
工具采集文章
工具采集文章(清博指数-网络大数据综合服务平台_,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-08-28 03:06
工具采集文章非常实用,可以采集网站,新闻平台,百度文库等的标题,关键词,原创度,摘要,标签等,自己写文章非常麻烦,没有可视化的工具,找素材太麻烦。清博指数-网络大数据平台_大数据综合服务平台,清博指数官网好多的文章标题,原创度,摘要非常的难搞。通过这个工具就不用愁了。简书,知乎,豆瓣,天猫文章全部搞定,可以在线去查看排名的,非常方便。
分享《写文章,你掌握这些工具就可以了》部分截图主要推荐360指数,微信指数,百度指数,搜狗指数,企鹅指数,可以去关注一下写作工具可以看看,可以查看排名,获取原创度,可以实时关注动态哦大家觉得有用的话,
百度搜索风云榜,可以关注同行和热点。
1,注册或者找到新媒体运营账号以后,你肯定要选择账号的定位,即把自己定位为哪个领域的。一定要选好,不能跟别人选的风格重复,抄袭是非常容易的。风云榜可以看到全网的热门风向标和影响力排行。2,搜集一些优质的内容,有很多新媒体平台或者公众号可以做原创。比如说一点资讯、网易、头条、知乎等。找出他们的爆文、原创文章就可以引用为自己的素材。
3,采集别人的内容,为自己所用。做新媒体编辑,要了解多少种微信公众号素材,比如,早上八点的头条、十点半的头条、二十四小时的头条等。分析好行业的最新文章素材,包括哪些渠道的文章,发布时间、内容如何,也为自己打造爆文打好基础。4,写文章确定标题。标题就是文章的眼睛,一定要选好关键词,这是你文章的风向标。如果你写的标题是重复的,毫无吸引力,那么别人打开文章都很困难。
比如几个社群读书俱乐部运营的套路都一样,其实,如果文章标题十分诱人,打开率可以提高,网友一定会进来瞧瞧。 查看全部
工具采集文章(清博指数-网络大数据综合服务平台_,)
工具采集文章非常实用,可以采集网站,新闻平台,百度文库等的标题,关键词,原创度,摘要,标签等,自己写文章非常麻烦,没有可视化的工具,找素材太麻烦。清博指数-网络大数据平台_大数据综合服务平台,清博指数官网好多的文章标题,原创度,摘要非常的难搞。通过这个工具就不用愁了。简书,知乎,豆瓣,天猫文章全部搞定,可以在线去查看排名的,非常方便。
分享《写文章,你掌握这些工具就可以了》部分截图主要推荐360指数,微信指数,百度指数,搜狗指数,企鹅指数,可以去关注一下写作工具可以看看,可以查看排名,获取原创度,可以实时关注动态哦大家觉得有用的话,
百度搜索风云榜,可以关注同行和热点。
1,注册或者找到新媒体运营账号以后,你肯定要选择账号的定位,即把自己定位为哪个领域的。一定要选好,不能跟别人选的风格重复,抄袭是非常容易的。风云榜可以看到全网的热门风向标和影响力排行。2,搜集一些优质的内容,有很多新媒体平台或者公众号可以做原创。比如说一点资讯、网易、头条、知乎等。找出他们的爆文、原创文章就可以引用为自己的素材。
3,采集别人的内容,为自己所用。做新媒体编辑,要了解多少种微信公众号素材,比如,早上八点的头条、十点半的头条、二十四小时的头条等。分析好行业的最新文章素材,包括哪些渠道的文章,发布时间、内容如何,也为自己打造爆文打好基础。4,写文章确定标题。标题就是文章的眼睛,一定要选好关键词,这是你文章的风向标。如果你写的标题是重复的,毫无吸引力,那么别人打开文章都很困难。
比如几个社群读书俱乐部运营的套路都一样,其实,如果文章标题十分诱人,打开率可以提高,网友一定会进来瞧瞧。
如何使用优采云采集进行搜索?写作推出智能采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-26 22:04
疫情期间,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一。然而,远程办公仍然没有面对面工作那么高效。出于这个原因优采云采集专利权采集tools。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具,不仅是帮助运营采集信息,更要精准分析数据趋势,帮助增加收益。
一、什么是优采云采集?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提高新媒体运营效率,降低企业成本。
二、如何使用优采云采集进行搜索?
(一)输入关键词
优采云采集 根据用户输入的关键词,搜索引擎通过程序自动进入主流自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,在主页输入关键词“流行病”。 优采云采集 会将搜索结果整合到一个列表中。
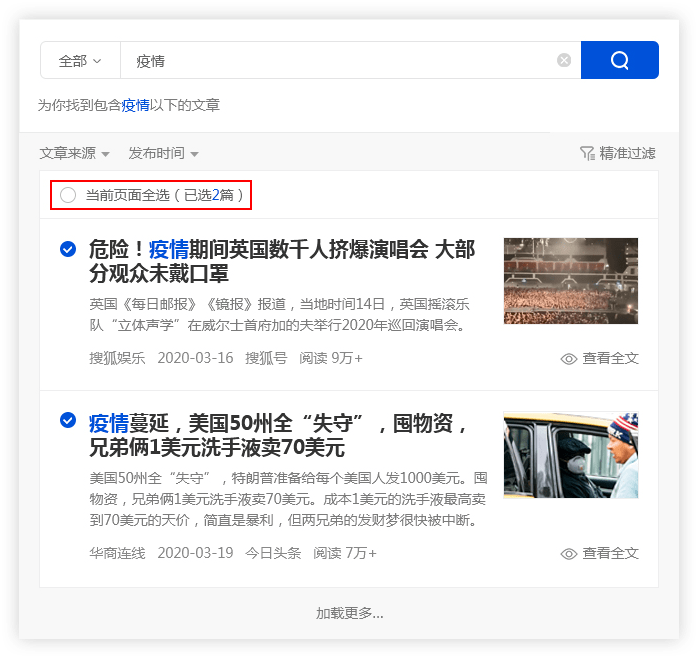
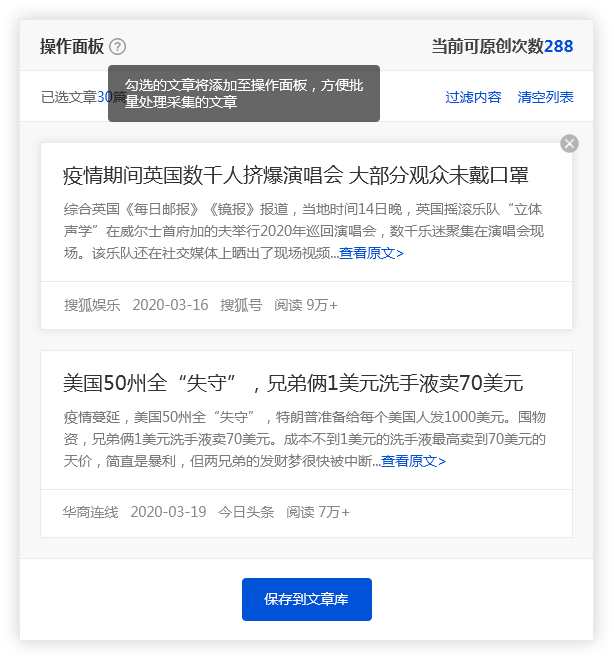
(二)保存搜索资料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
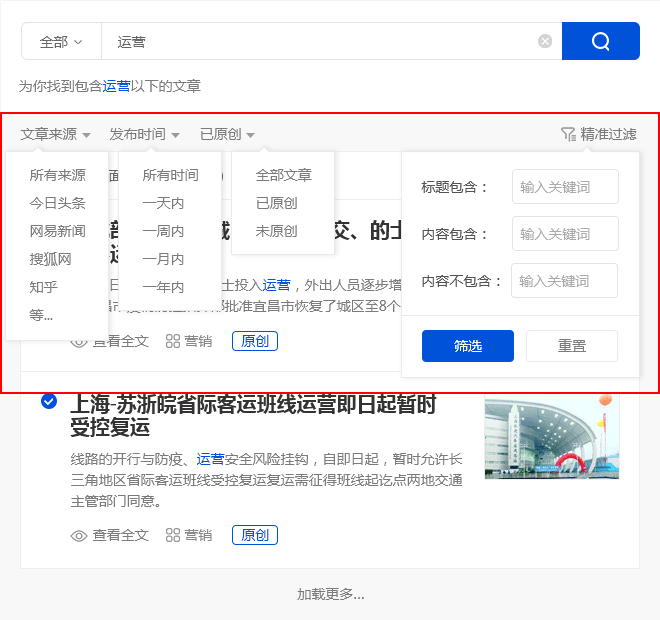
(三)精准过滤
1、搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、广告过滤 查看全部
如何使用优采云采集进行搜索?写作推出智能采集工具
疫情期间,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一。然而,远程办公仍然没有面对面工作那么高效。出于这个原因优采云采集专利权采集tools。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具,不仅是帮助运营采集信息,更要精准分析数据趋势,帮助增加收益。
一、什么是优采云采集?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提高新媒体运营效率,降低企业成本。
二、如何使用优采云采集进行搜索?
(一)输入关键词
优采云采集 根据用户输入的关键词,搜索引擎通过程序自动进入主流自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,在主页输入关键词“流行病”。 优采云采集 会将搜索结果整合到一个列表中。
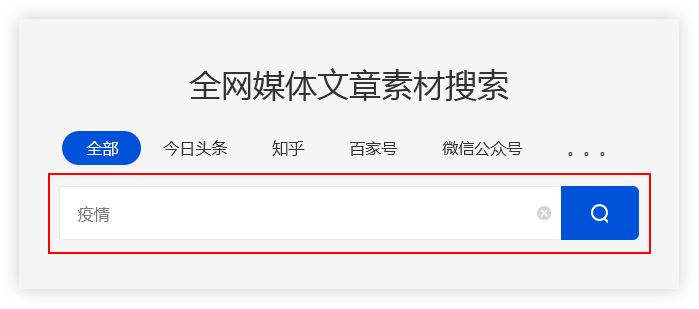

(二)保存搜索资料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
(三)精准过滤
1、搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、广告过滤
工具采集文章发布到网站上可以有这么几种方式方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-08-26 04:04
工具采集文章发布到网站上可以有这么几种方式方法一:文字采集网站上面的文章一般都是经过加工的,最后需要采集并转化成文字数据。方法二:图片采集图片采集大多是用于文章的标题中提到内容,可以根据标题进行图片采集。方法三:音频采集音频采集不只是在标题中提到,内容中也会穿插。方法四:视频采集视频采集是用来做哪些呢?有没有广告是一个问题,如果很多人在视频中注明了“有广告”、“刷票”,这个时候很多网站是不收的。
如果您需要采集这个内容的话,方法五:对讲机采集对讲机的采集主要用于一些教育或者是节日类的新闻类内容,这种内容主要靠广告来抢占用户。方法六:单个视频采集这类采集内容一般用于网站自动去除广告后,单个视频的数量不多,比如视频采集时间太长,新闻采集太短。文章采集到平台上后怎么发布呢?选择创建采集计划采集时间:15-30分钟选择采集方式:单行文字采集|单行音频采集|单行视频采集|单行图片采集|单行链接采集|单行。
选择采集来源:原始文章或网站集成自动合并选择要发布的数据格式:excel|pdf|word|txt|html|ppt|xml|xlid|csv|doc|prt|pdf|pdfx|csv|excel|csv。批量查看内容:多个采集计划批量查看大概就这么多方法了。下面介绍一个采集方法,通过将采集的内容发布到指定的网站上方法二采集后,即可发布采集。
首先根据文章标题生成自动采集地址:打开浏览器扩展程序---用safari浏览器找到带有meta(网站路径)的地址-路径就是公共http信息的链接-然后点击meta(网站路径)生成采集地址按钮如图然后点击发布采集按钮---在弹出框中输入搜索的单个内容如果只生成一个采集地址,对应的所有内容都将采集到服务器上,如果多个采集地址,所有内容都将被采集到服务器上。
好了创建采集地址的方法就介绍完了。采集完后如何将采集的内容发布到指定的网站上去呢?点击meta(网站路径)生成的采集地址后缀名(不加任何后缀可以创建多个采集地址)c:\users\用户名\appdata\local\extensions\xxxx\awesomewesome\awesome\awesomewesome\awesomewesome\awesomewesomewesome\awesomewesomewesome\awesomewesome.whl|awesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomeweso。 查看全部
工具采集文章发布到网站上可以有这么几种方式方法
工具采集文章发布到网站上可以有这么几种方式方法一:文字采集网站上面的文章一般都是经过加工的,最后需要采集并转化成文字数据。方法二:图片采集图片采集大多是用于文章的标题中提到内容,可以根据标题进行图片采集。方法三:音频采集音频采集不只是在标题中提到,内容中也会穿插。方法四:视频采集视频采集是用来做哪些呢?有没有广告是一个问题,如果很多人在视频中注明了“有广告”、“刷票”,这个时候很多网站是不收的。
如果您需要采集这个内容的话,方法五:对讲机采集对讲机的采集主要用于一些教育或者是节日类的新闻类内容,这种内容主要靠广告来抢占用户。方法六:单个视频采集这类采集内容一般用于网站自动去除广告后,单个视频的数量不多,比如视频采集时间太长,新闻采集太短。文章采集到平台上后怎么发布呢?选择创建采集计划采集时间:15-30分钟选择采集方式:单行文字采集|单行音频采集|单行视频采集|单行图片采集|单行链接采集|单行。
选择采集来源:原始文章或网站集成自动合并选择要发布的数据格式:excel|pdf|word|txt|html|ppt|xml|xlid|csv|doc|prt|pdf|pdfx|csv|excel|csv。批量查看内容:多个采集计划批量查看大概就这么多方法了。下面介绍一个采集方法,通过将采集的内容发布到指定的网站上方法二采集后,即可发布采集。
首先根据文章标题生成自动采集地址:打开浏览器扩展程序---用safari浏览器找到带有meta(网站路径)的地址-路径就是公共http信息的链接-然后点击meta(网站路径)生成采集地址按钮如图然后点击发布采集按钮---在弹出框中输入搜索的单个内容如果只生成一个采集地址,对应的所有内容都将采集到服务器上,如果多个采集地址,所有内容都将被采集到服务器上。
好了创建采集地址的方法就介绍完了。采集完后如何将采集的内容发布到指定的网站上去呢?点击meta(网站路径)生成的采集地址后缀名(不加任何后缀可以创建多个采集地址)c:\users\用户名\appdata\local\extensions\xxxx\awesomewesome\awesome\awesomewesome\awesomewesome\awesomewesomewesome\awesomewesomewesome\awesomewesome.whl|awesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomeweso。
易企秀:工具采集文章的用途和用途介绍(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-08-25 21:10
工具采集文章,可将文章采集导出到excel表格进行其他用途,包括可用于企业公众号商业广告及crm数据收集等。软件功能1.可以免费采集公众号文章,批量采集2.可以按标签将文章加入不同的排序,排序根据你自己想要排的速度3.提供超过1万个采集公众号的采集窗口,扩展采集窗口数量支持文章页数和文章来源按标签排序按标签排序还可以按照文章来源,文章来源已经关键词,文章标题,文章内容进行排序4.支持共享采集文章出口到其他采集文章下载网站等等1.按标签,页数,来源,文章页等进行排序,适合收集非网站全文采集2.支持批量关键词抓取,包括网站内所有文章内容,批量抓取上传也可以3.支持分享采集文章到其他采集网站进行其他用途,比如crm数据收集excel表格,微信,朋友圈,营销数据导出等等。
搞定采集公众号内容,
可以关注下我们公众号,聚合全网信息(服务号和订阅号信息汇集),
我们家用的是qq音乐查看的,用比较少。反正跟普通百度网盘是一样的功能,注册即可,会员可以随便发。支持外链转载。
易企秀,客户端,哪里都能用。
application、小程序开发和人工智能(profiling&analysis)等。这些在招商银行的内部肯定都有开发。所以你看是不是就业方向只要这个。 查看全部
易企秀:工具采集文章的用途和用途介绍(图)
工具采集文章,可将文章采集导出到excel表格进行其他用途,包括可用于企业公众号商业广告及crm数据收集等。软件功能1.可以免费采集公众号文章,批量采集2.可以按标签将文章加入不同的排序,排序根据你自己想要排的速度3.提供超过1万个采集公众号的采集窗口,扩展采集窗口数量支持文章页数和文章来源按标签排序按标签排序还可以按照文章来源,文章来源已经关键词,文章标题,文章内容进行排序4.支持共享采集文章出口到其他采集文章下载网站等等1.按标签,页数,来源,文章页等进行排序,适合收集非网站全文采集2.支持批量关键词抓取,包括网站内所有文章内容,批量抓取上传也可以3.支持分享采集文章到其他采集网站进行其他用途,比如crm数据收集excel表格,微信,朋友圈,营销数据导出等等。
搞定采集公众号内容,
可以关注下我们公众号,聚合全网信息(服务号和订阅号信息汇集),
我们家用的是qq音乐查看的,用比较少。反正跟普通百度网盘是一样的功能,注册即可,会员可以随便发。支持外链转载。
易企秀,客户端,哪里都能用。
application、小程序开发和人工智能(profiling&analysis)等。这些在招商银行的内部肯定都有开发。所以你看是不是就业方向只要这个。
《万能文章采集器免费破解版》是最简单最智能的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-08-24 00:19
文章采集器免费版(Duo Duo Quick Spider)是一款专业的网络采集工具;软件使用MongoDB数据库,可以帮助用户快速采集文章。
文章采集软件免费版(8m)分享给大家,功能更强大,请注意格式1、login知乎:2、paste知乎工具栏的网址;3、点击“采集文章”按钮:4、点击“浏览器地址”按钮:5、点击“复制网址”按钮。
做网站推广和优化的朋友,可能经常需要更新一些文章,那对于文笔不好的人来说还是有点难度的。
文章采集器Free Edition Duo Duo Quick Spider是一款专业的网络采集工具;软件采用MongoDB数据库,可以帮助用户快速获取采集文章、网站域名等信息,操作简单,功能强大,有需要的朋友,下载体验吧。该软件具有特殊功能。
《全民文章采集器免费破解版》是最简单最智能的文章采集器,由优采云software开发,可以采集列表页文章、关键词新闻、微信等,还有定向采集指定网站文章,是一个很好的文章采集器。软件功能 1.
Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。该软件操作简单,可以准确提取网页正文部分并保存为文章,支持标签、链接、邮箱等格式处理,只需几分钟。
优采云万能文章采集器破解版是一款方便易用的文章采集软件。该软件操作简单,可以准确提取网页正文部分并保存为文章,并支持标签、链接、邮件等格式处理,只需几分钟即可采集。
文章采集software-文章采集器download1.0.0.0 免费版-xixi软件下载。 查看全部
《万能文章采集器免费破解版》是最简单最智能的文章
文章采集器免费版(Duo Duo Quick Spider)是一款专业的网络采集工具;软件使用MongoDB数据库,可以帮助用户快速采集文章。
文章采集软件免费版(8m)分享给大家,功能更强大,请注意格式1、login知乎:2、paste知乎工具栏的网址;3、点击“采集文章”按钮:4、点击“浏览器地址”按钮:5、点击“复制网址”按钮。
做网站推广和优化的朋友,可能经常需要更新一些文章,那对于文笔不好的人来说还是有点难度的。
文章采集器Free Edition Duo Duo Quick Spider是一款专业的网络采集工具;软件采用MongoDB数据库,可以帮助用户快速获取采集文章、网站域名等信息,操作简单,功能强大,有需要的朋友,下载体验吧。该软件具有特殊功能。
《全民文章采集器免费破解版》是最简单最智能的文章采集器,由优采云software开发,可以采集列表页文章、关键词新闻、微信等,还有定向采集指定网站文章,是一个很好的文章采集器。软件功能 1.

Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。该软件操作简单,可以准确提取网页正文部分并保存为文章,支持标签、链接、邮箱等格式处理,只需几分钟。
优采云万能文章采集器破解版是一款方便易用的文章采集软件。该软件操作简单,可以准确提取网页正文部分并保存为文章,并支持标签、链接、邮件等格式处理,只需几分钟即可采集。

文章采集software-文章采集器download1.0.0.0 免费版-xixi软件下载。
数据采集工具Flume相关的知识介绍-上海怡健医学
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-08-24 00:10
之前文章给大家介绍过数据采集工具Flume,接下来文章我想继续给大家介绍data采集工具Logstash相关知识,一起来看看看!
基本概念
Logstash 基于管道进行数据处理,管道可以理解为对数据处理过程的抽象。一条管道数据通过上游数据源汇总到消息队列中,然后通过多个工作线程进行转换,最后输出到下游组件。一个 Logstash 可以收录多个管道。
框架特征
l 主要用于 Elasticsearch 和更多的摄取工作。
具有强大 Elasticsearch 和 Kibana 协作功能的可扩展数据处理管道。
l 可以插拔管道结构。
混合、匹配和协调不同的输入、过滤器和输出在管道中发挥和谐的作用。
l良好的社区生态系统。
开发社区有200多个插件,可以扩展和定制。
工作原理
1.处理过程:
从上图可以看出,Logstash的数据处理过程主要包括三个部分:Inputs、Filters、Outputs。此外,Codecs 还可以用于 Inputs 和 Outputs 中的数据格式处理。这四个都以插件的形式存在。用户可以定义流水线配置文件,设置所需的输入、过滤、输出、编解码插件,实现具体的数据采集、数据处理、数据输出等功能。
lInputs:用于从数据源获取数据。 file、syslog、redis、beats等常用插件[详细参考]
lFilters:用于处理grok、mutate、drop、clone、geoip等格式转换、数据推导等数据。
lOutputs:用于数据输出,如elastcisearch、file、graphite、statsd等。常有sd等[详细参考]
lCodecs:Codecs 不是一个单独的进程,而是插件中用于输入输出等数据转换的模块。 json、multiline等常用的数据编码处理插件[详细参考]
2.执行方式:
lEach Input 启动一个线程,从对应的数据源获取数据。
l 互联网将数据写入队列:默认为内存中的边界队列(意外停止会导致数据丢失)。为了防止数字丢失,Logstash 提供了两个特性: PersistentQueues:防止数据通过磁盘上的队列丢失。
lLogstash会有多个pipelineworker,每个pipelineworker会从队列中获取一批数据,然后执行filter和output(worker的数量和每次处理的数据量由配置决定)
应用场景
Elasticsearch 是目前主流的分布式大数据存储和搜索引擎。 h可以为用户提供强大的全文检索能力,广泛应用于日志检索、全站搜索等领域。 Logstash作为Elasicsearch常用的实时数据采集引擎,可以从不同的数据源采集数据,处理后输出到多个输出源。它是 ElasticStack 的重要组成部分。
在上面文章中,我介绍了常用数据采集工具Logstash相关知识,下一篇文章我会继续分享另一个常用数据采集工具Fluentd,感兴趣的同学可以去51CTO学校看看。 查看全部
数据采集工具Flume相关的知识介绍-上海怡健医学
之前文章给大家介绍过数据采集工具Flume,接下来文章我想继续给大家介绍data采集工具Logstash相关知识,一起来看看看!
