
文章采集
分享:微信公众号文章采集的几种方案(公众号的内容的采集需要注意什么)
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2022-11-28 14:27
目录:
1. 如何采集
公众号文章
公众号文章采集
,我们为什么要采集
公众号文章?由于公众号更多的是私域流量,直接面向用户,所以公众号的文章质量普遍较高,而且都是原创。今天教大家一个快速采集
公众号文章的方法,只需要输入关键词就可以采集
大量公众号文章。
2.微信公众号文章采集器
不仅支持公众号文章,还支持采集
全网各大媒体的文章。详情如图
3、如何采集
微信公众平台文章
一篇好的文章可以带来大量的搜索流量,但是大量的搜索流量是不够的。我们需要的是“大量可以转化为客户的搜索流量”。你的文章想吸引什么样的客户,就看你写什么了 那么,你应该写什么样的文章呢?很多外行会把公司活动、媒体报道等填满网站的文章版块,但你想想,你的潜在客户有多少想看你的吹嘘?您的潜在客户关心他们自己需要解决的问题!作为“XX数字营销公司”的潜在客户,他们可能关心什么?他们关心的是“选择SEO公司应该注意什么?”,或者“社交媒体营销应该怎么做?”,
4.采集
公众号内容需要注意什么
如果您使用文章来帮助客户回答这些问题,那么您的博客将对潜在客户有价值。不仅潜在客户看完文章会觉得你很专业,而且很多潜在客户会通过搜索这些问题找到你。你网站的
5、公众号内容自动采集发布
搜索引擎优化工作只有两个主要部分:站内搜索引擎优化(On Site)和站外搜索引擎优化(Off Site)。就这么简单,两部分!On-Site/On-page SEO(On-Site/On-page SEO)是指通过优化网站内部结构、提高网站速度、提高网站内容的相关性以及目标关键词;改善网站的用户体验等,这是在网站内运行的过程。
6.抓取微信公众号文章内容
站外搜索引擎优化(Off-Site/Off-page SEO)是指通过外部链接来推广自己的网站,以提高谷歌对网站的认可度/信任度。两者在站外运营过程中都很重要,但On-site SEO是整个优化过程的基础,因为站外SEO(获取外部链接)往往涉及到与其他网站的合作,或者涉及媒体购买等., 而这些事情的主动权往往不在你手里。
7、如何采集
微信公众号的文章
所以,对于SEO初学者来说,在做好站内SEO和优质内容创作之前,站外SEO可以顺便爽一把
八、公众号如何采集
文章
事实上,在很多搜索排名竞争并不激烈的情况下,只要做好站内SEO,基本上就可以让你的网站在页面上排名靠前。很多老板认为网站是可有可无的,更不用说花钱和时间做SEO了,这时候只要做好站内SEO,你的网站基本可以排在Google首页。
9. 如何采集
公众号文章
所以,如果你是刚开始做SEO,就把这部分作为你优化的重点
10.如何采集
微信公众号文章
页面/站点速度:页面速度对排名有直接和间接的影响。直接 - 速度本身就是一个排名因素;间接——网站速度影响网站访问者的跳出率、访问时长等访问者行为,而这些行为都会影响排名,因此间接影响排名。
主题测试文章,仅供测试使用。发布者:采集
,转载请注明出处:
推荐文章:百度伪原创文章收录低的原因(原创度低减少推荐多久恢复)
阅读本文提示语:原创度低,推荐减少 恢复需要多长时间?,百度不收录文章,伪原创文章会被百度收录吗
百度伪原创文章收率低还有一个原因:文章质量,教你快速写出高质量伪原创文章
百度搜索引擎(Baidu SEO)是一家专注于提供优质原创文章、新媒体和微博等新媒体传播技术的公司。可以根据客户要求修改文章,自然获得最低的收录标准
伪原创文章收录率低
伪原创文章的产生,文章质量差异比较大
首先,伪原创文章的生成必须先修改,再低级伪原创。
在学习的过程中,您可以找到自己可以采用的格式,然后进行练习。
先提交文章,然后检查文章质量,用词和内容是否达标。
通过这个阶段的研究,你的写作水平,以及是否容易通过审查。虽然你的伪原创度不够高,但是你的可读性、思维和逻辑是否能轻松达到标准。
您还可以在每个答案中收录
指向教程、博客或网站目录、论文、杂志或网站关键字的链接。按照这个排名,你的采集
采集
肯定会有分数的。
伪原创文章的生成过程由简单到简单。首先,选择一个主题,然后选择一篇文章,然后编辑文章。只需使用您的关键字作为文章标题。
伪原创文章生成软件哪个好,不值钱
然后找一些相关的资料,基本会写,插到我们的软文里。
哪个是最好的伪原创文章生成软件?如何写发电机组的伪原创文章。如果要修改论文内容,请使用工具中的在线工具。我用的就是这个软件,然后写了一篇文章供大家参考。哪个网站是假冒原创文章制作平台?
伪原创文章生成软件哪个好,谢谢伪原创文章生成软件。我使用这个软件生成的文章更好。这是更好的。我非常喜欢这个软件,它也可以帮助到你。
哪家伪原创文章生成软件最好,谢谢哪家是最好的伪原创文章生成软件,2 为什么作者自称是软件生成器,因为:软件文章对百度搜索引擎优化有特别大的作用。
哪个伪原创文章生成软件比较好,3 可见我心中有一个
相关文章 查看全部
分享:微信公众号文章采集的几种方案(公众号的内容的采集需要注意什么)
目录:
1. 如何采集
公众号文章
公众号文章采集
,我们为什么要采集
公众号文章?由于公众号更多的是私域流量,直接面向用户,所以公众号的文章质量普遍较高,而且都是原创。今天教大家一个快速采集
公众号文章的方法,只需要输入关键词就可以采集
大量公众号文章。
2.微信公众号文章采集器
不仅支持公众号文章,还支持采集
全网各大媒体的文章。详情如图
3、如何采集
微信公众平台文章
一篇好的文章可以带来大量的搜索流量,但是大量的搜索流量是不够的。我们需要的是“大量可以转化为客户的搜索流量”。你的文章想吸引什么样的客户,就看你写什么了 那么,你应该写什么样的文章呢?很多外行会把公司活动、媒体报道等填满网站的文章版块,但你想想,你的潜在客户有多少想看你的吹嘘?您的潜在客户关心他们自己需要解决的问题!作为“XX数字营销公司”的潜在客户,他们可能关心什么?他们关心的是“选择SEO公司应该注意什么?”,或者“社交媒体营销应该怎么做?”,
4.采集
公众号内容需要注意什么

如果您使用文章来帮助客户回答这些问题,那么您的博客将对潜在客户有价值。不仅潜在客户看完文章会觉得你很专业,而且很多潜在客户会通过搜索这些问题找到你。你网站的
5、公众号内容自动采集发布
搜索引擎优化工作只有两个主要部分:站内搜索引擎优化(On Site)和站外搜索引擎优化(Off Site)。就这么简单,两部分!On-Site/On-page SEO(On-Site/On-page SEO)是指通过优化网站内部结构、提高网站速度、提高网站内容的相关性以及目标关键词;改善网站的用户体验等,这是在网站内运行的过程。
6.抓取微信公众号文章内容
站外搜索引擎优化(Off-Site/Off-page SEO)是指通过外部链接来推广自己的网站,以提高谷歌对网站的认可度/信任度。两者在站外运营过程中都很重要,但On-site SEO是整个优化过程的基础,因为站外SEO(获取外部链接)往往涉及到与其他网站的合作,或者涉及媒体购买等., 而这些事情的主动权往往不在你手里。
7、如何采集
微信公众号的文章
所以,对于SEO初学者来说,在做好站内SEO和优质内容创作之前,站外SEO可以顺便爽一把

八、公众号如何采集
文章
事实上,在很多搜索排名竞争并不激烈的情况下,只要做好站内SEO,基本上就可以让你的网站在页面上排名靠前。很多老板认为网站是可有可无的,更不用说花钱和时间做SEO了,这时候只要做好站内SEO,你的网站基本可以排在Google首页。
9. 如何采集
公众号文章
所以,如果你是刚开始做SEO,就把这部分作为你优化的重点
10.如何采集
微信公众号文章
页面/站点速度:页面速度对排名有直接和间接的影响。直接 - 速度本身就是一个排名因素;间接——网站速度影响网站访问者的跳出率、访问时长等访问者行为,而这些行为都会影响排名,因此间接影响排名。
主题测试文章,仅供测试使用。发布者:采集
,转载请注明出处:
推荐文章:百度伪原创文章收录低的原因(原创度低减少推荐多久恢复)
阅读本文提示语:原创度低,推荐减少 恢复需要多长时间?,百度不收录文章,伪原创文章会被百度收录吗
百度伪原创文章收率低还有一个原因:文章质量,教你快速写出高质量伪原创文章
百度搜索引擎(Baidu SEO)是一家专注于提供优质原创文章、新媒体和微博等新媒体传播技术的公司。可以根据客户要求修改文章,自然获得最低的收录标准
伪原创文章收录率低
伪原创文章的产生,文章质量差异比较大
首先,伪原创文章的生成必须先修改,再低级伪原创。

在学习的过程中,您可以找到自己可以采用的格式,然后进行练习。
先提交文章,然后检查文章质量,用词和内容是否达标。
通过这个阶段的研究,你的写作水平,以及是否容易通过审查。虽然你的伪原创度不够高,但是你的可读性、思维和逻辑是否能轻松达到标准。
您还可以在每个答案中收录
指向教程、博客或网站目录、论文、杂志或网站关键字的链接。按照这个排名,你的采集
采集
肯定会有分数的。
伪原创文章的生成过程由简单到简单。首先,选择一个主题,然后选择一篇文章,然后编辑文章。只需使用您的关键字作为文章标题。
伪原创文章生成软件哪个好,不值钱

然后找一些相关的资料,基本会写,插到我们的软文里。
哪个是最好的伪原创文章生成软件?如何写发电机组的伪原创文章。如果要修改论文内容,请使用工具中的在线工具。我用的就是这个软件,然后写了一篇文章供大家参考。哪个网站是假冒原创文章制作平台?
伪原创文章生成软件哪个好,谢谢伪原创文章生成软件。我使用这个软件生成的文章更好。这是更好的。我非常喜欢这个软件,它也可以帮助到你。
哪家伪原创文章生成软件最好,谢谢哪家是最好的伪原创文章生成软件,2 为什么作者自称是软件生成器,因为:软件文章对百度搜索引擎优化有特别大的作用。
哪个伪原创文章生成软件比较好,3 可见我心中有一个
相关文章
最新版:【APP源码】绿豆 v5.1.8最新影视APP源码,安装教程,视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 1241 次浏览 • 2022-11-17 08:59
演示下载:
后台是第二个开放的苹果cms系统,使用mxone主题,后台有采集插件,网页版适配手机电脑,APP为原生安卓JAVA源代码。
APP有多个广告位,可接入信天翁广告联盟。源码有文字教程,根据教程修改即可成功搭建。本APP视频源码!
源码说明:
绿豆视频最新视频源码,源码完整
PC+wap+应用
有专题、短视频、排行榜功能等。
后台搭建教程:
1.宝塔新建数据库
2.安装宝塔插件环境
3.修改源码、后台文件、播放器配置文件的数据库地址
4. 创建网站
5.后台参数配置
注意:thinkphp需要配置伪静态网页
前端搭建教程:
1.下载jdk 1.8版本配置JDK环境
jdk1.8-下载安装及环境配置教程
2.下载Android studio 3.6版本进入前端包
Android studio 3.6下载环境搭建教程安装步骤
3.前端数据替换
4.打包导出
详细教程在源码里
前端对接:使用Android Studio工具打开前端加载项目后,搜索并选择名为app.java的文件打开文件,修改位置如下:
public static String SDKID = "888"; //广告媒体ID
公共静态字符串 UMENG_KEY = “8887db8242477110c5bb”;//友盟统计
public static String BASE_URL = "你的后台对接域名";
UI大幅改版,如首页热门影视搜索框、视频加载特效、分享视频显示当前分析的视频数据等。
去掉app端最下面的直播导航,这个直播功能没用!
找到文件:bottom nav menu.xml
打开文件,删除直播代码即可删除app底部的直播按钮。
如有打包错误,删除错误部分,不影响使用。
该版本有信天翁SDK广告版,前端源码+后端全部开源,无授权限制。
bilibili请求头设置
请求头:bilivideo.com
referer=> https://www.bilibili.com
User-Agent=>Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,
likeGecko)Chrome/88.0.4324.150Safari/537.36
使用请求的的链接:
.
.*?bilivideo.com.*
芒果请求头设置
请求头:
referer=> https://www.mgtv.com/
User-Agent=> Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/88.0.4324.150 Safari/537.36
使用请求的的链接:
.+?titan.mgtv.com.*
分析界面设置教程
网页解析只支持网页界面。
App分析可以是web也可以是json。推荐使用json接口。web可能会导致app跳转到浏览器,程序可能会崩溃。
json解析接口的格式必须有以下两个参数
{
“code”:200,
“url”:”http://baidu.com/mp4.com
}
修改APP筛选页面参数
最新版本:狂雨CMS网站不收录,关键词没排名?-SEO免费插件所有网站通用
编辑第一段时,尽量加文章关键词,加粗关键词。原理是蜘蛛爬行的时候是从左到右,从上到下。如果关键词出现在之前,蜘蛛会认为这是一个高度相关的文章,同时起到一个递增的作用,前提是不能影响阅读。
3重新排序也称为“段落替换法”
文章段落不是很紧凑,或者说是平行的。在不影响文章初衷和适合用户浏览的前提下,可以把原来的文章段落打乱,重新排序,这个方法不适合所有人,顺理成章文章一定不。
4 内容删除及修改方法
去掉某个内容,可以是一个段落,但是是某个段落中的几个点。这个要看你自己的尺度。就修改幅度而言,至少,整篇文章文章修改幅度应该保持在30%左右,当然修改越大越受搜索引擎欢迎。
添加了 5 张新图片
读者会知道一张图片抵得上一千个字。虽然目前大部分搜索引擎无法读取图片的内容,但是图片中的alt属性可以进行注释,这样也会让搜索引擎焕然一新,认为你的内容是新的收录 ;
3.图片数量
1. 一篇文章 文章 有 7 或 8 张图片?图片太多了。如果潜在用户使用手机网络,图片太多,打开速度慢会影响他们的阅读习惯和体验,所以一般一篇文章文章只放2~3张图片。
2. 图片来源
图片来自哪里,尤其是一些专业的图片。大部分都是在网上找的,百度,搜狗,360等等,有很多。
3 图片处理
如何处理?为什么要加工?
因为收录是kb的形式,也就是一张图片的大小,用截图工具重新截一张图片,或者用美图,或者PS等软件重新处理,这样的图片是伪原创 ,在图片或特定文本中增强您的形式(或添加水印)。
4.如何实现网站二次收货
秒收网站最大的特点之一就是每天都会发布大量优质的资讯和内容。是的,这些平台是蜘蛛的梦想天堂。但是很多人都是普通的网站,大家更多的面临的是发布的内容百度收录不更新,快照长期不更新的情况。从我们身边经过?接下来小编就把百度二次采集的详细解析分享给大家,让你的网站实现正常的收录和百度二次采集。
百度秒收详情分析
1.百度秒收详解,好的网站结构是基础。
这个非常重要。一个好的网站结构会帮助访问者了解你的网站结构和层级,更有利于蜘蛛爬行和索引。这里推荐首页-栏目-内容页这样的树状结构,要简单不要复杂。为了提高蜘蛛的爬行效率,非常有必要为网站创建网站地图和robots文件来引导蜘蛛。有条件的朋友尽量使用静态页面,对蜘蛛比较友好。
二、百度秒收详解,打造优质内容是重点。
高质量的内容是搜索引擎给网站打分的重要环节。主要有两点,第一是原创,第二是和网站相关的内容。不会写原创的朋友可以学学伪原创的一些技巧,其次发表的内容要和网站定位的话题相关,这样对双方都是最好的用户体验和搜索引擎。价值极高,也是打造优质网站的必由之路,对网站体重的提升有着决定性的作用。
3、详细分析百度二次收录,时机和量化发布是关键。
定期发布新内容,让网站形成一个持续稳定的更新规律,让蜘蛛发现这个规律实现规律爬取,这是百度二次收入非常关键的因素。就像定时吃饭、约饭一样。这样的更新模式形成后,该爬虫就来了。另一种是量化发布,每天保持一个固定的数量,避免今天一篇明天十篇,会让搜索引擎认为你的网站不稳定善变,避免被降级沙箱。
4.百度秒收详解,布局内链创造机会。
发布的新内容尽量展示在首页等重要页面,也可以在其他页面调用最新发布的内容和锚文本指向新内容页面。这样做的目的是阻止蜘蛛程序访问您网站上的其他页面。页面快速到达新内容页面,为百度秒收创造了机会和条件。从网站的长远发展来看,内链的建设对于网站的权重提升也是非常有利的。
5.百度秒收详解,外链渠道是保障。
天天发布优质内容很心酸,但百度蜘蛛不在意。所以,对于很多外链很强的老站来说,搭建高质量的外链和访问渠道是没有问题的。如果你的网站是一个新站,外链很少,可以采用这种方法。新内容页发布后,去一些热门论坛发出新文章的地址链接。快速蜘蛛将从这些站点爬行到您的新内容页面以进行爬行和索引。使用并掌握以上五个环节,坚持一到两周,你会发现你的网站收录是正常的,快照是第二天的,继续坚持一段时间和你的网站实现百度秒收几乎没问题。当然,这些链接还有一些细节问题,比如网站空间失效、批量删除外链、内链构建不当等,会导致网站被剥夺权限和二次采集不管用。我希望你不要忽略这些细节。看完这篇文章,如果您觉得还不错,不妨采集或转发给需要的朋友和同事。每天关注博主教你各种SEO经验,让你的网站也能快速收录和关键词排名!我希望你不要忽略这些细节。看完这篇文章,如果您觉得还不错,不妨采集或转发给需要的朋友和同事。每天关注博主教你各种SEO经验,让你的网站也能快速收录和关键词排名!我希望你不要忽略这些细节。看完这篇文章,如果您觉得还不错,不妨采集或转发给需要的朋友和同事。每天关注博主教你各种SEO经验,让你的网站也能快速收录和关键词排名! 查看全部
最新版:【APP源码】绿豆 v5.1.8最新影视APP源码,安装教程,视频教程
演示下载:
后台是第二个开放的苹果cms系统,使用mxone主题,后台有采集插件,网页版适配手机电脑,APP为原生安卓JAVA源代码。
APP有多个广告位,可接入信天翁广告联盟。源码有文字教程,根据教程修改即可成功搭建。本APP视频源码!
源码说明:
绿豆视频最新视频源码,源码完整
PC+wap+应用
有专题、短视频、排行榜功能等。
后台搭建教程:
1.宝塔新建数据库
2.安装宝塔插件环境
3.修改源码、后台文件、播放器配置文件的数据库地址
4. 创建网站
5.后台参数配置
注意:thinkphp需要配置伪静态网页
前端搭建教程:
1.下载jdk 1.8版本配置JDK环境
jdk1.8-下载安装及环境配置教程
2.下载Android studio 3.6版本进入前端包
Android studio 3.6下载环境搭建教程安装步骤
3.前端数据替换

4.打包导出
详细教程在源码里
前端对接:使用Android Studio工具打开前端加载项目后,搜索并选择名为app.java的文件打开文件,修改位置如下:
public static String SDKID = "888"; //广告媒体ID
公共静态字符串 UMENG_KEY = “8887db8242477110c5bb”;//友盟统计
public static String BASE_URL = "你的后台对接域名";
UI大幅改版,如首页热门影视搜索框、视频加载特效、分享视频显示当前分析的视频数据等。
去掉app端最下面的直播导航,这个直播功能没用!
找到文件:bottom nav menu.xml
打开文件,删除直播代码即可删除app底部的直播按钮。
如有打包错误,删除错误部分,不影响使用。
该版本有信天翁SDK广告版,前端源码+后端全部开源,无授权限制。
bilibili请求头设置
请求头:bilivideo.com
referer=> https://www.bilibili.com
User-Agent=>Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,
likeGecko)Chrome/88.0.4324.150Safari/537.36
使用请求的的链接:
.
.*?bilivideo.com.*
芒果请求头设置

请求头:
referer=> https://www.mgtv.com/
User-Agent=> Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/88.0.4324.150 Safari/537.36
使用请求的的链接:
.+?titan.mgtv.com.*
分析界面设置教程
网页解析只支持网页界面。
App分析可以是web也可以是json。推荐使用json接口。web可能会导致app跳转到浏览器,程序可能会崩溃。
json解析接口的格式必须有以下两个参数
{
“code”:200,
“url”:”http://baidu.com/mp4.com
}
修改APP筛选页面参数
最新版本:狂雨CMS网站不收录,关键词没排名?-SEO免费插件所有网站通用
编辑第一段时,尽量加文章关键词,加粗关键词。原理是蜘蛛爬行的时候是从左到右,从上到下。如果关键词出现在之前,蜘蛛会认为这是一个高度相关的文章,同时起到一个递增的作用,前提是不能影响阅读。
3重新排序也称为“段落替换法”
文章段落不是很紧凑,或者说是平行的。在不影响文章初衷和适合用户浏览的前提下,可以把原来的文章段落打乱,重新排序,这个方法不适合所有人,顺理成章文章一定不。
4 内容删除及修改方法
去掉某个内容,可以是一个段落,但是是某个段落中的几个点。这个要看你自己的尺度。就修改幅度而言,至少,整篇文章文章修改幅度应该保持在30%左右,当然修改越大越受搜索引擎欢迎。
添加了 5 张新图片
读者会知道一张图片抵得上一千个字。虽然目前大部分搜索引擎无法读取图片的内容,但是图片中的alt属性可以进行注释,这样也会让搜索引擎焕然一新,认为你的内容是新的收录 ;
3.图片数量
1. 一篇文章 文章 有 7 或 8 张图片?图片太多了。如果潜在用户使用手机网络,图片太多,打开速度慢会影响他们的阅读习惯和体验,所以一般一篇文章文章只放2~3张图片。

2. 图片来源
图片来自哪里,尤其是一些专业的图片。大部分都是在网上找的,百度,搜狗,360等等,有很多。
3 图片处理
如何处理?为什么要加工?
因为收录是kb的形式,也就是一张图片的大小,用截图工具重新截一张图片,或者用美图,或者PS等软件重新处理,这样的图片是伪原创 ,在图片或特定文本中增强您的形式(或添加水印)。
4.如何实现网站二次收货
秒收网站最大的特点之一就是每天都会发布大量优质的资讯和内容。是的,这些平台是蜘蛛的梦想天堂。但是很多人都是普通的网站,大家更多的面临的是发布的内容百度收录不更新,快照长期不更新的情况。从我们身边经过?接下来小编就把百度二次采集的详细解析分享给大家,让你的网站实现正常的收录和百度二次采集。
百度秒收详情分析
1.百度秒收详解,好的网站结构是基础。
这个非常重要。一个好的网站结构会帮助访问者了解你的网站结构和层级,更有利于蜘蛛爬行和索引。这里推荐首页-栏目-内容页这样的树状结构,要简单不要复杂。为了提高蜘蛛的爬行效率,非常有必要为网站创建网站地图和robots文件来引导蜘蛛。有条件的朋友尽量使用静态页面,对蜘蛛比较友好。
二、百度秒收详解,打造优质内容是重点。
高质量的内容是搜索引擎给网站打分的重要环节。主要有两点,第一是原创,第二是和网站相关的内容。不会写原创的朋友可以学学伪原创的一些技巧,其次发表的内容要和网站定位的话题相关,这样对双方都是最好的用户体验和搜索引擎。价值极高,也是打造优质网站的必由之路,对网站体重的提升有着决定性的作用。
3、详细分析百度二次收录,时机和量化发布是关键。
定期发布新内容,让网站形成一个持续稳定的更新规律,让蜘蛛发现这个规律实现规律爬取,这是百度二次收入非常关键的因素。就像定时吃饭、约饭一样。这样的更新模式形成后,该爬虫就来了。另一种是量化发布,每天保持一个固定的数量,避免今天一篇明天十篇,会让搜索引擎认为你的网站不稳定善变,避免被降级沙箱。
4.百度秒收详解,布局内链创造机会。
发布的新内容尽量展示在首页等重要页面,也可以在其他页面调用最新发布的内容和锚文本指向新内容页面。这样做的目的是阻止蜘蛛程序访问您网站上的其他页面。页面快速到达新内容页面,为百度秒收创造了机会和条件。从网站的长远发展来看,内链的建设对于网站的权重提升也是非常有利的。
5.百度秒收详解,外链渠道是保障。
天天发布优质内容很心酸,但百度蜘蛛不在意。所以,对于很多外链很强的老站来说,搭建高质量的外链和访问渠道是没有问题的。如果你的网站是一个新站,外链很少,可以采用这种方法。新内容页发布后,去一些热门论坛发出新文章的地址链接。快速蜘蛛将从这些站点爬行到您的新内容页面以进行爬行和索引。使用并掌握以上五个环节,坚持一到两周,你会发现你的网站收录是正常的,快照是第二天的,继续坚持一段时间和你的网站实现百度秒收几乎没问题。当然,这些链接还有一些细节问题,比如网站空间失效、批量删除外链、内链构建不当等,会导致网站被剥夺权限和二次采集不管用。我希望你不要忽略这些细节。看完这篇文章,如果您觉得还不错,不妨采集或转发给需要的朋友和同事。每天关注博主教你各种SEO经验,让你的网站也能快速收录和关键词排名!我希望你不要忽略这些细节。看完这篇文章,如果您觉得还不错,不妨采集或转发给需要的朋友和同事。每天关注博主教你各种SEO经验,让你的网站也能快速收录和关键词排名!我希望你不要忽略这些细节。看完这篇文章,如果您觉得还不错,不妨采集或转发给需要的朋友和同事。每天关注博主教你各种SEO经验,让你的网站也能快速收录和关键词排名!
免费的:网站文章数据采集,免费网站文章数据采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-11-13 07:42
网站文章数据采集是从我们的目标网站采集信息的过程。使用 网站文章Data采集 工具,我们可以从 网站 下载结构化数据进行自动化分析。
网站文章Data采集 表示从网站 中提取的内容和数据。然后以用户所需的格式提取此信息。网站文章Data采集 可以手动完成,但这是一项极其繁琐的工作。为了加快这个过程,我们可以使用自动化、成本更低、工作速度更快的 网站文章data采集 工具。
通过使用网站文章data采集工具,我们可以在不同的场景中帮助我们完成多种目的,比如市场研究的数据采集、联系信息提取、价格跟踪在不同平台上,关注网站的内容变化,实时数据监控等。
网站文章数据采集工具页面简洁易操作,可视化的操作页面不需要我们掌握复杂的配置规则,就可以完成网站内容和数据采集。
网站文章数据采集工具指定的采集功能可以通过输入目标URL并在工具的可视化页面选择采集元素来配置 下载模板。通过模板选择我们需要的内容或者保留相应的标签,或者通过模板去掉我们不想要的元素,比如电话号码、住址、作者信息等。
网站文章数据采集输入关键词后,该工具可以进行全网关键词匹配,完成平移采集。所有匹配的内容都是大平台上的实时热门资源。无论是通过强大的NLP自然语言处理系统采集资源进行二次创作和发布伪原创,都可以为我们网站提供优质的内容。
网站文章数据采集除了采集功能外,该工具还有文章内容SEO,支持保留原文相关标签、图片下载过程中去除水印和图像下载。云存储等,支持多种下载格式保存,无论是HTML、TXT还是excel等,方便我们在后续二次创作中放心创作和数据分析。
网站文章Data采集 是如何工作的?首先,网站文章data采集 在 采集 进程之前获取要加载的 URL。网站文章Data采集 工具然后加载所需页面的完整 HTML 代码。然后,网站文章Data采集会在项目运行前提取页面上的所有数据或者用户选择的特定数据。最后,网站文章Data采集 将所有采集的数据输出为可用格式。
网站文章data采集的用途和工作原理以及网站文章data采集工具应用的分享都在这里,网站文章数据的使用采集可以说是非常广泛了,不仅我们的网站可以使用采集不断更新内容,各行各业的生活可以使用采集@网站文章数据采集工具采集相关数据进行数据统计和分析,如果喜欢本内容,请点赞、采集并关注,您的支持是博主坚持不懈的动力。
技术文章:网站SEO外链的基本规律有哪些?
网站SEO外链的基本规则是什么?
如果你仔细总结一下,你会发现所有这些方法总是逃不过一些特定的规律。所以今天就对外链推广的SEO优化方法和规律做一个总结,希望对大家有所帮助。
因此,理解这个文章非常重要。看完这篇文章,如果你看任何一种外链推广的方法,都逃不过我总结的这些规律。
我们知道,从大的角度来看,SEO可以分为站内优化和站外推广。从规模上看,网站可以分为网站建设优化和页面优化。而当我们谈seo异地推广的时候,其实重点是外链的建设。
推广的时候最好注意对方的情况,然后可以用上面的标准来判断,但是我也想告诉大家,并不是一个网站必须满足所有条件,那你可以做外链,如果你很死板,按照所有的标准,你会很痛苦,你会发现你找到了这样一个网站,并且愿意为你做链接,比如机会很小!
所有的点都可以用一句话概括,做外链的时候,不能随便找个垃圾网站做外链,还是得有点标准。 查看全部
免费的:网站文章数据采集,免费网站文章数据采集工具
网站文章数据采集是从我们的目标网站采集信息的过程。使用 网站文章Data采集 工具,我们可以从 网站 下载结构化数据进行自动化分析。
网站文章Data采集 表示从网站 中提取的内容和数据。然后以用户所需的格式提取此信息。网站文章Data采集 可以手动完成,但这是一项极其繁琐的工作。为了加快这个过程,我们可以使用自动化、成本更低、工作速度更快的 网站文章data采集 工具。
通过使用网站文章data采集工具,我们可以在不同的场景中帮助我们完成多种目的,比如市场研究的数据采集、联系信息提取、价格跟踪在不同平台上,关注网站的内容变化,实时数据监控等。
网站文章数据采集工具页面简洁易操作,可视化的操作页面不需要我们掌握复杂的配置规则,就可以完成网站内容和数据采集。
网站文章数据采集工具指定的采集功能可以通过输入目标URL并在工具的可视化页面选择采集元素来配置 下载模板。通过模板选择我们需要的内容或者保留相应的标签,或者通过模板去掉我们不想要的元素,比如电话号码、住址、作者信息等。
网站文章数据采集输入关键词后,该工具可以进行全网关键词匹配,完成平移采集。所有匹配的内容都是大平台上的实时热门资源。无论是通过强大的NLP自然语言处理系统采集资源进行二次创作和发布伪原创,都可以为我们网站提供优质的内容。

网站文章数据采集除了采集功能外,该工具还有文章内容SEO,支持保留原文相关标签、图片下载过程中去除水印和图像下载。云存储等,支持多种下载格式保存,无论是HTML、TXT还是excel等,方便我们在后续二次创作中放心创作和数据分析。
网站文章Data采集 是如何工作的?首先,网站文章data采集 在 采集 进程之前获取要加载的 URL。网站文章Data采集 工具然后加载所需页面的完整 HTML 代码。然后,网站文章Data采集会在项目运行前提取页面上的所有数据或者用户选择的特定数据。最后,网站文章Data采集 将所有采集的数据输出为可用格式。
网站文章data采集的用途和工作原理以及网站文章data采集工具应用的分享都在这里,网站文章数据的使用采集可以说是非常广泛了,不仅我们的网站可以使用采集不断更新内容,各行各业的生活可以使用采集@网站文章数据采集工具采集相关数据进行数据统计和分析,如果喜欢本内容,请点赞、采集并关注,您的支持是博主坚持不懈的动力。
技术文章:网站SEO外链的基本规律有哪些?
网站SEO外链的基本规则是什么?
如果你仔细总结一下,你会发现所有这些方法总是逃不过一些特定的规律。所以今天就对外链推广的SEO优化方法和规律做一个总结,希望对大家有所帮助。

因此,理解这个文章非常重要。看完这篇文章,如果你看任何一种外链推广的方法,都逃不过我总结的这些规律。
我们知道,从大的角度来看,SEO可以分为站内优化和站外推广。从规模上看,网站可以分为网站建设优化和页面优化。而当我们谈seo异地推广的时候,其实重点是外链的建设。

推广的时候最好注意对方的情况,然后可以用上面的标准来判断,但是我也想告诉大家,并不是一个网站必须满足所有条件,那你可以做外链,如果你很死板,按照所有的标准,你会很痛苦,你会发现你找到了这样一个网站,并且愿意为你做链接,比如机会很小!
所有的点都可以用一句话概括,做外链的时候,不能随便找个垃圾网站做外链,还是得有点标准。
汇总:php采集文章中的图片获取替换到本地(实现代码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-11-05 03:27
代码如下:
/**
* 获取替换文章中图片的路径
* @param字符串$xstr内容
* @param字符串$keyword创建的照片的文件名
* @param字符串$oriweb网址
* @return字符串
*
*/
function replaceimg($xstr,$keyword, $oriweb){
保存路径
$d = 日期('Ymd', time());
$dirslsitss = '/var/www/weblist/uploads/'.$keyword.“ /'.$d;//分类是否存在
if(!is_dir($dirslsitss)) {
@mkdir($dirslsitss, 0777);
}
匹配图片的 SRC
preg_match_all('#
]*>#i', $xstr, $match);
foreach($match[1] as $imgurl){
$imgurl = $imgurl;
if(is_int(strpos($imgurl, 'http'))){
$arcurl = $imgurl;
} else {
$arcurl = $oriweb.$imgurl;
}
$img=file_get_contents($arcurl);
if(!empty($img)) {
将图片保存到服务器
$fileimgname = time().“ -”.rand(1000,9999).”。JPG“;
$filecachs=$dirslsitss.“ /”.$fileimgname;
$fanhuistr = file_put_contents( $filecachs, $img );
$saveimgfile = “/uploads/$keyword”.“ /”.$d.“ /”.$fileimgname;
$xstr=str_replace($imgurl,$saveimgfile,$xstr);
}
}
返回$xstr;
}
直观:【观点交锋】输入法可以收集用户上传的内容!要智能还是隐私?
“我在和朋友聊微波炉、纸尿裤、洗面奶等的时候,发现一个输入法会自动推送广告。” 近日,有网友在知乎上贴出了这样的问题描述。这个问题引起了很多网友的共鸣。
记者从华为应用商店下载了排名前5的输入法应用,发现其中4个都有提示加入或默认勾选的“用户体验改善计划”,该计划的主要内容是输入法可以采集。用户上传的内容。至于是否根据聊天内容推送广告,不同输入法的隐私政策有不同的解释。
对此,有专家表示,只有采集用户输入习惯,才能优化输入法的输入体验,这是技术发展的需要;但也有网友担心这会窥探用户隐私。
您认为输入法可以采集用户上传的内容是否合适?
意见冲突现在开始
实测:4种输入法用户服务协议
提供采集用户上传内容的权利
其中,搜狗输入法和QQ输入法在用户首次登录后会提示加入“用户体验计划”,而百度输入法和讯飞输入法则默认勾选加入“用户体验计划”(可手动取消),4款APP均规定加入用户体验计划即表示用户同意相关用户服务协议或隐私条款。
记者打开搜狗输入法用户服务协议发现,该协议的用户权利条款3.1规定“您理解并同意我们有权存储您上传的内容,您授权我们合理使用您上传的内容,包括但不限于产品分析、宣传、推广等”
网友:输入法推送广告也弹窗
专业人士:免费价格
当上述网友通过微信与朋友聊起“最怕换尿布”的内容时,搜狗输入法输入界面弹出了一个广告弹窗,上面写着“孩子容易出现尿布疹,看看怎么办”做!”。
记者搜索发现,除了输入法输入界面出现弹窗广告外,更多人对搜狗输入法PC端存在弹窗广告有着更深的“怨恨”。记者发现,有时使用搜狗输入法在搜索引擎中搜索关键词时,搜狗输入法会自动跳转到搜狗搜索。
“其实这是中国人不愿意为软件买单造成的。实际上,这样做只会让谋利行为隐藏起来,这样就很容易没有顾忌。” 知乎 认证为小输入法开发者 网友“随寒”吐槽:“中国人不愿意花钱买软件,甚至有很多老子用你的软件看不起你的嚣张。应用开发者,用户都不愿意付钱,对,没关系,总有办法让你吐钱。”
在记者测试的5款输入法App中,八达通输入法没有像其他4款输入法一样要求记者加入“用户体验计划”,但记者在使用App时发现大量弹窗广告. 此外,这款输入法号称具有“金币提现”功能,即输入的字符越多,获得的奖励就越多。对于此功能,表示输入的字符数是根据“点击键盘的次数”来确定的,不涉及打字。信息的具体内容。当记者点击足够多的时候,他发现了一个接收金币的选项。点击接收时,输入法再次跳出广告。从这个角度来看,
对此,有业内人士告诉记者,输入法广告和其他免费APP的广告一样,是目前免费模式下的无奈选择。“微软Smart ABC没有广告,但你看谁在用?如果你需要联想能弹出的便捷功能和表情,就需要一定的支出,这时候输入法只能是“通过广告和其他方式获利。另一方面,免费是最昂贵的。”
网友大红苹果天马林表示,目前带广告的输入法一般都是智能输入法,而且要有云词库,登陆账号即可。“智能是需要开销的,比如不同职业的人输入某个词时,输入法可以根据你以前的输入习惯和特点,把与专业相关的词汇放在相当高的位置,方便你输入。比较用离线输入法,这部分费用还是有点影响的智能输入法。”
你怎么看? 查看全部
汇总:php采集文章中的图片获取替换到本地(实现代码)
代码如下:
/**
* 获取替换文章中图片的路径
* @param字符串$xstr内容
* @param字符串$keyword创建的照片的文件名
* @param字符串$oriweb网址
* @return字符串
*
*/
function replaceimg($xstr,$keyword, $oriweb){
保存路径
$d = 日期('Ymd', time());
$dirslsitss = '/var/www/weblist/uploads/'.$keyword.“ /'.$d;//分类是否存在

if(!is_dir($dirslsitss)) {
@mkdir($dirslsitss, 0777);
}
匹配图片的 SRC
preg_match_all('#
]*>#i', $xstr, $match);
foreach($match[1] as $imgurl){
$imgurl = $imgurl;
if(is_int(strpos($imgurl, 'http'))){
$arcurl = $imgurl;
} else {
$arcurl = $oriweb.$imgurl;
}
$img=file_get_contents($arcurl);
if(!empty($img)) {
将图片保存到服务器
$fileimgname = time().“ -”.rand(1000,9999).”。JPG“;
$filecachs=$dirslsitss.“ /”.$fileimgname;
$fanhuistr = file_put_contents( $filecachs, $img );
$saveimgfile = “/uploads/$keyword”.“ /”.$d.“ /”.$fileimgname;
$xstr=str_replace($imgurl,$saveimgfile,$xstr);
}
}
返回$xstr;
}
直观:【观点交锋】输入法可以收集用户上传的内容!要智能还是隐私?
“我在和朋友聊微波炉、纸尿裤、洗面奶等的时候,发现一个输入法会自动推送广告。” 近日,有网友在知乎上贴出了这样的问题描述。这个问题引起了很多网友的共鸣。
记者从华为应用商店下载了排名前5的输入法应用,发现其中4个都有提示加入或默认勾选的“用户体验改善计划”,该计划的主要内容是输入法可以采集。用户上传的内容。至于是否根据聊天内容推送广告,不同输入法的隐私政策有不同的解释。
对此,有专家表示,只有采集用户输入习惯,才能优化输入法的输入体验,这是技术发展的需要;但也有网友担心这会窥探用户隐私。
您认为输入法可以采集用户上传的内容是否合适?
意见冲突现在开始
实测:4种输入法用户服务协议

提供采集用户上传内容的权利
其中,搜狗输入法和QQ输入法在用户首次登录后会提示加入“用户体验计划”,而百度输入法和讯飞输入法则默认勾选加入“用户体验计划”(可手动取消),4款APP均规定加入用户体验计划即表示用户同意相关用户服务协议或隐私条款。
记者打开搜狗输入法用户服务协议发现,该协议的用户权利条款3.1规定“您理解并同意我们有权存储您上传的内容,您授权我们合理使用您上传的内容,包括但不限于产品分析、宣传、推广等”
网友:输入法推送广告也弹窗
专业人士:免费价格

当上述网友通过微信与朋友聊起“最怕换尿布”的内容时,搜狗输入法输入界面弹出了一个广告弹窗,上面写着“孩子容易出现尿布疹,看看怎么办”做!”。
记者搜索发现,除了输入法输入界面出现弹窗广告外,更多人对搜狗输入法PC端存在弹窗广告有着更深的“怨恨”。记者发现,有时使用搜狗输入法在搜索引擎中搜索关键词时,搜狗输入法会自动跳转到搜狗搜索。
“其实这是中国人不愿意为软件买单造成的。实际上,这样做只会让谋利行为隐藏起来,这样就很容易没有顾忌。” 知乎 认证为小输入法开发者 网友“随寒”吐槽:“中国人不愿意花钱买软件,甚至有很多老子用你的软件看不起你的嚣张。应用开发者,用户都不愿意付钱,对,没关系,总有办法让你吐钱。”
在记者测试的5款输入法App中,八达通输入法没有像其他4款输入法一样要求记者加入“用户体验计划”,但记者在使用App时发现大量弹窗广告. 此外,这款输入法号称具有“金币提现”功能,即输入的字符越多,获得的奖励就越多。对于此功能,表示输入的字符数是根据“点击键盘的次数”来确定的,不涉及打字。信息的具体内容。当记者点击足够多的时候,他发现了一个接收金币的选项。点击接收时,输入法再次跳出广告。从这个角度来看,
对此,有业内人士告诉记者,输入法广告和其他免费APP的广告一样,是目前免费模式下的无奈选择。“微软Smart ABC没有广告,但你看谁在用?如果你需要联想能弹出的便捷功能和表情,就需要一定的支出,这时候输入法只能是“通过广告和其他方式获利。另一方面,免费是最昂贵的。”
网友大红苹果天马林表示,目前带广告的输入法一般都是智能输入法,而且要有云词库,登陆账号即可。“智能是需要开销的,比如不同职业的人输入某个词时,输入法可以根据你以前的输入习惯和特点,把与专业相关的词汇放在相当高的位置,方便你输入。比较用离线输入法,这部分费用还是有点影响的智能输入法。”
你怎么看?
干货教程:免费微信公众号数据采集提取软件-自动提取封面图文章内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 402 次浏览 • 2022-11-01 21:54
微信公众号数据采集,公众号封面图片提取,公众号文章提取。如何提取微信公众号数据如:内容、封面图,如何批量提取微信公众号数据并保存在本地进行修改。今天给大家分享一款免费的微信公众号数据自动提取软件采集。输入关键词或者输入域名自动提取文章到本地,自动解析文章核心很重要。
现在说到网站的seo优化,微信公众号数据采集会用到一些seo技术,seo理念,seo策略,分离用户体验,用户需求,网站建立,等。让网站在搜索引擎中排名靠前,让网站更有用,让内容更适合用户。SER 读取。这就是主动SEO,但是在有效SEO、被动SEO背后总有一个黑暗的中心,也就是说你的网站就是SEO,有光有影。
谈到公司的网站优化如何有效防止负面SEO干扰的话题,应该讨论两个概念:正面SEO和负面SEO。微信公众号数据采集主动搜索引擎优化就是我们常说的搜索引擎优化,也就是让网站在搜索引擎中排名。负搜索引擎优化和积极搜索引擎优化在运营商和应用程序上是对立的。负面 SEO 是指其他人(恶意网站管理员、竞争对手等)在您的 网站 上施加一些负面 SEO 元素(搜索引擎知道阻止这些元素),从而使您的 网站 排名更低,甚至变得严重受到惩罚。
在整个SEO网站优化过程中,难免会出现一些负面信息的优化技巧。负面信息是真实的。一般来说,它会基于一些故意的反向链接和草率的电子邮件破坏你的网站,这将极大地影响你的网站排名、总流量和权重值。冒险。一般来说,负面信息SEO是一种法律纠葛,很可能对搜索引擎的知名度和收益造成损害。微信公众号数据采集但是,在整个优化过程中,可以防止负面的SEO。如何预防?一般来说,SEO网站的负面信息都会被竞争对手阻止。这是在另一个 网站 上完成的黑帽 SEO 技术。通常来说,一般来说,竞争对手对降低 网站 排名的 SEO 攻击不满意。然而,在大多数情况下,很多SEO优化网站站长想要遵循SEO优化规范,却不得不伤人心,堵人心。
难免会有人羡慕你的网站排名,用几百个渣滓封杀你的网站,用不正确的评论吞下你的网站,或者马上破译你的网站。微信公众号数据采集注意你的网站速度。网站速度是一个非常有害的排名。如果你的网站越来越慢,你就得开机很久了。你永远不知道如何使用爬行工具来找到一切都不起作用的项目。如果你找不到他们,他们仍然不是很好,受害者可能就是你。大量爬网导致的 Web 服务器负载过重意味着您的 网站 会变慢并崩溃。如果您认为自己是网络爬虫攻击的受害者,可以联系您的服务器公司或 网站 管理员了解负载的来源。如果你擅长技术,你可以找到自己惹麻烦的人。
关于网站的优化,大家应该都遇到过这样的事情。我们努力做了一个网站,终于做出了网站的排名,但是不知怎的,网站的排名过了一段时间就下降了,而且排名很不稳定。在了解搜索引擎自然排名机制的基础上,对网站进行内外调整优化,提高网站在搜索引擎中的关键词自然排名,获得更多流量,从而达到网站销售和品牌建设的预期目的。为了从搜索引擎获得更多的免费流量,应该从网站结构、内容建立计划、用户交互传播、页面等角度进行合理规划,同时也会使网站网站 搜索引擎中显示的相关信息。它对用户更具吸引力。下面小编就告诉大家我们如何稳定网站和优化排名?
网站排名上升后,我们每天抽时间查看收录和网站的排名状态,以及查看搜索引擎来不来,查看网站当天更新内容还没有收录。关注竞争对手的网站,看看对手的网站有什么好主意。网站 的内容会及时更新。这是为了吸引蜘蛛去爬网站,从而增加网站的收录,同时也提高了快照的更新速度。如果网站长时间不更新,搜索引擎会认为这是一场致命的战斗,从而降低你的网站排名,严重的甚至会被降级。
网站 的外部链接也很重要。一个好的外链是你网站排名的背景,所以我们需要增加网站外链的数量。网站查看和好友链通讯,查看我通讯的好友链是否被删除,对方的网站是否可以正常打开,是否可以降级或暂停,是否显示及时处理。
干货教程:1毛钱的成本即可精准引流+变现
我们都知道,无论是网赚行业还是普通行业,玩自媒体最重要的就是推广引流,然后变现,对品牌优化有极好的效果。
即使是现在购买的账号,部分自媒体平台也需要刷脸认证。
为什么要推荐新浪博客?因为博客对我们来说比其他 自媒体 平台更好。
1、博客账号成本低。一个账号的价格根据不同档次基本在0.1元到2元之间。便宜的价格意味着投资成本低。
2、博客的权重不亚于百家号、搜狐等平台。
3.主要是博客的规则没有其他自媒体平台那么严格。
1. 准备
1.1 账户
我们首先需要准备一个博客帐户。我在哪里可以购买博客帐户?一般去QQ群或者卡联盟买个账号,反正渠道很多,很容易买到,价格一般0.1-2元
购买账号后,需要将个人信息更改为真实信息,不要让系统认为你是批量发行的营销账号。
注意:更改信息时,最好将昵称更改为与您的产品相关的名称关键词。
1.2 定位
你做什么工作?您的博客需要服务哪些用户群?你要输出什么值?您想销售产品还是提供服务?
这时会有10个相关词的搜索索引,然后你通过分析这些搜索索引的排名来定位你的博客。
这里我再告诉大家另一种方法,就是通过“词库软件”进行搜索。通过这个软件搜索,我们可以找到19万条与减肥相关的关键词,而且还有每天在电脑和手机上用百度搜索引擎搜索到这个关键词的数据。
2.博客内容
2.1 内容对应主题
如果你的写作能力不错,并且对这方面有很好的理解,那么你可以自己写原创。原创文章百度的机制越多,百度收录就越容易。
2.2伪原创
1)利用用户热搜词找到大家喜欢搜索减肥的关键词,然后根据你的产品需要展开词,挖出长尾关键词。抓住其中的 关键词 来定义您的 文章 标题。
比如“减肥”关键词,那么我可以制定如下标题:
一日三餐的减肥食谱有哪些?
2)我们可以在今日头条、知乎、公众号等平台上完全转移标题相关的内容,然后将里面的联系方式修改为我们自己的并发布到博客上。你也可以使用一些伪原创工具,或者使用“中英翻译”来伪原创。
3)你也可以找几篇内容相同的文章文章,复制整理每个文章写的比较好的段落,将多篇文章整理成一篇文章文章 .
3.提交搜索引擎条目
3.1 锚链接
我们可以在 文章 中添加“锚链接”。锚文本是 html 中链接的文本标记。只要是html编辑器,一般都可以编辑添加。
3.2 备注
如果是第一次点击发博,会进入编辑页面,提示编辑界面可以切换到新版本。这里个人建议直接关闭提示,因为新版编辑界面不利于百度收录。
4.插入广告
前期,我们主要以开户为主。毕竟没有流量,也没有相关的关键词排名。不管你放多少广告,基本上是没用的。虽然对博客的检查不严格,但还是建议大家去前期。不要做广告。
当搜索引擎认为您的博客有价值时,他们就会非常信任您的博客。然后你的 文章 也会出现在搜索引擎的顶部。
这时你可能会问我,什么时候投放广告最好?
这里我给大家提供一个很简单的方法,就是复制你的网址,直接去搜索引擎搜索。如果你的博客能出现,那基本上就说明你那天被录用了。
广告位:
1. 添加广告模板
2. 在文字中插入带有广告的图片 查看全部
干货教程:免费微信公众号数据采集提取软件-自动提取封面图文章内容
微信公众号数据采集,公众号封面图片提取,公众号文章提取。如何提取微信公众号数据如:内容、封面图,如何批量提取微信公众号数据并保存在本地进行修改。今天给大家分享一款免费的微信公众号数据自动提取软件采集。输入关键词或者输入域名自动提取文章到本地,自动解析文章核心很重要。
现在说到网站的seo优化,微信公众号数据采集会用到一些seo技术,seo理念,seo策略,分离用户体验,用户需求,网站建立,等。让网站在搜索引擎中排名靠前,让网站更有用,让内容更适合用户。SER 读取。这就是主动SEO,但是在有效SEO、被动SEO背后总有一个黑暗的中心,也就是说你的网站就是SEO,有光有影。

