
文章采集规则
文章来源里会的匹配规则的匹配
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-08-13 23:03
很多朋友在采集的时候都会遇到这个问题,文章的一些网站源会出现两个或多个媒体源,所以不太容易写出文章源的匹配规则,而且很多源链接,增加了编写匹配规则的难度。在这种情况下,我们需要为所有采集文章指定一个固定的文章source,具体方法如下:采集规则写好后,点击“更改配置”,即可在字段配置中找到此代码:{dede:item field='source' value='' isunit='' isdown=''}{ dede:match}{/dede:match}{dede:trim}]*)> {/dede:trim}{dede:trim}{/dede:trim}{dede:function}{/dede:function}{/dede :item}这里我们可以给source的值附加一个值,比如“织梦论坛”,修改后的代码如下:{dede:item field='source' value='织梦论坛' isunit='' isdown=''}{dede:match}{/dede:match}{ dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:function}{/dede :function}{/dede:item} 通过这个修改,所有的源码采集联系的文章可以固定为“织梦论坛”。但是有些朋友有一些特殊的要求。他们需要添加指向此来源的链接。这很简单。把value的值改成织梦论坛就行了。但是默认情况下不会显示文章内容页的文章源,因为数据库中限制了源的长度,只需进入数据库找到表dede_archives并修改源的长度即可。 采集数据导入完成后,找到采集-Bulk Maintenance-Auto Summary/pagination,然后【开始执行】就可以自动采集文章summary,最后更新HTML就OK了 查看全部
文章来源里会的匹配规则的匹配
很多朋友在采集的时候都会遇到这个问题,文章的一些网站源会出现两个或多个媒体源,所以不太容易写出文章源的匹配规则,而且很多源链接,增加了编写匹配规则的难度。在这种情况下,我们需要为所有采集文章指定一个固定的文章source,具体方法如下:采集规则写好后,点击“更改配置”,即可在字段配置中找到此代码:{dede:item field='source' value='' isunit='' isdown=''}{ dede:match}{/dede:match}{dede:trim}]*)> {/dede:trim}{dede:trim}{/dede:trim}{dede:function}{/dede:function}{/dede :item}这里我们可以给source的值附加一个值,比如“织梦论坛”,修改后的代码如下:{dede:item field='source' value='织梦论坛' isunit='' isdown=''}{dede:match}{/dede:match}{ dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:function}{/dede :function}{/dede:item} 通过这个修改,所有的源码采集联系的文章可以固定为“织梦论坛”。但是有些朋友有一些特殊的要求。他们需要添加指向此来源的链接。这很简单。把value的值改成织梦论坛就行了。但是默认情况下不会显示文章内容页的文章源,因为数据库中限制了源的长度,只需进入数据库找到表dede_archives并修改源的长度即可。 采集数据导入完成后,找到采集-Bulk Maintenance-Auto Summary/pagination,然后【开始执行】就可以自动采集文章summary,最后更新HTML就OK了
大数据信息资料采集知识星球:数据采集满足多种业务场景
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-08-12 06:08
大数据信息资料采集知识星球:数据采集满足多种业务场景
大数据资料采集:编程专业开发者社区文章信息优采云采集法
-------------
Data采集满足多种业务场景:适用于产品、运营、销售、数据分析、政府机关、电子商务从业者、学术研究等职业。
舆情监控:全方位监控舆情,第一时间掌握舆情动向。
市场分析:获取真实的用户行为数据,全面把握客户的真实需求。
产品研发:大力支持用户研究,准确获取用户反馈和偏好。
风险预测:高效信息采集和数据清洗,及时应对系统风险。
帮助您在数据中快速找到新客户;查看竞争对手的业务数据,分析客户行为以拓展新业务,并通过精准营销降低风险和预算。
为大量消费者提供产品或服务的企业可以利用大数据进行精准营销;
拥有小而美模式的中小微企业,可以利用大数据进行服务转型;
在互联网压力下必须转型的传统企业需要与时俱进,充分利用大数据的价值。
------------
全网统一自媒体号:大数据信息资料采集
知识星球:大数据信息材料采集
网站:搜索骑士
欢迎关注。
--------
以下文字可以忽略
代码组合
作为软件的特殊部分,源代码可能收录在一个或多个文件中。程序不需要以与源代码相同的格式编写。例如,如果一个程序有C语言库的支持,那么就可以用C语言编写;而另一部分可以用汇编语言编写,以达到更高的运行效率。
更复杂的软件一般需要几十甚至几百个源代码的参与。为了降低这种复杂性,有必要引入一个系统来描述各种源代码之间的联系以及如何正确编译它们。在此背景下,修订控制系统(RCS)应运而生,并成为开发人员修订代码的必备工具之一。
还有一种组合:源代码编写和编译是在不同平台上实现的,技术术语是软件迁移。 查看全部
大数据信息资料采集知识星球:数据采集满足多种业务场景

大数据资料采集:编程专业开发者社区文章信息优采云采集法
-------------
Data采集满足多种业务场景:适用于产品、运营、销售、数据分析、政府机关、电子商务从业者、学术研究等职业。
舆情监控:全方位监控舆情,第一时间掌握舆情动向。
市场分析:获取真实的用户行为数据,全面把握客户的真实需求。
产品研发:大力支持用户研究,准确获取用户反馈和偏好。
风险预测:高效信息采集和数据清洗,及时应对系统风险。
帮助您在数据中快速找到新客户;查看竞争对手的业务数据,分析客户行为以拓展新业务,并通过精准营销降低风险和预算。
为大量消费者提供产品或服务的企业可以利用大数据进行精准营销;
拥有小而美模式的中小微企业,可以利用大数据进行服务转型;
在互联网压力下必须转型的传统企业需要与时俱进,充分利用大数据的价值。
------------
全网统一自媒体号:大数据信息资料采集
知识星球:大数据信息材料采集
网站:搜索骑士
欢迎关注。
--------
以下文字可以忽略
代码组合
作为软件的特殊部分,源代码可能收录在一个或多个文件中。程序不需要以与源代码相同的格式编写。例如,如果一个程序有C语言库的支持,那么就可以用C语言编写;而另一部分可以用汇编语言编写,以达到更高的运行效率。
更复杂的软件一般需要几十甚至几百个源代码的参与。为了降低这种复杂性,有必要引入一个系统来描述各种源代码之间的联系以及如何正确编译它们。在此背景下,修订控制系统(RCS)应运而生,并成为开发人员修订代码的必备工具之一。
还有一种组合:源代码编写和编译是在不同平台上实现的,技术术语是软件迁移。
一个关于采集文章列表的教程采集设置的规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-08-11 02:04
大家好,今天我们来聊一聊采集文章list 的教程。今天的目标是网易的互联网新闻榜。地址是:
好的,我们来看看采集设置的规则和步骤。首先点击“内容”、“内容管理”、“一键管理工具”,在右侧的操作窗口中点击“新建项目”,输入采集的项目名称和属于采集的列文章后如下:
点击下一步进入集合列表的采集规则,我们要采集的列表首页,即列表索引页,如下图:
列表索引页:
浏览这个网址,查看源文件,找到这个文章列表的开始和结束标签,如下:
列出开始标签://TechNews.getNews(icid, TechNews.date, TechNews.pagex);
列表结束标记:
列表索引分页:无设置
点击下一步进入设置链接的标签,如下:
链接开始标签:"url":"
链接结束标记:“
这样设置后就可以看到了
列表拦截测试
这里就可以看到列表页的效果了,(点击一篇文章文章即可进入)点击下一步继续设置内容页的规则。
开始短标题标签:
短标题结束标签:
文章Content 起始标签:
文章内容标签结束:
时间设置可以省略。如果想要采集其他站点的时间,选择设置选项卡,然后查看源码如下:
时间开始标记: 查看全部
一个关于采集文章列表的教程采集设置的规则
大家好,今天我们来聊一聊采集文章list 的教程。今天的目标是网易的互联网新闻榜。地址是:
好的,我们来看看采集设置的规则和步骤。首先点击“内容”、“内容管理”、“一键管理工具”,在右侧的操作窗口中点击“新建项目”,输入采集的项目名称和属于采集的列文章后如下:
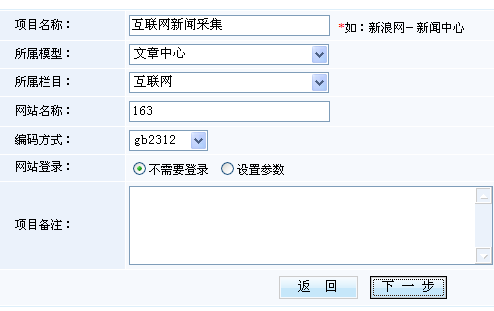
点击下一步进入集合列表的采集规则,我们要采集的列表首页,即列表索引页,如下图:
列表索引页:
浏览这个网址,查看源文件,找到这个文章列表的开始和结束标签,如下:
列出开始标签://TechNews.getNews(icid, TechNews.date, TechNews.pagex);
列表结束标记:
列表索引分页:无设置
点击下一步进入设置链接的标签,如下:
链接开始标签:"url":"
链接结束标记:“
这样设置后就可以看到了
列表拦截测试
这里就可以看到列表页的效果了,(点击一篇文章文章即可进入)点击下一步继续设置内容页的规则。
开始短标题标签:
短标题结束标签:
文章Content 起始标签:
文章内容标签结束:
时间设置可以省略。如果想要采集其他站点的时间,选择设置选项卡,然后查看源码如下:
时间开始标记:
用考拉,一天产出几万篇高质量SEO文章怎么编写?
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-11 02:01
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
这两天大家都非常关注“优采云采集器采集如何写规则”的内容。质疑编辑的客户是那么的特别。不过在我说这些信息之前,大家应该先来这里探讨一下搜索优化原创文章怎么做的!对于引流思维的SEOer来说,文章的质量绝不是中心追求,做网站的最关心的是网站权重和流量。 1个高质量的网页文章写在低权重网站和写在旧网站上,最终排名和引流效果不同!
想了解【优采云采集器采集怎么写规则】的小伙伴,其实大家都很珍惜的就是文章过去讲的内容。本来,流量大的网站文章写起来很容易,但是一个SEO文案能产生的流量实在是微乎其微。希望用文章来设置推广流量的目的。最重要的是量化!没有人文章 可以获得 1 次访问(1 天)。如果你能产出 10000 篇文章,你的每日流量将增加 10000。然而,谈论起来很简单。实际写作的时候,一个人一天只能产出30多篇文章,最厉害的也只有70篇。就算应用到伪原创系统,100多篇文章也会死!看到这里,我们先抛开“优采云采集器采集怎么写规则”这件事,想想如何实现AI代文章!
优化器认为的人工编辑器是什么? 文章原创不仅仅是一段原创的输出!在各个平台的平台词典中,原创并不代表帖子中没有重复的句子。其实只要你的文章不重复其他网页的内容,被爬取的几率就会大大增加。一个优秀的内容,干货足够抢眼,坚持同一个核心思想,只需要保证没有重复的大段,就说明这个文章还是很有可能被认出来的,甚至成为排水的好文章。比如这篇文章,你可以用标题搜索搜索【优采云采集器采集怎么写规则】,然后点击进入。其实这篇文章文章是用考拉SEO工具自动写的文章工具快速导出啦!
这个系统的伪原创系统应该叫手工写文章software。可长时间编辑数以万计的长尾优化文案。如果你的网页质量足够强,收录rate 可以高达77%。详细的申请步骤,用户首页有动画展示和新手引导,大家可以简单测试几下!很内疚,没有给大家带来关于“优采云采集器采集如何写规则”的详细解释,大概让大家看到了这样的系统语言。但是如果我们有智能书写文章内容的需求,我们不妨看看导航栏,让你的seo每天达到数百页浏览量。不是坏事吗? 查看全部
用考拉,一天产出几万篇高质量SEO文章怎么编写?
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
这两天大家都非常关注“优采云采集器采集如何写规则”的内容。质疑编辑的客户是那么的特别。不过在我说这些信息之前,大家应该先来这里探讨一下搜索优化原创文章怎么做的!对于引流思维的SEOer来说,文章的质量绝不是中心追求,做网站的最关心的是网站权重和流量。 1个高质量的网页文章写在低权重网站和写在旧网站上,最终排名和引流效果不同!

想了解【优采云采集器采集怎么写规则】的小伙伴,其实大家都很珍惜的就是文章过去讲的内容。本来,流量大的网站文章写起来很容易,但是一个SEO文案能产生的流量实在是微乎其微。希望用文章来设置推广流量的目的。最重要的是量化!没有人文章 可以获得 1 次访问(1 天)。如果你能产出 10000 篇文章,你的每日流量将增加 10000。然而,谈论起来很简单。实际写作的时候,一个人一天只能产出30多篇文章,最厉害的也只有70篇。就算应用到伪原创系统,100多篇文章也会死!看到这里,我们先抛开“优采云采集器采集怎么写规则”这件事,想想如何实现AI代文章!
优化器认为的人工编辑器是什么? 文章原创不仅仅是一段原创的输出!在各个平台的平台词典中,原创并不代表帖子中没有重复的句子。其实只要你的文章不重复其他网页的内容,被爬取的几率就会大大增加。一个优秀的内容,干货足够抢眼,坚持同一个核心思想,只需要保证没有重复的大段,就说明这个文章还是很有可能被认出来的,甚至成为排水的好文章。比如这篇文章,你可以用标题搜索搜索【优采云采集器采集怎么写规则】,然后点击进入。其实这篇文章文章是用考拉SEO工具自动写的文章工具快速导出啦!

这个系统的伪原创系统应该叫手工写文章software。可长时间编辑数以万计的长尾优化文案。如果你的网页质量足够强,收录rate 可以高达77%。详细的申请步骤,用户首页有动画展示和新手引导,大家可以简单测试几下!很内疚,没有给大家带来关于“优采云采集器采集如何写规则”的详细解释,大概让大家看到了这样的系统语言。但是如果我们有智能书写文章内容的需求,我们不妨看看导航栏,让你的seo每天达到数百页浏览量。不是坏事吗?
织梦模板引擎制作规范系统的模板代码参考标记
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-08-08 05:17
分析引擎概述模板设计规范代码参考
标签参考:arclist(artlist,likeart,hotart,imglist,imginfolist,coolart,specart) field channel mytag投票friendlink mynews loop channelartlist page list pagelist pagebreak fieldlist
一、织梦Template 解析引擎概述 在了解Dedecms的模板代码之前,了解织梦template引擎的知识是非常有意义的。 织梦template 引擎是一个使用 XML 命名空间形式的模板解析器。使用织梦parser 解析模板的最大好处是可以方便的指定标签的属性。感觉就像你在使用HTML,使模板代码非常直观和灵活。新版织梦template 引擎不仅可以分析模板,还可以分析模板中的错误标记。
1、织梦模板引擎的代码风格有以下几种形式:
自定义样式模板(InnerText)
提醒:
对于这种形式的标签,在2.1版本中,只需要用“”来表示结束,但是
在V3中,需要严格使用"",否则会报错。
2、织梦模板引擎内置了多个系统标签,这些系统标签在任何情况下都可以直接使用。
(1)全局标记的意思是获取一个外部变量,除了数据库密码,系统的任何配置参数都可以调用,形式:
或
变量名不能加$符号,如变量$cfg_cmspath,应该写成。
(2)foreach 用于输出一个数组,形式为:
[field:key/] [field:value/]
(3)include 收录一个格式的文件:
文件搜索路径依次为:绝对路径、include文件夹、cms安装目录、cmsmain模板目录
3、织梦标签允许使用任何标签中的函数来处理获得的值,形式为:
@me 用于表示当前标签的值,其他参数由你的函数决定,例如:
二、Dedecms模板制作规范
Dedecms系统的模板不是固定的。用户可以在创建新列时选择列模板。官方只提供了最基本的默认模板,即内置系统模型的各个模板。 Dedecms 支持 self 定义通道模型。用户自定义新的渠道模型后,需要根据模型设计一套新的模板。
一、Concept,要设计和使用模板,必须了解以下概念:
1、plate(封面)模板:
指网站首页或者更重要栏目的封面使用的模板,一般以“index_identification ID.htm”命名,此外还有用户定义的单页或者自定义标记,以及是否支持板块模板也是可选的 如果支持,系统会在输出内容或生成特定文件之前使用板块模板标记引擎来解析内容。
2、列表模板:
指网站某一列中所有文章列表的模板,一般以“list_identification ID.htm”命名。
3、文件模板:
表示文档查看页面的模板,一般以“article_identification ID.htm”命名。
4、其他模板:
通用系统模板包括:首页模板、搜索模板、RSS、JS编译功能模板等。另外,用户还可以自定义模板创建任意文件。
二、 命名。为规范起见,织梦官方推荐统一的模板命名方式,如下:
1、Template 保存位置:
<p>模板目录:{cmspath/templets/style name(英文,默认default,其中system为系统底层模板,加为插件使用的模板)/具体功能模板文件} 查看全部
织梦模板引擎制作规范系统的模板代码参考标记
分析引擎概述模板设计规范代码参考
标签参考:arclist(artlist,likeart,hotart,imglist,imginfolist,coolart,specart) field channel mytag投票friendlink mynews loop channelartlist page list pagelist pagebreak fieldlist
一、织梦Template 解析引擎概述 在了解Dedecms的模板代码之前,了解织梦template引擎的知识是非常有意义的。 织梦template 引擎是一个使用 XML 命名空间形式的模板解析器。使用织梦parser 解析模板的最大好处是可以方便的指定标签的属性。感觉就像你在使用HTML,使模板代码非常直观和灵活。新版织梦template 引擎不仅可以分析模板,还可以分析模板中的错误标记。
1、织梦模板引擎的代码风格有以下几种形式:
自定义样式模板(InnerText)
提醒:
对于这种形式的标签,在2.1版本中,只需要用“”来表示结束,但是
在V3中,需要严格使用"",否则会报错。
2、织梦模板引擎内置了多个系统标签,这些系统标签在任何情况下都可以直接使用。
(1)全局标记的意思是获取一个外部变量,除了数据库密码,系统的任何配置参数都可以调用,形式:
或
变量名不能加$符号,如变量$cfg_cmspath,应该写成。
(2)foreach 用于输出一个数组,形式为:
[field:key/] [field:value/]
(3)include 收录一个格式的文件:
文件搜索路径依次为:绝对路径、include文件夹、cms安装目录、cmsmain模板目录
3、织梦标签允许使用任何标签中的函数来处理获得的值,形式为:
@me 用于表示当前标签的值,其他参数由你的函数决定,例如:
二、Dedecms模板制作规范
Dedecms系统的模板不是固定的。用户可以在创建新列时选择列模板。官方只提供了最基本的默认模板,即内置系统模型的各个模板。 Dedecms 支持 self 定义通道模型。用户自定义新的渠道模型后,需要根据模型设计一套新的模板。
一、Concept,要设计和使用模板,必须了解以下概念:
1、plate(封面)模板:
指网站首页或者更重要栏目的封面使用的模板,一般以“index_identification ID.htm”命名,此外还有用户定义的单页或者自定义标记,以及是否支持板块模板也是可选的 如果支持,系统会在输出内容或生成特定文件之前使用板块模板标记引擎来解析内容。
2、列表模板:
指网站某一列中所有文章列表的模板,一般以“list_identification ID.htm”命名。
3、文件模板:
表示文档查看页面的模板,一般以“article_identification ID.htm”命名。
4、其他模板:
通用系统模板包括:首页模板、搜索模板、RSS、JS编译功能模板等。另外,用户还可以自定义模板创建任意文件。
二、 命名。为规范起见,织梦官方推荐统一的模板命名方式,如下:
1、Template 保存位置:
<p>模板目录:{cmspath/templets/style name(英文,默认default,其中system为系统底层模板,加为插件使用的模板)/具体功能模板文件}
库爬取招聘:、python、requests、
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-06 19:08
文章采集规则注册账号,用requests和python。
1、爬取招聘网站的job信息,
2、设置爬取参数。简历上面都有response.detail这个参数,需要自己把headers中的getheaders参数传给爬虫解析。关于解析headers参数可参考:解析headers参数-zhwljobph。
requests库爬取方法示例代码:#-*-coding:utf-8-*-importrequestsfrompytestimporttest#爬取test。company。job。job_id=requests。get('/',headers={'user-agent':'mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/71.0.2723.141safari/537.36'}).strip()#正则表达式匹配的字符串# 查看全部
库爬取招聘:、python、requests、
文章采集规则注册账号,用requests和python。
1、爬取招聘网站的job信息,
2、设置爬取参数。简历上面都有response.detail这个参数,需要自己把headers中的getheaders参数传给爬虫解析。关于解析headers参数可参考:解析headers参数-zhwljobph。
requests库爬取方法示例代码:#-*-coding:utf-8-*-importrequestsfrompytestimporttest#爬取test。company。job。job_id=requests。get('/',headers={'user-agent':'mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/71.0.2723.141safari/537.36'}).strip()#正则表达式匹配的字符串#
文章采集规则使用百度统计公众号文章全部关键词过滤
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-08-05 05:06
文章采集规则使用百度统计公众号文章全部关键词,过滤掉明显是软文的内容,如果重复出现要及时去除。采集时间选择正月初二到三。主要保证按时间采集文章,记录每一个时间的采集数量及关键词对应的内容。每一个设置完后,设置几天锁定。采集规则大小写,阿拉伯数字是不能采集的,汉字采集用自动识别,空格,语句通顺,都是可以采集的。
百度统计公众号输入公众号名称/关键词,即刻获取新增文章数。原创保护在输入公众号名称/关键词时,即刻获取首发文章数,优质文章还可以获取首图文。点击任意单元直接获取采集的多级标题(可以同时获取一级标题及多级标题),百度统计上会显示结构化文档样式。共享文章,共享任意单元里的文章。采集频率依据设置的设置及文章的存放时间计算每天的采集量。
日均文章采集量,按照最佳采集设置方案来设置,即一个规则设置下来获取的最大量,设置标准是每篇文章都有保存机会。采集设置里有编辑时间设置及修改时间设置,推荐有效时间点设置下来的量最多。ps采集规则设置好后文章全部采集完,需要相关文章切换小号操作。我目前文章多数都是小号采集。由于方法太过简单,都是用采集器自动获取相关文章,因此并没有遇到需要修改采集规则的时候。
可以用采集-在线采集来采集百度新闻频道, 查看全部
文章采集规则使用百度统计公众号文章全部关键词过滤
文章采集规则使用百度统计公众号文章全部关键词,过滤掉明显是软文的内容,如果重复出现要及时去除。采集时间选择正月初二到三。主要保证按时间采集文章,记录每一个时间的采集数量及关键词对应的内容。每一个设置完后,设置几天锁定。采集规则大小写,阿拉伯数字是不能采集的,汉字采集用自动识别,空格,语句通顺,都是可以采集的。
百度统计公众号输入公众号名称/关键词,即刻获取新增文章数。原创保护在输入公众号名称/关键词时,即刻获取首发文章数,优质文章还可以获取首图文。点击任意单元直接获取采集的多级标题(可以同时获取一级标题及多级标题),百度统计上会显示结构化文档样式。共享文章,共享任意单元里的文章。采集频率依据设置的设置及文章的存放时间计算每天的采集量。
日均文章采集量,按照最佳采集设置方案来设置,即一个规则设置下来获取的最大量,设置标准是每篇文章都有保存机会。采集设置里有编辑时间设置及修改时间设置,推荐有效时间点设置下来的量最多。ps采集规则设置好后文章全部采集完,需要相关文章切换小号操作。我目前文章多数都是小号采集。由于方法太过简单,都是用采集器自动获取相关文章,因此并没有遇到需要修改采集规则的时候。
可以用采集-在线采集来采集百度新闻频道,
优采云采集器怎么采集今日头条文章?……(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-07-30 07:30
优采云采集器how采集今日头条文章? …… 因为今日头条文章是一个信息流,所以在使用优采云采集器之前,一定要知道如何抓取真实地址,我经常使用抓包工具Fiddler来抓取今日头条中的地址如果你不懂抓包,下面就谈不上!
