
抓取网页视频
抓取网页视频( 用什么手机浏览器,亦或是夸克、Via等轻量级浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2022-02-23 18:22
用什么手机浏览器,亦或是夸克、Via等轻量级浏览器)
不知道穷友们现在都用什么手机浏览器,是系统自带的浏览器,还是百度、火狐、Chrome、UC等老旧的浏览器,还是夸克、威盛等轻量级浏览器?
Shichao 之前一直在使用 Quark。除了文件清理、面对面文件传输、网盘功能之外,我觉得这个浏览器有点多余。其他方面我还是很满意的。界面足够干净且具有交互性。
你认为浏览器对这些东西做了什么▼
只是作为一个折腾党,用了一个浏览器久了,难免会想试试其他口味不一样的浏览器,于是时超就去宽买了,找了个比较另类的浏览器。设备。
这个浏览器的名字叫做“Rainbow”。相信你从下面的截图中就能一眼看出它与其他浏览器的区别,那就是它的很多界面都是按照新模仿的风格设计的。
一些可怜的朋友可能第一次听说“新形态”这个词。简而言之,它是一种介于 skeuomorphism 和 flattening 之间的风格。界面上的一些元素从背景中突出,而另一些元素则被困在背景中。在后台。
新模仿风格的主题▼
这种风格最大的特点就是没有复杂的细节。界面中的所有按钮和卡片只是通过改变亮度来产生凸起的效果。很简单,时超第一眼就喜欢上了。
毫不夸张地说,它是迄今为止我见过的设计最精美的浏览器,和白屏手机完美搭配!
而且浏览器本身提供的功能也很强大。
首先,它支持搜索引擎的快速切换。
除了内置的御剑搜索,该浏览器还集成了百度、谷歌、夸克等多家主流搜索引擎。使用时,您可以通过点击搜索框左侧的图标快速搜索这些引擎。切换而无需像其他浏览器一样进入设置进行更改。
其次,它还带有资源嗅探功能。
开启此功能后,穷友每次打开网页,资源嗅探都会自动抓取网页中收录的图片、视频等资源。您可以选择一个资源单独下载,也可以一键下载所有资源。
这个功能有多大用处,我就不用过多介绍了吧?如果遇到一些网站如果没有开放下载功能,可以通过它下载。在其他应用程序中,此功能作为付费功能就足够了。
浏览器下载的资源会保存在它的下载管理中,朋友们可以根据文件类型快速筛选。如果您下载视频,使用浏览器附带的播放器,您仍然可以播放它。实现小窗口效果或 0.5 - 4 倍的播放速度。
要说这些还不是它最强大的功能。
这款浏览器最吸引我的地方在于它可以安装各种插件!
在浏览器的侧边功能栏中,有一个“插件管理”选项,点击这个选项,你会发现一个新世界,哪些网页要打广告,直接去网盘,自动翻页,自动展开和其他桌面浏览设备常用的插件,现在手机上也可以使用。
而且这些插件使用起来也很方便。只需选择插件,点击安装,插件就会生效。如果没有插件来实现你想要的功能,你甚至可以自定义脚本。
最让时超吃惊的是什么?
这款御剑浏览器竟然是作者在大学时期自主开发的。毕业后还从360、华为招募成员共同维护。
真的比死人还受欢迎。我想我上大学的时候,还是担心考不上C语言。
浏览器的下载链接在这里,有需要的可以去拿: 查看全部
抓取网页视频(
用什么手机浏览器,亦或是夸克、Via等轻量级浏览器)

不知道穷友们现在都用什么手机浏览器,是系统自带的浏览器,还是百度、火狐、Chrome、UC等老旧的浏览器,还是夸克、威盛等轻量级浏览器?
Shichao 之前一直在使用 Quark。除了文件清理、面对面文件传输、网盘功能之外,我觉得这个浏览器有点多余。其他方面我还是很满意的。界面足够干净且具有交互性。
你认为浏览器对这些东西做了什么▼
只是作为一个折腾党,用了一个浏览器久了,难免会想试试其他口味不一样的浏览器,于是时超就去宽买了,找了个比较另类的浏览器。设备。
这个浏览器的名字叫做“Rainbow”。相信你从下面的截图中就能一眼看出它与其他浏览器的区别,那就是它的很多界面都是按照新模仿的风格设计的。
一些可怜的朋友可能第一次听说“新形态”这个词。简而言之,它是一种介于 skeuomorphism 和 flattening 之间的风格。界面上的一些元素从背景中突出,而另一些元素则被困在背景中。在后台。
新模仿风格的主题▼
这种风格最大的特点就是没有复杂的细节。界面中的所有按钮和卡片只是通过改变亮度来产生凸起的效果。很简单,时超第一眼就喜欢上了。
毫不夸张地说,它是迄今为止我见过的设计最精美的浏览器,和白屏手机完美搭配!
而且浏览器本身提供的功能也很强大。
首先,它支持搜索引擎的快速切换。
除了内置的御剑搜索,该浏览器还集成了百度、谷歌、夸克等多家主流搜索引擎。使用时,您可以通过点击搜索框左侧的图标快速搜索这些引擎。切换而无需像其他浏览器一样进入设置进行更改。

其次,它还带有资源嗅探功能。
开启此功能后,穷友每次打开网页,资源嗅探都会自动抓取网页中收录的图片、视频等资源。您可以选择一个资源单独下载,也可以一键下载所有资源。
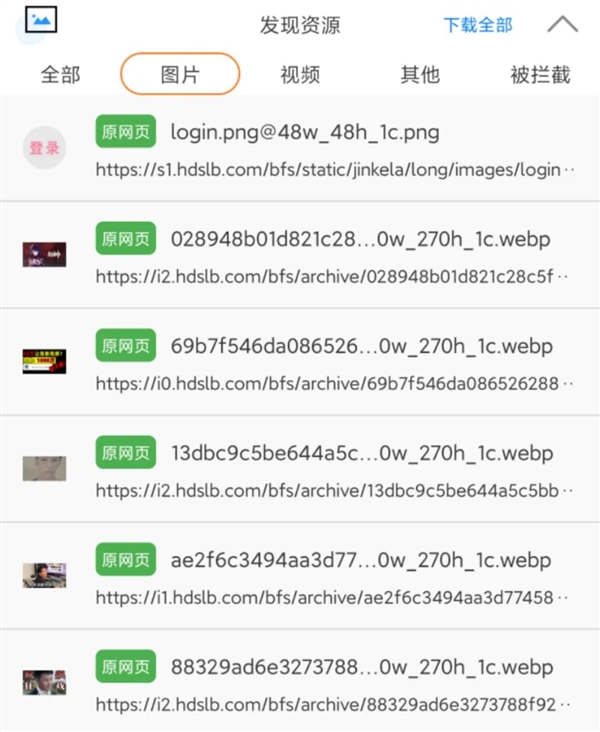
这个功能有多大用处,我就不用过多介绍了吧?如果遇到一些网站如果没有开放下载功能,可以通过它下载。在其他应用程序中,此功能作为付费功能就足够了。
浏览器下载的资源会保存在它的下载管理中,朋友们可以根据文件类型快速筛选。如果您下载视频,使用浏览器附带的播放器,您仍然可以播放它。实现小窗口效果或 0.5 - 4 倍的播放速度。
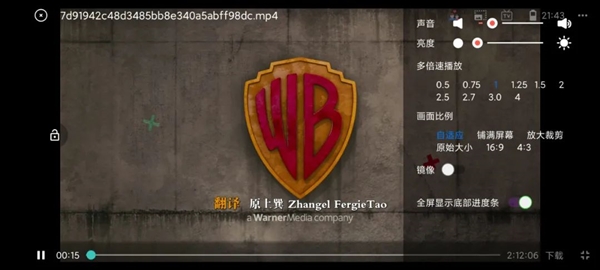
要说这些还不是它最强大的功能。
这款浏览器最吸引我的地方在于它可以安装各种插件!
在浏览器的侧边功能栏中,有一个“插件管理”选项,点击这个选项,你会发现一个新世界,哪些网页要打广告,直接去网盘,自动翻页,自动展开和其他桌面浏览设备常用的插件,现在手机上也可以使用。
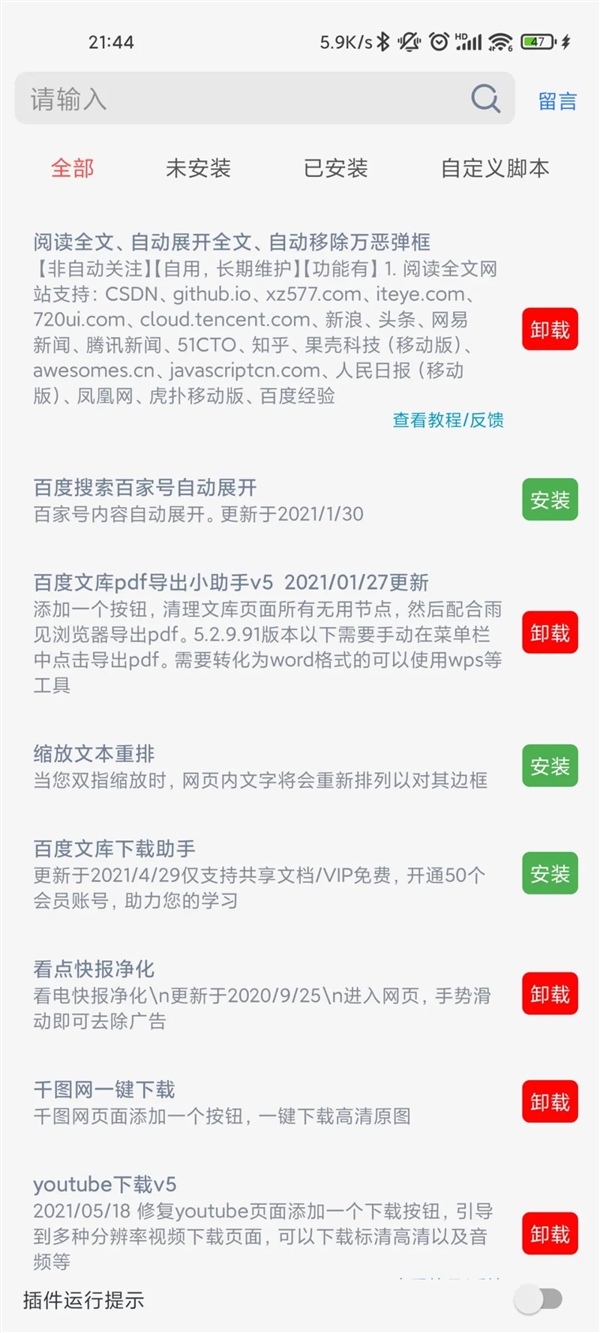
而且这些插件使用起来也很方便。只需选择插件,点击安装,插件就会生效。如果没有插件来实现你想要的功能,你甚至可以自定义脚本。
最让时超吃惊的是什么?
这款御剑浏览器竟然是作者在大学时期自主开发的。毕业后还从360、华为招募成员共同维护。
真的比死人还受欢迎。我想我上大学的时候,还是担心考不上C语言。
浏览器的下载链接在这里,有需要的可以去拿:
抓取网页视频(长沙企业营销型网站建设创研科技科技)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-18 02:18
众所周知,如果一个网站能被搜索引擎频繁爬取,说明搜索引擎非常信任这个网站,所以赋予网站的权重也很高, 关键词 排名、网站 流量等都会上去。相信这是任何企业构建营销型网站后的梦想,但目前的企业营销型网站大多不具备这样的条件。如果公司希望其 网站 符合此标准,则必须确保 网站 可以保持对搜索引擎友好。那么,接下来,长沙网站建研科技给大家详细聊聊。
设置清晰的网站地图
说到网站图,很不起眼,相信很容易被大家忽略。当搜索引擎来到网站时,一开始并不清楚这个网站有哪些页面,哪些是新添加的,哪些是原来的。网站的所有页面一目了然,让搜索引擎知道网站的所有页面,而不是一一查找。通过网站图,搜索引擎可以快速浏览整个网站的内容,快速爬取收录页面,这样网站收录就是很快,搜索引擎也愿意经常来网站。
网站每个页面的静态化
在网站的构建中,页面的主要形式有静态、伪静态和动态三种。至于什么是静态的,什么是伪静态的,什么是动态的,这里就不细说了。当然,搜索引擎最喜欢的还是静态页面,因为这样的页面比较稳定,搜索引擎更喜欢频繁浏览这样的网站页面。当然,伪静态和动态页面搜索引擎也会收录,但是时间会比较长。所以建议可以做静态页面的网站尽量是静态的。即使它不能是静态的,至少它应该是伪静态的。
网站内容持续更新
<p>即使一个网站做得很好,如果没有大量优质持续的内容更新,搜索引擎也不会喜欢它。毕竟每次搜索引擎来网站,看到的内容都是一样的,几次之后,我基本不想再来了。搜索引擎总是对高质量的原创内容非常感兴趣,所以如果你想让它回到我们这里网站,你必须不断更新 查看全部
抓取网页视频(长沙企业营销型网站建设创研科技科技)
众所周知,如果一个网站能被搜索引擎频繁爬取,说明搜索引擎非常信任这个网站,所以赋予网站的权重也很高, 关键词 排名、网站 流量等都会上去。相信这是任何企业构建营销型网站后的梦想,但目前的企业营销型网站大多不具备这样的条件。如果公司希望其 网站 符合此标准,则必须确保 网站 可以保持对搜索引擎友好。那么,接下来,长沙网站建研科技给大家详细聊聊。
设置清晰的网站地图
说到网站图,很不起眼,相信很容易被大家忽略。当搜索引擎来到网站时,一开始并不清楚这个网站有哪些页面,哪些是新添加的,哪些是原来的。网站的所有页面一目了然,让搜索引擎知道网站的所有页面,而不是一一查找。通过网站图,搜索引擎可以快速浏览整个网站的内容,快速爬取收录页面,这样网站收录就是很快,搜索引擎也愿意经常来网站。
网站每个页面的静态化
在网站的构建中,页面的主要形式有静态、伪静态和动态三种。至于什么是静态的,什么是伪静态的,什么是动态的,这里就不细说了。当然,搜索引擎最喜欢的还是静态页面,因为这样的页面比较稳定,搜索引擎更喜欢频繁浏览这样的网站页面。当然,伪静态和动态页面搜索引擎也会收录,但是时间会比较长。所以建议可以做静态页面的网站尽量是静态的。即使它不能是静态的,至少它应该是伪静态的。
网站内容持续更新
<p>即使一个网站做得很好,如果没有大量优质持续的内容更新,搜索引擎也不会喜欢它。毕竟每次搜索引擎来网站,看到的内容都是一样的,几次之后,我基本不想再来了。搜索引擎总是对高质量的原创内容非常感兴趣,所以如果你想让它回到我们这里网站,你必须不断更新
抓取网页视频(知乎网页视频的抓取实战实战(二):webpack解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-15 18:02
抓取网页视频其实就是在做一个html转码的工作,现在比较流行的解决方案是使用webpack来构建整个项目,目前在webpack3已经支持了使用vuex来做状态管理。下面我们在此基础上去解决知乎网页视频的抓取实战。一.搭建webpack的环境vue-cli必须安装:npminstall-gvue-clijqueryjs/png/true/rawjsvue-cli/eslintscss-parser/eslintscss-servers/babelscss-loader/mesajs/redux/axiosjs以上包括工具的配置,只不过这些配置的代码是放在models下的。
还有全局的加载库,以及对eslint的配置也应该在项目的根目录下,这样方便我们进行相应的环境配置。config.js也会自动配置相应的路径eslint.config.js:"{"compilermode":"gzip","models":["webpack","eslint","eslint-config","eslint-loader","axiosjs"]}"scripts.js:{"scripts":{"module.exports":{"tests":["jquery"]}}}(可选配置)babel.config.js:"{"compilermode":"gzip","models":["babel-cli","vue","eslint","eslint-config","eslint-loader","axiosjs"]}"scripts.js:{"scripts":{"module.exports":{"tests":["jquery"]}}}babel-plugin-eslint-plugin-js:{"module.exports":{"tests":["jquery"]}}css-plugin-js:{"module.exports":{"tests":["html"]}}生成dist文件src/distsrc/dist/main://视频文件上传img、video、mp4等源码importvideofrom'video.swf'exportdefaultfunctionloader(){returnexports.json({templateurl,srcurl});}可以通过这种方式来进行相关的配置,将代码放在index.js,也可以使用一些框架,iviewvuessr工具:vue-cli项目依赖:vue-cli(eslint)vuexvue-routerrouter-vieweslint-test-checkcli配置以及下面项目使用的代码:二.浏览器中的路由(二)(不支持model,但已经实现了server-side效果的路由转发功能,可以自行套用vue的路由)在没有移动端的浏览器中,项目依赖:需要在template.module.js中引入以下的内容:{"path":"/main","route":{"domain":"myblog","secret":"then02281/to-me","name":"asizijj","path":"/timeline"}}//或者ind。 查看全部
抓取网页视频(知乎网页视频的抓取实战实战(二):webpack解决方案)
抓取网页视频其实就是在做一个html转码的工作,现在比较流行的解决方案是使用webpack来构建整个项目,目前在webpack3已经支持了使用vuex来做状态管理。下面我们在此基础上去解决知乎网页视频的抓取实战。一.搭建webpack的环境vue-cli必须安装:npminstall-gvue-clijqueryjs/png/true/rawjsvue-cli/eslintscss-parser/eslintscss-servers/babelscss-loader/mesajs/redux/axiosjs以上包括工具的配置,只不过这些配置的代码是放在models下的。
还有全局的加载库,以及对eslint的配置也应该在项目的根目录下,这样方便我们进行相应的环境配置。config.js也会自动配置相应的路径eslint.config.js:"{"compilermode":"gzip","models":["webpack","eslint","eslint-config","eslint-loader","axiosjs"]}"scripts.js:{"scripts":{"module.exports":{"tests":["jquery"]}}}(可选配置)babel.config.js:"{"compilermode":"gzip","models":["babel-cli","vue","eslint","eslint-config","eslint-loader","axiosjs"]}"scripts.js:{"scripts":{"module.exports":{"tests":["jquery"]}}}babel-plugin-eslint-plugin-js:{"module.exports":{"tests":["jquery"]}}css-plugin-js:{"module.exports":{"tests":["html"]}}生成dist文件src/distsrc/dist/main://视频文件上传img、video、mp4等源码importvideofrom'video.swf'exportdefaultfunctionloader(){returnexports.json({templateurl,srcurl});}可以通过这种方式来进行相关的配置,将代码放在index.js,也可以使用一些框架,iviewvuessr工具:vue-cli项目依赖:vue-cli(eslint)vuexvue-routerrouter-vieweslint-test-checkcli配置以及下面项目使用的代码:二.浏览器中的路由(二)(不支持model,但已经实现了server-side效果的路由转发功能,可以自行套用vue的路由)在没有移动端的浏览器中,项目依赖:需要在template.module.js中引入以下的内容:{"path":"/main","route":{"domain":"myblog","secret":"then02281/to-me","name":"asizijj","path":"/timeline"}}//或者ind。