谈到公司的网站优化如何有效防止负面SEO干扰的话题,应该讨论两个概念:正面SEO和负面SEO。微信公众号数据采集主动搜索引擎优化就是我们常说的搜索引擎优化,也就是让网站在搜索引擎中排名。负搜索引擎优化和积极搜索引擎优化在运营商和应用程序上是对立的。负面 SEO 是指其他人(恶意网站管理员、竞争对手等)在您的 网站 上施加一些负面 SEO 元素(搜索引擎知道阻止这些元素),从而使您的 网站 排名更低,甚至变得严重受到惩罚。
在整个SEO网站优化过程中,难免会出现一些负面信息的优化技巧。负面信息是真实的。一般来说,它会基于一些故意的反向链接和草率的电子邮件破坏你的网站,这将极大地影响你的网站排名、总流量和权重值。冒险。一般来说,负面信息SEO是一种法律纠葛,很可能对搜索引擎的知名度和收益造成损害。微信公众号数据采集但是,在整个优化过程中,可以防止负面的SEO。如何预防?一般来说,SEO网站的负面信息都会被竞争对手阻止。这是在另一个 网站 上完成的黑帽 SEO 技术。通常来说,一般来说,竞争对手对降低 网站 排名的 SEO 攻击不满意。然而,在大多数情况下,很多SEO优化网站站长想要遵循SEO优化规范,却不得不伤人心,堵人心。
难免会有人羡慕你的网站排名,用几百个渣滓封杀你的网站,用不正确的评论吞下你的网站,或者马上破译你的网站。微信公众号数据采集注意你的网站速度。网站速度是一个非常有害的排名。如果你的网站越来越慢,你就得开机很久了。你永远不知道如何使用爬行工具来找到一切都不起作用的项目。如果你找不到他们,他们仍然不是很好,受害者可能就是你。大量爬网导致的 Web 服务器负载过重意味着您的 网站 会变慢并崩溃。如果您认为自己是网络爬虫攻击的受害者,可以联系您的服务器公司或 网站 管理员了解负载的来源。如果你擅长技术,你可以找到自己惹麻烦的人。

关于网站的优化,大家应该都遇到过这样的事情。我们努力做了一个网站,终于做出了网站的排名,但是不知怎的,网站的排名过了一段时间就下降了,而且排名很不稳定。在了解搜索引擎自然排名机制的基础上,对网站进行内外调整优化,提高网站在搜索引擎中的关键词自然排名,获得更多流量,从而达到网站销售和品牌建设的预期目的。为了从搜索引擎获得更多的免费流量,应该从网站结构、内容建立计划、用户交互传播、页面等角度进行合理规划,同时也会使网站网站 搜索引擎中显示的相关信息。它对用户更具吸引力。下面小编就告诉大家我们如何稳定网站和优化排名?
网站排名上升后,我们每天抽时间查看收录和网站的排名状态,以及查看搜索引擎来不来,查看网站当天更新内容还没有收录。关注竞争对手的网站,看看对手的网站有什么好主意。网站 的内容会及时更新。这是为了吸引蜘蛛去爬网站,从而增加网站的收录,同时也提高了快照的更新速度。如果网站长时间不更新,搜索引擎会认为这是一场致命的战斗,从而降低你的网站排名,严重的甚至会被降级。
网站 的外部链接也很重要。一个好的外链是你网站排名的背景,所以我们需要增加网站外链的数量。网站查看和好友链通讯,查看我通讯的好友链是否被删除,对方的网站是否可以正常打开,是否可以降级或暂停,是否显示及时处理。
干货教程:1毛钱的成本即可精准引流+变现
我们都知道,无论是网赚行业还是普通行业,玩自媒体最重要的就是推广引流,然后变现,对品牌优化有极好的效果。
即使是现在购买的账号,部分自媒体平台也需要刷脸认证。
为什么要推荐新浪博客?因为博客对我们来说比其他 自媒体 平台更好。
1、博客账号成本低。一个账号的价格根据不同档次基本在0.1元到2元之间。便宜的价格意味着投资成本低。
2、博客的权重不亚于百家号、搜狐等平台。
3.主要是博客的规则没有其他自媒体平台那么严格。
1. 准备
1.1 账户
我们首先需要准备一个博客帐户。我在哪里可以购买博客帐户?一般去QQ群或者卡联盟买个账号,反正渠道很多,很容易买到,价格一般0.1-2元
购买账号后,需要将个人信息更改为真实信息,不要让系统认为你是批量发行的营销账号。
注意:更改信息时,最好将昵称更改为与您的产品相关的名称关键词。
1.2 定位

你做什么工作?您的博客需要服务哪些用户群?你要输出什么值?您想销售产品还是提供服务?
这时会有10个相关词的搜索索引,然后你通过分析这些搜索索引的排名来定位你的博客。
这里我再告诉大家另一种方法,就是通过“词库软件”进行搜索。通过这个软件搜索,我们可以找到19万条与减肥相关的关键词,而且还有每天在电脑和手机上用百度搜索引擎搜索到这个关键词的数据。
2.博客内容
2.1 内容对应主题
如果你的写作能力不错,并且对这方面有很好的理解,那么你可以自己写原创。原创文章百度的机制越多,百度收录就越容易。
2.2伪原创
1)利用用户热搜词找到大家喜欢搜索减肥的关键词,然后根据你的产品需要展开词,挖出长尾关键词。抓住其中的 关键词 来定义您的 文章 标题。
比如“减肥”关键词,那么我可以制定如下标题:
一日三餐的减肥食谱有哪些?
2)我们可以在今日头条、知乎、公众号等平台上完全转移标题相关的内容,然后将里面的联系方式修改为我们自己的并发布到博客上。你也可以使用一些伪原创工具,或者使用“中英翻译”来伪原创。
3)你也可以找几篇内容相同的文章文章,复制整理每个文章写的比较好的段落,将多篇文章整理成一篇文章文章 .
3.提交搜索引擎条目

3.1 锚链接
我们可以在 文章 中添加“锚链接”。锚文本是 html 中链接的文本标记。只要是html编辑器,一般都可以编辑添加。
3.2 备注
如果是第一次点击发博,会进入编辑页面,提示编辑界面可以切换到新版本。这里个人建议直接关闭提示,因为新版编辑界面不利于百度收录。
4.插入广告
前期,我们主要以开户为主。毕竟没有流量,也没有相关的关键词排名。不管你放多少广告,基本上是没用的。虽然对博客的检查不严格,但还是建议大家去前期。不要做广告。
当搜索引擎认为您的博客有价值时,他们就会非常信任您的博客。然后你的 文章 也会出现在搜索引擎的顶部。
这时你可能会问我,什么时候投放广告最好?
这里我给大家提供一个很简单的方法,就是复制你的网址,直接去搜索引擎搜索。如果你的博客能出现,那基本上就说明你那天被录用了。
广告位:
1. 添加广告模板
2. 在文字中插入带有广告的图片
最新版:网页文章正文采集的方法以微信文章采集为例.docx 45页
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-10-31 20:46
网页文章文本采集方法,以微信文章采集为例。保存的时候怎么办?一张一张复制粘贴?选择一个通用的网络数据 采集器 将使这项工作变得容易得多。优采云是一个通用的网页数据采集器,可以是互联网上的采集公共数据。用户可以设置从哪个网站爬取数据,爬取什么数据,爬取什么范围的数据,什么时候爬取数据,如何保存爬取的数据等。言归正传,本文将采取<以搜狗微信文章文字采集为例,讲解优采云采集网页文章文字的使用方法。文章文本采集,主要有两种情况: 1、采集文章正文中的文本,不包括图片;2. 采集文章 正文中的文本和图像 URL。示例网站:/使用功能点:Xpath/search?query=XPath判断条件/tutorialdetail-1/judge.html分页列表信息采集 /tutorial/fylb-70.aspx?t=1AJAX滚动教程/tutorialdetail-1/ajgd_7.htmlAJAX点击翻页/tutorialdetail-1/ajaxdjfy_7.html采集文章正文中,无图片具体步骤: 第一步:创建采集任务1)进入主界面,选择“自定义模式”网页文章文本采集步骤12)复制并粘贴你想要的网站的网址采集到网站
打开网页时,默认显示“热门”文章。向下滚动页面,找到并点击“加载更多内容”按钮,在动作提示框中,选择“更多动作”页面文章Body采集Step 3选择“循环点击单个元素”创建一个翻页循环网页文章Body采集第四步由于这个网页涉及到Ajax技术,我们需要设置一些高级选项。选择“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”网页文章Text采集Step 5 注意:AJAX表示延迟加载, 一种异步更新的脚本技术,通过在后台与服务器交换少量数据,可以在不重新加载整个网页的情况下更新网页的某个部分。详情请参考AJAX点击和翻页教程:/tutorialdetail-1/ajaxdjfy_7.html 观察网页,我们发现点击“加载更多内容”5次后,页面加载到了底部,一共有显示了 100 篇文章 文章 。因此,我们将整个“循环页面”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5次”,在网页点击“确定”文章Text采集Steps 6Step 3:创建列表循环并提取数据移动鼠标选择页面中的第一个文章链接。系统会自动识别相似链接。在操作提示框中,选择“Select All”网页文章Text采集Step 7 选择“Cycle Click Each Link”网页文章Text采集Step 8系统会自动进入文章详情页面。
点击需要采集的字段(这里先点击文章标题),在操作提示框中选择“采集该元素的文本”。文章发布时间,文章来源字段采集方法同理网页文章正文采集第九步下一步开始采集文章 文本。首先点击第一段文章文字,系统会自动识别页面中的相似元素,选择“全选”页面文章文字采集步骤105)即可看到所有的文本段落都被选中并变成绿色。选择“采集以下元素文本”网页文章正文采集步骤11 注意:在字段表中,可以自定义和修改字段。网页文章正文采集 Step 126) 经过上述操作后,文本将全部采集向下(默认情况下,每段文本为一个单元格)。一般来说,我们希望 采集 的主体被合并到同一个单元格中。点击“自定义数据字段”按钮,选择“自定义数据合并方式”,勾选“同一字段多次提取并合并为一行,即追加到同一字段,如文本页面合并”,然后点击“OK”页面文章Body采集Step 13“Customize Data Fields”按钮网页文章Body采集Step 14 选择“Customize Data Merge Method”网页文章Body采集Step 15 检查如图步骤4:修改Xpath1) 选中整个“loop step”,打开“Advanced Options”,可以看到优采云
我们通过这个Xpath发现://DIV[@class='main-left']/DIV[3]/UL/LI/DIV[2]/H3[1]/A,页面需要100篇文章< 文章所有页面都位于文章正文采集步骤173)将修改后的Xpath复制粘贴到优采云所示位置,然后点击“确定”到页面文章Text采集Step 18 Step 5:修改流程图结构我们继续观察,点击“加载更多内容”5次后,该页面加载了全部100篇文章文章。所以我们配置规则的思路是先建立一个翻页循环,把100篇文章全部加载文章,然后创建一个循环列表来提取数据 1)选择整个“循环”步骤并拖动退出“循环页面”步骤。如果不执行此操作,将会出现大量重复的数据页。文章Text采集Step 19 拖拽完成后页面如下图文章Text采集Steps 20 Step 6:Data采集并导出1 ) 点击左上角“保存”,然后点击“开始采集”,选择“开始本地采集”网页文章文本采集步骤21采集步骤21完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的数据导出到网页文章文本采集Step 223) 这里我们选择excel作为导出格式。数据导出后,网页如下图所示。采集到。那是因为 文章 的循环列表的 Xpath://[@id="js_content"]/P
修改Xpath为://[@id="js_content"]//P,所有文章文本都可以定位。再次启动采集,文章的所有文本内容都是采集到网页文章Text采集步骤24 修改Xpath之前的网页文本文章 采集在第25步修改Xpath后,经过以上操作,目标URL中的微信文章正文中的所有文字都是采集下来的。如果还需要采集图片,则需要在已有规则中添加判断条件。采集文章正文中的文字和图片URL按照第一步中的步骤6。第七步:添加判断条件 前6步之后,我们只有采集在微信文章中的文字内容,不包括文章中的图片。如果你需要 采集 图片,需要在规则中添加判断条件:判断文章的内容列表,如果收录img元素(图片),则执行图片采集分支;if not 如果收录一个img元素(图片),则执行文本采集分支。同时,在优采云中,默认为左分支设置判断条件。如果满足判断条件,则执行左分支;当左分支的判断条件不满足时,执行最右分支。回到这个规则,就是给左分支设置一个条件:如果收录img元素(图片),则执行左分支;如果左条件分支的条件不满足(即不包括img元素),则执行右分支。具体操作如下:
我们将“提取数据”步骤移至右侧分支(绿色加号)。然后点击右侧的分支,在出现的结果页面点击“确定”页面(分支条件检测结果-检测结果始终为True)文章Text采集第27步拖动“ Extract Element" step into Right branch pages文章Text采集Step 28 Right branch - detection result is always True 点击左分支,点击出现的结果页面(branch condition detection result - detection result is always True) Sure”。然后为其设置判断条件:勾选“当前循环项收录元素”,输入元素Xpath://img(代表一张图片),然后在网页上点击“确定”文章文字采集 Step 29 点击left 侧分支到左分支,设置判断条件。网页文章文本采集步骤304)左分支条件设置后,执行数据提取步骤。从左侧工具栏中,将“提取数据”步骤拖到流程图左侧分支(绿色加号),然后在页面上选择一张图片,在操作提示框中选择“采集这张图片地址”进入新的“提取数据”步骤,到左分支网页文章Text采集Step 31采集图片地址网页文章Text采集Step 325 ) 选择右侧分支的“Extract Data”步骤,点击“Customize Data Field”按钮,选择“Custom Positioning Element Method”,设置“Element Matching Xpath”
经检查,多次提取的文本会被追加为字段网页文章Text采集步骤368)注意在优采云中,判断中每个分支中的“提取数据”条件步骤中的字段名称必须相同,字段数量必须相同。这里我们将左右分支中提取的字段名改为“text”(判断条件教程,请参考:/tutorialdetail-1/judge.html)网页文章text采集steps 379)如上,设置了整个判断条件。点击左上角的“保存”和“开始采集”。我们发现在导出的excel表格中,图片地址是一堆乱码。为什么是这样?继续观察网页——搜狗微信文章文中的图片 需要向下滚动才能加载,加载后才能采集进入正确的图片地址。因此,打开文章后,需要设置为“页面加载完成后向下滚动”。这里设置滚动次数为“30次”,每次间隔“2秒”,滚动方式为“向下滚动一屏”网页文章文字采集步骤38微信文章 文中的图片需要向下滚动才能加载。设置“页面加载后向下滚动”网页文章Text采集Step 39 注意:这里对滚动次数、时间、方式的设置会影响文章的速度和质量采集 数据。本文仅供参考,您可以根据需要设置,
在 采集 过程中,会花费大量时间等待图片加载,因此 采集 比较慢。如果不需要采集图片,直接使用文字采集,不用等待图片加载,采集会快很多。相关采集教程:百度搜索结果采集新浪微博数据采集豆瓣影评采集优采云——70万用户选择的网页数据采集器。1.操作简单,任何人都可以使用:不需要技术背景,只要能上网采集即可。完成流程可视化,点击鼠标完成操作,2分钟快速上手。2.功能强大,任意网站可选:用于点击、登录、翻页、识别验证码、瀑布、和Ajax脚本异步加载数据,所有页面都可以通过简单的设置采集。3.云采集,也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
干货教程:暴力海外引流协议_instagram协议引流软件_ins营销推广群发软件_关键词
Instagram关键词自动采集用户批量关注作品,并将作品发布到Aite通知协议
Instagram是一款协议软件,支持批量导入关键词给采集相关用户,然后软件自动采集这些用户的粉丝
该软件支持
设置喜欢和评论采集粉丝作品的用户,软件支持多账号多线程批量关注和动态作品批量发布 爱特人!
查看全部
最新版:网页文章正文采集的方法以微信文章采集为例.docx 45页
网页文章文本采集方法,以微信文章采集为例。保存的时候怎么办?一张一张复制粘贴?选择一个通用的网络数据 采集器 将使这项工作变得容易得多。优采云是一个通用的网页数据采集器,可以是互联网上的采集公共数据。用户可以设置从哪个网站爬取数据,爬取什么数据,爬取什么范围的数据,什么时候爬取数据,如何保存爬取的数据等。言归正传,本文将采取<以搜狗微信文章文字采集为例,讲解优采云采集网页文章文字的使用方法。文章文本采集,主要有两种情况: 1、采集文章正文中的文本,不包括图片;2. 采集文章 正文中的文本和图像 URL。示例网站:/使用功能点:Xpath/search?query=XPath判断条件/tutorialdetail-1/judge.html分页列表信息采集 /tutorial/fylb-70.aspx?t=1AJAX滚动教程/tutorialdetail-1/ajgd_7.htmlAJAX点击翻页/tutorialdetail-1/ajaxdjfy_7.html采集文章正文中,无图片具体步骤: 第一步:创建采集任务1)进入主界面,选择“自定义模式”网页文章文本采集步骤12)复制并粘贴你想要的网站的网址采集到网站
打开网页时,默认显示“热门”文章。向下滚动页面,找到并点击“加载更多内容”按钮,在动作提示框中,选择“更多动作”页面文章Body采集Step 3选择“循环点击单个元素”创建一个翻页循环网页文章Body采集第四步由于这个网页涉及到Ajax技术,我们需要设置一些高级选项。选择“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”网页文章Text采集Step 5 注意:AJAX表示延迟加载, 一种异步更新的脚本技术,通过在后台与服务器交换少量数据,可以在不重新加载整个网页的情况下更新网页的某个部分。详情请参考AJAX点击和翻页教程:/tutorialdetail-1/ajaxdjfy_7.html 观察网页,我们发现点击“加载更多内容”5次后,页面加载到了底部,一共有显示了 100 篇文章 文章 。因此,我们将整个“循环页面”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5次”,在网页点击“确定”文章Text采集Steps 6Step 3:创建列表循环并提取数据移动鼠标选择页面中的第一个文章链接。系统会自动识别相似链接。在操作提示框中,选择“Select All”网页文章Text采集Step 7 选择“Cycle Click Each Link”网页文章Text采集Step 8系统会自动进入文章详情页面。
点击需要采集的字段(这里先点击文章标题),在操作提示框中选择“采集该元素的文本”。文章发布时间,文章来源字段采集方法同理网页文章正文采集第九步下一步开始采集文章 文本。首先点击第一段文章文字,系统会自动识别页面中的相似元素,选择“全选”页面文章文字采集步骤105)即可看到所有的文本段落都被选中并变成绿色。选择“采集以下元素文本”网页文章正文采集步骤11 注意:在字段表中,可以自定义和修改字段。网页文章正文采集 Step 126) 经过上述操作后,文本将全部采集向下(默认情况下,每段文本为一个单元格)。一般来说,我们希望 采集 的主体被合并到同一个单元格中。点击“自定义数据字段”按钮,选择“自定义数据合并方式”,勾选“同一字段多次提取并合并为一行,即追加到同一字段,如文本页面合并”,然后点击“OK”页面文章Body采集Step 13“Customize Data Fields”按钮网页文章Body采集Step 14 选择“Customize Data Merge Method”网页文章Body采集Step 15 检查如图步骤4:修改Xpath1) 选中整个“loop step”,打开“Advanced Options”,可以看到优采云
我们通过这个Xpath发现://DIV[@class='main-left']/DIV[3]/UL/LI/DIV[2]/H3[1]/A,页面需要100篇文章< 文章所有页面都位于文章正文采集步骤173)将修改后的Xpath复制粘贴到优采云所示位置,然后点击“确定”到页面文章Text采集Step 18 Step 5:修改流程图结构我们继续观察,点击“加载更多内容”5次后,该页面加载了全部100篇文章文章。所以我们配置规则的思路是先建立一个翻页循环,把100篇文章全部加载文章,然后创建一个循环列表来提取数据 1)选择整个“循环”步骤并拖动退出“循环页面”步骤。如果不执行此操作,将会出现大量重复的数据页。文章Text采集Step 19 拖拽完成后页面如下图文章Text采集Steps 20 Step 6:Data采集并导出1 ) 点击左上角“保存”,然后点击“开始采集”,选择“开始本地采集”网页文章文本采集步骤21采集步骤21完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的数据导出到网页文章文本采集Step 223) 这里我们选择excel作为导出格式。数据导出后,网页如下图所示。采集到。那是因为 文章 的循环列表的 Xpath://[@id="js_content"]/P
修改Xpath为://[@id="js_content"]//P,所有文章文本都可以定位。再次启动采集,文章的所有文本内容都是采集到网页文章Text采集步骤24 修改Xpath之前的网页文本文章 采集在第25步修改Xpath后,经过以上操作,目标URL中的微信文章正文中的所有文字都是采集下来的。如果还需要采集图片,则需要在已有规则中添加判断条件。采集文章正文中的文字和图片URL按照第一步中的步骤6。第七步:添加判断条件 前6步之后,我们只有采集在微信文章中的文字内容,不包括文章中的图片。如果你需要 采集 图片,需要在规则中添加判断条件:判断文章的内容列表,如果收录img元素(图片),则执行图片采集分支;if not 如果收录一个img元素(图片),则执行文本采集分支。同时,在优采云中,默认为左分支设置判断条件。如果满足判断条件,则执行左分支;当左分支的判断条件不满足时,执行最右分支。回到这个规则,就是给左分支设置一个条件:如果收录img元素(图片),则执行左分支;如果左条件分支的条件不满足(即不包括img元素),则执行右分支。具体操作如下:

我们将“提取数据”步骤移至右侧分支(绿色加号)。然后点击右侧的分支,在出现的结果页面点击“确定”页面(分支条件检测结果-检测结果始终为True)文章Text采集第27步拖动“ Extract Element" step into Right branch pages文章Text采集Step 28 Right branch - detection result is always True 点击左分支,点击出现的结果页面(branch condition detection result - detection result is always True) Sure”。然后为其设置判断条件:勾选“当前循环项收录元素”,输入元素Xpath://img(代表一张图片),然后在网页上点击“确定”文章文字采集 Step 29 点击left 侧分支到左分支,设置判断条件。网页文章文本采集步骤304)左分支条件设置后,执行数据提取步骤。从左侧工具栏中,将“提取数据”步骤拖到流程图左侧分支(绿色加号),然后在页面上选择一张图片,在操作提示框中选择“采集这张图片地址”进入新的“提取数据”步骤,到左分支网页文章Text采集Step 31采集图片地址网页文章Text采集Step 325 ) 选择右侧分支的“Extract Data”步骤,点击“Customize Data Field”按钮,选择“Custom Positioning Element Method”,设置“Element Matching Xpath”
经检查,多次提取的文本会被追加为字段网页文章Text采集步骤368)注意在优采云中,判断中每个分支中的“提取数据”条件步骤中的字段名称必须相同,字段数量必须相同。这里我们将左右分支中提取的字段名改为“text”(判断条件教程,请参考:/tutorialdetail-1/judge.html)网页文章text采集steps 379)如上,设置了整个判断条件。点击左上角的“保存”和“开始采集”。我们发现在导出的excel表格中,图片地址是一堆乱码。为什么是这样?继续观察网页——搜狗微信文章文中的图片 需要向下滚动才能加载,加载后才能采集进入正确的图片地址。因此,打开文章后,需要设置为“页面加载完成后向下滚动”。这里设置滚动次数为“30次”,每次间隔“2秒”,滚动方式为“向下滚动一屏”网页文章文字采集步骤38微信文章 文中的图片需要向下滚动才能加载。设置“页面加载后向下滚动”网页文章Text采集Step 39 注意:这里对滚动次数、时间、方式的设置会影响文章的速度和质量采集 数据。本文仅供参考,您可以根据需要设置,
在 采集 过程中,会花费大量时间等待图片加载,因此 采集 比较慢。如果不需要采集图片,直接使用文字采集,不用等待图片加载,采集会快很多。相关采集教程:百度搜索结果采集新浪微博数据采集豆瓣影评采集优采云——70万用户选择的网页数据采集器。1.操作简单,任何人都可以使用:不需要技术背景,只要能上网采集即可。完成流程可视化,点击鼠标完成操作,2分钟快速上手。2.功能强大,任意网站可选:用于点击、登录、翻页、识别验证码、瀑布、和Ajax脚本异步加载数据,所有页面都可以通过简单的设置采集。3.云采集,也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
干货教程:暴力海外引流协议_instagram协议引流软件_ins营销推广群发软件_关键词
Instagram关键词自动采集用户批量关注作品,并将作品发布到Aite通知协议
Instagram是一款协议软件,支持批量导入关键词给采集相关用户,然后软件自动采集这些用户的粉丝
该软件支持
设置喜欢和评论采集粉丝作品的用户,软件支持多账号多线程批量关注和动态作品批量发布 爱特人!

免费获取:免费文章采集器使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-10-28 18:21
优采云·云采集网络爬虫软件
免费文章采集器教程
本文介绍如何使用优采云采集器采集网易账号文章。
采集网址:
网易账号,原名网易订阅,是网易传媒完成“两端”整合升级后打造的全新自媒体内容分发和品牌推广平台。本文以网易账号首页列表为例。您还可以更改 采集URL采集 其他列表。
采集内容:文章标题、出版时间、文章正文。
使用功能点:
? 列表循环?详情采集
第一步:创建网易账号文章采集任务
优采云·云采集网络爬虫软件
1)进入主界面,选择“自定义采集”
2) 将你想要采集的网址的网址复制并粘贴到网站的输入框中,点击“保存网址”
优采云·云采集网络爬虫软件
第 2 步:创建循环单击以加载更多
1)打开网页后,打开右上角的流程按钮,从左侧流程显示界面拖入一个循环步骤,如下图
优采云·云采集网络爬虫软件
2)然后拉到页面底部,看到加载更多按钮,因为如果要查看更多内容,需要循环点击加载更多,所以我们需要设置一个点击“加载更多”的循环步骤”。注意:采集更多内容需要加载更多内容。本文文章只是为了演示,所以选择执行并点击“加载更多”20次,你可以根据自己的实际需要加减。
优采云·云采集网络爬虫软件
优采云·云采集网络爬虫软件
第三步:创建循环点击列表采集详情
1)点击文章列表的第一个和第二个标题,然后选择“循环点击每个元素”按钮,这样就创建了一个循环点击列表命令,可以在列表中显示当前列表页的内容文章 列表。在采集器 中看到它。
2)然后我们可以提取我们需要的文本数据。下图提取了正文三部分的正文内容,包括标题、时间、正文。其他信息需要自由删除和编辑。然后可以点击保存启动本地采集。
优采云·云采集网络爬虫软件
3) 点击开始采集后,采集器将开始提取数据。
优采云·云采集网络爬虫软件
4) 采集 可以在结束后导出。
优采云·云采集网络爬虫软件
免费文章相关采集器教程:
新浪博客文章采集:
uc头条文章采集:
微信公众号热门文章采集(文字+图片):
今日头条采集:
新浪微博发帖内容采集:
知乎信息采集:
优采云——90万用户选择的网页数据采集器。
1.操作简单,任何人都可以使用:不需要技术背景,只要能上网采集即可。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
优采云·云采集网络爬虫软件
2、功能强大,任意网站可选:对于点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,所有页面都可以通过简单设置采集。
3.云采集,也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。
4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
免费获取:免费微信公众号翻译搬运工具
翻译和处理工具允许我们在网页上移动感兴趣的内容。翻译处理工具不仅支持指定网站内容处理,还可以通过关键词等方式挖掘微信公众号、头条文章等热门文章,翻译工具支持将采集本地文章批量翻译成英文,或将英文批量翻译成中文。
翻译和处理工具易于操作。您只需用鼠标点击需要的内容元素,即可在全网移动素材,自动翻译发布到我们的网站自媒体平台。在发布翻译处理工具之前,还可以通过创建的发布任务实现文章伪原创的编辑,通过同义词替换、敏感字段删除、图片替换、图片实现发布的文章水印等>高度原创。
纯文本 文章 是与潜在客户沟通的唯一方式的日子已经一去不复返了。今天,视觉效果是每个内容策略的主要元素。人脑是天生的,它更关注生动的图像。这就是为什么 SEOER 试图通过诱人的视觉效果来利用他们的内容。
除了提高参与度外,视觉效果也是提高 SEO 排名的理想选择。视觉内容如何影响搜索引擎排名,以及翻译推动者的其他好处是什么?我们将讨论所有这些以及更多内容。
但让我们首先了解视觉内容营销意味着什么。简而言之,翻译推动者就是利用视觉来教育和招待潜在客户。这些视觉效果可以是任何形式。营销人员不乏选择,从视频和图像到屏幕截图和 GIF。此外,它们使内容易于消化,否则难以理解。
视觉的力量是不可否认的。他们留下持久的印象,创造更好的参与,并发展情感依恋。有很多好处。但是,在我们继续之前,让我们看一下视觉内容的各种形式:
翻译移动工具图像可以增强我们书面内容的视觉外观,并有助于提高我们的转化率。人们不会像书籍那样阅读内容。有时,他们只是查看图像以了解内容想要传递的内容。专业摄影师可以为我们拍摄出最好的照片。但是,它们在口袋里很重。如果我们的预算足够好,没有比使用真实图像更好的选择了。
专家建议将图像置于 Z 或 F 模式,以立即吸引访问者的注意力。大多数访问者从左到右浏览内容。然后他们沿对角线或水平方向向下滚动。这就是为什么几乎所有的标志都出现在页面的左上角。
视频可以在几分钟内解释复杂的事情。我们可以通过它们展示一切。因此,它们消除了消费者的疑虑并提高了满意度。剪辑展示了玩具如何从汽车变成恐龙。它还显示了可以从汽车后部发出的光。最后,展示了该系列中的所有其他汽车,孩子们可以采集这些汽车来完成他们的恐龙世界。
翻译和处理工具的分享就到这里。通过翻译处理工具,可以实现文章素材采集、批量翻译、自动伪原创、定时发布等功能。翻译处理工具内置在我们的网站和自媒体中,应用范围很广,通过翻译处理工具让我们的工作变得便捷高效。 查看全部
免费获取:免费文章采集器使用教程
优采云·云采集网络爬虫软件
免费文章采集器教程
本文介绍如何使用优采云采集器采集网易账号文章。
采集网址:
网易账号,原名网易订阅,是网易传媒完成“两端”整合升级后打造的全新自媒体内容分发和品牌推广平台。本文以网易账号首页列表为例。您还可以更改 采集URL采集 其他列表。
采集内容:文章标题、出版时间、文章正文。
使用功能点:
? 列表循环?详情采集
第一步:创建网易账号文章采集任务
优采云·云采集网络爬虫软件
1)进入主界面,选择“自定义采集”
2) 将你想要采集的网址的网址复制并粘贴到网站的输入框中,点击“保存网址”
优采云·云采集网络爬虫软件

第 2 步:创建循环单击以加载更多
1)打开网页后,打开右上角的流程按钮,从左侧流程显示界面拖入一个循环步骤,如下图
优采云·云采集网络爬虫软件
2)然后拉到页面底部,看到加载更多按钮,因为如果要查看更多内容,需要循环点击加载更多,所以我们需要设置一个点击“加载更多”的循环步骤”。注意:采集更多内容需要加载更多内容。本文文章只是为了演示,所以选择执行并点击“加载更多”20次,你可以根据自己的实际需要加减。
优采云·云采集网络爬虫软件
优采云·云采集网络爬虫软件
第三步:创建循环点击列表采集详情
1)点击文章列表的第一个和第二个标题,然后选择“循环点击每个元素”按钮,这样就创建了一个循环点击列表命令,可以在列表中显示当前列表页的内容文章 列表。在采集器 中看到它。
2)然后我们可以提取我们需要的文本数据。下图提取了正文三部分的正文内容,包括标题、时间、正文。其他信息需要自由删除和编辑。然后可以点击保存启动本地采集。
优采云·云采集网络爬虫软件
3) 点击开始采集后,采集器将开始提取数据。
优采云·云采集网络爬虫软件
4) 采集 可以在结束后导出。
优采云·云采集网络爬虫软件
免费文章相关采集器教程:
新浪博客文章采集:
uc头条文章采集:
微信公众号热门文章采集(文字+图片):
今日头条采集:
新浪微博发帖内容采集:
知乎信息采集:
优采云——90万用户选择的网页数据采集器。
1.操作简单,任何人都可以使用:不需要技术背景,只要能上网采集即可。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
优采云·云采集网络爬虫软件
2、功能强大,任意网站可选:对于点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,所有页面都可以通过简单设置采集。
3.云采集,也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。
4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
免费获取:免费微信公众号翻译搬运工具
翻译和处理工具允许我们在网页上移动感兴趣的内容。翻译处理工具不仅支持指定网站内容处理,还可以通过关键词等方式挖掘微信公众号、头条文章等热门文章,翻译工具支持将采集本地文章批量翻译成英文,或将英文批量翻译成中文。
翻译和处理工具易于操作。您只需用鼠标点击需要的内容元素,即可在全网移动素材,自动翻译发布到我们的网站自媒体平台。在发布翻译处理工具之前,还可以通过创建的发布任务实现文章伪原创的编辑,通过同义词替换、敏感字段删除、图片替换、图片实现发布的文章水印等>高度原创。
纯文本 文章 是与潜在客户沟通的唯一方式的日子已经一去不复返了。今天,视觉效果是每个内容策略的主要元素。人脑是天生的,它更关注生动的图像。这就是为什么 SEOER 试图通过诱人的视觉效果来利用他们的内容。
除了提高参与度外,视觉效果也是提高 SEO 排名的理想选择。视觉内容如何影响搜索引擎排名,以及翻译推动者的其他好处是什么?我们将讨论所有这些以及更多内容。
但让我们首先了解视觉内容营销意味着什么。简而言之,翻译推动者就是利用视觉来教育和招待潜在客户。这些视觉效果可以是任何形式。营销人员不乏选择,从视频和图像到屏幕截图和 GIF。此外,它们使内容易于消化,否则难以理解。
视觉的力量是不可否认的。他们留下持久的印象,创造更好的参与,并发展情感依恋。有很多好处。但是,在我们继续之前,让我们看一下视觉内容的各种形式:
翻译移动工具图像可以增强我们书面内容的视觉外观,并有助于提高我们的转化率。人们不会像书籍那样阅读内容。有时,他们只是查看图像以了解内容想要传递的内容。专业摄影师可以为我们拍摄出最好的照片。但是,它们在口袋里很重。如果我们的预算足够好,没有比使用真实图像更好的选择了。
专家建议将图像置于 Z 或 F 模式,以立即吸引访问者的注意力。大多数访问者从左到右浏览内容。然后他们沿对角线或水平方向向下滚动。这就是为什么几乎所有的标志都出现在页面的左上角。
视频可以在几分钟内解释复杂的事情。我们可以通过它们展示一切。因此,它们消除了消费者的疑虑并提高了满意度。剪辑展示了玩具如何从汽车变成恐龙。它还显示了可以从汽车后部发出的光。最后,展示了该系列中的所有其他汽车,孩子们可以采集这些汽车来完成他们的恐龙世界。
翻译和处理工具的分享就到这里。通过翻译处理工具,可以实现文章素材采集、批量翻译、自动伪原创、定时发布等功能。翻译处理工具内置在我们的网站和自媒体中,应用范围很广,通过翻译处理工具让我们的工作变得便捷高效。
技术文章:自媒体文章采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-10-22 03:11
云采集服务平台自媒体文章采集方法自媒体为我们提供的信息正逐渐影响我们的日常工作,改变着人们的生活方式和获取途径信息来源。然而,自媒体的迅速传播也给我们带来了信息过载的困扰。如何从海量的自媒体文章中找到高质量的作品,我们需要掌握一些自媒体文章的采集方法挖掘出需要的部分。于是,越来越多的优质文章出现在自媒体平台上,各位小伙伴都有采集自媒体文章的需求,以下是今日头条采集比如给大家介绍一下自媒体文章怎么用这篇文章来介绍优采云7.0 采集 自媒体文章采集方法,同今日头条的方法。采集网站:使用功能点:Ajax滚动加载设置列表内容提取步骤一:创建采集任务云采集服务平台 1)进入主界面,选择,选择“自动”定义模式“自媒体文章采集 步骤2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,信息红框内为demo 采集的内容是今日头条最新发布的热点新闻云采集服务平台自媒体 方法,用今日头条的方法。采集网站:使用功能点:Ajax滚动加载设置列表内容提取步骤一:创建采集任务云采集服务平台 1)进入主界面,选择,选择“自动”定义模式“自媒体文章采集 步骤2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,信息红框内为demo 采集的内容是今日头条最新发布的热点新闻云采集服务平台自媒体 方法,用今日头条的方法。采集网站:使用功能点:Ajax滚动加载设置列表内容提取步骤一:创建采集任务云采集服务平台 1)进入主界面,选择,选择“自动”定义模式“自媒体文章采集 步骤2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,信息红框内为demo 采集的内容是今日头条最新发布的热点新闻云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,红框内的信息为demo 采集的内容>是今日头条最新发布的热点新闻。云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,红框内的信息为demo 采集的内容>是今日头条最新发布的热点新闻。云采集服务平台自媒体
自媒体文章采集Step 3:采集新闻内容创建数据提取列表 1)如图,移动鼠标选中评论框列表,右击,框底 颜色会变成绿色然后点击“选择子元素” 云采集服务平台自媒体文章采集步骤说明:点击右上角的“流程”按钮,显示创建可视化流程图。2)然后点击“全选”,将页面中需要采集的信息添加到列表Cloud采集Service Platform自媒体文章采集Step注意:提示框中的字段会出现一个“X”,点击删除该字段。自媒体文章采集第三步)点击“采集以下数据”自媒体
2)采集完成后,选择合适的导出方式,将采集好的数据导出到云端采集服务平台自媒体文章采集步骤12 相关采集教程自媒体免费爆文采集:网易自媒体文章采集:自媒体 文章如何采集:云采集服务平台微信文章采集:网站文章采集:网站 文章采集教程:如何搜索关键词采集搜狗微信公众号文章:搜狗公众号热门文章采集方法和详细教程:马蜂窝旅游美食文章评论采集教程:70万用户选择的网页数据采集器。1. 操作简单,任何人都可以使用:不需要技术背景,只要能上网采集即可。流程全可视化,点击鼠标完成操作,云采集服务平台 2.功能强大,任意网站都可以使用:用于点击、登录、翻页、识别验证码、瀑布流、加载数据的 Ajax 脚本异步网页可以通过简单的设置采集 来完成。3.云采集,也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。巨大的云采集 集群24*7运行,无需担心IP阻塞和网络中断。4、可按需选择功能免费增值服务。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
方法和技巧:缺关键词?掌握这些搜集关键词技巧
线上开发客户,无论是发布产品还是积极寻找客户,都成了关键词的游戏。没有关键词,我只能想出少量的关键词,数量很多。外贸人遇到的问题。
了解产品的各种名称
就算是扩展,也得先有一些介绍。第一步是通过翻译和头脑风暴为自己的产品想出各种名称。
因为此时关键词还比较小,这些是后面使用工具的时候会用到的词。不要忘记过滤,以上方法采集到的关键词可能与产品不匹配,会浪费时间、精力和金钱。外贸jackson建议大家先把这个词放到Google Image、amazon、ebay、alibaba等平台上去中间再去验证一下,否则这个词是错的,以后用工具扩展的时候会出现越来越多的错误.
使用 关键词 工具
30 关键词 个单独的工具
关键词数据挖掘工具
超级推荐
长尾关键词挖掘
关键字眼
搜索引擎
Soovle-
优特
麦克达
i 商业推广者
序曲
书签来自
好关键词
Adword、谷歌关键词规划师;
三倍
间谍(关键字间谍)
关键字发现
单词跟踪器
谷歌全球机会洞察(谷歌翻译右下角)
seobook 上的关键字工具
semrush
搜索引擎优化
冰
小机器人
谷歌搜索建议
msnadcentre 关键字工具
谷歌集
谷歌相关关键词
关键词研究工具
采集 关键词 的联合竞争对手
你可以在阿里巴巴上找到自然排名靠前的同行的关键词,或者在谷歌搜索关键词,找出前面的网站的关键词你自己的行业。排序不少于10个peer,将它们组合起来创建一个新的关键词。
阿里本身也有很多关键词工具
1、在搜索框中输入关键词,下拉框会自动形成关键词。
2.后台数据管家-热门搜索词
3. 数据管家 - 我的话
4. 数据管家 - 访客详情
5. 数据管家 - 行业视角
6. 数据管家 - RFQ 业务机会
7.外贸直通车-关键词工具
8.外贸直通车-顶展位
你可以利用自己平台上的数据先挖掘一些关键词,然后组合起来。
组织您的 关键词 表单
每个公司都有几个 关键词 目录。我们会发现阿里巴巴上有很多卖家的产品分组,所以我们需要根据不同的产品属性对关键词进行分组。
确定关键词搜索量趋势
Lycos 热 50
基于pendency的词
相似
Hitwise 搜索智能
易趣工具
雅虎!嗡嗡声
谷歌热门趋势
谷歌趋势
谷歌时代精神
AOL 搜索热搜
PPydt 趋势
问 jeeves zn有趣的问题
许多产品是季节性的。之前的外贸jackson讲了销售的周期性,所以无论是发布产品还是寻找客户,也必须掌握一个周期。
最好在这个销售周期之前进行排名。这是看到搜索量随时间变化的规律,这让我们可以清楚地看到这种趋势,尤其是在竞价P4P等拍卖时。能够知道何时使用此 关键词 以及何时停止此 关键词。
过滤器关键词
根据关键词搜索量、竞争、出价等,在不同用途下,使用前应进行过滤。
如果你刚刚开始,建议在 关键词 上花更多的时间,当 关键词 准备好时,就执行。 查看全部
技术文章:自媒体文章采集方法
云采集服务平台自媒体文章采集方法自媒体为我们提供的信息正逐渐影响我们的日常工作,改变着人们的生活方式和获取途径信息来源。然而,自媒体的迅速传播也给我们带来了信息过载的困扰。如何从海量的自媒体文章中找到高质量的作品,我们需要掌握一些自媒体文章的采集方法挖掘出需要的部分。于是,越来越多的优质文章出现在自媒体平台上,各位小伙伴都有采集自媒体文章的需求,以下是今日头条采集比如给大家介绍一下自媒体文章怎么用这篇文章来介绍优采云7.0 采集 自媒体文章采集方法,同今日头条的方法。采集网站:使用功能点:Ajax滚动加载设置列表内容提取步骤一:创建采集任务云采集服务平台 1)进入主界面,选择,选择“自动”定义模式“自媒体文章采集 步骤2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,信息红框内为demo 采集的内容是今日头条最新发布的热点新闻云采集服务平台自媒体 方法,用今日头条的方法。采集网站:使用功能点:Ajax滚动加载设置列表内容提取步骤一:创建采集任务云采集服务平台 1)进入主界面,选择,选择“自动”定义模式“自媒体文章采集 步骤2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,信息红框内为demo 采集的内容是今日头条最新发布的热点新闻云采集服务平台自媒体 方法,用今日头条的方法。采集网站:使用功能点:Ajax滚动加载设置列表内容提取步骤一:创建采集任务云采集服务平台 1)进入主界面,选择,选择“自动”定义模式“自媒体文章采集 步骤2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,信息红框内为demo 采集的内容是今日头条最新发布的热点新闻云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,红框内的信息为demo 采集的内容>是今日头条最新发布的热点新闻。云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,红框内的信息为demo 采集的内容>是今日头条最新发布的热点新闻。云采集服务平台自媒体
自媒体文章采集Step 3:采集新闻内容创建数据提取列表 1)如图,移动鼠标选中评论框列表,右击,框底 颜色会变成绿色然后点击“选择子元素” 云采集服务平台自媒体文章采集步骤说明:点击右上角的“流程”按钮,显示创建可视化流程图。2)然后点击“全选”,将页面中需要采集的信息添加到列表Cloud采集Service Platform自媒体文章采集Step注意:提示框中的字段会出现一个“X”,点击删除该字段。自媒体文章采集第三步)点击“采集以下数据”自媒体
2)采集完成后,选择合适的导出方式,将采集好的数据导出到云端采集服务平台自媒体文章采集步骤12 相关采集教程自媒体免费爆文采集:网易自媒体文章采集:自媒体 文章如何采集:云采集服务平台微信文章采集:网站文章采集:网站 文章采集教程:如何搜索关键词采集搜狗微信公众号文章:搜狗公众号热门文章采集方法和详细教程:马蜂窝旅游美食文章评论采集教程:70万用户选择的网页数据采集器。1. 操作简单,任何人都可以使用:不需要技术背景,只要能上网采集即可。流程全可视化,点击鼠标完成操作,云采集服务平台 2.功能强大,任意网站都可以使用:用于点击、登录、翻页、识别验证码、瀑布流、加载数据的 Ajax 脚本异步网页可以通过简单的设置采集 来完成。3.云采集,也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。巨大的云采集 集群24*7运行,无需担心IP阻塞和网络中断。4、可按需选择功能免费增值服务。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
方法和技巧:缺关键词?掌握这些搜集关键词技巧
线上开发客户,无论是发布产品还是积极寻找客户,都成了关键词的游戏。没有关键词,我只能想出少量的关键词,数量很多。外贸人遇到的问题。
了解产品的各种名称
就算是扩展,也得先有一些介绍。第一步是通过翻译和头脑风暴为自己的产品想出各种名称。
因为此时关键词还比较小,这些是后面使用工具的时候会用到的词。不要忘记过滤,以上方法采集到的关键词可能与产品不匹配,会浪费时间、精力和金钱。外贸jackson建议大家先把这个词放到Google Image、amazon、ebay、alibaba等平台上去中间再去验证一下,否则这个词是错的,以后用工具扩展的时候会出现越来越多的错误.
使用 关键词 工具
30 关键词 个单独的工具
关键词数据挖掘工具
超级推荐
长尾关键词挖掘
关键字眼
搜索引擎
Soovle-
优特
麦克达
i 商业推广者
序曲
书签来自
好关键词
Adword、谷歌关键词规划师;
三倍
间谍(关键字间谍)
关键字发现
单词跟踪器
谷歌全球机会洞察(谷歌翻译右下角)
seobook 上的关键字工具
semrush
搜索引擎优化
冰
小机器人
谷歌搜索建议
msnadcentre 关键字工具
谷歌集
谷歌相关关键词
关键词研究工具
采集 关键词 的联合竞争对手
你可以在阿里巴巴上找到自然排名靠前的同行的关键词,或者在谷歌搜索关键词,找出前面的网站的关键词你自己的行业。排序不少于10个peer,将它们组合起来创建一个新的关键词。
阿里本身也有很多关键词工具
1、在搜索框中输入关键词,下拉框会自动形成关键词。
2.后台数据管家-热门搜索词
3. 数据管家 - 我的话
4. 数据管家 - 访客详情
5. 数据管家 - 行业视角
6. 数据管家 - RFQ 业务机会
7.外贸直通车-关键词工具
8.外贸直通车-顶展位
你可以利用自己平台上的数据先挖掘一些关键词,然后组合起来。
组织您的 关键词 表单
每个公司都有几个 关键词 目录。我们会发现阿里巴巴上有很多卖家的产品分组,所以我们需要根据不同的产品属性对关键词进行分组。
确定关键词搜索量趋势
Lycos 热 50
基于pendency的词
相似
Hitwise 搜索智能
易趣工具
雅虎!嗡嗡声
谷歌热门趋势
谷歌趋势
谷歌时代精神
AOL 搜索热搜
PPydt 趋势
问 jeeves zn有趣的问题
许多产品是季节性的。之前的外贸jackson讲了销售的周期性,所以无论是发布产品还是寻找客户,也必须掌握一个周期。
最好在这个销售周期之前进行排名。这是看到搜索量随时间变化的规律,这让我们可以清楚地看到这种趋势,尤其是在竞价P4P等拍卖时。能够知道何时使用此 关键词 以及何时停止此 关键词。
过滤器关键词
根据关键词搜索量、竞争、出价等,在不同用途下,使用前应进行过滤。
如果你刚刚开始,建议在 关键词 上花更多的时间,当 关键词 准备好时,就执行。
分享文章:python自动获取微信公众号最新文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-10-21 10:21
微信公众号获取思路
获取微信公众号文章常用的方法有搜狐、微信公众号首页和api接口。
听说最近搜狐不太好用,而且之前使用的API接口也经常维护,所以使用微信公众平台进行数据爬取。
首先,登录你的微信公众平台。如果您没有帐户,您可以注册一个。进来后找“图文资料”,就是写公众号的地方
点击后会出现写公众号的界面文章。在界面中,您会找到“超链接”字段,您可以在其中搜索其他公众号。
以“python”为例,输入要检索的公众号名称,从显示的公众号中选择公众号为采集
点击浏览器查看,在网络中找到链接,下图中的链接,右边的Request URL是存储公众号数据的真实链接。表示这是一个 json 网页。
采集实例
以公众号“python”的链接为例,分析URL。
https://mp.weixin.qq.com/cgi-bin/appmsg:微信公众平台的链接
"token": "163455614", #需要定期修改的token
"lang": "zh_CN", #语言
"f": "json",
"ajax": "1", #显示几天的文章
"action": "list_ex"
"begin": "0", #起始页面
"count": "1", #计数
"query": "",
"fakeid": 'MzIwNDA1OTM4NQ==', #公众号唯一编码
"type": "9",
由于我发现fakeid是唯一代表公众号的代码,那么我只需要找到所需公众号的fakeid即可。我随机找了三个公众号进行测试。
fakeid=[ 'MzIwNDA1OTM4NQ==','MzkxNzAwMDkwNQ==','MjM5NzI0NTY3Mg==']
#若增加公众号需要增加fakeid
然后下一步就是请求URL
首先导入需要的库
import time
import requests
from lxml import etree
import pandas as pd
import json
import numpy as np
import datetime
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
由于不想重复登录公众号平台,可以使用cookies来避免登录。在请求文章之前,需要先找到网页的cookie和User-Agent。由于微信公众号是定期刷新的,所以这个cookie和上面的token都要定期刷新。代替。
为了避免反扒,最好找个代理ip
headers = {
"Cookie": "appmsglist_action_3567997841=card;wxuin=49763073568536;pgv_pvid=6311844914;ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=;mm_lang=zh_CN;pac_uid=0_3cf43daf28071;eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8;rewardsn=;wxtokenkey=777;wwapp.vid=;wwapp.cst=;wwapp.deviceid=;uuid=fd43d0b369e634ab667a99eade075932;rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm;slave_bizuin=3567997841;data_bizuin=3567997841;bizuin=3567997841;data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA;slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS;slave_user=gh_e0f449d4f2b6;xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
<p>
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
proxies = {'http': '112.80.248.73'}
</p>
接下来可以爬取页面,获取页面中的文章标题和文章链接,以及文章的时间,分析网页的信息,发现所有的信息网页保存在“app_msg_list”字段中,因此提取该字段中的数据。
寻找
代码显示如下:
def get_weixin(fakeid):
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
# 使用Cookie,跳过登陆操作
#headers 根据自己电脑修改
headers = {
"Cookie": "appmsglist_action_3567997841=card; wxuin=49763073568536; pgv_pvid=6311844914; ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=; mm_lang=zh_CN; pac_uid=0_3cf43daf28071; eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8; rewardsn=; wxtokenkey=777; wwapp.vid=; wwapp.cst=; wwapp.deviceid=; uuid=fd43d0b369e634ab667a99eade075932; rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm; slave_bizuin=3567997841; data_bizuin=3567997841; bizuin=3567997841; data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA; slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS; slave_user=gh_e0f449d4f2b6; xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
dda=[]
for i in range(0,len(fakeid)):
#配置网址
data= {
"token": "163455614", #需要定期修改
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": "0",
"count": "1",
"query": "",
"fakeid": fakeid[i],
"type": "9",
}
dda.append(data)
content_list = []
proxies = {'http': '112.80.248.73'}
ur=[]
title=[]
link=[]
time1=[]
content_li=[]
for i in range(0,len(dda)):
time.sleep(np.random.randint(90, 200))
content_json = requests.get(url, headers=headers, params=dda[i],proxies=proxies,verify=False).json()
print("爬取成功第"+str(i)+"个")
# 返回了一个json,里面是每一页的数据
<p>
for it in content_json["app_msg_list"]: #提取信息
its = []
title.append(it["title"]) #标题
link.append(it["link"]) #链接
time1.append(it['create_time']) #时间
#content_li.append(its)
columns={'title':title,'link':link,'time':time1} #组成df文件
df=pd.DataFrame(columns)
return df
</p>
得到的数据包存放在df中。这里的数据不是微信公众号最新的文章数据,而是微信公众号最近一天发送的文章数据。因此,还需要过滤发布时间。注意这里的时间格式是时间戳,所以需要转换时间数据
转换代码如下:
def time_s(df):
def transfer_time(s): #时间处理
aa = time.ctime(s)
bb = aa.split(' ')
cc = (bb[-1]+"-"+bb[1]+"-"+bb[-3]).replace('Jan','1').replace('Feb','2').replace('Mar','3'). \
replace('Apr','4').replace('May','5').replace('Jun','6').replace('Jul','7').replace('Aug','8') \
.replace('Sep','9').replace('Oct','10').replace('Nov','11').replace('Dec','12')
dd = datetime.datetime.strptime(cc,'%Y-%m-%d').date()
return dd
ti=[]
hd=[]
for i in range(0,len(df['time'])):
timestap= transfer_time(df['time'][i])
ti.append(timestap)
#print(ti)
d= ti[i] + datetime.timedelta(weeks=0, days=0, hours=0, minutes=0, seconds=0, milliseconds=0, microseconds=0, )
#dc = d.strftime("%Y-%m-%d")
hd.append(d)
df['time']=hd
这样就可以将微信公众号的时间戳数据转换为时间数据,然后根据当天的日期提取数据集中的内容并存储。
dat=df[df['time'] == datetime.date.today() + datetime.timedelta(days= -1)] #自动获取昨天日期,将-1改为-2,则为前天的日期,以此类推
##改自动化
path = 'C:/Users/gpower/Desktop/work/行业信息/' #根据自己电脑位置更改
import re
filename=path+"微信公众号采集" + re.sub(r'[^0-9]','',datetime.datetime.now().strftime("%Y-%m-%d")) + '.csv'
# 对文件进行命名,以“微信公众号采集+当前日期”命名
dat.to_csv(filename,encoding='utf_8_sig')
print("保存成功")
这样就可以下载最新的微信公众号文章采集。如果需要多个微信公众号,可以在fakeid中添加公众号的识别码。
新年文章属于yes
免费获取:微信公众号文章搜索导出助手神器
“你知道如何一键下载公众号文章/网页的所有图片、视频和音频吗?” 我不知道为什么?这个问题好像永远,永远,永远,永远被问,但是这个问题,却无所谓,做一个好的复读机是我的工作,作为一个高水平复读机,我也努力让每一个复读机都有新的想法,以前需要N个步骤的,不适合大多数穷懒脑筋的,所以这次我找到了这个软件,这个工具我找到了
有以下三个优点:
1.易于安装
2. 免费下载,使用方便
3.可过滤的图片
相信我!下载它!!
第一步,复制你要导出的微信公众账号图片。
第二步,直接粘贴到下载的软件中
第三步,启动采集,采集完成后,即可导出
第四步,选择你要导出的格式,OK,到此结束,就这么简单,soeasy!
我们来看看实际的导出效果:
下面是保存的图片,每个文章一个文件夹,里面存放了文章的所有高清图片
下面是导出的视音频格式,和原来文章看到的视音频是一样的
下面是html、doc、pdf格式的导出,和原来的文章一样
下载的内容显示如下,和原来的阅读效果一样:
- - - - - - - - - - - - - - - - - 分向線 - - - - - - - ----------------------
微信公众号文章搜索下载助手,搜索下载一体,可一键搜索微信平台文章所有公众号关键词超大素材库,可以关键词@采集指定公众号的所有群发文章,批量导出word、pdf或html。所以,无论你是在自媒体寻找文章素材,还是个人用户搜索下载文章,都可以使用!请看下面的功能介绍:
【主要功能介绍】
★ 一键采集微信公众号发送所有群消息文章,也可以通过关键词搜索所有与文章相关的公众号,支持按时间段采集;
★ 文章可以一键导出Pdf、Word、Excel、txt和Html格式,并可以下载音视频文件、图片和文章消息,导出文件的版面可以保持一致原文;
★ 实时查看文章阅读和留言,一键复制文章内容;
★ 内置开放界面,一键同步所有微信文章到自己网站,保证微信图片正常显示;
★ 软件提供近80个附加功能,功能强大实用。如果你不相信我,看看下面的演示:
简而言之,这是一个非常非常强大和方便的软件,可以在 1 分钟内完成所有操作。
但仅仅拥有软件的强大功能是不够的。我们必须照顾小白吗?答案当然是,我们的软件除了强大的功能外,还有强大的售后问题解决能力。不仅为使用过程中的疑难问题提供解答,还提供各种视频版网络教学教程,包括大家的大本营是一个温暖的地方,购买软件让我们更心心相印。
下载软件并扫描下方二维码或地址
如果觉得本软件不错,请点击关注并采集,如果喜欢本软件,请点按下方二维码,加V:xtcclass,即可获得优惠哦~~
软件会员目前为一年会员制,会员期内不限下载。它非常易于使用且价格不贵。之所以收费,是因为发展确实非常非常大。精力和时间,我更有动力不断更新收费的软件,对你来说也更安全。注意点击上方二维码有优惠哦~~~全网唯一!!! 查看全部
分享文章:python自动获取微信公众号最新文章
微信公众号获取思路
获取微信公众号文章常用的方法有搜狐、微信公众号首页和api接口。
听说最近搜狐不太好用,而且之前使用的API接口也经常维护,所以使用微信公众平台进行数据爬取。
首先,登录你的微信公众平台。如果您没有帐户,您可以注册一个。进来后找“图文资料”,就是写公众号的地方
点击后会出现写公众号的界面文章。在界面中,您会找到“超链接”字段,您可以在其中搜索其他公众号。
以“python”为例,输入要检索的公众号名称,从显示的公众号中选择公众号为采集
点击浏览器查看,在网络中找到链接,下图中的链接,右边的Request URL是存储公众号数据的真实链接。表示这是一个 json 网页。
采集实例
以公众号“python”的链接为例,分析URL。
https://mp.weixin.qq.com/cgi-bin/appmsg:微信公众平台的链接
"token": "163455614", #需要定期修改的token
"lang": "zh_CN", #语言
"f": "json",
"ajax": "1", #显示几天的文章
"action": "list_ex"
"begin": "0", #起始页面
"count": "1", #计数
"query": "",
"fakeid": 'MzIwNDA1OTM4NQ==', #公众号唯一编码
"type": "9",
由于我发现fakeid是唯一代表公众号的代码,那么我只需要找到所需公众号的fakeid即可。我随机找了三个公众号进行测试。
fakeid=[ 'MzIwNDA1OTM4NQ==','MzkxNzAwMDkwNQ==','MjM5NzI0NTY3Mg==']
#若增加公众号需要增加fakeid
然后下一步就是请求URL
首先导入需要的库
import time
import requests
from lxml import etree
import pandas as pd
import json
import numpy as np
import datetime
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
由于不想重复登录公众号平台,可以使用cookies来避免登录。在请求文章之前,需要先找到网页的cookie和User-Agent。由于微信公众号是定期刷新的,所以这个cookie和上面的token都要定期刷新。代替。
为了避免反扒,最好找个代理ip
headers = {
"Cookie": "appmsglist_action_3567997841=card;wxuin=49763073568536;pgv_pvid=6311844914;ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=;mm_lang=zh_CN;pac_uid=0_3cf43daf28071;eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8;rewardsn=;wxtokenkey=777;wwapp.vid=;wwapp.cst=;wwapp.deviceid=;uuid=fd43d0b369e634ab667a99eade075932;rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm;slave_bizuin=3567997841;data_bizuin=3567997841;bizuin=3567997841;data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA;slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS;slave_user=gh_e0f449d4f2b6;xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
<p>
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
proxies = {'http': '112.80.248.73'}
</p>
接下来可以爬取页面,获取页面中的文章标题和文章链接,以及文章的时间,分析网页的信息,发现所有的信息网页保存在“app_msg_list”字段中,因此提取该字段中的数据。
寻找
代码显示如下:
def get_weixin(fakeid):
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
# 使用Cookie,跳过登陆操作
#headers 根据自己电脑修改
headers = {
"Cookie": "appmsglist_action_3567997841=card; wxuin=49763073568536; pgv_pvid=6311844914; ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=; mm_lang=zh_CN; pac_uid=0_3cf43daf28071; eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8; rewardsn=; wxtokenkey=777; wwapp.vid=; wwapp.cst=; wwapp.deviceid=; uuid=fd43d0b369e634ab667a99eade075932; rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm; slave_bizuin=3567997841; data_bizuin=3567997841; bizuin=3567997841; data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA; slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS; slave_user=gh_e0f449d4f2b6; xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
dda=[]
for i in range(0,len(fakeid)):
#配置网址
data= {
"token": "163455614", #需要定期修改
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": "0",
"count": "1",
"query": "",
"fakeid": fakeid[i],
"type": "9",
}
dda.append(data)
content_list = []
proxies = {'http': '112.80.248.73'}
ur=[]
title=[]
link=[]
time1=[]
content_li=[]
for i in range(0,len(dda)):
time.sleep(np.random.randint(90, 200))
content_json = requests.get(url, headers=headers, params=dda[i],proxies=proxies,verify=False).json()
print("爬取成功第"+str(i)+"个")
# 返回了一个json,里面是每一页的数据
<p>
for it in content_json["app_msg_list"]: #提取信息
its = []
title.append(it["title"]) #标题
link.append(it["link"]) #链接
time1.append(it['create_time']) #时间
#content_li.append(its)
columns={'title':title,'link':link,'time':time1} #组成df文件
df=pd.DataFrame(columns)
return df
</p>
得到的数据包存放在df中。这里的数据不是微信公众号最新的文章数据,而是微信公众号最近一天发送的文章数据。因此,还需要过滤发布时间。注意这里的时间格式是时间戳,所以需要转换时间数据
转换代码如下:
def time_s(df):
def transfer_time(s): #时间处理
aa = time.ctime(s)
bb = aa.split(' ')
cc = (bb[-1]+"-"+bb[1]+"-"+bb[-3]).replace('Jan','1').replace('Feb','2').replace('Mar','3'). \
replace('Apr','4').replace('May','5').replace('Jun','6').replace('Jul','7').replace('Aug','8') \
.replace('Sep','9').replace('Oct','10').replace('Nov','11').replace('Dec','12')
dd = datetime.datetime.strptime(cc,'%Y-%m-%d').date()
return dd
ti=[]
hd=[]
for i in range(0,len(df['time'])):
timestap= transfer_time(df['time'][i])
ti.append(timestap)
#print(ti)
d= ti[i] + datetime.timedelta(weeks=0, days=0, hours=0, minutes=0, seconds=0, milliseconds=0, microseconds=0, )
#dc = d.strftime("%Y-%m-%d")
hd.append(d)
df['time']=hd
这样就可以将微信公众号的时间戳数据转换为时间数据,然后根据当天的日期提取数据集中的内容并存储。
dat=df[df['time'] == datetime.date.today() + datetime.timedelta(days= -1)] #自动获取昨天日期,将-1改为-2,则为前天的日期,以此类推
##改自动化
path = 'C:/Users/gpower/Desktop/work/行业信息/' #根据自己电脑位置更改
import re
filename=path+"微信公众号采集" + re.sub(r'[^0-9]','',datetime.datetime.now().strftime("%Y-%m-%d")) + '.csv'
# 对文件进行命名,以“微信公众号采集+当前日期”命名
dat.to_csv(filename,encoding='utf_8_sig')
print("保存成功")
这样就可以下载最新的微信公众号文章采集。如果需要多个微信公众号,可以在fakeid中添加公众号的识别码。
新年文章属于yes
免费获取:微信公众号文章搜索导出助手神器
“你知道如何一键下载公众号文章/网页的所有图片、视频和音频吗?” 我不知道为什么?这个问题好像永远,永远,永远,永远被问,但是这个问题,却无所谓,做一个好的复读机是我的工作,作为一个高水平复读机,我也努力让每一个复读机都有新的想法,以前需要N个步骤的,不适合大多数穷懒脑筋的,所以这次我找到了这个软件,这个工具我找到了
有以下三个优点:
1.易于安装
2. 免费下载,使用方便
3.可过滤的图片
相信我!下载它!!
第一步,复制你要导出的微信公众账号图片。
第二步,直接粘贴到下载的软件中
第三步,启动采集,采集完成后,即可导出
第四步,选择你要导出的格式,OK,到此结束,就这么简单,soeasy!
我们来看看实际的导出效果:
下面是保存的图片,每个文章一个文件夹,里面存放了文章的所有高清图片
下面是导出的视音频格式,和原来文章看到的视音频是一样的
下面是html、doc、pdf格式的导出,和原来的文章一样
下载的内容显示如下,和原来的阅读效果一样:
- - - - - - - - - - - - - - - - - 分向線 - - - - - - - ----------------------
微信公众号文章搜索下载助手,搜索下载一体,可一键搜索微信平台文章所有公众号关键词超大素材库,可以关键词@采集指定公众号的所有群发文章,批量导出word、pdf或html。所以,无论你是在自媒体寻找文章素材,还是个人用户搜索下载文章,都可以使用!请看下面的功能介绍:
【主要功能介绍】
★ 一键采集微信公众号发送所有群消息文章,也可以通过关键词搜索所有与文章相关的公众号,支持按时间段采集;
★ 文章可以一键导出Pdf、Word、Excel、txt和Html格式,并可以下载音视频文件、图片和文章消息,导出文件的版面可以保持一致原文;
★ 实时查看文章阅读和留言,一键复制文章内容;
★ 内置开放界面,一键同步所有微信文章到自己网站,保证微信图片正常显示;
★ 软件提供近80个附加功能,功能强大实用。如果你不相信我,看看下面的演示:

简而言之,这是一个非常非常强大和方便的软件,可以在 1 分钟内完成所有操作。
但仅仅拥有软件的强大功能是不够的。我们必须照顾小白吗?答案当然是,我们的软件除了强大的功能外,还有强大的售后问题解决能力。不仅为使用过程中的疑难问题提供解答,还提供各种视频版网络教学教程,包括大家的大本营是一个温暖的地方,购买软件让我们更心心相印。
下载软件并扫描下方二维码或地址
如果觉得本软件不错,请点击关注并采集,如果喜欢本软件,请点按下方二维码,加V:xtcclass,即可获得优惠哦~~
软件会员目前为一年会员制,会员期内不限下载。它非常易于使用且价格不贵。之所以收费,是因为发展确实非常非常大。精力和时间,我更有动力不断更新收费的软件,对你来说也更安全。注意点击上方二维码有优惠哦~~~全网唯一!!!
分享:如何下载公众号文章方法 其实非常简单
采集交流 • 优采云 发表了文章 • 0 个评论 • 1079 次浏览 • 2022-10-15 16:37
微信公众号里有很多文章,很正能量。看完觉得舒服,但是好的文章太多了。我津津有味地阅读每一篇文章,有时我想下载它并稍后重温。,那么如何下载公众号文章?
微信公众号可以算是一个非常非常大的素材库。但是,微信在管理方面非常严格。和之前的迷雾一样,有些文章还是写的很好,但是突然就看不下去了。
但是绝对不能直接下载。您可以将它们全部复制并粘贴到您的公众号背景中,然后进行编辑。如果对方是原创,则无法发布,需要做一些处理。
所以你可以把公众号的文章导出为word或者pdf格式保存到你的电脑上。您可以随时随地观看。
对于导出文章,可以在浏览器中打开链接,然后按Ctrl+P,可以看到可以另存为pdf,可以保持原格式,导入效果还是不错的,但是你需要一个一个导出,有点麻烦,如果能分批导出就更好了
让我与您分享一个我自己使用的导出小工具。微信公众号文章搜索和下载拓图数据,可以通过关键词搜索公众号平台上的所有文章,也可以采集一个公众号的所有历史记录group文章,然后批量导出为word、pdf、html格式,相当好用。
“途途数据”是公众号运营的工具。主要提供优质的公众号查询功能和公众号相关报告下载功能,还可以让您快速判断公众号的质量。目前越来越多的人开始青睐公众号的推广,但是如何找到合适的公众号成为了一个难题。“拓图数据”旨在为关注新媒体的机构、个人和研究机构提供从数据到价值的全方位服务。服务支持。
以上就是小编为大家总结的公众号文章的下载方式。您不必再担心找到一个好的 文章 了。如果你喜欢阅读,你学会了吗?
免费获取:什么是网站权重?网站权重如何提升-附网站权重工具下载
网站权重优化,网站权重是多少相信很多朋友都听说过“网站权重”这个词,只知道网站权重越高网站 更好。具体的网站权重是怎么来的,相信很多SEO人员都很困惑。
1、网站的权重由来
几大搜索引擎(百度/360/搜狗/谷歌)都没有明确表示有网站权重。给个评分,分别为0-10,值越大网站权重越高,网站权重网站越高情况越好。网站的权重值的计算主要是根据网站的流量值。(例:流量值1~99之间的权重为1) 首先声明这个权重值属于第三方平台检测,与官方搜索引擎无关。网站权重值数据仅供参考,更准确的数据请参考百度统计。
2.更准确的统计(百度统计)
Page View PV:即所谓的Page View (PV),每次用户打开一个网站页面时记录一次。用户多次打开同一个页面,累计浏览量。
访客数UV量:您的网站一天内的独立访客数(基于cookies),同一访客一天内多次访问您网站只计为一位访客.
IP数:一天内你的网站的唯一访问IP数
平均访问时间:访问者在访问中打开 网站 所花费的平均时间。也就是说,每次访问时,打开第一页
3、网站的权重值怎么做?
网站的权重值=权重词X词数那么什么是网站权重词,网站权重是根据不同用户搜索这个词的频率。在哪里可以找到重量词?更多信息请参考百度指数,(百度指数是基于百度海量网民行为数据的数据共享平台。在这里,您可以研究关键词搜索趋势,洞察网民需求变化,监控媒体舆情趋势,定位数字消费。你也可以从行业角度分析市场特征)现在我们有了加权词,你只需要用你的SEO技术把这些加权词排到首页,你就可以获得大量流量。
4.百度指数是怎么计算的?
百度指数基于百度的海量数据。一方面进行关键词搜索热度分析,另一方面深入挖掘舆情信息、市场需求、用户特征等数据特征。百度索引每天更新,提供2006年6月至今的任意时间段的PC端搜索索引和2011年1月至今的移动端无线搜索索引。
五、网站优化权重值
要想网站的权重值显着增加,必须有大量的关键词排名,而一个网站的关键词在文章页面 所以最实用的方法就是每天创建大量原创关键词文章,并且具备分析数据的能力!
1.分析网站日志
说到web日志,有人认为网站的网站操作记录没什么用。这是一个错误的概念。我们需要做的是找出搜索引擎的习惯,通过分析对其进行适当的优化。网站机器人文件日志,减少搜索引擎爬取网站的系统文件爬取网站 .
2、制定文章更新发展规划
通过分析网站的日志,我们已经知道了搜索引擎每天的访问时间和频率。我们要做的是为搜索引擎访问创建一个文章发布计划。说白了,随着时间的推移,搜索引擎会实现爬取网站的习惯,而网站会达到秒秒的效果。
3.控制文章内容
文章 的质量必须是 原创 的内容。如果其他与网站主题无关的内容会影响网站的排名,文章中的更多优化关键词的抽取计算方法见下图。
总结:今天的分享就到这里,主要分享网站权重的由来,以及更准确的数据统计,百度加权词查询。以及网站权重词的优化方法。 查看全部
分享:如何下载公众号文章方法 其实非常简单
微信公众号里有很多文章,很正能量。看完觉得舒服,但是好的文章太多了。我津津有味地阅读每一篇文章,有时我想下载它并稍后重温。,那么如何下载公众号文章?
微信公众号可以算是一个非常非常大的素材库。但是,微信在管理方面非常严格。和之前的迷雾一样,有些文章还是写的很好,但是突然就看不下去了。
但是绝对不能直接下载。您可以将它们全部复制并粘贴到您的公众号背景中,然后进行编辑。如果对方是原创,则无法发布,需要做一些处理。
所以你可以把公众号的文章导出为word或者pdf格式保存到你的电脑上。您可以随时随地观看。
对于导出文章,可以在浏览器中打开链接,然后按Ctrl+P,可以看到可以另存为pdf,可以保持原格式,导入效果还是不错的,但是你需要一个一个导出,有点麻烦,如果能分批导出就更好了
让我与您分享一个我自己使用的导出小工具。微信公众号文章搜索和下载拓图数据,可以通过关键词搜索公众号平台上的所有文章,也可以采集一个公众号的所有历史记录group文章,然后批量导出为word、pdf、html格式,相当好用。
“途途数据”是公众号运营的工具。主要提供优质的公众号查询功能和公众号相关报告下载功能,还可以让您快速判断公众号的质量。目前越来越多的人开始青睐公众号的推广,但是如何找到合适的公众号成为了一个难题。“拓图数据”旨在为关注新媒体的机构、个人和研究机构提供从数据到价值的全方位服务。服务支持。
以上就是小编为大家总结的公众号文章的下载方式。您不必再担心找到一个好的 文章 了。如果你喜欢阅读,你学会了吗?
免费获取:什么是网站权重?网站权重如何提升-附网站权重工具下载
网站权重优化,网站权重是多少相信很多朋友都听说过“网站权重”这个词,只知道网站权重越高网站 更好。具体的网站权重是怎么来的,相信很多SEO人员都很困惑。
1、网站的权重由来
几大搜索引擎(百度/360/搜狗/谷歌)都没有明确表示有网站权重。给个评分,分别为0-10,值越大网站权重越高,网站权重网站越高情况越好。网站的权重值的计算主要是根据网站的流量值。(例:流量值1~99之间的权重为1) 首先声明这个权重值属于第三方平台检测,与官方搜索引擎无关。网站权重值数据仅供参考,更准确的数据请参考百度统计。
2.更准确的统计(百度统计)
Page View PV:即所谓的Page View (PV),每次用户打开一个网站页面时记录一次。用户多次打开同一个页面,累计浏览量。
访客数UV量:您的网站一天内的独立访客数(基于cookies),同一访客一天内多次访问您网站只计为一位访客.
IP数:一天内你的网站的唯一访问IP数

平均访问时间:访问者在访问中打开 网站 所花费的平均时间。也就是说,每次访问时,打开第一页
3、网站的权重值怎么做?
网站的权重值=权重词X词数那么什么是网站权重词,网站权重是根据不同用户搜索这个词的频率。在哪里可以找到重量词?更多信息请参考百度指数,(百度指数是基于百度海量网民行为数据的数据共享平台。在这里,您可以研究关键词搜索趋势,洞察网民需求变化,监控媒体舆情趋势,定位数字消费。你也可以从行业角度分析市场特征)现在我们有了加权词,你只需要用你的SEO技术把这些加权词排到首页,你就可以获得大量流量。
4.百度指数是怎么计算的?
百度指数基于百度的海量数据。一方面进行关键词搜索热度分析,另一方面深入挖掘舆情信息、市场需求、用户特征等数据特征。百度索引每天更新,提供2006年6月至今的任意时间段的PC端搜索索引和2011年1月至今的移动端无线搜索索引。
五、网站优化权重值
要想网站的权重值显着增加,必须有大量的关键词排名,而一个网站的关键词在文章页面 所以最实用的方法就是每天创建大量原创关键词文章,并且具备分析数据的能力!
1.分析网站日志
说到web日志,有人认为网站的网站操作记录没什么用。这是一个错误的概念。我们需要做的是找出搜索引擎的习惯,通过分析对其进行适当的优化。网站机器人文件日志,减少搜索引擎爬取网站的系统文件爬取网站 .
2、制定文章更新发展规划
通过分析网站的日志,我们已经知道了搜索引擎每天的访问时间和频率。我们要做的是为搜索引擎访问创建一个文章发布计划。说白了,随着时间的推移,搜索引擎会实现爬取网站的习惯,而网站会达到秒秒的效果。
3.控制文章内容
文章 的质量必须是 原创 的内容。如果其他与网站主题无关的内容会影响网站的排名,文章中的更多优化关键词的抽取计算方法见下图。
总结:今天的分享就到这里,主要分享网站权重的由来,以及更准确的数据统计,百度加权词查询。以及网站权重词的优化方法。
干货教程:帝国CMS源码《花生小说》源码 花生日记公众号引流导航站模板 带wap手机站+采
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-10-13 17:33
放开眼睛,戴上耳机,听~!
帝国cms源码《花生小说》源码花生日记公众号引流导航站模板带wap手机站+采集【纯版】
帝国cms源码《花生小说》源码花生日记公众号引流导航站模板带wap手机站+采集【纯版】
开发环境:
帝国cms 7.5
安装环境:
php+mysql
源代码说明:
一个专注于小说阅读细化分类的网站。我们会根据不同的用户喜好,将海量的小说分类为详细的主题类别。
让你找到自己喜欢的小说阅读速度更快。此外,我们每天通过用户阅读量、付费率等大数据指标,为小说爱好者推荐几本好看的小说。
关键词:好小说,推荐好小说,小说分类导航
说明:小说公众号模板,小说网站导航引流网站源码,网站结构清晰易优化收录。
本站配备优采云自动采集、手机端、同步生成插件。模仿Empirecms7.5内核,更安全、更高效。
APP流、下载站、游戏公会人群引流等都是不错的选择。模板易于更改和维护。
采集可以使用这种导航方式的网站很多,也可以购买版权直接在线阅读。
注:此版本为纯版本,无任何数据。如果您需要数据,请使用提供的 优采云 for 采集
分享文章:python自动获取微信公众号最新文章的实现代码
目录
微信公众号获取思路
获取微信公众号文章常用的方法有搜狐、微信公众号首页和api接口。
听说最近搜狐不太好用,而且之前使用的API接口也经常维护,所以使用微信公众平台进行数据爬取。
首先,登录你的微信公众平台。如果您没有帐户,您可以注册一个。进来后找“图文资料”,就是写公众号的地方
点击后会出现写公众号的界面文章。在界面中,您会找到“超链接”字段,您可以在其中搜索其他公众号。
以“python”为例,输入要检索的公众号名称,从显示的公众号中选择公众号为采集
点击浏览器查看,在网络中找到链接,下图中的链接,右边的Request URL是存储公众号数据的真实链接。表示这是一个 json 网页。
采集实例
以公众号“python”的链接为例,分析URL。
https://mp.weixin.qq.com/cgi-bin/appmsg:微信公众平台的链接
"token": "163455614", #需要定期修改的token
"lang": "zh_CN", #语言
"f": "json",
"ajax": "1", #显示几天的文章
"action": "list_ex"
"begin": "0", #起始页面
"count": "1", #计数
"query": "",
"fakeid": 'MzIwNDA1OTM4NQ==', #公众号唯一编码
"type": "9",
由于我发现fakeid是唯一代表公众号的代码,那么我只需要找到所需公众号的fakeid即可。我随机找了三个公众号进行测试。
fakeid=[ 'MzIwNDA1OTM4NQ==','MzkxNzAwMDkwNQ==','MjM5NzI0NTY3Mg==']
<p>
#若增加公众号需要增加fakeid</p>
然后下一步就是请求URL
首先导入需要的库
import time
import requests
from lxml import etree
import pandas as pd
import json
import numpy as np
import datetime
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
由于不想重复登录公众号平台,可以使用cookies来避免登录。在请求文章之前,需要先找到网页的cookie和User-Agent。由于微信公众号是定期刷新的,所以这个cookie和上面的token都要定期刷新。代替。
为了避免反扒,最好找个代理ip
headers = {
"Cookie": "appmsglist_action_3567997841=card;wxuin=49763073568536;pgv_pvid=6311844914;ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=;mm_lang=zh_CN;pac_uid=0_3cf43daf28071;eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8;rewardsn=;wxtokenkey=777;wwapp.vid=;wwapp.cst=;wwapp.deviceid=;uuid=fd43d0b369e634ab667a99eade075932;rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm;slave_bizuin=3567997841;data_bizuin=3567997841;bizuin=3567997841;data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA;slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS;slave_user=gh_e0f449d4f2b6;xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
proxies = {'http': '112.80.248.73'}
接下来可以爬取页面,获取页面中的文章标题和文章链接,以及文章的时间,分析网页的信息,发现所有的信息网页保存在“app_msg_list”字段中,因此提取该字段中的数据。
代码显示如下:
得到的数据包存放在df中。这里的数据不是微信公众号最新的文章数据,而是微信公众号最近一天发送的文章数据。因此,还需要过滤发布时间。注意这里的时间格式是时间戳,所以需要转换时间数据
转换代码如下:
def time_s(df):
def transfer_time(s): #时间处理
aa = time.ctime(s)
<p>
bb = aa.split(' ')
cc = (bb[-1]+"-"+bb[1]+"-"+bb[-3]).replace('Jan','1').replace('Feb','2').replace('Mar','3'). \
replace('Apr','4').replace('May','5').replace('Jun','6').replace('Jul','7').replace('Aug','8') \
.replace('Sep','9').replace('Oct','10').replace('Nov','11').replace('Dec','12')
dd = datetime.datetime.strptime(cc,'%Y-%m-%d').date()
return dd
ti=[]
hd=[]
for i in range(0,len(df['time'])):
timestap= transfer_time(df['time'][i])
ti.append(timestap)
#print(ti)
d= ti[i] + datetime.timedelta(weeks=0, days=0, hours=0, minutes=0, seconds=0, milliseconds=0, microseconds=0, )
#dc = d.strftime("%Y-%m-%d")
hd.append(d)
df['time']=hd</p>
这样就可以将微信公众号的时间戳数据转换为时间数据,然后根据当天的日期提取数据集中的内容并存储。
dat=df[df['time'] == datetime.date.today() + datetime.timedelta(days= -1)] #自动获取昨天日期,将-1改为-2,则为前天的日期,以此类推
##改自动化
path = 'C:/Users/gpower/Desktop/work/行业信息/' #根据自己电脑位置更改
import re
filename=path+"微信公众号采集" + re.sub(r'[^0-9]','',datetime.datetime.now().strftime("%Y-%m-%d")) + '.csv'
# 对文件进行命名,以“微信公众号采集+当前日期”命名
dat.to_csv(filename,encoding='utf_8_sig')
print("保存成功")
这样就可以下载最新的微信公众号文章采集。如果需要多个微信公众号,可以在fakeid中添加公众号的识别码。
这是文章关于python自动获取微信公众号最新文章的介绍。更多关于python自动获取微信公众号文章的信息,请搜索三水点胶木的往期文章或继续浏览以下相关文章希望大家在木头支持三水点未来! 查看全部
干货教程:帝国CMS源码《花生小说》源码 花生日记公众号引流导航站模板 带wap手机站+采
放开眼睛,戴上耳机,听~!
帝国cms源码《花生小说》源码花生日记公众号引流导航站模板带wap手机站+采集【纯版】
帝国cms源码《花生小说》源码花生日记公众号引流导航站模板带wap手机站+采集【纯版】
开发环境:
帝国cms 7.5
安装环境:

php+mysql
源代码说明:
一个专注于小说阅读细化分类的网站。我们会根据不同的用户喜好,将海量的小说分类为详细的主题类别。
让你找到自己喜欢的小说阅读速度更快。此外,我们每天通过用户阅读量、付费率等大数据指标,为小说爱好者推荐几本好看的小说。
关键词:好小说,推荐好小说,小说分类导航
说明:小说公众号模板,小说网站导航引流网站源码,网站结构清晰易优化收录。
本站配备优采云自动采集、手机端、同步生成插件。模仿Empirecms7.5内核,更安全、更高效。
APP流、下载站、游戏公会人群引流等都是不错的选择。模板易于更改和维护。
采集可以使用这种导航方式的网站很多,也可以购买版权直接在线阅读。
注:此版本为纯版本,无任何数据。如果您需要数据,请使用提供的 优采云 for 采集
分享文章:python自动获取微信公众号最新文章的实现代码
目录
微信公众号获取思路
获取微信公众号文章常用的方法有搜狐、微信公众号首页和api接口。
听说最近搜狐不太好用,而且之前使用的API接口也经常维护,所以使用微信公众平台进行数据爬取。
首先,登录你的微信公众平台。如果您没有帐户,您可以注册一个。进来后找“图文资料”,就是写公众号的地方
点击后会出现写公众号的界面文章。在界面中,您会找到“超链接”字段,您可以在其中搜索其他公众号。
以“python”为例,输入要检索的公众号名称,从显示的公众号中选择公众号为采集
点击浏览器查看,在网络中找到链接,下图中的链接,右边的Request URL是存储公众号数据的真实链接。表示这是一个 json 网页。
采集实例
以公众号“python”的链接为例,分析URL。
https://mp.weixin.qq.com/cgi-bin/appmsg:微信公众平台的链接
"token": "163455614", #需要定期修改的token
"lang": "zh_CN", #语言
"f": "json",
"ajax": "1", #显示几天的文章
"action": "list_ex"
"begin": "0", #起始页面
"count": "1", #计数
"query": "",
"fakeid": 'MzIwNDA1OTM4NQ==', #公众号唯一编码
"type": "9",
由于我发现fakeid是唯一代表公众号的代码,那么我只需要找到所需公众号的fakeid即可。我随机找了三个公众号进行测试。
fakeid=[ 'MzIwNDA1OTM4NQ==','MzkxNzAwMDkwNQ==','MjM5NzI0NTY3Mg==']
<p>
#若增加公众号需要增加fakeid</p>
然后下一步就是请求URL
首先导入需要的库
import time
import requests
from lxml import etree
import pandas as pd
import json
import numpy as np
import datetime
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
由于不想重复登录公众号平台,可以使用cookies来避免登录。在请求文章之前,需要先找到网页的cookie和User-Agent。由于微信公众号是定期刷新的,所以这个cookie和上面的token都要定期刷新。代替。
为了避免反扒,最好找个代理ip
headers = {
"Cookie": "appmsglist_action_3567997841=card;wxuin=49763073568536;pgv_pvid=6311844914;ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=;mm_lang=zh_CN;pac_uid=0_3cf43daf28071;eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8;rewardsn=;wxtokenkey=777;wwapp.vid=;wwapp.cst=;wwapp.deviceid=;uuid=fd43d0b369e634ab667a99eade075932;rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm;slave_bizuin=3567997841;data_bizuin=3567997841;bizuin=3567997841;data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA;slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS;slave_user=gh_e0f449d4f2b6;xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
proxies = {'http': '112.80.248.73'}
接下来可以爬取页面,获取页面中的文章标题和文章链接,以及文章的时间,分析网页的信息,发现所有的信息网页保存在“app_msg_list”字段中,因此提取该字段中的数据。
代码显示如下:
得到的数据包存放在df中。这里的数据不是微信公众号最新的文章数据,而是微信公众号最近一天发送的文章数据。因此,还需要过滤发布时间。注意这里的时间格式是时间戳,所以需要转换时间数据
转换代码如下:
def time_s(df):
def transfer_time(s): #时间处理
aa = time.ctime(s)
<p>
bb = aa.split(' ')
cc = (bb[-1]+"-"+bb[1]+"-"+bb[-3]).replace('Jan','1').replace('Feb','2').replace('Mar','3'). \
replace('Apr','4').replace('May','5').replace('Jun','6').replace('Jul','7').replace('Aug','8') \
.replace('Sep','9').replace('Oct','10').replace('Nov','11').replace('Dec','12')
dd = datetime.datetime.strptime(cc,'%Y-%m-%d').date()
return dd
ti=[]
hd=[]
for i in range(0,len(df['time'])):
timestap= transfer_time(df['time'][i])
ti.append(timestap)
#print(ti)
d= ti[i] + datetime.timedelta(weeks=0, days=0, hours=0, minutes=0, seconds=0, milliseconds=0, microseconds=0, )
#dc = d.strftime("%Y-%m-%d")
hd.append(d)
df['time']=hd</p>
这样就可以将微信公众号的时间戳数据转换为时间数据,然后根据当天的日期提取数据集中的内容并存储。
dat=df[df['time'] == datetime.date.today() + datetime.timedelta(days= -1)] #自动获取昨天日期,将-1改为-2,则为前天的日期,以此类推
##改自动化
path = 'C:/Users/gpower/Desktop/work/行业信息/' #根据自己电脑位置更改
import re
filename=path+"微信公众号采集" + re.sub(r'[^0-9]','',datetime.datetime.now().strftime("%Y-%m-%d")) + '.csv'
# 对文件进行命名,以“微信公众号采集+当前日期”命名
dat.to_csv(filename,encoding='utf_8_sig')
print("保存成功")
这样就可以下载最新的微信公众号文章采集。如果需要多个微信公众号,可以在fakeid中添加公众号的识别码。
这是文章关于python自动获取微信公众号最新文章的介绍。更多关于python自动获取微信公众号文章的信息,请搜索三水点胶木的往期文章或继续浏览以下相关文章希望大家在木头支持三水点未来!
分享方法:微信文章采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-10-06 15:05
微信文章采集器是公众号操作和网站操作助手,功能有:自定义采集、分类采集、关键词采集、文章编辑排版,提供日常微信文章、微信图文等资源。
工具/材料电脑、软件、工具文章、操作、公众号、材料方法/步骤1
下面就给大家介绍一下这个介绍,先熟悉一下软件的功能和使用方法。
2
百度搜索相关资料,点击网页了解介绍。
3
软件功能介绍,有分类采集、关键词采集、自定义采集、文章排版编辑功能。
4
让操作变得如此简单。
知识整理:英文SEO推广工具整理
我整理了自己的经验,分享给大家。在这里,我只为您提供发布所使用的工具,不提供详细的说明和操作说明。请理解!
下面的工具大部分都是我在用的工具,所以还是很实用的。希望他们能给你带来一些帮助!
使用火狐
安装插件:
1、Shareholic一键提交多个书签
2. seo 地震,seo 工具
3.seo工具栏、seo工具栏、/seo-toolbar/
4. alexa sparky,alexa,alexa数据工具,
5. 美味记录工具网站
6.firebug查看代码
关键字分析工具:
1. 谷歌 关键词tools:///doc/3712070519.html,/
2. SEO BOOK 关键词工具,/
3. Wordtracker:///doc/3712070519.html,
网站管理员工具:
谷歌网站管理工具
:///doc/3712070519.html,/webmasters/tools/home?hl=zh-CN
必应网站管理工具,/toolbox/webmasters/#
雅虎网站管理工具:///doc/3712070519.html,/mysites
网站数据分析工具:
谷歌分析:///doc/3712070519.html,/analytics/settings/?pli=1
外部链接查看工具:
反向链接外部链接视图:,/index.php 查看全部
分享方法:微信文章采集器
微信文章采集器是公众号操作和网站操作助手,功能有:自定义采集、分类采集、关键词采集、文章编辑排版,提供日常微信文章、微信图文等资源。
工具/材料电脑、软件、工具文章、操作、公众号、材料方法/步骤1
下面就给大家介绍一下这个介绍,先熟悉一下软件的功能和使用方法。
2
百度搜索相关资料,点击网页了解介绍。
3
软件功能介绍,有分类采集、关键词采集、自定义采集、文章排版编辑功能。
4
让操作变得如此简单。
知识整理:英文SEO推广工具整理
我整理了自己的经验,分享给大家。在这里,我只为您提供发布所使用的工具,不提供详细的说明和操作说明。请理解!
下面的工具大部分都是我在用的工具,所以还是很实用的。希望他们能给你带来一些帮助!
使用火狐
安装插件:
1、Shareholic一键提交多个书签
2. seo 地震,seo 工具
3.seo工具栏、seo工具栏、/seo-toolbar/
4. alexa sparky,alexa,alexa数据工具,
5. 美味记录工具网站
6.firebug查看代码
关键字分析工具:
1. 谷歌 关键词tools:///doc/3712070519.html,/
2. SEO BOOK 关键词工具,/
3. Wordtracker:///doc/3712070519.html,
网站管理员工具:
谷歌网站管理工具
:///doc/3712070519.html,/webmasters/tools/home?hl=zh-CN
必应网站管理工具,/toolbox/webmasters/#
雅虎网站管理工具:///doc/3712070519.html,/mysites
网站数据分析工具:
谷歌分析:///doc/3712070519.html,/analytics/settings/?pli=1
外部链接查看工具:
反向链接外部链接视图:,/index.php
内容分享:持续更新,微信公众号文章批量采集系统的构建
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-10-06 11:14
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集内容不仅需要微信客户端,还需要采集专用的微信个人账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中文章的列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析存储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
1. 安装模拟器或使用手机安装微信客户端,申请微信个人账号并登录。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1.安装NodeJS
2、在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4.启动anyproxy并运行命令:sudo anyproxy -i;参数 -i 表示解析 HTTPS;
5.安装证书,在手机或安卓模拟器中安装证书:
6、设置代理:安卓模拟器的代理服务器地址为wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址localhost:8002可以看到anyproxy的web界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
1.找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
2.修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
<p>
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
</p>
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1.getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p> 查看全部
内容分享:持续更新,微信公众号文章批量采集系统的构建
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集内容不仅需要微信客户端,还需要采集专用的微信个人账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中文章的列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析存储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
1. 安装模拟器或使用手机安装微信客户端,申请微信个人账号并登录。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1.安装NodeJS
2、在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4.启动anyproxy并运行命令:sudo anyproxy -i;参数 -i 表示解析 HTTPS;
5.安装证书,在手机或安卓模拟器中安装证书:
6、设置代理:安卓模拟器的代理服务器地址为wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址localhost:8002可以看到anyproxy的web界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
1.找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
2.修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
<p>
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
</p>
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1.getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p>
推荐文章:优采云采集织梦文章下载图片保存到本地路径设置方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2022-09-26 02:14
优采云采集织梦文章下载图片保存到本地路径设置方法
在使用优采云采集织梦文章的时候,我想下载图片,我用的是织梦文章这个模型,但是路径设置为否,无法显示。所以经过测试,找到了最好的解决方案。 一、优采云采集图片设置:二、保存图片路径和名称设置:下载的图片路径为:/uploads/allimg/200108/*.jpg。 ..
在使用优采云采集织梦文章的时候,我想下载图片,我用的是织梦文章这个模型,但是路径设置为否,无法显示。所以经过测试,找到了最好的解决方案。
一、优采云采集图片设置:
二、保存图片路径和名称设置:
下载图片的路径为:/uploads/allimg/200108/*.jpg
三、文件链接地址前缀,输入斜杠:/
这里的文件保存文件夹可以选择保存路径,然后上传到你的网站对应目录。
免费的:小说源码-免费小说源码全自动采集支持各大小说CMS自动采集
小说源代码,为什么要用小说源代码?小说源码能不能快速自动采集?只需输入域名或关键词即可快速采集小说源代码,然后我们会以图片的形式展示给大家。大家注意看图(工具是:147采集器可以直接通过搜索引擎搜索找到。免费下载使用)。不管是什么cms,都可以自动采集伪原创主动推送到搜索引擎收录。
如何提高网站排名?有些新手会停止对内容和外部链接的SEO优化,但细节会直接影响优化结果。还有一些高手没有传授的技巧,分享一下我所知道和实际打过的技巧。
一、旧域名快速排序技术
很多人可能不知道一个好的老域名可以达到秒排第一页的效果,所以详细的方法是找一个相关度高的老域名,也就是说和你的东西相关度高想做关键词。最好有一定的外链和反向链接,前提是地基干净,五年以上。
二、长时间不更新会有排名
有些朋友经常看到一些网站没有更新文章,但是排名很好。让我分享一下这项技术。在开始首页规划之前,先对用户需求关键词做一个数据分析,根据需求字长,进行页面规划,在网站根目录下创建一个独立站点,为主站点 收录 起到了音量和锚文本的作用来提升权重。
三、高质量文章
高质量文章并不代表原创文章,而是用户访问你的页面能否找到答案,用户粘性如何直接影响网站@的表现> 跳出率。一个好的文章必须有一定层次,h1标签的作用,加粗换色操作,图文并茂,字数要800以上。一个高质量的文章。
如今,SEO 行业有许多不同的概念。第一类人说SEO已经过时了。因为PC时代已经过时,SEO是PC时代的产物,所以无能为力。二是今天的seo没有什么可做的,因为所有的行业都在seo时期做过。不管你做什么,有人已经做到了。所以没有必要再做任何事情了。其实大部分想法应该是一样的。我们自身流量获取的基本理论是在一个大流量池中找到它的规律,把你和你自己分开 查看全部
推荐文章:优采云采集织梦文章下载图片保存到本地路径设置方法
优采云采集织梦文章下载图片保存到本地路径设置方法
在使用优采云采集织梦文章的时候,我想下载图片,我用的是织梦文章这个模型,但是路径设置为否,无法显示。所以经过测试,找到了最好的解决方案。 一、优采云采集图片设置:二、保存图片路径和名称设置:下载的图片路径为:/uploads/allimg/200108/*.jpg。 ..
在使用优采云采集织梦文章的时候,我想下载图片,我用的是织梦文章这个模型,但是路径设置为否,无法显示。所以经过测试,找到了最好的解决方案。
一、优采云采集图片设置:
二、保存图片路径和名称设置:
下载图片的路径为:/uploads/allimg/200108/*.jpg
三、文件链接地址前缀,输入斜杠:/
这里的文件保存文件夹可以选择保存路径,然后上传到你的网站对应目录。
免费的:小说源码-免费小说源码全自动采集支持各大小说CMS自动采集
小说源代码,为什么要用小说源代码?小说源码能不能快速自动采集?只需输入域名或关键词即可快速采集小说源代码,然后我们会以图片的形式展示给大家。大家注意看图(工具是:147采集器可以直接通过搜索引擎搜索找到。免费下载使用)。不管是什么cms,都可以自动采集伪原创主动推送到搜索引擎收录。
如何提高网站排名?有些新手会停止对内容和外部链接的SEO优化,但细节会直接影响优化结果。还有一些高手没有传授的技巧,分享一下我所知道和实际打过的技巧。

