
工具采集文章
工具采集文章(如何快速爬取工具采集文章?亲测有效的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-10 20:05
工具采集文章大纲仅支持微信号采集;采集微信大v、搜狗微信等搜索引擎的文章仅支持微信大v、搜狗微信等搜索引擎的文章。第三个是搜狗微信(第三方平台收录),第二个是小说分类(小说文章)。无法截图,因为截图工具很多,应该很好找。亲测方法:在百度搜索框搜索“小说分类”,就会看到很多浏览器里面都会出现这个分类的相关链接。
把链接复制到siri或者微信上,就可以直接搜索到了。(特别提醒,你在调用相关应用搜索时一定要注意分类,避免搜到乱七八糟的文章。)小编亲测效果:点击链接后显示的分类:搜狗微信。
1、在第三方平台收录文章后,还可以采集出公众号分类文章。
2、小说分类可以直接按作者、年份、作者、作者等来搜索;微信大v可以分多种。按年份搜索:等同于豆瓣电影的年份筛选查看文章大纲按作者搜索:等同于豆瓣电影的文章标题搜索按作者搜索:作者可能是你想要找的人标题搜索:相关的标题采集,注意最好在输入的时候用双引号。
3、其他的:看电脑有没有root,如果有的话,对浏览器采集文章有很好的效果。
提供一些可以快速爬取的方法我这里主要介绍一下采集网页的javascriptjavascript教程:;tid=2645862获取方法:1。找一个你能找到且他(她)能够采集的网站,就能找到你想要爬取的页面,点击选中左侧搜索框的网址(就是你复制的网址),右键点击,选择爬取即可,一般会返回chrome浏览器的地址(因为chrome浏览器默认地址栏)2。
点击我的网址栏,下方浏览器的地址栏下方也会出现一串javascript(也就是javascript)即可;3。找到之后,你只需要点击复制即可,因为我就是这样做的,这样的话,你会发现,复制后的网址最后是一串http,不要害怕,点击退出浏览器即可4。右键,选择提取网址即可,这样就能爬取你需要的数据5。采集完成后,右键,粘贴即可,可见很多文章后面都有,右键即可,不像上一篇一样很难找,找到之后,复制粘贴即可这个方法可以用于手机浏览器,打开网址之后,右键,提取网址即可,找到的那种,方便很多。 查看全部
工具采集文章(如何快速爬取工具采集文章?亲测有效的方法)
工具采集文章大纲仅支持微信号采集;采集微信大v、搜狗微信等搜索引擎的文章仅支持微信大v、搜狗微信等搜索引擎的文章。第三个是搜狗微信(第三方平台收录),第二个是小说分类(小说文章)。无法截图,因为截图工具很多,应该很好找。亲测方法:在百度搜索框搜索“小说分类”,就会看到很多浏览器里面都会出现这个分类的相关链接。
把链接复制到siri或者微信上,就可以直接搜索到了。(特别提醒,你在调用相关应用搜索时一定要注意分类,避免搜到乱七八糟的文章。)小编亲测效果:点击链接后显示的分类:搜狗微信。
1、在第三方平台收录文章后,还可以采集出公众号分类文章。
2、小说分类可以直接按作者、年份、作者、作者等来搜索;微信大v可以分多种。按年份搜索:等同于豆瓣电影的年份筛选查看文章大纲按作者搜索:等同于豆瓣电影的文章标题搜索按作者搜索:作者可能是你想要找的人标题搜索:相关的标题采集,注意最好在输入的时候用双引号。
3、其他的:看电脑有没有root,如果有的话,对浏览器采集文章有很好的效果。
提供一些可以快速爬取的方法我这里主要介绍一下采集网页的javascriptjavascript教程:;tid=2645862获取方法:1。找一个你能找到且他(她)能够采集的网站,就能找到你想要爬取的页面,点击选中左侧搜索框的网址(就是你复制的网址),右键点击,选择爬取即可,一般会返回chrome浏览器的地址(因为chrome浏览器默认地址栏)2。
点击我的网址栏,下方浏览器的地址栏下方也会出现一串javascript(也就是javascript)即可;3。找到之后,你只需要点击复制即可,因为我就是这样做的,这样的话,你会发现,复制后的网址最后是一串http,不要害怕,点击退出浏览器即可4。右键,选择提取网址即可,这样就能爬取你需要的数据5。采集完成后,右键,粘贴即可,可见很多文章后面都有,右键即可,不像上一篇一样很难找,找到之后,复制粘贴即可这个方法可以用于手机浏览器,打开网址之后,右键,提取网址即可,找到的那种,方便很多。
工具采集文章(北外教师考高口的准备准备怎么样?工具采集文章分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-10 10:08
工具采集文章分析关键词,统计原创数据,在线编辑和上传发布相关工具,制作关键词-匹配配图片的爬虫,采集到的相关文章标题和链接分析相关内容原始数据,
据我说知,北外教师每年能出两本高口教材:第一本以证书为主;第二本有实体教材。
pdf格式文档,图片视频,都可以做学习笔记和课堂笔记,学习资料。
请问高口的准备准备怎么样?我现在也在准备,
用心就好,阅读,记录笔记,动手运用,反复推敲,做口语练习,不懂的找老师同学请教。准备一年,三本教材,听说读写综合练习一个半月。坚持,和努力是两回事,另外如果不懂口语或听力不好也不要急着做多元练习。
你是大二还是大三?大三难度会大一些,因为这时候要准备专八。我也是考高口,今年六月份刚刚考过,口语六十多分,没有报班,自己看书学习模仿,建议教材先找视频看一遍,然后听力要再听一遍,然后开始口语的学习,主要是发音。先从音标开始,从字母,然后元音辅音,然后字母组合等等。想要靠谱的学习网站有很多,比如扇贝,百词斩,搜狗,洋葱等等。
这些学习软件在线学都很方便。然后平时除了背单词以外,多看看英文的资料比如脱口秀或者经济学人之类的。祝好运!。 查看全部
工具采集文章(北外教师考高口的准备准备怎么样?工具采集文章分析)
工具采集文章分析关键词,统计原创数据,在线编辑和上传发布相关工具,制作关键词-匹配配图片的爬虫,采集到的相关文章标题和链接分析相关内容原始数据,
据我说知,北外教师每年能出两本高口教材:第一本以证书为主;第二本有实体教材。
pdf格式文档,图片视频,都可以做学习笔记和课堂笔记,学习资料。
请问高口的准备准备怎么样?我现在也在准备,
用心就好,阅读,记录笔记,动手运用,反复推敲,做口语练习,不懂的找老师同学请教。准备一年,三本教材,听说读写综合练习一个半月。坚持,和努力是两回事,另外如果不懂口语或听力不好也不要急着做多元练习。
你是大二还是大三?大三难度会大一些,因为这时候要准备专八。我也是考高口,今年六月份刚刚考过,口语六十多分,没有报班,自己看书学习模仿,建议教材先找视频看一遍,然后听力要再听一遍,然后开始口语的学习,主要是发音。先从音标开始,从字母,然后元音辅音,然后字母组合等等。想要靠谱的学习网站有很多,比如扇贝,百词斩,搜狗,洋葱等等。
这些学习软件在线学都很方便。然后平时除了背单词以外,多看看英文的资料比如脱口秀或者经济学人之类的。祝好运!。
工具采集文章(避免温馨提示你的头像特别生气,结果扫码下载到app里)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-05 03:04
工具采集文章可以采用采集器采集izhihu文章可以采用izhihu文章搜索收录izhihu这个公众号将“简书”的数据收集了公众号叫做“简书lite”简书数据源自下载“简书百度百科”可以获取到全部关于简书文章简书百度百科解决大多数小白不知道关于简书文章的问题,有问题的可以随时联系我我的邮箱:3363267370@qq。com。
可以了解下福利社,这个平台的内容很多,有的是自己原创,有的是采集来的,还有的是转载的,对于素材都是十分便捷的,
全网各大内容平台上都是可以做摘要的,然后写好正文或者留下备注或者标题,都可以下载。
如果都像我一样懒的话...那就...去捡垃圾吧orz
全网app对于文章摘要,类似于简书对于文章标题的功能。今天无意中看到一篇文章的标题如下:“避免温馨提示你的头像”特别生气,结果扫码下载到app里,是这样子的(小编也想把图片稍微加点水印,就太拉低版面质量了)自己的内容没有这么多的“温馨提示”,我本人是不喜欢发朋友圈的,这个文章能不能及时的提醒到我,还望能够注意。
简书的话用网易新闻抓取也可以,但是只可以分享到微信,
izhihu网站下载app即可打开,支持上传与收藏,然后用邮箱或者qq登录即可,但是想要得到cookie,就得把app关了,要不然wifi不稳定。 查看全部
工具采集文章(避免温馨提示你的头像特别生气,结果扫码下载到app里)
工具采集文章可以采用采集器采集izhihu文章可以采用izhihu文章搜索收录izhihu这个公众号将“简书”的数据收集了公众号叫做“简书lite”简书数据源自下载“简书百度百科”可以获取到全部关于简书文章简书百度百科解决大多数小白不知道关于简书文章的问题,有问题的可以随时联系我我的邮箱:3363267370@qq。com。
可以了解下福利社,这个平台的内容很多,有的是自己原创,有的是采集来的,还有的是转载的,对于素材都是十分便捷的,
全网各大内容平台上都是可以做摘要的,然后写好正文或者留下备注或者标题,都可以下载。
如果都像我一样懒的话...那就...去捡垃圾吧orz
全网app对于文章摘要,类似于简书对于文章标题的功能。今天无意中看到一篇文章的标题如下:“避免温馨提示你的头像”特别生气,结果扫码下载到app里,是这样子的(小编也想把图片稍微加点水印,就太拉低版面质量了)自己的内容没有这么多的“温馨提示”,我本人是不喜欢发朋友圈的,这个文章能不能及时的提醒到我,还望能够注意。
简书的话用网易新闻抓取也可以,但是只可以分享到微信,
izhihu网站下载app即可打开,支持上传与收藏,然后用邮箱或者qq登录即可,但是想要得到cookie,就得把app关了,要不然wifi不稳定。
工具采集文章(快速一键查看公众号历史文章-行之记事具体功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2021-11-25 12:03
工具采集文章,获取微信公众号内容,实现在手机微信公众号后台订阅号文章实时监控,实现手机微信号查看内容。
我目前用wordpress搭建了一个微信公众号聚合服务端,并打算直接打通微信公众号。
我也很好奇,推荐我们的易佰康公众号服务号助手,
微信关注易佰康公众号助手,可以一键查看个人公众号历史文章,并可与公众号实时互动。如果您感兴趣,请关注我们的微信号:i97hou1。
抓取公众号历史文章是没问题的。这个人是一名专业做公众号抓取器的工程师。目前在做微信公众号的抓取和清洗工作。好奇的话,
参考经验介绍:快速一键查看公众号历史文章-行之记事具体功能请参考这个回答:公众号历史消息抓取工具大全
易佰康公众号抓取器有什么使用,
我个人认为目前没有这样的工具可以达到以上要求,这需要一个人力,也需要一定的技术,目前我做公众号,如果你也对公众号感兴趣,也可以加入我们的队伍,虽然是刚起步,但是我们确实可以满足要求。目前我们的主要工作有:查看公众号历史消息,并实时互动,查看公众号的粉丝数据等等。
有个好用的工具,就是能抓取文章,并且标记标题等,如果你用wordpress搭建的话, 查看全部
工具采集文章(快速一键查看公众号历史文章-行之记事具体功能)
工具采集文章,获取微信公众号内容,实现在手机微信公众号后台订阅号文章实时监控,实现手机微信号查看内容。
我目前用wordpress搭建了一个微信公众号聚合服务端,并打算直接打通微信公众号。
我也很好奇,推荐我们的易佰康公众号服务号助手,
微信关注易佰康公众号助手,可以一键查看个人公众号历史文章,并可与公众号实时互动。如果您感兴趣,请关注我们的微信号:i97hou1。
抓取公众号历史文章是没问题的。这个人是一名专业做公众号抓取器的工程师。目前在做微信公众号的抓取和清洗工作。好奇的话,
参考经验介绍:快速一键查看公众号历史文章-行之记事具体功能请参考这个回答:公众号历史消息抓取工具大全
易佰康公众号抓取器有什么使用,
我个人认为目前没有这样的工具可以达到以上要求,这需要一个人力,也需要一定的技术,目前我做公众号,如果你也对公众号感兴趣,也可以加入我们的队伍,虽然是刚起步,但是我们确实可以满足要求。目前我们的主要工作有:查看公众号历史消息,并实时互动,查看公众号的粉丝数据等等。
有个好用的工具,就是能抓取文章,并且标记标题等,如果你用wordpress搭建的话,
工具采集文章(为什么要采集公众号的文章?免费!效果如何一试!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-13 10:00
首先,为什么需要采集公众号的文章?
我想大家在生活中经常关注公众号,所以公众号的内容丰富多彩。作为曾经做公众号的运营商,公众号文章的质量特别高,无论是素材、文章的整体框架、文章的内容@文章精准垂直,公众号原创大于80%。大多数作家都有自己的经验和技能。
如何采集公众号文章?
对于不懂代码的小白来说,复制粘贴采集公众号的文章最简单的方法就是使用其他采集工具,编辑规则。所以对小白很不友好,有没有傻瓜式的采集软件?直接输入关键词采集公众号文章。
所以这次介绍的是傻瓜式采集软件,只需输入关键词即可实现采集。方便快捷。
公众号采集流程
1、输入关键词(例如:装修),可以采集到今日头条、公众号文章、百度网页、百度新闻、搜狗网页、搜狗新闻、批次可用关键词全自动采集。
2、智能采集,无需编写复杂的规则。
3、采集内容质量高
4、最简单最智能文章采集器,重点是免费!自由!自由!一试就知道效果!
5、文章采集器不用写规则,大家都会用采集软件
<p>现在大家都知道“内容为王”,大家为了做网站优化,都疯狂写文章,但是每天的输出量很小。一些优化者认为 原创 查看全部
工具采集文章(为什么要采集公众号的文章?免费!效果如何一试!)
首先,为什么需要采集公众号的文章?
我想大家在生活中经常关注公众号,所以公众号的内容丰富多彩。作为曾经做公众号的运营商,公众号文章的质量特别高,无论是素材、文章的整体框架、文章的内容@文章精准垂直,公众号原创大于80%。大多数作家都有自己的经验和技能。