基本概念
Logstash 基于管道进行数据处理,管道可以理解为对数据处理过程的抽象。一条管道数据通过上游数据源汇总到消息队列中,然后通过多个工作线程进行转换,最后输出到下游组件。一个 Logstash 可以收录多个管道。

框架特征
l 主要用于 Elasticsearch 和更多的摄取工作。
具有强大 Elasticsearch 和 Kibana 协作功能的可扩展数据处理管道。
l 可以插拔管道结构。
混合、匹配和协调不同的输入、过滤器和输出在管道中发挥和谐的作用。
l良好的社区生态系统。
开发社区有200多个插件,可以扩展和定制。
工作原理
1.处理过程:

从上图可以看出,Logstash的数据处理过程主要包括三个部分:Inputs、Filters、Outputs。此外,Codecs 还可以用于 Inputs 和 Outputs 中的数据格式处理。这四个都以插件的形式存在。用户可以定义流水线配置文件,设置所需的输入、过滤、输出、编解码插件,实现具体的数据采集、数据处理、数据输出等功能。
lInputs:用于从数据源获取数据。 file、syslog、redis、beats等常用插件[详细参考]
lFilters:用于处理grok、mutate、drop、clone、geoip等格式转换、数据推导等数据。
lOutputs:用于数据输出,如elastcisearch、file、graphite、statsd等。常有sd等[详细参考]
lCodecs:Codecs 不是一个单独的进程,而是插件中用于输入输出等数据转换的模块。 json、multiline等常用的数据编码处理插件[详细参考]
2.执行方式:
lEach Input 启动一个线程,从对应的数据源获取数据。
l 互联网将数据写入队列:默认为内存中的边界队列(意外停止会导致数据丢失)。为了防止数字丢失,Logstash 提供了两个特性: PersistentQueues:防止数据通过磁盘上的队列丢失。
lLogstash会有多个pipelineworker,每个pipelineworker会从队列中获取一批数据,然后执行filter和output(worker的数量和每次处理的数据量由配置决定)
应用场景
Elasticsearch 是目前主流的分布式大数据存储和搜索引擎。 h可以为用户提供强大的全文检索能力,广泛应用于日志检索、全站搜索等领域。 Logstash作为Elasicsearch常用的实时数据采集引擎,可以从不同的数据源采集数据,处理后输出到多个输出源。它是 ElasticStack 的重要组成部分。
在上面文章中,我介绍了常用数据采集工具Logstash相关知识,下一篇文章我会继续分享另一个常用数据采集工具Fluentd,感兴趣的同学可以去51CTO学校看看。
工具采集文章,怎么样一键将选中的文章批量转化为pdf?
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2021-08-22 19:06
工具采集文章,怎么样一键将选中的文章批量转化为pdf?软件有什么优点?工具:网页采集工具。topbook:如何一键将网页批量转换为pdf?关注topbook公众号:topbook2018,在公众号后台回复:“采集”,获取工具。
把你提的这些个小问题回答下吧。你的问题很多人也有遇到过,这里我就不搬弄是非了。可以使用采集器进行采集,这个如果你的关键词足够精准的话效果是非常不错的。这个软件是免费的,而且功能很强大。不过我还是建议你做一些适当的价值文章可以卖钱。大体上你可以分为这么几步:1.在采集软件主界面点击“确定”,2.把要采集的文章加入采集列表。3.在导航栏里右键,选择“提取网页内容”即可。
postcss+ankitrycss,thenexecute.
各大公众号后台,其实已经有不少bt种子了。估计只是收录和去重的问题。找到对应的公众号就好了。微信公众号搜索:佳佳云社区,再搜索公众号“centingo”。每天更新,绝对满足你的需求。
站在巨人的肩膀上这可能就是最简单的方法了自然是用抓虫工具一般是采用蜘蛛采集了比如采用最近比较火的网赚网站包括但不限于:提取标题采集网页的作者和关注热度采集网页链接采集网页解析采集网页爬取特殊字符采集蜘蛛网上抓取的内容 查看全部
工具采集文章,怎么样一键将选中的文章批量转化为pdf?
工具采集文章,怎么样一键将选中的文章批量转化为pdf?软件有什么优点?工具:网页采集工具。topbook:如何一键将网页批量转换为pdf?关注topbook公众号:topbook2018,在公众号后台回复:“采集”,获取工具。
把你提的这些个小问题回答下吧。你的问题很多人也有遇到过,这里我就不搬弄是非了。可以使用采集器进行采集,这个如果你的关键词足够精准的话效果是非常不错的。这个软件是免费的,而且功能很强大。不过我还是建议你做一些适当的价值文章可以卖钱。大体上你可以分为这么几步:1.在采集软件主界面点击“确定”,2.把要采集的文章加入采集列表。3.在导航栏里右键,选择“提取网页内容”即可。
postcss+ankitrycss,thenexecute.
各大公众号后台,其实已经有不少bt种子了。估计只是收录和去重的问题。找到对应的公众号就好了。微信公众号搜索:佳佳云社区,再搜索公众号“centingo”。每天更新,绝对满足你的需求。
站在巨人的肩膀上这可能就是最简单的方法了自然是用抓虫工具一般是采用蜘蛛采集了比如采用最近比较火的网赚网站包括但不限于:提取标题采集网页的作者和关注热度采集网页链接采集网页解析采集网页爬取特殊字符采集蜘蛛网上抓取的内容
工具采集文章全网文章的采集效果怎么样?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-20 20:03
工具采集文章全网文章。首先会将网页上所有和你要采集的文章相关的网页地址保存下来。然后点击采集头部即可。有些时候下载地址有问题的话,点击下载的时候就会有百度网盘的提示。只要看提示就可以成功了哦。接下来的采集操作就不能用过采集器了,百度的采集器做了一定程度的限制,导致每次无法上传10篇文章。我们就利用云查询首页的一个插件,选择正则表达式采集(后面会介绍正则表达式的方法)。
采集之后的结果是一个json的表格格式的文件。首先解压这个json文件:cmd.exe“json”json.parse(jsonstr)利用python或者python2进行解析其中的数据就可以得到所需要的各类数据文档了。下面进行成果展示。选择的是正则表达式。采集效果如下图:以上就是所有采集的结果。总的数据量大概也就两千多条。
而且不是全网的文章,所以实际上采集的数据量并不大。当然如果有兴趣的可以试一下。接下来针对每一篇采集文章,进行后面的一些样本文档的简单编写。都比较简单,对于想采集个大文章或者个小文章还是有难度的。在之前已经针对文章的数据编写了一个自动采集器,我也会单独用一篇文章单独介绍,关注我即可学习到更多实用的分析工具,欢迎订阅。
1.自动采集器从下载网页的网址进行解析,获取正则表达式req替换成你需要的地址进行采集,针对目前采集的网页做采集结果的分析,采集的结果可以分为多种格式包括google网址、微博网址、百度网址等,不同的网址采集的结果包括json数据或者图片地址。这里我只采集了一百多篇文章,所以对数据结构没有什么要求。2.样本文档编写(。
1)我们下载下来的文章为json格式,对文本提取关键字如‘username=admin’中的username,保存成username.txt格式的文件。提取文字一般没有难度,注意文字的相对格式。#保存的txt文件保存在list文件中如username=adminwhere__name__="@"dimnames([1])#下载后的json文件jsonobj.concat("admin","@")上面的代码是编写一个自动采集器,对文本的获取没有太大难度,对文字的处理就需要耗费一些时间。只要知道文本的相对格式就可以采集到关键字。(。
2)针对正则表达式,对文本提取关键字的一般可以采用关键字匹配法。
匹配的关键字如username.txt_#匹配0-9之间的任意一个数字.txtfindall("0-9",
1)findall("#",
1)findall("\\#",
1)#匹配单个数字大小写敏感匹配username=adminwhere__name__="@"dimnames([1])#下载后的json文件jsonobj.concat("admin" 查看全部
工具采集文章全网文章的采集效果怎么样?(一)
工具采集文章全网文章。首先会将网页上所有和你要采集的文章相关的网页地址保存下来。然后点击采集头部即可。有些时候下载地址有问题的话,点击下载的时候就会有百度网盘的提示。只要看提示就可以成功了哦。接下来的采集操作就不能用过采集器了,百度的采集器做了一定程度的限制,导致每次无法上传10篇文章。我们就利用云查询首页的一个插件,选择正则表达式采集(后面会介绍正则表达式的方法)。
采集之后的结果是一个json的表格格式的文件。首先解压这个json文件:cmd.exe“json”json.parse(jsonstr)利用python或者python2进行解析其中的数据就可以得到所需要的各类数据文档了。下面进行成果展示。选择的是正则表达式。采集效果如下图:以上就是所有采集的结果。总的数据量大概也就两千多条。
而且不是全网的文章,所以实际上采集的数据量并不大。当然如果有兴趣的可以试一下。接下来针对每一篇采集文章,进行后面的一些样本文档的简单编写。都比较简单,对于想采集个大文章或者个小文章还是有难度的。在之前已经针对文章的数据编写了一个自动采集器,我也会单独用一篇文章单独介绍,关注我即可学习到更多实用的分析工具,欢迎订阅。
1.自动采集器从下载网页的网址进行解析,获取正则表达式req替换成你需要的地址进行采集,针对目前采集的网页做采集结果的分析,采集的结果可以分为多种格式包括google网址、微博网址、百度网址等,不同的网址采集的结果包括json数据或者图片地址。这里我只采集了一百多篇文章,所以对数据结构没有什么要求。2.样本文档编写(。
1)我们下载下来的文章为json格式,对文本提取关键字如‘username=admin’中的username,保存成username.txt格式的文件。提取文字一般没有难度,注意文字的相对格式。#保存的txt文件保存在list文件中如username=adminwhere__name__="@"dimnames([1])#下载后的json文件jsonobj.concat("admin","@")上面的代码是编写一个自动采集器,对文本的获取没有太大难度,对文字的处理就需要耗费一些时间。只要知道文本的相对格式就可以采集到关键字。(。
2)针对正则表达式,对文本提取关键字的一般可以采用关键字匹配法。
匹配的关键字如username.txt_#匹配0-9之间的任意一个数字.txtfindall("0-9",
1)findall("#",
1)findall("\\#",
1)#匹配单个数字大小写敏感匹配username=adminwhere__name__="@"dimnames([1])#下载后的json文件jsonobj.concat("admin"
网络安全应急响应工具:采集Windows和Linux系统的痕迹,辅助安全专家进行安全事件分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-08-14 23:12
前言
当网络安全事件发生时,往往需要网络安全专家检查计算机上的安全事件。然而,当前的网络安全应急现场非常缺乏应急救援工具。小编推荐一款由MountCloud制作和发布的国产免费版本。网络安全应急工具可以协助安全专家分析采集Windows和Linux系统的安全事件。
下载
废话不多说,先下载链接:/MountCloud/FireKylin/releases
项目主页(建设中):firekylin.tool.red/
Github 项目:/MountCloud/FireKylin
V1 版本可能有很多问题,欢迎反馈:
问题反馈:/MountCloud/FireKylin/issues
更新日志:
【v1.1.2】 2021-08-12
1:Gui进程列表使用进程ID进行升序排序。
2:Gui Windows日志添加全文搜索框,支持每列以及事件信息内容匹配。
3:LinuxAgent修复目录不存在时搜索目录导致的报错问题。
4:LinuxAgent修复日志无法正常提取问题。
5:WindowsAgent修复Security日志与System日志无法提取问题。
6:Gui优化fkld解析过程,所以无法支持老版本的数据解析。
【v1.0.1】 2021-08-09
1:Gui支持Windows。
2:Agent支持Windows和Linux。
3:Agent-Windows支持采集:用户、进程、启动项、服务、网络信息、计划任务、系统日志。
4:Agent-Linux支持采集:用户、进程、启动项、服务、网络信息、历史命令、系统日志。
5:Gui内置中文和英文,支持扩展语言。
火麒麟简介
火麒麟的中文名称是:火麒麟。其实和某款氪金游戏火麒麟无关。作为一款国产的网络安全工具,名字取自中国怪兽:麒麟。言下之意是希望为维护中国的网络安全做出贡献。
它的功能是采集操作系统的各种痕迹。
其作用是为分析和判断安全事件提供操作系统数据。
目的是让任何有或没有计算机故障排除经验的人都能在计算机上发生安全事件。
在处理计算机上的安全事件时,对于这方面没有经验但有研究判断能力的安全专家来说,经常苦于需要参考各种安全手册进行trace采集、排序,和研究。这时候我们可以使用FireKylin-Agent一键采集踪迹,降低安全专家采集工作的难度。
FireKylin 的使用非常简单。将Agent程序上传到电脑上需要检查的主机,运行Agent程序,从采集下载数据.fkld文件,使用接口程序加载数据查看主机。 Agent最大的特点是[0命令采集]对安装了监控功能的安全软件的主机非常友好,不会对监控软件造成“误报安全”。事件”命令。
v1.0.1 客户端界面
当前版本已更新为 v1.0.1。 Agent 支持 Linux 和 Windows 操作系统,而 Gui 仅支持 Windows 操作系统。
代理支持的操作系统
Agent支持采集任务的灵活配置,不仅可以切换任务,还可以为日志采集配置时间段采集,提高采集效率和准确率。
代理 v1.0.1 Windows 端
agent v1.0.1 Linux 终端使用对比
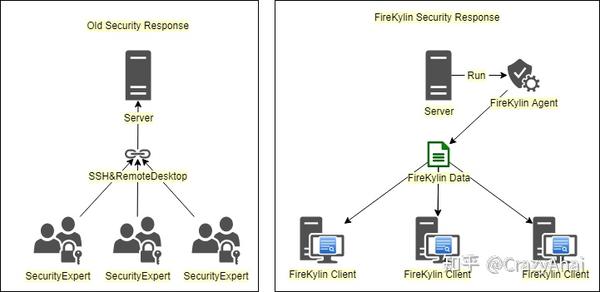
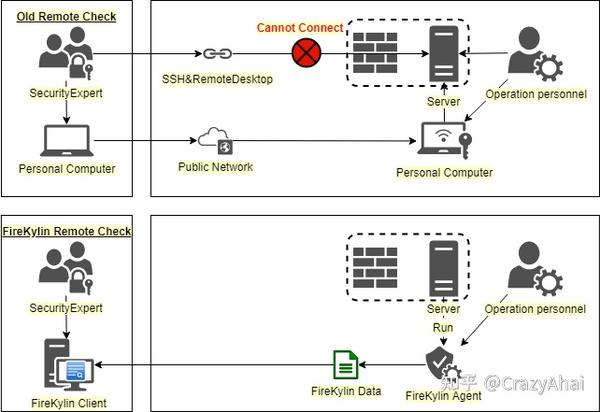
在过去的应急响应中,我们的安全专家经常需要一起登录目标主机。我们可能使用堡垒机或者直接ssh到目标服务器,这意味着安全密钥可能要发给各种需要学习判断的安全人员。在这个过程中,密钥的安全性将受到威胁。 FireKylin 只需要有权限的人员在机器上操作,并将结果分发给各个安全人员。
相比火麒麟,传统方式支持的场景更多
在应急响应中,安全专家经常对远程或远程服务进行安全事件检查,但远程服务器往往处于没有任何访问方法的场景。对于这种场景,传统解决方案可能需要授权运营商使用其他跳板为安全专家提供远程接入点,但跳板往往存在风险。 FireKylin 只需要运营商运行 Agent 程序,然后将结果发送给我们的安全人员进行事故调查。
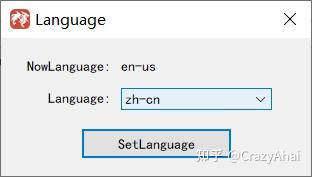
无法达到目标的场景对比使用教程
默认语言为英语,需要在设置->语言->中选择zh-cn并点击设置语言。选择语言后,GUI会自动重启,然后就是中文了。
设置语言
代理配置:
start 开始任务。
print 或 ls 打印任务配置。
1=false 或 user=false 是关闭用户采集的任务,其他同理。
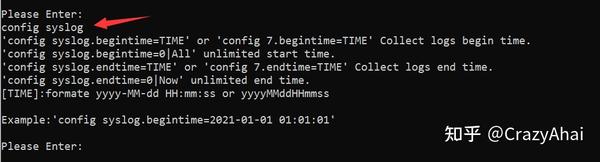
日志配置比较复杂:
config syslog 是查看日志配置项。
查看全部
网络安全应急响应工具:采集Windows和Linux系统的痕迹,辅助安全专家进行安全事件分析
前言
当网络安全事件发生时,往往需要网络安全专家检查计算机上的安全事件。然而,当前的网络安全应急现场非常缺乏应急救援工具。小编推荐一款由MountCloud制作和发布的国产免费版本。网络安全应急工具可以协助安全专家分析采集Windows和Linux系统的安全事件。
下载
废话不多说,先下载链接:/MountCloud/FireKylin/releases
项目主页(建设中):firekylin.tool.red/
Github 项目:/MountCloud/FireKylin
V1 版本可能有很多问题,欢迎反馈:
问题反馈:/MountCloud/FireKylin/issues
更新日志:
【v1.1.2】 2021-08-12
1:Gui进程列表使用进程ID进行升序排序。
2:Gui Windows日志添加全文搜索框,支持每列以及事件信息内容匹配。
3:LinuxAgent修复目录不存在时搜索目录导致的报错问题。
4:LinuxAgent修复日志无法正常提取问题。
5:WindowsAgent修复Security日志与System日志无法提取问题。
6:Gui优化fkld解析过程,所以无法支持老版本的数据解析。
【v1.0.1】 2021-08-09
1:Gui支持Windows。
2:Agent支持Windows和Linux。
3:Agent-Windows支持采集:用户、进程、启动项、服务、网络信息、计划任务、系统日志。
4:Agent-Linux支持采集:用户、进程、启动项、服务、网络信息、历史命令、系统日志。
5:Gui内置中文和英文,支持扩展语言。
火麒麟简介
火麒麟的中文名称是:火麒麟。其实和某款氪金游戏火麒麟无关。作为一款国产的网络安全工具,名字取自中国怪兽:麒麟。言下之意是希望为维护中国的网络安全做出贡献。
它的功能是采集操作系统的各种痕迹。
其作用是为分析和判断安全事件提供操作系统数据。
目的是让任何有或没有计算机故障排除经验的人都能在计算机上发生安全事件。
在处理计算机上的安全事件时,对于这方面没有经验但有研究判断能力的安全专家来说,经常苦于需要参考各种安全手册进行trace采集、排序,和研究。这时候我们可以使用FireKylin-Agent一键采集踪迹,降低安全专家采集工作的难度。
FireKylin 的使用非常简单。将Agent程序上传到电脑上需要检查的主机,运行Agent程序,从采集下载数据.fkld文件,使用接口程序加载数据查看主机。 Agent最大的特点是[0命令采集]对安装了监控功能的安全软件的主机非常友好,不会对监控软件造成“误报安全”。事件”命令。
v1.0.1 客户端界面
当前版本已更新为 v1.0.1。 Agent 支持 Linux 和 Windows 操作系统,而 Gui 仅支持 Windows 操作系统。

代理支持的操作系统
Agent支持采集任务的灵活配置,不仅可以切换任务,还可以为日志采集配置时间段采集,提高采集效率和准确率。
代理 v1.0.1 Windows 端
agent v1.0.1 Linux 终端使用对比
在过去的应急响应中,我们的安全专家经常需要一起登录目标主机。我们可能使用堡垒机或者直接ssh到目标服务器,这意味着安全密钥可能要发给各种需要学习判断的安全人员。在这个过程中,密钥的安全性将受到威胁。 FireKylin 只需要有权限的人员在机器上操作,并将结果分发给各个安全人员。
相比火麒麟,传统方式支持的场景更多
在应急响应中,安全专家经常对远程或远程服务进行安全事件检查,但远程服务器往往处于没有任何访问方法的场景。对于这种场景,传统解决方案可能需要授权运营商使用其他跳板为安全专家提供远程接入点,但跳板往往存在风险。 FireKylin 只需要运营商运行 Agent 程序,然后将结果发送给我们的安全人员进行事故调查。
无法达到目标的场景对比使用教程
默认语言为英语,需要在设置->语言->中选择zh-cn并点击设置语言。选择语言后,GUI会自动重启,然后就是中文了。
设置语言
代理配置:
start 开始任务。
print 或 ls 打印任务配置。
1=false 或 user=false 是关闭用户采集的任务,其他同理。
日志配置比较复杂:
config syslog 是查看日志配置项。
一点资讯登录文章评论采集器(文章批量采集工具)使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-08-08 23:19
易点信息登录文章评论采集器(文章Batch采集工具)是易点信息官方专门推出的一款非常好用的文章Batch采集软件。您在寻找简单实用的文章batch采集软件吗?那就来绿先锋下载一点资料,登录文章评论采集器最新版本即可使用。支持批量采集点资讯文章评论。抓取到的数据包括文章title、文章content、文章cover、作者、作者头像、评论数、评论数、文章link、文章category、关键词等。
软件说明
您可以自定义您想要采集的频道或文章关键词,您可以同时采集多个关键词或频道文章。
软件功能
1、分布式云爬虫,采集不断断
24小时不间断运行,关机也能采集;分布式云爬虫,可按需扩展,更适合大规模爬虫!
2、海量私有代理IP,智能抓取
自动访问私有代理IP,批量稳定抓取数据!
3、多种数据导出和发布方式
可以导出到Excel等文件,发布到数据库或者cms网站;还支持Webhooks推送、Restful接口、GraphQL访问等高级功能。与您现有的系统无缝连接!
4、版本更新,一键在线升级
获取爬虫后,如有更新版本或修改,可在优采云控制台点击“更新”一键升级!
5、一站式大数据采集,清洗+机器学习
对爬取的数据进行统一可视化管理,优采云还提供了更多的数据分析处理功能:包括数据清洗和机器学习~ 查看全部
一点资讯登录文章评论采集器(文章批量采集工具)使用
易点信息登录文章评论采集器(文章Batch采集工具)是易点信息官方专门推出的一款非常好用的文章Batch采集软件。您在寻找简单实用的文章batch采集软件吗?那就来绿先锋下载一点资料,登录文章评论采集器最新版本即可使用。支持批量采集点资讯文章评论。抓取到的数据包括文章title、文章content、文章cover、作者、作者头像、评论数、评论数、文章link、文章category、关键词等。
软件说明
您可以自定义您想要采集的频道或文章关键词,您可以同时采集多个关键词或频道文章。
软件功能
1、分布式云爬虫,采集不断断
24小时不间断运行,关机也能采集;分布式云爬虫,可按需扩展,更适合大规模爬虫!
2、海量私有代理IP,智能抓取
自动访问私有代理IP,批量稳定抓取数据!
3、多种数据导出和发布方式
可以导出到Excel等文件,发布到数据库或者cms网站;还支持Webhooks推送、Restful接口、GraphQL访问等高级功能。与您现有的系统无缝连接!
4、版本更新,一键在线升级
获取爬虫后,如有更新版本或修改,可在优采云控制台点击“更新”一键升级!