一、旧域名快速排序技术
很多人可能不知道一个好的老域名可以达到秒排第一页的效果,所以详细的方法是找一个相关度高的老域名,也就是说和你的东西相关度高想做关键词。最好有一定的外链和反向链接,前提是地基干净,五年以上。
二、长时间不更新会有排名
有些朋友经常看到一些网站没有更新文章,但是排名很好。让我分享一下这项技术。在开始首页规划之前,先对用户需求关键词做一个数据分析,根据需求字长,进行页面规划,在网站根目录下创建一个独立站点,为主站点 收录 起到了音量和锚文本的作用来提升权重。
三、高质量文章
高质量文章并不代表原创文章,而是用户访问你的页面能否找到答案,用户粘性如何直接影响网站@的表现> 跳出率。一个好的文章必须有一定层次,h1标签的作用,加粗换色操作,图文并茂,字数要800以上。一个高质量的文章。
如今,SEO 行业有许多不同的概念。第一类人说SEO已经过时了。因为PC时代已经过时,SEO是PC时代的产物,所以无能为力。二是今天的seo没有什么可做的,因为所有的行业都在seo时期做过。不管你做什么,有人已经做到了。所以没有必要再做任何事情了。其实大部分想法应该是一样的。我们自身流量获取的基本理论是在一个大流量池中找到它的规律,把你和你自己分开
免费的:本地TXT批量翻译器,免费TXT文档自动批量翻译
采集交流 • 优采云 发表了文章 • 0 个评论 • 665 次浏览 • 2022-09-24 17:07
TXT 批量翻译器允许我们批量翻译一个 TXT 文档和一个文件夹中的所有 TXT 文档。TXT批量翻译器连接百度、有道、谷歌及自带翻译接口,无需多个软件或网页。您可以通过跳跃进行批量翻译。TXT批量翻译器支持世界主流的几十种语言,只需简单的鼠标点击,我们就可以进行语言之间的互译、互译甚至回译。反向翻译功能允许我们通过将 文章 翻译成其他语言,然后将它们反向翻译成原创语言,在 网站中将一个 文章 拆分为多个 文章 @> 以及在 自媒体 中实现 文章 的质量 原创。
TXT Batch Translator 批量内容处理使我们能够采集 我们想要的文章 材料。访问全网只需要输入关键词文章采集,也可以输入目标网址鼠标点击对应元素,即可访问英文、日文、泰语、韩语等多种语言。网站前往采集。在采集之后批量翻译文章,保留原格式标签,去除原敏感信息。实现 文章 整洁干净。
TXT批量翻译器可用于网站SEO优化和自媒体文章批量编辑,在软文中建立外部链接和高权重网站是我们的日常推广工作,TXT 批量翻译器是一个很棒的链接构建工具,但重要的是要记住我们不能保证反向链接。确保我们的演示文稿与记者相关且有趣。如果是这样,那么我们很有可能会加入他们的文章。社交媒体是与目标受众建立联系和互动并建立有意义关系的好方法。这有助于我们建立信任和可信度,随着时间的推移会产生自然的反向链接。
为了充分利用社交媒体,请确保我们活跃在最有可能成为我们理想受众的平台上。与其他用户互动,分享我们的内容并关注我们行业的人。这些活动不仅帮助我们建立联系,还提高了品牌知名度和销量。
每个人都喜欢信息图表。它以易于理解的格式呈现复杂的数据,这种格式具有视觉吸引力、引人入胜且令人难忘。这有助于我们获得曝光并与其他 网站 建立关系。获得曝光和链接的另一个好方法是创建其他“可链接”资产,例如电子书、备忘单和模板。这些资产通常由其他 网站 共享并帮助我们自然连接。
创建信息图表和可连接资产显着增加了我们的内容创建工作流程,但这是值得的,因为它们非常有效。为了获得出色的效果,请确保: 与设计师合作创造高质量的视觉效果;在创建这些资产时留出更多时间;确保内容有价值并与我们的目标受众相关。
按照我们分享的提示开始建立链接,帮助我们实现营销和业务目标。实施白帽 SEO 链接构建策略可能比其他策略需要更多的时间和精力,但这是值得的,因为我们会看到长期的结果。然后使用一些与我们的业务最相关和适用的白帽 SEO 链接构建策略。
TXT批量翻译器的分享就到这里,可以批量替代人工重复的工作,让我们多思考工作生活中的规律和趋势,然后用TXT批量翻译器来获得更多意想不到的效果。每个人对此都有不同的看法,所以请在下面的评论中告诉我们。
免费获取:织梦采集-织梦采集器免费采集内容到织梦
如何使用织梦采集SEO工具优化网站?网站优化排名需要什么网站基本先决条件?网站参与搜索引擎有效排名的基本条件是什么?网站影响优化的重要因素有很多,决定了网站的基本排名状态和网站整体的排名周期。这里重点关注新人,哪些网站基本稳定的百度排名能得到有效保障?
1、域名和服务器/空间的选择
域名:在购买和使用域名的时候,我们不需要提及众所周知的,一定要简单记住,减少用户的记忆成本。并不是所有的网站都形成一个品牌。当然,并不是所有的 网站 都形成一个品牌。如何选择域名?网站域名的选择尽量以com和cn为主。其次,很多人还是比较喜欢买老域名,觉得老域名更有利于收录和推广。没错,但一定要注意重点,尽量购买老域名选择同行业竞争,而且一定要搜索老域名。
服务器/空间:在购买服务器/空间时,尽量不要选择不稳定的服务器/差的服务器,容易导致网站的用户体验和网站的排名。
2、网站结构优化
网站 层次结构,尽量树状,网站 内页尽量不要有孤岛链接,网站首页内容布局更丰富,考虑网站架构,结合有SEO基础知识,优化各个层级和相关性,nofollow不必要的栏目或页面,提高页面集中度,加快收录的性能,可以考虑如何减少不必要的爬取和权重稀释。
3、网站内容优化
网站内容是网站的灵魂,如何提升关键词的排名?如何改进网站收录?各种因素都关系到内容的质量,都离不开用户点击和留存率。优质的文章更容易获得搜索引擎的关注和认可,那么我们如何利用织梦采集插件大量创作网站内容呢?
这个织梦采集插件不需要学习更多的专业技能,只需要几个简单的步骤就可以轻松实现采集内容数据,只需在软件上进行简单的设置,软件会根据用户设置的关键词高精度匹配内容和图片,自动执行文章采集伪原创发布,提供方便快捷的内容填充服务!!
与其他采集插件相比,基本没有门槛,也不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词即可实现采集。一路挂断!设置任务自动执行采集发布任务。
无论是成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类织梦采集发布插件工具也配备了很多SEO功能,通过采集伪原创软件发布时也可以提升很多SEO方面。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。
自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
4、关键词 的选择
关键词作为SEO定位和发展的核心要素,如何选择成为SEO中思想斗争和对抗的话题,关键词选择可以是粗略的,也可以是合乎逻辑的工作,主要看你自己的发展方向。
5、用户体验提升
<p>网站在SEO优化前期的不断调整,不是为了用户,而是为了搜索引擎。首先,必须满足搜索引擎给出的排名基本条件,才能有机会向用户展示更多的曝光率。百度算法说到底是网站的一套点评机制,满足算法的基本要求,网站的基本元素更能满足用户体验,那么 查看全部
免费的:本地TXT批量翻译器,免费TXT文档自动批量翻译
TXT 批量翻译器允许我们批量翻译一个 TXT 文档和一个文件夹中的所有 TXT 文档。TXT批量翻译器连接百度、有道、谷歌及自带翻译接口,无需多个软件或网页。您可以通过跳跃进行批量翻译。TXT批量翻译器支持世界主流的几十种语言,只需简单的鼠标点击,我们就可以进行语言之间的互译、互译甚至回译。反向翻译功能允许我们通过将 文章 翻译成其他语言,然后将它们反向翻译成原创语言,在 网站中将一个 文章 拆分为多个 文章 @> 以及在 自媒体 中实现 文章 的质量 原创。
TXT Batch Translator 批量内容处理使我们能够采集 我们想要的文章 材料。访问全网只需要输入关键词文章采集,也可以输入目标网址鼠标点击对应元素,即可访问英文、日文、泰语、韩语等多种语言。网站前往采集。在采集之后批量翻译文章,保留原格式标签,去除原敏感信息。实现 文章 整洁干净。
TXT批量翻译器可用于网站SEO优化和自媒体文章批量编辑,在软文中建立外部链接和高权重网站是我们的日常推广工作,TXT 批量翻译器是一个很棒的链接构建工具,但重要的是要记住我们不能保证反向链接。确保我们的演示文稿与记者相关且有趣。如果是这样,那么我们很有可能会加入他们的文章。社交媒体是与目标受众建立联系和互动并建立有意义关系的好方法。这有助于我们建立信任和可信度,随着时间的推移会产生自然的反向链接。
为了充分利用社交媒体,请确保我们活跃在最有可能成为我们理想受众的平台上。与其他用户互动,分享我们的内容并关注我们行业的人。这些活动不仅帮助我们建立联系,还提高了品牌知名度和销量。
每个人都喜欢信息图表。它以易于理解的格式呈现复杂的数据,这种格式具有视觉吸引力、引人入胜且令人难忘。这有助于我们获得曝光并与其他 网站 建立关系。获得曝光和链接的另一个好方法是创建其他“可链接”资产,例如电子书、备忘单和模板。这些资产通常由其他 网站 共享并帮助我们自然连接。
创建信息图表和可连接资产显着增加了我们的内容创建工作流程,但这是值得的,因为它们非常有效。为了获得出色的效果,请确保: 与设计师合作创造高质量的视觉效果;在创建这些资产时留出更多时间;确保内容有价值并与我们的目标受众相关。
按照我们分享的提示开始建立链接,帮助我们实现营销和业务目标。实施白帽 SEO 链接构建策略可能比其他策略需要更多的时间和精力,但这是值得的,因为我们会看到长期的结果。然后使用一些与我们的业务最相关和适用的白帽 SEO 链接构建策略。
TXT批量翻译器的分享就到这里,可以批量替代人工重复的工作,让我们多思考工作生活中的规律和趋势,然后用TXT批量翻译器来获得更多意想不到的效果。每个人对此都有不同的看法,所以请在下面的评论中告诉我们。
免费获取:织梦采集-织梦采集器免费采集内容到织梦
如何使用织梦采集SEO工具优化网站?网站优化排名需要什么网站基本先决条件?网站参与搜索引擎有效排名的基本条件是什么?网站影响优化的重要因素有很多,决定了网站的基本排名状态和网站整体的排名周期。这里重点关注新人,哪些网站基本稳定的百度排名能得到有效保障?
1、域名和服务器/空间的选择
域名:在购买和使用域名的时候,我们不需要提及众所周知的,一定要简单记住,减少用户的记忆成本。并不是所有的网站都形成一个品牌。当然,并不是所有的 网站 都形成一个品牌。如何选择域名?网站域名的选择尽量以com和cn为主。其次,很多人还是比较喜欢买老域名,觉得老域名更有利于收录和推广。没错,但一定要注意重点,尽量购买老域名选择同行业竞争,而且一定要搜索老域名。
服务器/空间:在购买服务器/空间时,尽量不要选择不稳定的服务器/差的服务器,容易导致网站的用户体验和网站的排名。
2、网站结构优化
网站 层次结构,尽量树状,网站 内页尽量不要有孤岛链接,网站首页内容布局更丰富,考虑网站架构,结合有SEO基础知识,优化各个层级和相关性,nofollow不必要的栏目或页面,提高页面集中度,加快收录的性能,可以考虑如何减少不必要的爬取和权重稀释。
3、网站内容优化
网站内容是网站的灵魂,如何提升关键词的排名?如何改进网站收录?各种因素都关系到内容的质量,都离不开用户点击和留存率。优质的文章更容易获得搜索引擎的关注和认可,那么我们如何利用织梦采集插件大量创作网站内容呢?
这个织梦采集插件不需要学习更多的专业技能,只需要几个简单的步骤就可以轻松实现采集内容数据,只需在软件上进行简单的设置,软件会根据用户设置的关键词高精度匹配内容和图片,自动执行文章采集伪原创发布,提供方便快捷的内容填充服务!!
与其他采集插件相比,基本没有门槛,也不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词即可实现采集。一路挂断!设置任务自动执行采集发布任务。
无论是成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类织梦采集发布插件工具也配备了很多SEO功能,通过采集伪原创软件发布时也可以提升很多SEO方面。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。
自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
4、关键词 的选择
关键词作为SEO定位和发展的核心要素,如何选择成为SEO中思想斗争和对抗的话题,关键词选择可以是粗略的,也可以是合乎逻辑的工作,主要看你自己的发展方向。
5、用户体验提升
<p>网站在SEO优化前期的不断调整,不是为了用户,而是为了搜索引擎。首先,必须满足搜索引擎给出的排名基本条件,才能有机会向用户展示更多的曝光率。百度算法说到底是网站的一套点评机制,满足算法的基本要求,网站的基本元素更能满足用户体验,那么
文章采集(免费采集软件支持外链插入,外链就是指从别的网站导入到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2022-04-15 15:32
最近很多站长让我多管理网站,批量网站文章内容更新让他筋疲力尽。市场上没有免费且功能强大的免费 采集 软件。许多功能是有限的,没有限制。相信这也是很多站长头疼的问题。今天谈谈采集。
免费采集软件可以有多个采集来源采集。免费的 采集 软件支持外部链接插入。外部链接是指从其他网站导入到自己的网站的链接。导入链接是网站优化的一个非常重要的过程。传入链接的质量(即传入链接所在页面的权重)直接决定了我们的网站在搜索引擎中的权重。免费采集软件可以本地化图像或存储其他平台。外链的作用不仅是提高网站对于网站SEO的权重,也不是提高某个关键词的排名。一个高质量的外链可以给网站带来好的流量。
免费的采集软件根据关键词采集文章填充内容。免费采集软件是网站之间在资源上具有一定优势互补的简单合作形式,即把对方网站的图片或文字放在自己的网站。@网站名字,并设置对方网站的超链接,让用户可以从合作网站中发现自己的网站,达到相互促进的目的,所以它常被用作网站@网站推广的基本手段。免费采集软件全自动批量挂机采集伪原创自动发布推送到搜索引擎。一般来说,和相似的网站交换友情链接
免费的采集软件还配备了很多SEO功能,不仅通过免费的采集软件实现了采集伪原创的发布,还有很多的SEO功能. 分类目录是对网站的信息进行系统的分类整理。免费的采集 软件提供了一个按类别组织的网站 目录。在每个类别中,网站站点名称、URL链接、内容摘要和子类别,您可以通过类别浏览找到相关的网站。免费采集软件标题前缀和后缀设置。目录的权重很高,只要能加上,就能带来稳定的优质外链。显示 网站 相关性的最佳方法之一是提供 网站 定期更新内容。使用独特的内容进行更新绝对有助于吸引搜索引擎对您的关注。
免费的采集软件可以提高关键词密度和页面原创度,增加用户体验,实现优质内容。搜索引擎是用户获取信息的平台。因此,免费采集软件强调新鲜、独特的内容,用户可以从中找到有用的信息。免费采集软件内容关键词插入。所以,定期更新你的网站博客和相关内容可以确保你的网站排名更好。
免费的采集软件由数十万网站文章维护,更新不是问题。在这个科技发达的世界里,我们更喜欢用我们的手机或平板电脑在搜索引擎中采集有用的信息。因此,开发一款适合移动端的网站,让用户可以访问网站上的信息势在必行。关键词搜索是任何 SEO 策略的第一个元素。如今,对有竞争力的 关键词 进行排名非常困难,因此最好的办法是找到免费的 采集 软件。
免费采集软件内容与标题一致,定期自动发布内部链接。几十万个不同的cms网站可以实现统一管理。低竞争力的关键词 是每个月搜索量很大的关键词,缺乏竞争力。选择正确的 关键词 有助于吸引访问者访问您的 网站 并为您带来更好的排名。免费采集软件搜索引擎推送。借助 关键词 研究工具,您可以确定用户对您的 关键词 或类别的兴趣并确定搜索量。
浏览器选项卡和搜索结果显示您的内容的标题。因此,请创建一个收录多个 关键词 或短语的标题,以帮助搜索用户找到与其查询相关的内容。免费采集软件批量设置发布数量不同关键词文章可设置发布不同栏目。
免费的采集软件伪原创保留字软件直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等网站创建一个描述性强、规范、简单的URL,有利于用户更方便地记忆和判断网页内容,也有利于搜索引擎更有效地抓取你的网站。网站从设计之初就应该有合理的URL规划。
免费采集软件最重要的标题标签是H1标签,它指定了页面的内容,在一个网页上只能使用一次。H2、H3、H4、H5 和 H6 是没有 H1 标签重要的副标题标签。搜索引擎强调 H1 标签,而不是其他标题,并且当与其他 SEO 技术正确使用时,将产生最佳结果并提高您的搜索引擎排名。
这是关于您的页面的简短摘要,以便用户可以了解该页面的内容,而不是从您的标题中获取一些粗略的信息。元描述标签应该与优化的页面标题相关。免费采集软件批量监控不同cms网站数据,你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms@ >、人人展cms、Cyclone、站群、PB、Apple、搜外等主要cms工具,可同时管理和批量发布。用户应该能够很好地将标题与描述联系起来。您的元描述必须简短且少于 155 个字符。
免费 采集 软件为图像提供 alt 标签或可选文本标签,不仅使用户可以访问它们,而且还通知搜索引擎您的页面。图像 alt 标签和文件名应收录 关键词 以便搜索引擎可以将具有特定 关键词 的内容提供给搜索用户。
请记住,内容应该是自然的,不应与 关键词 混杂在一起。内容应该以用户认为可以理解和可读的简单易懂的语言编写。免费的采集软件可以直接查看每日蜘蛛、收录、网站权重。反向链接包括外部 网站 链接和内部 网站 链接。对于SEO来说,免费的采集软件是获得好的搜索引擎排名的一个非常重要的因素,所以反向链接的质量直接影响到整体网站SEO和网站搜索引擎排名的流量。引擎。
搜索引擎更信任拥有大量优质链接的网站s,并认为这些网站s比其他网站s提供更相关的搜索结果。今天关于免费采集软件的解释就到这里了。我希望它可以帮助你在搜索引擎优化的道路上。下期我会分享更多的SEO相关知识。下期再见。 查看全部
文章采集(免费采集软件支持外链插入,外链就是指从别的网站导入到)
最近很多站长让我多管理网站,批量网站文章内容更新让他筋疲力尽。市场上没有免费且功能强大的免费 采集 软件。许多功能是有限的,没有限制。相信这也是很多站长头疼的问题。今天谈谈采集。
免费采集软件可以有多个采集来源采集。免费的 采集 软件支持外部链接插入。外部链接是指从其他网站导入到自己的网站的链接。导入链接是网站优化的一个非常重要的过程。传入链接的质量(即传入链接所在页面的权重)直接决定了我们的网站在搜索引擎中的权重。免费采集软件可以本地化图像或存储其他平台。外链的作用不仅是提高网站对于网站SEO的权重,也不是提高某个关键词的排名。一个高质量的外链可以给网站带来好的流量。

免费的采集软件根据关键词采集文章填充内容。免费采集软件是网站之间在资源上具有一定优势互补的简单合作形式,即把对方网站的图片或文字放在自己的网站。@网站名字,并设置对方网站的超链接,让用户可以从合作网站中发现自己的网站,达到相互促进的目的,所以它常被用作网站@网站推广的基本手段。免费采集软件全自动批量挂机采集伪原创自动发布推送到搜索引擎。一般来说,和相似的网站交换友情链接
免费的采集软件还配备了很多SEO功能,不仅通过免费的采集软件实现了采集伪原创的发布,还有很多的SEO功能. 分类目录是对网站的信息进行系统的分类整理。免费的采集 软件提供了一个按类别组织的网站 目录。在每个类别中,网站站点名称、URL链接、内容摘要和子类别,您可以通过类别浏览找到相关的网站。免费采集软件标题前缀和后缀设置。目录的权重很高,只要能加上,就能带来稳定的优质外链。显示 网站 相关性的最佳方法之一是提供 网站 定期更新内容。使用独特的内容进行更新绝对有助于吸引搜索引擎对您的关注。
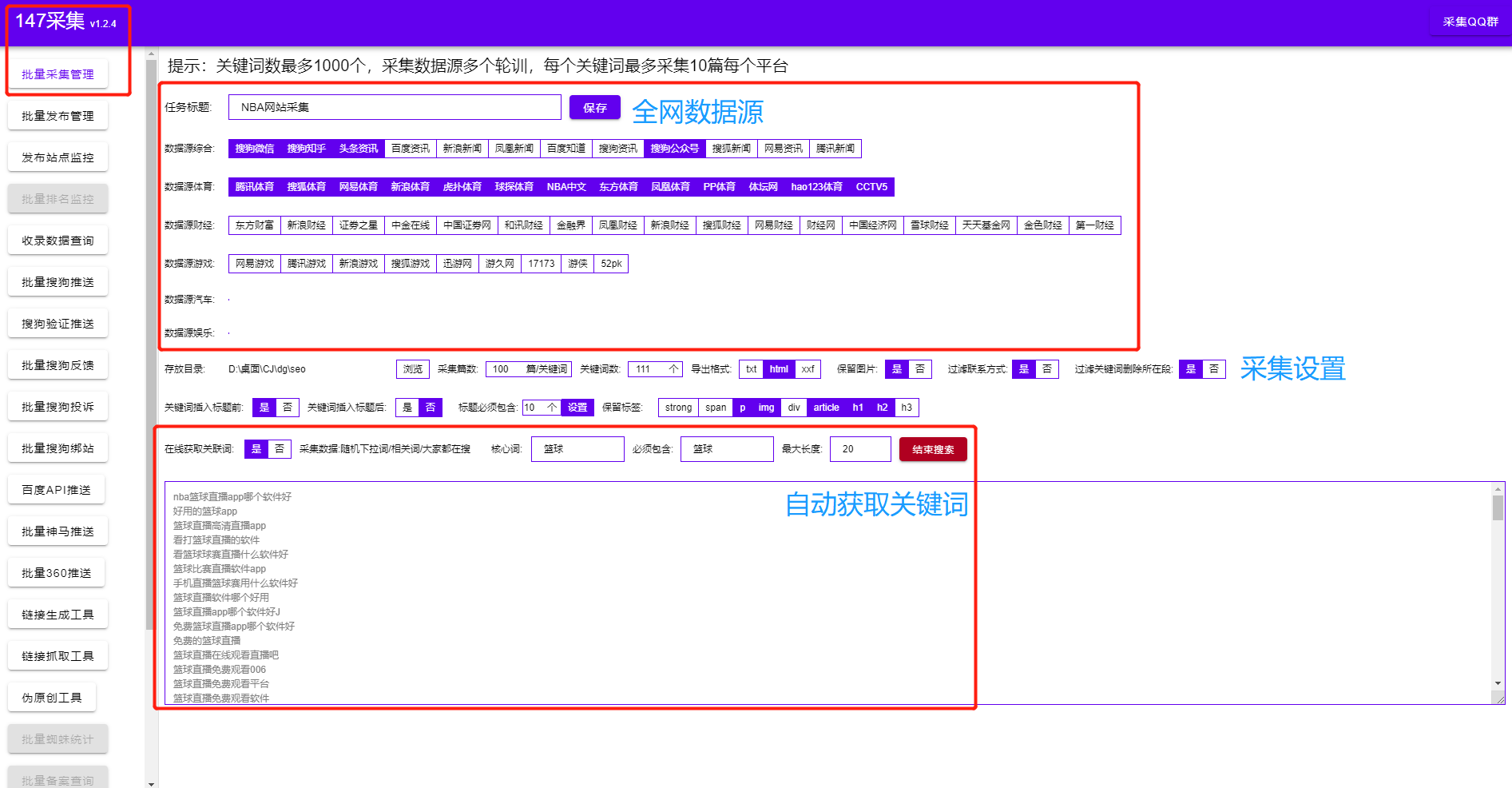
免费的采集软件可以提高关键词密度和页面原创度,增加用户体验,实现优质内容。搜索引擎是用户获取信息的平台。因此,免费采集软件强调新鲜、独特的内容,用户可以从中找到有用的信息。免费采集软件内容关键词插入。所以,定期更新你的网站博客和相关内容可以确保你的网站排名更好。
免费的采集软件由数十万网站文章维护,更新不是问题。在这个科技发达的世界里,我们更喜欢用我们的手机或平板电脑在搜索引擎中采集有用的信息。因此,开发一款适合移动端的网站,让用户可以访问网站上的信息势在必行。关键词搜索是任何 SEO 策略的第一个元素。如今,对有竞争力的 关键词 进行排名非常困难,因此最好的办法是找到免费的 采集 软件。
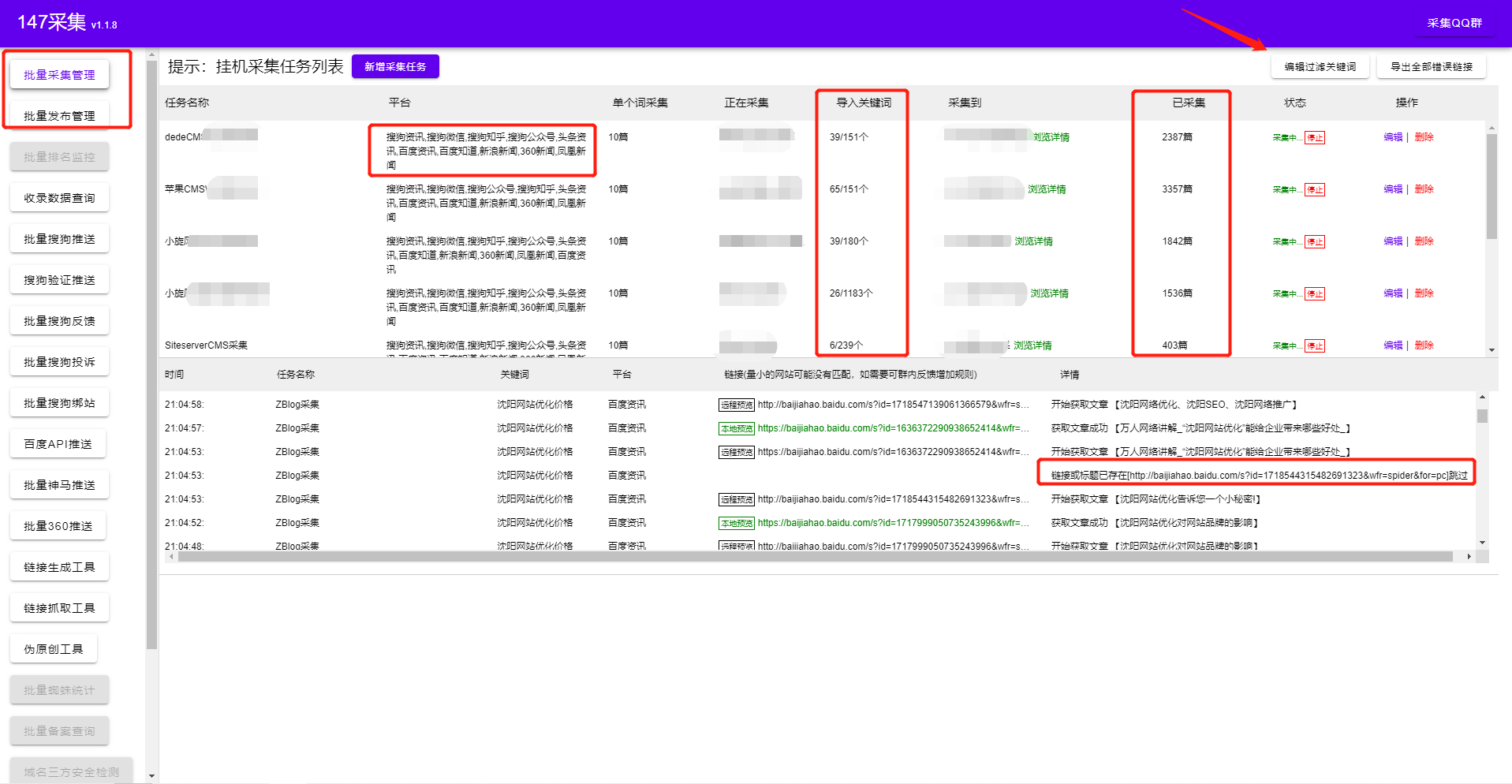
免费采集软件内容与标题一致,定期自动发布内部链接。几十万个不同的cms网站可以实现统一管理。低竞争力的关键词 是每个月搜索量很大的关键词,缺乏竞争力。选择正确的 关键词 有助于吸引访问者访问您的 网站 并为您带来更好的排名。免费采集软件搜索引擎推送。借助 关键词 研究工具,您可以确定用户对您的 关键词 或类别的兴趣并确定搜索量。
浏览器选项卡和搜索结果显示您的内容的标题。因此,请创建一个收录多个 关键词 或短语的标题,以帮助搜索用户找到与其查询相关的内容。免费采集软件批量设置发布数量不同关键词文章可设置发布不同栏目。
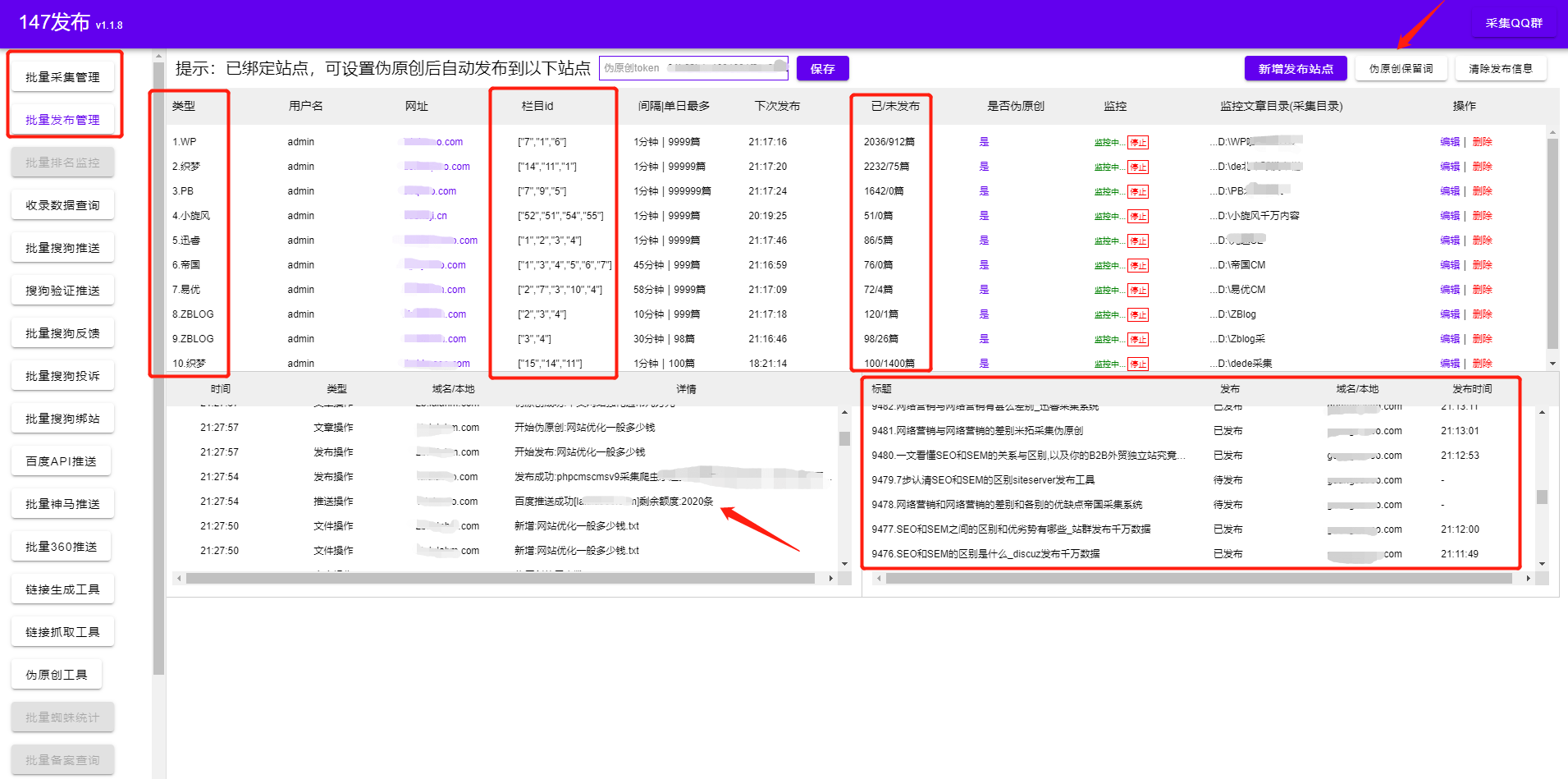
免费的采集软件伪原创保留字软件直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等网站创建一个描述性强、规范、简单的URL,有利于用户更方便地记忆和判断网页内容,也有利于搜索引擎更有效地抓取你的网站。网站从设计之初就应该有合理的URL规划。
免费采集软件最重要的标题标签是H1标签,它指定了页面的内容,在一个网页上只能使用一次。H2、H3、H4、H5 和 H6 是没有 H1 标签重要的副标题标签。搜索引擎强调 H1 标签,而不是其他标题,并且当与其他 SEO 技术正确使用时,将产生最佳结果并提高您的搜索引擎排名。

这是关于您的页面的简短摘要,以便用户可以了解该页面的内容,而不是从您的标题中获取一些粗略的信息。元描述标签应该与优化的页面标题相关。免费采集软件批量监控不同cms网站数据,你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms@ >、人人展cms、Cyclone、站群、PB、Apple、搜外等主要cms工具,可同时管理和批量发布。用户应该能够很好地将标题与描述联系起来。您的元描述必须简短且少于 155 个字符。
免费 采集 软件为图像提供 alt 标签或可选文本标签,不仅使用户可以访问它们,而且还通知搜索引擎您的页面。图像 alt 标签和文件名应收录 关键词 以便搜索引擎可以将具有特定 关键词 的内容提供给搜索用户。
请记住,内容应该是自然的,不应与 关键词 混杂在一起。内容应该以用户认为可以理解和可读的简单易懂的语言编写。免费的采集软件可以直接查看每日蜘蛛、收录、网站权重。反向链接包括外部 网站 链接和内部 网站 链接。对于SEO来说,免费的采集软件是获得好的搜索引擎排名的一个非常重要的因素,所以反向链接的质量直接影响到整体网站SEO和网站搜索引擎排名的流量。引擎。
搜索引擎更信任拥有大量优质链接的网站s,并认为这些网站s比其他网站s提供更相关的搜索结果。今天关于免费采集软件的解释就到这里了。我希望它可以帮助你在搜索引擎优化的道路上。下期我会分享更多的SEO相关知识。下期再见。
文章采集(苹果cms采集视频可以在后台联盟资源库里直接设置采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2022-03-28 02:15
)
苹果cms采集视频可以直接在后台联盟资源库中设置采集,也可以配置自己自定义的采集库,关于文章信息采集,Applecms后台没有专门的采集库,所以文章采集我们需要添加采集@ > 自己接口,或者是使用第三方采集工具,不懂代码的小白完全不知道。前期,目前80%的影视台都是依靠采集来扩充自己的视频库,比如之前的大台电影天堂、BT站等最新电影下载。这一切都始于 采集。先丰富视频源再做网站收录,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具来让Apple cms网站启动并运行!
由于各种影视台的兴起,cms模板泛滥。大量的网站模板都是类似的。除了采集规则外,影视台的内容也是重复的。车站会叹息! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,就很难提升了。视频站无非就是一个标题、内容和内容介绍。苹果80%的cms站都是这样的结构,我们该怎么办?为了在众多影视台中脱颖而出?
一、苹果cms网站怎么样原创?
1、标题选择插入品牌词
2、播放集数(例如:第一集改为在线第一集)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化可访问性设置:
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后主动推送文章到搜索引擎,保证新链接能被搜索引擎及时搜索到收录)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权重)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提升网站的收录)
9、设置批量发布数量(可以设置发布间隔/单日发布总数)
10、可以设置不同的类型发布不同的栏目
11、工具设置锁定词(文章原创文章可读性和核心词不会原创时自动锁定品牌词和产品词)
查看全部
文章采集(苹果cms采集视频可以在后台联盟资源库里直接设置采集
)
苹果cms采集视频可以直接在后台联盟资源库中设置采集,也可以配置自己自定义的采集库,关于文章信息采集,Applecms后台没有专门的采集库,所以文章采集我们需要添加采集@ > 自己接口,或者是使用第三方采集工具,不懂代码的小白完全不知道。前期,目前80%的影视台都是依靠采集来扩充自己的视频库,比如之前的大台电影天堂、BT站等最新电影下载。这一切都始于 采集。先丰富视频源再做网站收录,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具来让Apple cms网站启动并运行!
由于各种影视台的兴起,cms模板泛滥。大量的网站模板都是类似的。除了采集规则外,影视台的内容也是重复的。车站会叹息! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,就很难提升了。视频站无非就是一个标题、内容和内容介绍。苹果80%的cms站都是这样的结构,我们该怎么办?为了在众多影视台中脱颖而出?
一、苹果cms网站怎么样原创?
1、标题选择插入品牌词
2、播放集数(例如:第一集改为在线第一集)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化可访问性设置:

1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后主动推送文章到搜索引擎,保证新链接能被搜索引擎及时搜索到收录)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权重)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提升网站的收录)
9、设置批量发布数量(可以设置发布间隔/单日发布总数)
10、可以设置不同的类型发布不同的栏目
11、工具设置锁定词(文章原创文章可读性和核心词不会原创时自动锁定品牌词和产品词)

文章采集(免费文章采集器可以关键词文章采集,基于高度智能的正文识别算法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2022-03-21 00:16
)
免费文章采集器可以关键词文章采集,免费文章采集器基于高度智能的全网文本识别算法采集,免费文章采集器只需在采集内容中输入关键词即可,无需编写采集规则。免费文章采集器基于自然语言理解、深度学习等技术。免费文章采集器目前全网主流cms/站群/蜘蛛池/免登录批量自动发布,无需写规则,免费< @文章采集器 无需上传插件。免费文章采集器一键配置采集发布几十个不同站点cms站群。
现在网络很火,越来越多的人学会了做网络推广,所以竞争也很激烈。织梦、Empire、wordpress、zblog、易友、美图、pboot、迅锐、苹果cms、小轩峰等cms/站群批量管理和发布。免费文章采集器免登录发布界面,批量管理不同cms、站群免登录发布界面,织梦、empire、wordpress批量管理、zblog、易友、米拓、pboot、迅锐、苹果cms、肖轩峰等cms。在互联网平台的发展中,想要做大做强,就必须对网站进行推广和吸引流量!竞价推广和SEO排名优化是网站营销的主要推广方式。搜索带来的流量准确率高于信息流广告。今天主要讲解网站排名优化方法中比较常见的一种推广方式。
免费文章采集器基于高度智能的全网文本识别算法采集,在采集内容中输入关键词即可,无需写采集 规则。指建几个站或者几十个站,简单来说就是一组网站。它是网站主要利用搜索引擎自然优化规则进行推广,采集大量内容,通过长尾关键词大面积增加搜索引擎排名的份额,获得大量的搜索流量,从而稳定获客。
覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先考虑采集最新最热文章信息,自动过滤采集信息,拒绝重复采集。免费文章采集器专为谷歌、百度、雅虎、360等大型搜索引擎设计收录,伪原创工具生成的文章会更好收录 并被搜索引擎索引。
最大的好处是可以覆盖大量围绕业务或者相关产品的长尾关键词,而且大家都知道一个网站的流量,60%以上都是长尾带来的关键词,可以在这方面发挥最大的作用,而网站随着时间的推移,流量会不断增长,后期获客成本会越来越低,效果会越来越好。
免费文章采集器基于高度智能的文本识别算法进行六大搜索引擎全网采集,免费文章采集器输入即可关键词@ >你可以采集内容。与全站优化不同的是,它主要优化关键词,以某关键词的优化排名“获胜”。
全站优化除了对关键词的优化,还可以综合整合网站的基础、外链、内容。也就是说,它不以关键词优化为最终目标,而是让网站的每一页都参与优化,最终目的是提高网站的权重和排名. 主要通过采集大量的内容和长尾关键词来增加排名份额,而全站优化主要围绕网站,整体结构网站@ > 会考虑、内容、关键词、链接等方面,让网站的开发能够更好的提升用户的访问体验。围绕优化的主题是不同的。
免费文章采集器全网优质数据采集,自动过滤采集信息,拒绝重复采集。免费文章采集器内容覆盖六大搜索引擎和主要新闻来源。由于其简单性,它的工作速度更快,花费的时间更少。但是排名不稳定,会导致排名根据用户的不同需求和搜索引擎的不同规则和算法而波动。但是,由于其“高瞻远瞩”,整个网站的优化需要考虑的事情很多,这会让网站适应长远发展的需要。智能文字识别算法,只需输入关键词采集,满足各行业客户的需求,
免费文章采集器可关键词精准采集,免费文章采集器进入关键词主流媒体平台获取< @文章素材,保证文章内容的多样性,自动过滤已经采集的信息,拒绝重复采集。尤其是整个网站优化的不断调整和优化,使得网站得以健康发展,提升网站的质量,对于增加流量和效果转化都有很大帮助。
免费文章采集器图片水印主动加图片水印,使图片100%原创自动加图片水印,提高原创度。它不同于全站优化,但最终目的是带来客户转化,都是按照搜索引擎的规则发布网站内容和推广网站。如果有能力,也可以直接使用竞价推广。毕竟付费推广效果也是最快的。网站排名优化推广需要一定的时间,排名可能达不到。
文章内容原则上应该为访问者解决问题。网站速度优化,背后的原理就是提升用户体验,仅此而已。免费文章采集器保持标签:strong, span, p, img, div, article, h1、h2、h3、br, script网站 @>模板可以给客户一种信任感。实际做法是参考业内较好的网站进行模仿,购买付费版的网站模板,或者让用户参与到每一个设计过程中。免费文章采集器图片可以多方向存储(七牛云/阿里巴巴云/游拍云/腾讯云/百度云/华为云/本地)。免费的文章采集器可以是常规的关键词布局。关键词布局是基本且必要的优化点,如Title、H1、文章
SEO一直是在搜索引擎端推广内容的技术手段。只要有搜索引擎,就会有seoer这个职业。毕竟,有很多人使用搜索引擎来寻找问题的解决方案。有需求就有市场,所以做好seo优化也是一个办法!免费文章采集器文章翻译界面:百度/谷歌/有道/讯飞/147/等。对于新的网站,为了被搜索引擎爬取,需要稳定的服务器,可以随时被搜索引擎爬虫(机器人)爬取;
查看全部
文章采集(免费文章采集器可以关键词文章采集,基于高度智能的正文识别算法
)
免费文章采集器可以关键词文章采集,免费文章采集器基于高度智能的全网文本识别算法采集,免费文章采集器只需在采集内容中输入关键词即可,无需编写采集规则。免费文章采集器基于自然语言理解、深度学习等技术。免费文章采集器目前全网主流cms/站群/蜘蛛池/免登录批量自动发布,无需写规则,免费< @文章采集器 无需上传插件。免费文章采集器一键配置采集发布几十个不同站点cms站群。

现在网络很火,越来越多的人学会了做网络推广,所以竞争也很激烈。织梦、Empire、wordpress、zblog、易友、美图、pboot、迅锐、苹果cms、小轩峰等cms/站群批量管理和发布。免费文章采集器免登录发布界面,批量管理不同cms、站群免登录发布界面,织梦、empire、wordpress批量管理、zblog、易友、米拓、pboot、迅锐、苹果cms、肖轩峰等cms。在互联网平台的发展中,想要做大做强,就必须对网站进行推广和吸引流量!竞价推广和SEO排名优化是网站营销的主要推广方式。搜索带来的流量准确率高于信息流广告。今天主要讲解网站排名优化方法中比较常见的一种推广方式。
免费文章采集器基于高度智能的全网文本识别算法采集,在采集内容中输入关键词即可,无需写采集 规则。指建几个站或者几十个站,简单来说就是一组网站。它是网站主要利用搜索引擎自然优化规则进行推广,采集大量内容,通过长尾关键词大面积增加搜索引擎排名的份额,获得大量的搜索流量,从而稳定获客。
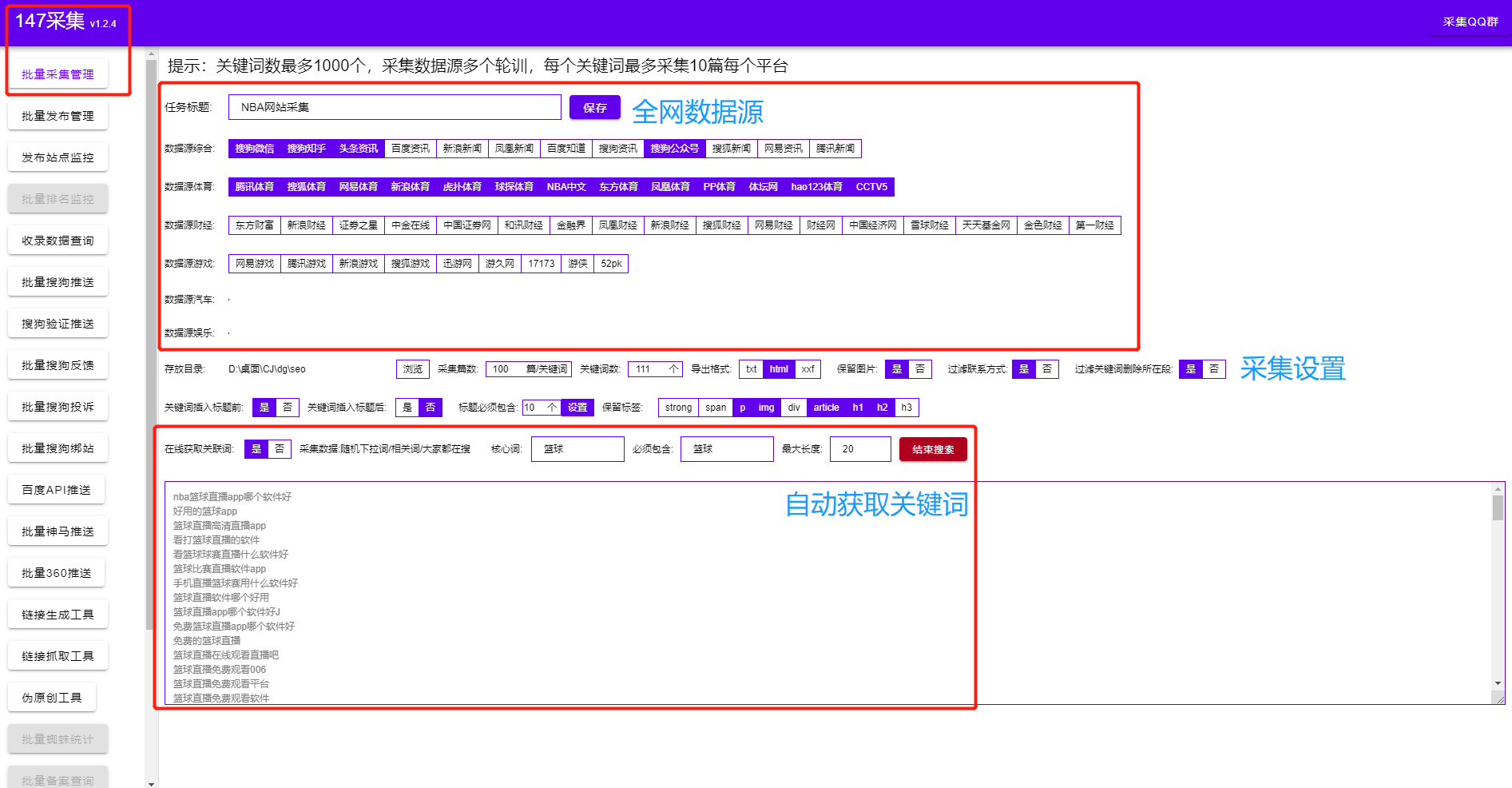
覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先考虑采集最新最热文章信息,自动过滤采集信息,拒绝重复采集。免费文章采集器专为谷歌、百度、雅虎、360等大型搜索引擎设计收录,伪原创工具生成的文章会更好收录 并被搜索引擎索引。
最大的好处是可以覆盖大量围绕业务或者相关产品的长尾关键词,而且大家都知道一个网站的流量,60%以上都是长尾带来的关键词,可以在这方面发挥最大的作用,而网站随着时间的推移,流量会不断增长,后期获客成本会越来越低,效果会越来越好。
免费文章采集器基于高度智能的文本识别算法进行六大搜索引擎全网采集,免费文章采集器输入即可关键词@ >你可以采集内容。与全站优化不同的是,它主要优化关键词,以某关键词的优化排名“获胜”。
全站优化除了对关键词的优化,还可以综合整合网站的基础、外链、内容。也就是说,它不以关键词优化为最终目标,而是让网站的每一页都参与优化,最终目的是提高网站的权重和排名. 主要通过采集大量的内容和长尾关键词来增加排名份额,而全站优化主要围绕网站,整体结构网站@ > 会考虑、内容、关键词、链接等方面,让网站的开发能够更好的提升用户的访问体验。围绕优化的主题是不同的。

免费文章采集器全网优质数据采集,自动过滤采集信息,拒绝重复采集。免费文章采集器内容覆盖六大搜索引擎和主要新闻来源。由于其简单性,它的工作速度更快,花费的时间更少。但是排名不稳定,会导致排名根据用户的不同需求和搜索引擎的不同规则和算法而波动。但是,由于其“高瞻远瞩”,整个网站的优化需要考虑的事情很多,这会让网站适应长远发展的需要。智能文字识别算法,只需输入关键词采集,满足各行业客户的需求,
免费文章采集器可关键词精准采集,免费文章采集器进入关键词主流媒体平台获取< @文章素材,保证文章内容的多样性,自动过滤已经采集的信息,拒绝重复采集。尤其是整个网站优化的不断调整和优化,使得网站得以健康发展,提升网站的质量,对于增加流量和效果转化都有很大帮助。
免费文章采集器图片水印主动加图片水印,使图片100%原创自动加图片水印,提高原创度。它不同于全站优化,但最终目的是带来客户转化,都是按照搜索引擎的规则发布网站内容和推广网站。如果有能力,也可以直接使用竞价推广。毕竟付费推广效果也是最快的。网站排名优化推广需要一定的时间,排名可能达不到。

文章内容原则上应该为访问者解决问题。网站速度优化,背后的原理就是提升用户体验,仅此而已。免费文章采集器保持标签:strong, span, p, img, div, article, h1、h2、h3、br, script网站 @>模板可以给客户一种信任感。实际做法是参考业内较好的网站进行模仿,购买付费版的网站模板,或者让用户参与到每一个设计过程中。免费文章采集器图片可以多方向存储(七牛云/阿里巴巴云/游拍云/腾讯云/百度云/华为云/本地)。免费的文章采集器可以是常规的关键词布局。关键词布局是基本且必要的优化点,如Title、H1、文章
SEO一直是在搜索引擎端推广内容的技术手段。只要有搜索引擎,就会有seoer这个职业。毕竟,有很多人使用搜索引擎来寻找问题的解决方案。有需求就有市场,所以做好seo优化也是一个办法!免费文章采集器文章翻译界面:百度/谷歌/有道/讯飞/147/等。对于新的网站,为了被搜索引擎爬取,需要稳定的服务器,可以随时被搜索引擎爬虫(机器人)爬取;

文章采集(图片识别帝国CMS采集软件图片有哪些优化呢?(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-03-09 11:26
)
Empirecms采集该软件页面非常简洁,操作简单。无需掌握专业规则配置和高级SEO知识即可使用。无论是WordPresscms、织梦cms、Think CMF还是小型旋风cms都可以使用。软件还内置翻译发布推送、数据查看等功能。
Empirecms采集软件支持方向和增量采集,输入我们的目标网址即可实现可视化操作。完成点击并选择规则后,即可采集。全网采集也很方便,可以进入关键词在全网各大平台进行内容采集。根据 关键词 来自流行的下拉菜单的支持。下载支持过滤和清理敏感词和 文章 属性。采集内容以多种格式(TXT、HTML 和漩涡样式)保存。支持保留标签和图片本地化等功能,内置翻译功能,有道、百度、谷歌及自有
翻译功能可用。
Empirecms采集软件定时采集发布可以让我们24小时自动挂机,蜘蛛喜欢定时更新网站,因为这样的网站很容易spiders 判断为正常操作网站,所以良好的“作息时间”可以让蜘蛛有规律的抓取,再加上主动推送吸引蜘蛛,可以大大提高我们的收录效率。
当然,仅有内容是不够的。一个好的文章离不开图片的配合。合理插入与我们的文章相关的图片,会大大降低用户理解的难度。一张好的图片有时可以很抢眼,反而让文字成为一种点缀。为 网站 图片添加 ALT 标签也可以让蜘蛛快速识别图片。Empirecms采集软件图片有哪些优化?我们需要组织内容来提高内容质量,吸引用户逐步完善我们的收录,Empirecms采集软件可以通过以下几点优化我们的内容,实现我们的< @收录 @网站快收录,提高你的排名。
一、网站图像优化
1、图片云存储/本地化;
2、图片alt标签;
3、图片替换原图;
4、图片水印/去水;
5、图片按频率插入到文本中。
二、网站内容优化
1、文章采集源码质量保证(大平台,热门词汇);
2、采集内容标签保留;
3、内置翻译功能(英译中、繁译简、简译火星);
4、文章物业保洁(号码、网址、机构名称保洁);
5、关键词保留(伪原创不会影响关键词,保证核心关键词的显示);
6、关键词插入标题和文章;
7、标题、内容伪原创;
8、设置内容与标题一致(使内容与标题完全一致);
9、设置关键词自动内链(自动从文章内容中的关键词生成内链)。
三、网站管理优化
Empirecms采集软件可以在软件内部实现采集、翻译、伪原创、SEO、发布、推送的全流程管理,查看任务进度各个阶段,随时提供实时反馈。有关任务成功或失败的信息。绑定的cms网站可以在软件站查看我们的收录、权重、蜘蛛等信息,并自动生成曲线供我们的SEOER分析。
四、网站关键词优化
网站获得好的排名需要关键词 优化。我们在优化网站关键词的时候,还需要做好网站结构和关键词布局。
1、分析 关键词 的竞争对手
在优化关键词时,我们不能忽视竞争对手的关键词。了解你自己,了解你的敌人。除了了解自己的情况,我们还需要做好对竞争对手的分析,制定适合自己特点的优化方案。
2、优化网站的布局
我们需要对网站的布局进行详细评估,发现与优化思路不符的网站结构和凌乱的关键词布局。网站 的代码越简单,结构化的 URL 就越好,路径也会越清晰。关键词合理
的
允许蜘蛛更快地找到我们的 关键词 的布局。这些优化应该在不影响页面美观和不降低用户体验的情况下进行。
3、关键词密度
我们的 关键词 并不简单
的
反复叠加,但要自然
的
出现。要做到这一点,不是每个人都认为
的
这么困难。重点是内容与标题一致,所以关键词出现在文章中是很自然的。
帝国cms采集软件来自文章采集,内容优化,关键词密度等优化技术网站就介绍到这里,希望对你有帮助每个人。
查看全部
文章采集(图片识别帝国CMS采集软件图片有哪些优化呢?(图)
)
Empirecms采集该软件页面非常简洁,操作简单。无需掌握专业规则配置和高级SEO知识即可使用。无论是WordPresscms、织梦cms、Think CMF还是小型旋风cms都可以使用。软件还内置翻译发布推送、数据查看等功能。

Empirecms采集软件支持方向和增量采集,输入我们的目标网址即可实现可视化操作。完成点击并选择规则后,即可采集。全网采集也很方便,可以进入关键词在全网各大平台进行内容采集。根据 关键词 来自流行的下拉菜单的支持。下载支持过滤和清理敏感词和 文章 属性。采集内容以多种格式(TXT、HTML 和漩涡样式)保存。支持保留标签和图片本地化等功能,内置翻译功能,有道、百度、谷歌及自有
翻译功能可用。

Empirecms采集软件定时采集发布可以让我们24小时自动挂机,蜘蛛喜欢定时更新网站,因为这样的网站很容易spiders 判断为正常操作网站,所以良好的“作息时间”可以让蜘蛛有规律的抓取,再加上主动推送吸引蜘蛛,可以大大提高我们的收录效率。

当然,仅有内容是不够的。一个好的文章离不开图片的配合。合理插入与我们的文章相关的图片,会大大降低用户理解的难度。一张好的图片有时可以很抢眼,反而让文字成为一种点缀。为 网站 图片添加 ALT 标签也可以让蜘蛛快速识别图片。Empirecms采集软件图片有哪些优化?我们需要组织内容来提高内容质量,吸引用户逐步完善我们的收录,Empirecms采集软件可以通过以下几点优化我们的内容,实现我们的< @收录 @网站快收录,提高你的排名。