如何采集公众号文章?
对于不懂代码的小白来说,复制粘贴采集公众号的文章最简单的方法就是使用其他采集工具,编辑规则。所以对小白很不友好,有没有傻瓜式的采集软件?直接输入关键词采集公众号文章。
所以这次介绍的是傻瓜式采集软件,只需输入关键词即可实现采集。方便快捷。
公众号采集流程
1、输入关键词(例如:装修),可以采集到今日头条、公众号文章、百度网页、百度新闻、搜狗网页、搜狗新闻、批次可用关键词全自动采集。
2、智能采集,无需编写复杂的规则。
3、采集内容质量高
4、最简单最智能文章采集器,重点是免费!自由!自由!一试就知道效果!
5、文章采集器不用写规则,大家都会用采集软件
<p>现在大家都知道“内容为王”,大家为了做网站优化,都疯狂写文章,但是每天的输出量很小。一些优化者认为 原创
工具采集文章(为什么要采集公众号的文章?免费!效果如何一试!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-13 03:15
首先,为什么需要采集公众号的文章?
我想大家在生活中经常关注公众号,所以公众号的内容丰富多彩。作为曾经做公众号的运营商,公众号文章的质量特别高,无论是素材、文章的整体框架、文章的内容@文章精准垂直,公众号原创大于80%。大多数作家都有自己的经验和技能。
如何采集公众号文章?
对于不懂代码的小白来说,复制粘贴采集公众号的文章最简单的方法就是使用其他采集工具,编辑规则。所以对小白很不友好,有没有傻瓜式的采集软件?直接输入关键词采集公众号文章。
所以这次介绍的是傻瓜式采集软件,只需输入关键词即可实现采集。方便快捷。
公众号采集流程
1、输入关键词(例如:装修),可以采集到今日头条、公众号文章、百度网页、百度新闻、搜狗网页、搜狗新闻、批次可用关键词全自动采集。
2、智能采集,无需编写复杂的规则。
3、采集内容质量高
4、最简单最智能文章采集器,重点是免费!自由!自由!一试就知道效果!
5、文章采集器不用写规则,大家都会用采集软件
<p>现在大家都知道“内容为王”,大家为了做网站优化,都疯狂写文章,但是每天的输出量很小。一些优化者认为 原创 查看全部
工具采集文章(为什么要采集公众号的文章?免费!效果如何一试!)
首先,为什么需要采集公众号的文章?
我想大家在生活中经常关注公众号,所以公众号的内容丰富多彩。作为曾经做公众号的运营商,公众号文章的质量特别高,无论是素材、文章的整体框架、文章的内容@文章精准垂直,公众号原创大于80%。大多数作家都有自己的经验和技能。
如何采集公众号文章?
对于不懂代码的小白来说,复制粘贴采集公众号的文章最简单的方法就是使用其他采集工具,编辑规则。所以对小白很不友好,有没有傻瓜式的采集软件?直接输入关键词采集公众号文章。
所以这次介绍的是傻瓜式采集软件,只需输入关键词即可实现采集。方便快捷。
公众号采集流程
1、输入关键词(例如:装修),可以采集到今日头条、公众号文章、百度网页、百度新闻、搜狗网页、搜狗新闻、批次可用关键词全自动采集。
2、智能采集,无需编写复杂的规则。
3、采集内容质量高
4、最简单最智能文章采集器,重点是免费!自由!自由!一试就知道效果!
5、文章采集器不用写规则,大家都会用采集软件
<p>现在大家都知道“内容为王”,大家为了做网站优化,都疯狂写文章,但是每天的输出量很小。一些优化者认为 原创
工具采集文章(微信公众号文章批量采集工具绿V2.60总结)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-11-08 21:11
微信公众号文章批次采集工具绿官方最新版为全(全)全新全自动微信公众号文章批次采集工具绿官方最新版,微信公众号文章批量采集绿色官方最新版工具功能强大,可以进行原(元)创(de)、批量伪原创@ > 等操作,让你可以轻松采集别人的公众号文章,有需要的朋友快来下载吧!
微信公众号文章批量采集绿色工具最新正式版介绍
1. 这个新版本的伪原创@>有着非常巧妙的玩法。是翻译。先从中文翻译成英文,再从英文翻译成中文。可惜一天翻译量有限,可以自行更改IP地址。 (其实不适合更新太多,一天几条就可以了,一般是老站的话。关键词可以快速重新排名),微信公众号文章批量采集工具绿色官方最新版,然后伪原创@>点击这些文章,然后更新为伪原创7@>。整个过程是全自动的。无需打开后台,通过数据库发送。因此,需要生成静态页面。
2.是为优采云站长准备的,也适合维护站、做伪原创8@>、跑流程的人。
3.本软件的功能,与上一版本对比: 和之前一样,微信公众号文章批量采集工具官方微信公众号最新版本Green文章 批处理采集 Tool Green 的最新正式版,采集 后来使用了伪原创@>。不知道这算不算伪原创@>,不过确实达到了伪原创@>的效果。
微信公众号文章批次采集工具绿最新正式版汇总
微信公众号文章批量采集工具绿V2.60是一款适用于安卓版其他软件的手机软件。如果您喜欢这个软件,请下载链接分享给您的朋友: 查看全部
工具采集文章(微信公众号文章批量采集工具绿V2.60总结)
微信公众号文章批次采集工具绿官方最新版为全(全)全新全自动微信公众号文章批次采集工具绿官方最新版,微信公众号文章批量采集绿色官方最新版工具功能强大,可以进行原(元)创(de)、批量伪原创@ > 等操作,让你可以轻松采集别人的公众号文章,有需要的朋友快来下载吧!
微信公众号文章批量采集绿色工具最新正式版介绍
1. 这个新版本的伪原创@>有着非常巧妙的玩法。是翻译。先从中文翻译成英文,再从英文翻译成中文。可惜一天翻译量有限,可以自行更改IP地址。 (其实不适合更新太多,一天几条就可以了,一般是老站的话。关键词可以快速重新排名),微信公众号文章批量采集工具绿色官方最新版,然后伪原创@>点击这些文章,然后更新为伪原创7@>。整个过程是全自动的。无需打开后台,通过数据库发送。因此,需要生成静态页面。
2.是为优采云站长准备的,也适合维护站、做伪原创8@>、跑流程的人。
3.本软件的功能,与上一版本对比: 和之前一样,微信公众号文章批量采集工具官方微信公众号最新版本Green文章 批处理采集 Tool Green 的最新正式版,采集 后来使用了伪原创@>。不知道这算不算伪原创@>,不过确实达到了伪原创@>的效果。
微信公众号文章批次采集工具绿最新正式版汇总
微信公众号文章批量采集工具绿V2.60是一款适用于安卓版其他软件的手机软件。如果您喜欢这个软件,请下载链接分享给您的朋友:
工具采集文章(一本系列随笔概览及产生的背景自己开发的豆约翰博客备份专家软件工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-11-06 07:24
一系列论文及其背景的概述
自主研发的DouJohnson博客备份专家软件工具自问世3年多以来,深受博客写作和阅读爱好者的喜爱。同时,也有一些技术爱好者向我咨询如何实现这个软件中的各种实用功能。
该软件是使用.NET 技术开发的。为了回馈社会,特开设软件使用的核心技术专栏,为广大技术爱好者写了一系列文章。
本系列文章不仅讲解了网络采集、编辑、发布中用到的各种重要技术,还提供了很多界面开发中的解题思路和编程经验。非常适合.NET开发的初学者和中级读者。希望请多多支持。
很多初学者经常会有这样的困惑,“为什么我看了这本书,对C#的方方面面都了解了,却写不出一个像样的应用程序?”,
其实我还没有学会综合运用所学的知识,锻炼编程思维,建立学习的兴趣。我认为这个系列文章 可以帮助你,我希望如此。
开发环境:VS2008
本节源码位置:
源码下载方法:安装SVN客户端(文末提供下载地址),然后查看以下地址:
文章系列大纲如下:
网络采集软件核心技术解析系列(1)---如何使用C#语言获取博客园中某博主的所有文章链接和标题
网络采集软件核心技术解析系列(2)---如何使用C#语言获取任意站点博文的正文和标题
网络采集软件核心技术解析系列(3)---如何用C#语言将博文中的所有图片下载到本地并离线浏览
网络采集软件核心技术解析系列(4)---如何使用C#语言将html网页转换成pdf(html2pdf)
网络采集软件核心技术解析系列(5)---将任意博主的所有博文下载到内存中,通过Webbrower展示
网络采集软件核心技术分析系列(6)---将任何博主的所有博文下载到SQLite数据库中,通过Webbrower展示
网络采集软件核心技术解析系列(7)---如何使用C#语言搭建程序框架(经典Winform界面、菜单栏、树形列表、多标签界面)
网络采集软件核心技术解析系列(综合实例)
2、第七节主要内容介绍(如何使用C#语言搭建程序框架(经典Winform界面,顶部菜单栏,工具栏,左侧树形列表,右侧多个Tab界面))
如何使用C#语言搭建程序框架(经典Winform界面,顶部菜单栏,工具栏,左侧树状列表,右侧多个Tab界面)解决方案,演示如下图:可执行文件下载
演示功能介绍:
程序启动后,扫描程序所在目录的WebSiteDB文件夹(见上一节,里面存放着每个博主的所有博文和xxx.db文件),在左边的树形控件上加载数据库名称; 双击树控件为子节点,在右侧添加类似浏览器的标签界面。在新打开的界面中,会自动加载博主的博文列表信息。
三个基本原则
这个简单的框架有三个要点:
1. 递归加载树控制节点;
2. 右侧tab窗体的创建(主要使用大名鼎鼎的WeifenLuo.WinFormsUI.Docking.dll);
3. 单击树节点打开一个新窗口(前两者的组合)。
先看第一点,树控件节点的递归加载,主要代码如下:
private void LoadWebSiteTree()
{
this.treeViewTask.Nodes.Clear();
TreeNode nodeRoot = new TreeNode();
nodeRoot.Text = "站点列表";
nodeRoot.Tag = -1;
this.treeViewTask.Nodes.Add(nodeRoot);
GetSubDirectoryNodes(nodeRoot, m_strDBFolder,true);
this.treeViewTask.SelectedNode = this.treeViewTask.TopNode;
}
创建根节点,然后调用GetSubDirectoryNodes函数递归加载子节点:
private void GetSubDirectoryNodes(TreeNode parentNode, string fullName, bool getFileNames)
{
if (!Directory.Exists(fullName))
{
Directory.CreateDirectory(fullName);
}
DirectoryInfo dir = new DirectoryInfo(fullName);
DirectoryInfo[] dirSubs = dir.GetDirectories();
// 为每个子目录添加一个子节点
foreach (DirectoryInfo dirSub in dirSubs)
{
// 不显示隐藏文件夹
if ((dirSub.Attributes & FileAttributes.Hidden) != 0)
{
continue;
}
TreeNode node = new TreeNode();
node.Text = dirSub.Name;
node.Tag = 0;
node.ImageIndex = 0;
parentNode.Nodes.Add(node);
// 递归调用
GetSubDirectoryNodes(node, dirSub.FullName, getFileNames);
}
// 为每个子目录添加一个子节点
foreach (DirectoryInfo dirSub in dirSubs)
{
// 不显示隐藏文件夹
if ((dirSub.Attributes & FileAttributes.Hidden) != 0)
{
continue;
}
}
if (getFileNames) // 书中源码中,这部分在foreach内部,不正确
{
// 获取此节点的所有文件
FileInfo[] files = dir.GetFiles();
// 放置节点后。放置子目录中的文件。
foreach (FileInfo file in files)
{
if (file.Extension.ToString() != ".db")
continue;
string strNodeName = file.Name.Remove(file.Name.Length - 3, 3);
if (strNodeName == "home")
continue;
TreeNode node = new TreeNode();
node.Text = strNodeName;
node.Tag = 1;
node.ImageIndex = 1;
parentNode.Nodes.Add(node);
}
}
}
接下来看第二点,2.右侧的tab窗体的创建(主要使用大名鼎鼎的WeifenLuo.WinFormsUI.Docking.dll),主要代码如下:
public DockContent ShowContent(string caption/*, Type formType*/)
{
DockContent frm = FindDocument(caption);
if (frm == null)
{
Frm_TargetUrlView frm_TargetUrlView = new Frm_TargetUrlView((string)this.treeViewTask.SelectedNode.Parent.Text
, m_strDBConStringPath + m_strTreeNodeName
, (string)this.treeViewTask.SelectedNode.Text, this);
frm_TargetUrlView.MdiParent = this;
frm_TargetUrlView.WindowState = FormWindowState.Maximized;
frm_TargetUrlView.Show(this.dockPanel1);
frm_TargetUrlView.Focus();
frm_TargetUrlView.BringToFront();
return frm_TargetUrlView;
}
frm.Show(this.dockPanel1);
frm.Focus();
frm.BringToFront();
return frm;
}
首先调用FindDocument(caption)判断当前标签窗口是否已经打开,如果已经打开,则激活它;如果尚未打开,则创建一个新的选项卡窗口并使这个新创建的窗口成为活动窗口。
3. 单击树节点打开一个新窗口(前两者的组合)。主要代码如下:
private void treeViewTask_MouseDoubleClick(object sender, MouseEventArgs e)
{
Point pos = new Point(e.X, e.Y);
TreeNode nodeClick = this.treeViewTask.GetNodeAt(pos);
if (nodeClick.Text == "站点列表")
{
this.treeViewTask.ContextMenuStrip = null;
return;
}
if (nodeClick != null && e.Button == MouseButtons.Left)
{
int nTag = (int)nodeClick.Tag;
if (nTag == 0)
return;
this.treeViewTask.SelectedNode = nodeClick;
LoadInfoByNode();
}
ShowContent(this.treeViewTask.SelectedNode.Text);
}
在树节点的双击处理函数中,调用上面第二步的ShowContent函数,就会弹出对应的tab窗体。
更详细的代码请自行下载学习。 查看全部
工具采集文章(一本系列随笔概览及产生的背景自己开发的豆约翰博客备份专家软件工具)
一系列论文及其背景的概述
自主研发的DouJohnson博客备份专家软件工具自问世3年多以来,深受博客写作和阅读爱好者的喜爱。同时,也有一些技术爱好者向我咨询如何实现这个软件中的各种实用功能。
该软件是使用.NET 技术开发的。为了回馈社会,特开设软件使用的核心技术专栏,为广大技术爱好者写了一系列文章。
本系列文章不仅讲解了网络采集、编辑、发布中用到的各种重要技术,还提供了很多界面开发中的解题思路和编程经验。非常适合.NET开发的初学者和中级读者。希望请多多支持。
很多初学者经常会有这样的困惑,“为什么我看了这本书,对C#的方方面面都了解了,却写不出一个像样的应用程序?”,
其实我还没有学会综合运用所学的知识,锻炼编程思维,建立学习的兴趣。我认为这个系列文章 可以帮助你,我希望如此。
开发环境:VS2008
本节源码位置:
源码下载方法:安装SVN客户端(文末提供下载地址),然后查看以下地址:
文章系列大纲如下:
网络采集软件核心技术解析系列(1)---如何使用C#语言获取博客园中某博主的所有文章链接和标题
网络采集软件核心技术解析系列(2)---如何使用C#语言获取任意站点博文的正文和标题
网络采集软件核心技术解析系列(3)---如何用C#语言将博文中的所有图片下载到本地并离线浏览
网络采集软件核心技术解析系列(4)---如何使用C#语言将html网页转换成pdf(html2pdf)
网络采集软件核心技术解析系列(5)---将任意博主的所有博文下载到内存中,通过Webbrower展示
网络采集软件核心技术分析系列(6)---将任何博主的所有博文下载到SQLite数据库中,通过Webbrower展示
网络采集软件核心技术解析系列(7)---如何使用C#语言搭建程序框架(经典Winform界面、菜单栏、树形列表、多标签界面)
网络采集软件核心技术解析系列(综合实例)
2、第七节主要内容介绍(如何使用C#语言搭建程序框架(经典Winform界面,顶部菜单栏,工具栏,左侧树形列表,右侧多个Tab界面))
如何使用C#语言搭建程序框架(经典Winform界面,顶部菜单栏,工具栏,左侧树状列表,右侧多个Tab界面)解决方案,演示如下图:可执行文件下载
演示功能介绍:
程序启动后,扫描程序所在目录的WebSiteDB文件夹(见上一节,里面存放着每个博主的所有博文和xxx.db文件),在左边的树形控件上加载数据库名称; 双击树控件为子节点,在右侧添加类似浏览器的标签界面。在新打开的界面中,会自动加载博主的博文列表信息。
三个基本原则
这个简单的框架有三个要点:
1. 递归加载树控制节点;
2. 右侧tab窗体的创建(主要使用大名鼎鼎的WeifenLuo.WinFormsUI.Docking.dll);
3. 单击树节点打开一个新窗口(前两者的组合)。
先看第一点,树控件节点的递归加载,主要代码如下:
private void LoadWebSiteTree()
{
this.treeViewTask.Nodes.Clear();
TreeNode nodeRoot = new TreeNode();
nodeRoot.Text = "站点列表";
nodeRoot.Tag = -1;
this.treeViewTask.Nodes.Add(nodeRoot);
GetSubDirectoryNodes(nodeRoot, m_strDBFolder,true);
this.treeViewTask.SelectedNode = this.treeViewTask.TopNode;
}
创建根节点,然后调用GetSubDirectoryNodes函数递归加载子节点:
private void GetSubDirectoryNodes(TreeNode parentNode, string fullName, bool getFileNames)
{
if (!Directory.Exists(fullName))
{
Directory.CreateDirectory(fullName);
}
DirectoryInfo dir = new DirectoryInfo(fullName);
DirectoryInfo[] dirSubs = dir.GetDirectories();
// 为每个子目录添加一个子节点
foreach (DirectoryInfo dirSub in dirSubs)
{
// 不显示隐藏文件夹
if ((dirSub.Attributes & FileAttributes.Hidden) != 0)
{
continue;
}
TreeNode node = new TreeNode();
node.Text = dirSub.Name;
node.Tag = 0;
node.ImageIndex = 0;
parentNode.Nodes.Add(node);
// 递归调用
GetSubDirectoryNodes(node, dirSub.FullName, getFileNames);
}
// 为每个子目录添加一个子节点
foreach (DirectoryInfo dirSub in dirSubs)
{
// 不显示隐藏文件夹
if ((dirSub.Attributes & FileAttributes.Hidden) != 0)
{
continue;
}
}
if (getFileNames) // 书中源码中,这部分在foreach内部,不正确
{
// 获取此节点的所有文件
FileInfo[] files = dir.GetFiles();
// 放置节点后。放置子目录中的文件。
foreach (FileInfo file in files)
{
if (file.Extension.ToString() != ".db")
continue;
string strNodeName = file.Name.Remove(file.Name.Length - 3, 3);
if (strNodeName == "home")
continue;
TreeNode node = new TreeNode();
node.Text = strNodeName;
node.Tag = 1;
node.ImageIndex = 1;
parentNode.Nodes.Add(node);
}
}
}
接下来看第二点,2.右侧的tab窗体的创建(主要使用大名鼎鼎的WeifenLuo.WinFormsUI.Docking.dll),主要代码如下:
public DockContent ShowContent(string caption/*, Type formType*/)
{
DockContent frm = FindDocument(caption);
if (frm == null)
{
Frm_TargetUrlView frm_TargetUrlView = new Frm_TargetUrlView((string)this.treeViewTask.SelectedNode.Parent.Text
, m_strDBConStringPath + m_strTreeNodeName
, (string)this.treeViewTask.SelectedNode.Text, this);
frm_TargetUrlView.MdiParent = this;
frm_TargetUrlView.WindowState = FormWindowState.Maximized;
frm_TargetUrlView.Show(this.dockPanel1);
frm_TargetUrlView.Focus();
frm_TargetUrlView.BringToFront();
return frm_TargetUrlView;
}
frm.Show(this.dockPanel1);
frm.Focus();
frm.BringToFront();
return frm;
}
首先调用FindDocument(caption)判断当前标签窗口是否已经打开,如果已经打开,则激活它;如果尚未打开,则创建一个新的选项卡窗口并使这个新创建的窗口成为活动窗口。
3. 单击树节点打开一个新窗口(前两者的组合)。主要代码如下:
private void treeViewTask_MouseDoubleClick(object sender, MouseEventArgs e)
{
Point pos = new Point(e.X, e.Y);
TreeNode nodeClick = this.treeViewTask.GetNodeAt(pos);
if (nodeClick.Text == "站点列表")
{
this.treeViewTask.ContextMenuStrip = null;
return;
}
if (nodeClick != null && e.Button == MouseButtons.Left)
{
int nTag = (int)nodeClick.Tag;
if (nTag == 0)
return;
this.treeViewTask.SelectedNode = nodeClick;
LoadInfoByNode();
}
ShowContent(this.treeViewTask.SelectedNode.Text);
}
在树节点的双击处理函数中,调用上面第二步的ShowContent函数,就会弹出对应的tab窗体。
更详细的代码请自行下载学习。
工具采集文章(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-04 05:10
大数据的来源有很多。在大数据时代背景下,如何从大数据中采集是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据阶段的工作采集是大数据的核心技术之一。为了高效地采集大数据,根据采集环境和数据类型选择合适的大数据采集方法和平台很重要。下面介绍一些常用的大数据采集平台和工具。
1 水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着Flume的不断完善,用户在开发过程中的便利性得到了极大的提升,Flume现在已经成为Apache Top项目之一。
Flume 提供了从 Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog 和 Exec(命令执行)等数据源采集数据的能力。
Flume 使用多 Master 方法。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身可以保证配置数据的一致性和高可用。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。使用 Gossip 协议在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集场景。由于 Flume 使用 JRuby 构建,因此它依赖于 Java 运行时环境。Flume 被设计为分布式管道架构,可以看作是数据源和目的地之间的 Agent 网络,支持数据路由。
Flume支持设置Sink的Failover和负载均衡,这样可以保证在Agent发生故障的情况下,整个系统仍然可以正常采集数据。Flume中传输的内容定义为一个事件,它由Headers(包括元数据,即Meta Data)和Payload组成。
Flume提供SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume Agent。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端有 Avro、Log4J、Syslog 和 HTTP Post。
2 流利
Fluentd是另一种开源的数据采集架构,如图1所示。Fluentd是用C/Ruby开发的,使用JSON文件统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,可以非常轻松地实现跟踪日志文件并对其进行过滤并将其转储到 MongoDB 等操作。Fluentd 可以完全将人们从繁琐的日志处理中解放出来。
图 1 Fluentd 架构
Fluentd 具有多个特点:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用JSON统一数据/日志格式是它的另一个特点。与Flume相比,Fluentd的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Fluent 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3 日志存储
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以它在运行时依赖于 JVM。Logstash的部署架构如图3所示,当然这只是一个部署选项。
图3 Logstash部署架构
一个典型的Logstash配置如下,包括Filter的Input和Output的设置。
输入 {
文件 {
类型 =>“Apache 访问”
路径 =>"/var/log/Apache2/other_vhosts_access.log"
}
文件 {
类型 =>“补丁错误”
路径 =>"/var/log/Apache2/error.log"
}
}
筛选 {
神通{
匹配 => {"message"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出{}
Redis {
主机=>“192.168.1.289”
数据类型 =>“列表”
键 => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。如果您的数据系统使用 ElasticSearch,Logstash 是首选。
4 楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,名气远不如其他平台。Chukwa 基于 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)构建,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据的显示、分析和监控。该项目目前处于非活动状态。
Chukwa 适应以下需求:
(1) 灵活、动态、可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)分析采集到的大规模数据的适当框架。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5 抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。它的官方网站已经很多年没有维护了。Scribe 为日志的“分布式采集、统一处理”提供了可扩展、高容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS,Hadoop 通过 MapReduce 作业进行定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe架构比较简单,主要包括三部分,分别是Scribe agent、Scribe和存储系统。
6 Splunk
在商业化的大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要作用。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,提供搜索过程中的信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、转换,并发送到Indexer。
Splunk 具有对 Syslog、TCP/UDP 和假脱机的内置支持。同时,用户可以通过开发Input和Modular Input来获取具体的数据。Splunk提供的软件仓库中有很多成熟的数据应用,如AWS、数据库(DBConnect)等,可以方便地从云端或数据库中获取数据,进入Splunk的数据平台进行分析。
Search Head 和Indexer 都支持Cluster 的配置,具有高可用和高扩展性,但Splunk 尚不具备Cluster for Forwarder 的功能。换句话说,如果一台 Forwarder 机器出现故障,数据采集会中断,并且正在运行的数据采集任务无法因故障转移而切换到其他 Forwarder。
7 Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一种由 Python 语言开发的快速、高级的屏幕抓取和网页抓取架构,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据自己的需要轻松修改的架构。它还提供了多种爬虫的基类,如BaseSpider、Sitemap爬虫等,最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 工作原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy的运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫得到第一个爬取到的URL。
(2)Scrapy 引擎首先从爬虫那里获取需要爬取的第一个 URL,然后在调度中作为请求进行调度。
(3)Scrapy 引擎从调度器中获取下一个要爬取的页面。
(4)调度返回下一个爬取的URL给引擎,引擎通过下载中间件发送给下载器。
(5) 当网页被下载器下载时,响应内容通过下载器中间件发送到 Scrapy 引擎。
(6)Scrapy 引擎收到下载器的响应,通过爬虫中间件发送给爬虫处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将捕获的项目放入项目管道,并向调度程序发送请求。
(9)系统重复以下步骤(2))的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。 查看全部
工具采集文章(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据的来源有很多。在大数据时代背景下,如何从大数据中采集是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据阶段的工作采集是大数据的核心技术之一。为了高效地采集大数据,根据采集环境和数据类型选择合适的大数据采集方法和平台很重要。下面介绍一些常用的大数据采集平台和工具。
1 水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着Flume的不断完善,用户在开发过程中的便利性得到了极大的提升,Flume现在已经成为Apache Top项目之一。
Flume 提供了从 Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog 和 Exec(命令执行)等数据源采集数据的能力。
Flume 使用多 Master 方法。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身可以保证配置数据的一致性和高可用。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。使用 Gossip 协议在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集场景。由于 Flume 使用 JRuby 构建,因此它依赖于 Java 运行时环境。Flume 被设计为分布式管道架构,可以看作是数据源和目的地之间的 Agent 网络,支持数据路由。
Flume支持设置Sink的Failover和负载均衡,这样可以保证在Agent发生故障的情况下,整个系统仍然可以正常采集数据。Flume中传输的内容定义为一个事件,它由Headers(包括元数据,即Meta Data)和Payload组成。
Flume提供SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume Agent。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端有 Avro、Log4J、Syslog 和 HTTP Post。
2 流利
Fluentd是另一种开源的数据采集架构,如图1所示。Fluentd是用C/Ruby开发的,使用JSON文件统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,可以非常轻松地实现跟踪日志文件并对其进行过滤并将其转储到 MongoDB 等操作。Fluentd 可以完全将人们从繁琐的日志处理中解放出来。

图 1 Fluentd 架构
Fluentd 具有多个特点:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用JSON统一数据/日志格式是它的另一个特点。与Flume相比,Fluentd的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Fluent 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。

图 2 Fluentd 架构
3 日志存储
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以它在运行时依赖于 JVM。Logstash的部署架构如图3所示,当然这只是一个部署选项。

图3 Logstash部署架构
一个典型的Logstash配置如下,包括Filter的Input和Output的设置。
输入 {
文件 {
类型 =>“Apache 访问”
路径 =>"/var/log/Apache2/other_vhosts_access.log"
}
文件 {
类型 =>“补丁错误”
路径 =>"/var/log/Apache2/error.log"
}
}
筛选 {
神通{
匹配 => {"message"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出{}
Redis {
主机=>“192.168.1.289”
数据类型 =>“列表”
键 => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。如果您的数据系统使用 ElasticSearch,Logstash 是首选。
4 楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,名气远不如其他平台。Chukwa 基于 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)构建,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据的显示、分析和监控。该项目目前处于非活动状态。
Chukwa 适应以下需求:
(1) 灵活、动态、可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)分析采集到的大规模数据的适当框架。
Chukwa 架构如图 4 所示。

图 4 Chukwa 架构
5 抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。它的官方网站已经很多年没有维护了。Scribe 为日志的“分布式采集、统一处理”提供了可扩展、高容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS,Hadoop 通过 MapReduce 作业进行定期处理。
Scribe 架构如图 5 所示。

图 5 Scribe 架构
Scribe架构比较简单,主要包括三部分,分别是Scribe agent、Scribe和存储系统。
6 Splunk
在商业化的大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要作用。Splunk 架构如图 6 所示。

图 6 Splunk 架构
搜索:负责数据的搜索和处理,提供搜索过程中的信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、转换,并发送到Indexer。
Splunk 具有对 Syslog、TCP/UDP 和假脱机的内置支持。同时,用户可以通过开发Input和Modular Input来获取具体的数据。Splunk提供的软件仓库中有很多成熟的数据应用,如AWS、数据库(DBConnect)等,可以方便地从云端或数据库中获取数据,进入Splunk的数据平台进行分析。
Search Head 和Indexer 都支持Cluster 的配置,具有高可用和高扩展性,但Splunk 尚不具备Cluster for Forwarder 的功能。换句话说,如果一台 Forwarder 机器出现故障,数据采集会中断,并且正在运行的数据采集任务无法因故障转移而切换到其他 Forwarder。
7 Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一种由 Python 语言开发的快速、高级的屏幕抓取和网页抓取架构,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据自己的需要轻松修改的架构。它还提供了多种爬虫的基类,如BaseSpider、Sitemap爬虫等,最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。

图 7 Scrapy 工作原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy的运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫得到第一个爬取到的URL。
(2)Scrapy 引擎首先从爬虫那里获取需要爬取的第一个 URL,然后在调度中作为请求进行调度。
(3)Scrapy 引擎从调度器中获取下一个要爬取的页面。
(4)调度返回下一个爬取的URL给引擎,引擎通过下载中间件发送给下载器。
(5) 当网页被下载器下载时,响应内容通过下载器中间件发送到 Scrapy 引擎。
(6)Scrapy 引擎收到下载器的响应,通过爬虫中间件发送给爬虫处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将捕获的项目放入项目管道,并向调度程序发送请求。
(9)系统重复以下步骤(2))的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
工具采集文章(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-01 12:22
可以免费下载还是可以直接将VIP会员资源商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:你可以对比下载后压缩包的容量和网盘的容量,如果小于网盘标示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专享、全站源码、程序插件、网站模板、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源 查看全部
工具采集文章(免费下载或者VIP会员资源能否直接商用?浏览器下载)
可以免费下载还是可以直接将VIP会员资源商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:你可以对比下载后压缩包的容量和网盘的容量,如果小于网盘标示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专享、全站源码、程序插件、网站模板、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源
工具采集文章(工具采集文章速度较慢,一些细节错误、结构错误)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-15 01:03
工具采集文章速度较慢,一些细节错误、结构错误也不易发现,自动采集有一定弊端,建议客户用人工采集慢慢修改,效率能提高不少,并且自动采集是不能保存,修改完成后得自己手动再提交下获取通过。核心功能功能1:原创文章自动生成机器文章功能2:自动布局正文功能3:自动排版文章功能4:自动标题生成机器文章功能5:自动收录,收录一次自动布局1~2篇文章功能6:ai,自动打标签机器文章功能7:手动挖掘关键词,自动关键词挖掘机器文章功能8:自动长尾词挖掘机器文章功能9:伪原创机器文章功能10:正则引擎,自动内容过滤机器文章功能11:h5模板,自动内容填充机器文章功能12:头条自动推荐,自动推荐机器文章功能13:伪原创机器文章功能14:发文批量删改标题功能15:文章关键词标签自动填充功能16:文章分类自动命名功能17:搜索以前发布的链接自动添加功能18:定时发文功能19:定时发文模块20:计时器自动定时发文功能21:定时发文管理自动发文功能22:ai自动标签机器文章功能23:文章分析机器文章功能24:自动发文规律机器文章功能25:自动上传图片、视频文件功能26:文章自动获取关键词,导入公众号文章库自动获取关键词17个ai,新建一个本地库ai采集会话时,我们正在收听,检测时刻另一种模式可以使用点击麦克风,并开始录音。然后我们所有的回答在麦克风上传。 查看全部
工具采集文章(工具采集文章速度较慢,一些细节错误、结构错误)
工具采集文章速度较慢,一些细节错误、结构错误也不易发现,自动采集有一定弊端,建议客户用人工采集慢慢修改,效率能提高不少,并且自动采集是不能保存,修改完成后得自己手动再提交下获取通过。核心功能功能1:原创文章自动生成机器文章功能2:自动布局正文功能3:自动排版文章功能4:自动标题生成机器文章功能5:自动收录,收录一次自动布局1~2篇文章功能6:ai,自动打标签机器文章功能7:手动挖掘关键词,自动关键词挖掘机器文章功能8:自动长尾词挖掘机器文章功能9:伪原创机器文章功能10:正则引擎,自动内容过滤机器文章功能11:h5模板,自动内容填充机器文章功能12:头条自动推荐,自动推荐机器文章功能13:伪原创机器文章功能14:发文批量删改标题功能15:文章关键词标签自动填充功能16:文章分类自动命名功能17:搜索以前发布的链接自动添加功能18:定时发文功能19:定时发文模块20:计时器自动定时发文功能21:定时发文管理自动发文功能22:ai自动标签机器文章功能23:文章分析机器文章功能24:自动发文规律机器文章功能25:自动上传图片、视频文件功能26:文章自动获取关键词,导入公众号文章库自动获取关键词17个ai,新建一个本地库ai采集会话时,我们正在收听,检测时刻另一种模式可以使用点击麦克风,并开始录音。然后我们所有的回答在麦克风上传。
工具采集文章(网站更新文章都有哪些规律?网络小编来给您解答)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-10-14 04:30
很多朋友在网站seo优化过程中遇到了一些网站优化问题,包括《seo文章采集工具:SEO更新文章都有哪些规则?》问题,那我搜索下面的网络编辑器来回答你的疑惑。
网站更新文章是SEO优化操作中比较重要的任务。大多数网站没做好SEO是因为他们没有做好网站文章更新,但是网站经常更新文章你能做SEO优化吗?为什么很多人几个月就更新了文章,却没有增加一点排名?可能没用。
内容丰富
获取搜索引擎采集的大量内容也很困难。在 Internet 上搜索 文章 重复项。其中大部分已在一些高性能平台上发布。搜索引擎也有相同的数据,因此搜索引擎不会抓取搜索。当然,可能有人会问,为什么别人的采集会增加重量,而自己的采集会减少力量呢?事实上,值得学习的因素有很多。例如,他人采集的内容经过优化处理后发布,或者他人采集的内容是比较新的内容。原创属性和时效性比较高,用户参考价值比较大,所以可以增加网站的权重。
所以,如果单纯的粘贴复制,那么这种偷懒的采集方式难免会受到搜索引擎的惩罚。seo采集 工具。
2.网站上更新的文章多为图片无文字说明
网站 的处理和布局对加载速度也有很大影响。如果服务器不是太大的问题,如果你使用别人的服务器,那么图片加载速度就成了一个大问题。在很多企业网站中,大部分内容更新都是产品,只放了部分产品图片,没有具体位置说明。搜索引擎根本无法识别图片。如果图片尺寸过大,也会影响加载速度。同时,文章更新必须有文字说明,更新文章必须坚持“以文字图片为补充”的原则。
3. 文章内无内链
要不要在更新底部留个链接文章?你要不要做以下相关的事情文章?所有这些问题都是大多数 SEOer 争论的主题。有人说不能添加,降低了每页的重复率。有人说需要添加,这样每个内页可以相互传递权重,同时增加用户体验,促进包容性。
seo文章采集工具:如何批量SEO站长采集文章
小编认为在文章底部添加文字链接利大于弊。在文章之后也需要添加相关性,但是要避免关键词堆叠的操作,否则内部链接弊大于利。
四、文章不确定更新重点方向
很多人更新文章的内容,没有结合数据就盲目更新,没有根据用户的基本搜索需求来写内容,或者还是保持着线下推广的思路。很多人直接用什么样的活动打折,然后放个二维码是如何吸引用户眼球的?很多聪明的公司已经抛开传统的线下销售思维,在网站的推广中转变了思路。seo文章 工具。seo文章采集工具
首先了解用户进行网络推广的目的?是通过互联网销售产品,用户不能满足面对面的条件,所以用户有选择的权利。他们希望用户在他们的时间选择我们。无需专人扫描二维码或致电咨询,以简单的形式呈现给客户。让客户一目了然地找到他们想要的东西。以产品内容为例。产品是一个关键点。然后我们要考虑用户关心什么。产品参数、价格和质量。
五、文章关键词匹配问题
文章关键词中的匹配也是优化工作的一个重要部分。大多数人都知道布局关键词的重要性。这里文方阁建议在文章标题中合理列出关键词,然后关键词合理出现在第一段和最后一段,属性ALT图片也可以合理出现关键词@ >,这使得搜索引擎更容易识别文章的核心关键词,并给出具体的关键词排名。ecshop文章seo.
6. 定期规则更新
文章为什么要更新,要注意规律?很多人想一次性发布所有文章,然后就不管了,所以很难开发出搜索引擎蜘蛛定时抓取和收录的效果,定时更新也很重要。首先通过网站日志分析进行搜索。引擎蜘蛛经常会来网站抓取时间段,找出频率时间段,然后在那个时间段发布。这也可以防止网站的内容被重量级的peer复制。建议更新。
以上是关于seo文章采集工具,SEO更新文章的规则是什么?文章内容,如果您有网站优化的意向,可以直接联系我们。很高兴为您服务! 查看全部
工具采集文章(网站更新文章都有哪些规律?网络小编来给您解答)
很多朋友在网站seo优化过程中遇到了一些网站优化问题,包括《seo文章采集工具:SEO更新文章都有哪些规则?》问题,那我搜索下面的网络编辑器来回答你的疑惑。
网站更新文章是SEO优化操作中比较重要的任务。大多数网站没做好SEO是因为他们没有做好网站文章更新,但是网站经常更新文章你能做SEO优化吗?为什么很多人几个月就更新了文章,却没有增加一点排名?可能没用。
内容丰富
获取搜索引擎采集的大量内容也很困难。在 Internet 上搜索 文章 重复项。其中大部分已在一些高性能平台上发布。搜索引擎也有相同的数据,因此搜索引擎不会抓取搜索。当然,可能有人会问,为什么别人的采集会增加重量,而自己的采集会减少力量呢?事实上,值得学习的因素有很多。例如,他人采集的内容经过优化处理后发布,或者他人采集的内容是比较新的内容。原创属性和时效性比较高,用户参考价值比较大,所以可以增加网站的权重。
所以,如果单纯的粘贴复制,那么这种偷懒的采集方式难免会受到搜索引擎的惩罚。seo采集 工具。
2.网站上更新的文章多为图片无文字说明
网站 的处理和布局对加载速度也有很大影响。如果服务器不是太大的问题,如果你使用别人的服务器,那么图片加载速度就成了一个大问题。在很多企业网站中,大部分内容更新都是产品,只放了部分产品图片,没有具体位置说明。搜索引擎根本无法识别图片。如果图片尺寸过大,也会影响加载速度。同时,文章更新必须有文字说明,更新文章必须坚持“以文字图片为补充”的原则。
3. 文章内无内链
要不要在更新底部留个链接文章?你要不要做以下相关的事情文章?所有这些问题都是大多数 SEOer 争论的主题。有人说不能添加,降低了每页的重复率。有人说需要添加,这样每个内页可以相互传递权重,同时增加用户体验,促进包容性。

