
抓取网页视频
抓取网页视频?那你只能是自己爬,哈哈哈
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-08-27 06:05
抓取网页视频?那肯定是javascript了。去淘宝,淘宝自己搜索,你会发现有很多分享按钮都提供给用户免费下载视频的。你根据个人资料,根据评价,那就有你想要的内容了。1元一个,1个月一次,那就6元一个。至于其他一些扩展功能,比如音乐啊,图片啊等等,你也可以自己去发掘的。
刚好,我前几天还刚刚回答了一个知友的疑问。个人推荐@chenqin答案上点的。
和视频点点没有什么关系吧,知乎如果本身不提供,那你只能是自己爬,现在各大视频网站都有大量的免费视频,即使你在知乎问的方式获取的,
刚刚遇到了这个问题,具体步骤如下:使用站长工具提供的免费下载视频的网站,按下图示意操作:第1步打开浏览器,在地址栏输入:url"";第2步切换到迅雷或其他下载软件;第3步,点击“免费下载”或者“试用期”第4步第5步...以上。完成。就酱紫。
我常用的是这个网站的页面
这个可以的,
亲测这个是可以的,国内的视频网站还是看不到这个功能,比如大白兔小白兔等等。
在看到是唯一的答案的时候忽然又想到了这个问题,还好不是国内的网站,万一呢,哈哈,顺便做个广告,希望能够帮到你。不过有个手机软件是可以解决这个问题的。 查看全部
抓取网页视频?那你只能是自己爬,哈哈哈
抓取网页视频?那肯定是javascript了。去淘宝,淘宝自己搜索,你会发现有很多分享按钮都提供给用户免费下载视频的。你根据个人资料,根据评价,那就有你想要的内容了。1元一个,1个月一次,那就6元一个。至于其他一些扩展功能,比如音乐啊,图片啊等等,你也可以自己去发掘的。
刚好,我前几天还刚刚回答了一个知友的疑问。个人推荐@chenqin答案上点的。

和视频点点没有什么关系吧,知乎如果本身不提供,那你只能是自己爬,现在各大视频网站都有大量的免费视频,即使你在知乎问的方式获取的,
刚刚遇到了这个问题,具体步骤如下:使用站长工具提供的免费下载视频的网站,按下图示意操作:第1步打开浏览器,在地址栏输入:url"";第2步切换到迅雷或其他下载软件;第3步,点击“免费下载”或者“试用期”第4步第5步...以上。完成。就酱紫。
我常用的是这个网站的页面

这个可以的,
亲测这个是可以的,国内的视频网站还是看不到这个功能,比如大白兔小白兔等等。
在看到是唯一的答案的时候忽然又想到了这个问题,还好不是国内的网站,万一呢,哈哈,顺便做个广告,希望能够帮到你。不过有个手机软件是可以解决这个问题的。
b站会将你视频标记为pro,上传到海外youtube,
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-08-01 14:01
抓取网页视频,要么采用python爬虫。要么爬文章。乐视平台视频,是alipx老版本,刚更新。解码有点烦,但无法避免。目前,是测试过的,由于每个视频第二天发布,你我打算用更新的版本爬取。url:"",size:165.65552210110"",解码问题,尝试了好多方法,全部无法成功,除非你像@唐昊那样留下邮箱。
国内是无法正常上传视频的。还需要翻墙。顺便附上链接。,大小是102.190万节点,也能正常播放。最后附上极限整站视频列表:/。
采用bilibili的方式爬去。安卓设备需要安装谷歌商店(最新的即可),手机上下载个bilibili客户端(你懂的),以浏览器为例,因为这个视频不是你本地浏览器直接保存下来的,所以必须要登录b站,找到相应的版块视频。先登录好后找视频下载入口,百度搜索/公司名会找到一大堆。首先选择你需要下载的板块视频,然后可以选择分享方式(比如在页面右上角)。
b站会将你视频标记为pro,上传到海外youtube,优酷,腾讯的youtube影子站点。保存到src/video/bilibili/video.bilibili.youtube.youtube/youtube.web/目录。这个方法就下载相应视频的视频结构化数据。
我们,做国内,
找百度去年的数据 查看全部
b站会将你视频标记为pro,上传到海外youtube,
抓取网页视频,要么采用python爬虫。要么爬文章。乐视平台视频,是alipx老版本,刚更新。解码有点烦,但无法避免。目前,是测试过的,由于每个视频第二天发布,你我打算用更新的版本爬取。url:"",size:165.65552210110"",解码问题,尝试了好多方法,全部无法成功,除非你像@唐昊那样留下邮箱。

国内是无法正常上传视频的。还需要翻墙。顺便附上链接。,大小是102.190万节点,也能正常播放。最后附上极限整站视频列表:/。
采用bilibili的方式爬去。安卓设备需要安装谷歌商店(最新的即可),手机上下载个bilibili客户端(你懂的),以浏览器为例,因为这个视频不是你本地浏览器直接保存下来的,所以必须要登录b站,找到相应的版块视频。先登录好后找视频下载入口,百度搜索/公司名会找到一大堆。首先选择你需要下载的板块视频,然后可以选择分享方式(比如在页面右上角)。

b站会将你视频标记为pro,上传到海外youtube,优酷,腾讯的youtube影子站点。保存到src/video/bilibili/video.bilibili.youtube.youtube/youtube.web/目录。这个方法就下载相应视频的视频结构化数据。
我们,做国内,
找百度去年的数据
nicetool开发nicetool免费的网页视频下载器,下载神器
网站优化 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2022-07-09 00:01
抓取网页视频不难,只要动动手指,点点鼠标,不用下载安装软件也能在本地快速找到。一个超级简单易用,且用很少的工具就能完成的视频下载工具——nicetool,使用起来方便快捷。nicetool是一款免费,傻瓜式的视频下载神器,其可以将各种视频免费下载,是初级使用者的好选择。视频下载:微信视频、哔哩哔哩视频、爱奇艺视频、优酷视频、芒果tv视频、河智工作室视频..包括央视、国家电视台视频一起下载!nicetool的视频下载是可以自定义搜索列表、包括地区、热度、时长等。
视频下载操作演示:百度网盘的音频、视频均可免费下载nicetool还支持批量下载。这是其他视频下载工具无法做到的。nicetool的下载比较简单,无需导入其他软件即可完成。视频下载:百度网盘、海量视频、百度云搜索api、黄金屋视频下载——tampermonkey开发nicetool成立于2017年3月5日,是nicethink公司推出的一款绿色集成式的网页视频下载神器。
nicetool免费开源,是世界上第一款免费绿色的网页视频下载器,截止目前,nicetool已经拥有140000+用户。nicetool已经全球应用于最多的国家地区,包括欧美、日韩等国家以及非洲和东南亚等地区。nicetool也是一款ios及android应用,共计下载量超过3亿次,基本是无需科学上网的视频下载工具。
nicetool,免费的网页视频下载器,在手机上、电脑上无需科学上网即可高速下载,极速无卡顿,让你轻松享受浏览网页视频所带来的愉悦。下载地址等更多内容请前往——nicetool喜欢的话就“赞”一个吧^^下载最美应用官方客户端。 查看全部
nicetool开发nicetool免费的网页视频下载器,下载神器
抓取网页视频不难,只要动动手指,点点鼠标,不用下载安装软件也能在本地快速找到。一个超级简单易用,且用很少的工具就能完成的视频下载工具——nicetool,使用起来方便快捷。nicetool是一款免费,傻瓜式的视频下载神器,其可以将各种视频免费下载,是初级使用者的好选择。视频下载:微信视频、哔哩哔哩视频、爱奇艺视频、优酷视频、芒果tv视频、河智工作室视频..包括央视、国家电视台视频一起下载!nicetool的视频下载是可以自定义搜索列表、包括地区、热度、时长等。

视频下载操作演示:百度网盘的音频、视频均可免费下载nicetool还支持批量下载。这是其他视频下载工具无法做到的。nicetool的下载比较简单,无需导入其他软件即可完成。视频下载:百度网盘、海量视频、百度云搜索api、黄金屋视频下载——tampermonkey开发nicetool成立于2017年3月5日,是nicethink公司推出的一款绿色集成式的网页视频下载神器。

nicetool免费开源,是世界上第一款免费绿色的网页视频下载器,截止目前,nicetool已经拥有140000+用户。nicetool已经全球应用于最多的国家地区,包括欧美、日韩等国家以及非洲和东南亚等地区。nicetool也是一款ios及android应用,共计下载量超过3亿次,基本是无需科学上网的视频下载工具。
nicetool,免费的网页视频下载器,在手机上、电脑上无需科学上网即可高速下载,极速无卡顿,让你轻松享受浏览网页视频所带来的愉悦。下载地址等更多内容请前往——nicetool喜欢的话就“赞”一个吧^^下载最美应用官方客户端。
xmlhttprequest对象代表向服务器传递特定格式数据的api
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-07-06 23:01
抓取网页视频,清晰度越高时间越短。xmlhttprequest对象代表向服务器传递特定格式的数据的api,相应的threadlocal是对这个api的封装。as15:howtorequestyourhttprequestonimageimageoptions分别为图片的个数(最多30个图片,最多20个mp。
4)、大小、格式、转码方式、视频xml头内容和内容(src、value、base6
4、md
5、aes加密算法)、xml转码方式(as
2、h2d)。
支持as
2、h2d。
你是不是让我写个爬虫,用户上传一个图片,然后我分析图片的特征,然后生成txt文件发给你。
楼上说了分析图片的特征,
做api接口,然后post到服务器,服务器转xml,验证,然后返回一个txt数据,
现在应该很少是一个xml、一个json在同一个请求,然后同一个xml要上传给相应的视频文件下吧。
你把图片的部分数据抓取到api上去,
imagequery
md5
分析好分析好分析好
参考1.youtube右上角右键-》属性-》xmlhttprequest-》,
存一个xml到xmlurl,然后就能xml获取视频了,更高级点的是弄个网页爬虫,
用jsonymlseter直接解析视频url 查看全部
xmlhttprequest对象代表向服务器传递特定格式数据的api
抓取网页视频,清晰度越高时间越短。xmlhttprequest对象代表向服务器传递特定格式的数据的api,相应的threadlocal是对这个api的封装。as15:howtorequestyourhttprequestonimageimageoptions分别为图片的个数(最多30个图片,最多20个mp。
4)、大小、格式、转码方式、视频xml头内容和内容(src、value、base6
4、md
5、aes加密算法)、xml转码方式(as
2、h2d)。

支持as
2、h2d。
你是不是让我写个爬虫,用户上传一个图片,然后我分析图片的特征,然后生成txt文件发给你。
楼上说了分析图片的特征,
做api接口,然后post到服务器,服务器转xml,验证,然后返回一个txt数据,
现在应该很少是一个xml、一个json在同一个请求,然后同一个xml要上传给相应的视频文件下吧。

你把图片的部分数据抓取到api上去,
imagequery
md5
分析好分析好分析好
参考1.youtube右上角右键-》属性-》xmlhttprequest-》,
存一个xml到xmlurl,然后就能xml获取视频了,更高级点的是弄个网页爬虫,
用jsonymlseter直接解析视频url
抓取网页视频的过程中的翻页查看视频(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-05-19 07:04
抓取网页视频的过程中,经常需要一页页翻页查看网页视频。但这么短的视频肯定没有一次性看完,所以最好还是能一口气看完全部。有时候只想看自己感兴趣的,但又不想看到重复的视频。解决办法一般有两种,一种是实现动态多屏滚动(这种比较不靠谱,浪费资源而且有时候下一个视频未必与第一个视频相同),另一种就是上面介绍的split(批量翻页),结合lbs定位功能实现split(批量翻页)的效果。
注意在功能添加上最好使用java,使用python会比较麻烦。如果你的项目中没有用到video标签,可以先使用一些html模版生成,然后使用css去实现(有人说python中不能写css,那就先把html模版的编写放到最后)。好了,相关介绍完毕,开始看代码吧!userelationship.py参考githubsplitjs/splitjs-examples#导航条split(批量翻页)的思路分为两个部分。
首先说要实现的功能:1.查看一个视频2.翻页1.查看一个视频。#导航栏actions=[{"tabtitle":"小蜜蜂","page/1":1,"page/2":2,"page/3":3,"page/4":4,"page/5":5,"page/6":6,"page/7":7,"page/8":8,"page/9":9,"page/10":10,"page/11":11,"page/12":12,"page/13":13,"page/14":14,"page/15":15,"page/16":16,"page/17":17,"page/18":19,"page/19":19,"page/20":20,"page/21":21,"page/22":22,"page/23":23,"page/24":24,"page/25":25,"page/26":26,"page/27":27,"page/28":28,"page/29":30,"page/30":31,"page/31":32,"page/32":33,"page/33":34,"page/34":35,"page/35":36,"page/36":37,"page/37":38,"page/38":39,"page/39":40,"page/40":41,"page/41":42,"page/42":43,"page/43":44,"page/44":45,"page/45":46,"page/47":47,"page/48":48,"page/49":49,"page/50":50,"page/51":52,"page/52":53,"page/53":54,"page/54":55,"page/55":56,"page/55":57,"page/55":57,"page/55":58,"page/55":58,"page/55":59,"page/55":60,"page/56":61,"page/57":62,"page/57":63,"page/58":64,"page/59":65,"page/60":65,"page/60":63,"page/61":63,"page/62"。 查看全部
抓取网页视频的过程中的翻页查看视频(组图)
抓取网页视频的过程中,经常需要一页页翻页查看网页视频。但这么短的视频肯定没有一次性看完,所以最好还是能一口气看完全部。有时候只想看自己感兴趣的,但又不想看到重复的视频。解决办法一般有两种,一种是实现动态多屏滚动(这种比较不靠谱,浪费资源而且有时候下一个视频未必与第一个视频相同),另一种就是上面介绍的split(批量翻页),结合lbs定位功能实现split(批量翻页)的效果。
注意在功能添加上最好使用java,使用python会比较麻烦。如果你的项目中没有用到video标签,可以先使用一些html模版生成,然后使用css去实现(有人说python中不能写css,那就先把html模版的编写放到最后)。好了,相关介绍完毕,开始看代码吧!userelationship.py参考githubsplitjs/splitjs-examples#导航条split(批量翻页)的思路分为两个部分。
首先说要实现的功能:1.查看一个视频2.翻页1.查看一个视频。#导航栏actions=[{"tabtitle":"小蜜蜂","page/1":1,"page/2":2,"page/3":3,"page/4":4,"page/5":5,"page/6":6,"page/7":7,"page/8":8,"page/9":9,"page/10":10,"page/11":11,"page/12":12,"page/13":13,"page/14":14,"page/15":15,"page/16":16,"page/17":17,"page/18":19,"page/19":19,"page/20":20,"page/21":21,"page/22":22,"page/23":23,"page/24":24,"page/25":25,"page/26":26,"page/27":27,"page/28":28,"page/29":30,"page/30":31,"page/31":32,"page/32":33,"page/33":34,"page/34":35,"page/35":36,"page/36":37,"page/37":38,"page/38":39,"page/39":40,"page/40":41,"page/41":42,"page/42":43,"page/43":44,"page/44":45,"page/45":46,"page/47":47,"page/48":48,"page/49":49,"page/50":50,"page/51":52,"page/52":53,"page/53":54,"page/54":55,"page/55":56,"page/55":57,"page/55":57,"page/55":58,"page/55":58,"page/55":59,"page/55":60,"page/56":61,"page/57":62,"page/57":63,"page/58":64,"page/59":65,"page/60":65,"page/60":63,"page/61":63,"page/62"。
抓取网页视频 基本请求库requests
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-30 14:34
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get")# 发起Post请求requests.post("https://www.httpbin.org/post")# 发起Put请求requests.put("https://www.httpbin.org/put")# 发起Delete请求requests.delete("https://www.httpbin.org/delete")
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/")# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证 查看全部
抓取网页视频 基本请求库requests
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get";)# 发起Post请求requests.post("https://www.httpbin.org/post";)# 发起Put请求requests.put("https://www.httpbin.org/put";)# 发起Delete请求requests.delete("https://www.httpbin.org/delete";)
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/";)# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证
抓取网页视频(【】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-20 18:29
目录完整代码视频缓存ts文件实现效果
实现目标和想法的运行环境
实现腾讯视频目标url的解析下载。由于第三方vip解析,只提供在线观看,隐藏目标视频的下载。
思考
先获取你想看的腾讯电影的url,通过第三方vip视频解析网站,抓包,模拟浏览器发送正常请求,下载视频ts通过获取缓存的ts文件,最后转换成mp4文件,就可以正常播放了
完整代码
import re
import os,shutil
import requests,threading
from urllib.request import urlretrieve
from pyquery import PyQuery as pq
from multiprocessing import Pool
'''
'''
class video_down():
def __init__(self,url):
# 拼接全民解析url
self.api='https://jx.618g.com'
self.get_url = 'https://jx.618g.com/?url=' + url
#设置UA模拟浏览器访问
self.head = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
#设置多线程数量
self.thread_num=32
#当前已经下载的文件数目
self.i = 0
# 调用网页获取
html = self.get_page(self.get_url)
if html:
# 解析网页
self.parse_page(html)
def get_page(self,get_url):
try:
print('正在请求目标网页....',get_url)
response=requests.get(get_url,headers=self.head)
if response.status_code==200:
#print(response.text)
print('请求目标网页完成....\n 准备解析....')
self.head['referer'] = get_url
return response.text
except Exception:
print('请求目标网页失败,请检查错误重试')
return None
def parse_page(self,html):
print('目标信息正在解析........')
doc=pq(html)
self.title=doc('head title').text()
print(self.title)
url = doc('#player').attr('src')[14:]
html=self.get_m3u8_1(url).strip()
#self.url = url + '800k/hls/index.m3u8'
self.url = url[:-10] +html
print(self.url)
print('解析完成,获取缓存ts文件.........')
self.get_m3u8_2(self.url)
def get_m3u8_1(self,url):
try:
response=requests.get(url,headers=self.head)
html=response.text
print('获取ts文件成功,准备提取信息')
return html[-20:]
except Exception:
print('缓存文件请求错误1,请检查错误')
def get_m3u8_2(self,url):
try:
response=requests.get(url,headers=self.head)
html=response.text
print('获取ts文件成功,准备提取信息')
self.parse_ts_2(html)
except Exception:
print('缓存文件请求错误2,请检查错误')
def parse_ts_2(self,html):
pattern=re.compile('.*?(.*?).ts')
self.ts_lists=re.findall(pattern,html)
print('信息提取完成......\n准备下载...')
self.pool()
def pool(self):
print('经计算需要下载%d个文件' % len(self.ts_lists))
self.ts_url = self.url[:-10]
if self.title not in os.listdir():
os.makedirs(self.title)
print('正在下载...所需时间较长,请耐心等待..')
#开启多进程下载
pool=Pool(16)
pool.map(self.save_ts,[ts_list for ts_list in self.ts_lists])
pool.close()
pool.join()
print('下载完成')
self.ts_to_mp4()
def ts_to_mp4(self):
print('ts文件正在进行转录mp4......')
str='copy /b '+self.title+'\*.ts '+self.title+'.mp4'
os.system(str)
filename=self.title+'.mp4'
if os.path.isfile(filename):
print('转换完成,祝你观影愉快')
shutil.rmtree(self.title)
def save_ts(self,ts_list):
try:
ts_urls = self.ts_url + '{}.ts'.format(ts_list)
self.i += 1
print('当前进度%d/%d'%(self.i,len(self.ts_lists)))
urlretrieve(url=ts_urls, filename=self.title + '/{}.ts'.format(ts_list))
except Exception:
print('保存文件出现错误')
if __name__ == '__main__':
#电影目标url:狄仁杰之四大天王
url='https://v.qq.com/x/cover/r6ri9qkcu66dna8.html'
#电影碟中谍5:神秘国度
url1='https://v.qq.com/x/cover/5c58griiqftvq00.html'
#电视剧斗破苍穹
url2='https://v.qq.com/x/cover/lcpwn26degwm7t3/z0027injhcq.html'
url3='https://v.qq.com/x/cover/33bfp8mmgakf0gi.html'
video_down(url2)
视频缓存ts文件
这里是一些缓存的视频文件,每个只播放几秒,最后需要合并成一个mp4格式的视频,可以正常播放,默认高清下载
注意这里的进度,因为使用了多进程下载。进度仅供参考。进度未准确显示。可以进入文件夹查看正常进度。可以理解为显示一次进度,下载一个ts文件
达到效果
以上是Python捕获所有腾讯视频电影的示例代码的详细内容。更多关于Python捕捉腾讯视频的内容,请关注脚本之家其他相关话题文章! 查看全部
抓取网页视频(【】)
目录完整代码视频缓存ts文件实现效果
实现目标和想法的运行环境
实现腾讯视频目标url的解析下载。由于第三方vip解析,只提供在线观看,隐藏目标视频的下载。
思考
先获取你想看的腾讯电影的url,通过第三方vip视频解析网站,抓包,模拟浏览器发送正常请求,下载视频ts通过获取缓存的ts文件,最后转换成mp4文件,就可以正常播放了
完整代码
import re
import os,shutil
import requests,threading
from urllib.request import urlretrieve
from pyquery import PyQuery as pq
from multiprocessing import Pool
'''
'''
class video_down():
def __init__(self,url):
# 拼接全民解析url
self.api='https://jx.618g.com'
self.get_url = 'https://jx.618g.com/?url=' + url
#设置UA模拟浏览器访问
self.head = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
#设置多线程数量
self.thread_num=32
#当前已经下载的文件数目
self.i = 0
# 调用网页获取
html = self.get_page(self.get_url)
if html:
# 解析网页
self.parse_page(html)
def get_page(self,get_url):
try:
print('正在请求目标网页....',get_url)
response=requests.get(get_url,headers=self.head)
if response.status_code==200:
#print(response.text)
print('请求目标网页完成....\n 准备解析....')
self.head['referer'] = get_url
return response.text
except Exception:
print('请求目标网页失败,请检查错误重试')
return None
def parse_page(self,html):
print('目标信息正在解析........')
doc=pq(html)
self.title=doc('head title').text()
print(self.title)
url = doc('#player').attr('src')[14:]
html=self.get_m3u8_1(url).strip()
#self.url = url + '800k/hls/index.m3u8'
self.url = url[:-10] +html
print(self.url)
print('解析完成,获取缓存ts文件.........')
self.get_m3u8_2(self.url)
def get_m3u8_1(self,url):
try:
response=requests.get(url,headers=self.head)
html=response.text
print('获取ts文件成功,准备提取信息')
return html[-20:]
except Exception:
print('缓存文件请求错误1,请检查错误')
def get_m3u8_2(self,url):
try:
response=requests.get(url,headers=self.head)
html=response.text
print('获取ts文件成功,准备提取信息')
self.parse_ts_2(html)
except Exception:
print('缓存文件请求错误2,请检查错误')
def parse_ts_2(self,html):
pattern=re.compile('.*?(.*?).ts')
self.ts_lists=re.findall(pattern,html)
print('信息提取完成......\n准备下载...')
self.pool()
def pool(self):
print('经计算需要下载%d个文件' % len(self.ts_lists))
self.ts_url = self.url[:-10]
if self.title not in os.listdir():
os.makedirs(self.title)
print('正在下载...所需时间较长,请耐心等待..')
#开启多进程下载
pool=Pool(16)
pool.map(self.save_ts,[ts_list for ts_list in self.ts_lists])
pool.close()
pool.join()
print('下载完成')
self.ts_to_mp4()
def ts_to_mp4(self):
print('ts文件正在进行转录mp4......')
str='copy /b '+self.title+'\*.ts '+self.title+'.mp4'
os.system(str)
filename=self.title+'.mp4'
if os.path.isfile(filename):
print('转换完成,祝你观影愉快')
shutil.rmtree(self.title)
def save_ts(self,ts_list):
try:
ts_urls = self.ts_url + '{}.ts'.format(ts_list)
self.i += 1
print('当前进度%d/%d'%(self.i,len(self.ts_lists)))
urlretrieve(url=ts_urls, filename=self.title + '/{}.ts'.format(ts_list))
except Exception:
print('保存文件出现错误')
if __name__ == '__main__':
#电影目标url:狄仁杰之四大天王
url='https://v.qq.com/x/cover/r6ri9qkcu66dna8.html'
#电影碟中谍5:神秘国度
url1='https://v.qq.com/x/cover/5c58griiqftvq00.html'
#电视剧斗破苍穹
url2='https://v.qq.com/x/cover/lcpwn26degwm7t3/z0027injhcq.html'
url3='https://v.qq.com/x/cover/33bfp8mmgakf0gi.html'
video_down(url2)
视频缓存ts文件
这里是一些缓存的视频文件,每个只播放几秒,最后需要合并成一个mp4格式的视频,可以正常播放,默认高清下载
注意这里的进度,因为使用了多进程下载。进度仅供参考。进度未准确显示。可以进入文件夹查看正常进度。可以理解为显示一次进度,下载一个ts文件
达到效果


