
抓取网页视频
抓取网页视频(搜了搜知乎,几万个人在看,结果在这)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-01 14:12
抓取网页视频,想看看有多少人在看,就搜了搜知乎,几万个人在看,结果在这给大家整理下我搜的app,可以说是相当的全了。分享给大家。1.快手快手,一款脱口秀小视频短视频分享app,极其搞笑搞笑。同时也是趣友社交软件,特有的拼团玩法可以获得更多的知识加强社交能力,推荐给有收藏快手的朋友,这是我从快手无意间收到的朋友推荐,现在依然在用,强烈推荐下。
2.映客映客主要也是用来录制视频的直播软件,这两年人是有多疯狂了,据说有人周末两天冲破了万人观看,同时也可以唱唱歌、聊聊天,偶尔录一段小段子,还是特别不错的。3.斗鱼斗鱼是我一直很推荐的一款直播软件,这里的主播还是相当不错的,也有自己的签约工会,在上面可以和知名主播进行近距离对话,并且到现在还在不断更新,这里的主播活跃度高,都特别有才,这里也是大家喜欢跳舞聊天的首选,在以前还是特别的喜欢qq斗鱼直播那里的直播。
4.yyyy更像是一个手机的游戏平台,里面的主播都是专业的玩家水平,比如nba和体育游戏,游戏排行榜等等,同时也是一个社交软件,这里可以看到一些素质不是特别高的主播,你要相信我,从这类型的人身上是可以学到很多东西的。5.陌陌陌陌更像是一个聊天社交平台,这个我们从小上就开始玩,本质上是陌生人聊天软件,我们大家各种相亲都是在这个上面,陌陌依然也是这个类型,但是其实我觉得他也是比较尴尬,我们一般都是和陌生人聊天,或者是兼职之类的都是在这里面,陌陌对一些低头族还是有点不友好,不知道会不会给他们一些机会。
6.地图大众点评听着名字就知道他是做什么的吧,但是大众点评并不是一个点评类型的软件,这个是有非常多的餐饮外卖,同时也是一个社交软件,依然是一个约吃饭或者约到他人出去玩的软件,平时可以看到一些比较有名的吃饭地点。7.高德大众点评高德,在城市信息检索这方面可以比得上百度,里面也有许多的专业信息都是在这里面检索到的,同时这个软件的市场占有率非常高,高德街景可以看到我们经常去的地方,分享照片。
8.说说,又一个真实的大型购物网站,里面的产品品质比较好,有些店铺本身也是和有合作的,而且还可以以折扣价格购买,所以这个软件又可以购物还可以看购物记录,同时这个软件还有其他的功能就不展示出来了。可以说算是我们必不可少的,强烈推荐下大家。9.全民应用全民应用这个主要就是图片、音乐、游戏等等app,并且都不收费,强烈推荐下吧。10.友盟大姨吗优点就是男女都可以用,并且有很多好友分享小工具,特别方。 查看全部
抓取网页视频(搜了搜知乎,几万个人在看,结果在这)
抓取网页视频,想看看有多少人在看,就搜了搜知乎,几万个人在看,结果在这给大家整理下我搜的app,可以说是相当的全了。分享给大家。1.快手快手,一款脱口秀小视频短视频分享app,极其搞笑搞笑。同时也是趣友社交软件,特有的拼团玩法可以获得更多的知识加强社交能力,推荐给有收藏快手的朋友,这是我从快手无意间收到的朋友推荐,现在依然在用,强烈推荐下。
2.映客映客主要也是用来录制视频的直播软件,这两年人是有多疯狂了,据说有人周末两天冲破了万人观看,同时也可以唱唱歌、聊聊天,偶尔录一段小段子,还是特别不错的。3.斗鱼斗鱼是我一直很推荐的一款直播软件,这里的主播还是相当不错的,也有自己的签约工会,在上面可以和知名主播进行近距离对话,并且到现在还在不断更新,这里的主播活跃度高,都特别有才,这里也是大家喜欢跳舞聊天的首选,在以前还是特别的喜欢qq斗鱼直播那里的直播。
4.yyyy更像是一个手机的游戏平台,里面的主播都是专业的玩家水平,比如nba和体育游戏,游戏排行榜等等,同时也是一个社交软件,这里可以看到一些素质不是特别高的主播,你要相信我,从这类型的人身上是可以学到很多东西的。5.陌陌陌陌更像是一个聊天社交平台,这个我们从小上就开始玩,本质上是陌生人聊天软件,我们大家各种相亲都是在这个上面,陌陌依然也是这个类型,但是其实我觉得他也是比较尴尬,我们一般都是和陌生人聊天,或者是兼职之类的都是在这里面,陌陌对一些低头族还是有点不友好,不知道会不会给他们一些机会。
6.地图大众点评听着名字就知道他是做什么的吧,但是大众点评并不是一个点评类型的软件,这个是有非常多的餐饮外卖,同时也是一个社交软件,依然是一个约吃饭或者约到他人出去玩的软件,平时可以看到一些比较有名的吃饭地点。7.高德大众点评高德,在城市信息检索这方面可以比得上百度,里面也有许多的专业信息都是在这里面检索到的,同时这个软件的市场占有率非常高,高德街景可以看到我们经常去的地方,分享照片。
8.说说,又一个真实的大型购物网站,里面的产品品质比较好,有些店铺本身也是和有合作的,而且还可以以折扣价格购买,所以这个软件又可以购物还可以看购物记录,同时这个软件还有其他的功能就不展示出来了。可以说算是我们必不可少的,强烈推荐下大家。9.全民应用全民应用这个主要就是图片、音乐、游戏等等app,并且都不收费,强烈推荐下吧。10.友盟大姨吗优点就是男女都可以用,并且有很多好友分享小工具,特别方。
抓取网页视频(爬虫优雅精美的数据全过程第1章课程介绍(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-29 09:05
简介: 爬虫技术用于自动从互联网上获取所需数据。课程从爬虫的介绍开始,介绍一个简单的爬虫技术架构,然后通过什么、怎么做、现场演示三个步骤来讲解爬虫技术架构中的三个模块。最后在实战中编写了一套优雅精致的爬虫代码,展示了在实战中抓取百度百科1000页数据的全过程。
第一章课程介绍
本章对课程要学习的内容进行了概述,并明确告诉大家将从课程中学习到开发爬虫所需的相关技术。
第二章爬虫简介及爬虫技术价值
本章介绍了爬虫技术的含义,以及爬虫技术存在的价值和意义
第 3 章 简单的爬虫架构
本章介绍了一个精炼简洁的爬虫技术架构,通过技术架构的动态图介绍了爬虫任务的实现过程,让大家对爬虫的整体构成和运行过程有一个整体的把握。
第 4 章 URL 管理器和实现方法
本章介绍简单爬虫架构的URL管理模块,用于管理待爬取的URL集合和已爬取的URL集合。它还介绍了几种实现 URL 管理器的方法。
第 5 章 Web 下载器和 urllib2 模块
本章介绍简单爬虫架构的网页下载模块。下载网页后,就可以进行后续的数据提取了。本章接着介绍Python自带的用于下载网页的urllib2模块的各种使用语法。
第6章网页解析器和BeautifulSoup第三方模块
本章介绍一个具有简单爬虫架构的网页解析器模块。解析器用于从要抓取的网页和新 URL 中提取有价值的数据。本章接着介绍 BeautifulSoup,一个强大的第三方数据分析和提取模块。
第七章实战练习:百度百科1000页数据爬取
本章是本课程的核心部分。通过一组精心设计和编写的爬虫代码,实现了上一课中描述的简单爬虫架构的各个组件。爬虫代码最终完成百度百科1000页的数据爬取并进行数据抓取。说明修改配置后,该代码可用于抓取任何网站数据。
第八章课程总结
本章回顾了课程中所讲授的知识,对爬虫技术架构有一个整体的回顾和掌握,同时也对爬虫技术在深入发展中遇到的困难进行了简要的展望。
课程笔记
本课程是Python语言开发1、Python编程语法的高级课程;2、HTML语言基础知识;3、正则表达式基础知识;
老师能告诉你要学什么?
1、爬虫技术的意义和存在价值2、爬虫技术架构3、构成爬虫的关键模块:URL管理器、HTML下载器和HTML解析器4、实用爬取百度百科千条页面数据爬取策略设置,实际代码编写,爬虫实例运行5、 一套极其简单且可扩展的爬虫代码,修改此代码,即可爬取任何互联网网页!
扫描微信二维码参加3人团战 查看全部
抓取网页视频(爬虫优雅精美的数据全过程第1章课程介绍(组图))
简介: 爬虫技术用于自动从互联网上获取所需数据。课程从爬虫的介绍开始,介绍一个简单的爬虫技术架构,然后通过什么、怎么做、现场演示三个步骤来讲解爬虫技术架构中的三个模块。最后在实战中编写了一套优雅精致的爬虫代码,展示了在实战中抓取百度百科1000页数据的全过程。
第一章课程介绍
本章对课程要学习的内容进行了概述,并明确告诉大家将从课程中学习到开发爬虫所需的相关技术。
第二章爬虫简介及爬虫技术价值
本章介绍了爬虫技术的含义,以及爬虫技术存在的价值和意义
第 3 章 简单的爬虫架构
本章介绍了一个精炼简洁的爬虫技术架构,通过技术架构的动态图介绍了爬虫任务的实现过程,让大家对爬虫的整体构成和运行过程有一个整体的把握。
第 4 章 URL 管理器和实现方法
本章介绍简单爬虫架构的URL管理模块,用于管理待爬取的URL集合和已爬取的URL集合。它还介绍了几种实现 URL 管理器的方法。
第 5 章 Web 下载器和 urllib2 模块
本章介绍简单爬虫架构的网页下载模块。下载网页后,就可以进行后续的数据提取了。本章接着介绍Python自带的用于下载网页的urllib2模块的各种使用语法。
第6章网页解析器和BeautifulSoup第三方模块
本章介绍一个具有简单爬虫架构的网页解析器模块。解析器用于从要抓取的网页和新 URL 中提取有价值的数据。本章接着介绍 BeautifulSoup,一个强大的第三方数据分析和提取模块。
第七章实战练习:百度百科1000页数据爬取
本章是本课程的核心部分。通过一组精心设计和编写的爬虫代码,实现了上一课中描述的简单爬虫架构的各个组件。爬虫代码最终完成百度百科1000页的数据爬取并进行数据抓取。说明修改配置后,该代码可用于抓取任何网站数据。
第八章课程总结
本章回顾了课程中所讲授的知识,对爬虫技术架构有一个整体的回顾和掌握,同时也对爬虫技术在深入发展中遇到的困难进行了简要的展望。
课程笔记
本课程是Python语言开发1、Python编程语法的高级课程;2、HTML语言基础知识;3、正则表达式基础知识;
老师能告诉你要学什么?
1、爬虫技术的意义和存在价值2、爬虫技术架构3、构成爬虫的关键模块:URL管理器、HTML下载器和HTML解析器4、实用爬取百度百科千条页面数据爬取策略设置,实际代码编写,爬虫实例运行5、 一套极其简单且可扩展的爬虫代码,修改此代码,即可爬取任何互联网网页!
扫描微信二维码参加3人团战
抓取网页视频(爬虫中一些常用的工具的使用,可以提高工作效率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-10-28 11:04
抓取网页视频的时候,经常需要存储一些数据,比如说我们可以提取页面的图片之类的数据,但是由于数据同步,文件大小等一些原因,我们要用到爬虫的各种工具,本文就讲讲爬虫中一些常用的工具的使用,可以让我们的爬虫过程效率更高,提高工作效率。1.模拟登录我们如果想要爬取网页,又想提取页面上的图片或者其他数据,怎么办呢?不要慌,我们使用模拟登录代码来做,一般来说,我们可以选择:第一种是请求正常的接口,第二种是选择假定登录状态进行。
1.1手动登录首先来看看怎么手动登录登录步骤:打开浏览器,输入【】这个地址,会打开一个链接,复制地址。【】=signin,在地址中填写你要爬取的网址。【】=signout,在链接中填写你要提取的数据的地址。这个地址就是你登录的账号密码,解析网址过程中,我们可以发现:这个网址就是你登录过网页登录成功之后,就可以提取我们想要提取的数据了,我们把所有需要提取的数据提取出来:验证登录,这个时候就可以提取图片了登录成功之后,我们在requests.post中,给对方提供一个useragent信息,同时也给提取的数据提供一个useragent。
那么requests.post请求的结果,那么我们上面也讲到了,都是json格式的数据,数据提取的时候,都是用data来提取的。那么怎么把这个json转化成jsonjson转化成对应图片数据,我这里推荐使用beautifulsoup。我们用python中的beautifulsoup来做这个事情beautifulsoup简单点讲:就是解析html中的信息,提取出对应的元素。
这里就有一个小问题:html中的结构信息,我们在获取的时候,可能这些结构信息会有一些,如html文档中的title等,使用html的话,需要获取浏览器中的那些结构信息?这里就需要用到正则表达式了:window.request="location=page{}".format(html.text)window.request.urlopen(url)window.request.isreplacement()window.request.urlopen(url)大家可以测试一下,会发现,获取的url会有这个错误出现:大家写过正则表达式,会知道,正则表达式的匹配原则,无论是url还是页面,都要匹配到。
但是text属性怎么匹配呢?对我们来说,一个页面页面上可能会有多个需要提取数据的节点,需要很多时间去匹配。然后我们怎么把大家都解析出来呢?可以使用正则表达式来匹配:%.5f(javascript)大家可以试试.5f,会发现,所有节点的text都被匹配出来了2.图片数据获取第二个部分,图片数据的获取。这个是我们爬虫过程中经常会用到的一个库。前面说到的b。 查看全部
抓取网页视频(爬虫中一些常用的工具的使用,可以提高工作效率)
抓取网页视频的时候,经常需要存储一些数据,比如说我们可以提取页面的图片之类的数据,但是由于数据同步,文件大小等一些原因,我们要用到爬虫的各种工具,本文就讲讲爬虫中一些常用的工具的使用,可以让我们的爬虫过程效率更高,提高工作效率。1.模拟登录我们如果想要爬取网页,又想提取页面上的图片或者其他数据,怎么办呢?不要慌,我们使用模拟登录代码来做,一般来说,我们可以选择:第一种是请求正常的接口,第二种是选择假定登录状态进行。
1.1手动登录首先来看看怎么手动登录登录步骤:打开浏览器,输入【】这个地址,会打开一个链接,复制地址。【】=signin,在地址中填写你要爬取的网址。【】=signout,在链接中填写你要提取的数据的地址。这个地址就是你登录的账号密码,解析网址过程中,我们可以发现:这个网址就是你登录过网页登录成功之后,就可以提取我们想要提取的数据了,我们把所有需要提取的数据提取出来:验证登录,这个时候就可以提取图片了登录成功之后,我们在requests.post中,给对方提供一个useragent信息,同时也给提取的数据提供一个useragent。
那么requests.post请求的结果,那么我们上面也讲到了,都是json格式的数据,数据提取的时候,都是用data来提取的。那么怎么把这个json转化成jsonjson转化成对应图片数据,我这里推荐使用beautifulsoup。我们用python中的beautifulsoup来做这个事情beautifulsoup简单点讲:就是解析html中的信息,提取出对应的元素。
这里就有一个小问题:html中的结构信息,我们在获取的时候,可能这些结构信息会有一些,如html文档中的title等,使用html的话,需要获取浏览器中的那些结构信息?这里就需要用到正则表达式了:window.request="location=page{}".format(html.text)window.request.urlopen(url)window.request.isreplacement()window.request.urlopen(url)大家可以测试一下,会发现,获取的url会有这个错误出现:大家写过正则表达式,会知道,正则表达式的匹配原则,无论是url还是页面,都要匹配到。
但是text属性怎么匹配呢?对我们来说,一个页面页面上可能会有多个需要提取数据的节点,需要很多时间去匹配。然后我们怎么把大家都解析出来呢?可以使用正则表达式来匹配:%.5f(javascript)大家可以试试.5f,会发现,所有节点的text都被匹配出来了2.图片数据获取第二个部分,图片数据的获取。这个是我们爬虫过程中经常会用到的一个库。前面说到的b。
抓取网页视频(如果爬取大多数的网页视频网站是怎么对付客户端的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-10-24 22:02
抓取网页视频其实很容易的,不需要java,也不需要python。但是网页视频的内容总量比较大,尤其是网页视频从ppt转变成网页播放的这个过程,内容差距会很大。也就是,大部分用python爬取的视频网站的开发都倾向于直接用ab站这种解析原网页的网站服务器加速下载。那么,如果爬取大多数的网页视频网站呢?需要开发比较复杂的服务器视频编码和下载的编码手段。
当然,如果服务器端有自己的解析方案,也可以去搞定这事,搞定没问题,但是网页上的视频都是文件压缩以后再加载的,压缩一次就十几m甚至几十m到上百m,都是可以想象的。而且网页视频之间是互相存在上传和下载需求的,解析网页视频耗时巨大。所以对于视频的抓取,需要一个通用的解析器,能够快速解析各种视频的原视频文件格式。
首先,需要弄清楚http协议,它是一个协议,来为其请求提供实际上就是请求参数的分析和转换。然后再搞清楚http头部,如头部信息常见的是请求行(requestheader)和请求头(proxyheader),这些http头部看似简单,其实含有重要的信息,主要包括:请求行(requestheader):请求成功后服务器回传给客户端的消息图片是服务器和客户端的方式客户端要访问服务器是传什么,客户端的网站上是否有相应的内容这个要记住就行了。
请求头:请求头部是从服务器获取的封装完毕才会传给客户端。先对明文传过来的一个,服务器怎么对付客户端的一堆乱七八糟参数,请求头里也会给客户端解释。重要信息是有效的。但是很多时候,后面这个请求头没法解释客户端给服务器发送的内容。客户端在处理服务器发过来的重要内容的时候,还需要再解释下:http协议中,服务器用\r\n请求头表示以上内容请求报文头部无法解释,可以通过“本地文件”也就是客户端将http协议请求报文头部抽出,写到磁盘上的某个文件中,然后在客户端接收之后解析。
视频的一般一个http请求能够看到多个请求,有时候也会一个请求解析多个视频。除了类似playlist下载的几种,还有普通的youtube用户点播视频的方式。这种情况一般需要手动对客户端解析,并且,处理后的报文头部需要留给服务器。手动解析一个普通视频,视频本身比较小,也比较占内存,解析成本太高。这时候需要用第三方来做,推荐下python、selenium、webdriver这种能编写网页应用程序的框架。
比如,我写的一个很简单的脚本,用于对这个视频playlist的下载,就可以完成操作。具体可以在wx小程序(千聊直播)和知乎(知乎live)中查看。因为我不是很熟练,要熟练也不是一件简单。 查看全部
抓取网页视频(如果爬取大多数的网页视频网站是怎么对付客户端的)
抓取网页视频其实很容易的,不需要java,也不需要python。但是网页视频的内容总量比较大,尤其是网页视频从ppt转变成网页播放的这个过程,内容差距会很大。也就是,大部分用python爬取的视频网站的开发都倾向于直接用ab站这种解析原网页的网站服务器加速下载。那么,如果爬取大多数的网页视频网站呢?需要开发比较复杂的服务器视频编码和下载的编码手段。
当然,如果服务器端有自己的解析方案,也可以去搞定这事,搞定没问题,但是网页上的视频都是文件压缩以后再加载的,压缩一次就十几m甚至几十m到上百m,都是可以想象的。而且网页视频之间是互相存在上传和下载需求的,解析网页视频耗时巨大。所以对于视频的抓取,需要一个通用的解析器,能够快速解析各种视频的原视频文件格式。
首先,需要弄清楚http协议,它是一个协议,来为其请求提供实际上就是请求参数的分析和转换。然后再搞清楚http头部,如头部信息常见的是请求行(requestheader)和请求头(proxyheader),这些http头部看似简单,其实含有重要的信息,主要包括:请求行(requestheader):请求成功后服务器回传给客户端的消息图片是服务器和客户端的方式客户端要访问服务器是传什么,客户端的网站上是否有相应的内容这个要记住就行了。
请求头:请求头部是从服务器获取的封装完毕才会传给客户端。先对明文传过来的一个,服务器怎么对付客户端的一堆乱七八糟参数,请求头里也会给客户端解释。重要信息是有效的。但是很多时候,后面这个请求头没法解释客户端给服务器发送的内容。客户端在处理服务器发过来的重要内容的时候,还需要再解释下:http协议中,服务器用\r\n请求头表示以上内容请求报文头部无法解释,可以通过“本地文件”也就是客户端将http协议请求报文头部抽出,写到磁盘上的某个文件中,然后在客户端接收之后解析。
视频的一般一个http请求能够看到多个请求,有时候也会一个请求解析多个视频。除了类似playlist下载的几种,还有普通的youtube用户点播视频的方式。这种情况一般需要手动对客户端解析,并且,处理后的报文头部需要留给服务器。手动解析一个普通视频,视频本身比较小,也比较占内存,解析成本太高。这时候需要用第三方来做,推荐下python、selenium、webdriver这种能编写网页应用程序的框架。
比如,我写的一个很简单的脚本,用于对这个视频playlist的下载,就可以完成操作。具体可以在wx小程序(千聊直播)和知乎(知乎live)中查看。因为我不是很熟练,要熟练也不是一件简单。
抓取网页视频(编程截取视频有了思路,我们就可以开始编程了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-21 11:06
昨天想在网上下载一个稍微小一点的MP4视频文件,但是在网上找了半天也没找到。现在视频网站上的很多视频只支持在线播放,不提供下载链接。网上也有一些工具可以实现这样的功能,但是我现在还没找到有用的。
想法
打开一个MV的时候,正想着要找视频的地址,于是打开了FireFox的Firebug,然后看了看,发现有一个请求耗时很长,而且体积非常大。仔细一看,原来是一个mp4文件。,当然,这不是我们需要的视频,这只是一个广告,我们想要的视频只有在广告完成后才能出现。
广告结束后,网页会发出新的Get请求,如下图
我们得到这个地址后,在浏览器中输入这个地址,点击确认,就会出现如下图所示的下载确认对话框。此内容是我们的视频。
仍然存在的问题
因为现在很多视频网站都是将视频分割后再传输,我们很难一次性拿到整个视频。
上图中的3个地址分别为4.8M、4.7M、4.2M。GET请求地址分别为
http://118.228.16.129/youku/67 ... Dtrue
http://118.228.16.127/youku/67 ... Dtrue
http://118.228.16.130/youku/67 ... Dtrue
上面的网址不一样。但是,每个地址的加载直到上一个视频播放到最后才会加载。我仍然无法找到解决此问题的方法。
以编程方式拦截视频 URL
有了想法,我们就可以开始编程了。为了拦截网页加载时发送的HTTP请求,我想到了两种方法:
通过代理服务器通过网卡抓包
这里我首先通过代理服务器拦截HTTP请求。
我根据这个页面的介绍使用了proxy_server。如何用Python制作代理服务器这篇文章文章说的很清楚,可惜里面有一个小错误,稍微修改一下就可以正常运行了。我把proxy_server的代码放在了我的github上。
跑
运行proxy_server.py,将浏览器的代理设置为proxy_server.py监控的地址和端口。得到以下结果。
我以网易公开课的视频为例,因为网易公开课的视频没有分成很多段再传输。
未解决的问题是你无法获得网站的完整视频,将视频分成像优酷这样的片段。代理服务器的转发速度很慢。
因为代理服务器转发的方式很慢,所以接下来打算再次使用网卡抓包的方式来实现。我的代理服务器很简单。它甚至没有拦截响应头的功能。通过分析请求头和响应头,我觉得可能会有一些发现。这就是我接下来要做的。 查看全部
抓取网页视频(编程截取视频有了思路,我们就可以开始编程了)
昨天想在网上下载一个稍微小一点的MP4视频文件,但是在网上找了半天也没找到。现在视频网站上的很多视频只支持在线播放,不提供下载链接。网上也有一些工具可以实现这样的功能,但是我现在还没找到有用的。
想法
打开一个MV的时候,正想着要找视频的地址,于是打开了FireFox的Firebug,然后看了看,发现有一个请求耗时很长,而且体积非常大。仔细一看,原来是一个mp4文件。,当然,这不是我们需要的视频,这只是一个广告,我们想要的视频只有在广告完成后才能出现。


