求安装):
打开后台应用中心-上传安装:填写应用对应的官网ID
身份证是什么?这很简单。刚刚下载应用的页面有“App ID:”字样,后面的数字就是ID(如下图):
填写ID并上传应用(如下图)
然后继续上传本地文件(如下图):
<p>上传成功后,点击“立即安装”,稍等片刻,页面会变成黑色背景绿色字体的“天人系列管理系统项目自动部署工具”(如下图)
网站采集软文信息的统计规则及统计02
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-08-16 21:03
文章采集规则:每一个点击,都对应一个参数,参数名称,参数值,参数个数统计规则:文章-参数数量-参数个数,
1)通过v2ex上面的介绍,可以分析出该网站可能会采集图片的url,判断有多少个图片会采集,
2)观察发现,做好商品的标题等一些标签信息,对应匹配有多少个图片会采集,
3)1a3e79521f88f89074d32e02df2277a你的采集规则是:某个网站已经采集多少个图片以及这些图片用户的点击情况,然后加上50%,10%和50%。举例一个例子,大于50%用户对于某个商品有1000个点击,然后加上50%,然后减去10%和50%,再加上50%=1人点击,然后乘以50%,最后如果总数还是50%的话,即:1a3e79521f88f89074d32e02df2277a然后再加上50%=5%点击的话,就是5%,则pulse:5%,加上50%=1%,则pulse:1%假设这些采集出来的信息按照用户特征来进行匹配。例如用户特征:喜欢打游戏,所以采集了该网站游戏信息;喜欢电影,所以采集了该网站电影信息。
或者1a3e79521f88f89074d32e02df2277a喜欢物流和购物的,就采集物流信息喜欢写软文的,就采集软文信息要是有大量用户合并内容,则进行合并,例如:有10万个用户喜欢写软文,那么就50%用户喜欢写软文,
1)通过这个例子,可以看出,为了达到比较好的人工智能采集效果,我们可以提前分析出来多少用户点击了哪些参数,然后根据点击数目的比例,适当进行百分比的调整就可以了,例如10%用户点击了5个参数,那么我们可以把该比例乘以5%,
2)写程序最好用nginx等,目前来说性能都不错,而且提供rewrite。一般是直接写10%服务器响应1000次,然后根据实际结果调整比例。例如程序比例为1%,那么只有1000次机会达到最佳人工智能效果。
2)一些代码上的语句要自己去理解,不要照搬。
3)各种图片格式使用jquery.extend.img(),必须从url中传入。例如:c.extend('image/jpg',{'data-image':url,'max10,0,0',5})实际效果:一图胜千言,看一下pulse, 查看全部
网站采集软文信息的统计规则及统计02
文章采集规则:每一个点击,都对应一个参数,参数名称,参数值,参数个数统计规则:文章-参数数量-参数个数,
1)通过v2ex上面的介绍,可以分析出该网站可能会采集图片的url,判断有多少个图片会采集,
2)观察发现,做好商品的标题等一些标签信息,对应匹配有多少个图片会采集,
3)1a3e79521f88f89074d32e02df2277a你的采集规则是:某个网站已经采集多少个图片以及这些图片用户的点击情况,然后加上50%,10%和50%。举例一个例子,大于50%用户对于某个商品有1000个点击,然后加上50%,然后减去10%和50%,再加上50%=1人点击,然后乘以50%,最后如果总数还是50%的话,即:1a3e79521f88f89074d32e02df2277a然后再加上50%=5%点击的话,就是5%,则pulse:5%,加上50%=1%,则pulse:1%假设这些采集出来的信息按照用户特征来进行匹配。例如用户特征:喜欢打游戏,所以采集了该网站游戏信息;喜欢电影,所以采集了该网站电影信息。
或者1a3e79521f88f89074d32e02df2277a喜欢物流和购物的,就采集物流信息喜欢写软文的,就采集软文信息要是有大量用户合并内容,则进行合并,例如:有10万个用户喜欢写软文,那么就50%用户喜欢写软文,
1)通过这个例子,可以看出,为了达到比较好的人工智能采集效果,我们可以提前分析出来多少用户点击了哪些参数,然后根据点击数目的比例,适当进行百分比的调整就可以了,例如10%用户点击了5个参数,那么我们可以把该比例乘以5%,