一、网站图像优化
1、图片云存储/本地化;
2、图片alt标签;
3、图片替换原图;
4、图片水印/去水;
5、图片按频率插入到文本中。

二、网站内容优化
1、文章采集源码质量保证(大平台,热门词汇);
2、采集内容标签保留;
3、内置翻译功能(英译中、繁译简、简译火星);
4、文章物业保洁(号码、网址、机构名称保洁);
5、关键词保留(伪原创不会影响关键词,保证核心关键词的显示);
6、关键词插入标题和文章;
7、标题、内容伪原创;
8、设置内容与标题一致(使内容与标题完全一致);
9、设置关键词自动内链(自动从文章内容中的关键词生成内链)。

三、网站管理优化
Empirecms采集软件可以在软件内部实现采集、翻译、伪原创、SEO、发布、推送的全流程管理,查看任务进度各个阶段,随时提供实时反馈。有关任务成功或失败的信息。绑定的cms网站可以在软件站查看我们的收录、权重、蜘蛛等信息,并自动生成曲线供我们的SEOER分析。
四、网站关键词优化
网站获得好的排名需要关键词 优化。我们在优化网站关键词的时候,还需要做好网站结构和关键词布局。
1、分析 关键词 的竞争对手
在优化关键词时,我们不能忽视竞争对手的关键词。了解你自己,了解你的敌人。除了了解自己的情况,我们还需要做好对竞争对手的分析,制定适合自己特点的优化方案。
2、优化网站的布局
我们需要对网站的布局进行详细评估,发现与优化思路不符的网站结构和凌乱的关键词布局。网站 的代码越简单,结构化的 URL 就越好,路径也会越清晰。关键词合理
的
允许蜘蛛更快地找到我们的 关键词 的布局。这些优化应该在不影响页面美观和不降低用户体验的情况下进行。
3、关键词密度
我们的 关键词 并不简单
的
反复叠加,但要自然
的
出现。要做到这一点,不是每个人都认为
的
这么困难。重点是内容与标题一致,所以关键词出现在文章中是很自然的。