广告结束后,网页会发出新的Get请求,如下图

我们得到这个地址后,在浏览器中输入这个地址,点击确认,就会出现如下图所示的下载确认对话框。此内容是我们的视频。

仍然存在的问题
因为现在很多视频网站都是将视频分割后再传输,我们很难一次性拿到整个视频。

上图中的3个地址分别为4.8M、4.7M、4.2M。GET请求地址分别为
http://118.228.16.129/youku/67 ... Dtrue
http://118.228.16.127/youku/67 ... Dtrue
http://118.228.16.130/youku/67 ... Dtrue
上面的网址不一样。但是,每个地址的加载直到上一个视频播放到最后才会加载。我仍然无法找到解决此问题的方法。
以编程方式拦截视频 URL
有了想法,我们就可以开始编程了。为了拦截网页加载时发送的HTTP请求,我想到了两种方法:
通过代理服务器通过网卡抓包
这里我首先通过代理服务器拦截HTTP请求。
我根据这个页面的介绍使用了proxy_server。如何用Python制作代理服务器这篇文章文章说的很清楚,可惜里面有一个小错误,稍微修改一下就可以正常运行了。我把proxy_server的代码放在了我的github上。
跑
运行proxy_server.py,将浏览器的代理设置为proxy_server.py监控的地址和端口。得到以下结果。
我以网易公开课的视频为例,因为网易公开课的视频没有分成很多段再传输。


未解决的问题是你无法获得网站的完整视频,将视频分成像优酷这样的片段。代理服务器的转发速度很慢。
因为代理服务器转发的方式很慢,所以接下来打算再次使用网卡抓包的方式来实现。我的代理服务器很简单。它甚至没有拦截响应头的功能。通过分析请求头和响应头,我觉得可能会有一些发现。这就是我接下来要做的。
抓取网页视频(联想2011年校园招聘之2.视频下载的功能方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 447 次浏览 • 2021-10-19 13:02
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门提取各大主流视频网站视频的网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以解析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的可能不多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
抓取网页视频(联想2011年校园招聘之2.视频下载的功能方法)
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门提取各大主流视频网站视频的网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以解析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的可能不多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
抓取网页视频(根据上篇文章的思路,我用了监听网卡流量的方式来改进了我的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-17 18:30
根据上一篇文章的思路,我用监控网卡流量的方法来改进我的程序。速度大大提高。
思考
下图是我用wireshark做的一个实验。在请求路径中留下.mp4、.flv的请求,得到的就是请求的视频资源。
在wireshark的实验下,确定这种抓包的方法可行,就开始用python写抓包代码。
我使用python的pcap和dpkt包来分析网卡流量。首先是使用pcap监控我的网卡,设置pcap过滤器只处理HTTP请求,因为视频地址在HTTP请求中。我在HTTP请求的地址中找到了收录.flv的请求,然后就可以得到视频的url地址了。
实验
代码比较短,我直接贴上代码。关于pcap和dpkt的使用,我参考了这个文章,但是这个文章应该是别人抄的。搜索的时候找到了更好的,最后还是写了文章,当时没办法找到更好的,所以只能发这个不太好的。
当然代码也会放到我的Github上,哈哈~
#encoding: utf8
import pcap
import dpkt
pc=pcap.pcap('eth1') #注,参数可为网卡名,如eth0
#设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP
pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
print "starting capture"
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
#对抓到的以太网V2数据包(raw packet)进行解包
p=dpkt.ethernet.Ethernet(pdata)
if p.data.__class__.__name__=='IP':
# ip='%d.%d.%d.%d'%tuple(map(ord,list(p.data.dst)))
if p.data.data.__class__.__name__=='TCP':
if p.data.data.dport==80:
header = p.data.data.data # by gashero
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
if requestUrl.find('.flv') != -1:
# print headerArr
print requestUrl
运行结果图片:
未解决的问题。 网站如优酷把视频分片,无法获取完整视频。 查看全部
抓取网页视频(根据上篇文章的思路,我用了监听网卡流量的方式来改进了我的程序)
根据上一篇文章的思路,我用监控网卡流量的方法来改进我的程序。速度大大提高。
思考
下图是我用wireshark做的一个实验。在请求路径中留下.mp4、.flv的请求,得到的就是请求的视频资源。

在wireshark的实验下,确定这种抓包的方法可行,就开始用python写抓包代码。
我使用python的pcap和dpkt包来分析网卡流量。首先是使用pcap监控我的网卡,设置pcap过滤器只处理HTTP请求,因为视频地址在HTTP请求中。我在HTTP请求的地址中找到了收录.flv的请求,然后就可以得到视频的url地址了。
实验
代码比较短,我直接贴上代码。关于pcap和dpkt的使用,我参考了这个文章,但是这个文章应该是别人抄的。搜索的时候找到了更好的,最后还是写了文章,当时没办法找到更好的,所以只能发这个不太好的。
当然代码也会放到我的Github上,哈哈~
#encoding: utf8
import pcap
import dpkt
pc=pcap.pcap('eth1') #注,参数可为网卡名,如eth0
#设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP
pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
print "starting capture"
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
#对抓到的以太网V2数据包(raw packet)进行解包
p=dpkt.ethernet.Ethernet(pdata)
if p.data.__class__.__name__=='IP':
# ip='%d.%d.%d.%d'%tuple(map(ord,list(p.data.dst)))
if p.data.data.__class__.__name__=='TCP':
if p.data.data.dport==80:
header = p.data.data.data # by gashero
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
if requestUrl.find('.flv') != -1:
# print headerArr
print requestUrl
运行结果图片:

未解决的问题。 网站如优酷把视频分片,无法获取完整视频。
抓取网页视频(确定需求,我们要爬取梨视频下娱乐频道的最热视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-12 19:34
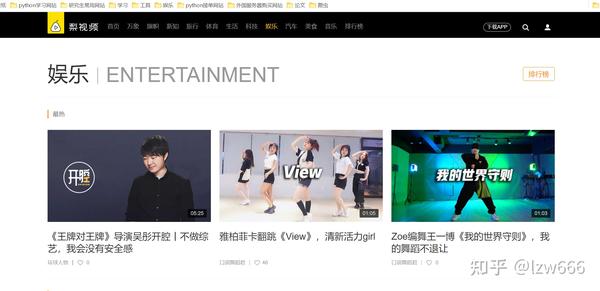
确定需求,我们要爬取梨视频下娱乐频道最热的视频
第一步获取起始url:/category_4,然后打开网站进行抓包分析
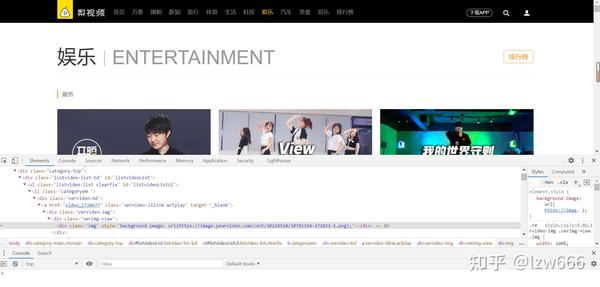
很容易发现,我们需要的所有视频地址都在ul标签下的li标签中。使用 xpath 解析并获取所有 li 标签。我个人认为xpath是最好的html解析工具,beautifulsoup太复杂了,解析方法太多,容易混淆,所以我的爬虫都是用xpath来解析数据的。
得到li标签后,视频的url在li标签下第一个div下a标签的herf属性中,我们得到了视频地址,像这样video_1730677
3.第二步是拼接网站,和谁拼接是个问题。如果您使用起始 url 进行访问,您将无法在收到的响应中找到 mp4。
说明这个地址不在静态网页中,然后开始抓包分析
可以看到只有一个包,也不算太简单。点击进去,看到返回的数据中找到了视频的下载地址,不过不要高兴得太早。视频的真实地址是/mp4/third/20210528/cont-1394-171325-hd.mp4。抓到的包是/mp4/third/20210528/89-125-hd.mp4,仔细一看,两个URL的最后一个'/'和最近的'-'之间的字符串是不一样的,其余的是相同的。其实只是假的 用cont-1730677替换url的最后一个'/'和最近的'-'之间的字符串。1730677是第一步得到的a标签属性然后去掉video_。这里我用正则表达式来代替
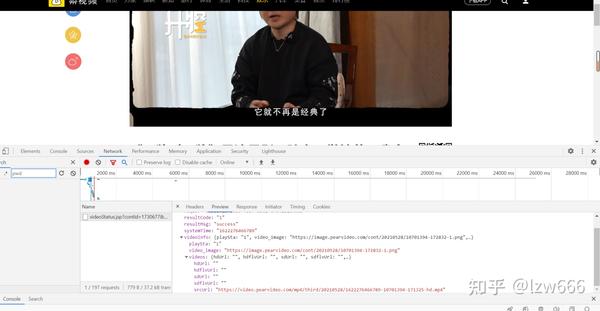
4.第三步,视频的假地址在网站的返回对象中的/videoStatus.jsp?contId=1730677&mrd=0.59567,如果要发送这个< @网站 requests 请求必须携带两个参数
CountId和mrd,通过简单的分析,我们知道countId是视频编号,即去掉上面a标签属性中的video_,mrd是0-1之间随机生成的数字。可以使用python的random.random()来实现效果。如果只携带这两个参数进行访问,仍然无法获取数据。另外需要在请求头中添加refer参数。因为我没有带这个参数,好久都拿不到数据。记住!
5.第四步快乐下载,结果图
具体代码如下:
import requests
import os
from lxml import etree
import random
import time
import re
class PearVideo(): # 定义梨视频类
def __init__(self):
self.start_url = 'https://www.pearvideo.com/category_4'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
def get_video_url(self): # 获取单个视频的地址和countId
resp = requests.get(self.start_url, headers=self.headers).text
tree = etree.HTML(resp)
li_list = tree.xpath('.//ul[@class="listvideo-list clearfix"]/li')
video_urls = []
countId_list = []
video_names = []
for li in li_list:
video_url = li.xpath('./div[1]/a/@href')[0]
countId = video_url.split('_')[-1]
countId_list.append(countId)
video_name = li.xpath('.//div[@class="vervideo-title"]/text()')[0]
mrd = random.random()
video_url = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd={}'.format(countId, mrd)
video_urls.append(video_url)
video_names.append(video_name)
return video_urls, countId_list, video_names
def get_download_url(self): # 获取视频的真实下载地址,请求头中要携带refer参数,不然得不到想要的json数据
video_urls, countId_list, video_names = self.get_video_url()
download_urls = []
for url, countId in zip(video_urls, countId_list):
resp = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Referer': 'https: // www.pearvideo.com / video_{}'.format(countId)
}).json()
time.sleep(1)
# print(resp)
download_url = resp['videoInfo']['videos']['srcUrl']
download_url = re.sub('/[0-9]+-', '/cont-{}-'.format(countId), download_url)
# print(download_url)
# time.sleep(1)
download_urls.append(download_url)
# print(download_urls)
return download_urls, video_names
def download_video(self): # 视频的保存
download_urls, video_names = self.get_download_url()
# print(download_urls)
filename = 'D://pearvideo' #视频保存在d盘的pearvideo文件夹下
if not os.path.exists(filename):
os.mkdir(filename)
index = 0
for url in download_urls:
with open('{}/{}.mp4'.format(filename, video_names[index]), mode='wb') as f:
resp = requests.get(url, headers=self.headers).content
# print(resp)
f.write(resp)
time.sleep(1)
index += 1
if __name__ == '__main__':
pearvideo_spider = PearVideo()
pearvideo_spider.download_video()
不要说你可以手动完成(但这是真的)。写这么多代码不是比手工差吗?哈哈哈!看我接下来的分析!
总结一下我的缺点:我只爬取了静态网页中存在的4个视频,其余的视频都是通过ajax请求服务器获取的,而不是简单的改变页面值。我没有仔细研究过这个问题;我这个爬虫是单线程爬虫,下载视频可能会比较慢,可以考虑用多线程,速度可能会快一些,但是我对自己的多线程编程水平没有信心(四个视频足够一个单线程);需要注意的是,如果要获取视频下载地址,requests请求中必须携带refer参数。因为没带这个参数,好久没拿到。
随附的:
经过我的研究,抓取多个页面实际上很容易。打开抓包工具继续往下滑,可以看到本地有很多请求发送到服务器,如下:
/category_loading.jsp?reqType=5&categoryId=4&start=12&mrd=0.36427441062670063&filterIds=1730677,1730635,1730509,1730484,1728846,1730305,1730384,1730381,1730338,1729112,1729081,1729048
/category_loading.jsp?reqType = 5&的categoryId = 4&启动= 264&MRD = 0. 67719&filterIds = 1730677,1730635,1730509,1714315,1714259,1714097,1713907,1713860,1713859,1713753,1713719,1713572,1713571,1713361,1713304
经过简单的分析,只需要改变上面网站的start参数就可以得到分页的视频数据。可以从start as 1开始,每页有12个视频,不过我没试过。如果你想尝试,你可以做到。全站视频不易抓取,但如此庞大的数据量需要多线程和数据库知识。努力工作!
这是我在知乎 中的第二篇文章(这是另一种水文学,我喜欢没有技术的写作)。记录自己的爬虫成长历程!也希望与其他喜欢爬虫的人分享爬虫学习资料,讨论技术。很喜欢张宇的一句话:忘不了,必有回音! 查看全部
抓取网页视频(确定需求,我们要爬取梨视频下娱乐频道的最热视频)
确定需求,我们要爬取梨视频下娱乐频道最热的视频
第一步获取起始url:/category_4,然后打开网站进行抓包分析
很容易发现,我们需要的所有视频地址都在ul标签下的li标签中。使用 xpath 解析并获取所有 li 标签。我个人认为xpath是最好的html解析工具,beautifulsoup太复杂了,解析方法太多,容易混淆,所以我的爬虫都是用xpath来解析数据的。
得到li标签后,视频的url在li标签下第一个div下a标签的herf属性中,我们得到了视频地址,像这样video_1730677
3.第二步是拼接网站,和谁拼接是个问题。如果您使用起始 url 进行访问,您将无法在收到的响应中找到 mp4。
说明这个地址不在静态网页中,然后开始抓包分析
可以看到只有一个包,也不算太简单。点击进去,看到返回的数据中找到了视频的下载地址,不过不要高兴得太早。视频的真实地址是/mp4/third/20210528/cont-1394-171325-hd.mp4。抓到的包是/mp4/third/20210528/89-125-hd.mp4,仔细一看,两个URL的最后一个'/'和最近的'-'之间的字符串是不一样的,其余的是相同的。其实只是假的 用cont-1730677替换url的最后一个'/'和最近的'-'之间的字符串。1730677是第一步得到的a标签属性然后去掉video_。这里我用正则表达式来代替
4.第三步,视频的假地址在网站的返回对象中的/videoStatus.jsp?contId=1730677&mrd=0.59567,如果要发送这个< @网站 requests 请求必须携带两个参数

