最新版:网页文章正文采集的方法以微信文章采集为例.docx 45页
优采云 发布时间: 2022-10-31 20:46最新版:网页文章正文采集的方法以微信文章采集为例.docx 45页
网页文章文本采集方法,以微信文章采集为例。保存的时候怎么办?一张一张复制粘贴?选择一个通用的网络数据 采集器 将使这项工作变得容易得多。优采云是一个通用的网页数据采集器,可以是互联网上的采集公共数据。用户可以设置从哪个网站爬取数据,爬取什么数据,爬取什么范围的数据,什么时候爬取数据,如何保存爬取的数据等。言归正传,本文将采取<以搜狗微信文章文字采集为例,讲解优采云采集网页文章文字的使用方法。文章文本采集,主要有两种情况: 1、采集文章正文中的文本,不包括图片;2. 采集文章 正文中的文本和图像 URL。示例网站:/使用功能点:Xpath/search?query=XPath判断条件/tutorialdetail-1/judge.html分页列表信息采集 /tutorial/fylb-70.aspx?t=1AJAX滚动教程/tutorialdetail-1/ajgd_7.htmlAJAX点击翻页/tutorialdetail-1/ajaxdjfy_7.html采集文章正文中,无图片具体步骤: 第一步:创建采集任务1)进入主界面,选择“自定义模式”网页文章文本采集步骤12)复制并粘贴你想要的网站的网址采集到网站
打开网页时,默认显示“热门”文章。向下滚动页面,找到并点击“加载更多内容”按钮,在动作提示框中,选择“更多动作”页面文章Body采集Step 3选择“循环点击单个元素”创建一个翻页循环网页文章Body采集第四步由于这个网页涉及到Ajax技术,我们需要设置一些高级选项。选择“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”网页文章Text采集Step 5 注意:AJAX表示延迟加载, 一种异步更新的脚本技术,通过在后台与服务器交换少量数据,可以在不重新加载整个网页的情况下更新网页的某个部分。详情请参考AJAX点击和翻页教程:/tutorialdetail-1/ajaxdjfy_7.html 观察网页,我们发现点击“加载更多内容”5次后,页面加载到了底部,一共有显示了 100 篇文章 文章 。因此,我们将整个“循环页面”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5次”,在网页点击“确定”文章Text采集Steps 6Step 3:创建列表循环并提取数据移动鼠标选择页面中的第一个文章链接。系统会自动识别相似链接。在操作提示框中,选择“Select All”网页文章Text采集Step 7 选择“Cycle Click Each Link”网页文章Text采集Step 8系统会自动进入文章详情页面。
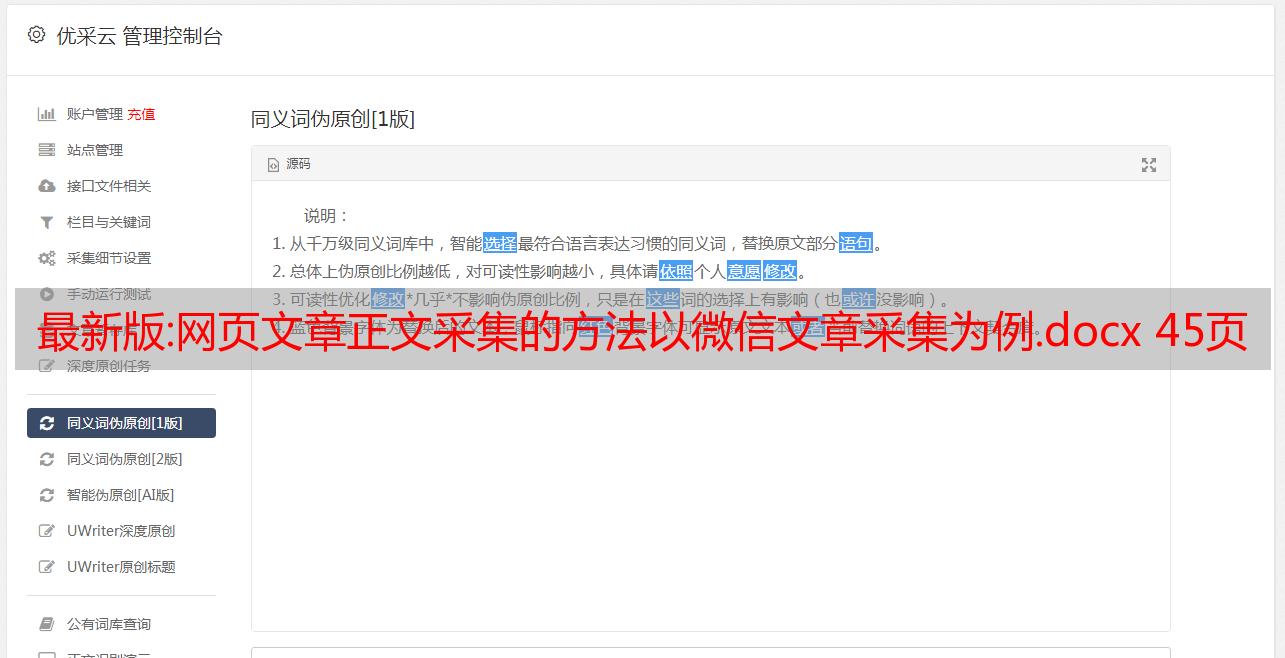
点击需要采集的字段(这里先点击文章标题),在操作提示框中选择“采集该元素的文本”。文章发布时间,文章来源字段采集方法同理网页文章正文采集第九步下一步开始采集文章 文本。首先点击第一段文章文字,系统会自动识别页面中的相似元素,选择“全选”页面文章文字采集步骤105)即可看到所有的文本段落都被选中并变成绿色。选择“采集以下元素文本”网页文章正文采集步骤11 注意:在字段表中,可以自定义和修改字段。网页文章正文采集 Step 126) 经过上述操作后,文本将全部采集向下(默认情况下,每段文本为一个单元格)。