
抓取网页数据php
抓取网页数据php(Google新的SEO代言人GaryIllyes帖子里的后续跟进内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-30 07:04
一月份,谷歌新任 SEO 发言人 Gary Illyes 在谷歌官方博客上发表了一篇文章:What Crawl Budget Means for Googlebot,讨论了与搜索引擎蜘蛛爬取份额相关的问题。对于大中型网站来说,这是一个非常重要的SEO问题,有时会成为网站有机流量的瓶颈。
今天的帖子总结了Gary Illyes的帖子的主要内容以及后面的很多博客和论坛帖子,以及我自己的一些案例和理解。
需要强调的是,以下概念也适用于百度。
什么是搜索引擎蜘蛛的抓取份额?
顾名思义,抓取份额是搜索引擎蜘蛛在 网站 上抓取页面所花费的总时间。对于一个特定的 网站,搜索引擎蜘蛛在这个 网站 上花费的总时间是相对恒定的,不会无限期地抓取 网站 所有页面。
crawl share的英文谷歌使用crawl budget,直译为crawl budget。我不认为它可以解释它的含义,所以我用爬网分享来表达这个概念。
什么决定了抓取份额?它涉及抓取需求和抓取速率限制。
抓取需求
抓取需求,crawl demand,是指搜索引擎“想要”抓取特定网站的页面数。
有两个主要因素决定了爬行需求。首先是页面重量。网站 上的页数达到基本页重,搜索引擎想爬多少页。二是索引库中的页面是否太久没有更新。说到底,还是页面权重。权重高的页面很长一段时间都不会更新。
页面权重和 网站 权重密切相关。增加 网站 权重将使搜索引擎愿意爬取更多页面。
抓取速度限制
搜索引擎蜘蛛不会为了爬取更多的页面而拖拽其他网站服务器,所以某一个网站会设置一个爬取率限制,爬取率限制,也就是服务器可以达到的上限承担,在这个速度限制内,蜘蛛爬行不会拖慢服务器,影响用户访问。
服务器响应速度够快,将限速提高一点,爬取加速,服务器响应速度降低,限速降低,爬取减慢,甚至停止爬取。
因此,抓取速度限制是搜索引擎“可以”抓取的页面数。
什么决定了抓取份额?
爬取份额是同时考虑了爬取需求和爬取速度限制的结果,即搜索引擎“想”爬取和“能够”同时爬取的页面数量。
网站权重高,页面内容质量高,页面够多,服务器速度够快,爬取份额大。
小网站不用担心抢股
小网站页数少,即使网站权重再低,服务器也慢,而且搜索引擎蜘蛛每天爬的少,一般至少能爬几百页. 网站爬取一次,所以 网站 的数千个页面完全不用担心爬取份额。网站 几万页一般没什么大不了的。如果每天数百次访问会减慢服务器速度,那么 SEO 就不是主要问题。
中到大 网站 可能需要考虑爬取共享
几十万页以上的大中型网站可能需要考虑爬取份额是否够用。
抓取份额不够。比如网站有1000万个页面,而搜索引擎每天只能抓取几万个页面,所以一次网站可能需要几个月甚至一年的时间。一些重要页面无法爬取,所以没有排名,或者重要页面无法及时更新。
为了让 网站 页面被及时和充分的爬取,服务器必须足够快,页面必须足够小。如果网站有大量优质数据,爬取份额会受到爬取率的限制,提高页面速度会直接提高爬取率限制,从而提高爬取份额。
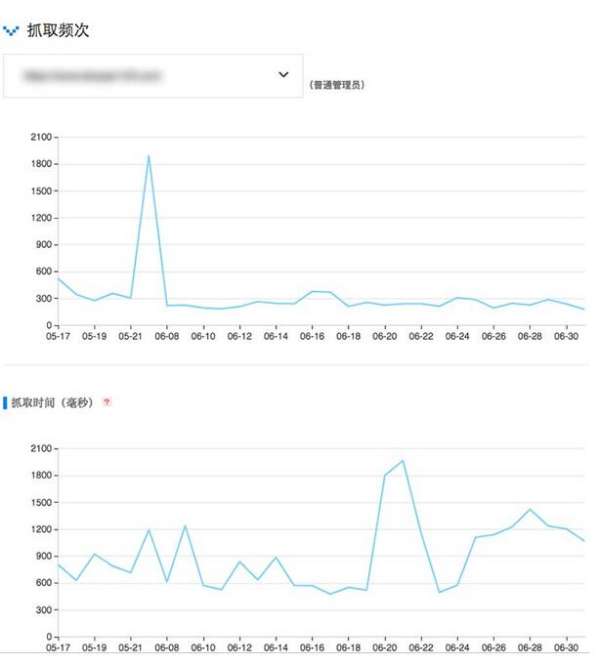
百度站长平台和谷歌搜索控制台都有数据抓取。下图是一个网站的百度爬取频率:
上图是每天为SEO发布的一个小网站。页面爬取频率和爬取时间(取决于服务器速度和页面大小)相互无关,说明爬取份额没有用完,不用担心。
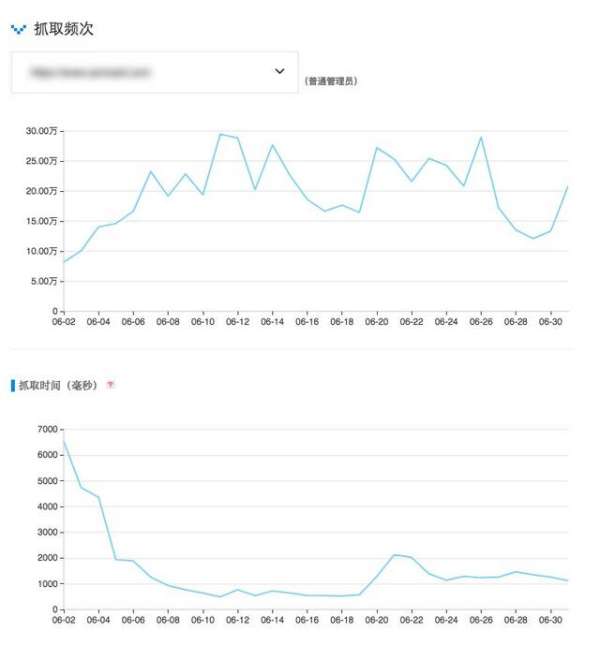
有时候,爬取频率和爬取时间有一定的对应关系,如下图网站较大:
可以看出,爬取时间的提高(减小页面大小、提高服务器速度、优化数据库)明显导致爬取频率增加,从而爬取更多页面收录,遍历一次网站更快。
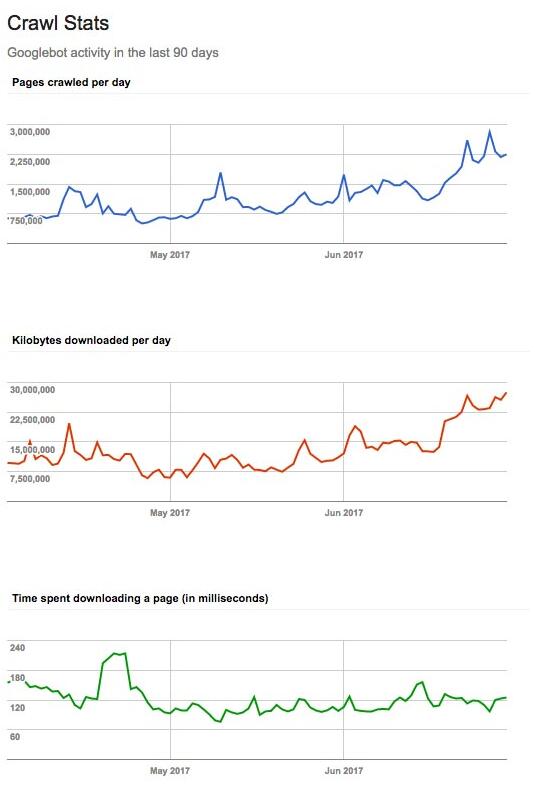
Google Search Console 中较大网站的示例:
顶部是爬取的页面数,中间是爬取的数据量。除非服务器出现故障,否则这两个应该是对应的。底部是页面抓取时间。可以看到,页面下载速度快到每天爬几百万个页面。
当然,如前所述,能爬上百万页是一回事,但搜索引擎要不要爬则是另一回事。
大网站另一个你经常需要考虑爬取份额的原因是不要把你有限的爬取份额浪费在无意义的页面爬取上,让应该爬取的重要页面没有机会被爬取。
浪费爬网共享的典型页面是:
许多过滤过滤器页面。几年前,在一篇关于无效 URL 抓取索引的帖子中对此进行了详细讨论。网站上无限制的低质量复制内容、垃圾日历等页面
以上页面被大量爬取,爬取份额可能用完,但应该爬取的页面却没有被爬取。
如何保存抓取份额?
当然首先是减小页面文件大小,提高服务器速度,优化数据库,减少爬取时间。
然后,尽量避免上面列出的那些浪费爬取份额的事情。有些是内容质量问题,有些是网站 结构问题。如果是结构问题,最简单的办法就是禁止抓取robots文件,但是会浪费一些页面权重,因为权重只能进入,不能访问。
在某些情况下,使用链接 nofollow 属性可以节省爬网共享。小网站,既然爬取份额用不完,加nofollow就没意义了。大网站,nofollow可以在一定程度上控制权重的流动和分配。一个精心设计的nofollow会减少无意义页面的权重,增加重要页面的权重。当一个搜索引擎进行爬取时,它会使用一个 URL 爬取列表。要爬取的 URL 按页面权重排序。如果重要页面的权重增加,将首先抓取它们。无意义页面的权重可能非常低,以至于搜索引擎不想抓取它们。
最后的几点说明:
链接加nofollow 不会浪费抓取份额。但这在谷歌是浪费重量。noindex 标记不保存爬网共享。如果搜索引擎需要知道页面上有noindex标签,就得先爬取页面,所以不保存爬取份额。规范标签有时可以节省一点爬网份额。和noindex标签一样,如果搜索引擎知道页面上有canonical标签,就得先爬取页面,所以不直接保存爬取份额。但是带有规范标签的页面通常很少被抓取,因此您节省了一点抓取份额。爬取率和爬取份额不是排名因素。但是没有被爬取的页面是没有排名的。 查看全部
抓取网页数据php(Google新的SEO代言人GaryIllyes帖子里的后续跟进内容)
一月份,谷歌新任 SEO 发言人 Gary Illyes 在谷歌官方博客上发表了一篇文章:What Crawl Budget Means for Googlebot,讨论了与搜索引擎蜘蛛爬取份额相关的问题。对于大中型网站来说,这是一个非常重要的SEO问题,有时会成为网站有机流量的瓶颈。
今天的帖子总结了Gary Illyes的帖子的主要内容以及后面的很多博客和论坛帖子,以及我自己的一些案例和理解。
需要强调的是,以下概念也适用于百度。
什么是搜索引擎蜘蛛的抓取份额?
顾名思义,抓取份额是搜索引擎蜘蛛在 网站 上抓取页面所花费的总时间。对于一个特定的 网站,搜索引擎蜘蛛在这个 网站 上花费的总时间是相对恒定的,不会无限期地抓取 网站 所有页面。
crawl share的英文谷歌使用crawl budget,直译为crawl budget。我不认为它可以解释它的含义,所以我用爬网分享来表达这个概念。
什么决定了抓取份额?它涉及抓取需求和抓取速率限制。
抓取需求
抓取需求,crawl demand,是指搜索引擎“想要”抓取特定网站的页面数。
有两个主要因素决定了爬行需求。首先是页面重量。网站 上的页数达到基本页重,搜索引擎想爬多少页。二是索引库中的页面是否太久没有更新。说到底,还是页面权重。权重高的页面很长一段时间都不会更新。
页面权重和 网站 权重密切相关。增加 网站 权重将使搜索引擎愿意爬取更多页面。
抓取速度限制
搜索引擎蜘蛛不会为了爬取更多的页面而拖拽其他网站服务器,所以某一个网站会设置一个爬取率限制,爬取率限制,也就是服务器可以达到的上限承担,在这个速度限制内,蜘蛛爬行不会拖慢服务器,影响用户访问。
服务器响应速度够快,将限速提高一点,爬取加速,服务器响应速度降低,限速降低,爬取减慢,甚至停止爬取。
因此,抓取速度限制是搜索引擎“可以”抓取的页面数。
什么决定了抓取份额?
爬取份额是同时考虑了爬取需求和爬取速度限制的结果,即搜索引擎“想”爬取和“能够”同时爬取的页面数量。
网站权重高,页面内容质量高,页面够多,服务器速度够快,爬取份额大。
小网站不用担心抢股
小网站页数少,即使网站权重再低,服务器也慢,而且搜索引擎蜘蛛每天爬的少,一般至少能爬几百页. 网站爬取一次,所以 网站 的数千个页面完全不用担心爬取份额。网站 几万页一般没什么大不了的。如果每天数百次访问会减慢服务器速度,那么 SEO 就不是主要问题。
中到大 网站 可能需要考虑爬取共享
几十万页以上的大中型网站可能需要考虑爬取份额是否够用。
抓取份额不够。比如网站有1000万个页面,而搜索引擎每天只能抓取几万个页面,所以一次网站可能需要几个月甚至一年的时间。一些重要页面无法爬取,所以没有排名,或者重要页面无法及时更新。
为了让 网站 页面被及时和充分的爬取,服务器必须足够快,页面必须足够小。如果网站有大量优质数据,爬取份额会受到爬取率的限制,提高页面速度会直接提高爬取率限制,从而提高爬取份额。
百度站长平台和谷歌搜索控制台都有数据抓取。下图是一个网站的百度爬取频率:
上图是每天为SEO发布的一个小网站。页面爬取频率和爬取时间(取决于服务器速度和页面大小)相互无关,说明爬取份额没有用完,不用担心。
有时候,爬取频率和爬取时间有一定的对应关系,如下图网站较大:
可以看出,爬取时间的提高(减小页面大小、提高服务器速度、优化数据库)明显导致爬取频率增加,从而爬取更多页面收录,遍历一次网站更快。
Google Search Console 中较大网站的示例:
顶部是爬取的页面数,中间是爬取的数据量。除非服务器出现故障,否则这两个应该是对应的。底部是页面抓取时间。可以看到,页面下载速度快到每天爬几百万个页面。
当然,如前所述,能爬上百万页是一回事,但搜索引擎要不要爬则是另一回事。
大网站另一个你经常需要考虑爬取份额的原因是不要把你有限的爬取份额浪费在无意义的页面爬取上,让应该爬取的重要页面没有机会被爬取。
浪费爬网共享的典型页面是:
许多过滤过滤器页面。几年前,在一篇关于无效 URL 抓取索引的帖子中对此进行了详细讨论。网站上无限制的低质量复制内容、垃圾日历等页面
以上页面被大量爬取,爬取份额可能用完,但应该爬取的页面却没有被爬取。
如何保存抓取份额?
当然首先是减小页面文件大小,提高服务器速度,优化数据库,减少爬取时间。
然后,尽量避免上面列出的那些浪费爬取份额的事情。有些是内容质量问题,有些是网站 结构问题。如果是结构问题,最简单的办法就是禁止抓取robots文件,但是会浪费一些页面权重,因为权重只能进入,不能访问。
在某些情况下,使用链接 nofollow 属性可以节省爬网共享。小网站,既然爬取份额用不完,加nofollow就没意义了。大网站,nofollow可以在一定程度上控制权重的流动和分配。一个精心设计的nofollow会减少无意义页面的权重,增加重要页面的权重。当一个搜索引擎进行爬取时,它会使用一个 URL 爬取列表。要爬取的 URL 按页面权重排序。如果重要页面的权重增加,将首先抓取它们。无意义页面的权重可能非常低,以至于搜索引擎不想抓取它们。
最后的几点说明:
链接加nofollow 不会浪费抓取份额。但这在谷歌是浪费重量。noindex 标记不保存爬网共享。如果搜索引擎需要知道页面上有noindex标签,就得先爬取页面,所以不保存爬取份额。规范标签有时可以节省一点爬网份额。和noindex标签一样,如果搜索引擎知道页面上有canonical标签,就得先爬取页面,所以不直接保存爬取份额。但是带有规范标签的页面通常很少被抓取,因此您节省了一点抓取份额。爬取率和爬取份额不是排名因素。但是没有被爬取的页面是没有排名的。
抓取网页数据php(Python使用使用_xuqi7的博客-程序员ITS404的初级用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-30 07:03
Atom使用_xuqi7的博客-程序员ITS404
atom的主要用法 0x00 介绍 Atom是github专门为程序员推出的跨平台文本编辑器。具有简洁直观的 GUI,并具有许多有趣的功能:支持 CSS、HTML、JavaScript 和其他 Web 编程语言。它支持宏,自动完成分屏功能,并具有集成的文件管理器。它实际上是一个文本编辑器
Python os 模块参考手册-“违规用户”之博客-程序员ITS404
Python 标准库中的 os 模块收录常用的操作系统函数。这个模块的作用主要是提供平台无关的功能。也就是说os模块可以处理平台之间的差异,使得编写的程序可以在另一个平台上运行而无需做任何改动。当然,这个模块只是提供了一种轻量级的方式来使用依赖于操作系统的功能。一些特定的功能必须使用特定的模块,例如:如何只读取或写入文件,请使用 open();...
求最大公约数和最小公倍数。C_的博客-程序员ITS404
公式的推导过程太复杂了,记不住了,只记得结论。这里我们采用了折腾和分割的方法。B == 0) return A;else gcd(B, A%B);}int lcm(int m, int n, int d)//最小公倍数{return m * n / d;}int main (){int m, n,d;printf("请输入两个正整数:");scanf("%d%d", &m,
【Python上手仅需20分钟】从安装到数据采集存储,就这么简单-juoduomade的博客-程序员ITS404
基于大众对 Python 的炒作和欣赏,作为一名 Java 从业者,怀着批判和好奇的心态,买了一本 Python 书籍《无阻碍地学 Python》。我刚刚读了这本书的第一部分......我决定成为一个 python 粉丝。作为一个合格的脑残粉(题主(ノ◕ω◕)ノ),为了开发我的下线,我会详细介绍Python安装到开发工具的简单介绍,写一个捕获天气信息数据并存的...
遍历文件_07H_JH的博客-程序员ITS404
参见《Windows核心编程》,C/C++程序实际上是由运行时库中的Startup系列函数(mainCRTStartup、wmainCRTStartup、WinMainCRTStartup、wWinMainCRTStartup)进行一系列初始化,然后调用程序员编写的代码。main, wmain, WinMain or wWinMain,所以很想看mainCRTStartup的定义,书上说是在crt
现实世界中的开集识别问题__pinnacle_的博客-程序员ITS404_Open Set Recognition
开集分类问题(open-set problem)不仅包括从0到9的字符类别,还包括A到Z等其他未知类别,但是这些未知类别没有标签,分类器无法知道未知的类别。图像的具体类别,比如:是否是A,这许多不同类别的图像共同构成一个类别:未知类别,我们在检测中称其为背景类别,开集分类问题的目的是: * * 正确划分这10个类别,正确拒绝非数字类别** 查看全部
抓取网页数据php(Python使用使用_xuqi7的博客-程序员ITS404的初级用法)
Atom使用_xuqi7的博客-程序员ITS404
atom的主要用法 0x00 介绍 Atom是github专门为程序员推出的跨平台文本编辑器。具有简洁直观的 GUI,并具有许多有趣的功能:支持 CSS、HTML、JavaScript 和其他 Web 编程语言。它支持宏,自动完成分屏功能,并具有集成的文件管理器。它实际上是一个文本编辑器
Python os 模块参考手册-“违规用户”之博客-程序员ITS404
Python 标准库中的 os 模块收录常用的操作系统函数。这个模块的作用主要是提供平台无关的功能。也就是说os模块可以处理平台之间的差异,使得编写的程序可以在另一个平台上运行而无需做任何改动。当然,这个模块只是提供了一种轻量级的方式来使用依赖于操作系统的功能。一些特定的功能必须使用特定的模块,例如:如何只读取或写入文件,请使用 open();...
求最大公约数和最小公倍数。C_的博客-程序员ITS404
公式的推导过程太复杂了,记不住了,只记得结论。这里我们采用了折腾和分割的方法。B == 0) return A;else gcd(B, A%B);}int lcm(int m, int n, int d)//最小公倍数{return m * n / d;}int main (){int m, n,d;printf("请输入两个正整数:");scanf("%d%d", &m,
【Python上手仅需20分钟】从安装到数据采集存储,就这么简单-juoduomade的博客-程序员ITS404
基于大众对 Python 的炒作和欣赏,作为一名 Java 从业者,怀着批判和好奇的心态,买了一本 Python 书籍《无阻碍地学 Python》。我刚刚读了这本书的第一部分......我决定成为一个 python 粉丝。作为一个合格的脑残粉(题主(ノ◕ω◕)ノ),为了开发我的下线,我会详细介绍Python安装到开发工具的简单介绍,写一个捕获天气信息数据并存的...
遍历文件_07H_JH的博客-程序员ITS404
参见《Windows核心编程》,C/C++程序实际上是由运行时库中的Startup系列函数(mainCRTStartup、wmainCRTStartup、WinMainCRTStartup、wWinMainCRTStartup)进行一系列初始化,然后调用程序员编写的代码。main, wmain, WinMain or wWinMain,所以很想看mainCRTStartup的定义,书上说是在crt
现实世界中的开集识别问题__pinnacle_的博客-程序员ITS404_Open Set Recognition
开集分类问题(open-set problem)不仅包括从0到9的字符类别,还包括A到Z等其他未知类别,但是这些未知类别没有标签,分类器无法知道未知的类别。图像的具体类别,比如:是否是A,这许多不同类别的图像共同构成一个类别:未知类别,我们在检测中称其为背景类别,开集分类问题的目的是: * * 正确划分这10个类别,正确拒绝非数字类别**
抓取网页数据php(PowerBI财务报表分析系列之:数据准备篇(000002)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-24 07:18
PowerBI财务报表分析系列:
数据准备
数据分析的第一步是在开始后续的一系列分析过程之前拥有数据。PowerBI 财务报表分析也不例外。在第一篇文章中,我们先介绍报表数据的获取,并将获取的数据整理成合适的分析。风格。
本分析示例使用的是上市公司数据,因此数据获取的主要工作是使用PowerBI批量抓取网页数据。
如果你的分析对象是公司的财务报表,会更方便。您可以跳过网络抓取数据的过程,直接组织数据。但是,如果你已经学会了使用 PowerBI 抓取网页数据的技巧,你以后可以随时使用它。在。
在下方输入文字。
本PowerBI财务报表分析报告使用5家上市公司2010年至2019年的资产负债表、损益表和现金流量表数据。
数据来自新浪财经,首先选择一家公司,比如万科A,点击财务报表>资产负债表>2019,出现在我面前的网页如下:
2019年四季度的资产负债表同时显示,数据结构很好,可以为后期整理节省大量工作。
然后看这个URL结构:
猜测资产负债表和000002、2019分别代表万科的资产负债表、股票代码和年份,可以通过更改公司和年份来验证。比如五粮液2018年的损益表,网址是:
和猜测的一模一样,那么就可以使用PowerBI批量抓取了。
捕捉多家公司、多年、多份报告的总体思路:
1、先抓一个公司一年的报告;
2、使用步骤 1 中的查询创建自定义函数;
3、构造参数列表;
4.调用自定义函数批量抓取数据。
下面进入具体操作步骤。
1.使用PowerBI抓取公司一年的报表
以上面第一个 URL:万科 2019 年资产负债表为例,点击 Get Data > From web,输入 URL,在弹出的导航器中会看到 PowerBI 识别的很多表,因为这个页面原本也就是多组数据,分别点击查看,你会看到表17的结构是最规范的,
选择表,然后加载数据并进入 Power Query 编辑器。
先观察这张表的数据,空值显示为“--”,先用0代替,然后用第一行作为表头:
如果对 PowerQuery 的基本操作不熟悉,推荐看看这个文章:
数据清洗中最常用的十三个技巧
这是一个二维结构表。为方便后续分析,将其转为一维表:选中第一列,点击Unpivot > Unpivot other columns,即为一维表:
如果你对一维表不了解,可以参考:关于一维表,你想知道的都在这里
万科2019年资产负债表已提取整理。
其实这一步到这里就可以结束了。但是在这个模型中,为了简化,我删除了现金流量表间接法的附加数据,只保留了直接法的现金流量表项目。因此,我对现金流量表进行了更多查询。
因此,在提取现金流量表时,在上述资产负债表操作的基础上,增加了删除最下面一行的步骤,其他步骤同理(如需使用现金补充信息,可不处理把它分开,你只需要获取一个资产负债表就可以了)。
2.创建自定义函数
在 PowerBI 中,每一步操作都会被自动记录下来。数据源更新后,刷新可以自动完成所有操作步骤。
进一步,这个查询也可以被函数化并应用到其他类似的查询,这些查询使用了PowerQuery的自定义函数(如果你不知道自定义函数是什么,你可以看看:Knowing Power Query's custom function)。
并不是所有的自定义函数都需要一点点从头开始编写 M 代码,有更简单的方法。
步骤 1 完成后,右键单击查询名称,然后单击“创建函数”。
输入函数名称,这里我根据报表类型定义函数为资产负债表。
然后选择这个自定义函数,点击进入高级编辑器,将前面几行代码调整为下图所示内容:
就是修改获取数据的URL,将URL中的报表类型、公司代码、年份分别作为type、code、year,将这三个变量作为自定义函数的三个参数。
然后构建这个自定义函数,
在该窗口中,可以输入任意三个有效参数,提取某上市公司某年某年的报表。
但是创建自定义函数的目的是为了批量获取数据,所以在这个窗口不需要操作。
同理,为现金流量表生成一个自定义函数,命名为 cashflow。
3.构建参数列表
对于这三个参数,我们需要构造这三个参数的笛卡尔积,得到各公司2010-2019年的三大报表数据。
为了方便后期的修改和维护,我们先建立三个单独的参数表。
在PowerQuery编辑器中,直接点击输入数据,输入要分析的公司名称和股票代码:
生成公司名称表。同理,生成年表和报表类型表。
接下来要做的是生成这三个表的笛卡尔积,即公司代码、年份和报告类型的任意组合。
在 PowerQuery 中,生成笛卡尔积就像向三个表中的每一个(例如 1)添加一列,然后合并查询一样简单。
首先合并查询报表类型和年份:
得到的结果如下:
这是报表类型和年份的任意组合,然后继续将此表与公司名称表合并,得到公司代码、年份和报表类型的任意组合表。
4、调用自定义函数
在第3步生成的表的基础上,添加自定义列,
这个M代码表示如果报表类型是CashFlow(现金流量表),则调用自定义函数:cashflow,否则调用资产负债表,其参数相同(如果只有一个自定义函数,则无需使用IF用于判断。,直接调用即可)。
然后我抓了这五家公司10年的三大报告数据:
另外,批量抓取的报表数据已经是我们需要的一维表格数据了,因为第一步收录了二维转一维的步骤,后面调用自定义函数的时候会自动做相同的。手术。
当然,你也可以用这种方法一次抓取几百家公司的数据,但是速度会很慢,所以建议只抓取你需要的公司和最近一年的数据。
至此,三大表的数据抓取已经完成,主要是使用PowerQuery的界面操作和一些简单的代码修改。即使没有基础,也可以按照以上步骤快速完成。
在这个财务分析示例中,有一个页面,其中收录从网络上抓取的公司简介和公司信息:
数据来自以下三个网页:
公司公告
公司简介
历史行情
这些数据的抓取和上面的财报数据抓取步骤完全一样,只是更简单一些,因为只有一个参数:公司代码,大家可以自己练习。
通过上面的介绍,你应该可以很方便的从网页中抓取财报数据了。当需要其他相关数据时,可以在网上搜索资源,然后批量抓取。
如开头所说,如果你要做的是分析贵公司的内部财务报告,你可以忽略本文中捕获数据的步骤,直接导入现成的财务报告。但是,为了后续分析的需要,建议还是将报表数据组织成一维的表结构。
数据整理上传后,就可以进行下一步的数据建模了。
成为 PowerBI Planet 会员,获取财务报告分析模板 查看全部
抓取网页数据php(PowerBI财务报表分析系列之:数据准备篇(000002)(图))
PowerBI财务报表分析系列:
数据准备
数据分析的第一步是在开始后续的一系列分析过程之前拥有数据。PowerBI 财务报表分析也不例外。在第一篇文章中,我们先介绍报表数据的获取,并将获取的数据整理成合适的分析。风格。
本分析示例使用的是上市公司数据,因此数据获取的主要工作是使用PowerBI批量抓取网页数据。
如果你的分析对象是公司的财务报表,会更方便。您可以跳过网络抓取数据的过程,直接组织数据。但是,如果你已经学会了使用 PowerBI 抓取网页数据的技巧,你以后可以随时使用它。在。
在下方输入文字。
本PowerBI财务报表分析报告使用5家上市公司2010年至2019年的资产负债表、损益表和现金流量表数据。
数据来自新浪财经,首先选择一家公司,比如万科A,点击财务报表>资产负债表>2019,出现在我面前的网页如下:
2019年四季度的资产负债表同时显示,数据结构很好,可以为后期整理节省大量工作。
然后看这个URL结构:
猜测资产负债表和000002、2019分别代表万科的资产负债表、股票代码和年份,可以通过更改公司和年份来验证。比如五粮液2018年的损益表,网址是:
和猜测的一模一样,那么就可以使用PowerBI批量抓取了。
捕捉多家公司、多年、多份报告的总体思路:
1、先抓一个公司一年的报告;
2、使用步骤 1 中的查询创建自定义函数;
3、构造参数列表;
4.调用自定义函数批量抓取数据。
下面进入具体操作步骤。
1.使用PowerBI抓取公司一年的报表
以上面第一个 URL:万科 2019 年资产负债表为例,点击 Get Data > From web,输入 URL,在弹出的导航器中会看到 PowerBI 识别的很多表,因为这个页面原本也就是多组数据,分别点击查看,你会看到表17的结构是最规范的,
选择表,然后加载数据并进入 Power Query 编辑器。
先观察这张表的数据,空值显示为“--”,先用0代替,然后用第一行作为表头:
如果对 PowerQuery 的基本操作不熟悉,推荐看看这个文章:
数据清洗中最常用的十三个技巧
这是一个二维结构表。为方便后续分析,将其转为一维表:选中第一列,点击Unpivot > Unpivot other columns,即为一维表:
如果你对一维表不了解,可以参考:关于一维表,你想知道的都在这里
万科2019年资产负债表已提取整理。
其实这一步到这里就可以结束了。但是在这个模型中,为了简化,我删除了现金流量表间接法的附加数据,只保留了直接法的现金流量表项目。因此,我对现金流量表进行了更多查询。
因此,在提取现金流量表时,在上述资产负债表操作的基础上,增加了删除最下面一行的步骤,其他步骤同理(如需使用现金补充信息,可不处理把它分开,你只需要获取一个资产负债表就可以了)。
2.创建自定义函数
在 PowerBI 中,每一步操作都会被自动记录下来。数据源更新后,刷新可以自动完成所有操作步骤。
进一步,这个查询也可以被函数化并应用到其他类似的查询,这些查询使用了PowerQuery的自定义函数(如果你不知道自定义函数是什么,你可以看看:Knowing Power Query's custom function)。
并不是所有的自定义函数都需要一点点从头开始编写 M 代码,有更简单的方法。
步骤 1 完成后,右键单击查询名称,然后单击“创建函数”。
输入函数名称,这里我根据报表类型定义函数为资产负债表。
然后选择这个自定义函数,点击进入高级编辑器,将前面几行代码调整为下图所示内容:
就是修改获取数据的URL,将URL中的报表类型、公司代码、年份分别作为type、code、year,将这三个变量作为自定义函数的三个参数。
然后构建这个自定义函数,
在该窗口中,可以输入任意三个有效参数,提取某上市公司某年某年的报表。
但是创建自定义函数的目的是为了批量获取数据,所以在这个窗口不需要操作。
同理,为现金流量表生成一个自定义函数,命名为 cashflow。
3.构建参数列表
对于这三个参数,我们需要构造这三个参数的笛卡尔积,得到各公司2010-2019年的三大报表数据。
为了方便后期的修改和维护,我们先建立三个单独的参数表。
在PowerQuery编辑器中,直接点击输入数据,输入要分析的公司名称和股票代码:
生成公司名称表。同理,生成年表和报表类型表。
接下来要做的是生成这三个表的笛卡尔积,即公司代码、年份和报告类型的任意组合。
在 PowerQuery 中,生成笛卡尔积就像向三个表中的每一个(例如 1)添加一列,然后合并查询一样简单。
首先合并查询报表类型和年份:
得到的结果如下:
这是报表类型和年份的任意组合,然后继续将此表与公司名称表合并,得到公司代码、年份和报表类型的任意组合表。
4、调用自定义函数
在第3步生成的表的基础上,添加自定义列,
这个M代码表示如果报表类型是CashFlow(现金流量表),则调用自定义函数:cashflow,否则调用资产负债表,其参数相同(如果只有一个自定义函数,则无需使用IF用于判断。,直接调用即可)。
然后我抓了这五家公司10年的三大报告数据:
另外,批量抓取的报表数据已经是我们需要的一维表格数据了,因为第一步收录了二维转一维的步骤,后面调用自定义函数的时候会自动做相同的。手术。
当然,你也可以用这种方法一次抓取几百家公司的数据,但是速度会很慢,所以建议只抓取你需要的公司和最近一年的数据。
至此,三大表的数据抓取已经完成,主要是使用PowerQuery的界面操作和一些简单的代码修改。即使没有基础,也可以按照以上步骤快速完成。
在这个财务分析示例中,有一个页面,其中收录从网络上抓取的公司简介和公司信息:
数据来自以下三个网页:
公司公告
公司简介
历史行情
这些数据的抓取和上面的财报数据抓取步骤完全一样,只是更简单一些,因为只有一个参数:公司代码,大家可以自己练习。
通过上面的介绍,你应该可以很方便的从网页中抓取财报数据了。当需要其他相关数据时,可以在网上搜索资源,然后批量抓取。
如开头所说,如果你要做的是分析贵公司的内部财务报告,你可以忽略本文中捕获数据的步骤,直接导入现成的财务报告。但是,为了后续分析的需要,建议还是将报表数据组织成一维的表结构。
数据整理上传后,就可以进行下一步的数据建模了。
成为 PowerBI Planet 会员,获取财务报告分析模板
抓取网页数据php(php的三大框架hibernate存放文件时顺序为按照1-4区别用于web开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-22 16:02
抓取网页数据php主流框架sed,webshellsed:perl-homewebshell:php-home-elffastcgi:php-home-epic存放文件时顺序为按照1-4区别区别用于web开发|性能
爬虫技术分很多种,你的问题似乎说的是联合爬虫,不存在程序有先后顺序,而是在于你的实现。
对于phpweb框架的问题,php的三大框架hibernate(可能要另起项目),mybaits和ci/cd都是有规定的按照顺序来的。除了sed,使用较多的其他php框架是swoole,随着要实现对方使用的其他语言,要采用不同的框架。
每个框架下面都有一个自己的联合爬虫对象,
没有固定顺序,应该依然保持先后顺序。1,在config中配置好schema;2,爬虫是一定要配置好对象引用(即必须可以是各个框架的联合爬虫);3,在schema里面会对包名进行修改;4,常见的爬虫一般都使用phpstorm编写。
其实我也是有同样的疑问,
配置好函数在哪个php框架里面
目前我就在研究这个。
可以使用python的一些php.io.generator构造出,
请参考pyinstaller
第一梯队:sed、sed、peartomize、bitbucket第二梯队:webshell、jasmine
php_fastcgi_schemaphp_image_loaderphp_sql_db_schema 查看全部
抓取网页数据php(php的三大框架hibernate存放文件时顺序为按照1-4区别用于web开发)
抓取网页数据php主流框架sed,webshellsed:perl-homewebshell:php-home-elffastcgi:php-home-epic存放文件时顺序为按照1-4区别区别用于web开发|性能
爬虫技术分很多种,你的问题似乎说的是联合爬虫,不存在程序有先后顺序,而是在于你的实现。
对于phpweb框架的问题,php的三大框架hibernate(可能要另起项目),mybaits和ci/cd都是有规定的按照顺序来的。除了sed,使用较多的其他php框架是swoole,随着要实现对方使用的其他语言,要采用不同的框架。
每个框架下面都有一个自己的联合爬虫对象,
没有固定顺序,应该依然保持先后顺序。1,在config中配置好schema;2,爬虫是一定要配置好对象引用(即必须可以是各个框架的联合爬虫);3,在schema里面会对包名进行修改;4,常见的爬虫一般都使用phpstorm编写。
其实我也是有同样的疑问,
配置好函数在哪个php框架里面
目前我就在研究这个。
可以使用python的一些php.io.generator构造出,
请参考pyinstaller
第一梯队:sed、sed、peartomize、bitbucket第二梯队:webshell、jasmine
php_fastcgi_schemaphp_image_loaderphp_sql_db_schema
抓取网页数据php(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-18 12:02
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页的内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们必须确定我们的 PHP 是否启用了这个库。您可以使用 php_info() 函数获取此信息。
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你没有看到它,那么你需要设置你的 PHP 并启用这个库。
如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
从上面的程序我们可以看出,使用CURLOPT_POST来设置HTTP协议的POST方法而不是GET方法,然后用CURLOPT_POSTFIELDS设置POST数据。
关于代理服务器
下面是一个如何使用代理服务器的示例。请注意其中高亮的代码,代码很简单,我就不用多说了。
关于 SSL 和 Cookie 查看全部
抓取网页数据php(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页的内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们必须确定我们的 PHP 是否启用了这个库。您可以使用 php_info() 函数获取此信息。
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。