seo文章采集工具:如何批量SEO站长采集文章
小编认为在文章底部添加文字链接利大于弊。在文章之后也需要添加相关性,但是要避免关键词堆叠的操作,否则内部链接弊大于利。
四、文章不确定更新重点方向
很多人更新文章的内容,没有结合数据就盲目更新,没有根据用户的基本搜索需求来写内容,或者还是保持着线下推广的思路。很多人直接用什么样的活动打折,然后放个二维码是如何吸引用户眼球的?很多聪明的公司已经抛开传统的线下销售思维,在网站的推广中转变了思路。seo文章 工具。seo文章采集工具
首先了解用户进行网络推广的目的?是通过互联网销售产品,用户不能满足面对面的条件,所以用户有选择的权利。他们希望用户在他们的时间选择我们。无需专人扫描二维码或致电咨询,以简单的形式呈现给客户。让客户一目了然地找到他们想要的东西。以产品内容为例。产品是一个关键点。然后我们要考虑用户关心什么。产品参数、价格和质量。
五、文章关键词匹配问题
文章关键词中的匹配也是优化工作的一个重要部分。大多数人都知道布局关键词的重要性。这里文方阁建议在文章标题中合理列出关键词,然后关键词合理出现在第一段和最后一段,属性ALT图片也可以合理出现关键词@ >,这使得搜索引擎更容易识别文章的核心关键词,并给出具体的关键词排名。ecshop文章seo.
6. 定期规则更新
文章为什么要更新,要注意规律?很多人想一次性发布所有文章,然后就不管了,所以很难开发出搜索引擎蜘蛛定时抓取和收录的效果,定时更新也很重要。首先通过网站日志分析进行搜索。引擎蜘蛛经常会来网站抓取时间段,找出频率时间段,然后在那个时间段发布。这也可以防止网站的内容被重量级的peer复制。建议更新。
以上是关于seo文章采集工具,SEO更新文章的规则是什么?文章内容,如果您有网站优化的意向,可以直接联系我们。很高兴为您服务!
工具采集文章(工具采集文章后发布到今日头条,只能算是个搬运工)
采集交流 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2021-10-12 10:03
工具采集文章后发布到今日头条,只要不发布到自媒体平台,只能算是个搬运工,并不是原创,也不会有广告收益。工具采集的文章仅仅保留标题、简介、内容等关键信息,并且无法关联到其他自媒体平台进行发布,被识别出来的机率很高。
前几天平台刚封,估计后面就不封了,这是传说中的,
可以的,我有个朋友在做这个,我看他每天2-3万左右收益,
根据什么原因封的,是平台对你违规的,还是你提供的素材不合规,有没有提供原创文章。
写什么东西,最好能发在什么地方,标题,关键词,要包含公众号文章中的,信息点,抄袭的时候最好用软件。
是正常的,因为现在的自媒体平台有很多账号审核是偏严格的,你提供的内容可能有抄袭,如果你能快速的做出原创内容,可以破原创的,如果审核不严格,一篇随便写个三五百字的文章,它可能也不会封你。
你好,你已经可以正常注册自媒体平台,比如今日头条、企鹅号、搜狐、网易等平台都是可以正常注册的,都需要个人身份证,企业提供法人,要去一些支持个人注册的平台去申请,有的平台,比如百家号已经出现大量抄袭账号的情况,所以建议先集中准备几个平台,以备不时之需。
可以,不用担心,收益都正常, 查看全部
工具采集文章(工具采集文章后发布到今日头条,只能算是个搬运工)
工具采集文章后发布到今日头条,只要不发布到自媒体平台,只能算是个搬运工,并不是原创,也不会有广告收益。工具采集的文章仅仅保留标题、简介、内容等关键信息,并且无法关联到其他自媒体平台进行发布,被识别出来的机率很高。
前几天平台刚封,估计后面就不封了,这是传说中的,
可以的,我有个朋友在做这个,我看他每天2-3万左右收益,
根据什么原因封的,是平台对你违规的,还是你提供的素材不合规,有没有提供原创文章。
写什么东西,最好能发在什么地方,标题,关键词,要包含公众号文章中的,信息点,抄袭的时候最好用软件。
是正常的,因为现在的自媒体平台有很多账号审核是偏严格的,你提供的内容可能有抄袭,如果你能快速的做出原创内容,可以破原创的,如果审核不严格,一篇随便写个三五百字的文章,它可能也不会封你。
你好,你已经可以正常注册自媒体平台,比如今日头条、企鹅号、搜狐、网易等平台都是可以正常注册的,都需要个人身份证,企业提供法人,要去一些支持个人注册的平台去申请,有的平台,比如百家号已经出现大量抄袭账号的情况,所以建议先集中准备几个平台,以备不时之需。
可以,不用担心,收益都正常,
工具采集文章(工具采集文章分享一下我的方法,中国移动的大数据api免费接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-10-11 16:15
工具采集文章分享一下我的方法,中国移动的大数据api免费接口,内容为5万篇移动端文章信息,支持手机端查看api,请点击,查看下载地址还有微信文章,文章内容在哪个文章详情内容,经过工具抓取和清洗清洗工具功能:过滤图片、分词、对齐去重提取时间列表信息抓取头图,工具里面有下载地址数据格式:高频词、重复词、尾词对应文章频次抓取抓取特定主题的信息工具设置:模拟用户点击,到工具页面多端查看更新文章不同时间点、不同地点、不同页面页面,个人用户免费,大量成本自行承担移动端抓取工具:抓取工具一览,内容采集工具站内信获取微信公众号对接地址自行下载基本抓取常规需求我大致做了下,第一遍抓取是你最基本需求,后续都是你的进阶需求。
另外可以通过二维码来抓取跳转h5链接,而且可以提取微信推文。抓取的时候不要按照我的记录定时抓取,工具抓取效率比较差,自己设置定时抓取,抓取的地址自己填写(抓取地址一般在工具中的站内信获取或者通过应用市场获取)。
应用商店直接搜索
fiddler,手机万能扫描器,足够了。
fiddler这个是我一直在用的工具,不过最近发现手机扫描器,也能达到这样的效果,例如:要抓取微信公众号文章a文章内容,那么就是抓取公众号指定文章的内容。fiddler配置和方法(需要先安装fiddler运行环境)如果做得比较精确的话,还可以再将文章指定目录下载下来, 查看全部
工具采集文章(工具采集文章分享一下我的方法,中国移动的大数据api免费接口)
工具采集文章分享一下我的方法,中国移动的大数据api免费接口,内容为5万篇移动端文章信息,支持手机端查看api,请点击,查看下载地址还有微信文章,文章内容在哪个文章详情内容,经过工具抓取和清洗清洗工具功能:过滤图片、分词、对齐去重提取时间列表信息抓取头图,工具里面有下载地址数据格式:高频词、重复词、尾词对应文章频次抓取抓取特定主题的信息工具设置:模拟用户点击,到工具页面多端查看更新文章不同时间点、不同地点、不同页面页面,个人用户免费,大量成本自行承担移动端抓取工具:抓取工具一览,内容采集工具站内信获取微信公众号对接地址自行下载基本抓取常规需求我大致做了下,第一遍抓取是你最基本需求,后续都是你的进阶需求。
另外可以通过二维码来抓取跳转h5链接,而且可以提取微信推文。抓取的时候不要按照我的记录定时抓取,工具抓取效率比较差,自己设置定时抓取,抓取的地址自己填写(抓取地址一般在工具中的站内信获取或者通过应用市场获取)。
应用商店直接搜索
fiddler,手机万能扫描器,足够了。
fiddler这个是我一直在用的工具,不过最近发现手机扫描器,也能达到这样的效果,例如:要抓取微信公众号文章a文章内容,那么就是抓取公众号指定文章的内容。fiddler配置和方法(需要先安装fiddler运行环境)如果做得比较精确的话,还可以再将文章指定目录下载下来,
工具采集文章(一点资讯登录文章评论采集器(文章批量采集工具)使用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-10-11 11:18
易点信息登录文章评论采集器(文章Batch采集Tool)是官方专门为易点信息文章Batch推出的一款非常实用的工具采集 软件。您在寻找简单实用的文章批处理采集软件吗?那就来绿先锋下载一点资料,登录文章评论采集器使用最新版本。支持批量采集单点信息文章评论。爬取的数据包括文章标题、文章内容、文章封面、作者、作者头像、评论编号、评论、文章链接、文章分类、关键词等
软件说明
您可以自定义您想要采集的频道或文章关键字,并且您可以同时采集多个关键字或频道文章。
软件功能
1、分布式云爬虫,采集不间断
24小时不间断运行,关机也能采集;分布式云爬虫,可按需扩展,更适合大规模爬虫!
2、海量私有代理IP,智能抓取
自动访问私有代理IP,批量稳定抓取数据!
3、多种数据导出和发布方式
可以导出到Excel等文件,发布到数据库或者cms网站;还支持Webhooks推送、Restful接口、GraphQL访问等高级功能,与您现有系统无缝对接!
4、版本更新,一键在线升级
获取爬虫后,如有更新版本或修改,可在优采云控制台点击“更新”一键升级!
5、一站式大数据采集,清洗+机器学习
对爬取的数据进行统一可视化管理,优采云还提供了更多的数据分析处理功能:包括数据清洗和机器学习~ 查看全部
工具采集文章(一点资讯登录文章评论采集器(文章批量采集工具)使用)
易点信息登录文章评论采集器(文章Batch采集Tool)是官方专门为易点信息文章Batch推出的一款非常实用的工具采集 软件。您在寻找简单实用的文章批处理采集软件吗?那就来绿先锋下载一点资料,登录文章评论采集器使用最新版本。支持批量采集单点信息文章评论。爬取的数据包括文章标题、文章内容、文章封面、作者、作者头像、评论编号、评论、文章链接、文章分类、关键词等
软件说明
您可以自定义您想要采集的频道或文章关键字,并且您可以同时采集多个关键字或频道文章。
软件功能
1、分布式云爬虫,采集不间断
24小时不间断运行,关机也能采集;分布式云爬虫,可按需扩展,更适合大规模爬虫!
2、海量私有代理IP,智能抓取
自动访问私有代理IP,批量稳定抓取数据!
3、多种数据导出和发布方式
可以导出到Excel等文件,发布到数据库或者cms网站;还支持Webhooks推送、Restful接口、GraphQL访问等高级功能,与您现有系统无缝对接!
4、版本更新,一键在线升级
获取爬虫后,如有更新版本或修改,可在优采云控制台点击“更新”一键升级!
5、一站式大数据采集,清洗+机器学习
对爬取的数据进行统一可视化管理,优采云还提供了更多的数据分析处理功能:包括数据清洗和机器学习~
工具采集文章(《灵棺夜行代码》第2季第16集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-08 00:19
本文将与大家分享使用Python制作爬虫的代码。采集小说代码非常简单实用。虽然还是有点瑕疵,但我们一起改变,一起进步
开发工具:python3.4
操作系统:win8
主要功能:到指定的小说网页抓取小说目录,按章节保存在本地,并将抓取到的网页保存到本地配置文件中。
爬行网站:
小说名称:灵棺夜行
代码来源:我自己编写的
import urllib.request
import http.cookiejar
import socket
import time
import re
timeout = 20
socket.setdefaulttimeout(timeout)
sleep_download_time = 10
time.sleep(sleep_download_time)
def makeMyOpener(head = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
def saveFile(save_path,txts):
f_obj = open(save_path,'w+')
for item in txts:
f_obj.write(item+'\n')
f_obj.close()
#get_code_list
code_list='http://www.cishuge.com/read/0/771/'
oper = makeMyOpener()
uop = oper.open(code_list,timeout=1000)
data = uop.read().decode('gbk','ignore')
pattern = re.compile('(.*?)',re.S)
items = re.findall(pattern,data)
print ('获取列表完成')
url_path='url_file.txt'
url_r=open(url_path,'r')
url_arr=url_r.readlines(100000)
url_r.close()
print (len(url_arr))
url_file=open(url_path,'a')
print ('获取已下载网址')
for tmp in items:
save_path = tmp[1].replace(' ','')+'.txt'
url = code_list+tmp[0]
if url+'\n' in url_arr:
continue
print('写日志:'+url+'\n')
url_file.write(url+'\n')
opene = makeMyOpener()
op1 = opene.open(url,timeout=1000)
data = op1.read().decode('gbk','ignore')
opene.close()
pattern = re.compile(' (.*?)<br />',re.S)
txts = re.findall(pattern,data)
saveFile(save_path,txts)
url_file.close()
虽然代码还是有点瑕疵,分享给大家,一起改进 查看全部
工具采集文章(《灵棺夜行代码》第2季第16集)
本文将与大家分享使用Python制作爬虫的代码。采集小说代码非常简单实用。虽然还是有点瑕疵,但我们一起改变,一起进步
开发工具:python3.4
操作系统:win8
主要功能:到指定的小说网页抓取小说目录,按章节保存在本地,并将抓取到的网页保存到本地配置文件中。
爬行网站:
小说名称:灵棺夜行
代码来源:我自己编写的
import urllib.request
import http.cookiejar
import socket
import time
import re
timeout = 20
socket.setdefaulttimeout(timeout)
sleep_download_time = 10
time.sleep(sleep_download_time)
def makeMyOpener(head = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
def saveFile(save_path,txts):
f_obj = open(save_path,'w+')
for item in txts:
f_obj.write(item+'\n')
f_obj.close()
#get_code_list
code_list='http://www.cishuge.com/read/0/771/'
oper = makeMyOpener()
uop = oper.open(code_list,timeout=1000)
data = uop.read().decode('gbk','ignore')
pattern = re.compile('(.*?)',re.S)
items = re.findall(pattern,data)
print ('获取列表完成')
url_path='url_file.txt'
url_r=open(url_path,'r')
url_arr=url_r.readlines(100000)
url_r.close()
print (len(url_arr))
url_file=open(url_path,'a')
print ('获取已下载网址')
for tmp in items:
save_path = tmp[1].replace(' ','')+'.txt'
url = code_list+tmp[0]
if url+'\n' in url_arr:
continue
print('写日志:'+url+'\n')
url_file.write(url+'\n')
opene = makeMyOpener()
op1 = opene.open(url,timeout=1000)
data = op1.read().decode('gbk','ignore')
opene.close()
pattern = re.compile(' (.*?)<br />',re.S)
txts = re.findall(pattern,data)
saveFile(save_path,txts)
url_file.close()
虽然代码还是有点瑕疵,分享给大家,一起改进
工具采集文章(浅谈一下中文WP站群的操作步骤及设置模板)
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-09-30 21:14
由于前几天写了一篇《简述英文站群SEO操作》文章的文章,发现转发量疯了,所以今天介绍一下中文WP站群@ > 详细。操作它。
首先说一下为什么要使用WP(wordpress)。因为WP功能强大,插件多,代码简单,收录速度快,在SE上也有一定的分量,所以在国外已经被广泛使用,但是国内一些个人博客都是基于WP程序搭建的. 相信用过WP的人都知道。而那些玩英文SEO站群的基本上都是用WP来玩自动博客的,哈哈。
接下来,我将一步步为您讲解:
第一步:注册一批域名
我们都知道站群域名必须是多元化的,不能挂在一个后缀下。如果你是新手,我推荐小批量操作。首先注册10个域名,可以是com、net、org、cc、me、tk等等。并且可以按照关键词注册,也可以是一个数字,但是一定要多样化。
第 2 步:租用 VPS 或虚拟主机
一般新手玩站群,大概有10个站,最好租个vps。当然,如果你想要不同的IP段,你也可以租用不同IP的虚拟主机。但是在这里,我建议一定是国外主机,国内主机玩站群的时候会死的很快。
第 3 步:网站 构建
确定好域名和空间后,我们会下载最新版的WP,手动安装。关于FTP工具,我推荐CuteFtp。该工具可以在线修改文件、移动文件、打开更多文件等,界面简洁。
第四步:WP站点设置(重点)
1. 模板主题:同样,模板也需要多样化。您需要设置不同的模板,它是关于您制作的主题的模板。最好使用中文原创或者已经汉化的模板。然后修改部分代码,比如头部和尾部的代码。关于模板下载可以到:
2.插件上传及设置:
(1)Akismet(垃圾邮件拦截插件):该插件默认有WP,开启即可,然后自己申请API key。
(2)All in One SEO Pack(seo插件):这个插件很好用,英文WP和中文WP都适用。可以设置首页,文章页面标题,描述等,不过貌似这个插件设置的描述对百度没有用,可以在WP的摘要上填写描述。
(3)Autoptimize(网站代码的自动压缩):本插件可以压缩网站代码,如css、js、html等,可自行设置。
(4)Dagon Design Sitemap Generator(网站地图插件):这个插件可以设置网站地图。
(5)Google XML Sitemaps(网站地图自动提交):这个插件可以自动生成网站地图并通知google、yahoo等。
(6)GZippy(gzip 压缩):这个不用说了。
(7)Optimize DB(优化数据库):这个就不用说了。
(8)Random Posts 小部件(Random 文章 插件):您可以将随机 文章 添加到侧边栏。
(9)Robots Meta(机器人设置):不用说了。
(10)WordPress相关帖子(相关文章插件):可以在文章页面下设置相关文章。
(11)WP Keyword Link(内链插件):百度可以点击详细设置。
关于插件和WP设置,当然还有更好的插件可以用,可以自己摸索,不要看那么多会晕,全部下载,批量上传,设置在后台就OK了。
第五步:文章采集/批量上传/定时发布(绝密)
由于以上步骤都是手动完成的,所以整个WP的构建比站群软件质量更高。那么,既然我们不需要站群软件,那么如何让采集文章自动更新呢?
答案是优采云采集、博君seo伪原创工具、以及锤子免费登录发布界面。
由于操作比较多,这里暂时不做详细操作,以免文章太长,下次用图文写个实际操作文章。先简单说一下原理。首先使用优采云采集大量文章,然后使用博君seo伪原创工具批量伪原创,最后通过Hammer豁免Log进入发布界面,定时批量发布文章,实现文章的自动发布和定时更新。
第六步:内外链建设
刚才说了,可以使用WP Keyword Link插件,也可以修改single.php同时插入相关字段。外链搭建请参考《中文SEO教程:链接轮》文章,或加我QQ详细讨论。
最后:总结
做站群记得要浮躁,耐心很重要,循序渐进。本文章中描述的操作主要是手动步骤占一半,但质量高于全自动软件。当然,软件也有自己的优点,方便快捷。以后文章我会讲中文站群软件的应用。
上面只是提到了站群的实际步骤。至于站群的策略、广告、链接策略等,还有待商榷。欢迎继续关注黑帽坦克博文。 查看全部
工具采集文章(浅谈一下中文WP站群的操作步骤及设置模板)
由于前几天写了一篇《简述英文站群SEO操作》文章的文章,发现转发量疯了,所以今天介绍一下中文WP站群@ > 详细。操作它。
首先说一下为什么要使用WP(wordpress)。因为WP功能强大,插件多,代码简单,收录速度快,在SE上也有一定的分量,所以在国外已经被广泛使用,但是国内一些个人博客都是基于WP程序搭建的. 相信用过WP的人都知道。而那些玩英文SEO站群的基本上都是用WP来玩自动博客的,哈哈。
接下来,我将一步步为您讲解:
第一步:注册一批域名
我们都知道站群域名必须是多元化的,不能挂在一个后缀下。如果你是新手,我推荐小批量操作。首先注册10个域名,可以是com、net、org、cc、me、tk等等。并且可以按照关键词注册,也可以是一个数字,但是一定要多样化。
第 2 步:租用 VPS 或虚拟主机
一般新手玩站群,大概有10个站,最好租个vps。当然,如果你想要不同的IP段,你也可以租用不同IP的虚拟主机。但是在这里,我建议一定是国外主机,国内主机玩站群的时候会死的很快。
第 3 步:网站 构建
确定好域名和空间后,我们会下载最新版的WP,手动安装。关于FTP工具,我推荐CuteFtp。该工具可以在线修改文件、移动文件、打开更多文件等,界面简洁。
第四步:WP站点设置(重点)
1. 模板主题:同样,模板也需要多样化。您需要设置不同的模板,它是关于您制作的主题的模板。最好使用中文原创或者已经汉化的模板。然后修改部分代码,比如头部和尾部的代码。关于模板下载可以到:
2.插件上传及设置:
(1)Akismet(垃圾邮件拦截插件):该插件默认有WP,开启即可,然后自己申请API key。
(2)All in One SEO Pack(seo插件):这个插件很好用,英文WP和中文WP都适用。可以设置首页,文章页面标题,描述等,不过貌似这个插件设置的描述对百度没有用,可以在WP的摘要上填写描述。
(3)Autoptimize(网站代码的自动压缩):本插件可以压缩网站代码,如css、js、html等,可自行设置。
(4)Dagon Design Sitemap Generator(网站地图插件):这个插件可以设置网站地图。
(5)Google XML Sitemaps(网站地图自动提交):这个插件可以自动生成网站地图并通知google、yahoo等。
(6)GZippy(gzip 压缩):这个不用说了。
(7)Optimize DB(优化数据库):这个就不用说了。
(8)Random Posts 小部件(Random 文章 插件):您可以将随机 文章 添加到侧边栏。
(9)Robots Meta(机器人设置):不用说了。
(10)WordPress相关帖子(相关文章插件):可以在文章页面下设置相关文章。
(11)WP Keyword Link(内链插件):百度可以点击详细设置。
关于插件和WP设置,当然还有更好的插件可以用,可以自己摸索,不要看那么多会晕,全部下载,批量上传,设置在后台就OK了。
第五步:文章采集/批量上传/定时发布(绝密)
由于以上步骤都是手动完成的,所以整个WP的构建比站群软件质量更高。那么,既然我们不需要站群软件,那么如何让采集文章自动更新呢?
答案是优采云采集、博君seo伪原创工具、以及锤子免费登录发布界面。
由于操作比较多,这里暂时不做详细操作,以免文章太长,下次用图文写个实际操作文章。先简单说一下原理。首先使用优采云采集大量文章,然后使用博君seo伪原创工具批量伪原创,最后通过Hammer豁免Log进入发布界面,定时批量发布文章,实现文章的自动发布和定时更新。
第六步:内外链建设
刚才说了,可以使用WP Keyword Link插件,也可以修改single.php同时插入相关字段。外链搭建请参考《中文SEO教程:链接轮》文章,或加我QQ详细讨论。
最后:总结
做站群记得要浮躁,耐心很重要,循序渐进。本文章中描述的操作主要是手动步骤占一半,但质量高于全自动软件。当然,软件也有自己的优点,方便快捷。以后文章我会讲中文站群软件的应用。
上面只是提到了站群的实际步骤。至于站群的策略、广告、链接策略等,还有待商榷。欢迎继续关注黑帽坦克博文。
工具采集文章(四款增强Windows7任务栏体验的小软件,让你的Win7用得更加得心应手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-30 05:34
使用Windows 7近一个月后,越来越觉得Windows 7的新任务栏(Taskbar)无疑是最好最直接的杀手锏。Windows7吸收了Mac OSX的很多优点,改进了任务栏预览(Taskbar Preview),也更加实用。在某种程度上,Win7 任务栏几乎可以说是传统任务栏和 Mac OSX Dock 的结合。如果使用得当,您不需要在桌面上放置任何图标,但 Mac OSX 仍在使用“旧”任务栏。
当然,虽然现在的任务栏已经足够好了,但我们的目标是让电脑体验更加完美。今天给大家介绍四款提升Windows7任务栏体验的小软件。让这些软件配合Windows7任务栏的新功能发挥更多实用强大的功能,让你的Win7更得心应手!
1、快速跳转列表
这是国内蓝冰工作室出品的一款小软件,旨在为任务栏节省更多空间。众所周知,Win7默认取消了快速启动栏。对于“桌面整洁”的朋友来说,快速启动栏的缺失让启动程序更加繁琐。但是 QuickJumplist 可以替代旧的 Quick Start,让“Quick Start”更加实用。QuickJumplist 基于 Win7 的 Jumplist 功能。你可以在里面添加你常用的程序,并把这个程序锁定在任务栏上,这样右键点击QuickJumplist图标后,就会出现这些程序的列表,作为替代“快速启动”的软件,它当之无愧。而且它不占用任何 CPU/内存资源,因为它根本不需要运行就可以工作。
2、Jumplist-Launcher
顾名思义,Jumplist-Launcher 类似于 QuickJumplist,都使用 Jumplist 来快速启动第三方程序。但是 Jumplist-Launcher 更强大。不仅支持启动程序,还支持从Jumplist打开指定文件夹(不支持二级目录),支持分组。Jumplist-Launcher软件里有一些德语,但基本不影响使用。
其实QuickJumplist也是基于Jumplist-Launcher的思路开发的,但是原来的Jumplist-Launcher最多只能支持10个程序(现在60个),所以蓝冰工作室开发了前者。另外,两款软件都支持同时运行多个进程,只需将它们放在不同的文件夹中并分别锁定到任务栏即可。
其实模仿Mac OSX的7stacks很早就实现了上述功能,但是在Win7推出后,7Stacks变得非常臃肿和缓慢,所以直接使用Jumplist比较好。
3、Gmail 通知程序
在 Windows 7 正式发布之前,Gmail Notifier 在互联网上开始流行。它收录了Win7任务栏几乎所有的新功能:跳转列表、任务栏预览,点击一两下即可查看和撰写邮件。Gmail Notifier支持多账户(不确定是否支持Google Apps),可以在预览窗口预览未读邮件,在预览窗口可以翻页直接打开,可以写新邮件,查看新邮件,在 Jumplist 中查看新邮件。打开收件箱等,真的很厉害。
4、任务栏仪表
Taskbar Meters利用Win7任务栏进度条的特性,以进度条的形式在任务栏上显示CPU使用率、内存使用率和硬盘使用率。Taskbar Meters 不需要安装,使用方法很简单,直接启动相应的程序即可。并且可以设置刷新数据的时间和进度条颜色变化的阈值。Taskbar Meters 还支持 Jumplist 功能,可以直接打开任务管理器和资源监视器,但不支持任务栏预览。
相关软件下载:
如果你还知道有什么小软件使用了Win7任务栏的这些新功能,欢迎留言或者来信推荐:)
官方 网站:QuickJumplist | Jumplist-启动器 | Gmail 通知程序 | 任务栏仪表
软件性质:以上均为免费软件
下载链接:QuickJumplist | Jumplist-启动器 | 来自不同维度 | Gmail 通知程序 | 任务栏仪表 查看全部
工具采集文章(四款增强Windows7任务栏体验的小软件,让你的Win7用得更加得心应手)
使用Windows 7近一个月后,越来越觉得Windows 7的新任务栏(Taskbar)无疑是最好最直接的杀手锏。Windows7吸收了Mac OSX的很多优点,改进了任务栏预览(Taskbar Preview),也更加实用。在某种程度上,Win7 任务栏几乎可以说是传统任务栏和 Mac OSX Dock 的结合。如果使用得当,您不需要在桌面上放置任何图标,但 Mac OSX 仍在使用“旧”任务栏。
当然,虽然现在的任务栏已经足够好了,但我们的目标是让电脑体验更加完美。今天给大家介绍四款提升Windows7任务栏体验的小软件。让这些软件配合Windows7任务栏的新功能发挥更多实用强大的功能,让你的Win7更得心应手!
1、快速跳转列表