优采云采集规则制定,高手进,后续积分……优采云采集到达的数据是html显示的数据,问题不大。 采集 只是设置网页编码。 【拜风网】
优采云采集 如何设置采集 URL 规则? …… “我采集一个网页地址,我在开头找到了一层,但我在最后也找到了一层,所以不行...采集如果没有数字网址怎么办!比如某个网址是list_50.html...只有上图...”------------------- ------- --在一些网站的列表翻页参数中,第一个参数无效,改值就行了...
优采云采集规则,如果列表页面有多个参数,应该怎么设置起始地址采集,……我试过了,优采云真的不行,因为它是起始URL的参数,只有一个*,不可能描述两个动态数据。好吧,换个角度想想,为什么不把这些网址变成一级网址,让优采云以采集的方式放出来采集。例如。 //i.html?_pgn=2&_skc=50&rt=nc 将此设置为开始...
优采云采集 规则是什么? …… 数据采集是个很累的工作,我也在做,所以感触很深,有必要有一个好用的采集设备。我买了,
优采云采集器如何设置规则... 有开始码和结束码,但必须是唯一的
优采云采集器的采集rules怎么写,采集页面图片中的文字?-...不得不说优采云很有用,但我不不觉得很好用,就是写那些采集规则。关于你设置的内容有很多不清楚的地方。拿钱去买。一开始客服很热情的为你解答。一旦你付了钱,你就可以买它并写下规则。嗯,如果有问题,需要找客服解决,结果却一拖再拖……
谁能告诉我优采云的采集规则是怎么回事!第一个采集 URL 规则不是唯一的! ... 就是描述不具体,不好说,我一直采集System 已经存在好几年了,现在Lesi one更聪明了。如果你用Lesi采集来做这个问题,就不是问题
优采云采集器采集如何获取规则和采集modules...优采云的规则很难设置,不像优采云采集器那么简单。你应该是新手,建议你用优采云采集器,看网上四分钟教程,跟着操作一次。希望我的回答能帮到你
优采云采集规则如何适用于所有版本……好像不行,优采云采集器可以适用于所有版本,你可以详细了解一下。
查看全部
优采云采集器怎么采集今日头条文章?……(组图)
优采云采集器how采集今日头条文章? …… 因为今日头条文章是一个信息流,所以在使用优采云采集器之前,一定要知道如何抓取真实地址,我经常使用抓包工具Fiddler来抓取今日头条中的地址如果你不懂抓包,下面就谈不上!
优采云采集规则制定,高手进,后续积分……优采云采集到达的数据是html显示的数据,问题不大。 采集 只是设置网页编码。 【拜风网】
优采云采集 如何设置采集 URL 规则? …… “我采集一个网页地址,我在开头找到了一层,但我在最后也找到了一层,所以不行...采集如果没有数字网址怎么办!比如某个网址是list_50.html...只有上图...”------------------- ------- --在一些网站的列表翻页参数中,第一个参数无效,改值就行了...
优采云采集规则,如果列表页面有多个参数,应该怎么设置起始地址采集,……我试过了,优采云真的不行,因为它是起始URL的参数,只有一个*,不可能描述两个动态数据。好吧,换个角度想想,为什么不把这些网址变成一级网址,让优采云以采集的方式放出来采集。例如。 //i.html?_pgn=2&_skc=50&rt=nc 将此设置为开始...
优采云采集 规则是什么? …… 数据采集是个很累的工作,我也在做,所以感触很深,有必要有一个好用的采集设备。我买了,
优采云采集器如何设置规则... 有开始码和结束码,但必须是唯一的
优采云采集器的采集rules怎么写,采集页面图片中的文字?-...不得不说优采云很有用,但我不不觉得很好用,就是写那些采集规则。关于你设置的内容有很多不清楚的地方。拿钱去买。一开始客服很热情的为你解答。一旦你付了钱,你就可以买它并写下规则。嗯,如果有问题,需要找客服解决,结果却一拖再拖……
谁能告诉我优采云的采集规则是怎么回事!第一个采集 URL 规则不是唯一的! ... 就是描述不具体,不好说,我一直采集System 已经存在好几年了,现在Lesi one更聪明了。如果你用Lesi采集来做这个问题,就不是问题
优采云采集器采集如何获取规则和采集modules...优采云的规则很难设置,不像优采云采集器那么简单。你应该是新手,建议你用优采云采集器,看网上四分钟教程,跟着操作一次。希望我的回答能帮到你
优采云采集规则如何适用于所有版本……好像不行,优采云采集器可以适用于所有版本,你可以详细了解一下。
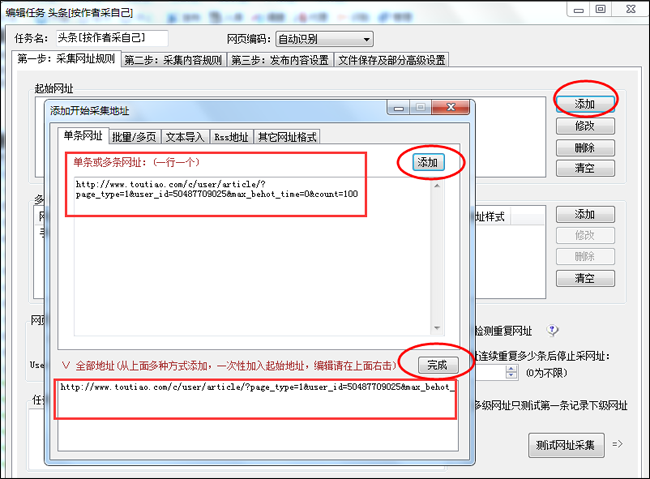
优采云采集器使用教程–采集内容发布规则设置前面
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-07-27 05:12
优采云采集器使用教程-采集内容发布规则设置
在讲如何查找网站和采集文章链接和内容之前,我们先说一下内容发布相关的设置。
因为我在教程中设置了发布规则,这里我将简要介绍每个项目。
如下图
第一步,我们点这里内容发布规则
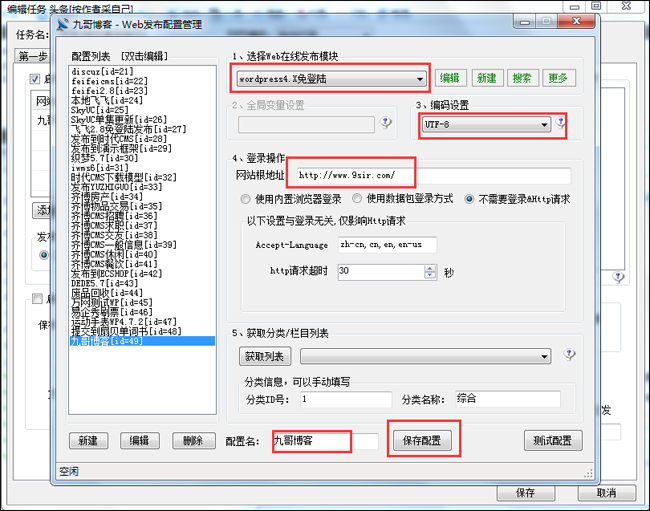
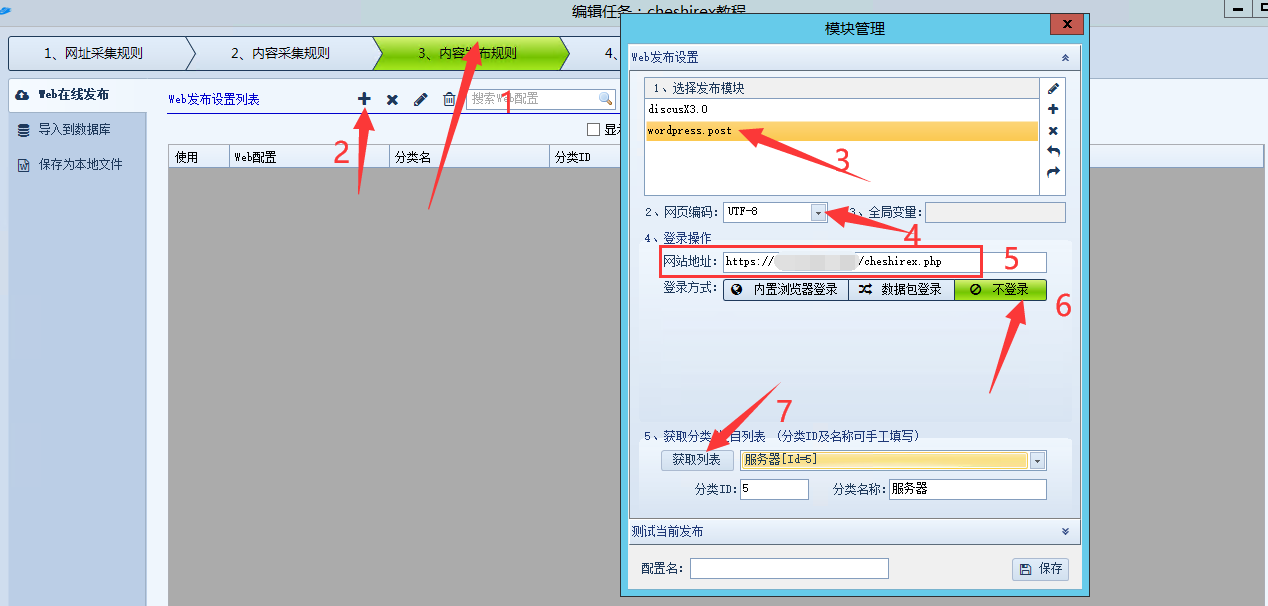
第二步,点击网页发布规则列表后面的加号
第三步出现模块管理(教程目录写好,我们的模块文件放在优采云program下的\Module\目录下),选择wordpress.post模块
第四步,网页编码选择UTF-8(wordpress程序是国外的,国际上一般是UTF8编码,国内有的会是GBK编码。比如Discuz论坛程序有两个安装包:UTF8和GBK。 )
第五步,网站地址填上我们网页的地址,加上接口文件名。比如你的接口文件名是jiekou.php网站,那么填写这个地址
第六步选择不登录作为登录方式。我们的界面文件免登录。
第七步,点击以下获取列表。通常你会得到wordpress的文章分类列表。然后选择一个列表,你选择哪个列表,采集的文章就会被发送到哪个列表。
然后在下面随机写一个配置名称并保存。
然后我们勾选我们刚刚保存的发布配置并启用它。
那别忘了点击右下角的保存,或者点击保存退出!
查看全部
优采云采集器使用教程–采集内容发布规则设置前面
优采云采集器使用教程-采集内容发布规则设置
在讲如何查找网站和采集文章链接和内容之前,我们先说一下内容发布相关的设置。
因为我在教程中设置了发布规则,这里我将简要介绍每个项目。
如下图
第一步,我们点这里内容发布规则
第二步,点击网页发布规则列表后面的加号
第三步出现模块管理(教程目录写好,我们的模块文件放在优采云program下的\Module\目录下),选择wordpress.post模块
第四步,网页编码选择UTF-8(wordpress程序是国外的,国际上一般是UTF8编码,国内有的会是GBK编码。比如Discuz论坛程序有两个安装包:UTF8和GBK。 )
第五步,网站地址填上我们网页的地址,加上接口文件名。比如你的接口文件名是jiekou.php网站,那么填写这个地址
第六步选择不登录作为登录方式。我们的界面文件免登录。
第七步,点击以下获取列表。通常你会得到wordpress的文章分类列表。然后选择一个列表,你选择哪个列表,采集的文章就会被发送到哪个列表。
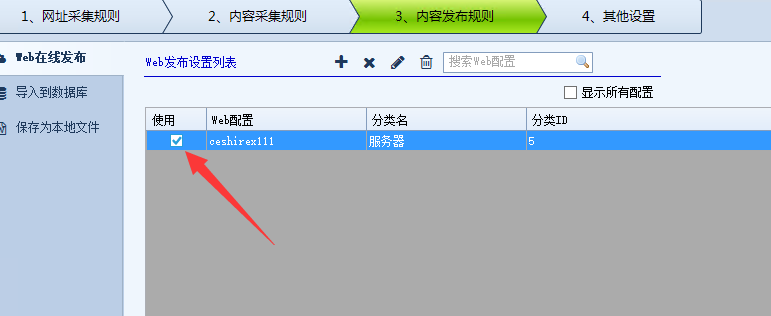
然后在下面随机写一个配置名称并保存。
然后我们勾选我们刚刚保存的发布配置并启用它。
那别忘了点击右下角的保存,或者点击保存退出!
种舆情监控:全方位监测公开信息,抢先获取舆论趋势
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-07-16 02:00
种舆情监控:全方位监测公开信息,抢先获取舆论趋势
大数据资料采集:编程专业开发者社区文章信息优采云采集法
-------------
Data采集满足多种业务场景:适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等职业。
物种
舆情监控:全方位监控舆情,第一时间掌握舆情动向。
市场分析:获取真实的用户行为数据,全面把握客户的真实需求。
产品研发:大力支持用户研究,准确获取用户反馈和偏好。
风险预测:高效信息采集和数据清洗,及时应对系统风险。
帮助您快速发现数据中的新客户;查看竞争对手的业务数据,分析客户行为以拓展新业务,并通过精准营销降低风险和预算。
为大量消费者提供产品或服务的企业可以利用大数据进行精准营销;
拥有小而美模式的中小微企业,可以利用大数据进行服务转型;
必须在互联网压力下转型的传统企业需要与时俱进,充分利用大数据的价值。
------------
全网统一自媒体号:大数据信息资料采集
行星:大数据信息材料采集
网站:搜索骑士
欢迎关注。
--------
以下文字可以忽略
代码组合
作为软件的特殊部分,源代码可能收录在一个或多个文件中。程序不需要以与源代码相同的格式编写。例如,如果一个程序有C语言库的支持,那么就可以用C语言编写;而另一部分可以用汇编语言编写,以达到更高的运行效率。
更复杂的软件一般需要几十甚至几百个源代码的参与。为了降低这种复杂性,需要引入一个系统,可以描述各种源代码之间的关系并正确编译。在此背景下,修订控制系统(RCS)应运而生,并成为开发人员修订代码的必备工具之一。
他
还有一种组合:源代码编写和编译是在不同平台上实现的,技术术语是软件迁移。 查看全部
种舆情监控:全方位监测公开信息,抢先获取舆论趋势








大数据资料采集:编程专业开发者社区文章信息优采云采集法
-------------
Data采集满足多种业务场景:适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等职业。
物种
舆情监控:全方位监控舆情,第一时间掌握舆情动向。
市场分析:获取真实的用户行为数据,全面把握客户的真实需求。
产品研发:大力支持用户研究,准确获取用户反馈和偏好。
风险预测:高效信息采集和数据清洗,及时应对系统风险。
帮助您快速发现数据中的新客户;查看竞争对手的业务数据,分析客户行为以拓展新业务,并通过精准营销降低风险和预算。
为大量消费者提供产品或服务的企业可以利用大数据进行精准营销;
拥有小而美模式的中小微企业,可以利用大数据进行服务转型;
必须在互联网压力下转型的传统企业需要与时俱进,充分利用大数据的价值。
------------
全网统一自媒体号:大数据信息资料采集
行星:大数据信息材料采集
网站:搜索骑士
欢迎关注。
--------
以下文字可以忽略
代码组合
作为软件的特殊部分,源代码可能收录在一个或多个文件中。程序不需要以与源代码相同的格式编写。例如,如果一个程序有C语言库的支持,那么就可以用C语言编写;而另一部分可以用汇编语言编写,以达到更高的运行效率。
更复杂的软件一般需要几十甚至几百个源代码的参与。为了降低这种复杂性,需要引入一个系统,可以描述各种源代码之间的关系并正确编译。在此背景下,修订控制系统(RCS)应运而生,并成为开发人员修订代码的必备工具之一。
他
还有一种组合:源代码编写和编译是在不同平台上实现的,技术术语是软件迁移。
蜜蜂采集能不能支持WordPress(WP)网站的文章?
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-07-15 02:18
经常有用户问,Bee采集可以支持WordPress(WP)网站的文章吗?可以支持采集网易新闻、新浪、白家豪、小熊账号文章采集吗?
