【岛】数据图示--逻辑方式数据设置页
优采云 发布时间: 2021-08-20 23:18【岛】数据图示--逻辑方式数据设置页
一、数据分页设置页面介绍
1、Description
我们在显示文章内容的时候经常会遇到一些网站,内容被分成几页显示,我们需要翻页依次阅读所有内容,当我们采集这种类型的网站文章,需要使用数据分页;在ET中,我们可以选择采集分页两种分页方式之一,分别是'采集method'和'logical method',【数据分页-逻辑模式设置页面】见图1:
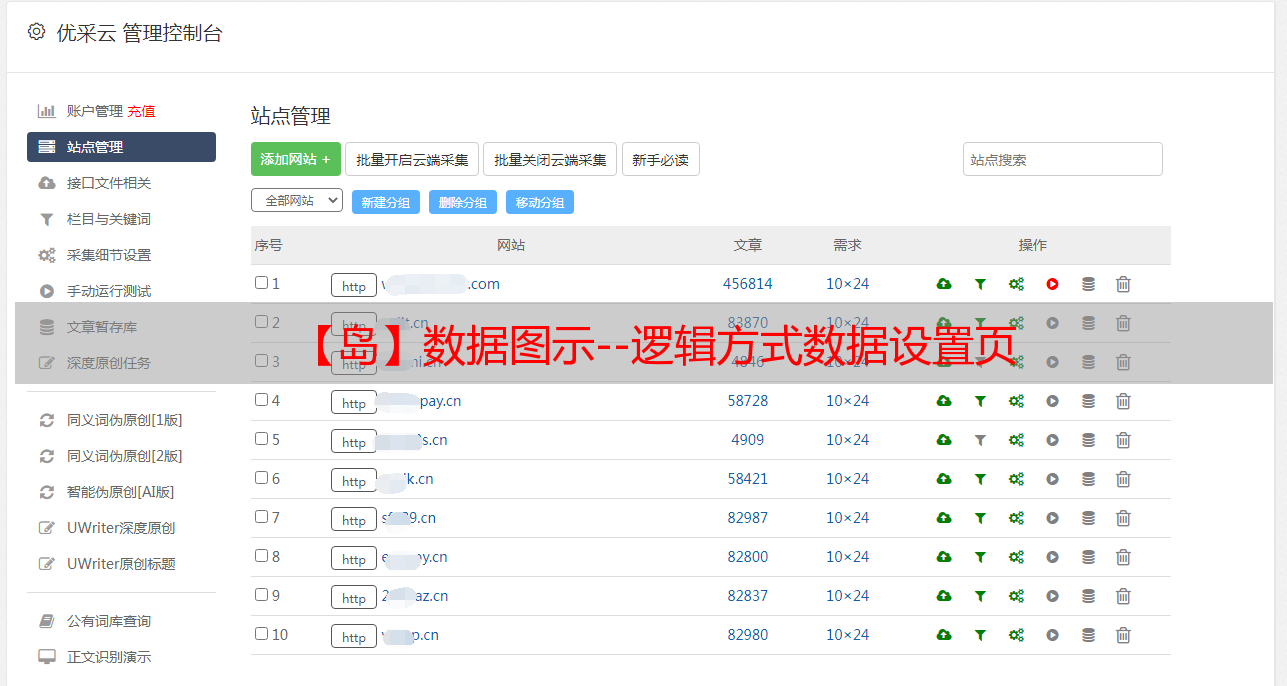
(图一:逻辑数据分页)
数据项从采集页面(即第一页)的源码中获取,使用数据项采集rule解析获取内容,然后数据项采集rule解析为单独使用,从每个页面的源代码中获取内容,将按顺序合并,并用【内容分离】标签“#-0-#”分隔;
注意:为了避免用户错误配置将采集分页陷入死循环,逻辑获取的页数上限为2000。
访问页面失败时,文章的采集不会中断。
注意:2.4 版本之前,分页只对文本数据项有效。从2.4 版本开始,每个数据项都可以从分页中获取内容。
2.4版本之前,将所有页面的源代码一一合并,然后使用数据项采集进行内容分析;从2.4 版本开始,每个页面的源代码都是单独获取的。使用数据项采集规则对获取的内容进行分析后,将获取的内容按顺序合并。因此,2.4版本之前使用正文分页功能的采集规则在升级到2.4版本后可能存在兼容性问题,需要进行调整。
二、开启逻辑模式
逻辑方法是指通过预设规则计算每个分页URL的方法。这种方法比采集方法简单,但使用范围稍微窄一些。只适用于分页网址按数律增减。情况;