一般来说,我们希望 采集 的主体被合并到同一个单元格中。点击“自定义数据字段”按钮,选择“自定义数据合并方式”,勾选“同一字段多次提取并合并为一行,即追加到同一字段,如文本页面合并”,然后点击“OK”页面文章Body采集Step 13“Customize Data Fields”按钮网页文章Body采集Step 14 选择“Customize Data Merge Method”网页文章Body采集Step 15 检查如图步骤4:修改Xpath1) 选中整个“loop step”,打开“Advanced Options”,可以看到优采云
我们通过这个Xpath发现://DIV[@class='main-left']/DIV[3]/UL/LI/DIV[2]/H3[1]/A,页面需要100篇文章< 文章所有页面都位于文章正文采集步骤173)将修改后的Xpath复制粘贴到优采云所示位置,然后点击“确定”到页面文章Text采集Step 18 Step 5:修改流程图结构我们继续观察,点击“加载更多内容”5次后,该页面加载了全部100篇文章文章。所以我们配置规则的思路是先建立一个翻页循环,把100篇文章全部加载文章,然后创建一个循环列表来提取数据 1)选择整个“循环”步骤并拖动退出“循环页面”步骤。如果不执行此操作,将会出现大量重复的数据页。文章Text采集Step 19 拖拽完成后页面如下图文章Text采集Steps 20 Step 6:Data采集并导出1 ) 点击左上角“保存”,然后点击“开始采集”,选择“开始本地采集”网页文章文本采集步骤21采集步骤21完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的数据导出到网页文章文本采集Step 223) 这里我们选择excel作为导出格式。数据导出后,网页如下图所示。采集到。那是因为 文章 的循环列表的 Xpath://[@id="js_content"]/P
修改Xpath为://[@id="js_content"]//P,所有文章文本都可以定位。再次启动采集,文章的所有文本内容都是采集到网页文章Text采集步骤24 修改Xpath之前的网页文本文章 采集在第25步修改Xpath后,经过以上操作,目标URL中的微信文章正文中的所有文字都是采集下来的。如果还需要采集图片,则需要在已有规则中添加判断条件。采集文章正文中的文字和图片URL按照第一步中的步骤6。第七步:添加判断条件 前6步之后,我们只有采集在微信文章中的文字内容,不包括文章中的图片。如果你需要 采集 图片,需要在规则中添加判断条件:判断文章的内容列表,如果收录img元素(图片),则执行图片采集分支;if not 如果收录一个img元素(图片),则执行文本采集分支。同时,在优采云中,默认为左分支设置判断条件。如果满足判断条件,则执行左分支;当左分支的判断条件不满足时,执行最右分支。回到这个规则,就是给左分支设置一个条件:如果收录img元素(图片),则执行左分支;如果左条件分支的条件不满足(即不包括img元素),则执行右分支。具体操作如下:
我们将“提取数据”步骤移至右侧分支(绿色加号)。然后点击右侧的分支,在出现的结果页面点击“确定”页面(分支条件检测结果-检测结果始终为True)文章Text采集第27步拖动“ Extract Element" step into Right branch pages文章Text采集Step 28 Right branch - detection result is always True 点击左分支,点击出现的结果页面(branch condition detection result - detection result is always True) Sure”。然后为其设置判断条件:勾选“当前循环项收录元素”,输入元素Xpath://img(代表一张图片),然后在网页上点击“确定”文章文字采集 Step 29 点击left 侧分支到左分支,设置判断条件。网页文章文本采集步骤304)左分支条件设置后,执行数据提取步骤。从左侧工具栏中,将“提取数据”步骤拖到流程图左侧分支(绿色加号),然后在页面上选择一张图片,在操作提示框中选择“采集这张图片地址”进入新的“提取数据”步骤,到左分支网页文章Text采集Step 31采集图片地址网页文章Text采集Step 325 ) 选择右侧分支的“Extract Data”步骤,点击“Customize Data Field”按钮,选择“Custom Positioning Element Method”,设置“Element Matching Xpath”
经检查,多次提取的文本会被追加为字段网页文章Text采集步骤368)注意在优采云中,判断中每个分支中的“提取数据”条件步骤中的字段名称必须相同,字段数量必须相同。这里我们将左右分支中提取的字段名改为“text”(判断条件教程,请参考:/tutorialdetail-1/judge.html)网页文章text采集steps 379)如上,设置了整个判断条件。点击左上角的“保存”和“开始采集”。我们发现在导出的excel表格中,图片地址是一堆乱码。为什么是这样?继续观察网页——搜狗微信文章文中的图片 需要向下滚动才能加载,加载后才能采集进入正确的图片地址。因此,打开文章后,需要设置为“页面加载完成后向下滚动”。这里设置滚动次数为“30次”,每次间隔“2秒”,滚动方式为“向下滚动一屏”网页文章文字采集步骤38微信文章 文中的图片需要向下滚动才能加载。设置“页面加载后向下滚动”网页文章Text采集Step 39 注意:这里对滚动次数、时间、方式的设置会影响文章的速度和质量采集 数据。本文仅供参考,您可以根据需要设置,
在 采集 过程中,会花费大量时间等待图片加载,因此 采集 比较慢。如果不需要采集图片,直接使用文字采集,不用等待图片加载,采集会快很多。相关采集教程:百度搜索结果采集新浪微博数据采集豆瓣影评采集优采云——70万用户选择的网页数据采集器。1.操作简单,任何人都可以使用:不需要技术背景,只要能上网采集即可。完成流程可视化,点击鼠标完成操作,2分钟快速上手。2.功能强大,任意网站可选:用于点击、登录、翻页、识别验证码、瀑布、和Ajax脚本异步加载数据,所有页面都可以通过简单的设置采集。3.云采集,也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、免费功能+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
干货教程:暴力海外引流协议_instagram协议引流软件_ins营销推广群发软件_关键词
Instagram关键词自动采集用户批量关注作品,并将作品发布到Aite通知协议
Instagram是一款协议软件,支持批量导入关键词给采集相关用户,然后软件自动采集这些用户的粉丝
该软件支持
设置喜欢和评论采集粉丝作品的用户,软件支持多账号多线程批量关注和动态作品批量发布 爱特人!