这是国内蓝冰工作室出品的一款小软件,旨在为任务栏节省更多空间。众所周知,Win7默认取消了快速启动栏。对于“桌面整洁”的朋友来说,快速启动栏的缺失让启动程序更加繁琐。但是 QuickJumplist 可以替代旧的 Quick Start,让“Quick Start”更加实用。QuickJumplist 基于 Win7 的 Jumplist 功能。你可以在里面添加你常用的程序,并把这个程序锁定在任务栏上,这样右键点击QuickJumplist图标后,就会出现这些程序的列表,作为替代“快速启动”的软件,它当之无愧。而且它不占用任何 CPU/内存资源,因为它根本不需要运行就可以工作。
2、Jumplist-Launcher

顾名思义,Jumplist-Launcher 类似于 QuickJumplist,都使用 Jumplist 来快速启动第三方程序。但是 Jumplist-Launcher 更强大。不仅支持启动程序,还支持从Jumplist打开指定文件夹(不支持二级目录),支持分组。Jumplist-Launcher软件里有一些德语,但基本不影响使用。
其实QuickJumplist也是基于Jumplist-Launcher的思路开发的,但是原来的Jumplist-Launcher最多只能支持10个程序(现在60个),所以蓝冰工作室开发了前者。另外,两款软件都支持同时运行多个进程,只需将它们放在不同的文件夹中并分别锁定到任务栏即可。
其实模仿Mac OSX的7stacks很早就实现了上述功能,但是在Win7推出后,7Stacks变得非常臃肿和缓慢,所以直接使用Jumplist比较好。
3、Gmail 通知程序

在 Windows 7 正式发布之前,Gmail Notifier 在互联网上开始流行。它收录了Win7任务栏几乎所有的新功能:跳转列表、任务栏预览,点击一两下即可查看和撰写邮件。Gmail Notifier支持多账户(不确定是否支持Google Apps),可以在预览窗口预览未读邮件,在预览窗口可以翻页直接打开,可以写新邮件,查看新邮件,在 Jumplist 中查看新邮件。打开收件箱等,真的很厉害。
4、任务栏仪表

Taskbar Meters利用Win7任务栏进度条的特性,以进度条的形式在任务栏上显示CPU使用率、内存使用率和硬盘使用率。Taskbar Meters 不需要安装,使用方法很简单,直接启动相应的程序即可。并且可以设置刷新数据的时间和进度条颜色变化的阈值。Taskbar Meters 还支持 Jumplist 功能,可以直接打开任务管理器和资源监视器,但不支持任务栏预览。
相关软件下载:
如果你还知道有什么小软件使用了Win7任务栏的这些新功能,欢迎留言或者来信推荐:)
官方 网站:QuickJumplist | Jumplist-启动器 | Gmail 通知程序 | 任务栏仪表
软件性质:以上均为免费软件
下载链接:QuickJumplist | Jumplist-启动器 | 来自不同维度 | Gmail 通知程序 | 任务栏仪表
工具采集文章( 【DBA+社群】收集日志信息是否是一个“高消耗”的体力活)
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-09-29 01:10
【DBA+社群】收集日志信息是否是一个“高消耗”的体力活)
转载声明:本文为DBA+社区原创文章,转载需附本订阅号二维码全文,并注明作者姓名及出处:DBA+社区(dbaplus) .
采集日志信息是一种“高消耗”的体力活动吗?在很多情况下。
想象一下,如果数据库发生了挂起故障,而这个数据库有8个节点,我们可能需要采集rdbms、ASM、grid、OS、osw等的日志信息,这个工作简直就是一场噩梦。即使是普通的两节点RAC环境,也可能需要很短的时间,后续的补充日志采集可能还要继续。
不熟悉环境,平台差异,故障时需要过滤采集特定的日志信息,数据库节点多,需要采集日志的环境中文件管控问题多,这可能会影响我们采集日志信息的速度。和准确性,这会影响问题分析和定位的进度。
那么我们有一个很现实的问题,如何减少日志采集消耗的时间,提高准确率,让更多的时间可以用于问题分析呢?
其实Oracle官方已经提供了一个解决方案——TFA(Trace File Analyzer Collector)。这个工具可以帮助我们真正实现一个命令来完成日志采集。
1 版本和安装
TFA支持的正式上市平台:
英特尔 Linux(企业 Linux、RedHat Linux、SUSE Linux)
Z 系统上的 Linux
安腾Linux
Oracle Solaris SPARC
Oracle Solaris x86-64
艾克斯
HPUX 安腾
HPUX PA-RISC
所有平台都需要 bash shell 3.2 或更高版本和 JRE 1.5 或更高版本才能支持。
TFA 工具理论上提供对所有数据库版本的支持,以及对 RAC 和非 RAC 数据库的支持。但是,从我目前看到的文档来看,没有提到 10.2.0.4 之前的版本。
TFA工具首先默认安装在网格软件11.2.0.4,默认安装路径为网格的家目录。11.2.0.4 之前版本的安装包中没有TFA工具,需要手动安装。
Oracle官方列出的详细支持和安装状态如下:
TFA 更新非常快。版本11.2.0.4于2013年8月发布,附带的TFA工具版本为2.5.1.5 . 目前(2015年10月)最新版本为12.1.2.5.2,我们可以从帮助菜单中看出两个版本的巨大差异:
2.5.1.5 版本帮助菜单:
12.1.2.5.2 版本帮助菜单:
可以看到,版本12.1.2.5.2 版本增加了很多Function。
Oracle 对 TFA 的支持也在增加,甚至 PSU 中也收录了 TFA 更新。以版本11.2.0.4为例,我们可以在GI PSU Fixed List中找到以下信息:
即从11.2.0.4.5开始,GI PSU收录TFA版本更新。TFA 将在安装 GI PSU 期间自动安装。
2TFA 的工作原理
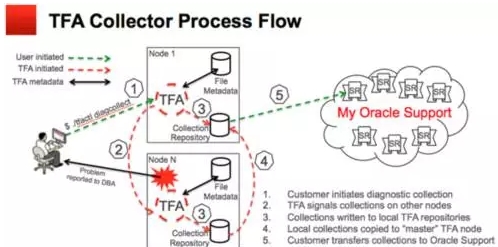
从Oracle官方提供的一张TFA工作流程图中,我们可以清楚地看到TFA是如何工作的:
DBA 发出 diagcollect 命令以启动 TFA 日志采集过程。
本地TFA向其他节点的TFA发送采集请求,并开始其他节点的日志采集。
本地TFA也同时开始了日志采集。
所涉及节点的所有 TFA 日志都存档到启动 diagcollect 命令的“主”节点。
DBA 提取存档的 TFA 日志信息,对其进行分析或提交 SR 进行处理
整个过程中,DBA只需要执行一个命令,然后提取归档的TFA日志即可。
3TFA的使用
以11.2.0.4版RAC和12.1.2.5.2版TFA环境为例:
先来看看最简单最通用的采集命令:
该命令会采集指定时间段内rdbms、ASM、Grid、OS的各类日志,如告警日志、跟踪文件、集群组件日志、监听器日志、操作系统日志等。在执行过程中,告警日志、监听日志等连续日志处理也更加智能,可以在不复制整个日志文件的情况下,拦截指定时间段的日志。如果部署了 osw 工具,也会自动采集 osw 日志。
如果需要指定日志采集范围,比如只采集数据库的相关日志,可以使用tfactl diagcollect -database命令。更多使用方法请参考tfactl diagcollect -help的输出。
最新版本的TFA(12.1.2.5.2))也可以采集AWR报告。命令示例如下:
但是在实际应用中发现,TFA的AWR报告采集功能并不完善。
对于-database参数,帮助菜单的说明是:
-database 从指定的数据库采集数据库日志
目前 -awrhtml 参数需要和 -database 参数一起使用,但是 -database 参数和 -awrhtml 参数一起使用时,不仅用于表示数据库名称,还是会出现这种情况其中采集了数据库警报日志和跟踪文件。. 即执行上述命令会采集指定时间段的AWR报告,以及数据库警报日志和跟踪文件。
TFA还有自动采集功能,可以自动采集一些预定的错误。可以在跟踪文件分析器采集器用户指南的附录 B. 扫描事件部分找到计划的错误和采集规则。此功能默认禁用,可以使用以下命令手动启用:
tfactl 设置 autodiagcollect=ON
建议在生产环境中使用该功能之前,先在测试环境中进行验证。
TFA还可以承担一定的日志分析功能,可以实现一个命令自动分析DB&ASM&CRS的告警日志、操作系统命令和一些osw日志,虽然相比其日志采集功能还不够强大。一个简单通用的分析命令:
tfactl 分析 - 从 7 天开始
该命令会在7天内分析查找所有(包括DB/ASM/CRS/ACFS/OS/OSW/OSWSLABINFO)日志ERROR级别的错误信息并提取出来。
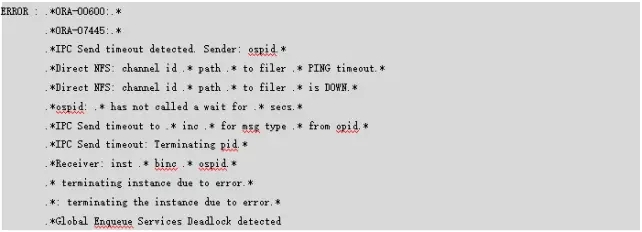
《Trace File Analyzer Collector User Guide》中列出的ERROR级别信息如下:
您还可以使用以下命令来搜索自定义字符串:
默认情况下,TFA 工具仅授予 root 用户和 grid 用户访问权限。如果使用oracle用户执行tfactl diagcollect命令,会报错:
用户 oracle 没有运行 TFA 的密钥。请与 TFA 管理员(root)核对
建议给oracle用户同样的权限使用TFA,方便日常使用。root用户可以使用以下命令将oracle用户添加到授权用户列表中:
tfactl 访问添加 -user oracle
如果有采集日志的空间管理需求,可以使用tfactl set命令进行设置。当前设置可以通过
tfactl 打印配置
命令输出,输出示例如下:
关于TFA的使用和设置的更多信息,请参考tfactl -h的输出和《Trace File Analyzer Collector User Guide》文档。
TFA操作时对DB或GI影响的描述在MOS上很少见到,主要是以下两个问题:
如果遇到Linux平台下RAC节点启动挂起的问题,并且环境中安装了TFA,可以根据1983567.1文档中的说明修改oracle-tfa.conf文件。1668630.1文档中提到的问题已在11.2.0.4.3及以上PSU中修复,如果安装的PSU版本为1< @1.2.0.4.3 及以上,这个问题可以忽略。
作者介绍:杨德胜
回复001,阅读杨志宏的《【职场心智】一个老DBA的自白》;
回复002,阅读丁俊的《【重磅干货】看完这篇文章,Oracle SQL优化文章别再看了!》;
回复003,看胡一文《PG,跨越oltp到olap的梦想之桥》;
回复004,见陈可的《Memcached & Redis等分布式缓存的实现原理》;
回复005,阅读宋日杰的《Oracle后端专家解决库缓存锁争用的终极利器》;
回复006,见郑晓辉《存储和数据库不得不讲的故事》;
回复007,见袁伟祥《揭秘Oracle数据库截断原理》;
回复008,阅读杨建荣的《Waiting for Desirable:工具定制让Oracle优化更轻松、更快》;
回复009,阅读丁其亮的《LINUX主机JAVA应用高CPU和内存占用的分析方法》;
回复010,阅读徐桂林的《以应用为中心的企业混合云管理》。
关于 DBA+ 社区
DBA+社区是中国最大的微信社区,涵盖各种架构师、数据库、中间件!线上分享2次/周,线下沙龙1次/月,顶峰6次/年,直接观众10000+,间接影响500000+ITer。DBA+社区致力于搭建学习交流、专业联系、跨行业合作的公益平台。更多精彩,请继续关注dbaplus微信订阅号!
扫描二维码关注
DBAplus 社区
在 DBA 圈子之外,连接的不仅仅是 DBA 查看全部
工具采集文章(
【DBA+社群】收集日志信息是否是一个“高消耗”的体力活)

转载声明:本文为DBA+社区原创文章,转载需附本订阅号二维码全文,并注明作者姓名及出处:DBA+社区(dbaplus) .
采集日志信息是一种“高消耗”的体力活动吗?在很多情况下。
想象一下,如果数据库发生了挂起故障,而这个数据库有8个节点,我们可能需要采集rdbms、ASM、grid、OS、osw等的日志信息,这个工作简直就是一场噩梦。即使是普通的两节点RAC环境,也可能需要很短的时间,后续的补充日志采集可能还要继续。
不熟悉环境,平台差异,故障时需要过滤采集特定的日志信息,数据库节点多,需要采集日志的环境中文件管控问题多,这可能会影响我们采集日志信息的速度。和准确性,这会影响问题分析和定位的进度。
那么我们有一个很现实的问题,如何减少日志采集消耗的时间,提高准确率,让更多的时间可以用于问题分析呢?
其实Oracle官方已经提供了一个解决方案——TFA(Trace File Analyzer Collector)。这个工具可以帮助我们真正实现一个命令来完成日志采集。
1 版本和安装
TFA支持的正式上市平台:
英特尔 Linux(企业 Linux、RedHat Linux、SUSE Linux)
Z 系统上的 Linux
安腾Linux
Oracle Solaris SPARC
Oracle Solaris x86-64
艾克斯
HPUX 安腾
HPUX PA-RISC
所有平台都需要 bash shell 3.2 或更高版本和 JRE 1.5 或更高版本才能支持。
TFA 工具理论上提供对所有数据库版本的支持,以及对 RAC 和非 RAC 数据库的支持。但是,从我目前看到的文档来看,没有提到 10.2.0.4 之前的版本。
TFA工具首先默认安装在网格软件11.2.0.4,默认安装路径为网格的家目录。11.2.0.4 之前版本的安装包中没有TFA工具,需要手动安装。
Oracle官方列出的详细支持和安装状态如下:

TFA 更新非常快。版本11.2.0.4于2013年8月发布,附带的TFA工具版本为2.5.1.5 . 目前(2015年10月)最新版本为12.1.2.5.2,我们可以从帮助菜单中看出两个版本的巨大差异:
2.5.1.5 版本帮助菜单:

12.1.2.5.2 版本帮助菜单:
可以看到,版本12.1.2.5.2 版本增加了很多Function。
Oracle 对 TFA 的支持也在增加,甚至 PSU 中也收录了 TFA 更新。以版本11.2.0.4为例,我们可以在GI PSU Fixed List中找到以下信息:

即从11.2.0.4.5开始,GI PSU收录TFA版本更新。TFA 将在安装 GI PSU 期间自动安装。
2TFA 的工作原理
从Oracle官方提供的一张TFA工作流程图中,我们可以清楚地看到TFA是如何工作的:
DBA 发出 diagcollect 命令以启动 TFA 日志采集过程。
本地TFA向其他节点的TFA发送采集请求,并开始其他节点的日志采集。
本地TFA也同时开始了日志采集。
所涉及节点的所有 TFA 日志都存档到启动 diagcollect 命令的“主”节点。
DBA 提取存档的 TFA 日志信息,对其进行分析或提交 SR 进行处理
整个过程中,DBA只需要执行一个命令,然后提取归档的TFA日志即可。
3TFA的使用
以11.2.0.4版RAC和12.1.2.5.2版TFA环境为例:
先来看看最简单最通用的采集命令:

该命令会采集指定时间段内rdbms、ASM、Grid、OS的各类日志,如告警日志、跟踪文件、集群组件日志、监听器日志、操作系统日志等。在执行过程中,告警日志、监听日志等连续日志处理也更加智能,可以在不复制整个日志文件的情况下,拦截指定时间段的日志。如果部署了 osw 工具,也会自动采集 osw 日志。
如果需要指定日志采集范围,比如只采集数据库的相关日志,可以使用tfactl diagcollect -database命令。更多使用方法请参考tfactl diagcollect -help的输出。
最新版本的TFA(12.1.2.5.2))也可以采集AWR报告。命令示例如下:

但是在实际应用中发现,TFA的AWR报告采集功能并不完善。
对于-database参数,帮助菜单的说明是:
-database 从指定的数据库采集数据库日志
目前 -awrhtml 参数需要和 -database 参数一起使用,但是 -database 参数和 -awrhtml 参数一起使用时,不仅用于表示数据库名称,还是会出现这种情况其中采集了数据库警报日志和跟踪文件。. 即执行上述命令会采集指定时间段的AWR报告,以及数据库警报日志和跟踪文件。
TFA还有自动采集功能,可以自动采集一些预定的错误。可以在跟踪文件分析器采集器用户指南的附录 B. 扫描事件部分找到计划的错误和采集规则。此功能默认禁用,可以使用以下命令手动启用:
tfactl 设置 autodiagcollect=ON
建议在生产环境中使用该功能之前,先在测试环境中进行验证。
TFA还可以承担一定的日志分析功能,可以实现一个命令自动分析DB&ASM&CRS的告警日志、操作系统命令和一些osw日志,虽然相比其日志采集功能还不够强大。一个简单通用的分析命令:
tfactl 分析 - 从 7 天开始
该命令会在7天内分析查找所有(包括DB/ASM/CRS/ACFS/OS/OSW/OSWSLABINFO)日志ERROR级别的错误信息并提取出来。
《Trace File Analyzer Collector User Guide》中列出的ERROR级别信息如下:
您还可以使用以下命令来搜索自定义字符串:

默认情况下,TFA 工具仅授予 root 用户和 grid 用户访问权限。如果使用oracle用户执行tfactl diagcollect命令,会报错:
用户 oracle 没有运行 TFA 的密钥。请与 TFA 管理员(root)核对
建议给oracle用户同样的权限使用TFA,方便日常使用。root用户可以使用以下命令将oracle用户添加到授权用户列表中:
tfactl 访问添加 -user oracle
如果有采集日志的空间管理需求,可以使用tfactl set命令进行设置。当前设置可以通过
tfactl 打印配置
命令输出,输出示例如下:

关于TFA的使用和设置的更多信息,请参考tfactl -h的输出和《Trace File Analyzer Collector User Guide》文档。
TFA操作时对DB或GI影响的描述在MOS上很少见到,主要是以下两个问题:

如果遇到Linux平台下RAC节点启动挂起的问题,并且环境中安装了TFA,可以根据1983567.1文档中的说明修改oracle-tfa.conf文件。1668630.1文档中提到的问题已在11.2.0.4.3及以上PSU中修复,如果安装的PSU版本为1< @1.2.0.4.3 及以上,这个问题可以忽略。
作者介绍:杨德胜
回复001,阅读杨志宏的《【职场心智】一个老DBA的自白》;
回复002,阅读丁俊的《【重磅干货】看完这篇文章,Oracle SQL优化文章别再看了!》;
回复003,看胡一文《PG,跨越oltp到olap的梦想之桥》;
回复004,见陈可的《Memcached & Redis等分布式缓存的实现原理》;
回复005,阅读宋日杰的《Oracle后端专家解决库缓存锁争用的终极利器》;
回复006,见郑晓辉《存储和数据库不得不讲的故事》;
回复007,见袁伟祥《揭秘Oracle数据库截断原理》;
回复008,阅读杨建荣的《Waiting for Desirable:工具定制让Oracle优化更轻松、更快》;
回复009,阅读丁其亮的《LINUX主机JAVA应用高CPU和内存占用的分析方法》;
回复010,阅读徐桂林的《以应用为中心的企业混合云管理》。
关于 DBA+ 社区
DBA+社区是中国最大的微信社区,涵盖各种架构师、数据库、中间件!线上分享2次/周,线下沙龙1次/月,顶峰6次/年,直接观众10000+,间接影响500000+ITer。DBA+社区致力于搭建学习交流、专业联系、跨行业合作的公益平台。更多精彩,请继续关注dbaplus微信订阅号!