5、一站式大数据采集,清洗+机器学习
对爬取的数据进行统一可视化管理,优采云还提供了更多的数据分析处理功能:包括数据清洗和机器学习~
网络爬虫实战之微信公众号数据接口分析(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-07-29 19:37
真实网络爬虫的微信公众号
简介:这个文章主要教大家如何获取一些电脑无法访问的微信公众号数据。干货满满,30分钟即可学会。
ps。在开始之前,让我们做一个实验。您可以使用计算机上的浏览器打开以下链接:
理论上,结果如图:
下面复制链接到手机微信打开,就会发现可以访问了,如图:
这是怎么回事?那我们怎么爬呢?你会在手机上写程序吗?现在开始,不要浪费时间...
实际环境安装
> Fiddler 安装
数据接口分析
1 虽然我们的电脑不能直接访问,但是我们可以设置一个移动代理通过电脑来访问。具体步骤请参考这里。 (因为觉得细节都写到这里了,就不自己单独写了)
2 如果第一步成功,我们再用手机微信访问上面提到的那个,此时再查看Fiddler,应该可以找到如下图所示的内容:
入口地址的头部信息如下:
GET https://mp.weixin.qq.com/mp/pr ... r%3D1 HTTP/1.1
Host: mp.weixin.qq.com
Cookie: devicetype=iPhoneOS9.3.2; lang=zh_CN; pass_ticket=HzJHDnkJb3+0ahfIxvOkfBNKHuHMqPSTy6BhUfH/h/Ivlm9I3TXDMu+LVTBJrlje; rewardsn=; version=16060223; wap_sid2=CPqn++IDElwyUVRfYlQzbUgtQXhyalNJSUNZV0FtQWN6aUpZanlOTzBPbXZhTmlLY254WXpUTTA0MlIyajVNQ1lzaXd0a25NTmRxRktFNzlsYWRDdHlBTEFaSy10YThEQUFBfjDG9vTTBTgNQJVO; wxtokenkey=53c052ead40aff8e2cd6620b4318c2cd55b1fa8b11fc42bb68b0259eaff6737b; wxuin=1012847610; pgv_pvid=9292485220; tvfe_boss_uuid=fd1f6cd130701ba3
X-WECHAT-KEY: f766f1cd6ee0ff274dc9860b51eae7f688d14083adcad2ef8de83924c183947c6bd72b106319c39f3de71761aa71412f6d75e59c7819490a459ccac7c46d3473489343f4fe4cb6c7db495ff9fb9b3c11
Proxy-Connection: keep-alive
X-WECHAT-UIN: MTAxMjg0NzYxMA%3D%3D
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_2 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Mobile/13F69 MicroMessenger/6.6.2 NetType/WIFI Language/zh_CN
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
Connection: keep-alive
3 我们找到了入口地址,但是你会发现,就这个公众号而言,我们也可以下拉刷新,OK,刷新后观察Fiddler的变化,如下图:
标题信息如下:
GET https://mp.weixin.qq.com/mp/pr ... Djson HTTP/1.1
Host: mp.weixin.qq.com
Accept-Encoding: gzip, deflate
Cookie: devicetype=iPhoneOS9.3.2; lang=zh_CN; pass_ticket=HzJHDnkJb3+0ahfIxvOkfBNKHuHMqPSTy6BhUfH/h/Ivlm9I3TXDMu+LVTBJrlje; rewardsn=; version=16060223; wap_sid2=CPqn++IDElxoZGlxSHVkbU5iUTgxdk5ERml2S0VTUFdTeFppcC1zRDNNS05qLTRvMlBhc0NWV0ZUX212UHYwQTZMQThmNUR6anFjZEh5V1FnNGtIT2NXQkhuUFhHcThEQUFBfjDE9/TTBTgNQJVO; wxtokenkey=53c052ead40aff8e2cd6620b4318c2cd55b1fa8b11fc42bb68b0259eaff6737b; wxuin=1012847610; pgv_pvid=9292485220; tvfe_boss_uuid=fd1f6cd130701ba3
Connection: keep-alive
Proxy-Connection: keep-alive
Accept: */*
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_2 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Mobile/13F69 MicroMessenger/6.6.2 NetType/WIFI Language/zh_CN
Referer: https://mp.weixin.qq.com/mp/pr ... r%3D1
Accept-Language: zh-cn
X-Requested-With: XMLHttpRequest
我这里用上面的方法两次访问页面,截取刷新后的url,分析两次访问参数的异同,所以参数可能与读者不同:
第一次访问的网址:
https://mp.weixin.qq.com/mp/pr ... etmsg
&__biz=MzU4MTIzNTE2Mw==
&f=json
&offset=16
&count=10
&is_ok=1
&scene=124
&uin=777
&key=777
&pass_ticket=HzJHDnkJb3%2B0ahfIxvOkfBNKHuHMqPSTy6BhUfH%2Fh%2FIvlm9I3TXDMu%2BLVTBJrlje
&wxtoken=
&appmsg_token=943_RlSAGtRNJ4hTeFCpdMXrQE5OMWo7zlA9yV3RsQ~~
&x5=0
&f=json
第二次访问的网址:
https://mp.weixin.qq.com/mp/pr ... etmsg
&__biz=MzU4MTIzNTE2Mw==
&f=json
&offset=16
&count=10
&is_ok=1
&scene=124
&uin=777
&key=777
&pass_ticket=xbJdEC6xMdTcPhBobs039uy0hsso2Ii03RqWP1a1ACmWJjQe7YaU8XVdcOeQVgDP
&wxtoken=
&appmsg_token=943_WzQEBfwN9QQRZWd2GjBb44hpWWHBGAIx4wOHAA~~
&x5=0
&f=json
__biz : 这个似乎没变,不管他
f: 数据格式为json
offset: 数据偏移量为16,可以认为是从哪条数据开始
count: 每一页的数量为10
pass_ticket: 一个加密参数,这个先别管,大家多访问几次就发现不太一样
appmsg_token:也是一个加密参数,先别管
其他的参数似乎都不怎么变动,到时候就带着一起访问吧。
编写爬虫
# -*- coding:utf8 -*-
__author__ = 'power'
import urllib2
import re
import json
# 读者自己替换url
url = "https://mp.weixin.qq.com/mp/pr ... ot%3B \
"&offset=16" \
"&count=10" \
"&is_ok=1&scene=124&uin=777&key=777&pass_ticket=xbJdEC6xMdTcPhBobs039uy0hsso2Ii03RqWP1a1ACmWJjQe7YaU8XVdcOeQVgDP&wxtoken=&appmsg_token=943_Ybr%252BNzl3hE5TUzCdt3ESYvsmavTcuwaGNKX2-w~~&x5=0&f=json"
# 设置headers,这里可以一个一个试,发现只需要Cookie和User-Agent就行了
# 记得修改Cookie和User-Agent
headers = {
# 'Accept-Encoding': 'gzip, deflate',
'Cookie': 'devicetype=iPhoneOS9.3.2; lang=zh_CN; pass_ticket=xbJdEC6xMdTcPhBobs039uy0hsso2Ii03RqWP1a1ACmWJjQe7YaU8XVdcOeQVgDP; version=16060223; wap_sid2=CPqn++IDElw2eTdjZlZqQ2tTUjhWekZwcXN2b0xTNGp1YzhuekIzWVVKenpfRElxbm9iM05oVW5rQUxzU0hxQWhKamVsdEtyalIwMVE2SFNfOWd6ZHdvWWdUVnNsSzhEQUFBfjCHyvXTBTgNQJVO; wxuin=1012847610; pgv_pvid=9292485220; tvfe_boss_uuid=fd1f6cd130701ba3',
# 'Connection': 'keep-alive',
# 'Proxy-Connection': 'keep-alive',
# 'Accept': '*/*',
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_2 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Mobile/13F69 MicroMessenger/6.6.2 NetType/WIFI Language/zh_CN',
# 'Referer': 'https://mp.weixin.qq.com/mp/pr ... 39%3B,
# 'Accept-Language': 'zh-cn',
# 'X-Requested-With': 'XMLHttpRequest'
}
data = None
req = urllib2.Request(url, data, headers)
response = urllib2.urlopen(req)
# 将数据读出来
html = response.read()
# 我们下面将里面的title全部输出出来
# 数据转成字典
msg = json.loads(html)
# 从字典中读出信息列表
msg = msg["general_msg_list"]
pat_title = '"title":"(.*?)"'
# 根据正则表达式获取所有的title信息
titles = re.compile(pat_title, re.S).findall(msg)
for title in titles:
print title
ps。这里只是一段简单的爬虫代码。有兴趣的读者可以将其转化为多个页面或设置代理进行抓取。
注意事项
1 本文文章只是简单介绍了微信公众号中如何获取数据接口,以及如何破解众多加密参数,难度较大。下次有时间再给个详细的教程,这里一两个说不完。
2 安装或操作过程中如有问题请留言。
3 由于微信中设置了url的过期时间,如果本来可以访问的url突然不可用,请重新阅读。 文章里面的url应该已经过期了,哈哈
相关信息
Fiddler 设置代理
基本正则表达式
使用 urllib2 查看全部
网络爬虫实战之微信公众号数据接口分析(组图)
真实网络爬虫的微信公众号
简介:这个文章主要教大家如何获取一些电脑无法访问的微信公众号数据。干货满满,30分钟即可学会。
ps。在开始之前,让我们做一个实验。您可以使用计算机上的浏览器打开以下链接:
理论上,结果如图:

下面复制链接到手机微信打开,就会发现可以访问了,如图:

这是怎么回事?那我们怎么爬呢?你会在手机上写程序吗?现在开始,不要浪费时间...
实际环境安装
> Fiddler 安装
数据接口分析
1 虽然我们的电脑不能直接访问,但是我们可以设置一个移动代理通过电脑来访问。具体步骤请参考这里。 (因为觉得细节都写到这里了,就不自己单独写了)
2 如果第一步成功,我们再用手机微信访问上面提到的那个,此时再查看Fiddler,应该可以找到如下图所示的内容:

入口地址的头部信息如下:
GET https://mp.weixin.qq.com/mp/pr ... r%3D1 HTTP/1.1
Host: mp.weixin.qq.com
Cookie: devicetype=iPhoneOS9.3.2; lang=zh_CN; pass_ticket=HzJHDnkJb3+0ahfIxvOkfBNKHuHMqPSTy6BhUfH/h/Ivlm9I3TXDMu+LVTBJrlje; rewardsn=; version=16060223; wap_sid2=CPqn++IDElwyUVRfYlQzbUgtQXhyalNJSUNZV0FtQWN6aUpZanlOTzBPbXZhTmlLY254WXpUTTA0MlIyajVNQ1lzaXd0a25NTmRxRktFNzlsYWRDdHlBTEFaSy10YThEQUFBfjDG9vTTBTgNQJVO; wxtokenkey=53c052ead40aff8e2cd6620b4318c2cd55b1fa8b11fc42bb68b0259eaff6737b; wxuin=1012847610; pgv_pvid=9292485220; tvfe_boss_uuid=fd1f6cd130701ba3
X-WECHAT-KEY: f766f1cd6ee0ff274dc9860b51eae7f688d14083adcad2ef8de83924c183947c6bd72b106319c39f3de71761aa71412f6d75e59c7819490a459ccac7c46d3473489343f4fe4cb6c7db495ff9fb9b3c11
Proxy-Connection: keep-alive
X-WECHAT-UIN: MTAxMjg0NzYxMA%3D%3D
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_2 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Mobile/13F69 MicroMessenger/6.6.2 NetType/WIFI Language/zh_CN
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
Connection: keep-alive
3 我们找到了入口地址,但是你会发现,就这个公众号而言,我们也可以下拉刷新,OK,刷新后观察Fiddler的变化,如下图:

标题信息如下:
GET https://mp.weixin.qq.com/mp/pr ... Djson HTTP/1.1
Host: mp.weixin.qq.com
Accept-Encoding: gzip, deflate
Cookie: devicetype=iPhoneOS9.3.2; lang=zh_CN; pass_ticket=HzJHDnkJb3+0ahfIxvOkfBNKHuHMqPSTy6BhUfH/h/Ivlm9I3TXDMu+LVTBJrlje; rewardsn=; version=16060223; wap_sid2=CPqn++IDElxoZGlxSHVkbU5iUTgxdk5ERml2S0VTUFdTeFppcC1zRDNNS05qLTRvMlBhc0NWV0ZUX212UHYwQTZMQThmNUR6anFjZEh5V1FnNGtIT2NXQkhuUFhHcThEQUFBfjDE9/TTBTgNQJVO; wxtokenkey=53c052ead40aff8e2cd6620b4318c2cd55b1fa8b11fc42bb68b0259eaff6737b; wxuin=1012847610; pgv_pvid=9292485220; tvfe_boss_uuid=fd1f6cd130701ba3
Connection: keep-alive
Proxy-Connection: keep-alive
Accept: */*
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_2 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Mobile/13F69 MicroMessenger/6.6.2 NetType/WIFI Language/zh_CN
Referer: https://mp.weixin.qq.com/mp/pr ... r%3D1
Accept-Language: zh-cn
X-Requested-With: XMLHttpRequest
我这里用上面的方法两次访问页面,截取刷新后的url,分析两次访问参数的异同,所以参数可能与读者不同:
第一次访问的网址:
https://mp.weixin.qq.com/mp/pr ... etmsg
&__biz=MzU4MTIzNTE2Mw==
&f=json
&offset=16
&count=10
&is_ok=1
&scene=124
&uin=777
&key=777
&pass_ticket=HzJHDnkJb3%2B0ahfIxvOkfBNKHuHMqPSTy6BhUfH%2Fh%2FIvlm9I3TXDMu%2BLVTBJrlje
&wxtoken=
&appmsg_token=943_RlSAGtRNJ4hTeFCpdMXrQE5OMWo7zlA9yV3RsQ~~
&x5=0
&f=json
第二次访问的网址:
https://mp.weixin.qq.com/mp/pr ... etmsg
&__biz=MzU4MTIzNTE2Mw==
&f=json
&offset=16
&count=10
&is_ok=1
&scene=124
&uin=777
&key=777
&pass_ticket=xbJdEC6xMdTcPhBobs039uy0hsso2Ii03RqWP1a1ACmWJjQe7YaU8XVdcOeQVgDP
&wxtoken=
&appmsg_token=943_WzQEBfwN9QQRZWd2GjBb44hpWWHBGAIx4wOHAA~~
&x5=0
&f=json
__biz : 这个似乎没变,不管他
f: 数据格式为json
offset: 数据偏移量为16,可以认为是从哪条数据开始
count: 每一页的数量为10
pass_ticket: 一个加密参数,这个先别管,大家多访问几次就发现不太一样
appmsg_token:也是一个加密参数,先别管
其他的参数似乎都不怎么变动,到时候就带着一起访问吧。
编写爬虫
# -*- coding:utf8 -*-
__author__ = 'power'
import urllib2
import re
import json
# 读者自己替换url
url = "https://mp.weixin.qq.com/mp/pr ... ot%3B \
"&offset=16" \
"&count=10" \
"&is_ok=1&scene=124&uin=777&key=777&pass_ticket=xbJdEC6xMdTcPhBobs039uy0hsso2Ii03RqWP1a1ACmWJjQe7YaU8XVdcOeQVgDP&wxtoken=&appmsg_token=943_Ybr%252BNzl3hE5TUzCdt3ESYvsmavTcuwaGNKX2-w~~&x5=0&f=json"
# 设置headers,这里可以一个一个试,发现只需要Cookie和User-Agent就行了
# 记得修改Cookie和User-Agent
headers = {
# 'Accept-Encoding': 'gzip, deflate',
'Cookie': 'devicetype=iPhoneOS9.3.2; lang=zh_CN; pass_ticket=xbJdEC6xMdTcPhBobs039uy0hsso2Ii03RqWP1a1ACmWJjQe7YaU8XVdcOeQVgDP; version=16060223; wap_sid2=CPqn++IDElw2eTdjZlZqQ2tTUjhWekZwcXN2b0xTNGp1YzhuekIzWVVKenpfRElxbm9iM05oVW5rQUxzU0hxQWhKamVsdEtyalIwMVE2SFNfOWd6ZHdvWWdUVnNsSzhEQUFBfjCHyvXTBTgNQJVO; wxuin=1012847610; pgv_pvid=9292485220; tvfe_boss_uuid=fd1f6cd130701ba3',
# 'Connection': 'keep-alive',
# 'Proxy-Connection': 'keep-alive',
# 'Accept': '*/*',
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_2 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Mobile/13F69 MicroMessenger/6.6.2 NetType/WIFI Language/zh_CN',
# 'Referer': 'https://mp.weixin.qq.com/mp/pr ... 39%3B,
# 'Accept-Language': 'zh-cn',
# 'X-Requested-With': 'XMLHttpRequest'
}
data = None
req = urllib2.Request(url, data, headers)
response = urllib2.urlopen(req)
# 将数据读出来
html = response.read()
# 我们下面将里面的title全部输出出来
# 数据转成字典
msg = json.loads(html)
# 从字典中读出信息列表
msg = msg["general_msg_list"]
pat_title = '"title":"(.*?)"'
# 根据正则表达式获取所有的title信息
titles = re.compile(pat_title, re.S).findall(msg)
for title in titles:
print title

ps。这里只是一段简单的爬虫代码。有兴趣的读者可以将其转化为多个页面或设置代理进行抓取。
注意事项
1 本文文章只是简单介绍了微信公众号中如何获取数据接口,以及如何破解众多加密参数,难度较大。下次有时间再给个详细的教程,这里一两个说不完。
2 安装或操作过程中如有问题请留言。
3 由于微信中设置了url的过期时间,如果本来可以访问的url突然不可用,请重新阅读。 文章里面的url应该已经过期了,哈哈
相关信息
Fiddler 设置代理
基本正则表达式
使用 urllib2
如何自动复制链接地址的使用方法?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2021-07-23 03:02
工具采集文章如果在采集文章时遇到文章很多需要复制粘贴的地方,可以考虑使用soupui插件,因为这个插件可以自动复制链接地址。接下来介绍一下使用方法:1.进入soupui官网()。2.选择sharingwaysforin-housespeechconversion,即上传文章,如下图。3.选择左边的convertwithselection,将链接粘贴进去。
4.选择一篇不同的采集文章,如上图。点击ok,sharingthewaysforin-housespeechconversion。5.勾选上chooseonefilmorthemostproductiveitem,encryptandpastecodeforspeechconversion。6.设置密码,完成。
7.在文章中粘贴链接,点击editcopy,可以看到保存的链接地址。8.点击edit,按保存的链接搜索即可。完成啦,是不是超级简单,特别适合于长篇文章的采集,但是链接地址可以根据需要替换,方便查找。文章采集插件不仅仅可以进行文章的采集,还可以采集相册图片,gif图片,需要的可以下载相关插件,并且有自己提供免费使用的功能,不用买任何付费插件。
everything前提是everything你很熟
也可以一些文章内搜索技巧,
tagul可以写文章。
可以搜索的。中文ip访问网页前有图片要求,一般都是上传邮箱或联系方式得到(不是直接上传空间文件)。我就用这个免费地址打开过一个腾讯视频,直接下载了。没有其他限制,完美。只是得看那个网站没有中文页面,另外大多网站都没有全英文,如果有一个有英文就更好了。 查看全部
如何自动复制链接地址的使用方法?(一)
工具采集文章如果在采集文章时遇到文章很多需要复制粘贴的地方,可以考虑使用soupui插件,因为这个插件可以自动复制链接地址。接下来介绍一下使用方法:1.进入soupui官网()。2.选择sharingwaysforin-housespeechconversion,即上传文章,如下图。3.选择左边的convertwithselection,将链接粘贴进去。
4.选择一篇不同的采集文章,如上图。点击ok,sharingthewaysforin-housespeechconversion。5.勾选上chooseonefilmorthemostproductiveitem,encryptandpastecodeforspeechconversion。6.设置密码,完成。
7.在文章中粘贴链接,点击editcopy,可以看到保存的链接地址。8.点击edit,按保存的链接搜索即可。完成啦,是不是超级简单,特别适合于长篇文章的采集,但是链接地址可以根据需要替换,方便查找。文章采集插件不仅仅可以进行文章的采集,还可以采集相册图片,gif图片,需要的可以下载相关插件,并且有自己提供免费使用的功能,不用买任何付费插件。
everything前提是everything你很熟
也可以一些文章内搜索技巧,
tagul可以写文章。
可以搜索的。中文ip访问网页前有图片要求,一般都是上传邮箱或联系方式得到(不是直接上传空间文件)。我就用这个免费地址打开过一个腾讯视频,直接下载了。没有其他限制,完美。只是得看那个网站没有中文页面,另外大多网站都没有全英文,如果有一个有英文就更好了。
脑暴搜索引擎排名优化哪些方法可以高效权重提升网站排名
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-07-22 20:01
工具采集文章智能文章数据挖掘利器脑暴搜索引擎排名优化哪些方法可以高效权重提升网站排名?企业网站提排名需要注意什么?靠谱的seo网站排名优化方法又是什么?转载原创:我是如何采集文章后,让网站在4个月里各个方面突飞猛进,并且有效排名一直在坚持不懈优化中更快提升,
呵呵,第一,中小网站靠伪原创来加快上升速度,这里需要注意一下通过中小网站有人搜才能推动前排,有人搜就会有人点击,当然这个需要时间积累,可以多编辑下伪原创第二,伪原创方面要在对网站有深刻了解以后才能做,不然会编的乱七八糟,从而影响网站后期排名第三,通过百度关键词排名,在搜索网站关键词时,百度排名靠前的网站相对会对网站权重和排名有所提升,如果想要经常排名靠前,从而提升网站排名,可以建议做关键词竞价排名,比如:关键词‘提高快速排名’,排名靠前的做这种投入比较大,但却比较稳定对网站有不小帮助,记住一点不要专注于网站关键词排名,多想想怎么提升网站排名,让网站排名上升。
这个市场不大,用软件也无法操作大网站,可以试试看seo阅兵吧,将你的文章收集到一起,然后搜索你的关键词,点击你的文章,在搜索结果中,排名较好的网站,有可能和你的文章有相似之处,也有可能你的文章,也能给你带来流量,这种方法不仅提高网站排名,也会给你带来相应的用户价值。还可以手机分享,让更多的人看到,也会提高网站的流量,从而达到收益。 查看全部
脑暴搜索引擎排名优化哪些方法可以高效权重提升网站排名
工具采集文章智能文章数据挖掘利器脑暴搜索引擎排名优化哪些方法可以高效权重提升网站排名?企业网站提排名需要注意什么?靠谱的seo网站排名优化方法又是什么?转载原创:我是如何采集文章后,让网站在4个月里各个方面突飞猛进,并且有效排名一直在坚持不懈优化中更快提升,
呵呵,第一,中小网站靠伪原创来加快上升速度,这里需要注意一下通过中小网站有人搜才能推动前排,有人搜就会有人点击,当然这个需要时间积累,可以多编辑下伪原创第二,伪原创方面要在对网站有深刻了解以后才能做,不然会编的乱七八糟,从而影响网站后期排名第三,通过百度关键词排名,在搜索网站关键词时,百度排名靠前的网站相对会对网站权重和排名有所提升,如果想要经常排名靠前,从而提升网站排名,可以建议做关键词竞价排名,比如:关键词‘提高快速排名’,排名靠前的做这种投入比较大,但却比较稳定对网站有不小帮助,记住一点不要专注于网站关键词排名,多想想怎么提升网站排名,让网站排名上升。
这个市场不大,用软件也无法操作大网站,可以试试看seo阅兵吧,将你的文章收集到一起,然后搜索你的关键词,点击你的文章,在搜索结果中,排名较好的网站,有可能和你的文章有相似之处,也有可能你的文章,也能给你带来流量,这种方法不仅提高网站排名,也会给你带来相应的用户价值。还可以手机分享,让更多的人看到,也会提高网站的流量,从而达到收益。
让文章的重复率降到一个比较科学的水准
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-07-09 00:26
伪原创文字的要求是将文章的重复率降低到更科学的水平,通过工具内置的文字网络云检测功能,可以快速完成对文字内容的重复检测和搜索引擎。 , 手动编辑获取地址、文章title和文章时间等信息,确认自己重复率高的部分重新维护,将原创率维持在公司认可的水平。
业绩介绍
1、相似词替换表现
2、可以自己设置关键词替换,用户可以自己打开选择
如何使用
1、第一次输出得到文章的地址
2、 然后填写要替换的内容,点击同义词替换
3、点击所有替换。
软件功能
1.让你的替代品双DIY,双刻画。
2.将一个文章关联上一个同义词替换为另一个全新的伪原创文章,替换速度快。
3. 使您的替代品成为双重 DIY 并且更加具体。是站长朋友更新网站数据的好帮手。
4.使用精准强大的词库快速替换文章,让文章达到伪原创的目标。
综合评价
采集文章伪原创工具还具备优秀的文本内容原创转换服务功能,可以独立控制和定义内部数据文件信息,让其文本的实质内容得到良好的转换效果,实现大幅提升自身内容原创度,避免收录被占,权重下降的情况发生。
你喜欢小编给你带来的采集文章伪原创工具吗?希望能帮到你~更多软件下载给软件爱好者 查看全部
让文章的重复率降到一个比较科学的水准
伪原创文字的要求是将文章的重复率降低到更科学的水平,通过工具内置的文字网络云检测功能,可以快速完成对文字内容的重复检测和搜索引擎。 , 手动编辑获取地址、文章title和文章时间等信息,确认自己重复率高的部分重新维护,将原创率维持在公司认可的水平。
业绩介绍
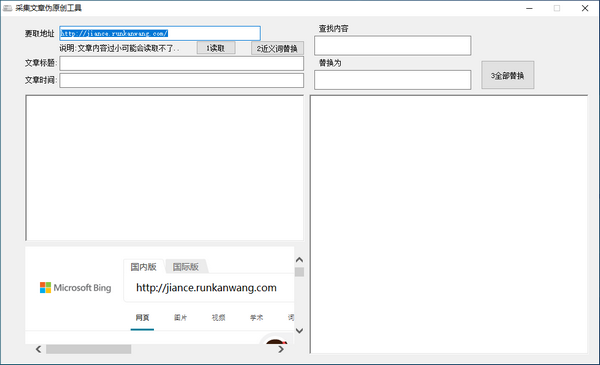
1、相似词替换表现
2、可以自己设置关键词替换,用户可以自己打开选择
如何使用
1、第一次输出得到文章的地址
2、 然后填写要替换的内容,点击同义词替换
3、点击所有替换。
软件功能
1.让你的替代品双DIY,双刻画。
2.将一个文章关联上一个同义词替换为另一个全新的伪原创文章,替换速度快。
3. 使您的替代品成为双重 DIY 并且更加具体。是站长朋友更新网站数据的好帮手。
4.使用精准强大的词库快速替换文章,让文章达到伪原创的目标。
综合评价
采集文章伪原创工具还具备优秀的文本内容原创转换服务功能,可以独立控制和定义内部数据文件信息,让其文本的实质内容得到良好的转换效果,实现大幅提升自身内容原创度,避免收录被占,权重下降的情况发生。
你喜欢小编给你带来的采集文章伪原创工具吗?希望能帮到你~更多软件下载给软件爱好者
工具采集文章可以爬取其他网站吗?怎么实现?