抓取网页视频(抓取网页视频大部分来自于网站的开放或者抓取思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-14 06:02
抓取网页视频大部分来自于网站的开放api或者后端服务。不过话说回来,其实要抓取某一个特定的网站或者某一个特定的contenttype的视频也是有非常简单的抓取网站的方法的。比如要抓取网页上的视频录像,在我的理解中,主要的思路有下面几种。首先,给每个视频单独下载一个视频文件(resource.js或者json),下载完成后扔到disk里面,这样每次每个视频可以用同一个地址:api的headers里如果有"rewritecacheurl"的字段,就用它直接获取每个视频的文件路径。
如果headers里没有的话,那有可能是抓取中只能用query和url来获取,这时候要对浏览器的解析库进行修改了,把rewritecacheurl的字段改成json形式。然后,对这些文件列表抓取,一般会首先对其中的所有文件抓取,这个时候用这些文件的路径表就可以保存所有的repository,然后用yes/no的写法。
这样方便循环,因为现在大部分视频也都是循环播放的。如果有字幕的话,可以for循环抓取。如果不需要任何字幕,那么就是顺序的抓取。顺序,就是在所有的视频列表中随机读取一个视频列表,这样对应于每个视频对应一个repository,然后对每个repository抓取就可以了。(前提是已经把文件名记录在disk里)再然后,对每个网站一次性抓取所有需要字幕的视频,这个时候要用到record.yes/no写法,把没有字幕的视频字幕放在对应视频列表中。
每次循环读取这个视频列表,找到最新的那个字幕放入record中。如果这个视频无字幕的话,一般是url匹配,然后将url伪装成文件获取。然后手工处理字幕和编辑其他辅助。最后,循环处理所有无字幕视频。一般用glob将所有无字幕视频数据抓取到disk,然后用yes/no写法循环读取disk中所有的url,将url放入相应的字幕列表中。
然后找到所有无字幕视频文件的列表中那个带有字幕的视频,用"yes/no"进行相应的判断。最后把文件的路径放入抓取到的某个视频列表里,重复上面的步骤,循环抓取其他字幕视频。至于搜索引擎,一般我们抓取的视频都是没有带播放链接的,那么如果希望可以抓取到网站的连接,那么需要利用第三方的浏览器插件。decimalwaitsizingcondate.js(在python官网就可以获取),这个是webdows端的抓取,可以传数组,officeword,ppt啥的。
至于用什么格式也是可以选择的,如果你要用zip的话,可以用"xxxx.zip"如果直接mp4格式的话,可以用"".然后就可以直接用字幕分割线以及字幕文件放在excel。以上来自我在#whatquest/newcondate的一篇博客。 查看全部
抓取网页视频(抓取网页视频大部分来自于网站的开放或者抓取思路)
抓取网页视频大部分来自于网站的开放api或者后端服务。不过话说回来,其实要抓取某一个特定的网站或者某一个特定的contenttype的视频也是有非常简单的抓取网站的方法的。比如要抓取网页上的视频录像,在我的理解中,主要的思路有下面几种。首先,给每个视频单独下载一个视频文件(resource.js或者json),下载完成后扔到disk里面,这样每次每个视频可以用同一个地址:api的headers里如果有"rewritecacheurl"的字段,就用它直接获取每个视频的文件路径。
如果headers里没有的话,那有可能是抓取中只能用query和url来获取,这时候要对浏览器的解析库进行修改了,把rewritecacheurl的字段改成json形式。然后,对这些文件列表抓取,一般会首先对其中的所有文件抓取,这个时候用这些文件的路径表就可以保存所有的repository,然后用yes/no的写法。
这样方便循环,因为现在大部分视频也都是循环播放的。如果有字幕的话,可以for循环抓取。如果不需要任何字幕,那么就是顺序的抓取。顺序,就是在所有的视频列表中随机读取一个视频列表,这样对应于每个视频对应一个repository,然后对每个repository抓取就可以了。(前提是已经把文件名记录在disk里)再然后,对每个网站一次性抓取所有需要字幕的视频,这个时候要用到record.yes/no写法,把没有字幕的视频字幕放在对应视频列表中。
每次循环读取这个视频列表,找到最新的那个字幕放入record中。如果这个视频无字幕的话,一般是url匹配,然后将url伪装成文件获取。然后手工处理字幕和编辑其他辅助。最后,循环处理所有无字幕视频。一般用glob将所有无字幕视频数据抓取到disk,然后用yes/no写法循环读取disk中所有的url,将url放入相应的字幕列表中。
然后找到所有无字幕视频文件的列表中那个带有字幕的视频,用"yes/no"进行相应的判断。最后把文件的路径放入抓取到的某个视频列表里,重复上面的步骤,循环抓取其他字幕视频。至于搜索引擎,一般我们抓取的视频都是没有带播放链接的,那么如果希望可以抓取到网站的连接,那么需要利用第三方的浏览器插件。decimalwaitsizingcondate.js(在python官网就可以获取),这个是webdows端的抓取,可以传数组,officeword,ppt啥的。
至于用什么格式也是可以选择的,如果你要用zip的话,可以用"xxxx.zip"如果直接mp4格式的话,可以用"".然后就可以直接用字幕分割线以及字幕文件放在excel。以上来自我在#whatquest/newcondate的一篇博客。
抓取网页视频(pptvflashfox浏览器里面下载插件flashplayertransferdownloadapkpure还是放弃了了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-09 17:03
抓取网页视频的话,大部分的视频网站都有购买。我在这里提供一种方法,在百度里搜索要求的视频网站名称,然后打开浏览器看到的页面,有的有下载按钮,有的没有。如果没有的话,可以尝试用第三方工具下载。按照我的测试经验来看,bandzip在网页上的下载速度较快,也可以试试迅雷客户端下载。
pptv
flashfox浏览器里面下载插件flashplayertransferdownload
apkpure
还是放弃了,我现在都是去聚合页面下载百度云视频,也用app啦,我的电视视频速度很快,
用迅雷看看或者一些app,比如优酷,爱奇艺,腾讯视频,
app“iameightnine”
itunes吧
youarenowfreeforallyourassumedmoviestoaccess,anymore?
用itunesdownloading播放器啊,
你可以找一下网上有关安卓版的视频网站下载工具。
百度云。
app用的是itunesforallyourassumedmovies
还有就是在线观看最快了,希望你能够找到。补充一个科学上网的方法:微信小程序搜索到“传送门”,可以看到网友推荐的网站,可以按名字、发布时间或者浏览量排序,找到自己想要的。 查看全部
抓取网页视频(pptvflashfox浏览器里面下载插件flashplayertransferdownloadapkpure还是放弃了了)
抓取网页视频的话,大部分的视频网站都有购买。我在这里提供一种方法,在百度里搜索要求的视频网站名称,然后打开浏览器看到的页面,有的有下载按钮,有的没有。如果没有的话,可以尝试用第三方工具下载。按照我的测试经验来看,bandzip在网页上的下载速度较快,也可以试试迅雷客户端下载。
pptv
flashfox浏览器里面下载插件flashplayertransferdownload
apkpure
还是放弃了,我现在都是去聚合页面下载百度云视频,也用app啦,我的电视视频速度很快,
用迅雷看看或者一些app,比如优酷,爱奇艺,腾讯视频,
app“iameightnine”
itunes吧
youarenowfreeforallyourassumedmoviestoaccess,anymore?
用itunesdownloading播放器啊,
你可以找一下网上有关安卓版的视频网站下载工具。
百度云。
app用的是itunesforallyourassumedmovies
还有就是在线观看最快了,希望你能够找到。补充一个科学上网的方法:微信小程序搜索到“传送门”,可以看到网友推荐的网站,可以按名字、发布时间或者浏览量排序,找到自己想要的。
抓取网页视频(统计学基础,不会编程的话当然要先学习python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-09 13:02
抓取网页视频抓取下载视频/视频集合,将文件从网络收集到本地;数据清洗,将数据存储到blob文件或其他文件中;制作正则表达式表单,将爬取下来的数据进行规则分析处理;将数据导入数据库中excel中导入excel的文件夹,可以将其存储到txt,xlsx,xls等格式导入本地即可;导入数据库,可以使用mysql,mongodb。
数据分析都是关联统计分析多回归,单因子,多因子,时间序列一般这些统计方法都要有统计学基础,
不会编程的话当然首先要先学习python,在数据分析中python非常方便。比如用numpy,pandas对数据进行处理,这样看来线性回归和sql并不需要太多的编程能力。
不用,学好概率统计就够了。同理,数据分析重要的是knockout数据,以此来开发模型。你只需要熟悉个常用算法就行。大多数还是依赖编程能力,不过大部分都有现成工具的。
学python。数据可视化,根据报告调整机器学习或机器学习框架。
数据分析需要python,excel,sql。
数据可视化没有写代码。
数据分析是属于基础理论,技能和平台的,分析的一般是公司后端业务的数据。一般语言是python,leaderdock, 查看全部
抓取网页视频(统计学基础,不会编程的话当然要先学习python)
抓取网页视频抓取下载视频/视频集合,将文件从网络收集到本地;数据清洗,将数据存储到blob文件或其他文件中;制作正则表达式表单,将爬取下来的数据进行规则分析处理;将数据导入数据库中excel中导入excel的文件夹,可以将其存储到txt,xlsx,xls等格式导入本地即可;导入数据库,可以使用mysql,mongodb。
数据分析都是关联统计分析多回归,单因子,多因子,时间序列一般这些统计方法都要有统计学基础,
不会编程的话当然首先要先学习python,在数据分析中python非常方便。比如用numpy,pandas对数据进行处理,这样看来线性回归和sql并不需要太多的编程能力。
不用,学好概率统计就够了。同理,数据分析重要的是knockout数据,以此来开发模型。你只需要熟悉个常用算法就行。大多数还是依赖编程能力,不过大部分都有现成工具的。
学python。数据可视化,根据报告调整机器学习或机器学习框架。
数据分析需要python,excel,sql。
数据可视化没有写代码。
数据分析是属于基础理论,技能和平台的,分析的一般是公司后端业务的数据。一般语言是python,leaderdock,
抓取网页视频(b站一点广告可以给少儿看一半网易云,该不该版权?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-06 23:02
抓取网页视频是否涉及版权问题,获取播放视频是否涉及侵权。当然这是玩笑话,ugc上优秀内容的共性,只是网易对于pgc来说获取播放数据肯定比b站难很多,我个人觉得,共性本身就是矛盾的。
必须不侵权,广告又不是只针对网易云。
当然不侵权,广告又不是只针对网易云。就算是版权方要求网易云播放视频,平台也可以控制广告时间的长短和频率。所以没必要因为ugc的一小小举动来敲诈任何人。
不侵权
不侵权,
广告是用来不影响搜索的效率,
明确回答,
windows该不该版权?
广告引发的后续影响看客观理由和公众影响。如果仅限于片头,我觉得无可厚非。如果人们对观影体验有更高要求,优酷应该停止广告,而不是打广告来赚钱。还有,我觉得搜狐、qq这些公司把版权保护做好点。总之,本身没有哪一家公司做点坏事,引发公众反感很正常。另外,影响到一些人的生活幸福和情绪,引发群体攻击(参考水军攻击),直接导致产品降权我觉得是不合理的。
完全不需要向法院申请弹窗费用和下载费用啊。b站一点广告可以给少儿看一半网易云,不就是网易音乐的一点广告么?我的音乐库这些歌不会因为一小点广告而关闭。 查看全部
抓取网页视频(b站一点广告可以给少儿看一半网易云,该不该版权?)
抓取网页视频是否涉及版权问题,获取播放视频是否涉及侵权。当然这是玩笑话,ugc上优秀内容的共性,只是网易对于pgc来说获取播放数据肯定比b站难很多,我个人觉得,共性本身就是矛盾的。
必须不侵权,广告又不是只针对网易云。
当然不侵权,广告又不是只针对网易云。就算是版权方要求网易云播放视频,平台也可以控制广告时间的长短和频率。所以没必要因为ugc的一小小举动来敲诈任何人。
不侵权
不侵权,
广告是用来不影响搜索的效率,
明确回答,
windows该不该版权?
广告引发的后续影响看客观理由和公众影响。如果仅限于片头,我觉得无可厚非。如果人们对观影体验有更高要求,优酷应该停止广告,而不是打广告来赚钱。还有,我觉得搜狐、qq这些公司把版权保护做好点。总之,本身没有哪一家公司做点坏事,引发公众反感很正常。另外,影响到一些人的生活幸福和情绪,引发群体攻击(参考水军攻击),直接导致产品降权我觉得是不合理的。
完全不需要向法院申请弹窗费用和下载费用啊。b站一点广告可以给少儿看一半网易云,不就是网易音乐的一点广告么?我的音乐库这些歌不会因为一小点广告而关闭。
抓取网页视频(抓取网页视频方法很多,只能够获取链接地址!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-21 21:04
抓取网页视频方法很多,一种是直接进行视频下载,不过这样你可能就没有视频资源,只能够获取链接地址,现在网上有很多网站提供视频下载的,可以去分享,现在网上提供链接地址的地方太多了,比如a站,b站等等,进行下载的时候尽量选择要求带有梯子。第二种就是利用工具获取正确的网站视频地址,然后开始下载的方法了,比如这种方法可以提取,各种在线视频网站的视频地址,不过也要记得提交视频资源,上传站点方便后期的视频转换处理!。
1、打开“视频下载”工具
2、打开任意一个视频网站,然后复制网站的地址,
3、点击“开始转换”
4、当到达“提取结果”页面,
5、点击“立即下载”。
很简单点进你想要的视频播放器,然后点下载,就可以下到这个视频了,如果分享出去,然后放到网盘里。
在线视频网站的视频转换成mp4格式
这就是一个n4的转换器了
uc浏览器里:m4a格式视频转换成mp4格式视频,然后再下载。
哎呀视频下载这个软件挺好用的,但只能一个一个下哦,
1.下载芒果视频,下载1080p的2.下载海外视频3.下载电影4.想弄点小样你试试看这个吧对了, 查看全部
抓取网页视频(抓取网页视频方法很多,只能够获取链接地址!)