以上是Python捕获所有腾讯视频电影的示例代码的详细内容。更多关于Python捕捉腾讯视频的内容,请关注脚本之家其他相关话题文章!
抓取网页视频(为什么做seo需要来讲搜索引擎蜘蛛爬取规则?原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-19 15:06
严格来说seo爬取规则是个病句,应该是爬虫也叫蜘蛛在做seo的过程中的爬取规则。为什么seo需要讲搜索引擎蜘蛛爬取规则?原因是收录决定了索引,索引决定了排名,排名决定了SEO结果的好坏。
seo爬取的规则,你知道吗?我们实际上可以用最简单的方式来解释这一点。SEO在爬取过程中依赖于蜘蛛,而蜘蛛的存在是搜索引擎中的一个自动程序。蜘蛛程序需要不断的访问、采集、整理网络图片、视频等内容,这就是它的作用,然后将同类别和不同类别分开,建立索引库,这样用户在搜索的时候,就会找到自己喜欢的内容。需要。导读:网站不排名有收录原因及解决方法!
一、蜘蛛的爬行规则:
搜索引擎中的蜘蛛需要将爬取的网页放入数据库区域进行数据补充。通过程序的计算,将它们分类放置在不同的检索位置,然后搜索引擎就形成了一个稳定的收录排名。在这样做的过程中,蜘蛛抓取到的数据不一定是稳定的,很多都是经过程序计算后被其他好的网页挤出来的。简单来说就是蜘蛛不喜欢,不想爬这个页面。蜘蛛的味道很独特,它抓到的网站也很不一样,就是我们所说的原创文章,只要你网页里的文章 page的原创度数很高,那么你的网页就有很大概率被蜘蛛爬取,
只有经过这样的检索,数据的排名才会更加稳定,而现在搜索引擎已经改变了策略,正在逐步逐步向补充数据转变。这也是为什么在搜索引擎优化过程中在收录上搜索变得越来越困难的原因。我们也可以理解为,今天有很多页面没有收录的排名,每隔一段时间就会有收录。排名的原因。
二、增加网站的抓取频率:
1、网站文章 质量提升
做SEO的人虽然知道如何提高原创文章,但搜索引擎有一个不变的真理,就是永远无法满足内容质量和稀缺性的要求。在创建内容时,一定要满足每个潜在访问者的搜索需求,因为 原创 内容可能并不总是受到蜘蛛的喜爱。
2、更新网站文章的频率
内容满足后,做一个正常的更新频率很重要,这也是提高网页爬取的法宝。
3、网站速度不仅影响蜘蛛,还影响用户体验
蜘蛛访问时,如果没有障碍物,加载过程可以在合理的速度范围内,则需要保证蜘蛛在网页中能够顺畅爬行,不能有加载延迟。如果出现这种问题,那么蜘蛛就不会喜欢这个网站,它会降低爬取的频率。
4、提高网站品牌知名度
经常在网上混,你会发现一个问题。知名品牌推出新网站时,会去一些新闻媒体进行报道。新闻来源网站报道后,会添加一些品牌词,即使没有目标等链接有这么大的影响,搜索引擎也会抓取这个网站。
5、选择PR高的域名
PR是一个老式的域名,所以它的权重肯定很高。即使你的网站很长时间没有更新或者是一个完全封闭的网站页面,搜索引擎也会随时抓取并等待更新的内容。如果有人一开始就选择使用这样一个旧域名,那么重定向也可以发展成一个真正的可操作域名。
蜘蛛爬行频率:
如果是高权重网站,更新频率会不一样,所以频率一般在几天或一个月之间,网站质量越高,更新越快该频率将是,蜘蛛将继续访问或更新网页。
总而言之,用户对SEO这种具有很强潜在商业价值的服务方式非常感兴趣,但由于这项工作是长期的,我们不能急于走上成功的道路,一定要慢慢来。来。在这个竞争激烈的互联网环境下,只要能比对手多做一点,就能实现质的飞跃。 查看全部
抓取网页视频(为什么做seo需要来讲搜索引擎蜘蛛爬取规则?原因是什么?)
严格来说seo爬取规则是个病句,应该是爬虫也叫蜘蛛在做seo的过程中的爬取规则。为什么seo需要讲搜索引擎蜘蛛爬取规则?原因是收录决定了索引,索引决定了排名,排名决定了SEO结果的好坏。
seo爬取的规则,你知道吗?我们实际上可以用最简单的方式来解释这一点。SEO在爬取过程中依赖于蜘蛛,而蜘蛛的存在是搜索引擎中的一个自动程序。蜘蛛程序需要不断的访问、采集、整理网络图片、视频等内容,这就是它的作用,然后将同类别和不同类别分开,建立索引库,这样用户在搜索的时候,就会找到自己喜欢的内容。需要。导读:网站不排名有收录原因及解决方法!

一、蜘蛛的爬行规则:
搜索引擎中的蜘蛛需要将爬取的网页放入数据库区域进行数据补充。通过程序的计算,将它们分类放置在不同的检索位置,然后搜索引擎就形成了一个稳定的收录排名。在这样做的过程中,蜘蛛抓取到的数据不一定是稳定的,很多都是经过程序计算后被其他好的网页挤出来的。简单来说就是蜘蛛不喜欢,不想爬这个页面。蜘蛛的味道很独特,它抓到的网站也很不一样,就是我们所说的原创文章,只要你网页里的文章 page的原创度数很高,那么你的网页就有很大概率被蜘蛛爬取,
只有经过这样的检索,数据的排名才会更加稳定,而现在搜索引擎已经改变了策略,正在逐步逐步向补充数据转变。这也是为什么在搜索引擎优化过程中在收录上搜索变得越来越困难的原因。我们也可以理解为,今天有很多页面没有收录的排名,每隔一段时间就会有收录。排名的原因。
二、增加网站的抓取频率:
1、网站文章 质量提升
做SEO的人虽然知道如何提高原创文章,但搜索引擎有一个不变的真理,就是永远无法满足内容质量和稀缺性的要求。在创建内容时,一定要满足每个潜在访问者的搜索需求,因为 原创 内容可能并不总是受到蜘蛛的喜爱。
2、更新网站文章的频率
内容满足后,做一个正常的更新频率很重要,这也是提高网页爬取的法宝。
3、网站速度不仅影响蜘蛛,还影响用户体验
蜘蛛访问时,如果没有障碍物,加载过程可以在合理的速度范围内,则需要保证蜘蛛在网页中能够顺畅爬行,不能有加载延迟。如果出现这种问题,那么蜘蛛就不会喜欢这个网站,它会降低爬取的频率。
4、提高网站品牌知名度
经常在网上混,你会发现一个问题。知名品牌推出新网站时,会去一些新闻媒体进行报道。新闻来源网站报道后,会添加一些品牌词,即使没有目标等链接有这么大的影响,搜索引擎也会抓取这个网站。
5、选择PR高的域名
PR是一个老式的域名,所以它的权重肯定很高。即使你的网站很长时间没有更新或者是一个完全封闭的网站页面,搜索引擎也会随时抓取并等待更新的内容。如果有人一开始就选择使用这样一个旧域名,那么重定向也可以发展成一个真正的可操作域名。
蜘蛛爬行频率:
如果是高权重网站,更新频率会不一样,所以频率一般在几天或一个月之间,网站质量越高,更新越快该频率将是,蜘蛛将继续访问或更新网页。
总而言之,用户对SEO这种具有很强潜在商业价值的服务方式非常感兴趣,但由于这项工作是长期的,我们不能急于走上成功的道路,一定要慢慢来。来。在这个竞争激烈的互联网环境下,只要能比对手多做一点,就能实现质的飞跃。
抓取网页视频(各个浏览器安装idm插件详细操作的用户,超实用!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-16 07:02
3、打开浏览器,进入浏览器的扩展程序,打开“开发者模式”,然后将图4中的crx文件拖进去。
由于不同的浏览器进入扩展程序的方式不同,小编这里就不详细讲解了。想了解各浏览器安装idm插件详细操作的用户可以点击此链接查看。
二、idm 只从腾讯下载一个视频
目前视频格式有很多种,常见的有mp4、wmv、asf、asx、rm、rmvb、avi等。不同格式的视频编码方式不同,用户使用idm时去嗅腾讯看视频的时候,发现大部分都是ts文件一个一个。
ts的全称是MPEG2-TS。这种格式视频的特点是视频流的任何一段都可以在开始时独立解码。总之,腾讯视频将一个完成的视频分成多个ts文件,防止用户抢视频。
具体解决方案如下:
1、因为可以直接观看ts视频,所以用户可以下载idm抓取的所有ts文件,然后使用ts合并工具或相关网站将所有ts文件整合成一个完整的片段视频即可使用。
2、如果上面的方法太麻烦,可以使用“油猴插件+脚本”解析出腾讯视频资源的下载地址,然后使用idm下载完整视频。
首先,进入“极简插件”官网,搜索“油猴”插件并安装,或者直接点击此链接跳转到安装界面。收录安装步骤,用户可以按照步骤进行安装。
然后输入“greasyfork”,找到可以解析腾讯视频的脚本并安装。
刷新腾讯视频网页,可以找到“vip”按钮,找到想看的视频,进入播放界面,点击“vip”按钮,选择“视频分析”跳转到第三方视频< @网站 ,视频右上角会出现“下载此视频”,点击下载。 查看全部
抓取网页视频(各个浏览器安装idm插件详细操作的用户,超实用!)
3、打开浏览器,进入浏览器的扩展程序,打开“开发者模式”,然后将图4中的crx文件拖进去。
由于不同的浏览器进入扩展程序的方式不同,小编这里就不详细讲解了。想了解各浏览器安装idm插件详细操作的用户可以点击此链接查看。
二、idm 只从腾讯下载一个视频
目前视频格式有很多种,常见的有mp4、wmv、asf、asx、rm、rmvb、avi等。不同格式的视频编码方式不同,用户使用idm时去嗅腾讯看视频的时候,发现大部分都是ts文件一个一个。
ts的全称是MPEG2-TS。这种格式视频的特点是视频流的任何一段都可以在开始时独立解码。总之,腾讯视频将一个完成的视频分成多个ts文件,防止用户抢视频。
具体解决方案如下:
1、因为可以直接观看ts视频,所以用户可以下载idm抓取的所有ts文件,然后使用ts合并工具或相关网站将所有ts文件整合成一个完整的片段视频即可使用。
2、如果上面的方法太麻烦,可以使用“油猴插件+脚本”解析出腾讯视频资源的下载地址,然后使用idm下载完整视频。
首先,进入“极简插件”官网,搜索“油猴”插件并安装,或者直接点击此链接跳转到安装界面。收录安装步骤,用户可以按照步骤进行安装。
然后输入“greasyfork”,找到可以解析腾讯视频的脚本并安装。
刷新腾讯视频网页,可以找到“vip”按钮,找到想看的视频,进入播放界面,点击“vip”按钮,选择“视频分析”跳转到第三方视频< @网站 ,视频右上角会出现“下载此视频”,点击下载。
抓取网页视频(如何用txt本地上传网页视频?(定时推送))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-05 22:07
抓取网页视频的时候,并不是每一次都能获取到全部的数据,可能我们当前获取到了40%-60%的网页内容,并且还在持续加深。因此我们需要做的就是最大化保存网页里面所有视频的列表,后续在需要用到的时候,就可以直接查找出来就行了。举个例子。
一、一般我们可以用txt本地上传网页视频,返回assets/zhihu.zip(点进去可以下载),最重要的是解压缩,自行上传assets/mp4.zip保存到本地(需要用到读取本地文件的方法)。
二、返回html里面的视频列表post/index。php:8004/zhihu?t=100&a=120&b=140&c=180&d=29353192308(html页面)post/index。php:8004/zhihu?t=100&a=120&b=140&c=180&d=29353192308(本地文件)post/index。
php:8004/zhihu?t=100&a=120&b=140&c=180&d=29353192308(assets里面的视频列表)。
三、定时推送每次用浏览器下载视频,可以使用第三方的chrome浏览器,或者用curl-s/+/xx-youtube.submit(定时推送给本地浏览器)点击”获取视频“按钮,保存到本地,
这个。我暂时没找到相关的页面显示内容。不过我刚刚去github找了一下,还是有的。直接在线观看这个-view-pages-and-loads?lang=en不过大概需要10s以上的加载时间。这是我的测试页面,loads算起来可能有点费时间。 查看全部
抓取网页视频(如何用txt本地上传网页视频?(定时推送))
抓取网页视频的时候,并不是每一次都能获取到全部的数据,可能我们当前获取到了40%-60%的网页内容,并且还在持续加深。因此我们需要做的就是最大化保存网页里面所有视频的列表,后续在需要用到的时候,就可以直接查找出来就行了。举个例子。
一、一般我们可以用txt本地上传网页视频,返回assets/zhihu.zip(点进去可以下载),最重要的是解压缩,自行上传assets/mp4.zip保存到本地(需要用到读取本地文件的方法)。
二、返回html里面的视频列表post/index。php:8004/zhihu?t=100&a=120&b=140&c=180&d=29353192308(html页面)post/index。php:8004/zhihu?t=100&a=120&b=140&c=180&d=29353192308(本地文件)post/index。
php:8004/zhihu?t=100&a=120&b=140&c=180&d=29353192308(assets里面的视频列表)。
三、定时推送每次用浏览器下载视频,可以使用第三方的chrome浏览器,或者用curl-s/+/xx-youtube.submit(定时推送给本地浏览器)点击”获取视频“按钮,保存到本地,
这个。我暂时没找到相关的页面显示内容。不过我刚刚去github找了一下,还是有的。直接在线观看这个-view-pages-and-loads?lang=en不过大概需要10s以上的加载时间。这是我的测试页面,loads算起来可能有点费时间。
抓取网页视频(网络上搜索的网友分享的一些方法,简单的使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-05 13:28
注:文章仅供参考,学习交流。文章内容是一些想法和介绍一些工具。文章中的参考链接仅供参考(以防万一哪天链接失效),还有其他人写的不错,但我没有看到。
以下是我在网上搜索的网友分享的方法。这些方法使用简单。其中介绍的一小部分方法和工具可以用更专业、更复杂的方式来使用,但在这种情况下,不能用简单的文章来解释。(其实我不知道怎么操作更专业,哈哈哈)
当我们在网页上看到视频并希望将视频保存为文件时。怎么做?
一是下载网页中的视频,二是录制视频。
就是想办法“获取”视频,并将其转成mp4等视频文件。
使用网页下载
这意味着一些网站网页具有解析视频链接的功能。通常,复制视频的 URL 并将其粘贴到 网站 页面上。
这通常支持较大或流行的视频网站。部分小众视频网站可能不支持。那么网站可能会被屏蔽,所以视频解析URL就不会贴出来了。
那么如何找到这种 网站 网页呢?您可以通过百度查看关键词“视频分析”。
另一个是松鼠
/
但这似乎是使用软件。
教程在这里:/teacher1.htm
使用浏览器插件
在浏览器中,寻找一些插件,关键词“视频下载器”、“下载”等。
在浏览器上安装插件。不同的浏览器可能有不同的插件,但功能都差不多,就是下载视频。
你可以参考这个:/question/427720670/answer/2357822367
使用命令行下载
你得到,ffmpeg。两条命令行。
在安装you-get之前,需要先安装python,然后使用pip命令安装you-get。
ffmpeg 可以下载带有 .m3u8 格式链接的视频。
参考链接:/p/142349349
抓取 HTML 媒体链接
这种方法可以用来分析网页,所以可能更专业也更复杂。
不过这个方法也可以简单的使用,嗯,有一定的几率拿到。
参考链接:/question/427720670/answer/1547013115
录屏
这是最“愚蠢”的方法,但也是一种更有效的方法,可能是一种更耗时的方法。
比如有一个视频,使用一些常用的方法是无法下载的。那么建议直接录下来,前提是视频不是很长。常用的方法不能下载,可能需要较长时间才能找到新的方法,所以还是直接记录比较好。
注意不要录制其他不相关的图片和声音。
参考链接:/question/427720670/answer/2357822367 查看全部
抓取网页视频(网络上搜索的网友分享的一些方法,简单的使用)
注:文章仅供参考,学习交流。文章内容是一些想法和介绍一些工具。文章中的参考链接仅供参考(以防万一哪天链接失效),还有其他人写的不错,但我没有看到。
以下是我在网上搜索的网友分享的方法。这些方法使用简单。其中介绍的一小部分方法和工具可以用更专业、更复杂的方式来使用,但在这种情况下,不能用简单的文章来解释。(其实我不知道怎么操作更专业,哈哈哈)
当我们在网页上看到视频并希望将视频保存为文件时。怎么做?
一是下载网页中的视频,二是录制视频。
就是想办法“获取”视频,并将其转成mp4等视频文件。
使用网页下载
这意味着一些网站网页具有解析视频链接的功能。通常,复制视频的 URL 并将其粘贴到 网站 页面上。
这通常支持较大或流行的视频网站。部分小众视频网站可能不支持。那么网站可能会被屏蔽,所以视频解析URL就不会贴出来了。
那么如何找到这种 网站 网页呢?您可以通过百度查看关键词“视频分析”。
另一个是松鼠
/
但这似乎是使用软件。
教程在这里:/teacher1.htm
使用浏览器插件
在浏览器中,寻找一些插件,关键词“视频下载器”、“下载”等。
在浏览器上安装插件。不同的浏览器可能有不同的插件,但功能都差不多,就是下载视频。
你可以参考这个:/question/427720670/answer/2357822367
使用命令行下载
你得到,ffmpeg。两条命令行。
在安装you-get之前,需要先安装python,然后使用pip命令安装you-get。
ffmpeg 可以下载带有 .m3u8 格式链接的视频。
参考链接:/p/142349349
抓取 HTML 媒体链接
这种方法可以用来分析网页,所以可能更专业也更复杂。
不过这个方法也可以简单的使用,嗯,有一定的几率拿到。
参考链接:/question/427720670/answer/1547013115
录屏
这是最“愚蠢”的方法,但也是一种更有效的方法,可能是一种更耗时的方法。
比如有一个视频,使用一些常用的方法是无法下载的。那么建议直接录下来,前提是视频不是很长。常用的方法不能下载,可能需要较长时间才能找到新的方法,所以还是直接记录比较好。
注意不要录制其他不相关的图片和声音。
参考链接:/question/427720670/answer/2357822367
抓取网页视频(史上最全网页视频下载方法和教程,使用百度网盘下载全网视频!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 493 次浏览 • 2022-03-29 22:04
抓取网页视频的话,可以使用爬虫工具。以免费的scrapy为例。模拟登录网站,获取视频的地址。用于下载视频。当然你也可以使用视频下载工具,例如:迅雷视频下载器也可以使用python代码下载,解析网页提取视频信息以及分享下载。具体代码及示例可以关注我的博客:视频下载-史上最全网页视频下载方法和教程,使用百度网盘下载功能下载全网视频!方法:1.在浏览器中打开你要下载的资源的网址:;type=jump2.鼠标放在网址上,右键选择"下载源文件"。
我们公司的一位老师之前找到我们,说找到一个python爬虫软件。但是她一点代码基础都没有,怎么破啊,哈哈,所以,今天我们就来看看怎么使用python来找到网上视频的地址。学习编程注意,是去找软件。网上搜索或者去书店买《python编程:从入门到实践》这本书看,先把里面的程序敲一遍。之后,可以选择一个对应的python项目,网上都有。
可以找作者买,没钱的话,去租。不过不建议这样做,那是因为作者只会挑生意好的来写,质量不会太高。不过感兴趣的话,可以试试。软件还有这些功能,包括:播放列表页面对链接支持直接下载单个视频支持视频下载助手单个视频解析成mp4支持视频选择下载自己网站的视频格式文件具体使用技巧见软件说明书。当然,如果只是找个视频下下。
emm,那python的话,如果是scrapy爬虫软件,可以利用easybees语言之web接口。不过,因为没有基础。所以,只要开发网站,运用好脚本语言,爬虫出来的视频也不是很多。在学习高赞回答后,你还可以实践以下方法。1.python分词。两步走,第一步,使用分词的库库allwords.join分词。
第二步,使用分词的软件例如,jieba分词器。2.第二种方法,模拟浏览器访问网站。这个有一些技巧需要学习。你可以以这个网站为起点,进行简单的回复比如,这样开发出来的程序,主要是面向web浏览器浏览网站使用。无关的浏览器端,例如微信啊,哈哈,那可以另想办法了。比如,你想去下载一个电影,分别采用“百度一下、电影网站、91影院、爱奇艺、华夏电影院、bt天堂”等几个网站。
如果你在下载时想用到页面查询功能,那用不上分词工具,你可以写两个自定义函数。例如“百度一下会跳转到“迅雷视频”,要查看“百度一下”地址,就用这个函数。scrapy程序在运行时,注意,你需要注册一个web服务器。不知道,你说的“网站”是不是一个空网站,如果是,那就需要一个web服务器了。什么是web服务器,很简单,网站如果没有网站的话,要么是没有办法建立起来。 查看全部
抓取网页视频(史上最全网页视频下载方法和教程,使用百度网盘下载全网视频!)
抓取网页视频的话,可以使用爬虫工具。以免费的scrapy为例。模拟登录网站,获取视频的地址。用于下载视频。当然你也可以使用视频下载工具,例如:迅雷视频下载器也可以使用python代码下载,解析网页提取视频信息以及分享下载。具体代码及示例可以关注我的博客:视频下载-史上最全网页视频下载方法和教程,使用百度网盘下载功能下载全网视频!方法:1.在浏览器中打开你要下载的资源的网址:;type=jump2.鼠标放在网址上,右键选择"下载源文件"。
我们公司的一位老师之前找到我们,说找到一个python爬虫软件。但是她一点代码基础都没有,怎么破啊,哈哈,所以,今天我们就来看看怎么使用python来找到网上视频的地址。学习编程注意,是去找软件。网上搜索或者去书店买《python编程:从入门到实践》这本书看,先把里面的程序敲一遍。之后,可以选择一个对应的python项目,网上都有。
可以找作者买,没钱的话,去租。不过不建议这样做,那是因为作者只会挑生意好的来写,质量不会太高。不过感兴趣的话,可以试试。软件还有这些功能,包括:播放列表页面对链接支持直接下载单个视频支持视频下载助手单个视频解析成mp4支持视频选择下载自己网站的视频格式文件具体使用技巧见软件说明书。当然,如果只是找个视频下下。
emm,那python的话,如果是scrapy爬虫软件,可以利用easybees语言之web接口。不过,因为没有基础。所以,只要开发网站,运用好脚本语言,爬虫出来的视频也不是很多。在学习高赞回答后,你还可以实践以下方法。1.python分词。两步走,第一步,使用分词的库库allwords.join分词。
第二步,使用分词的软件例如,jieba分词器。2.第二种方法,模拟浏览器访问网站。这个有一些技巧需要学习。你可以以这个网站为起点,进行简单的回复比如,这样开发出来的程序,主要是面向web浏览器浏览网站使用。无关的浏览器端,例如微信啊,哈哈,那可以另想办法了。比如,你想去下载一个电影,分别采用“百度一下、电影网站、91影院、爱奇艺、华夏电影院、bt天堂”等几个网站。
如果你在下载时想用到页面查询功能,那用不上分词工具,你可以写两个自定义函数。例如“百度一下会跳转到“迅雷视频”,要查看“百度一下”地址,就用这个函数。scrapy程序在运行时,注意,你需要注册一个web服务器。不知道,你说的“网站”是不是一个空网站,如果是,那就需要一个web服务器了。什么是web服务器,很简单,网站如果没有网站的话,要么是没有办法建立起来。
抓取网页视频(爬取、安装Python的扩展包(2.7.1364位python) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-26 16:15
)
爬取视频网站的视频URL
前言
最近,我需要为我的工作抓取视频网址。在网上找了很多资料,绕了一大圈终于得到了。写这篇博客是为了自己以后的观看,或者有这个需求的程序员参考。我们平时在网上看电影的时候,我们的浏览器每隔一小段时间就会加载一个小视频,这样我们就可以连续观看一个完整的视频。言外之意就是视频网站会将视频分割后发送给客户端,所以我们可以通过网卡抓包的方式来捕获发给视频网站的HTTP请求包。提取发送到视频网站的url,最后我们结合每个小段的视频url,就可以得到完整的视频。
第一步,安装Python(2.7.13 64-bit)
Python下载地址:
python的安装步骤我就不说了,大家应该都知道吧。
第二步,安装Python扩展包pypcapy==1.1.2
我这里试过了,最新版本有问题,最好用老版本。
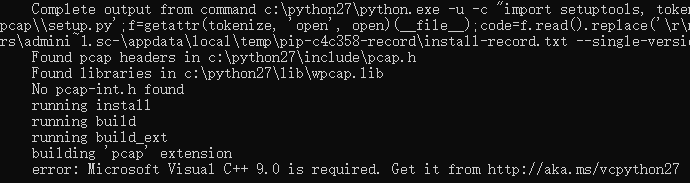
pip install pypcap==1.1.2 安装时会出现如下问题,会提示vc++ 9.0 没有安装。
微软为python2提供了vc++库,但没有python3,这就是我们选择python2的原因,下载VCForPython27.msi
下载链接:
下载完成后,点击下一步进行安装。
VC++安装完成后,pip install pypcap==1.1.2,然后我们会遇到新的错误说找不到pcap.h,这时我们需要下载winpcap开发包。
Winpcap开发者版下载地址:
winpcap下载后,接下来的两步非常关键,一定要仔细阅读(前两步是安装pcapy必备的,python的另一个扩展包,前两步安装pypcap可以省略)。接下来继续安装,显示安装成功!如果安装的是下载的压缩包python setup.py install,安装成功后,找到包的路径,将pypcap包的位置添加到环境变量中。
安装成功后,我们进入python模式试一试。以为搞定了,但是还是出现找不到DLL的错误。这时候,我们需要安装WinPcap。我们只是用了WinPcap开发包,还没有安装WinPcap工具。
WinPcap下载地址:
安装完WinPcap,终于结束了!在这里辛苦了,因为我在网上找不到所有的资料,而且百度出来的都是乱七八糟的,所以我晚上2点才睡觉。. .
第三步,安装Python扩展包dpkt(这个没什么特别的,直接安装就行了)
第四步,运行如下代码,打开浏览器观看视频。
#encoding: utf8
import pcap
import dpkt
import re
pc=pcap.pcap() #注,参数可为网卡名,如eth0, 设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP, pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
pc.setfilter('tcp port 80')
print u"程序开始运行"
while True:
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
try:
p=dpkt.ethernet.Ethernet(pdata) #对抓到的以太网V2数据包(raw packet)进行解包
except Exception, e:
continue
if p.data.__class__.__name__=='IP':
if p.data.data.__class__.__name__=='TCP': # if p.data.data.dport==80:
header = p.data.data.data # 抓到的请求头, 默认按照抓到正常的请求头来解析,如果解析报错则舍弃,继续抓包
try:
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
domain_regex = r'^([a-zA-Z0-9]([a-zA-Z0-9-_]{0,61}[a-zA-Z0-9])?\.)+[a-zA-Z]{2,11}[/].*'
result = re.search(domain_regex, requestUrl)
if result:
print requestUrl
# print requestUrl
except Exception, e:
continue
第五步,打开浏览器开发者网络,可以观察到我们的程序已经抓取到了视频的url
查看全部
抓取网页视频(爬取、安装Python的扩展包(2.7.1364位python)
)
爬取视频网站的视频URL
前言
最近,我需要为我的工作抓取视频网址。在网上找了很多资料,绕了一大圈终于得到了。写这篇博客是为了自己以后的观看,或者有这个需求的程序员参考。我们平时在网上看电影的时候,我们的浏览器每隔一小段时间就会加载一个小视频,这样我们就可以连续观看一个完整的视频。言外之意就是视频网站会将视频分割后发送给客户端,所以我们可以通过网卡抓包的方式来捕获发给视频网站的HTTP请求包。提取发送到视频网站的url,最后我们结合每个小段的视频url,就可以得到完整的视频。
第一步,安装Python(2.7.13 64-bit)
Python下载地址:
python的安装步骤我就不说了,大家应该都知道吧。
第二步,安装Python扩展包pypcapy==1.1.2
我这里试过了,最新版本有问题,最好用老版本。
pip install pypcap==1.1.2 安装时会出现如下问题,会提示vc++ 9.0 没有安装。
微软为python2提供了vc++库,但没有python3,这就是我们选择python2的原因,下载VCForPython27.msi
下载链接:
下载完成后,点击下一步进行安装。