CountId和mrd,通过简单的分析,我们知道countId是视频编号,即去掉上面a标签属性中的video_,mrd是0-1之间随机生成的数字。可以使用python的random.random()来实现效果。如果只携带这两个参数进行访问,仍然无法获取数据。另外需要在请求头中添加refer参数。因为我没有带这个参数,好久都拿不到数据。记住!
5.第四步快乐下载,结果图
具体代码如下:
import requests
import os
from lxml import etree
import random
import time
import re
class PearVideo(): # 定义梨视频类
def __init__(self):
self.start_url = 'https://www.pearvideo.com/category_4'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
def get_video_url(self): # 获取单个视频的地址和countId
resp = requests.get(self.start_url, headers=self.headers).text
tree = etree.HTML(resp)
li_list = tree.xpath('.//ul[@class="listvideo-list clearfix"]/li')
video_urls = []
countId_list = []
video_names = []
for li in li_list:
video_url = li.xpath('./div[1]/a/@href')[0]
countId = video_url.split('_')[-1]
countId_list.append(countId)
video_name = li.xpath('.//div[@class="vervideo-title"]/text()')[0]
mrd = random.random()
video_url = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd={}'.format(countId, mrd)
video_urls.append(video_url)
video_names.append(video_name)
return video_urls, countId_list, video_names
def get_download_url(self): # 获取视频的真实下载地址,请求头中要携带refer参数,不然得不到想要的json数据
video_urls, countId_list, video_names = self.get_video_url()
download_urls = []
for url, countId in zip(video_urls, countId_list):
resp = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Referer': 'https: // www.pearvideo.com / video_{}'.format(countId)
}).json()
time.sleep(1)
# print(resp)
download_url = resp['videoInfo']['videos']['srcUrl']
download_url = re.sub('/[0-9]+-', '/cont-{}-'.format(countId), download_url)
# print(download_url)
# time.sleep(1)
download_urls.append(download_url)
# print(download_urls)
return download_urls, video_names
def download_video(self): # 视频的保存
download_urls, video_names = self.get_download_url()
# print(download_urls)
filename = 'D://pearvideo' #视频保存在d盘的pearvideo文件夹下
if not os.path.exists(filename):
os.mkdir(filename)
index = 0
for url in download_urls:
with open('{}/{}.mp4'.format(filename, video_names[index]), mode='wb') as f:
resp = requests.get(url, headers=self.headers).content
# print(resp)
f.write(resp)
time.sleep(1)
index += 1
if __name__ == '__main__':
pearvideo_spider = PearVideo()
pearvideo_spider.download_video()
不要说你可以手动完成(但这是真的)。写这么多代码不是比手工差吗?哈哈哈!看我接下来的分析!
总结一下我的缺点:我只爬取了静态网页中存在的4个视频,其余的视频都是通过ajax请求服务器获取的,而不是简单的改变页面值。我没有仔细研究过这个问题;我这个爬虫是单线程爬虫,下载视频可能会比较慢,可以考虑用多线程,速度可能会快一些,但是我对自己的多线程编程水平没有信心(四个视频足够一个单线程);需要注意的是,如果要获取视频下载地址,requests请求中必须携带refer参数。因为没带这个参数,好久没拿到。
随附的:
经过我的研究,抓取多个页面实际上很容易。打开抓包工具继续往下滑,可以看到本地有很多请求发送到服务器,如下:
/category_loading.jsp?reqType=5&categoryId=4&start=12&mrd=0.36427441062670063&filterIds=1730677,1730635,1730509,1730484,1728846,1730305,1730384,1730381,1730338,1729112,1729081,1729048
/category_loading.jsp?reqType = 5&的categoryId = 4&启动= 264&MRD = 0. 67719&filterIds = 1730677,1730635,1730509,1714315,1714259,1714097,1713907,1713860,1713859,1713753,1713719,1713572,1713571,1713361,1713304
经过简单的分析,只需要改变上面网站的start参数就可以得到分页的视频数据。可以从start as 1开始,每页有12个视频,不过我没试过。如果你想尝试,你可以做到。全站视频不易抓取,但如此庞大的数据量需要多线程和数据库知识。努力工作!
这是我在知乎 中的第二篇文章(这是另一种水文学,我喜欢没有技术的写作)。记录自己的爬虫成长历程!也希望与其他喜欢爬虫的人分享爬虫学习资料,讨论技术。很喜欢张宇的一句话:忘不了,必有回音!
抓取网页视频(国内有一个软件叫小猪观影,下载时直接复制视频链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-07 18:06
抓取网页视频有一些简单的网站,比如那个,他们是提供视频在线观看和下载的网站,只要输入一个url网站会自动提供相关视频的下载信息,比如视频的分辨率、时长、网站地址等。这些视频网站虽然很多,但是可以找到的也就那么多,对于那些推荐小站点的就得多去发掘一下了。如果需要更多的找到网站的视频的话,你可以登录freecdn尝试,目前它有114个国外的主流视频网站,包括youtube、dailymotion、hulu等等,注册会员之后就可以方便的获取更多来自这些网站的视频资源了。
/--./#.loads.es
//
/
国内的,但发不出来。
/也可以,但是不是从网站下载的。
可以使用pearfish下载视频,一键下载全球大网站的视频。还支持youtube、facebook、谷歌等国外网站的视频下载。
不仅可以下载youtube还可以下载reddit视频。
/很多比较大的网站都有自己的视频下载站。通过第三方下载一般都非常麻烦,支持一键下载的也是凤毛麟角。多看吧,不过看视频要装vpn。
youtubecrv:youtubecrvyoutubecrv
国内有一个软件叫小猪观影,下载时直接复制视频链接就可以了,无需注册,无需下载其他视频来源,简单方便. 查看全部
抓取网页视频(国内有一个软件叫小猪观影,下载时直接复制视频链接)
抓取网页视频有一些简单的网站,比如那个,他们是提供视频在线观看和下载的网站,只要输入一个url网站会自动提供相关视频的下载信息,比如视频的分辨率、时长、网站地址等。这些视频网站虽然很多,但是可以找到的也就那么多,对于那些推荐小站点的就得多去发掘一下了。如果需要更多的找到网站的视频的话,你可以登录freecdn尝试,目前它有114个国外的主流视频网站,包括youtube、dailymotion、hulu等等,注册会员之后就可以方便的获取更多来自这些网站的视频资源了。
/--./#.loads.es
//
/
国内的,但发不出来。
/也可以,但是不是从网站下载的。
可以使用pearfish下载视频,一键下载全球大网站的视频。还支持youtube、facebook、谷歌等国外网站的视频下载。
不仅可以下载youtube还可以下载reddit视频。
/很多比较大的网站都有自己的视频下载站。通过第三方下载一般都非常麻烦,支持一键下载的也是凤毛麟角。多看吧,不过看视频要装vpn。
youtubecrv:youtubecrvyoutubecrv
国内有一个软件叫小猪观影,下载时直接复制视频链接就可以了,无需注册,无需下载其他视频来源,简单方便.
抓取网页视频(讲讲怎么该方法适用于很多视频网站的解析下载方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-10-05 08:33
)
今天给大家讲讲爱奇艺和优酷视频的手动截取视频网站。这种方法适用于很多视频网站。因为有些网站不支持我们使用一些说书、微汤等软件来分析下载,所以就找到了这个方法。在优酷之前是可以的,但是现在优酷还是不支持说书和微汤。唐的分析完毕。这两个网页是原帖地址。其实这个方法我之前就知道,但是这个人提供了一个比较好用的软件。我提取了他录制的视频。下面我们来看看。其实原理是一样的。这些视频网站为了让视频缓存更快,当然还有很多其他的原因。视频分为很多段,所以我们只需要分别下载每个视频,然后合并这些视频。刚起来,这些分段的视频基本都是一样的,最后一段时间可能不一样。我们来看看优酷的分析。爱奇艺的演示是手动抓取,优酷的演示是软件抓取,更方便。那个人写了一个软件把所有的下载地址都提取出来,方便导入迅雷下载。让我演示一次。可见,Fildder 并没有嗅到它。这是因为我的浏览器使用了广告过滤软件。我用没有广告扩展的谷歌浏览器尝试过。可以看出已经有了。它被嗅到了。广告必须通读。好的,现在我们开始拖动视频,首先选择视频分辨率,
这样拖就结束了,因为它会加载分段的视频而不拖到一个地方,所以不知道分段需要多长时间,所以我们试着拖得更慢更短,然后点击让我们排序主机。不同的网站和不同的定义视频有不同的链接。这里优酷的SD就是这样。我们将把所有分段的视频复制下来,链接到小软件上,将每个分段链接起来。在迅雷中提取并下载视频的链接。然后现在重命名,按编号重命名,合并时顺序正确。有时我们会错过一些视频。我们可以看看软件。比如订单写在前面。我可以看到第一个视频没有链接。可能会错过。我不会在这里演示。每个人都会再次抓住它。就是这样。等待下载完成。好的,然后您可以合并视频。您可以使用格式工厂或其他软件。请注意,由于这些视频格式相同,编码类型相同,因此合并过程会非常快。注意这里的顺序。可以看到漏掉了第一个视频,因为和刚才的第一个视频一样。你可以再次抓住它。我不会在这里演示。下面我讲另一种方法,可能更简单一些。,也就是很多浏览器都有嗅探视频或音频的扩展,比如火狐的这个扩展,请看,你看到了吗,如果我拖一个片段,它会自动嗅探下一个分段的视频,所以我们你只需要下载所有这些视频,然后合并下载的视频。但是因为名字一样 你需要注意视频的顺序。因为名字是一样的,看看谷歌浏览。还有类似的扩展,看,我们仍然需要下载所有这些视频并合并它们。
我发现微糖居然可以解析优酷的视频,只有爱奇艺不行。
上面说的方法很麻烦,这里我只说这个方法是可以的。不过还有很多其他更好的方法,这里就不介绍了,包括爱奇艺的视频,其实可以直接下载。
查看全部
抓取网页视频(讲讲怎么该方法适用于很多视频网站的解析下载方法
)
今天给大家讲讲爱奇艺和优酷视频的手动截取视频网站。这种方法适用于很多视频网站。因为有些网站不支持我们使用一些说书、微汤等软件来分析下载,所以就找到了这个方法。在优酷之前是可以的,但是现在优酷还是不支持说书和微汤。唐的分析完毕。这两个网页是原帖地址。其实这个方法我之前就知道,但是这个人提供了一个比较好用的软件。我提取了他录制的视频。下面我们来看看。其实原理是一样的。这些视频网站为了让视频缓存更快,当然还有很多其他的原因。视频分为很多段,所以我们只需要分别下载每个视频,然后合并这些视频。刚起来,这些分段的视频基本都是一样的,最后一段时间可能不一样。我们来看看优酷的分析。爱奇艺的演示是手动抓取,优酷的演示是软件抓取,更方便。那个人写了一个软件把所有的下载地址都提取出来,方便导入迅雷下载。让我演示一次。可见,Fildder 并没有嗅到它。这是因为我的浏览器使用了广告过滤软件。我用没有广告扩展的谷歌浏览器尝试过。可以看出已经有了。它被嗅到了。广告必须通读。好的,现在我们开始拖动视频,首先选择视频分辨率,
这样拖就结束了,因为它会加载分段的视频而不拖到一个地方,所以不知道分段需要多长时间,所以我们试着拖得更慢更短,然后点击让我们排序主机。不同的网站和不同的定义视频有不同的链接。这里优酷的SD就是这样。我们将把所有分段的视频复制下来,链接到小软件上,将每个分段链接起来。在迅雷中提取并下载视频的链接。然后现在重命名,按编号重命名,合并时顺序正确。有时我们会错过一些视频。我们可以看看软件。比如订单写在前面。我可以看到第一个视频没有链接。可能会错过。我不会在这里演示。每个人都会再次抓住它。就是这样。等待下载完成。好的,然后您可以合并视频。您可以使用格式工厂或其他软件。请注意,由于这些视频格式相同,编码类型相同,因此合并过程会非常快。注意这里的顺序。可以看到漏掉了第一个视频,因为和刚才的第一个视频一样。你可以再次抓住它。我不会在这里演示。下面我讲另一种方法,可能更简单一些。,也就是很多浏览器都有嗅探视频或音频的扩展,比如火狐的这个扩展,请看,你看到了吗,如果我拖一个片段,它会自动嗅探下一个分段的视频,所以我们你只需要下载所有这些视频,然后合并下载的视频。但是因为名字一样 你需要注意视频的顺序。因为名字是一样的,看看谷歌浏览。还有类似的扩展,看,我们仍然需要下载所有这些视频并合并它们。
我发现微糖居然可以解析优酷的视频,只有爱奇艺不行。
上面说的方法很麻烦,这里我只说这个方法是可以的。不过还有很多其他更好的方法,这里就不介绍了,包括爱奇艺的视频,其实可以直接下载。

抓取网页视频(编程截取视频有了思路,我们就可以开始编程了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-03 20:40
昨天想在网上下载一个稍微小一点的MP4视频文件,但是在网上找了半天也没找到。现在视频网站上的很多视频只支持在线播放,不提供下载链接。网上也有一些工具可以实现这样的功能,但是我现在还没找到有用的。
想法
打开一个MV的时候,正想着要找视频的地址,于是打开了FireFox的Firebug,然后看了看,发现有一个请求耗时很长,而且体积非常大。仔细一看,原来是一个mp4文件。, 当然,这不是我们需要的视频,这只是一个广告,我们想要的视频只有在广告完成后才能出现。
广告结束后,网页会发出新的Get请求,如下图
我们得到这个地址后,在浏览器中输入这个地址,点击确认,就会出现如下图所示的下载确认对话框。此内容是我们的视频。
仍然存在的问题
因为现在很多视频网站都是将视频分割后再传输,我们很难一次性拿到整个视频。
上图中的3个地址分别为4.8M、4.7M、4.2M。GET请求地址分别为
http://118.228.16.129/youku/67 ... Dtrue
http://118.228.16.127/youku/67 ... Dtrue
http://118.228.16.130/youku/67 ... Dtrue
上面的网址不一样。但是,每个地址的加载直到上一个视频播放到最后才会加载。我仍然无法找到解决此问题的方法。
以编程方式拦截视频 URL
有了想法,我们就可以开始编程了。为了拦截网页加载时发送的HTTP请求,我想到了两种方法:
通过代理服务器通过网卡抓包
这里我首先通过代理服务器拦截HTTP请求。
我根据这个页面的介绍使用了proxy_server。如何用Python制作代理服务器这篇文章文章说的很清楚,可惜里面有一个小错误,稍微修改一下就可以正常运行了。我把proxy_server的代码放在了我的github上。
跑
运行proxy_server.py,将浏览器的代理设置为proxy_server.py监控的地址和端口。得到以下结果。
我以网易公开课的视频为例,因为网易公开课的视频没有分成很多段再传输。
未解决的问题是你无法获得网站的完整视频,将视频分成像优酷这样的片段。代理服务器的转发速度很慢。
因为代理服务器转发方式很慢,打算再次使用网卡方式抓包。我的代理服务器很简单。它甚至没有拦截响应头的功能。通过分析请求头和响应头,我觉得可能会有一些发现。这就是我接下来要做的。 查看全部
抓取网页视频(编程截取视频有了思路,我们就可以开始编程了)
昨天想在网上下载一个稍微小一点的MP4视频文件,但是在网上找了半天也没找到。现在视频网站上的很多视频只支持在线播放,不提供下载链接。网上也有一些工具可以实现这样的功能,但是我现在还没找到有用的。
想法
打开一个MV的时候,正想着要找视频的地址,于是打开了FireFox的Firebug,然后看了看,发现有一个请求耗时很长,而且体积非常大。仔细一看,原来是一个mp4文件。, 当然,这不是我们需要的视频,这只是一个广告,我们想要的视频只有在广告完成后才能出现。
广告结束后,网页会发出新的Get请求,如下图
我们得到这个地址后,在浏览器中输入这个地址,点击确认,就会出现如下图所示的下载确认对话框。此内容是我们的视频。
仍然存在的问题
因为现在很多视频网站都是将视频分割后再传输,我们很难一次性拿到整个视频。
上图中的3个地址分别为4.8M、4.7M、4.2M。GET请求地址分别为
http://118.228.16.129/youku/67 ... Dtrue
http://118.228.16.127/youku/67 ... Dtrue
http://118.228.16.130/youku/67 ... Dtrue
上面的网址不一样。但是,每个地址的加载直到上一个视频播放到最后才会加载。我仍然无法找到解决此问题的方法。
以编程方式拦截视频 URL
有了想法,我们就可以开始编程了。为了拦截网页加载时发送的HTTP请求,我想到了两种方法:
通过代理服务器通过网卡抓包
这里我首先通过代理服务器拦截HTTP请求。
我根据这个页面的介绍使用了proxy_server。如何用Python制作代理服务器这篇文章文章说的很清楚,可惜里面有一个小错误,稍微修改一下就可以正常运行了。我把proxy_server的代码放在了我的github上。
跑
运行proxy_server.py,将浏览器的代理设置为proxy_server.py监控的地址和端口。得到以下结果。
我以网易公开课的视频为例,因为网易公开课的视频没有分成很多段再传输。
未解决的问题是你无法获得网站的完整视频,将视频分成像优酷这样的片段。代理服务器的转发速度很慢。
因为代理服务器转发方式很慢,打算再次使用网卡方式抓包。我的代理服务器很简单。它甚至没有拦截响应头的功能。通过分析请求头和响应头,我觉得可能会有一些发现。这就是我接下来要做的。
抓取网页视频(抓取网页视频一般分为几种方式,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-29 15:02
抓取网页视频一般分为几种方式,第一是后台的视频爬虫服务,像进程服务(webrtc),这种后台服务性能要求一般比较高,第二种是视频浏览网站,这个服务支持多种视频格式,比如最常见的h.264就是一种最好的视频格式,第三种是网页转码服务,这种后台服务支持不同的播放源文件如avi、mp4、mpeg等等视频格式,这种后台服务一般都是api供用户调用。
无论用哪种方式来爬取视频,对于服务器端代码来说,最低的要求都是支持http请求,服务器的性能有好有坏,大部分的企业是满足不了这一条件的,那些对服务器要求较高的我接触过的大部分都是视频站或者第三方的客户端进行了视频转码服务,比如快播的api;像一些视频站支持格式分的比较细,有avi、mp4、mkv、m4v、等视频格式转换,它的爬虫页面一般都可以明确的在他的网页下方看到他支持的视频类型,这个可以通过网站特定的tag查看的。
对于第三方客户端(qq、迅雷等等)网页上的视频来说,基本都是基于格式特定的网页协议视频解码,并不是所有的视频类型都支持,可以自己根据情况选择应用的网页协议。
分两种:一是转码服务,二是视频服务。对于转码服务是否用macromedia或其他解码格式转换器是分开收费的。
分情况1.从浏览器来说,支持的格式比较有限,可能仅有flv,wmv,mp4等最小格式2.从转码服务提供商来说,我认为应该有两种:1.根据转码服务商的协议支持,可以获得不同协议/视频的网络播放,2.根据接入的视频分类, 查看全部
抓取网页视频(抓取网页视频一般分为几种方式,你知道吗?)
抓取网页视频一般分为几种方式,第一是后台的视频爬虫服务,像进程服务(webrtc),这种后台服务性能要求一般比较高,第二种是视频浏览网站,这个服务支持多种视频格式,比如最常见的h.264就是一种最好的视频格式,第三种是网页转码服务,这种后台服务支持不同的播放源文件如avi、mp4、mpeg等等视频格式,这种后台服务一般都是api供用户调用。
无论用哪种方式来爬取视频,对于服务器端代码来说,最低的要求都是支持http请求,服务器的性能有好有坏,大部分的企业是满足不了这一条件的,那些对服务器要求较高的我接触过的大部分都是视频站或者第三方的客户端进行了视频转码服务,比如快播的api;像一些视频站支持格式分的比较细,有avi、mp4、mkv、m4v、等视频格式转换,它的爬虫页面一般都可以明确的在他的网页下方看到他支持的视频类型,这个可以通过网站特定的tag查看的。
对于第三方客户端(qq、迅雷等等)网页上的视频来说,基本都是基于格式特定的网页协议视频解码,并不是所有的视频类型都支持,可以自己根据情况选择应用的网页协议。
分两种:一是转码服务,二是视频服务。对于转码服务是否用macromedia或其他解码格式转换器是分开收费的。
分情况1.从浏览器来说,支持的格式比较有限,可能仅有flv,wmv,mp4等最小格式2.从转码服务提供商来说,我认为应该有两种:1.根据转码服务商的协议支持,可以获得不同协议/视频的网络播放,2.根据接入的视频分类,
抓取网页视频(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-26 04:03
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站视频热搜榜数据并存储为例,详细介绍Python爬虫的基本流程。如果您还处于初始爬虫阶段或者不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 27%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
在 Python 中有很多方法可以解析网页。您可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup 来解释它们。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写吗?
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜正是因为足够简单,希望通过这个案例,让大家了解爬取的基本过程,最后附上完整代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 27%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
-结尾- 查看全部
抓取网页视频(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站视频热搜榜数据并存储为例,详细介绍Python爬虫的基本流程。如果您还处于初始爬虫阶段或者不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 27%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
在 Python 中有很多方法可以解析网页。您可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup 来解释它们。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写吗?
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜正是因为足够简单,希望通过这个案例,让大家了解爬取的基本过程,最后附上完整代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 27%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
-结尾-
抓取网页视频(WebVideoCap是一个FLV视频抓取工具!是怎么捕获的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-25 03:13
)
WebVideoCap 是一个 FLV 视频捕捉工具!设置好后会自动加载浏览器,然后获取URL,可以设置直接下载到指定目录!
由于使用了防盗链工具,网上很多视频教程都无法下载。您可以使用这个小工具轻松记录它们。WebVideoCap可以从网站中截取和录制Flash视频教程,可以同时实时录制各种IM网络即时通讯软件和网页视频信息。如:QQ、MSN等,如果网站上有防盗链措施,WebVideoCap将无法录制。
WebVideoCap改变了常用的分析网页获取下载地址的方法,直接从网卡的数据包开始。使用TCP/IP 7层协议判断数据包是视频,所以不管网站,如果有使用网卡的视频数据包,都可以被WebVideoCap拦截。
WebVideoCap 适用于常用的 flv 和 wmv、mms、rtsp 格式
WebVideoCap可以实时记录各种IM网络通讯软件和网页视频信息,如MSN、QQ等,虽然体积小,但功能却非常强大。
注:WebVideoCap\FLV视频采集工具已更新至最新正式版!
如何使用 webvideocap:
1、 先设置好抓包方式和你本地的导出网卡,录制后选择保存位置
2、 点击开始抓取,即可抓取网页中的流媒体。可以捕获使用您设置的网卡的任何视频和音频。当然,格式必须是FLV/WMV/MMS/RTSP/SWF等格式,其他格式可能不行,但这些格式基本上可以走所有网络媒体。
捕获选项:
捕获 Flash 视频“.flv”文件
捕获 Flash .MP4 文件
捕获 Windows Media ".wmv" 文件
捕获 Windows Media ".wmv" 流
捕获 RTSP 流
捕获彩信流
捕获 Flash ".swf" 文件
界面预览:
查看全部
抓取网页视频(WebVideoCap是一个FLV视频抓取工具!是怎么捕获的?
)
WebVideoCap 是一个 FLV 视频捕捉工具!设置好后会自动加载浏览器,然后获取URL,可以设置直接下载到指定目录!
由于使用了防盗链工具,网上很多视频教程都无法下载。您可以使用这个小工具轻松记录它们。WebVideoCap可以从网站中截取和录制Flash视频教程,可以同时实时录制各种IM网络即时通讯软件和网页视频信息。如:QQ、MSN等,如果网站上有防盗链措施,WebVideoCap将无法录制。
WebVideoCap改变了常用的分析网页获取下载地址的方法,直接从网卡的数据包开始。使用TCP/IP 7层协议判断数据包是视频,所以不管网站,如果有使用网卡的视频数据包,都可以被WebVideoCap拦截。
WebVideoCap 适用于常用的 flv 和 wmv、mms、rtsp 格式
WebVideoCap可以实时记录各种IM网络通讯软件和网页视频信息,如MSN、QQ等,虽然体积小,但功能却非常强大。
注:WebVideoCap\FLV视频采集工具已更新至最新正式版!
如何使用 webvideocap:
1、 先设置好抓包方式和你本地的导出网卡,录制后选择保存位置
2、 点击开始抓取,即可抓取网页中的流媒体。可以捕获使用您设置的网卡的任何视频和音频。当然,格式必须是FLV/WMV/MMS/RTSP/SWF等格式,其他格式可能不行,但这些格式基本上可以走所有网络媒体。
捕获选项:
捕获 Flash 视频“.flv”文件
捕获 Flash .MP4 文件
捕获 Windows Media ".wmv" 文件
捕获 Windows Media ".wmv" 流
捕获 RTSP 流
捕获彩信流
捕获 Flash ".swf" 文件
界面预览:

抓取网页视频( 和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2021-09-15 20:04
和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
几天前,一位同学说他想下载一段网站视频,但找不到连接。他问我有没有办法。当时,我觉得应该很简单,所以我说我会花时间看看。然后我分析了目标网页并试图从网页源代码中找到连接,但失败了。F12调用开发人员工具,进入netwrok,发现网页是XHR请求通过Ajax获得的视频连接。难怪页面元素中没有下载地址。请求的是m3u8格式的文件。在检查这是一个分段流媒体文件,然后到处寻找下载此格式文件的工具后,这不是很理想。很多TS文件在切片后直接下载,但这个网站one是加密的,不能直接播放。最后,找到了视频插件伪影ffmpeg。视频转码、剪辑、合并和播放都不是问题。它还支持多种平台
ffmpeg简介
Ffmpeg开放Ffmpeg官方网站
对于工件,为什么不自己编写一个工具来下载它呢?当您准备开始时,您会被如何获得连接的问题所阻止。最初,您只需要编写一个小型爬虫程序并对web连接进行爬网。结果,它不起作用。Ajax动态地启动了请求。数据不在web页面元素中,我对JS也不熟悉。我不知道如何获得这些数据。学生手动打开浏览器F12然后查找连接是否困难?这不是我的风格:)然后继续搜索,获得结果,自己实现浏览器,并拦截网页上的所有请求。筛选后得到三个方案:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
首先,我试了一下网络浏览器。目标网站无法直接打开网页。我更改了谷歌浏览器并修改了useragent以打开它,但是网页没有完全显示出来,所以我放弃了。然后更改geokofx以直接打开它,速度也很快,但有些连接会单击并没有响应,因此只能放弃。最终,cefsharp测试达到了预期目标,即flash和H264视频一天之内无法打开和投掷。这位官员表示,版权问题不受支持,需要修改。查找修改过的库。查找支持flash和H264视频的库:
提取代码:DFDR
是nupkg的安装包。检查nupkg安装方法
然后编写代码:
视频地址获取只需要继承和集成默认的抽象类defaultrequesthandler
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定以下内容
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里,我提取URL中的文件名,然后通过判断扩展名来判断它是否是视频文件。我不知道是否有更普遍的方法。Resourcetype==Resourcetype。媒体无法评判。在许多情况下,该值返回XHR
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
以下是几天的辗转反侧的结果
在浏览器界面中,如果在打开网页后截获视频地址,则会在go后面的右上角显示[x]。X表示在当前页面上截获的视频文件数
点击左上角的数字或下载标签页,进入如下界面
您可以在此下载、播放和其他操作。界面有点难看,功能实现了
下载支持断点继续,但m3u8片段文件不保存断点。因此,软件关闭后无法执行断点继续。重新启动。无法预测实时流的大小,因此不会显示下一个进度,但会及时更新下载的数据大小
通常,TS文件不需要下载,但可以直接从m3u8下载。程序将自动分析TS片段文件,并在下载所有文件后自动合成MP4文件
软件下载:链接:
提取代码:n6q4
如果没有,请下载并安装net framework4.6.1
关于查找教程网络 查看全部
抓取网页视频(
和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)

几天前,一位同学说他想下载一段网站视频,但找不到连接。他问我有没有办法。当时,我觉得应该很简单,所以我说我会花时间看看。然后我分析了目标网页并试图从网页源代码中找到连接,但失败了。F12调用开发人员工具,进入netwrok,发现网页是XHR请求通过Ajax获得的视频连接。难怪页面元素中没有下载地址。请求的是m3u8格式的文件。在检查这是一个分段流媒体文件,然后到处寻找下载此格式文件的工具后,这不是很理想。很多TS文件在切片后直接下载,但这个网站one是加密的,不能直接播放。最后,找到了视频插件伪影ffmpeg。视频转码、剪辑、合并和播放都不是问题。它还支持多种平台
ffmpeg简介
Ffmpeg开放Ffmpeg官方网站
对于工件,为什么不自己编写一个工具来下载它呢?当您准备开始时,您会被如何获得连接的问题所阻止。最初,您只需要编写一个小型爬虫程序并对web连接进行爬网。结果,它不起作用。Ajax动态地启动了请求。数据不在web页面元素中,我对JS也不熟悉。我不知道如何获得这些数据。学生手动打开浏览器F12然后查找连接是否困难?这不是我的风格:)然后继续搜索,获得结果,自己实现浏览器,并拦截网页上的所有请求。筛选后得到三个方案:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
首先,我试了一下网络浏览器。目标网站无法直接打开网页。我更改了谷歌浏览器并修改了useragent以打开它,但是网页没有完全显示出来,所以我放弃了。然后更改geokofx以直接打开它,速度也很快,但有些连接会单击并没有响应,因此只能放弃。最终,cefsharp测试达到了预期目标,即flash和H264视频一天之内无法打开和投掷。这位官员表示,版权问题不受支持,需要修改。查找修改过的库。查找支持flash和H264视频的库:
提取代码:DFDR
是nupkg的安装包。检查nupkg安装方法
然后编写代码:
视频地址获取只需要继承和集成默认的抽象类defaultrequesthandler
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定以下内容
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里,我提取URL中的文件名,然后通过判断扩展名来判断它是否是视频文件。我不知道是否有更普遍的方法。Resourcetype==Resourcetype。媒体无法评判。在许多情况下,该值返回XHR
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
以下是几天的辗转反侧的结果

在浏览器界面中,如果在打开网页后截获视频地址,则会在go后面的右上角显示[x]。X表示在当前页面上截获的视频文件数
点击左上角的数字或下载标签页,进入如下界面




您可以在此下载、播放和其他操作。界面有点难看,功能实现了
下载支持断点继续,但m3u8片段文件不保存断点。因此,软件关闭后无法执行断点继续。重新启动。无法预测实时流的大小,因此不会显示下一个进度,但会及时更新下载的数据大小
通常,TS文件不需要下载,但可以直接从m3u8下载。程序将自动分析TS片段文件,并在下载所有文件后自动合成MP4文件
软件下载:链接:
提取代码:n6q4
如果没有,请下载并安装net framework4.6.1

关于查找教程网络
抓取网页视频( 可自动捕捉网页视频地址到软件即可进行网页下载(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 1057 次浏览 • 2021-09-13 05:17
可自动捕捉网页视频地址到软件即可进行网页下载(图))
ImovieBox 网络视频下载器是一款多功能的网络视频下载软件。 ImovieBox网页视频下载器可以自动抓取网页中的视频文件并下载到本地,安全稳定,无限存储,支持多线程,观看下载。 ImovieBox 使用简单方便。将视频地址复制到软件下载网络视频。
功能介绍1、批量下载
可以批量下载网络上的视频文件
2、生成目录
可以帮助用户生成高清视频目录
3、精准识别
可以有效识别网页上出现的视频
4、下载速度快
高效快速地下载网络视频
5、发送邮件
可以直接将视频文件发送到用户邮箱或手机
安装步骤1、在本站下载ImovieBox网页视频下载器软件包,进入安装界面。
2、点击下一步继续安装。
3、接受许可协议并选择安装位置
4、ImovieBox Web Video Downloader 安装完毕,打开软件即可使用。
如何使用 ImovieBox 网络视频下载器是如何下载网络视频的?
1.实时抓拍:点击开启实时抓拍功能后,软件界面右侧会弹出抓拍信息窗口,设置视频文件的下载方式,输入视频下载界面,软件会自动播放文件进行下载。
2.输入网址截取:将视频文件的播放地址复制粘贴到选择框中,点击“传统截取视频”按钮开始下载。
如何使用
1、 建议使用自己的邮箱登录,登录账号的邮箱空间为基础空间
2、 登录后可以添加任何其他邮局账号,添加的空间为扩展空间
3、软件自动将多个账户空间合并成一个海量空间,永久保存数据
4、只需将视频的网页地址提交给ImovieBox下载器,即可下载任何视频。并且可以自动存入邮箱,供您随时随地检索使用。
5、界面简单,功能齐全,可以下载任何网站视频。 ImovieBox网络视频下载器是您学习和生活中不可多得的好帮手。
专业版功能
1、任意网页批量下载海量图片。
可以指定任意图片格式,可以指定任意图片大小,可以指定任意图片宽高进行批量下载。
抓拍图片实时预览,所需图片集实时抓拍,支持多线程高速并发下载。
根据不同的宽度和高度自动对图片进行分类,显示实时梳理列表,选择指定宽度和高度的图片实时获取批次。
2、自动生成高分辨率相册。
3、即时下载和即时欣赏模式。
4、支持批量下载所有加密图片。
5、支持批量下载带有防盗链接的图片。
6、你看到的独特下载模式就是你得到的。即在观看网页图片时,ImovieBox 网络视频下载专家会自动下载图片。
7、友好的用户界面。界面颜色可以随意调整。
8、完整的单机软件,不仅可以下载到本地,还具有备份到您私人邮箱的功能。
9、支持图片自动批量下载并自动同步到您的私有云存储。 查看全部
抓取网页视频(
可自动捕捉网页视频地址到软件即可进行网页下载(图))

ImovieBox 网络视频下载器是一款多功能的网络视频下载软件。 ImovieBox网页视频下载器可以自动抓取网页中的视频文件并下载到本地,安全稳定,无限存储,支持多线程,观看下载。 ImovieBox 使用简单方便。将视频地址复制到软件下载网络视频。
功能介绍1、批量下载
可以批量下载网络上的视频文件
2、生成目录
可以帮助用户生成高清视频目录
3、精准识别
可以有效识别网页上出现的视频
4、下载速度快
高效快速地下载网络视频
5、发送邮件
可以直接将视频文件发送到用户邮箱或手机
安装步骤1、在本站下载ImovieBox网页视频下载器软件包,进入安装界面。
2、点击下一步继续安装。
3、接受许可协议并选择安装位置
4、ImovieBox Web Video Downloader 安装完毕,打开软件即可使用。
如何使用 ImovieBox 网络视频下载器是如何下载网络视频的?
1.实时抓拍:点击开启实时抓拍功能后,软件界面右侧会弹出抓拍信息窗口,设置视频文件的下载方式,输入视频下载界面,软件会自动播放文件进行下载。
2.输入网址截取:将视频文件的播放地址复制粘贴到选择框中,点击“传统截取视频”按钮开始下载。
如何使用
1、 建议使用自己的邮箱登录,登录账号的邮箱空间为基础空间
2、 登录后可以添加任何其他邮局账号,添加的空间为扩展空间
3、软件自动将多个账户空间合并成一个海量空间,永久保存数据
4、只需将视频的网页地址提交给ImovieBox下载器,即可下载任何视频。并且可以自动存入邮箱,供您随时随地检索使用。
5、界面简单,功能齐全,可以下载任何网站视频。 ImovieBox网络视频下载器是您学习和生活中不可多得的好帮手。

专业版功能
1、任意网页批量下载海量图片。
可以指定任意图片格式,可以指定任意图片大小,可以指定任意图片宽高进行批量下载。
抓拍图片实时预览,所需图片集实时抓拍,支持多线程高速并发下载。
根据不同的宽度和高度自动对图片进行分类,显示实时梳理列表,选择指定宽度和高度的图片实时获取批次。
2、自动生成高分辨率相册。
3、即时下载和即时欣赏模式。
4、支持批量下载所有加密图片。
5、支持批量下载带有防盗链接的图片。
6、你看到的独特下载模式就是你得到的。即在观看网页图片时,ImovieBox 网络视频下载专家会自动下载图片。
7、友好的用户界面。界面颜色可以随意调整。
8、完整的单机软件,不仅可以下载到本地,还具有备份到您私人邮箱的功能。
9、支持图片自动批量下载并自动同步到您的私有云存储。
抓取网页视频(智能识别模式WebHarvy自动识别网页中的数据抓取工具完美激活该软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-13 05:14
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。便于使用。小编为您带来WebHarvy破解版。附带的破解文件可以完美激活软件。有需要就来试试吧。
功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
软件功能
WebHarvy 是一个可视化的网页抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。 查看全部
抓取网页视频(智能识别模式WebHarvy自动识别网页中的数据抓取工具完美激活该软件)
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。便于使用。小编为您带来WebHarvy破解版。附带的破解文件可以完美激活软件。有需要就来试试吧。
功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。