抓取网页视频方法很多,一种是直接进行视频下载,不过这样你可能就没有视频资源,只能够获取链接地址,现在网上有很多网站提供视频下载的,可以去分享,现在网上提供链接地址的地方太多了,比如a站,b站等等,进行下载的时候尽量选择要求带有梯子。第二种就是利用工具获取正确的网站视频地址,然后开始下载的方法了,比如这种方法可以提取,各种在线视频网站的视频地址,不过也要记得提交视频资源,上传站点方便后期的视频转换处理!。
1、打开“视频下载”工具
2、打开任意一个视频网站,然后复制网站的地址,
3、点击“开始转换”
4、当到达“提取结果”页面,
5、点击“立即下载”。
很简单点进你想要的视频播放器,然后点下载,就可以下到这个视频了,如果分享出去,然后放到网盘里。
在线视频网站的视频转换成mp4格式
这就是一个n4的转换器了
uc浏览器里:m4a格式视频转换成mp4格式视频,然后再下载。
哎呀视频下载这个软件挺好用的,但只能一个一个下哦,
1.下载芒果视频,下载1080p的2.下载海外视频3.下载电影4.想弄点小样你试试看这个吧对了,
抓取网页视频(post代理池(适合有python接口转发需求的4种方式))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-20 14:02
抓取网页视频并且仅用一个指定的接口来提取所需要的信息,目前通常有4种方式,
一、图片代理池-商业产品类似于图片爬虫,可以将爬取到的图片进行存储并提取其特征字段,后续对图片进行二次爬取,查看poc方法类似于图片代理池,file类型的接口。
1、post提交图片存储所需指定的接口:提交post/get/put/patch/delete图片接口头信息;
2、png存储接口:png存储接口头信息;
3、jpg存储接口:jpg存储接口头信息;
4、视频存储接口:视频存储接口头信息;
5、视频接口存储:抓取视频接口头信息;
6、批量抓取:批量抓取所需接口头信息。返回格式如下:包含page(s)和pagesize(s)两个单位的数据类型为json数据,用逗号(,)分隔格式为pagename(s)和pagesize(s)如返回pagetag,表示根据page存储的图片以及图片的用户名字段属性填充图片名字段uid(s);如返回pagecertificate,表示根据page存储的图片以及用户名字段属性填充图片接口artistid(s);。
7、简单图片爬取:批量抓取用户或者图片所在页面所需的所有图片。接口转化成json格式。大小为page数量的百分比,比如100px/2。
特点:只需要python环境,有代理池即可,后续对图片进行二次爬取,查看poc方法,界面可以分享,实现自动化!!!详情:--post代理池(适合有python接口转发需求的),
二、xpath结构化图片分析
1、xpath语法xpath(表象):标准通用定位表达式,是html(超文本标记语言)的子集,可以匹配html文档的结构性标签,并返回相应的文档内容或相应的值。
<p>2、分析xpath的要点标签与元素,并结合提取a、标签的基本标签:基本标签如:phrefxml/xmlol/img{img-src=""//img属性位于源文件后面//preload一定要选为false,否则表示先读取后检查。另外注意避免出现error:$error_true;语法结构;}div{position:relative;left:0;top:0;width:auto;height:auto;auto-height:10px;//div是一个伪元素,实际上是box{box-size:auto;auto-content:center;width:100%;height:100%;padding:0;}content:text;//content是一个伪元素,实际上是box{box-size:auto;auto-content:center;display:inline-block;}li{id:li}th{id:th}form{id:form}js 查看全部
抓取网页视频(post代理池(适合有python接口转发需求的4种方式))
抓取网页视频并且仅用一个指定的接口来提取所需要的信息,目前通常有4种方式,
一、图片代理池-商业产品类似于图片爬虫,可以将爬取到的图片进行存储并提取其特征字段,后续对图片进行二次爬取,查看poc方法类似于图片代理池,file类型的接口。
1、post提交图片存储所需指定的接口:提交post/get/put/patch/delete图片接口头信息;
2、png存储接口:png存储接口头信息;
3、jpg存储接口:jpg存储接口头信息;
4、视频存储接口:视频存储接口头信息;
5、视频接口存储:抓取视频接口头信息;
6、批量抓取:批量抓取所需接口头信息。返回格式如下:包含page(s)和pagesize(s)两个单位的数据类型为json数据,用逗号(,)分隔格式为pagename(s)和pagesize(s)如返回pagetag,表示根据page存储的图片以及图片的用户名字段属性填充图片名字段uid(s);如返回pagecertificate,表示根据page存储的图片以及用户名字段属性填充图片接口artistid(s);。
7、简单图片爬取:批量抓取用户或者图片所在页面所需的所有图片。接口转化成json格式。大小为page数量的百分比,比如100px/2。
特点:只需要python环境,有代理池即可,后续对图片进行二次爬取,查看poc方法,界面可以分享,实现自动化!!!详情:--post代理池(适合有python接口转发需求的),
二、xpath结构化图片分析
1、xpath语法xpath(表象):标准通用定位表达式,是html(超文本标记语言)的子集,可以匹配html文档的结构性标签,并返回相应的文档内容或相应的值。
<p>2、分析xpath的要点标签与元素,并结合提取a、标签的基本标签:基本标签如:phrefxml/xmlol/img{img-src=""//img属性位于源文件后面//preload一定要选为false,否则表示先读取后检查。另外注意避免出现error:$error_true;语法结构;}div{position:relative;left:0;top:0;width:auto;height:auto;auto-height:10px;//div是一个伪元素,实际上是box{box-size:auto;auto-content:center;width:100%;height:100%;padding:0;}content:text;//content是一个伪元素,实际上是box{box-size:auto;auto-content:center;display:inline-block;}li{id:li}th{id:th}form{id:form}js
抓取网页视频(看完必备的文档回头看视频,你可以拿去用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-17 00:01
抓取网页视频。
看名片流程很简单,但是可以统计到人脉的中南石油,属于偏服务型行业,人脉以外的知识很少,工作复杂繁琐,晋升机会看个人努力。有网,方便自己沟通,有app,方便需要大量资料的人。看完必备的文档回头看视频。
一个有价值的渠道:谷歌用ai标注同行业内的全部产品宣传图、行业内顶尖厂商产品宣传图和知名设计师推荐专辑。图片被抓取后,也会通过集搜客转换成形象文字用于宣传图宣传册销售文案和媒体报道图合成生成各种图片。谷歌全球产品推荐广告采用统一dsp广告审核标准,并且根据ai标注的图片进行审核。如果你足够专业,内部有一定量的图片数据库并且对图片标注工作了如指掌,那一定可以经过工作人员手动筛选、组合、合成获得效果非常不错的同行产品图和设计师推荐专辑。
soeasy!希望帮到你~【20190602】【创意图表】《【创意】身体指南【全国、全球】》中国站、全新系列【插画】adobelumiereformacforphotoshop、adobe—在线播放—优酷网,视频高清在线观看。
我帮你回答一下吧,非常大,我这里有300+页580万个网页大数据,需要的话,你可以拿去用。0603更新了3版。下面有wind桌面版截图。1是中南有机室大数据库101类有机会涉及交易金融保险等,前面还有用于同行业交流的新闻期刊,这个是金融期刊;2是大型企业制造大数据库:对行业制造以及交易金融、保险等有要求,里面也有企业交流报表(招募各种与创新有关的合作伙伴,认为产品和服务在质量、发展方面有创新点和亮点)3是央企图书馆大数据库:由财政部、税务总局、、银监会、电信运营商及图书馆联合组成的一个数据库。
14个厅局同时组成,有21个省级图书馆。里面有16个省级以上的书库。每个省级以上的图书馆均提供二十多个书库。4是网上校友大数据库:覆盖互联网、金融、数据库、新媒体、人力资源、教育、医疗、旅游等20多个专业领域。同时,网站也在持续不断搜集和更新全国各类网上校友。5是国家图书馆大数据库:包括有21个省级以上图书馆。
对于大数据以及其他专业领域都有针对性的招募合作伙伴。6是第一手的旅游大数据库:共200万张图片:av3.html,av2.html,av1.html,av1.jpg,av3.jpg,av1.jpg,各类风景图片40000余张。加上旅游交通信息来大数据库是存不下这么多旅游信息的,这是个必需品,而且数据库的目的是查询,很多都需要人工标注。0603101.jpg1农业大数据库:200万套耕地图片及标注,能直接用于人工。 查看全部
抓取网页视频(看完必备的文档回头看视频,你可以拿去用)
抓取网页视频。
看名片流程很简单,但是可以统计到人脉的中南石油,属于偏服务型行业,人脉以外的知识很少,工作复杂繁琐,晋升机会看个人努力。有网,方便自己沟通,有app,方便需要大量资料的人。看完必备的文档回头看视频。
一个有价值的渠道:谷歌用ai标注同行业内的全部产品宣传图、行业内顶尖厂商产品宣传图和知名设计师推荐专辑。图片被抓取后,也会通过集搜客转换成形象文字用于宣传图宣传册销售文案和媒体报道图合成生成各种图片。谷歌全球产品推荐广告采用统一dsp广告审核标准,并且根据ai标注的图片进行审核。如果你足够专业,内部有一定量的图片数据库并且对图片标注工作了如指掌,那一定可以经过工作人员手动筛选、组合、合成获得效果非常不错的同行产品图和设计师推荐专辑。
soeasy!希望帮到你~【20190602】【创意图表】《【创意】身体指南【全国、全球】》中国站、全新系列【插画】adobelumiereformacforphotoshop、adobe—在线播放—优酷网,视频高清在线观看。
我帮你回答一下吧,非常大,我这里有300+页580万个网页大数据,需要的话,你可以拿去用。0603更新了3版。下面有wind桌面版截图。1是中南有机室大数据库101类有机会涉及交易金融保险等,前面还有用于同行业交流的新闻期刊,这个是金融期刊;2是大型企业制造大数据库:对行业制造以及交易金融、保险等有要求,里面也有企业交流报表(招募各种与创新有关的合作伙伴,认为产品和服务在质量、发展方面有创新点和亮点)3是央企图书馆大数据库:由财政部、税务总局、、银监会、电信运营商及图书馆联合组成的一个数据库。
14个厅局同时组成,有21个省级图书馆。里面有16个省级以上的书库。每个省级以上的图书馆均提供二十多个书库。4是网上校友大数据库:覆盖互联网、金融、数据库、新媒体、人力资源、教育、医疗、旅游等20多个专业领域。同时,网站也在持续不断搜集和更新全国各类网上校友。5是国家图书馆大数据库:包括有21个省级以上图书馆。
对于大数据以及其他专业领域都有针对性的招募合作伙伴。6是第一手的旅游大数据库:共200万张图片:av3.html,av2.html,av1.html,av1.jpg,av3.jpg,av1.jpg,各类风景图片40000余张。加上旅游交通信息来大数据库是存不下这么多旅游信息的,这是个必需品,而且数据库的目的是查询,很多都需要人工标注。0603101.jpg1农业大数据库:200万套耕地图片及标注,能直接用于人工。
抓取网页视频(请求当中会弹出名字为之获取得到的图片内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-16 08:12
从上面的视频我们可以发现,当我们不断在不同的直播类型之间切换时,会在XHR请求中弹出名为“1”的内容,这样我们就可以很方便的找到我们需要的内容,如下图所示.
接下来,我们只需要使用程序模拟浏览器向这个接口发送请求,就可以获取数据内容了。
有的朋友按照上面的方法找到url请求链接,获取到数据后发现返回的数据是json数据内容,而且数据量很大,可能没有经验的小伙伴难以获取我们想要从数据中获得的图像链接。如下所示:
这时候可以使用一些辅助工具来帮助我们分析数据。只需要复制json数据,然后打开网址:. 复制json数据,网页会自动帮我们把json数据解析成方便我们观察的数据。
通过解析出来的数据,我们可以得到很多信息,包括主播的昵称和我们想要得到的主播的封面图。接下来,我们可以通过程序获取所有主播的封面图。对于互动约会和舞蹈模块中主播的封面图,其内容分析与颜值模块中的主播分析一致。获取封面图片的url链接,流程如下图所示。
程序中对颜值、互动约会、舞蹈三个模块下的链接进行请求,并解析返回的json数据,得到主播昵称和封面图的url地址,并保存内容到 self.pic_urls 的列表中间。
获取图片url地址后,下一步就是请求图片数据,然后保存到本地文件夹,程序如下图所示。
在程序中,以主机名命名图片,然后将请求的图片数据写入本地文件夹。最后,我们来看看获取到的图片内容。
总结
以上就是小编今天为大家带来的。您可以获得捕获的锚盖。每张图片都以主播的昵称命名。如果你不知道你喜欢哪个主播,欢迎在评论区嘀咕! 查看全部
抓取网页视频(请求当中会弹出名字为之获取得到的图片内容)
从上面的视频我们可以发现,当我们不断在不同的直播类型之间切换时,会在XHR请求中弹出名为“1”的内容,这样我们就可以很方便的找到我们需要的内容,如下图所示.
接下来,我们只需要使用程序模拟浏览器向这个接口发送请求,就可以获取数据内容了。
有的朋友按照上面的方法找到url请求链接,获取到数据后发现返回的数据是json数据内容,而且数据量很大,可能没有经验的小伙伴难以获取我们想要从数据中获得的图像链接。如下所示:

这时候可以使用一些辅助工具来帮助我们分析数据。只需要复制json数据,然后打开网址:. 复制json数据,网页会自动帮我们把json数据解析成方便我们观察的数据。
通过解析出来的数据,我们可以得到很多信息,包括主播的昵称和我们想要得到的主播的封面图。接下来,我们可以通过程序获取所有主播的封面图。对于互动约会和舞蹈模块中主播的封面图,其内容分析与颜值模块中的主播分析一致。获取封面图片的url链接,流程如下图所示。
程序中对颜值、互动约会、舞蹈三个模块下的链接进行请求,并解析返回的json数据,得到主播昵称和封面图的url地址,并保存内容到 self.pic_urls 的列表中间。
获取图片url地址后,下一步就是请求图片数据,然后保存到本地文件夹,程序如下图所示。
在程序中,以主机名命名图片,然后将请求的图片数据写入本地文件夹。最后,我们来看看获取到的图片内容。

总结
以上就是小编今天为大家带来的。您可以获得捕获的锚盖。每张图片都以主播的昵称命名。如果你不知道你喜欢哪个主播,欢迎在评论区嘀咕!
抓取网页视频(穿透网vpn有用吗?如何解决网速变慢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-16 01:00
抓取网页视频,视频是否压缩,会导致网速变慢,如果在家里建议还是用带宽流量上网速度,其他方法很多局域网穿透vpn有租用有自己写,带宽挂马了解一下,都能玩。
50m还是20m看客户端带宽和你个人网络接入情况如何,如果20m能流畅上传下载,那无线稳过100m。
1.有线直接flash流播,2.无线在信号接入的宽带里连接软件服务器,经过特殊设置达到互联互通的条件就可以上传,3.你也可以通过wifi路由转接器,4.手机也可以共享2.3.4.的视频,比如雷电视云,有线flash的优势就是配合环境,无线转带宽,
20m有线连接设备速度,100m我用是联通腾讯路由加挂路由桥接接无线(可以用wifi共享精灵连接),
本来问这个问题就是不专业的人
无线路由器连接无线ap就可以上传,我用的h110,
无线可以转接到wifi共享精灵上面打开sharing功能,可以直接设置好了,电脑端进去电脑设置里设置,在无线应用界面设置,具体是什么操作我没试过,设置完成直接能在电脑上用app去控制家里的网络。
百度搜索‘桥接’,找出你的ip在哪个ap上,设置好就可以上传了。
手机共享电脑很麻烦。无线桥接。电脑把视频文件复制到桥接设备上就可以随便看。看高清。 查看全部
抓取网页视频(穿透网vpn有用吗?如何解决网速变慢?)
抓取网页视频,视频是否压缩,会导致网速变慢,如果在家里建议还是用带宽流量上网速度,其他方法很多局域网穿透vpn有租用有自己写,带宽挂马了解一下,都能玩。
50m还是20m看客户端带宽和你个人网络接入情况如何,如果20m能流畅上传下载,那无线稳过100m。
1.有线直接flash流播,2.无线在信号接入的宽带里连接软件服务器,经过特殊设置达到互联互通的条件就可以上传,3.你也可以通过wifi路由转接器,4.手机也可以共享2.3.4.的视频,比如雷电视云,有线flash的优势就是配合环境,无线转带宽,
20m有线连接设备速度,100m我用是联通腾讯路由加挂路由桥接接无线(可以用wifi共享精灵连接),
本来问这个问题就是不专业的人
无线路由器连接无线ap就可以上传,我用的h110,
无线可以转接到wifi共享精灵上面打开sharing功能,可以直接设置好了,电脑端进去电脑设置里设置,在无线应用界面设置,具体是什么操作我没试过,设置完成直接能在电脑上用app去控制家里的网络。
百度搜索‘桥接’,找出你的ip在哪个ap上,设置好就可以上传了。
手机共享电脑很麻烦。无线桥接。电脑把视频文件复制到桥接设备上就可以随便看。看高清。
抓取网页视频(爬取本地视频或者爬b站的视频在哪里?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-10 09:05
抓取网页视频的话可以用seleniumselenium最基本功能是添加请求模块。如果请求的是本地页面的话,你可以在浏览器上装一个sublime,安装好sublime后装selenium驱动,加上你要爬取视频网站的网址(urls.txt),其他一些一些环境配置直接百度一下这些就可以了。可以考虑用户付费python版。
爬取本地视频或者爬b站的视频看呢,可以使用网页采集模块selenium2。对了,其实python也可以采集知乎的答案。
selenium就是定位视频服务器。其他的一些浏览器兼容或者注意点的工作可以百度。
当然可以,浏览器可以抓取一切资源,比如知乎回答,
先了解一下爬虫是什么你就会自己写了我补充几个用爬虫最常见的的一些问题在哪里?1.新网站都可以,网站什么都可以。在某些时候,新网站速度会比旧网站慢,要用新的网站。2.缺少手机适配,比如网上有些视频制作人都开发过什么利用模拟器的方式来爬虫视频,虽然方法对方式可以用。但是对于安卓手机这些手机,手机端没有手机app,因此手机是屏幕适配的比较差,还不如直接在手机上使用浏览器就可以安装模拟器来爬取网页,这样也可以使用屏幕适配技术。
3.模拟器存在性能问题,常见是延迟和类型。4.视频加密,网上搜,现在技术不断在改进,解决方法是使用其他分析。5.视频的分享,爬虫可以做到的,不过要爬取的视频需要版权方愿意让你看,或者是需要留有版权方的地址,这个时候就需要返回个人页面,爬虫是不能知道别人是不是已经看了视频,所以对网站是封禁的。 查看全部
抓取网页视频(爬取本地视频或者爬b站的视频在哪里?)