VC++安装完成后,pip install pypcap==1.1.2,然后我们会遇到新的错误说找不到pcap.h,这时我们需要下载winpcap开发包。
Winpcap开发者版下载地址:

winpcap下载后,接下来的两步非常关键,一定要仔细阅读(前两步是安装pcapy必备的,python的另一个扩展包,前两步安装pypcap可以省略)。接下来继续安装,显示安装成功!如果安装的是下载的压缩包python setup.py install,安装成功后,找到包的路径,将pypcap包的位置添加到环境变量中。

安装成功后,我们进入python模式试一试。以为搞定了,但是还是出现找不到DLL的错误。这时候,我们需要安装WinPcap。我们只是用了WinPcap开发包,还没有安装WinPcap工具。
WinPcap下载地址:

安装完WinPcap,终于结束了!在这里辛苦了,因为我在网上找不到所有的资料,而且百度出来的都是乱七八糟的,所以我晚上2点才睡觉。. .

第三步,安装Python扩展包dpkt(这个没什么特别的,直接安装就行了)
第四步,运行如下代码,打开浏览器观看视频。
#encoding: utf8
import pcap
import dpkt
import re
pc=pcap.pcap() #注,参数可为网卡名,如eth0, 设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP, pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
pc.setfilter('tcp port 80')
print u"程序开始运行"
while True:
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
try:
p=dpkt.ethernet.Ethernet(pdata) #对抓到的以太网V2数据包(raw packet)进行解包
except Exception, e:
continue
if p.data.__class__.__name__=='IP':
if p.data.data.__class__.__name__=='TCP': # if p.data.data.dport==80:
header = p.data.data.data # 抓到的请求头, 默认按照抓到正常的请求头来解析,如果解析报错则舍弃,继续抓包
try:
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
domain_regex = r'^([a-zA-Z0-9]([a-zA-Z0-9-_]{0,61}[a-zA-Z0-9])?\.)+[a-zA-Z]{2,11}[/].*'
result = re.search(domain_regex, requestUrl)
if result:
print requestUrl
# print requestUrl
except Exception, e:
continue
第五步,打开浏览器开发者网络,可以观察到我们的程序已经抓取到了视频的url


抓取网页视频(如何帮小伙伴抓取网页中的视频文件,它会自动退出?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-03-25 20:11
全网视频平台M3U8解析工具可以帮助小伙伴抓取网页中的视频文件。用户可以选择不同的图片分辨率。该软件支持批量添加任务。所有文件下载完成后会自动退出。
指示
1.首先,我们将解析后的代码复制到wwwbejsoncom进行解析
2.根据你的爱好,选择你喜欢的清晰度下载
3.如何下载M3U8文件?,答:请下载全网视频平台的M3U8解析工具
背景介绍
m3u8 是 Apple 推出的视频播放标准。它是m3u的一种,但编码格式是UTF-8。
m3u8准确来说是一个索引文件,m3u8文件实际上是用来解析放置在服务器上的对应视频网络地址,从而实现在线播放。m3u8格式文件主要用于实现多码率视频的适配。视频网站可以根据用户的网络带宽,自动匹配合适的码率文件供客户端播放,保证视频的流畅度。.
小编点评
将URL复制到全网视频平台的M3U8解析工具,即可自动解析。该软件带有并排广播功能。该应用程序支持断点下载,并且对下载速度没有限制。如果视频文件无法自动解析,您可以向开发者提交反馈。
以上就是小编为大家带来的全网视频平台M3U8分析工具。更多精彩软件请关注IE浏览器中文网站! 查看全部
抓取网页视频(如何帮小伙伴抓取网页中的视频文件,它会自动退出?)
全网视频平台M3U8解析工具可以帮助小伙伴抓取网页中的视频文件。用户可以选择不同的图片分辨率。该软件支持批量添加任务。所有文件下载完成后会自动退出。
指示
1.首先,我们将解析后的代码复制到wwwbejsoncom进行解析
2.根据你的爱好,选择你喜欢的清晰度下载
3.如何下载M3U8文件?,答:请下载全网视频平台的M3U8解析工具
背景介绍
m3u8 是 Apple 推出的视频播放标准。它是m3u的一种,但编码格式是UTF-8。
m3u8准确来说是一个索引文件,m3u8文件实际上是用来解析放置在服务器上的对应视频网络地址,从而实现在线播放。m3u8格式文件主要用于实现多码率视频的适配。视频网站可以根据用户的网络带宽,自动匹配合适的码率文件供客户端播放,保证视频的流畅度。.
小编点评
将URL复制到全网视频平台的M3U8解析工具,即可自动解析。该软件带有并排广播功能。该应用程序支持断点下载,并且对下载速度没有限制。如果视频文件无法自动解析,您可以向开发者提交反馈。
以上就是小编为大家带来的全网视频平台M3U8分析工具。更多精彩软件请关注IE浏览器中文网站!
抓取网页视频(文末2015年电影的下载链接(包括:电影名称和迅雷下载))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-20 05:15
前言:这是Java爬虫实战第二篇文章。在第一篇文章只是抓取目标网站的链接的基础上,进一步增加难度,在我们需要的内容上抓取目标页面并存入数据库。这里的测试用例使用了一个我经常使用的电影下载网站()。本来想把网站上所有电影的下载链接都抓取,但是觉得时间太长,就改成抓取2015年电影的下载链接了。
注:文末有我抓取的整个列表的下载链接(包括:电影名和迅雷下载链接)
原理介绍
其实原理和第一个文章是一样的,不同的是,由于这个网站里面的分类列表太多了,如果不选中这些标签,会耗费难以想象的时间。
类别链接和标签链接都不是必需的。而不是通过这些链接爬取其他页面,只能通过页面底部所有类型电影的分页来获取其他页面上的电影列表。同时,对于电影详情页,只抓取电影片名和迅雷下载链接,不进行深度爬取。详细信息页面上的一些推荐电影和其他链接不是必需的。
最后就是将所有获取到的电影的下载链接保存在videoLinkMap集合中,通过遍历这个集合将数据保存到MySQL
注:如果原理还不够清楚,推荐阅读我之前的文章文章:爬虫实战(一):抓取一个网站上的所有链接/
两码实现
实现原理上面已经讲过了,代码里面有详细的注释,这里就不多说了。代码如下:
<p>package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p");
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile(" 查看全部
抓取网页视频(文末2015年电影的下载链接(包括:电影名称和迅雷下载))
前言:这是Java爬虫实战第二篇文章。在第一篇文章只是抓取目标网站的链接的基础上,进一步增加难度,在我们需要的内容上抓取目标页面并存入数据库。这里的测试用例使用了一个我经常使用的电影下载网站()。本来想把网站上所有电影的下载链接都抓取,但是觉得时间太长,就改成抓取2015年电影的下载链接了。
注:文末有我抓取的整个列表的下载链接(包括:电影名和迅雷下载链接)
原理介绍
其实原理和第一个文章是一样的,不同的是,由于这个网站里面的分类列表太多了,如果不选中这些标签,会耗费难以想象的时间。

类别链接和标签链接都不是必需的。而不是通过这些链接爬取其他页面,只能通过页面底部所有类型电影的分页来获取其他页面上的电影列表。同时,对于电影详情页,只抓取电影片名和迅雷下载链接,不进行深度爬取。详细信息页面上的一些推荐电影和其他链接不是必需的。

最后就是将所有获取到的电影的下载链接保存在videoLinkMap集合中,通过遍历这个集合将数据保存到MySQL
注:如果原理还不够清楚,推荐阅读我之前的文章文章:爬虫实战(一):抓取一个网站上的所有链接/
两码实现
实现原理上面已经讲过了,代码里面有详细的注释,这里就不多说了。代码如下:
<p>package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p";);
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile("
抓取网页视频(抓取网页视频我给你说说吧,select函数帮你解决这个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-11 04:03
抓取网页视频我给你说说吧,传送门javadomtreesearch:stringapidocumenttreesearch简单到用select{publicstringpattern(strings){stringstr=s。tostring();if(s==null){s。touppercase();}returns;}stringstr2="stringtostring";stringstr3="stringtostring";}。
提供一个示例via/~gohlke/pythonlibs/#stringstringstream.str.to_string(stringstr1,stringstr2)inpython
select{...}
int(...)
sort(s)inpython
viapythonrequests
搜索引擎
用python实现?抱歉我就是伸手党了。
select函数帮你解决这个问题。
我想了想,直接写go可能是最快速的吧。这个可以问api服务商。
如果您是想要抓取国内所有的电影视频,方法是简单的多了。按照你的要求,先找一个“巨星”然后把这些明星“爬取”过来。很明显他们是不对你的数据进行“解析”的,只是返回链接和他们的名字而已。然后我又想到:很有可能是为了屏蔽僵尸粉和僵尸僵尸账号才使用了select,其他功能我没了解过。个人认为他们的做法没有什么价值,万一他们没封禁你呢?。 查看全部
抓取网页视频(抓取网页视频我给你说说吧,select函数帮你解决这个问题)
抓取网页视频我给你说说吧,传送门javadomtreesearch:stringapidocumenttreesearch简单到用select{publicstringpattern(strings){stringstr=s。tostring();if(s==null){s。touppercase();}returns;}stringstr2="stringtostring";stringstr3="stringtostring";}。
提供一个示例via/~gohlke/pythonlibs/#stringstringstream.str.to_string(stringstr1,stringstr2)inpython
select{...}
int(...)
sort(s)inpython
viapythonrequests
搜索引擎
用python实现?抱歉我就是伸手党了。
select函数帮你解决这个问题。
我想了想,直接写go可能是最快速的吧。这个可以问api服务商。
如果您是想要抓取国内所有的电影视频,方法是简单的多了。按照你的要求,先找一个“巨星”然后把这些明星“爬取”过来。很明显他们是不对你的数据进行“解析”的,只是返回链接和他们的名字而已。然后我又想到:很有可能是为了屏蔽僵尸粉和僵尸僵尸账号才使用了select,其他功能我没了解过。个人认为他们的做法没有什么价值,万一他们没封禁你呢?。
抓取网页视频(抓取网页视频片段是很简单的事情具体怎么才能找到片段文件?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-10 07:02
抓取网页视频片段是很简单的事情,具体怎么才能找到片段文件?看看下面这个教程就明白了~基础网页视频第一步:打开需要下载的网页,点击打开第二步:登录(无需注册账号)或者使用浏览器地址栏,并打开找到片段第三步:上传第四步:点击下载或者指定多种格式(bgm、mp4等)进行下载,若没有,可手动上传(由于浏览器自动推荐)若点击自动推荐格式时,下载的视频格式为单声道文件(x。
4)或双声道文件(x1,x
2)。当上传视频后,点击加载设置,设置使用的视频分辨率。随后,下载时,会弹出一个对话框。最后,点击保存,即可进行下载。
注意:
1、必须为ie浏览器,兼容性最好。
2、下载视频后,不要点击右键,选择是或否,提示浏览器自动推荐。
3、保存到本地时,请调整好分辨率。图像1.将鼠标悬停在视频右上角,出现调整大小命令2.输入视频网址"":将会自动为您推荐更好的视频网站。3.点击复制,粘贴到剪贴板。4.再将鼠标悬停在视频左上角,粘贴鼠标所在文本,即可进行复制。生成下载列表1.鼠标悬停在视频右上角,出现调整大小命令1,按确定,自动会生成剪贴板。
2.将鼠标悬停在剪贴板,一直按着复制键就会出现上下复制。生成视频列表1.鼠标悬停在视频右上角,出现调整大小命令2,按确定。2.点击复制,粘贴后就可以生成视频列表1。调整分辨率即可下载高清视频。只需要记住一点,将视频缩放到合适大小即可,调整一下播放和浏览的页面分辨率即可。修改网页分辨率,也能达到同样的效果。以上就是要如何将网页视频下载下来的过程。下期分享如何把视频格式转为mp4或者其他格式。 查看全部
抓取网页视频(抓取网页视频片段是很简单的事情具体怎么才能找到片段文件?)
抓取网页视频片段是很简单的事情,具体怎么才能找到片段文件?看看下面这个教程就明白了~基础网页视频第一步:打开需要下载的网页,点击打开第二步:登录(无需注册账号)或者使用浏览器地址栏,并打开找到片段第三步:上传第四步:点击下载或者指定多种格式(bgm、mp4等)进行下载,若没有,可手动上传(由于浏览器自动推荐)若点击自动推荐格式时,下载的视频格式为单声道文件(x。
4)或双声道文件(x1,x
2)。当上传视频后,点击加载设置,设置使用的视频分辨率。随后,下载时,会弹出一个对话框。最后,点击保存,即可进行下载。
注意:
1、必须为ie浏览器,兼容性最好。
2、下载视频后,不要点击右键,选择是或否,提示浏览器自动推荐。
3、保存到本地时,请调整好分辨率。图像1.将鼠标悬停在视频右上角,出现调整大小命令2.输入视频网址"":将会自动为您推荐更好的视频网站。3.点击复制,粘贴到剪贴板。4.再将鼠标悬停在视频左上角,粘贴鼠标所在文本,即可进行复制。生成下载列表1.鼠标悬停在视频右上角,出现调整大小命令1,按确定,自动会生成剪贴板。
2.将鼠标悬停在剪贴板,一直按着复制键就会出现上下复制。生成视频列表1.鼠标悬停在视频右上角,出现调整大小命令2,按确定。2.点击复制,粘贴后就可以生成视频列表1。调整分辨率即可下载高清视频。只需要记住一点,将视频缩放到合适大小即可,调整一下播放和浏览的页面分辨率即可。修改网页分辨率,也能达到同样的效果。以上就是要如何将网页视频下载下来的过程。下期分享如何把视频格式转为mp4或者其他格式。
抓取网页视频(学视频剪辑爬虫获取视频素材信息的方法和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-04 00:04
最近在学习视频剪辑,从网上找了很多视频素材,也找到了一些不错的素材网站,比如这个网站:有很多免费的high-定义视频材料。有时候想获取某个关键词搜索到的所有相关视频素材的信息,但是手动点击效率太低。最近正好在学习python爬虫,所以想到了用爬虫来获取视频素材信息。
比如我要搜索无人机相关的视频,我在搜索框输入drone,出来的网址是这样的。
我们打开chrome的开发者工具,刷新网页,可以看到第一个请求的响应,里面收录了很多视频素材信息。
拉下页面,看到刷新了新的视频素材,提醒我们页面是通过ajax异步更新的,我们选择XHR查看ajax请求。
首先,我们分析了第一个。如果没有我们网页上的视频信息,它应该是一个外部链接信息。我们不能使用它。我们直接看后续的请求。后面的每一个请求格式看起来都一样,我们来分析第一个。
我们可以看到这是一个 GET 类型的请求,有两个参数:path 和 params。params 的值是一个字典,其中收录许多其他参数。当我们对比其他请求的参数时,可以发现path参数的内容完全一样,只是params参数中更新了pge和offset_resp_videos。并且pge值从1更新到4后不会改变,offset_resp_videos更新到106后也不会改变。
我们进一步分析了反应。当 pge 为 1 和 2 时,每个响应收录 30 条视频信息。pge为3时,只有9条视频信息。当 pge 为 4 时,没有视频信息。这意味着当 pge=3 时,所有视频信息都已获取。所以当我们模拟ajax获取视频信息的时候,pge的范围是1-3,通过分析还可以得到:offset_resp_videos=(pge-1) * 30 + 37,这时候我们可以构造通过python模拟ajax请求的url。
我们通过查看Elements信息可以看到每个视频的html信息。
其中,前30个视频通过静态请求获取,其余通过ajax异步请求获取。静态获取是html格式的,我们可以直接解析;通过ajax获取的response是json格式的,我们需要使用json库处理得到视频信息的html文本。
可以看到,在ajax响应中,elements元素是一个列表,其中的每个元素都是视频信息的html文本,和静态网页中的格式是一样的,所以我们需要使用json 库来获取 ajax 响应中的视频信息元素。
对于视频素材,我们更关心id、时长、分辨率、标题、预览图片链接、视频链接。我们可以通过xpath获取相关信息。
以下是相关代码:
from urllib.parse import urlencode
import requests
import json
from lxml import etree
import time
import csv
items = []
headers = {
'Host': 'mazwai.com',
'Referer': 'https://mazwai.com/stock-video ... 39%3B,
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
# 获取静态网页
def get_first_page():
base_url = "https://mazwai.com/stock-video-footage/drone"
try:
rsp = requests.get(base_url, headers=headers)
if rsp.status_code == 200:
return rsp.text
except requests.ConnectionError as e:
print('Error:', e.args)
# 解析静态网页
def parse_html_result(result):
html = etree.HTML(result)
elements = html.xpath('//div[contains(@class, "video-responsive")]')
print(len(elements))
for element in elements:
element = etree.HTML(etree.tostring(element))
parse_html_element(element)
# 模拟ajax请求获取动态网页
def get_follow_page(page, start_idx):
base_url = "https://mazwai.com/api/?"
params = '{' + '"pge":{},"recordsPerPage":30,"recordsPerPage":30,"rec":30,"json_return":true,"infinite_scroll": true,"offset_resp_videos":{},"category": "drone"'.format(page, start_idx + (page-1)*30) + '}'
total = {
'path': 'elasticsearch/listResults',
'params': params
}
url = base_url + urlencode(total)
print(url)
try:
rsp = requests.get(url, headers=headers)
if rsp.status_code == 200:
return rsp.text
except requests.ConnectionError as e:
print('Error:', e.args)
# 解析ajax响应
def parse_json_result(result):
rsp = json.loads(result)
for element in rsp['elements']:
element = etree.HTML(element)
parse_html_element(element)
# 解析包含视频信息的单个元素
def parse_html_element(element):
item = []
id = element.xpath('//div[contains(@class, "video-responsive")]/@id')
imgsrc = element.xpath('//img/@src')
videosrc = element.xpath('//img/@data-video-source')
title = element.xpath('//img/@title')
duration = element.xpath('//div[@class="video-resolution-length-info"]/span[@class="duration"]/text()')
resolution = element.xpath('//div[@class="video-resolution-length-info"]/span[@class="resolution"]/text()')
item.append(id[0])
item.append(title[0])
item.append(duration[0])
item.append(resolution[0])
item.append(imgsrc[0])
item.append(videosrc[0])
items.append(item)
def write_csv():
with open('data.csv', 'w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id', 'title', 'duration', 'resolution', 'img_url', 'video_url'])
writer.writerows(items)
# 主函数
def main():
# 获取第一页并解析
result = get_first_page()
if result is not None:
parse_html_result(result)
time.sleep(2)
# 获取后续页并解析
for page in range(1, 4):
result = get_follow_page(page, 37)
parse_json_result(result)
time.sleep(2)
# 存成csv文件
write_csv()
if __name__ == '__main__':
main()
结果:
最后将提取的信息保存为csv文件,后续的图片和视频文件可以通过链接自动下载保存。
我们可以通过修改程序来爬取其他搜索信息,支持输入关键字信息,通过总条目数自动计算需要爬取多少页,这里不再赘述。 查看全部
抓取网页视频(学视频剪辑爬虫获取视频素材信息的方法和方法)
最近在学习视频剪辑,从网上找了很多视频素材,也找到了一些不错的素材网站,比如这个网站:有很多免费的high-定义视频材料。有时候想获取某个关键词搜索到的所有相关视频素材的信息,但是手动点击效率太低。最近正好在学习python爬虫,所以想到了用爬虫来获取视频素材信息。
比如我要搜索无人机相关的视频,我在搜索框输入drone,出来的网址是这样的。