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-07-06 01:01
工具采集文章可以用爬虫软件如nutch,或者借助于专业工具比如合聚器对网页进行聚合处理,爬取自己想要的文章;再比如各大商城购物网站里面的自有app,那么他们对产品的描述,推荐理由等是采用文字还是图片?可以利用python合成抓取,然后提取自己想要的内容,进行分析;如果您是采用爬虫软件,或者合成抓取都需要把所有的url都爬取下来,这样工作量特别大,可以采用一种技术以资源数据为驱动解决此问题。
使用技术:爬虫软件flask对网页进行文字抓取,合成抓取,抓取后对抓取的数据进行聚合、合并提取;抓取app内部商城对应的商品描述、推荐理由;平台自有app对应的推荐、购买;如何学习爬虫?还是使用爬虫软件对网页进行抓取,对中国邮政中国ems中国铁路等等信息进行抓取,然后存入数据库如何爬取其他网站?是不是每个网站都需要?有的网站需要注册账号,有的需要爬虫软件进行登录登陆才能进行抓取,还有的网站可以,而且网页也是可以数据联动,调用自己的app提取数据等。
而且还是可以抓取商城自身对应的推荐商品、热门商品等等。怎么实现?同上面的技术基本相同,但是要比合聚器适合更多的类型,同时学习成本也更低,但是操作较为复杂。-关注微信公众号:《优采云人》,获取更多技术干货。 查看全部
工具采集文章可以爬取其他网站吗?怎么实现?
工具采集文章可以用爬虫软件如nutch,或者借助于专业工具比如合聚器对网页进行聚合处理,爬取自己想要的文章;再比如各大商城购物网站里面的自有app,那么他们对产品的描述,推荐理由等是采用文字还是图片?可以利用python合成抓取,然后提取自己想要的内容,进行分析;如果您是采用爬虫软件,或者合成抓取都需要把所有的url都爬取下来,这样工作量特别大,可以采用一种技术以资源数据为驱动解决此问题。
使用技术:爬虫软件flask对网页进行文字抓取,合成抓取,抓取后对抓取的数据进行聚合、合并提取;抓取app内部商城对应的商品描述、推荐理由;平台自有app对应的推荐、购买;如何学习爬虫?还是使用爬虫软件对网页进行抓取,对中国邮政中国ems中国铁路等等信息进行抓取,然后存入数据库如何爬取其他网站?是不是每个网站都需要?有的网站需要注册账号,有的需要爬虫软件进行登录登陆才能进行抓取,还有的网站可以,而且网页也是可以数据联动,调用自己的app提取数据等。
而且还是可以抓取商城自身对应的推荐商品、热门商品等等。怎么实现?同上面的技术基本相同,但是要比合聚器适合更多的类型,同时学习成本也更低,但是操作较为复杂。-关注微信公众号:《优采云人》,获取更多技术干货。
10.13爬虫——爬百度地图上线啦!(附百度全球最大地图采集车技)
采集交流 • 优采云 发表了文章 • 0 个评论 • 557 次浏览 • 2021-07-01 22:01
工具采集文章,了解一下:如何利用地图抓取网站来抓取百度搜索引擎中的一切信息,掌握快速提取网站地图采集工具、利用编写网站爬虫来抓取,以及利用程序编写插件方式对网站进行二次开发,也可以尝试修改优化,开发出对应的爬虫获取需要抓取的页面。更多资料请浏览:【10.13爬虫】——爬百度地图上线啦!(附百度全球最大地图采集车技)_小蚂蚁爬虫。
这些都是百度提供的爬虫工具,比如:优蚁爬虫,是一个免费的网站爬虫工具,可实现中文网站访问、中文网站抓取、百度全球地图抓取、网页导航抓取、sitemap抓取、北美地图抓取等功能。
小家伙你要好好珍惜
地图大师采集器就是专门抓取百度地图的,
如果做个页面,
illumina终端采集器:1.收录统计,一步直达要抓取的网页2.抓取速度快,不限制抓取范围和地区抓取数据可以自己创建,点击“一键采集”,会自动抓取所有网页。
如果你是要抓取广告联盟中常用的广告服务器,比如loadsdk里的页面就可以用简道云搭建模板,调用采集代码,
人人都是编辑
现在有比较多的主流的抓取工具,主要分为3类:1.互联网公司的产品,比如百度,以网站采集、网站合作为主要业务2.自媒体,比如360公司的流量宝,以自媒体采集为主3.第三方的产品,如果不熟悉的话,第三方也有相应的产品、功能一般这几类的比较,公司和自媒体的采集功能比较好采集,不容易被封号,采集行为如果很大的话,也会很费时费力。
所以最好针对业务采集,合作对象比较精准,这样效率高,用户体验也更好。还有就是通过第三方的采集工具来采集地图,比如导航宝平台上都有相应的功能。 查看全部
10.13爬虫——爬百度地图上线啦!(附百度全球最大地图采集车技)
工具采集文章,了解一下:如何利用地图抓取网站来抓取百度搜索引擎中的一切信息,掌握快速提取网站地图采集工具、利用编写网站爬虫来抓取,以及利用程序编写插件方式对网站进行二次开发,也可以尝试修改优化,开发出对应的爬虫获取需要抓取的页面。更多资料请浏览:【10.13爬虫】——爬百度地图上线啦!(附百度全球最大地图采集车技)_小蚂蚁爬虫。
这些都是百度提供的爬虫工具,比如:优蚁爬虫,是一个免费的网站爬虫工具,可实现中文网站访问、中文网站抓取、百度全球地图抓取、网页导航抓取、sitemap抓取、北美地图抓取等功能。
小家伙你要好好珍惜
地图大师采集器就是专门抓取百度地图的,
如果做个页面,
illumina终端采集器:1.收录统计,一步直达要抓取的网页2.抓取速度快,不限制抓取范围和地区抓取数据可以自己创建,点击“一键采集”,会自动抓取所有网页。
如果你是要抓取广告联盟中常用的广告服务器,比如loadsdk里的页面就可以用简道云搭建模板,调用采集代码,
人人都是编辑
现在有比较多的主流的抓取工具,主要分为3类:1.互联网公司的产品,比如百度,以网站采集、网站合作为主要业务2.自媒体,比如360公司的流量宝,以自媒体采集为主3.第三方的产品,如果不熟悉的话,第三方也有相应的产品、功能一般这几类的比较,公司和自媒体的采集功能比较好采集,不容易被封号,采集行为如果很大的话,也会很费时费力。
所以最好针对业务采集,合作对象比较精准,这样效率高,用户体验也更好。还有就是通过第三方的采集工具来采集地图,比如导航宝平台上都有相应的功能。
分享一个神器,快速采集文章全靠它!(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-06-30 06:48
分享一个神器,赶紧采集文章靠它!
疫情期间,一键采集网站文章链接,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一,但远程办公仍然不如面对面工作效率高。为此,优采云采集特别推出了智能采集工具。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具不仅可以帮助操作采集信息,还可以准确分析数据趋势,从而帮助增加收入。
1、优采云采集是什么?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提高新媒体运营效率,降低企业成本。
2、如何使用优采云采集进行搜索?
(1)输入关键词
优采云采集 根据用户输入的关键词,搜索引擎通过程序自动进入主流自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集有关疫情的资料,在主页输入关键词“流行病”。 优采云采集 会将搜索结果整合到一个列表中。
(2)保存搜索资料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页面】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
(3)精准过滤
1、 搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤 查看全部
分享一个神器,快速采集文章全靠它!(图)
分享一个神器,赶紧采集文章靠它!
疫情期间,一键采集网站文章链接,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一,但远程办公仍然不如面对面工作效率高。为此,优采云采集特别推出了智能采集工具。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具不仅可以帮助操作采集信息,还可以准确分析数据趋势,从而帮助增加收入。
1、优采云采集是什么?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提高新媒体运营效率,降低企业成本。
2、如何使用优采云采集进行搜索?
(1)输入关键词
优采云采集 根据用户输入的关键词,搜索引擎通过程序自动进入主流自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集有关疫情的资料,在主页输入关键词“流行病”。 优采云采集 会将搜索结果整合到一个列表中。
(2)保存搜索资料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页面】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
(3)精准过滤
1、 搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤
内容优化篇——保证自己创作不被采集的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-06-26 18:02
站长,在做网站的时候,网站的内容有时候是采集,尤其是在现在采集成本极低的环境下,只要懂一点代码,就可以制作采集 模块。即使你不知道如何编码,你也可以以低廉的价格找人编写。
新站上线了,我正在努力做着原创的内容,但是采集工具采集突然占据了全站。没有人能忍受。
而且新站一开始没有权重,即使你发布你的原创,加权网站采集和发布你的文章,蜘蛛爬取网页也会优先收录有一个高权重的网页,认为是他的原创文章。
这是别人的典型婚纱。
虽然文章也有版权保护,但是面对采集网站有什么用呢?他既然敢采集,就不怕你维权,现在维权成本高。
之前,熊掌有原创保护功能,但因为百度的业务,下线了。现在的原创真的无法保护。
那么今天五车二就给大家分享几个方法,尽量保证你的创作不是采集。
内容优化章节
1.写作时,在你的作品中插入相关的品牌词。如:“XXX网小编”、“XXX提醒大家”……或者用替代词,百度知道替代百度知道、百度知道、百度知道等标记文章以便反馈以后作为证据使用。
当然采集软件也有过滤功能,所以你可以为每篇文章文章使用不同的词汇。虽然有点累,但有些采集人不那么悲伤,总会错过一些细节。
2、图片水印处理,采集工具无法识别图片并过滤。 原创文章的图片可以使用水印。就算采集不见了,他要处理,也得重新编辑一下。
更新技能(技术层面)章节
采集器,会让工具通过网站的URL识别最新的文章。只要我不发布最新的文章,采集工具将无法获取相关代码。只要我的文章先行收录,他在做采集,就会被搜索引擎判断为复制转发而不是原创。
1、隐藏更新(延迟),你站点中的蜘蛛会抓取站点中所有的URL连接,采集工具不能。所以只要我们隐藏了一个页面,没有把它归入某个类别,就等着收录移入该类别。你可以避免第一次成为采集。
2、程序限制页面访问(在一定时间内只能访问多少页面),机器的速度比人的速度还快,不可能一个人访问每一篇文章@ 3分钟内各品类k13@,每个文章全开。 (注:有些采集工具可以延迟采集,因为他们也可以设置几分钟访问一篇文章。但成本很高。)
3、限制面向用户的页面显示,比如我只给你显示1页,第二页用于验证。
4.验证机制。其实有些网站可以在用户访问异常时弹出验证码框进行人机验证,也可以绕过采集tools的采集。
5、尽量不要对链接进行排序。 采集tools 最初使用源代码来识别 URL。一些有序的URL链接非常喜欢采集人,因为不麻烦,可以采集整站数据。星控站长网址是/1.html,工具甚至可以直接采集文章1-99999.html,无需进入分类。所以这是一个糟糕的 URL 设计习惯。
百度站长工具篇
百度站长工具可以手动提交链接。
结合上面【技术层面】章节的第一点,我们先延迟更新隐藏页面。
然后用百度的站长工具收录submit,提交我们的原创文章网址,等待百度收录。 查看全部
内容优化篇——保证自己创作不被采集的方法
站长,在做网站的时候,网站的内容有时候是采集,尤其是在现在采集成本极低的环境下,只要懂一点代码,就可以制作采集 模块。即使你不知道如何编码,你也可以以低廉的价格找人编写。
新站上线了,我正在努力做着原创的内容,但是采集工具采集突然占据了全站。没有人能忍受。
而且新站一开始没有权重,即使你发布你的原创,加权网站采集和发布你的文章,蜘蛛爬取网页也会优先收录有一个高权重的网页,认为是他的原创文章。
这是别人的典型婚纱。
虽然文章也有版权保护,但是面对采集网站有什么用呢?他既然敢采集,就不怕你维权,现在维权成本高。
之前,熊掌有原创保护功能,但因为百度的业务,下线了。现在的原创真的无法保护。
那么今天五车二就给大家分享几个方法,尽量保证你的创作不是采集。
内容优化章节
1.写作时,在你的作品中插入相关的品牌词。如:“XXX网小编”、“XXX提醒大家”……或者用替代词,百度知道替代百度知道、百度知道、百度知道等标记文章以便反馈以后作为证据使用。
当然采集软件也有过滤功能,所以你可以为每篇文章文章使用不同的词汇。虽然有点累,但有些采集人不那么悲伤,总会错过一些细节。
2、图片水印处理,采集工具无法识别图片并过滤。 原创文章的图片可以使用水印。就算采集不见了,他要处理,也得重新编辑一下。
更新技能(技术层面)章节
采集器,会让工具通过网站的URL识别最新的文章。只要我不发布最新的文章,采集工具将无法获取相关代码。只要我的文章先行收录,他在做采集,就会被搜索引擎判断为复制转发而不是原创。
1、隐藏更新(延迟),你站点中的蜘蛛会抓取站点中所有的URL连接,采集工具不能。所以只要我们隐藏了一个页面,没有把它归入某个类别,就等着收录移入该类别。你可以避免第一次成为采集。
2、程序限制页面访问(在一定时间内只能访问多少页面),机器的速度比人的速度还快,不可能一个人访问每一篇文章@ 3分钟内各品类k13@,每个文章全开。 (注:有些采集工具可以延迟采集,因为他们也可以设置几分钟访问一篇文章。但成本很高。)
3、限制面向用户的页面显示,比如我只给你显示1页,第二页用于验证。
4.验证机制。其实有些网站可以在用户访问异常时弹出验证码框进行人机验证,也可以绕过采集tools的采集。
5、尽量不要对链接进行排序。 采集tools 最初使用源代码来识别 URL。一些有序的URL链接非常喜欢采集人,因为不麻烦,可以采集整站数据。星控站长网址是/1.html,工具甚至可以直接采集文章1-99999.html,无需进入分类。所以这是一个糟糕的 URL 设计习惯。
百度站长工具篇
百度站长工具可以手动提交链接。
结合上面【技术层面】章节的第一点,我们先延迟更新隐藏页面。
然后用百度的站长工具收录submit,提交我们的原创文章网址,等待百度收录。
工具采集文章原链接按抓取规则抓取指的规则继续
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-06-22 21:01
工具采集文章原链接按抓取原链接的规则继续抓取每个页面都抓取抓取速度会根据文章抓取量而不同量决定速度,30秒的文章抓取量1w就是30秒量决定速度优秀的公众号工具在每一页都按抓取规则抓取是不会有重复数据的使用工具进行抓取请完整复制指定链接,
获取公众号平台可发布文章列表的网页地址。
我们说的抓取指的是针对某篇文章来说吧~因为我写的是模板软件,所以我在写脚本过程中是抓取编辑完文章就向后台保存,保存成list。单个接口我来举例我自己在写脚本过程中抓取了14个公众号~实测之后把抓取结果如下:可见,不同的公众号发布的文章是有区别的,你可以通过抓取编辑文章的方式再爬取一次~你想要抓取哪个公众号这个你就要设置好了~。
爬取微信文章不存在30秒抓取的问题,只能当你给文章先上链接,用微信js直接调用网页的验证码吧。最笨的方法是用js抓取,但是破解验证码并不容易。利用微信js只能抓取小部分公众号,所以为了增加破解技术的难度,我自己封装了个js抓取脚本,专门抓取js验证码,并封装了rsa加密。
在很多的公众号网站上抓取微信文章的抓取。因为篇幅限制,所以抓取公众号的文章目录页是只能抓取一遍。下面的链接可以算是微信第一页的公众号页面了,只有一个就是文章,没有后续。后续的大多数是简短微信的文章,因为没有多余的内容。这种情况可以试试去买一些公众号的尾部广告来抓取,甚至就去发软文,发链接发文章都可以,如果你微信好友多的话,被盗号人很容易就能够找到你。 查看全部
工具采集文章原链接按抓取规则抓取指的规则继续
工具采集文章原链接按抓取原链接的规则继续抓取每个页面都抓取抓取速度会根据文章抓取量而不同量决定速度,30秒的文章抓取量1w就是30秒量决定速度优秀的公众号工具在每一页都按抓取规则抓取是不会有重复数据的使用工具进行抓取请完整复制指定链接,
获取公众号平台可发布文章列表的网页地址。
我们说的抓取指的是针对某篇文章来说吧~因为我写的是模板软件,所以我在写脚本过程中是抓取编辑完文章就向后台保存,保存成list。单个接口我来举例我自己在写脚本过程中抓取了14个公众号~实测之后把抓取结果如下:可见,不同的公众号发布的文章是有区别的,你可以通过抓取编辑文章的方式再爬取一次~你想要抓取哪个公众号这个你就要设置好了~。
爬取微信文章不存在30秒抓取的问题,只能当你给文章先上链接,用微信js直接调用网页的验证码吧。最笨的方法是用js抓取,但是破解验证码并不容易。利用微信js只能抓取小部分公众号,所以为了增加破解技术的难度,我自己封装了个js抓取脚本,专门抓取js验证码,并封装了rsa加密。
在很多的公众号网站上抓取微信文章的抓取。因为篇幅限制,所以抓取公众号的文章目录页是只能抓取一遍。下面的链接可以算是微信第一页的公众号页面了,只有一个就是文章,没有后续。后续的大多数是简短微信的文章,因为没有多余的内容。这种情况可以试试去买一些公众号的尾部广告来抓取,甚至就去发软文,发链接发文章都可以,如果你微信好友多的话,被盗号人很容易就能够找到你。
一点资讯、uc订阅号、百度、谷歌的区别
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-06-20 20:21
工具采集文章:一点资讯、uc订阅号、百家号、网易订阅号、一点资讯;文章采集转发到公众号:ejiasyhong2016;意见反馈:即日起拉勾账号的文章可以出现在本账号,文章存在评论区。一、起始原因由于14年5月以来某公司被关闭公司主页,各种乱象滋生,包括机器群发,营销文案及其他流量软件助推网站诈骗、爬虫。
来源也多为各大门户网站;本人在14年时因为某公司关闭主页时申请了知乎账号,因为自认为对此事有所了解,对各大网站的错误评论和机器群发十分不屑,发表了些声音,确实有不少点赞,但绝大多数在各大门户网站评论的都是带有营销软文的小广告,各网站无非是文案写的好,产品很鸡肋或者“bat”实力公司,现在国内外都这样,就算国内,不乏各大网站的信息小广告大量存在。
这些评论大部分原因和成本几乎无关,不值得投入精力。我想起谷歌关闭主页的那次,很多大量广告信息,甚至包括1元软妹币的订阅,这样才比较少才对。如果不是为了赚钱,谁又愿意申请谷歌。网站,无论是门户网站或者其他独立站,所谓的“头条”,不过是其公司的利用关系炒作噱头。百度或者谷歌有其自身问题,但却依然作为公司占领用户大部分流量,百度内部baidu关掉仅仅一个周,但很多站都被谷歌或者百度搞僵。
其实,我不止一次说过百度如果要做出一款能够制霸互联网搜索引擎,就需要一个真正能够吸引广大网民信任的品牌形象,我一直感觉百度如果做出来并推出的,是无法成功。因为那个时候,百度就不该叫百度公司,应该叫谷歌公司,这就是我比较喜欢和百度合作的原因,大家理解我在说什么。老罗牛博出现如此巨大的争议,不也是谷歌基因问题,主要是谷歌没有遵循其客户标准。
中国互联网发展迅速,其所在的的环境已经在制约国内各大互联网公司的发展了,在这个问题上,作为一个有良知的网民真的不能在这些软件上花费太多的时间。二、社会风气的风向标很多人认为,在某种程度上,只要能够收割到大批用户,尽管不懂网络的软件应该有没有用的,只要让用户感觉到好用,就是牛逼,就是有用。具体好用有多牛逼,我不在这里多做发表。
让自己有用的,不能因为是利益驱使就抛弃,因为有些事情或者不便,比如“百度,上天台去吧”在我们国内,只要能够盈利就不能被取缔,即使利益驱使,也只能是鼓励;无用的(形容词),不用想着违反良心去使用。那些热衷于盗版的人,你们觉得他们是没有用吗?但实际上,他们不但用了这些软件,甚至还不止一款软件,其用途各异,有些人他为的是能在手机上接打电话,有些人他就是为了电脑多开,有些人想要。 查看全部
一点资讯、uc订阅号、百度、谷歌的区别
工具采集文章:一点资讯、uc订阅号、百家号、网易订阅号、一点资讯;文章采集转发到公众号:ejiasyhong2016;意见反馈:即日起拉勾账号的文章可以出现在本账号,文章存在评论区。一、起始原因由于14年5月以来某公司被关闭公司主页,各种乱象滋生,包括机器群发,营销文案及其他流量软件助推网站诈骗、爬虫。
来源也多为各大门户网站;本人在14年时因为某公司关闭主页时申请了知乎账号,因为自认为对此事有所了解,对各大网站的错误评论和机器群发十分不屑,发表了些声音,确实有不少点赞,但绝大多数在各大门户网站评论的都是带有营销软文的小广告,各网站无非是文案写的好,产品很鸡肋或者“bat”实力公司,现在国内外都这样,就算国内,不乏各大网站的信息小广告大量存在。
这些评论大部分原因和成本几乎无关,不值得投入精力。我想起谷歌关闭主页的那次,很多大量广告信息,甚至包括1元软妹币的订阅,这样才比较少才对。如果不是为了赚钱,谁又愿意申请谷歌。网站,无论是门户网站或者其他独立站,所谓的“头条”,不过是其公司的利用关系炒作噱头。百度或者谷歌有其自身问题,但却依然作为公司占领用户大部分流量,百度内部baidu关掉仅仅一个周,但很多站都被谷歌或者百度搞僵。