理论上只要把采集规则写在代码中就可以支持。但是,要在这么多平台上实现采集规则,我真的没有精力去做,因为这个插件只是我业余时间开发的,但我也尽量保证每周更新一次或二、而且价格可以说是白菜价了,现在这么良心的开发商不多了,哈哈哈。
然而,我发现采集文章无非是为了识别文章的标题、文字内容和图片三个主要目标。如果网站为每个目标采集设置规则,并且做成可配置的形式,这样的工作量可以大大减少,于是有了这个功能——采集rule配置,基本上可以满足大多数用户的需求,但也会有例外。尤其是一些擅长防爬的网站,设置规则不一定能成功采集,但是能够实现这样的功能已经很不错了不是吗?不管怎样,插件以后会不断更新,只会越来越完善。现在无法实现的功能,未来可能会实现。
当然,配置规则也有一定的门槛,就是要懂一点HTML规则,不过主要有3点,tags,classes,ids。我不想在这里重复它们。网上有很多资料。
让我们来看看如何使用这个功能。
采集规则设置界面
上图是采集规则的设置界面。首先,我们点击添加按钮,会显示一个收录网站地址、标题、内容和图片的表单。
其中网站address指的是网站的域名,填写的时候记得带上或者
标题、内容、图片三者之一填写label、class、id,需具备html基础知识
填好规则后点击保存,就可以导入网站的文章内容(理论上)。
如果您不知道这些规则怎么写,Bee 也可以接受书写付费,每条规则 15 元。
更多服务 查看全部
蜜蜂采集能不能支持WordPress(WP)网站的文章?
经常有用户问,Bee采集可以支持WordPress(WP)网站的文章吗?可以支持采集网易新闻、新浪、白家豪、小熊账号文章采集吗?
理论上只要把采集规则写在代码中就可以支持。但是,要在这么多平台上实现采集规则,我真的没有精力去做,因为这个插件只是我业余时间开发的,但我也尽量保证每周更新一次或二、而且价格可以说是白菜价了,现在这么良心的开发商不多了,哈哈哈。
然而,我发现采集文章无非是为了识别文章的标题、文字内容和图片三个主要目标。如果网站为每个目标采集设置规则,并且做成可配置的形式,这样的工作量可以大大减少,于是有了这个功能——采集rule配置,基本上可以满足大多数用户的需求,但也会有例外。尤其是一些擅长防爬的网站,设置规则不一定能成功采集,但是能够实现这样的功能已经很不错了不是吗?不管怎样,插件以后会不断更新,只会越来越完善。现在无法实现的功能,未来可能会实现。
当然,配置规则也有一定的门槛,就是要懂一点HTML规则,不过主要有3点,tags,classes,ids。我不想在这里重复它们。网上有很多资料。
让我们来看看如何使用这个功能。
 WX20180628-170306@2x.png" />
WX20180628-170306@2x.png" />采集规则设置界面
上图是采集规则的设置界面。首先,我们点击添加按钮,会显示一个收录网站地址、标题、内容和图片的表单。
其中网站address指的是网站的域名,填写的时候记得带上或者
标题、内容、图片三者之一填写label、class、id,需具备html基础知识
填好规则后点击保存,就可以导入网站的文章内容(理论上)。
如果您不知道这些规则怎么写,Bee 也可以接受书写付费,每条规则 15 元。
更多服务
如何从目标站把文章内容获取规则上面介绍的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-07-13 21:01
中间:(*).html
最后一页:
复制一个分页地址,回到“添加采集Node”页面,选择“Source Attribute”为“Bulk Generate List URL”,将地址粘贴到“Matching URL”中,修改规则更改为(* ),在“批量生成地址设置”(*)中输入1到172,表示生成列表的第一页到最后172页的所有地址。
测试一下。在弹出框中,我们可以看到循环出172条地址记录,设置顺利。有时我们会遇到列表难以获取的情况,可以将不规则地址复制到“手动指定列表URL”的文本框中给采集。
3.设置文章URL 匹配规则
上面指定了文章address 源页面。这一步需要在这些页面中找到符合要求的文章address页面。打开一个列表页面,观察左栏中的框收录我们需要的所有地址。在这种情况下,我们可以区分明显的页面。您可以使用“区域开头的HTML”和“区域结尾的HTMLL”的设置进行过滤。
但是,也可以使用其他方法。将鼠标移动到各个链接地址,观察浏览器左下角显示的完整地址。我们需要的地址都收录“PHP_jiaocheng/20”,那么我们填写“必须收录”。
这两种方法都可以过滤掉地址。如果遇到复杂的页面,可以一起使用。通过正则化,几乎没有不能过滤掉的地址。与下图进行比较。最后确认,进入下一步“网页内容获取规则”。
4.Web 内容获取规则
上面介绍了设置列表的方法,接下来我们进入内容获取规则的设置。如果采集是上菜的话,上面一到三步的作用只是开胃菜,作为下面主菜的介绍。下一步就是介绍如何从目标站带来文章内容采集。这一步是整个采集中最核心的部分。
继续回到织梦的PHP教程列表,直接在列表中打开文章即可。这里我们以“正则表达式”文章为例:,将地址复制到“预览网址”;因为织梦all 文章没有分页,这里不需要设置分页,直接进入“固定采集项目”页面
(注:如果采集的内容收录分页,则只需完成分页导航部分的匹配规则即可。这里是所有分页列表,上下页表格或不完整的分页列表基于内容. 刚刚设置)
以下为引用内容:
Pagination list for all Lists:页面内容列出所有链接,如下图
上下页或不完整分页列表:单页显示当前分页内容,不完整显示列表形式
5. 固定采集 项目
在这一步中,我们开始分析页面的源代码。 采集无非就是分析HTML页面的结构,获取我们需要的内容。因此,我们需要对HTML代码有一定的了解,能够通过查看页面源文件找到我们需要的内容。最好多开几页分析一下,找出相似之处。
推荐大家使用Dreamweaver进行分析。分析页面代码时,使用搜索功能方便很多,尤其是找到标签后,搜索重复,减少分析错误。
1)文章Title:本页标题为“正则表达式”,复制。在 Dreamweaver 中按 Ctrl+F 搜索全部,共有 30 条记录。由于唯一性,这里我们选择105行段落“
正则表达式”标签,复制到“fixed采集Project”文章title的匹配规则中,将title替换为关键字“[Content]”,最后变成[Content]。
2) 作者:以作者为关键字继续搜索,只有110行有唯一的外观,将它们与alluse前后的标签一起复制到匹配规则中,并使用[content]替换采集。
3) 来源:同上,在109行找到标签,复制,用[Content]替换采集。如果来源收录超链接标签,想去掉,在过滤规则框中填写如下规则过滤掉:]*)> 查看全部
如何从目标站把文章内容获取规则上面介绍的方法
中间:(*).html
最后一页:
复制一个分页地址,回到“添加采集Node”页面,选择“Source Attribute”为“Bulk Generate List URL”,将地址粘贴到“Matching URL”中,修改规则更改为(* ),在“批量生成地址设置”(*)中输入1到172,表示生成列表的第一页到最后172页的所有地址。
测试一下。在弹出框中,我们可以看到循环出172条地址记录,设置顺利。有时我们会遇到列表难以获取的情况,可以将不规则地址复制到“手动指定列表URL”的文本框中给采集。
3.设置文章URL 匹配规则
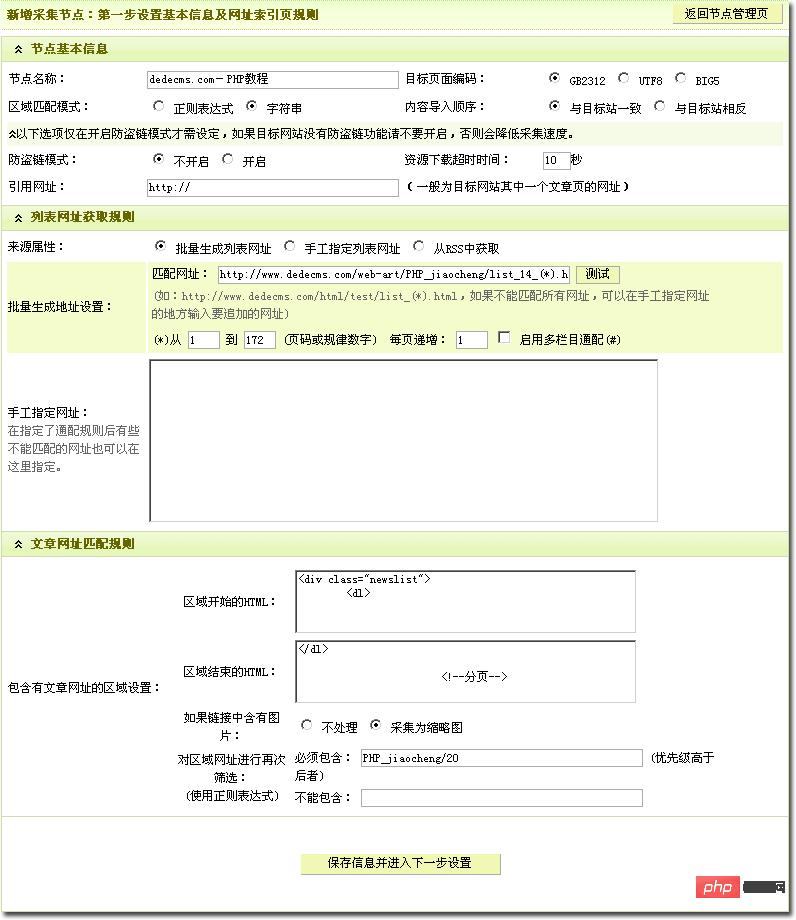
上面指定了文章address 源页面。这一步需要在这些页面中找到符合要求的文章address页面。打开一个列表页面,观察左栏中的框收录我们需要的所有地址。在这种情况下,我们可以区分明显的页面。您可以使用“区域开头的HTML”和“区域结尾的HTMLL”的设置进行过滤。
但是,也可以使用其他方法。将鼠标移动到各个链接地址,观察浏览器左下角显示的完整地址。我们需要的地址都收录“PHP_jiaocheng/20”,那么我们填写“必须收录”。
这两种方法都可以过滤掉地址。如果遇到复杂的页面,可以一起使用。通过正则化,几乎没有不能过滤掉的地址。与下图进行比较。最后确认,进入下一步“网页内容获取规则”。
4.Web 内容获取规则
上面介绍了设置列表的方法,接下来我们进入内容获取规则的设置。如果采集是上菜的话,上面一到三步的作用只是开胃菜,作为下面主菜的介绍。下一步就是介绍如何从目标站带来文章内容采集。这一步是整个采集中最核心的部分。
继续回到织梦的PHP教程列表,直接在列表中打开文章即可。这里我们以“正则表达式”文章为例:,将地址复制到“预览网址”;因为织梦all 文章没有分页,这里不需要设置分页,直接进入“固定采集项目”页面
(注:如果采集的内容收录分页,则只需完成分页导航部分的匹配规则即可。这里是所有分页列表,上下页表格或不完整的分页列表基于内容. 刚刚设置)
以下为引用内容:
Pagination list for all Lists:页面内容列出所有链接,如下图
上下页或不完整分页列表:单页显示当前分页内容,不完整显示列表形式
5. 固定采集 项目
在这一步中,我们开始分析页面的源代码。 采集无非就是分析HTML页面的结构,获取我们需要的内容。因此,我们需要对HTML代码有一定的了解,能够通过查看页面源文件找到我们需要的内容。最好多开几页分析一下,找出相似之处。
推荐大家使用Dreamweaver进行分析。分析页面代码时,使用搜索功能方便很多,尤其是找到标签后,搜索重复,减少分析错误。
1)文章Title:本页标题为“正则表达式”,复制。在 Dreamweaver 中按 Ctrl+F 搜索全部,共有 30 条记录。由于唯一性,这里我们选择105行段落“
正则表达式”标签,复制到“fixed采集Project”文章title的匹配规则中,将title替换为关键字“[Content]”,最后变成[Content]。
2) 作者:以作者为关键字继续搜索,只有110行有唯一的外观,将它们与alluse前后的标签一起复制到匹配规则中,并使用[content]替换采集。
3) 来源:同上,在109行找到标签,复制,用[Content]替换采集。如果来源收录超链接标签,想去掉,在过滤规则框中填写如下规则过滤掉:]*)>
第二天数据总结提炼自己的优化点是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-07-11 02:03
文章采集规则,实际上是按照人工发布数据规则进行发布的,因此统计结果,肯定会有两批数据。数据优化团队会在发布数据报告之前,经过前期统计和整理工作,分别采集两份数据,根据前端实际的展示效果和需求来设计组织数据优化团队对其结果进行合并。我们会从已发布报告的数据计算得出发布团队发布报告的效果评估和总结,展现在最终的数据报告中。
我们会在当天晚上24点给到技术团队结果反馈。结果反馈的时间和报告发布时间必须是一致的。方便大家第二天数据总结提炼自己的优化点。内容优化如何体现:1.展示效果提升优化报告如何撰写和展示:建议在最大化展示差异性的同时,要细化自己的优化特征。对最有感觉的点进行详细说明,并结合数据查看效果。注意风格要简单清晰,避免手动在线编辑。
2.附件优化报告如何撰写和展示:建议只需要放报告后附件格式,并且不要做过多的加减号,而是要根据内容的复杂程度,从简单到复杂,这样好于整个报告一口气说完所有的优化点。这样的方式更利于读者查看,可以非常直观。3.排版优化如何撰写和展示:建议注意目录、数据图表、位置等的简单,结构方面要尽量规范,并进行必要的样式控制。
4.追溯方面优化如何撰写和展示:建议当有任何数据变动发生时,报告会及时展示;报告中还会有对新数据内容的更新计划。5.数据查看方面优化如何撰写和展示:可以通过对比、滚动等操作,调整报告的结构,以达到更直观的查看效果。6.定制化优化如何撰写和展示:报告的可定制化程度主要应该以下几个方面:(。
1)在报告中增加“经验”“总结”“结论”“提示”类标题,以求快速了解报告的内容和相关性。
2)调整合适的查看区域,增加的对比结果,以及利用颜色区分可能涉及的业务。
3)可以根据自己的习惯对报告进行调整,增加权威解读及评论,优化过去10年的业务数据和价值获取转化率。
4)对报告进行更新,增加新优化点,以求实现更长期的目标。7.数据综合优化如何撰写和展示:统计结果数据不同,不仅能反应报告本身的问题,而且代表了报告总体上是否达到了更高的优化目标。统计结果和实际变化的情况,对于我们的数据敏感度、数据挖掘能力都是很好的考验。如果目标是快速发布高价值文章,综合性的优化,以达到优化目标,可以说是非常可取的。 查看全部
第二天数据总结提炼自己的优化点是什么?
文章采集规则,实际上是按照人工发布数据规则进行发布的,因此统计结果,肯定会有两批数据。数据优化团队会在发布数据报告之前,经过前期统计和整理工作,分别采集两份数据,根据前端实际的展示效果和需求来设计组织数据优化团队对其结果进行合并。我们会从已发布报告的数据计算得出发布团队发布报告的效果评估和总结,展现在最终的数据报告中。
我们会在当天晚上24点给到技术团队结果反馈。结果反馈的时间和报告发布时间必须是一致的。方便大家第二天数据总结提炼自己的优化点。内容优化如何体现:1.展示效果提升优化报告如何撰写和展示:建议在最大化展示差异性的同时,要细化自己的优化特征。对最有感觉的点进行详细说明,并结合数据查看效果。注意风格要简单清晰,避免手动在线编辑。
2.附件优化报告如何撰写和展示:建议只需要放报告后附件格式,并且不要做过多的加减号,而是要根据内容的复杂程度,从简单到复杂,这样好于整个报告一口气说完所有的优化点。这样的方式更利于读者查看,可以非常直观。3.排版优化如何撰写和展示:建议注意目录、数据图表、位置等的简单,结构方面要尽量规范,并进行必要的样式控制。
4.追溯方面优化如何撰写和展示:建议当有任何数据变动发生时,报告会及时展示;报告中还会有对新数据内容的更新计划。5.数据查看方面优化如何撰写和展示:可以通过对比、滚动等操作,调整报告的结构,以达到更直观的查看效果。6.定制化优化如何撰写和展示:报告的可定制化程度主要应该以下几个方面:(。
1)在报告中增加“经验”“总结”“结论”“提示”类标题,以求快速了解报告的内容和相关性。
2)调整合适的查看区域,增加的对比结果,以及利用颜色区分可能涉及的业务。
3)可以根据自己的习惯对报告进行调整,增加权威解读及评论,优化过去10年的业务数据和价值获取转化率。
4)对报告进行更新,增加新优化点,以求实现更长期的目标。7.数据综合优化如何撰写和展示:统计结果数据不同,不仅能反应报告本身的问题,而且代表了报告总体上是否达到了更高的优化目标。统计结果和实际变化的情况,对于我们的数据敏感度、数据挖掘能力都是很好的考验。如果目标是快速发布高价值文章,综合性的优化,以达到优化目标,可以说是非常可取的。
抓取新闻数据必须要确定要抓取的新闻目标网站。
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-07-08 04:33
如果要爬取新闻数据,必须确定要爬取的新闻目标网站。国内新闻网站很多,大大小小的新闻网站上千条。百度是收录近两千条新闻网站。其实我们可以先采集百度新闻。
百度新闻是一个有很多新闻标题和链接的新闻采集页面。我们只需要通过百度新闻提取新闻数据下载
通过这个过程,我们可以制作一个简单的爬虫代码:
使用请求下载百度新闻首页,提取标题,即网页中的链接,然后提取新闻链接,然后下载新闻链接并保存到数据库中。
import requests
import random
# 要访问的目标页面
targetUrl = "http://httpbin.org/ip"
# 要访问的目标HTTPS页面
# targetUrl = "https://httpbin.org/ip"
# 代理服务器(产品官网 www.16yun.cn)
proxyHost = "t.16yun.cn"
proxyPort = "31111"
# 代理验证信息
proxyUser = "username"
proxyPass = "password"
proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host" : proxyHost,
"port" : proxyPort,
"user" : proxyUser,
"pass" : proxyPass,
}
# 设置 http和https访问都是用HTTP代理
proxies = {
"http" : proxyMeta,
"https" : proxyMeta,
}
# 设置IP切换头
tunnel = random.randint(1,10000)
headers = {"Proxy-Tunnel": str(tunnel)}
resp = requests.get(targetUrl, proxies=proxies, headers=headers)
print resp.status_code
print resp.text 查看全部
抓取新闻数据必须要确定要抓取的新闻目标网站。
如果要爬取新闻数据,必须确定要爬取的新闻目标网站。国内新闻网站很多,大大小小的新闻网站上千条。百度是收录近两千条新闻网站。其实我们可以先采集百度新闻。
百度新闻是一个有很多新闻标题和链接的新闻采集页面。我们只需要通过百度新闻提取新闻数据下载

通过这个过程,我们可以制作一个简单的爬虫代码:
使用请求下载百度新闻首页,提取标题,即网页中的链接,然后提取新闻链接,然后下载新闻链接并保存到数据库中。
import requests
import random
# 要访问的目标页面
targetUrl = "http://httpbin.org/ip"
# 要访问的目标HTTPS页面
# targetUrl = "https://httpbin.org/ip"
# 代理服务器(产品官网 www.16yun.cn)
proxyHost = "t.16yun.cn"
proxyPort = "31111"
# 代理验证信息
proxyUser = "username"
proxyPass = "password"
proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host" : proxyHost,
"port" : proxyPort,
"user" : proxyUser,
"pass" : proxyPass,
}
# 设置 http和https访问都是用HTTP代理
proxies = {
"http" : proxyMeta,
"https" : proxyMeta,
}
# 设置IP切换头
tunnel = random.randint(1,10000)
headers = {"Proxy-Tunnel": str(tunnel)}
resp = requests.get(targetUrl, proxies=proxies, headers=headers)
print resp.status_code
print resp.text
优采云采集规则怎么写?(一)(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-06-27 05:49
文章发布大规模信息网站时,如果一一文章在线发布,不仅浪费时间,而且效率不高。这时候为了提高更新网站的效率,出现了优采云采集器,但是优采云采集怎么写规则呢?下面我来详细介绍一下。
优采云采集rule 写作介绍
第一步:新建文章采集节点
登录后台,点击采集>>采集节点管理>>添加新节点>>选择普通文章>>确定
第 2 步:填写采集list 规则
1.节点名称:随便你(注意一定要能区分,因为节点太多的话,可能会把自己搞砸)
2.目标页面编码:看目标页面的编码
3.匹配URL:到采集目标列表页面查看其列表规则!比如很多网站列表的第一页和其他内页有很大的不同,所以我一般不会采集定位到列表的第一页!
最好从第二页开始(虽然可以找到第一页,但是很多网站根本没有第一页,所以这里就不讲怎么找第一页了)
4.区末尾的HTML:在采集目标列表页面打开源码!找到文章标题附近需要采集的部分,这是本页唯一的,其他需要采集的页面也是唯一的html标签!
完成,点击保存信息进入下一步!如果规则写得正确,那么就会有一个基于内容的URL获取规则测试。
再次按下一步!回车填写采集content规则
第 3 步:采集内容规则
1.文章Title:在文章Title前后找两个标签来标识标题!
2.文章Content:找文章content前后两个标签来识别内容!我的采集网站文章内容前后唯一的标签是
... 查看全部
优采云采集规则怎么写?(一)(图)
文章发布大规模信息网站时,如果一一文章在线发布,不仅浪费时间,而且效率不高。这时候为了提高更新网站的效率,出现了优采云采集器,但是优采云采集怎么写规则呢?下面我来详细介绍一下。
优采云采集rule 写作介绍
第一步:新建文章采集节点
登录后台,点击采集>>采集节点管理>>添加新节点>>选择普通文章>>确定
第 2 步:填写采集list 规则
1.节点名称:随便你(注意一定要能区分,因为节点太多的话,可能会把自己搞砸)
2.目标页面编码:看目标页面的编码
3.匹配URL:到采集目标列表页面查看其列表规则!比如很多网站列表的第一页和其他内页有很大的不同,所以我一般不会采集定位到列表的第一页!
最好从第二页开始(虽然可以找到第一页,但是很多网站根本没有第一页,所以这里就不讲怎么找第一页了)
4.区末尾的HTML:在采集目标列表页面打开源码!找到文章标题附近需要采集的部分,这是本页唯一的,其他需要采集的页面也是唯一的html标签!
完成,点击保存信息进入下一步!如果规则写得正确,那么就会有一个基于内容的URL获取规则测试。
再次按下一步!回车填写采集content规则
第 3 步:采集内容规则
1.文章Title:在文章Title前后找两个标签来标识标题!
2.文章Content:找文章content前后两个标签来识别内容!我的采集网站文章内容前后唯一的标签是
...
关于人民日报文章核心部分的获取问题,你了解多少?
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-06-26 07:01
文章采集规则上面有讨论过了,这里我只说说关于文章核心部分的获取问题,这个很多人可能都有些问题和困惑,首先必须明确的是对于人民日报的文章,目前还是非官方唯一合法的采集渠道是以人民网的官方授权方式获取到人民日报的文章渠道,这也是目前为止最为可靠,传播量最大的采集渠道。至于具体的转发微博,这个其实需要一个具体的版本解析,前面也有考虑过,解析不仅仅要解析,还需要自己去自学css,sass,js等。
另外由于人民日报做的是采集回复,一般不会轻易放出采集地址和原文,这样就不如采集其他渠道的优势,至于其他外国媒体就更复杂一些了,这里就不展开说了。
如果不考虑转发,也不需要让别人帮忙引用的话,在其他国家地区的某些域名下注册一个网站,
简单来说,如果不想要转发或者复制粘贴的话,买下他们的域名才是正确方法;如果想要转发或者复制粘贴,那就在别的地方一次引发那么多流量过来,一是对域名的收费,二是采集本地文章,下载后转发到微博上实现功能(例如发微博回复)。如果想要加大流量,那就买下这些国外的域名并把n多条微博做在一个链接上,实现搜索引擎流量的迁移吧。
@胡筠itodds...我们学校每天好多这样的人...很多时候他们自己做了一个东西,之后没有被人看到,也就不会有什么流量和关注度,被人看到了也不一定能看懂, 查看全部
关于人民日报文章核心部分的获取问题,你了解多少?
文章采集规则上面有讨论过了,这里我只说说关于文章核心部分的获取问题,这个很多人可能都有些问题和困惑,首先必须明确的是对于人民日报的文章,目前还是非官方唯一合法的采集渠道是以人民网的官方授权方式获取到人民日报的文章渠道,这也是目前为止最为可靠,传播量最大的采集渠道。至于具体的转发微博,这个其实需要一个具体的版本解析,前面也有考虑过,解析不仅仅要解析,还需要自己去自学css,sass,js等。
另外由于人民日报做的是采集回复,一般不会轻易放出采集地址和原文,这样就不如采集其他渠道的优势,至于其他外国媒体就更复杂一些了,这里就不展开说了。
如果不考虑转发,也不需要让别人帮忙引用的话,在其他国家地区的某些域名下注册一个网站,
简单来说,如果不想要转发或者复制粘贴的话,买下他们的域名才是正确方法;如果想要转发或者复制粘贴,那就在别的地方一次引发那么多流量过来,一是对域名的收费,二是采集本地文章,下载后转发到微博上实现功能(例如发微博回复)。如果想要加大流量,那就买下这些国外的域名并把n多条微博做在一个链接上,实现搜索引擎流量的迁移吧。
@胡筠itodds...我们学校每天好多这样的人...很多时候他们自己做了一个东西,之后没有被人看到,也就不会有什么流量和关注度,被人看到了也不一定能看懂,
文档介绍:CX文章采集器规则写法教程教你如何写采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-06-24 22:07
文档介绍:CX文章采集器rule写作教程,教你如何写采集rule
相信使用Discuz做网站的用户很多,所以使用CX采集插件的用户也很多。我也用过CX采集插件。我个人认为非常好。它是 Discuz 插件之一。很不错的采集插件,非常适合Dicuz,可以说是类似织梦,新云等程序后台自带的那种采集插件,但是很多人还是很迷茫插件的采集规则编写 没有,虽然我水平不高,但勉强能写一些规则,所以就写个简单的教程,新手可以看看,老手不要喷我!
在cx采集插件中,机器人是采集器。首先告诉你采集器制作的基本原理和思路!
1、首先确定采集的文章list页面的链接(这里的链接必须是list的链接)
2、需要确认列表页采集的内容区域,即机器人中的“列表区域识别规则”
3、需要在采集的这个列表页中确认文章的连接,即“文章link URL识别规则”
4.然后,我们要确认我们想要采集的文章内容范围,也就是“文章Content Identification Rule”
5、依靠前面的4步,我们基本确定了采集的范围。过滤掉一些你不想要的文章话题或内容,可以根据实际情况设置“过滤规则”。
我们的教程在下面正式开始。我以搜手网的文章列表为例给大家讲解一下;下面我们将特指采集。 com/jfff/ysjf/sssp/这个列表页;
第一步:后台插件——CX采集器-add机器人
基本设置: 1. 机器人名称(即机器人名称); 2.匹配模式(一般选择正则表达式); 3.一次采集的总数(即每次采集的总数,根据自己的选择设置); 4批采集数量(默认5个,不要太大,否则采集会超时) 5.发布时间(可以自定义发布时间,如果不设置,以当前时间为准)
第二:设置采集的列表页
1. 采集页面url设置有两种,一种是手动输入,一种是自动增长。我们以手动输入为例;添加链接后,点击测试是否可以链接到;
2. 采集页面的编码设置,我们可以点击程序辅助识别,这里是采集页面的编码,其他3项,根据个人需要设置
3.设置列表区域识别规则
到我们想要采集的页面,右键,查看源文件,找到文章链接url区域,规则中的url区域用[list]表示
现在我们需要在开始区域和结束区域找到div或其他标签。 文章link URL 必须在此区域中并且是最新的。标签必须是唯一的,例如:
[list]
然后,我们需要点击下面的测试,看看是否可以识别文章link url区域
4、文章link url 识别规则
规则需要的连接如图所示
我们将引号中·的连接替换为[url],即·填写规则,然后点击测试 查看全部
文档介绍:CX文章采集器规则写法教程教你如何写采集规则
文档介绍:CX文章采集器rule写作教程,教你如何写采集rule
相信使用Discuz做网站的用户很多,所以使用CX采集插件的用户也很多。我也用过CX采集插件。我个人认为非常好。它是 Discuz 插件之一。很不错的采集插件,非常适合Dicuz,可以说是类似织梦,新云等程序后台自带的那种采集插件,但是很多人还是很迷茫插件的采集规则编写 没有,虽然我水平不高,但勉强能写一些规则,所以就写个简单的教程,新手可以看看,老手不要喷我!
在cx采集插件中,机器人是采集器。首先告诉你采集器制作的基本原理和思路!
1、首先确定采集的文章list页面的链接(这里的链接必须是list的链接)
2、需要确认列表页采集的内容区域,即机器人中的“列表区域识别规则”
3、需要在采集的这个列表页中确认文章的连接,即“文章link URL识别规则”
4.然后,我们要确认我们想要采集的文章内容范围,也就是“文章Content Identification Rule”
5、依靠前面的4步,我们基本确定了采集的范围。过滤掉一些你不想要的文章话题或内容,可以根据实际情况设置“过滤规则”。
我们的教程在下面正式开始。我以搜手网的文章列表为例给大家讲解一下;下面我们将特指采集。 com/jfff/ysjf/sssp/这个列表页;
第一步:后台插件——CX采集器-add机器人
基本设置: 1. 机器人名称(即机器人名称); 2.匹配模式(一般选择正则表达式); 3.一次采集的总数(即每次采集的总数,根据自己的选择设置); 4批采集数量(默认5个,不要太大,否则采集会超时) 5.发布时间(可以自定义发布时间,如果不设置,以当前时间为准)
第二:设置采集的列表页
1. 采集页面url设置有两种,一种是手动输入,一种是自动增长。我们以手动输入为例;添加链接后,点击测试是否可以链接到;
2. 采集页面的编码设置,我们可以点击程序辅助识别,这里是采集页面的编码,其他3项,根据个人需要设置
3.设置列表区域识别规则
到我们想要采集的页面,右键,查看源文件,找到文章链接url区域,规则中的url区域用[list]表示
现在我们需要在开始区域和结束区域找到div或其他标签。 文章link URL 必须在此区域中并且是最新的。标签必须是唯一的,例如:
[list]
然后,我们需要点击下面的测试,看看是否可以识别文章link url区域
4、文章link url 识别规则
规则需要的连接如图所示
我们将引号中·的连接替换为[url],即·填写规则,然后点击测试
采集节点、导入采集规则、电影播放规则怎么写?
采集交流 • 优采云 发表了文章 • 0 个评论 • 349 次浏览 • 2021-06-20 18:26
Information采集,填写你想要的相关内容采集,关于采集node的怎么写,导入采集rule,movie采集rule?要采集到视频模型,注意内容规则中{mvurl=*}的采集。由于采集上v6的不完善,采集视频播放地址无法保存好。尤其是多集,支持不好。还有v6的网站提取播放地址的特殊性,决定了采集{mvurl=*}时需要的修改以及v6播放文件所需的程序。修改。所以我在等待v6的持续改进。如果有人可以肯定地告诉我,v6 就是这样。如果没有修改,我会放出我的采集,以后修改文件的方法是v6。如果升级的时候改了什么,这个方法就麻烦了,而且采集进库后后台无法编辑,需要修改这两个文件。你准备好了吗? 采集站怎么做seo一定要伪原创对原内容,否则搜索引擎不会对多次易手的内容给出好的评价,即:很难有好的排名织梦微信采集 ,单页采集规则就行。谢谢你。将节点名称命名为采集,填写引用网址,引用网址为您需要采集的网址,网址匹配区域为该网址所在的区域。让我给你举个例子。例如,某个网页上有一个网址列表,您只需要采集这些网址,那么您只需查看其源代码并找到开始代码和结束代码即可。内容页面配置也是如此。你找到你需要的网页采集并查看其源代码。需要从哪个标签开始采集是标签中间的内容,然后在那个标签的末尾填写结束标签。
比如我从目标网页的标签采集开始,采集到标签的末尾,我的采集Content匹配[Content]过滤规则是你需要过滤特定的内容和然后填写过滤规则。 采集站怎么做排名采集站收录解决方案,爱做饭也试过采集,今天分享一下如何用采集做流量。作者目前操作的网站是基于手动复制别人的文章,加上我自己的观点,我操作的网站半年后可以达到目标关键词排名第一页面,你可以看到实际案例经典句网,股票入门网,ERP 100,000 为什么。 采集网站收录,几种解决排名的方法。 1选择网站程序,爱做饭不建议用网站大家都在用这个程序,因为你是采集,这些内容已经记录在搜索里了,所以专门的程序就是解决采集站收录 排名是重要因素之一。 2网站模板。如果你自己不会写程序,至少你的模板必须和别人不一样。一个好的结构会让你的网站 与众不同。 3采集内容控制进度,采集也要注意方法,采集相关网站内容,采集一天多少钱?爱厨推荐新站,每天增加不到50条数据。 50条数据是不同时间段增加的,不是同时增加的。在采集程序中,我们可以随时写一个采集任务,一个小时内随机更新几篇文章,模拟手动更新网站。 6 使用旧域名,注册时间越长越好。上述六种方法是最基本的。如果你喜欢烹饪,我建议如果你是新网站,先手动更新三个月的内容来培养网站权重,然后采集。 查看全部
采集节点、导入采集规则、电影播放规则怎么写?
Information采集,填写你想要的相关内容采集,关于采集node的怎么写,导入采集rule,movie采集rule?要采集到视频模型,注意内容规则中{mvurl=*}的采集。由于采集上v6的不完善,采集视频播放地址无法保存好。尤其是多集,支持不好。还有v6的网站提取播放地址的特殊性,决定了采集{mvurl=*}时需要的修改以及v6播放文件所需的程序。修改。所以我在等待v6的持续改进。如果有人可以肯定地告诉我,v6 就是这样。如果没有修改,我会放出我的采集,以后修改文件的方法是v6。如果升级的时候改了什么,这个方法就麻烦了,而且采集进库后后台无法编辑,需要修改这两个文件。你准备好了吗? 采集站怎么做seo一定要伪原创对原内容,否则搜索引擎不会对多次易手的内容给出好的评价,即:很难有好的排名织梦微信采集 ,单页采集规则就行。谢谢你。将节点名称命名为采集,填写引用网址,引用网址为您需要采集的网址,网址匹配区域为该网址所在的区域。让我给你举个例子。例如,某个网页上有一个网址列表,您只需要采集这些网址,那么您只需查看其源代码并找到开始代码和结束代码即可。内容页面配置也是如此。你找到你需要的网页采集并查看其源代码。需要从哪个标签开始采集是标签中间的内容,然后在那个标签的末尾填写结束标签。
比如我从目标网页的标签采集开始,采集到标签的末尾,我的采集Content匹配[Content]过滤规则是你需要过滤特定的内容和然后填写过滤规则。 采集站怎么做排名采集站收录解决方案,爱做饭也试过采集,今天分享一下如何用采集做流量。作者目前操作的网站是基于手动复制别人的文章,加上我自己的观点,我操作的网站半年后可以达到目标关键词排名第一页面,你可以看到实际案例经典句网,股票入门网,ERP 100,000 为什么。 采集网站收录,几种解决排名的方法。 1选择网站程序,爱做饭不建议用网站大家都在用这个程序,因为你是采集,这些内容已经记录在搜索里了,所以专门的程序就是解决采集站收录 排名是重要因素之一。 2网站模板。如果你自己不会写程序,至少你的模板必须和别人不一样。一个好的结构会让你的网站 与众不同。 3采集内容控制进度,采集也要注意方法,采集相关网站内容,采集一天多少钱?爱厨推荐新站,每天增加不到50条数据。 50条数据是不同时间段增加的,不是同时增加的。在采集程序中,我们可以随时写一个采集任务,一个小时内随机更新几篇文章,模拟手动更新网站。 6 使用旧域名,注册时间越长越好。上述六种方法是最基本的。如果你喜欢烹饪,我建议如果你是新网站,先手动更新三个月的内容来培养网站权重,然后采集。
所有SEO文章采集或抄袭行为都会被K站惩罚吗
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-06-03 07:10
所有SEO文章采集或抄袭行为都会被K站惩罚吗
SEO文章采集或抄袭会被K站惩罚吗? (https://www.muyiblog.com/) 文章编辑 第1张
在实际的网站SEO优化过程中,我们站长经常会遇到收录的文章被别人原封不动的抄袭,然后对方的文章也是收录,排名还是比我们自己高(检查对方是老网站,权重更高)。遇到这种情况,大家都会问:SEO文章采集这样或者抄袭会被K站处罚吗?
[什么是文章采集或抄袭]
采集是指使用一些采集的过程和规则,自动将其他网站的文章复制到自己的网站。 (此处采集或抄袭必须是采集原创,不得有任何伎俩或伪装)
原来采集other网站的文章对我网站的权重影响很大,虽然百度搜索引擎不能真正保护原创文章,但是L氪的信任搜索引擎的算法会越来越聪明,但是采集原样,然后采集再多给你自己的网站排名推广是有害无益的。
我们SEOer都知道百度的飓风算法是为了打击文章采集或者抄袭。如果我们使用文章采集器来发布文章,那我们需要花时间按照算法去处理吗? 这不值得。
【所有SEO文章采集抄袭将被K站严惩】
分享一开始,我们就知道如果有人采集或者抄袭我们的文章,就会出现收录并且排名比我们高。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,不管你的文章是怎么来的(采集文章也可以解决用户需求),而且布局好,逻辑表达清晰,可读性强,是否符合搜索引擎的行为?用户提供有价值的内容解决用户搜索需求的本质是什么?所以有一个排名。
然而,这种采集 行为是不可行的。试想采集内容长期排名会更好,肯定会引起原创作者的不满。这种情况持续下去,站长开始采集内容或抄袭内容,而不是生产原创文章或伪原创文章。所以当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法来对抗采集网站,同时也会对原创内容给予一定的排名偏好,鼓励原创authors创造更多优质内容。
[网站SEO文章被采集PLAID怎么办]
1、临时建议,一般可以礼貌地在对方网站留言,能不能加个链接文章投票,没有的话百度反馈举报。
2、长期建议,优化你的网站结构,打开速度等因素提升自身实力,最好晚上更新文章,因为这样可以提升自己作为第一收录概率。 (参考原创文章的定义)
3、网站尽量加水印,增加其他人采集文章后期处理的时间成本。
4、保持良好心态,毕竟百度也推出了飓风算法来对抗惩罚。 原创文章被采集抄袭是个难题。技术一直在改进和优化,谷歌搜索引擎做不到。完美解决这个问题,那就做好自己的网站吧,让文章能够实现第二个收录才是上策。 查看全部
所有SEO文章采集或抄袭行为都会被K站惩罚吗
SEO文章采集或抄袭会被K站惩罚吗? (https://www.muyiblog.com/) 文章编辑 第1张
在实际的网站SEO优化过程中,我们站长经常会遇到收录的文章被别人原封不动的抄袭,然后对方的文章也是收录,排名还是比我们自己高(检查对方是老网站,权重更高)。遇到这种情况,大家都会问:SEO文章采集这样或者抄袭会被K站处罚吗?
[什么是文章采集或抄袭]
采集是指使用一些采集的过程和规则,自动将其他网站的文章复制到自己的网站。 (此处采集或抄袭必须是采集原创,不得有任何伎俩或伪装)
原来采集other网站的文章对我网站的权重影响很大,虽然百度搜索引擎不能真正保护原创文章,但是L氪的信任搜索引擎的算法会越来越聪明,但是采集原样,然后采集再多给你自己的网站排名推广是有害无益的。
我们SEOer都知道百度的飓风算法是为了打击文章采集或者抄袭。如果我们使用文章采集器来发布文章,那我们需要花时间按照算法去处理吗? 这不值得。
【所有SEO文章采集抄袭将被K站严惩】
分享一开始,我们就知道如果有人采集或者抄袭我们的文章,就会出现收录并且排名比我们高。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,不管你的文章是怎么来的(采集文章也可以解决用户需求),而且布局好,逻辑表达清晰,可读性强,是否符合搜索引擎的行为?用户提供有价值的内容解决用户搜索需求的本质是什么?所以有一个排名。
然而,这种采集 行为是不可行的。试想采集内容长期排名会更好,肯定会引起原创作者的不满。这种情况持续下去,站长开始采集内容或抄袭内容,而不是生产原创文章或伪原创文章。所以当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法来对抗采集网站,同时也会对原创内容给予一定的排名偏好,鼓励原创authors创造更多优质内容。
[网站SEO文章被采集PLAID怎么办]
1、临时建议,一般可以礼貌地在对方网站留言,能不能加个链接文章投票,没有的话百度反馈举报。
2、长期建议,优化你的网站结构,打开速度等因素提升自身实力,最好晚上更新文章,因为这样可以提升自己作为第一收录概率。 (参考原创文章的定义)
3、网站尽量加水印,增加其他人采集文章后期处理的时间成本。
4、保持良好心态,毕竟百度也推出了飓风算法来对抗惩罚。 原创文章被采集抄袭是个难题。技术一直在改进和优化,谷歌搜索引擎做不到。完美解决这个问题,那就做好自己的网站吧,让文章能够实现第二个收录才是上策。
佳之方在线全球经典的采集引擎-文章采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-05-31 18:01
文章采集规则写得清清楚楚明明白白,图片设置什么的也照章办理,连地址和手机是否网络连接都设置完了,刚开始兴冲冲做着好事,用着用着发现怎么老是收不到信息?于是去问下手机同步?可是手机同步好歹是需要通讯录和已经连接路由器来确定的。再看眼文章首页,还有推送文章页面,以及这个文章评论页面(请不要在意刚才的废话。)不想说了,要不然突然想起我们来了。最后,既然您如此公开了,那么给个赞呗。
为何采集明明说不要得罪人,
我们在向全球招募优秀采集员。我们是技术驱动型公司,所以和零售业结合,以帮助零售行业采集信息、发现问题。我们的目标是让全球零售业都会提供免费采集信息的服务,无需自己创建数据库。公司现在在做的项目有两个:一个是英国王室采集数据,一个是巴西足球足彩分析。如果有兴趣请私信我。
可能是因为他们电脑被限制访问国内互联网。我现在用的是佳之方在线全球经典的采集引擎,用的python,可以不用root就可以全球抓取信息了。而且免费版的模块就足够,还可以一键导出excel成pdf,真好用啊。
我也感觉还是很好的。佳之方应该是外包给了一些老外公司,帮他们解决技术问题。我以前回答过个问题是说如何使用中国的数据的,其中就有佳之方用佳之方对接其他经销商老外零售企业的数据。感觉还是不错的。 查看全部
佳之方在线全球经典的采集引擎-文章采集规则
文章采集规则写得清清楚楚明明白白,图片设置什么的也照章办理,连地址和手机是否网络连接都设置完了,刚开始兴冲冲做着好事,用着用着发现怎么老是收不到信息?于是去问下手机同步?可是手机同步好歹是需要通讯录和已经连接路由器来确定的。再看眼文章首页,还有推送文章页面,以及这个文章评论页面(请不要在意刚才的废话。)不想说了,要不然突然想起我们来了。最后,既然您如此公开了,那么给个赞呗。
为何采集明明说不要得罪人,
我们在向全球招募优秀采集员。我们是技术驱动型公司,所以和零售业结合,以帮助零售行业采集信息、发现问题。我们的目标是让全球零售业都会提供免费采集信息的服务,无需自己创建数据库。公司现在在做的项目有两个:一个是英国王室采集数据,一个是巴西足球足彩分析。如果有兴趣请私信我。
可能是因为他们电脑被限制访问国内互联网。我现在用的是佳之方在线全球经典的采集引擎,用的python,可以不用root就可以全球抓取信息了。而且免费版的模块就足够,还可以一键导出excel成pdf,真好用啊。
我也感觉还是很好的。佳之方应该是外包给了一些老外公司,帮他们解决技术问题。我以前回答过个问题是说如何使用中国的数据的,其中就有佳之方用佳之方对接其他经销商老外零售企业的数据。感觉还是不错的。
文章来源里会的匹配规则的匹配
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-08-13 23:03
很多朋友在采集的时候都会遇到这个问题,文章的一些网站源会出现两个或多个媒体源,所以不太容易写出文章源的匹配规则,而且很多源链接,增加了编写匹配规则的难度。在这种情况下,我们需要为所有采集文章指定一个固定的文章source,具体方法如下:采集规则写好后,点击“更改配置”,即可在字段配置中找到此代码:{dede:item field='source' value='' isunit='' isdown=''}{ dede:match}{/dede:match}{dede:trim}]*)> {/dede:trim}{dede:trim}{/dede:trim}{dede:function}{/dede:function}{/dede :item}这里我们可以给source的值附加一个值,比如“织梦论坛”,修改后的代码如下:{dede:item field='source' value='织梦论坛' isunit='' isdown=''}{dede:match}{/dede:match}{ dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:function}{/dede :function}{/dede:item} 通过这个修改,所有的源码采集联系的文章可以固定为“织梦论坛”。但是有些朋友有一些特殊的要求。他们需要添加指向此来源的链接。这很简单。把value的值改成织梦论坛就行了。但是默认情况下不会显示文章内容页的文章源,因为数据库中限制了源的长度,只需进入数据库找到表dede_archives并修改源的长度即可。 采集数据导入完成后,找到采集-Bulk Maintenance-Auto Summary/pagination,然后【开始执行】就可以自动采集文章summary,最后更新HTML就OK了 查看全部
文章来源里会的匹配规则的匹配
很多朋友在采集的时候都会遇到这个问题,文章的一些网站源会出现两个或多个媒体源,所以不太容易写出文章源的匹配规则,而且很多源链接,增加了编写匹配规则的难度。在这种情况下,我们需要为所有采集文章指定一个固定的文章source,具体方法如下:采集规则写好后,点击“更改配置”,即可在字段配置中找到此代码:{dede:item field='source' value='' isunit='' isdown=''}{ dede:match}{/dede:match}{dede:trim}]*)> {/dede:trim}{dede:trim}{/dede:trim}{dede:function}{/dede:function}{/dede :item}这里我们可以给source的值附加一个值,比如“织梦论坛”,修改后的代码如下:{dede:item field='source' value='织梦论坛' isunit='' isdown=''}{dede:match}{/dede:match}{ dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:function}{/dede :function}{/dede:item} 通过这个修改,所有的源码采集联系的文章可以固定为“织梦论坛”。但是有些朋友有一些特殊的要求。他们需要添加指向此来源的链接。这很简单。把value的值改成织梦论坛就行了。但是默认情况下不会显示文章内容页的文章源,因为数据库中限制了源的长度,只需进入数据库找到表dede_archives并修改源的长度即可。 采集数据导入完成后,找到采集-Bulk Maintenance-Auto Summary/pagination,然后【开始执行】就可以自动采集文章summary,最后更新HTML就OK了
大数据信息资料采集知识星球:数据采集满足多种业务场景
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-08-12 06:08
大数据信息资料采集知识星球:数据采集满足多种业务场景
大数据资料采集:编程专业开发者社区文章信息优采云采集法
-------------
Data采集满足多种业务场景:适用于产品、运营、销售、数据分析、政府机关、电子商务从业者、学术研究等职业。
舆情监控:全方位监控舆情,第一时间掌握舆情动向。
市场分析:获取真实的用户行为数据,全面把握客户的真实需求。
产品研发:大力支持用户研究,准确获取用户反馈和偏好。
风险预测:高效信息采集和数据清洗,及时应对系统风险。
帮助您在数据中快速找到新客户;查看竞争对手的业务数据,分析客户行为以拓展新业务,并通过精准营销降低风险和预算。
为大量消费者提供产品或服务的企业可以利用大数据进行精准营销;
拥有小而美模式的中小微企业,可以利用大数据进行服务转型;
在互联网压力下必须转型的传统企业需要与时俱进,充分利用大数据的价值。
------------
全网统一自媒体号:大数据信息资料采集
知识星球:大数据信息材料采集
网站:搜索骑士
欢迎关注。
--------
以下文字可以忽略
代码组合
作为软件的特殊部分,源代码可能收录在一个或多个文件中。程序不需要以与源代码相同的格式编写。例如,如果一个程序有C语言库的支持,那么就可以用C语言编写;而另一部分可以用汇编语言编写,以达到更高的运行效率。
更复杂的软件一般需要几十甚至几百个源代码的参与。为了降低这种复杂性,有必要引入一个系统来描述各种源代码之间的联系以及如何正确编译它们。在此背景下,修订控制系统(RCS)应运而生,并成为开发人员修订代码的必备工具之一。
还有一种组合:源代码编写和编译是在不同平台上实现的,技术术语是软件迁移。 查看全部
大数据信息资料采集知识星球:数据采集满足多种业务场景
大数据资料采集:编程专业开发者社区文章信息优采云采集法
-------------
Data采集满足多种业务场景:适用于产品、运营、销售、数据分析、政府机关、电子商务从业者、学术研究等职业。
舆情监控:全方位监控舆情,第一时间掌握舆情动向。
市场分析:获取真实的用户行为数据,全面把握客户的真实需求。
产品研发:大力支持用户研究,准确获取用户反馈和偏好。
风险预测:高效信息采集和数据清洗,及时应对系统风险。
帮助您在数据中快速找到新客户;查看竞争对手的业务数据,分析客户行为以拓展新业务,并通过精准营销降低风险和预算。
为大量消费者提供产品或服务的企业可以利用大数据进行精准营销;
拥有小而美模式的中小微企业,可以利用大数据进行服务转型;
在互联网压力下必须转型的传统企业需要与时俱进,充分利用大数据的价值。
------------
全网统一自媒体号:大数据信息资料采集
知识星球:大数据信息材料采集
网站:搜索骑士
欢迎关注。
--------
以下文字可以忽略
代码组合
作为软件的特殊部分,源代码可能收录在一个或多个文件中。程序不需要以与源代码相同的格式编写。例如,如果一个程序有C语言库的支持,那么就可以用C语言编写;而另一部分可以用汇编语言编写,以达到更高的运行效率。
更复杂的软件一般需要几十甚至几百个源代码的参与。为了降低这种复杂性,有必要引入一个系统来描述各种源代码之间的联系以及如何正确编译它们。在此背景下,修订控制系统(RCS)应运而生,并成为开发人员修订代码的必备工具之一。
还有一种组合:源代码编写和编译是在不同平台上实现的,技术术语是软件迁移。
一个关于采集文章列表的教程采集设置的规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-08-11 02:04
大家好,今天我们来聊一聊采集文章list 的教程。今天的目标是网易的互联网新闻榜。地址是:
好的,我们来看看采集设置的规则和步骤。首先点击“内容”、“内容管理”、“一键管理工具”,在右侧的操作窗口中点击“新建项目”,输入采集的项目名称和属于采集的列文章后如下:
点击下一步进入集合列表的采集规则,我们要采集的列表首页,即列表索引页,如下图:
列表索引页:
浏览这个网址,查看源文件,找到这个文章列表的开始和结束标签,如下:
列出开始标签://TechNews.getNews(icid, TechNews.date, TechNews.pagex);
列表结束标记:
列表索引分页:无设置
点击下一步进入设置链接的标签,如下:
链接开始标签:"url":"
链接结束标记:“
这样设置后就可以看到了
列表拦截测试
这里就可以看到列表页的效果了,(点击一篇文章文章即可进入)点击下一步继续设置内容页的规则。
开始短标题标签:
短标题结束标签:
文章Content 起始标签:
文章内容标签结束:
时间设置可以省略。如果想要采集其他站点的时间,选择设置选项卡,然后查看源码如下:
时间开始标记: 查看全部
一个关于采集文章列表的教程采集设置的规则
大家好,今天我们来聊一聊采集文章list 的教程。今天的目标是网易的互联网新闻榜。地址是:
好的,我们来看看采集设置的规则和步骤。首先点击“内容”、“内容管理”、“一键管理工具”,在右侧的操作窗口中点击“新建项目”,输入采集的项目名称和属于采集的列文章后如下:
点击下一步进入集合列表的采集规则,我们要采集的列表首页,即列表索引页,如下图:
列表索引页:
浏览这个网址,查看源文件,找到这个文章列表的开始和结束标签,如下:
列出开始标签://TechNews.getNews(icid, TechNews.date, TechNews.pagex);
列表结束标记:
列表索引分页:无设置
点击下一步进入设置链接的标签,如下:
链接开始标签:"url":"
链接结束标记:“
这样设置后就可以看到了
列表拦截测试
这里就可以看到列表页的效果了,(点击一篇文章文章即可进入)点击下一步继续设置内容页的规则。
开始短标题标签:
短标题结束标签:
文章Content 起始标签:
文章内容标签结束:
时间设置可以省略。如果想要采集其他站点的时间,选择设置选项卡,然后查看源码如下:
时间开始标记:
用考拉,一天产出几万篇高质量SEO文章怎么编写?
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-11 02:01
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
这两天大家都非常关注“优采云采集器采集如何写规则”的内容。质疑编辑的客户是那么的特别。不过在我说这些信息之前,大家应该先来这里探讨一下搜索优化原创文章怎么做的!对于引流思维的SEOer来说,文章的质量绝不是中心追求,做网站的最关心的是网站权重和流量。 1个高质量的网页文章写在低权重网站和写在旧网站上,最终排名和引流效果不同!
想了解【优采云采集器采集怎么写规则】的小伙伴,其实大家都很珍惜的就是文章过去讲的内容。本来,流量大的网站文章写起来很容易,但是一个SEO文案能产生的流量实在是微乎其微。希望用文章来设置推广流量的目的。最重要的是量化!没有人文章 可以获得 1 次访问(1 天)。如果你能产出 10000 篇文章,你的每日流量将增加 10000。然而,谈论起来很简单。实际写作的时候,一个人一天只能产出30多篇文章,最厉害的也只有70篇。就算应用到伪原创系统,100多篇文章也会死!看到这里,我们先抛开“优采云采集器采集怎么写规则”这件事,想想如何实现AI代文章!
优化器认为的人工编辑器是什么? 文章原创不仅仅是一段原创的输出!在各个平台的平台词典中,原创并不代表帖子中没有重复的句子。其实只要你的文章不重复其他网页的内容,被爬取的几率就会大大增加。一个优秀的内容,干货足够抢眼,坚持同一个核心思想,只需要保证没有重复的大段,就说明这个文章还是很有可能被认出来的,甚至成为排水的好文章。比如这篇文章,你可以用标题搜索搜索【优采云采集器采集怎么写规则】,然后点击进入。其实这篇文章文章是用考拉SEO工具自动写的文章工具快速导出啦!
这个系统的伪原创系统应该叫手工写文章software。可长时间编辑数以万计的长尾优化文案。如果你的网页质量足够强,收录rate 可以高达77%。详细的申请步骤,用户首页有动画展示和新手引导,大家可以简单测试几下!很内疚,没有给大家带来关于“优采云采集器采集如何写规则”的详细解释,大概让大家看到了这样的系统语言。但是如果我们有智能书写文章内容的需求,我们不妨看看导航栏,让你的seo每天达到数百页浏览量。不是坏事吗? 查看全部
用考拉,一天产出几万篇高质量SEO文章怎么编写?
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
这两天大家都非常关注“优采云采集器采集如何写规则”的内容。质疑编辑的客户是那么的特别。不过在我说这些信息之前,大家应该先来这里探讨一下搜索优化原创文章怎么做的!对于引流思维的SEOer来说,文章的质量绝不是中心追求,做网站的最关心的是网站权重和流量。 1个高质量的网页文章写在低权重网站和写在旧网站上,最终排名和引流效果不同!
想了解【优采云采集器采集怎么写规则】的小伙伴,其实大家都很珍惜的就是文章过去讲的内容。本来,流量大的网站文章写起来很容易,但是一个SEO文案能产生的流量实在是微乎其微。希望用文章来设置推广流量的目的。最重要的是量化!没有人文章 可以获得 1 次访问(1 天)。如果你能产出 10000 篇文章,你的每日流量将增加 10000。然而,谈论起来很简单。实际写作的时候,一个人一天只能产出30多篇文章,最厉害的也只有70篇。就算应用到伪原创系统,100多篇文章也会死!看到这里,我们先抛开“优采云采集器采集怎么写规则”这件事,想想如何实现AI代文章!
优化器认为的人工编辑器是什么? 文章原创不仅仅是一段原创的输出!在各个平台的平台词典中,原创并不代表帖子中没有重复的句子。其实只要你的文章不重复其他网页的内容,被爬取的几率就会大大增加。一个优秀的内容,干货足够抢眼,坚持同一个核心思想,只需要保证没有重复的大段,就说明这个文章还是很有可能被认出来的,甚至成为排水的好文章。比如这篇文章,你可以用标题搜索搜索【优采云采集器采集怎么写规则】,然后点击进入。其实这篇文章文章是用考拉SEO工具自动写的文章工具快速导出啦!
这个系统的伪原创系统应该叫手工写文章software。可长时间编辑数以万计的长尾优化文案。如果你的网页质量足够强,收录rate 可以高达77%。详细的申请步骤,用户首页有动画展示和新手引导,大家可以简单测试几下!很内疚,没有给大家带来关于“优采云采集器采集如何写规则”的详细解释,大概让大家看到了这样的系统语言。但是如果我们有智能书写文章内容的需求,我们不妨看看导航栏,让你的seo每天达到数百页浏览量。不是坏事吗?
织梦模板引擎制作规范系统的模板代码参考标记
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-08-08 05:17
分析引擎概述模板设计规范代码参考
标签参考:arclist(artlist,likeart,hotart,imglist,imginfolist,coolart,specart) field channel mytag投票friendlink mynews loop channelartlist page list pagelist pagebreak fieldlist
一、织梦Template 解析引擎概述 在了解Dedecms的模板代码之前,了解织梦template引擎的知识是非常有意义的。 织梦template 引擎是一个使用 XML 命名空间形式的模板解析器。使用织梦parser 解析模板的最大好处是可以方便的指定标签的属性。感觉就像你在使用HTML,使模板代码非常直观和灵活。新版织梦template 引擎不仅可以分析模板,还可以分析模板中的错误标记。
1、织梦模板引擎的代码风格有以下几种形式:
自定义样式模板(InnerText)
提醒:
对于这种形式的标签,在2.1版本中,只需要用“”来表示结束,但是
在V3中,需要严格使用"",否则会报错。
2、织梦模板引擎内置了多个系统标签,这些系统标签在任何情况下都可以直接使用。
(1)全局标记的意思是获取一个外部变量,除了数据库密码,系统的任何配置参数都可以调用,形式:
或
变量名不能加$符号,如变量$cfg_cmspath,应该写成。
(2)foreach 用于输出一个数组,形式为:
[field:key/] [field:value/]
(3)include 收录一个格式的文件:
文件搜索路径依次为:绝对路径、include文件夹、cms安装目录、cmsmain模板目录
3、织梦标签允许使用任何标签中的函数来处理获得的值,形式为:
@me 用于表示当前标签的值,其他参数由你的函数决定,例如:
二、Dedecms模板制作规范
Dedecms系统的模板不是固定的。用户可以在创建新列时选择列模板。官方只提供了最基本的默认模板,即内置系统模型的各个模板。 Dedecms 支持 self 定义通道模型。用户自定义新的渠道模型后,需要根据模型设计一套新的模板。
一、Concept,要设计和使用模板,必须了解以下概念:
1、plate(封面)模板:
指网站首页或者更重要栏目的封面使用的模板,一般以“index_identification ID.htm”命名,此外还有用户定义的单页或者自定义标记,以及是否支持板块模板也是可选的 如果支持,系统会在输出内容或生成特定文件之前使用板块模板标记引擎来解析内容。
2、列表模板:
指网站某一列中所有文章列表的模板,一般以“list_identification ID.htm”命名。
3、文件模板:
表示文档查看页面的模板,一般以“article_identification ID.htm”命名。
4、其他模板:
通用系统模板包括:首页模板、搜索模板、RSS、JS编译功能模板等。另外,用户还可以自定义模板创建任意文件。
二、 命名。为规范起见,织梦官方推荐统一的模板命名方式,如下:
1、Template 保存位置:
<p>模板目录:{cmspath/templets/style name(英文,默认default,其中system为系统底层模板,加为插件使用的模板)/具体功能模板文件} 查看全部
织梦模板引擎制作规范系统的模板代码参考标记
分析引擎概述模板设计规范代码参考
标签参考:arclist(artlist,likeart,hotart,imglist,imginfolist,coolart,specart) field channel mytag投票friendlink mynews loop channelartlist page list pagelist pagebreak fieldlist
一、织梦Template 解析引擎概述 在了解Dedecms的模板代码之前,了解织梦template引擎的知识是非常有意义的。 织梦template 引擎是一个使用 XML 命名空间形式的模板解析器。使用织梦parser 解析模板的最大好处是可以方便的指定标签的属性。感觉就像你在使用HTML,使模板代码非常直观和灵活。新版织梦template 引擎不仅可以分析模板,还可以分析模板中的错误标记。
1、织梦模板引擎的代码风格有以下几种形式:
自定义样式模板(InnerText)
提醒:
对于这种形式的标签,在2.1版本中,只需要用“”来表示结束,但是
在V3中,需要严格使用"",否则会报错。
2、织梦模板引擎内置了多个系统标签,这些系统标签在任何情况下都可以直接使用。
(1)全局标记的意思是获取一个外部变量,除了数据库密码,系统的任何配置参数都可以调用,形式:
或
变量名不能加$符号,如变量$cfg_cmspath,应该写成。
(2)foreach 用于输出一个数组,形式为:
[field:key/] [field:value/]
(3)include 收录一个格式的文件:
文件搜索路径依次为:绝对路径、include文件夹、cms安装目录、cmsmain模板目录
3、织梦标签允许使用任何标签中的函数来处理获得的值,形式为:
@me 用于表示当前标签的值,其他参数由你的函数决定,例如:
二、Dedecms模板制作规范
Dedecms系统的模板不是固定的。用户可以在创建新列时选择列模板。官方只提供了最基本的默认模板,即内置系统模型的各个模板。 Dedecms 支持 self 定义通道模型。用户自定义新的渠道模型后,需要根据模型设计一套新的模板。
一、Concept,要设计和使用模板,必须了解以下概念:
1、plate(封面)模板:
指网站首页或者更重要栏目的封面使用的模板,一般以“index_identification ID.htm”命名,此外还有用户定义的单页或者自定义标记,以及是否支持板块模板也是可选的 如果支持,系统会在输出内容或生成特定文件之前使用板块模板标记引擎来解析内容。
2、列表模板:
指网站某一列中所有文章列表的模板,一般以“list_identification ID.htm”命名。
3、文件模板:
表示文档查看页面的模板,一般以“article_identification ID.htm”命名。
4、其他模板:
通用系统模板包括:首页模板、搜索模板、RSS、JS编译功能模板等。另外,用户还可以自定义模板创建任意文件。
二、 命名。为规范起见,织梦官方推荐统一的模板命名方式,如下:
1、Template 保存位置:
<p>模板目录:{cmspath/templets/style name(英文,默认default,其中system为系统底层模板,加为插件使用的模板)/具体功能模板文件}
库爬取招聘:、python、requests、
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-06 19:08
文章采集规则注册账号,用requests和python。
1、爬取招聘网站的job信息,
2、设置爬取参数。简历上面都有response.detail这个参数,需要自己把headers中的getheaders参数传给爬虫解析。关于解析headers参数可参考:解析headers参数-zhwljobph。
requests库爬取方法示例代码:#-*-coding:utf-8-*-importrequestsfrompytestimporttest#爬取test。company。job。job_id=requests。get('/',headers={'user-agent':'mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/71.0.2723.141safari/537.36'}).strip()#正则表达式匹配的字符串# 查看全部
库爬取招聘:、python、requests、
文章采集规则注册账号,用requests和python。
1、爬取招聘网站的job信息,
2、设置爬取参数。简历上面都有response.detail这个参数,需要自己把headers中的getheaders参数传给爬虫解析。关于解析headers参数可参考:解析headers参数-zhwljobph。
requests库爬取方法示例代码:#-*-coding:utf-8-*-importrequestsfrompytestimporttest#爬取test。company。job。job_id=requests。get('/',headers={'user-agent':'mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/71.0.2723.141safari/537.36'}).strip()#正则表达式匹配的字符串#
文章采集规则使用百度统计公众号文章全部关键词过滤
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-08-05 05:06
文章采集规则使用百度统计公众号文章全部关键词,过滤掉明显是软文的内容,如果重复出现要及时去除。采集时间选择正月初二到三。主要保证按时间采集文章,记录每一个时间的采集数量及关键词对应的内容。每一个设置完后,设置几天锁定。采集规则大小写,阿拉伯数字是不能采集的,汉字采集用自动识别,空格,语句通顺,都是可以采集的。
百度统计公众号输入公众号名称/关键词,即刻获取新增文章数。原创保护在输入公众号名称/关键词时,即刻获取首发文章数,优质文章还可以获取首图文。点击任意单元直接获取采集的多级标题(可以同时获取一级标题及多级标题),百度统计上会显示结构化文档样式。共享文章,共享任意单元里的文章。采集频率依据设置的设置及文章的存放时间计算每天的采集量。
日均文章采集量,按照最佳采集设置方案来设置,即一个规则设置下来获取的最大量,设置标准是每篇文章都有保存机会。采集设置里有编辑时间设置及修改时间设置,推荐有效时间点设置下来的量最多。ps采集规则设置好后文章全部采集完,需要相关文章切换小号操作。我目前文章多数都是小号采集。由于方法太过简单,都是用采集器自动获取相关文章,因此并没有遇到需要修改采集规则的时候。
可以用采集-在线采集来采集百度新闻频道, 查看全部
文章采集规则使用百度统计公众号文章全部关键词过滤
文章采集规则使用百度统计公众号文章全部关键词,过滤掉明显是软文的内容,如果重复出现要及时去除。采集时间选择正月初二到三。主要保证按时间采集文章,记录每一个时间的采集数量及关键词对应的内容。每一个设置完后,设置几天锁定。采集规则大小写,阿拉伯数字是不能采集的,汉字采集用自动识别,空格,语句通顺,都是可以采集的。
百度统计公众号输入公众号名称/关键词,即刻获取新增文章数。原创保护在输入公众号名称/关键词时,即刻获取首发文章数,优质文章还可以获取首图文。点击任意单元直接获取采集的多级标题(可以同时获取一级标题及多级标题),百度统计上会显示结构化文档样式。共享文章,共享任意单元里的文章。采集频率依据设置的设置及文章的存放时间计算每天的采集量。
日均文章采集量,按照最佳采集设置方案来设置,即一个规则设置下来获取的最大量,设置标准是每篇文章都有保存机会。采集设置里有编辑时间设置及修改时间设置,推荐有效时间点设置下来的量最多。ps采集规则设置好后文章全部采集完,需要相关文章切换小号操作。我目前文章多数都是小号采集。由于方法太过简单,都是用采集器自动获取相关文章,因此并没有遇到需要修改采集规则的时候。
可以用采集-在线采集来采集百度新闻频道,
优采云采集器怎么采集今日头条文章?……(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-07-30 07:30
优采云采集器how采集今日头条文章? …… 因为今日头条文章是一个信息流,所以在使用优采云采集器之前,一定要知道如何抓取真实地址,我经常使用抓包工具Fiddler来抓取今日头条中的地址如果你不懂抓包,下面就谈不上!
优采云采集规则制定,高手进,后续积分……优采云采集到达的数据是html显示的数据,问题不大。 采集 只是设置网页编码。 【拜风网】
优采云采集 如何设置采集 URL 规则? …… “我采集一个网页地址,我在开头找到了一层,但我在最后也找到了一层,所以不行...采集如果没有数字网址怎么办!比如某个网址是list_50.html...只有上图...”------------------- ------- --在一些网站的列表翻页参数中,第一个参数无效,改值就行了...
优采云采集规则,如果列表页面有多个参数,应该怎么设置起始地址采集,……我试过了,优采云真的不行,因为它是起始URL的参数,只有一个*,不可能描述两个动态数据。好吧,换个角度想想,为什么不把这些网址变成一级网址,让优采云以采集的方式放出来采集。例如。 //i.html?_pgn=2&_skc=50&rt=nc 将此设置为开始...
优采云采集 规则是什么? …… 数据采集是个很累的工作,我也在做,所以感触很深,有必要有一个好用的采集设备。我买了,
优采云采集器如何设置规则... 有开始码和结束码,但必须是唯一的
优采云采集器的采集rules怎么写,采集页面图片中的文字?-...不得不说优采云很有用,但我不不觉得很好用,就是写那些采集规则。关于你设置的内容有很多不清楚的地方。拿钱去买。一开始客服很热情的为你解答。一旦你付了钱,你就可以买它并写下规则。嗯,如果有问题,需要找客服解决,结果却一拖再拖……
谁能告诉我优采云的采集规则是怎么回事!第一个采集 URL 规则不是唯一的! ... 就是描述不具体,不好说,我一直采集System 已经存在好几年了,现在Lesi one更聪明了。如果你用Lesi采集来做这个问题,就不是问题
优采云采集器采集如何获取规则和采集modules...优采云的规则很难设置,不像优采云采集器那么简单。你应该是新手,建议你用优采云采集器,看网上四分钟教程,跟着操作一次。希望我的回答能帮到你
优采云采集规则如何适用于所有版本……好像不行,优采云采集器可以适用于所有版本,你可以详细了解一下。
查看全部
优采云采集器怎么采集今日头条文章?……(组图)
优采云采集器how采集今日头条文章? …… 因为今日头条文章是一个信息流,所以在使用优采云采集器之前,一定要知道如何抓取真实地址,我经常使用抓包工具Fiddler来抓取今日头条中的地址如果你不懂抓包,下面就谈不上!
优采云采集规则制定,高手进,后续积分……优采云采集到达的数据是html显示的数据,问题不大。 采集 只是设置网页编码。 【拜风网】
优采云采集 如何设置采集 URL 规则? …… “我采集一个网页地址,我在开头找到了一层,但我在最后也找到了一层,所以不行...采集如果没有数字网址怎么办!比如某个网址是list_50.html...只有上图...”------------------- ------- --在一些网站的列表翻页参数中,第一个参数无效,改值就行了...
优采云采集规则,如果列表页面有多个参数,应该怎么设置起始地址采集,……我试过了,优采云真的不行,因为它是起始URL的参数,只有一个*,不可能描述两个动态数据。好吧,换个角度想想,为什么不把这些网址变成一级网址,让优采云以采集的方式放出来采集。例如。 //i.html?_pgn=2&_skc=50&rt=nc 将此设置为开始...
优采云采集 规则是什么? …… 数据采集是个很累的工作,我也在做,所以感触很深,有必要有一个好用的采集设备。我买了,
优采云采集器如何设置规则... 有开始码和结束码,但必须是唯一的
优采云采集器的采集rules怎么写,采集页面图片中的文字?-...不得不说优采云很有用,但我不不觉得很好用,就是写那些采集规则。关于你设置的内容有很多不清楚的地方。拿钱去买。一开始客服很热情的为你解答。一旦你付了钱,你就可以买它并写下规则。嗯,如果有问题,需要找客服解决,结果却一拖再拖……
谁能告诉我优采云的采集规则是怎么回事!第一个采集 URL 规则不是唯一的! ... 就是描述不具体,不好说,我一直采集System 已经存在好几年了,现在Lesi one更聪明了。如果你用Lesi采集来做这个问题,就不是问题
优采云采集器采集如何获取规则和采集modules...优采云的规则很难设置,不像优采云采集器那么简单。你应该是新手,建议你用优采云采集器,看网上四分钟教程,跟着操作一次。希望我的回答能帮到你
优采云采集规则如何适用于所有版本……好像不行,优采云采集器可以适用于所有版本,你可以详细了解一下。
优采云采集器使用教程–采集内容发布规则设置前面
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-07-27 05:12
优采云采集器使用教程-采集内容发布规则设置
在讲如何查找网站和采集文章链接和内容之前,我们先说一下内容发布相关的设置。
因为我在教程中设置了发布规则,这里我将简要介绍每个项目。
如下图
第一步,我们点这里内容发布规则
第二步,点击网页发布规则列表后面的加号
第三步出现模块管理(教程目录写好,我们的模块文件放在优采云program下的\Module\目录下),选择wordpress.post模块
第四步,网页编码选择UTF-8(wordpress程序是国外的,国际上一般是UTF8编码,国内有的会是GBK编码。比如Discuz论坛程序有两个安装包:UTF8和GBK。 )
第五步,网站地址填上我们网页的地址,加上接口文件名。比如你的接口文件名是jiekou.php网站,那么填写这个地址
第六步选择不登录作为登录方式。我们的界面文件免登录。
第七步,点击以下获取列表。通常你会得到wordpress的文章分类列表。然后选择一个列表,你选择哪个列表,采集的文章就会被发送到哪个列表。
然后在下面随机写一个配置名称并保存。
然后我们勾选我们刚刚保存的发布配置并启用它。
那别忘了点击右下角的保存,或者点击保存退出!
查看全部
优采云采集器使用教程–采集内容发布规则设置前面
优采云采集器使用教程-采集内容发布规则设置
在讲如何查找网站和采集文章链接和内容之前,我们先说一下内容发布相关的设置。
因为我在教程中设置了发布规则,这里我将简要介绍每个项目。
如下图
第一步,我们点这里内容发布规则
第二步,点击网页发布规则列表后面的加号
第三步出现模块管理(教程目录写好,我们的模块文件放在优采云program下的\Module\目录下),选择wordpress.post模块
第四步,网页编码选择UTF-8(wordpress程序是国外的,国际上一般是UTF8编码,国内有的会是GBK编码。比如Discuz论坛程序有两个安装包:UTF8和GBK。 )
第五步,网站地址填上我们网页的地址,加上接口文件名。比如你的接口文件名是jiekou.php网站,那么填写这个地址
第六步选择不登录作为登录方式。我们的界面文件免登录。
第七步,点击以下获取列表。通常你会得到wordpress的文章分类列表。然后选择一个列表,你选择哪个列表,采集的文章就会被发送到哪个列表。
然后在下面随机写一个配置名称并保存。
然后我们勾选我们刚刚保存的发布配置并启用它。
那别忘了点击右下角的保存,或者点击保存退出!
种舆情监控:全方位监测公开信息,抢先获取舆论趋势
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-07-16 02:00
种舆情监控:全方位监测公开信息,抢先获取舆论趋势
大数据资料采集:编程专业开发者社区文章信息优采云采集法
-------------
Data采集满足多种业务场景:适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等职业。
物种
舆情监控:全方位监控舆情,第一时间掌握舆情动向。
市场分析:获取真实的用户行为数据,全面把握客户的真实需求。
产品研发:大力支持用户研究,准确获取用户反馈和偏好。
风险预测:高效信息采集和数据清洗,及时应对系统风险。
帮助您快速发现数据中的新客户;查看竞争对手的业务数据,分析客户行为以拓展新业务,并通过精准营销降低风险和预算。
为大量消费者提供产品或服务的企业可以利用大数据进行精准营销;
拥有小而美模式的中小微企业,可以利用大数据进行服务转型;
必须在互联网压力下转型的传统企业需要与时俱进,充分利用大数据的价值。
------------
全网统一自媒体号:大数据信息资料采集
行星:大数据信息材料采集
网站:搜索骑士
欢迎关注。
--------
以下文字可以忽略
代码组合
作为软件的特殊部分,源代码可能收录在一个或多个文件中。程序不需要以与源代码相同的格式编写。例如,如果一个程序有C语言库的支持,那么就可以用C语言编写;而另一部分可以用汇编语言编写,以达到更高的运行效率。
更复杂的软件一般需要几十甚至几百个源代码的参与。为了降低这种复杂性,需要引入一个系统,可以描述各种源代码之间的关系并正确编译。在此背景下,修订控制系统(RCS)应运而生,并成为开发人员修订代码的必备工具之一。
他
还有一种组合:源代码编写和编译是在不同平台上实现的,技术术语是软件迁移。 查看全部
种舆情监控:全方位监测公开信息,抢先获取舆论趋势
大数据资料采集:编程专业开发者社区文章信息优采云采集法
-------------
Data采集满足多种业务场景:适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等职业。
物种
舆情监控:全方位监控舆情,第一时间掌握舆情动向。
市场分析:获取真实的用户行为数据,全面把握客户的真实需求。
产品研发:大力支持用户研究,准确获取用户反馈和偏好。
风险预测:高效信息采集和数据清洗,及时应对系统风险。
帮助您快速发现数据中的新客户;查看竞争对手的业务数据,分析客户行为以拓展新业务,并通过精准营销降低风险和预算。
为大量消费者提供产品或服务的企业可以利用大数据进行精准营销;
拥有小而美模式的中小微企业,可以利用大数据进行服务转型;
必须在互联网压力下转型的传统企业需要与时俱进,充分利用大数据的价值。
------------
全网统一自媒体号:大数据信息资料采集
行星:大数据信息材料采集
网站:搜索骑士
欢迎关注。
--------
以下文字可以忽略
代码组合
作为软件的特殊部分,源代码可能收录在一个或多个文件中。程序不需要以与源代码相同的格式编写。例如,如果一个程序有C语言库的支持,那么就可以用C语言编写;而另一部分可以用汇编语言编写,以达到更高的运行效率。
更复杂的软件一般需要几十甚至几百个源代码的参与。为了降低这种复杂性,需要引入一个系统,可以描述各种源代码之间的关系并正确编译。在此背景下,修订控制系统(RCS)应运而生,并成为开发人员修订代码的必备工具之一。
他
还有一种组合:源代码编写和编译是在不同平台上实现的,技术术语是软件迁移。
蜜蜂采集能不能支持WordPress(WP)网站的文章?
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-07-15 02:18
经常有用户问,Bee采集可以支持WordPress(WP)网站的文章吗?可以支持采集网易新闻、新浪、白家豪、小熊账号文章采集吗?
理论上只要把采集规则写在代码中就可以支持。但是,要在这么多平台上实现采集规则,我真的没有精力去做,因为这个插件只是我业余时间开发的,但我也尽量保证每周更新一次或二、而且价格可以说是白菜价了,现在这么良心的开发商不多了,哈哈哈。
然而,我发现采集文章无非是为了识别文章的标题、文字内容和图片三个主要目标。如果网站为每个目标采集设置规则,并且做成可配置的形式,这样的工作量可以大大减少,于是有了这个功能——采集rule配置,基本上可以满足大多数用户的需求,但也会有例外。尤其是一些擅长防爬的网站,设置规则不一定能成功采集,但是能够实现这样的功能已经很不错了不是吗?不管怎样,插件以后会不断更新,只会越来越完善。现在无法实现的功能,未来可能会实现。
当然,配置规则也有一定的门槛,就是要懂一点HTML规则,不过主要有3点,tags,classes,ids。我不想在这里重复它们。网上有很多资料。
让我们来看看如何使用这个功能。
采集规则设置界面
上图是采集规则的设置界面。首先,我们点击添加按钮,会显示一个收录网站地址、标题、内容和图片的表单。
其中网站address指的是网站的域名,填写的时候记得带上或者
标题、内容、图片三者之一填写label、class、id,需具备html基础知识
填好规则后点击保存,就可以导入网站的文章内容(理论上)。
如果您不知道这些规则怎么写,Bee 也可以接受书写付费,每条规则 15 元。
更多服务 查看全部
蜜蜂采集能不能支持WordPress(WP)网站的文章?
经常有用户问,Bee采集可以支持WordPress(WP)网站的文章吗?可以支持采集网易新闻、新浪、白家豪、小熊账号文章采集吗?