使用逻辑方式获取分页,请勾选【使用逻辑方式】,见图:
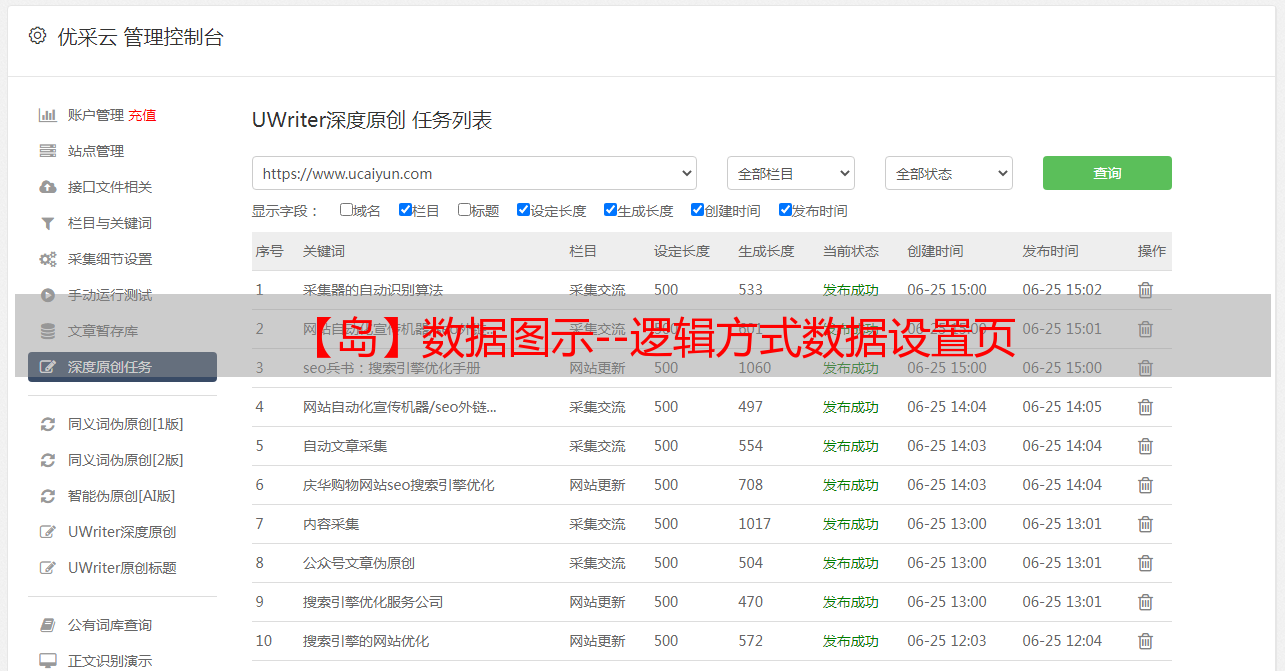
数据分页作为某个采集页面的分页存在,采集页面是第一个分页。比如一个文章内容页显示为多个分页,一个产品的评论页显示为多个页面,所以需要设置数据页属于哪个采集页面,见图:
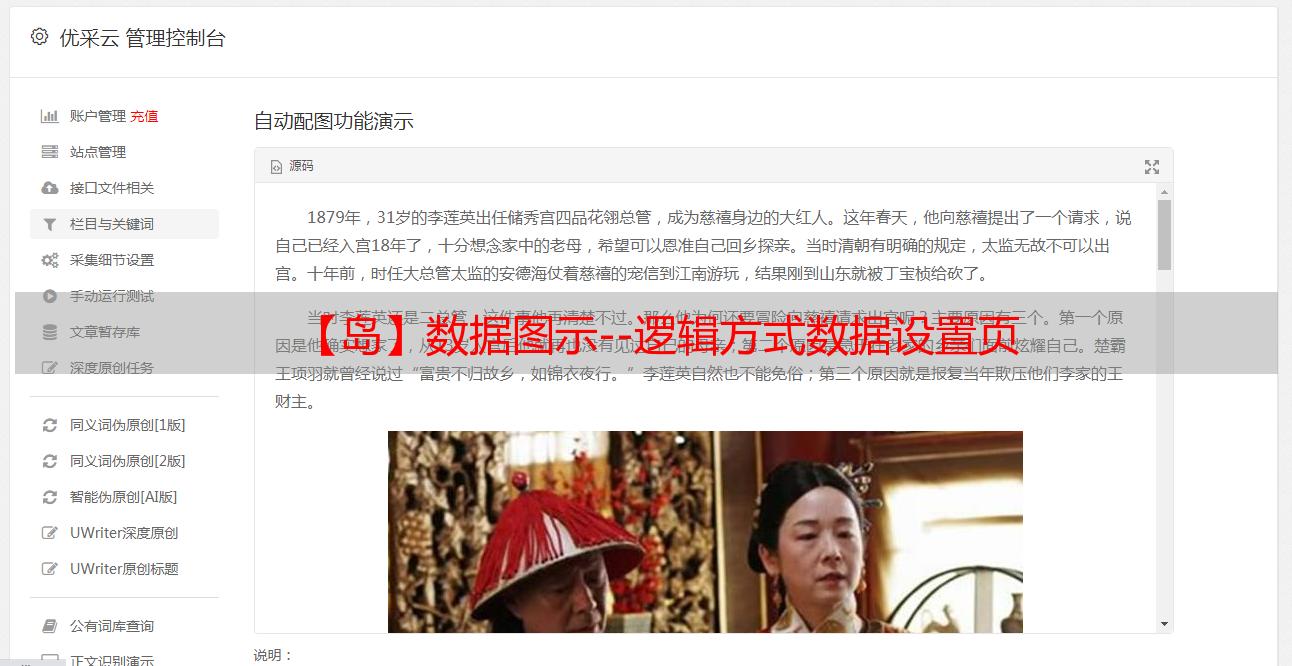
三、当前 URL 分解
1、Description
【当前URL分解】为必填项,用于从数据分页所属的采集页面的完整URL中提取出【页面地址】信息,用于形成如下逻辑的完整页面URL操作。见图3:
(icon3)
因为在大多数规则中,数据页所属的采集页是第一个采集页,所以【当前URL分解】的规则通常与;
注意:如果文章 URL 有重定向,则重定向后的完整 URL 应该用于 URL 分解;
点击
图标,可以测试[d当前URL分解];
2、tag 区域
【当前URL分解】有可用标记,见图3;
1、page 地址
标签代码用于指示用于区分当前 URL 与其他 URL 的唯一字符串。 [页面地址]标签在规则中只能使用一次;
有关标签的更多信息,请参阅相关主题;
3、参考示例
以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:
1、we 通过获取文章的完整网址如下:
2、在上面的示例 URL 中,字符串“348556”是该 URL 的唯一特征字符串。当然,我们选择像'tid=348556'这样的字符串是没有问题的。填写【当前网址分解】规则如下:
四、page 增量
1、Description