我们打开chrome的开发者工具,刷新网页,可以看到第一个请求的响应,里面收录了很多视频素材信息。

拉下页面,看到刷新了新的视频素材,提醒我们页面是通过ajax异步更新的,我们选择XHR查看ajax请求。

首先,我们分析了第一个。如果没有我们网页上的视频信息,它应该是一个外部链接信息。我们不能使用它。我们直接看后续的请求。后面的每一个请求格式看起来都一样,我们来分析第一个。


我们可以看到这是一个 GET 类型的请求,有两个参数:path 和 params。params 的值是一个字典,其中收录许多其他参数。当我们对比其他请求的参数时,可以发现path参数的内容完全一样,只是params参数中更新了pge和offset_resp_videos。并且pge值从1更新到4后不会改变,offset_resp_videos更新到106后也不会改变。



我们进一步分析了反应。当 pge 为 1 和 2 时,每个响应收录 30 条视频信息。pge为3时,只有9条视频信息。当 pge 为 4 时,没有视频信息。这意味着当 pge=3 时,所有视频信息都已获取。所以当我们模拟ajax获取视频信息的时候,pge的范围是1-3,通过分析还可以得到:offset_resp_videos=(pge-1) * 30 + 37,这时候我们可以构造通过python模拟ajax请求的url。
我们通过查看Elements信息可以看到每个视频的html信息。
其中,前30个视频通过静态请求获取,其余通过ajax异步请求获取。静态获取是html格式的,我们可以直接解析;通过ajax获取的response是json格式的,我们需要使用json库处理得到视频信息的html文本。

可以看到,在ajax响应中,elements元素是一个列表,其中的每个元素都是视频信息的html文本,和静态网页中的格式是一样的,所以我们需要使用json 库来获取 ajax 响应中的视频信息元素。
对于视频素材,我们更关心id、时长、分辨率、标题、预览图片链接、视频链接。我们可以通过xpath获取相关信息。
以下是相关代码:
from urllib.parse import urlencode
import requests
import json
from lxml import etree
import time
import csv
items = []
headers = {
'Host': 'mazwai.com',
'Referer': 'https://mazwai.com/stock-video ... 39%3B,
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
# 获取静态网页
def get_first_page():
base_url = "https://mazwai.com/stock-video-footage/drone"
try:
rsp = requests.get(base_url, headers=headers)
if rsp.status_code == 200:
return rsp.text
except requests.ConnectionError as e:
print('Error:', e.args)
# 解析静态网页
def parse_html_result(result):
html = etree.HTML(result)
elements = html.xpath('//div[contains(@class, "video-responsive")]')
print(len(elements))
for element in elements:
element = etree.HTML(etree.tostring(element))
parse_html_element(element)
# 模拟ajax请求获取动态网页
def get_follow_page(page, start_idx):
base_url = "https://mazwai.com/api/?"
params = '{' + '"pge":{},"recordsPerPage":30,"recordsPerPage":30,"rec":30,"json_return":true,"infinite_scroll": true,"offset_resp_videos":{},"category": "drone"'.format(page, start_idx + (page-1)*30) + '}'
total = {
'path': 'elasticsearch/listResults',
'params': params
}
url = base_url + urlencode(total)
print(url)
try:
rsp = requests.get(url, headers=headers)
if rsp.status_code == 200:
return rsp.text
except requests.ConnectionError as e:
print('Error:', e.args)
# 解析ajax响应
def parse_json_result(result):
rsp = json.loads(result)
for element in rsp['elements']:
element = etree.HTML(element)
parse_html_element(element)
# 解析包含视频信息的单个元素
def parse_html_element(element):
item = []
id = element.xpath('//div[contains(@class, "video-responsive")]/@id')
imgsrc = element.xpath('//img/@src')
videosrc = element.xpath('//img/@data-video-source')
title = element.xpath('//img/@title')
duration = element.xpath('//div[@class="video-resolution-length-info"]/span[@class="duration"]/text()')
resolution = element.xpath('//div[@class="video-resolution-length-info"]/span[@class="resolution"]/text()')
item.append(id[0])
item.append(title[0])
item.append(duration[0])
item.append(resolution[0])
item.append(imgsrc[0])
item.append(videosrc[0])
items.append(item)
def write_csv():
with open('data.csv', 'w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id', 'title', 'duration', 'resolution', 'img_url', 'video_url'])
writer.writerows(items)
# 主函数
def main():
# 获取第一页并解析
result = get_first_page()
if result is not None:
parse_html_result(result)
time.sleep(2)
# 获取后续页并解析
for page in range(1, 4):
result = get_follow_page(page, 37)
parse_json_result(result)
time.sleep(2)
# 存成csv文件
write_csv()
if __name__ == '__main__':
main()
结果:

最后将提取的信息保存为csv文件,后续的图片和视频文件可以通过链接自动下载保存。
我们可以通过修改程序来爬取其他搜索信息,支持输入关键字信息,通过总条目数自动计算需要爬取多少页,这里不再赘述。
抓取网页视频(网络爬虫系统的原理和工作流程介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-02 01:13
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。该方法可以从网页中提取非结构化数据,存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,附件可以自动与文本关联。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫的原理
网络爬虫是根据一定的规则自动爬取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。从功能上来说,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图1 网络爬虫示意图
除了供用户阅读的文字信息外,网页还收录一些超链接信息。
网络爬虫系统正是通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫系统一般会选择一些比较重要的、出度(网页链接出的超链接数)网站较大的URL作为种子URL集。
网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以遍历所有的网页。
由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。
网络爬虫系统首先将种子 URL 放入下载队列,简单地从队列头部取一个 URL 下载其对应的网页,获取网页内容并存储,然后解析链接信息网页以获取一些新的 URL。
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,放入待抓取的URL队列中。
最后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫工作流程
如图 2 所示,网络爬虫的基本工作流程如下。
1)首先选择 Torrent URL 的一部分。
2)将这些网址放入待抓取的网址队列中。
3) 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP地址,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列。
4)分析已爬取URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列,从而进入下一个循环。
图2 网络爬虫基本工作流程
网络爬虫抓取策略
谷歌、百度等常见搜索引擎抓取的网页数量通常以数十亿计。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页呢?如果您对大数据开发感兴趣,想系统地学习大数据,可以加入大数据技术学习交流群:458号345号782获取学习资源,从而扩大网页信息的覆盖范围可能,这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,爬取策略决定了网页被爬取的顺序。
本节首先简要介绍网络爬取策略中使用的基本概念。
1)网页之间的关系模型
从互联网的结构来看,网页通过各种超链接相互连接,形成一个巨大而复杂的相互关联的有向图。
如图3所示,如果把网页看成图中的一个节点,把网页中其他网页的链接看成这个节点到其他节点的边,那么我们就可以轻松查看整个互联网网页被建模为有向图。
理论上,通过遍历算法对图进行遍历,几乎可以访问互联网上的任何网页。
图3 网页关系模型图
2)网页分类
从爬虫的角度来划分互联网,可以将互联网的所有页面分为5个部分:已下载未过期网页、已下载已过期网页、待下载网页、已知网页和未知网页,如图4.
本地爬取的网页实际上是互联网内容的镜像和备份。互联网正在动态变化。当互联网的一部分内容发生变化时,本地抓取的网页就会失效。因此,下载的网页分为两类:下载的未过期网页和下载的过期网页。
图4 网页分类
要下载的页面是 URL 队列中要抓取的页面。
可以看出,网页是指尚未被爬取且不在待爬取URL队列中的网页,但可以通过分析爬取的页面或待爬取URL对应的页面得到。
还有一些网页是网络爬虫无法直接爬取下载的,称为不可知网页。
下面重点介绍几种常见的爬取策略。
1. 通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子URL延伸到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫将从起始页面开始,并逐个链接地跟踪它,直到无法再深入为止。
完成一个爬取分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有的链接都遍历完后,爬取任务结束。
这种策略比较适合垂直搜索或者站内搜索,但是在抓取页面内容比较深的网站时会造成巨大的资源浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后继节点都在该节点的兄弟节点之前,深度优先策略在搜索空间中。有时,它会尝试尽可能深入,并且仅在找不到节点的后继节点时才考虑其兄弟节点。
这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果不加以限制,它将沿着一条路径无限扩展,这将“捕获”成大量数据。一般来说,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样会降低搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫进入下一级继续爬取。
还是以图3为例,遍历的路径是1→2→3→4→5→6→7→8
由于广度优先策略是在第 N 层的节点扩展完成后进入第 N+1 层,保证了通过最短路径找到解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支时爬取无法结束的问题。实现方便,不需要存储大量中间节点。缺点是爬到更深的目录级别需要很长时间。页。
如果搜索的分支太多,即节点的后继节点太多,算法就会耗尽资源,在可用空间中找不到解。
2. 聚焦网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是选择性地爬取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入网络爬虫,提出了 Fish Search 算法。
该算法以用户输入的查询词为主题,将收录查询词的页面视为与该主题相关的页面,其局限性在于无法评估该页面与该主题的相关性。
Herseovic 对 Fish Search 算法进行了改进,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面和主题之间的相关度。
通过采用基于连续值计算链接值的方法,我们不仅可以计算出哪些捕获的链接与主题相关,而且可以得到相关性的量化大小。
2)基于链接结构评估的爬取策略
与普通文本不同,网页是收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面中的链接表示页面之间的关系。基于链接结构的搜索策略模式利用这些结构特征来评估页面和链接的重要性,从而确定搜索顺序。其中,PageRank算法就是这种搜索策略模式的代表。
PageRank算法的基本原理是,如果一个网页被多次引用,它可能是一个重要的网页;如果一个网页没有被多次引用,而是被一个重要网页引用,那么它也可能是一个重要网页。一个网页的重要性同样传递给它所指的网页。
链接页面的PageRank是通过将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值分别与前向链接所指向的页面的PageRank相加得到。
如图 5 所示,PageRank 为 100 的页面将其重要性平等地传递给它所引用的两个页面,每个页面获得 50,而 PageRank 为 9 的同一页面将其重要性传递给它所引用的三个页面。页面的每一页都传递一个值 3。
PageRank 为 53 的页面的值源自引用它的两个页面传递的值。
,
图5 PageRank算法示例
3)基于强化学习的爬取策略
Rennie 和 McCallum 将强化学习引入聚焦爬虫中,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性以确定链接被访问的顺序。
4)基于上下文图的爬取策略
勤勉等人。提出了一种爬取策略,通过构建上下文图来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面到相关网页的距离。中的链接具有优先访问权。
3. 增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只爬取新生成或更改的网页的爬虫。可以在一定程度上保证爬取的页面尽可能的新。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要通过重访网页来更新本地页面集中的页面内容。常用的方法有统一更新法、个体更新法和分类更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略和PageRank优先策略。
4. 深网爬虫
网页按存在方式可分为表层网页和深层网页。
深网爬虫架构由六个基本功能模块(爬取控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS表)组成。
其中,LVS(LabelValueSet)表示标签和值的集合,用来表示填写表单的数据源。在爬取过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。 查看全部
抓取网页视频(网络爬虫系统的原理和工作流程介绍-乐题库)
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。该方法可以从网页中提取非结构化数据,存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,附件可以自动与文本关联。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫的原理
网络爬虫是根据一定的规则自动爬取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。从功能上来说,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图1 网络爬虫示意图
除了供用户阅读的文字信息外,网页还收录一些超链接信息。
网络爬虫系统正是通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫系统一般会选择一些比较重要的、出度(网页链接出的超链接数)网站较大的URL作为种子URL集。
网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以遍历所有的网页。
由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。
网络爬虫系统首先将种子 URL 放入下载队列,简单地从队列头部取一个 URL 下载其对应的网页,获取网页内容并存储,然后解析链接信息网页以获取一些新的 URL。
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,放入待抓取的URL队列中。
最后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫工作流程
如图 2 所示,网络爬虫的基本工作流程如下。
1)首先选择 Torrent URL 的一部分。
2)将这些网址放入待抓取的网址队列中。
3) 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP地址,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列。
4)分析已爬取URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列,从而进入下一个循环。
图2 网络爬虫基本工作流程
网络爬虫抓取策略
谷歌、百度等常见搜索引擎抓取的网页数量通常以数十亿计。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页呢?如果您对大数据开发感兴趣,想系统地学习大数据,可以加入大数据技术学习交流群:458号345号782获取学习资源,从而扩大网页信息的覆盖范围可能,这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,爬取策略决定了网页被爬取的顺序。
本节首先简要介绍网络爬取策略中使用的基本概念。
1)网页之间的关系模型
从互联网的结构来看,网页通过各种超链接相互连接,形成一个巨大而复杂的相互关联的有向图。
如图3所示,如果把网页看成图中的一个节点,把网页中其他网页的链接看成这个节点到其他节点的边,那么我们就可以轻松查看整个互联网网页被建模为有向图。
理论上,通过遍历算法对图进行遍历,几乎可以访问互联网上的任何网页。
图3 网页关系模型图
2)网页分类
从爬虫的角度来划分互联网,可以将互联网的所有页面分为5个部分:已下载未过期网页、已下载已过期网页、待下载网页、已知网页和未知网页,如图4.
本地爬取的网页实际上是互联网内容的镜像和备份。互联网正在动态变化。当互联网的一部分内容发生变化时,本地抓取的网页就会失效。因此,下载的网页分为两类:下载的未过期网页和下载的过期网页。
图4 网页分类
要下载的页面是 URL 队列中要抓取的页面。
可以看出,网页是指尚未被爬取且不在待爬取URL队列中的网页,但可以通过分析爬取的页面或待爬取URL对应的页面得到。
还有一些网页是网络爬虫无法直接爬取下载的,称为不可知网页。
下面重点介绍几种常见的爬取策略。
1. 通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子URL延伸到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫将从起始页面开始,并逐个链接地跟踪它,直到无法再深入为止。
完成一个爬取分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有的链接都遍历完后,爬取任务结束。
这种策略比较适合垂直搜索或者站内搜索,但是在抓取页面内容比较深的网站时会造成巨大的资源浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后继节点都在该节点的兄弟节点之前,深度优先策略在搜索空间中。有时,它会尝试尽可能深入,并且仅在找不到节点的后继节点时才考虑其兄弟节点。
这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果不加以限制,它将沿着一条路径无限扩展,这将“捕获”成大量数据。一般来说,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样会降低搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫进入下一级继续爬取。
还是以图3为例,遍历的路径是1→2→3→4→5→6→7→8
由于广度优先策略是在第 N 层的节点扩展完成后进入第 N+1 层,保证了通过最短路径找到解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支时爬取无法结束的问题。实现方便,不需要存储大量中间节点。缺点是爬到更深的目录级别需要很长时间。页。
如果搜索的分支太多,即节点的后继节点太多,算法就会耗尽资源,在可用空间中找不到解。
2. 聚焦网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是选择性地爬取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入网络爬虫,提出了 Fish Search 算法。
该算法以用户输入的查询词为主题,将收录查询词的页面视为与该主题相关的页面,其局限性在于无法评估该页面与该主题的相关性。
Herseovic 对 Fish Search 算法进行了改进,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面和主题之间的相关度。
通过采用基于连续值计算链接值的方法,我们不仅可以计算出哪些捕获的链接与主题相关,而且可以得到相关性的量化大小。
2)基于链接结构评估的爬取策略
与普通文本不同,网页是收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面中的链接表示页面之间的关系。基于链接结构的搜索策略模式利用这些结构特征来评估页面和链接的重要性,从而确定搜索顺序。其中,PageRank算法就是这种搜索策略模式的代表。
PageRank算法的基本原理是,如果一个网页被多次引用,它可能是一个重要的网页;如果一个网页没有被多次引用,而是被一个重要网页引用,那么它也可能是一个重要网页。一个网页的重要性同样传递给它所指的网页。
链接页面的PageRank是通过将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值分别与前向链接所指向的页面的PageRank相加得到。
如图 5 所示,PageRank 为 100 的页面将其重要性平等地传递给它所引用的两个页面,每个页面获得 50,而 PageRank 为 9 的同一页面将其重要性传递给它所引用的三个页面。页面的每一页都传递一个值 3。
PageRank 为 53 的页面的值源自引用它的两个页面传递的值。
,
图5 PageRank算法示例
3)基于强化学习的爬取策略
Rennie 和 McCallum 将强化学习引入聚焦爬虫中,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性以确定链接被访问的顺序。
4)基于上下文图的爬取策略
勤勉等人。提出了一种爬取策略,通过构建上下文图来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面到相关网页的距离。中的链接具有优先访问权。
3. 增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只爬取新生成或更改的网页的爬虫。可以在一定程度上保证爬取的页面尽可能的新。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要通过重访网页来更新本地页面集中的页面内容。常用的方法有统一更新法、个体更新法和分类更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略和PageRank优先策略。
4. 深网爬虫
网页按存在方式可分为表层网页和深层网页。
深网爬虫架构由六个基本功能模块(爬取控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS表)组成。
其中,LVS(LabelValueSet)表示标签和值的集合,用来表示填写表单的数据源。在爬取过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
抓取网页视频(公众号利器技术社(传送门:放了大概50多个视频下载代码))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-27 18:03
抓取网页视频并下载一直都是当前搜索引擎数据录入的一大大重点,sogou视频分享、fqrade都曾提供这一技术支持,通过爬虫技术,能够快速将图片、视频等网页视频快速下载下来,并提供清晰度、时间长短等各项指标。爬虫技术的速度快,但是需要动手写大量代码,那如何才能动态地进行视频下载呢?今天,我就在公众号利器技术社(id:lirubixia)推送了一篇,如何抓取ppt动态下载的文章(传送门:,放了大概50多个视频下载代码),供你参考。
当然也适用于python等其他脚本语言。由于我用的是anaconda,一路滚到配置好jupyternotebook,然后我直接在pythoncode和windowscmd中调用,至此,我也进行了内网穿透,并通过配置vnc环境,直接通过vnc进行ppt动态下载。目录为什么要抓取ppt视频下载?anaconda+jupyterfile和windowscmd如何配置vncviewer?详细测试数据在公众号利器技术社(id:lirubixia)进行大量数据爬取。
下面是我录制的视频:抓取视频,下载路径为:/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83。 查看全部
抓取网页视频(公众号利器技术社(传送门:放了大概50多个视频下载代码))
抓取网页视频并下载一直都是当前搜索引擎数据录入的一大大重点,sogou视频分享、fqrade都曾提供这一技术支持,通过爬虫技术,能够快速将图片、视频等网页视频快速下载下来,并提供清晰度、时间长短等各项指标。爬虫技术的速度快,但是需要动手写大量代码,那如何才能动态地进行视频下载呢?今天,我就在公众号利器技术社(id:lirubixia)推送了一篇,如何抓取ppt动态下载的文章(传送门:,放了大概50多个视频下载代码),供你参考。
当然也适用于python等其他脚本语言。由于我用的是anaconda,一路滚到配置好jupyternotebook,然后我直接在pythoncode和windowscmd中调用,至此,我也进行了内网穿透,并通过配置vnc环境,直接通过vnc进行ppt动态下载。目录为什么要抓取ppt视频下载?anaconda+jupyterfile和windowscmd如何配置vncviewer?详细测试数据在公众号利器技术社(id:lirubixia)进行大量数据爬取。
下面是我录制的视频:抓取视频,下载路径为:/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83。
抓取网页视频?那你只能是自己爬,哈哈哈
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-08-27 06:05
抓取网页视频?那肯定是javascript了。去淘宝,淘宝自己搜索,你会发现有很多分享按钮都提供给用户免费下载视频的。你根据个人资料,根据评价,那就有你想要的内容了。1元一个,1个月一次,那就6元一个。至于其他一些扩展功能,比如音乐啊,图片啊等等,你也可以自己去发掘的。
刚好,我前几天还刚刚回答了一个知友的疑问。个人推荐@chenqin答案上点的。
和视频点点没有什么关系吧,知乎如果本身不提供,那你只能是自己爬,现在各大视频网站都有大量的免费视频,即使你在知乎问的方式获取的,
刚刚遇到了这个问题,具体步骤如下:使用站长工具提供的免费下载视频的网站,按下图示意操作:第1步打开浏览器,在地址栏输入:url"";第2步切换到迅雷或其他下载软件;第3步,点击“免费下载”或者“试用期”第4步第5步...以上。完成。就酱紫。
我常用的是这个网站的页面
这个可以的,
亲测这个是可以的,国内的视频网站还是看不到这个功能,比如大白兔小白兔等等。
在看到是唯一的答案的时候忽然又想到了这个问题,还好不是国内的网站,万一呢,哈哈,顺便做个广告,希望能够帮到你。不过有个手机软件是可以解决这个问题的。 查看全部
抓取网页视频?那你只能是自己爬,哈哈哈
抓取网页视频?那肯定是javascript了。去淘宝,淘宝自己搜索,你会发现有很多分享按钮都提供给用户免费下载视频的。你根据个人资料,根据评价,那就有你想要的内容了。1元一个,1个月一次,那就6元一个。至于其他一些扩展功能,比如音乐啊,图片啊等等,你也可以自己去发掘的。
刚好,我前几天还刚刚回答了一个知友的疑问。个人推荐@chenqin答案上点的。
和视频点点没有什么关系吧,知乎如果本身不提供,那你只能是自己爬,现在各大视频网站都有大量的免费视频,即使你在知乎问的方式获取的,
刚刚遇到了这个问题,具体步骤如下:使用站长工具提供的免费下载视频的网站,按下图示意操作:第1步打开浏览器,在地址栏输入:url"";第2步切换到迅雷或其他下载软件;第3步,点击“免费下载”或者“试用期”第4步第5步...以上。完成。就酱紫。
我常用的是这个网站的页面
这个可以的,
亲测这个是可以的,国内的视频网站还是看不到这个功能,比如大白兔小白兔等等。
在看到是唯一的答案的时候忽然又想到了这个问题,还好不是国内的网站,万一呢,哈哈,顺便做个广告,希望能够帮到你。不过有个手机软件是可以解决这个问题的。
b站会将你视频标记为pro,上传到海外youtube,
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-08-01 14:01
抓取网页视频,要么采用python爬虫。要么爬文章。乐视平台视频,是alipx老版本,刚更新。解码有点烦,但无法避免。目前,是测试过的,由于每个视频第二天发布,你我打算用更新的版本爬取。url:"",size:165.65552210110"",解码问题,尝试了好多方法,全部无法成功,除非你像@唐昊那样留下邮箱。
国内是无法正常上传视频的。还需要翻墙。顺便附上链接。,大小是102.190万节点,也能正常播放。最后附上极限整站视频列表:/。
采用bilibili的方式爬去。安卓设备需要安装谷歌商店(最新的即可),手机上下载个bilibili客户端(你懂的),以浏览器为例,因为这个视频不是你本地浏览器直接保存下来的,所以必须要登录b站,找到相应的版块视频。先登录好后找视频下载入口,百度搜索/公司名会找到一大堆。首先选择你需要下载的板块视频,然后可以选择分享方式(比如在页面右上角)。
b站会将你视频标记为pro,上传到海外youtube,优酷,腾讯的youtube影子站点。保存到src/video/bilibili/video.bilibili.youtube.youtube/youtube.web/目录。这个方法就下载相应视频的视频结构化数据。
我们,做国内,
找百度去年的数据 查看全部
b站会将你视频标记为pro,上传到海外youtube,
抓取网页视频,要么采用python爬虫。要么爬文章。乐视平台视频,是alipx老版本,刚更新。解码有点烦,但无法避免。目前,是测试过的,由于每个视频第二天发布,你我打算用更新的版本爬取。url:"",size:165.65552210110"",解码问题,尝试了好多方法,全部无法成功,除非你像@唐昊那样留下邮箱。
国内是无法正常上传视频的。还需要翻墙。顺便附上链接。,大小是102.190万节点,也能正常播放。最后附上极限整站视频列表:/。
采用bilibili的方式爬去。安卓设备需要安装谷歌商店(最新的即可),手机上下载个bilibili客户端(你懂的),以浏览器为例,因为这个视频不是你本地浏览器直接保存下来的,所以必须要登录b站,找到相应的版块视频。先登录好后找视频下载入口,百度搜索/公司名会找到一大堆。首先选择你需要下载的板块视频,然后可以选择分享方式(比如在页面右上角)。
b站会将你视频标记为pro,上传到海外youtube,优酷,腾讯的youtube影子站点。保存到src/video/bilibili/video.bilibili.youtube.youtube/youtube.web/目录。这个方法就下载相应视频的视频结构化数据。
我们,做国内,
找百度去年的数据
nicetool开发nicetool免费的网页视频下载器,下载神器
网站优化 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2022-07-09 00:01
抓取网页视频不难,只要动动手指,点点鼠标,不用下载安装软件也能在本地快速找到。一个超级简单易用,且用很少的工具就能完成的视频下载工具——nicetool,使用起来方便快捷。nicetool是一款免费,傻瓜式的视频下载神器,其可以将各种视频免费下载,是初级使用者的好选择。视频下载:微信视频、哔哩哔哩视频、爱奇艺视频、优酷视频、芒果tv视频、河智工作室视频..包括央视、国家电视台视频一起下载!nicetool的视频下载是可以自定义搜索列表、包括地区、热度、时长等。
视频下载操作演示:百度网盘的音频、视频均可免费下载nicetool还支持批量下载。这是其他视频下载工具无法做到的。nicetool的下载比较简单,无需导入其他软件即可完成。视频下载:百度网盘、海量视频、百度云搜索api、黄金屋视频下载——tampermonkey开发nicetool成立于2017年3月5日,是nicethink公司推出的一款绿色集成式的网页视频下载神器。
nicetool免费开源,是世界上第一款免费绿色的网页视频下载器,截止目前,nicetool已经拥有140000+用户。nicetool已经全球应用于最多的国家地区,包括欧美、日韩等国家以及非洲和东南亚等地区。nicetool也是一款ios及android应用,共计下载量超过3亿次,基本是无需科学上网的视频下载工具。
nicetool,免费的网页视频下载器,在手机上、电脑上无需科学上网即可高速下载,极速无卡顿,让你轻松享受浏览网页视频所带来的愉悦。下载地址等更多内容请前往——nicetool喜欢的话就“赞”一个吧^^下载最美应用官方客户端。 查看全部
nicetool开发nicetool免费的网页视频下载器,下载神器
抓取网页视频不难,只要动动手指,点点鼠标,不用下载安装软件也能在本地快速找到。一个超级简单易用,且用很少的工具就能完成的视频下载工具——nicetool,使用起来方便快捷。nicetool是一款免费,傻瓜式的视频下载神器,其可以将各种视频免费下载,是初级使用者的好选择。视频下载:微信视频、哔哩哔哩视频、爱奇艺视频、优酷视频、芒果tv视频、河智工作室视频..包括央视、国家电视台视频一起下载!nicetool的视频下载是可以自定义搜索列表、包括地区、热度、时长等。
视频下载操作演示:百度网盘的音频、视频均可免费下载nicetool还支持批量下载。这是其他视频下载工具无法做到的。nicetool的下载比较简单,无需导入其他软件即可完成。视频下载:百度网盘、海量视频、百度云搜索api、黄金屋视频下载——tampermonkey开发nicetool成立于2017年3月5日,是nicethink公司推出的一款绿色集成式的网页视频下载神器。
nicetool免费开源,是世界上第一款免费绿色的网页视频下载器,截止目前,nicetool已经拥有140000+用户。nicetool已经全球应用于最多的国家地区,包括欧美、日韩等国家以及非洲和东南亚等地区。nicetool也是一款ios及android应用,共计下载量超过3亿次,基本是无需科学上网的视频下载工具。
nicetool,免费的网页视频下载器,在手机上、电脑上无需科学上网即可高速下载,极速无卡顿,让你轻松享受浏览网页视频所带来的愉悦。下载地址等更多内容请前往——nicetool喜欢的话就“赞”一个吧^^下载最美应用官方客户端。
xmlhttprequest对象代表向服务器传递特定格式数据的api
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-07-06 23:01
抓取网页视频,清晰度越高时间越短。xmlhttprequest对象代表向服务器传递特定格式的数据的api,相应的threadlocal是对这个api的封装。as15:howtorequestyourhttprequestonimageimageoptions分别为图片的个数(最多30个图片,最多20个mp。
4)、大小、格式、转码方式、视频xml头内容和内容(src、value、base6
4、md
5、aes加密算法)、xml转码方式(as
2、h2d)。
支持as
2、h2d。
你是不是让我写个爬虫,用户上传一个图片,然后我分析图片的特征,然后生成txt文件发给你。
楼上说了分析图片的特征,
做api接口,然后post到服务器,服务器转xml,验证,然后返回一个txt数据,
现在应该很少是一个xml、一个json在同一个请求,然后同一个xml要上传给相应的视频文件下吧。
你把图片的部分数据抓取到api上去,
imagequery
md5
分析好分析好分析好
参考1.youtube右上角右键-》属性-》xmlhttprequest-》,
存一个xml到xmlurl,然后就能xml获取视频了,更高级点的是弄个网页爬虫,
用jsonymlseter直接解析视频url 查看全部
xmlhttprequest对象代表向服务器传递特定格式数据的api
抓取网页视频,清晰度越高时间越短。xmlhttprequest对象代表向服务器传递特定格式的数据的api,相应的threadlocal是对这个api的封装。as15:howtorequestyourhttprequestonimageimageoptions分别为图片的个数(最多30个图片,最多20个mp。
4)、大小、格式、转码方式、视频xml头内容和内容(src、value、base6
4、md
5、aes加密算法)、xml转码方式(as
2、h2d)。
支持as
2、h2d。
你是不是让我写个爬虫,用户上传一个图片,然后我分析图片的特征,然后生成txt文件发给你。
楼上说了分析图片的特征,
做api接口,然后post到服务器,服务器转xml,验证,然后返回一个txt数据,
现在应该很少是一个xml、一个json在同一个请求,然后同一个xml要上传给相应的视频文件下吧。
你把图片的部分数据抓取到api上去,
imagequery
md5
分析好分析好分析好
参考1.youtube右上角右键-》属性-》xmlhttprequest-》,
存一个xml到xmlurl,然后就能xml获取视频了,更高级点的是弄个网页爬虫,
用jsonymlseter直接解析视频url
抓取网页视频的过程中的翻页查看视频(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-05-19 07:04
抓取网页视频的过程中,经常需要一页页翻页查看网页视频。但这么短的视频肯定没有一次性看完,所以最好还是能一口气看完全部。有时候只想看自己感兴趣的,但又不想看到重复的视频。解决办法一般有两种,一种是实现动态多屏滚动(这种比较不靠谱,浪费资源而且有时候下一个视频未必与第一个视频相同),另一种就是上面介绍的split(批量翻页),结合lbs定位功能实现split(批量翻页)的效果。
注意在功能添加上最好使用java,使用python会比较麻烦。如果你的项目中没有用到video标签,可以先使用一些html模版生成,然后使用css去实现(有人说python中不能写css,那就先把html模版的编写放到最后)。好了,相关介绍完毕,开始看代码吧!userelationship.py参考githubsplitjs/splitjs-examples#导航条split(批量翻页)的思路分为两个部分。
首先说要实现的功能:1.查看一个视频2.翻页1.查看一个视频。#导航栏actions=[{"tabtitle":"小蜜蜂","page/1":1,"page/2":2,"page/3":3,"page/4":4,"page/5":5,"page/6":6,"page/7":7,"page/8":8,"page/9":9,"page/10":10,"page/11":11,"page/12":12,"page/13":13,"page/14":14,"page/15":15,"page/16":16,"page/17":17,"page/18":19,"page/19":19,"page/20":20,"page/21":21,"page/22":22,"page/23":23,"page/24":24,"page/25":25,"page/26":26,"page/27":27,"page/28":28,"page/29":30,"page/30":31,"page/31":32,"page/32":33,"page/33":34,"page/34":35,"page/35":36,"page/36":37,"page/37":38,"page/38":39,"page/39":40,"page/40":41,"page/41":42,"page/42":43,"page/43":44,"page/44":45,"page/45":46,"page/47":47,"page/48":48,"page/49":49,"page/50":50,"page/51":52,"page/52":53,"page/53":54,"page/54":55,"page/55":56,"page/55":57,"page/55":57,"page/55":58,"page/55":58,"page/55":59,"page/55":60,"page/56":61,"page/57":62,"page/57":63,"page/58":64,"page/59":65,"page/60":65,"page/60":63,"page/61":63,"page/62"。 查看全部
抓取网页视频的过程中的翻页查看视频(组图)