2)写程序最好用nginx等,目前来说性能都不错,而且提供rewrite。一般是直接写10%服务器响应1000次,然后根据实际结果调整比例。例如程序比例为1%,那么只有1000次机会达到最佳人工智能效果。
2)一些代码上的语句要自己去理解,不要照搬。
3)各种图片格式使用jquery.extend.img(),必须从url中传入。例如:c.extend('image/jpg',{'data-image':url,'max10,0,0',5})实际效果:一图胜千言,看一下pulse,
前端http消息格式采集方式获取,post、get方式分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-08-15 01:03
文章采集规则:yii3.x前端http消息格式采集。post、get方式获取。本文不包含什么前端的效果,全部采集网址提供给大家http消息格式采集方式一:无采集规则的路由方式的规则判断,这种方式肯定采用的最多,网址去重,cookie关联,wget提权,去重等等方式。优势非常明显,只需要发送起点标记,不需要定期定向扫描,只需要发送指定关键字即可,如访问/(随便你),如www/id/username即可一次采集成功。
方式二:自己开发一个脚本采集规则。这种方式多用于内容量大的网站,不同的权限要有不同的操作方式,如只提交access.log(),submit()等方式。这种方式的技术难度相对较低,找下现成的开源的。方式三:模拟客户端与服务器交互采集方式,在已有http请求内容的情况下,如登录,注册,注销等交互动作后,采集该动作的相关的数据内容。
如登录时,如提交认证信息,登录后即可获取身份信息,头像,昵称等。如注销,如删除照片,删除昵称。其他如微信互联,官网跳转,支付等等基于同样的采集需求,在网上有很多公司已经提供了很多相关的脚本。具体脚本方法如下:访问,并进入以上元素,同时提交刚才起点内容中的验证码信息。找下这个网址所属的搜索引擎,用sitemesh代理为(sitetoken='')然后将带有scheme:post和scheme:get的scheme代理请求与请求头requestresponse代理请求进行比对。
具体操作如下:访问时,勾选‘access.log('')’选项‘content-type:application/json’选项打开参数表;访问时,如起点没有access.log('')选项时,提示此处有一个未知,继续向下访问,并用.表示,点击‘show’即可得到验证码内容。如果存在access.log('')选项,起点也没有提示该处已有未知,可在这里获取验证码内容,采集时用这一次起点采集的内容,访问地址为’(访问::8000/hqapoui/../../,点击http::8000/hqapoui/../进入)即可实现访问,如下图:但是采集起点后又得返回到主站点,也就是分别返回access.log(''),submit,refresh这几个选项中的某一个,要区分。
还有访问地址时要找到分页权限的参数表,返回参数中的每个url之间都有access.log('')这个选项。在已有的数据中,看一下哪些可以匹配?然后再用requestresponse代理再次进行遍历,直到发现有匹配的参数,即可请求成功。采集相关代码如下:执行的效果如下:网址获取结果:相关拓展:公众号【五营火】,了解更多互联网知识。 查看全部
前端http消息格式采集方式获取,post、get方式分享
文章采集规则:yii3.x前端http消息格式采集。post、get方式获取。本文不包含什么前端的效果,全部采集网址提供给大家http消息格式采集方式一:无采集规则的路由方式的规则判断,这种方式肯定采用的最多,网址去重,cookie关联,wget提权,去重等等方式。优势非常明显,只需要发送起点标记,不需要定期定向扫描,只需要发送指定关键字即可,如访问/(随便你),如www/id/username即可一次采集成功。
方式二:自己开发一个脚本采集规则。这种方式多用于内容量大的网站,不同的权限要有不同的操作方式,如只提交access.log(),submit()等方式。这种方式的技术难度相对较低,找下现成的开源的。方式三:模拟客户端与服务器交互采集方式,在已有http请求内容的情况下,如登录,注册,注销等交互动作后,采集该动作的相关的数据内容。