扫描二维码关注
DBAplus 社区
在 DBA 圈子之外,连接的不仅仅是 DBA
工具采集文章(工具采集文章的网站,你了解多少?|英才网)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-28 02:03
工具采集文章的网站1.国内的搜狗网络平台2.国外的,经常有外部机构测试下载文件。有需要的话自己下载下来用。
多关注一些一手的外部数据网站,譬如中国人力资源和社会保障网、黑猫投诉,多看看权威机构的重要数据报告,尤其是人社部的《2016年度人力资源和社会保障事业发展统计公报》。
你可以去看看英才网
根据你自己的兴趣定方向。今年刚工作,因为目前市场机遇大,又正在积累中,所以建议你从事一些内容健康,网络红人比较多的行业,比如户外健康类,网红为主的服装,之类的。建议平时每个月看一下这个平台的前端新闻,
推荐pptstore,behance,华盖创意
不请自来,作为一名自主创业三年的人来讲。做外包工具这一块是必然会有市场的,外包的工具,我基本上没见有人用过,倒是后端web网站上很多人用,这些东西没有注册,那么成功案例也基本看不到。这里分析了2个做外包工具的做法:①直接竞价②seo方式。所以我得给题主简单的分析下为什么说做外包工具是一个不错的市场。①竞价方式。
这种方式呢,适合各行各业做ppt,做网站或者做crm的小公司,采用竞价方式呢,时间最为快速,但是一定要花在正确的地方,我举一个例子,这样的做法,你在做的时候你会发现那些拼多多之类的网站,他们一般使用这样的套路:首先通过竞价方式找到几家品牌的代理商,这些大品牌,都会找到几个品牌直销电商,这些电商成交几百甚至几千的佣金,就会返给这些大品牌一些资源,后期这些小公司就可以通过这些大品牌产品的销售,产生一定的数据回扣。
当然,做竞价的方式有利有弊,比如网店小卖家很难以成交单子,所以弊端就是容易被这些电商列为营销违规,而且随着竞价的成本越来越高,以往几十的单子现在基本都是千把块钱的。再说说优点,就是你可以拥有一个自己的网站,可以自己负责网站的所有流程,节省时间还节省资金成本,对于京东类的平台来讲,对于外包工具没有优势,所以用竞价方式来做外包工具的公司呢,现在很少了。
再说说wish等的广告模式。wish是个流量入口平台,但是它所带来的广告效果,毕竟比不上竞价方式。那么为什么有人觉得wish好做呢?因为它的竞价方式,通过你的关键词,将你卖产品的公司告诉wish平台的卖家,但这个卖家得不到一分钱,只是为卖货提供一个单子。这样对于外包工具来讲是一个很好的平台。而且现在可以使用wish平台上的免费工具,它有美工,有运营,有美工教学,这样平台的产品数目也会越来越多,对于有网站的做外包工具的公司。 查看全部
工具采集文章(工具采集文章的网站,你了解多少?|英才网)
工具采集文章的网站1.国内的搜狗网络平台2.国外的,经常有外部机构测试下载文件。有需要的话自己下载下来用。
多关注一些一手的外部数据网站,譬如中国人力资源和社会保障网、黑猫投诉,多看看权威机构的重要数据报告,尤其是人社部的《2016年度人力资源和社会保障事业发展统计公报》。
你可以去看看英才网
根据你自己的兴趣定方向。今年刚工作,因为目前市场机遇大,又正在积累中,所以建议你从事一些内容健康,网络红人比较多的行业,比如户外健康类,网红为主的服装,之类的。建议平时每个月看一下这个平台的前端新闻,
推荐pptstore,behance,华盖创意
不请自来,作为一名自主创业三年的人来讲。做外包工具这一块是必然会有市场的,外包的工具,我基本上没见有人用过,倒是后端web网站上很多人用,这些东西没有注册,那么成功案例也基本看不到。这里分析了2个做外包工具的做法:①直接竞价②seo方式。所以我得给题主简单的分析下为什么说做外包工具是一个不错的市场。①竞价方式。
这种方式呢,适合各行各业做ppt,做网站或者做crm的小公司,采用竞价方式呢,时间最为快速,但是一定要花在正确的地方,我举一个例子,这样的做法,你在做的时候你会发现那些拼多多之类的网站,他们一般使用这样的套路:首先通过竞价方式找到几家品牌的代理商,这些大品牌,都会找到几个品牌直销电商,这些电商成交几百甚至几千的佣金,就会返给这些大品牌一些资源,后期这些小公司就可以通过这些大品牌产品的销售,产生一定的数据回扣。
当然,做竞价的方式有利有弊,比如网店小卖家很难以成交单子,所以弊端就是容易被这些电商列为营销违规,而且随着竞价的成本越来越高,以往几十的单子现在基本都是千把块钱的。再说说优点,就是你可以拥有一个自己的网站,可以自己负责网站的所有流程,节省时间还节省资金成本,对于京东类的平台来讲,对于外包工具没有优势,所以用竞价方式来做外包工具的公司呢,现在很少了。
再说说wish等的广告模式。wish是个流量入口平台,但是它所带来的广告效果,毕竟比不上竞价方式。那么为什么有人觉得wish好做呢?因为它的竞价方式,通过你的关键词,将你卖产品的公司告诉wish平台的卖家,但这个卖家得不到一分钱,只是为卖货提供一个单子。这样对于外包工具来讲是一个很好的平台。而且现在可以使用wish平台上的免费工具,它有美工,有运营,有美工教学,这样平台的产品数目也会越来越多,对于有网站的做外包工具的公司。
工具采集文章(如何快速爬取工具采集文章?亲测有效的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-10 20:05
工具采集文章大纲仅支持微信号采集;采集微信大v、搜狗微信等搜索引擎的文章仅支持微信大v、搜狗微信等搜索引擎的文章。第三个是搜狗微信(第三方平台收录),第二个是小说分类(小说文章)。无法截图,因为截图工具很多,应该很好找。亲测方法:在百度搜索框搜索“小说分类”,就会看到很多浏览器里面都会出现这个分类的相关链接。
把链接复制到siri或者微信上,就可以直接搜索到了。(特别提醒,你在调用相关应用搜索时一定要注意分类,避免搜到乱七八糟的文章。)小编亲测效果:点击链接后显示的分类:搜狗微信。
1、在第三方平台收录文章后,还可以采集出公众号分类文章。
2、小说分类可以直接按作者、年份、作者、作者等来搜索;微信大v可以分多种。按年份搜索:等同于豆瓣电影的年份筛选查看文章大纲按作者搜索:等同于豆瓣电影的文章标题搜索按作者搜索:作者可能是你想要找的人标题搜索:相关的标题采集,注意最好在输入的时候用双引号。
3、其他的:看电脑有没有root,如果有的话,对浏览器采集文章有很好的效果。
提供一些可以快速爬取的方法我这里主要介绍一下采集网页的javascriptjavascript教程:;tid=2645862获取方法:1。找一个你能找到且他(她)能够采集的网站,就能找到你想要爬取的页面,点击选中左侧搜索框的网址(就是你复制的网址),右键点击,选择爬取即可,一般会返回chrome浏览器的地址(因为chrome浏览器默认地址栏)2。
点击我的网址栏,下方浏览器的地址栏下方也会出现一串javascript(也就是javascript)即可;3。找到之后,你只需要点击复制即可,因为我就是这样做的,这样的话,你会发现,复制后的网址最后是一串http,不要害怕,点击退出浏览器即可4。右键,选择提取网址即可,这样就能爬取你需要的数据5。采集完成后,右键,粘贴即可,可见很多文章后面都有,右键即可,不像上一篇一样很难找,找到之后,复制粘贴即可这个方法可以用于手机浏览器,打开网址之后,右键,提取网址即可,找到的那种,方便很多。 查看全部
工具采集文章(如何快速爬取工具采集文章?亲测有效的方法)
工具采集文章大纲仅支持微信号采集;采集微信大v、搜狗微信等搜索引擎的文章仅支持微信大v、搜狗微信等搜索引擎的文章。第三个是搜狗微信(第三方平台收录),第二个是小说分类(小说文章)。无法截图,因为截图工具很多,应该很好找。亲测方法:在百度搜索框搜索“小说分类”,就会看到很多浏览器里面都会出现这个分类的相关链接。
把链接复制到siri或者微信上,就可以直接搜索到了。(特别提醒,你在调用相关应用搜索时一定要注意分类,避免搜到乱七八糟的文章。)小编亲测效果:点击链接后显示的分类:搜狗微信。
1、在第三方平台收录文章后,还可以采集出公众号分类文章。
2、小说分类可以直接按作者、年份、作者、作者等来搜索;微信大v可以分多种。按年份搜索:等同于豆瓣电影的年份筛选查看文章大纲按作者搜索:等同于豆瓣电影的文章标题搜索按作者搜索:作者可能是你想要找的人标题搜索:相关的标题采集,注意最好在输入的时候用双引号。
3、其他的:看电脑有没有root,如果有的话,对浏览器采集文章有很好的效果。
提供一些可以快速爬取的方法我这里主要介绍一下采集网页的javascriptjavascript教程:;tid=2645862获取方法:1。找一个你能找到且他(她)能够采集的网站,就能找到你想要爬取的页面,点击选中左侧搜索框的网址(就是你复制的网址),右键点击,选择爬取即可,一般会返回chrome浏览器的地址(因为chrome浏览器默认地址栏)2。
点击我的网址栏,下方浏览器的地址栏下方也会出现一串javascript(也就是javascript)即可;3。找到之后,你只需要点击复制即可,因为我就是这样做的,这样的话,你会发现,复制后的网址最后是一串http,不要害怕,点击退出浏览器即可4。右键,选择提取网址即可,这样就能爬取你需要的数据5。采集完成后,右键,粘贴即可,可见很多文章后面都有,右键即可,不像上一篇一样很难找,找到之后,复制粘贴即可这个方法可以用于手机浏览器,打开网址之后,右键,提取网址即可,找到的那种,方便很多。
工具采集文章(北外教师考高口的准备准备怎么样?工具采集文章分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-10 10:08
工具采集文章分析关键词,统计原创数据,在线编辑和上传发布相关工具,制作关键词-匹配配图片的爬虫,采集到的相关文章标题和链接分析相关内容原始数据,
据我说知,北外教师每年能出两本高口教材:第一本以证书为主;第二本有实体教材。
pdf格式文档,图片视频,都可以做学习笔记和课堂笔记,学习资料。
请问高口的准备准备怎么样?我现在也在准备,
用心就好,阅读,记录笔记,动手运用,反复推敲,做口语练习,不懂的找老师同学请教。准备一年,三本教材,听说读写综合练习一个半月。坚持,和努力是两回事,另外如果不懂口语或听力不好也不要急着做多元练习。
你是大二还是大三?大三难度会大一些,因为这时候要准备专八。我也是考高口,今年六月份刚刚考过,口语六十多分,没有报班,自己看书学习模仿,建议教材先找视频看一遍,然后听力要再听一遍,然后开始口语的学习,主要是发音。先从音标开始,从字母,然后元音辅音,然后字母组合等等。想要靠谱的学习网站有很多,比如扇贝,百词斩,搜狗,洋葱等等。
这些学习软件在线学都很方便。然后平时除了背单词以外,多看看英文的资料比如脱口秀或者经济学人之类的。祝好运!。 查看全部
工具采集文章(北外教师考高口的准备准备怎么样?工具采集文章分析)
工具采集文章分析关键词,统计原创数据,在线编辑和上传发布相关工具,制作关键词-匹配配图片的爬虫,采集到的相关文章标题和链接分析相关内容原始数据,
据我说知,北外教师每年能出两本高口教材:第一本以证书为主;第二本有实体教材。
pdf格式文档,图片视频,都可以做学习笔记和课堂笔记,学习资料。
请问高口的准备准备怎么样?我现在也在准备,
用心就好,阅读,记录笔记,动手运用,反复推敲,做口语练习,不懂的找老师同学请教。准备一年,三本教材,听说读写综合练习一个半月。坚持,和努力是两回事,另外如果不懂口语或听力不好也不要急着做多元练习。
你是大二还是大三?大三难度会大一些,因为这时候要准备专八。我也是考高口,今年六月份刚刚考过,口语六十多分,没有报班,自己看书学习模仿,建议教材先找视频看一遍,然后听力要再听一遍,然后开始口语的学习,主要是发音。先从音标开始,从字母,然后元音辅音,然后字母组合等等。想要靠谱的学习网站有很多,比如扇贝,百词斩,搜狗,洋葱等等。
这些学习软件在线学都很方便。然后平时除了背单词以外,多看看英文的资料比如脱口秀或者经济学人之类的。祝好运!。
工具采集文章(避免温馨提示你的头像特别生气,结果扫码下载到app里)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-05 03:04
工具采集文章可以采用采集器采集izhihu文章可以采用izhihu文章搜索收录izhihu这个公众号将“简书”的数据收集了公众号叫做“简书lite”简书数据源自下载“简书百度百科”可以获取到全部关于简书文章简书百度百科解决大多数小白不知道关于简书文章的问题,有问题的可以随时联系我我的邮箱:3363267370@qq。com。
可以了解下福利社,这个平台的内容很多,有的是自己原创,有的是采集来的,还有的是转载的,对于素材都是十分便捷的,
全网各大内容平台上都是可以做摘要的,然后写好正文或者留下备注或者标题,都可以下载。
如果都像我一样懒的话...那就...去捡垃圾吧orz
全网app对于文章摘要,类似于简书对于文章标题的功能。今天无意中看到一篇文章的标题如下:“避免温馨提示你的头像”特别生气,结果扫码下载到app里,是这样子的(小编也想把图片稍微加点水印,就太拉低版面质量了)自己的内容没有这么多的“温馨提示”,我本人是不喜欢发朋友圈的,这个文章能不能及时的提醒到我,还望能够注意。
简书的话用网易新闻抓取也可以,但是只可以分享到微信,
izhihu网站下载app即可打开,支持上传与收藏,然后用邮箱或者qq登录即可,但是想要得到cookie,就得把app关了,要不然wifi不稳定。 查看全部
工具采集文章(避免温馨提示你的头像特别生气,结果扫码下载到app里)
工具采集文章可以采用采集器采集izhihu文章可以采用izhihu文章搜索收录izhihu这个公众号将“简书”的数据收集了公众号叫做“简书lite”简书数据源自下载“简书百度百科”可以获取到全部关于简书文章简书百度百科解决大多数小白不知道关于简书文章的问题,有问题的可以随时联系我我的邮箱:3363267370@qq。com。
可以了解下福利社,这个平台的内容很多,有的是自己原创,有的是采集来的,还有的是转载的,对于素材都是十分便捷的,
全网各大内容平台上都是可以做摘要的,然后写好正文或者留下备注或者标题,都可以下载。
如果都像我一样懒的话...那就...去捡垃圾吧orz
全网app对于文章摘要,类似于简书对于文章标题的功能。今天无意中看到一篇文章的标题如下:“避免温馨提示你的头像”特别生气,结果扫码下载到app里,是这样子的(小编也想把图片稍微加点水印,就太拉低版面质量了)自己的内容没有这么多的“温馨提示”,我本人是不喜欢发朋友圈的,这个文章能不能及时的提醒到我,还望能够注意。
简书的话用网易新闻抓取也可以,但是只可以分享到微信,
izhihu网站下载app即可打开,支持上传与收藏,然后用邮箱或者qq登录即可,但是想要得到cookie,就得把app关了,要不然wifi不稳定。
工具采集文章(快速一键查看公众号历史文章-行之记事具体功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2021-11-25 12:03
工具采集文章,获取微信公众号内容,实现在手机微信公众号后台订阅号文章实时监控,实现手机微信号查看内容。
我目前用wordpress搭建了一个微信公众号聚合服务端,并打算直接打通微信公众号。
我也很好奇,推荐我们的易佰康公众号服务号助手,
微信关注易佰康公众号助手,可以一键查看个人公众号历史文章,并可与公众号实时互动。如果您感兴趣,请关注我们的微信号:i97hou1。
抓取公众号历史文章是没问题的。这个人是一名专业做公众号抓取器的工程师。目前在做微信公众号的抓取和清洗工作。好奇的话,
参考经验介绍:快速一键查看公众号历史文章-行之记事具体功能请参考这个回答:公众号历史消息抓取工具大全
易佰康公众号抓取器有什么使用,
我个人认为目前没有这样的工具可以达到以上要求,这需要一个人力,也需要一定的技术,目前我做公众号,如果你也对公众号感兴趣,也可以加入我们的队伍,虽然是刚起步,但是我们确实可以满足要求。目前我们的主要工作有:查看公众号历史消息,并实时互动,查看公众号的粉丝数据等等。
有个好用的工具,就是能抓取文章,并且标记标题等,如果你用wordpress搭建的话, 查看全部
工具采集文章(快速一键查看公众号历史文章-行之记事具体功能)
工具采集文章,获取微信公众号内容,实现在手机微信公众号后台订阅号文章实时监控,实现手机微信号查看内容。
我目前用wordpress搭建了一个微信公众号聚合服务端,并打算直接打通微信公众号。
我也很好奇,推荐我们的易佰康公众号服务号助手,
微信关注易佰康公众号助手,可以一键查看个人公众号历史文章,并可与公众号实时互动。如果您感兴趣,请关注我们的微信号:i97hou1。
抓取公众号历史文章是没问题的。这个人是一名专业做公众号抓取器的工程师。目前在做微信公众号的抓取和清洗工作。好奇的话,
参考经验介绍:快速一键查看公众号历史文章-行之记事具体功能请参考这个回答:公众号历史消息抓取工具大全
易佰康公众号抓取器有什么使用,
我个人认为目前没有这样的工具可以达到以上要求,这需要一个人力,也需要一定的技术,目前我做公众号,如果你也对公众号感兴趣,也可以加入我们的队伍,虽然是刚起步,但是我们确实可以满足要求。目前我们的主要工作有:查看公众号历史消息,并实时互动,查看公众号的粉丝数据等等。
有个好用的工具,就是能抓取文章,并且标记标题等,如果你用wordpress搭建的话,
工具采集文章(为什么要采集公众号的文章?免费!效果如何一试!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-13 10:00
首先,为什么需要采集公众号的文章?
我想大家在生活中经常关注公众号,所以公众号的内容丰富多彩。作为曾经做公众号的运营商,公众号文章的质量特别高,无论是素材、文章的整体框架、文章的内容@文章精准垂直,公众号原创大于80%。大多数作家都有自己的经验和技能。
如何采集公众号文章?
对于不懂代码的小白来说,复制粘贴采集公众号的文章最简单的方法就是使用其他采集工具,编辑规则。所以对小白很不友好,有没有傻瓜式的采集软件?直接输入关键词采集公众号文章。
所以这次介绍的是傻瓜式采集软件,只需输入关键词即可实现采集。方便快捷。
公众号采集流程
1、输入关键词(例如:装修),可以采集到今日头条、公众号文章、百度网页、百度新闻、搜狗网页、搜狗新闻、批次可用关键词全自动采集。
2、智能采集,无需编写复杂的规则。
3、采集内容质量高
4、最简单最智能文章采集器,重点是免费!自由!自由!一试就知道效果!
5、文章采集器不用写规则,大家都会用采集软件
<p>现在大家都知道“内容为王”,大家为了做网站优化,都疯狂写文章,但是每天的输出量很小。一些优化者认为 原创 查看全部
工具采集文章(为什么要采集公众号的文章?免费!效果如何一试!)
首先,为什么需要采集公众号的文章?
我想大家在生活中经常关注公众号,所以公众号的内容丰富多彩。作为曾经做公众号的运营商,公众号文章的质量特别高,无论是素材、文章的整体框架、文章的内容@文章精准垂直,公众号原创大于80%。大多数作家都有自己的经验和技能。
如何采集公众号文章?
对于不懂代码的小白来说,复制粘贴采集公众号的文章最简单的方法就是使用其他采集工具,编辑规则。所以对小白很不友好,有没有傻瓜式的采集软件?直接输入关键词采集公众号文章。
所以这次介绍的是傻瓜式采集软件,只需输入关键词即可实现采集。方便快捷。
公众号采集流程
1、输入关键词(例如:装修),可以采集到今日头条、公众号文章、百度网页、百度新闻、搜狗网页、搜狗新闻、批次可用关键词全自动采集。
2、智能采集,无需编写复杂的规则。
3、采集内容质量高
4、最简单最智能文章采集器,重点是免费!自由!自由!一试就知道效果!
5、文章采集器不用写规则,大家都会用采集软件
<p>现在大家都知道“内容为王”,大家为了做网站优化,都疯狂写文章,但是每天的输出量很小。一些优化者认为 原创
工具采集文章(为什么要采集公众号的文章?免费!效果如何一试!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-13 03:15
首先,为什么需要采集公众号的文章?
我想大家在生活中经常关注公众号,所以公众号的内容丰富多彩。作为曾经做公众号的运营商,公众号文章的质量特别高,无论是素材、文章的整体框架、文章的内容@文章精准垂直,公众号原创大于80%。大多数作家都有自己的经验和技能。
如何采集公众号文章?
对于不懂代码的小白来说,复制粘贴采集公众号的文章最简单的方法就是使用其他采集工具,编辑规则。所以对小白很不友好,有没有傻瓜式的采集软件?直接输入关键词采集公众号文章。
所以这次介绍的是傻瓜式采集软件,只需输入关键词即可实现采集。方便快捷。
公众号采集流程
1、输入关键词(例如:装修),可以采集到今日头条、公众号文章、百度网页、百度新闻、搜狗网页、搜狗新闻、批次可用关键词全自动采集。
2、智能采集,无需编写复杂的规则。
3、采集内容质量高
4、最简单最智能文章采集器,重点是免费!自由!自由!一试就知道效果!
5、文章采集器不用写规则,大家都会用采集软件
<p>现在大家都知道“内容为王”,大家为了做网站优化,都疯狂写文章,但是每天的输出量很小。一些优化者认为 原创 查看全部
工具采集文章(为什么要采集公众号的文章?免费!效果如何一试!)
首先,为什么需要采集公众号的文章?
我想大家在生活中经常关注公众号,所以公众号的内容丰富多彩。作为曾经做公众号的运营商,公众号文章的质量特别高,无论是素材、文章的整体框架、文章的内容@文章精准垂直,公众号原创大于80%。大多数作家都有自己的经验和技能。
如何采集公众号文章?
对于不懂代码的小白来说,复制粘贴采集公众号的文章最简单的方法就是使用其他采集工具,编辑规则。所以对小白很不友好,有没有傻瓜式的采集软件?直接输入关键词采集公众号文章。
所以这次介绍的是傻瓜式采集软件,只需输入关键词即可实现采集。方便快捷。
公众号采集流程
1、输入关键词(例如:装修),可以采集到今日头条、公众号文章、百度网页、百度新闻、搜狗网页、搜狗新闻、批次可用关键词全自动采集。
2、智能采集,无需编写复杂的规则。
3、采集内容质量高
4、最简单最智能文章采集器,重点是免费!自由!自由!一试就知道效果!
5、文章采集器不用写规则,大家都会用采集软件
<p>现在大家都知道“内容为王”,大家为了做网站优化,都疯狂写文章,但是每天的输出量很小。一些优化者认为 原创
工具采集文章(微信公众号文章批量采集工具绿V2.60总结)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-11-08 21:11
微信公众号文章批次采集工具绿官方最新版为全(全)全新全自动微信公众号文章批次采集工具绿官方最新版,微信公众号文章批量采集绿色官方最新版工具功能强大,可以进行原(元)创(de)、批量伪原创@ > 等操作,让你可以轻松采集别人的公众号文章,有需要的朋友快来下载吧!
微信公众号文章批量采集绿色工具最新正式版介绍
1. 这个新版本的伪原创@>有着非常巧妙的玩法。是翻译。先从中文翻译成英文,再从英文翻译成中文。可惜一天翻译量有限,可以自行更改IP地址。 (其实不适合更新太多,一天几条就可以了,一般是老站的话。关键词可以快速重新排名),微信公众号文章批量采集工具绿色官方最新版,然后伪原创@>点击这些文章,然后更新为伪原创7@>。整个过程是全自动的。无需打开后台,通过数据库发送。因此,需要生成静态页面。
2.是为优采云站长准备的,也适合维护站、做伪原创8@>、跑流程的人。
3.本软件的功能,与上一版本对比: 和之前一样,微信公众号文章批量采集工具官方微信公众号最新版本Green文章 批处理采集 Tool Green 的最新正式版,采集 后来使用了伪原创@>。不知道这算不算伪原创@>,不过确实达到了伪原创@>的效果。
微信公众号文章批次采集工具绿最新正式版汇总
微信公众号文章批量采集工具绿V2.60是一款适用于安卓版其他软件的手机软件。如果您喜欢这个软件,请下载链接分享给您的朋友: 查看全部
工具采集文章(微信公众号文章批量采集工具绿V2.60总结)
微信公众号文章批次采集工具绿官方最新版为全(全)全新全自动微信公众号文章批次采集工具绿官方最新版,微信公众号文章批量采集绿色官方最新版工具功能强大,可以进行原(元)创(de)、批量伪原创@ > 等操作,让你可以轻松采集别人的公众号文章,有需要的朋友快来下载吧!
微信公众号文章批量采集绿色工具最新正式版介绍
1. 这个新版本的伪原创@>有着非常巧妙的玩法。是翻译。先从中文翻译成英文,再从英文翻译成中文。可惜一天翻译量有限,可以自行更改IP地址。 (其实不适合更新太多,一天几条就可以了,一般是老站的话。关键词可以快速重新排名),微信公众号文章批量采集工具绿色官方最新版,然后伪原创@>点击这些文章,然后更新为伪原创7@>。整个过程是全自动的。无需打开后台,通过数据库发送。因此,需要生成静态页面。
2.是为优采云站长准备的,也适合维护站、做伪原创8@>、跑流程的人。
3.本软件的功能,与上一版本对比: 和之前一样,微信公众号文章批量采集工具官方微信公众号最新版本Green文章 批处理采集 Tool Green 的最新正式版,采集 后来使用了伪原创@>。不知道这算不算伪原创@>,不过确实达到了伪原创@>的效果。
微信公众号文章批次采集工具绿最新正式版汇总
微信公众号文章批量采集工具绿V2.60是一款适用于安卓版其他软件的手机软件。如果您喜欢这个软件,请下载链接分享给您的朋友:
工具采集文章(一本系列随笔概览及产生的背景自己开发的豆约翰博客备份专家软件工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-11-06 07:24
一系列论文及其背景的概述
自主研发的DouJohnson博客备份专家软件工具自问世3年多以来,深受博客写作和阅读爱好者的喜爱。同时,也有一些技术爱好者向我咨询如何实现这个软件中的各种实用功能。
该软件是使用.NET 技术开发的。为了回馈社会,特开设软件使用的核心技术专栏,为广大技术爱好者写了一系列文章。
本系列文章不仅讲解了网络采集、编辑、发布中用到的各种重要技术,还提供了很多界面开发中的解题思路和编程经验。非常适合.NET开发的初学者和中级读者。希望请多多支持。
很多初学者经常会有这样的困惑,“为什么我看了这本书,对C#的方方面面都了解了,却写不出一个像样的应用程序?”,
其实我还没有学会综合运用所学的知识,锻炼编程思维,建立学习的兴趣。我认为这个系列文章 可以帮助你,我希望如此。
开发环境:VS2008
本节源码位置:
源码下载方法:安装SVN客户端(文末提供下载地址),然后查看以下地址:
文章系列大纲如下:
网络采集软件核心技术解析系列(1)---如何使用C#语言获取博客园中某博主的所有文章链接和标题
网络采集软件核心技术解析系列(2)---如何使用C#语言获取任意站点博文的正文和标题
网络采集软件核心技术解析系列(3)---如何用C#语言将博文中的所有图片下载到本地并离线浏览
网络采集软件核心技术解析系列(4)---如何使用C#语言将html网页转换成pdf(html2pdf)
网络采集软件核心技术解析系列(5)---将任意博主的所有博文下载到内存中,通过Webbrower展示
网络采集软件核心技术分析系列(6)---将任何博主的所有博文下载到SQLite数据库中,通过Webbrower展示
网络采集软件核心技术解析系列(7)---如何使用C#语言搭建程序框架(经典Winform界面、菜单栏、树形列表、多标签界面)
网络采集软件核心技术解析系列(综合实例)
2、第七节主要内容介绍(如何使用C#语言搭建程序框架(经典Winform界面,顶部菜单栏,工具栏,左侧树形列表,右侧多个Tab界面))
如何使用C#语言搭建程序框架(经典Winform界面,顶部菜单栏,工具栏,左侧树状列表,右侧多个Tab界面)解决方案,演示如下图:可执行文件下载
演示功能介绍:
程序启动后,扫描程序所在目录的WebSiteDB文件夹(见上一节,里面存放着每个博主的所有博文和xxx.db文件),在左边的树形控件上加载数据库名称; 双击树控件为子节点,在右侧添加类似浏览器的标签界面。在新打开的界面中,会自动加载博主的博文列表信息。
三个基本原则
这个简单的框架有三个要点:
1. 递归加载树控制节点;
2. 右侧tab窗体的创建(主要使用大名鼎鼎的WeifenLuo.WinFormsUI.Docking.dll);
3. 单击树节点打开一个新窗口(前两者的组合)。
先看第一点,树控件节点的递归加载,主要代码如下:
private void LoadWebSiteTree()
{
this.treeViewTask.Nodes.Clear();
TreeNode nodeRoot = new TreeNode();
nodeRoot.Text = "站点列表";
nodeRoot.Tag = -1;
this.treeViewTask.Nodes.Add(nodeRoot);
GetSubDirectoryNodes(nodeRoot, m_strDBFolder,true);
this.treeViewTask.SelectedNode = this.treeViewTask.TopNode;
}
创建根节点,然后调用GetSubDirectoryNodes函数递归加载子节点:
private void GetSubDirectoryNodes(TreeNode parentNode, string fullName, bool getFileNames)
{
if (!Directory.Exists(fullName))
{
Directory.CreateDirectory(fullName);
}
DirectoryInfo dir = new DirectoryInfo(fullName);
DirectoryInfo[] dirSubs = dir.GetDirectories();
// 为每个子目录添加一个子节点
foreach (DirectoryInfo dirSub in dirSubs)
{
// 不显示隐藏文件夹
if ((dirSub.Attributes & FileAttributes.Hidden) != 0)
{
continue;
}
TreeNode node = new TreeNode();
node.Text = dirSub.Name;
node.Tag = 0;
node.ImageIndex = 0;
parentNode.Nodes.Add(node);
// 递归调用
GetSubDirectoryNodes(node, dirSub.FullName, getFileNames);
}
// 为每个子目录添加一个子节点
foreach (DirectoryInfo dirSub in dirSubs)
{
// 不显示隐藏文件夹
if ((dirSub.Attributes & FileAttributes.Hidden) != 0)
{
continue;
}
}
if (getFileNames) // 书中源码中,这部分在foreach内部,不正确
{
// 获取此节点的所有文件
FileInfo[] files = dir.GetFiles();
// 放置节点后。放置子目录中的文件。
foreach (FileInfo file in files)
{
if (file.Extension.ToString() != ".db")
continue;
string strNodeName = file.Name.Remove(file.Name.Length - 3, 3);
if (strNodeName == "home")
continue;
TreeNode node = new TreeNode();
node.Text = strNodeName;
node.Tag = 1;