抓取网页视频的话可以用seleniumselenium最基本功能是添加请求模块。如果请求的是本地页面的话,你可以在浏览器上装一个sublime,安装好sublime后装selenium驱动,加上你要爬取视频网站的网址(urls.txt),其他一些一些环境配置直接百度一下这些就可以了。可以考虑用户付费python版。
爬取本地视频或者爬b站的视频看呢,可以使用网页采集模块selenium2。对了,其实python也可以采集知乎的答案。
selenium就是定位视频服务器。其他的一些浏览器兼容或者注意点的工作可以百度。
当然可以,浏览器可以抓取一切资源,比如知乎回答,
先了解一下爬虫是什么你就会自己写了我补充几个用爬虫最常见的的一些问题在哪里?1.新网站都可以,网站什么都可以。在某些时候,新网站速度会比旧网站慢,要用新的网站。2.缺少手机适配,比如网上有些视频制作人都开发过什么利用模拟器的方式来爬虫视频,虽然方法对方式可以用。但是对于安卓手机这些手机,手机端没有手机app,因此手机是屏幕适配的比较差,还不如直接在手机上使用浏览器就可以安装模拟器来爬取网页,这样也可以使用屏幕适配技术。
3.模拟器存在性能问题,常见是延迟和类型。4.视频加密,网上搜,现在技术不断在改进,解决方法是使用其他分析。5.视频的分享,爬虫可以做到的,不过要爬取的视频需要版权方愿意让你看,或者是需要留有版权方的地址,这个时候就需要返回个人页面,爬虫是不能知道别人是不是已经看了视频,所以对网站是封禁的。
抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-28 18:02
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集
了一个专门从各大主流视频网站提取视频的网站:(原名)。使用后发现各大主流视频分享网站基本都可以解析出最终的URL,但是对于公司这样的公司来说,知名度较低的网站上的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己找到的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集
了一个专门从各大主流视频网站提取视频的网站:(原名)。使用后发现各大主流视频分享网站基本都可以解析出最终的URL,但是对于公司这样的公司来说,知名度较低的网站上的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句

代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己找到的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
抓取网页视频(根据上篇文章的思路,我用了监听网卡流量的方式来改进了我的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-27 10:12
按照上一篇的思路,我用监控网卡流量的方法来改进我的程序。速度有了很大的提高。
想法
下图是我用wireshark做的一个实验。在请求路径中留下带有.mp4、.flv的请求,你得到的就是请求的视频资源。
用wireshark试验了一下,确定这种抓包的方法可行,就开始用python写抓包代码。
我使用python的pcap和dpkt包来分析网卡流量。首先是使用pcap监控我的网卡,设置pcap过滤器只处理HTTP请求,因为视频地址在HTTP请求中。我在HTTP请求的地址中找到了收录
.flv的请求,然后就可以得到视频的url地址了。
实验
代码比较短,我直接贴上代码。关于pcap和dpkt的使用我参考了这篇文章,但是这篇文章应该是抄袭别人的。当我搜索它时,我找到了一个更好的,但是当我写这篇文章时,我找不到更好的。,只能发这个不太好。
当然代码也会放到我的Github上,哈哈~
#encoding: utf8
import pcap
import dpkt
pc=pcap.pcap('eth1') #注,参数可为网卡名,如eth0
#设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP
pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
print "starting capture"
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
#对抓到的以太网V2数据包(raw packet)进行解包
p=dpkt.ethernet.Ethernet(pdata)
if p.data.__class__.__name__=='IP':
# ip='%d.%d.%d.%d'%tuple(map(ord,list(p.data.dst)))
if p.data.data.__class__.__name__=='TCP':
if p.data.data.dport==80:
header = p.data.data.data # by gashero
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
if requestUrl.find('.flv') != -1:
# print headerArr
print requestUrl
运行结果图:
未解决的问题是优酷等对视频进行分片的网站无法获取完整的视频。 查看全部
抓取网页视频(根据上篇文章的思路,我用了监听网卡流量的方式来改进了我的程序)
按照上一篇的思路,我用监控网卡流量的方法来改进我的程序。速度有了很大的提高。
想法
下图是我用wireshark做的一个实验。在请求路径中留下带有.mp4、.flv的请求,你得到的就是请求的视频资源。

用wireshark试验了一下,确定这种抓包的方法可行,就开始用python写抓包代码。
我使用python的pcap和dpkt包来分析网卡流量。首先是使用pcap监控我的网卡,设置pcap过滤器只处理HTTP请求,因为视频地址在HTTP请求中。我在HTTP请求的地址中找到了收录
.flv的请求,然后就可以得到视频的url地址了。
实验
代码比较短,我直接贴上代码。关于pcap和dpkt的使用我参考了这篇文章,但是这篇文章应该是抄袭别人的。当我搜索它时,我找到了一个更好的,但是当我写这篇文章时,我找不到更好的。,只能发这个不太好。
当然代码也会放到我的Github上,哈哈~
#encoding: utf8
import pcap
import dpkt
pc=pcap.pcap('eth1') #注,参数可为网卡名,如eth0
#设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP
pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
print "starting capture"
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
#对抓到的以太网V2数据包(raw packet)进行解包
p=dpkt.ethernet.Ethernet(pdata)
if p.data.__class__.__name__=='IP':
# ip='%d.%d.%d.%d'%tuple(map(ord,list(p.data.dst)))
if p.data.data.__class__.__name__=='TCP':
if p.data.data.dport==80:
header = p.data.data.data # by gashero
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
if requestUrl.find('.flv') != -1:
# print headerArr
print requestUrl
运行结果图:

未解决的问题是优酷等对视频进行分片的网站无法获取完整的视频。
抓取网页视频(根据上篇文章的思路,我用了监听网卡流量的方式来改进了我的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-27 10:08
按照上一篇的思路,我用监控网卡流量的方法来改进我的程序。速度有了很大的提高。
想法
下图是我用wireshark做的一个实验。在请求路径中留下带有.mp4、.flv的请求,你得到的就是请求的视频资源。
用wireshark试验了一下,确定这种抓包的方法可行,就开始用python写抓包代码。
我使用python的pcap和dpkt包来分析网卡流量。首先是使用pcap监控我的网卡,设置pcap过滤器只处理HTTP请求,因为视频地址在HTTP请求中。我在HTTP请求的地址中找到了收录
.flv的请求,然后就可以得到视频的url地址了。
实验
代码比较短,我直接贴上代码。关于pcap和dpkt的使用我参考了这篇文章,但是这篇文章应该是抄袭别人的。当我搜索它时,我找到了一个更好的,但是当我写这篇文章时,我找不到更好的。,只能发这个不太好。
当然代码也会放到我的Github上,哈哈~
#encoding: utf8
import pcap
import dpkt
pc=pcap.pcap('eth1') #注,参数可为网卡名,如eth0
#设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP
pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
print "starting capture"
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
#对抓到的以太网V2数据包(raw packet)进行解包
p=dpkt.ethernet.Ethernet(pdata)
if p.data.__class__.__name__=='IP':
# ip='%d.%d.%d.%d'%tuple(map(ord,list(p.data.dst)))
if p.data.data.__class__.__name__=='TCP':
if p.data.data.dport==80:
header = p.data.data.data # by gashero
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
if requestUrl.find('.flv') != -1:
# print headerArr
print requestUrl
运行结果图:
未解决的问题是优酷等对视频进行分片的网站无法获取完整的视频。 查看全部
抓取网页视频(根据上篇文章的思路,我用了监听网卡流量的方式来改进了我的程序)
按照上一篇的思路,我用监控网卡流量的方法来改进我的程序。速度有了很大的提高。
想法
下图是我用wireshark做的一个实验。在请求路径中留下带有.mp4、.flv的请求,你得到的就是请求的视频资源。
用wireshark试验了一下,确定这种抓包的方法可行,就开始用python写抓包代码。
我使用python的pcap和dpkt包来分析网卡流量。首先是使用pcap监控我的网卡,设置pcap过滤器只处理HTTP请求,因为视频地址在HTTP请求中。我在HTTP请求的地址中找到了收录
.flv的请求,然后就可以得到视频的url地址了。
实验
代码比较短,我直接贴上代码。关于pcap和dpkt的使用我参考了这篇文章,但是这篇文章应该是抄袭别人的。当我搜索它时,我找到了一个更好的,但是当我写这篇文章时,我找不到更好的。,只能发这个不太好。
当然代码也会放到我的Github上,哈哈~
#encoding: utf8
import pcap
import dpkt
pc=pcap.pcap('eth1') #注,参数可为网卡名,如eth0
#设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP
pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
print "starting capture"
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
#对抓到的以太网V2数据包(raw packet)进行解包
p=dpkt.ethernet.Ethernet(pdata)
if p.data.__class__.__name__=='IP':
# ip='%d.%d.%d.%d'%tuple(map(ord,list(p.data.dst)))
if p.data.data.__class__.__name__=='TCP':
if p.data.data.dport==80:
header = p.data.data.data # by gashero
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
if requestUrl.find('.flv') != -1:
# print headerArr
print requestUrl
运行结果图:
未解决的问题是优酷等对视频进行分片的网站无法获取完整的视频。
抓取网页视频(三招搞定看视频壁纸难题拿或其他社交网站的高清视频下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-04 16:01
抓取网页视频显示源代码,然后分析出视频里面的图片资源(图片地址,视频编码格式),然后爬下来之后返回就可以了,一般情况下,网页中通常是javascript+css,这个只是一个视频的下载工具而已,你只要知道文件路径,视频编码格式,然后找到这个格式就可以了。
三招搞定看视频壁纸难题
拿twitter或其他社交网站的高清视频下载下来,然后从mp4格式的视频文件中剪切一段就可以了。
你这是视频格式转换吧??
有以下方法,比如直接访问他们网站()或者通过邮件来发送过去的。
先把知乎页面复制粘贴然后剪切
比如我可以去哪儿网再刷新一下显示的是哪儿哪儿的电影我回来继续填坑
公开web:
1、baiduspider
2、脚本小子如果要抓的是生成的html,搜一下html解析脚本,
3、前面已经有人说过了,但是前面是基于html里有requests之类的东西上做出来的,loader估计能够写。这个完全没接触过,给不了太多建议。
windows/linux/osx中已经有抓包工具,例如wiresharkpython中有python自带的netutils。wireshark有一个api可以抓取其他地址的请求。netui也可以。requests抓包很快,但是网站对不定的url给你定制限制,你只能抓取固定地址的页面。netui可以抓取url固定,地址范围内的页面。python的模块可以自己抓取,如果有itchat,能快很多。 查看全部
抓取网页视频(三招搞定看视频壁纸难题拿或其他社交网站的高清视频下载)
抓取网页视频显示源代码,然后分析出视频里面的图片资源(图片地址,视频编码格式),然后爬下来之后返回就可以了,一般情况下,网页中通常是javascript+css,这个只是一个视频的下载工具而已,你只要知道文件路径,视频编码格式,然后找到这个格式就可以了。
三招搞定看视频壁纸难题
拿twitter或其他社交网站的高清视频下载下来,然后从mp4格式的视频文件中剪切一段就可以了。
你这是视频格式转换吧??
有以下方法,比如直接访问他们网站()或者通过邮件来发送过去的。
先把知乎页面复制粘贴然后剪切
比如我可以去哪儿网再刷新一下显示的是哪儿哪儿的电影我回来继续填坑
公开web:
1、baiduspider
2、脚本小子如果要抓的是生成的html,搜一下html解析脚本,
3、前面已经有人说过了,但是前面是基于html里有requests之类的东西上做出来的,loader估计能够写。这个完全没接触过,给不了太多建议。
windows/linux/osx中已经有抓包工具,例如wiresharkpython中有python自带的netutils。wireshark有一个api可以抓取其他地址的请求。netui也可以。requests抓包很快,但是网站对不定的url给你定制限制,你只能抓取固定地址的页面。netui可以抓取url固定,地址范围内的页面。python的模块可以自己抓取,如果有itchat,能快很多。
抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-20 19:09
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在之前采集了一个专门提取各大主流视频的网站网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以分析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在之前采集了一个专门提取各大主流视频的网站网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以分析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
抓取网页视频( 波波带你一步一步手动提取网页视频(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-20 19:08
波波带你一步一步手动提取网页视频(图))
生活中,我们经常会看一些网络视频,有的感觉很不错,都希望自己下载、采集,但往往就是不敢尝试。
这次Bobo就带你一步步手动提取网络视频。
首先,需要一些准备知识。
一、网络视频
网页上的视频一般是通过video标签播放的,还有一些其他的技术手段可以避开视频或者隐藏视频。避免视频可能会使用一些其他播放器来播放视频,隐藏视频一般是将视频放在一个iframe中,这将在后续具体案例中介绍。
二、视频链接类型
一般网页上的视频都有mp4链接和m3u8链接。前者解压下载方便,后者比较麻烦。
三、谷歌浏览器
谷歌浏览器是我们下一步的关键。当然,360浏览器、QQ浏览器等一些chrome内核的浏览器也是可以的。
在Chrome浏览器中,我们需要熟悉控制台,可以通过F12调用,也可以在菜单中打开JavaScript控制台。具体可以从百度打开到不同的浏览器,Windows下一般是F12。
下图显示了控制台的总体外观。后面我们会用到Network、Application这三个元素,主要是Network,其次是Elements,可能会用到一些Application场景。左上角还有一个箭头按钮,可以用来定位视频标签。
基础知识就到这里了,后面我们再做一些实际操作。
敬请期待后续文章。 查看全部
抓取网页视频(
波波带你一步一步手动提取网页视频(图))

生活中,我们经常会看一些网络视频,有的感觉很不错,都希望自己下载、采集,但往往就是不敢尝试。
这次Bobo就带你一步步手动提取网络视频。
首先,需要一些准备知识。
一、网络视频
网页上的视频一般是通过video标签播放的,还有一些其他的技术手段可以避开视频或者隐藏视频。避免视频可能会使用一些其他播放器来播放视频,隐藏视频一般是将视频放在一个iframe中,这将在后续具体案例中介绍。
二、视频链接类型
一般网页上的视频都有mp4链接和m3u8链接。前者解压下载方便,后者比较麻烦。
三、谷歌浏览器
谷歌浏览器是我们下一步的关键。当然,360浏览器、QQ浏览器等一些chrome内核的浏览器也是可以的。
在Chrome浏览器中,我们需要熟悉控制台,可以通过F12调用,也可以在菜单中打开JavaScript控制台。具体可以从百度打开到不同的浏览器,Windows下一般是F12。
下图显示了控制台的总体外观。后面我们会用到Network、Application这三个元素,主要是Network,其次是Elements,可能会用到一些Application场景。左上角还有一个箭头按钮,可以用来定位视频标签。
基础知识就到这里了,后面我们再做一些实际操作。
敬请期待后续文章。
抓取网页视频(雪山凌狐教程”超全fiddler详解如何提取网页视频50分问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-11-16 09:16
安卓软件视频采集工具是一款功能强大的安卓软件视频采集工具。APP具有强大的视频直链提取功能,支持蓝作云和秒杀。
以百度浏览器为例:1、输入要搜索的视频内容,进入网页。百度手机浏览器支持直接打开网页和进入网页。
如何在手机上检索互联网上的视频?未定义-提取、视频、网络、手机。
简介: 类型: 下载工具 更新时间: 2016-09-01 WebVideoDownloader 是一款非常好用的网络视频采集软件,可以轻松采集所有内容。
网页视频采集工具还支持视频格式转换、合并、裁剪等视频编辑功能,快来下载体验吧~
问题1:如何通过点击上方的搜索框来抓取手机网络视频是不行的。如果您认为答案已经解决了您的问题,请采纳。如果您有任何问题,请继续提问。如果您认为答案已经解决了您的问题,请采纳。如果您有任何问题,请继续提问。希望我的回答能帮到你。问题2:如何从手机中提取网络视频50分 问题2:如何从手机中提取网络视频50分 第三方视频软件下载视频存储位置,建议您尝试:我的文件-查找视频软件.