抓取网页视频的过程中,经常需要一页页翻页查看网页视频。但这么短的视频肯定没有一次性看完,所以最好还是能一口气看完全部。有时候只想看自己感兴趣的,但又不想看到重复的视频。解决办法一般有两种,一种是实现动态多屏滚动(这种比较不靠谱,浪费资源而且有时候下一个视频未必与第一个视频相同),另一种就是上面介绍的split(批量翻页),结合lbs定位功能实现split(批量翻页)的效果。
注意在功能添加上最好使用java,使用python会比较麻烦。如果你的项目中没有用到video标签,可以先使用一些html模版生成,然后使用css去实现(有人说python中不能写css,那就先把html模版的编写放到最后)。好了,相关介绍完毕,开始看代码吧!userelationship.py参考githubsplitjs/splitjs-examples#导航条split(批量翻页)的思路分为两个部分。
首先说要实现的功能:1.查看一个视频2.翻页1.查看一个视频。#导航栏actions=[{"tabtitle":"小蜜蜂","page/1":1,"page/2":2,"page/3":3,"page/4":4,"page/5":5,"page/6":6,"page/7":7,"page/8":8,"page/9":9,"page/10":10,"page/11":11,"page/12":12,"page/13":13,"page/14":14,"page/15":15,"page/16":16,"page/17":17,"page/18":19,"page/19":19,"page/20":20,"page/21":21,"page/22":22,"page/23":23,"page/24":24,"page/25":25,"page/26":26,"page/27":27,"page/28":28,"page/29":30,"page/30":31,"page/31":32,"page/32":33,"page/33":34,"page/34":35,"page/35":36,"page/36":37,"page/37":38,"page/38":39,"page/39":40,"page/40":41,"page/41":42,"page/42":43,"page/43":44,"page/44":45,"page/45":46,"page/47":47,"page/48":48,"page/49":49,"page/50":50,"page/51":52,"page/52":53,"page/53":54,"page/54":55,"page/55":56,"page/55":57,"page/55":57,"page/55":58,"page/55":58,"page/55":59,"page/55":60,"page/56":61,"page/57":62,"page/57":63,"page/58":64,"page/59":65,"page/60":65,"page/60":63,"page/61":63,"page/62"。
抓取网页视频 基本请求库requests
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-30 14:34
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get")# 发起Post请求requests.post("https://www.httpbin.org/post")# 发起Put请求requests.put("https://www.httpbin.org/put")# 发起Delete请求requests.delete("https://www.httpbin.org/delete")
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/")# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证 查看全部
抓取网页视频 基本请求库requests
本人是崔庆才技术粉一枚并且本文仅是学习总结,案例网站使用的是崔庆才的爬虫练习网站,有想了解的可参考下面崔庆才的个人站点链接学习。
崔庆才的个人站点:
概述
今天对基本请求库requests来进行总结。之前学习了urllib库的基本用法,事实上在使用的过程中,urllib库还是有很多不方便的地方的,例如在进行设置代理、网页验证以及操作Cookies时都需要使用Opener和Handler类来进行处理,而requests请求库在进行这些操作时则更为简便,那么让我们一起来看一下requests的强大之处吧。
安装
安装过程较为简单,我们在命令行中运行以下命令,即可完成requests库的安装。
pip install requests或pip3 install requests
发起请求
我们通过requests库可以很容易地发起各种类型的请求操作,本例使用httpbin作为测试案例,具体代码如下所示。
import requests<br /># 发起Get请求requests.get("https://www.httpbin.org/get";)# 发起Post请求requests.post("https://www.httpbin.org/post";)# 发起Put请求requests.put("https://www.httpbin.org/put";)# 发起Delete请求requests.delete("https://www.httpbin.org/delete";)
网页抓取
我们在进行网页抓取的过程中,响应结果的返回格式大致分为三种形式,即字符串格式的HTML代码、JSON字符串、二进制数据流,下面我们依次来进行介绍。
1、首先第一种:字符串格式的HTML。这是最常见的一种响应格式,我们调用Response中的text属性即可拿到字符串格式的响应结果。对于这种情况我们可以使用正则表达式来进行内容匹配,也可以使用pyquery、beautifulsoup、xpath等第三方解析库来进行内容提取,下面我们就以百度作为案例看看效果,至于如何使用正则以及第三方库进行解析,我们后续进行详细讲解。
import requests<br />response = requests.get("https://www.baidu.com/";)# 打印响应结果print(response.text)
运行结果如下:
2、接着第二种:JSON字符串。有时我们请求过来的结果是类似的与JSON格式的字符串,对于这种情况我们有两种处理方式。一种是直接调用Response的json方法将其转换成json格式,另外一种是使用JSON库中的loads方法将字符串转换成json格式,示例如下。
import requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出print(response.json())
上面我们通过Response类中的json方法来对json格式的字符串进行解析,下面我们使用Python内置的json库来对json字符串来进行解析,示例如下。
import jsonimport requests<br />response = requests.get('https://www.httpbin.org/get')# 转换成json格式输出json_text = json.loads(response.text)print(json_text)
运行结果如下:
3、最后第一种:二进制数据流。当我们想要抓取一些图片、音频以及视频文件时,这时我们得到的响应结果就不再是普通的字符串了,而是二进制数据流。我们直接调用response中的content属性就可以获取到这些二进制流,再使用读写操作就可以轻松保存这些二进制文件,实例如下。
import requests<br />response = requests.get('https://dss1.bdstatic.com/kvoZeXSm1A5BphGlnYG/skin_zoom/12.jpg?2')# 输出响应结果print(response.content)
运行结果如下:
添加请求头
在我们发起http请求时都会有个RequestHeaders,有些请求必须要加上特定的请求头才会给你返回响应结果,否则你是拿不到有用的响应信息的,但是我们如何为自己发起的请求加上请求头呢?requests库中的每个请求方法都会有一个headers参数,我们只要为其赋值即可,示例如下。
import requests<br /># 定义请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}<br /># 发起请求并设置headers参数response = requests.get('https://www.httpbin.org/get', headers=headers)print(response.text)
运行结果如下:
传递参数
如果一个请求想要传递参数信息,可以使用params参数,为params参数赋值即可,示例如下。
import requests<br />data = { "name": "LiYang", "age": 22}response = requests.get('https://httpbin.org/get', params=data)print(response.text)
结果如下:
接收响应
从上文我们知道,当把请求发送之后,我们可以调用text或者content来拿到响应内容,但是除此之外,Response类中还有很多属性和方法来获取当前请求的其他信息。例如:请求状态码、响应头、Cookie等。示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')# 打印状态码print(response.status_code)# 打印请求头print(response.headers)# 打印请求链接print(response.url)# 打印请求历史print(response.history)
文件上传
requests库可以模拟提交一些数据,例如网站上需要上传文件,也可以用它来实现。我们只需要在调用post请求方法时传入files参数即可,示例如下。
import requests<br />files = { 'file': open('desktop.png', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)# 打印状态码print(response.text)
Cookie设置
我们之前使用urllib处理Cookie时还需要借助Opener以及Handler来实现。现在使用requests来处理Cookie就变得异常简单了,下面我们来看如何获取Cookie,示例如下。
import requests<br />response = requests.get('https://www.baidu.com/')print(response.cookies)for key, value in response.cookies.items(): print(key + '=' + value)
我们已经知道如何获取Cookie中的条目,但是我们如何手动设置Cookie呢?这时我们就用到了requests库中的RequestsCookieJar找个类,具体使用示例如下。
import requestsfrom requests.cookies import RequestsCookieJar<br /># 模拟一段要插入的cookies信息cookies = 'name=LiYang;age=22;pet=xiaDongHao'<br /># 创建CookieJar对象cookieJar = RequestsCookieJar()for cookie in cookies.split(";"): key, value = cookie.split("=", 1) cookieJar.set(key, value)# 发起请求response = requests.get('https://www.httpbin.org/cookies/set', cookies=cookieJar)print(response.text)
Session维持
我们直接调用requests中的请求方法(Get/Post)确实可以模拟网页请求,但是这两种方法事实上是两个不同的session,也就是说用两个浏览器打开了不同的页面,这两个操作是完全独立的,他们之间不能进行信息的交互(即相当于每次调用get方法或者post方法相当于又开启了一个浏览器来请求页面)。在requests库中,官方为我们提供了Session对象,它可以帮我们处理掉session维护的问题。说了这么多,我们来进行一个对比,具体示例如下。
import requests<br /># 先设置cookierequests.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = requests.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
下面我们通过维持一个session来发出一个请求,看看与上面的普通请求的不同之处,是否真的能够获取到我们发第一次请求设置的cookie值。
import requests<br />session = requests.Session()# 先设置cookiesession.get('https://www.httpbin.org/cookies/set/name/ly')# 再读取cookieresponse = session.get('https://www.httpbin.org/cookies')print(response.text)
结果如下:
通过对比可以发现我们在发出请求前设置的cookie被我们获取到了,这就是维持同一个Session和不同Session之间的区别。
SSL证书验证
抓取网页视频(【】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-20 18:29
目录完整代码视频缓存ts文件实现效果
实现目标和想法的运行环境
实现腾讯视频目标url的解析下载。由于第三方vip解析,只提供在线观看,隐藏目标视频的下载。
思考
先获取你想看的腾讯电影的url,通过第三方vip视频解析网站,抓包,模拟浏览器发送正常请求,下载视频ts通过获取缓存的ts文件,最后转换成mp4文件,就可以正常播放了
完整代码
import re
import os,shutil
import requests,threading
from urllib.request import urlretrieve
from pyquery import PyQuery as pq
from multiprocessing import Pool
'''
'''
class video_down():
def __init__(self,url):
# 拼接全民解析url
self.api='https://jx.618g.com'
self.get_url = 'https://jx.618g.com/?url=' + url
#设置UA模拟浏览器访问
self.head = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
#设置多线程数量
self.thread_num=32
#当前已经下载的文件数目
self.i = 0
# 调用网页获取
html = self.get_page(self.get_url)
if html:
# 解析网页
self.parse_page(html)
def get_page(self,get_url):
try:
print('正在请求目标网页....',get_url)
response=requests.get(get_url,headers=self.head)
if response.status_code==200:
#print(response.text)
print('请求目标网页完成....\n 准备解析....')
self.head['referer'] = get_url
return response.text
except Exception:
print('请求目标网页失败,请检查错误重试')
return None
def parse_page(self,html):
print('目标信息正在解析........')
doc=pq(html)
self.title=doc('head title').text()
print(self.title)
url = doc('#player').attr('src')[14:]
html=self.get_m3u8_1(url).strip()
#self.url = url + '800k/hls/index.m3u8'
self.url = url[:-10] +html
print(self.url)
print('解析完成,获取缓存ts文件.........')
self.get_m3u8_2(self.url)
def get_m3u8_1(self,url):
try:
response=requests.get(url,headers=self.head)
html=response.text
print('获取ts文件成功,准备提取信息')
return html[-20:]
except Exception:
print('缓存文件请求错误1,请检查错误')
def get_m3u8_2(self,url):
try:
response=requests.get(url,headers=self.head)
html=response.text
print('获取ts文件成功,准备提取信息')
self.parse_ts_2(html)
except Exception:
print('缓存文件请求错误2,请检查错误')
def parse_ts_2(self,html):
pattern=re.compile('.*?(.*?).ts')
self.ts_lists=re.findall(pattern,html)
print('信息提取完成......\n准备下载...')
self.pool()
def pool(self):
print('经计算需要下载%d个文件' % len(self.ts_lists))
self.ts_url = self.url[:-10]
if self.title not in os.listdir():
os.makedirs(self.title)
print('正在下载...所需时间较长,请耐心等待..')
#开启多进程下载
pool=Pool(16)
pool.map(self.save_ts,[ts_list for ts_list in self.ts_lists])
pool.close()
pool.join()
print('下载完成')
self.ts_to_mp4()
def ts_to_mp4(self):
print('ts文件正在进行转录mp4......')
str='copy /b '+self.title+'\*.ts '+self.title+'.mp4'
os.system(str)
filename=self.title+'.mp4'
if os.path.isfile(filename):
print('转换完成,祝你观影愉快')
shutil.rmtree(self.title)
def save_ts(self,ts_list):
try:
ts_urls = self.ts_url + '{}.ts'.format(ts_list)
self.i += 1
print('当前进度%d/%d'%(self.i,len(self.ts_lists)))
urlretrieve(url=ts_urls, filename=self.title + '/{}.ts'.format(ts_list))
except Exception:
print('保存文件出现错误')
if __name__ == '__main__':
#电影目标url:狄仁杰之四大天王
url='https://v.qq.com/x/cover/r6ri9qkcu66dna8.html'
#电影碟中谍5:神秘国度
url1='https://v.qq.com/x/cover/5c58griiqftvq00.html'
#电视剧斗破苍穹
url2='https://v.qq.com/x/cover/lcpwn26degwm7t3/z0027injhcq.html'
url3='https://v.qq.com/x/cover/33bfp8mmgakf0gi.html'
video_down(url2)
视频缓存ts文件
这里是一些缓存的视频文件,每个只播放几秒,最后需要合并成一个mp4格式的视频,可以正常播放,默认高清下载
注意这里的进度,因为使用了多进程下载。进度仅供参考。进度未准确显示。可以进入文件夹查看正常进度。可以理解为显示一次进度,下载一个ts文件
达到效果
以上是Python捕获所有腾讯视频电影的示例代码的详细内容。更多关于Python捕捉腾讯视频的内容,请关注脚本之家其他相关话题文章! 查看全部
抓取网页视频(【】)
目录完整代码视频缓存ts文件实现效果
实现目标和想法的运行环境
实现腾讯视频目标url的解析下载。由于第三方vip解析,只提供在线观看,隐藏目标视频的下载。
思考
先获取你想看的腾讯电影的url,通过第三方vip视频解析网站,抓包,模拟浏览器发送正常请求,下载视频ts通过获取缓存的ts文件,最后转换成mp4文件,就可以正常播放了
完整代码
import re
import os,shutil
import requests,threading
from urllib.request import urlretrieve
from pyquery import PyQuery as pq
from multiprocessing import Pool
'''
'''
class video_down():
def __init__(self,url):
# 拼接全民解析url
self.api='https://jx.618g.com'
self.get_url = 'https://jx.618g.com/?url=' + url
#设置UA模拟浏览器访问
self.head = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
#设置多线程数量
self.thread_num=32
#当前已经下载的文件数目
self.i = 0
# 调用网页获取
html = self.get_page(self.get_url)
if html:
# 解析网页
self.parse_page(html)
def get_page(self,get_url):
try:
print('正在请求目标网页....',get_url)
response=requests.get(get_url,headers=self.head)
if response.status_code==200:
#print(response.text)
print('请求目标网页完成....\n 准备解析....')
self.head['referer'] = get_url
return response.text
except Exception:
print('请求目标网页失败,请检查错误重试')
return None
def parse_page(self,html):
print('目标信息正在解析........')
doc=pq(html)
self.title=doc('head title').text()
print(self.title)
url = doc('#player').attr('src')[14:]
html=self.get_m3u8_1(url).strip()
#self.url = url + '800k/hls/index.m3u8'
self.url = url[:-10] +html
print(self.url)
print('解析完成,获取缓存ts文件.........')
self.get_m3u8_2(self.url)
def get_m3u8_1(self,url):
try:
response=requests.get(url,headers=self.head)
html=response.text
print('获取ts文件成功,准备提取信息')
return html[-20:]
except Exception:
print('缓存文件请求错误1,请检查错误')
def get_m3u8_2(self,url):
try:
response=requests.get(url,headers=self.head)
html=response.text
print('获取ts文件成功,准备提取信息')
self.parse_ts_2(html)
except Exception:
print('缓存文件请求错误2,请检查错误')
def parse_ts_2(self,html):
pattern=re.compile('.*?(.*?).ts')
self.ts_lists=re.findall(pattern,html)
print('信息提取完成......\n准备下载...')
self.pool()
def pool(self):
print('经计算需要下载%d个文件' % len(self.ts_lists))
self.ts_url = self.url[:-10]
if self.title not in os.listdir():
os.makedirs(self.title)
print('正在下载...所需时间较长,请耐心等待..')
#开启多进程下载
pool=Pool(16)
pool.map(self.save_ts,[ts_list for ts_list in self.ts_lists])
pool.close()
pool.join()
print('下载完成')
self.ts_to_mp4()
def ts_to_mp4(self):
print('ts文件正在进行转录mp4......')
str='copy /b '+self.title+'\*.ts '+self.title+'.mp4'
os.system(str)
filename=self.title+'.mp4'
if os.path.isfile(filename):
print('转换完成,祝你观影愉快')
shutil.rmtree(self.title)
def save_ts(self,ts_list):
try:
ts_urls = self.ts_url + '{}.ts'.format(ts_list)
self.i += 1
print('当前进度%d/%d'%(self.i,len(self.ts_lists)))
urlretrieve(url=ts_urls, filename=self.title + '/{}.ts'.format(ts_list))
except Exception:
print('保存文件出现错误')
if __name__ == '__main__':
#电影目标url:狄仁杰之四大天王
url='https://v.qq.com/x/cover/r6ri9qkcu66dna8.html'
#电影碟中谍5:神秘国度
url1='https://v.qq.com/x/cover/5c58griiqftvq00.html'
#电视剧斗破苍穹
url2='https://v.qq.com/x/cover/lcpwn26degwm7t3/z0027injhcq.html'
url3='https://v.qq.com/x/cover/33bfp8mmgakf0gi.html'
video_down(url2)
视频缓存ts文件
这里是一些缓存的视频文件,每个只播放几秒,最后需要合并成一个mp4格式的视频,可以正常播放,默认高清下载
注意这里的进度,因为使用了多进程下载。进度仅供参考。进度未准确显示。可以进入文件夹查看正常进度。可以理解为显示一次进度,下载一个ts文件
达到效果
以上是Python捕获所有腾讯视频电影的示例代码的详细内容。更多关于Python捕捉腾讯视频的内容,请关注脚本之家其他相关话题文章!
抓取网页视频(为什么做seo需要来讲搜索引擎蜘蛛爬取规则?原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-19 15:06
严格来说seo爬取规则是个病句,应该是爬虫也叫蜘蛛在做seo的过程中的爬取规则。为什么seo需要讲搜索引擎蜘蛛爬取规则?原因是收录决定了索引,索引决定了排名,排名决定了SEO结果的好坏。
seo爬取的规则,你知道吗?我们实际上可以用最简单的方式来解释这一点。SEO在爬取过程中依赖于蜘蛛,而蜘蛛的存在是搜索引擎中的一个自动程序。蜘蛛程序需要不断的访问、采集、整理网络图片、视频等内容,这就是它的作用,然后将同类别和不同类别分开,建立索引库,这样用户在搜索的时候,就会找到自己喜欢的内容。需要。导读:网站不排名有收录原因及解决方法!
一、蜘蛛的爬行规则:
搜索引擎中的蜘蛛需要将爬取的网页放入数据库区域进行数据补充。通过程序的计算,将它们分类放置在不同的检索位置,然后搜索引擎就形成了一个稳定的收录排名。在这样做的过程中,蜘蛛抓取到的数据不一定是稳定的,很多都是经过程序计算后被其他好的网页挤出来的。简单来说就是蜘蛛不喜欢,不想爬这个页面。蜘蛛的味道很独特,它抓到的网站也很不一样,就是我们所说的原创文章,只要你网页里的文章 page的原创度数很高,那么你的网页就有很大概率被蜘蛛爬取,
只有经过这样的检索,数据的排名才会更加稳定,而现在搜索引擎已经改变了策略,正在逐步逐步向补充数据转变。这也是为什么在搜索引擎优化过程中在收录上搜索变得越来越困难的原因。我们也可以理解为,今天有很多页面没有收录的排名,每隔一段时间就会有收录。排名的原因。
二、增加网站的抓取频率:
1、网站文章 质量提升
做SEO的人虽然知道如何提高原创文章,但搜索引擎有一个不变的真理,就是永远无法满足内容质量和稀缺性的要求。在创建内容时,一定要满足每个潜在访问者的搜索需求,因为 原创 内容可能并不总是受到蜘蛛的喜爱。
2、更新网站文章的频率
内容满足后,做一个正常的更新频率很重要,这也是提高网页爬取的法宝。
3、网站速度不仅影响蜘蛛,还影响用户体验
蜘蛛访问时,如果没有障碍物,加载过程可以在合理的速度范围内,则需要保证蜘蛛在网页中能够顺畅爬行,不能有加载延迟。如果出现这种问题,那么蜘蛛就不会喜欢这个网站,它会降低爬取的频率。
4、提高网站品牌知名度
经常在网上混,你会发现一个问题。知名品牌推出新网站时,会去一些新闻媒体进行报道。新闻来源网站报道后,会添加一些品牌词,即使没有目标等链接有这么大的影响,搜索引擎也会抓取这个网站。
5、选择PR高的域名
PR是一个老式的域名,所以它的权重肯定很高。即使你的网站很长时间没有更新或者是一个完全封闭的网站页面,搜索引擎也会随时抓取并等待更新的内容。如果有人一开始就选择使用这样一个旧域名,那么重定向也可以发展成一个真正的可操作域名。
蜘蛛爬行频率:
如果是高权重网站,更新频率会不一样,所以频率一般在几天或一个月之间,网站质量越高,更新越快该频率将是,蜘蛛将继续访问或更新网页。
总而言之,用户对SEO这种具有很强潜在商业价值的服务方式非常感兴趣,但由于这项工作是长期的,我们不能急于走上成功的道路,一定要慢慢来。来。在这个竞争激烈的互联网环境下,只要能比对手多做一点,就能实现质的飞跃。 查看全部
抓取网页视频(为什么做seo需要来讲搜索引擎蜘蛛爬取规则?原因是什么?)
严格来说seo爬取规则是个病句,应该是爬虫也叫蜘蛛在做seo的过程中的爬取规则。为什么seo需要讲搜索引擎蜘蛛爬取规则?原因是收录决定了索引,索引决定了排名,排名决定了SEO结果的好坏。
seo爬取的规则,你知道吗?我们实际上可以用最简单的方式来解释这一点。SEO在爬取过程中依赖于蜘蛛,而蜘蛛的存在是搜索引擎中的一个自动程序。蜘蛛程序需要不断的访问、采集、整理网络图片、视频等内容,这就是它的作用,然后将同类别和不同类别分开,建立索引库,这样用户在搜索的时候,就会找到自己喜欢的内容。需要。导读:网站不排名有收录原因及解决方法!
一、蜘蛛的爬行规则:
搜索引擎中的蜘蛛需要将爬取的网页放入数据库区域进行数据补充。通过程序的计算,将它们分类放置在不同的检索位置,然后搜索引擎就形成了一个稳定的收录排名。在这样做的过程中,蜘蛛抓取到的数据不一定是稳定的,很多都是经过程序计算后被其他好的网页挤出来的。简单来说就是蜘蛛不喜欢,不想爬这个页面。蜘蛛的味道很独特,它抓到的网站也很不一样,就是我们所说的原创文章,只要你网页里的文章 page的原创度数很高,那么你的网页就有很大概率被蜘蛛爬取,
只有经过这样的检索,数据的排名才会更加稳定,而现在搜索引擎已经改变了策略,正在逐步逐步向补充数据转变。这也是为什么在搜索引擎优化过程中在收录上搜索变得越来越困难的原因。我们也可以理解为,今天有很多页面没有收录的排名,每隔一段时间就会有收录。排名的原因。
二、增加网站的抓取频率:
1、网站文章 质量提升
做SEO的人虽然知道如何提高原创文章,但搜索引擎有一个不变的真理,就是永远无法满足内容质量和稀缺性的要求。在创建内容时,一定要满足每个潜在访问者的搜索需求,因为 原创 内容可能并不总是受到蜘蛛的喜爱。
2、更新网站文章的频率
内容满足后,做一个正常的更新频率很重要,这也是提高网页爬取的法宝。
3、网站速度不仅影响蜘蛛,还影响用户体验
蜘蛛访问时,如果没有障碍物,加载过程可以在合理的速度范围内,则需要保证蜘蛛在网页中能够顺畅爬行,不能有加载延迟。如果出现这种问题,那么蜘蛛就不会喜欢这个网站,它会降低爬取的频率。
4、提高网站品牌知名度
经常在网上混,你会发现一个问题。知名品牌推出新网站时,会去一些新闻媒体进行报道。新闻来源网站报道后,会添加一些品牌词,即使没有目标等链接有这么大的影响,搜索引擎也会抓取这个网站。
5、选择PR高的域名
PR是一个老式的域名,所以它的权重肯定很高。即使你的网站很长时间没有更新或者是一个完全封闭的网站页面,搜索引擎也会随时抓取并等待更新的内容。如果有人一开始就选择使用这样一个旧域名,那么重定向也可以发展成一个真正的可操作域名。
蜘蛛爬行频率:
如果是高权重网站,更新频率会不一样,所以频率一般在几天或一个月之间,网站质量越高,更新越快该频率将是,蜘蛛将继续访问或更新网页。
总而言之,用户对SEO这种具有很强潜在商业价值的服务方式非常感兴趣,但由于这项工作是长期的,我们不能急于走上成功的道路,一定要慢慢来。来。在这个竞争激烈的互联网环境下,只要能比对手多做一点,就能实现质的飞跃。
抓取网页视频(各个浏览器安装idm插件详细操作的用户,超实用!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-16 07:02
3、打开浏览器,进入浏览器的扩展程序,打开“开发者模式”,然后将图4中的crx文件拖进去。
由于不同的浏览器进入扩展程序的方式不同,小编这里就不详细讲解了。想了解各浏览器安装idm插件详细操作的用户可以点击此链接查看。
二、idm 只从腾讯下载一个视频
目前视频格式有很多种,常见的有mp4、wmv、asf、asx、rm、rmvb、avi等。不同格式的视频编码方式不同,用户使用idm时去嗅腾讯看视频的时候,发现大部分都是ts文件一个一个。
ts的全称是MPEG2-TS。这种格式视频的特点是视频流的任何一段都可以在开始时独立解码。总之,腾讯视频将一个完成的视频分成多个ts文件,防止用户抢视频。
具体解决方案如下:
1、因为可以直接观看ts视频,所以用户可以下载idm抓取的所有ts文件,然后使用ts合并工具或相关网站将所有ts文件整合成一个完整的片段视频即可使用。
2、如果上面的方法太麻烦,可以使用“油猴插件+脚本”解析出腾讯视频资源的下载地址,然后使用idm下载完整视频。
首先,进入“极简插件”官网,搜索“油猴”插件并安装,或者直接点击此链接跳转到安装界面。收录安装步骤,用户可以按照步骤进行安装。
然后输入“greasyfork”,找到可以解析腾讯视频的脚本并安装。
刷新腾讯视频网页,可以找到“vip”按钮,找到想看的视频,进入播放界面,点击“vip”按钮,选择“视频分析”跳转到第三方视频< @网站 ,视频右上角会出现“下载此视频”,点击下载。 查看全部
抓取网页视频(各个浏览器安装idm插件详细操作的用户,超实用!)
3、打开浏览器,进入浏览器的扩展程序,打开“开发者模式”,然后将图4中的crx文件拖进去。
由于不同的浏览器进入扩展程序的方式不同,小编这里就不详细讲解了。想了解各浏览器安装idm插件详细操作的用户可以点击此链接查看。
二、idm 只从腾讯下载一个视频
目前视频格式有很多种,常见的有mp4、wmv、asf、asx、rm、rmvb、avi等。不同格式的视频编码方式不同,用户使用idm时去嗅腾讯看视频的时候,发现大部分都是ts文件一个一个。
ts的全称是MPEG2-TS。这种格式视频的特点是视频流的任何一段都可以在开始时独立解码。总之,腾讯视频将一个完成的视频分成多个ts文件,防止用户抢视频。
具体解决方案如下:
1、因为可以直接观看ts视频,所以用户可以下载idm抓取的所有ts文件,然后使用ts合并工具或相关网站将所有ts文件整合成一个完整的片段视频即可使用。