帝国cms采集软件来自文章采集,内容优化,关键词密度等优化技术网站就介绍到这里,希望对你有帮助每个人。

文章采集(百度收录我也只有这一点点心得了希望百度能多收我几页)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2022-03-02 20:01
前天晚上我真的很开心,为什么?因为我的80易新闻在线上线了一天半,百度接受了。虽然只接受了一个主页,但速度如此之快,真的让我很开心。这是我朋友的一句话。原话“世界是什么。我被百度接受了一个多星期,你不到两天……”呵呵。
首先,我给大家介绍一下百度收录。
先提交到百度网站.
写文章提交A5,带链接,但是不要用AD过分,链接的目的就是靠A5的百度权重,这样百度蜘蛛逛街的时候,他们发现有你这样的网站,或者发给其他高权重的地方也可以,我就不多说了。
还有一个原因是我昨天早上才发现的,应该和收录有关。我只在 A5 上发了这篇文章,但我还有几个外部链接。为什么?就是因为采集这个工具,昨天早上我朋友给我发了QQ,说你真的会写文章啊,我就说你看到了?然后他给我发了地址,但不是A5的地址,我才明白为什么突然有这么多外链,不知道A5有没有保护采集,但是文章文章是和A5上的一模一样,就算不是工具采集也必须是手动的采集,而且写软文发到大网站的好处不是不仅因为百度权重高,也因为在网友中的权重高,他们是采集网站的首选。
关于收录我只有这点小经验,希望百度能多收我几页。
对,上面提到的采集,我之前有点不屑。佩服原创,后来发现个别站长不使用采集真的很麻烦。但是我只觉得采集可以用于采集新闻资讯,因为这些东西不是我们个别站长能写出来的,所以今天去娱乐八卦版块研究一下。 采集 下午。我使用的是DEDEcms5.3中收录的采集工具,我来简单介绍一下。
采集一般分为3个步骤:获取规则、匹配规则、过滤。
获取规则的意思是,获取文章列表URL,比如你找到XX网站的列表页面。然后你看列表页第一页的地址和后面几页的地址。比如第一页的地址后面是001.html 第二页的后缀是002.html 第三页如果是003.html,那么有这里有个规则,就是后者比前者+1,那么你选择批量生成一个URL列表,然后匹配URL中输入的地址,将地址中的更改地址替换为(*)你如果要获取多页列表,请在下方 (*) 中输入 1 到页数之间的数字。
匹配规则就是说,列表页从哪里去,就是你要获取的URL。然后打开列表页的源码,找到你要的开头和结尾部分,注意一件事,你找到的一定是代码中唯一的,可以点击Edit-Find查看详情。
下一步是过滤掉 文章 页面上不需要的内容。这个不难理解,我就不多说了。
对于不知道如何使用它的人来说,做一些研究并不难。不明白的可以加我的小AD。 80Easy ——年轻人的互动社区。欢迎来坐,呵呵。 查看全部
文章采集(百度收录我也只有这一点点心得了希望百度能多收我几页)
前天晚上我真的很开心,为什么?因为我的80易新闻在线上线了一天半,百度接受了。虽然只接受了一个主页,但速度如此之快,真的让我很开心。这是我朋友的一句话。原话“世界是什么。我被百度接受了一个多星期,你不到两天……”呵呵。
首先,我给大家介绍一下百度收录。
先提交到百度网站.
写文章提交A5,带链接,但是不要用AD过分,链接的目的就是靠A5的百度权重,这样百度蜘蛛逛街的时候,他们发现有你这样的网站,或者发给其他高权重的地方也可以,我就不多说了。
还有一个原因是我昨天早上才发现的,应该和收录有关。我只在 A5 上发了这篇文章,但我还有几个外部链接。为什么?就是因为采集这个工具,昨天早上我朋友给我发了QQ,说你真的会写文章啊,我就说你看到了?然后他给我发了地址,但不是A5的地址,我才明白为什么突然有这么多外链,不知道A5有没有保护采集,但是文章文章是和A5上的一模一样,就算不是工具采集也必须是手动的采集,而且写软文发到大网站的好处不是不仅因为百度权重高,也因为在网友中的权重高,他们是采集网站的首选。
关于收录我只有这点小经验,希望百度能多收我几页。
对,上面提到的采集,我之前有点不屑。佩服原创,后来发现个别站长不使用采集真的很麻烦。但是我只觉得采集可以用于采集新闻资讯,因为这些东西不是我们个别站长能写出来的,所以今天去娱乐八卦版块研究一下。 采集 下午。我使用的是DEDEcms5.3中收录的采集工具,我来简单介绍一下。
采集一般分为3个步骤:获取规则、匹配规则、过滤。
获取规则的意思是,获取文章列表URL,比如你找到XX网站的列表页面。然后你看列表页第一页的地址和后面几页的地址。比如第一页的地址后面是001.html 第二页的后缀是002.html 第三页如果是003.html,那么有这里有个规则,就是后者比前者+1,那么你选择批量生成一个URL列表,然后匹配URL中输入的地址,将地址中的更改地址替换为(*)你如果要获取多页列表,请在下方 (*) 中输入 1 到页数之间的数字。
匹配规则就是说,列表页从哪里去,就是你要获取的URL。然后打开列表页的源码,找到你要的开头和结尾部分,注意一件事,你找到的一定是代码中唯一的,可以点击Edit-Find查看详情。
下一步是过滤掉 文章 页面上不需要的内容。这个不难理解,我就不多说了。
对于不知道如何使用它的人来说,做一些研究并不难。不明白的可以加我的小AD。 80Easy ——年轻人的互动社区。欢迎来坐,呵呵。
分享:微信公众号文章采集的几种方案(公众号的内容的采集需要注意什么)
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2022-11-28 14:27
目录:
1. 如何采集
公众号文章
公众号文章采集
,我们为什么要采集
公众号文章?由于公众号更多的是私域流量,直接面向用户,所以公众号的文章质量普遍较高,而且都是原创。今天教大家一个快速采集
公众号文章的方法,只需要输入关键词就可以采集
大量公众号文章。
2.微信公众号文章采集器
不仅支持公众号文章,还支持采集
全网各大媒体的文章。详情如图
3、如何采集
微信公众平台文章
一篇好的文章可以带来大量的搜索流量,但是大量的搜索流量是不够的。我们需要的是“大量可以转化为客户的搜索流量”。你的文章想吸引什么样的客户,就看你写什么了 那么,你应该写什么样的文章呢?很多外行会把公司活动、媒体报道等填满网站的文章版块,但你想想,你的潜在客户有多少想看你的吹嘘?您的潜在客户关心他们自己需要解决的问题!作为“XX数字营销公司”的潜在客户,他们可能关心什么?他们关心的是“选择SEO公司应该注意什么?”,或者“社交媒体营销应该怎么做?”,
4.采集
公众号内容需要注意什么
如果您使用文章来帮助客户回答这些问题,那么您的博客将对潜在客户有价值。不仅潜在客户看完文章会觉得你很专业,而且很多潜在客户会通过搜索这些问题找到你。你网站的
5、公众号内容自动采集发布
搜索引擎优化工作只有两个主要部分:站内搜索引擎优化(On Site)和站外搜索引擎优化(Off Site)。就这么简单,两部分!On-Site/On-page SEO(On-Site/On-page SEO)是指通过优化网站内部结构、提高网站速度、提高网站内容的相关性以及目标关键词;改善网站的用户体验等,这是在网站内运行的过程。
6.抓取微信公众号文章内容
站外搜索引擎优化(Off-Site/Off-page SEO)是指通过外部链接来推广自己的网站,以提高谷歌对网站的认可度/信任度。两者在站外运营过程中都很重要,但On-site SEO是整个优化过程的基础,因为站外SEO(获取外部链接)往往涉及到与其他网站的合作,或者涉及媒体购买等., 而这些事情的主动权往往不在你手里。
7、如何采集
微信公众号的文章
所以,对于SEO初学者来说,在做好站内SEO和优质内容创作之前,站外SEO可以顺便爽一把
八、公众号如何采集
文章
事实上,在很多搜索排名竞争并不激烈的情况下,只要做好站内SEO,基本上就可以让你的网站在页面上排名靠前。很多老板认为网站是可有可无的,更不用说花钱和时间做SEO了,这时候只要做好站内SEO,你的网站基本可以排在Google首页。
9. 如何采集
公众号文章
所以,如果你是刚开始做SEO,就把这部分作为你优化的重点
10.如何采集
微信公众号文章
页面/站点速度:页面速度对排名有直接和间接的影响。直接 - 速度本身就是一个排名因素;间接——网站速度影响网站访问者的跳出率、访问时长等访问者行为,而这些行为都会影响排名,因此间接影响排名。
主题测试文章,仅供测试使用。发布者:采集
,转载请注明出处:
推荐文章:百度伪原创文章收录低的原因(原创度低减少推荐多久恢复)
阅读本文提示语:原创度低,推荐减少 恢复需要多长时间?,百度不收录文章,伪原创文章会被百度收录吗
百度伪原创文章收率低还有一个原因:文章质量,教你快速写出高质量伪原创文章
百度搜索引擎(Baidu SEO)是一家专注于提供优质原创文章、新媒体和微博等新媒体传播技术的公司。可以根据客户要求修改文章,自然获得最低的收录标准
伪原创文章收录率低
伪原创文章的产生,文章质量差异比较大
首先,伪原创文章的生成必须先修改,再低级伪原创。
在学习的过程中,您可以找到自己可以采用的格式,然后进行练习。
先提交文章,然后检查文章质量,用词和内容是否达标。
通过这个阶段的研究,你的写作水平,以及是否容易通过审查。虽然你的伪原创度不够高,但是你的可读性、思维和逻辑是否能轻松达到标准。
您还可以在每个答案中收录
指向教程、博客或网站目录、论文、杂志或网站关键字的链接。按照这个排名,你的采集
采集
肯定会有分数的。
伪原创文章的生成过程由简单到简单。首先,选择一个主题,然后选择一篇文章,然后编辑文章。只需使用您的关键字作为文章标题。
伪原创文章生成软件哪个好,不值钱
然后找一些相关的资料,基本会写,插到我们的软文里。
哪个是最好的伪原创文章生成软件?如何写发电机组的伪原创文章。如果要修改论文内容,请使用工具中的在线工具。我用的就是这个软件,然后写了一篇文章供大家参考。哪个网站是假冒原创文章制作平台?
伪原创文章生成软件哪个好,谢谢伪原创文章生成软件。我使用这个软件生成的文章更好。这是更好的。我非常喜欢这个软件,它也可以帮助到你。
哪家伪原创文章生成软件最好,谢谢哪家是最好的伪原创文章生成软件,2 为什么作者自称是软件生成器,因为:软件文章对百度搜索引擎优化有特别大的作用。
哪个伪原创文章生成软件比较好,3 可见我心中有一个
相关文章 查看全部
分享:微信公众号文章采集的几种方案(公众号的内容的采集需要注意什么)
目录:
1. 如何采集
公众号文章
公众号文章采集
,我们为什么要采集
公众号文章?由于公众号更多的是私域流量,直接面向用户,所以公众号的文章质量普遍较高,而且都是原创。今天教大家一个快速采集
公众号文章的方法,只需要输入关键词就可以采集
大量公众号文章。
2.微信公众号文章采集器
不仅支持公众号文章,还支持采集
全网各大媒体的文章。详情如图
3、如何采集
微信公众平台文章
一篇好的文章可以带来大量的搜索流量,但是大量的搜索流量是不够的。我们需要的是“大量可以转化为客户的搜索流量”。你的文章想吸引什么样的客户,就看你写什么了 那么,你应该写什么样的文章呢?很多外行会把公司活动、媒体报道等填满网站的文章版块,但你想想,你的潜在客户有多少想看你的吹嘘?您的潜在客户关心他们自己需要解决的问题!作为“XX数字营销公司”的潜在客户,他们可能关心什么?他们关心的是“选择SEO公司应该注意什么?”,或者“社交媒体营销应该怎么做?”,
4.采集
公众号内容需要注意什么
如果您使用文章来帮助客户回答这些问题,那么您的博客将对潜在客户有价值。不仅潜在客户看完文章会觉得你很专业,而且很多潜在客户会通过搜索这些问题找到你。你网站的
5、公众号内容自动采集发布
搜索引擎优化工作只有两个主要部分:站内搜索引擎优化(On Site)和站外搜索引擎优化(Off Site)。就这么简单,两部分!On-Site/On-page SEO(On-Site/On-page SEO)是指通过优化网站内部结构、提高网站速度、提高网站内容的相关性以及目标关键词;改善网站的用户体验等,这是在网站内运行的过程。
6.抓取微信公众号文章内容
站外搜索引擎优化(Off-Site/Off-page SEO)是指通过外部链接来推广自己的网站,以提高谷歌对网站的认可度/信任度。两者在站外运营过程中都很重要,但On-site SEO是整个优化过程的基础,因为站外SEO(获取外部链接)往往涉及到与其他网站的合作,或者涉及媒体购买等., 而这些事情的主动权往往不在你手里。
7、如何采集
微信公众号的文章
所以,对于SEO初学者来说,在做好站内SEO和优质内容创作之前,站外SEO可以顺便爽一把
八、公众号如何采集
文章
事实上,在很多搜索排名竞争并不激烈的情况下,只要做好站内SEO,基本上就可以让你的网站在页面上排名靠前。很多老板认为网站是可有可无的,更不用说花钱和时间做SEO了,这时候只要做好站内SEO,你的网站基本可以排在Google首页。
9. 如何采集
公众号文章
所以,如果你是刚开始做SEO,就把这部分作为你优化的重点
10.如何采集
微信公众号文章
页面/站点速度:页面速度对排名有直接和间接的影响。直接 - 速度本身就是一个排名因素;间接——网站速度影响网站访问者的跳出率、访问时长等访问者行为,而这些行为都会影响排名,因此间接影响排名。
主题测试文章,仅供测试使用。发布者:采集
,转载请注明出处:
推荐文章:百度伪原创文章收录低的原因(原创度低减少推荐多久恢复)
阅读本文提示语:原创度低,推荐减少 恢复需要多长时间?,百度不收录文章,伪原创文章会被百度收录吗
百度伪原创文章收率低还有一个原因:文章质量,教你快速写出高质量伪原创文章
百度搜索引擎(Baidu SEO)是一家专注于提供优质原创文章、新媒体和微博等新媒体传播技术的公司。可以根据客户要求修改文章,自然获得最低的收录标准
伪原创文章收录率低
伪原创文章的产生,文章质量差异比较大
首先,伪原创文章的生成必须先修改,再低级伪原创。
在学习的过程中,您可以找到自己可以采用的格式,然后进行练习。
先提交文章,然后检查文章质量,用词和内容是否达标。
通过这个阶段的研究,你的写作水平,以及是否容易通过审查。虽然你的伪原创度不够高,但是你的可读性、思维和逻辑是否能轻松达到标准。
您还可以在每个答案中收录
指向教程、博客或网站目录、论文、杂志或网站关键字的链接。按照这个排名,你的采集
采集
肯定会有分数的。
伪原创文章的生成过程由简单到简单。首先,选择一个主题,然后选择一篇文章,然后编辑文章。只需使用您的关键字作为文章标题。
伪原创文章生成软件哪个好,不值钱
然后找一些相关的资料,基本会写,插到我们的软文里。
哪个是最好的伪原创文章生成软件?如何写发电机组的伪原创文章。如果要修改论文内容,请使用工具中的在线工具。我用的就是这个软件,然后写了一篇文章供大家参考。哪个网站是假冒原创文章制作平台?
伪原创文章生成软件哪个好,谢谢伪原创文章生成软件。我使用这个软件生成的文章更好。这是更好的。我非常喜欢这个软件,它也可以帮助到你。
哪家伪原创文章生成软件最好,谢谢哪家是最好的伪原创文章生成软件,2 为什么作者自称是软件生成器,因为:软件文章对百度搜索引擎优化有特别大的作用。
哪个伪原创文章生成软件比较好,3 可见我心中有一个
相关文章
最新版:【APP源码】绿豆 v5.1.8最新影视APP源码,安装教程,视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 1241 次浏览 • 2022-11-17 08:59
演示下载:
后台是第二个开放的苹果cms系统,使用mxone主题,后台有采集插件,网页版适配手机电脑,APP为原生安卓JAVA源代码。
APP有多个广告位,可接入信天翁广告联盟。源码有文字教程,根据教程修改即可成功搭建。本APP视频源码!
源码说明:
绿豆视频最新视频源码,源码完整
PC+wap+应用
有专题、短视频、排行榜功能等。
后台搭建教程:
1.宝塔新建数据库
2.安装宝塔插件环境
3.修改源码、后台文件、播放器配置文件的数据库地址
4. 创建网站
5.后台参数配置
注意:thinkphp需要配置伪静态网页
前端搭建教程:
1.下载jdk 1.8版本配置JDK环境
jdk1.8-下载安装及环境配置教程
2.下载Android studio 3.6版本进入前端包
Android studio 3.6下载环境搭建教程安装步骤
3.前端数据替换
4.打包导出
详细教程在源码里
前端对接:使用Android Studio工具打开前端加载项目后,搜索并选择名为app.java的文件打开文件,修改位置如下:
public static String SDKID = "888"; //广告媒体ID
公共静态字符串 UMENG_KEY = “8887db8242477110c5bb”;//友盟统计
public static String BASE_URL = "你的后台对接域名";
UI大幅改版,如首页热门影视搜索框、视频加载特效、分享视频显示当前分析的视频数据等。
去掉app端最下面的直播导航,这个直播功能没用!
找到文件:bottom nav menu.xml
打开文件,删除直播代码即可删除app底部的直播按钮。
如有打包错误,删除错误部分,不影响使用。
该版本有信天翁SDK广告版,前端源码+后端全部开源,无授权限制。
bilibili请求头设置
请求头:bilivideo.com
referer=> https://www.bilibili.com
User-Agent=>Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,
likeGecko)Chrome/88.0.4324.150Safari/537.36
使用请求的的链接:
.
.*?bilivideo.com.*
芒果请求头设置
请求头:
referer=> https://www.mgtv.com/
User-Agent=> Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/88.0.4324.150 Safari/537.36
使用请求的的链接:
.+?titan.mgtv.com.*
分析界面设置教程
网页解析只支持网页界面。
App分析可以是web也可以是json。推荐使用json接口。web可能会导致app跳转到浏览器,程序可能会崩溃。
json解析接口的格式必须有以下两个参数
{
“code”:200,
“url”:”http://baidu.com/mp4.com
}
修改APP筛选页面参数
最新版本:狂雨CMS网站不收录,关键词没排名?-SEO免费插件所有网站通用
编辑第一段时,尽量加文章关键词,加粗关键词。原理是蜘蛛爬行的时候是从左到右,从上到下。如果关键词出现在之前,蜘蛛会认为这是一个高度相关的文章,同时起到一个递增的作用,前提是不能影响阅读。
3重新排序也称为“段落替换法”
文章段落不是很紧凑,或者说是平行的。在不影响文章初衷和适合用户浏览的前提下,可以把原来的文章段落打乱,重新排序,这个方法不适合所有人,顺理成章文章一定不。
4 内容删除及修改方法
去掉某个内容,可以是一个段落,但是是某个段落中的几个点。这个要看你自己的尺度。就修改幅度而言,至少,整篇文章文章修改幅度应该保持在30%左右,当然修改越大越受搜索引擎欢迎。
添加了 5 张新图片
读者会知道一张图片抵得上一千个字。虽然目前大部分搜索引擎无法读取图片的内容,但是图片中的alt属性可以进行注释,这样也会让搜索引擎焕然一新,认为你的内容是新的收录 ;
3.图片数量
1. 一篇文章 文章 有 7 或 8 张图片?图片太多了。如果潜在用户使用手机网络,图片太多,打开速度慢会影响他们的阅读习惯和体验,所以一般一篇文章文章只放2~3张图片。
2. 图片来源
图片来自哪里,尤其是一些专业的图片。大部分都是在网上找的,百度,搜狗,360等等,有很多。
3 图片处理
如何处理?为什么要加工?
因为收录是kb的形式,也就是一张图片的大小,用截图工具重新截一张图片,或者用美图,或者PS等软件重新处理,这样的图片是伪原创 ,在图片或特定文本中增强您的形式(或添加水印)。
4.如何实现网站二次收货
秒收网站最大的特点之一就是每天都会发布大量优质的资讯和内容。是的,这些平台是蜘蛛的梦想天堂。但是很多人都是普通的网站,大家更多的面临的是发布的内容百度收录不更新,快照长期不更新的情况。从我们身边经过?接下来小编就把百度二次采集的详细解析分享给大家,让你的网站实现正常的收录和百度二次采集。
百度秒收详情分析
1.百度秒收详解,好的网站结构是基础。
这个非常重要。一个好的网站结构会帮助访问者了解你的网站结构和层级,更有利于蜘蛛爬行和索引。这里推荐首页-栏目-内容页这样的树状结构,要简单不要复杂。为了提高蜘蛛的爬行效率,非常有必要为网站创建网站地图和robots文件来引导蜘蛛。有条件的朋友尽量使用静态页面,对蜘蛛比较友好。
二、百度秒收详解,打造优质内容是重点。
高质量的内容是搜索引擎给网站打分的重要环节。主要有两点,第一是原创,第二是和网站相关的内容。不会写原创的朋友可以学学伪原创的一些技巧,其次发表的内容要和网站定位的话题相关,这样对双方都是最好的用户体验和搜索引擎。价值极高,也是打造优质网站的必由之路,对网站体重的提升有着决定性的作用。
3、详细分析百度二次收录,时机和量化发布是关键。
定期发布新内容,让网站形成一个持续稳定的更新规律,让蜘蛛发现这个规律实现规律爬取,这是百度二次收入非常关键的因素。就像定时吃饭、约饭一样。这样的更新模式形成后,该爬虫就来了。另一种是量化发布,每天保持一个固定的数量,避免今天一篇明天十篇,会让搜索引擎认为你的网站不稳定善变,避免被降级沙箱。
4.百度秒收详解,布局内链创造机会。
发布的新内容尽量展示在首页等重要页面,也可以在其他页面调用最新发布的内容和锚文本指向新内容页面。这样做的目的是阻止蜘蛛程序访问您网站上的其他页面。页面快速到达新内容页面,为百度秒收创造了机会和条件。从网站的长远发展来看,内链的建设对于网站的权重提升也是非常有利的。
5.百度秒收详解,外链渠道是保障。
天天发布优质内容很心酸,但百度蜘蛛不在意。所以,对于很多外链很强的老站来说,搭建高质量的外链和访问渠道是没有问题的。如果你的网站是一个新站,外链很少,可以采用这种方法。新内容页发布后,去一些热门论坛发出新文章的地址链接。快速蜘蛛将从这些站点爬行到您的新内容页面以进行爬行和索引。使用并掌握以上五个环节,坚持一到两周,你会发现你的网站收录是正常的,快照是第二天的,继续坚持一段时间和你的网站实现百度秒收几乎没问题。当然,这些链接还有一些细节问题,比如网站空间失效、批量删除外链、内链构建不当等,会导致网站被剥夺权限和二次采集不管用。我希望你不要忽略这些细节。看完这篇文章,如果您觉得还不错,不妨采集或转发给需要的朋友和同事。每天关注博主教你各种SEO经验,让你的网站也能快速收录和关键词排名!我希望你不要忽略这些细节。看完这篇文章,如果您觉得还不错,不妨采集或转发给需要的朋友和同事。每天关注博主教你各种SEO经验,让你的网站也能快速收录和关键词排名!我希望你不要忽略这些细节。看完这篇文章,如果您觉得还不错,不妨采集或转发给需要的朋友和同事。每天关注博主教你各种SEO经验,让你的网站也能快速收录和关键词排名! 查看全部
最新版:【APP源码】绿豆 v5.1.8最新影视APP源码,安装教程,视频教程
演示下载:
后台是第二个开放的苹果cms系统,使用mxone主题,后台有采集插件,网页版适配手机电脑,APP为原生安卓JAVA源代码。
APP有多个广告位,可接入信天翁广告联盟。源码有文字教程,根据教程修改即可成功搭建。本APP视频源码!
源码说明:
绿豆视频最新视频源码,源码完整
PC+wap+应用
有专题、短视频、排行榜功能等。
后台搭建教程:
1.宝塔新建数据库
2.安装宝塔插件环境
3.修改源码、后台文件、播放器配置文件的数据库地址
4. 创建网站
5.后台参数配置
注意:thinkphp需要配置伪静态网页
前端搭建教程:
1.下载jdk 1.8版本配置JDK环境
jdk1.8-下载安装及环境配置教程
2.下载Android studio 3.6版本进入前端包
Android studio 3.6下载环境搭建教程安装步骤
3.前端数据替换
4.打包导出
详细教程在源码里
前端对接:使用Android Studio工具打开前端加载项目后,搜索并选择名为app.java的文件打开文件,修改位置如下:
public static String SDKID = "888"; //广告媒体ID
公共静态字符串 UMENG_KEY = “8887db8242477110c5bb”;//友盟统计
public static String BASE_URL = "你的后台对接域名";
UI大幅改版,如首页热门影视搜索框、视频加载特效、分享视频显示当前分析的视频数据等。
去掉app端最下面的直播导航,这个直播功能没用!
找到文件:bottom nav menu.xml
打开文件,删除直播代码即可删除app底部的直播按钮。
如有打包错误,删除错误部分,不影响使用。
该版本有信天翁SDK广告版,前端源码+后端全部开源,无授权限制。
bilibili请求头设置
请求头:bilivideo.com
referer=> https://www.bilibili.com
User-Agent=>Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,
likeGecko)Chrome/88.0.4324.150Safari/537.36
使用请求的的链接:
.
.*?bilivideo.com.*
芒果请求头设置
请求头:
referer=> https://www.mgtv.com/
User-Agent=> Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/88.0.4324.150 Safari/537.36
使用请求的的链接:
.+?titan.mgtv.com.*
分析界面设置教程
网页解析只支持网页界面。
App分析可以是web也可以是json。推荐使用json接口。web可能会导致app跳转到浏览器,程序可能会崩溃。
json解析接口的格式必须有以下两个参数
{
“code”:200,
“url”:”http://baidu.com/mp4.com
}
修改APP筛选页面参数
最新版本:狂雨CMS网站不收录,关键词没排名?-SEO免费插件所有网站通用
编辑第一段时,尽量加文章关键词,加粗关键词。原理是蜘蛛爬行的时候是从左到右,从上到下。如果关键词出现在之前,蜘蛛会认为这是一个高度相关的文章,同时起到一个递增的作用,前提是不能影响阅读。
3重新排序也称为“段落替换法”
文章段落不是很紧凑,或者说是平行的。在不影响文章初衷和适合用户浏览的前提下,可以把原来的文章段落打乱,重新排序,这个方法不适合所有人,顺理成章文章一定不。
4 内容删除及修改方法
去掉某个内容,可以是一个段落,但是是某个段落中的几个点。这个要看你自己的尺度。就修改幅度而言,至少,整篇文章文章修改幅度应该保持在30%左右,当然修改越大越受搜索引擎欢迎。
添加了 5 张新图片
读者会知道一张图片抵得上一千个字。虽然目前大部分搜索引擎无法读取图片的内容,但是图片中的alt属性可以进行注释,这样也会让搜索引擎焕然一新,认为你的内容是新的收录 ;
3.图片数量
1. 一篇文章 文章 有 7 或 8 张图片?图片太多了。如果潜在用户使用手机网络,图片太多,打开速度慢会影响他们的阅读习惯和体验,所以一般一篇文章文章只放2~3张图片。
2. 图片来源
图片来自哪里,尤其是一些专业的图片。大部分都是在网上找的,百度,搜狗,360等等,有很多。
3 图片处理
如何处理?为什么要加工?
因为收录是kb的形式,也就是一张图片的大小,用截图工具重新截一张图片,或者用美图,或者PS等软件重新处理,这样的图片是伪原创 ,在图片或特定文本中增强您的形式(或添加水印)。
4.如何实现网站二次收货
秒收网站最大的特点之一就是每天都会发布大量优质的资讯和内容。是的,这些平台是蜘蛛的梦想天堂。但是很多人都是普通的网站,大家更多的面临的是发布的内容百度收录不更新,快照长期不更新的情况。从我们身边经过?接下来小编就把百度二次采集的详细解析分享给大家,让你的网站实现正常的收录和百度二次采集。
百度秒收详情分析
1.百度秒收详解,好的网站结构是基础。
这个非常重要。一个好的网站结构会帮助访问者了解你的网站结构和层级,更有利于蜘蛛爬行和索引。这里推荐首页-栏目-内容页这样的树状结构,要简单不要复杂。为了提高蜘蛛的爬行效率,非常有必要为网站创建网站地图和robots文件来引导蜘蛛。有条件的朋友尽量使用静态页面,对蜘蛛比较友好。
二、百度秒收详解,打造优质内容是重点。
高质量的内容是搜索引擎给网站打分的重要环节。主要有两点,第一是原创,第二是和网站相关的内容。不会写原创的朋友可以学学伪原创的一些技巧,其次发表的内容要和网站定位的话题相关,这样对双方都是最好的用户体验和搜索引擎。价值极高,也是打造优质网站的必由之路,对网站体重的提升有着决定性的作用。
3、详细分析百度二次收录,时机和量化发布是关键。
定期发布新内容,让网站形成一个持续稳定的更新规律,让蜘蛛发现这个规律实现规律爬取,这是百度二次收入非常关键的因素。就像定时吃饭、约饭一样。这样的更新模式形成后,该爬虫就来了。另一种是量化发布,每天保持一个固定的数量,避免今天一篇明天十篇,会让搜索引擎认为你的网站不稳定善变,避免被降级沙箱。
4.百度秒收详解,布局内链创造机会。
发布的新内容尽量展示在首页等重要页面,也可以在其他页面调用最新发布的内容和锚文本指向新内容页面。这样做的目的是阻止蜘蛛程序访问您网站上的其他页面。页面快速到达新内容页面,为百度秒收创造了机会和条件。从网站的长远发展来看,内链的建设对于网站的权重提升也是非常有利的。
5.百度秒收详解,外链渠道是保障。
天天发布优质内容很心酸,但百度蜘蛛不在意。所以,对于很多外链很强的老站来说,搭建高质量的外链和访问渠道是没有问题的。如果你的网站是一个新站,外链很少,可以采用这种方法。新内容页发布后,去一些热门论坛发出新文章的地址链接。快速蜘蛛将从这些站点爬行到您的新内容页面以进行爬行和索引。使用并掌握以上五个环节,坚持一到两周,你会发现你的网站收录是正常的,快照是第二天的,继续坚持一段时间和你的网站实现百度秒收几乎没问题。当然,这些链接还有一些细节问题,比如网站空间失效、批量删除外链、内链构建不当等,会导致网站被剥夺权限和二次采集不管用。我希望你不要忽略这些细节。看完这篇文章,如果您觉得还不错,不妨采集或转发给需要的朋友和同事。每天关注博主教你各种SEO经验,让你的网站也能快速收录和关键词排名!我希望你不要忽略这些细节。看完这篇文章,如果您觉得还不错,不妨采集或转发给需要的朋友和同事。每天关注博主教你各种SEO经验,让你的网站也能快速收录和关键词排名!我希望你不要忽略这些细节。看完这篇文章,如果您觉得还不错,不妨采集或转发给需要的朋友和同事。每天关注博主教你各种SEO经验,让你的网站也能快速收录和关键词排名!
免费的:网站文章数据采集,免费网站文章数据采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-11-13 07:42
网站文章数据采集是从我们的目标网站采集信息的过程。使用 网站文章Data采集 工具,我们可以从 网站 下载结构化数据进行自动化分析。
网站文章Data采集 表示从网站 中提取的内容和数据。然后以用户所需的格式提取此信息。网站文章Data采集 可以手动完成,但这是一项极其繁琐的工作。为了加快这个过程,我们可以使用自动化、成本更低、工作速度更快的 网站文章data采集 工具。
通过使用网站文章data采集工具,我们可以在不同的场景中帮助我们完成多种目的,比如市场研究的数据采集、联系信息提取、价格跟踪在不同平台上,关注网站的内容变化,实时数据监控等。
网站文章数据采集工具页面简洁易操作,可视化的操作页面不需要我们掌握复杂的配置规则,就可以完成网站内容和数据采集。
网站文章数据采集工具指定的采集功能可以通过输入目标URL并在工具的可视化页面选择采集元素来配置 下载模板。通过模板选择我们需要的内容或者保留相应的标签,或者通过模板去掉我们不想要的元素,比如电话号码、住址、作者信息等。
网站文章数据采集输入关键词后,该工具可以进行全网关键词匹配,完成平移采集。所有匹配的内容都是大平台上的实时热门资源。无论是通过强大的NLP自然语言处理系统采集资源进行二次创作和发布伪原创,都可以为我们网站提供优质的内容。
网站文章数据采集除了采集功能外,该工具还有文章内容SEO,支持保留原文相关标签、图片下载过程中去除水印和图像下载。云存储等,支持多种下载格式保存,无论是HTML、TXT还是excel等,方便我们在后续二次创作中放心创作和数据分析。
网站文章Data采集 是如何工作的?首先,网站文章data采集 在 采集 进程之前获取要加载的 URL。网站文章Data采集 工具然后加载所需页面的完整 HTML 代码。然后,网站文章Data采集会在项目运行前提取页面上的所有数据或者用户选择的特定数据。最后,网站文章Data采集 将所有采集的数据输出为可用格式。
网站文章data采集的用途和工作原理以及网站文章data采集工具应用的分享都在这里,网站文章数据的使用采集可以说是非常广泛了,不仅我们的网站可以使用采集不断更新内容,各行各业的生活可以使用采集@网站文章数据采集工具采集相关数据进行数据统计和分析,如果喜欢本内容,请点赞、采集并关注,您的支持是博主坚持不懈的动力。
技术文章:网站SEO外链的基本规律有哪些?
网站SEO外链的基本规则是什么?
如果你仔细总结一下,你会发现所有这些方法总是逃不过一些特定的规律。所以今天就对外链推广的SEO优化方法和规律做一个总结,希望对大家有所帮助。
因此,理解这个文章非常重要。看完这篇文章,如果你看任何一种外链推广的方法,都逃不过我总结的这些规律。
我们知道,从大的角度来看,SEO可以分为站内优化和站外推广。从规模上看,网站可以分为网站建设优化和页面优化。而当我们谈seo异地推广的时候,其实重点是外链的建设。
推广的时候最好注意对方的情况,然后可以用上面的标准来判断,但是我也想告诉大家,并不是一个网站必须满足所有条件,那你可以做外链,如果你很死板,按照所有的标准,你会很痛苦,你会发现你找到了这样一个网站,并且愿意为你做链接,比如机会很小!
所有的点都可以用一句话概括,做外链的时候,不能随便找个垃圾网站做外链,还是得有点标准。 查看全部
免费的:网站文章数据采集,免费网站文章数据采集工具
网站文章数据采集是从我们的目标网站采集信息的过程。使用 网站文章Data采集 工具,我们可以从 网站 下载结构化数据进行自动化分析。
网站文章Data采集 表示从网站 中提取的内容和数据。然后以用户所需的格式提取此信息。网站文章Data采集 可以手动完成,但这是一项极其繁琐的工作。为了加快这个过程,我们可以使用自动化、成本更低、工作速度更快的 网站文章data采集 工具。
通过使用网站文章data采集工具,我们可以在不同的场景中帮助我们完成多种目的,比如市场研究的数据采集、联系信息提取、价格跟踪在不同平台上,关注网站的内容变化,实时数据监控等。
网站文章数据采集工具页面简洁易操作,可视化的操作页面不需要我们掌握复杂的配置规则,就可以完成网站内容和数据采集。
网站文章数据采集工具指定的采集功能可以通过输入目标URL并在工具的可视化页面选择采集元素来配置 下载模板。通过模板选择我们需要的内容或者保留相应的标签,或者通过模板去掉我们不想要的元素,比如电话号码、住址、作者信息等。
网站文章数据采集输入关键词后,该工具可以进行全网关键词匹配,完成平移采集。所有匹配的内容都是大平台上的实时热门资源。无论是通过强大的NLP自然语言处理系统采集资源进行二次创作和发布伪原创,都可以为我们网站提供优质的内容。
网站文章数据采集除了采集功能外,该工具还有文章内容SEO,支持保留原文相关标签、图片下载过程中去除水印和图像下载。云存储等,支持多种下载格式保存,无论是HTML、TXT还是excel等,方便我们在后续二次创作中放心创作和数据分析。
网站文章Data采集 是如何工作的?首先,网站文章data采集 在 采集 进程之前获取要加载的 URL。网站文章Data采集 工具然后加载所需页面的完整 HTML 代码。然后,网站文章Data采集会在项目运行前提取页面上的所有数据或者用户选择的特定数据。最后,网站文章Data采集 将所有采集的数据输出为可用格式。
网站文章data采集的用途和工作原理以及网站文章data采集工具应用的分享都在这里,网站文章数据的使用采集可以说是非常广泛了,不仅我们的网站可以使用采集不断更新内容,各行各业的生活可以使用采集@网站文章数据采集工具采集相关数据进行数据统计和分析,如果喜欢本内容,请点赞、采集并关注,您的支持是博主坚持不懈的动力。
技术文章:网站SEO外链的基本规律有哪些?
网站SEO外链的基本规则是什么?
如果你仔细总结一下,你会发现所有这些方法总是逃不过一些特定的规律。所以今天就对外链推广的SEO优化方法和规律做一个总结,希望对大家有所帮助。
因此,理解这个文章非常重要。看完这篇文章,如果你看任何一种外链推广的方法,都逃不过我总结的这些规律。
我们知道,从大的角度来看,SEO可以分为站内优化和站外推广。从规模上看,网站可以分为网站建设优化和页面优化。而当我们谈seo异地推广的时候,其实重点是外链的建设。
推广的时候最好注意对方的情况,然后可以用上面的标准来判断,但是我也想告诉大家,并不是一个网站必须满足所有条件,那你可以做外链,如果你很死板,按照所有的标准,你会很痛苦,你会发现你找到了这样一个网站,并且愿意为你做链接,比如机会很小!
所有的点都可以用一句话概括,做外链的时候,不能随便找个垃圾网站做外链,还是得有点标准。
汇总:php采集文章中的图片获取替换到本地(实现代码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-11-05 03:27
代码如下:
/**
* 获取替换文章中图片的路径
* @param字符串$xstr内容
* @param字符串$keyword创建的照片的文件名
* @param字符串$oriweb网址
* @return字符串
*
*/
function replaceimg($xstr,$keyword, $oriweb){
保存路径
$d = 日期('Ymd', time());
$dirslsitss = '/var/www/weblist/uploads/'.$keyword.“ /'.$d;//分类是否存在
if(!is_dir($dirslsitss)) {
@mkdir($dirslsitss, 0777);
}
匹配图片的 SRC
preg_match_all('#
]*>#i', $xstr, $match);
foreach($match[1] as $imgurl){
$imgurl = $imgurl;
if(is_int(strpos($imgurl, 'http'))){
$arcurl = $imgurl;
} else {
$arcurl = $oriweb.$imgurl;
}
$img=file_get_contents($arcurl);
if(!empty($img)) {
将图片保存到服务器
$fileimgname = time().“ -”.rand(1000,9999).”。JPG“;
$filecachs=$dirslsitss.“ /”.$fileimgname;
$fanhuistr = file_put_contents( $filecachs, $img );
$saveimgfile = “/uploads/$keyword”.“ /”.$d.“ /”.$fileimgname;
$xstr=str_replace($imgurl,$saveimgfile,$xstr);
}
}
返回$xstr;
}
直观:【观点交锋】输入法可以收集用户上传的内容!要智能还是隐私?
“我在和朋友聊微波炉、纸尿裤、洗面奶等的时候,发现一个输入法会自动推送广告。” 近日,有网友在知乎上贴出了这样的问题描述。这个问题引起了很多网友的共鸣。
记者从华为应用商店下载了排名前5的输入法应用,发现其中4个都有提示加入或默认勾选的“用户体验改善计划”,该计划的主要内容是输入法可以采集。用户上传的内容。至于是否根据聊天内容推送广告,不同输入法的隐私政策有不同的解释。
对此,有专家表示,只有采集用户输入习惯,才能优化输入法的输入体验,这是技术发展的需要;但也有网友担心这会窥探用户隐私。
您认为输入法可以采集用户上传的内容是否合适?
意见冲突现在开始
实测:4种输入法用户服务协议
提供采集用户上传内容的权利
其中,搜狗输入法和QQ输入法在用户首次登录后会提示加入“用户体验计划”,而百度输入法和讯飞输入法则默认勾选加入“用户体验计划”(可手动取消),4款APP均规定加入用户体验计划即表示用户同意相关用户服务协议或隐私条款。
记者打开搜狗输入法用户服务协议发现,该协议的用户权利条款3.1规定“您理解并同意我们有权存储您上传的内容,您授权我们合理使用您上传的内容,包括但不限于产品分析、宣传、推广等”
网友:输入法推送广告也弹窗
专业人士:免费价格
当上述网友通过微信与朋友聊起“最怕换尿布”的内容时,搜狗输入法输入界面弹出了一个广告弹窗,上面写着“孩子容易出现尿布疹,看看怎么办”做!”。
记者搜索发现,除了输入法输入界面出现弹窗广告外,更多人对搜狗输入法PC端存在弹窗广告有着更深的“怨恨”。记者发现,有时使用搜狗输入法在搜索引擎中搜索关键词时,搜狗输入法会自动跳转到搜狗搜索。
“其实这是中国人不愿意为软件买单造成的。实际上,这样做只会让谋利行为隐藏起来,这样就很容易没有顾忌。” 知乎 认证为小输入法开发者 网友“随寒”吐槽:“中国人不愿意花钱买软件,甚至有很多老子用你的软件看不起你的嚣张。应用开发者,用户都不愿意付钱,对,没关系,总有办法让你吐钱。”
在记者测试的5款输入法App中,八达通输入法没有像其他4款输入法一样要求记者加入“用户体验计划”,但记者在使用App时发现大量弹窗广告. 此外,这款输入法号称具有“金币提现”功能,即输入的字符越多,获得的奖励就越多。对于此功能,表示输入的字符数是根据“点击键盘的次数”来确定的,不涉及打字。信息的具体内容。当记者点击足够多的时候,他发现了一个接收金币的选项。点击接收时,输入法再次跳出广告。从这个角度来看,
对此,有业内人士告诉记者,输入法广告和其他免费APP的广告一样,是目前免费模式下的无奈选择。“微软Smart ABC没有广告,但你看谁在用?如果你需要联想能弹出的便捷功能和表情,就需要一定的支出,这时候输入法只能是“通过广告和其他方式获利。另一方面,免费是最昂贵的。”
网友大红苹果天马林表示,目前带广告的输入法一般都是智能输入法,而且要有云词库,登陆账号即可。“智能是需要开销的,比如不同职业的人输入某个词时,输入法可以根据你以前的输入习惯和特点,把与专业相关的词汇放在相当高的位置,方便你输入。比较用离线输入法,这部分费用还是有点影响的智能输入法。”
你怎么看? 查看全部
汇总:php采集文章中的图片获取替换到本地(实现代码)
代码如下:
/**
* 获取替换文章中图片的路径
* @param字符串$xstr内容
* @param字符串$keyword创建的照片的文件名
* @param字符串$oriweb网址
* @return字符串
*
*/
function replaceimg($xstr,$keyword, $oriweb){
保存路径
$d = 日期('Ymd', time());
$dirslsitss = '/var/www/weblist/uploads/'.$keyword.“ /'.$d;//分类是否存在
if(!is_dir($dirslsitss)) {
@mkdir($dirslsitss, 0777);
}
匹配图片的 SRC
preg_match_all('#
]*>#i', $xstr, $match);
foreach($match[1] as $imgurl){
$imgurl = $imgurl;
if(is_int(strpos($imgurl, 'http'))){
$arcurl = $imgurl;
} else {
$arcurl = $oriweb.$imgurl;
}
$img=file_get_contents($arcurl);
if(!empty($img)) {
将图片保存到服务器
$fileimgname = time().“ -”.rand(1000,9999).”。JPG“;
$filecachs=$dirslsitss.“ /”.$fileimgname;
$fanhuistr = file_put_contents( $filecachs, $img );
$saveimgfile = “/uploads/$keyword”.“ /”.$d.“ /”.$fileimgname;
$xstr=str_replace($imgurl,$saveimgfile,$xstr);
}
}
返回$xstr;
}
直观:【观点交锋】输入法可以收集用户上传的内容!要智能还是隐私?
“我在和朋友聊微波炉、纸尿裤、洗面奶等的时候,发现一个输入法会自动推送广告。” 近日,有网友在知乎上贴出了这样的问题描述。这个问题引起了很多网友的共鸣。
记者从华为应用商店下载了排名前5的输入法应用,发现其中4个都有提示加入或默认勾选的“用户体验改善计划”,该计划的主要内容是输入法可以采集。用户上传的内容。至于是否根据聊天内容推送广告,不同输入法的隐私政策有不同的解释。
对此,有专家表示,只有采集用户输入习惯,才能优化输入法的输入体验,这是技术发展的需要;但也有网友担心这会窥探用户隐私。
您认为输入法可以采集用户上传的内容是否合适?
意见冲突现在开始
实测:4种输入法用户服务协议
提供采集用户上传内容的权利
其中,搜狗输入法和QQ输入法在用户首次登录后会提示加入“用户体验计划”,而百度输入法和讯飞输入法则默认勾选加入“用户体验计划”(可手动取消),4款APP均规定加入用户体验计划即表示用户同意相关用户服务协议或隐私条款。
记者打开搜狗输入法用户服务协议发现,该协议的用户权利条款3.1规定“您理解并同意我们有权存储您上传的内容,您授权我们合理使用您上传的内容,包括但不限于产品分析、宣传、推广等”
网友:输入法推送广告也弹窗
专业人士:免费价格
当上述网友通过微信与朋友聊起“最怕换尿布”的内容时,搜狗输入法输入界面弹出了一个广告弹窗,上面写着“孩子容易出现尿布疹,看看怎么办”做!”。
记者搜索发现,除了输入法输入界面出现弹窗广告外,更多人对搜狗输入法PC端存在弹窗广告有着更深的“怨恨”。记者发现,有时使用搜狗输入法在搜索引擎中搜索关键词时,搜狗输入法会自动跳转到搜狗搜索。
“其实这是中国人不愿意为软件买单造成的。实际上,这样做只会让谋利行为隐藏起来,这样就很容易没有顾忌。” 知乎 认证为小输入法开发者 网友“随寒”吐槽:“中国人不愿意花钱买软件,甚至有很多老子用你的软件看不起你的嚣张。应用开发者,用户都不愿意付钱,对,没关系,总有办法让你吐钱。”
在记者测试的5款输入法App中,八达通输入法没有像其他4款输入法一样要求记者加入“用户体验计划”,但记者在使用App时发现大量弹窗广告. 此外,这款输入法号称具有“金币提现”功能,即输入的字符越多,获得的奖励就越多。对于此功能,表示输入的字符数是根据“点击键盘的次数”来确定的,不涉及打字。信息的具体内容。当记者点击足够多的时候,他发现了一个接收金币的选项。点击接收时,输入法再次跳出广告。从这个角度来看,
对此,有业内人士告诉记者,输入法广告和其他免费APP的广告一样,是目前免费模式下的无奈选择。“微软Smart ABC没有广告,但你看谁在用?如果你需要联想能弹出的便捷功能和表情,就需要一定的支出,这时候输入法只能是“通过广告和其他方式获利。另一方面,免费是最昂贵的。”
网友大红苹果天马林表示,目前带广告的输入法一般都是智能输入法,而且要有云词库,登陆账号即可。“智能是需要开销的,比如不同职业的人输入某个词时,输入法可以根据你以前的输入习惯和特点,把与专业相关的词汇放在相当高的位置,方便你输入。比较用离线输入法,这部分费用还是有点影响的智能输入法。”
你怎么看?
干货教程:免费微信公众号数据采集提取软件-自动提取封面图文章内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 402 次浏览 • 2022-11-01 21:54
微信公众号数据采集,公众号封面图片提取,公众号文章提取。如何提取微信公众号数据如:内容、封面图,如何批量提取微信公众号数据并保存在本地进行修改。今天给大家分享一款免费的微信公众号数据自动提取软件采集。输入关键词或者输入域名自动提取文章到本地,自动解析文章核心很重要。
现在说到网站的seo优化,微信公众号数据采集会用到一些seo技术,seo理念,seo策略,分离用户体验,用户需求,网站建立,等。让网站在搜索引擎中排名靠前,让网站更有用,让内容更适合用户。SER 读取。这就是主动SEO,但是在有效SEO、被动SEO背后总有一个黑暗的中心,也就是说你的网站就是SEO,有光有影。
谈到公司的网站优化如何有效防止负面SEO干扰的话题,应该讨论两个概念:正面SEO和负面SEO。微信公众号数据采集主动搜索引擎优化就是我们常说的搜索引擎优化,也就是让网站在搜索引擎中排名。负搜索引擎优化和积极搜索引擎优化在运营商和应用程序上是对立的。负面 SEO 是指其他人(恶意网站管理员、竞争对手等)在您的 网站 上施加一些负面 SEO 元素(搜索引擎知道阻止这些元素),从而使您的 网站 排名更低,甚至变得严重受到惩罚。
在整个SEO网站优化过程中,难免会出现一些负面信息的优化技巧。负面信息是真实的。一般来说,它会基于一些故意的反向链接和草率的电子邮件破坏你的网站,这将极大地影响你的网站排名、总流量和权重值。冒险。一般来说,负面信息SEO是一种法律纠葛,很可能对搜索引擎的知名度和收益造成损害。微信公众号数据采集但是,在整个优化过程中,可以防止负面的SEO。如何预防?一般来说,SEO网站的负面信息都会被竞争对手阻止。这是在另一个 网站 上完成的黑帽 SEO 技术。通常来说,一般来说,竞争对手对降低 网站 排名的 SEO 攻击不满意。然而,在大多数情况下,很多SEO优化网站站长想要遵循SEO优化规范,却不得不伤人心,堵人心。
难免会有人羡慕你的网站排名,用几百个渣滓封杀你的网站,用不正确的评论吞下你的网站,或者马上破译你的网站。微信公众号数据采集注意你的网站速度。网站速度是一个非常有害的排名。如果你的网站越来越慢,你就得开机很久了。你永远不知道如何使用爬行工具来找到一切都不起作用的项目。如果你找不到他们,他们仍然不是很好,受害者可能就是你。大量爬网导致的 Web 服务器负载过重意味着您的 网站 会变慢并崩溃。如果您认为自己是网络爬虫攻击的受害者,可以联系您的服务器公司或 网站 管理员了解负载的来源。如果你擅长技术,你可以找到自己惹麻烦的人。
关于网站的优化,大家应该都遇到过这样的事情。我们努力做了一个网站,终于做出了网站的排名,但是不知怎的,网站的排名过了一段时间就下降了,而且排名很不稳定。在了解搜索引擎自然排名机制的基础上,对网站进行内外调整优化,提高网站在搜索引擎中的关键词自然排名,获得更多流量,从而达到网站销售和品牌建设的预期目的。为了从搜索引擎获得更多的免费流量,应该从网站结构、内容建立计划、用户交互传播、页面等角度进行合理规划,同时也会使网站网站 搜索引擎中显示的相关信息。它对用户更具吸引力。下面小编就告诉大家我们如何稳定网站和优化排名?
网站排名上升后,我们每天抽时间查看收录和网站的排名状态,以及查看搜索引擎来不来,查看网站当天更新内容还没有收录。关注竞争对手的网站,看看对手的网站有什么好主意。网站 的内容会及时更新。这是为了吸引蜘蛛去爬网站,从而增加网站的收录,同时也提高了快照的更新速度。如果网站长时间不更新,搜索引擎会认为这是一场致命的战斗,从而降低你的网站排名,严重的甚至会被降级。
网站 的外部链接也很重要。一个好的外链是你网站排名的背景,所以我们需要增加网站外链的数量。网站查看和好友链通讯,查看我通讯的好友链是否被删除,对方的网站是否可以正常打开,是否可以降级或暂停,是否显示及时处理。
干货教程:1毛钱的成本即可精准引流+变现
我们都知道,无论是网赚行业还是普通行业,玩自媒体最重要的就是推广引流,然后变现,对品牌优化有极好的效果。
即使是现在购买的账号,部分自媒体平台也需要刷脸认证。
为什么要推荐新浪博客?因为博客对我们来说比其他 自媒体 平台更好。
1、博客账号成本低。一个账号的价格根据不同档次基本在0.1元到2元之间。便宜的价格意味着投资成本低。
2、博客的权重不亚于百家号、搜狐等平台。
3.主要是博客的规则没有其他自媒体平台那么严格。
1. 准备
1.1 账户
我们首先需要准备一个博客帐户。我在哪里可以购买博客帐户?一般去QQ群或者卡联盟买个账号,反正渠道很多,很容易买到,价格一般0.1-2元
购买账号后,需要将个人信息更改为真实信息,不要让系统认为你是批量发行的营销账号。
注意:更改信息时,最好将昵称更改为与您的产品相关的名称关键词。
1.2 定位
你做什么工作?您的博客需要服务哪些用户群?你要输出什么值?您想销售产品还是提供服务?
这时会有10个相关词的搜索索引,然后你通过分析这些搜索索引的排名来定位你的博客。
这里我再告诉大家另一种方法,就是通过“词库软件”进行搜索。通过这个软件搜索,我们可以找到19万条与减肥相关的关键词,而且还有每天在电脑和手机上用百度搜索引擎搜索到这个关键词的数据。
2.博客内容
2.1 内容对应主题
如果你的写作能力不错,并且对这方面有很好的理解,那么你可以自己写原创。原创文章百度的机制越多,百度收录就越容易。
2.2伪原创
1)利用用户热搜词找到大家喜欢搜索减肥的关键词,然后根据你的产品需要展开词,挖出长尾关键词。抓住其中的 关键词 来定义您的 文章 标题。
比如“减肥”关键词,那么我可以制定如下标题:
一日三餐的减肥食谱有哪些?
2)我们可以在今日头条、知乎、公众号等平台上完全转移标题相关的内容,然后将里面的联系方式修改为我们自己的并发布到博客上。你也可以使用一些伪原创工具,或者使用“中英翻译”来伪原创。
3)你也可以找几篇内容相同的文章文章,复制整理每个文章写的比较好的段落,将多篇文章整理成一篇文章文章 .
3.提交搜索引擎条目
3.1 锚链接
我们可以在 文章 中添加“锚链接”。锚文本是 html 中链接的文本标记。只要是html编辑器,一般都可以编辑添加。
3.2 备注
如果是第一次点击发博,会进入编辑页面,提示编辑界面可以切换到新版本。这里个人建议直接关闭提示,因为新版编辑界面不利于百度收录。
4.插入广告
前期,我们主要以开户为主。毕竟没有流量,也没有相关的关键词排名。不管你放多少广告,基本上是没用的。虽然对博客的检查不严格,但还是建议大家去前期。不要做广告。
当搜索引擎认为您的博客有价值时,他们就会非常信任您的博客。然后你的 文章 也会出现在搜索引擎的顶部。
这时你可能会问我,什么时候投放广告最好?
这里我给大家提供一个很简单的方法,就是复制你的网址,直接去搜索引擎搜索。如果你的博客能出现,那基本上就说明你那天被录用了。
广告位:
1. 添加广告模板
2. 在文字中插入带有广告的图片 查看全部
干货教程:免费微信公众号数据采集提取软件-自动提取封面图文章内容
微信公众号数据采集,公众号封面图片提取,公众号文章提取。如何提取微信公众号数据如:内容、封面图,如何批量提取微信公众号数据并保存在本地进行修改。今天给大家分享一款免费的微信公众号数据自动提取软件采集。输入关键词或者输入域名自动提取文章到本地,自动解析文章核心很重要。
现在说到网站的seo优化,微信公众号数据采集会用到一些seo技术,seo理念,seo策略,分离用户体验,用户需求,网站建立,等。让网站在搜索引擎中排名靠前,让网站更有用,让内容更适合用户。SER 读取。这就是主动SEO,但是在有效SEO、被动SEO背后总有一个黑暗的中心,也就是说你的网站就是SEO,有光有影。
谈到公司的网站优化如何有效防止负面SEO干扰的话题,应该讨论两个概念:正面SEO和负面SEO。微信公众号数据采集主动搜索引擎优化就是我们常说的搜索引擎优化,也就是让网站在搜索引擎中排名。负搜索引擎优化和积极搜索引擎优化在运营商和应用程序上是对立的。负面 SEO 是指其他人(恶意网站管理员、竞争对手等)在您的 网站 上施加一些负面 SEO 元素(搜索引擎知道阻止这些元素),从而使您的 网站 排名更低,甚至变得严重受到惩罚。
在整个SEO网站优化过程中,难免会出现一些负面信息的优化技巧。负面信息是真实的。一般来说,它会基于一些故意的反向链接和草率的电子邮件破坏你的网站,这将极大地影响你的网站排名、总流量和权重值。冒险。一般来说,负面信息SEO是一种法律纠葛,很可能对搜索引擎的知名度和收益造成损害。微信公众号数据采集但是,在整个优化过程中,可以防止负面的SEO。如何预防?一般来说,SEO网站的负面信息都会被竞争对手阻止。这是在另一个 网站 上完成的黑帽 SEO 技术。通常来说,一般来说,竞争对手对降低 网站 排名的 SEO 攻击不满意。然而,在大多数情况下,很多SEO优化网站站长想要遵循SEO优化规范,却不得不伤人心,堵人心。
难免会有人羡慕你的网站排名,用几百个渣滓封杀你的网站,用不正确的评论吞下你的网站,或者马上破译你的网站。微信公众号数据采集注意你的网站速度。网站速度是一个非常有害的排名。如果你的网站越来越慢,你就得开机很久了。你永远不知道如何使用爬行工具来找到一切都不起作用的项目。如果你找不到他们,他们仍然不是很好,受害者可能就是你。大量爬网导致的 Web 服务器负载过重意味着您的 网站 会变慢并崩溃。如果您认为自己是网络爬虫攻击的受害者,可以联系您的服务器公司或 网站 管理员了解负载的来源。如果你擅长技术,你可以找到自己惹麻烦的人。
关于网站的优化,大家应该都遇到过这样的事情。我们努力做了一个网站,终于做出了网站的排名,但是不知怎的,网站的排名过了一段时间就下降了,而且排名很不稳定。在了解搜索引擎自然排名机制的基础上,对网站进行内外调整优化,提高网站在搜索引擎中的关键词自然排名,获得更多流量,从而达到网站销售和品牌建设的预期目的。为了从搜索引擎获得更多的免费流量,应该从网站结构、内容建立计划、用户交互传播、页面等角度进行合理规划,同时也会使网站网站 搜索引擎中显示的相关信息。它对用户更具吸引力。下面小编就告诉大家我们如何稳定网站和优化排名?
网站排名上升后,我们每天抽时间查看收录和网站的排名状态,以及查看搜索引擎来不来,查看网站当天更新内容还没有收录。关注竞争对手的网站,看看对手的网站有什么好主意。网站 的内容会及时更新。这是为了吸引蜘蛛去爬网站,从而增加网站的收录,同时也提高了快照的更新速度。如果网站长时间不更新,搜索引擎会认为这是一场致命的战斗,从而降低你的网站排名,严重的甚至会被降级。
网站 的外部链接也很重要。一个好的外链是你网站排名的背景,所以我们需要增加网站外链的数量。网站查看和好友链通讯,查看我通讯的好友链是否被删除,对方的网站是否可以正常打开,是否可以降级或暂停,是否显示及时处理。
干货教程:1毛钱的成本即可精准引流+变现
我们都知道,无论是网赚行业还是普通行业,玩自媒体最重要的就是推广引流,然后变现,对品牌优化有极好的效果。
即使是现在购买的账号,部分自媒体平台也需要刷脸认证。
为什么要推荐新浪博客?因为博客对我们来说比其他 自媒体 平台更好。
1、博客账号成本低。一个账号的价格根据不同档次基本在0.1元到2元之间。便宜的价格意味着投资成本低。
2、博客的权重不亚于百家号、搜狐等平台。
3.主要是博客的规则没有其他自媒体平台那么严格。
1. 准备
1.1 账户
我们首先需要准备一个博客帐户。我在哪里可以购买博客帐户?一般去QQ群或者卡联盟买个账号,反正渠道很多,很容易买到,价格一般0.1-2元
购买账号后,需要将个人信息更改为真实信息,不要让系统认为你是批量发行的营销账号。
注意:更改信息时,最好将昵称更改为与您的产品相关的名称关键词。
1.2 定位
你做什么工作?您的博客需要服务哪些用户群?你要输出什么值?您想销售产品还是提供服务?
这时会有10个相关词的搜索索引,然后你通过分析这些搜索索引的排名来定位你的博客。
这里我再告诉大家另一种方法,就是通过“词库软件”进行搜索。通过这个软件搜索,我们可以找到19万条与减肥相关的关键词,而且还有每天在电脑和手机上用百度搜索引擎搜索到这个关键词的数据。
2.博客内容
2.1 内容对应主题
如果你的写作能力不错,并且对这方面有很好的理解,那么你可以自己写原创。原创文章百度的机制越多,百度收录就越容易。
2.2伪原创
1)利用用户热搜词找到大家喜欢搜索减肥的关键词,然后根据你的产品需要展开词,挖出长尾关键词。抓住其中的 关键词 来定义您的 文章 标题。
比如“减肥”关键词,那么我可以制定如下标题:
一日三餐的减肥食谱有哪些?
2)我们可以在今日头条、知乎、公众号等平台上完全转移标题相关的内容,然后将里面的联系方式修改为我们自己的并发布到博客上。你也可以使用一些伪原创工具,或者使用“中英翻译”来伪原创。
3)你也可以找几篇内容相同的文章文章,复制整理每个文章写的比较好的段落,将多篇文章整理成一篇文章文章 .
3.提交搜索引擎条目
3.1 锚链接
我们可以在 文章 中添加“锚链接”。锚文本是 html 中链接的文本标记。只要是html编辑器,一般都可以编辑添加。
3.2 备注
如果是第一次点击发博,会进入编辑页面,提示编辑界面可以切换到新版本。这里个人建议直接关闭提示,因为新版编辑界面不利于百度收录。
4.插入广告
前期,我们主要以开户为主。毕竟没有流量,也没有相关的关键词排名。不管你放多少广告,基本上是没用的。虽然对博客的检查不严格,但还是建议大家去前期。不要做广告。
当搜索引擎认为您的博客有价值时,他们就会非常信任您的博客。然后你的 文章 也会出现在搜索引擎的顶部。
这时你可能会问我,什么时候投放广告最好?
这里我给大家提供一个很简单的方法,就是复制你的网址,直接去搜索引擎搜索。如果你的博客能出现,那基本上就说明你那天被录用了。
广告位:
1. 添加广告模板
2. 在文字中插入带有广告的图片
最新版:网页文章正文采集的方法以微信文章采集为例.docx 45页
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-10-31 20:46
网页文章文本采集方法,以微信文章采集为例。保存的时候怎么办?一张一张复制粘贴?选择一个通用的网络数据 采集器 将使这项工作变得容易得多。优采云是一个通用的网页数据采集器,可以是互联网上的采集公共数据。用户可以设置从哪个网站爬取数据,爬取什么数据,爬取什么范围的数据,什么时候爬取数据,如何保存爬取的数据等。言归正传,本文将采取<以搜狗微信文章文字采集为例,讲解优采云采集网页文章文字的使用方法。文章文本采集,主要有两种情况: 1、采集文章正文中的文本,不包括图片;2. 采集文章 正文中的文本和图像 URL。示例网站:/使用功能点:Xpath/search?query=XPath判断条件/tutorialdetail-1/judge.html分页列表信息采集 /tutorial/fylb-70.aspx?t=1AJAX滚动教程/tutorialdetail-1/ajgd_7.htmlAJAX点击翻页/tutorialdetail-1/ajaxdjfy_7.html采集文章正文中,无图片具体步骤: 第一步:创建采集任务1)进入主界面,选择“自定义模式”网页文章文本采集步骤12)复制并粘贴你想要的网站的网址采集到网站
打开网页时,默认显示“热门”文章。向下滚动页面,找到并点击“加载更多内容”按钮,在动作提示框中,选择“更多动作”页面文章Body采集Step 3选择“循环点击单个元素”创建一个翻页循环网页文章Body采集第四步由于这个网页涉及到Ajax技术,我们需要设置一些高级选项。选择“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”网页文章Text采集Step 5 注意:AJAX表示延迟加载, 一种异步更新的脚本技术,通过在后台与服务器交换少量数据,可以在不重新加载整个网页的情况下更新网页的某个部分。详情请参考AJAX点击和翻页教程:/tutorialdetail-1/ajaxdjfy_7.html 观察网页,我们发现点击“加载更多内容”5次后,页面加载到了底部,一共有显示了 100 篇文章 文章 。因此,我们将整个“循环页面”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5次”,在网页点击“确定”文章Text采集Steps 6Step 3:创建列表循环并提取数据移动鼠标选择页面中的第一个文章链接。系统会自动识别相似链接。在操作提示框中,选择“Select All”网页文章Text采集Step 7 选择“Cycle Click Each Link”网页文章Text采集Step 8系统会自动进入文章详情页面。
点击需要采集的字段(这里先点击文章标题),在操作提示框中选择“采集该元素的文本”。文章发布时间,文章来源字段采集方法同理网页文章正文采集第九步下一步开始采集文章 文本。首先点击第一段文章文字,系统会自动识别页面中的相似元素,选择“全选”页面文章文字采集步骤105)即可看到所有的文本段落都被选中并变成绿色。选择“采集以下元素文本”网页文章正文采集步骤11 注意:在字段表中,可以自定义和修改字段。网页文章正文采集 Step 126) 经过上述操作后,文本将全部采集向下(默认情况下,每段文本为一个单元格)。一般来说,我们希望 采集 的主体被合并到同一个单元格中。点击“自定义数据字段”按钮,选择“自定义数据合并方式”,勾选“同一字段多次提取并合并为一行,即追加到同一字段,如文本页面合并”,然后点击“OK”页面文章Body采集Step 13“Customize Data Fields”按钮网页文章Body采集Step 14 选择“Customize Data Merge Method”网页文章Body采集Step 15 检查如图步骤4:修改Xpath1) 选中整个“loop step”,打开“Advanced Options”,可以看到优采云
我们通过这个Xpath发现://DIV[@class='main-left']/DIV[3]/UL/LI/DIV[2]/H3[1]/A,页面需要100篇文章< 文章所有页面都位于文章正文采集步骤173)将修改后的Xpath复制粘贴到优采云所示位置,然后点击“确定”到页面文章Text采集Step 18 Step 5:修改流程图结构我们继续观察,点击“加载更多内容”5次后,该页面加载了全部100篇文章文章。所以我们配置规则的思路是先建立一个翻页循环,把100篇文章全部加载文章,然后创建一个循环列表来提取数据 1)选择整个“循环”步骤并拖动退出“循环页面”步骤。如果不执行此操作,将会出现大量重复的数据页。文章Text采集Step 19 拖拽完成后页面如下图文章Text采集Steps 20 Step 6:Data采集并导出1 ) 点击左上角“保存”,然后点击“开始采集”,选择“开始本地采集”网页文章文本采集步骤21采集步骤21完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的数据导出到网页文章文本采集Step 223) 这里我们选择excel作为导出格式。数据导出后,网页如下图所示。采集到。那是因为 文章 的循环列表的 Xpath://[@id="js_content"]/P
修改Xpath为://[@id="js_content"]//P,所有文章文本都可以定位。再次启动采集,文章的所有文本内容都是采集到网页文章Text采集步骤24 修改Xpath之前的网页文本文章 采集在第25步修改Xpath后,经过以上操作,目标URL中的微信文章正文中的所有文字都是采集下来的。如果还需要采集图片,则需要在已有规则中添加判断条件。采集文章正文中的文字和图片URL按照第一步中的步骤6。第七步:添加判断条件 前6步之后,我们只有采集在微信文章中的文字内容,不包括文章中的图片。如果你需要 采集 图片,需要在规则中添加判断条件:判断文章的内容列表,如果收录img元素(图片),则执行图片采集分支;if not 如果收录一个img元素(图片),则执行文本采集分支。同时,在优采云中,默认为左分支设置判断条件。如果满足判断条件,则执行左分支;当左分支的判断条件不满足时,执行最右分支。回到这个规则,就是给左分支设置一个条件:如果收录img元素(图片),则执行左分支;如果左条件分支的条件不满足(即不包括img元素),则执行右分支。具体操作如下:
我们将“提取数据”步骤移至右侧分支(绿色加号)。然后点击右侧的分支,在出现的结果页面点击“确定”页面(分支条件检测结果-检测结果始终为True)文章Text采集第27步拖动“ Extract Element" step into Right branch pages文章Text采集Step 28 Right branch - detection result is always True 点击左分支,点击出现的结果页面(branch condition detection result - detection result is always True) Sure”。然后为其设置判断条件:勾选“当前循环项收录元素”,输入元素Xpath://img(代表一张图片),然后在网页上点击“确定”文章文字采集 Step 29 点击left 侧分支到左分支,设置判断条件。网页文章文本采集步骤304)左分支条件设置后,执行数据提取步骤。从左侧工具栏中,将“提取数据”步骤拖到流程图左侧分支(绿色加号),然后在页面上选择一张图片,在操作提示框中选择“采集这张图片地址”进入新的“提取数据”步骤,到左分支网页文章Text采集Step 31采集图片地址网页文章Text采集Step 325 ) 选择右侧分支的“Extract Data”步骤,点击“Customize Data Field”按钮,选择“Custom Positioning Element Method”,设置“Element Matching Xpath”
经检查,多次提取的文本会被追加为字段网页文章Text采集步骤368)注意在优采云中,判断中每个分支中的“提取数据”条件步骤中的字段名称必须相同,字段数量必须相同。这里我们将左右分支中提取的字段名改为“text”(判断条件教程,请参考:/tutorialdetail-1/judge.html)网页文章text采集steps 379)如上,设置了整个判断条件。点击左上角的“保存”和“开始采集”。我们发现在导出的excel表格中,图片地址是一堆乱码。为什么是这样?继续观察网页——搜狗微信文章文中的图片 需要向下滚动才能加载,加载后才能采集进入正确的图片地址。因此,打开文章后,需要设置为“页面加载完成后向下滚动”。这里设置滚动次数为“30次”,每次间隔“2秒”,滚动方式为“向下滚动一屏”网页文章文字采集步骤38微信文章 文中的图片需要向下滚动才能加载。设置“页面加载后向下滚动”网页文章Text采集Step 39 注意:这里对滚动次数、时间、方式的设置会影响文章的速度和质量采集 数据。本文仅供参考,您可以根据需要设置,
在 采集 过程中,会花费大量时间等待图片加载,因此 采集 比较慢。如果不需要采集图片,直接使用文字采集,不用等待图片加载,采集会快很多。相关采集教程:百度搜索结果采集新浪微博数据采集豆瓣影评采集优采云——70万用户选择的网页数据采集器。1.操作简单,任何人都可以使用:不需要技术背景,只要能上网采集即可。完成流程可视化,点击鼠标完成操作,2分钟快速上手。2.功能强大,任意网站可选:用于点击、登录、翻页、识别验证码、瀑布、和Ajax脚本异步加载数据,所有页面都可以通过简单的设置采集。3.云采集,也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
干货教程:暴力海外引流协议_instagram协议引流软件_ins营销推广群发软件_关键词
Instagram关键词自动采集用户批量关注作品,并将作品发布到Aite通知协议
Instagram是一款协议软件,支持批量导入关键词给采集相关用户,然后软件自动采集这些用户的粉丝
该软件支持
设置喜欢和评论采集粉丝作品的用户,软件支持多账号多线程批量关注和动态作品批量发布 爱特人!
查看全部
最新版:网页文章正文采集的方法以微信文章采集为例.docx 45页
网页文章文本采集方法,以微信文章采集为例。保存的时候怎么办?一张一张复制粘贴?选择一个通用的网络数据 采集器 将使这项工作变得容易得多。优采云是一个通用的网页数据采集器,可以是互联网上的采集公共数据。用户可以设置从哪个网站爬取数据,爬取什么数据,爬取什么范围的数据,什么时候爬取数据,如何保存爬取的数据等。言归正传,本文将采取<以搜狗微信文章文字采集为例,讲解优采云采集网页文章文字的使用方法。文章文本采集,主要有两种情况: 1、采集文章正文中的文本,不包括图片;2. 采集文章 正文中的文本和图像 URL。示例网站:/使用功能点:Xpath/search?query=XPath判断条件/tutorialdetail-1/judge.html分页列表信息采集 /tutorial/fylb-70.aspx?t=1AJAX滚动教程/tutorialdetail-1/ajgd_7.htmlAJAX点击翻页/tutorialdetail-1/ajaxdjfy_7.html采集文章正文中,无图片具体步骤: 第一步:创建采集任务1)进入主界面,选择“自定义模式”网页文章文本采集步骤12)复制并粘贴你想要的网站的网址采集到网站
打开网页时,默认显示“热门”文章。向下滚动页面,找到并点击“加载更多内容”按钮,在动作提示框中,选择“更多动作”页面文章Body采集Step 3选择“循环点击单个元素”创建一个翻页循环网页文章Body采集第四步由于这个网页涉及到Ajax技术,我们需要设置一些高级选项。选择“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”网页文章Text采集Step 5 注意:AJAX表示延迟加载, 一种异步更新的脚本技术,通过在后台与服务器交换少量数据,可以在不重新加载整个网页的情况下更新网页的某个部分。详情请参考AJAX点击和翻页教程:/tutorialdetail-1/ajaxdjfy_7.html 观察网页,我们发现点击“加载更多内容”5次后,页面加载到了底部,一共有显示了 100 篇文章 文章 。因此,我们将整个“循环页面”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5次”,在网页点击“确定”文章Text采集Steps 6Step 3:创建列表循环并提取数据移动鼠标选择页面中的第一个文章链接。系统会自动识别相似链接。在操作提示框中,选择“Select All”网页文章Text采集Step 7 选择“Cycle Click Each Link”网页文章Text采集Step 8系统会自动进入文章详情页面。