node.ImageIndex = 1;
parentNode.Nodes.Add(node);
}
}
}
接下来看第二点,2.右侧的tab窗体的创建(主要使用大名鼎鼎的WeifenLuo.WinFormsUI.Docking.dll),主要代码如下:
public DockContent ShowContent(string caption/*, Type formType*/)
{
DockContent frm = FindDocument(caption);
if (frm == null)
{
Frm_TargetUrlView frm_TargetUrlView = new Frm_TargetUrlView((string)this.treeViewTask.SelectedNode.Parent.Text
, m_strDBConStringPath + m_strTreeNodeName
, (string)this.treeViewTask.SelectedNode.Text, this);
frm_TargetUrlView.MdiParent = this;
frm_TargetUrlView.WindowState = FormWindowState.Maximized;
frm_TargetUrlView.Show(this.dockPanel1);
frm_TargetUrlView.Focus();
frm_TargetUrlView.BringToFront();
return frm_TargetUrlView;
}
frm.Show(this.dockPanel1);
frm.Focus();
frm.BringToFront();
return frm;
}
首先调用FindDocument(caption)判断当前标签窗口是否已经打开,如果已经打开,则激活它;如果尚未打开,则创建一个新的选项卡窗口并使这个新创建的窗口成为活动窗口。
3. 单击树节点打开一个新窗口(前两者的组合)。主要代码如下:
private void treeViewTask_MouseDoubleClick(object sender, MouseEventArgs e)
{
Point pos = new Point(e.X, e.Y);
TreeNode nodeClick = this.treeViewTask.GetNodeAt(pos);
if (nodeClick.Text == "站点列表")
{
this.treeViewTask.ContextMenuStrip = null;
return;
}
if (nodeClick != null && e.Button == MouseButtons.Left)
{
int nTag = (int)nodeClick.Tag;
if (nTag == 0)
return;
this.treeViewTask.SelectedNode = nodeClick;
LoadInfoByNode();
}
ShowContent(this.treeViewTask.SelectedNode.Text);
}
在树节点的双击处理函数中,调用上面第二步的ShowContent函数,就会弹出对应的tab窗体。
更详细的代码请自行下载学习。 查看全部
工具采集文章(一本系列随笔概览及产生的背景自己开发的豆约翰博客备份专家软件工具)
一系列论文及其背景的概述
自主研发的DouJohnson博客备份专家软件工具自问世3年多以来,深受博客写作和阅读爱好者的喜爱。同时,也有一些技术爱好者向我咨询如何实现这个软件中的各种实用功能。
该软件是使用.NET 技术开发的。为了回馈社会,特开设软件使用的核心技术专栏,为广大技术爱好者写了一系列文章。
本系列文章不仅讲解了网络采集、编辑、发布中用到的各种重要技术,还提供了很多界面开发中的解题思路和编程经验。非常适合.NET开发的初学者和中级读者。希望请多多支持。
很多初学者经常会有这样的困惑,“为什么我看了这本书,对C#的方方面面都了解了,却写不出一个像样的应用程序?”,
其实我还没有学会综合运用所学的知识,锻炼编程思维,建立学习的兴趣。我认为这个系列文章 可以帮助你,我希望如此。
开发环境:VS2008
本节源码位置:
源码下载方法:安装SVN客户端(文末提供下载地址),然后查看以下地址:
文章系列大纲如下:
网络采集软件核心技术解析系列(1)---如何使用C#语言获取博客园中某博主的所有文章链接和标题
网络采集软件核心技术解析系列(2)---如何使用C#语言获取任意站点博文的正文和标题
网络采集软件核心技术解析系列(3)---如何用C#语言将博文中的所有图片下载到本地并离线浏览
网络采集软件核心技术解析系列(4)---如何使用C#语言将html网页转换成pdf(html2pdf)
网络采集软件核心技术解析系列(5)---将任意博主的所有博文下载到内存中,通过Webbrower展示
网络采集软件核心技术分析系列(6)---将任何博主的所有博文下载到SQLite数据库中,通过Webbrower展示
网络采集软件核心技术解析系列(7)---如何使用C#语言搭建程序框架(经典Winform界面、菜单栏、树形列表、多标签界面)
网络采集软件核心技术解析系列(综合实例)
2、第七节主要内容介绍(如何使用C#语言搭建程序框架(经典Winform界面,顶部菜单栏,工具栏,左侧树形列表,右侧多个Tab界面))
如何使用C#语言搭建程序框架(经典Winform界面,顶部菜单栏,工具栏,左侧树状列表,右侧多个Tab界面)解决方案,演示如下图:可执行文件下载
演示功能介绍:
程序启动后,扫描程序所在目录的WebSiteDB文件夹(见上一节,里面存放着每个博主的所有博文和xxx.db文件),在左边的树形控件上加载数据库名称; 双击树控件为子节点,在右侧添加类似浏览器的标签界面。在新打开的界面中,会自动加载博主的博文列表信息。
三个基本原则
这个简单的框架有三个要点:
1. 递归加载树控制节点;
2. 右侧tab窗体的创建(主要使用大名鼎鼎的WeifenLuo.WinFormsUI.Docking.dll);
3. 单击树节点打开一个新窗口(前两者的组合)。
先看第一点,树控件节点的递归加载,主要代码如下:
private void LoadWebSiteTree()
{
this.treeViewTask.Nodes.Clear();
TreeNode nodeRoot = new TreeNode();
nodeRoot.Text = "站点列表";
nodeRoot.Tag = -1;
this.treeViewTask.Nodes.Add(nodeRoot);
GetSubDirectoryNodes(nodeRoot, m_strDBFolder,true);
this.treeViewTask.SelectedNode = this.treeViewTask.TopNode;
}
创建根节点,然后调用GetSubDirectoryNodes函数递归加载子节点:
private void GetSubDirectoryNodes(TreeNode parentNode, string fullName, bool getFileNames)
{
if (!Directory.Exists(fullName))
{
Directory.CreateDirectory(fullName);
}
DirectoryInfo dir = new DirectoryInfo(fullName);
DirectoryInfo[] dirSubs = dir.GetDirectories();
// 为每个子目录添加一个子节点
foreach (DirectoryInfo dirSub in dirSubs)
{
// 不显示隐藏文件夹
if ((dirSub.Attributes & FileAttributes.Hidden) != 0)
{
continue;
}
TreeNode node = new TreeNode();
node.Text = dirSub.Name;
node.Tag = 0;
node.ImageIndex = 0;
parentNode.Nodes.Add(node);
// 递归调用
GetSubDirectoryNodes(node, dirSub.FullName, getFileNames);
}
// 为每个子目录添加一个子节点
foreach (DirectoryInfo dirSub in dirSubs)
{
// 不显示隐藏文件夹
if ((dirSub.Attributes & FileAttributes.Hidden) != 0)
{
continue;
}
}
if (getFileNames) // 书中源码中,这部分在foreach内部,不正确
{
// 获取此节点的所有文件
FileInfo[] files = dir.GetFiles();
// 放置节点后。放置子目录中的文件。
foreach (FileInfo file in files)
{
if (file.Extension.ToString() != ".db")
continue;
string strNodeName = file.Name.Remove(file.Name.Length - 3, 3);
if (strNodeName == "home")
continue;
TreeNode node = new TreeNode();
node.Text = strNodeName;
node.Tag = 1;
node.ImageIndex = 1;
parentNode.Nodes.Add(node);
}
}
}
接下来看第二点,2.右侧的tab窗体的创建(主要使用大名鼎鼎的WeifenLuo.WinFormsUI.Docking.dll),主要代码如下:
public DockContent ShowContent(string caption/*, Type formType*/)
{
DockContent frm = FindDocument(caption);
if (frm == null)
{
Frm_TargetUrlView frm_TargetUrlView = new Frm_TargetUrlView((string)this.treeViewTask.SelectedNode.Parent.Text
, m_strDBConStringPath + m_strTreeNodeName
, (string)this.treeViewTask.SelectedNode.Text, this);
frm_TargetUrlView.MdiParent = this;
frm_TargetUrlView.WindowState = FormWindowState.Maximized;
frm_TargetUrlView.Show(this.dockPanel1);
frm_TargetUrlView.Focus();
frm_TargetUrlView.BringToFront();
return frm_TargetUrlView;
}
frm.Show(this.dockPanel1);
frm.Focus();
frm.BringToFront();
return frm;
}
首先调用FindDocument(caption)判断当前标签窗口是否已经打开,如果已经打开,则激活它;如果尚未打开,则创建一个新的选项卡窗口并使这个新创建的窗口成为活动窗口。
3. 单击树节点打开一个新窗口(前两者的组合)。主要代码如下:
private void treeViewTask_MouseDoubleClick(object sender, MouseEventArgs e)
{
Point pos = new Point(e.X, e.Y);
TreeNode nodeClick = this.treeViewTask.GetNodeAt(pos);
if (nodeClick.Text == "站点列表")
{
this.treeViewTask.ContextMenuStrip = null;
return;
}
if (nodeClick != null && e.Button == MouseButtons.Left)
{
int nTag = (int)nodeClick.Tag;
if (nTag == 0)
return;
this.treeViewTask.SelectedNode = nodeClick;
LoadInfoByNode();
}
ShowContent(this.treeViewTask.SelectedNode.Text);
}
在树节点的双击处理函数中,调用上面第二步的ShowContent函数,就会弹出对应的tab窗体。
更详细的代码请自行下载学习。
工具采集文章(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-04 05:10
大数据的来源有很多。在大数据时代背景下,如何从大数据中采集是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据阶段的工作采集是大数据的核心技术之一。为了高效地采集大数据,根据采集环境和数据类型选择合适的大数据采集方法和平台很重要。下面介绍一些常用的大数据采集平台和工具。
1 水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着Flume的不断完善,用户在开发过程中的便利性得到了极大的提升,Flume现在已经成为Apache Top项目之一。
Flume 提供了从 Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog 和 Exec(命令执行)等数据源采集数据的能力。
Flume 使用多 Master 方法。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身可以保证配置数据的一致性和高可用。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。使用 Gossip 协议在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集场景。由于 Flume 使用 JRuby 构建,因此它依赖于 Java 运行时环境。Flume 被设计为分布式管道架构,可以看作是数据源和目的地之间的 Agent 网络,支持数据路由。
Flume支持设置Sink的Failover和负载均衡,这样可以保证在Agent发生故障的情况下,整个系统仍然可以正常采集数据。Flume中传输的内容定义为一个事件,它由Headers(包括元数据,即Meta Data)和Payload组成。
Flume提供SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume Agent。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端有 Avro、Log4J、Syslog 和 HTTP Post。
2 流利
Fluentd是另一种开源的数据采集架构,如图1所示。Fluentd是用C/Ruby开发的,使用JSON文件统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,可以非常轻松地实现跟踪日志文件并对其进行过滤并将其转储到 MongoDB 等操作。Fluentd 可以完全将人们从繁琐的日志处理中解放出来。
图 1 Fluentd 架构
Fluentd 具有多个特点:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用JSON统一数据/日志格式是它的另一个特点。与Flume相比,Fluentd的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Fluent 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3 日志存储
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以它在运行时依赖于 JVM。Logstash的部署架构如图3所示,当然这只是一个部署选项。
图3 Logstash部署架构
一个典型的Logstash配置如下,包括Filter的Input和Output的设置。
输入 {
文件 {
类型 =>“Apache 访问”
路径 =>"/var/log/Apache2/other_vhosts_access.log"
}
文件 {
类型 =>“补丁错误”
路径 =>"/var/log/Apache2/error.log"
}
}
筛选 {
神通{
匹配 => {"message"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出{}
Redis {
主机=>“192.168.1.289”
数据类型 =>“列表”
键 => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。如果您的数据系统使用 ElasticSearch,Logstash 是首选。
4 楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,名气远不如其他平台。Chukwa 基于 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)构建,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据的显示、分析和监控。该项目目前处于非活动状态。
Chukwa 适应以下需求:
(1) 灵活、动态、可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)分析采集到的大规模数据的适当框架。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5 抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。它的官方网站已经很多年没有维护了。Scribe 为日志的“分布式采集、统一处理”提供了可扩展、高容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS,Hadoop 通过 MapReduce 作业进行定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe架构比较简单,主要包括三部分,分别是Scribe agent、Scribe和存储系统。
6 Splunk
在商业化的大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要作用。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,提供搜索过程中的信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、转换,并发送到Indexer。
Splunk 具有对 Syslog、TCP/UDP 和假脱机的内置支持。同时,用户可以通过开发Input和Modular Input来获取具体的数据。Splunk提供的软件仓库中有很多成熟的数据应用,如AWS、数据库(DBConnect)等,可以方便地从云端或数据库中获取数据,进入Splunk的数据平台进行分析。
Search Head 和Indexer 都支持Cluster 的配置,具有高可用和高扩展性,但Splunk 尚不具备Cluster for Forwarder 的功能。换句话说,如果一台 Forwarder 机器出现故障,数据采集会中断,并且正在运行的数据采集任务无法因故障转移而切换到其他 Forwarder。
7 Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一种由 Python 语言开发的快速、高级的屏幕抓取和网页抓取架构,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据自己的需要轻松修改的架构。它还提供了多种爬虫的基类,如BaseSpider、Sitemap爬虫等,最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 工作原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy的运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫得到第一个爬取到的URL。
(2)Scrapy 引擎首先从爬虫那里获取需要爬取的第一个 URL,然后在调度中作为请求进行调度。
(3)Scrapy 引擎从调度器中获取下一个要爬取的页面。
(4)调度返回下一个爬取的URL给引擎,引擎通过下载中间件发送给下载器。
(5) 当网页被下载器下载时,响应内容通过下载器中间件发送到 Scrapy 引擎。
(6)Scrapy 引擎收到下载器的响应,通过爬虫中间件发送给爬虫处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将捕获的项目放入项目管道,并向调度程序发送请求。
(9)系统重复以下步骤(2))的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。 查看全部
工具采集文章(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据的来源有很多。在大数据时代背景下,如何从大数据中采集是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据阶段的工作采集是大数据的核心技术之一。为了高效地采集大数据,根据采集环境和数据类型选择合适的大数据采集方法和平台很重要。下面介绍一些常用的大数据采集平台和工具。
1 水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着Flume的不断完善,用户在开发过程中的便利性得到了极大的提升,Flume现在已经成为Apache Top项目之一。
Flume 提供了从 Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog 和 Exec(命令执行)等数据源采集数据的能力。
Flume 使用多 Master 方法。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身可以保证配置数据的一致性和高可用。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。使用 Gossip 协议在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集场景。由于 Flume 使用 JRuby 构建,因此它依赖于 Java 运行时环境。Flume 被设计为分布式管道架构,可以看作是数据源和目的地之间的 Agent 网络,支持数据路由。
Flume支持设置Sink的Failover和负载均衡,这样可以保证在Agent发生故障的情况下,整个系统仍然可以正常采集数据。Flume中传输的内容定义为一个事件,它由Headers(包括元数据,即Meta Data)和Payload组成。
Flume提供SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume Agent。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端有 Avro、Log4J、Syslog 和 HTTP Post。
2 流利
Fluentd是另一种开源的数据采集架构,如图1所示。Fluentd是用C/Ruby开发的,使用JSON文件统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,可以非常轻松地实现跟踪日志文件并对其进行过滤并将其转储到 MongoDB 等操作。Fluentd 可以完全将人们从繁琐的日志处理中解放出来。
图 1 Fluentd 架构
Fluentd 具有多个特点:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用JSON统一数据/日志格式是它的另一个特点。与Flume相比,Fluentd的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Fluent 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3 日志存储
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以它在运行时依赖于 JVM。Logstash的部署架构如图3所示,当然这只是一个部署选项。
图3 Logstash部署架构
一个典型的Logstash配置如下,包括Filter的Input和Output的设置。
输入 {
文件 {
类型 =>“Apache 访问”
路径 =>"/var/log/Apache2/other_vhosts_access.log"
}
文件 {
类型 =>“补丁错误”
路径 =>"/var/log/Apache2/error.log"
}
}
筛选 {
神通{
匹配 => {"message"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出{}
Redis {
主机=>“192.168.1.289”
数据类型 =>“列表”
键 => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。如果您的数据系统使用 ElasticSearch,Logstash 是首选。
4 楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,名气远不如其他平台。Chukwa 基于 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)构建,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据的显示、分析和监控。该项目目前处于非活动状态。
Chukwa 适应以下需求:
(1) 灵活、动态、可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)分析采集到的大规模数据的适当框架。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5 抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。它的官方网站已经很多年没有维护了。Scribe 为日志的“分布式采集、统一处理”提供了可扩展、高容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS,Hadoop 通过 MapReduce 作业进行定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe架构比较简单,主要包括三部分,分别是Scribe agent、Scribe和存储系统。
6 Splunk
在商业化的大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要作用。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,提供搜索过程中的信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、转换,并发送到Indexer。
Splunk 具有对 Syslog、TCP/UDP 和假脱机的内置支持。同时,用户可以通过开发Input和Modular Input来获取具体的数据。Splunk提供的软件仓库中有很多成熟的数据应用,如AWS、数据库(DBConnect)等,可以方便地从云端或数据库中获取数据,进入Splunk的数据平台进行分析。
Search Head 和Indexer 都支持Cluster 的配置,具有高可用和高扩展性,但Splunk 尚不具备Cluster for Forwarder 的功能。换句话说,如果一台 Forwarder 机器出现故障,数据采集会中断,并且正在运行的数据采集任务无法因故障转移而切换到其他 Forwarder。
7 Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一种由 Python 语言开发的快速、高级的屏幕抓取和网页抓取架构,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据自己的需要轻松修改的架构。它还提供了多种爬虫的基类,如BaseSpider、Sitemap爬虫等,最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 工作原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy的运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫得到第一个爬取到的URL。
(2)Scrapy 引擎首先从爬虫那里获取需要爬取的第一个 URL,然后在调度中作为请求进行调度。
(3)Scrapy 引擎从调度器中获取下一个要爬取的页面。
(4)调度返回下一个爬取的URL给引擎,引擎通过下载中间件发送给下载器。
(5) 当网页被下载器下载时,响应内容通过下载器中间件发送到 Scrapy 引擎。
(6)Scrapy 引擎收到下载器的响应,通过爬虫中间件发送给爬虫处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将捕获的项目放入项目管道,并向调度程序发送请求。
(9)系统重复以下步骤(2))的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
工具采集文章(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-01 12:22
可以免费下载还是可以直接将VIP会员资源商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:你可以对比下载后压缩包的容量和网盘的容量,如果小于网盘标示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专享、全站源码、程序插件、网站模板、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源 查看全部
工具采集文章(免费下载或者VIP会员资源能否直接商用?浏览器下载)
可以免费下载还是可以直接将VIP会员资源商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:你可以对比下载后压缩包的容量和网盘的容量,如果小于网盘标示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专享、全站源码、程序插件、网站模板、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源