如登录时,如提交认证信息,登录后即可获取身份信息,头像,昵称等。如注销,如删除照片,删除昵称。其他如微信互联,官网跳转,支付等等基于同样的采集需求,在网上有很多公司已经提供了很多相关的脚本。具体脚本方法如下:访问,并进入以上元素,同时提交刚才起点内容中的验证码信息。找下这个网址所属的搜索引擎,用sitemesh代理为(sitetoken='')然后将带有scheme:post和scheme:get的scheme代理请求与请求头requestresponse代理请求进行比对。
具体操作如下:访问时,勾选‘access.log('')’选项‘content-type:application/json’选项打开参数表;访问时,如起点没有access.log('')选项时,提示此处有一个未知,继续向下访问,并用.表示,点击‘show’即可得到验证码内容。如果存在access.log('')选项,起点也没有提示该处已有未知,可在这里获取验证码内容,采集时用这一次起点采集的内容,访问地址为’(访问::8000/hqapoui/../../,点击http::8000/hqapoui/../进入)即可实现访问,如下图:但是采集起点后又得返回到主站点,也就是分别返回access.log(''),submit,refresh这几个选项中的某一个,要区分。
还有访问地址时要找到分页权限的参数表,返回参数中的每个url之间都有access.log('')这个选项。在已有的数据中,看一下哪些可以匹配?然后再用requestresponse代理再次进行遍历,直到发现有匹配的参数,即可请求成功。采集相关代码如下:执行的效果如下:网址获取结果:相关拓展:公众号【五营火】,了解更多互联网知识。
选取与组织表单的元素设计如何与表单交互介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-08-14 04:10
选取与组织表单的元素设计如何与表单交互介绍
当我第一次接触表单的时候,所有的目光都是在标签是否对齐,输入框的位置是否合理,提示是否足够友好。后面会更深入的研究,思考label的不同对齐方式的区别。 .
但是重点总是离不开表单本身的几个组件,以至于每次表单优化效果总是不尽人意,不知道问题出在哪里。
PS:水平有限,踩过很多前辈的肩膀。请绕道。
似乎说到制作表单,就是要安排一些不同类型的输入框,明确标明必填和非必填字段,并添加解释,说明哪些表单更复杂、更合适。
其实表单设计远不止这些。表格本身也是一个小产品。也需要有需求支撑,也需要嵌套,也需要考虑用户的心智模型;从表单的生成到页面上的表单如何呈现,再到使用表单时与表单的交互,每一步都需要大量的思考来制作表单。
其实做好表格并不难,但是如果把问题往错误的方向思考(产品思维失败),相关的设计知识不够全面,很容易不知道出处遇到问题时开始。
为了不让我凄凉的过去在大家身上重演,也为了总结我的学习心得,特地写了这篇文章;因为想写的比较全面一点,所以构思成一个小系列,一共三篇文章,希望对大家有所帮助!
这个系列文章,从表单的诞生(选择表单)到表单的死亡(提交结束),我将从三个方面给大家全面讲解如何设计出优秀的表单方面。
由于内容较多,本系列文章分为三篇文章来介绍以下三个方面:
如何与组织表单的表单选择和元素设计进行交互
本文介绍第一个方面:表格的选择和组织
一、表单选择与组织
表格的选择和组织是表格生成的第一个过程。任何表单都需要先选择显示的问题,然后将选择的问题合理呈现在页面上;我们将把这个过程分成两个小节来解释:表格的选择,表格的组织。
1.表单选择
表格的选择是指表格中应收录哪些问题。我们需要遵循的原则是:
最好不要采集非必要信息,即用户看到的问题越少越好。必须采集的信息,如果可以延迟,则延迟采集。平衡用户和产品的利益。
1)非必要信息最好不要采集,即用户看到的问题越少越好。
每个用户都必须填写表单,但每个用户都不想填写表单,因为填写表单不是用户的目的。用户填写表单的唯一原因是不填写表单就无法继续。
想象一下,你购物时需要填写收货地址,登录微信前需要注册一个账号,雅思报名时需要填写个人信息,但这些是你的吗?目标?