点击需要采集的字段(这里先点击文章标题),在操作提示框中选择“采集该元素的文本”。文章发布时间,文章来源字段采集方法同理网页文章正文采集第九步下一步开始采集文章 文本。首先点击第一段文章文字,系统会自动识别页面中的相似元素,选择“全选”页面文章文字采集步骤105)即可看到所有的文本段落都被选中并变成绿色。选择“采集以下元素文本”网页文章正文采集步骤11 注意:在字段表中,可以自定义和修改字段。网页文章正文采集 Step 126) 经过上述操作后,文本将全部采集向下(默认情况下,每段文本为一个单元格)。一般来说,我们希望 采集 的主体被合并到同一个单元格中。点击“自定义数据字段”按钮,选择“自定义数据合并方式”,勾选“同一字段多次提取并合并为一行,即追加到同一字段,如文本页面合并”,然后点击“OK”页面文章Body采集Step 13“Customize Data Fields”按钮网页文章Body采集Step 14 选择“Customize Data Merge Method”网页文章Body采集Step 15 检查如图步骤4:修改Xpath1) 选中整个“loop step”,打开“Advanced Options”,可以看到优采云
我们通过这个Xpath发现://DIV[@class='main-left']/DIV[3]/UL/LI/DIV[2]/H3[1]/A,页面需要100篇文章< 文章所有页面都位于文章正文采集步骤173)将修改后的Xpath复制粘贴到优采云所示位置,然后点击“确定”到页面文章Text采集Step 18 Step 5:修改流程图结构我们继续观察,点击“加载更多内容”5次后,该页面加载了全部100篇文章文章。所以我们配置规则的思路是先建立一个翻页循环,把100篇文章全部加载文章,然后创建一个循环列表来提取数据 1)选择整个“循环”步骤并拖动退出“循环页面”步骤。如果不执行此操作,将会出现大量重复的数据页。文章Text采集Step 19 拖拽完成后页面如下图文章Text采集Steps 20 Step 6:Data采集并导出1 ) 点击左上角“保存”,然后点击“开始采集”,选择“开始本地采集”网页文章文本采集步骤21采集步骤21完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的数据导出到网页文章文本采集Step 223) 这里我们选择excel作为导出格式。数据导出后,网页如下图所示。采集到。那是因为 文章 的循环列表的 Xpath://[@id="js_content"]/P
修改Xpath为://[@id="js_content"]//P,所有文章文本都可以定位。再次启动采集,文章的所有文本内容都是采集到网页文章Text采集步骤24 修改Xpath之前的网页文本文章 采集在第25步修改Xpath后,经过以上操作,目标URL中的微信文章正文中的所有文字都是采集下来的。如果还需要采集图片,则需要在已有规则中添加判断条件。采集文章正文中的文字和图片URL按照第一步中的步骤6。第七步:添加判断条件 前6步之后,我们只有采集在微信文章中的文字内容,不包括文章中的图片。如果你需要 采集 图片,需要在规则中添加判断条件:判断文章的内容列表,如果收录img元素(图片),则执行图片采集分支;if not 如果收录一个img元素(图片),则执行文本采集分支。同时,在优采云中,默认为左分支设置判断条件。如果满足判断条件,则执行左分支;当左分支的判断条件不满足时,执行最右分支。回到这个规则,就是给左分支设置一个条件:如果收录img元素(图片),则执行左分支;如果左条件分支的条件不满足(即不包括img元素),则执行右分支。具体操作如下:
我们将“提取数据”步骤移至右侧分支(绿色加号)。然后点击右侧的分支,在出现的结果页面点击“确定”页面(分支条件检测结果-检测结果始终为True)文章Text采集第27步拖动“ Extract Element" step into Right branch pages文章Text采集Step 28 Right branch - detection result is always True 点击左分支,点击出现的结果页面(branch condition detection result - detection result is always True) Sure”。然后为其设置判断条件:勾选“当前循环项收录元素”,输入元素Xpath://img(代表一张图片),然后在网页上点击“确定”文章文字采集 Step 29 点击left 侧分支到左分支,设置判断条件。网页文章文本采集步骤304)左分支条件设置后,执行数据提取步骤。从左侧工具栏中,将“提取数据”步骤拖到流程图左侧分支(绿色加号),然后在页面上选择一张图片,在操作提示框中选择“采集这张图片地址”进入新的“提取数据”步骤,到左分支网页文章Text采集Step 31采集图片地址网页文章Text采集Step 325 ) 选择右侧分支的“Extract Data”步骤,点击“Customize Data Field”按钮,选择“Custom Positioning Element Method”,设置“Element Matching Xpath”
经检查,多次提取的文本会被追加为字段网页文章Text采集步骤368)注意在优采云中,判断中每个分支中的“提取数据”条件步骤中的字段名称必须相同,字段数量必须相同。这里我们将左右分支中提取的字段名改为“text”(判断条件教程,请参考:/tutorialdetail-1/judge.html)网页文章text采集steps 379)如上,设置了整个判断条件。点击左上角的“保存”和“开始采集”。我们发现在导出的excel表格中,图片地址是一堆乱码。为什么是这样?继续观察网页——搜狗微信文章文中的图片 需要向下滚动才能加载,加载后才能采集进入正确的图片地址。因此,打开文章后,需要设置为“页面加载完成后向下滚动”。这里设置滚动次数为“30次”,每次间隔“2秒”,滚动方式为“向下滚动一屏”网页文章文字采集步骤38微信文章 文中的图片需要向下滚动才能加载。设置“页面加载后向下滚动”网页文章Text采集Step 39 注意:这里对滚动次数、时间、方式的设置会影响文章的速度和质量采集 数据。本文仅供参考,您可以根据需要设置,
在 采集 过程中,会花费大量时间等待图片加载,因此 采集 比较慢。如果不需要采集图片,直接使用文字采集,不用等待图片加载,采集会快很多。相关采集教程:百度搜索结果采集新浪微博数据采集豆瓣影评采集优采云——70万用户选择的网页数据采集器。1.操作简单,任何人都可以使用:不需要技术背景,只要能上网采集即可。完成流程可视化,点击鼠标完成操作,2分钟快速上手。2.功能强大,任意网站可选:用于点击、登录、翻页、识别验证码、瀑布、和Ajax脚本异步加载数据,所有页面都可以通过简单的设置采集。3.云采集,也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
干货教程:暴力海外引流协议_instagram协议引流软件_ins营销推广群发软件_关键词
Instagram关键词自动采集用户批量关注作品,并将作品发布到Aite通知协议
Instagram是一款协议软件,支持批量导入关键词给采集相关用户,然后软件自动采集这些用户的粉丝
该软件支持
设置喜欢和评论采集粉丝作品的用户,软件支持多账号多线程批量关注和动态作品批量发布 爱特人!
免费获取:免费文章采集器使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-10-28 18:21
优采云·云采集网络爬虫软件
免费文章采集器教程
本文介绍如何使用优采云采集器采集网易账号文章。
采集网址:
网易账号,原名网易订阅,是网易传媒完成“两端”整合升级后打造的全新自媒体内容分发和品牌推广平台。本文以网易账号首页列表为例。您还可以更改 采集URL采集 其他列表。
采集内容:文章标题、出版时间、文章正文。
使用功能点:
? 列表循环?详情采集
第一步:创建网易账号文章采集任务
优采云·云采集网络爬虫软件
1)进入主界面,选择“自定义采集”
2) 将你想要采集的网址的网址复制并粘贴到网站的输入框中,点击“保存网址”
优采云·云采集网络爬虫软件
第 2 步:创建循环单击以加载更多
1)打开网页后,打开右上角的流程按钮,从左侧流程显示界面拖入一个循环步骤,如下图
优采云·云采集网络爬虫软件
2)然后拉到页面底部,看到加载更多按钮,因为如果要查看更多内容,需要循环点击加载更多,所以我们需要设置一个点击“加载更多”的循环步骤”。注意:采集更多内容需要加载更多内容。本文文章只是为了演示,所以选择执行并点击“加载更多”20次,你可以根据自己的实际需要加减。
优采云·云采集网络爬虫软件
优采云·云采集网络爬虫软件
第三步:创建循环点击列表采集详情
1)点击文章列表的第一个和第二个标题,然后选择“循环点击每个元素”按钮,这样就创建了一个循环点击列表命令,可以在列表中显示当前列表页的内容文章 列表。在采集器 中看到它。
2)然后我们可以提取我们需要的文本数据。下图提取了正文三部分的正文内容,包括标题、时间、正文。其他信息需要自由删除和编辑。然后可以点击保存启动本地采集。
优采云·云采集网络爬虫软件
3) 点击开始采集后,采集器将开始提取数据。
优采云·云采集网络爬虫软件
4) 采集 可以在结束后导出。
优采云·云采集网络爬虫软件
免费文章相关采集器教程:
新浪博客文章采集:
uc头条文章采集:
微信公众号热门文章采集(文字+图片):
今日头条采集:
新浪微博发帖内容采集:
知乎信息采集:
优采云——90万用户选择的网页数据采集器。
1.操作简单,任何人都可以使用:不需要技术背景,只要能上网采集即可。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
优采云·云采集网络爬虫软件
2、功能强大,任意网站可选:对于点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,所有页面都可以通过简单设置采集。
3.云采集,也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。
4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
免费获取:免费微信公众号翻译搬运工具
翻译和处理工具允许我们在网页上移动感兴趣的内容。翻译处理工具不仅支持指定网站内容处理,还可以通过关键词等方式挖掘微信公众号、头条文章等热门文章,翻译工具支持将采集本地文章批量翻译成英文,或将英文批量翻译成中文。
翻译和处理工具易于操作。您只需用鼠标点击需要的内容元素,即可在全网移动素材,自动翻译发布到我们的网站自媒体平台。在发布翻译处理工具之前,还可以通过创建的发布任务实现文章伪原创的编辑,通过同义词替换、敏感字段删除、图片替换、图片实现发布的文章水印等>高度原创。
纯文本 文章 是与潜在客户沟通的唯一方式的日子已经一去不复返了。今天,视觉效果是每个内容策略的主要元素。人脑是天生的,它更关注生动的图像。这就是为什么 SEOER 试图通过诱人的视觉效果来利用他们的内容。
除了提高参与度外,视觉效果也是提高 SEO 排名的理想选择。视觉内容如何影响搜索引擎排名,以及翻译推动者的其他好处是什么?我们将讨论所有这些以及更多内容。
但让我们首先了解视觉内容营销意味着什么。简而言之,翻译推动者就是利用视觉来教育和招待潜在客户。这些视觉效果可以是任何形式。营销人员不乏选择,从视频和图像到屏幕截图和 GIF。此外,它们使内容易于消化,否则难以理解。
视觉的力量是不可否认的。他们留下持久的印象,创造更好的参与,并发展情感依恋。有很多好处。但是,在我们继续之前,让我们看一下视觉内容的各种形式:
翻译移动工具图像可以增强我们书面内容的视觉外观,并有助于提高我们的转化率。人们不会像书籍那样阅读内容。有时,他们只是查看图像以了解内容想要传递的内容。专业摄影师可以为我们拍摄出最好的照片。但是,它们在口袋里很重。如果我们的预算足够好,没有比使用真实图像更好的选择了。
专家建议将图像置于 Z 或 F 模式,以立即吸引访问者的注意力。大多数访问者从左到右浏览内容。然后他们沿对角线或水平方向向下滚动。这就是为什么几乎所有的标志都出现在页面的左上角。
视频可以在几分钟内解释复杂的事情。我们可以通过它们展示一切。因此,它们消除了消费者的疑虑并提高了满意度。剪辑展示了玩具如何从汽车变成恐龙。它还显示了可以从汽车后部发出的光。最后,展示了该系列中的所有其他汽车,孩子们可以采集这些汽车来完成他们的恐龙世界。
翻译和处理工具的分享就到这里。通过翻译处理工具,可以实现文章素材采集、批量翻译、自动伪原创、定时发布等功能。翻译处理工具内置在我们的网站和自媒体中,应用范围很广,通过翻译处理工具让我们的工作变得便捷高效。 查看全部
免费获取:免费文章采集器使用教程
优采云·云采集网络爬虫软件
免费文章采集器教程
本文介绍如何使用优采云采集器采集网易账号文章。
采集网址:
网易账号,原名网易订阅,是网易传媒完成“两端”整合升级后打造的全新自媒体内容分发和品牌推广平台。本文以网易账号首页列表为例。您还可以更改 采集URL采集 其他列表。
采集内容:文章标题、出版时间、文章正文。
使用功能点:
? 列表循环?详情采集
第一步:创建网易账号文章采集任务
优采云·云采集网络爬虫软件
1)进入主界面,选择“自定义采集”
2) 将你想要采集的网址的网址复制并粘贴到网站的输入框中,点击“保存网址”
优采云·云采集网络爬虫软件
第 2 步:创建循环单击以加载更多
1)打开网页后,打开右上角的流程按钮,从左侧流程显示界面拖入一个循环步骤,如下图
优采云·云采集网络爬虫软件
2)然后拉到页面底部,看到加载更多按钮,因为如果要查看更多内容,需要循环点击加载更多,所以我们需要设置一个点击“加载更多”的循环步骤”。注意:采集更多内容需要加载更多内容。本文文章只是为了演示,所以选择执行并点击“加载更多”20次,你可以根据自己的实际需要加减。
优采云·云采集网络爬虫软件
优采云·云采集网络爬虫软件
第三步:创建循环点击列表采集详情
1)点击文章列表的第一个和第二个标题,然后选择“循环点击每个元素”按钮,这样就创建了一个循环点击列表命令,可以在列表中显示当前列表页的内容文章 列表。在采集器 中看到它。
2)然后我们可以提取我们需要的文本数据。下图提取了正文三部分的正文内容,包括标题、时间、正文。其他信息需要自由删除和编辑。然后可以点击保存启动本地采集。
优采云·云采集网络爬虫软件
3) 点击开始采集后,采集器将开始提取数据。
优采云·云采集网络爬虫软件
4) 采集 可以在结束后导出。
优采云·云采集网络爬虫软件
免费文章相关采集器教程:
新浪博客文章采集:
uc头条文章采集:
微信公众号热门文章采集(文字+图片):
今日头条采集:
新浪微博发帖内容采集:
知乎信息采集:
优采云——90万用户选择的网页数据采集器。
1.操作简单,任何人都可以使用:不需要技术背景,只要能上网采集即可。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
优采云·云采集网络爬虫软件
2、功能强大,任意网站可选:对于点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,所有页面都可以通过简单设置采集。
3.云采集,也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。
4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
免费获取:免费微信公众号翻译搬运工具
翻译和处理工具允许我们在网页上移动感兴趣的内容。翻译处理工具不仅支持指定网站内容处理,还可以通过关键词等方式挖掘微信公众号、头条文章等热门文章,翻译工具支持将采集本地文章批量翻译成英文,或将英文批量翻译成中文。
翻译和处理工具易于操作。您只需用鼠标点击需要的内容元素,即可在全网移动素材,自动翻译发布到我们的网站自媒体平台。在发布翻译处理工具之前,还可以通过创建的发布任务实现文章伪原创的编辑,通过同义词替换、敏感字段删除、图片替换、图片实现发布的文章水印等>高度原创。
纯文本 文章 是与潜在客户沟通的唯一方式的日子已经一去不复返了。今天,视觉效果是每个内容策略的主要元素。人脑是天生的,它更关注生动的图像。这就是为什么 SEOER 试图通过诱人的视觉效果来利用他们的内容。
除了提高参与度外,视觉效果也是提高 SEO 排名的理想选择。视觉内容如何影响搜索引擎排名,以及翻译推动者的其他好处是什么?我们将讨论所有这些以及更多内容。
但让我们首先了解视觉内容营销意味着什么。简而言之,翻译推动者就是利用视觉来教育和招待潜在客户。这些视觉效果可以是任何形式。营销人员不乏选择,从视频和图像到屏幕截图和 GIF。此外,它们使内容易于消化,否则难以理解。
视觉的力量是不可否认的。他们留下持久的印象,创造更好的参与,并发展情感依恋。有很多好处。但是,在我们继续之前,让我们看一下视觉内容的各种形式:
翻译移动工具图像可以增强我们书面内容的视觉外观,并有助于提高我们的转化率。人们不会像书籍那样阅读内容。有时,他们只是查看图像以了解内容想要传递的内容。专业摄影师可以为我们拍摄出最好的照片。但是,它们在口袋里很重。如果我们的预算足够好,没有比使用真实图像更好的选择了。
专家建议将图像置于 Z 或 F 模式,以立即吸引访问者的注意力。大多数访问者从左到右浏览内容。然后他们沿对角线或水平方向向下滚动。这就是为什么几乎所有的标志都出现在页面的左上角。
视频可以在几分钟内解释复杂的事情。我们可以通过它们展示一切。因此,它们消除了消费者的疑虑并提高了满意度。剪辑展示了玩具如何从汽车变成恐龙。它还显示了可以从汽车后部发出的光。最后,展示了该系列中的所有其他汽车,孩子们可以采集这些汽车来完成他们的恐龙世界。
翻译和处理工具的分享就到这里。通过翻译处理工具,可以实现文章素材采集、批量翻译、自动伪原创、定时发布等功能。翻译处理工具内置在我们的网站和自媒体中,应用范围很广,通过翻译处理工具让我们的工作变得便捷高效。
技术文章:自媒体文章采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-10-22 03:11
云采集服务平台自媒体文章采集方法自媒体为我们提供的信息正逐渐影响我们的日常工作,改变着人们的生活方式和获取途径信息来源。然而,自媒体的迅速传播也给我们带来了信息过载的困扰。如何从海量的自媒体文章中找到高质量的作品,我们需要掌握一些自媒体文章的采集方法挖掘出需要的部分。于是,越来越多的优质文章出现在自媒体平台上,各位小伙伴都有采集自媒体文章的需求,以下是今日头条采集比如给大家介绍一下自媒体文章怎么用这篇文章来介绍优采云7.0 采集 自媒体文章采集方法,同今日头条的方法。采集网站:使用功能点:Ajax滚动加载设置列表内容提取步骤一:创建采集任务云采集服务平台 1)进入主界面,选择,选择“自动”定义模式“自媒体文章采集 步骤2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,信息红框内为demo 采集的内容是今日头条最新发布的热点新闻云采集服务平台自媒体 方法,用今日头条的方法。采集网站:使用功能点:Ajax滚动加载设置列表内容提取步骤一:创建采集任务云采集服务平台 1)进入主界面,选择,选择“自动”定义模式“自媒体文章采集 步骤2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,信息红框内为demo 采集的内容是今日头条最新发布的热点新闻云采集服务平台自媒体 方法,用今日头条的方法。采集网站:使用功能点:Ajax滚动加载设置列表内容提取步骤一:创建采集任务云采集服务平台 1)进入主界面,选择,选择“自动”定义模式“自媒体文章采集 步骤2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,信息红框内为demo 采集的内容是今日头条最新发布的热点新闻云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,红框内的信息为demo 采集的内容>是今日头条最新发布的热点新闻。云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,红框内的信息为demo 采集的内容>是今日头条最新发布的热点新闻。云采集服务平台自媒体
自媒体文章采集Step 3:采集新闻内容创建数据提取列表 1)如图,移动鼠标选中评论框列表,右击,框底 颜色会变成绿色然后点击“选择子元素” 云采集服务平台自媒体文章采集步骤说明:点击右上角的“流程”按钮,显示创建可视化流程图。2)然后点击“全选”,将页面中需要采集的信息添加到列表Cloud采集Service Platform自媒体文章采集Step注意:提示框中的字段会出现一个“X”,点击删除该字段。自媒体文章采集第三步)点击“采集以下数据”自媒体
2)采集完成后,选择合适的导出方式,将采集好的数据导出到云端采集服务平台自媒体文章采集步骤12 相关采集教程自媒体免费爆文采集:网易自媒体文章采集:自媒体 文章如何采集:云采集服务平台微信文章采集:网站文章采集:网站 文章采集教程:如何搜索关键词采集搜狗微信公众号文章:搜狗公众号热门文章采集方法和详细教程:马蜂窝旅游美食文章评论采集教程:70万用户选择的网页数据采集器。1. 操作简单,任何人都可以使用:不需要技术背景,只要能上网采集即可。流程全可视化,点击鼠标完成操作,云采集服务平台 2.功能强大,任意网站都可以使用:用于点击、登录、翻页、识别验证码、瀑布流、加载数据的 Ajax 脚本异步网页可以通过简单的设置采集 来完成。3.云采集,也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。巨大的云采集 集群24*7运行,无需担心IP阻塞和网络中断。4、可按需选择功能免费增值服务。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
方法和技巧:缺关键词?掌握这些搜集关键词技巧
线上开发客户,无论是发布产品还是积极寻找客户,都成了关键词的游戏。没有关键词,我只能想出少量的关键词,数量很多。外贸人遇到的问题。
了解产品的各种名称
就算是扩展,也得先有一些介绍。第一步是通过翻译和头脑风暴为自己的产品想出各种名称。
因为此时关键词还比较小,这些是后面使用工具的时候会用到的词。不要忘记过滤,以上方法采集到的关键词可能与产品不匹配,会浪费时间、精力和金钱。外贸jackson建议大家先把这个词放到Google Image、amazon、ebay、alibaba等平台上去中间再去验证一下,否则这个词是错的,以后用工具扩展的时候会出现越来越多的错误.
使用 关键词 工具
30 关键词 个单独的工具
关键词数据挖掘工具
超级推荐
长尾关键词挖掘
关键字眼
搜索引擎
Soovle-
优特
麦克达
i 商业推广者
序曲
书签来自
好关键词
Adword、谷歌关键词规划师;
三倍
间谍(关键字间谍)
关键字发现
单词跟踪器
谷歌全球机会洞察(谷歌翻译右下角)
seobook 上的关键字工具
semrush
搜索引擎优化
冰
小机器人
谷歌搜索建议
msnadcentre 关键字工具
谷歌集
谷歌相关关键词
关键词研究工具
采集 关键词 的联合竞争对手
你可以在阿里巴巴上找到自然排名靠前的同行的关键词,或者在谷歌搜索关键词,找出前面的网站的关键词你自己的行业。排序不少于10个peer,将它们组合起来创建一个新的关键词。
阿里本身也有很多关键词工具
1、在搜索框中输入关键词,下拉框会自动形成关键词。
2.后台数据管家-热门搜索词
3. 数据管家 - 我的话
4. 数据管家 - 访客详情
5. 数据管家 - 行业视角
6. 数据管家 - RFQ 业务机会
7.外贸直通车-关键词工具
8.外贸直通车-顶展位
你可以利用自己平台上的数据先挖掘一些关键词,然后组合起来。
组织您的 关键词 表单
每个公司都有几个 关键词 目录。我们会发现阿里巴巴上有很多卖家的产品分组,所以我们需要根据不同的产品属性对关键词进行分组。
确定关键词搜索量趋势
Lycos 热 50
基于pendency的词
相似
Hitwise 搜索智能
易趣工具
雅虎!嗡嗡声
谷歌热门趋势
谷歌趋势
谷歌时代精神
AOL 搜索热搜
PPydt 趋势
问 jeeves zn有趣的问题
许多产品是季节性的。之前的外贸jackson讲了销售的周期性,所以无论是发布产品还是寻找客户,也必须掌握一个周期。
最好在这个销售周期之前进行排名。这是看到搜索量随时间变化的规律,这让我们可以清楚地看到这种趋势,尤其是在竞价P4P等拍卖时。能够知道何时使用此 关键词 以及何时停止此 关键词。
过滤器关键词
根据关键词搜索量、竞争、出价等,在不同用途下,使用前应进行过滤。
如果你刚刚开始,建议在 关键词 上花更多的时间,当 关键词 准备好时,就执行。 查看全部
技术文章:自媒体文章采集方法
云采集服务平台自媒体文章采集方法自媒体为我们提供的信息正逐渐影响我们的日常工作,改变着人们的生活方式和获取途径信息来源。然而,自媒体的迅速传播也给我们带来了信息过载的困扰。如何从海量的自媒体文章中找到高质量的作品,我们需要掌握一些自媒体文章的采集方法挖掘出需要的部分。于是,越来越多的优质文章出现在自媒体平台上,各位小伙伴都有采集自媒体文章的需求,以下是今日头条采集比如给大家介绍一下自媒体文章怎么用这篇文章来介绍优采云7.0 采集 自媒体文章采集方法,同今日头条的方法。采集网站:使用功能点:Ajax滚动加载设置列表内容提取步骤一:创建采集任务云采集服务平台 1)进入主界面,选择,选择“自动”定义模式“自媒体文章采集 步骤2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,信息红框内为demo 采集的内容是今日头条最新发布的热点新闻云采集服务平台自媒体 方法,用今日头条的方法。采集网站:使用功能点:Ajax滚动加载设置列表内容提取步骤一:创建采集任务云采集服务平台 1)进入主界面,选择,选择“自动”定义模式“自媒体文章采集 步骤2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,信息红框内为demo 采集的内容是今日头条最新发布的热点新闻云采集服务平台自媒体 方法,用今日头条的方法。采集网站:使用功能点:Ajax滚动加载设置列表内容提取步骤一:创建采集任务云采集服务平台 1)进入主界面,选择,选择“自动”定义模式“自媒体文章采集 步骤2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,信息红框内为demo 采集的内容是今日头条最新发布的热点新闻云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,红框内的信息为demo 采集的内容>是今日头条最新发布的热点新闻。云采集服务平台自媒体文章采集步骤3)保存URL后,会在优采云采集器中打开页面,红框内的信息为demo 采集的内容>是今日头条最新发布的热点新闻。云采集服务平台自媒体
自媒体文章采集Step 3:采集新闻内容创建数据提取列表 1)如图,移动鼠标选中评论框列表,右击,框底 颜色会变成绿色然后点击“选择子元素” 云采集服务平台自媒体文章采集步骤说明:点击右上角的“流程”按钮,显示创建可视化流程图。2)然后点击“全选”,将页面中需要采集的信息添加到列表Cloud采集Service Platform自媒体文章采集Step注意:提示框中的字段会出现一个“X”,点击删除该字段。自媒体文章采集第三步)点击“采集以下数据”自媒体
2)采集完成后,选择合适的导出方式,将采集好的数据导出到云端采集服务平台自媒体文章采集步骤12 相关采集教程自媒体免费爆文采集:网易自媒体文章采集:自媒体 文章如何采集:云采集服务平台微信文章采集:网站文章采集:网站 文章采集教程:如何搜索关键词采集搜狗微信公众号文章:搜狗公众号热门文章采集方法和详细教程:马蜂窝旅游美食文章评论采集教程:70万用户选择的网页数据采集器。1. 操作简单,任何人都可以使用:不需要技术背景,只要能上网采集即可。流程全可视化,点击鼠标完成操作,云采集服务平台 2.功能强大,任意网站都可以使用:用于点击、登录、翻页、识别验证码、瀑布流、加载数据的 Ajax 脚本异步网页可以通过简单的设置采集 来完成。3.云采集,也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。巨大的云采集 集群24*7运行,无需担心IP阻塞和网络中断。4、可按需选择功能免费增值服务。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
方法和技巧:缺关键词?掌握这些搜集关键词技巧
线上开发客户,无论是发布产品还是积极寻找客户,都成了关键词的游戏。没有关键词,我只能想出少量的关键词,数量很多。外贸人遇到的问题。
了解产品的各种名称
就算是扩展,也得先有一些介绍。第一步是通过翻译和头脑风暴为自己的产品想出各种名称。
因为此时关键词还比较小,这些是后面使用工具的时候会用到的词。不要忘记过滤,以上方法采集到的关键词可能与产品不匹配,会浪费时间、精力和金钱。外贸jackson建议大家先把这个词放到Google Image、amazon、ebay、alibaba等平台上去中间再去验证一下,否则这个词是错的,以后用工具扩展的时候会出现越来越多的错误.
使用 关键词 工具
30 关键词 个单独的工具
关键词数据挖掘工具
超级推荐
长尾关键词挖掘
关键字眼
搜索引擎
Soovle-
优特
麦克达
i 商业推广者
序曲
书签来自
好关键词
Adword、谷歌关键词规划师;
三倍
间谍(关键字间谍)
关键字发现
单词跟踪器
谷歌全球机会洞察(谷歌翻译右下角)
seobook 上的关键字工具
semrush
搜索引擎优化
冰
小机器人
谷歌搜索建议
msnadcentre 关键字工具
谷歌集
谷歌相关关键词
关键词研究工具
采集 关键词 的联合竞争对手
你可以在阿里巴巴上找到自然排名靠前的同行的关键词,或者在谷歌搜索关键词,找出前面的网站的关键词你自己的行业。排序不少于10个peer,将它们组合起来创建一个新的关键词。
阿里本身也有很多关键词工具
1、在搜索框中输入关键词,下拉框会自动形成关键词。
2.后台数据管家-热门搜索词
3. 数据管家 - 我的话
4. 数据管家 - 访客详情
5. 数据管家 - 行业视角
6. 数据管家 - RFQ 业务机会
7.外贸直通车-关键词工具
8.外贸直通车-顶展位
你可以利用自己平台上的数据先挖掘一些关键词,然后组合起来。
组织您的 关键词 表单
每个公司都有几个 关键词 目录。我们会发现阿里巴巴上有很多卖家的产品分组,所以我们需要根据不同的产品属性对关键词进行分组。
确定关键词搜索量趋势
Lycos 热 50
基于pendency的词
相似
Hitwise 搜索智能
易趣工具
雅虎!嗡嗡声
谷歌热门趋势
谷歌趋势
谷歌时代精神
AOL 搜索热搜
PPydt 趋势
问 jeeves zn有趣的问题
许多产品是季节性的。之前的外贸jackson讲了销售的周期性,所以无论是发布产品还是寻找客户,也必须掌握一个周期。
最好在这个销售周期之前进行排名。这是看到搜索量随时间变化的规律,这让我们可以清楚地看到这种趋势,尤其是在竞价P4P等拍卖时。能够知道何时使用此 关键词 以及何时停止此 关键词。
过滤器关键词
根据关键词搜索量、竞争、出价等,在不同用途下,使用前应进行过滤。
如果你刚刚开始,建议在 关键词 上花更多的时间,当 关键词 准备好时,就执行。
分享文章:python自动获取微信公众号最新文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-10-21 10:21
微信公众号获取思路
获取微信公众号文章常用的方法有搜狐、微信公众号首页和api接口。
听说最近搜狐不太好用,而且之前使用的API接口也经常维护,所以使用微信公众平台进行数据爬取。
首先,登录你的微信公众平台。如果您没有帐户,您可以注册一个。进来后找“图文资料”,就是写公众号的地方
点击后会出现写公众号的界面文章。在界面中,您会找到“超链接”字段,您可以在其中搜索其他公众号。
以“python”为例,输入要检索的公众号名称,从显示的公众号中选择公众号为采集
点击浏览器查看,在网络中找到链接,下图中的链接,右边的Request URL是存储公众号数据的真实链接。表示这是一个 json 网页。
采集实例
以公众号“python”的链接为例,分析URL。
https://mp.weixin.qq.com/cgi-bin/appmsg:微信公众平台的链接
"token": "163455614", #需要定期修改的token
"lang": "zh_CN", #语言
"f": "json",
"ajax": "1", #显示几天的文章
"action": "list_ex"
"begin": "0", #起始页面
"count": "1", #计数
"query": "",
"fakeid": 'MzIwNDA1OTM4NQ==', #公众号唯一编码
"type": "9",
由于我发现fakeid是唯一代表公众号的代码,那么我只需要找到所需公众号的fakeid即可。我随机找了三个公众号进行测试。
fakeid=[ 'MzIwNDA1OTM4NQ==','MzkxNzAwMDkwNQ==','MjM5NzI0NTY3Mg==']
#若增加公众号需要增加fakeid
然后下一步就是请求URL
首先导入需要的库
import time
import requests
from lxml import etree
import pandas as pd
import json
import numpy as np
import datetime
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
由于不想重复登录公众号平台,可以使用cookies来避免登录。在请求文章之前,需要先找到网页的cookie和User-Agent。由于微信公众号是定期刷新的,所以这个cookie和上面的token都要定期刷新。代替。
为了避免反扒,最好找个代理ip
headers = {
"Cookie": "appmsglist_action_3567997841=card;wxuin=49763073568536;pgv_pvid=6311844914;ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=;mm_lang=zh_CN;pac_uid=0_3cf43daf28071;eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8;rewardsn=;wxtokenkey=777;wwapp.vid=;wwapp.cst=;wwapp.deviceid=;uuid=fd43d0b369e634ab667a99eade075932;rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm;slave_bizuin=3567997841;data_bizuin=3567997841;bizuin=3567997841;data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA;slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS;slave_user=gh_e0f449d4f2b6;xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
<p>
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
proxies = {'http': '112.80.248.73'}
</p>
接下来可以爬取页面,获取页面中的文章标题和文章链接,以及文章的时间,分析网页的信息,发现所有的信息网页保存在“app_msg_list”字段中,因此提取该字段中的数据。
寻找
代码显示如下:
def get_weixin(fakeid):
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
# 使用Cookie,跳过登陆操作
#headers 根据自己电脑修改
headers = {
"Cookie": "appmsglist_action_3567997841=card; wxuin=49763073568536; pgv_pvid=6311844914; ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=; mm_lang=zh_CN; pac_uid=0_3cf43daf28071; eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8; rewardsn=; wxtokenkey=777; wwapp.vid=; wwapp.cst=; wwapp.deviceid=; uuid=fd43d0b369e634ab667a99eade075932; rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm; slave_bizuin=3567997841; data_bizuin=3567997841; bizuin=3567997841; data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA; slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS; slave_user=gh_e0f449d4f2b6; xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
dda=[]
for i in range(0,len(fakeid)):
#配置网址
data= {
"token": "163455614", #需要定期修改
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": "0",
"count": "1",
"query": "",
"fakeid": fakeid[i],
"type": "9",
}
dda.append(data)
content_list = []
proxies = {'http': '112.80.248.73'}
ur=[]
title=[]
link=[]
time1=[]
content_li=[]
for i in range(0,len(dda)):
time.sleep(np.random.randint(90, 200))
content_json = requests.get(url, headers=headers, params=dda[i],proxies=proxies,verify=False).json()
print("爬取成功第"+str(i)+"个")
# 返回了一个json,里面是每一页的数据
<p>
for it in content_json["app_msg_list"]: #提取信息
its = []
title.append(it["title"]) #标题
link.append(it["link"]) #链接
time1.append(it['create_time']) #时间
#content_li.append(its)
columns={'title':title,'link':link,'time':time1} #组成df文件
df=pd.DataFrame(columns)
return df
</p>
得到的数据包存放在df中。这里的数据不是微信公众号最新的文章数据,而是微信公众号最近一天发送的文章数据。因此,还需要过滤发布时间。注意这里的时间格式是时间戳,所以需要转换时间数据
转换代码如下:
def time_s(df):
def transfer_time(s): #时间处理
aa = time.ctime(s)
bb = aa.split(' ')
cc = (bb[-1]+"-"+bb[1]+"-"+bb[-3]).replace('Jan','1').replace('Feb','2').replace('Mar','3'). \
replace('Apr','4').replace('May','5').replace('Jun','6').replace('Jul','7').replace('Aug','8') \
.replace('Sep','9').replace('Oct','10').replace('Nov','11').replace('Dec','12')
dd = datetime.datetime.strptime(cc,'%Y-%m-%d').date()
return dd
ti=[]
hd=[]
for i in range(0,len(df['time'])):
timestap= transfer_time(df['time'][i])
ti.append(timestap)
#print(ti)
d= ti[i] + datetime.timedelta(weeks=0, days=0, hours=0, minutes=0, seconds=0, milliseconds=0, microseconds=0, )
#dc = d.strftime("%Y-%m-%d")
hd.append(d)
df['time']=hd
这样就可以将微信公众号的时间戳数据转换为时间数据,然后根据当天的日期提取数据集中的内容并存储。
dat=df[df['time'] == datetime.date.today() + datetime.timedelta(days= -1)] #自动获取昨天日期,将-1改为-2,则为前天的日期,以此类推
##改自动化
path = 'C:/Users/gpower/Desktop/work/行业信息/' #根据自己电脑位置更改
import re
filename=path+"微信公众号采集" + re.sub(r'[^0-9]','',datetime.datetime.now().strftime("%Y-%m-%d")) + '.csv'
# 对文件进行命名,以“微信公众号采集+当前日期”命名
dat.to_csv(filename,encoding='utf_8_sig')
print("保存成功")
这样就可以下载最新的微信公众号文章采集。如果需要多个微信公众号,可以在fakeid中添加公众号的识别码。
新年文章属于yes
免费获取:微信公众号文章搜索导出助手神器
“你知道如何一键下载公众号文章/网页的所有图片、视频和音频吗?” 我不知道为什么?这个问题好像永远,永远,永远,永远被问,但是这个问题,却无所谓,做一个好的复读机是我的工作,作为一个高水平复读机,我也努力让每一个复读机都有新的想法,以前需要N个步骤的,不适合大多数穷懒脑筋的,所以这次我找到了这个软件,这个工具我找到了
有以下三个优点:
1.易于安装
2. 免费下载,使用方便
3.可过滤的图片
相信我!下载它!!
第一步,复制你要导出的微信公众账号图片。
第二步,直接粘贴到下载的软件中
第三步,启动采集,采集完成后,即可导出
第四步,选择你要导出的格式,OK,到此结束,就这么简单,soeasy!
我们来看看实际的导出效果:
下面是保存的图片,每个文章一个文件夹,里面存放了文章的所有高清图片
下面是导出的视音频格式,和原来文章看到的视音频是一样的
下面是html、doc、pdf格式的导出,和原来的文章一样
下载的内容显示如下,和原来的阅读效果一样:
- - - - - - - - - - - - - - - - - 分向線 - - - - - - - ----------------------
微信公众号文章搜索下载助手,搜索下载一体,可一键搜索微信平台文章所有公众号关键词超大素材库,可以关键词@采集指定公众号的所有群发文章,批量导出word、pdf或html。所以,无论你是在自媒体寻找文章素材,还是个人用户搜索下载文章,都可以使用!请看下面的功能介绍:
【主要功能介绍】
★ 一键采集微信公众号发送所有群消息文章,也可以通过关键词搜索所有与文章相关的公众号,支持按时间段采集;
★ 文章可以一键导出Pdf、Word、Excel、txt和Html格式,并可以下载音视频文件、图片和文章消息,导出文件的版面可以保持一致原文;
★ 实时查看文章阅读和留言,一键复制文章内容;
★ 内置开放界面,一键同步所有微信文章到自己网站,保证微信图片正常显示;
★ 软件提供近80个附加功能,功能强大实用。如果你不相信我,看看下面的演示:
简而言之,这是一个非常非常强大和方便的软件,可以在 1 分钟内完成所有操作。
但仅仅拥有软件的强大功能是不够的。我们必须照顾小白吗?答案当然是,我们的软件除了强大的功能外,还有强大的售后问题解决能力。不仅为使用过程中的疑难问题提供解答,还提供各种视频版网络教学教程,包括大家的大本营是一个温暖的地方,购买软件让我们更心心相印。
下载软件并扫描下方二维码或地址
如果觉得本软件不错,请点击关注并采集,如果喜欢本软件,请点按下方二维码,加V:xtcclass,即可获得优惠哦~~
软件会员目前为一年会员制,会员期内不限下载。它非常易于使用且价格不贵。之所以收费,是因为发展确实非常非常大。精力和时间,我更有动力不断更新收费的软件,对你来说也更安全。注意点击上方二维码有优惠哦~~~全网唯一!!! 查看全部
分享文章:python自动获取微信公众号最新文章
微信公众号获取思路
获取微信公众号文章常用的方法有搜狐、微信公众号首页和api接口。
听说最近搜狐不太好用,而且之前使用的API接口也经常维护,所以使用微信公众平台进行数据爬取。
首先,登录你的微信公众平台。如果您没有帐户,您可以注册一个。进来后找“图文资料”,就是写公众号的地方
点击后会出现写公众号的界面文章。在界面中,您会找到“超链接”字段,您可以在其中搜索其他公众号。
以“python”为例,输入要检索的公众号名称,从显示的公众号中选择公众号为采集
点击浏览器查看,在网络中找到链接,下图中的链接,右边的Request URL是存储公众号数据的真实链接。表示这是一个 json 网页。
采集实例
以公众号“python”的链接为例,分析URL。
https://mp.weixin.qq.com/cgi-bin/appmsg:微信公众平台的链接
"token": "163455614", #需要定期修改的token
"lang": "zh_CN", #语言
"f": "json",
"ajax": "1", #显示几天的文章
"action": "list_ex"
"begin": "0", #起始页面
"count": "1", #计数
"query": "",
"fakeid": 'MzIwNDA1OTM4NQ==', #公众号唯一编码
"type": "9",
由于我发现fakeid是唯一代表公众号的代码,那么我只需要找到所需公众号的fakeid即可。我随机找了三个公众号进行测试。
fakeid=[ 'MzIwNDA1OTM4NQ==','MzkxNzAwMDkwNQ==','MjM5NzI0NTY3Mg==']
#若增加公众号需要增加fakeid
然后下一步就是请求URL
首先导入需要的库
import time
import requests
from lxml import etree
import pandas as pd
import json
import numpy as np
import datetime
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
由于不想重复登录公众号平台,可以使用cookies来避免登录。在请求文章之前,需要先找到网页的cookie和User-Agent。由于微信公众号是定期刷新的,所以这个cookie和上面的token都要定期刷新。代替。
为了避免反扒,最好找个代理ip
headers = {
"Cookie": "appmsglist_action_3567997841=card;wxuin=49763073568536;pgv_pvid=6311844914;ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=;mm_lang=zh_CN;pac_uid=0_3cf43daf28071;eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8;rewardsn=;wxtokenkey=777;wwapp.vid=;wwapp.cst=;wwapp.deviceid=;uuid=fd43d0b369e634ab667a99eade075932;rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm;slave_bizuin=3567997841;data_bizuin=3567997841;bizuin=3567997841;data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA;slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS;slave_user=gh_e0f449d4f2b6;xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
<p>
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
proxies = {'http': '112.80.248.73'}
</p>
接下来可以爬取页面,获取页面中的文章标题和文章链接,以及文章的时间,分析网页的信息,发现所有的信息网页保存在“app_msg_list”字段中,因此提取该字段中的数据。
寻找
代码显示如下:
def get_weixin(fakeid):
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
# 使用Cookie,跳过登陆操作
#headers 根据自己电脑修改
headers = {
"Cookie": "appmsglist_action_3567997841=card; wxuin=49763073568536; pgv_pvid=6311844914; ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=; mm_lang=zh_CN; pac_uid=0_3cf43daf28071; eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8; rewardsn=; wxtokenkey=777; wwapp.vid=; wwapp.cst=; wwapp.deviceid=; uuid=fd43d0b369e634ab667a99eade075932; rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm; slave_bizuin=3567997841; data_bizuin=3567997841; bizuin=3567997841; data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA; slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS; slave_user=gh_e0f449d4f2b6; xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
dda=[]
for i in range(0,len(fakeid)):
#配置网址
data= {
"token": "163455614", #需要定期修改
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": "0",
"count": "1",
"query": "",
"fakeid": fakeid[i],
"type": "9",
}
dda.append(data)
content_list = []
proxies = {'http': '112.80.248.73'}
ur=[]
title=[]
link=[]
time1=[]
content_li=[]
for i in range(0,len(dda)):
time.sleep(np.random.randint(90, 200))
content_json = requests.get(url, headers=headers, params=dda[i],proxies=proxies,verify=False).json()
print("爬取成功第"+str(i)+"个")
# 返回了一个json,里面是每一页的数据
<p>
for it in content_json["app_msg_list"]: #提取信息
its = []
title.append(it["title"]) #标题
link.append(it["link"]) #链接
time1.append(it['create_time']) #时间
#content_li.append(its)
columns={'title':title,'link':link,'time':time1} #组成df文件
df=pd.DataFrame(columns)
return df
</p>
得到的数据包存放在df中。这里的数据不是微信公众号最新的文章数据,而是微信公众号最近一天发送的文章数据。因此,还需要过滤发布时间。注意这里的时间格式是时间戳,所以需要转换时间数据
转换代码如下:
def time_s(df):
def transfer_time(s): #时间处理
aa = time.ctime(s)
bb = aa.split(' ')
cc = (bb[-1]+"-"+bb[1]+"-"+bb[-3]).replace('Jan','1').replace('Feb','2').replace('Mar','3'). \
replace('Apr','4').replace('May','5').replace('Jun','6').replace('Jul','7').replace('Aug','8') \
.replace('Sep','9').replace('Oct','10').replace('Nov','11').replace('Dec','12')
dd = datetime.datetime.strptime(cc,'%Y-%m-%d').date()
return dd
ti=[]
hd=[]
for i in range(0,len(df['time'])):
timestap= transfer_time(df['time'][i])
ti.append(timestap)
#print(ti)
d= ti[i] + datetime.timedelta(weeks=0, days=0, hours=0, minutes=0, seconds=0, milliseconds=0, microseconds=0, )
#dc = d.strftime("%Y-%m-%d")
hd.append(d)
df['time']=hd
这样就可以将微信公众号的时间戳数据转换为时间数据,然后根据当天的日期提取数据集中的内容并存储。
dat=df[df['time'] == datetime.date.today() + datetime.timedelta(days= -1)] #自动获取昨天日期,将-1改为-2,则为前天的日期,以此类推
##改自动化
path = 'C:/Users/gpower/Desktop/work/行业信息/' #根据自己电脑位置更改
import re
filename=path+"微信公众号采集" + re.sub(r'[^0-9]','',datetime.datetime.now().strftime("%Y-%m-%d")) + '.csv'
# 对文件进行命名,以“微信公众号采集+当前日期”命名
dat.to_csv(filename,encoding='utf_8_sig')
print("保存成功")
这样就可以下载最新的微信公众号文章采集。如果需要多个微信公众号,可以在fakeid中添加公众号的识别码。
新年文章属于yes
免费获取:微信公众号文章搜索导出助手神器
“你知道如何一键下载公众号文章/网页的所有图片、视频和音频吗?” 我不知道为什么?这个问题好像永远,永远,永远,永远被问,但是这个问题,却无所谓,做一个好的复读机是我的工作,作为一个高水平复读机,我也努力让每一个复读机都有新的想法,以前需要N个步骤的,不适合大多数穷懒脑筋的,所以这次我找到了这个软件,这个工具我找到了
有以下三个优点:
1.易于安装
2. 免费下载,使用方便
3.可过滤的图片
相信我!下载它!!
第一步,复制你要导出的微信公众账号图片。
第二步,直接粘贴到下载的软件中
第三步,启动采集,采集完成后,即可导出
第四步,选择你要导出的格式,OK,到此结束,就这么简单,soeasy!
我们来看看实际的导出效果:
下面是保存的图片,每个文章一个文件夹,里面存放了文章的所有高清图片
下面是导出的视音频格式,和原来文章看到的视音频是一样的
下面是html、doc、pdf格式的导出,和原来的文章一样
下载的内容显示如下,和原来的阅读效果一样:
- - - - - - - - - - - - - - - - - 分向線 - - - - - - - ----------------------
微信公众号文章搜索下载助手,搜索下载一体,可一键搜索微信平台文章所有公众号关键词超大素材库,可以关键词@采集指定公众号的所有群发文章,批量导出word、pdf或html。所以,无论你是在自媒体寻找文章素材,还是个人用户搜索下载文章,都可以使用!请看下面的功能介绍:
【主要功能介绍】
★ 一键采集微信公众号发送所有群消息文章,也可以通过关键词搜索所有与文章相关的公众号,支持按时间段采集;
★ 文章可以一键导出Pdf、Word、Excel、txt和Html格式,并可以下载音视频文件、图片和文章消息,导出文件的版面可以保持一致原文;
★ 实时查看文章阅读和留言,一键复制文章内容;
★ 内置开放界面,一键同步所有微信文章到自己网站,保证微信图片正常显示;
★ 软件提供近80个附加功能,功能强大实用。如果你不相信我,看看下面的演示:
简而言之,这是一个非常非常强大和方便的软件,可以在 1 分钟内完成所有操作。
但仅仅拥有软件的强大功能是不够的。我们必须照顾小白吗?答案当然是,我们的软件除了强大的功能外,还有强大的售后问题解决能力。不仅为使用过程中的疑难问题提供解答,还提供各种视频版网络教学教程,包括大家的大本营是一个温暖的地方,购买软件让我们更心心相印。
下载软件并扫描下方二维码或地址
如果觉得本软件不错,请点击关注并采集,如果喜欢本软件,请点按下方二维码,加V:xtcclass,即可获得优惠哦~~
软件会员目前为一年会员制,会员期内不限下载。它非常易于使用且价格不贵。之所以收费,是因为发展确实非常非常大。精力和时间,我更有动力不断更新收费的软件,对你来说也更安全。注意点击上方二维码有优惠哦~~~全网唯一!!!
分享:如何下载公众号文章方法 其实非常简单
采集交流 • 优采云 发表了文章 • 0 个评论 • 1079 次浏览 • 2022-10-15 16:37
微信公众号里有很多文章,很正能量。看完觉得舒服,但是好的文章太多了。我津津有味地阅读每一篇文章,有时我想下载它并稍后重温。,那么如何下载公众号文章?
微信公众号可以算是一个非常非常大的素材库。但是,微信在管理方面非常严格。和之前的迷雾一样,有些文章还是写的很好,但是突然就看不下去了。
但是绝对不能直接下载。您可以将它们全部复制并粘贴到您的公众号背景中,然后进行编辑。如果对方是原创,则无法发布,需要做一些处理。
所以你可以把公众号的文章导出为word或者pdf格式保存到你的电脑上。您可以随时随地观看。
对于导出文章,可以在浏览器中打开链接,然后按Ctrl+P,可以看到可以另存为pdf,可以保持原格式,导入效果还是不错的,但是你需要一个一个导出,有点麻烦,如果能分批导出就更好了
让我与您分享一个我自己使用的导出小工具。微信公众号文章搜索和下载拓图数据,可以通过关键词搜索公众号平台上的所有文章,也可以采集一个公众号的所有历史记录group文章,然后批量导出为word、pdf、html格式,相当好用。
“途途数据”是公众号运营的工具。主要提供优质的公众号查询功能和公众号相关报告下载功能,还可以让您快速判断公众号的质量。目前越来越多的人开始青睐公众号的推广,但是如何找到合适的公众号成为了一个难题。“拓图数据”旨在为关注新媒体的机构、个人和研究机构提供从数据到价值的全方位服务。服务支持。
以上就是小编为大家总结的公众号文章的下载方式。您不必再担心找到一个好的 文章 了。如果你喜欢阅读,你学会了吗?
免费获取:什么是网站权重?网站权重如何提升-附网站权重工具下载
网站权重优化,网站权重是多少相信很多朋友都听说过“网站权重”这个词,只知道网站权重越高网站 更好。具体的网站权重是怎么来的,相信很多SEO人员都很困惑。
1、网站的权重由来
几大搜索引擎(百度/360/搜狗/谷歌)都没有明确表示有网站权重。给个评分,分别为0-10,值越大网站权重越高,网站权重网站越高情况越好。网站的权重值的计算主要是根据网站的流量值。(例:流量值1~99之间的权重为1) 首先声明这个权重值属于第三方平台检测,与官方搜索引擎无关。网站权重值数据仅供参考,更准确的数据请参考百度统计。
2.更准确的统计(百度统计)
Page View PV:即所谓的Page View (PV),每次用户打开一个网站页面时记录一次。用户多次打开同一个页面,累计浏览量。
访客数UV量:您的网站一天内的独立访客数(基于cookies),同一访客一天内多次访问您网站只计为一位访客.
IP数:一天内你的网站的唯一访问IP数
平均访问时间:访问者在访问中打开 网站 所花费的平均时间。也就是说,每次访问时,打开第一页
3、网站的权重值怎么做?
网站的权重值=权重词X词数那么什么是网站权重词,网站权重是根据不同用户搜索这个词的频率。在哪里可以找到重量词?更多信息请参考百度指数,(百度指数是基于百度海量网民行为数据的数据共享平台。在这里,您可以研究关键词搜索趋势,洞察网民需求变化,监控媒体舆情趋势,定位数字消费。你也可以从行业角度分析市场特征)现在我们有了加权词,你只需要用你的SEO技术把这些加权词排到首页,你就可以获得大量流量。
4.百度指数是怎么计算的?
百度指数基于百度的海量数据。一方面进行关键词搜索热度分析,另一方面深入挖掘舆情信息、市场需求、用户特征等数据特征。百度索引每天更新,提供2006年6月至今的任意时间段的PC端搜索索引和2011年1月至今的移动端无线搜索索引。
五、网站优化权重值
要想网站的权重值显着增加,必须有大量的关键词排名,而一个网站的关键词在文章页面 所以最实用的方法就是每天创建大量原创关键词文章,并且具备分析数据的能力!
1.分析网站日志
说到web日志,有人认为网站的网站操作记录没什么用。这是一个错误的概念。我们需要做的是找出搜索引擎的习惯,通过分析对其进行适当的优化。网站机器人文件日志,减少搜索引擎爬取网站的系统文件爬取网站 .
2、制定文章更新发展规划
通过分析网站的日志,我们已经知道了搜索引擎每天的访问时间和频率。我们要做的是为搜索引擎访问创建一个文章发布计划。说白了,随着时间的推移,搜索引擎会实现爬取网站的习惯,而网站会达到秒秒的效果。
3.控制文章内容
文章 的质量必须是 原创 的内容。如果其他与网站主题无关的内容会影响网站的排名,文章中的更多优化关键词的抽取计算方法见下图。
总结:今天的分享就到这里,主要分享网站权重的由来,以及更准确的数据统计,百度加权词查询。以及网站权重词的优化方法。 查看全部
分享:如何下载公众号文章方法 其实非常简单
微信公众号里有很多文章,很正能量。看完觉得舒服,但是好的文章太多了。我津津有味地阅读每一篇文章,有时我想下载它并稍后重温。,那么如何下载公众号文章?
微信公众号可以算是一个非常非常大的素材库。但是,微信在管理方面非常严格。和之前的迷雾一样,有些文章还是写的很好,但是突然就看不下去了。
但是绝对不能直接下载。您可以将它们全部复制并粘贴到您的公众号背景中,然后进行编辑。如果对方是原创,则无法发布,需要做一些处理。
所以你可以把公众号的文章导出为word或者pdf格式保存到你的电脑上。您可以随时随地观看。
对于导出文章,可以在浏览器中打开链接,然后按Ctrl+P,可以看到可以另存为pdf,可以保持原格式,导入效果还是不错的,但是你需要一个一个导出,有点麻烦,如果能分批导出就更好了
让我与您分享一个我自己使用的导出小工具。微信公众号文章搜索和下载拓图数据,可以通过关键词搜索公众号平台上的所有文章,也可以采集一个公众号的所有历史记录group文章,然后批量导出为word、pdf、html格式,相当好用。
“途途数据”是公众号运营的工具。主要提供优质的公众号查询功能和公众号相关报告下载功能,还可以让您快速判断公众号的质量。目前越来越多的人开始青睐公众号的推广,但是如何找到合适的公众号成为了一个难题。“拓图数据”旨在为关注新媒体的机构、个人和研究机构提供从数据到价值的全方位服务。服务支持。
以上就是小编为大家总结的公众号文章的下载方式。您不必再担心找到一个好的 文章 了。如果你喜欢阅读,你学会了吗?
免费获取:什么是网站权重?网站权重如何提升-附网站权重工具下载
网站权重优化,网站权重是多少相信很多朋友都听说过“网站权重”这个词,只知道网站权重越高网站 更好。具体的网站权重是怎么来的,相信很多SEO人员都很困惑。
1、网站的权重由来
几大搜索引擎(百度/360/搜狗/谷歌)都没有明确表示有网站权重。给个评分,分别为0-10,值越大网站权重越高,网站权重网站越高情况越好。网站的权重值的计算主要是根据网站的流量值。(例:流量值1~99之间的权重为1) 首先声明这个权重值属于第三方平台检测,与官方搜索引擎无关。网站权重值数据仅供参考,更准确的数据请参考百度统计。
2.更准确的统计(百度统计)
Page View PV:即所谓的Page View (PV),每次用户打开一个网站页面时记录一次。用户多次打开同一个页面,累计浏览量。
访客数UV量:您的网站一天内的独立访客数(基于cookies),同一访客一天内多次访问您网站只计为一位访客.
IP数:一天内你的网站的唯一访问IP数
平均访问时间:访问者在访问中打开 网站 所花费的平均时间。也就是说,每次访问时,打开第一页
3、网站的权重值怎么做?
网站的权重值=权重词X词数那么什么是网站权重词,网站权重是根据不同用户搜索这个词的频率。在哪里可以找到重量词?更多信息请参考百度指数,(百度指数是基于百度海量网民行为数据的数据共享平台。在这里,您可以研究关键词搜索趋势,洞察网民需求变化,监控媒体舆情趋势,定位数字消费。你也可以从行业角度分析市场特征)现在我们有了加权词,你只需要用你的SEO技术把这些加权词排到首页,你就可以获得大量流量。
4.百度指数是怎么计算的?
百度指数基于百度的海量数据。一方面进行关键词搜索热度分析,另一方面深入挖掘舆情信息、市场需求、用户特征等数据特征。百度索引每天更新,提供2006年6月至今的任意时间段的PC端搜索索引和2011年1月至今的移动端无线搜索索引。
五、网站优化权重值
要想网站的权重值显着增加,必须有大量的关键词排名,而一个网站的关键词在文章页面 所以最实用的方法就是每天创建大量原创关键词文章,并且具备分析数据的能力!
1.分析网站日志
说到web日志,有人认为网站的网站操作记录没什么用。这是一个错误的概念。我们需要做的是找出搜索引擎的习惯,通过分析对其进行适当的优化。网站机器人文件日志,减少搜索引擎爬取网站的系统文件爬取网站 .
2、制定文章更新发展规划
通过分析网站的日志,我们已经知道了搜索引擎每天的访问时间和频率。我们要做的是为搜索引擎访问创建一个文章发布计划。说白了,随着时间的推移,搜索引擎会实现爬取网站的习惯,而网站会达到秒秒的效果。
3.控制文章内容
文章 的质量必须是 原创 的内容。如果其他与网站主题无关的内容会影响网站的排名,文章中的更多优化关键词的抽取计算方法见下图。
总结:今天的分享就到这里,主要分享网站权重的由来,以及更准确的数据统计,百度加权词查询。以及网站权重词的优化方法。
干货教程:帝国CMS源码《花生小说》源码 花生日记公众号引流导航站模板 带wap手机站+采
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-10-13 17:33
放开眼睛,戴上耳机,听~!
帝国cms源码《花生小说》源码花生日记公众号引流导航站模板带wap手机站+采集【纯版】
帝国cms源码《花生小说》源码花生日记公众号引流导航站模板带wap手机站+采集【纯版】
开发环境:
帝国cms 7.5
安装环境:
php+mysql
源代码说明:
一个专注于小说阅读细化分类的网站。我们会根据不同的用户喜好,将海量的小说分类为详细的主题类别。
让你找到自己喜欢的小说阅读速度更快。此外,我们每天通过用户阅读量、付费率等大数据指标,为小说爱好者推荐几本好看的小说。
关键词:好小说,推荐好小说,小说分类导航
说明:小说公众号模板,小说网站导航引流网站源码,网站结构清晰易优化收录。
本站配备优采云自动采集、手机端、同步生成插件。模仿Empirecms7.5内核,更安全、更高效。
APP流、下载站、游戏公会人群引流等都是不错的选择。模板易于更改和维护。
采集可以使用这种导航方式的网站很多,也可以购买版权直接在线阅读。
注:此版本为纯版本,无任何数据。如果您需要数据,请使用提供的 优采云 for 采集
分享文章:python自动获取微信公众号最新文章的实现代码
目录
微信公众号获取思路
获取微信公众号文章常用的方法有搜狐、微信公众号首页和api接口。
听说最近搜狐不太好用,而且之前使用的API接口也经常维护,所以使用微信公众平台进行数据爬取。
首先,登录你的微信公众平台。如果您没有帐户,您可以注册一个。进来后找“图文资料”,就是写公众号的地方
点击后会出现写公众号的界面文章。在界面中,您会找到“超链接”字段,您可以在其中搜索其他公众号。
以“python”为例,输入要检索的公众号名称,从显示的公众号中选择公众号为采集
点击浏览器查看,在网络中找到链接,下图中的链接,右边的Request URL是存储公众号数据的真实链接。表示这是一个 json 网页。
采集实例
以公众号“python”的链接为例,分析URL。
https://mp.weixin.qq.com/cgi-bin/appmsg:微信公众平台的链接
"token": "163455614", #需要定期修改的token
"lang": "zh_CN", #语言
"f": "json",
"ajax": "1", #显示几天的文章
"action": "list_ex"
"begin": "0", #起始页面
"count": "1", #计数
"query": "",
"fakeid": 'MzIwNDA1OTM4NQ==', #公众号唯一编码
"type": "9",
由于我发现fakeid是唯一代表公众号的代码,那么我只需要找到所需公众号的fakeid即可。我随机找了三个公众号进行测试。
fakeid=[ 'MzIwNDA1OTM4NQ==','MzkxNzAwMDkwNQ==','MjM5NzI0NTY3Mg==']
<p>
#若增加公众号需要增加fakeid</p>
然后下一步就是请求URL
首先导入需要的库
import time
import requests
from lxml import etree
import pandas as pd
import json
import numpy as np
import datetime
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
由于不想重复登录公众号平台,可以使用cookies来避免登录。在请求文章之前,需要先找到网页的cookie和User-Agent。由于微信公众号是定期刷新的,所以这个cookie和上面的token都要定期刷新。代替。
为了避免反扒,最好找个代理ip
headers = {
"Cookie": "appmsglist_action_3567997841=card;wxuin=49763073568536;pgv_pvid=6311844914;ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=;mm_lang=zh_CN;pac_uid=0_3cf43daf28071;eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8;rewardsn=;wxtokenkey=777;wwapp.vid=;wwapp.cst=;wwapp.deviceid=;uuid=fd43d0b369e634ab667a99eade075932;rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm;slave_bizuin=3567997841;data_bizuin=3567997841;bizuin=3567997841;data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA;slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS;slave_user=gh_e0f449d4f2b6;xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
proxies = {'http': '112.80.248.73'}
接下来可以爬取页面,获取页面中的文章标题和文章链接,以及文章的时间,分析网页的信息,发现所有的信息网页保存在“app_msg_list”字段中,因此提取该字段中的数据。