其实,我不止一次说过百度如果要做出一款能够制霸互联网搜索引擎,就需要一个真正能够吸引广大网民信任的品牌形象,我一直感觉百度如果做出来并推出的,是无法成功。因为那个时候,百度就不该叫百度公司,应该叫谷歌公司,这就是我比较喜欢和百度合作的原因,大家理解我在说什么。老罗牛博出现如此巨大的争议,不也是谷歌基因问题,主要是谷歌没有遵循其客户标准。
中国互联网发展迅速,其所在的的环境已经在制约国内各大互联网公司的发展了,在这个问题上,作为一个有良知的网民真的不能在这些软件上花费太多的时间。二、社会风气的风向标很多人认为,在某种程度上,只要能够收割到大批用户,尽管不懂网络的软件应该有没有用的,只要让用户感觉到好用,就是牛逼,就是有用。具体好用有多牛逼,我不在这里多做发表。
让自己有用的,不能因为是利益驱使就抛弃,因为有些事情或者不便,比如“百度,上天台去吧”在我们国内,只要能够盈利就不能被取缔,即使利益驱使,也只能是鼓励;无用的(形容词),不用想着违反良心去使用。那些热衷于盗版的人,你们觉得他们是没有用吗?但实际上,他们不但用了这些软件,甚至还不止一款软件,其用途各异,有些人他为的是能在手机上接打电话,有些人他就是为了电脑多开,有些人想要。
工具采集文章(清博指数-网络大数据综合服务平台_,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-08-28 03:06
工具采集文章非常实用,可以采集网站,新闻平台,百度文库等的标题,关键词,原创度,摘要,标签等,自己写文章非常麻烦,没有可视化的工具,找素材太麻烦。清博指数-网络大数据平台_大数据综合服务平台,清博指数官网好多的文章标题,原创度,摘要非常的难搞。通过这个工具就不用愁了。简书,知乎,豆瓣,天猫文章全部搞定,可以在线去查看排名的,非常方便。
分享《写文章,你掌握这些工具就可以了》部分截图主要推荐360指数,微信指数,百度指数,搜狗指数,企鹅指数,可以去关注一下写作工具可以看看,可以查看排名,获取原创度,可以实时关注动态哦大家觉得有用的话,
百度搜索风云榜,可以关注同行和热点。
1,注册或者找到新媒体运营账号以后,你肯定要选择账号的定位,即把自己定位为哪个领域的。一定要选好,不能跟别人选的风格重复,抄袭是非常容易的。风云榜可以看到全网的热门风向标和影响力排行。2,搜集一些优质的内容,有很多新媒体平台或者公众号可以做原创。比如说一点资讯、网易、头条、知乎等。找出他们的爆文、原创文章就可以引用为自己的素材。
3,采集别人的内容,为自己所用。做新媒体编辑,要了解多少种微信公众号素材,比如,早上八点的头条、十点半的头条、二十四小时的头条等。分析好行业的最新文章素材,包括哪些渠道的文章,发布时间、内容如何,也为自己打造爆文打好基础。4,写文章确定标题。标题就是文章的眼睛,一定要选好关键词,这是你文章的风向标。如果你写的标题是重复的,毫无吸引力,那么别人打开文章都很困难。
比如几个社群读书俱乐部运营的套路都一样,其实,如果文章标题十分诱人,打开率可以提高,网友一定会进来瞧瞧。 查看全部
工具采集文章(清博指数-网络大数据综合服务平台_,)
工具采集文章非常实用,可以采集网站,新闻平台,百度文库等的标题,关键词,原创度,摘要,标签等,自己写文章非常麻烦,没有可视化的工具,找素材太麻烦。清博指数-网络大数据平台_大数据综合服务平台,清博指数官网好多的文章标题,原创度,摘要非常的难搞。通过这个工具就不用愁了。简书,知乎,豆瓣,天猫文章全部搞定,可以在线去查看排名的,非常方便。
分享《写文章,你掌握这些工具就可以了》部分截图主要推荐360指数,微信指数,百度指数,搜狗指数,企鹅指数,可以去关注一下写作工具可以看看,可以查看排名,获取原创度,可以实时关注动态哦大家觉得有用的话,
百度搜索风云榜,可以关注同行和热点。
1,注册或者找到新媒体运营账号以后,你肯定要选择账号的定位,即把自己定位为哪个领域的。一定要选好,不能跟别人选的风格重复,抄袭是非常容易的。风云榜可以看到全网的热门风向标和影响力排行。2,搜集一些优质的内容,有很多新媒体平台或者公众号可以做原创。比如说一点资讯、网易、头条、知乎等。找出他们的爆文、原创文章就可以引用为自己的素材。
3,采集别人的内容,为自己所用。做新媒体编辑,要了解多少种微信公众号素材,比如,早上八点的头条、十点半的头条、二十四小时的头条等。分析好行业的最新文章素材,包括哪些渠道的文章,发布时间、内容如何,也为自己打造爆文打好基础。4,写文章确定标题。标题就是文章的眼睛,一定要选好关键词,这是你文章的风向标。如果你写的标题是重复的,毫无吸引力,那么别人打开文章都很困难。
比如几个社群读书俱乐部运营的套路都一样,其实,如果文章标题十分诱人,打开率可以提高,网友一定会进来瞧瞧。
如何使用优采云采集进行搜索?写作推出智能采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-26 22:04
疫情期间,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一。然而,远程办公仍然没有面对面工作那么高效。出于这个原因优采云采集专利权采集tools。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具,不仅是帮助运营采集信息,更要精准分析数据趋势,帮助增加收益。
一、什么是优采云采集?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提高新媒体运营效率,降低企业成本。
二、如何使用优采云采集进行搜索?
(一)输入关键词
优采云采集 根据用户输入的关键词,搜索引擎通过程序自动进入主流自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,在主页输入关键词“流行病”。 优采云采集 会将搜索结果整合到一个列表中。
(二)保存搜索资料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
(三)精准过滤
1、搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、广告过滤 查看全部
如何使用优采云采集进行搜索?写作推出智能采集工具
疫情期间,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一。然而,远程办公仍然没有面对面工作那么高效。出于这个原因优采云采集专利权采集tools。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具,不仅是帮助运营采集信息,更要精准分析数据趋势,帮助增加收益。
一、什么是优采云采集?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提高新媒体运营效率,降低企业成本。
二、如何使用优采云采集进行搜索?
(一)输入关键词
优采云采集 根据用户输入的关键词,搜索引擎通过程序自动进入主流自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,在主页输入关键词“流行病”。 优采云采集 会将搜索结果整合到一个列表中。
(二)保存搜索资料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
(三)精准过滤
1、搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、广告过滤
工具采集文章发布到网站上可以有这么几种方式方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-08-26 04:04
工具采集文章发布到网站上可以有这么几种方式方法一:文字采集网站上面的文章一般都是经过加工的,最后需要采集并转化成文字数据。方法二:图片采集图片采集大多是用于文章的标题中提到内容,可以根据标题进行图片采集。方法三:音频采集音频采集不只是在标题中提到,内容中也会穿插。方法四:视频采集视频采集是用来做哪些呢?有没有广告是一个问题,如果很多人在视频中注明了“有广告”、“刷票”,这个时候很多网站是不收的。
如果您需要采集这个内容的话,方法五:对讲机采集对讲机的采集主要用于一些教育或者是节日类的新闻类内容,这种内容主要靠广告来抢占用户。方法六:单个视频采集这类采集内容一般用于网站自动去除广告后,单个视频的数量不多,比如视频采集时间太长,新闻采集太短。文章采集到平台上后怎么发布呢?选择创建采集计划采集时间:15-30分钟选择采集方式:单行文字采集|单行音频采集|单行视频采集|单行图片采集|单行链接采集|单行。
选择采集来源:原始文章或网站集成自动合并选择要发布的数据格式:excel|pdf|word|txt|html|ppt|xml|xlid|csv|doc|prt|pdf|pdfx|csv|excel|csv。批量查看内容:多个采集计划批量查看大概就这么多方法了。下面介绍一个采集方法,通过将采集的内容发布到指定的网站上方法二采集后,即可发布采集。
首先根据文章标题生成自动采集地址:打开浏览器扩展程序---用safari浏览器找到带有meta(网站路径)的地址-路径就是公共http信息的链接-然后点击meta(网站路径)生成采集地址按钮如图然后点击发布采集按钮---在弹出框中输入搜索的单个内容如果只生成一个采集地址,对应的所有内容都将采集到服务器上,如果多个采集地址,所有内容都将被采集到服务器上。
好了创建采集地址的方法就介绍完了。采集完后如何将采集的内容发布到指定的网站上去呢?点击meta(网站路径)生成的采集地址后缀名(不加任何后缀可以创建多个采集地址)c:\users\用户名\appdata\local\extensions\xxxx\awesomewesome\awesome\awesomewesome\awesomewesome\awesomewesomewesome\awesomewesomewesome\awesomewesome.whl|awesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomeweso。 查看全部
工具采集文章发布到网站上可以有这么几种方式方法
工具采集文章发布到网站上可以有这么几种方式方法一:文字采集网站上面的文章一般都是经过加工的,最后需要采集并转化成文字数据。方法二:图片采集图片采集大多是用于文章的标题中提到内容,可以根据标题进行图片采集。方法三:音频采集音频采集不只是在标题中提到,内容中也会穿插。方法四:视频采集视频采集是用来做哪些呢?有没有广告是一个问题,如果很多人在视频中注明了“有广告”、“刷票”,这个时候很多网站是不收的。
如果您需要采集这个内容的话,方法五:对讲机采集对讲机的采集主要用于一些教育或者是节日类的新闻类内容,这种内容主要靠广告来抢占用户。方法六:单个视频采集这类采集内容一般用于网站自动去除广告后,单个视频的数量不多,比如视频采集时间太长,新闻采集太短。文章采集到平台上后怎么发布呢?选择创建采集计划采集时间:15-30分钟选择采集方式:单行文字采集|单行音频采集|单行视频采集|单行图片采集|单行链接采集|单行。
选择采集来源:原始文章或网站集成自动合并选择要发布的数据格式:excel|pdf|word|txt|html|ppt|xml|xlid|csv|doc|prt|pdf|pdfx|csv|excel|csv。批量查看内容:多个采集计划批量查看大概就这么多方法了。下面介绍一个采集方法,通过将采集的内容发布到指定的网站上方法二采集后,即可发布采集。
首先根据文章标题生成自动采集地址:打开浏览器扩展程序---用safari浏览器找到带有meta(网站路径)的地址-路径就是公共http信息的链接-然后点击meta(网站路径)生成采集地址按钮如图然后点击发布采集按钮---在弹出框中输入搜索的单个内容如果只生成一个采集地址,对应的所有内容都将采集到服务器上,如果多个采集地址,所有内容都将被采集到服务器上。
好了创建采集地址的方法就介绍完了。采集完后如何将采集的内容发布到指定的网站上去呢?点击meta(网站路径)生成的采集地址后缀名(不加任何后缀可以创建多个采集地址)c:\users\用户名\appdata\local\extensions\xxxx\awesomewesome\awesome\awesomewesome\awesomewesome\awesomewesomewesome\awesomewesomewesome\awesomewesome.whl|awesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomewesomeweso。
易企秀:工具采集文章的用途和用途介绍(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-08-25 21:10
工具采集文章,可将文章采集导出到excel表格进行其他用途,包括可用于企业公众号商业广告及crm数据收集等。软件功能1.可以免费采集公众号文章,批量采集2.可以按标签将文章加入不同的排序,排序根据你自己想要排的速度3.提供超过1万个采集公众号的采集窗口,扩展采集窗口数量支持文章页数和文章来源按标签排序按标签排序还可以按照文章来源,文章来源已经关键词,文章标题,文章内容进行排序4.支持共享采集文章出口到其他采集文章下载网站等等1.按标签,页数,来源,文章页等进行排序,适合收集非网站全文采集2.支持批量关键词抓取,包括网站内所有文章内容,批量抓取上传也可以3.支持分享采集文章到其他采集网站进行其他用途,比如crm数据收集excel表格,微信,朋友圈,营销数据导出等等。
搞定采集公众号内容,
可以关注下我们公众号,聚合全网信息(服务号和订阅号信息汇集),
我们家用的是qq音乐查看的,用比较少。反正跟普通百度网盘是一样的功能,注册即可,会员可以随便发。支持外链转载。
易企秀,客户端,哪里都能用。
application、小程序开发和人工智能(profiling&analysis)等。这些在招商银行的内部肯定都有开发。所以你看是不是就业方向只要这个。 查看全部
易企秀:工具采集文章的用途和用途介绍(图)
工具采集文章,可将文章采集导出到excel表格进行其他用途,包括可用于企业公众号商业广告及crm数据收集等。软件功能1.可以免费采集公众号文章,批量采集2.可以按标签将文章加入不同的排序,排序根据你自己想要排的速度3.提供超过1万个采集公众号的采集窗口,扩展采集窗口数量支持文章页数和文章来源按标签排序按标签排序还可以按照文章来源,文章来源已经关键词,文章标题,文章内容进行排序4.支持共享采集文章出口到其他采集文章下载网站等等1.按标签,页数,来源,文章页等进行排序,适合收集非网站全文采集2.支持批量关键词抓取,包括网站内所有文章内容,批量抓取上传也可以3.支持分享采集文章到其他采集网站进行其他用途,比如crm数据收集excel表格,微信,朋友圈,营销数据导出等等。
搞定采集公众号内容,
可以关注下我们公众号,聚合全网信息(服务号和订阅号信息汇集),
我们家用的是qq音乐查看的,用比较少。反正跟普通百度网盘是一样的功能,注册即可,会员可以随便发。支持外链转载。
易企秀,客户端,哪里都能用。
application、小程序开发和人工智能(profiling&analysis)等。这些在招商银行的内部肯定都有开发。所以你看是不是就业方向只要这个。
《万能文章采集器免费破解版》是最简单最智能的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-08-24 00:19
文章采集器免费版(Duo Duo Quick Spider)是一款专业的网络采集工具;软件使用MongoDB数据库,可以帮助用户快速采集文章。
文章采集软件免费版(8m)分享给大家,功能更强大,请注意格式1、login知乎:2、paste知乎工具栏的网址;3、点击“采集文章”按钮:4、点击“浏览器地址”按钮:5、点击“复制网址”按钮。
做网站推广和优化的朋友,可能经常需要更新一些文章,那对于文笔不好的人来说还是有点难度的。
文章采集器Free Edition Duo Duo Quick Spider是一款专业的网络采集工具;软件采用MongoDB数据库,可以帮助用户快速获取采集文章、网站域名等信息,操作简单,功能强大,有需要的朋友,下载体验吧。该软件具有特殊功能。
《全民文章采集器免费破解版》是最简单最智能的文章采集器,由优采云software开发,可以采集列表页文章、关键词新闻、微信等,还有定向采集指定网站文章,是一个很好的文章采集器。软件功能 1.
Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。该软件操作简单,可以准确提取网页正文部分并保存为文章,支持标签、链接、邮箱等格式处理,只需几分钟。
优采云万能文章采集器破解版是一款方便易用的文章采集软件。该软件操作简单,可以准确提取网页正文部分并保存为文章,并支持标签、链接、邮件等格式处理,只需几分钟即可采集。
文章采集software-文章采集器download1.0.0.0 免费版-xixi软件下载。 查看全部
《万能文章采集器免费破解版》是最简单最智能的文章
文章采集器免费版(Duo Duo Quick Spider)是一款专业的网络采集工具;软件使用MongoDB数据库,可以帮助用户快速采集文章。
文章采集软件免费版(8m)分享给大家,功能更强大,请注意格式1、login知乎:2、paste知乎工具栏的网址;3、点击“采集文章”按钮:4、点击“浏览器地址”按钮:5、点击“复制网址”按钮。
做网站推广和优化的朋友,可能经常需要更新一些文章,那对于文笔不好的人来说还是有点难度的。
文章采集器Free Edition Duo Duo Quick Spider是一款专业的网络采集工具;软件采用MongoDB数据库,可以帮助用户快速获取采集文章、网站域名等信息,操作简单,功能强大,有需要的朋友,下载体验吧。该软件具有特殊功能。
《全民文章采集器免费破解版》是最简单最智能的文章采集器,由优采云software开发,可以采集列表页文章、关键词新闻、微信等,还有定向采集指定网站文章,是一个很好的文章采集器。软件功能 1.
Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。该软件操作简单,可以准确提取网页正文部分并保存为文章,支持标签、链接、邮箱等格式处理,只需几分钟。
优采云万能文章采集器破解版是一款方便易用的文章采集软件。该软件操作简单,可以准确提取网页正文部分并保存为文章,并支持标签、链接、邮件等格式处理,只需几分钟即可采集。
文章采集software-文章采集器download1.0.0.0 免费版-xixi软件下载。
数据采集工具Flume相关的知识介绍-上海怡健医学
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-08-24 00:10
之前文章给大家介绍过数据采集工具Flume,接下来文章我想继续给大家介绍data采集工具Logstash相关知识,一起来看看看!
基本概念
Logstash 基于管道进行数据处理,管道可以理解为对数据处理过程的抽象。一条管道数据通过上游数据源汇总到消息队列中,然后通过多个工作线程进行转换,最后输出到下游组件。一个 Logstash 可以收录多个管道。
框架特征
l 主要用于 Elasticsearch 和更多的摄取工作。
具有强大 Elasticsearch 和 Kibana 协作功能的可扩展数据处理管道。
l 可以插拔管道结构。
混合、匹配和协调不同的输入、过滤器和输出在管道中发挥和谐的作用。
l良好的社区生态系统。
开发社区有200多个插件,可以扩展和定制。
工作原理
1.处理过程:
从上图可以看出,Logstash的数据处理过程主要包括三个部分:Inputs、Filters、Outputs。此外,Codecs 还可以用于 Inputs 和 Outputs 中的数据格式处理。这四个都以插件的形式存在。用户可以定义流水线配置文件,设置所需的输入、过滤、输出、编解码插件,实现具体的数据采集、数据处理、数据输出等功能。
lInputs:用于从数据源获取数据。 file、syslog、redis、beats等常用插件[详细参考]
lFilters:用于处理grok、mutate、drop、clone、geoip等格式转换、数据推导等数据。
lOutputs:用于数据输出,如elastcisearch、file、graphite、statsd等。常有sd等[详细参考]
lCodecs:Codecs 不是一个单独的进程,而是插件中用于输入输出等数据转换的模块。 json、multiline等常用的数据编码处理插件[详细参考]
2.执行方式:
lEach Input 启动一个线程,从对应的数据源获取数据。
l 互联网将数据写入队列:默认为内存中的边界队列(意外停止会导致数据丢失)。为了防止数字丢失,Logstash 提供了两个特性: PersistentQueues:防止数据通过磁盘上的队列丢失。
lLogstash会有多个pipelineworker,每个pipelineworker会从队列中获取一批数据,然后执行filter和output(worker的数量和每次处理的数据量由配置决定)
应用场景
Elasticsearch 是目前主流的分布式大数据存储和搜索引擎。 h可以为用户提供强大的全文检索能力,广泛应用于日志检索、全站搜索等领域。 Logstash作为Elasicsearch常用的实时数据采集引擎,可以从不同的数据源采集数据,处理后输出到多个输出源。它是 ElasticStack 的重要组成部分。
在上面文章中,我介绍了常用数据采集工具Logstash相关知识,下一篇文章我会继续分享另一个常用数据采集工具Fluentd,感兴趣的同学可以去51CTO学校看看。 查看全部
数据采集工具Flume相关的知识介绍-上海怡健医学
之前文章给大家介绍过数据采集工具Flume,接下来文章我想继续给大家介绍data采集工具Logstash相关知识,一起来看看看!