不,只是因为不填写收货地址没收到货,不注册就不能登录微信,也不能如果您不填写个人信息,则无法完成考试;因此,从需求的角度来看,填表不是用户的需求,而是产品的需求;事实上,填写表单的过程,尤其是长表单,阻碍了用户使用产品的流畅性,降低了用户体验。
所以,在表单的选择阶段,最重要的就是尽可能的简化表单,不问问题就不要问用户。例如:当你要求用户填写雅思报名表时,不需要要求用户填写家庭住址,除非你需要向用户发送纸质成绩单。
多余的问题不仅会增加用户的完成成本,而且往往会引起用户的警觉。
2)必须采集的信息,如果可以延迟采集就会延迟。
如果有些信息是产品需要的,但填表时不是必须的,可以考虑推迟,即:调整采集信息的时间,把原来繁重的填表任务拆分成几个简单的,随时可以执行的小任务;比如电商网站的收货地址在用户注册时不需要填写,但在用户购买商品时需要补充,就是一个很好的例子。
3) 平衡用户和产品的利益。
最后,在形式选择和组织阶段最难处理,但很重要的一点是必须平衡用户和产品的利益。填写表单时,用户需求和产品需求总是矛盾的。
用户希望尽可能少地填写表单,以便尽快进行。产品要采集(比如要把产品寄给用户,必须采集地址信息)或者更长远的战略考虑总是希望采集更多的用户信息,但是采集信息太多损害用户的利益。
没有硬性规定可以参考。只能根据不同的情况做不同的处理。您可以参考以下建议进行相应调整:
试图要求用户承担底线,两个更好的方法是选择真实用户进行可用性测试和数据嵌入。使用其他方法解决产品对用户信息采集的需求,比如大数据分析。采取适当的激励措施,鼓励用户提供更多的信息,如改进信息获取金币、参与抽奖等。好好学习这个由三部分组成的系列文章,用设计来降低用户填写表格的成本。 2.表单组织
表单的组织是指所选问题在页面上的呈现方式以及向用户呈现的方式。
我们需要遵循的原则是:
表单的命名与场景相匹配。考虑对长表格进行分组或分页。排版布局不会中断扫描视线。减少干扰。组织页面时考虑使用 Tab 键跳转。使用情感设计。
1)表单的命名与场景匹配。
表单名称用于告诉用户此次填写的主题。它可以让用户在表单开始时就对要填写的内容建立心理预期,也有助于在填写表单时理解表单的内容。
所以选择一个适合这个表单填写场景的表单名称是非常重要的。 “空头不对马头”的标题容易误导用户或增加用户的疑虑。
例如:
货运司机如果要接单,需要在接单前填写一份个人货运资质信息表。试想一下,点击“接受订单”后进入的页面最上方写着“填写个人信息”后面是“运费哪个更容易理解?
前者容易造成混乱(尤其是对新人而言)。为什么我收到订单时需要填写我的私人信息?会不会导致信息泄露?
相反,后者容易理解:我是做运输交易的,所以自然需要我的运输资质。
2)Long form 考虑分组或分页
当表格过多时,简单的堆叠排列方式让用户感到疲倦而放弃填写表格;这时候我们可以根据表单的类型对表单进行适当的分组,这样可以缓解用户的视觉压力。用户填写表格更容易、更舒适。
当所有表单都与同一主题相关时,使用分组是更好的选择,例如:姓名、身份证号码、性别、种族、政治地位、手机号码、QQ号码、电子邮件地址、家庭住址、雇主。
我们可以将“姓名、身份证号码、性别、种族、政治面貌”分成一组,分别命名为“身份信息”、“手机号码、QQ号码、邮箱地址、家庭住址、工作单位”。将组命名为“联系方式”;虽然分为两组,但都属于用户的基本个人信息,这种情况适合分组。
但如果需要填写的表格涉及不同的主题,可以考虑分页。
如姓名、身份证号码、性别、民族、政治地位、手机号码、QQ号码、邮箱地址、家庭住址、工作单位、驾照类型、货车型号、货龄、事故记录不正确等。
上述信息中,“姓名、身份证号码、性别、民族、政治面貌、手机号码、QQ号码、邮箱、家庭住址、工作单位”为个人基本信息; “驾照类型、货车型号、船龄”、“事故记录不正确”属于资质信息;我们可以将这两类信息拆分成两页展示,让用户逐步完成表格.