软件功能
WebHarvy 是一个可视化的网页抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
抓取网页视频( 2021-05-11摩旅 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-12 13:04
2021-05-11摩旅
)
抓取网页图片-以本地IIS网页为练习对象
时间:2021-05-11
本文章为大家介绍抓取网页图片-本地IIS网页为练习对象,主要包括抓取网页图片-本地IIS网页为练习对象使用实例、应用技巧、基础知识点总结及需要注意的内容有一定的参考价值,有需要的朋友可以参考。
#抓取网页图片
#适用于html页面结构为:li>img
#抓取单个网页图片小程序
#version:V1.0
#author:yxmichael
#更新时间:20210511
import requests
from bs4 import BeautifulSoup
import os,shutil
import time
def getHtmlText(url,code='utf-8'):
try:
r = requests.get(url,timeout = 30,headers = my_headers)
r.raise_for_status
r.encoding = code
return r.text
except:
return ""
def parseHtml(nlist,html):
try:
soup = BeautifulSoup(html,'html.parser')
div_main = soup.find('div',attrs={'id':'main'})
lis = div_main.findAll('li')
for li in lis:
a_href = li.find('a')['href']
if a_href != '#':
img_src = li.find('img')['src']
img_name = a_href.split('/')[-1]
#img_name =img_name[-1]
#print("{}\t{}\n".format(a_href,img_src))
nlist.append([img_name,a_href,img_src])
except:
print("")
def delOldDir(dir_path):
if os.path.exists(dir_path):
shutil.rmtree(dir_path)
def downImg(nlist,nums,site_url,dir_path):
if not os.path.exists(dir_path):
os.mkdir(dir_path)
os.chdir(dir_path)
print("\n正在获取原图……")
for i in range(nums):
img = nlist[i]
img_name = img[0]
img_href= site_url + img[1]
file_name = dir_path +'/' + img_name
r= requests.get(img_href,timeout=30)
with open(file_name,'wb') as f:
f.write(r.content)
progressBar(i,nums)
def downImgMicro(nlist,nums,site_url,dir_path):
if not os.path.exists(dir_path):
os.mkdir(dir_path)
os.chdir(dir_path)
print("\n正在获取缩微图……")
for i in range(nums):
img = nlist[i]
img_name = img[0]
img_src = site_url + img[2]
prefix = '缩微图_'
file_name = dir_path +'/' + prefix + img_name
r= requests.get(img_src,timeout=30)
with open(file_name,'wb') as f:
f.write(r.content)
progressBar(i,nums)
def progressBar(i,total):
print('\r当前进度:{0}{1:.0f}%'.format('▉'*(i+1),((i+1)/total*100)),end='')
def printHead():
num = 80
print("{}".format("*"*num))
str_intro = '''
抓取单个网页图片小程序
version:V1.0
author:yxmichael
更新时间:20210511
'''
print(str_intro)
print("{}".format("*"*num))
print("\n正在抓取……\n")
def main():
global my_headers
my_headers ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
site_url = 'http://127.0.0.1/pg/'
imgList = []
start_time = time.time()
cur_path = os.getcwd() + '/'
tmp = '老照片'
dir_path = cur_path + tmp
dir_path_micro = cur_path + tmp + '_缩微图'
printHead()
html = getHtmlText(site_url)
parseHtml(imgList,html)
nums = len(imgList)
#nums =3
delOldDir(dir_path)
delOldDir(dir_path_micro)
downImg(imgList,nums,site_url,dir_path)
downImgMicro(imgList,nums,site_url,dir_path_micro)
seconds = time.time() - start_time
print("\n成功下载{}张图片,耗时:{:.1f}秒。\n保存路径{}".format(nums,seconds,dir_path))
input("请按任意键退出……")
main() 查看全部
抓取网页视频(
2021-05-11摩旅
)
抓取网页图片-以本地IIS网页为练习对象
时间:2021-05-11
本文章为大家介绍抓取网页图片-本地IIS网页为练习对象,主要包括抓取网页图片-本地IIS网页为练习对象使用实例、应用技巧、基础知识点总结及需要注意的内容有一定的参考价值,有需要的朋友可以参考。
#抓取网页图片
#适用于html页面结构为:li>img
#抓取单个网页图片小程序
#version:V1.0
#author:yxmichael
#更新时间:20210511
import requests
from bs4 import BeautifulSoup
import os,shutil
import time
def getHtmlText(url,code='utf-8'):
try:
r = requests.get(url,timeout = 30,headers = my_headers)
r.raise_for_status
r.encoding = code
return r.text
except:
return ""
def parseHtml(nlist,html):
try:
soup = BeautifulSoup(html,'html.parser')
div_main = soup.find('div',attrs={'id':'main'})
lis = div_main.findAll('li')
for li in lis:
a_href = li.find('a')['href']
if a_href != '#':
img_src = li.find('img')['src']
img_name = a_href.split('/')[-1]
#img_name =img_name[-1]
#print("{}\t{}\n".format(a_href,img_src))
nlist.append([img_name,a_href,img_src])
except:
print("")
def delOldDir(dir_path):
if os.path.exists(dir_path):
shutil.rmtree(dir_path)
def downImg(nlist,nums,site_url,dir_path):
if not os.path.exists(dir_path):
os.mkdir(dir_path)
os.chdir(dir_path)
print("\n正在获取原图……")
for i in range(nums):
img = nlist[i]
img_name = img[0]
img_href= site_url + img[1]
file_name = dir_path +'/' + img_name
r= requests.get(img_href,timeout=30)
with open(file_name,'wb') as f:
f.write(r.content)
progressBar(i,nums)
def downImgMicro(nlist,nums,site_url,dir_path):
if not os.path.exists(dir_path):
os.mkdir(dir_path)
os.chdir(dir_path)
print("\n正在获取缩微图……")
for i in range(nums):
img = nlist[i]
img_name = img[0]
img_src = site_url + img[2]
prefix = '缩微图_'
file_name = dir_path +'/' + prefix + img_name
r= requests.get(img_src,timeout=30)
with open(file_name,'wb') as f:
f.write(r.content)
progressBar(i,nums)
def progressBar(i,total):
print('\r当前进度:{0}{1:.0f}%'.format('▉'*(i+1),((i+1)/total*100)),end='')
def printHead():
num = 80
print("{}".format("*"*num))
str_intro = '''
抓取单个网页图片小程序
version:V1.0
author:yxmichael
更新时间:20210511
'''
print(str_intro)
print("{}".format("*"*num))
print("\n正在抓取……\n")
def main():
global my_headers
my_headers ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
site_url = 'http://127.0.0.1/pg/'
imgList = []
start_time = time.time()
cur_path = os.getcwd() + '/'
tmp = '老照片'
dir_path = cur_path + tmp
dir_path_micro = cur_path + tmp + '_缩微图'
printHead()
html = getHtmlText(site_url)
parseHtml(imgList,html)
nums = len(imgList)
#nums =3
delOldDir(dir_path)
delOldDir(dir_path_micro)
downImg(imgList,nums,site_url,dir_path)
downImgMicro(imgList,nums,site_url,dir_path_micro)
seconds = time.time() - start_time
print("\n成功下载{}张图片,耗时:{:.1f}秒。\n保存路径{}".format(nums,seconds,dir_path))
input("请按任意键退出……")
main()
抓取网页视频(看看网易公开课是怎么选课的,这些才是王道)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-09 18:04
抓取网页视频地址:国内国外视频网站对比:斗鱼>爱奇艺>优酷>迅雷、ab站、天天动听=网易公开课,熊猫、pptv=腾讯公开课,b站=腾讯视频、新浪公开课=爱奇艺公开课,
百度,谷歌。我不会告诉你我曾经从优酷上看到,一个台湾方言被秒杀。
我不看youtube,但我知道知乎上不可以不看。
几个视频网站:网易公开课视频大部分比较老,比如coursera。但是个人觉得还不错。
网易公开课或新浪公开课
难道没人觉得用着自带浏览器看a站b站就可以了嘛,不用那些超贵的会员。
爱奇艺不是可以用电视机看么
会是电视机或者电脑,
新浪微博
b站,
猎奇也是需要资本的,虽然爱奇艺公开课被秒,但那毕竟是猎奇级别的,我还没到可以随便开心的打开视频一看就是一天的水平。期待网易,优酷的公开课,毕竟会员看主流电视剧,4,6,月,年几年年的那种。看看网易公开课是怎么选课的,又是怎么上课的,这些才是王道。
优酷。b站。
那就看你喜欢哪个用哪个咯,
网易公开课里面有些频道还不错
youtube。特别喜欢里面各类视频课程比如coursera,mooc等。 查看全部
抓取网页视频(看看网易公开课是怎么选课的,这些才是王道)
抓取网页视频地址:国内国外视频网站对比:斗鱼>爱奇艺>优酷>迅雷、ab站、天天动听=网易公开课,熊猫、pptv=腾讯公开课,b站=腾讯视频、新浪公开课=爱奇艺公开课,
百度,谷歌。我不会告诉你我曾经从优酷上看到,一个台湾方言被秒杀。
我不看youtube,但我知道知乎上不可以不看。
几个视频网站:网易公开课视频大部分比较老,比如coursera。但是个人觉得还不错。
网易公开课或新浪公开课
难道没人觉得用着自带浏览器看a站b站就可以了嘛,不用那些超贵的会员。
爱奇艺不是可以用电视机看么
会是电视机或者电脑,
新浪微博
b站,
猎奇也是需要资本的,虽然爱奇艺公开课被秒,但那毕竟是猎奇级别的,我还没到可以随便开心的打开视频一看就是一天的水平。期待网易,优酷的公开课,毕竟会员看主流电视剧,4,6,月,年几年年的那种。看看网易公开课是怎么选课的,又是怎么上课的,这些才是王道。
优酷。b站。
那就看你喜欢哪个用哪个咯,
网易公开课里面有些频道还不错
youtube。特别喜欢里面各类视频课程比如coursera,mooc等。
抓取网页视频(搜了搜知乎,几万个人在看,结果在这)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-01 14:12
抓取网页视频,想看看有多少人在看,就搜了搜知乎,几万个人在看,结果在这给大家整理下我搜的app,可以说是相当的全了。分享给大家。1.快手快手,一款脱口秀小视频短视频分享app,极其搞笑搞笑。同时也是趣友社交软件,特有的拼团玩法可以获得更多的知识加强社交能力,推荐给有收藏快手的朋友,这是我从快手无意间收到的朋友推荐,现在依然在用,强烈推荐下。
2.映客映客主要也是用来录制视频的直播软件,这两年人是有多疯狂了,据说有人周末两天冲破了万人观看,同时也可以唱唱歌、聊聊天,偶尔录一段小段子,还是特别不错的。3.斗鱼斗鱼是我一直很推荐的一款直播软件,这里的主播还是相当不错的,也有自己的签约工会,在上面可以和知名主播进行近距离对话,并且到现在还在不断更新,这里的主播活跃度高,都特别有才,这里也是大家喜欢跳舞聊天的首选,在以前还是特别的喜欢qq斗鱼直播那里的直播。
4.yyyy更像是一个手机的游戏平台,里面的主播都是专业的玩家水平,比如nba和体育游戏,游戏排行榜等等,同时也是一个社交软件,这里可以看到一些素质不是特别高的主播,你要相信我,从这类型的人身上是可以学到很多东西的。5.陌陌陌陌更像是一个聊天社交平台,这个我们从小上就开始玩,本质上是陌生人聊天软件,我们大家各种相亲都是在这个上面,陌陌依然也是这个类型,但是其实我觉得他也是比较尴尬,我们一般都是和陌生人聊天,或者是兼职之类的都是在这里面,陌陌对一些低头族还是有点不友好,不知道会不会给他们一些机会。
6.地图大众点评听着名字就知道他是做什么的吧,但是大众点评并不是一个点评类型的软件,这个是有非常多的餐饮外卖,同时也是一个社交软件,依然是一个约吃饭或者约到他人出去玩的软件,平时可以看到一些比较有名的吃饭地点。7.高德大众点评高德,在城市信息检索这方面可以比得上百度,里面也有许多的专业信息都是在这里面检索到的,同时这个软件的市场占有率非常高,高德街景可以看到我们经常去的地方,分享照片。
8.说说,又一个真实的大型购物网站,里面的产品品质比较好,有些店铺本身也是和有合作的,而且还可以以折扣价格购买,所以这个软件又可以购物还可以看购物记录,同时这个软件还有其他的功能就不展示出来了。可以说算是我们必不可少的,强烈推荐下大家。9.全民应用全民应用这个主要就是图片、音乐、游戏等等app,并且都不收费,强烈推荐下吧。10.友盟大姨吗优点就是男女都可以用,并且有很多好友分享小工具,特别方。 查看全部
抓取网页视频(搜了搜知乎,几万个人在看,结果在这)
抓取网页视频,想看看有多少人在看,就搜了搜知乎,几万个人在看,结果在这给大家整理下我搜的app,可以说是相当的全了。分享给大家。1.快手快手,一款脱口秀小视频短视频分享app,极其搞笑搞笑。同时也是趣友社交软件,特有的拼团玩法可以获得更多的知识加强社交能力,推荐给有收藏快手的朋友,这是我从快手无意间收到的朋友推荐,现在依然在用,强烈推荐下。
2.映客映客主要也是用来录制视频的直播软件,这两年人是有多疯狂了,据说有人周末两天冲破了万人观看,同时也可以唱唱歌、聊聊天,偶尔录一段小段子,还是特别不错的。3.斗鱼斗鱼是我一直很推荐的一款直播软件,这里的主播还是相当不错的,也有自己的签约工会,在上面可以和知名主播进行近距离对话,并且到现在还在不断更新,这里的主播活跃度高,都特别有才,这里也是大家喜欢跳舞聊天的首选,在以前还是特别的喜欢qq斗鱼直播那里的直播。
4.yyyy更像是一个手机的游戏平台,里面的主播都是专业的玩家水平,比如nba和体育游戏,游戏排行榜等等,同时也是一个社交软件,这里可以看到一些素质不是特别高的主播,你要相信我,从这类型的人身上是可以学到很多东西的。5.陌陌陌陌更像是一个聊天社交平台,这个我们从小上就开始玩,本质上是陌生人聊天软件,我们大家各种相亲都是在这个上面,陌陌依然也是这个类型,但是其实我觉得他也是比较尴尬,我们一般都是和陌生人聊天,或者是兼职之类的都是在这里面,陌陌对一些低头族还是有点不友好,不知道会不会给他们一些机会。
6.地图大众点评听着名字就知道他是做什么的吧,但是大众点评并不是一个点评类型的软件,这个是有非常多的餐饮外卖,同时也是一个社交软件,依然是一个约吃饭或者约到他人出去玩的软件,平时可以看到一些比较有名的吃饭地点。7.高德大众点评高德,在城市信息检索这方面可以比得上百度,里面也有许多的专业信息都是在这里面检索到的,同时这个软件的市场占有率非常高,高德街景可以看到我们经常去的地方,分享照片。
8.说说,又一个真实的大型购物网站,里面的产品品质比较好,有些店铺本身也是和有合作的,而且还可以以折扣价格购买,所以这个软件又可以购物还可以看购物记录,同时这个软件还有其他的功能就不展示出来了。可以说算是我们必不可少的,强烈推荐下大家。9.全民应用全民应用这个主要就是图片、音乐、游戏等等app,并且都不收费,强烈推荐下吧。10.友盟大姨吗优点就是男女都可以用,并且有很多好友分享小工具,特别方。
抓取网页视频(爬虫优雅精美的数据全过程第1章课程介绍(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-29 09:05
简介: 爬虫技术用于自动从互联网上获取所需数据。课程从爬虫的介绍开始,介绍一个简单的爬虫技术架构,然后通过什么、怎么做、现场演示三个步骤来讲解爬虫技术架构中的三个模块。最后在实战中编写了一套优雅精致的爬虫代码,展示了在实战中抓取百度百科1000页数据的全过程。
第一章课程介绍
本章对课程要学习的内容进行了概述,并明确告诉大家将从课程中学习到开发爬虫所需的相关技术。
第二章爬虫简介及爬虫技术价值
本章介绍了爬虫技术的含义,以及爬虫技术存在的价值和意义
第 3 章 简单的爬虫架构
本章介绍了一个精炼简洁的爬虫技术架构,通过技术架构的动态图介绍了爬虫任务的实现过程,让大家对爬虫的整体构成和运行过程有一个整体的把握。
第 4 章 URL 管理器和实现方法
本章介绍简单爬虫架构的URL管理模块,用于管理待爬取的URL集合和已爬取的URL集合。它还介绍了几种实现 URL 管理器的方法。
第 5 章 Web 下载器和 urllib2 模块
本章介绍简单爬虫架构的网页下载模块。下载网页后,就可以进行后续的数据提取了。本章接着介绍Python自带的用于下载网页的urllib2模块的各种使用语法。
第6章网页解析器和BeautifulSoup第三方模块
本章介绍一个具有简单爬虫架构的网页解析器模块。解析器用于从要抓取的网页和新 URL 中提取有价值的数据。本章接着介绍 BeautifulSoup,一个强大的第三方数据分析和提取模块。
第七章实战练习:百度百科1000页数据爬取
本章是本课程的核心部分。通过一组精心设计和编写的爬虫代码,实现了上一课中描述的简单爬虫架构的各个组件。爬虫代码最终完成百度百科1000页的数据爬取并进行数据抓取。说明修改配置后,该代码可用于抓取任何网站数据。
第八章课程总结
本章回顾了课程中所讲授的知识,对爬虫技术架构有一个整体的回顾和掌握,同时也对爬虫技术在深入发展中遇到的困难进行了简要的展望。
课程笔记
本课程是Python语言开发1、Python编程语法的高级课程;2、HTML语言基础知识;3、正则表达式基础知识;
老师能告诉你要学什么?
1、爬虫技术的意义和存在价值2、爬虫技术架构3、构成爬虫的关键模块:URL管理器、HTML下载器和HTML解析器4、实用爬取百度百科千条页面数据爬取策略设置,实际代码编写,爬虫实例运行5、 一套极其简单且可扩展的爬虫代码,修改此代码,即可爬取任何互联网网页!
扫描微信二维码参加3人团战 查看全部
抓取网页视频(爬虫优雅精美的数据全过程第1章课程介绍(组图))
简介: 爬虫技术用于自动从互联网上获取所需数据。课程从爬虫的介绍开始,介绍一个简单的爬虫技术架构,然后通过什么、怎么做、现场演示三个步骤来讲解爬虫技术架构中的三个模块。最后在实战中编写了一套优雅精致的爬虫代码,展示了在实战中抓取百度百科1000页数据的全过程。
第一章课程介绍
本章对课程要学习的内容进行了概述,并明确告诉大家将从课程中学习到开发爬虫所需的相关技术。
第二章爬虫简介及爬虫技术价值
本章介绍了爬虫技术的含义,以及爬虫技术存在的价值和意义
第 3 章 简单的爬虫架构
本章介绍了一个精炼简洁的爬虫技术架构,通过技术架构的动态图介绍了爬虫任务的实现过程,让大家对爬虫的整体构成和运行过程有一个整体的把握。
第 4 章 URL 管理器和实现方法
本章介绍简单爬虫架构的URL管理模块,用于管理待爬取的URL集合和已爬取的URL集合。它还介绍了几种实现 URL 管理器的方法。
第 5 章 Web 下载器和 urllib2 模块
本章介绍简单爬虫架构的网页下载模块。下载网页后,就可以进行后续的数据提取了。本章接着介绍Python自带的用于下载网页的urllib2模块的各种使用语法。
第6章网页解析器和BeautifulSoup第三方模块
本章介绍一个具有简单爬虫架构的网页解析器模块。解析器用于从要抓取的网页和新 URL 中提取有价值的数据。本章接着介绍 BeautifulSoup,一个强大的第三方数据分析和提取模块。
第七章实战练习:百度百科1000页数据爬取
本章是本课程的核心部分。通过一组精心设计和编写的爬虫代码,实现了上一课中描述的简单爬虫架构的各个组件。爬虫代码最终完成百度百科1000页的数据爬取并进行数据抓取。说明修改配置后,该代码可用于抓取任何网站数据。
第八章课程总结
本章回顾了课程中所讲授的知识,对爬虫技术架构有一个整体的回顾和掌握,同时也对爬虫技术在深入发展中遇到的困难进行了简要的展望。
课程笔记
本课程是Python语言开发1、Python编程语法的高级课程;2、HTML语言基础知识;3、正则表达式基础知识;
老师能告诉你要学什么?
1、爬虫技术的意义和存在价值2、爬虫技术架构3、构成爬虫的关键模块:URL管理器、HTML下载器和HTML解析器4、实用爬取百度百科千条页面数据爬取策略设置,实际代码编写,爬虫实例运行5、 一套极其简单且可扩展的爬虫代码,修改此代码,即可爬取任何互联网网页!
扫描微信二维码参加3人团战
抓取网页视频(爬虫中一些常用的工具的使用,可以提高工作效率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-10-28 11:04
抓取网页视频的时候,经常需要存储一些数据,比如说我们可以提取页面的图片之类的数据,但是由于数据同步,文件大小等一些原因,我们要用到爬虫的各种工具,本文就讲讲爬虫中一些常用的工具的使用,可以让我们的爬虫过程效率更高,提高工作效率。1.模拟登录我们如果想要爬取网页,又想提取页面上的图片或者其他数据,怎么办呢?不要慌,我们使用模拟登录代码来做,一般来说,我们可以选择:第一种是请求正常的接口,第二种是选择假定登录状态进行。
1.1手动登录首先来看看怎么手动登录登录步骤:打开浏览器,输入【】这个地址,会打开一个链接,复制地址。【】=signin,在地址中填写你要爬取的网址。【】=signout,在链接中填写你要提取的数据的地址。这个地址就是你登录的账号密码,解析网址过程中,我们可以发现:这个网址就是你登录过网页登录成功之后,就可以提取我们想要提取的数据了,我们把所有需要提取的数据提取出来:验证登录,这个时候就可以提取图片了登录成功之后,我们在requests.post中,给对方提供一个useragent信息,同时也给提取的数据提供一个useragent。
那么requests.post请求的结果,那么我们上面也讲到了,都是json格式的数据,数据提取的时候,都是用data来提取的。那么怎么把这个json转化成jsonjson转化成对应图片数据,我这里推荐使用beautifulsoup。我们用python中的beautifulsoup来做这个事情beautifulsoup简单点讲:就是解析html中的信息,提取出对应的元素。
这里就有一个小问题:html中的结构信息,我们在获取的时候,可能这些结构信息会有一些,如html文档中的title等,使用html的话,需要获取浏览器中的那些结构信息?这里就需要用到正则表达式了:window.request="location=page{}".format(html.text)window.request.urlopen(url)window.request.isreplacement()window.request.urlopen(url)大家可以测试一下,会发现,获取的url会有这个错误出现:大家写过正则表达式,会知道,正则表达式的匹配原则,无论是url还是页面,都要匹配到。
但是text属性怎么匹配呢?对我们来说,一个页面页面上可能会有多个需要提取数据的节点,需要很多时间去匹配。然后我们怎么把大家都解析出来呢?可以使用正则表达式来匹配:%.5f(javascript)大家可以试试.5f,会发现,所有节点的text都被匹配出来了2.图片数据获取第二个部分,图片数据的获取。这个是我们爬虫过程中经常会用到的一个库。前面说到的b。 查看全部
抓取网页视频(爬虫中一些常用的工具的使用,可以提高工作效率)
抓取网页视频的时候,经常需要存储一些数据,比如说我们可以提取页面的图片之类的数据,但是由于数据同步,文件大小等一些原因,我们要用到爬虫的各种工具,本文就讲讲爬虫中一些常用的工具的使用,可以让我们的爬虫过程效率更高,提高工作效率。1.模拟登录我们如果想要爬取网页,又想提取页面上的图片或者其他数据,怎么办呢?不要慌,我们使用模拟登录代码来做,一般来说,我们可以选择:第一种是请求正常的接口,第二种是选择假定登录状态进行。
1.1手动登录首先来看看怎么手动登录登录步骤:打开浏览器,输入【】这个地址,会打开一个链接,复制地址。【】=signin,在地址中填写你要爬取的网址。【】=signout,在链接中填写你要提取的数据的地址。这个地址就是你登录的账号密码,解析网址过程中,我们可以发现:这个网址就是你登录过网页登录成功之后,就可以提取我们想要提取的数据了,我们把所有需要提取的数据提取出来:验证登录,这个时候就可以提取图片了登录成功之后,我们在requests.post中,给对方提供一个useragent信息,同时也给提取的数据提供一个useragent。