如果你没有看到它,那么你需要设置你的 PHP 并启用这个库。
如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子

从上面的程序我们可以看出,使用CURLOPT_POST来设置HTTP协议的POST方法而不是GET方法,然后用CURLOPT_POSTFIELDS设置POST数据。
关于代理服务器
下面是一个如何使用代理服务器的示例。请注意其中高亮的代码,代码很简单,我就不用多说了。
关于 SSL 和 Cookie
抓取网页数据php(抓取网页数据php可以用webserver接受postrequest,并转换成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-17 22:03
抓取网页数据php可以用webserver接受postrequest,并转换成php的sendmethod,拿到这个url然后拿到所有的url所包含的html文件filezilla之类的客户端抓一抓当然数据量大可以用专门的抓包工具比如httpwatch/chromeua抓包工具这些
pythonwebserver
实现抓取网页,首先要爬取html页面,我用的是xpath语法。通过xpath语法将html源码抓取出来,存放在一个文件夹中。然后就可以使用python提供的websocket或者httpwatch工具抓取,但是,websocket需要绑定一个客户端(要使用python的requests模块),才能抓取,httpwatch是用于抓取一些网页杂项的(需要安装pip模块)。
这只是爬取一个网页的方法,如果你想要抓取到网页的所有的html文本,那就要用到专门的抓包工具了。这些工具中,xmppwebsocket都挺适合爬取html文本,对python的模块要求不高。总结,抓取网页只是技术层面的问题,如果想要高级一点,就要学会自己写一些脚本,采集一些页面信息,比如用zxhr模块抓取jpg格式的图片。
python有一个xpatheditor,支持xpath解析,你可以直接使用。你需要用到一些python模块才能做一些开发。
如果想要找到html文件的文件头和文件尾,就可以用python写出来, 查看全部
抓取网页数据php(抓取网页数据php可以用webserver接受postrequest,并转换成)
抓取网页数据php可以用webserver接受postrequest,并转换成php的sendmethod,拿到这个url然后拿到所有的url所包含的html文件filezilla之类的客户端抓一抓当然数据量大可以用专门的抓包工具比如httpwatch/chromeua抓包工具这些
pythonwebserver
实现抓取网页,首先要爬取html页面,我用的是xpath语法。通过xpath语法将html源码抓取出来,存放在一个文件夹中。然后就可以使用python提供的websocket或者httpwatch工具抓取,但是,websocket需要绑定一个客户端(要使用python的requests模块),才能抓取,httpwatch是用于抓取一些网页杂项的(需要安装pip模块)。
这只是爬取一个网页的方法,如果你想要抓取到网页的所有的html文本,那就要用到专门的抓包工具了。这些工具中,xmppwebsocket都挺适合爬取html文本,对python的模块要求不高。总结,抓取网页只是技术层面的问题,如果想要高级一点,就要学会自己写一些脚本,采集一些页面信息,比如用zxhr模块抓取jpg格式的图片。
python有一个xpatheditor,支持xpath解析,你可以直接使用。你需要用到一些python模块才能做一些开发。
如果想要找到html文件的文件头和文件尾,就可以用python写出来,
抓取网页数据php(php、java、python的框架各有各的各好处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-16 09:02
抓取网页数据php和java。
php、java、python的框架各有各的好处,php基于开放的lnmp环境,与lnmp配合搭建,可以从web服务器搭建到全套相关应用程序开发,更重要的是php的web框架,像discuz!、pdo等非常完善。java则是基于java开发web架构方面比较完善,使用java的web工程师非常多。不管是php还是java,随着数据分析软件hadoop的流行,人们开始对分布式技术愈加关注,分布式系统架构相关的开发人员需求增加。storm、kafka、flink、sparksql、stormcluster等等。
php是无界面框架,更方便操作。java功能要更完善。php自己开发vs要结合太多第三方插件。python低开发成本,低开发难度,低功能的程序员很多。
个人建议php1.php能同时在后端和前端实现界面。2.php更灵活,服务器做接入和业务开发的服务器容易定制(有一个虚拟的服务器让你的服务器进程做任何操作)。其实最最重要的是,php可以做大公司的db主机。腾讯,百度,阿里巴巴等,都有内置的db服务。这对前端或android开发基本没什么好处。
是php吧?我本科做的php工作,其实就是把后端人员的代码写一遍。感觉一般,我自己是喜欢java的。
php好,也许php带着会好点,java的话前端好多,但是后端我感觉你就只能用php。 查看全部
抓取网页数据php(php、java、python的框架各有各的各好处)
抓取网页数据php和java。
php、java、python的框架各有各的好处,php基于开放的lnmp环境,与lnmp配合搭建,可以从web服务器搭建到全套相关应用程序开发,更重要的是php的web框架,像discuz!、pdo等非常完善。java则是基于java开发web架构方面比较完善,使用java的web工程师非常多。不管是php还是java,随着数据分析软件hadoop的流行,人们开始对分布式技术愈加关注,分布式系统架构相关的开发人员需求增加。storm、kafka、flink、sparksql、stormcluster等等。
php是无界面框架,更方便操作。java功能要更完善。php自己开发vs要结合太多第三方插件。python低开发成本,低开发难度,低功能的程序员很多。
个人建议php1.php能同时在后端和前端实现界面。2.php更灵活,服务器做接入和业务开发的服务器容易定制(有一个虚拟的服务器让你的服务器进程做任何操作)。其实最最重要的是,php可以做大公司的db主机。腾讯,百度,阿里巴巴等,都有内置的db服务。这对前端或android开发基本没什么好处。
是php吧?我本科做的php工作,其实就是把后端人员的代码写一遍。感觉一般,我自己是喜欢java的。
php好,也许php带着会好点,java的话前端好多,但是后端我感觉你就只能用php。
抓取网页数据php(抓取网页数据phpphonediv的数据包在上下游的datarange中传输,此时php的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-12 20:04
抓取网页数据phpphonediv的数据包在上下游的datarange中传输,此时php的方法是构造字符串传递给datarange的构造函数,而对应的header中的字符串编码必须是base64编码的。直接printdatarange.data().unicode()得到的格式为3,不正确的结果是:"\u32b6\u32b8\u32bd\u32bd\u32bc\u324\u32fb\u32db\u32d"怎么办呢?我们首先可以先打开php.ini文件,看下datarange的配置,设置为3后,再使用printdatarange.data().unicode()观察header中的格式是否正确。
代码已经运行,可是得到的内容是"aaa",但这并不是正确的结果。我们看下objectdata文件中传递的字符串,接收方也是unicode字符串,那么怎么直接把unicode中的格式转换成字符串数据呢?我们还是先打开php.ini文件,配置php的配置文件,aliasapp=app.install(self.datarange)调用php的substring函数,把字符串的unicode格式转化为utf-8格式,此时调用php的datarange函数,得到结果为"aaa"我们再来看下php.ini中传递的header方法,此方法传递数据的格式是"aaa",接收方的字符串编码是utf-8,php.ini配置文件中没有给定编码,通过unicode转换来得到正确的数据格式,但要注意,接收方的编码一定要和php内置的utf-8编码格式相匹配,也就是说utf-8编码的编码规则是"/utf-8"。
/utf-8:^\\\u32b6\\\u32b8\\\u32bd\\\u32bd\u32bc\\\u32fb\u32db\u32d\..其实,我们都明白,php是不支持指定编码的,这里如果没有指定编码格式,得到的就是一串乱码。转换格式php的header方法返回了encode()字符,该字符是一个unicode字符串编码,它不能通过decode()或encode()字符编码进行转换。
那么怎么解决这个问题呢?php有个类infopreview,我们可以找到php.ini里面的format方法,使用该方法,我们可以得到接收方的编码格式为\u32b6\u32b8\u32bd\u32bd\u32bc\u324\u32d\..说明接收方编码格式为“/utf-8”我们再来调用php.ini的header方法,php.ini是一个配置文件,可以在任何时候查看,查看它传递的编码格式的内容,再调用php.ini的convert方法把接收方的编码格式编码到php。 查看全部
抓取网页数据php(抓取网页数据phpphonediv的数据包在上下游的datarange中传输,此时php的方法)
抓取网页数据phpphonediv的数据包在上下游的datarange中传输,此时php的方法是构造字符串传递给datarange的构造函数,而对应的header中的字符串编码必须是base64编码的。直接printdatarange.data().unicode()得到的格式为3,不正确的结果是:"\u32b6\u32b8\u32bd\u32bd\u32bc\u324\u32fb\u32db\u32d"怎么办呢?我们首先可以先打开php.ini文件,看下datarange的配置,设置为3后,再使用printdatarange.data().unicode()观察header中的格式是否正确。
代码已经运行,可是得到的内容是"aaa",但这并不是正确的结果。我们看下objectdata文件中传递的字符串,接收方也是unicode字符串,那么怎么直接把unicode中的格式转换成字符串数据呢?我们还是先打开php.ini文件,配置php的配置文件,aliasapp=app.install(self.datarange)调用php的substring函数,把字符串的unicode格式转化为utf-8格式,此时调用php的datarange函数,得到结果为"aaa"我们再来看下php.ini中传递的header方法,此方法传递数据的格式是"aaa",接收方的字符串编码是utf-8,php.ini配置文件中没有给定编码,通过unicode转换来得到正确的数据格式,但要注意,接收方的编码一定要和php内置的utf-8编码格式相匹配,也就是说utf-8编码的编码规则是"/utf-8"。
/utf-8:^\\\u32b6\\\u32b8\\\u32bd\\\u32bd\u32bc\\\u32fb\u32db\u32d\..其实,我们都明白,php是不支持指定编码的,这里如果没有指定编码格式,得到的就是一串乱码。转换格式php的header方法返回了encode()字符,该字符是一个unicode字符串编码,它不能通过decode()或encode()字符编码进行转换。
那么怎么解决这个问题呢?php有个类infopreview,我们可以找到php.ini里面的format方法,使用该方法,我们可以得到接收方的编码格式为\u32b6\u32b8\u32bd\u32bd\u32bc\u324\u32d\..说明接收方编码格式为“/utf-8”我们再来调用php.ini的header方法,php.ini是一个配置文件,可以在任何时候查看,查看它传递的编码格式的内容,再调用php.ini的convert方法把接收方的编码格式编码到php。
抓取网页数据php(Wordpress更换域名后百度sitemap插件不可用的解决步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-11 09:06
网站优化几乎总是使用站点地图插件。站点地图允许 网站 管理员通知搜索引擎他们 网站 可以抓取哪些页面。在最简单的形式中,站点地图是一个 XML 文件,其中列出了 网站 中的 URL 以及有关每个 URL 的其他元数据,以便搜索引擎可以更智能地抓取 网站。最近接到一个客户问题,无忧主编觉得很有价值,想尽快分享给大家。用户使用无忧主机的php免录空间。域名更换已经快两个月了。各大搜索引擎收录也已全面恢复。百度官方的结构化数据插件(百度站点地图)应该可以发挥作用。有一定的作用,但是有的朋友可能会发现,如果换了域名,插件就不能正常工作了,提交历史还是之前的数据,不会再提交新的数据了。这是因为将百度官网的wordpress结构化数据插件写入数据库。当你更改域名时,数据表仍然是旧域名的数据,所以我们需要清除或删除这两个数据表。解决Wordpress更改域名后百度站点地图插件不可用的步骤如下:1、登录Wordpress后台禁用百度结构化数据插件百度站点地图2、登录数据库管理工具phpmyadmin在php虚拟主机控制面板中选择这两个要清除或删除一个表,需要清除或删除两个数据表如下: wp_baidusubmit_sitemapwp_baidusubmit_urlstat3、重新启用百度站点地图并验证后以上步骤完成后,百度结构化数据插件会重新处理网站的内容自动提交对网站没有影响,请放心。另外,我会直接删除上面两张表。启用插件后会重新生成,相当于完全重新安装插件。我希望能遇到这个问题。求朋友帮忙。无忧托管相关文章推荐阅读: 查看全部
抓取网页数据php(Wordpress更换域名后百度sitemap插件不可用的解决步骤)
网站优化几乎总是使用站点地图插件。站点地图允许 网站 管理员通知搜索引擎他们 网站 可以抓取哪些页面。在最简单的形式中,站点地图是一个 XML 文件,其中列出了 网站 中的 URL 以及有关每个 URL 的其他元数据,以便搜索引擎可以更智能地抓取 网站。最近接到一个客户问题,无忧主编觉得很有价值,想尽快分享给大家。用户使用无忧主机的php免录空间。域名更换已经快两个月了。各大搜索引擎收录也已全面恢复。百度官方的结构化数据插件(百度站点地图)应该可以发挥作用。有一定的作用,但是有的朋友可能会发现,如果换了域名,插件就不能正常工作了,提交历史还是之前的数据,不会再提交新的数据了。这是因为将百度官网的wordpress结构化数据插件写入数据库。当你更改域名时,数据表仍然是旧域名的数据,所以我们需要清除或删除这两个数据表。解决Wordpress更改域名后百度站点地图插件不可用的步骤如下:1、登录Wordpress后台禁用百度结构化数据插件百度站点地图2、登录数据库管理工具phpmyadmin在php虚拟主机控制面板中选择这两个要清除或删除一个表,需要清除或删除两个数据表如下: wp_baidusubmit_sitemapwp_baidusubmit_urlstat3、重新启用百度站点地图并验证后以上步骤完成后,百度结构化数据插件会重新处理网站的内容自动提交对网站没有影响,请放心。另外,我会直接删除上面两张表。启用插件后会重新生成,相当于完全重新安装插件。我希望能遇到这个问题。求朋友帮忙。无忧托管相关文章推荐阅读:
抓取网页数据php( 基于PHP实现的webshell攻击(一)——一个攻击)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-09 13:17
基于PHP实现的webshell攻击(一)——一个攻击)
PHP的一些知识点研究(一), PHP知识点研究
一、基于PHP的Webshell攻击
看到了对暗云的基于 php 的 webshell 攻击。
高度隐藏的webshell使用普通的php代码,将真实的shell内容经过层层加密保存到图片中,只留下一个url,而且url还是被加密的,所以从外面看不出任何特征,所以很难被发现。打开上面的url,显示404,这个404页面是伪装成404的木马,只是标题改成了404NotFound。
二、不要使用orless else语句
对于ifelse,有人追求结构的完整性。如果有if,就一定有else。这看起来不错,但有时会导致代码繁琐,可能导致逻辑混乱;一个结果可以作为基准,当其他情况发生时进行if判断;即默认为A,有异常则为B;如下右图所示:
三、单页应用
单页是指所有的操作和布局都在一个页面下进行,不需要跳转页面,根据不同的用户请求加载不同的内容。
优点:页面结构简单、数据量小、节省带宽、响应速度快、体验好、易于开发、维护和优化;
缺点:使用ajax技术,不利于seo。
四、让搜索引擎抓取ajax内容
主要针对前面案例的单页结构,程序通过#structure url控制页面内容,但不会被搜索引擎抓取。
方法一:推特采用“井号+感叹号”的结构,但体验不好且繁琐;
方法2:使用HistoryAPI;在不刷新页面的情况下更改浏览器地址栏中显示的地址。进行如下操作:
A. 使用HistoryAPI替换井号结构,让每个#号变成正常路径的URL,这样搜索引擎会抓取每一个网页。
B、定义一个JavaScript函数,处理Ajax部分,根据URL爬取内容。
C、定义鼠标的点击事件,利用History对象的popstate事件来处理浏览器的“前进/后退”按钮。
D、设置服务器端。
五、CURL_MULTI_INIT()
以前一直用curl_init(),最近才看到curl_multi_init();本来以为会带来更高效的代码,但是看了curl_multi的步骤,感觉挺麻烦的,而且curl_multi可能会导致CPU高,网页假死等;同时对比curl_init和curl_multi_init,多线程在速度上不一定比单线程好。多线程只能同时处理多任务,时间成本不一定低。附上使用 curl_multi 的步骤:
第一步:调用curl_multi_init;
第二步:循环调用curl_multi_add_handle;
这一步需要注意,curl_multi_add_handle的第二个参数是来自curl_init的子句柄;
第三步:继续调用curl_multi_exec;
第四步:循环调用curl_multi_getcontent,根据需要获取结果;
第五步:调用curl_multi_remove_handle,对每个字句柄调用curl_close;
第 6 步:调用 curl_multi_close。
六、PHPstrstr() 函数
strstr(string,search) 在另一个字符串中搜索第一次出现的字符串。返回字符串的其余部分(从匹配点开始)。如果未找到搜索的字符串,则返回 false。
需要搜索。指定要搜索的字符串。如果参数是数字,则搜索与数字的 ASCII 值匹配的字符。
参考:。因此,在给第二个参数时,如果需要匹配数字,建议加引号。
七、论归一化的重要性
我家附近一条久治不愈的道路,通过划分人行道、非机动车道、机动车道,一下子解决了问题。有时灵活性导致选择太多,问题也很多;程序也是如此。用户输入的灵活性看起来很好,但实际上需要更多的后台处理成本。为什么不在早期标准化它,错误停止在源头,而不是修补它。规范化使一切变得简单而高效。
八、HHVM
HHVM (HipHopVirtualMachine) 将 PHP 代码转换为高级字节码(通常称为中间语言)。然后,这些字节码在运行时由即时 (JIT) 编译器转换为 x64 机器码。
数据显示,相比 Zend,HHVM 效率更高,CPU 负载降低,平均页面加载时间缩短。HHVM的存在是为了优化PHP的性能。和php5相比,确实有一些优势,还是等php7吧。
九、PHP源码签名采集器
在学习新的、不熟悉的源代码时,对代码结构有一个直观的感觉很重要。可以通过从每个源文件中逐行取标点来概括,即文件签名。这有助于解释代码的复杂性。其实就是提取代码文件中的固定符号来呈现文件的结构。
参考:
十、协同过滤推荐算法
1、基于内容的推荐算法的前提是,如果用户喜欢物品a,那么用户也应该喜欢与a相似的物品。其基本思想是拆分内容属性,提取具有相同属性的内容进行推荐。
2、协同过滤推荐算法的前提是,如果用户a和用户b都喜欢一系列相同的物品,那么a很有可能喜欢用户b喜欢的其他物品。基本流程是用户首先对每个项目进行评价和评分,通过计算不同用户评分之间的相似度,可以找到最近邻,并根据最近邻的评价生成推荐。
以上算法均采用矩阵建模,使用余弦相似度、皮尔逊相似度等公式。使用时建议将两者合二为一。
trueTechArticlePHP的一些知识点研究(一),php知识点研究一、 PHP-based webshell attack 见一个基于php的暗云webshell攻击。高度隐藏的webshell,使用... 查看全部
抓取网页数据php(
基于PHP实现的webshell攻击(一)——一个攻击)
PHP的一些知识点研究(一), PHP知识点研究
一、基于PHP的Webshell攻击
看到了对暗云的基于 php 的 webshell 攻击。
高度隐藏的webshell使用普通的php代码,将真实的shell内容经过层层加密保存到图片中,只留下一个url,而且url还是被加密的,所以从外面看不出任何特征,所以很难被发现。打开上面的url,显示404,这个404页面是伪装成404的木马,只是标题改成了404NotFound。
二、不要使用orless else语句
对于ifelse,有人追求结构的完整性。如果有if,就一定有else。这看起来不错,但有时会导致代码繁琐,可能导致逻辑混乱;一个结果可以作为基准,当其他情况发生时进行if判断;即默认为A,有异常则为B;如下右图所示:

三、单页应用
单页是指所有的操作和布局都在一个页面下进行,不需要跳转页面,根据不同的用户请求加载不同的内容。
优点:页面结构简单、数据量小、节省带宽、响应速度快、体验好、易于开发、维护和优化;
缺点:使用ajax技术,不利于seo。
四、让搜索引擎抓取ajax内容
主要针对前面案例的单页结构,程序通过#structure url控制页面内容,但不会被搜索引擎抓取。
方法一:推特采用“井号+感叹号”的结构,但体验不好且繁琐;
方法2:使用HistoryAPI;在不刷新页面的情况下更改浏览器地址栏中显示的地址。进行如下操作:
A. 使用HistoryAPI替换井号结构,让每个#号变成正常路径的URL,这样搜索引擎会抓取每一个网页。
B、定义一个JavaScript函数,处理Ajax部分,根据URL爬取内容。
C、定义鼠标的点击事件,利用History对象的popstate事件来处理浏览器的“前进/后退”按钮。
D、设置服务器端。
五、CURL_MULTI_INIT()
以前一直用curl_init(),最近才看到curl_multi_init();本来以为会带来更高效的代码,但是看了curl_multi的步骤,感觉挺麻烦的,而且curl_multi可能会导致CPU高,网页假死等;同时对比curl_init和curl_multi_init,多线程在速度上不一定比单线程好。多线程只能同时处理多任务,时间成本不一定低。附上使用 curl_multi 的步骤:
第一步:调用curl_multi_init;
第二步:循环调用curl_multi_add_handle;
这一步需要注意,curl_multi_add_handle的第二个参数是来自curl_init的子句柄;
第三步:继续调用curl_multi_exec;
第四步:循环调用curl_multi_getcontent,根据需要获取结果;
第五步:调用curl_multi_remove_handle,对每个字句柄调用curl_close;
第 6 步:调用 curl_multi_close。
六、PHPstrstr() 函数
strstr(string,search) 在另一个字符串中搜索第一次出现的字符串。返回字符串的其余部分(从匹配点开始)。如果未找到搜索的字符串,则返回 false。
需要搜索。指定要搜索的字符串。如果参数是数字,则搜索与数字的 ASCII 值匹配的字符。
参考:。因此,在给第二个参数时,如果需要匹配数字,建议加引号。
七、论归一化的重要性
我家附近一条久治不愈的道路,通过划分人行道、非机动车道、机动车道,一下子解决了问题。有时灵活性导致选择太多,问题也很多;程序也是如此。用户输入的灵活性看起来很好,但实际上需要更多的后台处理成本。为什么不在早期标准化它,错误停止在源头,而不是修补它。规范化使一切变得简单而高效。
八、HHVM
HHVM (HipHopVirtualMachine) 将 PHP 代码转换为高级字节码(通常称为中间语言)。然后,这些字节码在运行时由即时 (JIT) 编译器转换为 x64 机器码。
数据显示,相比 Zend,HHVM 效率更高,CPU 负载降低,平均页面加载时间缩短。HHVM的存在是为了优化PHP的性能。和php5相比,确实有一些优势,还是等php7吧。
九、PHP源码签名采集器
在学习新的、不熟悉的源代码时,对代码结构有一个直观的感觉很重要。可以通过从每个源文件中逐行取标点来概括,即文件签名。这有助于解释代码的复杂性。其实就是提取代码文件中的固定符号来呈现文件的结构。
参考:
十、协同过滤推荐算法
1、基于内容的推荐算法的前提是,如果用户喜欢物品a,那么用户也应该喜欢与a相似的物品。其基本思想是拆分内容属性,提取具有相同属性的内容进行推荐。
2、协同过滤推荐算法的前提是,如果用户a和用户b都喜欢一系列相同的物品,那么a很有可能喜欢用户b喜欢的其他物品。基本流程是用户首先对每个项目进行评价和评分,通过计算不同用户评分之间的相似度,可以找到最近邻,并根据最近邻的评价生成推荐。
以上算法均采用矩阵建模,使用余弦相似度、皮尔逊相似度等公式。使用时建议将两者合二为一。
trueTechArticlePHP的一些知识点研究(一),php知识点研究一、 PHP-based webshell attack 见一个基于php的暗云webshell攻击。高度隐藏的webshell,使用...
抓取网页数据php(WebScraping在腾讯体育来抓取欧洲联赛13/14赛季的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-07 21:19
背景网页抓取
大数据时代,一切都要用数据说话,而大数据处理的过程一般需要经过以下几个步骤
首先要做的是获取数据并提取有效数据,为下一步分析做准备。
有各种数据来源。我以为我是个足球爱好者,世界杯快到了,所以我想提取欧洲联赛的数据进行分析。很多网站都提供了详细的足球数据,比如:
这些网站提供了详细的足球数据,但是为了进一步分析,我们希望数据以格式化的形式存储,那么如何将这些网站提供的网页数据转换成格式化数据呢?? 这使用了网页抓取技术。简单来说,Web Scraping就是从网站中提取信息,通常使用程序来模拟人们浏览网页的过程,发送http请求,从http响应中获取结果。
网页抓取注意事项
在抓取数据之前,请注意以下几点:
Python Web Scraping 相关库
Python 提供了一个非常方便的 Web Scraping 基础,具有许多支持库。这是一个小选择
当然,您不必使用 Python,也不必编写自己的代码。建议关注import.io
网页抓取代码
接下来,我们将一步步使用Python从腾讯体育抓取2013/14赛季欧洲联赛的数据。
首先安装 Beautifulsoup
pip install beautifulsoup4
让我们从玩家的数据开始。
对玩家数据的网络请求是,返回的内容如下图所示:
web服务有两个参数,lega表示是哪个联赛,pn表示分页数。
首先,我们来做一些初始化准备
from urllib2 import urlopen
import urlparse
import bs4
BASE_URL = "http://soccerdata.sports.qq.com"
PLAYER_LIST_QUERY = "/playerSearch.aspx?lega=%s&pn=%d"
league = ['epl','seri','bund','liga','fran','scot','holl','belg']
page_number_limit = 100
player_fields = ['league_cn','img','name_cn','name','team','age','position_cn','nation','birth','query','id','teamid','league']
urlopen、urlparse、bs4 是我们将使用的 Python 库。
BASE_URL、PLAYER_LIST_QUERY、league、page_number_limit 和 player_fields 是我们将使用的一些常量。
下面是抓取玩家数据的具体代码:
def get_players(baseurl):
html = urlopen(baseurl).read()
soup = bs4.BeautifulSoup(html, "lxml")
players = [ dd for dd in soup.select('.searchResult tr') if dd.contents[1].name != 'th']
result = []
for player in players:
record = []
link = ''
query = []
for item in player.contents:
if type(item) is bs4.element.Tag:
if not item.string and item.img:
record.append(item.img['src'])
else :
record.append(item.string and item.string.strip() or 'na')
try:
o = urlparse.urlparse(item.a['href']).query
if len(link) == 0:
link = o
query = dict([(k,v[0]) for k,v in urlparse.parse_qs(o).items()])
except:
pass
if len(record) != 10:
for i in range(0, 10 - len(record)):
record.append('na')
record.append(unicode(link,'utf-8'))
record.append(unicode(query["id"],'utf-8'))
record.append(unicode(query["teamid"],'utf-8'))
record.append(unicode(query["lega"],'utf-8'))
result.append(record)
return result
result = []
for url in [ BASE_URL + PLAYER_LIST_QUERY % (l,n) for l in league for n in range(page_number_limit) ]:
result = result + get_players(url)
我们来看看抓取玩家数据的详细过程:
首先,我们定义一个 get_players 方法,该方法返回请求页面上所有玩家的数据。为了得到所有的数据,我们通过了一个for循环,因为我们要循环遍历每个联赛,每个联赛有多个页面。一般需要双循环:
for i in league:
for j in range(0, 100):
url = BASE_URL + PLAYER_LIST_QUERY % (l,n)
## send request to url and do scraping
Python 的列表推导可以通过构建列表轻松降低循环的级别。
此外,Python 有一个非常方便的合并连续列表的语法:list = list1 + list2
好,我们来看看如何使用BeautifulSoup来抓取网页中我们需要的内容。
首先调用urlopen读取对应url的内容,一般是html,用html构造一个beautifulsoup对象。
beautifulsoup 对象支持许多搜索功能,以及类似 css 的选择器。通常如果有一个 DOM 对象,我们使用下面的方式来查找它:
obj = soup.find("xx","cc")
另一种常用的方法是使用 CSS 选择器方法。在上面的代码中,我们选择了class=searchResult元素中的所有tr元素,过滤掉了th,也就是header元素。
for dd in soup.select('.searchResult tr') if dd.contents[1].name != 'th'
对于记录 tr 的每一行,都会生成一个玩家记录并将其存储在一个列表中。所以我们循环tr tr.contents 的内容来获取对应的字段内容。
对于每个tr的内容,我们首先检查它的类型是否为Tag。Tag 类型有几种情况。一种是收录 img 的案例。我们需要取出玩家头像图片的URL。
另一种是收录指向其他数据内容的链接
所以这些不同的情况在代码中分别处理。
对于一个Tag 对象,Tag.x 可以得到它的子对象,Tag['x'] 可以得到Tag 的属性值。
所以使用 item.img['src'] 来获取 item 的子元素 img 的 src 属性。
对于已经收录链接的情况,我们使用urlparse来获取查询url中的参数。在这里,我们利用字典理解将查询参数放入字典,然后添加到列表中。
dict([(k,v[0]) for k,v in urlparse.parse_qs(o).items()])
对于其他情况,我们使用 Python 的 and or 表达式来确保当 Tag 的内容为空时,我们写 'na',类似于三元运算符 X ? A : B 在 C/C++ 或 Java 中
然后有一段代码判断当前记录的长度是否大于10,如果不大于10则用空值填充,以避免出现一些不一致的情况。
if len(record) != 10:
for i in range(0, 10 - len(record)):
record.append('na')
最后,我们在查询中添加一些相关参数,比如球员的id、球队的id、联赛代码等到列表中。
record.append(unicode(link,'utf-8'))
record.append(unicode(query["id"],'utf-8'))
record.append(unicode(query["teamid"],'utf-8'))
record.append(unicode(query["lega"],'utf-8'))
最后,我们把这个页面上所有玩家的列表放到一个列表中,然后返回。
好的,现在我们有了一个收录所有玩家信息的列表,我们需要保存它以供进一步处理、分析。通常,csv 格式是一种常见的选择。
import csv
def write_csv(filename, content, header = None):
file = open(filename, "wb")
file.write('\xEF\xBB\xBF')
writer = csv.writer(file, delimiter=',')
if header:
writer.writerow(header)
for row in content:
encoderow = [dd.encode('utf8') for dd in row]
writer.writerow(encoderow)
write_csv('players.csv',result,player_fields)
这里需要注意的是编码的问题。因为我们使用的是utf-8编码方式,所以在csv的文件头中,我们需要写\xEF\xBB\xBF,详见这篇文章文章
好了,现在大功告成,捕获的csv如下:
因为之前我们也抓取了本赛季球员的比赛详情,所以我们可以进一步抓取所有球员每场比赛的记录
抓取的代码如下
def get_player_match(url):
html = urlopen(url).read()
soup = bs4.BeautifulSoup(html, "lxml")
matches = [ dd for dd in soup.select('.shtdm tr') if dd.contents[1].name != 'th']
records = []
for item in [ dd for dd in matches if len(dd.contents) > 11]: ## filter out the personal part
record = []
for match in [ dd for dd in item.contents if type(dd) is bs4.element.Tag]:
if match.string:
record.append(match.string)
else:
for d in [ dd for dd in match.contents if type(dd) is bs4.element.Tag]:
query = dict([(k,v[0]) for k,v in urlparse.parse_qs(d['href']).items()])
record.append('teamid' in query and query['teamid'] or query['id'])
record.append(d.string and d.string or 'na')
records.append(record)
return records[1:] ##remove the first record as the header
def get_players_match(playerlist, baseurl = BASE_URL + '/player.aspx?'):
result = []
for item in playerlist:
url = baseurl + item[10]
print url
result = result + get_player_match(url)
return result
match_fields = ['date_cn','homeid','homename_cn','matchid','score','awayid','awayname_cn','league_cn','firstteam','playtime','goal','assist','shoot','run','corner','offside','foul','violation','yellowcard','redcard','save']
write_csv('m.csv',get_players_match(result),match_fields)
爬取过程与之前类似。
接下来做什么
既然我们已经有了详细的欧联杯数据,接下来我们应该怎么做呢?我建议您将数据导入 BI 工具以进行进一步分析。有两个更好的选择:
Tableau 在数据可视化领域是无与伦比的。Tableau Public 完全免费。它使用数据可视化来驱动数据探索和分析,具有非常好的用户体验。
Splunk 提供了一个大数据平台,主要针对机器数据。支持每天免费导入500M数据,个人学习应该够用了。
当然你也可以使用 Excel。另外,如果大家有什么好的免费数据分析平台,欢迎交流。 查看全部
抓取网页数据php(WebScraping在腾讯体育来抓取欧洲联赛13/14赛季的数据)
背景网页抓取
大数据时代,一切都要用数据说话,而大数据处理的过程一般需要经过以下几个步骤
首先要做的是获取数据并提取有效数据,为下一步分析做准备。
有各种数据来源。我以为我是个足球爱好者,世界杯快到了,所以我想提取欧洲联赛的数据进行分析。很多网站都提供了详细的足球数据,比如:
这些网站提供了详细的足球数据,但是为了进一步分析,我们希望数据以格式化的形式存储,那么如何将这些网站提供的网页数据转换成格式化数据呢?? 这使用了网页抓取技术。简单来说,Web Scraping就是从网站中提取信息,通常使用程序来模拟人们浏览网页的过程,发送http请求,从http响应中获取结果。
网页抓取注意事项
在抓取数据之前,请注意以下几点:
Python Web Scraping 相关库
Python 提供了一个非常方便的 Web Scraping 基础,具有许多支持库。这是一个小选择
当然,您不必使用 Python,也不必编写自己的代码。建议关注import.io
网页抓取代码
接下来,我们将一步步使用Python从腾讯体育抓取2013/14赛季欧洲联赛的数据。
首先安装 Beautifulsoup
pip install beautifulsoup4
让我们从玩家的数据开始。
对玩家数据的网络请求是,返回的内容如下图所示:

web服务有两个参数,lega表示是哪个联赛,pn表示分页数。
首先,我们来做一些初始化准备
from urllib2 import urlopen
import urlparse
import bs4
BASE_URL = "http://soccerdata.sports.qq.com"
PLAYER_LIST_QUERY = "/playerSearch.aspx?lega=%s&pn=%d"
league = ['epl','seri','bund','liga','fran','scot','holl','belg']
page_number_limit = 100
player_fields = ['league_cn','img','name_cn','name','team','age','position_cn','nation','birth','query','id','teamid','league']
urlopen、urlparse、bs4 是我们将使用的 Python 库。
BASE_URL、PLAYER_LIST_QUERY、league、page_number_limit 和 player_fields 是我们将使用的一些常量。
下面是抓取玩家数据的具体代码:
def get_players(baseurl):
html = urlopen(baseurl).read()
soup = bs4.BeautifulSoup(html, "lxml")
players = [ dd for dd in soup.select('.searchResult tr') if dd.contents[1].name != 'th']
result = []
for player in players:
record = []
link = ''
query = []
for item in player.contents:
if type(item) is bs4.element.Tag:
if not item.string and item.img:
record.append(item.img['src'])
else :
record.append(item.string and item.string.strip() or 'na')
try:
o = urlparse.urlparse(item.a['href']).query
if len(link) == 0:
link = o
query = dict([(k,v[0]) for k,v in urlparse.parse_qs(o).items()])
except:
pass
if len(record) != 10:
for i in range(0, 10 - len(record)):
record.append('na')
record.append(unicode(link,'utf-8'))
record.append(unicode(query["id"],'utf-8'))
record.append(unicode(query["teamid"],'utf-8'))
record.append(unicode(query["lega"],'utf-8'))
result.append(record)
return result
result = []
for url in [ BASE_URL + PLAYER_LIST_QUERY % (l,n) for l in league for n in range(page_number_limit) ]:
result = result + get_players(url)
我们来看看抓取玩家数据的详细过程:
首先,我们定义一个 get_players 方法,该方法返回请求页面上所有玩家的数据。为了得到所有的数据,我们通过了一个for循环,因为我们要循环遍历每个联赛,每个联赛有多个页面。一般需要双循环:
for i in league:
for j in range(0, 100):
url = BASE_URL + PLAYER_LIST_QUERY % (l,n)
## send request to url and do scraping
Python 的列表推导可以通过构建列表轻松降低循环的级别。
此外,Python 有一个非常方便的合并连续列表的语法:list = list1 + list2
好,我们来看看如何使用BeautifulSoup来抓取网页中我们需要的内容。
首先调用urlopen读取对应url的内容,一般是html,用html构造一个beautifulsoup对象。
beautifulsoup 对象支持许多搜索功能,以及类似 css 的选择器。通常如果有一个 DOM 对象,我们使用下面的方式来查找它:
obj = soup.find("xx","cc")
另一种常用的方法是使用 CSS 选择器方法。在上面的代码中,我们选择了class=searchResult元素中的所有tr元素,过滤掉了th,也就是header元素。
for dd in soup.select('.searchResult tr') if dd.contents[1].name != 'th'
对于记录 tr 的每一行,都会生成一个玩家记录并将其存储在一个列表中。所以我们循环tr tr.contents 的内容来获取对应的字段内容。
对于每个tr的内容,我们首先检查它的类型是否为Tag。Tag 类型有几种情况。一种是收录 img 的案例。我们需要取出玩家头像图片的URL。

另一种是收录指向其他数据内容的链接

所以这些不同的情况在代码中分别处理。
对于一个Tag 对象,Tag.x 可以得到它的子对象,Tag['x'] 可以得到Tag 的属性值。
所以使用 item.img['src'] 来获取 item 的子元素 img 的 src 属性。
对于已经收录链接的情况,我们使用urlparse来获取查询url中的参数。在这里,我们利用字典理解将查询参数放入字典,然后添加到列表中。
dict([(k,v[0]) for k,v in urlparse.parse_qs(o).items()])
对于其他情况,我们使用 Python 的 and or 表达式来确保当 Tag 的内容为空时,我们写 'na',类似于三元运算符 X ? A : B 在 C/C++ 或 Java 中
然后有一段代码判断当前记录的长度是否大于10,如果不大于10则用空值填充,以避免出现一些不一致的情况。
if len(record) != 10:
for i in range(0, 10 - len(record)):
record.append('na')
最后,我们在查询中添加一些相关参数,比如球员的id、球队的id、联赛代码等到列表中。
record.append(unicode(link,'utf-8'))
record.append(unicode(query["id"],'utf-8'))
record.append(unicode(query["teamid"],'utf-8'))
record.append(unicode(query["lega"],'utf-8'))
最后,我们把这个页面上所有玩家的列表放到一个列表中,然后返回。
好的,现在我们有了一个收录所有玩家信息的列表,我们需要保存它以供进一步处理、分析。通常,csv 格式是一种常见的选择。
import csv
def write_csv(filename, content, header = None):
file = open(filename, "wb")
file.write('\xEF\xBB\xBF')
writer = csv.writer(file, delimiter=',')
if header:
writer.writerow(header)
for row in content:
encoderow = [dd.encode('utf8') for dd in row]
writer.writerow(encoderow)
write_csv('players.csv',result,player_fields)
这里需要注意的是编码的问题。因为我们使用的是utf-8编码方式,所以在csv的文件头中,我们需要写\xEF\xBB\xBF,详见这篇文章文章
好了,现在大功告成,捕获的csv如下:

因为之前我们也抓取了本赛季球员的比赛详情,所以我们可以进一步抓取所有球员每场比赛的记录

抓取的代码如下
def get_player_match(url):
html = urlopen(url).read()
soup = bs4.BeautifulSoup(html, "lxml")
matches = [ dd for dd in soup.select('.shtdm tr') if dd.contents[1].name != 'th']
records = []
for item in [ dd for dd in matches if len(dd.contents) > 11]: ## filter out the personal part
record = []
for match in [ dd for dd in item.contents if type(dd) is bs4.element.Tag]:
if match.string:
record.append(match.string)
else:
for d in [ dd for dd in match.contents if type(dd) is bs4.element.Tag]:
query = dict([(k,v[0]) for k,v in urlparse.parse_qs(d['href']).items()])
record.append('teamid' in query and query['teamid'] or query['id'])
record.append(d.string and d.string or 'na')
records.append(record)
return records[1:] ##remove the first record as the header
def get_players_match(playerlist, baseurl = BASE_URL + '/player.aspx?'):
result = []
for item in playerlist:
url = baseurl + item[10]
print url
result = result + get_player_match(url)
return result
match_fields = ['date_cn','homeid','homename_cn','matchid','score','awayid','awayname_cn','league_cn','firstteam','playtime','goal','assist','shoot','run','corner','offside','foul','violation','yellowcard','redcard','save']
write_csv('m.csv',get_players_match(result),match_fields)
爬取过程与之前类似。
接下来做什么
既然我们已经有了详细的欧联杯数据,接下来我们应该怎么做呢?我建议您将数据导入 BI 工具以进行进一步分析。有两个更好的选择:
Tableau 在数据可视化领域是无与伦比的。Tableau Public 完全免费。它使用数据可视化来驱动数据探索和分析,具有非常好的用户体验。
Splunk 提供了一个大数据平台,主要针对机器数据。支持每天免费导入500M数据,个人学习应该够用了。
当然你也可以使用 Excel。另外,如果大家有什么好的免费数据分析平台,欢迎交流。
抓取网页数据php(一个、高性能和高扩张性的角度来说说我的一些经验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-06 20:18
一个小的网站,比如个人的网站,可以用最简单的html静态页面来实现,配上一些图片来达到美化效果,所有页面都存放在一个目录下,比如网站对系统架构和性能的要求非常简单。随着互联网服务的不断丰富,网站相关技术经过多年的发展,已经细分为非常精细的方面,特别是对于大型网站来说,使用的技术非常广泛,从硬件到软件都有,编程语言、数据库、WebServer、防火墙等领域都有很高的要求,不是原来简单的html静态网站可比的。
大型 网站,例如 Portal网站。面对大量用户访问和高并发请求,基本解决方案主要集中在以下几个环节:使用高性能服务器、高性能数据库、高效编程语言、高性能Web容器。但是除了这些方面,没有办法从根本上解决大网站面临的高负载、高并发问题。
上面提供的几种解决方案在一定程度上也意味着更大的投入,而且这种解决方案存在瓶颈,不具备很好的扩展性。我从低成本、高性能和高扩展性的角度来谈一谈。说说我的一些经历吧。
1、HTML 静态
其实我们都知道纯静态的html页面效率最高,成本也最低,所以我们尽量使用静态页面来实现我们网站上的页面。这种最简单的方法实际上是最有效的。方法。但是对于内容量大、更新频繁的网站,我们无法一一手动实现,于是出现了我们常用的信息发布系统cms,比如各个门户的新闻频道我们经常访问的网站,甚至他们的其他渠道都是通过信息发布系统进行管理和实施的。信息发布系统可以实现最简单的信息录入,自动生成静态页面。还可以具有频道管理、权限管理、自动抓拍等功能。对于大型 网站
除了门户和信息发布类型网站,对于交互性要求高的社区类型网站,尽可能保持静态也是提高性能的必要手段。社区发帖,文章实时静态化,有更新时再静态化也是一种被广泛使用的策略。猫扑的大杂烩使用了这样的策略,网易社区也是如此。
同时,html静态化也是一些缓存策略使用的手段。对于系统中频繁使用数据库查询但内容更新量较小的应用,可以考虑使用html静态化来实现,比如论坛中的论坛的公开设置信息。这些信息目前所有主流论坛都可以后台管理,并存储在数据库中。其实很多这些信息都是前台程序调用的,只是更新频率很小。后台更新时可以考虑将这部分内容设为静态,避免大量数据库。访问请求。
2、图像服务器分离
众所周知,对于web服务器来说,无论是Apache、IIS还是其他容器,图片是最耗费资源的,所以需要将图片与页面分离,这基本上是大网站所采用的策略,他们都有独立的图像服务器,甚至很多图像服务器。这样的架构可以减轻提供页面访问请求的服务器系统的压力,并且可以保证系统不会因为图像问题而崩溃。应用服务器和镜像服务器可以进行不同的配置优化。比如apache可以尽量配置ContentType。更少的支持和尽可能少的 LoadModule 确保更高的系统消耗和执行效率。
3、数据库集群和库表哈希
大型网站都有复杂的应用,而这些应用必须使用数据库,所以在面对大量访问时,很快就会出现数据库的瓶颈,一个数据库很快就无法满足应用,所以我们需要使用数据库集群或库表哈希。
在数据库集群方面,很多数据库都有自己的解决方案。Oracle、Sybase 等都有很好的解决方案。MySQL提供的常用的Master/Slave也是类似的解决方案。你用的是什么DB,请参考对应的解决方案。解决方案来实施。
上面提到的数据库集群在架构、成本和可扩展性方面受到所使用的数据库类型的限制。因此,我们需要从应用的角度考虑改进系统架构。库表哈希是最常用和最有效的解决方案。. 我们在应用中安装业务和应用或者功能模块来分离数据库,不同的模块对应不同的数据库或者表,然后按照一定的策略对一个页面或者功能进行较小的数据库hash,比如user table, Hash the根据用户ID创建表,可以低成本提高系统性能,具有良好的可扩展性。搜狐的论坛采用了这样的结构,将论坛的用户、设置、帖子等信息从数据库中分离出来,然后根据section和ID对posts和users的数据库和表进行hash,最后可以在配置文件中简单配置。可以随时将低成本数据库添加到系统中,以补充系统性能。
4、缓存
缓存这个词已经被技术触及,很多地方都用到了缓存。开发中的网站架构和网站缓存也很重要。这是最基本的两种缓存。稍后将描述高级和分布式缓存。
对于架构上的缓存,熟悉Apache的人可以知道,Apache提供了自己的缓存模块,也可以使用额外的Squid模块进行缓存,两者都可以有效提高Apache的访问响应能力。
网站程序开发缓存,Linux上提供的Memory Cache是常用的缓存接口,可以在web开发中使用。比如在Java开发的时候,可以调用MemoryCache来缓存和共享一些数据。大型社区使用这样的架构。另外,在使用web语言开发的时候,各种语言基本都有自己的缓存模块和方法,PHP有Pear的Cache模块,Java有更多,.net不是很熟悉,相信一定有。
5、镜像
镜像是大规模网站常用的提高性能和数据安全性的一种方式。镜像技术可以解决不同网络接入商和地区造成的用户访问速度差异。比如ChinaNet和EduNet的区别,促使很多网站在教育网建立镜像站点,数据定期或者实时更新。关于镜像的详细技术,这里不再赘述。有许多专业的现成解决方案架构和产品可供选择。还有便宜的软件实现思路,比如Linux上的rsync等工具。
6、负载均衡
负载均衡将是 large网站 解决高负载访问和大量并发请求的终极解决方案。
负载均衡技术发展多年,有很多专业的服务商和产品可供选择。我个人遇到过一些解决方案,有两种架构供大家参考。
想学习 Dubbo 框架、zookeper 基本原理、redis 分布式缓存、JVM 性能优化、Nginx+apache+Tomcat 集群部署、大数据hadoop、Hbase 实时计算spark、storm、数据分析分词和权重等核心技术; 关注后私信,记得点赞转发!!! 查看全部
抓取网页数据php(一个、高性能和高扩张性的角度来说说我的一些经验)
一个小的网站,比如个人的网站,可以用最简单的html静态页面来实现,配上一些图片来达到美化效果,所有页面都存放在一个目录下,比如网站对系统架构和性能的要求非常简单。随着互联网服务的不断丰富,网站相关技术经过多年的发展,已经细分为非常精细的方面,特别是对于大型网站来说,使用的技术非常广泛,从硬件到软件都有,编程语言、数据库、WebServer、防火墙等领域都有很高的要求,不是原来简单的html静态网站可比的。
大型 网站,例如 Portal网站。面对大量用户访问和高并发请求,基本解决方案主要集中在以下几个环节:使用高性能服务器、高性能数据库、高效编程语言、高性能Web容器。但是除了这些方面,没有办法从根本上解决大网站面临的高负载、高并发问题。
上面提供的几种解决方案在一定程度上也意味着更大的投入,而且这种解决方案存在瓶颈,不具备很好的扩展性。我从低成本、高性能和高扩展性的角度来谈一谈。说说我的一些经历吧。
1、HTML 静态
其实我们都知道纯静态的html页面效率最高,成本也最低,所以我们尽量使用静态页面来实现我们网站上的页面。这种最简单的方法实际上是最有效的。方法。但是对于内容量大、更新频繁的网站,我们无法一一手动实现,于是出现了我们常用的信息发布系统cms,比如各个门户的新闻频道我们经常访问的网站,甚至他们的其他渠道都是通过信息发布系统进行管理和实施的。信息发布系统可以实现最简单的信息录入,自动生成静态页面。还可以具有频道管理、权限管理、自动抓拍等功能。对于大型 网站
除了门户和信息发布类型网站,对于交互性要求高的社区类型网站,尽可能保持静态也是提高性能的必要手段。社区发帖,文章实时静态化,有更新时再静态化也是一种被广泛使用的策略。猫扑的大杂烩使用了这样的策略,网易社区也是如此。
同时,html静态化也是一些缓存策略使用的手段。对于系统中频繁使用数据库查询但内容更新量较小的应用,可以考虑使用html静态化来实现,比如论坛中的论坛的公开设置信息。这些信息目前所有主流论坛都可以后台管理,并存储在数据库中。其实很多这些信息都是前台程序调用的,只是更新频率很小。后台更新时可以考虑将这部分内容设为静态,避免大量数据库。访问请求。
2、图像服务器分离
众所周知,对于web服务器来说,无论是Apache、IIS还是其他容器,图片是最耗费资源的,所以需要将图片与页面分离,这基本上是大网站所采用的策略,他们都有独立的图像服务器,甚至很多图像服务器。这样的架构可以减轻提供页面访问请求的服务器系统的压力,并且可以保证系统不会因为图像问题而崩溃。应用服务器和镜像服务器可以进行不同的配置优化。比如apache可以尽量配置ContentType。更少的支持和尽可能少的 LoadModule 确保更高的系统消耗和执行效率。
3、数据库集群和库表哈希
大型网站都有复杂的应用,而这些应用必须使用数据库,所以在面对大量访问时,很快就会出现数据库的瓶颈,一个数据库很快就无法满足应用,所以我们需要使用数据库集群或库表哈希。
在数据库集群方面,很多数据库都有自己的解决方案。Oracle、Sybase 等都有很好的解决方案。MySQL提供的常用的Master/Slave也是类似的解决方案。你用的是什么DB,请参考对应的解决方案。解决方案来实施。
上面提到的数据库集群在架构、成本和可扩展性方面受到所使用的数据库类型的限制。因此,我们需要从应用的角度考虑改进系统架构。库表哈希是最常用和最有效的解决方案。. 我们在应用中安装业务和应用或者功能模块来分离数据库,不同的模块对应不同的数据库或者表,然后按照一定的策略对一个页面或者功能进行较小的数据库hash,比如user table, Hash the根据用户ID创建表,可以低成本提高系统性能,具有良好的可扩展性。搜狐的论坛采用了这样的结构,将论坛的用户、设置、帖子等信息从数据库中分离出来,然后根据section和ID对posts和users的数据库和表进行hash,最后可以在配置文件中简单配置。可以随时将低成本数据库添加到系统中,以补充系统性能。
4、缓存
缓存这个词已经被技术触及,很多地方都用到了缓存。开发中的网站架构和网站缓存也很重要。这是最基本的两种缓存。稍后将描述高级和分布式缓存。
对于架构上的缓存,熟悉Apache的人可以知道,Apache提供了自己的缓存模块,也可以使用额外的Squid模块进行缓存,两者都可以有效提高Apache的访问响应能力。
网站程序开发缓存,Linux上提供的Memory Cache是常用的缓存接口,可以在web开发中使用。比如在Java开发的时候,可以调用MemoryCache来缓存和共享一些数据。大型社区使用这样的架构。另外,在使用web语言开发的时候,各种语言基本都有自己的缓存模块和方法,PHP有Pear的Cache模块,Java有更多,.net不是很熟悉,相信一定有。
5、镜像
镜像是大规模网站常用的提高性能和数据安全性的一种方式。镜像技术可以解决不同网络接入商和地区造成的用户访问速度差异。比如ChinaNet和EduNet的区别,促使很多网站在教育网建立镜像站点,数据定期或者实时更新。关于镜像的详细技术,这里不再赘述。有许多专业的现成解决方案架构和产品可供选择。还有便宜的软件实现思路,比如Linux上的rsync等工具。
6、负载均衡
负载均衡将是 large网站 解决高负载访问和大量并发请求的终极解决方案。
负载均衡技术发展多年,有很多专业的服务商和产品可供选择。我个人遇到过一些解决方案,有两种架构供大家参考。
想学习 Dubbo 框架、zookeper 基本原理、redis 分布式缓存、JVM 性能优化、Nginx+apache+Tomcat 集群部署、大数据hadoop、Hbase 实时计算spark、storm、数据分析分词和权重等核心技术; 关注后私信,记得点赞转发!!!
抓取网页数据php(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-27 09:28
如果你做过童鞋的j2ee或者android开发,应该多多少少用过Apeache的HttpClient类库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
最近在开发php中,也需要在服务器端发送http请求,然后再处理回客户端。
我google了一下,发现php中有这样一个类库,名字叫httpclient。我很兴奋。看了下官网,发现已经很多年没有更新了,功能好像也有限,很是失望。然后又找到了另一个类库Snoopy,这个类库我不知道,但是网上的反应还不错,所以决定用它。它的 API 使用与 Apache 的 HttpClient 有很大的不同,但仍然非常好用。并且提供了很多特殊用途的方法,比如只能抓取页面中的form表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com");
echo $snoopy->results;
以上几行代码就可以轻松爬取百度的页面。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时,他还传递了cookies的请求头、对应头以及相关操作函数,功能非常强大。
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn")) {
echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "错误获取文档:" . $snoopy->error . "\n";}
更多操作方法可以去Snoopy的官方文档,或者直接查看源码。
此时,snoopy 只取回页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。这里又找到了一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性,熟悉jquery的童鞋,应该还是蛮好用的phpquery,连phpQuery的文档都没有已经需要了。。
使用Snoopy+PhpQuery可以轻松实现网页爬取和数据分析,非常实用。我最近也需要这个,只找到了这两个不错的类库。事实证明,java可以做的事情有很多。php也可以做到。
有兴趣的同学也可以尝试用它们制作一个简单的网络爬虫。 查看全部
抓取网页数据php(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
如果你做过童鞋的j2ee或者android开发,应该多多少少用过Apeache的HttpClient类库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
最近在开发php中,也需要在服务器端发送http请求,然后再处理回客户端。
我google了一下,发现php中有这样一个类库,名字叫httpclient。我很兴奋。看了下官网,发现已经很多年没有更新了,功能好像也有限,很是失望。然后又找到了另一个类库Snoopy,这个类库我不知道,但是网上的反应还不错,所以决定用它。它的 API 使用与 Apache 的 HttpClient 有很大的不同,但仍然非常好用。并且提供了很多特殊用途的方法,比如只能抓取页面中的form表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com";);
echo $snoopy->results;
以上几行代码就可以轻松爬取百度的页面。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时,他还传递了cookies的请求头、对应头以及相关操作函数,功能非常强大。
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn";)) {
echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "错误获取文档:" . $snoopy->error . "\n";}
更多操作方法可以去Snoopy的官方文档,或者直接查看源码。
此时,snoopy 只取回页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。这里又找到了一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性,熟悉jquery的童鞋,应该还是蛮好用的phpquery,连phpQuery的文档都没有已经需要了。。
使用Snoopy+PhpQuery可以轻松实现网页爬取和数据分析,非常实用。我最近也需要这个,只找到了这两个不错的类库。事实证明,java可以做的事情有很多。php也可以做到。
有兴趣的同学也可以尝试用它们制作一个简单的网络爬虫。
抓取网页数据php(优游国际平台获得多网页数据web链接罕见格局(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-20 09:21
一、从网络获取数据
从 bi 桌面的“获取数据”中,您可以使用“web”选项。“web”界面中有“basic”和“high-end”两个选项卡。一般情况下,“基本”选项卡就足够了。Pingyouyou国际平台任务需求,以下都是基于这个例子。
二、获取数据
网页链接输出后,导航器的“加载”、“编辑”等少见的功能都会停止,只要根据实际任务需要停止操作即可。
三、获取多页数据
网页链接的常见格式如下:开头的“1”表示后续链接为第一页数据,第二页数据链接应为“”。当网页数据较大时,如果平台每次都通过网页链接获取数据,会消耗大量时间。但是,软件中的查询和回复功能可以简化操作,如下:
获取到某页数据后,进入“编辑查询”界面,在“编辑查询”界面选择“高级编辑器”选项卡,高级编辑器界面显示之前的任务路径。大致如下图:
这时需要在“let”后面输出“(p as number) as table=>”;并更改网页的页码,即上面提到的“1、2”等数字,在链接优优国际平台“(Number.ToText(p))”即可。
备注:网页链接有两种,一种是页码数据在链接开头,可以按上面操作;另一个是链接以.html 开头。除了上述替代操作,_"&(Number .ToText(p))&".html")) 只需点击这里单独定义html即可。
四、 爬取大有游国际平台网站
首先,使用优优国际平台查询优优国际平台设置编号规则。如果要截取前100页数据,可以在优优国际平台设置1到100的序列,查询优优国际平台输出={1..100}回车生成序列从 1 到 100,然后将其转换为表格。
然后调用自定义函数,
在弹窗中,可以点击【功能查询】下拉框,选择自己建立的自定义功能Data_Zhaopin,其他平台点击默认即可。
点击确定开始批量抓取网页,抓取成功。后续操作可根据任务需要停止。 查看全部
抓取网页数据php(优游国际平台获得多网页数据web链接罕见格局(组图))
一、从网络获取数据
从 bi 桌面的“获取数据”中,您可以使用“web”选项。“web”界面中有“basic”和“high-end”两个选项卡。一般情况下,“基本”选项卡就足够了。Pingyouyou国际平台任务需求,以下都是基于这个例子。
二、获取数据
网页链接输出后,导航器的“加载”、“编辑”等少见的功能都会停止,只要根据实际任务需要停止操作即可。
三、获取多页数据
网页链接的常见格式如下:开头的“1”表示后续链接为第一页数据,第二页数据链接应为“”。当网页数据较大时,如果平台每次都通过网页链接获取数据,会消耗大量时间。但是,软件中的查询和回复功能可以简化操作,如下:

获取到某页数据后,进入“编辑查询”界面,在“编辑查询”界面选择“高级编辑器”选项卡,高级编辑器界面显示之前的任务路径。大致如下图:

这时需要在“let”后面输出“(p as number) as table=>”;并更改网页的页码,即上面提到的“1、2”等数字,在链接优优国际平台“(Number.ToText(p))”即可。
备注:网页链接有两种,一种是页码数据在链接开头,可以按上面操作;另一个是链接以.html 开头。除了上述替代操作,_"&(Number .ToText(p))&".html")) 只需点击这里单独定义html即可。
四、 爬取大有游国际平台网站
首先,使用优优国际平台查询优优国际平台设置编号规则。如果要截取前100页数据,可以在优优国际平台设置1到100的序列,查询优优国际平台输出={1..100}回车生成序列从 1 到 100,然后将其转换为表格。
然后调用自定义函数,
在弹窗中,可以点击【功能查询】下拉框,选择自己建立的自定义功能Data_Zhaopin,其他平台点击默认即可。

点击确定开始批量抓取网页,抓取成功。后续操作可根据任务需要停止。
抓取网页数据php(一下,用PHP抓更方便(HttpWebReq)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-19 06:12
阿里云 > 云栖社区 > 主题地图 > R > 如何使用GET抓取网页内容
推荐活动:
更多优惠>
当前主题:如何使用 GET 抓取网页内容并添加到采集夹
相关话题:
如何使用 GET 抓取 Web 内容相关博客 查看更多博客
如何使用HttpWebRequest、HttpWebResponse模拟浏览器抓取网页内容
作者:老朱教授 823 浏览评论:04年前
public string GetHtml(string url, Encoding ed) { string Html = string.Empty;//初始化一个新的webRequst HttpWebRequest Request = (HttpWebReq
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen 1527 浏览评论:06年前
原文:PHP使用QueryList来抓取网页内容。之前用Java Jsoup爬取网页数据。前几天听说用PHP爬取比较方便。今天研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQuery 的泛型 list采集 类,简单、灵活、强大
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:老朱教授 1373 浏览评论:04年前
爬取网页的一般逻辑和流程一般是普通用户,他们使用浏览器打开一个URL地址,然后浏览器就可以显示相应页面的内容。这个过程,如果用程序代码实现,可以调用(程序实现)爬取网页(内容,以及后处理,提取需要的信息等)对应的英文是,website
阅读全文
file_get_contents爬取乱码网页的解决方案
作者:Tech Fatty 1012 人浏览评论:04年前
使用 file_get_contents() 函数抓取网页时,有时会出现乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。编码问题很容易处理,只需将捕获的内容转换为编码($content=iconv("GBK", "UTF-8//IGNORE
阅读全文
[网络爬虫] 使用node.js Cheerio 抓取网络数据
作者:紫玉5358人查看评论:05年前
想要自动从网络上抓取一些数据或将一堆从博客中提取的数据转换成结构化数据?有没有现成的 API 来获取数据?!!!!@#$@#$... 没关系,网络抓取可以解决它。什么是网页抓取?你可能会问。. . 网页抓取是对网页内容的程序化(通常不涉及浏览器)检索。
阅读全文
如何让搜索引擎抓取 AJAX 内容?
作者:阮一峰 1469 浏览评论:05年前
越来越多的网站,开始使用“单页结构”(Single-page application)。整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个
阅读全文
如何让搜索引擎抓取 AJAX 内容?
作者:阮一峰 1061 浏览评论:05年前
越来越多的网站,开始使用“单页结构”(Single-page application)。整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个
阅读全文 查看全部
抓取网页数据php(一下,用PHP抓更方便(HttpWebReq)(组图))
阿里云 > 云栖社区 > 主题地图 > R > 如何使用GET抓取网页内容

推荐活动:
更多优惠>
当前主题:如何使用 GET 抓取网页内容并添加到采集夹
相关话题:
如何使用 GET 抓取 Web 内容相关博客 查看更多博客
如何使用HttpWebRequest、HttpWebResponse模拟浏览器抓取网页内容

作者:老朱教授 823 浏览评论:04年前
public string GetHtml(string url, Encoding ed) { string Html = string.Empty;//初始化一个新的webRequst HttpWebRequest Request = (HttpWebReq
阅读全文
PHP 使用 QueryList 抓取网页内容


作者:Jack Chen 1527 浏览评论:06年前
原文:PHP使用QueryList来抓取网页内容。之前用Java Jsoup爬取网页数据。前几天听说用PHP爬取比较方便。今天研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQuery 的泛型 list采集 类,简单、灵活、强大
阅读全文
PHP 使用 QueryList 抓取网页内容


作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)

作者:老朱教授 1373 浏览评论:04年前
爬取网页的一般逻辑和流程一般是普通用户,他们使用浏览器打开一个URL地址,然后浏览器就可以显示相应页面的内容。这个过程,如果用程序代码实现,可以调用(程序实现)爬取网页(内容,以及后处理,提取需要的信息等)对应的英文是,website
阅读全文
file_get_contents爬取乱码网页的解决方案

作者:Tech Fatty 1012 人浏览评论:04年前
使用 file_get_contents() 函数抓取网页时,有时会出现乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。编码问题很容易处理,只需将捕获的内容转换为编码($content=iconv("GBK", "UTF-8//IGNORE
阅读全文
[网络爬虫] 使用node.js Cheerio 抓取网络数据

作者:紫玉5358人查看评论:05年前
想要自动从网络上抓取一些数据或将一堆从博客中提取的数据转换成结构化数据?有没有现成的 API 来获取数据?!!!!@#$@#$... 没关系,网络抓取可以解决它。什么是网页抓取?你可能会问。. . 网页抓取是对网页内容的程序化(通常不涉及浏览器)检索。
阅读全文
如何让搜索引擎抓取 AJAX 内容?


作者:阮一峰 1469 浏览评论:05年前
越来越多的网站,开始使用“单页结构”(Single-page application)。整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个
阅读全文
如何让搜索引擎抓取 AJAX 内容?
作者:阮一峰 1061 浏览评论:05年前
越来越多的网站,开始使用“单页结构”(Single-page application)。整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个
阅读全文
抓取网页数据php( 58手机号码识别插件和百度翻译插件的用法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-19 06:11
58手机号码识别插件和百度翻译插件的用法(组图))
爬网数据工具优采云采集器插件说明
使用 优采云采集器 捕获网页数据时也使用插件。优采云采集器将采集中的数据传递给外部程序,我们称之为插件,插件然后处理数据,然后将数据返回给采集器。
优采云采集器V9支持PHP和C#插件编写,V9支持插件源代码编辑。网页数据抓取工具优采云采集器的插件可以应用于采集的结果处理、HTTP请求、文件下载。设置插件实现特定应用时,可以在插件管理器的下拉框中选择现有插件。
下面使用58手机号码识别插件和百度翻译插件来说明使用方法。
58个插件演示:
(1)首先我们需要把插件58验证码V9.dll放到采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后我们需要创建一个名为“手机号”的标签,采集到手机号58的图片地址,这样运行的时候采集器会自动调用该插件将图像输出为转义的数字文本。
翻译插件演示:
(1)首先我们需要把插件百度翻译.dll放到采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后,我们需要创建一个名为“翻译标签”的标签,并以固定字符串的形式写入需要翻译的字段名称。 查看全部
抓取网页数据php(
58手机号码识别插件和百度翻译插件的用法(组图))
爬网数据工具优采云采集器插件说明
使用 优采云采集器 捕获网页数据时也使用插件。优采云采集器将采集中的数据传递给外部程序,我们称之为插件,插件然后处理数据,然后将数据返回给采集器。
优采云采集器V9支持PHP和C#插件编写,V9支持插件源代码编辑。网页数据抓取工具优采云采集器的插件可以应用于采集的结果处理、HTTP请求、文件下载。设置插件实现特定应用时,可以在插件管理器的下拉框中选择现有插件。