使用Chubbao你能得到什么?好消息:购买“专业版”可获得50个免费手机配额,购买“终极版”可获得120个免费手机配额。(手机配额是专门用来抢手机号的)。
更多精彩教程,请搜索关注“雪山令狐教程”。超全提琴手讲解如何连接手机抓包。为什么要在手机上抓包?一些网站。 查看全部
抓取网页视频(雪山凌狐教程”超全fiddler详解如何提取网页视频50分问题)
安卓软件视频采集工具是一款功能强大的安卓软件视频采集工具。APP具有强大的视频直链提取功能,支持蓝作云和秒杀。
以百度浏览器为例:1、输入要搜索的视频内容,进入网页。百度手机浏览器支持直接打开网页和进入网页。
如何在手机上检索互联网上的视频?未定义-提取、视频、网络、手机。
简介: 类型: 下载工具 更新时间: 2016-09-01 WebVideoDownloader 是一款非常好用的网络视频采集软件,可以轻松采集所有内容。
网页视频采集工具还支持视频格式转换、合并、裁剪等视频编辑功能,快来下载体验吧~

问题1:如何通过点击上方的搜索框来抓取手机网络视频是不行的。如果您认为答案已经解决了您的问题,请采纳。如果您有任何问题,请继续提问。如果您认为答案已经解决了您的问题,请采纳。如果您有任何问题,请继续提问。希望我的回答能帮到你。问题2:如何从手机中提取网络视频50分 问题2:如何从手机中提取网络视频50分 第三方视频软件下载视频存储位置,建议您尝试:我的文件-查找视频软件.
使用Chubbao你能得到什么?好消息:购买“专业版”可获得50个免费手机配额,购买“终极版”可获得120个免费手机配额。(手机配额是专门用来抢手机号的)。

更多精彩教程,请搜索关注“雪山令狐教程”。超全提琴手讲解如何连接手机抓包。为什么要在手机上抓包?一些网站。
抓取网页视频( 用什么手机浏览器,亦或是夸克、Via等轻量级浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2022-02-23 18:22
用什么手机浏览器,亦或是夸克、Via等轻量级浏览器)
不知道穷友们现在都用什么手机浏览器,是系统自带的浏览器,还是百度、火狐、Chrome、UC等老旧的浏览器,还是夸克、威盛等轻量级浏览器?
Shichao 之前一直在使用 Quark。除了文件清理、面对面文件传输、网盘功能之外,我觉得这个浏览器有点多余。其他方面我还是很满意的。界面足够干净且具有交互性。
你认为浏览器对这些东西做了什么▼
只是作为一个折腾党,用了一个浏览器久了,难免会想试试其他口味不一样的浏览器,于是时超就去宽买了,找了个比较另类的浏览器。设备。
这个浏览器的名字叫做“Rainbow”。相信你从下面的截图中就能一眼看出它与其他浏览器的区别,那就是它的很多界面都是按照新模仿的风格设计的。
一些可怜的朋友可能第一次听说“新形态”这个词。简而言之,它是一种介于 skeuomorphism 和 flattening 之间的风格。界面上的一些元素从背景中突出,而另一些元素则被困在背景中。在后台。
新模仿风格的主题▼
这种风格最大的特点就是没有复杂的细节。界面中的所有按钮和卡片只是通过改变亮度来产生凸起的效果。很简单,时超第一眼就喜欢上了。
毫不夸张地说,它是迄今为止我见过的设计最精美的浏览器,和白屏手机完美搭配!
而且浏览器本身提供的功能也很强大。
首先,它支持搜索引擎的快速切换。
除了内置的御剑搜索,该浏览器还集成了百度、谷歌、夸克等多家主流搜索引擎。使用时,您可以通过点击搜索框左侧的图标快速搜索这些引擎。切换而无需像其他浏览器一样进入设置进行更改。
其次,它还带有资源嗅探功能。
开启此功能后,穷友每次打开网页,资源嗅探都会自动抓取网页中收录的图片、视频等资源。您可以选择一个资源单独下载,也可以一键下载所有资源。
这个功能有多大用处,我就不用过多介绍了吧?如果遇到一些网站如果没有开放下载功能,可以通过它下载。在其他应用程序中,此功能作为付费功能就足够了。
浏览器下载的资源会保存在它的下载管理中,朋友们可以根据文件类型快速筛选。如果您下载视频,使用浏览器附带的播放器,您仍然可以播放它。实现小窗口效果或 0.5 - 4 倍的播放速度。
要说这些还不是它最强大的功能。
这款浏览器最吸引我的地方在于它可以安装各种插件!
在浏览器的侧边功能栏中,有一个“插件管理”选项,点击这个选项,你会发现一个新世界,哪些网页要打广告,直接去网盘,自动翻页,自动展开和其他桌面浏览设备常用的插件,现在手机上也可以使用。
而且这些插件使用起来也很方便。只需选择插件,点击安装,插件就会生效。如果没有插件来实现你想要的功能,你甚至可以自定义脚本。
最让时超吃惊的是什么?
这款御剑浏览器竟然是作者在大学时期自主开发的。毕业后还从360、华为招募成员共同维护。
真的比死人还受欢迎。我想我上大学的时候,还是担心考不上C语言。
浏览器的下载链接在这里,有需要的可以去拿: 查看全部
抓取网页视频(
用什么手机浏览器,亦或是夸克、Via等轻量级浏览器)
不知道穷友们现在都用什么手机浏览器,是系统自带的浏览器,还是百度、火狐、Chrome、UC等老旧的浏览器,还是夸克、威盛等轻量级浏览器?
Shichao 之前一直在使用 Quark。除了文件清理、面对面文件传输、网盘功能之外,我觉得这个浏览器有点多余。其他方面我还是很满意的。界面足够干净且具有交互性。
你认为浏览器对这些东西做了什么▼
只是作为一个折腾党,用了一个浏览器久了,难免会想试试其他口味不一样的浏览器,于是时超就去宽买了,找了个比较另类的浏览器。设备。
这个浏览器的名字叫做“Rainbow”。相信你从下面的截图中就能一眼看出它与其他浏览器的区别,那就是它的很多界面都是按照新模仿的风格设计的。
一些可怜的朋友可能第一次听说“新形态”这个词。简而言之,它是一种介于 skeuomorphism 和 flattening 之间的风格。界面上的一些元素从背景中突出,而另一些元素则被困在背景中。在后台。
新模仿风格的主题▼
这种风格最大的特点就是没有复杂的细节。界面中的所有按钮和卡片只是通过改变亮度来产生凸起的效果。很简单,时超第一眼就喜欢上了。
毫不夸张地说,它是迄今为止我见过的设计最精美的浏览器,和白屏手机完美搭配!
而且浏览器本身提供的功能也很强大。
首先,它支持搜索引擎的快速切换。
除了内置的御剑搜索,该浏览器还集成了百度、谷歌、夸克等多家主流搜索引擎。使用时,您可以通过点击搜索框左侧的图标快速搜索这些引擎。切换而无需像其他浏览器一样进入设置进行更改。
其次,它还带有资源嗅探功能。
开启此功能后,穷友每次打开网页,资源嗅探都会自动抓取网页中收录的图片、视频等资源。您可以选择一个资源单独下载,也可以一键下载所有资源。
这个功能有多大用处,我就不用过多介绍了吧?如果遇到一些网站如果没有开放下载功能,可以通过它下载。在其他应用程序中,此功能作为付费功能就足够了。
浏览器下载的资源会保存在它的下载管理中,朋友们可以根据文件类型快速筛选。如果您下载视频,使用浏览器附带的播放器,您仍然可以播放它。实现小窗口效果或 0.5 - 4 倍的播放速度。
要说这些还不是它最强大的功能。
这款浏览器最吸引我的地方在于它可以安装各种插件!
在浏览器的侧边功能栏中,有一个“插件管理”选项,点击这个选项,你会发现一个新世界,哪些网页要打广告,直接去网盘,自动翻页,自动展开和其他桌面浏览设备常用的插件,现在手机上也可以使用。
而且这些插件使用起来也很方便。只需选择插件,点击安装,插件就会生效。如果没有插件来实现你想要的功能,你甚至可以自定义脚本。
最让时超吃惊的是什么?
这款御剑浏览器竟然是作者在大学时期自主开发的。毕业后还从360、华为招募成员共同维护。
真的比死人还受欢迎。我想我上大学的时候,还是担心考不上C语言。
浏览器的下载链接在这里,有需要的可以去拿:
抓取网页视频(长沙企业营销型网站建设创研科技科技)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-18 02:18
众所周知,如果一个网站能被搜索引擎频繁爬取,说明搜索引擎非常信任这个网站,所以赋予网站的权重也很高, 关键词 排名、网站 流量等都会上去。相信这是任何企业构建营销型网站后的梦想,但目前的企业营销型网站大多不具备这样的条件。如果公司希望其 网站 符合此标准,则必须确保 网站 可以保持对搜索引擎友好。那么,接下来,长沙网站建研科技给大家详细聊聊。
设置清晰的网站地图
说到网站图,很不起眼,相信很容易被大家忽略。当搜索引擎来到网站时,一开始并不清楚这个网站有哪些页面,哪些是新添加的,哪些是原来的。网站的所有页面一目了然,让搜索引擎知道网站的所有页面,而不是一一查找。通过网站图,搜索引擎可以快速浏览整个网站的内容,快速爬取收录页面,这样网站收录就是很快,搜索引擎也愿意经常来网站。
网站每个页面的静态化
在网站的构建中,页面的主要形式有静态、伪静态和动态三种。至于什么是静态的,什么是伪静态的,什么是动态的,这里就不细说了。当然,搜索引擎最喜欢的还是静态页面,因为这样的页面比较稳定,搜索引擎更喜欢频繁浏览这样的网站页面。当然,伪静态和动态页面搜索引擎也会收录,但是时间会比较长。所以建议可以做静态页面的网站尽量是静态的。即使它不能是静态的,至少它应该是伪静态的。
网站内容持续更新
<p>即使一个网站做得很好,如果没有大量优质持续的内容更新,搜索引擎也不会喜欢它。毕竟每次搜索引擎来网站,看到的内容都是一样的,几次之后,我基本不想再来了。搜索引擎总是对高质量的原创内容非常感兴趣,所以如果你想让它回到我们这里网站,你必须不断更新 查看全部
抓取网页视频(长沙企业营销型网站建设创研科技科技)
众所周知,如果一个网站能被搜索引擎频繁爬取,说明搜索引擎非常信任这个网站,所以赋予网站的权重也很高, 关键词 排名、网站 流量等都会上去。相信这是任何企业构建营销型网站后的梦想,但目前的企业营销型网站大多不具备这样的条件。如果公司希望其 网站 符合此标准,则必须确保 网站 可以保持对搜索引擎友好。那么,接下来,长沙网站建研科技给大家详细聊聊。
设置清晰的网站地图
说到网站图,很不起眼,相信很容易被大家忽略。当搜索引擎来到网站时,一开始并不清楚这个网站有哪些页面,哪些是新添加的,哪些是原来的。网站的所有页面一目了然,让搜索引擎知道网站的所有页面,而不是一一查找。通过网站图,搜索引擎可以快速浏览整个网站的内容,快速爬取收录页面,这样网站收录就是很快,搜索引擎也愿意经常来网站。
网站每个页面的静态化
在网站的构建中,页面的主要形式有静态、伪静态和动态三种。至于什么是静态的,什么是伪静态的,什么是动态的,这里就不细说了。当然,搜索引擎最喜欢的还是静态页面,因为这样的页面比较稳定,搜索引擎更喜欢频繁浏览这样的网站页面。当然,伪静态和动态页面搜索引擎也会收录,但是时间会比较长。所以建议可以做静态页面的网站尽量是静态的。即使它不能是静态的,至少它应该是伪静态的。
网站内容持续更新
<p>即使一个网站做得很好,如果没有大量优质持续的内容更新,搜索引擎也不会喜欢它。毕竟每次搜索引擎来网站,看到的内容都是一样的,几次之后,我基本不想再来了。搜索引擎总是对高质量的原创内容非常感兴趣,所以如果你想让它回到我们这里网站,你必须不断更新
抓取网页视频(知乎网页视频的抓取实战实战(二):webpack解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-15 18:02
抓取网页视频其实就是在做一个html转码的工作,现在比较流行的解决方案是使用webpack来构建整个项目,目前在webpack3已经支持了使用vuex来做状态管理。下面我们在此基础上去解决知乎网页视频的抓取实战。一.搭建webpack的环境vue-cli必须安装:npminstall-gvue-clijqueryjs/png/true/rawjsvue-cli/eslintscss-parser/eslintscss-servers/babelscss-loader/mesajs/redux/axiosjs以上包括工具的配置,只不过这些配置的代码是放在models下的。
还有全局的加载库,以及对eslint的配置也应该在项目的根目录下,这样方便我们进行相应的环境配置。config.js也会自动配置相应的路径eslint.config.js:"{"compilermode":"gzip","models":["webpack","eslint","eslint-config","eslint-loader","axiosjs"]}"scripts.js:{"scripts":{"module.exports":{"tests":["jquery"]}}}(可选配置)babel.config.js:"{"compilermode":"gzip","models":["babel-cli","vue","eslint","eslint-config","eslint-loader","axiosjs"]}"scripts.js:{"scripts":{"module.exports":{"tests":["jquery"]}}}babel-plugin-eslint-plugin-js:{"module.exports":{"tests":["jquery"]}}css-plugin-js:{"module.exports":{"tests":["html"]}}生成dist文件src/distsrc/dist/main://视频文件上传img、video、mp4等源码importvideofrom'video.swf'exportdefaultfunctionloader(){returnexports.json({templateurl,srcurl});}可以通过这种方式来进行相关的配置,将代码放在index.js,也可以使用一些框架,iviewvuessr工具:vue-cli项目依赖:vue-cli(eslint)vuexvue-routerrouter-vieweslint-test-checkcli配置以及下面项目使用的代码:二.浏览器中的路由(二)(不支持model,但已经实现了server-side效果的路由转发功能,可以自行套用vue的路由)在没有移动端的浏览器中,项目依赖:需要在template.module.js中引入以下的内容:{"path":"/main","route":{"domain":"myblog","secret":"then02281/to-me","name":"asizijj","path":"/timeline"}}//或者ind。 查看全部
抓取网页视频(知乎网页视频的抓取实战实战(二):webpack解决方案)
抓取网页视频其实就是在做一个html转码的工作,现在比较流行的解决方案是使用webpack来构建整个项目,目前在webpack3已经支持了使用vuex来做状态管理。下面我们在此基础上去解决知乎网页视频的抓取实战。一.搭建webpack的环境vue-cli必须安装:npminstall-gvue-clijqueryjs/png/true/rawjsvue-cli/eslintscss-parser/eslintscss-servers/babelscss-loader/mesajs/redux/axiosjs以上包括工具的配置,只不过这些配置的代码是放在models下的。