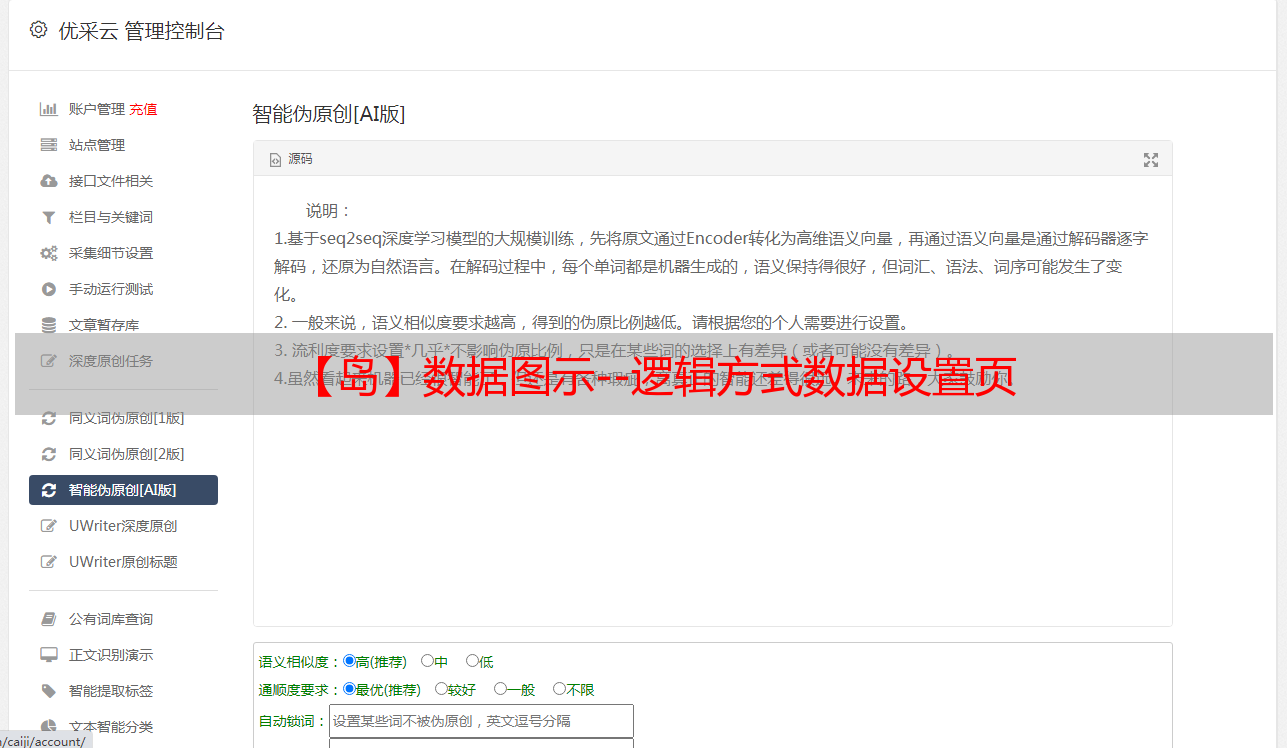
【Paging Increment】为必填项,此项用于计算在指定范围内有规律变化的每个分页URL的特征数编号,并与【分页URL合成】中的【分页地址】结合完整的页面 URL,见图 4:
(icon4)
开始号码和结束号码只能填写数字,位数要与真实列表网址一致,例如“01”不等于“1”;
如果起始编号大于结束编号,则[页增量]减少步长,如果起始编号小于结束编号,则[页增量]增加步长;
步长表示每次递增或递减的递增或递减量。不管是递增还是递减,步长都是正整数;
为了避免重复采集,起始编号一般不是'1'或'01'等数字,因为[body]数据项所属的采集页面,即第一页在执行体中分页采集已经是采集了,大多数网站的习惯就是把这个页面当成带有'1'和'01'等数字的页面;
结束编号通常设置为实际页数无法达到的较大数字,这样页增量会包括所有可能出现的有效编号,并判断该页是否实际上是最后一页,我们通过【有效分页特征码】;
2、参考示例
以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:
1、一个多页的帖子,每页的网址如下:
%3D1
%3D1&page=2
%3D1&page=3
%3D1&page=4
……
2、 删除不必要的参数,可以简化为:
……
3、 那么在上面的每一个网址中,经常变化且具有独特特征的数字很容易找到。它们是“2”、“3”、“4”等。这些数字相加1递增,所以我们得到步长1,我们设置一个更大的,通常没有达到的数字'100'作为结束数字,所以我们配置这个文本页面的[页面增量]如下:<//p
pimg src='http://www.zzcity.net/help/setup-cj-6-4.gif' alt=''//p
p4、注意,在上面的例子中,我们使用URL page=2的页面作为起始页码,所以起始编号设置为2。这是因为[body]数据项属于第一个页面,即【当前URL分解】中的“当前URL”,这个页面在采集分页符之前已经是采集了。/p
p五、Page URL 合成/p
p1、Description/p
p【Paging URL Synthesis】是必填项,这里使用【Page Address】和【Page Increment】合成一个完整的页面URL,见图5:/p
pimg src='http://www.zzcity.net/help/setup-cj-6-5.gif' alt=''//p
p(icon5)/p
p完整页面URL可以使用相对链接和相对于当前页面的完整链接,如:“../../page--.htm”、“page--.htm”、“-.htm”等;/p
p注意:文章地址为电脑本地文件路径时,页面URL必须是完整地址,不能使用相对地址;/p
p点击/p
pimg src='http://www.zzcity.net/help/icon-testtool.gif' alt=''//p
p图标,可以测试【分页网址合成】;/p
p2、tag 区域/p
p【Paging URL Synthesis】有2个可用标签,见图5;/p
p1、page 地址/p
p标签代码为必填项,用于表示每个页面URL中的固定特征字符串,与[当前URL分解]中的[页面地址]为同一个标签,用于引用其值;//p
p2、page 增量/p
p标记码是,是必填项,用于表示每个分页URL中定期变化的特征号编号,由本文第三节的逻辑规则计算得出;/p
p有关标记的更多说明,请参阅相关主题;/p
p3、参考示例/p
p以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:/p
p1、 我们在本文第二、三部分分别获得了【页面地址】和【页面增量】。根据这两个标签的表达,我们设置了【分页网址合成】的规则如下:/p
p&page=/p
p在上面的例子中,[Paging Address]替换了分页URL中的固定特征字符串'348556',[Paging Increment]替换了分页URL 4中经常变化的号码'2','3',' '等;/p
p六、功能码/p
p1、Description/p
p特征码由两部分组成,分别是【页面特征码】和【最后一页特征码】;/p
pimg src='http://www.zzcity.net/help/setup-cj-6-6.gif' alt=''//p
p(icon6)/p
p注:2.4版本之前,【页面特征码】为【有效页面特征码】,【末页特征码】为【非末页特征码】;从2.4开始,用户可以自行选择特征码类型。/p
p1、page 特征码/p
p[Pagination Feature Code]为必填项,内容为从网页源代码中选择的字符串,通过分页URL合成的网页是否有效通过网页源代码是否有效来判断收录字符串,见图6;/p
pEffective pages 勾选此项时,将网页源代码中收录特征码字符串的网页视为有效页面,以默认页面特征码作为有效页面特征码;/p