基本概念
Logstash 基于管道进行数据处理,管道可以理解为对数据处理过程的抽象。一条管道数据通过上游数据源汇总到消息队列中,然后通过多个工作线程进行转换,最后输出到下游组件。一个 Logstash 可以收录多个管道。
框架特征
l 主要用于 Elasticsearch 和更多的摄取工作。
具有强大 Elasticsearch 和 Kibana 协作功能的可扩展数据处理管道。
l 可以插拔管道结构。
混合、匹配和协调不同的输入、过滤器和输出在管道中发挥和谐的作用。
l良好的社区生态系统。
开发社区有200多个插件,可以扩展和定制。
工作原理
1.处理过程:
从上图可以看出,Logstash的数据处理过程主要包括三个部分:Inputs、Filters、Outputs。此外,Codecs 还可以用于 Inputs 和 Outputs 中的数据格式处理。这四个都以插件的形式存在。用户可以定义流水线配置文件,设置所需的输入、过滤、输出、编解码插件,实现具体的数据采集、数据处理、数据输出等功能。
lInputs:用于从数据源获取数据。 file、syslog、redis、beats等常用插件[详细参考]
lFilters:用于处理grok、mutate、drop、clone、geoip等格式转换、数据推导等数据。
lOutputs:用于数据输出,如elastcisearch、file、graphite、statsd等。常有sd等[详细参考]
lCodecs:Codecs 不是一个单独的进程,而是插件中用于输入输出等数据转换的模块。 json、multiline等常用的数据编码处理插件[详细参考]
2.执行方式:
lEach Input 启动一个线程,从对应的数据源获取数据。
l 互联网将数据写入队列:默认为内存中的边界队列(意外停止会导致数据丢失)。为了防止数字丢失,Logstash 提供了两个特性: PersistentQueues:防止数据通过磁盘上的队列丢失。
lLogstash会有多个pipelineworker,每个pipelineworker会从队列中获取一批数据,然后执行filter和output(worker的数量和每次处理的数据量由配置决定)
应用场景
Elasticsearch 是目前主流的分布式大数据存储和搜索引擎。 h可以为用户提供强大的全文检索能力,广泛应用于日志检索、全站搜索等领域。 Logstash作为Elasicsearch常用的实时数据采集引擎,可以从不同的数据源采集数据,处理后输出到多个输出源。它是 ElasticStack 的重要组成部分。
在上面文章中,我介绍了常用数据采集工具Logstash相关知识,下一篇文章我会继续分享另一个常用数据采集工具Fluentd,感兴趣的同学可以去51CTO学校看看。
工具采集文章,怎么样一键将选中的文章批量转化为pdf?
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2021-08-22 19:06
工具采集文章,怎么样一键将选中的文章批量转化为pdf?软件有什么优点?工具:网页采集工具。topbook:如何一键将网页批量转换为pdf?关注topbook公众号:topbook2018,在公众号后台回复:“采集”,获取工具。
把你提的这些个小问题回答下吧。你的问题很多人也有遇到过,这里我就不搬弄是非了。可以使用采集器进行采集,这个如果你的关键词足够精准的话效果是非常不错的。这个软件是免费的,而且功能很强大。不过我还是建议你做一些适当的价值文章可以卖钱。大体上你可以分为这么几步:1.在采集软件主界面点击“确定”,2.把要采集的文章加入采集列表。3.在导航栏里右键,选择“提取网页内容”即可。
postcss+ankitrycss,thenexecute.
各大公众号后台,其实已经有不少bt种子了。估计只是收录和去重的问题。找到对应的公众号就好了。微信公众号搜索:佳佳云社区,再搜索公众号“centingo”。每天更新,绝对满足你的需求。
站在巨人的肩膀上这可能就是最简单的方法了自然是用抓虫工具一般是采用蜘蛛采集了比如采用最近比较火的网赚网站包括但不限于:提取标题采集网页的作者和关注热度采集网页链接采集网页解析采集网页爬取特殊字符采集蜘蛛网上抓取的内容 查看全部
工具采集文章,怎么样一键将选中的文章批量转化为pdf?
工具采集文章,怎么样一键将选中的文章批量转化为pdf?软件有什么优点?工具:网页采集工具。topbook:如何一键将网页批量转换为pdf?关注topbook公众号:topbook2018,在公众号后台回复:“采集”,获取工具。
把你提的这些个小问题回答下吧。你的问题很多人也有遇到过,这里我就不搬弄是非了。可以使用采集器进行采集,这个如果你的关键词足够精准的话效果是非常不错的。这个软件是免费的,而且功能很强大。不过我还是建议你做一些适当的价值文章可以卖钱。大体上你可以分为这么几步:1.在采集软件主界面点击“确定”,2.把要采集的文章加入采集列表。3.在导航栏里右键,选择“提取网页内容”即可。
postcss+ankitrycss,thenexecute.
各大公众号后台,其实已经有不少bt种子了。估计只是收录和去重的问题。找到对应的公众号就好了。微信公众号搜索:佳佳云社区,再搜索公众号“centingo”。每天更新,绝对满足你的需求。
站在巨人的肩膀上这可能就是最简单的方法了自然是用抓虫工具一般是采用蜘蛛采集了比如采用最近比较火的网赚网站包括但不限于:提取标题采集网页的作者和关注热度采集网页链接采集网页解析采集网页爬取特殊字符采集蜘蛛网上抓取的内容
工具采集文章全网文章的采集效果怎么样?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-20 20:03
工具采集文章全网文章。首先会将网页上所有和你要采集的文章相关的网页地址保存下来。然后点击采集头部即可。有些时候下载地址有问题的话,点击下载的时候就会有百度网盘的提示。只要看提示就可以成功了哦。接下来的采集操作就不能用过采集器了,百度的采集器做了一定程度的限制,导致每次无法上传10篇文章。我们就利用云查询首页的一个插件,选择正则表达式采集(后面会介绍正则表达式的方法)。
采集之后的结果是一个json的表格格式的文件。首先解压这个json文件:cmd.exe“json”json.parse(jsonstr)利用python或者python2进行解析其中的数据就可以得到所需要的各类数据文档了。下面进行成果展示。选择的是正则表达式。采集效果如下图:以上就是所有采集的结果。总的数据量大概也就两千多条。
而且不是全网的文章,所以实际上采集的数据量并不大。当然如果有兴趣的可以试一下。接下来针对每一篇采集文章,进行后面的一些样本文档的简单编写。都比较简单,对于想采集个大文章或者个小文章还是有难度的。在之前已经针对文章的数据编写了一个自动采集器,我也会单独用一篇文章单独介绍,关注我即可学习到更多实用的分析工具,欢迎订阅。
1.自动采集器从下载网页的网址进行解析,获取正则表达式req替换成你需要的地址进行采集,针对目前采集的网页做采集结果的分析,采集的结果可以分为多种格式包括google网址、微博网址、百度网址等,不同的网址采集的结果包括json数据或者图片地址。这里我只采集了一百多篇文章,所以对数据结构没有什么要求。2.样本文档编写(。
1)我们下载下来的文章为json格式,对文本提取关键字如‘username=admin’中的username,保存成username.txt格式的文件。提取文字一般没有难度,注意文字的相对格式。#保存的txt文件保存在list文件中如username=adminwhere__name__="@"dimnames([1])#下载后的json文件jsonobj.concat("admin","@")上面的代码是编写一个自动采集器,对文本的获取没有太大难度,对文字的处理就需要耗费一些时间。只要知道文本的相对格式就可以采集到关键字。(。
2)针对正则表达式,对文本提取关键字的一般可以采用关键字匹配法。
匹配的关键字如username.txt_#匹配0-9之间的任意一个数字.txtfindall("0-9",
1)findall("#",
1)findall("\\#",
1)#匹配单个数字大小写敏感匹配username=adminwhere__name__="@"dimnames([1])#下载后的json文件jsonobj.concat("admin" 查看全部
工具采集文章全网文章的采集效果怎么样?(一)
工具采集文章全网文章。首先会将网页上所有和你要采集的文章相关的网页地址保存下来。然后点击采集头部即可。有些时候下载地址有问题的话,点击下载的时候就会有百度网盘的提示。只要看提示就可以成功了哦。接下来的采集操作就不能用过采集器了,百度的采集器做了一定程度的限制,导致每次无法上传10篇文章。我们就利用云查询首页的一个插件,选择正则表达式采集(后面会介绍正则表达式的方法)。
采集之后的结果是一个json的表格格式的文件。首先解压这个json文件:cmd.exe“json”json.parse(jsonstr)利用python或者python2进行解析其中的数据就可以得到所需要的各类数据文档了。下面进行成果展示。选择的是正则表达式。采集效果如下图:以上就是所有采集的结果。总的数据量大概也就两千多条。
而且不是全网的文章,所以实际上采集的数据量并不大。当然如果有兴趣的可以试一下。接下来针对每一篇采集文章,进行后面的一些样本文档的简单编写。都比较简单,对于想采集个大文章或者个小文章还是有难度的。在之前已经针对文章的数据编写了一个自动采集器,我也会单独用一篇文章单独介绍,关注我即可学习到更多实用的分析工具,欢迎订阅。
1.自动采集器从下载网页的网址进行解析,获取正则表达式req替换成你需要的地址进行采集,针对目前采集的网页做采集结果的分析,采集的结果可以分为多种格式包括google网址、微博网址、百度网址等,不同的网址采集的结果包括json数据或者图片地址。这里我只采集了一百多篇文章,所以对数据结构没有什么要求。2.样本文档编写(。
1)我们下载下来的文章为json格式,对文本提取关键字如‘username=admin’中的username,保存成username.txt格式的文件。提取文字一般没有难度,注意文字的相对格式。#保存的txt文件保存在list文件中如username=adminwhere__name__="@"dimnames([1])#下载后的json文件jsonobj.concat("admin","@")上面的代码是编写一个自动采集器,对文本的获取没有太大难度,对文字的处理就需要耗费一些时间。只要知道文本的相对格式就可以采集到关键字。(。
2)针对正则表达式,对文本提取关键字的一般可以采用关键字匹配法。
匹配的关键字如username.txt_#匹配0-9之间的任意一个数字.txtfindall("0-9",
1)findall("#",
1)findall("\\#",
1)#匹配单个数字大小写敏感匹配username=adminwhere__name__="@"dimnames([1])#下载后的json文件jsonobj.concat("admin"
网络安全应急响应工具:采集Windows和Linux系统的痕迹,辅助安全专家进行安全事件分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-08-14 23:12
前言
当网络安全事件发生时,往往需要网络安全专家检查计算机上的安全事件。然而,当前的网络安全应急现场非常缺乏应急救援工具。小编推荐一款由MountCloud制作和发布的国产免费版本。网络安全应急工具可以协助安全专家分析采集Windows和Linux系统的安全事件。
下载
废话不多说,先下载链接:/MountCloud/FireKylin/releases
项目主页(建设中):firekylin.tool.red/
Github 项目:/MountCloud/FireKylin
V1 版本可能有很多问题,欢迎反馈:
问题反馈:/MountCloud/FireKylin/issues
更新日志:
【v1.1.2】 2021-08-12
1:Gui进程列表使用进程ID进行升序排序。
2:Gui Windows日志添加全文搜索框,支持每列以及事件信息内容匹配。
3:LinuxAgent修复目录不存在时搜索目录导致的报错问题。
4:LinuxAgent修复日志无法正常提取问题。
5:WindowsAgent修复Security日志与System日志无法提取问题。
6:Gui优化fkld解析过程,所以无法支持老版本的数据解析。
【v1.0.1】 2021-08-09
1:Gui支持Windows。
2:Agent支持Windows和Linux。
3:Agent-Windows支持采集:用户、进程、启动项、服务、网络信息、计划任务、系统日志。
4:Agent-Linux支持采集:用户、进程、启动项、服务、网络信息、历史命令、系统日志。
5:Gui内置中文和英文,支持扩展语言。
火麒麟简介
火麒麟的中文名称是:火麒麟。其实和某款氪金游戏火麒麟无关。作为一款国产的网络安全工具,名字取自中国怪兽:麒麟。言下之意是希望为维护中国的网络安全做出贡献。
它的功能是采集操作系统的各种痕迹。
其作用是为分析和判断安全事件提供操作系统数据。
目的是让任何有或没有计算机故障排除经验的人都能在计算机上发生安全事件。
在处理计算机上的安全事件时,对于这方面没有经验但有研究判断能力的安全专家来说,经常苦于需要参考各种安全手册进行trace采集、排序,和研究。这时候我们可以使用FireKylin-Agent一键采集踪迹,降低安全专家采集工作的难度。
FireKylin 的使用非常简单。将Agent程序上传到电脑上需要检查的主机,运行Agent程序,从采集下载数据.fkld文件,使用接口程序加载数据查看主机。 Agent最大的特点是[0命令采集]对安装了监控功能的安全软件的主机非常友好,不会对监控软件造成“误报安全”。事件”命令。
v1.0.1 客户端界面
当前版本已更新为 v1.0.1。 Agent 支持 Linux 和 Windows 操作系统,而 Gui 仅支持 Windows 操作系统。
代理支持的操作系统
Agent支持采集任务的灵活配置,不仅可以切换任务,还可以为日志采集配置时间段采集,提高采集效率和准确率。
代理 v1.0.1 Windows 端
agent v1.0.1 Linux 终端使用对比
在过去的应急响应中,我们的安全专家经常需要一起登录目标主机。我们可能使用堡垒机或者直接ssh到目标服务器,这意味着安全密钥可能要发给各种需要学习判断的安全人员。在这个过程中,密钥的安全性将受到威胁。 FireKylin 只需要有权限的人员在机器上操作,并将结果分发给各个安全人员。
相比火麒麟,传统方式支持的场景更多
在应急响应中,安全专家经常对远程或远程服务进行安全事件检查,但远程服务器往往处于没有任何访问方法的场景。对于这种场景,传统解决方案可能需要授权运营商使用其他跳板为安全专家提供远程接入点,但跳板往往存在风险。 FireKylin 只需要运营商运行 Agent 程序,然后将结果发送给我们的安全人员进行事故调查。
无法达到目标的场景对比使用教程
默认语言为英语,需要在设置->语言->中选择zh-cn并点击设置语言。选择语言后,GUI会自动重启,然后就是中文了。
设置语言
代理配置:
start 开始任务。
print 或 ls 打印任务配置。
1=false 或 user=false 是关闭用户采集的任务,其他同理。
日志配置比较复杂:
config syslog 是查看日志配置项。
查看全部
网络安全应急响应工具:采集Windows和Linux系统的痕迹,辅助安全专家进行安全事件分析
前言
当网络安全事件发生时,往往需要网络安全专家检查计算机上的安全事件。然而,当前的网络安全应急现场非常缺乏应急救援工具。小编推荐一款由MountCloud制作和发布的国产免费版本。网络安全应急工具可以协助安全专家分析采集Windows和Linux系统的安全事件。
下载
废话不多说,先下载链接:/MountCloud/FireKylin/releases
项目主页(建设中):firekylin.tool.red/
Github 项目:/MountCloud/FireKylin
V1 版本可能有很多问题,欢迎反馈:
问题反馈:/MountCloud/FireKylin/issues
更新日志:
【v1.1.2】 2021-08-12
1:Gui进程列表使用进程ID进行升序排序。
2:Gui Windows日志添加全文搜索框,支持每列以及事件信息内容匹配。
3:LinuxAgent修复目录不存在时搜索目录导致的报错问题。
4:LinuxAgent修复日志无法正常提取问题。
5:WindowsAgent修复Security日志与System日志无法提取问题。
6:Gui优化fkld解析过程,所以无法支持老版本的数据解析。
【v1.0.1】 2021-08-09
1:Gui支持Windows。
2:Agent支持Windows和Linux。
3:Agent-Windows支持采集:用户、进程、启动项、服务、网络信息、计划任务、系统日志。
4:Agent-Linux支持采集:用户、进程、启动项、服务、网络信息、历史命令、系统日志。
5:Gui内置中文和英文,支持扩展语言。
火麒麟简介
火麒麟的中文名称是:火麒麟。其实和某款氪金游戏火麒麟无关。作为一款国产的网络安全工具,名字取自中国怪兽:麒麟。言下之意是希望为维护中国的网络安全做出贡献。
它的功能是采集操作系统的各种痕迹。
其作用是为分析和判断安全事件提供操作系统数据。
目的是让任何有或没有计算机故障排除经验的人都能在计算机上发生安全事件。
在处理计算机上的安全事件时,对于这方面没有经验但有研究判断能力的安全专家来说,经常苦于需要参考各种安全手册进行trace采集、排序,和研究。这时候我们可以使用FireKylin-Agent一键采集踪迹,降低安全专家采集工作的难度。
FireKylin 的使用非常简单。将Agent程序上传到电脑上需要检查的主机,运行Agent程序,从采集下载数据.fkld文件,使用接口程序加载数据查看主机。 Agent最大的特点是[0命令采集]对安装了监控功能的安全软件的主机非常友好,不会对监控软件造成“误报安全”。事件”命令。
v1.0.1 客户端界面
当前版本已更新为 v1.0.1。 Agent 支持 Linux 和 Windows 操作系统,而 Gui 仅支持 Windows 操作系统。
代理支持的操作系统
Agent支持采集任务的灵活配置,不仅可以切换任务,还可以为日志采集配置时间段采集,提高采集效率和准确率。
代理 v1.0.1 Windows 端
agent v1.0.1 Linux 终端使用对比
在过去的应急响应中,我们的安全专家经常需要一起登录目标主机。我们可能使用堡垒机或者直接ssh到目标服务器,这意味着安全密钥可能要发给各种需要学习判断的安全人员。在这个过程中,密钥的安全性将受到威胁。 FireKylin 只需要有权限的人员在机器上操作,并将结果分发给各个安全人员。
相比火麒麟,传统方式支持的场景更多
在应急响应中,安全专家经常对远程或远程服务进行安全事件检查,但远程服务器往往处于没有任何访问方法的场景。对于这种场景,传统解决方案可能需要授权运营商使用其他跳板为安全专家提供远程接入点,但跳板往往存在风险。 FireKylin 只需要运营商运行 Agent 程序,然后将结果发送给我们的安全人员进行事故调查。
无法达到目标的场景对比使用教程
默认语言为英语,需要在设置->语言->中选择zh-cn并点击设置语言。选择语言后,GUI会自动重启,然后就是中文了。
设置语言
代理配置:
start 开始任务。
print 或 ls 打印任务配置。
1=false 或 user=false 是关闭用户采集的任务,其他同理。
日志配置比较复杂:
config syslog 是查看日志配置项。
一点资讯登录文章评论采集器(文章批量采集工具)使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-08-08 23:19
易点信息登录文章评论采集器(文章Batch采集工具)是易点信息官方专门推出的一款非常好用的文章Batch采集软件。您在寻找简单实用的文章batch采集软件吗?那就来绿先锋下载一点资料,登录文章评论采集器最新版本即可使用。支持批量采集点资讯文章评论。抓取到的数据包括文章title、文章content、文章cover、作者、作者头像、评论数、评论数、文章link、文章category、关键词等。
软件说明
您可以自定义您想要采集的频道或文章关键词,您可以同时采集多个关键词或频道文章。
软件功能
1、分布式云爬虫,采集不断断
24小时不间断运行,关机也能采集;分布式云爬虫,可按需扩展,更适合大规模爬虫!
2、海量私有代理IP,智能抓取
自动访问私有代理IP,批量稳定抓取数据!
3、多种数据导出和发布方式
可以导出到Excel等文件,发布到数据库或者cms网站;还支持Webhooks推送、Restful接口、GraphQL访问等高级功能。与您现有的系统无缝连接!
4、版本更新,一键在线升级
获取爬虫后,如有更新版本或修改,可在优采云控制台点击“更新”一键升级!
5、一站式大数据采集,清洗+机器学习
对爬取的数据进行统一可视化管理,优采云还提供了更多的数据分析处理功能:包括数据清洗和机器学习~ 查看全部
一点资讯登录文章评论采集器(文章批量采集工具)使用
易点信息登录文章评论采集器(文章Batch采集工具)是易点信息官方专门推出的一款非常好用的文章Batch采集软件。您在寻找简单实用的文章batch采集软件吗?那就来绿先锋下载一点资料,登录文章评论采集器最新版本即可使用。支持批量采集点资讯文章评论。抓取到的数据包括文章title、文章content、文章cover、作者、作者头像、评论数、评论数、文章link、文章category、关键词等。
软件说明
您可以自定义您想要采集的频道或文章关键词,您可以同时采集多个关键词或频道文章。
软件功能
1、分布式云爬虫,采集不断断
24小时不间断运行,关机也能采集;分布式云爬虫,可按需扩展,更适合大规模爬虫!
2、海量私有代理IP,智能抓取
自动访问私有代理IP,批量稳定抓取数据!
3、多种数据导出和发布方式
可以导出到Excel等文件,发布到数据库或者cms网站;还支持Webhooks推送、Restful接口、GraphQL访问等高级功能。与您现有的系统无缝连接!
4、版本更新,一键在线升级
获取爬虫后,如有更新版本或修改,可在优采云控制台点击“更新”一键升级!
5、一站式大数据采集,清洗+机器学习
对爬取的数据进行统一可视化管理,优采云还提供了更多的数据分析处理功能:包括数据清洗和机器学习~
网络爬虫实战之微信公众号数据接口分析(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-07-29 19:37
真实网络爬虫的微信公众号
简介:这个文章主要教大家如何获取一些电脑无法访问的微信公众号数据。干货满满,30分钟即可学会。
ps。在开始之前,让我们做一个实验。您可以使用计算机上的浏览器打开以下链接:
理论上,结果如图:
下面复制链接到手机微信打开,就会发现可以访问了,如图:
这是怎么回事?那我们怎么爬呢?你会在手机上写程序吗?现在开始,不要浪费时间...