那么requests.post请求的结果,那么我们上面也讲到了,都是json格式的数据,数据提取的时候,都是用data来提取的。那么怎么把这个json转化成jsonjson转化成对应图片数据,我这里推荐使用beautifulsoup。我们用python中的beautifulsoup来做这个事情beautifulsoup简单点讲:就是解析html中的信息,提取出对应的元素。
这里就有一个小问题:html中的结构信息,我们在获取的时候,可能这些结构信息会有一些,如html文档中的title等,使用html的话,需要获取浏览器中的那些结构信息?这里就需要用到正则表达式了:window.request="location=page{}".format(html.text)window.request.urlopen(url)window.request.isreplacement()window.request.urlopen(url)大家可以测试一下,会发现,获取的url会有这个错误出现:大家写过正则表达式,会知道,正则表达式的匹配原则,无论是url还是页面,都要匹配到。
但是text属性怎么匹配呢?对我们来说,一个页面页面上可能会有多个需要提取数据的节点,需要很多时间去匹配。然后我们怎么把大家都解析出来呢?可以使用正则表达式来匹配:%.5f(javascript)大家可以试试.5f,会发现,所有节点的text都被匹配出来了2.图片数据获取第二个部分,图片数据的获取。这个是我们爬虫过程中经常会用到的一个库。前面说到的b。
抓取网页视频(如果爬取大多数的网页视频网站是怎么对付客户端的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-10-24 22:02
抓取网页视频其实很容易的,不需要java,也不需要python。但是网页视频的内容总量比较大,尤其是网页视频从ppt转变成网页播放的这个过程,内容差距会很大。也就是,大部分用python爬取的视频网站的开发都倾向于直接用ab站这种解析原网页的网站服务器加速下载。那么,如果爬取大多数的网页视频网站呢?需要开发比较复杂的服务器视频编码和下载的编码手段。
当然,如果服务器端有自己的解析方案,也可以去搞定这事,搞定没问题,但是网页上的视频都是文件压缩以后再加载的,压缩一次就十几m甚至几十m到上百m,都是可以想象的。而且网页视频之间是互相存在上传和下载需求的,解析网页视频耗时巨大。所以对于视频的抓取,需要一个通用的解析器,能够快速解析各种视频的原视频文件格式。
首先,需要弄清楚http协议,它是一个协议,来为其请求提供实际上就是请求参数的分析和转换。然后再搞清楚http头部,如头部信息常见的是请求行(requestheader)和请求头(proxyheader),这些http头部看似简单,其实含有重要的信息,主要包括:请求行(requestheader):请求成功后服务器回传给客户端的消息图片是服务器和客户端的方式客户端要访问服务器是传什么,客户端的网站上是否有相应的内容这个要记住就行了。
请求头:请求头部是从服务器获取的封装完毕才会传给客户端。先对明文传过来的一个,服务器怎么对付客户端的一堆乱七八糟参数,请求头里也会给客户端解释。重要信息是有效的。但是很多时候,后面这个请求头没法解释客户端给服务器发送的内容。客户端在处理服务器发过来的重要内容的时候,还需要再解释下:http协议中,服务器用\r\n请求头表示以上内容请求报文头部无法解释,可以通过“本地文件”也就是客户端将http协议请求报文头部抽出,写到磁盘上的某个文件中,然后在客户端接收之后解析。
视频的一般一个http请求能够看到多个请求,有时候也会一个请求解析多个视频。除了类似playlist下载的几种,还有普通的youtube用户点播视频的方式。这种情况一般需要手动对客户端解析,并且,处理后的报文头部需要留给服务器。手动解析一个普通视频,视频本身比较小,也比较占内存,解析成本太高。这时候需要用第三方来做,推荐下python、selenium、webdriver这种能编写网页应用程序的框架。
比如,我写的一个很简单的脚本,用于对这个视频playlist的下载,就可以完成操作。具体可以在wx小程序(千聊直播)和知乎(知乎live)中查看。因为我不是很熟练,要熟练也不是一件简单。 查看全部
抓取网页视频(如果爬取大多数的网页视频网站是怎么对付客户端的)
抓取网页视频其实很容易的,不需要java,也不需要python。但是网页视频的内容总量比较大,尤其是网页视频从ppt转变成网页播放的这个过程,内容差距会很大。也就是,大部分用python爬取的视频网站的开发都倾向于直接用ab站这种解析原网页的网站服务器加速下载。那么,如果爬取大多数的网页视频网站呢?需要开发比较复杂的服务器视频编码和下载的编码手段。
当然,如果服务器端有自己的解析方案,也可以去搞定这事,搞定没问题,但是网页上的视频都是文件压缩以后再加载的,压缩一次就十几m甚至几十m到上百m,都是可以想象的。而且网页视频之间是互相存在上传和下载需求的,解析网页视频耗时巨大。所以对于视频的抓取,需要一个通用的解析器,能够快速解析各种视频的原视频文件格式。
首先,需要弄清楚http协议,它是一个协议,来为其请求提供实际上就是请求参数的分析和转换。然后再搞清楚http头部,如头部信息常见的是请求行(requestheader)和请求头(proxyheader),这些http头部看似简单,其实含有重要的信息,主要包括:请求行(requestheader):请求成功后服务器回传给客户端的消息图片是服务器和客户端的方式客户端要访问服务器是传什么,客户端的网站上是否有相应的内容这个要记住就行了。
请求头:请求头部是从服务器获取的封装完毕才会传给客户端。先对明文传过来的一个,服务器怎么对付客户端的一堆乱七八糟参数,请求头里也会给客户端解释。重要信息是有效的。但是很多时候,后面这个请求头没法解释客户端给服务器发送的内容。客户端在处理服务器发过来的重要内容的时候,还需要再解释下:http协议中,服务器用\r\n请求头表示以上内容请求报文头部无法解释,可以通过“本地文件”也就是客户端将http协议请求报文头部抽出,写到磁盘上的某个文件中,然后在客户端接收之后解析。
视频的一般一个http请求能够看到多个请求,有时候也会一个请求解析多个视频。除了类似playlist下载的几种,还有普通的youtube用户点播视频的方式。这种情况一般需要手动对客户端解析,并且,处理后的报文头部需要留给服务器。手动解析一个普通视频,视频本身比较小,也比较占内存,解析成本太高。这时候需要用第三方来做,推荐下python、selenium、webdriver这种能编写网页应用程序的框架。
比如,我写的一个很简单的脚本,用于对这个视频playlist的下载,就可以完成操作。具体可以在wx小程序(千聊直播)和知乎(知乎live)中查看。因为我不是很熟练,要熟练也不是一件简单。
抓取网页视频(编程截取视频有了思路,我们就可以开始编程了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-21 11:06
昨天想在网上下载一个稍微小一点的MP4视频文件,但是在网上找了半天也没找到。现在视频网站上的很多视频只支持在线播放,不提供下载链接。网上也有一些工具可以实现这样的功能,但是我现在还没找到有用的。
想法
打开一个MV的时候,正想着要找视频的地址,于是打开了FireFox的Firebug,然后看了看,发现有一个请求耗时很长,而且体积非常大。仔细一看,原来是一个mp4文件。,当然,这不是我们需要的视频,这只是一个广告,我们想要的视频只有在广告完成后才能出现。
广告结束后,网页会发出新的Get请求,如下图
我们得到这个地址后,在浏览器中输入这个地址,点击确认,就会出现如下图所示的下载确认对话框。此内容是我们的视频。
仍然存在的问题
因为现在很多视频网站都是将视频分割后再传输,我们很难一次性拿到整个视频。
上图中的3个地址分别为4.8M、4.7M、4.2M。GET请求地址分别为
http://118.228.16.129/youku/67 ... Dtrue
http://118.228.16.127/youku/67 ... Dtrue
http://118.228.16.130/youku/67 ... Dtrue
上面的网址不一样。但是,每个地址的加载直到上一个视频播放到最后才会加载。我仍然无法找到解决此问题的方法。
以编程方式拦截视频 URL
有了想法,我们就可以开始编程了。为了拦截网页加载时发送的HTTP请求,我想到了两种方法:
通过代理服务器通过网卡抓包
这里我首先通过代理服务器拦截HTTP请求。
我根据这个页面的介绍使用了proxy_server。如何用Python制作代理服务器这篇文章文章说的很清楚,可惜里面有一个小错误,稍微修改一下就可以正常运行了。我把proxy_server的代码放在了我的github上。
跑
运行proxy_server.py,将浏览器的代理设置为proxy_server.py监控的地址和端口。得到以下结果。
我以网易公开课的视频为例,因为网易公开课的视频没有分成很多段再传输。
未解决的问题是你无法获得网站的完整视频,将视频分成像优酷这样的片段。代理服务器的转发速度很慢。
因为代理服务器转发的方式很慢,所以接下来打算再次使用网卡抓包的方式来实现。我的代理服务器很简单。它甚至没有拦截响应头的功能。通过分析请求头和响应头,我觉得可能会有一些发现。这就是我接下来要做的。 查看全部
抓取网页视频(编程截取视频有了思路,我们就可以开始编程了)
昨天想在网上下载一个稍微小一点的MP4视频文件,但是在网上找了半天也没找到。现在视频网站上的很多视频只支持在线播放,不提供下载链接。网上也有一些工具可以实现这样的功能,但是我现在还没找到有用的。
想法
打开一个MV的时候,正想着要找视频的地址,于是打开了FireFox的Firebug,然后看了看,发现有一个请求耗时很长,而且体积非常大。仔细一看,原来是一个mp4文件。,当然,这不是我们需要的视频,这只是一个广告,我们想要的视频只有在广告完成后才能出现。
广告结束后,网页会发出新的Get请求,如下图
我们得到这个地址后,在浏览器中输入这个地址,点击确认,就会出现如下图所示的下载确认对话框。此内容是我们的视频。
仍然存在的问题
因为现在很多视频网站都是将视频分割后再传输,我们很难一次性拿到整个视频。
上图中的3个地址分别为4.8M、4.7M、4.2M。GET请求地址分别为
http://118.228.16.129/youku/67 ... Dtrue
http://118.228.16.127/youku/67 ... Dtrue
http://118.228.16.130/youku/67 ... Dtrue
上面的网址不一样。但是,每个地址的加载直到上一个视频播放到最后才会加载。我仍然无法找到解决此问题的方法。
以编程方式拦截视频 URL
有了想法,我们就可以开始编程了。为了拦截网页加载时发送的HTTP请求,我想到了两种方法:
通过代理服务器通过网卡抓包
这里我首先通过代理服务器拦截HTTP请求。
我根据这个页面的介绍使用了proxy_server。如何用Python制作代理服务器这篇文章文章说的很清楚,可惜里面有一个小错误,稍微修改一下就可以正常运行了。我把proxy_server的代码放在了我的github上。
跑
运行proxy_server.py,将浏览器的代理设置为proxy_server.py监控的地址和端口。得到以下结果。
我以网易公开课的视频为例,因为网易公开课的视频没有分成很多段再传输。
未解决的问题是你无法获得网站的完整视频,将视频分成像优酷这样的片段。代理服务器的转发速度很慢。
因为代理服务器转发的方式很慢,所以接下来打算再次使用网卡抓包的方式来实现。我的代理服务器很简单。它甚至没有拦截响应头的功能。通过分析请求头和响应头,我觉得可能会有一些发现。这就是我接下来要做的。
抓取网页视频(联想2011年校园招聘之2.视频下载的功能方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 447 次浏览 • 2021-10-19 13:02
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门提取各大主流视频网站视频的网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以解析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的可能不多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
抓取网页视频(联想2011年校园招聘之2.视频下载的功能方法)
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门提取各大主流视频网站视频的网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以解析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的可能不多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
抓取网页视频(根据上篇文章的思路,我用了监听网卡流量的方式来改进了我的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-17 18:30
根据上一篇文章的思路,我用监控网卡流量的方法来改进我的程序。速度大大提高。
思考
下图是我用wireshark做的一个实验。在请求路径中留下.mp4、.flv的请求,得到的就是请求的视频资源。
在wireshark的实验下,确定这种抓包的方法可行,就开始用python写抓包代码。
我使用python的pcap和dpkt包来分析网卡流量。首先是使用pcap监控我的网卡,设置pcap过滤器只处理HTTP请求,因为视频地址在HTTP请求中。我在HTTP请求的地址中找到了收录.flv的请求,然后就可以得到视频的url地址了。
实验
代码比较短,我直接贴上代码。关于pcap和dpkt的使用,我参考了这个文章,但是这个文章应该是别人抄的。搜索的时候找到了更好的,最后还是写了文章,当时没办法找到更好的,所以只能发这个不太好的。
当然代码也会放到我的Github上,哈哈~
#encoding: utf8
import pcap
import dpkt
pc=pcap.pcap('eth1') #注,参数可为网卡名,如eth0
#设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP
pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
print "starting capture"
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
#对抓到的以太网V2数据包(raw packet)进行解包
p=dpkt.ethernet.Ethernet(pdata)
if p.data.__class__.__name__=='IP':
# ip='%d.%d.%d.%d'%tuple(map(ord,list(p.data.dst)))
if p.data.data.__class__.__name__=='TCP':
if p.data.data.dport==80:
header = p.data.data.data # by gashero
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
if requestUrl.find('.flv') != -1:
# print headerArr
print requestUrl
运行结果图片:
未解决的问题。 网站如优酷把视频分片,无法获取完整视频。 查看全部
抓取网页视频(根据上篇文章的思路,我用了监听网卡流量的方式来改进了我的程序)
根据上一篇文章的思路,我用监控网卡流量的方法来改进我的程序。速度大大提高。
思考
下图是我用wireshark做的一个实验。在请求路径中留下.mp4、.flv的请求,得到的就是请求的视频资源。
在wireshark的实验下,确定这种抓包的方法可行,就开始用python写抓包代码。
我使用python的pcap和dpkt包来分析网卡流量。首先是使用pcap监控我的网卡,设置pcap过滤器只处理HTTP请求,因为视频地址在HTTP请求中。我在HTTP请求的地址中找到了收录.flv的请求,然后就可以得到视频的url地址了。
实验
代码比较短,我直接贴上代码。关于pcap和dpkt的使用,我参考了这个文章,但是这个文章应该是别人抄的。搜索的时候找到了更好的,最后还是写了文章,当时没办法找到更好的,所以只能发这个不太好的。
当然代码也会放到我的Github上,哈哈~
#encoding: utf8
import pcap
import dpkt
pc=pcap.pcap('eth1') #注,参数可为网卡名,如eth0
#设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP
pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
print "starting capture"
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
#对抓到的以太网V2数据包(raw packet)进行解包
p=dpkt.ethernet.Ethernet(pdata)
if p.data.__class__.__name__=='IP':
# ip='%d.%d.%d.%d'%tuple(map(ord,list(p.data.dst)))
if p.data.data.__class__.__name__=='TCP':
if p.data.data.dport==80:
header = p.data.data.data # by gashero
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
if requestUrl.find('.flv') != -1:
# print headerArr
print requestUrl
运行结果图片:
未解决的问题。 网站如优酷把视频分片,无法获取完整视频。
抓取网页视频(确定需求,我们要爬取梨视频下娱乐频道的最热视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-12 19:34
确定需求,我们要爬取梨视频下娱乐频道最热的视频
第一步获取起始url:/category_4,然后打开网站进行抓包分析
很容易发现,我们需要的所有视频地址都在ul标签下的li标签中。使用 xpath 解析并获取所有 li 标签。我个人认为xpath是最好的html解析工具,beautifulsoup太复杂了,解析方法太多,容易混淆,所以我的爬虫都是用xpath来解析数据的。
得到li标签后,视频的url在li标签下第一个div下a标签的herf属性中,我们得到了视频地址,像这样video_1730677
3.第二步是拼接网站,和谁拼接是个问题。如果您使用起始 url 进行访问,您将无法在收到的响应中找到 mp4。
说明这个地址不在静态网页中,然后开始抓包分析
可以看到只有一个包,也不算太简单。点击进去,看到返回的数据中找到了视频的下载地址,不过不要高兴得太早。视频的真实地址是/mp4/third/20210528/cont-1394-171325-hd.mp4。抓到的包是/mp4/third/20210528/89-125-hd.mp4,仔细一看,两个URL的最后一个'/'和最近的'-'之间的字符串是不一样的,其余的是相同的。其实只是假的 用cont-1730677替换url的最后一个'/'和最近的'-'之间的字符串。1730677是第一步得到的a标签属性然后去掉video_。这里我用正则表达式来代替
4.第三步,视频的假地址在网站的返回对象中的/videoStatus.jsp?contId=1730677&mrd=0.59567,如果要发送这个< @网站 requests 请求必须携带两个参数
CountId和mrd,通过简单的分析,我们知道countId是视频编号,即去掉上面a标签属性中的video_,mrd是0-1之间随机生成的数字。可以使用python的random.random()来实现效果。如果只携带这两个参数进行访问,仍然无法获取数据。另外需要在请求头中添加refer参数。因为我没有带这个参数,好久都拿不到数据。记住!
5.第四步快乐下载,结果图
具体代码如下:
import requests
import os
from lxml import etree
import random
import time
import re
class PearVideo(): # 定义梨视频类
def __init__(self):
self.start_url = 'https://www.pearvideo.com/category_4'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
def get_video_url(self): # 获取单个视频的地址和countId
resp = requests.get(self.start_url, headers=self.headers).text
tree = etree.HTML(resp)
li_list = tree.xpath('.//ul[@class="listvideo-list clearfix"]/li')
video_urls = []
countId_list = []
video_names = []
for li in li_list:
video_url = li.xpath('./div[1]/a/@href')[0]
countId = video_url.split('_')[-1]
countId_list.append(countId)
video_name = li.xpath('.//div[@class="vervideo-title"]/text()')[0]
mrd = random.random()
video_url = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd={}'.format(countId, mrd)
video_urls.append(video_url)
video_names.append(video_name)
return video_urls, countId_list, video_names
def get_download_url(self): # 获取视频的真实下载地址,请求头中要携带refer参数,不然得不到想要的json数据
video_urls, countId_list, video_names = self.get_video_url()
download_urls = []
for url, countId in zip(video_urls, countId_list):
resp = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Referer': 'https: // www.pearvideo.com / video_{}'.format(countId)
}).json()
time.sleep(1)
# print(resp)
download_url = resp['videoInfo']['videos']['srcUrl']
download_url = re.sub('/[0-9]+-', '/cont-{}-'.format(countId), download_url)
# print(download_url)
# time.sleep(1)
download_urls.append(download_url)
# print(download_urls)
return download_urls, video_names
def download_video(self): # 视频的保存
download_urls, video_names = self.get_download_url()
# print(download_urls)
filename = 'D://pearvideo' #视频保存在d盘的pearvideo文件夹下
if not os.path.exists(filename):
os.mkdir(filename)
index = 0
for url in download_urls:
with open('{}/{}.mp4'.format(filename, video_names[index]), mode='wb') as f:
resp = requests.get(url, headers=self.headers).content
# print(resp)
f.write(resp)
time.sleep(1)
index += 1
if __name__ == '__main__':
pearvideo_spider = PearVideo()
pearvideo_spider.download_video()
不要说你可以手动完成(但这是真的)。写这么多代码不是比手工差吗?哈哈哈!看我接下来的分析!
总结一下我的缺点:我只爬取了静态网页中存在的4个视频,其余的视频都是通过ajax请求服务器获取的,而不是简单的改变页面值。我没有仔细研究过这个问题;我这个爬虫是单线程爬虫,下载视频可能会比较慢,可以考虑用多线程,速度可能会快一些,但是我对自己的多线程编程水平没有信心(四个视频足够一个单线程);需要注意的是,如果要获取视频下载地址,requests请求中必须携带refer参数。因为没带这个参数,好久没拿到。
随附的:
经过我的研究,抓取多个页面实际上很容易。打开抓包工具继续往下滑,可以看到本地有很多请求发送到服务器,如下:
/category_loading.jsp?reqType=5&categoryId=4&start=12&mrd=0.36427441062670063&filterIds=1730677,1730635,1730509,1730484,1728846,1730305,1730384,1730381,1730338,1729112,1729081,1729048
/category_loading.jsp?reqType = 5&的categoryId = 4&启动= 264&MRD = 0. 67719&filterIds = 1730677,1730635,1730509,1714315,1714259,1714097,1713907,1713860,1713859,1713753,1713719,1713572,1713571,1713361,1713304
经过简单的分析,只需要改变上面网站的start参数就可以得到分页的视频数据。可以从start as 1开始,每页有12个视频,不过我没试过。如果你想尝试,你可以做到。全站视频不易抓取,但如此庞大的数据量需要多线程和数据库知识。努力工作!
这是我在知乎 中的第二篇文章(这是另一种水文学,我喜欢没有技术的写作)。记录自己的爬虫成长历程!也希望与其他喜欢爬虫的人分享爬虫学习资料,讨论技术。很喜欢张宇的一句话:忘不了,必有回音! 查看全部
抓取网页视频(确定需求,我们要爬取梨视频下娱乐频道的最热视频)
确定需求,我们要爬取梨视频下娱乐频道最热的视频
第一步获取起始url:/category_4,然后打开网站进行抓包分析
很容易发现,我们需要的所有视频地址都在ul标签下的li标签中。使用 xpath 解析并获取所有 li 标签。我个人认为xpath是最好的html解析工具,beautifulsoup太复杂了,解析方法太多,容易混淆,所以我的爬虫都是用xpath来解析数据的。
得到li标签后,视频的url在li标签下第一个div下a标签的herf属性中,我们得到了视频地址,像这样video_1730677
3.第二步是拼接网站,和谁拼接是个问题。如果您使用起始 url 进行访问,您将无法在收到的响应中找到 mp4。
说明这个地址不在静态网页中,然后开始抓包分析
可以看到只有一个包,也不算太简单。点击进去,看到返回的数据中找到了视频的下载地址,不过不要高兴得太早。视频的真实地址是/mp4/third/20210528/cont-1394-171325-hd.mp4。抓到的包是/mp4/third/20210528/89-125-hd.mp4,仔细一看,两个URL的最后一个'/'和最近的'-'之间的字符串是不一样的,其余的是相同的。其实只是假的 用cont-1730677替换url的最后一个'/'和最近的'-'之间的字符串。1730677是第一步得到的a标签属性然后去掉video_。这里我用正则表达式来代替
4.第三步,视频的假地址在网站的返回对象中的/videoStatus.jsp?contId=1730677&mrd=0.59567,如果要发送这个< @网站 requests 请求必须携带两个参数