2、如果上面的方法太麻烦,可以使用“油猴插件+脚本”解析出腾讯视频资源的下载地址,然后使用idm下载完整视频。
首先,进入“极简插件”官网,搜索“油猴”插件并安装,或者直接点击此链接跳转到安装界面。收录安装步骤,用户可以按照步骤进行安装。
然后输入“greasyfork”,找到可以解析腾讯视频的脚本并安装。
刷新腾讯视频网页,可以找到“vip”按钮,找到想看的视频,进入播放界面,点击“vip”按钮,选择“视频分析”跳转到第三方视频< @网站 ,视频右上角会出现“下载此视频”,点击下载。
抓取网页视频(如何用txt本地上传网页视频?(定时推送))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-05 22:07
抓取网页视频的时候,并不是每一次都能获取到全部的数据,可能我们当前获取到了40%-60%的网页内容,并且还在持续加深。因此我们需要做的就是最大化保存网页里面所有视频的列表,后续在需要用到的时候,就可以直接查找出来就行了。举个例子。
一、一般我们可以用txt本地上传网页视频,返回assets/zhihu.zip(点进去可以下载),最重要的是解压缩,自行上传assets/mp4.zip保存到本地(需要用到读取本地文件的方法)。
二、返回html里面的视频列表post/index。php:8004/zhihu?t=100&a=120&b=140&c=180&d=29353192308(html页面)post/index。php:8004/zhihu?t=100&a=120&b=140&c=180&d=29353192308(本地文件)post/index。
php:8004/zhihu?t=100&a=120&b=140&c=180&d=29353192308(assets里面的视频列表)。
三、定时推送每次用浏览器下载视频,可以使用第三方的chrome浏览器,或者用curl-s/+/xx-youtube.submit(定时推送给本地浏览器)点击”获取视频“按钮,保存到本地,
这个。我暂时没找到相关的页面显示内容。不过我刚刚去github找了一下,还是有的。直接在线观看这个-view-pages-and-loads?lang=en不过大概需要10s以上的加载时间。这是我的测试页面,loads算起来可能有点费时间。 查看全部
抓取网页视频(如何用txt本地上传网页视频?(定时推送))
抓取网页视频的时候,并不是每一次都能获取到全部的数据,可能我们当前获取到了40%-60%的网页内容,并且还在持续加深。因此我们需要做的就是最大化保存网页里面所有视频的列表,后续在需要用到的时候,就可以直接查找出来就行了。举个例子。
一、一般我们可以用txt本地上传网页视频,返回assets/zhihu.zip(点进去可以下载),最重要的是解压缩,自行上传assets/mp4.zip保存到本地(需要用到读取本地文件的方法)。
二、返回html里面的视频列表post/index。php:8004/zhihu?t=100&a=120&b=140&c=180&d=29353192308(html页面)post/index。php:8004/zhihu?t=100&a=120&b=140&c=180&d=29353192308(本地文件)post/index。
php:8004/zhihu?t=100&a=120&b=140&c=180&d=29353192308(assets里面的视频列表)。
三、定时推送每次用浏览器下载视频,可以使用第三方的chrome浏览器,或者用curl-s/+/xx-youtube.submit(定时推送给本地浏览器)点击”获取视频“按钮,保存到本地,
这个。我暂时没找到相关的页面显示内容。不过我刚刚去github找了一下,还是有的。直接在线观看这个-view-pages-and-loads?lang=en不过大概需要10s以上的加载时间。这是我的测试页面,loads算起来可能有点费时间。
抓取网页视频(网络上搜索的网友分享的一些方法,简单的使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-05 13:28
注:文章仅供参考,学习交流。文章内容是一些想法和介绍一些工具。文章中的参考链接仅供参考(以防万一哪天链接失效),还有其他人写的不错,但我没有看到。
以下是我在网上搜索的网友分享的方法。这些方法使用简单。其中介绍的一小部分方法和工具可以用更专业、更复杂的方式来使用,但在这种情况下,不能用简单的文章来解释。(其实我不知道怎么操作更专业,哈哈哈)
当我们在网页上看到视频并希望将视频保存为文件时。怎么做?
一是下载网页中的视频,二是录制视频。
就是想办法“获取”视频,并将其转成mp4等视频文件。
使用网页下载
这意味着一些网站网页具有解析视频链接的功能。通常,复制视频的 URL 并将其粘贴到 网站 页面上。
这通常支持较大或流行的视频网站。部分小众视频网站可能不支持。那么网站可能会被屏蔽,所以视频解析URL就不会贴出来了。
那么如何找到这种 网站 网页呢?您可以通过百度查看关键词“视频分析”。
另一个是松鼠
/
但这似乎是使用软件。
教程在这里:/teacher1.htm
使用浏览器插件
在浏览器中,寻找一些插件,关键词“视频下载器”、“下载”等。
在浏览器上安装插件。不同的浏览器可能有不同的插件,但功能都差不多,就是下载视频。
你可以参考这个:/question/427720670/answer/2357822367
使用命令行下载
你得到,ffmpeg。两条命令行。
在安装you-get之前,需要先安装python,然后使用pip命令安装you-get。
ffmpeg 可以下载带有 .m3u8 格式链接的视频。
参考链接:/p/142349349
抓取 HTML 媒体链接
这种方法可以用来分析网页,所以可能更专业也更复杂。
不过这个方法也可以简单的使用,嗯,有一定的几率拿到。
参考链接:/question/427720670/answer/1547013115
录屏
这是最“愚蠢”的方法,但也是一种更有效的方法,可能是一种更耗时的方法。
比如有一个视频,使用一些常用的方法是无法下载的。那么建议直接录下来,前提是视频不是很长。常用的方法不能下载,可能需要较长时间才能找到新的方法,所以还是直接记录比较好。
注意不要录制其他不相关的图片和声音。
参考链接:/question/427720670/answer/2357822367 查看全部
抓取网页视频(网络上搜索的网友分享的一些方法,简单的使用)
注:文章仅供参考,学习交流。文章内容是一些想法和介绍一些工具。文章中的参考链接仅供参考(以防万一哪天链接失效),还有其他人写的不错,但我没有看到。
以下是我在网上搜索的网友分享的方法。这些方法使用简单。其中介绍的一小部分方法和工具可以用更专业、更复杂的方式来使用,但在这种情况下,不能用简单的文章来解释。(其实我不知道怎么操作更专业,哈哈哈)
当我们在网页上看到视频并希望将视频保存为文件时。怎么做?
一是下载网页中的视频,二是录制视频。
就是想办法“获取”视频,并将其转成mp4等视频文件。
使用网页下载
这意味着一些网站网页具有解析视频链接的功能。通常,复制视频的 URL 并将其粘贴到 网站 页面上。
这通常支持较大或流行的视频网站。部分小众视频网站可能不支持。那么网站可能会被屏蔽,所以视频解析URL就不会贴出来了。
那么如何找到这种 网站 网页呢?您可以通过百度查看关键词“视频分析”。
另一个是松鼠
/
但这似乎是使用软件。
教程在这里:/teacher1.htm
使用浏览器插件
在浏览器中,寻找一些插件,关键词“视频下载器”、“下载”等。
在浏览器上安装插件。不同的浏览器可能有不同的插件,但功能都差不多,就是下载视频。
你可以参考这个:/question/427720670/answer/2357822367
使用命令行下载
你得到,ffmpeg。两条命令行。
在安装you-get之前,需要先安装python,然后使用pip命令安装you-get。
ffmpeg 可以下载带有 .m3u8 格式链接的视频。
参考链接:/p/142349349
抓取 HTML 媒体链接
这种方法可以用来分析网页,所以可能更专业也更复杂。
不过这个方法也可以简单的使用,嗯,有一定的几率拿到。
参考链接:/question/427720670/answer/1547013115
录屏
这是最“愚蠢”的方法,但也是一种更有效的方法,可能是一种更耗时的方法。
比如有一个视频,使用一些常用的方法是无法下载的。那么建议直接录下来,前提是视频不是很长。常用的方法不能下载,可能需要较长时间才能找到新的方法,所以还是直接记录比较好。
注意不要录制其他不相关的图片和声音。
参考链接:/question/427720670/answer/2357822367
抓取网页视频(史上最全网页视频下载方法和教程,使用百度网盘下载全网视频!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 493 次浏览 • 2022-03-29 22:04
抓取网页视频的话,可以使用爬虫工具。以免费的scrapy为例。模拟登录网站,获取视频的地址。用于下载视频。当然你也可以使用视频下载工具,例如:迅雷视频下载器也可以使用python代码下载,解析网页提取视频信息以及分享下载。具体代码及示例可以关注我的博客:视频下载-史上最全网页视频下载方法和教程,使用百度网盘下载功能下载全网视频!方法:1.在浏览器中打开你要下载的资源的网址:;type=jump2.鼠标放在网址上,右键选择"下载源文件"。
我们公司的一位老师之前找到我们,说找到一个python爬虫软件。但是她一点代码基础都没有,怎么破啊,哈哈,所以,今天我们就来看看怎么使用python来找到网上视频的地址。学习编程注意,是去找软件。网上搜索或者去书店买《python编程:从入门到实践》这本书看,先把里面的程序敲一遍。之后,可以选择一个对应的python项目,网上都有。
可以找作者买,没钱的话,去租。不过不建议这样做,那是因为作者只会挑生意好的来写,质量不会太高。不过感兴趣的话,可以试试。软件还有这些功能,包括:播放列表页面对链接支持直接下载单个视频支持视频下载助手单个视频解析成mp4支持视频选择下载自己网站的视频格式文件具体使用技巧见软件说明书。当然,如果只是找个视频下下。
emm,那python的话,如果是scrapy爬虫软件,可以利用easybees语言之web接口。不过,因为没有基础。所以,只要开发网站,运用好脚本语言,爬虫出来的视频也不是很多。在学习高赞回答后,你还可以实践以下方法。1.python分词。两步走,第一步,使用分词的库库allwords.join分词。
第二步,使用分词的软件例如,jieba分词器。2.第二种方法,模拟浏览器访问网站。这个有一些技巧需要学习。你可以以这个网站为起点,进行简单的回复比如,这样开发出来的程序,主要是面向web浏览器浏览网站使用。无关的浏览器端,例如微信啊,哈哈,那可以另想办法了。比如,你想去下载一个电影,分别采用“百度一下、电影网站、91影院、爱奇艺、华夏电影院、bt天堂”等几个网站。
如果你在下载时想用到页面查询功能,那用不上分词工具,你可以写两个自定义函数。例如“百度一下会跳转到“迅雷视频”,要查看“百度一下”地址,就用这个函数。scrapy程序在运行时,注意,你需要注册一个web服务器。不知道,你说的“网站”是不是一个空网站,如果是,那就需要一个web服务器了。什么是web服务器,很简单,网站如果没有网站的话,要么是没有办法建立起来。 查看全部
抓取网页视频(史上最全网页视频下载方法和教程,使用百度网盘下载全网视频!)
抓取网页视频的话,可以使用爬虫工具。以免费的scrapy为例。模拟登录网站,获取视频的地址。用于下载视频。当然你也可以使用视频下载工具,例如:迅雷视频下载器也可以使用python代码下载,解析网页提取视频信息以及分享下载。具体代码及示例可以关注我的博客:视频下载-史上最全网页视频下载方法和教程,使用百度网盘下载功能下载全网视频!方法:1.在浏览器中打开你要下载的资源的网址:;type=jump2.鼠标放在网址上,右键选择"下载源文件"。
我们公司的一位老师之前找到我们,说找到一个python爬虫软件。但是她一点代码基础都没有,怎么破啊,哈哈,所以,今天我们就来看看怎么使用python来找到网上视频的地址。学习编程注意,是去找软件。网上搜索或者去书店买《python编程:从入门到实践》这本书看,先把里面的程序敲一遍。之后,可以选择一个对应的python项目,网上都有。
可以找作者买,没钱的话,去租。不过不建议这样做,那是因为作者只会挑生意好的来写,质量不会太高。不过感兴趣的话,可以试试。软件还有这些功能,包括:播放列表页面对链接支持直接下载单个视频支持视频下载助手单个视频解析成mp4支持视频选择下载自己网站的视频格式文件具体使用技巧见软件说明书。当然,如果只是找个视频下下。
emm,那python的话,如果是scrapy爬虫软件,可以利用easybees语言之web接口。不过,因为没有基础。所以,只要开发网站,运用好脚本语言,爬虫出来的视频也不是很多。在学习高赞回答后,你还可以实践以下方法。1.python分词。两步走,第一步,使用分词的库库allwords.join分词。
第二步,使用分词的软件例如,jieba分词器。2.第二种方法,模拟浏览器访问网站。这个有一些技巧需要学习。你可以以这个网站为起点,进行简单的回复比如,这样开发出来的程序,主要是面向web浏览器浏览网站使用。无关的浏览器端,例如微信啊,哈哈,那可以另想办法了。比如,你想去下载一个电影,分别采用“百度一下、电影网站、91影院、爱奇艺、华夏电影院、bt天堂”等几个网站。
如果你在下载时想用到页面查询功能,那用不上分词工具,你可以写两个自定义函数。例如“百度一下会跳转到“迅雷视频”,要查看“百度一下”地址,就用这个函数。scrapy程序在运行时,注意,你需要注册一个web服务器。不知道,你说的“网站”是不是一个空网站,如果是,那就需要一个web服务器了。什么是web服务器,很简单,网站如果没有网站的话,要么是没有办法建立起来。
抓取网页视频(爬取、安装Python的扩展包(2.7.1364位python) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-26 16:15
)
爬取视频网站的视频URL
前言
最近,我需要为我的工作抓取视频网址。在网上找了很多资料,绕了一大圈终于得到了。写这篇博客是为了自己以后的观看,或者有这个需求的程序员参考。我们平时在网上看电影的时候,我们的浏览器每隔一小段时间就会加载一个小视频,这样我们就可以连续观看一个完整的视频。言外之意就是视频网站会将视频分割后发送给客户端,所以我们可以通过网卡抓包的方式来捕获发给视频网站的HTTP请求包。提取发送到视频网站的url,最后我们结合每个小段的视频url,就可以得到完整的视频。
第一步,安装Python(2.7.13 64-bit)
Python下载地址:
python的安装步骤我就不说了,大家应该都知道吧。
第二步,安装Python扩展包pypcapy==1.1.2
我这里试过了,最新版本有问题,最好用老版本。
pip install pypcap==1.1.2 安装时会出现如下问题,会提示vc++ 9.0 没有安装。
微软为python2提供了vc++库,但没有python3,这就是我们选择python2的原因,下载VCForPython27.msi
下载链接:
下载完成后,点击下一步进行安装。
VC++安装完成后,pip install pypcap==1.1.2,然后我们会遇到新的错误说找不到pcap.h,这时我们需要下载winpcap开发包。
Winpcap开发者版下载地址:
winpcap下载后,接下来的两步非常关键,一定要仔细阅读(前两步是安装pcapy必备的,python的另一个扩展包,前两步安装pypcap可以省略)。接下来继续安装,显示安装成功!如果安装的是下载的压缩包python setup.py install,安装成功后,找到包的路径,将pypcap包的位置添加到环境变量中。
安装成功后,我们进入python模式试一试。以为搞定了,但是还是出现找不到DLL的错误。这时候,我们需要安装WinPcap。我们只是用了WinPcap开发包,还没有安装WinPcap工具。
WinPcap下载地址:
安装完WinPcap,终于结束了!在这里辛苦了,因为我在网上找不到所有的资料,而且百度出来的都是乱七八糟的,所以我晚上2点才睡觉。. .
第三步,安装Python扩展包dpkt(这个没什么特别的,直接安装就行了)
第四步,运行如下代码,打开浏览器观看视频。
#encoding: utf8
import pcap
import dpkt
import re
pc=pcap.pcap() #注,参数可为网卡名,如eth0, 设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP, pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
pc.setfilter('tcp port 80')
print u"程序开始运行"
while True:
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
try:
p=dpkt.ethernet.Ethernet(pdata) #对抓到的以太网V2数据包(raw packet)进行解包
except Exception, e:
continue
if p.data.__class__.__name__=='IP':
if p.data.data.__class__.__name__=='TCP': # if p.data.data.dport==80:
header = p.data.data.data # 抓到的请求头, 默认按照抓到正常的请求头来解析,如果解析报错则舍弃,继续抓包
try:
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
domain_regex = r'^([a-zA-Z0-9]([a-zA-Z0-9-_]{0,61}[a-zA-Z0-9])?\.)+[a-zA-Z]{2,11}[/].*'
result = re.search(domain_regex, requestUrl)
if result:
print requestUrl
# print requestUrl
except Exception, e:
continue
第五步,打开浏览器开发者网络,可以观察到我们的程序已经抓取到了视频的url
查看全部
抓取网页视频(爬取、安装Python的扩展包(2.7.1364位python)
)
爬取视频网站的视频URL
前言
最近,我需要为我的工作抓取视频网址。在网上找了很多资料,绕了一大圈终于得到了。写这篇博客是为了自己以后的观看,或者有这个需求的程序员参考。我们平时在网上看电影的时候,我们的浏览器每隔一小段时间就会加载一个小视频,这样我们就可以连续观看一个完整的视频。言外之意就是视频网站会将视频分割后发送给客户端,所以我们可以通过网卡抓包的方式来捕获发给视频网站的HTTP请求包。提取发送到视频网站的url,最后我们结合每个小段的视频url,就可以得到完整的视频。
第一步,安装Python(2.7.13 64-bit)
Python下载地址:
python的安装步骤我就不说了,大家应该都知道吧。
第二步,安装Python扩展包pypcapy==1.1.2
我这里试过了,最新版本有问题,最好用老版本。
pip install pypcap==1.1.2 安装时会出现如下问题,会提示vc++ 9.0 没有安装。
微软为python2提供了vc++库,但没有python3,这就是我们选择python2的原因,下载VCForPython27.msi
下载链接:
下载完成后,点击下一步进行安装。
VC++安装完成后,pip install pypcap==1.1.2,然后我们会遇到新的错误说找不到pcap.h,这时我们需要下载winpcap开发包。
Winpcap开发者版下载地址:
winpcap下载后,接下来的两步非常关键,一定要仔细阅读(前两步是安装pcapy必备的,python的另一个扩展包,前两步安装pypcap可以省略)。接下来继续安装,显示安装成功!如果安装的是下载的压缩包python setup.py install,安装成功后,找到包的路径,将pypcap包的位置添加到环境变量中。
安装成功后,我们进入python模式试一试。以为搞定了,但是还是出现找不到DLL的错误。这时候,我们需要安装WinPcap。我们只是用了WinPcap开发包,还没有安装WinPcap工具。
WinPcap下载地址:
安装完WinPcap,终于结束了!在这里辛苦了,因为我在网上找不到所有的资料,而且百度出来的都是乱七八糟的,所以我晚上2点才睡觉。. .
第三步,安装Python扩展包dpkt(这个没什么特别的,直接安装就行了)
第四步,运行如下代码,打开浏览器观看视频。
#encoding: utf8
import pcap
import dpkt
import re
pc=pcap.pcap() #注,参数可为网卡名,如eth0, 设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP, pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
pc.setfilter('tcp port 80')
print u"程序开始运行"
while True:
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
try:
p=dpkt.ethernet.Ethernet(pdata) #对抓到的以太网V2数据包(raw packet)进行解包
except Exception, e:
continue
if p.data.__class__.__name__=='IP':
if p.data.data.__class__.__name__=='TCP': # if p.data.data.dport==80:
header = p.data.data.data # 抓到的请求头, 默认按照抓到正常的请求头来解析,如果解析报错则舍弃,继续抓包
try:
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
domain_regex = r'^([a-zA-Z0-9]([a-zA-Z0-9-_]{0,61}[a-zA-Z0-9])?\.)+[a-zA-Z]{2,11}[/].*'
result = re.search(domain_regex, requestUrl)
if result:
print requestUrl
# print requestUrl
except Exception, e:
continue
第五步,打开浏览器开发者网络,可以观察到我们的程序已经抓取到了视频的url
抓取网页视频(如何帮小伙伴抓取网页中的视频文件,它会自动退出?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-03-25 20:11
全网视频平台M3U8解析工具可以帮助小伙伴抓取网页中的视频文件。用户可以选择不同的图片分辨率。该软件支持批量添加任务。所有文件下载完成后会自动退出。
指示
1.首先,我们将解析后的代码复制到wwwbejsoncom进行解析
2.根据你的爱好,选择你喜欢的清晰度下载
3.如何下载M3U8文件?,答:请下载全网视频平台的M3U8解析工具
背景介绍
m3u8 是 Apple 推出的视频播放标准。它是m3u的一种,但编码格式是UTF-8。
m3u8准确来说是一个索引文件,m3u8文件实际上是用来解析放置在服务器上的对应视频网络地址,从而实现在线播放。m3u8格式文件主要用于实现多码率视频的适配。视频网站可以根据用户的网络带宽,自动匹配合适的码率文件供客户端播放,保证视频的流畅度。.
小编点评
将URL复制到全网视频平台的M3U8解析工具,即可自动解析。该软件带有并排广播功能。该应用程序支持断点下载,并且对下载速度没有限制。如果视频文件无法自动解析,您可以向开发者提交反馈。
以上就是小编为大家带来的全网视频平台M3U8分析工具。更多精彩软件请关注IE浏览器中文网站! 查看全部
抓取网页视频(如何帮小伙伴抓取网页中的视频文件,它会自动退出?)
全网视频平台M3U8解析工具可以帮助小伙伴抓取网页中的视频文件。用户可以选择不同的图片分辨率。该软件支持批量添加任务。所有文件下载完成后会自动退出。
指示
1.首先,我们将解析后的代码复制到wwwbejsoncom进行解析
2.根据你的爱好,选择你喜欢的清晰度下载
3.如何下载M3U8文件?,答:请下载全网视频平台的M3U8解析工具
背景介绍
m3u8 是 Apple 推出的视频播放标准。它是m3u的一种,但编码格式是UTF-8。
m3u8准确来说是一个索引文件,m3u8文件实际上是用来解析放置在服务器上的对应视频网络地址,从而实现在线播放。m3u8格式文件主要用于实现多码率视频的适配。视频网站可以根据用户的网络带宽,自动匹配合适的码率文件供客户端播放,保证视频的流畅度。.
小编点评
将URL复制到全网视频平台的M3U8解析工具,即可自动解析。该软件带有并排广播功能。该应用程序支持断点下载,并且对下载速度没有限制。如果视频文件无法自动解析,您可以向开发者提交反馈。
以上就是小编为大家带来的全网视频平台M3U8分析工具。更多精彩软件请关注IE浏览器中文网站!
抓取网页视频(文末2015年电影的下载链接(包括:电影名称和迅雷下载))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-20 05:15
前言:这是Java爬虫实战第二篇文章。在第一篇文章只是抓取目标网站的链接的基础上,进一步增加难度,在我们需要的内容上抓取目标页面并存入数据库。这里的测试用例使用了一个我经常使用的电影下载网站()。本来想把网站上所有电影的下载链接都抓取,但是觉得时间太长,就改成抓取2015年电影的下载链接了。
注:文末有我抓取的整个列表的下载链接(包括:电影名和迅雷下载链接)
原理介绍
其实原理和第一个文章是一样的,不同的是,由于这个网站里面的分类列表太多了,如果不选中这些标签,会耗费难以想象的时间。
类别链接和标签链接都不是必需的。而不是通过这些链接爬取其他页面,只能通过页面底部所有类型电影的分页来获取其他页面上的电影列表。同时,对于电影详情页,只抓取电影片名和迅雷下载链接,不进行深度爬取。详细信息页面上的一些推荐电影和其他链接不是必需的。
最后就是将所有获取到的电影的下载链接保存在videoLinkMap集合中,通过遍历这个集合将数据保存到MySQL
注:如果原理还不够清楚,推荐阅读我之前的文章文章:爬虫实战(一):抓取一个网站上的所有链接/
两码实现
实现原理上面已经讲过了,代码里面有详细的注释,这里就不多说了。代码如下:
<p>package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p");
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile(" 查看全部
抓取网页视频(文末2015年电影的下载链接(包括:电影名称和迅雷下载))
前言:这是Java爬虫实战第二篇文章。在第一篇文章只是抓取目标网站的链接的基础上,进一步增加难度,在我们需要的内容上抓取目标页面并存入数据库。这里的测试用例使用了一个我经常使用的电影下载网站()。本来想把网站上所有电影的下载链接都抓取,但是觉得时间太长,就改成抓取2015年电影的下载链接了。
注:文末有我抓取的整个列表的下载链接(包括:电影名和迅雷下载链接)
原理介绍
其实原理和第一个文章是一样的,不同的是,由于这个网站里面的分类列表太多了,如果不选中这些标签,会耗费难以想象的时间。
类别链接和标签链接都不是必需的。而不是通过这些链接爬取其他页面,只能通过页面底部所有类型电影的分页来获取其他页面上的电影列表。同时,对于电影详情页,只抓取电影片名和迅雷下载链接,不进行深度爬取。详细信息页面上的一些推荐电影和其他链接不是必需的。
最后就是将所有获取到的电影的下载链接保存在videoLinkMap集合中,通过遍历这个集合将数据保存到MySQL
注:如果原理还不够清楚,推荐阅读我之前的文章文章:爬虫实战(一):抓取一个网站上的所有链接/
两码实现
实现原理上面已经讲过了,代码里面有详细的注释,这里就不多说了。代码如下:
<p>package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p";);
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile("
抓取网页视频(抓取网页视频我给你说说吧,select函数帮你解决这个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-11 04:03
抓取网页视频我给你说说吧,传送门javadomtreesearch:stringapidocumenttreesearch简单到用select{publicstringpattern(strings){stringstr=s。tostring();if(s==null){s。touppercase();}returns;}stringstr2="stringtostring";stringstr3="stringtostring";}。
提供一个示例via/~gohlke/pythonlibs/#stringstringstream.str.to_string(stringstr1,stringstr2)inpython
select{...}
int(...)
sort(s)inpython
viapythonrequests
搜索引擎
用python实现?抱歉我就是伸手党了。
select函数帮你解决这个问题。
我想了想,直接写go可能是最快速的吧。这个可以问api服务商。
如果您是想要抓取国内所有的电影视频,方法是简单的多了。按照你的要求,先找一个“巨星”然后把这些明星“爬取”过来。很明显他们是不对你的数据进行“解析”的,只是返回链接和他们的名字而已。然后我又想到:很有可能是为了屏蔽僵尸粉和僵尸僵尸账号才使用了select,其他功能我没了解过。个人认为他们的做法没有什么价值,万一他们没封禁你呢?。 查看全部
抓取网页视频(抓取网页视频我给你说说吧,select函数帮你解决这个问题)
抓取网页视频我给你说说吧,传送门javadomtreesearch:stringapidocumenttreesearch简单到用select{publicstringpattern(strings){stringstr=s。tostring();if(s==null){s。touppercase();}returns;}stringstr2="stringtostring";stringstr3="stringtostring";}。
提供一个示例via/~gohlke/pythonlibs/#stringstringstream.str.to_string(stringstr1,stringstr2)inpython
select{...}
int(...)
sort(s)inpython
viapythonrequests
搜索引擎
用python实现?抱歉我就是伸手党了。
select函数帮你解决这个问题。
我想了想,直接写go可能是最快速的吧。这个可以问api服务商。
如果您是想要抓取国内所有的电影视频,方法是简单的多了。按照你的要求,先找一个“巨星”然后把这些明星“爬取”过来。很明显他们是不对你的数据进行“解析”的,只是返回链接和他们的名字而已。然后我又想到:很有可能是为了屏蔽僵尸粉和僵尸僵尸账号才使用了select,其他功能我没了解过。个人认为他们的做法没有什么价值,万一他们没封禁你呢?。
抓取网页视频(抓取网页视频片段是很简单的事情具体怎么才能找到片段文件?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-10 07:02
抓取网页视频片段是很简单的事情,具体怎么才能找到片段文件?看看下面这个教程就明白了~基础网页视频第一步:打开需要下载的网页,点击打开第二步:登录(无需注册账号)或者使用浏览器地址栏,并打开找到片段第三步:上传第四步:点击下载或者指定多种格式(bgm、mp4等)进行下载,若没有,可手动上传(由于浏览器自动推荐)若点击自动推荐格式时,下载的视频格式为单声道文件(x。
4)或双声道文件(x1,x
2)。当上传视频后,点击加载设置,设置使用的视频分辨率。随后,下载时,会弹出一个对话框。最后,点击保存,即可进行下载。
注意:
1、必须为ie浏览器,兼容性最好。
2、下载视频后,不要点击右键,选择是或否,提示浏览器自动推荐。
3、保存到本地时,请调整好分辨率。图像1.将鼠标悬停在视频右上角,出现调整大小命令2.输入视频网址"":将会自动为您推荐更好的视频网站。3.点击复制,粘贴到剪贴板。4.再将鼠标悬停在视频左上角,粘贴鼠标所在文本,即可进行复制。生成下载列表1.鼠标悬停在视频右上角,出现调整大小命令1,按确定,自动会生成剪贴板。
2.将鼠标悬停在剪贴板,一直按着复制键就会出现上下复制。生成视频列表1.鼠标悬停在视频右上角,出现调整大小命令2,按确定。2.点击复制,粘贴后就可以生成视频列表1。调整分辨率即可下载高清视频。只需要记住一点,将视频缩放到合适大小即可,调整一下播放和浏览的页面分辨率即可。修改网页分辨率,也能达到同样的效果。以上就是要如何将网页视频下载下来的过程。下期分享如何把视频格式转为mp4或者其他格式。 查看全部
抓取网页视频(抓取网页视频片段是很简单的事情具体怎么才能找到片段文件?)
抓取网页视频片段是很简单的事情,具体怎么才能找到片段文件?看看下面这个教程就明白了~基础网页视频第一步:打开需要下载的网页,点击打开第二步:登录(无需注册账号)或者使用浏览器地址栏,并打开找到片段第三步:上传第四步:点击下载或者指定多种格式(bgm、mp4等)进行下载,若没有,可手动上传(由于浏览器自动推荐)若点击自动推荐格式时,下载的视频格式为单声道文件(x。
4)或双声道文件(x1,x
2)。当上传视频后,点击加载设置,设置使用的视频分辨率。随后,下载时,会弹出一个对话框。最后,点击保存,即可进行下载。
注意:
1、必须为ie浏览器,兼容性最好。
2、下载视频后,不要点击右键,选择是或否,提示浏览器自动推荐。
3、保存到本地时,请调整好分辨率。图像1.将鼠标悬停在视频右上角,出现调整大小命令2.输入视频网址"":将会自动为您推荐更好的视频网站。3.点击复制,粘贴到剪贴板。4.再将鼠标悬停在视频左上角,粘贴鼠标所在文本,即可进行复制。生成下载列表1.鼠标悬停在视频右上角,出现调整大小命令1,按确定,自动会生成剪贴板。
2.将鼠标悬停在剪贴板,一直按着复制键就会出现上下复制。生成视频列表1.鼠标悬停在视频右上角,出现调整大小命令2,按确定。2.点击复制,粘贴后就可以生成视频列表1。调整分辨率即可下载高清视频。只需要记住一点,将视频缩放到合适大小即可,调整一下播放和浏览的页面分辨率即可。修改网页分辨率,也能达到同样的效果。以上就是要如何将网页视频下载下来的过程。下期分享如何把视频格式转为mp4或者其他格式。
抓取网页视频(学视频剪辑爬虫获取视频素材信息的方法和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-04 00:04
最近在学习视频剪辑,从网上找了很多视频素材,也找到了一些不错的素材网站,比如这个网站:有很多免费的high-定义视频材料。有时候想获取某个关键词搜索到的所有相关视频素材的信息,但是手动点击效率太低。最近正好在学习python爬虫,所以想到了用爬虫来获取视频素材信息。
比如我要搜索无人机相关的视频,我在搜索框输入drone,出来的网址是这样的。
我们打开chrome的开发者工具,刷新网页,可以看到第一个请求的响应,里面收录了很多视频素材信息。
拉下页面,看到刷新了新的视频素材,提醒我们页面是通过ajax异步更新的,我们选择XHR查看ajax请求。
首先,我们分析了第一个。如果没有我们网页上的视频信息,它应该是一个外部链接信息。我们不能使用它。我们直接看后续的请求。后面的每一个请求格式看起来都一样,我们来分析第一个。
我们可以看到这是一个 GET 类型的请求,有两个参数:path 和 params。params 的值是一个字典,其中收录许多其他参数。当我们对比其他请求的参数时,可以发现path参数的内容完全一样,只是params参数中更新了pge和offset_resp_videos。并且pge值从1更新到4后不会改变,offset_resp_videos更新到106后也不会改变。
我们进一步分析了反应。当 pge 为 1 和 2 时,每个响应收录 30 条视频信息。pge为3时,只有9条视频信息。当 pge 为 4 时,没有视频信息。这意味着当 pge=3 时,所有视频信息都已获取。所以当我们模拟ajax获取视频信息的时候,pge的范围是1-3,通过分析还可以得到:offset_resp_videos=(pge-1) * 30 + 37,这时候我们可以构造通过python模拟ajax请求的url。
我们通过查看Elements信息可以看到每个视频的html信息。
其中,前30个视频通过静态请求获取,其余通过ajax异步请求获取。静态获取是html格式的,我们可以直接解析;通过ajax获取的response是json格式的,我们需要使用json库处理得到视频信息的html文本。
可以看到,在ajax响应中,elements元素是一个列表,其中的每个元素都是视频信息的html文本,和静态网页中的格式是一样的,所以我们需要使用json 库来获取 ajax 响应中的视频信息元素。