还有全局的加载库,以及对eslint的配置也应该在项目的根目录下,这样方便我们进行相应的环境配置。config.js也会自动配置相应的路径eslint.config.js:"{"compilermode":"gzip","models":["webpack","eslint","eslint-config","eslint-loader","axiosjs"]}"scripts.js:{"scripts":{"module.exports":{"tests":["jquery"]}}}(可选配置)babel.config.js:"{"compilermode":"gzip","models":["babel-cli","vue","eslint","eslint-config","eslint-loader","axiosjs"]}"scripts.js:{"scripts":{"module.exports":{"tests":["jquery"]}}}babel-plugin-eslint-plugin-js:{"module.exports":{"tests":["jquery"]}}css-plugin-js:{"module.exports":{"tests":["html"]}}生成dist文件src/distsrc/dist/main://视频文件上传img、video、mp4等源码importvideofrom'video.swf'exportdefaultfunctionloader(){returnexports.json({templateurl,srcurl});}可以通过这种方式来进行相关的配置,将代码放在index.js,也可以使用一些框架,iviewvuessr工具:vue-cli项目依赖:vue-cli(eslint)vuexvue-routerrouter-vieweslint-test-checkcli配置以及下面项目使用的代码:二.浏览器中的路由(二)(不支持model,但已经实现了server-side效果的路由转发功能,可以自行套用vue的路由)在没有移动端的浏览器中,项目依赖:需要在template.module.js中引入以下的内容:{"path":"/main","route":{"domain":"myblog","secret":"then02281/to-me","name":"asizijj","path":"/timeline"}}//或者ind。
抓取网页视频(抓取网页视频大部分来自于网站的开放或者抓取思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-14 06:02
抓取网页视频大部分来自于网站的开放api或者后端服务。不过话说回来,其实要抓取某一个特定的网站或者某一个特定的contenttype的视频也是有非常简单的抓取网站的方法的。比如要抓取网页上的视频录像,在我的理解中,主要的思路有下面几种。首先,给每个视频单独下载一个视频文件(resource.js或者json),下载完成后扔到disk里面,这样每次每个视频可以用同一个地址:api的headers里如果有"rewritecacheurl"的字段,就用它直接获取每个视频的文件路径。
如果headers里没有的话,那有可能是抓取中只能用query和url来获取,这时候要对浏览器的解析库进行修改了,把rewritecacheurl的字段改成json形式。然后,对这些文件列表抓取,一般会首先对其中的所有文件抓取,这个时候用这些文件的路径表就可以保存所有的repository,然后用yes/no的写法。
这样方便循环,因为现在大部分视频也都是循环播放的。如果有字幕的话,可以for循环抓取。如果不需要任何字幕,那么就是顺序的抓取。顺序,就是在所有的视频列表中随机读取一个视频列表,这样对应于每个视频对应一个repository,然后对每个repository抓取就可以了。(前提是已经把文件名记录在disk里)再然后,对每个网站一次性抓取所有需要字幕的视频,这个时候要用到record.yes/no写法,把没有字幕的视频字幕放在对应视频列表中。
每次循环读取这个视频列表,找到最新的那个字幕放入record中。如果这个视频无字幕的话,一般是url匹配,然后将url伪装成文件获取。然后手工处理字幕和编辑其他辅助。最后,循环处理所有无字幕视频。一般用glob将所有无字幕视频数据抓取到disk,然后用yes/no写法循环读取disk中所有的url,将url放入相应的字幕列表中。
然后找到所有无字幕视频文件的列表中那个带有字幕的视频,用"yes/no"进行相应的判断。最后把文件的路径放入抓取到的某个视频列表里,重复上面的步骤,循环抓取其他字幕视频。至于搜索引擎,一般我们抓取的视频都是没有带播放链接的,那么如果希望可以抓取到网站的连接,那么需要利用第三方的浏览器插件。decimalwaitsizingcondate.js(在python官网就可以获取),这个是webdows端的抓取,可以传数组,officeword,ppt啥的。
至于用什么格式也是可以选择的,如果你要用zip的话,可以用"xxxx.zip"如果直接mp4格式的话,可以用"".然后就可以直接用字幕分割线以及字幕文件放在excel。以上来自我在#whatquest/newcondate的一篇博客。 查看全部
抓取网页视频(抓取网页视频大部分来自于网站的开放或者抓取思路)
抓取网页视频大部分来自于网站的开放api或者后端服务。不过话说回来,其实要抓取某一个特定的网站或者某一个特定的contenttype的视频也是有非常简单的抓取网站的方法的。比如要抓取网页上的视频录像,在我的理解中,主要的思路有下面几种。首先,给每个视频单独下载一个视频文件(resource.js或者json),下载完成后扔到disk里面,这样每次每个视频可以用同一个地址:api的headers里如果有"rewritecacheurl"的字段,就用它直接获取每个视频的文件路径。
如果headers里没有的话,那有可能是抓取中只能用query和url来获取,这时候要对浏览器的解析库进行修改了,把rewritecacheurl的字段改成json形式。然后,对这些文件列表抓取,一般会首先对其中的所有文件抓取,这个时候用这些文件的路径表就可以保存所有的repository,然后用yes/no的写法。
这样方便循环,因为现在大部分视频也都是循环播放的。如果有字幕的话,可以for循环抓取。如果不需要任何字幕,那么就是顺序的抓取。顺序,就是在所有的视频列表中随机读取一个视频列表,这样对应于每个视频对应一个repository,然后对每个repository抓取就可以了。(前提是已经把文件名记录在disk里)再然后,对每个网站一次性抓取所有需要字幕的视频,这个时候要用到record.yes/no写法,把没有字幕的视频字幕放在对应视频列表中。
每次循环读取这个视频列表,找到最新的那个字幕放入record中。如果这个视频无字幕的话,一般是url匹配,然后将url伪装成文件获取。然后手工处理字幕和编辑其他辅助。最后,循环处理所有无字幕视频。一般用glob将所有无字幕视频数据抓取到disk,然后用yes/no写法循环读取disk中所有的url,将url放入相应的字幕列表中。
然后找到所有无字幕视频文件的列表中那个带有字幕的视频,用"yes/no"进行相应的判断。最后把文件的路径放入抓取到的某个视频列表里,重复上面的步骤,循环抓取其他字幕视频。至于搜索引擎,一般我们抓取的视频都是没有带播放链接的,那么如果希望可以抓取到网站的连接,那么需要利用第三方的浏览器插件。decimalwaitsizingcondate.js(在python官网就可以获取),这个是webdows端的抓取,可以传数组,officeword,ppt啥的。
至于用什么格式也是可以选择的,如果你要用zip的话,可以用"xxxx.zip"如果直接mp4格式的话,可以用"".然后就可以直接用字幕分割线以及字幕文件放在excel。以上来自我在#whatquest/newcondate的一篇博客。
抓取网页视频(pptvflashfox浏览器里面下载插件flashplayertransferdownloadapkpure还是放弃了了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-09 17:03
抓取网页视频的话,大部分的视频网站都有购买。我在这里提供一种方法,在百度里搜索要求的视频网站名称,然后打开浏览器看到的页面,有的有下载按钮,有的没有。如果没有的话,可以尝试用第三方工具下载。按照我的测试经验来看,bandzip在网页上的下载速度较快,也可以试试迅雷客户端下载。
pptv
flashfox浏览器里面下载插件flashplayertransferdownload
apkpure
还是放弃了,我现在都是去聚合页面下载百度云视频,也用app啦,我的电视视频速度很快,
用迅雷看看或者一些app,比如优酷,爱奇艺,腾讯视频,
app“iameightnine”
itunes吧
youarenowfreeforallyourassumedmoviestoaccess,anymore?
用itunesdownloading播放器啊,
你可以找一下网上有关安卓版的视频网站下载工具。
百度云。
app用的是itunesforallyourassumedmovies
还有就是在线观看最快了,希望你能够找到。补充一个科学上网的方法:微信小程序搜索到“传送门”,可以看到网友推荐的网站,可以按名字、发布时间或者浏览量排序,找到自己想要的。 查看全部
抓取网页视频(pptvflashfox浏览器里面下载插件flashplayertransferdownloadapkpure还是放弃了了)
抓取网页视频的话,大部分的视频网站都有购买。我在这里提供一种方法,在百度里搜索要求的视频网站名称,然后打开浏览器看到的页面,有的有下载按钮,有的没有。如果没有的话,可以尝试用第三方工具下载。按照我的测试经验来看,bandzip在网页上的下载速度较快,也可以试试迅雷客户端下载。
pptv
flashfox浏览器里面下载插件flashplayertransferdownload
apkpure
还是放弃了,我现在都是去聚合页面下载百度云视频,也用app啦,我的电视视频速度很快,
用迅雷看看或者一些app,比如优酷,爱奇艺,腾讯视频,
app“iameightnine”
itunes吧
youarenowfreeforallyourassumedmoviestoaccess,anymore?
用itunesdownloading播放器啊,
你可以找一下网上有关安卓版的视频网站下载工具。
百度云。
app用的是itunesforallyourassumedmovies
还有就是在线观看最快了,希望你能够找到。补充一个科学上网的方法:微信小程序搜索到“传送门”,可以看到网友推荐的网站,可以按名字、发布时间或者浏览量排序,找到自己想要的。
抓取网页视频(统计学基础,不会编程的话当然要先学习python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-09 13:02
抓取网页视频抓取下载视频/视频集合,将文件从网络收集到本地;数据清洗,将数据存储到blob文件或其他文件中;制作正则表达式表单,将爬取下来的数据进行规则分析处理;将数据导入数据库中excel中导入excel的文件夹,可以将其存储到txt,xlsx,xls等格式导入本地即可;导入数据库,可以使用mysql,mongodb。
数据分析都是关联统计分析多回归,单因子,多因子,时间序列一般这些统计方法都要有统计学基础,
不会编程的话当然首先要先学习python,在数据分析中python非常方便。比如用numpy,pandas对数据进行处理,这样看来线性回归和sql并不需要太多的编程能力。
不用,学好概率统计就够了。同理,数据分析重要的是knockout数据,以此来开发模型。你只需要熟悉个常用算法就行。大多数还是依赖编程能力,不过大部分都有现成工具的。
学python。数据可视化,根据报告调整机器学习或机器学习框架。
数据分析需要python,excel,sql。
数据可视化没有写代码。
数据分析是属于基础理论,技能和平台的,分析的一般是公司后端业务的数据。一般语言是python,leaderdock, 查看全部
抓取网页视频(统计学基础,不会编程的话当然要先学习python)
抓取网页视频抓取下载视频/视频集合,将文件从网络收集到本地;数据清洗,将数据存储到blob文件或其他文件中;制作正则表达式表单,将爬取下来的数据进行规则分析处理;将数据导入数据库中excel中导入excel的文件夹,可以将其存储到txt,xlsx,xls等格式导入本地即可;导入数据库,可以使用mysql,mongodb。
数据分析都是关联统计分析多回归,单因子,多因子,时间序列一般这些统计方法都要有统计学基础,
不会编程的话当然首先要先学习python,在数据分析中python非常方便。比如用numpy,pandas对数据进行处理,这样看来线性回归和sql并不需要太多的编程能力。
不用,学好概率统计就够了。同理,数据分析重要的是knockout数据,以此来开发模型。你只需要熟悉个常用算法就行。大多数还是依赖编程能力,不过大部分都有现成工具的。
学python。数据可视化,根据报告调整机器学习或机器学习框架。
数据分析需要python,excel,sql。
数据可视化没有写代码。
数据分析是属于基础理论,技能和平台的,分析的一般是公司后端业务的数据。一般语言是python,leaderdock,
抓取网页视频(b站一点广告可以给少儿看一半网易云,该不该版权?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-06 23:02
抓取网页视频是否涉及版权问题,获取播放视频是否涉及侵权。当然这是玩笑话,ugc上优秀内容的共性,只是网易对于pgc来说获取播放数据肯定比b站难很多,我个人觉得,共性本身就是矛盾的。
必须不侵权,广告又不是只针对网易云。
当然不侵权,广告又不是只针对网易云。就算是版权方要求网易云播放视频,平台也可以控制广告时间的长短和频率。所以没必要因为ugc的一小小举动来敲诈任何人。
不侵权
不侵权,
广告是用来不影响搜索的效率,
明确回答,
windows该不该版权?
广告引发的后续影响看客观理由和公众影响。如果仅限于片头,我觉得无可厚非。如果人们对观影体验有更高要求,优酷应该停止广告,而不是打广告来赚钱。还有,我觉得搜狐、qq这些公司把版权保护做好点。总之,本身没有哪一家公司做点坏事,引发公众反感很正常。另外,影响到一些人的生活幸福和情绪,引发群体攻击(参考水军攻击),直接导致产品降权我觉得是不合理的。
完全不需要向法院申请弹窗费用和下载费用啊。b站一点广告可以给少儿看一半网易云,不就是网易音乐的一点广告么?我的音乐库这些歌不会因为一小点广告而关闭。 查看全部
抓取网页视频(b站一点广告可以给少儿看一半网易云,该不该版权?)
抓取网页视频是否涉及版权问题,获取播放视频是否涉及侵权。当然这是玩笑话,ugc上优秀内容的共性,只是网易对于pgc来说获取播放数据肯定比b站难很多,我个人觉得,共性本身就是矛盾的。
必须不侵权,广告又不是只针对网易云。
当然不侵权,广告又不是只针对网易云。就算是版权方要求网易云播放视频,平台也可以控制广告时间的长短和频率。所以没必要因为ugc的一小小举动来敲诈任何人。
不侵权
不侵权,
广告是用来不影响搜索的效率,
明确回答,
windows该不该版权?
广告引发的后续影响看客观理由和公众影响。如果仅限于片头,我觉得无可厚非。如果人们对观影体验有更高要求,优酷应该停止广告,而不是打广告来赚钱。还有,我觉得搜狐、qq这些公司把版权保护做好点。总之,本身没有哪一家公司做点坏事,引发公众反感很正常。另外,影响到一些人的生活幸福和情绪,引发群体攻击(参考水军攻击),直接导致产品降权我觉得是不合理的。
完全不需要向法院申请弹窗费用和下载费用啊。b站一点广告可以给少儿看一半网易云,不就是网易音乐的一点广告么?我的音乐库这些歌不会因为一小点广告而关闭。
抓取网页视频(抓取网页视频方法很多,只能够获取链接地址!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-21 21:04
抓取网页视频方法很多,一种是直接进行视频下载,不过这样你可能就没有视频资源,只能够获取链接地址,现在网上有很多网站提供视频下载的,可以去分享,现在网上提供链接地址的地方太多了,比如a站,b站等等,进行下载的时候尽量选择要求带有梯子。第二种就是利用工具获取正确的网站视频地址,然后开始下载的方法了,比如这种方法可以提取,各种在线视频网站的视频地址,不过也要记得提交视频资源,上传站点方便后期的视频转换处理!。
1、打开“视频下载”工具
2、打开任意一个视频网站,然后复制网站的地址,
3、点击“开始转换”
4、当到达“提取结果”页面,
5、点击“立即下载”。
很简单点进你想要的视频播放器,然后点下载,就可以下到这个视频了,如果分享出去,然后放到网盘里。
在线视频网站的视频转换成mp4格式
这就是一个n4的转换器了
uc浏览器里:m4a格式视频转换成mp4格式视频,然后再下载。
哎呀视频下载这个软件挺好用的,但只能一个一个下哦,
1.下载芒果视频,下载1080p的2.下载海外视频3.下载电影4.想弄点小样你试试看这个吧对了, 查看全部
抓取网页视频(抓取网页视频方法很多,只能够获取链接地址!)