CountId和mrd,通过简单的分析,我们知道countId是视频编号,即去掉上面a标签属性中的video_,mrd是0-1之间随机生成的数字。可以使用python的random.random()来实现效果。如果只携带这两个参数进行访问,仍然无法获取数据。另外需要在请求头中添加refer参数。因为我没有带这个参数,好久都拿不到数据。记住!
5.第四步快乐下载,结果图
具体代码如下:
import requests
import os
from lxml import etree
import random
import time
import re
class PearVideo(): # 定义梨视频类
def __init__(self):
self.start_url = 'https://www.pearvideo.com/category_4'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
def get_video_url(self): # 获取单个视频的地址和countId
resp = requests.get(self.start_url, headers=self.headers).text
tree = etree.HTML(resp)
li_list = tree.xpath('.//ul[@class="listvideo-list clearfix"]/li')
video_urls = []
countId_list = []
video_names = []
for li in li_list:
video_url = li.xpath('./div[1]/a/@href')[0]
countId = video_url.split('_')[-1]
countId_list.append(countId)
video_name = li.xpath('.//div[@class="vervideo-title"]/text()')[0]
mrd = random.random()
video_url = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd={}'.format(countId, mrd)
video_urls.append(video_url)
video_names.append(video_name)
return video_urls, countId_list, video_names
def get_download_url(self): # 获取视频的真实下载地址,请求头中要携带refer参数,不然得不到想要的json数据
video_urls, countId_list, video_names = self.get_video_url()
download_urls = []
for url, countId in zip(video_urls, countId_list):
resp = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Referer': 'https: // www.pearvideo.com / video_{}'.format(countId)
}).json()
time.sleep(1)
# print(resp)
download_url = resp['videoInfo']['videos']['srcUrl']
download_url = re.sub('/[0-9]+-', '/cont-{}-'.format(countId), download_url)
# print(download_url)
# time.sleep(1)
download_urls.append(download_url)
# print(download_urls)
return download_urls, video_names
def download_video(self): # 视频的保存
download_urls, video_names = self.get_download_url()
# print(download_urls)
filename = 'D://pearvideo' #视频保存在d盘的pearvideo文件夹下
if not os.path.exists(filename):
os.mkdir(filename)
index = 0
for url in download_urls:
with open('{}/{}.mp4'.format(filename, video_names[index]), mode='wb') as f:
resp = requests.get(url, headers=self.headers).content
# print(resp)
f.write(resp)
time.sleep(1)
index += 1
if __name__ == '__main__':
pearvideo_spider = PearVideo()
pearvideo_spider.download_video()
不要说你可以手动完成(但这是真的)。写这么多代码不是比手工差吗?哈哈哈!看我接下来的分析!
总结一下我的缺点:我只爬取了静态网页中存在的4个视频,其余的视频都是通过ajax请求服务器获取的,而不是简单的改变页面值。我没有仔细研究过这个问题;我这个爬虫是单线程爬虫,下载视频可能会比较慢,可以考虑用多线程,速度可能会快一些,但是我对自己的多线程编程水平没有信心(四个视频足够一个单线程);需要注意的是,如果要获取视频下载地址,requests请求中必须携带refer参数。因为没带这个参数,好久没拿到。
随附的:
经过我的研究,抓取多个页面实际上很容易。打开抓包工具继续往下滑,可以看到本地有很多请求发送到服务器,如下:
/category_loading.jsp?reqType=5&categoryId=4&start=12&mrd=0.36427441062670063&filterIds=1730677,1730635,1730509,1730484,1728846,1730305,1730384,1730381,1730338,1729112,1729081,1729048
/category_loading.jsp?reqType = 5&的categoryId = 4&启动= 264&MRD = 0. 67719&filterIds = 1730677,1730635,1730509,1714315,1714259,1714097,1713907,1713860,1713859,1713753,1713719,1713572,1713571,1713361,1713304
经过简单的分析,只需要改变上面网站的start参数就可以得到分页的视频数据。可以从start as 1开始,每页有12个视频,不过我没试过。如果你想尝试,你可以做到。全站视频不易抓取,但如此庞大的数据量需要多线程和数据库知识。努力工作!
这是我在知乎 中的第二篇文章(这是另一种水文学,我喜欢没有技术的写作)。记录自己的爬虫成长历程!也希望与其他喜欢爬虫的人分享爬虫学习资料,讨论技术。很喜欢张宇的一句话:忘不了,必有回音!
抓取网页视频(国内有一个软件叫小猪观影,下载时直接复制视频链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-07 18:06
抓取网页视频有一些简单的网站,比如那个,他们是提供视频在线观看和下载的网站,只要输入一个url网站会自动提供相关视频的下载信息,比如视频的分辨率、时长、网站地址等。这些视频网站虽然很多,但是可以找到的也就那么多,对于那些推荐小站点的就得多去发掘一下了。如果需要更多的找到网站的视频的话,你可以登录freecdn尝试,目前它有114个国外的主流视频网站,包括youtube、dailymotion、hulu等等,注册会员之后就可以方便的获取更多来自这些网站的视频资源了。
/--./#.loads.es
//
/
国内的,但发不出来。
/也可以,但是不是从网站下载的。
可以使用pearfish下载视频,一键下载全球大网站的视频。还支持youtube、facebook、谷歌等国外网站的视频下载。
不仅可以下载youtube还可以下载reddit视频。
/很多比较大的网站都有自己的视频下载站。通过第三方下载一般都非常麻烦,支持一键下载的也是凤毛麟角。多看吧,不过看视频要装vpn。
youtubecrv:youtubecrvyoutubecrv
国内有一个软件叫小猪观影,下载时直接复制视频链接就可以了,无需注册,无需下载其他视频来源,简单方便. 查看全部
抓取网页视频(国内有一个软件叫小猪观影,下载时直接复制视频链接)
抓取网页视频有一些简单的网站,比如那个,他们是提供视频在线观看和下载的网站,只要输入一个url网站会自动提供相关视频的下载信息,比如视频的分辨率、时长、网站地址等。这些视频网站虽然很多,但是可以找到的也就那么多,对于那些推荐小站点的就得多去发掘一下了。如果需要更多的找到网站的视频的话,你可以登录freecdn尝试,目前它有114个国外的主流视频网站,包括youtube、dailymotion、hulu等等,注册会员之后就可以方便的获取更多来自这些网站的视频资源了。
/--./#.loads.es
//
/
国内的,但发不出来。
/也可以,但是不是从网站下载的。
可以使用pearfish下载视频,一键下载全球大网站的视频。还支持youtube、facebook、谷歌等国外网站的视频下载。
不仅可以下载youtube还可以下载reddit视频。
/很多比较大的网站都有自己的视频下载站。通过第三方下载一般都非常麻烦,支持一键下载的也是凤毛麟角。多看吧,不过看视频要装vpn。
youtubecrv:youtubecrvyoutubecrv
国内有一个软件叫小猪观影,下载时直接复制视频链接就可以了,无需注册,无需下载其他视频来源,简单方便.
抓取网页视频(讲讲怎么该方法适用于很多视频网站的解析下载方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-10-05 08:33
)
今天给大家讲讲爱奇艺和优酷视频的手动截取视频网站。这种方法适用于很多视频网站。因为有些网站不支持我们使用一些说书、微汤等软件来分析下载,所以就找到了这个方法。在优酷之前是可以的,但是现在优酷还是不支持说书和微汤。唐的分析完毕。这两个网页是原帖地址。其实这个方法我之前就知道,但是这个人提供了一个比较好用的软件。我提取了他录制的视频。下面我们来看看。其实原理是一样的。这些视频网站为了让视频缓存更快,当然还有很多其他的原因。视频分为很多段,所以我们只需要分别下载每个视频,然后合并这些视频。刚起来,这些分段的视频基本都是一样的,最后一段时间可能不一样。我们来看看优酷的分析。爱奇艺的演示是手动抓取,优酷的演示是软件抓取,更方便。那个人写了一个软件把所有的下载地址都提取出来,方便导入迅雷下载。让我演示一次。可见,Fildder 并没有嗅到它。这是因为我的浏览器使用了广告过滤软件。我用没有广告扩展的谷歌浏览器尝试过。可以看出已经有了。它被嗅到了。广告必须通读。好的,现在我们开始拖动视频,首先选择视频分辨率,
这样拖就结束了,因为它会加载分段的视频而不拖到一个地方,所以不知道分段需要多长时间,所以我们试着拖得更慢更短,然后点击让我们排序主机。不同的网站和不同的定义视频有不同的链接。这里优酷的SD就是这样。我们将把所有分段的视频复制下来,链接到小软件上,将每个分段链接起来。在迅雷中提取并下载视频的链接。然后现在重命名,按编号重命名,合并时顺序正确。有时我们会错过一些视频。我们可以看看软件。比如订单写在前面。我可以看到第一个视频没有链接。可能会错过。我不会在这里演示。每个人都会再次抓住它。就是这样。等待下载完成。好的,然后您可以合并视频。您可以使用格式工厂或其他软件。请注意,由于这些视频格式相同,编码类型相同,因此合并过程会非常快。注意这里的顺序。可以看到漏掉了第一个视频,因为和刚才的第一个视频一样。你可以再次抓住它。我不会在这里演示。下面我讲另一种方法,可能更简单一些。,也就是很多浏览器都有嗅探视频或音频的扩展,比如火狐的这个扩展,请看,你看到了吗,如果我拖一个片段,它会自动嗅探下一个分段的视频,所以我们你只需要下载所有这些视频,然后合并下载的视频。但是因为名字一样 你需要注意视频的顺序。因为名字是一样的,看看谷歌浏览。还有类似的扩展,看,我们仍然需要下载所有这些视频并合并它们。
我发现微糖居然可以解析优酷的视频,只有爱奇艺不行。
上面说的方法很麻烦,这里我只说这个方法是可以的。不过还有很多其他更好的方法,这里就不介绍了,包括爱奇艺的视频,其实可以直接下载。
查看全部
抓取网页视频(讲讲怎么该方法适用于很多视频网站的解析下载方法
)
今天给大家讲讲爱奇艺和优酷视频的手动截取视频网站。这种方法适用于很多视频网站。因为有些网站不支持我们使用一些说书、微汤等软件来分析下载,所以就找到了这个方法。在优酷之前是可以的,但是现在优酷还是不支持说书和微汤。唐的分析完毕。这两个网页是原帖地址。其实这个方法我之前就知道,但是这个人提供了一个比较好用的软件。我提取了他录制的视频。下面我们来看看。其实原理是一样的。这些视频网站为了让视频缓存更快,当然还有很多其他的原因。视频分为很多段,所以我们只需要分别下载每个视频,然后合并这些视频。刚起来,这些分段的视频基本都是一样的,最后一段时间可能不一样。我们来看看优酷的分析。爱奇艺的演示是手动抓取,优酷的演示是软件抓取,更方便。那个人写了一个软件把所有的下载地址都提取出来,方便导入迅雷下载。让我演示一次。可见,Fildder 并没有嗅到它。这是因为我的浏览器使用了广告过滤软件。我用没有广告扩展的谷歌浏览器尝试过。可以看出已经有了。它被嗅到了。广告必须通读。好的,现在我们开始拖动视频,首先选择视频分辨率,
这样拖就结束了,因为它会加载分段的视频而不拖到一个地方,所以不知道分段需要多长时间,所以我们试着拖得更慢更短,然后点击让我们排序主机。不同的网站和不同的定义视频有不同的链接。这里优酷的SD就是这样。我们将把所有分段的视频复制下来,链接到小软件上,将每个分段链接起来。在迅雷中提取并下载视频的链接。然后现在重命名,按编号重命名,合并时顺序正确。有时我们会错过一些视频。我们可以看看软件。比如订单写在前面。我可以看到第一个视频没有链接。可能会错过。我不会在这里演示。每个人都会再次抓住它。就是这样。等待下载完成。好的,然后您可以合并视频。您可以使用格式工厂或其他软件。请注意,由于这些视频格式相同,编码类型相同,因此合并过程会非常快。注意这里的顺序。可以看到漏掉了第一个视频,因为和刚才的第一个视频一样。你可以再次抓住它。我不会在这里演示。下面我讲另一种方法,可能更简单一些。,也就是很多浏览器都有嗅探视频或音频的扩展,比如火狐的这个扩展,请看,你看到了吗,如果我拖一个片段,它会自动嗅探下一个分段的视频,所以我们你只需要下载所有这些视频,然后合并下载的视频。但是因为名字一样 你需要注意视频的顺序。因为名字是一样的,看看谷歌浏览。还有类似的扩展,看,我们仍然需要下载所有这些视频并合并它们。
我发现微糖居然可以解析优酷的视频,只有爱奇艺不行。
上面说的方法很麻烦,这里我只说这个方法是可以的。不过还有很多其他更好的方法,这里就不介绍了,包括爱奇艺的视频,其实可以直接下载。
抓取网页视频(编程截取视频有了思路,我们就可以开始编程了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-03 20:40
昨天想在网上下载一个稍微小一点的MP4视频文件,但是在网上找了半天也没找到。现在视频网站上的很多视频只支持在线播放,不提供下载链接。网上也有一些工具可以实现这样的功能,但是我现在还没找到有用的。
想法
打开一个MV的时候,正想着要找视频的地址,于是打开了FireFox的Firebug,然后看了看,发现有一个请求耗时很长,而且体积非常大。仔细一看,原来是一个mp4文件。, 当然,这不是我们需要的视频,这只是一个广告,我们想要的视频只有在广告完成后才能出现。
广告结束后,网页会发出新的Get请求,如下图
我们得到这个地址后,在浏览器中输入这个地址,点击确认,就会出现如下图所示的下载确认对话框。此内容是我们的视频。
仍然存在的问题
因为现在很多视频网站都是将视频分割后再传输,我们很难一次性拿到整个视频。
上图中的3个地址分别为4.8M、4.7M、4.2M。GET请求地址分别为
http://118.228.16.129/youku/67 ... Dtrue
http://118.228.16.127/youku/67 ... Dtrue
http://118.228.16.130/youku/67 ... Dtrue
上面的网址不一样。但是,每个地址的加载直到上一个视频播放到最后才会加载。我仍然无法找到解决此问题的方法。
以编程方式拦截视频 URL
有了想法,我们就可以开始编程了。为了拦截网页加载时发送的HTTP请求,我想到了两种方法:
通过代理服务器通过网卡抓包
这里我首先通过代理服务器拦截HTTP请求。
我根据这个页面的介绍使用了proxy_server。如何用Python制作代理服务器这篇文章文章说的很清楚,可惜里面有一个小错误,稍微修改一下就可以正常运行了。我把proxy_server的代码放在了我的github上。
跑
运行proxy_server.py,将浏览器的代理设置为proxy_server.py监控的地址和端口。得到以下结果。
我以网易公开课的视频为例,因为网易公开课的视频没有分成很多段再传输。
未解决的问题是你无法获得网站的完整视频,将视频分成像优酷这样的片段。代理服务器的转发速度很慢。
因为代理服务器转发方式很慢,打算再次使用网卡方式抓包。我的代理服务器很简单。它甚至没有拦截响应头的功能。通过分析请求头和响应头,我觉得可能会有一些发现。这就是我接下来要做的。 查看全部
抓取网页视频(编程截取视频有了思路,我们就可以开始编程了)
昨天想在网上下载一个稍微小一点的MP4视频文件,但是在网上找了半天也没找到。现在视频网站上的很多视频只支持在线播放,不提供下载链接。网上也有一些工具可以实现这样的功能,但是我现在还没找到有用的。
想法
打开一个MV的时候,正想着要找视频的地址,于是打开了FireFox的Firebug,然后看了看,发现有一个请求耗时很长,而且体积非常大。仔细一看,原来是一个mp4文件。, 当然,这不是我们需要的视频,这只是一个广告,我们想要的视频只有在广告完成后才能出现。
广告结束后,网页会发出新的Get请求,如下图
我们得到这个地址后,在浏览器中输入这个地址,点击确认,就会出现如下图所示的下载确认对话框。此内容是我们的视频。
仍然存在的问题
因为现在很多视频网站都是将视频分割后再传输,我们很难一次性拿到整个视频。
上图中的3个地址分别为4.8M、4.7M、4.2M。GET请求地址分别为
http://118.228.16.129/youku/67 ... Dtrue
http://118.228.16.127/youku/67 ... Dtrue
http://118.228.16.130/youku/67 ... Dtrue
上面的网址不一样。但是,每个地址的加载直到上一个视频播放到最后才会加载。我仍然无法找到解决此问题的方法。
以编程方式拦截视频 URL
有了想法,我们就可以开始编程了。为了拦截网页加载时发送的HTTP请求,我想到了两种方法:
通过代理服务器通过网卡抓包
这里我首先通过代理服务器拦截HTTP请求。
我根据这个页面的介绍使用了proxy_server。如何用Python制作代理服务器这篇文章文章说的很清楚,可惜里面有一个小错误,稍微修改一下就可以正常运行了。我把proxy_server的代码放在了我的github上。
跑
运行proxy_server.py,将浏览器的代理设置为proxy_server.py监控的地址和端口。得到以下结果。
我以网易公开课的视频为例,因为网易公开课的视频没有分成很多段再传输。
未解决的问题是你无法获得网站的完整视频,将视频分成像优酷这样的片段。代理服务器的转发速度很慢。
因为代理服务器转发方式很慢,打算再次使用网卡方式抓包。我的代理服务器很简单。它甚至没有拦截响应头的功能。通过分析请求头和响应头,我觉得可能会有一些发现。这就是我接下来要做的。
抓取网页视频(抓取网页视频一般分为几种方式,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-29 15:02
抓取网页视频一般分为几种方式,第一是后台的视频爬虫服务,像进程服务(webrtc),这种后台服务性能要求一般比较高,第二种是视频浏览网站,这个服务支持多种视频格式,比如最常见的h.264就是一种最好的视频格式,第三种是网页转码服务,这种后台服务支持不同的播放源文件如avi、mp4、mpeg等等视频格式,这种后台服务一般都是api供用户调用。
无论用哪种方式来爬取视频,对于服务器端代码来说,最低的要求都是支持http请求,服务器的性能有好有坏,大部分的企业是满足不了这一条件的,那些对服务器要求较高的我接触过的大部分都是视频站或者第三方的客户端进行了视频转码服务,比如快播的api;像一些视频站支持格式分的比较细,有avi、mp4、mkv、m4v、等视频格式转换,它的爬虫页面一般都可以明确的在他的网页下方看到他支持的视频类型,这个可以通过网站特定的tag查看的。
对于第三方客户端(qq、迅雷等等)网页上的视频来说,基本都是基于格式特定的网页协议视频解码,并不是所有的视频类型都支持,可以自己根据情况选择应用的网页协议。
分两种:一是转码服务,二是视频服务。对于转码服务是否用macromedia或其他解码格式转换器是分开收费的。
分情况1.从浏览器来说,支持的格式比较有限,可能仅有flv,wmv,mp4等最小格式2.从转码服务提供商来说,我认为应该有两种:1.根据转码服务商的协议支持,可以获得不同协议/视频的网络播放,2.根据接入的视频分类, 查看全部
抓取网页视频(抓取网页视频一般分为几种方式,你知道吗?)
抓取网页视频一般分为几种方式,第一是后台的视频爬虫服务,像进程服务(webrtc),这种后台服务性能要求一般比较高,第二种是视频浏览网站,这个服务支持多种视频格式,比如最常见的h.264就是一种最好的视频格式,第三种是网页转码服务,这种后台服务支持不同的播放源文件如avi、mp4、mpeg等等视频格式,这种后台服务一般都是api供用户调用。
无论用哪种方式来爬取视频,对于服务器端代码来说,最低的要求都是支持http请求,服务器的性能有好有坏,大部分的企业是满足不了这一条件的,那些对服务器要求较高的我接触过的大部分都是视频站或者第三方的客户端进行了视频转码服务,比如快播的api;像一些视频站支持格式分的比较细,有avi、mp4、mkv、m4v、等视频格式转换,它的爬虫页面一般都可以明确的在他的网页下方看到他支持的视频类型,这个可以通过网站特定的tag查看的。
对于第三方客户端(qq、迅雷等等)网页上的视频来说,基本都是基于格式特定的网页协议视频解码,并不是所有的视频类型都支持,可以自己根据情况选择应用的网页协议。
分两种:一是转码服务,二是视频服务。对于转码服务是否用macromedia或其他解码格式转换器是分开收费的。
分情况1.从浏览器来说,支持的格式比较有限,可能仅有flv,wmv,mp4等最小格式2.从转码服务提供商来说,我认为应该有两种:1.根据转码服务商的协议支持,可以获得不同协议/视频的网络播放,2.根据接入的视频分类,
抓取网页视频(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-26 04:03
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站视频热搜榜数据并存储为例,详细介绍Python爬虫的基本流程。如果您还处于初始爬虫阶段或者不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 27%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
在 Python 中有很多方法可以解析网页。您可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup 来解释它们。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写吗?
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜正是因为足够简单,希望通过这个案例,让大家了解爬取的基本过程,最后附上完整代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 27%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
-结尾- 查看全部
抓取网页视频(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站视频热搜榜数据并存储为例,详细介绍Python爬虫的基本流程。如果您还处于初始爬虫阶段或者不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 27%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
在 Python 中有很多方法可以解析网页。您可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup 来解释它们。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写吗?
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜正是因为足够简单,希望通过这个案例,让大家了解爬取的基本过程,最后附上完整代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 27%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
-结尾-
抓取网页视频(WebVideoCap是一个FLV视频抓取工具!是怎么捕获的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-25 03:13
)
WebVideoCap 是一个 FLV 视频捕捉工具!设置好后会自动加载浏览器,然后获取URL,可以设置直接下载到指定目录!
由于使用了防盗链工具,网上很多视频教程都无法下载。您可以使用这个小工具轻松记录它们。WebVideoCap可以从网站中截取和录制Flash视频教程,可以同时实时录制各种IM网络即时通讯软件和网页视频信息。如:QQ、MSN等,如果网站上有防盗链措施,WebVideoCap将无法录制。
WebVideoCap改变了常用的分析网页获取下载地址的方法,直接从网卡的数据包开始。使用TCP/IP 7层协议判断数据包是视频,所以不管网站,如果有使用网卡的视频数据包,都可以被WebVideoCap拦截。
WebVideoCap 适用于常用的 flv 和 wmv、mms、rtsp 格式
WebVideoCap可以实时记录各种IM网络通讯软件和网页视频信息,如MSN、QQ等,虽然体积小,但功能却非常强大。
注:WebVideoCap\FLV视频采集工具已更新至最新正式版!
如何使用 webvideocap:
1、 先设置好抓包方式和你本地的导出网卡,录制后选择保存位置
2、 点击开始抓取,即可抓取网页中的流媒体。可以捕获使用您设置的网卡的任何视频和音频。当然,格式必须是FLV/WMV/MMS/RTSP/SWF等格式,其他格式可能不行,但这些格式基本上可以走所有网络媒体。
捕获选项:
捕获 Flash 视频“.flv”文件
捕获 Flash .MP4 文件
捕获 Windows Media ".wmv" 文件
捕获 Windows Media ".wmv" 流
捕获 RTSP 流
捕获彩信流
捕获 Flash ".swf" 文件
界面预览:
查看全部
抓取网页视频(WebVideoCap是一个FLV视频抓取工具!是怎么捕获的?
)
WebVideoCap 是一个 FLV 视频捕捉工具!设置好后会自动加载浏览器,然后获取URL,可以设置直接下载到指定目录!
由于使用了防盗链工具,网上很多视频教程都无法下载。您可以使用这个小工具轻松记录它们。WebVideoCap可以从网站中截取和录制Flash视频教程,可以同时实时录制各种IM网络即时通讯软件和网页视频信息。如:QQ、MSN等,如果网站上有防盗链措施,WebVideoCap将无法录制。
WebVideoCap改变了常用的分析网页获取下载地址的方法,直接从网卡的数据包开始。使用TCP/IP 7层协议判断数据包是视频,所以不管网站,如果有使用网卡的视频数据包,都可以被WebVideoCap拦截。
WebVideoCap 适用于常用的 flv 和 wmv、mms、rtsp 格式
WebVideoCap可以实时记录各种IM网络通讯软件和网页视频信息,如MSN、QQ等,虽然体积小,但功能却非常强大。
注:WebVideoCap\FLV视频采集工具已更新至最新正式版!
如何使用 webvideocap:
1、 先设置好抓包方式和你本地的导出网卡,录制后选择保存位置