下面使用58手机号码识别插件和百度翻译插件来说明使用方法。
58个插件演示:
(1)首先我们需要把插件58验证码V9.dll放到采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后我们需要创建一个名为“手机号”的标签,采集到手机号58的图片地址,这样运行的时候采集器会自动调用该插件将图像输出为转义的数字文本。
翻译插件演示:
(1)首先我们需要把插件百度翻译.dll放到采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后,我们需要创建一个名为“翻译标签”的标签,并以固定字符串的形式写入需要翻译的字段名称。
抓取网页数据php(finfo_if_else就用这个接口php面向对象的好处?#!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-14 13:01
抓取网页数据php内置接口::http(x)tokens,并进行判断?fei#!finfo_if_else就用这个接口php面向对象:(什么是面向对象?面向对象的好处?什么是闭包?闭包)闭包是php的一种重要的程序特性,它将一个函数独立出来,作为另一个函数的参数传递,从而建立一个单独的环境,而不再依赖它。
闭包的意义在于,提供了php编程的一种开源思想。现在有一些php框架,如果需要用到某个函数,你可以通过使用一个特殊函数或者变量,让php自动转换。php转发body_request:从远程服务器接收php请求,在所有请求处理完毕后,将处理后的内容return给客户端。token_manager:用来保存客户端请求的token。
bloompath:将路径分割开来,并保存路径名。$path=$this->__path__;btn->add_top?btn-s>ctx_msg_end:提示客户端已经完成一个请求eof:表示return。先判断是否是eof,才传递path,否则传递的是路径名。由于http并不是面向过程的,bs实现函数调用只是php中一种特殊的函数,因此不需要bind()等操作符;对于bind()等操作符,你只要用一个函数判断传递值是否是eof就行了。
所以bloompath会把值传递出去,而bind则不会,当然bind的返回值eof也可以忽略不计。table:简单的数据表。burl_info:(?=id):(?=baidu):baidu的下拉回车回车中的id表示从何处来purl_info是php中表单组成最简单的一个部分,但是正是这个小小的部分已经包含了php中500多个函数。
现在的问题是:很多时候,请求并不是从页面中取的,我们需要先从页面爬取到数据,然后进行一些处理,然后获取我们需要的信息。而大多数页面都要请求很多次,而且有可能返回的数据长度远超字符串的长度,这样对php代码的压力就比较大了。有没有一种办法可以代替purl_info呢?like:如果我们要从页面中拿数据,可以先从页面的url请求一下://当然这个地址是不可能请求出来的like</img>burl_login:从登录界面取数据likebaidu_username_login;取到username之后,获取其它数据:burl_getuser():获取该用户的上一个guid;burl_getname():获取该用户的名字;burl_gets():获取该用户上次访问的url。
burl_send():发送请求(自己创建一个token用于存储token,或者等到时候用token登录就行了),发送成功则等于一个字符串。值得注意的是,在自己的服务器上存取值的时候,不要用increment那种方式。 查看全部
抓取网页数据php(finfo_if_else就用这个接口php面向对象的好处?#!)
抓取网页数据php内置接口::http(x)tokens,并进行判断?fei#!finfo_if_else就用这个接口php面向对象:(什么是面向对象?面向对象的好处?什么是闭包?闭包)闭包是php的一种重要的程序特性,它将一个函数独立出来,作为另一个函数的参数传递,从而建立一个单独的环境,而不再依赖它。
闭包的意义在于,提供了php编程的一种开源思想。现在有一些php框架,如果需要用到某个函数,你可以通过使用一个特殊函数或者变量,让php自动转换。php转发body_request:从远程服务器接收php请求,在所有请求处理完毕后,将处理后的内容return给客户端。token_manager:用来保存客户端请求的token。
bloompath:将路径分割开来,并保存路径名。$path=$this->__path__;btn->add_top?btn-s>ctx_msg_end:提示客户端已经完成一个请求eof:表示return。先判断是否是eof,才传递path,否则传递的是路径名。由于http并不是面向过程的,bs实现函数调用只是php中一种特殊的函数,因此不需要bind()等操作符;对于bind()等操作符,你只要用一个函数判断传递值是否是eof就行了。
所以bloompath会把值传递出去,而bind则不会,当然bind的返回值eof也可以忽略不计。table:简单的数据表。burl_info:(?=id):(?=baidu):baidu的下拉回车回车中的id表示从何处来purl_info是php中表单组成最简单的一个部分,但是正是这个小小的部分已经包含了php中500多个函数。
现在的问题是:很多时候,请求并不是从页面中取的,我们需要先从页面爬取到数据,然后进行一些处理,然后获取我们需要的信息。而大多数页面都要请求很多次,而且有可能返回的数据长度远超字符串的长度,这样对php代码的压力就比较大了。有没有一种办法可以代替purl_info呢?like:如果我们要从页面中拿数据,可以先从页面的url请求一下://当然这个地址是不可能请求出来的like</img>burl_login:从登录界面取数据likebaidu_username_login;取到username之后,获取其它数据:burl_getuser():获取该用户的上一个guid;burl_getname():获取该用户的名字;burl_gets():获取该用户上次访问的url。
burl_send():发送请求(自己创建一个token用于存储token,或者等到时候用token登录就行了),发送成功则等于一个字符串。值得注意的是,在自己的服务器上存取值的时候,不要用increment那种方式。
抓取网页数据php(抓取网页数据php获取数据库信息可使用或mssql页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-13 00:01
抓取网页数据php获取数据库信息可使用mysql或mssql抓取页面,需要引入相应的api,如果是自己写代码可借助cijs来完成抓取首页-进入lbs信息,点击左侧工具条-index或者ctrl+f输入框,点击右边api_index的api,
因为这个网站做了点赞功能,这个功能是有网页版的。
howtoinstallphpwebappforyouriphone?
我猜,这个信息是从其他网站爬下来的,然后转到你这个网站。每个网站抓取的量不一样。所以一些网站是可以取到所有用户的点赞信息,按照顺序排列,然后通过各种形式呈现出来。但是针对这个网站,肯定是没法直接取出所有用户的信息的。除非在每个url中同时获取到用户的ip、点赞数,才能算。
可以参考csdn博客:php下载:twitter|lastwebsite可以获取最近6个发推的用户。
收集发帖用户信息
你可以搜索“谷歌浏览器地图”,它会提供“目标网站收藏夹”,根据地址收藏。关键是“随意填写目标网站,
抓取网站的ip信息,返回到我的主页,
全是渣。抓取个人页面,
python爬取链家网cityurl: 查看全部
抓取网页数据php(抓取网页数据php获取数据库信息可使用或mssql页面)
抓取网页数据php获取数据库信息可使用mysql或mssql抓取页面,需要引入相应的api,如果是自己写代码可借助cijs来完成抓取首页-进入lbs信息,点击左侧工具条-index或者ctrl+f输入框,点击右边api_index的api,
因为这个网站做了点赞功能,这个功能是有网页版的。
howtoinstallphpwebappforyouriphone?
我猜,这个信息是从其他网站爬下来的,然后转到你这个网站。每个网站抓取的量不一样。所以一些网站是可以取到所有用户的点赞信息,按照顺序排列,然后通过各种形式呈现出来。但是针对这个网站,肯定是没法直接取出所有用户的信息的。除非在每个url中同时获取到用户的ip、点赞数,才能算。
可以参考csdn博客:php下载:twitter|lastwebsite可以获取最近6个发推的用户。
收集发帖用户信息
你可以搜索“谷歌浏览器地图”,它会提供“目标网站收藏夹”,根据地址收藏。关键是“随意填写目标网站,
抓取网站的ip信息,返回到我的主页,
全是渣。抓取个人页面,
python爬取链家网cityurl:
抓取网页数据php(Python叶庭云微信公众号:谈及pandasread_html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-10 04:14
过去的一切都是序幕。真正的顺其自然,不是尽力而为,而是什么都不做。
文章目录一、简介
一般的爬虫套路无非就是发送请求、获取响应、解析网页、提取数据、保存数据的步骤。 requests 库主要用于构造请求,xpath 和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
说说pandas的read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),pd.read_html()很少用到,但是它的作用它非常强大,尤其是当它用于捕获Table数据时,它是一个神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存在本地。
二、原理
pandas适合抓取表格数据,先了解一下有表格数据结构的网页,例如:
用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共性。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有以上结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬虫实例1
爬取2019年成都空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range('20190101', '20191201', freq='MS').strftime('%Y%m') # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f'http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html', encoding='gbk', header=0)[0]
if i == 0:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False) # 追加写入
i += 1
else:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False, header=False)
9行代码就搞定了,爬取速度也很快。
查看保存的数据
示例 2
抓取新浪财经基金重仓股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv('新浪财经基金重仓股数据.csv', encoding='utf-8', index=False)
6行代码就搞定了,爬取速度也很快。
查看保存的数据:
以后爬一些小数据的时候,只要遇到这种Table数据,可以先试试pd.read_html()方法。
作者:叶婷云 微信公众号:培养Python CSDN:本文仅供交流学习,未经作者许可,禁止转载,更不得用于其他目的,违者必究。如果你觉得文章对你有帮助,让你有所收获,期待你的点赞。如有不足,也可以在评论区指正。 查看全部
抓取网页数据php(Python叶庭云微信公众号:谈及pandasread_html)
过去的一切都是序幕。真正的顺其自然,不是尽力而为,而是什么都不做。
文章目录一、简介
一般的爬虫套路无非就是发送请求、获取响应、解析网页、提取数据、保存数据的步骤。 requests 库主要用于构造请求,xpath 和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
说说pandas的read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),pd.read_html()很少用到,但是它的作用它非常强大,尤其是当它用于捕获Table数据时,它是一个神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存在本地。
二、原理
pandas适合抓取表格数据,先了解一下有表格数据结构的网页,例如:
用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共性。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有以上结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬虫实例1
爬取2019年成都空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range('20190101', '20191201', freq='MS').strftime('%Y%m') # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f'http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html', encoding='gbk', header=0)[0]
if i == 0:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False) # 追加写入
i += 1
else:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False, header=False)
9行代码就搞定了,爬取速度也很快。
查看保存的数据
示例 2
抓取新浪财经基金重仓股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv('新浪财经基金重仓股数据.csv', encoding='utf-8', index=False)
6行代码就搞定了,爬取速度也很快。
查看保存的数据:
以后爬一些小数据的时候,只要遇到这种Table数据,可以先试试pd.read_html()方法。
作者:叶婷云 微信公众号:培养Python CSDN:本文仅供交流学习,未经作者许可,禁止转载,更不得用于其他目的,违者必究。如果你觉得文章对你有帮助,让你有所收获,期待你的点赞。如有不足,也可以在评论区指正。
抓取网页数据php(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-10 04:03
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们要确定我们的 PHP 是否启用了这个库,你可以使用 php_info() 函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置需要抓取的网址
curl_setopt($curl, CURLOPT_URL, '');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置 cURL 参数,是否将结果保存为字符串或输出到屏幕。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行cURL,请求网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
//显示获取到的数据
var_dump($data);
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序我们可以看出,使用CURLOPT_POST来设置HTTP协议的POST方法而不是GET方法,然后用CURLOPT_POSTFIELDS设置POST数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie 查看全部
抓取网页数据php(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们要确定我们的 PHP 是否启用了这个库,你可以使用 php_info() 函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置需要抓取的网址
curl_setopt($curl, CURLOPT_URL, '');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置 cURL 参数,是否将结果保存为字符串或输出到屏幕。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行cURL,请求网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
//显示获取到的数据
var_dump($data);
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序我们可以看出,使用CURLOPT_POST来设置HTTP协议的POST方法而不是GET方法,然后用CURLOPT_POSTFIELDS设置POST数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie
抓取网页数据php(Google新的SEO代言人GaryIllyes帖子里的后续跟进内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-30 07:04
一月份,谷歌新任 SEO 发言人 Gary Illyes 在谷歌官方博客上发表了一篇文章:What Crawl Budget Means for Googlebot,讨论了与搜索引擎蜘蛛爬取份额相关的问题。对于大中型网站来说,这是一个非常重要的SEO问题,有时会成为网站有机流量的瓶颈。
今天的帖子总结了Gary Illyes的帖子的主要内容以及后面的很多博客和论坛帖子,以及我自己的一些案例和理解。
需要强调的是,以下概念也适用于百度。
什么是搜索引擎蜘蛛的抓取份额?
顾名思义,抓取份额是搜索引擎蜘蛛在 网站 上抓取页面所花费的总时间。对于一个特定的 网站,搜索引擎蜘蛛在这个 网站 上花费的总时间是相对恒定的,不会无限期地抓取 网站 所有页面。
crawl share的英文谷歌使用crawl budget,直译为crawl budget。我不认为它可以解释它的含义,所以我用爬网分享来表达这个概念。
什么决定了抓取份额?它涉及抓取需求和抓取速率限制。
抓取需求
抓取需求,crawl demand,是指搜索引擎“想要”抓取特定网站的页面数。
有两个主要因素决定了爬行需求。首先是页面重量。网站 上的页数达到基本页重,搜索引擎想爬多少页。二是索引库中的页面是否太久没有更新。说到底,还是页面权重。权重高的页面很长一段时间都不会更新。
页面权重和 网站 权重密切相关。增加 网站 权重将使搜索引擎愿意爬取更多页面。
抓取速度限制
搜索引擎蜘蛛不会为了爬取更多的页面而拖拽其他网站服务器,所以某一个网站会设置一个爬取率限制,爬取率限制,也就是服务器可以达到的上限承担,在这个速度限制内,蜘蛛爬行不会拖慢服务器,影响用户访问。
服务器响应速度够快,将限速提高一点,爬取加速,服务器响应速度降低,限速降低,爬取减慢,甚至停止爬取。
因此,抓取速度限制是搜索引擎“可以”抓取的页面数。
什么决定了抓取份额?
爬取份额是同时考虑了爬取需求和爬取速度限制的结果,即搜索引擎“想”爬取和“能够”同时爬取的页面数量。
网站权重高,页面内容质量高,页面够多,服务器速度够快,爬取份额大。
小网站不用担心抢股
小网站页数少,即使网站权重再低,服务器也慢,而且搜索引擎蜘蛛每天爬的少,一般至少能爬几百页. 网站爬取一次,所以 网站 的数千个页面完全不用担心爬取份额。网站 几万页一般没什么大不了的。如果每天数百次访问会减慢服务器速度,那么 SEO 就不是主要问题。
中到大 网站 可能需要考虑爬取共享
几十万页以上的大中型网站可能需要考虑爬取份额是否够用。
抓取份额不够。比如网站有1000万个页面,而搜索引擎每天只能抓取几万个页面,所以一次网站可能需要几个月甚至一年的时间。一些重要页面无法爬取,所以没有排名,或者重要页面无法及时更新。
为了让 网站 页面被及时和充分的爬取,服务器必须足够快,页面必须足够小。如果网站有大量优质数据,爬取份额会受到爬取率的限制,提高页面速度会直接提高爬取率限制,从而提高爬取份额。
百度站长平台和谷歌搜索控制台都有数据抓取。下图是一个网站的百度爬取频率:
上图是每天为SEO发布的一个小网站。页面爬取频率和爬取时间(取决于服务器速度和页面大小)相互无关,说明爬取份额没有用完,不用担心。
有时候,爬取频率和爬取时间有一定的对应关系,如下图网站较大:
可以看出,爬取时间的提高(减小页面大小、提高服务器速度、优化数据库)明显导致爬取频率增加,从而爬取更多页面收录,遍历一次网站更快。
Google Search Console 中较大网站的示例:
顶部是爬取的页面数,中间是爬取的数据量。除非服务器出现故障,否则这两个应该是对应的。底部是页面抓取时间。可以看到,页面下载速度快到每天爬几百万个页面。
当然,如前所述,能爬上百万页是一回事,但搜索引擎要不要爬则是另一回事。
大网站另一个你经常需要考虑爬取份额的原因是不要把你有限的爬取份额浪费在无意义的页面爬取上,让应该爬取的重要页面没有机会被爬取。
浪费爬网共享的典型页面是:
许多过滤过滤器页面。几年前,在一篇关于无效 URL 抓取索引的帖子中对此进行了详细讨论。网站上无限制的低质量复制内容、垃圾日历等页面
以上页面被大量爬取,爬取份额可能用完,但应该爬取的页面却没有被爬取。
如何保存抓取份额?
当然首先是减小页面文件大小,提高服务器速度,优化数据库,减少爬取时间。
然后,尽量避免上面列出的那些浪费爬取份额的事情。有些是内容质量问题,有些是网站 结构问题。如果是结构问题,最简单的办法就是禁止抓取robots文件,但是会浪费一些页面权重,因为权重只能进入,不能访问。
在某些情况下,使用链接 nofollow 属性可以节省爬网共享。小网站,既然爬取份额用不完,加nofollow就没意义了。大网站,nofollow可以在一定程度上控制权重的流动和分配。一个精心设计的nofollow会减少无意义页面的权重,增加重要页面的权重。当一个搜索引擎进行爬取时,它会使用一个 URL 爬取列表。要爬取的 URL 按页面权重排序。如果重要页面的权重增加,将首先抓取它们。无意义页面的权重可能非常低,以至于搜索引擎不想抓取它们。
最后的几点说明:
链接加nofollow 不会浪费抓取份额。但这在谷歌是浪费重量。noindex 标记不保存爬网共享。如果搜索引擎需要知道页面上有noindex标签,就得先爬取页面,所以不保存爬取份额。规范标签有时可以节省一点爬网份额。和noindex标签一样,如果搜索引擎知道页面上有canonical标签,就得先爬取页面,所以不直接保存爬取份额。但是带有规范标签的页面通常很少被抓取,因此您节省了一点抓取份额。爬取率和爬取份额不是排名因素。但是没有被爬取的页面是没有排名的。 查看全部
抓取网页数据php(Google新的SEO代言人GaryIllyes帖子里的后续跟进内容)
一月份,谷歌新任 SEO 发言人 Gary Illyes 在谷歌官方博客上发表了一篇文章:What Crawl Budget Means for Googlebot,讨论了与搜索引擎蜘蛛爬取份额相关的问题。对于大中型网站来说,这是一个非常重要的SEO问题,有时会成为网站有机流量的瓶颈。
今天的帖子总结了Gary Illyes的帖子的主要内容以及后面的很多博客和论坛帖子,以及我自己的一些案例和理解。
需要强调的是,以下概念也适用于百度。
什么是搜索引擎蜘蛛的抓取份额?
顾名思义,抓取份额是搜索引擎蜘蛛在 网站 上抓取页面所花费的总时间。对于一个特定的 网站,搜索引擎蜘蛛在这个 网站 上花费的总时间是相对恒定的,不会无限期地抓取 网站 所有页面。
crawl share的英文谷歌使用crawl budget,直译为crawl budget。我不认为它可以解释它的含义,所以我用爬网分享来表达这个概念。
什么决定了抓取份额?它涉及抓取需求和抓取速率限制。
抓取需求
抓取需求,crawl demand,是指搜索引擎“想要”抓取特定网站的页面数。
有两个主要因素决定了爬行需求。首先是页面重量。网站 上的页数达到基本页重,搜索引擎想爬多少页。二是索引库中的页面是否太久没有更新。说到底,还是页面权重。权重高的页面很长一段时间都不会更新。
页面权重和 网站 权重密切相关。增加 网站 权重将使搜索引擎愿意爬取更多页面。
抓取速度限制
搜索引擎蜘蛛不会为了爬取更多的页面而拖拽其他网站服务器,所以某一个网站会设置一个爬取率限制,爬取率限制,也就是服务器可以达到的上限承担,在这个速度限制内,蜘蛛爬行不会拖慢服务器,影响用户访问。
服务器响应速度够快,将限速提高一点,爬取加速,服务器响应速度降低,限速降低,爬取减慢,甚至停止爬取。
因此,抓取速度限制是搜索引擎“可以”抓取的页面数。
什么决定了抓取份额?
爬取份额是同时考虑了爬取需求和爬取速度限制的结果,即搜索引擎“想”爬取和“能够”同时爬取的页面数量。
网站权重高,页面内容质量高,页面够多,服务器速度够快,爬取份额大。
小网站不用担心抢股
小网站页数少,即使网站权重再低,服务器也慢,而且搜索引擎蜘蛛每天爬的少,一般至少能爬几百页. 网站爬取一次,所以 网站 的数千个页面完全不用担心爬取份额。网站 几万页一般没什么大不了的。如果每天数百次访问会减慢服务器速度,那么 SEO 就不是主要问题。
中到大 网站 可能需要考虑爬取共享
几十万页以上的大中型网站可能需要考虑爬取份额是否够用。
抓取份额不够。比如网站有1000万个页面,而搜索引擎每天只能抓取几万个页面,所以一次网站可能需要几个月甚至一年的时间。一些重要页面无法爬取,所以没有排名,或者重要页面无法及时更新。
为了让 网站 页面被及时和充分的爬取,服务器必须足够快,页面必须足够小。如果网站有大量优质数据,爬取份额会受到爬取率的限制,提高页面速度会直接提高爬取率限制,从而提高爬取份额。
百度站长平台和谷歌搜索控制台都有数据抓取。下图是一个网站的百度爬取频率:
上图是每天为SEO发布的一个小网站。页面爬取频率和爬取时间(取决于服务器速度和页面大小)相互无关,说明爬取份额没有用完,不用担心。
有时候,爬取频率和爬取时间有一定的对应关系,如下图网站较大:
可以看出,爬取时间的提高(减小页面大小、提高服务器速度、优化数据库)明显导致爬取频率增加,从而爬取更多页面收录,遍历一次网站更快。
Google Search Console 中较大网站的示例:
顶部是爬取的页面数,中间是爬取的数据量。除非服务器出现故障,否则这两个应该是对应的。底部是页面抓取时间。可以看到,页面下载速度快到每天爬几百万个页面。
当然,如前所述,能爬上百万页是一回事,但搜索引擎要不要爬则是另一回事。
大网站另一个你经常需要考虑爬取份额的原因是不要把你有限的爬取份额浪费在无意义的页面爬取上,让应该爬取的重要页面没有机会被爬取。
浪费爬网共享的典型页面是:
许多过滤过滤器页面。几年前,在一篇关于无效 URL 抓取索引的帖子中对此进行了详细讨论。网站上无限制的低质量复制内容、垃圾日历等页面
以上页面被大量爬取,爬取份额可能用完,但应该爬取的页面却没有被爬取。
如何保存抓取份额?
当然首先是减小页面文件大小,提高服务器速度,优化数据库,减少爬取时间。
然后,尽量避免上面列出的那些浪费爬取份额的事情。有些是内容质量问题,有些是网站 结构问题。如果是结构问题,最简单的办法就是禁止抓取robots文件,但是会浪费一些页面权重,因为权重只能进入,不能访问。
在某些情况下,使用链接 nofollow 属性可以节省爬网共享。小网站,既然爬取份额用不完,加nofollow就没意义了。大网站,nofollow可以在一定程度上控制权重的流动和分配。一个精心设计的nofollow会减少无意义页面的权重,增加重要页面的权重。当一个搜索引擎进行爬取时,它会使用一个 URL 爬取列表。要爬取的 URL 按页面权重排序。如果重要页面的权重增加,将首先抓取它们。无意义页面的权重可能非常低,以至于搜索引擎不想抓取它们。
最后的几点说明:
链接加nofollow 不会浪费抓取份额。但这在谷歌是浪费重量。noindex 标记不保存爬网共享。如果搜索引擎需要知道页面上有noindex标签,就得先爬取页面,所以不保存爬取份额。规范标签有时可以节省一点爬网份额。和noindex标签一样,如果搜索引擎知道页面上有canonical标签,就得先爬取页面,所以不直接保存爬取份额。但是带有规范标签的页面通常很少被抓取,因此您节省了一点抓取份额。爬取率和爬取份额不是排名因素。但是没有被爬取的页面是没有排名的。
抓取网页数据php(Python使用使用_xuqi7的博客-程序员ITS404的初级用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-30 07:03
Atom使用_xuqi7的博客-程序员ITS404
atom的主要用法 0x00 介绍 Atom是github专门为程序员推出的跨平台文本编辑器。具有简洁直观的 GUI,并具有许多有趣的功能:支持 CSS、HTML、JavaScript 和其他 Web 编程语言。它支持宏,自动完成分屏功能,并具有集成的文件管理器。它实际上是一个文本编辑器
Python os 模块参考手册-“违规用户”之博客-程序员ITS404
Python 标准库中的 os 模块收录常用的操作系统函数。这个模块的作用主要是提供平台无关的功能。也就是说os模块可以处理平台之间的差异,使得编写的程序可以在另一个平台上运行而无需做任何改动。当然,这个模块只是提供了一种轻量级的方式来使用依赖于操作系统的功能。一些特定的功能必须使用特定的模块,例如:如何只读取或写入文件,请使用 open();...
求最大公约数和最小公倍数。C_的博客-程序员ITS404
公式的推导过程太复杂了,记不住了,只记得结论。这里我们采用了折腾和分割的方法。B == 0) return A;else gcd(B, A%B);}int lcm(int m, int n, int d)//最小公倍数{return m * n / d;}int main (){int m, n,d;printf("请输入两个正整数:");scanf("%d%d", &m,
【Python上手仅需20分钟】从安装到数据采集存储,就这么简单-juoduomade的博客-程序员ITS404
基于大众对 Python 的炒作和欣赏,作为一名 Java 从业者,怀着批判和好奇的心态,买了一本 Python 书籍《无阻碍地学 Python》。我刚刚读了这本书的第一部分......我决定成为一个 python 粉丝。作为一个合格的脑残粉(题主(ノ◕ω◕)ノ),为了开发我的下线,我会详细介绍Python安装到开发工具的简单介绍,写一个捕获天气信息数据并存的...
遍历文件_07H_JH的博客-程序员ITS404
参见《Windows核心编程》,C/C++程序实际上是由运行时库中的Startup系列函数(mainCRTStartup、wmainCRTStartup、WinMainCRTStartup、wWinMainCRTStartup)进行一系列初始化,然后调用程序员编写的代码。main, wmain, WinMain or wWinMain,所以很想看mainCRTStartup的定义,书上说是在crt
现实世界中的开集识别问题__pinnacle_的博客-程序员ITS404_Open Set Recognition
开集分类问题(open-set problem)不仅包括从0到9的字符类别,还包括A到Z等其他未知类别,但是这些未知类别没有标签,分类器无法知道未知的类别。图像的具体类别,比如:是否是A,这许多不同类别的图像共同构成一个类别:未知类别,我们在检测中称其为背景类别,开集分类问题的目的是: * * 正确划分这10个类别,正确拒绝非数字类别** 查看全部
抓取网页数据php(Python使用使用_xuqi7的博客-程序员ITS404的初级用法)
Atom使用_xuqi7的博客-程序员ITS404
atom的主要用法 0x00 介绍 Atom是github专门为程序员推出的跨平台文本编辑器。具有简洁直观的 GUI,并具有许多有趣的功能:支持 CSS、HTML、JavaScript 和其他 Web 编程语言。它支持宏,自动完成分屏功能,并具有集成的文件管理器。它实际上是一个文本编辑器
Python os 模块参考手册-“违规用户”之博客-程序员ITS404
Python 标准库中的 os 模块收录常用的操作系统函数。这个模块的作用主要是提供平台无关的功能。也就是说os模块可以处理平台之间的差异,使得编写的程序可以在另一个平台上运行而无需做任何改动。当然,这个模块只是提供了一种轻量级的方式来使用依赖于操作系统的功能。一些特定的功能必须使用特定的模块,例如:如何只读取或写入文件,请使用 open();...
求最大公约数和最小公倍数。C_的博客-程序员ITS404
公式的推导过程太复杂了,记不住了,只记得结论。这里我们采用了折腾和分割的方法。B == 0) return A;else gcd(B, A%B);}int lcm(int m, int n, int d)//最小公倍数{return m * n / d;}int main (){int m, n,d;printf("请输入两个正整数:");scanf("%d%d", &m,
【Python上手仅需20分钟】从安装到数据采集存储,就这么简单-juoduomade的博客-程序员ITS404
基于大众对 Python 的炒作和欣赏,作为一名 Java 从业者,怀着批判和好奇的心态,买了一本 Python 书籍《无阻碍地学 Python》。我刚刚读了这本书的第一部分......我决定成为一个 python 粉丝。作为一个合格的脑残粉(题主(ノ◕ω◕)ノ),为了开发我的下线,我会详细介绍Python安装到开发工具的简单介绍,写一个捕获天气信息数据并存的...
遍历文件_07H_JH的博客-程序员ITS404
参见《Windows核心编程》,C/C++程序实际上是由运行时库中的Startup系列函数(mainCRTStartup、wmainCRTStartup、WinMainCRTStartup、wWinMainCRTStartup)进行一系列初始化,然后调用程序员编写的代码。main, wmain, WinMain or wWinMain,所以很想看mainCRTStartup的定义,书上说是在crt
现实世界中的开集识别问题__pinnacle_的博客-程序员ITS404_Open Set Recognition
开集分类问题(open-set problem)不仅包括从0到9的字符类别,还包括A到Z等其他未知类别,但是这些未知类别没有标签,分类器无法知道未知的类别。图像的具体类别,比如:是否是A,这许多不同类别的图像共同构成一个类别:未知类别,我们在检测中称其为背景类别,开集分类问题的目的是: * * 正确划分这10个类别,正确拒绝非数字类别**
抓取网页数据php(PowerBI财务报表分析系列之:数据准备篇(000002)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-24 07:18
PowerBI财务报表分析系列:
数据准备
数据分析的第一步是在开始后续的一系列分析过程之前拥有数据。PowerBI 财务报表分析也不例外。在第一篇文章中,我们先介绍报表数据的获取,并将获取的数据整理成合适的分析。风格。
本分析示例使用的是上市公司数据,因此数据获取的主要工作是使用PowerBI批量抓取网页数据。
如果你的分析对象是公司的财务报表,会更方便。您可以跳过网络抓取数据的过程,直接组织数据。但是,如果你已经学会了使用 PowerBI 抓取网页数据的技巧,你以后可以随时使用它。在。
在下方输入文字。
本PowerBI财务报表分析报告使用5家上市公司2010年至2019年的资产负债表、损益表和现金流量表数据。
数据来自新浪财经,首先选择一家公司,比如万科A,点击财务报表>资产负债表>2019,出现在我面前的网页如下:
2019年四季度的资产负债表同时显示,数据结构很好,可以为后期整理节省大量工作。
然后看这个URL结构:
猜测资产负债表和000002、2019分别代表万科的资产负债表、股票代码和年份,可以通过更改公司和年份来验证。比如五粮液2018年的损益表,网址是:
和猜测的一模一样,那么就可以使用PowerBI批量抓取了。
捕捉多家公司、多年、多份报告的总体思路:
1、先抓一个公司一年的报告;
2、使用步骤 1 中的查询创建自定义函数;
3、构造参数列表;
4.调用自定义函数批量抓取数据。
下面进入具体操作步骤。
1.使用PowerBI抓取公司一年的报表
以上面第一个 URL:万科 2019 年资产负债表为例,点击 Get Data > From web,输入 URL,在弹出的导航器中会看到 PowerBI 识别的很多表,因为这个页面原本也就是多组数据,分别点击查看,你会看到表17的结构是最规范的,
选择表,然后加载数据并进入 Power Query 编辑器。
先观察这张表的数据,空值显示为“--”,先用0代替,然后用第一行作为表头:
如果对 PowerQuery 的基本操作不熟悉,推荐看看这个文章:
数据清洗中最常用的十三个技巧
这是一个二维结构表。为方便后续分析,将其转为一维表:选中第一列,点击Unpivot > Unpivot other columns,即为一维表:
如果你对一维表不了解,可以参考:关于一维表,你想知道的都在这里
万科2019年资产负债表已提取整理。