抓取网页视频方法很多,一种是直接进行视频下载,不过这样你可能就没有视频资源,只能够获取链接地址,现在网上有很多网站提供视频下载的,可以去分享,现在网上提供链接地址的地方太多了,比如a站,b站等等,进行下载的时候尽量选择要求带有梯子。第二种就是利用工具获取正确的网站视频地址,然后开始下载的方法了,比如这种方法可以提取,各种在线视频网站的视频地址,不过也要记得提交视频资源,上传站点方便后期的视频转换处理!。
1、打开“视频下载”工具
2、打开任意一个视频网站,然后复制网站的地址,
3、点击“开始转换”
4、当到达“提取结果”页面,
5、点击“立即下载”。
很简单点进你想要的视频播放器,然后点下载,就可以下到这个视频了,如果分享出去,然后放到网盘里。
在线视频网站的视频转换成mp4格式
这就是一个n4的转换器了
uc浏览器里:m4a格式视频转换成mp4格式视频,然后再下载。
哎呀视频下载这个软件挺好用的,但只能一个一个下哦,
1.下载芒果视频,下载1080p的2.下载海外视频3.下载电影4.想弄点小样你试试看这个吧对了,
抓取网页视频(post代理池(适合有python接口转发需求的4种方式))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-20 14:02
抓取网页视频并且仅用一个指定的接口来提取所需要的信息,目前通常有4种方式,
一、图片代理池-商业产品类似于图片爬虫,可以将爬取到的图片进行存储并提取其特征字段,后续对图片进行二次爬取,查看poc方法类似于图片代理池,file类型的接口。
1、post提交图片存储所需指定的接口:提交post/get/put/patch/delete图片接口头信息;
2、png存储接口:png存储接口头信息;
3、jpg存储接口:jpg存储接口头信息;
4、视频存储接口:视频存储接口头信息;
5、视频接口存储:抓取视频接口头信息;
6、批量抓取:批量抓取所需接口头信息。返回格式如下:包含page(s)和pagesize(s)两个单位的数据类型为json数据,用逗号(,)分隔格式为pagename(s)和pagesize(s)如返回pagetag,表示根据page存储的图片以及图片的用户名字段属性填充图片名字段uid(s);如返回pagecertificate,表示根据page存储的图片以及用户名字段属性填充图片接口artistid(s);。
7、简单图片爬取:批量抓取用户或者图片所在页面所需的所有图片。接口转化成json格式。大小为page数量的百分比,比如100px/2。
特点:只需要python环境,有代理池即可,后续对图片进行二次爬取,查看poc方法,界面可以分享,实现自动化!!!详情:--post代理池(适合有python接口转发需求的),
二、xpath结构化图片分析
1、xpath语法xpath(表象):标准通用定位表达式,是html(超文本标记语言)的子集,可以匹配html文档的结构性标签,并返回相应的文档内容或相应的值。
<p>2、分析xpath的要点标签与元素,并结合提取a、标签的基本标签:基本标签如:phrefxml/xmlol/img{img-src=""//img属性位于源文件后面//preload一定要选为false,否则表示先读取后检查。另外注意避免出现error:$error_true;语法结构;}div{position:relative;left:0;top:0;width:auto;height:auto;auto-height:10px;//div是一个伪元素,实际上是box{box-size:auto;auto-content:center;width:100%;height:100%;padding:0;}content:text;//content是一个伪元素,实际上是box{box-size:auto;auto-content:center;display:inline-block;}li{id:li}th{id:th}form{id:form}js 查看全部
抓取网页视频(post代理池(适合有python接口转发需求的4种方式))
抓取网页视频并且仅用一个指定的接口来提取所需要的信息,目前通常有4种方式,
一、图片代理池-商业产品类似于图片爬虫,可以将爬取到的图片进行存储并提取其特征字段,后续对图片进行二次爬取,查看poc方法类似于图片代理池,file类型的接口。
1、post提交图片存储所需指定的接口:提交post/get/put/patch/delete图片接口头信息;
2、png存储接口:png存储接口头信息;
3、jpg存储接口:jpg存储接口头信息;
4、视频存储接口:视频存储接口头信息;
5、视频接口存储:抓取视频接口头信息;
6、批量抓取:批量抓取所需接口头信息。返回格式如下:包含page(s)和pagesize(s)两个单位的数据类型为json数据,用逗号(,)分隔格式为pagename(s)和pagesize(s)如返回pagetag,表示根据page存储的图片以及图片的用户名字段属性填充图片名字段uid(s);如返回pagecertificate,表示根据page存储的图片以及用户名字段属性填充图片接口artistid(s);。
7、简单图片爬取:批量抓取用户或者图片所在页面所需的所有图片。接口转化成json格式。大小为page数量的百分比,比如100px/2。
特点:只需要python环境,有代理池即可,后续对图片进行二次爬取,查看poc方法,界面可以分享,实现自动化!!!详情:--post代理池(适合有python接口转发需求的),
二、xpath结构化图片分析
1、xpath语法xpath(表象):标准通用定位表达式,是html(超文本标记语言)的子集,可以匹配html文档的结构性标签,并返回相应的文档内容或相应的值。
<p>2、分析xpath的要点标签与元素,并结合提取a、标签的基本标签:基本标签如:phrefxml/xmlol/img{img-src=""//img属性位于源文件后面//preload一定要选为false,否则表示先读取后检查。另外注意避免出现error:$error_true;语法结构;}div{position:relative;left:0;top:0;width:auto;height:auto;auto-height:10px;//div是一个伪元素,实际上是box{box-size:auto;auto-content:center;width:100%;height:100%;padding:0;}content:text;//content是一个伪元素,实际上是box{box-size:auto;auto-content:center;display:inline-block;}li{id:li}th{id:th}form{id:form}js
抓取网页视频(看完必备的文档回头看视频,你可以拿去用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-17 00:01
抓取网页视频。
看名片流程很简单,但是可以统计到人脉的中南石油,属于偏服务型行业,人脉以外的知识很少,工作复杂繁琐,晋升机会看个人努力。有网,方便自己沟通,有app,方便需要大量资料的人。看完必备的文档回头看视频。
一个有价值的渠道:谷歌用ai标注同行业内的全部产品宣传图、行业内顶尖厂商产品宣传图和知名设计师推荐专辑。图片被抓取后,也会通过集搜客转换成形象文字用于宣传图宣传册销售文案和媒体报道图合成生成各种图片。谷歌全球产品推荐广告采用统一dsp广告审核标准,并且根据ai标注的图片进行审核。如果你足够专业,内部有一定量的图片数据库并且对图片标注工作了如指掌,那一定可以经过工作人员手动筛选、组合、合成获得效果非常不错的同行产品图和设计师推荐专辑。
soeasy!希望帮到你~【20190602】【创意图表】《【创意】身体指南【全国、全球】》中国站、全新系列【插画】adobelumiereformacforphotoshop、adobe—在线播放—优酷网,视频高清在线观看。
我帮你回答一下吧,非常大,我这里有300+页580万个网页大数据,需要的话,你可以拿去用。0603更新了3版。下面有wind桌面版截图。1是中南有机室大数据库101类有机会涉及交易金融保险等,前面还有用于同行业交流的新闻期刊,这个是金融期刊;2是大型企业制造大数据库:对行业制造以及交易金融、保险等有要求,里面也有企业交流报表(招募各种与创新有关的合作伙伴,认为产品和服务在质量、发展方面有创新点和亮点)3是央企图书馆大数据库:由财政部、税务总局、、银监会、电信运营商及图书馆联合组成的一个数据库。
14个厅局同时组成,有21个省级图书馆。里面有16个省级以上的书库。每个省级以上的图书馆均提供二十多个书库。4是网上校友大数据库:覆盖互联网、金融、数据库、新媒体、人力资源、教育、医疗、旅游等20多个专业领域。同时,网站也在持续不断搜集和更新全国各类网上校友。5是国家图书馆大数据库:包括有21个省级以上图书馆。
对于大数据以及其他专业领域都有针对性的招募合作伙伴。6是第一手的旅游大数据库:共200万张图片:av3.html,av2.html,av1.html,av1.jpg,av3.jpg,av1.jpg,各类风景图片40000余张。加上旅游交通信息来大数据库是存不下这么多旅游信息的,这是个必需品,而且数据库的目的是查询,很多都需要人工标注。0603101.jpg1农业大数据库:200万套耕地图片及标注,能直接用于人工。 查看全部
抓取网页视频(看完必备的文档回头看视频,你可以拿去用)
抓取网页视频。
看名片流程很简单,但是可以统计到人脉的中南石油,属于偏服务型行业,人脉以外的知识很少,工作复杂繁琐,晋升机会看个人努力。有网,方便自己沟通,有app,方便需要大量资料的人。看完必备的文档回头看视频。
一个有价值的渠道:谷歌用ai标注同行业内的全部产品宣传图、行业内顶尖厂商产品宣传图和知名设计师推荐专辑。图片被抓取后,也会通过集搜客转换成形象文字用于宣传图宣传册销售文案和媒体报道图合成生成各种图片。谷歌全球产品推荐广告采用统一dsp广告审核标准,并且根据ai标注的图片进行审核。如果你足够专业,内部有一定量的图片数据库并且对图片标注工作了如指掌,那一定可以经过工作人员手动筛选、组合、合成获得效果非常不错的同行产品图和设计师推荐专辑。
soeasy!希望帮到你~【20190602】【创意图表】《【创意】身体指南【全国、全球】》中国站、全新系列【插画】adobelumiereformacforphotoshop、adobe—在线播放—优酷网,视频高清在线观看。
我帮你回答一下吧,非常大,我这里有300+页580万个网页大数据,需要的话,你可以拿去用。0603更新了3版。下面有wind桌面版截图。1是中南有机室大数据库101类有机会涉及交易金融保险等,前面还有用于同行业交流的新闻期刊,这个是金融期刊;2是大型企业制造大数据库:对行业制造以及交易金融、保险等有要求,里面也有企业交流报表(招募各种与创新有关的合作伙伴,认为产品和服务在质量、发展方面有创新点和亮点)3是央企图书馆大数据库:由财政部、税务总局、、银监会、电信运营商及图书馆联合组成的一个数据库。
14个厅局同时组成,有21个省级图书馆。里面有16个省级以上的书库。每个省级以上的图书馆均提供二十多个书库。4是网上校友大数据库:覆盖互联网、金融、数据库、新媒体、人力资源、教育、医疗、旅游等20多个专业领域。同时,网站也在持续不断搜集和更新全国各类网上校友。5是国家图书馆大数据库:包括有21个省级以上图书馆。
对于大数据以及其他专业领域都有针对性的招募合作伙伴。6是第一手的旅游大数据库:共200万张图片:av3.html,av2.html,av1.html,av1.jpg,av3.jpg,av1.jpg,各类风景图片40000余张。加上旅游交通信息来大数据库是存不下这么多旅游信息的,这是个必需品,而且数据库的目的是查询,很多都需要人工标注。0603101.jpg1农业大数据库:200万套耕地图片及标注,能直接用于人工。
抓取网页视频(请求当中会弹出名字为之获取得到的图片内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-16 08:12
从上面的视频我们可以发现,当我们不断在不同的直播类型之间切换时,会在XHR请求中弹出名为“1”的内容,这样我们就可以很方便的找到我们需要的内容,如下图所示.
接下来,我们只需要使用程序模拟浏览器向这个接口发送请求,就可以获取数据内容了。
有的朋友按照上面的方法找到url请求链接,获取到数据后发现返回的数据是json数据内容,而且数据量很大,可能没有经验的小伙伴难以获取我们想要从数据中获得的图像链接。如下所示:
这时候可以使用一些辅助工具来帮助我们分析数据。只需要复制json数据,然后打开网址:. 复制json数据,网页会自动帮我们把json数据解析成方便我们观察的数据。
通过解析出来的数据,我们可以得到很多信息,包括主播的昵称和我们想要得到的主播的封面图。接下来,我们可以通过程序获取所有主播的封面图。对于互动约会和舞蹈模块中主播的封面图,其内容分析与颜值模块中的主播分析一致。获取封面图片的url链接,流程如下图所示。
程序中对颜值、互动约会、舞蹈三个模块下的链接进行请求,并解析返回的json数据,得到主播昵称和封面图的url地址,并保存内容到 self.pic_urls 的列表中间。
获取图片url地址后,下一步就是请求图片数据,然后保存到本地文件夹,程序如下图所示。
在程序中,以主机名命名图片,然后将请求的图片数据写入本地文件夹。最后,我们来看看获取到的图片内容。
总结
以上就是小编今天为大家带来的。您可以获得捕获的锚盖。每张图片都以主播的昵称命名。如果你不知道你喜欢哪个主播,欢迎在评论区嘀咕! 查看全部
抓取网页视频(请求当中会弹出名字为之获取得到的图片内容)
从上面的视频我们可以发现,当我们不断在不同的直播类型之间切换时,会在XHR请求中弹出名为“1”的内容,这样我们就可以很方便的找到我们需要的内容,如下图所示.
接下来,我们只需要使用程序模拟浏览器向这个接口发送请求,就可以获取数据内容了。
有的朋友按照上面的方法找到url请求链接,获取到数据后发现返回的数据是json数据内容,而且数据量很大,可能没有经验的小伙伴难以获取我们想要从数据中获得的图像链接。如下所示:
这时候可以使用一些辅助工具来帮助我们分析数据。只需要复制json数据,然后打开网址:. 复制json数据,网页会自动帮我们把json数据解析成方便我们观察的数据。
通过解析出来的数据,我们可以得到很多信息,包括主播的昵称和我们想要得到的主播的封面图。接下来,我们可以通过程序获取所有主播的封面图。对于互动约会和舞蹈模块中主播的封面图,其内容分析与颜值模块中的主播分析一致。获取封面图片的url链接,流程如下图所示。
程序中对颜值、互动约会、舞蹈三个模块下的链接进行请求,并解析返回的json数据,得到主播昵称和封面图的url地址,并保存内容到 self.pic_urls 的列表中间。
获取图片url地址后,下一步就是请求图片数据,然后保存到本地文件夹,程序如下图所示。
在程序中,以主机名命名图片,然后将请求的图片数据写入本地文件夹。最后,我们来看看获取到的图片内容。
总结
以上就是小编今天为大家带来的。您可以获得捕获的锚盖。每张图片都以主播的昵称命名。如果你不知道你喜欢哪个主播,欢迎在评论区嘀咕!
抓取网页视频(穿透网vpn有用吗?如何解决网速变慢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-16 01:00
抓取网页视频,视频是否压缩,会导致网速变慢,如果在家里建议还是用带宽流量上网速度,其他方法很多局域网穿透vpn有租用有自己写,带宽挂马了解一下,都能玩。
50m还是20m看客户端带宽和你个人网络接入情况如何,如果20m能流畅上传下载,那无线稳过100m。
1.有线直接flash流播,2.无线在信号接入的宽带里连接软件服务器,经过特殊设置达到互联互通的条件就可以上传,3.你也可以通过wifi路由转接器,4.手机也可以共享2.3.4.的视频,比如雷电视云,有线flash的优势就是配合环境,无线转带宽,
20m有线连接设备速度,100m我用是联通腾讯路由加挂路由桥接接无线(可以用wifi共享精灵连接),
本来问这个问题就是不专业的人
无线路由器连接无线ap就可以上传,我用的h110,
无线可以转接到wifi共享精灵上面打开sharing功能,可以直接设置好了,电脑端进去电脑设置里设置,在无线应用界面设置,具体是什么操作我没试过,设置完成直接能在电脑上用app去控制家里的网络。
百度搜索‘桥接’,找出你的ip在哪个ap上,设置好就可以上传了。
手机共享电脑很麻烦。无线桥接。电脑把视频文件复制到桥接设备上就可以随便看。看高清。 查看全部
抓取网页视频(穿透网vpn有用吗?如何解决网速变慢?)
抓取网页视频,视频是否压缩,会导致网速变慢,如果在家里建议还是用带宽流量上网速度,其他方法很多局域网穿透vpn有租用有自己写,带宽挂马了解一下,都能玩。
50m还是20m看客户端带宽和你个人网络接入情况如何,如果20m能流畅上传下载,那无线稳过100m。
1.有线直接flash流播,2.无线在信号接入的宽带里连接软件服务器,经过特殊设置达到互联互通的条件就可以上传,3.你也可以通过wifi路由转接器,4.手机也可以共享2.3.4.的视频,比如雷电视云,有线flash的优势就是配合环境,无线转带宽,
20m有线连接设备速度,100m我用是联通腾讯路由加挂路由桥接接无线(可以用wifi共享精灵连接),
本来问这个问题就是不专业的人
无线路由器连接无线ap就可以上传,我用的h110,
无线可以转接到wifi共享精灵上面打开sharing功能,可以直接设置好了,电脑端进去电脑设置里设置,在无线应用界面设置,具体是什么操作我没试过,设置完成直接能在电脑上用app去控制家里的网络。
百度搜索‘桥接’,找出你的ip在哪个ap上,设置好就可以上传了。
手机共享电脑很麻烦。无线桥接。电脑把视频文件复制到桥接设备上就可以随便看。看高清。
抓取网页视频(爬取本地视频或者爬b站的视频在哪里?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-10 09:05
抓取网页视频的话可以用seleniumselenium最基本功能是添加请求模块。如果请求的是本地页面的话,你可以在浏览器上装一个sublime,安装好sublime后装selenium驱动,加上你要爬取视频网站的网址(urls.txt),其他一些一些环境配置直接百度一下这些就可以了。可以考虑用户付费python版。
爬取本地视频或者爬b站的视频看呢,可以使用网页采集模块selenium2。对了,其实python也可以采集知乎的答案。
selenium就是定位视频服务器。其他的一些浏览器兼容或者注意点的工作可以百度。
当然可以,浏览器可以抓取一切资源,比如知乎回答,
先了解一下爬虫是什么你就会自己写了我补充几个用爬虫最常见的的一些问题在哪里?1.新网站都可以,网站什么都可以。在某些时候,新网站速度会比旧网站慢,要用新的网站。2.缺少手机适配,比如网上有些视频制作人都开发过什么利用模拟器的方式来爬虫视频,虽然方法对方式可以用。但是对于安卓手机这些手机,手机端没有手机app,因此手机是屏幕适配的比较差,还不如直接在手机上使用浏览器就可以安装模拟器来爬取网页,这样也可以使用屏幕适配技术。
3.模拟器存在性能问题,常见是延迟和类型。4.视频加密,网上搜,现在技术不断在改进,解决方法是使用其他分析。5.视频的分享,爬虫可以做到的,不过要爬取的视频需要版权方愿意让你看,或者是需要留有版权方的地址,这个时候就需要返回个人页面,爬虫是不能知道别人是不是已经看了视频,所以对网站是封禁的。 查看全部
抓取网页视频(爬取本地视频或者爬b站的视频在哪里?)