2、 点击开始抓取,即可抓取网页中的流媒体。可以捕获使用您设置的网卡的任何视频和音频。当然,格式必须是FLV/WMV/MMS/RTSP/SWF等格式,其他格式可能不行,但这些格式基本上可以走所有网络媒体。
捕获选项:
捕获 Flash 视频“.flv”文件
捕获 Flash .MP4 文件
捕获 Windows Media ".wmv" 文件
捕获 Windows Media ".wmv" 流
捕获 RTSP 流
捕获彩信流
捕获 Flash ".swf" 文件
界面预览:
抓取网页视频( 和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2021-09-15 20:04
和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
几天前,一位同学说他想下载一段网站视频,但找不到连接。他问我有没有办法。当时,我觉得应该很简单,所以我说我会花时间看看。然后我分析了目标网页并试图从网页源代码中找到连接,但失败了。F12调用开发人员工具,进入netwrok,发现网页是XHR请求通过Ajax获得的视频连接。难怪页面元素中没有下载地址。请求的是m3u8格式的文件。在检查这是一个分段流媒体文件,然后到处寻找下载此格式文件的工具后,这不是很理想。很多TS文件在切片后直接下载,但这个网站one是加密的,不能直接播放。最后,找到了视频插件伪影ffmpeg。视频转码、剪辑、合并和播放都不是问题。它还支持多种平台
ffmpeg简介
Ffmpeg开放Ffmpeg官方网站
对于工件,为什么不自己编写一个工具来下载它呢?当您准备开始时,您会被如何获得连接的问题所阻止。最初,您只需要编写一个小型爬虫程序并对web连接进行爬网。结果,它不起作用。Ajax动态地启动了请求。数据不在web页面元素中,我对JS也不熟悉。我不知道如何获得这些数据。学生手动打开浏览器F12然后查找连接是否困难?这不是我的风格:)然后继续搜索,获得结果,自己实现浏览器,并拦截网页上的所有请求。筛选后得到三个方案:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
首先,我试了一下网络浏览器。目标网站无法直接打开网页。我更改了谷歌浏览器并修改了useragent以打开它,但是网页没有完全显示出来,所以我放弃了。然后更改geokofx以直接打开它,速度也很快,但有些连接会单击并没有响应,因此只能放弃。最终,cefsharp测试达到了预期目标,即flash和H264视频一天之内无法打开和投掷。这位官员表示,版权问题不受支持,需要修改。查找修改过的库。查找支持flash和H264视频的库:
提取代码:DFDR
是nupkg的安装包。检查nupkg安装方法
然后编写代码:
视频地址获取只需要继承和集成默认的抽象类defaultrequesthandler
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定以下内容
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里,我提取URL中的文件名,然后通过判断扩展名来判断它是否是视频文件。我不知道是否有更普遍的方法。Resourcetype==Resourcetype。媒体无法评判。在许多情况下,该值返回XHR
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
以下是几天的辗转反侧的结果
在浏览器界面中,如果在打开网页后截获视频地址,则会在go后面的右上角显示[x]。X表示在当前页面上截获的视频文件数
点击左上角的数字或下载标签页,进入如下界面
您可以在此下载、播放和其他操作。界面有点难看,功能实现了
下载支持断点继续,但m3u8片段文件不保存断点。因此,软件关闭后无法执行断点继续。重新启动。无法预测实时流的大小,因此不会显示下一个进度,但会及时更新下载的数据大小
通常,TS文件不需要下载,但可以直接从m3u8下载。程序将自动分析TS片段文件,并在下载所有文件后自动合成MP4文件
软件下载:链接:
提取代码:n6q4
如果没有,请下载并安装net framework4.6.1
关于查找教程网络 查看全部
抓取网页视频(
和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
几天前,一位同学说他想下载一段网站视频,但找不到连接。他问我有没有办法。当时,我觉得应该很简单,所以我说我会花时间看看。然后我分析了目标网页并试图从网页源代码中找到连接,但失败了。F12调用开发人员工具,进入netwrok,发现网页是XHR请求通过Ajax获得的视频连接。难怪页面元素中没有下载地址。请求的是m3u8格式的文件。在检查这是一个分段流媒体文件,然后到处寻找下载此格式文件的工具后,这不是很理想。很多TS文件在切片后直接下载,但这个网站one是加密的,不能直接播放。最后,找到了视频插件伪影ffmpeg。视频转码、剪辑、合并和播放都不是问题。它还支持多种平台
ffmpeg简介
Ffmpeg开放Ffmpeg官方网站
对于工件,为什么不自己编写一个工具来下载它呢?当您准备开始时,您会被如何获得连接的问题所阻止。最初,您只需要编写一个小型爬虫程序并对web连接进行爬网。结果,它不起作用。Ajax动态地启动了请求。数据不在web页面元素中,我对JS也不熟悉。我不知道如何获得这些数据。学生手动打开浏览器F12然后查找连接是否困难?这不是我的风格:)然后继续搜索,获得结果,自己实现浏览器,并拦截网页上的所有请求。筛选后得到三个方案:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
首先,我试了一下网络浏览器。目标网站无法直接打开网页。我更改了谷歌浏览器并修改了useragent以打开它,但是网页没有完全显示出来,所以我放弃了。然后更改geokofx以直接打开它,速度也很快,但有些连接会单击并没有响应,因此只能放弃。最终,cefsharp测试达到了预期目标,即flash和H264视频一天之内无法打开和投掷。这位官员表示,版权问题不受支持,需要修改。查找修改过的库。查找支持flash和H264视频的库:
提取代码:DFDR
是nupkg的安装包。检查nupkg安装方法
然后编写代码:
视频地址获取只需要继承和集成默认的抽象类defaultrequesthandler
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定以下内容
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里,我提取URL中的文件名,然后通过判断扩展名来判断它是否是视频文件。我不知道是否有更普遍的方法。Resourcetype==Resourcetype。媒体无法评判。在许多情况下,该值返回XHR
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
以下是几天的辗转反侧的结果
在浏览器界面中,如果在打开网页后截获视频地址,则会在go后面的右上角显示[x]。X表示在当前页面上截获的视频文件数
点击左上角的数字或下载标签页,进入如下界面
您可以在此下载、播放和其他操作。界面有点难看,功能实现了
下载支持断点继续,但m3u8片段文件不保存断点。因此,软件关闭后无法执行断点继续。重新启动。无法预测实时流的大小,因此不会显示下一个进度,但会及时更新下载的数据大小
通常,TS文件不需要下载,但可以直接从m3u8下载。程序将自动分析TS片段文件,并在下载所有文件后自动合成MP4文件
软件下载:链接:
提取代码:n6q4
如果没有,请下载并安装net framework4.6.1
关于查找教程网络
抓取网页视频( 可自动捕捉网页视频地址到软件即可进行网页下载(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 1057 次浏览 • 2021-09-13 05:17
可自动捕捉网页视频地址到软件即可进行网页下载(图))
ImovieBox 网络视频下载器是一款多功能的网络视频下载软件。 ImovieBox网页视频下载器可以自动抓取网页中的视频文件并下载到本地,安全稳定,无限存储,支持多线程,观看下载。 ImovieBox 使用简单方便。将视频地址复制到软件下载网络视频。
功能介绍1、批量下载
可以批量下载网络上的视频文件
2、生成目录
可以帮助用户生成高清视频目录
3、精准识别
可以有效识别网页上出现的视频
4、下载速度快
高效快速地下载网络视频
5、发送邮件
可以直接将视频文件发送到用户邮箱或手机
安装步骤1、在本站下载ImovieBox网页视频下载器软件包,进入安装界面。
2、点击下一步继续安装。
3、接受许可协议并选择安装位置
4、ImovieBox Web Video Downloader 安装完毕,打开软件即可使用。
如何使用 ImovieBox 网络视频下载器是如何下载网络视频的?
1.实时抓拍:点击开启实时抓拍功能后,软件界面右侧会弹出抓拍信息窗口,设置视频文件的下载方式,输入视频下载界面,软件会自动播放文件进行下载。
2.输入网址截取:将视频文件的播放地址复制粘贴到选择框中,点击“传统截取视频”按钮开始下载。
如何使用
1、 建议使用自己的邮箱登录,登录账号的邮箱空间为基础空间
2、 登录后可以添加任何其他邮局账号,添加的空间为扩展空间
3、软件自动将多个账户空间合并成一个海量空间,永久保存数据
4、只需将视频的网页地址提交给ImovieBox下载器,即可下载任何视频。并且可以自动存入邮箱,供您随时随地检索使用。
5、界面简单,功能齐全,可以下载任何网站视频。 ImovieBox网络视频下载器是您学习和生活中不可多得的好帮手。
专业版功能
1、任意网页批量下载海量图片。
可以指定任意图片格式,可以指定任意图片大小,可以指定任意图片宽高进行批量下载。
抓拍图片实时预览,所需图片集实时抓拍,支持多线程高速并发下载。
根据不同的宽度和高度自动对图片进行分类,显示实时梳理列表,选择指定宽度和高度的图片实时获取批次。
2、自动生成高分辨率相册。
3、即时下载和即时欣赏模式。
4、支持批量下载所有加密图片。
5、支持批量下载带有防盗链接的图片。
6、你看到的独特下载模式就是你得到的。即在观看网页图片时,ImovieBox 网络视频下载专家会自动下载图片。
7、友好的用户界面。界面颜色可以随意调整。
8、完整的单机软件,不仅可以下载到本地,还具有备份到您私人邮箱的功能。
9、支持图片自动批量下载并自动同步到您的私有云存储。 查看全部
抓取网页视频(
可自动捕捉网页视频地址到软件即可进行网页下载(图))
ImovieBox 网络视频下载器是一款多功能的网络视频下载软件。 ImovieBox网页视频下载器可以自动抓取网页中的视频文件并下载到本地,安全稳定,无限存储,支持多线程,观看下载。 ImovieBox 使用简单方便。将视频地址复制到软件下载网络视频。
功能介绍1、批量下载
可以批量下载网络上的视频文件
2、生成目录
可以帮助用户生成高清视频目录
3、精准识别
可以有效识别网页上出现的视频
4、下载速度快
高效快速地下载网络视频
5、发送邮件
可以直接将视频文件发送到用户邮箱或手机
安装步骤1、在本站下载ImovieBox网页视频下载器软件包,进入安装界面。
2、点击下一步继续安装。
3、接受许可协议并选择安装位置
4、ImovieBox Web Video Downloader 安装完毕,打开软件即可使用。
如何使用 ImovieBox 网络视频下载器是如何下载网络视频的?
1.实时抓拍:点击开启实时抓拍功能后,软件界面右侧会弹出抓拍信息窗口,设置视频文件的下载方式,输入视频下载界面,软件会自动播放文件进行下载。
2.输入网址截取:将视频文件的播放地址复制粘贴到选择框中,点击“传统截取视频”按钮开始下载。
如何使用
1、 建议使用自己的邮箱登录,登录账号的邮箱空间为基础空间
2、 登录后可以添加任何其他邮局账号,添加的空间为扩展空间
3、软件自动将多个账户空间合并成一个海量空间,永久保存数据
4、只需将视频的网页地址提交给ImovieBox下载器,即可下载任何视频。并且可以自动存入邮箱,供您随时随地检索使用。
5、界面简单,功能齐全,可以下载任何网站视频。 ImovieBox网络视频下载器是您学习和生活中不可多得的好帮手。
专业版功能
1、任意网页批量下载海量图片。
可以指定任意图片格式,可以指定任意图片大小,可以指定任意图片宽高进行批量下载。
抓拍图片实时预览,所需图片集实时抓拍,支持多线程高速并发下载。
根据不同的宽度和高度自动对图片进行分类,显示实时梳理列表,选择指定宽度和高度的图片实时获取批次。
2、自动生成高分辨率相册。
3、即时下载和即时欣赏模式。
4、支持批量下载所有加密图片。
5、支持批量下载带有防盗链接的图片。
6、你看到的独特下载模式就是你得到的。即在观看网页图片时,ImovieBox 网络视频下载专家会自动下载图片。
7、友好的用户界面。界面颜色可以随意调整。
8、完整的单机软件,不仅可以下载到本地,还具有备份到您私人邮箱的功能。
9、支持图片自动批量下载并自动同步到您的私有云存储。
抓取网页视频(智能识别模式WebHarvy自动识别网页中的数据抓取工具完美激活该软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-13 05:14
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。便于使用。小编为您带来WebHarvy破解版。附带的破解文件可以完美激活软件。有需要就来试试吧。
功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
软件功能
WebHarvy 是一个可视化的网页抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。 查看全部
抓取网页视频(智能识别模式WebHarvy自动识别网页中的数据抓取工具完美激活该软件)
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。便于使用。小编为您带来WebHarvy破解版。附带的破解文件可以完美激活软件。有需要就来试试吧。
功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
软件功能
WebHarvy 是一个可视化的网页抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
抓取网页视频( 2021-05-11摩旅 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-12 13:04
2021-05-11摩旅
)
抓取网页图片-以本地IIS网页为练习对象
时间:2021-05-11
本文章为大家介绍抓取网页图片-本地IIS网页为练习对象,主要包括抓取网页图片-本地IIS网页为练习对象使用实例、应用技巧、基础知识点总结及需要注意的内容有一定的参考价值,有需要的朋友可以参考。
#抓取网页图片
#适用于html页面结构为:li>img
#抓取单个网页图片小程序
#version:V1.0
#author:yxmichael
#更新时间:20210511
import requests
from bs4 import BeautifulSoup
import os,shutil
import time
def getHtmlText(url,code='utf-8'):
try:
r = requests.get(url,timeout = 30,headers = my_headers)
r.raise_for_status
r.encoding = code
return r.text
except:
return ""
def parseHtml(nlist,html):
try:
soup = BeautifulSoup(html,'html.parser')
div_main = soup.find('div',attrs={'id':'main'})
lis = div_main.findAll('li')
for li in lis:
a_href = li.find('a')['href']
if a_href != '#':
img_src = li.find('img')['src']
img_name = a_href.split('/')[-1]
#img_name =img_name[-1]
#print("{}\t{}\n".format(a_href,img_src))
nlist.append([img_name,a_href,img_src])
except:
print("")
def delOldDir(dir_path):
if os.path.exists(dir_path):
shutil.rmtree(dir_path)
def downImg(nlist,nums,site_url,dir_path):
if not os.path.exists(dir_path):
os.mkdir(dir_path)
os.chdir(dir_path)
print("\n正在获取原图……")
for i in range(nums):
img = nlist[i]
img_name = img[0]
img_href= site_url + img[1]
file_name = dir_path +'/' + img_name
r= requests.get(img_href,timeout=30)
with open(file_name,'wb') as f:
f.write(r.content)
progressBar(i,nums)
def downImgMicro(nlist,nums,site_url,dir_path):
if not os.path.exists(dir_path):
os.mkdir(dir_path)
os.chdir(dir_path)
print("\n正在获取缩微图……")
for i in range(nums):
img = nlist[i]
img_name = img[0]
img_src = site_url + img[2]
prefix = '缩微图_'
file_name = dir_path +'/' + prefix + img_name
r= requests.get(img_src,timeout=30)
with open(file_name,'wb') as f:
f.write(r.content)
progressBar(i,nums)
def progressBar(i,total):
print('\r当前进度:{0}{1:.0f}%'.format('▉'*(i+1),((i+1)/total*100)),end='')
def printHead():
num = 80
print("{}".format("*"*num))
str_intro = '''
抓取单个网页图片小程序
version:V1.0
author:yxmichael
更新时间:20210511
'''
print(str_intro)
print("{}".format("*"*num))
print("\n正在抓取……\n")
def main():
global my_headers
my_headers ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
site_url = 'http://127.0.0.1/pg/'
imgList = []
start_time = time.time()
cur_path = os.getcwd() + '/'
tmp = '老照片'
dir_path = cur_path + tmp
dir_path_micro = cur_path + tmp + '_缩微图'
printHead()
html = getHtmlText(site_url)
parseHtml(imgList,html)
nums = len(imgList)
#nums =3
delOldDir(dir_path)
delOldDir(dir_path_micro)
downImg(imgList,nums,site_url,dir_path)
downImgMicro(imgList,nums,site_url,dir_path_micro)
seconds = time.time() - start_time
print("\n成功下载{}张图片,耗时:{:.1f}秒。\n保存路径{}".format(nums,seconds,dir_path))
input("请按任意键退出……")
main() 查看全部
抓取网页视频(
2021-05-11摩旅
)
抓取网页图片-以本地IIS网页为练习对象
时间:2021-05-11
本文章为大家介绍抓取网页图片-本地IIS网页为练习对象,主要包括抓取网页图片-本地IIS网页为练习对象使用实例、应用技巧、基础知识点总结及需要注意的内容有一定的参考价值,有需要的朋友可以参考。
#抓取网页图片
#适用于html页面结构为:li>img
#抓取单个网页图片小程序
#version:V1.0
#author:yxmichael
#更新时间:20210511
import requests
from bs4 import BeautifulSoup
import os,shutil
import time
def getHtmlText(url,code='utf-8'):
try:
r = requests.get(url,timeout = 30,headers = my_headers)
r.raise_for_status
r.encoding = code
return r.text
except:
return ""
def parseHtml(nlist,html):
try:
soup = BeautifulSoup(html,'html.parser')
div_main = soup.find('div',attrs={'id':'main'})
lis = div_main.findAll('li')
for li in lis:
a_href = li.find('a')['href']
if a_href != '#':
img_src = li.find('img')['src']
img_name = a_href.split('/')[-1]
#img_name =img_name[-1]
#print("{}\t{}\n".format(a_href,img_src))
nlist.append([img_name,a_href,img_src])
except:
print("")
def delOldDir(dir_path):
if os.path.exists(dir_path):
shutil.rmtree(dir_path)
def downImg(nlist,nums,site_url,dir_path):
if not os.path.exists(dir_path):
os.mkdir(dir_path)
os.chdir(dir_path)
print("\n正在获取原图……")
for i in range(nums):
img = nlist[i]
img_name = img[0]
img_href= site_url + img[1]
file_name = dir_path +'/' + img_name
r= requests.get(img_href,timeout=30)
with open(file_name,'wb') as f:
f.write(r.content)
progressBar(i,nums)
def downImgMicro(nlist,nums,site_url,dir_path):
if not os.path.exists(dir_path):
os.mkdir(dir_path)
os.chdir(dir_path)
print("\n正在获取缩微图……")
for i in range(nums):
img = nlist[i]
img_name = img[0]
img_src = site_url + img[2]
prefix = '缩微图_'
file_name = dir_path +'/' + prefix + img_name
r= requests.get(img_src,timeout=30)
with open(file_name,'wb') as f:
f.write(r.content)
progressBar(i,nums)
def progressBar(i,total):
print('\r当前进度:{0}{1:.0f}%'.format('▉'*(i+1),((i+1)/total*100)),end='')
def printHead():
num = 80
print("{}".format("*"*num))
str_intro = '''
抓取单个网页图片小程序
version:V1.0
author:yxmichael
更新时间:20210511
'''
print(str_intro)
print("{}".format("*"*num))
print("\n正在抓取……\n")
def main():
global my_headers
my_headers ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
site_url = 'http://127.0.0.1/pg/'
imgList = []
start_time = time.time()
cur_path = os.getcwd() + '/'
tmp = '老照片'
dir_path = cur_path + tmp
dir_path_micro = cur_path + tmp + '_缩微图'
printHead()
html = getHtmlText(site_url)
parseHtml(imgList,html)
nums = len(imgList)
#nums =3
delOldDir(dir_path)
delOldDir(dir_path_micro)
downImg(imgList,nums,site_url,dir_path)
downImgMicro(imgList,nums,site_url,dir_path_micro)
seconds = time.time() - start_time
print("\n成功下载{}张图片,耗时:{:.1f}秒。\n保存路径{}".format(nums,seconds,dir_path))
input("请按任意键退出……")
main()
抓取网页视频(看看网易公开课是怎么选课的,这些才是王道)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-09 18:04
抓取网页视频地址:国内国外视频网站对比:斗鱼>爱奇艺>优酷>迅雷、ab站、天天动听=网易公开课,熊猫、pptv=腾讯公开课,b站=腾讯视频、新浪公开课=爱奇艺公开课,
百度,谷歌。我不会告诉你我曾经从优酷上看到,一个台湾方言被秒杀。
我不看youtube,但我知道知乎上不可以不看。
几个视频网站:网易公开课视频大部分比较老,比如coursera。但是个人觉得还不错。
网易公开课或新浪公开课
难道没人觉得用着自带浏览器看a站b站就可以了嘛,不用那些超贵的会员。
爱奇艺不是可以用电视机看么
会是电视机或者电脑,
新浪微博
b站,
猎奇也是需要资本的,虽然爱奇艺公开课被秒,但那毕竟是猎奇级别的,我还没到可以随便开心的打开视频一看就是一天的水平。期待网易,优酷的公开课,毕竟会员看主流电视剧,4,6,月,年几年年的那种。看看网易公开课是怎么选课的,又是怎么上课的,这些才是王道。
优酷。b站。
那就看你喜欢哪个用哪个咯,
网易公开课里面有些频道还不错
youtube。特别喜欢里面各类视频课程比如coursera,mooc等。 查看全部
抓取网页视频(看看网易公开课是怎么选课的,这些才是王道)
抓取网页视频地址:国内国外视频网站对比:斗鱼>爱奇艺>优酷>迅雷、ab站、天天动听=网易公开课,熊猫、pptv=腾讯公开课,b站=腾讯视频、新浪公开课=爱奇艺公开课,
百度,谷歌。我不会告诉你我曾经从优酷上看到,一个台湾方言被秒杀。
我不看youtube,但我知道知乎上不可以不看。
几个视频网站:网易公开课视频大部分比较老,比如coursera。但是个人觉得还不错。
网易公开课或新浪公开课
难道没人觉得用着自带浏览器看a站b站就可以了嘛,不用那些超贵的会员。
爱奇艺不是可以用电视机看么
会是电视机或者电脑,
新浪微博
b站,
猎奇也是需要资本的,虽然爱奇艺公开课被秒,但那毕竟是猎奇级别的,我还没到可以随便开心的打开视频一看就是一天的水平。期待网易,优酷的公开课,毕竟会员看主流电视剧,4,6,月,年几年年的那种。看看网易公开课是怎么选课的,又是怎么上课的,这些才是王道。
优酷。b站。
那就看你喜欢哪个用哪个咯,
网易公开课里面有些频道还不错
youtube。特别喜欢里面各类视频课程比如coursera,mooc等。