其实这一步到这里就可以结束了。但是在这个模型中,为了简化,我删除了现金流量表间接法的附加数据,只保留了直接法的现金流量表项目。因此,我对现金流量表进行了更多查询。
因此,在提取现金流量表时,在上述资产负债表操作的基础上,增加了删除最下面一行的步骤,其他步骤同理(如需使用现金补充信息,可不处理把它分开,你只需要获取一个资产负债表就可以了)。
2.创建自定义函数
在 PowerBI 中,每一步操作都会被自动记录下来。数据源更新后,刷新可以自动完成所有操作步骤。
进一步,这个查询也可以被函数化并应用到其他类似的查询,这些查询使用了PowerQuery的自定义函数(如果你不知道自定义函数是什么,你可以看看:Knowing Power Query's custom function)。
并不是所有的自定义函数都需要一点点从头开始编写 M 代码,有更简单的方法。
步骤 1 完成后,右键单击查询名称,然后单击“创建函数”。
输入函数名称,这里我根据报表类型定义函数为资产负债表。
然后选择这个自定义函数,点击进入高级编辑器,将前面几行代码调整为下图所示内容:
就是修改获取数据的URL,将URL中的报表类型、公司代码、年份分别作为type、code、year,将这三个变量作为自定义函数的三个参数。
然后构建这个自定义函数,
在该窗口中,可以输入任意三个有效参数,提取某上市公司某年某年的报表。
但是创建自定义函数的目的是为了批量获取数据,所以在这个窗口不需要操作。
同理,为现金流量表生成一个自定义函数,命名为 cashflow。
3.构建参数列表
对于这三个参数,我们需要构造这三个参数的笛卡尔积,得到各公司2010-2019年的三大报表数据。
为了方便后期的修改和维护,我们先建立三个单独的参数表。
在PowerQuery编辑器中,直接点击输入数据,输入要分析的公司名称和股票代码:
生成公司名称表。同理,生成年表和报表类型表。
接下来要做的是生成这三个表的笛卡尔积,即公司代码、年份和报告类型的任意组合。
在 PowerQuery 中,生成笛卡尔积就像向三个表中的每一个(例如 1)添加一列,然后合并查询一样简单。
首先合并查询报表类型和年份:
得到的结果如下:
这是报表类型和年份的任意组合,然后继续将此表与公司名称表合并,得到公司代码、年份和报表类型的任意组合表。
4、调用自定义函数
在第3步生成的表的基础上,添加自定义列,
这个M代码表示如果报表类型是CashFlow(现金流量表),则调用自定义函数:cashflow,否则调用资产负债表,其参数相同(如果只有一个自定义函数,则无需使用IF用于判断。,直接调用即可)。
然后我抓了这五家公司10年的三大报告数据:
另外,批量抓取的报表数据已经是我们需要的一维表格数据了,因为第一步收录了二维转一维的步骤,后面调用自定义函数的时候会自动做相同的。手术。
当然,你也可以用这种方法一次抓取几百家公司的数据,但是速度会很慢,所以建议只抓取你需要的公司和最近一年的数据。
至此,三大表的数据抓取已经完成,主要是使用PowerQuery的界面操作和一些简单的代码修改。即使没有基础,也可以按照以上步骤快速完成。
在这个财务分析示例中,有一个页面,其中收录从网络上抓取的公司简介和公司信息:
数据来自以下三个网页:
公司公告
公司简介
历史行情
这些数据的抓取和上面的财报数据抓取步骤完全一样,只是更简单一些,因为只有一个参数:公司代码,大家可以自己练习。
通过上面的介绍,你应该可以很方便的从网页中抓取财报数据了。当需要其他相关数据时,可以在网上搜索资源,然后批量抓取。
如开头所说,如果你要做的是分析贵公司的内部财务报告,你可以忽略本文中捕获数据的步骤,直接导入现成的财务报告。但是,为了后续分析的需要,建议还是将报表数据组织成一维的表结构。
数据整理上传后,就可以进行下一步的数据建模了。
成为 PowerBI Planet 会员,获取财务报告分析模板 查看全部
抓取网页数据php(PowerBI财务报表分析系列之:数据准备篇(000002)(图))
PowerBI财务报表分析系列:
数据准备
数据分析的第一步是在开始后续的一系列分析过程之前拥有数据。PowerBI 财务报表分析也不例外。在第一篇文章中,我们先介绍报表数据的获取,并将获取的数据整理成合适的分析。风格。
本分析示例使用的是上市公司数据,因此数据获取的主要工作是使用PowerBI批量抓取网页数据。
如果你的分析对象是公司的财务报表,会更方便。您可以跳过网络抓取数据的过程,直接组织数据。但是,如果你已经学会了使用 PowerBI 抓取网页数据的技巧,你以后可以随时使用它。在。
在下方输入文字。
本PowerBI财务报表分析报告使用5家上市公司2010年至2019年的资产负债表、损益表和现金流量表数据。
数据来自新浪财经,首先选择一家公司,比如万科A,点击财务报表>资产负债表>2019,出现在我面前的网页如下:
2019年四季度的资产负债表同时显示,数据结构很好,可以为后期整理节省大量工作。
然后看这个URL结构:
猜测资产负债表和000002、2019分别代表万科的资产负债表、股票代码和年份,可以通过更改公司和年份来验证。比如五粮液2018年的损益表,网址是:
和猜测的一模一样,那么就可以使用PowerBI批量抓取了。
捕捉多家公司、多年、多份报告的总体思路:
1、先抓一个公司一年的报告;
2、使用步骤 1 中的查询创建自定义函数;
3、构造参数列表;
4.调用自定义函数批量抓取数据。
下面进入具体操作步骤。
1.使用PowerBI抓取公司一年的报表
以上面第一个 URL:万科 2019 年资产负债表为例,点击 Get Data > From web,输入 URL,在弹出的导航器中会看到 PowerBI 识别的很多表,因为这个页面原本也就是多组数据,分别点击查看,你会看到表17的结构是最规范的,
选择表,然后加载数据并进入 Power Query 编辑器。
先观察这张表的数据,空值显示为“--”,先用0代替,然后用第一行作为表头:
如果对 PowerQuery 的基本操作不熟悉,推荐看看这个文章:
数据清洗中最常用的十三个技巧
这是一个二维结构表。为方便后续分析,将其转为一维表:选中第一列,点击Unpivot > Unpivot other columns,即为一维表:
如果你对一维表不了解,可以参考:关于一维表,你想知道的都在这里
万科2019年资产负债表已提取整理。
其实这一步到这里就可以结束了。但是在这个模型中,为了简化,我删除了现金流量表间接法的附加数据,只保留了直接法的现金流量表项目。因此,我对现金流量表进行了更多查询。
因此,在提取现金流量表时,在上述资产负债表操作的基础上,增加了删除最下面一行的步骤,其他步骤同理(如需使用现金补充信息,可不处理把它分开,你只需要获取一个资产负债表就可以了)。
2.创建自定义函数
在 PowerBI 中,每一步操作都会被自动记录下来。数据源更新后,刷新可以自动完成所有操作步骤。
进一步,这个查询也可以被函数化并应用到其他类似的查询,这些查询使用了PowerQuery的自定义函数(如果你不知道自定义函数是什么,你可以看看:Knowing Power Query's custom function)。
并不是所有的自定义函数都需要一点点从头开始编写 M 代码,有更简单的方法。
步骤 1 完成后,右键单击查询名称,然后单击“创建函数”。
输入函数名称,这里我根据报表类型定义函数为资产负债表。
然后选择这个自定义函数,点击进入高级编辑器,将前面几行代码调整为下图所示内容:
就是修改获取数据的URL,将URL中的报表类型、公司代码、年份分别作为type、code、year,将这三个变量作为自定义函数的三个参数。
然后构建这个自定义函数,
在该窗口中,可以输入任意三个有效参数,提取某上市公司某年某年的报表。
但是创建自定义函数的目的是为了批量获取数据,所以在这个窗口不需要操作。
同理,为现金流量表生成一个自定义函数,命名为 cashflow。
3.构建参数列表
对于这三个参数,我们需要构造这三个参数的笛卡尔积,得到各公司2010-2019年的三大报表数据。
为了方便后期的修改和维护,我们先建立三个单独的参数表。
在PowerQuery编辑器中,直接点击输入数据,输入要分析的公司名称和股票代码:
生成公司名称表。同理,生成年表和报表类型表。
接下来要做的是生成这三个表的笛卡尔积,即公司代码、年份和报告类型的任意组合。
在 PowerQuery 中,生成笛卡尔积就像向三个表中的每一个(例如 1)添加一列,然后合并查询一样简单。
首先合并查询报表类型和年份:
得到的结果如下:
这是报表类型和年份的任意组合,然后继续将此表与公司名称表合并,得到公司代码、年份和报表类型的任意组合表。
4、调用自定义函数
在第3步生成的表的基础上,添加自定义列,
这个M代码表示如果报表类型是CashFlow(现金流量表),则调用自定义函数:cashflow,否则调用资产负债表,其参数相同(如果只有一个自定义函数,则无需使用IF用于判断。,直接调用即可)。
然后我抓了这五家公司10年的三大报告数据:
另外,批量抓取的报表数据已经是我们需要的一维表格数据了,因为第一步收录了二维转一维的步骤,后面调用自定义函数的时候会自动做相同的。手术。
当然,你也可以用这种方法一次抓取几百家公司的数据,但是速度会很慢,所以建议只抓取你需要的公司和最近一年的数据。
至此,三大表的数据抓取已经完成,主要是使用PowerQuery的界面操作和一些简单的代码修改。即使没有基础,也可以按照以上步骤快速完成。
在这个财务分析示例中,有一个页面,其中收录从网络上抓取的公司简介和公司信息:
数据来自以下三个网页:
公司公告
公司简介
历史行情
这些数据的抓取和上面的财报数据抓取步骤完全一样,只是更简单一些,因为只有一个参数:公司代码,大家可以自己练习。
通过上面的介绍,你应该可以很方便的从网页中抓取财报数据了。当需要其他相关数据时,可以在网上搜索资源,然后批量抓取。
如开头所说,如果你要做的是分析贵公司的内部财务报告,你可以忽略本文中捕获数据的步骤,直接导入现成的财务报告。但是,为了后续分析的需要,建议还是将报表数据组织成一维的表结构。
数据整理上传后,就可以进行下一步的数据建模了。
成为 PowerBI Planet 会员,获取财务报告分析模板
抓取网页数据php(php的三大框架hibernate存放文件时顺序为按照1-4区别用于web开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-22 16:02
抓取网页数据php主流框架sed,webshellsed:perl-homewebshell:php-home-elffastcgi:php-home-epic存放文件时顺序为按照1-4区别区别用于web开发|性能
爬虫技术分很多种,你的问题似乎说的是联合爬虫,不存在程序有先后顺序,而是在于你的实现。
对于phpweb框架的问题,php的三大框架hibernate(可能要另起项目),mybaits和ci/cd都是有规定的按照顺序来的。除了sed,使用较多的其他php框架是swoole,随着要实现对方使用的其他语言,要采用不同的框架。
每个框架下面都有一个自己的联合爬虫对象,
没有固定顺序,应该依然保持先后顺序。1,在config中配置好schema;2,爬虫是一定要配置好对象引用(即必须可以是各个框架的联合爬虫);3,在schema里面会对包名进行修改;4,常见的爬虫一般都使用phpstorm编写。
其实我也是有同样的疑问,
配置好函数在哪个php框架里面
目前我就在研究这个。
可以使用python的一些php.io.generator构造出,
请参考pyinstaller
第一梯队:sed、sed、peartomize、bitbucket第二梯队:webshell、jasmine
php_fastcgi_schemaphp_image_loaderphp_sql_db_schema 查看全部
抓取网页数据php(php的三大框架hibernate存放文件时顺序为按照1-4区别用于web开发)
抓取网页数据php主流框架sed,webshellsed:perl-homewebshell:php-home-elffastcgi:php-home-epic存放文件时顺序为按照1-4区别区别用于web开发|性能
爬虫技术分很多种,你的问题似乎说的是联合爬虫,不存在程序有先后顺序,而是在于你的实现。
对于phpweb框架的问题,php的三大框架hibernate(可能要另起项目),mybaits和ci/cd都是有规定的按照顺序来的。除了sed,使用较多的其他php框架是swoole,随着要实现对方使用的其他语言,要采用不同的框架。
每个框架下面都有一个自己的联合爬虫对象,
没有固定顺序,应该依然保持先后顺序。1,在config中配置好schema;2,爬虫是一定要配置好对象引用(即必须可以是各个框架的联合爬虫);3,在schema里面会对包名进行修改;4,常见的爬虫一般都使用phpstorm编写。
其实我也是有同样的疑问,
配置好函数在哪个php框架里面
目前我就在研究这个。
可以使用python的一些php.io.generator构造出,
请参考pyinstaller
第一梯队:sed、sed、peartomize、bitbucket第二梯队:webshell、jasmine
php_fastcgi_schemaphp_image_loaderphp_sql_db_schema
抓取网页数据php(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-18 12:02
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页的内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们必须确定我们的 PHP 是否启用了这个库。您可以使用 php_info() 函数获取此信息。
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你没有看到它,那么你需要设置你的 PHP 并启用这个库。
如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
从上面的程序我们可以看出,使用CURLOPT_POST来设置HTTP协议的POST方法而不是GET方法,然后用CURLOPT_POSTFIELDS设置POST数据。
关于代理服务器
下面是一个如何使用代理服务器的示例。请注意其中高亮的代码,代码很简单,我就不用多说了。
关于 SSL 和 Cookie 查看全部
抓取网页数据php(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页的内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们必须确定我们的 PHP 是否启用了这个库。您可以使用 php_info() 函数获取此信息。
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你没有看到它,那么你需要设置你的 PHP 并启用这个库。
如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
从上面的程序我们可以看出,使用CURLOPT_POST来设置HTTP协议的POST方法而不是GET方法,然后用CURLOPT_POSTFIELDS设置POST数据。
关于代理服务器
下面是一个如何使用代理服务器的示例。请注意其中高亮的代码,代码很简单,我就不用多说了。
关于 SSL 和 Cookie
抓取网页数据php(抓取网页数据php可以用webserver接受postrequest,并转换成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-17 22:03
抓取网页数据php可以用webserver接受postrequest,并转换成php的sendmethod,拿到这个url然后拿到所有的url所包含的html文件filezilla之类的客户端抓一抓当然数据量大可以用专门的抓包工具比如httpwatch/chromeua抓包工具这些
pythonwebserver
实现抓取网页,首先要爬取html页面,我用的是xpath语法。通过xpath语法将html源码抓取出来,存放在一个文件夹中。然后就可以使用python提供的websocket或者httpwatch工具抓取,但是,websocket需要绑定一个客户端(要使用python的requests模块),才能抓取,httpwatch是用于抓取一些网页杂项的(需要安装pip模块)。
这只是爬取一个网页的方法,如果你想要抓取到网页的所有的html文本,那就要用到专门的抓包工具了。这些工具中,xmppwebsocket都挺适合爬取html文本,对python的模块要求不高。总结,抓取网页只是技术层面的问题,如果想要高级一点,就要学会自己写一些脚本,采集一些页面信息,比如用zxhr模块抓取jpg格式的图片。
python有一个xpatheditor,支持xpath解析,你可以直接使用。你需要用到一些python模块才能做一些开发。
如果想要找到html文件的文件头和文件尾,就可以用python写出来, 查看全部
抓取网页数据php(抓取网页数据php可以用webserver接受postrequest,并转换成)
抓取网页数据php可以用webserver接受postrequest,并转换成php的sendmethod,拿到这个url然后拿到所有的url所包含的html文件filezilla之类的客户端抓一抓当然数据量大可以用专门的抓包工具比如httpwatch/chromeua抓包工具这些
pythonwebserver
实现抓取网页,首先要爬取html页面,我用的是xpath语法。通过xpath语法将html源码抓取出来,存放在一个文件夹中。然后就可以使用python提供的websocket或者httpwatch工具抓取,但是,websocket需要绑定一个客户端(要使用python的requests模块),才能抓取,httpwatch是用于抓取一些网页杂项的(需要安装pip模块)。
这只是爬取一个网页的方法,如果你想要抓取到网页的所有的html文本,那就要用到专门的抓包工具了。这些工具中,xmppwebsocket都挺适合爬取html文本,对python的模块要求不高。总结,抓取网页只是技术层面的问题,如果想要高级一点,就要学会自己写一些脚本,采集一些页面信息,比如用zxhr模块抓取jpg格式的图片。
python有一个xpatheditor,支持xpath解析,你可以直接使用。你需要用到一些python模块才能做一些开发。
如果想要找到html文件的文件头和文件尾,就可以用python写出来,
抓取网页数据php(php、java、python的框架各有各的各好处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-16 09:02
抓取网页数据php和java。
php、java、python的框架各有各的好处,php基于开放的lnmp环境,与lnmp配合搭建,可以从web服务器搭建到全套相关应用程序开发,更重要的是php的web框架,像discuz!、pdo等非常完善。java则是基于java开发web架构方面比较完善,使用java的web工程师非常多。不管是php还是java,随着数据分析软件hadoop的流行,人们开始对分布式技术愈加关注,分布式系统架构相关的开发人员需求增加。storm、kafka、flink、sparksql、stormcluster等等。
php是无界面框架,更方便操作。java功能要更完善。php自己开发vs要结合太多第三方插件。python低开发成本,低开发难度,低功能的程序员很多。
个人建议php1.php能同时在后端和前端实现界面。2.php更灵活,服务器做接入和业务开发的服务器容易定制(有一个虚拟的服务器让你的服务器进程做任何操作)。其实最最重要的是,php可以做大公司的db主机。腾讯,百度,阿里巴巴等,都有内置的db服务。这对前端或android开发基本没什么好处。
是php吧?我本科做的php工作,其实就是把后端人员的代码写一遍。感觉一般,我自己是喜欢java的。
php好,也许php带着会好点,java的话前端好多,但是后端我感觉你就只能用php。 查看全部
抓取网页数据php(php、java、python的框架各有各的各好处)
抓取网页数据php和java。
php、java、python的框架各有各的好处,php基于开放的lnmp环境,与lnmp配合搭建,可以从web服务器搭建到全套相关应用程序开发,更重要的是php的web框架,像discuz!、pdo等非常完善。java则是基于java开发web架构方面比较完善,使用java的web工程师非常多。不管是php还是java,随着数据分析软件hadoop的流行,人们开始对分布式技术愈加关注,分布式系统架构相关的开发人员需求增加。storm、kafka、flink、sparksql、stormcluster等等。
php是无界面框架,更方便操作。java功能要更完善。php自己开发vs要结合太多第三方插件。python低开发成本,低开发难度,低功能的程序员很多。
个人建议php1.php能同时在后端和前端实现界面。2.php更灵活,服务器做接入和业务开发的服务器容易定制(有一个虚拟的服务器让你的服务器进程做任何操作)。其实最最重要的是,php可以做大公司的db主机。腾讯,百度,阿里巴巴等,都有内置的db服务。这对前端或android开发基本没什么好处。
是php吧?我本科做的php工作,其实就是把后端人员的代码写一遍。感觉一般,我自己是喜欢java的。
php好,也许php带着会好点,java的话前端好多,但是后端我感觉你就只能用php。
抓取网页数据php(抓取网页数据phpphonediv的数据包在上下游的datarange中传输,此时php的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-12 20:04
抓取网页数据phpphonediv的数据包在上下游的datarange中传输,此时php的方法是构造字符串传递给datarange的构造函数,而对应的header中的字符串编码必须是base64编码的。直接printdatarange.data().unicode()得到的格式为3,不正确的结果是:"\u32b6\u32b8\u32bd\u32bd\u32bc\u324\u32fb\u32db\u32d"怎么办呢?我们首先可以先打开php.ini文件,看下datarange的配置,设置为3后,再使用printdatarange.data().unicode()观察header中的格式是否正确。
代码已经运行,可是得到的内容是"aaa",但这并不是正确的结果。我们看下objectdata文件中传递的字符串,接收方也是unicode字符串,那么怎么直接把unicode中的格式转换成字符串数据呢?我们还是先打开php.ini文件,配置php的配置文件,aliasapp=app.install(self.datarange)调用php的substring函数,把字符串的unicode格式转化为utf-8格式,此时调用php的datarange函数,得到结果为"aaa"我们再来看下php.ini中传递的header方法,此方法传递数据的格式是"aaa",接收方的字符串编码是utf-8,php.ini配置文件中没有给定编码,通过unicode转换来得到正确的数据格式,但要注意,接收方的编码一定要和php内置的utf-8编码格式相匹配,也就是说utf-8编码的编码规则是"/utf-8"。
/utf-8:^\\\u32b6\\\u32b8\\\u32bd\\\u32bd\u32bc\\\u32fb\u32db\u32d\..其实,我们都明白,php是不支持指定编码的,这里如果没有指定编码格式,得到的就是一串乱码。转换格式php的header方法返回了encode()字符,该字符是一个unicode字符串编码,它不能通过decode()或encode()字符编码进行转换。
那么怎么解决这个问题呢?php有个类infopreview,我们可以找到php.ini里面的format方法,使用该方法,我们可以得到接收方的编码格式为\u32b6\u32b8\u32bd\u32bd\u32bc\u324\u32d\..说明接收方编码格式为“/utf-8”我们再来调用php.ini的header方法,php.ini是一个配置文件,可以在任何时候查看,查看它传递的编码格式的内容,再调用php.ini的convert方法把接收方的编码格式编码到php。 查看全部
抓取网页数据php(抓取网页数据phpphonediv的数据包在上下游的datarange中传输,此时php的方法)
抓取网页数据phpphonediv的数据包在上下游的datarange中传输,此时php的方法是构造字符串传递给datarange的构造函数,而对应的header中的字符串编码必须是base64编码的。直接printdatarange.data().unicode()得到的格式为3,不正确的结果是:"\u32b6\u32b8\u32bd\u32bd\u32bc\u324\u32fb\u32db\u32d"怎么办呢?我们首先可以先打开php.ini文件,看下datarange的配置,设置为3后,再使用printdatarange.data().unicode()观察header中的格式是否正确。
代码已经运行,可是得到的内容是"aaa",但这并不是正确的结果。我们看下objectdata文件中传递的字符串,接收方也是unicode字符串,那么怎么直接把unicode中的格式转换成字符串数据呢?我们还是先打开php.ini文件,配置php的配置文件,aliasapp=app.install(self.datarange)调用php的substring函数,把字符串的unicode格式转化为utf-8格式,此时调用php的datarange函数,得到结果为"aaa"我们再来看下php.ini中传递的header方法,此方法传递数据的格式是"aaa",接收方的字符串编码是utf-8,php.ini配置文件中没有给定编码,通过unicode转换来得到正确的数据格式,但要注意,接收方的编码一定要和php内置的utf-8编码格式相匹配,也就是说utf-8编码的编码规则是"/utf-8"。
/utf-8:^\\\u32b6\\\u32b8\\\u32bd\\\u32bd\u32bc\\\u32fb\u32db\u32d\..其实,我们都明白,php是不支持指定编码的,这里如果没有指定编码格式,得到的就是一串乱码。转换格式php的header方法返回了encode()字符,该字符是一个unicode字符串编码,它不能通过decode()或encode()字符编码进行转换。
那么怎么解决这个问题呢?php有个类infopreview,我们可以找到php.ini里面的format方法,使用该方法,我们可以得到接收方的编码格式为\u32b6\u32b8\u32bd\u32bd\u32bc\u324\u32d\..说明接收方编码格式为“/utf-8”我们再来调用php.ini的header方法,php.ini是一个配置文件,可以在任何时候查看,查看它传递的编码格式的内容,再调用php.ini的convert方法把接收方的编码格式编码到php。
抓取网页数据php(Wordpress更换域名后百度sitemap插件不可用的解决步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-11 09:06
网站优化几乎总是使用站点地图插件。站点地图允许 网站 管理员通知搜索引擎他们 网站 可以抓取哪些页面。在最简单的形式中,站点地图是一个 XML 文件,其中列出了 网站 中的 URL 以及有关每个 URL 的其他元数据,以便搜索引擎可以更智能地抓取 网站。最近接到一个客户问题,无忧主编觉得很有价值,想尽快分享给大家。用户使用无忧主机的php免录空间。域名更换已经快两个月了。各大搜索引擎收录也已全面恢复。百度官方的结构化数据插件(百度站点地图)应该可以发挥作用。有一定的作用,但是有的朋友可能会发现,如果换了域名,插件就不能正常工作了,提交历史还是之前的数据,不会再提交新的数据了。这是因为将百度官网的wordpress结构化数据插件写入数据库。当你更改域名时,数据表仍然是旧域名的数据,所以我们需要清除或删除这两个数据表。解决Wordpress更改域名后百度站点地图插件不可用的步骤如下:1、登录Wordpress后台禁用百度结构化数据插件百度站点地图2、登录数据库管理工具phpmyadmin在php虚拟主机控制面板中选择这两个要清除或删除一个表,需要清除或删除两个数据表如下: wp_baidusubmit_sitemapwp_baidusubmit_urlstat3、重新启用百度站点地图并验证后以上步骤完成后,百度结构化数据插件会重新处理网站的内容自动提交对网站没有影响,请放心。另外,我会直接删除上面两张表。启用插件后会重新生成,相当于完全重新安装插件。我希望能遇到这个问题。求朋友帮忙。无忧托管相关文章推荐阅读: 查看全部
抓取网页数据php(Wordpress更换域名后百度sitemap插件不可用的解决步骤)
网站优化几乎总是使用站点地图插件。站点地图允许 网站 管理员通知搜索引擎他们 网站 可以抓取哪些页面。在最简单的形式中,站点地图是一个 XML 文件,其中列出了 网站 中的 URL 以及有关每个 URL 的其他元数据,以便搜索引擎可以更智能地抓取 网站。最近接到一个客户问题,无忧主编觉得很有价值,想尽快分享给大家。用户使用无忧主机的php免录空间。域名更换已经快两个月了。各大搜索引擎收录也已全面恢复。百度官方的结构化数据插件(百度站点地图)应该可以发挥作用。有一定的作用,但是有的朋友可能会发现,如果换了域名,插件就不能正常工作了,提交历史还是之前的数据,不会再提交新的数据了。这是因为将百度官网的wordpress结构化数据插件写入数据库。当你更改域名时,数据表仍然是旧域名的数据,所以我们需要清除或删除这两个数据表。解决Wordpress更改域名后百度站点地图插件不可用的步骤如下:1、登录Wordpress后台禁用百度结构化数据插件百度站点地图2、登录数据库管理工具phpmyadmin在php虚拟主机控制面板中选择这两个要清除或删除一个表,需要清除或删除两个数据表如下: wp_baidusubmit_sitemapwp_baidusubmit_urlstat3、重新启用百度站点地图并验证后以上步骤完成后,百度结构化数据插件会重新处理网站的内容自动提交对网站没有影响,请放心。另外,我会直接删除上面两张表。启用插件后会重新生成,相当于完全重新安装插件。我希望能遇到这个问题。求朋友帮忙。无忧托管相关文章推荐阅读:
抓取网页数据php( 基于PHP实现的webshell攻击(一)——一个攻击)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-09 13:17
基于PHP实现的webshell攻击(一)——一个攻击)
PHP的一些知识点研究(一), PHP知识点研究
一、基于PHP的Webshell攻击
看到了对暗云的基于 php 的 webshell 攻击。
高度隐藏的webshell使用普通的php代码,将真实的shell内容经过层层加密保存到图片中,只留下一个url,而且url还是被加密的,所以从外面看不出任何特征,所以很难被发现。打开上面的url,显示404,这个404页面是伪装成404的木马,只是标题改成了404NotFound。
二、不要使用orless else语句
对于ifelse,有人追求结构的完整性。如果有if,就一定有else。这看起来不错,但有时会导致代码繁琐,可能导致逻辑混乱;一个结果可以作为基准,当其他情况发生时进行if判断;即默认为A,有异常则为B;如下右图所示:
三、单页应用
单页是指所有的操作和布局都在一个页面下进行,不需要跳转页面,根据不同的用户请求加载不同的内容。
优点:页面结构简单、数据量小、节省带宽、响应速度快、体验好、易于开发、维护和优化;
缺点:使用ajax技术,不利于seo。
四、让搜索引擎抓取ajax内容
主要针对前面案例的单页结构,程序通过#structure url控制页面内容,但不会被搜索引擎抓取。
方法一:推特采用“井号+感叹号”的结构,但体验不好且繁琐;
方法2:使用HistoryAPI;在不刷新页面的情况下更改浏览器地址栏中显示的地址。进行如下操作:
A. 使用HistoryAPI替换井号结构,让每个#号变成正常路径的URL,这样搜索引擎会抓取每一个网页。
B、定义一个JavaScript函数,处理Ajax部分,根据URL爬取内容。
C、定义鼠标的点击事件,利用History对象的popstate事件来处理浏览器的“前进/后退”按钮。
D、设置服务器端。
五、CURL_MULTI_INIT()
以前一直用curl_init(),最近才看到curl_multi_init();本来以为会带来更高效的代码,但是看了curl_multi的步骤,感觉挺麻烦的,而且curl_multi可能会导致CPU高,网页假死等;同时对比curl_init和curl_multi_init,多线程在速度上不一定比单线程好。多线程只能同时处理多任务,时间成本不一定低。附上使用 curl_multi 的步骤:
第一步:调用curl_multi_init;
第二步:循环调用curl_multi_add_handle;
这一步需要注意,curl_multi_add_handle的第二个参数是来自curl_init的子句柄;
第三步:继续调用curl_multi_exec;
第四步:循环调用curl_multi_getcontent,根据需要获取结果;
第五步:调用curl_multi_remove_handle,对每个字句柄调用curl_close;
第 6 步:调用 curl_multi_close。
六、PHPstrstr() 函数
strstr(string,search) 在另一个字符串中搜索第一次出现的字符串。返回字符串的其余部分(从匹配点开始)。如果未找到搜索的字符串,则返回 false。
需要搜索。指定要搜索的字符串。如果参数是数字,则搜索与数字的 ASCII 值匹配的字符。
参考:。因此,在给第二个参数时,如果需要匹配数字,建议加引号。
七、论归一化的重要性
我家附近一条久治不愈的道路,通过划分人行道、非机动车道、机动车道,一下子解决了问题。有时灵活性导致选择太多,问题也很多;程序也是如此。用户输入的灵活性看起来很好,但实际上需要更多的后台处理成本。为什么不在早期标准化它,错误停止在源头,而不是修补它。规范化使一切变得简单而高效。
八、HHVM
HHVM (HipHopVirtualMachine) 将 PHP 代码转换为高级字节码(通常称为中间语言)。然后,这些字节码在运行时由即时 (JIT) 编译器转换为 x64 机器码。
数据显示,相比 Zend,HHVM 效率更高,CPU 负载降低,平均页面加载时间缩短。HHVM的存在是为了优化PHP的性能。和php5相比,确实有一些优势,还是等php7吧。
九、PHP源码签名采集器
在学习新的、不熟悉的源代码时,对代码结构有一个直观的感觉很重要。可以通过从每个源文件中逐行取标点来概括,即文件签名。这有助于解释代码的复杂性。其实就是提取代码文件中的固定符号来呈现文件的结构。
参考:
十、协同过滤推荐算法
1、基于内容的推荐算法的前提是,如果用户喜欢物品a,那么用户也应该喜欢与a相似的物品。其基本思想是拆分内容属性,提取具有相同属性的内容进行推荐。
2、协同过滤推荐算法的前提是,如果用户a和用户b都喜欢一系列相同的物品,那么a很有可能喜欢用户b喜欢的其他物品。基本流程是用户首先对每个项目进行评价和评分,通过计算不同用户评分之间的相似度,可以找到最近邻,并根据最近邻的评价生成推荐。
以上算法均采用矩阵建模,使用余弦相似度、皮尔逊相似度等公式。使用时建议将两者合二为一。
trueTechArticlePHP的一些知识点研究(一),php知识点研究一、 PHP-based webshell attack 见一个基于php的暗云webshell攻击。高度隐藏的webshell,使用... 查看全部
抓取网页数据php(
基于PHP实现的webshell攻击(一)——一个攻击)
PHP的一些知识点研究(一), PHP知识点研究
一、基于PHP的Webshell攻击
看到了对暗云的基于 php 的 webshell 攻击。
高度隐藏的webshell使用普通的php代码,将真实的shell内容经过层层加密保存到图片中,只留下一个url,而且url还是被加密的,所以从外面看不出任何特征,所以很难被发现。打开上面的url,显示404,这个404页面是伪装成404的木马,只是标题改成了404NotFound。
二、不要使用orless else语句
对于ifelse,有人追求结构的完整性。如果有if,就一定有else。这看起来不错,但有时会导致代码繁琐,可能导致逻辑混乱;一个结果可以作为基准,当其他情况发生时进行if判断;即默认为A,有异常则为B;如下右图所示:
三、单页应用
单页是指所有的操作和布局都在一个页面下进行,不需要跳转页面,根据不同的用户请求加载不同的内容。
优点:页面结构简单、数据量小、节省带宽、响应速度快、体验好、易于开发、维护和优化;
缺点:使用ajax技术,不利于seo。
四、让搜索引擎抓取ajax内容
主要针对前面案例的单页结构,程序通过#structure url控制页面内容,但不会被搜索引擎抓取。
方法一:推特采用“井号+感叹号”的结构,但体验不好且繁琐;
方法2:使用HistoryAPI;在不刷新页面的情况下更改浏览器地址栏中显示的地址。进行如下操作:
A. 使用HistoryAPI替换井号结构,让每个#号变成正常路径的URL,这样搜索引擎会抓取每一个网页。
B、定义一个JavaScript函数,处理Ajax部分,根据URL爬取内容。
C、定义鼠标的点击事件,利用History对象的popstate事件来处理浏览器的“前进/后退”按钮。
D、设置服务器端。
五、CURL_MULTI_INIT()
以前一直用curl_init(),最近才看到curl_multi_init();本来以为会带来更高效的代码,但是看了curl_multi的步骤,感觉挺麻烦的,而且curl_multi可能会导致CPU高,网页假死等;同时对比curl_init和curl_multi_init,多线程在速度上不一定比单线程好。多线程只能同时处理多任务,时间成本不一定低。附上使用 curl_multi 的步骤:
第一步:调用curl_multi_init;
第二步:循环调用curl_multi_add_handle;