代码显示如下:
得到的数据包存放在df中。这里的数据不是微信公众号最新的文章数据,而是微信公众号最近一天发送的文章数据。因此,还需要过滤发布时间。注意这里的时间格式是时间戳,所以需要转换时间数据
转换代码如下:
def time_s(df):
def transfer_time(s): #时间处理
aa = time.ctime(s)
<p>
bb = aa.split(' ')
cc = (bb[-1]+"-"+bb[1]+"-"+bb[-3]).replace('Jan','1').replace('Feb','2').replace('Mar','3'). \
replace('Apr','4').replace('May','5').replace('Jun','6').replace('Jul','7').replace('Aug','8') \
.replace('Sep','9').replace('Oct','10').replace('Nov','11').replace('Dec','12')
dd = datetime.datetime.strptime(cc,'%Y-%m-%d').date()
return dd
ti=[]
hd=[]
for i in range(0,len(df['time'])):
timestap= transfer_time(df['time'][i])
ti.append(timestap)
#print(ti)
d= ti[i] + datetime.timedelta(weeks=0, days=0, hours=0, minutes=0, seconds=0, milliseconds=0, microseconds=0, )
#dc = d.strftime("%Y-%m-%d")
hd.append(d)
df['time']=hd</p>
这样就可以将微信公众号的时间戳数据转换为时间数据,然后根据当天的日期提取数据集中的内容并存储。
dat=df[df['time'] == datetime.date.today() + datetime.timedelta(days= -1)] #自动获取昨天日期,将-1改为-2,则为前天的日期,以此类推
##改自动化
path = 'C:/Users/gpower/Desktop/work/行业信息/' #根据自己电脑位置更改
import re
filename=path+"微信公众号采集" + re.sub(r'[^0-9]','',datetime.datetime.now().strftime("%Y-%m-%d")) + '.csv'
# 对文件进行命名,以“微信公众号采集+当前日期”命名
dat.to_csv(filename,encoding='utf_8_sig')
print("保存成功")
这样就可以下载最新的微信公众号文章采集。如果需要多个微信公众号,可以在fakeid中添加公众号的识别码。
这是文章关于python自动获取微信公众号最新文章的介绍。更多关于python自动获取微信公众号文章的信息,请搜索三水点胶木的往期文章或继续浏览以下相关文章希望大家在木头支持三水点未来! 查看全部
干货教程:帝国CMS源码《花生小说》源码 花生日记公众号引流导航站模板 带wap手机站+采
放开眼睛,戴上耳机,听~!
帝国cms源码《花生小说》源码花生日记公众号引流导航站模板带wap手机站+采集【纯版】
帝国cms源码《花生小说》源码花生日记公众号引流导航站模板带wap手机站+采集【纯版】
开发环境:
帝国cms 7.5
安装环境:
php+mysql
源代码说明:
一个专注于小说阅读细化分类的网站。我们会根据不同的用户喜好,将海量的小说分类为详细的主题类别。
让你找到自己喜欢的小说阅读速度更快。此外,我们每天通过用户阅读量、付费率等大数据指标,为小说爱好者推荐几本好看的小说。
关键词:好小说,推荐好小说,小说分类导航
说明:小说公众号模板,小说网站导航引流网站源码,网站结构清晰易优化收录。
本站配备优采云自动采集、手机端、同步生成插件。模仿Empirecms7.5内核,更安全、更高效。
APP流、下载站、游戏公会人群引流等都是不错的选择。模板易于更改和维护。
采集可以使用这种导航方式的网站很多,也可以购买版权直接在线阅读。
注:此版本为纯版本,无任何数据。如果您需要数据,请使用提供的 优采云 for 采集
分享文章:python自动获取微信公众号最新文章的实现代码
目录
微信公众号获取思路
获取微信公众号文章常用的方法有搜狐、微信公众号首页和api接口。
听说最近搜狐不太好用,而且之前使用的API接口也经常维护,所以使用微信公众平台进行数据爬取。
首先,登录你的微信公众平台。如果您没有帐户,您可以注册一个。进来后找“图文资料”,就是写公众号的地方
点击后会出现写公众号的界面文章。在界面中,您会找到“超链接”字段,您可以在其中搜索其他公众号。
以“python”为例,输入要检索的公众号名称,从显示的公众号中选择公众号为采集
点击浏览器查看,在网络中找到链接,下图中的链接,右边的Request URL是存储公众号数据的真实链接。表示这是一个 json 网页。
采集实例
以公众号“python”的链接为例,分析URL。
https://mp.weixin.qq.com/cgi-bin/appmsg:微信公众平台的链接
"token": "163455614", #需要定期修改的token
"lang": "zh_CN", #语言
"f": "json",
"ajax": "1", #显示几天的文章
"action": "list_ex"
"begin": "0", #起始页面
"count": "1", #计数
"query": "",
"fakeid": 'MzIwNDA1OTM4NQ==', #公众号唯一编码
"type": "9",
由于我发现fakeid是唯一代表公众号的代码,那么我只需要找到所需公众号的fakeid即可。我随机找了三个公众号进行测试。
fakeid=[ 'MzIwNDA1OTM4NQ==','MzkxNzAwMDkwNQ==','MjM5NzI0NTY3Mg==']
<p>
#若增加公众号需要增加fakeid</p>
然后下一步就是请求URL
首先导入需要的库
import time
import requests
from lxml import etree
import pandas as pd
import json
import numpy as np
import datetime
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
由于不想重复登录公众号平台,可以使用cookies来避免登录。在请求文章之前,需要先找到网页的cookie和User-Agent。由于微信公众号是定期刷新的,所以这个cookie和上面的token都要定期刷新。代替。
为了避免反扒,最好找个代理ip
headers = {
"Cookie": "appmsglist_action_3567997841=card;wxuin=49763073568536;pgv_pvid=6311844914;ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=;mm_lang=zh_CN;pac_uid=0_3cf43daf28071;eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8;rewardsn=;wxtokenkey=777;wwapp.vid=;wwapp.cst=;wwapp.deviceid=;uuid=fd43d0b369e634ab667a99eade075932;rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm;slave_bizuin=3567997841;data_bizuin=3567997841;bizuin=3567997841;data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA;slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS;slave_user=gh_e0f449d4f2b6;xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
proxies = {'http': '112.80.248.73'}
接下来可以爬取页面,获取页面中的文章标题和文章链接,以及文章的时间,分析网页的信息,发现所有的信息网页保存在“app_msg_list”字段中,因此提取该字段中的数据。
代码显示如下:
得到的数据包存放在df中。这里的数据不是微信公众号最新的文章数据,而是微信公众号最近一天发送的文章数据。因此,还需要过滤发布时间。注意这里的时间格式是时间戳,所以需要转换时间数据
转换代码如下:
def time_s(df):
def transfer_time(s): #时间处理
aa = time.ctime(s)
<p>
bb = aa.split(' ')
cc = (bb[-1]+"-"+bb[1]+"-"+bb[-3]).replace('Jan','1').replace('Feb','2').replace('Mar','3'). \
replace('Apr','4').replace('May','5').replace('Jun','6').replace('Jul','7').replace('Aug','8') \
.replace('Sep','9').replace('Oct','10').replace('Nov','11').replace('Dec','12')
dd = datetime.datetime.strptime(cc,'%Y-%m-%d').date()
return dd
ti=[]
hd=[]
for i in range(0,len(df['time'])):
timestap= transfer_time(df['time'][i])
ti.append(timestap)
#print(ti)
d= ti[i] + datetime.timedelta(weeks=0, days=0, hours=0, minutes=0, seconds=0, milliseconds=0, microseconds=0, )
#dc = d.strftime("%Y-%m-%d")
hd.append(d)
df['time']=hd</p>
这样就可以将微信公众号的时间戳数据转换为时间数据,然后根据当天的日期提取数据集中的内容并存储。
dat=df[df['time'] == datetime.date.today() + datetime.timedelta(days= -1)] #自动获取昨天日期,将-1改为-2,则为前天的日期,以此类推
##改自动化
path = 'C:/Users/gpower/Desktop/work/行业信息/' #根据自己电脑位置更改
import re
filename=path+"微信公众号采集" + re.sub(r'[^0-9]','',datetime.datetime.now().strftime("%Y-%m-%d")) + '.csv'
# 对文件进行命名,以“微信公众号采集+当前日期”命名
dat.to_csv(filename,encoding='utf_8_sig')
print("保存成功")
这样就可以下载最新的微信公众号文章采集。如果需要多个微信公众号,可以在fakeid中添加公众号的识别码。
这是文章关于python自动获取微信公众号最新文章的介绍。更多关于python自动获取微信公众号文章的信息,请搜索三水点胶木的往期文章或继续浏览以下相关文章希望大家在木头支持三水点未来!
分享方法:微信文章采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-10-06 15:05
微信文章采集器是公众号操作和网站操作助手,功能有:自定义采集、分类采集、关键词采集、文章编辑排版,提供日常微信文章、微信图文等资源。
工具/材料电脑、软件、工具文章、操作、公众号、材料方法/步骤1
下面就给大家介绍一下这个介绍,先熟悉一下软件的功能和使用方法。
2
百度搜索相关资料,点击网页了解介绍。
3
软件功能介绍,有分类采集、关键词采集、自定义采集、文章排版编辑功能。
4
让操作变得如此简单。
知识整理:英文SEO推广工具整理
我整理了自己的经验,分享给大家。在这里,我只为您提供发布所使用的工具,不提供详细的说明和操作说明。请理解!
下面的工具大部分都是我在用的工具,所以还是很实用的。希望他们能给你带来一些帮助!
使用火狐
安装插件:
1、Shareholic一键提交多个书签
2. seo 地震,seo 工具
3.seo工具栏、seo工具栏、/seo-toolbar/
4. alexa sparky,alexa,alexa数据工具,
5. 美味记录工具网站
6.firebug查看代码
关键字分析工具:
1. 谷歌 关键词tools:///doc/3712070519.html,/
2. SEO BOOK 关键词工具,/
3. Wordtracker:///doc/3712070519.html,
网站管理员工具:
谷歌网站管理工具
:///doc/3712070519.html,/webmasters/tools/home?hl=zh-CN
必应网站管理工具,/toolbox/webmasters/#
雅虎网站管理工具:///doc/3712070519.html,/mysites
网站数据分析工具:
谷歌分析:///doc/3712070519.html,/analytics/settings/?pli=1
外部链接查看工具:
反向链接外部链接视图:,/index.php 查看全部
分享方法:微信文章采集器
微信文章采集器是公众号操作和网站操作助手,功能有:自定义采集、分类采集、关键词采集、文章编辑排版,提供日常微信文章、微信图文等资源。
工具/材料电脑、软件、工具文章、操作、公众号、材料方法/步骤1
下面就给大家介绍一下这个介绍,先熟悉一下软件的功能和使用方法。
2
百度搜索相关资料,点击网页了解介绍。
3
软件功能介绍,有分类采集、关键词采集、自定义采集、文章排版编辑功能。
4
让操作变得如此简单。
知识整理:英文SEO推广工具整理
我整理了自己的经验,分享给大家。在这里,我只为您提供发布所使用的工具,不提供详细的说明和操作说明。请理解!
下面的工具大部分都是我在用的工具,所以还是很实用的。希望他们能给你带来一些帮助!
使用火狐
安装插件:
1、Shareholic一键提交多个书签
2. seo 地震,seo 工具
3.seo工具栏、seo工具栏、/seo-toolbar/
4. alexa sparky,alexa,alexa数据工具,
5. 美味记录工具网站
6.firebug查看代码
关键字分析工具:
1. 谷歌 关键词tools:///doc/3712070519.html,/
2. SEO BOOK 关键词工具,/
3. Wordtracker:///doc/3712070519.html,
网站管理员工具:
谷歌网站管理工具
:///doc/3712070519.html,/webmasters/tools/home?hl=zh-CN
必应网站管理工具,/toolbox/webmasters/#
雅虎网站管理工具:///doc/3712070519.html,/mysites
网站数据分析工具:
谷歌分析:///doc/3712070519.html,/analytics/settings/?pli=1
外部链接查看工具:
反向链接外部链接视图:,/index.php
内容分享:持续更新,微信公众号文章批量采集系统的构建
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-10-06 11:14
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集内容不仅需要微信客户端,还需要采集专用的微信个人账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中文章的列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析存储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
1. 安装模拟器或使用手机安装微信客户端,申请微信个人账号并登录。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1.安装NodeJS
2、在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4.启动anyproxy并运行命令:sudo anyproxy -i;参数 -i 表示解析 HTTPS;
5.安装证书,在手机或安卓模拟器中安装证书:
6、设置代理:安卓模拟器的代理服务器地址为wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址localhost:8002可以看到anyproxy的web界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
1.找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
2.修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
<p>
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
</p>
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1.getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p> 查看全部
内容分享:持续更新,微信公众号文章批量采集系统的构建
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集内容不仅需要微信客户端,还需要采集专用的微信个人账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中文章的列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析存储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
1. 安装模拟器或使用手机安装微信客户端,申请微信个人账号并登录。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1.安装NodeJS
2、在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4.启动anyproxy并运行命令:sudo anyproxy -i;参数 -i 表示解析 HTTPS;
5.安装证书,在手机或安卓模拟器中安装证书:
6、设置代理:安卓模拟器的代理服务器地址为wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址localhost:8002可以看到anyproxy的web界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
1.找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
2.修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
<p>
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
</p>
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1.getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p>
推荐文章:优采云采集织梦文章下载图片保存到本地路径设置方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2022-09-26 02:14
优采云采集织梦文章下载图片保存到本地路径设置方法
在使用优采云采集织梦文章的时候,我想下载图片,我用的是织梦文章这个模型,但是路径设置为否,无法显示。所以经过测试,找到了最好的解决方案。 一、优采云采集图片设置:二、保存图片路径和名称设置:下载的图片路径为:/uploads/allimg/200108/*.jpg。 ..
在使用优采云采集织梦文章的时候,我想下载图片,我用的是织梦文章这个模型,但是路径设置为否,无法显示。所以经过测试,找到了最好的解决方案。
一、优采云采集图片设置:
二、保存图片路径和名称设置:
下载图片的路径为:/uploads/allimg/200108/*.jpg
三、文件链接地址前缀,输入斜杠:/
这里的文件保存文件夹可以选择保存路径,然后上传到你的网站对应目录。
免费的:小说源码-免费小说源码全自动采集支持各大小说CMS自动采集
小说源代码,为什么要用小说源代码?小说源码能不能快速自动采集?只需输入域名或关键词即可快速采集小说源代码,然后我们会以图片的形式展示给大家。大家注意看图(工具是:147采集器可以直接通过搜索引擎搜索找到。免费下载使用)。不管是什么cms,都可以自动采集伪原创主动推送到搜索引擎收录。
如何提高网站排名?有些新手会停止对内容和外部链接的SEO优化,但细节会直接影响优化结果。还有一些高手没有传授的技巧,分享一下我所知道和实际打过的技巧。
一、旧域名快速排序技术
很多人可能不知道一个好的老域名可以达到秒排第一页的效果,所以详细的方法是找一个相关度高的老域名,也就是说和你的东西相关度高想做关键词。最好有一定的外链和反向链接,前提是地基干净,五年以上。
二、长时间不更新会有排名
有些朋友经常看到一些网站没有更新文章,但是排名很好。让我分享一下这项技术。在开始首页规划之前,先对用户需求关键词做一个数据分析,根据需求字长,进行页面规划,在网站根目录下创建一个独立站点,为主站点 收录 起到了音量和锚文本的作用来提升权重。
三、高质量文章
高质量文章并不代表原创文章,而是用户访问你的页面能否找到答案,用户粘性如何直接影响网站@的表现> 跳出率。一个好的文章必须有一定层次,h1标签的作用,加粗换色操作,图文并茂,字数要800以上。一个高质量的文章。
如今,SEO 行业有许多不同的概念。第一类人说SEO已经过时了。因为PC时代已经过时,SEO是PC时代的产物,所以无能为力。二是今天的seo没有什么可做的,因为所有的行业都在seo时期做过。不管你做什么,有人已经做到了。所以没有必要再做任何事情了。其实大部分想法应该是一样的。我们自身流量获取的基本理论是在一个大流量池中找到它的规律,把你和你自己分开 查看全部
推荐文章:优采云采集织梦文章下载图片保存到本地路径设置方法
优采云采集织梦文章下载图片保存到本地路径设置方法
在使用优采云采集织梦文章的时候,我想下载图片,我用的是织梦文章这个模型,但是路径设置为否,无法显示。所以经过测试,找到了最好的解决方案。 一、优采云采集图片设置:二、保存图片路径和名称设置:下载的图片路径为:/uploads/allimg/200108/*.jpg。 ..
在使用优采云采集织梦文章的时候,我想下载图片,我用的是织梦文章这个模型,但是路径设置为否,无法显示。所以经过测试,找到了最好的解决方案。
一、优采云采集图片设置:
二、保存图片路径和名称设置:
下载图片的路径为:/uploads/allimg/200108/*.jpg
三、文件链接地址前缀,输入斜杠:/
这里的文件保存文件夹可以选择保存路径,然后上传到你的网站对应目录。
免费的:小说源码-免费小说源码全自动采集支持各大小说CMS自动采集
小说源代码,为什么要用小说源代码?小说源码能不能快速自动采集?只需输入域名或关键词即可快速采集小说源代码,然后我们会以图片的形式展示给大家。大家注意看图(工具是:147采集器可以直接通过搜索引擎搜索找到。免费下载使用)。不管是什么cms,都可以自动采集伪原创主动推送到搜索引擎收录。
如何提高网站排名?有些新手会停止对内容和外部链接的SEO优化,但细节会直接影响优化结果。还有一些高手没有传授的技巧,分享一下我所知道和实际打过的技巧。
一、旧域名快速排序技术
很多人可能不知道一个好的老域名可以达到秒排第一页的效果,所以详细的方法是找一个相关度高的老域名,也就是说和你的东西相关度高想做关键词。最好有一定的外链和反向链接,前提是地基干净,五年以上。
二、长时间不更新会有排名
有些朋友经常看到一些网站没有更新文章,但是排名很好。让我分享一下这项技术。在开始首页规划之前,先对用户需求关键词做一个数据分析,根据需求字长,进行页面规划,在网站根目录下创建一个独立站点,为主站点 收录 起到了音量和锚文本的作用来提升权重。
三、高质量文章
高质量文章并不代表原创文章,而是用户访问你的页面能否找到答案,用户粘性如何直接影响网站@的表现> 跳出率。一个好的文章必须有一定层次,h1标签的作用,加粗换色操作,图文并茂,字数要800以上。一个高质量的文章。
如今,SEO 行业有许多不同的概念。第一类人说SEO已经过时了。因为PC时代已经过时,SEO是PC时代的产物,所以无能为力。二是今天的seo没有什么可做的,因为所有的行业都在seo时期做过。不管你做什么,有人已经做到了。所以没有必要再做任何事情了。其实大部分想法应该是一样的。我们自身流量获取的基本理论是在一个大流量池中找到它的规律,把你和你自己分开
免费的:本地TXT批量翻译器,免费TXT文档自动批量翻译
采集交流 • 优采云 发表了文章 • 0 个评论 • 665 次浏览 • 2022-09-24 17:07
TXT 批量翻译器允许我们批量翻译一个 TXT 文档和一个文件夹中的所有 TXT 文档。TXT批量翻译器连接百度、有道、谷歌及自带翻译接口,无需多个软件或网页。您可以通过跳跃进行批量翻译。TXT批量翻译器支持世界主流的几十种语言,只需简单的鼠标点击,我们就可以进行语言之间的互译、互译甚至回译。反向翻译功能允许我们通过将 文章 翻译成其他语言,然后将它们反向翻译成原创语言,在 网站中将一个 文章 拆分为多个 文章 @> 以及在 自媒体 中实现 文章 的质量 原创。
TXT Batch Translator 批量内容处理使我们能够采集 我们想要的文章 材料。访问全网只需要输入关键词文章采集,也可以输入目标网址鼠标点击对应元素,即可访问英文、日文、泰语、韩语等多种语言。网站前往采集。在采集之后批量翻译文章,保留原格式标签,去除原敏感信息。实现 文章 整洁干净。
TXT批量翻译器可用于网站SEO优化和自媒体文章批量编辑,在软文中建立外部链接和高权重网站是我们的日常推广工作,TXT 批量翻译器是一个很棒的链接构建工具,但重要的是要记住我们不能保证反向链接。确保我们的演示文稿与记者相关且有趣。如果是这样,那么我们很有可能会加入他们的文章。社交媒体是与目标受众建立联系和互动并建立有意义关系的好方法。这有助于我们建立信任和可信度,随着时间的推移会产生自然的反向链接。
为了充分利用社交媒体,请确保我们活跃在最有可能成为我们理想受众的平台上。与其他用户互动,分享我们的内容并关注我们行业的人。这些活动不仅帮助我们建立联系,还提高了品牌知名度和销量。
每个人都喜欢信息图表。它以易于理解的格式呈现复杂的数据,这种格式具有视觉吸引力、引人入胜且令人难忘。这有助于我们获得曝光并与其他 网站 建立关系。获得曝光和链接的另一个好方法是创建其他“可链接”资产,例如电子书、备忘单和模板。这些资产通常由其他 网站 共享并帮助我们自然连接。
创建信息图表和可连接资产显着增加了我们的内容创建工作流程,但这是值得的,因为它们非常有效。为了获得出色的效果,请确保: 与设计师合作创造高质量的视觉效果;在创建这些资产时留出更多时间;确保内容有价值并与我们的目标受众相关。
按照我们分享的提示开始建立链接,帮助我们实现营销和业务目标。实施白帽 SEO 链接构建策略可能比其他策略需要更多的时间和精力,但这是值得的,因为我们会看到长期的结果。然后使用一些与我们的业务最相关和适用的白帽 SEO 链接构建策略。
TXT批量翻译器的分享就到这里,可以批量替代人工重复的工作,让我们多思考工作生活中的规律和趋势,然后用TXT批量翻译器来获得更多意想不到的效果。每个人对此都有不同的看法,所以请在下面的评论中告诉我们。
免费获取:织梦采集-织梦采集器免费采集内容到织梦
如何使用织梦采集SEO工具优化网站?网站优化排名需要什么网站基本先决条件?网站参与搜索引擎有效排名的基本条件是什么?网站影响优化的重要因素有很多,决定了网站的基本排名状态和网站整体的排名周期。这里重点关注新人,哪些网站基本稳定的百度排名能得到有效保障?
1、域名和服务器/空间的选择
域名:在购买和使用域名的时候,我们不需要提及众所周知的,一定要简单记住,减少用户的记忆成本。并不是所有的网站都形成一个品牌。当然,并不是所有的 网站 都形成一个品牌。如何选择域名?网站域名的选择尽量以com和cn为主。其次,很多人还是比较喜欢买老域名,觉得老域名更有利于收录和推广。没错,但一定要注意重点,尽量购买老域名选择同行业竞争,而且一定要搜索老域名。
服务器/空间:在购买服务器/空间时,尽量不要选择不稳定的服务器/差的服务器,容易导致网站的用户体验和网站的排名。
2、网站结构优化
网站 层次结构,尽量树状,网站 内页尽量不要有孤岛链接,网站首页内容布局更丰富,考虑网站架构,结合有SEO基础知识,优化各个层级和相关性,nofollow不必要的栏目或页面,提高页面集中度,加快收录的性能,可以考虑如何减少不必要的爬取和权重稀释。
3、网站内容优化
网站内容是网站的灵魂,如何提升关键词的排名?如何改进网站收录?各种因素都关系到内容的质量,都离不开用户点击和留存率。优质的文章更容易获得搜索引擎的关注和认可,那么我们如何利用织梦采集插件大量创作网站内容呢?
这个织梦采集插件不需要学习更多的专业技能,只需要几个简单的步骤就可以轻松实现采集内容数据,只需在软件上进行简单的设置,软件会根据用户设置的关键词高精度匹配内容和图片,自动执行文章采集伪原创发布,提供方便快捷的内容填充服务!!
与其他采集插件相比,基本没有门槛,也不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词即可实现采集。一路挂断!设置任务自动执行采集发布任务。
无论是成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类织梦采集发布插件工具也配备了很多SEO功能,通过采集伪原创软件发布时也可以提升很多SEO方面。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。
自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
4、关键词 的选择
关键词作为SEO定位和发展的核心要素,如何选择成为SEO中思想斗争和对抗的话题,关键词选择可以是粗略的,也可以是合乎逻辑的工作,主要看你自己的发展方向。
5、用户体验提升
<p>网站在SEO优化前期的不断调整,不是为了用户,而是为了搜索引擎。首先,必须满足搜索引擎给出的排名基本条件,才能有机会向用户展示更多的曝光率。百度算法说到底是网站的一套点评机制,满足算法的基本要求,网站的基本元素更能满足用户体验,那么 查看全部
免费的:本地TXT批量翻译器,免费TXT文档自动批量翻译
TXT 批量翻译器允许我们批量翻译一个 TXT 文档和一个文件夹中的所有 TXT 文档。TXT批量翻译器连接百度、有道、谷歌及自带翻译接口,无需多个软件或网页。您可以通过跳跃进行批量翻译。TXT批量翻译器支持世界主流的几十种语言,只需简单的鼠标点击,我们就可以进行语言之间的互译、互译甚至回译。反向翻译功能允许我们通过将 文章 翻译成其他语言,然后将它们反向翻译成原创语言,在 网站中将一个 文章 拆分为多个 文章 @> 以及在 自媒体 中实现 文章 的质量 原创。
TXT Batch Translator 批量内容处理使我们能够采集 我们想要的文章 材料。访问全网只需要输入关键词文章采集,也可以输入目标网址鼠标点击对应元素,即可访问英文、日文、泰语、韩语等多种语言。网站前往采集。在采集之后批量翻译文章,保留原格式标签,去除原敏感信息。实现 文章 整洁干净。
TXT批量翻译器可用于网站SEO优化和自媒体文章批量编辑,在软文中建立外部链接和高权重网站是我们的日常推广工作,TXT 批量翻译器是一个很棒的链接构建工具,但重要的是要记住我们不能保证反向链接。确保我们的演示文稿与记者相关且有趣。如果是这样,那么我们很有可能会加入他们的文章。社交媒体是与目标受众建立联系和互动并建立有意义关系的好方法。这有助于我们建立信任和可信度,随着时间的推移会产生自然的反向链接。
为了充分利用社交媒体,请确保我们活跃在最有可能成为我们理想受众的平台上。与其他用户互动,分享我们的内容并关注我们行业的人。这些活动不仅帮助我们建立联系,还提高了品牌知名度和销量。
每个人都喜欢信息图表。它以易于理解的格式呈现复杂的数据,这种格式具有视觉吸引力、引人入胜且令人难忘。这有助于我们获得曝光并与其他 网站 建立关系。获得曝光和链接的另一个好方法是创建其他“可链接”资产,例如电子书、备忘单和模板。这些资产通常由其他 网站 共享并帮助我们自然连接。
创建信息图表和可连接资产显着增加了我们的内容创建工作流程,但这是值得的,因为它们非常有效。为了获得出色的效果,请确保: 与设计师合作创造高质量的视觉效果;在创建这些资产时留出更多时间;确保内容有价值并与我们的目标受众相关。
按照我们分享的提示开始建立链接,帮助我们实现营销和业务目标。实施白帽 SEO 链接构建策略可能比其他策略需要更多的时间和精力,但这是值得的,因为我们会看到长期的结果。然后使用一些与我们的业务最相关和适用的白帽 SEO 链接构建策略。
TXT批量翻译器的分享就到这里,可以批量替代人工重复的工作,让我们多思考工作生活中的规律和趋势,然后用TXT批量翻译器来获得更多意想不到的效果。每个人对此都有不同的看法,所以请在下面的评论中告诉我们。
免费获取:织梦采集-织梦采集器免费采集内容到织梦
如何使用织梦采集SEO工具优化网站?网站优化排名需要什么网站基本先决条件?网站参与搜索引擎有效排名的基本条件是什么?网站影响优化的重要因素有很多,决定了网站的基本排名状态和网站整体的排名周期。这里重点关注新人,哪些网站基本稳定的百度排名能得到有效保障?
1、域名和服务器/空间的选择
域名:在购买和使用域名的时候,我们不需要提及众所周知的,一定要简单记住,减少用户的记忆成本。并不是所有的网站都形成一个品牌。当然,并不是所有的 网站 都形成一个品牌。如何选择域名?网站域名的选择尽量以com和cn为主。其次,很多人还是比较喜欢买老域名,觉得老域名更有利于收录和推广。没错,但一定要注意重点,尽量购买老域名选择同行业竞争,而且一定要搜索老域名。
服务器/空间:在购买服务器/空间时,尽量不要选择不稳定的服务器/差的服务器,容易导致网站的用户体验和网站的排名。
2、网站结构优化
网站 层次结构,尽量树状,网站 内页尽量不要有孤岛链接,网站首页内容布局更丰富,考虑网站架构,结合有SEO基础知识,优化各个层级和相关性,nofollow不必要的栏目或页面,提高页面集中度,加快收录的性能,可以考虑如何减少不必要的爬取和权重稀释。
3、网站内容优化
网站内容是网站的灵魂,如何提升关键词的排名?如何改进网站收录?各种因素都关系到内容的质量,都离不开用户点击和留存率。优质的文章更容易获得搜索引擎的关注和认可,那么我们如何利用织梦采集插件大量创作网站内容呢?
这个织梦采集插件不需要学习更多的专业技能,只需要几个简单的步骤就可以轻松实现采集内容数据,只需在软件上进行简单的设置,软件会根据用户设置的关键词高精度匹配内容和图片,自动执行文章采集伪原创发布,提供方便快捷的内容填充服务!!
与其他采集插件相比,基本没有门槛,也不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词即可实现采集。一路挂断!设置任务自动执行采集发布任务。
无论是成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类织梦采集发布插件工具也配备了很多SEO功能,通过采集伪原创软件发布时也可以提升很多SEO方面。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。
自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
4、关键词 的选择
关键词作为SEO定位和发展的核心要素,如何选择成为SEO中思想斗争和对抗的话题,关键词选择可以是粗略的,也可以是合乎逻辑的工作,主要看你自己的发展方向。
5、用户体验提升
<p>网站在SEO优化前期的不断调整,不是为了用户,而是为了搜索引擎。首先,必须满足搜索引擎给出的排名基本条件,才能有机会向用户展示更多的曝光率。百度算法说到底是网站的一套点评机制,满足算法的基本要求,网站的基本元素更能满足用户体验,那么
文章采集(免费采集软件支持外链插入,外链就是指从别的网站导入到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2022-04-15 15:32
最近很多站长让我多管理网站,批量网站文章内容更新让他筋疲力尽。市场上没有免费且功能强大的免费 采集 软件。许多功能是有限的,没有限制。相信这也是很多站长头疼的问题。今天谈谈采集。
免费采集软件可以有多个采集来源采集。免费的 采集 软件支持外部链接插入。外部链接是指从其他网站导入到自己的网站的链接。导入链接是网站优化的一个非常重要的过程。传入链接的质量(即传入链接所在页面的权重)直接决定了我们的网站在搜索引擎中的权重。免费采集软件可以本地化图像或存储其他平台。外链的作用不仅是提高网站对于网站SEO的权重,也不是提高某个关键词的排名。一个高质量的外链可以给网站带来好的流量。
免费的采集软件根据关键词采集文章填充内容。免费采集软件是网站之间在资源上具有一定优势互补的简单合作形式,即把对方网站的图片或文字放在自己的网站。@网站名字,并设置对方网站的超链接,让用户可以从合作网站中发现自己的网站,达到相互促进的目的,所以它常被用作网站@网站推广的基本手段。免费采集软件全自动批量挂机采集伪原创自动发布推送到搜索引擎。一般来说,和相似的网站交换友情链接
免费的采集软件还配备了很多SEO功能,不仅通过免费的采集软件实现了采集伪原创的发布,还有很多的SEO功能. 分类目录是对网站的信息进行系统的分类整理。免费的采集 软件提供了一个按类别组织的网站 目录。在每个类别中,网站站点名称、URL链接、内容摘要和子类别,您可以通过类别浏览找到相关的网站。免费采集软件标题前缀和后缀设置。目录的权重很高,只要能加上,就能带来稳定的优质外链。显示 网站 相关性的最佳方法之一是提供 网站 定期更新内容。使用独特的内容进行更新绝对有助于吸引搜索引擎对您的关注。
免费的采集软件可以提高关键词密度和页面原创度,增加用户体验,实现优质内容。搜索引擎是用户获取信息的平台。因此,免费采集软件强调新鲜、独特的内容,用户可以从中找到有用的信息。免费采集软件内容关键词插入。所以,定期更新你的网站博客和相关内容可以确保你的网站排名更好。
免费的采集软件由数十万网站文章维护,更新不是问题。在这个科技发达的世界里,我们更喜欢用我们的手机或平板电脑在搜索引擎中采集有用的信息。因此,开发一款适合移动端的网站,让用户可以访问网站上的信息势在必行。关键词搜索是任何 SEO 策略的第一个元素。如今,对有竞争力的 关键词 进行排名非常困难,因此最好的办法是找到免费的 采集 软件。
免费采集软件内容与标题一致,定期自动发布内部链接。几十万个不同的cms网站可以实现统一管理。低竞争力的关键词 是每个月搜索量很大的关键词,缺乏竞争力。选择正确的 关键词 有助于吸引访问者访问您的 网站 并为您带来更好的排名。免费采集软件搜索引擎推送。借助 关键词 研究工具,您可以确定用户对您的 关键词 或类别的兴趣并确定搜索量。
浏览器选项卡和搜索结果显示您的内容的标题。因此,请创建一个收录多个 关键词 或短语的标题,以帮助搜索用户找到与其查询相关的内容。免费采集软件批量设置发布数量不同关键词文章可设置发布不同栏目。
免费的采集软件伪原创保留字软件直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等网站创建一个描述性强、规范、简单的URL,有利于用户更方便地记忆和判断网页内容,也有利于搜索引擎更有效地抓取你的网站。网站从设计之初就应该有合理的URL规划。
免费采集软件最重要的标题标签是H1标签,它指定了页面的内容,在一个网页上只能使用一次。H2、H3、H4、H5 和 H6 是没有 H1 标签重要的副标题标签。搜索引擎强调 H1 标签,而不是其他标题,并且当与其他 SEO 技术正确使用时,将产生最佳结果并提高您的搜索引擎排名。
这是关于您的页面的简短摘要,以便用户可以了解该页面的内容,而不是从您的标题中获取一些粗略的信息。元描述标签应该与优化的页面标题相关。免费采集软件批量监控不同cms网站数据,你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms@ >、人人展cms、Cyclone、站群、PB、Apple、搜外等主要cms工具,可同时管理和批量发布。用户应该能够很好地将标题与描述联系起来。您的元描述必须简短且少于 155 个字符。
免费 采集 软件为图像提供 alt 标签或可选文本标签,不仅使用户可以访问它们,而且还通知搜索引擎您的页面。图像 alt 标签和文件名应收录 关键词 以便搜索引擎可以将具有特定 关键词 的内容提供给搜索用户。
请记住,内容应该是自然的,不应与 关键词 混杂在一起。内容应该以用户认为可以理解和可读的简单易懂的语言编写。免费的采集软件可以直接查看每日蜘蛛、收录、网站权重。反向链接包括外部 网站 链接和内部 网站 链接。对于SEO来说,免费的采集软件是获得好的搜索引擎排名的一个非常重要的因素,所以反向链接的质量直接影响到整体网站SEO和网站搜索引擎排名的流量。引擎。
搜索引擎更信任拥有大量优质链接的网站s,并认为这些网站s比其他网站s提供更相关的搜索结果。今天关于免费采集软件的解释就到这里了。我希望它可以帮助你在搜索引擎优化的道路上。下期我会分享更多的SEO相关知识。下期再见。 查看全部
文章采集(免费采集软件支持外链插入,外链就是指从别的网站导入到)
最近很多站长让我多管理网站,批量网站文章内容更新让他筋疲力尽。市场上没有免费且功能强大的免费 采集 软件。许多功能是有限的,没有限制。相信这也是很多站长头疼的问题。今天谈谈采集。
免费采集软件可以有多个采集来源采集。免费的 采集 软件支持外部链接插入。外部链接是指从其他网站导入到自己的网站的链接。导入链接是网站优化的一个非常重要的过程。传入链接的质量(即传入链接所在页面的权重)直接决定了我们的网站在搜索引擎中的权重。免费采集软件可以本地化图像或存储其他平台。外链的作用不仅是提高网站对于网站SEO的权重,也不是提高某个关键词的排名。一个高质量的外链可以给网站带来好的流量。
免费的采集软件根据关键词采集文章填充内容。免费采集软件是网站之间在资源上具有一定优势互补的简单合作形式,即把对方网站的图片或文字放在自己的网站。@网站名字,并设置对方网站的超链接,让用户可以从合作网站中发现自己的网站,达到相互促进的目的,所以它常被用作网站@网站推广的基本手段。免费采集软件全自动批量挂机采集伪原创自动发布推送到搜索引擎。一般来说,和相似的网站交换友情链接
免费的采集软件还配备了很多SEO功能,不仅通过免费的采集软件实现了采集伪原创的发布,还有很多的SEO功能. 分类目录是对网站的信息进行系统的分类整理。免费的采集 软件提供了一个按类别组织的网站 目录。在每个类别中,网站站点名称、URL链接、内容摘要和子类别,您可以通过类别浏览找到相关的网站。免费采集软件标题前缀和后缀设置。目录的权重很高,只要能加上,就能带来稳定的优质外链。显示 网站 相关性的最佳方法之一是提供 网站 定期更新内容。使用独特的内容进行更新绝对有助于吸引搜索引擎对您的关注。
免费的采集软件可以提高关键词密度和页面原创度,增加用户体验,实现优质内容。搜索引擎是用户获取信息的平台。因此,免费采集软件强调新鲜、独特的内容,用户可以从中找到有用的信息。免费采集软件内容关键词插入。所以,定期更新你的网站博客和相关内容可以确保你的网站排名更好。
免费的采集软件由数十万网站文章维护,更新不是问题。在这个科技发达的世界里,我们更喜欢用我们的手机或平板电脑在搜索引擎中采集有用的信息。因此,开发一款适合移动端的网站,让用户可以访问网站上的信息势在必行。关键词搜索是任何 SEO 策略的第一个元素。如今,对有竞争力的 关键词 进行排名非常困难,因此最好的办法是找到免费的 采集 软件。
免费采集软件内容与标题一致,定期自动发布内部链接。几十万个不同的cms网站可以实现统一管理。低竞争力的关键词 是每个月搜索量很大的关键词,缺乏竞争力。选择正确的 关键词 有助于吸引访问者访问您的 网站 并为您带来更好的排名。免费采集软件搜索引擎推送。借助 关键词 研究工具,您可以确定用户对您的 关键词 或类别的兴趣并确定搜索量。
浏览器选项卡和搜索结果显示您的内容的标题。因此,请创建一个收录多个 关键词 或短语的标题,以帮助搜索用户找到与其查询相关的内容。免费采集软件批量设置发布数量不同关键词文章可设置发布不同栏目。
免费的采集软件伪原创保留字软件直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等网站创建一个描述性强、规范、简单的URL,有利于用户更方便地记忆和判断网页内容,也有利于搜索引擎更有效地抓取你的网站。网站从设计之初就应该有合理的URL规划。
免费采集软件最重要的标题标签是H1标签,它指定了页面的内容,在一个网页上只能使用一次。H2、H3、H4、H5 和 H6 是没有 H1 标签重要的副标题标签。搜索引擎强调 H1 标签,而不是其他标题,并且当与其他 SEO 技术正确使用时,将产生最佳结果并提高您的搜索引擎排名。
这是关于您的页面的简短摘要,以便用户可以了解该页面的内容,而不是从您的标题中获取一些粗略的信息。元描述标签应该与优化的页面标题相关。免费采集软件批量监控不同cms网站数据,你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms@ >、人人展cms、Cyclone、站群、PB、Apple、搜外等主要cms工具,可同时管理和批量发布。用户应该能够很好地将标题与描述联系起来。您的元描述必须简短且少于 155 个字符。
免费 采集 软件为图像提供 alt 标签或可选文本标签,不仅使用户可以访问它们,而且还通知搜索引擎您的页面。图像 alt 标签和文件名应收录 关键词 以便搜索引擎可以将具有特定 关键词 的内容提供给搜索用户。
请记住,内容应该是自然的,不应与 关键词 混杂在一起。内容应该以用户认为可以理解和可读的简单易懂的语言编写。免费的采集软件可以直接查看每日蜘蛛、收录、网站权重。反向链接包括外部 网站 链接和内部 网站 链接。对于SEO来说,免费的采集软件是获得好的搜索引擎排名的一个非常重要的因素,所以反向链接的质量直接影响到整体网站SEO和网站搜索引擎排名的流量。引擎。
搜索引擎更信任拥有大量优质链接的网站s,并认为这些网站s比其他网站s提供更相关的搜索结果。今天关于免费采集软件的解释就到这里了。我希望它可以帮助你在搜索引擎优化的道路上。下期我会分享更多的SEO相关知识。下期再见。
文章采集(苹果cms采集视频可以在后台联盟资源库里直接设置采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2022-03-28 02:15
)
苹果cms采集视频可以直接在后台联盟资源库中设置采集,也可以配置自己自定义的采集库,关于文章信息采集,Applecms后台没有专门的采集库,所以文章采集我们需要添加采集@ > 自己接口,或者是使用第三方采集工具,不懂代码的小白完全不知道。前期,目前80%的影视台都是依靠采集来扩充自己的视频库,比如之前的大台电影天堂、BT站等最新电影下载。这一切都始于 采集。先丰富视频源再做网站收录,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具来让Apple cms网站启动并运行!
由于各种影视台的兴起,cms模板泛滥。大量的网站模板都是类似的。除了采集规则外,影视台的内容也是重复的。车站会叹息! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,就很难提升了。视频站无非就是一个标题、内容和内容介绍。苹果80%的cms站都是这样的结构,我们该怎么办?为了在众多影视台中脱颖而出?
一、苹果cms网站怎么样原创?
1、标题选择插入品牌词
2、播放集数(例如:第一集改为在线第一集)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化可访问性设置:
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后主动推送文章到搜索引擎,保证新链接能被搜索引擎及时搜索到收录)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权重)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提升网站的收录)
9、设置批量发布数量(可以设置发布间隔/单日发布总数)
10、可以设置不同的类型发布不同的栏目
11、工具设置锁定词(文章原创文章可读性和核心词不会原创时自动锁定品牌词和产品词)
查看全部
文章采集(苹果cms采集视频可以在后台联盟资源库里直接设置采集
)
苹果cms采集视频可以直接在后台联盟资源库中设置采集,也可以配置自己自定义的采集库,关于文章信息采集,Applecms后台没有专门的采集库,所以文章采集我们需要添加采集@ > 自己接口,或者是使用第三方采集工具,不懂代码的小白完全不知道。前期,目前80%的影视台都是依靠采集来扩充自己的视频库,比如之前的大台电影天堂、BT站等最新电影下载。这一切都始于 采集。先丰富视频源再做网站收录,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具来让Apple cms网站启动并运行!
由于各种影视台的兴起,cms模板泛滥。大量的网站模板都是类似的。除了采集规则外,影视台的内容也是重复的。车站会叹息! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,就很难提升了。视频站无非就是一个标题、内容和内容介绍。苹果80%的cms站都是这样的结构,我们该怎么办?为了在众多影视台中脱颖而出?
一、苹果cms网站怎么样原创?
1、标题选择插入品牌词
2、播放集数(例如:第一集改为在线第一集)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化可访问性设置:
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后主动推送文章到搜索引擎,保证新链接能被搜索引擎及时搜索到收录)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权重)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提升网站的收录)
9、设置批量发布数量(可以设置发布间隔/单日发布总数)
10、可以设置不同的类型发布不同的栏目
11、工具设置锁定词(文章原创文章可读性和核心词不会原创时自动锁定品牌词和产品词)
文章采集(免费文章采集器可以关键词文章采集,基于高度智能的正文识别算法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2022-03-21 00:16
)
免费文章采集器可以关键词文章采集,免费文章采集器基于高度智能的全网文本识别算法采集,免费文章采集器只需在采集内容中输入关键词即可,无需编写采集规则。免费文章采集器基于自然语言理解、深度学习等技术。免费文章采集器目前全网主流cms/站群/蜘蛛池/免登录批量自动发布,无需写规则,免费< @文章采集器 无需上传插件。免费文章采集器一键配置采集发布几十个不同站点cms站群。
现在网络很火,越来越多的人学会了做网络推广,所以竞争也很激烈。织梦、Empire、wordpress、zblog、易友、美图、pboot、迅锐、苹果cms、小轩峰等cms/站群批量管理和发布。免费文章采集器免登录发布界面,批量管理不同cms、站群免登录发布界面,织梦、empire、wordpress批量管理、zblog、易友、米拓、pboot、迅锐、苹果cms、肖轩峰等cms。在互联网平台的发展中,想要做大做强,就必须对网站进行推广和吸引流量!竞价推广和SEO排名优化是网站营销的主要推广方式。搜索带来的流量准确率高于信息流广告。今天主要讲解网站排名优化方法中比较常见的一种推广方式。
免费文章采集器基于高度智能的全网文本识别算法采集,在采集内容中输入关键词即可,无需写采集 规则。指建几个站或者几十个站,简单来说就是一组网站。它是网站主要利用搜索引擎自然优化规则进行推广,采集大量内容,通过长尾关键词大面积增加搜索引擎排名的份额,获得大量的搜索流量,从而稳定获客。
覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先考虑采集最新最热文章信息,自动过滤采集信息,拒绝重复采集。免费文章采集器专为谷歌、百度、雅虎、360等大型搜索引擎设计收录,伪原创工具生成的文章会更好收录 并被搜索引擎索引。
最大的好处是可以覆盖大量围绕业务或者相关产品的长尾关键词,而且大家都知道一个网站的流量,60%以上都是长尾带来的关键词,可以在这方面发挥最大的作用,而网站随着时间的推移,流量会不断增长,后期获客成本会越来越低,效果会越来越好。
免费文章采集器基于高度智能的文本识别算法进行六大搜索引擎全网采集,免费文章采集器输入即可关键词@ >你可以采集内容。与全站优化不同的是,它主要优化关键词,以某关键词的优化排名“获胜”。
全站优化除了对关键词的优化,还可以综合整合网站的基础、外链、内容。也就是说,它不以关键词优化为最终目标,而是让网站的每一页都参与优化,最终目的是提高网站的权重和排名. 主要通过采集大量的内容和长尾关键词来增加排名份额,而全站优化主要围绕网站,整体结构网站@ > 会考虑、内容、关键词、链接等方面,让网站的开发能够更好的提升用户的访问体验。围绕优化的主题是不同的。
免费文章采集器全网优质数据采集,自动过滤采集信息,拒绝重复采集。免费文章采集器内容覆盖六大搜索引擎和主要新闻来源。由于其简单性,它的工作速度更快,花费的时间更少。但是排名不稳定,会导致排名根据用户的不同需求和搜索引擎的不同规则和算法而波动。但是,由于其“高瞻远瞩”,整个网站的优化需要考虑的事情很多,这会让网站适应长远发展的需要。智能文字识别算法,只需输入关键词采集,满足各行业客户的需求,
免费文章采集器可关键词精准采集,免费文章采集器进入关键词主流媒体平台获取< @文章素材,保证文章内容的多样性,自动过滤已经采集的信息,拒绝重复采集。尤其是整个网站优化的不断调整和优化,使得网站得以健康发展,提升网站的质量,对于增加流量和效果转化都有很大帮助。
免费文章采集器图片水印主动加图片水印,使图片100%原创自动加图片水印,提高原创度。它不同于全站优化,但最终目的是带来客户转化,都是按照搜索引擎的规则发布网站内容和推广网站。如果有能力,也可以直接使用竞价推广。毕竟付费推广效果也是最快的。网站排名优化推广需要一定的时间,排名可能达不到。
文章内容原则上应该为访问者解决问题。网站速度优化,背后的原理就是提升用户体验,仅此而已。免费文章采集器保持标签:strong, span, p, img, div, article, h1、h2、h3、br, script网站 @>模板可以给客户一种信任感。实际做法是参考业内较好的网站进行模仿,购买付费版的网站模板,或者让用户参与到每一个设计过程中。免费文章采集器图片可以多方向存储(七牛云/阿里巴巴云/游拍云/腾讯云/百度云/华为云/本地)。免费的文章采集器可以是常规的关键词布局。关键词布局是基本且必要的优化点,如Title、H1、文章
SEO一直是在搜索引擎端推广内容的技术手段。只要有搜索引擎,就会有seoer这个职业。毕竟,有很多人使用搜索引擎来寻找问题的解决方案。有需求就有市场,所以做好seo优化也是一个办法!免费文章采集器文章翻译界面:百度/谷歌/有道/讯飞/147/等。对于新的网站,为了被搜索引擎爬取,需要稳定的服务器,可以随时被搜索引擎爬虫(机器人)爬取;
查看全部
文章采集(免费文章采集器可以关键词文章采集,基于高度智能的正文识别算法
)
免费文章采集器可以关键词文章采集,免费文章采集器基于高度智能的全网文本识别算法采集,免费文章采集器只需在采集内容中输入关键词即可,无需编写采集规则。免费文章采集器基于自然语言理解、深度学习等技术。免费文章采集器目前全网主流cms/站群/蜘蛛池/免登录批量自动发布,无需写规则,免费< @文章采集器 无需上传插件。免费文章采集器一键配置采集发布几十个不同站点cms站群。
现在网络很火,越来越多的人学会了做网络推广,所以竞争也很激烈。织梦、Empire、wordpress、zblog、易友、美图、pboot、迅锐、苹果cms、小轩峰等cms/站群批量管理和发布。免费文章采集器免登录发布界面,批量管理不同cms、站群免登录发布界面,织梦、empire、wordpress批量管理、zblog、易友、米拓、pboot、迅锐、苹果cms、肖轩峰等cms。在互联网平台的发展中,想要做大做强,就必须对网站进行推广和吸引流量!竞价推广和SEO排名优化是网站营销的主要推广方式。搜索带来的流量准确率高于信息流广告。今天主要讲解网站排名优化方法中比较常见的一种推广方式。
免费文章采集器基于高度智能的全网文本识别算法采集,在采集内容中输入关键词即可,无需写采集 规则。指建几个站或者几十个站,简单来说就是一组网站。它是网站主要利用搜索引擎自然优化规则进行推广,采集大量内容,通过长尾关键词大面积增加搜索引擎排名的份额,获得大量的搜索流量,从而稳定获客。
覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先考虑采集最新最热文章信息,自动过滤采集信息,拒绝重复采集。免费文章采集器专为谷歌、百度、雅虎、360等大型搜索引擎设计收录,伪原创工具生成的文章会更好收录 并被搜索引擎索引。
最大的好处是可以覆盖大量围绕业务或者相关产品的长尾关键词,而且大家都知道一个网站的流量,60%以上都是长尾带来的关键词,可以在这方面发挥最大的作用,而网站随着时间的推移,流量会不断增长,后期获客成本会越来越低,效果会越来越好。
免费文章采集器基于高度智能的文本识别算法进行六大搜索引擎全网采集,免费文章采集器输入即可关键词@ >你可以采集内容。与全站优化不同的是,它主要优化关键词,以某关键词的优化排名“获胜”。
全站优化除了对关键词的优化,还可以综合整合网站的基础、外链、内容。也就是说,它不以关键词优化为最终目标,而是让网站的每一页都参与优化,最终目的是提高网站的权重和排名. 主要通过采集大量的内容和长尾关键词来增加排名份额,而全站优化主要围绕网站,整体结构网站@ > 会考虑、内容、关键词、链接等方面,让网站的开发能够更好的提升用户的访问体验。围绕优化的主题是不同的。
免费文章采集器全网优质数据采集,自动过滤采集信息,拒绝重复采集。免费文章采集器内容覆盖六大搜索引擎和主要新闻来源。由于其简单性,它的工作速度更快,花费的时间更少。但是排名不稳定,会导致排名根据用户的不同需求和搜索引擎的不同规则和算法而波动。但是,由于其“高瞻远瞩”,整个网站的优化需要考虑的事情很多,这会让网站适应长远发展的需要。智能文字识别算法,只需输入关键词采集,满足各行业客户的需求,
免费文章采集器可关键词精准采集,免费文章采集器进入关键词主流媒体平台获取< @文章素材,保证文章内容的多样性,自动过滤已经采集的信息,拒绝重复采集。尤其是整个网站优化的不断调整和优化,使得网站得以健康发展,提升网站的质量,对于增加流量和效果转化都有很大帮助。
免费文章采集器图片水印主动加图片水印,使图片100%原创自动加图片水印,提高原创度。它不同于全站优化,但最终目的是带来客户转化,都是按照搜索引擎的规则发布网站内容和推广网站。如果有能力,也可以直接使用竞价推广。毕竟付费推广效果也是最快的。网站排名优化推广需要一定的时间,排名可能达不到。
文章内容原则上应该为访问者解决问题。网站速度优化,背后的原理就是提升用户体验,仅此而已。免费文章采集器保持标签:strong, span, p, img, div, article, h1、h2、h3、br, script网站 @>模板可以给客户一种信任感。实际做法是参考业内较好的网站进行模仿,购买付费版的网站模板,或者让用户参与到每一个设计过程中。免费文章采集器图片可以多方向存储(七牛云/阿里巴巴云/游拍云/腾讯云/百度云/华为云/本地)。免费的文章采集器可以是常规的关键词布局。关键词布局是基本且必要的优化点,如Title、H1、文章
SEO一直是在搜索引擎端推广内容的技术手段。只要有搜索引擎,就会有seoer这个职业。毕竟,有很多人使用搜索引擎来寻找问题的解决方案。有需求就有市场,所以做好seo优化也是一个办法!免费文章采集器文章翻译界面:百度/谷歌/有道/讯飞/147/等。对于新的网站,为了被搜索引擎爬取,需要稳定的服务器,可以随时被搜索引擎爬虫(机器人)爬取;
文章采集(图片识别帝国CMS采集软件图片有哪些优化呢?(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-03-09 11:26
)
Empirecms采集该软件页面非常简洁,操作简单。无需掌握专业规则配置和高级SEO知识即可使用。无论是WordPresscms、织梦cms、Think CMF还是小型旋风cms都可以使用。软件还内置翻译发布推送、数据查看等功能。
Empirecms采集软件支持方向和增量采集,输入我们的目标网址即可实现可视化操作。完成点击并选择规则后,即可采集。全网采集也很方便,可以进入关键词在全网各大平台进行内容采集。根据 关键词 来自流行的下拉菜单的支持。下载支持过滤和清理敏感词和 文章 属性。采集内容以多种格式(TXT、HTML 和漩涡样式)保存。支持保留标签和图片本地化等功能,内置翻译功能,有道、百度、谷歌及自有
翻译功能可用。
Empirecms采集软件定时采集发布可以让我们24小时自动挂机,蜘蛛喜欢定时更新网站,因为这样的网站很容易spiders 判断为正常操作网站,所以良好的“作息时间”可以让蜘蛛有规律的抓取,再加上主动推送吸引蜘蛛,可以大大提高我们的收录效率。
当然,仅有内容是不够的。一个好的文章离不开图片的配合。合理插入与我们的文章相关的图片,会大大降低用户理解的难度。一张好的图片有时可以很抢眼,反而让文字成为一种点缀。为 网站 图片添加 ALT 标签也可以让蜘蛛快速识别图片。Empirecms采集软件图片有哪些优化?我们需要组织内容来提高内容质量,吸引用户逐步完善我们的收录,Empirecms采集软件可以通过以下几点优化我们的内容,实现我们的< @收录 @网站快收录,提高你的排名。
一、网站图像优化
1、图片云存储/本地化;
2、图片alt标签;
3、图片替换原图;
4、图片水印/去水;
5、图片按频率插入到文本中。
二、网站内容优化
1、文章采集源码质量保证(大平台,热门词汇);
2、采集内容标签保留;
3、内置翻译功能(英译中、繁译简、简译火星);
4、文章物业保洁(号码、网址、机构名称保洁);
5、关键词保留(伪原创不会影响关键词,保证核心关键词的显示);
6、关键词插入标题和文章;
7、标题、内容伪原创;
8、设置内容与标题一致(使内容与标题完全一致);
9、设置关键词自动内链(自动从文章内容中的关键词生成内链)。
三、网站管理优化
Empirecms采集软件可以在软件内部实现采集、翻译、伪原创、SEO、发布、推送的全流程管理,查看任务进度各个阶段,随时提供实时反馈。有关任务成功或失败的信息。绑定的cms网站可以在软件站查看我们的收录、权重、蜘蛛等信息,并自动生成曲线供我们的SEOER分析。
四、网站关键词优化
网站获得好的排名需要关键词 优化。我们在优化网站关键词的时候,还需要做好网站结构和关键词布局。
1、分析 关键词 的竞争对手
在优化关键词时,我们不能忽视竞争对手的关键词。了解你自己,了解你的敌人。除了了解自己的情况,我们还需要做好对竞争对手的分析,制定适合自己特点的优化方案。
2、优化网站的布局
我们需要对网站的布局进行详细评估,发现与优化思路不符的网站结构和凌乱的关键词布局。网站 的代码越简单,结构化的 URL 就越好,路径也会越清晰。关键词合理
的
允许蜘蛛更快地找到我们的 关键词 的布局。这些优化应该在不影响页面美观和不降低用户体验的情况下进行。
3、关键词密度
我们的 关键词 并不简单
的
反复叠加,但要自然
的
出现。要做到这一点,不是每个人都认为
的
这么困难。重点是内容与标题一致,所以关键词出现在文章中是很自然的。
帝国cms采集软件来自文章采集,内容优化,关键词密度等优化技术网站就介绍到这里,希望对你有帮助每个人。
查看全部
文章采集(图片识别帝国CMS采集软件图片有哪些优化呢?(图)
)
Empirecms采集该软件页面非常简洁,操作简单。无需掌握专业规则配置和高级SEO知识即可使用。无论是WordPresscms、织梦cms、Think CMF还是小型旋风cms都可以使用。软件还内置翻译发布推送、数据查看等功能。
Empirecms采集软件支持方向和增量采集,输入我们的目标网址即可实现可视化操作。完成点击并选择规则后,即可采集。全网采集也很方便,可以进入关键词在全网各大平台进行内容采集。根据 关键词 来自流行的下拉菜单的支持。下载支持过滤和清理敏感词和 文章 属性。采集内容以多种格式(TXT、HTML 和漩涡样式)保存。支持保留标签和图片本地化等功能,内置翻译功能,有道、百度、谷歌及自有
翻译功能可用。
Empirecms采集软件定时采集发布可以让我们24小时自动挂机,蜘蛛喜欢定时更新网站,因为这样的网站很容易spiders 判断为正常操作网站,所以良好的“作息时间”可以让蜘蛛有规律的抓取,再加上主动推送吸引蜘蛛,可以大大提高我们的收录效率。
当然,仅有内容是不够的。一个好的文章离不开图片的配合。合理插入与我们的文章相关的图片,会大大降低用户理解的难度。一张好的图片有时可以很抢眼,反而让文字成为一种点缀。为 网站 图片添加 ALT 标签也可以让蜘蛛快速识别图片。Empirecms采集软件图片有哪些优化?我们需要组织内容来提高内容质量,吸引用户逐步完善我们的收录,Empirecms采集软件可以通过以下几点优化我们的内容,实现我们的< @收录 @网站快收录,提高你的排名。
一、网站图像优化
1、图片云存储/本地化;
2、图片alt标签;
3、图片替换原图;
4、图片水印/去水;
5、图片按频率插入到文本中。
二、网站内容优化
1、文章采集源码质量保证(大平台,热门词汇);
2、采集内容标签保留;
3、内置翻译功能(英译中、繁译简、简译火星);
4、文章物业保洁(号码、网址、机构名称保洁);
5、关键词保留(伪原创不会影响关键词,保证核心关键词的显示);
6、关键词插入标题和文章;
7、标题、内容伪原创;
8、设置内容与标题一致(使内容与标题完全一致);
9、设置关键词自动内链(自动从文章内容中的关键词生成内链)。
三、网站管理优化
Empirecms采集软件可以在软件内部实现采集、翻译、伪原创、SEO、发布、推送的全流程管理,查看任务进度各个阶段,随时提供实时反馈。有关任务成功或失败的信息。绑定的cms网站可以在软件站查看我们的收录、权重、蜘蛛等信息,并自动生成曲线供我们的SEOER分析。
四、网站关键词优化
网站获得好的排名需要关键词 优化。我们在优化网站关键词的时候,还需要做好网站结构和关键词布局。
1、分析 关键词 的竞争对手
在优化关键词时,我们不能忽视竞争对手的关键词。了解你自己,了解你的敌人。除了了解自己的情况,我们还需要做好对竞争对手的分析,制定适合自己特点的优化方案。
2、优化网站的布局
我们需要对网站的布局进行详细评估,发现与优化思路不符的网站结构和凌乱的关键词布局。网站 的代码越简单,结构化的 URL 就越好,路径也会越清晰。关键词合理
的
允许蜘蛛更快地找到我们的 关键词 的布局。这些优化应该在不影响页面美观和不降低用户体验的情况下进行。
3、关键词密度
我们的 关键词 并不简单
的
反复叠加,但要自然
的
出现。要做到这一点,不是每个人都认为
的
这么困难。重点是内容与标题一致,所以关键词出现在文章中是很自然的。
帝国cms采集软件来自文章采集,内容优化,关键词密度等优化技术网站就介绍到这里,希望对你有帮助每个人。
文章采集(百度收录我也只有这一点点心得了希望百度能多收我几页)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2022-03-02 20:01
前天晚上我真的很开心,为什么?因为我的80易新闻在线上线了一天半,百度接受了。虽然只接受了一个主页,但速度如此之快,真的让我很开心。这是我朋友的一句话。原话“世界是什么。我被百度接受了一个多星期,你不到两天……”呵呵。
首先,我给大家介绍一下百度收录。
先提交到百度网站.
写文章提交A5,带链接,但是不要用AD过分,链接的目的就是靠A5的百度权重,这样百度蜘蛛逛街的时候,他们发现有你这样的网站,或者发给其他高权重的地方也可以,我就不多说了。
还有一个原因是我昨天早上才发现的,应该和收录有关。我只在 A5 上发了这篇文章,但我还有几个外部链接。为什么?就是因为采集这个工具,昨天早上我朋友给我发了QQ,说你真的会写文章啊,我就说你看到了?然后他给我发了地址,但不是A5的地址,我才明白为什么突然有这么多外链,不知道A5有没有保护采集,但是文章文章是和A5上的一模一样,就算不是工具采集也必须是手动的采集,而且写软文发到大网站的好处不是不仅因为百度权重高,也因为在网友中的权重高,他们是采集网站的首选。
关于收录我只有这点小经验,希望百度能多收我几页。
对,上面提到的采集,我之前有点不屑。佩服原创,后来发现个别站长不使用采集真的很麻烦。但是我只觉得采集可以用于采集新闻资讯,因为这些东西不是我们个别站长能写出来的,所以今天去娱乐八卦版块研究一下。 采集 下午。我使用的是DEDEcms5.3中收录的采集工具,我来简单介绍一下。
采集一般分为3个步骤:获取规则、匹配规则、过滤。
获取规则的意思是,获取文章列表URL,比如你找到XX网站的列表页面。然后你看列表页第一页的地址和后面几页的地址。比如第一页的地址后面是001.html 第二页的后缀是002.html 第三页如果是003.html,那么有这里有个规则,就是后者比前者+1,那么你选择批量生成一个URL列表,然后匹配URL中输入的地址,将地址中的更改地址替换为(*)你如果要获取多页列表,请在下方 (*) 中输入 1 到页数之间的数字。
匹配规则就是说,列表页从哪里去,就是你要获取的URL。然后打开列表页的源码,找到你要的开头和结尾部分,注意一件事,你找到的一定是代码中唯一的,可以点击Edit-Find查看详情。
下一步是过滤掉 文章 页面上不需要的内容。这个不难理解,我就不多说了。
对于不知道如何使用它的人来说,做一些研究并不难。不明白的可以加我的小AD。 80Easy ——年轻人的互动社区。欢迎来坐,呵呵。 查看全部
文章采集(百度收录我也只有这一点点心得了希望百度能多收我几页)
前天晚上我真的很开心,为什么?因为我的80易新闻在线上线了一天半,百度接受了。虽然只接受了一个主页,但速度如此之快,真的让我很开心。这是我朋友的一句话。原话“世界是什么。我被百度接受了一个多星期,你不到两天……”呵呵。
首先,我给大家介绍一下百度收录。
先提交到百度网站.
写文章提交A5,带链接,但是不要用AD过分,链接的目的就是靠A5的百度权重,这样百度蜘蛛逛街的时候,他们发现有你这样的网站,或者发给其他高权重的地方也可以,我就不多说了。
还有一个原因是我昨天早上才发现的,应该和收录有关。我只在 A5 上发了这篇文章,但我还有几个外部链接。为什么?就是因为采集这个工具,昨天早上我朋友给我发了QQ,说你真的会写文章啊,我就说你看到了?然后他给我发了地址,但不是A5的地址,我才明白为什么突然有这么多外链,不知道A5有没有保护采集,但是文章文章是和A5上的一模一样,就算不是工具采集也必须是手动的采集,而且写软文发到大网站的好处不是不仅因为百度权重高,也因为在网友中的权重高,他们是采集网站的首选。
关于收录我只有这点小经验,希望百度能多收我几页。
对,上面提到的采集,我之前有点不屑。佩服原创,后来发现个别站长不使用采集真的很麻烦。但是我只觉得采集可以用于采集新闻资讯,因为这些东西不是我们个别站长能写出来的,所以今天去娱乐八卦版块研究一下。 采集 下午。我使用的是DEDEcms5.3中收录的采集工具,我来简单介绍一下。
采集一般分为3个步骤:获取规则、匹配规则、过滤。
获取规则的意思是,获取文章列表URL,比如你找到XX网站的列表页面。然后你看列表页第一页的地址和后面几页的地址。比如第一页的地址后面是001.html 第二页的后缀是002.html 第三页如果是003.html,那么有这里有个规则,就是后者比前者+1,那么你选择批量生成一个URL列表,然后匹配URL中输入的地址,将地址中的更改地址替换为(*)你如果要获取多页列表,请在下方 (*) 中输入 1 到页数之间的数字。
匹配规则就是说,列表页从哪里去,就是你要获取的URL。然后打开列表页的源码,找到你要的开头和结尾部分,注意一件事,你找到的一定是代码中唯一的,可以点击Edit-Find查看详情。
下一步是过滤掉 文章 页面上不需要的内容。这个不难理解,我就不多说了。
对于不知道如何使用它的人来说,做一些研究并不难。不明白的可以加我的小AD。 80Easy ——年轻人的互动社区。欢迎来坐,呵呵。