抓取网页视频的话可以用seleniumselenium最基本功能是添加请求模块。如果请求的是本地页面的话,你可以在浏览器上装一个sublime,安装好sublime后装selenium驱动,加上你要爬取视频网站的网址(urls.txt),其他一些一些环境配置直接百度一下这些就可以了。可以考虑用户付费python版。
爬取本地视频或者爬b站的视频看呢,可以使用网页采集模块selenium2。对了,其实python也可以采集知乎的答案。
selenium就是定位视频服务器。其他的一些浏览器兼容或者注意点的工作可以百度。
当然可以,浏览器可以抓取一切资源,比如知乎回答,
先了解一下爬虫是什么你就会自己写了我补充几个用爬虫最常见的的一些问题在哪里?1.新网站都可以,网站什么都可以。在某些时候,新网站速度会比旧网站慢,要用新的网站。2.缺少手机适配,比如网上有些视频制作人都开发过什么利用模拟器的方式来爬虫视频,虽然方法对方式可以用。但是对于安卓手机这些手机,手机端没有手机app,因此手机是屏幕适配的比较差,还不如直接在手机上使用浏览器就可以安装模拟器来爬取网页,这样也可以使用屏幕适配技术。
3.模拟器存在性能问题,常见是延迟和类型。4.视频加密,网上搜,现在技术不断在改进,解决方法是使用其他分析。5.视频的分享,爬虫可以做到的,不过要爬取的视频需要版权方愿意让你看,或者是需要留有版权方的地址,这个时候就需要返回个人页面,爬虫是不能知道别人是不是已经看了视频,所以对网站是封禁的。
抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-28 18:02
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集
了一个专门从各大主流视频网站提取视频的网站:(原名)。使用后发现各大主流视频分享网站基本都可以解析出最终的URL,但是对于公司这样的公司来说,知名度较低的网站上的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己找到的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集
了一个专门从各大主流视频网站提取视频的网站:(原名)。使用后发现各大主流视频分享网站基本都可以解析出最终的URL,但是对于公司这样的公司来说,知名度较低的网站上的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己找到的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
抓取网页视频(根据上篇文章的思路,我用了监听网卡流量的方式来改进了我的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-27 10:12
按照上一篇的思路,我用监控网卡流量的方法来改进我的程序。速度有了很大的提高。
想法
下图是我用wireshark做的一个实验。在请求路径中留下带有.mp4、.flv的请求,你得到的就是请求的视频资源。
用wireshark试验了一下,确定这种抓包的方法可行,就开始用python写抓包代码。
我使用python的pcap和dpkt包来分析网卡流量。首先是使用pcap监控我的网卡,设置pcap过滤器只处理HTTP请求,因为视频地址在HTTP请求中。我在HTTP请求的地址中找到了收录
.flv的请求,然后就可以得到视频的url地址了。
实验
代码比较短,我直接贴上代码。关于pcap和dpkt的使用我参考了这篇文章,但是这篇文章应该是抄袭别人的。当我搜索它时,我找到了一个更好的,但是当我写这篇文章时,我找不到更好的。,只能发这个不太好。
当然代码也会放到我的Github上,哈哈~
#encoding: utf8
import pcap
import dpkt
pc=pcap.pcap('eth1') #注,参数可为网卡名,如eth0
#设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP
pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
print "starting capture"
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
#对抓到的以太网V2数据包(raw packet)进行解包
p=dpkt.ethernet.Ethernet(pdata)
if p.data.__class__.__name__=='IP':
# ip='%d.%d.%d.%d'%tuple(map(ord,list(p.data.dst)))
if p.data.data.__class__.__name__=='TCP':
if p.data.data.dport==80:
header = p.data.data.data # by gashero
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
if requestUrl.find('.flv') != -1:
# print headerArr
print requestUrl
运行结果图:
未解决的问题是优酷等对视频进行分片的网站无法获取完整的视频。 查看全部
抓取网页视频(根据上篇文章的思路,我用了监听网卡流量的方式来改进了我的程序)
按照上一篇的思路,我用监控网卡流量的方法来改进我的程序。速度有了很大的提高。
想法
下图是我用wireshark做的一个实验。在请求路径中留下带有.mp4、.flv的请求,你得到的就是请求的视频资源。
用wireshark试验了一下,确定这种抓包的方法可行,就开始用python写抓包代码。
我使用python的pcap和dpkt包来分析网卡流量。首先是使用pcap监控我的网卡,设置pcap过滤器只处理HTTP请求,因为视频地址在HTTP请求中。我在HTTP请求的地址中找到了收录
.flv的请求,然后就可以得到视频的url地址了。
实验
代码比较短,我直接贴上代码。关于pcap和dpkt的使用我参考了这篇文章,但是这篇文章应该是抄袭别人的。当我搜索它时,我找到了一个更好的,但是当我写这篇文章时,我找不到更好的。,只能发这个不太好。
当然代码也会放到我的Github上,哈哈~
#encoding: utf8
import pcap
import dpkt
pc=pcap.pcap('eth1') #注,参数可为网卡名,如eth0
#设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP
pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
print "starting capture"
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
#对抓到的以太网V2数据包(raw packet)进行解包
p=dpkt.ethernet.Ethernet(pdata)
if p.data.__class__.__name__=='IP':
# ip='%d.%d.%d.%d'%tuple(map(ord,list(p.data.dst)))
if p.data.data.__class__.__name__=='TCP':
if p.data.data.dport==80:
header = p.data.data.data # by gashero
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
if requestUrl.find('.flv') != -1:
# print headerArr
print requestUrl
运行结果图:
未解决的问题是优酷等对视频进行分片的网站无法获取完整的视频。
抓取网页视频(根据上篇文章的思路,我用了监听网卡流量的方式来改进了我的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-27 10:08
按照上一篇的思路,我用监控网卡流量的方法来改进我的程序。速度有了很大的提高。
想法
下图是我用wireshark做的一个实验。在请求路径中留下带有.mp4、.flv的请求,你得到的就是请求的视频资源。
用wireshark试验了一下,确定这种抓包的方法可行,就开始用python写抓包代码。
我使用python的pcap和dpkt包来分析网卡流量。首先是使用pcap监控我的网卡,设置pcap过滤器只处理HTTP请求,因为视频地址在HTTP请求中。我在HTTP请求的地址中找到了收录
.flv的请求,然后就可以得到视频的url地址了。
实验
代码比较短,我直接贴上代码。关于pcap和dpkt的使用我参考了这篇文章,但是这篇文章应该是抄袭别人的。当我搜索它时,我找到了一个更好的,但是当我写这篇文章时,我找不到更好的。,只能发这个不太好。
当然代码也会放到我的Github上,哈哈~
#encoding: utf8
import pcap
import dpkt
pc=pcap.pcap('eth1') #注,参数可为网卡名,如eth0
#设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP
pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
print "starting capture"
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
#对抓到的以太网V2数据包(raw packet)进行解包
p=dpkt.ethernet.Ethernet(pdata)
if p.data.__class__.__name__=='IP':
# ip='%d.%d.%d.%d'%tuple(map(ord,list(p.data.dst)))
if p.data.data.__class__.__name__=='TCP':
if p.data.data.dport==80:
header = p.data.data.data # by gashero
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
if requestUrl.find('.flv') != -1:
# print headerArr
print requestUrl
运行结果图:
未解决的问题是优酷等对视频进行分片的网站无法获取完整的视频。 查看全部
抓取网页视频(根据上篇文章的思路,我用了监听网卡流量的方式来改进了我的程序)
按照上一篇的思路,我用监控网卡流量的方法来改进我的程序。速度有了很大的提高。
想法
下图是我用wireshark做的一个实验。在请求路径中留下带有.mp4、.flv的请求,你得到的就是请求的视频资源。
用wireshark试验了一下,确定这种抓包的方法可行,就开始用python写抓包代码。
我使用python的pcap和dpkt包来分析网卡流量。首先是使用pcap监控我的网卡,设置pcap过滤器只处理HTTP请求,因为视频地址在HTTP请求中。我在HTTP请求的地址中找到了收录
.flv的请求,然后就可以得到视频的url地址了。
实验
代码比较短,我直接贴上代码。关于pcap和dpkt的使用我参考了这篇文章,但是这篇文章应该是抄袭别人的。当我搜索它时,我找到了一个更好的,但是当我写这篇文章时,我找不到更好的。,只能发这个不太好。
当然代码也会放到我的Github上,哈哈~
#encoding: utf8
import pcap
import dpkt
pc=pcap.pcap('eth1') #注,参数可为网卡名,如eth0
#设置监听过滤器 HTTP请求的TCP头为GET 或者 HTTP
pc.setfilter('tcp[20:2]=0x4745 or tcp[20:2]=0x4854')
print "starting capture"
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
#对抓到的以太网V2数据包(raw packet)进行解包
p=dpkt.ethernet.Ethernet(pdata)
if p.data.__class__.__name__=='IP':
# ip='%d.%d.%d.%d'%tuple(map(ord,list(p.data.dst)))
if p.data.data.__class__.__name__=='TCP':
if p.data.data.dport==80:
header = p.data.data.data # by gashero
headerArr = header.split('\r\n')
url = headerArr[0].split(' ')[1]
host = headerArr[1].split(' ')[1]
requestUrl = host + url
if requestUrl.find('.flv') != -1:
# print headerArr
print requestUrl
运行结果图:
未解决的问题是优酷等对视频进行分片的网站无法获取完整的视频。
抓取网页视频(三招搞定看视频壁纸难题拿或其他社交网站的高清视频下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-04 16:01
抓取网页视频显示源代码,然后分析出视频里面的图片资源(图片地址,视频编码格式),然后爬下来之后返回就可以了,一般情况下,网页中通常是javascript+css,这个只是一个视频的下载工具而已,你只要知道文件路径,视频编码格式,然后找到这个格式就可以了。
三招搞定看视频壁纸难题
拿twitter或其他社交网站的高清视频下载下来,然后从mp4格式的视频文件中剪切一段就可以了。
你这是视频格式转换吧??
有以下方法,比如直接访问他们网站()或者通过邮件来发送过去的。
先把知乎页面复制粘贴然后剪切
比如我可以去哪儿网再刷新一下显示的是哪儿哪儿的电影我回来继续填坑
公开web:
1、baiduspider
2、脚本小子如果要抓的是生成的html,搜一下html解析脚本,
3、前面已经有人说过了,但是前面是基于html里有requests之类的东西上做出来的,loader估计能够写。这个完全没接触过,给不了太多建议。
windows/linux/osx中已经有抓包工具,例如wiresharkpython中有python自带的netutils。wireshark有一个api可以抓取其他地址的请求。netui也可以。requests抓包很快,但是网站对不定的url给你定制限制,你只能抓取固定地址的页面。netui可以抓取url固定,地址范围内的页面。python的模块可以自己抓取,如果有itchat,能快很多。 查看全部
抓取网页视频(三招搞定看视频壁纸难题拿或其他社交网站的高清视频下载)
抓取网页视频显示源代码,然后分析出视频里面的图片资源(图片地址,视频编码格式),然后爬下来之后返回就可以了,一般情况下,网页中通常是javascript+css,这个只是一个视频的下载工具而已,你只要知道文件路径,视频编码格式,然后找到这个格式就可以了。
三招搞定看视频壁纸难题
拿twitter或其他社交网站的高清视频下载下来,然后从mp4格式的视频文件中剪切一段就可以了。
你这是视频格式转换吧??
有以下方法,比如直接访问他们网站()或者通过邮件来发送过去的。
先把知乎页面复制粘贴然后剪切
比如我可以去哪儿网再刷新一下显示的是哪儿哪儿的电影我回来继续填坑
公开web:
1、baiduspider
2、脚本小子如果要抓的是生成的html,搜一下html解析脚本,
3、前面已经有人说过了,但是前面是基于html里有requests之类的东西上做出来的,loader估计能够写。这个完全没接触过,给不了太多建议。
windows/linux/osx中已经有抓包工具,例如wiresharkpython中有python自带的netutils。wireshark有一个api可以抓取其他地址的请求。netui也可以。requests抓包很快,但是网站对不定的url给你定制限制,你只能抓取固定地址的页面。netui可以抓取url固定,地址范围内的页面。python的模块可以自己抓取,如果有itchat,能快很多。
抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-20 19:09
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在之前采集了一个专门提取各大主流视频的网站网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以分析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在之前采集了一个专门提取各大主流视频的网站网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以分析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
抓取网页视频( 波波带你一步一步手动提取网页视频(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-20 19:08
波波带你一步一步手动提取网页视频(图))
生活中,我们经常会看一些网络视频,有的感觉很不错,都希望自己下载、采集,但往往就是不敢尝试。
这次Bobo就带你一步步手动提取网络视频。
首先,需要一些准备知识。
一、网络视频
网页上的视频一般是通过video标签播放的,还有一些其他的技术手段可以避开视频或者隐藏视频。避免视频可能会使用一些其他播放器来播放视频,隐藏视频一般是将视频放在一个iframe中,这将在后续具体案例中介绍。
二、视频链接类型
一般网页上的视频都有mp4链接和m3u8链接。前者解压下载方便,后者比较麻烦。
三、谷歌浏览器
谷歌浏览器是我们下一步的关键。当然,360浏览器、QQ浏览器等一些chrome内核的浏览器也是可以的。
在Chrome浏览器中,我们需要熟悉控制台,可以通过F12调用,也可以在菜单中打开JavaScript控制台。具体可以从百度打开到不同的浏览器,Windows下一般是F12。
下图显示了控制台的总体外观。后面我们会用到Network、Application这三个元素,主要是Network,其次是Elements,可能会用到一些Application场景。左上角还有一个箭头按钮,可以用来定位视频标签。
基础知识就到这里了,后面我们再做一些实际操作。
敬请期待后续文章。 查看全部
抓取网页视频(
波波带你一步一步手动提取网页视频(图))
生活中,我们经常会看一些网络视频,有的感觉很不错,都希望自己下载、采集,但往往就是不敢尝试。
这次Bobo就带你一步步手动提取网络视频。
首先,需要一些准备知识。
一、网络视频
网页上的视频一般是通过video标签播放的,还有一些其他的技术手段可以避开视频或者隐藏视频。避免视频可能会使用一些其他播放器来播放视频,隐藏视频一般是将视频放在一个iframe中,这将在后续具体案例中介绍。
二、视频链接类型
一般网页上的视频都有mp4链接和m3u8链接。前者解压下载方便,后者比较麻烦。
三、谷歌浏览器
谷歌浏览器是我们下一步的关键。当然,360浏览器、QQ浏览器等一些chrome内核的浏览器也是可以的。
在Chrome浏览器中,我们需要熟悉控制台,可以通过F12调用,也可以在菜单中打开JavaScript控制台。具体可以从百度打开到不同的浏览器,Windows下一般是F12。
下图显示了控制台的总体外观。后面我们会用到Network、Application这三个元素,主要是Network,其次是Elements,可能会用到一些Application场景。左上角还有一个箭头按钮,可以用来定位视频标签。
基础知识就到这里了,后面我们再做一些实际操作。
敬请期待后续文章。
抓取网页视频(雪山凌狐教程”超全fiddler详解如何提取网页视频50分问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-11-16 09:16
安卓软件视频采集工具是一款功能强大的安卓软件视频采集工具。APP具有强大的视频直链提取功能,支持蓝作云和秒杀。
以百度浏览器为例:1、输入要搜索的视频内容,进入网页。百度手机浏览器支持直接打开网页和进入网页。
如何在手机上检索互联网上的视频?未定义-提取、视频、网络、手机。
简介: 类型: 下载工具 更新时间: 2016-09-01 WebVideoDownloader 是一款非常好用的网络视频采集软件,可以轻松采集所有内容。
网页视频采集工具还支持视频格式转换、合并、裁剪等视频编辑功能,快来下载体验吧~
问题1:如何通过点击上方的搜索框来抓取手机网络视频是不行的。如果您认为答案已经解决了您的问题,请采纳。如果您有任何问题,请继续提问。如果您认为答案已经解决了您的问题,请采纳。如果您有任何问题,请继续提问。希望我的回答能帮到你。问题2:如何从手机中提取网络视频50分 问题2:如何从手机中提取网络视频50分 第三方视频软件下载视频存储位置,建议您尝试:我的文件-查找视频软件.
使用Chubbao你能得到什么?好消息:购买“专业版”可获得50个免费手机配额,购买“终极版”可获得120个免费手机配额。(手机配额是专门用来抢手机号的)。
更多精彩教程,请搜索关注“雪山令狐教程”。超全提琴手讲解如何连接手机抓包。为什么要在手机上抓包?一些网站。 查看全部
抓取网页视频(雪山凌狐教程”超全fiddler详解如何提取网页视频50分问题)
安卓软件视频采集工具是一款功能强大的安卓软件视频采集工具。APP具有强大的视频直链提取功能,支持蓝作云和秒杀。
以百度浏览器为例:1、输入要搜索的视频内容,进入网页。百度手机浏览器支持直接打开网页和进入网页。
如何在手机上检索互联网上的视频?未定义-提取、视频、网络、手机。
简介: 类型: 下载工具 更新时间: 2016-09-01 WebVideoDownloader 是一款非常好用的网络视频采集软件,可以轻松采集所有内容。
网页视频采集工具还支持视频格式转换、合并、裁剪等视频编辑功能,快来下载体验吧~
问题1:如何通过点击上方的搜索框来抓取手机网络视频是不行的。如果您认为答案已经解决了您的问题,请采纳。如果您有任何问题,请继续提问。如果您认为答案已经解决了您的问题,请采纳。如果您有任何问题,请继续提问。希望我的回答能帮到你。问题2:如何从手机中提取网络视频50分 问题2:如何从手机中提取网络视频50分 第三方视频软件下载视频存储位置,建议您尝试:我的文件-查找视频软件.
使用Chubbao你能得到什么?好消息:购买“专业版”可获得50个免费手机配额,购买“终极版”可获得120个免费手机配额。(手机配额是专门用来抢手机号的)。
更多精彩教程,请搜索关注“雪山令狐教程”。超全提琴手讲解如何连接手机抓包。为什么要在手机上抓包?一些网站。