工具采集文章(工具采集文章速度较慢,一些细节错误、结构错误)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-15 01:03
工具采集文章速度较慢,一些细节错误、结构错误也不易发现,自动采集有一定弊端,建议客户用人工采集慢慢修改,效率能提高不少,并且自动采集是不能保存,修改完成后得自己手动再提交下获取通过。核心功能功能1:原创文章自动生成机器文章功能2:自动布局正文功能3:自动排版文章功能4:自动标题生成机器文章功能5:自动收录,收录一次自动布局1~2篇文章功能6:ai,自动打标签机器文章功能7:手动挖掘关键词,自动关键词挖掘机器文章功能8:自动长尾词挖掘机器文章功能9:伪原创机器文章功能10:正则引擎,自动内容过滤机器文章功能11:h5模板,自动内容填充机器文章功能12:头条自动推荐,自动推荐机器文章功能13:伪原创机器文章功能14:发文批量删改标题功能15:文章关键词标签自动填充功能16:文章分类自动命名功能17:搜索以前发布的链接自动添加功能18:定时发文功能19:定时发文模块20:计时器自动定时发文功能21:定时发文管理自动发文功能22:ai自动标签机器文章功能23:文章分析机器文章功能24:自动发文规律机器文章功能25:自动上传图片、视频文件功能26:文章自动获取关键词,导入公众号文章库自动获取关键词17个ai,新建一个本地库ai采集会话时,我们正在收听,检测时刻另一种模式可以使用点击麦克风,并开始录音。然后我们所有的回答在麦克风上传。 查看全部
工具采集文章(工具采集文章速度较慢,一些细节错误、结构错误)
工具采集文章速度较慢,一些细节错误、结构错误也不易发现,自动采集有一定弊端,建议客户用人工采集慢慢修改,效率能提高不少,并且自动采集是不能保存,修改完成后得自己手动再提交下获取通过。核心功能功能1:原创文章自动生成机器文章功能2:自动布局正文功能3:自动排版文章功能4:自动标题生成机器文章功能5:自动收录,收录一次自动布局1~2篇文章功能6:ai,自动打标签机器文章功能7:手动挖掘关键词,自动关键词挖掘机器文章功能8:自动长尾词挖掘机器文章功能9:伪原创机器文章功能10:正则引擎,自动内容过滤机器文章功能11:h5模板,自动内容填充机器文章功能12:头条自动推荐,自动推荐机器文章功能13:伪原创机器文章功能14:发文批量删改标题功能15:文章关键词标签自动填充功能16:文章分类自动命名功能17:搜索以前发布的链接自动添加功能18:定时发文功能19:定时发文模块20:计时器自动定时发文功能21:定时发文管理自动发文功能22:ai自动标签机器文章功能23:文章分析机器文章功能24:自动发文规律机器文章功能25:自动上传图片、视频文件功能26:文章自动获取关键词,导入公众号文章库自动获取关键词17个ai,新建一个本地库ai采集会话时,我们正在收听,检测时刻另一种模式可以使用点击麦克风,并开始录音。然后我们所有的回答在麦克风上传。
工具采集文章(网站更新文章都有哪些规律?网络小编来给您解答)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-10-14 04:30
很多朋友在网站seo优化过程中遇到了一些网站优化问题,包括《seo文章采集工具:SEO更新文章都有哪些规则?》问题,那我搜索下面的网络编辑器来回答你的疑惑。
网站更新文章是SEO优化操作中比较重要的任务。大多数网站没做好SEO是因为他们没有做好网站文章更新,但是网站经常更新文章你能做SEO优化吗?为什么很多人几个月就更新了文章,却没有增加一点排名?可能没用。
内容丰富
获取搜索引擎采集的大量内容也很困难。在 Internet 上搜索 文章 重复项。其中大部分已在一些高性能平台上发布。搜索引擎也有相同的数据,因此搜索引擎不会抓取搜索。当然,可能有人会问,为什么别人的采集会增加重量,而自己的采集会减少力量呢?事实上,值得学习的因素有很多。例如,他人采集的内容经过优化处理后发布,或者他人采集的内容是比较新的内容。原创属性和时效性比较高,用户参考价值比较大,所以可以增加网站的权重。
所以,如果单纯的粘贴复制,那么这种偷懒的采集方式难免会受到搜索引擎的惩罚。seo采集 工具。
2.网站上更新的文章多为图片无文字说明
网站 的处理和布局对加载速度也有很大影响。如果服务器不是太大的问题,如果你使用别人的服务器,那么图片加载速度就成了一个大问题。在很多企业网站中,大部分内容更新都是产品,只放了部分产品图片,没有具体位置说明。搜索引擎根本无法识别图片。如果图片尺寸过大,也会影响加载速度。同时,文章更新必须有文字说明,更新文章必须坚持“以文字图片为补充”的原则。
3. 文章内无内链
要不要在更新底部留个链接文章?你要不要做以下相关的事情文章?所有这些问题都是大多数 SEOer 争论的主题。有人说不能添加,降低了每页的重复率。有人说需要添加,这样每个内页可以相互传递权重,同时增加用户体验,促进包容性。
seo文章采集工具:如何批量SEO站长采集文章
小编认为在文章底部添加文字链接利大于弊。在文章之后也需要添加相关性,但是要避免关键词堆叠的操作,否则内部链接弊大于利。
四、文章不确定更新重点方向
很多人更新文章的内容,没有结合数据就盲目更新,没有根据用户的基本搜索需求来写内容,或者还是保持着线下推广的思路。很多人直接用什么样的活动打折,然后放个二维码是如何吸引用户眼球的?很多聪明的公司已经抛开传统的线下销售思维,在网站的推广中转变了思路。seo文章 工具。seo文章采集工具
首先了解用户进行网络推广的目的?是通过互联网销售产品,用户不能满足面对面的条件,所以用户有选择的权利。他们希望用户在他们的时间选择我们。无需专人扫描二维码或致电咨询,以简单的形式呈现给客户。让客户一目了然地找到他们想要的东西。以产品内容为例。产品是一个关键点。然后我们要考虑用户关心什么。产品参数、价格和质量。
五、文章关键词匹配问题
文章关键词中的匹配也是优化工作的一个重要部分。大多数人都知道布局关键词的重要性。这里文方阁建议在文章标题中合理列出关键词,然后关键词合理出现在第一段和最后一段,属性ALT图片也可以合理出现关键词@ >,这使得搜索引擎更容易识别文章的核心关键词,并给出具体的关键词排名。ecshop文章seo.
6. 定期规则更新
文章为什么要更新,要注意规律?很多人想一次性发布所有文章,然后就不管了,所以很难开发出搜索引擎蜘蛛定时抓取和收录的效果,定时更新也很重要。首先通过网站日志分析进行搜索。引擎蜘蛛经常会来网站抓取时间段,找出频率时间段,然后在那个时间段发布。这也可以防止网站的内容被重量级的peer复制。建议更新。
以上是关于seo文章采集工具,SEO更新文章的规则是什么?文章内容,如果您有网站优化的意向,可以直接联系我们。很高兴为您服务! 查看全部
工具采集文章(网站更新文章都有哪些规律?网络小编来给您解答)
很多朋友在网站seo优化过程中遇到了一些网站优化问题,包括《seo文章采集工具:SEO更新文章都有哪些规则?》问题,那我搜索下面的网络编辑器来回答你的疑惑。
网站更新文章是SEO优化操作中比较重要的任务。大多数网站没做好SEO是因为他们没有做好网站文章更新,但是网站经常更新文章你能做SEO优化吗?为什么很多人几个月就更新了文章,却没有增加一点排名?可能没用。
内容丰富
获取搜索引擎采集的大量内容也很困难。在 Internet 上搜索 文章 重复项。其中大部分已在一些高性能平台上发布。搜索引擎也有相同的数据,因此搜索引擎不会抓取搜索。当然,可能有人会问,为什么别人的采集会增加重量,而自己的采集会减少力量呢?事实上,值得学习的因素有很多。例如,他人采集的内容经过优化处理后发布,或者他人采集的内容是比较新的内容。原创属性和时效性比较高,用户参考价值比较大,所以可以增加网站的权重。
所以,如果单纯的粘贴复制,那么这种偷懒的采集方式难免会受到搜索引擎的惩罚。seo采集 工具。
2.网站上更新的文章多为图片无文字说明
网站 的处理和布局对加载速度也有很大影响。如果服务器不是太大的问题,如果你使用别人的服务器,那么图片加载速度就成了一个大问题。在很多企业网站中,大部分内容更新都是产品,只放了部分产品图片,没有具体位置说明。搜索引擎根本无法识别图片。如果图片尺寸过大,也会影响加载速度。同时,文章更新必须有文字说明,更新文章必须坚持“以文字图片为补充”的原则。
3. 文章内无内链
要不要在更新底部留个链接文章?你要不要做以下相关的事情文章?所有这些问题都是大多数 SEOer 争论的主题。有人说不能添加,降低了每页的重复率。有人说需要添加,这样每个内页可以相互传递权重,同时增加用户体验,促进包容性。
seo文章采集工具:如何批量SEO站长采集文章
小编认为在文章底部添加文字链接利大于弊。在文章之后也需要添加相关性,但是要避免关键词堆叠的操作,否则内部链接弊大于利。
四、文章不确定更新重点方向
很多人更新文章的内容,没有结合数据就盲目更新,没有根据用户的基本搜索需求来写内容,或者还是保持着线下推广的思路。很多人直接用什么样的活动打折,然后放个二维码是如何吸引用户眼球的?很多聪明的公司已经抛开传统的线下销售思维,在网站的推广中转变了思路。seo文章 工具。seo文章采集工具
首先了解用户进行网络推广的目的?是通过互联网销售产品,用户不能满足面对面的条件,所以用户有选择的权利。他们希望用户在他们的时间选择我们。无需专人扫描二维码或致电咨询,以简单的形式呈现给客户。让客户一目了然地找到他们想要的东西。以产品内容为例。产品是一个关键点。然后我们要考虑用户关心什么。产品参数、价格和质量。
五、文章关键词匹配问题
文章关键词中的匹配也是优化工作的一个重要部分。大多数人都知道布局关键词的重要性。这里文方阁建议在文章标题中合理列出关键词,然后关键词合理出现在第一段和最后一段,属性ALT图片也可以合理出现关键词@ >,这使得搜索引擎更容易识别文章的核心关键词,并给出具体的关键词排名。ecshop文章seo.
6. 定期规则更新
文章为什么要更新,要注意规律?很多人想一次性发布所有文章,然后就不管了,所以很难开发出搜索引擎蜘蛛定时抓取和收录的效果,定时更新也很重要。首先通过网站日志分析进行搜索。引擎蜘蛛经常会来网站抓取时间段,找出频率时间段,然后在那个时间段发布。这也可以防止网站的内容被重量级的peer复制。建议更新。
以上是关于seo文章采集工具,SEO更新文章的规则是什么?文章内容,如果您有网站优化的意向,可以直接联系我们。很高兴为您服务!
工具采集文章(工具采集文章后发布到今日头条,只能算是个搬运工)
采集交流 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2021-10-12 10:03
工具采集文章后发布到今日头条,只要不发布到自媒体平台,只能算是个搬运工,并不是原创,也不会有广告收益。工具采集的文章仅仅保留标题、简介、内容等关键信息,并且无法关联到其他自媒体平台进行发布,被识别出来的机率很高。
前几天平台刚封,估计后面就不封了,这是传说中的,
可以的,我有个朋友在做这个,我看他每天2-3万左右收益,
根据什么原因封的,是平台对你违规的,还是你提供的素材不合规,有没有提供原创文章。
写什么东西,最好能发在什么地方,标题,关键词,要包含公众号文章中的,信息点,抄袭的时候最好用软件。
是正常的,因为现在的自媒体平台有很多账号审核是偏严格的,你提供的内容可能有抄袭,如果你能快速的做出原创内容,可以破原创的,如果审核不严格,一篇随便写个三五百字的文章,它可能也不会封你。
你好,你已经可以正常注册自媒体平台,比如今日头条、企鹅号、搜狐、网易等平台都是可以正常注册的,都需要个人身份证,企业提供法人,要去一些支持个人注册的平台去申请,有的平台,比如百家号已经出现大量抄袭账号的情况,所以建议先集中准备几个平台,以备不时之需。
可以,不用担心,收益都正常, 查看全部
工具采集文章(工具采集文章后发布到今日头条,只能算是个搬运工)
工具采集文章后发布到今日头条,只要不发布到自媒体平台,只能算是个搬运工,并不是原创,也不会有广告收益。工具采集的文章仅仅保留标题、简介、内容等关键信息,并且无法关联到其他自媒体平台进行发布,被识别出来的机率很高。
前几天平台刚封,估计后面就不封了,这是传说中的,
可以的,我有个朋友在做这个,我看他每天2-3万左右收益,
根据什么原因封的,是平台对你违规的,还是你提供的素材不合规,有没有提供原创文章。
写什么东西,最好能发在什么地方,标题,关键词,要包含公众号文章中的,信息点,抄袭的时候最好用软件。
是正常的,因为现在的自媒体平台有很多账号审核是偏严格的,你提供的内容可能有抄袭,如果你能快速的做出原创内容,可以破原创的,如果审核不严格,一篇随便写个三五百字的文章,它可能也不会封你。
你好,你已经可以正常注册自媒体平台,比如今日头条、企鹅号、搜狐、网易等平台都是可以正常注册的,都需要个人身份证,企业提供法人,要去一些支持个人注册的平台去申请,有的平台,比如百家号已经出现大量抄袭账号的情况,所以建议先集中准备几个平台,以备不时之需。
可以,不用担心,收益都正常,
工具采集文章(工具采集文章分享一下我的方法,中国移动的大数据api免费接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-10-11 16:15
工具采集文章分享一下我的方法,中国移动的大数据api免费接口,内容为5万篇移动端文章信息,支持手机端查看api,请点击,查看下载地址还有微信文章,文章内容在哪个文章详情内容,经过工具抓取和清洗清洗工具功能:过滤图片、分词、对齐去重提取时间列表信息抓取头图,工具里面有下载地址数据格式:高频词、重复词、尾词对应文章频次抓取抓取特定主题的信息工具设置:模拟用户点击,到工具页面多端查看更新文章不同时间点、不同地点、不同页面页面,个人用户免费,大量成本自行承担移动端抓取工具:抓取工具一览,内容采集工具站内信获取微信公众号对接地址自行下载基本抓取常规需求我大致做了下,第一遍抓取是你最基本需求,后续都是你的进阶需求。
另外可以通过二维码来抓取跳转h5链接,而且可以提取微信推文。抓取的时候不要按照我的记录定时抓取,工具抓取效率比较差,自己设置定时抓取,抓取的地址自己填写(抓取地址一般在工具中的站内信获取或者通过应用市场获取)。
应用商店直接搜索
fiddler,手机万能扫描器,足够了。
fiddler这个是我一直在用的工具,不过最近发现手机扫描器,也能达到这样的效果,例如:要抓取微信公众号文章a文章内容,那么就是抓取公众号指定文章的内容。fiddler配置和方法(需要先安装fiddler运行环境)如果做得比较精确的话,还可以再将文章指定目录下载下来, 查看全部
工具采集文章(工具采集文章分享一下我的方法,中国移动的大数据api免费接口)
工具采集文章分享一下我的方法,中国移动的大数据api免费接口,内容为5万篇移动端文章信息,支持手机端查看api,请点击,查看下载地址还有微信文章,文章内容在哪个文章详情内容,经过工具抓取和清洗清洗工具功能:过滤图片、分词、对齐去重提取时间列表信息抓取头图,工具里面有下载地址数据格式:高频词、重复词、尾词对应文章频次抓取抓取特定主题的信息工具设置:模拟用户点击,到工具页面多端查看更新文章不同时间点、不同地点、不同页面页面,个人用户免费,大量成本自行承担移动端抓取工具:抓取工具一览,内容采集工具站内信获取微信公众号对接地址自行下载基本抓取常规需求我大致做了下,第一遍抓取是你最基本需求,后续都是你的进阶需求。
另外可以通过二维码来抓取跳转h5链接,而且可以提取微信推文。抓取的时候不要按照我的记录定时抓取,工具抓取效率比较差,自己设置定时抓取,抓取的地址自己填写(抓取地址一般在工具中的站内信获取或者通过应用市场获取)。
应用商店直接搜索
fiddler,手机万能扫描器,足够了。
fiddler这个是我一直在用的工具,不过最近发现手机扫描器,也能达到这样的效果,例如:要抓取微信公众号文章a文章内容,那么就是抓取公众号指定文章的内容。fiddler配置和方法(需要先安装fiddler运行环境)如果做得比较精确的话,还可以再将文章指定目录下载下来,
工具采集文章(一点资讯登录文章评论采集器(文章批量采集工具)使用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-10-11 11:18
易点信息登录文章评论采集器(文章Batch采集Tool)是官方专门为易点信息文章Batch推出的一款非常实用的工具采集 软件。您在寻找简单实用的文章批处理采集软件吗?那就来绿先锋下载一点资料,登录文章评论采集器使用最新版本。支持批量采集单点信息文章评论。爬取的数据包括文章标题、文章内容、文章封面、作者、作者头像、评论编号、评论、文章链接、文章分类、关键词等
软件说明
您可以自定义您想要采集的频道或文章关键字,并且您可以同时采集多个关键字或频道文章。
软件功能
1、分布式云爬虫,采集不间断
24小时不间断运行,关机也能采集;分布式云爬虫,可按需扩展,更适合大规模爬虫!
2、海量私有代理IP,智能抓取
自动访问私有代理IP,批量稳定抓取数据!
3、多种数据导出和发布方式
可以导出到Excel等文件,发布到数据库或者cms网站;还支持Webhooks推送、Restful接口、GraphQL访问等高级功能,与您现有系统无缝对接!
4、版本更新,一键在线升级
获取爬虫后,如有更新版本或修改,可在优采云控制台点击“更新”一键升级!
5、一站式大数据采集,清洗+机器学习
对爬取的数据进行统一可视化管理,优采云还提供了更多的数据分析处理功能:包括数据清洗和机器学习~ 查看全部
工具采集文章(一点资讯登录文章评论采集器(文章批量采集工具)使用)
易点信息登录文章评论采集器(文章Batch采集Tool)是官方专门为易点信息文章Batch推出的一款非常实用的工具采集 软件。您在寻找简单实用的文章批处理采集软件吗?那就来绿先锋下载一点资料,登录文章评论采集器使用最新版本。支持批量采集单点信息文章评论。爬取的数据包括文章标题、文章内容、文章封面、作者、作者头像、评论编号、评论、文章链接、文章分类、关键词等
软件说明
您可以自定义您想要采集的频道或文章关键字,并且您可以同时采集多个关键字或频道文章。
软件功能
1、分布式云爬虫,采集不间断
24小时不间断运行,关机也能采集;分布式云爬虫,可按需扩展,更适合大规模爬虫!
2、海量私有代理IP,智能抓取
自动访问私有代理IP,批量稳定抓取数据!
3、多种数据导出和发布方式
可以导出到Excel等文件,发布到数据库或者cms网站;还支持Webhooks推送、Restful接口、GraphQL访问等高级功能,与您现有系统无缝对接!
4、版本更新,一键在线升级
获取爬虫后,如有更新版本或修改,可在优采云控制台点击“更新”一键升级!
5、一站式大数据采集,清洗+机器学习
对爬取的数据进行统一可视化管理,优采云还提供了更多的数据分析处理功能:包括数据清洗和机器学习~
工具采集文章(《灵棺夜行代码》第2季第16集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-08 00:19
本文将与大家分享使用Python制作爬虫的代码。采集小说代码非常简单实用。虽然还是有点瑕疵,但我们一起改变,一起进步
开发工具:python3.4
操作系统:win8
主要功能:到指定的小说网页抓取小说目录,按章节保存在本地,并将抓取到的网页保存到本地配置文件中。
爬行网站:
小说名称:灵棺夜行
代码来源:我自己编写的
import urllib.request
import http.cookiejar
import socket
import time
import re
timeout = 20
socket.setdefaulttimeout(timeout)
sleep_download_time = 10
time.sleep(sleep_download_time)
def makeMyOpener(head = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
def saveFile(save_path,txts):
f_obj = open(save_path,'w+')
for item in txts:
f_obj.write(item+'\n')
f_obj.close()
#get_code_list
code_list='http://www.cishuge.com/read/0/771/'
oper = makeMyOpener()
uop = oper.open(code_list,timeout=1000)
data = uop.read().decode('gbk','ignore')
pattern = re.compile('(.*?)',re.S)
items = re.findall(pattern,data)
print ('获取列表完成')
url_path='url_file.txt'
url_r=open(url_path,'r')
url_arr=url_r.readlines(100000)
url_r.close()
print (len(url_arr))
url_file=open(url_path,'a')
print ('获取已下载网址')
for tmp in items:
save_path = tmp[1].replace(' ','')+'.txt'
url = code_list+tmp[0]
if url+'\n' in url_arr:
continue
print('写日志:'+url+'\n')
url_file.write(url+'\n')
opene = makeMyOpener()
op1 = opene.open(url,timeout=1000)
data = op1.read().decode('gbk','ignore')
opene.close()
pattern = re.compile(' (.*?)<br />',re.S)
txts = re.findall(pattern,data)
saveFile(save_path,txts)
url_file.close()
虽然代码还是有点瑕疵,分享给大家,一起改进 查看全部
工具采集文章(《灵棺夜行代码》第2季第16集)
本文将与大家分享使用Python制作爬虫的代码。采集小说代码非常简单实用。虽然还是有点瑕疵,但我们一起改变,一起进步
开发工具:python3.4
操作系统:win8
主要功能:到指定的小说网页抓取小说目录,按章节保存在本地,并将抓取到的网页保存到本地配置文件中。
爬行网站:
小说名称:灵棺夜行
代码来源:我自己编写的
import urllib.request
import http.cookiejar
import socket
import time
import re
timeout = 20
socket.setdefaulttimeout(timeout)
sleep_download_time = 10
time.sleep(sleep_download_time)
def makeMyOpener(head = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
def saveFile(save_path,txts):
f_obj = open(save_path,'w+')
for item in txts:
f_obj.write(item+'\n')
f_obj.close()
#get_code_list
code_list='http://www.cishuge.com/read/0/771/'
oper = makeMyOpener()
uop = oper.open(code_list,timeout=1000)
data = uop.read().decode('gbk','ignore')
pattern = re.compile('(.*?)',re.S)
items = re.findall(pattern,data)
print ('获取列表完成')
url_path='url_file.txt'
url_r=open(url_path,'r')
url_arr=url_r.readlines(100000)
url_r.close()
print (len(url_arr))
url_file=open(url_path,'a')
print ('获取已下载网址')
for tmp in items:
save_path = tmp[1].replace(' ','')+'.txt'
url = code_list+tmp[0]
if url+'\n' in url_arr:
continue
print('写日志:'+url+'\n')
url_file.write(url+'\n')
opene = makeMyOpener()
op1 = opene.open(url,timeout=1000)
data = op1.read().decode('gbk','ignore')
opene.close()
pattern = re.compile(' (.*?)<br />',re.S)
txts = re.findall(pattern,data)
saveFile(save_path,txts)
url_file.close()
虽然代码还是有点瑕疵,分享给大家,一起改进
工具采集文章(浅谈一下中文WP站群的操作步骤及设置模板)
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-09-30 21:14
由于前几天写了一篇《简述英文站群SEO操作》文章的文章,发现转发量疯了,所以今天介绍一下中文WP站群@ > 详细。操作它。
首先说一下为什么要使用WP(wordpress)。因为WP功能强大,插件多,代码简单,收录速度快,在SE上也有一定的分量,所以在国外已经被广泛使用,但是国内一些个人博客都是基于WP程序搭建的. 相信用过WP的人都知道。而那些玩英文SEO站群的基本上都是用WP来玩自动博客的,哈哈。
接下来,我将一步步为您讲解:
第一步:注册一批域名
我们都知道站群域名必须是多元化的,不能挂在一个后缀下。如果你是新手,我推荐小批量操作。首先注册10个域名,可以是com、net、org、cc、me、tk等等。并且可以按照关键词注册,也可以是一个数字,但是一定要多样化。
第 2 步:租用 VPS 或虚拟主机
一般新手玩站群,大概有10个站,最好租个vps。当然,如果你想要不同的IP段,你也可以租用不同IP的虚拟主机。但是在这里,我建议一定是国外主机,国内主机玩站群的时候会死的很快。
第 3 步:网站 构建
确定好域名和空间后,我们会下载最新版的WP,手动安装。关于FTP工具,我推荐CuteFtp。该工具可以在线修改文件、移动文件、打开更多文件等,界面简洁。
第四步:WP站点设置(重点)
1. 模板主题:同样,模板也需要多样化。您需要设置不同的模板,它是关于您制作的主题的模板。最好使用中文原创或者已经汉化的模板。然后修改部分代码,比如头部和尾部的代码。关于模板下载可以到:
2.插件上传及设置:
(1)Akismet(垃圾邮件拦截插件):该插件默认有WP,开启即可,然后自己申请API key。
(2)All in One SEO Pack(seo插件):这个插件很好用,英文WP和中文WP都适用。可以设置首页,文章页面标题,描述等,不过貌似这个插件设置的描述对百度没有用,可以在WP的摘要上填写描述。
(3)Autoptimize(网站代码的自动压缩):本插件可以压缩网站代码,如css、js、html等,可自行设置。
(4)Dagon Design Sitemap Generator(网站地图插件):这个插件可以设置网站地图。
(5)Google XML Sitemaps(网站地图自动提交):这个插件可以自动生成网站地图并通知google、yahoo等。
(6)GZippy(gzip 压缩):这个不用说了。
(7)Optimize DB(优化数据库):这个就不用说了。
(8)Random Posts 小部件(Random 文章 插件):您可以将随机 文章 添加到侧边栏。
(9)Robots Meta(机器人设置):不用说了。
(10)WordPress相关帖子(相关文章插件):可以在文章页面下设置相关文章。
(11)WP Keyword Link(内链插件):百度可以点击详细设置。
关于插件和WP设置,当然还有更好的插件可以用,可以自己摸索,不要看那么多会晕,全部下载,批量上传,设置在后台就OK了。
第五步:文章采集/批量上传/定时发布(绝密)
由于以上步骤都是手动完成的,所以整个WP的构建比站群软件质量更高。那么,既然我们不需要站群软件,那么如何让采集文章自动更新呢?
答案是优采云采集、博君seo伪原创工具、以及锤子免费登录发布界面。
由于操作比较多,这里暂时不做详细操作,以免文章太长,下次用图文写个实际操作文章。先简单说一下原理。首先使用优采云采集大量文章,然后使用博君seo伪原创工具批量伪原创,最后通过Hammer豁免Log进入发布界面,定时批量发布文章,实现文章的自动发布和定时更新。
第六步:内外链建设
刚才说了,可以使用WP Keyword Link插件,也可以修改single.php同时插入相关字段。外链搭建请参考《中文SEO教程:链接轮》文章,或加我QQ详细讨论。
最后:总结
做站群记得要浮躁,耐心很重要,循序渐进。本文章中描述的操作主要是手动步骤占一半,但质量高于全自动软件。当然,软件也有自己的优点,方便快捷。以后文章我会讲中文站群软件的应用。
上面只是提到了站群的实际步骤。至于站群的策略、广告、链接策略等,还有待商榷。欢迎继续关注黑帽坦克博文。 查看全部
工具采集文章(浅谈一下中文WP站群的操作步骤及设置模板)
由于前几天写了一篇《简述英文站群SEO操作》文章的文章,发现转发量疯了,所以今天介绍一下中文WP站群@ > 详细。操作它。
首先说一下为什么要使用WP(wordpress)。因为WP功能强大,插件多,代码简单,收录速度快,在SE上也有一定的分量,所以在国外已经被广泛使用,但是国内一些个人博客都是基于WP程序搭建的. 相信用过WP的人都知道。而那些玩英文SEO站群的基本上都是用WP来玩自动博客的,哈哈。
接下来,我将一步步为您讲解:
第一步:注册一批域名
我们都知道站群域名必须是多元化的,不能挂在一个后缀下。如果你是新手,我推荐小批量操作。首先注册10个域名,可以是com、net、org、cc、me、tk等等。并且可以按照关键词注册,也可以是一个数字,但是一定要多样化。
第 2 步:租用 VPS 或虚拟主机
一般新手玩站群,大概有10个站,最好租个vps。当然,如果你想要不同的IP段,你也可以租用不同IP的虚拟主机。但是在这里,我建议一定是国外主机,国内主机玩站群的时候会死的很快。
第 3 步:网站 构建
确定好域名和空间后,我们会下载最新版的WP,手动安装。关于FTP工具,我推荐CuteFtp。该工具可以在线修改文件、移动文件、打开更多文件等,界面简洁。
第四步:WP站点设置(重点)
1. 模板主题:同样,模板也需要多样化。您需要设置不同的模板,它是关于您制作的主题的模板。最好使用中文原创或者已经汉化的模板。然后修改部分代码,比如头部和尾部的代码。关于模板下载可以到:
2.插件上传及设置:
(1)Akismet(垃圾邮件拦截插件):该插件默认有WP,开启即可,然后自己申请API key。
(2)All in One SEO Pack(seo插件):这个插件很好用,英文WP和中文WP都适用。可以设置首页,文章页面标题,描述等,不过貌似这个插件设置的描述对百度没有用,可以在WP的摘要上填写描述。