3)布局不中断扫描视线
扫描视线是指用户浏览表单时视线的流动。清晰、线性的视线流动有助于用户快速响应问题,用户的思维在不同形式之间切换所需的时间最少。
因此,在布局时,表单应尽可能安排在视线更清晰的流程中。对比下面两种布局方式,很明显右边的布局更容易阅读。
4)减少干扰
用户填写表单的过程是一个任务过程,界面风格越简洁明了,越能提高用户填写的效率。
很多时候为了提升界面的视觉效果,一些设计师喜欢使用一些复杂的样式或者图案或者动画,这对于其他页面的设计来说无疑是有利的;但这种想法不适用于填表页面。过多的视觉干扰很容易打断填表的想法,降低填表的效率。 甚至当用户因为不必要的干扰挡住了填表的想法时,用户也会产生反感而放弃填写表格。
但并不是不能在表单填写页面上使用复杂的样式或一些冷色调。毕竟,我们需要依靠这些来区分和组织形式的不同群体或主题;所以请确保您可以有效区分和组织页面。接下来,尽可能减少更复杂元素的出现。
5)组织页面时考虑Tab键跳转
在PC网页上,用户大多使用键盘与表单进行交互,这涉及到鼠标光标在不同输入框之间切换时常用的Tab键。这是很多人的操作习惯。我们必须注意。
Tab键的影响主要是视线的跳跃。当有两列内容时,当光标定位在第一列的最后一个表格时,切换Tab键后,光标会继续下移或切换到第二列,第一个表格呢?
如果没有好的页面引导,很容易混淆用户(可能用户以为自己切换到了同一列的下一个表单,而在输入时发现内容出现在第二列的第一个表单中)。
另外,当表单过长时,有可能是切换Tab键后,光标已经切换到页面底部的表单了。但是因为一屏不能显示,激活的表单隐藏在页面底部,会导致用户不知道光标去哪里的尴尬。
所以在设计的时候尽量让表格出现在主流分辨率显示器的同屏上。当光标切换到屏幕外的表单时,可以使用锚定位,自动将视线切换到对应的表单位置。
6)使用情感设计
情感化设计是指在页面中使用能够与人类情感产生共鸣的元素,从而增加填写表单的乐趣或减少用户面对大量表单时的焦虑。情感设计可以贯穿整个表单设计。每个阶段。
比如在给表格命名时,可以适当使用图片背景,营造出与表格主题相匹配的氛围;采集地理位置信息时,将“国家”替换为“您来自哪个国家?”
通过这种方式,生硬的表单填写被构建为用户和计算机之间的对话;在分页设计中,适当使用动态效果,增加页面切换时的趣味性等。
二、结语
至此,360°全方位表单设计指南的第一篇文章就结束了。感谢大家花时间阅读这篇文章,希望对大家有所帮助。
下一部分文章我会讲解表单设计的第二个方面:表单的元素设计——表单元素设计中表单设计的核心部分,也是大家付出的部分最关注的,也是学习效果。有兴趣的同学可以立即关注最容易看到的部分!
进阶提问:在情感化设计中,表单的标签名称用疑问句代替。不是增加了标签的复杂度,增加了读取成本吗?
作为一个自认为填了很多表格的“伪老司机”,我将自己的一些理解和体会分享给大家。希望我们作为产品人一起进步,一起成长! 查看全部
选取与组织表单的元素设计如何与表单交互介绍
当我第一次接触表单的时候,所有的目光都是在标签是否对齐,输入框的位置是否合理,提示是否足够友好。后面会更深入的研究,思考label的不同对齐方式的区别。 .
但是重点总是离不开表单本身的几个组件,以至于每次表单优化效果总是不尽人意,不知道问题出在哪里。
PS:水平有限,踩过很多前辈的肩膀。请绕道。
似乎说到制作表单,就是要安排一些不同类型的输入框,明确标明必填和非必填字段,并添加解释,说明哪些表单更复杂、更合适。
其实表单设计远不止这些。表格本身也是一个小产品。也需要有需求支撑,也需要嵌套,也需要考虑用户的心智模型;从表单的生成到页面上的表单如何呈现,再到使用表单时与表单的交互,每一步都需要大量的思考来制作表单。
其实做好表格并不难,但是如果把问题往错误的方向思考(产品思维失败),相关的设计知识不够全面,很容易不知道出处遇到问题时开始。
为了不让我凄凉的过去在大家身上重演,也为了总结我的学习心得,特地写了这篇文章;因为想写的比较全面一点,所以构思成一个小系列,一共三篇文章,希望对大家有所帮助!