实际环境安装
> Fiddler 安装
数据接口分析
1 虽然我们的电脑不能直接访问,但是我们可以设置一个移动代理通过电脑来访问。具体步骤请参考这里。 (因为觉得细节都写到这里了,就不自己单独写了)
2 如果第一步成功,我们再用手机微信访问上面提到的那个,此时再查看Fiddler,应该可以找到如下图所示的内容:
入口地址的头部信息如下:
GET https://mp.weixin.qq.com/mp/pr ... r%3D1 HTTP/1.1
Host: mp.weixin.qq.com
Cookie: devicetype=iPhoneOS9.3.2; lang=zh_CN; pass_ticket=HzJHDnkJb3+0ahfIxvOkfBNKHuHMqPSTy6BhUfH/h/Ivlm9I3TXDMu+LVTBJrlje; rewardsn=; version=16060223; wap_sid2=CPqn++IDElwyUVRfYlQzbUgtQXhyalNJSUNZV0FtQWN6aUpZanlOTzBPbXZhTmlLY254WXpUTTA0MlIyajVNQ1lzaXd0a25NTmRxRktFNzlsYWRDdHlBTEFaSy10YThEQUFBfjDG9vTTBTgNQJVO; wxtokenkey=53c052ead40aff8e2cd6620b4318c2cd55b1fa8b11fc42bb68b0259eaff6737b; wxuin=1012847610; pgv_pvid=9292485220; tvfe_boss_uuid=fd1f6cd130701ba3
X-WECHAT-KEY: f766f1cd6ee0ff274dc9860b51eae7f688d14083adcad2ef8de83924c183947c6bd72b106319c39f3de71761aa71412f6d75e59c7819490a459ccac7c46d3473489343f4fe4cb6c7db495ff9fb9b3c11
Proxy-Connection: keep-alive
X-WECHAT-UIN: MTAxMjg0NzYxMA%3D%3D
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_2 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Mobile/13F69 MicroMessenger/6.6.2 NetType/WIFI Language/zh_CN
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
Connection: keep-alive
3 我们找到了入口地址,但是你会发现,就这个公众号而言,我们也可以下拉刷新,OK,刷新后观察Fiddler的变化,如下图:
标题信息如下:
GET https://mp.weixin.qq.com/mp/pr ... Djson HTTP/1.1
Host: mp.weixin.qq.com
Accept-Encoding: gzip, deflate
Cookie: devicetype=iPhoneOS9.3.2; lang=zh_CN; pass_ticket=HzJHDnkJb3+0ahfIxvOkfBNKHuHMqPSTy6BhUfH/h/Ivlm9I3TXDMu+LVTBJrlje; rewardsn=; version=16060223; wap_sid2=CPqn++IDElxoZGlxSHVkbU5iUTgxdk5ERml2S0VTUFdTeFppcC1zRDNNS05qLTRvMlBhc0NWV0ZUX212UHYwQTZMQThmNUR6anFjZEh5V1FnNGtIT2NXQkhuUFhHcThEQUFBfjDE9/TTBTgNQJVO; wxtokenkey=53c052ead40aff8e2cd6620b4318c2cd55b1fa8b11fc42bb68b0259eaff6737b; wxuin=1012847610; pgv_pvid=9292485220; tvfe_boss_uuid=fd1f6cd130701ba3
Connection: keep-alive
Proxy-Connection: keep-alive
Accept: */*
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_2 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Mobile/13F69 MicroMessenger/6.6.2 NetType/WIFI Language/zh_CN
Referer: https://mp.weixin.qq.com/mp/pr ... r%3D1
Accept-Language: zh-cn
X-Requested-With: XMLHttpRequest
我这里用上面的方法两次访问页面,截取刷新后的url,分析两次访问参数的异同,所以参数可能与读者不同:
第一次访问的网址:
https://mp.weixin.qq.com/mp/pr ... etmsg
&__biz=MzU4MTIzNTE2Mw==
&f=json
&offset=16
&count=10
&is_ok=1
&scene=124
&uin=777
&key=777
&pass_ticket=HzJHDnkJb3%2B0ahfIxvOkfBNKHuHMqPSTy6BhUfH%2Fh%2FIvlm9I3TXDMu%2BLVTBJrlje
&wxtoken=
&appmsg_token=943_RlSAGtRNJ4hTeFCpdMXrQE5OMWo7zlA9yV3RsQ~~
&x5=0
&f=json
第二次访问的网址:
https://mp.weixin.qq.com/mp/pr ... etmsg
&__biz=MzU4MTIzNTE2Mw==
&f=json
&offset=16
&count=10
&is_ok=1
&scene=124
&uin=777
&key=777
&pass_ticket=xbJdEC6xMdTcPhBobs039uy0hsso2Ii03RqWP1a1ACmWJjQe7YaU8XVdcOeQVgDP
&wxtoken=
&appmsg_token=943_WzQEBfwN9QQRZWd2GjBb44hpWWHBGAIx4wOHAA~~
&x5=0
&f=json
__biz : 这个似乎没变,不管他
f: 数据格式为json
offset: 数据偏移量为16,可以认为是从哪条数据开始
count: 每一页的数量为10
pass_ticket: 一个加密参数,这个先别管,大家多访问几次就发现不太一样
appmsg_token:也是一个加密参数,先别管
其他的参数似乎都不怎么变动,到时候就带着一起访问吧。
编写爬虫
# -*- coding:utf8 -*-
__author__ = 'power'
import urllib2
import re
import json
# 读者自己替换url
url = "https://mp.weixin.qq.com/mp/pr ... ot%3B \
"&offset=16" \
"&count=10" \
"&is_ok=1&scene=124&uin=777&key=777&pass_ticket=xbJdEC6xMdTcPhBobs039uy0hsso2Ii03RqWP1a1ACmWJjQe7YaU8XVdcOeQVgDP&wxtoken=&appmsg_token=943_Ybr%252BNzl3hE5TUzCdt3ESYvsmavTcuwaGNKX2-w~~&x5=0&f=json"
# 设置headers,这里可以一个一个试,发现只需要Cookie和User-Agent就行了
# 记得修改Cookie和User-Agent
headers = {
# 'Accept-Encoding': 'gzip, deflate',
'Cookie': 'devicetype=iPhoneOS9.3.2; lang=zh_CN; pass_ticket=xbJdEC6xMdTcPhBobs039uy0hsso2Ii03RqWP1a1ACmWJjQe7YaU8XVdcOeQVgDP; version=16060223; wap_sid2=CPqn++IDElw2eTdjZlZqQ2tTUjhWekZwcXN2b0xTNGp1YzhuekIzWVVKenpfRElxbm9iM05oVW5rQUxzU0hxQWhKamVsdEtyalIwMVE2SFNfOWd6ZHdvWWdUVnNsSzhEQUFBfjCHyvXTBTgNQJVO; wxuin=1012847610; pgv_pvid=9292485220; tvfe_boss_uuid=fd1f6cd130701ba3',
# 'Connection': 'keep-alive',
# 'Proxy-Connection': 'keep-alive',
# 'Accept': '*/*',
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_2 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Mobile/13F69 MicroMessenger/6.6.2 NetType/WIFI Language/zh_CN',
# 'Referer': 'https://mp.weixin.qq.com/mp/pr ... 39%3B,
# 'Accept-Language': 'zh-cn',
# 'X-Requested-With': 'XMLHttpRequest'
}
data = None
req = urllib2.Request(url, data, headers)
response = urllib2.urlopen(req)
# 将数据读出来
html = response.read()
# 我们下面将里面的title全部输出出来
# 数据转成字典
msg = json.loads(html)
# 从字典中读出信息列表
msg = msg["general_msg_list"]
pat_title = '"title":"(.*?)"'
# 根据正则表达式获取所有的title信息
titles = re.compile(pat_title, re.S).findall(msg)
for title in titles:
print title
ps。这里只是一段简单的爬虫代码。有兴趣的读者可以将其转化为多个页面或设置代理进行抓取。
注意事项
1 本文文章只是简单介绍了微信公众号中如何获取数据接口,以及如何破解众多加密参数,难度较大。下次有时间再给个详细的教程,这里一两个说不完。
2 安装或操作过程中如有问题请留言。
3 由于微信中设置了url的过期时间,如果本来可以访问的url突然不可用,请重新阅读。 文章里面的url应该已经过期了,哈哈
相关信息
Fiddler 设置代理
基本正则表达式
使用 urllib2 查看全部
网络爬虫实战之微信公众号数据接口分析(组图)
真实网络爬虫的微信公众号
简介:这个文章主要教大家如何获取一些电脑无法访问的微信公众号数据。干货满满,30分钟即可学会。
ps。在开始之前,让我们做一个实验。您可以使用计算机上的浏览器打开以下链接:
理论上,结果如图:
下面复制链接到手机微信打开,就会发现可以访问了,如图:
这是怎么回事?那我们怎么爬呢?你会在手机上写程序吗?现在开始,不要浪费时间...
实际环境安装
> Fiddler 安装
数据接口分析
1 虽然我们的电脑不能直接访问,但是我们可以设置一个移动代理通过电脑来访问。具体步骤请参考这里。 (因为觉得细节都写到这里了,就不自己单独写了)
2 如果第一步成功,我们再用手机微信访问上面提到的那个,此时再查看Fiddler,应该可以找到如下图所示的内容:
入口地址的头部信息如下:
GET https://mp.weixin.qq.com/mp/pr ... r%3D1 HTTP/1.1
Host: mp.weixin.qq.com
Cookie: devicetype=iPhoneOS9.3.2; lang=zh_CN; pass_ticket=HzJHDnkJb3+0ahfIxvOkfBNKHuHMqPSTy6BhUfH/h/Ivlm9I3TXDMu+LVTBJrlje; rewardsn=; version=16060223; wap_sid2=CPqn++IDElwyUVRfYlQzbUgtQXhyalNJSUNZV0FtQWN6aUpZanlOTzBPbXZhTmlLY254WXpUTTA0MlIyajVNQ1lzaXd0a25NTmRxRktFNzlsYWRDdHlBTEFaSy10YThEQUFBfjDG9vTTBTgNQJVO; wxtokenkey=53c052ead40aff8e2cd6620b4318c2cd55b1fa8b11fc42bb68b0259eaff6737b; wxuin=1012847610; pgv_pvid=9292485220; tvfe_boss_uuid=fd1f6cd130701ba3
X-WECHAT-KEY: f766f1cd6ee0ff274dc9860b51eae7f688d14083adcad2ef8de83924c183947c6bd72b106319c39f3de71761aa71412f6d75e59c7819490a459ccac7c46d3473489343f4fe4cb6c7db495ff9fb9b3c11
Proxy-Connection: keep-alive
X-WECHAT-UIN: MTAxMjg0NzYxMA%3D%3D
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_2 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Mobile/13F69 MicroMessenger/6.6.2 NetType/WIFI Language/zh_CN
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
Connection: keep-alive
3 我们找到了入口地址,但是你会发现,就这个公众号而言,我们也可以下拉刷新,OK,刷新后观察Fiddler的变化,如下图:
标题信息如下:
GET https://mp.weixin.qq.com/mp/pr ... Djson HTTP/1.1
Host: mp.weixin.qq.com
Accept-Encoding: gzip, deflate
Cookie: devicetype=iPhoneOS9.3.2; lang=zh_CN; pass_ticket=HzJHDnkJb3+0ahfIxvOkfBNKHuHMqPSTy6BhUfH/h/Ivlm9I3TXDMu+LVTBJrlje; rewardsn=; version=16060223; wap_sid2=CPqn++IDElxoZGlxSHVkbU5iUTgxdk5ERml2S0VTUFdTeFppcC1zRDNNS05qLTRvMlBhc0NWV0ZUX212UHYwQTZMQThmNUR6anFjZEh5V1FnNGtIT2NXQkhuUFhHcThEQUFBfjDE9/TTBTgNQJVO; wxtokenkey=53c052ead40aff8e2cd6620b4318c2cd55b1fa8b11fc42bb68b0259eaff6737b; wxuin=1012847610; pgv_pvid=9292485220; tvfe_boss_uuid=fd1f6cd130701ba3
Connection: keep-alive
Proxy-Connection: keep-alive
Accept: */*
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_2 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Mobile/13F69 MicroMessenger/6.6.2 NetType/WIFI Language/zh_CN
Referer: https://mp.weixin.qq.com/mp/pr ... r%3D1
Accept-Language: zh-cn
X-Requested-With: XMLHttpRequest
我这里用上面的方法两次访问页面,截取刷新后的url,分析两次访问参数的异同,所以参数可能与读者不同:
第一次访问的网址:
https://mp.weixin.qq.com/mp/pr ... etmsg
&__biz=MzU4MTIzNTE2Mw==
&f=json
&offset=16
&count=10
&is_ok=1
&scene=124
&uin=777
&key=777
&pass_ticket=HzJHDnkJb3%2B0ahfIxvOkfBNKHuHMqPSTy6BhUfH%2Fh%2FIvlm9I3TXDMu%2BLVTBJrlje
&wxtoken=
&appmsg_token=943_RlSAGtRNJ4hTeFCpdMXrQE5OMWo7zlA9yV3RsQ~~
&x5=0
&f=json
第二次访问的网址:
https://mp.weixin.qq.com/mp/pr ... etmsg
&__biz=MzU4MTIzNTE2Mw==
&f=json
&offset=16
&count=10
&is_ok=1
&scene=124
&uin=777
&key=777
&pass_ticket=xbJdEC6xMdTcPhBobs039uy0hsso2Ii03RqWP1a1ACmWJjQe7YaU8XVdcOeQVgDP
&wxtoken=
&appmsg_token=943_WzQEBfwN9QQRZWd2GjBb44hpWWHBGAIx4wOHAA~~
&x5=0
&f=json
__biz : 这个似乎没变,不管他
f: 数据格式为json
offset: 数据偏移量为16,可以认为是从哪条数据开始
count: 每一页的数量为10
pass_ticket: 一个加密参数,这个先别管,大家多访问几次就发现不太一样
appmsg_token:也是一个加密参数,先别管
其他的参数似乎都不怎么变动,到时候就带着一起访问吧。
编写爬虫
# -*- coding:utf8 -*-
__author__ = 'power'
import urllib2
import re
import json
# 读者自己替换url
url = "https://mp.weixin.qq.com/mp/pr ... ot%3B \
"&offset=16" \
"&count=10" \
"&is_ok=1&scene=124&uin=777&key=777&pass_ticket=xbJdEC6xMdTcPhBobs039uy0hsso2Ii03RqWP1a1ACmWJjQe7YaU8XVdcOeQVgDP&wxtoken=&appmsg_token=943_Ybr%252BNzl3hE5TUzCdt3ESYvsmavTcuwaGNKX2-w~~&x5=0&f=json"
# 设置headers,这里可以一个一个试,发现只需要Cookie和User-Agent就行了
# 记得修改Cookie和User-Agent
headers = {
# 'Accept-Encoding': 'gzip, deflate',
'Cookie': 'devicetype=iPhoneOS9.3.2; lang=zh_CN; pass_ticket=xbJdEC6xMdTcPhBobs039uy0hsso2Ii03RqWP1a1ACmWJjQe7YaU8XVdcOeQVgDP; version=16060223; wap_sid2=CPqn++IDElw2eTdjZlZqQ2tTUjhWekZwcXN2b0xTNGp1YzhuekIzWVVKenpfRElxbm9iM05oVW5rQUxzU0hxQWhKamVsdEtyalIwMVE2SFNfOWd6ZHdvWWdUVnNsSzhEQUFBfjCHyvXTBTgNQJVO; wxuin=1012847610; pgv_pvid=9292485220; tvfe_boss_uuid=fd1f6cd130701ba3',
# 'Connection': 'keep-alive',
# 'Proxy-Connection': 'keep-alive',
# 'Accept': '*/*',
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_2 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Mobile/13F69 MicroMessenger/6.6.2 NetType/WIFI Language/zh_CN',
# 'Referer': 'https://mp.weixin.qq.com/mp/pr ... 39%3B,
# 'Accept-Language': 'zh-cn',
# 'X-Requested-With': 'XMLHttpRequest'
}
data = None
req = urllib2.Request(url, data, headers)
response = urllib2.urlopen(req)
# 将数据读出来
html = response.read()
# 我们下面将里面的title全部输出出来
# 数据转成字典
msg = json.loads(html)
# 从字典中读出信息列表
msg = msg["general_msg_list"]
pat_title = '"title":"(.*?)"'
# 根据正则表达式获取所有的title信息
titles = re.compile(pat_title, re.S).findall(msg)
for title in titles:
print title
ps。这里只是一段简单的爬虫代码。有兴趣的读者可以将其转化为多个页面或设置代理进行抓取。
注意事项
1 本文文章只是简单介绍了微信公众号中如何获取数据接口,以及如何破解众多加密参数,难度较大。下次有时间再给个详细的教程,这里一两个说不完。
2 安装或操作过程中如有问题请留言。
3 由于微信中设置了url的过期时间,如果本来可以访问的url突然不可用,请重新阅读。 文章里面的url应该已经过期了,哈哈
相关信息
Fiddler 设置代理
基本正则表达式
使用 urllib2
如何自动复制链接地址的使用方法?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2021-07-23 03:02
工具采集文章如果在采集文章时遇到文章很多需要复制粘贴的地方,可以考虑使用soupui插件,因为这个插件可以自动复制链接地址。接下来介绍一下使用方法:1.进入soupui官网()。2.选择sharingwaysforin-housespeechconversion,即上传文章,如下图。3.选择左边的convertwithselection,将链接粘贴进去。
4.选择一篇不同的采集文章,如上图。点击ok,sharingthewaysforin-housespeechconversion。5.勾选上chooseonefilmorthemostproductiveitem,encryptandpastecodeforspeechconversion。6.设置密码,完成。
7.在文章中粘贴链接,点击editcopy,可以看到保存的链接地址。8.点击edit,按保存的链接搜索即可。完成啦,是不是超级简单,特别适合于长篇文章的采集,但是链接地址可以根据需要替换,方便查找。文章采集插件不仅仅可以进行文章的采集,还可以采集相册图片,gif图片,需要的可以下载相关插件,并且有自己提供免费使用的功能,不用买任何付费插件。
everything前提是everything你很熟
也可以一些文章内搜索技巧,
tagul可以写文章。
可以搜索的。中文ip访问网页前有图片要求,一般都是上传邮箱或联系方式得到(不是直接上传空间文件)。我就用这个免费地址打开过一个腾讯视频,直接下载了。没有其他限制,完美。只是得看那个网站没有中文页面,另外大多网站都没有全英文,如果有一个有英文就更好了。 查看全部
如何自动复制链接地址的使用方法?(一)
工具采集文章如果在采集文章时遇到文章很多需要复制粘贴的地方,可以考虑使用soupui插件,因为这个插件可以自动复制链接地址。接下来介绍一下使用方法:1.进入soupui官网()。2.选择sharingwaysforin-housespeechconversion,即上传文章,如下图。3.选择左边的convertwithselection,将链接粘贴进去。
4.选择一篇不同的采集文章,如上图。点击ok,sharingthewaysforin-housespeechconversion。5.勾选上chooseonefilmorthemostproductiveitem,encryptandpastecodeforspeechconversion。6.设置密码,完成。
7.在文章中粘贴链接,点击editcopy,可以看到保存的链接地址。8.点击edit,按保存的链接搜索即可。完成啦,是不是超级简单,特别适合于长篇文章的采集,但是链接地址可以根据需要替换,方便查找。文章采集插件不仅仅可以进行文章的采集,还可以采集相册图片,gif图片,需要的可以下载相关插件,并且有自己提供免费使用的功能,不用买任何付费插件。
everything前提是everything你很熟
也可以一些文章内搜索技巧,
tagul可以写文章。
可以搜索的。中文ip访问网页前有图片要求,一般都是上传邮箱或联系方式得到(不是直接上传空间文件)。我就用这个免费地址打开过一个腾讯视频,直接下载了。没有其他限制,完美。只是得看那个网站没有中文页面,另外大多网站都没有全英文,如果有一个有英文就更好了。
脑暴搜索引擎排名优化哪些方法可以高效权重提升网站排名
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-07-22 20:01
工具采集文章智能文章数据挖掘利器脑暴搜索引擎排名优化哪些方法可以高效权重提升网站排名?企业网站提排名需要注意什么?靠谱的seo网站排名优化方法又是什么?转载原创:我是如何采集文章后,让网站在4个月里各个方面突飞猛进,并且有效排名一直在坚持不懈优化中更快提升,
呵呵,第一,中小网站靠伪原创来加快上升速度,这里需要注意一下通过中小网站有人搜才能推动前排,有人搜就会有人点击,当然这个需要时间积累,可以多编辑下伪原创第二,伪原创方面要在对网站有深刻了解以后才能做,不然会编的乱七八糟,从而影响网站后期排名第三,通过百度关键词排名,在搜索网站关键词时,百度排名靠前的网站相对会对网站权重和排名有所提升,如果想要经常排名靠前,从而提升网站排名,可以建议做关键词竞价排名,比如:关键词‘提高快速排名’,排名靠前的做这种投入比较大,但却比较稳定对网站有不小帮助,记住一点不要专注于网站关键词排名,多想想怎么提升网站排名,让网站排名上升。
这个市场不大,用软件也无法操作大网站,可以试试看seo阅兵吧,将你的文章收集到一起,然后搜索你的关键词,点击你的文章,在搜索结果中,排名较好的网站,有可能和你的文章有相似之处,也有可能你的文章,也能给你带来流量,这种方法不仅提高网站排名,也会给你带来相应的用户价值。还可以手机分享,让更多的人看到,也会提高网站的流量,从而达到收益。 查看全部
脑暴搜索引擎排名优化哪些方法可以高效权重提升网站排名
工具采集文章智能文章数据挖掘利器脑暴搜索引擎排名优化哪些方法可以高效权重提升网站排名?企业网站提排名需要注意什么?靠谱的seo网站排名优化方法又是什么?转载原创:我是如何采集文章后,让网站在4个月里各个方面突飞猛进,并且有效排名一直在坚持不懈优化中更快提升,
呵呵,第一,中小网站靠伪原创来加快上升速度,这里需要注意一下通过中小网站有人搜才能推动前排,有人搜就会有人点击,当然这个需要时间积累,可以多编辑下伪原创第二,伪原创方面要在对网站有深刻了解以后才能做,不然会编的乱七八糟,从而影响网站后期排名第三,通过百度关键词排名,在搜索网站关键词时,百度排名靠前的网站相对会对网站权重和排名有所提升,如果想要经常排名靠前,从而提升网站排名,可以建议做关键词竞价排名,比如:关键词‘提高快速排名’,排名靠前的做这种投入比较大,但却比较稳定对网站有不小帮助,记住一点不要专注于网站关键词排名,多想想怎么提升网站排名,让网站排名上升。
这个市场不大,用软件也无法操作大网站,可以试试看seo阅兵吧,将你的文章收集到一起,然后搜索你的关键词,点击你的文章,在搜索结果中,排名较好的网站,有可能和你的文章有相似之处,也有可能你的文章,也能给你带来流量,这种方法不仅提高网站排名,也会给你带来相应的用户价值。还可以手机分享,让更多的人看到,也会提高网站的流量,从而达到收益。
让文章的重复率降到一个比较科学的水准
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-07-09 00:26
伪原创文字的要求是将文章的重复率降低到更科学的水平,通过工具内置的文字网络云检测功能,可以快速完成对文字内容的重复检测和搜索引擎。 , 手动编辑获取地址、文章title和文章时间等信息,确认自己重复率高的部分重新维护,将原创率维持在公司认可的水平。
业绩介绍
1、相似词替换表现
2、可以自己设置关键词替换,用户可以自己打开选择
如何使用
1、第一次输出得到文章的地址
2、 然后填写要替换的内容,点击同义词替换
3、点击所有替换。
软件功能
1.让你的替代品双DIY,双刻画。
2.将一个文章关联上一个同义词替换为另一个全新的伪原创文章,替换速度快。
3. 使您的替代品成为双重 DIY 并且更加具体。是站长朋友更新网站数据的好帮手。
4.使用精准强大的词库快速替换文章,让文章达到伪原创的目标。
综合评价
采集文章伪原创工具还具备优秀的文本内容原创转换服务功能,可以独立控制和定义内部数据文件信息,让其文本的实质内容得到良好的转换效果,实现大幅提升自身内容原创度,避免收录被占,权重下降的情况发生。
你喜欢小编给你带来的采集文章伪原创工具吗?希望能帮到你~更多软件下载给软件爱好者 查看全部
让文章的重复率降到一个比较科学的水准
伪原创文字的要求是将文章的重复率降低到更科学的水平,通过工具内置的文字网络云检测功能,可以快速完成对文字内容的重复检测和搜索引擎。 , 手动编辑获取地址、文章title和文章时间等信息,确认自己重复率高的部分重新维护,将原创率维持在公司认可的水平。
业绩介绍
1、相似词替换表现
2、可以自己设置关键词替换,用户可以自己打开选择
如何使用
1、第一次输出得到文章的地址
2、 然后填写要替换的内容,点击同义词替换
3、点击所有替换。
软件功能
1.让你的替代品双DIY,双刻画。
2.将一个文章关联上一个同义词替换为另一个全新的伪原创文章,替换速度快。
3. 使您的替代品成为双重 DIY 并且更加具体。是站长朋友更新网站数据的好帮手。
4.使用精准强大的词库快速替换文章,让文章达到伪原创的目标。
综合评价
采集文章伪原创工具还具备优秀的文本内容原创转换服务功能,可以独立控制和定义内部数据文件信息,让其文本的实质内容得到良好的转换效果,实现大幅提升自身内容原创度,避免收录被占,权重下降的情况发生。
你喜欢小编给你带来的采集文章伪原创工具吗?希望能帮到你~更多软件下载给软件爱好者
工具采集文章可以爬取其他网站吗?怎么实现?