理论上只要把采集规则写在代码中就可以支持。但是,要在这么多平台上实现采集规则,我真的没有精力去做,因为这个插件只是我业余时间开发的,但我也尽量保证每周更新一次或二、而且价格可以说是白菜价了,现在这么良心的开发商不多了,哈哈哈。
然而,我发现采集文章无非是为了识别文章的标题、文字内容和图片三个主要目标。如果网站为每个目标采集设置规则,并且做成可配置的形式,这样的工作量可以大大减少,于是有了这个功能——采集rule配置,基本上可以满足大多数用户的需求,但也会有例外。尤其是一些擅长防爬的网站,设置规则不一定能成功采集,但是能够实现这样的功能已经很不错了不是吗?不管怎样,插件以后会不断更新,只会越来越完善。现在无法实现的功能,未来可能会实现。
当然,配置规则也有一定的门槛,就是要懂一点HTML规则,不过主要有3点,tags,classes,ids。我不想在这里重复它们。网上有很多资料。
让我们来看看如何使用这个功能。
WX20180628-170306@2x.png" />采集规则设置界面
上图是采集规则的设置界面。首先,我们点击添加按钮,会显示一个收录网站地址、标题、内容和图片的表单。
其中网站address指的是网站的域名,填写的时候记得带上或者
标题、内容、图片三者之一填写label、class、id,需具备html基础知识
填好规则后点击保存,就可以导入网站的文章内容(理论上)。
如果您不知道这些规则怎么写,Bee 也可以接受书写付费,每条规则 15 元。
更多服务
如何从目标站把文章内容获取规则上面介绍的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-07-13 21:01
中间:(*).html
最后一页:
复制一个分页地址,回到“添加采集Node”页面,选择“Source Attribute”为“Bulk Generate List URL”,将地址粘贴到“Matching URL”中,修改规则更改为(* ),在“批量生成地址设置”(*)中输入1到172,表示生成列表的第一页到最后172页的所有地址。
测试一下。在弹出框中,我们可以看到循环出172条地址记录,设置顺利。有时我们会遇到列表难以获取的情况,可以将不规则地址复制到“手动指定列表URL”的文本框中给采集。
3.设置文章URL 匹配规则
上面指定了文章address 源页面。这一步需要在这些页面中找到符合要求的文章address页面。打开一个列表页面,观察左栏中的框收录我们需要的所有地址。在这种情况下,我们可以区分明显的页面。您可以使用“区域开头的HTML”和“区域结尾的HTMLL”的设置进行过滤。
但是,也可以使用其他方法。将鼠标移动到各个链接地址,观察浏览器左下角显示的完整地址。我们需要的地址都收录“PHP_jiaocheng/20”,那么我们填写“必须收录”。
这两种方法都可以过滤掉地址。如果遇到复杂的页面,可以一起使用。通过正则化,几乎没有不能过滤掉的地址。与下图进行比较。最后确认,进入下一步“网页内容获取规则”。
4.Web 内容获取规则
上面介绍了设置列表的方法,接下来我们进入内容获取规则的设置。如果采集是上菜的话,上面一到三步的作用只是开胃菜,作为下面主菜的介绍。下一步就是介绍如何从目标站带来文章内容采集。这一步是整个采集中最核心的部分。
继续回到织梦的PHP教程列表,直接在列表中打开文章即可。这里我们以“正则表达式”文章为例:,将地址复制到“预览网址”;因为织梦all 文章没有分页,这里不需要设置分页,直接进入“固定采集项目”页面
(注:如果采集的内容收录分页,则只需完成分页导航部分的匹配规则即可。这里是所有分页列表,上下页表格或不完整的分页列表基于内容. 刚刚设置)
以下为引用内容:
Pagination list for all Lists:页面内容列出所有链接,如下图
上下页或不完整分页列表:单页显示当前分页内容,不完整显示列表形式
5. 固定采集 项目
在这一步中,我们开始分析页面的源代码。 采集无非就是分析HTML页面的结构,获取我们需要的内容。因此,我们需要对HTML代码有一定的了解,能够通过查看页面源文件找到我们需要的内容。最好多开几页分析一下,找出相似之处。
推荐大家使用Dreamweaver进行分析。分析页面代码时,使用搜索功能方便很多,尤其是找到标签后,搜索重复,减少分析错误。
1)文章Title:本页标题为“正则表达式”,复制。在 Dreamweaver 中按 Ctrl+F 搜索全部,共有 30 条记录。由于唯一性,这里我们选择105行段落“
正则表达式”标签,复制到“fixed采集Project”文章title的匹配规则中,将title替换为关键字“[Content]”,最后变成[Content]。
2) 作者:以作者为关键字继续搜索,只有110行有唯一的外观,将它们与alluse前后的标签一起复制到匹配规则中,并使用[content]替换采集。
3) 来源:同上,在109行找到标签,复制,用[Content]替换采集。如果来源收录超链接标签,想去掉,在过滤规则框中填写如下规则过滤掉:]*)> 查看全部
如何从目标站把文章内容获取规则上面介绍的方法
中间:(*).html
最后一页:
复制一个分页地址,回到“添加采集Node”页面,选择“Source Attribute”为“Bulk Generate List URL”,将地址粘贴到“Matching URL”中,修改规则更改为(* ),在“批量生成地址设置”(*)中输入1到172,表示生成列表的第一页到最后172页的所有地址。
测试一下。在弹出框中,我们可以看到循环出172条地址记录,设置顺利。有时我们会遇到列表难以获取的情况,可以将不规则地址复制到“手动指定列表URL”的文本框中给采集。
3.设置文章URL 匹配规则
上面指定了文章address 源页面。这一步需要在这些页面中找到符合要求的文章address页面。打开一个列表页面,观察左栏中的框收录我们需要的所有地址。在这种情况下,我们可以区分明显的页面。您可以使用“区域开头的HTML”和“区域结尾的HTMLL”的设置进行过滤。
但是,也可以使用其他方法。将鼠标移动到各个链接地址,观察浏览器左下角显示的完整地址。我们需要的地址都收录“PHP_jiaocheng/20”,那么我们填写“必须收录”。
这两种方法都可以过滤掉地址。如果遇到复杂的页面,可以一起使用。通过正则化,几乎没有不能过滤掉的地址。与下图进行比较。最后确认,进入下一步“网页内容获取规则”。
4.Web 内容获取规则
上面介绍了设置列表的方法,接下来我们进入内容获取规则的设置。如果采集是上菜的话,上面一到三步的作用只是开胃菜,作为下面主菜的介绍。下一步就是介绍如何从目标站带来文章内容采集。这一步是整个采集中最核心的部分。
继续回到织梦的PHP教程列表,直接在列表中打开文章即可。这里我们以“正则表达式”文章为例:,将地址复制到“预览网址”;因为织梦all 文章没有分页,这里不需要设置分页,直接进入“固定采集项目”页面
(注:如果采集的内容收录分页,则只需完成分页导航部分的匹配规则即可。这里是所有分页列表,上下页表格或不完整的分页列表基于内容. 刚刚设置)
以下为引用内容:
Pagination list for all Lists:页面内容列出所有链接,如下图
上下页或不完整分页列表:单页显示当前分页内容,不完整显示列表形式
5. 固定采集 项目
在这一步中,我们开始分析页面的源代码。 采集无非就是分析HTML页面的结构,获取我们需要的内容。因此,我们需要对HTML代码有一定的了解,能够通过查看页面源文件找到我们需要的内容。最好多开几页分析一下,找出相似之处。
推荐大家使用Dreamweaver进行分析。分析页面代码时,使用搜索功能方便很多,尤其是找到标签后,搜索重复,减少分析错误。
1)文章Title:本页标题为“正则表达式”,复制。在 Dreamweaver 中按 Ctrl+F 搜索全部,共有 30 条记录。由于唯一性,这里我们选择105行段落“
正则表达式”标签,复制到“fixed采集Project”文章title的匹配规则中,将title替换为关键字“[Content]”,最后变成[Content]。
2) 作者:以作者为关键字继续搜索,只有110行有唯一的外观,将它们与alluse前后的标签一起复制到匹配规则中,并使用[content]替换采集。
3) 来源:同上,在109行找到标签,复制,用[Content]替换采集。如果来源收录超链接标签,想去掉,在过滤规则框中填写如下规则过滤掉:]*)>
第二天数据总结提炼自己的优化点是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-07-11 02:03
文章采集规则,实际上是按照人工发布数据规则进行发布的,因此统计结果,肯定会有两批数据。数据优化团队会在发布数据报告之前,经过前期统计和整理工作,分别采集两份数据,根据前端实际的展示效果和需求来设计组织数据优化团队对其结果进行合并。我们会从已发布报告的数据计算得出发布团队发布报告的效果评估和总结,展现在最终的数据报告中。
我们会在当天晚上24点给到技术团队结果反馈。结果反馈的时间和报告发布时间必须是一致的。方便大家第二天数据总结提炼自己的优化点。内容优化如何体现:1.展示效果提升优化报告如何撰写和展示:建议在最大化展示差异性的同时,要细化自己的优化特征。对最有感觉的点进行详细说明,并结合数据查看效果。注意风格要简单清晰,避免手动在线编辑。
2.附件优化报告如何撰写和展示:建议只需要放报告后附件格式,并且不要做过多的加减号,而是要根据内容的复杂程度,从简单到复杂,这样好于整个报告一口气说完所有的优化点。这样的方式更利于读者查看,可以非常直观。3.排版优化如何撰写和展示:建议注意目录、数据图表、位置等的简单,结构方面要尽量规范,并进行必要的样式控制。
4.追溯方面优化如何撰写和展示:建议当有任何数据变动发生时,报告会及时展示;报告中还会有对新数据内容的更新计划。5.数据查看方面优化如何撰写和展示:可以通过对比、滚动等操作,调整报告的结构,以达到更直观的查看效果。6.定制化优化如何撰写和展示:报告的可定制化程度主要应该以下几个方面:(。
1)在报告中增加“经验”“总结”“结论”“提示”类标题,以求快速了解报告的内容和相关性。
2)调整合适的查看区域,增加的对比结果,以及利用颜色区分可能涉及的业务。
3)可以根据自己的习惯对报告进行调整,增加权威解读及评论,优化过去10年的业务数据和价值获取转化率。
4)对报告进行更新,增加新优化点,以求实现更长期的目标。7.数据综合优化如何撰写和展示:统计结果数据不同,不仅能反应报告本身的问题,而且代表了报告总体上是否达到了更高的优化目标。统计结果和实际变化的情况,对于我们的数据敏感度、数据挖掘能力都是很好的考验。如果目标是快速发布高价值文章,综合性的优化,以达到优化目标,可以说是非常可取的。 查看全部
第二天数据总结提炼自己的优化点是什么?
文章采集规则,实际上是按照人工发布数据规则进行发布的,因此统计结果,肯定会有两批数据。数据优化团队会在发布数据报告之前,经过前期统计和整理工作,分别采集两份数据,根据前端实际的展示效果和需求来设计组织数据优化团队对其结果进行合并。我们会从已发布报告的数据计算得出发布团队发布报告的效果评估和总结,展现在最终的数据报告中。
我们会在当天晚上24点给到技术团队结果反馈。结果反馈的时间和报告发布时间必须是一致的。方便大家第二天数据总结提炼自己的优化点。内容优化如何体现:1.展示效果提升优化报告如何撰写和展示:建议在最大化展示差异性的同时,要细化自己的优化特征。对最有感觉的点进行详细说明,并结合数据查看效果。注意风格要简单清晰,避免手动在线编辑。
2.附件优化报告如何撰写和展示:建议只需要放报告后附件格式,并且不要做过多的加减号,而是要根据内容的复杂程度,从简单到复杂,这样好于整个报告一口气说完所有的优化点。这样的方式更利于读者查看,可以非常直观。3.排版优化如何撰写和展示:建议注意目录、数据图表、位置等的简单,结构方面要尽量规范,并进行必要的样式控制。
4.追溯方面优化如何撰写和展示:建议当有任何数据变动发生时,报告会及时展示;报告中还会有对新数据内容的更新计划。5.数据查看方面优化如何撰写和展示:可以通过对比、滚动等操作,调整报告的结构,以达到更直观的查看效果。6.定制化优化如何撰写和展示:报告的可定制化程度主要应该以下几个方面:(。
1)在报告中增加“经验”“总结”“结论”“提示”类标题,以求快速了解报告的内容和相关性。
2)调整合适的查看区域,增加的对比结果,以及利用颜色区分可能涉及的业务。
3)可以根据自己的习惯对报告进行调整,增加权威解读及评论,优化过去10年的业务数据和价值获取转化率。
4)对报告进行更新,增加新优化点,以求实现更长期的目标。7.数据综合优化如何撰写和展示:统计结果数据不同,不仅能反应报告本身的问题,而且代表了报告总体上是否达到了更高的优化目标。统计结果和实际变化的情况,对于我们的数据敏感度、数据挖掘能力都是很好的考验。如果目标是快速发布高价值文章,综合性的优化,以达到优化目标,可以说是非常可取的。
抓取新闻数据必须要确定要抓取的新闻目标网站。
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-07-08 04:33
如果要爬取新闻数据,必须确定要爬取的新闻目标网站。国内新闻网站很多,大大小小的新闻网站上千条。百度是收录近两千条新闻网站。其实我们可以先采集百度新闻。
百度新闻是一个有很多新闻标题和链接的新闻采集页面。我们只需要通过百度新闻提取新闻数据下载
通过这个过程,我们可以制作一个简单的爬虫代码:
使用请求下载百度新闻首页,提取标题,即网页中的链接,然后提取新闻链接,然后下载新闻链接并保存到数据库中。
import requests
import random
# 要访问的目标页面
targetUrl = "http://httpbin.org/ip"
# 要访问的目标HTTPS页面
# targetUrl = "https://httpbin.org/ip"
# 代理服务器(产品官网 www.16yun.cn)
proxyHost = "t.16yun.cn"
proxyPort = "31111"
# 代理验证信息
proxyUser = "username"
proxyPass = "password"
proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host" : proxyHost,
"port" : proxyPort,
"user" : proxyUser,
"pass" : proxyPass,
}
# 设置 http和https访问都是用HTTP代理
proxies = {
"http" : proxyMeta,
"https" : proxyMeta,
}
# 设置IP切换头
tunnel = random.randint(1,10000)
headers = {"Proxy-Tunnel": str(tunnel)}
resp = requests.get(targetUrl, proxies=proxies, headers=headers)
print resp.status_code
print resp.text 查看全部
抓取新闻数据必须要确定要抓取的新闻目标网站。
如果要爬取新闻数据,必须确定要爬取的新闻目标网站。国内新闻网站很多,大大小小的新闻网站上千条。百度是收录近两千条新闻网站。其实我们可以先采集百度新闻。
百度新闻是一个有很多新闻标题和链接的新闻采集页面。我们只需要通过百度新闻提取新闻数据下载
通过这个过程,我们可以制作一个简单的爬虫代码:
使用请求下载百度新闻首页,提取标题,即网页中的链接,然后提取新闻链接,然后下载新闻链接并保存到数据库中。
import requests
import random
# 要访问的目标页面
targetUrl = "http://httpbin.org/ip"
# 要访问的目标HTTPS页面
# targetUrl = "https://httpbin.org/ip"
# 代理服务器(产品官网 www.16yun.cn)
proxyHost = "t.16yun.cn"
proxyPort = "31111"
# 代理验证信息
proxyUser = "username"
proxyPass = "password"
proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host" : proxyHost,
"port" : proxyPort,
"user" : proxyUser,
"pass" : proxyPass,
}
# 设置 http和https访问都是用HTTP代理
proxies = {
"http" : proxyMeta,
"https" : proxyMeta,
}
# 设置IP切换头
tunnel = random.randint(1,10000)
headers = {"Proxy-Tunnel": str(tunnel)}
resp = requests.get(targetUrl, proxies=proxies, headers=headers)
print resp.status_code
print resp.text
优采云采集规则怎么写?(一)(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-06-27 05:49
文章发布大规模信息网站时,如果一一文章在线发布,不仅浪费时间,而且效率不高。这时候为了提高更新网站的效率,出现了优采云采集器,但是优采云采集怎么写规则呢?下面我来详细介绍一下。
优采云采集rule 写作介绍
第一步:新建文章采集节点
登录后台,点击采集>>采集节点管理>>添加新节点>>选择普通文章>>确定
第 2 步:填写采集list 规则
1.节点名称:随便你(注意一定要能区分,因为节点太多的话,可能会把自己搞砸)
2.目标页面编码:看目标页面的编码
3.匹配URL:到采集目标列表页面查看其列表规则!比如很多网站列表的第一页和其他内页有很大的不同,所以我一般不会采集定位到列表的第一页!
最好从第二页开始(虽然可以找到第一页,但是很多网站根本没有第一页,所以这里就不讲怎么找第一页了)
4.区末尾的HTML:在采集目标列表页面打开源码!找到文章标题附近需要采集的部分,这是本页唯一的,其他需要采集的页面也是唯一的html标签!
完成,点击保存信息进入下一步!如果规则写得正确,那么就会有一个基于内容的URL获取规则测试。
再次按下一步!回车填写采集content规则
第 3 步:采集内容规则
1.文章Title:在文章Title前后找两个标签来标识标题!
2.文章Content:找文章content前后两个标签来识别内容!我的采集网站文章内容前后唯一的标签是
... 查看全部
优采云采集规则怎么写?(一)(图)
文章发布大规模信息网站时,如果一一文章在线发布,不仅浪费时间,而且效率不高。这时候为了提高更新网站的效率,出现了优采云采集器,但是优采云采集怎么写规则呢?下面我来详细介绍一下。
优采云采集rule 写作介绍
第一步:新建文章采集节点
登录后台,点击采集>>采集节点管理>>添加新节点>>选择普通文章>>确定
第 2 步:填写采集list 规则
1.节点名称:随便你(注意一定要能区分,因为节点太多的话,可能会把自己搞砸)
2.目标页面编码:看目标页面的编码
3.匹配URL:到采集目标列表页面查看其列表规则!比如很多网站列表的第一页和其他内页有很大的不同,所以我一般不会采集定位到列表的第一页!
最好从第二页开始(虽然可以找到第一页,但是很多网站根本没有第一页,所以这里就不讲怎么找第一页了)
4.区末尾的HTML:在采集目标列表页面打开源码!找到文章标题附近需要采集的部分,这是本页唯一的,其他需要采集的页面也是唯一的html标签!
完成,点击保存信息进入下一步!如果规则写得正确,那么就会有一个基于内容的URL获取规则测试。
再次按下一步!回车填写采集content规则
第 3 步:采集内容规则
1.文章Title:在文章Title前后找两个标签来标识标题!
2.文章Content:找文章content前后两个标签来识别内容!我的采集网站文章内容前后唯一的标签是
...
关于人民日报文章核心部分的获取问题,你了解多少?
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-06-26 07:01
文章采集规则上面有讨论过了,这里我只说说关于文章核心部分的获取问题,这个很多人可能都有些问题和困惑,首先必须明确的是对于人民日报的文章,目前还是非官方唯一合法的采集渠道是以人民网的官方授权方式获取到人民日报的文章渠道,这也是目前为止最为可靠,传播量最大的采集渠道。至于具体的转发微博,这个其实需要一个具体的版本解析,前面也有考虑过,解析不仅仅要解析,还需要自己去自学css,sass,js等。
另外由于人民日报做的是采集回复,一般不会轻易放出采集地址和原文,这样就不如采集其他渠道的优势,至于其他外国媒体就更复杂一些了,这里就不展开说了。
如果不考虑转发,也不需要让别人帮忙引用的话,在其他国家地区的某些域名下注册一个网站,
简单来说,如果不想要转发或者复制粘贴的话,买下他们的域名才是正确方法;如果想要转发或者复制粘贴,那就在别的地方一次引发那么多流量过来,一是对域名的收费,二是采集本地文章,下载后转发到微博上实现功能(例如发微博回复)。如果想要加大流量,那就买下这些国外的域名并把n多条微博做在一个链接上,实现搜索引擎流量的迁移吧。
@胡筠itodds...我们学校每天好多这样的人...很多时候他们自己做了一个东西,之后没有被人看到,也就不会有什么流量和关注度,被人看到了也不一定能看懂, 查看全部
关于人民日报文章核心部分的获取问题,你了解多少?