这个系列文章,从表单的诞生(选择表单)到表单的死亡(提交结束),我将从三个方面给大家全面讲解如何设计出优秀的表单方面。
由于内容较多,本系列文章分为三篇文章来介绍以下三个方面:
如何与组织表单的表单选择和元素设计进行交互
本文介绍第一个方面:表格的选择和组织
一、表单选择与组织
表格的选择和组织是表格生成的第一个过程。任何表单都需要先选择显示的问题,然后将选择的问题合理呈现在页面上;我们将把这个过程分成两个小节来解释:表格的选择,表格的组织。
1.表单选择
表格的选择是指表格中应收录哪些问题。我们需要遵循的原则是:
最好不要采集非必要信息,即用户看到的问题越少越好。必须采集的信息,如果可以延迟,则延迟采集。平衡用户和产品的利益。
1)非必要信息最好不要采集,即用户看到的问题越少越好。
每个用户都必须填写表单,但每个用户都不想填写表单,因为填写表单不是用户的目的。用户填写表单的唯一原因是不填写表单就无法继续。
想象一下,你购物时需要填写收货地址,登录微信前需要注册一个账号,雅思报名时需要填写个人信息,但这些是你的吗?目标?
不,只是因为不填写收货地址没收到货,不注册就不能登录微信,也不能如果您不填写个人信息,则无法完成考试;因此,从需求的角度来看,填表不是用户的需求,而是产品的需求;事实上,填写表单的过程,尤其是长表单,阻碍了用户使用产品的流畅性,降低了用户体验。
所以,在表单的选择阶段,最重要的就是尽可能的简化表单,不问问题就不要问用户。例如:当你要求用户填写雅思报名表时,不需要要求用户填写家庭住址,除非你需要向用户发送纸质成绩单。
多余的问题不仅会增加用户的完成成本,而且往往会引起用户的警觉。
2)必须采集的信息,如果可以延迟采集就会延迟。
如果有些信息是产品需要的,但填表时不是必须的,可以考虑推迟,即:调整采集信息的时间,把原来繁重的填表任务拆分成几个简单的,随时可以执行的小任务;比如电商网站的收货地址在用户注册时不需要填写,但在用户购买商品时需要补充,就是一个很好的例子。
3) 平衡用户和产品的利益。
最后,在形式选择和组织阶段最难处理,但很重要的一点是必须平衡用户和产品的利益。填写表单时,用户需求和产品需求总是矛盾的。
用户希望尽可能少地填写表单,以便尽快进行。产品要采集(比如要把产品寄给用户,必须采集地址信息)或者更长远的战略考虑总是希望采集更多的用户信息,但是采集信息太多损害用户的利益。
没有硬性规定可以参考。只能根据不同的情况做不同的处理。您可以参考以下建议进行相应调整:
试图要求用户承担底线,两个更好的方法是选择真实用户进行可用性测试和数据嵌入。使用其他方法解决产品对用户信息采集的需求,比如大数据分析。采取适当的激励措施,鼓励用户提供更多的信息,如改进信息获取金币、参与抽奖等。好好学习这个由三部分组成的系列文章,用设计来降低用户填写表格的成本。 2.表单组织
表单的组织是指所选问题在页面上的呈现方式以及向用户呈现的方式。
我们需要遵循的原则是:
表单的命名与场景相匹配。考虑对长表格进行分组或分页。排版布局不会中断扫描视线。减少干扰。组织页面时考虑使用 Tab 键跳转。使用情感设计。
1)表单的命名与场景匹配。
表单名称用于告诉用户此次填写的主题。它可以让用户在表单开始时就对要填写的内容建立心理预期,也有助于在填写表单时理解表单的内容。
所以选择一个适合这个表单填写场景的表单名称是非常重要的。 “空头不对马头”的标题容易误导用户或增加用户的疑虑。
例如:
货运司机如果要接单,需要在接单前填写一份个人货运资质信息表。试想一下,点击“接受订单”后进入的页面最上方写着“填写个人信息”后面是“运费哪个更容易理解?
前者容易造成混乱(尤其是对新人而言)。为什么我收到订单时需要填写我的私人信息?会不会导致信息泄露?