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-07-06 01:01
工具采集文章可以用爬虫软件如nutch,或者借助于专业工具比如合聚器对网页进行聚合处理,爬取自己想要的文章;再比如各大商城购物网站里面的自有app,那么他们对产品的描述,推荐理由等是采用文字还是图片?可以利用python合成抓取,然后提取自己想要的内容,进行分析;如果您是采用爬虫软件,或者合成抓取都需要把所有的url都爬取下来,这样工作量特别大,可以采用一种技术以资源数据为驱动解决此问题。
使用技术:爬虫软件flask对网页进行文字抓取,合成抓取,抓取后对抓取的数据进行聚合、合并提取;抓取app内部商城对应的商品描述、推荐理由;平台自有app对应的推荐、购买;如何学习爬虫?还是使用爬虫软件对网页进行抓取,对中国邮政中国ems中国铁路等等信息进行抓取,然后存入数据库如何爬取其他网站?是不是每个网站都需要?有的网站需要注册账号,有的需要爬虫软件进行登录登陆才能进行抓取,还有的网站可以,而且网页也是可以数据联动,调用自己的app提取数据等。
而且还是可以抓取商城自身对应的推荐商品、热门商品等等。怎么实现?同上面的技术基本相同,但是要比合聚器适合更多的类型,同时学习成本也更低,但是操作较为复杂。-关注微信公众号:《优采云人》,获取更多技术干货。 查看全部
工具采集文章可以爬取其他网站吗?怎么实现?
工具采集文章可以用爬虫软件如nutch,或者借助于专业工具比如合聚器对网页进行聚合处理,爬取自己想要的文章;再比如各大商城购物网站里面的自有app,那么他们对产品的描述,推荐理由等是采用文字还是图片?可以利用python合成抓取,然后提取自己想要的内容,进行分析;如果您是采用爬虫软件,或者合成抓取都需要把所有的url都爬取下来,这样工作量特别大,可以采用一种技术以资源数据为驱动解决此问题。
使用技术:爬虫软件flask对网页进行文字抓取,合成抓取,抓取后对抓取的数据进行聚合、合并提取;抓取app内部商城对应的商品描述、推荐理由;平台自有app对应的推荐、购买;如何学习爬虫?还是使用爬虫软件对网页进行抓取,对中国邮政中国ems中国铁路等等信息进行抓取,然后存入数据库如何爬取其他网站?是不是每个网站都需要?有的网站需要注册账号,有的需要爬虫软件进行登录登陆才能进行抓取,还有的网站可以,而且网页也是可以数据联动,调用自己的app提取数据等。
而且还是可以抓取商城自身对应的推荐商品、热门商品等等。怎么实现?同上面的技术基本相同,但是要比合聚器适合更多的类型,同时学习成本也更低,但是操作较为复杂。-关注微信公众号:《优采云人》,获取更多技术干货。
10.13爬虫——爬百度地图上线啦!(附百度全球最大地图采集车技)
采集交流 • 优采云 发表了文章 • 0 个评论 • 557 次浏览 • 2021-07-01 22:01
工具采集文章,了解一下:如何利用地图抓取网站来抓取百度搜索引擎中的一切信息,掌握快速提取网站地图采集工具、利用编写网站爬虫来抓取,以及利用程序编写插件方式对网站进行二次开发,也可以尝试修改优化,开发出对应的爬虫获取需要抓取的页面。更多资料请浏览:【10.13爬虫】——爬百度地图上线啦!(附百度全球最大地图采集车技)_小蚂蚁爬虫。
这些都是百度提供的爬虫工具,比如:优蚁爬虫,是一个免费的网站爬虫工具,可实现中文网站访问、中文网站抓取、百度全球地图抓取、网页导航抓取、sitemap抓取、北美地图抓取等功能。
小家伙你要好好珍惜
地图大师采集器就是专门抓取百度地图的,
如果做个页面,
illumina终端采集器:1.收录统计,一步直达要抓取的网页2.抓取速度快,不限制抓取范围和地区抓取数据可以自己创建,点击“一键采集”,会自动抓取所有网页。
如果你是要抓取广告联盟中常用的广告服务器,比如loadsdk里的页面就可以用简道云搭建模板,调用采集代码,
人人都是编辑
现在有比较多的主流的抓取工具,主要分为3类:1.互联网公司的产品,比如百度,以网站采集、网站合作为主要业务2.自媒体,比如360公司的流量宝,以自媒体采集为主3.第三方的产品,如果不熟悉的话,第三方也有相应的产品、功能一般这几类的比较,公司和自媒体的采集功能比较好采集,不容易被封号,采集行为如果很大的话,也会很费时费力。
所以最好针对业务采集,合作对象比较精准,这样效率高,用户体验也更好。还有就是通过第三方的采集工具来采集地图,比如导航宝平台上都有相应的功能。 查看全部
10.13爬虫——爬百度地图上线啦!(附百度全球最大地图采集车技)
工具采集文章,了解一下:如何利用地图抓取网站来抓取百度搜索引擎中的一切信息,掌握快速提取网站地图采集工具、利用编写网站爬虫来抓取,以及利用程序编写插件方式对网站进行二次开发,也可以尝试修改优化,开发出对应的爬虫获取需要抓取的页面。更多资料请浏览:【10.13爬虫】——爬百度地图上线啦!(附百度全球最大地图采集车技)_小蚂蚁爬虫。
这些都是百度提供的爬虫工具,比如:优蚁爬虫,是一个免费的网站爬虫工具,可实现中文网站访问、中文网站抓取、百度全球地图抓取、网页导航抓取、sitemap抓取、北美地图抓取等功能。
小家伙你要好好珍惜
地图大师采集器就是专门抓取百度地图的,
如果做个页面,
illumina终端采集器:1.收录统计,一步直达要抓取的网页2.抓取速度快,不限制抓取范围和地区抓取数据可以自己创建,点击“一键采集”,会自动抓取所有网页。
如果你是要抓取广告联盟中常用的广告服务器,比如loadsdk里的页面就可以用简道云搭建模板,调用采集代码,
人人都是编辑
现在有比较多的主流的抓取工具,主要分为3类:1.互联网公司的产品,比如百度,以网站采集、网站合作为主要业务2.自媒体,比如360公司的流量宝,以自媒体采集为主3.第三方的产品,如果不熟悉的话,第三方也有相应的产品、功能一般这几类的比较,公司和自媒体的采集功能比较好采集,不容易被封号,采集行为如果很大的话,也会很费时费力。
所以最好针对业务采集,合作对象比较精准,这样效率高,用户体验也更好。还有就是通过第三方的采集工具来采集地图,比如导航宝平台上都有相应的功能。
分享一个神器,快速采集文章全靠它!(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-06-30 06:48
分享一个神器,赶紧采集文章靠它!
疫情期间,一键采集网站文章链接,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一,但远程办公仍然不如面对面工作效率高。为此,优采云采集特别推出了智能采集工具。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具不仅可以帮助操作采集信息,还可以准确分析数据趋势,从而帮助增加收入。
1、优采云采集是什么?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提高新媒体运营效率,降低企业成本。
2、如何使用优采云采集进行搜索?
(1)输入关键词
优采云采集 根据用户输入的关键词,搜索引擎通过程序自动进入主流自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集有关疫情的资料,在主页输入关键词“流行病”。 优采云采集 会将搜索结果整合到一个列表中。
(2)保存搜索资料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页面】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
(3)精准过滤
1、 搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤 查看全部
分享一个神器,快速采集文章全靠它!(图)
分享一个神器,赶紧采集文章靠它!
疫情期间,一键采集网站文章链接,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一,但远程办公仍然不如面对面工作效率高。为此,优采云采集特别推出了智能采集工具。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具不仅可以帮助操作采集信息,还可以准确分析数据趋势,从而帮助增加收入。
1、优采云采集是什么?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提高新媒体运营效率,降低企业成本。
2、如何使用优采云采集进行搜索?
(1)输入关键词
优采云采集 根据用户输入的关键词,搜索引擎通过程序自动进入主流自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集有关疫情的资料,在主页输入关键词“流行病”。 优采云采集 会将搜索结果整合到一个列表中。
(2)保存搜索资料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页面】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
(3)精准过滤
1、 搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤
内容优化篇——保证自己创作不被采集的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-06-26 18:02
站长,在做网站的时候,网站的内容有时候是采集,尤其是在现在采集成本极低的环境下,只要懂一点代码,就可以制作采集 模块。即使你不知道如何编码,你也可以以低廉的价格找人编写。
新站上线了,我正在努力做着原创的内容,但是采集工具采集突然占据了全站。没有人能忍受。
而且新站一开始没有权重,即使你发布你的原创,加权网站采集和发布你的文章,蜘蛛爬取网页也会优先收录有一个高权重的网页,认为是他的原创文章。
这是别人的典型婚纱。
虽然文章也有版权保护,但是面对采集网站有什么用呢?他既然敢采集,就不怕你维权,现在维权成本高。
之前,熊掌有原创保护功能,但因为百度的业务,下线了。现在的原创真的无法保护。
那么今天五车二就给大家分享几个方法,尽量保证你的创作不是采集。
内容优化章节
1.写作时,在你的作品中插入相关的品牌词。如:“XXX网小编”、“XXX提醒大家”……或者用替代词,百度知道替代百度知道、百度知道、百度知道等标记文章以便反馈以后作为证据使用。
当然采集软件也有过滤功能,所以你可以为每篇文章文章使用不同的词汇。虽然有点累,但有些采集人不那么悲伤,总会错过一些细节。
2、图片水印处理,采集工具无法识别图片并过滤。 原创文章的图片可以使用水印。就算采集不见了,他要处理,也得重新编辑一下。
更新技能(技术层面)章节
采集器,会让工具通过网站的URL识别最新的文章。只要我不发布最新的文章,采集工具将无法获取相关代码。只要我的文章先行收录,他在做采集,就会被搜索引擎判断为复制转发而不是原创。
1、隐藏更新(延迟),你站点中的蜘蛛会抓取站点中所有的URL连接,采集工具不能。所以只要我们隐藏了一个页面,没有把它归入某个类别,就等着收录移入该类别。你可以避免第一次成为采集。
2、程序限制页面访问(在一定时间内只能访问多少页面),机器的速度比人的速度还快,不可能一个人访问每一篇文章@ 3分钟内各品类k13@,每个文章全开。 (注:有些采集工具可以延迟采集,因为他们也可以设置几分钟访问一篇文章。但成本很高。)
3、限制面向用户的页面显示,比如我只给你显示1页,第二页用于验证。
4.验证机制。其实有些网站可以在用户访问异常时弹出验证码框进行人机验证,也可以绕过采集tools的采集。
5、尽量不要对链接进行排序。 采集tools 最初使用源代码来识别 URL。一些有序的URL链接非常喜欢采集人,因为不麻烦,可以采集整站数据。星控站长网址是/1.html,工具甚至可以直接采集文章1-99999.html,无需进入分类。所以这是一个糟糕的 URL 设计习惯。
百度站长工具篇
百度站长工具可以手动提交链接。
结合上面【技术层面】章节的第一点,我们先延迟更新隐藏页面。
然后用百度的站长工具收录submit,提交我们的原创文章网址,等待百度收录。 查看全部
内容优化篇——保证自己创作不被采集的方法
站长,在做网站的时候,网站的内容有时候是采集,尤其是在现在采集成本极低的环境下,只要懂一点代码,就可以制作采集 模块。即使你不知道如何编码,你也可以以低廉的价格找人编写。
新站上线了,我正在努力做着原创的内容,但是采集工具采集突然占据了全站。没有人能忍受。
而且新站一开始没有权重,即使你发布你的原创,加权网站采集和发布你的文章,蜘蛛爬取网页也会优先收录有一个高权重的网页,认为是他的原创文章。
这是别人的典型婚纱。
虽然文章也有版权保护,但是面对采集网站有什么用呢?他既然敢采集,就不怕你维权,现在维权成本高。
之前,熊掌有原创保护功能,但因为百度的业务,下线了。现在的原创真的无法保护。
那么今天五车二就给大家分享几个方法,尽量保证你的创作不是采集。
内容优化章节
1.写作时,在你的作品中插入相关的品牌词。如:“XXX网小编”、“XXX提醒大家”……或者用替代词,百度知道替代百度知道、百度知道、百度知道等标记文章以便反馈以后作为证据使用。
当然采集软件也有过滤功能,所以你可以为每篇文章文章使用不同的词汇。虽然有点累,但有些采集人不那么悲伤,总会错过一些细节。
2、图片水印处理,采集工具无法识别图片并过滤。 原创文章的图片可以使用水印。就算采集不见了,他要处理,也得重新编辑一下。
更新技能(技术层面)章节
采集器,会让工具通过网站的URL识别最新的文章。只要我不发布最新的文章,采集工具将无法获取相关代码。只要我的文章先行收录,他在做采集,就会被搜索引擎判断为复制转发而不是原创。
1、隐藏更新(延迟),你站点中的蜘蛛会抓取站点中所有的URL连接,采集工具不能。所以只要我们隐藏了一个页面,没有把它归入某个类别,就等着收录移入该类别。你可以避免第一次成为采集。
2、程序限制页面访问(在一定时间内只能访问多少页面),机器的速度比人的速度还快,不可能一个人访问每一篇文章@ 3分钟内各品类k13@,每个文章全开。 (注:有些采集工具可以延迟采集,因为他们也可以设置几分钟访问一篇文章。但成本很高。)
3、限制面向用户的页面显示,比如我只给你显示1页,第二页用于验证。
4.验证机制。其实有些网站可以在用户访问异常时弹出验证码框进行人机验证,也可以绕过采集tools的采集。
5、尽量不要对链接进行排序。 采集tools 最初使用源代码来识别 URL。一些有序的URL链接非常喜欢采集人,因为不麻烦,可以采集整站数据。星控站长网址是/1.html,工具甚至可以直接采集文章1-99999.html,无需进入分类。所以这是一个糟糕的 URL 设计习惯。
百度站长工具篇
百度站长工具可以手动提交链接。
结合上面【技术层面】章节的第一点,我们先延迟更新隐藏页面。
然后用百度的站长工具收录submit,提交我们的原创文章网址,等待百度收录。
工具采集文章原链接按抓取规则抓取指的规则继续
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-06-22 21:01
工具采集文章原链接按抓取原链接的规则继续抓取每个页面都抓取抓取速度会根据文章抓取量而不同量决定速度,30秒的文章抓取量1w就是30秒量决定速度优秀的公众号工具在每一页都按抓取规则抓取是不会有重复数据的使用工具进行抓取请完整复制指定链接,
获取公众号平台可发布文章列表的网页地址。
我们说的抓取指的是针对某篇文章来说吧~因为我写的是模板软件,所以我在写脚本过程中是抓取编辑完文章就向后台保存,保存成list。单个接口我来举例我自己在写脚本过程中抓取了14个公众号~实测之后把抓取结果如下:可见,不同的公众号发布的文章是有区别的,你可以通过抓取编辑文章的方式再爬取一次~你想要抓取哪个公众号这个你就要设置好了~。
爬取微信文章不存在30秒抓取的问题,只能当你给文章先上链接,用微信js直接调用网页的验证码吧。最笨的方法是用js抓取,但是破解验证码并不容易。利用微信js只能抓取小部分公众号,所以为了增加破解技术的难度,我自己封装了个js抓取脚本,专门抓取js验证码,并封装了rsa加密。
在很多的公众号网站上抓取微信文章的抓取。因为篇幅限制,所以抓取公众号的文章目录页是只能抓取一遍。下面的链接可以算是微信第一页的公众号页面了,只有一个就是文章,没有后续。后续的大多数是简短微信的文章,因为没有多余的内容。这种情况可以试试去买一些公众号的尾部广告来抓取,甚至就去发软文,发链接发文章都可以,如果你微信好友多的话,被盗号人很容易就能够找到你。 查看全部
工具采集文章原链接按抓取规则抓取指的规则继续
工具采集文章原链接按抓取原链接的规则继续抓取每个页面都抓取抓取速度会根据文章抓取量而不同量决定速度,30秒的文章抓取量1w就是30秒量决定速度优秀的公众号工具在每一页都按抓取规则抓取是不会有重复数据的使用工具进行抓取请完整复制指定链接,
获取公众号平台可发布文章列表的网页地址。
我们说的抓取指的是针对某篇文章来说吧~因为我写的是模板软件,所以我在写脚本过程中是抓取编辑完文章就向后台保存,保存成list。单个接口我来举例我自己在写脚本过程中抓取了14个公众号~实测之后把抓取结果如下:可见,不同的公众号发布的文章是有区别的,你可以通过抓取编辑文章的方式再爬取一次~你想要抓取哪个公众号这个你就要设置好了~。
爬取微信文章不存在30秒抓取的问题,只能当你给文章先上链接,用微信js直接调用网页的验证码吧。最笨的方法是用js抓取,但是破解验证码并不容易。利用微信js只能抓取小部分公众号,所以为了增加破解技术的难度,我自己封装了个js抓取脚本,专门抓取js验证码,并封装了rsa加密。
在很多的公众号网站上抓取微信文章的抓取。因为篇幅限制,所以抓取公众号的文章目录页是只能抓取一遍。下面的链接可以算是微信第一页的公众号页面了,只有一个就是文章,没有后续。后续的大多数是简短微信的文章,因为没有多余的内容。这种情况可以试试去买一些公众号的尾部广告来抓取,甚至就去发软文,发链接发文章都可以,如果你微信好友多的话,被盗号人很容易就能够找到你。
一点资讯、uc订阅号、百度、谷歌的区别
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-06-20 20:21
工具采集文章:一点资讯、uc订阅号、百家号、网易订阅号、一点资讯;文章采集转发到公众号:ejiasyhong2016;意见反馈:即日起拉勾账号的文章可以出现在本账号,文章存在评论区。一、起始原因由于14年5月以来某公司被关闭公司主页,各种乱象滋生,包括机器群发,营销文案及其他流量软件助推网站诈骗、爬虫。
来源也多为各大门户网站;本人在14年时因为某公司关闭主页时申请了知乎账号,因为自认为对此事有所了解,对各大网站的错误评论和机器群发十分不屑,发表了些声音,确实有不少点赞,但绝大多数在各大门户网站评论的都是带有营销软文的小广告,各网站无非是文案写的好,产品很鸡肋或者“bat”实力公司,现在国内外都这样,就算国内,不乏各大网站的信息小广告大量存在。
这些评论大部分原因和成本几乎无关,不值得投入精力。我想起谷歌关闭主页的那次,很多大量广告信息,甚至包括1元软妹币的订阅,这样才比较少才对。如果不是为了赚钱,谁又愿意申请谷歌。网站,无论是门户网站或者其他独立站,所谓的“头条”,不过是其公司的利用关系炒作噱头。百度或者谷歌有其自身问题,但却依然作为公司占领用户大部分流量,百度内部baidu关掉仅仅一个周,但很多站都被谷歌或者百度搞僵。
其实,我不止一次说过百度如果要做出一款能够制霸互联网搜索引擎,就需要一个真正能够吸引广大网民信任的品牌形象,我一直感觉百度如果做出来并推出的,是无法成功。因为那个时候,百度就不该叫百度公司,应该叫谷歌公司,这就是我比较喜欢和百度合作的原因,大家理解我在说什么。老罗牛博出现如此巨大的争议,不也是谷歌基因问题,主要是谷歌没有遵循其客户标准。
中国互联网发展迅速,其所在的的环境已经在制约国内各大互联网公司的发展了,在这个问题上,作为一个有良知的网民真的不能在这些软件上花费太多的时间。二、社会风气的风向标很多人认为,在某种程度上,只要能够收割到大批用户,尽管不懂网络的软件应该有没有用的,只要让用户感觉到好用,就是牛逼,就是有用。具体好用有多牛逼,我不在这里多做发表。
让自己有用的,不能因为是利益驱使就抛弃,因为有些事情或者不便,比如“百度,上天台去吧”在我们国内,只要能够盈利就不能被取缔,即使利益驱使,也只能是鼓励;无用的(形容词),不用想着违反良心去使用。那些热衷于盗版的人,你们觉得他们是没有用吗?但实际上,他们不但用了这些软件,甚至还不止一款软件,其用途各异,有些人他为的是能在手机上接打电话,有些人他就是为了电脑多开,有些人想要。 查看全部
一点资讯、uc订阅号、百度、谷歌的区别
工具采集文章:一点资讯、uc订阅号、百家号、网易订阅号、一点资讯;文章采集转发到公众号:ejiasyhong2016;意见反馈:即日起拉勾账号的文章可以出现在本账号,文章存在评论区。一、起始原因由于14年5月以来某公司被关闭公司主页,各种乱象滋生,包括机器群发,营销文案及其他流量软件助推网站诈骗、爬虫。
来源也多为各大门户网站;本人在14年时因为某公司关闭主页时申请了知乎账号,因为自认为对此事有所了解,对各大网站的错误评论和机器群发十分不屑,发表了些声音,确实有不少点赞,但绝大多数在各大门户网站评论的都是带有营销软文的小广告,各网站无非是文案写的好,产品很鸡肋或者“bat”实力公司,现在国内外都这样,就算国内,不乏各大网站的信息小广告大量存在。
这些评论大部分原因和成本几乎无关,不值得投入精力。我想起谷歌关闭主页的那次,很多大量广告信息,甚至包括1元软妹币的订阅,这样才比较少才对。如果不是为了赚钱,谁又愿意申请谷歌。网站,无论是门户网站或者其他独立站,所谓的“头条”,不过是其公司的利用关系炒作噱头。百度或者谷歌有其自身问题,但却依然作为公司占领用户大部分流量,百度内部baidu关掉仅仅一个周,但很多站都被谷歌或者百度搞僵。
其实,我不止一次说过百度如果要做出一款能够制霸互联网搜索引擎,就需要一个真正能够吸引广大网民信任的品牌形象,我一直感觉百度如果做出来并推出的,是无法成功。因为那个时候,百度就不该叫百度公司,应该叫谷歌公司,这就是我比较喜欢和百度合作的原因,大家理解我在说什么。老罗牛博出现如此巨大的争议,不也是谷歌基因问题,主要是谷歌没有遵循其客户标准。
中国互联网发展迅速,其所在的的环境已经在制约国内各大互联网公司的发展了,在这个问题上,作为一个有良知的网民真的不能在这些软件上花费太多的时间。二、社会风气的风向标很多人认为,在某种程度上,只要能够收割到大批用户,尽管不懂网络的软件应该有没有用的,只要让用户感觉到好用,就是牛逼,就是有用。具体好用有多牛逼,我不在这里多做发表。
让自己有用的,不能因为是利益驱使就抛弃,因为有些事情或者不便,比如“百度,上天台去吧”在我们国内,只要能够盈利就不能被取缔,即使利益驱使,也只能是鼓励;无用的(形容词),不用想着违反良心去使用。那些热衷于盗版的人,你们觉得他们是没有用吗?但实际上,他们不但用了这些软件,甚至还不止一款软件,其用途各异,有些人他为的是能在手机上接打电话,有些人他就是为了电脑多开,有些人想要。