p无效页面 勾选此选项后,网页源代码中收录特征码字符串的网页将被视为无效页面;/p
p特征代码是一个字符串,只收录所有有效或无效页面的源代码。设置页面的特征码不需要考虑第一页,也就是采集页。/p
p一旦逻辑计算出的页面URL采集的页面源代码不收录[有效页面]类型[页面特征码],系统会认为上一个页面采集是最后一个有效页面当系统结束采集page;/p
p如果逻辑计算到达的页面URL采集的页面源代码收录[无效页面]类型[页面特征码],则系统认为上一个页面采集是最后一个有效页面,则系统结束采集pagination;相反,如果页面源代码不收录[无效页面]类型[分页码],则该页面被视为有效页面。/p
p2、结束页面特征码/p
p[Last Page Feature Code] 可选,内容为从网页源代码中选择的字符串。网页源码中收录判断页面URL合成的网页是否为最后一页的字符串。 pass和[分页特征码]用于确定文本分页的结束页,见图6;/p
pNon-Last Page 勾选该选项后,网页源代码中收录特征码字符串的网页被视为不是最后一页,默认最后一页特征码为非最后一页特征代码;/p
p这是最后一页。勾选此项时,将网页源代码中收录特征码字符串的网页视为最后一页;/p
p特征码是只收录在最后一页或所有非最后一页的源代码中的字符串。设置最后一页特征码不需要考虑第一页,即采集页所属。/p
p当[Last Page Feature Code]不为空时,第一个不收录[Non-Last Page]类型[Last Page Feature Code]的有效页面为最后一个有效页面,系统结束采集分页;/p
p第一个收录[为最后一页]类型[最后一页特征码]的有效页面作为最后一个有效页面,系统结束采集分页;/p
p2、参考示例一/p
p以采集ET官方论坛‘ET2.0安装使用’版本(网址)为例:/p
p1、 论坛帖子分为两种,一种是分页的,一种是不分页的;比较特殊的是当分页网址越界时(分页增量超过实际最后一页的数量),Discuz论坛不会提示越界,而是直接显示最后一页,如果没有页面,会显示第一页;/p
p2、 通过对比没有分页的帖子和有分页的帖子,可以看到位于中间的所有分页页面在页面导航中都有向前和向后的页面链接,'‹‹'和'››' ,并且最后一页没有后页链接'››'。我们找到了他们的源代码如下:/p
p‹‹/p
p››/p
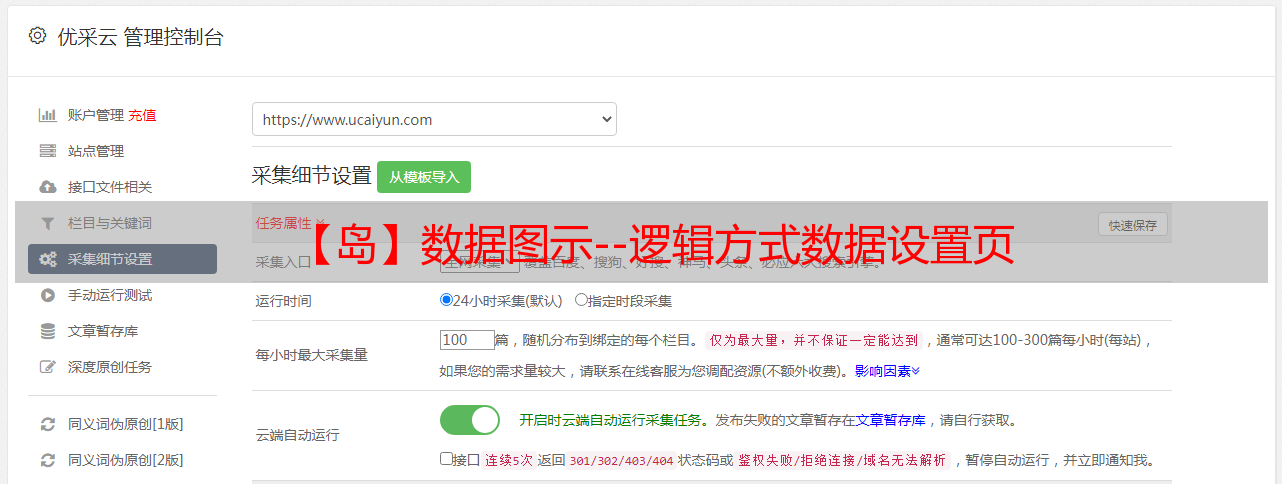
p3、去掉改动的部分,选择特征码如下:/p
pclass="prev"‹‹/p
p>››
4、在没有分页的帖子中搜索,但是没有找到这两个特征码;在最后一页搜索,没有找到特征代码'class="next">››';在任意一个中间页面搜索,都有这两个特征码,所以分页特征码填写如下:
(icon6)
3、参考例子二
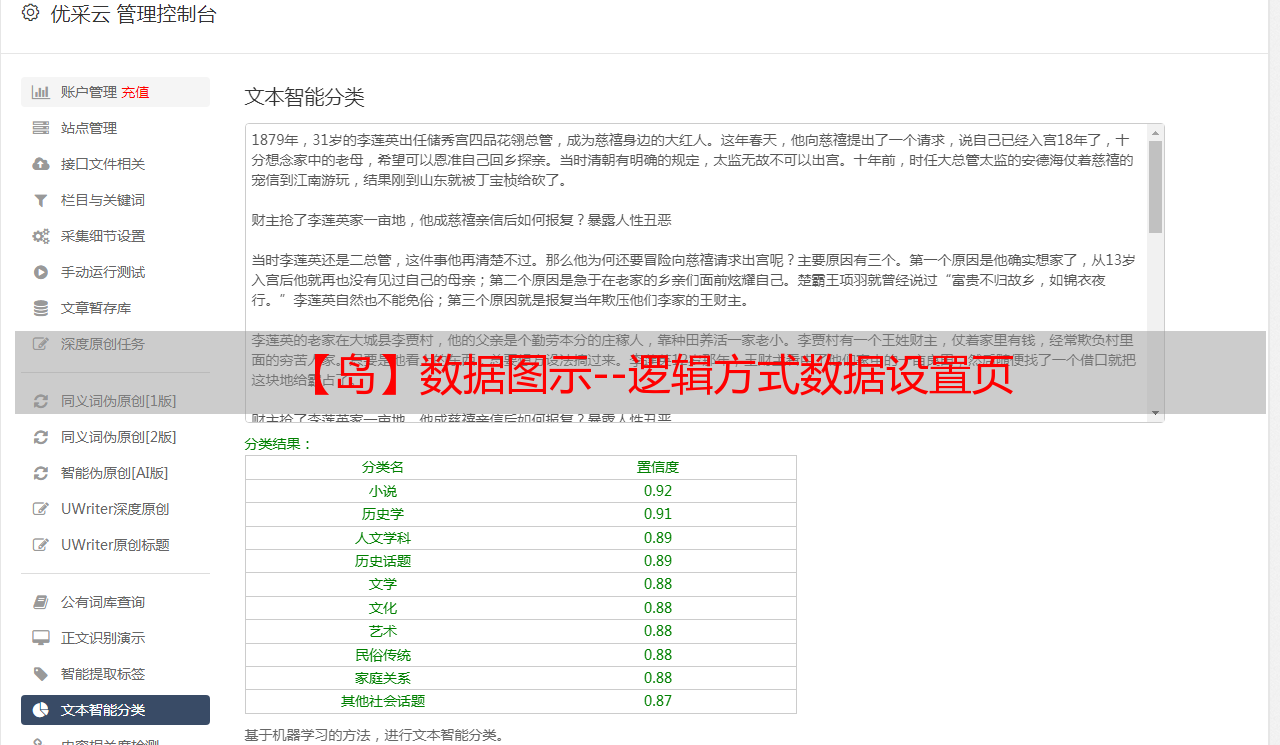
以采集某图片网站(见采集rule分页示例-逻辑上非主流图片)为例:
1、 这个网站文章分为有分页和无分页两种。当页面 URL 超出范围时,将显示“找不到页面”的错误消息。因此,我们只需要填写[Valid Pagination Feature Code]即可;
2、通过查看每个页面,我们发现了许多可以用作特征代码的字符串。我们选择其中之一并填写以下内容:
(icon7)