相反,后者容易理解:我是做运输交易的,所以自然需要我的运输资质。
2)Long form 考虑分组或分页
当表格过多时,简单的堆叠排列方式让用户感到疲倦而放弃填写表格;这时候我们可以根据表单的类型对表单进行适当的分组,这样可以缓解用户的视觉压力。用户填写表格更容易、更舒适。
当所有表单都与同一主题相关时,使用分组是更好的选择,例如:姓名、身份证号码、性别、种族、政治地位、手机号码、QQ号码、电子邮件地址、家庭住址、雇主。
我们可以将“姓名、身份证号码、性别、种族、政治面貌”分成一组,分别命名为“身份信息”、“手机号码、QQ号码、邮箱地址、家庭住址、工作单位”。将组命名为“联系方式”;虽然分为两组,但都属于用户的基本个人信息,这种情况适合分组。
但如果需要填写的表格涉及不同的主题,可以考虑分页。
如姓名、身份证号码、性别、民族、政治地位、手机号码、QQ号码、邮箱地址、家庭住址、工作单位、驾照类型、货车型号、货龄、事故记录不正确等。
上述信息中,“姓名、身份证号码、性别、民族、政治面貌、手机号码、QQ号码、邮箱、家庭住址、工作单位”为个人基本信息; “驾照类型、货车型号、船龄”、“事故记录不正确”属于资质信息;我们可以将这两类信息拆分成两页展示,让用户逐步完成表格.
3)布局不中断扫描视线
扫描视线是指用户浏览表单时视线的流动。清晰、线性的视线流动有助于用户快速响应问题,用户的思维在不同形式之间切换所需的时间最少。
因此,在布局时,表单应尽可能安排在视线更清晰的流程中。对比下面两种布局方式,很明显右边的布局更容易阅读。
4)减少干扰
用户填写表单的过程是一个任务过程,界面风格越简洁明了,越能提高用户填写的效率。
很多时候为了提升界面的视觉效果,一些设计师喜欢使用一些复杂的样式或者图案或者动画,这对于其他页面的设计来说无疑是有利的;但这种想法不适用于填表页面。过多的视觉干扰很容易打断填表的想法,降低填表的效率。 甚至当用户因为不必要的干扰挡住了填表的想法时,用户也会产生反感而放弃填写表格。
但并不是不能在表单填写页面上使用复杂的样式或一些冷色调。毕竟,我们需要依靠这些来区分和组织形式的不同群体或主题;所以请确保您可以有效区分和组织页面。接下来,尽可能减少更复杂元素的出现。
5)组织页面时考虑Tab键跳转
在PC网页上,用户大多使用键盘与表单进行交互,这涉及到鼠标光标在不同输入框之间切换时常用的Tab键。这是很多人的操作习惯。我们必须注意。
Tab键的影响主要是视线的跳跃。当有两列内容时,当光标定位在第一列的最后一个表格时,切换Tab键后,光标会继续下移或切换到第二列,第一个表格呢?
如果没有好的页面引导,很容易混淆用户(可能用户以为自己切换到了同一列的下一个表单,而在输入时发现内容出现在第二列的第一个表单中)。
另外,当表单过长时,有可能是切换Tab键后,光标已经切换到页面底部的表单了。但是因为一屏不能显示,激活的表单隐藏在页面底部,会导致用户不知道光标去哪里的尴尬。
所以在设计的时候尽量让表格出现在主流分辨率显示器的同屏上。当光标切换到屏幕外的表单时,可以使用锚定位,自动将视线切换到对应的表单位置。
6)使用情感设计
情感化设计是指在页面中使用能够与人类情感产生共鸣的元素,从而增加填写表单的乐趣或减少用户面对大量表单时的焦虑。情感设计可以贯穿整个表单设计。每个阶段。
比如在给表格命名时,可以适当使用图片背景,营造出与表格主题相匹配的氛围;采集地理位置信息时,将“国家”替换为“您来自哪个国家?”
通过这种方式,生硬的表单填写被构建为用户和计算机之间的对话;在分页设计中,适当使用动态效果,增加页面切换时的趣味性等。
二、结语
至此,360°全方位表单设计指南的第一篇文章就结束了。感谢大家花时间阅读这篇文章,希望对大家有所帮助。
下一部分文章我会讲解表单设计的第二个方面:表单的元素设计——表单元素设计中表单设计的核心部分,也是大家付出的部分最关注的,也是学习效果。有兴趣的同学可以立即关注最容易看到的部分!
进阶提问:在情感化设计中,表单的标签名称用疑问句代替。不是增加了标签的复杂度,增加了读取成本吗?
作为一个自认为填了很多表格的“伪老司机”,我将自己的一些理解和体会分享给大家。希望我们作为产品人一起进步,一起成长!