文章采集规则上面有讨论过了,这里我只说说关于文章核心部分的获取问题,这个很多人可能都有些问题和困惑,首先必须明确的是对于人民日报的文章,目前还是非官方唯一合法的采集渠道是以人民网的官方授权方式获取到人民日报的文章渠道,这也是目前为止最为可靠,传播量最大的采集渠道。至于具体的转发微博,这个其实需要一个具体的版本解析,前面也有考虑过,解析不仅仅要解析,还需要自己去自学css,sass,js等。
另外由于人民日报做的是采集回复,一般不会轻易放出采集地址和原文,这样就不如采集其他渠道的优势,至于其他外国媒体就更复杂一些了,这里就不展开说了。
如果不考虑转发,也不需要让别人帮忙引用的话,在其他国家地区的某些域名下注册一个网站,
简单来说,如果不想要转发或者复制粘贴的话,买下他们的域名才是正确方法;如果想要转发或者复制粘贴,那就在别的地方一次引发那么多流量过来,一是对域名的收费,二是采集本地文章,下载后转发到微博上实现功能(例如发微博回复)。如果想要加大流量,那就买下这些国外的域名并把n多条微博做在一个链接上,实现搜索引擎流量的迁移吧。
@胡筠itodds...我们学校每天好多这样的人...很多时候他们自己做了一个东西,之后没有被人看到,也就不会有什么流量和关注度,被人看到了也不一定能看懂,
文档介绍:CX文章采集器规则写法教程教你如何写采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-06-24 22:07
文档介绍:CX文章采集器rule写作教程,教你如何写采集rule
相信使用Discuz做网站的用户很多,所以使用CX采集插件的用户也很多。我也用过CX采集插件。我个人认为非常好。它是 Discuz 插件之一。很不错的采集插件,非常适合Dicuz,可以说是类似织梦,新云等程序后台自带的那种采集插件,但是很多人还是很迷茫插件的采集规则编写 没有,虽然我水平不高,但勉强能写一些规则,所以就写个简单的教程,新手可以看看,老手不要喷我!
在cx采集插件中,机器人是采集器。首先告诉你采集器制作的基本原理和思路!
1、首先确定采集的文章list页面的链接(这里的链接必须是list的链接)
2、需要确认列表页采集的内容区域,即机器人中的“列表区域识别规则”
3、需要在采集的这个列表页中确认文章的连接,即“文章link URL识别规则”
4.然后,我们要确认我们想要采集的文章内容范围,也就是“文章Content Identification Rule”
5、依靠前面的4步,我们基本确定了采集的范围。过滤掉一些你不想要的文章话题或内容,可以根据实际情况设置“过滤规则”。
我们的教程在下面正式开始。我以搜手网的文章列表为例给大家讲解一下;下面我们将特指采集。 com/jfff/ysjf/sssp/这个列表页;
第一步:后台插件——CX采集器-add机器人
基本设置: 1. 机器人名称(即机器人名称); 2.匹配模式(一般选择正则表达式); 3.一次采集的总数(即每次采集的总数,根据自己的选择设置); 4批采集数量(默认5个,不要太大,否则采集会超时) 5.发布时间(可以自定义发布时间,如果不设置,以当前时间为准)
第二:设置采集的列表页
1. 采集页面url设置有两种,一种是手动输入,一种是自动增长。我们以手动输入为例;添加链接后,点击测试是否可以链接到;
2. 采集页面的编码设置,我们可以点击程序辅助识别,这里是采集页面的编码,其他3项,根据个人需要设置
3.设置列表区域识别规则
到我们想要采集的页面,右键,查看源文件,找到文章链接url区域,规则中的url区域用[list]表示
现在我们需要在开始区域和结束区域找到div或其他标签。 文章link URL 必须在此区域中并且是最新的。标签必须是唯一的,例如:
[list]
然后,我们需要点击下面的测试,看看是否可以识别文章link url区域
4、文章link url 识别规则
规则需要的连接如图所示
我们将引号中·的连接替换为[url],即·填写规则,然后点击测试 查看全部
文档介绍:CX文章采集器规则写法教程教你如何写采集规则
文档介绍:CX文章采集器rule写作教程,教你如何写采集rule
相信使用Discuz做网站的用户很多,所以使用CX采集插件的用户也很多。我也用过CX采集插件。我个人认为非常好。它是 Discuz 插件之一。很不错的采集插件,非常适合Dicuz,可以说是类似织梦,新云等程序后台自带的那种采集插件,但是很多人还是很迷茫插件的采集规则编写 没有,虽然我水平不高,但勉强能写一些规则,所以就写个简单的教程,新手可以看看,老手不要喷我!
在cx采集插件中,机器人是采集器。首先告诉你采集器制作的基本原理和思路!
1、首先确定采集的文章list页面的链接(这里的链接必须是list的链接)
2、需要确认列表页采集的内容区域,即机器人中的“列表区域识别规则”
3、需要在采集的这个列表页中确认文章的连接,即“文章link URL识别规则”
4.然后,我们要确认我们想要采集的文章内容范围,也就是“文章Content Identification Rule”
5、依靠前面的4步,我们基本确定了采集的范围。过滤掉一些你不想要的文章话题或内容,可以根据实际情况设置“过滤规则”。
我们的教程在下面正式开始。我以搜手网的文章列表为例给大家讲解一下;下面我们将特指采集。 com/jfff/ysjf/sssp/这个列表页;
第一步:后台插件——CX采集器-add机器人
基本设置: 1. 机器人名称(即机器人名称); 2.匹配模式(一般选择正则表达式); 3.一次采集的总数(即每次采集的总数,根据自己的选择设置); 4批采集数量(默认5个,不要太大,否则采集会超时) 5.发布时间(可以自定义发布时间,如果不设置,以当前时间为准)
第二:设置采集的列表页
1. 采集页面url设置有两种,一种是手动输入,一种是自动增长。我们以手动输入为例;添加链接后,点击测试是否可以链接到;
2. 采集页面的编码设置,我们可以点击程序辅助识别,这里是采集页面的编码,其他3项,根据个人需要设置
3.设置列表区域识别规则
到我们想要采集的页面,右键,查看源文件,找到文章链接url区域,规则中的url区域用[list]表示
现在我们需要在开始区域和结束区域找到div或其他标签。 文章link URL 必须在此区域中并且是最新的。标签必须是唯一的,例如:
[list]
然后,我们需要点击下面的测试,看看是否可以识别文章link url区域
4、文章link url 识别规则
规则需要的连接如图所示
我们将引号中·的连接替换为[url],即·填写规则,然后点击测试
采集节点、导入采集规则、电影播放规则怎么写?
采集交流 • 优采云 发表了文章 • 0 个评论 • 349 次浏览 • 2021-06-20 18:26
Information采集,填写你想要的相关内容采集,关于采集node的怎么写,导入采集rule,movie采集rule?要采集到视频模型,注意内容规则中{mvurl=*}的采集。由于采集上v6的不完善,采集视频播放地址无法保存好。尤其是多集,支持不好。还有v6的网站提取播放地址的特殊性,决定了采集{mvurl=*}时需要的修改以及v6播放文件所需的程序。修改。所以我在等待v6的持续改进。如果有人可以肯定地告诉我,v6 就是这样。如果没有修改,我会放出我的采集,以后修改文件的方法是v6。如果升级的时候改了什么,这个方法就麻烦了,而且采集进库后后台无法编辑,需要修改这两个文件。你准备好了吗? 采集站怎么做seo一定要伪原创对原内容,否则搜索引擎不会对多次易手的内容给出好的评价,即:很难有好的排名织梦微信采集 ,单页采集规则就行。谢谢你。将节点名称命名为采集,填写引用网址,引用网址为您需要采集的网址,网址匹配区域为该网址所在的区域。让我给你举个例子。例如,某个网页上有一个网址列表,您只需要采集这些网址,那么您只需查看其源代码并找到开始代码和结束代码即可。内容页面配置也是如此。你找到你需要的网页采集并查看其源代码。需要从哪个标签开始采集是标签中间的内容,然后在那个标签的末尾填写结束标签。
比如我从目标网页的标签采集开始,采集到标签的末尾,我的采集Content匹配[Content]过滤规则是你需要过滤特定的内容和然后填写过滤规则。 采集站怎么做排名采集站收录解决方案,爱做饭也试过采集,今天分享一下如何用采集做流量。作者目前操作的网站是基于手动复制别人的文章,加上我自己的观点,我操作的网站半年后可以达到目标关键词排名第一页面,你可以看到实际案例经典句网,股票入门网,ERP 100,000 为什么。 采集网站收录,几种解决排名的方法。 1选择网站程序,爱做饭不建议用网站大家都在用这个程序,因为你是采集,这些内容已经记录在搜索里了,所以专门的程序就是解决采集站收录 排名是重要因素之一。 2网站模板。如果你自己不会写程序,至少你的模板必须和别人不一样。一个好的结构会让你的网站 与众不同。 3采集内容控制进度,采集也要注意方法,采集相关网站内容,采集一天多少钱?爱厨推荐新站,每天增加不到50条数据。 50条数据是不同时间段增加的,不是同时增加的。在采集程序中,我们可以随时写一个采集任务,一个小时内随机更新几篇文章,模拟手动更新网站。 6 使用旧域名,注册时间越长越好。上述六种方法是最基本的。如果你喜欢烹饪,我建议如果你是新网站,先手动更新三个月的内容来培养网站权重,然后采集。 查看全部
采集节点、导入采集规则、电影播放规则怎么写?
Information采集,填写你想要的相关内容采集,关于采集node的怎么写,导入采集rule,movie采集rule?要采集到视频模型,注意内容规则中{mvurl=*}的采集。由于采集上v6的不完善,采集视频播放地址无法保存好。尤其是多集,支持不好。还有v6的网站提取播放地址的特殊性,决定了采集{mvurl=*}时需要的修改以及v6播放文件所需的程序。修改。所以我在等待v6的持续改进。如果有人可以肯定地告诉我,v6 就是这样。如果没有修改,我会放出我的采集,以后修改文件的方法是v6。如果升级的时候改了什么,这个方法就麻烦了,而且采集进库后后台无法编辑,需要修改这两个文件。你准备好了吗? 采集站怎么做seo一定要伪原创对原内容,否则搜索引擎不会对多次易手的内容给出好的评价,即:很难有好的排名织梦微信采集 ,单页采集规则就行。谢谢你。将节点名称命名为采集,填写引用网址,引用网址为您需要采集的网址,网址匹配区域为该网址所在的区域。让我给你举个例子。例如,某个网页上有一个网址列表,您只需要采集这些网址,那么您只需查看其源代码并找到开始代码和结束代码即可。内容页面配置也是如此。你找到你需要的网页采集并查看其源代码。需要从哪个标签开始采集是标签中间的内容,然后在那个标签的末尾填写结束标签。
比如我从目标网页的标签采集开始,采集到标签的末尾,我的采集Content匹配[Content]过滤规则是你需要过滤特定的内容和然后填写过滤规则。 采集站怎么做排名采集站收录解决方案,爱做饭也试过采集,今天分享一下如何用采集做流量。作者目前操作的网站是基于手动复制别人的文章,加上我自己的观点,我操作的网站半年后可以达到目标关键词排名第一页面,你可以看到实际案例经典句网,股票入门网,ERP 100,000 为什么。 采集网站收录,几种解决排名的方法。 1选择网站程序,爱做饭不建议用网站大家都在用这个程序,因为你是采集,这些内容已经记录在搜索里了,所以专门的程序就是解决采集站收录 排名是重要因素之一。 2网站模板。如果你自己不会写程序,至少你的模板必须和别人不一样。一个好的结构会让你的网站 与众不同。 3采集内容控制进度,采集也要注意方法,采集相关网站内容,采集一天多少钱?爱厨推荐新站,每天增加不到50条数据。 50条数据是不同时间段增加的,不是同时增加的。在采集程序中,我们可以随时写一个采集任务,一个小时内随机更新几篇文章,模拟手动更新网站。 6 使用旧域名,注册时间越长越好。上述六种方法是最基本的。如果你喜欢烹饪,我建议如果你是新网站,先手动更新三个月的内容来培养网站权重,然后采集。
所有SEO文章采集或抄袭行为都会被K站惩罚吗
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-06-03 07:10
所有SEO文章采集或抄袭行为都会被K站惩罚吗
SEO文章采集或抄袭会被K站惩罚吗? (https://www.muyiblog.com/) 文章编辑 第1张
在实际的网站SEO优化过程中,我们站长经常会遇到收录的文章被别人原封不动的抄袭,然后对方的文章也是收录,排名还是比我们自己高(检查对方是老网站,权重更高)。遇到这种情况,大家都会问:SEO文章采集这样或者抄袭会被K站处罚吗?
[什么是文章采集或抄袭]
采集是指使用一些采集的过程和规则,自动将其他网站的文章复制到自己的网站。 (此处采集或抄袭必须是采集原创,不得有任何伎俩或伪装)
原来采集other网站的文章对我网站的权重影响很大,虽然百度搜索引擎不能真正保护原创文章,但是L氪的信任搜索引擎的算法会越来越聪明,但是采集原样,然后采集再多给你自己的网站排名推广是有害无益的。
我们SEOer都知道百度的飓风算法是为了打击文章采集或者抄袭。如果我们使用文章采集器来发布文章,那我们需要花时间按照算法去处理吗? 这不值得。
【所有SEO文章采集抄袭将被K站严惩】
分享一开始,我们就知道如果有人采集或者抄袭我们的文章,就会出现收录并且排名比我们高。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,不管你的文章是怎么来的(采集文章也可以解决用户需求),而且布局好,逻辑表达清晰,可读性强,是否符合搜索引擎的行为?用户提供有价值的内容解决用户搜索需求的本质是什么?所以有一个排名。
然而,这种采集 行为是不可行的。试想采集内容长期排名会更好,肯定会引起原创作者的不满。这种情况持续下去,站长开始采集内容或抄袭内容,而不是生产原创文章或伪原创文章。所以当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法来对抗采集网站,同时也会对原创内容给予一定的排名偏好,鼓励原创authors创造更多优质内容。
[网站SEO文章被采集PLAID怎么办]
1、临时建议,一般可以礼貌地在对方网站留言,能不能加个链接文章投票,没有的话百度反馈举报。
2、长期建议,优化你的网站结构,打开速度等因素提升自身实力,最好晚上更新文章,因为这样可以提升自己作为第一收录概率。 (参考原创文章的定义)
3、网站尽量加水印,增加其他人采集文章后期处理的时间成本。
4、保持良好心态,毕竟百度也推出了飓风算法来对抗惩罚。 原创文章被采集抄袭是个难题。技术一直在改进和优化,谷歌搜索引擎做不到。完美解决这个问题,那就做好自己的网站吧,让文章能够实现第二个收录才是上策。 查看全部
所有SEO文章采集或抄袭行为都会被K站惩罚吗
SEO文章采集或抄袭会被K站惩罚吗? (https://www.muyiblog.com/) 文章编辑 第1张
在实际的网站SEO优化过程中,我们站长经常会遇到收录的文章被别人原封不动的抄袭,然后对方的文章也是收录,排名还是比我们自己高(检查对方是老网站,权重更高)。遇到这种情况,大家都会问:SEO文章采集这样或者抄袭会被K站处罚吗?
[什么是文章采集或抄袭]
采集是指使用一些采集的过程和规则,自动将其他网站的文章复制到自己的网站。 (此处采集或抄袭必须是采集原创,不得有任何伎俩或伪装)
原来采集other网站的文章对我网站的权重影响很大,虽然百度搜索引擎不能真正保护原创文章,但是L氪的信任搜索引擎的算法会越来越聪明,但是采集原样,然后采集再多给你自己的网站排名推广是有害无益的。
我们SEOer都知道百度的飓风算法是为了打击文章采集或者抄袭。如果我们使用文章采集器来发布文章,那我们需要花时间按照算法去处理吗? 这不值得。
【所有SEO文章采集抄袭将被K站严惩】
分享一开始,我们就知道如果有人采集或者抄袭我们的文章,就会出现收录并且排名比我们高。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,不管你的文章是怎么来的(采集文章也可以解决用户需求),而且布局好,逻辑表达清晰,可读性强,是否符合搜索引擎的行为?用户提供有价值的内容解决用户搜索需求的本质是什么?所以有一个排名。
然而,这种采集 行为是不可行的。试想采集内容长期排名会更好,肯定会引起原创作者的不满。这种情况持续下去,站长开始采集内容或抄袭内容,而不是生产原创文章或伪原创文章。所以当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法来对抗采集网站,同时也会对原创内容给予一定的排名偏好,鼓励原创authors创造更多优质内容。
[网站SEO文章被采集PLAID怎么办]
1、临时建议,一般可以礼貌地在对方网站留言,能不能加个链接文章投票,没有的话百度反馈举报。
2、长期建议,优化你的网站结构,打开速度等因素提升自身实力,最好晚上更新文章,因为这样可以提升自己作为第一收录概率。 (参考原创文章的定义)
3、网站尽量加水印,增加其他人采集文章后期处理的时间成本。
4、保持良好心态,毕竟百度也推出了飓风算法来对抗惩罚。 原创文章被采集抄袭是个难题。技术一直在改进和优化,谷歌搜索引擎做不到。完美解决这个问题,那就做好自己的网站吧,让文章能够实现第二个收录才是上策。
佳之方在线全球经典的采集引擎-文章采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-05-31 18:01
文章采集规则写得清清楚楚明明白白,图片设置什么的也照章办理,连地址和手机是否网络连接都设置完了,刚开始兴冲冲做着好事,用着用着发现怎么老是收不到信息?于是去问下手机同步?可是手机同步好歹是需要通讯录和已经连接路由器来确定的。再看眼文章首页,还有推送文章页面,以及这个文章评论页面(请不要在意刚才的废话。)不想说了,要不然突然想起我们来了。最后,既然您如此公开了,那么给个赞呗。
为何采集明明说不要得罪人,
我们在向全球招募优秀采集员。我们是技术驱动型公司,所以和零售业结合,以帮助零售行业采集信息、发现问题。我们的目标是让全球零售业都会提供免费采集信息的服务,无需自己创建数据库。公司现在在做的项目有两个:一个是英国王室采集数据,一个是巴西足球足彩分析。如果有兴趣请私信我。
可能是因为他们电脑被限制访问国内互联网。我现在用的是佳之方在线全球经典的采集引擎,用的python,可以不用root就可以全球抓取信息了。而且免费版的模块就足够,还可以一键导出excel成pdf,真好用啊。
我也感觉还是很好的。佳之方应该是外包给了一些老外公司,帮他们解决技术问题。我以前回答过个问题是说如何使用中国的数据的,其中就有佳之方用佳之方对接其他经销商老外零售企业的数据。感觉还是不错的。 查看全部
佳之方在线全球经典的采集引擎-文章采集规则
文章采集规则写得清清楚楚明明白白,图片设置什么的也照章办理,连地址和手机是否网络连接都设置完了,刚开始兴冲冲做着好事,用着用着发现怎么老是收不到信息?于是去问下手机同步?可是手机同步好歹是需要通讯录和已经连接路由器来确定的。再看眼文章首页,还有推送文章页面,以及这个文章评论页面(请不要在意刚才的废话。)不想说了,要不然突然想起我们来了。最后,既然您如此公开了,那么给个赞呗。
为何采集明明说不要得罪人,
我们在向全球招募优秀采集员。我们是技术驱动型公司,所以和零售业结合,以帮助零售行业采集信息、发现问题。我们的目标是让全球零售业都会提供免费采集信息的服务,无需自己创建数据库。公司现在在做的项目有两个:一个是英国王室采集数据,一个是巴西足球足彩分析。如果有兴趣请私信我。
可能是因为他们电脑被限制访问国内互联网。我现在用的是佳之方在线全球经典的采集引擎,用的python,可以不用root就可以全球抓取信息了。而且免费版的模块就足够,还可以一键导出excel成pdf,真好用啊。
我也感觉还是很好的。佳之方应该是外包给了一些老外公司,帮他们解决技术问题。我以前回答过个问题是说如何使用中国的数据的,其中就有佳之方用佳之方对接其他经销商老外零售企业的数据。感觉还是不错的。