(3)Autoptimize(网站代码的自动压缩):本插件可以压缩网站代码,如css、js、html等,可自行设置。
(4)Dagon Design Sitemap Generator(网站地图插件):这个插件可以设置网站地图。
(5)Google XML Sitemaps(网站地图自动提交):这个插件可以自动生成网站地图并通知google、yahoo等。
(6)GZippy(gzip 压缩):这个不用说了。
(7)Optimize DB(优化数据库):这个就不用说了。
(8)Random Posts 小部件(Random 文章 插件):您可以将随机 文章 添加到侧边栏。
(9)Robots Meta(机器人设置):不用说了。
(10)WordPress相关帖子(相关文章插件):可以在文章页面下设置相关文章。
(11)WP Keyword Link(内链插件):百度可以点击详细设置。
关于插件和WP设置,当然还有更好的插件可以用,可以自己摸索,不要看那么多会晕,全部下载,批量上传,设置在后台就OK了。
第五步:文章采集/批量上传/定时发布(绝密)
由于以上步骤都是手动完成的,所以整个WP的构建比站群软件质量更高。那么,既然我们不需要站群软件,那么如何让采集文章自动更新呢?
答案是优采云采集、博君seo伪原创工具、以及锤子免费登录发布界面。
由于操作比较多,这里暂时不做详细操作,以免文章太长,下次用图文写个实际操作文章。先简单说一下原理。首先使用优采云采集大量文章,然后使用博君seo伪原创工具批量伪原创,最后通过Hammer豁免Log进入发布界面,定时批量发布文章,实现文章的自动发布和定时更新。
第六步:内外链建设
刚才说了,可以使用WP Keyword Link插件,也可以修改single.php同时插入相关字段。外链搭建请参考《中文SEO教程:链接轮》文章,或加我QQ详细讨论。
最后:总结
做站群记得要浮躁,耐心很重要,循序渐进。本文章中描述的操作主要是手动步骤占一半,但质量高于全自动软件。当然,软件也有自己的优点,方便快捷。以后文章我会讲中文站群软件的应用。
上面只是提到了站群的实际步骤。至于站群的策略、广告、链接策略等,还有待商榷。欢迎继续关注黑帽坦克博文。
工具采集文章(四款增强Windows7任务栏体验的小软件,让你的Win7用得更加得心应手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-30 05:34
使用Windows 7近一个月后,越来越觉得Windows 7的新任务栏(Taskbar)无疑是最好最直接的杀手锏。Windows7吸收了Mac OSX的很多优点,改进了任务栏预览(Taskbar Preview),也更加实用。在某种程度上,Win7 任务栏几乎可以说是传统任务栏和 Mac OSX Dock 的结合。如果使用得当,您不需要在桌面上放置任何图标,但 Mac OSX 仍在使用“旧”任务栏。
当然,虽然现在的任务栏已经足够好了,但我们的目标是让电脑体验更加完美。今天给大家介绍四款提升Windows7任务栏体验的小软件。让这些软件配合Windows7任务栏的新功能发挥更多实用强大的功能,让你的Win7更得心应手!
1、快速跳转列表
这是国内蓝冰工作室出品的一款小软件,旨在为任务栏节省更多空间。众所周知,Win7默认取消了快速启动栏。对于“桌面整洁”的朋友来说,快速启动栏的缺失让启动程序更加繁琐。但是 QuickJumplist 可以替代旧的 Quick Start,让“Quick Start”更加实用。QuickJumplist 基于 Win7 的 Jumplist 功能。你可以在里面添加你常用的程序,并把这个程序锁定在任务栏上,这样右键点击QuickJumplist图标后,就会出现这些程序的列表,作为替代“快速启动”的软件,它当之无愧。而且它不占用任何 CPU/内存资源,因为它根本不需要运行就可以工作。
2、Jumplist-Launcher
顾名思义,Jumplist-Launcher 类似于 QuickJumplist,都使用 Jumplist 来快速启动第三方程序。但是 Jumplist-Launcher 更强大。不仅支持启动程序,还支持从Jumplist打开指定文件夹(不支持二级目录),支持分组。Jumplist-Launcher软件里有一些德语,但基本不影响使用。
其实QuickJumplist也是基于Jumplist-Launcher的思路开发的,但是原来的Jumplist-Launcher最多只能支持10个程序(现在60个),所以蓝冰工作室开发了前者。另外,两款软件都支持同时运行多个进程,只需将它们放在不同的文件夹中并分别锁定到任务栏即可。
其实模仿Mac OSX的7stacks很早就实现了上述功能,但是在Win7推出后,7Stacks变得非常臃肿和缓慢,所以直接使用Jumplist比较好。
3、Gmail 通知程序
在 Windows 7 正式发布之前,Gmail Notifier 在互联网上开始流行。它收录了Win7任务栏几乎所有的新功能:跳转列表、任务栏预览,点击一两下即可查看和撰写邮件。Gmail Notifier支持多账户(不确定是否支持Google Apps),可以在预览窗口预览未读邮件,在预览窗口可以翻页直接打开,可以写新邮件,查看新邮件,在 Jumplist 中查看新邮件。打开收件箱等,真的很厉害。
4、任务栏仪表
Taskbar Meters利用Win7任务栏进度条的特性,以进度条的形式在任务栏上显示CPU使用率、内存使用率和硬盘使用率。Taskbar Meters 不需要安装,使用方法很简单,直接启动相应的程序即可。并且可以设置刷新数据的时间和进度条颜色变化的阈值。Taskbar Meters 还支持 Jumplist 功能,可以直接打开任务管理器和资源监视器,但不支持任务栏预览。
相关软件下载:
如果你还知道有什么小软件使用了Win7任务栏的这些新功能,欢迎留言或者来信推荐:)
官方 网站:QuickJumplist | Jumplist-启动器 | Gmail 通知程序 | 任务栏仪表
软件性质:以上均为免费软件
下载链接:QuickJumplist | Jumplist-启动器 | 来自不同维度 | Gmail 通知程序 | 任务栏仪表 查看全部
工具采集文章(四款增强Windows7任务栏体验的小软件,让你的Win7用得更加得心应手)
使用Windows 7近一个月后,越来越觉得Windows 7的新任务栏(Taskbar)无疑是最好最直接的杀手锏。Windows7吸收了Mac OSX的很多优点,改进了任务栏预览(Taskbar Preview),也更加实用。在某种程度上,Win7 任务栏几乎可以说是传统任务栏和 Mac OSX Dock 的结合。如果使用得当,您不需要在桌面上放置任何图标,但 Mac OSX 仍在使用“旧”任务栏。
当然,虽然现在的任务栏已经足够好了,但我们的目标是让电脑体验更加完美。今天给大家介绍四款提升Windows7任务栏体验的小软件。让这些软件配合Windows7任务栏的新功能发挥更多实用强大的功能,让你的Win7更得心应手!
1、快速跳转列表
这是国内蓝冰工作室出品的一款小软件,旨在为任务栏节省更多空间。众所周知,Win7默认取消了快速启动栏。对于“桌面整洁”的朋友来说,快速启动栏的缺失让启动程序更加繁琐。但是 QuickJumplist 可以替代旧的 Quick Start,让“Quick Start”更加实用。QuickJumplist 基于 Win7 的 Jumplist 功能。你可以在里面添加你常用的程序,并把这个程序锁定在任务栏上,这样右键点击QuickJumplist图标后,就会出现这些程序的列表,作为替代“快速启动”的软件,它当之无愧。而且它不占用任何 CPU/内存资源,因为它根本不需要运行就可以工作。
2、Jumplist-Launcher
顾名思义,Jumplist-Launcher 类似于 QuickJumplist,都使用 Jumplist 来快速启动第三方程序。但是 Jumplist-Launcher 更强大。不仅支持启动程序,还支持从Jumplist打开指定文件夹(不支持二级目录),支持分组。Jumplist-Launcher软件里有一些德语,但基本不影响使用。
其实QuickJumplist也是基于Jumplist-Launcher的思路开发的,但是原来的Jumplist-Launcher最多只能支持10个程序(现在60个),所以蓝冰工作室开发了前者。另外,两款软件都支持同时运行多个进程,只需将它们放在不同的文件夹中并分别锁定到任务栏即可。
其实模仿Mac OSX的7stacks很早就实现了上述功能,但是在Win7推出后,7Stacks变得非常臃肿和缓慢,所以直接使用Jumplist比较好。
3、Gmail 通知程序
在 Windows 7 正式发布之前,Gmail Notifier 在互联网上开始流行。它收录了Win7任务栏几乎所有的新功能:跳转列表、任务栏预览,点击一两下即可查看和撰写邮件。Gmail Notifier支持多账户(不确定是否支持Google Apps),可以在预览窗口预览未读邮件,在预览窗口可以翻页直接打开,可以写新邮件,查看新邮件,在 Jumplist 中查看新邮件。打开收件箱等,真的很厉害。
4、任务栏仪表
Taskbar Meters利用Win7任务栏进度条的特性,以进度条的形式在任务栏上显示CPU使用率、内存使用率和硬盘使用率。Taskbar Meters 不需要安装,使用方法很简单,直接启动相应的程序即可。并且可以设置刷新数据的时间和进度条颜色变化的阈值。Taskbar Meters 还支持 Jumplist 功能,可以直接打开任务管理器和资源监视器,但不支持任务栏预览。
相关软件下载:
如果你还知道有什么小软件使用了Win7任务栏的这些新功能,欢迎留言或者来信推荐:)
官方 网站:QuickJumplist | Jumplist-启动器 | Gmail 通知程序 | 任务栏仪表
软件性质:以上均为免费软件
下载链接:QuickJumplist | Jumplist-启动器 | 来自不同维度 | Gmail 通知程序 | 任务栏仪表
工具采集文章( 【DBA+社群】收集日志信息是否是一个“高消耗”的体力活)
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-09-29 01:10
【DBA+社群】收集日志信息是否是一个“高消耗”的体力活)
转载声明:本文为DBA+社区原创文章,转载需附本订阅号二维码全文,并注明作者姓名及出处:DBA+社区(dbaplus) .
采集日志信息是一种“高消耗”的体力活动吗?在很多情况下。
想象一下,如果数据库发生了挂起故障,而这个数据库有8个节点,我们可能需要采集rdbms、ASM、grid、OS、osw等的日志信息,这个工作简直就是一场噩梦。即使是普通的两节点RAC环境,也可能需要很短的时间,后续的补充日志采集可能还要继续。
不熟悉环境,平台差异,故障时需要过滤采集特定的日志信息,数据库节点多,需要采集日志的环境中文件管控问题多,这可能会影响我们采集日志信息的速度。和准确性,这会影响问题分析和定位的进度。
那么我们有一个很现实的问题,如何减少日志采集消耗的时间,提高准确率,让更多的时间可以用于问题分析呢?
其实Oracle官方已经提供了一个解决方案——TFA(Trace File Analyzer Collector)。这个工具可以帮助我们真正实现一个命令来完成日志采集。
1 版本和安装
TFA支持的正式上市平台:
英特尔 Linux(企业 Linux、RedHat Linux、SUSE Linux)
Z 系统上的 Linux
安腾Linux
Oracle Solaris SPARC
Oracle Solaris x86-64
艾克斯
HPUX 安腾
HPUX PA-RISC
所有平台都需要 bash shell 3.2 或更高版本和 JRE 1.5 或更高版本才能支持。
TFA 工具理论上提供对所有数据库版本的支持,以及对 RAC 和非 RAC 数据库的支持。但是,从我目前看到的文档来看,没有提到 10.2.0.4 之前的版本。
TFA工具首先默认安装在网格软件11.2.0.4,默认安装路径为网格的家目录。11.2.0.4 之前版本的安装包中没有TFA工具,需要手动安装。
Oracle官方列出的详细支持和安装状态如下:
TFA 更新非常快。版本11.2.0.4于2013年8月发布,附带的TFA工具版本为2.5.1.5 . 目前(2015年10月)最新版本为12.1.2.5.2,我们可以从帮助菜单中看出两个版本的巨大差异:
2.5.1.5 版本帮助菜单:
12.1.2.5.2 版本帮助菜单:
可以看到,版本12.1.2.5.2 版本增加了很多Function。
Oracle 对 TFA 的支持也在增加,甚至 PSU 中也收录了 TFA 更新。以版本11.2.0.4为例,我们可以在GI PSU Fixed List中找到以下信息:
即从11.2.0.4.5开始,GI PSU收录TFA版本更新。TFA 将在安装 GI PSU 期间自动安装。
2TFA 的工作原理
从Oracle官方提供的一张TFA工作流程图中,我们可以清楚地看到TFA是如何工作的:
DBA 发出 diagcollect 命令以启动 TFA 日志采集过程。
本地TFA向其他节点的TFA发送采集请求,并开始其他节点的日志采集。
本地TFA也同时开始了日志采集。
所涉及节点的所有 TFA 日志都存档到启动 diagcollect 命令的“主”节点。
DBA 提取存档的 TFA 日志信息,对其进行分析或提交 SR 进行处理
整个过程中,DBA只需要执行一个命令,然后提取归档的TFA日志即可。
3TFA的使用
以11.2.0.4版RAC和12.1.2.5.2版TFA环境为例:
先来看看最简单最通用的采集命令:
该命令会采集指定时间段内rdbms、ASM、Grid、OS的各类日志,如告警日志、跟踪文件、集群组件日志、监听器日志、操作系统日志等。在执行过程中,告警日志、监听日志等连续日志处理也更加智能,可以在不复制整个日志文件的情况下,拦截指定时间段的日志。如果部署了 osw 工具,也会自动采集 osw 日志。
如果需要指定日志采集范围,比如只采集数据库的相关日志,可以使用tfactl diagcollect -database命令。更多使用方法请参考tfactl diagcollect -help的输出。
最新版本的TFA(12.1.2.5.2))也可以采集AWR报告。命令示例如下:
但是在实际应用中发现,TFA的AWR报告采集功能并不完善。
对于-database参数,帮助菜单的说明是:
-database 从指定的数据库采集数据库日志
目前 -awrhtml 参数需要和 -database 参数一起使用,但是 -database 参数和 -awrhtml 参数一起使用时,不仅用于表示数据库名称,还是会出现这种情况其中采集了数据库警报日志和跟踪文件。. 即执行上述命令会采集指定时间段的AWR报告,以及数据库警报日志和跟踪文件。
TFA还有自动采集功能,可以自动采集一些预定的错误。可以在跟踪文件分析器采集器用户指南的附录 B. 扫描事件部分找到计划的错误和采集规则。此功能默认禁用,可以使用以下命令手动启用:
tfactl 设置 autodiagcollect=ON
建议在生产环境中使用该功能之前,先在测试环境中进行验证。
TFA还可以承担一定的日志分析功能,可以实现一个命令自动分析DB&ASM&CRS的告警日志、操作系统命令和一些osw日志,虽然相比其日志采集功能还不够强大。一个简单通用的分析命令:
tfactl 分析 - 从 7 天开始
该命令会在7天内分析查找所有(包括DB/ASM/CRS/ACFS/OS/OSW/OSWSLABINFO)日志ERROR级别的错误信息并提取出来。
《Trace File Analyzer Collector User Guide》中列出的ERROR级别信息如下:
您还可以使用以下命令来搜索自定义字符串:
默认情况下,TFA 工具仅授予 root 用户和 grid 用户访问权限。如果使用oracle用户执行tfactl diagcollect命令,会报错:
用户 oracle 没有运行 TFA 的密钥。请与 TFA 管理员(root)核对
建议给oracle用户同样的权限使用TFA,方便日常使用。root用户可以使用以下命令将oracle用户添加到授权用户列表中:
tfactl 访问添加 -user oracle
如果有采集日志的空间管理需求,可以使用tfactl set命令进行设置。当前设置可以通过
tfactl 打印配置
命令输出,输出示例如下:
关于TFA的使用和设置的更多信息,请参考tfactl -h的输出和《Trace File Analyzer Collector User Guide》文档。
TFA操作时对DB或GI影响的描述在MOS上很少见到,主要是以下两个问题:
如果遇到Linux平台下RAC节点启动挂起的问题,并且环境中安装了TFA,可以根据1983567.1文档中的说明修改oracle-tfa.conf文件。1668630.1文档中提到的问题已在11.2.0.4.3及以上PSU中修复,如果安装的PSU版本为1< @1.2.0.4.3 及以上,这个问题可以忽略。
作者介绍:杨德胜
回复001,阅读杨志宏的《【职场心智】一个老DBA的自白》;
回复002,阅读丁俊的《【重磅干货】看完这篇文章,Oracle SQL优化文章别再看了!》;
回复003,看胡一文《PG,跨越oltp到olap的梦想之桥》;
回复004,见陈可的《Memcached & Redis等分布式缓存的实现原理》;
回复005,阅读宋日杰的《Oracle后端专家解决库缓存锁争用的终极利器》;
回复006,见郑晓辉《存储和数据库不得不讲的故事》;
回复007,见袁伟祥《揭秘Oracle数据库截断原理》;
回复008,阅读杨建荣的《Waiting for Desirable:工具定制让Oracle优化更轻松、更快》;
回复009,阅读丁其亮的《LINUX主机JAVA应用高CPU和内存占用的分析方法》;
回复010,阅读徐桂林的《以应用为中心的企业混合云管理》。
关于 DBA+ 社区
DBA+社区是中国最大的微信社区,涵盖各种架构师、数据库、中间件!线上分享2次/周,线下沙龙1次/月,顶峰6次/年,直接观众10000+,间接影响500000+ITer。DBA+社区致力于搭建学习交流、专业联系、跨行业合作的公益平台。更多精彩,请继续关注dbaplus微信订阅号!
扫描二维码关注
DBAplus 社区
在 DBA 圈子之外,连接的不仅仅是 DBA 查看全部
工具采集文章(
【DBA+社群】收集日志信息是否是一个“高消耗”的体力活)
转载声明:本文为DBA+社区原创文章,转载需附本订阅号二维码全文,并注明作者姓名及出处:DBA+社区(dbaplus) .
采集日志信息是一种“高消耗”的体力活动吗?在很多情况下。
想象一下,如果数据库发生了挂起故障,而这个数据库有8个节点,我们可能需要采集rdbms、ASM、grid、OS、osw等的日志信息,这个工作简直就是一场噩梦。即使是普通的两节点RAC环境,也可能需要很短的时间,后续的补充日志采集可能还要继续。
不熟悉环境,平台差异,故障时需要过滤采集特定的日志信息,数据库节点多,需要采集日志的环境中文件管控问题多,这可能会影响我们采集日志信息的速度。和准确性,这会影响问题分析和定位的进度。
那么我们有一个很现实的问题,如何减少日志采集消耗的时间,提高准确率,让更多的时间可以用于问题分析呢?
其实Oracle官方已经提供了一个解决方案——TFA(Trace File Analyzer Collector)。这个工具可以帮助我们真正实现一个命令来完成日志采集。
1 版本和安装
TFA支持的正式上市平台:
英特尔 Linux(企业 Linux、RedHat Linux、SUSE Linux)
Z 系统上的 Linux
安腾Linux
Oracle Solaris SPARC
Oracle Solaris x86-64
艾克斯
HPUX 安腾
HPUX PA-RISC
所有平台都需要 bash shell 3.2 或更高版本和 JRE 1.5 或更高版本才能支持。
TFA 工具理论上提供对所有数据库版本的支持,以及对 RAC 和非 RAC 数据库的支持。但是,从我目前看到的文档来看,没有提到 10.2.0.4 之前的版本。
TFA工具首先默认安装在网格软件11.2.0.4,默认安装路径为网格的家目录。11.2.0.4 之前版本的安装包中没有TFA工具,需要手动安装。
Oracle官方列出的详细支持和安装状态如下:
TFA 更新非常快。版本11.2.0.4于2013年8月发布,附带的TFA工具版本为2.5.1.5 . 目前(2015年10月)最新版本为12.1.2.5.2,我们可以从帮助菜单中看出两个版本的巨大差异:
2.5.1.5 版本帮助菜单:
12.1.2.5.2 版本帮助菜单:
可以看到,版本12.1.2.5.2 版本增加了很多Function。
Oracle 对 TFA 的支持也在增加,甚至 PSU 中也收录了 TFA 更新。以版本11.2.0.4为例,我们可以在GI PSU Fixed List中找到以下信息:
即从11.2.0.4.5开始,GI PSU收录TFA版本更新。TFA 将在安装 GI PSU 期间自动安装。
2TFA 的工作原理
从Oracle官方提供的一张TFA工作流程图中,我们可以清楚地看到TFA是如何工作的:
DBA 发出 diagcollect 命令以启动 TFA 日志采集过程。
本地TFA向其他节点的TFA发送采集请求,并开始其他节点的日志采集。
本地TFA也同时开始了日志采集。
所涉及节点的所有 TFA 日志都存档到启动 diagcollect 命令的“主”节点。
DBA 提取存档的 TFA 日志信息,对其进行分析或提交 SR 进行处理
整个过程中,DBA只需要执行一个命令,然后提取归档的TFA日志即可。
3TFA的使用
以11.2.0.4版RAC和12.1.2.5.2版TFA环境为例:
先来看看最简单最通用的采集命令:
该命令会采集指定时间段内rdbms、ASM、Grid、OS的各类日志,如告警日志、跟踪文件、集群组件日志、监听器日志、操作系统日志等。在执行过程中,告警日志、监听日志等连续日志处理也更加智能,可以在不复制整个日志文件的情况下,拦截指定时间段的日志。如果部署了 osw 工具,也会自动采集 osw 日志。
如果需要指定日志采集范围,比如只采集数据库的相关日志,可以使用tfactl diagcollect -database命令。更多使用方法请参考tfactl diagcollect -help的输出。
最新版本的TFA(12.1.2.5.2))也可以采集AWR报告。命令示例如下:
但是在实际应用中发现,TFA的AWR报告采集功能并不完善。
对于-database参数,帮助菜单的说明是:
-database 从指定的数据库采集数据库日志
目前 -awrhtml 参数需要和 -database 参数一起使用,但是 -database 参数和 -awrhtml 参数一起使用时,不仅用于表示数据库名称,还是会出现这种情况其中采集了数据库警报日志和跟踪文件。. 即执行上述命令会采集指定时间段的AWR报告,以及数据库警报日志和跟踪文件。
TFA还有自动采集功能,可以自动采集一些预定的错误。可以在跟踪文件分析器采集器用户指南的附录 B. 扫描事件部分找到计划的错误和采集规则。此功能默认禁用,可以使用以下命令手动启用:
tfactl 设置 autodiagcollect=ON
建议在生产环境中使用该功能之前,先在测试环境中进行验证。
TFA还可以承担一定的日志分析功能,可以实现一个命令自动分析DB&ASM&CRS的告警日志、操作系统命令和一些osw日志,虽然相比其日志采集功能还不够强大。一个简单通用的分析命令:
tfactl 分析 - 从 7 天开始
该命令会在7天内分析查找所有(包括DB/ASM/CRS/ACFS/OS/OSW/OSWSLABINFO)日志ERROR级别的错误信息并提取出来。
《Trace File Analyzer Collector User Guide》中列出的ERROR级别信息如下:
您还可以使用以下命令来搜索自定义字符串:
默认情况下,TFA 工具仅授予 root 用户和 grid 用户访问权限。如果使用oracle用户执行tfactl diagcollect命令,会报错:
用户 oracle 没有运行 TFA 的密钥。请与 TFA 管理员(root)核对
建议给oracle用户同样的权限使用TFA,方便日常使用。root用户可以使用以下命令将oracle用户添加到授权用户列表中:
tfactl 访问添加 -user oracle
如果有采集日志的空间管理需求,可以使用tfactl set命令进行设置。当前设置可以通过
tfactl 打印配置
命令输出,输出示例如下:
关于TFA的使用和设置的更多信息,请参考tfactl -h的输出和《Trace File Analyzer Collector User Guide》文档。
TFA操作时对DB或GI影响的描述在MOS上很少见到,主要是以下两个问题:
如果遇到Linux平台下RAC节点启动挂起的问题,并且环境中安装了TFA,可以根据1983567.1文档中的说明修改oracle-tfa.conf文件。1668630.1文档中提到的问题已在11.2.0.4.3及以上PSU中修复,如果安装的PSU版本为1< @1.2.0.4.3 及以上,这个问题可以忽略。
作者介绍:杨德胜
回复001,阅读杨志宏的《【职场心智】一个老DBA的自白》;
回复002,阅读丁俊的《【重磅干货】看完这篇文章,Oracle SQL优化文章别再看了!》;
回复003,看胡一文《PG,跨越oltp到olap的梦想之桥》;
回复004,见陈可的《Memcached & Redis等分布式缓存的实现原理》;
回复005,阅读宋日杰的《Oracle后端专家解决库缓存锁争用的终极利器》;
回复006,见郑晓辉《存储和数据库不得不讲的故事》;
回复007,见袁伟祥《揭秘Oracle数据库截断原理》;
回复008,阅读杨建荣的《Waiting for Desirable:工具定制让Oracle优化更轻松、更快》;
回复009,阅读丁其亮的《LINUX主机JAVA应用高CPU和内存占用的分析方法》;
回复010,阅读徐桂林的《以应用为中心的企业混合云管理》。
关于 DBA+ 社区
DBA+社区是中国最大的微信社区,涵盖各种架构师、数据库、中间件!线上分享2次/周,线下沙龙1次/月,顶峰6次/年,直接观众10000+,间接影响500000+ITer。DBA+社区致力于搭建学习交流、专业联系、跨行业合作的公益平台。更多精彩,请继续关注dbaplus微信订阅号!
扫描二维码关注
DBAplus 社区
在 DBA 圈子之外,连接的不仅仅是 DBA
工具采集文章(工具采集文章的网站,你了解多少?|英才网)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-28 02:03
工具采集文章的网站1.国内的搜狗网络平台2.国外的,经常有外部机构测试下载文件。有需要的话自己下载下来用。
多关注一些一手的外部数据网站,譬如中国人力资源和社会保障网、黑猫投诉,多看看权威机构的重要数据报告,尤其是人社部的《2016年度人力资源和社会保障事业发展统计公报》。
你可以去看看英才网
根据你自己的兴趣定方向。今年刚工作,因为目前市场机遇大,又正在积累中,所以建议你从事一些内容健康,网络红人比较多的行业,比如户外健康类,网红为主的服装,之类的。建议平时每个月看一下这个平台的前端新闻,
推荐pptstore,behance,华盖创意
不请自来,作为一名自主创业三年的人来讲。做外包工具这一块是必然会有市场的,外包的工具,我基本上没见有人用过,倒是后端web网站上很多人用,这些东西没有注册,那么成功案例也基本看不到。这里分析了2个做外包工具的做法:①直接竞价②seo方式。所以我得给题主简单的分析下为什么说做外包工具是一个不错的市场。①竞价方式。
这种方式呢,适合各行各业做ppt,做网站或者做crm的小公司,采用竞价方式呢,时间最为快速,但是一定要花在正确的地方,我举一个例子,这样的做法,你在做的时候你会发现那些拼多多之类的网站,他们一般使用这样的套路:首先通过竞价方式找到几家品牌的代理商,这些大品牌,都会找到几个品牌直销电商,这些电商成交几百甚至几千的佣金,就会返给这些大品牌一些资源,后期这些小公司就可以通过这些大品牌产品的销售,产生一定的数据回扣。
当然,做竞价的方式有利有弊,比如网店小卖家很难以成交单子,所以弊端就是容易被这些电商列为营销违规,而且随着竞价的成本越来越高,以往几十的单子现在基本都是千把块钱的。再说说优点,就是你可以拥有一个自己的网站,可以自己负责网站的所有流程,节省时间还节省资金成本,对于京东类的平台来讲,对于外包工具没有优势,所以用竞价方式来做外包工具的公司呢,现在很少了。
再说说wish等的广告模式。wish是个流量入口平台,但是它所带来的广告效果,毕竟比不上竞价方式。那么为什么有人觉得wish好做呢?因为它的竞价方式,通过你的关键词,将你卖产品的公司告诉wish平台的卖家,但这个卖家得不到一分钱,只是为卖货提供一个单子。这样对于外包工具来讲是一个很好的平台。而且现在可以使用wish平台上的免费工具,它有美工,有运营,有美工教学,这样平台的产品数目也会越来越多,对于有网站的做外包工具的公司。 查看全部
工具采集文章(工具采集文章的网站,你了解多少?|英才网)
工具采集文章的网站1.国内的搜狗网络平台2.国外的,经常有外部机构测试下载文件。有需要的话自己下载下来用。
多关注一些一手的外部数据网站,譬如中国人力资源和社会保障网、黑猫投诉,多看看权威机构的重要数据报告,尤其是人社部的《2016年度人力资源和社会保障事业发展统计公报》。
你可以去看看英才网
根据你自己的兴趣定方向。今年刚工作,因为目前市场机遇大,又正在积累中,所以建议你从事一些内容健康,网络红人比较多的行业,比如户外健康类,网红为主的服装,之类的。建议平时每个月看一下这个平台的前端新闻,
推荐pptstore,behance,华盖创意
不请自来,作为一名自主创业三年的人来讲。做外包工具这一块是必然会有市场的,外包的工具,我基本上没见有人用过,倒是后端web网站上很多人用,这些东西没有注册,那么成功案例也基本看不到。这里分析了2个做外包工具的做法:①直接竞价②seo方式。所以我得给题主简单的分析下为什么说做外包工具是一个不错的市场。①竞价方式。
这种方式呢,适合各行各业做ppt,做网站或者做crm的小公司,采用竞价方式呢,时间最为快速,但是一定要花在正确的地方,我举一个例子,这样的做法,你在做的时候你会发现那些拼多多之类的网站,他们一般使用这样的套路:首先通过竞价方式找到几家品牌的代理商,这些大品牌,都会找到几个品牌直销电商,这些电商成交几百甚至几千的佣金,就会返给这些大品牌一些资源,后期这些小公司就可以通过这些大品牌产品的销售,产生一定的数据回扣。
当然,做竞价的方式有利有弊,比如网店小卖家很难以成交单子,所以弊端就是容易被这些电商列为营销违规,而且随着竞价的成本越来越高,以往几十的单子现在基本都是千把块钱的。再说说优点,就是你可以拥有一个自己的网站,可以自己负责网站的所有流程,节省时间还节省资金成本,对于京东类的平台来讲,对于外包工具没有优势,所以用竞价方式来做外包工具的公司呢,现在很少了。
再说说wish等的广告模式。wish是个流量入口平台,但是它所带来的广告效果,毕竟比不上竞价方式。那么为什么有人觉得wish好做呢?因为它的竞价方式,通过你的关键词,将你卖产品的公司告诉wish平台的卖家,但这个卖家得不到一分钱,只是为卖货提供一个单子。这样对于外包工具来讲是一个很好的平台。而且现在可以使用wish平台上的免费工具,它有美工,有运营,有美工教学,这样平台的产品数目也会越来越多,对于有网站的做外包工具的公司。