这一步需要注意,curl_multi_add_handle的第二个参数是来自curl_init的子句柄;
第三步:继续调用curl_multi_exec;
第四步:循环调用curl_multi_getcontent,根据需要获取结果;
第五步:调用curl_multi_remove_handle,对每个字句柄调用curl_close;
第 6 步:调用 curl_multi_close。
六、PHPstrstr() 函数
strstr(string,search) 在另一个字符串中搜索第一次出现的字符串。返回字符串的其余部分(从匹配点开始)。如果未找到搜索的字符串,则返回 false。
需要搜索。指定要搜索的字符串。如果参数是数字,则搜索与数字的 ASCII 值匹配的字符。
参考:。因此,在给第二个参数时,如果需要匹配数字,建议加引号。
七、论归一化的重要性
我家附近一条久治不愈的道路,通过划分人行道、非机动车道、机动车道,一下子解决了问题。有时灵活性导致选择太多,问题也很多;程序也是如此。用户输入的灵活性看起来很好,但实际上需要更多的后台处理成本。为什么不在早期标准化它,错误停止在源头,而不是修补它。规范化使一切变得简单而高效。
八、HHVM
HHVM (HipHopVirtualMachine) 将 PHP 代码转换为高级字节码(通常称为中间语言)。然后,这些字节码在运行时由即时 (JIT) 编译器转换为 x64 机器码。
数据显示,相比 Zend,HHVM 效率更高,CPU 负载降低,平均页面加载时间缩短。HHVM的存在是为了优化PHP的性能。和php5相比,确实有一些优势,还是等php7吧。
九、PHP源码签名采集器
在学习新的、不熟悉的源代码时,对代码结构有一个直观的感觉很重要。可以通过从每个源文件中逐行取标点来概括,即文件签名。这有助于解释代码的复杂性。其实就是提取代码文件中的固定符号来呈现文件的结构。
参考:
十、协同过滤推荐算法
1、基于内容的推荐算法的前提是,如果用户喜欢物品a,那么用户也应该喜欢与a相似的物品。其基本思想是拆分内容属性,提取具有相同属性的内容进行推荐。
2、协同过滤推荐算法的前提是,如果用户a和用户b都喜欢一系列相同的物品,那么a很有可能喜欢用户b喜欢的其他物品。基本流程是用户首先对每个项目进行评价和评分,通过计算不同用户评分之间的相似度,可以找到最近邻,并根据最近邻的评价生成推荐。
以上算法均采用矩阵建模,使用余弦相似度、皮尔逊相似度等公式。使用时建议将两者合二为一。
trueTechArticlePHP的一些知识点研究(一),php知识点研究一、 PHP-based webshell attack 见一个基于php的暗云webshell攻击。高度隐藏的webshell,使用...
抓取网页数据php(WebScraping在腾讯体育来抓取欧洲联赛13/14赛季的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-07 21:19
背景网页抓取
大数据时代,一切都要用数据说话,而大数据处理的过程一般需要经过以下几个步骤
首先要做的是获取数据并提取有效数据,为下一步分析做准备。
有各种数据来源。我以为我是个足球爱好者,世界杯快到了,所以我想提取欧洲联赛的数据进行分析。很多网站都提供了详细的足球数据,比如:
这些网站提供了详细的足球数据,但是为了进一步分析,我们希望数据以格式化的形式存储,那么如何将这些网站提供的网页数据转换成格式化数据呢?? 这使用了网页抓取技术。简单来说,Web Scraping就是从网站中提取信息,通常使用程序来模拟人们浏览网页的过程,发送http请求,从http响应中获取结果。
网页抓取注意事项
在抓取数据之前,请注意以下几点:
Python Web Scraping 相关库
Python 提供了一个非常方便的 Web Scraping 基础,具有许多支持库。这是一个小选择
当然,您不必使用 Python,也不必编写自己的代码。建议关注import.io
网页抓取代码
接下来,我们将一步步使用Python从腾讯体育抓取2013/14赛季欧洲联赛的数据。
首先安装 Beautifulsoup
pip install beautifulsoup4
让我们从玩家的数据开始。
对玩家数据的网络请求是,返回的内容如下图所示:
web服务有两个参数,lega表示是哪个联赛,pn表示分页数。
首先,我们来做一些初始化准备
from urllib2 import urlopen
import urlparse
import bs4
BASE_URL = "http://soccerdata.sports.qq.com"
PLAYER_LIST_QUERY = "/playerSearch.aspx?lega=%s&pn=%d"
league = ['epl','seri','bund','liga','fran','scot','holl','belg']
page_number_limit = 100
player_fields = ['league_cn','img','name_cn','name','team','age','position_cn','nation','birth','query','id','teamid','league']
urlopen、urlparse、bs4 是我们将使用的 Python 库。
BASE_URL、PLAYER_LIST_QUERY、league、page_number_limit 和 player_fields 是我们将使用的一些常量。
下面是抓取玩家数据的具体代码:
def get_players(baseurl):
html = urlopen(baseurl).read()
soup = bs4.BeautifulSoup(html, "lxml")
players = [ dd for dd in soup.select('.searchResult tr') if dd.contents[1].name != 'th']
result = []
for player in players:
record = []
link = ''
query = []
for item in player.contents:
if type(item) is bs4.element.Tag:
if not item.string and item.img:
record.append(item.img['src'])
else :
record.append(item.string and item.string.strip() or 'na')
try:
o = urlparse.urlparse(item.a['href']).query
if len(link) == 0:
link = o
query = dict([(k,v[0]) for k,v in urlparse.parse_qs(o).items()])
except:
pass
if len(record) != 10:
for i in range(0, 10 - len(record)):
record.append('na')
record.append(unicode(link,'utf-8'))
record.append(unicode(query["id"],'utf-8'))
record.append(unicode(query["teamid"],'utf-8'))
record.append(unicode(query["lega"],'utf-8'))
result.append(record)
return result
result = []
for url in [ BASE_URL + PLAYER_LIST_QUERY % (l,n) for l in league for n in range(page_number_limit) ]:
result = result + get_players(url)
我们来看看抓取玩家数据的详细过程:
首先,我们定义一个 get_players 方法,该方法返回请求页面上所有玩家的数据。为了得到所有的数据,我们通过了一个for循环,因为我们要循环遍历每个联赛,每个联赛有多个页面。一般需要双循环:
for i in league:
for j in range(0, 100):
url = BASE_URL + PLAYER_LIST_QUERY % (l,n)
## send request to url and do scraping
Python 的列表推导可以通过构建列表轻松降低循环的级别。
此外,Python 有一个非常方便的合并连续列表的语法:list = list1 + list2
好,我们来看看如何使用BeautifulSoup来抓取网页中我们需要的内容。
首先调用urlopen读取对应url的内容,一般是html,用html构造一个beautifulsoup对象。
beautifulsoup 对象支持许多搜索功能,以及类似 css 的选择器。通常如果有一个 DOM 对象,我们使用下面的方式来查找它:
obj = soup.find("xx","cc")
另一种常用的方法是使用 CSS 选择器方法。在上面的代码中,我们选择了class=searchResult元素中的所有tr元素,过滤掉了th,也就是header元素。
for dd in soup.select('.searchResult tr') if dd.contents[1].name != 'th'
对于记录 tr 的每一行,都会生成一个玩家记录并将其存储在一个列表中。所以我们循环tr tr.contents 的内容来获取对应的字段内容。
对于每个tr的内容,我们首先检查它的类型是否为Tag。Tag 类型有几种情况。一种是收录 img 的案例。我们需要取出玩家头像图片的URL。
另一种是收录指向其他数据内容的链接
所以这些不同的情况在代码中分别处理。
对于一个Tag 对象,Tag.x 可以得到它的子对象,Tag['x'] 可以得到Tag 的属性值。
所以使用 item.img['src'] 来获取 item 的子元素 img 的 src 属性。
对于已经收录链接的情况,我们使用urlparse来获取查询url中的参数。在这里,我们利用字典理解将查询参数放入字典,然后添加到列表中。
dict([(k,v[0]) for k,v in urlparse.parse_qs(o).items()])
对于其他情况,我们使用 Python 的 and or 表达式来确保当 Tag 的内容为空时,我们写 'na',类似于三元运算符 X ? A : B 在 C/C++ 或 Java 中
然后有一段代码判断当前记录的长度是否大于10,如果不大于10则用空值填充,以避免出现一些不一致的情况。
if len(record) != 10:
for i in range(0, 10 - len(record)):
record.append('na')
最后,我们在查询中添加一些相关参数,比如球员的id、球队的id、联赛代码等到列表中。
record.append(unicode(link,'utf-8'))
record.append(unicode(query["id"],'utf-8'))
record.append(unicode(query["teamid"],'utf-8'))
record.append(unicode(query["lega"],'utf-8'))
最后,我们把这个页面上所有玩家的列表放到一个列表中,然后返回。
好的,现在我们有了一个收录所有玩家信息的列表,我们需要保存它以供进一步处理、分析。通常,csv 格式是一种常见的选择。
import csv
def write_csv(filename, content, header = None):
file = open(filename, "wb")
file.write('\xEF\xBB\xBF')
writer = csv.writer(file, delimiter=',')
if header:
writer.writerow(header)
for row in content:
encoderow = [dd.encode('utf8') for dd in row]
writer.writerow(encoderow)
write_csv('players.csv',result,player_fields)
这里需要注意的是编码的问题。因为我们使用的是utf-8编码方式,所以在csv的文件头中,我们需要写\xEF\xBB\xBF,详见这篇文章文章
好了,现在大功告成,捕获的csv如下:
因为之前我们也抓取了本赛季球员的比赛详情,所以我们可以进一步抓取所有球员每场比赛的记录
抓取的代码如下
def get_player_match(url):
html = urlopen(url).read()
soup = bs4.BeautifulSoup(html, "lxml")
matches = [ dd for dd in soup.select('.shtdm tr') if dd.contents[1].name != 'th']
records = []
for item in [ dd for dd in matches if len(dd.contents) > 11]: ## filter out the personal part
record = []
for match in [ dd for dd in item.contents if type(dd) is bs4.element.Tag]:
if match.string:
record.append(match.string)
else:
for d in [ dd for dd in match.contents if type(dd) is bs4.element.Tag]:
query = dict([(k,v[0]) for k,v in urlparse.parse_qs(d['href']).items()])
record.append('teamid' in query and query['teamid'] or query['id'])
record.append(d.string and d.string or 'na')
records.append(record)
return records[1:] ##remove the first record as the header
def get_players_match(playerlist, baseurl = BASE_URL + '/player.aspx?'):
result = []
for item in playerlist:
url = baseurl + item[10]
print url
result = result + get_player_match(url)
return result
match_fields = ['date_cn','homeid','homename_cn','matchid','score','awayid','awayname_cn','league_cn','firstteam','playtime','goal','assist','shoot','run','corner','offside','foul','violation','yellowcard','redcard','save']
write_csv('m.csv',get_players_match(result),match_fields)
爬取过程与之前类似。
接下来做什么
既然我们已经有了详细的欧联杯数据,接下来我们应该怎么做呢?我建议您将数据导入 BI 工具以进行进一步分析。有两个更好的选择:
Tableau 在数据可视化领域是无与伦比的。Tableau Public 完全免费。它使用数据可视化来驱动数据探索和分析,具有非常好的用户体验。
Splunk 提供了一个大数据平台,主要针对机器数据。支持每天免费导入500M数据,个人学习应该够用了。
当然你也可以使用 Excel。另外,如果大家有什么好的免费数据分析平台,欢迎交流。 查看全部
抓取网页数据php(WebScraping在腾讯体育来抓取欧洲联赛13/14赛季的数据)
背景网页抓取
大数据时代,一切都要用数据说话,而大数据处理的过程一般需要经过以下几个步骤
首先要做的是获取数据并提取有效数据,为下一步分析做准备。
有各种数据来源。我以为我是个足球爱好者,世界杯快到了,所以我想提取欧洲联赛的数据进行分析。很多网站都提供了详细的足球数据,比如:
这些网站提供了详细的足球数据,但是为了进一步分析,我们希望数据以格式化的形式存储,那么如何将这些网站提供的网页数据转换成格式化数据呢?? 这使用了网页抓取技术。简单来说,Web Scraping就是从网站中提取信息,通常使用程序来模拟人们浏览网页的过程,发送http请求,从http响应中获取结果。
网页抓取注意事项
在抓取数据之前,请注意以下几点:
Python Web Scraping 相关库
Python 提供了一个非常方便的 Web Scraping 基础,具有许多支持库。这是一个小选择
当然,您不必使用 Python,也不必编写自己的代码。建议关注import.io
网页抓取代码
接下来,我们将一步步使用Python从腾讯体育抓取2013/14赛季欧洲联赛的数据。
首先安装 Beautifulsoup
pip install beautifulsoup4
让我们从玩家的数据开始。
对玩家数据的网络请求是,返回的内容如下图所示:
web服务有两个参数,lega表示是哪个联赛,pn表示分页数。
首先,我们来做一些初始化准备
from urllib2 import urlopen
import urlparse
import bs4
BASE_URL = "http://soccerdata.sports.qq.com"
PLAYER_LIST_QUERY = "/playerSearch.aspx?lega=%s&pn=%d"
league = ['epl','seri','bund','liga','fran','scot','holl','belg']
page_number_limit = 100
player_fields = ['league_cn','img','name_cn','name','team','age','position_cn','nation','birth','query','id','teamid','league']
urlopen、urlparse、bs4 是我们将使用的 Python 库。
BASE_URL、PLAYER_LIST_QUERY、league、page_number_limit 和 player_fields 是我们将使用的一些常量。
下面是抓取玩家数据的具体代码:
def get_players(baseurl):
html = urlopen(baseurl).read()
soup = bs4.BeautifulSoup(html, "lxml")
players = [ dd for dd in soup.select('.searchResult tr') if dd.contents[1].name != 'th']
result = []
for player in players:
record = []
link = ''
query = []
for item in player.contents:
if type(item) is bs4.element.Tag:
if not item.string and item.img:
record.append(item.img['src'])
else :
record.append(item.string and item.string.strip() or 'na')
try:
o = urlparse.urlparse(item.a['href']).query
if len(link) == 0:
link = o
query = dict([(k,v[0]) for k,v in urlparse.parse_qs(o).items()])
except:
pass
if len(record) != 10:
for i in range(0, 10 - len(record)):
record.append('na')
record.append(unicode(link,'utf-8'))
record.append(unicode(query["id"],'utf-8'))
record.append(unicode(query["teamid"],'utf-8'))
record.append(unicode(query["lega"],'utf-8'))
result.append(record)
return result
result = []
for url in [ BASE_URL + PLAYER_LIST_QUERY % (l,n) for l in league for n in range(page_number_limit) ]:
result = result + get_players(url)
我们来看看抓取玩家数据的详细过程:
首先,我们定义一个 get_players 方法,该方法返回请求页面上所有玩家的数据。为了得到所有的数据,我们通过了一个for循环,因为我们要循环遍历每个联赛,每个联赛有多个页面。一般需要双循环:
for i in league:
for j in range(0, 100):
url = BASE_URL + PLAYER_LIST_QUERY % (l,n)
## send request to url and do scraping
Python 的列表推导可以通过构建列表轻松降低循环的级别。
此外,Python 有一个非常方便的合并连续列表的语法:list = list1 + list2
好,我们来看看如何使用BeautifulSoup来抓取网页中我们需要的内容。
首先调用urlopen读取对应url的内容,一般是html,用html构造一个beautifulsoup对象。
beautifulsoup 对象支持许多搜索功能,以及类似 css 的选择器。通常如果有一个 DOM 对象,我们使用下面的方式来查找它:
obj = soup.find("xx","cc")
另一种常用的方法是使用 CSS 选择器方法。在上面的代码中,我们选择了class=searchResult元素中的所有tr元素,过滤掉了th,也就是header元素。
for dd in soup.select('.searchResult tr') if dd.contents[1].name != 'th'
对于记录 tr 的每一行,都会生成一个玩家记录并将其存储在一个列表中。所以我们循环tr tr.contents 的内容来获取对应的字段内容。
对于每个tr的内容,我们首先检查它的类型是否为Tag。Tag 类型有几种情况。一种是收录 img 的案例。我们需要取出玩家头像图片的URL。
另一种是收录指向其他数据内容的链接
所以这些不同的情况在代码中分别处理。
对于一个Tag 对象,Tag.x 可以得到它的子对象,Tag['x'] 可以得到Tag 的属性值。
所以使用 item.img['src'] 来获取 item 的子元素 img 的 src 属性。
对于已经收录链接的情况,我们使用urlparse来获取查询url中的参数。在这里,我们利用字典理解将查询参数放入字典,然后添加到列表中。
dict([(k,v[0]) for k,v in urlparse.parse_qs(o).items()])
对于其他情况,我们使用 Python 的 and or 表达式来确保当 Tag 的内容为空时,我们写 'na',类似于三元运算符 X ? A : B 在 C/C++ 或 Java 中
然后有一段代码判断当前记录的长度是否大于10,如果不大于10则用空值填充,以避免出现一些不一致的情况。
if len(record) != 10:
for i in range(0, 10 - len(record)):
record.append('na')
最后,我们在查询中添加一些相关参数,比如球员的id、球队的id、联赛代码等到列表中。
record.append(unicode(link,'utf-8'))
record.append(unicode(query["id"],'utf-8'))
record.append(unicode(query["teamid"],'utf-8'))
record.append(unicode(query["lega"],'utf-8'))
最后,我们把这个页面上所有玩家的列表放到一个列表中,然后返回。
好的,现在我们有了一个收录所有玩家信息的列表,我们需要保存它以供进一步处理、分析。通常,csv 格式是一种常见的选择。
import csv
def write_csv(filename, content, header = None):
file = open(filename, "wb")
file.write('\xEF\xBB\xBF')
writer = csv.writer(file, delimiter=',')
if header:
writer.writerow(header)
for row in content:
encoderow = [dd.encode('utf8') for dd in row]
writer.writerow(encoderow)
write_csv('players.csv',result,player_fields)
这里需要注意的是编码的问题。因为我们使用的是utf-8编码方式,所以在csv的文件头中,我们需要写\xEF\xBB\xBF,详见这篇文章文章
好了,现在大功告成,捕获的csv如下:
因为之前我们也抓取了本赛季球员的比赛详情,所以我们可以进一步抓取所有球员每场比赛的记录
抓取的代码如下
def get_player_match(url):
html = urlopen(url).read()
soup = bs4.BeautifulSoup(html, "lxml")
matches = [ dd for dd in soup.select('.shtdm tr') if dd.contents[1].name != 'th']
records = []
for item in [ dd for dd in matches if len(dd.contents) > 11]: ## filter out the personal part
record = []
for match in [ dd for dd in item.contents if type(dd) is bs4.element.Tag]:
if match.string:
record.append(match.string)
else:
for d in [ dd for dd in match.contents if type(dd) is bs4.element.Tag]:
query = dict([(k,v[0]) for k,v in urlparse.parse_qs(d['href']).items()])
record.append('teamid' in query and query['teamid'] or query['id'])
record.append(d.string and d.string or 'na')
records.append(record)
return records[1:] ##remove the first record as the header
def get_players_match(playerlist, baseurl = BASE_URL + '/player.aspx?'):
result = []
for item in playerlist:
url = baseurl + item[10]
print url
result = result + get_player_match(url)
return result
match_fields = ['date_cn','homeid','homename_cn','matchid','score','awayid','awayname_cn','league_cn','firstteam','playtime','goal','assist','shoot','run','corner','offside','foul','violation','yellowcard','redcard','save']
write_csv('m.csv',get_players_match(result),match_fields)
爬取过程与之前类似。
接下来做什么
既然我们已经有了详细的欧联杯数据,接下来我们应该怎么做呢?我建议您将数据导入 BI 工具以进行进一步分析。有两个更好的选择:
Tableau 在数据可视化领域是无与伦比的。Tableau Public 完全免费。它使用数据可视化来驱动数据探索和分析,具有非常好的用户体验。
Splunk 提供了一个大数据平台,主要针对机器数据。支持每天免费导入500M数据,个人学习应该够用了。
当然你也可以使用 Excel。另外,如果大家有什么好的免费数据分析平台,欢迎交流。
抓取网页数据php(一个、高性能和高扩张性的角度来说说我的一些经验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-06 20:18
一个小的网站,比如个人的网站,可以用最简单的html静态页面来实现,配上一些图片来达到美化效果,所有页面都存放在一个目录下,比如网站对系统架构和性能的要求非常简单。随着互联网服务的不断丰富,网站相关技术经过多年的发展,已经细分为非常精细的方面,特别是对于大型网站来说,使用的技术非常广泛,从硬件到软件都有,编程语言、数据库、WebServer、防火墙等领域都有很高的要求,不是原来简单的html静态网站可比的。
大型 网站,例如 Portal网站。面对大量用户访问和高并发请求,基本解决方案主要集中在以下几个环节:使用高性能服务器、高性能数据库、高效编程语言、高性能Web容器。但是除了这些方面,没有办法从根本上解决大网站面临的高负载、高并发问题。
上面提供的几种解决方案在一定程度上也意味着更大的投入,而且这种解决方案存在瓶颈,不具备很好的扩展性。我从低成本、高性能和高扩展性的角度来谈一谈。说说我的一些经历吧。
1、HTML 静态
其实我们都知道纯静态的html页面效率最高,成本也最低,所以我们尽量使用静态页面来实现我们网站上的页面。这种最简单的方法实际上是最有效的。方法。但是对于内容量大、更新频繁的网站,我们无法一一手动实现,于是出现了我们常用的信息发布系统cms,比如各个门户的新闻频道我们经常访问的网站,甚至他们的其他渠道都是通过信息发布系统进行管理和实施的。信息发布系统可以实现最简单的信息录入,自动生成静态页面。还可以具有频道管理、权限管理、自动抓拍等功能。对于大型 网站
除了门户和信息发布类型网站,对于交互性要求高的社区类型网站,尽可能保持静态也是提高性能的必要手段。社区发帖,文章实时静态化,有更新时再静态化也是一种被广泛使用的策略。猫扑的大杂烩使用了这样的策略,网易社区也是如此。
同时,html静态化也是一些缓存策略使用的手段。对于系统中频繁使用数据库查询但内容更新量较小的应用,可以考虑使用html静态化来实现,比如论坛中的论坛的公开设置信息。这些信息目前所有主流论坛都可以后台管理,并存储在数据库中。其实很多这些信息都是前台程序调用的,只是更新频率很小。后台更新时可以考虑将这部分内容设为静态,避免大量数据库。访问请求。
2、图像服务器分离
众所周知,对于web服务器来说,无论是Apache、IIS还是其他容器,图片是最耗费资源的,所以需要将图片与页面分离,这基本上是大网站所采用的策略,他们都有独立的图像服务器,甚至很多图像服务器。这样的架构可以减轻提供页面访问请求的服务器系统的压力,并且可以保证系统不会因为图像问题而崩溃。应用服务器和镜像服务器可以进行不同的配置优化。比如apache可以尽量配置ContentType。更少的支持和尽可能少的 LoadModule 确保更高的系统消耗和执行效率。
3、数据库集群和库表哈希
大型网站都有复杂的应用,而这些应用必须使用数据库,所以在面对大量访问时,很快就会出现数据库的瓶颈,一个数据库很快就无法满足应用,所以我们需要使用数据库集群或库表哈希。
在数据库集群方面,很多数据库都有自己的解决方案。Oracle、Sybase 等都有很好的解决方案。MySQL提供的常用的Master/Slave也是类似的解决方案。你用的是什么DB,请参考对应的解决方案。解决方案来实施。
上面提到的数据库集群在架构、成本和可扩展性方面受到所使用的数据库类型的限制。因此,我们需要从应用的角度考虑改进系统架构。库表哈希是最常用和最有效的解决方案。. 我们在应用中安装业务和应用或者功能模块来分离数据库,不同的模块对应不同的数据库或者表,然后按照一定的策略对一个页面或者功能进行较小的数据库hash,比如user table, Hash the根据用户ID创建表,可以低成本提高系统性能,具有良好的可扩展性。搜狐的论坛采用了这样的结构,将论坛的用户、设置、帖子等信息从数据库中分离出来,然后根据section和ID对posts和users的数据库和表进行hash,最后可以在配置文件中简单配置。可以随时将低成本数据库添加到系统中,以补充系统性能。
4、缓存
缓存这个词已经被技术触及,很多地方都用到了缓存。开发中的网站架构和网站缓存也很重要。这是最基本的两种缓存。稍后将描述高级和分布式缓存。
对于架构上的缓存,熟悉Apache的人可以知道,Apache提供了自己的缓存模块,也可以使用额外的Squid模块进行缓存,两者都可以有效提高Apache的访问响应能力。
网站程序开发缓存,Linux上提供的Memory Cache是常用的缓存接口,可以在web开发中使用。比如在Java开发的时候,可以调用MemoryCache来缓存和共享一些数据。大型社区使用这样的架构。另外,在使用web语言开发的时候,各种语言基本都有自己的缓存模块和方法,PHP有Pear的Cache模块,Java有更多,.net不是很熟悉,相信一定有。
5、镜像
镜像是大规模网站常用的提高性能和数据安全性的一种方式。镜像技术可以解决不同网络接入商和地区造成的用户访问速度差异。比如ChinaNet和EduNet的区别,促使很多网站在教育网建立镜像站点,数据定期或者实时更新。关于镜像的详细技术,这里不再赘述。有许多专业的现成解决方案架构和产品可供选择。还有便宜的软件实现思路,比如Linux上的rsync等工具。
6、负载均衡
负载均衡将是 large网站 解决高负载访问和大量并发请求的终极解决方案。
负载均衡技术发展多年,有很多专业的服务商和产品可供选择。我个人遇到过一些解决方案,有两种架构供大家参考。
想学习 Dubbo 框架、zookeper 基本原理、redis 分布式缓存、JVM 性能优化、Nginx+apache+Tomcat 集群部署、大数据hadoop、Hbase 实时计算spark、storm、数据分析分词和权重等核心技术; 关注后私信,记得点赞转发!!! 查看全部
抓取网页数据php(一个、高性能和高扩张性的角度来说说我的一些经验)
一个小的网站,比如个人的网站,可以用最简单的html静态页面来实现,配上一些图片来达到美化效果,所有页面都存放在一个目录下,比如网站对系统架构和性能的要求非常简单。随着互联网服务的不断丰富,网站相关技术经过多年的发展,已经细分为非常精细的方面,特别是对于大型网站来说,使用的技术非常广泛,从硬件到软件都有,编程语言、数据库、WebServer、防火墙等领域都有很高的要求,不是原来简单的html静态网站可比的。
大型 网站,例如 Portal网站。面对大量用户访问和高并发请求,基本解决方案主要集中在以下几个环节:使用高性能服务器、高性能数据库、高效编程语言、高性能Web容器。但是除了这些方面,没有办法从根本上解决大网站面临的高负载、高并发问题。
上面提供的几种解决方案在一定程度上也意味着更大的投入,而且这种解决方案存在瓶颈,不具备很好的扩展性。我从低成本、高性能和高扩展性的角度来谈一谈。说说我的一些经历吧。
1、HTML 静态
其实我们都知道纯静态的html页面效率最高,成本也最低,所以我们尽量使用静态页面来实现我们网站上的页面。这种最简单的方法实际上是最有效的。方法。但是对于内容量大、更新频繁的网站,我们无法一一手动实现,于是出现了我们常用的信息发布系统cms,比如各个门户的新闻频道我们经常访问的网站,甚至他们的其他渠道都是通过信息发布系统进行管理和实施的。信息发布系统可以实现最简单的信息录入,自动生成静态页面。还可以具有频道管理、权限管理、自动抓拍等功能。对于大型 网站
除了门户和信息发布类型网站,对于交互性要求高的社区类型网站,尽可能保持静态也是提高性能的必要手段。社区发帖,文章实时静态化,有更新时再静态化也是一种被广泛使用的策略。猫扑的大杂烩使用了这样的策略,网易社区也是如此。
同时,html静态化也是一些缓存策略使用的手段。对于系统中频繁使用数据库查询但内容更新量较小的应用,可以考虑使用html静态化来实现,比如论坛中的论坛的公开设置信息。这些信息目前所有主流论坛都可以后台管理,并存储在数据库中。其实很多这些信息都是前台程序调用的,只是更新频率很小。后台更新时可以考虑将这部分内容设为静态,避免大量数据库。访问请求。
2、图像服务器分离
众所周知,对于web服务器来说,无论是Apache、IIS还是其他容器,图片是最耗费资源的,所以需要将图片与页面分离,这基本上是大网站所采用的策略,他们都有独立的图像服务器,甚至很多图像服务器。这样的架构可以减轻提供页面访问请求的服务器系统的压力,并且可以保证系统不会因为图像问题而崩溃。应用服务器和镜像服务器可以进行不同的配置优化。比如apache可以尽量配置ContentType。更少的支持和尽可能少的 LoadModule 确保更高的系统消耗和执行效率。
3、数据库集群和库表哈希
大型网站都有复杂的应用,而这些应用必须使用数据库,所以在面对大量访问时,很快就会出现数据库的瓶颈,一个数据库很快就无法满足应用,所以我们需要使用数据库集群或库表哈希。
在数据库集群方面,很多数据库都有自己的解决方案。Oracle、Sybase 等都有很好的解决方案。MySQL提供的常用的Master/Slave也是类似的解决方案。你用的是什么DB,请参考对应的解决方案。解决方案来实施。