对于视频素材,我们更关心id、时长、分辨率、标题、预览图片链接、视频链接。我们可以通过xpath获取相关信息。
以下是相关代码:
from urllib.parse import urlencode
import requests
import json
from lxml import etree
import time
import csv
items = []
headers = {
'Host': 'mazwai.com',
'Referer': 'https://mazwai.com/stock-video ... 39%3B,
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
# 获取静态网页
def get_first_page():
base_url = "https://mazwai.com/stock-video-footage/drone"
try:
rsp = requests.get(base_url, headers=headers)
if rsp.status_code == 200:
return rsp.text
except requests.ConnectionError as e:
print('Error:', e.args)
# 解析静态网页
def parse_html_result(result):
html = etree.HTML(result)
elements = html.xpath('//div[contains(@class, "video-responsive")]')
print(len(elements))
for element in elements:
element = etree.HTML(etree.tostring(element))
parse_html_element(element)
# 模拟ajax请求获取动态网页
def get_follow_page(page, start_idx):
base_url = "https://mazwai.com/api/?"
params = '{' + '"pge":{},"recordsPerPage":30,"recordsPerPage":30,"rec":30,"json_return":true,"infinite_scroll": true,"offset_resp_videos":{},"category": "drone"'.format(page, start_idx + (page-1)*30) + '}'
total = {
'path': 'elasticsearch/listResults',
'params': params
}
url = base_url + urlencode(total)
print(url)
try:
rsp = requests.get(url, headers=headers)
if rsp.status_code == 200:
return rsp.text
except requests.ConnectionError as e:
print('Error:', e.args)
# 解析ajax响应
def parse_json_result(result):
rsp = json.loads(result)
for element in rsp['elements']:
element = etree.HTML(element)
parse_html_element(element)
# 解析包含视频信息的单个元素
def parse_html_element(element):
item = []
id = element.xpath('//div[contains(@class, "video-responsive")]/@id')
imgsrc = element.xpath('//img/@src')
videosrc = element.xpath('//img/@data-video-source')
title = element.xpath('//img/@title')
duration = element.xpath('//div[@class="video-resolution-length-info"]/span[@class="duration"]/text()')
resolution = element.xpath('//div[@class="video-resolution-length-info"]/span[@class="resolution"]/text()')
item.append(id[0])
item.append(title[0])
item.append(duration[0])
item.append(resolution[0])
item.append(imgsrc[0])
item.append(videosrc[0])
items.append(item)
def write_csv():
with open('data.csv', 'w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id', 'title', 'duration', 'resolution', 'img_url', 'video_url'])
writer.writerows(items)
# 主函数
def main():
# 获取第一页并解析
result = get_first_page()
if result is not None:
parse_html_result(result)
time.sleep(2)
# 获取后续页并解析
for page in range(1, 4):
result = get_follow_page(page, 37)
parse_json_result(result)
time.sleep(2)
# 存成csv文件
write_csv()
if __name__ == '__main__':
main()
结果:
最后将提取的信息保存为csv文件,后续的图片和视频文件可以通过链接自动下载保存。
我们可以通过修改程序来爬取其他搜索信息,支持输入关键字信息,通过总条目数自动计算需要爬取多少页,这里不再赘述。 查看全部
抓取网页视频(学视频剪辑爬虫获取视频素材信息的方法和方法)
最近在学习视频剪辑,从网上找了很多视频素材,也找到了一些不错的素材网站,比如这个网站:有很多免费的high-定义视频材料。有时候想获取某个关键词搜索到的所有相关视频素材的信息,但是手动点击效率太低。最近正好在学习python爬虫,所以想到了用爬虫来获取视频素材信息。
比如我要搜索无人机相关的视频,我在搜索框输入drone,出来的网址是这样的。
我们打开chrome的开发者工具,刷新网页,可以看到第一个请求的响应,里面收录了很多视频素材信息。
拉下页面,看到刷新了新的视频素材,提醒我们页面是通过ajax异步更新的,我们选择XHR查看ajax请求。
首先,我们分析了第一个。如果没有我们网页上的视频信息,它应该是一个外部链接信息。我们不能使用它。我们直接看后续的请求。后面的每一个请求格式看起来都一样,我们来分析第一个。
我们可以看到这是一个 GET 类型的请求,有两个参数:path 和 params。params 的值是一个字典,其中收录许多其他参数。当我们对比其他请求的参数时,可以发现path参数的内容完全一样,只是params参数中更新了pge和offset_resp_videos。并且pge值从1更新到4后不会改变,offset_resp_videos更新到106后也不会改变。
我们进一步分析了反应。当 pge 为 1 和 2 时,每个响应收录 30 条视频信息。pge为3时,只有9条视频信息。当 pge 为 4 时,没有视频信息。这意味着当 pge=3 时,所有视频信息都已获取。所以当我们模拟ajax获取视频信息的时候,pge的范围是1-3,通过分析还可以得到:offset_resp_videos=(pge-1) * 30 + 37,这时候我们可以构造通过python模拟ajax请求的url。
我们通过查看Elements信息可以看到每个视频的html信息。
其中,前30个视频通过静态请求获取,其余通过ajax异步请求获取。静态获取是html格式的,我们可以直接解析;通过ajax获取的response是json格式的,我们需要使用json库处理得到视频信息的html文本。
可以看到,在ajax响应中,elements元素是一个列表,其中的每个元素都是视频信息的html文本,和静态网页中的格式是一样的,所以我们需要使用json 库来获取 ajax 响应中的视频信息元素。
对于视频素材,我们更关心id、时长、分辨率、标题、预览图片链接、视频链接。我们可以通过xpath获取相关信息。
以下是相关代码:
from urllib.parse import urlencode
import requests
import json
from lxml import etree
import time
import csv
items = []
headers = {
'Host': 'mazwai.com',
'Referer': 'https://mazwai.com/stock-video ... 39%3B,
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
# 获取静态网页
def get_first_page():
base_url = "https://mazwai.com/stock-video-footage/drone"
try:
rsp = requests.get(base_url, headers=headers)
if rsp.status_code == 200:
return rsp.text
except requests.ConnectionError as e:
print('Error:', e.args)
# 解析静态网页
def parse_html_result(result):
html = etree.HTML(result)
elements = html.xpath('//div[contains(@class, "video-responsive")]')
print(len(elements))
for element in elements:
element = etree.HTML(etree.tostring(element))
parse_html_element(element)
# 模拟ajax请求获取动态网页
def get_follow_page(page, start_idx):
base_url = "https://mazwai.com/api/?"
params = '{' + '"pge":{},"recordsPerPage":30,"recordsPerPage":30,"rec":30,"json_return":true,"infinite_scroll": true,"offset_resp_videos":{},"category": "drone"'.format(page, start_idx + (page-1)*30) + '}'
total = {
'path': 'elasticsearch/listResults',
'params': params
}
url = base_url + urlencode(total)
print(url)
try:
rsp = requests.get(url, headers=headers)
if rsp.status_code == 200:
return rsp.text
except requests.ConnectionError as e:
print('Error:', e.args)
# 解析ajax响应
def parse_json_result(result):
rsp = json.loads(result)
for element in rsp['elements']:
element = etree.HTML(element)
parse_html_element(element)
# 解析包含视频信息的单个元素
def parse_html_element(element):
item = []
id = element.xpath('//div[contains(@class, "video-responsive")]/@id')
imgsrc = element.xpath('//img/@src')
videosrc = element.xpath('//img/@data-video-source')
title = element.xpath('//img/@title')
duration = element.xpath('//div[@class="video-resolution-length-info"]/span[@class="duration"]/text()')
resolution = element.xpath('//div[@class="video-resolution-length-info"]/span[@class="resolution"]/text()')
item.append(id[0])
item.append(title[0])
item.append(duration[0])
item.append(resolution[0])
item.append(imgsrc[0])
item.append(videosrc[0])
items.append(item)
def write_csv():
with open('data.csv', 'w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id', 'title', 'duration', 'resolution', 'img_url', 'video_url'])
writer.writerows(items)
# 主函数
def main():
# 获取第一页并解析
result = get_first_page()
if result is not None:
parse_html_result(result)
time.sleep(2)
# 获取后续页并解析
for page in range(1, 4):
result = get_follow_page(page, 37)
parse_json_result(result)
time.sleep(2)
# 存成csv文件
write_csv()
if __name__ == '__main__':
main()
结果:
最后将提取的信息保存为csv文件,后续的图片和视频文件可以通过链接自动下载保存。
我们可以通过修改程序来爬取其他搜索信息,支持输入关键字信息,通过总条目数自动计算需要爬取多少页,这里不再赘述。
抓取网页视频(网络爬虫系统的原理和工作流程介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-02 01:13
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。该方法可以从网页中提取非结构化数据,存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,附件可以自动与文本关联。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫的原理
网络爬虫是根据一定的规则自动爬取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。从功能上来说,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图1 网络爬虫示意图
除了供用户阅读的文字信息外,网页还收录一些超链接信息。
网络爬虫系统正是通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫系统一般会选择一些比较重要的、出度(网页链接出的超链接数)网站较大的URL作为种子URL集。
网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以遍历所有的网页。
由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。
网络爬虫系统首先将种子 URL 放入下载队列,简单地从队列头部取一个 URL 下载其对应的网页,获取网页内容并存储,然后解析链接信息网页以获取一些新的 URL。
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,放入待抓取的URL队列中。
最后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫工作流程
如图 2 所示,网络爬虫的基本工作流程如下。
1)首先选择 Torrent URL 的一部分。
2)将这些网址放入待抓取的网址队列中。
3) 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP地址,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列。
4)分析已爬取URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列,从而进入下一个循环。
图2 网络爬虫基本工作流程
网络爬虫抓取策略
谷歌、百度等常见搜索引擎抓取的网页数量通常以数十亿计。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页呢?如果您对大数据开发感兴趣,想系统地学习大数据,可以加入大数据技术学习交流群:458号345号782获取学习资源,从而扩大网页信息的覆盖范围可能,这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,爬取策略决定了网页被爬取的顺序。
本节首先简要介绍网络爬取策略中使用的基本概念。
1)网页之间的关系模型
从互联网的结构来看,网页通过各种超链接相互连接,形成一个巨大而复杂的相互关联的有向图。
如图3所示,如果把网页看成图中的一个节点,把网页中其他网页的链接看成这个节点到其他节点的边,那么我们就可以轻松查看整个互联网网页被建模为有向图。
理论上,通过遍历算法对图进行遍历,几乎可以访问互联网上的任何网页。
图3 网页关系模型图
2)网页分类
从爬虫的角度来划分互联网,可以将互联网的所有页面分为5个部分:已下载未过期网页、已下载已过期网页、待下载网页、已知网页和未知网页,如图4.
本地爬取的网页实际上是互联网内容的镜像和备份。互联网正在动态变化。当互联网的一部分内容发生变化时,本地抓取的网页就会失效。因此,下载的网页分为两类:下载的未过期网页和下载的过期网页。
图4 网页分类
要下载的页面是 URL 队列中要抓取的页面。
可以看出,网页是指尚未被爬取且不在待爬取URL队列中的网页,但可以通过分析爬取的页面或待爬取URL对应的页面得到。
还有一些网页是网络爬虫无法直接爬取下载的,称为不可知网页。
下面重点介绍几种常见的爬取策略。
1. 通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子URL延伸到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫将从起始页面开始,并逐个链接地跟踪它,直到无法再深入为止。
完成一个爬取分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有的链接都遍历完后,爬取任务结束。
这种策略比较适合垂直搜索或者站内搜索,但是在抓取页面内容比较深的网站时会造成巨大的资源浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后继节点都在该节点的兄弟节点之前,深度优先策略在搜索空间中。有时,它会尝试尽可能深入,并且仅在找不到节点的后继节点时才考虑其兄弟节点。
这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果不加以限制,它将沿着一条路径无限扩展,这将“捕获”成大量数据。一般来说,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样会降低搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫进入下一级继续爬取。
还是以图3为例,遍历的路径是1→2→3→4→5→6→7→8
由于广度优先策略是在第 N 层的节点扩展完成后进入第 N+1 层,保证了通过最短路径找到解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支时爬取无法结束的问题。实现方便,不需要存储大量中间节点。缺点是爬到更深的目录级别需要很长时间。页。
如果搜索的分支太多,即节点的后继节点太多,算法就会耗尽资源,在可用空间中找不到解。
2. 聚焦网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是选择性地爬取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入网络爬虫,提出了 Fish Search 算法。
该算法以用户输入的查询词为主题,将收录查询词的页面视为与该主题相关的页面,其局限性在于无法评估该页面与该主题的相关性。
Herseovic 对 Fish Search 算法进行了改进,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面和主题之间的相关度。
通过采用基于连续值计算链接值的方法,我们不仅可以计算出哪些捕获的链接与主题相关,而且可以得到相关性的量化大小。
2)基于链接结构评估的爬取策略
与普通文本不同,网页是收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面中的链接表示页面之间的关系。基于链接结构的搜索策略模式利用这些结构特征来评估页面和链接的重要性,从而确定搜索顺序。其中,PageRank算法就是这种搜索策略模式的代表。
PageRank算法的基本原理是,如果一个网页被多次引用,它可能是一个重要的网页;如果一个网页没有被多次引用,而是被一个重要网页引用,那么它也可能是一个重要网页。一个网页的重要性同样传递给它所指的网页。
链接页面的PageRank是通过将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值分别与前向链接所指向的页面的PageRank相加得到。
如图 5 所示,PageRank 为 100 的页面将其重要性平等地传递给它所引用的两个页面,每个页面获得 50,而 PageRank 为 9 的同一页面将其重要性传递给它所引用的三个页面。页面的每一页都传递一个值 3。
PageRank 为 53 的页面的值源自引用它的两个页面传递的值。
,
图5 PageRank算法示例
3)基于强化学习的爬取策略
Rennie 和 McCallum 将强化学习引入聚焦爬虫中,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性以确定链接被访问的顺序。
4)基于上下文图的爬取策略
勤勉等人。提出了一种爬取策略,通过构建上下文图来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面到相关网页的距离。中的链接具有优先访问权。
3. 增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只爬取新生成或更改的网页的爬虫。可以在一定程度上保证爬取的页面尽可能的新。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要通过重访网页来更新本地页面集中的页面内容。常用的方法有统一更新法、个体更新法和分类更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略和PageRank优先策略。
4. 深网爬虫
网页按存在方式可分为表层网页和深层网页。
深网爬虫架构由六个基本功能模块(爬取控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS表)组成。
其中,LVS(LabelValueSet)表示标签和值的集合,用来表示填写表单的数据源。在爬取过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。 查看全部
抓取网页视频(网络爬虫系统的原理和工作流程介绍-乐题库)
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。该方法可以从网页中提取非结构化数据,存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,附件可以自动与文本关联。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫的原理
网络爬虫是根据一定的规则自动爬取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。从功能上来说,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图1 网络爬虫示意图
除了供用户阅读的文字信息外,网页还收录一些超链接信息。
网络爬虫系统正是通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫系统一般会选择一些比较重要的、出度(网页链接出的超链接数)网站较大的URL作为种子URL集。
网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以遍历所有的网页。
由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。
网络爬虫系统首先将种子 URL 放入下载队列,简单地从队列头部取一个 URL 下载其对应的网页,获取网页内容并存储,然后解析链接信息网页以获取一些新的 URL。
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,放入待抓取的URL队列中。
最后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫工作流程
如图 2 所示,网络爬虫的基本工作流程如下。
1)首先选择 Torrent URL 的一部分。
2)将这些网址放入待抓取的网址队列中。
3) 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP地址,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列。
4)分析已爬取URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列,从而进入下一个循环。
图2 网络爬虫基本工作流程
网络爬虫抓取策略
谷歌、百度等常见搜索引擎抓取的网页数量通常以数十亿计。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页呢?如果您对大数据开发感兴趣,想系统地学习大数据,可以加入大数据技术学习交流群:458号345号782获取学习资源,从而扩大网页信息的覆盖范围可能,这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,爬取策略决定了网页被爬取的顺序。
本节首先简要介绍网络爬取策略中使用的基本概念。
1)网页之间的关系模型
从互联网的结构来看,网页通过各种超链接相互连接,形成一个巨大而复杂的相互关联的有向图。
如图3所示,如果把网页看成图中的一个节点,把网页中其他网页的链接看成这个节点到其他节点的边,那么我们就可以轻松查看整个互联网网页被建模为有向图。
理论上,通过遍历算法对图进行遍历,几乎可以访问互联网上的任何网页。
图3 网页关系模型图
2)网页分类
从爬虫的角度来划分互联网,可以将互联网的所有页面分为5个部分:已下载未过期网页、已下载已过期网页、待下载网页、已知网页和未知网页,如图4.
本地爬取的网页实际上是互联网内容的镜像和备份。互联网正在动态变化。当互联网的一部分内容发生变化时,本地抓取的网页就会失效。因此,下载的网页分为两类:下载的未过期网页和下载的过期网页。
图4 网页分类
要下载的页面是 URL 队列中要抓取的页面。
可以看出,网页是指尚未被爬取且不在待爬取URL队列中的网页,但可以通过分析爬取的页面或待爬取URL对应的页面得到。
还有一些网页是网络爬虫无法直接爬取下载的,称为不可知网页。
下面重点介绍几种常见的爬取策略。
1. 通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子URL延伸到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫将从起始页面开始,并逐个链接地跟踪它,直到无法再深入为止。
完成一个爬取分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有的链接都遍历完后,爬取任务结束。
这种策略比较适合垂直搜索或者站内搜索,但是在抓取页面内容比较深的网站时会造成巨大的资源浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后继节点都在该节点的兄弟节点之前,深度优先策略在搜索空间中。有时,它会尝试尽可能深入,并且仅在找不到节点的后继节点时才考虑其兄弟节点。
这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果不加以限制,它将沿着一条路径无限扩展,这将“捕获”成大量数据。一般来说,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样会降低搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫进入下一级继续爬取。
还是以图3为例,遍历的路径是1→2→3→4→5→6→7→8
由于广度优先策略是在第 N 层的节点扩展完成后进入第 N+1 层,保证了通过最短路径找到解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支时爬取无法结束的问题。实现方便,不需要存储大量中间节点。缺点是爬到更深的目录级别需要很长时间。页。
如果搜索的分支太多,即节点的后继节点太多,算法就会耗尽资源,在可用空间中找不到解。
2. 聚焦网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是选择性地爬取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入网络爬虫,提出了 Fish Search 算法。
该算法以用户输入的查询词为主题,将收录查询词的页面视为与该主题相关的页面,其局限性在于无法评估该页面与该主题的相关性。
Herseovic 对 Fish Search 算法进行了改进,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面和主题之间的相关度。
通过采用基于连续值计算链接值的方法,我们不仅可以计算出哪些捕获的链接与主题相关,而且可以得到相关性的量化大小。
2)基于链接结构评估的爬取策略
与普通文本不同,网页是收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面中的链接表示页面之间的关系。基于链接结构的搜索策略模式利用这些结构特征来评估页面和链接的重要性,从而确定搜索顺序。其中,PageRank算法就是这种搜索策略模式的代表。
PageRank算法的基本原理是,如果一个网页被多次引用,它可能是一个重要的网页;如果一个网页没有被多次引用,而是被一个重要网页引用,那么它也可能是一个重要网页。一个网页的重要性同样传递给它所指的网页。
链接页面的PageRank是通过将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值分别与前向链接所指向的页面的PageRank相加得到。
如图 5 所示,PageRank 为 100 的页面将其重要性平等地传递给它所引用的两个页面,每个页面获得 50,而 PageRank 为 9 的同一页面将其重要性传递给它所引用的三个页面。页面的每一页都传递一个值 3。
PageRank 为 53 的页面的值源自引用它的两个页面传递的值。
,
图5 PageRank算法示例
3)基于强化学习的爬取策略
Rennie 和 McCallum 将强化学习引入聚焦爬虫中,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性以确定链接被访问的顺序。
4)基于上下文图的爬取策略
勤勉等人。提出了一种爬取策略,通过构建上下文图来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面到相关网页的距离。中的链接具有优先访问权。
3. 增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只爬取新生成或更改的网页的爬虫。可以在一定程度上保证爬取的页面尽可能的新。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要通过重访网页来更新本地页面集中的页面内容。常用的方法有统一更新法、个体更新法和分类更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略和PageRank优先策略。
4. 深网爬虫
网页按存在方式可分为表层网页和深层网页。
深网爬虫架构由六个基本功能模块(爬取控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS表)组成。
其中,LVS(LabelValueSet)表示标签和值的集合,用来表示填写表单的数据源。在爬取过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
抓取网页视频(公众号利器技术社(传送门:放了大概50多个视频下载代码))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-27 18:03
抓取网页视频并下载一直都是当前搜索引擎数据录入的一大大重点,sogou视频分享、fqrade都曾提供这一技术支持,通过爬虫技术,能够快速将图片、视频等网页视频快速下载下来,并提供清晰度、时间长短等各项指标。爬虫技术的速度快,但是需要动手写大量代码,那如何才能动态地进行视频下载呢?今天,我就在公众号利器技术社(id:lirubixia)推送了一篇,如何抓取ppt动态下载的文章(传送门:,放了大概50多个视频下载代码),供你参考。
当然也适用于python等其他脚本语言。由于我用的是anaconda,一路滚到配置好jupyternotebook,然后我直接在pythoncode和windowscmd中调用,至此,我也进行了内网穿透,并通过配置vnc环境,直接通过vnc进行ppt动态下载。目录为什么要抓取ppt视频下载?anaconda+jupyterfile和windowscmd如何配置vncviewer?详细测试数据在公众号利器技术社(id:lirubixia)进行大量数据爬取。
下面是我录制的视频:抓取视频,下载路径为:/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83。 查看全部
抓取网页视频(公众号利器技术社(传送门:放了大概50多个视频下载代码))
抓取网页视频并下载一直都是当前搜索引擎数据录入的一大大重点,sogou视频分享、fqrade都曾提供这一技术支持,通过爬虫技术,能够快速将图片、视频等网页视频快速下载下来,并提供清晰度、时间长短等各项指标。爬虫技术的速度快,但是需要动手写大量代码,那如何才能动态地进行视频下载呢?今天,我就在公众号利器技术社(id:lirubixia)推送了一篇,如何抓取ppt动态下载的文章(传送门:,放了大概50多个视频下载代码),供你参考。
当然也适用于python等其他脚本语言。由于我用的是anaconda,一路滚到配置好jupyternotebook,然后我直接在pythoncode和windowscmd中调用,至此,我也进行了内网穿透,并通过配置vnc环境,直接通过vnc进行ppt动态下载。目录为什么要抓取ppt视频下载?anaconda+jupyterfile和windowscmd如何配置vncviewer?详细测试数据在公众号利器技术社(id:lirubixia)进行大量数据爬取。
下面是我录制的视频:抓取视频,下载路径为:/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83wnpryabvc2cm/root/jupyter_container_mirror_list.jupytj36y5vyazj8t7q83。