上面提到的数据库集群在架构、成本和可扩展性方面受到所使用的数据库类型的限制。因此,我们需要从应用的角度考虑改进系统架构。库表哈希是最常用和最有效的解决方案。. 我们在应用中安装业务和应用或者功能模块来分离数据库,不同的模块对应不同的数据库或者表,然后按照一定的策略对一个页面或者功能进行较小的数据库hash,比如user table, Hash the根据用户ID创建表,可以低成本提高系统性能,具有良好的可扩展性。搜狐的论坛采用了这样的结构,将论坛的用户、设置、帖子等信息从数据库中分离出来,然后根据section和ID对posts和users的数据库和表进行hash,最后可以在配置文件中简单配置。可以随时将低成本数据库添加到系统中,以补充系统性能。
4、缓存
缓存这个词已经被技术触及,很多地方都用到了缓存。开发中的网站架构和网站缓存也很重要。这是最基本的两种缓存。稍后将描述高级和分布式缓存。
对于架构上的缓存,熟悉Apache的人可以知道,Apache提供了自己的缓存模块,也可以使用额外的Squid模块进行缓存,两者都可以有效提高Apache的访问响应能力。
网站程序开发缓存,Linux上提供的Memory Cache是常用的缓存接口,可以在web开发中使用。比如在Java开发的时候,可以调用MemoryCache来缓存和共享一些数据。大型社区使用这样的架构。另外,在使用web语言开发的时候,各种语言基本都有自己的缓存模块和方法,PHP有Pear的Cache模块,Java有更多,.net不是很熟悉,相信一定有。
5、镜像
镜像是大规模网站常用的提高性能和数据安全性的一种方式。镜像技术可以解决不同网络接入商和地区造成的用户访问速度差异。比如ChinaNet和EduNet的区别,促使很多网站在教育网建立镜像站点,数据定期或者实时更新。关于镜像的详细技术,这里不再赘述。有许多专业的现成解决方案架构和产品可供选择。还有便宜的软件实现思路,比如Linux上的rsync等工具。
6、负载均衡
负载均衡将是 large网站 解决高负载访问和大量并发请求的终极解决方案。
负载均衡技术发展多年,有很多专业的服务商和产品可供选择。我个人遇到过一些解决方案,有两种架构供大家参考。
想学习 Dubbo 框架、zookeper 基本原理、redis 分布式缓存、JVM 性能优化、Nginx+apache+Tomcat 集群部署、大数据hadoop、Hbase 实时计算spark、storm、数据分析分词和权重等核心技术; 关注后私信,记得点赞转发!!!
抓取网页数据php(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-27 09:28
如果你做过童鞋的j2ee或者android开发,应该多多少少用过Apeache的HttpClient类库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
最近在开发php中,也需要在服务器端发送http请求,然后再处理回客户端。
我google了一下,发现php中有这样一个类库,名字叫httpclient。我很兴奋。看了下官网,发现已经很多年没有更新了,功能好像也有限,很是失望。然后又找到了另一个类库Snoopy,这个类库我不知道,但是网上的反应还不错,所以决定用它。它的 API 使用与 Apache 的 HttpClient 有很大的不同,但仍然非常好用。并且提供了很多特殊用途的方法,比如只能抓取页面中的form表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com");
echo $snoopy->results;
以上几行代码就可以轻松爬取百度的页面。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时,他还传递了cookies的请求头、对应头以及相关操作函数,功能非常强大。
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn")) {
echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "错误获取文档:" . $snoopy->error . "\n";}
更多操作方法可以去Snoopy的官方文档,或者直接查看源码。
此时,snoopy 只取回页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。这里又找到了一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性,熟悉jquery的童鞋,应该还是蛮好用的phpquery,连phpQuery的文档都没有已经需要了。。
使用Snoopy+PhpQuery可以轻松实现网页爬取和数据分析,非常实用。我最近也需要这个,只找到了这两个不错的类库。事实证明,java可以做的事情有很多。php也可以做到。
有兴趣的同学也可以尝试用它们制作一个简单的网络爬虫。 查看全部
抓取网页数据php(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
如果你做过童鞋的j2ee或者android开发,应该多多少少用过Apeache的HttpClient类库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
最近在开发php中,也需要在服务器端发送http请求,然后再处理回客户端。
我google了一下,发现php中有这样一个类库,名字叫httpclient。我很兴奋。看了下官网,发现已经很多年没有更新了,功能好像也有限,很是失望。然后又找到了另一个类库Snoopy,这个类库我不知道,但是网上的反应还不错,所以决定用它。它的 API 使用与 Apache 的 HttpClient 有很大的不同,但仍然非常好用。并且提供了很多特殊用途的方法,比如只能抓取页面中的form表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com";);
echo $snoopy->results;
以上几行代码就可以轻松爬取百度的页面。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时,他还传递了cookies的请求头、对应头以及相关操作函数,功能非常强大。
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn";)) {
echo "" . htmlspecialchars($snoopy->results) . "
\n";} else {echo "错误获取文档:" . $snoopy->error . "\n";}
更多操作方法可以去Snoopy的官方文档,或者直接查看源码。
此时,snoopy 只取回页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。这里又找到了一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性,熟悉jquery的童鞋,应该还是蛮好用的phpquery,连phpQuery的文档都没有已经需要了。。
使用Snoopy+PhpQuery可以轻松实现网页爬取和数据分析,非常实用。我最近也需要这个,只找到了这两个不错的类库。事实证明,java可以做的事情有很多。php也可以做到。
有兴趣的同学也可以尝试用它们制作一个简单的网络爬虫。
抓取网页数据php(优游国际平台获得多网页数据web链接罕见格局(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-20 09:21
一、从网络获取数据
从 bi 桌面的“获取数据”中,您可以使用“web”选项。“web”界面中有“basic”和“high-end”两个选项卡。一般情况下,“基本”选项卡就足够了。Pingyouyou国际平台任务需求,以下都是基于这个例子。
二、获取数据
网页链接输出后,导航器的“加载”、“编辑”等少见的功能都会停止,只要根据实际任务需要停止操作即可。
三、获取多页数据
网页链接的常见格式如下:开头的“1”表示后续链接为第一页数据,第二页数据链接应为“”。当网页数据较大时,如果平台每次都通过网页链接获取数据,会消耗大量时间。但是,软件中的查询和回复功能可以简化操作,如下:
获取到某页数据后,进入“编辑查询”界面,在“编辑查询”界面选择“高级编辑器”选项卡,高级编辑器界面显示之前的任务路径。大致如下图:
这时需要在“let”后面输出“(p as number) as table=>”;并更改网页的页码,即上面提到的“1、2”等数字,在链接优优国际平台“(Number.ToText(p))”即可。
备注:网页链接有两种,一种是页码数据在链接开头,可以按上面操作;另一个是链接以.html 开头。除了上述替代操作,_"&(Number .ToText(p))&".html")) 只需点击这里单独定义html即可。
四、 爬取大有游国际平台网站
首先,使用优优国际平台查询优优国际平台设置编号规则。如果要截取前100页数据,可以在优优国际平台设置1到100的序列,查询优优国际平台输出={1..100}回车生成序列从 1 到 100,然后将其转换为表格。
然后调用自定义函数,
在弹窗中,可以点击【功能查询】下拉框,选择自己建立的自定义功能Data_Zhaopin,其他平台点击默认即可。
点击确定开始批量抓取网页,抓取成功。后续操作可根据任务需要停止。 查看全部
抓取网页数据php(优游国际平台获得多网页数据web链接罕见格局(组图))
一、从网络获取数据
从 bi 桌面的“获取数据”中,您可以使用“web”选项。“web”界面中有“basic”和“high-end”两个选项卡。一般情况下,“基本”选项卡就足够了。Pingyouyou国际平台任务需求,以下都是基于这个例子。
二、获取数据
网页链接输出后,导航器的“加载”、“编辑”等少见的功能都会停止,只要根据实际任务需要停止操作即可。
三、获取多页数据
网页链接的常见格式如下:开头的“1”表示后续链接为第一页数据,第二页数据链接应为“”。当网页数据较大时,如果平台每次都通过网页链接获取数据,会消耗大量时间。但是,软件中的查询和回复功能可以简化操作,如下:
获取到某页数据后,进入“编辑查询”界面,在“编辑查询”界面选择“高级编辑器”选项卡,高级编辑器界面显示之前的任务路径。大致如下图:
这时需要在“let”后面输出“(p as number) as table=>”;并更改网页的页码,即上面提到的“1、2”等数字,在链接优优国际平台“(Number.ToText(p))”即可。
备注:网页链接有两种,一种是页码数据在链接开头,可以按上面操作;另一个是链接以.html 开头。除了上述替代操作,_"&(Number .ToText(p))&".html")) 只需点击这里单独定义html即可。
四、 爬取大有游国际平台网站
首先,使用优优国际平台查询优优国际平台设置编号规则。如果要截取前100页数据,可以在优优国际平台设置1到100的序列,查询优优国际平台输出={1..100}回车生成序列从 1 到 100,然后将其转换为表格。
然后调用自定义函数,
在弹窗中,可以点击【功能查询】下拉框,选择自己建立的自定义功能Data_Zhaopin,其他平台点击默认即可。
点击确定开始批量抓取网页,抓取成功。后续操作可根据任务需要停止。
抓取网页数据php(一下,用PHP抓更方便(HttpWebReq)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-19 06:12
阿里云 > 云栖社区 > 主题地图 > R > 如何使用GET抓取网页内容
推荐活动:
更多优惠>
当前主题:如何使用 GET 抓取网页内容并添加到采集夹
相关话题:
如何使用 GET 抓取 Web 内容相关博客 查看更多博客
如何使用HttpWebRequest、HttpWebResponse模拟浏览器抓取网页内容
作者:老朱教授 823 浏览评论:04年前
public string GetHtml(string url, Encoding ed) { string Html = string.Empty;//初始化一个新的webRequst HttpWebRequest Request = (HttpWebReq
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen 1527 浏览评论:06年前
原文:PHP使用QueryList来抓取网页内容。之前用Java Jsoup爬取网页数据。前几天听说用PHP爬取比较方便。今天研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQuery 的泛型 list采集 类,简单、灵活、强大
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:老朱教授 1373 浏览评论:04年前
爬取网页的一般逻辑和流程一般是普通用户,他们使用浏览器打开一个URL地址,然后浏览器就可以显示相应页面的内容。这个过程,如果用程序代码实现,可以调用(程序实现)爬取网页(内容,以及后处理,提取需要的信息等)对应的英文是,website
阅读全文
file_get_contents爬取乱码网页的解决方案
作者:Tech Fatty 1012 人浏览评论:04年前
使用 file_get_contents() 函数抓取网页时,有时会出现乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。编码问题很容易处理,只需将捕获的内容转换为编码($content=iconv("GBK", "UTF-8//IGNORE
阅读全文
[网络爬虫] 使用node.js Cheerio 抓取网络数据
作者:紫玉5358人查看评论:05年前
想要自动从网络上抓取一些数据或将一堆从博客中提取的数据转换成结构化数据?有没有现成的 API 来获取数据?!!!!@#$@#$... 没关系,网络抓取可以解决它。什么是网页抓取?你可能会问。. . 网页抓取是对网页内容的程序化(通常不涉及浏览器)检索。
阅读全文
如何让搜索引擎抓取 AJAX 内容?
作者:阮一峰 1469 浏览评论:05年前
越来越多的网站,开始使用“单页结构”(Single-page application)。整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个
阅读全文
如何让搜索引擎抓取 AJAX 内容?
作者:阮一峰 1061 浏览评论:05年前
越来越多的网站,开始使用“单页结构”(Single-page application)。整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个
阅读全文 查看全部
抓取网页数据php(一下,用PHP抓更方便(HttpWebReq)(组图))
阿里云 > 云栖社区 > 主题地图 > R > 如何使用GET抓取网页内容
推荐活动:
更多优惠>
当前主题:如何使用 GET 抓取网页内容并添加到采集夹
相关话题:
如何使用 GET 抓取 Web 内容相关博客 查看更多博客
如何使用HttpWebRequest、HttpWebResponse模拟浏览器抓取网页内容
作者:老朱教授 823 浏览评论:04年前
public string GetHtml(string url, Encoding ed) { string Html = string.Empty;//初始化一个新的webRequst HttpWebRequest Request = (HttpWebReq
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen 1527 浏览评论:06年前
原文:PHP使用QueryList来抓取网页内容。之前用Java Jsoup爬取网页数据。前几天听说用PHP爬取比较方便。今天研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQuery 的泛型 list采集 类,简单、灵活、强大
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:老朱教授 1373 浏览评论:04年前
爬取网页的一般逻辑和流程一般是普通用户,他们使用浏览器打开一个URL地址,然后浏览器就可以显示相应页面的内容。这个过程,如果用程序代码实现,可以调用(程序实现)爬取网页(内容,以及后处理,提取需要的信息等)对应的英文是,website
阅读全文
file_get_contents爬取乱码网页的解决方案
作者:Tech Fatty 1012 人浏览评论:04年前
使用 file_get_contents() 函数抓取网页时,有时会出现乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。编码问题很容易处理,只需将捕获的内容转换为编码($content=iconv("GBK", "UTF-8//IGNORE
阅读全文
[网络爬虫] 使用node.js Cheerio 抓取网络数据
作者:紫玉5358人查看评论:05年前
想要自动从网络上抓取一些数据或将一堆从博客中提取的数据转换成结构化数据?有没有现成的 API 来获取数据?!!!!@#$@#$... 没关系,网络抓取可以解决它。什么是网页抓取?你可能会问。. . 网页抓取是对网页内容的程序化(通常不涉及浏览器)检索。
阅读全文
如何让搜索引擎抓取 AJAX 内容?
作者:阮一峰 1469 浏览评论:05年前
越来越多的网站,开始使用“单页结构”(Single-page application)。整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个
阅读全文
如何让搜索引擎抓取 AJAX 内容?
作者:阮一峰 1061 浏览评论:05年前
越来越多的网站,开始使用“单页结构”(Single-page application)。整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个
阅读全文
抓取网页数据php( 58手机号码识别插件和百度翻译插件的用法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-19 06:11
58手机号码识别插件和百度翻译插件的用法(组图))
爬网数据工具优采云采集器插件说明
使用 优采云采集器 捕获网页数据时也使用插件。优采云采集器将采集中的数据传递给外部程序,我们称之为插件,插件然后处理数据,然后将数据返回给采集器。
优采云采集器V9支持PHP和C#插件编写,V9支持插件源代码编辑。网页数据抓取工具优采云采集器的插件可以应用于采集的结果处理、HTTP请求、文件下载。设置插件实现特定应用时,可以在插件管理器的下拉框中选择现有插件。
下面使用58手机号码识别插件和百度翻译插件来说明使用方法。
58个插件演示:
(1)首先我们需要把插件58验证码V9.dll放到采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后我们需要创建一个名为“手机号”的标签,采集到手机号58的图片地址,这样运行的时候采集器会自动调用该插件将图像输出为转义的数字文本。
翻译插件演示:
(1)首先我们需要把插件百度翻译.dll放到采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后,我们需要创建一个名为“翻译标签”的标签,并以固定字符串的形式写入需要翻译的字段名称。 查看全部
抓取网页数据php(
58手机号码识别插件和百度翻译插件的用法(组图))
爬网数据工具优采云采集器插件说明
使用 优采云采集器 捕获网页数据时也使用插件。优采云采集器将采集中的数据传递给外部程序,我们称之为插件,插件然后处理数据,然后将数据返回给采集器。
优采云采集器V9支持PHP和C#插件编写,V9支持插件源代码编辑。网页数据抓取工具优采云采集器的插件可以应用于采集的结果处理、HTTP请求、文件下载。设置插件实现特定应用时,可以在插件管理器的下拉框中选择现有插件。
下面使用58手机号码识别插件和百度翻译插件来说明使用方法。
58个插件演示:
(1)首先我们需要把插件58验证码V9.dll放到采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后我们需要创建一个名为“手机号”的标签,采集到手机号58的图片地址,这样运行的时候采集器会自动调用该插件将图像输出为转义的数字文本。
翻译插件演示:
(1)首先我们需要把插件百度翻译.dll放到采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后,我们需要创建一个名为“翻译标签”的标签,并以固定字符串的形式写入需要翻译的字段名称。
抓取网页数据php(finfo_if_else就用这个接口php面向对象的好处?#!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-14 13:01
抓取网页数据php内置接口::http(x)tokens,并进行判断?fei#!finfo_if_else就用这个接口php面向对象:(什么是面向对象?面向对象的好处?什么是闭包?闭包)闭包是php的一种重要的程序特性,它将一个函数独立出来,作为另一个函数的参数传递,从而建立一个单独的环境,而不再依赖它。
闭包的意义在于,提供了php编程的一种开源思想。现在有一些php框架,如果需要用到某个函数,你可以通过使用一个特殊函数或者变量,让php自动转换。php转发body_request:从远程服务器接收php请求,在所有请求处理完毕后,将处理后的内容return给客户端。token_manager:用来保存客户端请求的token。
bloompath:将路径分割开来,并保存路径名。$path=$this->__path__;btn->add_top?btn-s>ctx_msg_end:提示客户端已经完成一个请求eof:表示return。先判断是否是eof,才传递path,否则传递的是路径名。由于http并不是面向过程的,bs实现函数调用只是php中一种特殊的函数,因此不需要bind()等操作符;对于bind()等操作符,你只要用一个函数判断传递值是否是eof就行了。
所以bloompath会把值传递出去,而bind则不会,当然bind的返回值eof也可以忽略不计。table:简单的数据表。burl_info:(?=id):(?=baidu):baidu的下拉回车回车中的id表示从何处来purl_info是php中表单组成最简单的一个部分,但是正是这个小小的部分已经包含了php中500多个函数。
现在的问题是:很多时候,请求并不是从页面中取的,我们需要先从页面爬取到数据,然后进行一些处理,然后获取我们需要的信息。而大多数页面都要请求很多次,而且有可能返回的数据长度远超字符串的长度,这样对php代码的压力就比较大了。有没有一种办法可以代替purl_info呢?like:如果我们要从页面中拿数据,可以先从页面的url请求一下://当然这个地址是不可能请求出来的like</img>burl_login:从登录界面取数据likebaidu_username_login;取到username之后,获取其它数据:burl_getuser():获取该用户的上一个guid;burl_getname():获取该用户的名字;burl_gets():获取该用户上次访问的url。
burl_send():发送请求(自己创建一个token用于存储token,或者等到时候用token登录就行了),发送成功则等于一个字符串。值得注意的是,在自己的服务器上存取值的时候,不要用increment那种方式。 查看全部
抓取网页数据php(finfo_if_else就用这个接口php面向对象的好处?#!)
抓取网页数据php内置接口::http(x)tokens,并进行判断?fei#!finfo_if_else就用这个接口php面向对象:(什么是面向对象?面向对象的好处?什么是闭包?闭包)闭包是php的一种重要的程序特性,它将一个函数独立出来,作为另一个函数的参数传递,从而建立一个单独的环境,而不再依赖它。
闭包的意义在于,提供了php编程的一种开源思想。现在有一些php框架,如果需要用到某个函数,你可以通过使用一个特殊函数或者变量,让php自动转换。php转发body_request:从远程服务器接收php请求,在所有请求处理完毕后,将处理后的内容return给客户端。token_manager:用来保存客户端请求的token。
bloompath:将路径分割开来,并保存路径名。$path=$this->__path__;btn->add_top?btn-s>ctx_msg_end:提示客户端已经完成一个请求eof:表示return。先判断是否是eof,才传递path,否则传递的是路径名。由于http并不是面向过程的,bs实现函数调用只是php中一种特殊的函数,因此不需要bind()等操作符;对于bind()等操作符,你只要用一个函数判断传递值是否是eof就行了。
所以bloompath会把值传递出去,而bind则不会,当然bind的返回值eof也可以忽略不计。table:简单的数据表。burl_info:(?=id):(?=baidu):baidu的下拉回车回车中的id表示从何处来purl_info是php中表单组成最简单的一个部分,但是正是这个小小的部分已经包含了php中500多个函数。
现在的问题是:很多时候,请求并不是从页面中取的,我们需要先从页面爬取到数据,然后进行一些处理,然后获取我们需要的信息。而大多数页面都要请求很多次,而且有可能返回的数据长度远超字符串的长度,这样对php代码的压力就比较大了。有没有一种办法可以代替purl_info呢?like:如果我们要从页面中拿数据,可以先从页面的url请求一下://当然这个地址是不可能请求出来的like</img>burl_login:从登录界面取数据likebaidu_username_login;取到username之后,获取其它数据:burl_getuser():获取该用户的上一个guid;burl_getname():获取该用户的名字;burl_gets():获取该用户上次访问的url。
burl_send():发送请求(自己创建一个token用于存储token,或者等到时候用token登录就行了),发送成功则等于一个字符串。值得注意的是,在自己的服务器上存取值的时候,不要用increment那种方式。
抓取网页数据php(抓取网页数据php获取数据库信息可使用或mssql页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-13 00:01
抓取网页数据php获取数据库信息可使用mysql或mssql抓取页面,需要引入相应的api,如果是自己写代码可借助cijs来完成抓取首页-进入lbs信息,点击左侧工具条-index或者ctrl+f输入框,点击右边api_index的api,
因为这个网站做了点赞功能,这个功能是有网页版的。
howtoinstallphpwebappforyouriphone?
我猜,这个信息是从其他网站爬下来的,然后转到你这个网站。每个网站抓取的量不一样。所以一些网站是可以取到所有用户的点赞信息,按照顺序排列,然后通过各种形式呈现出来。但是针对这个网站,肯定是没法直接取出所有用户的信息的。除非在每个url中同时获取到用户的ip、点赞数,才能算。
可以参考csdn博客:php下载:twitter|lastwebsite可以获取最近6个发推的用户。
收集发帖用户信息
你可以搜索“谷歌浏览器地图”,它会提供“目标网站收藏夹”,根据地址收藏。关键是“随意填写目标网站,
抓取网站的ip信息,返回到我的主页,
全是渣。抓取个人页面,
python爬取链家网cityurl: 查看全部
抓取网页数据php(抓取网页数据php获取数据库信息可使用或mssql页面)
抓取网页数据php获取数据库信息可使用mysql或mssql抓取页面,需要引入相应的api,如果是自己写代码可借助cijs来完成抓取首页-进入lbs信息,点击左侧工具条-index或者ctrl+f输入框,点击右边api_index的api,
因为这个网站做了点赞功能,这个功能是有网页版的。
howtoinstallphpwebappforyouriphone?
我猜,这个信息是从其他网站爬下来的,然后转到你这个网站。每个网站抓取的量不一样。所以一些网站是可以取到所有用户的点赞信息,按照顺序排列,然后通过各种形式呈现出来。但是针对这个网站,肯定是没法直接取出所有用户的信息的。除非在每个url中同时获取到用户的ip、点赞数,才能算。
可以参考csdn博客:php下载:twitter|lastwebsite可以获取最近6个发推的用户。
收集发帖用户信息
你可以搜索“谷歌浏览器地图”,它会提供“目标网站收藏夹”,根据地址收藏。关键是“随意填写目标网站,
抓取网站的ip信息,返回到我的主页,
全是渣。抓取个人页面,
python爬取链家网cityurl:
抓取网页数据php(Python叶庭云微信公众号:谈及pandasread_html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-10 04:14
过去的一切都是序幕。真正的顺其自然,不是尽力而为,而是什么都不做。
文章目录一、简介
一般的爬虫套路无非就是发送请求、获取响应、解析网页、提取数据、保存数据的步骤。 requests 库主要用于构造请求,xpath 和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
说说pandas的read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),pd.read_html()很少用到,但是它的作用它非常强大,尤其是当它用于捕获Table数据时,它是一个神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存在本地。
二、原理
pandas适合抓取表格数据,先了解一下有表格数据结构的网页,例如:
用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共性。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有以上结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬虫实例1
爬取2019年成都空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range('20190101', '20191201', freq='MS').strftime('%Y%m') # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f'http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html', encoding='gbk', header=0)[0]
if i == 0:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False) # 追加写入
i += 1
else:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False, header=False)
9行代码就搞定了,爬取速度也很快。
查看保存的数据
示例 2
抓取新浪财经基金重仓股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv('新浪财经基金重仓股数据.csv', encoding='utf-8', index=False)
6行代码就搞定了,爬取速度也很快。
查看保存的数据:
以后爬一些小数据的时候,只要遇到这种Table数据,可以先试试pd.read_html()方法。
作者:叶婷云 微信公众号:培养Python CSDN:本文仅供交流学习,未经作者许可,禁止转载,更不得用于其他目的,违者必究。如果你觉得文章对你有帮助,让你有所收获,期待你的点赞。如有不足,也可以在评论区指正。 查看全部
抓取网页数据php(Python叶庭云微信公众号:谈及pandasread_html)
过去的一切都是序幕。真正的顺其自然,不是尽力而为,而是什么都不做。
文章目录一、简介
一般的爬虫套路无非就是发送请求、获取响应、解析网页、提取数据、保存数据的步骤。 requests 库主要用于构造请求,xpath 和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
说说pandas的read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),pd.read_html()很少用到,但是它的作用它非常强大,尤其是当它用于捕获Table数据时,它是一个神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存在本地。
二、原理
pandas适合抓取表格数据,先了解一下有表格数据结构的网页,例如:
用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共性。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有以上结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬虫实例1
爬取2019年成都空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range('20190101', '20191201', freq='MS').strftime('%Y%m') # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f'http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html', encoding='gbk', header=0)[0]
if i == 0:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False) # 追加写入
i += 1
else:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False, header=False)
9行代码就搞定了,爬取速度也很快。
查看保存的数据
示例 2
抓取新浪财经基金重仓股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv('新浪财经基金重仓股数据.csv', encoding='utf-8', index=False)
6行代码就搞定了,爬取速度也很快。
查看保存的数据:
以后爬一些小数据的时候,只要遇到这种Table数据,可以先试试pd.read_html()方法。
作者:叶婷云 微信公众号:培养Python CSDN:本文仅供交流学习,未经作者许可,禁止转载,更不得用于其他目的,违者必究。如果你觉得文章对你有帮助,让你有所收获,期待你的点赞。如有不足,也可以在评论区指正。
抓取网页数据php(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-10 04:03
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们要确定我们的 PHP 是否启用了这个库,你可以使用 php_info() 函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置需要抓取的网址
curl_setopt($curl, CURLOPT_URL, '');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置 cURL 参数,是否将结果保存为字符串或输出到屏幕。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行cURL,请求网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
//显示获取到的数据
var_dump($data);
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序我们可以看出,使用CURLOPT_POST来设置HTTP协议的POST方法而不是GET方法,然后用CURLOPT_POSTFIELDS设置POST数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie 查看全部
抓取网页数据php(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们要确定我们的 PHP 是否启用了这个库,你可以使用 php_info() 函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置需要抓取的网址
curl_setopt($curl, CURLOPT_URL, '');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置 cURL 参数,是否将结果保存为字符串或输出到屏幕。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行cURL,请求网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
//显示获取到的数据
var_dump($data);
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序我们可以看出,使用CURLOPT_POST来设置HTTP协议的POST方法而不是GET方法,然后用CURLOPT_POSTFIELDS设置POST数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie

